
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
wpark/Artificial_Intelligence_multiagent
|
https://github.com/wpark/Artificial_Intelligence_multiagent
|
a6d830d784a630fadd7630ac12d060266d6c2ae2
|
73fc4c0c64eb4e96ad7fa5ef70f283b7126ce62e
|
94e7aed997a917e65331225010cca4443b8260b2
|
refs/heads/master
| 2021-05-16T16:14:29.779818 | 2018-02-02T05:47:18 | 2018-02-02T05:47:18 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6556826829910278,
"alphanum_fraction": 0.6616014838218689,
"avg_line_length": 38.39910125732422,
"blob_id": "83a80376c382128f4566a1f429d81c8870f8f133",
"content_id": "06345dec983d341b669143cc7fe72af4b2fc77e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17571,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 446,
"path": "/multiAgents.py",
"repo_name": "wpark/Artificial_Intelligence_multiagent",
"src_encoding": "UTF-8",
"text": "# multiAgents.py\n# --------------\n# Licensing Information: You are free to use or extend these projects for\n# educational purposes provided that (1) you do not distribute or publish\n# solutions, (2) you retain this notice, and (3) you provide clear\n# attribution to UC Berkeley, including a link to http://ai.berkeley.edu.\n# \n# Attribution Information: The Pacman AI projects were developed at UC Berkeley.\n# The core projects and autograders were primarily created by John DeNero\n# ([email protected]) and Dan Klein ([email protected]).\n# Student side autograding was added by Brad Miller, Nick Hay, and\n# Pieter Abbeel ([email protected]).\n\n\nfrom util import manhattanDistance\nfrom game import Directions\nimport random, util, math\nfrom game import Agent\n\nclass ReflexAgent(Agent):\n \"\"\"\n A reflex agent chooses an action at each choice point by examining\n its alternatives via a state evaluation function.\n The code below is provided as a guide. You are welcome to change\n it in any way you see fit, so long as you don't touch our method\n headers.\n \"\"\"\n\n # Bailey (Ahhyun Ahn) and I pair-programmed only on the first problem, Reflex Agent.\n def getAction(self, gameState):\n \"\"\"\n You do not need to change this method, but you're welcome to.\n getAction chooses among the best options according to the evaluation function.\n Just like in the previous project, getAction takes a GameState and returns\n some Directions.X for some X in the set {North, South, West, East, Stop}\n \"\"\"\n # Collect legal moves and successor states\n legalMoves = gameState.getLegalActions()\n\n # Choose one of the best actions\n scores = [self.evaluationFunction(gameState, action) for action in legalMoves]\n bestScore = max(scores)\n bestIndices = [index for index in range(len(scores)) if scores[index] == bestScore]\n chosenIndex = random.choice(bestIndices) # Pick randomly among the best\n\n \"Add more of your code here if you want to\"\n\n return legalMoves[chosenIndex]\n\n def gridToList(self, grid):\n \"\"\" this returns a list of positions of stuff in stuffGrid (substitute stuff to either food/wall)\"\"\"\n gridList =[]\n for i in range(grid.width):\n for j in range(grid.height):\n if grid[i][j] == True:\n # print \"grid[i][j]\", grid[i][j]\n gridList.append((i,j))\n return gridList\n\n def getSuccessors(self, currentPos, wallList, grid):\n \"\"\" this returns a list of successors from current location \"\"\"\n x, y = currentPos\n fourDirections = [(x-1, y, Directions.WEST), (x+1, y, Directions.EAST), \\\n (x, y+1, Directions.NORTH), (x, y-1, Directions.SOUTH)]\n return filter(lambda successorPos: self.isValidPos(successorPos[0], successorPos[1], wallList, grid), fourDirections)\n\n \n def isValidPos(self, x, y, wallList, grid):\n \"\"\" returns true if the position is valid in grid, and not a wall \"\"\"\n if (x, y) not in wallList:\n return x > 0 and x < grid.width and y > 0 and y < grid.height\n\n def evaluationFunction(self, currentGameState, action):\n \"\"\"\n Design a better evaluation function here.\n The evaluation function takes in the current and proposed successor\n GameStates (pacman.py) and returns a number, where higher numbers are better.\n The code below extracts some useful information from the state, like the\n remaining food (newFood) and Pacman position after moving (newPos).\n newScaredTimes holds the number of moves that each ghost will remain\n scared because of Pacman having eaten a power pellet.\n Print out these variables to see what you're getting, then combine them\n to create a masterful evaluation function.\n \"\"\"\n # Useful information you can extract from a GameState (pacman.py)\n successorGameState = currentGameState.generatePacmanSuccessor(action)\n newPos = successorGameState.getPacmanPosition()\n newFood = successorGameState.getFood()\n newGhostStates = successorGameState.getGhostStates()\n newScaredTimes = [ghostState.scaredTimer for ghostState in newGhostStates]\n newGhostPoses = [ghostState.getPosition() for ghostState in newGhostStates]\n\n numberOfFood = successorGameState.getNumFood()\n\n if numberOfFood == 0:\n return 1000\n\n closestFoodDistance = min([manhattanDistance(newPos, foodPos) for foodPos in self.gridToList(successorGameState.getFood())])\n\n stopPoint = 0\n if action == Directions.STOP:\n stopPoint = 20\n\n closestGhostDistance = min([manhattanDistance(newPos, ghostPosition) for ghostPosition in successorGameState.getGhostPositions()])\n\n if newPos in newGhostPoses:\n return -1000\n\n return - closestFoodDistance + 3*math.sqrt(closestGhostDistance) + 1.3*successorGameState.getScore()\n\ndef scoreEvaluationFunction(currentGameState):\n \"\"\"\n This default evaluation function just returns the score of the state.\n The score is the same one displayed in the Pacman GUI.\n This evaluation function is meant for use with adversarial search agents\n (not reflex agents).\n \"\"\"\n return currentGameState.getScore()\n\nclass MultiAgentSearchAgent(Agent):\n \"\"\"\n This class provides some common elements to all of your\n multi-agent searchers. Any methods defined here will be available\n to the MinimaxPacmanAgent, AlphaBetaPacmanAgent & ExpectimaxPacmanAgent.\n You *do not* need to make any changes here, but you can if you want to\n add functionality to all your adversarial search agents. Please do not\n remove anything, however.\n Note: this is an abstract class: one that should not be instantiated. It's\n only partially specified, and designed to be extended. Agent (game.py)\n is another abstract class.\n \"\"\"\n\n def __init__(self, evalFn = 'scoreEvaluationFunction', depth = '2'):\n self.index = 0 # Pacman is always agent index 0\n self.evaluationFunction = util.lookup(evalFn, globals())\n self.depth = int(depth)\n\nclass MinimaxAgent(MultiAgentSearchAgent):\n \"\"\"\n Your minimax agent (question 2)\n \"\"\"\n\n def getAction(self, gameState):\n \"\"\"\n Returns the minimax action from the current gameState using self.depth\n and self.evaluationFunction.\n Here are some method calls that might be useful when implementing minimax.\n gameState.getLegalActions(agentIndex):\n Returns a list of legal actions for an agent\n agentIndex=0 means Pacman, ghosts are >= 1\n gameState.generateSuccessor(agentIndex, action):\n Returns the successor game state after an agent takes an action\n gameState.getNumAgents():\n Returns the total number of agents in the game\n gameState.isWin():\n Returns whether or not the game state is a winning state\n gameState.isLose():\n Returns whether or not the game state is a losing state\n \"\"\"\n value = float(\"-inf\")\n \n #self.index = 0 -> pacman \n optimalList = [value, None]\n for action in gameState.getLegalActions(self.index):\n sucessorState = gameState.generateSuccessor(self.index, action)\n tempValue = self.value(sucessorState, self.depth, 1)\n if tempValue > value:\n value = tempValue\n optimalList = [value, action]\n # return optimal action \n return optimalList[1]\n\n\n def value(self, state, depth, agentIndex):\n # check if we reached the terminal state or the bottom layer\n if state.isWin() or state.isLose() or (depth < 1):\n return self.evaluationFunction(state)\n\n # It's packman/maximizer\n if agentIndex == 0:\n #print \"agentIndex: \", agentIndex\n return self.max_value(state, depth,agentIndex)\n\n # It's a ghost/minimizer\n else:\n return self.min_value(state, depth, agentIndex)\n\n def max_value(self, state, depth, agentIndex):\n value = float(\"-inf\")\n\n for action in state.getLegalActions(agentIndex):\n successorState = state.generateSuccessor(agentIndex,action)\n # increment agentIndex by 1 to go to the next layer/agent\n tempValue = self.value(successorState, depth, agentIndex+1)\n value = max(tempValue, value)\n return value\n\n def min_value(self, state, depth, agentIndex):\n value = float(\"inf\")\n # numGhosts = numAgents-1 because we want to get the number of agents excluding pacman\n numGhosts = state.getNumAgents()-1\n\n for action in state.getLegalActions(agentIndex):\n successorState = state.generateSuccessor(agentIndex,action)\n # Check if we have evaluated all the ghosts' sucessor states\n if agentIndex >= numGhosts:\n # We're done evaluating successor states for the minimizers \n tempValue = self.value(successorState, depth-1, 0)\n else:\n # increment agentIndex by 1 to get to the next ghost\n tempValue = self.value(successorState, depth, agentIndex+1)\n\n value = min(tempValue, value)\n return value\n\n\nclass AlphaBetaAgent(MultiAgentSearchAgent):\n \"\"\"\n Your minimax agent with alpha-beta pruning (question 3)\n \"\"\"\n\n def getAction(self, gameState):\n \"\"\"\n Returns the minimax action using self.depth and self.evaluationFunction\n \"\"\"\n value = float(\"-inf\")\n alpha = float(\"-inf\")\n beta = float(\"inf\")\n \n #self.index = 0 -> pacman \n optimalList = [value, None]\n for action in gameState.getLegalActions(self.index):\n sucessorState = gameState.generateSuccessor(self.index, action)\n tempValue = self.value(sucessorState, self.depth, 1, alpha, beta)\n\n if max(tempValue,value) > alpha:\n alpha = max(tempValue,value)\n\n if tempValue > value:\n value = tempValue\n optimalList = [value, action]\n # return optimal action \n return optimalList[1]\n \n\n def value(self, state, depth, agentIndex, alpha, beta):\n # check if we reached the terminal state or the bottom layer\n if state.isWin() or state.isLose() or (depth < 1):\n return self.evaluationFunction(state)\n\n # It's packman/maximizer\n if agentIndex == 0:\n return self.max_value(state, depth, agentIndex, alpha, beta)\n\n # It's a ghost/minimizer\n else:\n return self.min_value(state, depth, agentIndex, alpha, beta)\n\n def max_value(self, state, depth, agentIndex, alpha, beta):\n value = float(\"-inf\")\n\n for action in state.getLegalActions(agentIndex):\n successorState = state.generateSuccessor(agentIndex,action)\n # increment agentIndex by 1 to go to the next layer/agent\n tempValue = self.value(successorState, depth, agentIndex+1, alpha, beta)\n \n if max(tempValue, value) > beta:\n value = max(tempValue, value)\n return value\n\n else:\n value = max(tempValue, value)\n #alpha -> maximizer's best option to root\n alpha = max(alpha, value)\n \n return value\n\n def min_value(self, state, depth, agentIndex, alpha, beta):\n value = float(\"inf\")\n # numGhosts = numAgents-1 because we want to get the number of agents excluding pacman\n numGhosts = state.getNumAgents()-1\n\n for action in state.getLegalActions(agentIndex):\n successorState = state.generateSuccessor(agentIndex,action)\n # numAgents-1 because we want to get the number of agents excluding pacman\n # Check if we have evaluated all the ghosts' sucessor states\n if agentIndex >= numGhosts:\n # We're done evaluating sucessor states for the minimizers \n tempValue = self.value(successorState, depth-1, 0, alpha, beta)\n else:\n # increment agentIndex by 1 to get to the next ghost\n tempValue = self.value(successorState, depth, agentIndex+1, alpha, beta)\n\n if min(tempValue, value) < alpha:\n value = min(tempValue, value)\n return value\n\n else:\n value = min(tempValue, value)\n #beta -> minimizer's best option to root\n beta = min(beta, value)\n\n return value\n\nclass ExpectimaxAgent(MultiAgentSearchAgent):\n \"\"\"\n Your expectimax agent (question 4)\n \"\"\"\n\n def getAction(self, gameState):\n \"\"\"\n Returns the expectimax action using self.depth and self.evaluationFunction\n All ghosts should be modeled as choosing uniformly at random from their\n legal moves.\n \"\"\"\n value = float(\"-inf\")\n \n #self.index = 0 -> pacman \n optimalList = [value, None]\n for action in gameState.getLegalActions(self.index):\n sucessorState = gameState.generateSuccessor(self.index, action)\n tempValue = self.value(sucessorState, self.depth, 1)\n if tempValue > value:\n value = tempValue\n optimalList = [value, action]\n # return optimal action \n return optimalList[1]\n \n def value(self, state, depth, agentIndex):\n \"\"\"\n This acts the same as minimax, except it calls the helper function exp_value\n in the place of where it used to call min_value. exp_value() returns the average\n of the values of the successor(children) states\n \"\"\"\n # check if we reached the terminal state or the bottom layer\n if state.isWin() or state.isLose() or (depth < 1):\n return self.evaluationFunction(state)\n\n # It's packman/maximizer\n if agentIndex == 0:\n #print \"agentIndex: \", agentIndex\n return self.max_value(state, depth,agentIndex)\n\n # It's a ghost\n else:\n return self.exp_value(state, depth, agentIndex)\n\n def max_value(self, state, depth, agentIndex):\n value = float(\"-inf\")\n\n for action in state.getLegalActions(agentIndex):\n successorState = state.generateSuccessor(agentIndex,action)\n # increment agentIndex by 1 to go to the next layer/agent\n tempValue = self.value(successorState, depth, agentIndex+1)\n value = max(tempValue, value)\n return value\n\n def exp_value(self, state, depth, agentIndex):\n value = 0\n # numGhosts = numAgents-1 because we want to get the number of agents excluding pacman\n numGhosts = state.getNumAgents()-1\n\n valueList = []\n # Store the values of all the successor states \n for action in state.getLegalActions(agentIndex):\n successorState = state.generateSuccessor(agentIndex,action)\n # Check if we have evaluated all the ghosts' sucessor states\n if agentIndex >= numGhosts:\n # We're done evaluating successor states for the ghosts\n valueList += [self.value(successorState, depth-1, 0)]\n else:\n # increment agentIndex by 1 to get to the next ghost\n valueList += [self.value(successorState, depth, agentIndex+1)]\n\n # We take the average of the values of the successor states because the ghosts\n # are supposed to be acting uniformly at random\n value = sum(valueList)/len(valueList)\n\n return value\n\n\ndef betterEvaluationFunction(currentGameState):\n \"\"\"\n Your extreme ghost-hunting, pellet-nabbing, food-gobbling, unstoppable\n evaluation function (question 5).\n DESCRIPTION: This evaluation function is not that different from my code\n for the reflex agent, except for a few things such as that it evaluates \n states, rather than actions. \n It rewards pacman for getting close to food, by taking the reciprocal of \n the manhattan distance to the closest food into consideration, then subtracting\n the manhattan distance to the closest ghost. Lastly, pacman gets rewarded as \n the current game score increases. It does NOT have any effect on this evaluation\n function when a ghost is \"scared\". \n \"\"\"\n score = 0\n\n if currentGameState.isWin():\n score += 10000000\n elif currentGameState.isLose():\n score -= 10000000\n\n pacmanPos = currentGameState.getPacmanPosition()\n foodList = gridToList(currentGameState.getFood())\n\n closestFoodDistance = distanceToClosestFood(pacmanPos, foodList) \n\n ghostPoses = currentGameState.getGhostPositions()\n closestGhostDistance = distanceToClosestGhost(pacmanPos, ghostPoses)\n\n score = (10/closestFoodDistance) - closestGhostDistance*10 + currentGameState.getScore()\n return score\n\ndef distanceToClosestFood(pacmanPos, foodList):\n foodDistance = 0\n manhattanToFood = [manhattanDistance(pacmanPos, foodPos) for foodPos in foodList]\n if len(manhattanToFood) != 0:\n foodDistance = min(manhattanToFood)\n else:\n foodDistance = 10\n return foodDistance\n\ndef distanceToClosestGhost(pacmanPos, ghostPoses):\n ghostDistance = 0\n\n for ghostPos in ghostPoses:\n manhattanToGhost = [manhattanDistance(pacmanPos, ghostPos)]\n if len(manhattanToGhost) != 0:\n ghostDistance = min(manhattanToGhost)\n else:\n ghostDistance = 0\n return ghostDistance\n\n\ndef gridToList(grid):\n \"\"\" this returns a list of positions of stuff in stuffGrid (substitute stuff to either food/wall)\"\"\"\n gridList =[]\n for i in range(grid.width):\n for j in range(grid.height):\n if grid[i][j] == True:\n gridList.append((i,j))\n return gridList\n\n\n \n# Abbreviation\nbetter = betterEvaluationFunction"
}
] | 1 |
zhangzhihui19950725/appfgj3
|
https://github.com/zhangzhihui19950725/appfgj3
|
5d36efd243b4b3a9d7c9e72d7e03a2481df42693
|
904fafb2ade19cf5a170b235766684d93f881172
|
b38c71f7456f16e9fc1a47214675c67c7b2decef
|
refs/heads/master
| 2023-02-18T20:15:11.163178 | 2021-01-22T07:18:17 | 2021-01-22T07:18:17 | 331,865,163 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.508537769317627,
"alphanum_fraction": 0.5165848731994629,
"avg_line_length": 26.387096405029297,
"blob_id": "9a0a83ed39c45c30443822f2b17ac8e9a5f26217",
"content_id": "df8d4272cc98c1897570620246ec856a42504311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5611,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 186,
"path": "/common/base.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\n\n# @FileName :base_methods.py\n# @Description :将appium中的部分函数进行封装\n\nimport os\nimport time\n\nfrom appium import webdriver\nfrom appium.webdriver.webdriver import WebDriver\nfrom selenium.common.exceptions import NoSuchElementException\n\nfrom common.get_deviceinfo import get_device_info\n\n\nclass BasePage:\n \"\"\"\n 将appium中的内容封装到该类下,供上一级使用\n Attributes:\n \"\"\"\n def __init__(self,driver: WebDriver=None):\n \"\"\"\n 此类的构造函数,将driver传入\n\n \"\"\"\n self.driver = driver\n self.foldpath = os.path.abspath(os.path.join(os.path.dirname(__file__), \"..\")) + '//screen//'\n\n\n\n def find_element(self, selector):\n \"\"\"\n 查找元素\n Args:\n selector:\n 1、id=>abd,通过id来查找一个元素\n 2、text=>淘房,通过text来查找一个元素\n 3、elements=>id=>abd=>0,通过id来查找一组元素,并返回pos位置的元素,目前仅支持id查找\n 4、abd,直接通过id来查找\n 5、xpath=>abd,通过xpath来查找一个元素\n Returns:\n element:查找到的元素\n \"\"\"\n print(\"find_element: \", selector)\n if \"=>\" not in selector:\n return self.driver.find_element_by_id(selector)\n\n if self.driver is None:\n print(\"+++++++++\")\n\n if \"elements\" in selector:\n type = selector.split('=>')[1]\n value = selector.split('=>')[2]\n pos = selector.split('=>')[3]\n\n try:\n elements = self.driver.find_elements_by_id(value)\n except NoSuchElementException as e:\n print(\"No Such Element Exception: %s\" % e)\n\n return elements[int(pos)]\n\n type = selector.split('=>')[0]\n value = selector.split('=>')[1]\n\n if type == \"id\":\n try:\n element = self.driver.find_element_by_id(value)\n except NoSuchElementException as e:\n print(\"%s cant click: %s\" % (selector, e))\n if type == \"text\":\n try:\n element = self.driver.find_element_by_android_uiautomator('new UiSelector().text(\\\"' + value + '\\\")')\n except NoSuchElementException as e:\n print(\"%s cant click: %s\" % (selector, e))\n\n if type == \"xpath\":\n try:\n element = self.driver.find_element_by_xpath(value)\n except NoSuchElementException as e:\n print(\"%s cant click: %s\" % (selector, e))\n\n return element\n\n def click(self, selector):\n \"\"\"\n 点击元素\n \"\"\"\n el = self.find_element(selector)\n print(\"click: \", el)\n try:\n self.tsleep()\n el.click()\n self.tsleep()\n except NoSuchElementException as e:\n print(\"%s cant click: %s\" % selector % e)\n\n def send_text(self, selector, text):\n \"\"\"\n 输入文本框内容\n \"\"\"\n el = self.find_element(selector)\n el.clear()\n try:\n self.tsleep(1)\n el.send_keys(text)\n except NoSuchElementException as e:\n print(\"%s cant send keys %s:%s\" % selector % text % e)\n\n def is_in_pagesource(self, selector):\n \"\"\"\n 判断selector是否在页面中\n 1、在的话,返回True\n 2、不在的话,返回False\n \"\"\"\n if selector in self.driver.page_source:\n return True\n else:\n return False\n\n def wait(self, page_name=None, seconds=10):\n \"\"\"\n 等待,包括2个:\n 1、等待页面加载,超时默认为10s\n 2、等待查找到元素page_name=None,超时默认为10s\n \"\"\"\n print(\"wait le ma ~\")\n if (page_name == None):\n self.driver.implicitly_wait(seconds)\n else:\n self.driver.wait_activity(page_name, seconds)\n\n def tsleep(self, sec=3):\n \"\"\"\n 休息时长,默认为3s\n \"\"\"\n time.sleep(3)\n\n def swipe_to_buttom(self, text=None):\n \"\"\"\n text=None:\t直接滑动到页面底部\n text!=None:\t滑动到text的地方\n \"\"\"\n device_size = self.driver.get_window_size()\n p_e = self.driver.page_source\n\n while (1):\n p_s = p_e\n if text != None and (text in p_s):\n break\n s_x = device_size['width'] * 0.5\n s_y = device_size['height'] * 0.75\n e_y = device_size['height'] * 0.5\n self.driver.swipe(s_x, s_y, s_x, e_y, 500)\n p_e = self.driver.page_source\n time.sleep(1)\n if p_s == p_e:\n print(\"找到所需要的地方!退出\")\n break\n\n def get_current_activity(self):\n \"\"\"\n 返回当前页面activity\n \"\"\"\n return self.driver.current_activity\n\n def save_screenshot_as_file(self, filename):\n \"\"\"\n 保存当前页面的截图到项目文件夹下的screen文件夹下\n \"\"\"\n self.tsleep(3)\n #foldpath = os.path.abspath(os.path.join(os.path.dirname(__file__), \"..\")) + '//screen//'\n filepath = self.foldpath + filename + '.png'\n self.driver.get_screenshot_as_file(filepath)\n self.tsleep(3)\n\n def waitActivity(self, page_name, seconds):\n \"\"\"\n 等待页面activity\n \"\"\"\n self.driver.wait_activity(page_name, seconds)\n\n\n def quit(self):\n self.driver.quit()\n\n"
},
{
"alpha_fraction": 0.6619318127632141,
"alphanum_fraction": 0.6732954382896423,
"avg_line_length": 23.928571701049805,
"blob_id": "385e2778aa4608e61533503c34781db5ef9c2fdf",
"content_id": "417b248b35060d6740fbccd88de52b66c8383a88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 356,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 14,
"path": "/page/userdetail.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\nfrom page.edituser import Edituser\n\n\nclass Userdetail(BasePage):\n\n def click_uesredit(self):\n self.click(\"text=>编辑\")\n return Edituser(self.driver)\n\n def click_phone(self):\n self.click(\"id=>com.house365.xinfangbao:id/customer_detail_call_img\")\n\n\n\n"
},
{
"alpha_fraction": 0.5783365368843079,
"alphanum_fraction": 0.5844616293907166,
"avg_line_length": 24.93277359008789,
"blob_id": "8abb9cbbc8ec76760ae31886bc3b779e789da6e9",
"content_id": "937c913912852636a0526d924719c24b46668a49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3334,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 119,
"path": "/page/index.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\nfrom page.detail import Hdetail\nfrom page.kh import Kh\nfrom page.list import List\nfrom page.login import Login\nfrom page.mine import Mine\nfrom page.msg import Msg\nfrom page.search import Search\n\n\nclass Index(BasePage):\n\n\n\n def goto_index(self):\n self.click(\"text=>首页\")\n\n def goto_kh(self):\n self.click(\"text=>客户\")\n\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n\n return Kh(self.driver)\n else:\n return Kh(self.driver)\n\n def goto_msg(self):\n \"\"\"\n 如果未登录,先登录,再跳转至消息页面\n 如果已登录,直接跳转至消息页面\n :return:\n \"\"\"\n self.click(\"text=>消息\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n return Msg(self.driver)\n else:\n return Msg(self.driver)\n\n\n def goto_mine(self):\n \"\"\"\n 未登录,先登录,再跳转我的页面\n 如果已登录,直接跳转至消我的页面\n :return:\n \"\"\"\n self.click(\"text=>我的\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n return Mine(self.driver)\n else:\n return Mine(self.driver)\n\n def click_index_search(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_index_search\")\n return Search(self.driver)\n\n\n def click_all(self):\n self.click(\"text=>全部\")\n return List(self.driver)\n\n def click_zz(self):\n self.click(\"text=>住宅\")\n return List(self.driver)\n\n def click_shy(self):\n self.click(\"text=>商业\")\n return List(self.driver)\n\n def click_gy(self):\n self.click(\"text=>公寓\")\n return List(self.driver)\n\n\n def click_sz(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_index_recommend_setting\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n if self.find_element(\"text=确定\"):\n self.click(\"text=确定\")\n\n\n def click_zh(self):\n self.swipe_to_buttom(\"综合排序\")\n self.click(\"text=>综合排序\")\n return self\n\n def click_zx(self):\n self.swipe_to_buttom(\"最新上架\")\n self.click(\"text=>最新上架\")\n return self\n\n def click_rm(self):\n self.swipe_to_buttom(\"热门报备\")\n self.click(\"text=>热门报备\")\n return self\n\n def swap_zntj(self):\n self.swipe_to_buttom(\"智能推荐\")\n return self\n\n def swap_jxtj(self):\n self.swipe_to_buttom(\"精选推荐\")\n return self\n\n def click_znfirstlp(self):\n self.click(\"elements=>id=>com.house365.xinfangbao:id/iv_house_recommend_image=>0\")\n #ele = self.find_element(\"xpath=>//*[@resource-id='com.house365.xinfangbao:id/iv_house_recommend_image]'[1]\")\n #self.click(ele)\n return Hdetail(self.driver)\n\n\n def click_jxfirstlp(self):\n self.click(\"elements=>id=>com.house365.xinfangbao:id/iv_image=>0\")\n return Hdetail(self.driver)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6488222479820251,
"alphanum_fraction": 0.6563169360160828,
"avg_line_length": 24.77777862548828,
"blob_id": "531a8d512eeca3a9787aa1016cfd9dadaf2f066c",
"content_id": "8b670302fb5f1e1cb3f6da5ce7fe85af74878dea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 966,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 36,
"path": "/page/kh.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\nfrom page.adduser import Adduser\nfrom page.bbkh import Bbkh\nfrom page.bbsx import Bbsx\nfrom page.mdbb import Bblist\nfrom page.mykh import Mykh\nfrom page.uesrsearch import Usersearch\n\n\nclass Kh(BasePage):\n\n def goto_mykh(self):\n self.click(\"text=>我的客户\")\n return Mykh(self.driver)\n\n def goto_wdbb(self):\n self.click(\"text=>我的报备\")\n return Bblist(self.driver)\n\n def goto_addkh(self):\n self.click(\"text=>添加客户\")\n return Adduser(self.driver)\n\n def goto_qbb(self):\n self.click(\"text=>快速报备\")\n return Bbkh(self.driver)\n\n def goto_search(self):\n self.click(\"id=>com.house365.xinfangbao:id/ib_customers_search\")\n return Usersearch(self.driver)\n\n def goto_khsx(self):\n self.click(\"id=>com.house365.xinfangbao:id/ib_customers_choice\")\n return Bbsx(self.driver)\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6018264889717102,
"alphanum_fraction": 0.6301369667053223,
"avg_line_length": 27.842105865478516,
"blob_id": "f2375da1adfb454e20eb45d5bb322e0202949910",
"content_id": "c7732cce89ddc0fbd80a654580fdc8801e005dd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1095,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 38,
"path": "/common/app.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom appium import webdriver\n\nfrom common.base import BasePage\nfrom common.get_deviceinfo import get_device_info\nfrom page.index import Index\n\n\nclass App(BasePage):\n def start(self):\n\n\n caps = {}\n caps[\"platformName\"] = \"Android\"\n caps[\"platformVersion\"] = \"7\"\n #caps[\"deviceName\"] = \"OB6585TSDYUGNJSC\"\n caps[\"deviceName\"]=\"2e72982d\"\n caps['unicodeKeyboard'] = \"true\"\n caps[\"appPackage\"] = \"com.house365.xinfangbao\"\n caps[\"appActivity\"] = \"com.house365.xinfangbao.ui.activity.SplashActivity\"\n caps[\"noReset\"] = \"true\"\n self.driver = webdriver.Remote(\"http://127.0.0.1:4723/wd/hub\", caps)\n self.driver.implicitly_wait(\"10\")\n\n\n #self.url, self.desired_caps = get_device_info('D:\\\\appium\\\\appfgj3\\common\\device_info_file.txt')\n # print(self.desired_caps)\n #self.driver = webdriver.Remote(self.url, self.desired_caps)\n\n return self\n\n\n def stop(self):\n self.driver.quit()\n\n def index(self) -> Index:\n return Index(self.driver)"
},
{
"alpha_fraction": 0.5103734731674194,
"alphanum_fraction": 0.5186722278594971,
"avg_line_length": 16.214284896850586,
"blob_id": "3adaa4915a9df6f367405c2dd6fcb491e97ac55f",
"content_id": "701a6228dc9cc74f191d73d9f83e876b0899c7cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 14,
"path": "/page/bbsx.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Bbsx(BasePage):\n\n def click_state1(self):\n \"\"\"\n 选中“已签约”\n :return:\n \"\"\"\n self.click(\"text=>已签约\")\n return self\n"
},
{
"alpha_fraction": 0.6164383292198181,
"alphanum_fraction": 0.6232876777648926,
"avg_line_length": 14.88888931274414,
"blob_id": "a2035dd4c4e856cb5f3508d27d89596d678c5c89",
"content_id": "603c52433340e82269a4bf3ce45fbb999b1d107a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/page/mdbb.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Bblist(BasePage):\n\n def bbsearch(self):\n pass\n\n\n\n"
},
{
"alpha_fraction": 0.6185682415962219,
"alphanum_fraction": 0.6208053827285767,
"avg_line_length": 18.45652198791504,
"blob_id": "811436e88299d02183443de139c764cec4976652",
"content_id": "f55f292f1807c8bea0ef317d4be83449a41d4adc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 46,
"path": "/common/get_deviceinfo.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\n\nfrom appium import webdriver\nimport sys\nimport os.path\n\n\n\n# driver = None\ndesired_caps = {}\nurl = None\n\n\ndef get_device_info(device_info_filepath):\n if not os.path.exists(device_info_filepath):\n print(\"输入的设备信息文件不存在:%s\" % device_info_filepath)\n sys.exit(0)\n\n fp = open(device_info_filepath)\n infos = fp.readlines()\n\n global desired_caps\n global url\n\n for info in infos:\n key, value = info.strip().split('||')\n if 'url' not in key:\n desired_caps[key] = value\n else:\n url = value\n # print(\"设备参数化信息:%s\" %desired_caps)\n # print(\"配置的appium url参数地址:%s\" %url)\n return (url, desired_caps)\n\n\n'''\n\n\nurl, desired_caps = get_device_info('device_info_file.txt')\nprint(url, desired_caps)\n\nget_device_info('device_info_file.txt')\ndevice = webdriver.Remote(url, desired_caps)\n\n'''"
},
{
"alpha_fraction": 0.5637750029563904,
"alphanum_fraction": 0.5705748796463013,
"avg_line_length": 29.777070999145508,
"blob_id": "31adaa46f27bb79d275913fa2aacaf00cc3c18dd",
"content_id": "917fc12a613561f6d0b7a1647e4ed6f44e285033",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5283,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 157,
"path": "/testcase/test_index.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.app import App\n\n\nclass TestIndex:\n def setup(self):\n self.app = App()\n self.app.start()\n\n def teardown(self):\n self.app.quit()\n\n\n def test_open_index(self):\n \"\"\"\n 打开首页\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index()\n assert self.app.find_element(\"text=>首页\")\n self.app.save_screenshot_as_file(\"test_open_index\")\n\n def test_search(self):\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_index_search().search_lp(\"万\")\n self.app.tsleep(1)\n\n def test_search2(self):\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_index_search().search_lp(\"万\").action_seach()\n\n\n\n def test_click_all(self):\n \"\"\"\n 首页=》功能入口=》全部\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_all()\n assert self.app.find_element(\"text=>请输入楼盘名称\")\n self.app.save_screenshot_as_file(\"test_click_all\")\n\n def test_click_zz(self):\n \"\"\"\n 首页=》功能入口=》住宅\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zz()\n assert self.app.find_element(\"text=>请输入楼盘名称\")\n self.app.save_screenshot_as_file(\"test_click_zz\")\n\n def test_click_shy(self):\n \"\"\"\n 首页=》功能入口=》商业\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_shy()\n assert self.app.find_element(\"text=>请输入楼盘名称\")\n self.app.save_screenshot_as_file(\"test_click_shy\")\n\n def test_click_gy(self):\n \"\"\"\n 首页=》功能入口=》公寓\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_gy()\n assert self.app.find_element(\"text=>请输入楼盘名称\")\n self.app.save_screenshot_as_file(\"test_click_gy\")\n\n def test_click_sz_logged(self):\n \"\"\"\n 点击首页->我的->若未登录则登录->智能推荐->设置\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().swap_zntj().click_sz()\n assert self.app.find_element(\"text=>偏好设置\")\n self.app.save_screenshot_as_file(\"test_click_sz_logged\")\n\n def test_click_znyj_lp(self):\n \"\"\"\n 点击首页->智能推荐->楼盘\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zh().swap_zntj().click_znfirstlp()\n assert self.app.find_element(\"text=>楼盘详情\")\n self.app.save_screenshot_as_file(\"test_click_znyj_lp\")\n\n\n\n def test_click_zxpx(self):\n \"\"\"\n 点击首页->精选推荐->综合排序\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zh()\n assert self.app.find_element(\"text=>综合排序\")\n self.app.save_screenshot_as_file(\"test_click_zhpv\")\n\n\n def test_click_zxsj(self):\n \"\"\"\n 点击首页->精选推荐->最新上架\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zx()\n assert self.app.find_element(\"text=>最新上架\")\n self.app.save_screenshot_as_file(\"test_click_zxsj\")\n\n def test_click_rmbb(self):\n \"\"\"\n 点击首页->精选推荐->热门报备\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_rm()\n assert self.app.find_element(\"text=>热门报备\")\n self.app.save_screenshot_as_file(\"test_click_rmbb\")\n\n def test_click_zh_lp(self):\n \"\"\"\n 点击首页->精选推荐->综合排序->楼盘\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zh().swap_jxtj().click_jxfirstlp()\n assert self.app.find_element(\"text=>楼盘详情\")\n self.app.save_screenshot_as_file(\"test_click_zh_lp\")\n\n def test_click_zx_lp(self):\n \"\"\"\n 点击首页->精选推荐->最新上架->楼盘\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zh().swap_jxtj().click_zx().click_jxfirstlp()\n assert self.app.find_element(\"text=>楼盘详情\")\n self.app.save_screenshot_as_file(\"test_click_zx_lp\")\n\n def test_click_rm_lp(self):\n \"\"\"\n 点击首页->精选推荐->热门报备->楼盘\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().click_zh().swap_jxtj().click_rm().click_jxfirstlp()\n assert self.app.find_element(\"text=>楼盘详情\")\n self.app.save_screenshot_as_file(\"test_click_rm_lp\")\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5885714292526245,
"alphanum_fraction": 0.5942857265472412,
"avg_line_length": 12.538461685180664,
"blob_id": "2a430e3bea0cf4bbefae399df8fd1677fa61d565",
"content_id": "5eb0da7e90e96575fab71b9dfdb76f7bea03c89f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/page/phsz.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "from common.base import BasePage\n\n\nclass Phsz(BasePage):\n\n def click_qy(self):\n pass\n\n def click_lx(self):\n pass\n\n def click_button1(self):\n pass"
},
{
"alpha_fraction": 0.5973218679428101,
"alphanum_fraction": 0.6087996363639832,
"avg_line_length": 28.45070457458496,
"blob_id": "c944290cac2da618788b2b825ca68cb29d68aca4",
"content_id": "f5cf4377d170392548965a3ee00d4de82282590c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2173,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 71,
"path": "/page/detail.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "from common.base import BasePage\nfrom page.login import Login\n\n\nclass Hdetail(BasePage):\n\n def click_xc(self): #点击相册\n self.click(\"id=>com.house365.xinfangbao:id/tv_housedetail_imagecount\")\n\n def click_share(self):\n self.click(\"id=>com.house365.xinfangbao:id/ib_nav_right\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n return self\n else:\n return self\n\n def click_pfa(self):\n self.click(\"text=>项目方案\")\n return self\n\n def click_pdt(self):\n self.click(\"text=>项目动态\")\n return self\n\n def click_pdetail(self):\n self.click(\"text=>项目详情\")\n return self\n\n\n def click_moredetail(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_housedetail_projectinfo_more\")\n\n def swap_moredetail(self):\n self.swipe_to_buttom(\"更多项目信息\")\n return self\n\n def swap_detaildb(self):\n if self.find_element(\"text=>合作动态\"):\n self.swipe_to_buttom(\"合作动态\")\n else:\n self.swipe_to_buttom(\"已报备客户\")\n\n\n\n def click_sc(self):\n self.click(\"id=>com.house365.xinfangbao:id/iv_housedetail_collect\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n self.click(\"id=>com.house365.xinfangbao:id/iv_housedetail_collect\")\n return self\n else:\n return self\n\n def click_hb(self):\n self.click(\"text=>海报\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n\n\n def click_gt(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_detail_tel\")\n\n\n def click_bb(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_detail_baobei\")\n if self.driver.current_activity == '.ui.activity.sign.SignInActivity':\n Login(self.driver).login()\n self.click(\"id=>com.house365.xinfangbao:id/tv_detail_baobei\")\n if self.find_element(\"text=>确定\"):\n self.click(\"text=>确定\")\n"
},
{
"alpha_fraction": 0.5998755693435669,
"alphanum_fraction": 0.6129433512687683,
"avg_line_length": 22.30434799194336,
"blob_id": "e2fdc0f81b26c96fbd24db9b008c54b0d597bf01",
"content_id": "a705127a4b5b9410aac0b565ef3f95924ef85cb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1701,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 69,
"path": "/page/mine.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "from common.base import BasePage\nfrom page.bblist import Bblist\nfrom page.mykh import Mykh\nfrom page.sz import Sz\n\n\nclass Mine(BasePage):\n\n def click_mypic(self):\n self.click(\"id=>com.house365.xinfangbao:id/my_avatar\")\n return self\n\n def click_mypicxc(self):\n self.click((\"id=>com.house365.xinfangbao:id/more_service_layout\"))\n\n\n\n def click_mysz(self):\n self.click(\"id=>com.house365.xinfangbao:id/iv_setting\")\n return Sz(self.driver)\n\n def click_khnum(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_data_title_1\")\n return Mykh(self.driver)\n\n def click_qynum(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_data_title_2\")\n return Bblist(self.driver)\n\n def click_succesnum(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_data_title_3\")\n return Bblist(self.driver)\n\n def click_myshop(self):\n self.click(\"text=>我的店铺\")\n\n def click_mygz(self):\n self.click(\"text=>我的关注\")\n\n def click_rz(self):\n self.click(\"text=>认证\")\n\n\n def click_quan(self):\n self.click(\"text=>带看券\")\n\n\n def click_dkjs(self):\n self.click(\"text=>贷款计算\")\n\n def click_sfjs(self):\n self.click(\"text=>税费计算\")\n\n def click_gfzg(self):\n self.click(\"text=>购房资格\")\n\n def click_telbook(self):\n self.click(\"text=>通讯录\")\n\n def click_tgb(self):\n self.click(\"text=>推广宝\")\n\n def click_mdrz(self):\n self.swipe_to_buttom(\"门店入住\")\n self.click(\"text=>门店入驻\")\n\n def click_phz(self):\n self.swipe_to_buttom(\"项目合作\")\n self.click(\"text=>项目合作\")"
},
{
"alpha_fraction": 0.6275861859321594,
"alphanum_fraction": 0.6399999856948853,
"avg_line_length": 25.814815521240234,
"blob_id": "483f68b6b5b6043fbe374c590ce30757abc4ce17",
"content_id": "3ac9e1d61130a9b7f82b157a3bc2a2526ae0271a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 739,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 27,
"path": "/page/mykh.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\nfrom page.adduser import Adduser\nfrom page.uesrsearch import Usersearch\nfrom page.userdetail import Userdetail\n\n\nclass Mykh(BasePage):\n\n\n def click_add(self):\n self.click(\"id=>com.house365.xinfangbao:id/tv_nav_right\")\n return Adduser(self.driver)\n pass\n\n def click_search(self):\n self.click('xpath=>//*[@class=\"android.widget.ImageView\"][1]')\n return Usersearch(self.driver)\n\n def goto_userdetail(self):\n \"\"\"\n 点击第一个客户\n :return:\n \"\"\"\n self.click('xpath=>//*[@resource-id=\"com.house365.xinfangbao:id/customer_list_name_tx\"][1]')\n return Userdetail(self.driver)\n\n"
},
{
"alpha_fraction": 0.5774853825569153,
"alphanum_fraction": 0.6191520690917969,
"avg_line_length": 35.02631759643555,
"blob_id": "b204b611fffff088070327f5940a4cf8fb637f29",
"content_id": "a06127de7487ea8c153e3f92da2bbb28943f56ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1396,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 38,
"path": "/testcase/testdemo1.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nimport time\n\nfrom appium import webdriver\nimport pytest\n\nclass Testdemo():\n def setup(self):\n caps = {}\n caps[\"platformName\"] = \"Android\"\n caps[\"platformVersion\"] = \"7\"\n caps[\"deviceName\"] = \"2e72982d\"\n caps[\"appPackage\"] = \"com.house365.xinfangbao\"\n caps[\"appActivity\"] = \"com.house365.xinfangbao.ui.activity.SplashActivity\"\n caps[\"noReset\"] = \"true\"\n self.driver = webdriver.Remote(\"http://127.0.0.1:4723/wd/hub\", caps)\n self.driver.implicitly_wait(\"10\")\n\n\n def teardown(self):\n self.driver.quit()\n\n def waitActivity(self, page_name, seconds):\n self.driver.wait_activity(page_name, seconds)\n print(\"-----wait %s ----\" %page_name)\n\n def test_login(self):\n self.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.driver.find_element_by_android_uiautomator('new UiSelector().text(\"客户\")').click()\n print(\"------\")\n self.driver.find_element_by_id('com.house365.xinfangbao:id/ed_ss_phone').send_keys('13813996588')\n print(\"开始输入密码\")\n self.driver.find_element_by_id('com.house365.xinfangbao:id/ed_ss_pwd').send_keys('123456qwe')\n print(\"开始点击登录\")\n e2 = self.driver.find_element_by_id('com.house365.xinfangbao:id/bt_ss_commit')\n time.sleep(1)\n e2.click()"
},
{
"alpha_fraction": 0.5902777910232544,
"alphanum_fraction": 0.59375,
"avg_line_length": 15.882352828979492,
"blob_id": "e542c9f49969ce6f5cf34ba1725cc4ddb73547d9",
"content_id": "c42027c2e492a158c0288b7e1a181f9431abdedc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 17,
"path": "/page/msg.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Msg(BasePage):\n\n def click_khmsg(self):\n self.click(\"text=>客户提醒\")\n\n\n def click_xtmsg(self):\n self.click(\"text=>系统消息\")\n\n\n def click_lpmsg(self):\n self.click(\"text=>楼盘动态\")\n\n"
},
{
"alpha_fraction": 0.6808510422706604,
"alphanum_fraction": 0.6808510422706604,
"avg_line_length": 14.833333015441895,
"blob_id": "6493b37ff2fdb45900c3c5b62db7247103209e75",
"content_id": "f85899f629a59782612b2bd8ca8fdd82cf5bd4ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 6,
"path": "/page/list.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "from common.base import BasePage\n\n\nclass List(BasePage):\n def lp_search(self):\n pass"
},
{
"alpha_fraction": 0.5626240372657776,
"alphanum_fraction": 0.5688105225563049,
"avg_line_length": 30.07272720336914,
"blob_id": "3ac9907fb6d6706f538ab137f14d073a3c828ea5",
"content_id": "0e4b4b6118e80e144f4ac4143a8d722e86c1fadd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9051,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 275,
"path": "/testcase/test_my.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\n\nfrom common.app import App\n\n\nclass Testmy:\n def setup(self):\n self.app = App()\n self.app.start()\n\n def teardown(self):\n self.app.quit()\n\n\n def test_mine(self):\n \"\"\"\n 点击我的\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine()\n assert self.app.find_element(\"text=>客户数\")\n self.app.save_screenshot_as_file(\"test_mine\")\n\n\n def test_click_mypic(self):\n \"\"\"\n 进入我的页面,点击头像\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mypic()\n self.app.save_screenshot_as_file(\"test_click_mypic\")\n\n def test_click_mupic_xc(self):\n \"\"\"\n 进入我的页面,点击头像\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mypic().click_mypicxc()\n assert self.app.find_element(\"text=>图片\")\n self.app.save_screenshot_as_file(\"test_click_mypic_xc\")\n\n\n def test_click_mysz(self):\n \"\"\"\n 我的-设置\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz()\n assert self.app.find_element(\"text=>设置\")\n self.app.save_screenshot_as_file(\"test_click_mysz\")\n\n def test_click_khnum(self):\n \"\"\"\n 我的-客户数\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_khnum()\n assert self.app.find_element(\"text=>我的客户\")\n self.app.save_screenshot_as_file(\"test_click_khnum\")\n\n def test_click_qynum(self):\n \"\"\"\n 我的-签约量\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_qynum()\n assert self.app.find_element(\"text=>报备列表\")\n self.app.save_screenshot_as_file(\"test_click_qynum\")\n\n\n def test_click_successnum(self):\n \"\"\"\n 我的-成交额\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_succesnum()\n assert self.app.find_element(\"text=>报备列表\")\n self.app.save_screenshot_as_file(\"test_click_successnum\")\n\n def test_click_myshop(self):\n \"\"\"\n 我的-我的店铺\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_myshop()\n assert self.app.find_element(\"text=>推广我的店铺\")\n self.app.save_screenshot_as_file(\"test_click_myshop\")\n\n def test_click_mygz(self):\n \"\"\"\n 我的-我的关注\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mygz()\n assert self.app.find_element(\"text=>收藏\")\n self.app.save_screenshot_as_file(\"test_click_mugz\")\n\n def test_click_rz(self):\n \"\"\"\n 我的-认证\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_rz()\n assert self.app.find_element(\"text=>认证\")\n self.app.save_screenshot_as_file(\"test_click_rz\")\n\n def test_click_dkquan(self):\n \"\"\"\n 我的-带看券\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_quan()\n assert self.app.find_element(\"text=>奖券\")\n self.app.save_screenshot_as_file(\"test_click_dkquan\")\n\n def test_click_dkjs(self):\n \"\"\"\n 我的-贷款计算\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_dkjs()\n assert self.app.find_element(\"text=>贷款计算\")\n self.app.save_screenshot_as_file(\"test_click_dkjs\")\n\n def test_click_sfjs(self):\n \"\"\"\n 我的-税费计算\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_sfjs()\n assert self.app.find_element(\"text=>税费计算\")\n self.app.save_screenshot_as_file(\"test_click_sfjs\")\n\n\n def test_click_gfzg(self):\n \"\"\"\n 我的-购房资格\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_gfzg()\n self.app.save_screenshot_as_file(\"test_click_gfzg\")\n\n def test_click_txl(self):\n \"\"\"\n 我的-通讯录\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_telbook()\n self.app.save_screenshot_as_file(\"test_click_txl\")\n\n def test_click_tgb(self):\n \"\"\"\n 我的-推广宝\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_tgb()\n assert self.app.find_element(\"text=>推广宝\")\n self.app.save_screenshot_as_file(\"test_click_tgb\")\n\n def test_click_mdrz(self):\n \"\"\"\n 我的-门店入驻\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mdrz()\n assert self.app.find_element(\"text=>门店入驻\")\n self.app.save_screenshot_as_file(\"test_click_mdrz\")\n\n def test_click_phz(self):\n \"\"\"\n 我的-项目合作\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_phz()\n assert self.app.find_element(\"text=>合作留言\")\n self.app.save_screenshot_as_file(\"test_click_phz\")\n\n def test_click_sz_grzl(self):\n \"\"\"\n 我的-设置-个人资料\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_grzl()\n assert self.app.find_element(\"text=>个人资料\")\n self.app.save_screenshot_as_file(\"test_click_sz_grzl\")\n\n def test_click_sz_edittel(self):\n \"\"\"\n 我的-设置-修改手机\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_edittel()\n assert self.app.find_element(\"text=>修改手机\")\n self.app.save_screenshot_as_file(\"test_click_sz_edittel\")\n\n def test_click_sz_editpwd(self):\n \"\"\"\n 我的-设置-修改密码\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_editpwd()\n assert self.app.find_element(\"text=>修改密码\")\n self.app.save_screenshot_as_file(\"test_click_sz_editpwd\")\n\n def test_click_sz_phsz(self):\n \"\"\"\n 我的-设置-偏好设置\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_phsz()\n assert self.app.find_element(\"text=>偏好设置\")\n self.app.save_screenshot_as_file(\"test_click_sz_phsz\")\n\n def test_click_qchc(self):\n \"\"\"\n 我的-设置-清理缓存\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_qchz()\n self.app.save_screenshot_as_file(\"test_click_sz_qchc\")\n\n def test_click_sz_yjfk(self):\n \"\"\"\n 我的-设置-意见反馈\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_yj()\n assert self.app.find_element(\"text=>意见反馈\")\n self.app.save_screenshot_as_file(\"test_click_sz_yjgk\")\n\n\n def test_click_sz_gy(self):\n \"\"\"\n 我的-设置-关于\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_sz_gy()\n assert self.app.find_element(\"text=>关于\")\n self.app.save_screenshot_as_file(\"test_click_sz_gy\")\n\n def test_click_sz_logout(self):\n \"\"\"\n 我的-设置-退出\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_mine().click_mysz().click_logout()\n assert self.app.find_element(\"text=>全部\")\n self.app.save_screenshot_as_file(\"test_click_sz_logout\")\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6638655662536621,
"alphanum_fraction": 0.6722689270973206,
"avg_line_length": 13.875,
"blob_id": "af544d38268cdd3b65fd6dbb47d897d0fdfd20b8",
"content_id": "c3c3cbf69194e74783e1a4ed7ea00853989def6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 8,
"path": "/page/uesrsearch.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Usersearch(BasePage):\n\n pass\n"
},
{
"alpha_fraction": 0.5479429960250854,
"alphanum_fraction": 0.5570132732391357,
"avg_line_length": 23.700000762939453,
"blob_id": "d5ca40f9946d75aae9e657ad45c9cc9344340320",
"content_id": "cf428e98c3bd91c136d2df04f5d06beceaf823a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6944,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 250,
"path": "/testcase/test_kh.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nimport time\n\nfrom appium import webdriver\nimport pytest\n\nfrom common.app import App\nfrom common.base import BasePage\nfrom common.get_deviceinfo import get_device_info\nfrom page.index import Index\n\n\nclass Testkh():\n def setup(self):\n self.app = App()\n self.app.start()\n\n def teardown(self):\n self.app.quit()\n\n def test_kh(self):\n \"\"\"\n 首页,点击客户,进入客户页面\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 60)\n self.app.index().goto_kh()\n assert self.app.find_element(\"text=>我的客户\")\n self.app.save_screenshot_as_file(\"test_kh\")\n\n\n def test_kh_clickwdbb(self):\n \"\"\"\n 已登录,客户->点击我的客户\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_mykh()\n assert self.app.find_element(\"text=>我的客户\")\n self.app.save_screenshot_as_file(\"test_kh_clickwdbb\")\n\n\n def test_kh_mybb(self):\n \"\"\"\n 已登录,客户->点击我的报备\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_wdbb()\n assert self.app.find_element(\"text=>报备列表\")\n self.app.save_screenshot_as_file(\"test_kh_mybb\")\n\n\n\n def test_kh_clickaddkh(self):\n \"\"\"\n 已登录,客户->点击添加客户\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_addkh()\n assert self.app.find_element(\"text=>添加客户\")\n self.app.save_screenshot_as_file(\"test_kh_clickaddkh\")\n\n\n def test_kh_clickqbb(self):\n \"\"\"\n 已登录,点击客户->点击快速报备\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_qbb()\n assert self.app.find_element(\"text=>报备客户\")\n self.app.save_screenshot_as_file(\"test_kh_clickqbb\")\n\n def test_kh_search(self):\n \"\"\"\n 已登录,客户->点击搜索\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_search()\n assert self.app.find_element(\"text=>请输入客户姓名、手机号码\")\n self.app.save_screenshot_as_file(\"test_kh_search\")\n\n\n def test_kh_sx(self):\n \"\"\"\n 已登录,客户->点击筛选\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_khsx()\n\n def test_kh_sx1(self):\n \"\"\"\n 已登录,客户—>筛选,点击‘已签约’\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_khsx().click_state1()\n\n def test_kh_mykh_add(self):\n \"\"\"\n 已登录,客户—>我的客户->点击“+’\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_mykh().click_add()\n\n\n def test_kh_mykh_search(self):\n \"\"\"\n 已登录,客户—>我的客户->点击“搜索’\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_mykh().click_search()\n\n\n def test_kh_mykh_clickkh(self):\n \"\"\"\n 已登录,客户—>我的客户->点击客户\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_mykh().goto_userdetail()\n\n\n def test_kh_mykh_detailedit(self):\n \"\"\"\n 已登录,客户->我的客户,客户详情页->编辑\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_mykh().goto_userdetail().click_uesredit()\n\n def test_kh_mykh_detailtel(self):\n \"\"\"\n 客户->我的客户,客户详情页->点击电话\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_mykh().goto_userdetail().click_phone()\n\n def test_kh_addkh_tel(self):\n \"\"\"\n 已登录,点击客户->点击添加客户,点击通讯录导入\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_addkh().click_phone1()\n\n def test_kh_addkh_edit1(self):\n \"\"\"\n 已登录,点击客户->点击添加客户,输入手机号和姓名\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_addkh().send_name().send_phone()\n\n def test_kh_addkh_edit2(self):\n \"\"\"\n 已登录,点击客户->点击添加客户,点击“江宁区”\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_addkh().click_qy()\n\n def test_kh_addkh_edit3(self):\n \"\"\"\n 已登录,点击客户->点击添加客户,滑动到底部\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_addkh().slid_page()\n\n def test_kh_quickbb1(self):\n \"\"\"\n 已登录,点击客户->点击快速报备,点击“从客户列表添加”\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_qbb().click_ueselistadd()\n\n def test_kh_quickbb1(self):\n \"\"\"\n 已登录,点击客户->点击快速报备,点击“请选择楼盘”\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_kh().goto_qbb().click_lp()\n\n def test_msg_clickmsg1(self):\n \"\"\"\n 已登录,点击消息->点击客户提醒\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_msg().click_khmsg()\n\n def test_msg_clickmsg2(self):\n \"\"\"\n 已登录,点击消息->点击系统消息\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_msg().click_xtmsg()\n\n def test_msg_clickmsg3(self):\n \"\"\"\n 点击消息->点击楼盘动态\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().goto_msg().click_lpmsg()\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nif __name__ == \"__main__\":\n pytest.main()"
},
{
"alpha_fraction": 0.6576576828956604,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 15,
"blob_id": "c8db3ba76938cd7d5ee69ef92cae443245c56997",
"content_id": "95e1ca166f067500337c943e16cbb670cca48401",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/page/bblp.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Bblp(BasePage):\n pass"
},
{
"alpha_fraction": 0.5712328553199768,
"alphanum_fraction": 0.5726027488708496,
"avg_line_length": 20.969696044921875,
"blob_id": "3ebf58f8d3ac9cf87190d45d00e6c111f7692607",
"content_id": "3bc705cda5742f7e8e883984a8416543825dc333",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 794,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 33,
"path": "/page/sz.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\nclass Sz(BasePage):\n\n def click_sz_grzl(self):\n self.click(\"text=>个人资料\")\n\n def click_sz_edittel(self):\n self.click(\"text=>修改资料\")\n\n def click_sz_editpwd(self):\n self.click(\"text=>修改密码\")\n\n def click_sz_phsz(self):\n self.click(\"text=>偏好设置\")\n\n def click_sz_qchz(self):\n self.click(\"text=>清理缓存\")\n return self\n\n def click_sz_yj(self):\n self.click(\"text=>意见反馈\")\n\n def click_sz_gy(self):\n self.click(\"text=>关于\")\n\n def click_logout(self):\n self.click(\"text=>退出登录\")\n self.click(\"text=>确定\")\n from page.index import Index\n return Index(self.driver)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.552293598651886,
"alphanum_fraction": 0.594495415687561,
"avg_line_length": 28.77777862548828,
"blob_id": "a0a64baa846ea3fd5e4c6a4c067c0eb1d3863dd1",
"content_id": "761174ab60547a8960e7b2c64b8eca9ce5f4c4ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 18,
"path": "/page/login.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Login(BasePage):\n\n def login(self):\n print(\"开始输入手机\")\n phone = self.find_element('id=>com.house365.xinfangbao:id/ed_ss_phone')\n self.tsleep(1)\n phone.send_keys('15100000002')\n print(\"开始输入密码\")\n pwd = self.find_element('id=>com.house365.xinfangbao:id/ed_ss_pwd')\n self.tsleep(1)\n pwd.send_keys('123456qwe')\n print(\"开始点击登录\")\n self.click('id=>com.house365.xinfangbao:id/bt_ss_commit')\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5717118382453918,
"alphanum_fraction": 0.5786516666412354,
"avg_line_length": 29.414140701293945,
"blob_id": "800d02f3c9a124a2f1b5e91634d35aa7f267ce9e",
"content_id": "83f8b34db87e38b980eef131b54f9cbf0d774ce2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3326,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 99,
"path": "/testcase/test_detail.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.app import App\n\n\nclass TestDetail:\n def setup(self):\n self.app = App()\n self.app.start()\n\n def teardown(self):\n self.app.quit()\n\n def test_click_xc(self):\n \"\"\"\n 进入楼盘详情页,点击楼盘相册\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_xc()\n self.app.find_element(\"text=>楼盘相册\")\n self.app.save_screenshot_as_file(\"test_click_xc\")\n\n def test_click_share(self):\n \"\"\"\n 进入楼盘详情页,点击分享\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_share()\n self.app.save_screenshot_as_file(\"test_click_share\")\n\n def test_click_pfa(self):\n \"\"\"\n 进入楼盘详情页,点击项目方案\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_pfa()\n self.app.save_screenshot_as_file(\"test_click_pfa\")\n\n def test_click_pdetail(self):\n \"\"\"\n 进入楼盘详情页,点击项目详情\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_pdetail()\n self.app.save_screenshot_as_file(\"test_click_pdetail\")\n\n\n def test_click_pdetail2(self):\n \"\"\"\n 楼盘详情页-切换至项目详情,点击更多项目信息\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_pdetail().swap_moredetail().click_moredetail()\n assert self.app.find_element(\"text=>项目信息\")\n self.app.save_screenshot_as_file(\"test_click_pdetail2\")\n\n\n def test_click_sc(self):\n \"\"\"\n 楼盘详情页,点击关注,若未登录,则登录\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_sc()\n self.app.save_screenshot_as_file(\"test_click_sc\")\n\n def test_click_hb(self):\n \"\"\"\n 楼盘详情页,点击海报,若未登录,则登录\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_hb()\n self.app.save_screenshot_as_file(\"test_click_hb\")\n\n\n def test_click_gt(self):\n \"\"\"\n 楼盘详情页,点击沟通\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_gt()\n self.app.save_screenshot_as_file(\"test_click_gt\")\n\n\n def test_click_lp_bb(self):\n \"\"\"\n 楼盘详情页,点击报备,若未登录,则登录\n :return:\n \"\"\"\n self.app.waitActivity(\".ui.activity.index.IndexActivity\", 50)\n self.app.index().swap_zntj().click_znfirstlp().click_bb()\n self.app.save_screenshot_as_file(\"test_click_p_bb\")\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6305084824562073,
"alphanum_fraction": 0.6338983178138733,
"avg_line_length": 19.85714340209961,
"blob_id": "cf4653d37b41c6c5b9cb8b2d751fe57f1ea8c841",
"content_id": "86338969665ffbc70a9d6b39fdc553e030b9e3d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 319,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 14,
"path": "/page/bbkh.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\nfrom page.mykh import Mykh\n\n\nclass Bbkh(BasePage):\n\n def click_ueselistadd(self):\n self.click(\"text=>从客户列表添加\")\n return Mykh(self.driver)\n\n def click_lp(self):\n self.click(\"text=>请选择楼盘\")\n\n\n\n"
},
{
"alpha_fraction": 0.6245059370994568,
"alphanum_fraction": 0.6482213735580444,
"avg_line_length": 30.41666603088379,
"blob_id": "678e51dd25bfd57a7f3e110906202ab2243ee775",
"content_id": "6c5f5c5deb07807c482ea6065781b11271d41d1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 24,
"path": "/page/search.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\nimport os\n\n\nclass Search(BasePage):\n\n def search_lp(self,value):\n self.send_text(\"id=>com.house365.xinfangbao:id/edit_search_query\",value)\n return self\n\n def adbshell(self,command):\n os.system(command)\n\n def action_seach(self):\n self.adbshell('adb shell ime set com.sohu.inputmethod.sogou.xiaomi/.SogouIME')\n self.tsleep(3)\n self.click(\"id=>com.house365.xinfangbao:id/edit_search_query\")\n self.driver.press_keycode('66') # os.system(\"adb shell input keyevent 66\"),66:回车,84:搜索\n self.tsleep(3)\n self.adbshell('adb shell ime set io.appium.settings/.UnicodeIME')\n self.tsleep(3)\n return self\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5589586496353149,
"alphanum_fraction": 0.5880551338195801,
"avg_line_length": 22.25,
"blob_id": "4928ba11deed6d93c3cc89054befca11631df670",
"content_id": "0d425ceaa3c954040041225612d4357bdc254c36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 28,
"path": "/page/adduser.py",
"repo_name": "zhangzhihui19950725/appfgj3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- coding:utf-8 -*-\nfrom common.base import BasePage\n\n\nclass Adduser(BasePage):\n def click_phone1(self):\n self.click(\"text=>通讯录导入\")\n\n\n def send_name(self):\n self.find_element(\"text=>请输入客户姓名\").send_keys(\"ceshi1\")\n self.tsleep(1)\n return self\n\n def send_phone(self):\n self.find_element(\"text=>请输入客户手机号码\").send_keys(\"17751300501\")\n self.tsleep(1)\n return self\n\n def click_qy(self):\n self.find_element(\"text=>江宁区\")\n self.tsleep(1)\n return self\n\n def slid_page(self):\n e1 = self.find_element(\"text=>大户型\")\n self.swipe_to_buttom(e1)\n\n\n"
}
] | 26 |
snidarian/raspi_programs
|
https://github.com/snidarian/raspi_programs
|
7d4fbf1e8f53a155762b86e61201933f9b93d967
|
7a76d6fb987000b0322a98a8faec9717a2c188aa
|
b7a70d17f930f453cfc4c22ad26a3f2db00f163a
|
refs/heads/main
| 2023-07-14T06:21:02.631472 | 2021-08-21T19:06:59 | 2021-08-21T19:06:59 | 354,616,714 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.41860464215278625,
"alphanum_fraction": 0.42790699005126953,
"avg_line_length": 15.538461685180664,
"blob_id": "a0913712d46f48f54960273135b6826e57f11c10",
"content_id": "a936ab05e18a44ae9984f6e43e80ebd79efff0d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 13,
"path": "/watch_raspi4_cpu.sh",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/bash\n\n\nwhile [ 1 ];\ndo\n echo -e \"\\n\\n\\n\\n\"\n echo \"#########################\"\n vcgencmd measure_temp\n vcgencmd measure_clock arm\n echo \"#########################\"\n sleep 1\n clear\ndone\n"
},
{
"alpha_fraction": 0.594366192817688,
"alphanum_fraction": 0.5995975732803345,
"avg_line_length": 26.5,
"blob_id": "6bf21d33aa1dd0cb1cfc53638bc64b08b96a19e5",
"content_id": "f526f9754068809ca77aaa1f0c70c59cf3ee8c65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2485,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 90,
"path": "/morse_code_message_generator.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\n\nimport RPi.GPIO as GPIO\nimport time\n\n\nGPIO.setmode(GPIO.BOARD)\nGPIO.setwarnings(False)\nGPIO.setup(7, GPIO.OUT, initial=GPIO.LOW)\n\n\n# two functions for blip and beep that make the sound when called\ndef blip():\n GPIO.output(7, GPIO.HIGH)\n time.sleep(.1)\n GPIO.output(7, GPIO.LOW)\n # length of pause after blip\n time.sleep(.1)\n\ndef beep():\n GPIO.output(7, GPIO.HIGH)\n time.sleep(.3)\n GPIO.output(7, GPIO.LOW)\n # length of pause after beep\n time.sleep(.1)\n\ndef letter_pause():\n time.sleep(.6)\n\ndef word_pause():\n time.sleep(.8)\n\ndef sentence_pause():\n time.sleep(2)\n\n# set two global variables 'blip' and 'beep'\n# blip represents dots and beep represents dashes.\n#blip = make_blip()\n#beep = make_beep()\n\n# dictionary of lists (Each letter and its beep lengths)\nmorse_alphabet = {\n \"a\" : [blip, beep, letter_pause],\n \"b\" : [beep, blip, blip, blip, letter_pause],\n \"c\" : [blip, beep, blip, beep, letter_pause],\n \"d\" : [beep, blip, blip, letter_pause],\n \"e\" : [blip, letter_pause],\n \"f\" : [blip, blip, beep, blip, letter_pause],\n \"g\" : [beep, beep, blip, letter_pause],\n \"h\" : [blip, blip, blip, blip, letter_pause],\n \"i\" : [blip, blip, letter_pause],\n \"j\" : [blip, beep, beep, beep, letter_pause],\n \"k\" : [beep, blip, beep, letter_pause],\n \"l\" : [blip, beep, blip, blip, letter_pause],\n \"m\" : [beep, beep, letter_pause],\n \"n\" : [beep, blip, letter_pause],\n \"o\" : [beep, beep, beep, letter_pause],\n \"p\" : [blip, beep, beep, blip, letter_pause],\n \"q\" : [beep, beep, blip, beep, letter_pause],\n \"r\" : [blip, beep, blip, letter_pause],\n \"s\" : [blip, blip, blip, letter_pause],\n \"t\" : [beep, letter_pause],\n \"u\" : [blip, blip, beep, letter_pause],\n \"v\" : [blip, blip, blip, beep, letter_pause],\n \"w\" : [blip, beep, beep, letter_pause],\n \"x\" : [beep, blip, blip, beep, letter_pause],\n \"y\" : [beep, blip, beep, beep, letter_pause],\n \"z\" : [beep, beep, blip, blip, letter_pause],\n \".\" : [sentence_pause],\n \" \" : [word_pause]\n}\n\n\ndef main(message_for_conversion):\n text_message = message_for_conversion\n for letter in text_message:\n print(letter)\n for function_item in morse_alphabet[letter]:\n function_item()\n\n\n\n\nif __name__ == '__main__':\n print(\"Attach LED and beeper to data BOARD pin seven and ground...\")\n message = input(\"Type message to convert to morse code: \")\n main(message)\n GPIO.cleanup()\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.46181368827819824,
"alphanum_fraction": 0.556323230266571,
"avg_line_length": 38.50731658935547,
"blob_id": "b65b810e2a117e3d03ead24cc8b4d24288bce9e1",
"content_id": "cf67f7b4e3cbd6f01c3b6e03b599746347816d3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8105,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 205,
"path": "/beeper_music.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n# prelude in C major by JS Bach\n# incomplete\n\nimport RPi.GPIO as GPIO\nimport time\n\n\nGPIO.setwarnings(False)\nGPIO.setmode(GPIO.BOARD)\nGPIO.setup(16, GPIO.OUT)\nbeeper = GPIO.PWM(16, 1000)\n# set initial duty cycle - adjusting this is crucial to tone clarity\nbeeper.start(5)\n\ntones = {\n\"B0\": 30.87,\"C1\": 32.70,\"CS1\": 34.65,\"D1\": 36.71,\"DS1\": 38.89,\"E1\": 41,\"F1\": 44,\"FS1\": 46,\"G1\": 49,\"GS1\": 52,\"A1\": 55,\n\"AS1\": 58,\"B1\": 62,\n\n\"C2\": 65,\"CS2\": 69,\"D2\": 73.42,\"DS2\": 78,\"E2\": 82,\"F2\": 87,\"FS2\": 93,\"G2\": 98,\"GS2\": 104,\"A2\": 110,\"AS2\": 117,\"B2\": 123.47,\n\n\"C3\": 130.81,\"CS3\": 139,\"D3\": 146.83,\"DS3\": 156,\"E3\": 165,\"F3\": 175,\"FS3\": 185,\"G3\": 196,\"GS3\": 208,\"A3\": 220,\"AS3\": 233,\"B3\": 247,\n\n\"C4\": 262,\"CS4\": 277,\"D4\": 294,\"DS4\": 311,\"E4\": 330,\"F4\": 349,\"FS4\": 370,\"G4\": 392.0,\"GS4\": 415,\"A4\": 440.0,\"AS4\": 466,\"B4\": 494,\n\n\"C5\": 523.25,\"CS5\": 554,\"D5\": 587,\"DS5\": 622,\"E5\": 659.25,\"F5\": 698.46,\"FS5\": 740,\"G5\": 784,\"GS5\": 831,\"A5\": 880,\"AS5\": 932,\"B5\": 988,\n\n\"C6\": 1047,\"CS6\": 1109,\"D6\": 1175,\"DS6\": 1245,\"E6\": 1319,\"F6\": 1397,\"FS6\": 1480,\"G6\": 1568,\"GS6\": 1661,\"A6\": 1760,\n\"AS6\": 1865,\"B6\": 1976,\n\n\"C7\": 2093,\"CS7\": 2217,\"D7\": 2349,\"DS7\": 2489,\"E7\": 2637,\"F7\": 2794,\"FS7\": 2960,\"G7\": 3136,\"GS7\": 3322,\"A7\": 3520,\"AS7\": 3729,\"B7\": 3951,\n\n\"C8\": 4186,\"CS8\": 4435,\"D8\": 4699,\"DS8\": 4978\n}\n\n\npattern_list = [\n # First measure - used twice\n [tones[\"C3\"],tones[\"E3\"],tones[\"G4\"],tones[\"C5\"], tones[\"E5\"]],\n # Second measure\n [tones[\"C3\"],tones[\"D3\"],tones[\"A4\"],tones[\"D5\"], tones[\"F5\"]],\n # Third measure\n [tones[\"B2\"],tones[\"D3\"],tones[\"G4\"],tones[\"D5\"], tones[\"F5\"]],\n [tones[\"C3\"],tones[\"E3\"],tones[\"A4\"],tones[\"E5\"], tones[\"A5\"]],\n [tones[\"C3\"],tones[\"D3\"],tones[\"FS4\"],tones[\"A4\"], tones[\"C5\"]],\n [tones[\"B2\"],tones[\"D3\"],tones[\"G4\"],tones[\"D5\"], tones[\"G5\"]],\n [tones[\"B2\"],tones[\"C3\"],tones[\"E4\"],tones[\"G4\"], tones[\"C5\"]],\n [tones[\"A2\"],tones[\"C3\"],tones[\"E4\"],tones[\"G4\"], tones[\"C5\"]],\n [tones[\"D2\"],tones[\"A2\"],tones[\"D4\"],tones[\"FS4\"], tones[\"C5\"]],\n [tones[\"G2\"],tones[\"B2\"],tones[\"D4\"],tones[\"G4\"], tones[\"B4\"]],\n [tones[\"B2\"],tones[\"C3\"],tones[\"E4\"],tones[\"G4\"], tones[\"C5\"]],\n [tones[\"A2\"],tones[\"C3\"],tones[\"E4\"],tones[\"G4\"], tones[\"C5\"]],\n [tones[\"D2\"],tones[\"A2\"],tones[\"D4\"],tones[\"FS4\"], tones[\"C5\"]],\n [tones[\"G2\"],tones[\"B2\"],tones[\"D4\"],tones[\"G4\"], tones[\"B4\"]],\n [tones[\"G2\"],tones[\"AS2\"],tones[\"E4\"],tones[\"G4\"], tones[\"CS5\"]],\n [tones[\"F2\"],tones[\"A2\"],tones[\"D4\"],tones[\"A4\"], tones[\"D5\"]],\n [tones[\"F2\"],tones[\"GS2\"],tones[\"D4\"],tones[\"F4\"], tones[\"B4\"]],\n [tones[\"E2\"],tones[\"G2\"],tones[\"C4\"],tones[\"G4\"], tones[\"C5\"]],\n [tones[\"E2\"],tones[\"F2\"],tones[\"A3\"],tones[\"C4\"], tones[\"F4\"]],\n [tones[\"D2\"],tones[\"F2\"],tones[\"A3\"],tones[\"C4\"], tones[\"F4\"]],\n [tones[\"G1\"],tones[\"D2\"],tones[\"G3\"],tones[\"B3\"], tones[\"F4\"]],\n [tones[\"C2\"],tones[\"E2\"],tones[\"G3\"],tones[\"C4\"], tones[\"E4\"]],\n # Second page\n [tones[\"C2\"],tones[\"G2\"],tones[\"AS3\"],tones[\"C4\"], tones[\"E4\"]],\n [tones[\"F1\"],tones[\"F2\"],tones[\"A3\"],tones[\"C4\"], tones[\"E4\"]],\n # 3rd measure\n [tones[\"FS1\"],tones[\"C2\"],tones[\"A3\"],tones[\"C4\"], tones[\"DS4\"]],\n # 4th measure\n [tones[\"GS1\"],tones[\"F2\"],tones[\"B3\"],tones[\"C4\"], tones[\"D4\"]],\n # 5th measure 2nd row\n [tones[\"G1\"],tones[\"F2\"],tones[\"G3\"],tones[\"B3\"], tones[\"D4\"]],\n # 6th measure 2nd row\n [tones[\"G1\"],tones[\"E2\"],tones[\"G3\"],tones[\"C4\"], tones[\"E4\"]],\n # 7th measure 2nd row\n [tones[\"G1\"],tones[\"D2\"],tones[\"G3\"],tones[\"C4\"], tones[\"F4\"]],\n # 8th measure 2nd row\n [tones[\"G1\"],tones[\"D2\"],tones[\"G3\"],tones[\"B3\"], tones[\"F4\"]],\n # 9th measure 3rd row\n [tones[\"G2\"],tones[\"DS3\"],tones[\"A3\"],tones[\"C4\"], tones[\"FS4\"]],\n # 10th measure 3rd row\n [tones[\"G1\"],tones[\"E2\"],tones[\"G3\"],tones[\"C4\"], tones[\"G4\"]],\n # 11th measure 3rd row\n [tones[\"G1\"],tones[\"D2\"],tones[\"G3\"],tones[\"C4\"], tones[\"F4\"]],\n # 12th measure 3rd row\n [tones[\"G1\"],tones[\"D2\"],tones[\"G3\"],tones[\"B3\"], tones[\"F4\"]],\n # 13th measure 4th row\n [tones[\"C1\"],tones[\"C2\"],tones[\"G3\"],tones[\"AS3\"], tones[\"E4\"]],\n\n \n]\n\n\ndef play_main_pattern(note_set, rate) -> None:\n for _ in range(2):\n beeper.ChangeFrequency(note_set[0])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[1])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[2])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[3])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[4])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[2])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[3])\n time.sleep(rate)\n beeper.ChangeFrequency(note_set[4])\n time.sleep(rate)\n\ndef play_ending(rate) -> None:\n for note in [\"C1\",\"C2\",\"F3\",\"A3\",\"C4\",\"F4\",\"C4\",\"A3\",\n \"C4\",\"A2\",\"F2\",\"A2\",\"F2\",\"D2\",\"F2\",\"D2\",\n \"C1\", \"B1\", \"G4\",\"B4\",\"D5\",\"F5\",\"D5\",\"B4\",\n \"D5\",\"B4\",\"G4\",\"B4\",\"D4\",\"F4\",\"E4\",\"D4\",\n \"C2\",\"C2\",\"C2\",\"C2\"]:\n beeper.ChangeFrequency(tones[note])\n time.sleep(rate)\n\n\ndef main(rate):\n try:\n print(\"1 measure\")\n play_main_pattern(pattern_list[0], rate)\n print(\"2 measure\")\n play_main_pattern(pattern_list[1], rate)\n print(\"3 measure\")\n play_main_pattern(pattern_list[2], rate)\n # pattern 0 repeats once\n print(\"4 measure\")\n play_main_pattern(pattern_list[0], rate)\n print(\"5 measure\")\n play_main_pattern(pattern_list[3], rate)\n print(\"6 measure\")\n play_main_pattern(pattern_list[4], rate)\n print(\"7 measure\")\n play_main_pattern(pattern_list[5], rate)\n print(\"8 measure\")\n play_main_pattern(pattern_list[6], rate)\n print(\"9 measure\")\n play_main_pattern(pattern_list[7], rate)\n print(\"10 measure\")\n play_main_pattern(pattern_list[8], rate)\n print(\"11 measure\") #\n play_main_pattern(pattern_list[9], rate)\n print(\"12 measure\")\n play_main_pattern(pattern_list[10], rate)\n print(\"13 measure\")\n play_main_pattern(pattern_list[12], rate)\n print(\"14 measure\")\n play_main_pattern(pattern_list[13], rate)\n print(\"15 measure\")\n play_main_pattern(pattern_list[14], rate)\n print(\"16 measure\")\n play_main_pattern(pattern_list[15], rate)\n print(\"17 measure\")\n play_main_pattern(pattern_list[16], rate)\n print(\"18 measure\")\n play_main_pattern(pattern_list[17], rate)\n print(\"19 measure\")\n play_main_pattern(pattern_list[18], rate)\n print(\"20 measure\")\n play_main_pattern(pattern_list[19], rate)\n print(\"21 measure\")\n play_main_pattern(pattern_list[20], rate)\n print(\"22 measure\")\n play_main_pattern(pattern_list[21], rate)\n print(\"23 measure\")\n play_main_pattern(pattern_list[22], rate)\n print(\"24 measure\")\n play_main_pattern(pattern_list[23], rate)\n print(\"25 measure\")\n play_main_pattern(pattern_list[24], rate)\n print(\"26 measure\")\n play_main_pattern(pattern_list[25], rate)\n print(\"27 measure\")\n play_main_pattern(pattern_list[26], rate)\n print(\"28 measure\")\n play_main_pattern(pattern_list[27], rate)\n print(\"29 measure\")\n play_main_pattern(pattern_list[28], rate)\n print(\"30 measure\")\n play_main_pattern(pattern_list[29], rate)\n print(\"31 measure\")\n play_main_pattern(pattern_list[30], rate)\n print(\"32 measure\")\n play_main_pattern(pattern_list[31], rate)\n print(\"33 measure\")\n play_main_pattern(pattern_list[32], rate)\n print(\"34 measure\")\n play_main_pattern(pattern_list[33], rate)\n print(\"35 measure\")\n play_main_pattern(pattern_list[34], rate)\n # finish with the ending function which plays the final notes\n play_ending(rate + .2)\n except KeyboardInterrupt:\n print(\"KeyboardInterrupt Exception handled\")\n GPIO.cleanup()\n\n\n\n\nif __name__ == '__main__':\n main(.1)\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5477612018585205,
"alphanum_fraction": 0.5656716227531433,
"avg_line_length": 20.19354820251465,
"blob_id": "b5f12a87bbcb8e6036995efee633cae94cbf8b6f",
"content_id": "c9a871846d0bee528e8da2e4a27b95cc70e21a52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 31,
"path": "/rgb_color_flash.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport RPi.GPIO as GPIO\nimport threading\nimport time as t\nimport random as r\n\nPINS = [12, 32, 33]\n\n\ndef select_and_set_next_pin():\n next_pin = PINS[r.randint(0,2)]\n GPIO.output(next_pin, not GPIO.input(next_pin))\n\ndef main():\n try:\n GPIO.setmode(GPIO.BOARD)\n GPIO.setup(PINS, GPIO.OUT, initial=GPIO.LOW)\n while True:\n select_and_set_next_pin()\n if all(GPIO.input(pin) == GPIO.LOW for pin in PINS):\n select_and_set_next_pin()\n t.sleep(0.75)\n except KeyboardInterrupt:\n pass\n finally:\n GPIO.cleanup()\n\n\nif __name__ == '__main__':\n main()\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.604651153087616,
"avg_line_length": 17.25,
"blob_id": "bd56584e2f883589b35db8f3b67e3a64dfaeda9f",
"content_id": "cee659b2bd5a29c92090abf4ac9655c5f073d84c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 16,
"path": "/cleanup_pins.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport RPi.GPIO as GPIO\n\n# reset all non-ground, non-power pins.\nPINS= [3, 5, 7, 8, 10, 11, 12, 13, 15, 16, 18, 19, 21, 22, 23, 24, 26, 27, 28, 29, 31, 32, 33, 35, 36, 37, 38, 40]\n\nGPIO.setmode(GPIO.BOARD)\n\n\nGPIO.setup(PINS, GPIO.OUT, initial=GPIO.LOW)\n\n\n\nGPIO.cleanup()\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6155878305435181,
"alphanum_fraction": 0.6472919583320618,
"avg_line_length": 22.90322494506836,
"blob_id": "b99713c30eca041868d3f3889d69a070c205a021",
"content_id": "1c3b6f83029d4f498f53db31c3db773ec5c2fb23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 31,
"path": "/led_run_status_test.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n# physical gpio pinouts\n# uses the board not the bcm pin layout\n# there are two leds (pin 23, pin 24) and both send their power through..\n# a beeper that grounds them. In this way the beeper is on whenever one of the lights is\n# It ends up sounding like an heart monitor which is what I want.\n\n\nimport RPi.GPIO as GPIO\nimport time\n\n\nGPIO.setmode(GPIO.BCM)\nGPIO.setwarnings(False)\nGPIO.setup(23, GPIO.OUT)\nGPIO.setup(24, GPIO.OUT)\n\n\nfor _ in range(5):\n print(\"led on\")\n GPIO.output(23,GPIO.HIGH)\n time.sleep(.1)\n print(\"led off\")\n GPIO.output(23, GPIO.LOW)\n time.sleep(1)\n if _ % 2 == 0:\n GPIO.output(24, GPIO.HIGH)\n time.sleep(1)\n GPIO.output(24, GPIO.LOW)\n time.sleep(1)\n \n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6253520846366882,
"alphanum_fraction": 0.6507042050361633,
"avg_line_length": 11.357142448425293,
"blob_id": "9379f0139347cfffdfb37cfe993f57bad2a19515",
"content_id": "9582f1c019b4eae21c26b249aa6fba0ec27eb8fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 28,
"path": "/led_first_time.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport RPi.GPIO as GPIO\nimport time\n\n\n\n\n# set the pinmodes to either broadcom or board\nGPIO.setmode(GPIO.BOARD)\n\n# Set up gpio channel as output\nGPIO.setup(8, GPIO.OUT)\n\n\n\ncount=0\n\nwhile count < 8:\n GPIO.output(8, GPIO.HIGH)\n time.sleep(.5)\n GPIO.output(8, GPIO.LOW)\n time.sleep(.5)\n count+=1\n\n\nGPIO.cleanup()\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7164015173912048,
"alphanum_fraction": 0.7290180921554565,
"avg_line_length": 29.11570167541504,
"blob_id": "8e1c66a941d59ded7d2944659e8c866d6af864d9",
"content_id": "6e0a6a0c5b2430ce09f1f7f0a4444aab221a889a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3658,
"license_type": "no_license",
"max_line_length": 271,
"num_lines": 121,
"path": "/setup_apache_mysql_php_on_raspi.sh",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/bash\n# This script installs and sets up Apache, mysql and php on a raspi pi 3 namely\n\n\n\n# Update and upgrade the current system\nsudo apt update && sudo apt upgrade\n\n\necho \"updating system...\"\n\n\n# Install Apache\necho \"Installing apache2\"\nsudo apt install apache2\n\n# installing apache will create a folder called 'www' in the /var/ directory. In that folder it creates a directory names 'html'. We need to now give our 'pi' user ownership of those directories because they are created with root ownership originally.\n\n\necho \"changing ownership and permissions of /var/www/html/ folder\"\n# Recursively (for the whole folder) change ownership to user 'pi' and group 'www-data'\nsudo chown -R pi:www-data /var/www/html/\n\n# change rwx permissions for the '/var/www/html/' folder\n# add rwx for user and group (www-data)\nsudo chmod -R 770 /var/www/html/\n\n\n# now its time to check if apache is working.\n\n# should be able to reach it on 127.0.0.1 at port 80 (default apache server port)\n# you can also reach the server by putting in the ip address of the raspberry pi device or\n# you can also reach the server by putting in the hostname of the raspberry pi\n\n\necho \"Check if the apache server is working by visiting 127.0.0.1 (port 80)...\"\nsleep 3\n\n\n# CONTROLLING THE APACHE2 DAEMON\n\n# start\n# sudo apache2ctl start\n# stop\n# sudo apache2ctl stop\n# restart\n# sudo apache2ctl restart\n# check status\n# systemctl status apache2 \n\n\necho \"Press Enter to continue...\"\nread continuevar\n\n\n# ------------------------------------------------------------\n# INSTALLING PHP ONTO THE RASPI\n\nsudo apt install php php-mbstring\n\n\n# to check if php is working:\n\n# To know if PHP is working properly the method is the same to the one used for Apache.\n# but first delete the file “index.html” in the directory “/var/www/html”.\n# sudo rm /var/www/html/index.html\n# Then create an “index.php” file in this directory, with this command line\n# echo \"<?php phpinfo ();?>\" > /var/www/html/index.php\n\n# then visit 127.0.0.1 the same way you did before to see the php infopage\n\n\n# if you want to keep hold of the index.html file without creating problems,\n# rename it to index.html.unavailable\n\n\n\n\n# ---------------------------------------------------------------------\n# INSTALLING MYSQL SERVER\n\n\nsudo apt install mariadb-server php-mysql\n\n\n# verify that MySQL is working correctly\n\n# sudo mysql --user=root\n\n\n# Installing PHPMyAdmin\n# This is not essential but is a security measure\n\nsudo apt install phpmyadmin\n\n# PHPMyAdmin installation program will ask you few question. About the dbconfig-common part, choose to not use it (as we have already configure our database). About the server to configure PHPMyAdmin for, choose Apache. And the root password is the one you set for MySQL.\n\n\n# You should also enable mysqli extension\n\n# install php-mysqli\nsudo apt-get install php-mysqli\n\n# DONT CONFIGURE MYSQL through phpmyadmin. Just configure root password for mysql with the program itself.\n\n\n# check that PHPMyAdmin is working properly\n# http://127.0.0.1/phpadmin\n\n# if it's not working create a symbolic link between /usr/share/phpmyadmin and /var/www/html/phpmyadmin\nsudo ln -s /usr/share/phpmyadmin /var/www/html/phpmyadmin\n\n# Now visit 127.0.0.1/phpmyadmin and login as the root MySQL user!\n\n# Now you have a GUI remote access interface to your MySQL server.\n\n# Create databases, tables, write SQL queries all like you normally would with MySQL command, BUT if you want/need to use a GUI to interact with database information and control systems, you can.\n\n\n\n# this was originally sourced from https://howtoraspberrypi.com/how-to-install-web-server-raspberry-pi-lamp/\n\n\n"
},
{
"alpha_fraction": 0.559900164604187,
"alphanum_fraction": 0.5940099954605103,
"avg_line_length": 21.092592239379883,
"blob_id": "4236455fbbdb9e33fd891877d8520f6c63057386",
"content_id": "434d89ecc79187f026858611858f01682dabab23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 54,
"path": "/pwm_rgb.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\n\nimport RPi.GPIO as GPIO\nimport threading\nimport time\nimport random\n\nR = 12\nG = 33\nB = 32\n\nPINS = [R,G,B]\n\ndef initialize_gpio():\n GPIO.setmode(GPIO.BOARD)\n GPIO.setup(PINS, GPIO.OUT, initial=GPIO.LOW)\n\ndef color_test(channel, frequency, speed, step):\n p = GPIO.PWM(channel, frequency)\n p.start(0)\n while True:\n for duty_cycle in range(0, 101, step):\n p.ChangeDutyCycle(duty_cycle)\n time.sleep(speed)\n for duty_cycle in range(100, -1, step):\n p.ChangeDutyCycle(duty_cycle)\n time.sleep(speed)\n\ndef color_test_thread():\n threads = []\n threads.append(threading.Thread(target=color_test, args=(R, 300, 0.02, 5)))\n threads.append(threading.Thread(target=color_test, args=(G, 300, 0.0352, 5)))\n threads.append(threading.Thread(target=color_test, args=(B, 300, 0.045, 5)))\n for t in threads:\n t.daemon = True\n t.start()\n for t in threads:\n t.join()\n\n\ndef main():\n try:\n initialize_gpio()\n print(\"mark1\")\n color_test_thread()\n except KeyboardInterrupt:\n pass\n finally:\n GPIO.cleanup()\n\nif __name__ == '__main__':\n main()\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6203473806381226,
"alphanum_fraction": 0.6476426720619202,
"avg_line_length": 22.294116973876953,
"blob_id": "69e08488a805a556b9ccb1372c6d0dfc366f1e00",
"content_id": "0dab6ddf3c6534763a74af1749a88922a1d6dea8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 17,
"path": "/test_dht11.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport Adafruit_DHT as afd\nimport time\n\n\nDHT_SENSOR = afd.DHT11\nDHT_PIN = 4\n\nwhile True:\n humidity, temperature = afd.read(DHT_SENSOR, DHT_PIN)\n if humidity is not None and temperature is not None:\n print(\"Temp = {0:0.1f}C, Humidity = {1:0.1f}%\".format(temperature, humidity))\n else:\n print(\"Sensor Slur (or ill-performed wiring)\");\n time.sleep(1);\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.6457725763320923,
"avg_line_length": 22.65517234802246,
"blob_id": "4b35e5edf65a2daf6cd4dbf837f13a66c7dc554a",
"content_id": "01c9edbd8b924dafccbdcbb5d6e95fd1c8fef75b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1372,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 58,
"path": "/rgb_ideal_temp.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport RPi.GPIO as GPIO\nimport time\nimport random\n\nR, G, B = 32, 12, 33\n\nPINS = [R,G,B]\n\n# set up pins 12 32 and 33 as PWM pins\nGPIO.setmode(GPIO.BOARD)\nGPIO.setup(PINS, GPIO.OUT, initial=GPIO.LOW)\nGPIO.setwarnings(False)\n\nred = GPIO.PWM(R, 50)\ngreen = GPIO.PWM(G, 50)\nblue = GPIO.PWM(B, 50)\n\ncycles=0\n\nred.start(5)\ngreen.start(5)\nblue.start(5)\n\nwhile cycles < 10:\n temp = random.randint(60, 90)\n ideal_temp = 73\n precision = 2\n print(f\"Ideal temp: {temp}\")\n # if the temperature is within {precision} show pure green color\n if ((abs(temp - ideal_temp)) <= precision):\n green.ChangeDutyCycle(100)\n red.ChangeDutyCycle(0)\n blue.ChangeDutyCycle(0)\n time.sleep(1)\n # Temp + precision is higher than ideal: TOO HOT\n # Red/green color ratio that grows more red and less green as it gets hotter\n elif ((temp - precision) > ideal_temp):\n green.ChangeDutyCycle(10)\n red.ChangeDutyCycle(100)\n blue.ChangeDutyCycle(0)\n time.sleep(1)\n # Temp - precision is lesser than ideal: TOO COLD\n # Green/green color ratio that grows more blue and less green as it gets colder\n elif ((temp + precision) < ideal_temp):\n green.ChangeDutyCycle(10)\n blue.ChangeDutyCycle(100)\n red.ChangeDutyCycle(0)\n time.sleep(1)\n cycles+=1\n \n\n\n\n\nGPIO.cleanup()\n"
},
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 20,
"blob_id": "eaa19f2bc319ad19e3c78279eeedab6d318761e5",
"content_id": "2a9bbbbac9e803a4dfccdd5746cb61e886fb0c23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/README.md",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "# raspi_programs\nRaspi programs - python3\n"
},
{
"alpha_fraction": 0.6035842299461365,
"alphanum_fraction": 0.6286738514900208,
"avg_line_length": 13.329896926879883,
"blob_id": "04e80fda8ac62e4df9089a180e50562eda21483d",
"content_id": "3500cd8e8595ce0f8176d11dc344d80e2379b769",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1395,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 97,
"path": "/remote_control_leds_with_API.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\n\nimport RPi.GPIO as GPIO \n\nimport time\n\nfrom flask import Flask\n\nGPIO.setmode(GPIO.BOARD)\n\nGPIO.setwarnings(False)\n\nGPIO.setup(35, GPIO.OUT) \n\nGPIO.setup(36, GPIO.OUT)\n\nGPIO.setup(37, GPIO.OUT)\n\nGPIO.setup(38, GPIO.OUT)\n\nGPIO.setup(40, GPIO.OUT)\n\n\n\napp = Flask(__name__)\n\[email protected]('/') \n\ndef hello_world():\n return 'Hello, World!'\n\[email protected]('/rlon') \n\ndef redledon():\n GPIO.output(36, GPIO.HIGH)\n return \"Red LED on\"\n\[email protected]('/rloff') \n\ndef redledoff():\n GPIO.output(36, GPIO.LOW)\n return \"Red LED off\" \n\[email protected]('/glon')\n\ndef greenledon():\n GPIO.output(40, GPIO.HIGH)\n return \"Green LED on\"\n\[email protected]('/gloff')\n\ndef greenledoff():\n GPIO.output(40, GPIO.LOW)\n return \"Green LED off\"\n\[email protected]('/blon')\n\ndef blueledon():\n GPIO.output(38, GPIO.HIGH)\n return \"Blue LED on\"\n\[email protected]('/bloff')\n\ndef blueledoff():\n GPIO.output(38, GPIO.LOW)\n return \"Blue LED off\"\n\[email protected]('/ylon')\n\ndef yellowledon():\n GPIO.output(37, GPIO.HIGH)\n return \"Yellow LED on\"\n\[email protected]('/yloff')\n\ndef yellowledoff():\n GPIO.output(37, GPIO.LOW)\n return \"Yellow LED off\"\n\[email protected]('/wlon')\n\ndef whiteledon():\n GPIO.output(35, GPIO.HIGH)\n return \"White LED on\"\n\[email protected]('/wloff')\n\ndef whiteledoff():\n GPIO.output(35, GPIO.LOW)\n return \"White LED off\"\n\n\n\nif __name__ == \"__main__\":\n app.run(host=\"0.0.0.0\")\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7517321109771729,
"alphanum_fraction": 0.7655889391899109,
"avg_line_length": 31.884614944458008,
"blob_id": "c069b55fb8084746e187c4371be830a33b2d31af",
"content_id": "f6df0c38dbfec41f4961c0303682c2e0628c961f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 26,
"path": "/setup_sugarpi.sh",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/bash\n\n\n# First you need to install raspi-config or use raspi-config\n# enable the i2c interface in raspi-config\n# sudo raspi-config\n\n# Information about interacting with the server and settuping the module\n# https://github.com/PiSugar/PiSugar/wiki/PiSugar-Power-Manager-(Software)\n\n\n\n# run the following script on your pi\ncurl http://cdn.pisugar.com/release/Pisugar-power-manager.sh | sudo bash\n\n\n# by default the sugarpi-server is disables so it must be enabled to start serving battery data\nsudo systemctl enable pisugar-server\n# start the 'pisugar-server' server\nsudo systemctl start pisugar-server\n# Check the status of the daemon/server with this command\nsudo systemctl status pisugar-server\n# The server daemon will also respond to 'stop' and 'disable'\n\n# test if the sugar-pi server is running\necho \"get battery\" | nc -q 0 127.0.0.1 8423\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5573505759239197,
"alphanum_fraction": 0.569736123085022,
"avg_line_length": 18.967391967773438,
"blob_id": "225ecabfbc55028a936ab0ecbf452b386a9d747c",
"content_id": "9eb0536030a0267c480278aad314fc6db91a15e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1857,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 92,
"path": "/alternating_leds.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport RPi.GPIO as GPIO\nimport random\nimport time\n\n# wire each BOARD pin to the corresponding LED color\n# pin colors\nR=40\nB=35\nG=36\nY=37\nW=38\n\n# board pin numbers\nPINS = [ R, B, G, Y, W]\n\n# groun pin is pin 39\n\n# setup led pins\nGPIO.setmode(GPIO.BOARD)\nGPIO.setwarnings(False)\nGPIO.setup(PINS, GPIO.OUT)\n\n\n\ndef straight_through(freq) -> None:\n for pin in PINS:\n GPIO.output(pin, GPIO.HIGH)\n time.sleep(freq)\n GPIO.output(pin, GPIO.LOW)\n time.sleep(freq)\n\n\ndef there_and_back(freq) -> None:\n for pin in [R, B, G, Y, W, W, Y, G, B, R]:\n GPIO.output(pin, GPIO.HIGH)\n time.sleep(freq)\n GPIO.output(pin, GPIO.LOW)\n time.sleep(freq)\n\ndef slow_mo(freq) -> None:\n for pin in PINS:\n GPIO.output(pin, GPIO.HIGH)\n time.sleep(freq + .5)\n GPIO.output(pin, GPIO.LOW)\n time.sleep(freq + .5)\n\ndef leapfrog(freq) -> None:\n for pin in [R, G, B, Y, W, W, G, Y, B, R]:\n GPIO.output(pin, GPIO.HIGH)\n time.sleep(freq)\n GPIO.output(pin, GPIO.LOW)\n time.sleep(freq)\n\ndef flash_all(freq) -> None:\n for pin in PINS:\n GPIO.output(pin, GPIO.HIGH)\n time.sleep(freq + .5)\n for pin in PINS:\n GPIO.output(pin, GPIO.LOW)\n time.sleep(freq + .5)\n\ndef all_on_onebyone_off(freq) -> None:\n for pin in PINS:\n GPIO.output(pin, GPIO.HIGH)\n time.sleep(freq + 1)\n for pin in PINS:\n GPIO.output(pin, GPIO.LOW)\n time.sleep(freq + 1)\n \n\ndef main(freq) -> None:\n for _ in range(10):\n straight_through(freq)\n there_and_back(freq)\n slow_mo(freq)\n leapfrog(freq)\n flash_all(freq)\n all_on_onebyone_off(freq)\n\n\n\nif __name__ == \"__main__\":\n try:\n main(.05)\n except KeyboardInterrupt:\n GPIO.cleanup()\n\n\nGPIO.cleanup()\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6061026453971863,
"alphanum_fraction": 0.67128986120224,
"avg_line_length": 18.486486434936523,
"blob_id": "4eb9611f630b08d98425c6107cb79b05dcede9ad",
"content_id": "34090d60bcbd8dd601c319d1efb472dfcc32984b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 37,
"path": "/test_pulse_width_modulation.py",
"repo_name": "snidarian/raspi_programs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport RPi.GPIO as GPIO\nimport random\nimport time\n\n\n# Setup pins - pins 12, 32, and 33 wired to RGB pins on RGB module\nGPIO.setmode(GPIO.BOARD)\nGPIO.setup(12, GPIO.OUT)\nGPIO.setup(32, GPIO.OUT)\nGPIO.setup(33, GPIO.OUT)\n\n# So we can refer to the pins namely by their LED color production\nR, G, B = 32, 12, 33\n\n\n# We'll use p variable as an alias for GPIO pulse width modulation method\nred = GPIO.PWM(32, 0.1)\ngreen = GPIO.PWM(12, 0.1)\nblue = GPIO.PWM(33, 0.1)\n\n\nfor _ in range(10):\n red.start(random.randint(0, 100))\n green.start(random.randint(0, 100))\n blue.start(random.randint(0, 100))\n time.sleep(1)\n red.stop()\n green.stop()\n blue.stop()\n time.sleep(1)\n\n\n\nGPIO.cleanup()\n"
}
] | 16 |
ummarshaik/Hello-World
|
https://github.com/ummarshaik/Hello-World
|
030d33c9675cdc26586d814df30792b30a565071
|
3750d45f11079afc30bc2f1f5c168a89eb0b91b1
|
18f3b6eabbb3bcf971a342d7300ec9b585e9b7b4
|
refs/heads/master
| 2022-01-15T19:51:50.703533 | 2019-07-22T06:26:28 | 2019-07-22T06:26:28 | 198,156,203 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7714285850524902,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 16.5,
"blob_id": "4211203279dd4568161ab3a7c71b6b5bb051feb9",
"content_id": "fe96b4e853e7bb1618083d3179d80d59e8f69251",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ummarshaik/Hello-World",
"src_encoding": "UTF-8",
"text": "# Hello-World\nMy first file Github\n"
},
{
"alpha_fraction": 0.717391312122345,
"alphanum_fraction": 0.717391312122345,
"avg_line_length": 22,
"blob_id": "02f03b3762d1acd6793aecdaedf4ecab878b89aa",
"content_id": "fd730050f911a11f0b37bd0d48ae99e891e2bea0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/HelloWorld2.py",
"repo_name": "ummarshaik/Hello-World",
"src_encoding": "UTF-8",
"text": "print(\"Hello World\")\nprint(\"create new file\")\n"
},
{
"alpha_fraction": 0.7936508059501648,
"alphanum_fraction": 0.7936508059501648,
"avg_line_length": 62,
"blob_id": "36d093944afe923e9d579ff1758d3c4c03e0bfc3",
"content_id": "3b9a1553628613a63983b46db90af1d22ef02bec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 1,
"path": "/HelloWorld3.py",
"repo_name": "ummarshaik/Hello-World",
"src_encoding": "UTF-8",
"text": "print(\"third file i created from local system after clonning\")\n"
}
] | 3 |
pnomolos/DEXBot
|
https://github.com/pnomolos/DEXBot
|
54b2b5c0c49951d0692e3f658518594d5affd203
|
e09715fdb0ba9d8ae7ec5d98cb704337f113fe8f
|
14d350a421076471732fdf87500755a9f8066b87
|
refs/heads/master
| 2021-01-25T14:38:48.768759 | 2018-02-27T23:59:04 | 2018-02-27T23:59:04 | 123,718,998 | 0 | 0 | null | 2018-03-03T18:17:00 | 2018-02-16T14:06:01 | 2018-02-27T23:59:30 | null |
[
{
"alpha_fraction": 0.45897725224494934,
"alphanum_fraction": 0.4685261845588684,
"avg_line_length": 34.690582275390625,
"blob_id": "417afcf0bb780baee4fa6281172818024279d117",
"content_id": "68812fc4fa0a7e72adf84e99e99bb8431987c47c",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7959,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 223,
"path": "/dexbot/strategies/follow_orders.py",
"repo_name": "pnomolos/DEXBot",
"src_encoding": "UTF-8",
"text": "from math import fabs\nfrom pprint import pprint\nfrom collections import Counter\nfrom bitshares.amount import Amount\nfrom bitshares.price import Price, Order, FilledOrder\nfrom dexbot.basestrategy import BaseStrategy, ConfigElement\nimport time\n\n\nclass Strategy(BaseStrategy):\n\n @classmethod\n def configure(cls):\n return BaseStrategy.configure() + [\n ConfigElement(\n \"spread\",\n \"float\",\n 5,\n \"Percentage difference between buy and sell\",\n (0,\n 100)),\n ConfigElement(\n \"wall\",\n \"float\",\n 0.0,\n \"the default amount to buy/sell, in quote\",\n (0.0,\n None)),\n ConfigElement(\n \"max\",\n \"float\",\n 100.0,\n \"bot will not trade if price above this\",\n (0.0,\n None)),\n ConfigElement(\n \"min\",\n \"float\",\n 100.0,\n \"bot will not trade if price below this\",\n (0.0,\n None)),\n ConfigElement(\n \"start\",\n \"float\",\n 100.0,\n \"Starting price, as percentage of bid/ask spread\",\n (0.0,\n 100.0)),\n ConfigElement(\n \"reset\",\n \"bool\",\n False,\n \"bot will alwys reset orders on start\",\n (0.0,\n None)),\n ConfigElement(\n \"staggers\",\n \"int\",\n 1,\n \"Number of additional staggered orders to place\",\n (1,\n 100)),\n ConfigElement(\n \"staggerspread\",\n \"float\",\n 5,\n \"Percentage difference between staggered orders\",\n (1,\n 100))\n ]\n\n def safe_dissect(self, thing, name):\n try:\n self.log.debug(\n \"%s() returned type: %r repr: %r dict: %r\" %\n (name, type(thing), repr(thing), dict(thing)))\n except BaseException:\n self.log.debug(\n \"%s() returned type: %r repr: %r\" %\n (name, type(thing), repr(thing)))\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n # Define Callbacks\n self.onMarketUpdate += self.onmarket\n if self.bot.get(\"reset\", False):\n self.cancel_all()\n self.reassess()\n\n def updateorders(self, newprice):\n \"\"\" Update the orders\n \"\"\"\n self.log.info(\"Replacing orders. Baseprice is %f\" % newprice)\n self['price'] = newprice\n step1 = self.bot['spread'] / 200.0 * newprice\n step2 = self.bot['staggerspread'] / 100.0 * newprice\n # Canceling orders\n self.cancel_all()\n # record balances\n self.record_balances(newprice)\n\n myorders = {}\n\n if newprice < self.bot[\"min\"]:\n self.disabled = True\n self.log.critical(\n \"Price %f is below minimum %f\" %\n (newprice, self.bot[\"min\"]))\n return\n if newprice > self.bot[\"max\"]:\n self.disabled = True\n self.log.critical(\n \"Price %f is above maximum %f\" %\n (newprice, self.bot[\"max\"]))\n return\n\n if float(self.balance(self.market[\"quote\"])\n ) < self.bot[\"wall\"] * self.bot['staggers']:\n self.log.critical(\n \"insufficient sell balance: %r (needed %f)\" %\n (self.balance(\n self.market[\"quote\"]),\n self.bot[\"wall\"]))\n self.disabled = True # now we get no more events\n return\n\n if self.balance(self.market[\"base\"]) < newprice * \\\n self.bot[\"wall\"] * self.bot['staggers']:\n self.disabled = True\n self.log.critical(\n \"insufficient buy balance: %r (need: %f)\" %\n (self.balance(\n self.market[\"base\"]),\n self.bot[\"wall\"] *\n buy_price))\n return\n\n amt = Amount(self.bot[\"wall\"], self.market[\"quote\"])\n\n sell_price = newprice + step1\n for i in range(0, self.bot['staggers']):\n self.log.info(\"SELL {amt} at {price:.4g} {base}/{quote} (= {inv_price:.4g} {quote}/{base})\".format(\n amt=repr(amt),\n price=sell_price,\n inv_price=1 / sell_price,\n quote=self.market['quote']['symbol'],\n base=self.market['base']['symbol']))\n ret = self.market.sell(\n sell_price,\n amt,\n account=self.account,\n returnOrderId=\"head\"\n )\n self.log.debug(\"SELL order done\")\n myorders[ret['orderid']] = sell_price\n sell_price += step2\n\n buy_price = newprice - step1\n for i in range(0, self.bot['staggers']):\n self.log.info(\"BUY {amt} at {price:.4g} {base}/{quote} (= {inv_price:.4g} {quote}/{base})\".format(\n amt=repr(amt),\n price=buy_price,\n inv_price=1 / buy_price,\n quote=self.market['quote']['symbol'],\n base=self.market['base']['symbol']))\n ret = self.market.buy(\n buy_price,\n amt,\n account=self.account,\n returnOrderId=\"head\",\n )\n self.log.debug(\"BUY order done\")\n myorders[ret['orderid']] = buy_price\n buy_price -= step2\n self['myorders'] = myorders\n # ret = self.execute() this doesn't seem to work reliably\n # self.safe_dissect(ret,\"execute\")\n\n def onmarket(self, data):\n if isinstance(\n data, FilledOrder) and data['account_id'] == self.account['id']:\n self.log.debug(\n \"data['quote']['asset'] = %r self.market['quote'] = %r\" %\n (data['quote']['asset'], self.market['quote']))\n if data['quote']['asset'] == self.market['quote']:\n self.log.debug(\"Quote = quote\")\n if repr(data['quote']['asset']['id']) == repr(\n self.market['quote']['id']):\n self.log.debug(\"quote['id'] = quote['id']\")\n self.reassess()\n\n def reassess(self):\n # sadly no smart way to match a FilledOrder to an existing order\n # even price-matching won't work as we can buy at a better price than we asked for\n # so look at what's missing\n self.log.debug(\"reassessing...\")\n self.account.refresh()\n still_open = set(i['id'] for i in self.account.openorders)\n self.log.debug(\"still_open: %r\" % still_open)\n if len(still_open) == 0:\n self.log.info(\"no open orders, recalculating the startprice\")\n t = self.market.ticker()\n bid = float(t['highestBid'])\n ask = float(t['lowestAsk'])\n self.updateorders(bid + ((ask - bid) * self.bot['start'] / 100.0))\n time.sleep(1)\n self.reassess()\n return\n missing = set(self['myorders'].keys()) - still_open\n if missing:\n found_price = 0.0\n highest_diff = 0.0\n for i in missing:\n diff = fabs(self['price'] - self['myorders'][i])\n if diff > highest_diff:\n found_price = self['myorders'][i]\n highest_diff = diff\n self.updateorders(found_price)\n time.sleep(1)\n self.reassess() # check if order has been filled while we were busy entering orders\n else:\n self.log.debug(\"nothing missing, no action\")\n"
},
{
"alpha_fraction": 0.5788344144821167,
"alphanum_fraction": 0.5809803605079651,
"avg_line_length": 39.06334686279297,
"blob_id": "d8bce7561fead8815e5fc5a513e9df640de237f8",
"content_id": "457abec734d68366b8e08deaf8d2bd8e4f3c14d8",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8854,
"license_type": "permissive",
"max_line_length": 198,
"num_lines": 221,
"path": "/dexbot/cli_conf.py",
"repo_name": "pnomolos/DEXBot",
"src_encoding": "UTF-8",
"text": "\"\"\"\nA module to provide an interactive text-based tool for dexbot configuration\nThe result is takemachine can be run without having to hand-edit config files.\nIf systemd is detected it will offer to install a user service unit (under ~/.local/share/systemd\nThis requires a per-user systemd process to be runnng\n\nRequires the 'whiptail' tool: so UNIX-like sytems only\n\nNote there is some common cross-UI configuration stuff: look in basestrategy.py\nIt's expected GUI/web interfaces will be re-implementing code in this file, but they should\nunderstand the common code so bot strategy writers can define their configuration once\nfor each strategy class.\n\n\"\"\"\n\n\nimport importlib\nimport os\nimport os.path\nimport sys\nimport collections\nimport re\nimport tempfile\nimport shutil\nfrom dexbot.bot import STRATEGIES\nfrom dexbot.whiptail import get_whiptail\nfrom dexbot.find_node import start_pings, best_node\n\nSYSTEMD_SERVICE_NAME = os.path.expanduser(\n \"~/.local/share/systemd/user/dexbot.service\")\n\nSYSTEMD_SERVICE_FILE = \"\"\"\n[Unit]\nDescription=Dexbot\n\n[Service]\nType=notify\nWorkingDirectory={homedir}\nExecStart={exe} --systemd run\nEnvironment=PYTHONUNBUFFERED=true\nEnvironment=UNLOCK={passwd}\n\n[Install]\nWantedBy=default.target\n\"\"\"\n\n\ndef select_choice(current, choices):\n \"\"\"for the radiolist, get us a list with the current value selected\"\"\"\n return [(tag, text, (current == tag and \"ON\") or \"OFF\")\n for tag, text in choices]\n\n\ndef process_config_element(elem, d, config):\n \"\"\"\n process an item of configuration metadata display a widget as appropriate\n d: the Dialog object\n config: the config dctionary for this bot\n \"\"\"\n if elem.type == \"string\":\n txt = d.prompt(elem.description, config.get(elem.key, elem.default))\n if elem.extra:\n while not re.match(elem.extra, txt):\n d.alert(\"The value is not valid\")\n txt = d.prompt(\n elem.description, config.get(\n elem.key, elem.default))\n config[elem.key] = txt\n if elem.type == \"bool\":\n config[elem.key] = d.confirm(elem.description)\n if elem.type in (\"float\", \"int\"):\n txt = d.prompt(\n elem.description, config.get(\n elem.key, str(\n elem.default)))\n while True:\n try:\n if elem.type == \"int\":\n val = int(txt)\n else:\n val = float(txt)\n if val < elem.extra[0]:\n d.alert(\"The value is too low\")\n elif elem.extra[1] and val > elem.extra[1]:\n d.alert(\"the value is too high\")\n else:\n break\n except ValueError:\n d.alert(\"Not a valid value\")\n txt = d.prompt(\n elem.description, config.get(\n elem.key, str(\n elem.default)))\n config[elem.key] = val\n if elem.type == \"choice\":\n config[elem.key] = d.radiolist(elem.description, select_choice(\n config.get(elem.key, elem.default), elem.extra))\n\n\ndef setup_systemd(d, config):\n if config.get(\"systemd_status\", \"install\") == \"reject\":\n return # don't nag user if previously said no\n if not os.path.exists(\"/etc/systemd\"):\n return # no working systemd\n if os.path.exists(SYSTEMD_SERVICE_NAME):\n # dexbot already installed\n # so just tell cli.py to quietly restart the daemon\n config[\"systemd_status\"] = \"installed\"\n return\n if d.confirm(\n \"Do you want to install dexbot as a background (daemon) process?\"):\n for i in [\"~/.local\", \"~/.local/share\",\n \"~/.local/share/systemd\", \"~/.local/share/systemd/user\"]:\n j = os.path.expanduser(i)\n if not os.path.exists(j):\n os.mkdir(j)\n passwd = d.prompt(\n \"The wallet password entered with uptick\\nNOTE: this will be saved on disc so the bot can run unattended. This means anyone with access to this computer's file can spend all your money\",\n password=True)\n # because we hold password be restrictive\n fd = os.open(SYSTEMD_SERVICE_NAME, os.O_WRONLY | os.O_CREAT, 0o600)\n with open(fd, \"w\") as fp:\n fp.write(\n SYSTEMD_SERVICE_FILE.format(\n exe=sys.argv[0],\n passwd=passwd,\n homedir=os.path.expanduser(\"~\")))\n # signal cli.py to set the unit up after writing config file\n config['systemd_status'] = 'install'\n else:\n config['systemd_status'] = 'reject'\n\n\ndef configure_bot(d, bot):\n strategy = bot.get('module', 'dexbot.strategies.echo')\n bot['module'] = d.radiolist(\n \"Choose a bot strategy\", select_choice(\n strategy, STRATEGIES))\n # its always Strategy now, for backwards compatibilty only\n bot['bot'] = 'Strategy'\n # import the bot class but we don't __init__ it here\n klass = getattr(\n importlib.import_module(bot[\"module\"]),\n bot[\"bot\"]\n )\n # use class metadata for per-bot configuration\n configs = klass.configure()\n if configs:\n for c in configs:\n process_config_element(c, d, bot)\n else:\n d.alert(\"This bot type does not have configuration information. You will have to check the bot code and add configuration values to config.yml if required\")\n return bot\n\ndef setup_reporter(d, config):\n reporter_config = config.get('reports',{})\n frequency = d.radiolist(\"DEXBot can send an e-mail report on its activities at regular intervals\", select_choice(\n str(reporter_config.get('days',0)),\n [(\"0\",'Never'), ('1','Daily'), ('2','Second-daily'), ('3','Third-daily'), ('7','Weekly')]))\n if frequency == '0':\n if 'reporter' in config:\n del config['reporter']\n return\n reporter_config['days'] = int(frequency)\n reporter_config['send_to'] = d.prompt(\"E-mail address to send to\",default=reporter_config.get('send_to',''))\n reporter_config['send_from'] = d.prompt(\"E-mail address to send from (blank will use local user and host name)\",\n default=reporter_config.get('send_from',reporter_config['send_to']))\n reporter_config['server'] = d.prompt(\"SMTP server to use (blank means this server)\",\n default=reporter_config.get('server',''))\n reporter_config['port'] = d.prompt(\"SMTP server port to use\",\n default=reporter_config.get('port','25'))\n reporter_config['login'] = d.prompt(\"Login username for the SMTP server (blank means don't login)\",\n default=reporter_config.get('login',\n reporter_config['send_to'].split('@')[0]))\n if reporter_config['login']:\n reporter_config['password'] = d.prompt(\"SMTP server password to use\",password=True)\n config['reports'] = reporter_config\n\ndef configure_dexbot(config):\n d = get_whiptail()\n bots = config.get('bots', {})\n if len(bots) == 0:\n ping_results = start_pings()\n while True:\n txt = d.prompt(\"Your name for the bot\")\n config['bots'] = {txt: configure_bot(d, {})}\n if not d.confirm(\"Set up another bot?\\n(DEXBOt can run multiple bots in one instance)\"):\n break\n setup_reporter(d, config)\n setup_systemd(d, config)\n node = best_node(ping_results)\n if node:\n config['node'] = node\n else:\n # search failed, ask the user\n config['node'] = d.prompt(\n \"Search for best BitShares node failed.\\n\\nPlease enter wss:// url of chosen node.\")\n else:\n action = d.menu(\"You have an existing configuration.\\nSelect an action:\",\n [('NEW', 'Create a new bot'),\n ('DEL', 'Delete a bot'),\n ('EDIT', 'Edit a bot'),\n ('CONF', 'Redo general config')])\n if action == 'EDIT':\n botname = d.menu(\"Select bot to edit\", [(i, i) for i in bots])\n config['bots'][botname] = configure_bot(d, config['bots'][botname])\n elif action == 'DEL':\n botname = d.menu(\"Select bot to delete\", [(i, i) for i in bots])\n del config['bots'][botname]\n if action == 'NEW':\n txt = d.prompt(\"Your name for the new bot\")\n config['bots'][txt] = configure_bot(d, {})\n else:\n setup_reporter(d, config)\n config['node'] = d.prompt(\"BitShares node to use\",default=config['node'])\n d.clear()\n return config\n\n\nif __name__ == '__main__':\n print(repr(configure({})))\n"
},
{
"alpha_fraction": 0.5816208720207214,
"alphanum_fraction": 0.583121657371521,
"avg_line_length": 29.392982482910156,
"blob_id": "c9c7c013a434a9b86b986c8ebf715717daed18a6",
"content_id": "4898e15078bbfdc9fe518fb0e7174ecf3a112993",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8662,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 285,
"path": "/dexbot/storage.py",
"repo_name": "pnomolos/DEXBot",
"src_encoding": "UTF-8",
"text": "import sqlalchemy\nfrom sqlalchemy import create_engine, Table, Column, String, Integer, MetaData, DateTime, Float\nimport os\nimport json\nimport threading\nimport queue\nimport uuid\nimport time\nimport datetime\nimport re\nimport logging\n\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy.orm import sessionmaker\nfrom appdirs import user_data_dir\nBase = declarative_base()\n\n# For dexbot.sqlite file\nappname = \"dexbot\"\nappauthor = \"ChainSquad GmbH\"\nstorageDatabase = \"dexbot.sqlite\"\n\n\ndef mkdir_p(d):\n if os.path.isdir(d):\n return\n else:\n try:\n os.makedirs(d)\n except FileExistsError:\n return\n except OSError:\n raise\n\n\nclass Config(Base):\n __tablename__ = 'config'\n\n id = Column(Integer, primary_key=True)\n category = Column(String)\n key = Column(String)\n value = Column(String)\n\n def __init__(self, c, k, v):\n self.category = c\n self.key = k\n self.value = v\n\n\nclass Journal(Base):\n __tablename__ = 'journal'\n id = Column(Integer, primary_key=True)\n category = Column(String)\n key = Column(String)\n amount = Column(Float)\n stamp = Column(DateTime, default=datetime.datetime.now)\n\nclass Log(Base):\n __tablename__ = 'log'\n id = Column(Integer, primary_key=True)\n category = Column(String)\n severity = Column(Integer)\n message = Column(String)\n stamp = Column(DateTime, default=datetime. datetime.now)\n \nclass Storage(dict):\n \"\"\" Storage class\n\n :param string category: The category to distinguish\n different storage namespaces\n \"\"\"\n\n def __init__(self, category):\n self.category = category\n\n def __setitem__(self, key, value):\n worker.execute_noreturn(worker.set_item, self.category, key, value)\n\n def __getitem__(self, key):\n return worker.execute(worker.get_item, self.category, key)\n\n def __delitem__(self, key):\n worker.execute_noreturn(worker.del_item, self.category, key)\n\n def __contains__(self, key):\n return worker.execute(worker.contains, self.category, key)\n\n def items(self):\n return worker.execute(worker.get_items, self.category)\n\n def clear(self):\n worker.execute_noreturn(worker.clear, self.category)\n\n def save_journal(self, amounts):\n worker.execute_noreturn(worker.save_journal, self.category, amounts)\n\n def query_journal(self, start, end_=None):\n return worker.execute(worker.query_journal, self.category, start, end_)\n\n def query_log(self, start, end_=None):\n return worker.execute(worker.query_log, self.category, start, end_)\n\nclass DatabaseWorker(threading.Thread):\n \"\"\"\n Thread safe database worker\n \"\"\"\n\n def __init__(self):\n super().__init__()\n\n # Obtain engine and session\n engine = create_engine('sqlite:///%s' % sqlDataBaseFile, echo=False)\n Session = sessionmaker(bind=engine)\n self.session = Session()\n Base.metadata.create_all(engine)\n self.session.commit()\n\n self.task_queue = queue.Queue()\n self.results = {}\n self.lock = threading.Lock()\n self.event = threading.Event()\n self.daemon = True\n self.start()\n\n def run(self):\n for func, args, token in iter(self.task_queue.get, None):\n args = args + (token,)\n func(*args)\n\n def get_result(self, token):\n while True:\n with self.lock:\n if token in self.results:\n return_value = self.results[token]\n del self.results[token]\n return return_value\n else:\n self.event.clear()\n self.event.wait()\n\n def set_result(self, token, result):\n with self.lock:\n self.results[token] = result\n self.event.set()\n\n def execute(self, func, *args):\n token = str(uuid.uuid4)\n self.task_queue.put((func, args, token))\n return self.get_result(token)\n\n def execute_noreturn(self, func, *args):\n self.task_queue.put((func, args, None))\n\n def set_item(self, category, key, value, token):\n value = json.dumps(value)\n e = self.session.query(Config).filter_by(\n category=category,\n key=key\n ).first()\n if e:\n e.value = value\n else:\n e = Config(category, key, value)\n self.session.add(e)\n self.session.commit()\n\n def get_item(self, category, key, token):\n e = self.session.query(Config).filter_by(\n category=category,\n key=key\n ).first()\n if not e:\n result = None\n else:\n result = json.loads(e.value)\n self.set_result(token, result)\n\n def del_item(self, category, key, token):\n e = self.session.query(Config).filter_by(\n category=category,\n key=key\n ).first()\n self.session.delete(e)\n self.session.commit()\n\n def contains(self, category, key, token):\n e = self.session.query(Config).filter_by(\n category=category,\n key=key\n ).first()\n self.set_result(token, bool(e))\n\n def get_items(self, category, token):\n es = self.session.query(Config).filter_by(\n category=category\n ).all()\n result = [(e.key, e.value) for e in es]\n self.set_result(token, result)\n\n def clear(self, category, token):\n rows = self.session.query(Config).filter_by(\n category=category\n )\n for row in rows:\n self.session.delete(row)\n self.session.commit()\n\n def save_journal(self, category, amounts, token):\n now_t = datetime.datetime.now()\n for key, amount in amounts:\n e = Journal(key=key, category=category, amount=amount, stamp=now_t)\n self.session.add(e)\n self.session.commit()\n\n def query_journal(self, category, start, end_, token):\n \"\"\"Query this bots journal\n start: datetime of start time\n end_: datetime of end (None means up to now)\n \"\"\"\n r = self.session.query(Journal).filter(Journal.category == category)\n if isinstance(start, str):\n m = re.match(\"(\\\\d+)([dw])\", start)\n if m:\n n = int(m.group(1))\n start = datetime.datetime.now()\n if m.group(2) == 'w':\n n *= 7\n start -= datetime.timedelta(days=n)\n if end_:\n r = r.filter(Journal.stamp > start, Journal.stamp < end_)\n else:\n r = r.filter(Journal.stamp > start)\n self.set_result(token, r.all())\n\n\n def save_log(self, category, severity, message, created, token):\n e = Log(category=category,severity=severity,message=message,stamp=created)\n self.session.add(e)\n self.session.commit()\n\n def query_log(self, category, start, end_, token):\n \"\"\"Query this bots log\n start: datetime of start time\n end_: datetime of end (None means up to now)\n \"\"\"\n r = self.session.query(Log).filter(Log.category == category)\n if type(start) is str:\n m = re.match(\"(\\\\d+)([dw])\",start)\n if m:\n n = int(m.group(1))\n start = datetime.datetime.now()\n if m.group(2) == 'w': n *= 7\n start -= datetime.timedelta(days=n)\n if end_: \n r = r.filter(Log.stamp > start,Log.stamp < end_)\n else:\n r = r.filter(Log.stamp > start)\n r = r.order_by(Log.stamp)\n self.set_result(token,r.all())\n \nMAP_LEVELS={logging.DEBUG: 0, logging.INFO: 1, logging.ERROR: 2, logging.WARN: 2, logging.CRITICAL: 3, logging.FATAL: 3}\n\nclass SQLiteHandler(logging.Handler):\n \"\"\"\n Logging handler for SQLite.\n Based on Vinay Sajip's DBHandler class (http://www.red-dove.com/python_logging.html)\n \"\"\"\n def emit(self, record):\n # Use default formatting:\n self.format(record)\n level = MAP_LEVELS.get(record.levelno, 0)\n notes = record.msg\n if record.exc_info:\n notes += \" \"+logging._defaultFormatter.formatException(record.exc_info)\n # Insert log record:\n worker.execute_noreturn(worker.save_log,record.botname,level,notes,datetime.datetime.fromtimestamp(record.created))\n \n# Derive sqlite file directory\ndata_dir = user_data_dir(appname, appauthor)\nsqlDataBaseFile = os.path.join(data_dir, storageDatabase)\n\n# Create directory for sqlite file\nmkdir_p(data_dir)\n\nworker = DatabaseWorker()\n"
},
{
"alpha_fraction": 0.7180020809173584,
"alphanum_fraction": 0.7287547588348389,
"avg_line_length": 32.52325439453125,
"blob_id": "d42efb3d97521bbf57f5282db1dd62094a1ac6a9",
"content_id": "f9d34fcac2ffdb786dec3b1ac3cd545eb35e7646",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2883,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 86,
"path": "/docs/follow_orders.rst",
"repo_name": "pnomolos/DEXBot",
"src_encoding": "UTF-8",
"text": "**********************\nFollow Orders Strategy\n**********************\n\nThis strategy places a buy and a sell walls into a specific market.\nIt buys below a base price, and sells aboe the base price.\n\nIt then reacts to orders filled (hence the name), when one order is\ncompletely filled, new walls are constructed using the filled order\nas the new base price.\n\nConfiguration Questions\n=======================\n\nSpread\n------\n\nPercentage difference between buy and sell price. So a spread of 5% means the bot sells at 2.5%\nabove the base price and buys 2.5% below.\n\nWall\n----\n\nThis is the \"wall height\": the default amount to buy/sell, in quote. So if you are on the AUD:BTS\nmarket, this is the amount to buy/sell in AUD.\n\nMax\n---\n\nThe bot will stop trading if the base price goes above this value, it will shut down until you manually\nrestart it. (i.e. it won't restart itself if the price drops)\n\nRemember prices are base/quote, so on AUD:BTS, that's the price of 1 AUD in BTS.\n\nMin\n---\n\nSame in reverse: stop running if prices go below this value.\n\nStart\n-----\n\nThe initial price, as a percentage of the spread between the highest bid and lowest ask. So \"0\" means\nthe highest bid, \"100\" means the lowest ask, 50 means the midpoint between them, and so on.\n\n*Important*: you need to look at the market and get a sense of its orderbook for setting this,\njusting setting \"50\" blind can lead to stupid prices especially in illiquid markets.\n\nReset\n-----\n\nNormally the bot checks if it has previously placed orders in the market and uses those. If true,\nthis option forces the bot to cancel any existing orders when it starts up, and re-calculate\nthe starting price as above.\n\nStaggers\n--------\n\nNumber of additional (or \"staggered\") orders to place. By default this is \"1\" (so\nno additional orders). 2 or more means multiple sell and buy orders at different prices.\n\nStagger Spread\n--------------\n\nThe gap between each staggered order (as a percentage of the base price).\n\nSo say the spread is 5%, staggers is \"2\", and \"stagger spread\" is 4%, then there will be 2\nbuy orders: 2.5% and 6.5% (4% + 2.5%) below the base price, and two sells 2.5% and 6.5% above.\nThe order amounts are all the same (see `wall` option).\n\nBot problems\n============\n\nLike all liquidity bots, the bot really works best with a \"even\"\nmarket, i.e. where are are counterparties both buying and selling.\n\nWith a severe \"bear\" market, the\nbot can be stuck being the sole participant that is still buying against panicked humans frantically selling.\nIt repeatingly buys into the market and so it can\nrun out of one asset quite quickly (although it will have bought it at\nlower and lower prices).\n\nI don't have a simple good solution (and happy to hear suggestions from experienced traders)\n\nI plan a smarter bot that will change its behaviour when it starts to runs low on an asset,\nbut this will have a different name.\n"
},
{
"alpha_fraction": 0.5301897525787354,
"alphanum_fraction": 0.5303335189819336,
"avg_line_length": 32.60386657714844,
"blob_id": "c2c106f822ced5877c58e351bbe4895842f588b3",
"content_id": "d17c3a603ce16176f9abe01a601b7fed588d0cee",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6956,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 207,
"path": "/dexbot/bot.py",
"repo_name": "pnomolos/DEXBot",
"src_encoding": "UTF-8",
"text": "import importlib\nimport time\nimport sys\nimport logging\nimport os.path\nimport threading\n\nfrom dexbot.basestrategy import BaseStrategy\n\nfrom bitshares.notify import Notify\nfrom bitshares.instance import shared_bitshares_instance\n\nfrom . import errors\nfrom . import reports\n\nlog = logging.getLogger(__name__)\n\n\n# FIXME: currently static list of bot strategies: ? how to enumerate bots\n# available and deploy new bot strategies.\n\nSTRATEGIES = [('dexbot.strategies.echo', \"Echo Test\"),\n ('dexbot.strategies.follow_orders', \"Haywood's Follow Orders\")]\n\nlog_bots = logging.getLogger('dexbot.per_bot')\n# NOTE this is the special logger for per-bot events\n# it returns LogRecords with extra fields: botname, account, market and is_disabled\n# is_disabled is a callable returning True if the bot is currently disabled.\n# GUIs can add a handler to this logger to get a stream of events re the\n# running bots.\n\n\nclass BotInfrastructure(threading.Thread):\n\n bots = dict()\n\n def __init__(\n self,\n config,\n bitshares_instance=None,\n view=None\n ):\n \"\"\"Initialise variables. But no bot setup, therefore fast\"\"\"\n super().__init__()\n\n # BitShares instance\n self.bitshares = bitshares_instance or shared_bitshares_instance()\n self.config = config\n self.view = view\n self.jobs = set()\n\n def init_bots(self):\n \"\"\"Do the actual initialisation of bots\n Potentially quite slow (tens of seconds)\n So called as part of run()\n \"\"\"\n # set the module search path\n user_bot_path = os.path.expanduser(\"~/bots\")\n if os.path.exists(user_bot_path):\n sys.path.append(user_bot_path)\n\n # Load all accounts and markets in use to subscribe to them\n accounts = set()\n markets = set()\n # Initialize bots:\n for botname, bot in self.config[\"bots\"].items():\n if \"account\" not in bot:\n log_bots.critical(\n \"Bot has no account\",\n extra={\n 'botname': botname,\n 'account': 'unknown',\n 'market': 'unknown',\n 'is_dsabled': (\n lambda: True)})\n continue\n if \"market\" not in bot:\n log_bots.critical(\n \"Bot has no market\",\n extra={\n 'botname': botname,\n 'account': bot['account'],\n 'market': 'unknown',\n 'is_disabled': (\n lambda: True)})\n continue\n try:\n klass = getattr(\n importlib.import_module(bot[\"module\"]),\n 'Strategy'\n )\n self.bots[botname] = klass(\n config=self.config,\n name=botname,\n bitshares_instance=self.bitshares,\n view=self.view\n )\n markets.add(bot['market'])\n accounts.add(bot['account'])\n except BaseException:\n log_bots.exception(\n \"Bot initialisation\",\n extra={\n 'botname': botname,\n 'account': bot['account'],\n 'market': 'unknown',\n 'is_disabled': (\n lambda: True)})\n\n if len(markets) == 0:\n log.critical(\"No bots to launch, exiting\")\n raise errors.NoBotsAvailable()\n\n # Create notification instance\n # Technically, this will multiplex markets and accounts and\n # we need to demultiplex the events after we have received them\n self.notify = Notify(\n markets=list(markets),\n accounts=list(accounts),\n on_market=self.on_market,\n on_account=self.on_account,\n on_block=self.on_block,\n bitshares_instance=self.bitshares\n )\n\n # set up reporting\n\n if \"reports\" in self.config:\n self.reporter = reports.Reporter(self.config['reports'], self.bots)\n else:\n self.reporter = None\n \n # Events\n def on_block(self, data):\n if self.jobs:\n try: \n for i in self.jobs:\n i ()\n finally:\n self.jobs = set()\n if self.reporter is not None:\n self.reporter.ontick()\n for botname, bot in self.config[\"bots\"].items():\n if botname not in self.bots or self.bots[botname].disabled:\n continue\n try:\n self.bots[botname].ontick(data)\n except Exception as e:\n self.bots[botname].error_ontick(e)\n self.bots[botname].log.exception(\"in .tick()\")\n\n def on_market(self, data):\n if data.get(\"deleted\", False): # no info available on deleted orders\n return\n for botname, bot in self.config[\"bots\"].items():\n if self.bots[botname].disabled:\n continue\n if bot[\"market\"] == data.market:\n try:\n self.bots[botname].onMarketUpdate(data)\n except Exception as e:\n self.bots[botname].error_onMarketUpdate(e)\n self.bots[botname].log.exception(\".onMarketUpdate()\")\n\n def on_account(self, accountupdate):\n account = accountupdate.account\n for botname, bot in self.config[\"bots\"].items():\n if self.bots[botname].disabled:\n self.bots[botname].log.info(\"bot disabled\" % botname)\n continue\n if bot[\"account\"] == account[\"name\"]:\n try:\n self.bots[botname].onAccount(accountupdate)\n except Exception as e:\n self.bots[botname].error_onAccount(e)\n self.bots[botname].log.exception(\".onAccountUpdate()\")\n\n def run(self):\n self.init_bots()\n self.notify.listen()\n\n def stop(self,*args):\n self.notify.websocket.close()\n\n def remove_bot(self):\n for bot in self.bots:\n self.bots[bot].purge()\n\n @staticmethod\n def remove_offline_bot(config, bot_name):\n # Initialize the base strategy to get control over the data\n strategy = BaseStrategy(config, bot_name)\n strategy.purge()\n\n def report_now(self):\n \"\"\"Force-generate a report if we can\"\"\"\n if self.reporter is not None:\n self.reporter.run_report_week()\n else:\n log.warn(\"No reporter available\")\n\n def do_next_tick(self, job):\n \"\"\"Add a callable to be executed on the next tick\"\"\"\n self.jobs.add(job)\n\n def reread_config(self):\n log.warn(\"reread_config not implemented yet\")\n"
},
{
"alpha_fraction": 0.5496591925621033,
"alphanum_fraction": 0.5618305802345276,
"avg_line_length": 30.121212005615234,
"blob_id": "88932a8bfd80031e57cda94fff74fd81d4a4dc39",
"content_id": "4509e2f5bd9b54da7a4aed2e969ed177ce828714",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2054,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 66,
"path": "/dexbot/find_node.py",
"repo_name": "pnomolos/DEXBot",
"src_encoding": "UTF-8",
"text": "\"\"\"\nRoutines for finding the closest node\n\"\"\"\n\n# list kindly provided by Cryptick from the DEXBot Telegram channel\nALL_NODES = [\"wss://eu.openledger.info/ws\",\n \"wss://bitshares.openledger.info/ws\",\n \"wss://dexnode.net/ws\",\n \"wss://japan.bitshares.apasia.tech/ws\",\n \"wss://bitshares-api.wancloud.io/ws\",\n \"wss://openledger.hk/ws\",\n \"wss://bitshares.apasia.tech/ws\",\n \"wss://uptick.rocks\"\n \"wss://bitshares.crypto.fans/ws\",\n \"wss://kc-us-dex.xeldal.com/ws\",\n \"wss://api.bts.blckchnd.com\",\n \"wss://btsza.co.za:8091/ws\",\n \"wss://bitshares.dacplay.org/ws\",\n \"wss://bit.btsabc.org/ws\",\n \"wss://bts.ai.la/ws\",\n \"wss://ws.gdex.top\",\n \"wss://us.nodes.bitshares.works\",\n \"wss://eu.nodes.bitshares.works\",\n \"wss://sg.nodes.bitshares.works\"]\n\nimport re\nfrom urllib.parse import urlsplit\nfrom subprocess import Popen, STDOUT, PIPE\nfrom platform import system\n\nif system() == 'Windows':\n def ping_cmd(x): return ('ping', '-n', '5', '-w', '1500', x)\n ping_re = re.compile(r'Average = ([\\d.]+)ms')\nelse:\n def ping_cmd(x): return ('ping', '-c5', '-n', '-w5', '-i0.3', x)\n ping_re = re.compile(r'min/avg/max/mdev = [\\d.]+/([\\d.]+)')\n\n\ndef make_ping_proc(host):\n host = urlsplit(host).netloc.split(':')[0]\n return Popen(ping_cmd(host), stdout=PIPE,\n stderr=STDOUT, universal_newlines=True)\n\n\ndef process_ping_result(host, proc):\n out = proc.communicate()[0]\n try:\n return (float(ping_re.search(out).group(1)), host)\n except AttributeError:\n return (1000000, host) # hosts that fail are last\n\n\ndef start_pings():\n return [(i, make_ping_proc(i)) for i in ALL_NODES]\n\n\ndef best_node(results):\n try:\n r = sorted([process_ping_result(*i) for i in results])\n return r[0][1]\n except BaseException:\n return None\n\n\nif __name__ == '__main__':\n print(best_node(start_pings()))\n"
}
] | 6 |
palinkapro/WordGameBot
|
https://github.com/palinkapro/WordGameBot
|
383d497126755e73e6961aa5f96219d18202ad61
|
f38211258d752200a980c1ceb89596ae82d8ca43
|
ca3126ac545aeffa747f796c8255487dd58a471e
|
refs/heads/main
| 2023-06-25T04:00:28.679166 | 2021-07-15T07:23:35 | 2021-07-15T07:23:35 | 386,022,168 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7086614370346069,
"alphanum_fraction": 0.7086614370346069,
"avg_line_length": 62.5,
"blob_id": "650596cc0c79a2504b9ab2678c20ef6db129f680",
"content_id": "7668c537a2bd686e9f4eaa85be6d3ff8470b9d39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 127,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 2,
"path": "/readme.md",
"repo_name": "palinkapro/WordGameBot",
"src_encoding": "UTF-8",
"text": "## Telegram bot for a simple word game. \nCheck this out and play here [@word_city_game_bot](https://t.me/word_city_game_bot)\n"
},
{
"alpha_fraction": 0.6374045610427856,
"alphanum_fraction": 0.6444509625434875,
"avg_line_length": 45.02702713012695,
"blob_id": "20c966f3743eb21ab045afafea6ca4a653126882",
"content_id": "60d62b61b713a93dd175f59d47d1d1d5158933b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4065,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 74,
"path": "/bot.py",
"repo_name": "palinkapro/WordGameBot",
"src_encoding": "UTF-8",
"text": "import telebot\nimport json\nimport random\nfrom bot_token import token\n\n#load cities\njson_file_path = 'cities.json'\nwith open(json_file_path, 'r', encoding='utf-8') as j:\n cities = json.loads(j.read())['city']\n\n#russian cities\nrus_cities = tuple([city['name'].lower() for city in cities if city['country_id'] == '3159'])\ncity_names = rus_cities\n\n#rare characters\nbad_chars = ('ё','ж','й','ф','ц','ш','щ','ъ','ы','ь','э','ю')\n\n#used cities and mistakes count\nused = []\nmistakes = []\n\n#bot init\nbot = telebot.TeleBot(token)\n#start\[email protected]_handler(commands=['start'])\ndef send_welcome(message):\n bot.send_message(message.chat.id, \"Привет, поиграем в города?\")\n bot.send_message(message.chat.id, \"Чтобы узнать правила - отправь /help \\nЧтобы окончить игру - отправь /end \\nБот ходит первым - Москва. Введи название любого российского города на букву 'а'\")\n used.clear()\n used.append('москва')\[email protected]_handler(commands=['help'])\ndef help(message):\n bot.send_message(message.from_user.id,'Бот и игрок называют российские города по очереди. \\nКаждое следующее название города должно начинаться на ту букву, на которую заканчивается предыдущее название. \\nУ вас всего три права на ошибку, затем игра будет окончена. \\nЕсли в словаре бота закончатся города - победа за вами!')\n\[email protected]_handler(commands=['end'])\ndef end(message):\n bot.send_message(message.from_user.id,'Увы, в этот раз победа осталась за мной :) Чтобы начать заново - отправь /start')\n used.clear() \n#game\[email protected]_handler(content_types=['text']) \ndef get_text_messages(message): \n #user input handling\n curr_city = message.text.lower()\n if used:\n #check if first letter meets criteria\n char = used[-1][-1] if (used[-1][-1] not in bad_chars) else used[-1][-2]\n if curr_city[0] != char:\n #check if number of mistakes exceeds 3\n mistakes.append('curr_city')\n if len(mistakes) < 3:\n bot.send_message(message.chat.id, f'Неверно. Введите город на букву {char}: ')\n else:\n bot.send_message(message.from_user.id, \"Неверно. Игра окончена :( Чтобы начать заново - отправь /start\")\n used.clear()\n #response if city is used or unknown \n elif curr_city in used or curr_city not in city_names:\n bot.send_message(message.from_user.id,'Этот город уже участвовал в игре или такого города еще нет в моем словаре')\n else:\n next_char = curr_city[-1] if curr_city[-1] not in bad_chars else curr_city[-2]\n next_cities = [name for name in city_names if name.startswith(next_char) and name not in used]\n if next_cities:\n next_city = random.choice(next_cities)\n used.append(curr_city)\n used.append(next_city)\n bot.send_message(message.from_user.id, next_city.capitalize())\n char = used[-1][-1] if (used[-1][-1] not in bad_chars) else used[-1][-2]\n bot.send_message(message.from_user.id, f'Введите город на букву {char}:')\n else:\n bot.send_message(message.from_user.id, \"Победа! :) Чтобы начать заново - отправь /start\")\n used.clear()\n else:\n bot.send_message(message.from_user.id, 'Чтобы начать игру - отправь /start, чтобы узнать правила - отправь /help')\n\nbot.polling(none_stop=True, interval=0)\n"
}
] | 2 |
StevenASam/Work-Projects
|
https://github.com/StevenASam/Work-Projects
|
83d41db259335dc873481bc07dd58944bbbe5472
|
ea0cc9544fce4408bc87f0acc16fe070592fd2d7
|
6aa8b659fd374c2da7bc65784e991cfe54032f21
|
refs/heads/master
| 2020-08-05T20:18:43.927505 | 2020-01-08T03:00:58 | 2020-01-08T03:00:58 | 212,693,444 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8111110925674438,
"alphanum_fraction": 0.8111110925674438,
"avg_line_length": 44,
"blob_id": "d868ac6e61695b5349f0cf7aaf3121ff756ba489",
"content_id": "610ab192110689dccc3c2993dc3d549067ddf7d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 2,
"path": "/README.md",
"repo_name": "StevenASam/Work-Projects",
"src_encoding": "UTF-8",
"text": "# Email Automater\nThis is an email automater that sends emails through a python launcher!\n"
},
{
"alpha_fraction": 0.6223486661911011,
"alphanum_fraction": 0.6249353289604187,
"avg_line_length": 26.01449203491211,
"blob_id": "cba154d17cf5545a1f908f11987bee1c1237f746",
"content_id": "84a8ded7c67381e4564c1c3715952cfaf5417e3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1933,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 69,
"path": "/Email Automater - Thursday.py",
"repo_name": "StevenASam/Work-Projects",
"src_encoding": "UTF-8",
"text": "import smtplib\r\n\r\nfrom string import Template\r\n\r\nfrom email.mime.multipart import MIMEMultipart\r\nfrom email.mime.text import MIMEText\r\n\r\nMY_ADDRESS = -Email Here-\r\nPASSWORD = -Email Access Code Here-\r\n\r\n#Accesses information in contacts file\r\ndef get_contacts(filename):\r\n \"\"\"\r\n Return emails containing email addresses\r\n read from a file specified by filename.\r\n \"\"\"\r\n \r\n emails = []\r\n length = None\r\n with open(filename, mode='r', encoding='utf-8') as contacts_file:\r\n for a_contact in contacts_file:\r\n emails.append(a_contact.strip())\r\n length = len(emails)\r\n return length, emails\r\n\r\n#Reads the contacts file\r\ndef read_file(filename):\r\n \"\"\"\r\n Returns a Template object comprising the contents of the \r\n file specified by filename.\r\n \"\"\"\r\n \r\n with open(filename, 'r', encoding='utf-8') as template_file:\r\n message_file_content = template_file.read()\r\n return MIMEText(message_file_content)\r\n\r\ndef main():\r\n length, emails = get_contacts('mycontacts.txt') # read contacts\r\n message_txt = read_file('message-thursday.txt')\r\n\r\n # Prints out the message body for our sake\r\n print(message_txt)\r\n\r\n # set up the SMTP server\r\n s = smtplib.SMTP(host='smtp.gmail.com', port=587)\r\n s.starttls()\r\n s.login(MY_ADDRESS, PASSWORD)\r\n\r\n separator = ', '\r\n email_list = separator.join(emails)\r\n \r\n # setup the parameters of the message\r\n message_txt['From']='-Enter First & Last Name Here- <'+MY_ADDRESS+'>'\r\n message_txt['Subject']=\"[Pre Sales]: Check OA Buckets\"\r\n message_txt['To'] = '-Enter Pre-Sales email here-'\r\n message_txt['Bcc'] = email_list\r\n \r\n\r\n # send the message via the server set up earlier.\r\n s.send_message(message_txt) \r\n \r\n # Terminate the SMTP session and close the connection\r\n s.quit()\r\n\r\n\r\n print('Success!!!')\r\n \r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.6056052446365356,
"alphanum_fraction": 0.6153976321220398,
"avg_line_length": 33.255950927734375,
"blob_id": "e758d52735988eab6b2bb28b19be30887d01f29a",
"content_id": "c71f28242d5cd4003ec984ef4b8d6ee4f99c23bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5923,
"license_type": "no_license",
"max_line_length": 483,
"num_lines": 168,
"path": "/Email Automater - Wednesday.py",
"repo_name": "StevenASam/Work-Projects",
"src_encoding": "UTF-8",
"text": "import smtplib\r\nimport datetime\r\nfrom datetime import date\r\n\r\nfrom string import Template\r\n\r\nfrom email.mime.multipart import MIMEMultipart\r\nfrom email.mime.text import MIMEText\r\n\r\nMY_ADDRESS = '-Enter Email Here-'\r\nPASSWORD = '-Enter Email Access Code Here-'\r\n\r\ndef check_date_number(date):\r\n d = date\r\n d2 = d[len(date)-4]\r\n if d2 == '0':\r\n d = d[1:]\r\n\r\n return d\r\n\r\ndef adjust_date(date):\r\n d = date[len(date)-1]\r\n d2 = date[len(date)-2]\r\n\r\n if d == '1' and d2 != '1':\r\n adjusted_date = date + 'st'\r\n elif d == '2' and d2 != '1':\r\n adjusted_date = date + 'nd'\r\n elif d == '3' and d2 != '1':\r\n adjusted_date = date + 'rd'\r\n else:\r\n adjusted_date = date + 'th'\r\n\r\n return check_date_number(adjusted_date)\r\n\r\n#Get's the date you send the email\r\ndef getDate(date):\r\n d1 = date.strftime(\"%B\") #Current date's month\r\n d2 = date.strftime(\"%d\") #Current day in month\r\n d2 = adjust_date(d2) #Adds wording at end of date (ex. 10 == 10th)\r\n d3 = date.strftime(\"%w\") #Current weekday as a number (ex. Sunday = 1)\r\n print(d1,d2,d3) #for reference internal\r\n d = d1 + ' ' + d2\r\n return d, d3\r\n\r\ndef get_contacts(filename):\r\n \"\"\"\r\n Return emails containing email addresses\r\n read from a file specified by filename.\r\n \"\"\"\r\n \r\n emails = []\r\n length = None\r\n with open(filename, mode='r', encoding='utf-8') as contacts_file:\r\n for a_contact in contacts_file:\r\n emails.append(a_contact.strip())\r\n length = len(emails)\r\n return length, emails\r\n\r\ndef read_file(filename):\r\n \"\"\"\r\n Returns a Template object comprising the contents of the \r\n file specified by filename.\r\n \"\"\"\r\n \r\n with open(filename, 'r', encoding='utf-8') as template_file:\r\n message_file_content = template_file.read()\r\n return MIMEText(message_file_content)\r\n\r\n#Sends emails to PM Group\r\ndef submit_opps_email(text, date):\r\n message_txt = MIMEText(text, 'html')\r\n\r\n # set up the SMTP server\r\n s = smtplib.SMTP(host='smtp.gmail.com', port=587)\r\n s.starttls()\r\n s.login(MY_ADDRESS, PASSWORD)\r\n\r\n #separator = ', '\r\n #email_list = separator.join(emails)\r\n \r\n # setup the parameters of the message\r\n message_txt['From']='-Enter First & Last Name Here- <'+MY_ADDRESS+'>'\r\n message_txt['Subject']=\"Submitting Pre Sales Opps - Week of \" + date\r\n message_txt['To'] = '-Enter Receiver Emails Here-'\r\n\r\n # send the message via the server set up earlier.\r\n s.send_message(message_txt) \r\n \r\n # Terminate the SMTP session and close the connection\r\n s.quit()\r\n\r\n#Sends emails to Sales Group\r\ndef allocations_email(text, date):\r\n message_txt = MIMEText(text, 'html')\r\n\r\n # set up the SMTP server\r\n s = smtplib.SMTP(host='smtp.gmail.com', port=587)\r\n s.starttls()\r\n s.login(MY_ADDRESS, PASSWORD)\r\n\r\n #separator = ', '\r\n #email_list = separator.join(emails)\r\n \r\n # setup the parameters of the message\r\n message_txt['From']='-Enter First & Last Name Here- <'+MY_ADDRESS+'>'\r\n message_txt['Subject']=\"[Pre Sales] Allocation - Week of \" + date + \" - Calling for Resource Requests\"\r\n message_txt['To'] = '-Enter Reciever Emails Here'\r\n \r\n # send the message via the server set up earlier.\r\n s.send_message(message_txt) \r\n \r\n # Terminate the SMTP session and close the connection\r\n s.quit()\r\n\r\n\r\ndef main():\r\n my_date = datetime.datetime.today() + datetime.timedelta(days=5)\r\n d1, d2 = getDate(my_date)\r\n #length, emails = get_contacts('mycontacts.txt') # read contacts\r\n # message_txt = read_file('message.txt')\r\n \r\n text_1 = \"\"\"\\\r\n <html>\r\n <head></head>\r\n <body>\r\n <p>Hi Sales team,<br>\r\n <br>\r\n <u>The asks:</u><br>\r\n <br>\r\n 1. Please submit any new opps intending to start next week no later than Thursday 9AM PST to -Enter Pre-Sales Email Here- for housekeeping processing & to allow delivery PMs to be able to work with the Domain Leads & request resources from Resourcing with some buffer time for back and forth discussions. You can still submit opps to -Enter Pre-Sale Email Here- after the Thursday deadline but when times get busy it's best to get them in as soon as possible on Thursday.<br>\r\n <br> \r\n <u>The nags (if you have not done so already):</u><br>\r\n <br>\r\n 2. Please send any finalized proposals to -Enter Pre-Sale Email Here- so that we can archive and document them as needed.<br>\r\n <br>\r\n Thank you for your diligence in updating these.\r\n </p>\r\n </body>\r\n </html>\"\"\"\r\n text_2 = \"\"\"\\\r\n <html>\r\n <head></head>\r\n <body>\r\n <p>Hi All,<br>\r\n <br>\r\n <b><ul style=\"list-style-type:circle;\">\r\n<li>Sending a friendly reminder to Pre Sales PMs to ensure they input their staffing requests onto the sheet <a href=\"-Enter Resource Request Sheet Link Here-\">here</a> by Thursday 10:00am PST for pre-sales efforts for next week.</li>\r\n<li>Please click on last Friday's sheet and fill in any opp notes that you have in <a href=\"-Enter Opp Summary Sheet Link Here-\">here</a>.</li>\r\n </ul></b><br>\r\n This covers all pre-sales that are scheduled to start, finish, continue, or have been delayed to next week or possibly require follow-up. If you are not sure as to the status of your opportunity (i.e. if there will be activity on the opp), please reach out to the BD/CS representative in question.\r\n <br> \r\n <ul style=\"list-style-type:circle;\">\r\n<li>Please update your opp statuses this week on NS if you have not already!</li>\r\n</ul>\r\n Thank you for your diligence in updating these\r\n </p> <br>\r\n </body>\r\n </html>\"\"\"\r\n\r\n # sends 2 separate emails\r\n submit_opps_email(text_1, d1)\r\n allocations_email(text_2, d1)\r\n\r\n print('Success!!!')\r\n \r\nif __name__ == '__main__':\r\n main()\r\n"
}
] | 3 |
Krzem5/Python-WebSocket_Chat
|
https://github.com/Krzem5/Python-WebSocket_Chat
|
6743ed1ab51691701480e88b024661f6f09a38ea
|
9912444bff887900d72872317e5b67647b0c5c13
|
b1cb8a5b61e9c09e8fdea8c1e5e386915ff519c9
|
refs/heads/main
| 2023-06-08T07:53:50.165254 | 2022-12-31T18:12:27 | 2022-12-31T18:12:27 | 250,789,896 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6842105388641357,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 18,
"blob_id": "43678db1b90f8a0f9a5a6f0a3d486928bae4a090",
"content_id": "7849ce87233c5175e4b30ad775a2fa99b5a69dd3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Krzem5/Python-WebSocket_Chat",
"src_encoding": "UTF-8",
"text": "# Websocket - Chat\n"
},
{
"alpha_fraction": 0.6495819687843323,
"alphanum_fraction": 0.6619411110877991,
"avg_line_length": 32.14457702636719,
"blob_id": "1a4dad7dce590674935837e04cefad5eefe277ce",
"content_id": "724eecdade4a7585ba1032fd296f19a399d5318c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2751,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 83,
"path": "/src/main.py",
"repo_name": "Krzem5/Python-WebSocket_Chat",
"src_encoding": "UTF-8",
"text": "from SimpleWebSocketServer import SimpleWebSocketServer, WebSocket\nimport random\nimport threading\n\n\n\nADMIN_PASSWD=\"\"\nDATA_DICT={}\nLIST_ADDR=[]\nUSED_NAMES=[]\nclass LWebSocketServer(WebSocket):\n\tdef handleMessage(self):\n\t\tthr=threading.Thread(target=self.process_message,args=(),kwargs={})\n\t\tthr.start()\n\tdef handleConnected(self):\n\t\tpass\n\tdef handleClose(self):\n\t\tUSED_NAMES.remove(self.CHAT_NAME)\n\t\tdel DATA_DICT[self.address]\n\t\tLIST_ADDR.remove(self.address)\n\t\tprint(\"leave:\\t\"+self.CHAT_NAME)\n\t\tself.sendall(\"leave:\"+self.CHAT_NAME)\n\tdef sendall(self,m):\n\t\tfor c in LIST_ADDR:\n\t\t\tDATA_DICT[c][\"socket\"].sendMessage(m)\n\tdef process_message(self,*args):\n\t\tmsg=self.data\n\t\tself.sendMessage(\"null\")\n\t\tif ((not hasattr(self,\"CHAT_NAME\") and msg!=\"setup\") or (msg==\"setup\" and hasattr(self,\"CHAT_NAME\"))):\n\t\t\treturn\n\t\tif (msg[:4]==\"txt:\"):\n\t\t\tprint(\"Message:\\t\"+self.CHAT_NAME+\":\\t\"+msg[4:])\n\t\t\tself.sendall(\"txt:\"+str(len(self.CHAT_NAME))+\":\"+self.CHAT_NAME+msg[4:])\n\t\t\treturn\n\t\tif (msg[:10]==\"admin_req:\"):\n\t\t\tprint(\"Admin req:\\t\"+self.CHAT_NAME+\"(\"+str(msg[10:]==ADMIN_PASSWD)+\")\")\n\t\t\tmsg=msg[10:]\n\t\t\tif (msg==ADMIN_PASSWD):\n\t\t\t\tDATA_DICT[self.address][\"rank\"]=\"admin\"\n\t\t\t\tself.sendMessage(\"rank:1:admin\")\n\t\t\t\treturn\n\t\t\tself.sendMessage(\"rank:0:admin:\"+DATA_DICT[self.address][\"rank\"])\n\t\t\treturn\n\t\tif (msg==\"setup\"):\n\t\t\tpid=1\n\t\t\twhile True:\n\t\t\t\tself.CHAT_NAME=\"Person #%s\"%(pid)\n\t\t\t\tpid+=1\n\t\t\t\tif (USED_NAMES.count(self.CHAT_NAME)==0):break\n\t\t\tUSED_NAMES.append(self.CHAT_NAME)\n\t\t\tprint(\"join:\\t\"+self.CHAT_NAME)\n\t\t\tDATA_DICT[self.address]={\"address\":self.address,\"name\":self.CHAT_NAME,\"rank\":\"normal\",\"socket\":self}\n\t\t\tLIST_ADDR.append(self.address)\n\t\t\tself.sendall(\"join:\"+self.CHAT_NAME)\n\t\t\treturn\n\t\tif (msg[:4]==\"chn:\"):\n\t\t\tmsg=msg[4:]\n\t\t\tif (len(msg)<3):\n\t\t\t\tprint(\"Chn:\\t\"+self.CHAT_NAME+\"-unsuccessfull (Too short)\")\n\t\t\t\tself.sendMessage(\"chn:0:\"+msg)\n\t\t\t\treturn\n\t\t\tif (len(msg)>20):\n\t\t\t\tprint(\"Chn:\\t\"+self.CHAT_NAME+\"-unsuccessfull (Too long)\")\n\t\t\t\tself.sendMessage(\"chn:1:\"+msg)\n\t\t\t\treturn\n\t\t\tif (USED_NAMES.count(msg)>0):\n\t\t\t\tprint(\"Chn:\\t\"+self.CHAT_NAME+\"-unsuccessfull (Already used)\")\n\t\t\t\tself.sendMessage(\"chn:2:\"+msg)\n\t\t\t\treturn\n\t\t\tprint(\"Chn:\\t\"+self.CHAT_NAME+\"-successfull (Changed to:\"+msg+\")\")\n\t\t\tself.sendMessage(\"chn:true:\"+msg)\n\t\t\tUSED_NAMES.remove(self.CHAT_NAME)\n\t\t\tself.CHAT_NAME=msg\n\t\t\tUSED_NAMES.append(self.CHAT_NAME)\n\t\t\tDATA_DICT[self.address][\"name\"]=self.CHAT_NAME\n\t\t\treturn\nfor _ in range(0,50):\n\tADMIN_PASSWD+=random.choice(list(\"\"\"`1234567890-=qwertyuiop[]asdfghjkl;'zxcvbnm,./~!@#$%^&*()_+QWERTYUIOP{}|ASDFGHJKL:\"ZXCVBNM<>?\"\"\"))# removed '\\'\nwith open(\"./admin.txt\",\"w\") as f:\n\tf.write(ADMIN_PASSWD)\nserver=SimpleWebSocketServer(\"\",8080,LWebSocketServer)\nprint(\"\\nWebSocketServer has started on port 8080!\\n\")\nserver.serveforever()\n"
}
] | 2 |
vivekpunar/resumebuilder
|
https://github.com/vivekpunar/resumebuilder
|
60ebe51d762e939080015a4eac9ceba127df3bef
|
cc6a131ceb8f67e0268b6a8fa2dfd1f27eeab683
|
8deedb70031537ce5b52d229774d249b1d488d6b
|
refs/heads/main
| 2023-07-09T03:00:16.446063 | 2021-08-14T09:29:45 | 2021-08-14T09:29:45 | 395,957,995 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6571637392044067,
"alphanum_fraction": 0.6571637392044067,
"avg_line_length": 39.264705657958984,
"blob_id": "ff7e231b1e4176860db3350d2db9f4ce85ecefce",
"content_id": "0343a398b5b1dc6e5a1c1a0a531bf01f1c4fc86d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1368,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 34,
"path": "/myapp/forms.py",
"repo_name": "vivekpunar/resumebuilder",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Resume\n\nGENDER_CHOICES = [\n ('Male', 'Male'),\n ('Female', 'Female')\n]\n\nJOB_CITY_CHOICE = [\n ('Delhi', 'Delhi'),\n ('Pune', 'Pune'),\n ('Ranchi', 'Ranchi'),\n ('Mumbai', 'Mumbai'),\n ('Dhanbad', 'Dhanbad'),\n ('Banglore', 'Banglore')\n]\n\nclass ResumeForm(forms.ModelForm):\n gender = forms.ChoiceField(choices=GENDER_CHOICES, widget=forms.RadioSelect)\n job_city = forms.MultipleChoiceField(label='Preferred Job Locations', choices=JOB_CITY_CHOICE, widget=forms.CheckboxSelectMultiple)\n class Meta:\n model = Resume\n fields = ['name', 'dob', 'gender', 'locality', 'city', 'pin', 'state', 'mobile', 'email', 'job_city', 'profile_image', 'my_file']\n labels = {'name':'Full Name', 'dob': 'Date of Birth', 'pin':'Pin Code', 'mobile':'Mobile No.', 'email':'Email ID', 'profile_image':'Profile Image', 'my_file':'Document'}\n widgets = {\n 'name':forms.TextInput(attrs={'class':'form-control'}),\n 'dob':forms.DateInput(attrs={'class':'form-control', 'id':'datepicker'}),\n 'locality':forms.TextInput(attrs={'class':'form-control'}),\n 'city':forms.TextInput(attrs={'class':'form-control'}),\n 'pin':forms.NumberInput(attrs={'class':'form-control'}),\n 'state':forms.Select(attrs={'class':'form-select'}),\n 'mobile':forms.NumberInput(attrs={'class':'form-control'}),\n 'email':forms.EmailInput(attrs={'class':'form-control'}),\n }"
},
{
"alpha_fraction": 0.6973180174827576,
"alphanum_fraction": 0.6973180174827576,
"avg_line_length": 42.5,
"blob_id": "8209ae82f2dc8d7f5ad11448f715164a0d89c2e4",
"content_id": "74d44fc91b992b58b88432b2e402eb1ab6738f40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 6,
"path": "/myapp/admin.py",
"repo_name": "vivekpunar/resumebuilder",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Resume\n\[email protected](Resume)\nclass ResumeModelAdmin(admin.ModelAdmin):\n list_display = ['id', 'name', 'dob', 'gender', 'locality', 'city', 'pin', 'state', 'mobile', 'job_city', 'profile_image', 'my_file']\n"
}
] | 2 |
wanglihua/Speed
|
https://github.com/wanglihua/Speed
|
2dc17fc21330ceb3a1ee57c0395d41d2ca402347
|
d6cec75e0384cea9f86f56dd2e5b1e35ec6ddb94
|
505c59c014e7ab19d1a9416122d7d46b202e968a
|
refs/heads/master
| 2018-01-16T04:59:54.786295 | 2016-06-03T13:29:29 | 2016-06-03T13:29:29 | 33,816,595 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6950757503509521,
"alphanum_fraction": 0.7102272510528564,
"avg_line_length": 57.77777862548828,
"blob_id": "1b5ca6074e5f206e416634228628d8d3c8fadb8c",
"content_id": "b5968197479af19f0a846b5db95bca4b83d965f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 596,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 9,
"path": "/inventory/models.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Warehouse(models.Model):\n wh_code = models.CharField('编码', max_length=20, unique=True, null=False, blank=False, error_messages={'unique': '编码不能相重!'})\n wh_name = models.CharField('仓库名称', max_length=100, unique=True, null=False, blank=False, error_messages={'unique': '仓库名称不能相重!'})\n wh_desc = models.CharField('仓库描述', max_length=255, null=True, blank=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)"
},
{
"alpha_fraction": 0.4235786497592926,
"alphanum_fraction": 0.4304701089859009,
"avg_line_length": 25.100000381469727,
"blob_id": "d4fdc2120bcf3183c82f0d4d88fba4c4428847c5",
"content_id": "28ce8535e79718ceed6c55afb2081579af26ed48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4123,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 150,
"path": "/common/static/common/js/site.js",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "Ext.onReady(function () {\r\n Ext.define('speed.GridDataStore', {\r\n extend: 'Ext.data.Store',\r\n remoteSort: true,\r\n pageSize: 10,\r\n proxy: {\r\n type: 'ajax',\r\n actionMethods: {\r\n read: 'POST'\r\n },\r\n reader: {\r\n type: 'json',\r\n totalProperty: 'total',\r\n root: 'rows'\r\n }\r\n },\r\n listeners: {\r\n load: function (store, records, successful, eOpts) {\r\n if (successful == false) {\r\n var data = Ext.decode(eOpts._response.responseText);\r\n Ext.Msg.alert('失败', data.message);\r\n }\r\n }\r\n }\r\n });\r\n\r\n Ext.define('speed.TreeDataStore', {\r\n extend: 'Ext.data.TreeStore',\r\n proxy: {\r\n type: 'ajax',\r\n actionMethods: {\r\n read: 'POST'\r\n }\r\n },\r\n remoteSort: true,\r\n sorters: [{property: 'text', direction: 'ASC'}],\r\n listeners: {\r\n load: function (store, records, successful, eOpts) {\r\n if (successful == false) {\r\n var data = Ext.decode(eOpts._response.responseText);\r\n Ext.Msg.alert('失败', data.message);\r\n }\r\n }\r\n }\r\n });\r\n\r\n Ext.define('speed.PageSizeComboBox', {\r\n extend: 'Ext.form.ComboBox',\r\n width: 50,\r\n store: new Ext.data.ArrayStore({\r\n fields: ['pagesize'],\r\n data: [\r\n ['10'],\r\n ['15'],\r\n ['25'],\r\n ['50']\r\n ]\r\n }),\r\n mode: 'local',\r\n value: '15',\r\n\r\n listWidth: 40,\r\n triggerAction: 'all',\r\n displayField: 'pagesize',\r\n valueField: 'pagesize',\r\n editable: false,\r\n forceSelection: true\r\n });\r\n\r\n Ext.define('speed.PagingToolbar', {\r\n extend: 'Ext.PagingToolbar',\r\n displayInfo: true,\r\n displayMsg: '显示第 {0} 条到 {1} 条记录,一共 {2} 条',\r\n emptyMsg: \"没有记录\",\r\n\r\n initComponent: function () {\r\n var pageSizeComboBox = Ext.create('speed.PageSizeComboBox');\r\n\r\n Ext.apply(this, {\r\n items: [\r\n '-',\r\n '每页',\r\n pageSizeComboBox,\r\n '条'\r\n ]\r\n });\r\n\r\n var pagingToolbar = this;\r\n\r\n pageSizeComboBox.on('select', function (combo) {\r\n pagingToolbar.getStore().pageSize = parseInt(combo.getValue());\r\n pagingToolbar.moveFirst();\r\n });\r\n\r\n\r\n this.callParent();\r\n }\r\n });\r\n\r\n Ext.define('speed.GridPanel', {\r\n extend: 'Ext.grid.GridPanel',\r\n viewConfig: {emptyText: '暂时没有数据!'},\r\n enableColumnMove: false,\r\n loadMask: true,\r\n forceFit: true,\r\n selModel: 'checkboxmodel',\r\n\r\n initComponent: function () {\r\n var grid = this;\r\n var pagingToolbar = Ext.create('speed.PagingToolbar', {\r\n store: grid.getStore()\r\n });\r\n\r\n this.pagingToolbar = pagingToolbar;\r\n\r\n Ext.apply(this, {\r\n bbar: pagingToolbar\r\n });\r\n\r\n this.callParent();\r\n },\r\n getPagingToolbar: function () {\r\n return this.pagingToolbar;\r\n }\r\n });\r\n\r\n Ext.define('speed.FormPanel', {\r\n extend: 'Ext.form.FormPanel',\r\n region: 'center',\r\n layout: 'form',\r\n bodyStyle: 'padding: 5px 20px;',\r\n defaultType: 'textfield',\r\n frame: false,\r\n fieldDefaults: {\r\n labelAlign: 'left',\r\n labelWidth: 80\r\n }\r\n });\r\n\r\n Ext.define('speed.Dialog', {\r\n extend: 'Ext.Window',\r\n layout: 'fit',\r\n modal: true,\r\n closeAction: 'destroy',\r\n width: 600,\r\n defaultButton: 0,\r\n buttonAlign: 'right',\r\n resizable: false\r\n });\r\n});"
},
{
"alpha_fraction": 0.556382954120636,
"alphanum_fraction": 0.5613152980804443,
"avg_line_length": 51.75510025024414,
"blob_id": "89f86567101a66589bffdd2de1cdaac82630ead6",
"content_id": "3f7e055309888ee224d5b1ee4e561924e9f88283",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10780,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 196,
"path": "/auth/migrations/0001_initial.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='User',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('login_name', models.CharField(error_messages={'unique': '登录名不能相重!'}, max_length=20, verbose_name='登录名', unique=True)),\n ('nick_name', models.CharField(verbose_name='用户名', max_length=20)),\n ('password', models.CharField(verbose_name='密码', max_length=100)),\n ('last_login', models.DateTimeField(null=True, verbose_name='最近登录', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ],\n ),\n migrations.CreateModel(\n name='Admin',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('admin_desc', models.CharField(null=True, max_length=255, verbose_name='描述', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('user', models.ForeignKey(verbose_name='用户', to='auth.User')),\n ],\n ),\n migrations.CreateModel(\n name='App',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('app_code', models.CharField(error_messages={'unique': '编码不能相重!'}, max_length=20, verbose_name='编码', unique=True)),\n ('app_name', models.CharField(error_messages={'unique': '应用名称不能相重!'}, max_length=100, verbose_name='应用名称', unique=True)),\n ('app_desc', models.CharField(null=True, max_length=255, verbose_name='应用描述', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ],\n ),\n migrations.CreateModel(\n name='AuthResult',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('res_label', models.CharField(verbose_name='资源标签', max_length=200)),\n ('app', models.ForeignKey(verbose_name='应用', to='auth.App')),\n ],\n ),\n migrations.CreateModel(\n name='Department',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('dept_code', models.CharField(error_messages={'unique': '编码不能相重!'}, max_length=20, verbose_name='编码', unique=True)),\n ('dept_name', models.CharField(verbose_name='部门名称', max_length=20)),\n ('dept_desc', models.CharField(null=True, max_length=255, verbose_name='部门描述', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ('parent', models.ForeignKey(verbose_name='上级部门', to='auth.Department', null=True, blank=True)),\n ],\n ),\n migrations.CreateModel(\n name='DepartmentUser',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('department', models.ForeignKey(verbose_name='部门', to='auth.Department')),\n ('user', models.ForeignKey(verbose_name='用户', to='auth.User')),\n ],\n ),\n migrations.CreateModel(\n name='Group',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('group_code', models.CharField(verbose_name='编码', max_length=20)),\n ('group_name', models.CharField(verbose_name='群组名称', max_length=100)),\n ('group_desc', models.CharField(null=True, max_length=255, verbose_name='群组描述', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ('app', models.ForeignKey(verbose_name='应用', to='auth.App', null=True, blank=True)),\n ],\n ),\n migrations.CreateModel(\n name='GroupResource',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('group', models.ForeignKey(verbose_name='群组', to='auth.Group')),\n ],\n ),\n migrations.CreateModel(\n name='GroupUser',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('group', models.ForeignKey(verbose_name='群组', to='auth.Group')),\n ('user', models.ForeignKey(verbose_name='用户', to='auth.User')),\n ],\n ),\n migrations.CreateModel(\n name='Resource',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('res_code', models.CharField(verbose_name='编码', max_length=50)),\n ('res_name', models.CharField(verbose_name='资源名称', max_length=100)),\n ('res_desc', models.CharField(null=True, max_length=255, verbose_name='资源描述', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ('app', models.ForeignKey(verbose_name='应用', to='auth.App')),\n ('groups', models.ManyToManyField(to='auth.Group', verbose_name='群组', through='auth.GroupResource', blank=True)),\n ],\n ),\n migrations.CreateModel(\n name='ResourceMenu',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('menu_name', models.CharField(verbose_name='菜单名称', max_length=100)),\n ('menu_url', models.CharField(verbose_name='菜单Url', max_length=255)),\n ('menu_order', models.IntegerField(null=True, verbose_name='菜单排序', blank=True)),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ('app', models.ForeignKey(verbose_name='应用', to='auth.App')),\n ('parent', models.ForeignKey(verbose_name='父菜单', to='auth.ResourceMenu', null=True, blank=True)),\n ('resource', models.ForeignKey(verbose_name='资源', to='auth.Resource')),\n ],\n ),\n migrations.CreateModel(\n name='UserResource',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('resource', models.ForeignKey(verbose_name='资源', to='auth.Resource')),\n ('user', models.ForeignKey(verbose_name='用户', to='auth.User')),\n ],\n ),\n migrations.AddField(\n model_name='resource',\n name='users',\n field=models.ManyToManyField(to='auth.User', verbose_name='用户', through='auth.UserResource', blank=True),\n ),\n migrations.AddField(\n model_name='groupresource',\n name='resource',\n field=models.ForeignKey(verbose_name='资源', to='auth.Resource'),\n ),\n migrations.AddField(\n model_name='group',\n name='resources',\n field=models.ManyToManyField(to='auth.Resource', verbose_name='资源', through='auth.GroupResource', blank=True),\n ),\n migrations.AddField(\n model_name='group',\n name='users',\n field=models.ManyToManyField(to='auth.User', verbose_name='用户', through='auth.GroupUser', blank=True),\n ),\n migrations.AddField(\n model_name='department',\n name='users',\n field=models.ManyToManyField(to='auth.User', verbose_name='用户', through='auth.DepartmentUser', blank=True),\n ),\n migrations.AddField(\n model_name='authresult',\n name='group',\n field=models.ForeignKey(verbose_name='群组', to='auth.Group', null=True),\n ),\n migrations.AddField(\n model_name='authresult',\n name='resource',\n field=models.ForeignKey(verbose_name='资源', to='auth.Resource'),\n ),\n migrations.AddField(\n model_name='authresult',\n name='user',\n field=models.ForeignKey(verbose_name='用户', to='auth.User'),\n ),\n migrations.AddField(\n model_name='user',\n name='resources',\n field=models.ManyToManyField(to='auth.Resource', verbose_name='资源', through='auth.UserResource', blank=True),\n ),\n migrations.AlterUniqueTogether(\n name='resource',\n unique_together=set([('app', 'res_name'), ('app', 'res_code')]),\n ),\n migrations.AlterUniqueTogether(\n name='group',\n unique_together=set([('app', 'group_code'), ('app', 'group_name')]),\n ),\n migrations.AlterUniqueTogether(\n name='departmentuser',\n unique_together=set([('user', 'department')]),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6912718415260315,
"alphanum_fraction": 0.6912718415260315,
"avg_line_length": 38.918365478515625,
"blob_id": "ed461a18bbc49acff6615898fdb7ac8c3dae03dd",
"content_id": "9ed65c2c9f217d7c4224292095652754f842f4f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2059,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 49,
"path": "/auth/views/result.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.models import AuthResult\r\nfrom auth.permission import permission_required\r\nfrom auth.service.authresult import AuthResultService\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.result_view')\r\ndef result_search(request):\r\n return render(request, 'auth/result.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.result_view')\r\ndef result_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n result_query = AuthResult.objects.all()\r\n # extra filters here\r\n result_query = result_query.values('app__app_name', 'res_label', 'resource__res_name', 'user__login_name', 'user__nick_name', 'group__group_code', 'group__group_name')\r\n if sort_property is not None:\r\n result_query = result_query.order_by(sort_direction + sort_property)\r\n total_count = result_query.count()\r\n result_list = list(result_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': result_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.result_regenerate')\r\ndef result_regenerate(request):\r\n try:\r\n auth_result_service = AuthResultService()\r\n auth_result_service.refresh_all_result()\r\n return JsonResponse({'success': True, 'message': '重新生成成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '重新生成失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.6090719699859619,
"alphanum_fraction": 0.610995352268219,
"avg_line_length": 38.51298522949219,
"blob_id": "ba3ac8b896443afcc48d60f0e472e43bd793f7c8",
"content_id": "587c9222ac8d27b38bb20b02dfd8a9131c9bb94a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6595,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 154,
"path": "/auth/views/user.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django import forms\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q, Count\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.service.login import LoginService\r\nfrom auth.permission import permission_required\r\nfrom auth.models import User, UserResource, Admin\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\nlogin_service = LoginService()\r\n\r\n\r\n@permission_required('auth.user_view')\r\ndef user_search(request):\r\n return render(request, 'auth/user.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.user_view')\r\ndef user_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n user_query = User.objects.all()\r\n user_query = user_query.values(*field_names(User))\r\n if sort_property is not None:\r\n user_query = user_query.order_by(sort_direction + sort_property)\r\n total_count = user_query.count()\r\n user_list = list(user_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.user_view')\r\ndef user_detail_data(request):\r\n user_id_data = request.POST.get('id')\r\n if user_id_data is None:\r\n user = User()\r\n else:\r\n user_id = int(user_id_data)\r\n user = User.objects.filter(pk=user_id).values(*field_names(User))[0]\r\n user['new_password'] = ''\r\n return JsonResponse(user)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.user_delete')\r\ndef user_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n count = Admin.objects.filter(user_id__in=id_list).count()\r\n if count != 0:\r\n return JsonResponse({'success': False, 'message': '删除失败,不能删除管理员用户!'})\r\n User.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass UserDetailForm(ModelForm):\r\n new_password = forms.CharField(required=False)\r\n\r\n class Meta:\r\n model = User\r\n fields = '__all__'\r\n # exclude = ['groups']\r\n error_messages = {\r\n 'login_name': {\r\n 'required': '登录名是必填项!',\r\n 'max_length': '登录名不能超过20个字符!',\r\n },\r\n 'nick_name': {\r\n 'required': '用户名是必填项!',\r\n 'max_length': '用户名不能超过20个字符!',\r\n },\r\n 'password': {\r\n 'required': '密码是必填项!',\r\n 'max_length': '密码不能超过100个字符!',\r\n },\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.user_save')\r\ndef user_save(request):\r\n try:\r\n user_id = request.POST.get('id')\r\n is_create = user_id is None or user_id == '' or user_id == '0'\r\n if is_create:\r\n user_form = UserDetailForm(request.POST)\r\n else:\r\n user = User.objects.get(pk=user_id)\r\n user_form = UserDetailForm(request.POST, instance=user)\r\n if not user_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(user_form)})\r\n user = user_form.save(commit=False)\r\n if is_create: # 新建用户时加密密码\r\n # user.password = make_password(user.password, None, 'pbkdf2_sha256')\r\n user.password = login_service.encrypt_password(user.password)\r\n else: # 如果新密码存在于表单,就加密保存,如果不存在就不更新密码(取表单上的值)\r\n new_password = user_form.data.get('new_password').strip()\r\n if new_password != '':\r\n # user.password = make_password(new_password, None, 'pbkdf2_sha256')\r\n user.password = login_service.encrypt_password(new_password)\r\n user.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n\r\n\r\nclass UserIdListForm(forms.Form):\r\n user_id_list = forms.IntegerField()\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.user_resource_view')\r\ndef user_auth_resource_list_data(request):\r\n try:\r\n if request.POST.get('user_id_list') is None:\r\n return JsonResponse({'total': 0, 'rows': []})\r\n user_id_list_form = UserIdListForm(request.POST)\r\n user_id_list = user_id_list_form.data.getlist('user_id_list')\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n user_id_count = len(user_id_list)\r\n auth_resource_query = UserResource.objects.all() \\\r\n .values('resource_id').annotate(user_count=Count('user')) \\\r\n .filter(user__in=user_id_list, user_count=user_id_count)\r\n if user_id_count == 1:\r\n auth_resource_query = auth_resource_query.values('resource__app__app_name', 'resource__res_code', 'resource__res_name', 'create_time')\r\n else:\r\n auth_resource_query = auth_resource_query.values('resource__app__app_name', 'resource__res_code', 'resource__res_name')\r\n if sort_property is not None:\r\n auth_resource_query = auth_resource_query.order_by(sort_direction + sort_property)\r\n total_count = auth_resource_query.count()\r\n resource_list = list(auth_resource_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': resource_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.6880500912666321,
"alphanum_fraction": 0.6880500912666321,
"avg_line_length": 82.4000015258789,
"blob_id": "e41806bc72f9e31e4a79c9bb6707c0a66a91813c",
"content_id": "95944640670a06367886a499789590743080cc10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5908,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 70,
"path": "/auth/urls.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\r\n\r\nurlpatterns = [\r\n url(r'^user/list/$', 'auth.views.user.user_search', name='user_list'),\r\n url(r'^user/listdata/$', 'auth.views.user.user_list_data', name='user_list_data'),\r\n url(r'^user/detaildata/$', 'auth.views.user.user_detail_data', name='user_detail_data'),\r\n url(r'^user/save/$', 'auth.views.user.user_save', name='user_save'),\r\n url(r'^user/delete/$', 'auth.views.user.user_delete', name='user_delete'),\r\n url(r'^user/authresourcedata/$', 'auth.views.user.user_auth_resource_list_data', name='user_auth_resource_list_data'),\r\n\r\n url(r'^admin/list/$', 'auth.views.admin.admin_search', name='admin_list'),\r\n url(r'^admin/listdata/$', 'auth.views.admin.admin_list_data', name='admin_list_data'),\r\n url(r'^admin/detaildata/$', 'auth.views.admin.admin_detail_data', name='admin_detail_data'),\r\n url(r'^admin/save/$', 'auth.views.admin.admin_save', name='admin_save'),\r\n url(r'^admin/delete/$', 'auth.views.admin.admin_delete', name='admin_delete'),\r\n url(r'^admin/selectuserdata/$', 'auth.views.admin.admin_select_user_list_data', name='admin_select_user_data'),\r\n\r\n url(r'^app/list/$', 'auth.views.app.app_search', name='app_list'),\r\n url(r'^app/listdata/$', 'auth.views.app.app_list_data', name='app_list_data'),\r\n url(r'^app/detaildata/$', 'auth.views.app.app_detail_data', name='app_detail_data'),\r\n url(r'^app/save/$', 'auth.views.app.app_save', name='app_save'),\r\n url(r'^app/delete/$', 'auth.views.app.app_delete', name='app_delete'),\r\n\r\n url(r'^group/list/$', 'auth.views.group.group_search', name='group_list'),\r\n url(r'^group/listdata/$', 'auth.views.group.group_list_data', name='group_list_data'),\r\n url(r'^group/detaildata/$', 'auth.views.group.group_detail_data', name='group_detail_data'),\r\n url(r'^group/save/$', 'auth.views.group.group_save', name='group_save'),\r\n url(r'^group/delete/$', 'auth.views.group.group_delete', name='group_delete'),\r\n url(r'^group/authresourcedata/$', 'auth.views.group.group_auth_resource_list_data', name='group_auth_resource_list_data'),\r\n\r\n url(r'^dept/list/$', 'auth.views.dept.dept_search', name='dept_list'),\r\n url(r'^dept/treedata/$', 'auth.views.dept.dept_tree_data', name='dept_tree_data'),\r\n url(r'^dept/listdata/$', 'auth.views.dept.dept_list_data', name='dept_list_data'),\r\n url(r'^dept/detaildata/$', 'auth.views.dept.dept_detail_data', name='dept_detail_data'),\r\n url(r'^dept/save/$', 'auth.views.dept.dept_save', name='dept_save'),\r\n url(r'^dept/delete/$', 'auth.views.dept.dept_delete', name='dept_delete'),\r\n\r\n url(r'^deptuser/list/$', 'auth.views.deptuser.deptuser_search', name='deptuser_list'),\r\n url(r'^deptuser/depttreedata/$', 'auth.views.deptuser.deptuser_dept_tree_data', name='deptuser_dept_tree_data'),\r\n url(r'^deptuser/deptuserdata/$', 'auth.views.deptuser.deptuser_user_list_data', name='deptuser_user_list_data'),\r\n url(r'^deptuser/selectuserdata/$', 'auth.views.deptuser.deptuser_select_user_list_data', name='deptuser_select_user_data'),\r\n url(r'^deptuser/adduser/$', 'auth.views.deptuser.deptuser_add_user', name='deptuser_add_user'),\r\n url(r'^deptuser/removeuser/$', 'auth.views.deptuser.deptuser_remove_user', name='deptuser_remove_user'),\r\n\r\n url(r'^groupuser/list/$', 'auth.views.groupuser.groupuser_search', name='groupuser_list'),\r\n url(r'^groupuser/grouptreedata/$', 'auth.views.groupuser.groupuser_group_tree_data', name='groupuser_group_tree_data'),\r\n url(r'^groupuser/groupuserdata/$', 'auth.views.groupuser.groupuser_user_list_data', name='groupuser_user_list_data'),\r\n url(r'^groupuser/selectuserdata/$', 'auth.views.groupuser.groupuser_select_user_list_data', name='groupuser_select_user_data'),\r\n url(r'^groupuser/adduser/$', 'auth.views.groupuser.groupuser_add_user', name='groupuser_add_user'),\r\n url(r'^groupuser/removeuser/$', 'auth.views.groupuser.groupuser_remove_user', name='groupuser_remove_user'),\r\n\r\n url(r'^resource/list/$', 'auth.views.resource.resource_search', name='resource_list'),\r\n url(r'^resource/apptreedata/$', 'auth.views.resource.resource_app_tree_data', name='resource_app_tree_data'),\r\n url(r'^resource/listdata/$', 'auth.views.resource.resource_list_data', name='resource_list_data'),\r\n url(r'^resource/detaildata/$', 'auth.views.resource.resource_detail_data', name='resource_detail_data'),\r\n url(r'^resource/save/$', 'auth.views.resource.resource_save', name='resource_save'),\r\n url(r'^resource/delete/$', 'auth.views.resource.resource_delete', name='resource_delete'),\r\n url(r'^resource/authuserdata/$', 'auth.views.resource.resource_auth_user_list_data', name='resource_auth_user_list_data'),\r\n url(r'^resource/authselectuserdata/$', 'auth.views.resource.resource_auth_user_select_list_data', name='resource_auth_user_select_list_data'),\r\n url(r'^resource/authusersave/$', 'auth.views.resource.resource_auth_user_save', name='resource_auth_user_save'),\r\n url(r'^resource/authuserremove/$', 'auth.views.resource.resource_auth_user_remove', name='resource_auth_user_remove'),\r\n url(r'^resource/authgroupdata/$', 'auth.views.resource.resource_auth_group_list_data', name='resource_auth_group_list_data'),\r\n url(r'^resource/authselectgroupdata/$', 'auth.views.resource.resource_auth_group_select_list_data', name='resource_auth_group_select_list_data'),\r\n url(r'^resource/authgroupsave/$', 'auth.views.resource.resource_auth_group_save', name='resource_auth_group_save'),\r\n url(r'^resource/authgroupremove/$', 'auth.views.resource.resource_auth_group_remove', name='resource_auth_group_remove'),\r\n\r\n url(r'^result/list/$', 'auth.views.result.result_search', name='result_list'),\r\n url(r'^result/listdata/$', 'auth.views.result.result_list_data', name='result_list_data'),\r\n url(r'^result/regenerate/$', 'auth.views.result.result_regenerate', name='result_regenerate'),\r\n]\r\n"
},
{
"alpha_fraction": 0.6117742657661438,
"alphanum_fraction": 0.6142159700393677,
"avg_line_length": 34.86000061035156,
"blob_id": "161246ea6c0cddaa21aad84cea8182e1378e75ca",
"content_id": "ef88fb22d0ed8d1ff34263159e49fc6bbd45feff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3896,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 100,
"path": "/inventory/views/warehouse.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom inventory.models import Warehouse\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\ndef warehouse_search(request):\r\n return render(request, 'inventory/warehouse.html')\r\n\r\n\r\n@require_POST\r\ndef warehouse_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n warehouse_query = Warehouse.objects.all()\r\n # extra filters here\r\n warehouse_query = warehouse_query.values(*field_names(Warehouse))\r\n if sort_property is not None:\r\n warehouse_query = warehouse_query.order_by(sort_direction + sort_property)\r\n total_count = warehouse_query.count()\r\n warehouse_list = list(warehouse_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': warehouse_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\ndef warehouse_detail_data(request):\r\n warehouse_id_data = request.POST.get('id')\r\n if warehouse_id_data is None:\r\n warehouse = Warehouse()\r\n else:\r\n warehouse_id = int(warehouse_id_data)\r\n warehouse = Warehouse.objects.filter(pk=warehouse_id).values(*field_names(Warehouse))[0]\r\n return JsonResponse(warehouse)\r\n\r\n\r\n@require_POST\r\ndef warehouse_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n Warehouse.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass WarehouseDetailForm(ModelForm):\r\n class Meta:\r\n model = Warehouse\r\n fields = '__all__'\r\n # exclude = []\r\n error_messages = {\r\n 'wh_code': {\r\n 'required': '编码是必填项!',\r\n 'max_length': '编码不能超过20个字符!',\r\n },\r\n 'wh_name': {\r\n 'required': '仓库名称是必填项!',\r\n 'max_length': '仓库名称不能超过100个字符!',\r\n },\r\n 'wh_desc': {\r\n\r\n 'max_length': '仓库描述不能超过255个字符!',\r\n },\r\n }\r\n\r\n\r\n@require_POST\r\ndef warehouse_save(request):\r\n try:\r\n warehouse_id = request.POST.get('id')\r\n if warehouse_id.strip() == '':\r\n warehouse_form = WarehouseDetailForm(request.POST)\r\n else:\r\n warehouse = Warehouse.objects.get(pk=warehouse_id)\r\n warehouse_form = WarehouseDetailForm(request.POST, instance=warehouse)\r\n if not warehouse_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(warehouse_form)})\r\n warehouse_form.save()\r\n # warehouse = warehouse_form.save(commit=False)\r\n # setup foreign key fields etc\r\n # warehouse.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.5948467254638672,
"alphanum_fraction": 0.5984007120132446,
"avg_line_length": 31.597015380859375,
"blob_id": "5283cc07b4a8e9d83c6ad48b0ba02bf9f40663e9",
"content_id": "2d40460f41c0813061e24a206b903b888c72e498",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2465,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 67,
"path": "/auth/views/profile.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.forms import ModelForm\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django import forms\r\nimport logging\r\n\r\nfrom auth.models import User\r\nfrom common.service.util import get_form_error_msg, field_names\r\nfrom auth.permission import permission_required\r\nfrom auth.service.login import LoginService\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\nlogin_service = LoginService()\r\n\r\n\r\n@require_POST\r\n@permission_required()\r\ndef profile_user_detail_data(request):\r\n user_id = login_service.get_login_user(request).user_id\r\n user = User.objects.filter(pk=user_id).values(*field_names(User))[0]\r\n user['new_password'] = ''\r\n return JsonResponse(user)\r\n\r\n\r\nclass UserDetailForm(ModelForm):\r\n new_password = forms.CharField(required=False)\r\n\r\n class Meta:\r\n model = User\r\n fields = '__all__'\r\n # exclude = ['groups']\r\n error_messages = {\r\n 'login_name': {\r\n 'required': '登录名是必填项!',\r\n 'max_length': '登录名不能超过20个字符!',\r\n },\r\n 'nick_name': {\r\n 'required': '用户名是必填项!',\r\n 'max_length': '用户名不能超过20个字符!',\r\n },\r\n 'password': {\r\n 'required': '密码是必填项!',\r\n 'max_length': '密码不能超过100个字符!',\r\n },\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required()\r\ndef profile_user_detail_save(request):\r\n try:\r\n user_id = login_service.get_login_user(request).user_id\r\n user = User.objects.get(pk=user_id)\r\n user_form = UserDetailForm(request.POST, instance=user)\r\n if not user_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(user_form)})\r\n user = user_form.save(commit=False)\r\n # 如果新密码存在于表单,就加密保存,如果不存在就不更新密码(取表单上的值)\r\n new_password = user_form.data.get('new_password').strip()\r\n if new_password != '':\r\n user.password = login_service.encrypt_password(new_password)\r\n user.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.60140061378479,
"alphanum_fraction": 0.6034432649612427,
"avg_line_length": 32.96938705444336,
"blob_id": "d94c7bdab42eccb56586c728df7ed122fa00db48",
"content_id": "a46b1ae72ebc36cda737aeb06f2fb170823afe4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3605,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 98,
"path": "/auth/views/app.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import App\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.app_view')\r\ndef app_search(request):\r\n return render(request, 'auth/app.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.app_view')\r\ndef app_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n app_query = App.objects.all()\r\n app_query = app_query.values(*field_names(App))\r\n if sort_property is not None:\r\n app_query = app_query.order_by(sort_direction + sort_property)\r\n total_count = app_query.count()\r\n app_list = list(app_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': app_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.app_view')\r\ndef app_detail_data(request):\r\n app_id_data = request.POST.get('id')\r\n if app_id_data is None:\r\n app = App()\r\n else:\r\n app_id = int(app_id_data)\r\n app = App.objects.filter(pk=app_id).values(*field_names(App))[0]\r\n return JsonResponse(app)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.app_delete')\r\ndef app_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n App.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass AppDetailForm(ModelForm):\r\n class Meta:\r\n model = App\r\n fields = '__all__'\r\n # exclude = []\r\n error_messages = {\r\n 'app_code': {\r\n 'required': '编码是必填项!',\r\n 'max_length': '编码不能超过20个字符!',\r\n },\r\n 'app_name': {\r\n 'required': '名称是必填项!',\r\n 'max_length': '名称不能超过100个字符!',\r\n }\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.app_save')\r\ndef app_save(request):\r\n try:\r\n app_id = request.POST.get('id')\r\n if app_id is None or app_id == '' or app_id == '0':\r\n app_form = AppDetailForm(request.POST)\r\n else:\r\n app = App.objects.get(pk=app_id)\r\n app_form = AppDetailForm(request.POST, instance=app)\r\n if not app_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(app_form)})\r\n app_form.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.5741396546363831,
"alphanum_fraction": 0.5774291753768921,
"avg_line_length": 38.32653045654297,
"blob_id": "bdeed92929ee560f6fc1064cb9d3cdfbc3e41fcf",
"content_id": "e826819a0dbf0a83609a795f324fb323d1a75425",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4370,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 98,
"path": "/auth/permission.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from functools import wraps\r\nfrom django.core.urlresolvers import reverse\r\nfrom django.http import HttpResponse, HttpResponseRedirect, JsonResponse, Http404\r\nfrom urllib.parse import quote, urlencode\r\nimport logging\r\nfrom auth.service.login import LoginService\r\nfrom auth.service.authresult import AuthResultService\r\nfrom auth.models import Resource\r\nfrom web import config\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\nlogin_service = LoginService()\r\n\r\n\r\ndef permission_required(permission=''):\r\n def _permission_required(view_func):\r\n @wraps(view_func)\r\n def __permission_required(request, *args, **kwargs):\r\n \"\"\"\r\n :type request: django.http.HttpRequest\r\n \"\"\"\r\n if config.DEBUG and permission.strip() != '': # 仅在开发测试时做这类检查\r\n if permission.find('.') != -1:\r\n app_and_res_code = permission.split('.')\r\n app_code = app_and_res_code[0]\r\n resource_code = app_and_res_code[1]\r\n else:\r\n message = '对不起,view中设置的应用资源标签不对!标签编码:' + permission\r\n logger.error(message)\r\n if request.is_ajax():\r\n return JsonResponse({'success': False, 'message': message})\r\n else:\r\n return HttpResponse(message)\r\n count = Resource.objects.filter(app__app_code=app_code, res_code=resource_code).count()\r\n if count == 0:\r\n message = '对不起,view中设置的应用资源标签不存在!标签编码:' + permission\r\n logger.error(message)\r\n if request.is_ajax():\r\n return JsonResponse({'success': False, 'message': message})\r\n else:\r\n return HttpResponse(message)\r\n if not login_service.is_user_login(request): # 如果没有登录,显示登录界面\r\n # return HttpResponseRedirect(reverse('login') + '?' + urlencode({'return_url': quote(request.get_full_path())}))\r\n if request.is_ajax():\r\n return JsonResponse({'success': False, 'message': '请重新登录!'})\r\n else:\r\n return HttpResponseRedirect(reverse('common:login'))\r\n else:\r\n login_user = login_service.get_login_user(request)\r\n if login_user.is_admin or permission == '': # 如果是管理员或不检查权限\r\n return view_func(request, *args, **kwargs)\r\n if not has_permission(request, permission): # 如果是登录了但没权限,ajax提示没权限,或提示404\r\n if request.is_ajax():\r\n return JsonResponse({'success': False, 'message': '对不起,您没有相应权限!'})\r\n else:\r\n raise Http404()\r\n return view_func(request, *args, **kwargs)\r\n\r\n return __permission_required\r\n\r\n return _permission_required\r\n\r\n\r\ndef has_permission(request, permission):\r\n \"\"\"\r\n :type request: django.http.HttpRequest\r\n :type permission: str\r\n :rtype: bool\r\n\r\n 一个Http请求过程中, 检查已登录用户是否有某个权限, 假设用户已登录\r\n :param request: HttpRequest\r\n :param permission: 资源编码\r\n :return: True or False\r\n \"\"\"\r\n if not hasattr(request, 'permission_list'):\r\n load_user_permissions(request)\r\n permission_list = getattr(request, 'permission_list')\r\n if permission in permission_list:\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef load_user_permissions(request):\r\n \"\"\"\r\n :type request: django.http.HttpRequest\r\n :rtype: None\r\n\r\n 从数据库中加载用户权限,存于当前request中request.permissions,便于接下来在请求中的权限判断, 假设用户已登录\r\n :param request: django.http.HttpRequest\r\n :return: None\r\n \"\"\"\r\n login_user = login_service.get_login_user(request)\r\n user_id = login_user.user_id\r\n permission_list = AuthResultService().get_user_resource_code_list(user_id)\r\n # 如果没有任何权限, permission_list应该为空列表 []\r\n setattr(request, 'permission_list', permission_list)\r\n"
},
{
"alpha_fraction": 0.6261985898017883,
"alphanum_fraction": 0.6279863715171814,
"avg_line_length": 43.917911529541016,
"blob_id": "3ab5940334e4ee61354421ac8ac86b066bd881fc",
"content_id": "d9df130585e4959adf8af3e16e6c39e7cdd9f416",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6455,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 134,
"path": "/auth/views/groupuser.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django import forms\r\nfrom django.db import transaction\r\nfrom django.db.models import Q, F\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import App, Group, GroupUser, User\r\nfrom auth.service.authresult import AuthResultService\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.groupuser_view')\r\ndef groupuser_search(request):\r\n return render(request, 'auth/groupuser.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.groupuser_view')\r\ndef groupuser_group_tree_data(request):\r\n node_id = request.POST.get('node')\r\n if node_id is None or node_id == '' or node_id == '0':\r\n app_query = App.objects.annotate(text=F('app_name')).values('id', 'text').order_by('app_name')\r\n app_list = [{'id': 'app_' + str(app.get('id')), 'text': app.get('text')} for app in app_query]\r\n app_list.insert(0, {'id': 'app_0', 'text': '全局群组'})\r\n return JsonResponse(app_list, safe=False)\r\n elif node_id.startswith('app_'):\r\n app_id = request.POST.get('node')\r\n app_id = app_id.split('_')[1]\r\n if app_id == '0':\r\n app_id = None\r\n else:\r\n app_id = int(app_id)\r\n group_query = Group.objects.filter(app=app_id).annotate(text=F('group_name')).values('id', 'text').order_by('group_name')\r\n group_list = [{'id': 'group_' + str(g.get('id')), 'text': g.get('text'), 'leaf': True} for g in group_query]\r\n return JsonResponse(group_list, safe=False)\r\n else: # node_id.startswith('group_'):\r\n return JsonResponse([], safe=False)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.groupuser_view')\r\ndef groupuser_user_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n groupuser_query = GroupUser.objects.all()\r\n node_id = request.POST.get('node_id')\r\n if node_id is None or node_id == '0' or node_id.startswith('app_'):\r\n return JsonResponse(({'total': 0, 'rows': []}))\r\n else: # node_id.startswith('group_'):\r\n group_id = int(node_id.split('_')[1])\r\n groupuser_query = groupuser_query.filter(group=group_id)\r\n groupuser_query = groupuser_query.values('group__group_name', 'user__login_name', 'user__nick_name', *field_names(GroupUser))\r\n if sort_property is not None:\r\n groupuser_query = groupuser_query.order_by(sort_direction + sort_property)\r\n total_count = groupuser_query.count()\r\n user_list = list(groupuser_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.groupuser_add')\r\ndef groupuser_select_user_list_data(request):\r\n try:\r\n group_id = request.POST.get('group_id')\r\n group_id = int(group_id.split('_')[1])\r\n # user_id_list = GroupUser.objects.filter(group=group_id).values_list('user_id', flat=True)\r\n # 下面一句的写法更为简洁,最终会和再下面的语句会生成一个单独的SQL, 前一个查询很变成后一个查询的子查询\r\n user_id_list = GroupUser.objects.filter(group=group_id).values('user_id')\r\n user_query = User.objects.exclude(id__in=user_id_list).values(*field_names(User))\r\n total_count = user_query.count()\r\n user_list = list(user_query)\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\nclass UserAddForm(forms.Form):\r\n group_id = forms.IntegerField()\r\n user_id_list = forms.IntegerField()\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.groupuser_add')\r\ndef groupuser_add_user(request):\r\n try:\r\n group_id = request.POST.get('group_id')\r\n if group_id is None or group_id.startswith('group_') == False:\r\n return JsonResponse({'success': False, 'message': '请先选择群组再进行添加!'})\r\n if request.POST.get('user_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行添加!'})\r\n user_add_form = UserAddForm(request.POST)\r\n group_id = int(group_id.split('_')[1])\r\n user_id_list = user_add_form.data.getlist('user_id_list')\r\n group_user_list_to_add = []\r\n for user_id in user_id_list:\r\n group_user_list_to_add.append(GroupUser(group_id=group_id, user_id=user_id))\r\n with transaction.atomic():\r\n GroupUser.objects.bulk_create(group_user_list_to_add)\r\n AuthResultService().refresh_group_result([group_id])\r\n return JsonResponse({'success': True, 'message': '用户添加成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.groupuser_remove')\r\ndef groupuser_remove_user(request):\r\n try:\r\n group_id = request.POST.get('group_id')\r\n if group_id is None:\r\n return JsonResponse({'success': False, 'message': '请先选择群组再进行移除!'})\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行移除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n group_id = int(group_id.split('_')[1])\r\n with transaction.atomic():\r\n GroupUser.objects.filter(id__in=id_list).delete()\r\n AuthResultService().refresh_group_result([group_id])\r\n return JsonResponse({'success': True, 'message': '移除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '移除失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.5845997929573059,
"alphanum_fraction": 0.5937183499336243,
"avg_line_length": 40.125,
"blob_id": "41789ebeeb78507c267774bf50f7d5806ddde798",
"content_id": "fe1e8f1db1b99e7ad73f45fc5441bb5242c71d88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 24,
"path": "/inventory/migrations/0001_initial.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Warehouse',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, auto_created=True, verbose_name='ID')),\n ('wh_code', models.CharField(error_messages={'unique': '编码不能相重!'}, max_length=20, unique=True, verbose_name='编码')),\n ('wh_name', models.CharField(error_messages={'unique': '仓库名称不能相重!'}, max_length=100, unique=True, verbose_name='仓库名称')),\n ('wh_desc', models.CharField(null=True, max_length=255, blank=True, verbose_name='仓库描述')),\n ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),\n ('modify_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6776061654090881,
"alphanum_fraction": 0.6776061654090881,
"avg_line_length": 55.55555725097656,
"blob_id": "3cd79b7a90733fd0e3d86d9c09a1c981e04b5cc3",
"content_id": "ff48a40e39789e0956d1e78f034454843994551c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 518,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 9,
"path": "/pm/urls.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\r\n\r\nurlpatterns = [\r\n url(r'^project/list/$', 'pm.views.project.project_search', name='project_list'),\r\n url(r'^project/listdata/$', 'pm.views.project.project_list_data', name='project_list_data'),\r\n url(r'^project/detaildata/$', 'pm.views.project.project_detail_data', name='project_detail_data'),\r\n url(r'^project/save/$', 'pm.views.project.project_save', name='project_save'),\r\n url(r'^project/delete/$', 'pm.views.project.project_delete', name='project_delete'),\r\n]\r\n"
},
{
"alpha_fraction": 0.6125330924987793,
"alphanum_fraction": 0.6148278713226318,
"avg_line_length": 38.755393981933594,
"blob_id": "68150fc7679bc823a1e7ca9edfb6afaf87cd4af5",
"content_id": "2955f671448f4359f40c17ff348b46e48d3438ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5883,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 139,
"path": "/auth/views/group.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django import forms\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q, Count\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import Group, GroupResource\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.group_view')\r\ndef group_search(request):\r\n return render(request, 'auth/group.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.group_view')\r\ndef group_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n group_query = Group.objects.all()\r\n group_query = group_query.annotate(user_count=Count('users')).values('app__app_name', 'user_count', *field_names(Group))\r\n if sort_property is not None:\r\n group_query = group_query.order_by(sort_direction + sort_property)\r\n total_count = group_query.count()\r\n group_list = list(group_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': group_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.group_view')\r\ndef group_detail_data(request):\r\n group_id = request.POST.get('id')\r\n if group_id is None:\r\n group = Group()\r\n else:\r\n group_id = int(group_id)\r\n group = Group.objects.filter(pk=group_id).values('app_id', 'app__app_name', *field_names(Group))[0]\r\n return JsonResponse(group)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.group_delete')\r\ndef group_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n Group.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass GroupDetailForm(ModelForm):\r\n class Meta:\r\n model = Group\r\n fields = '__all__'\r\n exclude = ['users']\r\n error_messages = {\r\n 'group_code': {\r\n 'required': '编码是必填项!',\r\n 'max_length': '编码不能超过20个字符!',\r\n },\r\n 'group_name': {\r\n 'required': '名称是必填项!',\r\n 'max_length': '名称不能超过100个字符!',\r\n },\r\n 'group_desc': {\r\n 'max_length': '描述不能超过255个字符!',\r\n },\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.group_save')\r\ndef group_save(request):\r\n try:\r\n group_id = request.POST.get('id')\r\n if group_id is None or group_id == '' or group_id == '0':\r\n group_form = GroupDetailForm(request.POST)\r\n else:\r\n group = Group.objects.get(pk=group_id)\r\n group_form = GroupDetailForm(request.POST, instance=group)\r\n if not group_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(group_form)})\r\n group = group_form.save(commit=False)\r\n app_id = request.POST.get('app_id')\r\n if app_id is not None and app_id.strip() != '' and app_id != '0':\r\n # group.app = App.objects.get(pk=app_id)\r\n group.app_id = app_id\r\n group.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n\r\n\r\nclass GroupIdListForm(forms.Form):\r\n group_id_list = forms.IntegerField()\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.group_resource_view')\r\ndef group_auth_resource_list_data(request):\r\n try:\r\n if request.POST.get('group_id_list') is None:\r\n return JsonResponse({'total': 0, 'rows': []})\r\n group_id_list_form = GroupIdListForm(request.POST)\r\n group_id_list = group_id_list_form.data.getlist('group_id_list')\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n group_id_count = len(group_id_list)\r\n auth_resource_query = GroupResource.objects.all() \\\r\n .values('resource_id').annotate(group_count=Count('group')) \\\r\n .filter(group__in=group_id_list, group_count=group_id_count)\r\n if group_id_count == 1:\r\n auth_resource_query = auth_resource_query.values('resource__app__app_name', 'resource__res_code', 'resource__res_name', 'create_time')\r\n else:\r\n auth_resource_query = auth_resource_query.values('resource__app__app_name', 'resource__res_code', 'resource__res_name')\r\n if sort_property is not None:\r\n auth_resource_query = auth_resource_query.order_by(sort_direction + sort_property)\r\n total_count = auth_resource_query.count()\r\n resource_list = list(auth_resource_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': resource_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.7564575672149658,
"alphanum_fraction": 0.7564575672149658,
"avg_line_length": 28.11111068725586,
"blob_id": "eeb7d1a11ca23118b32e1f92bb4edd9ec554103b",
"content_id": "8e3f69fe74c3be9cffa7fdd9a1bd59b6ad884e77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 9,
"path": "/auth/templatetags/common.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.template import Library\r\nfrom common.templatetags import common\r\n\r\nregister = Library()\r\n\r\n\r\[email protected]_tag('common/pagination.html')\r\ndef pagination(list_page, url_name, search_form):\r\n return common.pagination(list_page, url_name, search_form)\r\n"
},
{
"alpha_fraction": 0.6586538553237915,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 28.714284896850586,
"blob_id": "559ffdaf9a9c053de2cc9dc43787d7beb2ed90fa",
"content_id": "ed90c6a57cc67def1026026ca5facc690a653059",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 7,
"path": "/pm/models.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Project(models.Model):\n code = models.CharField('编码', max_length=20)\n name = models.CharField('名称', max_length=100)\n pm = models.CharField('项目经理', max_length=20)\n"
},
{
"alpha_fraction": 0.7294520735740662,
"alphanum_fraction": 0.7294520735740662,
"avg_line_length": 63.88888931274414,
"blob_id": "355245d4c60d75cc5b002f38ee233d2113964abe",
"content_id": "36aa2826f17971a2d18e0a8fcebf1d3b306071fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 9,
"path": "/inventory/urls.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\n\nurlpatterns = [\n url(r'^warehouse/list/$', 'inventory.views.warehouse.warehouse_search', name='warehouse_list'),\n url(r'^warehouse/listdata/$', 'inventory.views.warehouse.warehouse_list_data', name='warehouse_list_data'),\n url(r'^warehouse/detaildata/$', 'inventory.views.warehouse.warehouse_detail_data', name='warehouse_detail_data'),\n url(r'^warehouse/save/$', 'inventory.views.warehouse.warehouse_save', name='warehouse_save'),\n url(r'^warehouse/delete/$', 'inventory.views.warehouse.warehouse_delete', name='warehouse_delete'),\n]\n"
},
{
"alpha_fraction": 0.6987979412078857,
"alphanum_fraction": 0.6987979412078857,
"avg_line_length": 62.56716537475586,
"blob_id": "6db34e4e9f1e0c4154e5bc8cd49499e3d1b6d0e9",
"content_id": "73e6b4167d15f4e13316f6308beee5f5c9a864d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4722,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 67,
"path": "/auth/service/init_data.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from auth.models import App, User, Admin, Resource\r\nfrom auth.service.login import LoginService\r\n\r\n\r\ndef init_basic_data(apps, schema_editor):\r\n # init user\r\n init_password = LoginService().encrypt_password('123456')\r\n user = User(login_name='admin', nick_name=\"管理员\", password=init_password)\r\n user.save()\r\n\r\n # init admin\r\n admin = Admin(user_id=user.id)\r\n admin.save()\r\n\r\n # init app\r\n # App = apps.get_model('auth', \"App\")\r\n app = App(app_code='auth', app_name='权限管理', app_desc='权限管理系统')\r\n app.save()\r\n app_id = app.id\r\n\r\n # init resource\r\n resource_list_to_insert = list()\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='admin_view', res_name='管理员查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='admin_save', res_name='管理员保存'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='admin_delete', res_name='管理员删除'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='user_view', res_name='用户查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='user_save', res_name='用户保存'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='user_delete', res_name='用户删除'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='user_resource_view', res_name='用户资源查看'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='app_view', res_name='应用查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='app_save', res_name='应用保存'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='app_delete', res_name='应用删除'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='dept_view', res_name='部门查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='dept_save', res_name='部门保存'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='dept_delete', res_name='部门删除'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='deptuser_view', res_name='部门用户查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='deptuser_add', res_name='部门用户添加'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='deptuser_remove', res_name='部门用户移除'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='group_view', res_name='群组查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='group_save', res_name='群组保存'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='group_delete', res_name='群组删除'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='group_resource_view', res_name='群组资源查看'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='groupuser_view', res_name='群组用户查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='groupuser_add', res_name='群组用户添加'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='groupuser_remove', res_name='群组用户移除'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_view', res_name='资源查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_save', res_name='资源保存'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_delete', res_name='资源删除'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_auth_user_view', res_name='资源用户授权查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_auth_user_add', res_name='资源用户授权添加'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_auth_user_remove', res_name='资源用户授权移除'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_auth_group_view', res_name='资源群组授权查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_auth_group_add', res_name='资源群组授权添加'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='resource_auth_group_remove', res_name='资源群组授权移除'))\r\n\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='result_view', res_name='授权结果查看'))\r\n resource_list_to_insert.append(Resource(app_id=app_id, res_code='result_regenerate', res_name='授权结果重新生成'))\r\n\r\n Resource.objects.bulk_create(resource_list_to_insert)\r\n"
},
{
"alpha_fraction": 0.6857428550720215,
"alphanum_fraction": 0.6928785443305969,
"avg_line_length": 52.08333206176758,
"blob_id": "fa799a5abb9245de6f2bbfd088a5c5a1985801bf",
"content_id": "0040113111dc07debae816d6cd194804872bd4c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7693,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 132,
"path": "/auth/models.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass User(models.Model):\n login_name = models.CharField('登录名', max_length=20, unique=True, null=False, blank=False, error_messages={'unique': '登录名不能相重!'})\n nick_name = models.CharField('用户名', max_length=20, null=False, blank=False, )\n password = models.CharField('密码', max_length=100, null=False, blank=False, )\n last_login = models.DateTimeField('最近登录', blank=True, null=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)\n # groups = models.ManyToManyField('Group', verbose_name='群组', through='GroupUser')\n resources = models.ManyToManyField('Resource', verbose_name='资源', through='UserResource', blank=True)\n\n\nclass Admin(models.Model):\n user = models.ForeignKey(User, verbose_name='用户', blank=False, null=False)\n admin_desc = models.CharField('描述', max_length=255, blank=True, null=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n\n\nclass App(models.Model):\n app_code = models.CharField('编码', max_length=20, unique=True, null=False, blank=False, error_messages={'unique': '编码不能相重!'})\n app_name = models.CharField('应用名称', max_length=100, unique=True, null=False, blank=False, error_messages={'unique': '应用名称不能相重!'})\n app_desc = models.CharField('应用描述', max_length=255, null=True, blank=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)\n\n\nclass Group(models.Model):\n app = models.ForeignKey(App, verbose_name='应用', blank=True, null=True) # 可为空,可不为空,为空时是公共群组,不为空时为App内群组\n group_code = models.CharField('编码', max_length=20, null=False, blank=False)\n group_name = models.CharField('群组名称', max_length=100, null=False, blank=False)\n group_desc = models.CharField('群组描述', max_length=255, null=True, blank=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)\n users = models.ManyToManyField('User', verbose_name='用户', through='GroupUser', blank=True)\n resources = models.ManyToManyField('Resource', verbose_name='资源', through='GroupResource', blank=True)\n\n class Meta:\n unique_together = (('app', 'group_code'), ('app', 'group_name'))\n\n def unique_error_message(self, model_class, unique_check):\n if model_class == type(self) and unique_check == ('app', 'group_code'):\n return '应用和群组编码的组合必须唯一!'\n elif model_class == type(self) and unique_check == ('app', 'group_name'):\n return '应用和群组名称的组合必须唯一!'\n else:\n return super(Group, self).unique_error_message(model_class, unique_check)\n\n\nclass GroupUser(models.Model):\n user = models.ForeignKey(User, verbose_name='用户', blank=False, null=False)\n group = models.ForeignKey(Group, verbose_name='群组', blank=False, null=False)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n\n\nclass Department(models.Model):\n dept_code = models.CharField('编码', max_length=20, null=False, blank=False, unique=True, error_messages={'unique': '编码不能相重!'})\n dept_name = models.CharField('部门名称', max_length=20, null=False, blank=False) # 也许有些子部门的名称可以相同\n dept_desc = models.CharField('部门描述', max_length=255, null=True, blank=True)\n parent = models.ForeignKey('Department', verbose_name='上级部门', blank=True, null=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)\n users = models.ManyToManyField('User', verbose_name='用户', through='DepartmentUser', blank=True)\n\n\nclass DepartmentUser(models.Model):\n user = models.ForeignKey(User, verbose_name='用户', blank=False, null=False)\n department = models.ForeignKey(Department, verbose_name='部门', blank=False, null=False)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n\n class Meta:\n unique_together = ('user', 'department')\n\n def unique_error_message(self, model_class, unique_check):\n if model_class == type(self) and unique_check == ('user', 'department'):\n return '用户和部门的组合必须唯一!'\n else:\n return super(DepartmentUser, self).unique_error_message(model_class, unique_check)\n\n\nclass Resource(models.Model):\n app = models.ForeignKey(App, verbose_name='应用', blank=False, null=False)\n res_code = models.CharField('编码', max_length=50, null=False, blank=False)\n res_name = models.CharField('资源名称', max_length=100, null=False, blank=False)\n res_desc = models.CharField('资源描述', max_length=255, null=True, blank=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)\n users = models.ManyToManyField('User', verbose_name='用户', through='UserResource', blank=True)\n groups = models.ManyToManyField('Group', verbose_name='群组', through='GroupResource', blank=True)\n\n class Meta:\n unique_together = (('app', 'res_code'), ('app', 'res_name'))\n\n def unique_error_message(self, model_class, unique_check):\n if model_class == type(self) and unique_check == ('app', 'res_code'):\n return '应用和资源编码的组合必须唯一!'\n elif model_class == type(self) and unique_check == ('app', 'res_name'):\n return '应用和资源名称的组合必须唯一!'\n else:\n return super(Resource, self).unique_error_message(model_class, unique_check)\n\n\nclass ResourceMenu(models.Model):\n app = models.ForeignKey(App, verbose_name='应用', blank=False, null=False)\n resource = models.ForeignKey(Resource, verbose_name='资源', blank=False, null=False)\n parent = models.ForeignKey('ResourceMenu', verbose_name='父菜单', blank=True, null=True)\n menu_name = models.CharField('菜单名称', max_length=100, blank=False, null=False)\n menu_url = models.CharField('菜单Url', max_length=255, blank=False, null=False)\n menu_order = models.IntegerField('菜单排序', blank=True, null=True)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n modify_time = models.DateTimeField('修改时间', auto_now=True)\n\n\nclass UserResource(models.Model):\n user = models.ForeignKey(User, verbose_name='用户', blank=False, null=False)\n resource = models.ForeignKey(Resource, verbose_name='资源', blank=False, null=False)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n\n\nclass GroupResource(models.Model):\n group = models.ForeignKey(Group, verbose_name='群组', blank=False, null=False)\n resource = models.ForeignKey(Resource, verbose_name='资源', blank=False, null=False)\n create_time = models.DateTimeField('创建时间', auto_now_add=True)\n\n\nclass AuthResult(models.Model):\n app = models.ForeignKey(App, verbose_name='应用', blank=False, null=False)\n res_label = models.CharField('资源标签', max_length=200, null=False) # 资源的全局标示, app_code.res_code\n resource = models.ForeignKey(Resource, verbose_name='资源', null=False)\n user = models.ForeignKey(User, verbose_name='用户', null=False)\n group = models.ForeignKey(Group, verbose_name='群组', null=True)\n"
},
{
"alpha_fraction": 0.6217123866081238,
"alphanum_fraction": 0.6228315830230713,
"avg_line_length": 43.56090545654297,
"blob_id": "cf4e351fb298d7dbf60075be3016c6dcb871f9ae",
"content_id": "b1051628410bb6c3d3f76f52773197d68f913160",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16691,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 353,
"path": "/auth/views/resource.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django import forms\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q, F, Count\r\nfrom django.db import transaction, IntegrityError\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import App, Resource, User, UserResource, Group, GroupResource\r\nfrom auth.service.authresult import AuthResultService\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.resource_view')\r\ndef resource_search(request):\r\n return render(request, 'auth/resource.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_view')\r\ndef resource_app_tree_data(request):\r\n try:\r\n node_id = request.POST.get('node')\r\n if node_id is None or node_id == '' or node_id == '0':\r\n app_query = App.objects.annotate(text=F('app_name')).values('id', 'text').order_by('app_name')\r\n app_list = [dict(app, leaf='true') for app in app_query]\r\n return JsonResponse(app_list, safe=False)\r\n else:\r\n return JsonResponse([], safe=False)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_view')\r\ndef resource_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n resource_query = Resource.objects.all()\r\n app_id = request.POST.get('app_id')\r\n if app_id is not None and app_id.strip() != '' and app_id != '0':\r\n resource_query = resource_query.filter(app=app_id)\r\n if sort_property is not None:\r\n resource_query = resource_query.order_by(sort_direction + sort_property)\r\n resource_query = resource_query \\\r\n .annotate(user_count=Count('users', distinct=True)) \\\r\n .annotate(group_count=Count('groups', distinct=True)) \\\r\n .values('app__app_name', 'user_count', 'group_count', *field_names(Resource))\r\n total_count = resource_query.count()\r\n resource_list = list(resource_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': resource_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_view')\r\ndef resource_detail_data(request):\r\n resource_id = request.POST.get('id')\r\n if resource_id is None:\r\n resource = Resource()\r\n else:\r\n resource_id = int(resource_id)\r\n resource = Resource.objects.filter(pk=resource_id).values('app', 'app__app_name', *field_names(Resource))[0]\r\n return JsonResponse(resource)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_delete')\r\ndef resource_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n Resource.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass ResourceDetailForm(ModelForm):\r\n class Meta:\r\n model = Resource\r\n fields = '__all__'\r\n exclude = ['users', 'groups']\r\n error_messages = {\r\n 'app': {\r\n 'required': '应用是必填项!'\r\n },\r\n 'res_code': {\r\n 'required': '编码是必填项!',\r\n 'max_length': '编码不能超过50个字符!',\r\n },\r\n 'res_name': {\r\n 'required': '名称是必填项!',\r\n 'max_length': '名称不能超过100个字符!',\r\n },\r\n 'res_desc': {\r\n 'max_length': '描述不能超过255个字符!',\r\n }\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_save')\r\ndef resource_save(request):\r\n try:\r\n resource_id = request.POST.get('id')\r\n if resource_id is None or resource_id == '' or resource_id == '0':\r\n resource_form = ResourceDetailForm(request.POST)\r\n else:\r\n resource = Resource.objects.get(pk=resource_id)\r\n resource_form = ResourceDetailForm(request.POST, instance=resource)\r\n if not resource_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(resource_form)})\r\n resource_form.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n\r\n\r\nclass ResourceIdListForm(forms.Form):\r\n res_id_list = forms.IntegerField()\r\n\r\n\r\n# resource auth begin\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_user_view')\r\ndef resource_auth_user_list_data(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'total': 0, 'rows': []})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n res_id_count = len(res_id_list)\r\n user_query = UserResource.objects.all().values('user_id').annotate(res_count=Count('resource'))\r\n user_query = user_query.filter(resource__in=res_id_list, res_count=res_id_count)\r\n if res_id_count == 1:\r\n user_query = user_query.values('user_id', 'user__login_name', 'user__nick_name', 'create_time')\r\n else:\r\n user_query = user_query.values('user_id', 'user__login_name', 'user__nick_name')\r\n if sort_property is not None:\r\n user_query = user_query.order_by(sort_direction + sort_property)\r\n total_count = user_query.count()\r\n user_list = list(user_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_user_add')\r\ndef resource_auth_user_select_list_data(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'total': 0, 'rows': []})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n user_query = User.objects.all()\r\n res_id_count = len(res_id_list)\r\n auth_user_id_query = UserResource.objects.all() \\\r\n .values('user_id').annotate(res_count=Count('resource')) \\\r\n .filter(resource__in=res_id_list, res_count=res_id_count) \\\r\n .values('user_id')\r\n user_query = user_query.exclude(id__in=auth_user_id_query)\r\n total_count = user_query.count()\r\n user_query = user_query.values(*field_names(User))\r\n if sort_property is not None:\r\n user_query = user_query.order_by(sort_direction + sort_property)\r\n user_list = list(user_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\nclass UserIdListForm(forms.Form):\r\n user_id_list = forms.IntegerField()\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_user_add')\r\ndef resource_auth_user_save(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '保存失败,资源列表为空!'})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n if request.POST.get('user_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '保存失败,用户列表为空!'})\r\n user_id_list_form = UserIdListForm(request.POST)\r\n user_id_list = user_id_list_form.data.getlist('user_id_list')\r\n with transaction.atomic():\r\n UserResource.objects.filter(resource__in=res_id_list, user__in=user_id_list).delete()\r\n user_resource_list_to_insert = []\r\n for user_id in user_id_list:\r\n for res_id in res_id_list:\r\n user_resource_list_to_insert.append(UserResource(resource_id=res_id, user_id=user_id))\r\n UserResource.objects.bulk_create(user_resource_list_to_insert)\r\n AuthResultService().refresh_user_result(user_id_list)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_user_remove')\r\ndef resource_auth_user_remove(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '移除失败,资源列表为空!'})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n if request.POST.get('user_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '移除失败,用户列表为空!'})\r\n user_id_list_form = UserIdListForm(request.POST)\r\n user_id_list = user_id_list_form.data.getlist('user_id_list')\r\n with transaction.atomic():\r\n UserResource.objects.filter(resource__in=res_id_list, user__in=user_id_list).delete()\r\n AuthResultService().refresh_user_result(user_id_list)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '移除失败!详细:%s' % exp})\r\n return JsonResponse({'success': True, 'message': '移除成功!'})\r\n\r\n\r\n# resource auth end\r\n\r\n# resource group begin\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_group_view')\r\ndef resource_auth_group_list_data(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'total': 0, 'rows': []})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n res_id_count = len(res_id_list)\r\n group_query = GroupResource.objects.all().values('group_id').annotate(res_count=Count('resource'))\r\n group_query = group_query.filter(resource__in=res_id_list, res_count=res_id_count)\r\n if res_id_count == 1:\r\n group_query = group_query.values('group_id', 'group__app__app_name', 'group__group_code', 'group__group_name', 'create_time')\r\n else:\r\n group_query = group_query.values('group_id', 'group__app__app_name', 'group__group_code', 'group__group_name')\r\n if sort_property is not None:\r\n group_query = group_query.order_by(sort_direction + sort_property)\r\n total_count = group_query.count()\r\n group_list = list(group_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': group_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_group_add')\r\ndef resource_auth_group_select_list_data(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'total': 0, 'rows': []})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n group_query = Group.objects.all()\r\n res_id_count = len(res_id_list)\r\n auth_group_id_query = GroupResource.objects.all() \\\r\n .values('group_id').annotate(res_count=Count('resource')) \\\r\n .filter(resource__in=res_id_list, res_count=res_id_count) \\\r\n .values('group_id')\r\n group_query = group_query.exclude(id__in=auth_group_id_query)\r\n group_query = group_query.values('app__app_name', *field_names(Group))\r\n if sort_property is not None:\r\n group_query = group_query.order_by(sort_direction + sort_property)\r\n total_count = group_query.count()\r\n group_list = list(group_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': group_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\nclass GroupIdListForm(forms.Form):\r\n group_id_list = forms.IntegerField()\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_group_add')\r\ndef resource_auth_group_save(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '保存失败,资源列表为空!'})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n if request.POST.get('group_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '保存失败,群组列表为空!'})\r\n group_id_list_form = GroupIdListForm(request.POST)\r\n group_id_list = group_id_list_form.data.getlist('group_id_list')\r\n with transaction.atomic():\r\n GroupResource.objects.filter(resource__in=res_id_list, group__in=group_id_list).delete()\r\n group_resource_list_to_insert = []\r\n for group_id in group_id_list:\r\n for res_id in res_id_list:\r\n group_resource_list_to_insert.append(GroupResource(resource_id=res_id, group_id=group_id))\r\n GroupResource.objects.bulk_create(group_resource_list_to_insert)\r\n AuthResultService().refresh_group_result(group_id_list)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.resource_auth_group_remove')\r\ndef resource_auth_group_remove(request):\r\n try:\r\n if request.POST.get('res_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '移除失败,资源列表为空!'})\r\n res_id_list_form = ResourceIdListForm(request.POST)\r\n res_id_list = res_id_list_form.data.getlist('res_id_list')\r\n if request.POST.get('group_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '移除失败,群组列表为空!'})\r\n group_id_list_form = GroupIdListForm(request.POST)\r\n group_id_list = group_id_list_form.data.getlist('group_id_list')\r\n with transaction.atomic():\r\n GroupResource.objects.filter(resource__in=res_id_list, group__in=group_id_list).delete()\r\n AuthResultService().refresh_group_result(group_id_list)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '移除失败!详细:%s' % exp})\r\n return JsonResponse({'success': True, 'message': '移除成功!'})\r\n\r\n# resource group end\r\n"
},
{
"alpha_fraction": 0.6332330107688904,
"alphanum_fraction": 0.6342360377311707,
"avg_line_length": 32.379310607910156,
"blob_id": "7ad159aaab1ae7119da1524c46fbafa0b08ddc5b",
"content_id": "ae9264be1a22b5e365b730869f39132ddc16bf38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3039,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 87,
"path": "/pm/views/project.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "# from django.views.decorators.csrf import csrf_exempt\r\nfrom django.shortcuts import render\r\nfrom django.http import HttpResponse, JsonResponse\r\nfrom django.forms.models import model_to_dict\r\nfrom django.forms import ModelForm\r\nfrom django.views.decorators.http import require_POST\r\nimport logging\r\nfrom pm.models import Project\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\ndef project_search(request):\r\n return render(request, 'pm/project/list.html')\r\n\r\n\r\n# @csrf_exempt\r\n@require_POST\r\ndef project_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n project_query = Project.objects.all().values('id', 'code', 'name', 'pm')\r\n if sort_property is not None:\r\n project_query = project_query.order_by(sort_direction + sort_property)\r\n total_count = project_query.count()\r\n project_list = list(project_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': project_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\ndef project_detail_data(request):\r\n if request.method == 'POST':\r\n project_id_data = request.POST.get('id')\r\n if project_id_data is None:\r\n project = Project()\r\n else:\r\n project_id = int(project_id_data)\r\n project = Project.objects.get(pk=project_id)\r\n return JsonResponse(model_to_dict(project))\r\n\r\n\r\ndef project_create(request):\r\n for x in range(1, 55):\r\n project = Project()\r\n project.code = 'code' + str(x)\r\n project.name = 'name' + str(x)\r\n project.pm = 'pm' + str(x)\r\n\r\n project.save()\r\n\r\n return HttpResponse('true')\r\n\r\n\r\n# @csrf_exempt\r\ndef project_delete(request):\r\n if request.method == 'POST':\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n Project.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True})\r\n\r\n\r\ndef project_detail(request):\r\n return render(request, 'pm/project/detail.html')\r\n\r\n\r\nclass ProjectDetailForm(ModelForm):\r\n class Meta:\r\n model = Project\r\n fields = ['id', 'code', 'name', 'pm']\r\n\r\n\r\ndef project_save(request):\r\n if request.method == 'POST':\r\n project_form = ProjectDetailForm(request.POST)\r\n project_id = project_form.data.get('id')\r\n if project_id is not None and project_id.strip() != '':\r\n project = Project.objects.get(pk=project_id)\r\n project_form = ProjectDetailForm(request.POST, instance=project)\r\n project_form.save()\r\n return JsonResponse({'success': True})\r\n"
},
{
"alpha_fraction": 0.6321138143539429,
"alphanum_fraction": 0.6355013847351074,
"avg_line_length": 42.727272033691406,
"blob_id": "e05b91eea043638dd5b7615895e8e74273ecada5",
"content_id": "5ed4de6a5ed3146ed4a9d3ac2786eefeb69958e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1476,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 33,
"path": "/auth/tests/test_login.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.contrib.staticfiles.testing import StaticLiveServerTestCase\r\nfrom django.core.urlresolvers import reverse\r\nfrom selenium import webdriver\r\n\r\n\r\nclass LoginTestCase(StaticLiveServerTestCase):\r\n def test_login_success(self):\r\n '''\r\n client = Client()\r\n response = client.post(reverse('common:login'), {'login_name': 'admin', 'password': '123456'})\r\n json_data = json.loads(bytes.decode(response.content))\r\n self.assertTrue(json_data['success'])\r\n response = client.post(reverse('common:login'), {'login_name': 'admin', 'password': '123'})\r\n json_data = json.loads(bytes.decode(response.content))\r\n self.assertFalse(json_data['success'])\r\n '''\r\n driver = webdriver.Chrome()\r\n driver.implicitly_wait(30)\r\n driver.get(self.live_server_url + reverse('common:login'))\r\n # input user name\r\n login_name_input = driver.find_element_by_id(\"login_name-inputEl\")\r\n login_name_input.clear()\r\n login_name_input.send_keys(\"admin\")\r\n # input password\r\n password_input = driver.find_element_by_id(\"password-inputEl\")\r\n password_input.clear()\r\n password_input.send_keys(\"123456\")\r\n # click login button\r\n driver.find_element_by_id(\"btnLogin-btnInnerEl\").click()\r\n # verify home logo text\r\n logo_text = driver.find_element_by_id('logoText')\r\n self.assertIsNotNone(logo_text)\r\n driver.quit()\r\n"
},
{
"alpha_fraction": 0.6283114552497864,
"alphanum_fraction": 0.6285790801048279,
"avg_line_length": 48.171051025390625,
"blob_id": "edc2c7d2600849cf48f2c033f53db3f7e4923182",
"content_id": "b2bbf79fc095c01a57ba14ba20572a73de9c955b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3853,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 76,
"path": "/common/views.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.core.urlresolvers import reverse\nfrom django.db.models import Count, F\nfrom django.http import JsonResponse\nfrom django.views.decorators.http import require_POST\nfrom django.shortcuts import render\nimport logging\nfrom auth.models import AuthResult\nfrom auth.service.login import LoginService\nfrom auth.permission import permission_required, has_permission\n\nlogger = logging.getLogger(__name__)\n\nlogin_service = LoginService()\n\n\n@permission_required()\ndef home(request):\n login_user = login_service.get_login_user(request)\n nick_name = login_user.nick_name\n return render(request, 'common/home.html', {'nick_name': nick_name})\n\n\n@require_POST\n@permission_required()\ndef home_nav_menu_data(request):\n try:\n login_user = login_service.get_login_user(request)\n login_user_id = login_user.user_id\n is_admin = login_user.is_admin\n nav_menu = list()\n user_app_list = list(AuthResult.objects.filter(user_id=login_user_id).values_list('app__app_code', flat=True).distinct())\n if is_admin or 'auth' in user_app_list:\n auth_menu_children = list()\n if is_admin or has_permission(request, 'auth.user_view'):\n auth_menu_children.append({'text': '用户管理', 'url': reverse('auth:user_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.admin_view'):\n auth_menu_children.append({'text': '管理员组', 'url': reverse('auth:admin_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.dept_view'):\n auth_menu_children.append({'text': '部门管理', 'url': reverse('auth:dept_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.deptuser_view'):\n auth_menu_children.append({'text': '部门用户', 'url': reverse('auth:deptuser_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.app_view'):\n auth_menu_children.append({'text': '应用管理', 'url': reverse('auth:app_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.group_view'):\n auth_menu_children.append({'text': '群组管理', 'url': reverse('auth:group_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.groupuser_view'):\n auth_menu_children.append({'text': '群组用户', 'url': reverse('auth:groupuser_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.resource_view'):\n auth_menu_children.append({'text': '应用资源', 'url': reverse('auth:resource_list'), 'leaf': True})\n if is_admin or has_permission(request, 'auth.result_view'):\n auth_menu_children.append({'text': '授权结果', 'url': reverse('auth:result_list'), 'leaf': True})\n auth_menu = {'text': '应用授权', 'expanded': True, 'leaf': False, 'children': auth_menu_children}\n if len(auth_menu_children) > 0:\n nav_menu.append(auth_menu)\n inventory_menu_children = list()\n inventory_menu_children.append({'text': '仓库管理', 'url': reverse('inventory:warehouse_list'), 'leaf': True})\n inventory_menu = {'text': '库存管理', 'expanded': True, 'leaf': False, 'children': inventory_menu_children}\n nav_menu.append(inventory_menu)\n return JsonResponse(nav_menu, safe=False)\n except Exception as exp:\n logger.exception(exp)\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\n\n\ndef test(request):\n # request.session.clear()\n posts = request.POST\n print(posts.lists())\n for x, y in posts.lists():\n print(x, y)\n print(len(posts))\n '''\n for k, v in posts.iterlists():\n print(k + \":\" + v)\n '''\n return render(request, 'common/test.html')\n"
},
{
"alpha_fraction": 0.6512484550476074,
"alphanum_fraction": 0.6516578197479248,
"avg_line_length": 41.625,
"blob_id": "5bf26f035438093f5601dc601b3614e623bb6173",
"content_id": "26a8bfbbf0b9a1647e4f7abc6b1704056025fabf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5176,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 112,
"path": "/auth/views/deptuser.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django import forms\r\nfrom django.db.models import Q, F\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import Department, DepartmentUser, User\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.deptuser_view')\r\ndef deptuser_search(request):\r\n return render(request, 'auth/deptuser.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.deptuser_view')\r\ndef deptuser_dept_tree_data(request):\r\n try:\r\n dept_id = request.POST.get('node')\r\n if dept_id is None or dept_id == '' or dept_id == '0':\r\n dept_id = None\r\n else:\r\n dept_id = int(dept_id)\r\n dept_query = Department.objects.filter(parent=dept_id).annotate(text=F('dept_name')).values('id', 'text')\r\n dept_list = list(dept_query)\r\n return JsonResponse(dept_list, safe=False)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n@require_POST\r\n@permission_required('auth.deptuser_view')\r\ndef deptuser_user_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n deptuser_query = DepartmentUser.objects.all()\r\n dept_id = request.POST.get('dept_id')\r\n if dept_id is not None and dept_id.strip() != '' and dept_id != '0':\r\n deptuser_query = deptuser_query.filter(department=dept_id)\r\n deptuser_query = deptuser_query.values('department__dept_name', 'user__login_name', 'user__nick_name', *field_names(DepartmentUser))\r\n if sort_property is not None:\r\n deptuser_query = deptuser_query.order_by(sort_direction + sort_property)\r\n total_count = deptuser_query.count()\r\n user_list = list(deptuser_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.deptuser_add')\r\ndef deptuser_select_user_list_data(request):\r\n try:\r\n dept_id = request.POST.get('dept_id')\r\n # user_id_list = DepartmentUser.objects.filter(department=dept_id).values_list('user_id', flat=True)\r\n # 下面一句的写法更为简洁,最终会和再下面的语句会生成一个单独的SQL, 前一个查询很变成后一个查询的子查询\r\n user_id_list = DepartmentUser.objects.filter(department=dept_id).values('user_id')\r\n user_query = User.objects.exclude(id__in=user_id_list).values(*field_names(User))\r\n total_count = user_query.count()\r\n user_list = list(user_query)\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\nclass UserAddForm(forms.Form):\r\n dept_id = forms.IntegerField()\r\n user_id_list = forms.IntegerField()\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.deptuser_add')\r\ndef deptuser_add_user(request):\r\n try:\r\n if request.POST.get('dept_id') is None:\r\n return JsonResponse({'success': False, 'message': '请先选择部门再进行添加!'})\r\n if request.POST.get('user_id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行添加!'})\r\n user_add_form = UserAddForm(request.POST)\r\n dept_id = user_add_form.data.get('dept_id')\r\n user_id_list = user_add_form.data.getlist('user_id_list')\r\n dept_user_list_to_add = []\r\n for user_id in user_id_list:\r\n dept_user_list_to_add.append(DepartmentUser(department_id=dept_id, user_id=user_id))\r\n DepartmentUser.objects.bulk_create(dept_user_list_to_add)\r\n return JsonResponse({'success': True, 'message': '用户添加成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.deptuser_remove')\r\ndef deptuser_remove_user(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行移除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n DepartmentUser.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '移除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '移除失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.6182898283004761,
"alphanum_fraction": 0.6191385388374329,
"avg_line_length": 35.70399856567383,
"blob_id": "e569ac9e55f17c198a7571d1beba1621e2742596",
"content_id": "b886d2355ca15ab1eecf17b920d683fe51490ee0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4903,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 125,
"path": "/auth/views/admin.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import Admin, User\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.admin_view')\r\ndef admin_search(request):\r\n return render(request, 'auth/admin.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.admin_view')\r\ndef admin_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n admin_query = Admin.objects.all()\r\n # extra filters here\r\n admin_query = admin_query.values('user__login_name', 'user__nick_name', *field_names(Admin))\r\n if sort_property is not None:\r\n admin_query = admin_query.order_by(sort_direction + sort_property)\r\n total_count = admin_query.count()\r\n admin_list = list(admin_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': admin_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.admin_view')\r\ndef admin_detail_data(request):\r\n admin_id_data = request.POST.get('id')\r\n if admin_id_data is None:\r\n admin = Admin()\r\n else:\r\n admin_id = int(admin_id_data)\r\n admin = Admin.objects.filter(pk=admin_id).values('user__nick_name', *field_names(Admin))[0]\r\n return JsonResponse(admin)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.admin_delete')\r\ndef admin_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n admin_count = Admin.objects.count()\r\n if admin_count <= len(id_list):\r\n return JsonResponse({'success': False, 'message': '不能把所有管理员全部删除!'})\r\n Admin.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass AdminDetailForm(ModelForm):\r\n class Meta:\r\n model = Admin\r\n fields = '__all__'\r\n # exclude = []\r\n error_messages = {\r\n 'user': {\r\n 'required': '用户是必填项!',\r\n\r\n },\r\n 'admin_desc': {\r\n\r\n 'max_length': '描述不能超过255个字符!',\r\n },\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.admin_save')\r\ndef admin_save(request):\r\n try:\r\n admin_id = request.POST.get('id')\r\n if admin_id.strip() == '':\r\n admin_form = AdminDetailForm(request.POST)\r\n else:\r\n admin = Admin.objects.get(pk=admin_id)\r\n admin_form = AdminDetailForm(request.POST, instance=admin)\r\n if not admin_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(admin_form)})\r\n admin_form.save()\r\n # admin = admin_form.save(commit=False)\r\n # setup foreign key fields etc\r\n # admin.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.admin_save')\r\ndef admin_select_user_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n user_query = User.objects.all()\r\n admin_user_id_query = Admin.objects.all().values('user_id')\r\n user_query = user_query.exclude(id__in=admin_user_id_query)\r\n user_query = user_query.values(*field_names(User))\r\n if sort_property is not None:\r\n user_query = user_query.order_by(sort_direction + sort_property)\r\n total_count = user_query.count()\r\n user_list = list(user_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': user_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.6488673090934753,
"alphanum_fraction": 0.6488673090934753,
"avg_line_length": 49.5,
"blob_id": "c7d4ea827fa40d7eb676e33633c7e4df796bda0f",
"content_id": "e8a9d35010b11805f4e56880bcbe4c71bcb9c593",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 618,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 12,
"path": "/common/urls.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\r\n\r\nurlpatterns = [\r\n url(r'^$', 'common.views.home', name='home'),\r\n url(r'^navmenudata/$', 'common.views.home_nav_menu_data', name='nav_menu_data'),\r\n url(r'^login/$', 'auth.views.login.login_login', name='login'),\r\n url(r'^logout/$', 'auth.views.login.login_logout', name='logout'),\r\n url(r'^profileuserdata/$', 'auth.views.profile.profile_user_detail_data', name='profile_user_detail_data'),\r\n url(r'^profileusersave/$', 'auth.views.profile.profile_user_detail_save', name='profile_user_detail_save'),\r\n\r\n url(r'^test/$', 'common.views.test', name='test'),\r\n]\r\n"
},
{
"alpha_fraction": 0.8450704216957092,
"alphanum_fraction": 0.8450704216957092,
"avg_line_length": 15.75,
"blob_id": "31481847da881a1a6ce47d001a1546e8476eb311",
"content_id": "8374cb204faabeca3daddfa56be846afa84efead",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 165,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 4,
"path": "/doc/todo.txt",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "可以把 Group 改成部门用户和组用户那样的界面\r\n列表数据的组合查询\r\napi token授权\r\n一个应用的资源只能授权给本应用的群组\r\n"
},
{
"alpha_fraction": 0.5987654328346252,
"alphanum_fraction": 0.6010288000106812,
"avg_line_length": 35.38461685180664,
"blob_id": "d1a88fc680a2c3cbf8e89ac52d14c4e2ee3e348e",
"content_id": "838388c5825018e3baa89e1c9187a4a491d663c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5078,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 130,
"path": "/auth/views/dept.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom django.views.decorators.http import require_POST\r\nfrom django.http import JsonResponse\r\nfrom django.forms import ModelForm\r\nfrom django.db.models import Q, F\r\nimport logging\r\nfrom common.service.util import field_names, get_form_error_msg\r\nfrom common.forms import GridSearchForm, GridDeleteForm\r\nfrom auth.permission import permission_required\r\nfrom auth.models import Department\r\n\r\nlogger = logging.getLogger(__name__)\r\n\r\n\r\n@permission_required('auth.dept_view')\r\ndef dept_search(request):\r\n return render(request, 'auth/dept.html')\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.dept_view')\r\ndef dept_list_data(request):\r\n try:\r\n search_form = GridSearchForm(request.POST)\r\n start, limit, sort_property, sort_direction = search_form.get_search_data()\r\n dept_query = Department.objects.all()\r\n parent_id = request.POST.get('parentId')\r\n if parent_id is None or parent_id == '' or parent_id == '0':\r\n parent_id = None\r\n else:\r\n parent_id = int(parent_id)\r\n dept_query = dept_query.filter(parent=parent_id)\r\n dept_query = dept_query.values(*field_names(Department))\r\n if sort_property is not None:\r\n dept_query = dept_query.order_by(sort_direction + sort_property)\r\n total_count = dept_query.count()\r\n dept_list = list(dept_query[start: start + limit])\r\n return JsonResponse({'total': total_count, 'rows': dept_list})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.dept_view')\r\ndef dept_tree_data(request):\r\n try:\r\n parent_id = request.POST.get('node')\r\n if parent_id is None or parent_id == '' or parent_id == '0':\r\n parent_id = None\r\n else:\r\n parent_id = int(parent_id)\r\n dept_query = Department.objects.filter(parent=parent_id).annotate(text=F('dept_name')).values('id', 'text')\r\n dept_list = list(dept_query)\r\n return JsonResponse(dept_list, safe=False)\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '加载数据失败!详细:%s' % exp})\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.dept_view')\r\ndef dept_detail_data(request):\r\n dept_id_data = request.POST.get('id')\r\n if dept_list_data is None:\r\n dept = Department()\r\n else:\r\n dept_id = int(dept_id_data)\r\n dept = Department.objects.filter(pk=dept_id).values('parent__id', 'parent__dept_name', *field_names(Department))[0]\r\n return JsonResponse(dept)\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.dept_delete')\r\ndef dept_delete(request):\r\n try:\r\n if request.POST.get('id_list') is None:\r\n return JsonResponse({'success': False, 'message': '请至少选择一条记录进行删除!'})\r\n delete_form = GridDeleteForm(request.POST)\r\n id_list = delete_form.data.getlist('id_list')\r\n Department.objects.filter(id__in=id_list).delete()\r\n return JsonResponse({'success': True, 'message': '删除成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '删除失败!详细:%s' % exp})\r\n\r\n\r\nclass DepartmentDetailForm(ModelForm):\r\n class Meta:\r\n model = Department\r\n fields = '__all__'\r\n exclude = ['parent', 'users']\r\n error_messages = {\r\n 'dept_code': {\r\n 'required': '编码是必填项!',\r\n 'max_length': '编码不能超过20个字符!',\r\n },\r\n 'dept_name': {\r\n 'required': '名称是必填项!',\r\n 'max_length': '名称不能超过20个字符!',\r\n },\r\n 'dept_desc': {\r\n\r\n 'max_length': '描述不能超过255个字符!',\r\n },\r\n }\r\n\r\n\r\n@require_POST\r\n@permission_required('auth.dept_save')\r\ndef dept_save(request):\r\n try:\r\n dept_id = request.POST.get('id')\r\n if dept_id == '':\r\n dept_form = DepartmentDetailForm(request.POST)\r\n else:\r\n dept = Department.objects.get(pk=dept_id)\r\n dept_form = DepartmentDetailForm(request.POST, instance=dept)\r\n if not dept_form.is_valid():\r\n return JsonResponse({'success': False, 'message': '验证失败!' + get_form_error_msg(dept_form)})\r\n dept = dept_form.save(commit=False)\r\n parent_id = request.POST.get('parent__id')\r\n if parent_id is not None and parent_id.strip() != '' and parent_id != '0':\r\n # dept.parent = Department.objects.get(pk=parent_id)\r\n dept.parent_id = parent_id\r\n dept.save()\r\n return JsonResponse({'success': True, 'message': '保存成功!'})\r\n except Exception as exp:\r\n logger.exception(exp)\r\n return JsonResponse({'success': False, 'message': '保存失败!详细:%s' % exp})\r\n"
},
{
"alpha_fraction": 0.6051996946334839,
"alphanum_fraction": 0.6051996946334839,
"avg_line_length": 69.75,
"blob_id": "55bbb2627f3d532f5448dd8f3a79a5f5da9121c6",
"content_id": "07c091b93c6fdc4cc64ce54e3c391e3c433a0546",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3731,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 52,
"path": "/auth/service/authresult.py",
"repo_name": "wanglihua/Speed",
"src_encoding": "UTF-8",
"text": "from django.db import transaction\r\nfrom auth.models import Resource, UserResource, GroupUser, GroupResource, AuthResult\r\n\r\n\r\nclass AuthResultService:\r\n def refresh_all_result(self):\r\n auth_result_to_insert = []\r\n user_resource_list = list(UserResource.objects.all().select_related('resource', 'resource__app'))\r\n for user_resource in user_resource_list:\r\n auth_result_to_insert.append(AuthResult(app_id=user_resource.resource.app.id,\r\n res_label=user_resource.resource.app.app_code + '.' + user_resource.resource.res_code,\r\n resource_id=user_resource.resource_id, user_id=user_resource.user_id))\r\n all_group_user_list = list(GroupUser.objects.all())\r\n group_resource_list = list(GroupResource.objects.all())\r\n for group_resource in group_resource_list:\r\n group_user_list = [x for x in all_group_user_list if x.group_id == group_resource.group_id]\r\n for group_user in group_user_list:\r\n auth_result_to_insert.append(AuthResult(app_id=group_resource.resource.app.id,\r\n res_label=group_resource.resource.app.app_code + '.' + group_resource.resource.res_code,\r\n resource_id=group_resource.resource_id, user_id=group_user.user_id, group_id=group_resource.group_id))\r\n with transaction.atomic():\r\n AuthResult.objects.all().delete()\r\n AuthResult.objects.bulk_create(auth_result_to_insert)\r\n\r\n def refresh_group_result(self, group_id_list):\r\n auth_result_to_insert = []\r\n all_group_user_list = list(GroupUser.objects.filter(group_id__in=group_id_list))\r\n group_resource_list = list(GroupResource.objects.filter(group_id__in=group_id_list).select_related('resource', 'resource__app'))\r\n for group_resource in group_resource_list:\r\n group_user_list = [x for x in all_group_user_list if x.group_id == group_resource.group_id]\r\n for group_user in group_user_list:\r\n auth_result_to_insert.append(AuthResult(app_id=group_resource.resource.app.id,\r\n res_label=group_resource.resource.app.app_code + '.' + group_resource.resource.res_code,\r\n resource_id=group_resource.resource_id, user_id=group_user.user_id, group_id=group_resource.group_id))\r\n with transaction.atomic():\r\n AuthResult.objects.filter(group_id__in=group_id_list).delete()\r\n AuthResult.objects.bulk_create(auth_result_to_insert)\r\n\r\n def refresh_user_result(self, user_id_list):\r\n auth_result_to_insert = []\r\n user_resource_list = list(UserResource.objects.filter(user_id__in=user_id_list).select_related('resource', 'resource__app'))\r\n for user_resource in user_resource_list:\r\n auth_result_to_insert.append(AuthResult(app_id=user_resource.resource.app.id,\r\n res_label=user_resource.resource.app.app_code + '.' + user_resource.resource.res_code,\r\n resource_id=user_resource.resource_id, user_id=user_resource.user_id))\r\n with transaction.atomic():\r\n AuthResult.objects.filter(user_id__in=user_id_list).delete()\r\n AuthResult.objects.bulk_create(auth_result_to_insert)\r\n\r\n def get_user_resource_code_list(self, user_id):\r\n res_code_list = list(AuthResult.objects.filter(user_id=user_id).values_list('res_label', flat=True).distinct())\r\n return res_code_list\r\n"
}
] | 29 |
pindos11/tkinter-roguelike
|
https://github.com/pindos11/tkinter-roguelike
|
3a9d10ac24662b353946ecdd8acb101e5f7cbce2
|
e2e5dfbf2ce97bcc9af49e31457391769218b1d7
|
f52db35707e83220f29c8cce103a149ee38f633c
|
refs/heads/master
| 2022-11-14T14:10:49.140331 | 2022-10-22T17:06:19 | 2022-10-22T17:06:19 | 74,212,803 | 1 | 0 | null | 2016-11-19T14:17:36 | 2016-11-19T15:27:56 | 2016-11-20T15:06:32 |
Python
|
[
{
"alpha_fraction": 0.5340364575386047,
"alphanum_fraction": 0.5520613789558411,
"avg_line_length": 33.73287582397461,
"blob_id": "66fa844c1ad2fec22246287add78e2056c005495",
"content_id": "fd4594c594f596645ccd7fb08441ae9dbca2879c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5215,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 146,
"path": "/Player.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "from Item import *\r\nimport tkinter\r\nclass Player:\r\n def __init__(self,master):\r\n self.strength=0\r\n self.dexterity=0\r\n self.endurance=0\r\n \r\n self.add_strength=0\r\n self.add_dexterity=0\r\n self.add_endurance=0\r\n self.health=0\r\n self.add_health=0\r\n self.add_damage=0\r\n self.add_armor=0\r\n self.master=master\r\n self.inventory=[]\r\n self.inventory.append(Item('wpn',1))\r\n self.inventory.append(Item('arm',1))\r\n self.inventory.append(Item('utl',1))\r\n self.chartype='player'\r\n self.level=1\r\n self.exp=0\r\n self.nexp=10\r\n self.preset_chars()\r\n self.upd_stats()\r\n self.health=self.maxhealth\r\n\r\n def give_item(self,item):\r\n if(item.itype=='wpn'):\r\n to_ret=self.inventory[0]\r\n self.inventory[0]=item\r\n if(item.itype=='arm'):\r\n to_ret=self.inventory[1]\r\n self.inventory[1]=item\r\n if(item.itype=='utl'):\r\n to_ret=self.inventory[2]\r\n self.inventory[2]=item\r\n self.upd_stats()\r\n return to_ret\r\n \r\n\r\n def heal(self,addhp):\r\n self.health+=addhp\r\n if(self.health>self.maxhealth):\r\n self.health=self.maxhealth\r\n \r\n def add_exp(self,amount):\r\n self.exp+=amount\r\n self.exp = round(self.exp,2)\r\n if(self.exp>=self.nexp):\r\n self.levelup()\r\n nx=self.nexp\r\n self.nexp+=self.level+5\r\n self.level+=1\r\n self.exp-=nx\r\n self.exp = round(self.exp,2)\r\n self.upd_stats()\r\n self.health+=self.level*2\r\n if(self.health>=self.maxhealth):\r\n self.health=self.maxhealth\r\n return('Welcome to level '+str(self.level)+'!')\r\n return('Gained '+str(amount)+' exp')\r\n\r\n def levelup(self):\r\n self.lvlup=tkinter.Toplevel(self.master)\r\n self.lvlup.title(\"Choose charasteristic to upgrade\")\r\n self.lvlup.geometry('300x200+100+100')\r\n self.charact=tkinter.IntVar()\r\n stren = tkinter.Radiobutton(self.lvlup,variable=self.charact,text=\"Strength: +2 dmg +1% crit mul\",value=1)\r\n dex = tkinter.Radiobutton(self.lvlup,variable=self.charact,text=\"Dexterity +1% dodge chance +1% crit chance\",value=2)\r\n end = tkinter.Radiobutton(self.lvlup,variable=self.charact,text=\"Endurance +3 hp +0.5 armor\",value=3)\r\n stren.place(x=20,y=20)\r\n dex.place(x=20,y=45)\r\n end.place(x=20,y=70)\r\n acbtn=tkinter.Button(self.lvlup,text='Accept',command=self.add_char)\r\n acbtn.place(x=20,y=95)\r\n self.lvlup.mainloop()\r\n \r\n def add_char(self):\r\n to_add=self.charact.get()\r\n if(to_add==1):\r\n self.nat_strength+=1\r\n elif(to_add==2):\r\n self.nat_dexterity+=1\r\n elif(to_add==3):\r\n self.nat_endurance+=1\r\n else:\r\n return(0)\r\n self.lvlup.quit()\r\n self.lvlup.destroy()\r\n \r\n def preset_chars(self):\r\n random.seed()\r\n self.nat_strength = random.randint(1+self.level,4+self.level)\r\n self.nat_dexterity = random.randint(1+self.level,4+self.level)\r\n self.nat_endurance = random.randint(2+self.level,3+self.level)\r\n\r\n\r\n def apply_items(self):\r\n self.add_strength=0\r\n self.add_dexterity=0\r\n self.add_endurance=0\r\n self.add_health=0\r\n self.maxhealth=0\r\n self.add_damage=0\r\n self.add_armor=0\r\n self.mh=0\r\n if(self.health==self.maxhealth):\r\n self.mh=1 \r\n for i in self.inventory:\r\n if(i.itype=='wpn'):\r\n self.add_strength+=int(i.in_strength+i.add_strength)\r\n self.add_dexterity+=int(i.in_dexterity+i.add_dexterity)\r\n self.add_damage+=int(i.in_damage+i.add_damage)\r\n if(i.itype=='arm'):\r\n self.add_endurance+=int(i.in_endurance+i.add_endurance)\r\n self.add_dexterity+=int(i.in_dexterity+i.add_dexterity)\r\n self.add_armor+=int(i.in_armor+i.add_armor)\r\n self.add_health+=int(i.in_health+i.add_health)\r\n if(i.itype=='utl'):\r\n self.add_endurance+=int(i.add_endurance)\r\n self.add_dexterity+=int(i.add_dexterity)\r\n \r\n \r\n def upd_stats(self):\r\n self.apply_items()\r\n self.strength=self.nat_strength+self.add_strength\r\n self.dexterity=self.nat_dexterity+self.add_dexterity\r\n self.endurance=self.nat_endurance+self.add_endurance\r\n #str\r\n self.nat_damage = float(self.strength*2)\r\n self.crit_addmul = float(self.strength*2)\r\n #dex\r\n self.dodge_chance = self.dexterity\r\n self.crit_chance = float(self.dexterity)/2\r\n #end\r\n self.maxhealth = float(self.endurance*3)+self.add_health\r\n self.nat_armor = self.endurance/2\r\n\r\n self.damage=self.nat_damage+self.add_damage\r\n self.armor=self.nat_armor+self.add_armor\r\n if(self.health>self.maxhealth):\r\n self.health=self.maxhealth\r\n if(self.mh==1):\r\n self.health=self.maxhealth"
},
{
"alpha_fraction": 0.5138949751853943,
"alphanum_fraction": 0.5508752465248108,
"avg_line_length": 48.50828552246094,
"blob_id": "87d8c2aba4ab0d1dc1d83d07081f39b8082c6edc",
"content_id": "366280ceb497da633f75a3ff611ba639bee9966b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9140,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 181,
"path": "/Drawing.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "import tkinter\r\nclass Drawing:\r\n def __init__(self,curf):\r\n self.mainwindow=tkinter.Tk()\r\n self.mainwindow.geometry('800x600+0+0')\r\n self.canv = tkinter.Canvas(self.mainwindow,width=800,height=600)\r\n self.canv.place(x=0,y=0)\r\n self.draw_field(curf)\r\n self.mobs_c=[]\r\n self.npcs_c=[]\r\n self.mobhp_c = []\r\n self.msg_log=[]\r\n \r\n\t\r\n def get_mwin(self):\r\n return(self.mainwindow)\r\n\t\t\r\n def draw_npcs(self,npcs):\r\n for i in self.npcs_c:\r\n self.canv.delete(i)\r\n self.npcs_c=[]\r\n self.npcimgs=[]\r\n for i in npcs:\r\n self.npcimgs.append(tkinter.PhotoImage(file='images/chars/npc/'+i.ntype+'.gif'))\r\n self.npcs_c.append(self.canv.create_image((i.posx*60,i.posy*60),image=self.npcimgs[len(self.npcimgs)-1],anchor='nw'))\r\n \r\n def draw_monsters(self,mobs):\r\n for i in self.mobs_c:\r\n self.canv.delete(i)\r\n for i in self.mobhp_c:\r\n self.canv.delete(i)\r\n self.mobs_c = []\r\n self.mobhp_c = []\r\n self.mgimgs=[]\r\n for i in mobs:\r\n self.mgimgs.append(tkinter.PhotoImage(file='images/chars/mobs/'+i.model+'.gif'))\r\n self.mobs_c.append(self.canv.create_image((i.posx*60,i.posy*60),image=self.mgimgs[len(self.mgimgs)-1],anchor='nw'))\r\n self.mobhp_c.append(self.canv.create_rectangle(i.posx*60,i.posy*60,i.posx*60+50,i.posy*60+2,fill='white',outline='red'))\r\n self.mobhp_c.append(self.canv.create_rectangle(i.posx*60,i.posy*60,i.posx*60+50*(i.health/i.maxhealth),i.posy*60+2,fill='red',outline='red'))\r\n \r\n def draw_gui(self,plr,curfpos,wrd,qposes):\r\n self.canv.create_text((610,2),text=\"Moves log\",anchor='nw')\r\n self.msgboximg=tkinter.PhotoImage(file='images/gui/msg.png')\r\n self.msgboxic=self.canv.create_image((600,20),image=self.msgboximg,anchor='nw')\r\n #all text in img after img\r\n self.msgbox=[]\r\n for i in range(0,6):\r\n self.msgbox.append(self.canv.create_text((610,30+i*14),text='',anchor='nw'))\r\n self.wpnimgc = 1000\r\n self.armimgc = 1000\r\n self.utlimgc = 1000\r\n self.canv.create_text((610,132),text=\"Status\",anchor='nw')\r\n self.statusboximg=tkinter.PhotoImage(file='images/gui/stats.png')\r\n self.statusboxic=self.canv.create_image((600,150),image=self.statusboximg,anchor='nw')\r\n self.canv.create_rectangle(610,160,700,175,fill='white',outline='red')\r\n self.canv.create_rectangle(610,160,610+90*(plr.health/plr.maxhealth),175,fill='red',outline='red')\r\n self.canv.create_text((610,160),text='Health: '+str(round(plr.health,1))+'/'+str(plr.maxhealth),anchor='nw')\r\n self.canv.create_text((610,200),text='Strength: '+str(plr.strength),anchor='nw')\r\n self.canv.create_text((610,215),text='Dexterity: '+str(plr.dexterity),anchor='nw')\r\n self.canv.create_text((610,230),text='Endurance: '+str(plr.endurance),anchor='nw')\r\n self.canv.create_text((710,160),text='Exp '+str(plr.exp)+'/'+str(plr.nexp),anchor='nw')\r\n self.canv.create_text((610,185),text='Level: '+str(plr.level),anchor='nw')\r\n self.canv.create_text((710,185),text='Damage: '+str(plr.damage),anchor='nw')\r\n self.canv.create_text((710,200),text='Armor: '+str(plr.armor),anchor='nw')\r\n self.canv.create_text((700,215),text='You are in '+str(curfpos),anchor='nw')\r\n \r\n self.invboximg = tkinter.PhotoImage(file='images/gui/stats.png')\r\n self.inventimg = tkinter.PhotoImage(file='images/gui/inv_box.png')\r\n self.invboxc=self.canv.create_image((600,280),image=self.invboximg,anchor='nw')\r\n self.invbox1=self.canv.create_image((608,322),image=self.inventimg,anchor='nw')\r\n self.invbox2=self.canv.create_image((670,322),image=self.inventimg,anchor='nw')\r\n self.invbox3=self.canv.create_image((732,322),image=self.inventimg,anchor='nw')\r\n self.q_logt = self.canv.create_text((605,390),text='Minimap (quest NPC - blue):',anchor='nw')\r\n #if(len(self.qposes)>0):\r\n # qposc = []\r\n # for i in self.qposes:\r\n # qposc.append(self.canv.create_text((610,420+self.qposes.index(i)*15),text=str(i),anchor='nw'))\r\n \r\n self.draw_minimap(wrd,curfpos,qposes)\r\n #items\r\n self.invtext=self.canv.create_text((620,300),text='Inventory',anchor='nw')\r\n if(len(plr.inventory)>0):\r\n for i in plr.inventory:\r\n if(i.itype=='wpn'):\r\n self.wpnimg=tkinter.PhotoImage(file='images/items/'+i.model+'.gif')\r\n if(self.wpnimgc!=1000):\r\n self.canv.itemconfig(self.wpnimgc,image=self.wpnimg)\r\n else:\r\n self.wpnimgc=self.canv.create_image((623,337),image=self.wpnimg,anchor='nw')\r\n if(i.itype=='arm'):\r\n self.armimg=tkinter.PhotoImage(file='images/items/'+i.model+'.gif')\r\n if(self.armimgc!=1000):\r\n self.canv.itemconfig(self.armimgc,image=self.armimg)\r\n else:\r\n self.armimgc=self.canv.create_image((685,337),image=self.armimg,anchor='nw')\r\n if(i.itype=='utl'):\r\n self.utlimg=tkinter.PhotoImage(file='images/items/'+i.model+'.gif')\r\n if(self.utlimgc!=1000):\r\n self.canv.itemconfig(self.utlimgc,image=self.utlimg)\r\n else:\r\n self.utlimgc=self.canv.create_image((747,337),image=self.utlimg,anchor='nw')\r\n self.chargec=self.canv.create_text((747,337),text=i.charges,anchor='nw')\r\n\r\n\r\n def draw_minimap(self,wrd,curfpos,qposes):\r\n mpos = (700,500)\r\n mmsize=8\r\n offset = (curfpos[0]*mmsize,curfpos[1]*mmsize)\r\n cpos = curfpos\r\n mpos = (mpos[0]-offset[0],mpos[1]-offset[1])\r\n for pos,fld in wrd.items():\r\n if(pos[0]>10+cpos[0] or pos[0]<-10+curfpos[0] or pos[1]>10+cpos[1] or pos[1]<-10+curfpos[1]):\r\n continue\r\n color = 'white'\r\n if(fld.ztype==1):\r\n color='green'\r\n elif(fld.ztype==2):\r\n color='yellow'\r\n elif(fld.ztype==3):\r\n color='red'\r\n elif(fld.ztype==4):\r\n color='black'\r\n if(pos in qposes):\r\n color = 'blue2'\r\n if(pos==curfpos):\r\n color = 'white'\r\n self.canv.create_rectangle((mpos[0]+pos[0]*mmsize,mpos[1]+pos[1]*mmsize,mpos[0]+pos[0]*mmsize+mmsize,mpos[1]+pos[1]*mmsize+mmsize),fill=color)\r\n \r\n def draw_field(self,curf):\r\n self.canv.delete('all')\r\n self.terrain = []\r\n self.lootimgs=[]\r\n self.texlist={}\r\n tlist=curf.terrains()\r\n for i in tlist:\r\n if('3_h' in i):\r\n self.texlist.update([(i,tkinter.PhotoImage(file='images/buildings/'+str(i)+'.gif'))])\r\n else: \r\n self.texlist.update([(i,tkinter.PhotoImage(file='images/60x60terrain/'+str(i)+'.gif'))])\r\n for i in range(0,10):\r\n tmp = []\r\n self.terrain.append(tmp)\r\n for j in range(0,10):\r\n ttype=curf.cur_cond()[i][j].get_terrain()\r\n if('3_h' in ttype):\r\n self.terrain[i].append(self.canv.create_image((i*60,j*60),image=self.texlist['1'],anchor='nw'))\r\n self.terrain[i].append(self.canv.create_image((i*60,j*60),image=self.texlist[ttype],anchor='nw'))\r\n else: \r\n self.terrain[i].append(self.canv.create_image((i*60,j*60),image=self.texlist[ttype],anchor='nw'))\r\n if(curf.cur_cond()[i][j].hasloot==1):\r\n loot = curf.cur_cond()[i][j].loot\r\n self.lootimgs.append(tkinter.PhotoImage(file='images/items/'+loot.model+'.gif'))\r\n self.canv.create_image((i*60,j*60),image=self.lootimgs[len(self.lootimgs)-1],anchor='nw')\r\n self.draw_player(curf)\r\n \r\n def draw_player(self,curf):\r\n self.psprite=tkinter.PhotoImage(file='images/chars/player/girl.gif') \r\n pposx = curf.pposx\r\n pposy = curf.pposy\r\n self.plabel=self.canv.create_image((pposx*60,pposy*60),image=self.psprite,tags='player',anchor='nw')\r\n\t\t\r\n def edit_msg(self,text):\r\n if(text!=''):\r\n self.msg_log.append(text)\r\n if(len(self.msg_log)>6):\r\n self.msg_log=self.msg_log[len(self.msg_log)-6:len(self.msg_log)]\r\n for i in range(0,6):\r\n if(len(self.msg_log)==0):\r\n break\r\n try:\r\n outtext=self.msg_log[i]\r\n except:\r\n break\r\n color='black'\r\n if('Received' in outtext):\r\n color='red'\r\n elif('Dealt' in outtext):\r\n color='green'\r\n elif('Entering' in outtext):\r\n color='blue'\r\n self.canv.itemconfig(self.msgbox[i],text=outtext,fill=color)"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.7670454382896423,
"avg_line_length": 57.66666793823242,
"blob_id": "ddbbc48d2f65a72371977c9b51b0812fe7b5ac3f",
"content_id": "33ddbd552cf8285df2bd953d311382ab3cfb102c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 277,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 3,
"path": "/README.md",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "# tkinter-roguelike\nЕА ВАИВАЛ С МОНСТРАМИ\\n\nЧТОБ ИГРАТИ НУЖНО python 3.4\\n WASD ходить C,X - ждать, C - взаимодействовать с лутом/набирать воду из колодца, 3 - пить из бутылки\n"
},
{
"alpha_fraction": 0.5387930870056152,
"alphanum_fraction": 0.5517241358757019,
"avg_line_length": 21.399999618530273,
"blob_id": "bcc536b86d4b660f410c82deb5c3363a32b3a5d1",
"content_id": "048213bc522d87117551f3b7ad22b823ac1805dc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 232,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 10,
"path": "/NPC.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "from quest import*\r\n\r\nclass NPC:\r\n def __init__(self,pos,ntype):\r\n self.posx=pos[0]\r\n self.posy=pos[1]\r\n self.ntype=ntype\r\n self.create_quest()\r\n def create_quest(self):\r\n self.quest=quest(1)"
},
{
"alpha_fraction": 0.4420471787452698,
"alphanum_fraction": 0.4770028293132782,
"avg_line_length": 32.761627197265625,
"blob_id": "1e19d3f68229719326b3349a7ba16eaf90700442",
"content_id": "c52d7c022e6deaf39d0e08d98e0407f58981a811",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5979,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 172,
"path": "/Monster.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "import random\r\nimport math\r\nclass Monster:\r\n def __init__(self,player,mtype,pos):\r\n #player\r\n #97 - 122\r\n random.seed()\r\n self.posx=pos[0]\r\n self.posy=pos[1]\r\n if(mtype=='skele_war'):\r\n random.seed()\r\n self.model=mtype+str(random.randint(1,2))\r\n else:\r\n self.model=mtype\r\n self.level = player.level+random.randint(-1,2)\r\n if(self.level<1):\r\n self.level=1\r\n self.ap = 0\r\n self.rewardexp=(self.level+random.randint(0,4))*2\r\n self.preset_chars()\r\n self.upd_stats()\r\n self.apply_type()\r\n self.fix_mob()\r\n self.maxhealth=self.health\r\n def fix_mob(self):\r\n if(self.dodge_chance>15):\r\n self.dodge_chance=15 \r\n \r\n def apply_type(self):\r\n if(self.model=='skele_war1'):\r\n self.rewardexp = round(self.rewardexp*0.6,2)\r\n self.nat_armor = self.nat_armor/2\r\n self.health = self.health*0.75\r\n self.dodge_chance=self.dodge_chance*1.3\r\n self.nat_damage = self.nat_damage*0.9\r\n self.ap = 0.15\r\n elif(self.model=='skele_war2'):\r\n self.rewardexp = round(self.rewardexp*0.65,2)\r\n self.nat_armor = self.nat_armor*0.85\r\n self.health = self.health*0.70\r\n self.dodge_chance=self.dodge_chance*0.3\r\n self.nat_damage = self.nat_damage*0.8\r\n self.ap = 0.1\r\n elif(self.model=='cobra'):\r\n self.rewardexp = round(self.rewardexp*0.7,2)\r\n self.nat_armor = self.nat_armor*0.3\r\n self.health = self.health*0.6\r\n self.dodge_chance=self.dodge_chance*2.6\r\n self.ap = 0.35\r\n elif(self.model=='rat'):\r\n self.rewardexp = round(self.rewardexp*0.45,2)\r\n self.nat_armor = self.nat_armor/3\r\n self.health = self.health*0.5\r\n self.dodge_chance=self.dodge_chance*0.3\r\n self.nat_damage = self.nat_damage*0.3\r\n self.ap = 0.1\r\n elif(self.model=='knight_f'):\r\n self.rewardexp = round(self.rewardexp*1.1,2)\r\n self.nat_armor = self.nat_armor*1.5\r\n self.health = self.health*1.1\r\n self.dodge_chance=1\r\n self.nat_damage = self.nat_damage*1.3\r\n self.ap = 0.25\r\n elif(self.model=='drago'):\r\n self.rewardexp = round(self.rewardexp*1.4,2)\r\n self.nat_armor = self.nat_armor*0.9\r\n self.health = self.health*1.1\r\n self.nat_damage = self.nat_damage*1.6\r\n self.ap = 0.35\r\n \r\n \r\n def preset_chars(self):\r\n random.seed()\r\n mul=2\r\n self.strength = random.randint(1+self.level*mul,4+self.level*mul)\r\n self.dexterity = random.randint(1+self.level*mul,4+self.level*mul)\r\n self.endurance = random.randint(0+self.level*mul,1+self.level*mul)\r\n\r\n def move(self,newx,newy):\r\n self.posx=newx\r\n self.posy=newy\r\n\r\n def get_where_to_go(self,x_rest,y_rest,plr_pos,mobs):\r\n result = []\r\n result.append((self.posx+1,self.posy))\r\n result.append((self.posx-1,self.posy))\r\n result.append((self.posx,self.posy+1))\r\n result.append((self.posx,self.posy-1))\r\n possible_results = []\r\n filtered_results = []\r\n mobs_near = []\r\n ok_pos1 = 0\r\n ok_pos2 = 0\r\n go_pos = [self.posx,self.posy]\r\n go_pos2 = [self.posx,self.posy]\r\n for i in result:\r\n if i[0]<x_rest[0] or i[1]<y_rest[0] or i[0]>=x_rest[1] or i[1]>=y_rest[1]:\r\n continue\r\n filtered_results.append(i)\r\n\r\n for i in mobs:\r\n for j in filtered_results:\r\n if i.posx == j[0] and i.posy == j[1]:\r\n mobs_near.append(j)\r\n \r\n\r\n for i in filtered_results:\r\n ok = 1\r\n for j in mobs_near:\r\n if j[0]==i[0] and j[1]==i[1]:\r\n ok = 0\r\n \r\n if ok==1:\r\n possible_results.append(i)\r\n \r\n go_px = self.posx - plr_pos[0]\r\n go_py = self.posy - plr_pos[1]\r\n if go_px == 0:\r\n if go_py<0:\r\n go_pos[1] = go_pos[1]+1\r\n elif go_py>0:\r\n go_pos[1] = go_pos[1]-1\r\n if go_py == 0:\r\n if go_px<0:\r\n go_pos[0] = go_pos[0]+1\r\n elif go_px>0:\r\n go_pos[0] = go_pos[0]-1\r\n if go_py != 0 and go_px !=0:\r\n ang = math.atan2(go_px,go_py)\r\n ang += math.pi\r\n if ang<math.pi/2:\r\n go_pos[0]+=1\r\n go_pos2[1]+=1\r\n if ang>math.pi/2 and ang<math.pi:\r\n go_pos[1]-=1\r\n go_pos2[0]+=1\r\n if ang>math.pi and ang<math.pi*3/2:\r\n go_pos[0]-=1\r\n go_pos2[1]-=1\r\n if ang>math.pi*3/2:\r\n go_pos[1]+=1\r\n go_pos2[0]-=1\r\n\r\n myresult = []\r\n \r\n for i in possible_results:\r\n if i[0] == go_pos[0] and i[1] == go_pos[1]:\r\n ok_pos1 = 1\r\n for i in possible_results:\r\n if i[0] == go_pos2[0] and i[1] == go_pos2[1]:\r\n ok_pos2 = 1\r\n if ok_pos1 == 1:\r\n myresult.append(go_pos)\r\n else:\r\n myresult.append([self.posx,self.posy])\r\n\r\n if ok_pos2 == 1:\r\n myresult.append(go_pos2)\r\n else:\r\n myresult.append([self.posx,self.posy])\r\n return myresult #go_pos\r\n \r\n def upd_stats(self):\r\n #str\r\n self.nat_damage = float(self.strength/2)\r\n self.crit_addmul = float(self.strength*1)\r\n #dex\r\n self.dodge_chance = self.dexterity\r\n self.crit_chance = float(self.dexterity)/3\r\n #end\r\n self.health = float(self.endurance*2)\r\n self.nat_armor = float(self.endurance/4)\r\n"
},
{
"alpha_fraction": 0.7169811129570007,
"alphanum_fraction": 0.7245283126831055,
"avg_line_length": 14.5625,
"blob_id": "2a22793bc90c1743df2b2ee71f1803276f820746",
"content_id": "de9fb6a3108cf23a016b172162b8c75d6e7fc7f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 16,
"path": "/PLAYTHIS.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "import random\r\nimport tkinter\r\nimport base64\r\nimport math\r\nimport time\r\n\r\nfrom FieldPos import *\r\nfrom Field import *\r\nfrom Item import *\r\nfrom MainGame import *\r\nfrom Monster import *\r\nfrom NPC import *\r\nfrom Player import *\r\nfrom quest import*\r\n\r\na = MainGame()\r\n"
},
{
"alpha_fraction": 0.39429908990859985,
"alphanum_fraction": 0.42490309476852417,
"avg_line_length": 40.27303695678711,
"blob_id": "b86422c4e8baac2de6d98da1bd8e3417c198c0ee",
"content_id": "bb12a54feb27079b893855982318f5b5701bf4e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12384,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 293,
"path": "/Field.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "from FieldPos import *\r\nfrom NPC import *\r\nimport random\r\n\r\nclass Field:\r\n def __init__(self,sizex,sizey,plr,ztype):\r\n self.vil=plr\r\n self.ztype = ztype\r\n self.sizex = sizex\r\n self.sizey = sizey\r\n self.monsters = []\r\n self.npcs = []\r\n self.vilposes=[]\r\n #creating and filling storage for field points\r\n self.storage=[]\r\n self.walkable=['1','2','4','5','6','7','9','10','2_1','13']\r\n for i in range(0,sizex):\r\n tmp=[]\r\n self.storage.append(tmp)\r\n for j in range(0,sizey):\r\n self.storage[i].append(FieldPos(i,j,'1'))\r\n random.seed()\r\n if(self.vil==1):\r\n self.make_vil()\r\n if(self.vil==2 and self.ztype==1):\r\n self.make_smallvil()\r\n self.make_zone(ztype)\r\n self.clear_paths(ztype)\r\n self.set_player_start()\r\n #self.print_task('player')\r\n\r\n def make_smallvil(self):\r\n qpos = random.randint(1,2)\r\n if(qpos==1):\r\n nwpos=(1,2)\r\n elif(qpos==2):\r\n nwpos=(7,2)\r\n for i in range(0,2):\r\n for j in range(0,2):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('1')\r\n self.vilposes.append((i+nwpos[0],j+nwpos[1]))\r\n self.storage[nwpos[0]+1][nwpos[1]].set_terrain('3_h_w')\r\n self.storage[nwpos[0]][nwpos[1]].set_terrain('3_h_s')\r\n npc = NPC((nwpos[0],nwpos[1]+1),str(random.randint(2,3)))\r\n self.add_npc(npc)\r\n \r\n \r\n def make_vil(self):\r\n sx=self.sizex\r\n sy=self.sizey\r\n nwpos=(2,2)\r\n for i in range(0,6):\r\n for j in range(0,6):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('1')\r\n self.vilposes.append((i+nwpos[0],j+nwpos[1]))\r\n for i in range(3,5):\r\n for j in range(0,2):\r\n if(i==3):\r\n if(j==0):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('3_h_1')\r\n elif(j==1):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('3_h_4')\r\n if(i==4):\r\n if(j==0):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('3_h_2')\r\n elif(j==1):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('3_h_3')\r\n self.storage[6][4].set_terrain('3_h_w')\r\n self.storage[7][2].set_terrain('3_h_b')\r\n self.storage[7][3].set_terrain('3_h_b2')\r\n self.storage[3][6].set_terrain('3_h_t')\r\n npc = NPC((2,6),'1')\r\n self.add_npc(npc)\r\n \r\n def add_monster(self,monster):\r\n self.monsters.append(monster)\r\n def kill_monster(self,monster):\r\n self.monsters.pop(self.monsters.index(monster))\r\n def ret_monsters(self):\r\n return(self.monsters)\r\n \r\n def add_npc(self,npc):\r\n self.npcs.append(npc)\r\n \r\n def clear_paths(self,ztype):\r\n if(ztype==1):\r\n water=['3','3_1','3_2','3_3','3_4','3_5','3_6','3_7','3_8']\r\n road='2'\r\n bridge='2_1'\r\n elif(ztype==3):\r\n water=['8','8_1','8_2','8_3','8_4','8_5','8_6','8_7','8_8']\r\n road='7'\r\n bridge='10'\r\n elif(ztype==2):\r\n water=['5_1','5_2','5_3','5_4','5_5','5_6','5_7','5_8']\r\n road='5'\r\n bridge='5'\r\n elif(ztype==4):\r\n water=['11']\r\n road='13'\r\n bridge='13'\r\n for i in range(0,self.sizex):\r\n if(((i,4) not in self.vilposes)):\r\n if(self.storage[i][4].get_terrain() in water):\r\n self.storage[i][4].set_terrain(bridge)\r\n else:\r\n self.storage[i][4].set_terrain(road)\r\n if(ztype==4):\r\n self.storage[i][5].set_terrain('12')\r\n for j in range(0,self.sizey):\r\n if(((4,j) not in self.vilposes)):\r\n if(self.storage[4][j].get_terrain() in water and ztype==3):\r\n self.storage[4][j].set_terrain(bridge)\r\n else:\r\n self.storage[4][j].set_terrain(road) \r\n def set_player_start(self):\r\n if(self.vil==1):\r\n self.pposx=4\r\n self.pposy=4\r\n return\r\n while(1):\r\n random.seed()\r\n self.pposx = random.randint(0,self.sizex-1)\r\n self.pposy = random.randint(0,self.sizey-1)\r\n if(self.storage[self.pposx][self.pposy].get_terrain() in self.walkable):\r\n break\r\n self.storage[self.pposx][self.pposy].set_player()\r\n \r\n def make_zone(self,zone):\r\n vil = self.vil\r\n if(vil==2):\r\n vil = 0\r\n random.seed()\r\n if(zone==1):\r\n lakes=random.randint(4+vil*3,6+vil*3)\r\n for k in range(0,lakes):\r\n sizex=random.randint(3+vil*3,4+vil*3)\r\n sizey=random.randint(3+vil*3,4+vil*3)\r\n nwpos=(random.randint(0,self.sizex-sizex),random.randint(0,self.sizey-sizey))\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n if((i+nwpos[0],j+nwpos[1]) not in self.vilposes):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('3')\r\n \r\n sizex=self.sizex\r\n sizey=self.sizey\r\n if(self.vil==0):\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n if(i==0):\r\n self.storage[i][j].set_terrain('1')\r\n if(i==sizex-1):\r\n self.storage[i][j].set_terrain('1')\r\n if(j==0):\r\n self.storage[i][j].set_terrain('1')\r\n if(j==sizey-1):\r\n self.storage[i][j].set_terrain('1')\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n if(self.storage[i][j].get_terrain()!='3'):\r\n continue\r\n left=self.storage[i-1][j].get_terrain()\r\n top=self.storage[i][j-1].get_terrain()\r\n try:\r\n right=self.storage[i+1][j].get_terrain()\r\n except:\r\n right=left\r\n try:\r\n down=self.storage[i][j+1].get_terrain()\r\n except:\r\n down=top\r\n if(left=='1' and top=='1'):\r\n self.storage[i][j].set_terrain('3_2')\r\n elif(right=='1' and top=='1'):\r\n self.storage[i][j].set_terrain('3_4')\r\n elif(left=='1' and down=='1'):\r\n self.storage[i][j].set_terrain('3_8')\r\n elif(right=='1' and down=='1'):\r\n self.storage[i][j].set_terrain('3_6')\r\n elif(left=='1'):\r\n self.storage[i][j].set_terrain('3_1')\r\n elif(top=='1'):\r\n self.storage[i][j].set_terrain('3_3')\r\n elif(right=='1'):\r\n self.storage[i][j].set_terrain('3_5')\r\n elif(down=='1' or '3_h' in down):\r\n self.storage[i][j].set_terrain('3_7')\r\n \r\n if(zone==2):\r\n for i in range(0,self.sizex):\r\n for j in range(0,self.sizey):\r\n self.storage[i][j].set_terrain('5')\r\n if(i==0 and j==0):\r\n self.storage[i][j].set_terrain('5_2')\r\n elif(i==0 and j==self.sizey-1):\r\n self.storage[i][j].set_terrain('5_8')\r\n elif(i==self.sizex-1 and j==0):\r\n self.storage[i][j].set_terrain('5_4')\r\n elif(i==self.sizex-1 and j==self.sizey-1):\r\n self.storage[i][j].set_terrain('5_6')\r\n elif(i==0):\r\n self.storage[i][j].set_terrain('5_1')\r\n elif(j==0):\r\n self.storage[i][j].set_terrain('5_3')\r\n elif(i==self.sizex-1):\r\n self.storage[i][j].set_terrain('5_5')\r\n elif(j==self.sizey-1):\r\n self.storage[i][j].set_terrain('5_7')\r\n obsts=random.randint(3,7)\r\n for i in range(0,obsts):\r\n px=random.randint(1,self.sizex-2)\r\n py=random.randint(1,self.sizey-2)\r\n obst=random.randint(9,10)\r\n self.storage[px][py].set_terrain('5_'+str(obst))\r\n if(zone==3):\r\n for i in range(0,self.sizex):\r\n for j in range(0,self.sizey):\r\n self.storage[i][j].set_terrain('9')\r\n lakes=random.randint(4,6)\r\n for k in range(0,lakes):\r\n sizex=random.randint(3,4)\r\n sizey=random.randint(3,4)\r\n nwpos=(random.randint(0,self.sizex-1-sizex),random.randint(0,self.sizey-1-sizey))\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n self.storage[i+nwpos[0]][j+nwpos[1]].set_terrain('8')\r\n \r\n sizex=self.sizex\r\n sizey=self.sizey\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n if(i==0):\r\n self.storage[i][j].set_terrain('9')\r\n if(i==sizex-1):\r\n self.storage[i][j].set_terrain('9')\r\n if(j==0):\r\n self.storage[i][j].set_terrain('9')\r\n if(j==sizey-1):\r\n self.storage[i][j].set_terrain('9')\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n if(self.storage[i][j].get_terrain()!='8'):\r\n continue\r\n left=self.storage[i-1][j].get_terrain()\r\n top=self.storage[i][j-1].get_terrain()\r\n right=self.storage[i+1][j].get_terrain()\r\n down=self.storage[i][j+1].get_terrain()\r\n if(left=='9' and top=='9'):\r\n self.storage[i][j].set_terrain('8_2')\r\n elif(right=='9' and top=='9'):\r\n self.storage[i][j].set_terrain('8_4')\r\n elif(left=='9' and down=='9'):\r\n self.storage[i][j].set_terrain('8_8')\r\n elif(right=='9' and down=='9'):\r\n self.storage[i][j].set_terrain('8_6')\r\n elif(left=='9'):\r\n self.storage[i][j].set_terrain('8_1')\r\n elif(top=='9'):\r\n self.storage[i][j].set_terrain('8_3')\r\n elif(right=='9'):\r\n self.storage[i][j].set_terrain('8_5')\r\n elif(down=='9'):\r\n self.storage[i][j].set_terrain('8_7')\r\n if(zone==4):\r\n sizex=self.sizex\r\n sizey=self.sizey\r\n for i in range(0,sizex):\r\n for j in range(0,sizey):\r\n self.storage[i][j].set_terrain('11')\r\n def print_task(self,task):\r\n if(task==\"player\"):\r\n self.storage[self.pposx][self.pposy].output_str('pos')\r\n if(task==\"out\"):\r\n print(\"No such point on field\")\r\n def move_player(self,newx,newy): \r\n self.storage[self.pposx][self.pposy].unset_player()\r\n if(newx<self.sizex and newy<self.sizey):\r\n self.pposx = newx\r\n self.pposy = newy\r\n self.storage[self.pposx][self.pposy].set_player()\r\n else:\r\n self.print_task(\"out\")\r\n def cur_cond(self):\r\n return self.storage\r\n def size(self):\r\n return self.sizex,self.sizey\r\n def terrains(self):\r\n terrains=[]\r\n for i in range(0,self.sizex):\r\n for j in range(0,self.sizey):\r\n if(self.storage[i][j].get_terrain() not in terrains):\r\n terrains.append(self.storage[i][j].get_terrain())\r\n return terrains"
},
{
"alpha_fraction": 0.5249500870704651,
"alphanum_fraction": 0.538922131061554,
"avg_line_length": 39.91666793823242,
"blob_id": "9636e68889dd6f44f18c244295e7f98ae0b85bc7",
"content_id": "066d09b3962a45426ab535b457ae8992bafa3d93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 501,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 12,
"path": "/quest.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "import random\r\nclass quest:\r\n def __init__(self,qtype):\r\n self.qtype=qtype\r\n self.completed = 0\r\n if(qtype==1):\r\n self.mobs = ['skele','drago','knight','cobra','rat','goblin']\r\n self.mob_targ = self.mobs[random.randint(0,len(self.mobs)-1)]\r\n self.amount = random.randint(1,5)\r\n self.qtext = 'Please, hero, kill '+str(self.amount)+' '+self.mob_targ\r\n self.qtext += 's to keep our village safe!'\r\n self.killed = 0"
},
{
"alpha_fraction": 0.5044543147087097,
"alphanum_fraction": 0.5122494697570801,
"avg_line_length": 27.032258987426758,
"blob_id": "b86825eeecc0b65aed8c408ce16e9d00a5ea81c9",
"content_id": "72f862959fc2442614fcfe95298289d01e217869",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 898,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 31,
"path": "/FieldPos.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "class FieldPos:\r\n def __init__(self,x,y,ttype):\r\n self.posx = x\r\n self.posy = y\r\n self.player = 0\r\n self.terrain=ttype\r\n self.hasloot=0\r\n def place_loot(self,loot):\r\n self.loot=loot\r\n self.hasloot=1\r\n def remove_loot(self):\r\n self.hasloot=0\r\n def set_terrain(self,ttype):\r\n self.terrain=ttype\r\n def get_terrain(self):\r\n return self.terrain\r\n def set_player(self):\r\n self.player = 1\r\n def unset_player(self):\r\n self.player = 0\r\n def contains(self,what):\r\n if(what==\"player\"):\r\n return self.player\r\n def output_str(self,task):\r\n print(\"##\")\r\n print(\"Output from FieldPos: \")\r\n if(task=='pos'):\r\n print(\"Pos \"+str(self.posx)+\",\"+str(self.posy))\r\n if(self.player==1):\r\n print(\"Contains player\")\r\n print(\"##\")"
},
{
"alpha_fraction": 0.4727323353290558,
"alphanum_fraction": 0.49091076850891113,
"avg_line_length": 39.2840690612793,
"blob_id": "aefc4495487ecb75bba605d80d514e86e6b86079",
"content_id": "442a84b9bcaa8dce87b739c397ddae18dac65311",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21509,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 521,
"path": "/MainGame.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "from Field import *\r\nfrom Item import *\r\nfrom MainGame import *\r\nfrom Monster import *\r\nfrom NPC import *\r\nfrom Player import *\r\nfrom quest import*\r\nfrom Drawing import*\r\n\r\nimport math\r\nimport tkinter\r\nclass MainGame:\r\n def __init__(self):\r\n self.started = 0\r\n self.qposes = []\r\n self.curquests = []\r\n self.state='move'\r\n self.curf=Field(10,10,1,1)\r\n self.world={(0,0):self.curf}\r\n self.curfpos=(0,0)\r\n self.Drawing = Drawing(self.curf)\r\n self.bind_moves()\r\n self.player = Player(self.Drawing.mainwindow)\r\n self.Drawing.draw_gui(self.player,self.curfpos,self.world,self.qposes)\r\n self.Drawing.draw_npcs(self.curf.npcs)\r\n self.Drawing.mainwindow.mainloop()\r\n\r\n def create_mobs(self,field):\r\n random.seed()\r\n num=random.randint(2,4)\r\n zone = field.ztype\r\n if(zone==4):\r\n return\r\n mobs=[]\r\n if(zone==1):\r\n mobs.append('goblin')\r\n mobs.append('rat')\r\n elif(zone==3):\r\n mobs.append('drago')\r\n mobs.append('knight_f')\r\n elif(zone==2):\r\n mobs.append('skele_war')\r\n mobs.append('cobra')\r\n ctr=0\r\n fld=field.cur_cond()\r\n while(ctr<num):\r\n mposx=random.randint(0,9)\r\n mposy=random.randint(0,9)\r\n mob_type=mobs[random.randint(0,len(mobs)-1)]\r\n if(fld[mposx][mposy].get_terrain() in field.walkable):\r\n field.add_monster(Monster(self.player,mob_type,(mposx,mposy)))\r\n ctr+=1\r\n\r\n \r\n \r\n \r\n\r\n def make_field(self,side):\r\n try:\r\n curpos=(self.curfpos[0]+side[0],self.curfpos[1]+side[1])\r\n fld=self.world[curpos]\r\n \r\n except:\r\n \r\n curpos=(self.curfpos[0]+side[0],self.curfpos[1]+side[1])\r\n random.seed()\r\n vil = random.randint(0,4)\r\n ztype=random.randint(1,4)\r\n if(vil):\r\n vil=0\r\n else:\r\n vil = 2\r\n fld=Field(10,10,vil,ztype)\r\n if(vil==0 or ztype!=1):\r\n self.create_mobs(fld)\r\n if(side==(0,1)):\r\n newpy=0\r\n newpx=self.curf.pposx\r\n elif(side==(0,-1)):\r\n newpy=fld.sizey-1\r\n newpx=self.curf.pposx\r\n elif(side==(1,0)):\r\n newpy=self.curf.pposy\r\n newpx=0\r\n elif(side==(-1,0)):\r\n newpy=self.curf.pposy\r\n newpx=fld.sizex-1\r\n else:\r\n newpx=self.curf.pposx\r\n newpy=self.curf.pposy\r\n self.world.update([(curpos,fld)])\r\n if(fld.cur_cond()[newpx][newpy].get_terrain() in fld.walkable):\r\n fld.move_player(newpx,newpy)\r\n \r\n self.curf=fld\r\n self.curfpos=curpos\r\n self.Drawing.draw_field(self.curf)\r\n self.Drawing.draw_gui(self.player,self.curfpos,self.world,self.qposes)\r\n self.Drawing.draw_monsters(self.curf.ret_monsters())\r\n self.Drawing.draw_npcs(self.curf.npcs)\r\n self.Drawing.edit_msg('')\r\n if(side!=(0,0)):\r\n self.Drawing.edit_msg(\"Entering in: \"+str(curpos))\r\n\r\n \r\n def get_dist(self,x2,x1,y2,y1):\r\n return(math.sqrt((x2-x1)*(x2-x1)+(y2-y1)*(y2-y1)))\r\n # 2\r\n #1 mob 3\r\n # 4\r\n #keep this in mind\r\n def move_mobs(self):\r\n mobs=self.curf.ret_monsters()\r\n pposx = float(self.curf.pposx)\r\n pposy = float(self.curf.pposy)\r\n for i in mobs: \r\n pdist=self.get_dist(pposx,i.posx,pposy,i.posy)\r\n if(pdist<3 and pdist>1):\r\n poses = i.get_where_to_go((0,self.curf.sizex),(0,self.curf.sizey),(pposx,pposy),mobs)\r\n pos = poses[0]\r\n if self.curf.cur_cond()[pos[0]][pos[1]].get_terrain() in self.curf.walkable:\r\n i.move(pos[0],pos[1])\r\n else:\r\n pos = poses[1]\r\n if self.curf.cur_cond()[pos[0]][pos[1]].get_terrain() in self.curf.walkable:\r\n i.move(pos[0],pos[1])\r\n if(pdist==1):\r\n plr = self.player\r\n dodge = random.randint(0,99)+plr.dodge_chance\r\n if(dodge>=100):\r\n continue\r\n fin_damage=i.nat_damage+i.ap*plr.armor\r\n crit_bonus = i.crit_addmul*0.01*i.nat_damage\r\n crit = random.randint(0,99)+i.crit_chance\r\n if(crit>=100):\r\n fin_damage+=crit_bonus\r\n fin_damage-=plr.armor\r\n if(fin_damage<0):\r\n fin_damage=0\r\n plr.health-=fin_damage\r\n plr.health=round(plr.health,2)\r\n if(plr.health<=0):\r\n self.finish_game()\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg('Received '+str(fin_damage)+' damage')\r\n self.Drawing.draw_monsters(self.curf.ret_monsters())\r\n\r\n def attack_mob(self,pos):\r\n random.seed()\r\n tmob = []\r\n mobs=self.curf.ret_monsters()\r\n for i in mobs:\r\n if(pos[0]==i.posx and pos[1]==i.posy):\r\n tmob.append(i)\r\n break\r\n tmobi = tmob[0]\r\n plr = self.player\r\n dodge = random.randint(0,99)+tmobi.dodge_chance\r\n if(dodge>=100):\r\n self.Drawing.edit_msg('You missed')\r\n return\r\n fin_damage=plr.damage\r\n crit_bonus = plr.crit_addmul*0.01*plr.damage\r\n crit = random.randint(0,99)+plr.crit_chance\r\n if(crit>=100):\r\n fin_damage+=crit_bonus\r\n self.Drawing.edit_msg('Critical! Plus '+str(plr.crit_addmul)+'% damage')\r\n fin_damage-=tmobi.nat_armor\r\n if(fin_damage<0):\r\n fin_damage=0\r\n tmobi.health-=fin_damage\r\n self.Drawing.edit_msg('Dealt '+str(fin_damage)+' damage')\r\n if(tmobi.health<=0):\r\n rewexp=tmobi.rewardexp\r\n drop=0\r\n random.seed(random.randint(0,1000))\r\n if(random.randint(0,14)==14):\r\n drop=1\r\n if(drop==1):\r\n dtype=random.randint(1,3)\r\n if(dtype==1):\r\n dropped=Item('wpn',plr.level)\r\n elif(dtype==2):\r\n dropped=Item('arm',plr.level)\r\n elif(dtype==3):\r\n dropped=Item('utl',plr.level)\r\n self.curf.cur_cond()[tmobi.posx][tmobi.posy].place_loot(dropped)\r\n self.upd_quest(tmobi.model)\r\n self.Drawing.edit_msg((tmobi.model+' is slain').capitalize())\r\n self.curf.kill_monster(tmobi)\r\n self.unbind_moves()\r\n text = self.player.add_exp(rewexp)\r\n self.bind_moves()\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg(text)\r\n\r\n def upd_quest(self,mob):\r\n for i in self.curquests:\r\n if(i.mob_targ in mob):\r\n if(i.completed==0):\r\n i.killed+=1\r\n if(i.killed==i.amount):\r\n i.completed=1\r\n\r\n \r\n def interact_npc(self,pos):\r\n npcs=self.curf.npcs\r\n tnpc = []\r\n for i in npcs:\r\n if(pos[0]==i.posx and pos[1]==i.posy):\r\n tnpc.append(i)\r\n break\r\n tnpci=tnpc[0]\r\n if(tnpci.quest.qtype==1 and tnpci.quest.completed==0):\r\n self.qst = tnpci.quest\r\n self.qwindow = tkinter.Toplevel()\r\n self.qwindow.geometry('170x200+30+30')\r\n self.qlabel = tkinter.Label(self.qwindow,text=tnpci.quest.qtext, wrap=150)\r\n self.qlabel.place(x=10,y=10)\r\n self.acceptbtn = tkinter.Button(self.qwindow,text='Accept',command=self.take_quest)\r\n self.acceptbtn.place(x=10,y=170)\r\n self.denybtn = tkinter.Button(self.qwindow,text='Deny',command=self.deny_quest)\r\n self.denybtn.place(x=100,y=170)\r\n self.qwindow.mainloop()\r\n\r\n \r\n elif(tnpci.quest.completed==1):\r\n self.qwindow = tkinter.Toplevel()\r\n self.qwindow.geometry('170x200+30+30')\r\n self.qlabel = tkinter.Label(self.qwindow,text=\"Thank you a lot! Take this as a reward\", wrap=150)\r\n self.qlabel.place(x=10,y=10)\r\n self.denybtn = tkinter.Button(self.qwindow,text='OK',command=self.deny_quest)\r\n self.denybtn.place(x=100,y=170)\r\n tnpci.quest.completed = 2\r\n plr = self.player\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n self.qposes.remove(self.curfpos)\r\n self.qwindow.mainloop()\r\n dtype=random.randint(1,3)\r\n if(dtype==1):\r\n dropped=Item('wpn',plr.level+2)\r\n elif(dtype==2):\r\n dropped=Item('arm',plr.level+2)\r\n elif(dtype==3):\r\n dropped=Item('utl',plr.level+2)\r\n self.curf.cur_cond()[pposx][pposy].place_loot(dropped)\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg('')\r\n\r\n elif(tnpci.quest.completed==2):\r\n self.qwindow = tkinter.Toplevel()\r\n self.qwindow.geometry('170x200+30+30')\r\n self.qlabel = tkinter.Label(self.qwindow,text=\"I have nothing to tell you\", wrap=150)\r\n self.qlabel.place(x=10,y=10)\r\n self.denybtn = tkinter.Button(self.qwindow,text='OK',command=self.deny_quest)\r\n self.denybtn.place(x=100,y=170)\r\n \r\n \r\n def take_quest(self):\r\n if(self.qst not in self.curquests):\r\n self.curquests.append(self.qst)\r\n self.qposes.append(self.curfpos)\r\n #print(len(self.curquests))\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg('')\r\n self.qwindow.quit()\r\n self.qwindow.destroy()\r\n\r\n def deny_quest(self):\r\n self.qwindow.quit()\r\n self.qwindow.destroy()\r\n\r\n def hitext(self):\r\n text = '''\r\nOLOLO.'''\r\n return text\r\n\r\n \r\n def move(self,event):\r\n if(self.state!='move'):\r\n self.player_act(event)\r\n if(self.started==0):\r\n self.started=1\r\n self.hiwindow = tkinter.Toplevel()\r\n self.hilabel = tkinter.Label(self.hiwindow,text=self.hitext())\r\n self.hilabel.place(x=10,y=10)\r\n self.hiwindow.geometry('500x300+10+10')\r\n self.hiwindow.mainloop()\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n mobs = self.curf.ret_monsters()\r\n npcs = self.curf.npcs\r\n npcposes = []\r\n mposes = []\r\n #(pposx,pposy-1) in mposes\r\n for i in mobs:\r\n mposes.append((i.posx,i.posy))\r\n for i in npcs:\r\n npcposes.append((i.posx,i.posy))\r\n if(event.char=='w'):\r\n if(pposy-1<0):\r\n self.make_field((0,-1))\r\n return\r\n if(self.curf.cur_cond()[pposx][pposy-1].get_terrain() in self.curf.walkable):\r\n if((pposx,pposy-1) in mposes):\r\n self.attack_mob((pposx,pposy-1))\r\n self.move_mobs()\r\n return\r\n if((pposx,pposy-1) in npcposes):\r\n self.interact_npc((pposx,pposy-1))\r\n return\r\n self.curf.move_player(pposx,pposy-1)\r\n \r\n self.Drawing.draw_player(self.curf)\r\n self.bind_moves()\r\n if(event.char=='s'):\r\n if(pposy+1>self.curf.sizey-1):\r\n self.make_field((0,1))\r\n return\r\n if(self.curf.cur_cond()[pposx][pposy+1].get_terrain() in self.curf.walkable):\r\n if((pposx,pposy+1) in mposes):\r\n self.attack_mob((pposx,pposy+1))\r\n self.move_mobs()\r\n return\r\n if((pposx,pposy+1) in npcposes):\r\n self.interact_npc((pposx,pposy+1))\r\n return\r\n self.curf.move_player(pposx,pposy+1)\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n self.Drawing.draw_player(self.curf)\r\n if(event.char=='a'):\r\n if(pposx-1<0):\r\n self.make_field((-1,0))\r\n return\r\n if(self.curf.cur_cond()[pposx-1][pposy].get_terrain() in self.curf.walkable):\r\n if((pposx-1,pposy) in mposes):\r\n self.attack_mob((pposx-1,pposy))\r\n self.move_mobs()\r\n return\r\n if((pposx-1,pposy) in npcposes):\r\n self.interact_npc((pposx-1,pposy))\r\n return\r\n self.curf.move_player(pposx-1,pposy)\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n self.Drawing.draw_player(self.curf)\r\n if(event.char=='d'):\r\n if(pposx+1>self.curf.sizex-1):\r\n self.make_field((1,0))\r\n return\r\n if(self.curf.cur_cond()[pposx+1][pposy].get_terrain() in self.curf.walkable):\r\n if((pposx+1,pposy) in mposes):\r\n self.attack_mob((pposx+1,pposy))\r\n self.move_mobs()\r\n return\r\n if((pposx+1,pposy) in npcposes):\r\n self.interact_npc((pposx+1,pposy))\r\n return\r\n self.curf.move_player(pposx+1,pposy)\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n self.Drawing.draw_player(self.curf)\r\n if(event.char=='3'):\r\n itms=self.player.inventory\r\n has_bottle=0\r\n bottle = 0\r\n for i in itms:\r\n if(i.itype=='utl'):\r\n has_bottle=1\r\n bottle=itms.index(i)\r\n break\r\n if(has_bottle==1):\r\n if(self.player.inventory[bottle].charges>0):\r\n self.player.heal(self.player.inventory[bottle].in_regen+self.player.inventory[bottle].add_regen)\r\n self.player.inventory[bottle].charges-=1\r\n self.make_field((0,0))\r\n else:\r\n return\r\n else:\r\n return\r\n if(event.char=='x'):\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n plr=self.player\r\n if(pposx<9 and pposy<9):\r\n wells = []\r\n wells.append((pposx-1,pposy))\r\n wells.append((pposx+1,pposy))\r\n wells.append((pposx,pposy-1))\r\n wells.append((pposx,pposy+1))\r\n for w in wells:\r\n if(self.curf.cur_cond()[w[0]][w[1]].get_terrain()=='3_h_w'):\r\n plr.inventory[2].charges=plr.inventory[2].max_charges\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg('')\r\n break\r\n if(event.char=='c'):\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n plr=self.player\r\n if(self.curf.cur_cond()[pposx][pposy].hasloot==1):\r\n n_item=self.curf.cur_cond()[pposx][pposy].loot\r\n nitype=n_item.itype\r\n for i in plr.inventory:\r\n if(i.itype==nitype):\r\n o_item=i\r\n break\r\n self.pick_thingw=tkinter.Toplevel(self.Drawing.mainwindow)\r\n self.pick_thingw.title(\"Picking item\")\r\n self.pick_thingw.geometry('550x200+100+100')\r\n o_name=o_item.name\r\n n_name=n_item.name\r\n if(o_item.itype=='wpn'):\r\n o_text=o_name+'\\nDamage: '+str(o_item.in_damage)+'+'+str(o_item.add_damage)\r\n o_text+='\\nStrength: '+str(o_item.in_strength)+'+'+str(o_item.add_strength)\r\n o_text+='\\nDexterity: '+str(o_item.in_dexterity)+'+'+str(o_item.add_dexterity)\r\n n_text=n_name+'\\nDamage: '+str(n_item.in_damage)+'+'+str(n_item.add_damage)\r\n n_text+='\\nStrength: '+str(n_item.in_strength)+'+'+str(n_item.add_strength)\r\n n_text+='\\nDexterity: '+str(n_item.in_dexterity)+'+'+str(n_item.add_dexterity)\r\n\r\n if(o_item.itype=='arm'):\r\n o_text=o_name+'\\nArmor: '+str(o_item.in_armor)+'+'+str(o_item.add_armor)\r\n o_text+='\\nHealth: '+str(o_item.in_health)+'+'+str(o_item.add_health)\r\n o_text+='\\nDexterity: '+str(o_item.in_dexterity)+'+'+str(o_item.add_dexterity)\r\n o_text+='\\nEndurance: '+str(o_item.in_endurance)+'+'+str(o_item.add_endurance)\r\n n_text=n_name+'\\nArmor: '+str(n_item.in_armor)+'+'+str(n_item.add_armor)\r\n n_text+='\\nHealth: '+str(n_item.in_health)+'+'+str(n_item.add_health)\r\n n_text+='\\nDexterity: '+str(n_item.in_dexterity)+'+'+str(n_item.add_dexterity)\r\n n_text+='\\nEndurance: '+str(n_item.in_endurance)+'+'+str(n_item.add_endurance)\r\n\r\n if(o_item.itype=='utl'):\r\n o_text=o_name+'\\nRegen: '+str(o_item.in_regen)+'+'+str(o_item.add_regen)\r\n o_text+='\\nMax charges: '+str(o_item.max_charges)\r\n o_text+='\\nPassive properties:\\n'\r\n o_text+='\\nDexterity: '+str(o_item.add_dexterity)\r\n o_text+='\\nEndurance: '+str(o_item.add_endurance)\r\n n_text=n_name+'\\nRegen: '+str(n_item.in_regen)+'+'+str(n_item.add_regen)\r\n n_text+='\\nMax charges: '+str(n_item.max_charges)\r\n n_text+='\\nPassive properties:\\n'\r\n n_text+='\\nDexterity: '+str(n_item.add_dexterity)\r\n n_text+='\\nEndurance: '+str(n_item.add_endurance)\r\n self.o_text=o_text\r\n self.n_text=n_text\r\n self.o_item=o_item\r\n self.n_item=n_item\r\n self.o_label=tkinter.Label(self.pick_thingw,text=o_text)\r\n self.n_label=tkinter.Label(self.pick_thingw,text=n_text)\r\n self.o_label.place(x=10,y=30)\r\n self.n_label.place(x=280,y=30)\r\n self.choice=tkinter.IntVar()\r\n self.o_rb = tkinter.Radiobutton(self.pick_thingw,variable=self.choice,value=0,text='Keep yours')\r\n self.n_rb = tkinter.Radiobutton(self.pick_thingw,variable=self.choice,value=1,text='Take this')\r\n self.o_rb.place(x=10,y=5)\r\n self.n_rb.place(x=280,y=5)\r\n\r\n self.y_btn = tkinter.Button(self.pick_thingw,text='Accept',command=self.pick_item) \r\n self.y_btn.place(x=30,y=170)\r\n self.pick_thingw.mainloop()\r\n else:\r\n if(pposx<9 and pposy<9):\r\n wells = []\r\n wells.append((pposx-1,pposy))\r\n wells.append((pposx+1,pposy))\r\n wells.append((pposx,pposy-1))\r\n wells.append((pposx,pposy+1))\r\n for w in wells:\r\n if(self.curf.cur_cond()[w[0]][w[1]].get_terrain()=='3_h_w'):\r\n plr.inventory[2].charges=plr.inventory[2].max_charges\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg('')\r\n break\r\n self.move_mobs()\r\n\r\n \r\n def pick_item(self):\r\n if(self.choice.get()==0):\r\n self.pick_thingw.quit()\r\n self.pick_thingw.destroy()\r\n else:\r\n to_drop=self.player.give_item(self.n_item)\r\n pposx = self.curf.pposx\r\n pposy = self.curf.pposy\r\n self.curf.cur_cond()[pposx][pposy].place_loot(to_drop)\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg('')\r\n self.pick_thingw.quit()\r\n self.pick_thingw.destroy()\r\n \r\n def add_exp(self,event):\r\n text=self.player.add_exp(5)\r\n self.make_field((0,0))\r\n self.Drawing.edit_msg(text)\r\n def bind_moves(self):\r\n self.Drawing.mainwindow.bind('w',self.move)\r\n self.Drawing.mainwindow.bind('s',self.move)\r\n self.Drawing.mainwindow.bind('a',self.move)\r\n self.Drawing.mainwindow.bind('d',self.move)\r\n self.Drawing.mainwindow.bind('3',self.move)\r\n self.Drawing.mainwindow.bind('x',self.move)\r\n self.Drawing.mainwindow.bind('c',self.move)\r\n\r\n def unbind_moves(self):\r\n self.Drawing.mainwindow.unbind('w')\r\n self.Drawing.mainwindow.unbind('s')\r\n self.Drawing.mainwindow.unbind('a')\r\n self.Drawing.mainwindow.unbind('d')\r\n self.Drawing.mainwindow.unbind('3')\r\n self.Drawing.mainwindow.unbind('x')\r\n self.Drawing.mainwindow.unbind('c')\r\n #self.Drawing.mainwindow.bind('h',self.add_exp)\r\n def finish_game(self):\r\n self.Drawing.canv.delete('all')\r\n you_dead=tkinter.Label(self.Drawing.mainwindow,text='You dead')\r\n you_dead.place(x=200,y=200)\r\n self.Drawing.mainwindow.unbind('w')\r\n self.Drawing.mainwindow.unbind('s')\r\n self.Drawing.mainwindow.unbind('a')\r\n self.Drawing.mainwindow.unbind('d')\r\n raise\r\n"
},
{
"alpha_fraction": 0.5276710987091064,
"alphanum_fraction": 0.5547775030136108,
"avg_line_length": 42.73737335205078,
"blob_id": "523becc016a393596c083fda4ede5f1e07b6bc28",
"content_id": "bb8590ff6519f25ae95c35259e461a87cbe2e390",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4427,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 99,
"path": "/Item.py",
"repo_name": "pindos11/tkinter-roguelike",
"src_encoding": "UTF-8",
"text": "import random\r\nclass Item:\r\n def __init__(self,itype,level):\r\n random.seed()\r\n self.level = level+random.randint(-1,1)\r\n if(self.level<=0):\r\n self.level=1\r\n self.itype=itype\r\n if(itype=='wpn'):\r\n self.generate_wpn()\r\n if(itype=='arm'):\r\n self.generate_arm()\r\n if(itype=='utl'):\r\n self.generate_utl()\r\n def generate_wpn(self):\r\n prefixes = ['Bitter','Convex','Curved','Hard','Hot','Narrow','Strong','Unpleasant','Awful']\r\n suffixes = ['evil','loyalty','justice','despair','honor','pain','faith','hate','courage']\r\n mod = random.randint(1,3)\r\n self.model='wpn'+str(mod)\r\n if(mod==1):\r\n self.name='sword'\r\n self.model=self.name\r\n elif(mod==2):\r\n self.name='axe'\r\n self.model=self.name\r\n elif(mod==3):\r\n self.name='mace'\r\n self.model=self.name\r\n self.in_damage = self.level + random.randint(0,5)\r\n self.add_damage = 0\r\n self.add_strength = 0\r\n self.add_dexterity = 0\r\n self.in_dexterity = 0\r\n self.in_strength = self.level/2 + random.randint(0,2)\r\n if(self.in_strength<1):\r\n self.in_strength=1\r\n if(random.randint(0,1)):\r\n self.add_damage+=random.randint(int(self.level/3),int(self.level*0.75))\r\n self.add_strength+= self.level/1.5 + random.randint(0,2)\r\n self.name=prefixes[random.randint(0,len(prefixes)-1)] +' '+ self.name\r\n if(random.randint(0,9)>=9):\r\n self.add_damage+=random.randint(self.level,int(self.level*1.5))\r\n self.add_strength+= self.level + random.randint(1,5)\r\n self.add_dexterity+= random.randint(3,4)+self.level/3\r\n self.name += ' of '+suffixes[random.randint(0,len(suffixes)-1)]\r\n self.name = self.name.capitalize()\r\n print(self.name)\r\n def generate_arm(self):\r\n prefixes = ['Bitter','Convex','Curved','Hard','Hot','Narrow','Strong','Unpleasant','Awful']\r\n suffixes = ['evil','loyalty','justice','despair','honor','pain','faith','hate','courage']\r\n mod = random.randint(1,2)\r\n if(mod==1):\r\n self.name='mail'\r\n self.model=self.name\r\n elif(mod==2):\r\n self.name='cuirass'\r\n self.model=self.name\r\n self.in_armor = self.level + random.randint(0,2)\r\n self.add_armor = 0\r\n self.in_endurance = 1 + random.randint(0,self.level)\r\n self.add_endurance = 0\r\n self.in_dexterity = random.randint(0,int(self.level*0.3))*(mod%2)\r\n self.add_dexterity = 0\r\n self.in_health = self.level*2 + random.randint(0,int(self.level*1.5))\r\n self.add_health = 0\r\n if(random.randint(0,1)):\r\n self.add_armor+=random.randint(0,int(self.level*1.5))\r\n self.add_endurance+=random.randint(0,int(self.level*0.5))\r\n self.name=prefixes[random.randint(0,len(prefixes)-1)] +' '+ self.name\r\n if(random.randint(0,9)>=9):\r\n self.add_armor+=random.randint(int(self.level*0.5),int(self.level*1.5))\r\n self.add_endurance+=random.randint(1,int(self.level*0.5)+1)\r\n self.add_health+=random.randint(int(self.level*0.5),int(self.level*1.5))\r\n self.add_dexterity+=random.randint(1,int(self.level*0.5)+1)\r\n self.name += ' of '+suffixes[random.randint(0,len(suffixes)-1)]\r\n self.name = self.name.capitalize()\r\n print(self.name)\r\n def generate_utl(self):\r\n self.model='bottle'\r\n self.name=self.model\r\n self.model+=str(random.randint(1,4))\r\n self.in_regen = self.level*2\r\n self.add_regen=0\r\n self.add_dexterity = int(self.level/2)\r\n self.add_endurance = int(self.level/2)\r\n addc=0\r\n if(random.randint(0,100)>80):\r\n addc=1\r\n self.name='Big '+self.name\r\n self.max_charges=3+addc\r\n if(random.randint(0,50)>37):\r\n self.name+=' of baltika 9'\r\n self.add_regen=random.randint(0,self.level)\r\n self.add_endurance+=random.randint(1,int(self.level/3)+2)\r\n self.name = self.name.capitalize()\r\n self.charges=self.max_charges\r\n print(self.name)\r\n print('\\tRegens: '+str(self.in_regen+self.add_regen))\r\n print('\\tAdds: '+str(self.add_dexterity)+'dex '+str(self.add_endurance)+'end')"
}
] | 11 |
wouter173/sha256-decoder
|
https://github.com/wouter173/sha256-decoder
|
d22f1a058f4b8e79e17a647b0153324be4486f21
|
b8c80b409fb10e13540c71b7cf384fa97389532f
|
bc0198a869a91f5523e8f627895db5898bd49757
|
refs/heads/master
| 2020-05-07T20:10:16.375410 | 2019-04-14T13:28:51 | 2019-04-14T13:28:51 | 180,847,544 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5718849897384644,
"alphanum_fraction": 0.6437699794769287,
"avg_line_length": 26.217391967773438,
"blob_id": "f8110cec8c55c3090b706600a72585e19b25c304",
"content_id": "023f746ab6ea1ebe93012188193eb60a84b5044b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 23,
"path": "/index.py",
"repo_name": "wouter173/sha256-decoder",
"src_encoding": "UTF-8",
"text": "from hashlib import sha256\nfrom itertools import permutations\nfrom time import time \nimport deco\n\ntries = 0\nstart_time = time()\n\nfor res in permutations(\"ZjyOGzsKQ\"):\n res = ''.join(res)\n string = \"ctf{\" + res + \"}\"\n Hash = sha256(string.encode()).hexdigest()\n #comment the line below to get a higher performance \n print(Hash + \" : \" + res)\n tries +=1\n\n if(Hash == \"327cad4cbe16f0a7aed9abf024b7fcdc37b684cee3369728f08e471176f94c25\"):\n print(deco.center(\"=\"))\n print(\"hash: \" + Hash)\n print(\"key: \" + string)\n print(\"tries: \" + str(round(tries / (time() - start_time))) + \"p/s\")\n print(\"\\n\")\n exit()\n"
},
{
"alpha_fraction": 0.5761317014694214,
"alphanum_fraction": 0.6090534925460815,
"avg_line_length": 21.090909957885742,
"blob_id": "37862b9d7ba0aadb49b3bfb206008754d9a41e6f",
"content_id": "6b3cec0eaa07dcdd78ce77b8d131aafe57672a24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/deco.py",
"repo_name": "wouter173/sha256-decoder",
"src_encoding": "UTF-8",
"text": "import os\nEND = \"\\x1b[0m\"\n\ndef green(text):\n text = \"\\033[92m\" + text + END\n return text\n\ndef center(text, spacer = \"=\"):\n space = spacer * int(((os.get_terminal_size().columns - len(text)) / 2))\n text = space + text + space\n return text\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 16,
"blob_id": "85b50f8ec0f468ba8dc8ceb0370ced92b909382d",
"content_id": "7721496934c2b350e3ed3f1cc82fdb661f6c8da5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 17,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 1,
"path": "/README.md",
"repo_name": "wouter173/sha256-decoder",
"src_encoding": "UTF-8",
"text": "# sha256-decoder\n"
}
] | 3 |
GeekJamesO/Python_Animal
|
https://github.com/GeekJamesO/Python_Animal
|
deeb6237eff06b577d10f9549bbe439d8ffb92c3
|
9c903625f8f12174045d27137ab09ca2f808fe4b
|
95674d29baa93daee52e720629210260153d4241
|
refs/heads/master
| 2021-01-02T09:17:13.952464 | 2017-09-09T23:15:56 | 2017-09-09T23:15:56 | 99,182,670 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6737116575241089,
"alphanum_fraction": 0.6823972463607788,
"avg_line_length": 33.198020935058594,
"blob_id": "d99bdec82b2bceb1f2a7ff3cafa55c278545238c",
"content_id": "2af96ddf16bf3783d354973a23b744135fc951d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3454,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 101,
"path": "/animal.py",
"repo_name": "GeekJamesO/Python_Animal",
"src_encoding": "UTF-8",
"text": "# Assignment: Animal\n# Create an Animal class and give it the below attributes and methods. Extend the\n# Animal class to two child classes, Dog and Dragon.\n#\n# Objective\n# The objective of this assignment is to help you understand inheritance.\n# Remember that a class is more than just a collection of properties and methods.\n# If you want to create a new class with attributes and methods that are already\n# defined in another class, you can have this new class inherit from that other\n# class (called the parent) instead of copying and pasting code from the original class.\n# Child classes can access all the attributes and methods of a parent class AND\n# have new attributes and methods of its own, for child instances to call. As we\n# see with Wizard / Ninja / Samurai (that are each descended from Human), we can\n# have numerous unique child classes that inherit from the same parent class.\n#\n# Animal Class\n# Attributes:\n# name\n# health\n# Methods:\n# walk: decreases health by one\n# run: health decreases by five\n# display health: print to the terminal the animal's health.\n\nclass Animal(object):\n def __init__(self, name, health):\n self.name = name\n self.health = health\n def walk(self):\n self.health -= 1\n return self\n def run(self):\n self.health -= 5\n return self\n def displayHealth(self):\n print \" {0} {1}\".format(self.name, self.health)\n return self\n# Create an instance of the Animal, have it walk() three times, run() twice, and\n# finally displayHealth() to confirm that the health attribute has changed.\n#\n# Dog Class\n# inherits everything from Animal\n# Attributes:\n# default health of 150\n# Methods:\n# pet: increases health by 5\n\nclass Dog(Animal):\n def __init__(self, name, health=150):\n super(Dog, self).__init__(name, health)\n def pet(self):\n self.health += 5\n return self\n\n# Have the Dog walk() three times, run() twice, pet() once, and have it displayHealth().\nprint \"Taking Fido out for a bit.\"\ndog1 = Dog(\"Fido\")\ndog1.walk().walk().walk().run().run().pet().displayHealth()\nprint \"\"\n#\n# Dragon Class\n# inherits everything from Animal\n# Attributes:\n# default health of 170\n# Methods:\n# fly: decreases health by 10\n# display health: prints health by calling the parent method and prints \"I am a Dragon\"\nclass Dragon(Animal):\n def __init__(self, name, health=170):\n super(Dragon, self).__init__(name, health)\n def fly(self):\n self.health -= 10\n return self\n def displayHealth(self):\n super(Dragon, self).displayHealth()\n print \" I am a Dragon\"\n return self\nprint \"Taking the black dragon out for a bit.\"\ndragon1 = Dragon(\"Toothless\")\ndragon1.walk().fly().displayHealth()\nprint \"\"\n\n# Now try creating a new Animal and confirm that it can not call the pet() and\n# fly() methods, and its displayHealth() is not saying 'this is a dragon!'.\n# Also confirm that your Dog class can not fly().\n\n# lucky = Dog(\"Lucky\")\n# lucky.fly()\n\"\"\"\n File \"/Users/jamesorourke/Desktop/DojoAssignments/Python/animal/animal.py\", line 88, in <module>\n lucky.fly()\n AttributeError: 'Dog' object has no attribute 'fly'\n\"\"\"\n\nRedDragon = Dragon(\"Mr. Angry\")\nRedDragon.pet()\n\"\"\"\n File \"/Users/jamesorourke/Desktop/DojoAssignments/Python/animal/animal.py\", line 96, in <module>\n RedDragon.pet()\n AttributeError: 'Dragon' object has no attribute 'pet'\n\"\"\"\n"
},
{
"alpha_fraction": 0.6193205118179321,
"alphanum_fraction": 0.6295538544654846,
"avg_line_length": 33.900001525878906,
"blob_id": "ea9ec6ac8870cacfb74d5392ba5b4ea3bbb2dfdf",
"content_id": "591df9397fb8c08ae1118051b526c636e52f346e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2443,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 70,
"path": "/animal_2.py",
"repo_name": "GeekJamesO/Python_Animal",
"src_encoding": "UTF-8",
"text": "class Animal(object):\n def __init__(self, name, health):\n self.name = name\n self.health = health\n def walk(self):\n print \" {} is walking.\".format(self.name)\n self.health -= 1\n return self\n def run(self):\n print \" {} is running.\".format(self.name)\n self.health -= 5\n return self\n def displayHealth(self):\n print \" {} health = '{}'\".format(self.name, self.health)\n return self\n\nclass Dog(Animal):\n def __init__(self, name, health=150):\n super(Dog, self).__init__(name, health)\n def pet(self):\n print \" The dog {} is getting petted.\".format(self.name)\n self.health += 5\n return self\n\n\nclass Dragon(Animal):\n def __init__(self, name, health=170):\n super(Dragon, self).__init__(name, health)\n def fly(self):\n print \" The dragon {} is flying over its domain.\".format(self.name)\n self.health -= 10\n return self\n def displayHealth(self):\n super(Dragon, self).displayHealth()\n print \" I am a Dragon!\"\n return self\n\nprint \"Animal tests:\"\nchuck = Animal(\"Chuck\", 30)\nchuck.displayHealth()\nchuck.walk().walk().walk().run().run().displayHealth()\n\nprint \"Dog tests:\"\nfido = Dog(\"Fido\")\nfido.displayHealth()\nfido.walk().walk().walk().run().run().pet().displayHealth()\n\nprint \"Dragon tests\"\nsmug = Dragon(\"Smog\")\nsmug.displayHealth()\nsmug.walk().walk().walk().run().run().fly().displayHealth()\nprint ' '\nprint \"Tests that show that inherietance does works correctly.\"\nprint '--> chuck.pet()'\nprint '--> Traceback (most recent call last):'\nprint '--> File \"/Users/jamesorourke/Desktop/DojoAssignments/Python/Module2_Python_OOP/Animal/animal_2.py\", line 54, in <module>'\nprint '--> chuck.pet()'\nprint \"--> AttributeError: 'Animal' object has no attribute 'pet'\"\nprint ' '\nprint '--> chuck.fly()'\nprint '--> Traceback (most recent call last):'\nprint '--> File \"/Users/jamesorourke/Desktop/DojoAssignments/Python/Module2_Python_OOP/Animal/animal_2.py\", line 60, in <module>'\nprint '--> chuck.fly()'\nprint \"--> AttributeError: 'Animal' object has no attribute 'fly' \"\nprint ' '\nprint '--> fido.fly()'\nprint '--> Traceback (most recent call last):'\nprint '--> File \"/Users/jamesorourke/Desktop/DojoAssignments/Python/Module2_Python_OOP/Animal/animal_2.py\", line 66, in <module>'\nprint '--> fido.fly()'\nprint \"--> AttributeError: 'Dog' object has no attribute 'fly' \"\n"
}
] | 2 |
fsaporito/pyTriangle
|
https://github.com/fsaporito/pyTriangle
|
056214acc9967eb471da0ab60842ae3a2827b388
|
fb13ea67689ffb8430df2f93c3b545ff96396c8e
|
6f4fa636f5b1ec201f547ba05af6b5db111b1b0c
|
refs/heads/master
| 2021-05-04T13:06:04.484883 | 2018-02-05T13:48:18 | 2018-02-05T13:48:18 | 120,308,235 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7632850408554077,
"alphanum_fraction": 0.7681159377098083,
"avg_line_length": 28.428571701049805,
"blob_id": "d68f9d29ccef56de04e88082a1a0e9b5c150fc6a",
"content_id": "5102b5d105d3925be9e9d78340a20d389bf5e422",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 207,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 7,
"path": "/README.md",
"repo_name": "fsaporito/pyTriangle",
"src_encoding": "UTF-8",
"text": "# pyTriangle\nReads the mesh files generated by Triangle and converts them into protobuffer format.\n\n----\n\nBased upond the 2D meshing software Triangle by Jonathan Richard Shewchuk:\nhttps://www.cs.cmu.edu/~quake/triangle.html\n\n"
},
{
"alpha_fraction": 0.6424418687820435,
"alphanum_fraction": 0.6424418687820435,
"avg_line_length": 25.461538314819336,
"blob_id": "2005594ed81f71c436eac75cd18f4b6c4e16036e",
"content_id": "096e2e7930042220165825c0327c905c750a7b04",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 13,
"path": "/setup.py",
"repo_name": "fsaporito/pyTriangle",
"src_encoding": "UTF-8",
"text": "import os\n\n# Make Clean\nos.system(\"cd triangle && make distclean && cd ..\")\nos.system(\"cd proto && make clean && cd ..\")\nos.system(\"rm -f triangle.bin\")\nos.system(\"rm -f showme.bin\")\n\n# Make Triangle\nos.system(\"cd triangle && make all && cp triangle ../triangle.bin && cd ..\")\n\n# Compile ProtoBuffers\nos.system(\"cd proto && make all && cd ..\")\n"
},
{
"alpha_fraction": 0.7168949842453003,
"alphanum_fraction": 0.7214611768722534,
"avg_line_length": 31.899999618530273,
"blob_id": "cc35a58cfd30eba91f388256d498daed95ff7886",
"content_id": "cde1a1796ae87329c436ecf26cd70d32d2fc7ec7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 657,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 20,
"path": "/make_mesh.py",
"repo_name": "fsaporito/pyTriangle",
"src_encoding": "UTF-8",
"text": "# Generates the mesh from the .poly file\n# Uses the software triangle: https://www.cs.cmu.edu/~quake/triangle.html\n\n# Triangle Options\n# -p Triangulates a .poly file\n# -q Quality mesh generation with no angles smaller than 20 degrees. \n# -a Imposes a maximum triangle area constraint (Read from the .poly file)\n# -I Suppresses mesh iteration numbers\n# -Q No output except for errors\n\nimport os\nimport sys\n\nprint(\"Number of arguments: \" + str(len(sys.argv)) + \" arguments.\")\nprint(\"Argument List: \" + str(sys.argv))\n\npoly_file_name = sys.argv[1]\n\n# Generate the mesh specified in the .poly file\nos.system(\"./triangle.bin -pqaI \" + poly_file_name + \".poly\");"
},
{
"alpha_fraction": 0.5861344337463379,
"alphanum_fraction": 0.5945377945899963,
"avg_line_length": 21.64285659790039,
"blob_id": "955737e781a47f4d824e142c8d794f9aa80c954a",
"content_id": "0e5f165b9b8879c13eda8dae17ddcaf2a15582ca",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 952,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 42,
"path": "/proto/makefile",
"repo_name": "fsaporito/pyTriangle",
"src_encoding": "UTF-8",
"text": "# Protocol Buffer Compiler\nPROTOC=protoc\n\n# PROTO INPUT and OUTPUT\nPROTO_IN = .\nPROTO_OUT = ../protopy\n\n# PROTO\nPROTO_SOURCE = ${PROTO_IN}/point.proto \\\n\t\t\t ${PROTO_IN}/edge.proto \\\n\t\t\t ${PROTO_IN}/triangle.proto \\\n\t\t\t ${PROTO_IN}/mesh.proto\n\t\t\t \n# PROTO_PY\nPROTO_PY = ${PROTO_OUT}/point_pb2.py \\\n\t\t ${PROTO_OUT}/edge_pb2.py \\\n\t\t ${PROTO_OUT}/triangle_pb2.py \\\n\t\t ${PROTO_OUT}/mesh_pb2.py\n\t\t \n# PROTO_PYC\nPROTO_PYC = ${PROTO_OUT}/point_pb2.pyc \\\n\t\t ${PROTO_OUT}/edge_pb2.pyc \\\n\t\t ${PROTO_OUT}/triangle_pb2.pyc \\\n\t\t ${PROTO_OUT}/mesh_pb2.pyc\n\t\t\t \n# Make\nall:\n\tmake clean\n\tmake build\n\nbuild:\n\tmkdir -p ${PROTO_OUT}\n\tmkdir -p ${PROTO_PYC}\n\techo \"${PROTOC} -I=${PROTO_IN} --python_out=${PROTO_OUT} ${PROTO_SOURCE}\"\n\t${PROTOC} -I=${PROTO_IN} --python_out=${PROTO_OUT} ${PROTO_SOURCE}\n\ttouch ${PROTO_OUT}/__init__.py\n\t\nclean:\n\trm -f ${PROTO_PY}\n\trm -f ${PROTO_PYC}\n\trm -f ${PROTO_OUT}/__init__.py\n\trm -f ${PROTO_OUT}/__init__.pyc\n\n"
},
{
"alpha_fraction": 0.5751445293426514,
"alphanum_fraction": 0.5751445293426514,
"avg_line_length": 33.70000076293945,
"blob_id": "a21a3b85ff6ec55df8076733e513630c68c77f7b",
"content_id": "661b79ba5eaff5f4c6fb35c6ba1ee5e6ed620f13",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 10,
"path": "/clean.py",
"repo_name": "fsaporito/pyTriangle",
"src_encoding": "UTF-8",
"text": "import os\n\n# Make Clean\nos.system(\"cd triangle && make distclean && cd ..\")\nos.system(\"cd proto && make clean && cd ..\")\nos.system(\"cd proto && make clean && cd ..\")\nos.system(\"cd __pycache__ && rm -f * && cd ..\")\nos.system(\"cd protopy && cd __pycache__ && rm -f * && cd .. && cd ..\")\nos.system(\"rm -f triangle.bin\")\nos.system(\"rm -f showme.bin\")"
},
{
"alpha_fraction": 0.5338189601898193,
"alphanum_fraction": 0.5413631796836853,
"avg_line_length": 27.22058868408203,
"blob_id": "fb8169a8322f508ab3ba3ece6765bbc534547155",
"content_id": "066b2780592cbc5368fb1911d2fa9678e9e9583a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3844,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 136,
"path": "/read_mesh.py",
"repo_name": "fsaporito/pyTriangle",
"src_encoding": "UTF-8",
"text": "import sys\n\nsys.path.insert(0, './protopy')\n#import point_pb2 \n#import edge_pb2\n#import triangle_pb2\nimport mesh_pb2\n\n#from protopy import point_pb2 \n#from protopy import edge_pb2\n#from protopy import triangle_pb2\n#from protopy import mesh_pb2\n\n\ndef read_mesh(poly_file_name):\n\n mesh = mesh_pb2.Mesh()\n #points = {}\n #edges = []\n #triangles = {}\n\n\n #-----------------#\n # --- Vertices ---#\n #-----------------#\n\n # Open .node File\n mesh_node = open(poly_file_name + \".node\", \"r\")\n\n # Read First Line\n # Which holds information on the file:\n # Vertices Number - Dimension - 0 - Flag\n firstLine = mesh_node.readline()\n #print(firstLine)\n\n # Lines Number\n line_num = 0\n\n # Read Points\n # Read Each Line and Break It Up Using The Following Template\n # point_number (iv) - x coordinate - y coordinate - border flag\n for line in mesh_node:\n line_num += 1\n #print(\"Line {}:\".format(line_num) + line)\n tmp = []\n for t in line.split():\n try:\n tmp.append(float(t))\n except ValueError:\n pass\n #print(tmp) # Print each parsed line\n if not tmp: # Empty list is false in Python \n # line_num-1 because last line is only text information:\n # \"Generated by ./triangle.bin -pqaI square.poly\" \n print(\"[*] Read {} Points\".format(line_num-1))\n else: # List is not empty\n #print(\"[*] Creating point Object ...\")\n point_id = int(tmp[0])\n mesh.points[point_id].p_num = point_id\n mesh.points[point_id].x = tmp[1]\n mesh.points[point_id].y = tmp[2]\n if tmp[3] == 1:\n mesh.points[point_id].border = True\n else:\n mesh.points[point_id].border = False\n\n # Close .node File\n mesh_node.close()\n\n\n #-----------------#\n # --- Elements ---#\n #-----------------#\n\n # Open .node File\n mesh_ele = open(poly_file_name + \".ele\", \"r\")\n\n # Read First Line\n # Which holds information on the file:\n # Triangles Number - Dimension - 0 - Flag\n firstLine = mesh_ele.readline()\n #print(firstLine)\n\n # Lines Number\n line_num = 0\n\n # Read Elements (Triangles)\n # Read Each Line and Break It Up Using The Following Template\n # triangle id - first point id - second point id - third point id\n for line in mesh_ele:\n line_num += 1\n #print(\"Line {}:\".format(line_num) + line)\n tmp = []\n for t in line.split():\n try:\n tmp.append(int(t))\n except ValueError:\n pass\n #print(tmp) # Print each parsed line\n if not tmp: # Empty list is false in Python \n # line_num-1 because last line is only text information:\n # \"Generated by ./triangle.bin -pqaI square.poly\"\n print(\"[*] Read {} Triangles\".format(line_num-1))\n else: # List is not empty\n tr_id = int(tmp[0])\n A = int(tmp[1])\n B = int(tmp[2])\n C = int(tmp[3])\n mesh.triangles[tr_id].t_num = tr_id\n mesh.triangles[tr_id].pointA = A\n mesh.triangles[tr_id].pointB = B\n mesh.triangles[tr_id].pointC = C\n\n # Close .ele File\n mesh_ele.close()\n \n\n # Return the Mesh\n return mesh\n\n\ndef print_points(mesh):\n for p in mesh.points:\n print(\"Point {}: {} - {} - {}\".format(mesh.points[p].p_num, mesh.points[p].x, mesh.points[p].y, mesh.points[p].border))\n\n\ndef print_triangles(mesh):\n for t in mesh.triangles:\n print(\"Triangle {}: {} - {} - {}\".format(mesh.triangles[t].t_num, mesh.triangles[t].pointA, mesh.triangles[t].pointB, mesh.triangles[t].pointC))\n\n\n\nname = \"square\"\nm = read_mesh(name)\n#print_points(m)\n#print_triangles(m)\n\n\n\n\n\n\n"
}
] | 6 |
laurensila/markov-dictionary
|
https://github.com/laurensila/markov-dictionary
|
1d9da159d664bf6abcc7186c4db839e00d3f1dfc
|
b5ec490fe8cb100bf836159b1933683a83d21e90
|
beb09e3b28026f8abacd7e9c9a67c6ef7e8ac077
|
refs/heads/master
| 2020-12-31T04:17:43.753053 | 2016-04-13T23:05:17 | 2016-04-13T23:05:17 | 56,109,782 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6057866215705872,
"alphanum_fraction": 0.6094032526016235,
"avg_line_length": 23.04347801208496,
"blob_id": "71f6746c1c1e9472a5a86942f7ae9b39e20f137b",
"content_id": "78c5171ecd103ff7f11cf7b0318721f1c9655c21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2212,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 92,
"path": "/markov.py",
"repo_name": "laurensila/markov-dictionary",
"src_encoding": "UTF-8",
"text": "from random import choice\n\n\ndef open_and_read_file(file_path):\n \"\"\"Takes file path as string; returns text as string.\n\n Takes a string that is a file path, opens the file, and turns\n the file's contents as one string of text.\n \"\"\"\n\n contents = open(file_path).read()\n return contents \n\ndef make_chains(text_string):\n \"\"\"Takes input text as string; returns _dictionary_ of markov chains.\n\n A chain will be a key that consists of a tuple of (word1, word2)\n and the value would be a list of the word(s) that follow those two\n words in the input text.\n\n For example:\n\n >>> make_chains(\"hi there mary hi there juanita\")\n {('hi', 'there'): ['mary', 'juanita'], ('there', 'mary'): ['hi'], ('mary', 'hi': ['there']}\n \"\"\"\n\n\n words = text_string.split() #splitting text string into indiviual word strings\n\n chains = {} \n\n for index in range(len(words)-2):\n keys = words[index], words[index + 1]\n value = words[index + 2]\n\n if keys in chains:\n chains[keys].append(value)\n else: \n chains[keys] = [value]\n \n\n print chains\n return chains\n\n\n\ndef make_text(chains):\n \"\"\"Takes dictionary of markov chains; returns random text.\"\"\"\n\n\n\n # random_key = choice(chains.keys())\n\n\n # if random_key in chains.keys():\n # print random_key\n # print chains[random_key]\n\n # random_value = choice(chains[random_key])\n\n # brand_new_key = ()\n # return \" \".join()\n\n key = choice(chains.keys())\n words = [key[0], key[1]]\n\n while key in chains:\n # Keep looping until we have a key that isn't in the chains\n # (which would mean it was the end of our original text)\n #\n # Note that for long texts (like a full book), this might mean\n # it would run for a very long time.\n\n word = choice(chains[key])\n words.append(word)\n key = (key[1], word)\n\n return \" \".join(words)\n\n\ninput_path = \"green-eggs.txt\"\n\n# Open the file and turn it into one long string\ninput_text = open_and_read_file(input_path)\n\n# Get a Markov chain\nchains = make_chains(input_text)\n\n# Produce random text\nrandom_text = make_text(chains)\n\nprint random_text\n"
}
] | 1 |
jjsmit/TenJProjects
|
https://github.com/jjsmit/TenJProjects
|
bdac3f83f4c55083fe189da8d7e2e96613fd41d2
|
5ec9e5c4fa17c8c599a387aed62ec6ea949a6b6e
|
ce6ee5036dd9626a2caab10f21e29b6e0ffa83f5
|
refs/heads/master
| 2021-06-10T04:13:35.239017 | 2021-05-23T21:03:44 | 2021-05-23T21:03:44 | 143,778,995 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5327102541923523,
"alphanum_fraction": 0.5453546047210693,
"avg_line_length": 22.907894134521484,
"blob_id": "26bf33daad0c74e7aacf6205e7eca55c6209ef52",
"content_id": "6e8546886595879245d23dd8da0edc2795bab0a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1819,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 76,
"path": "/Chat/Client.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "import socket\nimport sys\nimport threading\nimport time\n\n\ndef create_client():\n try:\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n print ('socket created')\n host = '127.0.0.1'\n port = 8002\n remote_ip = socket.gethostbyname(host)\n print ('connecting to', remote_ip)\n s.connect((remote_ip, port))\n print ('connected')\n return s\n \n except (socket.error) as msg:\n print (' Failed' , + str(msg[0]), 'Message', + msg[1])\n\n except (excpet.gaierror):\n print ('host not found')\n sys.exit()\n \ndef send(s):\n\n try:\n while True:\n message = input('cin>> \\n')\n message = str.encode(message)\n s.sendall(message)\n time.sleep(0.1)\n except (socket.error):\n print ('send failed')\n sys.exit() \n finally:\n print ('closing socket')\n## s.close\n \ndef receive(s):\n while True:\n time.sleep(0.1)\n data = s.recv(16)\n print ('cout<< \\n',data.decode())\n\ndef ComputeKey(s):\n\n # Recieve info server (Base, Mod, and Server public key)\n Key = s.recv(16)\n Key = Key.decode()\n Base, Mod, RKey = Key.split()\n Number = 5\n Base, Mod, RKey = int(Base), int(Mod), int(RKey)\n\n #Compute local public key\n PublicKey = str(Base**Number%Mod)\n\n #Send Local public key to server\n message = str.encode(PublicKey)\n s.sendall(message)\n\n #Compute private key\n SecretKey = RKey**Number%Mod\n print(SecretKey)\n return(SecretKey)\n\ntry:\n s = create_client()\n K = ComputeKey(s)\n threading._start_new_thread( receive,(s,))\n threading._start_new_thread( send, (s,))\n while True:\n time.sleep(0.1)\nexcept:\n print('exception')\n\n\n"
},
{
"alpha_fraction": 0.7069536447525024,
"alphanum_fraction": 0.7086092829704285,
"avg_line_length": 19.133333206176758,
"blob_id": "e407e2d13a5d822e5a4ca73bf51c3396d982f1ef",
"content_id": "f5ca3c78242794e73eb3b4db5c341bf63ef5ed9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 30,
"path": "/Chat/ChatGUI2.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import ttk\n##from Tkinter import *\nfrom tkinter.messagebox import *\nimport tkinter.messagebox\n\n\n\nwindow = Tk()\nwindow.title(\"J2T Chat\")\nmessage = Text(window)\nmessage.pack()\n\ninput_user = StringVar()\ninput_field = Entry(window, text=input_user)\ninput_field.pack(side=BOTTOM, fill=X)\n\ndef Enter_pressed(event):\n input_get = input_field.get()\n print(input_get)\n message.insert(INSERT, ' typed message: %s\\n' %input_get)\n input_user.set('')\n return \"berak\"\n\nframe = Frame(window)\ninput_field.bind(\"<Return>\", Enter_pressed)\nframe.pack()\n\n\nwindow.mainloop()\n"
},
{
"alpha_fraction": 0.6133333444595337,
"alphanum_fraction": 0.6133333444595337,
"avg_line_length": 11.583333015441895,
"blob_id": "f4e11cf732eaa0ff670dbe42d12d2c35708cffed",
"content_id": "c238e982f2b281796a3850db4b0cad31e70b1a3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 12,
"path": "/Makefile",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "output: server.o main.o\n\tg++ -g main.o -o tenj\n\nserver.o: server.cpp\n\tg++ -c -g server.cpp\n\nmain.o: main.cpp\n\tg++ -c -g main.cpp\n\n\nclean:\n\trm *.o tenj"
},
{
"alpha_fraction": 0.6532066464424133,
"alphanum_fraction": 0.6627078652381897,
"avg_line_length": 21.105262756347656,
"blob_id": "de2689a7bcc0336c71bd131bad9f30fa639334b3",
"content_id": "4cd15b9799df718de79792ad6dec12886619481a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 19,
"path": "/Robotarm/Communication.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "import re\nimport serial\nimport serial.tools.list_ports as port_list\n\nfor port in port_list.comports():\n i = 0\n print(i,\" \", port)\n i += 1\n\n# comIndex = input(\"select comport number:\")\nport = port_list.comports()[0]\n\nportString = re.search(\"\\S+\", str(port)).group()\nprint(portString)\nser = serial.Serial(portString)\n\nwhile(True):\n angle = input(\"angle:\")\n ser.write(int(angle).to_bytes(1,byteorder='big'))\n\n"
},
{
"alpha_fraction": 0.6096408367156982,
"alphanum_fraction": 0.6417769193649292,
"avg_line_length": 26.076923370361328,
"blob_id": "87a1a22efa8c74362fbd022df80245c1c22695b0",
"content_id": "c20b38c7840ba912d4d367d89401904fb502819d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1058,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 39,
"path": "/Robotarm/ServoTest/ServoTest.ino",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "//https://www.instructables.com/Creating-a-DualShock-4-Controlled-Arduino/\n#include <Servo.h> //Servo library\n#define TURN_TIME 555\n Servo servo_test; //initialize a servo object for the connected servo \n \n int angle = 90; \n int potentio = A0; // initialize the A0analog pin for potentiometer\n\n \n void setup() \n {\n Serial.begin(9600); \n\n servo_test.attach(9); // attach the signal pin of servo to pin9 of arduino\n servo_test.write(90);\n \n } \n \n void loop()\n { \n\n #if(true)\n if (Serial.available())\n {\n Serial.println(\"inside if statement\");\n angle = Serial.read();\n Serial.println(angle,DEC);\n servo_test.write(angle);\n }\n #endif\n\n #if(false)\n angle = analogRead(potentio); // reading the potentiometer value between 0 and 1023 \n angle = map(angle, 0, 1023, 0, 180); // scaling the potentiometer value to angle value for servo between 0 and 180) \n Serial.println(angle);\n //command to rotate the servo to the specified angle \n servo_test.write(angle);\n #endif\n } \n"
},
{
"alpha_fraction": 0.6722365021705627,
"alphanum_fraction": 0.6902313828468323,
"avg_line_length": 19.473684310913086,
"blob_id": "a71471b370274f2fd8cb4b2160105614f890609f",
"content_id": "6810d5dd5831c445c6e9c91a27b1443ed9967fad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 38,
"path": "/Chat/ChatGUI.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import ttk\nfrom tkinter.messagebox import *\nimport tkinter.messagebox\n\n\ndef show_answer():\n Ans = num1.get()\n tkinter.messagebox.showinf('message',Ans)\n\nroot = Tk()\n\nroot.title(\"First Window\")\n##ttk.Button(root, text = \"Hello\").grid()\nframe = Frame(root)\n\nLabel(root, text=\"Enter Num 1:\").grid(row=0)\nLabel(root, text = \"Response\").grid(row=2)\nnum1 = Entry(root)\nblank = Entry(root)\nButton(root,text='Show',command=show_answer).grid(row=4,column=1,sticky=W,pady=4)\nnum1.grid(row=0, column=1)\nblank.grid(row=2, column=1)\n\n\n##labelText = StringVar()\n##label = Label(frame, textvariable=labelText)\n##\n##\n##button = Button(frame, text=\"Click Me\")\n##labelText.set(\"label 1\")\n##\n##label.pack()\n##button.pack()\n##frame.pack()\n\n\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.6264591217041016,
"alphanum_fraction": 0.6303501725196838,
"avg_line_length": 16.785715103149414,
"blob_id": "4333adadb39bd4cf202306abee710ccba03a446d",
"content_id": "14b21917d07057a54028f720afdaaa9af0c60fcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 257,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 14,
"path": "/encrypt.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "def encrypt(message):\n myInt = 3\n encMessage = \"\"\n for x in message: \n encMessage += chr(ord(x)^myInt)\n\n return encMessage\n \n\n\nmessage = \"hello world\"\nencMessage= encrypt(message)\nprint(encMessage) \nprint(encrypt(encMessage))\n\n\n\n \n\n"
},
{
"alpha_fraction": 0.7678571343421936,
"alphanum_fraction": 0.7678571343421936,
"avg_line_length": 19,
"blob_id": "95c530836897c01f9e3dd9a08e341bfebeade40e",
"content_id": "398179be61bdc7afb5342aeafd50612b78066630",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 14,
"path": "/Chat/keyTranmission.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "def as_server():\n#recieve connection\n#get key exchange question\n#send base, mod, public key(generate)\n#recive extern-publickey\n#compute secret key\n\n\ndef as_client():\n#start connection\n#ask for key exchange\n#revice base, mod, extern-public key\n#send public key\n#compute secret key\n"
},
{
"alpha_fraction": 0.6101694703102112,
"alphanum_fraction": 0.6101694703102112,
"avg_line_length": 11.642857551574707,
"blob_id": "7e12899b812af686ab0f93286bb666a1aa1a4a34",
"content_id": "8081858be4dc55a520b5fb07da2fc330bc37b18c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 14,
"path": "/GPIOraspberry/include/GPIOClass.h",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "#ifndef GPIOCLASS_H\n#define GPIOCLASS_H\n\n\nclass GPIOClass\n{\n public:\n GPIOClass();\n virtual ~GPIOClass();\n protected:\n private:\n};\n\n#endif // GPIOCLASS_H\n"
},
{
"alpha_fraction": 0.6694386601448059,
"alphanum_fraction": 0.6756756901741028,
"avg_line_length": 36,
"blob_id": "fbb9a61951eeb3bfee21b24ea7fe0b5096bd4512",
"content_id": "faedd0e2e8aa37fa29b0c9f4d0173313a76b6334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 13,
"path": "/Chat/Setup.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "class DiffEnt():\n PublicMod = 23\n PublicBase = 5\n\n def __init__(self, PickedNumber, otherDiffEnt = None):\n self.PickedNumber = PickedNumber\n self.publicKey = self.PublicBase**self.PickedNumber % self.PublicMod\n if otherDiffEnt != None:\n self.ComputeKey(otherDiffEnt.publicKey)\n otherDiffEnt.ComputeKey(self.publicKey)\n\n def ComputeKey(self, PublicKey):\n self.SecretKey= PublicKey**self.PickedNumber % DiffEnt.PublicMod\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 14.375,
"blob_id": "21ea07fe7729a11027a9654a9447c58c5e03b14c",
"content_id": "e1ba3c6be281ef424b9bbec31c22569e30989458",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 123,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 8,
"path": "/helloworld/Makefile",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "output: main.o\n\tgcc main.o -o bin/HelloProgram -lstdc++\n\nmain.o: main.cpp\n\tgcc -c main.cpp -lstdc++\n\nclean:\n\trm *.o output\n"
},
{
"alpha_fraction": 0.5973451137542725,
"alphanum_fraction": 0.5973451137542725,
"avg_line_length": 16.384614944458008,
"blob_id": "3237403cb49349ac800facad50aad47074951ea9",
"content_id": "96a9c1e291579ccbfaf9d53d4822ac3ecdd0c529",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 13,
"path": "/Chat/MkKey.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "from cryptography.fernet import Fernet\n\ndef write_key():\n\n key = Fernet.generate_key()\n \n with open(\"key.key\",\"w\") as key_file:\n key_file.write(key)\n\n\ndef load_key():\n \n return open(\"key.key\",\"r\").read()\n"
},
{
"alpha_fraction": 0.7182662487030029,
"alphanum_fraction": 0.7182662487030029,
"avg_line_length": 14.285714149475098,
"blob_id": "ac7315b40a5d9bb00e1e41357fab195d0c3ada17",
"content_id": "e038c3388230ef4a0410b55ad2e13e90b5fdfbed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 21,
"path": "/Chat/Test.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "import MkKey\nfrom cryptography.fernet import Fernet\n\n\nMkKey.write_key()\n\nkey = MkKey.load_key()\n\nf = Fernet(key)\n\nmessage = raw_input (\"Enter message:\")\n\nencrypted = f.encrypt(message)\n\ndecrypted = f.decrypt(encrypted)\n\nprint \"key is:\" + key\n\nprint \"encrypted message:\" + encrypted\n\nprint \"decypted message:\" + decrypted \n\n"
},
{
"alpha_fraction": 0.5980392098426819,
"alphanum_fraction": 0.5980392098426819,
"avg_line_length": 8.272727012634277,
"blob_id": "90329c3abf4f8238afdb82931c46374d1a6d8ea3",
"content_id": "a8134733bf1d83fe0a858fa18e00d2f27c373231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 11,
"path": "/GPIOraspberry/src/GPIOClass.cpp",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "#include \"GPIOClass.h\"\n\nGPIOClass::GPIOClass()\n{\n //ctor\n}\n\nGPIOClass::~GPIOClass()\n{\n //dtor\n}\n"
},
{
"alpha_fraction": 0.5453481674194336,
"alphanum_fraction": 0.5599765777587891,
"avg_line_length": 19.841463088989258,
"blob_id": "ada0e55a03f6e0b0f74512acbbddbb32943e51cc",
"content_id": "6203eff025c9b2c2993e7febcfc2c906566b2f44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1709,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 82,
"path": "/Chat/server.py",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "import socket\nimport sys\nimport threading\nimport time\n\nHOST = ''\nPORT = 8002\n\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nprint ('Socket created')\n\n\ndef create_server():\n try:\n s.bind((HOST, PORT))\n except (socket.error) as msg:\n print ('Bind Failed', +str(msg[0]), 'Message', + msg[1])\n sys.exit()\n \n s.listen(1)\n\n\ndef receive(conn , addr):\n try:\n while True:\n\n time.sleep(0.1)\n data = conn.recv(16)\n print('cout<< \\n',data.decode())\n \n\n if not data:\n print('no more data from', addr)\n break\n\n finally:\n conn.close()\n\n\ndef send(conn):\n while True:\n message = input(\"cin>> \\n\")\n message = str.encode(message)\n conn.sendall(message)\n time.sleep(0.1)\n\ndef ComputeKey(conn):\n #Pick numbers for base, power and modulo\n Base = 7\n Number = 3\n Mod = 123\n\n #Compute Local public key\n PublicKey = str(Base**Number%Mod)\n\n #Combine base mod and local public key for sending and send to client\n Smessage = str(Base)+' '+str(Mod)+' '+str(PublicKey)\n message = str.encode(Smessage)\n conn.sendall(message)\n time.sleep(0.1)\n\n #Recieve public key client \n Key = conn.recv(16)\n K = int(Key.decode())\n\n #Compute private key\n SecretKey = K**Number%Mod\n print(SecretKey)\n return (SecretKey)\n\ntry:\n create_server()\n conn, addr = s.accept()\n K = ComputeKey(conn)\n threading._start_new_thread( receive,(conn,addr))\n threading._start_new_thread( send, (conn,))\n\n while True:\n time.sleep(100)\n \nexcept:\n print(\"exception\")\n"
},
{
"alpha_fraction": 0.7096773982048035,
"alphanum_fraction": 0.7096773982048035,
"avg_line_length": 18.727272033691406,
"blob_id": "b8ff546e94f9d289b577325223d4d801a6838465",
"content_id": "89321092a8af2a59a6c8496662f7d0f937130471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 11,
"path": "/GPIOraspberry/Makefile",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "\noutput: main.o GPIOClass.o\n\tgcc main.o GPIOClass.o -o Awesomeprogram -lstdc++\n\nmain.o: main.cpp\n\tgcc -c main.cpp -lstdc++\n\nGPIOClass.o: GPIOClass.h GPIOClass.cpp \n\tgcc -c GPIOClass.cpp -lstdc++\n\nclean:\n\trm *.o output"
},
{
"alpha_fraction": 0.5668147206306458,
"alphanum_fraction": 0.5809447169303894,
"avg_line_length": 29.962499618530273,
"blob_id": "393b314a69781776bf2b2c1f9e45e6e09a8243f5",
"content_id": "b9778cda7348d1fca0684b8eb4e735328a01e70a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2477,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 80,
"path": "/server.cpp",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "//socket includes\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n#include <sys/types.h> \n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <iostream>\n\n//i found some information about how this works here: http://www.cplusplus.com/forum/articles/13355/\nint main(int argc, char *argv[])\n{\n //Create a socket with the socket() system call\n socklen_t clilen;\t//moeten we nog opzoeken\n struct sockaddr_in serv_addr, cli_addr;\t//moet noet uitgezet\n // return value of read and write?? iets\n\t\n if (argc < 2) {\n fprintf(stderr,\"ERROR, no port provided\\n\");\n exit(1);\n }\n else {\n std::cout << \"argc =\" << argc << \"argv =\" << argv[1] << \"\\n\";\n sleep(5);\n }\n \n auto sockfd = socket(AF_INET, SOCK_STREAM, 0);\n if (sockfd < 0) \n {\n perror(\"ERROR opening socket\");\n exit(2);\n }\n\tbzero((char *) &serv_addr, sizeof(serv_addr)); //zet alles in server_addr naar 0. for infor on sizeof see: https://en.cppreference.com/w/cpp/language/sizeof\n auto portno = atoi(argv[1]);\t//poort argument van int naar string\n \n //The variable serv_addr is a structure of type struct sockaddr_in. This structure has four fields. The first field is short sin_family, which contains a code for the address family. It should always be set to the symbolic constant AF_INET.\n serv_addr.sin_family = AF_INET;\n serv_addr.sin_addr.s_addr = INADDR_ANY;\n serv_addr.sin_port = htons(portno);\n if (bind(sockfd, (struct sockaddr *) &serv_addr,sizeof(serv_addr)) < 0)\n\t\t{\n\t\t\tperror(\"ERROR on binding\");\n exit(1);\n }\n listen(sockfd,5);\n clilen = sizeof(cli_addr);\n\n int newsockfd{};\n while (true)\n {\n newsockfd = accept(sockfd,(struct sockaddr *) &cli_addr, &clilen);\n if (newsockfd < 0)\n {\n perror(\"ERROR on accept\");\n exit(3);\n }\n //char buffer[256];\t//buffer voor read and write;\n char buffer[256];\n bzero(buffer,sizeof(buffer));\n int n = read(newsockfd,buffer,255);\n if (n < 0) \n {\n perror(\"Error reading from socket\");\n exit(4);\n }\n printf(\"Here is the message: %s\\n\",buffer);\n n = write(newsockfd,\"I got your message\",18);\n if (n < 0) \n {\n perror(\"Error reading from socket\");\n exit(5);\n }\n }\n\n\n close(newsockfd);\n close(sockfd);\n return 0;\t\n}\n"
},
{
"alpha_fraction": 0.488178014755249,
"alphanum_fraction": 0.4993045926094055,
"avg_line_length": 18.97222137451172,
"blob_id": "b0936601161d2f71f92cb722224e7134d438fb44",
"content_id": "fe2f6fe6ee6c0370284e6b3afe34cbdf8aba36f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 719,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 36,
"path": "/main.cpp",
"repo_name": "jjsmit/TenJProjects",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstring>\n\nvoid parse_arguments(int &argc, const char* argv[]){\n if (argc < 2){\n std::cout << \"not enough pylons\\n\";\n exit(1);\n }\n\n if (std::strcmp(argv[1] , \"client\")== 0){\n std::cout << \"client jdfsjf\\n\";\n //something client related\n return;\n }\n else\n {\n\t std::cout << \"err\\n\";\n\t std::cout << argv[1];\n }\n //else if (*argv[1] == \"server\"){\n // //somthing serverlike\n // std::cout << \"SERVER related stuff booting\\n\";\n // return;\n //}\n //else{\n //std::cout << \"Input is onzim\\n\";\n //exit(1);\n //}\n\n}\n\nint main(int argc, char const *argv[])\n{\n parse_arguments(argc, argv);\n return 0;\n}\n"
}
] | 18 |
ngoctung4him/SketchToApp
|
https://github.com/ngoctung4him/SketchToApp
|
6e77d5634582d85ca8f3e0cdc82dac5fa07368fa
|
23b3d439597818e98567d1645e424ff7a43c6cd5
|
362f5cac928fb04150e5ff303dd7e6b8c93d3d58
|
refs/heads/master
| 2020-04-08T05:56:49.643984 | 2018-11-25T22:20:55 | 2018-11-25T22:20:55 | 159,079,949 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6222391724586487,
"alphanum_fraction": 0.6534653306007385,
"avg_line_length": 29.55813980102539,
"blob_id": "523397ff237b2bab9d0c29b17766a488df8e8d9d",
"content_id": "a872367ee4baeea927132116a42828431dc1e045",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1313,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 43,
"path": "/SketchToApp/viewProcessor/CropWindow.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Apr 7 19:54:10 2018\n\n@author: soumi\n\"\"\"\n\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Oct 5 16:29:44 2017\n\n@author: soumi\n\"\"\"\nimport numpy as np\nfrom RectUtils.Rect import Rect\nfrom RectUtils.RectView import RectView\nimport cv2\nfrom RectUtils.Point import Point\nimport RectUtils.RectUtil as RectUtil\nfrom viewProcessor.ContourAnalysis import ContourAnalysis\nclass CropWindow:\n \n def __init__(self,img):\n contourAnalysis = ContourAnalysis()\n contoursdata = contourAnalysis.findContoursWithCanny(img)\n contours = contoursdata['contours']\n \n points = []\n for i in range(len(contours)):\n (x1,y1,width,height)= cv2.boundingRect(contours[i])\n points.append(Point(x1,y1))\n points.append(Point(x1+width,y1+height))\n points.append(Point(x1+width,y1))\n points.append(Point(x1,y1+height))\n RectUtil.sortleftRight(points)\n self.leftX = points[0].x\n self.rightX = points[len(points)-1].x\n RectUtil.sortTopBottom(points)\n self.topY = points[0].y\n self.bottomY = points[len(points)-1].y\n \n def cropImg(self,img,threshold=2):\n return img[self.topY-threshold:self.bottomY+threshold, self.leftX-threshold:self.rightX+threshold]"
},
{
"alpha_fraction": 0.6784452199935913,
"alphanum_fraction": 0.6784452199935913,
"avg_line_length": 31.941177368164062,
"blob_id": "9daa4cde4e6fc1fd917ccbd04d4a2f1e387ea070",
"content_id": "4c0d9a4d3d0e6421ac99eef75babd68290cc642b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 566,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 17,
"path": "/SketchToApp/Rules/RuleNoChildren.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "from Rules.ASingleRule import ASingleRule\nfrom Rules.TextValidator import TextValidator\nimport ocr.TextProcessorUtil as TextProcessorUtil\nfrom Utils.ColorUtil import CColor\n\nclass RuleNoChildren (ASingleRule):\n def __init__(self,ocrs, views):\n super().__init__( ocrs, views)\n\n# @Override\n def accept(self, ocr):\n# return None\n hasChildren = TextProcessorUtil.hasParent(ocr, self.mOcrs)\n if not hasChildren:\n return None\n tv = TextValidator(ocr, CColor.Magenta, False, \"no children\")\n return tv\n \n\n"
},
{
"alpha_fraction": 0.7254277467727661,
"alphanum_fraction": 0.7254277467727661,
"avg_line_length": 44.54545593261719,
"blob_id": "e6523c637495ab083689af4be58e947a7aa212d8",
"content_id": "2bc9a5da814676285dee77f0d61e001cdcd81967",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2513,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 55,
"path": "/SketchToApp/Rules/RuleManager.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "from Rules.RuleInvalidCharacter import RuleInvalidCharacter\nfrom Rules.RuleSingleCharacter import RuleSingleCharacter\nfrom Rules.RuleNoHeight import RuleNoHeight\nfrom Rules.RuleNoWidth import RuleNoWidth\nfrom Rules.RuleBoxHasWordTooSmall import RuleBoxHasWordTooSmall\nfrom Rules.RuleNoChildren import RuleNoChildren\nfrom Rules. RuleBoxHasOneWordTooSmall import RuleBoxHasOneWordTooSmall\nfrom Utils import Logger\n\n\nclass RuleManager:\n \n def __init__(self,ocrTextWrappers, views):\n self.mOCRRules = []\n self.mVisionRules = []\n self.mViews = views\n self.mOcrTextWrappers = ocrTextWrappers\n self.initOCRRules()\n self.initVisionRules()\n\n\n def initVisionRules(self):\n return\n# self.mVisionRules.append( RuleTextTooBigCompWords(self.mDipCalculator, self.mOcrTesseractOCR, self.mMatLog, self.mOcrTextWrappers, self.mViews))\n# self.mVisionRules.append( RuleVisionBoxHasSoManyInvalidTexts(self.mDipCalculator, self.mOcrTesseractOCR, self.mMatLog, self.mOcrTextWrappers, self.mViews))\n# self.mVisionRules.append( RuleBaseOnNeighbour(self.mDipCalculator, self.mOcrTesseractOCR, self.mMatLog, self.mOcrTextWrappers, self.mViews))\n \n\n def initOCRRules(self): \n self.mOCRRules.append(RuleInvalidCharacter(self.mOcrTextWrappers, self.mViews))\n self.mOCRRules.append(RuleSingleCharacter(self.mOcrTextWrappers, self.mViews))\n self.mOCRRules.append(RuleNoHeight(self.mOcrTextWrappers, self.mViews))\n self.mOCRRules.append(RuleNoWidth(self.mOcrTextWrappers, self.mViews))\n self.mOCRRules.append(RuleBoxHasWordTooSmall(self.mOcrTextWrappers, self.mViews))\n self.mOCRRules.append(RuleNoChildren(self.mOcrTextWrappers, self.mViews))\n self.mOCRRules.append(RuleBoxHasOneWordTooSmall(self.mOcrTextWrappers, self.mViews))\n\n def acceptOCRRules(self,ocr):\n firstTextValidator = None\n for rule in self.mOCRRules:\n textValidator = rule.accept(ocr)\n if textValidator != None and not textValidator.valid :\n firstTextValidator = textValidator\n# print(textValidator.log)\n break\n \n \n return firstTextValidator\n \n\n def acceptVisionRules(self,invalidTexts, acceptedOcrTextWrappers):\n for rule in self.mVisionRules:\n match = rule.run(invalidTexts, acceptedOcrTextWrappers)\n if match:\n Logger.append(Logger.RULE_INFO_LOG, \"\\t\" + type(rule).__name__)\n "
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 21.200000762939453,
"blob_id": "a30d79db8ec967d72fcd59daf60841360f1bb983",
"content_id": "23c8f7eba136ecfa2e168362b540156fce7cf62d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 5,
"path": "/SketchToApp/Rules/AVisionRule.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "\nclass AVisionRule:\n\n def __init__(self, ocrs, views):\n self.mOcrs = ocrs\n self.mViews = views\n"
},
{
"alpha_fraction": 0.5736224055290222,
"alphanum_fraction": 0.5826558470726013,
"avg_line_length": 25.33333396911621,
"blob_id": "60b40849a94cac5e08847c128713ab7bc4548022",
"content_id": "3fee99525a2c862385b98a6cbbc4021b178f2365",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1107,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 42,
"path": "/SketchToApp/Rules/RuleSingleCharacter.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "from Rules.ASingleRule import ASingleRule\nfrom Utils import ColorUtil\nfrom RectUtils import RectUtil\nfrom Rules.TextValidator import TextValidator\nfrom Utils import Constants\nfrom Utils import GroupUtil\nfrom Utils import TextUtils\nfrom string import printable\n\n\n \n\nclass RuleSingleCharacter(ASingleRule):\n \n def __init__(self,ocrs, views):\n super().__init__(ocrs, views)\n \n def singleCharacterofDots(self,text):\n singleInvalidCharacters = [',','.','+','-','o',')','(','/','\\\\','|','~']\n if(len(text)==1):\n if text not in singleInvalidCharacters:\n return True\n else:\n return False\n return True\n# @Override\n def accept(self,ocr): \n if self.singleCharacterofDots(ocr.text):\n return None \n \n \n# return None\n# \n tv = TextValidator(ocr, ( 130, 238, 255), False, \"There is not text. it is all spaces\")\n return tv\n\n \n# Contain: all spaces, all invisible chars, or all non-ascii chars\n# * \n# * @param text\n# * @return\n# */\n\n"
},
{
"alpha_fraction": 0.43888887763023376,
"alphanum_fraction": 0.46666666865348816,
"avg_line_length": 18.321428298950195,
"blob_id": "aa22437bcc6004d0c53faf7c5d9c7c2be7ce8d27",
"content_id": "ca0fa2d2df5be7815285df62ab2abd3bb846d69a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 540,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 28,
"path": "/SketchToApp/RectUtils/Point.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 10 18:54:39 2017\n\n@author: soumi\n\"\"\"\n\nclass Point:\n x = 0 \n y = 0\n def __init__(self,x,y):\n self.x = x\n self.y= y\n \n def cvPoint(self):\n return (self.x, self.y)\n def __hash__(self):\n return hash((self.x, self.y))\n\n def __eq__(self, other):\n \n if other is None:\n return False\n else:\n return (self.x, self.y) == (other.x, other.y)\n\n def __ne__(self, other):\n return not(self.__eq__(other))"
},
{
"alpha_fraction": 0.6967741847038269,
"alphanum_fraction": 0.7139784693717957,
"avg_line_length": 23.756755828857422,
"blob_id": "6735739f14212fedc577d948173986b4e1d036a6",
"content_id": "14a50c19ed0884e3fc17cc7d5c9b2ca7a7ea976f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 930,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 37,
"path": "/SketchToApp/viewProcessor/HierarchyInfo.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Oct 15 22:00:11 2017\n\n@author: soumi\n\"\"\"\nimport RectUtils.RectUtil as RectUtil\nfrom RectUtils.RectView import RectView\nimport RectUtils.RectView as RectViewType\nfrom RectUtils.Rect import Rect\nimport numpy as np\nfrom Utils import ImageUtil\nfrom Utils import ColorUtil\nimport cv2\nimport copy\nfrom ocr.OCRTextWrapper import OCRTextWrapper\nimport ocr.TextProcessorUtil as TextProcessorUtil\nfrom Utils.ColorUtil import CColor, ColorWrapper\nimport Utils.ColorUtil as ColorUtil\nfrom ocr.TextInfo import TextInfo\n\nclass HierarchyInfo:\n rootView = RectView()\n biMapViewRect ={}\n\nclass OrderViewWraper:\n otherView= None\n\n def __init__(self,view, ranking):\n self.view = view\n self.ranking = ranking\n\n def getRank(self):\n if (self.otherView == None):\n return self.ranking\n else:\n return self.otherView.getRank() + 0.1\n \n\n"
},
{
"alpha_fraction": 0.5570767521858215,
"alphanum_fraction": 0.5860636234283447,
"avg_line_length": 35.77430725097656,
"blob_id": "6566ece244eae30f1cded7573acdbb4b5a1719d8",
"content_id": "a74f2af5857c5c524424cc860233205d0aa1c775",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10591,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 288,
"path": "/SketchToApp/sketchProcessing.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 21 14:52:03 2018\n\n@author: sxm6202xx\n\"\"\"\n\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 4 00:16:19 2017\n\n@author: soumi\n\"\"\"\nfrom time import sleep\n#import numpy as np\nimport cv2\nfrom viewProcessor.Canny import Canny\nfrom viewProcessor.ContourAnalysis import ContourAnalysis\nfrom viewProcessor.ContourAnalysis import ContourInfo\nfrom Utils.Project import Project\nfrom viewProcessor.ViewHierarchyProcessor import ViewHierarchyProcessor\nfrom Utils.Resolution import Resolution\nfrom ocr.TextProcessor import TextProcessor\nfrom Utils import Util\nimport copy\nfrom Utils import XmlUtil\nfrom Utils import Constants\nfrom Utils.Profile import Profile\nfrom Utils.Profile import DeviceDensity\nfrom Utils.DipCalculator import DipCalculator\nimport os\nfrom Utils import ImageUtil\nfrom viewProcessor import Transform\nfrom shutil import copyfile\nfrom ocr import AzureVision\nimport numpy as np\nfrom Screen import Screen2 as Scr\nimport math\n\n\ndef Distance(aLine): \n return math.sqrt(math.pow((aLine[0][2]-aLine[0][0]),2) + math.pow((aLine[0][3]-aLine[0][1]),2) )\n\ndef RecognizeLines(fileLocation):\n img = cv2.imread(fileLocation)\n gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\n \n kernel_size = 5\n blur_gray = cv2.GaussianBlur(gray,(kernel_size, kernel_size),0)\n \n low_threshold = 50\n high_threshold = 150\n edges = cv2.Canny(blur_gray, low_threshold, high_threshold)\n \n rho = 1 # distance resolution in pixels of the Hough grid\n theta = np.pi / 180 # angular resolution in radians of the Hough grid\n threshold = 15 # minimum number of votes (intersections in Hough grid cell)\n min_line_length = 10 # minimum number of pixels making up a line\n max_line_gap = 10 # maximum gap in pixels between connectable line segments\n line_image = np.copy(img) * 0 # creating a blank to draw lines on\n \n # Run Hough on edge detected image\n # Output \"lines\" is an array containing endpoints of detected line segments\n lines = cv2.HoughLinesP(edges, rho, theta, threshold, np.array([]),\n min_line_length, max_line_gap)\n #print(lines)\n for line in lines:\n #print(Distance(line))\n if (Distance(line)<25):\n for x1, y1, x2, y2 in line:\n #points.append(((x1 + 0.0, y1 + 0.0), (x2 + 0.0, y2 + 0.0)))\n cv2.line(line_image, (x1, y1), (x2, y2), (255, 0, 0), 5)\n\n lines_edges = cv2.addWeighted(img, 0.8, line_image, 1, 0)\n print(lines_edges.shape)\n cv2.imwrite('image_out.png', lines_edges)\n return lines \n \n\ndef checkValidScreen(fileLocation):\n fileExitst = os.path.isfile(fileLocation)\n if(not fileExitst):\n return \"Can't access the file\"\n img_raw = cv2.imread(fileLocation)\n\n\n img_raw = cv2.fastNlMeansDenoising(img_raw,30.0, 7, 21)\n \n img_gray = copy.deepcopy(img_raw)\n \n if len(img_raw.shape) == 3 :\n img_gray = cv2.cvtColor(img_raw, cv2.COLOR_BGR2GRAY)\n return AzureVision.getTextfromNA(img_gray) \n\n\n \ndef generateProject(fileLocation):\n \n fileExitst = os.path.isfile(fileLocation)\n if(not fileExitst):\n return \"Can't access the file\"\n img_raw = cv2.imread(fileLocation)\n\n\n img_raw = cv2.fastNlMeansDenoising(img_raw,30.0, 7, 21)\n \n img_gray = copy.deepcopy(img_raw)\n \n if len(img_raw.shape) == 3 :\n img_gray = cv2.cvtColor(img_raw, cv2.COLOR_BGR2GRAY)\n \n\n\n # dilate and find edges in the provided screenshot\n\n # This part is for finding window \n adaptiveThresholding = cv2.adaptiveThreshold(img_gray,255,cv2.ADAPTIVE_THRESH_MEAN_C,\\\n cv2.THRESH_BINARY,11,2)\n \n canny = Canny()\n \n dst_edge = canny.findEdge(adaptiveThresholding) \n dst_edge_dilate = canny.addDilate(dst_edge)\n#\n#\n contourAnalysis = ContourAnalysis()\n contours = contourAnalysis.findContoursWithCanny(dst_edge_dilate)\n contoursOutput = contourAnalysis.analyzeforCrop(dst_edge_dilate, contours) \n \n img_raw,img_gray = Transform.transform_Single(contoursOutput,img_raw,img_gray)\n\n # After Finding window process hierarchy\n \n# dst_denoised = cv2.fastNlMeansDenoising(img_draw,30.0, 7, 21)\n adaptiveThresholding = cv2.adaptiveThreshold(img_gray,255,cv2.ADAPTIVE_THRESH_MEAN_C,\\\n cv2.THRESH_BINARY,11,2)\n\n \n canny = Canny()\n \n dst_edge = canny.findEdge(adaptiveThresholding) \n dst_edge_dilate = canny.addDilate(dst_edge)\n#\n# ImageUtil.drawWindow(\"AdaptiveImage\",dst_edge_dilate )\n contourAnalysis = ContourAnalysis()\n contours = contourAnalysis.findContoursWithCanny(dst_edge_dilate)\n contoursOutput = contourAnalysis.analyze(dst_edge_dilate, contours)\n \n hierarchyProcessor = ViewHierarchyProcessor(contoursOutput.rootView, adaptiveThresholding, canny)\n hierarchyInfo = hierarchyProcessor.process()\n# use tesseract to detect the text \n textProcessor = TextProcessor(img_gray, hierarchyInfo.biMapViewRect)\n## process text to remove invalid texts \n textInfo = textProcessor.processText()\n## Add text boxes to hierarchy \n hierarchyProcessor.addTextToHierarchy(textInfo,img_raw)\n\n\n #cv2.waitKey(0)\n\ndef splitImage(fileLocation):\n #fileLocation=\"sketchImage.jpg\"\n fileExitst = os.path.isfile(fileLocation)\n if(not fileExitst):\n print(\"Can't access the file\")\n # Reading image\n img_raw = cv2.imread(fileLocation)\n image = copy.deepcopy(img_raw)\n #cv2.imshow(\"Raw Image\", image)\n cv2.waitKey(0)\n height, width = image.shape[:2]\n print (image.shape)\n # Let's get the starting pixel coordiantes (top left of cropped top)\n \n starting_row, starting_col = int(0), int(0)\n ending_row, ending_col = int(0), int(0)\n \n name=''\n for i in range(1,4): #row =3 if range is 3\n starting_row=ending_row\n ending_row=int(height* (i/3)) \n ending_col= int(0)\n for j in range(1,4): #col =3\n \n starting_col= ending_col\n ending_col=int(width*(j/3)) \n name='screen'+str(i-1)+str(j-1);\n name= image[starting_row:ending_row, starting_col:ending_col]\n screenid='screen'+str(i-1)+str(j-1)\n #print('('+str(starting_row)+','+str(starting_col)+') - ('+str(ending_row)+','+str(ending_col)+')')\n screen = Scr.Screen(screenid,starting_row,ending_row,starting_col,ending_col)\n screens.append(screen)\n #cv2.imshow('crop'+str(i)+str(j), name) \n cv2.imwrite('screen'+str(i-1)+str(j-1)+'.jpg',name)\nif __name__ ==\"__main__\":\n screens=[]\n screen=np.full((3, 3), False)\n splitImage(\"Capture7.JPG\")\n #generateProject(\"sketchImage.jpg\")\n for i in range (0,3):\n for j in range (0,3):\n print('Processing '+ 'screen'+str(i)+str(j)+'.jpg')\n #generateProject('crop'+str(i)+str(j)+'.jpg')\n if (checkValidScreen('screen'+str(i)+str(j)+'.jpg')):\n screen[i][j]=True\n else:\n screen[i][j]=False\n #sleep(3)\n #create folder\n for i in range(0,3):\n for j in range(0,3):\n if(screen[i][j]):\n if not os.path.exists(\"column\"+str(i)):\n os.makedirs(\"column\"+str(i))\n continue\n #recognize relationship on col\n for i in range (0,3):\n if(screen[0][i]) and (screen[1][i]):\n print (\"screen0\"+str(i)+\" is parent of screen1\"+str(i)+\"\\n\") \n copyfile('screen'+str(0)+str(i)+'.jpg','column'+str(i)+'/'+'screen'+str(0)+str(i)+'.jpg')\n copyfile('screen'+str(1)+str(i)+'.jpg','column'+str(i)+'/'+'screen'+str(1)+str(i)+'.jpg')\n if(screen[1][i]) and (screen[2][i]): \n print (\"screen1\"+str(i)+\" is parent of screen2\"+str(i)+\"\\n\")\n copyfile('screen'+str(1)+str(i)+'.jpg','column'+str(i)+'/'+'screen'+str(1)+str(i)+'.jpg')\n copyfile('screen'+str(2)+str(i)+'.jpg','column'+str(i)+'/'+'screen'+str(2)+str(i)+'.jpg')\n #recognize relationship on row\n if(screen[0][0]) and (screen[0][1]):\n print (\"screen00 is peer of screen01\")\n if(screen[0][1]) and (screen[0][2]):\n print (\"screen01 is peer of screen02\")\n \n for x in screens:\n x.displayScreen()\n lines=RecognizeLines('Capture7.JPG') \n \n temp=[]\n\n img = cv2.imread('Capture7.JPG')\n \n line_image= np.copy(img) * 0 \n \n for line in lines:\n try:\n if (Distance(line)<25):\n # print(Distance(line))\n #print(line)\n #for item in line: #x1 y1 x2 y2\n for i in range(0, len(screens) -1):\n for j in range(i+1, len(screens)):\n # if ((x1<=screens[i].x_end) and (y1<=screens[i].y_end) and (x2>=screens[j].x_start) and (y2>=screens[j].y_start)): \n if( (line[0][0]<=line[0][2]) and (line[0][1]<=line[0][3]) ):\n if ((line[0][0]<=screens[i].x_end) and (line[0][1]<=screens[i].y_end) and (line[0][2]>=screens[j].x_start) and (line[0][3]>=screens[j].y_start)): \n print(line)\n print(screens[i].name )\n screens[i].displayScreen()\n print(screens[j].name)\n screens[j].displayScreen()\n print(\"x1:\"+str(line[0][0])+\" y1:\"+str(line[0][1])+\" x2:\"+str(line[0][2])+\" y2:\"+str(line[0][3]))\n \n #points.append(((x1 + 0.0, y1 + 0.0), (x2 + 0.0, y2 + 0.0)))\n cv2.line(line_image, (line[0][0], line[0][1]), (line[0][2], line[0][3]), (0, 0, 255), 5)\n #HL_lines.append(line.tolist())\n temp.append((screens[i].name,screens[j].name))\n raise StopIteration \n except StopIteration: \n pass \n lines_edges = cv2.addWeighted(img, 0.8, line_image, 1, 0)\n #print(lines_edges.shape)\n cv2.imwrite('lines_edges.png', lines_edges)\n \n print(temp)\n\n\n\n \n\n\n \n# for i in range (0,3):#col\n# for j in range (0,3):#row\n# if (screen[j][i]):\n# file='screen'+str(j)+str(i)+'.jpg'\n# \n# #folder = os.path.join('column'+str(i), file)\n# folder='column'+str(i)+'/'+file\n# print('file '+file)\n# print('folder '+folder)\n# copyfile(file,folder)\n"
},
{
"alpha_fraction": 0.7179487347602844,
"alphanum_fraction": 0.75,
"avg_line_length": 21.428571701049805,
"blob_id": "717ee81efeac0b38a345312977b00a5efac86c27",
"content_id": "03e09bf2288eb718fbef27bad997cd67c0919d7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 7,
"path": "/SketchToApp/demo1.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# import the necessary packages\nimport cv2\n \n# load the image and show it\nimage = cv2.imread(\"sketchImage.jpg\")\ncv2.imshow(\"original\", image)\ncv2.waitKey(0)"
},
{
"alpha_fraction": 0.5364490747451782,
"alphanum_fraction": 0.5464704036712646,
"avg_line_length": 35.931148529052734,
"blob_id": "0b9d881dfebb4d4eefaa7f6b13c5e7f404d100cb",
"content_id": "546a946db60c6a66d5d5069c338a8e485373804a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11276,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 305,
"path": "/SketchToApp/ocr/TextProcessor.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 24 22:24:31 2017\n\n@author: soumi\n\"\"\"\n\nimport copy\nfrom Utils.ColorUtil import CColor, ColorWrapper\nfrom RectUtils import RectUtil\nfrom RectUtils.Rect import Rect\nfrom Utils import ColorUtil\nfrom Utils import ImageUtil\nfrom Rules.FilterRuleManager import *\nfrom ocr import AzureVision\nfrom functools import cmp_to_key\nfrom ocr.OCRTextWrapper import OCRTextWrapper\nfrom Utils import Constants\nfrom Rules.FilterRuleManager import FilterRuleManager\nfrom ocr.TextInfo import TextInfo\nfrom ocr.VisionAPI import VisionApi\n\nclass TextProcessor :\n isDebugMode = False\n\n def __init__(self, image, biMapViewRect) :\n self.mImage = image\n self.mBiMapViewRect = biMapViewRect\n# self.mOcr = VisionApi()\n values = set([k for k in biMapViewRect])\n self.mViewBounds = []\n self.mViewBounds.extend(values)\n RectUtil.sortLeftRightTopBottom(self.mViewBounds)\n self.mViews = [k for k in biMapViewRect]\n \n\n def invalidWord(self,text):\n singleInvalidCharacters = [',','.','+','-','o',')','(','/','\\\\','|','~']\n if(len(text)==1):\n if text not in singleInvalidCharacters:\n return True\n else:\n return False\n return True\n\n\n \n def recalCulateOCR(self, ocrWrapper, validWords):\n validOcrs = []\n for validWord in validWords:\n indexOfX = int(((ocrWrapper.text.index(validWord)/ len(ocrWrapper.text))* ocrWrapper.width)+ ocrWrapper.x)\n width = int((len(validWord)/ len(ocrWrapper.text))* ocrWrapper.width)\n wrapper = OCRTextWrapper()\n wrapper.text = validWord\n wrapper.x = indexOfX\n wrapper.y = ocrWrapper.y\n wrapper.width = width\n wrapper.height = ocrWrapper.height\n \n validOcrs.append(wrapper) \n return validOcrs\n\n\n # split into word and check if it a valid word and seperate with other words\n def getValidWords(self,visionResponses):\n blockVisionResponse = []\n for visionResponse in visionResponses:\n splitWords = visionResponse.text.split()\n if(len(splitWords) != 1):\n validSplitWord = []\n currenWord= \"\"\n for i in range(len(splitWords)):\n if(self.invalidWord(splitWords[i])):\n currenWord += splitWords[i] \n else:\n validSplitWord.append(currenWord)\n currenWord =\"\"\n if(i!=len(splitWords)-1):\n currenWord +=\" \"\n validSplitWord.append(currenWord)\n blockVisionResponse.extend(self.recalCulateOCR(visionResponse,validSplitWord))\n else:\n blockVisionResponse.append(visionResponse)\n return blockVisionResponse\n\n \n \n\n def processText(self):\n# visionresponse= self.get_response()\n ocrResponse = self.extract_vertices_azure()\n visionresponse = self.getValidWords(ocrResponse) \n width = 0\n height = 0\n copyImage = copy.deepcopy(self.mImage)\n \n if len(copyImage.shape) == 2 :\n height, width = copyImage.shape\n else:\n height, width,channels = copyImage.shape\n\n \n acceptedvisionresponses = []\n ruleManager = FilterRuleManager(visionresponse, self.mViews)\n invalidTexts = []\n \n for ocrTextWrapper in visionresponse: \n textValidator = ruleManager.acceptOCRRules(ocrTextWrapper)\n if textValidator != None and not textValidator.valid:\n invalidTexts.append(ocrTextWrapper)\n else :\n acceptedvisionresponses.append(ocrTextWrapper)\n\n\n validTexts = []\n validTexts.extend(acceptedvisionresponses) \n validTexts = [x for x in validTexts if x not in invalidTexts]\n \n\n for ocrTextWrapper in validTexts: \n print(ocrTextWrapper.text)\n textInfo = TextInfo()\n textInfo.lines = validTexts\n\n return textInfo\n \n def getValidLines(self,lines):\n validLines = []\n for line in lines:\n allWords = line.words\n RectUtil.sortleftRight(allWords)\n firstWord = allWords[0]\n currentLine = OCRTextWrapper()\n currentLine.words.append(firstWord)\n for i in range(1,len(allWords)):\n currentWord = allWords[i]\n if(currentWord.x < firstWord.x + firstWord.width+ firstWord.height):\n currentLine.words.append(currentWord)\n else:\n validLines.append(currentLine)\n firstWord = allWords[i]\n currentLine = OCRTextWrapper()\n currentLine.words.append(firstWord)\n \n validLines.append(currentLine)\n \n \n \n \n def reCalculateBoundBaseOnWordList(self, validline):\n if (len(self.words) == 0):\n return validline \n unionRect = self.words[0]\n unionRect.text = self.words[0].text\n for i in range(1,len(self.words)):\n word = self.words[i]\n unionRect = RectUtil.union(unionRect, word)\n unionRect.text = \" \" +self.words[0].text\n return unionRect\n \n \n def getWordsInLine(self, textWrappers):\n RectUtil.sortTopBottom(textWrappers)\n validLines = [] \n firstWord = textWrappers[0]\n currentLine = OCRTextWrapper()\n currentLine.words.append(firstWord)\n for i in range(1,len(textWrappers)):\n currentWord = textWrappers[i]\n if(currentWord.y < firstWord.y + firstWord.height/2):\n currentLine.words.append(currentWord)\n else:\n validLines.append(currentLine)\n firstWord = textWrappers[i]\n currentLine = OCRTextWrapper()\n currentLine.words.append(firstWord)\n \n validLines.append(currentLine)\n\n \n return validLines\n \n \n\n def getNotHorizontalAlignmentWords(self, words) :\n if len(words) <= 1 :\n return []\n\n invalidWords = []\n textWrappers = []\n textWrappers.extend(words)\n first = textWrappers[0].bound()\n for i in range(1,len(words)):\n # Assume that the first item is correct\n current = textWrappers[i].bound();\n if (first.y + first.height <= current.y) :\n invalidWords.append(textWrappers[i])\n\n return invalidWords\n \n def validateWordWithAllViews(self, tv, ocrTextWrapper) :\n ocrBound = ocrTextWrapper.bound();\n for view in self.mViews :\n # woa this word is big and have a lot of children, not good\n # this may okay with url or special texts\n if (RectUtil.contains(ocrBound, view.bound())and len(view.getChildren()) > 0) :\n tv.scalar = ColorUtil.getScalar(CColor.Cyan)\n tv.valid = False\n tv.log = \"This word is big and have a lot of children\";\n return\n\n if RectUtil.contains(ocrBound, view.bound()) and len(view.getChildren()) == 0 :\n # make sure this view did not intersect with other view,\n # include is accepted in this case\n hasIntersection = False\n for otherView in self.mViews:\n if otherView != view and RectUtil.intersectsNotInclude(ocrBound,otherView.bound()) :\n hasIntersection = True\n break \n \n if (not hasIntersection) :\n if (RectUtil.dimesionSmallerThan(view, ocrTextWrapper, 0.8)) :\n # this is wrong, ignore this word\n tv.scalar = CColor.Black\n tv.valid = False\n tv.log = \"The box may has the word is too small compare with the word itself\"\n return\n \n if (self.areChildrenIsTooSmall(self.mDipCalculator, view) and RectUtil.contains(view.bound(), ocrBound)) :\n if (RectUtil.dimesionSmallerThan(ocrTextWrapper, view, 0.8)) :\n # this is wrong, ignore this word\n tv.scalar = CColor.Pink\n tv.valid = False\n tv.log = \"The box may has the word is too big compare to the word, and there is only one word in here. This view may also have other view but it so tiny\"\n return\n \n \n def extract_vertices_azure(self):\n \"\"\"Returns all the text in text annotations as a single string\"\"\"\n listOcrData = []\n polygons= AzureVision.getTextfromNA(self.mImage)\n for polygon in polygons:\n# print(polygon)\n wrapper = OCRTextWrapper()\n wrapper.text = polygon[1]\n print(wrapper.text)\n posX = polygon[0][0]\n if(polygon[0][0]>polygon[0][6]):\n posX = polygon[0][6]\n \n posY = polygon[0][1]\n if(polygon[0][1]>polygon[0][3]):\n posY = polygon[0][3]\n \n tailX = polygon[0][2]\n if(polygon[0][2]<polygon[0][4]):\n tailX = polygon[0][4]\n \n tailY = polygon[0][5]\n if(polygon[0][5]<polygon[0][7]):\n tailY = polygon[0][7]\n \n wrapper.x = posX\n wrapper.y = posY\n wrapper.width = tailX - posX\n wrapper.height = tailY - posY\n listOcrData.append(wrapper)\n return listOcrData\n \n \n def extract_vertices_azure_crop(self,mImage):\n \"\"\"Returns all the text in text annotations as a single string\"\"\"\n wrapper = OCRTextWrapper()\n polygons= AzureVision.getTextfromNA(mImage)\n height_factor = self.mImage.shape[1]/768\n width_factor = self.mImage.shape[0]/1200\n \n for polygon in polygons:\n wrapper = OCRTextWrapper()\n wrapper.text = polygon[1]\n posX = polygon[0][0]*width_factor\n if(polygon[0][0]>polygon[0][6]):\n posX = polygon[0][6]*width_factor\n \n posY = polygon[0][1]*height_factor\n if(polygon[0][1]>polygon[0][3]):\n posY = polygon[0][3]*height_factor\n \n tailX = polygon[0][2]*width_factor\n if(polygon[0][2]<polygon[0][4]):\n tailX = polygon[0][4]*width_factor\n \n tailY = polygon[0][5]*height_factor\n if(polygon[0][5]<polygon[0][7]):\n tailY = polygon[0][7]*height_factor\n \n wrapper.x = posX\n wrapper.y = posY\n wrapper.width = tailX - posX\n wrapper.height = tailY - posY\n print(wrapper.x)\n print(wrapper.y)\n print(wrapper.width)\n print(wrapper.height)\n return wrapper\n \n \n\n\n"
},
{
"alpha_fraction": 0.584645688533783,
"alphanum_fraction": 0.5925197005271912,
"avg_line_length": 22.136363983154297,
"blob_id": "8cb5022e45f007cdfdf9a0f3bff9982f8e66af89",
"content_id": "57c658a7974cc91c928d2bdfc02470534f352437",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 22,
"path": "/SketchToApp/New folder (2)/New folder/test_FormatText.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# test_mymath.py\nimport FormatText\nimport unittest\n \nclass TestFormatText(unittest.TestCase):\n \"\"\"\n Test the add function from the mymath library\n \"\"\"\n \n def test_formatText(self):\n \"\"\"\n Test that the addition of two integers returns the correct total\n \"\"\"\n result = FormatText.formatText(\"Hello ? @\"+chr(39)+chr(ord(' ')-2)+\"World\")\n self.assertEqual(result, 'Hello \\? \\@\\ World')\n \n \n \nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.4935205280780792,
"alphanum_fraction": 0.5950323939323425,
"avg_line_length": 24.054054260253906,
"blob_id": "83906ca598c8a3b5c6e6876c3a3eacb56b907c3e",
"content_id": "867998bc8cdd5a4aca7d9670a39c7ed7636a41eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 926,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 37,
"path": "/SketchToApp/hough.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport cv2\nimport numpy as np\n\nimg = cv2.imread('Capture7.jpg')\ngray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\ncv2.imwrite('Capture6_gray.jpg',gray)\nedges = cv2.Canny(gray,50,250,apertureSize = 5)\ncv2.imwrite('Capture6_edges.jpg',edges)\n#minLineLength = 100\n#maxLineGap = 1\n#lines = cv2.HoughLinesP(edges,1,np.pi/180,400,minLineLength,maxLineGap)\n#\n#for item in lines:\n# \n# for x1,y1,x2,y2 in item:\n# cv2.line(img,(x1,y1),(x2,y2),(255,0,0),2)\n#\n#cv2.imwrite('Capture6_out.jpg',img)\n\nlines = cv2.HoughLines(edges,1,np.pi/180,250)\nfor item in lines:\n \n for rho,theta in item:\n a = np.cos(theta)\n b = np.sin(theta)\n x0 = a*rho\n y0 = b*rho\n x1 = int(x0 + 1000*(-b))\n y1 = int(y0 + 1000*(a))\n x2 = int(x0 - 1000*(-b))\n y2 = int(y0 - 1000*(a))\n \n cv2.line(img,(x1,y1),(x2,y2),(0,0,255),3)\n\ncv2.imwrite('Capture6_out.jpg',img)"
},
{
"alpha_fraction": 0.5302096009254456,
"alphanum_fraction": 0.5380188822746277,
"avg_line_length": 34.260868072509766,
"blob_id": "79940f7efedb4b0033d875915e31e2fdaa40f22e",
"content_id": "9932dddd66a17288779cde17dc614b67c5f82ed1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2433,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 69,
"path": "/SketchToApp/ocr/VisionAPI.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "import base64\n#from googleapiclient import discovery\n#from googleapiclient import errors\nimport cv2\nimport os\n\n#from oauth2client.client import GoogleCredentials\n\nDISCOVERY_URL = 'https://{api}.googleapis.com/$discovery/rest?version={apiVersion}' # noqa\nBATCH_SIZE = 10\n\nclass VisionApi:\n \"\"\"Construct and use the Google Vision API service.\"\"\"\n\n def __init__(self, api_discovery_file='vision_api.json'):\n self.credentials = GoogleCredentials.get_application_default()\n self.service = discovery.build(\n 'vision', 'v1', credentials=self.credentials,\n discoveryServiceUrl=DISCOVERY_URL)\n\n def detect_text(self, input_filename, num_retries=3, max_results=6):\n \"\"\"Uses the Vision API to detect text in the given file.\n \"\"\"\n image = []\n with open(input_filename, 'rb') as image_file:\n image = image_file.read()\n batch_request = []\n batch_request.append({\n 'image': {\n 'content': base64.b64encode(\n image).decode('UTF-8')\n },\n 'features': [{\n 'type': 'TEXT_DETECTION',\n 'maxResults': max_results,\n }]\n })\n request = self.service.images().annotate(\n body={'requests': batch_request})\n\n try:\n responses = request.execute(num_retries=num_retries)\n if 'responses' not in responses:\n return \n response = responses[ 'responses']\n singleResponse = response[0]\n if 'error' in singleResponse:\n print(\"API Error for %s: %s\" % (\n input_filename,\n singleResponse[0]['error']['message']\n if 'message' in responses['error']\n else ''))\n return \n if 'textAnnotations' in singleResponse:\n return singleResponse['textAnnotations']\n else:\n return\n\n except errors.HttpError as e:\n print(\"Http Error for %s: %s\" % (\"not working\", e))\n except KeyError as e2:\n print(\"Key error: %s\" % e2)\n\n\n def getTextfromNA(self, mImage):\n cv2.imwrite(\"vision_temp.jpg\",mImage)\n textOut = self.detect_text(\"vision_temp.jpg\")\n os.remove(\"vision_temp.jpg\")\n return textOut\n"
},
{
"alpha_fraction": 0.5508058667182922,
"alphanum_fraction": 0.58163982629776,
"avg_line_length": 30.733333587646484,
"blob_id": "3ac1d287a3ff1e3993a69612f4b9db61b90f3c7e",
"content_id": "7c33298e6c552488bedf4ff0e905cd7d8eea2955",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1427,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 45,
"path": "/SketchToApp/Coverage.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Oct 26 23:06:00 2018\n\n@author: vo00timo\n\"\"\"\nimport cv2\nimport copy\nimport os\nimport numpy as np\ndef splitImage(fileLocation):\n #fileLocation=\"sketchImage.jpg\"\n fileExitst = os.path.isfile(fileLocation)\n if(not fileExitst):\n print(\"Can't access the file\")\n # Reading image\n img_raw = cv2.imread(fileLocation)\n image = copy.deepcopy(img_raw)\n #cv2.imshow(\"Raw Image\", image)\n cv2.waitKey(0)\n height, width = image.shape[:2]\n print (image.shape)\n # Let's get the starting pixel coordiantes (top left of cropped top)\n \n starting_row, starting_col = int(0), int(0)\n ending_row, ending_col = int(0), int(0)\n name=''\n for i in range(1,4): #row =3 if range is 3\n starting_row=ending_row\n ending_row=int(height* (i/3)) \n ending_col= int(0)\n for j in range(1,4): #col =3\n \n starting_col= ending_col\n ending_col=int(width*(j/3)) \n name='screen'+str(i-1)+str(j-1);\n name= image[starting_row:ending_row, starting_col:ending_col]\n #print('('+str(starting_row)+','+str(starting_col)+') - ('+str(ending_row)+','+str(ending_col)+')')\n \n #cv2.imshow('crop'+str(i)+str(j), name) \n cv2.imwrite('screen'+str(i-1)+str(j-1)+'.jpg',name)\n\nif __name__ ==\"__main__\":\n screen=np.full((3, 3), False)\n splitImage(\"Capture2.JPG\")"
},
{
"alpha_fraction": 0.5961995124816895,
"alphanum_fraction": 0.6318289637565613,
"avg_line_length": 20.100000381469727,
"blob_id": "1286e2de80cfbf970d565759fd7fe88c56afcfa6",
"content_id": "8c02fe7243536434836a1f6138bd9fcd5fceed30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 20,
"path": "/SketchToApp/MockTest.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Oct 27 00:47:54 2018\n\n@author: vo00timo\n\"\"\"\n\nimport unittest\nfrom FormatText import formatText \nfrom mock import Mock\nclass MyTest(unittest.TestCase):\n def test_something(self):\n mock_formatText= Mock()\n formatText(mock_formatText,\"Hello ? @ World\");\n print(mock_formatText.mock_calls)\n \n pass\n\nif __name__ == \"__main__\":\n unittest.main()"
},
{
"alpha_fraction": 0.38902437686920166,
"alphanum_fraction": 0.4231707453727722,
"avg_line_length": 20.605262756347656,
"blob_id": "31d7a5211be31160e71804b91e7cae13a4f66469",
"content_id": "9115e695e3765da96c20103ca30a909a2d641e29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 820,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 38,
"path": "/SketchToApp/FormatText.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Oct 26 23:38:44 2018\n\n@author: vo00timo\n\"\"\"\n\n\ndef isEmpty(text):\n return text == None or len(text) == 0\ndef formatText(text):\n if (isEmpty(text)):\n return text\n buffer = \"\"\n\t\t# remove no ASCII character\n for c in text:\n \n if (c < ' ' or c > '~'):\n buffer+= ' '\n \n elif (c == chr(63)):\n buffer+=\"\\\\?\"\n \n elif (c == chr(64)):\n buffer += '\\\\@'\n \n elif (c == chr(39)):\n buffer += '\\\\'\n \n else:\n buffer+=c\n return buffer.strip().replace(\"\\\\n\", \" \")\n\nif __name__ ==\"__main__\":\n print(formatText(\"Hello ? @\"+chr(39)+chr(ord(' ')-2)+\"World\"))\n \n \n #print(formatText(\"Hello@\"+chr(ord(' ')-2)) +\"World\"+chr(63)) \"? @ \"+"
},
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.6495237946510315,
"avg_line_length": 28.16666603088379,
"blob_id": "c4b97f94e2dd740c8961bcde41de79b50a2e5eec",
"content_id": "046fa010dea9a617eed223d51dc79047dce51078",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1050,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 36,
"path": "/SketchToApp/Rules/RuleInvalidCharacter.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "from Rules.ASingleRule import ASingleRule\nfrom Utils import ColorUtil\nfrom RectUtils import RectUtil\nfrom Rules.TextValidator import TextValidator\nfrom Utils import Constants\nfrom ocr.OCRTextWrapper import OCRTextWrapper\nfrom Utils import GroupUtil\nfrom Utils import TextUtils\nfrom Utils.ColorUtil import CColor\nfrom string import printable\n\n\nclass RuleInvalidCharacter(ASingleRule):\n def __init__(self,ocrs, views):\n super().__init__(ocrs, views)\n\n# @Override\n \n \n def validCharacters(self,text):\n asciiContain = all([ord(char) < 33 or ord(char)>126 for char in text])\n invalidChar = len([char for char in text if char not in printable]) != 0 \n allSpace = all([\" \" == c or '\\n'== c for c in text])\n return not(allSpace or invalidChar or asciiContain)\n \n\n \n \n \n def accept(self, ocr):\n if self.validCharacters(ocr.text):\n return None\n \n \n tv = TextValidator(ocr, CColor.Magenta, False,\"width is 0\")\n return tv\n"
},
{
"alpha_fraction": 0.5666818618774414,
"alphanum_fraction": 0.5903504490852356,
"avg_line_length": 29.957746505737305,
"blob_id": "04471d024767256449af87d5d94b1db2799a1d7e",
"content_id": "4b127dd4bb80c41f2cf329885b9401cc7243c875",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2197,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 71,
"path": "/SketchToApp/ocr/AzureVision.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Apr 17 20:12:48 2018\n\n@author: sxm6202xx\n\"\"\"\n\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Apr 17 19:21:06 2018\n\n@author: sxm6202xx\n\"\"\"\nimport requests\nfrom matplotlib.patches import Polygon\nimport time\nimport cv2\nimport os\n\ndef detectText(imagePath):\n try:\n vision_base_url = \"https://westcentralus.api.cognitive.microsoft.com/vision/v1.0/\"\n ocr_url = vision_base_url + \"recognizeText\"\n subscription_key = \"294807076f4d4dd2a65cc461f2901aa3\"\n image_data = open(imagePath, \"rb\").read()\n headers = {'Ocp-Apim-Subscription-Key': subscription_key, \"Content-Type\": \"application/octet-stream\" }\n params = {'handwriting' : True}\n response = requests.post(ocr_url, \n headers=headers, \n params=params, \n data=image_data)\n response.raise_for_status()\n # operation_url = response.headers[\"Operation-Location\"]\n analysis = {}\n while not \"recognitionResult\" in analysis:\n response_final = requests.get(response.headers[\"Operation-Location\"], headers=headers)\n analysis = response_final.json()\n time.sleep(1)\n #polygons = [(line[\"boundingBox\"], line[\"text\"]) for line in analysis[\"recognitionResult\"][\"lines\"]]\n polygons = [(line[\"text\"]) for line in analysis[\"recognitionResult\"][\"lines\"]]\n print(polygons)\n if (polygons!=[]):\n print(\"sketch is a screen\\n\")\n return True\n else:\n print(\"sketh is not a screen\\n\")\n return False\n \n except:\n print(\"Getting Error, maybe blank image\")\n \n return False\n#plt.figure(figsize=(15,15))\n#\n#image = Image.open(BytesIO(requests.get(image_url).content))\n#ax = plt.imshow(image)\n\n\n\n\n\ndef getTextfromNA(mImage):\n# resizedImage = cv2.resize(mImage,(1200,768), interpolation = cv2.INTER_CUBIC)\n cv2.imwrite(\"vision_temp.jpg\",mImage)\n textOut = detectText(\"vision_temp.jpg\")\n os.remove(\"vision_temp.jpg\")\n return textOut\n\nif __name__ ==\"__main__\":\n filename = r\"vision_temp.jpg\"\n detectText(filename)"
},
{
"alpha_fraction": 0.5492487549781799,
"alphanum_fraction": 0.5559265613555908,
"avg_line_length": 27.571428298950195,
"blob_id": "4b6bfb865f596695e11a4df1d9c991e67cf0007e",
"content_id": "59e30a48abe833904ba17a717add5b1ba6ea7ded",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 21,
"path": "/SketchToApp/Screen/Screen2.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# -*- coding: utf-8 -*-\n\nclass Screen:\n 'Common base class for all employees'\n scrCount = 0\n\n def __init__(self, name, x_start, x_end, y_start, y_end):\n self.name = name\n self.x_start = x_start\n self.x_end = x_end\n self.y_start = y_start\n self.y_end = y_end\n Screen.scrCount += 1\n \n def displayCount(self):\n print (\"Total Screen %d\" % Screen.scrCount)\n\n def displayScreen(self):\n print (\"screen : \", self.name,\"x_start : \", self.x_start, \", x_end: \", self.x_end, \"y_start : \", self.y_start, \", y_end: \", self.y_end)"
},
{
"alpha_fraction": 0.5891647934913635,
"alphanum_fraction": 0.6085779070854187,
"avg_line_length": 31.58823585510254,
"blob_id": "624923772392864436fdbf0fad06a332f038be46",
"content_id": "619349e582c9520c4b2e10be59646999a073bc95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2215,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 68,
"path": "/SketchToApp/SplitImage.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimport copy\n# Numbers of rows\nnRows = 4\n# Number of columns\nmCols = 2\nfileLocation=\"sketchImage.jpg\"\nfileExitst = os.path.isfile(fileLocation)\nif(not fileExitst):\n print(\"Can't access the file\")\n# Reading image\nimg_raw = cv2.imread(fileLocation)\nimage = copy.deepcopy(img_raw)\n#cv2.imshow(\"Raw Image\", image)\ncv2.waitKey(0)\nheight, width = image.shape[:2]\nprint (image.shape)\n# Let's get the starting pixel coordiantes (top left of cropped top)\nstart_row, start_col = int(0), int(0)\nstarting_row, starting_col = int(0), int(0)\nending_row, ending_col = int(0), int(0)\ncount=int(0)\nname=''\ncrop_image=[20]\nfor i in range(1,4):\n starting_row=ending_row\n ending_row=int(height* (i/3))\n ending_col= int(0)\n for j in range(1,4):\n \n starting_col= ending_col\n ending_col=int(width*(j/3))\n name='crop'+str(i)+str(j);\n name= image[starting_row:ending_row, starting_col:ending_col]\n print('('+str(starting_row)+','+str(starting_col)+') - ('+str(ending_row)+','+str(ending_col)+')')\n \n #cv2.imshow('crop'+str(i)+str(j), name) \n cv2.imwrite('crop'+str(i)+str(j)+'.jpg',name)\n \n \n \n#cv2.imshow('crop'+str(i)+str(j), name) \n#cv2.waitKey(0) \n#cv2.imwrite('temp.jpg', img_raw)\n# =============================================================================\n# # Let's get the ending pixel coordinates (bottom right of cropped top)\n# end_row, end_col = int(height * .5), int(width)\n# cropped_top = image[start_row:end_row , start_col:end_col]\n# print (start_row, end_row) \n# print (start_col, end_col)\n# \n# cv2.imshow(\"Cropped Top\", cropped_top) \n# cv2.waitKey(0) \n# cv2.destroyAllWindows()\n# \n# # Let's get the starting pixel coordiantes (top left of cropped bottom)\n# start_row, start_col = int(height * .5), int(0)\n# # Let's get the ending pixel coordinates (bottom right of cropped bottom)\n# end_row, end_col = int(height), int(width)\n# cropped_bot = image[start_row:end_row , start_col:end_col]\n# print (start_row, end_row) \n# print (start_col, end_col)\n# \n# cv2.imshow(\"Cropped Bot\", cropped_bot) \ncv2.waitKey(100) \n# =============================================================================\n#cv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.5780808925628662,
"alphanum_fraction": 0.5860771536827087,
"avg_line_length": 28.943662643432617,
"blob_id": "9462911a2310978456a0656333c14845a40033d1",
"content_id": "64b7232ef4c996278c692a742f8e1453ec51c4ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2126,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 71,
"path": "/SketchToApp/ocr/OCRTextWrapper.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 24 12:43:56 2017\n\n@author: soumi\n\"\"\"\n#from RectUtils.RectUtil import *\nfrom RectUtils.Rect import Rect\nfrom Utils import Constants\nimport RectUtils.RectUtil as RectUtil\nfrom RectUtils.RectView import RectView\n\n\n\nclass OCRTextWrapper(RectView):\n def __init__(self, x=0 ,y=0 , width=0, height=0,text=None):\n super().__init__(x,y,width,height)\n self.text = \"\"\n self.words = []\n \n \n def isSameTextInfoAndSameLine(self, other):\n \n if (not(self.height == other.height and self.top == other.top or other.bottom <= self.bottom\n and other.top <= self.top or self.bottom <= other.bottom and self.top <= other.top\n or other.bottom <= self.bottom and self.top <= other.top or self.bottom <= other.bottom\n and other.top <= self.top)):\n return False\n \n spaceBetweenWord = int (Constants.SPACE_BETWEEN_WORD_RATIO * self.fontSize)\n\n #not to far from each other\n if (not(self.right + spaceBetweenWord > other.left and self.right < other.left or other.right+ spaceBetweenWord > self.left and other.right < self.left)):\n return False\n\n\n return True\n \n \n\n\n\n \n \n def getTextAttributes(self):\n properties = []\n# wrapper = self\n \n #TODO\n# properties.append((Constants.ATTRIBUTE_TEXT_SIZE, str(tesseractOCR.getPreferenceFontSize(wrapper, height))+ Constants.UNIT_DIP))\n# properties.append((Constants.ATTRIBUTE_TEXT_SIZE, str(self.fontSize)+ Constants.UNIT_DIP))\n\n buffer = \"normal\"\n# if self.bold :\n# buffer += \"|bold\"\n# \n# if (self.italic) :\n# buffer += \"|italic\"\n# \n# properties.append((Constants.ATTRIBUTE_TEXT_STYLE, buffer))\n# \n# buffer = \"\"\n# if self.serif :\n# buffer += \"serif\"\n# elif self.monospace :\n# buffer += \"monospace\"\n# else :\n# buffer += \"normal\"\n \n properties.append((Constants.ATTRIBUTE_TYPEFACE, buffer))\n return properties\n"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7258771657943726,
"avg_line_length": 49.55555725097656,
"blob_id": "44787a52c85ed59e51cf0fa255d89d423007ab69",
"content_id": "c82efec40fa0b9cd449e1d723aa7a1fd50c8df5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 311,
"num_lines": 9,
"path": "/SketchToApp/.spyproject/workspace.ini",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "[workspace]\nrestore_data_on_startup = True\nsave_data_on_exit = True\nsave_history = True\nsave_non_project_files = False\n\n[main]\nversion = 0.1.0\nrecent_files = ['C:\\\\Users\\\\vo00timo\\\\.spyder-py3\\\\temp.py', 'T:\\\\ImageProcess\\\\ImageProcess\\\\sketchProcessing.py', 'T:\\\\ImageProcess\\\\ImageProcess\\\\hough.py', 'T:\\\\ImageProcess\\\\ImageProcess\\\\hough2.py', 'T:\\\\ImageProcess\\\\ImageProcess\\\\Screen\\\\Screen.py', 'T:\\\\ImageProcess\\\\ImageProcess\\\\Screen\\\\Screen2.py']\n\n"
},
{
"alpha_fraction": 0.5926477909088135,
"alphanum_fraction": 0.6517635583877563,
"avg_line_length": 32.01639175415039,
"blob_id": "18cc4828206765f810e5de9dde616a12bfb68e6f",
"content_id": "fe00f56cf33e5178c5c23112e59d03c849a523da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2013,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 61,
"path": "/SketchToApp/hough2.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Nov 4 10:00:08 2018\n\n@author: vo00timo\n\"\"\"\n\nimport cv2\nimport numpy as np\nimport math\n#import isect_segments_bentley_ottmann.poly_point_isect as bot\n\ndef Distance(aLine):\n \n return math.sqrt(math.pow((aLine[0][2]-aLine[0][0]),2) + math.pow((aLine[0][3]-aLine[0][1]),2) )\n \n\nimg = cv2.imread('Capture7.jpg')\ngray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\n\nkernel_size = 5\nblur_gray = cv2.GaussianBlur(gray,(kernel_size, kernel_size),0)\n\nlow_threshold = 50\nhigh_threshold = 150\nedges = cv2.Canny(blur_gray, low_threshold, high_threshold)\n\nrho = 1 # distance resolution in pixels of the Hough grid\ntheta = np.pi / 180 # angular resolution in radians of the Hough grid\nthreshold = 15 # minimum number of votes (intersections in Hough grid cell)\nmin_line_length = 10 # minimum number of pixels making up a line\nmax_line_gap = 10 # maximum gap in pixels between connectable line segments\nline_image = np.copy(img) * 0 # creating a blank to draw lines on\n\n# Run Hough on edge detected image\n# Output \"lines\" is an array containing endpoints of detected line segments\nlines = cv2.HoughLinesP(edges, rho, theta, threshold, np.array([]),\n min_line_length, max_line_gap)\n#print(lines)\npoints=[]\nfor line in lines:\n #print(Distance(line))\n if (Distance(line)<25):\n for x1, y1, x2, y2 in line:\n points.append(((x1 + 0.0, y1 + 0.0), (x2 + 0.0, y2 + 0.0)))\n cv2.line(line_image, (x1, y1), (x2, y2), (255, 0, 0), 5)\n\nlines_edges = cv2.addWeighted(img, 0.8, line_image, 1, 0)\nprint(lines_edges.shape)\ncv2.imwrite('line_parking.png', lines_edges)\n #print (item.tolist())\n #break;\n#points = []\n#for line in lines:\n# for x1, y1, x2, y2 in line:\n# points.append(((x1 + 0.0, y1 + 0.0), (x2 + 0.0, y2 + 0.0)))\n# cv2.line(line_image, (x1, y1), (x2, y2), (255, 0, 0), 5)\n#\n#lines_edges = cv2.addWeighted(img, 0.8, line_image, 1, 0)\n##print(lines_edges.shape)\n#cv2.imwrite('line_parking.png', lines_edges)"
},
{
"alpha_fraction": 0.6000896692276001,
"alphanum_fraction": 0.6088321208953857,
"avg_line_length": 32.79545593261719,
"blob_id": "0c1fc982415ccdf0762fa14fe2e1c8463eaba552",
"content_id": "f0b9d4a1ed9b1b21e0ea5f3cbb28fbb129df0940",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4461,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 132,
"path": "/SketchToApp/RectUtils/RectView.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Oct 5 17:20:53 2017\n\n@author: soumi\n\"\"\"\n\nfrom RectUtils.Rect import Rect\nimport RectUtils.RectUtil as RectUtil\nfrom Utils import FileMetadata\nimport RectUtils.RectViewUtil as RectViewTypes\nfrom RectUtils.RectViewUtil import ListInfo, ListItemInfo, ListItemMetadata, ListItemType, ListMetadataRoot,TextInfo \n\n\n\nclass RectView(Rect):\n\n def __init__(self, x=0 ,y=0 , width=0, height=0,contour=None):\n super().__init__(x,y,width,height)\n self.contour = contour\n self.mChildren = []\n\t\t#mTextWithLocations = new ArrayList<OCRTextWrapper>();\n# self.mImageInfo = ImageInfo()\n self.mListInfo = ListInfo();\n self.mTextInfo = TextInfo()\n self.mType = RectViewTypes.VIEW_TYPE_DEFAULT\n self.mColor= None\n self.mAlpha=0.0\n self.mTextChildren = []\n self.mTextWithLocations = []\n self.mIconInfo = \"\"\n self.mListItemInfo = ListItemInfo()\n self.textColor = 0\n self.elementID = -1\n self.iconID = -1\n \n def __hash__(self):\n return hash((self.tl(), self.br(), self.mType))\n\n def __eq__(self, other):\n \n if other is None:\n return self.area() == 0\n elif type(other) != type(self):\n return False\n else:\n return (self.x, self.y,self.width, self.height)== (other.x, other.y,other.width, other.height) and (self.mType == other.mType)\n\n def __ne__(self, other):\n return not(self.__eq__(other))\n\n\n def includes(self,bound):\n return RectUtil.contains(self.rect, bound)\n\n def hasText(self):\n return len(self.mTextWithLocations) > 0\n\n\n def getOverlapRatio(self):\n overlapRatio = 0.0\n for rawView in self.mChildren :\n overlapRatio += rawView.area()\n \n return overlapRatio / self.rect.area()\n \n def addAllChild(self,child):\n self.mChildren.extend(child)\n \n def addChild(self,rawView):\n self.mChildren.append(rawView)\n \n# def getChildren(self):\n# return self.mChildren\n# \n#\n# def getTextChildren(self):\n# return self.mTextChildren\n\n\n def toString(self):\n textInfo = \"Info: \"\n if self.mType == self.VIEW_TYPE_TEXT:\n textInfo += \"TEXT: \" + self.mTextInfo.textWrapper.getText();\n \n elif self.mType == self.VIEW_TYPE_IMAGE:\n textInfo += \"IMAGE: \" + self.mImageInfo.drawableId + \", drawable_id: \" + self.mImageInfo.drawableId;\n\t\t\t\n else:\n textInfo += \"RECT: \" + self.mTextWithLocations;\n\t\t\t\n return \"Bound: \" + self.bound() + \", Text Children: \" + self.mTextChildren + \", \" + self.textInfo\n\n def hasTextRecusive(self):\n if self.hasText():\n return True\n \n hasText = False\n \n for rectView in self.mChildren:\n hasText = rectView.hasTextRecusive()\n if (hasText):\n return True\n return hasText\n\n def isIconButton(self):\n nonImageClass = [5, 6 ,13, 16, 14, 17, 19]\n if(self.iconID not in nonImageClass):\n return True\n else:\n return False\n \n \n def getIconName(self):\n className = ['addbutton','binbutton','camerabutton','chatbutton','checkbutton','radiobutton','chatbutton','homebutton'\n ,'userimage','locationbutton','lovebutton','musicbutton','switch','searchbutton','settingbutton','sliders','starbutton'\n ,'volumebutton','vsliders']\n return className[self.iconID-1]\n \n \n def getViewTypeForAtomicElement(self):\n \n viewTypes = [RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,\n RectViewTypes.VIEW_TYPE_CHECK_BOX,RectViewTypes.VIEW_TYPE_RADIO_BUTTON,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,\n RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_ICON,\n RectViewTypes.VIEW_TYPE_SWITCH,RectViewTypes.VIEW_TYPE_SEARCH,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_SEEK,\n RectViewTypes.VIEW_TYPE_RATING,RectViewTypes.VIEW_TYPE_ICON,RectViewTypes.VIEW_TYPE_VIR_SEEK]\n \n return viewTypes[self.iconID-1]\n \n def getElementID(self):\n return \"element\" + str(self.elementID)\n"
},
{
"alpha_fraction": 0.5639860033988953,
"alphanum_fraction": 0.618881106376648,
"avg_line_length": 33.86585235595703,
"blob_id": "728d2c701e60a92e3e5f49a6f2465f94b6815200",
"content_id": "ce5bd5b309e6b1f08bc4fb14d3a8cf0bc9e523c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2860,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 82,
"path": "/SketchToApp/viewProcessor/Transform.py",
"repo_name": "ngoctung4him/SketchToApp",
"src_encoding": "UTF-8",
"text": "\"\"\"\nCreated on Wed May 2 14:06:21 2018\n\n@author: sxm6202xx\n\"\"\"\nimport numpy as np\nimport cv2\ndef order_points(pts,maxVal):\n \n rect = np.zeros((4, 2), dtype = \"float32\")\n rect=[[0,0],[0,0],[0,0],[0,0]]\n maxSum = 0 \n maxDif1 = 0\n maxDif2 = 0\n minSum = maxVal\n for pt in pts:\n sumVal = pt[0][0] + pt[0][1]\n difVal1 = pt[0][1] - pt[0][0]\n difVal2 = pt[0][0] - pt[0][1]\n \n if(sumVal<minSum):\n minSum = sumVal\n rect[0] = [pt[0][0], pt[0][1]] \n \n if(sumVal>maxSum):\n maxSum = sumVal\n rect[1] = [pt[0][0], pt[0][1]] \n \n if(difVal1>maxDif1):\n maxDif1 = difVal1\n rect[2] = [pt[0][0], pt[0][1]] \n \n if(difVal2>maxDif2):\n maxDif2 = difVal2\n rect[3] = [pt[0][0], pt[0][1]] \n return rect\n\n\ndef transform_Single(contourInfo, orgPic, orgPic_gray):\n \n maxVal = orgPic.shape[0] + orgPic.shape[1]\n rect = order_points(contourInfo.rootViewContour,maxVal)\n maxWidth = contourInfo.rootView.width\n maxHeight = contourInfo.rootView.height\n src = np.array([rect[0],rect[3],rect[1],rect[2]], dtype = \"float32\") \n dst = np.array([[0, 0],[maxWidth - 1, 0],[maxWidth - 1, maxHeight - 1],[0, maxHeight - 1]], dtype = \"float32\")\n \n\t# compute the perspective transform matrix and then apply it\n M = cv2.getPerspectiveTransform(src, dst)\n wrapOrg = cv2.warpPerspective(orgPic, M, (maxWidth, maxHeight))\n wrapOrg_gray = cv2.warpPerspective(orgPic_gray, M, (maxWidth, maxHeight))\n# wrapthrPicd = cv2.warpPerspective(thrPic, M, (maxWidth, maxHeight))\n# wrapOrg = cv2.resize(wrapOrg,(1200,768), interpolation = cv2.INTER_CUBIC)\n# wrapthrPicd = cv2.resize(wrapthrPicd,(1200,768), interpolation = cv2.INTER_CUBIC)\n\n return wrapOrg,wrapOrg_gray\n\ndef transform(contourInfo, orgPic, thrPic):\n \n maxVal = orgPic.shape[0] + orgPic.shape[1]\n rect = order_points(contourInfo.rootViewContour,maxVal)\n maxWidth = contourInfo.rootView.width\n maxHeight = contourInfo.rootView.height\n src = np.array([rect[0],rect[3],rect[1],rect[2]], dtype = \"float32\") \n dst = np.array([[0, 0],[maxWidth - 1, 0],[maxWidth - 1, maxHeight - 1],[0, maxHeight - 1]], dtype = \"float32\")\n \n\t# compute the perspective transform matrix and then apply it\n M = cv2.getPerspectiveTransform(src, dst)\n wrapOrg = cv2.warpPerspective(orgPic, M, (maxWidth, maxHeight))\n wrapthrPicd = cv2.warpPerspective(thrPic, M, (maxWidth, maxHeight))\n# wrapOrg = cv2.resize(wrapOrg,(1200,768), interpolation = cv2.INTER_CUBIC)\n# wrapthrPicd = cv2.resize(wrapthrPicd,(1200,768), interpolation = cv2.INTER_CUBIC)\n\n return (wrapOrg,wrapthrPicd)\n \n \n\n\n#include \"opencv2/imgproc.hpp\"\n#include \"opencv2/imgcodecs.hpp\"\n#include \"opencv2/highgui.hpp\"\n#include <iostream>\n\n"
}
] | 25 |
jtfromus/DiscordBot
|
https://github.com/jtfromus/DiscordBot
|
602f45af4a306281051d79db81324e3f5d23ecf8
|
fc7567856ab1bea31b4116214fc80b186f6e6fec
|
38990f627d470971540e1e1ed1ecaaf02961184c
|
refs/heads/master
| 2023-09-01T05:05:13.293572 | 2021-10-26T23:21:12 | 2021-10-26T23:21:12 | 410,077,812 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5422338843345642,
"alphanum_fraction": 0.5529084205627441,
"avg_line_length": 32.842933654785156,
"blob_id": "03755663b2091bcb161a4c486bee62834529efb0",
"content_id": "cf087f88fe17e8d85e60cd2c950f7d139ba596c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6464,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 191,
"path": "/main.py",
"repo_name": "jtfromus/DiscordBot",
"src_encoding": "UTF-8",
"text": "import os\nimport random\n\nimport discord\nimport db\nimport re\n\nfrom discord.ext import commands\nfrom discord_slash import SlashCommand, SlashContext\nfrom discord_slash.utils.manage_commands import create_choice, create_option\nfrom dotenv import load_dotenv\nfrom model.MapList import MapList\n\n\ndef main(args=None):\n # load env infos\n load_dotenv()\n DISCORD_TOKEN = os.getenv('TOKEN')\n TEST_SERVER_ID = os.getenv('DS_TEST_SERVER_ID')\n SERVER_ID = os.getenv('SERVER_ID')\n BUNGIE_URL = os.getenv('BUNGIE_URL')\n GUILD_ID_LIST = [int(TEST_SERVER_ID), int(SERVER_ID)]\n\n hashes = {\n 'DestinyActivityDefinition': 'hash',\n 'DestinyInventoryItemDefinition': 'hash',\n 'DestinyPlugSetDefinition': 'hash'\n }\n\n # bot command settings\n bot = commands.Bot(command_prefix='~')\n slash = SlashCommand(bot, sync_commands=True)\n\n # check if db exists, if not create one.\n if not os.path.isfile(r'manifest.content'):\n db.get_manifest()\n else:\n print('DB Exists')\n\n # Put all the info into all_data\n all_data = db.built_dict(hashes)\n\n # set up the lists\n cl, gl = db.get_maps(all_data['DestinyActivityDefinition'])\n gambit_list = MapList(gl)\n crucible_list = MapList(cl)\n kinetic, energy, power = db.get_all_weapons(all_data['DestinyInventoryItemDefinition'])\n\n @bot.event\n async def on_ready() -> None:\n print(f'{bot.user.name} has joined Discord!')\n\n # Slash command\n @slash.slash(\n name='rand',\n description=\"This function will give you a randomized choice out of each option category\",\n guild_ids=GUILD_ID_LIST,\n options=[\n create_option(\n name=\"playlist\",\n description=\"chose what to be random\",\n required=True,\n option_type=3,\n choices=[\n create_choice(\n name=\"crucible\",\n value=\"c\"\n ),\n create_choice(\n name=\"gambit\",\n value=\"g\"\n )\n ]\n ),\n create_option(\n name=\"weapon\",\n description=\"generate random weapon types\",\n required=False,\n option_type=5\n )\n ]\n )\n async def _rand(ctx: SlashContext, playlist: str, weapon: bool = None) -> None:\n if playlist == 'c':\n chosen_map = crucible_list.chose_rand_map()\n thumbnail = 'https://www.bungie.net/common/destiny2_content/icons/DestinyActivityModeDefinition_5b371fef4ecafe733ad487a8fae3b9f5.png'\n elif playlist == 'g':\n chosen_map = gambit_list.chose_rand_map()\n thumbnail = 'https://www.bungie.net/common/destiny2_content/icons/DestinyActivityModeDefinition_96f7e9009d4f26e30cfd60564021925e.png'\n\n embed = discord.Embed(title=chosen_map.get_name(),\n url=BUNGIE_URL + chosen_map.get_image_url(),\n description=chosen_map.get_description(),\n color=0xFF5733)\n embed.set_thumbnail(url=thumbnail)\n embed.set_image(url=BUNGIE_URL + chosen_map.get_image_url())\n\n if weapon is not None and weapon:\n kin = random.choice(kinetic)\n embed.add_field(name='Kinetic', value=kin.get_weapon_type(), inline=True)\n ene = random.choice(energy)\n embed.add_field(name='Energy', value=ene.get_weapon_type(), inline=True)\n heavy = random.choice(power)\n embed.add_field(name='Power', value=heavy.get_weapon_type(), inline=True)\n\n await ctx.send(embed=embed)\n\n @slash.slash(\n name='dice_rolls',\n description=\"This function return a random dice roll for you ;)\",\n guild_ids=GUILD_ID_LIST,\n options=[\n create_option(\n name=\"value\",\n description=\"<int>d<int> ex: 2d4\",\n required=True,\n option_type=3\n )\n ]\n )\n async def _dice_roll(ctx: SlashContext, value: str) -> None:\n # pattern for input validation\n pattern = '^[1-9]\\d*d[1-9]\\d*$'\n result = []\n total = 0\n\n if re.match(pattern, value):\n # split the two numbers\n dice = value.split('d')\n\n # roll the dice\n for x in range(int(dice[0])):\n v = random.randint(1, int(dice[1]))\n total += v\n result.append(str(v))\n\n result_str = f\"Total: {str(total)}\\nRoll result: \\n{' | '.join(result)}\"\n embed = discord.Embed(title=value,\n description=result_str,\n color=0xFF5733)\n await ctx.send(embed=embed)\n else:\n embed = discord.Embed(title='ERROR',\n description=f'You entered an invalid value: {value}\\n'\n f'it should\\'ve been <int>d<int> and int > 0',\n color=0xFF5733)\n await ctx.send(embed=embed)\n\n @slash.slash(\n name='updateDB',\n description=\"This function will update the database from bungie, and refresh the lists for the bot\",\n guild_ids=GUILD_ID_LIST,\n )\n async def _update_db(ctx: SlashContext) -> None:\n await ctx.defer()\n db.get_manifest()\n\n # Put all the info into all_data\n global all_data\n all_data = db.built_dict(hashes)\n\n c, g = db.get_maps(all_data['DestinyActivityDefinition'])\n gambit_list.reset_maps(g)\n crucible_list.reset_maps(c)\n global kinetic, energy, power\n kinetic, energy, power = db.get_all_weapons(all_data['DestinyInventoryItemDefinition'])\n\n await ctx.send('Database is updated')\n\n # Bot chat\n @bot.event\n async def on_message(message) -> None:\n if message.author == bot.user:\n return\n\n if message.content.startswith('SSlave'):\n await message.channel.send('SSlave sees you...')\n await bot.process_commands(message)\n\n # Text channel commands\n @bot.command()\n async def rand(ctx, *args) -> None:\n for arg in args:\n if arg == '-m':\n await ctx.send(rand.chose_rand_map())\n\n bot.run(DISCORD_TOKEN)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5965189933776855,
"alphanum_fraction": 0.5965189933776855,
"avg_line_length": 25.33333396911621,
"blob_id": "9e76e543c29c4f2fa712359e839c9faf9024e9f0",
"content_id": "37568db967cf5f53183b08df5b398604230a1a44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 632,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 24,
"path": "/model/Map.py",
"repo_name": "jtfromus/DiscordBot",
"src_encoding": "UTF-8",
"text": "# define map class\nclass Map:\n def __init__(self, name: str, url: str, description: str) -> None:\n self.name = name\n self.image_url = url\n self.description = description\n\n def get_name(self) -> str:\n return self.name\n\n def get_image_url(self) -> str:\n return self.image_url\n\n def get_description(self) -> str:\n return self.description\n\n def set_name(self, name: str) -> None:\n self.name = name\n\n def set_image_url(self, url: str) -> None:\n self.image_url = url\n\n def set_description(self, description: str) -> None:\n self.description = description\n"
},
{
"alpha_fraction": 0.5751173496246338,
"alphanum_fraction": 0.5751173496246338,
"avg_line_length": 25.625,
"blob_id": "73e338276e376bff8f44f803296272d7c6af2eff",
"content_id": "1ac983d4d9e73630a720dc5f09590a821a1f0a00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 852,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 32,
"path": "/model/MapList.py",
"repo_name": "jtfromus/DiscordBot",
"src_encoding": "UTF-8",
"text": "import random\nfrom model.Map import Map\n\n\nclass MapList:\n def __init__(self, maps: [Map]) -> None:\n self.used_maps = []\n self.maps = maps\n print(str(len(self.maps)) + \" maps loaded\")\n\n # This function returns a random map object\n def chose_rand_map(self) -> Map:\n # If the maps list is exhausted reset it\n if not self.maps:\n print('list exhausted')\n self.maps = self.used_maps\n self.used_maps = []\n\n # Chose a random map\n currentMap = random.choice(self.maps)\n self.maps.remove(currentMap)\n self.used_maps.append(currentMap)\n\n return currentMap\n\n # reset the list from database\n def reset_maps(self, maps: [Map]) -> None:\n self.used_maps = []\n self.maps = maps\n\n def get_maps(self) -> [Map]:\n return self.maps\n"
},
{
"alpha_fraction": 0.5652642846107483,
"alphanum_fraction": 0.5652642846107483,
"avg_line_length": 24.054054260253906,
"blob_id": "908251fa06d2d64b3f3ef4f7883b9fd17875cd2c",
"content_id": "8d76d5fa90136a1c13e2a452f8403e8128d9a8ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 927,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 37,
"path": "/model/Weapon.py",
"repo_name": "jtfromus/DiscordBot",
"src_encoding": "UTF-8",
"text": "class Weapon:\n def __init__(self,hash: int, name: str, url: str, weapon_type: str, rarity: str) -> None:\n self.hash = hash\n self.name = name\n self.url = url\n self.weapon_type = weapon_type\n self.rarity = rarity\n\n def get_hash(self) -> int:\n return self.hash\n\n def get_name(self) -> str:\n return self.name\n\n def get_url(self) -> str:\n return self.url\n\n def get_weapon_type(self) -> str:\n return self.weapon_type\n\n def get_rarity(self) -> str:\n return self.rarity\n\n def set_hash(self, hash: int) -> None:\n self.hash = hash\n\n def set_name(self, name: str) -> None:\n self.name = name\n\n def set_url(self, url: str) -> None:\n self.url = url\n\n def set_weapon_type(self, weapon_type: str) -> None:\n self.weapon_type = weapon_type\n\n def set_rarity(self, rarity: str) -> None:\n self.rarity = rarity\n"
},
{
"alpha_fraction": 0.7924528121948242,
"alphanum_fraction": 0.7924528121948242,
"avg_line_length": 104,
"blob_id": "17c4dfc638dad933dece82ad6a74703061b32522",
"content_id": "dc9799c85b7265e2c1b53123e400a05b6d799630",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 1,
"path": "/README.md",
"repo_name": "jtfromus/DiscordBot",
"src_encoding": "UTF-8",
"text": "This is Silent's Discord bot, adding more functions to the bot on top of the random crucible map chooser\n\n"
},
{
"alpha_fraction": 0.597601056098938,
"alphanum_fraction": 0.612884521484375,
"avg_line_length": 35.408451080322266,
"blob_id": "9515fadb784de20c8e81903364d92dd44268032a",
"content_id": "d6c1fbfd61873a89304c4d94a8fb59f21be5a780",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5169,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 142,
"path": "/db.py",
"repo_name": "jtfromus/DiscordBot",
"src_encoding": "UTF-8",
"text": "import requests, zipfile, os, json, sqlite3\nfrom dotenv import load_dotenv\n\nfrom model.Map import Map\nfrom model.Weapon import Weapon\n\nload_dotenv()\nBUNGIE_API_KEY = os.getenv('BUNGIE_API_KEY')\nBASE_URL = 'https://bungie.net/Platform/Destiny2'\nBASE_URL_GROUP_V2 = 'https://bungie.net/Platform/GroupV2'\n\n\n# This code was altered from JAMeador13's code from http://destinydevs.github.io/BungieNetPlatform/docs/Manifest.\n# This function downloads Destiny2's database (manifest)\ndef get_manifest() -> None:\n my_headers = {\"X-API-Key\": BUNGIE_API_KEY}\n manifest_url = BASE_URL + '/Manifest/'\n\n # get the manifest location from the json\n r = requests.get(manifest_url, headers=my_headers)\n manifest = r.json()\n mani_url = 'http://www.bungie.net' + manifest['Response']['mobileWorldContentPaths']['en']\n\n # Download the file, write it to 'MANZIP'\n r = requests.get(mani_url)\n with open(\"MANZIP\", \"wb\") as zip:\n zip.write(r.content)\n print(\"Download Complete!\")\n\n # Extract the file contents, and rename the extracted file\n # to 'Manifest.content'\n with zipfile.ZipFile('MANZIP') as zip:\n name = zip.namelist()\n zip.extractall()\n os.rename(name[0], 'Manifest.content')\n print('Unzipped!')\n\n\n# return a list crucible Map objects\ndef get_maps(activity_dict: {}) -> tuple[[Map], [Map]]:\n crucible_maps = []\n gambit_maps = []\n\n place_holder_image = '/img/theme/destiny/bgs/pgcrs/placeholder.jpg'\n\n for key in activity_dict:\n # Check if the item is a crucible map. 4088006058 is the crucible\n if activity_dict[key]['activityTypeHash'] == 4088006058 and \\\n activity_dict[key]['placeHash'] == 4088006058 and not \\\n activity_dict[key]['isPvP'] and \\\n activity_dict[key]['pgcrImage'] != place_holder_image:\n\n newMap = Map(activity_dict[key]['originalDisplayProperties']['name'],\n activity_dict[key]['pgcrImage'],\n activity_dict[key]['originalDisplayProperties']['description'])\n\n if not check_for_dupe(newMap, crucible_maps):\n crucible_maps.append(newMap)\n\n # Check if the item is a gambit map. 248695599 is gambit\n if activity_dict[key]['activityTypeHash'] == 248695599 and \\\n activity_dict[key]['placeHash'] == 248695599 and \\\n activity_dict[key]['pgcrImage'] != place_holder_image:\n\n newMap = Map(activity_dict[key]['originalDisplayProperties']['name'],\n activity_dict[key]['pgcrImage'],\n activity_dict[key]['originalDisplayProperties']['description'])\n\n if not check_for_dupe(newMap, gambit_maps):\n gambit_maps.append(newMap)\n\n return crucible_maps, gambit_maps\n\n\n# This function checks weather a map list contains a map\ndef check_for_dupe(new_map: Map, map_list: [Map]) -> bool:\n for m in map_list:\n if m.get_name().__contains__(new_map.get_name()):\n return True\n return False\n\n\n# This function will return 3 list of weapons\ndef get_all_weapons(item_def_dict: {}) -> tuple[[Weapon], [Weapon], [Weapon]]:\n kinetic = []\n energy = []\n power = []\n\n for key in item_def_dict:\n # itemType 3 is weapon\n if item_def_dict[key]['itemType'] == 3:\n current_weapon = Weapon(\n key,\n item_def_dict[key]['displayProperties']['name'],\n item_def_dict[key]['screenshot'],\n item_def_dict[key]['itemTypeDisplayName'],\n item_def_dict[key]['inventory']['tierTypeName']\n )\n\n # itemCategoryHashes 3 = energy, 2 = kinetic, 4 = power\n if item_def_dict[key]['itemCategoryHashes'][0] == 3:\n energy.append(current_weapon)\n elif item_def_dict[key]['itemCategoryHashes'][0] == 2:\n kinetic.append(current_weapon)\n elif item_def_dict[key]['itemCategoryHashes'][0] == 4:\n power.append(current_weapon)\n\n return kinetic, energy, power\n\n\n# This function will return the hash table of the manifest\ndef built_dict(hash_dict: {}) -> {}:\n # connect to the manifest\n con = sqlite3.connect('manifest.content')\n print('Connected')\n # create a cursor object\n cur = con.cursor()\n\n all_data = {}\n\n for table_name in hash_dict:\n # get a list of all jsons from the DestinyActivityDefinition\n cur.execute('SELECT json from ' + table_name)\n print('Generating ' + table_name + ' dictionary....')\n\n # this returns a list of tuples: the first item in each tuple is our json\n items = cur.fetchall()\n\n # create a lists of jsons\n item_jsons = [json.loads(item[0]) for item in items]\n\n # Create a dictionary with the hashes as keys and the jsons as values\n item_dict = {}\n hash = hash_dict[table_name]\n for item in item_jsons:\n item_dict[item[hash]] = item\n\n # Add that dictionary to our all_data using the name of the table as a key.\n all_data[table_name] = item_dict\n\n print('Dictionary Generated!')\n return all_data"
}
] | 6 |
limsehyuk/RealTime3DPoseTracker-OpenPose
|
https://github.com/limsehyuk/RealTime3DPoseTracker-OpenPose
|
8c70e65560dd1c2cf81e8f82d02fee9f51f3f10c
|
41f413f73fc8659d427a4c99c71fb7c1c68a7a0d
|
e55af45cf3c374b5a1c2595348815b63b835992e
|
refs/heads/master
| 2022-01-06T23:53:48.577623 | 2018-06-01T15:38:40 | 2018-06-01T15:38:40 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7569563984870911,
"alphanum_fraction": 0.7804877758026123,
"avg_line_length": 54.39047622680664,
"blob_id": "dc52fbd657e720c3ad716205411a3f1ecc9a78f9",
"content_id": "65a671d7d09f10cd56bd2fd6f30bb09f551ce69b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5852,
"license_type": "permissive",
"max_line_length": 268,
"num_lines": 105,
"path": "/README.md",
"repo_name": "limsehyuk/RealTime3DPoseTracker-OpenPose",
"src_encoding": "UTF-8",
"text": "# RealTime3DPoseTracker-OpenPose\nReal time 3D pose tracking and Hand Gesture Recognition using OpenPose, Python Machine Learning Toolkits, Realsense and Kinect libraries. \n\nINSTALLATION STEPS: \nOpenPose and PyOpenPose\nMachine: 4 GPU, GeForce GTX 1080\nOS: Ubuntu 16.04\n\n1) Clone the OpenPose repository: \n\t\"git clone https://github.com/CMU-Perceptual-Computing-Lab/openpose\"\n2) Check the currently integrated OpenPose version from PyOpenPose from the link: https://\tgithub.com/FORTH-ModelBasedTracker/PyOpenPose\n\n3) Reset the OpenPose version to this commit by: \n git reset --hard #version\n4) Download and install CMake GUI: sudo apt-get install cmake-qt-gui\n\n5) INSTALL CUDA 8: \nsudo apt-get update && sudo apt-get install wget -y --no-install-recommends\nwget -c \"https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb\"\nsudo dpkg --install cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb\nsudo apt-get update\nsudo apt-get install cuda\n\n6) INSTALL CUDNN5.1: Run from the openpose root directory: \n\tsudo ubuntu/install_cudnn.sh . \n\n7) Run from the OpenPose root directory: \n\tsudo ubuntu/install_caffe_and_openpose_if_cuda8.sh\n8) OpenPose need to be built with OpenCV3, In order to correctly install it follow the instructions here: https://github.com/BVLC/caffe/wiki/OpenCV-3.2-Installation-Guide-on-Ubuntu-16.04\n\n9) Caffe prerequisites: By default, OpenPose uses Caffe under the hood. If you have not used Caffe previously, install its dependencies by running:\n sudo bash ./ubuntu/install_cmake.sh\n10) - Open CMake GUI and select the OpenPose directory as project source directory, and a non-existing or empty sub-directory (e.g., build) where the Makefile files will be generated. If build does not exist, it will ask you whether to create it. Press Yes.\n -Press the Configure button, keep the generator in Unix Makefile, and press Finish.\n -Change the OpenCV directory to OpenCV/build folder that you previously generated while installing OpenCV3. \n -Press the Generate button and proceed to building the project. You can now close CMake.\n10) Create an “install” folder under the OpenPose root directory. \n11) Open a terminal in the root directory and type: \ncd build/\nmake -j`nproc` (i.e. I use -j8)\n\n12) Change the installation folder under build/cmake_install.cmake using gedit to the install folder that you previously created such as: \nset(CMAKE_INSTALL_PREFIX \"/home/burcak/Desktop/openpose/install\")\n13) If you get access errors, just change the permissions to the file as: chmod 777 “fileName”\n14) Back to the terminal and : \n\t- cd build/ \nand then: \n\t- sudo make install\n15) Copy the MODELS folder in OpenPose root directory to this INSTALL folder. If you get access errors, just change the permissions to the file as: chmod 777 “folderName”\n16) Set an environment variable named OPENPOSE_ROOT pointing to the openpose INSTALL folder.\n17) Install python3.5 and pip3. \n18) Change current python version to 3.5: \n\tgedit ~/.bashrc\n\talias python=’/usr/bin/python3.5’\n\tsource ~/.bashrc\n\n19) Clone the PyOpenPose repository using : \n git clone https://github.com/FORTH-ModelBasedTracker/PyOpenPose.git\n20) Open a terminal at the root directory of PyOpenPose and type: \n\tmkdir build \n\tcd build \n\tcmake .. -DWITH_PYTHON3=True\n\tmake \n\n21) Add the folder containing PyOpenPose.so to your PYTHONPATH such as adding a line to your bash profile: \n export PYTHONPATH=/home/burcak/Desktop/PyOpenPose/build/PyOpenPose.lib\n22) In order to check if its working properly, run the scripts folder for python examples using PyOpenPose.\n\n\n\n\nRealSense and Kinect libraries integration: \n\ni) Realsense: \n1) Remove any connected RealSense cameras first. \n2) Follow the Realsense Ubuntu installation steps at: \n\thttps://github.com/IntelRealSense/librealsense/blob/master/doc/installation.md\n3) CAREFUL! Instead of \"sudo apt-get install cmake3 libglfw3-dev\" for installing glfw libraries, use the following commands, otherwise you’ll get version mismatch error(see issue https://github.com/IntelRealSense/librealsense/issues/1525 for details) :\n\tsudo apt-get update\n\tsudo apt-get install build-essential cmake git xorg-dev libglu1-mesa-dev\n\tgit clone https://github.com/glfw/glfw.git /tmp/glfw\n\tcd /tmp/glfw\n\tgit checkout latest\n\tcmake . -DBUILD_SHARED_LIBS=ON\n\tmake\n\tsudo make install\n\tsudo ldconfig\n\trm -rf /tmp/glfw\n\n4) Install the Python Wrapper PyRealSense by following the instructions here and update your Python PATH variable accordingly: \n\thttps://github.com/IntelRealSense/librealsense/tree/master/wrappers/python\n\texport PYTHONPATH=$PYTHONPATH:/home/burcak/Desktop/librealsense/wrappers/python\n\n5) Install PyCharm and start a project by running ./pycharm.sh in the PyCharm bin folder. OR create an application shortcut on the desktop or wherever you want to. \n\n6) For the codes using the visualization of the skeleton only, install pygame for python3: sudo pip3 install pygame, OpenGL: \"sudo apt-get install python3-opengl\" and don’t forget to upgrade it otherwise some functions might not work: \"pip3 install --upgrade PyOpenGL\"\n\n7) Create a Project in PyCharm and click and expand Project INterpreter tab, select Python3 and inherit all the packages that are installed. Install the other required packages such as python numpy, sklearn, matplotlib, pandas, etc. \n\n\nii) Kinect: \n1) Follow the installation steps: https://github.com/r9y9/pylibfreenect2 and http://r9y9.github.io/pylibfreenect2/latest/installation.html\n2) Don’t forget to add the pylibfreenect2 library to your PYTHONPATH and the other related installation paths, as an example, on my computer they are set as: \n export LD_LIBRARY_PATH=”/home/burcak/Desktop/libfreenect2/build/lib”\n export LIBFREENECT2_INSTALL_PREFIX=”/home/burcak/freenect2” \n\n\n"
},
{
"alpha_fraction": 0.7201449275016785,
"alphanum_fraction": 0.7326634526252747,
"avg_line_length": 42.9782600402832,
"blob_id": "9e7de6abb588f8e87e95b89d691b28333770bf25",
"content_id": "77a6b341be82117e0d8d9f1a149629b154779497",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6071,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 138,
"path": "/pandasAnalysis.py",
"repo_name": "limsehyuk/RealTime3DPoseTracker-OpenPose",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\nimport os\nimport numpy as np\n\ncwd = os.getcwd()\n\npathProcessed = cwd + \"/newTrain/\"\n\npathNew = cwd + \"/trainData/\"\n\ndef processData():\n\n trialTime = input(\"Enter the trial time for cleaning:\")\n fileNamePunch = \"keyPointsPersonRightHandPunch{0}.csv\".format(trialTime)\n fileNameWave = \"keyPointsPersonRightHandWave{0}.csv\".format(trialTime)\n fileNameShoot = \"keyPointsPersonRightHandShoot{0}.csv\".format(trialTime)\n fileNameStill = \"keyPointsPersonRightHandStill{0}.csv\".format(trialTime)\n fileNamePunchLabels = \"labelsPersonRightHandPunch{0}.csv\".format(trialTime)\n fileNameWaveLabels = \"labelsPersonRightHandWave{0}.csv\".format(trialTime)\n fileNameShootLabels = \"labelsPersonRightHandShoot{0}.csv\".format(trialTime)\n fileNameStillLabels = \"labelsPersonRightHandStill{0}.csv\".format(trialTime)\n\n # READ THE LEFT HAND TRAINING DATA\n\n fileNamePunchL = \"keyPointsPersonLeftHandPunch{0}.csv\".format(trialTime)\n fileNameWaveL = \"keyPointsPersonLeftHandWave{0}.csv\".format(trialTime)\n fileNameShootL = \"keyPointsPersonLeftHandShoot{0}.csv\".format(trialTime)\n fileNameStillL = \"keyPointsPersonLeftHandStill{0}.csv\".format(trialTime)\n fileNamePunchLabelsL = \"labelsPersonLeftHandPunch{0}.csv\".format(trialTime)\n fileNameWaveLabelsL = \"labelsPersonLeftHandWave{0}.csv\".format(trialTime)\n fileNameShootLabelsL = \"labelsPersonLeftHandShoot{0}.csv\".format(trialTime)\n fileNameStillLabelsL = \"labelsPersonLeftHandStill{0}.csv\".format(trialTime)\n\n\n dataPunch = pd.read_csv(pathNew + fileNamePunch, header=None)\n colLength= dataPunch.shape[1]\n dataPunch= dataPunch.replace(0,np.nan)\n dataPunch = dataPunch.dropna(thresh=52, axis=0) #drop the row if more than 7 joint info is missing\n dataPunch= dataPunch.fillna(0)\n\n\n dataPunch.to_csv(pathProcessed + fileNamePunch, sep= ',', index= False, header = None)\n\n dataWave = pd.read_csv(pathNew + fileNameWave, header=None)\n dataWave= dataWave.replace(0,np.nan)\n dataWave = dataWave.dropna(thresh= 52, axis=0)\n dataWave= dataWave.fillna(0)\n\n\n dataWave.to_csv(pathProcessed + fileNameWave, sep= ',', index= False, header=None)\n\n dataShoot = pd.read_csv(pathNew + fileNameShoot, header= None)\n dataShoot= dataShoot.replace(0,np.nan)\n dataShoot = dataShoot.dropna(thresh = 52, axis=0)\n dataShoot= dataShoot.fillna(0)\n dataShoot.to_csv(pathProcessed + fileNameShoot, sep= ',', index= False, header=None)\n\n dataStill = pd.read_csv(pathNew + fileNameStill, header= None)\n #dataStill= dataStill.replace(0,np.nan)\n #dataStill = dataStill.dropna(thresh = 52, axis=0)\n #dataStill= dataStill.fillna(0)\n dataStill.to_csv(pathProcessed + fileNameStill, sep= ',', index= False, header=None)\n\n nRowsPunch = dataPunch.shape[0]\n nRowsWave = dataWave.shape[0]\n nRowsShoot = dataShoot.shape[0]\n nRowsStill = dataStill.shape[0]\n\n labelsPunch = pd.read_csv(pathNew + fileNamePunchLabels, header=None)\n labelsPunch = labelsPunch[0:nRowsPunch]\n labelsPunch.to_csv(pathProcessed + fileNamePunchLabels, sep= ',', index= False, header=None)\n\n labelsWave = pd.read_csv(pathNew + fileNameWaveLabels, header=None)\n labelsWave = labelsWave[0:nRowsWave]\n labelsWave.to_csv(pathProcessed + fileNameWaveLabels, sep= ',', index= False, header=None)\n\n\n labelsShoot = pd.read_csv(pathNew + fileNameShootLabels, header=None)\n labelsShoot = labelsShoot[0:nRowsShoot]\n labelsShoot.to_csv(pathProcessed + fileNameShootLabels, sep= ',', index= False, header=None)\n\n labelsStill = pd.read_csv(pathNew + fileNameStillLabels, header=None)\n labelsStill = labelsStill[0:nRowsStill]\n labelsStill.to_csv(pathProcessed + fileNameStillLabels, sep= ',', index= False, header=None)\n\n\n\n ###LEFT HAND\n\n dataPunchL = pd.read_csv(pathNew + fileNamePunchL, header=None)\n colLengthL= dataPunchL.shape[1]\n dataPunchL= dataPunchL.replace(0,np.nan)\n dataPunchL = dataPunchL.dropna(thresh=52, axis=0) #drop the row if more than 7 joint info is missing\n dataPunchL= dataPunchL.fillna(0)\n dataPunchL.to_csv(pathProcessed + fileNamePunchL, sep= ',', index= False, header = None)\n\n\n\n dataWaveL = pd.read_csv(pathNew + fileNameWaveL, header=None)\n dataWaveL= dataWaveL.replace(0,np.nan)\n dataWaveL = dataWaveL.dropna(thresh= 52, axis=0)\n dataWaveL= dataWaveL.fillna(0)\n dataWaveL.to_csv(pathProcessed + fileNameWaveL, sep= ',', index= False, header=None)\n\n dataShootL = pd.read_csv(pathNew + fileNameShootL, header= None)\n dataShootL= dataShootL.replace(0,np.nan)\n dataShootL = dataShootL.dropna(thresh = 52, axis=0)\n dataShootL= dataShootL.fillna(0)\n dataShootL.to_csv(pathProcessed + fileNameShootL, sep= ',', index= False, header=None)\n\n dataStillL = pd.read_csv(pathNew + fileNameStillL, header= None)\n #dataStill= dataStill.replace(0,np.nan)\n #dataStill = dataStill.dropna(thresh = 52, axis=0)\n #dataStill= dataStill.fillna(0)\n dataStillL.to_csv(pathProcessed + fileNameStillL, sep= ',', index= False, header=None)\n\n nRowsPunchL = dataPunchL.shape[0]\n nRowsWaveL = dataWaveL.shape[0]\n nRowsShootL = dataShootL.shape[0]\n nRowsStillL = dataStillL.shape[0]\n\n labelsPunchL = pd.read_csv(pathNew + fileNamePunchLabelsL, header=None)\n labelsPunchL = labelsPunchL[0:nRowsPunchL]\n labelsPunchL.to_csv(pathProcessed + fileNamePunchLabelsL, sep= ',', index= False, header=None)\n\n labelsWaveL = pd.read_csv(pathNew + fileNameWaveLabelsL, header=None)\n labelsWaveL = labelsWaveL[0:nRowsWaveL]\n labelsWaveL.to_csv(pathProcessed + fileNameWaveLabelsL, sep= ',', index= False, header=None)\n\n\n labelsShootL = pd.read_csv(pathNew + fileNameShootLabelsL, header=None)\n labelsShootL = labelsShootL[0:nRowsShootL]\n labelsShootL.to_csv(pathProcessed + fileNameShootLabelsL, sep= ',', index= False, header=None)\n\n labelsStillL = pd.read_csv(pathNew + fileNameStillLabelsL, header=None)\n labelsStillL = labelsStillL[0:nRowsStillL]\n labelsStillL.to_csv(pathProcessed + fileNameStillLabelsL, sep= ',', index= False, header=None)\n\n\n"
},
{
"alpha_fraction": 0.2939389646053314,
"alphanum_fraction": 0.5829076170921326,
"avg_line_length": 22.4433650970459,
"blob_id": "785c1bf928cb77d5385556688f284c4527f2deb5",
"content_id": "bc5b6e516beb4239bd66526dddf408df0f998ba5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7243,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 309,
"path": "/glVisualizeSampleOutput.py",
"repo_name": "limsehyuk/RealTime3DPoseTracker-OpenPose",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom OpenGL.GLUT import *\nfrom OpenGL.GLU import *\nfrom OpenGL.GL import *\n\nname = \"3d vis\"\nheight = 400\nwidth = 400\nrotate = 0\nbeginx = 0.0\nbeginy = 0.0\nrotx = 0.0\nroty = 0.0\nzoom = 0.0\naction = \"\"\n\n\nedgesPose = (\n (0,1),\n (1,2),\n (1,5),\n (2,3),\n (3,4),\n (5,6),\n (6,7),\n (1,8),\n (1,11),\n (8,9),\n (11,12),\n (9,10),\n (12,13),\n (0,15),\n (0,14),\n (14,16),\n (15,17)\n )\n\nverticesPose= (\n (-0.176, 0.474, 1.677),\n (-0.190, 0.273, 1.678),\n (-0.343, 0.274, 1.678),\n (-0.438, 0.144, 1.483),\n (-0.382, 0.196, 1.318),\n (-0.0469, 0.2851, 1.751),\n (0.121, 0.170, 1.575),\n (0.117, 0.204, 1.428),\n (-0.244, -0.1498, 1.528),\n (-0.237, -0.544, 1.536),\n (-0.238, -0.721, 1.462),\n (-0.046, -0.1506, 1.565),\n (-0.0596, -0.5285, 1.574),\n (0.0, 0.0, 0.0),\n (-0.216, 0.5025, 1.698),\n (-0.156, 0.505, 1.706),\n (-0.278, 0.485, 1.768),\n (-0.125, 0.490, 1.786)\n )\n\nverticesPoseStraightH= (\n (0.09290609, 0.3911047, 1.6204202),\n (0.07812399, 0.16361818, 1.593983),\n (-0.07601932, 0.17788392, 1.6440828),\n (-0.15906775, -0.04952209, 1.6227571),\n (-0.22482367, 0.08362344, 1.482427),\n (0.23522063, 0.1660381, 1.6624902),\n (0.3060596, -0.04951069, 1.6223674),\n (0.37223142, 0.05219481, 1.485316),\n (-0.02705169, -0.25156453, 1.4625621),\n (-0.02648423, -0.6091409, 1.4319735),\n (0., 0., 0.),\n (0.17252973, -0.26898307, 1.4690416),\n (0.14653692, -0.6096989, 1.4148316),\n (0., 0., 0.),\n (0.05975833, 0.41830748, 1.6569456),\n (0.1275641, 0.41957837, 1.6619792),\n (0. , 0.38584808, 1.6892524),\n (0.16757679, 0.39048553, 1.7095553)\n )\n\nedgesHand = (\n (0,1),\n (0,5),\n (0,9),\n (0,13),\n (0,17),\n (1,2),\n (2,3),\n (3,4),\n (5,6),\n (6,7),\n (7,8),\n (9,10),\n (10,11),\n (11,12),\n (13,14),\n (14,15),\n (15,16),\n (17,18),\n (18,19),\n (19,20)\n )\n\nverticesLeftHand= (\n (-0.36178762, 0.20952047, 1.3172593),\n (-0.35002673, 0.20904374, 1.3142678),\n (-0.32848334, 0.21326905, 1.3254206),\n (-0.3237308, 0.22673282, 1.3111365),\n (-0.32959238, 0.23405835, 1.2913479),\n (-0.33671224, 0.25253403, 1.3003991),\n (-0.3254543, 0.25339818, 1.2986575),\n (-0.32195157, 0.25107393, 1.2990696),\n (-0.32378894, 0.24617663, 1.311372),\n (-0.35234106, 0.26243335, 1.3138337),\n (-0.33990347, 0.2465497, 1.2942328),\n (-0.3489648, 0.23304531, 1.3057513),\n (-0.35420978, 0.23090127, 1.3072784),\n (-0.36924505, 0.2639194, 1.3091518),\n (-0.35866064, 0.24508427, 1.2928241),\n (-0.36638403, 0.23216414, 1.3075824),\n (-0.37396476, 0.23115546, 1.3087289),\n (-0.3868784, 0.26032937, 1.3033006),\n (-0.37806267, 0.24406578, 1.2937545),\n (-0.3792922, 0.23045602, 1.297962),\n (-0.38277858, 0.2287042, 1.3016543)\n )\n\n\n\nverticesLeftHandStraight= (\n (-0.2278364, 0.09140742, 1.4753048),\n (-0.21035226, 0.13028269, 1.4675423),\n (-0.18762484, 0.14927751, 1.4809908),\n (-0.17461264, 0.1718843, 1.4751743),\n (-0.15842775, 0.19227982, 1.4642677),\n (-0.22614539, 0.1792616, 1.491142),\n (-0.22949776, 0.2141979, 1.5040755),\n (-0.23165897, 0.23584558, 1.509098),\n (-0.23526779, 0.2576741, 1.5143485),\n (-0.24715796, 0.17397717, 1.4931258),\n (-0.25644553, 0.2146337, 1.507138),\n (-0.2614681, 0.23365235, 1.5039591),\n (-0.26522183, 0.25545043, 1.5094995),\n (-0.26100892, 0.16433895, 1.4933743),\n (-0.27114886, 0.20023298, 1.5036561),\n (-0.27763754, 0.2204361, 1.5086834),\n (-0.2808583, 0.24313104, 1.5110077),\n (-0.27648628, 0.15268645, 1.4874852),\n (-0.2911439, 0.17468607, 1.4992174),\n (-0.30196822, 0.18786082, 1.5047873),\n (-0.31172568, 0.20178664, 1.5048738)\n )\n\n\n\n\ndef display():\n glClear(GL_COLOR_BUFFER_BIT|GL_DEPTH_BUFFER_BIT)\n glLoadIdentity()\n gluLookAt(0,0,10,0,0,0,0,1,0)\n glRotatef(roty,0,1,0)\n glRotatef(rotx,1,0,0)\n glCallList(1)\n glutSwapBuffers()\n return\n\ndef mouse(button,state,x,y):\n global beginx,beginy,rotate\n if button == GLUT_LEFT_BUTTON and state == GLUT_DOWN:\n rotate = 1\n beginx = x\n beginy = y\n if button == GLUT_LEFT_BUTTON and state == GLUT_UP:\n rotate = 0\n return\n\ndef motion(x,y):\n global rotx,roty,beginx,beginy,rotate\n if rotate:\n rotx = rotx + (y - beginy)\n roty = roty + (x - beginx)\n beginx = x\n beginy = y\n glutPostRedisplay()\n\n return\n\ndef keyboard():\n return\n\n\ndef drawAxis():\n glColor3f(1.0, 0.0, 0.0)\n glBegin(GL_LINES)\n#x-coordinate-red\n glVertex3f(-4.0, 0.0, 0.0)\n glVertex3f(4.0, 0.0, 0.0)\n\n glVertex3f(4.0, 0.0, 0.0)\n glVertex3f(3.0, 1.0, 0.0)\n\n glVertex3f(4.0, 0.0, 0.0)\n glVertex3f(3.0, -1.0, 0.0)\n glEnd()\n glFlush()\n\n\n# y- coordinate-green\n glColor3f(0.0, 1.0, 0.0)\n\n glBegin(GL_LINES)\n glVertex3f(0.0, -4.0, 0.0)\n glVertex3f(0.0, 4.0, 0.0)\n\n glVertex3f(0.0, 4.0, 0.0)\n glVertex3f(1.0, 3.0, 0.0)\n\n glVertex3f(0.0, 4.0, 0.0)\n glVertex3f(-1.0, 3.0, 0.0)\n glEnd()\n glFlush()\n\n\n#z-coordinate-blue\n glColor3f(0.0, 0.0, 1.0)\n glBegin(GL_LINES)\n glVertex3f(0.0, 0.0, -4.0)\n glVertex3f(0.0, 0.0, 4.0)\n\n glVertex3f(0.0, 0.0, 4.0)\n glVertex3f(0.0, 1.0, 3.0)\n\n glVertex3f(0.0, 0.0, 4.0)\n glVertex3f(0.0, -1.0, 3.0)\n glEnd()\n glFlush()\n\nglutInit(name)\nglutInitDisplayMode(GLUT_DOUBLE | GLUT_RGB | GLUT_DEPTH)\nglutInitWindowSize(height,width)\nglutCreateWindow(name)\nglClearColor(0.0,0.0,0.0,1.0)\n\n\n\n# setup display list\nglNewList(1,GL_COMPILE)\nglPushMatrix()\n#glTranslatef(0.0,1.0,0.0) #move to where we want to put object\n\n#glScalef(2.0,2.0,2.0)\ndrawAxis()\n\n\nglLineWidth(2.0)\nglColor3f(1.0, 0.9, 0.4)\nglBegin(GL_LINES)\nfor edge in edgesPose:\n for vertex in edge:\n if (verticesPoseStraightH[vertex][0] == 0 and verticesPoseStraightH[vertex][1] == 0):\n continue\n glVertex3fv(verticesPoseStraightH[vertex])\nglEnd()\n\n\nglColor3f(0.6, 0.3, 0.5)\nglBegin(GL_LINES)\nfor edge in edgesHand:\n for vertex in edge:\n # if (verticesPose[vertex][0] == 0 and verticesPose[vertex][1] == 0):\n # continue\n glVertex3fv(verticesLeftHandStraight[vertex])\nglEnd()\n\n\n\n#glutSolidSphere(1,20,20) # make radius 1 sphere of res 10x10\nglPopMatrix()\nglPushMatrix()\nglTranslatef(0.0,-1.0,0.0) #move to where we want to put object\n#glutSolidSphere(1,20,20) # make radius 1 sphere of res 10x10\nglPopMatrix()\nglEndList()\n\n#setup lighting\nglEnable(GL_CULL_FACE)\n#glEnable(GL_DEPTH_TEST)\n#glEnable(GL_LIGHTING)\n#lightZeroPosition = [10.,4.,10.,1.]\n#lightZeroColor = [0.8,1.0,0.8,1.0] # greenish\n#glLightfv(GL_LIGHT0, GL_POSITION, lightZeroPosition)\n#glLightfv(GL_LIGHT0, GL_DIFFUSE, lightZeroColor)\n#glLightf(GL_LIGHT0, GL_CONSTANT_ATTENUATION, 0.1)\nglLightf(GL_LIGHT0, GL_LINEAR_ATTENUATION, 0.05)\nglEnable(GL_LIGHT0)\n\n#setup cameras\nglMatrixMode(GL_PROJECTION)\ngluPerspective(20.,1.,1.,30.)\nglMatrixMode(GL_MODELVIEW)\ngluLookAt(0,0,10,0,0,0,0,1,0)\nglPushMatrix()\n\n#setup callbacks\nglutDisplayFunc(display)\nglutMouseFunc(mouse)\nglutMotionFunc(motion)\nglutKeyboardFunc(keyboard)\n\nglutMainLoop()"
},
{
"alpha_fraction": 0.60428786277771,
"alphanum_fraction": 0.6266088485717773,
"avg_line_length": 35.12611389160156,
"blob_id": "0b36e9bdfb348671d13bd63327259e46cf7b8488",
"content_id": "68fbeae6a15eaafea51e4c67fb923fa7cd148912",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28359,
"license_type": "permissive",
"max_line_length": 180,
"num_lines": 785,
"path": "/APP.py",
"repo_name": "limsehyuk/RealTime3DPoseTracker-OpenPose",
"src_encoding": "UTF-8",
"text": "\nimport sys\nimport pyrealsense2 as rs\nimport csv\n\nimport pandasAnalysis\nimport pandas as pd\n\nsys.path.append('/home/burcak/Desktop/PyOpenPose/build/PyOpenPoseLib')\nsys.path.append('/home/burcak/Desktop/libfreenect2/build/lib')\n\nimport PyOpenPose as OP\nimport time\nimport cv2\nimport numpy as np\nimport math\nimport os\nimport itertools\n\nfrom sklearn import svm\nfrom sklearn import preprocessing, linear_model\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.decomposition import PCA\nimport matplotlib.pyplot as plt\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.svm import SVC\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import confusion_matrix\n\n\n\ncwd= os.getcwd()\n\nOPENPOSE_ROOT = os.environ[\"OPENPOSE_ROOT\"]\n\nWIDTH = 640\nHEIGHT = 480\n\n#set the variables for data analysis\n\n##RIGHT HAND\nxPunchR= []\nxWaveR=[]\nxShootR= []\nxStillR= []\n\nlTrainR = []\nlabelsR = []\nxTrainR= []\n\n##LEFT HAND\nxPunchL= []\nxWaveL=[]\nxShootL= []\nxStillL= []\n\nlTrainL = []\nlabelsL = []\nxTrainL= []\n\npath = cwd + \"/newTrain/\"\n\npathNew = cwd + \"/trainData/\"\n\npathProc= cwd + \"/processedTrain/\"\n\ntrainAmount = input(\"Enter the trial time for training:\")\n\npandasAnalysis.processData()\n\nfor i in range(0, int(trainAmount)):\n\n #READ THE RIGHT HAND TRAINING DATA\n fileNamePunchR = \"keyPointsPersonRightHandPunch{0}.csv\".format(i)\n fileNameWaveR = \"keyPointsPersonRightHandWave{0}.csv\".format(i)\n fileNameShootR = \"keyPointsPersonRightHandShoot{0}.csv\".format(i)\n fileNameStillR = \"keyPointsPersonRightHandStill{0}.csv\".format(i)\n fileNamePunchLabelsR = \"labelsPersonRightHandPunch{0}.csv\".format(i)\n fileNameWaveLabelsR = \"labelsPersonRightHandWave{0}.csv\".format(i)\n fileNameShootLabelsR = \"labelsPersonRightHandShoot{0}.csv\".format(i)\n fileNameStillLabelsR = \"labelsPersonRightHandStill{0}.csv\".format(i)\n\n\n punchR = open(path + fileNamePunchR, 'r')\n waveR = open(path + fileNameWaveR, 'r')\n shootR= open(path + fileNameShootR, 'r')\n stillR= open(path + fileNameStillR, 'r')\n punchLabelsR = open(path + fileNamePunchLabelsR, 'r')\n waveLabelsR = open(path + fileNameWaveLabelsR, 'r')\n shootLabelsR = open(path + fileNameShootLabelsR, 'r')\n stillLabelsR = open(path + fileNameStillLabelsR, 'r')\n\n #READ THE LEFT HAND TRAINING DATA\n\n fileNamePunchL = \"keyPointsPersonLeftHandPunch{0}.csv\".format(i)\n fileNameWaveL = \"keyPointsPersonLeftHandWave{0}.csv\".format(i)\n fileNameShootL = \"keyPointsPersonLeftHandShoot{0}.csv\".format(i)\n fileNameStillL = \"keyPointsPersonLeftHandStill{0}.csv\".format(i)\n fileNamePunchLabelsL= \"labelsPersonLeftHandPunch{0}.csv\".format(i)\n fileNameWaveLabelsL = \"labelsPersonLeftHandWave{0}.csv\".format(i)\n fileNameShootLabelsL = \"labelsPersonLeftHandShoot{0}.csv\".format(i)\n fileNameStillLabelsL = \"labelsPersonLeftHandStill{0}.csv\".format(i)\n\n\n punchL = open(path + fileNamePunchL, 'r')\n waveL = open(path + fileNameWaveL, 'r')\n shootL= open(path + fileNameShootL, 'r')\n stillL= open(path + fileNameStillL, 'r')\n punchLabelsL = open(path + fileNamePunchLabelsL, 'r')\n waveLabelsL = open(path + fileNameWaveLabelsL, 'r')\n shootLabelsL = open(path + fileNameShootLabelsL, 'r')\n stillLabelsL = open(path + fileNameStillLabelsL, 'r')\n\n print(\"reading RIGHT training data\")\n with punchR:\n reader = csv.reader(punchR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainPunchR = []\n for i in range(0,len(row)):\n xTrainPunchR.append(float(row[i]))\n xy=np.asarray(xTrainPunchR)\n xPunchR.append(xy)\n xTrainR.append(xy)\n\n\n with waveR:\n reader = csv.reader(waveR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainWaveR = []\n for i in range(0,len(row)):\n xTrainWaveR.append(float(row[i]))\n xx= np.asarray(xTrainWaveR)\n xWaveR.append(xx)\n xTrainR.append(xx)\n\n with shootR:\n reader = csv.reader(shootR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainShootR = []\n for i in range(0,len(row)):\n xTrainShootR.append(float(row[i]))\n xz= np.asarray(xTrainShootR)\n xShootR.append(xz)\n xTrainR.append(xz)\n\n with stillR:\n reader = csv.reader(stillR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainStillR = []\n for i in range(0,len(row)):\n xTrainStillR.append(float(row[i]))\n xn= np.asarray(xTrainStillR)\n xStillR.append(xn)\n xTrainR.append(xn)\n\n with punchLabelsR:\n reader = csv.reader(punchLabelsR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsR.append(float(row[0]))\n\n with waveLabelsR:\n reader = csv.reader(waveLabelsR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsR.append(float(row[0]))\n\n with shootLabelsR:\n reader = csv.reader(shootLabelsR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsR.append(float(row[0]))\n\n with stillLabelsR:\n reader = csv.reader(stillLabelsR, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsR.append(float(row[0]))\n\n lTrainR= np.asarray(labelsR)\n\n print(\"reading LEFT training data\")\n with punchL:\n reader = csv.reader(punchL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainPunchL = []\n for i in range(0,len(row)):\n xTrainPunchL.append(float(row[i]))\n xy=np.asarray(xTrainPunchL)\n xPunchL.append(xy)\n xTrainL.append(xy)\n\n with waveL:\n reader = csv.reader(waveL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainWaveL = []\n for i in range(0,len(row)):\n xTrainWaveL.append(float(row[i]))\n xx= np.asarray(xTrainWaveL)\n xWaveL.append(xx)\n xTrainL.append(xx)\n\n with shootL:\n reader = csv.reader(shootL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainShootL = []\n for i in range(0,len(row)):\n xTrainShootL.append(float(row[i]))\n xz= np.asarray(xTrainShootL)\n xShootL.append(xz)\n xTrainL.append(xz)\n\n with stillL:\n reader = csv.reader(stillL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n xTrainStillL = []\n for i in range(0,len(row)):\n xTrainStillL.append(float(row[i]))\n xn= np.asarray(xTrainStillL)\n xStillL.append(xn)\n xTrainL.append(xn)\n\n with punchLabelsL:\n reader = csv.reader(punchLabelsL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsL.append(float(row[0]))\n\n with waveLabelsL:\n reader = csv.reader(waveLabelsL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsL.append(float(row[0]))\n\n with shootLabelsL:\n reader = csv.reader(shootLabelsL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsL.append(float(row[0]))\n\n with stillLabelsL:\n reader = csv.reader(stillLabelsL, delimiter=',')\n for _ in range(5): # skip the first 5 rows\n next(reader)\n for row in reader:\n labelsL.append(float(row[0]))\n\n lTrainL= np.asarray(labelsL)\n\nprint(\"Finished reading the training data\")\n\n#COMMENT OUT IF YOU WANT TO PLOT THE CONFUSION MATRIX\n'''\ndef plot_confusion_matrix(cm, classes,\n normalize=False,\n title='Confusion matrix',\n cmap=plt.cm.Purples):\n \"\"\"\n This function prints and plots the confusion matrix.\n Normalization can be applied by setting `normalize=True`.\n \"\"\"\n if normalize:\n cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]\n print(\"Normalized confusion matrix\")\n else:\n print('Confusion matrix, without normalization')\n\n print(cm)\n\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(classes))\n plt.xticks(tick_marks, classes, rotation=45)\n plt.yticks(tick_marks, classes)\n\n fmt = '.2f' if normalize else 'd'\n thresh = cm.max() / 2.\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n plt.text(j, i, format(cm[i, j], fmt),\n horizontalalignment=\"center\",\n color=\"white\" if cm[i, j] > thresh else \"black\")\n\n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predicted label')\n'''\n\n#DEFINE THE CLASSIFIERS TO COMPARE\n\n##RIGHT HAND\n\nkNeighborsCLF = KNeighborsClassifier(n_neighbors=30)\n\nlinearSVCCLF= svm.LinearSVC(penalty='l2', C=3000,multi_class='ovr', max_iter=5000)\n\nsvcCLF = svm.SVC(kernel='rbf', C=2000, probability=True)\n\nmodelLinearRegressionCLF = LinearRegression(normalize=False)\n\nlinearLogisticRegressionCLF = linear_model.LogisticRegression(C=10)\n\ndecisionTreeCLF = DecisionTreeClassifier(random_state=10)\n\n\n\n\n# Split into a training set and a test set using a stratified k fold\n\n# split into a training and testing set\n\nX_train, X_test, y_train, y_test = train_test_split(\n xTrainR, lTrainR, test_size=0.25, random_state=42)\n\n\nprint(\"Fitting the classifier to the training set\")\nparam_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],\n 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }\nclf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)\nclf = clf.fit(X_train, y_train)\nprint(\"Best estimator found by grid search:\")\nprint(clf.best_estimator_)\n\nclassifier = clf.fit(xTrainR, lTrainR)\n\n\n#COMMENT OUT IF YOU WANT TO ENABLE CONFUSION MATRIX\n# #############################################################################\n'''\ny_pred = clf.predict(X_test)\n\nprint(classification_report(y_test, y_pred, target_names=[\"Punch\", \"Wave\", \"Shoot\", \"Stand_Still\"]))\n\nprint(confusion_matrix(y_test, y_pred))\n\ncnf_matrix = confusion_matrix(y_test, y_pred)\n\nplt.figure()\nplot_confusion_matrix(cnf_matrix, classes=[\"Punch\", \"Wave\", \"Shoot\", \"Stand_Still\"],title='Confusion matrix, without normalization')\n\nplt.show()\n\n\n# Plot normalized confusion matrix\nplt.figure()\nplot_confusion_matrix(cnf_matrix, classes=[\"Punch\", \"Wave\", \"Shoot\", \"Stand_Still\"], normalize=True,\n title='Normalized confusion matrix')\n\nplt.show()\n'''\n\n\n##########################################################################\n\n##LEFT HAND\n'''\n\nkNeighborsCLF_Left = KNeighborsClassifier(n_neighbors=30)\n\nlinearSVCCLF_Left= svm.LinearSVC(penalty='l2', C=3000,multi_class='ovr', max_iter=5000)\n\nsvcCLF_Left = svm.SVC(kernel='rbf', C=2000, probability=True)\n\nmodelLinearRegressionCLF_Left = LinearRegression(normalize=False)\n\nlinearLogisticRegressionCLF_Left = linear_model.LogisticRegression(C=10)\n\ndecisionTreeCLF_Left = DecisionTreeClassifier(random_state=10)\n\n'''\n\n#CHECK OUTLIERS IN THE DATA USING BOXPLOT\n'''\nplt.boxplot(xTrain, notch=True, vert=True)\n\nplt.boxplot(xWave, notch=True, vert=True)\n\nplt.boxplot(xShoot, notch= True, vert= True)\n'''\n\n\nprint(\"Fitting to the model- Right Hand \")\n\nsvcCLF.fit(xTrainR, lTrainR) #train the svm\ndecisionTreeCLF.fit(xTrainR, lTrainR) #train the decision tree\nkNeighborsCLF.fit(xTrainR, lTrainR) #train the kNN\n\nlinearLogisticRegressionCLF.fit(xTrainR, lTrainR)\n\nlinearSVCCLF.fit(xTrainR,lTrainR)\n\nmodelLinearRegressionCLF.fit(xTrainR, lTrainR)\n\nprint(\"Fitting to the model- Left Hand \")\n\n#svcCLF_Left.fit(xTrainL, lTrainL) #train the svm\n#decisionTreeCLF_Left.fit(xTrainL, lTrainL) #train the decision tree\n#kNeighborsCLF_Left.fit(xTrainL, lTrainL) #train the kNN\n\n#linearLogisticRegressionCLF_Left.fit(xTrainL, lTrainL)\n\n#linearSVCCLF_Left.fit(xTrainL,lTrainL)\n\n#modelLinearRegressionCLF_Left.fit(xTrainL, lTrainL)\n\n###################################\n###COMMENT OUT TO ENABLE THE PCA PLOT\n'''\n#principal component analysis\npca = PCA(n_components=3)\nproj = pca.fit_transform(xTrainR)\nplt.scatter(proj[:, 0], proj[:, 1], c=lTrainR)\nplt.colorbar()\nproj = pca.fit_transform(xTrainL)\nplt.scatter(proj[:, 0], proj[:, 1], c=lTrainL)\nplt.colorbar()\n'''\n#################################\n\nscoresLinearSVC = cross_val_score(linearSVCCLF, xTrainR, lTrainR, cv=5)\n\nprint(scoresLinearSVC)\n\nprint(\"Accuracy Linear SVC: %0.2f (+/- %0.2f)\" % (scoresLinearSVC.mean(), scoresLinearSVC.std() * 2))\n\n##############################################\nscoresSVM = cross_val_score(svcCLF, xTrainR, lTrainR, cv=5)\n\nprint(scoresSVM)\n\nprint(\"Accuracy SVM: %0.2f (+/- %0.2f)\" % (scoresSVM.mean(), scoresSVM.std() * 2))\n\n################################################\n\nscoresKNeighbors = cross_val_score(kNeighborsCLF, xTrainR, lTrainR, cv=5)\n\nprint(scoresKNeighbors)\n\nprint(\"Accuracy Nearest Neighbors: %0.2f (+/- %0.2f)\" % (scoresKNeighbors.mean(), scoresKNeighbors.std() * 2))\n\n###############################################\nscoresLinearRegression = cross_val_score(modelLinearRegressionCLF, xTrainR, lTrainR, cv=5)\n\nprint(scoresLinearRegression)\n\nprint(\"Accuracy Linear Regression: %0.2f (+/- %0.2f)\" % (scoresLinearRegression.mean(), scoresLinearRegression.std() * 2))\n\n#############################################\n\nscoresLinearLogisticRegression = cross_val_score(linearLogisticRegressionCLF, xTrainR, lTrainR, cv=5)\n\nprint(scoresLinearLogisticRegression)\n\nprint(\"Accuracy Linear LOgistig REgression: %0.2f (+/- %0.2f)\" % (scoresLinearLogisticRegression.mean(), scoresLinearLogisticRegression.std() * 2))\n\n#############################################\n\nscoresDecisionTree= cross_val_score(decisionTreeCLF, xTrainR, lTrainR, cv=5)\n\nprint(scoresDecisionTree)\n\nprint(\"Accuracy Decision Tree: %0.2f (+/- %0.2f)\" % (scoresDecisionTree.mean(), scoresDecisionTree.std() * 2))\n############################################\n\n\n# Create a pipeline\npipeline = rs.pipeline()\n\n# Create a config and configure the pipeline to stream\n# different resolutions of color and depth streams\nconfig = rs.config()\n\nconfig.enable_stream(rs.stream.depth, 640, 360, rs.format.z16, 30)\nconfig.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)\n\n# Start streaming\nprofile = pipeline.start(config)\n\n# Getting the depth sensor's depth scale (see rs-align example for explanation)\ndepth_sensor = profile.get_device().first_depth_sensor()\ndepth_scale = depth_sensor.get_depth_scale()\nprint(\"Depth Scale is: \", depth_scale)\n\n# We will be removing the background of objects more than\n# clipping_distance_in_meters meters away\nclipping_distance_in_meters = 10 # 1 meter\nclipping_distance = clipping_distance_in_meters / depth_scale\n\n# Create an align object\n# rs.align allows us to perform alignment of depth frames to others frames\n# The \"align_to\" is the stream type to which we plan to align depth frames.\nalign_to = rs.stream.color\nalign = rs.align(align_to)\n\n\n# Declare pointcloud object, for calculating pointclouds and texture mappings\npc = rs.pointcloud()\n\n# We want the points object to be persistent so we can display the last cloud when a frame drops\npoints = rs.points()\n\nrightData = []\n\ndef get3DPosWorld(pose, x, isBody, verticeList):\n if isBody:\n persons = pose[0][x]\n else:\n persons= pose[x]\n\n hSz = len(persons)\n persons3DWorld = np.zeros((hSz, 3), np.float32)\n for c in range(0, hSz):\n xCoor1 = math.ceil(persons[c][0])\n xCoor2 = xCoor1 - 1\n yCoor1 = math.ceil(persons[c][1])\n yCoor2 = yCoor1 - 1\n\n if xCoor1>=WIDTH or xCoor2>=WIDTH or yCoor1>=HEIGHT or yCoor2>=HEIGHT:\n continue\n\n#UPDATE THE Z COORDINATE FROM THE VERTICE LIST ACCORDINGLY\n if xCoor2 == -1 or yCoor2 ==-1:\n verticeIndex = yCoor1*WIDTH + xCoor1\n xCoorWorld = verticeList[verticeIndex][0]\n yCoorWorld = verticeList[verticeIndex][1]\n zCoorWorld = verticeList[verticeIndex][2]\n else:\n verticeIndex1 = yCoor1*WIDTH + xCoor1\n verticeIndex2 = yCoor2*WIDTH + xCoor2\n xCoorWorld1= verticeList[verticeIndex1][0]\n yCoorWorld1= verticeList[verticeIndex1][1]\n zCoorWorld1= verticeList[verticeIndex1][2]\n\n xCoorWorld2= verticeList[verticeIndex2][0]\n yCoorWorld2= verticeList[verticeIndex2][1]\n zCoorWorld2= verticeList[verticeIndex2][2]\n\n zCoorWorld = (zCoorWorld1 + zCoorWorld2) / 2\n yCoorWorld = (yCoorWorld1 + yCoorWorld2) / 2\n xCoorWorld = (xCoorWorld1 + xCoorWorld2) / 2\n\n #check the range of the values\n persons3DWorld[c][0] = xCoorWorld\n persons3DWorld[c][1] = yCoorWorld\n persons3DWorld[c][2] = zCoorWorld\n\n rightData.append(xCoorWorld)\n rightData.append(yCoorWorld)\n rightData.append(zCoorWorld)\n return persons3DWorld\n\ndef run():\n with_face = False\n with_hands = True\n download_heatmaps = False\n # with_face = with_hands = False\n #op = OP.OpenPose((320, 240), (368, 368), (640, 480), \"COCO\", OPENPOSE_ROOT + os.sep + \"models\" + os.sep, 0,\n #download_heatmaps, OP.OpenPose.ScaleMode.ZeroToOne, with_face, with_hands)\n op = OP.OpenPose((320, 240), (368, 368), (640, 480), \"COCO\", OPENPOSE_ROOT + os.sep + \"models\" + os.sep, 0, download_heatmaps)\n actual_fps = 0\n #numberWave = 0\n #numberPunch = 0\n paused = False\n delay = {True: 0, False: 1}\n\n print(\"Entering main Loop.\")\n\n# Streaming loop\n while True:\n start_time = time.time()\n try:\n\n # Get frameset of color and depth\n frames = pipeline.wait_for_frames()\n # frames.get_depth_frame() is a 640x360 depth image\n\n # Align the depth frame to color frame\n aligned_frames = align.process(frames)\n\n # Get aligned frames\n aligned_depth_frame = aligned_frames.get_depth_frame() # aligned_depth_frame is a 640x480 depth image\n color_frame = aligned_frames.get_color_frame()\n\n # Validate that both frames are valid\n if not aligned_depth_frame or not color_frame:\n continue\n\n depth_image = np.asanyarray(aligned_depth_frame.get_data())\n color_image = np.asanyarray(color_frame.get_data())\n\n pc.map_to(color_frame)\n\n #visual = pcl.pcl_visualization.CloudViewing()\n points = pc.calculate(aligned_depth_frame)\n\n vtx = np.asanyarray(points.get_vertices())\n #dfVTX = pd.DataFrame(data=vtx)\n #dfVTX.to_csv(cwd + \"PointCloud.csv\", sep=',', index=False, header=None)\n lstPersons3dRealWorld = []\n lstHandRight3dRealWorld = []\n lstHandLeft3dRealWorld = []\n\n except Exception as e:\n print(\"Failed to grab\", e)\n break\n\n t = time.time()\n op.detectPose(color_image)\n #op.detectFace(rgb)\n op.detectHands(color_image)\n t = time.time() - t\n op_fps = 1.0 / t\n\n pose = op.getKeypoints(op.KeypointType.POSE)\n leftTemp = op.getKeypoints(op.KeypointType.HAND)[0]\n rightTemp = op.getKeypoints(op.KeypointType.HAND)[1]\n\n\n\n\n print(\"Open Pose FPS: \", op_fps)\n print(\"Actual Pose FPS: \", actual_fps)\n\n np.set_printoptions(suppress=True)\n\n blank_image = np.zeros((HEIGHT, WIDTH, 3), np.uint8)\n res = op.render(color_image)\n\n if pose[0] is not None:\n # comment out for enabling for multi person\n #numberPersons= len(pose[0])\n #for x in range(0,numberPersons):\n #lstPersons3dRealWorld.append(get3DPosWorld(pose, x, True, vtx))\n lstPersons3dRealWorld.extend(get3DPosWorld(pose, 0, True, vtx))\n normalizedTrainPose = preprocessing.Normalizer().fit_transform(np.asarray(lstPersons3dRealWorld).reshape(1, -1))\n\n\n\n\n if rightTemp is not None:\n # comment out for enabling for multi person\n #numberRightHands = len(rightTemp)\n #for y in range(0, numberRightHands):\n # lstHandRight3dRealWorld.append(get3DPosWorld(rightTemp, y, False, vtx))\n lstHandRight3dRealWorld.extend(get3DPosWorld(rightTemp, 0, False, vtx))\n\n # add relbow and rshoulder and rwrist and the joint btw shoulders(BODY JOINT NUMBER 1)\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[2][0], lstPersons3dRealWorld[2][1], lstPersons3dRealWorld[2][2]]))\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[3][0], lstPersons3dRealWorld[3][1], lstPersons3dRealWorld[3][2]]))\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[4][0], lstPersons3dRealWorld[4][1], lstPersons3dRealWorld[4][2]]))\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[1][0], lstPersons3dRealWorld[1][1], lstPersons3dRealWorld[1][2]]))\n\n # GET THE RELATIVE POSITIONS OF THE JOINTS ACORDINGLY TO THE MIDDLE OF THE SHOULDERS JOINT(BODY JOINT NUMBER 1)\n lenA= len(lstHandRight3dRealWorld)\n for i in range(0, lenA):\n lstHandRight3dRealWorld[i][0] = lstHandRight3dRealWorld[i][0] - lstHandRight3dRealWorld[24][0]\n lstHandRight3dRealWorld[i][1] = lstHandRight3dRealWorld[i][1] - lstHandRight3dRealWorld[24][1]\n lstHandRight3dRealWorld[i][2] = lstHandRight3dRealWorld[i][2] - lstHandRight3dRealWorld[24][2]\n\n # REMOVE JOINT #1 FROM THE JOINT LIST FOR BETTER RESULTS IN TRAINING\n lstHandRight3dRealWorld = lstHandRight3dRealWorld[0:24]\n normalizedTrainRightHand = preprocessing.Normalizer().fit_transform(np.asarray(lstHandRight3dRealWorld).reshape(1, -1))\n\n if leftTemp is not None:\n # comment out for enabling for multi person\n #numberLeftHands = len(leftTemp)\n #for z in range(0, numberLeftHands):\n #lstHandLeft3dRealWorld.append(get3DPosWorld(leftTemp, z, False, vtx))\n lstHandLeft3dRealWorld.extend(get3DPosWorld(leftTemp, 0, False, vtx))\n\n # add lelbow and lshoulder and lwrist and the joint btw shoulders(BODY JOINT NUMBER 1)\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[5][0], lstPersons3dRealWorld[5][1], lstPersons3dRealWorld[5][2]]))\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[6][0], lstPersons3dRealWorld[6][1], lstPersons3dRealWorld[6][2]]))\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[7][0], lstPersons3dRealWorld[7][1], lstPersons3dRealWorld[7][2]]))\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[1][0], lstPersons3dRealWorld[1][1], lstPersons3dRealWorld[1][2]]))\n\n # GET THE RELATIVE POSITIONS OF THE JOINTS ACORDINGLY TO THE MIDDLE OF THE SHOULDERS JOINT(BODY JOINT NUMBER 1)\n lenA = len(lstHandLeft3dRealWorld)\n for i in range(0, lenA):\n lstHandLeft3dRealWorld[i][0] = -(lstHandLeft3dRealWorld[i][0] - lstHandLeft3dRealWorld[24][0])\n lstHandLeft3dRealWorld[i][1] = lstHandLeft3dRealWorld[i][1] - lstHandLeft3dRealWorld[24][1]\n lstHandLeft3dRealWorld[i][2] = lstHandLeft3dRealWorld[i][2] - lstHandLeft3dRealWorld[24][2]\n # REMOVE JOINT #1 FROM THE JOINT LIST FOR BETTER RESULTS IN TRAINING\n lstHandLeft3dRealWorld = lstHandLeft3dRealWorld[0:24]\n normalizedTrainLeftHand = preprocessing.Normalizer().fit_transform(np.asarray(lstHandLeft3dRealWorld).reshape(1, -1))\n\n\n #if rightTemp.max() > 0 or leftTemp.max() > 0 :\n try:\n #resultsvcCLF_Right = svcCLF.predict(normalizedTrainRightHand)[0] # svm result\n\n ##the other prediction models are just made for testing- can be used if wanted\n #resultGestureTree_Right = decisionTreeCLF.predict(normalizedTrainRightHand)[0]\n #resultKnn_Right = kNeighborsCLF.predict(normalizedTrainRightHand)\n #resultLinearRegressionCLF_Right = linearLogisticRegressionCLF.predict(normalizedTrainRightHand)\n #resultLinearRegression_Right = modelLinearRegressionCLF.predict(normalizedTrainRightHand)\n #resultLinearSVC_Right = linearSVCCLF.predict(normalizedTrainRightHand)\n #rr= svcCLF.decision_function(normalizedTrainRightHand)\n #nn = kNeighborsCLF.decision_function(normalizedTrainRightHand)\n #mm= linearSVCCLF.decision_function(normalizedTrainRightHand)\n\n resultsvcCLF_Right = classifier.predict(normalizedTrainRightHand)[0] # BEST FITTER RESULT\n\n resultsvcCLF_Left = classifier.predict(normalizedTrainLeftHand)[0] # BEST FITTER RESULT\n except IndexError:\n print(\"This class has no label\")\n\n\n if rightTemp.max() > 0:\n if resultsvcCLF_Right == 1:\n rightGestureName = \"Punch\"\n elif resultsvcCLF_Right == 2:\n rightGestureName = \"Wave\"\n elif resultsvcCLF_Right == 3:\n rightGestureName = \"Shoot\"\n elif resultsvcCLF_Right == 4:\n rightGestureName = \"NoGesture\"\n else:\n rightGestureName=\"NoRightHandData\"\n\n if leftTemp.max() > 0 :\n if resultsvcCLF_Left == 1:\n leftGestureName = \"Punch\"\n elif resultsvcCLF_Left == 2:\n leftGestureName = \"Wave\"\n elif resultsvcCLF_Left == 3:\n leftGestureName = \"Shoot\"\n elif resultsvcCLF_Left == 4:\n leftGestureName = \"NoGesture\"\n else:\n leftGestureName=\"NoLeftHandData\"\n\n cv2.putText(blank_image, 'RightGESTURE= %s' % (rightGestureName), (0, 100), 50, 1,(255, 255, 255))\n\n cv2.putText(blank_image,'LeftGESTURE= %s' % (leftGestureName),(0, 200), 50, 1, (255, 255, 255))\n cv2.putText(res, 'UI FPS = %f, OP FPS = %f, RightGESTURE= %s, LeftGESTURE= %s' % (actual_fps, op_fps, rightGestureName, leftGestureName), (20, 20), 0, 0.4, (0, 0, 255))\n images = np.hstack((blank_image, res))\n cv2.imshow(\"OpenPose result\", images)\n #cv2.imshow(\"OpenPose result\", res)\n\n\n\n #else:\n #cv2.putText(res, 'UI FPS = %f, OP FPS = %f, Gesture= No gesture' % (actual_fps, op_fps), (20, 20), 0, 0.5, (0, 0, 255))\n #cv2.imshow(\"OpenPose result\", res)\n else:\n cv2.putText(color_image, 'No skeleton detected', (20, 20), 0, 0.5, (0, 0, 255))\n cv2.imshow(\"OpenPose result\", color_image)\n\n actual_fps = 1.0 / (time.time() - start_time)\n key = cv2.waitKey(delay[paused])\n if key & 255 == ord('p'):\n paused = not paused\n\n if key & 255 == ord('q'):\n pipeline.stop()\n break\nif __name__ == '__main__':\n run()"
},
{
"alpha_fraction": 0.5980741381645203,
"alphanum_fraction": 0.6259045004844666,
"avg_line_length": 43.69154357910156,
"blob_id": "6a1e693c7baa87107cbebc6d9d0b1c7aa107b78e",
"content_id": "cc7095319618195da521e1db6c406b511ab642c1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17966,
"license_type": "permissive",
"max_line_length": 147,
"num_lines": 402,
"path": "/createTrainingSet.py",
"repo_name": "limsehyuk/RealTime3DPoseTracker-OpenPose",
"src_encoding": "UTF-8",
"text": "\nimport sys\nimport xlsxwriter\nimport pyrealsense2 as rs\nimport csv\nimport time\n\nfrom sklearn import preprocessing\n\nsys.path.append('/home/burcak/Desktop/PyOpenPose/build/PyOpenPoseLib')\nsys.path.append('/home/burcak/Desktop/libfreenect2/build/lib')\nimport PyOpenPose as OP\nimport time\nimport cv2\nimport numpy as np\nimport math\nimport os\n\ncwd= os.getcwd()\npathNew = cwd + \"/trainData/\"\n\nif not os.path.exists(pathNew):\n os.makedirs(pathNew)\n\nOPENPOSE_ROOT = os.environ[\"OPENPOSE_ROOT\"]\n\nWIDTH = 640\nHEIGHT = 480\n\n\n\n# Create a pipeline\npipeline = rs.pipeline()\n\n# Create a config and configure the pipeline to stream\n# different resolutions of color and depth streams\nconfig = rs.config()\n\nconfig.enable_stream(rs.stream.depth, 640, 360, rs.format.z16, 30)\nconfig.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)\n\n# Start streaming\nprofile = pipeline.start(config)\n\n# Getting the depth sensor's depth scale (see rs-align example for explanation)\ndepth_sensor = profile.get_device().first_depth_sensor()\ndepth_scale = depth_sensor.get_depth_scale()\nprint(\"Depth Scale is: \", depth_scale)\n\n# We will be removing the background of objects more than\n# clipping_distance_in_meters meters away\nclipping_distance_in_meters = 10 # 1 meter\nclipping_distance = clipping_distance_in_meters / depth_scale\n\n# Create an align object\n# rs.align allows us to perform alignment of depth frames to others frames\n# The \"align_to\" is the stream type to which we plan to align depth frames.\nalign_to = rs.stream.color\nalign = rs.align(align_to)\n\n\n# Declare pointcloud object, for calculating pointclouds and texture mappings\npc = rs.pointcloud()\n\n# We want the points object to be persistent so we can display the last cloud when a frame drops\npoints = rs.points()\n\n\n\n#GET 3D POSITIONS OUT OF OPENPOSE\n\ndef get3DPos(pose, alignedArr, x, isBody):\n if isBody:\n persons = pose[0][x] #if the array is a Pose array, then get the first person\n else:\n persons= pose[x] #if the array belongs to hands it has no person ID, so just read it.\n\n hSz = len(persons)\n persons3D = np.zeros((hSz, 4), np.float32)\n for c in range(0, hSz):\n xCoor1 = math.ceil(persons[c][0])\n xCoor2 = xCoor1 - 1\n yCoor1 = math.ceil(persons[c][1])\n yCoor2 = yCoor1 - 1\n\n\n #if the coordinates are out of range, continue(for the edges)\n if xCoor1>=WIDTH or xCoor2>=WIDTH or yCoor1>=HEIGHT or yCoor2>=HEIGHT:\n continue\n\n if xCoor2 == -1 or yCoor2 ==-1:\n zCoor = alignedArr[yCoor1][xCoor1]\n else:\n zCoor1 = alignedArr[yCoor1][xCoor1]\n zCoor2 = alignedArr[yCoor2][xCoor2]\n zCoor = (zCoor1 + zCoor2) / 2\n\n\n persons3D[c][0] = persons[c][0]\n persons3D[c][1] = persons[c][1]\n if np.isinf(zCoor):\n persons3D[c][2] = 0\n else:\n persons3D[c][2] = zCoor\n persons3D[c][3] = persons[c][2]\n return persons3D\n\ndef get3DPosWorld(pose, x, isBody, verticeList):\n if isBody:\n persons = pose[0][x] #if the array is a Pose array, then get the first person\n else:\n persons= pose[x] #if the array belongs to hands it has no person ID, so just read it.\n\n hSz = len(persons)\n persons3DWorld = np.zeros((hSz, 3), np.float32)\n for c in range(0, hSz):\n xCoor1 = math.ceil(persons[c][0])\n xCoor2 = xCoor1 - 1\n yCoor1 = math.ceil(persons[c][1])\n yCoor2 = yCoor1 - 1\n\n # if the coordinates are out of range, continue(for the edges)\n if xCoor1>=WIDTH or xCoor2>=WIDTH or yCoor1>=HEIGHT or yCoor2>=HEIGHT:\n continue\n\n#UPDATE THE Z COORDINATE FROM THE VERTICE LIST ACCORDINGLY\n if xCoor2 == -1 or yCoor2 ==-1:\n verticeIndex = yCoor1*WIDTH + xCoor1\n xCoorWorld = verticeList[verticeIndex][0]\n yCoorWorld = verticeList[verticeIndex][1]\n zCoorWorld = verticeList[verticeIndex][2]\n else:\n verticeIndex1 = yCoor1*WIDTH + xCoor1\n verticeIndex2 = yCoor2*WIDTH + xCoor2\n xCoorWorld1= verticeList[verticeIndex1][0]\n yCoorWorld1= verticeList[verticeIndex1][1]\n zCoorWorld1= verticeList[verticeIndex1][2]\n\n xCoorWorld2= verticeList[verticeIndex2][0]\n yCoorWorld2= verticeList[verticeIndex2][1]\n zCoorWorld2= verticeList[verticeIndex2][2]\n\n zCoorWorld = (zCoorWorld1 + zCoorWorld2) / 2\n yCoorWorld = (yCoorWorld1 + yCoorWorld2) / 2\n xCoorWorld = (xCoorWorld1 + xCoorWorld2) / 2\n #if the confidentiality is smaller than 0.2, write 0 as the keypoints\n #check the range of the values\n if(persons[c][2] < 0.2):\n persons3DWorld[c][0] = 0.0\n persons3DWorld[c][1] = 0.0\n persons3DWorld[c][2] = 0.0\n else:\n persons3DWorld[c][0] = xCoorWorld\n persons3DWorld[c][1] = yCoorWorld\n persons3DWorld[c][2] = zCoorWorld\n #don't include the confidentiality score in the final data- if you want to include uncomment\n #persons3DWorld[c][3] = persons[c][2]\n return persons3DWorld\n\n\n\n\ndef run():\n startProcess = False\n with_face = False #enable face if you want to detect face\n with_hands = True\n download_heatmaps = False\n op = OP.OpenPose((320, 240), (368, 368), (640, 480), \"COCO\", OPENPOSE_ROOT + os.sep + \"models\" + os.sep, 0,\n download_heatmaps, OP.OpenPose.ScaleMode.ZeroToOne, with_face, with_hands)\n # op = OP.OpenPose((320, 240), (240, 240), (640, 480), \"COCO\", OPENPOSE_ROOT + os.sep + \"models\" + os.sep, 0, download_heatmaps)\n actual_fps = 0\n\n paused = False\n delay = {True: 0, False: 1}\n\n print(\"Entering main Loop for TRAINING.\")\n\n #GET THE USER INPUTS\n gestureID = input(\"Enter the gesture you want to store: PUNCH(1) OR WAVE(2) OR SHOOT(3) OR (4) for STILL..:\")\n trialTime = input(\"Enter the training document number:\")\n handNumber= input(\"Enter the hand to to train: RIGHT(1) AND LEFT(2): \")\n timeToTrain = float(input(\"Enter the amount of time(seconds) that you want to train the data, 20-30 seconds are suggested:\"))\n startTrigger = input(\"Enter (S) to start ..:\")\n\n if startTrigger == 'S' or 's':\n startProcess = True\n\n print(\"Starting in 3 seconds...\")\n\n time.sleep(3)\n\n start = time.time()\n timeLeft = timeToTrain\n\n # Streaming loop\n while startProcess:\n start_time = time.time()\n try:\n # Get frameset of color and depth\n frames = pipeline.wait_for_frames()\n # frames.get_depth_frame() is a 640x360 depth image\n\n # Align the depth frame to color frame\n aligned_frames = align.process(frames)\n # Get aligned frames\n aligned_depth_frame = aligned_frames.get_depth_frame() # aligned_depth_frame is a 640x480 depth image\n color_frame = aligned_frames.get_color_frame()\n # Validate that both frames are valid\n if not aligned_depth_frame or not color_frame:\n continue\n\n depth_image = np.asanyarray(aligned_depth_frame.get_data())\n color_image = np.asanyarray(color_frame.get_data())\n\n pc.map_to(color_frame)\n points = pc.calculate(aligned_depth_frame)\n\n vtx = np.asanyarray(points.get_vertices()) #create a vertex list from the point cloud\n\n lstPersons3d = []\n lstRightHand3d = []\n lstLeftHand3d = []\n lstPersons3dRealWorld = []\n lstHandRight3dRealWorld = []\n lstHandLeft3dRealWorld = []\n\n\n except Exception as e:\n print(\"Failed to grab\", e)\n break\n\n t = time.time()\n op.detectPose(color_image)\n #op.detectFace(rgb)\n op.detectHands(color_image)\n t = time.time() - t\n op_fps = 1.0 / t\n\n pose = op.getKeypoints(op.KeypointType.POSE)\n leftTemp = op.getKeypoints(op.KeypointType.HAND)[0]\n rightTemp = op.getKeypoints(op.KeypointType.HAND)[1]\n\n res = op.render(color_image)\n cv2.putText(res, 'UI FPS = %f, OP FPS = %f, timeLeft = %f' % (actual_fps, op_fps, timeLeft), (20, 20), 0, 0.5, (0, 0, 255))\n\n print(\"Open Pose FPS: \", op_fps)\n print(\"Actual Pose FPS: \", actual_fps)\n\n np.set_printoptions(suppress=True)\n\n\n if pose[0] is not None:\n #comment out for multi person\n #numberPersons= len(pose[0])\n #for x in range(0,numberPersons):\n #lstPersons3d.append(get3DPos(pose,depth_image, x, True))m\n lstPersons3dRealWorld.extend(get3DPosWorld(pose, 0, True, vtx))\n normalizedTrainPose = preprocessing.Normalizer().fit_transform(np.asarray(lstPersons3dRealWorld).reshape(1, -1))\n\n if rightTemp is not None and int(handNumber) == 1:\n #comment out for multi person\n #numberRightHands = len(rightTemp)\n #for y in range(0, numberRightHands):\n #lstRightHand3d.append(get3DPos(rightTemp,depth_image, y, False))\n lstHandRight3dRealWorld.extend(get3DPosWorld(rightTemp, 0, False, vtx))\n\n #add relbow and rshoulder and rwrist, and the joint btw shoulders(BODY JOINT NUMBER 1)\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[2][0],lstPersons3dRealWorld[2][1], lstPersons3dRealWorld[2][2]]))\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[3][0], lstPersons3dRealWorld[3][1], lstPersons3dRealWorld[3][2]]))\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[4][0], lstPersons3dRealWorld[4][1], lstPersons3dRealWorld[4][2]]))\n lstHandRight3dRealWorld.append(np.asarray([lstPersons3dRealWorld[1][0], lstPersons3dRealWorld[1][1], lstPersons3dRealWorld[1][2]]))\n\n #GET THE RELATIVE POSITIONS OF THE JOINTS ACORDINGLY TO THE MIDDLE OF THE SHOULDERS JOINT(BODY JOINT NUMBER 1)\n lenA = len(lstHandRight3dRealWorld)\n for i in range(0, lenA):\n lstHandRight3dRealWorld[i][0] = lstHandRight3dRealWorld[i][0] - lstHandRight3dRealWorld[24][0]\n lstHandRight3dRealWorld[i][1] = lstHandRight3dRealWorld[i][1] - lstHandRight3dRealWorld[24][1]\n lstHandRight3dRealWorld[i][2] = lstHandRight3dRealWorld[i][2] - lstHandRight3dRealWorld[24][2]\n # REMOVE JOINT #1 FROM THE JOINT LIST FOR BETTER RESULTS IN TRAINING\n lstHandRight3dRealWorld = lstHandRight3dRealWorld[0:24]\n normalizedTrainRightHand = preprocessing.Normalizer().fit_transform(np.asarray(lstHandRight3dRealWorld).reshape(1, -1))\n\n if leftTemp is not None and int(handNumber) == 2:\n #comment out for multi person\n #numberLeftHands = len(leftTemp)\n #for z in range(0, numberLeftHands):\n #lstLeftHand3d.append(get3DPos(leftTemp,depth_image, z, False))\n lstHandLeft3dRealWorld.extend(get3DPosWorld(leftTemp, 0, False, vtx))\n #add lelbow and lshoulder and lwrist and the joint btw shoulders(BODY JOINT NUMBER 1)\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[5][0], lstPersons3dRealWorld[5][1], lstPersons3dRealWorld[5][2]]))\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[6][0], lstPersons3dRealWorld[6][1], lstPersons3dRealWorld[6][2]]))\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[7][0], lstPersons3dRealWorld[7][1], lstPersons3dRealWorld[7][2]]))\n lstHandLeft3dRealWorld.append(np.asarray([lstPersons3dRealWorld[1][0], lstPersons3dRealWorld[1][1], lstPersons3dRealWorld[1][2]]))\n\n # GET THE RELATIVE POSITIONS OF THE JOINTS ACORDINGLY TO THE MIDDLE OF THE SHOULDERS JOINT(BODY JOINT NUMBER 1)\n lenA = len(lstHandLeft3dRealWorld)\n for i in range(0, lenA):\n lstHandLeft3dRealWorld[i][0] = lstHandLeft3dRealWorld[i][0] - lstHandLeft3dRealWorld[24][0]\n lstHandLeft3dRealWorld[i][1] = lstHandLeft3dRealWorld[i][1] - lstHandLeft3dRealWorld[24][1]\n lstHandLeft3dRealWorld[i][2] = lstHandLeft3dRealWorld[i][2] - lstHandLeft3dRealWorld[24][2]\n #REMOVE JOINT #1 FROM THE JOINT LIST FOR BETTER RESULTS IN TRAINING\n lstHandLeft3dRealWorld = lstHandLeft3dRealWorld[0:24]\n normalizedTrainLeftHand = preprocessing.Normalizer().fit_transform(np.asarray(lstHandLeft3dRealWorld).reshape(1, -1))\n\n #fieldnames = ['X', 'Y', 'Z', 'LABEL']\n if lstPersons3dRealWorld: #just write the pose keypoints once\n #comment out for multi person\n #for personIndex in range(0, numberPersons):\n\n ##comment out to enable storing pose keypoints\n #if gestureID == '1':\n #fileNamePose = \"keyPointsPersonPosePunch{0}.csv\".format(personIndex)\n #labelsPose = \"labelsPersonPosePunch{0}.csv\".format(personIndex)\n #fileNamePose = \"keyPointsPersonPosePunch{0}.csv\".format(trialTime)\n #labelsPose = \"labelsPersonPosePunch{0}.csv\".format(trialTime)\n #elif gestureID == '2':\n #fileNamePose = \"keyPointsPoseWave{0}.csv\".format(personIndex)\n #labelsPose = \"labelsPoseWave{0}.csv\".format(personIndex)\n #fileNamePose = \"keyPointsPersonPoseWave{0}.csv\".format(trialTime)\n #labelsPose = \"labelsPersonPoseWave{0}.csv\".format(trialTime)\n #elif gestureID == '3':\n #fileNamePose = \"keyPointsPersonPoseShoot{0}.csv\".format(trialTime)\n #labelsPose = \"labelsPersonPoseShoot{0}.csv\".format(trialTime)\n #elif gestureID == '4':\n #fileNamePose = \"keyPointsPersonPoseStill{0}.csv\".format(trialTime)\n #labelsPose = \"labelsPersonPoseStill{0}.csv\".format(trialTime)\n #fileNamePose = \"keyPointsPoseOk{0}.csv\".format(personIndex)\n #labelsPose = \"labelsPoseOk{0}.csv\".format(personIndex)\n\n #poseFile = open(pathNew+fileNamePose, 'a+')\n #poseLabels = open(pathNew + labelsPose, 'a+')\n\n #with poseFile and poseLabels:\n #writerPose = csv.writer(poseFile)\n #writerPoseLabels = csv.writer(poseLabels)\n #writerPoseLabels.writerow(gestureID)\n #writerPose.writerows(normalizedTrainPose)\n\n #GET DATA FOR THE RIGHT HAND\n if lstHandRight3dRealWorld and int(handNumber) == 1:\n if gestureID == '1':\n fileNameRightHand = \"keyPointsPersonRightHandPunch{0}.csv\".format(trialTime)\n labelsRightHand = \"labelsPersonRightHandPunch{0}.csv\".format(trialTime)\n elif gestureID == '2':\n fileNameRightHand = \"keyPointsPersonRightHandWave{0}.csv\".format(trialTime)\n labelsRightHand = \"labelsPersonRightHandWave{0}.csv\".format(trialTime)\n elif gestureID == '3':\n fileNameRightHand = \"keyPointsPersonRightHandShoot{0}.csv\".format(trialTime)\n labelsRightHand = \"labelsPersonRightHandShoot{0}.csv\".format(trialTime)\n elif gestureID == '4':\n fileNameRightHand = \"keyPointsPersonRightHandStill{0}.csv\".format(trialTime)\n labelsRightHand = \"labelsPersonRightHandStill{0}.csv\".format(trialTime)\n\n rightHandFile = open(pathNew+fileNameRightHand, 'a+')\n rightHandLabels = open(pathNew+labelsRightHand, 'a+')\n with rightHandFile and rightHandLabels:\n writerRightHand= csv.writer(rightHandFile)\n writerRightHandLabels = csv.writer(rightHandLabels)\n writerRightHandLabels.writerow(gestureID)\n writerRightHand.writerows(normalizedTrainRightHand)\n # GET DATA FOR THE LEFT HAND\n if lstHandLeft3dRealWorld and int(handNumber) == 2:\n if gestureID == '1':\n fileNameLeftHand = \"keyPointsPersonLeftHandPunch{0}.csv\".format(trialTime)\n labelsLeftHand = \"labelsPersonLeftHandPunch{0}.csv\".format(trialTime)\n elif gestureID == '2':\n fileNameLeftHand = \"keyPointsPersonLeftHandWave{0}.csv\".format(trialTime)\n labelsLeftHand = \"labelsPersonLeftHandWave{0}.csv\".format(trialTime)\n elif gestureID == '3':\n fileNameLeftHand = \"keyPointsPersonLeftHandShoot{0}.csv\".format(trialTime)\n labelsLeftHand = \"labelsPersonLeftHandShoot{0}.csv\".format(trialTime)\n elif gestureID == '4':\n fileNameLeftHand = \"keyPointsPersonLeftHandStill{0}.csv\".format(trialTime)\n labelsLeftHand = \"labelsPersonLeftHandStill{0}.csv\".format(trialTime)\n\n\n leftHandFile = open(pathNew+fileNameLeftHand, 'a+')\n leftHandLabels = open(pathNew+labelsLeftHand, 'a+')\n with leftHandFile and leftHandLabels:\n writerLeftHand= csv.writer(leftHandFile)\n writerLeftHandLabels = csv.writer(leftHandLabels)\n writerLeftHandLabels.writerow(gestureID)\n writerLeftHand.writerows(normalizedTrainLeftHand)\n\n timeLeft = timeToTrain - (time.time() - start)\n if timeLeft < 0:\n pipeline.stop()\n break\n\n\n actual_fps = 1.0 / (time.time() - start_time)\n cv2.imshow(\"OpenPose result\", res)\n\n\n key = cv2.waitKey(delay[paused])\n if key & 255 == ord('p'):\n paused = not paused\n\n if key & 255 == ord('q'):\n pipeline.stop()\n break\nif __name__ == '__main__':\n run()"
}
] | 5 |
Raigm/Python_course
|
https://github.com/Raigm/Python_course
|
196f70e5251782461b62d1fefd68b1ae0ae9fd80
|
11f0f8e678328fa153e75105849ccfd4fb375e41
|
66d566853dfae26e90e5a9d4c82dd926ca3a0dae
|
refs/heads/master
| 2020-12-14T00:31:36.175414 | 2020-04-09T16:30:47 | 2020-04-09T16:30:47 | 234,578,543 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6006191968917847,
"alphanum_fraction": 0.6021671891212463,
"avg_line_length": 25.95833396911621,
"blob_id": "e8fd3cf41a28016bb24c5a5a377aac5820018de3",
"content_id": "ef24eb713cb61578ee979bf5228015defdc9ad73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 24,
"path": "/inheritance.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "class Parent():\n def __init__(self, last_name, eye_color):\n print (\"parent instructor code\")\n self.last_name = last_name\n self.eye_color = eye_color\n\n def show_info(self):\n print (\"Last name - \" + self.last_name)\n print (\"Eye color - \" + self.eye_color)\n\nclass Child(Parent):\n def __init__(self, last_name, eye_color, toys):\n print (\"child instructor code\")\n Parent.__init__(self,last_name,eye_color)\n self.toys = toys\n\nraimundo = Parent(\"Gordejuela\", \"verdes\")\n# raimundo.show_info()\nrai = Child(\"Gordejuela\", \"azul\",3)\nrai.show_info()\n\n\n# print (rai.toys)\n# print (rai.last_name)"
},
{
"alpha_fraction": 0.6313725709915161,
"alphanum_fraction": 0.6627451181411743,
"avg_line_length": 16,
"blob_id": "a2491799de23e9cbffc947ff631e234fb8fb2428",
"content_id": "61a0fc2680c21f146fd751b93df55bc14969dc9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 255,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 15,
"path": "/break.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nSpyder Editor\n\nThis is a temporary script file.\n\"\"\"\n\nimport webbrowser\nimport time \n\ncounter = 0\nwhile counter < 3:\n time.sleep(5)\n webbrowser.open(\"https://www.youtube.com/watch?v=2Vss3avr0cs\")\n counter = counter + 1\n"
},
{
"alpha_fraction": 0.6317365169525146,
"alphanum_fraction": 0.697604775428772,
"avg_line_length": 21.200000762939453,
"blob_id": "a15e039cabcfd06b6d896c05e5735c81c76efd2c",
"content_id": "51294c88a2ea11f7b8e0ccb81304c8f5e3327efc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 15,
"path": "/message.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "\nfrom twilio import rest\n\n# Your Account SID from twilio.com/console\naccount_sid = \"ACe4f3ce204efc2c5b4404bcb8aeb895dc\"\n# Your Auth Token from twilio.com/console\nauth_token = \"1019d5579b0379d9f36c3b3ebdfae14b\"\n\nclient = rest.Client(account_sid, auth_token)\n\nmessage = client.messages.create(\n body = \"Puchica\",\n to=\"++34644964208\",\n from_=\"+17252667058\")\n\nprint(message.sid)\n"
},
{
"alpha_fraction": 0.5365344285964966,
"alphanum_fraction": 0.5720250606536865,
"avg_line_length": 14.899999618530273,
"blob_id": "706b733feb7fe609764339fc266ced43ba074a33",
"content_id": "4070510ed97222629f200a0dce29520c4c114c19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 30,
"path": "/draw.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "import turtle\n\n#Define the functino squal\n#Crate n squares increasing the angle\n\ndef draw_square(form):\n i = 1\n while i < 5:\n form.forward(100)\n form.right(90)\n i = i +1\n\n\ndef draw_art():\n window = turtle.Screen()\n window.bgcolor(\"navy\")\n\n angie = turtle.Turtle()\n angie.shape(\"turtle\")\n angie.color(\"white\")\n angie.speed(1000)\n\n for i in range(380):\n draw_square(angie)\n angie.right(13)\n\n\n\n\ndraw_art()\n\n\n"
},
{
"alpha_fraction": 0.6211180090904236,
"alphanum_fraction": 0.6242235898971558,
"avg_line_length": 28.136363983154297,
"blob_id": "64e56fbf4bcdf14e7d0ed9a8667b2a2f8d2e31c9",
"content_id": "6a0bca0b5361e7b7da39e2a39884e364d374af35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 644,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 22,
"path": "/media.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "import webbrowser\n\nclass Video():\n def __init__(self, title, duration ):\n self.title = title\n self.duration = duration\n\nclass Movie(Video):\n \"\"\"\" This calls provides pelis\"\"\"\n VALID_RATINGS = [\"P\" ,\"PG\", \"PG-13\", \"R\"]\n def __init__(self, title, duration, movie_storyline, movies_poster, movie_trailer):\n self.storyline = movie_storyline\n self.poster_image_url = movies_poster\n self.trailer_youtube_url = movie_trailer\n\n def show_trailer(self):\n webbrowser.open(self.trailer)\n\nclass TVShow(Video):\n \"This class provides shows\"\n def __init__(self,title, duration):\n self.\n\n\n\n"
},
{
"alpha_fraction": 0.610859751701355,
"alphanum_fraction": 0.610859751701355,
"avg_line_length": 21.100000381469727,
"blob_id": "8907daf284c320b05c583ecd8b6a1cfed29e783f",
"content_id": "669012ac8d3314024bc58e20af27ed199411bed4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 20,
"path": "/profanity.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "import urllib\n\ndef read_txt():\n file = open(r'C:/Users/raigo/Documents/Python_course/movie_quotes.txt')\n content = file.read()\n #print (content)\n file.close()\n check(content)\n\ndef check(text):\n connection = urllib.urlopen (\"http://www.wdylike.appspot.com/?q=\" + text)\n output = connection.read()\n #print(output)\n if output == \"true\":\n print (\"Palabrota\")\n else:\n print (\"We're fine!\")\n\n\nread_txt()\n"
},
{
"alpha_fraction": 0.6161048412322998,
"alphanum_fraction": 0.6591760516166687,
"avg_line_length": 25.75,
"blob_id": "9d0edbe1026b529ec709372174a0c1f2a06f8e22",
"content_id": "79c8bb0958cabf2d761f56e57641fbe1accb1e97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 534,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 20,
"path": "/secret.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Jan 14 23:06:40 2019\n\n@author: raigo\n\"\"\"\nimport os \ndef rename_files():\n #get the filenames\n file_list = os.listdir(r'C:/Users/raigo/Documents/Python_course/prank/prank')\n print (file_list)\n saved_path = os.getcwd()\n print (\"the current path is \"+ saved_path)\n os.chdir(r'C:/Users/raigo/Documents/Python_course/prank/prank')\n \n #change the filenames\n for file_name in file_list:\n os.rename(file_name, file_name.translate(None, \"0123456789\"))\n \nrename_files()"
},
{
"alpha_fraction": 0.5340136289596558,
"alphanum_fraction": 0.5374149680137634,
"avg_line_length": 27.047618865966797,
"blob_id": "777c3b52a60b064b4573e3ef3b0555a32e562733",
"content_id": "18085f01ab8fd2bd5325ac56d1597f4f4cd20156",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 21,
"path": "/entertaining.py",
"repo_name": "Raigm/Python_course",
"src_encoding": "UTF-8",
"text": "import media\nimport fresh_tomatoes\n\ntoy_story = media.Movie(\"Toy Story\",\n \"BlaBla\",\n \"https://goo.gl/images/vMYBup\",\n \"https://www.youtube.com/watch?v=fOFgtfdRmw0\")\n\navatar = media.Movie(\"Avatar\",\n \"BlaBlaBla\",\n \"https://goo.gl/images/jBLRmC\",\n \"https://www.youtube.com/watch?v=_Tmz_ot3nnY\")\n\n\n\n# print (toy_story.storyline)\n# avatar.show_trailer()\nmovies = [toy_story, avatar]\n\nprint (media.Movie.__name__)\n# fresh_tomatoes.open_movies_page(movies)"
}
] | 8 |
diogo-as/ud036_StarterCode
|
https://github.com/diogo-as/ud036_StarterCode
|
5184da788bfce9d1832fd480c111f9889d5280b5
|
46345ae4f231e7281c8175eb6f35cb744e6a7fa4
|
3689749dd7da62dae7304d2837ecb4f3b0adf68a
|
refs/heads/master
| 2020-04-16T05:16:45.156372 | 2019-03-17T02:09:10 | 2019-03-17T02:09:10 | 165,298,573 | 0 | 0 | null | 2019-01-11T19:32:37 | 2019-01-01T23:40:32 | 2018-11-14T03:58:01 | null |
[
{
"alpha_fraction": 0.694958508014679,
"alphanum_fraction": 0.7077217698097229,
"avg_line_length": 47.9375,
"blob_id": "d373c57b9b6de960b9650b7bb553409ed0d4a596",
"content_id": "7088282d6534e0baac499e2bce992b3046d069b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1569,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 32,
"path": "/README.md",
"repo_name": "diogo-as/ud036_StarterCode",
"src_encoding": "UTF-8",
"text": "# ud036_StarterCode\nSource code for a Movie Trailer website.\n\nThis program contains 3 main python files:\n - media.py\n - entertainment_center.py\n - fresh_tomatoes.py\n\nThe credits of this codes are from udacity and IMDbPY code examples.\n\nThe media.py file contains a class named Movie that defines the structure for a movies.\n\nThe entertainment_center.py is the file where the objects of the class movie are created\nand initiates the fresh_tomatoes method to create the .html page.\n\nThe module IMDbPY is used in this program as an API to get movies data. (source: https://imdbpy.sourceforge.io/)\n\n Example of how to choose a list of movies:\n mybestmovies = {\n '%mission: impossible - fallout%':'https://www.youtube.com/watch?v=XiHiW4N7-bo',\n 'The Angel':'https://www.youtube.com/watch?v=z0q2WbXQWbw',\n 'Avengers: Infinity War':'https://www.youtube.com/watch?v=hA6hldpSTF8',\n '007 Spectre':'https://www.youtube.com/watch?v=z4UDNzXD3qA',\n 'The Resistence Banker':'https://www.youtube.com/watch?v=31pzuZSvzvU',\n 'The Revenant':'https://www.youtube.com/watch?v=LoebZZ8K5N0'\n }\nThis list of movies is used as input for the search of movie´s data using IMDb API. This API can´t get movie trailer url, so we need to insert it.\n\nOn fresh_tomatoes.py file are defined the html, css and javascript to create the mains page.\nTwo main methods are create_movie_tiles_content and open_movies_page.\n\nThe css and html model was modified to include the movie storyline.\n\n"
},
{
"alpha_fraction": 0.67113196849823,
"alphanum_fraction": 0.6831881999969482,
"avg_line_length": 47.16128921508789,
"blob_id": "c5a06c8fb329ff8d499721b0bebaed3ddecd35fe",
"content_id": "0301a54b786329645f569932ac168bc64d50fd0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1493,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 31,
"path": "/entertainment_center.py",
"repo_name": "diogo-as/ud036_StarterCode",
"src_encoding": "UTF-8",
"text": "import fresh_tomatoes\nimport media\nfrom imdb import IMDb\n\n\n# create an instance of imbd class\nia = IMDb()\n# Creating a dictionarie with my best movies title and trailer url\nmybestmovies = {\n '%mission: impossible - fallout%': 'https://www.youtube.com/watch?v=XiHiW4N7-bo',\n 'The Angel': 'https://www.youtube.com/watch?v=z0q2WbXQWbw',\n 'Avengers: Infinity War': ' https://www.youtube.com/watch?v=hA6hldpSTF8',\n '007 Spectre': 'https://www.youtube.com/watch?v=z4UDNzXD3qA',\n 'The Resistence Banker': 'https://www.youtube.com/watch?v=31pzuZSvzvU',\n 'The Revenant': 'https://www.youtube.com/watch?v=LoebZZ8K5N0'\n }\n# Creating a list of movie objects\nbestmovieslist = []\n\nfor name in mybestmovies.keys():\n movielist = ia.search_movie(name) # search movie by the string of title\n moviechoice = movielist[0] # choice the first result\n ia.update(moviechoice) # update with full data\n storylist = moviechoice.get('plot') # get list of storylist\n storyline = storylist[0] # get the first storyline\n cover = moviechoice.get('full-size cover url') # get the full cover url\n movie_trailer = mybestmovies[name] # get the movie trailer\n bestmovieslist.append(media.Movie(moviechoice, storyline, cover, movie_trailer)) # create an object movie with the variables needded\n\n# Passing movie list to the method open_movies_page\nfresh_tomatoes.open_movies_page(bestmovieslist)\n"
},
{
"alpha_fraction": 0.6993007063865662,
"alphanum_fraction": 0.6993007063865662,
"avg_line_length": 32,
"blob_id": "7e742287f9ea42629fc67bd28de13113e6e34205",
"content_id": "91deab30ce2f1a71af7444b16f5e9e40a137425e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 13,
"path": "/media.py",
"repo_name": "diogo-as/ud036_StarterCode",
"src_encoding": "UTF-8",
"text": "import webbrowser\n\"\"\"class Movie\nThis class permits create objects of movies\n\"\"\"\n\n\nclass Movie():\n # The init method is called when create new instance of the movie Class\n def __init__(self, movie_title, movie_storyline, poster_image, trailer_youtube):\n self.title = movie_title\n self.storyline = movie_storyline\n self.poster_image_url = poster_image\n self.trailer_youtube_url = trailer_youtube\n"
}
] | 3 |
arokem/testy
|
https://github.com/arokem/testy
|
4293f2a6da11fa887720ff9545b25157ecd28dcc
|
d4adef92dd2f9a7f12bcd3f25a3073ec9d586cb1
|
73ee75806b22b2d485acf63a94cc555cc58552ea
|
refs/heads/master
| 2022-09-10T13:48:45.920036 | 2020-02-11T23:12:28 | 2020-02-11T23:12:28 | 236,062,704 | 0 | 0 | null | 2020-01-24T18:48:05 | 2020-02-11T23:12:31 | 2022-08-23T18:01:24 |
Jupyter Notebook
|
[
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 21.100000381469727,
"blob_id": "89182380ea7bdcda7d448f18e1c34c75963995f5",
"content_id": "61c10e88b06279eb3d66c41ae2eaf21f9ef48716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 20,
"path": "/test_tools.py",
"repo_name": "arokem/testy",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom tools import calculate_area\nimport pytest\n\n\ndef test_calculate_area_negative():\n with pytest.raises(AssertionError):\n calculate_area(-1)\n\n\ndef test_calculate_area_pi():\n assert calculate_area(1) == np.pi, \"For radius of 1, area should be pi\"\n\n\ndef test_calculate_area_zero():\n assert calculate_area(0) == 0\n\n\ndef test_calculate_area_exp10():\n assert calculate_area(np.exp(10)) == 1524191413.6768537\n"
},
{
"alpha_fraction": 0.5070707201957703,
"alphanum_fraction": 0.5494949221611023,
"avg_line_length": 16.068965911865234,
"blob_id": "7a88563b7b8aae923d583e72be9916c8c2a18197",
"content_id": "967b152cf1b6ad5ff9624c4c0391f014433ec7be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 29,
"path": "/tools.py",
"repo_name": "arokem/testy",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\ndef calculate_area(r):\n \"\"\"\n Calculates area of a circle\n\n Parameters\n ----------\n r : number\n\n Returns\n -------\n area : the area of circle with radius r\n\n Examples\n --------\n >>> calculate_area(1)\n 3.141592653589793\n \"\"\"\n assert r >= 0, \"Radius can only be non-negative\"\n area = np.pi * r **2\n return area\n\n\ndef calculate_circ(r):\n assert r >= 0, \"Radius can only be non-negative\"\n circ = 2 * np.pi * r\n return circ\n"
}
] | 2 |
plievana/dramatiq
|
https://github.com/plievana/dramatiq
|
6d3122d0c0654a75da16003686c0198a785b3d1f
|
9ebd2a0123f741ce3b35420403ab79f0b561d72b
|
67db6ab6254f84f31fff87810259483c4a7b0345
|
refs/heads/master
| 2023-01-30T04:40:03.709615 | 2020-11-12T23:11:47 | 2020-11-12T23:11:47 | 310,120,054 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.65143883228302,
"alphanum_fraction": 0.6586331129074097,
"avg_line_length": 32.095237731933594,
"blob_id": "51ab99036cde9ea46a824d808211f84755bc97e8",
"content_id": "31fe051b201b0223d9249225632e82951b7aa897",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2780,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 84,
"path": "/tasks.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from functools import reduce\n\nfrom dramatiq.middleware import CurrentMessage\nfrom dramatiq.results import ResultTimeout\nfrom flask import current_app\nimport time\nimport random\nfrom app import dramatiq, cache\nfrom dramatiq.rate_limits import ConcurrentRateLimiter\nfrom dramatiq.rate_limits.backends import RedisBackend\n\n\[email protected]\ndef test():\n current_app.logger.info('test actor')\n\n\[email protected](max_retries=0)\ndef single_task(name: str, duration: int):\n current_app.logger.info(f'[{name}] Starting single-task of {duration} secs')\n for i in range(duration):\n current_app.logger.info(f'[{name}] ... Current value {i}')\n time.sleep(1)\n current_app.logger.info(f'[{name}] Finishing single-task')\n\n\[email protected](max_retries=0)\ndef parent_task(name: str, n_subtasks: int):\n current_app.logger.info(f'[{name}] Starting parent-task with {n_subtasks} subtasks')\n t1 = time.time()\n pipe = dramatiq.pipeline(\n (\n create_subtasks.message(name, n_subtasks),\n close_task.message_with_options(pipe_ignore=True, kwargs=dict(name=name, started=t1))\n )\n ).run()\n\n\[email protected](max_retries=0, store_results=True)\ndef run_subtask(msg_id, parent_name: str, i: int):\n try:\n to_sleep = random.randint(1, 5)\n current_app.logger.info(f'[{parent_name}] ... [{i}] Starts ({to_sleep})')\n time.sleep(to_sleep)\n current_app.logger.info(f'[{parent_name}] ... [{i}] Ends ({to_sleep})')\n return to_sleep\n finally:\n cache.decr(msg_id, 1)\n\n\[email protected](max_retries=0, store_results=True)\ndef create_subtasks(parent_name: str, n_subtasks):\n msg_id = CurrentMessage.get_current_message().message_id\n cache.set(msg_id, n_subtasks)\n current_app.logger.info(f'[{parent_name}] Creating subtasks')\n g = dramatiq.group(\n (run_subtask.message(msg_id, parent_name, i) for i in range(n_subtasks))\n ).run()\n\n while int(cache.get(msg_id)) > 0:\n try:\n g.wait(timeout=10_000)\n res = g.get_results()\n total = reduce(lambda x, y: x + y, res)\n except ResultTimeout:\n current_app.logger.warn(f'[{parent_name}] timeout')\n\n current_app.logger.info(f'[{parent_name}] Subtasks created. Should take {total} seconds')\n return None\n\n\[email protected](max_retries=0)\ndef close_task(name: str, started: time):\n current_app.logger.info(f'[{name}] Finished parent-task in {time.time() - started} secs')\n\n\[email protected]()\ndef one_at_a_time(locker):\n backend = RedisBackend()\n mutex = ConcurrentRateLimiter(backend, f\"locker::{locker}\", limit=1)\n with mutex.acquire():\n current_app.logger.info(f\"[{locker}] - Starts\")\n time.sleep(20)\n current_app.logger.info(f\"[{locker}] - Done\")\n"
},
{
"alpha_fraction": 0.8474576473236084,
"alphanum_fraction": 0.8474576473236084,
"avg_line_length": 14,
"blob_id": "e007a62d99a0b3d09fd4176a18a3780f28aafc51",
"content_id": "1dcf4fc446a674a4950dd360ed195ed2f94a6019",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "flask\ndramatiq[redis, watch]\nflask-melodramatiq\nflask-login"
},
{
"alpha_fraction": 0.7131979465484619,
"alphanum_fraction": 0.7174280881881714,
"avg_line_length": 24.69565200805664,
"blob_id": "6e67bc5a8377ddcde7c2019ea9a0b1c3475e3d7c",
"content_id": "3de538cf7bacc6097be6bb934a484b179296eda8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1182,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 46,
"path": "/app.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "import dramatiq\nfrom dramatiq.results.backends import RedisBackend\nfrom dramatiq.middleware import CurrentMessage\nfrom dramatiq.results import Results\nfrom flask import Flask\nfrom flask_melodramatiq import RedisBroker\nfrom flask_login import LoginManager\nimport redis\n\nfrom models import User\n\nlm = LoginManager()\nlm.login_view = \"auth.login\"\nbroker = RedisBroker()\ndramatiq.set_broker(broker)\nresult_backend = RedisBackend()\nbroker.add_middleware(Results(backend=result_backend))\nbroker.add_middleware(CurrentMessage())\ncache = redis.Redis()\n\n\[email protected]_loader\ndef load_user(user_name):\n return User.get(user_name)\n\n\ndef register_blueprints(app):\n from auth import auth as auth_bp\n app.register_blueprint(auth_bp)\n\n from private import private as private_bp\n app.register_blueprint(private_bp)\n\n\ndef create_app():\n app = Flask(__name__)\n app.config.from_pyfile('config.py')\n lm.init_app(app)\n broker.init_app(app)\n cache = redis.Redis(host=app.config.get('REDIS_HOST', 'localhost'),\n port=app.config.get('REDIS_PORT', 6379),\n db=app.config.get('REDIS_DB', 0))\n\n register_blueprints(app)\n\n return app\n"
},
{
"alpha_fraction": 0.6269633769989014,
"alphanum_fraction": 0.6269633769989014,
"avg_line_length": 22.90625,
"blob_id": "7c1572ef6be28190ae36ef1c30a522cc1d50683f",
"content_id": "b173e3d8fd22a85ee7265bba7d5a3b16f6fdecdf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 32,
"path": "/auth/routes.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from flask import redirect, url_for, request, render_template, flash\nfrom flask_login import login_user, login_required, current_user\nfrom models import User\n\n\ndef index():\n return redirect(url_for('auth.login'))\n\n\ndef login():\n if request.method == \"POST\":\n name = request.form.get(\"name\")\n account = request.form.get(\"account\")\n if not name.strip():\n flash(\"Empty name\", \"error\")\n\n user = User()\n user.name = name\n user.account = account\n User.save(user)\n\n login_user(user)\n\n return redirect(url_for(\"private.index\"))\n else:\n return render_template(\"auth/login.html\")\n\n\n@login_required\ndef logout():\n User.delete(current_user)\n return redirect(url_for('auth.index'))"
},
{
"alpha_fraction": 0.7155172228813171,
"alphanum_fraction": 0.7155172228813171,
"avg_line_length": 37.77777862548828,
"blob_id": "de9fa834d70002fc92f2b9ccb3a5648ec26a90ae",
"content_id": "653ba2f2da084b523e7f083d80c13cfe0c79d3ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 9,
"path": "/auth/__init__.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint\n\nauth = Blueprint(\"auth\", __name__, template_folder=\"templates\")\n\nfrom . import routes\n\nauth.add_url_rule('/', view_func=routes.index, endpoint=\"index\")\nauth.add_url_rule('/login', view_func=routes.login, endpoint=\"login\", methods=['GET', 'POST'])\nauth.add_url_rule('/logout', view_func=routes.logout, endpoint=\"logout\")"
},
{
"alpha_fraction": 0.6590163707733154,
"alphanum_fraction": 0.6688524484634399,
"avg_line_length": 15.94444465637207,
"blob_id": "f6d0bce120065f9ebd80d295546f409aede85c15",
"content_id": "5b91b703847cd5d85026635bc8f94327e15b221d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 18,
"path": "/README.md",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "# About\nThis is just a flask + dramatiq example project\n\n## Run Redis\n```bash\n> cd Downloads/redis-5.0.5/src\n> ./redis-server\n```\n\n## Run Flask app\n```bash\n> export FLASK_ENV=development && env FLASK_APP=app.py venv/bin/flask run\n```\n\n## Run dramatiq\n```bash\n> venv/bin/dramatiq wsgi:broker --watch .\n``` "
},
{
"alpha_fraction": 0.7019867300987244,
"alphanum_fraction": 0.7350993156433105,
"avg_line_length": 18,
"blob_id": "ae5ae35b53f1789d0789f46f565a5ce3b3216663",
"content_id": "14dc2ccdc92822f588147bc962387ee2a7eb046d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 8,
"path": "/config.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "SECRET_KEY = \"la_secreta\"\n\nREDIS_HOST = 'localhost'\nREDIS_PORT = 6379\nREDIS_DB = 0\n\nDRAMATIQ_BROKER_HOST = REDIS_HOST\nDRAMATIQ_BROKER_PORT = REDIS_PORT"
},
{
"alpha_fraction": 0.5558739304542542,
"alphanum_fraction": 0.5558739304542542,
"avg_line_length": 18.94285774230957,
"blob_id": "3514390940b40bab3641bbc74216f9cb1d27a5a1",
"content_id": "6c41a9d00f56bc0d1d8a11649fda878ef3286725",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 35,
"path": "/models/__init__.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from flask_login import UserMixin\n\n\nclass User(UserMixin):\n __users__ = {}\n __slots__ = ('name', 'account')\n\n @property\n def is_authenticated(self):\n \"\"\"return True if the user is authenticated\n \"\"\"\n return True\n\n @property\n def is_active(self):\n return True\n\n def is_anonymous(self):\n return False\n\n def get_id(self):\n return self.name\n\n @staticmethod\n def get(name):\n return User.__users__.get(name)\n\n @staticmethod\n def save(user):\n User.__users__[user.get_id()] = user\n\n @staticmethod\n def delete(user):\n if User.__users__.get(user.get_id()):\n del User.__users__[user.get_id()]\n"
},
{
"alpha_fraction": 0.7457627058029175,
"alphanum_fraction": 0.7457627058029175,
"avg_line_length": 18.66666603088379,
"blob_id": "f92d9d7c231924fd83bc50424a5e9aeeb544dfed",
"content_id": "cbcf1df0e41da39c8d67ef56cbb81c3bf8d25ea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 3,
"path": "/wsgi.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from private import create_app, broker\n\napp = create_app()\n"
},
{
"alpha_fraction": 0.6389201283454895,
"alphanum_fraction": 0.6411698460578918,
"avg_line_length": 24.399999618530273,
"blob_id": "b84bff59adb5c9c9c03968e9cd68216d663d8250",
"content_id": "53b4d805c6f7616996699dc0737e3b54d1ed9f8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 889,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 35,
"path": "/private/routes.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from flask import request, render_template\nfrom tasks import single_task, parent_task, one_at_a_time, test\n\n\ndef index():\n return render_template(\"private/layout.html\")\n\n\ndef test_task():\n test.send()\n return render_template(\"private/test.html\")\n\n\ndef single_task_view():\n if request.method == \"POST\":\n name = request.form.get(\"name\", \"-\")\n duration = int(request.form.get(\"duration\", 1))\n single_task.send(name, duration)\n\n return render_template(\"private/single_task.html\")\n\n\ndef sub_tasks():\n if request.method == \"POST\":\n name = request.form.get(\"name\", \"-\")\n n_subtasks = int(request.form.get(\"subtasks\", 1))\n parent_task.send(name, n_subtasks)\n\n return render_template(\"private/sub_tasks.html\")\n\n\ndef one_at_a_time_view():\n name = request.args.get('name', 'asdf')\n one_at_a_time.send(name)\n return f\"OK {name}\"\n"
},
{
"alpha_fraction": 0.7208706736564636,
"alphanum_fraction": 0.7208706736564636,
"avg_line_length": 42.33333206176758,
"blob_id": "1d60a84136dfcc4fac1f4bd0f15c73e20216a8ba",
"content_id": "2b2b0a5f1e77f4518758d6f1e4e8c945e6ddc337",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 18,
"path": "/private/__init__.py",
"repo_name": "plievana/dramatiq",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, g\nfrom flask_login import login_required, current_user\n\nprivate = Blueprint(\"private\", __name__, template_folder=\"templates\", url_prefix=\"/private\")\n\n\[email protected]_request\n@login_required\ndef do_login():\n g.user = current_user\n\nfrom . import routes\n\nprivate.add_url_rule('/', view_func=routes.index, endpoint=\"index\")\nprivate.add_url_rule('/test', view_func=routes.test_task, endpoint=\"test_task\")\nprivate.add_url_rule('/single-task', view_func=routes.single_task_view, endpoint=\"single_task\", methods=['GET', 'POST'])\nprivate.add_url_rule('/subtasks', view_func=routes.sub_tasks, endpoint=\"subtasks\", methods=['GET', 'POST'])\nprivate.add_url_rule('/one-at-a-time', view_func=routes.sub_tasks, endpoint=\"one_at_a_time\", methods=['GET', 'POST'])\n\n"
}
] | 11 |
sekhar989/Udacity-DAND
|
https://github.com/sekhar989/Udacity-DAND
|
1e1558a481d14df73230eaf9f63c68045b68aa96
|
4dd0539ce07444477f883e27113b261cabc4e5a2
|
81c841f56833690ed9ca57e3e02a264c09695c35
|
refs/heads/master
| 2020-12-30T13:40:29.432340 | 2020-03-30T23:21:45 | 2020-03-30T23:21:45 | 91,244,189 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5047414302825928,
"alphanum_fraction": 0.636110782623291,
"avg_line_length": 42.4560432434082,
"blob_id": "fd02405dc8d2e9ec4f70675dbb68759edc43a30d",
"content_id": "38b8fb7291b84948457415884a8b26b2a913ce94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7913,
"license_type": "no_license",
"max_line_length": 518,
"num_lines": 182,
"path": "/P5-Data Wrangling -Mongo - Python/README.md",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "## Wrangling OpenStreetMap Data of Kolkata, West Bengal, India\n- by Krishnendu S. Kar\n\n**Area of study**: \n **City**: [Kolkata](https://www.openstreetmap.org/node/245707150)\n\n**Objective**: Audit and clean the data set, converting it from XML to JSON format and load it to MongoDB.\n\n**References**:\n- Lesson 6 from Udacity course, “Data Wrangling with MongoDB”\n- [Python 're' - documentation](https://docs.python.org/2.6/library/re.html)\n- [Python 'strip' - documentation](https://docs.python.org/2/library/stdtypes.html?highlight=strip#str.strip)\n- [MongoDB data import from JSON file](https://docs.mongodb.com/manual/reference/program/mongoimport/)\n\n### Getting the data\n\nThe data was extracted from the [Overpass API](http://overpass-api.de/query_form.html), by passing the below query:\n```sql\n(\n node(22.4678, 88.3309, 22.6039, 88.4035);\n <;\n);\nout meta;\n```\n\n### Tags\n\n`iterparse.py` was used to count occurrences of each tag, with a result:\n\n```json\n{'member': 4437,\n 'meta': 1,\n 'nd': 861202,\n 'node': 692730,\n 'note': 1,\n 'osm': 1,\n 'relation': 763,\n 'tag': 159164,\n 'way': 148337}\n```\nFurther modifications were made to `iterparse.py` to examine the keys stored in each `tag` element, in the `k` attribute. Few of the most :\n\n```tuple\n('building', 130748), ('highway', 13468), ('name', 3960), ('landuse', 1542), ('service', 1200), ('type', 762), ('railway', 708), ('natural', 561), ('amenity', 511), ('oneway', 342), ('leisure', 331), ('voltage', 267), ('electrified', 264), ('frequency', 262), ('gauge', 260), ('bridge', 241), ('layer', 212), ('addr:street', 204), ('addr:housenumber', 190), ('ref', 147), ('addr:postcode', 139), ('passenger_lines', 129), ('source', 128), ('name:en', 123), ('lanes', 112), ('addr:city', 106), ('public_transport', 106)\n```\nFurther parsing was done through the 'tag'-data and a sample of 15 data points were taken for each tag(key, value).\n\nInconcistencies were noticed in:\n\n### 1. Postcodes/Zip-Codes\nPostcodes/Zip-codes were present under *`addr:postcode`* tag. Kolkata postcodes are of 6-digits and ranges from *`700001`* to *`700120`*.\nWhile checking the data, several inconsistencies were noticed in the postcodes present in the raw dataset. e.g.: *`7017`* (less than 6-digits), *`700 073`*, *`7000 026`*.\n\n### 2. Phone Numbers\nPhone numbers were present under ***`phone`*** . Issues viz. ***`+91906285598`*** , ***`033 2227 2625`*** .\n***`+91`*** & gaps along with dash(-) should be removed from phone numbers\n\n\n### 3. Street Names\nThere were inconsistencies with street name abbreviations.Issues in Streets viz. ***`Rameswar Shaw Rd`*** , ***`Karbala Tank Ln`*** . Acronyms like ***`Rd`*** & ***`Ln`*** are used, which are actually ***`Road`*** & ***`Lane`*** .\n\nIn depth studies related to isseues were made using the *`audit_db.py`* program.\n\n### Special Tags\nThere were quite a number of `tag k-v pairs`, which are present only once. \nThey are some special tags, which came into the picture just for a specific scenario.\ne.g.: ***`toilets:disposal`*** , ***`name:ml`*** , ***`name:hr`*** etc.\n\nAs part of the cleaning process, a manual selection of `tag k-v pairs` was made based on the amount of occurence.\nTags which have occured less than equal to 4-times, were ignored.\n\n### MongoDB\nThe json output file was loaded to a mongoDB database using the terminal command shown below.\n\n```terminal\n$: mongoimport --db cities --collection kolkata --type json --file ~/'Udacity DAND'/Calcutta.osm.json\n\n2017-08-25T03:06:18.648+0530\tconnected to: localhost\n2017-08-25T03:06:21.646+0530\t[........................] cities.kolkata\t6.34MB/173MB (3.7%)\n2017-08-25T03:06:24.646+0530\t[#.......................] cities.kolkata\t13.9MB/173MB (8.0%)\n2017-08-25T03:06:27.646+0530\t[##......................] cities.kolkata\t21.5MB/173MB (12.4%)\n2017-08-25T03:06:30.646+0530\t[####....................] cities.kolkata\t29.2MB/173MB (16.9%)\n2017-08-25T03:06:33.646+0530\t[#####...................] cities.kolkata\t36.3MB/173MB (21.0%)\n2017-08-25T03:06:36.646+0530\t[######..................] cities.kolkata\t43.8MB/173MB (25.3%)\n2017-08-25T03:06:39.646+0530\t[#######.................] cities.kolkata\t51.5MB/173MB (29.7%)\n2017-08-25T03:06:42.646+0530\t[########................] cities.kolkata\t59.3MB/173MB (34.3%)\n2017-08-25T03:06:45.646+0530\t[#########...............] cities.kolkata\t67.1MB/173MB (38.7%)\n2017-08-25T03:06:48.646+0530\t[##########..............] cities.kolkata\t74.6MB/173MB (43.1%)\n2017-08-25T03:06:51.646+0530\t[###########.............] cities.kolkata\t82.3MB/173MB (47.5%)\n2017-08-25T03:06:54.646+0530\t[############............] cities.kolkata\t90.3MB/173MB (52.1%)\n2017-08-25T03:06:57.646+0530\t[#############...........] cities.kolkata\t97.5MB/173MB (56.3%)\n2017-08-25T03:07:00.646+0530\t[##############..........] cities.kolkata\t105MB/173MB (60.6%)\n2017-08-25T03:07:03.646+0530\t[###############.........] cities.kolkata\t113MB/173MB (65.2%)\n2017-08-25T03:07:06.646+0530\t[################........] cities.kolkata\t120MB/173MB (69.5%)\n2017-08-25T03:07:09.646+0530\t[#################.......] cities.kolkata\t128MB/173MB (74.1%)\n2017-08-25T03:07:12.646+0530\t[##################......] cities.kolkata\t137MB/173MB (78.9%)\n2017-08-25T03:07:15.646+0530\t[####################....] cities.kolkata\t146MB/173MB (84.0%)\n2017-08-25T03:07:18.646+0530\t[#####################...] cities.kolkata\t154MB/173MB (89.1%)\n2017-08-25T03:07:21.646+0530\t[######################..] cities.kolkata\t161MB/173MB (92.7%)\n2017-08-25T03:07:24.646+0530\t[#######################.] cities.kolkata\t169MB/173MB (97.7%)\n2017-08-25T03:07:26.057+0530\t[########################] cities.kolkata\t173MB/173MB (100.0%)\n\n2017-08-25T03:07:26.057+0530\timported 841067 documents\n```\n\nFile sizes:\n- `Calcutta.osm: 156.9 MB`\n- `Calcutta.osm.json: 181.6 MB`\n\nChecking total number of documents:\n\n```python\n> db.kolkata.find().count()\n```\nOutput: 1682134\n\nTotal `\"node\"` count:\n```python\n> db.kolkata.find({\"type\":\"node\"}).count()\n```\nOutput: 1385460\n\nTotal `\"way\"` count:\n```python\n> db.kolkata.find({\"type\":\"way\"}).count()\n```\nOutput: 148337\n\nTotal number of unique users:\n```python\n> x = db.kolkata.distinct(\"created.user\")\n> print len(x)\n```\nOutput: 314\n\nTotal entries having an address:\n```python\n> db.kolkata.find({\"address\" : {\"$exists\" : 1}}).count()\n```\nOutput: 478\n\nSome more queries were made, using the `mongodb_queries.py` program. The ouput are shown below:\n\nTop 5 users with higherst contribution...\n```json\n{'$group': {'_id': '$created.user','count': {'$sum': 1}}}, {'$sort': {'count': -1}}, {'$limit': 5}\n\n```\n\nOutput:\n\n```json\n {u'_id': u'Rondon237', u'count': 147882},\n {u'_id': u'pvprasad', u'count': 138692},\n {u'_id': u'hareesh11', u'count': 128650},\n {u'_id': u'rajureddyvudem', u'count': 127720},\n {u'_id': u'udaykanth', u'count': 109344}\n ```\n \n Number of users, who contributed the least... \n```json\n{'$group': {'_id': '$created.user','count': {'$sum': 1}}}, {'$group': {'_id': '$count','num_users': {'$sum': 1}}}, {'$sort': {'_id': 1}}, {'$limit': 1}\n```\n\n\nOutput:\n```json\n{u'_id': 2, u'num_users': 76}\n```\n\n### Conclusion\n\nThe queries were conducted mostly on the users. It is also noticed that there are very few nodes with actual address. The raw-data is extracted here only from one source, hence further raw-data collection from different sources are recommended.\n\nI believe, there are still few opportunities for cleaning and validation of data, which is left unexplored. Keeping that in mind, I would like to state that the data set was well-cleaned for the purposes of this exercise.\n\n#### Files\n- `subset.py`: Creates data subset\n- `iterparse.py`: Parsing through the dataset and getting an initial idea of the raw dataset\n- `audit_db.py`: Auditing the identified issues\n- `final_db_data.py`: Parsing, Editing & Cleaning the identified/considered flaws and dumping a <file>.json file.\n- `mongodb_queries.py`: Creating basic queries over the database after moving the json data to mongodb database.\n"
},
{
"alpha_fraction": 0.45920637249946594,
"alphanum_fraction": 0.4872983396053314,
"avg_line_length": 35.92808151245117,
"blob_id": "07eec0f80b00d5400f170d5d3b59a52c45ae502b",
"content_id": "7ae2968db8ed0e4c30688242d2e1b7066cf9611a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 10786,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 292,
"path": "/P6-Data Viz -Dimple.js/dimple_01_01.js",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "d3.csv(\"airline_dimple_01.csv\",\n function(d) {\n var format = d3.time.format(\"%Y\");\n return {\n 'Year': format.parse(d.year),\n 'Carrier Name': d.carrier_name,\n 'On Time': +d.on_time,\n 'Arrivals': +d.arrivals,\n 'Carrier Delay': +d.carrier_delay,\n 'Weather Delay': +d.wthr_delay,\n 'NAS Delay': +d.ns_delay,\n 'Security Delay': +d.sec_delay,\n 'Late Aircraft Delay': +d.lt_air_delay,\n };\n},\nfunction(data) {\n\n//** ***************************** Carrier Delay *********************************** **//\n\"use strict\";\n // Set the dimensions of the canvas / graph\n var margin_01 = {top: 5, right: 1, bottom: 5, left: 1},\n width_01 = 600 - margin_01.left - margin_01.right,\n height_01 = 500 - margin_01.top - margin_01.bottom;\n \n // d3.select('#content_01')\n // .append('h3')\n // .attr('id', 'title')\n // .text('U.S. Airlines Delay (Carrier)');\n\n // Adds the svg canvas\n var chart_01 = d3.select(\"#content_01\")\n .append(\"svg\")\n .attr(\"width\", width_01 + margin_01.left + margin_01.right)\n .attr(\"height\", height_01 + margin_01.top + margin_01.bottom)\n .append(\"g\")\n .attr(\"transform\", \"translate(\" + margin_01.left + \",\" + margin_01.top + \")\");\n\n /*Dimple.js Chart construction code*/ \n var y_min = 0;\n var y_max = 0.6;\n \n var myChart = new dimple.chart(chart_01, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n // var x = myChart.addTimeAxis(\"x\", \"year\"); \n var y = myChart.addMeasureAxis('y', 'Carrier Delay');\n // var y = myChart.addMeasureAxis('y', 'on_time');\n\n // x.dateParseFormat = \"%Y\"\n x.tickFormat = '%Y';\n x.timeInterval = 1;\n // x.title = 'Year';\n\n y.tickFormat = '%';\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n // y.title = 'On Time';\n\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n myChart.addLegend(width_01*0.95, height_01*0.075, 50, 80, \"right\");\n // myChart.addSeries('carrier_name', dimple.plot.line);\n // myChart.addSeries('carrier_name', dimple.plot.scatter);\n myChart.draw();\n\n//** ***************************** Weather Delay *********************************** **//\n\n // d3.select('#content_02')\n // .append('h3')\n // .attr('id', 'title')\n // .text('U.S. Airlines Delay (Weather)');\n\n // Adds the svg canvas\n var chart_02 = d3.select(\"#content_02\")\n .append(\"svg\")\n .attr(\"width\", width_01 + margin_01.left + margin_01.right)\n .attr(\"height\", height_01 + margin_01.top + margin_01.bottom)\n .append(\"g\")\n .attr(\"transform\", \"translate(\" + margin_01.left + \",\" + margin_01.top + \")\");\n\n /*Dimple.js Chart construction code*/ \n var y_min = 0;\n var y_max = 0.25;\n \n var myChart = new dimple.chart(chart_02, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n // var x = myChart.addTimeAxis(\"x\", \"year\"); \n var y = myChart.addMeasureAxis('y', 'Weather Delay');\n // var y = myChart.addMeasureAxis('y', 'on_time');\n\n // x.dateParseFormat = \"%Y\"\n x.tickFormat = '%Y';\n x.timeInterval = 1;\n // x.title = 'Year';\n\n y.tickFormat = '%';\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n // y.title = 'On Time';\n\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n myChart.addLegend(width_01*0.95, height_01*0.075, 50, 80, \"right\");\n // myChart.addSeries('carrier_name', dimple.plot.line);\n // myChart.addSeries('carrier_name', dimple.plot.scatter);\n myChart.draw();\n\n\n//** ***************************** NAS Delay **************************************** **//\n\n // d3.select('#content_03')\n // .append('h3')\n // .attr('id', 'title')\n // .text('U.S. Airlines Delay (NAS)');\n\n // Adds the svg canvas\n var chart_03 = d3.select(\"#content_03\")\n .append(\"svg\")\n .attr(\"width\", width_01 + margin_01.left + margin_01.right)\n .attr(\"height\", height_01 + margin_01.top + margin_01.bottom)\n .append(\"g\")\n .attr(\"transform\", \"translate(\" + margin_01.left + \",\" + margin_01.top + \")\");\n\n /*Dimple.js Chart construction code*/ \n var y_min = 0;\n var y_max = 0.7;\n \n var myChart = new dimple.chart(chart_03, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n // var x = myChart.addTimeAxis(\"x\", \"year\"); \n var y = myChart.addMeasureAxis('y', 'NAS Delay');\n // var y = myChart.addMeasureAxis('y', 'on_time');\n\n // x.dateParseFormat = \"%Y\"\n x.tickFormat = '%Y';\n x.timeInterval = 1;\n // x.title = 'Year';\n\n y.tickFormat = '%';\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n // y.title = 'On Time';\n\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n myChart.addLegend(width_01*0.95, height_01*0.075, 50, 80, \"right\");\n // myChart.addSeries('carrier_name', dimple.plot.line);\n // myChart.addSeries('carrier_name', dimple.plot.scatter);\n myChart.draw();\n\n//** ***************************** Late Aircraft Delay ****************************** **//\n \n // d3.select('#content_04')\n // .append('h3')\n // .attr('id', 'title')\n // .text('U.S. Airlines Delay (Late Aircraft Delay)');\n\n // Adds the svg canvas\n var chart_04 = d3.select(\"#content_04\")\n .append(\"svg\")\n .attr(\"width\", width_01 + margin_01.left + margin_01.right)\n .attr(\"height\", height_01 + margin_01.top + margin_01.bottom)\n .append(\"g\")\n .attr(\"transform\", \"translate(\" + margin_01.left + \",\" + margin_01.top + \")\");\n\n /*Dimple.js Chart construction code*/ \n var y_min = 0;\n var y_max = 0.7;\n \n var myChart = new dimple.chart(chart_04, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n // var x = myChart.addTimeAxis(\"x\", \"year\"); \n var y = myChart.addMeasureAxis('y', 'Late Aircraft Delay');\n // var y = myChart.addMeasureAxis('y', 'on_time');\n\n // x.dateParseFormat = \"%Y\"\n x.tickFormat = '%Y';\n x.timeInterval = 1;\n // x.title = 'Year';\n\n y.tickFormat = '%';\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n // y.title = 'On Time';\n\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n myChart.addLegend(width_01*0.95, height_01*0.075, 50, 80, \"right\");\n // myChart.addSeries('carrier_name', dimple.plot.line);\n // myChart.addSeries('carrier_name', dimple.plot.scatter);\n myChart.draw();\n\n//** ***************************** Security Delay *********************************** **//\n \n // d3.select('#content_05')\n // .append('h3')\n // .attr('id', 'title')\n // .text('U.S. Airlines Delay (Security Delay)');\n\n // Adds the svg canvas\n var chart_05 = d3.select(\"#content_05\")\n .append(\"svg\")\n .attr(\"width\", width_01 + margin_01.left + margin_01.right)\n .attr(\"height\", height_01 + margin_01.top + margin_01.bottom)\n .append(\"g\")\n .attr(\"transform\", \"translate(\" + margin_01.left + \",\" + margin_01.top + \")\");\n\n /*Dimple.js Chart construction code*/ \n var y_min = 0;\n var y_max = 0.02;\n \n var myChart = new dimple.chart(chart_05, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n // var x = myChart.addTimeAxis(\"x\", \"year\"); \n var y = myChart.addMeasureAxis('y', 'Security Delay');\n // var y = myChart.addMeasureAxis('y', 'on_time');\n\n // x.dateParseFormat = \"%Y\"\n x.tickFormat = '%Y';\n x.timeInterval = 1;\n // x.title = 'Year';\n\n y.tickFormat = '%';\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n // y.title = 'On Time';\n\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n myChart.addLegend(width_01*0.95, height_01*0.075, 50, 80, \"right\");\n // myChart.addSeries('carrier_name', dimple.plot.line);\n // myChart.addSeries('carrier_name', dimple.plot.scatter);\n myChart.draw();\n\n\n//** ***************************** On Time Percentage *********************************** **//\n\n /*\n D3.js setup code\n */\n d3.select('#content_06')\n .append('h3')\n .attr('id', 'title')\n .text('U.S. Airlines On Time Arrivals Percantage');\n\n \"use strict\";\n var margin = 50,\n width = 1200 - margin,\n height = 600 - margin;\n\n // debugger;\n\n var svg = d3.select(\"#content_06\")\n .append(\"svg\")\n .attr(\"width\", width + margin)\n .attr(\"height\", height + margin)\n .append('g')\n .attr('class','chart');\n\n /*\n Dimple.js Chart construction code\n */\n \n\n var y_min = 0.70;\n var y_max = 0.90;\n \n var myChart = new dimple.chart(svg, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n // var x = myChart.addTimeAxis(\"x\", \"year\"); \n var y = myChart.addMeasureAxis('y', 'On Time');\n // var y = myChart.addMeasureAxis('y', 'on_time');\n\n // x.dateParseFormat = \"%Y\"\n x.tickFormat = '%Y';\n x.timeInterval = 1;\n // x.title = 'Year';\n\n y.tickFormat = '%';\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n // y.title = 'On Time';\n\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n // myChart.addLegend(width*0.80, 90, width*0.25, 60);\n myChart.addLegend(width*0.95, height*0.8, 50, 60, \"right\")\n\n // myChart.addSeries('carrier_name', dimple.plot.line);\n // myChart.addSeries('carrier_name', dimple.plot.scatter);\n myChart.draw();\n\n });\n\n\n\n"
},
{
"alpha_fraction": 0.7012470364570618,
"alphanum_fraction": 0.7402493953704834,
"avg_line_length": 47.31623840332031,
"blob_id": "83be0f3efae2e0d9c1a20db492411fe643e567d8",
"content_id": "2ac484ad9a1ef619b53880d8abb0fefa778d265f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11307,
"license_type": "no_license",
"max_line_length": 353,
"num_lines": 234,
"path": "/P6-Data Viz -Dimple.js/README.md",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "\n**Data Visualization of U.S. Airline Delays & On-Time Performance, 2003-2017**\n-- by Krish\n\n***\n\n**Summary**\n\nThere are 6 visualizations shown here. The first 5 graphs try to show which type of delay actually affects the most to a U.S. Airline Carrier. The last one shows each airlines' annual average of on-time arrivals. The data was collected from RITA for the period of 2003 - 2017.\n\n**Design, EDA & Data Preparation**\n\nThe data was downloaded from RITA for the time period of June 2003 to June 2017. It included all domestic flights from all carriers to and from major airports. EDA (Exploratory Data Analysis) was conducted using Rstudio.\n\nAt first we loaded the data into a data-frame and checked first 10 values. NA values were then replaced with zeros (0).\n\nConsidering the variables at hand, we can focus our analysis on many things. I decided to focus on 2 things:\n\n1. The type of delay which affects the most in the overall delay of a particular carrier\n2. The overall performance of a carrier based on the \"On Time\" arrival percentage.\nOn Time = Arrival/(Total Flights)\n\nWhile studying the data, I presumed that there might be trends in individual airline performance (Arrival/(Total Flights)) over the period.\nA line chart for each carrier might best show the different trends across different airline carriers.\n\nAn initial plot of the arrival flights to year for each carrier is made. From the plot nothing is clear as it's too chaotic with high number of carriers present and hence we need to check with smaller number of carriers.\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,fig.width=13}\n\nlibrary(ggplot2)\nlibrary(dplyr)\n\nairlines <- read.csv(\"airline_delay_causes.csv\")\nhead(airlines, 10)\nairlines[is.na(airlines)] <- 0\n\nggplot(data = airlines,\n aes(x = year, y = arr_flights)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\n```\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,}\n\na_new <- airlines %>%\n group_by(carrier_name) %>%\n summarise(n = n()) %>%\n arrange(desc(n))\n\na_new <- head(a_new, 5)\n\ncr_nm <- a_new$carrier_name\ndroplevels(a_new$carrier_name)\n\nairlines_sub <- subset(airlines, carrier_name == cr_nm)\n```\nAfter replacing the NA values, a check was made with the number of occurences of a Flight Carrier. We took a count of the carrier names which were present in the dataset and sorted the count in descending order. We selected top 5 carriers from that list and created a subset of the main data-frame which has only those 5 carriers. They are listed below:\n\na. SkyWest Airlines Inc.\nb. ExpressJet Airlines Inc.\nc. Delta Air Lines Inc.\nd. American Eagle Airlines Inc.\ne. American Airlines Inc.\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,}\nairlines_sub <- airlines_sub %>%\n group_by(year, carrier_name) %>%\n summarise(arrival = sum(arr_flights),\n delay = sum(arr_del15),\n cancelled = sum(arr_cancelled),\n diverted = sum(arr_diverted),\n arrival_delay = sum(X.arr_delay),\n carrier_delay = sum(X.carrier_delay),\n wthr_delay = sum(weather_delay),\n ns_delay = sum(nas_delay),\n sec_delay = sum(security_delay),\n lt_air_delay = sum(late_aircraft_delay)) %>%\n transform(on_time = arrival/(delay + cancelled + diverted + arrival)) %>%\n transform(carrier_delay = carrier_delay/arrival_delay) %>%\n transform(wthr_delay = wthr_delay/arrival_delay) %>%\n transform(ns_delay = ns_delay/arrival_delay) %>%\n transform(sec_delay = sec_delay/arrival_delay) %>%\n transform(lt_air_delay = lt_air_delay/arrival_delay)\n```\n\nAfter filtering the data with the top 5 carriers occuring in the dataset, we plot the same plot again along with another plot (on_time vs year for each carrier). Things are easier to handle now.\n\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = arrival)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\nggplot(data = airlines_sub,\n aes(x = year, y = on_time)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n\n\nThe frist thing which is noticed is that \"American Eagle Airlines\" do not have data after 2014.\nFurther analyis on delay was made by potting the different delays with time for each carrier.\nThere are 5 types of delay mentioned in the data set, listed below:\n\n1. Carrier Delay: Delay caused by the carriers\n2. Weather Delay: Delay caused due to weather conditions\n3. NAS Delay: Delay caused by National Aviation Services\n4. Security Delay: Delay caused due to Security\n5. Late Arrival Delay: Delay by late arrival of flights\n\n```{r, fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = carrier_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n```{r, fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = wthr_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n```{r, fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = ns_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n```{r, fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = sec_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n```{r, fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = lt_air_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n\nFrom the visualizations it's clearly visible that \"security delay\"\" has the least amount of contribution among all the delay types. So, our focus will be on the other delay types.\n\nOur cleaned & modified dataset seems good and hence, we write this data-frame to a .csv file\n```{r}\nwrite.csv(airlines_sub, file=\"airline_dimple_01.csv\", row.names=FALSE)\n```\n\nInitial evaluation of these charts is that they are able to visualize the different trends of the 5 airlines properly. It can be seen how some airlines improved or deteriorated over time. We can also see which airline is currently performing better than the other four.\n\nIt also showed the general trends that all 5 airlines experienced: an aggregate dip in performance from 2005 to 2007 and another dip between 2012 to 2014.\n\nA significant increase in the performace between 2011 to 2013 and again in between 2014 to 2016.\n\nMoving on to the delay section, it's seen that delays caused by carrier, NAS & Late Arrival of flight are the main contributors in the overall delay.\n\nThough with time the contribution in delay from NAS side has reduced, the other two i.e. the contribution from Airlines Carrier & Late Arrival of flight, has still a contribution of 30-40%.\n\n**Data Visualization (dimple.js)**\n\nA re-evaluation of the design was made, and still considered that a line chart is the best way to represent a trend of over time. Each line is given a specific color in order to visually encode each airline in a better fashion.\nIn order to improve the initial data visualization I improved it with dimple.js in the following ways:\n\na. Fix scaling in the y-axis, by converting the values to percentage for easier understanding.\n\nb. Overlay scatter plot points to emphasize each airline's individual data points at each year.\n\nc. Add transparency, as some areas of the graph (2010-2012) have considerable overlap.\n\nThis initial iteration can be viewed at index-initial.html, or below:\n\n\n**Feedback**\n\nI requested for feedback from 3 individuals with a small set of questions. Their comments from them are listed below:\n\nFeedback #1\n\n***\n\n> There are a number of graphs one after the other and it's hard to keep up if the 2nd or 3rd graph is related to the initial heading/title.\n\n> The carrier and flight arrival delay has a similar percentage value for most of the airlines.\n\n> The main takeaway here is that the on-time performance of the airlines fall and rise and again fall with time. Carrier and Late Arrival are the main reasons for delays.\n\n> Highlighting a particular line and fading the rest will help in better focus on the area of study.\n\nFeedback #2\n\n***\n\n> Line are easier to follow each \"path\" of points. It would have been a lot more confusing if there were only points.\n\n> Large dips in in 2007, 2014 & again in 2017 is noticed showcasing the airlines' performance.\n\n> A more explanatory title would've been better.\n\nFeedback #3\n\n***\n\n> The lines and points are colored differently, but I think it would be good to highlight or emphasize individual line when it is selected. It's a bit hard to follow a specific trend line.\n\n> After having an idea of what the graphs were, I looked all the way to the right, because I wanted to know which airlines is delayed the most because of their carrier itself.\n\n> Overall, it's clean.\n\n**Post-feedback Modifications***\n\nAfter receiving the feedback, I did the following changes:\n\ni. Changed the chart title to be more consistent with the data presented.\nii. Made the delay graphs smaller in size and made them place in one grid.\niii. Added a mouseover event for the lines, in order to highlight the path. It'll help in better understanding a particular line of focus.\niv. Subdued and muted the grid lines.\nv. Excluded the security delay related chart as the target is to showcase the main reasons which ultimately cause a delay.\n\nBelow is the final form of the data visualization:\n\n\n\n**Resources**\n\n* [dimple.js Documentation](http://dimplejs.org/)\n* [Dimple.js Lessons (Udacity)](https://classroom.udacity.com/nanodegrees/nd002/parts/00213454010/modules/318423863275460/lessons/3168988586/concepts/30639889960923)\n* Stack Overflow posts\n"
},
{
"alpha_fraction": 0.5484101176261902,
"alphanum_fraction": 0.5548410415649414,
"avg_line_length": 31.546510696411133,
"blob_id": "6adf16720fac4dbec0a33c14aaffa7c06bcc1964",
"content_id": "ac54041aadfa1b36c5d36e5a0d92478118effacf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2799,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 86,
"path": "/P5-Data Wrangling -Mongo - Python/iterparse.py",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "\n####>>>>>Iterative Parsing through an XML File<<<<<####\n\nimport xml.etree.cElementTree as ET\nimport pprint as pp\nimport re\nfrom collections import defaultdict\nimport operator\n\n# filename = 'calcutta_subset.xml'\nfilename = 'Calcutta.osm'\n\nlower = re.compile(r'^([a-z]|_)*$')\nlower_colon = re.compile(r'^([a-z]|_)*:([a-z]|_)*$')\nproblemchars = re.compile(r'[=\\+/&<>;\\'\"\\?%#$@\\,\\. \\t\\r\\n]')\nkeys = {\"lower\": 0, \"lower_colon\": 0, \"problemchars\": 0, \"other\": 0}\n\n####>>>>> Basic Tags count <<<<<####\ndef count_tags(filename):\n tree = ET.iterparse(filename)\n tags = dict()\n for event, element in tree:\n tags.setdefault(element.tag, 0)\n tags[element.tag] += 1\n return tags\n\n####>>>>>Checking for regex characters in tags == \"tags\"<<<<<####\ndef char_check(filename, keys):\n for event, element in ET.iterparse(filename):\n if element.tag == \"tag\":\n if lower.search(element.attrib['k']):\n keys['lower'] += 1\n elif lower_colon.search(element.attrib['k']):\n keys['lower_colon'] += 1\n elif problemchars.search(element.attrib['k']):\n keys['problemchars'] += 1\n else:\n keys['other'] += 1\n return keys\n\n####>>>>> keys stored in each `tag` element, in the `k` attribute <<<<<####\ndef count_k_tags(filename):\n tag_keys_count = {}\n t_k_cnt = 0\n for _, element in ET.iterparse(filename, events=(\"start\",)):\n if element.tag == 'tag' and 'k' in element.attrib:\n tag_keys_count.setdefault(element.get('k'), 0)\n tag_keys_count[element.get('k')] += 1\n \n # t_k_cnt = sum(tag_keys_count.values())\n tag_keys_count = sorted(tag_keys_count.items(), key=operator.itemgetter(1))[::-1]\n \n return tag_keys_count\n\ndef sample_k_data(filename, tags, data_limit=15):\n tags = [i[0] for i in tags]\n data = defaultdict(set)\n\n for _, elem in ET.iterparse(filename, events=(\"start\",)):\n if elem.tag == \"node\" or elem.tag == \"way\":\n for tag in elem.iter(\"tag\"):\n if 'k' not in tag.attrib or 'v' not in tag.attrib:\n continue\n key = tag.get('k')\n val = tag.get('v')\n if key in tags and len(data[key]) < data_limit:\n data[key].add(val)\n return dict(data)\n\n## ***** Main **** ##\ndef main(filename):\n print \"Tags Count: \\n\"\n pp.pprint(count_tags(filename))\n print \"\\n\"\n print \"'k' atrribute Char Check: \\n\"\n pp.pprint(char_check(filename, keys))\n print \"\\n\"\n print \"'k' Tags Count: \\n\"\n tags_k_count = count_k_tags(filename)\n pp.pprint(tags_k_count)\n print \"\\n\"\n print \"sample'k' data: \\n\"\n pp.pprint(sample_k_data(filename, tags_k_count))\n\n\nif __name__ == '__main__':\n main(filename)"
},
{
"alpha_fraction": 0.7130374312400818,
"alphanum_fraction": 0.7407215237617493,
"avg_line_length": 45.9878044128418,
"blob_id": "d9e0b8bdb02438cc656bf2c05c63c57738ebdb4c",
"content_id": "3de6b377539d610af381069e45813a340571aea4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 11559,
"license_type": "no_license",
"max_line_length": 409,
"num_lines": 246,
"path": "/P6-Data Viz -Dimple.js/Data_Viz_Dimple.Rmd",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "\n###**Data Visualization of U.S. Airline Delays & On-Time Performance, 2003-2017**###\n-- by Krish\n\n***\n\n####**Summary**####\n\nFrom RITA, for the time period of June 2003 to June 2017 a data is collected in order to understand the different reasons a flight of an airline carrier is delayed and also the overall performance of the airlines. The overall performance is calculated with the help of the delay/cancelled data and arrival data. It is measured by the percentage value of \"ON TIME\" arrival of any airline for a particular year.\nThere are 6 visualizations shown here. The first 5 graphs try to show which type of delay actually affects the most to a U.S. Airline Carrier. The last one shows each airlines' annual average of on-time arrivals.\n\nAt the end of this Analysis we'll see how the overall performance of airlines fall and rise with time. Performance of Airlines vary between 70% - 90%.\n\n####**Design, EDA & Data Preparation**####\n\nThe data was downloaded from RITA for the time period of June 2003 to June 2017. It included all domestic flights from all carriers to and from major airports. EDA (Exploratory Data Analysis) was conducted using Rstudio.\n\nAt first we loaded the data into a data-frame and checked first 10 values. NA values were then replaced with zeros (0).\n\nConsidering the variables at hand, we can focus our analysis on many things. I decided to focus on 2 things:\n\n1. The type of delay which affects the most in the overall delay of a particular carrier\n2. The overall performance of a carrier based on the \"On Time\" arrival percentage.\nOn Time = Arrival/(Total Flights)\n\nWhile studying the data, I presumed that there might be trends in individual airline performance (Arrival/(Total Flights)) over the period.\nA line chart for each carrier might best show the different trends across different airline carriers.\n\nAn initial plot of the arrival flights to year for each carrier is made. From the plot nothing is clear as it's too chaotic with high number of carriers present and hence we need to check with smaller number of carriers.\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,fig.width=13}\nknitr::opts_chunk$set(fig.path = \"images/\")\n\nlibrary(ggplot2)\nlibrary(dplyr)\n\nairlines <- read.csv(\"airline_delay_causes.csv\")\nhead(airlines, 10)\nairlines[is.na(airlines)] <- 0\n\nggplot(data = airlines,\n aes(x = year, y = arr_flights)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\n```\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,}\n\na_new <- airlines %>%\n group_by(carrier_name) %>%\n summarise(n = n()) %>%\n arrange(desc(n))\n\na_new <- head(a_new, 5)\n\ncr_nm <- a_new$carrier_name\ndroplevels(a_new$carrier_name)\n\nairlines_sub <- subset(airlines, carrier_name == cr_nm)\n\n```\nAfter replacing the NA values, a check was made with the number of occurences of a Flight Carrier. We took a count of the carrier names which were present in the dataset and sorted the count in descending order. We selected top 5 carriers from that list and created a subset of the main data-frame which has only those 5 carriers. They are listed below:\n\na. SkyWest Airlines Inc.\nb. ExpressJet Airlines Inc.\nc. Delta Air Lines Inc.\nd. American Eagle Airlines Inc.\ne. American Airlines Inc.\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,}\nairlines_sub <- airlines_sub %>%\n group_by(year, carrier_name) %>%\n summarise(arrival = sum(arr_flights),\n delay = sum(arr_del15),\n cancelled = sum(arr_cancelled),\n diverted = sum(arr_diverted),\n arrival_delay = sum(X.arr_delay),\n carrier_delay = sum(X.carrier_delay),\n wthr_delay = sum(weather_delay),\n ns_delay = sum(nas_delay),\n sec_delay = sum(security_delay),\n lt_air_delay = sum(late_aircraft_delay)) %>%\n transform(on_time = arrival/(delay + cancelled + diverted + arrival)) %>%\n transform(carrier_delay = carrier_delay/arrival_delay) %>%\n transform(wthr_delay = wthr_delay/arrival_delay) %>%\n transform(ns_delay = ns_delay/arrival_delay) %>%\n transform(sec_delay = sec_delay/arrival_delay) %>%\n transform(lt_air_delay = lt_air_delay/arrival_delay)\n```\n\nAfter filtering the data with the top 5 carriers occuring in the dataset, we plot the same plot again along with another plot (on_time vs year for each carrier). Things are easier to handle now.\n\n\n```{r, echo=FALSE, message=FALSE, warning=FALSE,fig.width=13, fig.height=9}\nknitr::opts_chunk$set(fig.path = \"images/\")\nggplot(data = airlines_sub,\n aes(x = year, y = arrival)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\nggplot(data = airlines_sub,\n aes(x = year, y = on_time)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\n\nThe frist thing which is noticed is that \"American Eagle Airlines\" do not have data after 2014.\nFurther analyis on delay was made by potting the different delays with time for each carrier.\nThere are 5 types of delay mentioned in the data set, listed below:\n\n1. Carrier Delay: Delay caused by the carriers\n2. Weather Delay: Delay caused due to weather conditions\n3. NAS Delay: Delay caused by National Aviation Services\n4. Security Delay: Delay caused due to Security\n5. Late Arrival Delay: Delay by late arrival of flights\n\n```{r, fig.width=13, fig.height=9}\nggplot(data = airlines_sub,\n aes(x = year, y = carrier_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\n\nggplot(data = airlines_sub,\n aes(x = year, y = wthr_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\n\nggplot(data = airlines_sub,\n aes(x = year, y = ns_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\n\nggplot(data = airlines_sub,\n aes(x = year, y = sec_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n\n\nggplot(data = airlines_sub,\n aes(x = year, y = lt_air_delay)) +\n geom_line(aes(color = carrier_name)) +\n scale_x_continuous(limits=c(2003, 2017), breaks=c(2003:2017))\n```\n\nFrom the visualizations it's clearly visible that \"security delay\"\" has the least amount of contribution among all the delay types. So, our focus will be on the other delay types.\n\nOur cleaned & modified dataset seems good and hence, we write this data-frame to a .csv file\n```{r}\nwrite.csv(airlines_sub, file=\"airline_dimple_01.csv\", row.names=FALSE)\n```\n\nInitial evaluation of these charts is that they are able to visualize the different trends of the 5 airlines properly. It can be seen how some airlines improved or deteriorated over time. We can also see which airline is currently performing better than the other four.\n\nIt also showed the general trends that all 5 airlines experienced: an aggregate dip in performance from 2005 to 2007 and another dip between 2012 to 2014.\n\nA significant increase in the performace between 2011 to 2013 and again in between 2014 to 2016.\n\nMoving on to the delay section, it's seen that delays caused by carrier, NAS & Late Arrival of flight are the main contributors in the overall delay.\n\nThough with time the contribution in delay from NAS side has reduced, the other two i.e. the contribution from Airlines Carrier & Late Arrival of flight, has still a contribution of 30-40%.\n\n####**Data Visualization (dimple.js)**####\n\nA re-evaluation of the design was made, and still considered that a line chart is the best way to represent a trend of over time. Each line is given a specific color in order to visually encode each airline in a better fashion.\nIn order to improve the initial data visualization I improved it with dimple.js in the following ways:\n\na. Fix scaling in the y-axis, by converting the values to percentage for easier understanding.\n\nb. Overlay scatter plot points to emphasize each airline's individual data points at each year.\n\nc. Add transparency, as some areas of the graph (2010-2012) have considerable overlap.\n\nThis initial iteration can be viewed at index-initial.html, or below:\n\n\n####**Feedback**####\n\nI requested for feedback from 3 individuals with a small set of questions. Their comments from them are listed below:\n\nFeedback #1\n\n***\n\n> There are a number of graphs one after the other and it's hard to keep up if the 2nd or 3rd graph is related to the initial heading/title.\n\n> The carrier and flight arrival delay has a similar percentage value for most of the airlines.\n\n> The main takeaway here is that the on-time performance of the airlines fall and rise and again fall with time. Carrier and Late Arrival are the main reasons for delays.\n\n> Highlighting a particular line and fading the rest will help in better focus on the area of study.\n\nFeedback #2\n\n***\n\n> Line are easier to follow each \"path\" of points. It would have been a lot more confusing if there were only points.\n\n> Large dips in in 2007, 2014 & again in 2017 is noticed showcasing the airlines' performance.\n\n> A more explanatory title would've been better.\n\nFeedback #3\n\n***\n\n> The lines and points are colored differently, but I think it would be good to highlight or emphasize individual line when it is selected. It's a bit hard to follow a specific trend line.\n\n> After having an idea of what the graphs were, I looked all the way to the right, because I wanted to know which airlines is delayed the most because of their carrier itself.\n\n> Overall, it's clean.\n\nFeedback #3\n\n***\n\n> I see that on_time variable contains the aggregate of delays, so we can use only the final plot in the .html page of this project and remove the other four plots.\n\n> Readers need to see what each on_time data point is composed of. The easiest way to do this is by presenting a detailed information in a tooltip when the cursor hovers over a data point, but I encourage you to try visualizing this information in a more readable way e.g. by using stacked bar chart that shows only when a line is highlighted (warning: It can be quite involved to implement this suggestion).\n\n> Include a paragraph on the visualization page explaining your findings to readers.\n\n####**Post-feedback Modifications***####\n\nAfter receiving the feedback, I did the following changes:\n\ni. Changed the chart title to be more consistent with the data presented.\nii. Made the delay graphs smaller in size and made them place in one grid.\niii. Added a mouseover event for the lines, in order to highlight the path. It'll help in better understanding a particular line of focus.\niv. Subdued and muted the grid lines.\nv. Excluded the other four plots as the 'on_time' variable contains the aggregate of delays. We can use only the final plot.\nvi. Included a paragraph on the visualization page explaining my findings to readers.\nvii. The tooltip when the cursor hovers over a data point, helps a user to understand the performance of the airline carrier for a particular year in a better fashion.\n\nBelow is the final form of the data visualization:\n\n\n\n####**Resources**####\n\n* [dimple.js Documentation](http://dimplejs.org/)\n* [Dimple.js Lessons (Udacity)](https://classroom.udacity.com/nanodegrees/nd002/parts/00213454010/modules/318423863275460/lessons/3168988586/concepts/30639889960923)\n* Stack Overflow posts"
},
{
"alpha_fraction": 0.7248061895370483,
"alphanum_fraction": 0.7984496355056763,
"avg_line_length": 50.599998474121094,
"blob_id": "50a1a622f3fdcc15e3baa7159359405a8214ee53",
"content_id": "40e48bbffca11cda2ba0d5a582cebc93bf980bd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 5,
"path": "/README.md",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "## Data Analyst Nano Degree\n\nA Nano-Degree Certified by Udacity. This repository contains all the Projects done during the Nano-Degree.\n\n\n"
},
{
"alpha_fraction": 0.4651597738265991,
"alphanum_fraction": 0.4734216630458832,
"avg_line_length": 39.35219955444336,
"blob_id": "844231e7848d7794dc1991d9c297033fda49d437",
"content_id": "a548607489f29c0d10fe6e1b478ba07abbc0707c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6415,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 159,
"path": "/P5-Data Wrangling -Mongo - Python/final_db_data.py",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom pprint import pprint\nimport codecs\nimport json\nimport re\nimport xml.etree.ElementTree as ET\nimport audit_db\n\n## ********** Builds JSON file from OSM. Parses, cleans, and shapes data accordingly ********** ##\n\n# filename = \"calcutta_subset.xml\"\nfilename = \"Calcutta.osm\"\n\nlower = re.compile(r'^([a-z]|_)*$')\nlower_colon = re.compile(r'^([a-z]|_)*:([a-z]|_)*$')\nproblemchars = re.compile(r'[=\\+/&<>;\\'\"\\?%#$@\\,\\. \\t\\r\\n]')\naddress_regex = re.compile(r'^addr\\:')\nstreet_regex = re.compile(r'^street')\ngnis_regex = re.compile(r'^gnis\\:')\n\n## All zipcodes in Calcutta are between 700001 & 700120 ###\nzipcodes = [str(i) for i in range(700001,700110)]\n\n## Regex Compiler ##\nstreet_type_re = re.compile(r'\\b\\S+\\.?$', re.IGNORECASE)\ndigit_only = re.compile(r'\\d+')\n\nexpected = [\"Street\", \"Avenue\", \"Boulevard\", \"Drive\", \"Court\", \"Place\", \"Square\", \"Lane\", \"Road\", \n \"Trail\", \"Parkway\", \"Commons\", \"Sarani\", \"Park\", \"Connector\", \"Gardens\"]\n\nmapping = { \"St\": \"Street\", \"St.\": \"Street\", \"street\" : \"Street\", \"Sarani\" : \"Sarani\",\n \"Ave\" : \"Avenue\", \"Rd.\" : \"Road\", \"road\" : \"Road\", \"ROAD\" : \"Road\", \"ROad\" : \"Road\",\n \"Rd\" : \"Road\", \"N.\" : \"North\", \"Ln\" : \"Lane\" }\n\n\n\nCREATED = ['version', 'changeset', 'timestamp', 'user', 'uid']\nIGNORED_TAGS = ['name:ta', 'name:te', 'is_in:city', 'name:de','fax', 'source:name', 'name:uk', 'payment:bitcoin', \n 'name:eo','name:zh', 'AND_a_nosr_r', 'internet_access:fee', 'name:et', 'name:es', 'internet_access',\n 'is_capital', 'ref:new', 'area:highway', 'name:it', 'loc_name', 'name:ru', 'phone_2', 'phone_3',\n 'phone_1', 'local_ref', 'brand:wikidata', 'capital', 'is_in', 'ref','contact:email', 'name:ja',\n 'is_in:continent', 'electrified', 'denomination', 'water', 'name:bn', 'ref:old', 'footway', 'place:cca',\n 'craft', 'alt_name:pl','drive_through', 'name_1', 'name:pl', 'admin_level', 'end_date', 'name:hi', 'building_1', \n 'is_in:state', 'old_name', 'passenger_lines', 'AND:importance_level', 'country', 'wheelchair', 'bridge',\n 'alt_name:eo', 'toilets:disposal', 'surface', 'wikidata', 'foot_1','emergency', 'is_in:country',\n 'building:levels', 'cycleway', 'note', 'name:fr', 'GNS:id', 'description', 'drink', 'is_in:country_code',\n 'name:abbr', 'delivery', 'IR:zone','artwork_type', 'url', 'colour', 'outdoor_seating', 'is_in:iso_3166_2',\n 'takeaway','created_by']\n\ndef format_data(element):\n ignored_tags = IGNORED_TAGS\n node = {}\n if element.tag == \"node\" or element.tag == \"way\" :\n \n node['type'] = element.tag\n\n # Parse attributes\n for a in element.attrib:\n if a in CREATED:\n if 'created' not in node:\n node['created'] = {}\n node['created'][a] = element.attrib[a]\n\n elif a in ['lat', 'lon']:\n if 'pos' not in node:\n node['pos'] = [None, None]\n if a == 'lat':\n node['pos'][0] = float(element.attrib[a])\n else:\n node['pos'][1] = float(element.attrib[a])\n\n else:\n node[a] = element.attrib[a]\n\n # Iterate tag children\n for tag in element.iter(\"tag\"):\n if not problemchars.search(tag.attrib['k']):\n # Tags with single colon\n if lower_colon.search(tag.attrib['k']):\n\n # Ignored Tags\n if tag.attrib['k'] in ignored_tags:\n continue\n\n # Single colon beginning with addr\n if tag.attrib['k'].find('addr') == 0:\n if 'address' not in node:\n node['address'] = {}\n\n sub_attr = tag.attrib['k'].split(':', 1)\n\n #*******if addr:city, city = Kolkata *******\n if sub_attr[1] == \"city\":\n node['address'][sub_attr[1]] = \"Kolkata\"\n\n #*******if addr:state, state = West Bengal *******\n if sub_attr[1] == \"state\":\n node['address'][sub_attr[1]] = \"West Bengal\"\n\n #*******if addr:country, country = India *******\n if sub_attr[1] == \"country\":\n node['address'][sub_attr[1]] = \"India\"\n\n #*******if street name, audit as street *******\n if sub_attr[1] == \"street\":\n strt = audit_db.dirt_clean(tag.attrib['v'])\n node['address'][sub_attr[1]] = audit_db.clean_streets(strt, mapping)\n\n \n #******* if zipcode, audit as zipcode *******\n elif sub_attr[1] == \"postcode\":\n node['address'][sub_attr[1]] = audit_db.final_zipcode(tag.attrib['v'])\n\n # All other single colons processed normally\n else:\n node[tag.attrib['k']] = tag.attrib['v']\n\n # Tags with no colon\n #******* if phone, audit as phone ******* \n elif tag.attrib['k'] == \"phone\":\n node[\"phone\"] = audit_db.final_phone(tag.attrib['v'])\n\n elif tag.attrib['k'].find(':') == -1:\n node[tag.attrib['k']] = tag.attrib['v']\n\n # Iterate 'nd'\n for nd in element.iter(\"nd\"):\n if 'node_refs' not in node:\n node['node_refs'] = []\n node['node_refs'].append(nd.attrib['ref'])\n \n return node\n else:\n return None\n\n\ndef json_convert(file_in, pretty = False):\n # You do not need to change this file\n file_out = \"{0}.json\".format(file_in)\n data = []\n with codecs.open(file_out, \"w\") as fo:\n for _, element in ET.iterparse(file_in):\n el = format_data(element)\n if el:\n data.append(el)\n if pretty:\n fo.write(json.dumps(el, indent=2)+\"\\n\")\n else:\n fo.write(json.dumps(el) + \"\\n\")\n return data\n\n\ndef main():\n data = json_convert(filename, pretty=False)\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.6761597990989685,
"alphanum_fraction": 0.6990475058555603,
"avg_line_length": 36.55160140991211,
"blob_id": "7b0f6e51c389713ae229eb7994f0a5595c11ae97",
"content_id": "b75667aa9978aac364bab258bd4268b08ab1b8ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 21103,
"license_type": "no_license",
"max_line_length": 425,
"num_lines": 562,
"path": "/P3-EDA -R/White_Wine_Quality.Rmd",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "# White Wine Quality\n### by __*Krish*__\n______________________________________________________________________________________________\n\nWhite wine is a wine whose color can be straw-yellow, yellow-green, or yellow-gold coloured. It is produced by the alcoholic fermentation of the non-colored pulp of grapes which may have a white or black skin. It is treated so as to maintain a yellow transparent color in the final product. The wide variety of white wines comes from the large number of varieties, methods of winemaking, and also the ratio of residual sugar.\n\nIn the below dataset I'll analyze the factors which contribute to determine the quality of wine.\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, packages}\n# Load all of the packages that you end up using\n# in your analysis in this code chunk.\n\nsuppressMessages(library(ggplot2))\nsuppressMessages(library(dplyr))\nsuppressMessages(library(tidyr))\nsuppressMessages(library(psych))\nsuppressMessages(library(gridExtra))\nsuppressMessages(library(grid))\nsuppressMessages(library(GGally))\nsuppressMessages(library(corrplot))\n\n# Notice that the parameter \"echo\" was set to FALSE for this code chunk.\n# This prevents the code from displaying in the knitted HTML output.\n# You should set echo=FALSE for all code chunks in your file.\n```\n```{r echo=FALSE, Load_the_Data}\n# Load the Data\nwine <- read.csv(\"wineQualityWhites.csv\")\n#head(wine)\n#names(wine)\n#str(wine)\n# describe(wine)\nwine$color <- 'White'\n```\n\nThis is a Multivariate DataSet, with different characteristics which helps in understanding the factors which results in a higher quality of wine.\n\nIt's a Tidy dataset. All the variables are having numeric data.\nThe dataset consists of few variables which will help us to determine why a specific wine variant is having a particular rating.\n\nMain Feature of Interest is ***Quality***. Other features which will help support the investigation into the feature of interest are:\n\n1. Residual Sugar\n2. Density\n3. Alcohol\n4. Chlorides\n5. Total Sulphar Dioxide\n6. Sulphates\n7. Fixed Acidity\n8. pH\n\nWe'll start with Univariate analysis i.ev. analyzing the variables individually. This will be done with the help of Histograms & Box-Plots which will help us understand the type of distribution the variables are having and also the amount of outliers(if any).\n\nA new variable *\"COLOR\"* is created for easier Box-Plots.\n\n#### **Quality**\n\nQuality is having a positively skewed normal distribution. From the histogram we can see that most of the samples have quality 5, 6 & 7.\nThe boxplot indicates that there are very few outliers present.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE}\nsummary(wine$quality)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = quality)) +\n geom_histogram(binwidth = 1, color = 'white') +\n scale_x_continuous(breaks = seq(0, 9, 1))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = quality)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Fixed Acidity**\n\nFixed acidity is having a normal distribution. From the histogram we can see that most of the samples have a fixed acidity level between 6.25 and 7.25.\nCitric Acid is a part of Fixed Acidity.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for Fixed Acidity:*\n\n```{r echo=FALSE, Univariate_Plots}\nsummary(wine$fixed.acidity)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = fixed.acidity)) +\n geom_histogram(binwidth = 0.5, color = 'white') +\n scale_x_continuous(breaks = seq(3, 15, 0.5))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = fixed.acidity)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Volatile Acidity**\n\nVolatile acidity is having a positively skewed normal distribution. From the histogram we can see that most of the samples have a volatile acidity level between 0.21 and 0.32.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE}\nsummary(wine$volatile.acidity)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = volatile.acidity)) +\n geom_histogram(binwidth = 0.025, color = 'white') +\n scale_x_continuous(breaks = seq(0.05, 1.15, 0.05))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = fixed.acidity)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **pH**\n\npH is having a normal distribution. From the histogram we can see that most of the samples have pH level between 3.1 and 3.3.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for pH:*\n\n```{r, echo=FALSE}\nsummary(wine$pH)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = pH)) +\n geom_histogram(binwidth = 0.05, color = 'white') +\n scale_x_continuous(breaks = seq(2.5, 4, 0.1))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = pH)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Residual Sugar**\n\nResidual Sugar is having a positively skewed normal distribution. From the histogram we can see that most of the samples have residual sugar level between 1.7 and 2.5.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for Residual Sugar:*\n\n```{r echo=FALSE}\nsummary(wine$residual.sugar)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = residual.sugar)) +\n geom_histogram(binwidth = 1, color = 'white') +\n scale_x_continuous(breaks = seq(0, 30, 2.5), limits = c(0, 30))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = residual.sugar)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Alcohol**\n\nAlcohol is having a positively skewed normal distribution. From the histogram we can see that most of the samples have .\nThe boxplot indicates that there are very few outliers present.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE}\nsummary(wine$alcohol)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = alcohol)) + \n geom_histogram(binwidth = 0.1, color = 'white') + \n scale_x_continuous(breaks = seq(8, 15, 0.5))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = alcohol)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Density**\n\nDensity is having a positively skewed normal distribution. From the histogram we can see that most of the samples between 0.990 & 0.998.\nThe boxplot indicates that there are very few outliers present.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE}\nsummary(wine$quality)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = density)) + \n geom_histogram(binwidth = 0.001, color = 'white') + \n scale_x_continuous(breaks = seq(0, 1.02, 0.005))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = density)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Chlorides**\n\nChloride is having a positively skewed normal distribution. From the histogram we can see that most of the samples have chloride level between 0.03 and 0.55.\nThe boxplot indicates that there are excessive outliers present.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE}\nsummary(wine$chlorides)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = chlorides)) +\n geom_histogram(binwidth = 0.005, color = 'white') +\n scale_x_continuous(breaks = seq(0, 0.20, 0.01), limits = c(0, 0.20))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = chlorides)) +\n geom_boxplot(outlier.shape = 2)\n```\n\n#### **Sulphates**\n\nSulphates is having a positively skewed normal distribution. From the histogram we can see that most of the samples have sulphate level between 0.40 and 0.55.\nThe boxplot indicates that there are huge number of outliers present.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE}\nsummary(wine$sulphates)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = sulphates)) + \n geom_histogram(binwidth = 0.05, color = 'white') + \n scale_x_continuous(breaks = seq(0, 1.1, 0.05))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = sulphates)) +\n geom_boxplot(outlier.shape = 2)\n```\n\nAll the variables are normally distributed & mostly positively skewed. There are a lot of outliers which will be ignored in the future investigations.\n\nIn order to start the bivariate analysis, it's required to understand the correlation between variables.\n\nWe'll subset the data by removing the columns *\"X\"* & *\"color\"* as they are irrelevant for calculating correlation.\n\n```{r, echo=FALSE, Bivariate_Plots}\nwine.corr <- subset(wine, select = -c(X, color))\nwine.corr <- round(cor(wine.corr), digits = 3)\n\nggcorr(wine.corr, label = TRUE, label_size = 3,\n label_round = 2, hjust = 1, layout.exp = 3)\n\n```\n\nPositive Correlations\n\n1. Alcohol --> Quality\n2. Residual Sugar --> Density\n3. Free Sulphar Dioxide --> Total Sulphar Dioxide\n4. Density --> Total Sulphar Dioxide\n\nNegative Correlations\n\n1. Total Sulphar Dioxide --> Alcohol\n2. Density --> Alcohol\n3. Residual Sugar --> Alcohol\n4. Fixed Acidity --> pH\n\n*Fixed Acidity* will always be having a negative correlation with *pH* level, as higher the acidity level, lower will be pH level & vice-versae.\n\nTwo compnents which are having a strong correlation with the other variables are:\n\na. Alcohol\nb. Total Sulphar Dioxide\n\nHence, the capability to affect the wine quality by these 2 variables is much more compared to the others. It is to be checked with how the above relations are affecting *Quality.* \n\nConsidering the above correlations, let's take a closer look in the scatter prlots for better understanding how the variables are affecting the quality.\n\n#### _**Alcohol VS. Quality**_\n\n```{r echo = FALSE}\n\nggplot(data = wine,\n aes(x = quality, y = alcohol)) +\n geom_point(alpha = 1/5, position = position_jitter(h = 1), size = 1) +\n scale_x_continuous(breaks = seq(3, 10, 1)) +\n geom_smooth(method = 'lm') +\n labs(subtitle = \"Correlation Coefficient: 0.74\")\n\n```\n\nThere is strong and positive correlation between Alcohol & Quality. Most of the wine samples belong to Quality 5, 6 & 7. For Quality = 5, most of the samples have lower alcohol content. For 6, the alcohol content is uniform i.e. both high & low alcohol content wine with quality = 6 can be found. For quality = 7, most of the samples are having higher content of alcohol. \n\n#### _**Residual Sugar VS. Density**_\n\nHigher Residual Sugar will cuase a higher Density. Comparing how it's affecting quality with the below plot.\n```{r echo = FALSE}\n\nggplot(data = subset(wine, residual.sugar <= 55),\n aes(x = residual.sugar, y = density)) +\n geom_point(alpha = 1/4, aes(color = as.factor(quality))) +\n geom_smooth(method = \"lm\") +\n labs(subtitle = \"Correlation Coefficient: 0.94\") +\n facet_wrap(~as.factor(quality))\n```\n\nHigher quality of wine, which generally has a higher alcohol content has lower residual sugar and hence the density is lower.\n\n#### _**Density VS. Total Sulfur Dioxide**_\n\nThe use of sulfur dioxide (SO2) is widely accepted as a useful winemaking aide. It is used as a preservative because of its anti-oxidative and anti-microbial properties in wine, but also as a cleaning agent for barrels and winery facilities. SO2 as it is a by-product of fermentation. It's having a positive correlation with density which means higher the presence of Sulfur Dioxide will create a wine with higher density.\n\nThe effect to quality is to be determined.\n\n```{r echo = FALSE}\n\nggplot(data = subset(wine, density <= 1.03),\n aes(x = total.sulfur.dioxide, y = density)) +\n geom_point(alpha = 1/5, aes(color = as.factor(quality))) +\n geom_smooth(method = \"lm\") +\n facet_wrap(~as.factor(quality)) +\n labs(subtitle = \"Correlation Coefficient: 0.8\")\n\n```\n\nHigh Quality Wine (i.e. above 6), has lower Total Sulfur Dioxide content, lower Residual Sugar and lower Density.\n\n#### _**Fixed Acidity VS. pH**_\n\n```{r echo = FALSE}\n\nggplot(data = wine,\n aes(x = pH, y = fixed.acidity)) +\n geom_point(alpha = 1/5, aes(color = quality),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(subtitle = \"Correlation Coefficient: -0.77\")\n```\n\nFixed Acidity & pH is having a strong negative correlation. Citric acid is having a strong +ve correlation with fixed acidity & a strong -ve correlation with pH.\n\nAcidity & pH level are inversely related and hence the correlation is negative. Citric acid is considered with Fixed Acidity. Acid content is used in Wine as a preservative.\nFrom the above plots we can't understand how acidity-level/pH-lvel is affecting the quality of wine.\n\nAs this dataset is of white wine which generally has high acidic content, major distinguishable features are not noticed here. A general trend is noticed that a high quality wine has a lower acidic content.\n\n#### _**Total Sulphar Dioxide VS. Alcohol**_\n\n```{r echo = FALSE}\n\nggplot(data = wine,\n aes(x = total.sulfur.dioxide, y = alcohol)) +\n geom_point(alpha = 1/5, aes(color = as.factor(quality))) +\n geom_smooth(method = \"lm\") +\n scale_color_brewer(type = 'qual') +\n facet_wrap(~as.factor(quality)) +\n labs(subtitle = \"Correlation Coefficient: -0.83\")\n\n```\n\nHigher Sulfur Dioxide content reduces the alcohol content which in turn reduces the wine quality. High quality wine are those which will have a higher alcohol content (above 11) with a total sulfur dioxide content below 175.\n\n#### _**Density VS. Alcohol**_\n\n```{r echo = FALSE}\n\nggplot(data = subset(wine, density <= 1.03),\n aes(x = density, y = alcohol)) +\n geom_point(alpha = 1/5, aes(color = as.factor(quality))) +\n geom_smooth(method = \"lm\")+\n facet_wrap(~as.factor(quality)) +\n labs(subtitle = \"Correlation Coefficient: -0.97\")\n\n```\n\nHigh presence of residual Sugar increases density which reduces the quality as seen before. From the above scatter plot it is seen that wine of quality 6, 7, 8 & 9 are having higher alcohol content and lower density.\n\n#### _**Residual Sugar VS. Alcohol**_\n\n```{r echo = FALSE}\n\nggplot(data = subset(wine, residual.sugar <= 55),\n aes(x = residual.sugar, y = alcohol)) +\n geom_point(alpha = 1/5, aes(color = density)) +\n geom_smooth(method = \"lm\", color = \"black\")+\n facet_wrap(~as.factor(quality)) +\n labs(subtitle = \"Correlation Coefficient: -0.84\")\n\n```\n\nAs we've seen before, higher residual sugar results in higher density. From the above picture it's clear that a wine higher alcohol content, which is having a lower residual sugar resulting in lower density tends to have a higher quality score.\n\n#### _**Alcohol VS. Chlorides**_\n\n```{r echo=FALSE}\n\nggplot(data = subset(wine, chlorides <= 0.15),\n aes(x = chlorides, y = alcohol)) +\n geom_jitter(alpha = 1/5, aes(color = as.factor(quality))) +\n geom_smooth(method = \"lm\")+\n facet_wrap(~as.factor(quality)) +\n labs(subtitle = \"Correlation Coefficient: -0.65\")\n\n```\n\n\nLower chloride content in wine has higher alcohol content. Higher quality wine has lower chloride content i.e. it's less salty. If a wine is salty then the wine is more likely to of low quality.\n\nAnother interesting relationship is how Sulfur Dioxide content is affecting density & alcohol, which in turn becomes one of the major factor to determine the quality.\n\nStrongest relationships are found in:\n\n1. Density & Alcohol\n2. Residual Sugar & Density\n3. Sulphar Dioxide & Alcohol\n4. Sulphar Dioxide & Density\n5. Chlorides & Alcohol\n\nFrom the above bivariate analysis it's clear that density and alcohol are the prime factors to determine White Wine Quality. These 2 variables are highly affected by Residual Sugar, Total Sulfur Dioxode & Chloride content.\n\nThe above factors will be analyzed with the help scatter plots. There are a significant number of outliers and so considering the data which are within the IQR.\n\nFor better understandng of the plots 2 new sub-variables are created from alcohol & density by creating slices.\n\n#### _**Alcohol VS. Residual Sugar VS. Density**_\n\n```{r echo=FALSE, Plot_One}\n\n\n#ggplot(data = subset(wine, residual.sugar <= 20 & density <= 1),\n# aes(x = residual.sugar, y = alcohol)) +\n# geom_point(alpha = 1/2, aes(color = density)) +\n# geom_smooth(method = \"lm\", color = \"black\")+\n# facet_wrap(~as.factor(quality))\n\n#ggplot(data = subset(wine, residual.sugar <= 20 & density <= 1),\n# aes(x = residual.sugar, y = alcohol)) + \n# geom_point(alpha = 1/2, aes(color = density)) +\n# geom_line(stat = \"summary\", aes(color = quality))\n# geom_line(stat = 'summary') +\n# facet_wrap(~as.factor(quality))\n\n#wine.quality.bucket <- cut(wine$quality, breaks = c(2, 4, 6, 7, 8, 10))\n\n#wine2 <- wine\n\n#wine2$wine.density.bucket <- cut(wine2$density,\n# breaks = c(0, 0.988, 0.990, 0.992, 0.994, 0.996, 0.998, 1.0))\n\n#wine2$wine.d2.bucket <- cut(wine2$density, breaks = c(0, 0.988, 0.992, 0.996, 1.0, 0.996, 0.998, 1.0))\n\n#wine2$wine.q.bucket <- cut(wine2$quality, breaks = c(2, 4, 5, 6, 7, 8, 10))\n\n#wine2$wine.alc.bucket <- cut(wine2$alcohol, breaks = c(8, 10, 12, 14, 16))\n\n#ggplot(data = subset(wine2, !is.na(wine.density.bucket)),\n# aes(x = residual.sugar, y = alcohol)) +\n# geom_smooth(method = \"lm\",aes(color = wine.q.bucket)) +\n# geom_point(alpha = 1/2, aes(color = wine.density.bucket))\n# facet_wrap(~as.factor(quality))\n \n# geom_line(stat = \"summary\", aes(color = quality))\n\n#wine2 %>%\n# group_by(quality, wine.density.bucket) %>%\n# filter(density <= 1.02) %>%\n# summarise(\n# n = n()) %>%\n# arrange(wine.density.bucket) %>%\n# ungroup()\n\n#wine3 <- wine2 %>%\n# group_by(wine.density.bucket, wine.q.bucket, density) %>%\n# filter(density <= 1.02) %>%\n# summarise(\n# mean_density = mean(density),\n# n = n()) %>%\n# ungroup()\n\n#left_join(wine2, wine3, by = c(\"wine.density.bucket\", \"wine.q.bucket\"))\n\n#merge(wine2, wine3, by.x = c(wine.q.bucket, wine.density.bucket))\n\n#pf.fc_by_age_gender <- pf %>%\n# filter(!is.na(gender))%>%\n# group_by(age, gender) %>%\n# summarise(\n# frnd_cnt_mean = mean(friend_count),\n# frnd_cnt_median = median(friend_count),\n# n = n()) %>%\n# ungroup() %>%\n\nwine$wine.density.bucket <- cut(wine$density,\n breaks = c(0, 0.988, 0.990, 0.992, 0.994, 0.996, 0.998, 1.0))\n\nwine$wine.alc.bucket <- cut(wine$alcohol, breaks = c(8, 10, 12, 14, 16))\n\nggplot(data = subset(wine, residual.sugar <= 30 & !is.na(wine.alc.bucket) & !is.na(wine.density.bucket)),\n aes(x = wine.density.bucket, y = residual.sugar)) +\n geom_point(aes(color = wine.alc.bucket), alpha = 1/2,\n position = position_jitter(h = 1), size = 0.25) +\n facet_wrap(~as.factor(quality)) +\n theme(legend.position = \"bottom\", legend.direction = \"horizontal\")\n\n```\n\nQuality = 3, 4 & 5, has higher density because of higher residual sugar. Alcohol content is mostly between 8 to 10.\n\nQuality = 6,7 & 8, has lower density, generally apporx 0.988 to 0.994 with a residual sugar less that 10. Average alcohol content is between 10 & 12.\n\n#### _**Alcohol VS. Total Sulfur Dioxide VS. Density**_\n\n```{r echo=FALSE, Plot_Two}\n\n#ggplot(data = subset(wine, total.sulfur.dioxide <= 200 & density <= 1),\n# aes(x = total.sulfur.dioxide, y = alcohol)) +\n# geom_point(alpha = 1/2, aes(color = density)) +\n# geom_smooth(method = \"lm\", color = \"black\")+\n# facet_wrap(~as.factor(quality))\n\nggplot(data = subset(wine, total.sulfur.dioxide <= 200 & !is.na(wine.alc.bucket) & !is.na(wine.density.bucket)),\n aes(x = wine.density.bucket, y = total.sulfur.dioxide)) +\n geom_point(aes(color = wine.alc.bucket), alpha = 1/2,\n position = position_jitter(h = 1), size = 0.25) +\n facet_wrap(~as.factor(quality)) +\n theme(legend.position = \"bottom\", legend.direction = \"horizontal\")\n\n```\n\nQuality = 3, 4 & 5, has higher density with a total sulphar dioxide between 150 to 200. Alcohol content is mostly below 10.\n\nQuality = 6,7 & 8, has lower density, generally apporx 0.988 to 0.994 with total sulfur dioxide content between 75 & 150. Average alcohol content is above 11.\n\n#### _**Alcohol VS. Chlorides VS. Density**_\n\n```{r echo=FALSE, Plot_Three}\n\n#ggplot(data = subset(wine, chlorides <= 0.1 & density <= 1),\n# aes(x = chlorides, y = alcohol)) +\n# geom_point(alpha = 1/2, aes(color = density)) +\n# geom_smooth(method = \"lm\", color = \"black\")+\n# facet_wrap(~as.factor(quality))\n\nggplot(data = subset(wine, chlorides <= 0.1 & !is.na(wine.alc.bucket) & !is.na(wine.density.bucket)),\n aes(x = wine.density.bucket, y = chlorides)) +\n geom_point(aes(color = wine.alc.bucket), alpha = 1/2,\n position = position_jitter(h = 1), size = 0.25) +\n facet_wrap(~as.factor(quality)) +\n theme(legend.position = \"bottom\", legend.direction = \"horizontal\")\n\n```\n\nFrom the above plot it's clear that chloride content is mostly uniform for all quality of wine.\n\n#### *Reflection*\n\nAnalyzing the data we can come up the following conclusion:\n\nSugar, Density & Alchol are the major factor which are checked before grading the quality of a particular variety of wine. A wine with with low sugar content, low density & high alcohol content is more likely to be rated as a higher quality of wine.\n\nIt's also notices that a wine of high quality (i.e. >= 6) has a lower Sulpfur Dioxide content. Mostly frequent quality level of white wine is 6.\n\nOther variables like year of production, grape types, wine brand, type of oak used for tha barret etc. are not considered here. If these variables are considered we might get some more insights."
},
{
"alpha_fraction": 0.5698392987251282,
"alphanum_fraction": 0.5957973003387451,
"avg_line_length": 34.21739196777344,
"blob_id": "5f8a08c96803e7b7813563ee1144775095f1bc46",
"content_id": "92ac0881d9696c4e23b9f118468d127a07402074",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 809,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 23,
"path": "/P5-Data Wrangling -Mongo - Python/mongodb_queries.py",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "from pymongo import MongoClient\nimport pprint as pp\n\n## Getting the database ##\ndef get_db(db_name):\n client = MongoClient('localhost:27017')\n db = client[db_name]\n return db\n\n## Query output\ndef mongo_query(db, query):\n return [doc for doc in db.kolkata.aggregate(query)]\n\nquery_01 = [{'$group': {'_id': '$created.user','count': {'$sum': 1}}}, {'$sort': {'count': -1}}, {'$limit': 5}]\nquery_02 = [{'$group': {'_id': '$created.user','count': {'$sum': 1}}}, {'$group': {'_id': '$count','num_users': {'$sum': 1}}}, {'$sort': {'_id': 1}}, {'$limit': 1}]\n\n\nif __name__ == '__main__':\n\tdb = get_db('cities')\n\tprint \"Top 5 users, according to order of contribution... \\n\"\n\tpp.pprint(mongo_query(db, query_01))\n\tprint \"\\nNumber of users, who contributed least... \\n\"\n\tpp.pprint(mongo_query(db, query_02))"
},
{
"alpha_fraction": 0.5509344935417175,
"alphanum_fraction": 0.5576696395874023,
"avg_line_length": 28.700000762939453,
"blob_id": "448b2e8a5519a55cc76eac162992e14efc662150",
"content_id": "e93b12995e4facf98fd68686d73a9baa74a36eb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5939,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 200,
"path": "/P5-Data Wrangling -Mongo - Python/audit_db.py",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "import xml.etree.cElementTree as ET\nimport pprint as pp\nimport re\nfrom collections import defaultdict\n\"\"\"\"\"\nAudits the zipcodes & gives correct zipcode output\n\"\"\"\"\"\n\n## Raw Source File ##\n# filename = \"calcutta_subset.xml\"\nfilename = \"Calcutta.osm\"\n\n## All zipcodes in Calcutta are between 700001 & 700110 ###\nzipcodes = [str(i) for i in range(700001,700110)]\n\n## Regex Compiler ##\nstreet_type_re = re.compile(r'\\b\\S+\\.?$', re.IGNORECASE)\nproblemchars = re.compile(r'[=\\+/&<>;\\'\"\\?%#$@\\,\\. \\t\\r\\n]')\ndigit_only = re.compile(r'\\d+')\n\nexpected = [\"Street\", \"Avenue\", \"Boulevard\", \"Drive\", \"Court\", \"Place\", \"Square\", \"Lane\", \"Road\", \n \"Trail\", \"Parkway\", \"Commons\", \"Sarani\", \"Park\", \"Connector\", \"Gardens\"]\n\nmapping = { \"St\": \"Street\", \"St.\": \"Street\", \"street\" : \"Street\", \"Sarani\" : \"Sarani\",\n \"Ave\" : \"Avenue\", \"Rd.\" : \"Road\", \"road\" : \"Road\", \"ROAD\" : \"Road\", \"ROad\" : \"Road\",\n \"Rd\" : \"Road\", \"N.\" : \"North\", \"Ln\" : \"Lane\" }\n\n## ********** ZipCodes ********** ##\n\n## returns if zip-code like ##\ndef is_zipcode(elem):\n return 'addr:postcode' in elem.attrib['k']\n\n\n## Correct zipcode as output ##\ndef right_zipcode(code): \n for z in zipcodes:\n if code in z:\n return z \n\n## adds any invalid zipcodes (not in format 'dddddd') to a dict ##\ndef audit_zipcode(bad_zipcodes, zipcode):\n if not re.match(r'^\\d{6}$', zipcode):\n bad_zipcodes[zipcode] += 1\n\n# ## Audit plus Edit Zipcodes ##\n# def final_zipcode(final_zipcodes, zipcode):\n# if not re.match(r'^\\d{6}$', zipcode):\n# z = right_zipcode(zipcode[-3:])\n# final_zipcodes[z] += 1\n# else:\n# final_zipcodes[zipcode] += 1\n\n# return final_zipcodes\n\n\n## Audit plus Edit Zipcodes ##\ndef final_zipcode(zipcode):\n if not re.match(r'^\\d{6}$', zipcode):\n z = right_zipcode(zipcode[-3:])\n return z\n else:\n return zipcode\n\n\n## ********** Streets ********** ##\n\ndef is_street_name(elem):\n return (elem.attrib['k'] == \"addr:street\")\n\ndef audit_street_type(street_types, street_name):\n m = street_type_re.search(street_name)\n if m:\n street_type = m.group()\n if street_type not in expected:\n street_types[street_type].add(street_name)\n # print street_type\n\ndef dirt_clean(string):\n string = string.replace(\",\", \"\")\n string = string.strip(')')\n string = string.split(' ')\n string = string[:3]\n string = \" \".join(string)\n return string\n\ndef clean_streets(name, mapping):\n m = street_type_re.search(name)\n if m:\n street_type = m.group()\n if street_type in expected:\n return name\n # clean_street[street_type].add(name)\n elif street_type not in expected:\n if street_type in mapping.keys():\n name = re.sub(street_type_re, mapping[street_type], name)\n return name\n # clean_street[mapping[street_type]].add(name)\n else:\n return name\n # clean_street[\"Others\"].add(name)\n \n # return clean_streets\n\n\n## ********** Phone Numbers ********** ##\ndef is_phone(elem):\n return 'phone' in elem.attrib['k']\n\ndef audit_phone(number_types, phone):\n if digit_only.match(phone):\n number_types['digit_only'] += 1\n else:\n number_types['other'] += 1\n return number_types\n\ndef right_phone(phone_number):\n return re.sub(r'[\\D|\\s]+', '', phone_number)[-10: ]\n\ndef final_phone(phone):\n if digit_only.match(phone):\n return phone\n else:\n d = right_phone(phone)\n return d\n\n# def final_phone(final_phone, phone):\n# if digit_only.match(phone):\n# final_phone[phone] += 1\n# else:\n# d = right_phone(phone)\n# final_phone[d] += 1\n# return final_phone\n\n## ##\ndef audit(osmfile, limit=-1):\n \n # open osm file\n osm_file = open(osmfile, \"r\")\n\n # initialize dictionaries\n street_types = defaultdict(set)\n cln_strt = defaultdict(set)\n bad_zipcodes = defaultdict(int)\n final_zipcodes = defaultdict(int)\n bad_phone = defaultdict(int)\n final_phone_nums = defaultdict(int)\n audit_phone_nums = defaultdict(int)\n\n ## Parsing through elements\n for _, elem in ET.iterparse(osm_file, events=(\"start\",)):\n # check if node or way type\n if elem.tag == \"node\" or elem.tag == \"way\":\n # iterate through `tag` children\n for tag in elem.iter(\"tag\"):\n \n #*******if street name, audit as street*******\n if is_street_name(tag):\n strt = dirt_clean(tag.attrib['v'])\n audit_street_type(street_types, strt)\n # clean_streets(cln_strt, strt, mapping)\n\n \n #******* if zipcode, audit as zipcode ******* \n if is_zipcode(tag):\n audit_zipcode(bad_zipcodes, tag.attrib['v'])\n # final_zipcode(final_zipcodes, tag.attrib['v'])\n\n #******* if phone, audit as phone ******* \n if is_phone(tag):\n audit_phone(bad_phone, tag.attrib['v'])\n # final_phone(final_phone_nums, tag.attrib['v'])\n\n\n # for i in final_phone_nums.keys():\n # audit_phone(audit_phone_nums, i)\n\n # return data\n print \"Bad zipcodes: \\n\"\n pp.pprint(dict(bad_zipcodes))\n # print \"\\n\"\n # print \"Final corrected zipcodes of Calcutta: \\n\"\n # pp.pprint(dict(final_zipcodes))\n\n print \"Bad Streets: \\n\"\n pp.pprint(dict(street_types))\n # print \"\\n\"\n # print \"Final Cleaned Streets of Calcutta: \\n\"\n # pp.pprint(dict(cln_strt))\n\n print \"Bad Phone Numbers: \\n\"\n pp.pprint(dict(bad_phone))\n # print \"\\n\"\n # print \"Final corrected Phone Numbers of Calcutta: \\n\"\n # pp.pprint(dict(final_phone_nums))\n # print \"Recheck: \\n\"\n # pp.pprint(dict(audit_phone_nums))\n\nif __name__ == \"__main__\":\n audit(filename)"
},
{
"alpha_fraction": 0.6758243441581726,
"alphanum_fraction": 0.6966103315353394,
"avg_line_length": 42.61781692504883,
"blob_id": "616dcaac9d310d76d55e966783616be7ed7fcc15",
"content_id": "9526703b9c243f5f69229e7a0361380345b235c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 30357,
"license_type": "no_license",
"max_line_length": 509,
"num_lines": 696,
"path": "/P3-EDA -R/White_Wine_Quality_V-2.0.Rmd",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "# White Wine Quality\n### by __*Krish*__\n______________________________________________________________________________________________\n\nWhite wine is a wine whose color can be straw-yellow, yellow-green, or yellow-gold coloured. It is produced by the alcoholic fermentation of the non-colored pulp of grapes which may have a white or black skin. It is treated so as to maintain a yellow transparent color in the final product. The wide variety of white wines comes from the large number of varieties, methods of winemaking, and also the ratio of residual sugar.\n\nIn the below dataset I'll analyze the factors which contribute to determine the quality of wine.\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, packages}\n# Load all of the packages that you end up using\n# in your analysis in this code chunk.\n\nsuppressMessages(library(ggplot2))\nsuppressMessages(library(dplyr))\nsuppressMessages(library(tidyr))\nsuppressMessages(library(GGally))\nsuppressMessages(library(corrplot))\n\n# Notice that the parameter \"echo\" was set to FALSE for this code chunk.\n# This prevents the code from displaying in the knitted HTML output.\n# You should set echo=FALSE for all code chunks in your file.\n```\n\n```{r echo=FALSE, Load_the_Data}\n# Load the Data\nwine <- read.csv(\"wineQualityWhites.csv\")\n#head(wine)\n#names(wine)\n#str(wine)\n# describe(wine)\nwine$color <- 'White'\n```\n\nThis is a Multivariate DataSet, with different characteristics which helps in understanding the factors which results in a higher quality of wine.\n\nIt's a Tidy dataset. All the variables are having numeric data.\nThe dataset consists of few variables which will help us to determine why a specific wine variant is having a particular rating.\n\nMain Feature of Interest is ***Quality***. Other features which will help support the investigation into the feature of interest are:\n\n1. Residual Sugar\n2. Density\n3. Alcohol\n4. Chlorides\n5. Total Sulphar Dioxide\n6. Sulphates\n7. Fixed Acidity\n8. pH\n\nWe'll start with Univariate analysis i.ev. analyzing the variables individually. This will be done with the help of Histograms & Box-Plots which will help us understand the type of distribution the variables are having and also the amount of outliers(if any).\n\nA new variable *\"COLOR\"* is created for easier Box-Plots.\n\n#### **Quality**\n\nQuality is having a positively skewed normal distribution. From the histogram we can see that most of the samples have quality 5, 6 & 7.\nThe boxplot indicates that there are very few outliers present.\n\n*Summary Statistics for Wine Quality:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$quality)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = quality)) +\n geom_histogram(binwidth = 1, color = \"white\") +\n scale_x_continuous(breaks = seq(0, 9, 1)) +\n labs(list(x = \"Quality\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = quality)) +\n geom_boxplot(outlier.shape = 2) +\n labs(y = \"Quality\")\n\n```\n\n#### **Fixed Acidity**\n\nFixed acidity is having a normal distribution. From the histogram we can see that most of the samples have a fixed acidity level between 6.25 and 7.25.\nCitric Acid is a part of Fixed Acidity.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for Fixed Acidity:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$fixed.acidity)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = fixed.acidity)) +\n geom_histogram(binwidth = 0.01, color = 'white') +\n scale_x_log10(breaks = seq(3, 10, 1)) +\n labs(list(x = \"Fixed Acidity (g/dm^3)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = subset(wine, fixed.acidity <=10),\n aes(x = color, y = fixed.acidity)) +\n geom_boxplot(outlier.shape = 2) +\n labs(y = \"Fixed Acidity\")\n\n```\n\n#### **Volatile Acidity**\n\nVolatile acidity is having a positively skewed normal distribution. From the histogram we can see that most of the samples have a volatile acidity level between 0.21 and 0.32.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for Volatile Acidity:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$volatile.acidity)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = volatile.acidity)) +\n geom_histogram(binwidth = 0.025, color = 'white') +\n scale_x_log10(breaks = seq(0.05, 0.7, 0.05)) +\n theme(axis.text.x = element_text(angle = 90, hjust = 1)) +\n labs(list(x = \"Volatile Acidity (g/dm^3)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine,\n aes(x = color, y = volatile.acidity)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(y = \"Volatile Acidity (g/dm^3)\", x = \"Color\"))\n\n```\n\n#### **pH**\n\npH is having a normal distribution. From the histogram we can see that most of the samples have pH level between 3.1 and 3.3.\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for pH:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$pH)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = pH)) +\n geom_histogram(binwidth = 0.05, color = 'white') +\n scale_x_continuous(breaks = seq(2.5, 4, 0.1)) +\n labs(list(x = \"pH\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = pH)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(x = \"Color\", y = \"pH\"))\n```\n\n#### **Residual Sugar**\n\nResidual Sugar is having a bimodal distribution. From the histogram we can see that most of the samples have residual sugar between the below 2 range.\n\n1. Below 2\n2. 8 to 14\n\nThe boxplot indicates there are lot of outliers present in the dataset.\n\n*Summary Statistics for Residual Sugar:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$residual.sugar)\n\n## HISTOGRAM\nggplot(data = wine, aes(x = residual.sugar)) +\n geom_histogram(binwidth = 0.05, color = 'white') +\n scale_x_log10(breaks = seq(0, 20, 2)) +\n theme(axis.text.x = element_text(angle = 90, hjust = 1)) +\n labs(list(x = \"Residual Sugar (g/dm^3)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = residual.sugar)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(y = \"Residual Sugar (g/dm^3)\", x = \"Color\"))\n```\n\n#### **Alcohol**\n\nAlcohol is having a positively skewed normal distribution, hence the histogram plot is done with a logarithmic scale. From the histogram we can see there are sudden spikes, indicating a lot of samples falling within that range.\n\nMajor samples have alcohol content between 9.4 & 9.6.\n\nThe boxplot indicates that there are very few outliers present.\n\n*Summary Statistics for Alcohol:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$alcohol)\n\n## HISTOGRAM\nggplot(data = subset(wine, alcohol <= 13), aes(x = alcohol)) + \n geom_histogram(binwidth = 0.005, color = 'white') + \n scale_x_log10(breaks = seq(8, 15, 0.1)) +\n theme(axis.text.x = element_text(angle = 90, hjust = 1)) +\n labs(list(x = \"Alcohol (% by vol.)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = alcohol)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(y = \"Alcohol (% by vol.)\", x = \"Color\"))\n```\n\n#### **Density**\n\nDensity is having a positively skewed normal distribution. From the histogram we can see that most of the samples between 0.990 & 0.998.\nThe boxplot indicates that there are very few outliers present.\n\n*Summary Statistics for Density:*\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$quality)\n\n## HISTOGRAM\nggplot(data = subset(wine, density <= 1), aes(x = density)) + \n geom_histogram(binwidth = 0.001, color = 'white') + \n scale_x_continuous(breaks = seq(0, 1, 0.001)) +\n theme(axis.text.x = element_text(angle = 45, hjust = 1)) +\n labs(list(x = \"Density (g/cm^3)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = density)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(y = \"Density (g/cm^3)\", x = \"Color\"))\n```\n\n#### **Chlorides**\n\nChloride is having a positively skewed normal distribution. From the histogram we can see that most of the samples have chloride level between 0.03 and 0.55.\nThe boxplot indicates that there are excessive outliers present.\n\n*Summary Statistics for Chlorides:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$chlorides)\n\n## HISTOGRAM\nggplot(data = subset(wine, chlorides <=0.08), aes(x = chlorides)) +\n geom_histogram(binwidth = 0.0025, color = 'white') +\n scale_x_continuous(breaks = seq(0, 0.10, 0.01)) +\n labs(list(x = \"Chlorides (g/cm^3)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = chlorides)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(y = \"Chlorides (g/cm^3)\", x = \"Color\"))\n```\n\n#### **Total Sulfur Dioxide**\n\nTotal Sulfur Dioxide (SO2) is having a positively skewed normal distribution. From the histogram we can see that most of the samples have SO2 level between 100 and 170.\nThe boxplot indicates that there are huge number of outliers present.\n\n*Summary Statistics for Total Sulfur Dioxide:*\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\nsummary(wine$total.sulfur.dioxide)\n\n## HISTOGRAM\nggplot(data = subset(wine, total.sulfur.dioxide <= 300),\n aes(x = total.sulfur.dioxide)) + \n geom_histogram(color =\"white\", binwidth = 5) +\n scale_x_continuous(breaks = seq(0, 300, 20)) +\n labs(list(x = \"Total Sulfur Dioxide (mg/cm^3)\", y = \"Count\"))\n\n## BOXPLOT\nggplot(data = wine, aes(x = color, y = total.sulfur.dioxide)) +\n geom_boxplot(outlier.shape = 2) +\n labs(list(y = \"Total Sulfur Dioxide (mg/cm^3)\", x = \"Color\"))\n```\n\nAll the variables are normally distributed & mostly positively skewed. There are a lot of outliers which will be ignored in the future investigations.\n\nIn order to start the bivariate analysis, it's required to understand the correlation between variables.\n\nWe'll subset the data by removing the columns *\"X\"* & *\"color\"* as they are irrelevant for calculating correlation.\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\n\nwine.corr <- subset(wine, select = -c(X, color))\nwine.corr <- round(cor(wine.corr), digits = 3)\n\nggcorr(wine.corr, label = TRUE, label_size = 3,\n label_round = 2, hjust = 1, layout.exp = 3)\n\n```\n\nPositive Correlations\n\n1. Alcohol --> Quality\n2. Residual Sugar --> Density\n3. Free Sulphar Dioxide --> Total Sulphar Dioxide\n4. Density --> Total Sulphar Dioxide\n\nNegative Correlations\n\n1. Total Sulphar Dioxide --> Alcohol\n2. Density --> Alcohol\n3. Residual Sugar --> Alcohol\n4. Fixed Acidity --> pH\n\n*Fixed Acidity* will always be having a negative correlation with *pH* level, as higher the acidity level, lower will be pH level & vice-versae.\n\nTwo compnents which are having a strong correlation with the other variables are:\n\na. Alcohol\nb. Total Sulphar Dioxide\n\nHence, the capability to affect the wine quality by these 2 variables is much more compared to the others. It is to be checked with how the above relations are affecting *Quality.* \n\nConsidering the above correlations, let's take a closer look in the scatter prlots for better understanding how the variables are affecting the quality.\n\n#### _**Alcohol VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE}\n\nggplot(data = wine,\n aes(x = quality, y = alcohol)) +\n geom_point(alpha = 1/5, color = I(\"#888888\"),\n position = position_jitter(h = 1), size = 1) +\n scale_x_continuous(breaks = seq(3, 10, 1)) +\n geom_smooth(method = 'lm', color = \"black\") +\n labs(subtitle = \"Correlation Coefficient: 0.74\") +\n labs(list(y = \"Alcohol (g/cm^3)\", x = \"Quality\"))\n\n```\n\nThere is strong and positive correlation between Alcohol & Quality. Most of the wine samples belong to Quality 5, 6 & 7. For Quality = 5, most of the samples have lower alcohol content. For 6, the alcohol content is uniform i.e. both high & low alcohol content wine with quality = 6 can be found. For quality = 7, most of the samples are having higher content of alcohol. \n\n#### _**Residual Sugar VS. Density**_\n\nHigher Residual Sugar will cuase a higher Density. Comparing how it's affecting quality with the below plot.\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=6, fig.width=6}\n\nggplot(data = subset(wine, residual.sugar <= 55),\n aes(x = residual.sugar, y = density)) +\n geom_point(alpha = 1/4, color = I(\"#888888\"),\n position = position_jitter(h = 0), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n labs(subtitle = \"Correlation Coefficient: 0.94\") +\n labs(list(x = \"Residual Sugar (g/cm^3)\", y = \"Density (g/cm^3)\"))\n\n```\n\nWine samples which have higher level of residual sugar content has higher density.\nIt is to be analyzed how residual sugar level is affecting the quality.\n\n#### _**Density VS. Total Sulfur Dioxide**_\n\nThe use of sulfur dioxide (SO2) is widely accepted as a useful winemaking aide. It is used as a preservative because of its anti-oxidative and anti-microbial properties in wine, but also as a cleaning agent for barrels and winery facilities. SO2 as it is a by-product of fermentation. It's having a positive correlation with density which means higher the presence of Sulfur Dioxide will create a wine with higher density.\n\nThe effect to quality is to be determined.\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=6, fig.width=6}\n\nggplot(data = subset(wine, density <= 1.03),\n aes(x = total.sulfur.dioxide, y = density)) +\n geom_point(alpha = 1/5, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\") +\n labs(subtitle = \"Correlation Coefficient: 0.8\") +\n labs(list(x = \"Total Sulfur Dioxide (mg/dm^3)\", y = \"Density (g/cm^3)\"))\n\n```\n\nWine samples which have higher level of total sulfur dioxide content has higher density.\nIt is to be analyzed how total sulfur ioxide level is affecting the quality.\n\n#### _**Fixed Acidity VS. pH**_\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=6, fig.width=6}\n\nggplot(data = wine,\n aes(x = pH, y = fixed.acidity)) +\n geom_point(alpha = 1/2, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\") +\n labs(subtitle = \"Correlation Coefficient: -0.77\") +\n labs(list(x = \"pH\",\n y = \"Fixed Acidity (Tartaric Acid - g/dm^3)\"))\n```\n\nFixed Acidity & pH is having a strong negative correlation. Citric acid is having a strong +ve correlation with fixed acidity & a strong -ve correlation with pH.\n\nAcidity & pH level are inversely related and hence the correlation is negative. Citric acid is considered with Fixed Acidity. Acid content is used in Wine as a preservative.\nFrom the above plots we can't understand how acidity-level/pH-lvel is affecting the quality of wine.\n\nAs this dataset is of white wine which generally has high acidic content, major distinguishable features are not noticed here. A general trend is noticed that a high quality wine has a lower acidic content.\n\n#### _**Total Sulphar Dioxide VS. Alcohol**_\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=6, fig.width=6}\n\nggplot(data = wine,\n aes(x = total.sulfur.dioxide, y = alcohol)) +\n geom_point(alpha = 1/2, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\") +\n labs(subtitle = \"Correlation Coefficient: -0.83\") +\n labs(list(x = \"Total Sulfur Dioxide (mg/dm^3)\", y = \"Alcohol (% by volume)\"))\n\n```\n\nHigher Sulfur Dioxide content reduces the alcohol content which in turn reduces the wine quality. High quality wine are those which will have a higher alcohol content (above 11) with a total sulfur dioxide content below 175.\n\n#### _**Density VS. Alcohol**_\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=6, fig.width=6}\n\nggplot(data = subset(wine, density <= 1.03),\n aes(x = density, y = alcohol)) +\n geom_point(alpha = 1/5, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\") +\n labs(subtitle = \"Correlation Coefficient: -0.97\") +\n labs(list(x = \"Density (g/cm^3)\", y = \"Alcohol (% by volume)\"))\n\n```\n\nHigh presence of residual Sugar increases density. From the above scatter plot it is seen that wine samples having higher alcohol content have lower density. Hence, the 3 variables are to be analyzed together to check the effect on quailty.\n\n#### _**Alcohol VS. Chlorides**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=6, fig.width=6}\n\nggplot(data = subset(wine, chlorides <= 0.15),\n aes(x = chlorides, y = alcohol)) +\n geom_point(alpha = 1/2, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\")+\n labs(subtitle = \"Correlation Coefficient: -0.65\") +\n labs(list(x = \"Chloride (Chloride - g/dm^3)\", y = \"Alcohol (% by volume)\"))\n\n```\n\nLower chloride content in wine has higher alcohol content. Higher quality wine has lower chloride content i.e. it's less salty. If a wine is salty then the wine is more likely to of low quality.\n\nAnother interesting relationship is how Sulfur Dioxide content is affecting density & alcohol, which in turn becomes one of the major factor to determine the quality.\n\nStrongest relationships are found in:\n\n1. Density & Alcohol\n2. Residual Sugar & Density\n3. Sulphar Dioxide & Alcohol\n4. Sulphar Dioxide & Density\n5. Chlorides & Alcohol\n\nFrom the above bivariate analysis it's clear that density and alcohol are the prime factors to determine White Wine Quality. These 2 variables are highly affected by Residual Sugar, Total Sulfur Dioxode & Chloride content.\n\nThe above factors will be analyzed with the help scatter plots. There are a significant number of outliers and so considering the data which are within the IQR.\n\nWell start with the multivariate plots.\n\n#### _**Residual Sugar VS. Density VS. Quality**_\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, residual.sugar <= 25),\n aes(x = residual.sugar, y = density)) +\n geom_point(alpha = 1/2, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Residual Sugar\", y = \"Density\"))\n\n```\n\nAs we've seen before, higher residual sugar results in higher density. From the above picture it's clear that a wine sample, which is having a lower residual sugar resulting in lower density tends to have a higher quality score.\n\n#### _**Alcohol VS. Density VS. Quality**_\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\n#ggplot(data = subset(wine, density <= 1),\n# aes(x = alcohol, y = density)) +\n# geom_point(alpha = 1/2, color = I(\"#888888\")) +\n# geom_smooth(method = \"lm\", color = \"black\") +\n# facet_wrap(~as.factor(quality)) +\n# labs(list(x = \"Alcohol (% by volume)\", y = \"Density (g/cm^3)\"))\n\nggplot(data = subset(wine, density <= 1),\n aes(x = alcohol, y = density)) +\n geom_point(alpha = 1/4, aes(color = density)) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Density (g/cm^3)\"))\n\n```\n\nFrom the above picture it's clear that a wine sample, which is having a lower alcohol content with a higher density tends to have a lower quality score.\nIt's is to be analyzed how residual sugar & total sulfur dioxide content are playing a part in affecting the resulting quality.\n\n#### _**Alcohol VS. Residual Sugar VS. Quality**_\n\n```{r echo = FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & residual.sugar <= 25),\n aes(x = alcohol, y = residual.sugar)) +\n geom_point(alpha = 1/2, color = I(\"#888888\"),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Residual Sugar (g/cm^3)\"))\n\n```\n\nIn quality 5, 6 & 7, there's a dense population of wine samples at (0 - 5 g/cm^3) residual sugar accross alcohol content. But it is seen that for quality level 7, there are very few wine samples with higher residual sugar an lower alcohol content. For quality level 5, it's just the opposite i.e. there's a very high population of wine sample with lower alcohol content but the residual sugar level is varied. To get a further clear picture a multivariate plot is to checked w.r.t. density & alcohol content. \n\n#### _**Alcohol VS. Residual Sugar VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & residual.sugar <= 25),\n aes(x = alcohol, y = residual.sugar)) +\n geom_point(alpha = 1/2, aes(color = density),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Residual Sugar (g/cm^3)\")) +\n theme(legend.title = element_text())\n\n```\n\nFrom the above graph we get a clear picture and also a proof that correlatio does not lead to causation. Here we can see that the residual sugar is direct effect on the density of wine & that too directly proportional but not on alchol. The wine sample with lower residual sugar & density which are having a higher alcohol content of more that 11% by volume tends to have a higher quality level.\n\nTo get a further clear picture on that the below plot is created.\n\n#### _**Residual Sugar VS. Density VS. Alcohol VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nwine$wine.alc.bucket <- cut(wine$alcohol, breaks = c(8, 10, 12, 14, 16))\n\nggplot(data = subset(wine, density <= 1 & residual.sugar <= 25 & !is.na(wine.alc.bucket)),\n aes(x = residual.sugar, y = density)) +\n geom_point(alpha = 1/2, aes(color = wine.alc.bucket)) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Residual Sugar (g/cm^3)\", y = \"Density (g/cm^3)\"))\n```\n\nMost wine samples which are of quality level 6, have an alcohol content between 10-12% by volume. As the quality increases the residual sugar level is found less & hence lower density of the wine. The alcohol content is within 12-14% by volume.\n\n#### _**Total Sulfur Dioxide VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & total.sulfur.dioxide <= 250),\n aes(x = total.sulfur.dioxide, y = density)) +\n geom_point(alpha = 1/2, color = I(\"#888888\")) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Total Sulfur Dioxide(mg/dm^3)\", y = \"Density (g/cm^3)\"))\n\n```\n\nTotal Sulfur Dioxide content has a positive correlation with density. As the quality increases the total sulfur dioxide content decreases and ranges between 50-200 mg/dm^3. If the total sulfur dioxide content is less the density is also less for a particular wine sample.\n\n#### _**Residual Sugar VS. Total Sulfur Dioxide VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & residual.sugar <= 25 & total.sulfur.dioxide <= 250),\n aes(x = total.sulfur.dioxide, y = residual.sugar)) +\n geom_point(alpha = 1/2, aes(color = density),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Total Sulfur Dioxide(mg/dm^3)\", y = \"Residual Sugar (g/cm^3)\"))\n\n```\n\nThe above plot a gives us a better picture about Residual Sugar & Total Sulfur Dioxide and it's relation with density. Total Sufur Dioxide does not affect the density of wine directly.\n\n#### _**Alcohol VS. Total Sulfur Dioxide VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & total.sulfur.dioxide <= 250),\n aes(x = alcohol, y = total.sulfur.dioxide)) +\n geom_point(alpha = 1/2, aes(color = density),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Total Sulfur Dioxide(mg/dm^3)\"))\n\n```\n\nWine with lower Total Sulfur Dioxide content has a higher alcohol content and lower density. A more clear picture is visible from the below plot.\n\n#### _**Total Sulfur Dioxide VS. Density VS. Alcohol VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & total.sulfur.dioxide <= 250 & !is.na(wine.alc.bucket)),\n aes(x = density, y = total.sulfur.dioxide)) +\n geom_point(alpha = 1/2, aes(color = wine.alc.bucket)) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Density (g/cm^3)\", y = \"Total Sulfur Dioxide(mg/dm^3)\"))\n\n```\n\nAs the quality increases the total sulfur dioxide content decreases and alcohol content increases from 10-12% by to 12-14% by volume. The density decreases subsequently.\n\n#### _**Alcohol VS. Chlorides VS. Density**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=7, fig.width=12}\n\nggplot(data = subset(wine, chlorides <= 0.1 & density <= 1),\n aes(x = alcohol, y = chlorides)) +\n geom_point(alpha = 1/2, aes(color = density)) +\n geom_smooth(method = \"lm\", color = \"black\")+\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Chlorides (g/dm^3\"))\n\n#ggplot(data = subset(wine, chlorides <= 0.1 & !is.na(wine.alc.bucket) & !is.na(wine.density.bucket)),\n# aes(x = wine.density.bucket, y = chlorides)) +\n# geom_point(aes(color = wine.alc.bucket), alpha = 1/2,\n# position = position_jitter(h = 1), size = 0.25) +\n# facet_wrap(~as.factor(quality)) +\n# theme(legend.position = \"bottom\", legend.direction = \"horizontal\")\n\n```\n\nFrom the above plot it's clear that chloride content is mostly uniform for all quality of wine. A wine containing salt less than 0.05 g/dm^3 is preferred.\n\n#### **Final Plots and Summary**\n\nAfter analyzing the variables in various ways, I woul like to go back to the below 3 plots which gives us a clear picture about the major factors that define a wine a is ofgood quality.\n\n#### _**1. Residual Sugar VS. Total Sulfur Dioxide VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=10, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & residual.sugar <= 25 & total.sulfur.dioxide <= 250),\n aes(x = total.sulfur.dioxide, y = residual.sugar)) +\n geom_point(alpha = 1/2, aes(color = density),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n scale_y_continuous(limits = c(0, 25)) +\n labs(list(x = \"Total Sulfur Dioxide(mg/dm^3)\", y = \"Residual Sugar (g/cm^3)\"))\n\n```\n\nFrom the above plot we can see that Residual Sugar is main factor for wine density. There can exist a wine with higher Sulfur content but less residual sugar. As the residual sugar is less the density is also less. Both quality 5 & 6 have wine with \nvery low sugar content but most the samples have higher sugar content of above 10g/dm^3. The sulfur content ranges between 50-200 mg/dm^3.\n\nFor quality 7 & 8 residual sugar content is below 10g/dm^3 & the sulfur content ranges between 50-150 mg/dm^3.\n\nSulfur is not affecting density. Density is affected by Residual Sugar which in turn affects the overall quality of wine. As seen before in *Density VS. Alcohol*, density directly affects the alcohol content. Hence, we need to see the effect of residual sugar on density & alcohol.\n\n#### _**2. Alcohol VS. Residual Sugar VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=10, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & residual.sugar <= 25),\n aes(x = alcohol, y = residual.sugar)) +\n geom_point(alpha = 1/2, aes(color = density),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Residual Sugar (g/cm^3)\")) +\n scale_y_continuous(limits = c(0, 25))\n\n```\n\nResidual Sugar is affecting higher density which in turn is affecting the alcohol content. Quality 5 is having mostly alcohol content between 8-10% by volume. Whereas 6 & 7 are having alcohol content between 10-12% for Quality-6 and mostly above 12-14% for Quality-7. Higher the quality the residual sugar content is lower i.e. below 10g/dm^3 approx.\n\nThe effect of sulfur content on density is minimal. Hence the effect on alcohol content is also minimal. It's clearly visible from the below plot.\n\n#### _**3. Alcohol VS. Total Sulfur Dioxide VS. Density VS. Quality**_\n\n```{r echo=FALSE, message=FALSE, warning=FALSE, fig.height=10, fig.width=12}\n\nggplot(data = subset(wine, density <= 1 & total.sulfur.dioxide <= 250),\n aes(x = alcohol, y = total.sulfur.dioxide)) +\n geom_point(alpha = 1/2, aes(color = density),\n position = position_jitter(h = 1), size = 1) +\n geom_smooth(method = \"lm\", color = \"black\") +\n facet_wrap(~as.factor(quality)) +\n labs(list(x = \"Alcohol (% by volume)\", y = \"Total Sulfur Dioxide(mg/dm^3)\"))\n\n```\n\nThe sulfur content ranges between 50-250mg/dm^3. Wine with sulfur content below 200mb/dm^3 is given preference.\n\nAnalyzing the data we can come up the following conclusion:\n\nSugar, Density & Alchol are the major factor which are checked before grading the quality of a particular variety of wine. A wine with with low sugar content, low density & high alcohol content is more likely to be rated as a higher quality of wine.\n\nIt's also noticed that a wine of high quality (i.e. >= 6) has a lower Sulpfur Dioxide content. Mostly frequent quality level of white wine is 6.\n\nOther variables like year of production, grape types, wine brand, type of oak used for tha barret etc. are not considered here. If these variables are considered we might get some more insights.\n\n#### *Reflection*\n\n\nAnalyzing the white wine dataset a great experience. There were some initial challenges on the domain knowledge side. I overcame it by using the power of WWW (World Wide Web).\n\n1. http://waterhouse.ucdavis.edu/whats-in-wine\n2. http://winemakersacademy.com/category/wine-making-science/\n\nThe overall experience helped me in gaining an in depth knowledge about different factors affecting a quality of wine. With the help of this knowledge I'll be able to suggest people the kind of white wine one should buy. A further analysis on red wine will be required to be able to answer questions on both the types."
},
{
"alpha_fraction": 0.542553186416626,
"alphanum_fraction": 0.5438829660415649,
"avg_line_length": 28.079999923706055,
"blob_id": "f3a4d57d8ed27d22041cbc9aaad476965755b63a",
"content_id": "30e5ac4c12e5b92440aae9489ccb061ed24e3b10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 752,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 25,
"path": "/P5-Data Wrangling -Mongo - Python/subset.py",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "\r\nfrom pprint import pprint\r\nimport xml.etree.ElementTree as ET\r\n\r\nin_file = 'Calcutta.osm'\r\nout_file = 'calcutta_subset.xml'\r\n\r\n\r\ndef main(file_in, file_out):\r\n\r\n root = ET.Element('osm')\r\n\r\n for _, elem in ET.iterparse(file_in, events=(\"start\",)):\r\n if elem.tag == \"node\" or elem.tag == \"way\":\r\n tag_type = elem.tag\r\n if len([child.tag for child in elem.iter(\"tag\")]) >= 2:\r\n print '.'\r\n node = ET.SubElement(root, tag_type, attrib=elem.attrib)\r\n for tag in elem.iter(\"tag\"):\r\n child = ET.SubElement(node, 'tag', attrib=tag.attrib)\r\n\r\n tree = ET.ElementTree(root)\r\n tree.write(file_out)\r\n\r\nif __name__ == '__main__':\r\n main(in_file, out_file)"
},
{
"alpha_fraction": 0.6702961325645447,
"alphanum_fraction": 0.7408232092857361,
"avg_line_length": 52.64159393310547,
"blob_id": "b269b707d37637fa8edbf1a14e5bb542f1c18571",
"content_id": "e893a9f7b4119d80469e735bf818cf3b7116f8c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 12187,
"license_type": "no_license",
"max_line_length": 699,
"num_lines": 226,
"path": "/P4-ML/README.md",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "## Intro\n\nThe goal of this project is to build a model to identify “Persons of Interest” (POI) within an organization. The\ntarget will be reached by training our model based on the ENRON Email data set which consists of emails between\nemployees within the organization ENRON.\n\nENRON was one of the largest companies in the United States which collapsed into bankruptcy due to widespread\ncorporate fraud. In the resulting Federal investigation, there was a significant amount of typically confidential\ninformation entered the public record, including tens of thousands of emails and detailed financial data for to\nexecutives.\n\nHence, this data set will be a good training data set for our algorithm.\n\nThe dataset contains a total of 146 data points with 21 features. Among the 146 records, 18 records are labeled\nas persons of interest i.e. 18 people are tagged as POI. All the records have 14 financial features, 6 email features, and\n1 labeled feature (POI). The POI labelled feature is 0 (zero) for a Non-POI & 1 (one) for a POI.\n\nThere was an outlier in the data set, which was a cumulative sum of the financial details of all employees. This\nwas detected by plotting a scatter plot between “Salary” & “Bonus”, followed by checking the name of the persons\nwho are having a salary of more than **“1000000”**. Data points having salary more than **“1000000”**:\n\n- **LAY KENNETH L** \n- **SKILLING JEFFREY K** \n- **TOTAL** \n- **FREVERT MARK A** \n\nThe outlier **TOTAL** was deleted from the data set as it’s not representing a person. The rest were not deleted as\nthey can be important in our analysis & model.\n\n## Feature Selection & Tuning:\n\n*Available Features:*\n\nFinancial Features: ['salary', 'deferral_payments', 'total_payments', 'loan_advances', 'bonus',\n'restricted_stock_deferred', 'deferred_income', 'total_stock_value', 'expenses', 'exercised_stock_options', 'other',\n'long_term_incentive', 'restricted_stock', 'director_fees'] (all units are in US dollars)\n\nEmail Features: ['to_messages', 'email_address', 'from_poi_to_this_person', 'from_messages',\n'from_this_person_to_poi', 'shared_receipt_with_poi'] (units are generally number of emails messages; notable\nexception is ‘email_address’, which is a text string)\n\nFrom the available features 3 new features were created:\n\n- `fraction_to_poi`\n- `fraction_from_poi`\n- `wealth`\n\n**‘fraction_to_poi’** & **‘fraction_from_poi’:** These 2 features are basically calculating the frequency of emails which\nwere exchanged between an employee & a POI. For a person who is not identified as a POI but any of the frequency\nis too high for him, then the person can himself be a POI.\n\n**‘wealth’:** A sum of all the money received by a person within the organization. This gives us an overall idea about\nhow much a person was earning by working in ENRON. A person with lower salary at a lower designation might turn\nout to have a higher wealth than a person of higher designation because of the bonus he’s receiving or the\nlong-term incentive he’s receiving or something else. Hence, this person can be a POI.\n\n*Calculation:*\n\nfraction_to_poi = total count of \"from_this_person_to_poi\" / total count of \"from_messages\"\nfraction_from_poi = total count of “from_poi_to_this_person” / total count of “to_messages”\nwealth = ['salary', 'total_stock_value', 'exercised_stock_options', 'bonus', 'long_term_incentive']\n\nA Feature Selection is made by using **SelectKBest** on all the available features except *'email_address’*.\n*'email_address’* contains a text string and it does not act as an important feature to identify if a person is a POI or\nnot. Below is the score output of **SelectKBest**.\n\n*Feature Scores:*\n\n ('expenses', 25.097541528735491) \n ('deferred_income', 24.467654047526398) \n ('loan_advances', 21.060001707536571) \n ('wealth', 18.575703268041785) \n ('fraction_from_poi', 16.641707070468989) \n ('fraction_to_poi', 16.518618271965217) \n ('restricted_stock_deferred', 11.595547659730601) \n ('other', 10.072454529369441) \n ('long_term_incentive', 9.3467007910514877) \n ('deferral_payments', 8.8667215371077717) \n ('from_this_person_to_poi', 8.7464855321290802) \n ('total_payments', 7.2427303965360181) \n ('total_stock_value', 6.2342011405067401) \n ('to_messages', 5.3449415231473374) \n ('exercised_stock_options', 4.204970858301416) \n ('poi', 3.2107619169667441) \n ('from_messages', 2.4265081272428781) \n ('restricted_stock', 2.1076559432760908) \n ('director_fees', 1.6988243485808501) \n ('salary', 0.2170589303395084) \n ('from_poi_to_this_person', 0.16416449823428736) \n ('bonus', 0.06498431172371151) \n\nNow in order to choose the number of features, we create a plot where accuracy, precision and recall are presented\nfor different values of k. Based on the below plot we can decide on a specific value of k considering on our recall\nthreshold value of 0.3.\n\n\n\nTarget is to have minimum features with maximum information. From the above graph we can see that if k = 7, we\ncan reach our target. Hence, finally 7 features are selected. They are listed below:\n- `exercised_stock_options`\n- `total_stock_value`\n- `bonus`\n- `salary`\n- `fraction_to_poi`\n- `wealth`\n- `deferred_income`\n\nAltogether 3 algorithms were tried & validated, but finally only one was chosen. All the 3 algorithms were run 10\ntimes with different parameter selections. Below are the details for each algorithm which parameters were tuned:\n\ni. *Gaussian NB*: No parameter tuning was done for GaussianNB\n\nii. *Random Forest Classifier*: Random Forest is an ensemble learning method for classification. It runs multiple\ndecision tree algorithms & gives a cumulative output. Below are the results: \n\n a. Mean Accuracy: **0.861111111111** \n b. Mean Precision: **0.461904761905** \n c. Mean Recall: **0.461904761905** \n\nTuned parameters are mentioned below: \n a. n_estimators = [10, 20, 50, 100] \n b. min_samples_split = [2, 3, 4, 5] \n \niii. *SVC (Support Vector Classifier)*: SVC is a supervised learning model with associated learning algorithms that\nanalyze data used for classification. Tuned parameters are mentioned below: \n a. kernel = [\"rbf\"] \n b. C = [1, 10, 20, 30, 50] \n\nEach algorithm was ran for 20 times. Below are the best results for each algorithm. \n i. *Gaussian NB*:\n \n Report: \n precision recall f1-score support \n 0.0 0.93 0.95 0.94 41 \n 1.0 0.60 0.50 0.55 6 \n avg / total 0.89 0.89 0.89 47 \n \nii. *Random Forest Classifier*: \n\n Best Paramters: {'randomforestclassifier__min_samples_split': 2, 'randomforestclassifier__n_estimators': 50}\n Report: \n precision recall f1-score support \n 0.0 0.95 1.00 0.98 41 \n 1.0 1.00 0.67 0.80 6 \n avg / total 0.96 0.96 0.95 47 \n \niii. *SVC*: \n\n Best Paramters: {'svc__kernel': 'rbf', 'svc__C': 1}\n Report: \n precision recall f1-score support \n 0.0 0.87 1.00 0.93 41 \n 1.0 0.00 0.00 0.00 6 \n avg / total 0.76 0.87 0.81 47 \n\n*Final Algorithm*: \n Finally, based on the accuracy scores, precision scores & recall scores of GaussianNB, Rnadom Forest Classifer & SVC, GaussiaNB & Random Forest Classifier(min_samples_split: 2, n_estimators: 50) were chosen. SVC had zero precision\nscore & recall score for POI = 1. \n Now each algorithm with the selected parameters are ran with a ***KFold Split = 3*** for 20 iterations. After 20 iterations\nthe mean accuracy, precision & recall are calculated. Below is the result: \n\n1. *GaussianNB*: \n a) **Mean Accuracy: 0.86463151403** \n b) **Mean Precision: 0.466666666667** \n c) **Mean Recall: 0.414285714286** \n\n2. *Random Forest Classifier(min_samples_split: 4, n_estimators: 50)*: \n a) **Mean Accuracy: 0.871569534382** \n b) **Mean Precision: 0.222222222222** \n c) **Mean Recall: 0.111111111111** \n\n3. *SVC*: \n a) **Mean Accuracy: 0.871569534382** \n b) **Mean Precision: 0.0** \n c) **Mean Recall: 0.0** \n\nFine Tuning an algorithm means adjusting the parameters of the algorithm to get best possible prediction results on\na validation data set (any other data set other than the training data set). The validation should always be\nperformed on a data set other than the training data set to avoid over tuning & over fitting of the classifier. This can\nbe achieved by running the algorithm multiple times with different parameter selection. But doing this can be tedious job & hence, two Sklearn tools (Pipeline & GridSearchCV) can be used to achieve the best possible tuned parameters of any algorithm. Based on the recall score, finally GaussianNB is chosen. Here, GaussianNB is being used which is not having any\ntuning parameter. So no tuning is being done for the algorithm.\n\n*Result*: Classifier -> Gaussian NB\n\n**Validation**:\n Validation is the process of checking if the model which is being created is a generalized model, i.e. It’s not only\nworking on the trained data set it’s working on other similar data sets as well. To achieve this we divide the data set at hand into two parts. \n A. `Training Set` \n B. `Validation Set` \n We create train-test partitions to provide us honest assessments of the performance of our predictive models. The data at hand is almost similar to the data which the algorithm will be fed with in the real world. Our target is to make sure the algorithm will work well enough with the real world data. As we don’t have real world data to test with, we divide the data set at hand into two parts. We train the classifier with one part and check how the classifier is working with the test part of the data set. \n The division of the data into train and test must be executed carefully to avoid introducing any systematic differences between train and test. If we test the classifier with the same data set with which we are training the data set then we’ll over-fit the classifier. The results will be pretty good as we are predicting the same labels with which we have trained the classifier. But we’ll not be able to understand how the classifier will perform in the real world. \n Multiple iterations of training & testing of the classifier on train & validation set and taking note of few Evaluation Metrics for each iteration is a process of validating the model. A validation set is created by partitioning the training set into two parts. During the validation process, this validation set is used to tune the algorithm and evaluate how the algorithm would hypothetically perform on unseen data. KFold is one of the process of validating a model. It splits the data set into multiple splits based on the n_split parameter. Each split will contain a train set & a validation set. Here a KFold Validation is done will *n_split = 3*. Below is the mean score for each metrics. \n- `Mean Accuracy: 0.86463151403`\n- `Mean Precision: 0.466666666667`\n- `Mean Recall: 0.414285714286`\n\nWe get a final score on the GaussianNB:\n- `GNB Accuracy: 0.86463151403`\n- `Tester.py Results: GaussianNB(priors=None)`\n- `Accuracy: 0.85186`\n- `Precision: 0.47459`\n- `Recall: 0.34550`\n- `F1: 0.39988`\n- `F2: 0.36538`\n- `True positives: 691`\n- `False positives:765`\n- `False negatives: 1309`\n- `True negatives: 11235`\n- `Total predictions: 14000` \n\n**Evaluation**:\n\nEvaluation Metrics is a metric which helps a person to understand how the model is working.\n - Precision Score: Precision Score is the ratio of true positives to the records that are POIs, essentially describing how often 'false alarms' are not raised.\n - Accuracy Score: Accuracy Score is the ratio of right predictions & wrong predictions\n - Recall Score: Recall is the ratio of true positives to the people who are tagged as POIs.\n \n Below are the mean results after the final run of GaussianNB for 100 iterations: \n ***Mean Accuracy: 0.86463151403 \n Mean Precision: 0.466666666667 \n Mean Recall: 0.414285714286*** \n\n**Reference**:\n- [Civis Analytics](https://www.civisanalytics.com/blog/)\n- [Intro to Machine Learning](https://in.udacity.com/course/intro-to-machine-learning--ud120)\n- [Scikit Learn Documentation](http://scikit-learn.org/stable/documentation.html)\n"
},
{
"alpha_fraction": 0.5736263990402222,
"alphanum_fraction": 0.5854753851890564,
"avg_line_length": 33.7707633972168,
"blob_id": "613ce427620b9a56745db64857d2a13fbe10f510",
"content_id": "2180425786bbebf87e522214483ec82c92165da3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10465,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 301,
"path": "/P4-ML/poi_id.py",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"../tools/\")\nimport numpy\nfrom numpy import mean\nimport pickle\nimport pandas\nimport matplotlib.mlab as mlab\nimport matplotlib.pyplot as plt\nfrom pandas.tools.plotting import scatter_matrix\n#plt.style.use('ggplot')\nfrom sklearn.feature_selection import SelectKBest\nfrom sklearn.feature_selection import SelectPercentile, f_classif\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.decomposition import PCA\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.metrics import accuracy_score, precision_score, recall_score\nfrom sklearn import tree\nfrom sklearn.pipeline import *\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.svm import SVC\nfrom sklearn.metrics import *\nfrom sklearn.model_selection import *\nfrom sklearn.pipeline import make_pipeline\n\n\nfrom feature_format import featureFormat, targetFeatureSplit\nfrom tester import dump_classifier_and_data\n\n\nfeatures_list = ['poi']\n\nwith open(\"final_project_dataset.pkl\", \"r\") as data_file:\n data_dict = pickle.load(data_file)\n\nmy_dataset = data_dict\n\nprint \"\\nChecking for outliers based on salary more than 1000000.. \\n\"\nfor k, v in data_dict.items():\n if v['salary'] != 'NaN' and v['salary'] > 1000000: print k\n\nprint \"\\nTOTAL is not a person. It's a cumulative data of numerical features.\\nHence it should be removed. \\n\"\n\ndel data_dict[\"TOTAL\"]\nmy_dataset = data_dict\n\n\n### Email\nfor item in my_dataset:\n person = my_dataset[item]\n if (all([person['from_poi_to_this_person'] != 'NaN',\n person['from_this_person_to_poi'] != 'NaN',\n person['to_messages'] != 'NaN',\n person['from_messages'] != 'NaN'\n ])):\n fraction_from_poi = float(person[\"from_poi_to_this_person\"]) / float(person[\"to_messages\"])\n person[\"fraction_from_poi\"] = fraction_from_poi\n fraction_to_poi = float(person[\"from_this_person_to_poi\"]) / float(person[\"from_messages\"])\n person[\"fraction_to_poi\"] = fraction_to_poi\n else:\n person[\"fraction_from_poi\"] = person[\"fraction_to_poi\"] = 0\n\n### Financial:\n\nfor item in my_dataset:\n person = my_dataset[item]\n if (all([person['salary'] != 'NaN',\n person['total_stock_value'] != 'NaN',\n person['exercised_stock_options'] != 'NaN',\n person['bonus'] != 'NaN',\n person['long_term_incentive'] != 'NaN'\n ])):\n person['wealth'] = sum([person[value] for value in ['salary',\n 'total_stock_value',\n 'exercised_stock_options',\n 'bonus',\n 'long_term_incentive']])\n else:\n person['wealth'] = 'NaN'\n\n\nmy_features = features_list + ['fraction_from_poi',\n 'fraction_to_poi','wealth',\n 'salary', 'deferral_payments', 'total_payments',\n 'loan_advances', 'bonus',\n 'restricted_stock_deferred', 'deferred_income',\n 'total_stock_value', 'expenses',\n 'exercised_stock_options', 'other',\n 'long_term_incentive',\n 'restricted_stock', 'director_fees',\n 'to_messages',\n 'from_poi_to_this_person',\n 'from_messages', 'from_this_person_to_poi',\n 'shared_receipt_with_poi']\n\n\n\n### *****Feature Selection Function*****\n\ndef Selection(data, feature_range, s_features):\n \n data = featureFormat(data, s_features, sort_keys = True)\n labels, features = targetFeatureSplit(data)\n features_iter = []\n \n for i in feature_range:\n \n select = SelectKBest(k = i)\n select.fit(features, labels)\n \n results_list = zip(select.get_support(), my_features[1:], select.scores_)\n results_list = sorted(results_list, key = lambda x: x[2], reverse=True)\n \n iter_feat = [i[1] for i in results_list if i[0] == True]\n \n features_iter.append(iter_feat)\n \n score_list = zip(my_features[:], select.scores_)\n score_list = sorted(score_list, key = lambda x: x[1], reverse=True)\n \n for i in score_list: print i\n return features_iter\n\n\n### *****Feature Plotting Function******\n\ndef Plotting(clf, f_list, input_data):\n \n accuracy = []\n precision = []\n recall = []\n \n for i in f_list:\n feat = ['poi'] + i\n\n data = input_data\n data = featureFormat(data, feat, sort_keys = True)\n f_labels, f_features = targetFeatureSplit(data)\n \n f_features_train, f_features_test, f_labels_train, f_labels_test = train_test_split(f_features, f_labels, test_size=0.33, random_state=42)\n \n clf.fit(f_features_train, f_labels_train)\n pred = clf.predict(f_features_test)\n \n accuracy.append(accuracy_score(f_labels_test, pred))\n recall.append(recall_score(f_labels_test, pred))\n precision.append(precision_score(f_labels_test, pred))\n \n x = [i + 1 for i in range(len(f_list))]\n y1 = accuracy\n y2 = recall\n y3 = precision\n \n fig = plt.figure()\n ax1 = fig.add_subplot(111)\n \n ax1.plot(x, y1, c='r', label='Accuracy')\n ax1.plot(x, y2, c='g', label='Recall')\n ax1.plot(x, y3, c='b', label='Precision')\n plt.axis([0, 18, 0, 1])\n plt.grid(True)\n plt.legend(loc='lower right')\n plt.xlabel('Number of \"K\" in SelectKBest')\n plt.ylabel('Scores')\n plt.title('K vs Accuracy, Recall, Precision')\n plt.show()\n\n\n\n### *****Classifier Tuning Function*****\n\ndef Grid(clf, data, selected_features, parameters, iterations = 20):\n\n data = featureFormat(data, selected_features, sort_keys = True)\n labels, features = targetFeatureSplit(data)\n\n for i in range(iterations):\n\n features_train, features_test, labels_train, labels_test = train_test_split(features, labels, test_size=0.33, random_state=42)\n pipeline = make_pipeline(clf)\n\n cv = GridSearchCV(pipeline, param_grid = parameters)\n cv.fit(features_train,labels_train)\n pred = cv.predict(features_test)\n\n print \"\\nIteration Num.:\", (i + 1)\n print \"\\nBest Paramters:\", cv.best_params_\n print \"\\nReport:\\n\", classification_report(labels_test, pred)\n\n\n\n### ******Validation Function*****\n\ndef Classifer(clf, data, features, iterations = 100):\n\n data = featureFormat(data, features, sort_keys = True)\n labels, features = targetFeatureSplit(data)\n\n for i in range(iterations):\n kf = KFold(n_splits = 3, shuffle = False)\n clf = clf\n\n accuracy = []\n precision = []\n recall = []\n print \"\\nIteration Num.:\", (i + 1)\n\n for train, test in kf.split(features):\n features_train = []\n features_test = []\n labels_train = []\n labels_test = []\n\n for m in train:\n features_train.append( features[m] )\n labels_train.append( labels[m] )\n\n for n in test:\n features_test.append( features[n] )\n labels_test.append( labels[n] )\n clf.fit(features_train, labels_train)\n pred = clf.predict(features_test)\n accuracy.append(accuracy_score(labels_test, pred))\n precision.append(precision_score(labels_test, pred))\n recall.append(recall_score(labels_test, pred))\n\n print \"\\nMean Accuracy:\", mean(accuracy)\n print \"\\nMean Precision:\", mean(precision)\n print \"\\nMean Recall:\", mean(recall)\n\n\nprint \"\\n*******************************************************************\\n\"\nprint \"\\nRunning Feature Selection..\\n\"\n\nfeature_range = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , 11, 12, 13, 14, 15, 16, 17, 18]\nkbest_features = Selection(my_dataset, feature_range, my_features)\n\nPlotting(GaussianNB(), kbest_features, my_dataset)\n\n#my_features = [\"poi\"] + kbest_features[6]\n\ndata = featureFormat(my_dataset, my_features, sort_keys = True)\nlabels, features = targetFeatureSplit(data)\n\nprint '\\nRunning Final Feature Selection of 7 features..\\n'\n\nselect = SelectKBest(k = 7)\nselect.fit(features, labels)\n\nresults_list = zip(select.get_support(), my_features[1:], select.scores_)\nresults_list = sorted(results_list, key = lambda x: x[2], reverse=True)\nfor i in results_list: print i\nmy_features = features_list + [i[1] for i in results_list if i[0] == True]\n\nprint '\\n'\nprint \"Final Selected features..\\n\"\nfor i in my_features[1:]: print i\n\n#print \"\\n*******************************************************************\\n\"\n#print \"\\nRunning GaussianNB.. Wait for some time \\n\"\n#params = dict()\n#Grid(GaussianNB(), my_dataset, my_features, params)\n\n#print \"\\nRunning GaussianNB.. Wait for some time \\n\"\n#clf = GaussianNB()\n#Classifer(clf, my_dataset , my_features, iterations = 20)\n\n#print \"\\n*******************************************************************\\n\"\n\n#print \"\\nRunning RandomForestClassifier.. Please Wait for some more time \\n\"\n#\n#params = dict(randomforestclassifier__n_estimators=[10, 20, 50, 100],\n# randomforestclassifier__min_samples_split=[2, 3, 4, 5])\n#\n#Grid(RandomForestClassifier(), my_dataset, my_features, params)\n\n#print \"\\nRunning Final RandomForestClassifier.. Please Wait for some more time \\n\"\n#\n#clf = RandomForestClassifier(n_estimators = 20, min_samples_split = 2)\n#Classifer(clf, my_dataset , my_features, iterations = 20)\n\n#print \"\\n*******************************************************************\\n\"\n\n#print \"\\nRunning SVC.. Almost done.. Please Wait for some more time \\n\"\n#\n#params = dict(svc__kernel = ['rbf'],\n# svc__C = [1, 10, 20 ,30, 50])\n#Grid(SVC(), my_dataset, my_features, params)\n\n#print \"\\nRunning SVC.. Wait for some more time \\n\"\n#clf = SVC(C = 1, kernel = 'rbf')\n#Classifer(clf, my_dataset , my_features, iterations = 20)\n\nprint \"\\n*******************************************************************\\n\"\n\nprint \"\\nRunning Final GaussianNB.. Final Run..\\n\"\nclf = GaussianNB()\nClassifer(clf, my_dataset , my_features)\n\ndump_classifier_and_data(clf, my_dataset, my_features)"
},
{
"alpha_fraction": 0.48164862394332886,
"alphanum_fraction": 0.5024067163467407,
"avg_line_length": 30.367923736572266,
"blob_id": "3ce721b9cf1591a5d7e35b51f35fdd208b20f25a",
"content_id": "0fcd06f2cf5b675c53f68e4c3215da9b9ad31405",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3324,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 106,
"path": "/P6-Data Viz -Dimple.js/dimple_final_01.js",
"repo_name": "sekhar989/Udacity-DAND",
"src_encoding": "UTF-8",
"text": "\"use strict\";\n// Getting the data\nd3.csv(\"airline_dimple_01.csv\",\n // Formatting the column names for better readability\n function(d) {\n var format = d3.time.format(\"%Y\");\n return {\n 'Year': format.parse(d.year),\n 'Carrier Name': d.carrier_name,\n 'On Time': +d.on_time,\n 'Arrivals': +d.arrivals,\n 'Carrier Delay': +d.carrier_delay,\n 'Weather Delay': +d.wthr_delay,\n 'NAS Delay': +d.ns_delay,\n 'Security Delay': +d.sec_delay,\n 'Late Aircraft Delay': +d.lt_air_delay,\n };\n},\n\n// Creating the canvas, Setting up the axis & drawing the chart\nfunction(data) {\n\n//** ***************************** On Time Percentage *********************************** **//\n /*\n D3.js setup code\n */\n\n // Adding a header title to the graph by selecting the selction tag using #id\n d3.select('#content_02')\n .append('h3')\n .attr('id', 'title')\n .text('On Time Arrivals Performance of U.S. Airlines, 2003 - 2017');\n\n // Setting margin, height & width value\n var margin = 50,\n width = 1000 - margin,\n height = 500 - margin;\n\n // Constructing the canvas\n var svg = d3.select(\"#content_02\")\n .append(\"svg\")\n .attr(\"width\", width + margin)\n .attr(\"height\", height + margin)\n .append('g')\n .attr('class','chart');\n\n /*\n Dimple.js Chart construction code\n */\n // Setting limit for y axis, by providing the minimum and maximum values\n var y_min = 0.70;\n var y_max = 0.90;\n \n // Chart Contruction\n var myChart = new dimple.chart(svg, data);\n var x = myChart.addTimeAxis(\"x\", \"Year\"); \n var y = myChart.addMeasureAxis('y', 'On Time');\n\n // Formatting x-axis to year format\n x.tickFormat = '%Y';\n\n // Setting x-axis interval to 1 year\n x.timeInterval = 1;\n\n // Formatting y-axis to Percentage format\n y.tickFormat = '%';\n\n // Overriding y-minimum & maximum values\n y.overrideMin = y_min;\n y.overrideMax = y_max;\n\n // Drawing the graph\n myChart.addSeries('Carrier Name', dimple.plot.scatter);\n myChart.addSeries('Carrier Name', dimple.plot.line);\n myChart.addLegend(width*0.95, height*0.8, 50, 70, \"right\");\n\n // Drawing the graph\n myChart.draw();\n\n // handle mouse events on gridlines\n y.gridlineShapes.selectAll('line')\n .style('opacity', 0.25)\n .on('mouseover', function(e) {\n d3.select(this)\n .style('opacity', 1);\n }).on('mouseleave', function(e) {\n d3.select(this)\n .style('opacity', 0.25);\n });\n\n // handle mouse events on paths\n d3.selectAll('path')\n .style('opacity', 0.25)\n .on('mouseover', function(e) {\n d3.select(this)\n .style('stroke-width', '8px')\n .style('opacity', 1)\n .attr('z-index', '1');\n }).on('mouseleave', function(e) {\n d3.select(this)\n .style('stroke-width', '2px')\n .style('opacity', 0.25)\n .attr('z-index', '0');\n });\n\n });"
}
] | 15 |
AbhishekBose/Pytorch-Codes
|
https://github.com/AbhishekBose/Pytorch-Codes
|
3d1474ad12c87e758bc24de35e90e8108419c4cc
|
95db40dc5302dc9a6ad9e5cbf8dba1b52ab9ab44
|
bbf80e17ec8d41ffbaeb0e139ee6f1c033110342
|
refs/heads/master
| 2020-04-17T22:29:52.717009 | 2019-02-08T12:56:50 | 2019-02-08T12:56:50 | 166,996,553 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8452380895614624,
"alphanum_fraction": 0.8452380895614624,
"avg_line_length": 40.5,
"blob_id": "077e2545d281fd9a99746f0138b9fcaddcab4bcd",
"content_id": "678f44a543a14e2c12703aa2060a910791c2949f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 2,
"path": "/README.md",
"repo_name": "AbhishekBose/Pytorch-Codes",
"src_encoding": "UTF-8",
"text": "# Pytorch-Codes\nContains pytorch implementation of Different Deep Learning modules \n"
},
{
"alpha_fraction": 0.5437802076339722,
"alphanum_fraction": 0.5703502297401428,
"avg_line_length": 27.756521224975586,
"blob_id": "f75bc4165195cb297b0f31c53221cd7692029943",
"content_id": "8a389e289827c04a35e38451876824052ebeed30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3312,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 115,
"path": "/basic_chatbot.py",
"repo_name": "AbhishekBose/Pytorch-Codes",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Feb 7 15:43:30 2019\n\n@author: techject\n\"\"\"\n\nimport torch\nimport torch.nn as nn\nfrom torch.autograd import Variable\nimport torch.nn.functional as F\nimport torch.optim as optim\n#import gym\n\nsentences = ['How may I help you?',\n 'Can I be of assistance?',\n 'May I help you with something?',\n 'May I assist you?','Do you need any help?','Can I assist you with something?','How can I help you?']\n\n#tokenize the data\nwords = dict()\nreverse = dict()\ni = 0\nfor s in sentences:\n s = s.replace('?',' <unk>')\n for w in s.split():\n if w.lower() not in words:\n words[w.lower()] = i\n reverse[i] = w.lower()\n i = i + 1\n \n#tokenize the data\n\n#embedding layer is treated as any other, getting parameter updates via backpropagation\n \nclass DataGenerator():\n def __init__(self, dset):\n self.dset = dset\n self.len = len(self.dset)\n self.idx = 0\n def __len__(self):\n return self.len\n def __iter__(self):\n return self\n def __next__(self):\n x = Variable(torch.LongTensor([[self.dset[self.idx]]]), requires_grad=False)\n if self.idx == self.len - 1:\n raise StopIteration\n y = Variable(torch.LongTensor([self.dset[self.idx+1]]), requires_grad=False)\n self.idx = self.idx + 1\n return (x, y)\n \n\n\n#class simpleBot(nn.Module):\n# def __init__(self):\n# super().__init__()\n# self.embedding = nn.Embedding(len(words), 10)\n# self.rnn = nn.LSTM(10, 20, 2, dropout=0.5)\n# self.h = (Variable(torch.zeros(2, 1, 20)), Variable(torch.zeros(2, 1, 20)))\n# self.l_out = nn.Linear(20, len(words))\n# \n# def forward(self, cs):\n# inp = self.embedding(cs)\n# outp,h = self.rnn(inp, self.h)\n# out = F.log_softmax(self.l_out(outp), dim=-1).view(-1, len(words))\n# return out\n\n\nclass simpleBot(nn.Module):\n def __init__(self):\n super().__init__()\n self.embedding = nn.Embedding(len(words), 10)\n self.rnn = nn.LSTM(10, 20, 2, dropout=0.5,bidirectional=True)\n self.rnn2=nn.LSTM(40,20,2,bidirectional=True)\n self.h = (Variable(torch.zeros(4, 1, 20)), Variable(torch.zeros(4, 1, 20)))\n self.l_out = nn.Linear(40, len(words))\n \n def forward(self, cs):\n inp = self.embedding(cs)\n outp,h = self.rnn(inp, self.h)\n outp2,h2=self.rnn2(outp,h)\n out = F.log_softmax(self.l_out(outp2), dim=-1).view(-1, len(words))\n return out\n\n\n\n\n \nm= simpleBot()\ncriterion = nn.CrossEntropyLoss()\noptimizer = optim.SGD(m.parameters(), lr=0.01)\nfor epoch in range(0,600):\n gen = DataGenerator([words[word.lower()] for word in ' '.join(sentences).replace('?',' <unk>').split(' ')])\n for x1, y1 in gen:\n m.zero_grad()\n output = m(x1)\n loss = criterion(output, y1)\n loss.backward()\n optimizer.step()\nprint(loss)\n\ndef get_next(word_):\n word = word_.lower()\n out = m(Variable(torch.LongTensor([words[word_]])).unsqueeze(0))\n return reverse[int(out.max(dim=1)[1].data)]\n\ndef get_next_n(word_, n=3):\n print(word_)\n for i in range(0, n):\n word_ = get_next(word_)\n print(word_)\n\nget_next_n('can', n=3)\n \n"
},
{
"alpha_fraction": 0.5700594782829285,
"alphanum_fraction": 0.5973231792449951,
"avg_line_length": 34.816566467285156,
"blob_id": "114d5fe9669d0de623aa7050a1303941102c841d",
"content_id": "5a5b3d3f7d0d0220d81af278fd0eb654d953d150",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6052,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 169,
"path": "/pytorch_CNN.py",
"repo_name": "AbhishekBose/Pytorch-Codes",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nSpyder Editor\n\nThis is a temporary script file.\n\"\"\"\n\nimport torch\nimport torchvision\nimport torchvision.transforms as transforms\nimport numpy as np\n\nfrom torch.autograd import Variable\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\nprint(device)\n\nseed = 42\nnp.random.seed(seed)\ntorch.manual_seed(seed)\n\ntransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\ntrain_set = torchvision.datasets.CIFAR10(root='./cifardata', train=True, download=True, transform=transform)\ntest_set = torchvision.datasets.CIFAR10(root='./cifardata', train=False, download=True, transform=transform)\n\n\nclasses = ('plane', 'car', 'bird', 'cat',\n 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')\n\nfrom torch.utils.data.sampler import SubsetRandomSampler\n\n#Training\nn_training_samples = 20000\ntrain_sampler = SubsetRandomSampler(np.arange(n_training_samples, dtype=np.int64))\n\n#Validation\nn_val_samples = 5000\nval_sampler = SubsetRandomSampler(np.arange(n_training_samples, n_training_samples + n_val_samples, dtype=np.int64))\n\n#Tests\nn_test_samples = 5000\ntest_sampler = SubsetRandomSampler(np.arange(n_test_samples, dtype=np.int64))\n\nclass SimpleCnn(nn.Module):\n def __init__(self):\n super(SimpleCnn, self).__init__()\n self.conv1 = nn.Conv2d(3,6,5)\n self.pool = nn.MaxPool2d(2,2)\n self.conv2 = nn.Conv2d(6,16,5)\n self.fc1 = nn.Linear(16*5*5,120)\n self.fc2 = nn.Linear(120,84)\n self.fc3 = nn.Linear(84,10)\n \n def forward(self, x):\n x = self.pool(F.relu(self.conv1(x)))\n x = self.pool(F.relu(self.conv2(x)))\n x = x.view(-1,16*5*5)\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n def outputSize(in_size, kernel_size, stride, padding):\n output = int((in_size - kernel_size + 2*(padding)) / stride) + 1\n return(output)\n \n\ndef get_train_loader(batch_size):\n train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size,\n sampler=train_sampler, num_workers=2)\n return train_loader\n\ntrain_loader = torch.utils.data.DataLoader(train_set, batch_size=4,\n shuffle=True, num_workers=2)\n\n\ntest_loader = torch.utils.data.DataLoader(test_set, batch_size=4, sampler=test_sampler, num_workers=2)\nval_loader = torch.utils.data.DataLoader(train_set, batch_size=128, sampler=val_sampler, num_workers=2)\n\nimport torch.optim as Optim\n\ndef createLossAndOptimizer(net,learning_rate=0.001):\n loss=nn.CrossEntropyLoss()\n #Optimizer\n# optimizer = Optim.Adam(net.parameters(),lr=learning_rate)\n optimizer = Optim.SGD(net.parameters(), lr=0.001, momentum=0.9)\n\n return loss,optimizer\n \nimport time\n\ndef trainNet(net,batch_size,n_epochs,learning_rate):\n print('---------Hyperparameters-------')\n print('batch size::::',batch_size)\n print('epochs::::::',n_epochs)\n print(\"learning_rate=\", learning_rate)\n print(\"=\" * 30)\n \n train_loader = get_train_loader(batch_size)\n n_batches = len(train_loader)\n loss,optimizer = createLossAndOptimizer(net,learning_rate)\n training_start_time = time.time()\n for epoch in range(0,n_epochs):\n running_loss = 0.0\n print_every = n_batches // 10\n start_time= time.time()\n total_train_loss = 0\n for i,data in enumerate(train_loader,0):\n inputs,labels=data \n inputs,labels = Variable(inputs), Variable(labels)\n optimizer.zero_grad()\n outputs= net(inputs.to(device))\n loss_size = loss(outputs,labels.to(device))\n loss_size.backward()\n# outputs = net(inputs.to(device))\n# loss = criterion(outputs, labels.to(device))\n optimizer.step()\n running_loss += loss_size.data.item()\n total_train_loss += loss_size.data.item()\n if (i + 1) % (print_every + 1) == 0:\n print(\"Epoch {}, {:d}% \\t train_loss: {:.2f} took: {:.2f}s\".format(\n epoch+1, int(100 * (i+1) / n_batches), running_loss / print_every, time.time() - start_time))\n #Reset running loss and time\n running_loss = 0.0\n start_time = time.time()\n\n total_val_loss=0\n for inputs, labels in val_loader:\n inputs, labels = Variable(inputs), Variable(labels)\n val_outputs = net(inputs.to(device))\n val_loss_size = loss(val_outputs, labels.to(device))\n total_val_loss += val_loss_size.data.item()\n \n print(\"Validation loss = {:.2f}\".format(total_val_loss / len(val_loader)))\n print(\"Training finished, took {:.2f}s\".format(time.time() - training_start_time))\n#def trainNet(net):\n# for epoch in range(2): # loop over the dataset multiple times\n# print('epoch is:::'+str(epoch))\n# running_loss = 0.0\n## trainloader= get_train_loader(4)\n# for i, data in enumerate(train_loader, 0):\n# print('number is:::'+str(i))\n#\n# # get the inputs\n# inputs, labels = data\n# loss,optimizer=createLossAndOptimizer(cnn,0.001)\n# # zero the parameter gradients\n# optimizer.zero_grad()\n# # forward + backward + optimize\n# outputs = cnn(inputs.to(device))\n# loss = loss(outputs, labels.to(device))\n# loss.backward()\n# optimizer.step()\n# \n# # print statisticssss\n# running_loss += loss.item()\n# if i % 2000 == 1999: # print every 2000 mini-batches\n# print('[%d, %5d] loss: %.3f' %\n# (epoch + 1, i + 1, running_loss / 2000))\n# running_loss = 0.0\n# print('Finished Training')\n#\n \ncnn = SimpleCnn()\ncnn.to(device)\ncnn=cnn.cuda()\ntrainNet(cnn,32,2,0.001)"
}
] | 3 |
Pato-99/Sudoku-solver
|
https://github.com/Pato-99/Sudoku-solver
|
f6380047d170b41a98d78cad7900f2915c8466e0
|
a8e66bbc896ffc45f6264037d4d574e11c830545
|
f38d3bed3dd102ed8f807953ddafdaea8b2bc7bc
|
refs/heads/main
| 2023-08-25T18:39:01.150515 | 2021-10-22T22:06:29 | 2021-10-22T22:06:29 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.36239054799079895,
"alphanum_fraction": 0.381423681974411,
"avg_line_length": 27.55434799194336,
"blob_id": "498d511f20c0123f647f88de47999dc3b76b1378",
"content_id": "8911f34e359445fd94ff69eedd99a5a0cc5883c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2627,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 92,
"path": "/sudoku_solver.py",
"repo_name": "Pato-99/Sudoku-solver",
"src_encoding": "UTF-8",
"text": "class SudokuSolver:\n def __init__(self, board=None):\n if not board:\n self.board = [[0 for i in range(9)] for j in range(9)]\n else:\n self.board = board\n\n def __str__(self):\n string = \"\"\n for i in range(9):\n if i > 0 and i % 3 == 0:\n string += 6 * \"-\" + \"|\" + 7 * \"-\" + \"|\" + 6 * \"-\" + \"\\n\"\n for j in range(9):\n if j > 0 and j % 3 == 0:\n string += \"| \"\n if self.board[i][j] == 0:\n string += \"_\"\n else:\n string += f\"{self.board[i][j]}\"\n if j < 8:\n string += \" \"\n string += \"\\n\"\n return string\n\n def check_if_possible(self, value, row, col):\n # check if free\n if self.board[row][col] != 0:\n return False\n\n # check row and column\n for i in range(9):\n if self.board[i][col] == value:\n return False\n if self.board[row][i] == value:\n return False\n\n # check chunk\n # 0-2 | 3-5 | 6-8\n chunk_row = row // 3\n chunk_col = col // 3\n\n row_start = chunk_row * 3\n row_end = row_start + 3\n\n col_start = chunk_col * 3\n col_end = col_start + 3\n\n for i in range(row_start, row_end):\n for j in range(col_start, col_end):\n if self.board[i][j] == value:\n return False\n return True\n\n def validate_board(self):\n for i in range(9):\n for j in range(9):\n if self.board[i][j] == 0:\n continue\n tmp = self.board[i][j]\n self.board[i][j] = 0\n if not self.check_if_possible(tmp, i, j):\n self.board[i][j] = tmp\n return False\n self.board[i][j] = tmp\n return True\n\n def solve(self, i=0, j=0):\n if i > 8:\n return True\n\n if self.board[i][j] != 0:\n if j == 8:\n if self.solve(i + 1, 0):\n return True\n else:\n if self.solve(i, j + 1):\n return True\n\n for k in range(1, 10):\n if self.check_if_possible(k, i, j):\n self.board[i][j] = k\n\n if j == 8:\n if self.solve(i + 1, 0):\n return True\n else:\n if self.solve(i, j + 1):\n return True\n\n self.board[i][j] = 0\n\n return False\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 29,
"blob_id": "99c98951d8b9088706a35a0a8e72ca3e09acf39c",
"content_id": "b4969b0e630c545cadceac8ab181f346bde830fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Pato-99/Sudoku-solver",
"src_encoding": "UTF-8",
"text": "# Sudoku-solver\nSudoku solver using backtracking algorithm.\n"
},
{
"alpha_fraction": 0.2737704813480377,
"alphanum_fraction": 0.4065573811531067,
"avg_line_length": 28,
"blob_id": "662f4b3ee4a3de8401d6e13ede34a5409c2cf0dc",
"content_id": "8e1769780016b159866ab1da7e4d47c9306e878b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 21,
"path": "/main.py",
"repo_name": "Pato-99/Sudoku-solver",
"src_encoding": "UTF-8",
"text": "from sudoku_solver import SudokuSolver\n\ntest_board = [[9, 0, 0, 0, 0, 0, 0, 0, 0],\n [0, 0, 0, 1, 0, 0, 5, 0, 0],\n [0, 3, 2, 0, 0, 6, 0, 8, 0],\n [6, 0, 0, 0, 0, 0, 0, 9, 0],\n [0, 7, 9, 0, 5, 0, 8, 0, 0],\n [4, 0, 0, 0, 0, 7, 0, 0, 0],\n [0, 0, 0, 0, 6, 0, 0, 0, 3],\n [0, 4, 0, 0, 0, 0, 0, 0, 0],\n [0, 8, 7, 0, 0, 3, 0, 2, 0]]\n\n\nsolver = SudokuSolver(test_board)\nif not solver.validate_board():\n raise ValueError(\"Not a valid board.\")\n\nif solver.solve():\n print(solver)\nelse:\n print(\"Not solvable.\")\n\n"
}
] | 3 |
rajsaurabh1000/techical_exam_ey_gds
|
https://github.com/rajsaurabh1000/techical_exam_ey_gds
|
d50275191d4dce3353f6d1f98f378a890e1aec54
|
5150881e4f4305b09908a4283e327430aea9ba79
|
de60a353afcf2cf6d6d90cbe1e37c029616a2b01
|
refs/heads/master
| 2023-02-13T18:33:56.852473 | 2021-01-09T14:01:38 | 2021-01-09T14:01:38 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7139587998390198,
"alphanum_fraction": 0.7139587998390198,
"avg_line_length": 23.27777862548828,
"blob_id": "9f7a5f171c853b7e08c01cf45392617e4cdaa4ba",
"content_id": "448a0057fd8397684031a7a9f25634adfcbf766f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 18,
"path": "/README.md",
"repo_name": "rajsaurabh1000/techical_exam_ey_gds",
"src_encoding": "UTF-8",
"text": "# SCHELLING MODEL\n\n### Usage\nThis program takes in an input file (a grid of 'o','x' and space) characters and calculates the their schelling point according to the input threshold. \n\n``` \nmain.py [-h] --input_file \"input file path\" [--t THRESHOLD] [--it ITERATIONS]\n```\n### Prerequisites\n\nInstall Dependencies\n\n```\npip install -r requirements.txt \n```\n## Acknowledgments\n\n* Thanks for EY for giving me the opportunity to take this exam "
},
{
"alpha_fraction": 0.581123948097229,
"alphanum_fraction": 0.5972622632980347,
"avg_line_length": 36.92349624633789,
"blob_id": "83a3fcd0c868e8b31bb7ba063cb37c91d802342b",
"content_id": "2595e308e804138d99d1af662b9123ea39806b88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6940,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 183,
"path": "/main.py",
"repo_name": "rajsaurabh1000/techical_exam_ey_gds",
"src_encoding": "UTF-8",
"text": "import argparse\n\nimport numpy as np\nimport networkx as nx\nimport csv\nimport matplotlib.pyplot as plt\nimport random\n\nfrom loguru import logger\n\n\n# item 1 on the exam\ndef load_to_array(csv_file):\n \"\"\" Loads CSV to array \"\"\"\n data = list(csv.reader(open(csv_file)))\n return np.array(data)\n\n\ndef display_graph(G, grid_title = 'Figure 1'):\n \"\"\" Load G (grid) customized it according to data types and displays the plot\"\"\"\n # initialize graph\n pos = dict((n, n) for n in G.nodes())\n # create labels for nodes\n labels = dict((n, G.nodes[n]['type']) for n in G.nodes())\n\n # group node types according to list\n type1_node_list = [n for (n, d) in G.nodes(data=True) if d['type'] == 'x']\n type2_node_list = [n for (n, d) in G.nodes(data=True) if d['type'] == 'o']\n empty_cells = [n for (n, d) in G.nodes(data=True) if d['type'] == ' ']\n\n # draw network and label nodes according to type\n nodes_y = nx.draw_networkx_nodes(G, pos, node_color='yellow', nodelist=type1_node_list)\n nodes_b = nx.draw_networkx_nodes(G, pos, node_color='blue', nodelist=type2_node_list)\n nodes_w = nx.draw_networkx_nodes(G, pos, node_color='white', nodelist=empty_cells)\n\n nx.draw_networkx_edges(G, pos)\n nx.draw_networkx_labels(G, pos, labels=labels)\n\n plt.suptitle(grid_title)\n plt.show()\n\n\ndef get_boundary_nodes(G, max_row, max_col):\n nodes_list = []\n for (x, y) in G.nodes():\n if x == 0 or y == max_row-1 or y == 0 or x == max_col-1:\n nodes_list.append((x, y))\n return nodes_list\n\n\ndef get_neighbor_for_internal(x, y):\n \"\"\" returns a list of neighbor nodes within the internal nodes \"\"\"\n return [(x-1, y), (x+1, y), (x, y+1), (x, y-1), (x-1, y+1), (x+1, y-1), (x-1, y-1), (x+1, y+1)]\n\n\ndef get_neighbor_for_boundary(x, y, numrows, numcols):\n \"\"\" returns a list of neighbor nodes within the boundary nodes \"\"\"\n if x == 0 and y == 0:\n return [(0, 1), (1, 1), (1, 0)]\n elif x == numcols-1 and y == numrows - 1:\n return [(numrows-2, numcols-2), (numrows-1, numcols-2), (numrows-2, numcols-1)]\n elif x == numcols-1 and y == 0:\n return [(x-1, y), (x, y+1), (x-1, y+1)]\n elif x == 0 and y == numrows-1:\n return [(x+1, y), (x+1, y-1), (x, y-1)]\n elif x == 0:\n return [(x, y-1), (x, y+1), (x+1, y), (x+1, y-1), (x+1, y+1)]\n elif x == numcols-1:\n return [(x-1, y), (x, y-1), (x, y+1), (x-1, y+1), (x-1, y-1)]\n elif y == numrows-1:\n return [(x, y-1), (x-1, y), (x+1, y), (x-1, y-1), (x+1, y-1)]\n elif y == 0:\n return [(x-1, y), (x+1, y), (x, y+1), (x-1, y+1), (x+1, y+1)]\n\n\ndef make_node_satisfied(G, unsatisfied_nodes_list, empty_cells):\n labels = dict((n, G.nodes[n]['type']) for n in G.nodes())\n if len(unsatisfied_nodes_list) != 0:\n # choose from the random unsatisfied nodes\n node_to_shift = random.choice(unsatisfied_nodes_list)\n # choose a random empty cell\n new_position = random.choice(empty_cells)\n\n # move the unsatisfied node to the empty cell and switch values\n G.nodes[new_position]['type'] = G.nodes[node_to_shift]['type']\n # make the previous node empty\n G.nodes[node_to_shift]['type'] = ' '\n labels[node_to_shift], labels[new_position] = labels[new_position], labels[node_to_shift]\n else:\n pass\n\n\ndef get_unsatisfied_nodes_list(G, internal_nodes_list, boundary_nodes_list, threshold, numrows, numcols):\n \"\"\" returns the list of unsatisfied nodes \"\"\"\n unsatisfied_nodes_list = []\n # set threshold / criteria if the neighboring nodes are within the same type\n t = int(threshold)\n # iterate all nodes\n for (x, y) in G.nodes():\n type_of_this_node = G.nodes[(x, y)]['type']\n # if type is empty then do nothing\n if type_of_this_node == ' ':\n continue\n else:\n # initiate value of similar nodes to 0\n similar_nodes = 0\n\n # get the neighboring nodes\n if (x, y) in internal_nodes_list:\n neighbors = get_neighbor_for_internal(x, y)\n elif (x, y) in boundary_nodes_list:\n neighbors = get_neighbor_for_boundary(x, y, numrows, numcols)\n\n # iterate neighbor nodes and check if they are similar with the target node\n for each in neighbors:\n if G.nodes[each]['type'] == type_of_this_node:\n similar_nodes += 1\n # check if the number of neighboring nodes is less or equal to the\n # threshold then append it to the unsatisfied_nodes_list\n if similar_nodes <= t:\n unsatisfied_nodes_list.append((x, y))\n\n return unsatisfied_nodes_list\n\n\n# item 3\ndef schelling_model(grid_source, threshold, iterations):\n \"\"\" Shows schelling model \"\"\"\n # get max rows and columns from the input grid\n numrows = len(grid_source)\n numcols = len(grid_source[0])\n\n # create grid\n G = nx.grid_2d_graph(numrows, numcols)\n\n # map nodes to grid\n for i, j in G.nodes():\n G.nodes[(i, j)]['type'] = grid_source[i][j]\n\n # add diagonal edges\n for ((x, y), d) in G.nodes(data=True):\n if (x + 1 <= numcols - 1) and (y + 1 <= numrows - 1):\n G.add_edge((x, y), (x + 1, y + 1))\n for ((x, y), d) in G.nodes(data=True):\n if (x + 1 <= numcols - 1) and (y - 1 >= 0):\n G.add_edge((x, y), (x + 1, y - 1))\n\n # display initial graph\n display_graph(G, 'Initial Grid (Please close to continue)')\n\n # get boundary and internal nodes\n boundary_nodes_list = get_boundary_nodes(G, numrows, numcols)\n internal_nodes_list = list(set(G.nodes()) - set(boundary_nodes_list))\n\n # make calculations according to threshold\n # accuracy is based on the number of iterations\n logger.info(\"Starting Calculations\")\n for i in range(int(iterations)):\n # get list of unsatisfied nodes first\n unsatisfied_nodes_list = get_unsatisfied_nodes_list(G, internal_nodes_list, boundary_nodes_list, threshold, numrows, numcols)\n logger.info(\"iteration: {}\".format(i))\n # move an unsatisfied node to an empty cell\n empty_cells = [n for (n, d) in G.nodes(data=True) if d['type'] == ' ']\n make_node_satisfied(G, unsatisfied_nodes_list, empty_cells)\n # display final graph\n display_graph(G, 'Schelling model Implemented')\n logger.info(\"Schelling model Complete\")\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--input_file\", dest=\"input_file\", type=str, required=True)\n # threshold : default is 3 and iterations default is 1000\n parser.add_argument(\"--t\", dest='threshold', default=3, type=str)\n parser.add_argument(\"--iter\", dest='iterations', default=1000)\n\n args = parser.parse_args()\n\n grid = load_to_array(args.input_file)\n print(grid)\n # show schelling model based on 2d grid\n schelling_model(grid, args.threshold, args.iterations)\n"
}
] | 2 |
MichaelG368/Week_1_In_Your_Interface
|
https://github.com/MichaelG368/Week_1_In_Your_Interface
|
4b91a1a254033ba70d7b02d5223e2b9aa6786664
|
35c55ee7d497558978a0f3722b7b4af1c9c4e36b
|
e6ea81f0030e1ad842d910028b60ded9944fbfad
|
refs/heads/master
| 2022-06-18T21:07:48.501536 | 2020-05-07T22:29:37 | 2020-05-07T22:29:37 | 262,166,809 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7615384459495544,
"alphanum_fraction": 0.7769230604171753,
"avg_line_length": 42.33333206176758,
"blob_id": "51598cd3bbfb02a42fcb573dc116998b6a8f93ad",
"content_id": "d504b0f90ecf91f3ee36d8ee1cb37e0f6a82b1f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 3,
"path": "/README.md",
"repo_name": "MichaelG368/Week_1_In_Your_Interface",
"src_encoding": "UTF-8",
"text": "# Week_1_In_Your_Interface\n\nThis repository should contain all the files relating to the \"Week 1 - In Your Interface\" assignment.\n"
},
{
"alpha_fraction": 0.4924554228782654,
"alphanum_fraction": 0.49519890546798706,
"avg_line_length": 20.15151596069336,
"blob_id": "b9b1aa39b834e408cbd5a71fa8d046752b58569c",
"content_id": "4c118222ca322cb05ee5b587cf1eac5c8ddb4b9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 729,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 33,
"path": "/Week 1 - In your Interface.py",
"repo_name": "MichaelG368/Week_1_In_Your_Interface",
"src_encoding": "UTF-8",
"text": "class Teams:\r\n def __init__(self, members):\r\n self.__myTeam = members\r\n self.index = 0\r\n\r\n def __len__(self):\r\n return len(self.__myTeam)\r\n\r\n def __contains__(self, person):\r\n if person in self.__myTeam:\r\n return True\r\n \r\n def __iter__(self):\r\n return self\r\n \r\n def __next__(self):\r\n try:\r\n person = self.__myTeam[self.index]\r\n except IndexError:\r\n raise StopIteration\r\n self.index +=1\r\n return person\r\n \r\n \r\ndef main():\r\n classmates = Teams(['John', 'Steve', 'Tim'])\r\n print('Tim' in classmates)\r\n print('Sam' in classmates)\r\n \r\n for people in classmates:\r\n print(people)\r\n\r\nmain()"
}
] | 2 |
python-workshop/fsdse-python-assignment-195
|
https://github.com/python-workshop/fsdse-python-assignment-195
|
2e110f30c021f03f0b132c5b79da35a57c646f68
|
8cdcc1cd034730e135fa650d3b0e1f85614de8b3
|
fc1ce34ba5e3120c21d814a0eeffe87048215bf5
|
refs/heads/master
| 2020-12-30T14:45:04.063657 | 2017-05-23T06:27:30 | 2017-05-23T06:27:30 | 91,083,323 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5973684191703796,
"alphanum_fraction": 0.6236842274665833,
"avg_line_length": 32.08695602416992,
"blob_id": "3fac078efadd17bccc20be871e57f1931162ae4d",
"content_id": "a3b11a8ce096df123ad3ef23b30f82309e9ac8c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 23,
"path": "/tests/test_is_prime.py",
"repo_name": "python-workshop/fsdse-python-assignment-195",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\n\nclass TestIs_prime(TestCase):\n def test_is_prime(self):\n try:\n from build import is_prime\n except ImportError:\n self.assertFalse(\"no function found\")\n\n self.assertEqual(False, is_prime(0))\n self.assertEqual(False, is_prime(1))\n\n self.assertEqual(True, is_prime(2))\n self.assertEqual(True, is_prime(3))\n self.assertEqual(True, is_prime(7))\n self.assertEqual(True, is_prime(5))\n self.assertEqual(True, is_prime(11))\n self.assertEqual(True, is_prime(13))\n self.assertEqual(True, is_prime(17))\n self.assertEqual(True, is_prime(19))\n self.assertEqual(True, is_prime(199))\n self.assertEqual(True, is_prime(197))"
},
{
"alpha_fraction": 0.7241379022598267,
"alphanum_fraction": 0.8275862336158752,
"avg_line_length": 29,
"blob_id": "0ead569a1a5d46f5435552f1a62f5e8c0057ebf8",
"content_id": "c71e6d5481355ad11b4037db14f58c676ba1b7a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 1,
"path": "/README.md",
"repo_name": "python-workshop/fsdse-python-assignment-195",
"src_encoding": "UTF-8",
"text": "# fsdse-python-assignment-195"
}
] | 2 |
theSekyi/DS-Unit-3-Sprint-1-Software-Engineering
|
https://github.com/theSekyi/DS-Unit-3-Sprint-1-Software-Engineering
|
0ecfa3c0e4cda05447508e03cfe3cae147a3ab1c
|
b6803bc2e81c593123d19a61048892e123a6faaf
|
bf5565b61316c12266527f44afd69be9b5b23769
|
refs/heads/master
| 2023-08-22T06:19:57.794771 | 2019-02-16T03:41:24 | 2019-02-16T03:41:24 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6127208471298218,
"alphanum_fraction": 0.6240282654762268,
"avg_line_length": 27.87755012512207,
"blob_id": "178a3b333387a660ad13a6928f53e9fa82883b9d",
"content_id": "ceb7f43b502210743fdb5b6591b3859e80eb58cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1415,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 49,
"path": "/Sprint-Challenge/acme_report.py",
"repo_name": "theSekyi/DS-Unit-3-Sprint-1-Software-Engineering",
"src_encoding": "UTF-8",
"text": "import random\nfrom acme import Product\nfrom collections import defaultdict\nfrom functools import reduce\n\nproducts = []\nADJECTIVES = ['Awesome', 'Shiny', 'Impressive', 'Portable', 'Improved']\nNOUNS = ['Anvil', 'Catapult', 'Disguise', 'Mousetrap', '???']\n\ndef generate_products(n=30):\n count = n\n while(count > 0):\n price = random.randint(5, 100)\n weight = random.randint(5, 100)\n flammability = random.uniform(0, 2.5)\n name = f'{random.choice(ADJECTIVES)} {random.choice(NOUNS)}'\n P = Product(name, price, weight, flammability)\n products.append(P)\n count -= 1\n return products\n\ndef inventory_report(arr):\n # identifying all the names created\n names = [arr[i].name for i in range(len(arr))]\n # using defaultdict to count unique names (products)\n IR = defaultdict(int)\n for name in names:\n IR[name] += 1\n\n print('Unique Products : ', len(IR))\n\n price = []\n weight = []\n flammability = []\n for dict in products:\n price.append(dict.price)\n weight.append(dict.weight)\n flammability.append(dict.flammability)\n\n def mean(arr):\n mean = reduce(lambda x, y: x+y, arr)/len(arr)\n return mean\n\n print('Average Price:', mean(price))\n print('Average Weight:', mean(weight))\n print('Average Price:', mean(flammability))\n\nif __name__ == '__main__':\n inventory_report(generate_products())\n"
},
{
"alpha_fraction": 0.5161957144737244,
"alphanum_fraction": 0.5561681389808655,
"avg_line_length": 28.020000457763672,
"blob_id": "10e3c0816fdc2efeaf08ec12ee2606749084b53e",
"content_id": "3ea1499fd5a3338b33df71bd5a3ad4bc2e54e21d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1451,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 50,
"path": "/Sprint-Challenge/acme.py",
"repo_name": "theSekyi/DS-Unit-3-Sprint-1-Software-Engineering",
"src_encoding": "UTF-8",
"text": "class Product(object):\n \"\"\"\n A Python Class from which Acme Co. can build specific product instances\n \"\"\"\n import random\n ri = random.randint(1000000, 9999999)\n def __init__(self, name, price=10, weight=20, flammability=0.5, identifier=ri):\n self.name=name\n self.price=price\n self.weight=weight\n self.flammability=flammability\n self.identifier=identifier\n\n def stealability(self):\n x = (self.price)/(self.weight)\n strA = [\"Not so stealable...\", \"Kinda stealable.\", \"Very stealable!\"]\n if(x < 0.5):\n return strA[0]\n elif(0.5 <= x and x < 1.0):\n return strA[1]\n else:\n return strA[2]\n\n def explode(self):\n y = (self.flammability)*(self.weight)\n strA = [\"...fizzle\", \"...boom!\", \"...BABOOM!\"]\n if(y < 10):\n return strA[0]\n elif(10 <= y and y < 50):\n return strA[1]\n else:\n return strA[2]\n\nclass BoxingGlove(Product):\n import random\n ri = random.randint(1000000, 9999999)\n def __init__(self, name, price=10, weight=10, flammability=0.5, identifier=ri):\n self.name=name\n self.price=price\n self.weight=weight\n self.flammability=flammability\n self.identifier=identifier\n\n def explode(self):\n str = '...it\\'s a glove.'\n return str\n\n def punch(self):\n str = 'Hey that hurt!'\n return str\n"
},
{
"alpha_fraction": 0.698113203048706,
"alphanum_fraction": 0.7106918096542358,
"avg_line_length": 18.875,
"blob_id": "96a3d1a22aa65dda6c2043f96c217044290375fe",
"content_id": "f4754a9ab151232e8701ee20b95120116e2bc129",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 8,
"path": "/module3-containers-and-reproducible-builds/Dockerfile",
"repo_name": "theSekyi/DS-Unit-3-Sprint-1-Software-Engineering",
"src_encoding": "UTF-8",
"text": "FROM debian\n\nENV PYTHONUNBUFFERED=1\n\n### Basic Python dev dependencies\nRUN apt-get update && \\\n apt-get upgrade -y && \\\n apt-get install python3-pip curl -y\n"
},
{
"alpha_fraction": 0.7817796468734741,
"alphanum_fraction": 0.7833686470985413,
"avg_line_length": 41.90909194946289,
"blob_id": "6fac7814944957dd992c1cb6335ed31640e45946",
"content_id": "e557746b692bb5e3917320bedea1c26721a4e67b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1888,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 44,
"path": "/module1-python-modules-packages-and-environments/README.md",
"repo_name": "theSekyi/DS-Unit-3-Sprint-1-Software-Engineering",
"src_encoding": "UTF-8",
"text": "# Python Modules, Packages, and Environments\n\nPlaces for your code (and dependencies) to live.\n\n## Learning Objectives\n\n- Understand and follow Python namespaces and imports\n- Create a Python package and install dependencies in a dedicated environment\n\n## Before Lecture\n\nInstall [Anaconda](https://www.anaconda.com/distribution) on your local machine\nif you haven't already, and read the official documentation for\n[Python modules](https://docs.python.org/3.7/tutorial/modules.html).\n\n## Live Lecture Task\n\nWe're going to start our own Python package the right way - by making an\nenvironment with `pipenv`, installing our dependencies, and making some classes.\n\n## Assignment\n\nImplement at least 3 of the following \"helper\" utility functions in `lambdata`:\n\n- Check a dataframe for nulls, print/report them in a nice \"pretty\" format\n- Report a confusion matrix, with labels for easier interpretation\n- Train/*validate*/test split function for a dataframe\n- \"Generate more data\" function, takes dataframes and makes more rows\n- Contingency table + Chi-squared report function: takes two categorical\n variables, outputs a contingency table and corresponding Chi-squared test\n- Your idea here!\n\nMany of the above can be done with the right clever calls to `pandas`, `numpy`,\nand other libraries - that's fine! Use those as dependencies. There's still\nvalue in a package that encapsulates more complicated libraries and exposes\nstreamlined functionality with a simplified API.\n\n## Resources and Stretch Goals\n\nCheck out the source code for [pandas](https://github.com/pandas-dev/pandas),\nand see if you can make sense of it. Try to find the actual logic behind\nspecific functions you use (e.g. `pd.DataFrame`, `df.replace`, etc.). Reading\nsource code is challenging, especially from large codebases, but it's a skill\nthat will help you debug and fix real issues in professional situations.\n"
},
{
"alpha_fraction": 0.5828571319580078,
"alphanum_fraction": 0.6011428833007812,
"avg_line_length": 34,
"blob_id": "943c031201025b87ba6f106945addd4fa548a028",
"content_id": "aaca150ffcf04440051500ecbf81a064495f7b79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1750,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 50,
"path": "/Sprint-Challenge/acme_test.py",
"repo_name": "theSekyi/DS-Unit-3-Sprint-1-Software-Engineering",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom acme import Product\nfrom acme_report import generate_products, ADJECTIVES, NOUNS\n\n\nclass AcmeProductTests(unittest.TestCase):\n \"\"\"Making sure Acme products are the tops!\"\"\"\n\n def test_default_product_price(self):\n \"\"\"Test default product price being 10.\"\"\"\n prod = Product('Test Product')\n self.assertEqual(prod.price, 10)\n\n def test_default_product_weight(self):\n \"\"\"Test default product weight being 10.\"\"\"\n prod = Product('Test Product')\n self.assertEqual(prod.weight, 20)\n\n def test_stealability(self):\n \"\"\"Test stealability() method.\"\"\"\n test_arr = [30, 18, 5]\n s_arr = [\"Not so stealable...\", \"Kinda stealable.\", \"Very stealable!\"]\n for i, item in enumerate(test_arr):\n prod = Product('Test Product', weight=test_arr[i])\n self.assertEqual(prod.stealability(), s_arr[i])\n\n def test_explode(self):\n \"\"\"Test explode() method.\"\"\"\n test_arr = [1, 20, 200]\n e_arr = [\"...fizzle\", \"...boom!\", \"...BABOOM!\"]\n for i, item in enumerate(test_arr):\n prod = Product('Test Product', weight=test_arr[i])\n self.assertEqual(prod.explode(), e_arr[i])\n\nclass AcmeReportTests(unittest.TestCase):\n \"\"\" Test that generate_products returns 30 resuts by default \"\"\"\n def test_default_num_products(self):\n prods = generate_products()\n self.assertEqual(len(prods), 30)\n\n def test_legal_names(self):\n \"\"\" Tests if the names are in the appropriate format \"\"\"\n prods = generate_products()\n for obj in prods:\n self.assertRegexpMatches(\n '(\\w{2,10} \\w{0,12}|\\?{0,3}){1}', obj.name)\n\n\nif __name__ == '__main__':\n unittest.main()\n"
}
] | 5 |
PythonAmapa/ExemplosStringPy
|
https://github.com/PythonAmapa/ExemplosStringPy
|
1e02c0d9a9139db223511cebae3e1c4d6b033501
|
bd89d86a6896c23686ab8b5365ddf2c593e65725
|
e94594c6d5b583ea8f751b0f52eed82e1e8f3c95
|
refs/heads/master
| 2020-04-02T03:21:50.178663 | 2018-10-26T13:48:58 | 2018-10-26T13:48:58 | 153,960,884 | 0 | 2 | null | 2018-10-21T00:41:57 | 2018-10-22T18:07:37 | 2018-10-26T13:48:58 |
Jupyter Notebook
|
[
{
"alpha_fraction": 0.6306042671203613,
"alphanum_fraction": 0.6306042671203613,
"avg_line_length": 14.890625,
"blob_id": "9e336b04046607b253bc2a2a608749e90ba4d648",
"content_id": "e51e4fb7a271bd6ca4dffd773367fc236321597d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1034,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 64,
"path": "/README.md",
"repo_name": "PythonAmapa/ExemplosStringPy",
"src_encoding": "UTF-8",
"text": "# ExemplosStringPy\nExemplos com String em Python\n\n\n<p> Definir <p>\n<code>\n test = 'This is just a simple string.'\n</code>\n \n<p> Contar o tamanho <p>\n<code>\n len(teste)\n</code>\n \n<p> Substituir <p>\n<code>\nteste = teste.replace('basico', 'avancado')\n</code>\n\n\n<p> Encontrar a posição <p>\n<code>\nteste.count('a')\n</code>\n \n<p> Quebrar em palavras <p>\n<code>\nteste.split()\n</code>\n \n <p> Separar uma string <p>\n<code>\nteste.split()\n</code>\n \n<p> Podemos escolher o ponto a ser separado. <p>\n<code>\nteste.split('a')\n</code>\n \n<p> Para juntar nossa string separada, podemos usar o método join. <p>\n<code>\n' some '.join(teste.split('a'))\n </code>\n \n <p> Agora vamos deixar tudo minúsculo. <p>\n<code>\nteste.lower()\n </code>\n \n <p> Agora vamos deixar tudo maiúsculo. <p>\n<code>\nteste.upper()\n </code>\n \n <p> Agora vamos criar um tipo title. <p>\n<code>\nteste.title()\n </code>\n \n <p> Vamos deixar apenas a primeira letra maiúscula de uma string minúscula. <p>\n<code>\nteste.lower().capitalize()\n </code>\n \n \n \n"
},
{
"alpha_fraction": 0.4991663992404938,
"alphanum_fraction": 0.5671890377998352,
"avg_line_length": 6.549118518829346,
"blob_id": "c8650bb6d0420b6f7c0b11112cfa8c6bd05e3120",
"content_id": "073cb12dd0bda1f63a30d0bb8d9124325072a185",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3000,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 397,
"path": "/notebook.py",
"repo_name": "PythonAmapa/ExemplosStringPy",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[22]:\n\n\nteste = \"Aula de analise de sentimentos e python basico\"\n# In[23]:\n\n\nlen(teste)\n\n#teste de inversao\nprint(teste[::-1])\n\n#retorna a posicao onde inicia uma palavra\nprint(teste.find('python'))\n\n#multiplica string\nprint((teste + ' ') *2)\n\n#uso de apostrofes: para usar palavras com apostrofe, use aspas duplas\nprint(\"levi's\")\n\n#quebrando a linha em uma string. basta colocar o \"\\n\"\nprint(\"Aula de analise de sentimentos e\\n python basico.\")\n\n# In[24]:\n\n\nteste = teste.replace('basico', 'avancado')\nprint (teste)\n\n\n# In[33]:\n\n\nteste.count('a')\n\n\n# In[34]:\n\n\nteste.find('l')\n\n\n# In[35]:\n\n\nteste[2]\n\n\n# In[36]:\n\n\nteste.split()\n\n\n# In[37]:\n\n\n' some '.join(teste.split('a'))\n\n\n# In[38]:\n\n\nteste.upper()\n\n\n# In[39]:\n\n\nteste.lower()\n\n\n# In[25]:\n\n\nteste.lower().capitalize()\n\n\n# In[26]:\n\n\nteste.lower().title()\n\n\n# In[27]:\n\n\nteste.swapcase()\n\n\n# In[28]:\n\n\n'UPPER'.isupper()\n\n\n# In[29]:\n\n\n'UpperR'.isupper()\n\n\n# In[30]:\n\n\n'UpperR'.isupper()\n\n\n# In[31]:\n\n\n'lower'.islower()\n\n\n# In[32]:\n\n\n'Lower'.islower()\n\n\n# In[40]:\n\n\n'Isso E Um Titulo'.istitle()\n\n\n# In[41]:\n\n\n'Isso e um Titulo'.istitle()\n\n\n# In[42]:\n\n\n'aa44'.isalnum()\n\n\n# In[43]:\n\n\n'a$44'.isalnum()\n\n\n# In[44]:\n\n\n'letters'.isalpha()\n\n\n# In[45]:\n\n\n'letters4'.isalpha()\n\n\n# In[46]:\n\n\n'306090'.isdigit()\n\n\n# In[47]:\n\n\n'30-60-90 Triangle'.isdigit()\n\n\n# In[48]:\n\n\n' '.isspace()\n\n\n# In[49]:\n\n\n''.isspace()\n\n\n# In[50]:\n\n\n'A string.'.ljust(15)\n\n\n# In[51]:\n\n\n'A string.'.rjust(15)\n\n\n# In[52]:\n\n\n'A string.'.center(15)\n\n\n# In[53]:\n\n\n'String.'.rjust(15).strip()\n\n\n# In[54]:\n\n\n'String.'.ljust(15).rstrip()\n\n\n# In[55]:\n\n\nimport re\n\n\n# In[56]:\n\n\ntest = 'This is for testing regular expressions in Python.'\n\n\n# In[58]:\n\n\nresult = re.search('This', test)\nprint(result)\n\n\n# In[59]:\n\n\nresult = re.search ('(Th)(is)',test)\n\n\n# In[60]:\n\n\nresult.group(1)\n\n\n# In[61]:\n\n\nresult.group(2)\n\n\n# In[62]:\n\n\nresult.group(0)\n\n\n# In[65]:\n\n\nresult = re.match ('regular', test)\nprint(result)\n\n\n# In[67]:\n\n\nresult = re.match ('(....................)(regular)', test)\nprint (result)\n\n\n# In[68]:\n\n\nresult.group(0)\n\n\n# In[69]:\n\n\nresult.group(2)\n\n\n# In[70]:\n\n\nresult = re.match('(.{20})(regular)', test)\n\n\n# In[71]:\n\n\nresult.group(0)\n\n\n# In[72]:\n\n\nresult.group(1)\n\n\n# In[73]:\n\n\nresult.group(2)\n\n\n# In[74]:\n\n\nresult = re.match ('(.{10,20})(regular)', test)\n\n\n# In[75]:\n\n\nresult.group(0)\n\n\n# In[76]:\n\n\nresult = re.match('(.{10,20})(testing)', test)\n\n\n# In[78]:\n\n\nresult.group(0)\n\n\n# In[79]:\n\n\nanotherTest = 'a cat, a dog, a goat, a person'\n\n\n# In[80]:\n\n\nresult = re.match('(.{5,20})(,)', anotherTest)\n\n\n# In[81]:\n\n\nresult.group(1)\n\n\n# In[82]:\n\n\nresult = re.match('(.{5,20}?)(,)', anotherTest)\n\n\n# In[83]:\n\n\nresult.group(1)\n\n\n# In[84]:\n\n\nanotherTest = '012345'\n\n\n# In[85]:\n\n\nresult = re.match('01?', anotherTest)\n\n\n# In[86]:\n\n\nresult.group(0)\n\n\n# In[87]:\n\n\nresult = re.match('0123456?', anotherTest)\n\n\n# In[90]:\n\n\nresult.group(0)\n\n\n# In[98]:\n\n\n#substituindo strings com expressão regulares\nprint(anotherTest)\nresult = re.sub('01?', 'gab',anotherTest)\nprint(result)\n\n"
}
] | 2 |
shanto12/Twitter_Automation
|
https://github.com/shanto12/Twitter_Automation
|
f2434e05fda0ef92b590697ec86db9e143c22b3f
|
4ab5c127453da158ff8abbce17297cea817c930a
|
11c6def8e472b8640ba18aeddc8245ecbc168eae
|
refs/heads/master
| 2022-11-25T06:57:32.685504 | 2020-08-06T12:05:40 | 2020-08-06T12:05:40 | 282,571,304 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5661857724189758,
"alphanum_fraction": 0.5841559171676636,
"avg_line_length": 32.2100830078125,
"blob_id": "27ad3dbd241116fac626b22607dedd0f59f52966",
"content_id": "60c30463fce741f671e7e6614f40abe5280c3b2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3951,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 119,
"path": "/get_tweets_automation.py",
"repo_name": "shanto12/Twitter_Automation",
"src_encoding": "UTF-8",
"text": "import requests\nfrom bs4 import BeautifulSoup as bs\nimport tweepy as tw\nimport pandas as pd\n\nAPI_KEY=\"udjdOw1ZGdTbu2YcolgRtkYjJ\"\nAPI_SECRET_KEY=\"2g1Beh94iUB7iECbcBNzmDmP2RHFxqsZwaolCoZ0HlRGohEx4e\"\nACCESS_TOKEN = \"66484327-tJuAYcOw2ISPswSfwK3xyoObdghtn3xhJRgNmSeqg\"\nACCESS_TOKEN_SECRET=\"QmEc58vTdWOt2o9KfKgxv0e4XMRXW8Sf1NjkmGgV5KNZZ\"\n\n\n\ndef tw_auth():\n auth = tw.OAuthHandler(API_KEY, API_SECRET_KEY)\n auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)\n api = tw.API(auth, wait_on_rate_limit=True)\n\n return api\n\n\ndef test_tweet(api):\n api.update_status(\"Look, I'm tweeting from #Python in my #earthanalytics class! @EarthLabCU\")\n\n\ndef all_user_twets(api, user_name):\n for status in tw.Cursor(api.user_timeline, id=user_name).items(10):\n # process status here\n print(status.text)\n\n # api.user_timeline(id=user_name)\n # user = api.get_user(user_name)\n # print(user.screen_name)\n # print(user.followers_count)\n # for friend in user:\n # print(friend.screen_name)\n\ndef create_csv(df_dict, file_name):\n df = pd.DataFrame(df_dict)\n df.to_csv(file_name, index=False)\n\ndef friends_list(api):\n csv_file_name = \"followers_list_exported.csv\"\n columns = ['description', 'friends_count', 'id', 'location', 'name', 'screen_name', 'statuses_count', 'verified']\n\n friends_dict = {col_name: [] for col_name in columns}\n\n\n # raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],\n # 'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],\n # 'age': [42, 52, 36, 24, 73],\n # 'preTestScore': [4, 24, 31, 2, 3],\n # 'postTestScore': [25, 94, 57, 62, 70]}\n\n\n\n\n\n for user in tw.Cursor(api.friends).items():\n for col_name in columns:\n friends_dict[col_name].append(getattr(user, col_name, \"nothing shanto\"))\n\n # process status here\n print(user)\n\n df = pd.DataFrame(friends_dict, columns=columns)\n df.to_csv(csv_file_name, index=False)\n\ndef hashtag_search(api, hashtag):\n csv_file_name = \"hashtag_tweets_exported.csv\"\n columns = ['id', {'author': ['screen_name', 'friends_count', 'followers_count', 'created_at']},\n 'retweet_count', 'location', 'source', 'text', 'statuses_count', {'user': 'verified'}]\n\n hashtag_dict = dict()\n for value1 in columns:\n if isinstance(value1, str):\n hashtag_dict[value1] = []\n elif isinstance(value1, dict):\n for col2, value2 in value1.items():\n if isinstance(value2, str):\n hashtag_dict[value2] = []\n elif isinstance(value2, list):\n for value3 in value2:\n hashtag_dict[value3] = []\n\n hashtag_dict['url'] = []\n\n # hashtag_dict = {col_name: [] for col_name in columns}\n for tweet in tw.Cursor(api.search, q=hashtag, count=200).items(200):\n for value1 in columns:\n if isinstance(value1, str):\n hashtag_dict[value1].append(getattr(tweet, value1, None))\n elif isinstance(value1, dict):\n for col2, value2 in value1.items():\n if isinstance(value2, str):\n hashtag_dict[value2].append(getattr(getattr(tweet, col2), value2, None))\n # hashtag_dict[value2] = []\n elif isinstance(value2, list):\n for value3 in value2:\n hashtag_dict[value3].append(getattr(getattr(tweet, col2), value3, None))\n # hashtag_dict[value3] = []\n\n hashtag_dict['url'].append(f\"https://twitter.com/{hashtag_dict['screen_name'][-1]}/status/{hashtag_dict['id'][-1]}\")\n print(hashtag_dict)\n\n create_csv(hashtag_dict, csv_file_name)\n # df = pd.DataFrame(hashtag_dict, columns=columns)\n # df.to_csv(csv_file_name, index=False)\n\n # r = api.search(hashtag)\n # for tweet in api.search(hashtag):\n #\n\n\napi = tw_auth()\n# test_tweet(api)\n# all_user_twets(api, \"eugenegu\")\n# friends_list(api)\nhashtag_search(api, \"#HCQWorks\")\nprint(\"DONE\")"
}
] | 1 |
TonyTheLion/hokodo
|
https://github.com/TonyTheLion/hokodo
|
7f1048a509565d3c2c63926d7a6d733e718b14a4
|
76fb469fbe71426265d88ec47025a64c41bdd23a
|
b7833d9821d4bf3bb390ebb9882a52b5ac7cee55
|
refs/heads/master
| 2020-06-13T23:18:02.413671 | 2019-07-02T08:05:45 | 2019-07-02T08:05:45 | 194,819,860 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5668662786483765,
"alphanum_fraction": 0.57485032081604,
"avg_line_length": 25.36842155456543,
"blob_id": "322ec6c2acc1ee9d1eb648dad18954b94aa63865",
"content_id": "284f6ceeb4222c10f824314ad7a3c03d546b4d37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 501,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 19,
"path": "/exc1.py",
"repo_name": "TonyTheLion/hokodo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport sys\nfrom collections import Counter\n\n# main\n# use Counter to count items in string given as argument to script\ndef main():\n if (len(sys.argv) > 1):\n # Split by space\n sentence = sys.argv[1].split()\n cnt = Counter(sentence)\n for k,v in cnt.items():\n print(k + \":\" + str(v))\n else:\n print(\"Please pass argument of type string to script e.g:'\" + sys.argv[0] + \" 'my foobar arg''\")\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6081081032752991,
"alphanum_fraction": 0.6554054021835327,
"avg_line_length": 8.866666793823242,
"blob_id": "527fe9a7d3c21384cbf2da5e4b66067110bd376d",
"content_id": "0497a547dc6eccd4d28c3a43014adc9886809d89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 148,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 15,
"path": "/README.md",
"repo_name": "TonyTheLion/hokodo",
"src_encoding": "UTF-8",
"text": "# Using exc1.py\n\nYou can run it as follows:\n\n`./exc1.py \"tony tony hello from the UK\"`\n\nwhich will return\n\n```\ntony:2\nhello:1\nfrom:1\nthe:1\nUK:1\n```\n"
}
] | 2 |
mdlee1998/NeuralNetwork
|
https://github.com/mdlee1998/NeuralNetwork
|
b7cb86b7deb0d22e709b3f0d1bec671cd18a3ff8
|
4faeb89c7b14ad1da451e2ec7eec63c25f6bde89
|
6ca38c946fdf224a90f17ac1718d05c3865e060c
|
refs/heads/master
| 2023-01-20T14:38:15.874013 | 2020-11-28T02:34:56 | 2020-11-28T02:34:56 | 316,580,291 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5523511171340942,
"alphanum_fraction": 0.5805642604827881,
"avg_line_length": 34.44444274902344,
"blob_id": "4d99b0ab334a4950137553d4e53a6071a570bc91",
"content_id": "aaa8dd985c9ed6583dfa115ccaa34f70c2151d20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1595,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 45,
"path": "/Layer.py",
"repo_name": "mdlee1998/NeuralNetwork",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass Layer:\n\n def __init__(self, n_inputs, n_nodes,\n weight_regularizer_l1 = 0, weight_regularizer_l2 = 0,\n bias_regularizer_l1 = 0, bias_regularizer_l2 = 0):\n\n #Initializes weights and biases\n self.weights = 0.01 * np.random.randn(n_inputs, n_nodes)\n self.biases = np.zeros((1, n_nodes))\n self.weight_regularizer_l1 = weight_regularizer_l1\n self.weight_regularizer_l2 = weight_regularizer_l2\n self.bias_regularizer_l1 = bias_regularizer_l1\n self.bias_regularizer_l2 = bias_regularizer_l2\n\n def forwardProp(self, input):\n self.output = np.dot(input, self.weights) + self.biases\n self.input = input\n\n def backProp(self, dvalues):\n self.dweights = np.dot(self.input.T, dvalues)\n self.dbiases = np.sum(dvalues, axis=0, keepdims=True)\n\n if self.weight_regularizer_l1 > 0:\n dL1 = np.ones_like(self.weights)\n dL1[self.weights < 0] = -1\n self.dweights += self.weight_regularizer_l1 * dL1\n\n if self.weight_regularizer_l2 > 0:\n self.dweights += 2 * self.weight_regularizer_l2 * \\\n self.weights\n\n if self.bias_regularizer_l1 > 0:\n dL1 = np.ones_like(self.biases)\n dL1[self.biases < 0] = -1\n self.dbiases += self.bias_regularizer_l1 * dL1\n\n if self.bias_regularizer_l2 > 0:\n self.dbiases += 2 * self.bias_regularizer_l2 * \\\n self.biases\n\n\n self.dinputs = np.dot(dvalues, self.weights.T)\n"
},
{
"alpha_fraction": 0.5947006940841675,
"alphanum_fraction": 0.601570188999176,
"avg_line_length": 26.54054069519043,
"blob_id": "7c8af59d03a7d2a9de33c6e294e1c9b79a037214",
"content_id": "0791224987ac077a62764d8d10d5cdb8efdf8cdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 37,
"path": "/Activations.py",
"repo_name": "mdlee1998/NeuralNetwork",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nclass ReLU:\n\n def forwardProp(self, input):\n self.output = np.maximum(0, input)\n self.input = input\n\n\n def backProp(self, dvalues):\n self.dinputs = dvalues.copy()\n\n self.dinputs[self.input <= 0] = 0\n\nclass Softmax:\n\n def forwardProp(self, input):\n\n #Gets unnormalized probabilities\n exp_val = np.exp(input - np.max(input, axis=1, keepdims=True))\n\n #Normalize probabilites for each sample\n self.output = exp_val / np.sum(exp_val, axis=1, keepdims=True)\n self.input = input\n\n\n def backProp(self, dvalues):\n self.dinputs = np.empty_like(dvalues)\n\n for index, (single_output, single_dvalues) in \\\n enumerate(zip(self.output, dvalues)):\n\n single_output = single_output.reshape(-1, 1)\n jacobian_matrix = np.diagflat(single_output) - \\\n np.dot(single_output, single_output.T)\n\n self.dinputs[index] = np.dot(jacobian_matrix, single_dvalues)\n"
},
{
"alpha_fraction": 0.5179910063743591,
"alphanum_fraction": 0.5277361273765564,
"avg_line_length": 25.949495315551758,
"blob_id": "a1cbf6461d8dfdd0bd7f7404206fa2f7546fccff",
"content_id": "8b95f42acd5d15b739e8717df4856f8a80f05799",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2668,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 99,
"path": "/Cost.py",
"repo_name": "mdlee1998/NeuralNetwork",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom Activations import Softmax\n\nclass Cost:\n\n def regularization_cost(self, layer):\n\n regularization_cost = 0\n\n if layer.weight_regularizer_l1 > 0:\n regularization_cost += layer.weight_regularizer_l1 * \\\n np.sum(np.abs(layer.weights))\n\n if layer.weight_regularizer_l2 > 0:\n regularization_cost += layer.weight_regularizer_l2 * \\\n np.sum(layer.weights *\n layer.weights)\n\n if layer.bias_regularizer_l1 > 0:\n regularization_cost += layer.bias_regularizer_l1 * \\\n np.sum(np.abs(layer.biases))\n\n if layer.bias_regularizer_l2 > 0:\n regularization_cost += layer.bias_regularizer_l2 * \\\n np.sum(layer.biases *\n layer.biases)\n\n return regularization_cost\n\n\n def calc(self, output, true_y):\n\n sample_costs = self.forwardProp(output, true_y)\n\n return np.mean(sample_costs)\n\n\nclass CategoricalCrossentropy(Cost):\n\n def forwardProp(self, pred, true_y):\n\n samples = len(pred)\n\n #Clip data to prevent division by zero, to both sides to prevent\n #altering of the mean\n pred_clipped = np.clip(pred, 1e-7, 1 - 1e-7)\n\n if len(true_y.shape) == 1:\n confidence = pred_clipped[\n range(samples),\n true_y\n ]\n elif len(true_y.shape) == 2:\n confidence = np.sum(\n pred_clipped * true_y,\n axis=1\n )\n\n return -np.log(confidence)\n\n def backProp(self, dvalues, true_y):\n\n samples = len(dvalues)\n\n\n labels = len(dvalues[0])\n\n if len(true_y.shape) == 1:\n true_y = np.eye(labels)[true_y]\n\n self.dinputs = -true_y / dvalues\n self.dinputs = self.dinputs / samples\n\n\n\nclass Softmax_CategoricalCrossentropy(Cost):\n\n def __init__(self):\n self.activation = Softmax()\n self.cost = CategoricalCrossentropy()\n\n def forwardProp(self, input, true_y):\n\n self.activation.forwardProp(input)\n\n self.output = self.activation.output\n\n return self.cost.calc(self.output, true_y)\n\n def backProp(self, dvalues, true_y):\n\n samples = len(dvalues)\n\n if len(true_y.shape) == 2:\n true_y = np.argmax(true_y, axis=1)\n\n self.dinputs = dvalues.copy()\n self.dinputs[range(samples), true_y] -= 1\n self.dinputs = self.dinputs / samples\n"
},
{
"alpha_fraction": 0.5737847089767456,
"alphanum_fraction": 0.6050347089767456,
"avg_line_length": 28.1645565032959,
"blob_id": "6eb550cf1586b6a01fe9bf00f4e8d90c17189ba4",
"content_id": "108bffbeee8758f4d25538a3582a974a699e64ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2304,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 79,
"path": "/Main.py",
"repo_name": "mdlee1998/NeuralNetwork",
"src_encoding": "UTF-8",
"text": "from Layer import Layer\nfrom Activations import Softmax, ReLU\nfrom Cost import Softmax_CategoricalCrossentropy as Soft_Ce\nfrom Optimizer import Adam\nimport numpy as np\nimport nnfs\nfrom nnfs.datasets import spiral_data\n\ndef main():\n nnfs.init()\n X, y = spiral_data(samples = 1000, classes = 3)\n\n dense1 = Layer(2, 512, weight_regularizer_l2 = 5e-4,\n bias_regularizer_l2 = 5e-4)\n activation1 = ReLU()\n\n dense2 = Layer(512,3)\n\n cost_act = Soft_Ce()\n\n optimizer = Adam(learning_rate = 0.02, decay = 5e-7)\n\n for epoch in range(10001):\n\n dense1.forwardProp(X)\n activation1.forwardProp(dense1.output)\n\n dense2.forwardProp(activation1.output)\n\n data_cost = cost_act.forwardProp(dense2.output, y)\n\n regularization_cost = \\\n cost_act.cost.regularization_cost(dense1) + \\\n cost_act.cost.regularization_cost(dense2)\n\n cost = data_cost + regularization_cost\n\n predictions = np.argmax(cost_act.output, axis=1)\n if len(y.shape) == 2:\n y = np.argmax(y, axis=1)\n accuracy = np.mean(predictions == y)\n\n\n if not epoch % 100:\n print(f'epoch: {epoch}, ' +\n f'acc: {accuracy:.3f}, ' +\n f'cost: {cost:.3f}, (' +\n f'data_cost: {data_cost:.3f}, ' +\n f'reg_cost: {regularization_cost:.3f}), ' +\n f'lr: {optimizer.curr_learning_rate}')\n\n\n cost_act.backProp(cost_act.output, y)\n dense2.backProp(cost_act.dinputs)\n activation1.backProp(dense2.dinputs)\n dense1.backProp(activation1.dinputs)\n\n optimizer.pre_update_params()\n optimizer.update_params(dense1)\n optimizer.update_params(dense2)\n optimizer.post_update_params()\n\n X_test, y_test = spiral_data(samples = 100, classes = 3)\n dense1.forwardProp(X_test)\n activation1.forwardProp(dense1.output)\n dense2.forwardProp(activation1.output)\n\n cost = cost_act.forwardProp(dense2.output, y_test)\n\n predictions = np.argmax(cost_act.output, axis=1)\n if len(y.shape) == 2:\n y_test = np.argmax(y_test, axis=1)\n accuracy = np.mean(predictions == y_test)\n\n print(f'validation, acc: {accuracy:.3f}, cost: {cost:.3f}')\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 4 |
drahtkabel8/rasa1
|
https://github.com/drahtkabel8/rasa1
|
5f2a8cf81d1ead2a20af66c5027c2953f87537ac
|
8e76a7a320920179606a3e7ec385102a16bcd3ff
|
d29cf5ad23b96b5d84287ce12de34850fed7afe8
|
refs/heads/main
| 2023-03-14T07:48:36.677579 | 2021-02-26T01:12:02 | 2021-02-26T01:12:02 | 312,018,787 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6238381862640381,
"alphanum_fraction": 0.6267085671424866,
"avg_line_length": 49.79861068725586,
"blob_id": "0ef00de9b4ab54e5cba5ba67b7de3c127a45c020",
"content_id": "e25a9b1ee8050b59f917ccdc715e17eb17acfa0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7316,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 144,
"path": "/actions/actions.py",
"repo_name": "drahtkabel8/rasa1",
"src_encoding": "UTF-8",
"text": "from typing import Any, Text, Dict, List\n\nfrom rasa_sdk import Action, Tracker\nfrom rasa_sdk.events import SlotSet\nfrom rasa_sdk.executor import CollectingDispatcher\n\nlook_descriptions = {\n \"window\": \"A huge window with curtains on either side of it. They look expensive.\",\n \"terminal\": \"That's the terminal. The admin account is password protected.\",\n \"key\": \"A small golden key.\",\n \"door\": \"The door fell shut behind me when I entered the room. I'm a dumbass and forgot to check for a key or doorstopper and of course it locks when it shuts, so basically I'm stuck in here.\",\n \"curtains\": \"Those curtains are made from thick, high quality fabric. Naturally. Gotta stop the outside from peeking in... Or the inside from peeking out.\",\n \"room\": \"The room is kinda plain. There's a window across from the door, a desk, and a terminal on top of it.\",\n \"printer\": \"It's a high-end printer.\",\n \"drawer\": \"A drawer with a small lock. I can't open it without a key.\",\n \"desk\": \"A desk with a printer and a terminal on it. There's a drawer on the side.\",\n \"documents\": \"Some pretty interesting documents. I can't take them with me if I don't want to get caught, but perhaps the files are still on the terminal...\"\n}\n\n\nable_to_pick_up = [\"key\", \"curtains\"]\n\n\nclass ActionLook(Action):\n def name(self) -> Text:\n return \"action_look\"\n\n def run(self, dispatcher: CollectingDispatcher,\n tracker: Tracker,\n domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:\n spoken = False\n for blob in tracker.latest_message['entities']:\n if blob['entity'] == 'object':\n dispatcher.utter_message(text=look_descriptions[blob['value']])\n spoken = True\n if not spoken:\n dispatcher.utter_message(text=\"I can't seem to see anything like that in here.\")\n return []\n\n\n# class ActionCheckSlot(Action):\n # def name(self) -> Text:\n # return \"action_slot\"\n\n #def run(self, dispatcher: CollectingDispatcher,\n # tracker: Tracker,\n # domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:\n # bool1 = tracker.get_slot('key')\n # if bool1 == True:\n \n #return [] \n\n\nclass ActionPickUp(Action):\n def name(self) -> Text:\n return \"action_pickup\"\n\n def run(self, dispatcher: CollectingDispatcher,\n tracker: Tracker,\n domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:\n items_to_add = []\n # We need to check what objects the user wants to pick up. We cannot pick up\n # all objects and we need to check if the object is already in your inventory.\n for blob in tracker.latest_message['entities']:\n if blob['entity'] == 'object':\n item = blob['value']\n if item not in able_to_pick_up:\n dispatcher.utter_message(text=f\"Why and how would I pick up the {item}? I can't do that.\")\n else:\n item_in_inventory = tracker.get_slot(item)\n if item_in_inventory:\n dispatcher.utter_message(text=f\"I already picked up the {item}.\")\n else:\n items_to_add.append(SlotSet(item, True))\n dispatcher.utter_message(text=f\"Alright, picked the {item} up. What next?\")\n\n # We could add multiple items here.\n if len(items_to_add) > 0:\n return items_to_add\n dispatcher.utter_message(text=\"Are you sure you spelled that right? What do you want me to pick up?\")\n return []\n\n\nclass ActionInventory(Action):\n def name(self) -> Text:\n return \"action_inventory\"\n\n def run(self, dispatcher: CollectingDispatcher,\n tracker: Tracker,\n domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:\n items_in_inventory = [item for item in able_to_pick_up if tracker.get_slot(item)]\n if len(items_in_inventory) == 0:\n dispatcher.utter_message(text=\"I'm not carrying anything right now, chief.\")\n return []\n dispatcher.utter_message(text=\"Right now, I'm carrying:\")\n for item in items_in_inventory:\n dispatcher.utter_message(text=f\"- {item}\")\n return []\n\n\ncombinations = {\n ('key', 'door'): \"That doesn't fit. The key is too small for the door lock. Maybe there's another lock in the room?\",\n ('key', 'window'): \"Even if that key worked for the window - which it doesn't, for the record - I wouldn't jump outta there. We're on the 3rd floor, I could break something. Would be convenient if I had a ladder...\",\n ('curtains', 'window'): \"Honestly? That's insane. But it just might work out. [ Per ties the curtains together, attaches one of them to the curtain bar, and starts climbing down. ] Congrats! You've solved the level.\",\n ('key', 'drawer'): \"[ The lock clicks and the drawer opens. Inside is a stack of documents. ] ...Nice.\",\n ('key', 'printer'): \"How is that supposed to work?\",\n ('documents', 'printer'): \"It's a printer, not a scanner. It's connected to the terminal.\",\n ('terminal', 'password'): \"[ Per enters the password and the terminal grants access. ] Hell yeah. There's an important document with a good few pages of sensitive information on here. If only there was a way to take them with me...\",\n ('terminal', 'printer'): \"[ the printer starts reproducing the documents from the drawer. ] Sweet. That's it. Let's take these and get me outta here.'\"\n}\n\n\ncombinations.update({(i2, i1): v for (i1, i2), v in combinations.items()})\n\n\nclass ActionUse(Action):\n def name(self) -> Text:\n return \"action_use\"\n\n def run(self, dispatcher: CollectingDispatcher,\n tracker: Tracker,\n domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:\n entities = [e['value'] for e in tracker.latest_message['entities'] if e['entity'] == 'object']\n if len(entities) == 0:\n dispatcher.utter_message(text=\"I think you want me to combine some items, but I don't really get which two.\")\n dispatcher.utter_message(text=\"I'm pretty sure you're misspelling something. Could you try again?\")\n return []\n elif len(entities) == 1:\n dispatcher.utter_message(text=\"I think you want me to combine some items, but I don't really get which two.\")\n dispatcher.utter_message(text=f\"I need a second item to use with {entities[0]}.\")\n dispatcher.utter_message(text=\"Any other ideas?\")\n return []\n elif len(entities) > 2:\n dispatcher.utter_message(text=\"I think you want me to combine some items, but I don't really get which two.\")\n dispatcher.utter_message(text=f\"I could only make out that you wanted me to combine {' and '.join(entities)}.\")\n dispatcher.utter_message(text=\"I can only combine two items at a time. I only have two hands, bro...\")\n return []\n # there are two items and they are confirmed\n item1, item2 = entities\n if (item1, item2) in combinations.keys():\n dispatcher.utter_message(text=combinations[(item1, item2)])\n else:\n dispatcher.utter_message(text=f\"I don't think combining the {item1} with the {item2} makes a lot of sense.\")\n return []\n\n"
}
] | 1 |
initmike/Random-CTF-Stuff
|
https://github.com/initmike/Random-CTF-Stuff
|
2da42c310f9dbf180bf7d9f29bc99fc0b1829cee
|
18cc9d2f2d456af1b7e0f6a9a9425990be52b794
|
38f35e6288101271dcfbe7fd7765bae97650429a
|
refs/heads/master
| 2020-05-01T15:05:12.225887 | 2019-03-25T07:45:04 | 2019-03-25T07:45:04 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4658227860927582,
"alphanum_fraction": 0.47088608145713806,
"avg_line_length": 13.666666984558105,
"blob_id": "2057e9d96a31135e73bfa7469ef91c4985d5c709",
"content_id": "e581eb0b413c3d1bb494e75a08bda80ca961e717",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 27,
"path": "/cryptotools/euclidalgo.cpp",
"repo_name": "initmike/Random-CTF-Stuff",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<math.h>\n\nusing namespace std;\n\nint GCD(int a, int b)\n{\n int rem = a%b;\n while(rem != 0)\n {\n a = b;\n b = rem;\n rem = a%b;\n }\nreturn b;\n \n}\nint main()\n{\n int a,b;\n cout<<\"Enter Value:\"<<endl;\n cin>>a;\n cout<<\"Enter Second Value\"<<endl;\n cin>>b;\n cout<<\"The GCD of \"<<a<<\" and \"<<b<<\" is \"<<GCD(a,b);\n return 0;\n}"
},
{
"alpha_fraction": 0.6070640087127686,
"alphanum_fraction": 0.7902869582176208,
"avg_line_length": 24.11111068725586,
"blob_id": "05d4bd800c120d209741194c6199fb897b3930a9",
"content_id": "00544cf6909bd7d983f3bf013d632d7a5ae546ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 18,
"path": "/cryptotools/hextodecimalconvert.py",
"repo_name": "initmike/Random-CTF-Stuff",
"src_encoding": "UTF-8",
"text": "#/usr/bin/python\nprime1hex = \"00e90c8d273b9ac885928e1eca3e5553f4fad19534f039a505\"\nprint prime1hex\nprime2hex = \"00dc81a421afdcf749c732859106f80fb909b54fd7963abd47\"\nprint prime2hex\ndeci = \":\"\nfor char in deci:\n\tprime1hex = prime1hex.replace(char,\"\")\n\tprime2hex = prime2hex.replace(char,\"\")\n\n\n\ndecimal1 = int(prime1hex, 16)\ndecimal2 = int(prime2hex, 16)\nprint \"First decimal conversion: \"\nprint decimal1\nprint \"Second Decimal conversion: \"\nprint decimal2\n\n"
},
{
"alpha_fraction": 0.6632026433944702,
"alphanum_fraction": 0.6745394468307495,
"avg_line_length": 37.490909576416016,
"blob_id": "f3a76ce2966a53ec20a3677aee065f96bb35aca8",
"content_id": "0cde23d5600575d0694e13211d9909a483a0df8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2117,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 55,
"path": "/cryptotools/rangedcaesar.py",
"repo_name": "initmike/Random-CTF-Stuff",
"src_encoding": "UTF-8",
"text": "#Michael Gonzalez\n#September 30 2017\n#CSCI360\n# IMPORT SLEEP/ FROM TIME IS NOT NECESSARY FOR SIMPLE CIPHERS LIKE CEASAR WOULD BE NICE IN HIGHER END CIPHER.\nfrom time import sleep\nperform = raw_input(\"D or Decrypt to decrypt and DBF or Decrypt using brute force to Decrypt ustilizing Brute Force \").upper()\n\nif perform == \"D\" or perform == \"DECRYPT\":\n\tprint \"You choose to decrypt a string\"\n\tdef decrypt(ciphertext,shift):\n\t\talphabet=[\"a\",\"b\",\"c\",\"d\",\"e\",\"f\",\"g\",\"h\",\"i\",\"j\",\"k\",\"l\",\n\t\t\"m\",\"n\",\"o\",\"p\",\"q\",\"r\",\"s\",\"t\",\"u\",\"v\",\"w\",\"x\",\"y\",\"z\"]\n\t\tmod_alphabet={} \n\t\tfor i in range(0,len(alphabet)):\n\t\t\tmod_alphabet[alphabet[i]]=alphabet[(i-shift)%len(alphabet)]\n\t\tplaintext=\"\"\n\t\tfor letters in ciphertext.lower():\n\t\t\tif letters in mod_alphabet:\n\t\t\t\tletters=mod_alphabet[letters]\n\t\t\tplaintext+=letters\n\t\treturn plaintext\n\tsleep(0.3)\n\tciphertext = raw_input(\"Input the string you wish to decrypt \")\n\tmagnitude_of_shift = input(\"Input the magnitude of the shift \") \n\tsleep(0.7)\n\tprint \"Decrypting...\"\n\tsleep(1)\n\tprint \"Decrypted text is as follows:\" , decrypt(ciphertext,magnitude_of_shift)\n\nelif perform == \"DBF\" or perform == \"DECRYPT USING BRUTE FORCE\":\n\tprint \"You choose to decrypt a string using bruteforce\"\n\tdef decrypt(ciphertext,shift):\n\t\talphabet=[\"a\",\"b\",\"c\",\"d\",\"e\",\"f\",\"g\",\"h\",\"i\",\"j\",\"k\",\"l\",\n\t\t\"m\",\"n\",\"o\",\"p\",\"q\",\"r\",\"s\",\"t\",\"u\",\"v\",\"w\",\"x\",\"y\",\"z\"]\n\t\tmod_alphabet={}\n\t\tfor i in range(0,len(alphabet)):\n\t\t\tmod_alphabet[alphabet[i]]=alphabet[(i-shift)%len(alphabet)]\n\t\tplaintext=\"\"\n\t\tfor letters in ciphertext.lower():\n\t\t\tif letters in mod_alphabet:\n\t\t\t\tletters=mod_alphabet[letters]\n\t\t\tplaintext+=letters\n\t\treturn plaintext\n\tsleep (0.3)\n\tciphertext = raw_input(\"Input the string you want to decrypt by brute force \")\n\tmagnitude_of_shift = 0\n\twhile (magnitude_of_shift < 25):\n\t\tmagnitude_of_shift= magnitude_of_shift + 1\n\t\tprint\"Computing...\"\n\t\tsleep(0.7)\n\t\tprint \"Decrypted text MIGHT be as follows:\", decrypt(ciphertext,magnitude_of_shift)\t\n\t\tprint \"With a shift of \", magnitude_of_shift\n\t\t\t\nelse:\n\tprint \"You did not input neither E or Encrypt, D or Decrypt, nor DBF or Decrypt using Brute Force. Please try again\"\n"
}
] | 3 |
tvarney/GameBreaker
|
https://github.com/tvarney/GameBreaker
|
a40cf4d93a59a03e9cfe994a522ca074e4fb8b9b
|
9b6a2840635caf2f3027ff2fcaca4120e0e90f99
|
7f9301d6ca44a8a40af0e4b6f04c2423a55c73d0
|
refs/heads/master
| 2021-01-20T14:59:58.012373 | 2017-05-13T05:10:39 | 2017-05-13T05:10:39 | 90,704,411 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.565055787563324,
"alphanum_fraction": 0.5881571769714355,
"avg_line_length": 31.309734344482422,
"blob_id": "ab491003543bd9862c4b0856057cdc6bc4eeed47",
"content_id": "0a0a346ac3bba7fdfb1914e5eba4180eeaad35f3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3766,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 113,
"path": "/gamebreaker/image.py",
"repo_name": "tvarney/GameBreaker",
"src_encoding": "UTF-8",
"text": "\r\nimport cv2\r\nimport mss\r\nimport numpy\r\nfrom PIL import Image\r\n\r\nTM_CCOEFF = cv2.TM_CCOEFF\r\nTM_CCOEFF_NORMED = cv2.TM_CCOEFF_NORMED\r\nTM_CCORR = cv2.TM_CCORR\r\nTM_CCORR_NORMED = cv2.TM_CCORR_NORMED\r\nTM_SQDIFF = cv2.TM_SQDIFF\r\nTM_SQDIFF_NORMED = cv2.TM_SQDIFF_NORMED\r\n\r\nFormat = 'RGB'\r\n\r\n\r\nclass ImageGrabber(object):\r\n AllMonitors = 0\r\n FirstMonitor = 1\r\n\r\n def __init__(self):\r\n self.sct = mss.mss()\r\n self.displays = self.sct.enum_display_monitors()\r\n\r\n @staticmethod\r\n def make_bbox(x, y, width, height):\r\n return {'left': x, 'top': y, 'width': width, 'height': height}\r\n\r\n def monitor_dimensions(self, monitor: int):\r\n return self.displays[monitor]['width'], self.displays[monitor]['height']\r\n\r\n # Timings:\r\n # 3840x1080: 200 ms\r\n # 1920x1080: 90 ms\r\n # 800x600: 35 ms\r\n def grab_screen(self, monitor: int, convert: bool = False, grayscale: bool = False):\r\n pixels = self.sct.get_pixels(self.displays[monitor])\r\n img = Image.frombytes(Format, (self.monitor_dimensions(monitor)), pixels)\r\n if grayscale:\r\n print(\"Converting to Grayscale\")\r\n img.convert('L').convert(Format)\r\n return numpy.array(img) if convert else img\r\n\r\n def grab_area(self, bbox, convert: bool = False, grayscale: bool = False):\r\n img = Image.frombytes(Format, (bbox['width'], bbox['height']), self.sct.get_pixels(bbox))\r\n if grayscale:\r\n print(\"Converting to Grayscale\")\r\n img = img.convert('L').convert(Format)\r\n return numpy.array(img) if convert else img\r\n\r\n\r\ndef find_match(img_source, img_object, method: int):\r\n result_image = cv2.matchTemplate(img_source, img_object, method)\r\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result_image)\r\n\r\n if method in [TM_SQDIFF, TM_SQDIFF_NORMED]:\r\n return min_val, min_loc\r\n return max_val, max_loc\r\n\r\n\r\ndef load_from_file(filename, convert: bool = False, grayscale: bool = False):\r\n img = Image.open(filename, \"r\")\r\n print(\"Loaded {} as {}\".format(filename, img.mode))\r\n if grayscale:\r\n print(\"Converting to Grayscale\")\r\n img = img.convert('L').convert(Format)\r\n if img.mode == \"RGBA\":\r\n img = img.convert(\"RGB\")\r\n return numpy.array(img) if convert else img\r\n\r\n\r\ndef apply_mask(source, mask, mask_color = (0, 0, 0)):\r\n dim = min(source.width, mask.width), min(source.height, mask.height)\r\n result = Image.new('RGB', dim)\r\n for y in range(dim[1]):\r\n for x in range(dim[0]):\r\n pixel = mask.getpixel((x, y))\r\n if pixel != (0, 0, 0):\r\n pixel = source.getpixel((x, y))\r\n else:\r\n pixel = mask_color\r\n\r\n result.putpixel((x, y), pixel)\r\n return result\r\n\r\n\r\ndef _get_pixel(pos, offset, width, data):\r\n return data[(pos[0] + offset[0]) + (pos[1] + offset[1]) * width]\r\n\r\n\r\ndef _set_pixel(pos, offset, image, color):\r\n image.putpixel((pos[0] + offset[0], pos[1] + offset[1]), color)\r\n\r\n\r\ndef check_rect(pos, data, width, colors, radius: int = 2):\r\n for i in range(-radius, radius, 1):\r\n for j in range(-radius, radius, 1):\r\n npos = pos[0] + i, pos[1] + j\r\n print(\"Pixel at {} = {}\".format(npos, _get_pixel(pos, (i, j), width, data)))\r\n if not _get_pixel(pos, (i, j), width, data) in colors:\r\n return False\r\n return True\r\n\r\n\r\nif __name__ == \"__main__\":\r\n im = ImageGrabber()\r\n area_pil = im.grab_area(ImageGrabber.make_bbox(10, 10, 800, 600), False, False)\r\n area_cv2 = im.grab_area(ImageGrabber.make_bbox(10, 10, 800, 600), True, False)\r\n\r\n cv2.imshow(\"CV2 Area\", area_cv2)\r\n cv2.waitKey()\r\n cv2.destroyAllWindows()\r\n\r\n area_pil.show(\"PIL Area\")\r\n"
},
{
"alpha_fraction": 0.4331222474575043,
"alphanum_fraction": 0.4750121831893921,
"avg_line_length": 28.82582664489746,
"blob_id": "c25c9f6b72098b98b6234856850de5a1a3b16a08",
"content_id": "ceadc38fdb2acd4336157b4e64ccd407a4aa81ab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10265,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 333,
"path": "/gamebreaker/neopets/sutekstomb.py",
"repo_name": "tvarney/GameBreaker",
"src_encoding": "UTF-8",
"text": "\r\nimport pyautogui\r\nfrom PIL import Image, ImageDraw\r\nimport gamebreaker.color as Color\r\nimport gamebreaker.image as img\r\nimport os.path\r\nimport time\r\nimport win32gui, win32con\r\n\r\n\r\nclass Tile(object):\r\n AllTiles = []\r\n\r\n @staticmethod\r\n def GetTileId(pixel):\r\n for id, tile in enumerate(Tile.AllTiles):\r\n if tile.matches(pixel):\r\n return id\r\n if pixel in _backgrounds:\r\n return -2\r\n return -1\r\n\r\n def __init__(self, name, color):\r\n self._name = name\r\n self._color = color\r\n self._id = len(Tile.AllTiles)\r\n Tile.AllTiles.append(self)\r\n\r\n def matches(self, pixel):\r\n return self._color == pixel\r\n\r\n def id(self):\r\n return self._id\r\n\r\n def color(self):\r\n return self._color\r\n\r\n def __str__(self):\r\n return self._name\r\n\r\n\r\nTile.Head = Tile(\"Head\", (106, 130, 240))\r\nTile.Scarab = Tile(\"Scarab\", (0, 51, 0))\r\nTile.Tree = Tile(\"Tree\", (102, 153, 0))\r\nTile.Gem = Tile(\"Gem\", (245, 10, 81))\r\nTile.Obelisk = Tile(\"Obelisk\", (241, 241, 82))\r\nTile.Sun = Tile(\"Sun\", (255, 102, 0))\r\nTile.Pyramid = Tile(\"Pyramid\", (255, 153, 0))\r\nTile.Bomb = Tile(\"Bomb\", (255, 0, 0))\r\nTile.Amulet = Tile(\"Amulet\", (105, 1, 1))\r\nTile.Special = Tile(\"Special\", (0, 0, 0))\r\nTile.Ankh = Tile(\"Ankh\", (102, 102, 102))\r\n\r\n_backgrounds = [(202, 150, 98), (220, 183, 146)]\r\n_time_up_text = (255, 255, 49)\r\n_no_moves_bg = (41, 30, 19)\r\n\r\n\r\nclass Move(object):\r\n def __init__(self, old_pos, new_pos):\r\n self.old_pos = old_pos\r\n self.new_pos = new_pos\r\n\r\n def commit(self, ul, grid_space, click_delay = 0.03):\r\n if self.old_pos == self.new_pos:\r\n return True\r\n\r\n pos = ul[0] + 20 + self.old_pos[0] * grid_space, ul[1] + 20 + self.old_pos[1] * grid_space\r\n #win32gui.SetCursor(pos)\r\n pyautogui.moveTo(pos[0], pos[1])\r\n pyautogui.click()\r\n time.sleep(click_delay)\r\n\r\n pos = ul[0] + 20 + self.new_pos[0] * grid_space, ul[1] + 20 + self.new_pos[1] * grid_space\r\n pyautogui.moveTo(pos[0], pos[1])\r\n #win32gui.SetCursor(pos)\r\n pyautogui.click()\r\n\r\n\r\nclass Suteks(object):\r\n def __init__(self):\r\n self.sshot = img.ImageGrabber()\r\n self.data_path = \"./data/\"\r\n self.running = False\r\n self._last_screen = None\r\n self._final_screen = None\r\n\r\n def _find_area(self):\r\n img_id = img.load_from_file(os.path.join(self.data_path, \"suteks_id.png\"), True, False)\r\n screen = self.sshot.grab_screen(0, True)\r\n mval, ul = img.find_match(screen, img_id, img.TM_CCOEFF_NORMED)\r\n if mval <= 0.85:\r\n return None\r\n return ul[0] + img_id.shape[0], ul[1] + img_id.shape[1]\r\n\r\n def fill_grid(self, bbox, grid, ul):\r\n breakout = True\r\n while breakout:\r\n area = self.sshot.grab_area(bbox)\r\n self._last_screen = area\r\n\r\n if area.getpixel((139, 145)) == _time_up_text:\r\n print(\"Game Over!\")\r\n self.running = False\r\n return False\r\n if area.getpixel((10,10)) == (226, 199, 171):\r\n #area.show()\r\n pos = pyautogui.position()\r\n time.sleep(1.0)\r\n if pos != pyautogui.position():\r\n exit(1) # TODO: Change this so we don't kill the process!\r\n pyautogui.moveTo(ul[0] + 140, ul[1] + 300)\r\n pyautogui.click()\r\n continue\r\n\r\n breakout = False\r\n for y in range(10):\r\n for x in range(10):\r\n pixel = area.getpixel((20 + x * 40, 20 + y * 40))\r\n t_id = Tile.GetTileId(pixel)\r\n if t_id == -1:\r\n print(\"Found unknown tile at {}x{}: Color = {}\".format(x, y, pixel))\r\n if t_id == -2:\r\n breakout = True\r\n break\r\n grid[y][x] = t_id\r\n if breakout:\r\n break\r\n return True\r\n\r\n def play(self, stime=0.3):\r\n ul = self._find_area()\r\n bbox = img.ImageGrabber.make_bbox(ul[0], ul[1], 400, 400)\r\n print(\"Found Game at {}x{}\".format(bbox['left'], bbox['top']))\r\n grid = [[-1 for i in range(10)] for j in range(10)]\r\n\r\n pyautogui.moveTo(10,10)\r\n pos = pyautogui.position()\r\n\r\n self.running = True\r\n while self.running:\r\n if pyautogui.position() != pos:\r\n print(\"Mouse moved! Quitting...\")\r\n return\r\n\r\n if not self.fill_grid(bbox, grid, ul):\r\n self.running = False\r\n break\r\n\r\n move = find_move(grid)\r\n\r\n pos = pyautogui.position()\r\n time.sleep(stime)\r\n if pos != pyautogui.position():\r\n exit(1) #TODO: Change this so we aren't killing the process!\r\n\r\n if move is not None:\r\n move.commit(ul, 40)\r\n pos = pyautogui.position()\r\n else:\r\n #print(\"Could not find move!\")\r\n #generate_grid_image(grid).show(\"Current Grid\")\r\n self._final_screen = self._last_screen\r\n\r\n time.sleep(0.4)\r\n\r\n\r\ndef generate_grid_image(grid):\r\n img = Image.new('RGB', (400,400), Color.White)\r\n context = ImageDraw.Draw(img)\r\n for y in range(10):\r\n for x in range(10):\r\n tile_id = grid[y][x]\r\n t_color = Color.White\r\n if tile_id >= 0:\r\n t_color = Tile.AllTiles[tile_id].color()\r\n elif tile_id == -1:\r\n t_color = Color.Gray50\r\n context.rectangle((x*40, y*40, x*40+40, y*40+40), t_color, t_color)\r\n return img\r\n\r\n\r\ndef find_move(grid):\r\n move = None\r\n value = 0\r\n for y in range(10):\r\n for x in range(10):\r\n if grid[y][x] < 0:\r\n continue\r\n if x >= 1:\r\n nvalue = _test_move_left(x, y, grid) + _test_move_right(x - 1, y, grid)\r\n if nvalue >= value:\r\n move = Move((x, y), (x - 1, y))\r\n value = nvalue\r\n #if x <= 8:\r\n # nvalue = _test_move_right(x, y, grid)\r\n # if nvalue > value:\r\n # move = Move((x, y), (x + 1, y))\r\n # value = nvalue\r\n if y >= 1:\r\n nvalue = _test_move_up(x, y, grid) + _test_move_down(x, y - 1, grid)\r\n if nvalue >= value:\r\n move = Move((x, y), (x, y - 1))\r\n value = nvalue\r\n #if y <= 8:\r\n # nvalue = _test_move_down(x, y, grid)\r\n # if nvalue > value:\r\n # move = Move((x, y), (x, y + 1))\r\n # value = nvalue\r\n # Stop as soon as we find the best move possible rating 4\r\n if value == 4:\r\n return move\r\n return move\r\n\r\n\r\ndef _bomb_above(x, y, grid):\r\n if y <= 1:\r\n return False\r\n for i in range(y-1):\r\n if grid[i][x] == Tile.Bomb.id():\r\n return True\r\n return False\r\n\r\n\r\ndef _test_move_up(x, y, grid) -> int:\r\n matches = [grid[y][x], Tile.Amulet.id()]\r\n xm2 = False if x < 2 else grid[y-1][x-2] in matches\r\n xm1 = False if x < 1 else grid[y-1][x-1] in matches\r\n xp1 = False if x > 8 else grid[y-1][x+1] in matches\r\n xp2 = False if x > 7 else grid[y-1][x+2] in matches\r\n\r\n ym3 = False if y < 3 else grid[y-3][x] in matches\r\n ym2 = False if y < 2 else grid[y-2][x] in matches\r\n\r\n r = 0\r\n if xm2 and xm1:\r\n r += 1\r\n if xp1 and xp2:\r\n r += 1\r\n if xp1 and xm1:\r\n r += 1\r\n if ym3 and ym2:\r\n r += 1.25 + (0.5 if _bomb_above(x, y-3, grid) else 0.0)\r\n return r\r\n\r\n\r\ndef _test_move_down(x, y, grid) -> int:\r\n matches = [grid[y][x], Tile.Amulet.id()]\r\n xm2 = False if x < 2 else grid[y + 1][x - 2] in matches\r\n xm1 = False if x < 1 else grid[y + 1][x - 1] in matches\r\n xp1 = False if x > 8 else grid[y + 1][x + 1] in matches\r\n xp2 = False if x > 7 else grid[y + 1][x + 2] in matches\r\n\r\n yp3 = False if y > 6 else grid[y + 3][x] in matches\r\n yp2 = False if y > 7 else grid[y + 2][x] in matches\r\n\r\n r = 0\r\n if xm2 and xm1:\r\n r += 1\r\n if xp1 and xp2:\r\n r += 1\r\n if xp1 and xm1:\r\n r += 1\r\n if yp3 and yp2:\r\n r += 1.25 + (0.5 if _bomb_above(x, y, grid) else 0.0)\r\n return r\r\n\r\n\r\ndef _test_move_left(x, y, grid) -> int:\r\n matches = [grid[y][x], Tile.Amulet.id()]\r\n ym2 = False if y < 2 else grid[y - 2][x - 1] in matches\r\n ym1 = False if y < 1 else grid[y - 1][x - 1] in matches\r\n yp1 = False if y > 8 else grid[y + 1][x - 1] in matches\r\n yp2 = False if y > 7 else grid[y + 2][x - 1] in matches\r\n\r\n xm3 = False if x < 3 else grid[y][x - 3] in matches\r\n xm2 = False if x < 2 else grid[y][x - 2] in matches\r\n\r\n r = 0\r\n vert = False\r\n b_y = y\r\n if ym2 and ym1:\r\n r += 1.25\r\n vert = True\r\n b_y = y - 2\r\n if yp2 and yp1:\r\n r += 1.25\r\n vert = True\r\n if yp1 and ym1:\r\n r += 1.25\r\n vert = True\r\n b_y = y - 1\r\n if xm3 and xm2:\r\n r += 1\r\n if vert and _bomb_above(x, b_y, grid):\r\n r += 0.5\r\n return r\r\n\r\n\r\ndef _test_move_right(x, y, grid) -> int:\r\n matches = [grid[y][x], Tile.Amulet.id()]\r\n\r\n ym2 = False if y < 2 else grid[y - 2][x + 1] in matches\r\n ym1 = False if y < 1 else grid[y - 1][x + 1] in matches\r\n yp1 = False if y > 8 else grid[y + 1][x + 1] in matches\r\n yp2 = False if y > 7 else grid[y + 2][x + 1] in matches\r\n\r\n xp3 = False if x > 6 else grid[y][x + 3] in matches\r\n xp2 = False if x > 7 else grid[y][x + 2] in matches\r\n\r\n r = 0\r\n vert = False\r\n b_y = y\r\n if ym2 and ym1:\r\n r += 1.25\r\n vert = True\r\n b_y = y - 2\r\n if yp1 and yp2:\r\n r += 1.25\r\n vert = True\r\n if yp1 and ym1:\r\n r += 1.25\r\n vert = True\r\n b_y = y - 1\r\n if xp3 and xp2:\r\n r += 1\r\n if vert and _bomb_above(x, b_y, grid):\r\n r += 0.5\r\n return r\r\n\r\nif __name__ == \"__main__\":\r\n s = Suteks()\r\n s.data_path = \"../../data/\"\r\n s.play()"
},
{
"alpha_fraction": 0.5735124945640564,
"alphanum_fraction": 0.5976967215538025,
"avg_line_length": 44.48214340209961,
"blob_id": "19cbc160f16b4def559239fb9d772b17eaa7f9c9",
"content_id": "13baabb649eeb75b15d1d55c5378831194c6789d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2605,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 56,
"path": "/gamebreaker/neopets/common.py",
"repo_name": "tvarney/GameBreaker",
"src_encoding": "UTF-8",
"text": "\r\nimport gamebreaker.image as image\r\nimport os.path\r\nimport cv2\r\n\r\n\r\ndef GetGameArea(data_path : str = \"./data\", match_value: float = 0.70):\r\n im = image.ImageGrabber()\r\n\r\n img_ul = image.load_from_file(os.path.join(data_path, \"neopets_top_left.png\"), True, False)\r\n img_br = image.load_from_file(os.path.join(data_path, \"neopets_bottom_right.png\"), True, False)\r\n screen = im.grab_screen(im.FirstMonitor, True, False)\r\n match_ul = image.find_match(screen, img_ul, image.TM_CCOEFF_NORMED)\r\n if match_ul[0] < match_value:\r\n img_ul = image.load_from_file(os.path.join(data_path, \"neopets_top_left_alt.png\"), True, False)\r\n match_ul = image.find_match(screen, img_ul, image.TM_CCOEFF_NORMED)\r\n match_br = image.find_match(screen, img_br, image.TM_CCOEFF_NORMED)\r\n if match_br[0] < match_value:\r\n img_br = image.load_from_file(os.path.join(data_path, \"neopets_bottom_right_alt.png\"), True, False)\r\n match_br = image.find_match(screen, img_br, image.TM_CCOEFF_NORMED)\r\n\r\n if match_ul[0] < match_value or match_br[0] < match_value:\r\n print(\"UL_Value: {}\\nBR_Value: {}\".format(match_ul[0], match_br[0]))\r\n return None\r\n\r\n if match_ul[0] < 0.85:\r\n print(\"Upper left corner match is of low quality: {}\".format(match_ul))\r\n if match_br[0] < 0.85:\r\n print(\"Bottom right corner match is of low quality: {}\".format(match_br))\r\n\r\n top_left = match_ul[1]\r\n bottom_right = match_br[1]\r\n ul_w, ul_h, br_w, br_h = img_ul.shape[0], img_ul.shape[1], img_br.shape[0], img_br.shape[1]\r\n top_left = top_left[0] + ul_h, top_left[1] + ul_w\r\n if top_left[0] >= bottom_right[0] or top_left[1] >= bottom_right[1]:\r\n print(\"Bad coordinates: ul{} < br{}\".format(top_left, bottom_right))\r\n w, h = img_ul.shape[1], img_ul.shape[0]\r\n cv2.rectangle(screen, top_left, (top_left[0] + w, top_left[1] + h), (0,0,255), 2)\r\n w, h = img_br.shape[1], img_br.shape[0]\r\n cv2.rectangle(screen, bottom_right, (bottom_right[0] + w, bottom_right[1] + h), (255, 0, 0), 2)\r\n cv2.imshow(\"Screen\", screen)\r\n cv2.imshow(\"img_br\", img_br)\r\n cv2.imshow(\"img_ul\", img_ul)\r\n cv2.waitKey()\r\n cv2.destroyAllWindows()\r\n return None\r\n return im.make_bbox(top_left[0], top_left[1], bottom_right[0] - top_left[0], bottom_right[1] - top_left[1])\r\n\r\n\r\nif __name__ == \"__main__\":\r\n bbox = GetGameArea(\"../../data/\")\r\n if bbox is None:\r\n print(\"Could not find game area\")\r\n else:\r\n im = image.ImageGrabber()\r\n area = im.grab_area(bbox)\r\n area.show()\r\n"
},
{
"alpha_fraction": 0.6528925895690918,
"alphanum_fraction": 0.6528925895690918,
"avg_line_length": 21.799999237060547,
"blob_id": "ef1557ad6b9428497db08a00802312052db19a9f",
"content_id": "b214eef77185bfaf227f32aa7ef962bcf1ecbf1b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 5,
"path": "/main.py",
"repo_name": "tvarney/GameBreaker",
"src_encoding": "UTF-8",
"text": "\r\nimport gamebreaker.image\r\nimport gamebreaker.neopets.buzzer as buzzer\r\n\r\nif __name__ == \"__main__\":\r\n buzzer.run()\r\n"
},
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 22,
"blob_id": "08ba2ab53c4b0e5804fd6ec81619c4749ced682f",
"content_id": "f0ca6b0d1339e9ad8e8ce3c180b3efbef49ef0bf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 2,
"path": "/README.md",
"repo_name": "tvarney/GameBreaker",
"src_encoding": "UTF-8",
"text": "# GameBreaker\nPython tools for breaking games\n"
},
{
"alpha_fraction": 0.4971655309200287,
"alphanum_fraction": 0.5308957099914551,
"avg_line_length": 30.357797622680664,
"blob_id": "9292816e8dd00dffe3cddd7b6034304f7c0719f6",
"content_id": "310811094e7bbc76a74e5c6dcaf5f375e2bdd62d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7056,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 218,
"path": "/gamebreaker/neopets/buzzer.py",
"repo_name": "tvarney/GameBreaker",
"src_encoding": "UTF-8",
"text": "\r\nfrom gamebreaker import image\r\nimport pyautogui\r\nimport gamebreaker.neopets.common as np\r\nfrom PIL import Image\r\nimport win32api, win32con\r\nfrom time import sleep\r\nimport random\r\nimport os.path\r\n\r\ntarget_color = (204, 0, 0)\r\n\r\nwire_color = (0, 0, 0)\r\nused_color = (255, 0, 255)\r\n\r\nstart_colors = [(0, g, 0) for g in range(142, 206)]\r\n_offsets = [(0, 1), (0, -1), (-1, 0), (1, 0), (-1, 1), (1, 1), (-1, -1), (1, -1)]\r\n\r\n\r\ndef add_pos(vec, add):\r\n return vec[0] + add[0], vec[1] + add[1]\r\n\r\n\r\ndef _get_pixel(pos, offset, width, data):\r\n return data[(pos[0] + offset[0]) + (pos[1] + offset[1]) * width]\r\n\r\n\r\ndef _set_pixel(pos, offset, image, color):\r\n image.putpixel((pos[0] + offset[0], pos[1] + offset[1]), color)\r\n\r\n\r\ndef check_rect(pos, data, width, colors, radius: int = 2):\r\n for i in range(-radius, radius, 1):\r\n for j in range(-radius, radius, 1):\r\n if not _get_pixel(pos, (i, j), width, data) in colors:\r\n return False\r\n return True\r\n\r\n\r\ndef draw_centered_rect(img, pos, radius: int, color = (0, 0, 0)):\r\n for i in range(-radius, radius, 1):\r\n for j in range(-radius, radius, 1):\r\n _set_pixel(pos, (i, j), img, color)\r\n\r\n\r\ndef create_mask(area):\r\n start = None\r\n end = None\r\n mask = Image.new('RGB', (area.width, area.height), (255,255,255))\r\n data = area.getdata()\r\n # print(\"Area: {}x{}\".format(area.width, area.height))\r\n for y in range(area.height - 1):\r\n for x in range(area.width - 1):\r\n pixel = area.getpixel((x, y))\r\n if pixel == (0, 0, 0):\r\n if check_rect((x, y), data, area.width, [(0,0,0)]):\r\n mask.putpixel((x, y), (0, 0, 0))\r\n elif pixel == (204, 0, 0):\r\n if end is None and check_rect((x, y), data, area.width, [(204, 0, 0)]):\r\n end = x, y\r\n mask.putpixel((x, y), (0, 0, 0))\r\n elif pixel in start_colors:\r\n if start is None and check_rect((x, y), data, area.width, start_colors):\r\n start = x, y\r\n mask.putpixel((x, y), (0, 0, 0))\r\n # Reduce the mask\r\n data = mask.getdata()\r\n newmask = Image.new('RGB', (area.width, area.height), (255, 255, 255))\r\n for y in range(area.height - 1):\r\n for x in range(area.width - 1):\r\n pixel = mask.getpixel((x, y))\r\n if pixel == (0, 0, 0):\r\n if y < 10 or check_rect((x, y), data, area.width, [(0, 0, 0), 0]):\r\n newmask.putpixel((x, y), (0,0,0))\r\n\r\n return start, end, newmask\r\n\r\n\r\ndef _sssp_put(array, pos, width, value):\r\n array[pos[0]+pos[1]*width] = value\r\n\r\n\r\ndef _sssp_get(array, pos, width):\r\n return array[pos[0]+pos[1]*width]\r\n\r\n\r\ndef dijkstra_sssp(mask, start, stop):\r\n if start is None:\r\n print(\"SSSP: Invalid start value of None\")\r\n return []\r\n\r\n if stop is None:\r\n print(\"SSSP: Invalid stop value of None\")\r\n return []\r\n\r\n width = mask.width\r\n height = mask.height\r\n\r\n mask_data = mask.getdata()\r\n edge = [stop]\r\n visited = [(2**32-1) for i in range(width*height)]\r\n _sssp_put(visited, stop, width, 0)\r\n while len(edge) > 0:\r\n position = edge.pop(0)\r\n value = _sssp_get(visited, position, width) + 1\r\n for offset in _offsets:\r\n npos = (position[0] + offset[0], position[1] + offset[1])\r\n old_value = _sssp_get(visited, npos, width)\r\n if old_value > value:\r\n if _get_pixel(position, offset, width, mask_data) == (0, 0, 0):\r\n _sssp_put(visited, npos, width, value)\r\n # Should probably use a set instead of an array (meh)\r\n edge.append(npos)\r\n\r\n # Follow the path\r\n path = []\r\n pos = start\r\n while pos != stop:\r\n minval = 2**32-1\r\n move = None\r\n for offset in _offsets:\r\n npos = (pos[0] + offset[0], pos[1] + offset[1])\r\n value = _sssp_get(visited, npos, width)\r\n if value < minval:\r\n move = npos\r\n minval = value\r\n if move is None:\r\n print(\"SSSP: Failed; could not find valid path\")\r\n break\r\n path.append(move)\r\n pos = move\r\n\r\n return path\r\n\r\n\r\ndef follow_path(path, ul, start, end, random_timing : bool = False):\r\n win32api.SetCursorPos((start[0] + ul[0], start[1] + ul[1]))\r\n pyautogui.click()\r\n if random_timing:\r\n sleep(random.random()*2.0)\r\n for pos in path:\r\n win32api.SetCursorPos((pos[0] + ul[0], pos[1] + ul[1]))\r\n sleep(0.0022)\r\n\r\n win32api.SetCursorPos((end[0] + ul[0], end[1] + ul[1]))\r\n\r\n\r\ndef draw_path(screen, path, start, end):\r\n screen.putpixel(start, (255, 0, 255))\r\n for pos in path:\r\n screen.putpixel(pos, (255, 0, 255))\r\n screen.putpixel(end, (255, 0, 255))\r\n\r\n\r\ndef find_game(im: image.ImageGrabber, data_path: str = \"./data/\"):\r\n # Load the image id we use to find the game\r\n img_id = image.load_from_file(os.path.join(data_path, \"buzzer_id.png\"), True, False)\r\n screen = im.grab_screen(image.ImageGrabber.AllMonitors, True, False)\r\n match_value, ul = image.find_match(screen, img_id, image.TM_CCOEFF_NORMED)\r\n if match_value < 0.85:\r\n return None\r\n\r\n return im.make_bbox(ul[0]-10, ul[1]-10, 800, 600)\r\n\r\n\r\ndef play(is_main: bool = False, move_cursor: bool = True, random_timing: bool = False):\r\n print(is_main)\r\n im = image.ImageGrabber()\r\n bbox = None\r\n if is_main:\r\n bbox = find_game(im, \"../../data\")\r\n else:\r\n bbox = find_game(im)\r\n if bbox is None:\r\n print(\"Could not locate neopets game area\")\r\n return\r\n\r\n area = im.grab_area(bbox, False)\r\n start, end, mask = create_mask(area)\r\n start_mask = mask.copy()\r\n print(\"Start: {}\\nEnd: {}\".format(start, end))\r\n if start is not None:\r\n draw_centered_rect(mask, start, 5, (0, 0, 0))\r\n else:\r\n print(\"Invalid Start Value!\")\r\n pos = pyautogui.position()\r\n print(\"Color under cursor: {}\".format(pyautogui.pixel(pos[0], pos[1])))\r\n return\r\n if end is not None:\r\n draw_centered_rect(mask, end, 5, (0, 0, 0))\r\n else:\r\n print(\"Invalid end Value!\")\r\n return\r\n\r\n #print(start)\r\n #mask.show(\"Game Mask\")\r\n\r\n path = dijkstra_sssp(mask, start, end)\r\n ul = bbox['left'], bbox['top']\r\n size = 6\r\n while len(path) == 0:\r\n draw_centered_rect(mask, start, size, (0, 0, 0))\r\n draw_centered_rect(mask, end, size, (0, 0, 0))\r\n size += 1\r\n print(\"Adjusting start area: {}\".format(size))\r\n path = dijkstra_sssp(mask, start, end)\r\n if size >= 20:\r\n start_mask.show()\r\n image.apply_mask(area, start_mask, (255, 0, 255)).show()\r\n return\r\n\r\n if move_cursor:\r\n follow_path(path, ul, start, end, random_timing)\r\n else:\r\n draw_path(area, path, start, end)\r\n area.show(\"Solution Path\")\r\n\r\nif __name__ == \"__main__\":\r\n play(True, True, True)\r\n"
}
] | 6 |
JMComstock/Users-with-Bank-Accounts
|
https://github.com/JMComstock/Users-with-Bank-Accounts
|
f1088a1cd862588eacc9bb5558ee850e225976f1
|
3803e27ca9407d3c7dfa2840a4a9f2c8cf3c9277
|
f4cee1e7f0485f414ee0046dbf426ad968fee2bb
|
refs/heads/main
| 2022-12-22T01:34:08.986108 | 2020-10-01T18:34:33 | 2020-10-01T18:34:33 | 300,384,863 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5965961217880249,
"alphanum_fraction": 0.6205151677131653,
"avg_line_length": 26.578947067260742,
"blob_id": "25ccd1009a54ae730645b8c41c24298dd4b1c0e9",
"content_id": "56f16bd4c1ba1a415a8f6ef2c330f6ee8aec4369",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2174,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 76,
"path": "/UsersWithBankAccounts.py",
"repo_name": "JMComstock/Users-with-Bank-Accounts",
"src_encoding": "UTF-8",
"text": "class User:\r\n def __init__(self, name, email):\r\n self.username = name\r\n self.email = email\r\n self.account = BankAccount (int_rate=0.02, balance = 0)\r\n self.balance = 0\r\n\r\n # def example_method(self):\r\n # self.account.deposit(100)\r\n # print(self.account.balance)\r\n\r\n def make_deposit(self, amount):\r\n self.balance += amount\r\n return self\r\n\r\n def make_withdrawl(self, amount):\r\n self.balance -= amount\r\n if self.balance < amount:\r\n print(\"Insufficient funds to make a withdrawl\")\r\n return self\r\n\r\n def transfer_money(self, other_user, amount):\r\n if self.balance < amount:\r\n print(\"insifficient funds to make transfer\")\r\n else:\r\n self.balance -= amount\r\n other_user.balance += amount\r\n print(\"You have successfully transfered the funds\")\r\n\r\n def display_user_balance(self):\r\n print(f\"Username: {self.username}, Balance: {self.balance}\")\r\n\r\nclass BankAccount:\r\n\tdef __init__(self, int_rate, balance = 0):\r\n\t\tself.rate = int_rate\r\n\t\tself.account = balance\r\n\r\n\t# def deposit(self, amount):\r\n\t# \tself.account += amount\r\n\t# \treturn self\r\n\t\r\n\t# def withdraw(self, amount):\r\n\t# \tself.account -= amount\r\n\t# \tif self.account < amount:\r\n\t# \t\tprint(\"Insufficient funds: Charging a $5 fee\")\r\n\t# \t\tself.account -= 5\r\n\t# \treturn self\r\n\r\n\t# def display_account_info(self):\r\n\t# \tprint(f\"Balance: {self.balance}\")\r\n\t# \treturn self\r\n\t\r\n\tdef yield_interest(self):\r\n\t\tif self.balance > 0:\r\n\t\t\tself.balance = self.balance * (self.rate)+self.balance\r\n\t\treturn self\r\n\r\n\r\n\r\n\r\nuser1 = User(\"Ron\" , \"[email protected]\")\r\nuser2 = User(\"Missy\", \"[email protected]\")\r\nuser3 = User(\"Jason\", \"[email protected]\")\r\n\r\nuser1.make_deposit(100).make_withdrawl(20).display_user_balance()\r\n# user2.make_deposit(600).make_deposit(100).make_withdrawl(50).make_withdrawl(50).display_user_balance()\r\n# user3.make_deposit(1000).make_withdrawl(20).make_withdrawl(200).make_withdrawl(50).display_user_balance()\r\n\r\n\r\n# user1.transfer_money(user3, 40)\r\n\r\n# user1.display_user_balance()\r\n\r\n# user1.display_user_balance()\r\n# user2.display_user_balance()\r\n# user3.display_user_balance()\r\n\r\n"
}
] | 1 |
cyder-ironman/portfolio-project
|
https://github.com/cyder-ironman/portfolio-project
|
fc74a90111554f8c398186e5f750729e928a4ee6
|
0ed5724b7ba449ba3d7dcc91ba53c3df23ef733b
|
1bd00ae274a0abda4f31ebb508b7257b02d437d0
|
refs/heads/master
| 2020-04-29T11:21:58.230675 | 2019-03-17T15:18:43 | 2019-03-17T15:18:43 | 176,095,008 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4526315927505493,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 14.833333015441895,
"blob_id": "e6f77232789e9534e51929069dd0bf9d4bf5afe6",
"content_id": "190ec41946612385fa993288c2fc0cd3d14d7d1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "cyder-ironman/portfolio-project",
"src_encoding": "UTF-8",
"text": "Django==2.1.3\ngunicorn==19.9.0\nPillow==5.4.1\npkg-resources==0.0.0\npsycopg2==2.7.7\npytz==2018.9\n"
},
{
"alpha_fraction": 0.6324582099914551,
"alphanum_fraction": 0.6443914175033569,
"avg_line_length": 25.1875,
"blob_id": "840331fbdf62c4e0e5e0220ebc8f8c8410dff869",
"content_id": "b92266bbad277cf7b4c7d0b19809df313baedc1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 16,
"path": "/blog/models.py",
"repo_name": "cyder-ironman/portfolio-project",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\nclass Blog(models.Model):\n title = models.CharField(max_length=255)\n post_date = models.DateTimeField()\n post_body = models.TextField()\n image = models.ImageField(upload_to='images/')\n\n def __str__(self):\n return self.title\n\n def summary(self):\n return self.post_body[:50]\n\n def post_date_pretty(self):\n return self.post_date.strftime('%b %e %Y')\n"
}
] | 2 |
BilalMir135/Compiler-Construction
|
https://github.com/BilalMir135/Compiler-Construction
|
4b902cad2142d146b2637b10ce6fa5a5e90cdd08
|
340094e3e1ea227e7bfb027c1b51282b64bbdb3a
|
9ec43b29e903c94dee2f6ae223e12d68741b0045
|
refs/heads/master
| 2021-01-14T20:55:36.639815 | 2020-02-24T17:11:25 | 2020-02-24T17:11:25 | 242,756,906 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.40239542722702026,
"alphanum_fraction": 0.40818527340888977,
"avg_line_length": 43.15538787841797,
"blob_id": "15e1e3bed73fd1c84d4af2ad487886de2e1556ef",
"content_id": "79f29eec61613305fb72f107fd1d3c946aa2bfec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17617,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 399,
"path": "/lexer.py",
"repo_name": "BilalMir135/Compiler-Construction",
"src_encoding": "UTF-8",
"text": "import re\n\nclass Lexical_Analyzer():\n def __init__(self): pass\n \n #split code into lines\n def line_splitter(self,source_code):\n code = {} #dict that will store line num as key and line as value\n source_index = 0\n line_num = 1\n word = ''\n #run loop until the whole source code parsing completed\n while(source_index<len(source_code)):\n #multiple line comment\n #checking for /*\n if source_code[source_index] == '/' and source_code[source_index+1] == '*':\n if word!='':\n code[line_num] = word\n word=''\n word += ' '\n #run loop until we get */\n while(source_code[source_index]!='*' or source_code[source_index+1]!='/'): \n #check if line ends so we can increment line num\n if(source_code[source_index]=='\\n'):\n line_num +=1\n source_index +=1\n else:\n #to pass the index from */\n source_index +=2\n\n #single line comments\n #checking for //\n elif source_code[source_index] == '/' and source_code[source_index+1] == '/':\n #run loop until we get new line\n while(source_code[source_index]!='\\n'): \n source_index +=1\n else:\n if word!='':\n code[line_num] = word.strip()\n word = ''\n line_num +=1\n source_index +=1\n \n\n #for string\n #checking for \"\n elif source_code[source_index] == '\"':\n #adding $$$ sign so we can combine string after passing through .split() in word_split() function\n word += ' $$$ '\n start = True\n #run loop until we get \" but in first iteration we are on \" that's why we use start=True\n while((source_code[source_index]!= '\"' or start) and source_code[source_index]!='\\n'): \n start = False \n #checking for \\\"\n if source_code[source_index+1] == '\\\\' and source_code[source_index+2] == '\"' and source_code[source_index]!='\\\\':\n #adding \\\" in word and doing +2 increment in source_index so we can skip \\\" from loop\n word += source_code[source_index:source_index+2]\n source_index +=2\n #adding our characters of string in word to get back our string \n word += source_code[source_index] \n source_index +=1\n if source_code[source_index] == '\\n':\n word += ' $$$ '\n code[line_num] = word.strip()\n # line_num +=1\n word = ''\n else:\n #when the loop breaks on \" we will add \" on our word to complete our string\n word += source_code[source_index]\n source_index +=1 \n #adding $$$ sign so we can combine string after passing through .split() in word_split() function \n word += ' $$$ '\n \n #if the code is not comment and string \n else:\n #if the line ends then we store our code in dict with line num as key and code as value\n if source_code[source_index] == '\\n':\n #avoiding empty lines\n if word.strip() != '':\n #storing code with removing useless spaces\n code[line_num] = word.strip()\n word = '' \n line_num +=1\n source_index +=1\n else: \n #if line doesn't ends then continue parsing\n word += source_code[source_index]\n source_index +=1\n return code\n \n #change the invalid escape sequences readed from text file into valid one\n def correct_escape_sequence(self,lines):\n for key,value in lines.items(): \n temp_line = ''\n index=0\n while(index<len(value)):\n if value[index] == '\\\\':\n if value[index+1] == '\\\\' and value[index+2]!='\"':\n temp_line += '\\\\'\n elif value[index+1] == 'n':\n temp_line += '\\n'\n elif value[index+1] == 't':\n temp_line += '\\t'\n else:\n temp_line += '\\\\'+ value[index+1]\n index += 2\n else:\n temp_line += value[index]\n index +=1\n lines[key] = temp_line\n return lines\n \n #identify the characters from the code\n def mark_char(self,lines):\n for key,value in lines.items():\n temp_line = ''\n index = 0\n while(index<len(value)):\n if value[index:index+3]=='$$$':\n temp_line += value[index:index+3]\n index += 3\n while(index<len(value)):\n if value[index:index+3]=='$$$':\n temp_line += value[index:index+3]\n index += 3\n break\n else:\n temp_line += value[index]\n index +=1\n\n elif value[index]=='\\'':\n if value[index+1] == '\\'':\n temp_line += ' $$$ ' + value[index:index+2] + ' $$$ '\n index += 2\n else:\n temp_line += ' $$$ ' + value[index:index+3] + ' $$$ '\n index += 3\n else:\n temp_line += value[index]\n index +=1\n lines[key] = temp_line\n return lines\n \n #split code on the basis of space\n def space_split(self,word):\n temp_line=[] \n temp_word=''\n working_on_string = False\n for i,char in enumerate(word):\n if word[i:i+3]=='$$$':\n working_on_string = not working_on_string\n if char == ' ':\n if temp_word!='':\n temp_line.append(temp_word)\n if working_on_string:\n temp_line.append(' ')\n temp_word=''\n else:\n temp_word += char \n if temp_word!='':\n temp_line.append(temp_word)\n return temp_line\n \n #split code on the basis of operators\n def split_operators(self,word_list):\n operators = '+-*%/|&<>=!'\n double_operators = ['+=','-=','*=','/=','%=','++','--','<<','>>','!=','==','>=','<=','||','&&']\n for index,word in enumerate(word_list):\n #if word is an operator like just continue loop\n if word in operators:\n continue\n else:\n new_word = '' #this new word will store just the first half of operator eg: store x from x+y\n char_index = 0\n new_index = index\n #run loop until the word completes\n while(char_index<len(word)):\n #if character of word is an operator\n if word[char_index] in operators:\n #checking if the operator length is greater than 1 like ++ /=\n if char_index+1<len(word) and word[char_index+1] in operators and word[char_index:char_index+2] in double_operators: \n #insert operator in list of words \n word_list.insert(new_index+1,word[char_index:char_index+2])\n #checking that after opeartor it is something\n if char_index+2 < len(word):\n #checking that after opeartor it is something\n if word[char_index+2]!='':\n #insert the second part of operator \n word_list.insert(new_index+2,word[char_index+2:])\n #if there is any first half of operator like sum in sum+=x then add it inplace of sum\n if new_word !='':\n word_list[new_index] = new_word\n #if not then del the +=x else it will store null in it's place\n else:\n del word_list[new_index]\n new_word = ''\n break\n \n #if operator is of length one like + or -\n else:\n #insert operator in list\n word_list.insert(new_index+1,word[char_index])\n if char_index+1<len(word) and word[char_index+1]!='':\n #add the second part of operator in list\n word_list.insert(new_index+2,word[char_index+1:]) \n #add the first part of operator like x in x+y \n if new_word !='':\n word_list[new_index] = new_word\n else:\n del word_list[new_index] \n new_word = ''\n break\n else:\n #if the char. of word is not an operator than add it in new_word \n new_word += word[char_index]\n char_index +=1\n return word_list \n \n \n #split code on the basis of punctuators\n def split_punctuators(self,word_list): \n punctuators = ';,:.(){}[]'\n for index,word in enumerate(word_list):\n if word in punctuators and len(word)<2:\n continue\n else:\n new_word = ''\n new_index = index\n i=0\n for char in word: \n if char in punctuators: \n #insert the punctuators in list\n word_list.insert(new_index+1,char)\n if word[i+1:]!='':\n #insert the secod half of word after punc\n word_list.insert(new_index+2,word[i+1:]) \n if new_word!='':\n word_list[new_index] = new_word\n else:\n del word_list[new_index] \n new_word = ''\n break\n else:\n new_word += char\n i +=1\n return word_list\n \n #combine the splitted floating numbers\n def combine_floating(self,word_list):\n index = 0\n while(index<len(word_list)):\n if index+2<len(word_list):\n if re.match('[0-9]+$',word_list[index]) and word_list[index+1] == '.' and re.match('[0-9]+$',word_list[index+2]):\n word_list[index] = word_list[index] + word_list[index+1] + word_list[index+2]\n del word_list[index+1]\n del word_list[index+1]\n index +=1\n return word_list\n \n #split words \n def word_splitter(self,sc): \n code_set = {} #store line num as a key and splitted word as a list of code\n for k,v in sc.items():\n #word_list = v.split() #split code on the basis of space\n word_list = self.space_split(v)\n word_list = self.split_operators(word_list) #split code on the basis of operators\n #this will split code on the basis of punctuators\n word_list = self.split_punctuators(word_list)\n word_list = self.combine_floating(word_list)\n code_set[k] = word_list\n return code_set\n \n #combine the splitted strings and characters\n def combine_string(self,code_set):\n for k,v in code_set.items():\n for index,words in enumerate(v):\n string = ''\n #if word start from $$$ means its our start of string\n if words[0:3] == '$$$':\n string += words[3:]\n new_index = index\n iteration = 0\n #run loop until we find the end of string\n while(True):\n new_index +=1\n iteration +=1\n words = v[new_index]\n #if we get $$$ in the end means it is the last piece of our string\n if(words[len(words)-3:len(words)] == '$$$'):\n string += words[:len(words)-3]\n string = string[1:len(string)-1].replace('\\\\\\\\','\\\\')\n break\n #if not then add the words to combine string\n else:\n #if words=='':\n #string += ' '\n string += words\n #delete the words from word list that are the parts of string\n for x in range(iteration):\n del code_set[k][index+1]\n code_set[k][index] = string\n return code_set\n \n \n #check that the word is valid or not\n def isValidWord(self,valid_words,word):\n for key in valid_words:\n if word in valid_words[key]:\n return True\n else:\n False\n \n #hence the word is valid not build it's token\n def build_token(self,line_num,valid_words,word):\n for key,values in valid_words.items():\n for x in values:\n if x == word:\n return (key,word,line_num)\n \n \n #create tokens \n def tokenization(self,source_code):\n tokens = []\n try:\n lines = self.line_splitter(source_code)\n lines = self.correct_escape_sequence(lines)\n lines = self.mark_char(lines)\n words = self.word_splitter(lines)\n code_set = self.combine_string(words)\n except Exception as e:\n print(e) \n else:\n valid_words = {\n 'Data Type' : ['int','double','char','bool','string'],\n 'Access Modifier' : ['public', 'private', 'protected'],\n 'Constant' : ['constant'],\n 'Break' : ['break'],\n 'Continue' : ['continue'],\n 'Else' : ['else'],\n 'Base' : ['base'],\n 'Bool Constant' : ['true','false'],\n 'For' : ['for'],\n 'If' : ['if'],\n 'Interface' : ['interface'],\n 'Class' : ['class'],\n 'New' : ['new'],\n 'Null' : ['null'],\n 'Override' : ['override'],\n 'Reference' : ['ref'],\n 'Return' : ['return'],\n 'Sealed' : ['sealed'],\n 'Static' : ['static'],\n 'This' : ['this'],\n 'Virtual' : ['virtual'],\n 'Void' : ['void'],\n 'While' : ['while'],\n 'Abstract' : ['abstract'],\n 'In' : ['in'],\n 'Var' : ['var'],\n ';' : [';'],\n ',' : [','],\n '.' : ['.'],\n ':' : [':'],\n '{' : ['{'],\n '}' : ['}'],\n '(' : ['('],\n ')' : [')'],\n '[' : ['['],\n ']' : [']'],\n 'Increment/Decrement Opeartor ' : ['++','--'],\n 'Arithmetaic Operator' : ['+','-','*','/','%'],\n 'Logical Operator' : ['&&','||','!'],\n 'Relational Operator' : ['<','>','<=','>=','!=','=='],\n 'Bitwise Operator' : ['&','|','~'],\n 'Assignment Operator' : ['=','+=','-=','*=','%=','/='],\n 'Shift Operator' : ['<<','>>']\n }\n\n \n #classify words\n for k,v in code_set.items():\n for word in v:\n if word.strip() is '':\n continue\n if self.isValidWord(valid_words,word):\n tokens.append(self.build_token(k,valid_words,word)) \n elif re.match('^(@|_|[a-zA-Z])(_|[a-zA-Z]|[0-9])*$',word):\n tokens.append(('Identifier',word,k))\n elif re.match('[+|-]?[0-9]+$',word):\n tokens.append(('Integer Constant',word,k))\n elif re.match('[+|-]?[0-9]*[.][0-9]+$',word):\n tokens.append(('Float Constant',word,k))\n elif re.match(\"'[A-Z|\\w|\\W|\\s]{1}'$\",word):\n tokens.append(('Char Constant',word,k))\n elif re.match('\"[A-z\\s\\w\\W]*\"',word):\n tokens.append(('String Constant',word,k))\n else:\n tokens.append(('Invalid Token', word, k)) \n return tokens"
},
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 32.5,
"blob_id": "5b7a60d1813b676b3f3e0c28fe5cbdc245404b79",
"content_id": "93664f79f2116853d93f5746260ea01963210add",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 2,
"path": "/README.md",
"repo_name": "BilalMir135/Compiler-Construction",
"src_encoding": "UTF-8",
"text": "# Compiler-Construction\nUniversity project of building C# compiler \n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7117646932601929,
"avg_line_length": 19.058822631835938,
"blob_id": "e6a291c54905ee3fe6944eca567ba94e924881e3",
"content_id": "be9c38840f23d49f6c05f33cfdb0de1637e212f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 17,
"path": "/main.py",
"repo_name": "BilalMir135/Compiler-Construction",
"src_encoding": "UTF-8",
"text": "import lexer\nimport json\n\n#read code from file\nwith open('code12.txt','r') as file:\n source_code = file.read()\n\n#create tokens\nlex = lexer.Lexical_Analyzer()\ntokens = lex.tokenization(source_code)\n#print tokens\nfor token in tokens:\n print(token)\n\n#store tokens in file\nwith open ('tokens.json','w') as file:\n json.dump(tokens,file)"
}
] | 3 |
Danil-phy-cmp-120/Elast
|
https://github.com/Danil-phy-cmp-120/Elast
|
f1b9445af247377b76479d209eae1b27452163d8
|
83d0a673e75f8ec691c6627489704d4571c93df5
|
d1295ec43356350d903108d56f5064aaafafb753
|
refs/heads/main
| 2023-02-02T06:05:23.582251 | 2020-12-22T13:11:29 | 2020-12-22T13:11:29 | 311,010,792 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5218579173088074,
"alphanum_fraction": 0.5491803288459778,
"avg_line_length": 16.428571701049805,
"blob_id": "b9c6221398b5814cb0c39f6ffae83042fa7b0cf8",
"content_id": "8393d9c07b1e09a5995aa633a85ecd0fd97466db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 42,
"path": "/vasp_qsub_elast",
"repo_name": "Danil-phy-cmp-120/Elast",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#PBS -d .\n#PBS -l nodes=1:ppn=24\n#PBS -N Elast\n#PBS -j oe\n#PBS -l walltime=2000:00:00\n\ncurrDir=`pwd`\n\nLD_LIBRARY_PATH=/share/intel/mkl/lib/intel64/:$LD_LIBRARY_PATH\n. /share/intel/compilers_and_libraries/linux/mpi/intel64/bin/mpivars.sh\nexport I_MPI_FALLBACK_DEVICE=disable\nexport I_MPI_FABRICS=shm\nexport I_MPI_PIN=disable\nexport LD_LIBRARY_PATH\n\n#python create_task.py\n\ncd bulk/\n\nfor f in `ls`; do \n if test -d \"./$f\"\n then\n\n cd $f\n\n for d in `ls`; do \n if test -d \"./$d\"\n then\n\n echo $f, $d\n cd \"./$d\"\n mpirun /share/vasp/vasp.6.1.1/vasp_std > vasp.out 2>&1\n\n fi\n cd ..\n done\n\n cd ..\n\n fi\ndone\n"
},
{
"alpha_fraction": 0.8067567348480225,
"alphanum_fraction": 0.8135135173797607,
"avg_line_length": 104.42857360839844,
"blob_id": "d865083a17a60a6effea5c259460784afc3076bc",
"content_id": "7e13805c4b13c61e419e145eb28a67323f7f2d87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Danil-phy-cmp-120/Elast",
"src_encoding": "UTF-8",
"text": "# Elast\nCode for calculating elastic modulus with VASP\n\n1) Создайте папку \"ION\". Проведите ионную релаксацию в этой папке используя VASP и сведите внешнее давление к нулю (приемлимое значение порядка 1 кбар). Поместите файлы проекта рядом с папкой \"ION\". \n2) Запустите программу create_task.py. Данная программа создаст файлы задачи для кода VASP с искаженным базисами в POSCAR.\n3) Запстите скрипт vasp_qsub_elast командой \"qsub -q node vasp_qsub_elast\". Данный скрипт поочередно запустист рассчеты VASP во всех вложенных папках в директории \"bulk\".\n4) После завершения рассчетов запустите программу Read_out.py. Эта программа считает значения полной энергии из файлов OUTCAR и вычислит отдельные коэффициенты тензора упругих постоянных.\n\n\n"
},
{
"alpha_fraction": 0.40751200914382935,
"alphanum_fraction": 0.4486020803451538,
"avg_line_length": 32.72380828857422,
"blob_id": "6b00456fe70e94c18739a7990ac4146c91b7d05d",
"content_id": "9bee2a2a1b205b09740153276ed80f57d6f1f916",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7333,
"license_type": "no_license",
"max_line_length": 250,
"num_lines": 210,
"path": "/create_task.py",
"repo_name": "Danil-phy-cmp-120/Elast",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nimport subprocess\nimport os\nimport shutil\n\n######### Ввести директорию с рассчетом a0 #########\npath0 = raw_input('Enter the path to the calculation of equilibrium lattice parameter:\\n')\n\n######### Считывание CONTCAR #########\n\nf = open(path0 + '/CONTCAR',\"r\")\ncontcar = f.readlines()\nf.close()\n\n# Считывание векторов трансляций #\nprimitive_vectors = np.zeros((3, 3))\nn = 0\nfor i in [2,3,4]:\n inp = contcar[i].split()\n for j in range(3):\n primitive_vectors[n,j] = inp[j]\n n = n + 1\nprimitive_vectors = primitive_vectors * float(contcar[1])\n\n# Число атомов #\nnum_atoms = sum([int(x) for x in contcar[6].split()])\n\n# Считывание базиса #\nbasis = []\nn = 0\nfor line in contcar[8:8+num_atoms]:\n inp = line.split()\n for i in inp:\n basis += [float(i)]\nbasis = np.array(basis)\nbasis.shape = ((len(basis)/3, 3))\n\n\n# Рассчет длины векторов трансляций и углов между ними #\nlen_pv = np.zeros(3)\nang_pv = np.zeros(3)\nfor i in range(3):\n len_pv[i] = float(\"{:.3f}\".format((sum(primitive_vectors[i,:]**2))**0.5))\n\nang_pv[0] = float(\"{:.3f}\".format(sum(primitive_vectors[0,:] * primitive_vectors[1,:]) / (abs(len_pv[0])*abs(len_pv[1]))))\nang_pv[1] = float(\"{:.3f}\".format(sum(primitive_vectors[1,:] * primitive_vectors[2,:]) / (abs(len_pv[1])*abs(len_pv[2]))))\nang_pv[2] = float(\"{:.3f}\".format(sum(primitive_vectors[0,:] * primitive_vectors[2,:]) / (abs(len_pv[0])*abs(len_pv[2]))))\nang_pv = (np.arccos(ang_pv)*180.0)/np.pi\n\n\n# Определение сингонии #\nif (len_pv[0] == len_pv[1] and len_pv[1] == len_pv[2]) or (len_pv[0] % len_pv[1] == 0 and len_pv[0] % len_pv[2] == 0):\n crystal_system = 'cube' \n n_max = 3\nelif ((len_pv[0] == len_pv[1] and len_pv[1] != len_pv[2]) or (len_pv[1] == len_pv[2] and len_pv[0] != len_pv[1]) or (len_pv[2] == len_pv[0] and len_pv[2] != len_pv[1])) and (int(ang_pv[0]) != 120 and int(ang_pv[1]) != 120 and int(ang_pv[2]) != 120):\n crystal_system = 'tetr'\n n_max = 6\nelif ((len_pv[0] == len_pv[1] and len_pv[1] != len_pv[2]) or (len_pv[1] == len_pv[2] and len_pv[0] != len_pv[1]) or (len_pv[2] == len_pv[0] and len_pv[2] != len_pv[1])) and (int(ang_pv[0]) == 120 or int(ang_pv[1]) == 120 or int(ang_pv[2]) == 120):\n crystal_system = 'hex'\n n_max = 5\nelse:\n print 'Calculation is possible only for cubic and tetragonal crystal system'\n\nprint \"Crystal system: {}\".format(crystal_system)\n\n######### Считывание OUTCAR #########\n\nf = open(path0 + '/OUTCAR',\"r\")\noutcar = f.readlines()\nf.close()\n\nflag = False\nmagmom = np.zeros(basis.shape[0])\nn = 0\nfor line in outcar[len(outcar)-200:len(outcar)]:\n inp = line.split()\n\n if len(inp) > 3 and inp[0] == 'external' and inp[1] == 'pressure':\n print 'external pressure =', inp[3]\n if abs(float(inp[3])) > 5.0:\n print('The pressure is high, restart the ionic relaxation with a small EDIFG')\n\n if len(inp) > 3 and flag == True and inp[0].isdigit() == True and n < basis.shape[0]:\n magmom[n] = float(inp[len(inp)-1])\n n = n + 1\n if len(inp) > 1 and inp[0] == 'magnetization':\n flag = True\n\n\n######### Изменение некоторых тегов в INCAR #########\n\nf = open(path0 + '/INCAR',\"r\")\nincar = f.readlines()\nf.close()\n\nfor i in range(len(incar)):\n inp = incar[i].split()\n if len(inp) > 2 and inp[0] == 'NSW':\n incar[i] = 'NSW = 0\\n'\n if len(inp) > 2 and inp[0] == 'MAGMOM':\n incar[i] = 'MAGMOM ='\n for j in range(magmom.size):\n incar[i] = incar[i] + ' {}'.format(magmom[j])\n incar[i] = incar[i] + '\\n'\n\n######### Создание искаженных POSCAR и запись INCAR, KPOINTS, POTCAR #########\nif os.path.exists('bulk') == False:\n os.mkdir('bulk')\n\nDELTAS = np.linspace(-0.03, 0.03, 7) # Искажения от -3 до 3 %\n\nfor n in range(n_max):\n\n if os.path.exists('bulk/D{}'.format(n)) == False:\n os.mkdir('bulk/D{}'.format(n))\n\n for delta in DELTAS:\n\n if os.path.exists('bulk/D{}/{}'.format(n, delta)) == False:\n os.mkdir('bulk/D{}/{}'.format(n, delta))\n\n if crystal_system == 'cube':\n T = np.array([[1 + delta, 0, 0],\n [0, 1 + delta, 0],\n [0, 0, 1 + delta],\n \n [1 + delta, 0, 0],\n [0, 1 - delta, 0],\n [0, 0, 1/(1-delta**2)],\n \n [1, delta, 0],\n [delta, 1, 0],\n [0, 0, 1/(1-delta**2)]])\n\n elif crystal_system == 'tetr':\n T = np.array([[1/(1-delta**2), 0, delta], \n [0, 1, 0],\n [delta, 0, 1],\n \n [1, delta, 0], \n [delta, 1, 0],\n [0, 0, 1/(1-delta**2)],\n \n [1 + delta, 0, 0], \n [0, 1 - delta, 0],\n [0, 0, 1/(1-delta**2)],\n\n [1 + delta, 0, 0], \n [0, 1/(1-delta**2), 0],\n [0, 0, 1-delta],\n \n [1 + delta, 0, 0], \n [0, 1 + delta, 0],\n [0, 0, 1 + delta],\n\n [1, 0, 0], \n [0, 1, 0],\n [0, 0, 1 + delta]])\n\n elif crystal_system == 'hex':\n T = np.array([[1 + delta, 0, 0],\n [0, 1 + delta, 0],\n [0, 0, 1],\n \n [1 + delta, 0, 0], \n [0, 1 - delta, 0],\n [0, 0, 1],\n \n [1, 0, 0], \n [0, 1, 0],\n [0, 0, 1+delta],\n\n [1, 0, delta], \n [0, 1, 0],\n [delta, 0, 1],\n\n [1 + delta, 0, 0],\n [0, 1 + delta, 0],\n [0, 0, 1 + delta]])\n\n D = T[n*3:n*3+3,:]\n primitive_vectors_new = np.dot(primitive_vectors, D)\n \n poscar = contcar\n poscar[1] = ' 1.0\\n'\n for i in range(3):\n poscar[2+i] = ' '\n for j in range(3):\n poscar[2+i] = poscar[2+i] + str(primitive_vectors_new[i, j]) + ' '\n poscar[2+i] = poscar[2+i] + '\\n'\n\n f = open('bulk/D{}/{}/POSCAR'.format(n, delta), \"wb\") # Запись POSCAR\n for i in range(len(poscar)):\n f.write(poscar[i])\n f.close\n\n f = open('bulk/D{}/{}/INCAR'.format(n, delta), \"wb\") # Запись INCAR\n for i in range(len(incar)):\n f.write(incar[i])\n f.close\n\n shutil.copyfile(path0 + '/POTCAR', 'bulk/D{}/{}/POTCAR'.format(n, delta)) # Запись POTCAR\n\n shutil.copyfile(path0 + '/KPOINTS', 'bulk/D{}/{}/KPOINTS'.format(n, delta)) # Запись KPOINTS\n\n if n == 0:\n DELTAS = np.delete(DELTAS, 3)\n"
}
] | 3 |
teh/rps_dojo
|
https://github.com/teh/rps_dojo
|
23215d4b08273818178043443303521da21be1d7
|
ba2262052d19d83b7fafcf5ad7468771c29ee90d
|
8a4c7e571f9afd5d22d1217dc87663bce08a252e
|
refs/heads/master
| 2018-12-29T02:45:38.906220 | 2014-07-22T16:28:38 | 2014-07-22T16:28:38 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.553939938545227,
"alphanum_fraction": 0.5778611898422241,
"avg_line_length": 22.688888549804688,
"blob_id": "478c7a9ee1019b95bf9bcbd933d0362b2f5b49ff",
"content_id": "e46101b36947fb21b0b84c9219f70ca55a1a5114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2132,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 90,
"path": "/driver.py",
"repo_name": "teh/rps_dojo",
"src_encoding": "UTF-8",
"text": "import itertools\nimport argparse\nimport collections\n\nITERATIONS = 100\nDEADLOCK = int(1e6)\n\n\ndef win(me, other):\n if me == other:\n return 'draw'\n if (me, other) in [('rock', 'scissors'), ('paper', 'rock'), ('scissors', 'paper')]:\n return 'win'\n return 'loss'\n\n\ndef play(player1, player2):\n outcomes = []\n i, deadlock = 0, DEADLOCK\n\n while i < ITERATIONS:\n choice1 = player1.choose()\n choice2 = player2.choose()\n\n assert choice1 in ('rock', 'paper', 'scissors')\n assert choice2 in ('rock', 'paper', 'scissors')\n\n player1.played(win(choice1, choice2), choice2)\n player2.played(win(choice2, choice1), choice1)\n\n if win(choice1, choice2) != 'draw':\n i += 1\n\n outcomes.append(win(choice1, choice2))\n\n deadlock -= 1\n if deadlock == 0:\n raise Exception(\"Bots drew for {} iterations.\".format(DEADLOCK))\n\n return outcomes\n\n\ndef summarize(outcomes):\n return collections.Counter(outcomes)\n\n\ndef decide(outcomes):\n c = collections.Counter(outcomes)\n return c.get('win', 0) > c.get('loss', 0)\n\n\ndef main():\n parser = argparse.ArgumentParser()\n parser.add_argument('paths', nargs='+')\n args = parser.parse_args()\n\n players = []\n for path in args.paths:\n vars = {}\n execfile(path, vars)\n \n player = vars.get('Player')\n if player is None:\n parser.error(\"Could not find 'Player' class in {}\".format(path))\n players.append((player, path))\n\n if len(players) < 2:\n parser.error(\"Not enough players (need more than one).\")\n\n\n\n win_counter = collections.Counter()\n for (p1_class, p1_name), (p2_class, p2_name) in itertools.combinations(players, 2):\n p1, p2 = p1_class(), p2_class()\n\n outcomes = play(p1, p2)\n\n if decide(outcomes):\n win_counter.update([(p1_class, p1_name)])\n else:\n win_counter.update([(p2_class, p2_name)])\n\n print 'wins player'\n\n for (k, name), v in win_counter.most_common(100):\n print '{:4d} {}'.format(v, name)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5581395626068115,
"alphanum_fraction": 0.5581395626068115,
"avg_line_length": 22.230770111083984,
"blob_id": "f941b50b1aae5e91dff1b69636fd691e8de93030",
"content_id": "3b4f42657cbaf99f7f3b024771486a94f2706596",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 13,
"path": "/bots/randomplayer.py",
"repo_name": "teh/rps_dojo",
"src_encoding": "UTF-8",
"text": "import random\n\nclass Player:\n\n def choose(self):\n return random.choice(['rock', 'paper', 'scissors'])\n\n def played(self, outcome, other_played):\n \"\"\"\n outcome will be 'win', 'draw' or 'loss'\n other_played will be 'rock', 'paper' or 'scissors'\n \"\"\"\n pass"
},
{
"alpha_fraction": 0.5433962345123291,
"alphanum_fraction": 0.5433962345123291,
"avg_line_length": 19.384614944458008,
"blob_id": "7472b602aaf9de7965b491e1a6d49e6054527381",
"content_id": "ae524ce6234b7cfc6fe14c711522a68d65e6154b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 13,
"path": "/bots/paperplayer.py",
"repo_name": "teh/rps_dojo",
"src_encoding": "UTF-8",
"text": "import random\n\nclass Player:\n\n def choose(self):\n return 'paper'\n\n def played(self, outcome, other_played):\n \"\"\"\n outcome will be 'win', 'draw' or 'loss'\n other_played will be 'rock', 'paper' or 'scissors'\n \"\"\"\n pass\n"
}
] | 3 |
RajaAyyanar/Neural_Network_without_library
|
https://github.com/RajaAyyanar/Neural_Network_without_library
|
41557ac15c7f5db6a3a40a3262f6719b9973ad99
|
8cb47c2cfc43bb12a2790ea64648d720b00d0a31
|
0308103ff2a42cc135ef6108eedb73eba9f1cfd2
|
refs/heads/master
| 2020-03-19T09:28:53.483952 | 2018-06-06T07:56:24 | 2018-06-06T07:56:24 | 136,292,517 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4980870485305786,
"alphanum_fraction": 0.559540867805481,
"avg_line_length": 27.244754791259766,
"blob_id": "da8eeb9e5eba8b111048101b818f9d2d9eb723e9",
"content_id": "2c7fcb8fc8c11f45bb334263b16a95b8a5c7aaff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4182,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 143,
"path": "/final_mod3.py",
"repo_name": "RajaAyyanar/Neural_Network_without_library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jan 19 14:07:05 2018\r\n\r\n@author: Raja Ayyanar\r\n\r\n\"\"\"\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport timeit\r\ndef reluDerivative(x):\r\n \r\n \r\n x[x<=0] = 0\r\n x[x>0] = 1\r\n return x\r\n \r\ne1=np.zeros(20)\r\ne2=np.zeros(20)\r\ne3=np.zeros(20)\r\n\r\nfor trial in range(0,20):\r\n\r\n \r\n \r\n start = timeit.timeit()\r\n #Creating Training Datasets\r\n x1=np.random.uniform(-1, 1,1000)\r\n x2=np.random.uniform(-1,1,1000)\r\n y=x1**2 - x2**2\r\n train_dataset=np.array([x1,x2,y])\r\n train_dataset=np.transpose(train_dataset)\r\n del x1,x2,y\r\n \r\n \r\n #Layer H1 parameters\r\n no_of_inputs_h1=3\r\n no_of_hidden_neurons_h1=4\r\n no_of_output_h1=no_of_hidden_neurons_h1\r\n MaxItertaion=1000\r\n del_v1=np.random.uniform(0,1,(no_of_output_h1,no_of_hidden_neurons_h1))\r\n del_v1=np.transpose(del_v1)\r\n del_w1=np.random.uniform(0,1,(no_of_hidden_neurons_h1,no_of_inputs_h1))\r\n gamma_g_h1=0.8\r\n gamma_m_h1=0.2\r\n \r\n \r\n #Layer H2 Parameters\r\n no_of_inputs_h2=no_of_output_h1 + 1\r\n no_of_hidden_neurons_h2=4\r\n no_of_output_h2=1\r\n MaxItertaion=1000\r\n del_v2=np.random.uniform(0,1,(no_of_output_h2,no_of_hidden_neurons_h2))\r\n del_v2=np.transpose(del_v2)\r\n del_w2=np.random.uniform(0,1,(no_of_hidden_neurons_h2,no_of_inputs_h2))\r\n gamma_g_h2=0.8\r\n gamma_m_h2=0.2\r\n total_cycle=5000\r\n \r\n \r\n # inputs for H1 \r\n x1=train_dataset[:,0]\r\n x2=train_dataset[:,1]\r\n x0=train_dataset[:,0]**0\r\n \r\n all_x=np.array([x0 , x1, x2])\r\n all_x=np.transpose(all_x)\r\n target_y=train_dataset[:,2]\r\n \r\n #weight initialization\r\n w1=np.random.uniform(0,1,(no_of_hidden_neurons_h1,no_of_inputs_h1))\r\n v1=np.random.uniform(0,1,(no_of_output_h1,no_of_hidden_neurons_h1))\r\n w2=np.random.uniform(0,1,(no_of_hidden_neurons_h2,no_of_inputs_h2))\r\n v2=np.random.uniform(0,1,(no_of_output_h2,no_of_hidden_neurons_h2))\r\n \r\n e=np.zeros(total_cycle)\r\n ew1=np.zeros((total_cycle,no_of_hidden_neurons_h1,no_of_inputs_h1))\r\n \r\n for cycle in range(0,total_cycle):\r\n \r\n j=np.random.randint(0,np.size(target_y))\r\n one_x=np.array([all_x[j,:]]);\r\n a=w1 @ one_x.transpose();\r\n d=np.maximum(0,a); #ReLu Activation on H1\r\n bias1=np.ones((1,1))\r\n bd=np.concatenate((d,bias1), axis=0) #adding bias for layer2\r\n a2=w2@bd\r\n d2=np.maximum(0,a2)\r\n \r\n y_cap=v2 @ d2;\r\n \r\n error_y=target_y[j]- y_cap;\r\n \r\n error_d2=v2.transpose() @ error_y;\r\n error_a2=reluDerivative(d2)*error_d2\r\n \r\n error_d=w2.transpose() @ a2;\r\n error_a=reluDerivative(d)*error_d[:-1,:]\r\n \r\n del_v2=gamma_g_h2 * d2*error_y + gamma_m_h2 * del_v2\r\n #del_v1=gamma_g_h1 * d*a2 + gamma_m_h1 * del_v1\r\n bd2=np.concatenate((a2,bias1), axis=0) #backprop for bias\r\n del_w2=gamma_g_h1 * ([email protected]) + gamma_m_h2 * del_w2\r\n del_w1=gamma_g_h1 * ( error_a @ one_x) +gamma_m_h1* del_w1\r\n v2=v2-del_v2.transpose()\r\n #v1=v1-del_v1.transpose()\r\n w2=w2-del_w2\r\n w1=w1-del_w1\r\n e[cycle]=error_y\r\n ew1[cycle,:,:]=w1\r\n \r\n \r\n #print('Final weights are',w1,w2,v1)\r\n \r\n \r\n \r\n #Testing\r\n x_test=np.random.uniform(-1, 1,1000)\r\n x2_test=np.random.uniform(-1,1,1000)\r\n y_test=x_test**2 - x2_test**2\r\n x0_test=x_test**0\r\n testdata=np.array([x0_test, x_test,x2_test, y_test])\r\n testdata=testdata.transpose()\r\n \r\n test_in=testdata[:,0:3]\r\n e_test=np.zeros(max(np.shape(test_in)))\r\n for test in range(0,max(np.shape(test_in))):\r\n one_x=np.array([test_in[test,:]])\r\n a=w1 @ one_x.transpose();\r\n d=np.maximum(0,a); #ReLu Activation on H1\r\n bias1=np.ones((1,1))\r\n bd=np.concatenate((d,bias1), axis=0) #adding bias for layer2\r\n a2=w2@bd\r\n d2=np.maximum(0,a2)\r\n \r\n y_cap=v2 @ d2; \r\n e_test[test]=y_cap-y_test[test]\r\n \r\n print(np.mean(np.abs(e_test)))\r\n end = timeit.timeit()\r\n e1[trial]=np.mean((e_test*e_test))\r\n e2[trial]=np.std(np.abs(e_test))\r\n e3[trial]=end-start\r\n"
},
{
"alpha_fraction": 0.5639943480491638,
"alphanum_fraction": 0.6323487758636475,
"avg_line_length": 24.41044807434082,
"blob_id": "02b773121c9bc6051580711299f5b64587a483ad",
"content_id": "3e8d5e3be4a88f6a09fa4d9ade1ccd6848bfe8f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3555,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 134,
"path": "/Deep_saddle3.py",
"repo_name": "RajaAyyanar/Neural_Network_without_library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jan 18 20:16:59 2018\r\n\r\n@author: Raja Ayyanar\r\n\"\"\"\r\n\r\ndef reluDerivative(x):\r\n \r\n x[x<=0] = 0\r\n x[x>0] = 1\r\n return x\r\n\r\n\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport timeit\r\nstart = timeit.timeit()\r\n\r\n#Creating Training Datasets\r\nx1=np.random.uniform(-1, 1,1000)\r\nx2=np.random.uniform(-1,1,1000)\r\ny=x1**2 - x2**2\r\ntrain_dataset=np.array([x1,x2,y])\r\ntrain_dataset=np.transpose(train_dataset)\r\ndel x1,x2,y\r\n\r\n\r\n#Layer H1 parameters\r\nno_of_inputs_h1=3\r\nno_of_hidden_neurons_h1=50\r\nno_of_output_h1=no_of_hidden_neurons_h1\r\nMaxItertaion=1000\r\ndel_v1=np.random.uniform(0,1,(no_of_output_h1,no_of_hidden_neurons_h1))\r\ndel_v1=np.transpose(del_v1)\r\ndel_w1=np.random.uniform(0,1,(no_of_hidden_neurons_h1,no_of_inputs_h1))\r\ngamma_g_h1=0.8\r\ngamma_m_h1=0.2\r\n\r\n\r\n#Layer H2 Parameters\r\nno_of_inputs_h2=no_of_output_h1 + 1\r\nno_of_hidden_neurons_h2=30\r\nno_of_output_h2=1\r\nMaxItertaion=1000\r\ndel_v2=np.random.uniform(0,1,(no_of_output_h2,no_of_hidden_neurons_h2))\r\ndel_v2=np.transpose(del_v2)\r\ndel_w2=np.random.uniform(0,1,(no_of_hidden_neurons_h2,no_of_inputs_h2))\r\ngamma_g_h2=0.8\r\ngamma_m_h2=0.2\r\ntotal_cycle=5000\r\n\r\n\r\n# inputs for H1 \r\nx1=train_dataset[:,0]\r\nx2=train_dataset[:,1]\r\nx0=train_dataset[:,0]**0\r\n\r\nall_x=np.array([x0 , x1, x2])\r\nall_x=np.transpose(all_x)\r\ntarget_y=train_dataset[:,2]\r\n\r\n#weight initialization\r\nw1=np.random.uniform(0,1,(no_of_hidden_neurons_h1,no_of_inputs_h1))\r\nv1=np.random.uniform(0,1,(no_of_output_h1,no_of_hidden_neurons_h1))\r\nw2=np.random.uniform(0,1,(no_of_hidden_neurons_h2,no_of_inputs_h2))\r\nv2=np.random.uniform(0,1,(no_of_output_h2,no_of_hidden_neurons_h2))\r\n\r\ne=np.zeros(total_cycle)\r\new1=np.zeros((total_cycle,no_of_hidden_neurons_h1,no_of_inputs_h1))\r\n\r\nfor cycle in range(0,total_cycle):\r\n \r\n j=np.random.randint(0,np.size(target_y))\r\n one_x=np.array([all_x[j,:]]);\r\n a=w1 @ one_x.transpose();\r\n d=np.maximum(0,a); #ReLu Activation on H1\r\n bias1=np.ones((1,1))\r\n bd=np.concatenate((d,bias1), axis=0) #adding bias for layer2\r\n a2=w2@bd\r\n d2=np.maximum(0,a2)\r\n\r\n y_cap=v2 @ d2;\r\n \r\n error_y=target_y[j]- y_cap;\r\n\r\n error_d2=v2.transpose() @ error_y;\r\n error_a2=reluDerivative(d2)*error_d2\r\n \r\n error_d=w2.transpose() @ a2;\r\n error_a=reluDerivative(d)*error_d[:-1,:]\r\n\r\n del_v2=gamma_g_h2 * d2*error_y + gamma_m_h2 * del_v2\r\n #del_v1=gamma_g_h1 * d*a2 + gamma_m_h1 * del_v1\r\n bd2=np.concatenate((a2,bias1), axis=0) #backprop for bias\r\n del_w2=gamma_g_h1 * ([email protected]) + gamma_m_h2 * del_w2\r\n del_w1=gamma_g_h1 * ( error_a @ one_x) +gamma_m_h1* del_w1\r\n v2=v2-del_v2.transpose()\r\n #v1=v1-del_v1.transpose()\r\n w2=w2-del_w2\r\n w1=w1-del_w1\r\n e[cycle]=error_y\r\n ew1[cycle,:,:]=w1\r\n \r\n \r\n#print('Final weights are',w1,w2,v1)\r\n \r\n\r\n\r\n#Testing\r\nx_test=np.random.uniform(-1, 1,1000)\r\nx2_test=np.random.uniform(-1,1,1000)\r\ny_test=x_test**2 - x2_test**2\r\nx0_test=x_test**0\r\ntestdata=np.array([x0_test, x_test,x2_test, y_test])\r\ntestdata=testdata.transpose()\r\n\r\ntest_in=testdata[:,0:3]\r\ne_test=np.zeros(max(np.shape(test_in)))\r\nfor test in range(0,max(np.shape(test_in))):\r\n one_x=np.array([test_in[test,:]])\r\n a=w1 @ one_x.transpose();\r\n d=np.maximum(0,a); #ReLu Activation on H1\r\n bias1=np.ones((1,1))\r\n bd=np.concatenate((d,bias1), axis=0) #adding bias for layer2\r\n a2=w2@bd\r\n d2=np.maximum(0,a2)\r\n\r\n y_cap=v2 @ d2; \r\n e_test[test]=y_cap-y_test[test]\r\n\r\nend = timeit.timeit()\r\nprint(np.mean(np.square(e_test)))\r\nprint(end-start)\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5646295547485352,
"alphanum_fraction": 0.604651153087616,
"avg_line_length": 22.905405044555664,
"blob_id": "58d9f50f088599d924dfd083d0914c63c94d8cae",
"content_id": "d75e263d1fe48a19a00d73a4058c5bb8c5f0128d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1849,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 74,
"path": "/Neuron1.py",
"repo_name": "RajaAyyanar/Neural_Network_without_library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 29 14:26:41 2017\r\n\r\n@author: Raja Ayyanar\r\n\"\"\"\r\n\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\nx=np.linspace(-1, 1, 21)\r\ny=1+2 *(x**2)\r\ntrain_dataset=np.array([x,y])\r\ntrain_dataset=np.transpose(train_dataset)\r\ndel x,y\r\n\r\nno_of_inputs=2\r\nno_of_hidden_neurons=5\r\nno_of_output=1\r\nMaxItertaion=200\r\ndel_v=np.random.uniform(0,1,(no_of_output,no_of_hidden_neurons))\r\ndel_v=np.transpose(del_v)\r\ndel_w=np.random.uniform(0,1,(no_of_hidden_neurons,no_of_inputs))\r\ngamma_g=0.7\r\ngamma_m=0.2\r\ntotal_cycle=2000\r\n\r\nx1=train_dataset[:,0]\r\nx0=train_dataset[:,0]**0\r\nall_x=np.array([x0 , x1])\r\nall_x=np.transpose(all_x)\r\ntarget_y=train_dataset[:,1]\r\n\r\nw=np.random.uniform(0,1,(no_of_hidden_neurons,no_of_inputs))\r\nv=np.random.uniform(0,1,(no_of_output,no_of_hidden_neurons))\r\n\r\nfor cycle in range(0,total_cycle):\r\n \r\n j=np.random.randint(0,np.size(target_y))\r\n one_x=np.array([all_x[j,:]]);\r\n a=w @ one_x.transpose();\r\n d=1/(1+np.exp(-a));\r\n y_cap=v @ d;\r\n \r\n error_y=target_y[j]- y_cap;\r\n error_d=v.transpose() @ error_y;\r\n error_a=(d*(1-d))*error_d\r\n del_v=gamma_g * d*error_y + gamma_m * del_v\r\n del_w=gamma_g * ( error_a @ one_x) +gamma_m* del_w\r\n v=v+del_v.transpose()\r\n w=w+del_w\r\n \r\nprint('Final weights are',w)\r\n \r\n#Testing\r\n\r\nx_test=np.linspace(-1, 1, 201)\r\ny_test=1+2*x_test*x_test\r\nx0_test=x_test**0\r\ntestdata=np.array([x0_test, x_test, y_test])\r\ntestdata=testdata.transpose()\r\n\r\ntest_in=testdata[:,0:2]\r\ne=np.zeros(max(np.shape(test_in)))\r\nfor test in range(0,max(np.shape(test_in))):\r\n one_x=np.array([test_in[test,:]])\r\n a=w@one_x.transpose();\r\n d=1/(1+np.exp(-a));\r\n y_cap=v@d;\r\n e[test]=y_cap-y_test[test]\r\n plt.plot(one_x[0,1],y_test[test],'ro')\r\n plt.hold(True)\r\n plt.plot(one_x[0,1],y_cap,'ko')\r\n plt.hold(True)\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.8383233547210693,
"alphanum_fraction": 0.8383233547210693,
"avg_line_length": 82.5,
"blob_id": "e817fdbbae8186f2a47e980fa3256df548d0ff3c",
"content_id": "c627c3652785c5c347a8c093973cb00d9d4253c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 2,
"path": "/README.md",
"repo_name": "RajaAyyanar/Neural_Network_without_library",
"src_encoding": "UTF-8",
"text": "# Neural_Network_without_library\nBuilding a Neural network without using any libraries like teansorflow, keras or theano. Helps to understand flow and backpropagation\n"
}
] | 4 |
SahanaSrivathsa/WMaze_Analysis
|
https://github.com/SahanaSrivathsa/WMaze_Analysis
|
7a0e89236d5cee7519d517302424722868bbf105
|
b852e97ba1280c5464edd4eed47633ac4e80b867
|
9fcc11501cc0f0643e3d5b236bb969b9b76f90f7
|
refs/heads/master
| 2023-05-11T13:01:29.226504 | 2023-05-05T20:15:12 | 2023-05-05T20:15:12 | 175,093,220 | 0 | 0 | null | 2019-03-11T22:26:07 | 2017-07-25T22:57:48 | 2018-02-26T22:27:13 | null |
[
{
"alpha_fraction": 0.8393194675445557,
"alphanum_fraction": 0.8487712740898132,
"avg_line_length": 74.57142639160156,
"blob_id": "31b7107c8d6fa8a3879fe3e79a9a75764110b8c8",
"content_id": "62f754debd6d81b0531eb8d736af33a7e7009190",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 7,
"path": "/analyzeData.sh",
"repo_name": "SahanaSrivathsa/WMaze_Analysis",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\npython C:\\Users\\sahanasrivathsa\\Documents\\SYNC\\Work\\BarnesLab\\WMAZE\\WMAZE_Analysis\\Analysis_Behaviour\\WMaze_Analysis_master\\PrelimProcessing\\TransformData.py\n\npython C:\\Users\\sahanasrivathsa\\Documents\\SYNC\\Work\\BarnesLab\\WMAZE\\WMAZE_Analysis\\Analysis_Behaviour\\WMaze_Analysis_master\\StochasticVolatility\\BySession\\createPropCSV.py\n\npython C:\\Users\\sahanasrivathsa\\Documents\\SYNC\\Work\\BarnesLab\\WMAZE\\WMAZE_Analysis\\Analysis_Behaviour\\WMaze_Analysis_master\\StochasticVolatility\\BySession\\runBothBin.py $1 $2 $3 $4 $5\n"
},
{
"alpha_fraction": 0.6809253692626953,
"alphanum_fraction": 0.701003909111023,
"avg_line_length": 41.03669738769531,
"blob_id": "6daaebfdac3ebdf2e556e4d8a85196ea947a6184",
"content_id": "9317ece68062cd3e3c540e5957bd61d5b7862fb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4582,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 109,
"path": "/StochasticVolatility/BySession/createPropCSV.py",
"repo_name": "SahanaSrivathsa/WMaze_Analysis",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport os\n\n\n#INPUT PARAMETERS\nsessionNum = 23\ndf = pd.read_csv(r'C:\\Users\\sahanasrivathsa\\Documents\\SYNC\\Work\\BarnesLab\\WMAZE\\WMAZE_Analysis\\Analysis_Behaviour\\WMaze_Analysis_master\\pandas_viz\\rats.csv') # Path to rats.csv\nbaseDir = 'G:\\WMAZE_Data\\Data_Behaviour\\\\' # Path to raw data file folders\ndir = baseDir + 'ProcessedData\\\\' #Path to processed data\nnewdir = dir+'PRE'\n\noldRats = list(df[df['AGE'] == 25]['RAT'])\nyoungRats = list(df[df['AGE'] == 10]['RAT'])\n\n\n\ndef BySession(rat):\n data = pd.read_csv('{0}{1}/{1}_DATA.csv'.format(dir,str(rat)))\n return (data.groupby(['Session']).count()['Correct/Incorrect'],data.groupby(['Session']).sum()['Correct/Incorrect'])\n\ndef Inbound(rat):\n inboundData = pd.read_csv('{0}{1}/{1}_IN.csv'.format(dir,str(rat)))\n return (inboundData.groupby(['Session']).count()['Correct/Incorrect'],inboundData.groupby(['Session']).sum()['Correct/Incorrect'])\n\ndef Outbound(rat):\n outboundData = pd.read_csv('{0}{1}/{1}_OUT.csv'.format(dir,str(rat)))\n return (outboundData.groupby(['Session']).count()['Correct/Incorrect'],outboundData.groupby(['Session']).sum()['Correct/Incorrect'])\n\noverallYngDenom = pd.DataFrame()\ninboundYngDenom = pd.DataFrame()\noutboundYngDenom = pd.DataFrame()\noverallOldDenom = pd.DataFrame()\ninboundOldDenom = pd.DataFrame()\noutboundOldDenom = pd.DataFrame()\n\noverallYngCorrect = pd.DataFrame()\ninboundYngCorrect = pd.DataFrame()\noutboundYngCorrect = pd.DataFrame()\noverallOldCorrect = pd.DataFrame()\ninboundOldCorrect = pd.DataFrame()\noutboundOldCorrect = pd.DataFrame()\n\n\nfor rat in youngRats:\n overallYngDenom[str(rat)],overallYngCorrect[str(rat)] = BySession(rat)\n inboundYngDenom[str(rat)],inboundYngCorrect[str(rat)] = Inbound(rat)\n outboundYngDenom[str(rat)],outboundYngCorrect[str(rat)] = Outbound(rat)\n\nfor oldRat in oldRats:\n overallOldDenom[str(oldRat)],overallOldCorrect[str(oldRat)] = BySession(oldRat)\n inboundOldDenom[str(oldRat)],inboundOldCorrect[str(oldRat)] = Inbound(oldRat)\n outboundOldDenom[str(oldRat)],outboundOldCorrect[str(oldRat)] = Outbound(oldRat)\n\n\noverallYngDenom.transpose().to_csv(dir+'PREoverallYoungDenom.csv')\noverallYngCorrect.transpose().to_csv(dir+'PREoverallYoungNum.csv')\ninboundYngDenom.transpose().to_csv(dir+'PREinboundYoungDenom.csv')\ninboundYngCorrect.transpose().to_csv(dir+'PREinboundYoungNum.csv')\noutboundYngDenom.transpose().to_csv(dir+'PREoutboundYoungDenom.csv')\noutboundYngCorrect.transpose().to_csv(dir+'PREoutboundYoungNum.csv')\n\n\noverallOldDenom.transpose().to_csv(dir+'PREoverallOldDenom.csv')\noverallOldCorrect.transpose().to_csv(dir+'PREoverallOldNum.csv')\ninboundOldDenom.transpose().to_csv(dir+'PREinboundOldDenom.csv')\ninboundOldCorrect.transpose().to_csv(dir+'PREinboundOldNum.csv')\noutboundOldDenom.transpose().to_csv(dir+'PREoutboundOldDenom.csv')\noutboundOldCorrect.transpose().to_csv(dir+'PREoutboundOldNum.csv')\n\nprint (\"|||||||||||||||||Created Session Data|||||||||||||||||\")\n\n\n\n\ndenomFiles = [newdir+'inboundOldDenom.csv',newdir+'outboundOldDenom.csv',newdir+'inboundYoungDenom.csv',newdir+'outboundYoungDenom.csv',\n newdir+'overallOldDenom.csv',newdir+'overallYoungDenom.csv']\nnumFiles = [newdir+'inboundOldNum.csv',newdir+'outboundOldNum.csv',newdir+'inboundYoungNum.csv',newdir+'outboundYoungNum.csv',\n newdir+'overallOldNum.csv',newdir+'overallYoungNum.csv']\ndenomFilesNew = [dir+'inboundOldDenom.csv',dir+'outboundOldDenom.csv',dir+'inboundYoungDenom.csv',dir+'outboundYoungDenom.csv',\n dir+'overallOldDenom.csv',dir+'overallYoungDenom.csv']\nnumFilesNew = [dir+'inboundOldNum.csv',dir+'outboundOldNum.csv',dir+'inboundYoungNum.csv',dir+'outboundYoungNum.csv',\n dir+'overallOldNum.csv',dir+'overallYoungNum.csv']\n\n\ndef runFix(fileList,type,newFileList):\n if type == 'd':\n value = '10'\n else:\n value = '5'\n\n for index in range(len(fileList)):\n with open(fileList[index],'r') as read:\n lines = read.readlines()\n\n with open(newFileList[index],'w') as write:\n if sessionNum == 21:\n write.write('0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20\\n')\n if sessionNum == 23:\n write.write('0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22\\n')\n for line in lines:\n if line != lines[0]:\n write.write(value + ',' + line[6:])\n os.remove(fileList[index])\n\n\nrunFix(denomFiles,'d',denomFilesNew)\nrunFix(numFiles,'n',numFilesNew)\n\nprint (\"||||||||||||||||Cleaned up Session Data|||||||||||||||\")\n"
}
] | 2 |
rexxmagtar/LandscapeGeneration
|
https://github.com/rexxmagtar/LandscapeGeneration
|
73d9659d0e94fce04b642715b069889775f26c77
|
becd59d535b4b966a54aef72c03dbbde7a4d1762
|
2327c8ce7dc33bb0ae339149269d95ff40be6a10
|
refs/heads/main
| 2023-04-23T19:07:23.776160 | 2021-05-11T10:42:26 | 2021-05-11T10:42:26 | 358,988,540 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6030974388122559,
"alphanum_fraction": 0.6163497567176819,
"avg_line_length": 35.17304992675781,
"blob_id": "b6df7f7f2a577d8d58b7b3c11ae49d60c0830c74",
"content_id": "6c8998c9deea1fad908b3349359633746ce20809",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25513,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 705,
"path": "/LandscapeGeneration/Main.py",
"repo_name": "rexxmagtar/LandscapeGeneration",
"src_encoding": "UTF-8",
"text": "import bpy\nimport colorsys\n\n\"\"\"Erosion\"\"\"\nimport numpy as np\nimport util\n\n\n# Smooths out slopes of `terrain` that are too steep. Rough approximation of the\n# phenomenon described here: https://en.wikipedia.org/wiki/Angle_of_repose\ndef apply_slippage(terrain, repose_slope, cell_width):\n delta = util.simple_gradient(terrain) / cell_width\n smoothed = util.gaussian_blur(terrain, sigma=1.5)\n should_smooth = np.abs(delta) > repose_slope\n result = np.select([np.abs(delta) > repose_slope], [smoothed], terrain)\n return result\n\n\ndef main(terrain, iterationNumber: int):\n # Grid dimension constants\n full_width = len(terrain)\n dim = len(terrain)\n shape = [dim] * 2\n cell_width = full_width / dim\n cell_area = cell_width ** 2\n\n # Snapshotting parameters. Only needed for generating the simulation\n # timelapse.\n # enable_snapshotting = False\n # my_dir = os.path.dirname(argv[0])\n # snapshot_dir = os.path.join(my_dir, 'sim_snaps')\n # snapshot_file_template = 'sim-%05d.png'\n # if enable_snapshotting:\n # try:\n # os.mkdir(snapshot_dir)\n # except:\n # pass\n\n # Water-related constants\n rain_rate = 0.0008 * cell_area\n evaporation_rate = 0.0005\n\n # Slope constants\n min_height_delta = 0.05\n repose_slope = 0.03\n gravity = 30.0\n gradient_sigma = 0.5\n\n # Sediment constants\n sediment_capacity_constant = 50.0\n dissolving_rate = 0.25\n deposition_rate = 0.001\n\n # The numer of iterations is proportional to the grid dimension. This is to\n # allow changes on one side of the grid to affect the other side.\n iterations = iterationNumber\n\n # `terrain` represents the actual terrain height we're interested in\n # terrain = util.fbm(shape, -2.0)\n\n # `sediment` is the amount of suspended \"dirt\" in the water. Terrain will be\n # transfered to/from sediment depending on a number of different factors.\n sediment = np.zeros_like(terrain)\n\n # The amount of water. Responsible for carrying sediment.\n water = np.zeros_like(terrain)\n\n # The water velocity.\n velocity = np.zeros_like(terrain)\n\n for i in range(0, iterations):\n print('%d / %d' % (i + 1, iterations))\n\n # Add precipitation. This is done by via simple uniform random distribution,\n # although other models use a raindrop model\n water += np.random.rand(*shape) * rain_rate\n\n # Compute the normalized gradient of the terrain height to determine where\n # water and sediment will be moving.\n gradient = np.zeros_like(terrain, dtype='complex')\n gradient = util.simple_gradient(terrain)\n gradient = np.select([np.abs(gradient) < 1e-10],\n [np.exp(2j * np.pi * np.random.rand(*shape))],\n gradient)\n gradient /= np.abs(gradient)\n\n # Compute the difference between teh current height the height offset by\n # `gradient`.\n neighbor_height = util.sample(terrain, -gradient)\n height_delta = terrain - neighbor_height\n\n # The sediment capacity represents how much sediment can be suspended in\n # water. If the sediment exceeds the quantity, then it is deposited,\n # otherwise terrain is eroded.\n sediment_capacity = (\n (np.maximum(height_delta, min_height_delta) / cell_width) * velocity *\n water * sediment_capacity_constant)\n deposited_sediment = np.select(\n [\n height_delta < 0,\n sediment > sediment_capacity,\n ], [\n np.minimum(height_delta, sediment),\n deposition_rate * (sediment - sediment_capacity),\n ],\n # If sediment <= sediment_capacity\n dissolving_rate * (sediment - sediment_capacity))\n\n # Don't erode more sediment than the current terrain height.\n deposited_sediment = np.maximum(-height_delta, deposited_sediment)\n\n # Update terrain and sediment quantities.\n sediment -= deposited_sediment\n terrain += deposited_sediment\n sediment = util.displace(sediment, gradient)\n water = util.displace(water, gradient)\n\n # Smooth out steep slopes.\n terrain = apply_slippage(terrain, repose_slope, cell_width)\n\n # Update velocity\n velocity = gravity * height_delta / cell_width\n\n # Apply evaporation\n water *= 1 - evaporation_rate\n\n # Snapshot, if applicable.\n # if enable_snapshotting:\n # output_path = os.path.join(snapshot_dir, snapshot_file_template % i)\n # util.save_as_png(terrain, output_path)\n\n # normalizedterrain = util.normalize(terrain)\n return terrain\n\n\n\"\"\"Perlin noise implementation.\"\"\"\n# Licensed under ISC\nfrom itertools import product\nimport math\nimport random\n\n\ndef smoothstep(t):\n \"\"\"Smooth curve with a zero derivative at 0 and 1, making it useful for\n interpolating.\n \"\"\"\n return t * t * (3. - 2. * t)\n\n\ndef lerp(t, a, b):\n \"\"\"Linear interpolation between a and b, given a fraction t.\"\"\"\n return a + t * (b - a)\n # return (a - b) * ((t * (t * 6.0 - 15.0) + 10.0) * t * t*t) + a\n\n\nclass PerlinNoiseFactory(object):\n \"\"\"Callable that produces Perlin noise for an arbitrary point in an\n arbitrary number of dimensions. The underlying grid is aligned with the\n integers.\n There is no limit to the coordinates used; new gradients are generated on\n the fly as necessary.\n \"\"\"\n\n def __init__(self, dimension, octaves=1, tile=(), unbias=False):\n \"\"\"Create a new Perlin noise factory in the given number of dimensions,\n which should be an integer and at least 1.\n More octaves create a foggier and more-detailed noise pattern. More\n than 4 octaves is rather excessive.\n ``tile`` can be used to make a seamlessly tiling pattern. For example:\n pnf = PerlinNoiseFactory(2, tile=(0, 3))\n This will produce noise that tiles every 3 units vertically, but never\n tiles horizontally.\n If ``unbias`` is true, the smoothstep function will be applied to the\n output before returning it, to counteract some of Perlin noise's\n significant bias towards the center of its output range.\n \"\"\"\n self.dimension = dimension\n self.octaves = octaves\n self.tile = tile + (0,) * dimension\n self.unbias = unbias\n\n # For n dimensions, the range of Perlin noise is ±sqrt(n)/2; multiply\n # by this to scale to ±1\n self.scale_factor = 2 * dimension ** -0.5\n\n self.gradient = {}\n\n def _generate_gradient(self):\n # Generate a random unit vector at each grid point -- this is the\n # \"gradient\" vector, in that the grid tile slopes towards it\n\n # 1 dimension is special, since the only unit vector is trivial;\n # instead, use a slope between -1 and 1\n if self.dimension == 1:\n return (random.uniform(-1, 1),)\n\n # Generate a random point on the surface of the unit n-hypersphere;\n # this is the same as a random unit vector in n dimensions. Thanks\n # to: http://mathworld.wolfram.com/SpherePointPicking.html\n # Pick n normal random variables with stddev 1\n random_point = [random.gauss(0, 1) for _ in range(self.dimension)]\n # Then scale the result to a unit vector\n scale = sum(n * n for n in random_point) ** -0.5\n return tuple(coord * scale for coord in random_point)\n\n def get_plain_noise(self, *point):\n \"\"\"Get plain noise for a single point, without taking into account\n either octaves or tiling.\n \"\"\"\n if len(point) != self.dimension:\n raise ValueError(\"Expected {} values, got {}\".format(\n self.dimension, len(point)))\n\n # Build a list of the (min, max) bounds in each dimension\n grid_coords = []\n for coord in point:\n min_coord = math.floor(coord)\n max_coord = min_coord + 1\n grid_coords.append((min_coord, max_coord))\n\n # Compute the dot product of each gradient vector and the point's\n # distance from the corresponding grid point. This gives you each\n # gradient's \"influence\" on the chosen point.\n dots = []\n for grid_point in product(*grid_coords):\n if grid_point not in self.gradient:\n self.gradient[grid_point] = self._generate_gradient()\n gradient = self.gradient[grid_point]\n\n dot = 0\n for i in range(self.dimension):\n dot += gradient[i] * (point[i] - grid_point[i])\n dots.append(dot)\n\n # Interpolate all those dot products together. The interpolation is\n # done with smoothstep to smooth out the slope as you pass from one\n # grid cell into the next.\n # Due to the way product() works, dot products are ordered such that\n # the last dimension alternates: (..., min), (..., max), etc. So we\n # can interpolate adjacent pairs to \"collapse\" that last dimension. Then\n # the results will alternate in their second-to-last dimension, and so\n # forth, until we only have a single value left.\n dim = self.dimension\n while len(dots) > 1:\n dim -= 1\n s = smoothstep(point[dim] - grid_coords[dim][0])\n\n next_dots = []\n while dots:\n next_dots.append(lerp(s, dots.pop(0), dots.pop(0)))\n\n dots = next_dots\n\n return dots[0] * self.scale_factor\n\n def __call__(self, *point):\n \"\"\"Get the value of this Perlin noise function at the given point. The\n number of values given should match the number of dimensions.\n \"\"\"\n ret = 0\n for o in range(self.octaves):\n o2 = 1 << o\n new_point = []\n for i, coord in enumerate(point):\n coord *= o2\n if self.tile[i]:\n coord %= self.tile[i] * o2\n new_point.append(coord)\n ret += self.get_plain_noise(*new_point) / o2\n\n # Need to scale n back down since adding all those extra octaves has\n # probably expanded it beyond ±1\n # 1 octave: ±1\n # 2 octaves: ±1½\n # 3 octaves: ±1¾\n ret /= 2 - 2 ** (1 - self.octaves)\n\n if self.unbias:\n # The output of the plain Perlin noise algorithm has a fairly\n # strong bias towards the center due to the central limit theorem\n # -- in fact the top and bottom 1/8 virtually never happen. That's\n # a quarter of our entire output range! If only we had a function\n # in [0..1] that could introduce a bias towards the endpoints...\n r = (ret + 1) / 2\n # Doing it this many times is a completely made-up heuristic.\n for _ in range(int(self.octaves / 2 + 0.5)):\n r = smoothstep(r)\n ret = r * 2 - 1\n\n return ret\n\n\ndef diamond_square(shape: (int, int),\n min_height: [float or int],\n max_height: [float or int],\n roughness: [float or int],\n random_seed=None,\n as_ndarray: bool = True):\n \"\"\"Runs a diamond square algorithm and returns an array (or list) with the landscape\n An important difference (possibly) between this, and other implementations of the\n diamond square algorithm is how I use the roughness parameter. For each \"perturbation\"\n I pull a random number from a uniform distribution between min_height and max_height.\n I then take the weighted average between that value, and the average value of the\n \"neighbors\", whether those be in the diamond or in the square step, as normal. The\n weights used for the weighted sum are (roughness) and (1-roughness) for the random\n number and the average, respectively, where roughness is a float that always falls\n between 0 and 1.\n The roughness value used in each iteration is based on the roughness parameter\n passed in, and is computed as follows:\n this_iteration_roughness = roughness**iteration_number\n where the first iteration has iteration_number = 0. The first roughness value\n actually used (in the very first diamond and square step) is roughness**0 = 1. Thus,\n the values for those first diamond and square step entries will be entirely random.\n This effectively means that I am seeding with A 3x3 grid of random values, rather\n than with just the four corners.\n As the process continues, the weight placed on the random number draw falls from\n the original value of 1, to roughness**1, to roughness**2, and so on, ultimately\n approaching 0. This means that the values of new cells will slowly shift from being\n purely random, to pure averages.\n OTHER NOTES:\n Internally, all heights are between 0 and 1, and are rescaled at the end.\n PARAMETERS\n ----------\n :param shape\n tuple of ints, (int, int): the shape of the resulting landscape\n :param min_height\n Int or Float: The minimum height allowed on the landscape\n :param max_height\n Int or Float: The maximum height allowed on the landscape\n :param roughness\n Float with value between 0 and 1, reflecting how bumpy the landscape should be.\n Values near 1 will result in landscapes that are extremely rough, and have almost no\n cell-to-cell smoothness. Values near zero will result in landscapes that are almost\n perfectly smooth.\n Values above 1.0 will be interpreted as 1.0\n Values below 0.0 will be interpreted as 0.0\n :param random_seed\n Any value. Defaults to None. If a value is given, the algorithm will use it to seed the random\n number generator, ensuring replicability.\n :param as_ndarray\n Bool: whether the landscape should be returned as a numpy array. If set\n to False, the method will return list of lists.\n :returns [list] or nd_array\n \"\"\"\n\n # sanitize inputs\n if roughness > 1:\n roughness = 1.0\n if roughness < 0:\n roughness = 0.0\n\n working_shape, iterations = _get_working_shape_and_iterations(shape)\n\n # create the array\n diamond_square_array = np.full(working_shape, -1, dtype='float')\n\n # seed the random number generator\n random.seed(random_seed)\n\n # seed the corners\n diamond_square_array[0, 0] = random.uniform(0, 1)\n diamond_square_array[working_shape[0] - 1, 0] = random.uniform(0, 1)\n diamond_square_array[0, working_shape[1] - 1] = random.uniform(0, 1)\n diamond_square_array[working_shape[0] - 1, working_shape[1] - 1] = random.uniform(0, 1)\n\n # do the algorithm\n for i in range(iterations):\n r = math.pow(roughness, i)\n\n step_size = math.floor((working_shape[0] - 1) / math.pow(2, i))\n\n _diamond_step(diamond_square_array, step_size, r)\n _square_step(diamond_square_array, step_size, r)\n\n # rescale the array to fit the min and max heights specified\n diamond_square_array = min_height + (diamond_square_array * (max_height - min_height))\n\n # trim array, if needed\n final_array = diamond_square_array[:shape[0], :shape[1]]\n\n if as_ndarray:\n return final_array\n else:\n return final_array.tolist()\n\n\ndef _get_working_shape_and_iterations(requested_shape, max_power_of_two=13):\n \"\"\"Returns the necessary size for a square grid which is usable in a DS algorithm.\n The Diamond Square algorithm requires a grid of size n x n where n = 2**x + 1, for any\n integer value of x greater than two. To accomodate a requested map size other than these\n dimensions, we simply create the next largest n x n grid which can entirely contain the\n requested size, and return a subsection of it.\n This method computes that size.\n PARAMETERS\n ----------\n requested_shape\n A 2D list-like object reflecting the size of grid that is ultimately desired.\n max_power_of_two\n an integer greater than 2, reflecting the maximum size grid that the algorithm can EVER\n attempt to make, even if the requested size is too big. This limits the algorithm to\n sizes that are manageable, unless the user really REALLY wants to have a bigger one.\n The maximum grid size will have an edge of size (2**max_power_of_two + 1)\n RETURNS\n -------\n An integer of value n, as described above.\n \"\"\"\n if max_power_of_two < 3:\n max_power_of_two = 3\n\n largest_edge = max(requested_shape)\n\n for power in range(1, max_power_of_two + 1):\n d = (2 ** power) + 1\n if largest_edge <= d:\n return (d, d), power\n\n # failsafe: no values in the dimensions array were allowed, so print a warning and return\n # the maximum size.\n d = 2 ** max_power_of_two + 1\n print(\"DiamondSquare Warning: Requested size was too large. Grid of size {0} returned\"\"\".format(d))\n return (d, d), max_power_of_two\n\n\ndef _diamond_step(DS_array, step_size, roughness):\n \"\"\"Does the diamond step for a given iteration.\n During the diamond step, the diagonally adjacent cells are filled:\n Value None Value None Value ...\n None FILLING None FILLING None ...\n\n Value None Value None Value ...\n ... ... ... ... ... ...\n So we'll step with increment step_size over BOTH axes\n \"\"\"\n # calculate where all the diamond corners are (the ones we'll be filling)\n half_step = math.floor(step_size / 2)\n x_steps = range(half_step, DS_array.shape[0], step_size)\n y_steps = x_steps[:]\n\n for i in x_steps:\n for j in y_steps:\n if DS_array[i, j] == -1.0:\n DS_array[i, j] = _diamond_displace(DS_array, i, j, half_step, roughness)\n\n\ndef _square_step(DS_array, step_size, roughness):\n \"\"\"Does the square step for a given iteration.\n During the diamond step, the diagonally adjacent cells are filled:\n Value FILLING Value FILLING Value ...\n FILLING DIAMOND FILLING DIAMOND FILLING ...\n\n Value FILLING Value FILLING Value ...\n ... ... ... ... ... ...\n So we'll step with increment step_size over BOTH axes\n \"\"\"\n\n # doing this in two steps: the first, where the every other column is skipped\n # and the second, where every other row is skipped. For each, iterations along\n # the half-steps go vertically or horizontally, respectively.\n\n # set the half-step for the calls to square_displace\n half_step = math.floor(step_size / 2)\n\n # vertical step\n steps_x_vert = range(half_step, DS_array.shape[0], step_size)\n steps_y_vert = range(0, DS_array.shape[1], step_size)\n\n # horizontal step\n steps_x_horiz = range(0, DS_array.shape[0], step_size)\n steps_y_horiz = range(half_step, DS_array.shape[1], step_size)\n\n for i in steps_x_horiz:\n for j in steps_y_horiz:\n DS_array[i, j] = _square_displace(DS_array, i, j, half_step, roughness)\n\n for i in steps_x_vert:\n for j in steps_y_vert:\n DS_array[i, j] = _square_displace(DS_array, i, j, half_step, roughness)\n\n\ndef _diamond_displace(DS_array, i, j, half_step, roughness):\n \"\"\"\n defines the midpoint displacement for the diamond step\n :param DS_array:\n :param i:\n :param j:\n :param half_step:\n :param roughness:\n :return:\n \"\"\"\n ul = DS_array[i - half_step, j - half_step]\n ur = DS_array[i - half_step, j + half_step]\n ll = DS_array[i + half_step, j - half_step]\n lr = DS_array[i + half_step, j + half_step]\n\n ave = (ul + ur + ll + lr) / 4.0\n\n rand_val = random.uniform(0, 1)\n\n return (roughness * rand_val) + (1.0 - roughness) * ave\n\n\ndef _square_displace(DS_array, i, j, half_step, roughness):\n \"\"\"\n Defines the midpoint displacement for the square step\n :param DS_array:\n :param i:\n :param j:\n :param half_step:\n :param roughness:\n :return:\n \"\"\"\n _sum = 0.0\n divide_by = 4\n\n # check cell \"above\"\n if i - half_step >= 0:\n _sum += DS_array[i - half_step, j]\n else:\n divide_by -= 1\n\n # check cell \"below\"\n if i + half_step < DS_array.shape[0]:\n _sum += DS_array[i + half_step, j]\n else:\n divide_by -= 1\n\n # check cell \"left\"\n if j - half_step >= 0:\n _sum += DS_array[i, j - half_step]\n else:\n divide_by -= 1\n\n # check cell \"right\"\n if j + half_step < DS_array.shape[0]:\n _sum += DS_array[i, j + half_step]\n else:\n divide_by -= 1\n\n ave = _sum / divide_by\n\n rand_val = random.uniform(0, 1)\n\n return (roughness * rand_val) + (1.0 - roughness) * ave\n\n\ndef create_see():\n vertices = [(0, 0, 0), (0, 100, 0), (100, 100, 0), (100, 0, 0)]\n edges = []\n faces = [(0, 1, 2, 3)]\n flat_mesh = bpy.data.meshes.new('see_mesh')\n flat_mesh.from_pydata(vertices, edges, faces)\n flat_mesh.update()\n # make object from mesh\n new_flat = bpy.data.objects.new('new_see', flat_mesh)\n # make collection\n flat_collection = bpy.data.collections.new('see_see')\n bpy.context.scene.collection.children.link(flat_collection)\n # add object to scene collection\n flat_collection.objects.link(new_flat)\n\n if flat_mesh.vertex_colors:\n vcol_layer = flat_mesh.vertex_colors.active\n else:\n vcol_layer = flat_mesh.vertex_colors.new()\n\n for poly in flat_mesh.polygons:\n for loop_index in poly.loop_indices:\n loop_vert_index = flat_mesh.loops[loop_index].vertex_index\n\n vcol_layer.data[loop_index].color = (0, 0, 1, 0.5)\n\n\ndef drawPlots(Z, title):\n \"\"\"Draws plots for specified height map\"\"\"\n import matplotlib.pyplot as plt\n import numpy as np\n\n length = len(Z)\n\n z = np.array([[Z[x, y] for x in range(length)] for y in range(length)])\n x, y = np.meshgrid(range(z.shape[0]), range(z.shape[1]))\n\n # show hight map in 3d\n fig = plt.figure()\n ax = fig.add_subplot(111, projection='3d')\n ax.plot_surface(x, y, z)\n plt.title(title + '. 3d height map')\n plt.show()\n\n # show hight map in 2d\n plt.figure()\n plt.title(title + '. 2d height map')\n p = plt.imshow(z, cmap='Greys')\n plt.colorbar(p)\n plt.show()\n\n\ndef generatePerlinNoize(length, octaves, maxHeight, minHeight):\n perl = PerlinNoiseFactory(2, octaves, tile=(5, 5), unbias=True)\n\n import numpy as np\n\n Z = np.zeros((length, length))\n\n for i in range(length):\n for j in range(length):\n Z[i][j] = minHeight + (perl(i / (length - 1), j / (length - 1))) * (maxHeight - minHeight)\n\n return Z\n\n\ndef generateTerrain(Z):\n \"\"\"Generates mesh in blender studio\"\"\"\n quadsCount = len(Z) - 1\n\n length = len(Z);\n\n map1 = Z\n\n print(\"Started\")\n\n vertices = []\n edges = []\n\n faces = []\n\n quadLength = 1\n\n vertices = []\n\n for i in range(length):\n for j in range(length):\n vertices.append((i * quadLength, j * quadLength, map1[i, j]))\n\n # TODO: now we have to create Faces based on vertices.\n\n # for i in range(quadsCount + 1):\n # for j in range(quadsCount + 1):\n # vertices.append((i, j, random.randint(0, 0)))\n # print(\"added vertices: \" + str(i) + \", \" + str(j))\n\n for i in range(((quadsCount + 1) * (quadsCount))):\n if i != 0 and ((i + 1) % (quadsCount + 1) == 0):\n continue\n faces.append([i, i + 1, i + quadsCount + 2, i + quadsCount + 1])\n # print(\"added face: \" + str(faces[-1][0]) + \", \" + str(faces[-1][1]) + \", \" + str(faces[-1][2]) + \", \" + str(\n # faces[-1][3]))\n\n flat_mesh = bpy.data.meshes.new('flat_mesh')\n flat_mesh.from_pydata(vertices, edges, faces)\n flat_mesh.update()\n # make object from mesh\n new_flat = bpy.data.objects.new('new_flat', flat_mesh)\n # make collection\n flat_collection = bpy.data.collections.new('flat_collection')\n bpy.context.scene.collection.children.link(flat_collection)\n # add object to scene collection\n flat_collection.objects.link(new_flat)\n\n maxHeight = max(vertices, key=lambda v: v[2])[2]\n minHeight = 0\n\n print(\"Max height = \" + str(maxHeight))\n print(\"Min height = \" + str(minHeight))\n\n dif = maxHeight - minHeight\n\n if flat_mesh.vertex_colors:\n vcol_layer = flat_mesh.vertex_colors.active\n else:\n vcol_layer = flat_mesh.vertex_colors.new()\n\n for poly in flat_mesh.polygons:\n for loop_index in poly.loop_indices:\n loop_vert_index = flat_mesh.loops[loop_index].vertex_index\n color = colorsys.hsv_to_rgb(\n min(0.70, (maxHeight - flat_mesh.vertices[loop_vert_index].co[2]) / (dif * 2.4)),\n 1, 1)\n vcol_layer.data[loop_index].color = (color[0], color[1], color[2], 0.5)\n\n\nif __name__ == '__main__':\n\n #length must be a power of 2 for diamond square algorithm\n length = 2 ** 8;\n\n max_height = 150;\n min_height = -10;\n\n map1 = diamond_square(shape=(length, length),\n min_height=min_height,\n max_height=max_height,\n roughness=0.49, random_seed=228)\n\n drawPlots(map1, 'Diamond algorithm')\n\n map2 = generatePerlinNoize(length, 4, minHeight=min_height, maxHeight=max_height)\n\n drawPlots(map2, 'Perlin noise')\n\n map2 = main(util.normalize(map2), 200)\n\n map2 = util.normalize(map2, (min_height, max_height))\n\n drawPlots(map2, 'Perlin noise after erosion')\n\n\n\n"
},
{
"alpha_fraction": 0.6252108812332153,
"alphanum_fraction": 0.8071824312210083,
"avg_line_length": 42.16666793823242,
"blob_id": "4e5b4b8bc369abead051822272b13d6c5219dcd3",
"content_id": "86deb5cbd4266baab410bc4844518046839cd206",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4195,
"license_type": "no_license",
"max_line_length": 382,
"num_lines": 96,
"path": "/README.md",
"repo_name": "rexxmagtar/LandscapeGeneration",
"src_encoding": "UTF-8",
"text": "# Realistic landscape generation\n\n\n\nMain aim of this project is to research different methods for realistic landscape generation.\n\n\n\n## Short description\n\nIn projects terms, landscape generation means generation of a 2D heights map. So all algorithms provide a n x m matrix as a result. All calculations are done using python. Fast visualisation is also done from the scratch. Project also provides methods for landscape visualisation in \"Blender studio\". It is always a huge time-consuming task, though it provides better visualization.\n\n\n\n# Algorithms\n\nSo far the following algorithms were implemented:\n\n## Noise algorithm (Perlin noise)\n\nClassic noise algorithm for generation smooth fractal landscape.\n\n[Perlin noise info](https://en.wikipedia.org/wiki/Perlin_noise#:~:text=Perlin%20noise%20is%20a%20procedural,details%20are%20the%20same%20size)\n\nResults:\n\n\n\n\n\n\n\n\n\n## Diamond algorithm \n\nAnother fractal algorithm that provides much more flexibility and realism to generated landscapes.\n\n[Classic algorithm info](https://en.wikipedia.org/wiki/Diamond-square_algorithm)\n\nResults:\n\n\n\n\n\n\n\n\n## Hydraulic erosion\n\nReal world hydraulic erosion was simulated. A lot of arguments such as sediment, evaporation, rain rate and e.t.c can be configured.\n\nErosion can be applied to already configured landscape only, overwise, no result could be achieved. So some noise, for example, can be used to prepare terrain for the erosion.\n\n\n\nResults:\n\nErosion applied to terrain generated using diamond algorithm.\n\n\n\n\n\nLandscape before erosion:\n\n\n\n\n\nLandscape after erosion:\n\n\n\n# Usage\nProject \"LandscapeGeneration\" contains all files needed for testing. Just run \"Main.py\" file for example demonstration.\nNotice that if you want to use blender integration you will also need to put necessary python libs in Blender_root_path\\startup folder.\n\n# Some beautiful examples\n\n\n\n\n\n\n\n\nПесчаные степи без эрозии.\n\nПесчаные степи после эрозии.\n\n\n\n\n\n\n\n\n\n\n"
}
] | 2 |
vst42/radio-grab-now-playing
|
https://github.com/vst42/radio-grab-now-playing
|
975d627b06d20d58dc1ae0291a587d212807bee1
|
d94f8f0cd325865a695f2d132816e7fc3e937406
|
405f37a6362e91152018dd156b3431e925086a77
|
refs/heads/master
| 2021-10-28T04:25:29.164264 | 2019-04-22T01:58:38 | 2019-04-22T01:58:38 | 14,930,529 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7516869306564331,
"alphanum_fraction": 0.7591093182563782,
"avg_line_length": 37,
"blob_id": "5f3e1e3fe2656874a7fccf34478e3501dec4a7cf",
"content_id": "19363344f1f5147ca5f5d07ae40b9d516f85c744",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1482,
"license_type": "permissive",
"max_line_length": 337,
"num_lines": 39,
"path": "/README.md",
"repo_name": "vst42/radio-grab-now-playing",
"src_encoding": "UTF-8",
"text": "## radio-grab-now-playing\n\nPython script to grab \"Now Playing\" info from radio stations.\n\nradio-grab-now-playing uses server-based webpage rendering to get this information.\n\n## Required Libraries\n\n* [spynner](https://github.com/makinacorpus/spynner) (Server-based HTML5/JavaScript renderer)\n* [BeautifulSoup4](http://www.crummy.com/software/BeautifulSoup/#Download) (HTML DOM Parser)\n* [Jinja2](https://github.com/mitsuhiko/jinja2) (Template Engine)\n\n## Installation\n\nThe installation might be a little bit tricky on some platforms, especially on OS X. The reason for that is simple - this script requires [spynner](https://github.com/makinacorpus/spynner) library, which is responsible for server-based HTML5/JavaScript rendering. It has numerous dependencies, which can be difficult to install properly.\n\nIf you're interested in detailed installation instructions or have problems with required libs on any platform - please let me know and I will help you.\n\n## Usage\n\nAdd URLs to ```etc/radio-grab-now-playing.conf``` file and launch ```radio-grab-now-playing.py``` script.\n\n```output/now-playing.csv``` file will be generated.\n\n```\nusage: radio-grab-now-playing.py [-h] [--version]\n\nGrabs Now Playing from radio stations\n \noptional arguments:\n -h, --help show this help message and exit\n --version show program's version number and exit\n```\n\n## License\n\nThis software is released under the [MIT License](http://opensource.org/licenses/MIT).\n\nCopyright (c) 2013 vst42\n"
},
{
"alpha_fraction": 0.7202436923980713,
"alphanum_fraction": 0.7253983020782471,
"avg_line_length": 28.63888931274414,
"blob_id": "c6715bfba2b75ca958cd87878375cc111af0fee5",
"content_id": "76b942d24644deed0df78750716aa4c9e1516aee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2134,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 72,
"path": "/radio-grab-now-playing.py",
"repo_name": "vst42/radio-grab-now-playing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport logging\nimport ConfigParser\nimport argparse\n\nimport spynner\nfrom bs4 import BeautifulSoup\nfrom jinja2 import Environment, PackageLoader\n\n# Setup logging\nscript_name = os.path.splitext(os.path.basename(__file__))[0]\nlogger = logging.getLogger(script_name)\nlogger.setLevel(logging.DEBUG)\n\n# Logging to file\nch = logging.FileHandler(os.path.join('log', script_name + '.log'))\nch.setLevel(logging.DEBUG)\nch.setFormatter(logging.Formatter('%(asctime)s;%(levelname)s;%(message)s'))\nlogger.addHandler(ch)\n\n# Logging to console\nconsole = logging.StreamHandler()\nconsole.setLevel(logging.DEBUG)\nconsole.setFormatter(logging.Formatter('%(asctime)s;%(levelname)s;%(message)s'))\nlogger.addHandler(console)\n\n# Parse command line options\nparser = argparse.ArgumentParser(\n description='Grabs Now Playing from radio stations')\nparser.add_argument('--version', action='version', version='%(prog)s 0.1.8')\nargs = parser.parse_args()\n\n# Read config file\nconfig = ConfigParser.SafeConfigParser()\nconfig.read(os.path.join('etc', script_name + '.conf'))\n\n# Get URL list\nbrowser_urls = config.get('Type1', 'url').replace(\"\\n\", '').split(',')\n\n# Open virtual browser\nbrowser = spynner.Browser()\n\n# Process URLs\nnow_playing = []\nfor browser_url in browser_urls:\n browser.load(browser_url, 30)\n browser.wait(5)\n radio_doc = BeautifulSoup(browser.html)\n logger.info('Fetched URL %s', browser_url)\n\n # Process DOM tree\n now_playing_table = radio_doc.find('div', 'trackInfo')\n artist = now_playing_table.find('span', 'artistName').string.strip()\n song = now_playing_table.find('a', 'trackTitle').string.strip()\n now_playing.append([ artist, song ])\n\n# Close virtual browser\nbrowser.close()\n\n# Prepare template\nenv = Environment(loader=PackageLoader('__main__', 'templates'))\ntemplate = env.get_template('now-playing.tmpl')\n\n# Write CSV file\noutput_file = os.path.join('output', config.get('General', 'output'))\noutput = open(output_file, 'w')\noutput.write(template.render(now_playing=now_playing).encode('utf-8'))\noutput.close()\n\nlogger.info('CSV now-playing list \"%s\" written', output_file)\n"
}
] | 2 |
niconicoding/SmartMobile
|
https://github.com/niconicoding/SmartMobile
|
0eeba01a05460b9104249ca9b191f3b335329156
|
79c2c78a087efbf7cea287aa10313dd3949745ae
|
6da300057f2d213420c89564b91546483c3a2138
|
refs/heads/master
| 2020-09-21T12:28:08.939980 | 2019-11-29T07:12:05 | 2019-11-29T07:12:05 | 224,788,863 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5624432563781738,
"alphanum_fraction": 0.5893991589546204,
"avg_line_length": 34.42765426635742,
"blob_id": "2e5a30f56a2df489d5b6829179b2b0354eaa3ec2",
"content_id": "2c4186a33d8f857959436e23c1da92dff4e2c16d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11280,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 311,
"path": "/FIRST_MOBILE/smartmobile_first_client.py",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "# USAGE\n#python3 smartmobile_first_client.py --prototxt MobileNetSSD_deploy.prototxt --model MobileNetSSD_deploy.caffemodel\n\n\n# import the necessary packages\nfrom imutils.video import VideoStream\nfrom imutils.video import FPS\nfrom gpiozero import Buzzer\nfrom time import sleep\nimport socket\nimport numpy as np\nimport argparse\nimport imutils\nimport cv2\nimport serial\nimport datetime\nimport os\nimport telepot\n\nimport RPi.GPIO as GPIO\n\nport = 8888\nclient_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nclient_socket.connect((\"SERVER ADDRESS\", port))\nclient_socket.send(\"first\".encode())\n#텔레그램 봇 토큰과 봇 생성\nmy_token = 'INSERT TELEGRAM BOT TOKEN'\nbot = telepot.Bot(my_token)\n\ntelegram_id = 'INSERT TELEGRAM ID'\nos.system(\"sudo rfcomm bind rfcomm0 BLUETOOTH ADDRESS\")\n#경고 메세지\nmsg_face = '뒤집힘 경고'\nmsg_object = '관심영역 경고'\n\n#GPIO input/output 설정\nGPIO.setmode(GPIO.BCM)\nGPIO.setup(17, GPIO.IN, pull_up_down=GPIO.PUD_UP)\n\n#부저 생성\nbuzzer = Buzzer(3)\n\n#현재 시간을 초로 계산하여 반환\ndef total():\n now = datetime.datetime.now()\n nowTuple = now.timetuple()\n total_sec = nowTuple.tm_sec +(nowTuple.tm_min*60) + (nowTuple.tm_hour*3600) + (nowTuple.tm_mday * 3600 * 24) + (nowTuple.tm_mon * 3600 * 24 * nowTuple.tm_mday) + (nowTuple.tm_year * 3600 * 24 * 365.25)\n\n return int(total_sec)\n\n\n# construct the argument parse and parse the arguments\n#ap = argparse.ArgumentParser()\n#ap.add_argument(\"-p\", \"--prototxt\", required=True,\n#\thelp=\"path to Caffe 'deploy' prototxt file\")\n#ap.add_argument(\"-m\", \"--model\", required=True,\n#\thelp=\"path to Caffe pre-trained model\")\n#ap.add_argument(\"-c\", \"--confidence\", type=float, default=0.2,\n#\thelp=\"minimum probability to filter weak detections\")\n#ap.add_argument(\"-u\", \"--movidius\", type=bool, default=0,\n#\thelp=\"boolean indicating if the Movidius should be used\")\n#args = vars(ap.parse_args())\n\n\n\n# initialize the list of class labels MobileNet SSD was trained to\n# detect, then generate a set of bounding box colors for each class\n\nIGNORE = set([\"background\", \"aeroplane\", \"bicycle\", \"bird\", \"boat\",\n \"bottle\", \"bus\", \"car\", \"cat\", \"chair\", \"cow\", \"diningtable\",\n \"dog\", \"horse\", \"motorbike\", \"pottedplant\", \"sheep\",\n \"sofa\", \"train\", \"tvmonitor\"])\n\n\nCLASSES = [\"background\", \"aeroplane\", \"bicycle\", \"bird\", \"boat\",\n\t\"bottle\", \"bus\", \"car\", \"cat\", \"chair\", \"cow\", \"diningtable\",\n\t\"dog\", \"horse\", \"motorbike\", \"person\", \"pottedplant\", \"sheep\",\n\t\"sofa\", \"train\", \"tvmonitor\"]\n##------edited COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))\n\n\n\n# load our serialized model from disk\nprint(\"[INFO] loading model...\")\n#people_net = cv2.dnn.readNetFromCaffe(args[\"prototxt\"], args[\"model\"])\npeople_net = cv2.dnn.readNetFromCaffe(\"/home/pi/infant_accident_prevention_system_development/MobileNetSSD_deploy.prototxt\",\"/home/pi/infant_accident_prevention_system_development/MobileNetSSD_deploy.caffemodel\")\nface_net = cv2.dnn.readNetFromCaffe(\"/home/pi/infant_accident_prevention_system_development/deploy.prototxt.txt\",\"/home/pi/infant_accident_prevention_system_development/res10_300x300_ssd_iter_140000.caffemodel\")\n\nfps = FPS().start()\n#vs = VideoStream(src=0).start()\n#USE WebCam\n\nframe = 0\n\n# specify the target device as the Myriad processor on the NCS\npeople_net.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)\nface_net.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)\n# initialize the video stream, allow the cammera sensor to warmup,\n# and initialize the FPS counter\n\n#----------------------------------------------------------------------------------------\n#print(\"[INFO] starting video stream...\")\n\n\n#vs = VideoStream(usePiCamera=True).start()\nvs = cv2.VideoCapture(2, cv2.CAP_V4L)\n\n#time.sleep(2.0)\n#fps = FPS().start()\n\n\ndef total():\n now = datetime.datetime.now()\n nowTuple = now.timetuple()\n total_sec = nowTuple.tm_sec +(nowTuple.tm_min*60) + (nowTuple.tm_hour*3600) + (nowTuple.tm_mday * 3600 * 24) + (nowTuple.tm_mon * 3600 * 24 * nowTuple.tm_mday) + (nowTuple.tm_year * 3600 * 24 * 365.25)\n\n return int(total_sec)\n\ndef imgprocessing_people():\n # loop over the frames from the video stream\n global frame\n global people_net\n global fps\n global vs\n global CLASSES\n global count\n global buzzer\n\n global serial\n\n global msg_face\n global msg_object\n global bot\n global telegram_id\n global client_socket\n\n ROI_EVENT_FLAG = False\n ROI_EVENT_START_TIME = 0\n ROI_EVENT_START_TIME_FLAG = False\n\n\n FACE_EVENT_FLAG = False\n FACE_EVENT_START_TIME = 0\n FACE_EVENT_START_TIME_FLAG = False\n\n # loop over the frames from the video stream\n bluetoothSerial = serial.Serial(\"/dev/rfcomm0\", baudrate=9600)\n\n# face_num = 0\n while True:\n if GPIO.input(17) == 0:\n print(\"reset!\")\n ROI_EVENT_FLAG = False\n ROI_EVENT_START_TIME_FLAG = False\n FACE_EVENT_START_TIME_FLAG = False\n buzzer.off()\n\n\t# grab the frame from the threaded video stream and resize it\n\t# to have a maximum width of 400 pixels\n ret, frame = vs.read()\n\n #frame = imutils.resize(frame, width=800)\n\t# grab the frame dimensions and convert it to a blob\n (h, w) = frame.shape[:2]\n#-----------------------------------------------------------------------------\n people_blob = cv2.dnn.blobFromImage(frame, 0.007843, (300, 300), 127.5)\n face_blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0,(300, 300), (104.0, 177.0, 123.0))\n # pass the blob through the network and obtain the detections and\n\t# predictions\n people_net.setInput(people_blob)\n people_detections = people_net.forward()\n\n face_net.setInput(face_blob)\n face_detections = face_net.forward()\n\n line_left_topx = 100\n line_left_topy = 50\n line_right_botx = 500\n line_right_boty = 550\n weight = 10\n cv2.rectangle(frame, (line_left_topx, line_left_topy), (line_right_botx, line_right_boty),(255,255,255), 2)\n ROI_EVENT_FLAG = True\n\t# loop over the detections\n for i in np.arange(0, people_detections.shape[2]):\n people_confidence = people_detections[0, 0, i, 2]\n #print(people_idx)\n #print(CLASSES[people_idx])\n people_idx = int(people_detections[0, 0, i, 1])\n if CLASSES[people_idx] in IGNORE:\n continue\n\n if people_confidence > 0.2:\n #people_idx = int(people_detections[0, 0, i, 1])\n #print(people_idx)\n #print(CLASSES[people_idx])\n #if CLASSES[people_idx] in IGNORE:\n # continue\n\n people_box = people_detections[0, 0, i, 3:7] * np.array([w, h, w, h])\n (people_startX, people_startY, people_endX, people_endY) = people_box.astype(\"int\")\n\n #영역 이탈 감지\n if people_startX < line_left_topx+weight or people_endX > line_right_botx-weight or people_startY < line_left_topy+weight or people_endY > line_right_boty-weight:\n print('ROI WARNING')\n ROI_EVENT_FLAG = True\n\n else :\n\n print('ROI_safety')\n ROI_EVENT_FLAG = False\n\n\n cv2.rectangle(frame, (people_startX, people_startY), (people_endX, people_endY),(255,0,0), 2)\n\n\n if ROI_EVENT_FLAG: #영역 이탈한 경우\n\n if not ROI_EVENT_START_TIME_FLAG: #영역 이탈 첫 발생\n ROI_EVENT_START_TIME = total()\n ROI_EVENT_START_TIME_FLAG = True\n\n else : #이미 영역 이탈 발생\n diff_sec = total() - ROI_EVENT_START_TIME\n print(\"ROI event warning \"+str(diff_sec))\n\n if diff_sec % 2 == 0 : #관심영역 경고 텔레그램 알림\n bot.sendMessage(chat_id = telegram_id, text = msg_object)\n\n if diff_sec >= 5: #관심영역 경고가 5초이상 지속되었을 시 시간에따라 진동 혹은 부저 알림\n #ROI_now = datetime.datetime.now()\n #ROI_event_time = ROI_now.replace(hour=10, minute=59, second=0,microsecond=0)\n #if ROI_now > ROI_event_time: #기준점과 시간 비교\n # buzzer.off()\n # bluetoothSerial.write(str(\"w\").encode('utf-8'))\n #else:\n # buzzer.on()\n bluetoothSerial.write(str(\"w\").encode('utf-8'))\n\n else : #영역 이탈 정상 경우\n ROI_EVENT_START_TIME_FLAG = False\n\n\n\n face_num = 0\n\n #for i in range(0, face_detections.shape[2]):\n for i in np.arange(0, face_detections.shape[2]):\n face_confidence = face_detections[0, 0, i, 2]\n if face_confidence < 0.25:\n continue\n else:\n face_num += 1\n face_box = face_detections[0, 0, i, 3:7] * np.array([w,h,w,h])\n (face_startX, face_startY, face_endX, face_endY) = face_box.astype(\"int\")\n #face_text = \"{:.2f}%\".format(face_confidence * 100)\n #face_y = face_startY - 10 if face_startY - 10 > 10 else face_startY + 10\n cv2.rectangle(frame, (face_startX, face_startY), (face_endX, face_endY),(0, 0, 255), 2)\n #cv2.putText(frame, face_text, (face_startX, face_y),cv2.FONT_HERSHEY_SIMPLEX, 0.45,(0,0,255),2)\n print(face_num)\n if face_num == 0:\n if not FACE_EVENT_START_TIME_FLAG:\n FACE_EVENT_START_TIME = total()\n FACE_EVENT_START_TIME_FLAG = True\n else :\n diff_sec = total() - FACE_EVENT_START_TIME\n print(\"FACE event warning \"+str(diff_sec))\n if diff_sec % 2 == 0:\n bot.sendMessage(chat_id = telegram_id, text = msg_face)\n if diff_sec >= 5:\n #FACE_now = datetime.datetime.now()\n #FACE_event_time = FACE_now.replace(hour=10, minute=59, second=0,microsecond=0)\n #if FACE_now > FACE_event_time:\n # buzzer.off()\n # bluetoothSerial.write(str(\"w\").encode('utf-8'))\n #else:\n # buzzer.on()\n buzzer.on()\n else:\n FACE_EVENT_START_TIME_FLAG = False\n if not ROI_EVENT_FLAG:\n buzzer.off()\n\n\n #cv2.putText(frame, label, (startX, y),\n #cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)\n client_socket.send(\"send\".encode())\n # show the output frame\n cv2.imshow(\"frame\", frame)\n key = cv2.waitKey(1) & 0xFF\n\n\t# if the `q` key was pressed, break from the loop\n if key == ord(\"q\"):\n break\n\n\t# update the FPS counter\n fps.update()\n\n# stop the timer and display FPS information\n fps.stop()\n print(\"[INFO] elasped time: {:.2f}\".format(fps.elapsed()))\n print(\"[INFO] approx. FPS: {:.2f}\".format(fps.fps()))\n\n# do a bit of cleanup\n cv2.destroyAllWindows()\n vs.stop()\n buzzer.off()\n\n os.system('kill -9 '+str(os.getpid()))\n\nif __name__ == '__main__':\n imgprocessing_people()\n"
},
{
"alpha_fraction": 0.576815664768219,
"alphanum_fraction": 0.5942737460136414,
"avg_line_length": 25.518518447875977,
"blob_id": "fc7af8ab0f3757c98a2231ccfa7f6248edf2490d",
"content_id": "4e3378a51fdc112dc7b1c1315670bb8375ec217f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1432,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 54,
"path": "/tcp/server/server.py",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "import socket\nimport sys\nfrom time import sleep\nport = int(sys.argv[1])\nserver_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nserver_socket.bind((\"\", port))\nserver_socket.listen(5)\n\n\nprint (\"TCPServer Waiting for client on port \"+str(port))\n\nfirst_client_socket = 0\nfirst_address = 0\nsecond_client_socket = 0\nsecond_address = 0\n\n\ndef errorProcessing(socket):\n print(\"E: Original Mobile Messaage Time Out. I Will Turn On Alternative Mobile\")\n socket.send(\"Turn On\".encode())\n\n\nwhile True:\n clients = [0,0]\n while clients[0] != 1 or clients[1] != 1:\n\n socket, address = server_socket.accept()\n data = socket.recv(512).decode()\n if data == 'first':\n first_client_socket = socket\n first_address = address\n clients[0] = 1\n print(\"Main Board Comming\")\n else :\n second_client_socket = socket\n second_address = address\n clients[1] = 1\n print(\"Alternative Board Comming\")\n\n print (\"I got a connection\")\n first_client_socket.settimeout(10)\n\n while True:\n try:\n data = first_client_socket.recv(512).decode()\n if len(data) == 0:\n errorProcessing(second_client_socket)\n break\n except:\n errorProcessing(second_client_socket)\n break\n\nserver_socket.close()\nprint(\"SOCKET closed... END\")\n"
},
{
"alpha_fraction": 0.6486296653747559,
"alphanum_fraction": 0.6591707468032837,
"avg_line_length": 25.33333396911621,
"blob_id": "9e2ca85c6a1537b9926639a9e50600c10f8ca258",
"content_id": "5487f564c97bf45dd68e68a5a766be24ea4e7421",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1423,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 54,
"path": "/etc/telegram.py",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "import boto3\nimport time\nimport telepot\nimport os\n\nfrom telepot.loop import MessageLoop\n\ngenietoken = \"INSERT YOUR TELEGRAM SERVER TOKEN\"\nbot = telepot.Bot(genietoken)\n\n\nInfoMsg = \"press the Number\\n\" \\\n \"1. Streaming URL\"\n\nstatus = True\n\ndef requestURL(): \n STREAM_ARN = \"INSERT YOUR KINESSIS ARN\"\n kvs = boto3.client(\"kinesisvideo\",\"INSERT YOUR REGION\")\n #kvs = boto3.client(\"kinesisvideo\")\n # Grab the endpoint from GetDataEndpoint\n endpoint = kvs.get_data_endpoint(\n APIName=\"GET_HLS_STREAMING_SESSION_URL\",\n StreamARN=STREAM_ARN\n )['DataEndpoint']\n\n # Grab the HLS Stream URL from the endpoint\n kvam = boto3.client(\"kinesis-video-archived-media\", endpoint_url=endpoint)\n url = kvam.get_hls_streaming_session_url(\n StreamARN=STREAM_ARN,\n PlaybackMode='LIVE'\n )['HLSStreamingSessionURL']\n from IPython.display import HTML\n HTML(data='<video src=\"{0}\" autoplay=\"autoplay\" controls=\"controls\" width=\"300\" height=\"400\"></video>'.format(url))\n return url\n\n\n\n\ndef handle(msg):\n content, chat, id = telepot.glance(msg)\n print(content, chat, id)\n\n if content == 'text':\n if msg['text'] == '1':\n sendURL = requestURL()\n bot.sendMessage(id, sendURL)\n else:\n bot.sendMessage(id, InfoMsg)\n\n#bot.message_loop(handle)\nMessageLoop(bot, handle).run_as_thread()\nwhile status == True:\n time.sleep(10)\n\n"
},
{
"alpha_fraction": 0.6973684430122375,
"alphanum_fraction": 0.7105262875556946,
"avg_line_length": 11.5,
"blob_id": "42098301c908c68e65aed64cbd2debf99ad74445",
"content_id": "c855813f0ba223e90955bef6ce36593373762eb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 6,
"path": "/etc/buzzer.py",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "from gpiozero import Buzzer\n\nbuzzer = Buzzer(3)\n\nwhile True :\n\tbuzzer.on()\n\n"
},
{
"alpha_fraction": 0.6648044586181641,
"alphanum_fraction": 0.7039105892181396,
"avg_line_length": 24.571428298950195,
"blob_id": "6535f42cb7a9bb126f7ada537400b1772f013061",
"content_id": "6a9c1c47253e4aa3a9ef2b57bb5fe1780e43d4e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 7,
"path": "/etc/vibration.py",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "import serial\nfrom time import sleep\n\nwhile True:\n bluetoothSerial = serial.Serial(\"/dev/rfcomm0\", baudrate=9600)\n bluetoothSerial.write((\"w\").encode('utf-8'))\n sleep(1)\n"
},
{
"alpha_fraction": 0.5161290168762207,
"alphanum_fraction": 0.526451587677002,
"avg_line_length": 21.14285659790039,
"blob_id": "280fbd06b3bfac42df22181c6a4d1439a6f4af41",
"content_id": "7a31b27f474af310ac957ef27010d3e11f6d7b06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 775,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 35,
"path": "/FIRST_MOBILE/process_check.sh",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nMOBILE_FILE=smartmobile_first_client.py\nKINESIS_FILE=./kinesis_video_gstreamer_sample_app\n\n\nwhile :\ndo\n MOBILE=$(ps -ef |grep $MOBILE_FILE |grep -v grep|awk '{print $2}')\n KINESIS=$(ps -ef |grep $KINESIS_FILE|grep -v grep|awk '{print $2}')\n CHECK=$(ps -ef |grep process_check.sh|grep -v grep|awk '{print $2}')\n\n if [[ -z $MOBILE ]]; then\n if [ ! -z $KINESIS ]; then\n kill -9 $KINESIS\n sudo rfcomm release 0\n fi\n\n elif [[ -z $KINESIS ]]; then\n if [ ! -z $MOBILE ]; then\n kill -9 $MOBILE\n sudo rfcomm release 0\n fi\n fi\n\n echo $MOBILE\n echo $KINESIS\n\n sleep 1\n\n if [[ -z $MOBILE ]]; then\n if [[ -z $KINESIS ]]; then\n break\n fi\n fi\ndone\n"
},
{
"alpha_fraction": 0.6703296899795532,
"alphanum_fraction": 0.7985348105430603,
"avg_line_length": 44.16666793823242,
"blob_id": "b3d4bac46f26cd2564ccc1cceea0d95b9d92cb69",
"content_id": "fd460d18fd3f7e6c233a8441f8d4823bdb867b2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 283,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 6,
"path": "/README.md",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "\n\nI was very much for help on the link below.\nAdditional information on image processing and Raspberry Pi is recommended here.\n\nhttps://www.pyimagesearch.com/\n\n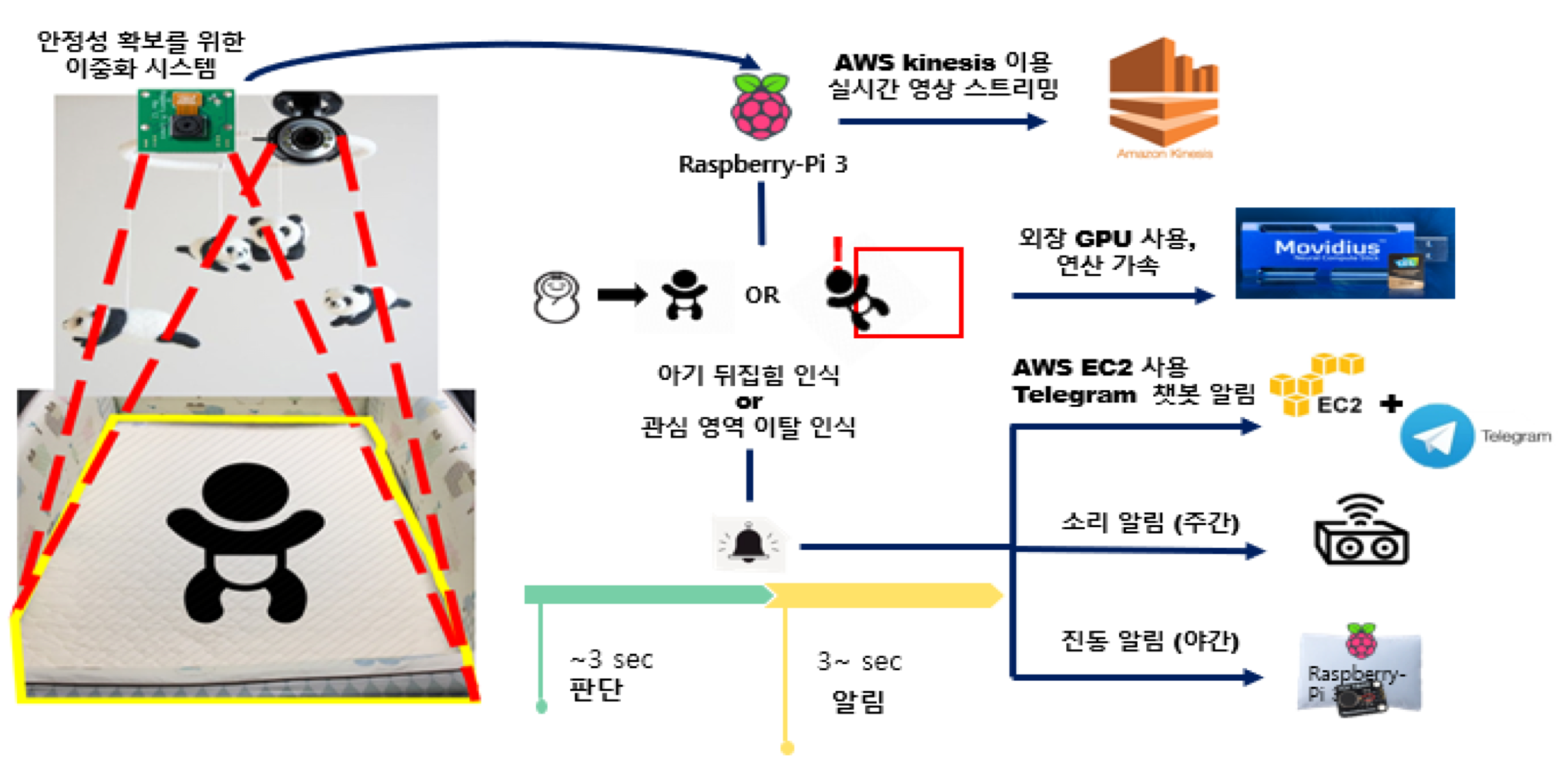\n"
},
{
"alpha_fraction": 0.5400384664535522,
"alphanum_fraction": 0.5566944479942322,
"avg_line_length": 22.65151596069336,
"blob_id": "8cf806f153453d322c71c9122dfe124dd556d038",
"content_id": "ddc7c037c8cb38b9cb27caab4d63c51251cf366c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1563,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 66,
"path": "/SECOND_MOBILE/multiprocessing.c",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "#include <sys/socket.h>\n#include<sys/types.h>\n#include <unistd.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n\nint main(int argc, char **argv)\n{\n\n int client_len;\n int client_sockfd;\n\n char buf_get[255];\n char buf_in[7] = \"second\";\n\n\n struct sockaddr_in clientaddr;\n\n if (argc != 2)\n {\n printf(\"Usage : ./client [port]\\n\");\n printf(\"예 : ./client 4444\\n\");\n exit(0);\n }\n\n client_sockfd = socket(AF_INET, SOCK_STREAM, 0);\n clientaddr.sin_family = AF_INET;\n clientaddr.sin_addr.s_addr = inet_addr(\"INSERT SERVER ADDRESS\");\n clientaddr.sin_port = htons(atoi(argv[1]));\n\n client_len = sizeof(clientaddr);\n\n if (connect(client_sockfd, (struct sockaddr *)&clientaddr, client_len) < 0)\n {\n perror(\"Connect error: \");\n exit(0);\n }\n write(client_sockfd, buf_in, 7);\n read(client_sockfd, buf_get, 255);\n\n pid_t pid = fork();\n if(pid>0){\n close(client_sockfd);\n exit(0);\n }else if(pid == 0){\n\n pid_t ppid = fork();\n if(ppid > 0){\n printf(\"son\\n\");\n execl(\"kinesis_video_gstreamer_sample_app\",\"./kinesis_video_gstreamer_sample_app\",\"KINESIS STREAM ID\",0);\n }\n else if(ppid == 0){\n printf(\"baby\\n\");\n execl(\"/bin/bash\",\"bash\",\"/home/pi/infant_accident_prevention_system_development/smartmobile.py\",0);\n }else{\n printf(\"error\\n\");\n }\n }else{\n printf(\"error fork()\\n\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5482062697410583,
"alphanum_fraction": 0.5594170689582825,
"avg_line_length": 26.030303955078125,
"blob_id": "dc0de1d0926f1db1718be814a77296bd93fb5eab",
"content_id": "0e2c9fca4608130a97c611da7b90a364b6e19237",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 892,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 33,
"path": "/FIRST_MOBILE/multiprocessing_first_client.c",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#include<unistd.h>\n#include<sys/types.h>\n\nint main(){\n pid_t pid;\n\n printf(\"Process Start\\n\");\n\n pid = fork();\n\n if(pid > 0){\n printf(\"parent\\n\");\n execl(\"/home/pi/.virtualenvs/openvino/bin/python3\",\"python3\",\"/home/pi/infant_accident_prevention_system_development/smartmobile_first_client.py\", 0);\n }else if(pid == 0){\n\n pid_t ppid = fork();\n if(ppid > 0){\n printf(\"son\\n\");\n execl(\"kinesis_video_gstreamer_sample_app\",\"./kinesis_video_gstreamer_sample_app\",\"KINESSIS STREAM ID\",0);\n }\n else if(ppid == 0){\n printf(\"baby\\n\");\n execl(\"/bin/bash\",\"bash\",\"/home/pi/infant_accident_prevention_system_development/process_check.sh\",0);\n }else{\n printf(\"error\\n\");\n }\n }else{\n printf(\"error fork()\\n\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5828571319580078,
"alphanum_fraction": 0.6228571534156799,
"avg_line_length": 16.5,
"blob_id": "5dfbc3131222bc873b7041df391a18482d7272fa",
"content_id": "c3419800ca45a4ee23864c52af6abc0ffa7bf275",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 10,
"path": "/etc/button.py",
"repo_name": "niconicoding/SmartMobile",
"src_encoding": "UTF-8",
"text": "import RPi.GPIO as GPIO\nimport time\nGPIO.setmode(GPIO.BCM)\n\nGPIO.setup(18, GPIO.IN)\n\nwhile True:\n if GPIO.input(18) == 0:\n print(\"button!\")\n #time.sleep(0.5)\n"
}
] | 10 |
borjarojo/csc161
|
https://github.com/borjarojo/csc161
|
b6fa0ce98f4f592e7be6e13830e3e3964685101d
|
2121f4dea1aa08f38a282fa95e7a0dd364bbc042
|
d6c222c80bb18ff6ad3cf964836a6903b2fcf4c9
|
refs/heads/master
| 2020-07-27T09:23:17.275061 | 2017-03-18T20:06:25 | 2017-03-18T20:06:25 | 73,433,566 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5571293830871582,
"alphanum_fraction": 0.5873465538024902,
"avg_line_length": 27.62162208557129,
"blob_id": "344009bc02bdab6033e185d945dc47c22ce517a8",
"content_id": "5498b321d081df7fadcaadc79b8e57df4be59634",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1059,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 37,
"path": "/labs/lab_sequences.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Sequences\n\nThe programs reads a file with data and displays it nicely.\n\nBorja Rojo\nLab Section TR 2:00-3:15\nFall 2016\n\"\"\"\n\n\ndef main():\n # Introduction\n print(\"This program read in financial information from a file\\n\"\n \"and prints it neatly to the user's screen.\\n\")\n\n # Read file\n fileName = input(\"Please enter the filename of the financial data: \")\n print(\"\")\n readFile = open(fileName, \"r\")\n lineList = readFile.readlines()\n readFile.close() # File close\n\n # Print first three lines\n print(\"Length of the term (years): {0}\".format(lineList[0].split()[1]))\n print(\"The initial principal is: \"\n \"${0:0.2f}\".format(float(lineList[1].split()[1])))\n print(\"Annual percentage rate is: \"\n \"{0:0.3f}%\".format(float(lineList[2].split()[1])))\n\n # Print the rest of the lines\n print(\"\\nYear\\tValue\\n\"\n \"------------------\")\n for i in range(3, len(lineList)):\n print(\"|{0:>3}\\t${1:>0.2f}|\".format(str(i), float(lineList[i])))\n print(\"------------------\")\n\nmain()\n"
},
{
"alpha_fraction": 0.6446808576583862,
"alphanum_fraction": 0.6734042763710022,
"avg_line_length": 27.059701919555664,
"blob_id": "631c6c95619709e0f8a1259c56ad899a37bf084b",
"content_id": "65de2987f600eab8ac0e339662be94420cb6b598",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1880,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 67,
"path": "/labs/lab_objects_graphics.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Objects & Graphics\n\nThis program creates a GUI to draw a house.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\nimport graphics\n\n\ndef main():\n # Create window\n window = graphics.GraphWin(\"Making a House\", 600, 600)\n\n # Step 1: Draw the frame\n click1 = window.getMouse()\n click2 = window.getMouse()\n frame = graphics.Rectangle(click1, click2)\n frame.draw(window)\n\n # Step 2: Draw the door\n click3 = window.getMouse()\n\n houseWidth = click1.getX() - click2.getX()\n doorWidth = houseWidth / 5\n\n doorBottomRightX = click3.getX() - doorWidth / 2\n doorBottomRightY = click1.getY()\n doorBottomRight = graphics.Point(doorBottomRightX, doorBottomRightY)\n\n doorTopLeftX = click3.getX() + doorWidth / 2\n doorTopLeftY = click3.getY()\n doorTopLeft = graphics.Point(doorTopLeftX, doorTopLeftY)\n\n door = graphics.Rectangle(doorBottomRight, doorTopLeft)\n door.draw(window)\n\n # Step 4: Draw the window (fenetre is window in French)\n click4 = window.getMouse()\n fenetreWidth = doorWidth * 3 / 4\n\n fenetreBottomLeftX = click4.getX() - fenetreWidth / 2\n fenetreBottomLeftY = click4.getY() + fenetreWidth / 2\n fenetreBottomLeft = graphics.Point(fenetreBottomLeftX,\n fenetreBottomLeftY)\n\n fenetreTopRightX = click4.getX() + fenetreWidth / 2\n fenetreTopRightY = click4.getY() - fenetreWidth / 2\n fenetreTopRight = graphics.Point(fenetreTopRightX, fenetreTopRightY)\n\n fenetre = graphics.Rectangle(fenetreBottomLeft, fenetreTopRight)\n fenetre.draw(window)\n\n # Step 5: Draw the roof\n click5 = window.getMouse()\n rightSide = graphics.Line(graphics.Point(click1.getX(), click2.getY()),\n click5)\n leftSide = graphics.Line(click5, click2)\n\n rightSide.draw(window)\n leftSide.draw(window)\n\n window.getMouse()\n\nmain()\n"
},
{
"alpha_fraction": 0.4970684051513672,
"alphanum_fraction": 0.5068404078483582,
"avg_line_length": 33.8863639831543,
"blob_id": "4d67d520f829dfa1df75f28d8d412a1fc8273baf",
"content_id": "9a00b5b6a2409d5041479182987925a0b38d8808",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1535,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 44,
"path": "/project/Data.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "class Data:\n def __init__(self):\n self.data = self.read_AAPL_file()\n self.max = len(self.data) - 1\n self.min = 1\n\n # Read the file in and return as a list of lists\n def read_AAPL_file(self):\n infile = open(\"AAPL.csv\", \"r\") # Open the file\n\n data = infile.readlines() # Read file as list of lines\n for i in range(len(data)): # Run through each line\n data[i] = data[i].split(\",\") # And split the data into a list\n data[i][6] = data[i][6].strip() # also trim the endline char off\n\n for i in range(1, len(data)):\n for j in range(1, 7):\n data[i][j] = float(data[i][j])\n\n data.reverse() # Reverse list\n last = data.pop() # Pop column names\n data.insert(0, last) # Insert it to the front\n\n return data\n\n # Converts the col key to the index in the list of stock data for one day\n def col_convert(self, col):\n if col == \"open\":\n return 1\n elif col == \"high\":\n return 2\n elif col == \"low\":\n return 3\n elif col == \"close\":\n return 4\n elif col == \"volume\":\n return 5\n elif col == \"adj_close\":\n return 6\n\n # Returns the stock price for the given day and type. \n # Day is between 1 and max\n def getStock(self, dayNumber, stockType):\n return self.data[dayNumber][self.col_convert(stockType)]\n"
},
{
"alpha_fraction": 0.5399239659309387,
"alphanum_fraction": 0.5961977243423462,
"avg_line_length": 24.288461685180664,
"blob_id": "5fb57f58bc8e2f2a37e0721a3bece529c82427f3",
"content_id": "415481a96eb9f4f4bd351ad447d718bfd64a34e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1315,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 52,
"path": "/labs/lab_decision_control.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Decision Control\n\nThis program demonstrates the use of 'if' statements.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\n# I'm not sure what the extra credit means by exception\n# handling, but I do have the 400 and 100 year rule\n# incorporated with my leap year funcion. My program\n# should be able to handle any date.\n\n\ndef dateCheck(m, d, y):\n mmax = 12\n dmax = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]\n\n # Bool set\n validMonthAndDay = m >= 1 and m <= mmax and d >= 1 and d <= dmax[m - 1]\n validLeap = checkLeap(m, d, y)\n\n # Control statements\n if validMonthAndDay or validLeap:\n return True\n else:\n return False\n\n\ndef checkLeap(m, d, y):\n # 29th, Feb, a year divisible by 400 or one divisible by 4 but not 100\n if d == 29 and m == 2 and ((y % 4 == 0 and y % 100 != 0) or y % 400 == 0):\n return True\n else:\n return False\n\n\ndef main():\n # Intro\n print(\"This program accepts a date in the form month/day/year\\n\"\n \"and outputs whether or not the date is valid\")\n\n # Querry\n date = input(\"Please enter a date (mm/dd/yyyy): \")\n m, d, y = [int(i) for i in date.split(\"/\")]\n\n # Formated print\n print(\"{0}/{1}/{2} is {3} valid\".format(\n m, d, y, \"\\b\" if dateCheck(m, d, y) else \"not\"))\n\nmain()\n"
},
{
"alpha_fraction": 0.5351018905639648,
"alphanum_fraction": 0.5450681447982788,
"avg_line_length": 33.81122589111328,
"blob_id": "0fe00b8c94b0765f2308e823a2eaac4cb66882b3",
"content_id": "306617c453a5729d626a9d80df32d3c4b88dd2cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6823,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 196,
"path": "/project/tradinglib.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"Borja Rojo\nCSC161\n\ntradinglib has classes to handle stock Analysis\n\n\"\"\"\n\n\nclass Data:\n def __init__(self):\n self.data = self.read_AAPL_file()\n self.max = len(self.data) - 1\n self.min = 1\n\n # Read the file in and return as a list of lists\n def read_AAPL_file(self):\n infile = open(\"AAPL.csv\", \"r\") # Open the file\n\n data = infile.readlines() # Read file as list of lines\n for i in range(len(data)): # Run through each line\n data[i] = data[i].split(\",\") # And split the data into a list\n data[i][6] = data[i][6].strip() # also trim the endline char off\n\n for i in range(1, len(data)):\n for j in range(1, 7):\n data[i][j] = float(data[i][j])\n\n data.reverse() # Reverse list\n last = data.pop() # Pop column names\n data.insert(0, last) # Insert it to the front\n\n return data\n\n # Converts the col key to the index in the list of stock data for one day\n def col_convert(self, col):\n if col == \"open\":\n return 1\n elif col == \"high\":\n return 2\n elif col == \"low\":\n return 3\n elif col == \"close\":\n return 4\n elif col == \"volume\":\n return 5\n elif col == \"adj_close\":\n return 6\n\n # Returns the stock price for the given day and type.\n # Day is between 1 and max\n def getStock(self, dayNumber, stockType):\n return self.data[dayNumber][self.col_convert(stockType)]\n\n\nclass Account:\n def __init__(self):\n self.capital = 1000\n self.stocks = 0\n\n def get_capital(self):\n return self.capital\n\n def get_stocks(self):\n return self.stocks\n\n def set_stocks(self, num):\n self.stocks = num\n\n def add_capital(self, num):\n self.capital += num\n\n def add_stocks(self, num):\n self.stocks += num\n\n def sub_capital(self, num):\n self.capital -= num\n\n def sub_stocks(self, num):\n self.stocks -= num\n\n def __repr__(self):\n return \"Capital: ${0:.2f} Stocks: {1}\".format(self.capital,\n self.stocks)\n\n\nclass Analysis:\n def __init__(self, data, account):\n self.data = data\n self.account = account\n\n # Arguments are optional. Cleared with professor.\n def alg_moving_average(self, column=\"close\", margin=20, perc_margin=.2):\n \"\"\"The running average will be aquired by holding a continuously\n updated total average. that average will then be divided by the\n amount of active data points to aquire the average. These parameters\n will be played with to come up with the best strategy.\n\n \"\"\"\n\n \"\"\"Trading parameters\n\n Column: Stock price type used\n Margin: The amount of data being used for the average\n perc_margin: The percentage used to buy and sell stocks\n \"\"\"\n data_margin_total = 0\n perc_diff_var = 0\n\n # Get the first span of data totaled\n for i in range(1, margin + 1):\n data_margin_total += self.data.getStock(i, column)\n # Now, the total is calculated to the full margin\n\n # Running average evaluations\n for i in range(margin + 1, len(self.data.data)):\n # Calculate precentage difference\n perc_diff_var = self.perc_diff(data_margin_total /\n margin,\n self.data.getStock(i, column))\n\n # Make a decision\n # If diff larger than 20%\n if (perc_diff_var >= perc_margin and\n self.account.get_capital() > self.data.getStock(i, column)):\n self.account.add_stocks(1) # Buy a stock\n # Reduce capital\n self.account.sub_capital(self.data.getStock(i, column))\n # If diff smaller than -20%\n elif (perc_diff_var <= (-1 * perc_margin) and\n self.account.get_stocks() > 0):\n self.account.sub_stocks(1) # Sell a stock\n # Return some capital\n self.account.add_capital(self.data.getStock(i, column))\n\n # Move average\n data_margin_total -= self.data.getStock(i - margin, column)\n data_margin_total += self.data.getStock(i, column)\n\n self.account.add_capital(self.data.getStock(len(self.data.data) - 1,\n column) *\n self.account.get_stocks())\n self.account.set_stocks(0)\n\n # Args are optional, cleared with professor.\n def alg_mine(self, column=\"close\"):\n \"\"\"This is a version of the stock trading algorithm that is determined\n by a custom parameter. The idea is that the current stock price being\n looked at will be compared to the alphabet. If it is a vowel, sell,\n otherwise buy.\n\n This will be done by modding the stock price by 26 and then checking to\n see if the number returned matches with a vowel.\n\n A = 0 | E = 4 | I = 8 | O = 14 | U = 21\n\n This will be evaluated using another function that returns True or\n False depending on the result: is_vowel\n\n The data will be run through each day and determine the decision.\n Specifically, it will buy a stock for each consinent and sell all the\n stocks for each vowel..\n\n \"\"\"\n\n for i in range(1, len(self.data.data)): # For every peice of data\n current_stock_price = self.data.getStock(i, column)\n current_stock_is_vowel = self.is_vowel(current_stock_price)\n if (current_stock_is_vowel is False and\n self.account.get_capital() >= current_stock_price):\n self.account.add_stocks(1) # Buy a stock\n # Reduce capital\n self.account.sub_capital(self.data.getStock(i, column))\n elif current_stock_is_vowel is True:\n self.account.add_capital(self.data.getStock(i, column))\n self.account.set_stocks(0)\n\n self.account.add_capital(self.data.getStock(i, column) *\n self.account.get_stocks())\n self.account.set_stocks(0)\n\n def is_vowel(self, num):\n modded = (num % 26) // 1 # Mod and floor\n if (modded == 0 or\n modded == 4 or\n modded == 8 or\n modded == 14 or\n modded == 21):\n return True\n\n return False\n\n def perc_diff(self, num_one, num_two):\n return (num_one / num_two) - 1\n\n def __repr__(self):\n return self.account.__repr__()\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.625,
"avg_line_length": 15.25,
"blob_id": "2e3d5563125f3b11d8beacae7768809152cf67ce",
"content_id": "978efc5c95a3068b06e3fd56a3cecc7c9dfa513b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 4,
"path": "/workshop/workshop2.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "day = 24\nmonth = 10\nyear = 1995\nprint(month, day, year, sep=\"/\")"
},
{
"alpha_fraction": 0.420560747385025,
"alphanum_fraction": 0.4579439163208008,
"avg_line_length": 11,
"blob_id": "37db59e8eef19ec289da7c24fe9aca41b3854a1d",
"content_id": "7be45be93514751973716399bfdb461245a34b78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 107,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 9,
"path": "/workshop/quiz1.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "def main():\n\tn = 3\n\tprint(\"n =\", n)\n\tfor i in range(5):\n\t\tn = 2 + n * 2\n\t\tprint(n)\n\tprint(\"n =\", n)\n\nmain()"
},
{
"alpha_fraction": 0.5313531160354614,
"alphanum_fraction": 0.5517051815986633,
"avg_line_length": 23.567567825317383,
"blob_id": "11941d61a98bd08c67f94f0ba861cd2501c807dd",
"content_id": "09e494dcedaeae199598cb02ac51a5d8137f1a90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1818,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 74,
"path": "/labs/lab_loops_booleans.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Loops && Booleans\n\nThis program tests if a number is a prime.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\n\n# Returns an even integer, persists\ndef get_input():\n while True: # Keep looping\n val = input(\"Please enter an even integer larger than 2: \")\n if val.isdigit(): # If val is a number\n val = eval(val) # Evaluate\n\n if val % 2 == 0: # If it is even, return val\n return val\n else:\n print(\"Wrong Input!\")\n\n else:\n print(\"Bad Input!\")\n\n\n# I used a seive to generate a prime list. This warrents extra credit.\ndef primeSeiveBooleanList(n):\n primeArray = [True] * (n)\n\n for i in range(2, n):\n for j in range((i + i), n, i):\n primeArray[j] = False\n\n primeArray[0] = False\n primeArray[1] = False\n\n return primeArray\n\n\ndef is_prime(n):\n primes = primeSeiveBooleanList(n + 1)\n return primes[n]\n\n\ndef main():\n # Intro\n print(\"This program tests Goldbach's conjecture\")\n\n # Querry\n number = get_input()\n\n # Start at 2\n prime1 = 2\n prime2 = 2\n notfound = True\n while notfound: # Always continue until broken\n if is_prime(prime1): # If prime1 is a prime\n prime2 = number - prime1 # Get prime2 by subracting from number\n if is_prime(prime2): # If prime2 is a prime\n print(number, \"=\", prime1, \"+\", prime2) # Print result\n break\n\n # Won't work, but is done for posterity\n if(prime1 == number):\n print(\"Goldbach's conjecture doesn't hold for\", number)\n break\n\n # If nothing works, check next number\n prime1 += 1\n\nif __name__ == \"__main__\":\n # execute only if run as a script\n main()\n"
},
{
"alpha_fraction": 0.6374269127845764,
"alphanum_fraction": 0.6374269127845764,
"avg_line_length": 18,
"blob_id": "467488762aaceaf329291f54a4b9713cdc8114bf",
"content_id": "73f7f3f647df855a9176a8b9ffcca14fd0342e3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 171,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 9,
"path": "/workshop/read_file_example.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "def main():\n\tinFile = open(\"inFile.txt\", \"r\")\n\tlines = inFile.readlines()\n\tlines.reverse()\n\toutFile = open(\"outFile.txt\", \"w\")\n\tfor i in lines:\n\t\toutFile.write(i)\n\nmain()\n"
},
{
"alpha_fraction": 0.7250000238418579,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 40,
"blob_id": "336ce40197ce18e06972a2e2b032f1e6a6749ab2",
"content_id": "1a7a9dd24be2b005970f1cd3eddc1345dd5d86f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 40,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 1,
"path": "/README.md",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "Thsi holds my code for the class CSC 161"
},
{
"alpha_fraction": 0.594994306564331,
"alphanum_fraction": 0.6211603879928589,
"avg_line_length": 20.975000381469727,
"blob_id": "6dc59a2da608696616c7fd92eedd076a7d9fabfd",
"content_id": "5dfa673e016fcf2c5208f8d2e3adfb2ad5ad87df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1758,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 80,
"path": "/labs/lab_simulation_design.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Simulation & Design\n\nThis lab helps estimate the expected distance a man would move from a\nstarting point with a random walk.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\nimport random\n\n# Returns a list of ints from 0-3 which represent the 4 directions\n# someone could walk in a grid pattern\n\n\ndef random_walk_2d(step_count):\n path = []\n\n # Generate random ints between 0 and 3\n for i in range(step_count):\n path.append(random.randrange(0, 4))\n\n return path\n\n\n\"\"\"This funciton takes a path which is a list of numbers 0-3 and\ncalculates the distance from it's start point.\n\n0 = up, 1 = right, 2 = down, 3 = left\n\"\"\"\n\n\ndef distance_walked(path):\n # Distance Vars\n x_distance = 0\n y_distance = 0\n\n # Path eval\n for i in range(len(path)):\n if path[i] == 0:\n y_distance += 1\n elif path[i] == 1:\n x_distance += 1\n elif path[i] == 2:\n y_distance -= 1\n elif path[i] == 3:\n x_distance -= 1\n\n # Distance Eval\n distance = (x_distance ** 2 + y_distance ** 2)**(1 / 2)\n\n return distance\n\n\ndef average_walk_distance(walk_count, step_count):\n average_distance = 0\n\n # Calculate total\n for i in range(walk_count):\n average_distance += distance_walked(random_walk_2d(step_count))\n\n # Divide to get average\n average_distance /= walk_count\n\n return average_distance\n\n\ndef main():\n print(\"Simulation of two dimensional random walk\")\n\n walks = eval(input(\"How many walks should I do? \"))\n steps = eval(input(\"How many steps should I take on each? \"))\n\n av_dist = average_walk_distance(walks, steps)\n print(\"Average distance from start: {0:0.2f}\".format(av_dist))\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6499068737030029,
"alphanum_fraction": 0.6741154789924622,
"avg_line_length": 19.653846740722656,
"blob_id": "0cd7e37fa4a68d13e43fcbe386d206f60e4d43bf",
"content_id": "be3e0a9dc1abd1106efe2eff21b6844a5e2837a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 26,
"path": "/project/project.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Project\n\nThis program:\n\nReads in stock data from Apple and can look up certain stock values\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\nfrom tradinglib import Data, Account, Analysis\n\n\ndef main():\n alg_moving_average = Analysis(Data(), Account())\n alg_moving_average.alg_moving_average()\n\n alg_mine = Analysis(Data(), Account())\n alg_mine.alg_mine()\n\n print(\"Result for moving average algorithm:\", alg_moving_average)\n print(\"Result for my algorithm:\", alg_mine)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5884560942649841,
"alphanum_fraction": 0.598310649394989,
"avg_line_length": 40.77450942993164,
"blob_id": "89ae353041f1093d57ca54c9fd9e7b7ad56173f2",
"content_id": "e748227d76c1936c447887f6d0ec7732e7874950",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4262,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 102,
"path": "/project/Analysis.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "class Analysis:\n def __init__(self, data, account):\n self.data = data\n self.account = account\n # Arguments are optional. Cleared with professor.\n def alg_moving_average(self, column=\"close\", margin=20, perc_margin=.2):\n \"\"\"The running average will be aquired by holding a continuously\n updated total average. that average will then be divided by the\n amount of active data points to aquire the average. These parameters\n will be played with to come up with the best strategy.\n\n \"\"\"\n\n \"\"\"Trading parameters\n\n Column: Stock price type used\n Margin: The amount of data being used for the average\n perc_margin: The percentage used to buy and sell stocks\n \"\"\"\n data_margin_total = 0\n perc_diff_var = 0\n\n # Get the first span of data totaled\n for i in range(1, margin + 1):\n data_margin_total += self.data.getStock(i, column)\n # Now, the total is calculated to the full margin\n\n # Running average evaluations\n for i in range(margin + 1, len(self.data.data)):\n # Calculate precentage difference\n perc_diff_var = self.perc_diff(data_margin_total / margin, self.data.getStock(i, column))\n\n # Make a decision\n # If diff larger than 20%\n if perc_diff_var >= perc_margin and self.account.get_capital() > self.data.getStock(i, column):\n self.account.add_stocks(1) # Buy a stock\n self.account.sub_capital(self.data.getStock(i, column)) # Reduce capital\n # If diff smaller than -20%\n elif perc_diff_var <= (-1 * perc_margin) and self.account.get_stocks() > 0:\n self.account.sub_stocks(1) # Sell a stock\n self.account.add_capital(self.data.getStock(i, column)) # Return some capital\n\n # Move average\n data_margin_total -= self.data.getStock(i - margin, column)\n data_margin_total += self.data.getStock(i, column)\n\n self.account.add_capital(self.data.getStock(len(self.data.data) - 1, column) * self.account.get_stocks())\n self.account.set_stocks(0)\n\n\n # Args are optional, cleared with professor.\n def alg_mine(self, column=\"close\"):\n \"\"\"This is a version of the stock trading algorithm that is determined\n by a custom parameter. The idea is that the current stock price being\n looked at will be compared to the alphabet. If it is a vowel, sell,\n otherwise buy.\n\n This will be done by modding the stock price by 26 and then checking to\n see if the number returned matches with a vowel.\n\n A = 0 | E = 4 | I = 8 | O = 14 | U = 21\n\n This will be evaluated using another function that returns True of False\n depending on the result: is_vowel\n\n The data will be run through each day and determine the decision.\n Specifically, it will buy a stock for each consinent and sell all the\n stocks for each vowel..\n\n \"\"\"\n\n for i in range(1, len(self.data.data)): # For every peice of data\n current_stock_price = self.data.getStock(i, column)\n current_stock_is_vowel = self.is_vowel(current_stock_price)\n if current_stock_is_vowel is False and self.account.get_capital() >= current_stock_price:\n self.account.add_stocks(1) # Buy a stock\n self.account.sub_capital(self.data.getStock(i, column)) # Reduce capital\n elif current_stock_is_vowel is True:\n self.account.add_capital(self.data.getStock(i, column)) \n self.account.set_stocks(0)\n\n self.account.add_capital(self.data.getStock(i, column) * self.account.get_stocks())\n self.account.set_stocks(0)\n\n\n def is_vowel(self, num):\n modded = (num % 26) // 1 # Mod and floor\n if (modded == 0 or\n modded == 4 or\n modded == 8 or\n modded == 14 or\n modded == 21):\n return True\n\n return False\n\n\n def perc_diff(self, num_one, num_two):\n return (num_one / num_two) - 1\n\n def __repr__(self):\n return self.account.__repr__()\n\n"
},
{
"alpha_fraction": 0.39393940567970276,
"alphanum_fraction": 0.4610389471054077,
"avg_line_length": 11.184210777282715,
"blob_id": "e70f2db25b68c6acdfd0c638f2fa0196a2915a7f",
"content_id": "3ba28ef41f3a79aa1fc14295c3b43c8369bb54e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 38,
"path": "/workshop/quiz_sequences.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "#Quiz stuff\n\n#1.\ns1 = \"Live long\"\ns2 = \"and prosper!\"\n\ndef ai():\n\tprint(s1 + s1[4] + s2)\n\ndef aii():\n\tprint(\"Peace \" + s2[0:3] + s2[3] + s1[5:9] + \" life\" + s2[-1])\n\ndef aiii():\n\tprint(s1[:4] + \",\" + s2[3] + \"be\" + s1[4] + s2[4:-1] + \"ous.\")\n\ndef aiv():\n\ta = s1.split()\n\tprint(a)\n\tb = s2.split()\n\tprint(b)\n\tc = a + b\n\tprint(c)\n\ndef bi():\n\tprint(\"7\" - ord(\"3\"))\n\ndef bii():\n\tprint(\"W\" + \"O\" * 4 + \"!\")\n\ndef main():\n\tai()\n\taii()\n\taiii()\n\taiv()\n\tbi()\n\tbii()\n\nmain()"
},
{
"alpha_fraction": 0.623115599155426,
"alphanum_fraction": 0.6582914590835571,
"avg_line_length": 14.307692527770996,
"blob_id": "7a0965e0cd18c64c265853db51c30313aeefe665",
"content_id": "b5e39292a62d4ad140b7581421064664d2090c2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/workshop/workshop_functions_4.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "from math import pi\n\ndef sphereArea(radius):\n\treturn 4 * pi * radius**2\n\ndef sphereVolume(radius):\n\treturn (4 / 3) * pi * radius**3\n\ndef main():\n\tfor i in range(10):\n\t\tprint(sphereVolume(i))\n\nmain()\n"
},
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.5675675868988037,
"avg_line_length": 8.789473533630371,
"blob_id": "c166aa47648512beadc6033359a5e82fd19aae68",
"content_id": "f604632b88b63c240c2da6ab9ce0f57816f684b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 19,
"path": "/workshop/temp.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "def addOne(num):\n\ta = num + 1\n\treturn a\n\ndef subOne(num):\n\ta = num - 1\n\ndef someMath(num):\n\ta = num - 1\n\tb = num + 1\n\treturn a, b\n\ndef main():\n\tnum = 5\n\tsubOne(num)\n\tprint(num)\n\n\nmain()"
},
{
"alpha_fraction": 0.5487603545188904,
"alphanum_fraction": 0.5619834661483765,
"avg_line_length": 20.60714340209961,
"blob_id": "7e6490b9a1c483dd3f071517f8705db2746734c9",
"content_id": "1187c3b6668c9e62134576e457d25b529d68a176",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 605,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 28,
"path": "/project/Account.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "class Account:\n def __init__(self):\n self.capital = 1000\n self.stocks = 0\n\n def get_capital(self):\n return self.capital\n\n def get_stocks(self):\n return self.stocks\n\n def set_stocks(self, num):\n self.stocks = num\n\n def add_capital(self, num):\n self.capital += num\n\n def add_stocks(self, num):\n self.stocks += num\n\n def sub_capital(self, num):\n self.capital -= num\n\n def sub_stocks(self, num):\n self.stocks -= num\n\n def __repr__(self):\n return \"Capital: ${0:.2f} Stocks: {1}\".format(self.capital, self.stocks)\n"
},
{
"alpha_fraction": 0.6155473589897156,
"alphanum_fraction": 0.6361713409423828,
"avg_line_length": 24.904109954833984,
"blob_id": "acfceb29c79555876878f04a6007eb02e677c0fd",
"content_id": "c71e4112829f38131db2bf49dd601a1c3c59bd04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1891,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 73,
"path": "/labs/lab_functions.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Functions\n\nThe programs exemplifies the use of functions in Python.\n\nBorja Rojo\nLab Section TR 2:00-3:15\nFall 2016\n\"\"\"\n\n\nimport re\n\n\ndef squareEach(nums):\n for i in range(len(nums)):\n nums[i] = nums[i]**2\n\n\ndef sumList(nums):\n total = 0\n for i in range(len(nums)):\n total += nums[i]\n return total\n\n\ndef toNumbers(strList):\n for i in range(len(strList)):\n strList[i] = float(strList[i])\n\n\ndef main():\n # Intro\n print(\"This programs exemplifies many different kinds of functions.\")\n # Test squareEach\n numberList = [1, 2, 3, 4]\n print(\"\\nnumberList before going through squareEach():\", numberList)\n squareEach(numberList)\n print(\"numberList after going through squareEach()\", numberList)\n\n # Test sumList\n toSum = [1000, 300, 30, 7]\n print(\"\\ntoSum:\", toSum)\n print(\"sumList(toSum):\", sumList(toSum)) # Returns a summed list\n\n # Test toNumbers\n stringNumbers = [\"40\", \"92\", \"77\", \"16\"]\n print(\"\\nstringNumbers type before toNumbers():\", type(stringNumbers[0]))\n toNumbers(stringNumbers)\n print(\"stringNumbers type after toNumbers():\", type(stringNumbers[0]))\n\n # Combo!!! (Can use either file)\n print(\"\\nThis program will now attempt to use all three functions\\n\"\n \"to convert a list of numbers in a file to the sum of thier\\n\"\n \"squares.\\n\")\n\n fileName = input(\"File to be read: \")\n print(\"Openning file...\")\n toRead = open(fileName, \"r\")\n print(\"Reading file...\")\n readFile = toRead.readline()\n print(\"Closing file...\")\n toRead.close()\n\n print(\"Seperating numbers in single-line file...\")\n numbers = re.split(\" |,\", readFile)\n print(\"Converting strings into numbers...\")\n toNumbers(numbers)\n print(\"Squaring all numbers...\")\n squareEach(numbers)\n print(\"Adding up all numbers...\")\n print(\"Result:\", sumList(numbers))\n\nmain()\n"
},
{
"alpha_fraction": 0.5178288221359253,
"alphanum_fraction": 0.5348653197288513,
"avg_line_length": 23.269229888916016,
"blob_id": "3aa14333bbf10b7acfd98173471061a037d15381",
"content_id": "7621e06cb282f2f1874ddb8cf5e1cf19ed92f4dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2524,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 104,
"path": "/labs/lab_class_design.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC161: Class Design\n\nThis lab exemplifies the creation of classes in Python using\nplayng cards.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\nimport random\n\n\n# Playing Card Class\nclass PlayingCard:\n def __init__(self, rank, suit):\n self.rank = rank\n self.suit = suit\n\n def get_rank(self):\n return self.rank\n\n def get_suit(self):\n return self.suit\n\n def bj_value(self):\n if self.rank > 10:\n return 10\n return self.rank\n\n # Converts the int rank into a string\n def str_rank(self):\n if self.rank == 1:\n return \"Ace\"\n elif self.rank == 2:\n return \"Two\"\n elif self.rank == 3:\n return \"Three\"\n elif self.rank == 4:\n return \"Four\"\n elif self.rank == 5:\n return \"Five\"\n elif self.rank == 6:\n return \"Six\"\n elif self.rank == 7:\n return \"Seven\"\n elif self.rank == 8:\n return \"Eight\"\n elif self.rank == 9:\n return \"Nine\"\n elif self.rank == 10:\n return \"Ten\"\n elif self.rank == 11:\n return \"Jack\"\n elif self.rank == 12:\n return \"Queen\"\n elif self.rank == 13:\n return \"King\"\n\n # Converts the letter of suit into a more full string\n def str_suit(self):\n if self.suit == \"s\":\n return \"Spades\"\n elif self.suit == \"c\":\n return \"Clubs\"\n elif self.suit == \"h\":\n return \"Hearts\"\n elif self.suit == \"d\":\n return \"Diamonds\"\n\n # Uses the string convertion functions to create a __repr__ string\n def __repr__(self):\n return self.str_rank() + \" of \" + self.str_suit()\n\n\ndef num_to_suit(num):\n num = num % 4\n if num == 0:\n return \"s\"\n elif num == 1:\n return \"c\"\n elif num == 2:\n return \"h\"\n elif num == 3:\n return \"d\"\n\n\ndef main():\n print(\"Testing card class\")\n\n card_count = eval(input(\"How many cards would you like to see? \"))\n\n \"\"\"EXTRA CREDIT: The one line solution with a string and a randrange\n can be improved with the choice() function. Other wise, the solution\n is putting \"schd\"[random.randrange(4)] as the argument for the suit\n in the initialization for a playing card.\n \"\"\"\n for i in range(card_count):\n card = PlayingCard(random.randrange(1, 14), random.choice(\"schd\"))\n print(card, \"counts\", card.bj_value())\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6166166067123413,
"alphanum_fraction": 0.6356356143951416,
"avg_line_length": 25.289474487304688,
"blob_id": "fa0f2164f5538680eb362555740d70e0ad975172",
"content_id": "7b7ae6e2858c71bf95249a58034ca4e3e8883d1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 999,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 38,
"path": "/labs/lab_numbers.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Numbers\n\nThis program estimates square roots using Newton's Method\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\n# Some lines are longer than 80 characters.\n# This was done to emulate the examples given.\n\n\nimport math\n\n\ndef main():\n # Intro\n print(\"This program calculates the square root\"\n \"of a given number using the Newton's method\")\n\n # Querry\n number = eval(input(\"What is the number for which you want\"\n \"to calculate the square root? \"))\n count = eval(input(\"How many iterations do you want to use? \"))\n\n # Estimation\n guess = number / 2\n for i in range(count):\n # Loop# Guess Difference between guess and actual root\n guess = (guess + (number / guess)) / 2.0\n print(i + 1, guess, guess - math.sqrt(number))\n\n print(\"My guess for the square root of\", number, \"is\", guess)\n print(\"The difference between my guess and the real result is\",\n guess - math.sqrt(number))\n\nmain()\n"
},
{
"alpha_fraction": 0.6335541009902954,
"alphanum_fraction": 0.6688741445541382,
"avg_line_length": 24.16666603088379,
"blob_id": "99e31207bdf1c1e6bd51afe617efe40fc5c21439",
"content_id": "a315844d9096b25c82592efdf9994563fd35868a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 18,
"path": "/labs/lab_writing_programs.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Writing Programs\n\nThis program implements a basic interactive calculator.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\n\ndef main():\n print(\"This program evaluates arithmetic expresions!\")\n n = eval(input(\"How many calculations would you like to make? \"))\n for i in range(n): # Changed from 100 to the input 'n' for extra credit\n x = input(\"Enter a mathematical expression: \")\n print(x, \"=\", eval(x))\n\nmain()\n"
},
{
"alpha_fraction": 0.5630252361297607,
"alphanum_fraction": 0.5798319578170776,
"avg_line_length": 14,
"blob_id": "07bf127e452a5ef3e0287e20240e539ed643f012",
"content_id": "841aa0b015fb326b8bdb71f4db5b524cf192f4fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 8,
"path": "/workshop/write_file_example.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "def main():\n\toutput = open(\"file.txt\", \"w\")\n\tfor i in range(10):\n\t\toutput.write(str(i) + \"\\n\")\n\n\toutput.close()\n\nmain()"
},
{
"alpha_fraction": 0.5895367860794067,
"alphanum_fraction": 0.6095947027206421,
"avg_line_length": 28.487804412841797,
"blob_id": "910d0e40794dc31ec9aa39f81b68b9f92d1f18e1",
"content_id": "5a3cf3920053dac8a6426af82b05af3d11083c34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4836,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 164,
"path": "/labs/lab_data_collections.py",
"repo_name": "borjarojo/csc161",
"src_encoding": "UTF-8",
"text": "\"\"\"CSC 161 Lab: Data Collections\n\nThis lab runs a statistical analysis on a set of randomly\ngenerated cards.\n\nBorja Rojo\nLab Section TR 2:00-3:15pm\nFall 2016\n\"\"\"\n\nfrom random import randrange, choice\nfrom lab_class_design import PlayingCard\nfrom math import sqrt\n\nsuit_size = 13 # Number of cards in a suit.\ndeck_size = 52 # Number of cards in a deck.\nnum_cards = 260 # Number of cards to create with random rank & suit values\n\n\ndef make_random_cards():\n \"\"\"Generate num_cards number of random PlayingCard objects.\n\n This function will generate num_cards RANDOM playing cards\n using your PlayingCard class. That means you will have to choose a random\n suit and rank for a card num_cards times.\n\n Printing:\n Nothing\n\n Positional arguments:\n None\n\n Returns:\n cards_list -- a list of PlayingCard objects.\n \"\"\"\n\n cards_list = []\n for i in range(num_cards):\n card = PlayingCard(randrange(1, 14), choice(\"schd\"))\n cards_list.append(card)\n\n return cards_list\n\n\ndef freq_count(cards_list):\n \"\"\"Count every suit-rank combination.\n\n Returns a dictionary whose keys are the card suit-rank and value is the\n count.\n\n Printing:\n Nothing\n\n Positional arguments:\n cards_list -- A list of PlayingCard objects.\n\n Returns:\n card_freqs -- A dictionary whose keys are the single letter in the set\n 'd', 'c', 'h', 's' representing each card suit. The value for each key\n is a list containing the number of cards at each rank, using the index\n position to represent the rank. For example, {'s': [0, 3, 4, 2, 5]}\n says that the key 's', for 'spades' has three rank 1's (aces), four\n rank 2's (twos), two rank 3's (threes) and 5 rank 4's (fours). Index\n position 0 is 0 since no cards have a rank 0, so make note.\n \"\"\"\n # DO NOT REMOVE BELOW\n if type(cards_list) != list or \\\n list(filter(lambda x: type(x) != PlayingCard, cards_list)):\n raise TypeError(\"cards_list is required to be a list of PlayingCard \\\n objects.\")\n # DO NOT REMOVE ABOVE\n\n # Set up dictionary\n card_freqs = {'d': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],\n 'c': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],\n 'h': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],\n 's': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}\n\n # For every card in card_list, add 1 to the frequency of the suit-rank\n for card in cards_list:\n card_freqs[card.get_suit()][card.get_rank()] += 1\n\n return card_freqs\n\n\ndef std_dev(counts):\n \"\"\"Calculate the standard deviation of a list of numbers.\n\n Positional arguments:\n counts -- A list of ints representing frequency counts.\n\n Printing:\n Nothing\n\n Returns:\n _stdev -- The standard deviation as a single float value.\n \"\"\"\n # DO NOT REMOVE BELOW\n if type(counts) != list or \\\n list(filter(lambda x: type(x) != int, counts)):\n raise TypeError(\"counts is required to be a list of int values.\")\n # DO NOT REMOVE ABOVE\n\n # Find mean\n mean = 0\n for num in counts:\n mean += num\n mean /= len(counts)\n\n # Sum squares of distances to mean\n mean_dist_square_sum = 0\n for num in counts:\n mean_dist_square_sum += (num - mean)**2\n\n # Sqrt the average of the sums\n _stdev = sqrt(mean_dist_square_sum / len(counts))\n\n return _stdev\n\n\ndef print_stats(card_freqs):\n \"\"\"Print the final stats of the PlayingCard objects.\n\n Positional arguments:\n card_freqs -- A dictionary whose keys are the single letter in the set\n 'dchs' representing each card suit. The value for each key is a list of\n numbers where each index position is a card rank, and its value is its\n card frequency.\n\n You will probably want to call th std_dev function in somewhere in\n here.\n\n Printing:\n Prints the statistic for each suit to the screen, see assignment page\n for an example output.\n\n Returns:\n None\n \"\"\"\n # DO NOT REMOVE BELOW\n if type(card_freqs) != dict or \\\n list(filter(lambda x: type(card_freqs[x]) != list, card_freqs)):\n raise TypeError(\"card_freqs is required to be a list of int values.\")\n # DO NOT REMOVE ABOVE\n\n # Dictionary to convert suit key to name\n suit_name = {'d': 'Diamonds', 'h': 'Hearts', 's': 'Spades', 'c': 'Clubs'}\n\n # Printing\n print(\"Standard deviation for the frequency counts of each rank in suit:\")\n for suit in card_freqs:\n print(\"\\t\" + suit_name[suit] + \":\",\n std_dev(card_freqs[suit]),\n \"cards\")\n\n\ndef main():\n cards = make_random_cards()\n suit_counts = freq_count(cards)\n print_stats(suit_counts)\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 23 |
rafwiewiora/autoprotocol-python
|
https://github.com/rafwiewiora/autoprotocol-python
|
bbe3596dd6f6e57352a40d13517c628df45f5ebe
|
6961cfe4bb50ffa44e67125fa488238a5ac4ae19
|
40ba09a69f0b4428275584803f220afebbf758ca
|
refs/heads/master
| 2021-01-22T15:01:03.962021 | 2016-03-23T20:10:27 | 2016-03-23T20:10:27 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5562191605567932,
"alphanum_fraction": 0.570068359375,
"avg_line_length": 35.21630096435547,
"blob_id": "d41a6aba10d7480cdacecb717f45daf5d3f80a1f",
"content_id": "9bbb26a4e72094be838233db327981072a20fd36",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-generic-cla",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11553,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 319,
"path": "/autoprotocol/util.py",
"repo_name": "rafwiewiora/autoprotocol-python",
"src_encoding": "UTF-8",
"text": "from .unit import Unit\n\n'''\n :copyright: 2016 by The Autoprotocol Development Team, see AUTHORS\n for more details.\n :license: BSD, see LICENSE for more details\n\n'''\n\n\ndef quad_ind_to_num(q):\n \"\"\"\n Convert a 384-well plate quadrant well index into its corresponding\n integer form.\n\n \"A1\" -> 0\n \"A2\" -> 1\n \"B1\" -> 2\n \"B2\" -> 3\n\n Parameters\n ----------\n q : int, str\n A string or integer representing a well index that corresponds to a\n quadrant on a 384-well plate.\n\n \"\"\"\n if isinstance(q, str):\n q = q.lower()\n if q in [\"a1\", 0]:\n return 0\n elif q in [\"a2\", 1]:\n return 1\n elif q in [\"b1\", 24]:\n return 2\n elif q in [\"b2\", 25]:\n return 3\n else:\n raise ValueError(\"Invalid quadrant index.\")\n\n\ndef quad_num_to_ind(q, human=False):\n \"\"\"\n Convert a 384-well plate quadrant integer into its corresponding well index.\n\n 0 -> \"A1\" or 0\n 1 -> \"A2\" or 1\n 2 -> \"B1\" or 24\n 3 -> \"B2\" or 25\n\n Parameters\n ----------\n q : int\n An integer representing a quadrant number of a 384-well plate.\n human : bool, optional\n Return the corresponding well index in human readable form instead of\n as an integer if True.\n\n \"\"\"\n if q == 0:\n if human:\n return \"A1\"\n else:\n return 0\n elif q == 1:\n if human:\n return \"A2\"\n else:\n return 1\n elif q == 2:\n if human:\n return \"B1\"\n else:\n return 24\n elif q == 3:\n if human:\n return \"B2\"\n else:\n return 25\n else:\n raise ValueError(\"Invalid quadrant number.\")\n\n\ndef check_valid_origin(origin, stamp_type, columns, rows):\n # Checks if selected well is a valid origin destination for the given plate\n # Assumption: SBS formatted plates and 96-tip layout\n robotized_origin = origin.index\n well_count = origin.container.container_type.well_count\n col_count = origin.container.container_type.col_count\n row_count = well_count // col_count\n\n if well_count == 96:\n if stamp_type == \"full\":\n if robotized_origin != 0:\n raise ValueError(\"For full 96-well transfers, origin has \"\n \"to be well 0.\")\n elif stamp_type == \"row\":\n if (robotized_origin % col_count) != 0 or robotized_origin > ((\n row_count - rows) * col_count):\n raise ValueError(\"For row transfers, origin \"\n \"has to be specified within the left \"\n \"column and not more than allowed by shape.\")\n else:\n if robotized_origin > (col_count - columns) or robotized_origin < 0:\n raise ValueError(\"For column transfers, origin \"\n \"has to be specified within the top \"\n \"column and not more than allowed by shape.\")\n elif well_count == 384:\n if stamp_type == \"full\":\n if robotized_origin not in [0, 1, 24, 25]:\n raise ValueError(\"For full 384-well transfers, origin has \"\n \"to be well 0, 1, 24 or 25.\")\n elif stamp_type == \"row\":\n if (robotized_origin % col_count) not in [0, 1] or (\n robotized_origin >= ((row_count - ((\n rows - 1) * 2)) * col_count)):\n raise ValueError(\"For row transfers, origin\"\n \"has to be specified within the left \"\n \"two columns and not more than allowed by \"\n \"shape.\")\n else:\n if robotized_origin >= col_count * 2 or (\n robotized_origin < 0) or (\n robotized_origin % col_count >= (\n col_count - ((columns - 1) * 2))):\n raise ValueError(\"For column transfers, origin \"\n \"has to be specified within the top \"\n \"two columns and not more than allowed by \"\n \"shape.\")\n else:\n raise RuntimeError(\"Unsupported plate type for checking origin.\")\n\n\ndef check_stamp_append(current_xfer, prev_xfer_list, maxTransfers=3,\n maxContainers=3,\n volumeSwitch=Unit.fromstring(\"31:microliter\")):\n \"\"\"\n Checks whether current stamp can be appended to previous stamp instruction.\n \"\"\"\n # Ensure Instruction contains either all full plate or selective (all rows\n # or all columns)\n if ((prev_xfer_list[0][\"shape\"][\"columns\"] == 12 and prev_xfer_list[0][\n \"shape\"][\"rows\"] == 8) and (current_xfer[\"shape\"][\"columns\"] == 12 and current_xfer[\"shape\"][\"rows\"] == 8)):\n axis_key = None\n elif prev_xfer_list[0][\"shape\"][\"columns\"] == 12:\n axis_key = \"rows\"\n if current_xfer[\"shape\"][\"columns\"] != 12:\n return False\n elif prev_xfer_list[0][\"shape\"][\"rows\"] == 8:\n axis_key = \"columns\"\n if current_xfer[\"shape\"][\"rows\"] != 8:\n return False\n\n # Ensure Instruction contain the same volume type as defined by TCLE\n # Currently volumeSwitch is hardcoded to check against the two tip volume\n # types used in TCLE\n if prev_xfer_list[0][\"transfer\"][0][\"volume\"] <= volumeSwitch:\n if current_xfer[\"transfer\"][0][\"volume\"] > volumeSwitch:\n return False\n elif prev_xfer_list[0][\"transfer\"][0][\"volume\"] > volumeSwitch:\n if current_xfer[\"transfer\"][0][\"volume\"] <= volumeSwitch:\n return False\n\n # Check if maximum Transfers/Containers is reached\n originList = ([y[\"from\"] for x in prev_xfer_list for y in x[\"transfer\"]] +\n [y[\"to\"] for x in prev_xfer_list for y in x[\"transfer\"]] +\n [y[\"from\"] for y in current_xfer[\"transfer\"]] +\n [y[\"to\"] for y in current_xfer[\"transfer\"]])\n\n if axis_key:\n num_prev_xfers = sum([x[\"shape\"][axis_key] for x in prev_xfer_list])\n num_current_xfers = current_xfer[\"shape\"][axis_key]\n else:\n num_prev_xfers = len(prev_xfer_list)\n num_current_xfers = 1\n\n if (num_prev_xfers + num_current_xfers > maxTransfers or\n len(set(map(lambda x: x.container, originList))) > maxContainers):\n return False\n\n return True\n\n\ndef check_valid_mag(container, head):\n if head == \"96-deep\":\n if container.container_type.shortname not in [\"96-v-kf\", \"96-deep-kf\", \"96-deep\"]:\n raise ValueError(\"%s container is not compatible with %s head\" % (container.container_type.shortname, head))\n elif head == \"96-pcr\":\n if container.container_type.shortname not in [\"96-pcr\", \"96-v-kf\", \"96-flat\", \"96-flat-uv\"]:\n raise ValueError(\"%s container is not compatible with %s head\" % (container.container_type.shortname, head))\n\n\ndef check_valid_mag_params(mag_dict):\n if \"frequency\" in mag_dict:\n if Unit.fromstring(mag_dict[\"frequency\"]) < Unit.fromstring(\"0:hertz\"):\n raise ValueError(\"Frequency set at %s, must not be less than 0:hertz\" % mag_dict[\"frequency\"])\n if \"temperature\" in mag_dict and mag_dict[\"temperature\"]:\n if Unit.fromstring(mag_dict[\"temperature\"]) < Unit.fromstring(\"-273.15:celsius\"):\n raise ValueError(\"Temperature set at %s, must not be less than absolute zero'\" % mag_dict[\"temperature\"])\n elif \"temperature\" in mag_dict and not mag_dict[\"temperature\"]:\n del mag_dict[\"temperature\"]\n if \"amplitude\" in mag_dict:\n if mag_dict[\"amplitude\"] > mag_dict[\"center\"]:\n raise ValueError(\"'amplitude': %s, must be less than 'center': %s\" % (mag_dict[\"amplitude\"], mag_dict[\"center\"]))\n if mag_dict[\"amplitude\"] < 0:\n raise ValueError(\"Amplitude set at %s, must not be negative\" % mag_dict[\"amplitude\"])\n if any(kw in mag_dict for kw in (\"center\", \"bottom_position\", \"tip_position\")):\n position = mag_dict.get(\"center\", mag_dict.get(\"bottom_position\", mag_dict.get(\"tip_position\")))\n if position < 0:\n raise ValueError(\"Tip head position set at %s, must not be negative\" % position)\n if \"magnetize\" in mag_dict:\n if not isinstance(mag_dict[\"magnetize\"], bool):\n raise ValueError(\"Magnetize set at: %s, must be boolean\" % mag_dict[\"magnetize\"])\n\n\nclass make_dottable_dict(dict):\n\n '''Enable dictionaries to be accessed using dot notation instead of bracket\n notation. This class should probably never be used.\n\n Example\n -------\n .. code-block:: python\n\n >>> d = {\"foo\": {\n \"bar\": {\n \"bat\": \"Hello!\"\n }\n }\n }\n\n >>> print d[\"foo\"][\"bar\"][\"bat\"]\n Hello!\n\n >>> d = make_dottable_dict(d)\n\n >>> print d.foo.bar.bat\n Hello!\n\n Parameters\n ----------\n dict : dict\n Dictionary to be made dottable.\n\n '''\n\n def __getattr__(self, attr):\n if type(self[attr]) == dict:\n return make_dottable_dict(self[attr])\n return self[attr]\n\n __setattr__ = dict.__setitem__\n __delattr__ = dict.__delitem__\n\n\ndef deep_merge_params(defaults, override):\n \"\"\"Merge two dictionaries while retaining common key-value pairs.\n\n Parameters\n ----------\n defaults : dict\n Default dictionary to compare with overrides.\n override : dict\n Dictionary containing additional keys and/or values to override those\n corresponding to keys in the defaults dicitonary.\n\n \"\"\"\n defaults = make_dottable_dict(defaults.copy())\n for key, value in override.items():\n if isinstance(value, dict):\n # get node or create one\n defaults[key] = deep_merge_params(defaults.get(key, {}), value)\n else:\n defaults[key] = value\n\n return defaults\n\n\ndef incubate_params(duration, shake_amplitude=None, shake_orbital=None):\n \"\"\"\n Create a dictionary with incubation parameters which can be used as input\n for instructions. Currenly supports plate reader instructions and could be\n extended for use with other instructions.\n\n Parameters\n ----------\n shake_amplitude: str, Unit\n amplitude of shaking between 1 and 6:millimeter\n shake_orbital: bool\n True for oribital and False for linear shaking\n duration: str, Unit\n time for shaking\n \"\"\"\n\n incubate_dict = {}\n if Unit.fromstring(duration) < Unit.fromstring(\"0:second\"):\n raise ValueError(\"duration: %s must be positive\" % duration)\n else:\n incubate_dict[\"duration\"] = duration\n\n if (shake_amplitude is not None) and (shake_orbital is not None):\n shake_dict = {}\n\n if Unit.fromstring(shake_amplitude) < Unit.fromstring(\"0:millimeter\"):\n raise ValueError(\"shake_amplitude: %s must be positive\" % shake_amplitude)\n else:\n shake_dict[\"amplitude\"] = shake_amplitude\n\n if not isinstance(shake_orbital, bool):\n raise ValueError(\"shake_orbital: %s must be a boolean\" % shake_orbital)\n else:\n shake_dict[\"orbital\"] = shake_orbital\n\n incubate_dict[\"shaking\"] = shake_dict\n\n if (shake_amplitude is not None) ^ (shake_orbital is not None):\n raise RuntimeError(\"Both `shake_amplitude`: %s and `shake_orbital`: %s must not be None for shaking to be set\" % (shake_amplitude, shake_orbital))\n\n return incubate_dict\n"
},
{
"alpha_fraction": 0.5413188338279724,
"alphanum_fraction": 0.5821973085403442,
"avg_line_length": 48.28645706176758,
"blob_id": "3873a46fd2bc42a797c572ad2292b40165d7ef51",
"content_id": "7d2e7ec88b6f160e8f3b426d4d479c32dd58b0b0",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-generic-cla",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 56778,
"license_type": "permissive",
"max_line_length": 220,
"num_lines": 1152,
"path": "/test/protocol_test.py",
"repo_name": "rafwiewiora/autoprotocol-python",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom autoprotocol.protocol import Protocol, Ref\nfrom autoprotocol.instruction import Instruction, Thermocycle, Incubate, Pipette, Spin\nfrom autoprotocol.container_type import ContainerType\nfrom autoprotocol.container import Container, WellGroup, Well\nfrom autoprotocol.unit import Unit\nfrom autoprotocol.pipette_tools import *\nimport json\n\n\nclass ProtocolMultipleExistTestCase(unittest.TestCase):\n def runTest(self):\n p1 = Protocol()\n p2 = Protocol()\n\n p1.spin(\"dummy_ref\", \"2000:rpm\", \"560:second\")\n self.assertEqual(len(p2.instructions), 0,\n \"incorrect number of instructions in empty protocol\")\n\n\nclass ProtocolBasicTestCase(unittest.TestCase):\n def runTest(self):\n protocol = Protocol()\n resource = protocol.ref(\"resource\", None, \"96-flat\", discard=True)\n pcr = protocol.ref(\"pcr\", None, \"96-flat\", discard=True)\n bacteria = protocol.ref(\"bacteria\", None, \"96-flat\", discard=True)\n self.assertEqual(len(protocol.as_dict()['refs']), 3, 'incorrect number of refs')\n self.assertEqual(protocol.as_dict()['refs']['resource'], {\"new\": \"96-flat\",\n \"discard\": True})\n\n bacteria_wells = WellGroup([bacteria.well(\"B1\"), bacteria.well(\"C5\"),\n bacteria.well(\"A5\"), bacteria.well(\"A1\")])\n\n protocol.distribute(resource.well(\"A1\").set_volume(\"40:microliter\"),\n pcr.wells_from('A1',5), \"5:microliter\")\n protocol.distribute(resource.well(\"A1\").set_volume(\"40:microliter\"),\n bacteria_wells, \"5:microliter\")\n\n self.assertEqual(len(protocol.instructions), 1)\n self.assertEqual(protocol.instructions[0].op, \"pipette\")\n self.assertEqual(len(protocol.instructions[0].groups), 2)\n\n protocol.incubate(bacteria, \"warm_37\", \"30:minute\")\n\n self.assertEqual(len(protocol.instructions), 2)\n self.assertEqual(protocol.instructions[1].op, \"incubate\")\n self.assertEqual(protocol.instructions[1].duration, \"30:minute\")\n\n\nclass ProtocolAppendTestCase(unittest.TestCase):\n def runTest(self):\n p = Protocol()\n self.assertEqual(len(p.instructions), 0,\n \"should not be any instructions before appending to empty protocol\")\n\n p.append(Spin(\"dummy_ref\", \"100:meter/second^2\", \"60:second\"))\n self.assertEqual(len(p.instructions), 1,\n \"incorrect number of instructions after single instruction append\")\n self.assertEqual(p.instructions[0].op, \"spin\",\n \"incorrect instruction appended\")\n\n p.append([\n Incubate(\"dummy_ref\", \"ambient\", \"30:second\"),\n Spin(\"dummy_ref\", \"2000:rpm\", \"120:second\")\n ])\n self.assertEqual(len(p.instructions), 3,\n \"incorrect number of instructions after appending instruction list\")\n self.assertEqual(p.instructions[1].op, \"incubate\",\n \"incorrect instruction order after list append\")\n self.assertEqual(p.instructions[2].op, \"spin\",\n \"incorrect instruction at end after list append.\")\n\n\nclass RefTestCase(unittest.TestCase):\n def test_duplicates_not_allowed(self):\n p = Protocol()\n p.ref(\"test\", None, \"96-flat\", discard=True)\n with self.assertRaises(RuntimeError):\n p.ref(\"test\", None, \"96-flat\", storage=\"cold_20\")\n self.assertTrue(p.refs[\"test\"].opts[\"discard\"])\n self.assertFalse(\"where\" in p.refs[\"test\"].opts)\n\n\nclass ThermocycleTestCase(unittest.TestCase):\n def test_thermocycle_append(self):\n t = Thermocycle(\"plate\", [\n { \"cycles\": 1, \"steps\": [\n { \"temperature\": \"95:celsius\", \"duration\": \"60:second\" },\n ] },\n { \"cycles\": 30, \"steps\": [\n { \"temperature\": \"95:celsius\", \"duration\": \"15:second\" },\n { \"temperature\": \"55:celsius\", \"duration\": \"15:second\" },\n { \"temperature\": \"72:celsius\", \"duration\": \"10:second\" },\n ] },\n { \"cycles\": 1, \"steps\": [\n { \"temperature\": \"72:celsius\", \"duration\": \"600:second\" },\n { \"temperature\": \"12:celsius\", \"duration\": \"120:second\" },\n ] },\n ], \"20:microliter\")\n self.assertEqual(len(t.groups), 3, 'incorrect number of groups')\n self.assertEqual(t.volume, \"20:microliter\")\n\n def test_thermocycle_dyes_and_datarefs(self):\n self.assertRaises(ValueError,\n Thermocycle,\n \"plate\",\n [{\"cycles\": 1,\n \"steps\": [{\n \"temperature\": \"50: celsius\",\n \"duration\": \"20:minute\"\n }]\n }],\n dyes={\"FAM\": [\"A1\"]})\n self.assertRaises(ValueError,\n Thermocycle,\n \"plate\",\n [{\"cycles\": 1,\n \"steps\": [{\n \"temperature\": \"50: celsius\",\n \"duration\": \"20:minute\"\n }]\n }],\n dataref=\"test_dataref\")\n self.assertRaises(ValueError,\n Thermocycle,\n \"plate\",\n [{\"cycles\": 1,\n \"steps\": [{\n \"temperature\": \"50: celsius\",\n \"duration\": \"20:minute\"\n }]\n }],\n dyes={\"ThisDyeIsInvalid\": [\"A1\"]})\n\n def test_thermocycle_melting(self):\n self.assertRaises(ValueError,\n Thermocycle,\n \"plate\",\n [{\"cycles\": 1,\n \"steps\": [{\n \"temperature\": \"50: celsius\",\n \"duration\": \"20:minute\"\n }]\n }],\n melting_start = \"50:celsius\")\n self.assertRaises(ValueError,\n Thermocycle,\n \"plate\",\n [{\"cycles\": 1,\n \"steps\": [{\n \"temperature\": \"50: celsius\",\n \"duration\": \"20:minute\"\n }]\n }],\n melting_start = \"50:celsius\",\n melting_end = \"60:celsius\",\n melting_increment = \"1:celsius\",\n melting_rate = \"2:minute\")\n\n\nclass DistributeTestCase(unittest.TestCase):\n def test_distribute_one_well(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.distribute(c.well(0).set_volume(\"20:microliter\"),\n c.well(1),\n \"5:microliter\")\n self.assertEqual(1, len(p.instructions))\n self.assertEqual(\"distribute\",\n list(p.as_dict()[\"instructions\"][0][\"groups\"][0].keys())[0])\n self.assertTrue(Unit(5, 'microliter'), c.well(1).volume)\n self.assertTrue(Unit(15, 'microliter'), c.well(0).volume)\n\n def test_distribute_multiple_wells(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.distribute(c.well(0).set_volume(\"20:microliter\"),\n c.wells_from(1, 3),\n \"5:microliter\")\n self.assertEqual(1, len(p.instructions))\n self.assertEqual(\"distribute\",\n list(p.as_dict()[\"instructions\"][0][\"groups\"][0].keys())[0])\n for w in c.wells_from(1, 3):\n self.assertTrue(Unit(5, 'microliter'), w.volume)\n self.assertTrue(Unit(5, 'microliter'), c.well(0).volume)\n\n def test_fill_wells(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n srcs = c.wells_from(1, 2).set_volume(\"100:microliter\")\n dests = c.wells_from(7, 4)\n p.distribute(srcs, dests, \"30:microliter\", allow_carryover=True)\n self.assertEqual(2, len(p.instructions[0].groups))\n\n # track source vols\n self.assertEqual(Unit(10, 'microliter'), c.well(1).volume)\n self.assertEqual(Unit(70, 'microliter'), c.well(2).volume)\n\n # track dest vols\n self.assertEqual(Unit(30, 'microliter'), c.well(7).volume)\n self.assertIs(None, c.well(6).volume)\n\n # test distribute from Well to Well\n p.distribute(c.well(\"A1\").set_volume(\"20:microliter\"), c.well(\"A2\"), \"5:microliter\")\n self.assertTrue(\"distribute\" in p.instructions[-1].groups[-1])\n\n def test_unit_conversion(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.distribute(c.well(0).set_volume(\"100:microliter\"), c.well(1), \"200:nanoliter\")\n self.assertTrue(str(p.instructions[0].groups[0][\"distribute\"][\"to\"][0][\"volume\"]) == \"0.2:microliter\")\n p.distribute(c.well(2).set_volume(\"100:microliter\"), c.well(3), \".1:milliliter\", new_group=True)\n self.assertTrue(str(p.instructions[-1].groups[0][\"distribute\"][\"to\"][0][\"volume\"]) == \"100.0:microliter\")\n\n\nclass TransferTestCase(unittest.TestCase):\n def test_single_transfer(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.transfer(c.well(0), c.well(1), \"20:microliter\")\n self.assertEqual(Unit(20, \"microliter\"), c.well(1).volume)\n self.assertEqual(None, c.well(0).volume)\n self.assertTrue(\"transfer\" in p.instructions[-1].groups[-1])\n\n def test_gt_900uL_transfer(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-deep\", discard=True)\n p.transfer(\n c.well(0),\n c.well(1),\n \"2000:microliter\"\n )\n self.assertEqual(3, len(p.instructions[0].groups))\n self.assertEqual(\n Unit(900, 'microliter'),\n p.instructions[0].groups[0]['transfer'][0]['volume']\n )\n self.assertEqual(\n Unit(900, 'microliter'),\n p.instructions[0].groups[1]['transfer'][0]['volume']\n )\n self.assertEqual(\n Unit(200, 'microliter'),\n p.instructions[0].groups[2]['transfer'][0]['volume']\n )\n\n def test_gt_900uL_wellgroup_transfer(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-deep\", discard=True)\n p.transfer(\n c.wells_from(0, 8, columnwise=True),\n c.wells_from(1, 8, columnwise=True),\n '2000:microliter'\n )\n self.assertEqual(\n 24,\n len(p.instructions[0].groups)\n )\n\n def test_transfer_option_propagation(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-deep\", discard=True)\n p.transfer(\n c.well(0),\n c.well(1),\n \"2000:microliter\",\n aspirate_source=aspirate_source(\n depth(\"ll_bottom\", distance=\".004:meter\")\n )\n )\n self.assertEqual(\n len(p.instructions[0].groups[0]['transfer'][0]),\n len(p.instructions[0].groups[1]['transfer'][0])\n )\n self.assertEqual(\n len(p.instructions[0].groups[0]['transfer'][0]),\n len(p.instructions[0].groups[2]['transfer'][0])\n )\n\n def test_max_transfer(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"micro-2.0\", storage=\"cold_4\")\n p.transfer(c.well(0), c.well(0), \"3050:microliter\")\n\n def test_multiple_transfers(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.transfer(c.wells_from(0, 2), c.wells_from(2, 2), \"20:microliter\")\n self.assertEqual(c.well(2).volume, c.well(3).volume)\n self.assertEqual(2, len(p.instructions[0].groups))\n\n def test_one_tip(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.transfer(c.wells_from(0, 2), c.wells_from(2, 2), \"20:microliter\",\n one_tip=True)\n self.assertEqual(c.well(2).volume, c.well(3).volume)\n self.assertEqual(1, len(p.instructions[0].groups))\n\n def test_one_source(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n with self.assertRaises(RuntimeError):\n p.transfer(c.wells_from(0, 2),\n c.wells_from(2, 2), \"40:microliter\", one_source=True)\n with self.assertRaises(RuntimeError):\n p.transfer(c.wells_from(0, 2).set_volume(\"1:microliter\"),\n c.wells_from(1, 5), \"10:microliter\", one_source=True)\n p.transfer(c.wells_from(0, 2).set_volume(\"50:microliter\"),\n c.wells_from(2, 2), \"40:microliter\", one_source=True)\n self.assertEqual(2, len(p.instructions[0].groups))\n self.assertFalse(p.instructions[0].groups[0][\"transfer\"][0][\"from\"] == p.instructions[0].groups[1][\"transfer\"][0][\"from\"])\n p.transfer(c.wells_from(0, 2).set_volume(\"100:microliter\"),\n c.wells_from(2, 4), \"40:microliter\", one_source=True)\n self.assertEqual(7, len(p.instructions[0].groups))\n self.assertTrue(p.instructions[0].groups[2][\"transfer\"][0][\"from\"] == p.instructions[0].groups[4][\"transfer\"][0][\"from\"])\n self.assertTrue(p.instructions[0].groups[4][\"transfer\"][0][\"volume\"] == Unit.fromstring(\"20:microliter\"))\n p.transfer(c.wells_from(0, 2).set_volume(\"100:microliter\"),\n c.wells_from(2, 4), [\"20:microliter\", \"40:microliter\", \"60:microliter\", \"80:microliter\"], one_source=True)\n self.assertEqual(12, len(p.instructions[0].groups))\n self.assertTrue(p.instructions[0].groups[7][\"transfer\"][0][\"from\"] == p.instructions[0].groups[9][\"transfer\"][0][\"from\"])\n self.assertFalse(p.instructions[0].groups[9][\"transfer\"][0][\"from\"] == p.instructions[0].groups[10][\"transfer\"][0][\"from\"])\n self.assertEqual(Unit.fromstring(\"20:microliter\"), p.instructions[0].groups[10][\"transfer\"][0][\"volume\"])\n p.transfer(c.wells_from(0, 2).set_volume(\"50:microliter\"), c.wells(2), \"100:microliter\", one_source=True)\n c.well(0).set_volume(\"50:microliter\")\n c.well(1).set_volume(\"200:microliter\")\n p.transfer(c.wells_from(0, 2), c.well(1), \"100:microliter\", one_source=True)\n self.assertFalse(p.instructions[0].groups[14][\"transfer\"][0][\"from\"] == p.instructions[0].groups[15][\"transfer\"][0][\"from\"])\n c.well(0).set_volume(\"100:microliter\")\n c.well(1).set_volume(\"0:microliter\")\n c.well(2).set_volume(\"100:microliter\")\n p.transfer(c.wells_from(0, 3), c.wells_from(3, 2), \"100:microliter\", one_source=True)\n\n def test_one_tip_true_gt_750(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-deep\", discard=True)\n p.transfer(c.well(0), c.well(1), \"1000:microliter\", one_tip=True)\n self.assertEqual(1, len(p.instructions[0].groups))\n\n def test_unit_conversion(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.transfer(c.well(0), c.well(1), \"200:nanoliter\")\n self.assertTrue(str(p.instructions[0].groups[0]['transfer'][0]['volume']) == \"0.2:microliter\")\n p.transfer(c.well(1), c.well(2), \".5:milliliter\", new_group=True)\n self.assertTrue(str(p.instructions[-1].groups[0]['transfer'][0]['volume']) == \"500.0:microliter\")\n\n def test_volume_rounding(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n c.well(0).set_volume(\"100.0000000000005:microliter\")\n c.well(1).set_volume(\"100:microliter\")\n p.transfer(c.wells_from(0, 2), c.wells_from(3, 3), \"50:microliter\", one_source=True)\n self.assertEqual(3, len(p.instructions[0].groups))\n\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n c.well(0).set_volume(\"50:microliter\")\n c.well(1).set_volume(\"101:microliter\")\n p.transfer(c.wells_from(0, 2), c.wells_from(3, 3), \"50.0000000000005:microliter\", one_source=True)\n self.assertEqual(3, len(p.instructions[0].groups))\n\n def test_mix_before_and_after(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n with self.assertRaises(RuntimeError):\n p.transfer(c.well(0), c.well(1), \"10:microliter\", mix_vol=\"15:microliter\")\n p.transfer(c.well(0), c.well(1), \"10:microliter\", repetitions_a=21)\n p.transfer(c.well(0), c.well(1), \"10:microliter\", repetitions=21)\n p.transfer(c.well(0), c.well(1), \"10:microliter\", repetitions_b=21)\n p.transfer(c.well(0), c.well(1), \"10:microliter\", flowrate_a=\"200:microliter/second\")\n p.transfer(c.well(0), c.well(1), \"12:microliter\", mix_after=True,\n mix_vol=\"10:microliter\", repetitions_a=20)\n self.assertTrue(int(p.instructions[-1].groups[0]['transfer'][0]['mix_after']['repetitions']) == 20)\n p.transfer(c.well(0), c.well(1), \"12:microliter\", mix_after=True,\n mix_vol=\"10:microliter\", repetitions_b=20)\n self.assertTrue(int(p.instructions[-1].groups[-1]['transfer'][0]['mix_after']['repetitions']) == 10)\n p.transfer(c.well(0), c.well(1), \"12:microliter\", mix_after=True)\n self.assertTrue(int(p.instructions[-1].groups[-1]['transfer'][0]['mix_after']['repetitions']) == 10)\n self.assertTrue(str(p.instructions[-1].groups[-1]['transfer'][0]['mix_after']['speed']) == \"100:microliter/second\")\n self.assertTrue(str(p.instructions[-1].groups[-1]['transfer'][0]['mix_after']['volume']) == \"6.0:microliter\")\n p.transfer(c.well(0), c.well(1), \"12:microliter\", mix_before=True,\n mix_vol=\"10:microliter\", repetitions_b=20)\n self.assertTrue(int(p.instructions[-1].groups[-1]['transfer'][-1]['mix_before']['repetitions']) == 20)\n p.transfer(c.well(0), c.well(1), \"12:microliter\", mix_before=True,\n mix_vol=\"10:microliter\", repetitions_a=20)\n self.assertTrue(int(p.instructions[-1].groups[-1]['transfer'][-1]['mix_before']['repetitions']) == 10)\n p.transfer(c.well(0), c.well(1), \"12:microliter\", mix_before=True)\n self.assertTrue(int(p.instructions[-1].groups[-1]['transfer'][-1]['mix_before']['repetitions']) == 10)\n self.assertTrue(str(p.instructions[-1].groups[-1]['transfer'][-1]['mix_before']['speed']) == \"100:microliter/second\")\n self.assertTrue(str(p.instructions[-1].groups[-1]['transfer'][-1]['mix_before']['volume']) == \"6.0:microliter\")\n\n def test_mix_false(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-deep\", discard=True)\n p.transfer(c.well(0), c.well(1), \"20:microliter\", mix_after=False)\n self.assertFalse(\"mix_after\" in p.instructions[0].groups[0][\"transfer\"][0])\n p.transfer(c.well(0), c.well(1), \"20:microliter\", mix_before=False)\n self.assertFalse(\"mix_before\" in p.instructions[0].groups[1][\"transfer\"][0])\n p.transfer(c.well(0), c.well(1), \"2000:microliter\", mix_after=False)\n for i in range(2, 5):\n self.assertFalse(\"mix_after\" in p.instructions[0].groups[i][\"transfer\"][0])\n p.transfer(c.well(0), c.well(1), \"2000:microliter\", mix_before=False)\n for i in range(5, 8):\n self.assertFalse(\"mix_before\" in p.instructions[0].groups[i][\"transfer\"][0])\n\n\nclass ConsolidateTestCase(unittest.TestCase):\n def test_multiple_sources(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n with self.assertRaises(TypeError):\n p.consolidate(c.wells_from(0, 3), c.wells_from(2, 3), \"10:microliter\")\n with self.assertRaises(ValueError):\n p.consolidate(c.wells_from(0, 3), c.well(4), [\"10:microliter\"])\n p.consolidate(c.wells_from(0, 3), c.well(4), \"10:microliter\")\n self.assertEqual(Unit(30, \"microliter\"), c.well(4).volume)\n self.assertEqual(3, len(p.instructions[0].groups[0][\"consolidate\"][\"from\"]))\n\n def test_one_source(self):\n p = Protocol()\n c = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.consolidate(c.well(0), c.well(4), \"30:microliter\")\n self.assertEqual(Unit(30, \"microliter\"), c.well(4).volume)\n\n\nclass StampTestCase(unittest.TestCase):\n def test_volume_tracking(self):\n p = Protocol()\n plate_96 = p.ref(\"plate_96\", None, \"96-pcr\", discard=True)\n plate_96_2 = p.ref(\"plate_96_2\", None, \"96-pcr\", discard=True)\n plate_384 = p.ref(\"plate_384\", None, \"384-pcr\", discard=True)\n plate_384_2 = p.ref(\"plate_384_2\", None, \"384-pcr\", discard=True)\n p.stamp(plate_96.well(0), plate_384.well(0), \"5:microliter\",\n {\"columns\": 12, \"rows\": 1})\n self.assertEqual(plate_384.well(0).volume, Unit(5, 'microliter'))\n self.assertTrue(plate_384.well(1).volume is None)\n p.stamp(plate_96.well(0), plate_96_2.well(0), \"10:microliter\",\n {\"columns\": 12, \"rows\": 1})\n p.stamp(plate_96.well(0), plate_96_2.well(0), \"10:microliter\",\n {\"columns\": 1, \"rows\": 8})\n self.assertTrue(plate_96_2.well(0).volume == Unit(20, \"microliter\"))\n for w in plate_96_2.wells_from(1, 11):\n self.assertTrue(w.volume == Unit(10, \"microliter\"))\n p.stamp(plate_96.well(0), plate_384_2.well(0), \"5:microliter\",\n {\"columns\": 1, \"rows\": 8})\n for w in plate_384_2.wells_from(0, 16, columnwise=True)[0::2]:\n self.assertTrue(w.volume == Unit(5, \"microliter\"))\n for w in plate_384_2.wells_from(1, 16, columnwise=True)[0::2]:\n self.assertTrue(w.volume is None)\n for w in plate_384_2.wells_from(1, 24)[0::2]:\n self.assertTrue(w.volume is None)\n plate_384_2.all_wells().set_volume(\"0:microliter\")\n p.stamp(plate_96.well(0), plate_384_2.well(0), \"15:microliter\", {\"columns\": 3, \"rows\": 8})\n self.assertEqual(plate_384_2.well(\"C3\").volume, Unit(15, \"microliter\"))\n self.assertEqual(plate_384_2.well(\"B2\").volume, Unit(0, \"microliter\"))\n\n def test_single_transfers(self):\n p = Protocol()\n plate_1_6 = p.ref(\"plate_1_6\", None, \"6-flat\", discard=True)\n plate_1_96 = p.ref(\"plate_1_96\", None, \"96-flat\", discard=True)\n plate_2_96 = p.ref(\"plate_2_96\", None, \"96-flat\", discard=True)\n plate_1_384 = p.ref(\"plate_1_384\", None, \"384-flat\", discard=True)\n plate_2_384 = p.ref(\"plate_2_384\", None, \"384-flat\", discard=True)\n p.stamp(plate_1_96.well(\"G1\"), plate_2_96.well(\"H1\"),\n \"10:microliter\", dict(rows=1, columns=12))\n p.stamp(plate_1_96.well(\"A1\"), plate_1_384.well(\"A2\"),\n \"10:microliter\", dict(rows=8, columns=2))\n # Verify full plate to full plate transfer works for 96, 384 container input\n p.stamp(plate_1_96, plate_2_96, \"10:microliter\")\n p.stamp(plate_1_384, plate_2_384, \"10:microliter\")\n\n with self.assertRaises(ValueError):\n p.stamp(plate_1_96.well(\"A1\"), plate_2_96.well(\"A2\"),\n \"10:microliter\", dict(rows=9, columns=1))\n with self.assertRaises(ValueError):\n p.stamp(plate_1_96.well(\"A1\"), plate_2_96.well(\"B1\"),\n \"10:microliter\", dict(rows=1, columns=13))\n with self.assertRaises(ValueError):\n p.stamp(plate_1_384.well(\"A1\"), plate_2_384.well(\"A2\"),\n \"10:microliter\", dict(rows=9, columns=1))\n with self.assertRaises(ValueError):\n p.stamp(plate_1_384.well(\"A1\"), plate_2_384.well(\"B1\"),\n \"10:microliter\", dict(rows=1, columns=13))\n with self.assertRaises(ValueError):\n p.stamp(plate_1_96.well(\"A1\"), plate_2_96.well(\"A2\"),\n \"10:microliter\", dict(rows=1, columns=12))\n with self.assertRaises(ValueError):\n p.stamp(plate_1_96.well(\"A1\"), plate_2_96.well(\"D1\"),\n \"10:microliter\", dict(rows=6, columns=12))\n\n def test_multiple_transfers(self):\n # Set maximum number of full plate transfers (limited by maximum\n # number of tip boxes)\n maxFullTransfers = 4\n\n # Test: Ensure individual transfers are appended one at a time\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(2)]\n\n for i in range(maxFullTransfers):\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\")\n self.assertEqual(i+1, len(p.instructions[0].groups))\n\n # Ensure new stamp operation overflows into new instruction\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\")\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(1, len(p.instructions[1].groups))\n\n # Test: Maximum number of containers on a deck\n maxContainers = 3\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(maxContainers+1)]\n\n for i in range(maxContainers-1):\n p.stamp(plateList[i], plateList[i+1], \"10:microliter\")\n self.assertEqual(1, len(p.instructions))\n self.assertEqual(maxContainers-1, len(p.instructions[0].groups))\n\n p.stamp(plateList[maxContainers-1].well(\"A1\"),\n plateList[maxContainers].well(\"A1\"), \"10:microliter\")\n self.assertEqual(2, len(p.instructions))\n\n # Test: Ensure col/row/full plate stamps are in separate instructions\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(2)]\n\n p.stamp(plateList[0].well(\"G1\"), plateList[1].well(\"G1\"),\n \"10:microliter\", dict(rows=1, columns=12))\n self.assertEqual(len(p.instructions), 1)\n p.stamp(plateList[0].well(\"G1\"), plateList[1].well(\"G1\"),\n \"10:microliter\", dict(rows=2, columns=12))\n self.assertEqual(len(p.instructions), 1)\n self.assertEqual(len(p.instructions[0].groups), 2)\n\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=2))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A12\"),\n \"10:microliter\", dict(rows=8, columns=1))\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(len(p.instructions[1].groups), 2)\n\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=12))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=12))\n self.assertEqual(len(p.instructions), 3)\n self.assertEqual(len(p.instructions[2].groups), 2)\n\n # Test: Check on max transfer limit - Full plate\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(2)]\n\n for i in range(maxFullTransfers):\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=12))\n self.assertEqual(len(p.instructions), 1)\n\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=12))\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(maxFullTransfers, len(p.instructions[0].groups))\n self.assertEqual(1, len(p.instructions[1].groups))\n\n # Test: Check on max transfer limit - Row-wise\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(2)]\n # Mixture of rows\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=3, columns=12))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=1, columns=12))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=2, columns=12))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=2, columns=12))\n self.assertEqual(len(p.instructions), 1)\n # Maximum number of row transfers\n for i in range(8):\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=1, columns=12))\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(len(p.instructions[0].groups), 4)\n self.assertEqual(len(p.instructions[1].groups), 8)\n # Overflow check\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=1, columns=12))\n self.assertEqual(len(p.instructions), 3)\n\n # Test: Check on max transfer limit - Col-wise\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(2)]\n # Mixture of columns\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=4))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=6))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=2))\n self.assertEqual(len(p.instructions), 1)\n # Maximum number of col transfers\n for i in range(12):\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=1))\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(len(p.instructions[0].groups), 3)\n self.assertEqual(len(p.instructions[1].groups), 12)\n\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"10:microliter\", dict(rows=8, columns=1))\n self.assertEqual(len(p.instructions), 3)\n\n # Test: Check on switching between tip volume types\n p = Protocol()\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\",\n discard=True) for x in range(2)]\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"31:microliter\")\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"31:microliter\")\n self.assertEqual(len(p.instructions), 1)\n self.assertEqual(2, len(p.instructions[0].groups))\n\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"90:microliter\")\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(2, len(p.instructions[0].groups))\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"90:microliter\")\n self.assertEqual(len(p.instructions), 2)\n self.assertEqual(2, len(p.instructions[1].groups))\n\n p.stamp(plateList[0].well(\"A1\"), plateList[1].well(\"A1\"),\n \"31:microliter\")\n self.assertEqual(len(p.instructions), 3)\n\n def test_one_tip(self):\n\n p = Protocol()\n plateCount = 2\n plateList = [p.ref(\"plate_%s_384\" % str(x+1), None, \"384-flat\", discard=True) for x in range(plateCount)]\n p.stamp(plateList[0], plateList[1], \"330:microliter\", one_tip=True)\n self.assertEqual(len(p.instructions[0].groups[0][\"transfer\"]), 12)\n self.assertEqual(len(p.instructions[0].groups), 1)\n\n def test_one_tip_variable_volume(self):\n\n p = Protocol()\n plateCount = 2\n plateList = [p.ref(\"plate_%s_384\" % str(x+1), None, \"384-flat\", discard=True) for x in range(plateCount)]\n with self.assertRaises(RuntimeError):\n p.stamp(WellGroup([plateList[0].well(0), plateList[0].well(1)]), WellGroup([plateList[1].well(0), plateList[1].well(1)]), [\"20:microliter\", \"90:microliter\"], one_tip=True)\n p.stamp(WellGroup([plateList[0].well(0), plateList[0].well(1)]), WellGroup([plateList[1].well(0), plateList[1].well(1)]), [\"20:microliter\", \"90:microliter\"], mix_after=True, mix_vol=\"40:microliter\", one_tip=True)\n self.assertEqual(len(p.instructions[0].groups[0][\"transfer\"]), 2)\n self.assertEqual(len(p.instructions[0].groups), 1)\n\n def test_wellgroup(self):\n p = Protocol()\n plateCount = 2\n plateList = [p.ref(\"plate_%s_384\" % str(x+1), None, \"384-flat\", discard=True) for x in range(plateCount)]\n p.stamp(plateList[0].wells(list(range(12))), plateList[1].wells(list(range(12))), \"30:microliter\", shape={\"rows\": 8, \"columns\": 1})\n self.assertEqual(len(p.instructions[0].groups), 12)\n\n def test_gt_148uL_transfer(self):\n p = Protocol()\n plateCount = 2\n plateList = [p.ref(\"plate_%s_96\" % str(x+1), None, \"96-flat\", discard=True) for x in range(plateCount)]\n p.stamp(plateList[0], plateList[1], \"296:microliter\")\n self.assertEqual(2, len(p.instructions[0].groups))\n self.assertEqual(\n Unit(148, 'microliter'),\n p.instructions[0].groups[0]['transfer'][0]['volume']\n )\n self.assertEqual(\n Unit(148, 'microliter'),\n p.instructions[0].groups[1]['transfer'][0]['volume']\n )\n\n def test_one_source(self):\n p = Protocol()\n plateCount = 2\n plateList = [p.ref(\"plate_%s_384\" % str(x+1), None, \"384-flat\", discard=True) for x in range(plateCount)]\n with self.assertRaises(RuntimeError):\n p.stamp(plateList[0].wells(list(range(4))), plateList[1].wells(list(range(12))), \"30:microliter\", shape={\"rows\": 8, \"columns\": 1}, one_source=True)\n plateList[0].wells_from(0, 64, columnwise=True).set_volume(\"10:microliter\")\n with self.assertRaises(RuntimeError):\n p.stamp(plateList[0].wells(list(range(4))), plateList[1].wells(list(range(12))), \"30:microliter\", shape={\"rows\": 8, \"columns\": 1}, one_source=True)\n plateList[0].wells_from(0, 64, columnwise=True).set_volume(\"15:microliter\")\n p.stamp(plateList[0].wells(list(range(4))), plateList[1].wells(list(range(12))), \"5:microliter\", shape={\"rows\": 8, \"columns\": 1}, one_source=True)\n self.assertEqual(len(p.instructions[0].groups), 12)\n\nclass RefifyTestCase(unittest.TestCase):\n def test_refifying_various(self):\n p = Protocol()\n # refify container\n refs = {\"plate\": p.ref(\"test\", None, \"96-flat\", \"cold_20\")}\n self.assertEqual(p._refify(refs[\"plate\"]), \"test\")\n # refify dict\n self.assertEqual(p._refify(refs), {\"plate\": \"test\"})\n\n # refify Well\n well = refs[\"plate\"].well(\"A1\")\n self.assertEqual(p._refify(well), \"test/0\")\n\n # refify WellGroup\n wellgroup = refs[\"plate\"].wells_from(\"A2\", 3)\n self.assertEqual(p._refify(wellgroup), [\"test/1\", \"test/2\", \"test/3\"])\n\n # refify other\n s = \"randomstring\"\n i = 24\n self.assertEqual(\"randomstring\", p._refify(s))\n self.assertEqual(24, p._refify(i))\n\nclass OutsTestCase(unittest.TestCase):\n def test_outs(self):\n p = Protocol()\n self.assertFalse('outs' in p.as_dict())\n plate = p.ref(\"plate\", None, \"96-pcr\", discard=True)\n plate.well(0).set_name(\"test_well\")\n plate.well(0).set_properties({\"test\": \"foo\"})\n self.assertTrue(plate.well(0).name == \"test_well\")\n self.assertTrue(list(p.as_dict()['outs'].keys()) == ['plate'])\n self.assertTrue(list(list(p.as_dict()['outs'].values())[0].keys()) == ['0'])\n self.assertTrue(list(p.as_dict()['outs'].values())[0]['0']['name'] == 'test_well')\n self.assertTrue(list(p.as_dict()['outs'].values())[0]['0']['properties']['test'] == 'foo')\n\n\nclass AbsorbanceTestCase(unittest.TestCase):\n def test_single_well(self):\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\",\n \"test_reading\")\n self.assertTrue(isinstance(p.instructions[0].wells, list))\n\n def test_temperature(self):\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\",\n \"test_reading\", temperature=\"30:celsius\")\n self.assertEqual(p.instructions[0].temperature, \"30:celsius\")\n\n def test_incubate(self):\n from autoprotocol.util import incubate_params\n\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\",\n \"test_reading\",\n incubate_before=incubate_params(\n \"10:second\",\n \"3:millimeter\",\n True\n )\n )\n\n self.assertEqual(p.instructions[0].incubate_before[\"shaking\"][\"orbital\"], True)\n self.assertEqual(p.instructions[0].incubate_before[\"shaking\"][\"amplitude\"], \"3:millimeter\")\n self.assertEqual(p.instructions[0].incubate_before[\"duration\"], \"10:second\")\n\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\",\n \"test_reading\",\n incubate_before=incubate_params(\"10:second\"))\n\n self.assertFalse(\"shaking\" in p.instructions[1].incubate_before)\n self.assertEqual(p.instructions[1].incubate_before[\"duration\"], \"10:second\")\n\n with self.assertRaises(ValueError):\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\", \"test_reading\", incubate_before=incubate_params(\"10:second\", \"-3:millimeter\", True))\n\n with self.assertRaises(ValueError):\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\", \"test_reading\", incubate_before=incubate_params(\"10:second\", \"3:millimeter\", \"foo\"))\n\n with self.assertRaises(ValueError):\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\", \"test_reading\", incubate_before=incubate_params(\"-10:second\", \"3:millimeter\", True))\n\n with self.assertRaises(RuntimeError):\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\", \"test_reading\", incubate_before=incubate_params(\"10:second\", \"3:millimeter\"))\n\n with self.assertRaises(RuntimeError):\n p.absorbance(test_plate, test_plate.well(0), \"475:nanometer\", \"test_reading\", incubate_before=incubate_params(\"10:second\", shake_orbital=True))\n\n\nclass FluorescenceTestCase(unittest.TestCase):\n def test_single_well(self):\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.fluorescence(test_plate, test_plate.well(0),\n excitation=\"587:nanometer\", emission=\"610:nanometer\",\n dataref=\"test_reading\")\n self.assertTrue(isinstance(p.instructions[0].wells, list))\n\n def test_temperature(self):\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.fluorescence(test_plate, test_plate.well(0), excitation=\"587:nanometer\", emission=\"610:nanometer\", dataref=\"test_reading\", temperature=\"30:celsius\")\n self.assertEqual(p.instructions[0].temperature, \"30:celsius\")\n\n def test_incubate(self):\n from autoprotocol.util import incubate_params\n\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.fluorescence(test_plate, test_plate.well(0),\n excitation=\"587:nanometer\", emission=\"610:nanometer\",\n dataref=\"test_reading\",\n incubate_before=incubate_params(\"10:second\",\n \"3:millimeter\",\n True))\n\n self.assertEqual(p.instructions[0].incubate_before[\"shaking\"][\"orbital\"], True)\n self.assertEqual(p.instructions[0].incubate_before[\"shaking\"][\"amplitude\"], \"3:millimeter\")\n self.assertEqual(p.instructions[0].incubate_before[\"duration\"], \"10:second\")\n\n p.fluorescence(test_plate, test_plate.well(0),\n excitation=\"587:nanometer\", emission=\"610:nanometer\",\n dataref=\"test_reading\",\n incubate_before=incubate_params(\"10:second\"))\n\n self.assertFalse(\"shaking\" in p.instructions[1].incubate_before)\n self.assertEqual(p.instructions[1].incubate_before[\"duration\"], \"10:second\")\n\n with self.assertRaises(ValueError):\n p.fluorescence(test_plate, test_plate.well(0), excitation=\"587:nanometer\", emission=\"610:nanometer\", dataref=\"test_reading\", incubate_before=incubate_params(\"10:second\", \"-3:millimeter\", True))\n\n with self.assertRaises(ValueError):\n p.fluorescence(test_plate, test_plate.well(0), excitation=\"587:nanometer\", emission=\"610:nanometer\", dataref=\"test_reading\", incubate_before=incubate_params(\"10:second\", \"3:millimeter\", \"foo\"))\n\n with self.assertRaises(ValueError):\n p.fluorescence(test_plate, test_plate.well(0), excitation=\"587:nanometer\", emission=\"610:nanometer\", dataref=\"test_reading\", incubate_before=incubate_params(\"-10:second\", \"3:millimeter\", True))\n\n with self.assertRaises(RuntimeError):\n p.fluorescence(test_plate, test_plate.well(0), excitation=\"587:nanometer\", emission=\"610:nanometer\", dataref=\"test_reading\", incubate_before=incubate_params(\"10:second\", \"3:millimeter\"))\n\n with self.assertRaises(RuntimeError):\n p.fluorescence(test_plate, test_plate.well(0), excitation=\"587:nanometer\", emission=\"610:nanometer\", dataref=\"test_reading\", incubate_before=incubate_params(\"10:second\", shake_orbital=True))\n\n\nclass LuminescenceTestCase(unittest.TestCase):\n def test_single_well(self):\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\")\n self.assertTrue(isinstance(p.instructions[0].wells, list))\n\n def test_temperature(self):\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\", temperature=\"30:celsius\")\n self.assertEqual(p.instructions[0].temperature, \"30:celsius\")\n\n def test_incubate(self):\n from autoprotocol.util import incubate_params\n\n p = Protocol()\n test_plate = p.ref(\"test\", None, \"96-flat\", discard=True)\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\",\n incubate_before=incubate_params(\"10:second\",\n \"3:millimeter\",\n True))\n\n self.assertEqual(p.instructions[0].incubate_before[\"shaking\"][\"orbital\"], True)\n self.assertEqual(p.instructions[0].incubate_before[\"shaking\"][\"amplitude\"], \"3:millimeter\")\n self.assertEqual(p.instructions[0].incubate_before[\"duration\"], \"10:second\")\n\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\",\n incubate_before=incubate_params(\"10:second\"))\n\n self.assertFalse(\"shaking\" in p.instructions[1].incubate_before)\n self.assertEqual(p.instructions[1].incubate_before[\"duration\"], \"10:second\")\n\n with self.assertRaises(ValueError):\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\", incubate_before=incubate_params(\"10:second\", \"-3:millimeter\", True))\n\n with self.assertRaises(ValueError):\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\", incubate_before=incubate_params(\"10:second\", \"3:millimeter\", \"foo\"))\n\n with self.assertRaises(ValueError):\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\", incubate_before=incubate_params(\"-10:second\", \"3:millimeter\", True))\n\n with self.assertRaises(RuntimeError):\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\", incubate_before=incubate_params(\"10:second\", \"3:millimeter\"))\n\n with self.assertRaises(RuntimeError):\n p.luminescence(test_plate, test_plate.well(0), \"test_reading\", incubate_before=incubate_params(\"10:second\", shake_orbital=True))\n\n\nclass AcousticTransferTestCase(unittest.TestCase):\n def test_append(self):\n p = Protocol()\n echo = p.ref(\"echo\", None, \"384-echo\", discard=True)\n dest = p.ref(\"dest\", None, \"384-flat\", discard=True)\n dest2 = p.ref(\"dest2\", None, \"384-flat\", discard=True)\n p.acoustic_transfer(echo.well(0), dest.wells(1,3,5), \"25:microliter\")\n self.assertTrue(len(p.instructions) == 1)\n p.acoustic_transfer(echo.well(0), dest.wells(0,2,4), \"25:microliter\")\n self.assertTrue(len(p.instructions) == 1)\n p.acoustic_transfer(echo.well(0), dest.wells(0,2,4), \"25:microliter\",\n droplet_size=\"0.50:microliter\")\n self.assertTrue(len(p.instructions) == 2)\n p.acoustic_transfer(echo.well(0), dest2.wells(0,2,4), \"25:microliter\")\n self.assertTrue(len(p.instructions) == 3)\n\n def test_one_source(self):\n p = Protocol()\n echo = p.ref(\"echo\", None, \"384-echo\", discard=True)\n dest = p.ref(\"dest\", None, \"384-flat\", discard=True)\n p.acoustic_transfer(echo.wells(0,1).set_volume(\"2:microliter\"),\n dest.wells(0,1,2,3), \"1:microliter\", one_source=True)\n self.assertTrue(p.instructions[-1].data[\"groups\"][0][\"transfer\"][-1][\"from\"] == echo.well(1))\n self.assertTrue(p.instructions[-1].data[\"groups\"][0][\"transfer\"][0][\"from\"] == echo.well(0))\n\nclass MagneticTransferTestCase(unittest.TestCase):\n\n def test_head_type(self):\n p = Protocol()\n pcr = p.ref(\"pcr\", None, \"96-pcr\", discard=True)\n\n with self.assertRaises(ValueError):\n p.mag_dry(\"96-flat\", pcr, \"30:minute\", new_tip=False, new_instruction=False)\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=False, new_instruction=False)\n self.assertEqual(len(p.instructions), 1)\n\n def test_head_compatibility(self):\n p = Protocol()\n\n pcrs = [p.ref(\"pcr_%s\" % cont_type, None, cont_type, discard=True) for cont_type in [\"96-pcr\", \"96-v-kf\", \"96-flat\", \"96-flat-uv\"]]\n deeps = [p.ref(\"deep_%s\" % cont_type, None, cont_type, discard=True) for cont_type in [\"96-v-kf\", \"96-deep-kf\", \"96-deep\"]]\n\n for i, pcr in enumerate(pcrs):\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=False, new_instruction=False)\n self.assertEqual(len(p.instructions[-1].groups[0]), i+1)\n\n for i, deep in enumerate(deeps):\n if i == 0:\n n_i = True\n else:\n n_i = False\n p.mag_dry(\"96-deep\", deep, \"30:minute\", new_tip=False, new_instruction=n_i)\n self.assertEqual(len(p.instructions[-1].groups[0]), i+1)\n\n bad_pcrs = [p.ref(\"bad_pcr_%s\" % cont_type, None, cont_type, discard=True) for cont_type in [\"96-pcr\"]]\n bad_deeps = [p.ref(\"bad_deep_%s\" % cont_type, None, cont_type, discard=True) for cont_type in [\"96-deep-kf\", \"96-deep\"]]\n\n for pcr in bad_pcrs:\n with self.assertRaises(ValueError):\n p.mag_dry(\"96-deep\", pcr, \"30:minute\", new_tip=False, new_instruction=False)\n\n for deep in bad_deeps:\n with self.assertRaises(ValueError):\n p.mag_dry(\"96-pcr\", deep, \"30:minute\", new_tip=False, new_instruction=False)\n\n def test_temperature_valid(self):\n p = Protocol()\n\n pcr = p.ref(\"pcr\", None, \"96-pcr\", discard=True)\n\n for i in range(27, 96):\n p.mag_incubate(\"96-pcr\", pcr, \"30:minute\", temperature=\"%s:celsius\" % i)\n self.assertEqual(len(p.instructions[-1].groups[0]), i-26)\n\n for i in range(-300, -290):\n with self.assertRaises(ValueError):\n p.mag_incubate(\"96-pcr\", pcr, \"30:minute\", temperature=\"%s:celsius\" % i)\n\n def test_frequency_valid(self):\n p = Protocol()\n\n pcr = p.ref(\"pcr\", None, \"96-pcr\", discard=True)\n\n for i in range(27, 96):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"%s:hertz\" % i, center=1, amplitude=0)\n self.assertEqual(len(p.instructions[-1].groups[0]), i-26)\n\n for i in range(-10, -5):\n with self.assertRaises(ValueError):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"%s:hertz\" % i, center=1, amplitude=0)\n\n def test_magnetize_valid(self):\n p = Protocol()\n\n pcr = p.ref(\"pcr\", None, \"96-pcr\", discard=True)\n\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=1, amplitude=0, magnetize=True)\n self.assertEqual(len(p.instructions[-1].groups[0]), 1)\n\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=1, amplitude=0, magnetize=False)\n self.assertEqual(len(p.instructions[-1].groups[0]), 2)\n\n with self.assertRaises(ValueError):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=1, amplitude=0, magnetize=\"Foo\")\n\n def test_center_valid(self):\n p = Protocol()\n\n pcr = p.ref(\"pcr\", None, \"96-pcr\", discard=True)\n\n for i in range(0, 200):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=float(i)/100, amplitude=0)\n self.assertEqual(len(p.instructions[-1].groups[0]), i*4+1)\n p.mag_collect(\"96-pcr\", pcr, 5, \"30:second\", bottom_position=float(i)/100)\n self.assertEqual(len(p.instructions[-1].groups[0]), i*4+2)\n p.mag_incubate(\"96-pcr\", pcr, \"30:minute\", tip_position=float(i)/100)\n self.assertEqual(len(p.instructions[-1].groups[0]), i*4+3)\n p.mag_release(\"96-pcr\", pcr, \"30:second\", \"1:hertz\", center=float(i)/100, amplitude=0)\n self.assertEqual(len(p.instructions[-1].groups[0]), i*4+4)\n\n for i in range(-1, 3, 4):\n with self.assertRaises(ValueError):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=i, amplitude=0)\n with self.assertRaises(ValueError):\n p.mag_collect(\"96-pcr\", pcr, 5, \"30:second\", bottom_position=i)\n with self.assertRaises(ValueError):\n p.mag_incubate(\"96-pcr\", pcr, \"30:minute\", tip_position=i)\n with self.assertRaises(ValueError):\n p.mag_release(\"96-pcr\", pcr, \"30:second\", \"1:hertz\", center=i, amplitude=0)\n\n def test_amplitude_valid(self):\n p = Protocol()\n\n pcr = p.ref(\"pcr\", None, \"96-pcr\", discard=True)\n\n for i in range(0, 100):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=1, amplitude=float(i)/100)\n self.assertEqual(len(p.instructions[-1].groups[0]), i*2+1)\n p.mag_release(\"96-pcr\", pcr, \"30:second\", \"1:hertz\", center=1, amplitude=float(i)/100)\n self.assertEqual(len(p.instructions[-1].groups[0]), i*2+2)\n\n for i in range(-1, 2, 3):\n with self.assertRaises(ValueError):\n p.mag_mix(\"96-pcr\", pcr, \"30:second\", \"60:hertz\", center=1, amplitude=i)\n with self.assertRaises(ValueError):\n p.mag_release(\"96-pcr\", pcr, \"30:second\", \"1:hertz\", center=1, amplitude=i)\n\n def test_mag_append(self):\n p = Protocol()\n\n pcrs = [p.ref(\"pcr_%s\" % i, None, \"96-pcr\", storage=\"cold_20\") for i in range(7)]\n\n pcr = pcrs[0]\n\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=False, new_instruction=False)\n self.assertEqual(len(p.instructions[-1].groups[0]), 1)\n self.assertEqual(len(p.instructions[-1].groups), 1)\n\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=True, new_instruction=False)\n self.assertEqual(len(p.instructions[-1].groups), 2)\n self.assertEqual(len(p.instructions), 1)\n\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=True, new_instruction=True)\n self.assertEqual(len(p.instructions), 2)\n\n for plate in pcrs:\n p.mag_dry(\"96-pcr\", plate, \"30:minute\", new_tip=False, new_instruction=False)\n self.assertEqual(len(p.instructions), 2)\n\n with self.assertRaises(RuntimeError):\n pcr_too_many = p.ref(\"pcr_7\", None, \"96-pcr\", discard=True)\n p.mag_dry(\"96-pcr\", pcr_too_many, \"30:minute\", new_tip=False, new_instruction=False)\n\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=True, new_instruction=True)\n self.assertEqual(len(p.instructions), 3)\n\n p.mag_dry(\"96-pcr\", pcr, \"30:minute\", new_tip=True, new_instruction=False)\n self.assertEqual(len(p.instructions[-1].groups), 2)\n\n with self.assertRaises(RuntimeError):\n for plate in pcrs:\n p.mag_dry(\"96-pcr\", plate, \"30:minute\", new_tip=False, new_instruction=False)\n\n\nclass AutopickTestCase(unittest.TestCase):\n\n def test_autopick(self):\n p = Protocol()\n dest_plate = p.ref(\"dest\", None, \"96-flat\", discard=True)\n\n p.refs[\"agar_plate\"] = Ref(\"agar_plate\", {\"reserve\": \"ki17reefwqq3sq\", \"discard\": True}, Container(None, p.container_type(\"6-flat\"), name=\"agar_plate\"))\n\n agar_plate = Container(None, p.container_type(\"6-flat\"), name=\"agar_plate\")\n\n p.refs[\"agar_plate_1\"] = Ref(\"agar_plate_1\", {\"reserve\": \"ki17reefwqq3sq\", \"discard\": True}, Container(None, p.container_type(\"6-flat\"), name=\"agar_plate_1\"))\n\n agar_plate_1 = Container(None, p.container_type(\"6-flat\"), name=\"agar_plate_1\")\n\n p.autopick([agar_plate.well(0), agar_plate.well(1)], [dest_plate.well(1)]*4, min_abort=0, dataref=\"0\", newpick=False)\n\n self.assertEqual(len(p.instructions), 1)\n self.assertEqual(len(p.instructions[0].groups), 1)\n self.assertEqual(len(p.instructions[0].groups[0][\"from\"]), 2)\n\n p.autopick([agar_plate.well(0), agar_plate.well(1)], [dest_plate.well(1)]*4, min_abort=0, dataref=\"1\", newpick=True)\n\n self.assertEqual(len(p.instructions), 2)\n\n p.autopick([agar_plate.well(0), agar_plate.well(1)], [dest_plate.well(1)]*4, min_abort=0, dataref=\"1\", newpick=False)\n\n self.assertEqual(len(p.instructions), 2)\n\n for i in range(20):\n p.autopick([agar_plate.well(i % 6), agar_plate.well((i+1) % 6)], [dest_plate.well(i % 96)]*4, min_abort=i, dataref=\"1\", newpick=False)\n\n self.assertEqual(len(p.instructions), 2)\n\n p.autopick([agar_plate_1.well(0), agar_plate_1.well(1)], [dest_plate.well(1)]*4, min_abort=0, dataref=\"1\", newpick=False)\n\n self.assertEqual(len(p.instructions), 3)\n\n p.autopick([agar_plate_1.well(0), agar_plate_1.well(1)], [dest_plate.well(1)]*4, min_abort=0, dataref=\"2\", newpick=False)\n\n self.assertEqual(len(p.instructions), 4)\n\n with self.assertRaises(RuntimeError):\n p.autopick([agar_plate.well(0), agar_plate_1.well(1)], [dest_plate.well(1)]*4, min_abort=0, dataref=\"1\", newpick=False)\n\n\nclass MeasureConcentrationTestCase(unittest.TestCase):\n def test_measure_concentration_single_well(self):\n p = Protocol()\n test_plate = p.ref(\"test_plate\", id=None, cont_type=\"96-flat\", storage=None, discard=True)\n for well in test_plate.all_wells():\n well.set_volume(\"150:microliter\")\n p.measure_concentration(wells=test_plate.well(0), dataref=\"mc_test\", measurement=\"DNA\", volume=Unit(2, \"microliter\"))\n self.assertEqual(len(p.instructions), 1)\n\n def test_measure_concentration_multi_well(self):\n p = Protocol()\n test_plate = p.ref(\"test_plate\", id=None, cont_type=\"96-flat\", storage=None, discard=True)\n for well in test_plate.all_wells():\n well.set_volume(\"150:microliter\")\n p.measure_concentration(wells=test_plate.wells_from(0, 96), dataref=\"mc_test\", measurement=\"DNA\", volume=Unit(2, \"microliter\"))\n self.assertEqual(len(p.instructions), 1)\n\n def test_measure_concentration_multi_sample_class(self):\n sample_classes = [\"ssDNA\", \"DNA\", \"RNA\", \"protein\"]\n p = Protocol()\n test_plate = p.ref(\"test_plate\", id=None, cont_type=\"96-flat\", storage=None, discard=True)\n for well in test_plate.all_wells():\n well.set_volume(\"150:microliter\")\n for i, sample_class in enumerate(sample_classes):\n p.measure_concentration(wells=test_plate.well(i), dataref=\"mc_test_%s\" % sample_class, measurement=sample_class, volume=Unit(2, \"microliter\"))\n self.assertEqual(p.as_dict()[\"instructions\"][i][\"measurement\"], sample_class)\n self.assertEqual(len(p.instructions), 4)\n"
},
{
"alpha_fraction": 0.6170088052749634,
"alphanum_fraction": 0.6170088052749634,
"avg_line_length": 21.57615852355957,
"blob_id": "14ea69b68d1a21f4c245b778a5bf6393903a0d28",
"content_id": "4625cd9a7892f5aad5e87a4dc336d8f480be158e",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-generic-cla",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 6820,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 302,
"path": "/docs/autoprotocol.rst",
"repo_name": "rafwiewiora/autoprotocol-python",
"src_encoding": "UTF-8",
"text": "============\nautoprotocol\n============\n\nautoprotocol.protocol\n---------------------\n\nprotocol.Protocol\n~~~~~~~~~~~~~~~~~\n\n.. autoclass:: autoprotocol.protocol.Protocol\n\nProtocol.container_type()\n^^^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.container_type\n\nProtocol.ref()\n^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.ref\n\n\nProtocol.append()\n^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.append\n\nProtocol.as_dict()\n^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.as_dict\n\nProtocol.distribute()\n^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.distribute\n\nProtocol.transfer()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.transfer\n\nProtocol.consolidate()\n^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.consolidate\n\nProtocol.dispense()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.dispense\n\nProtocol.dispense_full_plate()\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.dispense_full_plate\n\nProtocol.stamp()\n^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.stamp\n\nProtocol.sangerseq()\n^^^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.sangerseq\n\nProtocol.mix()\n^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.mix\n\nProtocol.spin()\n^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.spin\n\nProtocol.thermocycle()\n^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.thermocycle\n\nProtocol.incubate()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.incubate\n\nProtocol.absorbance()\n^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.absorbance\n\nProtocol.fluorescence()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.fluorescence\n\nProtocol.luminescence()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.luminescence\n\nProtocol.gel_separate()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.gel_separate\n\nProtocol.seal()\n^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.seal\n\nProtocol.unseal()\n^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.unseal\n\nProtocol.cover()\n^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.cover\n\nProtocol.uncover()\n^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.uncover\n\nProtocol.flow_analyze()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.flow_analyze\n\nProtocol.oligosynthesize()\n^^^^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.oligosynthesize\n\nProtocol.spread()\n^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.spread\n\nProtocol.autopick()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.autopick\n\nProtocol.image_plate()\n^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.image_plate\n\nProtocol.provision()\n^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.provision\n\nProtocol.flash_freeze()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.protocol.Protocol.flash_freeze\n\nprotocol.Ref\n~~~~~~~~~~~~\n\n.. autoclass:: autoprotocol.protocol.Ref\n\n\nautoprotocol.container\n----------------------\n\ncontainer.Container\n~~~~~~~~~~~~~~~~~~~\n.. autoclass:: autoprotocol.container.Container\n\nContainer.well()\n^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.well\n\nContainer.wells()\n^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.wells\n\nContainer.robotize()\n^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.robotize\n\nContainer.humanize()\n^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.humanize\n\nContainer.decompose()\n^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.decompose\n\nContainer.all_wells()\n^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.all_wells\n\nContainer.wells_from()\n^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.wells_from\n\nContainer.inner_wells()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Container.inner_wells\n\ncontainer.Well\n~~~~~~~~~~~~~~\n.. autoclass:: autoprotocol.container.Well\n\nWell.set_properties()\n^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Well.set_properties\n\nWell.add_properties()\n^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Well.add_properties\n\nWell.set_volume()\n^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Well.set_volume\n\nWell.humanize()\n^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Well.humanize\n\nWell.__repr__()\n^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.Well.__repr__\n\ncontainer.WellGroup\n~~~~~~~~~~~~~~~~~~~\n.. autoclass:: autoprotocol.container.WellGroup\n\nWellGroup.set_properties()\n^^^^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.set_properties\n\nWellGroup.indices()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.indices\n\nWellGroup.append()\n^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.append\n\nWellGroup.__getitem__()\n^^^^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.__getitem__\n\nWellGroup.__len__()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.__len__\n\nWellGroup.__repr__()\n^^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.__repr__\n\nWellGroup.__add__()\n^^^^^^^^^^^^^^^^^^^\n.. automethod:: autoprotocol.container.WellGroup.__add__\n\nautoprotocol.container_type\n---------------------------\n\ncontainer_type.ContainerType\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n.. autoclass:: autoprotocol.container_type.ContainerType\n\nContainerType.robotize()\n^^^^^^^^^^^^^^^^^^^^^^^^\n\n.. automethod:: autoprotocol.container_type.ContainerType.robotize\n\nContainerType.humanize()\n^^^^^^^^^^^^^^^^^^^^^^^^\n\n.. automethod:: autoprotocol.container_type.ContainerType.humanize\n\nContainerType.decompose()\n^^^^^^^^^^^^^^^^^^^^^^^^^\n\n.. automethod:: autoprotocol.container_type.ContainerType.decompose\n\nContainerType.row_count()\n^^^^^^^^^^^^^^^^^^^^^^^^^\n\n.. automethod:: autoprotocol.container_type.ContainerType.row_count\n\n\nautoprotocol.unit\n-----------------\n\nunit.Unit\n~~~~~~~~~\n\n.. autoclass:: autoprotocol.unit.Unit\n\nUnit.fromstring()\n^^^^^^^^^^^^^^^^^\n\n.. automethod:: autoprotocol.unit.Unit.fromstring\n\n\nautoprotocol.util\n-----------------\n\nutil.make_dottable_dict\n~~~~~~~~~~~~~~~~~~~~~~~\n\n.. autoclass:: autoprotocol.util.make_dottable_dict\n\nutil.deep_merge_params()\n~~~~~~~~~~~~~~~~~~~~~~~~\n\n.. autofunction:: autoprotocol.util.deep_merge_params\n\nautoprotocol.harness\n--------------------\n\nharness.run()\n~~~~~~~~~~~~~\n\n.. autofunction:: autoprotocol.harness.run\n\nharness.Manifest\n~~~~~~~~~~~~~~~~\n\n.. autoclass:: autoprotocol.harness.Manifest\n\n\n"
},
{
"alpha_fraction": 0.6259739995002747,
"alphanum_fraction": 0.6415584683418274,
"avg_line_length": 23.0625,
"blob_id": "f2390f2fe6a58b09cab53d0d164d4e7aab268da0",
"content_id": "332787dd3171fa982ca7cae890fd91d895763402",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-generic-cla",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 16,
"path": "/setup.py",
"repo_name": "rafwiewiora/autoprotocol-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom setuptools import setup\n\nsetup(\n name='autoprotocol',\n url='http://github.com/autoprotocol/autoprotocol-python',\n author='Vanessa Biggers',\n description='Python library for generating Autoprotocol',\n author_email=\"[email protected]\",\n version='3.0.0',\n test_suite='test',\n install_requires=[\n 'Pint>=0.7.2'\n ],\n packages=['autoprotocol']\n)\n"
},
{
"alpha_fraction": 0.538922131061554,
"alphanum_fraction": 0.5508981943130493,
"avg_line_length": 11.84615421295166,
"blob_id": "ef3aaf018a6702cf2358f6786fddec66722cbe8a",
"content_id": "00356997b9a33a1d555b96803c1f63d8e1a62045",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-generic-cla",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 167,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 13,
"path": "/docs/_build/html/_sources/AUTHORS.txt",
"repo_name": "rafwiewiora/autoprotocol-python",
"src_encoding": "UTF-8",
"text": "=======\nCredits\n=======\n\n\nContributors\n------------\n\n* Tali Herzka <https://github.com/therzka>\n\n* Jeremy Apthorp <https://github.com/nornagon>\n\n* Christopher Beitel <https://github.com/cb01>\n"
}
] | 5 |
leonsp95/BuscaDDD
|
https://github.com/leonsp95/BuscaDDD
|
781b45553f7aa814f907c3ecd66857b165fa3d06
|
e5ee81cd283816265e5a5c07a3fae36dbb7c2d1e
|
8a3d3a48104305da8fd05976ad4be95cca69be9a
|
refs/heads/main
| 2023-07-07T11:25:37.150648 | 2021-08-18T18:32:24 | 2021-08-18T18:32:24 | 385,733,691 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3453815281391144,
"alphanum_fraction": 0.4100847840309143,
"avg_line_length": 37.63793182373047,
"blob_id": "d4e6529df74a05d81793d203023fe8a2aa9b8171",
"content_id": "aa5c1df16772c6378b9cc91b204fc3998b120b46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2262,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 58,
"path": "/BuscaDDD_(PyVersion).py",
"repo_name": "leonsp95/BuscaDDD",
"src_encoding": "UTF-8",
"text": "import re\n\nopcao = True\ndddTel = 0\nwhile opcao == True:\n regexTel = r\"^(\\+55)?[\\s]?\\(?(\\d{2})?\\)?[\\s-]?(9?\\d{4}[\\s-]?\\d{4})$\"\n retornoEstado=\"\"\n DDDs = {'Acre': [68],\n 'Alagoas' : [82],\n 'Amazonas' : [92, 97],\n 'Amapá' : [96],\n 'Bahia' : [71, 73, 74, 75, 77],\n 'Ceará' : [85, 88],\n 'Distrito Federal' : [61],\n 'Espírito Santo' : [27, 28],\n 'Goiás' : [62, 64],\n 'Maranhão' : [98, 99],\n 'Minas Gerais' : [31, 32, 33, 34, 35, 37, 38],\n 'Mato Grosso do Sul' : [67],\n 'Mato Grosso' : [65, 66],\n 'Pará' : [91, 93, 94],\n 'Paraíba' : [83],\n 'Pernambuco' : [81, 87],\n 'Piauí' : [86, 89],\n 'Paraná' : [41, 42, 43, 44, 45, 46],\n 'Rio de Janeiro' : [21, 22, 24],\n 'Rio Grande do Norte' : [84],\n 'Rondônia' : [69],\n 'Roraima' : [95],\n 'Rio Grande do Sul' : [51, 53, 54, 55],\n 'Santa Catarina' : [47, 48, 49],\n 'Sergipe' : [79],\n 'São Paulo' : [11, 12, 13, 14, 15, 16, 17, 18, 19],\n 'Tocantins' : [63]\n }\n numeroTel = input(\"Digite o número de telefone:\\n\")\n telValid = re.search(regexTel, numeroTel)\n\n try:\n if telValid.group(2) == None:\n print(\"Número do telefone: \", telValid.group(3), \"\\n\", \"DDD não fornecido.\\n\")\n else:\n dddTel = int(telValid.group(2))\n for (cidade, dddDisp) in DDDs.items():\n if dddTel in dddDisp:\n retornoEstado = cidade\n break\n if retornoEstado != \"\" :\n print(\"Número do telefone: \", telValid.group(3), \"\\n\",\n \"DDD do número: \", dddTel, \"\\n\",\n \"Estado: \", retornoEstado, \"\\n\")\n else:\n print(\"DDD inválido, favor verificar o número digitado.\\n\")\n except:\n print(\"Isto não é um numero de telefone\")\n option = input(\"Deseja continuar?\\ns = SIM; n = NÃO\\n\")\n if option != \"s\":\n opcao = False\n"
},
{
"alpha_fraction": 0.751724123954773,
"alphanum_fraction": 0.7793103456497192,
"avg_line_length": 30.071428298950195,
"blob_id": "d97bb7032bf8761a4c026361caf52a4d0a3c3847",
"content_id": "531144f7b2ddc05c7a769f621ef4c57440831ed5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 14,
"path": "/README.md",
"repo_name": "leonsp95/BuscaDDD",
"src_encoding": "UTF-8",
"text": "# BuscaDDD\n\nSimples(?) programa para verificar e retornar a qual estado pertence um telefone especificado, de acordo com seu DDD.\nCódigo feito na linguagem Julia com o auxílio de Regex\n\n## Changelog\n### 18 de julho de 2021:\n\n- Adicionado loop para que o usuário possa continuar realizando pesquisas\n- Adicionado método try/catch para verificação de validade de número digitado\n\n### 18 de agosto de 2021:\n\n- Adicionada versão em Python\n"
}
] | 2 |
savoga/deutsch-app
|
https://github.com/savoga/deutsch-app
|
21baf41fe11c533cade39fd6a825979f246faea3
|
911fc25f5698473999ebce1c855f8a23e4ce2306
|
91b9068a73f0b6f30e5bb5e87b3a6e78f336fb70
|
refs/heads/main
| 2023-02-10T09:46:58.288524 | 2020-12-31T10:51:37 | 2020-12-31T10:51:37 | 323,593,148 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6731424927711487,
"avg_line_length": 31.977527618408203,
"blob_id": "2a4f9792ec4f04199c36c612c23c567cb8534447",
"content_id": "ea652d2cba656aa8c74bbca58506b9bc831d4475",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2938,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 89,
"path": "/deutsch-app.py",
"repo_name": "savoga/deutsch-app",
"src_encoding": "UTF-8",
"text": "'''\n// Important notes about Streamlit \\\\\nThe framework doesn't handle event binding (i.e. a specific function to be\ncalled when a user clicks on a button)! When a button is pressed, the whole\nscript is rerun.\n'''\n\nimport pandas as pd\nfrom googleapiclient.discovery import build\nfrom google_auth_oauthlib.flow import InstalledAppFlow\nfrom google.auth.transport.requests import Request\nimport os\nimport pickle\nimport streamlit as st\n\nimport dataclasses\nfrom gamestate import persistent_game_state\n\nSCOPES = ['https://www.googleapis.com/auth/spreadsheets']\n\n# here enter the id of your google sheet\nSAMPLE_SPREADSHEET_ID_input = '1lMkLiPKYXT1qCDeLK1qRDF3yPMkCWJtHrJ1LTsHhlgA'\nSAMPLE_RANGE_NAME = 'A1:AA1000'\nCOLUMN_VOC = 'Voc'\nCOLUMN_TRANSLATION_VOC = 'Traduction voc'\n\n# decorator automatically does the __init__() and __repr__()\[email protected]\nclass GameState:\n word: str = ''\n translation: str = ''\n game_number : int = 0\n game_over: bool = False\n\ndef loadSpreadsheet():\n global values_input, service\n creds = None\n if os.path.exists('token.pickle'):\n with open('token.pickle', 'rb') as token:\n creds = pickle.load(token)\n if not creds or not creds.valid:\n if creds and creds.expired and creds.refresh_token:\n creds.refresh(Request())\n else:\n flow = InstalledAppFlow.from_client_secrets_file(\n 'credentials.json', SCOPES) # here enter the name of your downloaded JSON file\n creds = flow.run_local_server(port=0)\n with open('token.pickle', 'wb') as token:\n pickle.dump(creds, token)\n\n service = build('sheets', 'v4', credentials=creds, cache_discovery=False)\n\n # Call the Sheets API\n sheet = service.spreadsheets()\n result_input = sheet.values().get(spreadsheetId=SAMPLE_SPREADSHEET_ID_input,\n range=SAMPLE_RANGE_NAME).execute()\n values_input = result_input.get('values', [])\n\n if not values_input:\n print('No data found.')\n\ndef randomWord(df, column_name):\n translation = None\n while(not translation or translation==''):\n random_word = df[column_name].sample(n=1).values[0]\n translation = df[df[column_name]==random_word]['Traduction ' + column_name.lower()].values[0]\n return random_word, translation\n\nloadSpreadsheet()\n\ndf_data = pd.DataFrame(values_input[1:], columns=values_input[0])\n\nstate = persistent_game_state(initial_state=GameState())\n\nif st.button('Générer un mot'):\n state.word, state.translation = randomWord(df_data, COLUMN_VOC)\n state.game_number += 1\n state.game_over = False\n\nif not state.game_over:\n guess = None\n st.write(state.word)\n guess = st.text_input(\"Votre traduction :\", key=state.game_number)\n if guess:\n if guess != state.translation:\n st.write(\"Mauvaise réponse !\")\n else:\n st.write(\"Bonne réponse !\")\n state.game_over = True"
},
{
"alpha_fraction": 0.6078431606292725,
"alphanum_fraction": 0.7450980544090271,
"avg_line_length": 19.399999618530273,
"blob_id": "4f720230c8a033b74b594f974a8d434395018dbe",
"content_id": "3942b555c869a23eaab2e2190a56122d669e37d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "savoga/deutsch-app",
"src_encoding": "UTF-8",
"text": "streamlit\ngoogle_auth_oauthlib==0.4.1\npandas==1.1.3\ngoogle_api_python_client==1.12.8\nprotobuf==3.14.0\n"
}
] | 2 |
Albertorz31/Logica
|
https://github.com/Albertorz31/Logica
|
ece64d9983de20ed5d1b7228ab7711b1ff3bfeee
|
0ad1fba783228a5cd60093b829795465090ab7ba
|
e29dca70d6a91116a70f070c8ae77cdcb53cad2e
|
refs/heads/main
| 2023-01-06T05:05:17.107036 | 2020-10-26T13:50:42 | 2020-10-26T13:50:42 | 307,387,973 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6224799156188965,
"alphanum_fraction": 0.6471325755119324,
"avg_line_length": 37.60483932495117,
"blob_id": "fdd045bc86ebfb811106ef69e4b298a15b0b7166",
"content_id": "f2aad30d7f37a9b6c0573f4e7bf638e485c7e451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9587,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 248,
"path": "/Taller 2/Lab2-Logica/Lab2-Logica.py",
"repo_name": "Albertorz31/Logica",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# Laboratorio N°2 Lógica y Teoría de la Computación\n# Tema: Lógica Difusa\n# Profesor: Daniel Vega Araya\n# Integrantes: Diego Águila Tornería\n# Carlos Alvarez Silva\n# Alberto Rodríguez Zamorano\n# Chun-Zen Yu Chávez\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport networkx as nx\nimport skfuzzy as fuzz\nfrom skfuzzy import control as ctrl\nimport sys\nimport random\nimport getopt\n\n\n############ BASE DE CONOCIMIENTOS #################\n\n'''\n#Proceso: Define los rangos y las funciones de pertenencia para los antecentes que son la forma,firmeza y cobertura\n#Salida: Funciones de pertenencia de las entradas.\ndef definirAntecedentes():\n forma = ctrl.Antecedent(np.arange(0, 101, 1), 'forma')\n firmeza = ctrl.Antecedent(np.arange(0, 101, 1), 'firmeza')\n cobertura = ctrl.Antecedent(np.arange(0, 101, 1), 'cobertura')\n'''\n\n\ndef generar_selector(altura,diametro,transparencia,coberturaE):\n\n #FUSIFICADOR\n\n # Antecedentes \n # functions\n forma = ctrl.Antecedent(np.arange(0, 101, 1), 'forma')\n firmeza = ctrl.Antecedent(np.arange(0, 101, 1), 'firmeza')\n cobertura = ctrl.Antecedent(np.arange(0, 101, 1), 'cobertura')\n\n #Consecuentes\n calidad = ctrl.Consequent(np.arange(0, 11, 1), 'calidad')\n \n\n\n # Funcion de membresia de cada conjunto difuso \n #Antecedentes\n etiqueta_forma = ['Angosta', 'Normal', 'Ancha']\n forma.automf(names=etiqueta_forma)\n etiqueta_firmeza = ['Podrida', 'Madura', 'Verde']\n firmeza.automf(names=etiqueta_firmeza)\n etiqueta_cobertura = ['Leve', 'Parcial', 'Completa']\n cobertura.automf(names=etiqueta_cobertura)\n\n #Consecuentes\n etiqueta_calidad = ['Desecho', 'Comercial', 'Exportable']\n calidad.automf(names=etiqueta_calidad)\n\n\n #La salida por la cual saldrá el fruto depende del diametro ingresado por el usuario\n if(diametro>= 18 and diametro<19):\n salida = 1\n elif(diametro>= 19 and diametro<20):\n salida = 2\n elif(diametro>= 20 and diametro<21):\n salida = 3\n elif(diametro>= 21 and diametro<22):\n salida = 4\n elif(diametro>=22 and diametro<23):\n salida = 5 \n elif(diametro>= 23 and diametro<24):\n salida=6\n elif(diametro>= 24 and diametro<25):\n salida=7\n elif(diametro>= 25 and diametro<26):\n salida=8\n elif(diametro>=26 and diametro<27):\n salida=9\n elif(diametro>=27 and diametro<28):\n salida=10\n elif(diametro>=28 and diametro<29):\n salida=11\n elif(diametro>=29 and diametro<30):\n salida=12\n elif(diametro>=30 and diametro<31):\n salida=13\n elif(diametro>= 31 and diametro<32):\n salida=14\n elif(diametro>=32 and diametro<33):\n salida=15\n\n # Caso particular menor a 18 mm o mayor a 33 (Desecho)\n elif(diametro<18 or diametro >=33):\n salida=16\n\n\n ############################DESCOMENTAR SI SE QUIERE VER GRAFICOS#############################\n # Mostrar gráficas componentes modelo\n #graficos antecedentes\n forma.view()\n #pausa()\n firmeza.view()\n #pausa()\n cobertura.view()\n #pausa()\n \n\n\n ###################SISTEMA DE INFERENCIA##########################\n\n #Aqui ocurre la logica principal del programa ya que se definen las reglas de la logica difusa de antecedentes->consecuencias y luego se calculan las \n #defusificaciones de los valores concecuentes, los cuales son enviados para ser escritos en un archivo de texto.\n\n #####Reglas difusas####\n\n #La funcion Rule, crea las reglas a utilizar en la logica difusa, donde se anotan los antecedentes, con las variables logicas and, or, not segun corresponda\n #aplicando internamente mamdani\n\n #Finalmente, al realizar la defusificacion se usa ControlSystem para poder juntar todas las reglas y obtener los valores que mas se acomoden a las reglas.\n #Con controlSystemSimulation se simula el sistema difuso, y finalmente con input se ingresan las entradas. \n \n\n #EL diametro definirá a cual salida debe ir cada cereza \n \n rule1 = ctrl.Rule(forma['Angosta'] & firmeza['Verde'] & cobertura['Leve'], calidad['Exportable'])\n rule2 = ctrl.Rule(forma['Angosta'] & firmeza['Verde'] & cobertura['Parcial'], calidad['Comercial'])\n rule3 = ctrl.Rule(forma['Angosta'] & firmeza['Verde'] & cobertura['Completa'], calidad['Desecho'])\n rule4 = ctrl.Rule(forma['Angosta'] & firmeza['Madura'] & cobertura['Leve'], calidad['Exportable'])\n rule5 = ctrl.Rule(forma['Angosta'] & firmeza['Madura'] & cobertura['Parcial'], calidad['Comercial'])\n rule6 = ctrl.Rule(forma['Angosta'] & firmeza['Madura'] & cobertura['Completa'], calidad['Desecho'])\n rule7 = ctrl.Rule(forma['Angosta'] & firmeza['Podrida'] & cobertura['Leve'], calidad['Desecho'])\n rule8 = ctrl.Rule(forma['Angosta'] & firmeza['Podrida'] & cobertura['Parcial'], calidad['Desecho'])\n rule9 = ctrl.Rule(forma['Angosta'] & firmeza['Podrida'] & cobertura['Completa'], calidad['Desecho'])\n\n rule10 = ctrl.Rule(forma['Normal'] & firmeza['Verde'] & cobertura['Leve'], calidad['Exportable'])\n rule11 = ctrl.Rule(forma['Normal'] & firmeza['Verde'] & cobertura['Parcial'], calidad['Exportable'])\n rule12 = ctrl.Rule(forma['Normal'] & firmeza['Verde'] & cobertura['Completa'], calidad['Desecho'])\n rule13 = ctrl.Rule(forma['Normal'] & firmeza['Madura'] & cobertura['Leve'], calidad['Exportable'])\n rule14 = ctrl.Rule(forma['Normal'] & firmeza['Madura'] & cobertura['Parcial'], calidad['Exportable'])\n rule15 = ctrl.Rule(forma['Normal'] & firmeza['Madura'] & cobertura['Completa'], calidad['Desecho'])\n rule16 = ctrl.Rule(forma['Normal'] & firmeza['Podrida'] & cobertura['Leve'], calidad['Desecho'])\n rule17 = ctrl.Rule(forma['Normal'] & firmeza['Podrida'] & cobertura['Parcial'], calidad['Desecho'])\n rule18 = ctrl.Rule(forma['Normal'] & firmeza['Podrida'] & cobertura['Completa'], calidad['Desecho'])\n\n rule19 = ctrl.Rule(forma['Ancha'] & firmeza['Verde'] & cobertura['Leve'], calidad['Exportable'])\n rule20 = ctrl.Rule(forma['Ancha'] & firmeza['Verde'] & cobertura['Parcial'], calidad['Exportable'])\n rule21 = ctrl.Rule(forma['Ancha'] & firmeza['Verde'] & cobertura['Completa'], calidad['Desecho'])\n rule22 = ctrl.Rule(forma['Ancha'] & firmeza['Madura'] & cobertura['Leve'], calidad['Exportable'])\n rule23 = ctrl.Rule(forma['Ancha'] & firmeza['Madura'] & cobertura['Parcial'], calidad['Comercial'])\n rule24 = ctrl.Rule(forma['Ancha'] & firmeza['Madura'] & cobertura['Completa'], calidad['Desecho'])\n rule25 = ctrl.Rule(forma['Ancha'] & firmeza['Podrida'] & cobertura['Leve'], calidad['Desecho'])\n rule26 = ctrl.Rule(forma['Ancha'] & firmeza['Podrida'] & cobertura['Parcial'], calidad['Desecho'])\n rule27 = ctrl.Rule(forma['Ancha'] & firmeza['Podrida'] & cobertura['Completa'], calidad['Desecho'])\n \n\n # Control system\n selector_ctrl = ctrl.ControlSystem([rule1, rule2, rule3, rule4, rule5, rule6, rule7, rule8, rule9, rule10,\n rule11, rule12, rule13, rule14, rule15, rule16, rule17, rule18, rule19, rule20,\n rule21, rule22, rule23, rule24, rule25, rule26, rule27])\n\n selector = ctrl.ControlSystemSimulation(selector_ctrl)\n # Entradas de la Simulación\n selector.input['forma'] = diametro/altura\n selector.input['firmeza'] = transparencia\n selector.input['cobertura'] = coberturaE\n # Computar resultados\n selector.compute()\n # Mostrar resultados\n #calidad.view(sim=selector)\n #pausa()\n\n escribir_archivo( (altura,diametro,transparencia,coberturaE), (forma, firmeza,cobertura,calidad,salida))\n\n\n plt.show() # Descomentar si se quieren observar los graficos\n\n #escribir_archivo(altura,diametro,transparencia,coberturaE,forma,)\n\n return\n\n\n'''\nFunción que escribe en un archivo de texto las salidas\nEntrada: antecedentes->Arreglo con antecedentes, salidas->Arreglo con salidas defusificada\nProceso: Se escribe en el archivo los elementos de los arreglos de entrada\nSalida:\n'''\ndef escribir_archivo(antecedentes,salidas): \n file = open(\"Cereza_\" + str(antecedentes[0]) + \"_\" + str(antecedentes[1]) + \"_\" + str(antecedentes[2]) + \"_\" + str(antecedentes[3])+\".txt\", 'w')\n file.write(\"Niveles capturados: \\n\")\n file.write(\"\\t Calibre:\" +str(antecedentes[1])+\"mm\\n\")\n file.write(\"\\t Forma:\" + str(salidas[0])+\"\\n\")\n file.write(\"\\t Firmeza de la pulpa:\"+str(salidas[1])+\"\\n\")\n file.write(\"\\t Cobertura de manchas:\"+str(salidas[2])+\"\\n\")\n file.write(\"Comercialización:\" + str(salidas[3])+\"\\n\")\n file.write(\"Número salida:\"+str(salidas[4])+ \"\\n\")\n file.close()\n\n\n\n\n''' \nFunción que pausa la ejecución del programa\nEntrada:\nProceso: Se printea un mensaje y se espera a una entrada cualquiera\nSalida:\n'''\ndef pausa():\n print(\"Ingrese un caracter para continuar: \")\n input()\n\n\n\ndef main(argv):\n #### MAIN ####\n\n altura = 1\n diametro = 1\n transparencia = 10\n cobertura = 15\n\n #Puede tener maximo\n\n try:\n opts, _ = getopt.getopt(sys.argv[1:], 'a:d:t:c:', ['altura=', 'diametro=', 'transparencia=', 'cobertura='])\n except getopt.GetoptError:\n sys.exit(2)\n\n for opt, arg in opts:\n if opt in ('-a', '--altura'):\n altura = int(arg)\n elif opt in ('-d', '--diametro'):\n diametro = int(arg)\n elif opt in ('-t', '--transparencia'):\n transparencia = int(arg)\n elif opt in ('-c', '--cobertura'):\n cobertura = int(arg)\n\n generar_selector(altura,diametro,transparencia,cobertura)\n\n return\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])"
}
] | 1 |
vijaybw/modelkbdataset
|
https://github.com/vijaybw/modelkbdataset
|
63ba890345e9bb207935e193409c27aa784ff563
|
36eb5fceb7f9b6d6596645aae24b54f05bc0ba04
|
985508e171531a6e3f55c87793618fc502025e1a
|
refs/heads/master
| 2022-11-09T05:45:38.716056 | 2020-06-19T14:43:31 | 2020-06-19T14:43:31 | 270,533,269 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6505178809165955,
"alphanum_fraction": 0.6592048406600952,
"avg_line_length": 38.3815803527832,
"blob_id": "0e72ad0caeec401bab54dba515ec9aa0db3aea30",
"content_id": "5d896d3a65317f37d0670ffaf80cd2023ae22932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2993,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 76,
"path": "/app.py",
"repo_name": "vijaybw/modelkbdataset",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask, request, redirect, url_for, render_template, send_from_directory, send_file\nfrom matplotlib import image\nfrom werkzeug.utils import secure_filename\nfrom pathlib import Path\nfrom modelb_dataset import *\n\nUPLOAD_FOLDER = os.path.dirname(os.path.abspath(__file__)) + '/uploads/'\nDOWNLOAD_FOLDER = os.path.dirname(os.path.abspath(__file__)) + '/downloads/'\nPROCESSED_FOLDER = os.path.dirname(os.path.abspath(__file__)) + '\\\\processed\\\\'\nALLOWED_EXTENSIONS = {'csv', 'txt'}\n\napp = Flask(__name__, static_url_path=\"/static\")\nDIR_PATH = os.path.dirname(os.path.realpath(__file__))\napp.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER\napp.config['DOWNLOAD_FOLDER'] = DOWNLOAD_FOLDER\napp.config['PROCESSED_FOLDER'] = PROCESSED_FOLDER\n# limit upload size upto 5mb\napp.config['MAX_CONTENT_LENGTH'] = 5 * 1024 * 1024\n\ndef allowed_file(filename):\n return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS\n\[email protected]('/', methods=['GET', 'POST'])\ndef index():\n if request.method == 'POST':\n if 'file' not in request.files:\n print('No file attached in request')\n return redirect(request.url)\n file = request.files['file']\n if file.filename == '':\n print('No file selected')\n return redirect(request.url)\n if file and allowed_file(file.filename):\n filename = secure_filename(file.filename)\n file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))\n outputs= process_file(os.path.join(app.config['UPLOAD_FOLDER'], filename), filename)\n user_table = outputs[0]\n user_image = outputs[1]\n return render_template('results.html', user_image=user_image, tables=[user_table], file_name = filename)\n return render_template('index.html')\n\ndef process_file(path, filename):\n input_file = os.path.join(app.config['UPLOAD_FOLDER'], filename)\n output_file = Path(app.config['DOWNLOAD_FOLDER'], filename)\n from shutil import copyfile\n copyfile(input_file, app.config['DOWNLOAD_FOLDER'] + filename)\n return process_csv(input_file, filename)\n\ndef get_image(path, filename):\n import io\n output = io.BytesIO()\n image.convert('RGBA').save(output, format='PNG')\n output.seek(0, 0)\n\n return send_file(output, mimetype='image/png', as_attachment=False)\n\[email protected]('/testimage')\ndef get_testimage():\n\n testimage = request.values.get(\"file_name\")\n\n if str(testimage).endswith(\".csv\"):\n filename = str(testimage).replace(\".csv\",\".png\")\n elif str(testimage).endswith(\".txt\"):\n filename = str(testimage).replace(\".txt\", \".png\")\n\n if testimage == '':\n testimage = os.path.join(app.config['PROCESSED_FOLDER'], 'sample.png')\n else:\n testimage = os.path.join(app.config['PROCESSED_FOLDER'], filename)\n\n return send_file(testimage, mimetype='image/png')\nif __name__ == '__main__':\n port = int(os.environ.get(\"PORT\", 5000))\n app.run(host = '127.0.0.1')\n"
},
{
"alpha_fraction": 0.7559943795204163,
"alphanum_fraction": 0.8067700862884521,
"avg_line_length": 29.826086044311523,
"blob_id": "48f48e5322caa8fbc23c8807e7cb75c0de750bdf",
"content_id": "fa5a145d75d36629c4836050e15124f6ba477504",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 23,
"path": "/README.md",
"repo_name": "vijaybw/modelkbdataset",
"src_encoding": "UTF-8",
"text": "# modelkb-dataset\nThis Flask App would process the dataset \nand return top 10 features and its correlation with each other .\n\n1. Upload dataset with csv format with first line as columns.\n\n2. Program would automatically identify the column data types.\n\n3. And then it would calculate top 10 features through kbest method \nhttps://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectKBest.html\n\n4. Also, we show the correlation among top 10 features so that users can study all the 10 features and its relationships with each other.\n\nTypical AI process\n\nFraming the problem\n\nCollecting the Data\n\nPreparing the Data\n\nVideo Demo:\nhttps://www.loom.com/share/1ce100290d38414ba877a40b8655a706\n"
},
{
"alpha_fraction": 0.5584228038787842,
"alphanum_fraction": 0.5708092451095581,
"avg_line_length": 32.599998474121094,
"blob_id": "040f23035621d31eb94b87fb2f84123b16b7074b",
"content_id": "ce56747d946327879bbe374bd1032c91e58f169c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4844,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 140,
"path": "/modelb_dataset.py",
"repo_name": "vijaybw/modelkbdataset",
"src_encoding": "UTF-8",
"text": "# libraries\r\nimport pandas as pd\r\nimport numpy as np\r\nfrom keras.utils import np_utils\r\nfrom sklearn.preprocessing import LabelEncoder\r\nfrom flask_table import Table, Col\r\nimport networkx as nx\r\nimport os\r\nPROCESSED_FOLDER = os.path.dirname(os.path.abspath(__file__)) + '/processed/'\r\nimport matplotlib.pyplot as plt\r\n#Infer Data Types for Individual Columns in DataFrame\r\nimport app\r\n\r\n\r\ndef infer_df(df, hard_mode=False, float_to_int=False, mf=None):\r\n\r\n # set multiplication factor\r\n mf = 1 if hard_mode else 0.5\r\n\r\n # set supported datatype\r\n integers = ['int8', 'int16', 'int32', 'int64']\r\n floats = ['float16', 'float32', 'float64']\r\n\r\n # ToDo: Unsigned Integer\r\n\r\n # generate borders for each datatype\r\n b_integers = [(np.iinfo(i).min, np.iinfo(i).max, i) for i in integers]\r\n b_floats = [(np.finfo(f).min, np.finfo(f).max, f) for f in floats]\r\n\r\n for c in df.columns:\r\n _type = df[c].dtype\r\n # if a column is set to float, but could be int\r\n if float_to_int and np.issubdtype(_type, np.floating):\r\n if np.sum(np.remainder(df[c], 1)) == 0:\r\n df[c] = df[c].astype('int64')\r\n _type = df[c].dtype\r\n\r\n # convert type of column to smallest possible\r\n if np.issubdtype(_type, np.integer) or np.issubdtype(_type, np.floating):\r\n borders = b_integers if np.issubdtype(_type, np.integer) else b_floats\r\n\r\n _min = df[c].min()\r\n _max = df[c].max()\r\n\r\n for b in borders:\r\n if b[0] * mf < _min and _max < b[1] * mf:\r\n _type = b[2]\r\n break\r\n\r\n if _type == 'object' and len(df[c].unique()) / len(df) < 0.1:\r\n _type = 'category'\r\n\r\n df[c] = df[c].astype(_type)\r\n\r\ndef encode_category(df, column_name):\r\n encoder = LabelEncoder()\r\n encoder.fit(df[column_name])\r\n encoded_X = encoder.transform(df[column_name])\r\n df[column_name] = np_utils.to_categorical(encoded_X)\r\n\r\ndef process_csv(file_path, file_name):\r\n df = pd.read_csv(file_path, header=0)\r\n print(df.columns, sep='\\n\\n')\r\n infer_df(df)\r\n\r\n # Get a Dictionary containing the pairs of column names & data type objects.\r\n dataTypeDict = dict(df.dtypes)\r\n\r\n print('Data type of each column of Dataframe :')\r\n print(dataTypeDict)\r\n\r\n for c in df.select_dtypes(include=['category']):\r\n encode_category(df,c)\r\n\r\n c = df.corr().abs()\r\n s = c.unstack()\r\n s = pd.Series(s).where(lambda x: x < 1).dropna()\r\n so = s.sort_values(ascending=False)\r\n\r\n list_of_processed = []\r\n\r\n print(df.dtypes, sep='\\n\\n')\r\n\r\n # Feature Importance - Works\r\n\r\n # apply SelectKBest class to extract top 10 best features\r\n from sklearn.ensemble import ExtraTreesRegressor\r\n import matplotlib.pyplot as plt\r\n model = ExtraTreesRegressor()\r\n Y = df.iloc[:, -1]\r\n X = df.drop(df.columns[-1],axis=1)\r\n model.fit(X,Y)\r\n for i in model.feature_importances_:\r\n print(float(i))\r\n feat_importances = pd.Series(model.feature_importances_, index=X.columns)\r\n top_10_features = feat_importances.nlargest(10)\r\n list_of_features = []\r\n for rownum, (indx, val) in enumerate(top_10_features.iteritems()):\r\n list_of_features.append(indx)\r\n print('row number: ', rownum, 'index: ', indx, 'value: ', val)\r\n # Declare your table\r\n class ItemTable(Table):\r\n one = Col('Feature 1')\r\n two = Col('Feature 2')\r\n cvalue = Col('Correlation Value')\r\n # Get some objects\r\n class Item(object):\r\n def __init__(self, name_one, name_two, correlation_value):\r\n self.one = name_one\r\n self.two = name_two\r\n self.cvalue = round(correlation_value, 4)\r\n\r\n # Build your graph\r\n G = nx.Graph()\r\n G.add_nodes_from(list_of_features)\r\n\r\n # Populate the table\r\n list_of_entries = []\r\n for items in so.iteritems():\r\n if (items[0][0] != items[0][1]):\r\n if (items[0][0] < items[0][1]):\r\n x = items[0][0]\r\n y = items[0][1]\r\n else:\r\n x = items[0][1]\r\n y = items[0][0]\r\n if (x + \"-\" + y) not in list_of_processed:\r\n if x in list_of_features and y in list_of_features:\r\n G.add_edge(x, y, weight=round(items[1],4))\r\n list_of_entries.append(Item(x, y, items[1]))\r\n list_of_processed.append(x + \"-\" + y)\r\n table = ItemTable(list_of_entries)\r\n\r\n # Plot it\r\n nx.draw(G, with_labels=True)\r\n plt.savefig(PROCESSED_FOLDER + str(file_name).replace(\".csv\",\"\") + \".png\", format=\"PNG\")\r\n # plt.savefig(app.config['PROCESSED_FOLDER'] + file_name + \".png\", format=\"PNG\")\r\n # Print the html\r\n return [table.__html__(), plt.figimage]\r\n# process_csv('adult.data')\r\n"
}
] | 3 |
Sfaurat/py_lesson1
|
https://github.com/Sfaurat/py_lesson1
|
09b2ead321aee24a2cf96a1e4e428fa46736db05
|
20ad2a2e78ff6be33399f04d13b90f1a70e112be
|
916f1251c6acf126a8b467b2d7f4cece630dac13
|
refs/heads/master
| 2020-03-24T19:00:19.060621 | 2018-07-30T17:48:17 | 2018-07-30T17:48:17 | 142,906,481 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48571428656578064,
"alphanum_fraction": 0.7428571581840515,
"avg_line_length": 35,
"blob_id": "bac3438f51bce91fbcef6bc7e96afe428c5f283d",
"content_id": "3fe78401aa4f77433c86b6860654e76f5571bf14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 1,
"path": "/helloworld.py",
"repo_name": "Sfaurat/py_lesson1",
"src_encoding": "UTF-8",
"text": "print('\\033[34mHello World\\033[0m')"
}
] | 1 |
jgsorio/Jogo_da_Velha_IA
|
https://github.com/jgsorio/Jogo_da_Velha_IA
|
580d5b3bef415b8a02eef45eb461d207424bda62
|
488ae32e890e996f7f2fe7fdd65cfb44a0a1290e
|
250784f7eeac245a920aa9630ba3d5bcbc419ff4
|
refs/heads/master
| 2023-04-15T04:20:12.085593 | 2021-04-28T04:27:26 | 2021-04-28T04:27:26 | 362,334,202 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48252299427986145,
"alphanum_fraction": 0.5017082691192627,
"avg_line_length": 27.60902214050293,
"blob_id": "93bb6ffc7a314532ff9f0a0155a410d48be2d4b8",
"content_id": "55bb4db7b5895b7d5b095310b1aae3bcd453a051",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3813,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 133,
"path": "/jogo_da_velha.py",
"repo_name": "jgsorio/Jogo_da_Velha_IA",
"src_encoding": "UTF-8",
"text": "import random\n\n\ndef create_body():\n return [' ' for x in range(10)]\n\n\ndef draw_body(body):\n print(f' | | ')\n print(f' {body[1]} | {body[2]} | {body[3]} ')\n print(' | | ')\n print('-----------')\n print(' | | ')\n print(f' {body[4]} | {body[5]} | {body[6]} ')\n print(' | | ')\n print('-----------')\n print(' | | ')\n print(f' {body[7]} | {body[8]} | {body[9]} ')\n print(' | | ')\n print('\\n')\n\n\ndef insert_letter(letter, position, body):\n if verify_if_empty_position(position, body):\n body[position] = letter\n draw_body(body)\n else:\n print('Essa posição já foi escolhida!')\n position = int(input('Digite a posição que deseja jogar 1 a 9: '))\n insert_letter('x', position, body)\n\n\ndef player_time(body):\n run = True\n while run:\n try:\n choice = int(input('Escolha um numero entre 1 e 9 '))\n if choice <= 0 or choice >= 10:\n print('Por favor digite um numero entre 1 e 9 ')\n else:\n insert_letter('x', choice, body)\n run = False\n except:\n print('Por favor digite um numero válido')\n\n\ndef ai_time(body):\n run = True\n while run:\n choice = play_ia_choice(body)\n if verify_if_empty_position(choice, body):\n run = False\n insert_letter('o', choice, body)\n print(f'IA escolhe a posicao {choice}')\n\n\ndef verify_if_empty_position(position, body):\n return body[position] == ' '\n\n\ndef play_ia_choice(body):\n for (indice, i) in enumerate(body):\n if i == 'x':\n posibilities = posible_combinations()\n for posibility in posibilities:\n if indice in posibility:\n count = 0\n for x in posibility:\n if body[x] == 'x':\n count += 1\n if count == 2:\n for position in posibility:\n if body[position] == ' ':\n return position\n choice = random.choice(random.choice(posibilities))\n return choice\n\n\ndef posible_combinations():\n return [[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 4, 7], [2, 5, 8], [3, 6, 9], [1, 5, 9], [3, 5, 7]]\n\n\ndef verify_won(body, letter):\n if body[1] == letter and body[2] == letter and body[3] == letter:\n return True\n elif body[4] == letter and body[5] == letter and body[6] == letter:\n return True\n elif body[7] == letter and body[8] == letter and body[9] == letter:\n return True\n elif body[1] == letter and body[4] == letter and body[7] == letter:\n return True\n elif body[2] == letter and body[5] == letter and body[8] == letter:\n return True\n elif body[3] == letter and body[6] == letter and body[9] == letter:\n return True\n elif body[1] == letter and body[5] == letter and body[9] == letter:\n return True\n elif body[3] == letter and body[5] == letter and body[7] == letter:\n return True\n else:\n return False\n\n\ndef body_is_not_complete(body):\n return body.count(' ') > 1\n\n\ndef play_again():\n answer = input('Gostaria de jogar novamente? Digite s ou n')\n if answer.lower() == 's':\n game()\n else:\n exit()\n\n\ndef game():\n body = create_body()\n draw_body(body)\n while body_is_not_complete(body):\n player_time(body)\n if verify_won(body, 'x'):\n print('Parabéns você ganhou!')\n play_again()\n ai_time(body)\n if verify_won(body, 'o'):\n print('O computador ganhou!')\n play_again()\n if body.count(' ') == 2:\n print('Humm, parece que deu empate')\n play_again()\n\n\ngame()\n"
},
{
"alpha_fraction": 0.7259259223937988,
"alphanum_fraction": 0.7259259223937988,
"avg_line_length": 33,
"blob_id": "76e4d251ebf7477120c496800df21778a11a5187",
"content_id": "a9c4490bc94772460a4480d796150e1bfcb00296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 4,
"path": "/readme.md",
"repo_name": "jgsorio/Jogo_da_Velha_IA",
"src_encoding": "UTF-8",
"text": "# Projeto jogo da velha com IA\n\n## Para rodar o projeto basta acessar a pasta do mesmo e rodar o comando:\n```python jogo_da_velha.py```"
}
] | 2 |
zutn/King_of_the_Hill
|
https://github.com/zutn/King_of_the_Hill
|
1901cadc3cac6c6465c0d50c87060d92210f51cc
|
fdec5022a5456e3cdec58e5688a1e560e2cd7801
|
764de90965def1fd429e7983037a1b1cd8a6ad77
|
refs/heads/master
| 2021-05-24T04:26:42.837845 | 2017-08-28T11:28:18 | 2017-08-28T11:28:18 | 64,652,777 | 1 | 2 | null | 2016-08-01T09:09:48 | 2016-08-03T09:42:46 | 2016-08-04T15:32:18 |
Python
|
[
{
"alpha_fraction": 0.5730274319648743,
"alphanum_fraction": 0.5847789645195007,
"avg_line_length": 28.766666412353516,
"blob_id": "ec5076598a246d4d39afb63d588cb26e043f4a8f",
"content_id": "88f5af1ae342e06238bdf92fbf5dc2c093b9017d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1787,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 60,
"path": "/Code/circular_arc.py",
"repo_name": "zutn/King_of_the_Hill",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Sep 7 19:31:11 2016\n\n@author: Florian Jehn\n\"\"\"\nimport pygame\nfrom pygame.locals import *\nimport sys\nfrom math import atan2, pi\n\nclass CircularArc:\n \"\"\"\n a class of circular arcs, where it is easier to determine if an arc was clicked\n or not\n \"\"\"\n\n def __init__(self, color, center, radius, start_angle, stop_angle, width=1):\n \"\"\"\n \n \"\"\"\n self.color = color\n self.x = center[0] # center x position\n self.y = center[1] # center y position\n self.rect = [self.x - radius, self.y - radius, radius*2, radius*2]\n self.radius = radius\n self.start_angle = start_angle\n self.stop_angle = stop_angle\n self.width = width\n\n def draw(self, canvas):\n \"\"\"\n draws the arc\n \"\"\"\n pygame.draw.arc(canvas, self.color, self.rect, self.start_angle, self.stop_angle, self.width)\n\n def contains(self, x, y):\n \"\"\"\n checks if a given x,y is part of the arc\n \"\"\"\n\n dx = x - self.x # x distance\n dy = y - self.y # y distance\n\n greater_than_outside_radius = dx*dx + dy*dy >= self.radius*self.radius\n\n less_than_inside_radius = dx*dx + dy*dy <= (self.radius- self.width)*(self.radius- self.width)\n\n # Quickly check if the distance is within the right range\n if greater_than_outside_radius or less_than_inside_radius:\n return False\n\n rads = atan2(-dy, dx) # Grab the angle\n\n # convert the angle to match up with pygame format. Negative angles don't work with pygame.draw.arc\n if rads < 0:\n rads = 2 * pi + rads\n\n # Check if the angle is within the arc start and stop angles\n return self.start_angle <= rads <= self.stop_angle\n\n"
},
{
"alpha_fraction": 0.7537524104118347,
"alphanum_fraction": 0.7561301589012146,
"avg_line_length": 75.45454406738281,
"blob_id": "944f2107455c2488470d94768a1116f7a1a1c357",
"content_id": "4eff60e852f277936eeea5ea9baf0d4abd37db00",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6729,
"license_type": "permissive",
"max_line_length": 663,
"num_lines": 88,
"path": "/README.md",
"repo_name": "zutn/King_of_the_Hill",
"src_encoding": "UTF-8",
"text": "# King of the Hill\nA repository for the board game I am currently working on. If you want to now more about how the game works, you can find the rules here. If you have any questions regarding the game feel free to contact me ([email protected])\n\n## Rules ##\na tactical board game by Florian Jehn\n\n### 1. Game material ###\n- a board with a center piece and four rings that become decreasingly smaller. Each ring has seven tiles \n- Two runner, five warriors and two blocker per player\n- Four six-sided dice per player\n- 28 tiles with different terrain: 12 light, eight normal, eight difficult\n- Four starting areas (numbered from one to four)\n\n\n### 2. Game setup ###\nEvery tile gets a randomly assigned terrain, such that every ring has three light, two normal and two difficult terrain. Every player gets his dice and units. Each player draws a random starting area. The player who got the starting area numbered four is allowed to place this starting area alongside any tile of the outer ring. Player three to one to the same, but two players are not allowed to place their starting area alongside the same tile of the outer ring. \n\n### 3. Game flow ###\nThis game is for two (better three) to four players. Every player has the same amount of units and dice. At the beginning of a round each player rolls his dice. The player with the starting area one begins. Every player is allowed to use two dice at a time. Using two dice is seen as one turn and two turns as one round. If a player can't use one or both dice during his turn than those dice are forfeited and can't be used in this round, with the following exceptions:\n- If one has recruited all his units recruitment dice can be used as movement dice\n- If one has no unit in the game movement dice can be used as recruitment dice\n- A player is allowed to use three or four dice in his turn if this occurred because two or four turning dice where transformed to one respectively two movement dice. If the player does not have dice for his second turn because of this, the second turn is forfeited\n\n### 4. Goal of the game ###\nTo win the game a player needs to place on of his units for 30 not consecutive turns on the center piece. Every turn is counted on which the unit is on the center piece at the end of the turn, including the one the unit reached the center piece. Won points can't be lost. Every player counts his own points. If a player forgets to count his points, the points are lost. \n\n### 5. Units ###\n#### General ####\nIn the starting area unlimited units can be placed. In the outer ring only 5 units of one player are allowed. With each ring more inward one unit less per player is allowed at one tiles, thus the center piece allows only one unit per player. If a unit dies it is returned to the players hand. \n#### Runners ####\nA runner can access all terrain types , and move up to three tiles. He can't attack and has one hitpoint. He can only be recruited after round three has ended. Runners can't move on or over tiles with fighters or blockers. \n#### Fighters ####\nA fighter can access light and normal terrain. He can attack and has one hitpoint. Fighters are only allowed to move to a tile with a blocker on it if a second fighter come to the same tile in the same turn to fight the blocker (see fighting rules). \n#### Blockers ####\nBlocker can access light terrain. He can't attack and has two hitpoints. Blocker can't move to a tile with a enemy fighter. If they move to a tile with an enemy runner, pushed away (see pushing rules). \n\n### 6. Possible actions ###\n#### General ####\nIf no moves are possible, the dice are forfeited. One does not have to use all dice. Dice eye assignment:\n\n- one and two: Recruitment\n- three and four: Move and fight\n- five and six: Turning\n\n\n#### Recruitment ####\nA recruitment dice can be used to recruit one unit in ones starting area. \n\n#### Move and fight ####\nYou can move every unit according to their type and fight with it if it is a fighter or push runners down if it is a blocker. \n##### Moving #####\nYou are only allowed to move left, right, up or down. Diagonal moves are not allowed. The number of tiles moved depends on the unit (see units)\n##### Fighting #####\nA fight automatically starts if a fighter moves into a tile with enemy units. Fights follow this rules:\n\n- Fighter vs. fighter: Both die\n- Fighter vs. runners: All runners die\n- Fighter vs. blocker: One of the fighters and the blocker die\n\nIf there are different types of enemy units in a tile a fighter moves to the following rules apply:\n\n- First the blockers need to be destroyed. If this is not possible the fighter cannot move to this tile\n- Are there no blockers, the fighters fight each other\n- Runners are only attacked if there a no other units to attack\n\nTwo players can help each other to destroy the blocker of a third player. This is only possible if two players have a least each one fighter on a tile next to a blocker of a third player. The player whose currently making his turn can offer the other player to attack the blocker of the third player. If the other player agrees, the active player must use on of his dice to attack and the blocker dies. To decide which fighter dies a dice is cast. If the dice eye shows one to three the fighter of the active player dies. If the dice eye shows four to six the fighter of the other player dies. The surviving fighter must move to the tile where the blocker was. \n\n##### Pushing #####\nIf a blocker pushes away a runner, the runner is moved one ring outwards to an adjacent tile. If it is pushed on the most outward ring, the runner is pushed to the field where the blocker started its move. \n\n#### Turning\nWith a turning dice three moves are possible:\n\n- One ring can be turned one tile left or right\n- the starting area with all units on it can be moved adjanced to another tile of the most outward ring, if there isn't another starting area\n- The terrain of two neighbouring tiles (left, right, up, down) can be swapped, but only if no unit gets into a terrain is isn't meant to be\n\nTwo turning dice can be used as an move and fight dice\n\n### 7. Alternate play styles ###\n#### Counting down ####\nFor every turn a unit stands at the center piece one is subtracted from a counter (starting with 50). Once the counter reaches zero, the player with a unit in the center piece wins. If there is no unit in the center piece when the counter reaches zero, the next player who gets a unit to the center piece wins\n\n#### One excluded ####\nPlayers choose one unit that they are not allowed to use for the rest of the game, resulting in a less mirroring game-play. \n\n#### Teamplay ####\nThe player team up in two teams. The points made count for the team and not for the one player who scored it. \n"
},
{
"alpha_fraction": 0.5444305539131165,
"alphanum_fraction": 0.5657071471214294,
"avg_line_length": 17.06818199157715,
"blob_id": "c3263bea356d86f2aed2263d219ad30ee8f69e41",
"content_id": "09c8a0c84692507a9835e87cc0d983046d359b70",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 799,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 44,
"path": "/Code/run.py",
"repo_name": "zutn/King_of_the_Hill",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Sep 13 09:03:17 2016\n\n@author: Florian Jehn\n\"\"\"\n\nimport mechanics as mec\nimport board\nimport pygame as pg\nimport sys\n\n \n\n\ndef update(board):\n \"\"\"\n periodically updates the game, calls the graphics and receives user input\n \"\"\"\n # sleep to make the game 60 fps\n board.clock.tick(30)\n\n # make the screen white\n board.screen.fill(board.white)\n \n # draw the board\n board.draw_board()\n \n for event in pg.event.get():\n # quit if the quit button was pressed\n if event.type == pg.QUIT:\n pg.quit(); sys.exit()\n \n #update the screen\n pg.display.flip()\n \n \nif __name__ == \"__main__\": \n koth = board.Board() # calls init\n \n while True:\n update(koth)\n \n pg.quit()\n "
},
{
"alpha_fraction": 0.3863636255264282,
"alphanum_fraction": 0.5340909361839294,
"avg_line_length": 13.166666984558105,
"blob_id": "76da81fcef43e2f3804201f86b1a66ad3600ea26",
"content_id": "d03084e860d7adbbeaf4d4ca3f85ba987e59ee32",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 6,
"path": "/Code/mechanics.py",
"repo_name": "zutn/King_of_the_Hill",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Sep 13 09:03:18 2016\n\n@author: Florian Jehn\n\"\"\"\n\n\n\n"
},
{
"alpha_fraction": 0.5186339020729065,
"alphanum_fraction": 0.5368784070014954,
"avg_line_length": 29.88965606689453,
"blob_id": "114b0c793c5859f003ad5320b4b3ae5f9215e3c8",
"content_id": "e21d9a2af08e2ef1921a9301a9f64f43882805c7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8989,
"license_type": "permissive",
"max_line_length": 323,
"num_lines": 290,
"path": "/Code/board.py",
"repo_name": "zutn/King_of_the_Hill",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Aug 3 10:43:16 2016\n\n@author: Florian Jehn\n\"\"\"\n\nimport pygame as pg\nimport math\nimport random\nimport copy\nimport circular_arc as ca\n\nclass Board():\n \"\"\"\n draws all the things needed to start and play the game\n \"\"\"\n # Define the colors we will use in RGB format as class attributes\n black = ( 0, 0, 0)\n white = (255, 255, 255)\n light_ter = ( 0, 255, 0) # green\n normal_ter = (255,255,0) # yellow\n diff_ter = (255, 0, 0) # red\n col_play_1 = ( 0, 0, 255) # blue\n col_play_2 = (186, 143, 43) # brown\n col_play_3 = (150, 43, 186) # purple\n col_play_4 = (177, 171, 179) # grey\n \n # order the colors for easier access\n tile_colors = [black, light_ter, normal_ter, diff_ter]\n player_colors = [col_play_1, col_play_2, col_play_4, col_play_4]\n \n # prepare the tiles list of list for all tiles\n # explanation of order in __init__\n tiles = []\n for section in range(6):\n tiles.append([])\n \n # define additional class attributes\n width = 800\n height = 800\n center_rad = (height//7//2) \n ring_width = center_rad \n num_players = 4\n num_rings = 4\n tiles_per_ring = 7\n \n def __init__(self):\n \"\"\"\n define and call the screen for the game\n \"\"\"\n pg.init()\n global width, height\n # initialize the screen\n self.screen = pg.display.set_mode((self.width, self.height))\n pg.display.set_caption(\"King of the Hill\")\n # initialize pygame clock\n self.clock = pg.time.Clock()\n \n\n # write something here that creates all tiles for the first time \n # and sorts them into a list of list that represent all tile\n # sorted by the ring their in \n \n # Order of tiles in the tiles list of lists\n # tiles [0] = most inward ring\n # tiles [1] = second most inward ring\n # tiles [2] = third most inward ring\n # tiles [3] = outer ring\n # tiles [4] = center piece\n # tiles [5] = starting areas\n \n # reshuffle the terrain for each ring\n \n terrains = self.shuffle_terrain()\n # add all ring tiles \n for ring in range(self.num_rings):\n for tile in range(self.tiles_per_ring):\n # calculate distance of the rectangle of the arc (tile) from the center\n distance = (ring*self.ring_width)+ 0.5*self.ring_width + self.center_rad\n rect_x = 0.5*self.width-distance\n rect_y = 0.5*self.height-distance\n rect_height = distance * 2\n rect_width = distance * 2\n # each arc is 2*pi/7 wide\n radi_start = tile*(2*math.pi/7)\n radi_end = (tile*(2*math.pi/7))+2*math.pi/7\n terrain = terrains[ring][tile]\n ring_width = int(self.ring_width*0.5)\n\n self.tiles[ring].append(Tile(rect_x, rect_y, rect_height, rect_width, radi_start, radi_end, terrain, ring_width)) \n \n # add center\n self.tiles[4].append(Center_Piece(self.width//2, self.height//2, self.center_rad-20))\n \n # add starting areas\n # self.tiles[5].append(Starting_Area())\n \n\n def shuffle_terrain(self):\n \"\"\"\n creates and returns a list of list which contains the randomized terrain\n for all tiles of a ring\n \"\"\"\n terrains = []\n ring = [1,1,1,2,2,3,3] \n for ring_num in range(4):\n ring_copy = copy.copy(ring)\n random.shuffle(ring_copy) # shuffle it, so that the starting order of terrains is random for every ring \n terrains.append(ring_copy) \n return terrains\n \n \n def draw_board(self):\n \"\"\"\n calls all method which draw the seperate pieces of the board\n \"\"\"\n self.draw_center()\n for ring in range(self.num_rings):\n self.draw_ring(ring) \n \n for player_num in range(self.num_players):\n self.draw_counter(player_num)\n self.draw_start_area(player_num) \n \n def draw_center(self):\n \"\"\"\n draws the center piece\n \"\"\"\n # - 20 to adjust it in size \n pg.draw.circle(self.screen, self.black, [self.tiles[4][0].x, self.tiles[4][0].y], self.tiles[4][0].rad)\n \n def draw_ring(self, ring):\n \"\"\"\n draws the outer rings\n \"\"\"\n # draw all tiles\n for tile in range(self.tiles_per_ring):\n self.draw_tile(tile, ring)\n \n def draw_tile(self, tile, ring):\n \"\"\" \n draws one arc tile of a ring\n depending on the number of players and the size of the screen\n \"\"\"\n pg.draw.arc(self.screen, self.tile_colors[self.tiles[ring][tile].terrain], [self.tiles[ring][tile].rect_x, self.tiles[ring][tile].rect_y, self.tiles[ring][tile].rect_width, self.tiles[ring][tile].rect_height], self.tiles[ring][tile].radi_start, self.tiles[ring][tile].radi_end, self.tiles[ring][tile].ring_width) \n \n \n def draw_counter(self, player_num):\n \"\"\"\n draws the counters for the score of each player\n \"\"\"\n \n pass\n \n def draw_start_area(self, player_num):\n \"\"\"\n draws the starting area for each player\n \"\"\"\n pass\n \n def rotate_ring_right(self, ring_num):\n \"\"\"\n rotates a ring one field to the right\n \"\"\"\n # to accomplish this save the pos of the first tile in the ring\n # in a temporary variable, then interchange clockwise the position data \n # of all tiles\n pass \n \n def rotate_ring_left(self, ring_num):\n \"\"\"\n rotates a ring one field to the right\n \"\"\"\n pass\n\nclass Tile:\n \"\"\"\n class for the instances of the tiles on the board\n \"\"\"\n \n # Somehow the units must be asociated with a given tile \n \n # define the terrains\n ter_names = [\"center\", \"light\", \"normal\", \"difficult\"]\n\n \n def __init__(self, rect_x = 0, rect_y = 0 ,rect_height = 0, rect_width = 0, radi_start = 0, radi_end = 0, terrain = 0, ring_width = 0, units = None):\n \"\"\"\n defines the instance attributes for every tile on call\n \"\"\"\n # terrain 0 = black (center), 1 = light/green, 2 normal/yellow, 3 difficult/red\n self.rect_x = rect_x\n self.rect_y = rect_y\n self.radi_start = radi_start\n self.radi_end = radi_end\n self.terrain = terrain\n self.rect_width = rect_width\n self.rect_height = rect_height\n self.ring_width = ring_width\n if units == None:\n self.units = []\n else:\n self.units = units\n \n def __str__(self):\n \"\"\"\n string output for the class\n \"\"\"\n pass\n \n def change_terrain(self, new_ter):\n \"\"\"changes the terrain\"\"\"\n self.terrain = new_ter\n \n def change_pos(self, new_radi_start, new_radi_end):\n \"\"\"\n changes the position of a tile\n \"\"\"\n self.radi_start = new_radi_start\n self.radi_end = new_radi_end\n \n def add_unit(self, unit):\n \"\"\"\n adds a unit to the tile\n \"\"\"\n pass\n \n def del_unit(self, unit):\n \"\"\"\n deletes a unit from a tile\n \"\"\"\n pass\n \nclass Center_Piece:\n \"\"\"\n class for the instance of the center piece\n \"\"\"\n def __init__(self,x = 0, y = 0, rad = 0, col = 0):\n \"\"\"\n defines the instance attributes\n \"\"\"\n self.x = x\n self.y = y\n self.rad = rad\n self.col = col\n \nclass Counter:\n \"\"\"\n class for the instances of the counters\n \"\"\"\n def __init__(self, x = 0, y = 0, player = None, points = 0):\n \"\"\"\n defines the instance attributes for every counter on call\n \"\"\"\n self.x = x\n self.y = y\n self.player = player\n self.points = points\n \n def increment(self):\n \"\"\"increments the points by one\"\"\"\n self.points += 1\n \nclass Start_Area:\n \"\"\"\n class for the instances of the starting areas\n \"\"\"\n def __init__(self, rect_x = 0, rect_y = 0, radi_start = 0, radi_end = 0, player = None):\n \"\"\"\n defines the instance attributes for every start area on call\n \"\"\"\n self.rect_x = rect_x\n self.rect_y = rect_y\n self.radi_start = radi_start\n self.radi_end = radi_end\n self.player = player\n \n def change_pos(self, new_radi_start, new_radi_end):\n \"\"\"\n changes the position of the start are\n \"\"\"\n self.radi_start = new_radi_start\n self.radi_end = new_radi_end\n \nclass Unit:\n # 0 = runner, 1 = warrior, 2 = blocker\n # define the units\n unit_names = [\"runner\", \"warrior\", \"blocker\"] \n pass\n\n \n\n\n\n \n \n\n "
}
] | 5 |
rafael6/onepk
|
https://github.com/rafael6/onepk
|
a3cc3089640a8e06f98d86ad3cbf82264950eaf1
|
fdcb495ca21211c086137926fd5890f9a9fd55c2
|
7793735aadad21f929502855cb8b59f1292ca1c8
|
refs/heads/master
| 2020-12-25T18:20:16.165099 | 2015-02-25T01:59:47 | 2015-02-25T01:59:47 | 31,241,350 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5788090825080872,
"alphanum_fraction": 0.6085814237594604,
"avg_line_length": 28.28205108642578,
"blob_id": "05e61ebc9dc20dc015db15a4008cf7e92879feb7",
"content_id": "2e4a30981acf82730f12cebbafce523938a1e94d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1142,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 39,
"path": "/w6e3.py",
"repo_name": "rafael6/onepk",
"src_encoding": "UTF-8",
"text": "__author__ = 'rafael'\n\nfrom onepk_helper import NetworkDevice\nfrom onep.vty import VtyService\n\nrtr1 = {'ip': '50.242.94.227', 'username': 'pyclass', 'password': '88newclass',\n 'pin_file': 'pynet-rtr1-pin.txt', 'port': 15002}\nrtr2 = {'ip': '50.242.94.227', 'username': 'pyclass', 'password': '88newclass',\n 'pin_file': 'pynet-rtr2-pin.txt', 'port': 8002}\n\n\ndef set_command(vty, cmd):\n \"\"\"\n :param vty: OnePK VtyService object\n :param cmd: CLI command\n :return:CLI command output\n \"\"\"\n cli = vty.write(cmd)\n return cli\n \n\ndef main():\n \"\"\"\n reate an onep object, establish a connection with an element\n :return: output of the show version CLI command\n \"\"\"\n for rtr in (rtr1, rtr2):\n rtr_obj = NetworkDevice(**rtr)\n rtr_obj.establish_session()\n vty_service = VtyService(rtr_obj.net_element)\n vty_service.open()\n print 'Stats for {}:'.format(rtr_obj.net_element.properties.sys_name)\n set_command(vty_service, 'terminal length 0')\n print set_command(vty_service, 'show version')\n rtr_obj.disconnect()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5949152708053589,
"alphanum_fraction": 0.6177965998649597,
"avg_line_length": 29.921052932739258,
"blob_id": "e5ba1392cf62eba3e265429f811d2972c8a2e99f",
"content_id": "e308f2b86c5efe3e66dbf4b85058a54dbc2c8c1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1180,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 38,
"path": "/w6e2.py",
"repo_name": "rafael6/onepk",
"src_encoding": "UTF-8",
"text": "__author__ = 'rafael'\n\nfrom onepk_helper import NetworkDevice\nfrom onep.interfaces import NetworkInterface, InterfaceFilter\n\nrtr1 = {'ip': '10.1.1.1', 'username': 'a_user', 'password': 'a_password',\n 'pin_file': 'pynet-rtr1-pin.txt', 'port': 12345}\nrtr2 = {'ip': '10.2.2.2', 'username': 'a_user', 'password': 'a_password',\n 'pin_file': 'pynet-rtr2-pin.txt', 'port': 6789}\n\n\ndef get_intstat(obj):\n \"\"\"\n :param obj:\n :return:interface list\n \"\"\"\n a_filter = InterfaceFilter(None, NetworkInterface.InterfaceTypes.ONEP_IF_TYPE_ETHERNET)\n intf_list = obj.net_element.get_interface_list(a_filter)\n return intf_list\n\n\ndef main():\n \"\"\"\n Create an onep object and establish a connection with an element.\n :return:system name and interface FastEthernet4 stats.\n \"\"\"\n for rtr in (rtr1, rtr2):\n rtr_obj = NetworkDevice(**rtr)\n rtr_obj.establish_session()\n print 'Stats for {}:'.format(rtr_obj.net_element.properties.sys_name)\n for i in get_intstat(rtr_obj):\n if 'FastEthernet4' in i.name:\n print i.get_statistics()\n rtr_obj.disconnect()\n\n\nif __name__ == \"__main__\":\n main()\n \n"
},
{
"alpha_fraction": 0.6258890628814697,
"alphanum_fraction": 0.6514936089515686,
"avg_line_length": 32.47618865966797,
"blob_id": "f0a210d0a9ec218ca6c615a7373cae37e9958943",
"content_id": "da997a2e875d93836f1d1a58648a56b3a3e5a287",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 703,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 21,
"path": "/w6e1.py",
"repo_name": "rafael6/onepk",
"src_encoding": "UTF-8",
"text": "__author__ = 'rafael'\n\nfrom onepk_helper import NetworkDevice\n\nrtr1 = {'ip': '10.1.2.3', 'username': 'auname', 'password': 'apassword',\n 'pin_file': 'devicename', 'port': 12345}\n\n\ndef main():\n '''Create an onep object, establish a connection with an element, \n and return its system name, product ID, and serial number.''' \n rtr1_obj = NetworkDevice(**rtr1)\n rtr1_obj.establish_session()\n print 'Stats for {}:'.format(rtr1_obj.net_element.properties.sys_name)\n print 'Product ID: {}'.format(rtr1_obj.net_element.properties.product_id)\n print 'Serial No.: {}'.format(rtr1_obj.net_element.properties.SerialNo)\n rtr1_obj.disconnect()\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 3 |
Mazwi007/theBeginning
|
https://github.com/Mazwi007/theBeginning
|
963e905a222b7d9e9c6de39fae4f6a44382e5147
|
89275df45a28f74758f59bde0082bd854752a86c
|
a0457680fbca17637aac938c151b2b19a2c5fa71
|
refs/heads/main
| 2023-08-23T12:30:18.199406 | 2021-10-02T15:38:27 | 2021-10-02T15:38:27 | 412,837,068 | 0 | 0 | null | 2021-10-02T15:33:57 | 2021-10-02T15:38:29 | 2021-10-02T15:57:17 |
Python
|
[
{
"alpha_fraction": 0.717391312122345,
"alphanum_fraction": 0.717391312122345,
"avg_line_length": 22,
"blob_id": "f6d25f4bf1017b82694eede9b091c473fd3937e4",
"content_id": "2a712996210e50c5abdfd46f91724e74aa0f0b39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/test.py",
"repo_name": "Mazwi007/theBeginning",
"src_encoding": "UTF-8",
"text": "#print something form me\nPrint(\"\"I WAS HERE\")\n"
},
{
"alpha_fraction": 0.7555555701255798,
"alphanum_fraction": 0.7555555701255798,
"avg_line_length": 21.5,
"blob_id": "ecbd0e344249cb8137b844f6fed1ade41defe9cb",
"content_id": "ed0a692879bac8eca652eb696e662acf00b5f8aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Mazwi007/theBeginning",
"src_encoding": "UTF-8",
"text": "# theBeginning\nI was here and i did the test\n"
}
] | 2 |
alexras/kiosk
|
https://github.com/alexras/kiosk
|
e4ce7e763df7f0ab34f5d18ff0b6010e4533763b
|
5b3d746f8bc1ee61c2b7c1035fa61581aedeb327
|
31dc3056f99ad2f3796bd860ac9cb7d1558e0921
|
refs/heads/master
| 2020-06-08T13:27:11.968844 | 2012-05-13T01:57:08 | 2012-05-13T01:57:08 | 3,371,697 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5966340899467468,
"alphanum_fraction": 0.6009771823883057,
"avg_line_length": 25.314285278320312,
"blob_id": "5747d267b7f06501cc72b7af26751c1d8186da08",
"content_id": "cda102ca82a868e7d6aeed129664263a10a2cae0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1842,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 70,
"path": "/modules/HTMLModule.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "import gtk\nimport webkit\nimport random\n\nimport gtk\nimport os\nimport random\nfrom BaseModule import BaseModule\nimport feedparser\nimport logging\nimport urllib\n\nSCRIPT_DIR = os.path.dirname(__file__)\n\nclass BrowserPage(webkit.WebView):\n def __init__(self):\n webkit.WebView.__init__(self)\n settings = self.get_settings()\n settings.set_property(\"enable-developer-extras\", True)\n self.set_full_content_zoom(True)\n\n # Disable plugins and scripts to be on the safe side\n settings.set_property(\"enable-plugins\", False)\n\nclass HTMLModule(BaseModule):\n def __init__(self, config):\n super(HTMLModule, self).__init__(config)\n self.webview = BrowserPage()\n self.widget = gtk.ScrolledWindow()\n self.widget.add(self.webview)\n\n self.feeds = config[\"rss_feeds\"]\n\n self.update_urls()\n\n self.update_count = 0\n\n def update_urls(self):\n self.urls = set()\n\n for feed in self.feeds:\n parsed_feed = feedparser.parse(feed)\n\n if parsed_feed.bozo == 1:\n continue\n\n for entry in parsed_feed.entries:\n self.urls.add(entry.link)\n\n self.urls = list(self.urls)\n random.shuffle(self.urls)\n\n if len(self.urls) == 0:\n logging.error(\"URL list is empty\")\n\n def get_widget(self, monitor_number):\n return self.widget\n\n def update(self):\n if len(self.urls) == 0 or self.update_count % len(self.urls) == 0:\n self.update_urls()\n self.update_count += 1\n\n if len(self.urls) > 0:\n current_url = self.urls[self.update_count % len(self.urls)]\n else:\n current_url = \"file:\" + urllib.pathname2url(\n os.path.join(SCRIPT_DIR, \"html_module_error.html\"))\n\n self.webview.load_uri(current_url)\n"
},
{
"alpha_fraction": 0.6662895679473877,
"alphanum_fraction": 0.6662895679473877,
"avg_line_length": 25.787878036499023,
"blob_id": "b375047c6303c6ff30967995d83f9307ece6f2d1",
"content_id": "89e3f1b434d84eedfaabc46086f24217a8cf0559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 884,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 33,
"path": "/modules/ArcadeModule.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "import gtk\nimport webkit\nimport random\n\nimport gtk\nimport os\nimport random\nfrom BaseModule import BaseModule\nimport logging\n\nclass BrowserPage(webkit.WebView):\n def __init__(self):\n webkit.WebView.__init__(self)\n settings = self.get_settings()\n settings.set_property(\"enable-developer-extras\", True)\n self.set_full_content_zoom(True)\n settings.set_property(\"enable-plugins\", True)\n\nclass ArcadeModule(BaseModule):\n def __init__(self, config):\n super(ArcadeModule, self).__init__(config)\n self.arcade_url = \"http://www.twitch.tv/ucsdcsearcade/popout\"\n self.webview = BrowserPage()\n self.widget = gtk.ScrolledWindow()\n self.widget.add(self.webview)\n\n self.webview.load_uri(self.arcade_url)\n\n def get_widget(self, monitor_number):\n return self.widget\n\n def update(self):\n return None\n"
},
{
"alpha_fraction": 0.5994415283203125,
"alphanum_fraction": 0.605026364326477,
"avg_line_length": 32.92631530761719,
"blob_id": "d5a43cae1e6faa39b84e83c5e76edd6be28fd502",
"content_id": "e8c30d93236485b8782dc5ccc3a6ab7b9bf0f989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3223,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 95,
"path": "/modules/BaseMediaViewerModule.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "import os\nimport random\nfrom BaseModule import BaseModule\nimport logging\nimport time\nimport pprint\n\nclass BaseMediaViewerModule(BaseModule):\n def __init__(self, config, media_dir, suffixes):\n super(BaseMediaViewerModule, self).__init__(config)\n\n self.update_count = 0\n self.refresh_interval = config[\"refresh_interval\"]\n\n self.initial_freshness = config[\"initial_freshness\"]\n self.freshness_decay_rate = config[\"freshness_decay_rate\"]\n self.freshness_decay_time_days = config[\"freshness_decay_time_days\"]\n self.minimum_freshness = config[\"minimum_freshness\"]\n\n self.total_freshness = 0\n\n self.media_dir = media_dir\n self.valid_suffixes = list(suffixes)\n\n def filter_suffixes(filename):\n for suffix in self.valid_suffixes:\n if filename.find(suffix) != -1:\n return True\n return False\n\n self.suffix_filter = filter_suffixes\n\n self.refresh_content_list()\n\n def compute_freshness(self, content_file):\n content_file = os.path.join(self.media_dir, content_file)\n\n # To hack around Windows' silliness, if the modification time is older\n # than the creation time, use the modification time as the file's age\n file_creation_time = min(os.path.getctime(content_file),\n os.path.getmtime(content_file))\n\n days_since_file_creation = ((time.time() - file_creation_time) /\n (60 * 60 * 24))\n\n decays_since_file_creation = int(\n days_since_file_creation / self.freshness_decay_time_days)\n\n freshness = self.initial_freshness\n\n for i in xrange(decays_since_file_creation):\n freshness *= (1.0 - self.freshness_decay_rate)\n\n freshness = int(max(freshness, self.minimum_freshness))\n\n self.total_freshness += freshness\n\n return (content_file, freshness)\n\n def refresh_content_list(self):\n self.total_freshness = 0\n\n try:\n logging.debug(\"Refreshing content list ...\")\n self.content_list = map(\n self.compute_freshness,\n filter(self.suffix_filter, os.listdir(self.media_dir)))\n except OSError, e:\n logging.error(\"Caught OSError while listing content directory \"\n \"'%s': %s\" % (self.media_dir, e))\n\n self.content_list.sort(key=lambda x: x[1], reverse=True)\n\n for (filename, freshness) in self.content_list:\n logging.debug(\"File: %s, Freshness: %d\" % (\n filename, freshness))\n logging.debug(\"Total freshness: %d\" % (self.total_freshness))\n\n def get_random_content(self):\n random_freshness = random.randint(0, self.total_freshness - 1)\n\n for (content_file, freshness) in self.content_list:\n random_freshness -= freshness\n\n if random_freshness <= 0:\n return content_file\n\n def update(self):\n if self.update_count % self.refresh_interval == 0:\n self.refresh_content_list()\n self.update_count += 1\n\n media_file = self.get_random_content()\n\n self.update_from_media(media_file)\n"
},
{
"alpha_fraction": 0.6544502377510071,
"alphanum_fraction": 0.6544502377510071,
"avg_line_length": 28.346153259277344,
"blob_id": "77c09c94e7fb83c1d86468fac91a5ad6f94d7670",
"content_id": "b0ee7bd81c598bf43e81cbc1fce22b813856b9bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 26,
"path": "/modules/utils.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "import gtk\n\ndef scale_pixbuf(pixbuf, width, height):\n pixbuf_width = int(pixbuf.get_width())\n pixbuf_height = int(pixbuf.get_height())\n\n # By default, attempt to match the display's height\n image_height = int(height)\n image_width = int(\n float(image_height * pixbuf_width) / float(pixbuf_height))\n\n # If the resulting width is wider than needed, match the display's width\n # instead\n\n if image_width > width:\n image_width = int(width)\n image_height = int(\n float(image_width * pixbuf_height) / float(pixbuf_width))\n\n assert image_width <= width\n assert image_height <= height\n\n scaled_pixbuf = pixbuf.scale_simple(\n image_width, image_height, gtk.gdk.INTERP_HYPER)\n\n return scaled_pixbuf\n\n"
},
{
"alpha_fraction": 0.5447761416435242,
"alphanum_fraction": 0.5597015023231506,
"avg_line_length": 25.799999237060547,
"blob_id": "70264b154becee55a6001eda692beef77d869891",
"content_id": "4fb30a37311509b3d8c49caf6accc6dd2ee7ea98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 5,
"path": "/modules/BaseModule.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "class BaseModule(object):\n def __init__(self, config):\n self.config = config\n self.width = 0\n self.height = 0\n"
},
{
"alpha_fraction": 0.6209677457809448,
"alphanum_fraction": 0.6209677457809448,
"avg_line_length": 28.931034088134766,
"blob_id": "c9c0732a480c72f023a77a79dd16e4221cbb2634",
"content_id": "a62e884719cede5c8f6a130a59a4401eabae0a37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 29,
"path": "/modules/ImageModule.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "import gtk\nimport os\nfrom BaseMediaViewerModule import BaseMediaViewerModule\nimport utils\nimport logging\n\nclass ImageModule(BaseMediaViewerModule):\n def __init__(self, config):\n super(ImageModule, self).__init__(\n config, config[\"images\"], config[\"formats\"])\n\n self.image = gtk.Image()\n\n def get_widget(self, monitor_number):\n return self.image\n\n def update_from_media(self, image_file):\n assert os.path.exists(image_file)\n\n logging.debug(\"Displaying image '%s'\" % (image_file))\n\n pixbuf = utils.scale_pixbuf(gtk.gdk.pixbuf_new_from_file(image_file),\n self.width, self.height)\n\n logging.debug(\"width: %d, height: %d\" % (\n pixbuf.get_width(), pixbuf.get_height()))\n\n self.image.set_from_pixbuf(None)\n self.image.set_from_pixbuf(pixbuf)\n"
},
{
"alpha_fraction": 0.5346171259880066,
"alphanum_fraction": 0.5359926819801331,
"avg_line_length": 34.14516067504883,
"blob_id": "7ccbd1e7b993042780b6ce9d29dbcff0c8c0988d",
"content_id": "62f9aec1afd85b17e4a1d2205314eb02214e6519",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2181,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/modules/PDFModule.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "import gtk\nimport urllib\nimport random\nimport os\nfrom BaseMediaViewerModule import BaseMediaViewerModule\nimport utils\nimport glib\nimport logging\nimport subprocess\n\nclass PDFModule(BaseMediaViewerModule):\n def __init__(self, config):\n super(PDFModule, self).__init__(\n config, config[\"pdfs\"], [\".pdf\"])\n\n self.pdf_image = gtk.Image()\n\n def get_widget(self, monitor_number):\n return self.pdf_image\n\n def convert_pdfs(self):\n for (filename, freshness) in self.content_list:\n png_filename = filename[:-4] + \".png\"\n\n if not os.path.exists(png_filename):\n logging.debug(\"Converting '%s' to png\" % (filename))\n\n cmd = ('\"%s\" -sOutputFile=\"%s\" -sDEVICE=%s -r%d '\n '-dBATCH -dNOPAUSE -dSAFER \"%s\"' %\n (self.config[\"ghostscript\"][\"binary_path\"],\n png_filename,\n self.config[\"ghostscript\"][\"output_device\"],\n self.config[\"ghostscript\"][\"ppi\"],\n filename))\n subproc = subprocess.Popen(\n cmd, shell=True, stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT)\n (stdout, stderr) = subproc.communicate()\n\n if subproc.returncode != 0:\n logging.error(\"PNG conversion failed: %s\" % (stdout))\n\n def update_from_media(self, pdf_file):\n self.convert_pdfs()\n\n try:\n png_file = pdf_file[:-4] + \".png\"\n\n # Skip PDFs that failed to convert to PNGs successfully\n if not os.path.exists(png_file):\n return\n\n pixbuf = utils.scale_pixbuf(gtk.gdk.pixbuf_new_from_file(png_file),\n self.width, self.height)\n\n logging.debug(\"Opening PNG convert of PDF %s'\" % (pdf_file))\n self.pdf_image.set_from_pixbuf(None)\n self.pdf_image.set_from_pixbuf(pixbuf)\n except Exception, e:\n logging.error(\"Converted PNG for '%s' is corrupted or inaccessible\"\n % (pdf_file))\n logging.exception(e)\n\n\n"
},
{
"alpha_fraction": 0.582830548286438,
"alphanum_fraction": 0.5893811583518982,
"avg_line_length": 31.774011611938477,
"blob_id": "2047bfe636efbbc5c343a7b6ce592f4e1c6972f2",
"content_id": "af917037db86d97ba327a2cd21bd6c9b1567e29a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5801,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 177,
"path": "/kiosk.py",
"repo_name": "alexras/kiosk",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport pygtk\npygtk.require(\"2.0\")\nimport gtk\nimport gobject\nimport json\nimport os\nimport sys\nimport time\nimport logging\nimport logging.handlers\nimport time\n\nimport modules\n\n# From http://stackoverflow.com/a/452981\ndef get_class(classname):\n classname_parts = classname.split('.')\n module = '.'.join(classname_parts[:-1])\n class_obj = __import__(module)\n\n for component in classname_parts[1:]:\n class_obj = getattr(class_obj, component)\n\n return class_obj\n\nSCRIPT_DIR = os.path.dirname(__file__)\nKIOSK_LOG_FILE = os.path.join(SCRIPT_DIR, \"kiosk.log\")\n\n# Configure logging to roll over after 10 MB of logs, keeping the most recent 5\n# copies\nlogger = logging.getLogger()\nlogger.setLevel(logging.DEBUG)\nlog_file_handler = logging.handlers.RotatingFileHandler(\n KIOSK_LOG_FILE, maxBytes=10000000, backupCount=5)\nlog_file_handler.setFormatter(logging.Formatter(\n fmt='%(process)s\\t%(asctime)-15s\\t%(message)s'))\nlogger.addHandler(log_file_handler)\n\nclass Kiosk(object):\n def update_module_handler(self, module, monitor_number):\n def handler(widget, event):\n if event.width > 200:\n module.width = event.width\n module.height = event.height\n widget.disconnect(self.initial_update_handler_ids[widget])\n\n try:\n logging.debug(\"Refreshing monitor %d\" % (monitor_number))\n module.update()\n except Exception, e:\n logging.exception(e)\n return handler\n\n def realize_callback(self, widget):\n widget.window.set_cursor(self.get_invisible_cursor())\n\n def get_invisible_cursor(self):\n pix_data = \"\"\"/* XPM */\n static char * invisible_xpm[] = {\n \"1 1 1 1\",\n \" c None\",\n \" \"};\"\"\"\n color = gtk.gdk.Color()\n pix = gtk.gdk.pixmap_create_from_data(\n None, pix_data, 1, 1, 1, color, color)\n invisible = gtk.gdk.Cursor(pix, pix, color, color, 0, 0)\n return invisible\n\n def update_modules(self):\n for monitor_number, monitor in enumerate(self.monitors):\n module = self.display_modules[monitor_number]\n\n try:\n logging.debug(\"Refreshing monitor %d\" % (monitor_number))\n module.update()\n except Exception, e:\n logging.exception(e)\n\n self.update_timer = gobject.timeout_add_seconds(\n self.config[\"kiosk\"][\"transition_time\"], self.update_modules)\n\n def get_monitor_bounds(self):\n monitor_bounds = {}\n\n for monitor_number, monitor in self.monitors.items():\n monitor_geometry = self.screen.get_monitor_geometry(monitor_number)\n\n monitor_bounds[monitor_number] = {\n \"width\" : monitor.width,\n \"height\" : monitor.height,\n \"x\" : monitor_geometry.x,\n \"y\" : monitor_geometry.y\n }\n\n return monitor_bounds\n\n def load_config(self):\n \"\"\"\n Loads the current configuration from the file named by self.config_path\n into self.config as a dictionary. If you fail to parse the config file,\n roll back, wait 5 seconds, and re-try until you read a config file\n successfully\n \"\"\"\n parsed_config = False\n old_config = self.config\n\n while not parsed_config:\n try:\n with open(self.config_path, 'r') as fp:\n self.config = json.load(fp)\n parsed_config = True\n except ValueError, e:\n self.config = old_config\n logging.exception(e)\n time.sleep(5)\n\n def init_display_module(self, module, module_config):\n return get_class(\"modules.%(module_name)s.%(module_name)s\" %\n {\"module_name\" : module})(module_config)\n\n def __init__(self, config_file):\n self.config_path = config_file\n self.config = {}\n\n self.load_config()\n\n self.screen = gtk.gdk.screen_get_default()\n\n if self.screen is None:\n sys.exit(\"Can't initialize screen\")\n\n self.monitors = []\n self.display_modules = []\n\n for module_config in self.config[\"modules\"]:\n self.display_modules.append(self.init_display_module(\n module_config[\"type\"], module_config))\n\n self.initial_update_handler_ids = {}\n\n for monitor_number in xrange(self.screen.get_n_monitors()):\n monitor = gtk.Window(gtk.WINDOW_TOPLEVEL)\n color = gtk.gdk.color_parse(\n self.config[\"kiosk\"][\"background_color\"])\n monitor.modify_bg(gtk.STATE_NORMAL, color)\n\n monitor_rect = self.screen.get_monitor_geometry(monitor_number)\n monitor.move(monitor_rect.x, monitor_rect.y)\n monitor.connect(\"realize\", self.realize_callback)\n monitor.connect(\"destroy\", gtk.main_quit)\n\n monitor.fullscreen()\n monitor.set_decorated(False)\n self.monitors.append(monitor)\n\n for monitor_number, monitor in enumerate(self.monitors):\n module = self.display_modules[monitor_number]\n handler_id = monitor.connect(\"configure_event\",\n self.update_module_handler(\n module, monitor_number))\n self.initial_update_handler_ids[monitor] = handler_id\n\n monitor.add(module.get_widget(monitor_number))\n monitor.show_all()\n\n self.update_timer = gobject.timeout_add_seconds(\n self.config[\"kiosk\"][\"transition_time\"], self.update_modules)\n\n def main(self):\n gobject.threads_init()\n gtk.main()\n\nif __name__ == '__main__':\n kiosk = Kiosk(\"config.json\")\n kiosk.main()\n"
}
] | 8 |
samirMeziane/sentiment-analysis-with-Dynet-using-CNN
|
https://github.com/samirMeziane/sentiment-analysis-with-Dynet-using-CNN
|
589e355b523c6dc09aebf3e9733ca86c7ee14bf6
|
ce36511295d8d509338eff21e56a669be7cb49d4
|
93ccf69cd8c13b443254a2de55e76dfe1defbef2
|
refs/heads/master
| 2021-01-03T02:19:35.631689 | 2020-02-14T20:00:51 | 2020-02-14T20:00:51 | 239,877,002 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5639890432357788,
"alphanum_fraction": 0.5798017978668213,
"avg_line_length": 38.88793182373047,
"blob_id": "4afd7af66e744a40d84d4a84cd710058a1a27ef8",
"content_id": "fc47fa0dc1e2d8b8591ea04465ec9dcec4ab9220",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4743,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 116,
"path": "/predict_cnn.py",
"repo_name": "samirMeziane/sentiment-analysis-with-Dynet-using-CNN",
"src_encoding": "UTF-8",
"text": "import os\r\nimport pickle\r\nimport argparse\r\nimport pandas as pd\r\nimport dynet as dy\r\nfrom tqdm import tqdm\r\n\r\nfrom cnn_text_classification_project.utils import build_dataset_1 , associate_parameters , binary_pred , forwards\r\n\r\nparser = argparse.ArgumentParser (description='Convolutional Neural Networks for Sentence Classification in DyNet')\r\nparser.add_argument ('--gpu' , type=int , default=-1 , help='GPU ID to use. For cpu, set -1 [default: -1]')\r\nparser.add_argument ('--model_file' , type=str , default='../data/models/cnn_text_classification/model_e10' ,\r\n help='Model to use for prediction [default: ./model]')\r\nparser.add_argument ('--input_file' , type=str ,\r\n default='D:/Users/wissam/Documents/These/these/Datasets/Paraphrases_sentiment_datasets/news_headlines_paraphrases_sentiment.csv' ,\r\n help='Input file path [default: ./data/annotation_S2]')\r\nparser.add_argument ('--out_file' , type=str , default='../data/results/sentiment_dataset_cnn.csv' ,\r\n help='Output file path [default: ./pred_yannotation_S2.txt]')\r\nparser.add_argument ('--w2i_file' , type=str , default='../data/models/cnn_text_classification/w2i.dump' ,\r\n help='Word2Index file path [default: ../data/models/cnn_text_classification/w2i.dump]')\r\nparser.add_argument ('--i2w_file' , type=str , default='../data/models/cnn_text_classification/i2w.dump' ,\r\n help='Index2Word file path [default: ../data/models/cnn_text_classification/i2w.dump]')\r\nparser.add_argument ('--alloc_mem' , type=int , default=1024 ,\r\n help='Amount of memory to allocate [mb] [default: 1024]')\r\n\r\nargs = parser.parse_args ()\r\n\r\ndef main(args):\r\n\r\n os.environ['CUDA_VISIBLE_DEVICES'] = str (args.gpu)\r\n\r\n MODEL_FILE = args.model_file\r\n INPUT_FILE = args.input_file\r\n OUTPUT_FILE = args.out_file\r\n W2I_FILE = args.w2i_file\r\n I2W_FILE = args.i2w_file\r\n ALLOC_MEM = args.alloc_mem\r\n df_input = pd.read_csv (INPUT_FILE , sep=\";\" , encoding=\"ISO-8859-1\")\r\n df_input.columns = [\"Id\" , \"Review\" , \"Golden\"]\r\n # DyNet setting\r\n dyparams = dy.DynetParams ()\r\n dyparams.set_mem (ALLOC_MEM)\r\n dyparams.init ()\r\n print (MODEL_FILE)\r\n # Load model\r\n model = dy.Model ()\r\n pretrained_model = dy.load (MODEL_FILE , model)\r\n\r\n\r\n\r\n\r\n if len (pretrained_model) == 3:\r\n V1 , layers = pretrained_model[0] , pretrained_model[1:]\r\n MULTICHANNEL = False\r\n else:\r\n V1 , V2 , layers = pretrained_model[0] , pretrained_model[1] , pretrained_model[2:]\r\n MULTICHANNEL = True\r\n\r\n EMB_DIM = V1.shape ()[0]\r\n WIN_SIZES = layers[0].win_sizes\r\n\r\n # Load test data\r\n with open (W2I_FILE , 'rb') as f_w2i , open (I2W_FILE , 'rb') as f_i2w:\r\n w2i = pickle.load (f_w2i)\r\n i2w = pickle.load (f_i2w)\r\n\r\n max_win = max (WIN_SIZES)\r\n test_X = build_dataset_1 (INPUT_FILE , w2i=w2i , unksym='unk')\r\n # test_X , Golden= build_dataset_df(INPUT_FILE)\r\n print (test_X)\r\n test_X = [[0] * max_win + instance_x + [0] * max_win for instance_x in test_X]\r\n\r\n # Pred\r\n pred_y = []\r\n for instance_x in tqdm (test_X):\r\n # Create a new computation graph\r\n dy.renew_cg ()\r\n associate_parameters (layers)\r\n\r\n sen_len = len (instance_x)\r\n\r\n if MULTICHANNEL:\r\n x_embs1 = dy.concatenate ([dy.lookup (V1 , x_t , update=False) for x_t in instance_x] , d=1)\r\n x_embs2 = dy.concatenate ([dy.lookup (V2 , x_t , update=False) for x_t in instance_x] , d=1)\r\n x_embs1 = dy.transpose (x_embs1)\r\n x_embs2 = dy.transpose (x_embs2)\r\n x_embs = dy.concatenate ([x_embs1 , x_embs2] , d=2)\r\n else:\r\n x_embs = dy.concatenate ([dy.lookup (V1 , x_t , update=False) for x_t in instance_x] , d=1)\r\n x_embs = dy.transpose (x_embs)\r\n # x_embs = dy.reshape(x_embs, (sen_len, EMB_DIM, 1))\r\n\r\n y = forwards (layers , x_embs)\r\n pred_y.append (str (float ( (y.value ()))))\r\n pred_y = pred_y[1:]\r\n P = pd.Series (pred_y).rename (\"Pred_sentiment\")\r\n print (P , df_input[\"Review\"])\r\n df = pd.DataFrame ()\r\n df[\"Id\"] = df_input[\"Id\"]\r\n df[\"Review\"] = df_input[\"Review\"]\r\n df[\"Golden\"] = df_input[\"Golden\"]\r\n df[\"Pred_sentiment\"] = P\r\n \"\"\"\r\n df= pd.DataFrame({\"Id\":df_input[\"Id\"] },\r\n {\"Review\": df_input[\"Golden\"] },\r\n {\"Pred_sentiment\": P })\r\n #{\"Pred_sentiment\": P} )\"\"\"\r\n print(df)\r\n df.to_csv (OUTPUT_FILE , sep=\";\" , index=False)\r\n\r\n # with open(OUTPUT_FILE, 'w') as f:\r\n # f.write('\\n'.join(pred_y))\r\n\r\n\r\nif __name__ == '__main__':\r\n main (args)\r\n"
}
] | 1 |
forsolver/DAT210x-python
|
https://github.com/forsolver/DAT210x-python
|
71c968c90b9f7cd72454b15955ea5ddd8aab0d0f
|
270c8a845e9b5b8928afc649557df298b1e6e430
|
b8cd8fd74794e14213a20c0535812b996c558259
|
refs/heads/master
| 2020-05-25T12:43:00.248041 | 2017-03-14T07:24:20 | 2017-03-14T07:24:20 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5871211886405945,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 23.090909957885742,
"blob_id": "9630fb120ded5f08582238ba7800f9d4e92f92b0",
"content_id": "eeccc26a4780c48d0941d6231da20e93a78d9b81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 11,
"path": "/lab3/pca.py",
"repo_name": "forsolver/DAT210x-python",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom sklearn.decomposition import PCA\n\nX = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])\npca = PCA(n_components=2)\nprint(pca.fit(X))\n#pca.fit(df)\n#pca.transform(df)\n\n#print(pca.explained_variance_ratio_)\nprint(pca.components_)"
},
{
"alpha_fraction": 0.7289048433303833,
"alphanum_fraction": 0.7791741490364075,
"avg_line_length": 30,
"blob_id": "e00cbe6e177ee841c6e64de842e5b8f95463b3a8",
"content_id": "e27510b5253d1e5e7fe671b05dda0549da5987f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 557,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 18,
"path": "/applied_ml/pry2.py",
"repo_name": "forsolver/DAT210x-python",
"src_encoding": "UTF-8",
"text": "import rpy2.robjects as robjects\nfrom rpy2.robjects.packages import importr\nts=robjects.r('ts')\nforecast = importr(\"forecast\", lib_loc = \"C:/Users/sand9888/Documents/sand9888/R/win-library/3.3\")\nimport os\nimport pandas as pd\n\nfrom rpy2.robjects import pandas2ri\npandas2ri.activate()\n\n\ntrain = os.path.join('C:/DAT203.3x/Lab01/cadairydata.csv')\ntraindf=pd.read_csv(train, index_col=0)\ntraindf.index=traindf.index.to_datetime()\n\nrdata=ts(traindf.Price.values,frequency=4)\nfit=forecast.auto_arima(rdata)\nforecast_output=forecast.forecast(fit,h=16,level=(95.0))"
}
] | 2 |
hatlabcz/HDLSimVisualizer
|
https://github.com/hatlabcz/HDLSimVisualizer
|
eae513d5836e1c41bf72fd1c86d0fb12695f6415
|
8feffbbd4c67ffd77138812989df8f56f801d8fb
|
d93d4a71e1dade0c2a83d069cfcdef4d64c1ec25
|
refs/heads/main
| 2023-01-07T10:25:44.726919 | 2020-11-14T19:58:08 | 2020-11-14T19:58:08 | 308,364,207 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5143112540245056,
"alphanum_fraction": 0.5465116500854492,
"avg_line_length": 26.615385055541992,
"blob_id": "c973781037a4c2831f1dc4ab58d140a2c2be6b83",
"content_id": "7066a60490b208596205a8be3a7a9fcabc214ba6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1118,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 39,
"path": "/HDLSimVisualizer/test_demo_int.py",
"repo_name": "hatlabcz/HDLSimVisualizer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Oct 27 20:46:24 2020\r\n\r\n@author: Chao\r\n\"\"\"\r\n\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport HDLSimVisualizer_pkg as hsv\r\nfrom HDLSimVisualizer_pkg import HDLSim\r\n\r\n# ----------- generics ---------------------\r\ngenerics = {\"input_width\": 31,\r\n \"input_ss\": 5, # supersample\r\n \"output_width\": 35,\r\n \"output_ss\": 1\r\n }\r\n# --------- data----------------------------\r\ninput_data = np.arange(0, 100, 1)\r\n\r\n\r\n# --------- Design function -----------------\r\ndef demo_int(input_data):\r\n dout = [np.sum(input_data[i*5: i*5+10]) for i in range(len(input_data)//5)]\r\n return np.array(dout)\r\n\r\n\r\n# ------------main---------------------\r\nsim_dir = r\"C:\\Users\\zctid.LAPTOP-150KME16\\OneDrive\\Lab\\FPGA\\VivadoPorjects\" \\\r\n r\"\\\\Demodulator\\Demodulator\\Demodulator.sim\\sim_1\\behav\\xsim\\\\\"\r\n\r\nhsv.export_binary(\"input_vectors.txt\",\r\n input_data, generics[\"input_width\"], generics[\"input_ss\"])\r\n\r\nlatency = 2\r\nsim = HDLSim(generics, input_data, sim_dir, demo_int, latency)\r\n\r\nsim.compareSimWithDesign()\r\n\r\n"
},
{
"alpha_fraction": 0.5744211673736572,
"alphanum_fraction": 0.5942668318748474,
"avg_line_length": 32.574073791503906,
"blob_id": "e8df3372446ed1868ad4e5c5d7d69eff71b66ef8",
"content_id": "29bfe2c9268c66f3e825747ab96ff2cfcb2ab9e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1814,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 54,
"path": "/HDLSimVisualizer/test_slice_otf.py",
"repo_name": "hatlabcz/HDLSimVisualizer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 27 20:46:24 2020\n\n@author: Chao\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport HDLSimVisualizer_pkg as hsv\nfrom HDLSimVisualizer_pkg import HDLSim\nfrom os.path import expanduser\nHOME = expanduser(\"~\")\n# ----------- generics ---------------------\ngenerics = {\"input_width\": 31,\n \"input_ss\": 5, # supersample\n \"output_width\": 16\n }\ngenerics[\"output_ss\"] = generics[\"input_ss\"]\n# --------- data----------------------------\ninput_data = np.arange(0, 100, 1)\noffset_lower_bit = np.arange(1, 3, 1).repeat(50)\n\n# --------- Design function -----------------\ndef slice_otf(input_data):\n w_in = generics[\"input_width\"]\n w_out = generics[\"output_width\"]\n dout = []\n for i in range(len(input_data)):\n offset = offset_lower_bit[i]\n if w_out+offset>w_in:\n raise ValueError\n\n din_bin = hsv.int_to_slv(input_data[i], w_in)\n dout_bin = din_bin[-w_out-offset: -offset if offset!=0 else None]\n dout.append(hsv.slv_to_int(dout_bin))\n return np.array(dout)\n\nexpected_out = slice_otf(input_data)\n\n# ------------main---------------------\nsim_in_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Demodulator\\Demodulator\\Demodulator.srcs\\sim_1\\imports\\sim\\\\\"\nsim_out_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Demodulator\\Demodulator\\Demodulator.sim\\sim_1\\behav\\xsim\\\\\"\nlatency = 1\n\nhsv.export_binary(sim_in_dir + \"input_vectors_1.txt\",\n input_data, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"input_vectors_2.txt\",\n offset_lower_bit, 32, generics[\"input_ss\"])\n\n\nsim_pass = hsv.compareSimWithDesign(generics, latency, expected_out,\n sim_out_dir+\"output_results.txt\")\n#\n\n"
},
{
"alpha_fraction": 0.5864219069480896,
"alphanum_fraction": 0.6092829704284668,
"avg_line_length": 36.506492614746094,
"blob_id": "c664965b4a53c2310fb528cbf5a85ea57cce89fa",
"content_id": "bec7f786d54f49160bc2d8f6521d8432785aab08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2887,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 77,
"path": "/HDLSimVisualizer/test_phase_correction.py",
"repo_name": "hatlabcz/HDLSimVisualizer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 27 20:46:24 2020\n\n@author: Chao\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport HDLSimVisualizer_pkg as hsv\nfrom HDLSimVisualizer_pkg import HDLSim\nfrom os.path import expanduser\nHOME = expanduser(\"~\")\nPI = np.pi\n# ----------- generics ---------------------\ngenerics = {\"input_width\": 16,\n \"input_ss\": 1, # supersample\n \"output_width\": 32\n }\ngenerics[\"output_ss\"] = generics[\"input_ss\"]\n# --------- data----------------------------\nrand_seed = 10\nnp.random.seed(rand_seed)\nn_data = 50\nRef_amp = 25000 + (np.random.rand(n_data) - 0.5) * 10000\nRef_phase = np.random.rand(n_data) * 2 * PI\nRI = (Ref_amp * np.cos(Ref_phase)).astype(np.int)\nRQ = (Ref_amp * np.sin(Ref_phase)).astype(np.int)\n\nSig_amp = 20000\nSig_phase = np.linspace(0, 2 * PI, n_data+1)[: n_data]\nSI = (Sig_amp * np.cos(Ref_phase + Sig_phase)).astype(np.int)\nSQ = (Sig_amp * np.sin(Ref_phase + Sig_phase)).astype(np.int)\ndata_phase = np.angle(SI + 1j*SQ)\n# --------- Design function -----------------\ndef phase_correction(si, sq, ri, rq):\n R_norm = (ri + 1j * rq)/np.abs(ri + 1j * rq)\n S_complex = si + 1j * sq\n i = np.real(S_complex * R_norm.conj())\n q = np.imag(S_complex * R_norm.conj())\n return i, q\n\nexpected_out_I, expected_out_Q = phase_correction(SI, SQ, RI, RQ)\n# ------------main---------------------\nsim_in_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Phase_Correction\\Phase_Correction.srcs\\sim_1\\imports\\InputVectors\\\\\"\n# sim_out_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Phase_Correction\\Phase_Correction.sim\\sim_1\\behav\\xsim\\\\\"\nsim_out_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Phase_Correction\\Phase_Correction.sim\\sim_1\\impl\\func\\xsim\\\\\"\nlatency = 8\n\nhsv.export_binary(sim_in_dir + \"SI_vectors.txt\",\n SI, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"SQ_vectors.txt\",\n SQ, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"RI_vectors.txt\",\n RI, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"RQ_vectors.txt\",\n RQ, generics[\"input_width\"], generics[\"input_ss\"])\n\n\npass_check = hsv.compareSimWithDesign(generics, latency, expected_out_I*2**9,\n sim_out_dir+\"output_results_1.txt\")\n\npass_check = hsv.compareSimWithDesign(generics, latency, expected_out_Q*2**9,\n sim_out_dir+\"output_results_2.txt\")\n\n\n# plt.figure()\n# plt.plot(SI, SQ)\n# plt.plot(RI, RQ)\n# plt.plot(*phase_correction(SI, SQ, RI, RQ))\n# SIM_I = hsv.import_binary(sim_out_dir+\"output_results_1.txt\", 32, 1)\n# SIM_Q = hsv.import_binary(sim_out_dir+\"output_results_2.txt\", 32, 1)\n# sim_phase = np.unwrap(np.angle(SIM_I + 1j*SIM_Q))\n#\n# plt.figure()\n# plt.plot(Sig_phase)\n# plt.plot(sim_phase)"
},
{
"alpha_fraction": 0.5932651162147522,
"alphanum_fraction": 0.6170353293418884,
"avg_line_length": 35.95121765136719,
"blob_id": "c5e992b5a1881ea293af6a508fd21c7879fe40fa",
"content_id": "6e723b08fbcdb42e11fc5fd88b5e7de08faab9dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3029,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 82,
"path": "/HDLSimVisualizer/test_phase_correction_v2.py",
"repo_name": "hatlabcz/HDLSimVisualizer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 27 20:46:24 2020\n\n@author: Chao\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport HDLSimVisualizer_pkg as hsv\nfrom HDLSimVisualizer_pkg import HDLSim\nfrom os.path import expanduser\nHOME = expanduser(\"~\")\nPI = np.pi\n# ----------- generics ---------------------\ngenerics = {\"input_width\": 16,\n \"input_ss\": 1, # supersample\n \"output_width\": 32\n }\ngenerics[\"output_ss\"] = generics[\"input_ss\"]\n# --------- data----------------------------\nrand_seed = 10\nnp.random.seed(rand_seed)\nn_data = 50\n\n\nRef_amp = 25000 + (np.random.rand(n_data) - 0.5) * 10000\nRef_phase = np.random.rand(n_data) * 2 * PI\nRI = (Ref_amp * np.cos(Ref_phase)).astype(np.int)\nRQ = (Ref_amp * np.sin(Ref_phase)).astype(np.int)\n\nSig_amp = 20000\nSig_phase = np.linspace(0, 2 * PI, n_data+1)[: n_data]\n# Add or subtract Ref phase here\nSI = (Sig_amp * np.cos(Sig_phase - Ref_phase)).astype(np.int)\nSQ = (Sig_amp * np.sin(Sig_phase - Ref_phase)).astype(np.int)\ndata_phase = np.angle(SI + 1j*SQ)\n\nexpected_out_I = (Sig_amp * np.cos(Sig_phase)).astype(np.int)\nexpected_out_Q = (Sig_amp * np.sin(Sig_phase)).astype(np.int)\n\n\n# ------------main---------------------\nsim_in_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Phase_Correction_v2\\Phase_Correction.srcs\\sim_1\\imports\\InputVectors\\\\\"\n# sim_out_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Phase_Correction_v2\\Phase_Correction.sim\\sim_1\\behav\\xsim\\\\\"\nsim_out_dir = HOME + r\"\\OneDrive\\Lab\\FPGA\\VivadoPorjects\\Phase_Correction_v2\\Phase_Correction.sim\\sim_1\\impl\\func\\xsim\\\\\"\nlatency = 8\n\nhsv.export_binary(sim_in_dir + \"SI_vectors.txt\",\n SI, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"SQ_vectors.txt\",\n SQ, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"RI_vectors.txt\",\n RI, generics[\"input_width\"], generics[\"input_ss\"])\nhsv.export_binary(sim_in_dir + \"RQ_vectors.txt\",\n RQ, generics[\"input_width\"], generics[\"input_ss\"])\n\n\npass_check = hsv.compareSimWithDesign(generics, latency, expected_out_I*2**8,\n sim_out_dir+\"output_results_1.txt\")\n\npass_check = hsv.compareSimWithDesign(generics, latency, expected_out_Q*2**8,\n sim_out_dir+\"output_results_2.txt\")\n\n\n\npass_check = hsv.compareSimWithDesign(generics, latency, expected_out_I*2**8,\n sim_out_dir+\"output_results_3.txt\")\npass_check = hsv.compareSimWithDesign(generics, latency, expected_out_Q*2**8,\n sim_out_dir+\"output_results_4.txt\")\n\n# plt.figure()\n# plt.plot(SI, SQ)\n# plt.plot(RI, RQ)\n# plt.plot(*phase_correction(SI, SQ, RI, RQ))\n# SIM_I = hsv.import_binary(sim_out_dir+\"output_results_1.txt\", 32, 1)\n# SIM_Q = hsv.import_binary(sim_out_dir+\"output_results_2.txt\", 32, 1)\n# sim_phase = np.unwrap(np.angle(SIM_I + 1j*SIM_Q))\n#\n# plt.figure()\n# plt.plot(Sig_phase)\n# plt.plot(sim_phase)"
},
{
"alpha_fraction": 0.540768027305603,
"alphanum_fraction": 0.543792724609375,
"avg_line_length": 31.946428298950195,
"blob_id": "d34dd89558b228bad2cfd48c663e202a8fce8898",
"content_id": "957462b09a1b2647fc97b426caa7dc40aa074c85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7604,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 224,
"path": "/HDLSimVisualizer/HDLSimVisualizer_pkg.py",
"repo_name": "hatlabcz/HDLSimVisualizer",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Oct 28 23:22:43 2020\r\n\r\n@author: Chao\r\n\r\nThis package contains helper functions and classes that can be used to verify \r\nand visualize the simulation results from HDL simulators. The purpose is to \r\nmake it easier to generate data file for simulation input, import simulation \r\noutput and compare it with expected block outputs.\r\n\"\"\"\r\nimport numpy as np\r\nfrom typing import Dict, Callable\r\nimport matplotlib.pyplot as plt\r\nimport os.path\r\n\r\n\r\ndef int_to_slv(val: int, width: int) -> str:\r\n \"\"\"\r\n int to std_logic_vector\r\n \"\"\"\r\n return np.binary_repr(val, width)\r\n\r\n\r\ndef slv_to_int(s: str) -> int:\r\n \"\"\"\r\n std_logic_vector to int\r\n \"\"\"\r\n if s[0] == '0': # positive\r\n return int(s, 2)\r\n else: # negative\r\n width = len(s)\r\n return int(s, 2) - (1 << width)\r\n\r\n\r\ndef export_binary(file_name: str, data: np.array(int), data_width: int,\r\n supersample: int):\r\n \"\"\"\r\n export data to a txt file. Each line in the txt file is a super sampled \r\n std_logic_vector data.\r\n\r\n Parameters\r\n ----------\r\n file_name : str\r\n name of target file.\r\n data : np.array(int)\r\n data to be exported.\r\n data_width : int\r\n width of the std_logic_vector that the data is going to be writted as\r\n supersample : int\r\n data supersample.\r\n\r\n Returns\r\n -------\r\n None.\r\n\r\n \"\"\"\r\n # fill in zeros if number of data points is not multiples of data_ss\r\n data = np.concatenate((data, np.zeros(len(data) % supersample, dtype=int)))\r\n if not os.path.exists(file_name):\r\n file_name = file_name.split('\\\\')[-1]\r\n print(file_name.split('\\\\'), file_name)\r\n file_name = r\".\\InputVectors\\\\\" + file_name\r\n print(\r\n \"File is exported to .\\InputVectors, please manually import it in \"\r\n \"Vivado. After that the new file will be automatically exported \"\r\n \"to the simulation folder\")\r\n with open(file_name, \"w\") as text_file:\r\n n_lines = len(data) // supersample\r\n for i in range(n_lines):\r\n w_line = ''\r\n for j in range(supersample):\r\n w_line = int_to_slv(data[i * supersample + j], data_width) \\\r\n + w_line\r\n text_file.write(w_line)\r\n if i != n_lines - 1:\r\n text_file.write('\\n')\r\n\r\n\r\ndef import_binary(file_name: str, data_width: int,\r\n supersample: int) -> np.array(int):\r\n \"\"\"\r\n import data from the output of hdl simulation, change it to np.array\r\n\r\n Parameters\r\n ----------\r\n file_name : str\r\n name of target file.\r\n data_width : int\r\n width of the each std_logic_vector in the output file\r\n supersample : int\r\n data supersample.\r\n\r\n Returns\r\n -------\r\n data : np.array(int).\r\n\r\n \"\"\"\r\n with open(file_name, \"r\") as text_file:\r\n data = []\r\n lines = text_file.readlines()\r\n for line in lines:\r\n r_line = line.strip()\r\n for i in range(supersample):\r\n r_data = r_line[-data_width:]\r\n r_line = r_line[:-data_width]\r\n data.append(slv_to_int(r_data))\r\n return np.array(data)\r\n\r\n\r\nclass HDLSim:\r\n def __init__(self, generics: Dict, data_in: np.array(int), sim_dir: str,\r\n design_func: Callable, latency: int):\r\n \"\"\"\r\n\r\n Parameters\r\n ----------\r\n generics : Dict\r\n dictionary that contains the generics of the HDL block\r\n data_in : np.array(int)\r\n input test data\r\n sim_dir : str\r\n HDL simulation directory that where the input and output data\r\n files are located\r\n design_func : Callable\r\n the function that does the job that the hdl code is expected to\r\n do, for compare and verify the HDL simulation result.\r\n latency : int\r\n latency of the HDL IP block in cycles\r\n \"\"\"\r\n self.generics = generics\r\n self.input_width = generics[\"input_width\"]\r\n self.input_ss = generics.get(\"input_ss\", 1)\r\n self.output_width = generics[\"output_width\"]\r\n self.output_ss = generics.get(\"output_ss\", 1)\r\n self.sim_dir = sim_dir\r\n self.design_func = design_func\r\n # fill in zeros if number of data points is not multiples of supersample\r\n self.data_in = np.concatenate(\r\n (data_in, np.zeros(len(data_in) % self.input_ss, dtype=int)))\r\n self.cycles = len(data_in) // self.input_ss\r\n self.cyc_list = range(self.cycles)\r\n\r\n # expected output data\r\n data_out_exp = design_func(self.data_in)\r\n self.data_out_exp = np.roll(data_out_exp, latency * self.output_ss)\r\n\r\n def compareSimWithDesign(self,\r\n sim_output_file: str = \"output_results.txt\",\r\n plot: bool = True) -> bool:\r\n \"\"\"\r\n compare HDL simulation data with the expected design output data.\r\n Parameters\r\n ----------\r\n sim_output_file : str\r\n file name of the output data from HDL simulation\r\n\r\n plot : bool\r\n when True, plot the comparision between simulation and design\r\n Returns\r\n -------\r\n pass_exam : bool\r\n \"\"\"\r\n self.data_out = import_binary(self.sim_dir + sim_output_file,\r\n self.output_width,\r\n self.output_ss)\r\n print(self.data_out)\r\n if (self.data_out == self.data_out_exp).all:\r\n pass_exam = True\r\n else:\r\n pass_exam = False\r\n if plot:\r\n for i in range(self.output_ss):\r\n plt.figure(i)\r\n plt.plot(self.cyc_list, self.data_out_exp[i::self.output_ss],\r\n '-', label='expected output')\r\n plt.plot(self.cyc_list, self.data_out[i::self.output_ss],\r\n \"*\", label='simulation output')\r\n plt.legend()\r\n return pass_exam\r\n\r\n\r\ndef compareSimWithDesign(generics: Dict, latency: int,\r\n expected_output: np.array(int), sim_output_file: str,\r\n plot: bool = True):\r\n \"\"\"\r\n compare HDL simulation data with the expected design output data.\r\n Parameters\r\n ----------\r\n generics : Dict\r\n dictionary that contains the generics of the HDL block\r\n expected_output : np.array(int)\r\n expected output result of the design function\r\n sim_output_file : str\r\n file name of the output data from HDL simulation\r\n plot : bool\r\n when True, plot the comparision between simulation and design\r\n Returns\r\n -------\r\n pass_exam : bool\r\n \"\"\"\r\n output_width = generics[\"output_width\"]\r\n output_ss = generics.get(\"output_ss\", 1)\r\n data_out = import_binary(sim_output_file, output_width, output_ss)\r\n print(data_out)\r\n\r\n data_out_exp = np.roll(expected_output, latency * output_ss)\r\n print(data_out_exp)\r\n\r\n if (data_out == data_out_exp).all():\r\n pass_exam = True\r\n else:\r\n pass_exam = False\r\n\r\n cyc_list = range(len(data_out) // output_ss)\r\n if plot:\r\n for i in range(output_ss):\r\n plt.figure()\r\n plt.plot(cyc_list, data_out_exp[i::output_ss],\r\n '-', label='expected output')\r\n plt.plot(cyc_list, data_out[i::output_ss],\r\n \"*\", label='simulation output')\r\n plt.legend()\r\n return pass_exam\r\n"
}
] | 5 |
miferrei/GraficalPasswords
|
https://github.com/miferrei/GraficalPasswords
|
cd78ba07c1d2563cf2542c3567743818bc7fa614
|
bb793f3ad5ac49d02b594ac9d4a89377c91dfee5
|
6fccd51b91ce4c7e91e0d57fb3469d0970b964af
|
refs/heads/master
| 2017-12-22T12:49:12.788158 | 2017-01-06T09:30:02 | 2017-01-06T09:30:02 | 72,731,019 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3915938436985016,
"alphanum_fraction": 0.4178110659122467,
"avg_line_length": 29.80769157409668,
"blob_id": "f31c0e792c4bc49a9bf2795a45a203b95bd6d6c6",
"content_id": "dd1e1f99bb2faf12f4cdf584bd58e838a0d16bcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2403,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 78,
"path": "/attacks/stats.py",
"repo_name": "miferrei/GraficalPasswords",
"src_encoding": "UTF-8",
"text": "### Import Libraries ###\nimport math\nimport sys\nimport random\n\ndef intersectionAttack(M,m,N,n):\n\tportf=set(range(N))\n\tdecoy=set(range(N,M+N))\n\tdic={}\n\tfor i in range(N+M): dic[i]=0\n\n\tfor i in range(10000):\n\t\ttmp1=random.sample(portf,n)\n\t\ttmp2=random.sample(decoy,m)\n\t\tfor item in tmp1: dic[item]+=1\n\t\tfor item in tmp2: dic[item]+=1\n\treturn sorted(dic,key=dic.get,reverse=True)\n\ndef bruteforceAttack(m,n): return 1/float(m**n)\n\ndef observerAttack(N,g):\n\tdef nCr(n,k):\n\t\tf = math.factorial\n\t\treturn f(n)/f(n-k)/f(k)\n\tacc=0\n\tfor i in range(g,N):\n\t\tacc+=nCr(N,N-i)*1/(1-float(nCr(i,g))/nCr(N,g))*((-1)**(N+1-i))\n\tfor i in range(1,g+1):\n\t\tacc+=((-1)**(N-g+i+1))*nCr(N,N-g+i)\n\treturn acc\n\ndef main():\n\n\tN1=3;N2=12;n1=1;n2=10\n\tprint \"\\n--------------------------------------------------------------------------------------------------------------------\"\n\tprint \"| Observer Attack : Challenge Size | Portfolio Size |\"\n\tprint \"--------------------------------------------------------------------------------------------------------------------\"\n\ttmp=\"|XXXX|\"\n\tfor i in range(N1,N2+1): \n\t\tif i<10:tmp+=\" %d |\" % (i)\n\t\telse:tmp+=\" %d |\" % (i)\n\tprint tmp\n\tfor k in range(n1,n2+1):\n\t\tif k<10: tmp=\"| %d |\" % (k)\n\t\telse: tmp=\"| %d |\" % (k)\n\t\tfor i in range(N1,N2+1): \n\t\t\tif (k>i):tmp+=\" -------- |\"\n\t\t\telse:tmp+=\" %.2e |\" % (observerAttack(i,k))\n\t\tprint tmp\n\tprint \"--------------------------------------------------------------------------------------------------------------------\\n\"\n\n\tm=20\n\tprint \"--------------------------------\"\n\tprint \"|Single Brute Force Attack m=%d|\" % (m)\n\tprint \"--------------------------------\"\n\tfor n in range(1,15):\n\t\tif n<10: print \"| n=%d | p(Succ): %.2e |\" % (n,bruteforceAttack(m,n))\n\t\telse: print \"| n=%d | p(Succ): %.2e |\" % (n,bruteforceAttack(m,n))\n\tprint \"--------------------------------\\n\"\n\n\tM=40;m=20;N=8;n=4\n\tkey=intersectionAttack(M,m,N,n)\n\tprint \"-\"+\"-----\"*N\n\tif set(key[:N])==set(range(N)): tmp=\"Success\"\n\telse: tmp=\"Fault \"\n\tprint \"| Intersection Attack:%s |\" % (tmp)\n\tprint \"-\"+\"-----\"*N\n\tprint \"| M:%d | m:%d | N:%d | n:%d |\" % (M,m,N,n)\n\tprint \"-\"+\"-----\"*N\n\ttmp=\"|\"\n\tfor i in range(N): \n\t\tif key[i]<10 :tmp+=\" %d |\" % (key[i])\n\t\telse: tmp+=\" %d |\" % (key[i])\n\tprint tmp\n\tprint \"-\"+\"-----\"*N+\"\\n\"\n\nif __name__ == \"__main__\":\n\tmain()\n"
},
{
"alpha_fraction": 0.8153846263885498,
"alphanum_fraction": 0.8153846263885498,
"avg_line_length": 42.33333206176758,
"blob_id": "1167bbdd786d1d0dcc77dbe72ac537139e173a37",
"content_id": "5894a87656d030a31959425c8e56658e9d14c99d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 9,
"path": "/README.md",
"repo_name": "miferrei/GraficalPasswords",
"src_encoding": "UTF-8",
"text": "# Graphical Passwords for User Authentification\n\nAbstract: Demo implementation of a secure and usable human-machine authentication scheme using Graphical Passwords. The demo is running locally. Semester project for Cryptography and Network Security.\n\nStart the application by running the command below on the terminal.\n```shell\n$ python main.py\n```\nConsult the report and our presentation.\n"
}
] | 2 |
lightme16/hi-dollar-claimer
|
https://github.com/lightme16/hi-dollar-claimer
|
d8032f1a879dc6719e4f34ebdecef7a4ed27c034
|
d57251d4d2473401bfc594cb2721dc3597d8cf2e
|
cfbcd529855583baf133c107e915df41d452c023
|
refs/heads/master
| 2023-07-26T04:07:52.410341 | 2021-09-09T07:57:57 | 2021-09-09T07:57:57 | 404,129,637 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7307692170143127,
"alphanum_fraction": 0.7307692170143127,
"avg_line_length": 16.66666603088379,
"blob_id": "50d029546b4b6172b7e60ba03d1a1836b9548c81",
"content_id": "975dd1a79e20861bea755d395d4d76edbfe0c351",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 3,
"path": "/config.ini",
"repo_name": "lightme16/hi-dollar-claimer",
"src_encoding": "UTF-8",
"text": "[pyrogram]\napi_id = REPLACE ME\napi_hash = REPLACE ME"
},
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.7736842036247253,
"avg_line_length": 37,
"blob_id": "0ae03d12ee197e89a21203c17dd03e27661db827",
"content_id": "fdedb0ed4a07b344e93040ee0ed15bf697aac94e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 10,
"path": "/README.md",
"repo_name": "lightme16/hi-dollar-claimer",
"src_encoding": "UTF-8",
"text": "# Hi bot claimer\n\nClaims HI dollars daily by answering bot's questions in chat\n\n# How to use\n\n1. Get telegram api token, insert it into `config.ini`.\n2. Install pipenv requirements `pipenv sync`\n3. Ensure you started conversation with HI Bot in Telegram\n4. Run script with `pipenv run python main.py <YOUR_ACCOUNT_NAME>`. Open multiple ternmial session to set up several accounts\n"
},
{
"alpha_fraction": 0.6123954653739929,
"alphanum_fraction": 0.6178061962127686,
"avg_line_length": 28.897058486938477,
"blob_id": "79b9796da83810b9cfdcfe870fee4609211f2547",
"content_id": "b325516d7089ba747b7d63502df22ee4e7e4863f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2036,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 68,
"path": "/main.py",
"repo_name": "lightme16/hi-dollar-claimer",
"src_encoding": "UTF-8",
"text": "import asyncio\nimport sys\n\nfrom pyrogram import Client, filters\nfrom pyrogram.types import Dialog, Message\n\nHI_BOT = \"hiofficialbot\"\n\nname = sys.argv[1]\nif len(sys.argv) != 2:\n print(\"Pass session name in arguments\")\n sys.exit(1)\n\napp = Client(name)\n\n\nclaim_msg = \"👋 Claim Daily Reward\"\n\n\nasync def find_hi_chat(app: Client) -> Dialog:\n async for d in app.iter_dialogs():\n if d.chat.username == HI_BOT and d.chat.type == \"bot\":\n print(f\"Hi chat id is {d.chat.id}\")\n return d\n\n\nasync def main() -> None:\n await app.start()\n\n claim_request_processed = False\n\n @app.on_message(filters.bot)\n def claimer(client: Client, message: Message) -> None:\n chat_id = message.chat.id\n if message.chat.username != HI_BOT:\n return\n markup = message.reply_markup\n nonlocal claim_request_processed\n if not markup and not claim_request_processed:\n rv = client.send_message(chat_id, \"Replying to bot question\")\n print(f\"Replied to bot question, return value {rv}\")\n # sometimes bot asks open ended questions and we want to reply only once\n claim_request_processed = True\n return\n keyboard = getattr(markup, \"inline_keyboard\", None)\n if not keyboard:\n return\n option = keyboard[0][0]\n data = option.callback_data\n if not data or data == \"NICKNAME_CB\":\n return\n print(f\"Callback answer is {option.text}\")\n rv = client.request_callback_answer(chat_id, message.message_id, data)\n claim_request_processed = True\n print(f\"replied, {rv}\")\n\n hi = await find_hi_chat(app)\n if not hi:\n raise Exception(\"Cannot find HI bot, ensure you started converstaion with bot\")\n while True:\n print(\"Sending claim message\")\n claim_request_processed = False\n await app.send_message(hi.chat.id, claim_msg)\n print(\"Sleeping for a day...\")\n await asyncio.sleep(60 * 60 * 24)\n\n\napp.run(main())\n"
}
] | 3 |
AfoninZ/memfight
|
https://github.com/AfoninZ/memfight
|
0f5d46a46ccb7e997b55ff38f5bbc029c13a1628
|
dd8414a7cade96d6e8c0d840c317ba12f86dcda6
|
7d5fa05d51a391e88af653abc31da51d9484e0d1
|
refs/heads/master
| 2020-09-27T22:36:29.453250 | 2019-12-08T08:47:33 | 2019-12-08T08:47:33 | 226,626,397 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.46046510338783264,
"alphanum_fraction": 0.5273255705833435,
"avg_line_length": 29.175437927246094,
"blob_id": "715a14d7809e15c1af4b818eeb0350eaa5916244",
"content_id": "0471046eef9939a2e4ac86e91de749519e1079f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1720,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 57,
"path": "/game.py",
"repo_name": "AfoninZ/memfight",
"src_encoding": "UTF-8",
"text": "import pygame\nimport pygame.freetype\n\nimport virtual.machine as vm\nfrom virtual.cell import CellFlags\nimport colors\n\n\npygame.init()\nsize = width, height = 800, 600\n\nscreen = pygame.display.set_mode(size)\ngrid = pygame.Surface((720, 300))\n\nfont = pygame.freetype.Font(pygame.freetype.match_font('consolas'), 24)\nfont.antialiased = True\n\nm = vm.VirtualMachine()\n\nrunning = True\nc = 0\nwhile running:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n running = False\n\n screen.fill((24, 24, 24))\n\n for y in range(25):\n for x in range(60):\n cell = m.mem_getidx(y * 60 + x)\n if cell.get_flag() == CellFlags.EMPTY:\n pygame.draw.rect(grid, colors.flag_colors[0], ((\n (x * 12), (y * 12)), (10, 10)), 0)\n elif cell.get_flag() == CellFlags.DAMAGED:\n pygame.draw.rect(grid, colors.flag_colors[1], ((\n (x * 12), (y * 12)), (10, 10)), 0)\n else:\n color = cell.get_color()\n rgb = colors.team_colors[color]\n if cell.get_flag() == CellFlags.MODIFIED:\n rgb = tuple(map(lambda a: min(255, a * 2), rgb))\n pygame.draw.rect(\n grid, rgb, ((2 + (x * 12), 2 + (y * 12)), (10, 10)), 0)\n\n screen.blit(grid, ((800 - 720) // 2, 50))\n\n font.render_to(screen, (4, 404), f'Ticks: {c}', (200, 200, 200))\n font.render_to(screen, (4, 430),\n f'Millis: {pygame.time.get_ticks()}', (200, 200, 200))\n font.render_to(\n screen, (4, 456), f'TPS: {c / pygame.time.get_ticks() * 1000}', (\n 200, 200, 200))\n c += 1\n pygame.display.flip()\n\npygame.quit()\n"
},
{
"alpha_fraction": 0.5114213228225708,
"alphanum_fraction": 0.5304568409919739,
"avg_line_length": 29.30769157409668,
"blob_id": "8078fa4bc8758db24e65eabb5fc7f25a19598918",
"content_id": "c2bda78c71a75af06dc342441776ed14116fbd06",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 788,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 26,
"path": "/virtual/machine.py",
"repo_name": "AfoninZ/memfight",
"src_encoding": "UTF-8",
"text": "from virtual.cell import Cell, CellFlags\nfrom random import random, randint\n\n\nclass VirtualMachine:\n def __init__(self):\n self.mem = [Cell(CellFlags.EMPTY, 0, 0x00) for i in range(1500)]\n\n def mem_populate(self):\n for cell in self.mem:\n if cell.get_flag() == CellFlags.DAMAGED:\n r = randint(0, 6)\n if r != 0:\n cell.set_flag(CellFlags.ORIGINAL)\n cell.set_color(r)\n else:\n cell.set_flag(CellFlags.EMPTY)\n\n def mem_damage(self, prob):\n for cell in self.mem:\n if random() < prob:\n cell.set_flag(CellFlags.DAMAGED)\n cell.set_value(randint(0, 255))\n\n def mem_getidx(self, idx):\n return self.mem[idx]\n"
},
{
"alpha_fraction": 0.7441860437393188,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 20.5,
"blob_id": "cc0d8e8004367eb6809aa8aaee060dd387c3b4cc",
"content_id": "21b8cf6f2934edf0b801f70d3e8efb3501851729",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 2,
"path": "/README.md",
"repo_name": "AfoninZ/memfight",
"src_encoding": "UTF-8",
"text": "# MemFight\nA Core War-like game in Python.\n"
},
{
"alpha_fraction": 0.5605536103248596,
"alphanum_fraction": 0.5674740672111511,
"avg_line_length": 16.515151977539062,
"blob_id": "1f7972e1bcd85e44a28705dfb64aef75739e71ce",
"content_id": "4817653de1b3815690d20b5fecd25f1472a5b3c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 578,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 33,
"path": "/virtual/cell.py",
"repo_name": "AfoninZ/memfight",
"src_encoding": "UTF-8",
"text": "from enum import Enum\n\n\nclass CellFlags(Enum):\n EMPTY = 0\n DAMAGED = 1\n ORIGINAL = 2\n MODIFIED = 3\n\n\nclass Cell:\n def __init__(self, flag, color, value):\n self.flag = flag\n self.color = color\n self.value = value\n\n def set_flag(self, flag):\n self.flag = flag\n\n def set_color(self, color):\n self.color = color\n\n def set_value(self, value):\n self.value = value\n\n def get_flag(self):\n return self.flag\n\n def get_color(self):\n return self.color\n\n def get_value(self):\n return self.value\n"
}
] | 4 |
zhengow/Awesome-Quant
|
https://github.com/zhengow/Awesome-Quant
|
7bd200de442004a61384a2f38a3b06962146a15a
|
0387fb1151042228c8a667fe8cc560816503d47d
|
3320e09a1f3cd72d4783180302909f2fcd245e80
|
refs/heads/master
| 2021-02-09T12:18:43.583261 | 2020-07-22T15:04:27 | 2020-07-22T15:04:27 | 244,281,437 | 1 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6891472935676575,
"alphanum_fraction": 0.711240291595459,
"avg_line_length": 32.07692337036133,
"blob_id": "96ff25e0fdf5037488e8072292db7ab2272a96bd",
"content_id": "64c371e299f35dc67cfd27595a4aee7ce31cfcd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2580,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 78,
"path": "/05-Intern/alphacode/alpha15.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport time\nimport datetime,requests\nfrom my.data import meta_api, config, quote, my_types\nfrom my.data.daily_factor_generate import StockEvGenerateFactor\nfrom my.data.factor_cache import helpfunc_loadcache\n\ndef get_datelist(begT, endT, dback=0, dnext=0):\n days = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT), int(endT), 'SSE')]\n dates = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT) - 40000, int(endT), 'SSE')]\n days = dates[len(dates) - len(days) - dback:len(dates)+dnext]\n actdays = np.array([int(d) for d in days])\n\n return actdays\n\ndef Rankop_rank(xmatrix):\n return pd.DataFrame(xmatrix).rank(pct=True,axis=1).values\n\n''' Constants'''\ndelay = 1\nstart_date = str(20100101)\nend_date = str(20181231)\n\nhistdays = 20 # need histdays >= delay\nactdays = get_datelist(start_date,end_date,histdays,-1)#trading day + hist\n\ndays = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(start_date), int(end_date), 'SSE')]\n#days is just trading day from start to end\n\ndaysdata = helpfunc_loadcache(actdays[0],actdays[-1],'days')\n#trading day + hist\n\nsymbols = helpfunc_loadcache(actdays[0],actdays[-1],'stocks')\n\ninstruments = len(symbols)\n\nstartdi = daysdata.tolist().index(days[0])\n#find first day\nenddi = startdi + len(days) - 1\n\n'Data Part'\nops = helpfunc_loadcache(actdays[0],actdays[-1],'open','basedata')\nclose = helpfunc_loadcache(actdays[0],actdays[-1],'close','basedata')\n\ngroupdata = helpfunc_loadcache(actdays[0],actdays[-1],'WIND01','basedata')\n\n'Alpha Part'\nalpha = np.full([1, enddi - startdi + 1, instruments], np.nan)\nfor di in range(startdi,enddi+1):\n print(di)\n for ii in range(instruments):\n alpha[0][di-startdi][ii] = ops[di-delay,ii]/close[di-1-delay,ii]-1\n\n \n\n'Other Part'\nfrom my.operator import IndNeutralize\nalpha[0] = IndNeutralize(alpha[0],groupdata[startdi-1:enddi])\n#alpha[1] = IndNeutralize(alpha[1],groupdata[startdi-1:enddi])\n\n#local backtesting\nfrom my_factor.factor import localsimulator2\nx = [ str(i) for i in range(alpha.shape[0])]\npnlroute = './pnl/sample'\nlog = localsimulator2.simu(alpha.copy(),start_date,end_date,pnlroute,x)\nfrom my_factor.factor import summary\npnlfiles = []\nfor pnl in x:\n pnlfiles.append('./pnl/sample_'+pnl)\n simres = summary.simsummary('./pnl/sample_'+pnl)\n##correlation\nfrom my_factor.factor import localcorrelation\ntry:\n corres = localcorrelation.bcorsummary(pnlfiles)\nexcept:\n localcorrelation.rm_shm_pnl_dep()\n corres = localcorrelation.bcorsummary(pnlfiles)\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 39,
"blob_id": "29c81ebe6c0b036222903f9e87c4d63c65df2814",
"content_id": "5873bc18b95c8fefb38e4d49ec873cb6624cdb8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 40,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 1,
"path": "/01-Contest/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This folder is to save contest related.\n"
},
{
"alpha_fraction": 0.824999988079071,
"alphanum_fraction": 0.824999988079071,
"avg_line_length": 39,
"blob_id": "ab563ae971573218a5b6fb823bd96c06b030e4c8",
"content_id": "bdc3bae312f4580d67652189cac2c9d5dd1ff8a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 40,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 1,
"path": "/04-Others/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "Other related information will be here.\n"
},
{
"alpha_fraction": 0.6319957971572876,
"alphanum_fraction": 0.6533790826797485,
"avg_line_length": 31.350427627563477,
"blob_id": "55daa0cc77cc331bb31638fb4ef171f00bb9e209",
"content_id": "04a71c1277b1ee093e3f053950e00997f51e9d51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3788,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 117,
"path": "/05-Intern/alphacode/alpha1.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport time\nimport datetime,requests\nfrom my.data import meta_api, config, quote, my_types\nfrom my.data.daily_factor_generate import StockEvGenerateFactor\nfrom my.data.factor_cache import helpfunc_loadcache\n\ndef get_datelist(begT, endT, dback=0, dnext=0):\n days = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT), int(endT), 'SSE')]\n dates = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT) - 40000, int(endT), 'SSE')]\n days = dates[len(dates) - len(days) - dback:len(dates)+dnext]\n actdays = np.array([int(d) for d in days])\n\n return actdays\n\ndef cal_corr(A,B):\n\n # Rowwise mean of input arrays & subtract from input arrays themeselves\n A = A.transpose()\n B = B.transpose()\n A_mA = A - A.mean(1)[:,None]\n B_mB = B - B.mean(1)[:,None]\n # Sum of squares across rows\n ssA = (A_mA**2).sum(1);\n ssB = (B_mB**2).sum(1);\n \n # Finally get corr coeff\n tmp = np.dot(A_mA,B_mB.T)/np.sqrt(np.dot(ssA[:,None],ssB[None]))\n corr = np.ones(A.shape[0])\n for i in range(A.shape[0]):\n corr[i] = tmp[i,i]\n return corr\n\n''' Constants'''\ndelay = 1\nstart_date = str(20100101)\nend_date = str(20181231)\n\nfactor_columns = ['5dr_close','5dr_open']\n\nhistdays = 10 # need histdays >= delay\nactdays = get_datelist(start_date,end_date,histdays,-1)\n\ndays = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(start_date), int(end_date), 'SSE')]\n\ndaysdata = helpfunc_loadcache(actdays[0],actdays[-1],'days')\nsymbols = helpfunc_loadcache(actdays[0],actdays[-1],'stocks')\n\ninstruments = len(symbols)\n\nstartdi = daysdata.tolist().index(days[0])\nenddi = startdi + len(days) - 1\n\n'Data Part'\nvolume = helpfunc_loadcache(actdays[0],actdays[-1],'vol','basedata')\nindex = np.argwhere(volume == 0) \nfor item in index:\n volume[item[0],item[1]]=np.nan\nlnvol = np.log(volume)\n\nclose = helpfunc_loadcache(actdays[0],actdays[-1],'close','basedata')\nops = helpfunc_loadcache(actdays[0],actdays[-1],'open','basedata')\ngroupdata = helpfunc_loadcache(actdays[0],actdays[-1],'WIND01','basedata')\n\nalpha = np.full([1, enddi - startdi + 1, instruments], np.nan)\n\n'Alpha Part'\nfor di in range(startdi,enddi+1):\n 'start =time.time()'\n dlnvol = lnvol[di-6:di,:]-lnvol[di-7:di-1,:]\n co = (close[di-6:di,:] - ops[di-6:di,:])/ops[di-6:di,:]\n volRank = []\n coRank = []\n 'print(\"1:\",time.time()-start)'\n 'start =time.time()'\n for jj in range(6):\n ser = pd.Series(dlnvol[jj,:].tolist())\n volRank.append(ser.rank())\n ser = pd.Series(co[jj,:].tolist())\n coRank.append(ser.rank())\n corr = np.ones(instruments)\n volRank = np.array(volRank)\n coRank = np.array(coRank)\n 'print(\"2:\",time.time()-start)'\n 'start =time.time()'\n corr = cal_corr(volRank,coRank)\n 'print(\"3:\",time.time()-start)'\n 'start = time.time()'\n for ii in range(instruments):\n alpha[0][di-startdi][ii] = -1*corr[ii]\n 'print(\"4:\",time.time()-start)'\n \n\n \n'Other Part'\nfrom my.operator import IndNeutralize\nalpha[0] = IndNeutralize(alpha[0],groupdata[startdi-1:enddi])\n#alpha[1] = IndNeutralize(alpha[1],groupdata[startdi-1:enddi])\n\n#local backtesting\nfrom my_factor.factor import localsimulator2\nx = [ str(i) for i in range(alpha.shape[0])]\npnlroute = './pnl/sample'\nlog = localsimulator2.simu(alpha.copy(),start_date,end_date,pnlroute,x)\nfrom my_factor.factor import summary\npnlfiles = []\nfor pnl in x:\n pnlfiles.append('./pnl/sample_'+pnl)\n simres = summary.simsummary('./pnl/sample_'+pnl)\n##correlation\nfrom my_factor.factor import localcorrelation\ntry:\n corres = localcorrelation.bcorsummary(pnlfiles)\nexcept:\n localcorrelation.rm_shm_pnl_dep()\n corres = localcorrelation.bcorsummary(pnlfiles)\n\n\n\n"
},
{
"alpha_fraction": 0.7784430980682373,
"alphanum_fraction": 0.8143712282180786,
"avg_line_length": 22.714284896850586,
"blob_id": "17252fec3d6de727b29b9447c0a463a6eb32d9a2",
"content_id": "cd006ac558df4f237383203b9ecfb8bc57938405",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 7,
"path": "/02-Job/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This is about job information:\n\n#公司性质主要以量化相关,以日历方式呈现各家公司申请截止时间,点击时间旁边的链接可查看详情\n\n#《2020 量化求职信息》,可复制链接后用石墨文档 App 或小程序打开\n\nhttps://shimo.im/sheets/vXdYt8hDv6YHdtXv/knVAS/ \n"
},
{
"alpha_fraction": 0.4687350392341614,
"alphanum_fraction": 0.5205400586128235,
"avg_line_length": 40.632652282714844,
"blob_id": "c8cef88ee9b9e9a4620bf2c9b1dfdf54577aa41f",
"content_id": "dfc84d930ff1f27b605ee10f867d9747c7446c01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10443,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 245,
"path": "/04-Others/MultiFactors/backtest.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport pandas as pd\r\nimport matplotlib.pyplot as plt\r\nfrom data import Data\r\nimport math\r\nimport time\r\n\r\nclass BacktestEngine(object):\r\n\r\n \"\"\"\r\n This class is used to read data,\r\n process data to standard form.\r\n \"\"\"\r\n \r\n def __init__(self, alpha, trade_date, name):\r\n self.name = name\r\n self.trade_date = trade_date\r\n self.dailyret = Data.get('ret2', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n self.inxret = Data.get('inxret', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n self.all = Data.get('all', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n #stop = (1-pd.isnull(self.all)).astype(np.bool)\r\n self.dailyret[pd.isnull(self.all)] = np.nan\r\n self.trade_days = self.trade_date.shape[0]\r\n self.cash = np.full([self.trade_days+1],1000000.0)\r\n self.mktcash = np.full([self.trade_days+1],1000000.0)\r\n self.posret = np.full([self.trade_days],np.nan)\r\n self.negret = np.full([self.trade_days],np.nan)\r\n self.ret = np.full([self.trade_days],np.nan)\r\n self.shrp = np.full([11],np.nan)\r\n #dummy = alpha.alpha.copy()\r\n self.run(alpha)\r\n \r\n def run(self, alpha):\r\n for ii in range(self.trade_days):\r\n ret = self.dailyret.iloc[ii,:]\r\n cond = pd.isnull(ret)\r\n ret[cond] = 0\r\n pos = alpha[ii,:].copy()\r\n pos[pos<0] = 0\r\n pos[pd.isnull(pos)|cond] = 0\r\n pos = pos/np.sum(pos)\r\n neg = alpha[ii,:].copy()\r\n neg[neg>0] = 0\r\n neg[pd.isnull(neg)|cond] = 0\r\n neg = -neg/np.sum(neg)\r\n self.posret[ii] = np.dot(pos, ret)\r\n self.negret[ii] = np.dot(neg, ret)\r\n if(np.isnan(self.posret[ii])):\r\n self.ret[ii] = self.negret[ii]\r\n if(np.isnan(self.negret[ii])):\r\n self.ret[ii] = self.posret[ii]\r\n if( not np.isnan(self.posret[ii]) and not np.isnan(self.negret[ii])):\r\n self.ret[ii] = (self.posret[ii]+self.negret[ii])/2\r\n if(np.isnan(self.ret[ii])):\r\n self.ret[ii] = 0\r\n \r\n for ii in range(self.trade_days):\r\n self.mktcash[ii+1] = self.mktcash[ii]*(1+self.inxret.iloc[ii,0])\r\n if(np.isnan(self.ret[ii])):\r\n self.cash[ii+1] = self.cash[ii]\r\n else:\r\n self.cash[ii+1] = self.cash[ii]*(1+self.ret[ii])\r\n \r\n \r\n def prints(self):\r\n idx = [242,486,729,967,1212,1456,1700,1944,2187,2431]\r\n print(self.name)\r\n ret_11 = []\r\n ret_11.append(self.ret[:idx[0]])\r\n for ii in range(9):\r\n ret_11.append(self.ret[idx[ii]:idx[ii+1]])\r\n ret_11.append(self.ret[idx[-1]:])\r\n for ii in range(10):\r\n ret_mean = np.nanmean(ret_11[ii])\r\n ret_std = np.nanstd(ret_11[ii])\r\n IC = ret_mean/ret_std\r\n self.shrp[ii] = IC*np.sqrt(252)\r\n print(\"%d.1.1 to %d.1.1 shrp/ret: %2.4f / %2.4f%%\"%(ii+2010,ii+2011,self.shrp[ii], 100*np.nansum(ret_11[ii])))\r\n ret_mean = np.nanmean(ret_11[-1])\r\n ret_std = np.nanstd(ret_11[-1])\r\n IC = ret_mean/ret_std\r\n self.shrp[-1] = IC*np.sqrt(252)\r\n print(\"%d.1.1 to %d.4.1 shrp/ret: %2.4f / %2.4f%%\"%(2020,2020,self.shrp[-1], 100*252*np.nanmean(ret_11[-1])))\r\n shrp = np.nanmean(self.ret)/np.nanstd(self.ret)*np.sqrt(252)\r\n print(\"average shrp: %2.4f\" % shrp)\r\n print(\"average return: %2.4f%%\" % (100*np.nanmean(self.ret)*252))\r\n \r\n def show(self):\r\n #len_10 = len(self.trade_date)//10\r\n locs = np.linspace(1,len(self.trade_date)-1,num=5,endpoint=True,dtype=int)\r\n labels=[]\r\n for ii in locs:\r\n labels.append(self.trade_date.iloc[ii])\r\n x = np.arange(len(self.dailyret.index))\r\n p1, = plt.plot(x, self.cash[1:])\r\n p2, = plt.plot(self.mktcash)\r\n plt.legend([p1, p2],[self.name, \"Market:inx500\"])\r\n plt.xticks(locs,(labels))\r\n plt.show()\r\n\r\nclass BacktestML(BacktestEngine):\r\n\r\n \"\"\"\r\n This class is used to read data,\r\n process data to standard form.\r\n \"\"\"\r\n def prints(self):\r\n idx = [242,486,729,967,1212,1456,1700,1944,2187,2431]\r\n print(self.name)\r\n ret_11 = []\r\n ret_11.append(self.ret[:idx[0]])\r\n for ii in range(9):\r\n ret_11.append(self.ret[idx[ii]:idx[ii+1]])\r\n ret_11.append(self.ret[idx[-1]:])\r\n for ii in range(1):\r\n ret_mean = np.nanmean(ret_11[ii])\r\n ret_std = np.nanstd(ret_11[ii])\r\n IC = ret_mean/ret_std\r\n self.shrp[ii] = IC*np.sqrt(252)\r\n print(\"%d.1.1 to %d.1.1(InSample) shrp/ret: %2.4f / %2.4f%%\"%(ii+2010,ii+2011,self.shrp[ii], 100*np.nansum(ret_11[ii])))\r\n for ii in range(1,10):\r\n ret_mean = np.nanmean(ret_11[ii])\r\n ret_std = np.nanstd(ret_11[ii])\r\n IC = ret_mean/ret_std\r\n self.shrp[ii] = IC*np.sqrt(252)\r\n print(\"%d.1.1 to %d.1.1(OutSample) shrp/ret: %2.4f / %2.4f%%\"%(ii+2010,ii+2011,self.shrp[ii], 100*np.nansum(ret_11[ii])))\r\n ret_mean = np.nanmean(ret_11[-1])\r\n ret_std = np.nanstd(ret_11[-1])\r\n IC = ret_mean/ret_std\r\n self.shrp[-1] = IC*np.sqrt(252)\r\n print(\"%d.1.1 to %d.4.1(OutSample) shrp/ret: %2.4f / %2.4f%%\"%(2020,2020,self.shrp[-1], 100*252*np.nanmean(ret_11[-1])))\r\n shrp = np.nanmean(self.ret[250:])/np.nanstd(self.ret[250:])*np.sqrt(252)\r\n print(\"average shrp(Out Sample): %2.4f\" % shrp)\r\n print(\"average return(Out Sample): %2.4f%%\" % (100*np.nanmean(self.ret[250:])*252))\r\n \r\n def prints2(self):\r\n print(self.name)\r\n len_10 = len(self.ret)//10\r\n ret_10 = []\r\n for ii in range(9):\r\n ret_10.append(self.ret[len_10*ii:len_10*(ii+1)])\r\n ret_10.append(self.ret[len_10*9:])\r\n for ii in range(1):\r\n ret_mean = np.nanmean(ret_10[ii])\r\n ret_std = np.nanstd(ret_10[ii])\r\n IC = ret_mean/ret_std\r\n self.shrp[ii] = IC*np.sqrt(252)\r\n print(\"average shrp(In Sample): %2.4f\" % self.shrp[0])\r\n print(\"average return(In Sample): %2.4f%%\" % (100*np.nansum(ret_10[0])))\r\n \r\n for ii in range(1,10):\r\n ret_mean = np.nanmean(ret_10[ii])\r\n ret_std = np.nanstd(ret_10[ii])\r\n IC = ret_mean/ret_std\r\n self.shrp[ii] = IC*np.sqrt(252)\r\n\r\n shrp = np.nanmean(self.ret[250:])/np.nanstd(self.ret[250:])*np.sqrt(252)\r\n print(\"average shrp(Out Sample): %2.4f\" % shrp)\r\n print(\"average return(Out Sample): %2.4f%%\" % (100*np.nanmean(self.ret[250:])*252))\r\n \r\n \r\n def show(self):\r\n cash = np.full([self.trade_days+1],1000000.0)\r\n mktcash = np.full([self.trade_days+1],1000000.0)\r\n window = 250\r\n for ii in range(self.trade_days-window):\r\n mktcash[ii+window+1] = mktcash[ii+window]*(1+self.inxret.iloc[ii+window,0])\r\n if(np.isnan(self.ret[ii+window])):\r\n cash[window+ii+1] = cash[ii+window]\r\n else:\r\n cash[window+ii+1] = cash[ii+window]*(1+self.ret[ii+window])\r\n #len_10 = len(self.trade_date)//10\r\n locs = np.linspace(window,len(self.trade_date)-1,num=5,endpoint=True,dtype=int)\r\n labels=[]\r\n for ii in locs:\r\n labels.append(self.trade_date.iloc[ii])\r\n locs = np.linspace(1,len(self.trade_date)-window-1,num=5,endpoint=True,dtype=int)\r\n #x = np.arange(len(self.dailyret.index)-window)\r\n p1, = plt.plot(cash[window:])\r\n p2, = plt.plot(mktcash[window:])\r\n plt.legend([p1, p2],[self.name, \"Market:inx500\"])\r\n plt.xticks(locs,(labels))\r\n plt.show()\r\n\r\nclass BacktestPerson(BacktestEngine):\r\n\r\n \"\"\"\r\n This class is used to read data,\r\n process data to standard form.\r\n \"\"\"\r\n \r\n def __init__(self, alpha, trade_date):\r\n \r\n self.trade_date = trade_date\r\n self.symbols = Data.get('symbols', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n self.dailyret = Data.get('ret2', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n self.inxret = Data.get('inxret', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n self.all = Data.get('all', self.trade_date.iloc[0], self.trade_date.iloc[-1])\r\n #stop = (1-pd.isnull(self.all)).astype(np.bool)\r\n self.dailyret[pd.isnull(self.all)] = np.nan\r\n self.trade_days = self.trade_date.shape[0]\r\n self.stocks = np.full([self.trade_days, 5], '11111111111111')\r\n self.cash = np.full([self.trade_days+1],1000000.0)\r\n self.mktcash = np.full([self.trade_days+1],1000000.0)\r\n self.posret = np.full([self.trade_days],np.nan)\r\n self.negret = np.full([self.trade_days],np.nan)\r\n self.ret = np.full([self.trade_days],np.nan)\r\n self.shrp = np.full([10],np.nan)\r\n #dummy = alpha.alpha.copy()\r\n self.run(alpha)\r\n \r\n def run(self, alpha):\r\n \r\n for ii in range(self.trade_days):\r\n idx = np.where(alpha[ii,:]>0)\r\n #print(\"idx:\",idx[0])\r\n if(len(idx[0])>0):\r\n self.stocks[ii,:] = self.symbols.iloc[idx[0],0]\r\n ret = self.dailyret.iloc[ii,:]\r\n cond = pd.isnull(ret)\r\n ret[cond] = 0\r\n pos = alpha[ii,:].copy()\r\n pos[pos<0] = 0\r\n pos[pd.isnull(pos)|cond] = 0\r\n pos = pos/np.sum(pos)\r\n \r\n self.posret[ii] = np.dot(pos, ret)\r\n #self.negret[ii] = -self.inxret.iloc[ii,0]*0.1\r\n if(np.isnan(self.posret[ii])):\r\n self.ret[ii] = self.negret[ii]\r\n continue\r\n if(np.isnan(self.negret[ii])):\r\n self.ret[ii] = self.posret[ii]\r\n continue\r\n self.ret[ii] = (self.posret[ii]+self.negret[ii])/2\r\n \r\n for ii in range(self.trade_days):\r\n self.mktcash[ii+1] = self.mktcash[ii]*(1+self.inxret.iloc[ii,0])\r\n if(np.isnan(self.ret[ii])):\r\n self.cash[ii+1] = self.cash[ii]\r\n else:\r\n if(ii%5==0):\r\n self.cash[ii+1] = self.cash[ii]*(1+self.ret[ii]-0.0015)\r\n else:\r\n self.cash[ii+1] = self.cash[ii]*(1+self.ret[ii])"
},
{
"alpha_fraction": 0.5932333469390869,
"alphanum_fraction": 0.6309111714363098,
"avg_line_length": 30.92405128479004,
"blob_id": "62c075b28873706e3d5104dad7aa7e55a45e108a",
"content_id": "23dc5ee205b83d7cebf4fafb09280bf96e814917",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2601,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 79,
"path": "/04-Others/MultiFactors/mldemo.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "from ML import Mlalpha\r\nfrom backtest import BacktestML\r\nfrom data import Data\r\nimport numpy as np\r\nimport pandas as pd\r\nfrom sklearn.linear_model import Lasso\r\nfrom sklearn.linear_model import Ridge\r\nfrom sklearn.linear_model import LinearRegression\r\nfrom sklearn import tree\r\nfrom sklearn import svm\r\nfrom sklearn import neighbors\r\nfrom sklearn import ensemble\r\nfrom sklearn.tree import ExtraTreeRegressor\r\nfrom sklearn import preprocessing\r\nimport xgboost as xgb\r\n\r\n\r\nif __name__ == '__main__':\r\n \r\n start = '2010-01-01'\r\n end = '2020-04-01'\r\n trade_date = Data.get('date', start, end)\r\n \r\n alpha1 = np.load('alpha1_1.npy')\r\n alpha1 = preprocessing.scale(alpha1,axis=1)\r\n alpha2 = np.load('alpha2_1.npy')\r\n alpha2 = preprocessing.scale(alpha2,axis=1)\r\n alpha3 = np.load('alpha3_1.npy')\r\n alpha3 = preprocessing.scale(alpha3,axis=1)\r\n alpha4 = np.load('alpha4_1.npy')\r\n alpha4 = preprocessing.scale(alpha4,axis=1)\r\n alpha5 = np.load('alpha5_1.npy')\r\n alpha5 = preprocessing.scale(alpha5,axis=1)\r\n alpha6 = np.load('alpha6_1.npy')\r\n alpha6 = preprocessing.scale(alpha6,axis=1)\r\n alpha7 = np.load('alpha7_1.npy')\r\n alpha7 = preprocessing.scale(alpha7,axis=1)\r\n alphas = [alpha1, alpha2, alpha3, alpha4, alpha5, alpha6, alpha7]\r\n \r\n #which alpha\r\n window = 250\r\n print(\"window:\",window)\r\n mlalpha = Mlalpha(alphas, trade_date)\r\n \r\n\r\n# name = \"LASSO:lambda=0.00001\"\r\n# models = {name:Lasso(alpha=0.00001)}\r\n# name = \"XGBOOST\"\r\n# models = {name:xgb.XGBRegressor()}\r\n name = \"GBR\"\r\n models = {name:ensemble.GradientBoostingRegressor(n_estimators=10)}\r\n mlalpha.set_model(models)\r\n mlalpha.train(window)\r\n mlalpha.predict()\r\n alpha = mlalpha._alpha\r\n bte = BacktestML(alpha, trade_date, name)\r\n bte.prints()\r\n bte.show()\r\n# n_estimator = []\r\n# ISS = []\r\n# OSR = []\r\n# OSS = []\r\n# for i in range(10,50,5):\r\n# n_estimator.append(i)\r\n# name = \"GBR\"+str(i)\r\n# print(name)\r\n# models = {name:ensemble.GradientBoostingRegressor(n_estimators=i)}\r\n#\r\n# mlalpha.set_model(models)\r\n# mlalpha.train(window)\r\n# mlalpha.predict()\r\n# alpha = mlalpha._alpha\r\n# bte = BacktestML(alpha, trade_date, name)\r\n# bte.prints2()\r\n# ISS.append(bte.shrp[0])\r\n# OSS.append(np.nanmean(bte.ret[window:])/np.nanstd(bte.ret[window:])*np.sqrt(252))\r\n# OSR.append(100*np.nanmean(bte.ret[window:])*252)\r\n# data = {'n_estimator':n_estimator,'IS_shrp':ISS,'OS_shrp':OSS,'OS_ret':OSR}\r\n# data = pd.DataFrame(data)\r\n"
},
{
"alpha_fraction": 0.513939380645752,
"alphanum_fraction": 0.521212100982666,
"avg_line_length": 26.517240524291992,
"blob_id": "7ecb5dbad48047701fc690eefe5c37c61fbde58f",
"content_id": "3eaabb8db3c5c8dd4534c83f61b6c2cec5744d8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 29,
"path": "/05-Intern/IntimeSpyder/key_word.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nimport time\r\n\r\ndef getkeywords(filename):\r\n keywords = []\r\n df = pd.read_csv(filename, encoding='gbk')\r\n for i in range(df.shape[0]):\r\n stock = df.iloc[i,0]\r\n code = stock.split('.')[0]\r\n stkname = stock.split()[1]\r\n 'clean stock name'\r\n stkname = cleanStk(stkname)\r\n keywords.append(code+'+'+stkname)\r\n return keywords\r\n\r\n\r\ndef cleanStk(stkname):\r\n if('(' in stkname):\r\n stkname = stkname.split('(')[0] #tuishi company\r\n stkname = stkname.lower()\r\n if('st' in stkname):\r\n if('*' in stkname):\r\n tmp = stkname.split('*')[1]\r\n stkname = tmp + '+' + stkname\r\n else:\r\n tmp = '*' + stkname\r\n stkname = stkname + '+' + tmp\r\n stkname = stkname.replace('\\t','')\r\n return stkname"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 24,
"blob_id": "067f98fe8098c1cbd1a488f2be84e31eab0ebbbe",
"content_id": "f51fabaf6df269b56e0275172bc634890574002d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/01-Contest/Tianchi/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This is tianchi related.\n"
},
{
"alpha_fraction": 0.603515625,
"alphanum_fraction": 0.61328125,
"avg_line_length": 25.55555534362793,
"blob_id": "30e3caf7202a77b6928297bc9dd0351c15d0c8d9",
"content_id": "a6d547292468d9df4eb838ec1223cf8da04ae344",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 512,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 18,
"path": "/05-Intern/IntimeSpyder/run.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nfrom key_word import *\r\nimport datetime\r\nimport time\r\nfrom get_index import BaiduIndex\r\n\r\nif __name__ == \"__main__\":\r\n start = time.time()\r\n today = datetime.datetime.now().strftime('%Y-%m-%d')\r\n keywords = getkeywords('stockname.csv')\r\n keywords = keywords[:500]\r\n\r\n \r\n index = BaiduIndex(keywords)\r\n index.run(10) #the parameter is how many thread we want\r\n res = index.get_index()\r\n res.to_csv(today+'-index.csv')\r\n print(time.time()-start)\r\n \r\n \r\n "
},
{
"alpha_fraction": 0.49253731966018677,
"alphanum_fraction": 0.5044776201248169,
"avg_line_length": 31.94936752319336,
"blob_id": "520a89bb581344c8cb140e17b0763db46742b3b9",
"content_id": "51bb47fa5a5f78a9d0e7c2339486ab50e15fc5b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2680,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 79,
"path": "/04-Others/MultiFactors/ML.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport pandas as pd\r\nfrom Operator import Op\r\nfrom data import Data\r\n\r\nclass Mlalpha(object):\r\n \r\n def __init__(self, alphas, trade_date):\r\n \r\n dailyret = Data.get('ret2', trade_date.iloc[0], trade_date.iloc[-1])\r\n self.start = np.where(dailyret.index == trade_date.iloc[0])[0].tolist()[0]\r\n self.end = np.where(dailyret.index == trade_date.iloc[-1])[0].tolist()[0]\r\n \r\n stop = Data.get('all', trade_date.iloc[0], trade_date.iloc[-1])\r\n dailyret[pd.isnull(stop)] = np.nan\r\n dailyret = np.array(dailyret)\r\n \r\n self.num = len(alphas)\r\n self.row = alphas[0].shape[0]\r\n self.col = alphas[0].shape[1]\r\n self._alpha = np.full([self.row, self.col], np.nan)\r\n self._y = dailyret.reshape(-1,1)\r\n self._trainalpha = np.full([self.num, self.row, self.col], np.nan)\r\n self._x = np.full([self.row*self.col, self.num], np.nan)\r\n self.resize(alphas)\r\n\r\n \r\n def set_model(self, models):\r\n '''\r\n add the model we want to use here\r\n '''\r\n self._models = models\r\n \r\n def resize(self, alphas):\r\n '''\r\n version 1\r\n '''\r\n\r\n for ii, alpha in enumerate(alphas):\r\n self._trainalpha[ii,:,:] = alpha\r\n \r\n row = -1\r\n for ii in range(self._trainalpha.shape[1]):\r\n for jj in range(self._trainalpha.shape[2]):\r\n row = row + 1\r\n self._x[row, :] = self._trainalpha[:,ii,jj]\r\n \r\n def get(self):\r\n return self._alphas\r\n \r\n def train(self, window = 1):\r\n window = self.col*window\r\n x = self._x[:window,:]\r\n y = self._y[:window,:]\r\n \r\n xnanrow = np.where(pd.isnull(x))[0]\r\n ynanrow = np.where(pd.isnull(y))[0]\r\n deleterow = np.unique(np.append(ynanrow, xnanrow))\r\n x = np.delete(x, deleterow, axis = 0)\r\n y = np.delete(y, deleterow, axis = 0)\r\n\r\n for key,model in self._models.items():\r\n model.fit(x,y)\r\n \r\n def predict(self):\r\n nums = self.col #each time feed how much data\r\n \r\n for key, model in self._models.items():\r\n for ii in range(self.row):\r\n x = self._x[ii*nums:(ii+1)*nums,:]\r\n xnanrow = np.where(pd.isnull(x))[0]\r\n nanrow = np.unique(xnanrow)\r\n x[pd.isnull(x)] = 0\r\n y = model.predict(x)\r\n y[nanrow] = np.nan\r\n self._alpha[ii,:] = y.reshape(1,-1)\r\n \r\n self._alpha = Op.Neutralize('IND', self._alpha, self.start, self.end)\r\n print(\"Neutralize is finished!\")"
},
{
"alpha_fraction": 0.5920959711074829,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 36.297298431396484,
"blob_id": "1607340bb45795c32f42a278af3dbee20a4ac5da",
"content_id": "618a4fa1fc6b4363fffdf56d0effe783d2257159",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1417,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 37,
"path": "/04-Others/MultiFactors/demo.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "from alf import Alpha8\r\nfrom backtest import BacktestEngine\r\nfrom data import Data\r\nimport numpy as np\r\nimport pandas as pd\r\n\r\nif __name__ == '__main__':\r\n \r\n start = '2010-01-01'\r\n end = '2020-04-01'\r\n trade_date = Data.get('date', start, end)\r\n tradedays = trade_date.shape[0]\r\n start_trade = trade_date.iloc[0]\r\n end_trade = trade_date.iloc[-1]\r\n hist = 50\r\n ops = Data.get('open', start_trade, end_trade, hist)\r\n high = Data.get('high', start_trade, end_trade, hist)\r\n low = Data.get('low', start_trade, end_trade, hist)\r\n vwap = Data.get('vwap', start_trade, end_trade, hist)\r\n close = Data.get('close', start_trade, end_trade, hist)\r\n volume = Data.get('volume', start_trade, end_trade, hist)\r\n amount = Data.get('amount', start_trade, end_trade, hist)\r\n volume[volume==0] = np.nan\r\n stknums = close.shape[1]\r\n startidx = np.where(close.index == start_trade)[0].tolist()[0]\r\n endidx = np.where(close.index == end_trade)[0].tolist()[0]\r\n hd = {'amount':amount, 'close':close, 'open':ops, 'high':high, 'low':low, 'vwap':vwap, 'volume':volume, 'startidx':startidx, 'endidx':endidx, 'stknums':stknums}\r\n\r\n #which alpha\r\n# alpha = Alpha8(tradedays, stknums)\r\n# alpha.run(hd)\r\n# alpha.save('alpha8_1')\r\n name = \"alpha8_1\"\r\n alpha = np.load(name+'.npy')\r\n bte = BacktestEngine(alpha, trade_date, name)\r\n bte.prints()\r\n bte.show()\r\n"
},
{
"alpha_fraction": 0.7599999904632568,
"alphanum_fraction": 0.7599999904632568,
"avg_line_length": 24,
"blob_id": "615cc89e1750a373473bbe68cadf8e1846e1ebea",
"content_id": "c4de429078bef527a2e928950080301dad5fcec9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/04-Others/Option/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This is for option part.\n"
},
{
"alpha_fraction": 0.8135592937469482,
"alphanum_fraction": 0.8135592937469482,
"avg_line_length": 58,
"blob_id": "482c17f86daafdb4facc22409a254e30aae84c03",
"content_id": "c06b5cef9c8c58f428a4c14e1b8e83163b239354",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 1,
"path": "/05-Intern/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This folder records what I have done during my intern time\n"
},
{
"alpha_fraction": 0.6261186599731445,
"alphanum_fraction": 0.6509777903556824,
"avg_line_length": 32.488887786865234,
"blob_id": "224838098ab9c96c668049fabf06b1606a045485",
"content_id": "2cceabe32f9805968f676aa29c410f17a4fc9a6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3017,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 90,
"path": "/05-Intern/alphacode/alpha3.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport time\nimport datetime,requests\nfrom my.data import meta_api, config, quote, my_types\nfrom my.data.daily_factor_generate import StockEvGenerateFactor\nfrom my.data.factor_cache import helpfunc_loadcache\n\ndef get_datelist(begT, endT, dback=0, dnext=0):\n days = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT), int(endT), 'SSE')]\n dates = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT) - 40000, int(endT), 'SSE')]\n days = dates[len(dates) - len(days) - dback:len(dates)+dnext]\n actdays = np.array([int(d) for d in days])\n\n return actdays\n\n''' Constants'''\ndelay = 1\nstart_date = str(20100101)\nend_date = str(20181231)\n\nhistdays = 10 # need histdays >= delay\nactdays = get_datelist(start_date,end_date,histdays,-1)\n\ndays = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(start_date), int(end_date), 'SSE')]\n\ndaysdata = helpfunc_loadcache(actdays[0],actdays[-1],'days')\nsymbols = helpfunc_loadcache(actdays[0],actdays[-1],'stocks')\n\ninstruments = len(symbols)\n\nstartdi = daysdata.tolist().index(days[0])\nenddi = startdi + len(days) - 1\n\n'Data Part'\nlow = helpfunc_loadcache(actdays[0],actdays[-1],'low','basedata')\nhigh = helpfunc_loadcache(actdays[0],actdays[-1],'high','basedata')\nclose = helpfunc_loadcache(actdays[0],actdays[-1],'close','basedata')\ngroupdata = helpfunc_loadcache(actdays[0],actdays[-1],'WIND01','basedata')\n\nalpha = np.full([1, enddi - startdi + 1, instruments], np.nan)\n\n'Alpha Part'\nfor di in range(startdi,enddi+1):\n for ii in range(instruments):\n data = np.full([6],np.nan)\n for jj in range(6):\n res = 0\n close1 = close[di-delay-jj][ii]\n close2 = close[di-delay-1-jj][ii]\n low1 = low[di-delay-jj][ii]\n high1 = high[di-delay-jj][ii]\n if(close1==close2):\n data[jj]=res\n continue\n tmp = 0\n if(close1>close2):\n tmp = min(low1,close2)\n else:\n tmp = max(high1,close2)\n res = close1-tmp\n data[jj]=res\n alpha[0][di-startdi][ii] = sum(data)\n print(di)\n 'print(\"4:\",time.time()-start)'\n \n\n \n'Other Part'\nfrom my.operator import IndNeutralize\nalpha[0] = IndNeutralize(alpha[0],groupdata[startdi-1:enddi])\n#alpha[1] = IndNeutralize(alpha[1],groupdata[startdi-1:enddi])\n\n#local backtesting\nfrom my_factor.factor import localsimulator2\nx = [ str(i) for i in range(alpha.shape[0])]\npnlroute = './pnl/sample'\nlog = localsimulator2.simu(alpha.copy(),start_date,end_date,pnlroute,x)\nfrom my_factor.factor import summary\npnlfiles = []\nfor pnl in x:\n pnlfiles.append('./pnl/sample_'+pnl)\n simres = summary.simsummary('./pnl/sample_'+pnl)\n##correlation\nfrom my_factor.factor import localcorrelation\ntry:\n corres = localcorrelation.bcorsummary(pnlfiles)\nexcept:\n localcorrelation.rm_shm_pnl_dep()\n corres = localcorrelation.bcorsummary(pnlfiles)\n\n\n\n"
},
{
"alpha_fraction": 0.45093631744384766,
"alphanum_fraction": 0.45917603373527527,
"avg_line_length": 29.340909957885742,
"blob_id": "b8e3c77d0bd2a1cde70c84fd05c094f070b5766c",
"content_id": "ee8da090f5aa490c18f8c6e1788858f7179f2298",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 44,
"path": "/04-Others/MultiFactors/Person/data.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\n\nclass Data():\n \n def __init__():\n pass\n #self.trade_date = self.get_trade_date(start_date, end_date)\n \n '''\n def get_trade_date(start_date, end_date):\n \n date = pd.read_csv('date.csv')\n return date.loc[start_date:end_date,:]\n '''\n \n def get(data, startdate, enddate, hist = 0):\n \n if(data=='symbols'):\n return pd.read_csv('symbols.csv', header=None)\n \n if(data=='date'):\n start = 0\n end = 0\n df = pd.read_csv('date.csv')\n for ii in range(df.shape[0]):\n if(df['date'][ii]>startdate):\n start = ii\n break\n for ii in range(start+1, df.shape[0]):\n if(df['date'][ii]>enddate):\n end = ii\n break\n print(\"load date is finished!\")\n return df['date'][start:end]\n \n try:\n df = pd.read_csv(data+'.csv', index_col='date')\n start = np.where(df.index == startdate)[0].tolist()[0]-hist\n end = np.where(df.index == enddate)[0].tolist()[0]\n print(\"load\", data, \"is finished!\")\n return df.iloc[start:end+1,:]\n except Exception as e:\n print(e)\n"
},
{
"alpha_fraction": 0.5015081167221069,
"alphanum_fraction": 0.5204277634620667,
"avg_line_length": 28.598360061645508,
"blob_id": "c1ee100e8d56d9972244bc8d627f35dd6d699a4e",
"content_id": "c8933a1eea7b6248a938e64d0b8fd3343debc4c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3693,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 122,
"path": "/04-Others/MultiFactors/Person/run.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import tushare as ts\nimport pandas as pd\nimport numpy as np\nimport time\nfrom Operator import Op\nimport smtplib\nfrom email.mime.text import MIMEText\n\ndef run():\n pro = ts.pro_api()\n today = time.strftime('%Y.%m.%d',time.localtime(time.time()))\n today = today.replace('.','') #consider +1\n lastMonth = time.strftime('%Y.%m.%d',time.localtime(time.time()-2592000))\n lastMonth = lastMonth.replace('.','')\n close = pd.DataFrame()\n volume = pd.DataFrame()\n \n stkdata = pro.query('stock_basic', exchange='', list_status='L', fields='ts_code, name, industry')\n i = 1\n for code in stkdata['ts_code']:\n if(i%1000==0):\n print(\"finish\", i//1000, \"* 25% work\")\n i = i + 1\n try:\n df = ts.pro_bar(ts_code=code, adj='hfq', start_date=lastMonth, end_date=today)\n close[code] = df['close'].iloc[::-1]\n volume[code] = (df['amount']/df['close']*10).iloc[::-1]\n except Exception as e:\n print(e)\n \n # close = oclose.copy()\n # volume = ovolume.copy()\n \n cols = np.where(pd.isnull(close)|pd.isnull(volume))[1]\n colnames = close.columns[cols].unique()\n for name in colnames:\n del close[name]\n del volume[name]\n \n rank1 = Op.rank_col(volume)\n rank2 = Op.rank_col(close)\n \n corr = rank1.rolling(5).corr(rank2)\n rank3 = Op.rank_col(corr)\n \n tsmax = rank3.rolling(5).max()\n \n data = -tsmax\n \n #alpha = np.full([1, close.shape[1]], np.nan)\n alpha = data.iloc[-1,:]\n print(\"Alpha is finished!\")\n \n alpha = Neutralize(alpha, stkdata)\n #print(\"Neutralize is finished!\")\n alpha[pd.isnull(alpha)] = -10\n idx = np.argpartition(alpha, -5)[-5:]\n \n stks = alpha[idx]\n \n inx = pro.index_daily(ts_code='000905.SH', start_date=lastMonth, end_date=today)['close'][::-1]\n \n trend = (inx.rolling(5).mean()-1.01*inx.rolling(10).mean()).iloc[-1]\n \n content = 'trend: '+str(trend)+'\\n'\n for ii in range(stks.shape[0]):\n content = content+str(stks.index[ii])+':'+str(stks.iloc[ii])+'\\n'\n \n send(content)\n \n return\n\ndef Neutralize(alphas, data):\n data.set_index(data['ts_code'], inplace=True)\n inds = data['industry'].unique()\n for ind in inds:\n idx = []\n for ii in range(alphas.shape[0]):\n if(ind == data.loc[alphas.index[ii]]['industry']):\n idx.append(ii)\n mean = np.nanmean(alphas[idx])\n for ii in idx:\n alphas[ii] = alphas[ii] - mean\n return alphas\n\ndef send(content):\n msg_from='[email protected]' #发送方邮箱\n passwd='************' #填入发送方邮箱的授权码\n msg_to='[email protected]' #收件人邮箱\n \n subject=\"This Week Stocks\" #主题 \n msg = MIMEText(content)\n msg['Subject'] = subject\n msg['From'] = msg_from\n msg['To'] = msg_to\n \n try:\n s = smtplib.SMTP_SSL(\"smtp.qq.com\",465)\n s.login(msg_from, passwd)\n s.sendmail(msg_from, msg_to, msg.as_string())\n print('success')\n except Exception as e:\n print(e)\n print('fail')\n finally:\n s.quit()\n\n\nif __name__ == '__main__':\n \n\n while True:\n localTime = time.localtime()\n weekDay = time.strftime(\"%A\", localTime)\n hour = time.strftime(\"%H\", localTime)\n print(time.strftime(\"%c\", localTime))\n if(hour == 20):\n run()\n print(\"running\")\n time.sleep(3600)\n else:\n time.sleep(300)\n \n \n \n \n"
},
{
"alpha_fraction": 0.5839100480079651,
"alphanum_fraction": 0.6392733454704285,
"avg_line_length": 23.826086044311523,
"blob_id": "593d36d158496d77af7c6e88fc855c33e0f87dbb",
"content_id": "453501254be69dfd9df78594ed01ea45e7fa746d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1176,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 46,
"path": "/04-Others/Option/option.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jul 22 20:43:16 2020\n\n@author: Asus\n\"\"\"\nimport tushare as ts\nimport pandas as pd\nimport numpy as np\nimport datetime\nimport black_scholes as bs\nimport matplotlib.pyplot as plt\n\npro = ts.pro_api()\n\nSSE = pro.opt_basic(exchange='SSE')\n\noptionCode = '10002647.SH'\n#华泰柏瑞沪深300ETF期权2008认购4.80\nOption = pro.opt_daily(ts_code=optionCode)\n\nHS300 = pro.fund_daily(ts_code='510300.SH')\n\ndf = pd.DataFrame()\ndf['date'] = Option['trade_date']\ndf['C'] = Option['close']\ncond = HS300['trade_date']>=df['date'].iloc[-1]\ndf['S'] = HS300['close'][cond]\ndf['K'] = 4.8\ndf['r'] = 0.02\ncond2 = SSE.ts_code==optionCode\nexpiration = SSE.maturity_date[cond2].values[0]\nexpiration = datetime.datetime.strptime(expiration,'%Y%m%d').date()\n#calculate T\n\ndf['T'] = 1.00\nfor ii in range(len(df)):\n cur = datetime.datetime.strptime(df['date'][ii],'%Y%m%d').date()\n df['T'][ii] = ((expiration-cur).days)/360\n\ndf['sigma'] = 1.00\nfor ii in range(len(df)):\n df['sigma'][ii] = bs.blackScholesSolveImpliedVol(df['C'][ii], 'Call', df['S'][ii], df['K'][ii], df['T'][ii], df['r'][ii])\n\nplt.plot(df['date'], df['sigma'])\nplt.show()\n \n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.49271300435066223,
"alphanum_fraction": 0.5162556171417236,
"avg_line_length": 28.733333587646484,
"blob_id": "456e29914a2bf44a8dd1000ad17924eb9532be6f",
"content_id": "2823c8311ce7c80a948c223514fa98566fecf775",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1784,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 60,
"path": "/05-Intern/Spyder/demo.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "from get_index import BaiduIndex\nimport numpy as np\nimport pandas as pd\n\ndef get_keywords(start):\n keywords = []\n filename = \"stockname.csv\"\n df = pd.read_csv(filename)\n totalLen = df.shape[0]\n if start>totalLen:\n return keywords\n 'for i in range(df.shape[0]):'\n for i in range(10):\n if(i+start>totalLen):\n break\n tmp = df.iloc[i+start,0].split('.')\n code = tmp[0]\n stkname = tmp[1].split(' ')[1]\n 'clean stock name'\n if('(' in stkname):\n stkname = stkname.split('(')[0]\n stkname = stkname.lower()\n if('st' in stkname):\n if('*' in stkname):\n tmp = stkname.split('*')[1]\n stkname = tmp + '+' + stkname\n else:\n tmp = '*' + stkname\n stkname = stkname + '+' + tmp\n keywords.append(code+'+'+stkname)\n return keywords\n\nif __name__ == \"__main__\":\n 'if i want to write ith file, i = i-1, start = i*10'\n start = 1870\n keywords = get_keywords(start)\n\n i = 187\n while(keywords and i<200):\n print(i)\n i = i + 1\n start_time = '2011-01-01'\n end_time = '2020-04-01'\n\n 'create a res_dataframe'\n date_index = pd.date_range(start_time, end_time)\n resDf = pd.DataFrame(index=date_index,columns=keywords)\n\n baidu_index = BaiduIndex(keywords, start_time, end_time)\n\n for index in baidu_index.get_index():\n 'print(index)'\n for item in keywords:\n if(index['keyword'] in item):\n resDf.loc[index['date'], item] = index['index']\n break\n\n resDf.to_csv('./index/stkindex_'+str(i)+'.csv')\n start = start + 10\n keywords = get_keywords(start)\n"
},
{
"alpha_fraction": 0.6611077785491943,
"alphanum_fraction": 0.6855270862579346,
"avg_line_length": 30.660377502441406,
"blob_id": "8ccd6b3686fa98c010f3dffc3040b68cc23f96c4",
"content_id": "ebe9faceed4f345331b6ef269ba18c4865e73541",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3358,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 106,
"path": "/05-Intern/alphacode/alpha5.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport time\nimport datetime,requests\nfrom my.data import meta_api, config, quote, my_types\nfrom my.data.daily_factor_generate import StockEvGenerateFactor\nfrom my.data.factor_cache import helpfunc_loadcache\n\ndef get_datelist(begT, endT, dback=0, dnext=0):\n days = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT), int(endT), 'SSE')]\n dates = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(begT) - 40000, int(endT), 'SSE')]\n days = dates[len(dates) - len(days) - dback:len(dates)+dnext]\n actdays = np.array([int(d) for d in days])\n\n return actdays\n\ndef Rankop_rank(xmatrix):\n return pd.DataFrame(xmatrix).rank(pct=True,axis=0).values\n\n''' Constants'''\ndelay = 1\nstart_date = str(20100101)\nend_date = str(20181231)\n\nhistdays = 20 # need histdays >= delay\nactdays = get_datelist(start_date,end_date,histdays,-1)\n\ndays = [int(d.replace('-', '')) for d in meta_api.get_trading_date_range(int(start_date), int(end_date), 'SSE')]\n\ndaysdata = helpfunc_loadcache(actdays[0],actdays[-1],'days')\nsymbols = helpfunc_loadcache(actdays[0],actdays[-1],'stocks')\n\ninstruments = len(symbols)\n\nstartdi = daysdata.tolist().index(days[0])\nenddi = startdi + len(days) - 1\n\n'Data Part'\nvolume = helpfunc_loadcache(actdays[0],actdays[-1],'vol','basedata')\nindex = np.argwhere(volume == 0) \nfor item in index:\n volume[item[0],item[1]]=np.nan\n\nhigh = helpfunc_loadcache(actdays[0],actdays[-1],'high','basedata')\ngroupdata = helpfunc_loadcache(actdays[0],actdays[-1],'WIND01','basedata')\n\nalpha = np.full([1, enddi - startdi + 1, instruments], np.nan)\n\n'Alpha Part'\nrankHigh = np.full([high.shape[0],instruments],np.nan)\nrankVol = np.full([volume.shape[0],instruments],np.nan)\ncorr = np.full([high.shape[0],instruments],np.nan)\nmaxCorr = np.full([high.shape[0],instruments],np.nan)\n\n\nfor di in range(startdi,enddi+1):\n print(di)\n for ii in range(5):\n high5 = high[di-5-ii:di-ii,:]\n volume5 = volume[di-5-ii:di-ii,:]\n\n rankHigh[di-delay,:] = Rankop_rank(high5)[4,:]\n rankVol[di-delay,:] = Rankop_rank(volume5)[4,:]\n\n\n #alpha[0][di-startdi] = np.max(corr)\nfor ii in range(instruments):\n ser1 = pd.Series(rankHigh[:,ii].tolist())\n ser2 = pd.Series(rankVol[:,ii].tolist())\n corr[:,ii] = pd.rolling_corr(ser1,ser2,5)\n\n\nfor ii in range(instruments):\n ser3 = pd.Series(corr[:,ii].tolist())\n maxCorr[:,ii] = pd.rolling_max(ser3,3)\n\n\nfor di in range(startdi,enddi+1):\n for ii in range(instruments):\n alpha[0][di-startdi][ii] = -1*maxCorr[di,ii]\n \n\n\n \n'Other Part'\nfrom my.operator import IndNeutralize\nalpha[0] = IndNeutralize(alpha[0],groupdata[startdi-1:enddi])\n#alpha[1] = IndNeutralize(alpha[1],groupdata[startdi-1:enddi])\n\n#local backtesting\nfrom my_factor.factor import localsimulator2\nx = [ str(i) for i in range(alpha.shape[0])]\npnlroute = './pnl/sample'\nlog = localsimulator2.simu(alpha.copy(),start_date,end_date,pnlroute,x)\nfrom my_factor.factor import summary\npnlfiles = []\nfor pnl in x:\n pnlfiles.append('./pnl/sample_'+pnl)\n simres = summary.simsummary('./pnl/sample_'+pnl)\n##correlation\nfrom my_factor.factor import localcorrelation\ntry:\n corres = localcorrelation.bcorsummary(pnlfiles)\nexcept:\n localcorrelation.rm_shm_pnl_dep()\n corres = localcorrelation.bcorsummary(pnlfiles)\n\n\n"
},
{
"alpha_fraction": 0.4936192035675049,
"alphanum_fraction": 0.52271568775177,
"avg_line_length": 38.119998931884766,
"blob_id": "f16cc06a589f8c58efba50790f127f3cddd5af45",
"content_id": "c175a1d16df91a6f7862de32536cf3e870aded32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5877,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 150,
"path": "/04-Others/MultiFactors/Person/backtest.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom data import Data\nimport math\nimport time\n\nclass BacktestEngine(object):\n\n \"\"\"\n This class is used to read data,\n process data to standard form.\n \"\"\"\n \n def __init__(self, alpha, trade_date):\n \n self.trade_date = trade_date\n self.dailyret = Data.get('ret2', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n self.inxret = Data.get('inxret', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n self.all = Data.get('all', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n #stop = (1-pd.isnull(self.all)).astype(np.bool)\n self.dailyret[pd.isnull(self.all)] = np.nan\n self.trade_days = self.trade_date.shape[0]\n self.cash = np.full([self.trade_days+1],1000000.0)\n self.mktcash = np.full([self.trade_days+1],1000000.0)\n self.posret = np.full([self.trade_days],np.nan)\n self.negret = np.full([self.trade_days],np.nan)\n self.ret = np.full([self.trade_days],np.nan)\n self.shrp = np.full([10],np.nan)\n #dummy = alpha.alpha.copy()\n self.run(alpha)\n \n def run(self, alpha):\n for ii in range(self.trade_days):\n ret = self.dailyret.iloc[ii,:]\n cond = pd.isnull(ret)\n ret[cond] = 0\n pos = alpha[ii,:].copy()\n pos[pos<0] = 0\n pos[pd.isnull(pos)|cond] = 0\n pos = pos/np.sum(pos)\n neg = alpha[ii,:].copy()\n neg[neg>0] = 0\n neg[pd.isnull(neg)|cond] = 0\n neg = -neg/np.sum(neg)\n self.posret[ii] = np.dot(pos, ret)\n self.negret[ii] = np.dot(neg, ret)\n if(np.isnan(self.posret[ii])):\n self.ret[ii] = self.negret[ii]\n if(np.isnan(self.negret[ii])):\n self.ret[ii] = self.posret[ii]\n if( not np.isnan(self.posret[ii]) and not np.isnan(self.negret[ii])):\n self.ret[ii] = (self.posret[ii]+self.negret[ii])/2\n if(np.isnan(self.ret[ii])):\n self.ret[ii] = 0\n \n for ii in range(self.trade_days):\n self.mktcash[ii+1] = self.mktcash[ii]*(1+self.inxret.iloc[ii,0])\n if(np.isnan(self.ret[ii])):\n self.cash[ii+1] = self.cash[ii]\n else:\n self.cash[ii+1] = self.cash[ii]*(1+self.ret[ii])\n \n \n def prints(self):\n len_10 = len(self.ret)//10\n ret_10 = []\n for ii in range(9):\n ret_10.append(self.ret[len_10*ii:len_10*(ii+1)])\n ret_10.append(self.ret[len_10*9:])\n for ii in range(10):\n ret_mean = np.nanmean(ret_10[ii])\n ret_std = np.nanstd(ret_10[ii])\n IC = ret_mean/ret_std\n self.shrp[ii] = IC*np.sqrt(252)\n print(\"Year\", ii+2010, '.1.1 to', ii+2011, '.1.1 shrp/ret: ', self.shrp[ii], np.nansum(ret_10[ii]))\n print(\"average shrp: \", np.mean(self.shrp[1:]))\n \n def show(self):\n len_10 = len(self.trade_date)//10\n xticks = []\n for ii in range(10):\n xticks.append(self.trade_date.iloc[ii*len_10])\n x = np.arange(len(self.dailyret.index))\n plt.plot(x, self.cash[1:])\n plt.plot(self.mktcash)\n #plt.xticks(xticks)\n plt.show()\n\nclass BacktestPerson(BacktestEngine):\n\n \"\"\"\n This class is used to read data,\n process data to standard form.\n \"\"\"\n \n def __init__(self, alpha, trade_date):\n \n self.trade_date = trade_date\n self.symbols = Data.get('symbols', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n self.dailyret = Data.get('ret2', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n self.inxret = Data.get('inxret', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n self.all = Data.get('all', self.trade_date.iloc[0], self.trade_date.iloc[-1])\n #stop = (1-pd.isnull(self.all)).astype(np.bool)\n self.dailyret[pd.isnull(self.all)] = np.nan\n self.trade_days = self.trade_date.shape[0]\n self.stocks = np.full([self.trade_days, 5], '11111111111111')\n self.cash = np.full([self.trade_days+1],1000000.0)\n self.mktcash = np.full([self.trade_days+1],1000000.0)\n self.posret = np.full([self.trade_days],np.nan)\n self.negret = np.full([self.trade_days],np.nan)\n self.ret = np.full([self.trade_days],np.nan)\n self.shrp = np.full([10],np.nan)\n #dummy = alpha.alpha.copy()\n self.run(alpha)\n \n def run(self, alpha):\n \n for ii in range(self.trade_days):\n idx = np.where(alpha[ii,:]>0)\n #print(\"idx:\",idx[0])\n if(len(idx[0])>0):\n self.stocks[ii,:] = self.symbols.iloc[idx[0],0]\n ret = self.dailyret.iloc[ii,:]\n cond = pd.isnull(ret)\n ret[cond] = 0\n pos = alpha[ii,:].copy()\n pos[pos<0] = 0\n pos[pd.isnull(pos)|cond] = 0\n pos = pos/np.sum(pos)\n \n self.posret[ii] = np.dot(pos, ret)\n #self.negret[ii] = -self.inxret.iloc[ii,0]*0.1\n if(np.isnan(self.posret[ii])):\n self.ret[ii] = self.negret[ii]\n continue\n if(np.isnan(self.negret[ii])):\n self.ret[ii] = self.posret[ii]\n continue\n self.ret[ii] = (self.posret[ii]+self.negret[ii])/2\n \n for ii in range(self.trade_days):\n self.mktcash[ii+1] = self.mktcash[ii]*(1+self.inxret.iloc[ii,0])\n if(np.isnan(self.ret[ii])):\n self.cash[ii+1] = self.cash[ii]\n else:\n if(ii%5==0):\n self.cash[ii+1] = self.cash[ii]*(1+self.ret[ii]-0.0015)\n else:\n self.cash[ii+1] = self.cash[ii]*(1+self.ret[ii])\n \n"
},
{
"alpha_fraction": 0.46634259819984436,
"alphanum_fraction": 0.48880138993263245,
"avg_line_length": 25.77227783203125,
"blob_id": "677b82d1a2415e29b9c91ecbbe5bfebf53b2bff8",
"content_id": "4126e0986711ddd8167ac6790e1bb7d02a0ee01f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16252,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 606,
"path": "/04-Others/MultiFactors/Person/alf.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nfrom Operator import Op\n\n\nclass Alpha(object):\n \n def __init__(self, daynums, stknums):\n self._alpha = np.full([daynums, stknums], np.nan)\n\n def run(self, hd):\n '''\n Calculate your alpha here.\n '''\n pass\n \n def save(self, name):\n \n np.save(name, self._alpha)\n print(\"save successfully!\")\n \n def get(self):\n return self._alpha\n \n \nclass Alphatest(Alpha):\n \n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 0\n #data = self.close.shift(5)-self.close\n data = hd['close']-hd['open']\n\n start = hd['startidx']\n end = hd['endidx']\n #start = np.where(data.index == self.start)[0].tolist()[0]\n #end = np.where(data.index == self.end)[0].tolist()[0]\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n #print(\"Neutralize is finished!\")\n \n \n\nclass Alpha1(Alpha):\n '''\n shrp 3.86\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data = -hd['close'].rolling(10).corr(hd['volume'])\n\n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\nclass Alpha1P(Alpha):\n '''\n shrp 0.7147\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data = -hd['close'].rolling(10).corr(hd['volume'])\n\n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n self._alpha = Op.personalize(self._alpha)\n print(\"Personize is finished!\")\n \n \nclass Alpha2(Alpha):\n '''\n shrp 3.3\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data = hd['close'].rolling(10).corr(hd['volume'])\n data = -Op.rank_col(data)\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n \nclass Alpha3(Alpha):\n '''\n shrp 4.097\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data = -hd['amount'].rolling(10).std()\n #data = self.Rank(data)\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\n\nclass Alpha3P(Alpha):\n '''\n shrp 0.7828\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data = -hd['amount'].rolling(10).std()\n #data = self.Rank(data)\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\n self._alpha = Op.personalize(self._alpha)\n print(\"Personize is finished!\")\n \n \nclass Alpha4(Alpha):\n '''\n shrp 6.048\n GTJA 1\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n lnvol = np.log(hd['volume'])\n lnvol_d = lnvol-lnvol.shift()\n rank1 = Op.rank_col(lnvol_d)\n rank2 = Op.rank_col((hd['close']-hd['open'])/hd['open'])\n corr = rank1.rolling(6).corr(rank2)\n data = -corr\n #data = self.Rank(data)\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\nclass Alpha4P(Alpha):\n '''\n shrp 0.6\n GTJA 1\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n lnvol = np.log(hd['volume'])\n lnvol_d = lnvol-lnvol.shift()\n rank1 = Op.rank_col(lnvol_d)\n rank2 = Op.rank_col((hd['close']-hd['open'])/hd['open'])\n corr = rank1.rolling(6).corr(rank2)\n data = -corr\n #data = self.Rank(data)\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n self._alpha = Op.personalize(self._alpha)\n print(\"Personize is finished!\")\n\nclass Alpha5(Alpha):\n '''\n shrp 2.91\n GTJA 2\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data1 = ((hd['close']-hd['low'])-(hd['high']-hd['close']))/(hd['high']-hd['low'])\n data = (data1-data1.shift())*-1\n #data = self.Rank(data)\n \n start = hd['startidx']\n end = hd['endidx']\n\n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n \nclass Alpha6(Alpha):\n '''\n shrp 4.619\n GTJA 7\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data1 = hd['vwap']-hd['close']\n data1[data1<3] = 3\n rank1 = Op.rank_col(data1)\n \n data2 = hd['vwap']-hd['close']\n data2[data2>3] = 3\n rank2 = Op.rank_col(data2)\n volume = hd['volume']\n volume[volume==0] = np.nan\n rank3 = Op.rank_col(volume-volume.shift(3))\n data = rank1+rank2*rank3\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\nclass Alpha6P(Alpha):\n '''\n shrp -0.538\n GTJA 7\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n data1 = hd['vwap']-hd['close']\n data1[data1<3] = 3\n rank1 = Op.rank_col(data1)\n \n data2 = hd['vwap']-hd['close']\n data2[data2>3] = 3\n rank2 = Op.rank_col(data2)\n volume = hd['volume']\n volume[volume==0] = np.nan\n rank3 = Op.rank_col(volume-volume.shift(3))\n data = rank1+rank2*rank3\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n self._alpha = Op.personalize(self._alpha)\n print(\"Personize is finished!\")\n\nclass Alpha7(Alpha):\n '''\n shrp 3.797\n GTJA 16\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n rank1 = Op.rank_col(hd['volume'])\n rank2 = Op.rank_col(hd['vwap'])\n corr = rank1.rolling(5).corr(rank2)\n rank3 = Op.rank_col(corr)\n data = -1*rank3.rolling(5).max()\n #for ii in range(window, corr.shape[0]+1):\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n \nclass Alpha7P(Alpha):\n '''\n shrp 0.815\n GTJA 16\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n #data = self.close.shift(5)-self.close\n rank1 = Op.rank_col(hd['volume'])\n rank2 = Op.rank_col(hd['vwap'])\n corr = rank1.rolling(5).corr(rank2)\n rank3 = Op.rank_col(corr)\n data = -1*rank3.rolling(5).max()\n #for ii in range(window, corr.shape[0]+1):\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n self._alpha = Op.personalize(self._alpha)\n print(\"Personize is finished!\")\n \nclass Alpha8(Alpha):\n '''\n shrp 4.621\n GTJA 114\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n\n data1 = (hd['high']-hd['low'])/(hd['close'].rolling(5).sum()/5)\n\n #rank1 = self.rank_col(data1)\n rank1 = Op.rank_col(data1.shift(2))\n rank2 = Op.rank_col(hd['volume'])\n \n data3 = data1/(hd['vwap']-hd['close'])\n data3[data3==0] = np.nan\n data = rank1*rank2/data3\n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n for di in range(start, end+1):\n self.alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \nclass Alpha8P(Alpha):\n '''\n shrp 0.231\n GTJA 114\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n\n data1 = (hd['high']-hd['low'])/(hd['close'].rolling(5).sum()/5)\n\n #rank1 = self.rank_col(data1)\n rank1 = Op.rank_col(data1.shift(2))\n rank2 = Op.rank_col(hd['volume'])\n \n data3 = data1/(hd['vwap']-hd['close'])\n data3[data3==0] = np.nan\n data = rank1*rank2/data3\n \n \n \n start = hd['startidx']\n end = hd['endidx']\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n\n alpha = np.full([self._alpha.shape[0], self._alpha.shape[1]], np.nan)\n \n for di in range(start, end+1):\n alpha[di-start,:] = data.iloc[di-delay,:]\n \n print(\"Alpha is finished!\")\n \n alpha = Op.Neutralize('IND', alpha, start, end)\n print(\"Neutralize is finished!\")\n \n self._alpha = Op.personalize(alpha)\n print(\"Person is finished!\")\n \n\nclass Alpha9(Alpha):\n '''\n shrp 7.588 fake!\n GTJA 119\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n\n self.volume[self.volume==0] = np.nan\n\n data1 = self.volume.rolling(5).mean()\n data1 = data1.rolling(26).sum()\n corr = self.vwap.rolling(5).corr(data1)\n data1 = corr.ewm(7).mean()\n rank1 = self.rank_col(data1)\n rank1 = np.array(rank1)\n rank2 = self.rank_col(self.open)\n rank3 = self.rank_col(self.volume.rolling(15).mean())\n corr2 = rank2.rolling(21).corr(rank3)\n window = 7\n rank4 = Op.tsrank(corr2, window)\n #rank4 = np.full([corr2.shape[0], corr2.shape[1]], np.nan)\n #for ii in range(window, corr2.shape[0]+1):\n # tmp = corr2.iloc[ii-window:ii,:]\n # rank4[ii-1,:] = self.rank_row(tmp).iloc[-1,:]\n \n data2 = pd.DataFrame(rank4)\n data2 = data2.ewm(8).mean()\n rank5 = self.rank_col(data2)\n rank5 = np.array(rank5)\n data = rank5-rank1\n data = pd.DataFrame(data)\n #start = np.where(data.index == self.start)[0].tolist()[0]\n #end = np.where(data.index == self.end)[0].tolist()[0]\n \n #self.alpha = data.iloc[start-delay:end+1,:]\n \n start = hd['startidx']\n end = hd['endidx']\n \n for di in range(start, end+1):\n self.alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\nclass Alpha10(Alpha):\n '''\n shrp 2.684\n GTJA 16\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n\n rank1 = Op.rank_col(hd['volume'])\n rank2 = Op.rank_col(hd['vwap'])\n \n corr = rank1.rolling(5).corr(rank2)\n rank3 = Op.rank_col(corr)\n \n tsmax = rank3.rolling(5).max()\n \n data = -tsmax\n \n start = hd['startidx']\n end = hd['endidx']\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n\nclass Alpha10P(Alpha):\n '''\n shrp 0.815\n GTJA 16\n '''\n def run(self, hd):\n '''\n Calculate!\n '''\n delay = 1\n\n rank1 = Op.rank_col(hd['volume'])\n rank2 = Op.rank_col(hd['close'])\n \n corr = rank1.rolling(5).corr(rank2)\n rank3 = Op.rank_col(corr)\n \n tsmax = rank3.rolling(5).max()\n \n data = -tsmax\n \n startdate = hd['startdate']\n enddate = hd['enddate']\n start = hd['startidx']\n end = hd['endidx']\n \n for di in range(start, end+1):\n self._alpha[di-start,:] = data.iloc[di-delay,:]\n print(\"Alpha is finished!\")\n \n self._alpha = Op.Neutralize('IND', self._alpha, start, end)\n print(\"Neutralize is finished!\")\n \n self._alpha = Op.personalize(self._alpha)\n print(\"Person is finished!\")\n \n self._alpha, self.trend = Op.trend(self._alpha, startdate, enddate)\n print(\"Trend is finished!\")\n\n \n \n \n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 44,
"blob_id": "82c1deac310a775be55f980f8bc6e58dffa9d264",
"content_id": "0eec99853d4347a59b03c9955ecc5fe7452efc35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 1,
"path": "/03-Study/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "There will be some study materials to share.\n"
},
{
"alpha_fraction": 0.608013927936554,
"alphanum_fraction": 0.6498258113861084,
"avg_line_length": 14.94444465637207,
"blob_id": "81fc307bd26f8084783ed406849c9267356fa059",
"content_id": "abac03cd55e9227f128b28892b579cb2a0de87bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 36,
"path": "/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "# A platform for quant friends\n\n\n## 内容相关\n\n- [Kaggle/天池算法竞赛](https://github.com/zhengow/Awesome-Quant/tree/master/01-Contest)\n- [量化工作求职信息](https://github.com/zhengow/Awesome-Quant/tree/master/02-Job)\n- [量化相关学习资料](https://github.com/zhengow/Awesome-Quant/tree/master/03-Study)\n- [其他信息](https://github.com/zhengow/Awesome-Quant/tree/master/04-Others)\n\n\n## 更新日志:\n**20200302:**\n- 项目创建\n\n## 项目结构\n\n```sh\n.\n├── 01-Contest\n └──README.md\n├── 02-Job\n └──README.md\n├── 03-Study\n └──README.md\n├── 04-Others\n └──README.md\n```\n\n## 参与贡献\n\n提交你的Pull Request.\n\n## 联系我\n\n- 邮箱: [email protected]\n"
},
{
"alpha_fraction": 0.7951807379722595,
"alphanum_fraction": 0.7951807379722595,
"avg_line_length": 82,
"blob_id": "7f9295f7762e45b68c83ca49f6ebb77318a400bd",
"content_id": "0f77719e479c2c5799586bf3bc0391cd2a25b438",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 1,
"path": "/03-Study/机器学习/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "Because machine learning involves both math and code skills, so let's put ML here.\n"
},
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 25,
"blob_id": "26db616a311d56c3b63ee34f5b61fc4a0dd3c799",
"content_id": "23908dbd57e6e4d8b43b4665dba68d64baebd114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 26,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 1,
"path": "/01-Contest/Kaggle/ZC/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "The folder for zc-kaggle.\n"
},
{
"alpha_fraction": 0.7916666865348816,
"alphanum_fraction": 0.7916666865348816,
"avg_line_length": 23,
"blob_id": "113de38e80603cacedaaadd3ee2ce5b094a19f6d",
"content_id": "5abb4808c011e072567a616c3c682e2002a89b85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 1,
"path": "/01-Contest/Kaggle/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This is kaggle related.\n"
},
{
"alpha_fraction": 0.4725703001022339,
"alphanum_fraction": 0.4862155318260193,
"avg_line_length": 31.655502319335938,
"blob_id": "875daf0db393fca0bf04dfb5aaaf86ed4b736ca7",
"content_id": "a359db6a059fcf350f0425099fafe5be7216d1f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7238,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 209,
"path": "/05-Intern/IntimeSpyder/get_index.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\r\nfrom selenium.webdriver.chrome.options import Options\r\nfrom config import COOKIES\r\nfrom urllib.parse import quote\r\nimport datetime\r\nimport time\r\nimport queue\r\nimport math\r\nimport pandas as pd\r\nimport numpy as np\r\nimport threading\r\nimport sys \r\nimport signal\r\n\r\ndef quit(signum, frame):\r\n print()\r\n print('stop fusion')\r\n sys.exit()\r\n\r\nclass BaiduIndex:\r\n \"\"\"\r\n 股票baidu搜索指数\r\n :keywords; list\r\n \"\"\"\r\n '''\r\n _cookies = [{'name': cookie.split('=')[0],\r\n 'value': cookie.split('=')[1]}\r\n for cookie in COOKIES.replace(' ', '').split(';')]\r\n '''\r\n\r\n \r\n _all_kind = ['all', 'pc', 'wise']\r\n _params_queue = queue.Queue()\r\n def __init__(self, keywords: list):\r\n self.keywords = keywords\r\n self._init_queue(keywords)\r\n self.index = self._init_df(keywords)\r\n self.count = 0\r\n self.duration = time.time()\r\n\r\n def _init_queue(self, keywords):\r\n \"\"\"\r\n 初始化参数队列\r\n \"\"\"\r\n keywords_list = self._split_keywords(keywords)\r\n for keywords in keywords_list:\r\n self._params_queue.put(keywords)\r\n \r\n def _init_df(self, keywords):\r\n \"\"\"\r\n 初始化最终结果\r\n \"\"\"\r\n index_time = np.full([24],'2000-01-01 00:00:00')\r\n index_time[0] = self.open_browser()\r\n for i in range(23):\r\n tmp = datetime.datetime.strptime(index_time[i], '%Y-%m-%d %H:%M:%S')+datetime.timedelta(hours=1)\r\n index_time[i+1] = datetime.datetime.strftime(tmp, \"%Y-%m-%d %H:%M:%S\")\r\n initial = {'time': index_time}\r\n for item in keywords:\r\n tmp = np.full([24],np.nan)\r\n initial[item] = tmp\r\n \r\n df = pd.DataFrame(initial)\r\n df = df.set_index(['time'])\r\n print(\"init_df is finished!!\")\r\n return df\r\n \r\n \r\n def _split_keywords(self, keywords: list) -> [list]:\r\n \"\"\"\r\n 对关键词进行切分\r\n \"\"\"\r\n return [keywords[i*5: (i+1)*5] for i in range(math.ceil(len(keywords)/5))]\r\n \r\n def open_browser(self, which = 20):\r\n \r\n cookies = [{'name': cookie.split('=')[0],\r\n 'value': cookie.split('=')[1]}\r\n for cookie in COOKIES[which].replace(' ', '').split(';')]\r\n\r\n chrome_options = Options()\r\n chrome_options.add_argument('--headless')\r\n chrome_options.add_argument('--disable-gpu')\r\n browser = webdriver.Chrome(chrome_options=chrome_options)\r\n browser.get('https://index.baidu.com/#/')\r\n browser.set_window_size(1500, 900)\r\n browser.delete_all_cookies()\r\n for cookie in cookies:\r\n browser.add_cookie(cookie)\r\n stk = '000001'\r\n url = 'https://index.baidu.com/v2/main/index.html#/trend/%s?words=%s' % (stk,quote(stk))\r\n browser.get(url)\r\n time.sleep(1)\r\n browser.find_elements_by_xpath('//*[@class=\"veui-button\"]')[1].click()\r\n browser.find_elements_by_xpath('//*[@class=\"list-item\"]')[0].click()\r\n time.sleep(1)\r\n if(which == 20):\r\n starttime = self.move(browser, '', which)\r\n browser.quit()\r\n return starttime\r\n \r\n return browser\r\n \r\n \r\n def move(self, browser, keyword, which = 0):\r\n #there will be some problems\r\n try:\r\n base_node = browser.find_elements_by_xpath('//*[@class=\"index-trend-chart\"]')[0]\r\n except Exception as e:\r\n print(\"The message is from here!!!\")\r\n #print(base_node)\r\n chart_size = base_node.size\r\n move_step = 24 - 1\r\n step_px = chart_size['width'] / move_step\r\n cur_offset = {\r\n 'x': step_px,\r\n 'y': chart_size['height'] - 50\r\n }\r\n\r\n webdriver.ActionChains(browser).move_to_element_with_offset(\r\n base_node, 1, cur_offset['y']).perform()\r\n \r\n date = base_node.find_element_by_xpath('./div[2]/div[1]').text\r\n\r\n \r\n if(which != 0):\r\n print(date)\r\n return date\r\n \r\n index = base_node.find_element_by_xpath('./div[2]/div[2]/div[2]').text\r\n \r\n index = index.replace(',', '')\r\n index = index.replace(' ', '')\r\n if(index!=''):\r\n self.index.loc[date,keyword] = int(index)\r\n \r\n \r\n for _ in range(24-1):\r\n #time.sleep(0.05)\r\n webdriver.ActionChains(browser).move_to_element_with_offset(\r\n base_node, int(cur_offset['x']), cur_offset['y']).perform()\r\n cur_offset['x'] += step_px\r\n date = base_node.find_element_by_xpath('./div[2]/div[1]').text\r\n index = base_node.find_element_by_xpath('./div[2]/div[2]/div[2]').text\r\n index = index.replace(',', '')\r\n index = index.replace(' ', '')\r\n if(index!=''):\r\n self.index.loc[date,keyword] = int(index)\r\n if(self.count%100 == 0 and self.count != 0):\r\n print(\"100 stocks use \",time.time()-self.duration,\"s\")\r\n self.duration = time.time()\r\n else:\r\n print(keyword,': ',self.count,\" stocks is finished\")\r\n self.count = self.count + 1\r\n \r\n \r\n def visit(self, browser, stks):\r\n for keyword in stks:\r\n url = 'https://index.baidu.com/v2/main/index.html#/trend/%s?words=%s' % (keyword,quote(keyword))\r\n browser.get(url)\r\n time.sleep(0.5)\r\n if(browser.find_elements_by_xpath('//*[@class=\"not-in\"]')):\r\n continue\r\n else:\r\n self.move(browser, keyword)\r\n \r\n \r\n def doTask(self, i):\r\n browser = self.open_browser(i)\r\n #signal.signal(signal.SIGINT, quit)\r\n #signal.signal(signal.SIGTERM, quit)\r\n error = 0\r\n while 1:\r\n try:\r\n params_data = self._params_queue.get(timeout=1)\r\n self.visit(browser, params_data)\r\n\r\n except queue.Empty:\r\n break\r\n except Exception as e:\r\n error = error + 1\r\n print(e)\r\n self._params_queue.put(params_data)\r\n if(error > 50):\r\n break\r\n browser.quit()\r\n print(\"thread \", i, \"is finished!!!\")\r\n \r\n \r\n \r\n def run(self, numThread = 5):\r\n \"\"\"\r\n open multi thread to run tasks:\r\n first it open browser, then \r\n each tasks will do for loop to get keywords and save the res to self._index\r\n \"\"\"\r\n threads = []\r\n for i in range(numThread):\r\n thread = threading.Thread(target=self.doTask, args=(i,))\r\n threads.append(thread)\r\n thread.start()\r\n \r\n for th in threads:\r\n th.join()\r\n print(\"all the threads are finished!\")\r\n \r\n \r\n def get_index(self):\r\n return self.index\r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n "
},
{
"alpha_fraction": 0.8787878751754761,
"alphanum_fraction": 0.8787878751754761,
"avg_line_length": 32,
"blob_id": "0ce9733a032b38a79cf1c17de2da848172187321",
"content_id": "e4bd617d57fb0d8a56770e9250cd875f6fac1cf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 1,
"path": "/04-Others/MultiFactors/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "Backtest Engine for MultiFactors\n"
},
{
"alpha_fraction": 0.4215686321258545,
"alphanum_fraction": 0.5490196347236633,
"avg_line_length": 14.333333015441895,
"blob_id": "48910909f2d86a9091d921f618ddd86c44e7a69f",
"content_id": "634cc19717a4f0fb52e0c301789407e9b4812142",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 6,
"path": "/05-Intern/IntimeSpyder/__init__.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Apr 17 11:28:34 2020\r\n\r\n@author: Administrator\r\n\"\"\"\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 26,
"blob_id": "83559f98f5e309fa29d2eb2118ee95c228fa5abc",
"content_id": "1a1fa6d05c5468a4cd5e9d2e8d016ade09cff91d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 1,
"path": "/01-Contest/Kaggle/LLZ/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "The folder for lzz-kaggle.\n"
},
{
"alpha_fraction": 0.4667207896709442,
"alphanum_fraction": 0.4853896200656891,
"avg_line_length": 34.20000076293945,
"blob_id": "2fb8406b77f3372d9b53d6a768925caceadc87f8",
"content_id": "5e57c1d7e93009f62e8d325123eeac0749304e67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2464,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 70,
"path": "/04-Others/MultiFactors/Person/Operator.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nfrom data import Data\nclass Op(object):\n \n def __init__(self):\n pass\n \n def Neutralize(method, alpha, start = 0, end = 0):\n print(method)\n if(method == 'test'):\n for ii in range(alpha.shape[0]):\n mean = np.nanmean(alpha[ii,:])\n alpha[ii,:] = alpha[ii,:] - mean\n \n if(method == \"IND\"):\n inds = pd.read_csv('groupdata.csv', index_col='date')\n #start = np.where(inds.index == start)[0].tolist()[0]\n #end = np.where(inds.index == end)[0].tolist()[0]\n for di in range(start, end+1):\n series = inds.iloc[di,:]\n for ind in series.unique():\n cond = (series==ind)\n mean = np.nanmean(alpha[di-start][cond])\n alpha[di-start][cond] = alpha[di-start][cond] - mean\n '''\n if(method == \"MV\"):\n 1\n else:\n print(\"No such Neutralization!!\")\n '''\n return alpha\n \n def personalize(data):\n alpha = np.full([data.shape[0], data.shape[1]], np.nan)\n for di in range(data.shape[0]):\n tmp = data[di,:]\n tmp[pd.isnull(tmp)] = -10\n idx = np.argpartition(tmp, -5)[-5:]\n if(di%5==0):\n for ii in idx:\n alpha[di,ii] = tmp[ii]\n else:\n alpha[di,:] = alpha[di-1,:]\n \n return alpha\n \n def trend(data, startdate, enddate):\n alpha = data\n inx = Data.get('inx500', startdate, enddate, hist = 120)\n #inx = inx.iloc[start:end, :]\n trend = inx.rolling(5).mean()-inx.rolling(10).mean()*1.01\n start = np.where(trend.index == startdate)[0].tolist()[0]\n end = np.where(trend.index == enddate)[0].tolist()[0]\n for di in range(alpha.shape[0]):\n if(trend.iloc[start+di-1,0]<0):\n alpha[di,:] = np.nan\n return alpha, trend\n \n def rank_col(data):\n return pd.DataFrame(data).rank(pct=True, axis=1)\n def rank_row(data):\n return pd.DataFrame(data).rank(pct=True, axis=0)\n def tsrank(data, window):\n rank = data.copy()\n rank.iloc[:window-1,:] = np.nan\n for ii in range(window, data.shape[0]+1):\n tmp = data.iloc[ii-window:ii,:]\n rank.iloc[ii-1,:] = Op.rank_row(tmp).iloc[-1]\n return rank\n"
},
{
"alpha_fraction": 0.6024138927459717,
"alphanum_fraction": 0.6208732724189758,
"avg_line_length": 31.379310607910156,
"blob_id": "1bec274a4f84b2356e00d776fa244e507c86d5c3",
"content_id": "8ff418ff7785dd57658eb00ff4702711b0cfd44d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2817,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 87,
"path": "/04-Others/Option/black_scholes.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "\"\"\"\nId: black_scholes.py\nCopyright: 2018 xiaokang.guan All rights reserved.\nDescription: Black-Scholes utility functions.\n\"\"\"\n\nimport numpy as np\nimport math\nimport logging\n\n\ndef ncdf(x):\n \"\"\"\n Cumulative distribution function for the standard normal distribution.\n Alternatively, we can use below:\n from scipy.stats import norm\n norm.cdf(x)\n \"\"\"\n return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0\n\n\ndef npdf(x):\n \"\"\"\n Probability distribution function for the standard normal distribution.\n Alternatively, we can use below:\n from scipy.stats import norm\n norm.pdf(x)\n \"\"\"\n return np.exp(-np.square(x) / 2) / np.sqrt(2 * np.pi)\n\n\ndef blackScholesOptionPrice(callPut, spot, strike, tenor, rate, sigma):\n \"\"\"\n Black-Scholes option pricing\n tenor is float in years. e.g. tenor for 6 month is 0.5\n \"\"\"\n d1 = (np.log(spot / strike) + (rate + 0.5 * sigma ** 2) * tenor) / (sigma * np.sqrt(tenor))\n d2 = d1 - sigma * np.sqrt(tenor)\n\n if callPut == 'Call':\n return spot * ncdf(d1) - strike * np.exp(-rate * tenor) * ncdf(d2)\n elif callPut == 'Put':\n return -spot * ncdf(-d1) + strike * np.exp(-rate * tenor) * ncdf(-d2)\n\n\ndef blackScholesVega(callPut, spot, strike, tenor, rate, sigma):\n \"\"\" Black-Scholes vega \"\"\"\n d1 = (np.log(spot / strike) + (rate + 0.5 * sigma ** 2) * tenor) / (sigma * np.sqrt(tenor))\n return spot * np.sqrt(tenor) * npdf(d1)\n\n\ndef blackScholesDelta(callPut, spot, strike, tenor, rate, sigma):\n \"\"\" Black-Scholes delta \"\"\"\n d1 = (np.log(spot / strike) + (rate + 0.5 * sigma ** 2) * tenor) / (sigma * np.sqrt(tenor))\n if callPut == 'Call':\n return ncdf(d1)\n elif callPut == 'Put':\n return ncdf(d1) - 1\n\n\ndef blackScholesGamma(callPut, spot, strike, tenor, rate, sigma):\n \"\"\"\" Black-Scholes gamma \"\"\"\n d1 = (np.log(spot / strike) + (rate + 0.5 * sigma ** 2) * tenor) / (sigma * np.sqrt(tenor))\n return npdf(d1) / (spot * sigma * np.sqrt(tenor))\n\n\ndef blackScholesSolveImpliedVol(targetPrice, callPut, spot, strike, tenor, rate):\n \"\"\"\" Solve for implied volatility using Black-Scholes \"\"\"\n MAX_ITERATIONS = 100\n PRECISION = 1.0e-5\n\n sigma = 0.5\n i = 0\n while i < MAX_ITERATIONS:\n optionPrice = blackScholesOptionPrice(callPut, spot, strike, tenor, rate, sigma)\n vega = blackScholesVega(callPut, spot, strike, tenor, rate, sigma)\n diff = targetPrice - optionPrice\n logging.debug('blackScholesSolveImpliedVol: iteration={}, sigma={}, diff={}'.format(i, sigma, diff))\n\n if abs(diff) < PRECISION:\n return sigma\n\n sigma = sigma + diff/vega\n i = i + 1\n\n logging.debug('blackScholesSolveImpliedVol: After MAX_ITERATIONS={}, best sigma={}'.format(MAX_ITERATIONS, sigma))\n return sigma\n"
},
{
"alpha_fraction": 0.8169013857841492,
"alphanum_fraction": 0.8169013857841492,
"avg_line_length": 70,
"blob_id": "bfd80c16be5ed70cfd78e8297ec83e69a726670a",
"content_id": "ee35adde4f60efe17c695aa1061bc46ff052fc35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 1,
"path": "/04-Others/MultiFactors/Person/README.md",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "This strategy will choose five stocks, which can be traded personally.\n"
},
{
"alpha_fraction": 0.584814190864563,
"alphanum_fraction": 0.625201940536499,
"avg_line_length": 25,
"blob_id": "b7cc21cbd8a522607a551153dea9cdb136632bbe",
"content_id": "500f6dfdd2b2fee0368b8534126d91595a6d98fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 23,
"path": "/04-Others/MultiFactors/process.py",
"repo_name": "zhengow/Awesome-Quant",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nimport numpy as np\r\n#3234 rows 3933 cols\r\n#date = pd.read_csv('date.csv')\r\n\r\n#alpha1 = np.load(\"alpha1.npy\")\r\n#data = 'vol'\r\ndf = pd.read_csv('ret2.csv')\r\ndf.rename(columns={'Unnamed: 0':'date'},inplace=True)\r\ni = {'date': a}\r\ndf.set_index(df['date'], inplace=True)\r\ndel df['date']\r\n\r\n#df.drop([len(df)-1], inplace=True)\r\n#del df['3934']\r\n#del df['3933']\r\n#df = pd.read_csv('volume.csv', index_col='date')\r\n#df2 = pd.read_csv('close.csv', index_col='date')\r\n#df.set_index(date['date'], inplace=True)\r\n#df.rename(columns={'0':'inxret'}, inplace=True)\r\n#del df['Unnamed: 0']\r\n\r\ndf.to_csv('ret2.csv')"
}
] | 35 |
zengfhui/week2_c1
|
https://github.com/zengfhui/week2_c1
|
bdf1c37bff7575a690c7caf779439f0ece2a0ece
|
9fca8e5dbb54ff139bd596a170f83c2a8e7cb012
|
0e61117eaa42885570582d5d08c5bc7ab444c781
|
refs/heads/master
| 2021-05-07T17:38:07.161941 | 2017-11-04T06:45:42 | 2017-11-04T06:45:42 | 108,699,374 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6345475912094116,
"alphanum_fraction": 0.6462984681129456,
"avg_line_length": 18.340909957885742,
"blob_id": "f54d7a49954971db55e3a940ffe9f7c942729367",
"content_id": "ede102e7bdcc9fe86c1b2d5ec59c7a339aba205c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 851,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 44,
"path": "/test.py",
"repo_name": "zengfhui/week2_c1",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding:UTF-8 -*-\n#from flask import Flask \n#from flask import render_template\nimport os\nimport json\n\n#print(os.getcwd())\npath = '/home/shiyanlou/files'\ns = os.listdir('/home/shiyanlou/files')\n\nf_path = '/home/shiyanlou/files'\nfilename_list = os.listdir('/home/shiyanlou/files')\n\n\nfile_dict = {}\n\n\nfor filename in filename_list:\n\twith open(f_path + '/' + filename) as file:\n\t\t file_dict[filename] = json.load(file)\n\ndef dict_operation(file_dict):\n\tdata = {}\n\tfor key,value in file_dict.items():\n\t\tkey = key.encode()\n\t\tvalue = value.encode()\n\t\tdata[key] = value\n\tdata['content'] = data['content'].split(' \\\\n ')\n\n\treturn data\n\n#a = filename_list[1]\n#print(dict_operation(file_dict[a]))\n#d = dict_operation(file_dict[a])\n#for line in d['content']:\n#\tprint(line)\n\n\na ={1:1}\nb ={2:2}\nc ={3:3}\ns ={'a':a,'b':b}\nprint(s['a'][1])\n"
}
] | 1 |
Perrogramador/Concesionario_Odoo
|
https://github.com/Perrogramador/Concesionario_Odoo
|
312d162d12f1d192f11f6a5abb5521e7a45f9af6
|
de5faf0d8ae92c9c0c442765f91f1050d7bc6784
|
0d6e46ef8206d09b3e98581db9b3603f3afe2f45
|
refs/heads/master
| 2020-05-27T21:09:33.062915 | 2017-03-09T11:22:29 | 2017-03-09T11:22:29 | 83,601,252 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6895522475242615,
"alphanum_fraction": 0.7014925479888916,
"avg_line_length": 32.5,
"blob_id": "2fab469a4633f4b038d3443f965958672e4fc9c5",
"content_id": "88f444c3b77154fd14e2883076a98e84354ea1d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 10,
"path": "/models/venta.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import fields, models\n\nclass Venta(models.Model):\n _name = 'concesionario.venta'\n\n comercial_id = fields.One2many('concesionario.comercial', 'venta_id')\n cliente_id = fields.One2many('concesionario.cliente', 'venta_id')\n vehiculo_id = fields.One2many('concesionario.vehiculo','venta_id')\n"
},
{
"alpha_fraction": 0.6718146800994873,
"alphanum_fraction": 0.6795367002487183,
"avg_line_length": 27.66666603088379,
"blob_id": "cfeb63875255d432c106638f82c30a2b046acaed",
"content_id": "b14581e84f56f5f8775d2ce384cde10ffd9f7724",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 9,
"path": "/models/marca.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import models, fields, api\n\nclass Marca(models.Model):\n _name = 'concesionario.marca'\n \n nombre = fields.Char(string=\"Nombre de la marca\", required=True)\n vehiculo_id = fields.Many2one('concesionario.vehiculo')\n\n"
},
{
"alpha_fraction": 0.6905829310417175,
"alphanum_fraction": 0.6995515823364258,
"avg_line_length": 26.875,
"blob_id": "71501b7d139e4c3ab1ea8e3400cfaea4e5dab359",
"content_id": "b172f5fafd00250682bf84348f784a1409fad956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 8,
"path": "/models/comercial.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom odoo import fields, models\n\nclass Comercial(models.Model):\n _name = 'concesionario.comercial'\n _inherit = 'concesionario.trabajador'\n\n venta_id = fields.Many2one('concesionario.venta')\n"
},
{
"alpha_fraction": 0.6772486567497253,
"alphanum_fraction": 0.682539701461792,
"avg_line_length": 22.625,
"blob_id": "006779c1718ddc81ae78984c54c68fe40b07fc7a",
"content_id": "f3726a408794fa6d8e16300179c4b6456a08d883",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 8,
"path": "/models/persona.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import fields, models\n\nclass Persona(models.Model):\n _name = 'concesionario.persona'\n\n nombre = fields.Char(string=\"Nombre de pila\", required=True)\n"
},
{
"alpha_fraction": 0.5047748684883118,
"alphanum_fraction": 0.515688955783844,
"avg_line_length": 20.558822631835938,
"blob_id": "7440d412e7d431ea312cf1f54b3682bbfc04205c",
"content_id": "9c95fc8bdef38a6f69e38d237ab2adeafdae669b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 34,
"path": "/__manifest__.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n{\n 'name': \"Concesionario\",\n\n 'summary': \"\"\"\n Arranque la gestión virtual de su concesionario y todo irá sobre ruedas. \n \"\"\",\n\n 'description': \"\"\"\n ¡Ahora 100% de eficiencia en 10 segundos!\n Administración asistida.\n ¿Le gusta gestionar?\n Wir lieben Odoo.\n \"\"\",\n\n 'author': \"Perrogramadores\",\n 'website': \"localhost.com\",\n\n 'category': 'Ventas',\n 'version': '1.0',\n\n 'depends': ['base'],\n\n 'data': [\n 'views/cliente.xml',\n 'views/trabajador.xml',\n 'views/comercial.xml',\n 'views/marca.xml',\n 'views/mecanico.xml',\n 'views/tarea.xml',\n 'views/vehiculo.xml',\n 'views/venta.xml',\n ],\n}\n"
},
{
"alpha_fraction": 0.6962962746620178,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 28.88888931274414,
"blob_id": "fb4a84063fff6b11d2557d4a58c5c7ac83fa99d7",
"content_id": "5eeeae544bd49a8e726c7f8157711247d195c8c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 9,
"path": "/models/trabajador.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import fields, models\n\nclass Tabajador(models.Model):\n _name = 'concesionario.trabajador'\n _inherit = 'concesionario.persona' \n \n departamento = fields.Char(string=\"Departamento en que trabaja el empleado\", required=True) \n"
},
{
"alpha_fraction": 0.6950819492340088,
"alphanum_fraction": 0.7016393542289734,
"avg_line_length": 26.727272033691406,
"blob_id": "2e7766b90eb616562efc0b1ba71d8a2072d8ed3f",
"content_id": "cb205580c02cd6d9db1f7775ebfe1d24bb894735",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/models/tarea.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import fields, models\n\nclass Tarea(models.Model):\n _name = 'concesionario.tarea'\n\n nombre = fields.Char(string=\"Denominación de la tarea\", required=True)\n descrip = fields.Text(string=\"Descripción\")\n\n mecanico_id = fields.Many2many('concesionario.mecanico')\n"
},
{
"alpha_fraction": 0.6805555820465088,
"alphanum_fraction": 0.6898148059844971,
"avg_line_length": 26,
"blob_id": "3457660aba99fea0bf9830b639ae4fa1314d3a59",
"content_id": "acfb9f9bd337b06d051d6d2749bc47ce662242f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 8,
"path": "/models/cliente.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom odoo import fields, models\n\nclass Cliente(models.Model):\n _name = 'concesionario.cliente'\n _inherit = 'concesionario.persona'\n\n venta_id = fields.Many2one('concesionario.venta')\n"
},
{
"alpha_fraction": 0.6974790096282959,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 39,
"blob_id": "e258bbcb1b2ca85128ef0821d8bfff8a75edb78e",
"content_id": "7ef5d357a35d6bc26c5d72b1505606165f5896c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 3,
"path": "/models/__init__.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom . import persona, trabajador, cliente, comercial, marca, mecanico, tarea, vehiculo, venta"
},
{
"alpha_fraction": 0.6740087866783142,
"alphanum_fraction": 0.6828193664550781,
"avg_line_length": 24.22222137451172,
"blob_id": "cfb662f1d2c2957696b020c22c9c39b3b3456ff7",
"content_id": "2fe5736d40d4531433980f77eb63de18787d7f1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 9,
"path": "/models/mecanico.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import fields, models\n\nclass Mecanico(models.Model):\n _name = 'concesionario.mecanico'\n _inherit = 'concesionario.trabajador'\n \n tarea_id = fields.Many2many('concesionario.tarea')\n"
},
{
"alpha_fraction": 0.6215053796768188,
"alphanum_fraction": 0.6279569864273071,
"avg_line_length": 30,
"blob_id": "5da5ef2c989c3c3e928b7fb0927441371ab918a8",
"content_id": "ca0f5c859a379a5220c15a061fa4e45cb7fbb5b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 15,
"path": "/models/vehiculo.py",
"repo_name": "Perrogramador/Concesionario_Odoo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom odoo import models, fields, api\n\nclass Vehiculo(models.Model):\n _name = 'concesionario.vehiculo'\n \n nombre = fields.Char(string=\"Nombre del vehiculo\", required=True)\n motor = fields.Selection([\n ('diese', \"Diesel\"),\n ('gasolina', \"Gasolina\"),\n ('electrico', \"Eléctrico\"),\n ])\n marca_id = fields.One2many('concesionario.marca', 'vehiculo_id')\n venta_id = fields.Many2one('concesionario.venta')\n"
}
] | 11 |
josecarlosduran/python_tutorial
|
https://github.com/josecarlosduran/python_tutorial
|
b2c15014c53b525697fd94484c1bb03440dcf45b
|
c63d4387f7acba2308f61bd6d0f1892e7b1bde99
|
f9dbcc4c8aa57cdb1fc5b6584e0d50d9586cd69c
|
refs/heads/master
| 2021-02-09T15:03:25.202898 | 2020-03-02T06:23:25 | 2020-03-02T06:23:25 | 244,295,571 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6719160079956055,
"alphanum_fraction": 0.7060367465019226,
"avg_line_length": 14.199999809265137,
"blob_id": "b088ac4fd1acadbfbc3658923a882bad65d398bb",
"content_id": "5b11d9a99f10472c49a29436399d8f09dfbff655",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 381,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 25,
"path": "/03_variables.py",
"repo_name": "josecarlosduran/python_tutorial",
"src_encoding": "UTF-8",
"text": "\nx = 100\n\n# case sensitive\nbook = \"Digital Fortress\"\nBook = \"Another book\"\n\nprint(x)\nprint(book)\nprint(Book)\n\na,b = \"a string\",100\nprint(a)\nprint(b)\nprint (a,b)\n\n# In python not exist constant, but using a convention we represent the constants with UPCASE letters\n\nPI = 3.1416\n\n# pyton is a dinamically typed language\n\nname = \"Josep\"\nprint(type (name))\nname = 34\nprint(type(name))\n"
},
{
"alpha_fraction": 0.7153558135032654,
"alphanum_fraction": 0.7215980291366577,
"avg_line_length": 20.052631378173828,
"blob_id": "afb6da195fa992e10ebf2fc4aed190973b0aad4c",
"content_id": "9d958b00fb4126f906c9c02cdd52399f33f96180",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 801,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 38,
"path": "/04_strings.py",
"repo_name": "josecarlosduran/python_tutorial",
"src_encoding": "UTF-8",
"text": "myString = \"This is a string\"\nmyString2 = \"This_is_a_string\"\nallLetters =\"AFSFSF\"\n\n#print(dir(myString))\n\nprint(myString.upper())\nprint(myString.lower())\nprint(myString.swapcase())\nprint(myString.capitalize())\nprint(myString.replace(\"string\",\"replaced string\").upper())\nprint(myString.count(\"i\"))\nprint(myString.startswith(\"This\"))\nprint(myString.endswith(\"string\"))\n\nprint(myString.split())\nmyList = myString2.split(\"_\")\nprint(myList)\nprint(type(myList))\n\nprint(myString.find(\"a\"))\nprint(myString.find(\"string\"))\nprint(len(myString))\nprint(myString.isalnum())\nprint(myString.isnumeric())\n\nprint(allLetters.isalpha())\nprint(myString[5])\nprint(myString[-1])\n\n\n#another form of concatenate\n\nname = \"Josep\"\n\nprint (\"My name is \" + name)\nprint (f\"My name is {name}\")\nprint(\"My name is {0}\".format(name))\n\n"
},
{
"alpha_fraction": 0.7209302186965942,
"alphanum_fraction": 0.7209302186965942,
"avg_line_length": 20.5,
"blob_id": "049f7da3053a9d594aff7e4ec2e0eaa1d6ba373e",
"content_id": "3e3cda055ab1ec4deda56bfe47a3b2531a59878d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/01_hello_world.py",
"repo_name": "josecarlosduran/python_tutorial",
"src_encoding": "UTF-8",
"text": "# this is a comentary\nprint(\"Hello World\") "
},
{
"alpha_fraction": 0.5613811016082764,
"alphanum_fraction": 0.6176470518112183,
"avg_line_length": 16.35555648803711,
"blob_id": "cfbfcbe3b394872953506c802941f6e805fe89b6",
"content_id": "132a8fb28280d3fca1fa29ada766faafc31de7cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 782,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 45,
"path": "/02_data_types.py",
"repo_name": "josecarlosduran/python_tutorial",
"src_encoding": "UTF-8",
"text": "# strings\nprint(\"Hello World\")\nprint('Hello World')\nprint('''Hello World''')\nprint(\"\"\"Hello World\"\"\")\nprint(type(\"Hello World\"))\n# Concatenate strings\nprint(\"Bye\" + \"World\")\n\n# Numbers\n# int\nprint(30)\nprint(type(30))\n# float\nprint(30.1)\nprint(type(30.1))\n\n# Boolean (First letter UPCASE)\nprint(False)\nprint(True)\nprint(type(False))\n\n# List\nprint([10, 20, 30, 55])\nprint([\"a\", \"b\", \"c\"])\nprint([10, 20, 30, \"hello\"])\nprint(type([10, 20, 30, 55]))\n\n# Tuples (its like a list that cannot change INMUTABLE) \nprint(10,20, 30)\nprint(type((10,20, 30)))\n\n# Dictionaries (group of key value)\nprint(\n {\"name\" : \"Ryan\",\n \"lastname\" : \"Ray\",\n \"nickname\" : \"Fazt\"}\n)\nprint(type({\"name\" : \"Ryan\",\n \"lastname\" : \"Ray\",\n \"nickname\" : \"Fazt\"}))\n\n# None\nprint(None)\nprint(type(None))\n\n"
}
] | 4 |
arshad1986/portfolio
|
https://github.com/arshad1986/portfolio
|
dcddc24378b7ca4deb8127164537cca3f111ff8f
|
671902eeb5d858cfb9ffa5b616d30ce39f90b72c
|
f5b339b90a8c61d99e744e22e50d9b277688eddd
|
refs/heads/master
| 2021-01-14T07:42:44.733445 | 2020-03-03T12:40:41 | 2020-03-03T12:40:41 | 242,642,516 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5756798386573792,
"alphanum_fraction": 0.6038994193077087,
"avg_line_length": 28.530303955078125,
"blob_id": "4908c158e9aa8792e2fc32ba96db934eb10f9760",
"content_id": "a41408282d1f58c9d5299100c9cc4a9c0439aaba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1949,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 66,
"path": "/9febassignment.py",
"repo_name": "arshad1986/portfolio",
"src_encoding": "UTF-8",
"text": "# Assignment part-1 9th february submitted by \n# Muhammad arshad PIAIC67442\npi=3.14\ndef calcArea(r):\n return r*r*pi \nprint(calcArea(8.7))\n\n\n# Assignment part-2 9th february submitted by \n# Muhammad arshad PIAIC67442\npiaic=['python', 'r', 'java', 'pascal', 'c', 'javascript', 'assembley', 'html','c++']\n\ndef func1(piaic):\n for i in piaic:\n if i==\"python\":\n print(\"the value of python is available\")\n elif i==\"html\":\n print(\"the value of html is available\")\n elif i==\"c++\":\n print(\"the value of C++ is available\")\n else:\n print(\" none of the value is available\")\n \nfunc1(piaic) \n\n# Assignment part-3 9th february submitted by \n# Muhammad arshad PIAIC67442\ndata = [\"python\", \"r\", \"java\", \"pascal\", \"c\", \"javascript\", \"assembley\", \"html\", \"c++\"]\nrotate_num = 2\ndef rightRotate(data, num): \n output_data = [] \n \n # Will add values from n to the new list \n for item in range(len(data) - num, len(data)): \n output_data.append(data[item]) \n \n # Will add the values before \n # n to the end of new list \n for item in range(0, len(data) - num): \n output_data.append(data[item]) \n \n return output_data \n\nprint(rightRotate(data, rotate_num)) \n \n# Assignment part-4 9th february submitted by \n# Muhammad arshad PIAIC67442\nfrom math import pi\nwhile True:\n r= input('please enter an integer( 0 to exit):\\n')\n r=float(r)\n if r==0:\n print(\"loop is breaked or exited\")\n break\n print(\"the arae of the circle is \",str(pi*r**2))\n\n# Assignment part-5 9th february submitted by \n# Muhammad arshad PIAIC67442\ndef print_showdetails(args,*kwargs):\n print(\"hello Ali \\n\",\"Here is your result for class of AI\\n\",\"Your score card is as follows\")\n for k, v in kwargs.items():\n print(f'{k} : {v}')\n print(\"the total marks are\")\n print(sum(kwargs.values()))\n \nprint_showdetails(math = 50, physics = 80, biology= 90, computer =67)\n"
},
{
"alpha_fraction": 0.5460526347160339,
"alphanum_fraction": 0.571052610874176,
"avg_line_length": 18.33333396911621,
"blob_id": "65994c30d8ec2197619efcaf641f7464f8068d04",
"content_id": "e071c9891b85594f1c0abd1bcec21cc80ead1bab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 39,
"path": "/25febassignment.py",
"repo_name": "arshad1986/portfolio",
"src_encoding": "UTF-8",
"text": "# Assignment part-1 \n# class Circle():\n# def __init__(self, r):\n# self.radius = r\n\n# def area(self):\n# return self.radius**2*3.14\n \n# def perimeter(self):\n# return 2*self.radius*3.14\n\n# NewCircle = Circle(10)\n# print(NewCircle.area())\n# print(NewCircle.perimeter())\n\n# Assignment part-2\n\n# class IOString():\n# def __init__(self):\n# self.str1 = \"\"\n\n# def get_String(self):\n# self.str1 = input()\n\n# def print_String(self):\n# print(self.str1.upper())\n\n# str1 = IOString()\n# str1.get_String()\n# str1.print_String()\n\n# Assignment part-3\n\nclass py_solution:\n def reverse_words(self, s):\n return ' '.join(reversed(s.split()))\n\n\nprint(py_solution().reverse_words('hello .py'))\n\n\n\n\n\n\n"
}
] | 2 |
amsmith828/build-a-blog
|
https://github.com/amsmith828/build-a-blog
|
15866d027d0d2cb3a659daa5e42f9290343d3c7b
|
d00ff3218d456b972fc2c10e45f200d54e171512
|
8bebf5f492437b83297d258c53902908d9bebe6c
|
refs/heads/master
| 2020-04-21T14:41:09.869552 | 2019-02-10T21:19:01 | 2019-02-10T21:19:01 | 169,641,878 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6717592477798462,
"avg_line_length": 31.238805770874023,
"blob_id": "bc0c151cf7d1aab5e49fbbae5930b7b3033281ce",
"content_id": "69d72ef19a4894a8fe2e03939dce28ca8ef17b54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2160,
"license_type": "no_license",
"max_line_length": 228,
"num_lines": 67,
"path": "/main.py",
"repo_name": "amsmith828/build-a-blog",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, redirect, render_template\nfrom flask_sqlalchemy import SQLAlchemy\n\napp = Flask(__name__)\napp.config['DEBUG'] = True\napp.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://build-a-blog:build-a-blog@localhost:8889/build-a-blog'\napp.config['SQLALCHEMY_ECHO'] = True\ndb = SQLAlchemy(app)\n\n\"\"\"The /blog route displays all the blog posts.\n\nYou're able to submit a new post at the /newpost route. After submitting a new post, your app displays the main blog page.\n\nYou have two templates, one each for the /blog (main blog listings) and /newpost (post new blog entry) views. Your templates should extend a base.html template which includes some boilerplate HTML that will be used on each page.\n\nIn your base.html template, you have some navigation links that link to the main blog page and to the add new blog page.\n\nIf either the blog title or blog body is left empty in the new post form, the form is rendered again, with a helpful error message and any previously-entered content in the same form inputs.\n\"\"\"\n\n\nclass Blog(db.Model):\n\n id = db.Column(db.Integer, primary_key=True)\n title = db.Column(db.String(120))\n body = db.Column(db.String(8000))\n\n def __init__(self, title, body):\n self.title = title\n self.body = body\n\n\[email protected]('/')\ndef index():\n return redirect('/blog')\n\n\[email protected]('/blog', methods=['POST', 'GET'])\ndef blog():\n\n blog_id = request.args.get('id')\n\n if blog_id is None:\n blogs = Blog.query.all()\n return render_template('blog.html', blogs=blogs, title=\"Build a Blog\")\n else:\n blog = Blog.query.get(blog_id)\n return render_template('view-blog.html', blog=blog)\n\n\[email protected]('/newpost', methods=['POST', 'GET'])\ndef new_post():\n\n if request.method == 'POST':\n blog_title = request.form['title']\n blog_body = request.form['body']\n new_post = Blog(blog_title, blog_body)\n db.session.add(new_post)\n db.session.commit()\n return redirect('/blog?id={}'.format(new_post.id))\n\n else:\n return render_template('new-blog.html', title='New Blog Post')\n\n\nif __name__ == '__main__':\n app.run()\n"
}
] | 1 |
briansukhnandan/Bass-Guitar-Tuner
|
https://github.com/briansukhnandan/Bass-Guitar-Tuner
|
f66ff9d6f8724d438ccc3e4394cc5bd88dda805b
|
a91120e1e79a39e172615b2983fd8196e89bacd8
|
65c7aa49db9ffa088c37a1e4eee876d5deee19b8
|
refs/heads/master
| 2020-12-15T05:00:42.803027 | 2020-06-01T04:12:12 | 2020-06-01T04:12:12 | 235,001,509 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7441364526748657,
"alphanum_fraction": 0.7505330443382263,
"avg_line_length": 45.79999923706055,
"blob_id": "88c4c2d48049463a84a2837f7651503bd89e61d4",
"content_id": "ff2a84887079ce0cde6a88e534477ad80f0682ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 10,
"path": "/README.md",
"repo_name": "briansukhnandan/Bass-Guitar-Tuner",
"src_encoding": "UTF-8",
"text": "# Bass Guitar Tuner #\nA simple bass guitar tuner capable of 5 different tuning modes (Drop C, Drop D, Full-Step, Full-Step (Drop C), and Standard.\n\n# How do I use it? #\n- Navigate to Bass-Guitar-Tuner/src/ and execute 'python3.6 TunerGUI.py'\n- To change tuning, click on the Menu button 'Change tuning' and select whatever mode you want. The GUI will automatically update the buttons and sounds.\n\n- Dependencies: tkinter, playsound, Pillow\n\n\n\n"
},
{
"alpha_fraction": 0.6458632349967957,
"alphanum_fraction": 0.6597321629524231,
"avg_line_length": 20.01507568359375,
"blob_id": "93b0e528750b8631196a34e0e9d0c35f81d7f388",
"content_id": "b23265c1395cdc4db4ef7b725d617e5553a19acb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4182,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 199,
"path": "/src/TunerGUI.py",
"repo_name": "briansukhnandan/Bass-Guitar-Tuner",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nimport playsound\nfrom tkinter import *\nfrom PIL import Image, ImageTk\n\n# Globals\nWIDTH = 394\nHEIGHT = 525\nFILENAME = 'bass_guitar.PNG'\n\n# Change these depending on system location.\nEfile = \"../Samples/4E.wav\"\nAfile = \"../Samples/3A.wav\"\nDfile = \"../Samples/2D.wav\"\nGfile = \"../Samples/1G.wav\"\n\n# Open the file and resize\nbass_guitar_image = Image.open(\"../images/bass_guitar.PNG\")\nbass_guitar_image = bass_guitar_image.resize((HEIGHT, WIDTH), Image.ANTIALIAS)\n\n# TODO: Import WAV files\n\n\ndef playE():\n playsound.playsound(Efile)\n print(\"Played an E\")\n\n\ndef playA():\n playsound.playsound(Afile)\n print(\"Played an A\")\n\n\ndef playD():\n playsound.playsound(Dfile)\n print(\"Played a D\")\n\n\ndef playG():\n playsound.playsound(Gfile)\n print(\"Played a G\")\n\n\ndef updateDropD():\n E_string.set(\"D\")\n global Efile\n Efile = \"../Samples/4D.wav\"\n\n A_string.set(\"A\")\n global Afile\n Afile = \"../Samples/3A.wav\"\n\n D_string.set(\"D\")\n global Dfile\n Dfile = \"../Samples/2D.wav\"\n\n G_string.set(\"G\")\n global Gfile\n Gfile = \"../Samples/1G.wav\"\n\n print(\"Updated to Drop D\")\n\ndef updateDropC():\n E_string.set(\"C\")\n global Efile\n Efile = \"../Samples/4C.wav\"\n\n A_string.set(\"A\")\n global Afile\n Afile = \"../Samples/3A.wav\"\n\n D_string.set(\"D\")\n global Dfile\n Dfile = \"../Samples/2D.wav\"\n\n G_string.set(\"G\")\n global Gfile\n Gfile = \"../Samples/1G.wav\"\n\n print(\"Updated to Drop C\")\n\n\ndef updateFullStep():\n E_string.set(\"D\")\n global Efile\n Efile = \"../Samples/4D.wav\"\n\n A_string.set(\"G\")\n global Afile\n Afile = \"../Samples/3G.wav\"\n\n D_string.set(\"C\")\n global Dfile\n Dfile = \"../Samples/2C.wav\"\n\n G_string.set(\"F\")\n global Gfile\n Gfile = \"../Samples/1F.wav\"\n\n print(\"Updated to Full Step\")\n\n\ndef updateFullStepDropC():\n E_string.set(\"C\")\n global Efile\n Efile = \"../Samples/4C.wav\"\n\n A_string.set(\"G\")\n global Afile\n Afile = \"../Samples/3G.wav\"\n\n D_string.set(\"C\")\n global Dfile\n Dfile = \"../Samples/2C.wav\"\n\n G_string.set(\"F\")\n global Gfile\n Gfile = \"../Samples/1F.wav\"\n\n print(\"Updated to Full Step (Drop C)\")\n\n\ndef updateStd():\n E_string.set(\"E\")\n global Efile\n Efile = \"../Samples/4E.wav\"\n\n A_string.set(\"A\")\n global Afile\n Afile = \"../Samples/3A.wav\"\n\n D_string.set(\"D\")\n global Dfile\n Dfile = \"../Samples/2D.wav\"\n\n G_string.set(\"G\")\n global Gfile\n Gfile = \"../Samples/1G.wav\"\n\n print(\"Updated to Standard Tuning\")\n\n\n\nroot = tk.Tk()\nroot.title(\"Bass Guitar Tuner by Brian Sukhnandan\")\ncanvas = tk.Canvas(root, width=500, height=400)\ncanvas.pack()\n\nE_string = tk.StringVar()\nE_string.set(\"E\")\n\nA_string = tk.StringVar()\nA_string.set(\"A\")\n\nD_string = tk.StringVar()\nD_string.set(\"D\")\n\nG_string = tk.StringVar()\nG_string.set(\"G\")\n\nbass_guitar = ImageTk.PhotoImage(bass_guitar_image)\ncanvas.create_image(263, 202, image=bass_guitar)\n\ntopFrame = Frame(root)\ntopFrame.pack(side=TOP)\n\nmenu = Menu(root)\nroot.config(menu=menu)\nfilemenu = Menu(menu)\nmenu.add_cascade(label='Change Tuning', menu=filemenu)\nfilemenu.add_command(label='Standard Tuning', command=updateStd)\nfilemenu.add_command(label='Drop D', command=updateDropD)\nfilemenu.add_command(label='Drop C', command=updateDropC)\nfilemenu.add_command(label='Full Step', command=updateFullStep)\nfilemenu.add_command(label='Full Step (Drop C)', command=updateFullStepDropC)\nfilemenu.add_separator()\nfilemenu.add_command(label='Exit', command=root.quit)\n\n\nbottomFrame = Frame(root)\nbottomFrame.pack(side=BOTTOM)\n\nrightFrame = Frame(root)\nrightFrame.pack(side=RIGHT)\n\nbuttonE = Button(bottomFrame, textvariable=E_string, command=playE, height = 5, width = 5)\nbuttonA = Button(bottomFrame, textvariable=A_string, command=playA, height = 5, width = 5)\nbuttonD = Button(bottomFrame, textvariable=D_string, command=playD, height = 5, width = 5)\nbuttonG = Button(bottomFrame, textvariable=G_string, command=playG, height = 5, width = 5)\n\nbuttonE.grid(column=0, row=1)\nbuttonA.grid(column=1, row=1)\nbuttonD.grid(column=2, row=1)\nbuttonG.grid(column=3, row=1)\n\nroot.configure(background='black')\ncanvas.configure(background='black')\n\nroot.mainloop()\n"
}
] | 2 |
CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul
|
https://github.com/CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul
|
ab1b9e82e3a964c84eae7c940eb8c3c68eaa4251
|
d940b5f6ecdb345d1ed73ff0012d99de7b8a59cb
|
b3f0a455820f5cbe93e1c0842582874afcddc90b
|
refs/heads/main
| 2023-05-02T23:33:18.920282 | 2021-05-19T01:00:18 | 2021-05-19T01:00:18 | 349,080,186 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5783050656318665,
"alphanum_fraction": 0.5884745717048645,
"avg_line_length": 29.12244987487793,
"blob_id": "c0a01090b01ab4b29ba7adb4d939750573b4cdac",
"content_id": "e87dfa118bc523f5fd1826d16d22d3d5674e5937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1475,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 49,
"path": "/controller/dislikes.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from re import error\nfrom flask import jsonify\nfrom model.dislikes import DislikesDAO\n\nclass BaseDislikes:\n def build_map_dict(self, row):\n result = {}\n result['did'] = row[0]\n result['mid'] = row[1]\n result['uid'] = row[2]\n return result\n\n def build_dislike_attr_dict(self, did):\n result = {}\n result['did'] = did\n return result\n\n def getDislikedById(self, d_mid):\n dao = DislikesDAO()\n disliked_list = dao.getLikedById(d_mid)\n result_list = []\n for row in disliked_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n def getAllDislikesId(self, d_mid):\n dao = DislikesDAO()\n disliked_list = dao.getAllDislikesId(d_mid)\n result_list = []\n for row in disliked_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n\n def dislikeMessage(self, json, d_mid):\n uid = json['RegisteredUser']\n dao = DislikesDAO()\n did = dao.dislikeMessage(d_mid, uid)\n result = self.build_dislike_attr_dict(did)\n return jsonify(result), 201\n\n def undislikeMessage(self, json, d_mid):\n r_uid = json['RegisteredUser']\n dao = DislikesDAO()\n did = dao.undislikeMessage(d_mid, r_uid)\n result = self.build_dislike_attr_dict(did)\n return jsonify(result), 201"
},
{
"alpha_fraction": 0.5594900846481323,
"alphanum_fraction": 0.5701133012771606,
"avg_line_length": 27.836734771728516,
"blob_id": "187a6fce314ac3801ca7813083f96fd3d7188238",
"content_id": "b7859654298773de8f9afdb93d8268503fc2717a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1412,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 49,
"path": "/controller/likes.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from re import error\nfrom flask import jsonify\nfrom model.likes import LikesDAO\n\nclass BaseLikes:\n def build_map_dict(self, row):\n result = {}\n result['lid'] = row[0]\n result['mid'] = row[1]\n result['uid'] = row[2]\n return result\n\n def build_like_attr_dict(self, lid):\n result = {}\n result['lid'] = lid\n return result\n\n def getLikedById(self, l_mid):\n dao = LikesDAO()\n liked_list = dao.getLikedById(l_mid)\n result_list = []\n for row in liked_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n def getAllLikesId(self, l_mid):\n dao = LikesDAO()\n liked_list = dao.getAllLikesId(l_mid)\n result_list = []\n for row in liked_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n\n def likeMessage(self, json, l_mid):\n uid = json['RegisteredUser']\n dao = LikesDAO()\n lid = dao.likeMessage(l_mid, uid)\n result = self.build_like_attr_dict(lid)\n return jsonify(result), 201\n\n def unlikeMessage(self, json, l_mid):\n r_uid = json['RegisteredUser']\n dao = LikesDAO()\n lid = dao.unlikeMessage(l_mid, r_uid)\n result = self.build_like_attr_dict(lid)\n return jsonify(result), 201"
},
{
"alpha_fraction": 0.5614187121391296,
"alphanum_fraction": 0.5670415163040161,
"avg_line_length": 41.05454635620117,
"blob_id": "7d9aee7a763827fbb8bd2b3a10328223d4e85039",
"content_id": "26e7e06603b9b717932135e67a51a55f2589f753",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2312,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 55,
"path": "/model/follows.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from config.config import DATABASE\nimport psycopg2\n\nclass FollowsDAO:\n def __init__(self):\n connection_url = \"dbname=%s user=%s password=%s port=%s host=%s\" %(DATABASE['dbname'], DATABASE['user'],\n DATABASE['password'], DATABASE['dbport'], DATABASE['host'])\n print(\"connection url: \", connection_url)\n self.conn = psycopg2.connect(connection_url)\n\n def getFollowedById(self, r_uid):\n cursor = self.conn.cursor()\n query = \"select fid, uid, followed_user from \\\"Follows\\\" where uid = %s and is_deleted=false;\"\n cursor.execute(query, (r_uid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def getAllUsersFollowingId(self, f_uid):\n cursor = self.conn.cursor()\n query = \"select fid, uid, followed_user from \\\"Follows\\\" where followed_user = %s and is_deleted=false;\"\n cursor.execute(query, (f_uid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def followUser(self, r_uid, f_uid):\n cursor = self.conn.cursor()\n query = \"Select fid from \\\"Follows\\\" where uid = %s and followed_user= %s;\"\n cursor.execute(query, (r_uid, f_uid))\n fid = cursor.fetchone()\n query2 = \"select blocked_uid from \\\"Blocks\\\" where (is_deleted = false and blocked_uid = %s and registered_uid = %s);\"\n cursor.execute(query2, (r_uid, f_uid))\n fid3 = cursor.fetchone()\n if(fid):\n query1 = \"update \\\"Follows\\\" set is_deleted = false where fid = %s;\"\n cursor.execute(query1, (fid,)) \n elif(fid3 == None and fid == None):\n query2 = \"Insert into \\\"Follows\\\" (uid, followed_user) values (%s,%s) returning fid;\"\n cursor.execute(query2, (r_uid, f_uid))\n fid = cursor.fetchone()[0]\n else:\n fid = 0\n self.conn.commit()\n return fid\n\n def unfollowUser(self, r_uid, f_uid):\n cursor = self.conn.cursor()\n query = \"update \\\"Follows\\\" set is_deleted=true where uid = %s and followed_user= %s returning fid;\"\n cursor.execute(query, (r_uid, f_uid))\n result = cursor.fetchone()[0]\n self.conn.commit()\n return result"
},
{
"alpha_fraction": 0.5982300639152527,
"alphanum_fraction": 0.6008849740028381,
"avg_line_length": 40.703704833984375,
"blob_id": "8979e52df183b3318f441570692e61f6ea6879a5",
"content_id": "728d07d1b1335d4549dee076c612faa906173e78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2260,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 54,
"path": "/model/users.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from config.config import DATABASE\nimport psycopg2\nfrom flask_bcrypt import Bcrypt\nfrom flask import jsonify\n\nbcrypt = Bcrypt()\n\nclass UsersDAO:\n def __init__(self):\n connection_url = \"dbname=%s user=%s password=%s port=%s host=%s\" %(DATABASE['dbname'], DATABASE['user'],\n DATABASE['password'], DATABASE['dbport'], DATABASE['host'])\n print(\"conection url: \", connection_url)\n self.conn = psycopg2.connect(connection_url)\n\n def getAllUsers(self):\n cursor = self.conn.cursor()\n query = \"select * from \\\"Users\\\" where is_deleted = false;\"\n cursor.execute(query)\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def getUserById(self, uid):\n cursor = self.conn.cursor()\n query = \"select * from \\\"Users\\\" where uid = %s and is_deleted = false;\"\n cursor.execute(query, (uid,))\n result = cursor.fetchone()\n return result\n \n def insertUser(self, first_name, last_name, username, password, email):\n cursor = self.conn.cursor()\n query = \"insert into \\\"Users\\\" (first_name, last_name, username, password, email) values (%s,%s,%s,%s,%s) returning uid;\"\n password = bcrypt.generate_password_hash(password).decode(\"utf-8\")\n cursor.execute(query, (first_name, last_name, username, password, email))\n pid = cursor.fetchone()[0]\n self.conn.commit()\n return pid\n\n def updateUser(self, uid, first_name, last_name, username, password, email):\n cursor = self.conn.cursor()\n query= \"update \\\"Users\\\" set first_name=%s, last_name = %s, username=%s, password =%s, email=%s where uid=%s and is_deleted = false;\"\n password = bcrypt.generate_password_hash(password).decode(\"utf-8\")\n cursor.execute(query, (first_name, last_name, username, password, email, uid))\n self.conn.commit()\n return True\n\n def deleteUser(self, uid):\n cursor = self.conn.cursor()\n query = \"update \\\"Users\\\" set is_deleted = true where uid=%s;\"\n cursor.execute(query,(uid,))\n affected_rows = cursor.rowcount\n self.conn.commit()\n return affected_rows !=0\n "
},
{
"alpha_fraction": 0.5713648796081543,
"alphanum_fraction": 0.5753791332244873,
"avg_line_length": 42.13461685180664,
"blob_id": "95064b05a1f4ba6bbc81bdd4cf8e81a7d53ac7b3",
"content_id": "8794d719e4ba911618b6701a291534f7f8955e6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2242,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 52,
"path": "/model/blocks.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from config.config import DATABASE\nimport psycopg2\n\nclass BlocksDAO:\n def __init__(self):\n connection_url = \"dbname=%s user=%s password=%s port=%s host=%s\" %(DATABASE['dbname'], DATABASE['user'],\n DATABASE['password'], DATABASE['dbport'], DATABASE['host'])\n print(\"connection url: \", connection_url)\n self.conn = psycopg2.connect(connection_url)\n\n def getBlockedById(self, r_uid):\n cursor = self.conn.cursor()\n query = \"select bid, registered_uid, blocked_uid from \\\"Blocks\\\" where registered_uid = %s and is_deleted=false;\"\n cursor.execute(query, (r_uid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def getAllUsersBlockingId(self, b_uid):\n cursor = self.conn.cursor()\n query = \"select bid, registered_uid, blocked_uid from \\\"Blocks\\\" where blocked_uid = %s and is_deleted=false;\"\n cursor.execute(query, (b_uid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def blockUser(self, r_uid, b_uid):\n cursor = self.conn.cursor()\n query = \"Select * from \\\"Blocks\\\" where registered_uid = %s and blocked_uid= %s;\"\n cursor.execute(query, (r_uid, b_uid))\n bid = cursor.fetchone()[0]\n if(bid):\n query1 = \"update \\\"Blocks\\\" set is_deleted = false where bid = %s;\"\n cursor.execute(query1, (bid,))\n else:\n query2 = \"Insert into \\\"Blocks\\\" (registered_uid, blocked_uid) values (%s,%s) returning bid;\"\n cursor.execute(query2, (r_uid, b_uid))\n bid = cursor.fetchone()[0]\n queryUpdate = \"Update \\\"Follows\\\" set is_deleted = true where uid = %s and followed_user = %s;\"\n cursor.execute(queryUpdate, (r_uid, b_uid)) \n self.conn.commit()\n return bid\n\n def unblockUser(self, r_uid, b_uid):\n cursor = self.conn.cursor()\n query = \"update \\\"Blocks\\\" set is_deleted=true where registered_uid = %s and blocked_uid= %s returning bid;\"\n cursor.execute(query, (r_uid, b_uid))\n result = cursor.fetchone()[0]\n self.conn.commit()\n return result"
},
{
"alpha_fraction": 0.552930474281311,
"alphanum_fraction": 0.5565652251243591,
"avg_line_length": 39.0363655090332,
"blob_id": "129ac1d55ccaaef1a2aeeee0b70a39ec9e8a6794",
"content_id": "9a84aece1a52f4c1685e5d9b3e21d33c2e68e1af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2201,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 55,
"path": "/model/likes.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from config.config import DATABASE\nimport psycopg2\n\nclass LikesDAO:\n def __init__(self):\n connection_url = \"dbname=%s user=%s password=%s port=%s host=%s\" %(DATABASE['dbname'], DATABASE['user'],\n DATABASE['password'], DATABASE['dbport'], DATABASE['host'])\n print(\"connection url: \", connection_url)\n self.conn = psycopg2.connect(connection_url)\n\n def getLikedById(self, l_mid):\n cursor = self.conn.cursor()\n query = \"select lid, mid, uid from \\\"Likes\\\" where mid = %s and isLiked=true;\"\n cursor.execute(query, (l_mid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def getAllLikesId(self, l_mid):\n cursor = self.conn.cursor()\n query = \"select lid, mid, uid from \\\"Likes\\\" where mid = %s and isLiked=true;\"\n cursor.execute(query, (l_mid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def likeMessage(self, l_mid, r_uid):\n cursor = self.conn.cursor()\n cursorCheck = self.conn.cursor()\n query = \"Select lid from \\\"Likes\\\" where mid = %s and uid= %s;\"\n queryCheck= \"update \\\"Dislikes\\\" set isDisliked = false where (mid = %s and uid = %s);\"\n cursor.execute(query, (l_mid, r_uid))\n lid = cursor.fetchone()\n if(lid):\n query1 = \"update \\\"Likes\\\" set isLiked = true where lid = %s;\"\n cursor.execute(query1, (lid,))\n cursorCheck.execute(queryCheck, (l_mid, r_uid))\n else:\n query2 = \"Insert into \\\"Likes\\\" (mid, uid) values (%s,%s) returning lid;\"\n cursor.execute(query2, (l_mid, r_uid))\n cursorCheck.execute(queryCheck, (l_mid, r_uid))\n\n lid = cursor.fetchone()[0]\n self.conn.commit()\n return lid\n\n def unlikeMessage(self, l_mid, r_uid):\n cursor = self.conn.cursor()\n query = \"update \\\"Likes\\\" set isLiked = false where mid = %s and uid= %s returning lid;\"\n cursor.execute(query, (l_mid, r_uid))\n result = cursor.fetchone()[0]\n self.conn.commit()\n return result"
},
{
"alpha_fraction": 0.6979166865348816,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 33.160919189453125,
"blob_id": "bfea04de0fe57a987b9fa785cae7ffa6dcbf2350",
"content_id": "816624cb9fff65c919da32fd8b81835bad26960f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2978,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 87,
"path": "/README.md",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "Miembros del Grupo:\n1. Anthony Márquez Camacho: [email protected]\n2. David Carrión Beníquez: [email protected]\n3. Estefanía Torres Collado: [email protected]\n4. Christopher Vegerano López: [email protected]\n\nVideo de Fase 1: https://youtu.be/Vogf6cMRgPo\n\nRest API\n\n -Ruta Principal: https://pichon-azul.herokuapp.com/PichonAzul\n \n 1. Usuarios\n\n -Obtener todos los usuarios: https://pichon-azul.herokuapp.com/PichonAzul/users\n \n -Crear nuevo usuario: https://pichon-azul.herokuapp.com/PichonAzul/users\n \n -Obtener usuario por id: https://pichon-azul.herokuapp.com/PichonAzul/users/uid \n \n -Poner o cambiar informacion en usuario existente: https://pichon-azul.herokuapp.com/PichonAzul/users/uid\n \n -Borrar usuario: https://pichon-azul.herokuapp.com/PichonAzul/users/uid \n \n 2. Mensajes\n \n -Obtener todos los mensajes: https://pichon-azul.herokuapp.com/PichonAzul/msg\n \n -Obtener mensaje por id: https://pichon-azul.herokuapp.com/PichonAzul/msg/mid \n \n -Crear un nuevo mensaje: https://pichon-azul.herokuapp.com/PichonAzul/posts\n \n -Responder a un mensaje existente: https://pichon-azul.herokuapp.com/PichonAzul/reply\n \n -Compartir un mensaje: https://pichon-azul.herokuapp.com/PichonAzul/share\n \n 3. Seguidores\n\n -Seguir un usuario en específico: https://pichon-azul.herokuapp.com/PichonAzul/follow/fid\n\n -Obtener todos los usuarios seguidos por un usuario: https://pichon-azul.herokuapp.com/PichonAzul/followedby/fid\n\n -Obtener todos los usuarios que siguen a un usuario: https://pichon-azul.herokuapp.com/PichonAzul/follows/fid\n\n -Parar de seguir un usuario específico : https://pichon-azul.herokuapp.com/PichonAzul/unfollow/fid\n\n 4. Me gusta\n\n -Obtener todos los likes por mensaje: https://pichon-azul.herokuapp.com/PichonAzul/liked/mid \n \n -Crear un like al mensaje: https://pichon-azul.herokuapp.com/PichonAzul/like/mid\n \n -Remover like del mensaje: https://pichon-azul.herokuapp.com/PichonAzul/like/remove/mid\n \n 5. No me gusta\n\n -Obtener todos los dislikes por mensaje: https://pichon-azul.herokuapp.com/PichonAzul/disliked/mid \n \n -Crear un dislike al mensaje: https://pichon-azul.herokuapp.com/PichonAzul/dislike/mid\n \n -Remover dislike del mensaje: https://pichon-azul.herokuapp.com/PichonAzul/dislike/remove/mid\n \n 6. Bloqueos\n \n -El usuario registrado bloquea a un usuario: https://pichon-azul.herokuapp.com/PichonAzul/block/uid\n \n -Obtener todos los usuarios blockeados por el id: https://pichon-azul.herokuapp.com/PichonAzul/blockedby/uid\n \n -Obtener todos los usuarios que blockean a un id en particular: https://pichon-azul.herokuapp.com/PichonAzul/blocking/uid\n \n -El usuario registrado desbloquea a un usuario: https://pichon-azul.herokuapp.com/PichonAzul/unblock/uid\n \n 7. Credenciales de la Base de Datos\n \n {\n \n 'host': 'ec2-34-233-0-64.compute-1.amazonaws.com',\n \n 'user': 'qxnzmozhofunpq',\n \n 'password': '2fcc078dcb79a138242190ef2becdf2241b919f495e0bff0561cba47112529dd',\n \n 'dbname': 'd5mdc734arlvfo',\n \n 'dbport': 5432\n \n }\n \n"
},
{
"alpha_fraction": 0.5544472336769104,
"alphanum_fraction": 0.5644222497940063,
"avg_line_length": 32.71831130981445,
"blob_id": "ca3c08ec0681ff2ec871da7ed77de1568d17a42f",
"content_id": "0aed7071c06cf91681a0b0c3010062a25ef585d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2406,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 71,
"path": "/controller/users.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from flask import jsonify\nfrom model.users import UsersDAO\n\nclass BaseUsers:\n def build_map_dict(self, row):\n result = {}\n result['uid'] = row[0]\n result['first_name'] = row[1]\n result['last_name'] = row[2]\n result['username'] = row[3]\n result['password'] = row[4]\n result['email'] = row[5]\n return result\n\n def build_attr_dict(self, uid, first_name, last_name, username, password, email):\n result = {}\n result['uid'] = uid\n result['first_name'] = first_name\n result['last_name'] = last_name\n result['username'] = username\n result['password'] = password\n result['email'] = email\n return result\n\n def getAllUsers(self):\n dao = UsersDAO()\n user_list = dao.getAllUsers()\n result_list = []\n for row in user_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list)\n\n def getUserById(self, uid):\n dao = UsersDAO()\n user_tuple = dao.getUserById(uid)\n if not user_tuple:\n return jsonify(\"Not Found\"), 404\n else:\n result = self.build_map_dict(user_tuple)\n return jsonify(result), 200\n \n def addNewUser(self, json):\n first_name = json['first_name']\n last_name = json['last_name']\n username = json['username']\n password = json['password']\n email = json['email']\n dao = UsersDAO()\n uid = dao.insertUser(first_name, last_name, username, password, email)\n result = self.build_attr_dict(uid, first_name, last_name, username, password, email)\n return jsonify(result), 201\n\n def updateUser(self, uid, json):\n first_name = json['first_name']\n last_name = json['last_name']\n username = json['username']\n password = json['password']\n email = json['email'] \n dao = UsersDAO()\n updated_code = dao.updateUser(uid, first_name, last_name, username, password, email)\n result = self.build_attr_dict(uid, first_name, last_name, username, password, email)\n return jsonify(result), 200\n\n def deleteUser(self, uid):\n dao = UsersDAO()\n result = dao.deleteUser(uid)\n if result:\n return jsonify(\"DELETED\"), 200\n else:\n return jsonify(\"NOT FOUND\"), 404\n "
},
{
"alpha_fraction": 0.5498915314674377,
"alphanum_fraction": 0.5574837327003479,
"avg_line_length": 38.400001525878906,
"blob_id": "bcf1b10250647dce0a1fda896c89de5216ec20ca",
"content_id": "d6913fab3aea47048a9fc3861ef32a022ab78c2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2766,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 70,
"path": "/model/messages.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from config.config import DATABASE\nimport psycopg2\n\n\n\nclass MessagesDAO:\n def __init__(self):\n connection_url = \"dbname=%s user=%s password=%s port=%s host=%s\" %(DATABASE['dbname'], DATABASE['user'],\n DATABASE['password'], DATABASE['dbport'], DATABASE['host'])\n print(\"conection url: \", connection_url)\n self.conn = psycopg2.connect(connection_url)\n\n def getAllMessages(self):\n cursor = self.conn.cursor()\n query = \"select mid, uid, text, created_date, created_time from \\\"Messages\\\" where isdeleted = false;\"\n cursor.execute(query)\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def getMessageById(self, mid):\n cursor = self.conn.cursor()\n query = \"select mid, uid, text, created_date, created_time from \\\"Messages\\\" where mid = %s and isdeleted = false;\"\n cursor.execute(query, (mid,))\n result = cursor.fetchone()\n return result\n \n def postMessage(self, uid, text):\n cursor = self.conn.cursor()\n query = \"insert into \\\"Messages\\\" (uid, text) values (%s,%s) returning mid;\"\n cursor.execute(query, (uid, text))\n mid = cursor.fetchone()[0]\n self.conn.commit()\n return mid\n \n def replyMessage(self, uid, text, mid):\n cursor = self.conn.cursor()\n muid = \"select uid from \\\"Messages\\\" where mid = %s;\"\n cursor.execute(muid, (mid,))\n muid = cursor.fetchone()[0]\n query2 = \"select blocked_uid from \\\"Blocks\\\" where (is_deleted = false and blocked_uid = %s and registered_uid = %s);\"\n cursor.execute(query2, (uid, muid))\n query2 = cursor.fetchone()\n if(query2 == None):\n query3 = \"insert into \\\"Replies\\\" (uid, text, mid) values (%s,%s,%s) returning rid;\"\n cursor.execute(query3, (uid, text, mid))\n rid = cursor.fetchone()[0]\n else:\n rid = 0\n self.conn.commit()\n return rid\n \n \n def shareMessage(self, uid, mid):\n cursor = self.conn.cursor()\n muid = \"select uid from \\\"Messages\\\" where mid = %s;\"\n cursor.execute(muid, (mid,))\n muid = cursor.fetchone()[0]\n query2 = \"select blocked_uid from \\\"Blocks\\\" where (is_deleted = false and blocked_uid = %s and registered_uid = %s);\"\n cursor.execute(query2, (uid, muid))\n query2 = cursor.fetchone()\n if(query2 == None):\n query3 = \"insert into \\\"Shares\\\" (uid, mid) values (%s,%s) returning sid;\"\n cursor.execute(query3, (uid, mid))\n sid = cursor.fetchone()[0]\n else:\n sid = 0\n self.conn.commit()\n return sid\n "
},
{
"alpha_fraction": 0.5695958733558655,
"alphanum_fraction": 0.5811417698860168,
"avg_line_length": 29.58823585510254,
"blob_id": "6197d63dc58825da7a8db3927172630ded7fda4f",
"content_id": "4d824fd786d9e4180828e51366a43301e479ff59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1559,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 51,
"path": "/controller/blocks.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from re import error\nfrom flask import jsonify\nfrom model.blocks import BlocksDAO\n\nclass BaseBlocks:\n def build_map_dict(self, row):\n result = {}\n result['bid'] = row[0]\n result['registered_uid'] = row[1]\n result['blocked_uid'] = row[2]\n return result\n\n def build_block_attr_dict(self, bid):\n result = {}\n result['bid'] = bid\n return result\n\n def getBlockedById(self, r_uid):\n dao = BlocksDAO()\n blocked_list = dao.getBlockedById(r_uid)\n result_list = []\n for row in blocked_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n def getAllUsersBlockingId(self, b_uid):\n dao = BlocksDAO()\n blocked_list = dao.getAllUsersBlockingId(b_uid)\n result_list = []\n for row in blocked_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n\n def blockUser(self, json, b_uid):\n r_uid = json['RegisteredUser']\n if(r_uid == b_uid):\n return jsonify(\"Users cannot block themselves.\"), 400\n dao = BlocksDAO()\n bid = dao.blockUser(r_uid, b_uid)\n result = self.build_block_attr_dict(bid)\n return jsonify(result), 201\n\n def unblockUser(self, json, b_uid):\n r_uid = json['RegisteredUser']\n dao = BlocksDAO()\n bid = dao.unblockUser(r_uid, b_uid)\n result = self.build_block_attr_dict(bid)\n return jsonify(result), 201"
},
{
"alpha_fraction": 0.471615731716156,
"alphanum_fraction": 0.6855894923210144,
"avg_line_length": 15.357142448425293,
"blob_id": "80f9287fb64a6bd360705912c6f3e4e4540f64a4",
"content_id": "3576a87bf6d4622f9d0d813fa6608d535afa1ee1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 14,
"path": "/requirements.txt",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "bcrypt==3.2.0\ncffi==1.14.5\nclick==7.1.2\nFlask==1.1.2\nFlask-Bcrypt==0.7.1\nFlask-Cors==3.0.10\ngunicorn==20.1.0\nitsdangerous==1.1.0\nJinja2==2.11.3\nMarkupSafe==1.1.1\npsycopg2-binary==2.8.6\npycparser==2.20\nsix==1.15.0\nWerkzeug==1.0.1\n"
},
{
"alpha_fraction": 0.5233370065689087,
"alphanum_fraction": 0.5361999273300171,
"avg_line_length": 29.584270477294922,
"blob_id": "1e335c10ea24d6efb0d68029cf4f0f34c1511d23",
"content_id": "38d0e03c958b923e8e81c43854e5c70e036f1176",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2721,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 89,
"path": "/controller/messages.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from flask import jsonify\nfrom model.messages import MessagesDAO\n\nclass BaseMsg: \n def build_map_dict(self, row):\n result = {}\n result['mid'] = row[0]\n result['uid'] = row[1]\n result['text'] = row[2]\n result['created_date'] = str(row[3])\n result['created_time'] = str(row[4])\n return result\n \n def build_map_dict2(self, row):\n result = {}\n result['mid'] = row[0]\n result['uid'] = row[1]\n result['text'] = row[2]\n result['created_date'] = str(row[3])\n result['created_time'] = str(row[4])\n return result\n \n def build_post_attr_dict(self, uid, text):\n result = {}\n result['uid'] = uid\n result['text'] = text\n return result\n \n def build_reply_attr_dict(self, uid, text, mid):\n result = {}\n result['uid'] = uid\n result['text'] = text\n result['mid'] = mid\n return result\n \n def build_share_attr_dict(self, uid, mid):\n result = {}\n result['uid'] = uid\n result['mid'] = mid\n return result\n\n def getAllMessages(self):\n dao = MessagesDAO()\n message_list = dao.getAllMessages()\n result_list = []\n for row in message_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list)\n\n def getMessageById(self, mid):\n dao = MessagesDAO()\n message_tuple = dao.getMessageById(mid)\n if not message_tuple:\n return jsonify(\"Not Found\"), 404\n else:\n result = self.build_map_dict2(message_tuple)\n return jsonify(result), 200\n \n def postMessage(self, json):\n uid = json['RegisteredUser']\n text = json['Text']\n dao = MessagesDAO()\n mid = dao.postMessage(uid, text)\n result = self.build_post_attr_dict(uid, text)\n return jsonify(result), 201\n \n def replyMessage(self, json):\n uid = json['RegisteredUser']\n text = json['Text']\n mid = json['mid']\n dao = MessagesDAO()\n rid = dao.replyMessage(uid, text, mid)\n if(rid == 0):\n return \"You can't reply, because you are blocked.\", 401\n else:\n result = self.build_reply_attr_dict(uid, text, mid)\n return jsonify(result), 201\n \n def shareMessage(self, json):\n uid = json['RegisteredUser']\n mid = json['mid']\n dao = MessagesDAO()\n sid = dao.shareMessage(uid, mid)\n if(sid == 0):\n return \"You can't share, because you are blocked.\", 401\n else:\n result = self.build_share_attr_dict(uid, mid)\n return jsonify(result), 201"
},
{
"alpha_fraction": 0.4917127192020416,
"alphanum_fraction": 0.591160237789154,
"avg_line_length": 24.85714340209961,
"blob_id": "7e1b5c9a42a69a93fb1e8c37d9ba580b5e1d0fb7",
"content_id": "00f337781f664596507ac4a8ba42b7afd9bc713a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 7,
"path": "/config/config.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "DATABASE = {\n 'host': 'ec2-34-233-0-64.compute-1.amazonaws.com',\n 'user': 'qxnzmozhofunpq',\n 'password': '2fcc078dcb79a138242190ef2becdf2241b919f495e0bff0561cba47112529dd',\n 'dbname': 'd5mdc734arlvfo',\n 'dbport': 5432\n}\n"
},
{
"alpha_fraction": 0.6537999510765076,
"alphanum_fraction": 0.6646080017089844,
"avg_line_length": 30.344085693359375,
"blob_id": "7a92dbe2654eb97558344de191f785e1883dc4e6",
"content_id": "3a154025c79d0cbb1428747e554d473ca608ed13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5829,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 186,
"path": "/app.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, jsonify\nfrom flask_cors import CORS\nfrom controller.users import BaseUsers\nfrom controller.messages import BaseMsg\nfrom controller.blocks import BaseBlocks\nfrom controller.follows import BaseFollows\nfrom controller.likes import BaseLikes\nfrom controller.dislikes import BaseDislikes\n\n\napp = Flask(__name__)\n#apply CORS\nCORS(app)\n\[email protected]('/')\ndef pichonAzul():\n return 'To access the app start with /PichonAzul'\n\[email protected]('/PichonAzul')\ndef pichonAzulHome():\n return 'Pichon Azul App'\n\n#Users\[email protected]('/PichonAzul/users', methods=['GET', 'POST'])\ndef handleUsers():\n if request.method == 'POST':\n return BaseUsers().addNewUser(request.json)\n elif request.method == 'GET':\n return BaseUsers().getAllUsers()\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/users/<int:uid>', methods=['GET', 'PUT', 'DELETE'])\ndef handleUserById(uid):\n if request.method == 'GET':\n return BaseUsers().getUserById(uid=uid)\n elif request.method == 'PUT':\n return BaseUsers().updateUser(uid, request.json)\n elif request.method == 'DELETE':\n return BaseUsers().deleteUser(uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\n#Messages\[email protected]('/PichonAzul/msg', methods=['GET'])\ndef handleMessages():\n if request.method == 'GET':\n return BaseMsg().getAllMessages()\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/msg/<int:mid>', methods=['GET'])\ndef handleMessageById(mid):\n if request.method == 'GET':\n return BaseMsg().getMessageById(mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/posts', methods=['POST'])\ndef postMessage():\n if request.method == 'POST':\n return BaseMsg().postMessage(request.json)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/reply', methods=['POST'])\ndef replyMessage():\n if request.method == 'POST':\n return BaseMsg().replyMessage(request.json)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/share', methods=['POST'])\ndef shareMessage():\n if request.method == 'POST':\n return BaseMsg().shareMessage(request.json)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\n#Blocks\[email protected]('/PichonAzul/block/<int:uid>', methods=['POST'])\ndef blockUser(uid):\n if request.method == 'POST':\n return BaseBlocks().blockUser(request.json, b_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/blockedby/<int:uid>', methods=['GET'])\ndef getAllUsersBlockedById(uid):\n if request.method == 'GET':\n return BaseBlocks().getBlockedById(r_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/blocking/<int:uid>', methods=['GET'])\ndef getUsersBlocking(uid):\n if request.method == 'GET':\n return BaseBlocks().getAllUsersBlockingId(b_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/unblock/<int:uid>', methods=['POST'])\ndef unblockUser(uid):\n if request.method == 'POST':\n return BaseBlocks().unblockUser(request.json, b_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\n#Follows\[email protected]('/PichonAzul/follow/<int:uid>', methods=['POST'])\ndef followUser(uid):\n if request.method == 'POST':\n return BaseFollows().followUser(request.json, f_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/followedby/<int:uid>', methods=['GET'])\ndef getAllUsersFollowedById(uid):\n if request.method == 'GET':\n return BaseFollows().getFollowedById(r_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/follows/<int:uid>', methods=['GET'])\ndef getUsersFollowing(uid):\n if request.method == 'GET':\n return BaseFollows().getAllUsersFollowingId(f_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/unfollow/<int:uid>', methods=['POST'])\ndef unfollowUser(uid):\n if request.method == 'POST':\n return BaseFollows().unfollowUser(request.json, f_uid=uid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\n#Likes\n\[email protected]('/PichonAzul/like/<int:mid>', methods=['POST'])\ndef likeMessage(mid):\n if request.method == 'POST':\n return BaseLikes().likeMessage(request.json, l_mid=mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/liked/<int:mid>', methods=['GET'])\ndef getMessageLikes(mid):\n if request.method == 'GET':\n return BaseLikes().getAllLikesId(l_mid=mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/like/remove/<int:mid>', methods=['POST'])\ndef unlikeMessage(mid):\n if request.method == 'POST':\n return BaseLikes().unlikeMessage(request.json, l_mid=mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\n\n#Dislikes\n\[email protected]('/PichonAzul/dislike/<int:mid>', methods=['POST'])\ndef dislikeMessage(mid):\n if request.method == 'POST':\n return BaseDislikes().dislikeMessage(request.json, d_mid=mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/disliked/<int:mid>', methods=['GET'])\ndef getMessageDislikes(mid):\n if request.method == 'GET':\n return BaseDislikes().getAllDislikesId(d_mid=mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\[email protected]('/PichonAzul/dislike/remove/<int:mid>', methods=['POST'])\ndef undislikeMessage(mid):\n if request.method == 'POST':\n return BaseDislikes().undislikeMessage(request.json, d_mid=mid)\n else:\n return jsonify(\"Method Not Allowed\"), 405\n\nif __name__ == '__main__':\n app.run()"
},
{
"alpha_fraction": 0.5624263882637024,
"alphanum_fraction": 0.5753828287124634,
"avg_line_length": 31.056604385375977,
"blob_id": "1d97e8c7bd86d530a7c75e819956a524470af329",
"content_id": "0f0c8bb26925046a98fba11494b91afb200b1164",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1698,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 53,
"path": "/controller/follows.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from re import error\nfrom flask import jsonify\nfrom model.follows import FollowsDAO\n\nclass BaseFollows:\n def build_map_dict(self, row):\n result = {}\n result['fid'] = row[0]\n result['uid'] = row[1]\n result['followed_user'] = row[2]\n return result\n\n def build_follow_attr_dict(self, fid):\n result = {}\n result['fid'] = fid\n return result\n\n def getFollowedById(self, r_uid):\n dao = FollowsDAO()\n followed_list = dao.getFollowedById(r_uid)\n result_list = []\n for row in followed_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n def getAllUsersFollowingId(self, f_uid):\n dao = FollowsDAO()\n followed_list = dao.getAllUsersFollowingId(f_uid)\n result_list = []\n for row in followed_list:\n obj = self.build_map_dict(row)\n result_list.append(obj)\n return jsonify(result_list), 200\n\n def followUser(self, json, f_uid):\n r_uid = json['RegisteredUser']\n dao = FollowsDAO()\n fid = dao.followUser(r_uid, f_uid)\n if(fid == 0):\n return \"You can't follow them, because you are blocked.\", 401\n else:\n if(r_uid == f_uid):\n return jsonify(\"Users cannot follow themselves.\"), 400\n result = self.build_follow_attr_dict(fid)\n return jsonify(result), 201\n\n def unfollowUser(self, json, f_uid):\n r_uid = json['RegisteredUser']\n dao = FollowsDAO()\n fid = dao.unfollowUser(r_uid, f_uid)\n result = self.build_follow_attr_dict(fid)\n return jsonify(result), 201"
},
{
"alpha_fraction": 0.4526558816432953,
"alphanum_fraction": 0.570438802242279,
"avg_line_length": 16.31999969482422,
"blob_id": "565e0ebcb18fd7bced5b882efda441e853f93004",
"content_id": "90470c82e4d9bcf7a6b1f6a5be811f2050fb7b5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 433,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 25,
"path": "/Pipfile",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nbcrypt= \"==3.2.0\"\ncffi= \"==1.14.5\"\nclick = \"==7.1.2\"\ngunicorn = \"==20.1.0\"\nitsdangerous = \"==1.1.0\"\npsycopg2-binary = \"==2.8.6\"\npycparser= \"==2.20\"\nsix = \"==1.15.0\"\nFlask = \"==1.1.2\"\nFlask-Bcrypt= \"==0.7.1\"\nFlask-Cors = \"==3.0.10\"\nJinja2 = \"==2.11.3\"\nMarkupSafe = \"==1.1.1\"\nWerkzeug = \"==1.0.1\"\n\n[dev-packages]\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.5607143044471741,
"alphanum_fraction": 0.5642856955528259,
"avg_line_length": 39.745452880859375,
"blob_id": "7f1ad428f079c27887c14bfedbec2653f3e5e030",
"content_id": "1dde7118dd2b643ea4b8e3a8adfda43ef27ce70b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2240,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 55,
"path": "/model/dislikes.py",
"repo_name": "CIIC4060-ICOM5016-Spring-2020/microblogging-project-pichonazul",
"src_encoding": "UTF-8",
"text": "from config.config import DATABASE\nimport psycopg2\n\nclass DislikesDAO:\n def __init__(self):\n connection_url = \"dbname=%s user=%s password=%s port=%s host=%s\" %(DATABASE['dbname'], DATABASE['user'],\n DATABASE['password'], DATABASE['dbport'], DATABASE['host'])\n print(\"connection url: \", connection_url)\n self.conn = psycopg2.connect(connection_url)\n\n def getDislikedById(self, d_mid):\n cursor = self.conn.cursor()\n query = \"select did, mid, uid from \\\"Dislikes\\\" where mid = %s and isDisliked=true;\"\n cursor.execute(query, (d_mid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def getAllDislikesId(self, d_mid):\n cursor = self.conn.cursor()\n query = \"select did, mid, uid from \\\"Dislikes\\\" where mid = %s and isDisliked=true;\"\n cursor.execute(query, (d_mid,))\n result = []\n for row in cursor:\n result.append(row)\n return result\n\n def dislikeMessage(self, d_mid, r_uid):\n cursor = self.conn.cursor()\n cursorCheck = self.conn.cursor()\n\n query = \"Select did from \\\"Dislikes\\\" where mid = %s and uid= %s;\"\n queryCheck= \"update \\\"Likes\\\" set isLiked = false where (mid = %s and uid = %s);\"\n cursor.execute(query, (d_mid, r_uid))\n did = cursor.fetchone()\n if(did):\n query1 = \"update \\\"Dislikes\\\" set isDisliked = true where did = %s;\"\n cursor.execute(query1, (did,))\n cursorCheck.execute(queryCheck, (d_mid, r_uid))\n else:\n query2 = \"Insert into \\\"Dislikes\\\" (mid, uid) values (%s,%s) returning did;\"\n cursor.execute(query2, (d_mid, r_uid))\n cursorCheck.execute(queryCheck, (d_mid, r_uid))\n did = cursor.fetchone()[0]\n self.conn.commit()\n return did\n\n def undislikeMessage(self, d_mid, r_uid):\n cursor = self.conn.cursor()\n query = \"update \\\"Dislikes\\\" set isDisliked = false where mid = %s and uid= %s returning did;\"\n cursor.execute(query, (d_mid, r_uid))\n result = cursor.fetchone()[0]\n self.conn.commit()\n return result"
}
] | 17 |
boyali/pytorch-mixture_of_density_networks
|
https://github.com/boyali/pytorch-mixture_of_density_networks
|
ed57c5a34ed1ee98158a6609c1c874bc73cc7136
|
87f80dae19b421aa127062eacbabe8fc97cfd772
|
6617ae720c8f5553192563551718f88bda67534f
|
refs/heads/master
| 2021-03-12T12:05:58.827745 | 2020-03-11T16:21:10 | 2020-03-11T16:21:10 | 246,619,046 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6702898740768433,
"alphanum_fraction": 0.6811594367027283,
"avg_line_length": 22.04166603088379,
"blob_id": "22238e0056bb9000cf3de47e630a3f98f3b292e9",
"content_id": "5db6f79c0260e191c6d02055a3393f6b3bc485a4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 552,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 24,
"path": "/a01_run_mdn.py",
"repo_name": "boyali/pytorch-mixture_of_density_networks",
"src_encoding": "UTF-8",
"text": "import torch.nn as nn\nimport torch.optim as optim\nimport mdn\n\n# initialize the model\nmodel = nn.Sequential(\n nn.Linear(5, 6),\n nn.Tanh(),\n mdn.MDN(6, 7, 20)\n)\noptimizer = optim.Adam(model.parameters())\n\n# train the model\nfor minibatch, labels in train_set:\n model.zero_grad()\n pi, sigma, mu = model(minibatch)\n loss = mdn.mdn_loss(pi, sigma, mu, labels)\n loss.backward()\n optimizer.step()\n\n# sample new points from the trained model\nminibatch = next(test_set)\npi, sigma, mu = model(minibatch)\nsamples = mdn.sample(pi, sigma, mu)"
}
] | 1 |
bkhvezda/titanic
|
https://github.com/bkhvezda/titanic
|
bb3b8fe1d3d030138e71f9796ada3287c19d9592
|
11c718c04f9dd4ae13502fbd95b4d03f980eea2e
|
e208d9d346d6d6f4cf3065d99109508609132552
|
refs/heads/master
| 2020-03-31T02:58:50.499496 | 2019-11-08T12:32:50 | 2019-11-08T12:32:50 | 151,847,155 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6647619009017944,
"alphanum_fraction": 0.6952381134033203,
"avg_line_length": 14.028571128845215,
"blob_id": "091d99fde5700f61405bf2c560e43770c3247ac8",
"content_id": "7d01d07ac9342f7e1e5bc8f0ec7d5046eaac9f89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 525,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 35,
"path": "/titanic.py",
"repo_name": "bkhvezda/titanic",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Oct 21 09:16:09 2018\n\n@author: bkhve\n\"\"\"\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\n\ntest = pd.read_csv(\"test.csv\")\ntrain = pd.read_csv(\"train.csv\")\n\nplt.plot(test)\n\n\ntest.sort_values('Name')\ntest.sort_index()\n\nlen(test)\n\ntest.index\n\ntest.rename(columns = {'PassengerId':'passenger_id', 'Pclass':'passenger_class'})\n\ntest.columns\n\n\ntest2 = test.rename(columns = {'PassengerId':'passenger_id', 'Pclass':'passenger_class'})\ntest2.columns\n\ntest2.describe"
},
{
"alpha_fraction": 0.7890625,
"alphanum_fraction": 0.7890625,
"avg_line_length": 24.600000381469727,
"blob_id": "d94823055db1dc3767e96d7c70c2ec27ac040fa4",
"content_id": "1b1e73ea373d58d15d402a4fa85008ec91f74269",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 5,
"path": "/README.md",
"repo_name": "bkhvezda/titanic",
"src_encoding": "UTF-8",
"text": "# Titanic\nBeginner data science project\n\n## Code in this repository\nThis is where I will put some code links in this repository\n"
}
] | 2 |
kun-qian/proj_wall
|
https://github.com/kun-qian/proj_wall
|
80838d5f217cccc06831db879863fc888f756c96
|
2723d3b1e6193a559743fa704eb449d427858043
|
9340a34b3374baf269db4fb7c0326ebdea30b966
|
refs/heads/master
| 2018-11-26T08:37:20.209729 | 2018-09-05T02:39:53 | 2018-09-05T02:39:53 | 138,559,506 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48827293515205383,
"alphanum_fraction": 0.7078891396522522,
"avg_line_length": 16.370370864868164,
"blob_id": "7e3e3afd4f2a65bb24c4a499df7b8ca8317341b5",
"content_id": "bc3fcd4c505c8f33d457eb429762ec16b56e7dc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 27,
"path": "/requirements.txt",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "asn1crypto==0.24.0\nattrs==18.1.0\nautobahn==18.6.1\nAutomat==0.7.0\ncertifi==2018.4.16\ncffi==1.11.5\nchardet==3.0.4\nconstantly==15.1.0\ncryptography==2.2.2\nDjango==2.0.6\nhyperlink==18.0.0\nidna==2.7\nincremental==17.5.0\npyasn1==0.4.3\npyasn1-modules==0.2.1\npycparser==2.18\npyOpenSSL==18.0.0\npython-dateutil==2.7.3\npytz==2018.4\nrequests==2.19.1\nservice-identity==17.0.0\nsix==1.11.0\nTwisted==18.4.0\ntxaio==2.10.0\nurllib3==1.23\nwatson-developer-cloud==1.4.0\nzope.interface==4.5.0\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 12.333333015441895,
"blob_id": "2c558b9f0f48cde9997606d4da41fb60f9cc05d4",
"content_id": "0abc712b89670b2ab81bed081c993257452dc744",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 6,
"path": "/chat/utils/status.py",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "from enum import Enum, unique\n\n\n@unique\nclass Status(Enum):\n SLEEP = 'sleep'\n"
},
{
"alpha_fraction": 0.5398860573768616,
"alphanum_fraction": 0.6139600872993469,
"avg_line_length": 27.079999923706055,
"blob_id": "bef996642ff85fe4b8df177435a64cc3ea7760b5",
"content_id": "27a6b975ef80aaa3d8491ebc475ef4e7dabece92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 702,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 25,
"path": "/chat/utils/watson_utils.py",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# -*- coding: utf-8 -*-\nfrom watson_developer_cloud import ConversationV1\nimport requests\n\n\nclass ChatUtil(object):\n\n @staticmethod\n def chat(text):\n conversation = ConversationV1(\n username='cf0adfa1-407b-4cc5-842d-f84800ec5524',\n password='0nAR6CWe2kXL',\n version='2018-02-16')\n workspace_id = '3f5a650d-3d37-44f0-8f4f-b2a7f42992c4'\n try:\n response = conversation.message(\n workspace_id=workspace_id, input={'text': text})\n except requests.RequestException:\n raise\n return response\n\n\nif __name__ == '__main__':\n print(ChatUtil.chat(\"I want to see IOT interaction\"))\n"
},
{
"alpha_fraction": 0.6837209463119507,
"alphanum_fraction": 0.7178294658660889,
"avg_line_length": 57.6363639831543,
"blob_id": "60bdffe8b5f972f1c9e899ce6919187ae00f2420",
"content_id": "c74b8ae96b9e47011d888a1d4ecf52a1e3c089dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 645,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 11,
"path": "/README.md",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "# Project wall \n\n## How to build a Docker image\n1. enter into the root directory by terminal.\n2. If you want to deploy the app in a x86 machine, go to Step 3 directly. If you would use ARM machine, open Dockerfile and comment 1st line, uncomment second line!!\n3. Create `config.py` in the root directory. And add `command_server_url = \"http://[ip]:[port]\"\n` in the `config.py`. \n4. execute `docker build -t proj_wall:v0 .` to build the image.\n5. `docker image ls` you should see the `proj_wall:v0` image.\n6. `docker run -d -p 8000:8000 proj_wall:v0` you then run the container.\n7. 'docker logs [container_id]' check the server log if you want.\n"
},
{
"alpha_fraction": 0.5290931463241577,
"alphanum_fraction": 0.5367814302444458,
"avg_line_length": 36.40522766113281,
"blob_id": "374bc07abb12ca89623a709886545b60d34cef44",
"content_id": "527877e5126306da1baf7573f73dbaf3d0335137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5723,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 153,
"path": "/chat/views.py",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.http import JsonResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.decorators.http import require_POST\nfrom .utils.watson_utils import ChatUtil\nfrom chat.utils.status import Status\nimport config\nimport logging\nimport json\nimport os\nimport requests\n\nlogging.basicConfig(level=logging.INFO)\n\nCOMMAND_SERVER_URL = config.command_server_url or os.environ.get(\"command_server_url\") or \"http://192.168.50.230:8080\"\nlogging.info(\"The command server url is: \".format(COMMAND_SERVER_URL))\n\n\n@require_POST\n@csrf_exempt\ndef process_text(request):\n if request.method == 'POST':\n # parse the receiving params\n params = request.POST\n text = params.get('text')\n person_id = params.get('person_id')\n person_name = params.get('person_name')\n logging.info(\n \"The params received: \\ntext: {text}\\nperson_id: {person_id}\\nperson_name: {person_name}\".\n format(text=text, person_id=person_id, person_name=person_name))\n\n # get intent and entity by IBM watson api\n try:\n response = ChatUtil.chat(text)\n except requests.RequestException:\n logging.info(\"Some exception occurred in the watson \")\n res = {\n \"status\": \"KO\",\n \"status_code\": 401,\n \"result\": \"watson parse error\"\n }\n return JsonResponse(res)\n logging.info(\"the raw response of watson is: {}\".format(json.dumps(response, indent=4)))\n\n # find the most possible intent and entity\n possible_intents = response['intents']\n intent_most_possible = None\n biggest_confidence_of_intent = 0\n for item in possible_intents:\n if item['confidence'] > biggest_confidence_of_intent:\n biggest_confidence_of_intent = item['confidence']\n intent_most_possible = item['intent']\n entity = None\n entity_confidence = 0\n if len(response['entities']) > 0:\n entity = response['entities'][0]['value']\n entity_confidence = response['entities'][0]['confidence']\n entity = entity or config.project_name\n if entity is None:\n res = {\n \"status\": \"KO\",\n \"status_code\": 402,\n \"result\": \"Please provide project name\"\n }\n return JsonResponse(res)\n # if entity is not None, remember current project name\n config.project_name = entity\n # send the intent and entity to command server to execute\n command_url = COMMAND_SERVER_URL\n payload = {\n \"action\": intent_most_possible,\n \"person_id\": person_id,\n \"project_name\": entity\n }\n try:\n r = requests.post(url=command_url, data=json.dumps(payload),\n headers={\"Content-Type\": \"application/x-www-form-urlencoded\"},\n timeout=3)\n except requests.RequestException:\n res = {\n \"status\": \"OK\",\n \"status_Code\": 200,\n \"result\": {\n 'person_id': person_id,\n 'person_name': person_name,\n 'intent': intent_most_possible,\n 'intent_confidence': biggest_confidence_of_intent,\n 'entity': entity,\n 'entity_confidence': entity_confidence,\n 'command_status': \"KO\",\n 'command_result': \"sending command error\"\n }\n }\n return JsonResponse(res)\n\n command_response = r.json()\n logging.info(\"the response from command server: {}\".format(r.text))\n res = {\n \"status\": \"OK\",\n \"status_code\": 200,\n \"result\": {\n 'person_id': person_id,\n 'person_name': person_name,\n 'intent': intent_most_possible,\n 'intent_confidence': biggest_confidence_of_intent,\n 'entity': entity,\n 'entity_confidence': entity_confidence,\n 'command_status': command_response[\"status\"],\n 'command_result': command_response[\"result\"]\n }}\n return JsonResponse(res)\n\n\n@csrf_exempt\ndef handle_status(request):\n if request.method == 'POST':\n params = request.POST\n status = params.get('status')\n if status == Status.SLEEP.value:\n config.project_name = None\n\n res = {\n \"status\": \"OK\",\n \"status_code\": 200,\n \"result\": status + \" status has been set.\"\n }\n command_url = COMMAND_SERVER_URL\n payload = {\n \"action\": status,\n \"person_id\": '',\n \"project_name\": ''\n }\n try:\n r = requests.post(url=command_url, data=json.dumps(payload),\n headers={\"Content-Type\": \"application/x-www-form-urlencoded\"},\n timeout=3)\n except requests.RequestException:\n logging.info(\"Exception occurred when sending action '{}' to command server.\".format(status))\n return JsonResponse(res)\n res = {\n \"status\": \"OK\",\n \"status_code\": 403,\n \"result\": \"please provide a legal status value\"\n }\n return JsonResponse(res)\n\n if request.method == 'GET':\n res = {\n \"status\": \"OK\",\n \"status_code\": 200,\n \"result\": \"The status is: {}\".format(config.project_name)\n }\n return JsonResponse(res)\n"
},
{
"alpha_fraction": 0.6123188138008118,
"alphanum_fraction": 0.7137681245803833,
"avg_line_length": 18.714284896850586,
"blob_id": "f2c15b74bf793d2da3f64c2f022d7f2eee94376b",
"content_id": "935911b0c0707eb590928eace02f6f1613c65b81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 14,
"path": "/Dockerfile",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "FROM python:3.6\n# FROM resin/raspberry-pi-alpine-python:3.6\n\nWORKDIR /proj_wall\n\nCOPY . .\n\nENV command_server_url=\"http://192.168.50.230:8080\"\n\nRUN pip install --trusted-host pypi.python.org -r requirements.txt\n\nEXPOSE 8000\n\nCMD [\"python\", \"manage.py\", \"runserver\", \"0:8000\"]\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6747967600822449,
"avg_line_length": 23.600000381469727,
"blob_id": "408f06b0c7e165ecd3686f60b556d43f11cc1023",
"content_id": "891ebba1c5a9b359bdd0634d50289e492d61e27d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 246,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 10,
"path": "/chat/urls.py",
"repo_name": "kun-qian/proj_wall",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom django.urls import path\nfrom . import views\n\nurlpatterns = [\n path('conversation/', views.process_text, name='process_text'),\n path('status/', views.handle_status, name='handle_status')\n]\n"
}
] | 7 |
linneaross/twitterFreq
|
https://github.com/linneaross/twitterFreq
|
c8d8cc7bf9b9fe9d490100a9235800e307cdf343
|
1b9a570f3305d50c995465920b9030396ee1ab8a
|
762495aa3eddd21613712b82cc2bd26c87db1d76
|
refs/heads/master
| 2020-04-26T07:13:34.165278 | 2019-03-02T01:11:38 | 2019-03-02T01:11:38 | 173,388,197 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8354430198669434,
"alphanum_fraction": 0.8354430198669434,
"avg_line_length": 38.5,
"blob_id": "4df9ccc8e34121fa41982e26e1c47fd43a2ee74b",
"content_id": "14bf2160afd1531c4f5fd4142807f81e8400f1a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 2,
"path": "/README.md",
"repo_name": "linneaross/twitterFreq",
"src_encoding": "UTF-8",
"text": "# twitterFreq\nCalculate word frequency values from a library of scraped tweets\n"
},
{
"alpha_fraction": 0.6187198758125305,
"alphanum_fraction": 0.6393668055534363,
"avg_line_length": 23.420167922973633,
"blob_id": "34df43fbb12e37437616c120553fb788172bb019",
"content_id": "af6846235dfa93ba49eb1473024865f843604728",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2906,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 119,
"path": "/twitterFrequency.py",
"repo_name": "linneaross/twitterFreq",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nimport sys\nimport re\nfrom collections import defaultdict\nimport random\nimport math\n\n## EXTRA CREDIT ##\ndef rand(hist):\n\trnum = random.uniform(0,1)\n\tfor x in hist:\n\t\trnum -= hist[x]\n\t\tif rnum < 0: return x\n\treturn x\n\n## PART 1 ##\ndef clean(line):\n\tline = line.decode('utf8')\n\tline = re.sub(u'(https://t.co/)(\\w+)', 'www', line)\n\t\t#urls\n\tline = re.sub(u'[!$%^&*()-+=,.?:;(\\u2026)(\\u0022)(\\u201C)(\\u201D)]', '', line)\n\t\t#punctuation\n\tline = re.sub(u'(@)(\\w+)', '@@@', line)\n\t\t#usernames\n\tline = re.sub(u'(#)(\\w+)', '###', line)\n\t\t#hashtags\n\tline = re.sub(u'((^\\s+)|(\\s+\\Z))', '', line)\n\t\t#leading and trailing whitespace\n\tline = line.lower()\n\t\t#set it all to lowercase\n\treturn line\n\n## PART 2 ##\ndef normalize(hist):\n\tsum = 0.0\n\tfor key in hist:\n\t\tsum = sum + hist[key]\n\tfor item in hist:\n\t\thist[item] = hist[item]/sum\n\ndef get_freqs(f):\n\twordfreqs = defaultdict(lambda: 0)\n\tlenfreqs = defaultdict(lambda: 0)\n\n\tfor line in f.readlines():\n\t\t#print line\n\t\tline = clean(line)\n\t\twords = re.split(u'\\s+|\\s+[-]+\\s+', line)\n\t\t#print line\n\t\t#print '============='\n\t\tlenfreqs[len(words)]+=1\n\t\tfor word in words:\n\t\t\twordfreqs[word.encode('utf8')]+=1\n\n\tnormalize(wordfreqs)\n\tnormalize(lenfreqs)\n\treturn (wordfreqs,lenfreqs)\n\n## PART 3 ##\ndef save_histogram(hist,filename):\n\toutfilename = re.sub(\"\\.txt$\",\"_out.txt\",filename)\n\toutfile = open(outfilename,'w')\n\tprint \"Printing Histogram for\", filename, \"to\", outfilename\n\trank = 0\n\tfor word, count in sorted(hist.items(), key = lambda pair: pair[1], reverse = True):\n\t\trank = rank+1\n\t\tlog1 = math.log(count)\n\t\tlog2 = math.log(rank)\n\t\toutput = \"%-13.6f\\t%s\\t%f\\t%f\\n\" % (count,word,log1,log2)\n\t\toutfile.write(output)\n\n## PART 4 ##\ndef get_top(hist,N):\n\tresult = []\n\tticker = 0\n\trank = 0\n\tfor word, count in sorted(hist.items(), key = lambda pair: pair[1], reverse = True):\n\t\tif (ticker==N):\n\t\t\tbreak\n\t\trank = rank+1\n\t\tlog1 = math.log(count)\n\t\tlog2 = math.log(rank)\n\t\tresult.append(word)\n\t\tticker = ticker +1\n\t# return a list of the N most frequent words in hist\n\treturn result\n\ndef filter(hist,stop):\n\tfor word in stop:\n\t\tif word in hist: hist.pop(word)\n\tnormalize(hist)\n\ndef main():\n\tfile1 = open(sys.argv[1])\n\t(wordf1, lenf1) = get_freqs(file1)\n\tstopwords = get_top(wordf1, 100)\n\tsave_histogram(wordf1,sys.argv[1])\n\n\tfor fn in sys.argv[2:]:\n\t\tfile = open(fn)\n\t\t(wordfreqs, lenfreqs) = get_freqs(file)\n\t\tfilter(wordfreqs, stopwords)\n\t\tsave_histogram(wordfreqs,fn)\n\n\t\t## EXTRA CREDIT ##\n\t\tprint \"Printing random tweets from\",fn\n\t\tfor x in range(5):\n\t\t\tn = rand(lenfreqs)\n\t\t\tprint n, \"random words:\"\n\t\t\tfor i in range(n):\n\t\t\t\tprint ' ',rand(wordfreqs),\n\t\t\tprint\n\n## This is special syntax that tells python what to do (call main(), in this case) if this script is called directly\n## this gives us the flexibility so that we could also import this python code in another script and use the functions\n## we defined here\nif __name__ == \"__main__\":\n main()\n"
}
] | 2 |
leethomason/saberCNC
|
https://github.com/leethomason/saberCNC
|
4193c422b6610947175dbb6187910a76de98ad58
|
f59d429e5abcd97f773a5992ec3bc1bdc5ad5ded
|
893137e711d8eb2cdd0da25c261cde52f74da311
|
refs/heads/master
| 2023-06-06T23:02:15.857002 | 2023-04-21T22:38:33 | 2023-04-21T22:38:33 | 100,075,563 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4858796298503876,
"alphanum_fraction": 0.49444442987442017,
"avg_line_length": 27.05194854736328,
"blob_id": "3ac167b61d36895d1ccb1d21c949e57353191425",
"content_id": "4eca281d50208a9fba7ad4a5fd2bb5651cf11701",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4320,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 154,
"path": "/hill.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "from mecode import G\nfrom material import init_material\nfrom utility import CNC_TRAVEL_Z, GContext, nomad_header, tool_change\nimport argparse\nimport math\nfrom rectangleTool import rectangleTool\nfrom hole import hole\n\ndef z_tool_hill_ball(dx, r_ball, r_hill):\n zhc = math.sqrt(r_hill * r_hill - dx * dx)\n return zhc - r_hill\n\ndef z_tool_hill_flat(dx, ht, r_hill):\n if (dx <= ht): \n return 0.0\n\n zhc = math.sqrt(r_hill * r_hill - math.pow((dx - ht), 2.0))\n return zhc - r_hill\n\ndef hill(g, mat, diameter, dx, dy):\n r_hill = diameter / 2\n ht = mat['tool_size'] * 0.5\n hy = dy / 2\n doc = mat['pass_depth'] \n step = 0.5\n\n def rough_arc(bias):\n y = 0\n end = hy + ht\n last_plane = 0\n last_y = 0\n step = ht / 4\n\n g.move(x=dx)\n g.move(x=-dx/2)\n\n while y < end:\n do_plane = False\n\n y += step\n if y >= end:\n do_plane = True\n y = end\n if last_plane - height_func(y + step, ht, r_hill) >= doc:\n do_plane = True\n \n if do_plane:\n # move to the beginning of the plane\n g.move(y = bias * (y - last_y))\n\n # cut the plane\n z = height_func(y, ht, r_hill)\n dz = z - last_plane\n g.comment(\"Cutting plane. y={} z={} dx={} dy={} dz={}\".format(y, z, dx, end - y, dz))\n rectangleTool(g, mat, dz, dx, end - y, 0.0, \"bottom\" if bias > 0 else \"top\", \"center\", True)\n\n # move to the bottom of the plane we just cut\n g.move(z=dz)\n g.comment(\"Cutting plane done.\")\n\n last_y = y\n last_plane += dz\n \n g.move(-dx/2) \n g.abs_move(z=origin_z)\n g.move(y=-end*bias)\n\n def arc(bias, step):\n y = 0\n low_x = True\n end = hy + ht\n\n while y < end:\n if y + step > end:\n g.move(y = (end - y) * bias)\n y = end\n else:\n y += step\n g.move(y = step * bias)\n\n dz = height_func(y, ht, r_hill)\n g.feed(mat['plunge_rate'])\n g.abs_move(z=origin_z + dz)\n g.feed(mat['feed_rate'])\n\n if low_x is True:\n g.move(x=dx)\n low_x = False\n else:\n g.move(x=-dx)\n low_x = True\n\n if low_x is False:\n g.move(x = -dx)\n g.abs_move(z=origin_z)\n g.move(y=-end*bias)\n\n with GContext(g):\n g.comment('hill')\n g.relative()\n mult = 0.2\n\n # rough pass\n origin_z = g.current_position['z']\n\n g.spindle()\n g.dwell(0.5)\n g.spindle('CW', mat['spindle_speed'])\n rough_arc(1)\n\n g.spindle()\n g.dwell(0.5)\n g.spindle('CCW', mat['spindle_speed'])\n rough_arc(-1)\n\n # smooth pass\n g.spindle()\n\n g.spindle()\n g.dwell(0.5)\n g.spindle('CW', mat['spindle_speed'])\n \n arc(1, mult*ht)\n \n g.spindle()\n g.dwell(0.5)\n g.spindle('CCW', mat['spindle_speed'])\n \n arc(-1, mult*ht) \n \n g.spindle()\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut out a cylinder or valley. Very carefully accounts for tool geometry.')\n parser.add_argument('material', help='the material to cut (wood, aluminum, etc.)')\n parser.add_argument('diameter', help='diameter of the cylinder.', type=float)\n parser.add_argument('dx', help='dx of the cut, flat over the x direction', type=float)\n parser.add_argument('dy', help='dy of the cut, curves over the y direction', type=float)\n parser.add_argument('-o', '--overlap', help='overlap between each cut', type=float, default=0.5)\n parser.add_argument('-b', '--ball', help=\"use ball cutter\", action=\"store_true\")\n\n args = parser.parse_args()\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n mat = init_material(args.material)\n \n nomad_header(g, mat, CNC_TRAVEL_Z)\n g.move(z=0)\n hill(g, mat, args.diameter, args.dx, args.dy, args.ball)\n g.spindle()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.46431607007980347,
"alphanum_fraction": 0.4747946858406067,
"avg_line_length": 31.54838752746582,
"blob_id": "f4855d778f87f6fa54a4e9a447f3e2e437d0d602",
"content_id": "07776a2e2feee9a21c2208e6d326da69597c6e53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7062,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 217,
"path": "/rectangleTool.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import argparse\nimport sys\nfrom mecode import G\nfrom material import init_material\nfrom utility import calc_steps, run_3_stages, GContext, CNC_TRAVEL_Z\nfrom rectangle import rectangle\n\n# from lower left. it's an inner cut, with outer dim x,y\ndef overCut(g, mat, cut_depth, _dx, _dy):\n g.feed(mat['travel_feed'])\n g.spindle('CW', mat['spindle_speed'])\n\n with GContext(g):\n g.relative()\n\n tool = mat['tool_size']\n half = tool / 2\n dx = _dx - tool\n dy = _dy - tool\n length = dx * 2 + dy * 2\n\n g.move(z=1)\n g.move(x=half, y=half)\n g.move(z=-1)\n\n def path(g, plunge, total_plunge):\n g.move(x=dx, z=plunge * dx / length)\n g.move(x=half)\n g.move(x=-half, y=-half)\n g.move(y=half)\n\n g.move(y=dy, z=plunge * dy / length)\n g.move(y=half)\n g.move(x=half, y=-half)\n g.move(x=-half)\n\n g.move(x=-dx, z=plunge * dx / length)\n g.move(x=-half)\n g.move(x=half, y=half)\n g.move(y=-half)\n\n g.move(y=-dy, z=plunge * dy / length)\n g.move(y=-half)\n g.move(x=-half, y=half)\n g.move(x=half)\n\n steps = calc_steps(cut_depth, -mat['pass_depth'])\n run_3_stages(path, g, steps)\n\n g.move(z=-cut_depth)\n g.move(z=1)\n g.move(x=-half, y=-half)\n g.move(z=-1)\n\n\ndef rectangleTool(g, mat, cut_depth, dx, dy, fillet, origin, align, fill=False, adjust_trim=False):\n\n if cut_depth >= 0:\n raise RuntimeError('Cut depth must be less than zero.')\n\n with GContext(g):\n g.relative()\n\n g.feed(mat['travel_feed'])\n g.spindle('CW', mat['spindle_speed'])\n\n tool_size = mat['tool_size']\n half_tool = tool_size / 2\n x = 0\n y = 0\n x_sign = 0\n y_sign = 0\n rect_origin = origin\n\n if origin == \"left\":\n x_sign = 1\n elif origin == \"bottom\":\n y_sign = 1\n elif origin == \"right\":\n x_sign = -1\n elif origin == \"top\":\n y_sign = -1\n elif origin == \"center\":\n x_sign = 1\n rect_origin = \"left\"\n else:\n raise RuntimeError(\"unrecognized origin\")\n\n if origin == \"center\":\n g.move(x=-dx/2)\n\n if align == 'inner':\n x = half_tool * x_sign\n y = half_tool * y_sign\n dx -= tool_size\n dy -= tool_size\n if adjust_trim:\n fillet -= half_tool\n if fillet < 0:\n fillet = 0\n elif align == 'outer':\n x = -half_tool * x_sign\n y = -half_tool * y_sign\n dx += tool_size\n dy += tool_size\n if adjust_trim:\n if fillet > 0:\n fillet += half_tool\n elif align == \"center\":\n pass\n else:\n raise RuntimeError(\"unrecognized align\")\n\n if dx == 0 and dy == 0:\n raise RuntimeError('dx and dy may not both be zero')\n if dx < 0 or dy < 0:\n raise RuntimeError('dx and dy must be positive')\n\n if abs(x) or abs(y):\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=x, y=y)\n g.move(z=-CNC_TRAVEL_Z)\n\n if fill == False or dx == 0 or dy == 0:\n rectangle(g, mat, cut_depth, dx, dy, fillet, rect_origin)\n\n else:\n z_depth = 0\n z_step = mat['pass_depth']\n single_pass = True\n\n # the outer loop walks downward.\n while z_depth > cut_depth:\n this_cut = 0\n\n if z_depth - z_step <= cut_depth:\n this_cut = cut_depth - z_depth\n single_pass = False\n z_depth = cut_depth\n else:\n this_cut = -z_step\n z_depth -= z_step\n\n dx0 = dx\n dy0 = dy\n fillet0 = fillet\n step = tool_size * 0.7\n\n first = True\n total_step = 0\n\n #print(\"dx={} dy={}\".format(dx, dy))\n\n # the inner loop walks inward.\n # note that the cut hasn't happened at the top of the loop;\n # so only abort when they cross\n while dx0 > 0 and dy0 > 0: \n #print(\" dx={} dy={} step={}\".format(dx0, dy0, step)); \n if first:\n first = False\n rectangle(g, mat, this_cut, dx0, dy0, fillet0, rect_origin, single_pass=single_pass, restore_z=False)\n\n else:\n g.move(x=step * x_sign, y=step * y_sign)\n total_step += step\n rectangle(g, mat, 0.0, dx0, dy0, fillet0, rect_origin, single_pass=True) \n\n # subtle the last cut doesn't overlap itself.\n # probably a better algorithm for this\n if dx0 - step * 2 < 0 or dy0 - step * 2 < 0:\n dx0 -= step\n dy0 -= step\n else:\n dx0 -= step * 2\n dy0 -= step * 2\n\n fillet0 -= step\n if fillet0 < 0:\n fillet0 = 0\n\n g.move(x=-total_step * x_sign, y=-total_step * y_sign)\n # don't need to move down; z is not restored g.move(z=this_cut)\n g.move(z=-cut_depth)\n\n if abs(x) or abs(y):\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=-x, y=-y)\n if origin == \"center\":\n g.move(x=dx/2)\n g.move(z=-CNC_TRAVEL_Z)\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut a rectangle accounting for tool size.')\n parser.add_argument('material', help='the material to cut (wood, aluminum, etc.)')\n parser.add_argument('depth', help='depth of the cut. must be negative.', type=float)\n parser.add_argument('dx', help='x width of the cut.', type=float)\n parser.add_argument('dy', help='y width of the cut.', type=float)\n parser.add_argument('-f', '--fillet', help='fillet radius', type=float, default=0)\n parser.add_argument('-a', '--align', help=\"'center', 'inner', 'outer'\", type=str, default='center')\n parser.add_argument('-i', '--inside_fill', help=\"fill inside area\", action='store_true')\n parser.add_argument('-o', '--origin', help=\"origin, can be 'left', 'bottom', 'right', or 'top'\", type=str, default=\"left\")\n\n args = parser.parse_args()\n mat = init_material(args.material)\n\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n g.feed(mat['feed_rate'])\n g.absolute()\n g.move(x=0, y=0, z=0)\n g.relative()\n rectangleTool(g, mat, args.depth, args.dx, args.dy, args.fillet, args.origin, args.align, args.inside_fill)\n g.spindle()\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.6048485040664673,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 18.20930290222168,
"blob_id": "3c66ac57562828d60f69e314e5f73d2b355e124f",
"content_id": "3b2ef570d0bf04ae874925012feef5fd43483c18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 43,
"path": "/sisters.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "# The cut for the \"Sisters\" saber-staff (2nd version).\n\nfrom hole import hole\nfrom material import init_material\nfrom rectangle import rectangle\nfrom utility import CNC_TRAVEL_Z\nfrom mecode import G\n\n# start at transition line\nTOOLSIZE = 3.175\n\nY0 = 27.5\nD0 = 16.0\n\nY1 = 7.5\nD1 = 11.0\n\nW = 15\nH = 8.5\nY2 = -8.4 - H\n\nmat = init_material(\"np883-aluminum-3.175\")\nHALFTOOL = TOOLSIZE / 2\n\ng = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\ng.absolute()\n\ng.feed(mat['travel_feed'])\ng.move(z=CNC_TRAVEL_Z)\n\ng.move(y=Y0)\ng.spindle('CW', mat['spindle_speed'])\nhole(g, mat, -10, D0/2)\n\ng.move(y=Y1)\nhole(g, mat, -10, D1/2)\n\ng.move(x=-W/2 + HALFTOOL, y=Y2 + HALFTOOL)\ng.move(z=0)\nrectangle(g, mat, -8, W - TOOLSIZE, H - TOOLSIZE)\ng.move(z=CNC_TRAVEL_Z)\ng.spindle()\ng.move(x=0, y=0)"
},
{
"alpha_fraction": 0.5800981521606445,
"alphanum_fraction": 0.605533242225647,
"avg_line_length": 21.636363983154297,
"blob_id": "46e88ac4137d2f7054187f3e96c17745370a99f8",
"content_id": "6d0746c1e3e6bf8e4f1a702d2233230e45cd6b80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2241,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 99,
"path": "/baffle3.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "from hole import *\nfrom mecode import G\nfrom material import *\n\nFRONT_PLATE = True\nBACK_PLATE = False\n\nmat = init_material(sys.argv[1])\ntool_size = mat['tool_size']\n\nif FRONT_PLATE or BACK_PLATE:\n inner_d = 5 - tool_size\nelse:\n inner_d = 11 - tool_size\n\nouter_d = 32 + tool_size\ncut_depth = -2.0\n\ntheta0 = math.radians(-20) # theta0 -> 1 is the window to the center\ntheta1 = math.radians(20)\ntheta2 = math.radians(165) # theta2 -> 3 is the inset\ntheta3 = math.radians(245)\n\nouter_r = outer_d / 2\ninner_r = inner_d / 2\ninset_r = outer_r - 5\n\nrod_d = 3.5\nrod_x = 0\nrod_y = 11\n\nif FRONT_PLATE:\n channel_d = 4.6\nelse:\n channel_d = 5.8\nchannel_x = -8\nchannel_y = 8\n\ng = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\ng.comment(\"Material: \" + mat['name'])\ng.comment(\"Tool Size: \" + str(mat['tool_size']))\n\n\ndef x_r(theta, r):\n return math.cos(theta) * r\n\n\ndef y_r(theta, r):\n return math.sin(theta) * r\n\n\ndef g_arc(g, theta, r, direction, z=None):\n x = x_r(theta, r)\n y = y_r(theta, r)\n\n i = -g.current_position['x']\n j = -g.current_position['y']\n\n if z is not None:\n g.arc2(x=x, y=y, i=i, j=j, direction=direction, helix_dim='z', helix_len=z)\n else:\n g.arc2(x=x, y=y, i=i, j=j, direction=direction)\n pass\n\n\ndef g_move(g, theta, r, z=None):\n if z is None:\n g.abs_move(x=x_r(theta, r), y=y_r(theta, r))\n else:\n g.abs_move(x=x_r(theta, r), y=y_r(theta, r), z=z)\n\n\ndef path(g, z, dz):\n g_move(g, theta0, inner_r, z + dz / 2)\n g_arc(g, theta1, inner_r, 'CW')\n g_move(g, theta1, outer_r, z + dz)\n g_arc(g, theta2, outer_r, 'CCW')\n g_move(g, theta2, inset_r)\n g_arc(g, theta3, inset_r, 'CCW')\n g_move(g, theta3, outer_r)\n g_arc(g, theta0, outer_r, 'CCW')\n\n\n# rods that hold it together\nhole_abs(g, mat, cut_depth, rod_d / 2, rod_x, rod_y)\nhole_abs(g, mat, cut_depth, rod_d / 2, -rod_x, -rod_y)\n# channel for wires\nhole_abs(g, mat, cut_depth, channel_d / 2, channel_x, channel_y)\n\ng.feed(mat['feed_rate'])\ng.absolute()\n\ng.abs_move(z=CNC_TRAVEL_Z)\ng_move(g, theta0, inner_r)\ng.spindle('CW', mat['spindle_speed'])\ng.abs_move(z=0)\n\nsteps = calc_steps(cut_depth, -mat['pass_depth'])\nrun_3_stages_abs(path, g, steps)\n"
},
{
"alpha_fraction": 0.5406485795974731,
"alphanum_fraction": 0.5487931370735168,
"avg_line_length": 33.45408248901367,
"blob_id": "d8a6874a69cde33435fafa7a788989437575040f",
"content_id": "955abb4f3c0f0011dfd136888a05fb58546af66c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6753,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 196,
"path": "/hole.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "from mecode import G\nfrom material import init_material\nfrom utility import nomad_header, CNC_TRAVEL_Z, GContext, calc_steps, run_3_stages\nfrom drill import drill\nimport argparse\nimport math\n\n\n# Assume we are at (x, y, 0)\n# Accounts for tool size\n# 'r' radius\n# 'd' diameter\n# 'di' inner diameter to reserve (if fill)\n# 'offset' = 'inside', 'outside', 'middle'\n# 'fill' = True\n# 'z' if specified, the z move to issue before cutting\n# 'return_center' = True, returns to center at the end\n#\ndef hole(g, mat, cut_depth, **kwargs):\n radius = 0\n offset = \"inside\"\n fill = True\n di = None\n\n if 'r' in kwargs:\n radius = kwargs['r']\n if 'd' in kwargs:\n radius = kwargs['d'] / 2\n if 'offset' in kwargs:\n offset = kwargs['offset']\n if 'fill' in kwargs:\n fill = kwargs['fill']\n if 'di' in kwargs:\n di = kwargs['di']\n\n tool_size = mat['tool_size']\n half_tool = tool_size / 2\n\n if offset == 'inside':\n radius_inner = radius - half_tool\n elif offset == 'outside':\n radius_inner = radius + half_tool\n elif offset == 'middle':\n radius_inner = radius\n else:\n raise RuntimeError(\"offset not correctly specified\")\n\n if radius_inner < 0.2:\n raise RuntimeError(f\"Radius too small. Consider a drill. Radius={radius} Inner={radius_inner} (must be 0.2 or greater)\")\n if cut_depth >= 0:\n raise RuntimeError('Cut depth must be less than zero.')\n if mat[\"tool_size\"] < 0:\n raise RuntimeError('Tool size must be zero or greater.')\n\n was_relative = g.is_relative\n\n with GContext(g):\n g.relative()\n\n g.comment(\"hole\")\n g.comment(\"depth=\" + str(cut_depth))\n g.comment(\"tool size=\" + str(mat['tool_size']))\n g.comment(\"radius=\" + str(radius))\n g.comment(\"pass depth=\" + str(mat['pass_depth']))\n g.comment(\"feed rate=\" + str(mat['feed_rate']))\n g.comment(\"plunge rate=\" + str(mat['plunge_rate']))\n\n # The trick is to neither exceed the plunge or the depth-of-cut/pass_depth.\n # Approaches below.\n\n feed_rate = mat['feed_rate']\n path_len_mm = 2.0 * math.pi * radius_inner\n path_time_min = path_len_mm / feed_rate\n plunge_from_path = mat['pass_depth'] / path_time_min\n depth_of_cut = mat['pass_depth']\n\n # Both 1) fast little holes and 2) too fast plunge are bad.\n # Therefore, apply corrections to both. (If for some reason\n # alternate approaches need to be reviewed, they are in\n # source control.)\n if plunge_from_path > mat['plunge_rate']:\n factor = mat['plunge_rate'] / plunge_from_path\n if factor < 0.3:\n factor = 0.3 # slowing down to less than 10% (factor * factor) seems excessive\n depth_of_cut = mat['pass_depth'] * factor\n feed_rate = mat['feed_rate'] * factor\n g.comment('adjusted pass depth=' + str(depth_of_cut))\n g.comment('adjusted feed rate =' + str(feed_rate))\n\n g.spindle('CW', mat['spindle_speed'])\n g.feed(mat['travel_plunge'])\n\n g.move(x=radius_inner)\n if 'z' in kwargs:\n if was_relative:\n g.move(z=kwargs['z'])\n else:\n g.abs_move(z=kwargs['z'])\n\n g.feed(feed_rate)\n\n def path(g, plunge, total_plunge):\n g.arc2(x=-radius_inner, y=radius_inner, i=-radius_inner, j=0, direction='CCW', helix_dim='z',\n helix_len=plunge / 4)\n g.arc2(x=-radius_inner, y=-radius_inner, i=0, j=-radius_inner, direction='CCW', helix_dim='z',\n helix_len=plunge / 4)\n g.arc2(x=radius_inner, y=-radius_inner, i=radius_inner, j=0, direction='CCW', helix_dim='z',\n helix_len=plunge / 4)\n g.arc2(x=radius_inner, y=radius_inner, i=0, j=radius_inner, direction='CCW', helix_dim='z',\n helix_len=plunge / 4)\n\n if fill and radius_inner > half_tool:\n r = radius_inner\n dr = 0\n step = tool_size * 0.8\n min_rad = half_tool * 0.8\n if di:\n min_rad = di / 2\n\n while r > min_rad:\n if r - step < min_rad:\n step = r - min_rad\n r -= step\n\n #print(\"r={} step={}\".format(r, step))\n\n dr += step\n g.move(x=-step)\n g.arc2(x=-r, y=r, i=-r, j=0, direction='CCW')\n g.arc2(x=-r, y=-r, i=0, j=-r, direction='CCW')\n g.arc2(x=r, y=-r, i=r, j=0, direction='CCW')\n g.arc2(x=r, y=r, i=0, j=r, direction='CCW')\n g.move(x=dr)\n\n steps = calc_steps(cut_depth, -depth_of_cut)\n run_3_stages(path, g, steps)\n\n g.move(z=-cut_depth) # up to the starting point\n g.feed(mat['travel_plunge']) # go fast again...else. wow. boring.\n\n g.move(z=1.0)\n\n return_center = True\n if 'return_center' in kwargs:\n return_center = kwargs['return_center']\n\n if return_center:\n g.move(x=-radius_inner) # back to center of the circle\n\n\ndef hole_abs(g, mat, cut_depth, radius, x, y):\n with GContext(g):\n g.absolute()\n g.feed(mat['travel_feed'])\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=x, y=y)\n hole(g, mat, cut_depth, r=radius)\n g.absolute()\n\n\n# assume we are at (x, y, CNC_TRAVEL_Z)\ndef hole_or_drill(g, mat, cut_depth, radius):\n if radius == 0:\n return \"mark\"\n elif mat['tool_size'] + 0.1 < radius * 2:\n if g:\n hole(g, mat, cut_depth, r=radius)\n return \"hole\"\n else:\n if g:\n drill(g, mat, cut_depth)\n return \"drill\"\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut a hole at given radius and depth. Implemented with helical arcs,' +\n 'and avoids plunging.')\n parser.add_argument('material', help='The material to cut in standard machine-material-size format.', type=str)\n parser.add_argument('depth', help='Depth of the cut. Must be negative.', type=float)\n parser.add_argument('radius', help='Radius of the hole.', type=float)\n parser.add_argument('offset', help=\"inside, outside, middle\", type=str)\n args = parser.parse_args()\n\n mat = init_material(args.material)\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n\n nomad_header(g, mat, CNC_TRAVEL_Z)\n g.spindle('CW', mat['spindle_speed'])\n g.move(z=0)\n hole(g, mat, args.depth, r=args.radius, offset=args.offset)\n g.spindle()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6659619212150574,
"alphanum_fraction": 0.6913319230079651,
"avg_line_length": 28.5625,
"blob_id": "ed8068704d605506c700f44e47b1ea6f290c067c",
"content_id": "91e239aebdedd64a29806b810a25a9ec02054434",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 16,
"path": "/test.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import sys\nfrom hole import hole\nfrom utility import *\nfrom material import init_material\nfrom mecode import G\n\nmat = init_material(sys.argv[1])\ng = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\nnomad_header(g, mat, CNC_TRAVEL_Z)\n\n# travel(g, mat, x=5, y=5)\n# hole(g, mat, -5, d=5.0, offset=\"outside\", fill=False, z=-CNC_TRAVEL_Z)\n\ng.absolute()\ntravel(g, mat, x=5, y=5)\nhole(g, mat, -5, d=5.0, offset=\"outside\", fill=False, z=0)\n"
},
{
"alpha_fraction": 0.4203222692012787,
"alphanum_fraction": 0.46526867151260376,
"avg_line_length": 30.180288314819336,
"blob_id": "f0a77d497390ee059d479b04094ddcd9e514d24b",
"content_id": "cee7d2dd67e2421784a2b0aba54073708f493df2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12971,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 416,
"path": "/material.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import sys\nimport argparse\nimport pprint\n\npp = pprint.PrettyPrinter()\n\nmaterials = [\n {\n \"id\": \"np883\",\n \"machine\": \"Nomad Pro 883\",\n \"travel_feed\": 2500, \n \"travel_plunge\": 400,\n\n \"materials\": [\n {\"name\": \"acrylic\",\n \"quality\": \"Carbide3D test\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.49,\n \"spindle_speed\": 9000,\n \"feed_rate\": 1100,\n \"plunge_rate\": 355},\n\n {\"name\": \"hdpe\",\n \"quality\": \"Carbide3D test\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.51,\n \"spindle_speed\": 6250,\n \"feed_rate\": 2000,\n \"plunge_rate\": 500},\n \n {\"name\": \"polycarb\",\n \"quality\": \"Carbide3D test\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.33,\n \"spindle_speed\": 9000,\n \"feed_rate\": 1300,\n \"plunge_rate\": 450},\n\n {\"name\": \"pine\",\n \"quality\": \"Verified Carbide3D test\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.76,\n \"spindle_speed\": 4500,\n \"feed_rate\": 2100,\n \"plunge_rate\": 500},\n\n {\"name\": \"pine\",\n \"quality\": \"Test run (success after broken bit)\",\n \"tool_size\": 2.0,\n \"pass_depth\": 0.30,\n \"spindle_speed\": 4500,\n \"feed_rate\": 800,\n \"plunge_rate\": 500},\n\n {\"name\": \"pine\",\n \"quality\": \"Guided guess\",\n \"tool_size\": 1.0,\n \"pass_depth\": 0.20,\n \"spindle_speed\": 4500,\n \"feed_rate\": 400,\n \"plunge_rate\": 300},\n\n {\"name\": \"plywood\",\n \"quality\": \"carbide data tested\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.86,\n \"spindle_speed\": 7800,\n \"feed_rate\": 1200,\n \"plunge_rate\": 500}, \n\n {\"name\": \"hardwood\",\n \"quality\": \"Carbide3D test, experiment\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.40,\n \"spindle_speed\": 9200,\n \"feed_rate\": 900,\n \"plunge_rate\": 300},\n\n {\"name\": \"hdpe\",\n \"quality\": \"Carbide3D test\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.50,\n \"spindle_speed\": 6250,\n \"feed_rate\": 2400,\n \"plunge_rate\": 200},\n\n {\"name\": \"hdpe\",\n \"quality\": \"Guess - bantam data\",\n \"tool_size\": 1.0,\n \"pass_depth\": 0.30,\n \"spindle_speed\": 6250,\n \"feed_rate\": 600,\n \"plunge_rate\": 100},\n\n {\"name\": \"evafoam\",\n \"quality\": \"Wild guess\",\n \"tool_size\": 1.0,\n \"pass_depth\": 1.0,\n \"spindle_speed\": 6250,\n \"feed_rate\": 600,\n \"plunge_rate\": 100},\n\n {\"name\": \"copper\",\n \"quality\": \"guess from brass.\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.30,\n \"spindle_speed\": 9200,\n \"feed_rate\": 250,\n \"plunge_rate\": 25,\n \"comment\": \"copper\"},\n\n {\"name\": \"brass230\",\n \"quality\": \"Guess from 260.\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.30,\n \"spindle_speed\": 9200,\n \"feed_rate\": 250,\n \"plunge_rate\": 25,\n \"comment\": \"red brass\"},\n\n {\"name\": \"brass260\", \n \"quality\": \"Test and refined. Plunge can lock bit.\",\n \"tool_size\": 3.175, # there used to be other sizes, but good luck with any other bit.\n \"pass_depth\": 0.20, # wrestle with this value. Was 0.25.\n \"spindle_speed\": 9200,\n \"feed_rate\": 200,\n \"plunge_rate\": 25,\n \"comment\": \"cartridge brass\"},\n\n {\"name\": \"brass360\",\n \"quality\": \"From 260 + refined.\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.10,\n \"spindle_speed\": 9200,\n \"feed_rate\": 220,\n \"plunge_rate\": 25,\n \"comment\":\"free machining brass\"},\n\n {\"name\": \"aluminum\",\n \"quality\": \"Carbide3D test\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.30, # tried .30 fine with lubricant. aggressive w/o 0.25 more conservative\n \"spindle_speed\": 9200,\n \"feed_rate\": 120,\n \"plunge_rate\": 25},\n\n {\"name\": \"aluminum\",\n \"quality\": \"implied from othermill data\",\n \"tool_size\": 2.0,\n \"pass_depth\": 0.25,\n \"spindle_speed\": 9200,\n \"feed_rate\": 120,\n \"plunge_rate\": 25},\n\n {\"name\": \"aluminum\",\n \"quality\": \"implied from othermill data\",\n \"tool_size\": 1.0,\n \"pass_depth\": 0.15,\n \"spindle_speed\": 9200,\n \"feed_rate\": 100,\n \"plunge_rate\": 10}, # suggested: 55\n\n {\"name\": \"fr\",\n \"quality\": \"othermill data\",\n \"tool_size\": 3.175,\n \"pass_depth\": 0.40, # kicked up from 0.13 the 0.30.\n \"spindle_speed\": 12000,\n \"feed_rate\": 360,\n \"plunge_rate\": 80, # kicked up from 30 (sloww....)\n \"comment\": \"printed circuit board\"},\n\n {\"name\": \"fr\",\n \"quality\": \"othermill data\",\n \"tool_size\": 1.6,\n \"pass_depth\": 0.70,\n \"spindle_speed\": 12000,\n \"feed_rate\": 360,\n \"plunge_rate\": 80,\n \"comment\": \"printed circuit board\"},\n\n {'name': 'fr',\n 'quality': 'significant testing',\n 'tool_size': 1.0,\n 'pass_depth': 0.60, # up 50% so slow before\n 'spindle_speed': 12000,\n 'feed_rate': 202.5,\n 'plunge_rate': 65.0,\n 'comment': 'printed circuit board'\n },\n\n {\"name\": \"fr\",\n \"quality\": \"othermill data guess\",\n \"tool_size\": 0.8,\n \"pass_depth\": 0.30,\n \"spindle_speed\": 12000,\n \"feed_rate\": 150,\n \"plunge_rate\": 60,\n \"comment\": \"printed circuit board\"},\n ]\n },\n\n {\n \"id\": \"em\",\n \"machine\": \"Eleksmill\",\n \"travel_feed\": 1000,\n \"travel_plunge\": 100,\n\n \"materials\": [\n {\"name\": \"wood\",\n \"tool_size\": 3.125,\n \"feed_rate\": 1000,\n \"pass_depth\": 0.5,\n \"spindle_speed\": 1000,\n \"plunge_rate\": 100},\n\n {\"name\": \"aluminum\",\n \"tool_size\": 3.125,\n \"feed_rate\": 150,\n \"pass_depth\": 0.05, # woh. slow and easy for aluminum\n \"spindle_speed\": 1000,\n \"plunge_rate\": 12},\n\n {\"name\": \"fr\",\n \"tool_size\": 1.0,\n \"feed_rate\": 200, # was: 280 felt a little fast?\n \"pass_depth\": 0.15,\n \"spindle_speed\": 1000,\n \"plunge_rate\": 30},\n\n {\"name\": \"fr\",\n \"tool_size\": 0.8,\n \"feed_rate\": 160,\n \"pass_depth\": 0.15,\n \"spindle_speed\": 1000,\n \"plunge_rate\": 30},\n\n {\"name\": \"air\",\n \"tool_size\": 3.125,\n \"feed_rate\": 1200,\n \"pass_depth\": 2.0,\n \"spindle_speed\": 0,\n \"plunge_rate\": 150}]\n }\n]\n\n\ndef find_machine(machine_ID: str):\n machine = None\n\n for m in materials:\n if m['id'] == machine_ID:\n machine = m\n break\n\n return machine\n\n\ndef get_quality(m):\n if 'quality' in m:\n return m['quality']\n return '(not specified)'\n\n\ndef preprocess_material(m, machine, tool_size):\n m['travel_feed'] = machine[\"travel_feed\"]\n m['travel_plunge'] = machine[\"travel_plunge\"]\n m['tool_size'] = tool_size\n\n for key, value in m.items():\n if type(value) is float:\n m[key] = round(value, 5)\n\n return m\n\n\ndef material_data(machine_ID: str, material: str, tool_size: float):\n machine = find_machine(machine_ID)\n\n if machine is None:\n raise RuntimeError(\"Machine \" + machine_ID + \" not found.\")\n\n min_greater_size = 1000.0\n min_greater_mat = None\n max_lesser_size = 0\n max_lesser_mat = None\n\n print(\"Machine:\", machine_ID, \"Material:\", material, \"Size:\", tool_size)\n\n for m in machine['materials']:\n if material == m['name']:\n if m['tool_size'] == tool_size:\n return_m = m.copy()\n return_m['quality'] = 'match: ' + get_quality(m)\n return preprocess_material(return_m, machine, tool_size)\n\n if m['tool_size'] >= tool_size and m['tool_size'] < min_greater_size:\n min_greater_size = m['tool_size']\n min_greater_mat = m\n if m['tool_size'] <= tool_size and m['tool_size'] > max_lesser_size:\n max_lesser_size = m['tool_size']\n max_lesser_mat = m\n\n if (not min_greater_mat) and (not max_lesser_mat):\n raise RuntimeError(\"No material found\")\n\n if min_greater_mat and max_lesser_mat and (min_greater_size != max_lesser_size):\n # interpolate. cool.\n fraction = (tool_size - max_lesser_size) / (min_greater_size - max_lesser_size)\n m = max_lesser_mat.copy()\n\n params = ['tool_size', 'feed_rate', 'pass_depth', 'plunge_rate']\n for p in params:\n m[p] = max_lesser_mat[p] + fraction * (min_greater_mat[p] - max_lesser_mat[p])\n\n m['quality'] = '{}%: {} < {}% {}'.format(round((1.0 - fraction) * 100.0, 0), get_quality(max_lesser_mat),\n round(fraction * 100, 0), get_quality(min_greater_mat))\n return preprocess_material(m, machine, tool_size)\n\n elif min_greater_mat is not None:\n m = min_greater_mat.copy()\n m['quality'] = '{} under: {}'.format(round(m['tool_size'] - tool_size, 2), get_quality(m))\n return preprocess_material(m, machine, tool_size)\n\n else:\n m = max_lesser_mat.copy()\n m['quality'] = '{} over: {}'.format(round(tool_size - m['tool_size'], 2), get_quality(m))\n return preprocess_material(m, machine, tool_size)\n\n\ndef parse_name(name: str):\n material = None\n tool_size = None\n\n dash0 = name.find('-')\n dash1 = name.find('-', dash0 + 1)\n\n if dash1 > 0:\n machine = name[0:dash0]\n material = name[dash0 + 1:dash1]\n tool_size = float(name[dash1 + 1:])\n elif dash0 > 0:\n machine = name[0:dash0]\n material = name[dash0 + 1:]\n else:\n machine = name\n\n # print(\"machine= \" + machine)\n # print(\"material= \" + material)\n # print(\"tool= \" + str(tool_size))\n return [machine, material, tool_size]\n\n\ndef init_material(name: str):\n info = parse_name(name)\n tool_size = 3.125\n if info[2] is not None:\n tool_size = info[2]\n return material_data(info[0], info[1], tool_size)\n\n\ndef main():\n if len(sys.argv) == 1:\n print(\"\"\"List information about the machines and materials.\nIf not machine is provided, then will list the available machines. \nFormat is the same as used by the command line. Examples:\n 'material list'\n 'material em'\n 'material em-wood'\n 'material np883-pine-3.0'.\"\"\")\n\n machine = None\n info = [None, None]\n\n if len(sys.argv) == 2:\n info = parse_name(sys.argv[1])\n # print(info)\n if info is not None:\n machine = find_machine(info[0])\n\n if machine and info[1] and info[2]:\n data = material_data(info[0], info[1], info[2])\n print(\"*** Millimeters ***\")\n pp.pprint(data)\n\n # Conversion to inches, when working with grumpy software.\n data_in = data.copy()\n data_in['feed_rate'] = round(data_in['feed_rate'] / 25.4, 5)\n data_in['pass_depth'] = round(data_in['pass_depth'] / 25.4, 5)\n data_in['plunge_rate'] = round(data_in['plunge_rate'] / 25.4, 5)\n data_in['tool_size'] = round(data_in['tool_size'] / 25.4, 4)\n data_in['travel_feed'] = round(data_in['travel_feed'] / 25.4, 2)\n data_in['travel_plunge'] = round(data_in['travel_plunge'] / 25.4, 2)\n print(\"\")\n print(\"*** Inches ***\")\n pp.pprint(data_in)\n\n elif machine and info[1]:\n for m in machine[\"materials\"]:\n if m[\"name\"] == info[1]:\n print(m[\"name\"] + \" \" + str(m[\"tool_size\"]))\n elif machine:\n mat_set = set()\n for m in machine[\"materials\"]:\n s = m['name']\n if 'comment' in m:\n s += \" (\" + m['comment'] + \")\"\n mat_set.add(s)\n for s in mat_set:\n print(s)\n else:\n for m in materials:\n print(m[\"id\"] + \" \" + m[\"machine\"])\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5130403637886047,
"alphanum_fraction": 0.5262593626976013,
"avg_line_length": 29.423913955688477,
"blob_id": "c2f6d956ba6b090c96c2bb22297cce2643821603",
"content_id": "7652ae9e4a8bc13c36cbe4ac71f56912749ec832",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2799,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 92,
"path": "/drill.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import sys\nfrom mecode import G\nfrom material import init_material\nfrom utility import calc_steps, run_3_stages, GContext, CNC_TRAVEL_Z, nomad_header, read_DRL, sort_shortest_path\n\n# assume we are at (x, y)\ndef drill(g, mat, cut_depth):\n if cut_depth >= 0:\n raise RuntimeError('Cut depth must be less than zero.')\n\n with GContext(g):\n g.relative()\n\n num_plunge = 1 + int(-cut_depth / (0.05 * mat['plunge_rate']))\n dz = cut_depth / num_plunge\n\n g.comment(\"Drill depth={} num_taps={}\".format(cut_depth, num_plunge))\n g.spindle('CW', mat['spindle_speed'])\n g.feed(mat['plunge_rate'])\n\n if num_plunge > 1:\n # move up and down in stages.\n for i in range(0, num_plunge):\n g.move(z=dz)\n g.move(z=-dz)\n g.move(z=dz)\n else:\n g.move(z=cut_depth)\n\n g.move(z=-cut_depth)\n\ndef drill_points(g, mat, cut_depth, points):\n with GContext(g):\n g.absolute()\n sort_shortest_path(points)\n\n for p in points:\n g.feed(mat['travel_feed'])\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=p['x'], y=p['y'])\n g.move(z=0)\n drill(g, mat, cut_depth)\n\n # Leaves the head at CNC_TRAVEL_Z)\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=0, y=0)\n\ndef main():\n try:\n float(sys.argv[3])\n is_number_pairs = True\n except:\n is_number_pairs = len(sys.argv) > 3 and (sys.argv[3].find(',') >= 0)\n\n if len(sys.argv) < 4:\n print('Drill a set of holes.')\n print('Usage:')\n print(' drill material depth file')\n print(' drill material depth x0,y0 x1,y1 (etc)')\n print(' drill material depth x0 y0 x1 y1 (etc)')\n print('Notes:')\n print(' Runs in absolute coordinates.')\n print(' Travel Z={}'.format(CNC_TRAVEL_Z))\n sys.exit(1)\n\n mat = init_material(sys.argv[1])\n cut_depth = float(sys.argv[2])\n points = []\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n nomad_header(g, mat, CNC_TRAVEL_Z)\n\n if not is_number_pairs:\n filename = sys.argv[3]\n points = read_DRL(filename)\n else:\n # Comma separated or not?\n if sys.argv[3].find(',') > 0:\n for i in range(3, len(sys.argv)):\n comma = sys.argv[i].find(',')\n x = float(sys.argv[i][0:comma])\n y = float(sys.argv[i][comma + 1:])\n points.append({'x': x, 'y': y})\n else:\n for i in range(3, len(sys.argv), 2):\n points.append({'x': float(sys.argv[i + 0]), 'y': float(sys.argv[i + 1])})\n\n drill_points(g, mat, cut_depth, points)\n g.spindle()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.4883551597595215,
"alphanum_fraction": 0.511499285697937,
"avg_line_length": 25.941177368164062,
"blob_id": "d36de3e079e24835e4e7d1855ecf37b6828948a8",
"content_id": "337089d9ebfd88632d0bd8ff78eccee2b49ae16b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6870,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 255,
"path": "/utility.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import math\nimport re\n\nCNC_TRAVEL_Z = 3.0\n\ndef nomad_header(g, mat, z_start):\n g.absolute()\n g.feed(mat['feed_rate'])\n g.rapid(x=0, y=0, z=z_start)\n g.spindle('CW', mat['spindle_speed'])\n\n\ndef tool_change(g, mat, name: int):\n # this isn't as seamless as I would hope; need to save and\n # restore the absolute position. (spindle as well, but needing\n # to set the spindle again is a little more obvious)\n with GContext(g):\n g.absolute()\n x = g.current_position[0]\n y = g.current_position[1]\n z = g.current_position[2]\n g.write(\"M6 {0}\".format(name))\n g.feed(mat['travel_feed'])\n g.rapid(x=x, y=y)\n g.rapid(z=z + CNC_TRAVEL_Z)\n g.spindle('CW', mat['spindle_speed'])\n g.move(z=z)\n\n\nclass Rectangle:\n def __init__(self, x0: float = 0, y0: float = 0, x1: float = 0, y1: float = 0):\n self.x0 = min(x0, x1)\n self.y0 = min(y0, y1)\n self.x1 = max(x0, x1)\n self.y1 = max(y0, y1)\n self.dx = self.x1 - self.x0\n self.dy = self.y1 - self.y0\n\n\nclass Bounds:\n def __init__(self, tool_size :float, center :Rectangle):\n ht = tool_size / 2\n self.center = center\n self.outer = Rectangle(center.x0 - ht, center.y0 - ht, center.x1 + ht, center.y1 + ht)\n self.inner = None\n self.cx = (center.x0 + center.x1) / 2\n self.cy = (center.y0 + center.y1) / 2\n\n if center.x0 + ht < center.x1 - ht and center.y0 + ht < center.y1 + ht:\n self.inner = Rectangle(center.x0 + ht, center.y0 + ht, center.x1 - ht, center.y1 - ht)\n\n\n# Calculates relative moves to get to a final goal.\n# A goal='5' and a step='2' generates: [2, 2, 1]\ndef calc_steps(goal, step):\n if goal * step < 0:\n raise RuntimeError(\"Goal and step must be both positive or both negative.\")\n bias = 1\n if goal < 0:\n bias = -1\n step = -step\n goal = -goal\n\n steps = []\n total = 0\n while total + step < goal:\n steps.append(step)\n total += step\n\n if total < goal:\n steps.append(goal - total)\n\n return list(map(lambda x: round(x * bias, 5), steps))\n\n\ndef run_3_stages(path, g, steps):\n g.comment(\"Path: initial pass\")\n total_d = 0\n path(g, 0, total_d)\n\n for d in steps:\n if d > 0:\n raise RuntimeError(\"Positive value for step: \" + str(d))\n if d > -0.0000001:\n d = 0\n total_d += d\n g.comment('Path: depth={} total_depth={}'.format(d, total_d))\n path(g, d, total_d)\n\n g.comment('Path: final pass')\n path(g, 0, total_d)\n g.comment('Path: complete')\n\n\ndef run_3_stages_abs(path, g, steps):\n g.comment(\"initial pass\")\n path(g, 0, 0)\n base_z = 0\n\n for d in steps:\n if d > 0:\n raise RuntimeError(\"Positive value for step: \" + str(d))\n if d > -0.0000001:\n d = 0\n\n g.comment('pass: depth={}'.format(d))\n path(g, base_z, d)\n base_z += d\n\n g.comment('final pass')\n path(g, base_z, 0)\n g.comment('complete')\n\n\n# returns a negative value or none\ndef z_on_cylinder(dy, rad):\n if dy >= rad:\n return None\n h = math.sqrt(rad ** 2 - dy ** 2)\n z = h - rad\n return z\n\n\ndef read_DRL(fname):\n result = []\n with open(fname) as f:\n content = f.read()\n # print(content)\n\n prog = re.compile('X[+-]?[0-9]+Y[+-]?[0-9]+')\n points = prog.findall(content)\n\n for p in points:\n numbers = re.findall('[+-]?[0-9]+', p)\n scale = 100.0\n result.append({'x': float(numbers[0]) / scale, 'y': float(numbers[1]) / scale})\n\n return result\n\n\n'''\n fname: file to read (input)\n tool_size: size of the bit (input)\n drills: list of {x, y} holes to drill\n holes: list of {x, y, d} holes to cut\n'''\n\ndef read_DRL_2(fname):\n tool = {}\n current = 1\n all_holes = []\n\n prog_tool_change = re.compile('T[0-9][0-9]')\n prog_tool_size = re.compile('T[0-9][0-9]C')\n prog_position = re.compile('X[+-]?[0-9]+Y[+-]?[0-9]+')\n\n with open(fname) as f:\n for line in f:\n pos = prog_tool_size.search(line)\n if pos is not None:\n s = pos.group()\n index = int(s[1:3])\n tool[index] = float(line[4:])\n continue\n pos = prog_tool_change.search(line)\n if pos is not None:\n s = pos.group()\n current = int(s[1:])\n continue\n pos = prog_position.search(line)\n if pos is not None:\n s = pos.group()\n numbers = re.findall('[+-]?[0-9]+', s)\n scale = 100.0\n all_holes.append(\n {'size': tool[current], 'x': float(numbers[0]) / scale, 'y': float(numbers[1]) / scale})\n return all_holes\n\n\ndef index_of_closest_point(origin, points):\n index = 0\n min_error = 10000.0 * 10000.0\n x = origin['x']\n y = origin['y']\n\n for i in range(0, len(points)):\n p = points[i]\n err = (p['x'] - x) ** 2 + (p['y'] - y) ** 2\n if err < min_error:\n min_error = err\n index = i\n\n return index\n\n\ndef sort_shortest_path(points):\n new_points = []\n c = {'x': 0, 'y': 0}\n while len(points) > 0:\n i = index_of_closest_point(c, points)\n c = points[i]\n new_points.append(points.pop(i))\n for p in new_points:\n points.append(p)\n\n\nclass GContext:\n def __init__(self, g, **kwargs):\n self.g = g\n self.check_z = None\n if 'z' in kwargs:\n self.check_z = kwargs[\"z\"]\n\n def __enter__(self):\n self.is_relative = self.g.is_relative\n if self.check_z:\n assert(self.g.current_position[\"z\"] > self.check_z - 0.1)\n assert(self.g.current_position[\"z\"] < self.check_z + 0.1)\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n if self.check_z:\n assert(self.g.current_position[\"z\"] > self.check_z - 0.1)\n assert(self.g.current_position[\"z\"] < self.check_z + 0.1)\n if self.is_relative:\n self.g.relative()\n else:\n self.g.absolute()\n\n\n# moves the head up, over, down\ndef travel(g, mat, **kwargs):\n if g.is_relative:\n g.move(z=CNC_TRAVEL_Z)\n \n if 'x' in kwargs and 'y' in kwargs:\n g.rapid(x=kwargs['x'], y=kwargs['y'])\n elif 'x' in kwargs:\n g.rapid(x=kwargs['x'])\n elif 'y' in kwargs:\n g.rapid(y=kwargs['y'])\n \n g.move(z=-CNC_TRAVEL_Z)\n\n else:\n z = g.current_position['z']\n g.move(z=z + CNC_TRAVEL_Z)\n \n if 'x' in kwargs and 'y' in kwargs:\n g.rapid(x=kwargs['x'], y=kwargs['y'])\n elif 'x' in kwargs:\n g.rapid(x=kwargs['x'])\n elif 'y' in kwargs:\n g.rapid(y=kwargs['y'])\n \n g.move(z=z)\n"
},
{
"alpha_fraction": 0.5897920727729797,
"alphanum_fraction": 0.613736629486084,
"avg_line_length": 32.0625,
"blob_id": "bb2332a1b829c2d2c9d7f7c71ce0b31d0c5c7fd2",
"content_id": "2561a44fe5ca6c0e77e90eeb3b42e251df55ce13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1587,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 48,
"path": "/wasteboard.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "from material import init_material\nfrom mecode import G\nfrom hole import hole\nfrom utility import nomad_header, CNC_TRAVEL_Z, GContext, travel\nimport argparse\n\nBASE_OF_HEAD = 6.0 # FIXME\nD_OF_HEAD = 10.5 # FIXME\nD_OF_BOLT = 6.2 # FIXME\nIN_TO_MM = 25.4\n\ndef bolt(g, mat, stock_height, x, y):\n travel(g, mat, x=x*IN_TO_MM, y=y*IN_TO_MM)\n g.feed(mat['travel_feed'])\n g.move(z=0)\n hole(g, mat, -(stock_height - BASE_OF_HEAD), d=D_OF_HEAD)\n hole(g, mat, -(stock_height - BASE_OF_HEAD) - 2.0, d=D_OF_BOLT)\n\ndef board(g, mat, stock_height):\n with GContext(g):\n g.absolute()\n\n bolt(g, mat, stock_height, 0.5, 0.5)\n bolt(g, mat, stock_height, 0.5, 7.5)\n bolt(g, mat, stock_height, 7.5, 0.5)\n bolt(g, mat, stock_height, 7.5, 7.5)\n bolt(g, mat, stock_height, 4.75, 4.0)\n\n # get back to the origin, assuming the next step is a plane\n travel(g, mat, x=0, y=0)\n g.move(z=0)\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut holes for wasteboard. Assumes bit at lower left of plate.')\n parser.add_argument('material', help='the material to cut (wood, aluminum, etc.)')\n parser.add_argument('stock_height', help='height of stock. z=0 is top of stock.', type=float)\n args = parser.parse_args()\n\n mat = init_material(args.material)\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n nomad_header(g, mat, CNC_TRAVEL_Z)\n board(g, mat, args.stock_height)\n g.spindle()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6031175255775452,
"alphanum_fraction": 0.61031174659729,
"avg_line_length": 37.41447448730469,
"blob_id": "c8352bac7302e0c14d18481981be91441a446bd2",
"content_id": "e128ca604000684382685c9ec1fb14b83887f23c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5838,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 152,
"path": "/rectangle.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import argparse\nimport sys\nfrom mecode import G\nfrom material import init_material\nfrom utility import calc_steps, run_3_stages, GContext\n\n\ndef set_feed(g, mat, x, z):\n if abs(x) < 0.1 or (abs(z) > 0.01 and abs(z) / abs(x) > 1.0):\n g.feed(mat['plunge_rate'])\n else:\n g.feed(mat['feed_rate'])\n\ndef calc_move_plunge(dx, dy, fillet, pass_plunge):\n x_move = (dx - fillet * 2) / 2\n y_move = (dy - fillet * 2) / 2\n plunge = pass_plunge / 4\n\n if (x_move + y_move > 1):\n x_plunge = plunge * x_move / (x_move + y_move)\n y_plunge = plunge * y_move / (x_move + y_move)\n else:\n x_plunge = y_plunge = plunge / 2\n\n return x_move, y_move, x_plunge, y_plunge\n\ndef x_segment(g, mat, x_move, x_plunge, cut_depth, total_plunge):\n set_feed(g, mat, x_move, x_plunge) \n g.move(x=x_move, z=x_plunge)\n\ndef y_segment(g, mat, y_move, y_plunge, cut_depth, total_plunge):\n set_feed(g, mat, y_move, y_plunge) \n g.move(y=y_move, z=y_plunge)\n\ndef lower_left(g, mat, dx, dy, fillet, pass_plunge, total_plunge, cut_depth):\n\n x_move, y_move, x_plunge, y_plunge = calc_move_plunge(dx, dy, fillet, pass_plunge)\n \n y_segment(g, mat, -y_move, y_plunge, cut_depth, total_plunge)\n if fillet > 0:\n g.arc2(x=fillet, y=-fillet, i=fillet, j=0, direction=\"CCW\")\n x_segment(g, mat, x_move, x_plunge, cut_depth, total_plunge)\n\ndef lower_right(g, mat, dx, dy, fillet, pass_plunge, total_plunge, cut_depth):\n x_move, y_move, x_plunge, y_plunge = calc_move_plunge(dx, dy, fillet, pass_plunge)\n \n x_segment(g, mat, x_move, x_plunge, cut_depth, total_plunge)\n \n if fillet > 0:\n g.arc2(x=fillet, y=fillet, i=0, j=fillet, direction=\"CCW\")\n \n y_segment(g, mat, y_move, y_plunge, cut_depth, total_plunge)\n\ndef upper_right(g, mat, dx, dy, fillet, pass_plunge, total_plunge, cut_depth):\n x_move, y_move, x_plunge, y_plunge = calc_move_plunge(dx, dy, fillet, pass_plunge)\n\n y_segment(g, mat, y_move, y_plunge, cut_depth, total_plunge)\n if fillet > 0:\n g.arc2(x=-fillet, y=fillet, i=-fillet, j=0, direction=\"CCW\")\n x_segment(g, mat, -x_move, x_plunge, cut_depth, total_plunge)\n\ndef upper_left(g, mat, dx, dy, fillet, pass_plunge, total_plunge, cut_depth):\n x_move, y_move, x_plunge, y_plunge = calc_move_plunge(dx, dy, fillet, pass_plunge)\n \n x_segment(g, mat, -x_move, x_plunge, cut_depth, total_plunge)\n if fillet > 0:\n g.arc2(x=-fillet, y=-fillet, i=0, j=-fillet, direction=\"CCW\")\n y_segment(g, mat, -y_move, y_plunge, cut_depth, total_plunge)\n\n# from current location\n# no accounting for tool size\ndef rectangle(g, mat, cut_depth, dx, dy, fillet, origin, single_pass=False, restore_z=True):\n if cut_depth > 0:\n raise RuntimeError('Cut depth must be less than, or equal to, zero.')\n if dx == 0 and dy == 0:\n raise RuntimeError('dx and dy may not both be zero')\n if dx < 0 or dy < 0:\n raise RuntimeError('dx and dy must be positive')\n\n if fillet < 0 or fillet*2 > dx or fillet*2 > dy:\n raise RuntimeError(\"Invalid fillet. dx=\" + str(dx) + \" dy= \" + str(dy) + \" fillet=\" + str(fillet))\n\n corners = []\n\n if origin == \"left\":\n corners.append(lower_left)\n corners.append(lower_right) \n corners.append(upper_right)\n corners.append(upper_left)\n elif origin == \"bottom\":\n corners.append(lower_right)\n corners.append(upper_right)\n corners.append(upper_left)\n corners.append(lower_left)\n elif origin == \"right\":\n corners.append(upper_right)\n corners.append(upper_left)\n corners.append(lower_left)\n corners.append(lower_right)\n elif origin == \"top\":\n corners.append(upper_left)\n corners.append(lower_left)\n corners.append(lower_right)\n corners.append(upper_right)\n else:\n raise RuntimeError(\"Origin isn't valid.\")\n\n with GContext(g):\n g.comment(\"Rectangular cut\")\n g.relative()\n\n g.spindle('CW', mat['spindle_speed'])\n g.feed(mat['feed_rate'])\n\n def path(g, plunge, total_plunge):\n corners[0](g, mat, dx, dy, fillet, plunge, total_plunge, cut_depth)\n corners[1](g, mat, dx, dy, fillet, plunge, total_plunge, cut_depth)\n corners[2](g, mat, dx, dy, fillet, plunge, total_plunge, cut_depth)\n corners[3](g, mat, dx, dy, fillet, plunge, total_plunge, cut_depth)\n\n if single_pass:\n path(g, cut_depth, cut_depth)\n else:\n steps = calc_steps(cut_depth, -mat['pass_depth'])\n run_3_stages(path, g, steps)\n\n #path(g, 0)\n if restore_z:\n g.move(z=-cut_depth)\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut a rectangle. Careful to return to original position so it can be used in other ' +\n 'calls. Can also cut an axis aligned line. Does not account for tool size. Also ' +\n 'careful to not travel where it does not cut.')\n parser.add_argument('material', help='the material to cut (wood, aluminum, etc.)')\n parser.add_argument('depth', help='depth of the cut. must be negative.', type=float)\n parser.add_argument('dx', help='x width of the cut.', type=float)\n parser.add_argument('dy', help='y width of the cut.', type=float)\n parser.add_argument('-f', '--fillet', help='fillet radius', type=float, default=0)\n parser.add_argument('-o', '--origin', help=\"origin. can be 'left', 'bottom', 'right', or 'top'\", type=str, default=\"left\")\n\n args = parser.parse_args()\n mat = init_material(args.material)\n\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n rectangle(g, mat, args.depth, args.dx, args.dy, args.fillet, args.origin)\n g.spindle()\n\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.5848776698112488,
"alphanum_fraction": 0.5922905802726746,
"avg_line_length": 27.10416603088379,
"blob_id": "bd19d663961991a35b7bda3b6582e8dc42aa1762",
"content_id": "b0f4a34e98109c4efd7b72a20b3f57e996f1825a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 48,
"path": "/README.md",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "# saberCNC\nA collection of CNC code for saber construction.\n\n# NanoPCB\nNano PCB takes an text-art PCB and creates gcode for sending to a CNC.\nBasically markdown for printed circuit board cutting.\n\n## Goals:\n1. Simple: from a text file to gcode in one step\n2. Basic CNC machine.\n - Isolate circuit, drill, and cut PCB without a bit change. (I use 1.0mm\n bits, although 0.8mm might be better.)\n - Account for significant runout. NanoPCB creates straight cuts that are\n as long as possible. It doesn't use any curves or detail work.\n\nCurrently it only works single-sided. It would be straightforward to support\nthe flip, the code just needs a way to define the two sides and the flipping\naxis. It can print the circuit flipped if you want to solder on the down side.\n\n## Legend\n\n* ````#```` Starts a comment line.\n* ````[ ]```` Square brackets define a cutting border.\n* ````a-z```` Letters define drill holes.\n* ````# +M 2.2```` Defines a mounting hole, drill hole, etc. Not isolated. If size is zero, then just a mark point.\n\n## Example\n\n````\n#################################\n# +M 2.2 Mounting\n# # # # # # # # # # # # # # # # #\n[ ]\n M M \n\nV o o-r g b\n| | | |\nV o o---o o\n\nG o o o o\n|\nG---o-o---o---o\n|\nG o-o o-o o-o o-o \n\n M M \n[ ]\n````\n"
},
{
"alpha_fraction": 0.47498905658721924,
"alphanum_fraction": 0.4941665530204773,
"avg_line_length": 28.30341911315918,
"blob_id": "d23bf1ec7e2a158c5ed682b434c2b6df6b89ac91",
"content_id": "e8ff97231be163cfe554273ce27708679013ab4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13714,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 468,
"path": "/nanopcb.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "# turn ascii art into a pcb. for real.\n\nfrom mecode import G\nfrom material import init_material\nfrom utility import CNC_TRAVEL_Z\nfrom drill import drill_points\nfrom hole import hole_or_drill\nfrom rectangle import rectangle\nimport argparse\nimport sys\nimport math\nimport re\n\nSCALE = 2.54 / 2\nNOT_INIT = 0\nCOPPER = 1\nISOLATE = -1\n\nclass Point:\n def __init__(self, x: float = 0, y: float = 0):\n self.x = x\n self.y = y\n\n def __eq__(self, other):\n return self.x == other.x and self.y == other.y\n\n def __ne__(self, other):\n return self.x != other.x or self.y != other.y\n\n def __getitem__(self, item):\n if item == 'x':\n return self.x\n if item == 'y':\n return self.y\n return None\n\n\nclass PtPair:\n def __init__(self, x0: float, y0: float, x1: float, y1: float):\n self.x0 = x0\n self.y0 = y0\n self.x1 = x1\n self.y1 = y1\n\n def swap_points(self):\n self.x0, self.x1 = self.x1, self.x0\n self.y0, self.y1 = self.y1, self.y0\n\n def do_order(self):\n if self.x0 > self.x1:\n self.x0, self.x1 = self.x1, self.x0\n if self.y0 > self.y1:\n self.y0, self.y1 = self.y1, self.y0\n\n def add(self, x, y):\n self.x0 += x\n self.y0 += y\n self.x1 += x\n self.y1 += y\n\n def flip(self, w):\n self.y0 = h - self.y0\n self.y1 = h - self.y1\n\n def dx(self):\n return abs(self.x1 - self.x0)\n\n def dy(self):\n return abs(self.y1 - self.y0)\n\n\ndef sign(x):\n if x > 0:\n return 1\n if x < 0:\n return -1\n return 0\n\n\ndef distance(p0, p1):\n return math.sqrt((p0.x - p1.x) ** 2 + (p0.y - p1.y) ** 2)\n\n\ndef bounds_of_points(arr):\n pmin = Point(arr[0].x, arr[0].y)\n pmax = Point(arr[0].x, arr[0].y)\n for p in arr:\n pmin.x = min(pmin.x, p.x)\n pmin.y = min(pmin.y, p.y)\n pmax.x = max(pmax.x, p.x)\n pmax.y = max(pmax.y, p.y)\n return pmin, pmax\n\n\ndef pop_closest_pt_pair(x: PtPair, y: PtPair, arr):\n error = 1000.0 * 1000.0\n index = 0\n\n for i in range(0, len(arr)):\n p = arr[i]\n err = (p.x0 - x) ** 2 + (p.y0 - y) ** 2\n if err == 0:\n return arr.pop(i)\n if err < error:\n index = i\n error = err\n err = (p.x1 - x) ** 2 + (p.y1 - y) ** 2\n if err == 0:\n p.swap_points()\n return arr.pop(i)\n if err < error:\n p.swap_points()\n index = i\n error = err\n return arr.pop(index)\n\n\ndef scan_isolation(vec):\n result = []\n\n x0 = 0\n while x0 < len(vec):\n if vec[x0] != ISOLATE:\n x0 = x0 + 1\n continue\n x1 = x0\n while x1 < len(vec) and vec[x1] == ISOLATE:\n x1 = x1 + 1\n if x1 > x0 + 1:\n result.append(x0)\n result.append(x1)\n x0 = x1\n return result\n\n\ndef scan_file(filename: str):\n # first get the list of strings that are the lines of the file.\n ascii_pcb = []\n max_char_w = 0\n holes = {}\n offset_cut = Point(0, 0)\n\n re_hole_definition = re.compile('[\\+\\&][a-zA-Z]\\s')\n re_number = re.compile('[\\d.-]+')\n\n with open(filename, \"r\") as ins:\n for line in ins:\n line = line.rstrip('\\n')\n line = line.replace('\\t', ' ')\n line = line.rstrip(' ')\n index = line.find('#')\n\n if index >= 0:\n m = re_hole_definition.search(line)\n offset_x = line.find(\"+offset_x:\")\n offset_y = line.find(\"+offset_y:\")\n\n if m:\n key = m.group()[1]\n digit_index = m.end(0)\n m = re_number.match(line[digit_index:])\n diameter = float(m.group())\n holes[key] = {\"d\":diameter, \"break\":(m[0] == '+')}\n\n if offset_x >= 0:\n offset_cut.x = float(line[offset_x + 10:])\n\n if offset_y >= 0:\n offset_cut.y = float(line[offset_y + 10:])\n\n else:\n ascii_pcb.append(line)\n\n while len(ascii_pcb) > 0 and len(ascii_pcb[0]) == 0:\n ascii_pcb.pop(0)\n while len(ascii_pcb) > 0 and len(ascii_pcb[-1]) == 0:\n ascii_pcb.pop(-1)\n\n for line in ascii_pcb:\n max_char_w = max(len(line), max_char_w)\n\n return ascii_pcb, max_char_w, holes, offset_cut\n\n\ndef print_to_console(pcb, mat, n_cols, n_rows, drill_ascii, cut_path_on_center, holes):\n output_rows = []\n for y in range(n_rows):\n out = \"\"\n for x in range(n_cols):\n c = pcb[y][x]\n p = {'x': x, 'y': y}\n if p in drill_ascii:\n out = out + 'o'\n elif c == ISOLATE:\n out = out + '.'\n elif c == NOT_INIT:\n out = out + ' '\n elif c == COPPER:\n out = out + '+'\n output_rows.append(out)\n\n for r in output_rows:\n print(r)\n\n half_tool = mat[\"tool_size\"] / 2 \n\n for h in holes:\n diameter = h[\"diameter\"]\n cut_type = hole_or_drill(None, mat, -1.0, diameter / 2)\n\n d_north = cut_path_on_center.y1 - (h['y'] + half_tool)\n d_south = (h['y'] - half_tool) - cut_path_on_center.y0\n d_east = cut_path_on_center.x1 - (h['x'] + half_tool)\n d_west = (h['x'] - half_tool) - cut_path_on_center.x0\n\n warning = \"\"\n pos_x = round(h[\"x\"] - half_tool, 3)\n pos_y = round(h[\"y\"] - half_tool, 3)\n\n if d_north < 1 or d_south < 1 or d_east < 1 or d_west < 1:\n warning = \"Warning: hole within 1mm of edge.\"\n print(\"Hole ({}): d = {} pos = {}, {} pos(no tool) = {}, {} {}\".format(\n cut_type, diameter, pos_x, pos_y, \n round(h[\"x\"], 3), round(h[\"y\"], 3),\n warning))\n\n print('Number of drill holes = {}'.format(len(drill_ascii)))\n print('Rows/Cols = {} x {}'.format(n_cols, n_rows))\n print(\"Cutting offset = {}, {}\".format(0.0 - cut_path_on_center.x0, 0.0 - cut_path_on_center.y0))\n\n sx = cut_path_on_center.dx() - mat['tool_size']\n sy = cut_path_on_center.dy() - mat['tool_size']\n print('Size (after cut) = {} x {} mm ({:.2f} x {:.2f} in)'.format(\n sx, sy, sx/25.4, sy/25.4))\n\n\ndef print_for_openscad(mat, cut_path_on_center, holes):\n\n EDGE_OFFSET = mat[\"tool_size\"] / 2 \n sx = cut_path_on_center.dx() - mat['tool_size']\n # sy = cut_path_on_center.dy() - mat['tool_size']\n\n center_line = sx / 2\n\n print(\"\")\n print(\"openscad:\")\n print(\"[\")\n\n for h in holes:\n diameter = h[\"diameter\"]\n hx = h['x'] - EDGE_OFFSET\n hy = h['y'] - EDGE_OFFSET\n\n cut_type = hole_or_drill(None, mat, -1.0, diameter / 2)\n if cut_type == \"hole\":\n support = \"buttress\"\n if (hx > sx / 3) and (hx < 2 * sx / 3):\n support = \"column\"\n \n print(' [{:.3f}, {:.3f}, \"{}\" ], // d={}'.format(hx - center_line, hy, support, diameter))\n\n print(\"]\")\n\n\ndef rc_to_xy_normal(x: float, y: float, n_cols, n_rows):\n dx = (n_cols - 1) * SCALE\n dy = (n_rows - 1) * SCALE\n return Point(x * SCALE - dx/2, (n_rows - 1 - y) * SCALE - dy/2)\n\n\ndef rc_to_xy_flip(x: float, y: float, n_cols, n_rows):\n dx = (n_cols - 1) * SCALE\n dy = (n_rows - 1) * SCALE\n return Point(x * SCALE - dx/2, y * SCALE - dy/2)\n\n\ndef nanopcb(filename, g, mat, pcb_depth, drill_depth,\n do_cutting, info_mode, do_drilling, \n flip, openscad):\n\n if pcb_depth > 0:\n raise RuntimeError(\"cut depth must be less than zero.\")\n if drill_depth > 0:\n raise RuntimeError(\"drill depth must be less than zero\")\n\n rc_to_xy = rc_to_xy_normal\n if flip:\n rc_to_xy = rc_to_xy_flip\n\n ascii_pcb, max_char_w, hole_def, offset_cut = scan_file(filename)\n PAD = 1\n n_cols = max_char_w + PAD * 2\n n_rows = len(ascii_pcb) + PAD * 2\n\n # use the C notation\n # pcb[y][x]\n pcb = [[NOT_INIT for _ in range(n_cols)] for _ in range(n_rows)]\n\n drill_ascii = []\n holes = [] # {diameter, x, y}\n\n for j in range(len(ascii_pcb)):\n out = ascii_pcb[j]\n for i in range(len(out)):\n c = out[i]\n x = i + PAD\n y = j + PAD\n if c != ' ':\n # Handle the cutting borders of the board.\n if c == '[' or c == ']':\n continue\n\n # Handle cutting holes\n if c in hole_def:\n diameter = hole_def[c][\"d\"]\n point = rc_to_xy(x, y, n_cols, n_rows)\n holes.append(\n {'diameter': diameter, 'x': point.x, 'y': point.y})\n if hole_def[c][\"break\"]:\n continue\n\n pcb[y][x] = COPPER\n for dx in range(-1, 2, 1):\n for dy in range(-1, 2, 1):\n x_prime = x + dx\n y_prime = y + dy\n if x_prime in range(0, n_cols) and y_prime in range(0, n_rows):\n if pcb[y_prime][x_prime] == NOT_INIT:\n pcb[y_prime][x_prime] = ISOLATE\n\n if c != '-' and c != '|' and c != '+':\n drill_ascii.append(\n {'x': x, 'y': y})\n\n c0 = rc_to_xy(0, 0, n_cols, n_rows)\n c1 = rc_to_xy(n_cols-1, n_rows-1, n_cols, n_rows) \n\n cut_path_on_center = PtPair(c0.x - offset_cut.x, c1.y - offset_cut.y, \n c1.x + offset_cut.x, c0.y + offset_cut.y)\n cut_path_on_center.do_order()\n\n print_to_console(pcb, mat, n_cols, n_rows, drill_ascii, cut_path_on_center, holes)\n\n if openscad:\n print_for_openscad(mat, cut_path_on_center, holes)\n\n if info_mode is True:\n sys.exit(0)\n\n isolation_pairs = []\n\n for y in range(n_rows):\n pairs = scan_isolation(pcb[y])\n while len(pairs) > 0:\n x0 = pairs.pop(0)\n x1 = pairs.pop(0)\n\n p0 = rc_to_xy(x0, y, n_cols, n_rows)\n p1 = rc_to_xy(x1 - 1, y, n_cols, n_rows)\n\n c = PtPair(p0.x, p0.y, p1.x, p1.y)\n isolation_pairs.append(c)\n\n for x in range(n_cols):\n vec = []\n for y in range(n_rows):\n vec.append(pcb[y][x])\n\n pairs = scan_isolation(vec)\n while len(pairs) > 0:\n y0 = pairs.pop(0)\n y1 = pairs.pop(0)\n\n p0 = rc_to_xy(x, y0, n_cols, n_rows)\n p1 = rc_to_xy(x, y1 - 1, n_cols, n_rows)\n\n c = PtPair(p0.x, p0.y, p1.x, p1.y)\n isolation_pairs.append(c)\n\n g.comment(\"NanoPCB\")\n\n g.absolute()\n g.feed(mat['feed_rate'])\n g.move(z=CNC_TRAVEL_Z)\n\n g.spindle('CW', mat['spindle_speed'])\n\n # impossible starting value to force moving to\n # the cut depth on the first point.\n c_x = -0.1\n c_y = -0.1\n\n while len(isolation_pairs) > 0:\n cut = pop_closest_pt_pair(c_x, c_y, isolation_pairs)\n\n g.comment(\n '{},{} -> {},{}'.format(cut.x0, cut.y0, cut.x1, cut.y1))\n\n if cut.x0 != c_x or cut.y0 != c_y:\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=cut.x0, y=cut.y0)\n g.move(z=pcb_depth)\n g.move(x=cut.x1, y=cut.y1)\n c_x = cut.x1\n c_y = cut.y1\n\n g.move(z=CNC_TRAVEL_Z)\n\n if do_drilling:\n drill_pts = []\n for da in drill_ascii:\n drill_pts.append(rc_to_xy(da['x'], da['y'], n_cols, n_rows))\n\n drill_points(g, mat, drill_depth, drill_pts)\n for hole in holes:\n diameter = hole[\"diameter\"]\n g.feed(mat[\"travel_feed\"])\n g.move(z=CNC_TRAVEL_Z)\n g.move(x=hole[\"x\"], y=hole[\"y\"])\n g.move(z=0)\n hole_or_drill(g, mat, drill_depth, diameter / 2)\n g.move(z=CNC_TRAVEL_Z)\n\n if do_cutting:\n g.move(x=0, y=cut_path_on_center.y0)\n g.move(z=0)\n # g.move(x=cut_path_on_center.dx()/2)\n rectangle(g, mat, drill_depth, cut_path_on_center.dx(), cut_path_on_center.dy(), 1.0, \"bottom\")\n g.move(z=CNC_TRAVEL_Z)\n\n g.move(z=CNC_TRAVEL_Z)\n g.spindle()\n g.move(x=0, y=0)\n\n return cut_path_on_center.dx(), cut_path_on_center.dy()\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut a printed circuit board from a text file.')\n parser.add_argument('filename', help='the source of the ascii art PCB')\n parser.add_argument(\n 'material', help='the material to cut (wood, aluminum, etc.)')\n parser.add_argument(\n 'pcbDepth', help='depth of the cut. must be negative.', type=float)\n parser.add_argument(\n 'drillDepth', help='depth of the drilling and pcb cutting. must be negative.', type=float)\n parser.add_argument(\n '-c', '--no-cut', help='disable cut out the final pcb', action='store_true')\n parser.add_argument(\n '-i', '--info', help='display info and exit', action='store_true')\n parser.add_argument(\n '-d', '--no-drill', help='disable drill holes in the pcb', action='store_true')\n parser.add_argument(\n '-f', '--flip', help='flip in the y axis for pcb under and mounting over', action='store_true')\n parser.add_argument(\n '-o', '--openscad', help='OpenScad printout.', action='store_true')\n\n args = parser.parse_args()\n mat = init_material(args.material)\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n\n nanopcb(args.filename, g, mat, args.pcbDepth,\n args.drillDepth, args.no_cut is False, args.info, args.no_drill is False, args.flip, args.openscad)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.49196985363960266,
"alphanum_fraction": 0.501474916934967,
"avg_line_length": 28.05714225769043,
"blob_id": "284e04173f69280830e969d2b6eebd5750537dca",
"content_id": "170088d1e76784352ae139c1d921de6949f53200",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3051,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 105,
"path": "/plane.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "import math\nimport sys\nfrom mecode import G\nfrom material import init_material\nfrom utility import calc_steps, run_3_stages, GContext, CNC_TRAVEL_Z, nomad_header\nimport argparse\n\nOVERLAP = 0.80\n\ndef square(g, mat, dx, dy, fill : bool):\n with GContext(g):\n g.relative()\n\n if fill:\n num_lines = int(math.ceil(abs(dy) / (mat['tool_size'] * OVERLAP))) + 1\n \n line_step = 0\n if num_lines > 1:\n line_step = dy / (num_lines - 1)\n\n g.comment(\"Square fill={0}\".format(fill))\n is_out = False\n for i in range(0, num_lines):\n if is_out:\n g.move(x=-dx)\n else:\n g.move(x=dx)\n is_out = not is_out\n if i < num_lines - 1:\n g.move(y=line_step)\n\n if is_out:\n g.move(x=-dx)\n g.move(y=-dy)\n\n else:\n g.move(x=dx)\n g.move(y=dy)\n g.move(x=-dx)\n g.move(y=-dy)\n\ndef plane(g, mat, depth, x0, y0, x1, y1):\n dx = x1 - x0\n dy = y1 - y0\n\n # print(\"plane\", dx, dy)\n\n with GContext(g):\n g.comment(\"Plane depth = {} size = {}, {}\".format(depth, dx, dy))\n g.relative()\n\n g.spindle('CW', mat['spindle_speed'])\n g.feed(mat['feed_rate'])\n g.move(x=x0, y=y0)\n\n z = 0\n while(z > depth):\n dz = -mat['pass_depth']\n if z + dz < depth:\n dz = depth - z\n z = depth\n else:\n z = z + dz\n\n # first line to distribute depth cut.\n g.move(x=dx, z=dz/2)\n g.move(x=-dx, z=dz/2)\n\n # nice edges\n g.move(x=dx)\n g.move(y=dy)\n g.move(x=-dx)\n g.move(y=-dy)\n\n # now the business of cutting.\n square(g, mat, dx, dy, True)\n\n g.move(z=-depth)\n g.move(x=-x0, y=-y0)\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Cut a plane. Origin of the plane is the current location. ' +\n 'Does not account for tool thickness, so the dx, dy will be fully cut and ' +\n 'on the tool center. dx/dy can be positive or negative.')\n parser.add_argument('material', help='The material to cut in standard machine-material-size format.', type=str)\n parser.add_argument('depth', help='Depth of the cut. Must be negative.', type=float)\n parser.add_argument('dx', help=\"Size in x.\", type=float)\n parser.add_argument('dy', help=\"Size in y.\", type=float)\n args = parser.parse_args()\n\n mat = init_material(args.material)\n g = G(outfile='path.nc', aerotech_include=False, header=None, footer=None, print_lines=False)\n\n nomad_header(g, mat, CNC_TRAVEL_Z)\n g.spindle('CW', mat['spindle_speed'])\n g.feed(mat['feed_rate'])\n g.move(z=0)\n\n plane(g, mat, args.depth, 0, 0, args.dx, args.dy)\n g.abs_move(z=CNC_TRAVEL_Z)\n g.spindle()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6050458550453186,
"alphanum_fraction": 0.634403645992279,
"avg_line_length": 28.863014221191406,
"blob_id": "d15e6f38106c532040b86c3ebc6e65f29a930794",
"content_id": "743701b182214ff47cb2e5cfc302ffec3f4c30e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2180,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 73,
"path": "/aquatic.py",
"repo_name": "leethomason/saberCNC",
"src_encoding": "UTF-8",
"text": "# The cut for the \"Aquatic\" saber.\n# Center hole - narrow passage - display\n\nfrom hole import *\nfrom material import *\n\n# start at hole center,\n# all measurements from the hole center,\n# origin at hole center\nCNC_STD_TOOL = 3.175 # 1/8 inch bit\n\nTOOLSIZE = CNC_STD_TOOL\nCYLINDER_DIAMETER = 37\n\nHOLE_DIAMETER = 16\nHOLE_DEPTH = -8\n\nBODY_DEPTH = -5\nNECK_W = 11\nDISPLAY_W = 15\nDISPLAY_X0 = 15\nDISPLAY_X1 = 35\nFILLET = 1\n\nmat = init_material(\"wood\")\nhalfTool = TOOLSIZE / 2\ncrad = CYLINDER_DIAMETER / 2\n\ng = G(outfile='path.nc', aerotech_include=False, header=None, footer=None)\ng.abs_move(0, 0, 0)\nhole(g, mat, HOLE_DEPTH, TOOLSIZE, HOLE_DIAMETER/2)\ng.abs_move(0, 0, 0)\n\n# give ourselves 10 seconds to rest, opportunity to pause the job.\ng.dwell(10)\n\ndef path(g, plunge):\n if plunge > 0:\n raise RuntimeError(\"positive plunge:\" + str(plunge))\n\n # Really tricky in relative. Had to sketch it all out, and\n # even then hard to be sure everything added correctly.\n # Much easier in absolute. Although still needed to sketch it out.\n # ...of course the plunge logic won't work if absolute. Grr. And\n # absolute turns out to be tricky as well.\n zNeck = z_on_cylinder(NECK_W / 2 - halfTool, crad)\n zDisplay = z_on_cylinder(DISPLAY_W / 2 - halfTool, crad)\n\n dy0 = NECK_W/2 - halfTool\n dx0 = DISPLAY_X0 - FILLET\n dy1 = DISPLAY_W/2 - NECK_W/2 - FILLET\n dx1 = DISPLAY_X1 - DISPLAY_X0 - TOOLSIZE\n\n g.move(y=dy0, z=zNeck)\n g.move(x=dx0, z=plunge/2)\n g.arc(x=FILLET, y=FILLET, direction='CCW', radius=FILLET) # technically there should be a z change here, but close enough.\n g.move(y=dy1, z=zDisplay - zNeck)\n g.move(x=dx1)\n\n g.arc(y=-(DISPLAY_W - TOOLSIZE), z=0, direction='CCW', radius=crad)\n\n g.move(x=-dx1)\n g.move(y=dy1, z=zNeck - zDisplay)\n g.arc(x=-FILLET, y=FILLET, direction='CCW', radius=FILLET)\n g.move(x=-dx0, z=plunge/2)\n g.move(y=dy0, z=-zNeck)\n\nsteps = calc_steps(BODY_DEPTH, -mat['pass_depth'])\nrun_3_stages(path, g, steps)\n\ng.move(z=-BODY_DEPTH) # up to the starting point\ng.spindle()\ng.abs_move(0, 0, 0)\n"
}
] | 15 |
ineveraskedforthis/gold
|
https://github.com/ineveraskedforthis/gold
|
4f714ed9e799953093acb7f5a91d0d73550ad3cf
|
fb6890960820b9f22b74ad31003738cd102d16a7
|
831487e525b595e19b0273fdf1784b12192e0fcd
|
refs/heads/master
| 2021-04-27T04:04:10.665039 | 2018-02-27T18:40:43 | 2018-02-27T18:40:43 | 122,725,300 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6007391214370728,
"alphanum_fraction": 0.604286789894104,
"avg_line_length": 36.58333206176758,
"blob_id": "3fb96ddd18c8c3f8ede42c65d0930207736f36a8",
"content_id": "98c77d1107dd42f8c9b8d4a0dc036aa1bfc763b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6765,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 180,
"path": "/AIStates.py",
"repo_name": "ineveraskedforthis/gold",
"src_encoding": "UTF-8",
"text": "from current_settings import *\nfrom StateTemplates import *\nfrom random import randint\n\nclass ActorIdle(State):\n def Enter(agent):\n agent.state = 'idle'\n\n def Execute(agent):\n pass\n\nclass ActorGoLeft(State):\n def Enter(agent):\n agent.set_orientation('L')\n agent.move_tick = 0\n agent.state = 'move_left'\n\n def Execute(agent):\n agent.move_tick += 1\n if agent.move_tick >= agent.speed:\n agent.move(-1)\n agent.move_tick = 0\n\nclass ActorGoRight(State):\n def Enter(agent):\n agent.set_orientation('R')\n agent.move_tick = 0\n agent.state = 'move_right'\n\n def Execute(agent):\n agent.move_tick += 1\n if agent.move_tick >= agent.speed:\n agent.move(1)\n agent.move_tick = 0\n\n\nclass PeasantIdle(State):\n def Execute(agent):\n tmp = agent.game.get_unrepaired_buildings()\n if tmp != None:\n agent.AI.change_state(PeasantRepairTarget)\n agent.target = tmp\n\nclass PeasantRepairTarget(State):\n def Execute(agent):\n if agent.target.repair_status == 'None' or agent.target.dead:\n agent.AI.change_state(PeasantIdle)\n elif agent.dist(agent.target) == 0:\n agent.target.increase_hp(1)\n elif agent.state == 'idle':\n if agent.target.x > agent.x:\n agent.sm.change_state(ActorGoRight)\n else:\n agent.sm.change_state(ActorGoLeft)\n\n\nclass TaxCollectorIdle(State):\n def Execute(agent):\n tmp = agent.game.get_untaxed_building()\n if tmp != None:\n agent.AI.change_state(TaxCollectorTaxTarget)\n tmp.tax_status = 'In process'\n tmp.tax_collector = agent\n agent.target = tmp\n\nclass TaxCollectorTaxTarget(State):\n def Execute(agent):\n if agent.target == None or agent.target.dead:\n agent.change_state(TaxCollectorIdle)\n return\n if agent.dist(agent.target) == 0:\n agent.target.transfer_cash(agent, agent.target.cash)\n agent.target.tax_status = 'None'\n agent.sm.change_state(ActorIdle)\n agent.AI.change_state(TaxCollectorReturnCashToCastle)\n agent.target = None\n elif agent.state == 'idle':\n if agent.target.x > agent.x:\n agent.sm.change_state(ActorGoRight)\n else:\n agent.sm.change_state(ActorGoLeft)\n\nclass TaxCollectorReturnCashToCastle(State):\n def Execute(agent):\n if agent.dist(agent.game.castle) == 0:\n agent.transfer_cash(agent.game.castle, agent.cash)\n agent.sm.change_state(ActorIdle)\n agent.AI.change_state(TaxCollectorIdle)\n elif agent.state == 'idle':\n agent.sm.change_state(ActorGoLeft)\n\n\nclass EnemyPatrol(State):\n def Execute(agent):\n tmp = agent.game.find_closest_enemy(agent)\n if tmp != None:\n agent.AI.change_state(EnemyAttackClosestEnemy)\n elif agent.state == 'idle':\n agent.sm.change_state(ActorGoLeft)\n elif agent.state == 'move_left' and -agent.x + agent.patrol_point > agent.patrol_dist:\n agent.sm.change_state(ActorGoRight)\n elif agent.state == 'move_right' and agent.x - agent.patrol_point > agent.patrol_dist:\n agent.sm.change_state(ActorGoLeft)\n\nclass EnemyAttackClosestEnemy(State):\n def Execute(agent):\n tmp = agent.game.find_closest_enemy(agent)\n if tmp == None:\n agent.AI.change_state(EnemyPatrol)\n elif agent.dist(tmp) <= agent.get('attack_range'):\n agent.sm.change_state(ActorIdle)\n agent.attack(tmp)\n elif agent.x > tmp.x and (agent.state == 'move_right' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoLeft)\n elif agent.x < tmp.x and (agent.state == 'move_left' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoRight)\n\n\nclass WarriorPatrol(State):\n def Execute(agent):\n if agent.max_hp - agent.hp >= 100 and agent.healing_potions > 0:\n agent.use_healing_potion()\n tmp = agent.game.get_closest_market(agent)\n if agent.cash >= HEALING_POTION_COST and agent.healing_potions < 3 and tmp != None:\n agent.AI.change_state(WarriorBuyHealingPotion)\n return\n tmp = agent.game.find_closest_enemy(agent)\n if tmp != None:\n agent.AI.change_state(WarriorAttackClosestEnemy)\n elif agent.state == 'idle':\n agent.sm.change_state(ActorGoLeft)\n elif agent.state == 'move_left' and -agent.x + agent.patrol_point > agent.patrol_dist:\n agent.sm.change_state(ActorGoRight)\n elif agent.state == 'move_right' and agent.x - agent.patrol_point > agent.patrol_dist:\n agent.sm.change_state(ActorGoLeft)\n\nclass WarriorAttackClosestEnemy(State):\n def Execute(agent):\n if agent.hp < 50 and agent.healing_potions > 0:\n agent.use_healing_potion()\n if agent.hp < 50:\n agent.AI.change_state(WarriorRunAway)\n tmp = agent.game.find_closest_enemy(agent)\n if tmp == None:\n agent.AI.change_state(WarriorPatrol)\n elif agent.dist(tmp) <= agent.get('attack_range'):\n agent.sm.change_state(ActorIdle)\n agent.attack(tmp)\n elif agent.x > tmp.x and (agent.state == 'move_right' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoLeft)\n elif agent.x < tmp.x and (agent.state == 'move_left' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoRight)\n\nclass WarriorBuyHealingPotion(State):\n def Execute(agent):\n tmp = agent.game.get_closest_market(agent)\n if agent.dist(tmp) == 0:\n agent.buy(tmp, 'healing_potion')\n agent.AI.change_state(WarriorPatrol)\n elif agent.x > tmp.x and (agent.state == 'move_right' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoLeft)\n elif agent.x < tmp.x and (agent.state == 'move_left' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoRight)\n\nclass WarriorRunAway(State):\n def Execute(agent):\n tmp = agent.home\n if agent.dist(tmp) == 0:\n agent.enter(tmp)\n agent.AI.change_state(WarrriorRest)\n elif agent.x > tmp.x and (agent.state == 'move_right' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoLeft)\n elif agent.x < tmp.x and (agent.state == 'move_left' or agent.state == 'idle'):\n agent.sm.change_state(ActorGoRight)\n\nclass WarrriorRest(State):\n def Execute(agent):\n if agent.hp == agent.max_hp:\n agent.exit(agent.building)\n agent.AI.change_state(WarriorPatrol)\n"
},
{
"alpha_fraction": 0.558571457862854,
"alphanum_fraction": 0.5713839530944824,
"avg_line_length": 34.387046813964844,
"blob_id": "262253f241150a3da676e6ad86924a354e614235",
"content_id": "52173dd4f5205c7143304f7ab4865e08d214e904",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22400,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 633,
"path": "/main.py",
"repo_name": "ineveraskedforthis/gold",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport pygame\nimport random\nimport tkinter as tk\nimport copy\nfrom current_settings import *\nfrom math import sqrt\nfrom GameClasses import *\nfrom StateTemplates import *\nfrom pygame.locals import *\nfrom AIStates import *\n\n\npygame.init()\npygame.font.init()\nscreen = pygame.display.set_mode((500, 500))\npygame.display.set_caption('game')\nmyfont = pygame.font.SysFont('timesnewroman', 18)\n\n\ndef load_image(name, colorkey=None):\n fullname = os.path.join('data', name)\n image = pygame.image.load(fullname)\n image = image.convert_alpha()\n if colorkey is not None:\n if colorkey is None:\n colorkey = image.get_at((0,0))\n image.set_colorkey(colorkey, RLEACCEL)\n return image, image.get_rect()\n\ndef get_random_color():\n return (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))\n\ngame_background, tmp = load_image('game_background.png')\ninfo_bar_image, info_bar_rect = load_image('info_bar.png')\nimage_pause_button_idle, tmp = load_image('pause_button_idle.png')\nimage_pause_button_hovered, tmp = load_image('pause_button_hovered.png')\nimage_pause_button_pressed, tmp = load_image('pause_button_pressed.png')\nimage_choose_button_idle, tmp = load_image('choose_fleet_button_idle.png')\nimage_choose_button_hovered, tmp = load_image('choose_fleet_button_hovered.png')\nimage_choose_button_pressed, tmp = load_image('choose_fleet_button_pressed.png')\nsystem_image, tmp = load_image('system.png')\nsystem_info_image, tmp = load_image('system_info_image.png')\nground_image, tmp = load_image('ground.png')\ncastle_image, castle_rect = load_image('castle.png')\nhouse_image, house_rect = load_image('house.png')\nbarracks_image, barracks_rect = load_image('barracks.png')\nmarket_image, market_rect = load_image('market.png')\nratspawner_image, ratspawner_rect = load_image('rat_spawner.png')\n\n\nclass GameManager(TreeNode):\n def __init__(self):\n TreeNode.__init__(self)\n self.scenes_dict = dict()\n self.main_scene = None\n self.deleted_childs = set()\n\n def run(self):\n while 1:\n for i in self.deleted_childs:\n self.del_child(i)\n self.deleted_childs.clear()\n event_queue = pygame.event.get()\n for event in event_queue:\n if event.type == QUIT:\n return\n self.update_current_scene(event_queue)\n pygame.display.update()\n pygame.time.delay(10)\n\n def update_current_scene(self, events):\n if self.get_len() != 0:\n for i in self.childs:\n if i.interactive:\n i.update_events(events)\n i.update()\n i.draw()\n\n def delete_child(self, node):\n self.deleted_childs.add(node)\n\n\nclass InterfaceBlock(TreeNode):\n def __init__(self, rect, background_image, is_interactive = True):\n TreeNode.__init__(self)\n self.rect = rect\n self.background_image = background_image\n self.deleted_childs = set()\n self.interactive = is_interactive\n\n def update(self):\n for i in self.deleted_childs:\n self.del_child(i)\n self.deleted_childs.clear()\n for i in self.childs:\n i.update()\n\n def update_events(self, events):\n for i in self.childs:\n i.update_events(events)\n\n def draw(self):\n screen.blit(self.background_image, self.rect)\n for i in self.childs:\n i.draw()\n\n def delete_child(self, node):\n self.deleted_childs.add(node)\n\nclass Game(InterfaceBlock):\n def __init__(self):\n InterfaceBlock.__init__(self, (0, 0, 500, 500), game_background)\n self.tick = 0\n self.topinfobar = TopInfoBar()\n self.add_node(self.topinfobar)\n self.paused = False\n self.camera = (0, 0)\n self.buildings = set()\n self.actors = set()\n self.infobar = InfoBar()\n self.add_node(self.infobar)\n self.next_building_x = 0\n self.castle = Castle(self, self.next_building_x)\n self.castle.cash = 9000 #for testing purpose\n self.add_buiding(self.castle)\n self.actors.add(Peasant(self, 0))\n self.actors.add(TaxCollector(self, 10))\n self.actors.add(TaxCollector(self, 15))\n self.actors.add(TaxCollector(self, 20))\n self.build_queue = Queue()\n self.build('house')\n self.buildings.add(RatSpawner(self, 500))\n self.destroyed_buildings = set()\n self.dead_actors = set()\n\n def update(self):\n InterfaceBlock.update(self)\n if not self.paused:\n self.tick += 1\n\n for i in self.dead_actors:\n self.actors.discard(i)\n for i in self.destroyed_buildings:\n self.buildings.discard(i)\n self.destroyed_buildings = set()\n self.dead_actors = set()\n\n for i in self.buildings:\n i.update()\n for i in self.actors:\n i.update()\n\n def get_tick(self):\n return self.tick()\n\n def press_pause_button(self):\n self.paused = not self.paused\n\n def draw(self):\n screen.blit(self.background_image, self.rect)\n (x, y) = self.camera\n for i in self.buildings:\n if x + 500 >= i.x >= x - 60:\n screen.blit(i.get_image(), i.get_rect(self.camera))\n for i in self.actors:\n if x + 500 >= i.x >= x and not i.in_building:\n screen.blit(i.get_image(), i.get_rect(self.camera))\n screen.blit(ground_image, (0, GROUND_LEVEL - y))\n for i in self.childs:\n i.draw()\n\n\n def update_events(self, events):\n InterfaceBlock.update_events(self, events)\n (x, y) = self.camera\n for event in events:\n if event.type == MOUSEBUTTONDOWN:\n choose_flag = True\n x2, y2 = event.pos[0], event.pos[1]\n for child in self.childs:\n if pygame.Rect(child.rect).colliderect((x2, y2, 1, 1)):\n choose_flag = False\n if choose_flag:\n for i in self.actors:\n if x + 500 >= i.x >= x - 3:\n if pygame.Rect(i.get_rect(self.camera)).colliderect((x2, y2, 1, 1)):\n self.infobar.show_info(i, 'Actor')\n choose_flag = False\n if choose_flag:\n for i in self.buildings:\n if x + 500 >= i.x >= x - 60:\n if pygame.Rect(i.get_rect(self.camera)).colliderect((x2, y2, 1, 1)):\n self.infobar.show_info(i, 'Building')\n if event.type == KEYUP:\n if event.key == K_UP:\n self.camera = (x, y - 5)\n if event.key == K_DOWN:\n self.camera = (x, y + 5)\n if event.key == K_LEFT:\n self.camera = (x - 5, y)\n if event.key == K_RIGHT:\n self.camera = (x + 5, y)\n\n def add_buiding(self, building):\n self.buildings.add(building)\n self.next_building_x += BASE_DIST_BETWEEN_BUILDINGS\n\n def del_building(self, building):\n self.destroyed_buildings.add(building)\n\n def del_actor(self, actor):\n self.dead_actors.add(actor)\n\n def build(self, building):\n if building == 'house':\n if self.castle.cash >= HOUSE_COST:\n self.add_buiding(House(self, self.next_building_x))\n self.castle.cash -= HOUSE_COST\n if building == 'market':\n if self.castle.cash >= MARKET_COST:\n self.add_buiding(Market(self, self.next_building_x))\n self.castle.cash -= MARKET_COST\n if building == 'barracks':\n if self.castle.cash >= BARRACKS_COST:\n self.add_buiding(Barracks(self, self.next_building_x))\n self.castle.cash -= BARRACKS_COST\n\n def get_untaxed_building(self):\n curr = None\n for i in self.buildings:\n if i.tax_status == 'Can be taxed' and (curr == None or (curr != None and i.cash > curr.cash)):\n curr = i\n return curr\n\n def get_unrepaired_buildings(self):\n for i in self.buildings:\n if i.tax_status == 'Need repairing':\n return i\n\n def find_closest_enemy(self, agent):\n curr = None\n curr_dist = 9999\n for i in self.actors:\n tmp = agent.dist(i)\n if tmp <= agent.get('agr_range') and tmp <= curr_dist and agent.side != i.side:\n curr = i\n curr_dist = tmp\n return curr\n\n def get_closest_market(self, agent):\n curr = None\n curr_dist = 9999\n for i in self.buildings:\n tmp = agent.dist(i)\n if tmp <= curr_dist and i.name == 'Market':\n curr = i\n curr_dist = tmp\n return curr\n\nclass TopInfoBar(InterfaceBlock):\n def __init__(self):\n InterfaceBlock.__init__(self, info_bar_rect, info_bar_image)\n self.add_node(Button(image_pause_button_idle, image_pause_button_hovered, image_pause_button_pressed, (0, 0, 70, 31), action = lambda: self.parent.press_pause_button()))\n\n def draw(self):\n InterfaceBlock.draw(self)\n screen.blit(myfont.render('Tick: ' + str(self.parent.tick), True, BASE_TEXT_COLOR), (400, 5))\n\nclass InfoBar(InterfaceBlock):\n def __init__(self):\n InterfaceBlock.__init__(self, (0, 400, 500, 500), system_info_image)\n self.system = None\n\n def show_info(self, obj, type):\n self.clear()\n self.obj = obj\n self.shift = 0\n self.add_node(Label(obj.name, (10, 410)))\n self.add_node(UpdatingLabel(lambda: 'Cash: ' + str(obj.cash), (10, 430)))\n if obj.name == 'Castle':\n self.add_node(Label('Build:', (150, 410)))\n self.add_node(Label('House(' + str(HOUSE_COST) + ')', (160, 430)))\n self.add_node(ChooseButton((270, 430, 20, 20), lambda: self.parent.build('house')))\n self.add_node(Label('Market(' + str(MARKET_COST) + ')', (160, 450)))\n self.add_node(ChooseButton((270, 450, 20, 20), lambda: self.parent.build('market')))\n self.add_node(Label('Barracks(' + str(BARRACKS_COST) + ')', (160, 470)))\n self.add_node(ChooseButton((270, 470, 20, 20), lambda: self.parent.build('barracks')))\n if obj.name == 'Barracks':\n self.add_node(Label('Hire warrior(' + str(WARRIOR_COST) + ')', (150, 410)))\n self.add_node(ChooseButton((300, 410, 20, 20), lambda: obj.hire()))\n\n def update(self):\n InterfaceBlock.update(self)\n\nclass Label(InterfaceBlock):\n def __init__(self, text, pos, color = BASE_TEXT_COLOR):\n InterfaceBlock.__init__(self, pos, myfont.render(text, True, color))\n\nclass UpdatingLabel(InterfaceBlock):\n def __init__(self, text, pos, color = lambda: BASE_TEXT_COLOR):\n InterfaceBlock.__init__(self, pos, myfont.render(text(), True, color()))\n self.text = text\n self.color = color\n\n def draw(self):\n screen.blit(myfont.render(self.text(), True, self.color()), self.rect)\n\nclass Button(InterfaceBlock):\n def __init__(self, image_idle, image_hovered, image_pressed, rect, text = None, action = lambda: None):\n InterfaceBlock.__init__(self, rect, image_idle)\n self.image = dict()\n self.image['idle'] = image_idle\n self.image['hovered'] = image_hovered\n self.image['pressed'] = image_pressed\n self.rect = pygame.Rect(rect)\n self.status = 'idle'\n self.text = text\n self.action = action\n self.prev_status = 'idle'\n\n def draw(self):\n screen.blit(self.image[self.status], self.rect)\n if self.text != None:\n screen.blit(myfont.render(self.text, True, (210, 210, 210)), self.rect)\n\n def update_events(self, events):\n for event in events:\n if event.type == MOUSEMOTION:\n if self.rect.colliderect((event.pos[0], event.pos[1], 1, 1)) and self.status != 'pressed':\n self.status = 'hovered'\n elif self.status != 'pressed':\n self.status = 'idle'\n if event.type == MOUSEBUTTONDOWN:\n if self.status == 'hovered':\n if self.status != 'pressed':\n self.prev_status = self.status\n self.status = 'pressed'\n if event.type == MOUSEBUTTONUP:\n if self.status == 'pressed':\n self.action()\n self.status = self.prev_status\n\nclass ChooseButton(Button):\n def __init__(self, rect, action = lambda: None):\n Button.__init__(self, image_choose_button_idle, image_choose_button_hovered, image_choose_button_pressed, rect, action = action)\n\nclass GameObject():\n def __init__(self, game, name = None):\n self.game = game\n self.name = name\n self.dead = False\n self.attributes = dict()\n\n def get(self, tag):\n if tag in self.attributes:\n return self.attributes[tag]\n return 0\n\n def transfer_cash(self, target, amount):\n if self.cash < amount:\n amount = self.cash\n target.cash += amount\n self.cash -= amount\n\n def take_damage(self, amount):\n tmp = self.hp - amount\n if tmp <= 0:\n tmp = 0\n self.dead = True\n self.hp = tmp\n\n def increase_hp(self, amount):\n tmp = self.hp + amount\n if tmp >= self.max_hp:\n tmp = self.max_hp\n self.hp = tmp\n\nclass GameObjectWithImage(GameObject):\n def __init__(self, game, x, image, image_rect, name = None):\n GameObject.__init__(self, game, name)\n self.x = x\n self.image = image\n self.image_rect = image_rect\n\n def get_rect(self, camera):\n (x, y) = camera\n return Rect(self.x - x, GROUND_LEVEL - self.image_rect.height - y, self.image_rect.width, self.image_rect.height)\n\n def get_image(self):\n return self.image\n\n def dist(self, item):\n tmp = self.get_rect(self.game.camera)\n rect = item.get_rect(self.game.camera)\n if tmp.colliderect(rect):\n return 0\n return min(abs(tmp.left - rect.right), abs(tmp.right - rect.left))\n\nclass AnimatedGameObject(GameObjectWithImage):\n def __init__(self, game, x, image_prefix, side = 0):\n image, image_rect = load_image(image_prefix + '_idle_0.png')\n GameObjectWithImage.__init__(self, game, x, image, image_rect, name = image_prefix)\n self.animation = dict()\n self.current_animation_tick = 0\n self.current_animation = 'idle'\n self.tick = 0\n\n file = open(image_prefix + '_animations.txt')\n for i in file.readlines():\n anim_tag = i.split()[0]\n anim_count = int(i.split()[1])\n self.add_animation_from_tag(anim_tag, anim_count)\n\n self.side = side\n self.orientation = 'R'\n\n def get_image(self):\n if self.orientation == 'R':\n return self.animation[self.current_animation][self.current_animation_tick]\n return pygame.transform.flip(self.animation[self.current_animation][self.current_animation_tick], True, False)\n\n def move(self, x):\n self.x += x\n\n def move_to(self, x):\n self.move(-self.x + x)\n\n def set_orientation(self, orientation):\n if self.orientation == orientation:\n return\n self.orientation = orientation\n self.image = pygame.transform.flip(self.image, True, False)\n\n def add_animation(self, tag, list_of_image):\n self.animation[tag] = list_of_image\n\n def add_animation_from_tag(self, tag, count):\n self.animation[tag] = []\n for i in range(count):\n image, tmp = load_image(self.name + '_' + tag + '_' + str(i) + '.png')\n self.animation[tag].append(image)\n\n def change_animation(self, tag):\n self.current_animation_tick = 0\n self.current_animation = tag\n\n def next_image(self):\n self.current_animation_tick += 1\n if self.current_animation_tick >= len(self.animation[self.current_animation]):\n self.current_animation_tick = 0\n return self.animation[self.current_animation][self.current_animation_tick]\n\n def update(self):\n self.tick += 1\n if self.tick % 5 == 0:\n self.image = self.next_image()\n if self.orientation == 'L':\n self.image = pygame.transform.flip(self.image, True, False)\n self.tick = 0\n\n def check_collisions_after(self, dist):\n checking_rect = self.get_rect().inflate(dist, 0)\n if self.orientation == 'L':\n checking_rect.move_ip(dist, 0)\n for item in self.scene.Objects:\n if checking_rect.colliderect(item.get_rect()) and item.root.char.side != self.root.char.side:\n self.root.action(item)\n if self.get('pierce') == self.get('max_pierce'):\n self.destroy()\n else:\n self.set('pierce', self.get('pierce') + 1)\n\n\n\nclass Building(GameObjectWithImage):\n def __init__(self, game, x, image, image_rect, name, income, side = 0):\n GameObjectWithImage.__init__(self, game, x, image, image_rect, name)\n self.cash = 0\n self.income = income\n self.max_hp = BASE_BUILDING_HP\n self.hp = self.max_hp\n self.tax_status = 'None'\n self.repair_status = 'None'\n self.side = side\n\n def update(self):\n if self.game.tick % 600 == 0:\n self.cash += self.income\n if self.name != 'Castle' and self.cash > 0 and self.tax_status == 'None':\n self.tax_status = 'Can be taxed'\n if self.hp < self.max_hp:\n self.repair_status = 'Need repairing'\n else:\n self.repair_status = 'None'\n if self.dead:\n self.game.del_building(self)\n if self.tax_status == 'In process':\n self.tax_collector.target = None\n\nclass Castle(Building):\n def __init__(self, game, x):\n Building.__init__(self, game, x, castle_image, castle_rect, 'Castle', 100)\n self.cash = 1000\n\nclass House(Building):\n def __init__(self, game, x):\n Building.__init__(self, game, x, house_image, house_rect, 'House', 10)\n\nclass Barracks(Building):\n def __init__(self, game, x):\n Building.__init__(self, game, x, barracks_image, barracks_rect, 'Barracks', 0)\n\n def hire(self):\n if self.game.castle.cash >= WARRIOR_COST:\n tmp = Warrior(self.game, self.x)\n tmp.home = self\n self.game.castle.cash -= WARRIOR_COST\n self.game.actors.add(tmp)\n\nclass Market(Building):\n def __init__(self, game, x):\n Building.__init__(self, game, x, market_image, market_rect, 'Market', 100)\n\nclass RatSpawner(Building):\n def __init__(self, game, x):\n Building.__init__(self, game, x, ratspawner_image, ratspawner_rect, 'Rat spawner', 0, side = 1)\n self.spawn_tick = 0\n\n def update(self):\n self.spawn_tick += 1\n if self.spawn_tick == 1000:\n self.game.actors.add(Rat(self.game, self.x + 20))\n self.spawn_tick = 0\n\nclass Actor(AnimatedGameObject):\n def __init__(self, game, x, image_prefix, side = 0):\n AnimatedGameObject.__init__(self, game, x, image_prefix, side)\n self.speed = 5\n self.sm = StateMachine(self, ActorIdle)\n self.state = 'idle'\n self.max_hp = BASE_ACTOR_HP\n self.hp = self.max_hp\n self.cash = 0\n self.attributes['attack_range'] = 1\n self.attributes['attack_damage'] = 2\n self.attributes['agr_range'] = 100\n self.healing_potions = 0\n self.in_building = False\n\n def update(self):\n if self.dead:\n self.game.del_actor(self)\n AnimatedGameObject.update(self)\n self.sm.update()\n if self.in_building:\n self.increase_hp(1)\n\n def attack(self, target):\n target.take_damage(self.attributes['attack_damage'])\n\n def buy(self, market, purchase):\n if purchase == 'healing_potion' and self.cash >= HEALING_POTION_COST:\n self.transfer_cash(market, HEALING_POTION_COST)\n self.healing_potions += 1\n\n def enter(self, building):\n if self.dist(building) == 0:\n self.in_building = True\n self.building = building\n self.sm.change_state(ActorIdle)\n\n def exit(self, building):\n self.in_building = False\n self.building = None\n\nclass AIActor(Actor):\n def update(self):\n Actor.update(self)\n self.AI.update()\n # print(self.AI.curr_state)\n # print(self.sm.curr_state)\n\nclass Peasant(AIActor):\n def __init__(self, game, x):\n AIActor.__init__(self, game, x, 'peasant')\n self.AI = StateMachine(self, PeasantIdle)\n\nclass TaxCollector(AIActor):\n def __init__(self, game, x):\n AIActor.__init__(self, game, x, 'taxcollector')\n self.AI = StateMachine(self, TaxCollectorIdle)\n self.target = None\n\n def update(self):\n AIActor.update(self)\n if self.dead and self.target != None:\n self.target.tax_status = 'None'\n\nclass Rat(AIActor):\n def __init__(self, game, x):\n AIActor.__init__(self, game, x, 'rat', side = 1)\n self.max_hp = BASE_RAT_HP\n self.hp = self.max_hp\n self.AI = StateMachine(self, EnemyPatrol)\n self.patrol_point = self.x\n self.patrol_dist = 40\n\nclass Warrior(AIActor):\n def __init__(self, game, x):\n AIActor.__init__(self, game, x, 'warrior')\n self.AI = StateMachine(self, WarriorPatrol)\n self.patrol_point = self.game.next_building_x + 40\n self.patrol_dist = 40\n self.cash = STARTING_WARRIOR_MONEY\n self.healing_potions = STARTING_WARRIOR_NUMBER_OF_POTIONS\n\n def update(self):\n AIActor.update(self)\n self.patrol_point = self.game.next_building_x + 40\n\n def use_healing_potion(self):\n if self.healing_potions > 0:\n self.increase_hp(BASE_HEALING_POTION_HEAL)\n self.healing_potions -= 1\n\n\n\nManager = GameManager()\nCurrentGame = Game()\nManager.add_node(CurrentGame)\nManager.run()\n"
},
{
"alpha_fraction": 0.6162790656089783,
"alphanum_fraction": 0.7412790656089783,
"avg_line_length": 23.571428298950195,
"blob_id": "770c96628291bcb31c116c5c4ffd1b868f24f503",
"content_id": "1fd511c967419b2f0e5b8c1aa6584d9970049073",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 14,
"path": "/current_settings.py",
"repo_name": "ineveraskedforthis/gold",
"src_encoding": "UTF-8",
"text": "BASE_TEXT_COLOR = (210, 210, 210)\nGROUND_LEVEL = 390\nBASE_DIST_BETWEEN_BUILDINGS = 45\nHOUSE_COST = 200\nMARKET_COST = 500\nBARRACKS_COST = 500\nWARRIOR_COST = 300\nBASE_BUILDING_HP = 1000\nBASE_ACTOR_HP = 200\nBASE_RAT_HP = 100\nHEALING_POTION_COST = 50\nBASE_HEALING_POTION_HEAL = 100\nSTARTING_WARRIOR_NUMBER_OF_POTIONS = 0\nSTARTING_WARRIOR_MONEY = 0\n"
}
] | 3 |
Esen-Q2-Progra-Aplicada/esen-prograApli-s4-c1
|
https://github.com/Esen-Q2-Progra-Aplicada/esen-prograApli-s4-c1
|
c1b07bb0426fe54fe3b16738cd113ef9cafe0457
|
da1eaf47a281d2863dbefc86ff72c7d0b6f78dff
|
e4b8779dc2defe7a3a81d248fb105851f5f67598
|
refs/heads/master
| 2023-05-07T14:06:41.748338 | 2021-06-02T02:05:17 | 2021-06-02T02:05:17 | 372,995,000 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5504504442214966,
"alphanum_fraction": 0.5540540814399719,
"avg_line_length": 27.461538314819336,
"blob_id": "a2a035d105f8b92a4abf188721e04ca10f808bf2",
"content_id": "0d5f63d547016fddf296ddff7cdd6010e9d2f10b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1110,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 39,
"path": "/app.py",
"repo_name": "Esen-Q2-Progra-Aplicada/esen-prograApli-s4-c1",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nimport requests\n\napp = Flask(__name__)\n\n\[email protected](\"/\")\ndef home():\n return render_template(\"index.html\")\n\n\[email protected](\"/login\", methods=[\"GET\", \"POST\"])\ndef login():\n data = {}\n if request.method == \"GET\":\n company = \"balcorp\"\n return render_template(\"login.html\", company=company)\n elif request.method == \"POST\":\n data[\"secret\"] = \"6LeAdQcbAAAAAGNn732kkStupieUDdKjQTl38KL_\"\n data[\"response\"] = request.form[\"g-recaptcha-response\"]\n response = requests.post(\n \"https://www.google.com/recaptcha/api/siteverify\", params=data\n )\n print(response)\n if response.status_code == 200:\n messageJson = response.json()\n print(messageJson)\n if messageJson[\"success\"]:\n user = request.form[\"user\"]\n passwd = request.form[\"passwd\"]\n return f\"posted {user}::{passwd}\"\n else:\n return f\"posted {messageJson['error-codes'][0]}\"\n else:\n return f\"posted error\"\n\n\nif __name__ == \"__main__\":\n app.run(debug=True)\n"
}
] | 1 |
jasonzqchen/buildingdata
|
https://github.com/jasonzqchen/buildingdata
|
f3e170285149c79001f858193d84139b58885357
|
9407f0f494cb16c0e5d6713323547f72d4d0f9fe
|
2acde05539ad83cb67617c4a47f3c8a85d96e2af
|
refs/heads/master
| 2020-03-24T02:28:37.637890 | 2019-01-05T16:08:40 | 2019-01-05T16:08:40 | 142,377,306 | 1 | 2 | null | 2018-07-26T02:24:26 | 2018-07-26T06:29:30 | 2018-07-26T07:08:32 | null |
[
{
"alpha_fraction": 0.5839694738388062,
"alphanum_fraction": 0.5901924967765808,
"avg_line_length": 32.292816162109375,
"blob_id": "83bad761f80d90a8591636c09cae1dc99d1cf207",
"content_id": "deae841f20b2e0e5e40f86fb8a3fc5707325a796",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13148,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 362,
"path": "/idea/jason/readEPR.py",
"repo_name": "jasonzqchen/buildingdata",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jul 25 14:22:47 2018\n\n@author: jason.chen\n@contact: [email protected]\n@company: ARUP\n\n\"\"\"\nimport docx\nimport time\nimport numpy as np\nimport re\n\n# to solve:\n# 1.一开始要筛选一个EPR里有几个项目,分割报告。 难点:doc.paragraphs和tables怎么去关联?? 要自己重新写一套读word文档的数据库吗??\n# 2.table的定义太乱了,每个EPR都不一样的。。有什么好的方法呢??\n# 3.steel tonnage,从哪里去拿\n# 4.柱和墙的尺寸?\n# 5.**[IMPORTANT] we need to develop a checking program to check dictionary at the end and to warn user whcih data may not be correct\n# **** 用生成器 yield to speed up the search?? <--- to modify the code\n# output: BuildingDataDict\n# it stores all the date got from the file\n# units: KN, m\n\n# %% create data dictionary\ninputData = ['Project ID','Project Name','Location',\\\n 'Building Height','Nos of Floors','Building Functions','Structural System',\\\n 'SW','SDL','LL',\\\n 'Base_shear_x','Base_moment_x','Base_shear_y','Base_moment_y', \\\n 'Period:1st Mode','Period:2nd Mode','Period:3rd Mode']\nprojects = ['project1','project2']\n\ndef _createdict(inputdata1, inputdata2):\n value = ''\n datadict = dict()\n for data in inputdata1:\n innerdict = {}\n for key in inputdata2:\n innerdict.update({key:value})\n tempdict = {data:innerdict}\n datadict.update(tempdict)\n return datadict\nBuildingDataDict = _createdict(projects,inputData)\n\n# %%\n# functions.....\ndef _flatten(l):\n out = []\n for item in l:\n if isinstance(item, (list, tuple)):\n out.extend(_flatten(item))\n else:\n out.append(item)\n return out\n\n# find the table\ndef _findtable(tables, pattern):\n flag_old = 0\n for i in range(len(tables)):\n f_list = _flatten(tables[i])\n list_new = \"\".join(f_list)\n flag = 0\n for each in pattern:\n if re.search(each,list_new) is None:\n pass\n else:\n flag += 1\n #print('_findtable succesfully found the table...iterating')\n if flag_old < flag:\n foundindex = i\n flag_old = flag\n print('_findtable: found the table index:', foundindex, '\\n')\n return foundindex\n\n# find position in the table based on input search string\ndef _findTablePos(array, str_row, str_col, row_c = []):\n # find col\n from collections import Counter\n (row, col) = array.shape\n colf = []\n \n # find col\n colf = [j for string in str_col for i in range(row) for j in range(col) \\\n if re.search(string, array[i,j]) is not None]\n\n colf = Counter(colf).most_common(1)[0][0]\n #print('colf: ', colf)\n \n # find row\n if row_c == []:\n rowf = [i for string in str_row for i in range(row) for j in range(col) \\\n if re.search(string, array[i,j]) is not None]\n else:\n #if row_c to be defined, then only search row in that column\n rowc = [j for string in row_c for j in range(col) \\\n if re.search(string, array[0,j]) is not None][0]\n rowf = [i for string in str_row for i in range(row)\\\n if re.search(string, array[i,rowc]) is not None]\n\n rowf = Counter(rowf).most_common(1)[0][0]\n #print('rowf: ', rowf)\n \n string = array[rowf,colf]\n print('_findtpos: located the item in the table:', '[',\\\n rowf, ',', colf,']', 'data=', string)\n return string\n \n# let's add table to nested list first\n# this is slow...is there any faster method???\ndef _table2list(tables):\n list_tables = []\n for table in tables:\n list_rows = []\n for row in table.rows:\n list_cells = []\n for cell in row.cells:\n list_cells.append(cell.text)\n list_rows.append(list_cells)\n list_tables.append(list_rows)\n print('_table2list: stored the table into nested list.\\n')\n return list_tables\n\ndef _outTableData(list_tables, pattern, str_row, str_col, row_c=[], datakey=[], \\\n datadict={}, project=[]):\n '''\n ***use this functon when dealing with tables***\n list_table: tables from word document in a list\n pattern: to search for tables\n str_row: keywords to search for rows\n str_col: keywords to search for cols\n row_c: identify which column to locate the rows (optional)\n datakey: key names (if no fill then same as str_row)\n project: project name\n '''\n if datakey == []:\n datakey = str_row\n index = _findtable(list_tables, pattern)\n \n # find units\n f_list = _flatten(list_tables[index])\n joinedstring = \"\".join(f_list)\n\n # convert to KN\n mulfactor = 1\n if re.search('万吨',joinedstring) is not None:\n mulfactor = 100000\n if re.search('顿|t',joinedstring) is not None:\n mulfactor = 10\n if re.search('MN',joinedstring) is not None:\n mulfactor = 1000\n \n # find table based on keywords\n aTable = np.array(list_tables[index])\n i = 0\n for c in str_col:\n print(c)\n for r in str_row:\n print(r)\n value = _findTablePos(aTable, r, c, row_c)\n \n # apply multiplier for unit\n value = re.sub(',','',value)\n if value.isalpha():\n value = value\n elif type(float(value)) == float:\n value = '%g' % (float(value) * mulfactor)\n \n if project == []:\n datadict[datakey[i]] = value\n else:\n print(project)\n datadict[project][datakey[i]] = value\n i += 1\n #print(c,r,value)\n print('_outdata: stored the found data into dictionary.\\n')\n return datadict\n\ndef _parseParaOne(docText, pattern, splitmark = \" \"):\n ''' \n use this function when you want to loop through a text file to find\n the specific 'numbers' or 'words' in one sentence and output that \n sentence\n DONOT use this function to search keywords that are NOT in ONE sentence!!\n '''\n para = re.search(pattern,docText)\n parsetext = docText[para.start():para.end()]\n # chinese mark\n parsetext_r = re.sub('[,,。;;]', splitmark, parsetext)\n \n parsedtextlist = parsetext_r.split(splitmark)\n parsedstring = []\n for parsedtext in parsedtextlist:\n match = re.search(pattern, parsedtext)\n if match is not None:\n parsedstring.append(match.string)\n print('_parsepara found ', len(parsedstring), 'strings: ', parsedstring)\n return parsedstring\n\ndef _parsePara(docText, title, keywords):\n '''\n find the target sentence in the doc based on keywords searching and return\n with found string joined with '&'\n '''\n para = re.search(title, docText)\n #print(para)\n parsetext = docText[para.start():para.end()]\n templist = []\n for keyword in keywords:\n if re.search(keyword,parsetext) is not None:\n keyword = re.sub('[.+*(?)\\[\\]{}|]','',keyword)\n templist.append(keyword)\n parsedstring = \"&\".join(templist)\n return parsedstring\n\n# main logic for EPR, to be customised\ndef _mainEPR(path, datadict):\n doc = docx.Document(path)\n \n docTextlist = [para.text for para in doc.paragraphs]\n docText = \" \".join(docTextlist)\n \n list_tables = _table2list(doc.tables)\n \n project = 'project1' ## now use 1 file as example, can loop through multiple\n #datadict = {project:{}}\n \n # project name\n # this best get from folder name while data mining the files\n # 使用文件名, 文件名在 digfiles.py 文档中根据寻找到文件的文件夹名重新命名。\n \n # Location\n pattern = r'((项目概况)|(工程概括))\\s+.+' \n keywords = ['香港','深圳','上海','北京','广州','天津','武汉','重庆'] \n location = _parsePara(docText, pattern, keywords)\n datadict[project]['Location'] = location\n \n # building height\n # 结构高度 建筑高度 高度 and 附件有数字 加上m或者米\n pattern = r'(塔楼)?((楼体高度)|(结构高度)|(建筑高度)|(高度)|高).+\\d\\d\\d\\d?.?\\d?(m|米)'\n splitpara = _parseParaOne(docText, pattern)[0]\n height = re.search(\"\\d+.?\\d?\", splitpara).group()\n datadict[project]['Building Height'] = height\n \n # nos. of floors\n # the reason why this is so complicated is I wanted to write a logic that\n # if found multiple xx层 in an array, there's no good way to justify which\n # one is correct, so I used the method estimation nos. of floors comparing \n # with the found array and return the minimum difference one.\n # the estimated nos. of floors use 4 as storey floor which is a typical\n # floor height for typical buildings\n \n pattern = r'结?构?高?度?.?\\d\\d\\d?层'\n estfloors = float(height)/4\n splitparas = _parseParaOne(docText, pattern)\n \n splitpara_n = []\n for splitpara in splitparas:\n splitpara_n.append(float(re.findall('\\d+',splitpara)[0]))\n \n adiff = np.array(splitpara_n) - estfloors\n index = np.where(adiff==np.max(adiff))[0][0]\n floors = re.findall(pattern, splitpara)[index]\n floors = re.findall('\\d+',floors)[0]\n datadict[project]['Nos of Floors'] = floors\n \n # building functions..e.g office, comercial..etc\n # 搜索 楼面结构 or 楼板体系 or 楼面体系 办公楼 酒店 公寓\n pattern = r'((楼面布置)|(楼面结构)|(楼板体系))\\s+.+' \n keywords = ['办公','商业','公寓'] \n functions = _parsePara(docText, pattern, keywords)\n datadict[project]['Building Functions'] = functions\n\n # structural system\n # 搜索结构体系, 伸臂, 桁架, 巨柱, 框架, 核心筒, 斜撑\n pattern = r'(结构体系)\\s+.+' \n keywords = ['矩形钢管混凝土柱','型钢混凝土柱','钢筋混凝土柱'\\\n '巨型框架','巨型钢管混凝土柱','巨型型钢混凝土柱','巨型钢筋混凝土柱',\\\n '巨型钢?斜支撑(框架)?',\\\n '钢筋混凝土梁','钢梁(外框)?',\\\n '核心筒',\\\n '组合楼板','钢筋混凝土楼?梁?板',\\\n '伸臂桁架','腰桁架']\n strsys = _parsePara(docText, pattern, keywords)\n datadict[project]['Structural System'] = strsys\n \n # steel tonnage <--- how to get??\n # 从给QS的报告里挖?\n # 从模型里挖?\n \n # building period\n # use key words to search tables first, \n # then use key\n pattern = ['振型','周期','YJK','(ETABS)|(Etabs)']\n row_c = ['(周期)|(振型)']\n str_row = ['{:.0f}'.format(x) for x in range(1,4)]\n str_col = [['YJK','周期']]\n datakey = ['Period:1st Mode','Period:2nd Mode','Period:3rd Mode']\n datadict = _outTableData(list_tables,pattern,str_row,str_col,row_c,datakey,datadict,project)\n\n \n # building weight\n pattern = ['质量','活载','(自重)|(恒载)','YJK','(ETABS)|(Etabs)']\n row_c = ['项目']\n str_row = ['自重','附加恒载','活载']\n str_col = ['质量']\n datakey = ['SW','SDL','LL']\n datadict = _outTableData(list_tables,pattern,str_row,str_col,row_c,datakey,datadict,project)\n \n # wind load and seismic load \n # 这个还需要仔细研究一下,基本上很多EPR都是不同的格式,可能要写很多个情况。\n pattern = ['剪力','(倾覆弯矩)|(倾覆弯矩)','YJK','(ETABS)|(Etabs)']\n row_c = ['荷载工况']\n str_row = [\n ['剪力','(X|x)'],['倾覆弯矩','(X|x)'],['剪力','(Y|y)'],['倾覆弯矩','(Y|y)']\n ]\n str_col = ['YJK']\n datakey = ['Base_shear_x','Base_moment_x','Base_shear_y','Base_moment_y']\n datadict = _outTableData(list_tables,pattern,str_row,str_col,row_c,datakey,datadict,project)\n \n return list_tables\n\n# to be developed\ndef _checkunit(project, datadict):\n bsx = datadict[project]['Base_shear_x']\n bsy = datadict[project]['Base_shear_y']\n bmx = datadict[project]['Base_moment_x']\n bmy = datadict[project]['Base_moment_y']\n \n# %% running the file\nstart = time.time()\nif __name__ == '__main__':\n path = u'test_report.docx'\n list_tables = _mainEPR(path, BuildingDataDict)\n\nprint('run time: ', (time.time()-start)*1000)\n\n# %%\n\npath = u'test_report.docx'\ndoc = docx.Document(path)\n \ndocTextlist = [para.text for para in doc.paragraphs]\ndocText = \" \".join(docTextlist)\n\npattern = r'(结构体系)\\s+.+' \npara = re.search(pattern,docText)\nparsetext = docText[para.start():para.end()]\n\nkeywords = ['矩形钢管混凝土柱','型钢混凝土柱','钢筋混凝土柱'\\\n '巨型框架','巨型钢管混凝土柱','巨型型钢混凝土柱','巨型钢筋混凝土柱',\\\n '巨型钢?斜支撑(框架)?',\\\n '钢筋混凝土梁','钢梁(外框)?',\\\n '核心筒',\\\n '组合楼板','钢筋混凝土楼?梁?板',\\\n '伸臂桁架','腰桁架']\nfunctions = []\nfor keyword in keywords:\n if re.search(keyword,parsetext) is not None:\n keyword = re.sub('[.+*(?)\\[\\]{}|]','',keyword)\n functions.append(keyword)\n\"&\".join(functions)\n"
},
{
"alpha_fraction": 0.5195906758308411,
"alphanum_fraction": 0.5237012505531311,
"avg_line_length": 38.843204498291016,
"blob_id": "5f285e275f026c9890ce2c23ebacc9fd666b14fa",
"content_id": "c205a443bdc13ff2461f9e1b09ca51a70c938ff4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11454,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 287,
"path": "/idea/jason/digfiles.py",
"repo_name": "jasonzqchen/buildingdata",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Jul 28 14:05:23 2018\n\n@author: jason.chen\n@contact: [email protected]\n@company: ARUP\n\n\"\"\"\nimport os \nimport re \nimport time \nimport shutil\n\n# %% \nclass Digfiles:\n def __init__(self, paths, savepath): \n self.paths = paths # main search master path\n self.savepath = savepath # save to which path\n self.folderkey = [] # the keywords for searching prioritised folders\n self.filekey = [] # the keywords for searching prioritised files\n self.datadict = dict() # dictionary to store all the files for all projects\n \n def runsetting(self, save=0, overwrite=0, semiwalk= 0, fullwalk=0):\n '''\n ******run settings*******\n save: save the found files to the target folder\n overwrite: save the found files to the target folder and overwrite \n if there's same files\n semiwalk: semiwalk is in between keywords and full os.walk method, it use os.walk\n when cannot use keywords to find the file\n fullwalk: call os.walk functions (slowfindfile) for full path search, very slow..\n \n '''\n self.save = save\n self.overwrite = overwrite\n self.semiwalk = semiwalk\n self.fullwalk = fullwalk\n \n @property\n def setfolderkey(self):\n return self._setfolderkey\n \n @property\n def setfilekey(self):\n return self._setfilekey\n \n @setfolderkey.setter \n def setfolderkey(self, key):\n self.folderkey = re.compile(key, re.IGNORECASE)\n self._setfolderkey = self.folderkey\n \n @setfilekey.setter\n def setfilekey(self, key):\n self.filekey = re.compile(key, re.IGNORECASE)\n self._setfilekey = self.filekey\n \n def subdirs(self, path):\n \"\"\"Yield directory names not starting with '.' under given path.\"\"\"\n try:\n for entry in os.scandir(path):\n if not entry.name.startswith('.') and entry.is_dir():\n yield entry\n except PermissionError as reason:\n pass #print('No permission'+ str(reason))\n except:\n pass #print('Error..')\n \n def subfiles(self, path):\n \"\"\"Yield directory names not starting with '.' under given path.\"\"\"\n try:\n for entry in os.scandir(path):\n if not entry.name.startswith('.') and entry.is_file():\n yield entry\n except PermissionError as reason:\n pass #print('No permission'+ str(reason))\n except:\n pass #print('Error..')\n#---------------------------------------------------------------------------- \n # this is a recursive function to update path and store all the files found \n def loop(self, path, store):\n entries = Digfiles.subdirs(self, path)\n for eachEntry in entries:\n if self.folderkey.search(eachEntry.name): #search the shallow layer\n Digfiles.loop(self, eachEntry.path, store) # search the deeper layer\n \n files = Digfiles.subfiles(self, path)\n for eachFile in files:\n if not eachFile.name.startswith('~') and \\\n self.filekey.search(eachFile.name): # this is to find the files, to be modified\n store.append(eachFile.path) \n return store\n \n#---------------------------------------------------------------------------- \n def loopfoldersName(self, paths):\n names = []\n for path in paths:\n entries = Digfiles.subdirs(self, path)\n for eachEntry in entries:\n names.append(eachEntry.name)\n return names\n \n def loopfolders(self, paths):\n for path in paths:\n folders = [eachEntry.path for eachEntry in Digfiles.subdirs(self, path)]\n files = [eachFile.path for eachFile in Digfiles.subfiles(self, path)]\n return folders, files\n\n def findfolders(self, folders, files): \n ffolders = [folder for folder in folders if self.folderkey.search(folder)]\n ffiles = [file for file in files if self.filekey.search(file)]\n return ffolders, ffiles\n \n def ziploop(self, newpaths):\n (listoffolders, listoffiles) = Digfiles.loopfolders(self, newpaths)\n (newpaths, ffiles) = Digfiles.findfolders(self, listoffolders, listoffiles)\n #print(newpaths)\n return listoffolders, listoffiles, newpaths, ffiles\n#----------------------------------------------------------------------------\n # others \n def createFolder(self, directory):\n '''\n this function can be used to create folders\n '''\n try:\n if not os.path.exists(directory):\n os.makedirs(directory)\n except OSError:\n print ('Error: Creating directory. ' + directory)\n \n def copyfile(self, files, saveto):\n '''\n this function can be used to copy files\n files: a list of file paths\n saveto: a path that all files will be copied to\n '''\n try:\n for each in files:\n #print('each: ', each)\n fullpath = saveto + os.sep + each.split('\\\\')[-1]\n if not os.path.exists(fullpath):\n shutil.copy2(each, saveto)\n elif os.path.exists(fullpath):\n if self.overwrite == 0:\n temp = '(1)' + each.split('\\\\')[-1]\n modifiedpath = saveto + os.sep + temp\n shutil.copy2(each, modifiedpath)\n else:\n shutil.copy2(each, saveto) ## can this overwrite??\n except OSError:\n print ('Error: Creating directory. ' + savepath) \n \n def slowfindfile(self, path):\n '''\n this function use os.walk to walk through all directories in path, and\n return with a stored function storing all the file path that meet the\n filekey search\n \n use with cautions -> very slow\n '''\n store = []\n for root, dirs, files in os.walk(path):\n for file in files:\n if self.filekey.search(file) is not None:\n store.append(os.path.join(root, file))\n return store\n \n#----------------------------main execution code---------------------------------\n\n def main(self, path):\n '''\n main function to define logic to find the targeted folders and files\n Basic logic:\n Three senerios:\n 1. if there's folderkey found in the layer.\n this speeds up the searching logic a lot; however, may have chance to miss\n the file if the wanted files are not put into the folder searched by\n folderkey.\n 2. if there no folderkey in the layer, then go to deeper layer to find\n 3. semi-walking is in between keywords and full os.walk method, it use os.walk\n when cannot use keywords to find the file\n 4. call os.walk functions (slowfindfile) for full path search, very slow..\n \n '''\n store = []\n \n while True:\n #print('method 1...shallow.digging...', path)\n store = Digfiles.loop(self, path, store) # step 1\n if self.fullwalk:\n #print('method 4...fullwalking....', path)\n store = Digfiles.slowfindfile(self, path)\n return store\n elif store != []: \n # if there's folderkey found in the layer\n # this speeds up the searching logic a lot, however, may have chance to miss\n # the file if the wanted files are not put into the folder searched by\n # folderkey.\n return store\n else:\n #print('method 2...deep.digging..', path)\n # if there no folderkey in the layer, go deeper\n newpaths = []\n newpaths.append(path)\n counter = 0\n \n (listoffolders, lfis, newpaths, ffis) = Digfiles.ziploop(self, newpaths)\n \n while True:\n # here is to loop to search the folder based on keywords\n if newpaths == []: \n # if the first search didn't get the anything, then we need to\n # feed back the all the folderpath back to loop and find the\n # next layer of folders\n if listoffolders != []:\n (listoffolders, lfis, newpaths, ffis) = Digfiles.ziploop(self, listoffolders)\n if ffis != []:\n for ffi in ffis:\n store.append(ffi)\n if len(newpaths) == 1:\n store = Digfiles.loop(self, newpaths[0], store)\n return store\n if len(newpaths) > 1:\n for newpath in newpaths:\n #print(newpath)\n store = Digfiles.loop(self, newpath, store)\n return store\n \n counter += 1\n if counter > 100: #ok...if cannot search through finding folderkey...then let's do os.walk..\n # through all files....\n if self.semiwalk:\n #print('method 3...deep.digging..', path)\n store = Digfiles.slowfindfile(self, path)\n #print('\\n',path,'\\n')\n #print(store)\n return store\n \n def store2dict(self, path, name): \n '''\n store the data into dictionary with each main folder name\n and copy to the target folder\n '''\n store = Digfiles.main(self, path)\n #print('\\n' + name)\n #print(store)\n if store == []:\n pass #print('!Warning: cannot find the files, please review the targeted folder or filekey')\n else:\n self.datadict[name] = [store]\n \n if self.save and store !=[]:\n Digfiles.createFolder(self, self.savepath + os.sep + name)\n savepathfull = self.savepath + os.sep + name\n print('copying...', name)\n Digfiles.copyfile(self, store, savepathfull)\n \n def run(self):\n (projectpaths,files) = df.loopfolders(self.paths)\n projectnames = df.loopfoldersName(self.paths)\n for projectpath, projectname in zip(projectpaths, projectnames):\n Digfiles.store2dict(self, projectpath, projectname)\n\n \nif __name__ == '__main__': \n start = time.time()\n \n paths = paths = [r'C:\\Users\\Ziqiang\\OneDrive - Arup']\n savepath = r'C:\\Users\\Ziqiang\\Desktop\\EPR'\n df = Digfiles(paths, savepath)\n \n folderkeyword = '(超限)|(抗震)|(EPR)|(报告)|(Report(s)?)'\n filekeyword = '(超限)|(抗震)|(EPR)'\n df.setfolderkey = folderkeyword\n df.setfilekey = filekeyword\n #df.setfolderkey(folderkeyword)\n #df.setfilekey(filekeyword) \n df.runsetting(0,0,0,0)\n # save\n # overwrite\n # semiwalk\n # fullwalk\n \n df.run()\n filedict = df.datadict\n \n print(time.time() - start)"
},
{
"alpha_fraction": 0.7853403091430664,
"alphanum_fraction": 0.801047146320343,
"avg_line_length": 190,
"blob_id": "59e2f6781a0184b0e553ed2c830882157f1af836",
"content_id": "f490c8814570241251cf61b2a55ab107daa42ad3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 1,
"path": "/README.md",
"repo_name": "jasonzqchen/buildingdata",
"src_encoding": "UTF-8",
"text": "# buildingdata. stage 1: a project of mining tall building data and form database. stage 2: data analysis on building database. stage 3: smart design using machine learning/big data approach\n"
},
{
"alpha_fraction": 0.4810810685157776,
"alphanum_fraction": 0.5216216444969177,
"avg_line_length": 12.666666984558105,
"blob_id": "0897f764120c21fd652eaefb7ff817cc1c99731d",
"content_id": "4188177337145558a9102d454585472c814980af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 370,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 27,
"path": "/idea/jason/readYJK.py",
"repo_name": "jasonzqchen/buildingdata",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Aug 11 20:01:25 2018\n\n@author: jason.chen\n@contact: [email protected]\n@company: ARUP\n\"\"\"\nimport os \nimport re \nimport time \n\nclass ReadYJK:\n def __init__(self, path):\n pass\n \n def wmass(self):\n pass\n \n def wdisp(self):\n pass\n \n def wzq(self):\n pass\n \n def w02q(self):\n pass\n\n"
}
] | 4 |
matthewblue177/cheese
|
https://github.com/matthewblue177/cheese
|
6e29bd4a32ba45fde9b36175c90a6965fca440bd
|
49a21a9e34d187c960fa159d123d7209b2150512
|
bbf4b2e737a1f9855173dcf2aff3d0ffdc566688
|
refs/heads/main
| 2023-08-20T21:13:38.782680 | 2021-10-01T16:22:33 | 2021-10-01T16:22:33 | 412,535,548 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5731511116027832,
"alphanum_fraction": 0.5932475924491882,
"avg_line_length": 27.930233001708984,
"blob_id": "3b2cde9890b4f8995844880d7ae9d3116d0b6906",
"content_id": "af30be065c395400f7766ba13d26977aaa19ee63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1244,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 43,
"path": "/cheeseOrder.py",
"repo_name": "matthewblue177/cheese",
"src_encoding": "UTF-8",
"text": "# Price per pound $10\n# Min amount - 5 pounds\n# Max ammound - 100 pounds\nimport time\n\ndef cheeseOrder(cheese):\n int(cheese)\n total = int(cheese) * 10\n return str(total)\n\nvalid = 0\nwhile valid == 0:\n cheeseAmount = input ('How much cheese would you like in lbs? : ')\n if int(cheeseAmount) < 5:\n print (\"That is not enough cheese to make an order!\")\n time.sleep (2)\n elif int(cheeseAmount) > 100:\n print ('That is too much cheese to ship!')\n time.sleep(2)\n elif cheeseAmount.isalpha():\n print ('The ammount must be a number!')\n else:\n print ('Ok... let me just price it out for you!')\n time.sleep (2)\n print ('Adding up cheese!')\n time.sleep (2)\n valid = 1\nprint ('The price of your cheese will be $' + cheeseOrder(cheeseAmount))\ntime.sleep (2)\nvalid = 0\nwhile valid == 0:\n print ('Would you like to place your order?')\n confirmation = input()\n confirmation = confirmation.lower()\n if confirmation == \"yes\":\n print ('Order placed!')\n valid = 1\n elif confirmation == 'no':\n print ('Ok, order canceled!')\n valid = 1\n else:\n print (\"Sorry! I didn't get that, please try again!\")\n time.sleep (2)\n"
}
] | 1 |
VicZamRol/Usb_connection_ARDvsRasp
|
https://github.com/VicZamRol/Usb_connection_ARDvsRasp
|
1c6f5cd7b7953d3f411c9c5d8454e32d153b936c
|
cc03c6d460abb256d1c7ee5d1f09d258bfed59d6
|
b47bce2ec0c089c39b4f11eb5017191f9fda5db3
|
refs/heads/master
| 2020-03-22T08:39:33.723008 | 2018-07-05T01:52:56 | 2018-07-05T01:52:56 | 139,781,716 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8474576473236084,
"alphanum_fraction": 0.8474576473236084,
"avg_line_length": 57,
"blob_id": "16e6fda99e2686b1ef143738eebd674ec8902498",
"content_id": "fc704be7b4e8b44bd4e69fa3ab590eca0bbcff5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 1,
"path": "/README.md",
"repo_name": "VicZamRol/Usb_connection_ARDvsRasp",
"src_encoding": "UTF-8",
"text": "USB Comunnication Between Arduino device and RaspBerry Pi\n\n"
},
{
"alpha_fraction": 0.5259133577346802,
"alphanum_fraction": 0.5480033755302429,
"avg_line_length": 42.592594146728516,
"blob_id": "4c9b86664578729b619bc1378d9bba835902eae8",
"content_id": "42f82f927df648e8924474ebc019357fb8f5ec8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1177,
"license_type": "no_license",
"max_line_length": 378,
"num_lines": 27,
"path": "/ard2rasp.c",
"repo_name": "VicZamRol/Usb_connection_ARDvsRasp",
"src_encoding": "UTF-8",
"text": "\n###################################################\n## USB Comunication ARDUI-Rasp /Arduino Code ##\n###################################################\n\nchar incomingData;\nString receivedCommand;\n \nint stringToNumber(String thisString) \n{\n int i, value, length;\n length = thisString.length();\n char blah[(length+1)];\n for(i=0; i<length; i++) { blah[i] = thisString.charAt(i); } blah[i]=0; value = atoi(blah); return value; } void setup() { Serial.begin(9600); Serial.println(\"Arduino Ready\"); pinMode(13, OUTPUT); pinMode(12, OUTPUT); pinMode(11, OUTPUT); pinMode(10, OUTPUT); pinMode(9, OUTPUT); } void loop() { if (Serial.available() > 0) \n {\n incomingData = Serial.read();\n receivedCommand+=incomingData;\n if (receivedCommand.length()==3)\n {\n digitalWrite(stringToNumber(receivedCommand.substring(0,2)),(receivedCommand[2]=='0')?LOW:HIGH);\n Serial.print(\"pin: \");\n Serial.print(receivedCommand.substring(0,2));\n Serial.print(\" at level: \");\n Serial.println((receivedCommand[2]=='0')?\"LOW\":\"HIGH\");\n receivedCommand=\"\";\n }\n } \n}"
},
{
"alpha_fraction": 0.38655462861061096,
"alphanum_fraction": 0.4257703125476837,
"avg_line_length": 22.866666793823242,
"blob_id": "cdf2e22b0fc40922d80672b54ec7e6b020f8da3c",
"content_id": "8f9859189b213cbcd1d10051861f827126af1c85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 357,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 15,
"path": "/ard2rasp.py",
"repo_name": "VicZamRol/Usb_connection_ARDvsRasp",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\n\n###################################################\n## USB Comunication ARDUI-Rasp /Raspberry Code ##\n###################################################\n\n\nser=serial.Serial('/dev/ttyACM0',9600)\nwhile 1:\n print(ser.readline())\n ser.write('091')\n time.sleep(1)\n ser.write('090')\n time.sleep(1)"
}
] | 3 |
futilities/string_bash_to_list
|
https://github.com/futilities/string_bash_to_list
|
290ec09c6650e81e034518cdf2b6394304701f8c
|
3ed58bb4a508b63568031abd0085288b709dc6da
|
fe45edf56404415bc09624998d3cf3daecbaa539
|
refs/heads/master
| 2021-07-10T13:07:54.448122 | 2017-10-09T19:58:49 | 2017-10-09T19:58:49 | 106,329,051 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7542372941970825,
"alphanum_fraction": 0.7542372941970825,
"avg_line_length": 58,
"blob_id": "7f15ff765d8aab7049632eac99c38d7b8d17f227",
"content_id": "f6319ccb0f890ed48d9ea841d32bb113ffba4a6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 118,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 2,
"path": "/README.md",
"repo_name": "futilities/string_bash_to_list",
"src_encoding": "UTF-8",
"text": "# string_bash_to_list\nThis class converts a string of a bash command with its arguments into a list for some use ....\n"
},
{
"alpha_fraction": 0.5254350900650024,
"alphanum_fraction": 0.5475234389305115,
"avg_line_length": 41.68571472167969,
"blob_id": "2fa94c3be56dcb13bffc458a6f86554ea6ca23df",
"content_id": "e075636e78fd02b20c8b263dd8765d2285964eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 508,
"num_lines": 35,
"path": "/bashstrToList.py",
"repo_name": "futilities/string_bash_to_list",
"src_encoding": "UTF-8",
"text": "import sys\nclass BashStringToList:\n \"\"\"\n This class converts a string of a bash command with its arguments into a list for some use ....\n \"\"\"\n\n def __init__(self):\n pass\n\n def convert(self,bash_command_string):\n split_bash = bash_command_string.split()\n\n bash_command_argument_list = []\n temp_arg = ''\n for i,c in enumerate(split_bash):\n if i == 0:\n bash_command_argument_list.append(c)\n continue\n if split_bash[i][0] == '-':\n temp_arg = c\n elif split_bash[i][0] != '-':\n temp_arg = temp_arg + ' ' + c \n\n if len(split_bash) < i+2 or split_bash[i+1][0] == '-':\n bash_command_argument_list.append(temp_arg)\n return bash_command_argument_list\n\nif __name__ == \"__main__\":\n \n if len(sys.argv) > 1:\n bash_string = sys.argv[1]\n else:\n bash_string = '/path/to/some/command -y -hide_banner -loglevel panic -i /some/stuff/gif -i /I/am/a/cat/ -i /poof/puff/stfuf/Tem -filter_complex \" [0:v]trim=duration=7[a]; [1:v]trim=duration=5[b]; [2:v]trim=duration=5[c]; [3:v]trim=duration=3[d]; [a][b][c][d] concat=n=4:v=1:a=0 [v]\" -filter_complex \" [0:a]atrim=duration=7[a]; [1:a]atrim=duration=5[b]; [2:a]atrim=duration=5[c]; [3:a]atrim=duration=3[d]; [a][b][c][d] concat=n=4:v=0:a=1 [a]\" -map \"[v]\" -map \"[a]\" /Users/pewpewl.mp4'\n bs2l = BashStringToList()\n print bs2l.convert(bash_string)\n"
}
] | 2 |
FallenApart/2048-py
|
https://github.com/FallenApart/2048-py
|
54c545506e6395adbdb92eb45bf7616eb919c249
|
5ed9de5107f18b20759100da23dc8c12aef9c97b
|
68514d149a11e52f86062964bd3b6dccbe8ab3ec
|
refs/heads/main
| 2023-02-18T19:38:47.857974 | 2021-01-17T18:44:53 | 2021-01-17T18:44:53 | 314,930,741 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5220469236373901,
"alphanum_fraction": 0.5380259156227112,
"avg_line_length": 33.32638931274414,
"blob_id": "752c68ee28adaacb20e41ccc46267cab07f30e83",
"content_id": "ccbd8d3cad6c748ad374995603a2f2a0230cc5e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4944,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 144,
"path": "/env.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom time import time\nfrom copy import deepcopy\n\nclass Env:\n def __init__(self, nb_rows=4, nb_cols=4, normalisation=1):\n self.nb_actions = 4\n self.nb_rows, self.nb_cols = nb_rows, nb_cols\n self.normalisation = normalisation\n self.reset()\n\n def reset(self):\n # start = time()\n self.max_value = 0\n self.invalid_moves_cnt = 0\n self.done = False\n self.score = 0\n self.state = np.zeros((self.nb_rows, self.nb_cols))\n self.update_empty_cells()\n self.add_number()\n self.add_number()\n # print('reset time: {:.3f} ms'.format((time() - start) * 1000))\n return self.state\n\n def step(self, action):\n old_state = deepcopy(self.state)\n if action == 0:\n self.state, reward = self.move_right(self.state)\n elif action == 1:\n self.state, reward = self.move_left(self.state)\n elif action == 2:\n self.state, reward = self.move_up(self.state)\n elif action == 3:\n self.state, reward = self.move_down(self.state)\n if np.array_equal(old_state, self.state):\n reward = 0\n self.invalid_moves_cnt += 1\n else:\n self.update_empty_cells()\n self.add_number()\n self.is_done()\n self.score += reward\n reward += 1 / self.normalisation\n self.max_value = np.max(self.state)\n return self.state, reward, self.done, None\n\n def update_empty_cells(self):\n self.empty_cells = self.state == 0\n\n def add_number(self):\n # start = time()\n empty_cells_idxs = np.transpose(self.empty_cells.nonzero())\n selected_cell = empty_cells_idxs[np.random.choice(empty_cells_idxs.shape[0], 1, replace=False)][0]\n r = np.random.rand(1)[0]\n self.state[selected_cell[0], selected_cell[1]] = 2 / self.normalisation if r < 0.9 else 4 / self.normalisation\n self.update_empty_cells()\n # print('Add number: {:.3f} ms'.format((time() - start) * 1000))\n\n @staticmethod\n def slide_row_right(row):\n non_empty = row[row!=0]\n missing = row.shape[0] - non_empty.shape[0]\n new_row = np.append(np.zeros(missing), non_empty)\n return new_row\n\n def move_row_right(self, row):\n row = self.slide_row_right(row)\n col_reward = 0\n for col in reversed(range(1, self.nb_cols)):\n if row[col] == row[col-1]:\n col_reward += 2 * row[col]\n row[col] = 2 * row[col]\n row[col-1] = 0\n row = self.slide_row_right(row)\n return row, col_reward\n\n def move_right(self, state):\n new_state = np.copy(state)\n reward = 0\n for row in range(self.nb_rows):\n new_state[row], col_reward = self.move_row_right(state[row])\n reward += col_reward\n return new_state, reward\n\n def move_left(self, state):\n new_state = np.flip(state, axis=1)\n new_state, reward = self.move_right(new_state)\n new_state = np.flip(new_state, axis=1)\n return new_state, reward\n\n def move_down(self, state):\n new_state = state.T\n new_state, reward = self.move_right(new_state)\n new_state = new_state.T\n return new_state, reward\n\n def move_up(self, state):\n new_state = state.T\n new_state = np.flip(new_state, axis=1)\n new_state, reward = self.move_right(new_state)\n new_state = np.flip(new_state, axis=1)\n new_state = new_state.T\n return new_state, reward\n\n def is_done(self):\n # start = time()\n if np.sum(self.empty_cells) == 0:\n for row in range(self.nb_rows):\n for col in range(self.nb_cols):\n if col != self.nb_cols-1 and self.state[row][col] == self.state[row][col+1]:\n return None\n if row != self.nb_rows-1 and self.state[row][col] == self.state[row+1][col]:\n return None\n self.done = True\n # print('Check if done: {:.3f} ms'.format((time() - start) * 1000))\n\n\nif __name__ == '__main__':\n env = Env()\n\n scores = []\n\n for _ in range(100):\n start = time()\n step = 0\n score = 0\n env.reset()\n done = False\n while not done:\n action = np.random.randint(0, 4, size=1)[0]\n new_state, reward, done, info = env.step(action)\n step += 1\n # print('Step: {}'.format(step))\n # print(new_state)\n # score += reward\n # if env.invalid_moves_cnt >= 100:\n # done = True\n print('Simulation time: {:.3f} ms'.format((time() - start) * 1000))\n\n print('Game done, Score: {}. Max tile: {}'.format(env.score, env.max_value))\n\n scores.append(env.score)\n\n print(\"Avg score: {}, std: {}\".format(np.mean(scores), np.std(scores)))\n\n"
},
{
"alpha_fraction": 0.9074074029922485,
"alphanum_fraction": 0.9074074029922485,
"avg_line_length": 12.75,
"blob_id": "f9483150237bc882682793ad124f5b072bc7a3d6",
"content_id": "8d6fc16c51ce20a44b13682741787a2037d5c445",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 54,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "numpy\ntensorflow-gpu\ntensorflow_probability\nmatplotlib"
},
{
"alpha_fraction": 0.582897424697876,
"alphanum_fraction": 0.592449426651001,
"avg_line_length": 42.10784149169922,
"blob_id": "b3007ab3420202d91b87a3adad3c906c3087c61b",
"content_id": "fb59b03038caab31dca88383afb7a031a225d1e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4397,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 102,
"path": "/train_dnn_agent.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "import os\nimport time\nimport numpy as np\nfrom dnn_agent import DNNAgent\nfrom env import Env\nimport tensorflow as tf\nfrom argparse import ArgumentParser\nimport subprocess\n\nrc = subprocess.call(\"echo $LD_LIBRARY_PATH\", shell=True)\ngpus = tf.config.experimental.list_physical_devices('GPU')\nprint(\"Num GPUs Available: \", len(gpus))\nfor gpu in gpus:\n tf.config.experimental.set_memory_growth(gpu, True)\n\ndef main(args):\n logs_dir = 'logs/{}_{}_{}_{}_{}_{}_{}_{}'.format(args.dnn_name, args.gamma, args.lr, args.max_invalid_moves,\n args.normalisation, args.batch_size, args.mode, args.idx)\n os.makedirs(logs_dir, exist_ok=True)\n os.makedirs(os.path.join(logs_dir, 'model'), exist_ok=True)\n\n agent = DNNAgent(mode=args.mode, lr=args.lr, gamma=args.gamma, nb_actions=4, dnn_name=args.dnn_name)\n env = Env(normalisation=args.normalisation)\n\n score_history, game_score_history, avg_score_history, avg_game_score_history = [], [], [], []\n nb_episodes = 100000\n\n window = 100\n\n tb_logs_dir = os.path.join(logs_dir, 'tb_logs')\n tb_summary_writer = tf.summary.create_file_writer(tb_logs_dir)\n\n best_score = 0\n\n i = 0\n\n while i < nb_episodes:\n batch_time_start = time.time()\n batch_state_memory, batch_action_memory, batch_reward_memory, batch_terminal_state = [], [], [], []\n batch_scores = []\n for j in range(args.batch_size):\n done = False\n state_np = env.reset()\n step = 0\n while not done:\n action_np = agent.choose_actions(np.expand_dims(state_np, axis=0))[0]\n new_state_np, reward_np, done, info = env.step(action_np)\n score_np = env.score * args.normalisation\n agent.store_transition(state_np, action_np, reward_np, score_np)\n state_np = new_state_np\n if env.invalid_moves_cnt >= args.max_invalid_moves:\n print(\"Max invalid mover reached\")\n done = True\n step += 1\n\n terminal_state = state_np\n\n batch_scores.append(score_np)\n batch_state_memory.append(agent.state_memory)\n batch_action_memory.append(agent.action_memory)\n batch_reward_memory.append(agent.reward_memory)\n batch_terminal_state.append(terminal_state)\n agent.reset_memory()\n\n if score_np > best_score:\n best_score = env.score * args.normalisation\n # agent.policy.save(os.path.join(logs_dir, 'model', 'model.hdf5'))\n # print('New best score: {}; New model has been saved'.format(best_score))\n\n score_history.append(env.score * args.normalisation)\n avg_score = np.mean(score_history[-window:])\n avg_score_history.append(avg_score)\n\n print('Episode: {}; Score: {}; Avg score: {:.1f}; Max value: {}'.format(\n i, score_history[-1], avg_score, int(env.max_value * args.normalisation)))\n\n with tb_summary_writer.as_default():\n tf.summary.scalar('score', score_np, step=i)\n tf.summary.scalar('avg score', avg_score, step=i)\n tf.summary.scalar('max value', env.max_value * args.normalisation, step=i)\n tf.summary.scalar('nb invalid moves', env.invalid_moves_cnt, step=i)\n tf.summary.scalar('nb steps', step, step=i)\n i += 1\n\n agent.learn(batch_state_memory, batch_action_memory, batch_reward_memory, batch_terminal_state)\n\n print('Batch time: {:.2f} sec.; Avg batch game score: {:.1f}'.format(time.time() - batch_time_start,\n np.array(batch_scores).mean()))\n\n\nif __name__ == '__main__':\n parser = ArgumentParser()\n parser.add_argument('--dnn_name', type=str, default='dnn5')\n parser.add_argument('--batch_size', type=int, default=1)\n parser.add_argument('--gamma', type=float, default=0.99)\n parser.add_argument('--lr', type=float, default=0.001)\n parser.add_argument('--max_invalid_moves', type=int, default=1000)\n parser.add_argument('--normalisation', type=float, default=1024.0)\n parser.add_argument('--mode', type=str, default='a2c')\n parser.add_argument('--idx', type=int, default=0)\n args = parser.parse_args()\n main(args)\n"
},
{
"alpha_fraction": 0.6583850979804993,
"alphanum_fraction": 0.6677018404006958,
"avg_line_length": 22,
"blob_id": "6a5b39074026a617e36b5733b6519cecfa939e84",
"content_id": "1b7b259ca8b9684f410e6ad0d422c8e8ddd55468",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 14,
"path": "/utils.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "import io\nimport matplotlib.pyplot as plt\nimport tensorflow as tf\n\n\ndef fig_to_ftimage(figure):\n buf = io.BytesIO()\n plt.savefig(buf, format='png')\n plt.close(figure)\n buf.seek(0)\n image = tf.image.decode_png(buf.getvalue(), channels=4)\n image = tf.expand_dims(image, 0)\n plt.close()\n return image\n"
},
{
"alpha_fraction": 0.6238625049591064,
"alphanum_fraction": 0.6334681510925293,
"avg_line_length": 34.9636344909668,
"blob_id": "657d9fd47ab3d483c00fc6bb5b70bc65efd3dea5",
"content_id": "a63a207f34fd65f63a56d9fbdbd60d7ff2437ccf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1978,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 55,
"path": "/evaluate_agnet.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport tensorflow as tf\nfrom tqdm import tqdm\nfrom argparse import ArgumentParser\nfrom rand_agent import RandAgent\nfrom dnn_agent import DNNAgent\nfrom dlru_agent import DLRUAgent\nfrom env import Env\n\n\ndef main(args):\n env = Env(normalisation=args.normalisation)\n\n if args.agent_type == 'rand':\n agent = RandAgent(nb_actions=4)\n elif args.agent_type == 'dlru':\n agent = DLRUAgent(nb_actions=4, env=Env(normalisation=args.normalisation))\n elif args.agent_type == 'dnn':\n agent = DNNAgent(nb_actions=4, dnn_name=args.dnn_name)\n agent.policy = tf.keras.models.load_model('example/model.hdf5')\n\n scores = []\n for idx in tqdm(range(args.nb_episodes), desc='Episodes'):\n step = 0\n state_np = env.reset()\n done = False\n while not done:\n action_np = agent.choose_actions(np.expand_dims(state_np, axis=0))[0]\n new_state_np, reward_np, done, info = env.step(action_np)\n score_np = env.score * args.normalisation\n agent.store_transition(state_np, action_np, reward_np, score_np)\n state_np = new_state_np\n if env.invalid_moves_cnt >= args.max_invalid_moves:\n print(\"Max invalid mover reached\")\n done = True\n step += 1\n scores.append(score_np)\n\n agent.terminal_state = state_np\n agent.dump_trajectory(args.normalisation, idx)\n\n agent.reset_memory()\n\n print(\"Avg score: {}, std: {}\".format(np.mean(scores), np.std(scores)))\n\n\nif __name__ == '__main__':\n parser = ArgumentParser()\n parser.add_argument('--agent_type', type=str, default='dnn')\n parser.add_argument('--nb_episodes', type=int, default=1)\n parser.add_argument('--max_invalid_moves', type=int, default=2000)\n parser.add_argument('--dnn_name', type=str, default='dnn5')\n parser.add_argument('--normalisation', type=float, default=1024.0)\n args = parser.parse_args()\n main(args)\n"
},
{
"alpha_fraction": 0.4866732358932495,
"alphanum_fraction": 0.499506413936615,
"avg_line_length": 35.21428680419922,
"blob_id": "e5beb570a514e72bd14dcc12c1c58536c9f3f5b2",
"content_id": "3950ab15d519b48c310afb91e3df83330cdf5d73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1013,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 28,
"path": "/dlru_agent.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "from abc_agent import ABCAgent\nimport numpy as np\n\n\nclass DLRUAgent(ABCAgent):\n def __init__(self, nb_actions=4, env=None):\n super(DLRUAgent, self).__init__(nb_actions=nb_actions)\n self.env = env\n\n def choose_actions(self, states):\n #TODO Not available for batches\n new_state, _ = self.env.move_down(states[0])\n if not np.array_equal(states[0], new_state):\n return [3]\n else:\n new_state, _ = self.env.move_left(states[0])\n if not np.array_equal(states[0], new_state):\n return [1]\n else:\n new_state, _ = self.env.move_right(states[0])\n if not np.array_equal(states[0], new_state):\n return [2]\n else:\n new_state, _ = self.env.move_up(states[0])\n if not np.array_equal(states[0], new_state):\n return [0]\n else:\n print('Error! No valid moves')"
},
{
"alpha_fraction": 0.6410635113716125,
"alphanum_fraction": 0.6418020725250244,
"avg_line_length": 41.3125,
"blob_id": "c298828eefaacd70759f9b3b74c00ba0c457f6d4",
"content_id": "17369ce55ee6ff560ce35800b2664da262f7298a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1354,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 32,
"path": "/abc_agent.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nimport json\n\n\nclass ABCAgent(ABC):\n def __init__(self, nb_actions=4):\n self.nb_actions = nb_actions\n self.state_memory, self.action_memory, self.reward_memory, self.score_memory = [], [], [], []\n\n @abstractmethod\n def choose_actions(self, states):\n pass\n\n def store_transition(self, state_np, action_np, reward_np, score_np):\n self.state_memory.append(state_np)\n self.action_memory.append(action_np)\n self.reward_memory.append(reward_np)\n self.score_memory.append(score_np)\n\n def reset_memory(self):\n self.state_memory, self.action_memory, self.reward_memory, self.score_memory = [], [], [], []\n\n def dump_trajectory(self, normalisation, idx):\n states_list = [(state.flatten() * normalisation).astype(int).tolist() for state in self.state_memory]\n actions_list = [int(action) for action in self.action_memory]\n scores_list = [int(score) for score in self.score_memory]\n terminal_state = (self.terminal_state.flatten() * normalisation).astype(int).tolist()\n trajectory = {'states': states_list, 'actions': actions_list, 'scores': scores_list,\n 'terminal_state': terminal_state}\n\n with open('example/trajectory_{}.json'.format(idx), 'w') as fp:\n json.dump(trajectory, fp)\n"
},
{
"alpha_fraction": 0.47230464220046997,
"alphanum_fraction": 0.4935707151889801,
"avg_line_length": 31.11111068725586,
"blob_id": "e371ae9d31e8d792fdc03b97e5e5c42f9e28b8f0",
"content_id": "b6df46f609e345a7645683d360db128065751df3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2022,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 63,
"path": "/gui/script.js",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "var trajectory_json;\nvar trajectory_length;\n\nfunction updateGrid(flat_grid, score) {\n this.score = score\n $(\"#score\").text(\"Score: \" + this.score);\n $('.cell-value').each(function(cell, obj) {\n let cell_value = flat_grid[cell];\n if (cell_value == 0) {\n $(this).text(\"\");\n $(this).parent().css({'background-color': '#e6f0ff'});\n } else {\n $(this).text(flat_grid[cell]);\n let color_lightness = 50 / (Math.log2(flat_grid[cell]) + 1) + 50;\n let hsl_color = 'hsl(255, 100%, ' + color_lightness.toString() + '%)';\n $(this).parent().css({'background-color': hsl_color});\n }\n })\n}\n\n$(document).ready(function() {\n\n let intervalId = false;\n let flat_grid = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0];\n let done = false;\n let game_score = 0;\n\n $.getJSON(\"../example/trajectory_0.json\", function(json){trajectory_json = json;});\n\n $('#run').click(() => {\n run()\n });\n\n function run() {\n done = false;\n this.game_score = 0\n trajectory_length = trajectory_json['actions'].length;\n let step = 0;\n if (intervalId) {\n clearInterval(intervalId);\n intervalId = false;\n }\n intervalId = setInterval(function(){\n if (done) {\n clearInterval(intervalId);\n intervalId = false;\n $(\"#status\").text(\"Game Over\");\n return;\n }\n if (step == 0) {\n updateGrid(trajectory_json['states'][step], 0);\n } else if (0 < step && step < trajectory_length) {\n console.log('active')\n updateGrid(trajectory_json['states'][step], trajectory_json['scores'][step-1]);\n } else if (step == trajectory_length) {\n updateGrid(trajectory_json['terminal_state'], trajectory_json['scores'][step-1]);\n done = true;\n }\n step++;\n }, 100)\n }\n\n})"
},
{
"alpha_fraction": 0.5325301289558411,
"alphanum_fraction": 0.5376171469688416,
"avg_line_length": 48.79999923706055,
"blob_id": "1c1a8c02e269abc5a80692c5db6cda00c2d697f2",
"content_id": "1e6385ff58cb1b6a192df1fc3209aa044528aebb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3735,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 75,
"path": "/dnn_agent.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport tensorflow_probability as tfp\nfrom tensorflow.keras.optimizers import Adam\nimport numpy as np\nfrom models import get_policy_network\nfrom abc_agent import ABCAgent\n\n\nclass DNNAgent(ABCAgent):\n def __init__(self, mode='pg', lr=0.0005, gamma=0.99, nb_actions=4, dnn_name='dnn3'):\n super(DNNAgent, self).__init__(nb_actions=nb_actions)\n self.mode = mode\n self.lr = lr\n self.gamma = gamma\n self.dnn_name = dnn_name\n self.policy = get_policy_network(self.nb_actions, self.dnn_name, self.mode)\n self.policy.compile(optimizer=Adam(learning_rate=self.lr))\n # self.policy.summary()\n\n def get_action_probs(self, states, training=None):\n if self.mode == 'pg':\n probs = self.policy(states, training=training)\n elif self.mode == 'a2c':\n _, probs = self.policy(states, training=training)\n action_probs = tfp.distributions.Categorical(probs=probs)\n return action_probs\n\n def choose_actions(self, states):\n with tf.device(\"/cpu:0\"):\n actions_probs = self.get_action_probs(states, training=False)\n actions = actions_probs.sample()\n return actions.numpy()\n\n def learn(self, batch_state_memory, batch_action_memory, batch_reward_memory, batch_terminal_state):\n if self.mode == 'pg':\n batch_G = []\n for reward_memory in batch_reward_memory:\n G = np.zeros_like(reward_memory)\n G_tmp = 0\n for t in reversed(range(len(reward_memory))):\n G[t] = G_tmp * self.gamma + reward_memory[t]\n G_tmp = G[t]\n batch_G.append(G)\n\n with tf.GradientTape() as tape:\n losses = []\n if self.mode == 'pg':\n for state_memory, action_memory, G in zip(batch_state_memory, batch_action_memory, batch_G):\n action_probs = self.get_action_probs(state_memory, training=True)\n log_probs = action_probs.log_prob(action_memory)\n loss = - tf.reduce_sum(log_probs * G)\n losses.append(loss)\n elif self.mode == 'a2c':\n for state_memory, action_memory, reward_memory, terminal_state in zip(batch_state_memory,\n batch_action_memory,\n batch_reward_memory,\n batch_terminal_state):\n state_value, probs = self.policy(np.array(state_memory), training=True)\n next_state_value, _ = self.policy(np.array(state_memory[1:] + [terminal_state]), training=True)\n action_probs = tfp.distributions.Categorical(probs=probs)\n log_probs = action_probs.log_prob(np.array(action_memory))\n dones = np.ones((next_state_value.shape[0],))\n dones[-1] = 0\n deltas = np.array(reward_memory) + self.gamma * next_state_value * dones - state_value\n actor_loss = - tf.reduce_sum(log_probs * deltas)\n critic_loss = tf.reduce_sum(deltas ** 2)\n loss = actor_loss + critic_loss\n losses.append(loss)\n loss = tf.reduce_mean(losses)\n\n if tf.math.is_nan(loss):\n print('loss is nan')\n else:\n grads = tape.gradient(loss, self.policy.trainable_variables)\n self.policy.optimizer.apply_gradients(zip(grads, self.policy.trainable_variables))\n"
},
{
"alpha_fraction": 0.6734693646430969,
"alphanum_fraction": 0.6836734414100647,
"avg_line_length": 28.399999618530273,
"blob_id": "14b0e85529ed3aac53d7d1cdff19e613c4b16f66",
"content_id": "a06498e613b82d9de7c5982058e120d7cefff581",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 294,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 10,
"path": "/rand_agent.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "from abc_agent import ABCAgent\nimport numpy as np\n\n\nclass RandAgent(ABCAgent):\n def __init__(self, nb_actions=4):\n super(RandAgent, self).__init__(nb_actions=nb_actions)\n\n def choose_actions(self, states):\n return np.random.randint(0, self.nb_actions, size=states.shape[0])\n"
},
{
"alpha_fraction": 0.4621647596359253,
"alphanum_fraction": 0.4992816150188446,
"avg_line_length": 35.955753326416016,
"blob_id": "7000d5c3f1c13126b8211dec90219cd051dead6e",
"content_id": "3c884aadb11c3e506c5a918e39d73f33f17b0bd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4176,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 113,
"path": "/models.py",
"repo_name": "FallenApart/2048-py",
"src_encoding": "UTF-8",
"text": "from tensorflow.keras import Sequential, Model\nfrom tensorflow.keras.layers import Dense, Flatten, Dropout, Conv2D, GlobalAvgPool2D, Softmax, Input\n\n\ndef minidnn(nb_actions=4):\n model = Sequential([Input(shape=(4, 4, 1)),\n Flatten(),\n Dense(64, activation='relu'),\n Dense(64, activation='relu'),\n Dense(nb_actions, activation='softmax')])\n return model\n\n\ndef dnn3(nb_actions=4):\n model = Sequential([Input(shape=(4, 4, 1)),\n Flatten(),\n Dense(64, activation='relu'),\n Dense(64, activation='relu'),\n Dense(64, activation='relu'),\n Dense(nb_actions, activation='softmax')])\n return model\n\n\ndef dnn5(nb_actions=4):\n model = Sequential([Input(shape=(4, 4, 1)),\n Flatten(),\n Dense(256, activation='relu'),\n Dense(256, activation='relu'),\n Dense(256, activation='relu'),\n Dense(256, activation='relu'),\n Dense(256, activation='relu'),\n Dense(nb_actions, activation='softmax')])\n return model\n\n\nclass ActorCriticModel(Model):\n def __init__(self, nb_actions=4):\n super(ActorCriticModel, self).__init__()\n self.nb_actions = nb_actions\n\n self.flatten = Flatten()\n self.fc1 = Dense(256, activation='relu')\n self.fc2 = Dense(256, activation='relu')\n self.fc3 = Dense(256, activation='relu')\n self.fc4 = Dense(256, activation='relu')\n self.fc5 = Dense(256, activation='relu')\n self.v = Dense(1)\n self.pi = Dense(self.nb_actions, activation='softmax')\n\n def call(self, state, *args):\n x = self.flatten(state)\n x = self.fc1(x)\n x = self.fc2(x)\n x = self.fc3(x)\n x = self.fc4(x)\n x = self.fc5(x)\n v = self.v(x)\n pi = self.pi(x)\n return v, pi\n\n\ndef cnn(nb_actions=4):\n model = Sequential([Input(shape=(4, 4, 1)),\n Conv2D(128, (4, 4), padding='same', activation='relu'),\n Conv2D(256, (4, 4), padding='same', activation='relu'),\n Conv2D(512, (4, 4), padding='same', activation='relu'),\n Conv2D(256, (4, 4), padding='same', activation='relu'),\n Conv2D(64, (4, 4), padding='same', activation='relu'),\n Conv2D(nb_actions, (4, 4), padding='same'),\n GlobalAvgPool2D(),\n Softmax()])\n return model\n\n\ndef cnnd(nb_actions=4):\n model = Sequential([Input(shape=(4, 4, 1)),\n Conv2D(128, (4, 4), padding='same', activation='relu'),\n Conv2D(256, (4, 4), padding='same', activation='relu'),\n GlobalAvgPool2D(),\n Dense(256, activation='relu'),\n Dense(256, activation='relu'),\n Dense(nb_actions, activation='softmax')])\n return model\n\n\ndef cnndv2(nb_actions=4):\n model = Sequential([Input(shape=(4, 4, 1)),\n Conv2D(512, (4, 4), padding='valid', activation='relu'),\n GlobalAvgPool2D(),\n Dense(256, activation='relu'),\n Dense(256, activation='relu'),\n Dense(nb_actions, activation='softmax')])\n return model\n\n\ndef get_policy_network(nb_actions=4, dnn_name='dnn3', mode='pg'):\n if dnn_name == 'dnn3':\n model = dnn3(nb_actions=nb_actions)\n elif dnn_name == 'dnn5':\n if mode == 'pg':\n model = dnn5(nb_actions=nb_actions)\n elif mode == 'a2c':\n model = ActorCriticModel()\n elif dnn_name == 'cnn':\n model = cnn(nb_actions=nb_actions)\n elif dnn_name == 'cnnd':\n model = cnnd(nb_actions=nb_actions)\n elif dnn_name == 'cnndv2':\n model = cnndv2(nb_actions=nb_actions)\n elif dnn_name == 'minidnn':\n model = minidnn(nb_actions=nb_actions)\n\n return model\n"
}
] | 11 |
davidghedix/smartDTcomposer
|
https://github.com/davidghedix/smartDTcomposer
|
3adbc23bd6b5e53ef1a677d2b830eaee79f88f5d
|
d3040968fc96ffb20ad6d915fc3d6e027e0edcdc
|
ca36279a8e9c98002c0fa5a40455bc409bc51288
|
refs/heads/main
| 2022-12-31T00:26:33.983150 | 2020-10-25T13:40:54 | 2020-10-25T13:40:54 | 306,901,101 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6241433620452881,
"alphanum_fraction": 0.629941999912262,
"avg_line_length": 31.427350997924805,
"blob_id": "d5fa7801636af22a07439546155888de633ac3cb",
"content_id": "4e7d3228810b2ff4523caaa924ba0941c592af1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3794,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 117,
"path": "/device/robot.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "import netifaces\nimport paho.mqtt.client as mqtt\nimport datetime, threading, time\nimport json\n\n\n# DEVICE CONFIG GOES HERE\ntenantId = \"YOUR-TENANT-ID\"\ndevice_password = \"YOUR-DEVICE-PASSWORD\"\nhub_adapter_host = \"mqtt.bosch-iot-hub.com\"\ndeviceId = \"com.myThings:robot\"\nclientId = deviceId\nauthId = \"com.myThings_robot\"\ncertificatePath = \"./iothub.crt\"\nditto_topic = \"com.myThings/robot\"\n\n\n# The callback for when the client receives a CONNACK response from the server.\ndef on_connect(client, userdata, flags, rc):\n\n if rc != 0:\n print(\"Connection to MQTT broker failed: \" + str(rc))\n return\n\n # Subscribing in on_connect() means that if we lose the connection and\n # reconnect then subscriptions will be renewed.\n\n # BEGIN SAMPLE CODE\n client.subscribe(\"command///req/#\")\n # END SAMPLE CODE\n print(\"Connected\")\n\n# The callback for when a PUBLISH message is received from the server.\ndef on_message(client, userdata, msg):\n \n print(\"Command received...\")\n cmd = json.loads(msg.payload.decode(\"utf-8\"))\n cmdName = cmd[\"topic\"].split(\"/\")[-1]\n params = cmd[\"value\"]\n changeStatus(json.dumps(\"busy\"))\n executeCommand(cmdName, params)\n changeStatus(json.dumps(\"terminated\"))\n\ndef executeCommand(name, params):\n if name == \"move\":\n added = []\n deleted = []\n added.append(\"at:\" + params[1])\n deleted.append(\"at:\" + params[0])\n output = dict(added = added, deleted = deleted)\n \n updateState(\"at\", json.dumps(params[1]))\n publishOutput(json.dumps(output))\n \n elif name == \"load\":\n added = []\n deleted = []\n added.append(\"carries:\" + params[0])\n deleted.append(params[0] + \".at:\" + params[1] )\n output = dict(added = added, deleted = deleted)\n \n updateState(\"carries\", json.dumps(params[0]))\n publishOutput(json.dumps(output))\n \n elif name == \"unload\":\n added = []\n deleted = []\n added.append(params[0] + \".at:\" + params[1])\n deleted.append(\"carries:\" + params[0])\n output = dict(added = added, deleted = deleted)\n \n updateState(\"carries\", json.dumps(None))\n publishOutput(json.dumps(output))\n \ndef updateState(feature, value):\n payload = '{\"topic\": \"' + ditto_topic + \\\n '/things/twin/commands/modify\",\"headers\": {\"response-required\": false},' + \\\n '\"path\": \"/features/' + feature + '/properties/value/current\",\"value\" : ' + value + '}'\n client.publish(publishTopic, payload)\n\ndef publishOutput(output):\n payload = '{\"topic\": \"' + ditto_topic + \\\n '/things/twin/commands/modify\",\"headers\": {\"response-required\": false},' + \\\n '\"path\": \"/features/output/properties/value\",\"value\" : ' + output + '}'\n client.publish(publishTopic, payload)\n\n\ndef changeStatus(status):\n payload = '{\"topic\": \"' + ditto_topic + \\\n '/things/twin/commands/modify\",\"headers\": {\"response-required\": false},' + \\\n '\"path\": \"/features/status/properties/value\",\"value\" : ' + status + '}'\n client.publish(publishTopic, payload)\n\n \n# Period for publishing data to the MQTT broker in seconds\ntimePeriod = 10\n\n# Configuration of client ID and publish topic\t\npublishTopic = \"telemetry/\" + tenantId + \"/\" + deviceId\n\n# Output relevant information for consumers of our information\nprint(\"Connecting client: \", clientId)\nprint(\"Publishing to topic: \", publishTopic)\n\n# Create the MQTT client\nclient = mqtt.Client(clientId)\nclient.on_connect = on_connect\nclient.on_message = on_message\nclient.tls_set(certificatePath)\nusername = authId + \"@\" + tenantId\nclient.username_pw_set(username, device_password)\nclient.connect(hub_adapter_host, 8883, 60)\n\nclient.loop_start()\n\nwhile (1):\n pass\n"
},
{
"alpha_fraction": 0.42819616198539734,
"alphanum_fraction": 0.4929947555065155,
"avg_line_length": 25.55813980102539,
"blob_id": "96fdcaa76749a58683200f60b487fdab64f2df85",
"content_id": "c34cd77a17b5b03cff594f41961de1fa61a7544f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1142,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 43,
"path": "/src/context.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "from Description import *\n\n#Sample context data\n\ninstances = {\"Object\":[\"o1\",\"o2\"],\\\n\n \"Location\":[\"l00\",\"l01\",\"l02\",\"l03\",\"l04\",\"l05\",\"l06\",\\\n\n \"l10\",\"l11\",\"l12\",\"l13\",\"l14\",\"l15\",\"l16\",\\\n\n \"l20\",\"l21\",\"l22\",\"l23\",\"l24\",\"l25\",\"l26\",\\\n\n \"l30\",\"l31\",\"l32\",\"l33\",\"l34\",\"l35\",\"l36\"],\n\n \"Boolean\":[\"true\",\"false\"]}\n\natomicTerms = [atomicTerm(\"heated\",\"o - Object\", \"b - Boolean\"),\n\n atomicTerm(\"processed\",\"o - Object\", \"b - Boolean\"),\n\n atomicTerm(\"cooled\",\"o - Object\", \"b - Boolean\"),\n\n atomicTerm(\"movable\",\"o - Object\", \"b - Boolean\")]\n\ngroundAtomicTerms = [groundAtomicTerm(\"at\",\"o1\",\"l00\"),\n\n groundAtomicTerm(\"at\",\"o2\",\"l00\"),\n\n groundAtomicTerm(\"movable\",\"o1\",\"true\"),\n\n groundAtomicTerm(\"movable\",\"o2\",\"true\")]\n\n\n\nrequirements = [\"strips\",\"equality\",\"typing\"]\n\n\n\ngoal = [groundAtomicTerm(\"at\",\"o1\",\"l36\"),groundAtomicTerm(\"at\",\"o2\",\"l36\"),\n\n groundAtomicTerm(\"cooled\",\"o1\",\"true\"),\n\n groundAtomicTerm(\"cooled\",\"o2\",\"true\")]\n"
},
{
"alpha_fraction": 0.41352248191833496,
"alphanum_fraction": 0.4144280254840851,
"avg_line_length": 15.226600646972656,
"blob_id": "a7a80428b03aed7155e0fc70b428eb33459f51cd",
"content_id": "80e18c9502a8e9ab67671a57d0ae9ea55a0341f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3313,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 203,
"path": "/src/BuildPDDL.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "from Description import *\n\nfrom ThingsAPI import *\n\nimport config\n\nimport context\n\n\n\ndef buildPDDL():\n\n things = searchThings(config.ThingsAPI[\"namespace\"])\n\n\n\n services = [] \n\n capabilities = [] \n\n instances = context.instances \n\n tasks = [] \n\n atomicTerms = context.atomicTerms \n\n groundAtomicTerms = context.groundAtomicTerms\n\n\n\n goal = context.goal\n\n requirements = context.requirements\n\n\n\n for t in things:\n\n \n\n s = t[\"thingId\"].split(\":\")[1]\n\n services.append(s)\n\n \n\n\n\n features = t[\"features\"]\n\n \n\n for f in features:\n\n feature = features[f]\n\n props = features[f][\"properties\"]\n\n featureType = props[\"type\"]\n\n \n\n if featureType == \"state\":\n\n domain = props[\"domain\"]\n\n valueType = props[\"value\"][\"type\"]\n\n a = atomicTerm(f,\n\n domain[0].lower()+\":\"+domain,\n\n valueType[0].lower()+\":\"+valueType,\n\n )\n\n atomicTerms.append(a)\n\n g = groundAtomicTerm(f,s,\n\n props[\"value\"][\"current\"]\n\n )\n\n groundAtomicTerms.append(g) \n\n \n\n elif featureType == \"operation\":\n\n capabilities.append(f)\n\n name = props[\"command\"]\n\n print(t[\"thingId\"])\n\n cost = props[\"cost\"]\n\n params = props[\"parameters\"]\n\n \n\n posPrec = []\n\n negPrec = []\n\n addEff = []\n\n delEff = []\n\n try:\n\n posPrec = props[\"requirements\"][\"positive\"]\n\n except KeyError:\n\n pass\n\n try:\n\n negPrec = props[\"requirements\"][\"negative\"]\n\n except KeyError:\n\n pass\n\n try:\n\n addEff = props[\"effects\"][\"added\"]\n\n except KeyError:\n\n pass\n\n try:\n\n delEff = props[\"effects\"][\"deleted\"]\n\n except KeyError:\n\n pass\n\n\n\n providedBy = s \n\n \n\n task = Task(name,\n\n params,\n\n posPrec,\n\n negPrec,\n\n addEff,\n\n delEff,\n\n providedBy,\n\n f,\n\n cost\n\n )\n\n tasks.append(task)\n\n \n\n desc = Description(services,capabilities,\n\n instances,tasks,atomicTerms,\n\n groundAtomicTerms)\n\n\n\n domainFile = open(config.PDDL[\"domainFile\"], 'w+')\n\n domainFile.write(desc.getPDDLDomain(config.PDDL[\"domainName\"],requirements))\n\n domainFile.close()\n\n\n\n problemFile = open(config.PDDL[\"problemFile\"], 'w+')\n\n problemFile.write(desc.getPDDLProblem(config.PDDL[\"domainName\"],config.PDDL[\"problemName\"],goal))\n\n problemFile.close()\n\n\n\n return desc\n\n \n\nif __name__ == \"__main__\":\n\n buildPDDL() \n\n \n"
},
{
"alpha_fraction": 0.4741058647632599,
"alphanum_fraction": 0.4801144599914551,
"avg_line_length": 18.209945678710938,
"blob_id": "fcedd054ed014fcb8a7cc3987265ab6fbdb5790a",
"content_id": "773e77b82ef3805361592c15ef34550bb745044a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3495,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 181,
"path": "/src/Engine.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "import asyncio\n\nimport websockets\n\nimport base64\n\nimport time\n\nimport requests\n\nimport json\n\nimport config\n\nimport Description\n\nimport subprocess\n\nfrom ThingsAPI import *\n\nfrom BuildPDDL import *\n\n\n\n\n\n\n\nasync def executionEngine():\n\n print(\"Opening websocket endpoint...\")\n\n uri = \"wss://things.eu-1.bosch-iot-suite.com/ws/2\"\n\n async with websockets.connect(uri,\n\n extra_headers = websockets.http.Headers({\n\n 'Authorization': 'Bearer ' + getToken()\n\n })) as websocket:\n\n print(\"Collecting problem data...\")\n\n desc = buildPDDL()\n\n #Call planner\n\n #If plan not found, return 2 \n\n print(\"Invoking planner...\")\n\n command = #INSERT THE COMMAND TO INVOKE YOUR PLANNER\n\n result = subprocess.run(command, shell = True, stdout=subprocess.PIPE)\n\n #print(result.returncode)\n\n if (result.returncode > 9):\n\n return 2\n\n print(\"Plan found! Proceeding to orchestrate devices...\")\n\n with open(config.PDDL[\"planFile\"]) as file_in:\n\n for line in file_in:\n\n if line[0] == \";\":\n\n break\n\n tokens = line.replace(\"(\",\"\").replace(\")\",\"\").strip().split(\" \")\n\n thingId = config.ThingsAPI[\"namespace\"] + \":\" + tokens[1]\n\n cmd = tokens[0]\n\n params = []\n\n for i in range(2, len(tokens)):\n\n params.append(tokens[i])\n\n\n\n eventCmd = \"START-SEND-EVENTS?filter=\"\n\n eventCmd += '(eq(thingId,\"' + thingId + \\\n\n '\")'\n\n eventCmd = urllib.parse.quote(eventCmd,\n\n safe='')\n\n \n\n await websocket.send(eventCmd)\n\n await websocket.recv()\n\n print(\"Listening to events originating from \" + thingId)\n\n\n\n expected = desc.getGroundedEffect(cmd, params)\n\n print(\"Issuing command \" + tokens[0] +\n\n \" to \" + thingId + \" with parameters \" +\n\n str(params))\n\n \n\n print(\"Expected result: \" + str(expected))\n\n sendMessage(thingId, cmd, json.dumps(params), 0)\n\n \n\n output = None\n\n while True:\n\n try:\n\n event = await asyncio.wait_for(websocket.recv(), timeout=10.0)\n\n except asyncio.TimeoutError:\n\n print(\"Expired timer! Adapting...\")\n\n return 1\n\n event = json.loads(event)\n\n value = event[\"value\"]\n\n path = event[\"path\"]\n\n if value == \"terminated\":\n\n break\n\n if \"output\" in path:\n\n output = value\n\n print(\"Received output: \" + str(output))\n\n await websocket.send(\"STOP-SEND-EVENTS\")\n\n await websocket.recv()\n\n if output != expected:\n\n print(\"Discrepancy detected! Adapting...\")\n\n return 1\n\n return 0\n\n \n\nresult = asyncio.get_event_loop().run_until_complete(executionEngine())\n\nwhile result == 1:\n\n result = asyncio.get_event_loop().run_until_complete(executionEngine())\n\n\n\nif result == 0:\n\n print(\"Success!\")\n\nelse:\n\n print(\"Plan not found!\")\n\n \n"
},
{
"alpha_fraction": 0.5870634317398071,
"alphanum_fraction": 0.5905066132545471,
"avg_line_length": 14.224719047546387,
"blob_id": "7ce893b42737027a0b499ad3e67398ade2795a9a",
"content_id": "c5937503815f1b3e701be2e51728590bff1b9558",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4066,
"license_type": "no_license",
"max_line_length": 203,
"num_lines": 267,
"path": "/src/ThingsAPI.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "import requests\n\nimport time\n\nimport json\n\nimport urllib.parse\n\nimport config\n\n\n\n\n\n\n\ndef getToken():\n\n clientId = config.ThingsAPI[\"clientId\"]\n\n clientSecret = config.ThingsAPI[\"clientSecret\"]\n\n scope = config.ThingsAPI[\"scope\"]\n\n\n\n headers = {\n\n 'accept': '*/*',\n\n 'Content-Type': 'application/x-www-form-urlencoded',\n\n }\n\n \n\n payload = {\n\n 'grant_type': 'client_credentials',\n\n 'client_id': clientId,\n\n 'client_secret': clientSecret,\n\n 'scope': scope\n\n }\n\n\n\n response = requests.post('https://access.bosch-iot-suite.com/token', headers=headers, data=payload)\n\n token = json.loads(response.content)[\"access_token\"]\n\n return token\n\n \n\ndef getThing(thingId):\n\n\n\n headers = {\n\n 'accept': 'application/json',\n\n 'Authorization': 'Bearer ' + getToken(),\n\n }\n\n\n\n params = (\n\n ('ids', thingId),\n\n )\n\n\n\n response = requests.get('https://things.eu-1.bosch-iot-suite.com/api/2/things', headers=headers, params=params)\n\n\n\n return json.loads(response.content)\n\n\n\ndef getFeature(thingId, featureId, propertyPath):\n\n\n\n headers = {\n\n 'accept': '*/*',\n\n 'Authorization': 'Bearer' + getToken(),\n\n }\n\n \n\n thingId = urllib.parse.quote(thingId, safe='')\n\n propertyPath = urllib.parse.quote(propertyPath, safe='')\n\n\n\n response = requests.get('https://things.eu-1.bosch-iot-suite.com/api/2/things/' + thingId + \"/features/\" + featureId + \"/properties/\" + propertyPath, headers=headers)\n\n\n\n return json.loads(response.content)\n\n\n\ndef sendMessageToFeature(thingId, featureId, messageSubject, body, timeout):\n\n\n\n headers = {\n\n 'accept': '*/*',\n\n 'Authorization': 'Bearer ' + getToken(),\n\n 'Content-Type': 'application/json',\n\n }\n\n\n\n params = (\n\n ('timeout', str(timeout)),\n\n )\n\n \n\n thingId = urllib.parse.quote(thingId, safe='')\n\n\n\n response = requests.post('https://things.eu-1.bosch-iot-suite.com/api/2/things/' + thingId + \"/features/\" + featureId + \"/inbox/messages/\" + messageSubject, headers=headers, params=params, data=body)\n\n\n\n return json.loads(response)\n\n\n\ndef searchThingsWithField(namespace, field):\n\n headers = {\n\n 'accept': 'application/json',\n\n 'Authorization': 'Bearer' + getToken(),\n\n }\n\n\n\n params = (\n\n ('namespaces', namespace),\n\n ('fields', field),\n\n )\n\n\n\n response = requests.get('https://things.eu-1.bosch-iot-suite.com/api/2/search/things', headers=headers, params=params)\n\n\n\n return json.loads(response.content)[\"items\"]\n\n\n\ndef searchThings(namespace):\n\n headers = {\n\n 'accept': 'application/json',\n\n 'Authorization': 'Bearer' + getToken(),\n\n }\n\n\n\n response = requests.get('https://things.eu-1.bosch-iot-suite.com/api/2/search/things', headers=headers)\n\n\n\n return json.loads(response.content)[\"items\"]\n\n\n\ndef sendMessage(thingId, messageSubject, body, timeout):\n\n headers = {\n\n 'accept': '*/*',\n\n 'Authorization': 'Bearer ' + getToken(),\n\n 'Content-Type': 'application/json',\n\n }\n\n\n\n params = (\n\n ('timeout', str(timeout)),\n\n )\n\n\n\n thingId = urllib.parse.quote(thingId, safe='')\n\n response = requests.post('https://things.eu-1.bosch-iot-suite.com/api/2/things/' + thingId\n\n + '/inbox/messages/' + messageSubject, headers=headers, params=params, data=body)\n\n\n\n return (response)\n\n\n\ndef changeProperty(thingId, featureId, propertyPath, body):\n\n headers = {\n\n 'accept': '*/*',\n\n 'Authorization': 'Bearer ' + getToken(),\n\n 'Content-Type': 'application/json',\n\n }\n\n\n\n data = body\n\n thingId = urllib.parse.quote(thingId, safe='')\n\n propertyPath = urllib.parse.quote(propertyPath, safe='')\n\n response = requests.put('https://things.eu-1.bosch-iot-suite.com/api/2/things/' +\n\n thingId +\n\n '/features/' + featureId + '/properties/' + propertyPath,\n\n headers=headers, data=data)\n\n\n\n return response\n\n"
},
{
"alpha_fraction": 0.3943976163864136,
"alphanum_fraction": 0.39861181378364563,
"avg_line_length": 13.136841773986816,
"blob_id": "a160519d6966b522daa17c0843ee96e88d8e7ca7",
"content_id": "93730dd418ff34bf54794c827aa407c4a2c9d74d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4034,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 285,
"path": "/src/PDDLUtils.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "def getInit(groundAtomicTerms, tasks):\n\n res = \"(:init \\n\"\n\n \n\n for t in tasks:\n\n res += \"(provides\" + \" \" + \\\n\n t.providedBy + \\\n\n \" \" + t.capability + \")\\n\"\n\n \n\n for a in groundAtomicTerms:\n\n if a.out == None:\n\n continue\n\n res += \"(\" + a.name + \" \" + a.inp + \" \" + a.out + \")\\n\"\n\n\n\n #res += \"(= (total-cost) 0)\" + \"\\n\"\n\n res += \")\\n\"\n\n return res\n\n\n\ndef getGoal(goal):\n\n res = \"(:goal \\n\"\n\n res += \"(and \\n\"\n\n for a in goal:\n\n res += \"(\" + a.name + \" \" + a.inp + \" \" + a.out + \")\\n\"\n\n\n\n res += \")\\n\"\n\n res += \")\\n\"\n\n return res\n\n\n\ndef getObjects(instances, tasks): #{\"Object\":[\"ball\",\"box\"]}\n\n res = \"(:objects \\n\"\n\n \n\n for k in instances:\n\n for v in instances[k]:\n\n res += v + \" - \" + k + \"\\n\"\n\n\n\n capabilities = []\n\n for t in tasks:\n\n if t.capability in capabilities:\n\n continue\n\n res += t.capability + \" - \" + \"Capability\" + \"\\n\"\n\n capabilities.append(t.capability)\n\n\n\n services = []\n\n for t in tasks:\n\n if t.providedBy in services:\n\n continue\n\n res += t.providedBy + \" - \" + \"Service\" + \"\\n\"\n\n services.append(t.providedBy)\n\n \n\n res += \")\\n\"\n\n\n\n return res\n\n\n\ndef getTypes(instances):\n\n res = \"(:types \\nService - Thing\\nCapability\\n\"\n\n\n\n for k in instances:\n\n if k == \"Object\":\n\n res += k + \" - \" + \"Thing\" + \"\\n\"\n\n continue\n\n res += k + \"\\n\"\n\n\n\n res += \")\\n\"\n\n\n\n return res\n\n \n\ndef getFormula(f):\n\n res = \"\"\n\n for p in f:\n\n l = p.strip().split(\":\")\n\n if \".\" in l[0]:\n\n s = l[0].strip().split(\".\")\n\n res += \"(\" + s[1] + \" \" + \"?\" + s[0] + \" \" + \"?\" + l[1] + \")\" + \" \"\n\n continue\n\n res += \"(\" + l[0] + \" \" + \"?srv\" + \" \" + \"?\" + l[1] + \")\" + \" \"\n\n res = res.replace(\"?true\",\"true\")\n\n res = res.replace(\"?false\",\"false\")\n\n return res\n\n\n\ndef getNegativeFormula(f):\n\n res = \"\"\n\n for p in f:\n\n l = p.strip().split(\":\")\n\n if \".\" in l[0]:\n\n s = l[0].strip().split(\".\")\n\n res += \"(not(\" + s[1] + \" \" + \"?\" + s[0] + \" \" + \"?\" + l[1] + \"))\" + \" \"\n\n continue\n\n res += \"(not(\" + l[0] + \" \" + \"?srv\" + \" \" + \"?\" + l[1] + \"))\" + \" \"\n\n res = res.replace(\"?true\",\"true\")\n\n res = res.replace(\"?false\",\"false\")\n\n return res\n\n\n\ndef getActions(tasks):\n\n res = \"\"\n\n names = []\n\n for t in tasks:\n\n if t.name in names:\n\n continue\n\n names.append(t.name)\n\n \n\n params = \":parameters (?srv - \" + \"Service\"\n\n for p in t.params:\n\n params += \" \" + \"?\" + \\\n\n p.strip().split(\" - \")[1] + \" - \" + \\\n\n p.strip().split(\" - \")[0]\n\n params += \")\\n\"\n\n prec = \":precondition (and (provides ?srv \" + t.capability + \")\" + \" \"\n\n prec += getFormula(t.posPrec)\n\n prec += getNegativeFormula(t.negPrec)\n\n prec += \")\" + \"\\n\"\n\n\n\n eff = \":effect (and \"\n\n eff += getFormula(t.addEff)\n\n eff += getNegativeFormula(t.delEff)\n\n #eff += \"(increase (total-cost)\" + \" \" + str(t.cost) + \")\"\n\n eff += \")\" + \"\\n\"\n\n res += \"(:action\" + \" \" + t.name + \"\\n\" + params + prec + eff + \")\\n\"\n\n return res\n\n \n\ndef getPredicates(atomicTerms):\n\n res = \"(:predicates \\n\" + \\\n\n \"(provides ?srv - Service ?c - Capability) \\n\"\n\n\n\n names = []\n\n for a in atomicTerms:\n\n if a.name in names:\n\n continue\n\n names.append(a.name)\n\n inp = \"?\" + a.inp.strip().replace(\":\", \" - \")\n\n out = \"?\" + a.out.strip().replace(\":\", \" - \")\n\n s = \"(\" + a.name + \" \" + \\\n\n inp + \" \" + out + \")\" + \"\\n\"\n\n res += s\n\n \n\n res += \")\\n\"\n\n return res\n\n\n\n\n\ndef getRequirements(requirements):\n\n res = \"(:requirements\"\n\n for r in requirements:\n\n res += \" \" + \":\" + r\n\n res += \")\\n\"\n\n return res \n"
},
{
"alpha_fraction": 0.6035503149032593,
"alphanum_fraction": 0.6035503149032593,
"avg_line_length": 11.518518447875977,
"blob_id": "c62ec5c4aba434d9ba8ea0fd5411ffa43f2a3da4",
"content_id": "6d10e87a024dfd605616953b0d0633970e8588a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 27,
"path": "/src/config.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "ThingsAPI = dict(\n\n namespace = 'YOUR-NAMESPACE',\n\n clientId = 'YOUR-CLIENT-ID',\n\n clientSecret = 'YOUR-CLIENT-SECRET',\n\n scope = 'YOUR-SCOPE'\n\n)\n\n\n\nPDDL = dict(\n\n domainName = 'myDomain',\n\n problemName = 'myProblem',\n\n domainFile = 'myDomain.pddl',\n\n problemFile = 'myProblem.pddl',\n\n planFile = 'sas_plan'\n\n)\n"
},
{
"alpha_fraction": 0.7736943960189819,
"alphanum_fraction": 0.7775628566741943,
"avg_line_length": 63.60416793823242,
"blob_id": "e5dc7bdc853929ceebd2614374fbdcf9789d5a45",
"content_id": "378fac05253ab9145cc136796d2e70c7ba588c25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3102,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 48,
"path": "/README.md",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "# Smart DT Composer\n\nSmart DT Composer is a software that automatically orchestrate digital twins to accomplish a specified goal. It relies on classical planning, a well-established field of artificial intelligence, and on Bosch IoT Things, a platform to manage digital twins.\n\n<p align=\"center\">\n <img width=\"460\" src=\"img/architecture.png\">\n</p>\n\nThe image above depicts the system architecture. Its main components are:\n* Bosch IoT Things, which provides the API for interacting with the Digital Twins and the actual devices\n* Bosch IoT Hub, which allows the devices to securely communicate in a wide range of protocols:\n * It receives the messages from the devices and it forwards them to Bosch IoT Thing\n * It receives the messages from Bosch IoT Thing and it forwards them to the appropriate devices. For the sake of simplicity, in the architecture and in the later example the devices communicate with Bosch IoT Hub via MQTT only\n\n* Context, a file which encodes the following data:\n * Type hierarchy of the domain\n * Definitions and initial state of passive objects\n * PDDL requirements\n * Goal state\n* Translator, which takes the Digital Twin descriptions, their current values\nand contextual information as inputs and generates the PDDL domain and\nproblem files\n* Planner, a state-of-the-art classical planner (in the example, Fast Downward is\nused, which, given the problem and the domain files, generates a sequential\nplan\n* Engine, which is in charge of performing three sequential tasks:\n 1. It collects the Digital Twin descriptions and their current values and send them as an input to the translator, which outputs a PDDL domain and problem files \n 2. It invokes the planner, which takes the two files as input and it outputs a plan, which consists of a linear sequence of actions\n 3. It reads the plan action by action and for each one: \n 1. It obtains the correspondent API call. In fact, each action in the plan provides the necessary information to send a command to a device, namely: the name of the task, the thing that has to perform it and the required parameters\n 2. It issues the so-generated API call and it waits for the device output\n 3. It checks if there is any discrepancy between the device output and the expected output\n \n Below, a picture of the application workflow.\n <p align=\"center\">\n <img width=\"700\" src=\"img/workflowApp.png\">\n</p>\n\n## Run Smart DT Composer\nThe \"src\" folder includes the modules for the orhestrator and the translator. The \"device\" folder, instead, contains a script that emulates a physical device. Before running the software, the following operations must be done:\n * Provision one or more devices in Bosch IoT Things (see Bosch IoT Things documentation)\n * Descript each device following the DTPL conventions\n * Edit the context file to relfect the conditions of the factory environemnt\n * Download and install a PDDL compatible planner\n * Edit the \"Engine.py\" script in order to invoke the planner\n * Edit the config file to change the credentials\n \nTo run the software, execute the \"Engine.py\" script.\n\n"
},
{
"alpha_fraction": 0.38479751348495483,
"alphanum_fraction": 0.39364486932754517,
"avg_line_length": 15.823899269104004,
"blob_id": "1fb691188e3065b822cae2ab73cd72053aaf4e7c",
"content_id": "8527dbfbdc175d2cdc57506545afbee649942ff4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8025,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 477,
"path": "/src/Description.py",
"repo_name": "davidghedix/smartDTcomposer",
"src_encoding": "UTF-8",
"text": "from PDDLUtils import *\n\n\n\nclass Description:\n\n def __init__(self,services,capabilities,\n\n instances,tasks,\n\n atomicTerms,groundAtomicTerms):\n\n self.services = services\n\n self.capabilities = capabilities\n\n self.instances = instances\n\n self.tasks = tasks\n\n self.atomicTerms = atomicTerms\n\n self.groundAtomicTerms = groundAtomicTerms\n\n\n\n def getPDDLDomain(self,domainName,requirements):\n\n res = \"(define\" + \" \" + \"(domain\" + \" \" \\\n\n + domainName + \")\" + \"\\n\"\n\n res += getRequirements(requirements)\n\n res += getTypes(self.instances)\n\n res += getPredicates(self.atomicTerms)\n\n res += getActions(self.tasks)\n\n #res += \"(:functions (total-cost))\" + \"\\n\"\n\n res += \"\\n\"\n\n res += \")\"\n\n return res\n\n\n\n def getPDDLProblem(self,domainName,problemName,goal):\n\n res = \"(define\" + \" \" + \"(problem\" + \" \" \\\n\n + problemName + \")\" + \"\\n\"\n\n res += \"(:domain\" + \" \" + domainName + \")\" + \"\\n\"\n\n res += getObjects(self.instances, self.tasks)\n\n res += getInit(self.groundAtomicTerms, self.tasks)\n\n res += getGoal(goal)\n\n #res += \"(:metric minimize (total-cost))\" + \"\\n\"\n\n res += \"\\n\"\n\n res += \")\"\n\n return res\n\n\n\n def getGroundedEffect(self, name, inp):\n\n for t in self.tasks:\n\n if t.name == name:\n\n addEff = list(t.addEff)\n\n added = []\n\n\n\n for a in t.addEff:\n\n temp = a.strip().split(\":\")[1]\n\n if temp == \"true\" or temp == \"false\":\n\n added.append(a)\n\n i = 0\n\n for p in t.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in t.addEff:\n\n temp = a.strip().split(\":\")\n\n if p == temp[1]:\n\n added.append(temp[0] + \":\" + inp[i])\n\n i += 1\n\n\n\n added2 = []\n\n for a in added:\n\n if not(\".\" in a):\n\n added2.append(a)\n\n \n\n i = 0\n\n for p in t.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in added:\n\n if \".\" in a:\n\n temp = a.strip().split(\".\")\n\n if p == temp[0]:\n\n added2.append(inp[i] + \".\" + temp[1])\n\n i += 1\n\n \n\n delEff = list(t.delEff)\n\n deleted = []\n\n\n\n for a in t.delEff:\n\n temp = a.strip().split(\":\")[1]\n\n if temp == \"true\" or temp == \"false\":\n\n deleted.append(a)\n\n i = 0\n\n for p in t.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in t.delEff:\n\n temp = a.strip().split(\":\")\n\n if p == temp[1]:\n\n deleted.append(temp[0] + \":\" + inp[i])\n\n i += 1\n\n\n\n deleted2 = []\n\n for a in deleted:\n\n if not(\".\" in a):\n\n deleted2.append(a)\n\n \n\n i = 0\n\n for p in t.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in deleted:\n\n if \".\" in a:\n\n temp = a.strip().split(\".\")\n\n if p == temp[0]:\n\n deleted2.append(inp[i] + \".\" + temp[1])\n\n i += 1\n\n\n\n return dict(added = added2, deleted = deleted2)\n\n \n\n \n\nclass Task:\n\n def __init__(self, name, params,\\\n\n posPrec, negPrec, addEff,\\\n\n delEff,providedBy, capability, cost):\n\n self.name = name #\"move\"\n\n self.params = params #[\"Location - from\", \"Location - to\"]\n\n self.posPrec = posPrec #[\"o.at:from\"]\n\n self.negPrec = negPrec #[\"at:to\"]\n\n self.addEff = addEff\n\n self.delEff = delEff\n\n self.providedBy = providedBy # \"rb1\"\n\n self.capability = capability # \"movement\"\n\n self.cost = cost\n\n\n\n def getGroundedEffect(self, inp):\n\n \n\n addEff = list(self.addEff)\n\n added = []\n\n\n\n for a in self.addEff:\n\n temp = a.strip().split(\":\")[1]\n\n if temp == \"true\" or temp == \"false\":\n\n added.append(a)\n\n i = 0\n\n for p in self.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in self.addEff:\n\n temp = a.strip().split(\":\")\n\n if p == temp[1]:\n\n added.append(temp[0] + \":\" + inp[i])\n\n i += 1\n\n\n\n added2 = []\n\n for a in added:\n\n if not(\".\" in a):\n\n added2.append(a)\n\n \n\n i = 0\n\n for p in self.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in added:\n\n if \".\" in a:\n\n temp = a.strip().split(\".\")\n\n if p == temp[0]:\n\n added2.append(inp[i] + \".\" + temp[1])\n\n i += 1\n\n \n\n delEff = list(self.delEff)\n\n deleted = []\n\n\n\n for a in self.delEff:\n\n temp = a.strip().split(\":\")[1]\n\n if temp == \"true\" or temp == \"false\":\n\n deleted.append(a)\n\n i = 0\n\n for p in self.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in self.delEff:\n\n temp = a.strip().split(\":\")\n\n if p == temp[1]:\n\n deleted.append(temp[0] + \":\" + inp[i])\n\n i += 1\n\n\n\n deleted2 = []\n\n for a in deleted:\n\n if not(\".\" in a):\n\n deleted2.append(a)\n\n \n\n i = 0\n\n for p in self.params:\n\n p = p.strip().split(\" - \")[1]\n\n for a in deleted:\n\n if \".\" in a:\n\n temp = a.strip().split(\".\")\n\n if p == temp[0]:\n\n deleted2.append(inp[i] + \".\" + temp[1])\n\n i += 1\n\n\n\n return dict(added = added2, deleted = deleted2)\n\n\n\n \n\n\n\nclass groundAtomicTerm:\n\n def __init__(self, name, inp, out):\n\n self.name = name #\"at\"\n\n self.inp = inp #\"s\"\n\n self.out = out #\"l\"\n\n\n\nclass atomicTerm:\n\n def __init__(self, name, inp, out):\n\n self.name = name #\"at\"\n\n self.inp = inp #\"s - Service\"\n\n self.out = out #\"l - Location\"\n\n\n\nif __name__ == \"__main__\":\n\n \n\n\n\n services = [\"rb1\"]\n\n capabilities = [\"movement\"] \n\n subclasses = {\"Robot\":[\"rb1\",\"rb2\"]}\n\n #####\n\n name = \"move\"\n\n params = [\"Object - o\", \"Location - l\"]\n\n posPrec = []\n\n negPrec = []\n\n addEff = [\"o.at:l\",\"carries:o\",\"o.movable:true\"]\n\n delEff = [\"o.at:l\"]\n\n providedBy = \"rb1 - Robot\"\n\n capability = \"movement\"\n\n cost = 5\n\n move = Task(name, params,posPrec,negPrec,addEff,delEff,providedBy,capability,cost)\n\n print(move.getGroundedEffect([\"o1\",\"x\"]))\n\n \n\n tasks = [move]\n\n #####\n\n name = \"at\"\n\n inp = \"s:Service\"\n\n out = \"l:Location\"\n\n at1 = atomicTerm(name,inp,out)\n\n atomicTerms = [at1]\n\n #####\n\n instances = {\"Object\":[\"ball\",\"box\"]}\n\n #####\n\n name = \"at\"\n\n inp = \"s\"\n\n out = \"l\"\n\n at1 = groundAtomicTerm(name,inp,out)\n\n groundAtomicTerms = [at1]\n\n #####\n\n desc = Description(services,capabilities,subclasses,\n\n instances,tasks,atomicTerms,\n\n groundAtomicTerms)\n\n print(desc.getPDDLDomain(\"factory\",[\"strips\"]))\n\n print(desc.getPDDLProblem(\"factory_p\",\"factory_d\",[]))\n"
}
] | 9 |
Tiago4k/Sherlock
|
https://github.com/Tiago4k/Sherlock
|
7cce520ee8b3377e9c642f0f841221d6264005b0
|
7517954eb67d601d759ffa98c9c23cdef49107d3
|
ad13a2b0feacc06df4cd1cf83c508f42f1de059b
|
refs/heads/master
| 2022-12-20T16:50:52.625736 | 2020-09-15T13:03:54 | 2020-09-15T13:03:54 | 218,602,933 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6005887985229492,
"alphanum_fraction": 0.6084396243095398,
"avg_line_length": 21.64444351196289,
"blob_id": "af30f0a85ef18bb3a7ac765dbb95bb3cad935351",
"content_id": "ae3307e54a0be44d7aebe5c54c36ca85c5d23b41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 45,
"path": "/Backend/Cloud_Functions/send_to_bucket.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "from flask import jsonify\nfrom google.cloud import storage\n\n\ndef main(request):\n\n data = request.get_json()\n\n if data and 'img_bytes' in data:\n filename = data['img_bytes']\n bucket_name = data['bucket_name']\n bucket_dir = data['bucket_dir']\n dest_filename = data['uuid']\n else:\n return '400 - No data received!'\n\n r = upload_blob(bucket_dir, dest_filename, filename, bucket_name)\n\n resp = {\n 'status': 201,\n 'message': r[0],\n 'filepath': r[1]\n }\n\n return jsonify(resp)\n\n\ndef upload_blob(folder, dest_filename, file, bucket_name):\n\n storage_client = storage.Client()\n\n # Create Bucket Object\n bucket = storage_client.get_bucket(bucket_name)\n\n # Name blob\n filepath = \"%s/%s\" % (folder, dest_filename)\n blob = bucket.blob(filepath)\n\n # Upload from string\n blob.upload_from_string(file)\n\n response = 'File {} uploaded to {}.'.format(\n dest_filename, bucket_name + '/' + folder)\n\n return (response, filepath)\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6479430198669434,
"avg_line_length": 20.066667556762695,
"blob_id": "c024002c2dd90af14efe3a9a4d3e0ace37684b7a",
"content_id": "25c20ec6df0b5ebe7951a3f95526931f1f99fee1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1264,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 60,
"path": "/frontend/src/components/Progressbar/ProgressBar.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import styled from \"styled-components\";\nimport { string, number } from \"prop-types\";\n\nimport ProgressBarBase from \"./ProgressBarBase\";\n\nconst ProgressBar = styled(ProgressBarBase)`\n width: ${props => props.size};\n text-align: center;\n vertical-align: center;\n .chart-text {\n fill: ${props => props.textColor};\n transform: translateY(0.25em);\n }\n .chart-number {\n font-size: 0.6em;\n line-height: 1;\n text-anchor: middle;\n transform: translateY(-0.25em);\n }\n .chart-label {\n font-size: 0.3em;\n text-transform: uppercase;\n text-anchor: middle;\n transform: translateY(0.7em);\n }\n .figure-key [class*=\"shape-\"] {\n margin-right: 8px;\n }\n .figure-key-list {\n list-style: none;\n display: flex;\n justify-content: space-between;\n }\n .figure-key-list li {\n margin: 5px auto;\n }\n .shape-circle {\n display: inline-block;\n vertical-align: middle;\n width: 21px;\n height: 21px;\n background-color: ${props => props.strokeColor};\n text-transform: capitalize;\n }\n`;\n\nProgressBar.propTypes = {\n textColor: string,\n strokeColor: string,\n size: string,\n percentage: number\n};\n\nProgressBar.defaultProps = {\n textColor: \"#54535a\",\n strokeColor: \"#ffb347\",\n size: \"70%\"\n};\n\nexport default ProgressBar;\n"
},
{
"alpha_fraction": 0.4001533091068268,
"alphanum_fraction": 0.4016864597797394,
"avg_line_length": 26.755319595336914,
"blob_id": "1a09b343f82f698f9b7be902885ad3046f15a103",
"content_id": "2853c63bc2e4352e6c4eda26b8a0e41927012ecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3527,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 94,
"path": "/README.md",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "# Sherlock\n\n\n\nSherlock is a web-based application that detects forgery in photos that users upload to the web app. <br />\nThe application is free to use, but does require a user to sign up to the service in order to be able to use it. <br />\nAuthentication is provided Auth0 (https://www.auth0.com) allowing users to log in securely with an email address or via socials, Google and Facebook. <p>\n\nSystem breakdown: <br />\n\n- Backend developed using Python and Flask.\n - Backend being hosted on Google Cloud Platform, made possible through the use of containers and cloud functions.\n- ML model built using the Fastai library.\n- Frontend developed using Reactjs, hosted with Heroku.\n- Authentication by Auth0.\n\nAccessible via:\n<br />\nhttps://uk-sherlock.herokuapp.com/\n\nDummy data to test system available at:\n<br />\nhttps://storage.googleapis.com/sherlock-ux-images/Sherlock_Images.zip\n\n<p>\nProject Structure:\n\n```\n├───Sherlock/\n│ ├───Backend/\n│ │ ├───Cloud_Functions/\n│ │ │ └───...\n│ │ ├───ELA_API/\n│ │ │ └───...\n│ │ ├───Helper_Scripts/\n│ │ │ ├───Constants/\n│ │ │ │ └───...\n│ │ │ └───...\n│ │ ├───Prediction_API/\n│ │ │ └───...\n│ │ ├───Router_API/\n│ │ │ ├───config/\n│ │ │ │ └───...\n│ │ │ └───...\n│ ├───Diagrams/\n│ │ ├───Drawio/\n│ │ │ └───...\n│ │ ├───SVG's/\n│ │ │ └───...\n│ ├───ML_Notebooks/\n│ │ │ └───...\n│ ├───Unit Tests/\n│ │ ├───Assets/\n│ │ │ └───...\n│ │ └───...\n│ ├───frontend/\n│ │ ├───public/\n│ │ │ ├───icons/\n│ │ │ │ └───...\n│ │ │ └───...\n│ │ ├───src/\n│ │ │ ├───assets/\n│ │ │ │ └───...\n│ │ │ ├───components/\n│ │ │ │ ├───Loading/\n│ │ │ │ │ └───...\n│ │ │ │ ├───Progressbar/\n│ │ │ │ │ └───...\n│ │ │ │ └───...\n│ │ │ ├───contexts/\n│ │ │ │ └───...\n│ │ │ ├───pages/\n│ │ │ │ └───...\n│ │ │ ├───style/\n│ │ │ │ ├───abstracts/\n│ │ │ │ │ └───...\n│ │ │ │ ├───base/\n│ │ │ │ │ └───...\n│ │ │ │ ├───components/\n│ │ │ │ │ └───...\n│ │ │ │ ├───layout/\n│ │ │ │ │ └───...\n│ │ │ │ ├───sections/\n│ │ │ │ │ └───...\n│ │ │ │ ├───vendor/\n│ │ │ │ │ └───...\n│ │ │ │ └───...\n│ │ │ ├───utils/\n│ │ │ │ └───...\n│ │ │ └───...\n│ │ ├───...\n│ ├───.gitignore\n│ ├───README.md\n```\n"
},
{
"alpha_fraction": 0.5759493708610535,
"alphanum_fraction": 0.5759493708610535,
"avg_line_length": 25.33333396911621,
"blob_id": "fba866fc22e3190fb1b3e405b51255aa93921d31",
"content_id": "e7b646d69301c74ce678b2b44f634879b34d1d49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 12,
"path": "/Backend/ELA_API/cleanup.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\n\n\ndef delete_upload(upload_file):\n \"\"\"Deletes saved files produced during ela creation.\"\"\"\n cwd = os.getcwd()\n filename = upload_file\n folder = os.listdir(cwd)\n for f in folder:\n if filename in f:\n os.remove(cwd + '/' + f)\n print('File \"{}\" removed!'.format(f))\n"
},
{
"alpha_fraction": 0.5504322648048401,
"alphanum_fraction": 0.5518732070922852,
"avg_line_length": 26.760000228881836,
"blob_id": "499b8b571b64786c8d96df98b8d08bf3dd9822a2",
"content_id": "10fc3036b190ce9a6cb6d0cc45b4ae7aa3ecb34c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 25,
"path": "/frontend/src/components/Footer.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import React from \"react\";\nimport { Container } from \"react-bootstrap\";\n\nfunction Footer() {\n return (\n <footer className=\"footer navbar-static-bottom\">\n <Container>\n <a href=\"#top\" aria-label=\"Back To Top\" className=\"back-to-top\">\n <i className=\"fa fa-angle-up fa-2x\" aria-hidden=\"true\" />\n </a>\n <p className=\"footer__text\">\n © {new Date().getFullYear()} - Created by Tiago Ramalho\n </p>\n <p className=\"footer__text\">\n Theme by{\" \"}\n <a href=\"https://www.gatsbyjs.org/starters/cobidev/gatsby-simplefolio/\">\n cobidev\n </a>\n </p>\n </Container>\n </footer>\n );\n}\n\nexport default Footer;\n"
},
{
"alpha_fraction": 0.6539179086685181,
"alphanum_fraction": 0.6641790866851807,
"avg_line_length": 28.77777862548828,
"blob_id": "e5325fd4bae15d517932ea20fe8c0e4de2861cbf",
"content_id": "b81fa5ce7a772fb63aa724b8d3adc3809ba1cf46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 36,
"path": "/Backend/ELA_API/ela.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "from PIL import Image, ImageChops, ImageEnhance\n\n\ndef convert_to_ela(path):\n \"\"\" Returns ela filename as a string.\n Converts image by intentionally resaving an image at a known error rate and then \n computing the difference between the two images.\n\n Params:\n path: path to the image to be converted using ELA\n \"\"\"\n\n fname = path\n resaved_fname = fname.split('.')[0] + '.resaved.jpg'\n ela_fname = fname.split('.')[0] + '.ela.png'\n\n img = Image.open(fname).convert('RGB')\n img.save(resaved_fname, 'JPEG', quality=95)\n\n img_resaved = Image.open(resaved_fname)\n ela_img = ImageChops.difference(img, img_resaved)\n\n # Gets the the minimum and maximum pixel values for each band in the image.\n extrema = ela_img.getextrema()\n\n # Calculate max difference between the pixel values in the image\n max_diff = max([ex[1] for ex in extrema])\n if max_diff == 0:\n max_diff = 1\n scale = 255.0 / max_diff\n\n ela_img = ImageEnhance.Brightness(ela_img).enhance(scale)\n\n ela_img.save(ela_fname, 'PNG')\n\n return ela_fname\n"
},
{
"alpha_fraction": 0.5448330044746399,
"alphanum_fraction": 0.5512753129005432,
"avg_line_length": 30.691667556762695,
"blob_id": "85775d42d9c03af00ca0dbac427b6e2db2afdfd6",
"content_id": "23acb0f86942a5c03d6a1f67894d4a9c435dcbcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7606,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 240,
"path": "/Backend/Router_API/app.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport uuid\nfrom configparser import ConfigParser\n\nimport requests\nfrom flask import Flask, jsonify, request\nfrom flask_cors import CORS\nfrom flask_restful import Api, Resource\nfrom werkzeug.exceptions import BadRequest, InternalServerError\n\napp = Flask(__name__)\nCORS(app)\napi = Api(app)\n\nconfig_path = 'config/config.ini'\nconfig = ConfigParser()\nconfig.read(config_path)\n\nsend_to_bucket_url = config.get('instance', 'send_to_bucket')\nresize_url = config.get('instance', 'resize')\nela_url = config.get('instance', 'ela')\nprediction_url = config.get('instance', 'prediction')\nfirestore_post_url = config.get('instance', 'post')\nfirestore_get_url = config.get('instance', 'get_from_firestre')\ndownload_url = config.get('instance', 'download_url')\n\nbucket_name = config.get('bucket', 'name')\nbucket_path = config.get('bucket', 'path')\nresize_flag = False\n\n\nclass Uploads(Resource):\n def get(self, email):\n # empty list for user uploads\n uploads_list = []\n\n # payload for firestore request\n payload = {\n 'username': email\n }\n\n fire_resp = requests.post(firestore_get_url, json=payload).json()\n\n # check if user has any documents, if they do not, return.\n if(len(fire_resp['documents']) == 0):\n return jsonify({'status': 204})\n\n # While there are documents in the list keep iterating. When i == 4, break.\n # This means we have 5 documents to return to the user which is all that will\n # be returned due to latency.\n i = 0\n while(i <= len(fire_resp['documents'])):\n\n # if the lenght of the list - i != 0, it means we still have more items\n # to iterate through.\n if(len(fire_resp['documents'])-i != 0):\n payload = {\n 'bucket_name': fire_resp['documents'][i]['bucket_name'],\n 'filepath': bucket_path + '/' + fire_resp['documents'][i]['uuid']\n }\n\n download_resp = requests.post(\n download_url, json=payload).json()\n\n # append the image, uuid and prediction to the list to be returned to the user\n uploads_list.append({\n 'uuid': fire_resp['documents'][i]['uuid'],\n 'prediction': fire_resp['documents'][i]['prediction'],\n 'image': download_resp['image_file']\n })\n else:\n break\n\n if(i == 4):\n break\n # increment i\n i += 1\n\n resp = {\n 'status': 200,\n 'uploads': uploads_list\n }\n\n return jsonify(resp)\n\n\nclass Prediction(Resource):\n\n def post(self):\n\n data = request.get_json()\n email = None\n\n # Check if the request is empty.\n if 'file' not in data:\n raise BadRequest()\n\n # Check if their is an email\n if 'email' in data:\n email = data['email']\n else:\n email = '[email protected]'\n\n image_str = data['file']\n image_str = image_str.split(',')\n image_base64 = image_str[1]\n\n # Generate UUID\n generated_uuid = uuid.uuid4()\n generated_uuid = str(generated_uuid)\n\n # Payload for send_to_bucket function\n payload = {\n \"bucket_dir\": bucket_path,\n \"bucket_name\": bucket_name,\n \"img_bytes\": image_base64,\n \"uuid\": generated_uuid\n }\n\n # Check if the service is up before sending post request\n try:\n response = requests.head(send_to_bucket_url)\n except requests.RequestException as err:\n raise err\n else:\n # Trigger send_to_bucket function with HTTP\n response = requests.post(send_to_bucket_url, json=payload)\n data = response.json()\n\n # If the image was not successful saved to the bucket,\n # raise an internal error response.\n if data['status'] != 201:\n raise InternalServerError()\n\n # Set resize flag to false if you do NOT want to run the resize function\n if resize_flag:\n\n # Payload for Resize function\n payload_2 = {\n 'bucket_name': bucket_name,\n 'img_bytes': image_base64,\n 'uuid': generated_uuid\n }\n\n # Check if the service is up before sending post request\n try:\n response = requests.head(resize_url)\n except requests.RequestException as err:\n raise err\n else:\n # Trigger Resize function with HTTP\n response = requests.post(resize_url, json=payload_2)\n data = response.json()\n\n # Check if the image was successfully resized, if it has continue with the resized image.\n # If an error occurred during the resizing and/or saving of the image, continue with the\n # process but by utilising the original bytes sent by the client.\n if data['status'] == 200:\n img_bytes = data['img_bytes']\n else:\n img_bytes = image_base64\n\n # COMMENT THIS LINE OUT IF USING RESIZE\n img_bytes = image_base64\n\n # Payload for ELA container\n payload_3 = {\n 'bucket_name': bucket_name,\n 'img_bytes': img_bytes,\n 'uuid': generated_uuid\n }\n\n # Check if the service is up before sending post request.\n try:\n response = requests.head(ela_url)\n except requests.RequestException as err:\n raise err\n else:\n # Ensuring that ELA conversion has worked as it's crucial for making a prediction.\n try:\n # Send to ELA Container to produce ELA image\n response = requests.post(ela_url, json=payload_3)\n except requests.RequestException as err:\n raise err\n\n data = response.json()\n ela_bytes = data['img_bytes']\n\n payload_4 = {\n 'img_bytes': ela_bytes,\n 'uuid': generated_uuid\n }\n\n # Check if the service is up before sending post request.\n try:\n response = requests.head(prediction_url)\n except requests.RequestException as err:\n raise err\n else:\n # Check that service has produced a prediction.\n try:\n # Send to Prediction container for analysis.\n response = requests.post(prediction_url, json=payload_4)\n except requests.RequestException as err:\n raise err\n\n data = response.json()\n prediction = data['Prediction']\n confidence = data['Confidence']\n\n firestore_payload = {\n 'uuid': generated_uuid,\n 'username': email,\n 'prediction': prediction,\n 'confidence': confidence,\n 'bucket_name': bucket_name\n }\n\n response = requests.post(\n firestore_post_url, json=firestore_payload).json()\n\n # Response to be sent back to the Client.\n resp = {\n 'status': 200,\n 'prediction': prediction,\n 'confidence': confidence,\n 'ela_img': ela_bytes,\n 'message': response['message']\n }\n\n return jsonify(resp)\n\n\napi.add_resource(Uploads, '/user', '/user/<string:email>')\napi.add_resource(Prediction, '/')\n\n\nif __name__ == '__main__':\n app.run(debug=False, host='0.0.0.0',\n port=int(os.environ.get('PORT', 8080)))\n"
},
{
"alpha_fraction": 0.7129629850387573,
"alphanum_fraction": 0.7314814925193787,
"avg_line_length": 17.08333396911621,
"blob_id": "c0b5b8e86cc7adad5c90cdce0bdc23444092e60a",
"content_id": "464d9d56a25602e3b76be849e6ec9b55771d6318",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 12,
"path": "/Backend/ELA_API/Dockerfile",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "FROM python:3.7-slim \n\nENV APP_HOME /app\n\nCOPY requirements.txt /app/requirements.txt\n\nWORKDIR $APP_HOME\n\nRUN pip install -r requirements.txt\nCOPY . ./\n\nCMD exec gunicorn --bind :$PORT --workers 1 --threads 8 app:app"
},
{
"alpha_fraction": 0.605042040348053,
"alphanum_fraction": 0.610084056854248,
"avg_line_length": 22.799999237060547,
"blob_id": "d636b776a6c81e70525a9a597b955c218fd8faf6",
"content_id": "7e58675a1ca17c954685ccf69a0654d3c96ca938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 595,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 25,
"path": "/Backend/Cloud_Functions/post_to_firestore.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "from google.cloud import firestore\nfrom flask import jsonify\n\ndb = firestore.Client()\n\n\ndef main(request):\n\n data = request.get_json()\n\n user_ref = db.collection(u'Users').document(data['username'])\n doc_ref = user_ref.collection(u'Uploads').document(data['uuid'])\n\n doc_ref.set({\n u'prediction': data['prediction'],\n u'confidence': data['confidence'],\n u'bucket name': data['bucket_name']\n })\n\n resp = {\n 'status': 201,\n 'message': '{} successfully added to user \"{}\".'.format(data['uuid'], data['username'])\n }\n\n return jsonify(resp)\n"
},
{
"alpha_fraction": 0.6072943210601807,
"alphanum_fraction": 0.6140797138214111,
"avg_line_length": 28.974576950073242,
"blob_id": "46fde1569ab59a2973b0ca5fac7096d649ba324c",
"content_id": "afd2be92635f4a3780aedb87eda807b83df4d1a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3537,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 118,
"path": "/Unit Tests/function_tests.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport unittest\nimport json\nimport imghdr\nfrom PIL import Image\n\nsys.path.append(os.getcwd())\nfrom Backend.Prediction_API.predict import get_prediction\nfrom Backend.ELA_API.ela import convert_to_ela\nfrom Backend.Cloud_Functions.resize import decode_base64, encode_base64, process, resize_image\n\nclass TestPrediction(unittest.TestCase):\n def test_prediction(self):\n \"\"\"\n Test that a prediction has been made.\n This test is highly dependent on the model that has been produced.\n If the model changes, the result of this test may change.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_prediction.jpg'\n ela = convert_to_ela(img_path)\n prediction = get_prediction(ela)\n\n self.assertTrue((prediction != None) and (prediction != 0))\n\n def test_unable_predict(self):\n \"\"\"\n Test that a prediction could not be made.\n This test is highly dependent on the model that has been produced.\n If the model changes, the result of this test may change.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_unpredictable.jpg'\n ela = convert_to_ela(img_path)\n prediction = get_prediction(ela)\n\n self.assertTrue((prediction != None) and (prediction == 0))\n\n\nclass TestEla(unittest.TestCase):\n def test_ela(self):\n \"\"\"\n Test that an ela image as been produced.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_resize.jpg'\n ela = convert_to_ela(img_path)\n\n self.assertIn('ela', ela)\n\n\nclass TestResize(unittest.TestCase):\n\n def test_resize(self):\n \"\"\"\n Test that resizing of an image has occurred.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_resize.jpg'\n img = Image.open(img_path)\n\n current_dimension = img.size\n\n resized = resize_image(img)\n self.assertIsNot(current_dimension, resized.size, msg=(\n {'Old Dimension': current_dimension, 'New Dimension': resized.size}))\n\n def test_landscape(self):\n \"\"\"\n Test that a landscape image has NOT been rotated but has been resized.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_resize.jpg'\n img = Image.open(img_path)\n\n results = process(img)\n w, h = results.size\n self.assertIsNot(img.size, results.size)\n self.assertGreater(w, h)\n\n def test_portrait(self):\n \"\"\"\n Test that a portrait image has been rotated and has been resized.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_rotate.jpg'\n img = Image.open(img_path)\n\n results = process(img)\n w, h = results.size\n self.assertIsNot(img.size, results.size)\n self.assertGreater(w, h)\n\n\nclass TestBase64(unittest.TestCase):\n def test_encoding(self):\n \"\"\"\n Test that encoding has taken place.\n \"\"\"\n img_path = os.getcwd() + '/Unit Tests/Assets/test_rotate.jpg'\n img = Image.open(img_path)\n\n result = encode_base64(img)\n self.assertEqual(type(result), bytes)\n\n def test_decoding(self):\n \"\"\"\n Test that decoding has occurred.\n \"\"\"\n\n with open(os.getcwd() + '/Unit Tests/Assets/base64.json', 'r') as base64:\n data = base64.read()\n\n base64_img = json.loads(data)\n\n result = decode_base64(str(base64_img['base64_img']))\n\n self.assertEqual(result.format, \"PNG\")\n\n\nif __name__ == \"__main__\":\n\n unittest.main()\n"
},
{
"alpha_fraction": 0.5816686153411865,
"alphanum_fraction": 0.5846063494682312,
"avg_line_length": 33.040000915527344,
"blob_id": "d3ab5642d9d5232a2780ac9d438cfe6c0490c1d9",
"content_id": "3743717ae331b0ce626c50735ff8842003a3b6ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3404,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 100,
"path": "/Backend/Helper_Scripts/directory_helper.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\n\nfrom tqdm import tqdm\n\n\ndef make_train_test_dir(dataset_name):\n \"\"\"Creates all needed directories to place the train/test splitted images into.\"\"\"\n\n cwd = os.getcwd()\n new_dir = cwd + '/Dataset/' + dataset_name + '/'\n train_dir = new_dir + 'Train/'\n # valid_dir = new_dir + 'Valid/'\n test_dir = new_dir + 'Test/'\n\n sub_folder_names = ['Train/', 'Test/']\n sub_sub_folder_names = ['Authentic/', 'Tampered/']\n\n if os.path.exists(new_dir):\n\n delete_dir_files(new_dir)\n\n if(len(os.listdir(new_dir)) == 0):\n create_directory(new_dir, sub_folder_names)\n create_directory(train_dir, sub_sub_folder_names)\n create_directory(test_dir, sub_sub_folder_names)\n # create_directory(valid_dir, sub_sub_folder_names)\n\n return 'Train/Test and Authentic/Tampered directories created!'\n\n else:\n if os.path.exists(train_dir) and os.path.exists(test_dir):\n len_train = len(os.listdir(train_dir))\n len_test = len(os.listdir(test_dir))\n # len_valid = len(os.listdir(valid_dir))\n\n if(len_train != 0) and (len_test != 0):\n\n delete_dir_files(train_dir)\n delete_dir_files(test_dir)\n # delete_dir_files(valid_dir)\n\n if(len_train == 0) and (len_test == 0):\n create_directory(train_dir, sub_sub_folder_names)\n create_directory(test_dir, sub_sub_folder_names)\n # create_directory(valid_dir, sub_sub_folder_names)\n delete_dir_files(train_dir + sub_sub_folder_names[0])\n delete_dir_files(test_dir + sub_sub_folder_names[1])\n # delete_dir_files(valid_dir + sub_sub_folder_names[2])\n\n\n return 'Authentic/Tampered Folders created in Train/Test/ directories!'\n\n else:\n return 'All necessary folders already exist!'\n\n else:\n create_directory(new_dir)\n create_directory(new_dir, sub_folder_names)\n create_directory(train_dir, sub_sub_folder_names)\n create_directory(test_dir, sub_sub_folder_names)\n # create_directory(valid_dir, sub_sub_folder_names)\n\n return 'All directories needed created!'\n\n\ndef create_directory(directory, sub_folder=None):\n \"\"\"Creates new directories and subfolders. Deletes any MacOS auto generated files(.DS_Store).\n Params: directory to create, optional=sub_folder.\n \"\"\"\n\n if(sub_folder == None):\n os.makedirs(directory)\n else:\n for folder in tqdm(sub_folder):\n os.makedirs(os.path.join(directory, folder))\n\n delete_dir_files(directory)\n\n\ndef delete_dir_files(directory):\n \"\"\"Deletes any files found in a directory.\"\"\"\n\n folder = os.listdir(directory)\n for f in tqdm(folder):\n if(os.path.isfile(directory + f)):\n os.remove(directory + f)\n print('File \"{}\" removed!'.format(f))\n\n\ndef move_to_folder(x_, y_, src_reals, src_fakes, dest_reals, dest_fakes):\n \"\"\"Places train/test splitted images into the correct directories.\"\"\"\n\n for i, x in tqdm(enumerate(x_)):\n if(y_[i] == 0):\n shutil.move(src_reals + x, dest_reals + x)\n elif(y_[i] == 1):\n shutil.move(src_fakes + x, dest_fakes + x)\n\n return 'Move Complete!'\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.726190447807312,
"avg_line_length": 15.866666793823242,
"blob_id": "409bf2a92a18c8fe7cfff0c4dd76a8e6c1515fbc",
"content_id": "67097b7b0cf11569a10c68e4310af934cb4f42bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 15,
"path": "/Backend/Prediction_API/Dockerfile",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "FROM python:3.7-slim-stretch\n\nRUN apt update && apt install --no-install-recommends -y python3-dev gcc build-essential\n\nENV APP_HOME /app\n\nWORKDIR $APP_HOME\n\nCOPY . ./\n\nRUN pip install -r requirements.txt\n\nRUN chmod +x boot.sh\n\nENTRYPOINT [\"./boot.sh\"]"
},
{
"alpha_fraction": 0.6002330780029297,
"alphanum_fraction": 0.6019813418388367,
"avg_line_length": 29.105262756347656,
"blob_id": "d9699d1a45829f049726eccc3b12b864cb778580",
"content_id": "7d8d8777d0b24af6a38ce8ba88d40b845232ca66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1716,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 57,
"path": "/Backend/Helper_Scripts/train_ela_mover.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\nimport sys\nimport cv2 as cv2\nfrom tqdm import tqdm\n\nimport directory_helper as dh\nfrom image_converter import ImageHandler\nfrom Constants import const\n\ncwd = os.getcwd()\nsys.path.insert(1, cwd + '/Backend/')\n\n\ndef convert_all_to_ela(baseDir):\n\n for root, _, files in os.walk(baseDir):\n for fname in tqdm(files):\n if fname != '.DS_Store':\n img_path = os.path.join(root, fname)\n img_obj = ImageHandler(img_path)\n img_obj.convert_to_ela()\n\n\ndef move_to_ela_folder(src, dest):\n \"\"\"Places train splitted images into the correct Train/Authentic - Train/Tampered directories.\"\"\"\n folder = os.listdir(src)\n for f in tqdm(folder):\n if 'ela' in f:\n shutil.move(src + f, dest + f)\n if(os.path.isfile(src + f)):\n if 'resaved' in f:\n os.remove(src + f)\n print(\"Done!\")\n\n\ndef delete_resaved_files(directory):\n \"\"\"Deletes any files found in a directory.\"\"\"\n\n folder = os.listdir(directory)\n for f in tqdm(folder):\n if(os.path.isfile(directory + f)):\n if 'resaved' in f or 'ela' in f:\n os.remove(directory + f)\n print(\"Done!\")\n\n\nif __name__ == \"__main__\":\n pass\n # convert_all_to_ela(const.PATH_TO_TRAIN)\n # convert_all_to_ela(const.PATH_TO_TEST)\n # move_to_ela_folder(const.PATH_TO_TRAIN_REALS,\n # const.PATH_TO_TRAIN_REALS_ELA)\n # move_to_ela_folder(const.PATH_TO_TRAIN_FAKES,\n # const.PATH_TO_TRAIN_FAKES_ELA)\n # move_to_ela_folder(const.PATH_TO_TEST_REALS, const.PATH_TO_TEST_REALS_ELA)\n # move_to_ela_folder(const.PATH_TO_TEST_FAKES, const.PATH_TO_TEST_FAKES_ELA)\n"
},
{
"alpha_fraction": 0.5964912176132202,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 27.5,
"blob_id": "e5d7785227c4041f6c450b90bb8ba6eac1fd176f",
"content_id": "e6e6ab065823a3b06999c1f1f7e7c542e114ba78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 2,
"path": "/Backend/Prediction_API/boot.sh",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nexec gunicorn --bind :8080 --workers 2 app:app\n"
},
{
"alpha_fraction": 0.6059701442718506,
"alphanum_fraction": 0.6156716346740723,
"avg_line_length": 30.904762268066406,
"blob_id": "e0037cc3e69e9cbea9be89cc66f6ede343904b42",
"content_id": "3768765e0376baa1dc1486bc6b5f15f10d000733",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1340,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 42,
"path": "/Backend/Helper_Scripts/image_converter.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom PIL import Image, ImageChops, ImageEnhance\n\nclass ImageHandler:\n\n def __init__(self, path, quality=95):\n self.path = path\n self.quality = quality\n\n def convert_to_ela(self):\n \"\"\"Converts image by intentionally resaving an image at a known error rate and then computing the difference\n between the two images.\n Params:\n path: path to the image to be converted using ELA\n quality: quality in which to resave the image to. Defaults to 95%.\n \"\"\"\n\n fname = self.path\n resaved_fname = fname.split('.')[0] + '.resaved.jpg'\n ela_fname = fname.split('.')[0] + '.ela.png'\n\n img = Image.open(fname).convert('RGB')\n img.save(resaved_fname, 'JPEG', quality=self.quality)\n\n img_resaved = Image.open(resaved_fname)\n ela_img = ImageChops.difference(img, img_resaved)\n\n # Gets the the minimum and maximum pixel values for each band in the image.\n extrema = ela_img.getextrema()\n\n # Calculate max different between the pixel values in the image\n max_diff = max([ex[1] for ex in extrema])\n if max_diff == 0:\n max_diff = 1\n scale = 255.0 / max_diff\n\n ela_img = ImageEnhance.Brightness(ela_img).enhance(scale)\n\n ela_img.save(ela_fname, 'PNG')\n\n return ela_img\n"
},
{
"alpha_fraction": 0.6116504669189453,
"alphanum_fraction": 0.6227461695671082,
"avg_line_length": 22.25806427001953,
"blob_id": "875fbbd9694c47b9925c6189145a325ea5e6ead4",
"content_id": "4fc3078dbfd6d2129a6f478f6b5ed844026aa8d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 31,
"path": "/Backend/Prediction_API/predict.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom fastai.vision import Path, load_learner, open_image\n\n\ndef get_prediction(path):\n \"\"\"Returns confidence level and prediction of a given image.\n Params:\n path: path of the image to be predicted\n \"\"\"\n\n cwd = os.getcwd()\n # weights_path = Path(cwd + '/Backend/Prediction_API/weights/')\n weights_path = Path(cwd + '/weights/')\n\n learn = load_learner(weights_path)\n img = open_image(path)\n\n pred_class, _, confidence = learn.predict(img)\n\n if str(pred_class) == 'Tampered':\n conf = float(confidence[1])\n elif str(pred_class) == 'Authentic':\n conf = float(confidence[0])\n\n conf = conf * 100\n\n if conf >= 65:\n return (pred_class, conf)\n\n return 0\n"
},
{
"alpha_fraction": 0.6517341136932373,
"alphanum_fraction": 0.6575144529342651,
"avg_line_length": 22.066667556762695,
"blob_id": "ed92296803438795069a0cc36debd90d4f399ef7",
"content_id": "c600a7a994828a222e1f1d586ca905bdcd75ffae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 30,
"path": "/Backend/Cloud_Functions/download_img.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import jsonify\nfrom google.cloud import storage\n\nservice_acc = os.environ['SERVICE_ACC']\n\n\ndef main(request):\n\n data = request.get_json()\n\n # Parse json data\n bucket_name = data['bucket_name']\n filepath = data['filepath']\n\n # Initialise a client\n storage_client = storage.Client(service_acc)\n # Create a bucket object for our bucket\n bucket = storage_client.get_bucket(bucket_name)\n # Create a blob object from the filepath\n blob = bucket.blob(filepath)\n # Download the file to a variable\n file = blob.download_as_string()\n\n resp = {\n 'status': 200,\n 'image_file': file.decode('utf-8')\n }\n\n return jsonify(resp)\n"
},
{
"alpha_fraction": 0.6063618063926697,
"alphanum_fraction": 0.6063618063926697,
"avg_line_length": 26.94444465637207,
"blob_id": "af6cf3851baf7616507d78c877f538cbd08fd6cb",
"content_id": "b8b7bf731afe5468717af80d03643c0f2e04bd7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 503,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 18,
"path": "/frontend/src/components/Loading/LoadingResults.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import React, { Fragment } from \"react\";\nimport { Container, Row } from \"react-bootstrap\";\nimport Loading from \"./Loading\";\n\nexport default function LoadingResults() {\n return (\n <Fragment>\n <Container>\n <Row className=\"align-self-center justify-content-sm-center\">\n <p className=\"hero-subtitle-analyse\">\n Sherlock is analysing your image...\n </p>\n </Row>\n <Loading className={\"spinner--container\"} />\n </Container>\n </Fragment>\n );\n}\n"
},
{
"alpha_fraction": 0.5153933763504028,
"alphanum_fraction": 0.5182440280914307,
"avg_line_length": 27.754098892211914,
"blob_id": "7d0ea66b16d6af7d4aa3279399a7c35485b28ed1",
"content_id": "5b406ffdc8e4cc86355000bedb4c0e37039d86dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1754,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 61,
"path": "/frontend/src/components/Navigation.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "/* eslint-disable jsx-a11y/anchor-is-valid */\nimport React from \"react\";\nimport { Nav, Navbar, Container } from \"react-bootstrap\";\nimport { Link } from \"react-router-dom\";\nimport { Button, Icon } from \"semantic-ui-react\";\n\n// context imports\nimport { useAuth0 } from \"../contexts/auth0-context\";\n\nimport Logo from \"../assets/Sherlock_logo.svg\";\nimport \"bulma/css/bulma.css\";\n\nfunction Navigation() {\n const { isLoading, user, logout } = useAuth0();\n\n let username = \"\";\n if (user) {\n if (user.given_name) {\n username = user.given_name;\n } else {\n username = user.nickname;\n }\n }\n\n return (\n <Navbar collapseOnSelect expand=\"lg\" sticky=\"top\">\n <Container>\n <Navbar.Brand>\n <Link to=\"/\">\n <img src={Logo} className=\"logo\" alt=\"Sherlock logo\" />\n </Link>\n </Navbar.Brand>\n <Navbar.Toggle aria-controls=\"responsive-navbar-nav\" />\n <Navbar.Collapse className=\"justify-content-end\">\n <Nav>\n {!isLoading && user && (\n <React.Fragment>\n <span className=\"greeting\">Hi {username}!</span>\n <Button\n color=\"yellow\"\n size=\"huge\"\n animated\n onClick={() => logout({ returnTo: window.location.origin })}\n >\n <Button.Content type=\"submit\" visible>\n Logout\n </Button.Content>\n <Button.Content hidden>\n <Icon name=\"sign-out\" />\n </Button.Content>\n </Button>\n </React.Fragment>\n )}\n </Nav>\n </Navbar.Collapse>\n </Container>\n </Navbar>\n );\n}\n\nexport default Navigation;\n"
},
{
"alpha_fraction": 0.8730158805847168,
"alphanum_fraction": 0.8730158805847168,
"avg_line_length": 8.142857551574707,
"blob_id": "12d0706418940740a196eae230613f834da8a88c",
"content_id": "e124f72783041ffcdbe3c813c3754d1429048716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 7,
"path": "/Backend/ELA_API/requirements.txt",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "flask\nflask_restful\nflask_cors\nimageio\nPillow\ngunicorn\nrequests"
},
{
"alpha_fraction": 0.6073232293128967,
"alphanum_fraction": 0.6212121248245239,
"avg_line_length": 25.10988998413086,
"blob_id": "cc1a5f31263378a3afc727719e1479e56f19bb79",
"content_id": "735ba20913673f3fde5152558665b6c851c40065",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2376,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 91,
"path": "/Backend/ELA_API/app.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport base64\nfrom io import BytesIO\nfrom configparser import ConfigParser\n\nimport requests\nfrom flask import Flask, jsonify, request\nfrom flask_cors import CORS\nfrom flask_restful import Api, Resource\nfrom PIL import Image\n\nfrom cleanup import delete_upload\nfrom ela import convert_to_ela\n\napp = Flask(__name__)\nCORS(app)\napi = Api(app)\n\nconfig_path = 'config/config.ini'\nconfig = ConfigParser()\nconfig.read(config_path)\n\nsend_to_bucket_url = config.get('instance', 'send_to_bucket')\n\n\nclass Converted(Resource):\n def post(self):\n\n data = request.get_json()\n\n # Parse json data\n uuid = data['uuid']\n bucket_name = data['bucket_name']\n img_bytes = data['img_bytes']\n\n decoded_img = decode_base64(img_bytes)\n # Image must first be saved to the local drive before being converted\n decoded_img.save(uuid + '.png')\n img = uuid + '.png'\n\n # Convert image to ELA and Open image\n ela_img = convert_to_ela(img)\n ela_img = Image.open(ela_img)\n # Encode resized_img and upload to Resized Bucket\n encoded_ela = encode_base64(ela_img)\n\n # Clean up - delete produced images\n delete_upload(uuid)\n\n # Prepare payload for send_to_bucket request\n payload = {\n \"bucket_dir\": \"ELA\",\n \"bucket_name\": bucket_name,\n \"img_bytes\": encoded_ela.decode('utf-8'),\n \"uuid\": uuid\n }\n\n # Trigger send_to_bucket function with HTTP\n response = requests.post(send_to_bucket_url, json=payload)\n data = response.json()\n\n resp = {\n 'status': 200,\n 'img_bytes': encoded_ela.decode('utf-8'),\n 'filepath': data['filepath'],\n 'message': 'Image successfully converted to ELA and stored.'\n }\n\n return jsonify(resp)\n\n\ndef decode_base64(image_str):\n \"\"\"Decodes a string image and opens it using PIL.\n \"\"\"\n return Image.open(BytesIO(base64.b64decode(image_str)))\n\n\ndef encode_base64(image):\n \"\"\"Encodes an image into base64 with a file format PNG\n \"\"\"\n buffered = BytesIO()\n image.save(buffered, format=\"PNG\")\n img_str = base64.b64encode(buffered.getvalue())\n\n return img_str\n\n\napi.add_resource(Converted, '/')\n\nif __name__ == '__main__':\n app.run(debug=True, host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))\n"
},
{
"alpha_fraction": 0.6739130616188049,
"alphanum_fraction": 0.6739130616188049,
"avg_line_length": 22,
"blob_id": "202e08ef0c45cd4c7b3f3d874e8a34992f271321",
"content_id": "e6c424bc165ef35de74769a0122943e508319a84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 2,
"path": "/Backend/Router_API/boot.sh",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nexec gunicorn --bind :$PORT app:app\n"
},
{
"alpha_fraction": 0.5869420170783997,
"alphanum_fraction": 0.6042638421058655,
"avg_line_length": 22.825397491455078,
"blob_id": "5b300eea6a090b792e5ecaf6a07ae30cc79fb4cc",
"content_id": "845a43d2df7304e86845bc724bd555c96570ab99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1501,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 63,
"path": "/Backend/Prediction_API/app.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import base64\nfrom io import BytesIO\n\nimport requests\nfrom flask import Flask, jsonify, request\nfrom flask_cors import CORS\nfrom flask_restful import Api, Resource\nfrom PIL import Image\n\nfrom cleanup import delete_upload\nfrom predict import get_prediction\n\napp = Flask(__name__)\nCORS(app)\napi = Api(app)\n\n\nclass Prediction(Resource):\n\n def post(self):\n data = request.get_json()\n\n # Parse json data\n uuid = data['uuid']\n img_bytes = data['img_bytes']\n\n decoded_img = decode_base64(img_bytes)\n # Image must first be saved to the local drive before a prediction can be made.\n decoded_img.save(uuid + '.png')\n img = uuid + '.png'\n\n result = get_prediction(img)\n\n if result != 0:\n prediction = str(result[0])\n confidence = str('{:.2f}%'.format(result[1]))\n else:\n prediction = 'Unable to confidently provide a prediction for this image.'\n confidence = '0'\n\n # Clean up - delete produced images\n delete_upload(img)\n\n # Prep Response\n resp = {\n 'Status': 200,\n 'Prediction': prediction,\n 'Confidence': confidence\n }\n\n return jsonify(resp)\n\n\ndef decode_base64(image_str):\n \"\"\"Decodes a string image and opens it using PIL.\n \"\"\"\n return Image.open(BytesIO(base64.b64decode(image_str)))\n\n\napi.add_resource(Prediction, '/')\n\nif __name__ == '__main__':\n app.run(debug=True, host='0.0.0.0', port=8080)\n"
},
{
"alpha_fraction": 0.5302610993385315,
"alphanum_fraction": 0.5346123576164246,
"avg_line_length": 28.057470321655273,
"blob_id": "63a03c1461213cefb2c8210ef01ac1b5a256ee0c",
"content_id": "c4406ba94473243009b2f4242bb882700ba66e92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5056,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 174,
"path": "/frontend/src/components/FileUpload.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "/* eslint-disable jsx-a11y/anchor-is-valid */\nimport React, { useContext, useState } from \"react\";\nimport { Container, Form, Row } from \"react-bootstrap\";\nimport { Button, Icon, Label } from \"semantic-ui-react\";\nimport axios from \"axios\";\n\n// context imports\nimport { GlobalContext } from \"../contexts/GlobalState\";\nimport { useAuth0 } from \"../contexts/auth0-context\";\n\n// component imports\nimport LoadingResults from \"./Loading/LoadingResults\";\n\nimport \"bulma/css/bulma.css\";\n\nconst url = process.env.REACT_APP_API_URL;\n\nconst Input = (props) => (\n <input\n className=\"file-input\"\n type=\"file\"\n accept=\".png, .jpg, .jpeg, .tif, .bmp\"\n id=\"customFile\"\n {...props}\n />\n);\n\nfunction FileUpload() {\n const { uploaded, updateStates } = useContext(GlobalContext);\n const { user } = useAuth0();\n\n const [file, setFile] = useState(\"\");\n const [filename, setFilename] = useState(\"Choose File\");\n const [showLoading, setShowLoading] = useState(false);\n\n let email = \"[email protected]\";\n\n if (user) {\n email = user.email;\n }\n\n const onChange = (e) => {\n setFile(e.target.files[0]);\n setFilename(e.target.files[0].name);\n };\n\n const submitForm = async (e) => {\n e.preventDefault();\n try {\n // Send converted img to uploadToServer\n await fileToBase64(filename, file).then((result) => {\n uploadToServer(result);\n });\n } catch (err) {\n console.log(err);\n }\n };\n\n const fileToBase64 = (fname, filepath) => {\n return new Promise((resolve) => {\n let tempFile = new File([filepath], fname);\n let reader = new FileReader();\n // Read file content on file loaded event\n reader.onload = function (event) {\n resolve(event.target.result);\n };\n\n // Convert data to base64\n reader.readAsDataURL(tempFile);\n });\n };\n\n const uploadToServer = async (imgFile) => {\n setShowLoading(true);\n const payload = {\n file: imgFile,\n email: email,\n };\n\n const options = {\n headers: {\n \"Access-Control-Allow-Origin\": \"*\",\n \"Content-Type\": \"application/json\",\n \"Access-Control-Allow-Methods\": \"GET, POST\",\n },\n };\n\n try {\n const response = await axios.post(url, payload, options);\n const elaImage = response.data.ela_img;\n const prediction = response.data.prediction;\n const confidence = response.data.confidence;\n setShowLoading(false);\n console.log(\"File Successfully Uploaded!\");\n // calls updateStates() from GlobalContext to update results\n updateStates(true, prediction, confidence, file, filename, elaImage);\n } catch (err) {\n setShowLoading(false);\n if (err.response.status === 400) {\n console.log(\"No File Uploaded!\");\n } else if (err.response.status === 500) {\n console.log(\"There seems to be an issue with the server.\");\n } else {\n console.log(\"Unexpected error occurred.\");\n }\n }\n };\n const Clear = () => {\n setFile(\"\");\n setFilename(\"Choose File\");\n };\n\n if (showLoading) {\n return <LoadingResults />;\n }\n\n return (\n <React.Fragment>\n {!uploaded ? (\n <React.Fragment>\n <Container>\n <p className=\"hero-subtitle-analyse\">\n Upload an image to check for forgery.\n <br />\n Receive a<span className=\"text-color-main\"> prediction </span>in\n seconds!\n </p>\n </Container>\n <Form onSubmit={submitForm}>\n <Container>\n <Row className=\"justify-content-center\">\n <label>\n <Input onChange={onChange} />\n <Icon size=\"massive\" name=\"cloud upload\" />\n {!file && (\n <Row className=\"justify-content-center mt-3\">\n <Label size=\"huge\" pointing>\n Choose a file\n </Label>\n </Row>\n )}\n </label>\n </Row>\n </Container>\n {filename !== \"Choose File\" ? (\n <React.Fragment>\n <Row className=\"justify-content-center align-items-center mt-4\">\n <span className=\"filename\" htmlFor=\"customFile\">\n {filename}\n </span>\n <span onClick={() => Clear()}>\n <Icon color=\"red\" name=\"close\" />\n </span>\n </Row>\n <Row className=\"justify-content-center mt-5\">\n <Button basic color=\"blue\" size=\"massive\" animated>\n <Button.Content type=\"submit\" visible>\n Start\n </Button.Content>\n <Button.Content hidden>\n <Icon name=\"arrow right\" />\n </Button.Content>\n </Button>\n </Row>\n </React.Fragment>\n ) : null}\n </Form>\n </React.Fragment>\n ) : null}\n </React.Fragment>\n );\n}\n\nexport default FileUpload;\n"
},
{
"alpha_fraction": 0.6978557705879211,
"alphanum_fraction": 0.7105262875556946,
"avg_line_length": 41.75,
"blob_id": "9b0177a95495df465b14ea8d46a00cc6f12aff98",
"content_id": "d748756a7641099a259267573905c59fa88703cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1026,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 24,
"path": "/Backend/Helper_Scripts/Constants/const.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\n\n# Root directories\nROOT_PATH = '/Users/tiagoramalho/FinalYearProject/Datasets/CASIA/'\nPATH_TO_FAKES = ROOT_PATH + 'Tp/'\nPATH_TO_REALS = ROOT_PATH + 'Au/'\n\n# New working directories\ncwd = os.getcwd()\nPATH_TO_TRAIN_REALS = cwd + '/Dataset/CASIA-V2/Train/Authentic/'\nPATH_TO_TRAIN_FAKES = cwd + '/Dataset/CASIA-V2/Train/Tampered/'\nPATH_TO_VALID_REALS = cwd + '/Dataset/CASIA-V2/Valid/Authentic/'\nPATH_TO_VALID_FAKES = cwd + '/Dataset/CASIA-V2/Valid/Tampered/'\nPATH_TO_TEST_REALS = cwd + '/Dataset/CASIA-V2/Test/Authentic/'\nPATH_TO_TEST_FAKES = cwd + '/Dataset/CASIA-V2/Test/Tampered/'\n\nPATH_TO_TRAIN_REALS_ELA = cwd + '/Dataset/CASIA-V2_ELA/Train/Authentic/'\nPATH_TO_TRAIN_FAKES_ELA = cwd + '/Dataset/CASIA-V2_ELA/Train/Tampered/'\nPATH_TO_TEST_REALS_ELA = cwd + '/Dataset/CASIA-V2_ELA/Test/Authentic/'\nPATH_TO_TEST_FAKES_ELA = cwd + '/Dataset/CASIA-V2_ELA/Test/Tampered/'\n\nPATH_TO_TRAIN = cwd + '/Dataset/CASIA-V2/Train/'\nPATH_TO_VALID = cwd + '/Dataset/CASIA-V2/Valid/'\nPATH_TO_TEST = cwd + '/Dataset/CASIA-V2/Test/'\n"
},
{
"alpha_fraction": 0.6363636255264282,
"alphanum_fraction": 0.6414141654968262,
"avg_line_length": 21.846153259277344,
"blob_id": "ca9dd67386d968c2a0a0c81d4ca22b826f0a737a",
"content_id": "86e0577676866bf2e10d5afef66c905fd35132ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 52,
"path": "/Backend/Helper_Scripts/image_loader.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport random\n\nimport cv2 as cv2\nimport numpy as np\nfrom imageio import imread\nfrom tqdm import tqdm\n\nsys.path.append(os.getcwd())\n\nfrom Constants import const\n\n\ndef load_img_name_array(path_to_reals, path_to_fakes):\n \"\"\"Returns a numpy array of all image names.\"\"\"\n\n real_images = os.listdir(path_to_reals)\n tamp_images = os.listdir(path_to_fakes)\n image_names = []\n for i in tqdm(range(0, len(real_images))):\n image_names.append(real_images[i])\n for j in tqdm(range(0, len(tamp_images))):\n image_names.append(tamp_images[j])\n\n image_names = np.array(image_names)\n return image_names\n\n\ndef load_img_array(path):\n \"\"\"Returns an array of all images.\n\n Params: \n path = path of train or test directories.\n \"\"\"\n images = []\n\n for folder in os.listdir(path):\n for i in tqdm(os.listdir(path + folder + '/')):\n img = read_img(i, path + folder + '/')\n images.append(img)\n\n images = np.array(images)\n\n return images\n\n\ndef read_img(img_name, train_or_test):\n \"\"\"Reads an image and resizes it accordingly\"\"\"\n\n img = cv2.imread(train_or_test + img_name)\n return cv2.resize(img)\n"
},
{
"alpha_fraction": 0.875,
"alphanum_fraction": 0.875,
"avg_line_length": 9.428571701049805,
"blob_id": "283d94bbe5ad0f790803302b437e859a443bb543",
"content_id": "11ac3a5f114a10e89225c460f4d37bff03cd3906",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 7,
"path": "/Backend/Router_API/requirements.txt",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "flask\nflask_cors\nflask_restful\nfirebase-admin\ngunicorn\nrequests\nWerkzeug"
},
{
"alpha_fraction": 0.5472826361656189,
"alphanum_fraction": 0.5664855241775513,
"avg_line_length": 26.46268653869629,
"blob_id": "7e9a9a251b2df9e3ac54ecdf62a3e7846a8f8dce",
"content_id": "c344e8da91a5f79036095bb3e2732d43bbaaa8b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5520,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 201,
"path": "/Unit Tests/cloud_tests.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nimport unittest\nimport requests\n\nwith open(os.getcwd() + '/Unit Tests/config.json', 'r') as config:\n data = config.read()\n\nconfig_data = json.loads(data)\n\nget_url = str(config_data['get_url'])\nela_url = str(config_data['ela_url'])\npost_url = str(config_data['post_url'])\nrouter_url = str(config_data['router_url'])\nresize_url = str(config_data['resize_url'])\ndownload_url = str(config_data['download_url'])\nprediction_url = str(config_data['prediction_url'])\nsend_to_bucket_url = str(config_data['send_to_bucket_url'])\nbucket_name = str(config_data['bucket_name'])\n\n\nclass TestBucket(unittest.TestCase):\n\n def test_send_to_bucket(self):\n \"\"\"\n Test send_to_bucket cloud function.\n \"\"\"\n\n with open(os.getcwd() + '/Unit Tests/Assets/base64.json', 'r') as base64:\n data = base64.read()\n\n base64_img = json.loads(data)\n\n payload = {\n 'bucket_dir': 'ORIGINALS',\n 'bucket_name': bucket_name,\n 'img_bytes': str(base64_img['base64_img']),\n 'uuid': 'unit-testing-bucket'\n }\n\n response = requests.post(send_to_bucket_url, json=payload).json()\n self.assertEqual(response['status'], 201)\n\n\nclass TestDownload(unittest.TestCase):\n\n def test_download_img(self):\n \"\"\"\n Test download_img cloud function.\n \"\"\"\n\n payload = {\n 'bucket_name': bucket_name,\n 'filepath': 'ORIGINALS/unit-testing-bucket'\n }\n\n download_resp = requests.post(download_url, json=payload).json()\n self.assertEqual(download_resp['status'], 200)\n\n\nclass TestResize(unittest.TestCase):\n\n def test_resize(self):\n\n with open(os.getcwd() + '/Unit Tests/Assets/base64.json', 'r') as base64:\n data = base64.read()\n\n base64_img = json.loads(data)\n\n payload = {\n 'bucket_name': bucket_name,\n 'img_bytes': str(base64_img['base64_img']),\n 'uuid': 'unit-testing-resize'\n }\n\n response = requests.post(resize_url, json=payload).json()\n self.assertEqual(response['status'], 200)\n\n\nclass TestFirestore(unittest.TestCase):\n\n def test_post(self):\n \"\"\"\n Test post_to_firestore http request.\n \"\"\"\n\n payload = {\n 'uuid': 'unit-testing-post',\n 'username': '[email protected]',\n 'prediction': 'Authentic',\n 'confidence': '93.3',\n 'bucket_name': bucket_name\n }\n\n response = requests.post(post_url, json=payload).json()\n self.assertEqual(response['status'], 201)\n\n def test_get(self):\n \"\"\"\n Test get_from_firestore http request.\n \"\"\"\n\n payload = {\n 'username': '[email protected]'\n }\n\n response = requests.post(get_url, json=payload).json()\n self.assertEqual(response['status'], 200)\n\n\nclass TestAPIs(unittest.TestCase):\n\n def test_ela_api(self):\n \"\"\"\n Test to see if an ELA image is produced by the ELA_API.\n If successful, a 200 response will be returned.\n \"\"\"\n\n with open(os.getcwd() + '/Unit Tests/Assets/base64.json', 'r') as base64:\n data = base64.read()\n\n base64_img = json.loads(data)\n\n payload = {\n 'uuid': 'testing-ela-api',\n 'bucket_name': bucket_name,\n 'img_bytes': str(base64_img['base64_img'])\n }\n\n response = requests.post(ela_url, json=payload).json()\n self.assertEqual(response['status'], 200)\n\n def test_prediction_api(self):\n \"\"\"\n Test to see if a prediction is produced by the Prediction_API.\n If successful, a 200 response will be returned.\n \"\"\"\n\n with open(os.getcwd() + '/Unit Tests/Assets/base64.json', 'r') as base64:\n data = base64.read()\n\n base64_img = json.loads(data)\n\n payload = {\n 'uuid': 'testing-ela-api',\n 'img_bytes': str(base64_img['base64_img'])\n }\n\n response = requests.post(prediction_url, json=payload).json()\n self.assertEqual(response['Status'], 200)\n\n def test_post_router_api(self):\n \"\"\"\n Test to see if the router carries out it's instructions. \n If successful, a 200 response will be returned.\n \"\"\"\n\n with open(os.getcwd() + '/Unit Tests/Assets/base64.json', 'r') as base64:\n data = base64.read()\n\n base64_img = json.loads(data)\n\n payload = {\n 'file': 'data:application/octet-stream;base64,' + str(base64_img['base64_img']),\n 'email': '[email protected]'\n }\n\n response = requests.post(router_url, json=payload).json()\n\n self.assertEqual(response['status'], 200)\n\n def test_post_router_bad_request(self):\n \"\"\"\n Test to see if the router raises a bad request error.\n Produced by not sending the API an image\n \"\"\"\n\n payload = {\n 'email': '',\n 'file': ''\n }\n\n response = requests.post(router_url, json=payload).json()\n\n self.assertEqual(response['message'], 'Internal Server Error')\n\n def test_get_router_api(self):\n \"\"\"\n Test to see if a router is returns a list of all the images a user has uploaded.\n If successful, a 200 response will be returned.\n \"\"\"\n\n r = requests.get(router_url + '/user/' +\n 'unit_testing%40test.com').json()\n\n self.assertEqual(r['status'], 200)\n\n\nif __name__ == \"__main__\":\n\n unittest.main()\n"
},
{
"alpha_fraction": 0.8591549396514893,
"alphanum_fraction": 0.8591549396514893,
"avg_line_length": 7.875,
"blob_id": "05e74185379875d8a484f6fd98cd1673eb1ea27d",
"content_id": "7707d14865a57da63a6812a7e3e15c4f33c3b762",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 8,
"path": "/Backend/Prediction_API/requirements.txt",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "flask\nflask_restful\nflask_cors\nfastai\ngunicorn\nimageio\nPillow\nrequests\n"
},
{
"alpha_fraction": 0.4071856141090393,
"alphanum_fraction": 0.4149700701236725,
"avg_line_length": 32.400001525878906,
"blob_id": "bee7b2f75b6147913c5c38be0b9f98a5744a2798",
"content_id": "af903206b43269df52895af1a5f4128f45b26478",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3340,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 100,
"path": "/frontend/src/components/Carousel.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import React, { useState, useEffect } from \"react\";\nimport { Container, Col, Row } from \"react-bootstrap\";\nimport Slider from \"react-slick\";\n\n// context imports\nimport { useAuth0 } from \"../contexts/auth0-context\";\n\nconst url = process.env.REACT_APP_API_URL;\n\nexport default function Carousel() {\n const [userUploads, setUserUploads] = useState([]);\n const [isEmpty, setIsEmpty] = useState(false);\n const { user } = useAuth0();\n const email = encodeURIComponent(user.email);\n\n useEffect(() => {\n fetch(url + \"/user/\" + email)\n .then(res => res.json())\n .then(data => {\n if (data.uploads.length !== 0) {\n setUserUploads(data.uploads);\n setIsEmpty(false);\n } else {\n throw new Error(\"No Previous Uploads\");\n }\n })\n .catch(error => setIsEmpty(true));\n\n // eslint-disable-next-line react-hooks/exhaustive-deps\n }, []);\n\n let settings = {\n infinite: false,\n dots: true,\n speed: 1000,\n arrows: true,\n slidesToShow: 1,\n slidesToScroll: 1\n };\n return (\n <React.Fragment>\n <Container>\n <Row className=\"align-items-center justify-content-center\">\n <h1 className=\"text-muted\" style={{ paddingBottom: \"2vh\" }}>\n Previous Uploads\n </h1>\n </Row>\n <Row className=\"align-items-center justify-content-center\">\n {!isEmpty ? (\n <React.Fragment>\n {userUploads.length === 0 ? (\n <div className=\"spinner-border\" role=\"status\">\n <span className=\"sr-only\">Loading...</span>\n </div>\n ) : (\n <Col xl={3} lg={3} md={3}>\n <Slider {...settings}>\n {userUploads.map(({ uuid, image, prediction }) => (\n <div className=\"out\" key={uuid}>\n <div className=\"card\">\n <img\n className=\"carousel-img\"\n alt=\"\"\n src={`data:application/octet-stream;base64,${image}`}\n />\n <div className=\"card-body\">\n <p className=\"card-title\">Prediction</p>\n {prediction === \"Authentic\" ? (\n <p\n className=\"card-text\"\n style={{ color: \"#1db954\" }}\n >\n {prediction}\n </p>\n ) : (\n <p\n className=\"card-text\"\n style={{ color: \"#cd212a\" }}\n >\n {prediction}\n </p>\n )}\n </div>\n </div>\n </div>\n ))}\n </Slider>\n </Col>\n )}\n </React.Fragment>\n ) : (\n <div className=\"card\" style={{ justifyContent: \"center\" }}>\n <p className=\"card-no-uploads\">No Previous Uploads</p>\n </div>\n )}\n </Row>\n </Container>\n </React.Fragment>\n );\n}\n"
},
{
"alpha_fraction": 0.6274131536483765,
"alphanum_fraction": 0.6274131536483765,
"avg_line_length": 21.042552947998047,
"blob_id": "684dd32ab0f6735d49ef27fe90be0fe877701788",
"content_id": "d66a7d029b084212c7baf1ca48c23a062ba7b311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 47,
"path": "/frontend/src/contexts/GlobalState.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import React, { createContext, useReducer } from \"react\";\nimport AppReducer from \"./AppReducer\";\n// initial state\nconst initialState = {\n uploaded: false,\n uploadInfo: {\n file: \"\",\n filename: \"Choose File\",\n },\n results: { prediction: \"\", confidence: \"\" },\n elaImage: \"\",\n};\n\n// create context\nexport const GlobalContext = createContext(initialState);\n\n// provider component\nexport const GlobalProvider = ({ children }) => {\n const [state, dispatch] = useReducer(AppReducer, initialState);\n\n function updateStates(\n uploaded,\n prediction,\n confidence,\n file,\n filename,\n elaImage\n ) {\n dispatch({\n type: \"UPDATE_STATES\",\n payload: { uploaded, prediction, confidence, file, filename, elaImage },\n });\n }\n return (\n <GlobalContext.Provider\n value={{\n results: state.results,\n uploaded: state.uploaded,\n uploadInfo: state.uploadInfo,\n elaImage: state.elaImage,\n updateStates,\n }}\n >\n {children}\n </GlobalContext.Provider>\n );\n};\n"
},
{
"alpha_fraction": 0.6284722089767456,
"alphanum_fraction": 0.64453125,
"avg_line_length": 22.75257682800293,
"blob_id": "6dc15e16059cbc7aacd7a2c68f0dd0521b6722b5",
"content_id": "0d4e6ca791cba5d1944a19262c35863beb4a42e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2304,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 97,
"path": "/Backend/Cloud_Functions/resize.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport base64\nfrom io import BytesIO\n\nimport requests\nfrom flask import jsonify\nfrom imageio import imread\nfrom PIL import Image\n\n# Comment for unit testing\nsend_to_bucket_url = os.environ['BUCKET_URL']\n\n\ndef main(request):\n\n data = request.get_json()\n\n # Parse json data\n uuid = data['uuid']\n bucket_name = data['bucket_name']\n img_bytes = data['img_bytes']\n\n decoded_img = decode_base64(img_bytes)\n encoded_resized = process(decoded_img)\n\n # Prepare payload for send_to_bucket request\n payload_2 = {\n \"bucket_dir\": \"RESIZED\",\n \"bucket_name\": bucket_name,\n \"img_bytes\": encoded_resized.decode('utf-8'),\n \"uuid\": uuid\n }\n\n # Trigger send_to_bucket function with HTTP\n response = requests.post(send_to_bucket_url, json=payload_2)\n data = response.json()\n\n resp = {\n 'status': 200,\n 'img_bytes': encoded_resized.decode('utf-8'),\n 'filepath': data['filepath'],\n 'message': 'Image successfully resized and stored.'\n }\n\n return jsonify(resp)\n\n\ndef process(img):\n\n # Get image's dimensions\n w, h = img.size\n # Check whether image needs to be rotated or not\n if h > w:\n rotated = img.transpose(Image.ROTATE_90)\n img_to_resize = rotated\n else:\n img_to_resize = img\n\n # Resize image\n resized_img = resize_image(img_to_resize)\n\n # Encode resized_img and upload to Resized Bucket\n encoded_img = encode_base64(resized_img)\n\n # Uncomment for unit testing\n # return resized_img\n\n return encoded_img\n\n\ndef resize_image(input_img):\n \"\"\"Resizes an image to a width of 384.\n Params: \n input_img: Image to be resized.\n \"\"\"\n width = 384\n width_percent = (width/float(input_img.size[0]))\n height_size = int((float(input_img.size[1])*float(width_percent)))\n resized = input_img.resize((width, height_size), Image.ANTIALIAS)\n\n return resized\n\n\ndef decode_base64(image_str):\n \"\"\"Decodes a string image and opens it using PIL.\n \"\"\"\n return Image.open(BytesIO(base64.b64decode(image_str)))\n\n\ndef encode_base64(image):\n \"\"\"Encodes an image into base64 with a file format JPEG\n \"\"\"\n buffered = BytesIO()\n image.save(buffered, format=\"JPEG\")\n img_str = base64.b64encode(buffered.getvalue())\n\n return img_str\n"
},
{
"alpha_fraction": 0.6470154523849487,
"alphanum_fraction": 0.6492262482643127,
"avg_line_length": 32.92499923706055,
"blob_id": "9c642cd2a1f717679b13cbfa8552062c805f6cd9",
"content_id": "26d4dc6d0f33d6fc770a2a93b67a6342a1298500",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1357,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 40,
"path": "/Backend/Cloud_Functions/get_from_firestore.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "from google.cloud import firestore\nfrom flask import jsonify\n\ndb = firestore.Client()\n\n\ndef main(request):\n\n data = request.get_json()\n\n user_ref = db.collection(u'Users').document(data['username'])\n docs = user_ref.collection(u'Uploads').stream()\n\n # Simple list comprehension to return all documents found under a single user.\n user_docs = {doc.id: doc.to_dict() for doc in docs}\n\n # user_docs holds a dictonary of documents returned from firestore. Must convert it\n # into a list so we can iterate through the uuids.\n uuid_list = list(user_docs)\n\n # Iterate through each of the uuid's and append it's information into a new dictonary.\n # Dictonary returned is structured in which it is hard to pull out the correct information.\n results_list = []\n\n for i in range(len(uuid_list)):\n results_dict = {\n 'uuid': uuid_list[i],\n 'prediction': user_docs[uuid_list[i]]['prediction'],\n 'confidence': user_docs[uuid_list[i]]['confidence'],\n 'bucket_name': user_docs[uuid_list[i]]['bucket name']\n }\n # Append the newly structured data to a list to send back to the client.\n results_list.append(results_dict)\n\n resp = {\n 'status': 200,\n 'message': 'Data Successfully Retrieved.',\n 'documents': results_list}\n\n return jsonify(resp)\n"
},
{
"alpha_fraction": 0.5391978025436401,
"alphanum_fraction": 0.5533272624015808,
"avg_line_length": 38.17856979370117,
"blob_id": "f4f3dea5103508e5cc3cf54e8c3c4999bf00ca2f",
"content_id": "18c75abbc7845242c1019dea1ad780955ba4b296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2194,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 56,
"path": "/Backend/Helper_Scripts/helper_main.py",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport shutil\n\nsys.path.append(os.getcwd())\n\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom tqdm import tqdm\n\nfrom Constants import const\nimport directory_helper as dh\nfrom image_loader import load_img_name_array\n\n# Display total images for each category\nprint('Number of Tampered = {}'.format(len(os.listdir(const.PATH_TO_FAKES))))\nprint('Number of Originals = {}'.format(len(os.listdir(const.PATH_TO_REALS))))\n\n# Load image names into X so we can Train/Test Split.\n# Load Y with an array of 12616 values, 7492 real, 5124 fake.\nX = load_img_name_array(const.PATH_TO_REALS, const.PATH_TO_FAKES)\nY = [0]*7492+[1]*5124\n\n# Stratifying so we have approximately the same percentage of samples for in the train/test/val set.\n\n# Train/Test Split\nx_train, x_test, y_train, y_test = train_test_split(X,\n Y,\n test_size=0.1,\n stratify=Y)\n\n\n# Uncomment for Train/Val Split\n# x_train, x_valid, y_train, y_valid = train_test_split(X,\n# Y,\n# test_size=0.20)\n# x_train, x_test, y_train, y_test = train_test_split(x_train,\n# y_train,\n# test_size=0.1,\n# stratify=Y)\n\n\nif __name__ == '__main__':\n\n # Create all needed directories\n print(dh.make_train_test_dir('CASIA-V2'))\n\n # Move splitted images into the correct folders\n print(dh.move_to_folder(x_train, y_train, const.PATH_TO_REALS,\n const.PATH_TO_FAKES, const.PATH_TO_TRAIN_REALS, const.PATH_TO_TRAIN_FAKES))\n\n # print(dh.move_to_folder(x_valid, y_valid, const.PATH_TO_REALS,\n # const.PATH_TO_FAKES, const.PATH_TO_VALID_REALS, const.PATH_TO_VALID_FAKES))\n\n print(dh.move_to_folder(x_test, y_test, const.PATH_TO_REALS,\n const.PATH_TO_FAKES, const.PATH_TO_TEST_REALS, const.PATH_TO_TEST_FAKES))\n"
},
{
"alpha_fraction": 0.5353319048881531,
"alphanum_fraction": 0.5471091866493225,
"avg_line_length": 30.133333206176758,
"blob_id": "527a9a07a733797333ad13bfc4f9fea5a7d3e9bd",
"content_id": "e80d69b2132154d5bfa059032bfda7043a50b602",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 30,
"path": "/frontend/src/pages/NotFound.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import React from \"react\";\nimport { Link } from \"react-router-dom\";\nimport { Container, Image } from \"react-bootstrap\";\nimport NotFound404 from \"../assets/NotFound404.png\";\n\nconst NotFoundPage = () => ({\n render() {\n return (\n <React.Fragment>\n <section id=\"hero\" className=\"jumbotron\">\n <Container>\n <h1 className=\"hero-subtitle flex-center\">\n WHOOPS! SOMETHING HAS GONE WRONG\n </h1>\n <Image className=\"flex-center\" src={NotFound404} />\n <p className=\"hero-subtitle-analyse flex-center\">\n Even Sherlock couldn't find this page!\n </p>\n <div className=\"hero-cta flex-center\">\n <Link to=\"/\" className=\"cta-btn cta-btn--hero\">\n Take Me Home\n </Link>\n </div>\n </Container>\n </section>\n </React.Fragment>\n );\n }\n});\nexport default NotFoundPage;\n"
},
{
"alpha_fraction": 0.6364494562149048,
"alphanum_fraction": 0.6392823457717896,
"avg_line_length": 23.627906799316406,
"blob_id": "8492593c46a49bad67a66305b08afdc55d1c2769",
"content_id": "4e2947ddf788abc1bdd94b21672c6a0151f3e6d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1059,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 43,
"path": "/frontend/src/App.js",
"repo_name": "Tiago4k/Sherlock",
"src_encoding": "UTF-8",
"text": "import React from \"react\";\nimport { Router, Route, Switch } from \"react-router-dom\";\nimport history from \"./utils/history\";\n\n// context imports\nimport { GlobalProvider } from \"./contexts/GlobalState\";\nimport { useAuth0 } from \"./contexts/auth0-context\";\n\n// component imports\nimport PrivateRoute from \"./components/PrivateRoute\";\nimport Loading from \"./components/Loading/Loading\";\n\n// pages\nimport Home from \"./pages/Home\";\nimport Analyse from \"./pages/Analyse\";\nimport NotFound from \"./pages/NotFound\";\n\n// styles\nimport \"bulma/css/bulma.css\";\n\nfunction App() {\n const { loading } = useAuth0();\n\n if (loading) {\n return <Loading className={\"spinner\"} />;\n }\n\n return (\n <React.Fragment>\n <GlobalProvider>\n <Router history={history}>\n <Switch>\n <Route exact path=\"/\" component={Home} />\n <PrivateRoute path=\"/analyse\" component={Analyse} />\n <Route path=\"*\" component={NotFound} />\n </Switch>\n </Router>\n </GlobalProvider>\n </React.Fragment>\n );\n}\n\nexport default App;\n"
}
] | 36 |
virresh/hyperpartisan-semeval19-task4
|
https://github.com/virresh/hyperpartisan-semeval19-task4
|
4d9f0ff75fe510ba799368ebef6ce5bd07124d7e
|
cc9f3fbc1cf3ce230b6c541ae413770f7e1de5b5
|
59f521b7e0cbe79db98b14c073e6ff4dacc4ce11
|
refs/heads/master
| 2020-03-29T08:39:09.346243 | 2019-02-18T10:46:45 | 2019-02-18T10:46:45 | 149,721,650 | 2 | 3 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7093551158905029,
"alphanum_fraction": 0.7420526742935181,
"avg_line_length": 29.61111068725586,
"blob_id": "7c3c70a0e901a560578d2b51b499676864ba08a0",
"content_id": "36a5cc18fcfbc06e56c2e0987cc316c09781a1ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1101,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 36,
"path": "/old_stuff/model_knn/knn_sample.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "from sklearn.model_selection import train_test_split\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.neighbors import KNeighborsClassifier\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n# Train on the whole dataset\n# Test on the vallidation part\ndata = pd.read_csv('../consolidated.csv')\nfeatures = data.drop(['articleId','hyperpartisan','orientation','article_date'], axis=1)\ntruth = data['hyperpartisan']\n\n# train_X, test_X, train_y, test_y = train_test_split(features, truth, test_size=0.20)\ntrain_X = features[:800000]\ntest_X = features[800000:]\ntrain_y = truth[:800000]\ntest_y = truth[800000:]\n\nerror_rate = []\nfor i in range(1,50):\n\tmodel = KNeighborsClassifier(n_neighbors=i)\n\tmodel.fit(train_X,train_y)\n\twee = model.predict(test_X)\n\tacc = accuracy_score(wee, test_y)\n\terror_rate.append(acc)\nmodel = KNeighborsClassifier(n_neighbors=10)\nmodel.fit(train_X,train_y)\nprint(accuracy_score(wee, test_y))\nprint(model.score(test_X, test_y))\n\nplt.figure()\nplt.plot(range(1,50), error_rate)\nplt.title('accuracy_score vs knn input k')\nplt.xlabel('K')\nplt.ylabel('accuracy_score')\nplt.show()"
},
{
"alpha_fraction": 0.7515923380851746,
"alphanum_fraction": 0.7515923380851746,
"avg_line_length": 61.79999923706055,
"blob_id": "3212b8867c728a1e8b495ae96028d114168e5874",
"content_id": "ea98a74de8d91173e6a4731a446fe5da7f32d86e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 5,
"path": "/runner.sh",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "set -e\npython data_extractor.py -d ../hyperpartisan_data/by_articles/train/ -t ../hyperpartisan_data/by_articles/truth/ -o data/\npython save_model.py\npython new_model.py -d ../hyperpartisan_data/by_articles/train/ -o output/\npython evaluator.py -d ../hyperpartisan_data/by_articles/truth/ -r output/ -o evaluated/\n"
},
{
"alpha_fraction": 0.6803004741668701,
"alphanum_fraction": 0.7086811065673828,
"avg_line_length": 29.71794891357422,
"blob_id": "c3f7820166c11421e48a7245077260e610a070be",
"content_id": "37a859ae8024a53cfba67dfcc4b11e004c7b0304",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1198,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 39,
"path": "/old_stuff/model_svm/svm.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "from sklearn import svm\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import accuracy_score\nimport pandas as pd\nimport pickle\n# import matplotlib.pyplot as plt\n\n# Train on the whole dataset\n# Test on the vallidation part\ndata = pd.read_csv('../consolidated.csv')\nfeatures = data.drop(['articleId','hyperpartisan','orientation','article_date'], axis=1)\ntruth = data['hyperpartisan']\n\n# train_X, test_X, train_y, test_y = train_test_split(features, truth, test_size=0.20)\ntrain_X = features[:800000]\ntest_X = features[800000:]\ntrain_y = truth[:800000]\ntest_y = truth[800000:]\n\n# error_rate = []\n# for i in range(1,50):\n# \tmodel = KNeighborsClassifier(n_neighbors=i)\n# \tmodel.fit(train_X,train_y)\n# \twee = model.predict(test_X)\n# \tacc = accuracy_score(wee, test_y)\n# \terror_rate.append(acc)\nmodel = svm.SVC(kernel='linear')\nmodel.fit(train_X,train_y)\n# wee = model.predict(test_X)\n# print(accuracy_score(wee, test_y))\nprint(model.score(test_X, test_y))\nwith open('svm_model.pkl', 'wb') as f:\n\tpickle.dump(model, f)\n# plt.figure()\n# plt.plot(range(1,50), error_rate)\n# plt.title('accuracy_score vs knn input k')\n# plt.xlabel('K')\n# plt.ylabel('accuracy_score')\n# plt.show()\n"
},
{
"alpha_fraction": 0.49066853523254395,
"alphanum_fraction": 0.4966573715209961,
"avg_line_length": 36.39583206176758,
"blob_id": "38b50f8b8281cf38874aaa5d975bb75ec41bbe47",
"content_id": "bb866c595a1ca63ba289f84870fddfdbbc01d07c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7180,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 192,
"path": "/library/sentiment.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "\"\"\"\nClass to score sentiment of text.\n\nUse domain-independent method of dictionary lookup of sentiment words,\nhandling negations and multiword expressions. Based on SentiWordNet 3.0.\n\n\nCredits - https://github.com/anelachan/sentimentanalysis\n\"\"\"\n\nimport nltk\nimport re\n\n\nclass SentimentAnalysis(object):\n \"\"\"Class to get sentiment score based on analyzer.\"\"\"\n\n def __init__(self, filename='SentiWordNet.txt', weighting='geometric'):\n \"\"\"Initialize with filename and choice of weighting.\"\"\"\n if weighting not in ('geometric', 'harmonic', 'average'):\n raise ValueError(\n 'Allowed weighting options are geometric, harmonic, average')\n # parse file and build sentiwordnet dicts\n self.swn_pos = {'a': {}, 'v': {}, 'r': {}, 'n': {}}\n self.swn_all = {}\n self.build_swn(filename, weighting)\n\n def average(self, score_list):\n \"\"\"Get arithmetic average of scores.\"\"\"\n if(score_list):\n return sum(score_list) / float(len(score_list))\n else:\n return 0\n\n def geometric_weighted(self, score_list):\n \"\"\"\"Get geometric weighted sum of scores.\"\"\"\n weighted_sum = 0\n num = 1\n for el in score_list:\n weighted_sum += (el * (1 / float(2**num)))\n num += 1\n return weighted_sum\n\n # another possible weighting instead of average\n def harmonic_weighted(self, score_list):\n \"\"\"Get harmonic weighted sum of scores.\"\"\"\n weighted_sum = 0\n num = 2\n for el in score_list:\n weighted_sum += (el * (1 / float(num)))\n num += 1\n return weighted_sum\n\n def build_swn(self, filename, weighting):\n \"\"\"Build class's lookup based on SentiWordNet 3.0.\"\"\"\n records = [line.split('\\t') for line in open(filename)]\n for rec in records:\n # has many words in 1 entry\n words = rec[4].split()\n pos = rec[0]\n for word_num in words:\n word = word_num.split('#')[0]\n sense_num = int(word_num.split('#')[1])\n\n # build a dictionary key'ed by sense number\n if word not in self.swn_pos[pos]:\n self.swn_pos[pos][word] = {}\n self.swn_pos[pos][word][sense_num] = float(\n rec[2]) - float(rec[3])\n if word not in self.swn_all:\n self.swn_all[word] = {}\n self.swn_all[word][sense_num] = float(rec[2]) - float(rec[3])\n\n # convert innermost dicts to ordered lists of scores\n for pos in self.swn_pos.keys():\n for word in self.swn_pos[pos].keys():\n newlist = [self.swn_pos[pos][word][k] for k in sorted(\n self.swn_pos[pos][word].keys())]\n if weighting == 'average':\n self.swn_pos[pos][word] = self.average(newlist)\n if weighting == 'geometric':\n self.swn_pos[pos][word] = self.geometric_weighted(newlist)\n if weighting == 'harmonic':\n self.swn_pos[pos][word] = self.harmonic_weighted(newlist)\n\n for word in self.swn_all.keys():\n newlist = [self.swn_all[word][k] for k in sorted(\n self.swn_all[word].keys())]\n if weighting == 'average':\n self.swn_all[word] = self.average(newlist)\n if weighting == 'geometric':\n self.swn_all[word] = self.geometric_weighted(newlist)\n if weighting == 'harmonic':\n self.swn_all[word] = self.harmonic_weighted(newlist)\n\n def pos_short(self, pos):\n \"\"\"Convert NLTK POS tags to SWN's POS tags.\"\"\"\n if pos in set(['VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ']):\n return 'v'\n elif pos in set(['JJ', 'JJR', 'JJS']):\n return 'a'\n elif pos in set(['RB', 'RBR', 'RBS']):\n return 'r'\n elif pos in set(['NNS', 'NN', 'NNP', 'NNPS']):\n return 'n'\n else:\n return 'a'\n\n def score_word(self, word, pos):\n \"\"\"Get sentiment score of word based on SWN and part of speech.\"\"\"\n try:\n return self.swn_pos[pos][word]\n except KeyError:\n try:\n return self.swn_all[word]\n except KeyError:\n return 0\n\n def score(self, sentence):\n \"\"\"Sentiment score a sentence.\"\"\"\n # init sentiwordnet lookup/scoring tools\n impt = set(['NNS', 'NN', 'NNP', 'NNPS', 'JJ', 'JJR', 'JJS',\n 'RB', 'RBR', 'RBS', 'VB', 'VBD', 'VBG', 'VBN',\n 'VBP', 'VBZ', 'unknown'])\n non_base = set(['VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'NNS', 'NNPS'])\n negations = set(['not', 'n\\'t', 'less', 'no', 'never',\n 'nothing', 'nowhere', 'hardly', 'barely',\n 'scarcely', 'nobody', 'none'])\n stopwords = nltk.corpus.stopwords.words('english')\n wnl = nltk.WordNetLemmatizer()\n\n scores = []\n tokens = nltk.tokenize.word_tokenize(sentence)\n tagged = nltk.pos_tag(tokens)\n\n index = 0\n for el in tagged:\n\n pos = el[1]\n try:\n word = re.match('(\\w+)', el[0]).group(0).lower()\n start = index - 5\n if start < 0:\n start = 0\n neighborhood = tokens[start:index]\n\n # look for trailing multiword expressions\n word_minus_one = tokens[index-1:index+1]\n word_minus_two = tokens[index-2:index+1]\n\n # if multiword expression, fold to one expression\n if(self.is_multiword(word_minus_two)):\n if len(scores) > 1:\n scores.pop()\n scores.pop()\n if len(neighborhood) > 1:\n neighborhood.pop()\n neighborhood.pop()\n word = '_'.join(word_minus_two)\n pos = 'unknown'\n\n elif(self.is_multiword(word_minus_one)):\n if len(scores) > 0:\n scores.pop()\n if len(neighborhood) > 0:\n neighborhood.pop()\n word = '_'.join(word_minus_one)\n pos = 'unknown'\n\n # perform lookup\n if (pos in impt) and (word not in stopwords):\n if pos in non_base:\n word = wnl.lemmatize(word, self.pos_short(pos))\n score = self.score_word(word, self.pos_short(pos))\n if len(negations.intersection(set(neighborhood))) > 0:\n score = -score\n scores.append(score)\n\n except AttributeError:\n pass\n\n index += 1\n\n if len(scores) > 0:\n return sum(scores) / float(len(scores))\n else:\n return 0\n\n def is_multiword(self, words):\n \"\"\"Test if a group of words is a multiword expression.\"\"\"\n joined = '_'.join(words)\n return joined in self.swn_all\n"
},
{
"alpha_fraction": 0.7321428656578064,
"alphanum_fraction": 0.7410714030265808,
"avg_line_length": 43.599998474121094,
"blob_id": "179046fdd2427bd493affc163d4e8666ae55bcf7",
"content_id": "cd000bbe691637cbd427b3c88a4a34716a349896",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 10,
"path": "/README.md",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "# clark-kent at Semeval 2019 \n\nThe code for both buzzfeed corpus is in located in `old_stuff/buzz` and the \nsubmission on TIRA was our best model on BuzzFeed corpus, i.e the XGBoost Model. \nRunner scripts for the same are in the root directory by the name `runner.sh` \n\nOn semeval training corpus that was released by publisher, we got a high accuracy using FastText model by FAIR. \n\nTeam Name - Clark Kent \nTeam Members - Viresh Gupta, Baani Leen Kaur Jolly, Ramneek Kaur \n"
},
{
"alpha_fraction": 0.5889797210693359,
"alphanum_fraction": 0.5963616967201233,
"avg_line_length": 31.689655303955078,
"blob_id": "74252f842271c48b4c4581ba63fab4fd2093068f",
"content_id": "693dd9aa86dd281ad4ecab045206e35f6792e96c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3793,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 116,
"path": "/old_stuff/save_to_csv_groundtruth.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"Extract information from the articles about time.\"\"\"\n# Version: 2018-09-21\n\n# Parameters:\n# --inputDataset=<directory>\n# Directory that contains the articles XML file with the articles for which a prediction should be made.\n# --outputDir=<directory>\n# Directory to which the predictions will be written. Will be created if it does not exist.\n\nfrom __future__ import division\n\nimport os\nimport getopt\nimport sys\nimport xml.sax\nimport random\n\nrandom.seed(42)\nrunOutputFileName = \"truth.txt\"\n\n# Assign Left = -10\n# Assign Left Center = -5\n# Assign Least = 0\n# Assign Right Center = +5\n# Assign Right = +10\n\ndef parse_options():\n \"\"\"Parses the command line options.\"\"\"\n try:\n long_options = [\"inputDataset=\", \"outputDir=\"]\n opts, _ = getopt.getopt(sys.argv[1:], \"d:o:\", long_options)\n except getopt.GetoptError as err:\n print(str(err))\n sys.exit(2)\n\n inputDataset = \"undefined\"\n outputDir = \"undefined\"\n\n for opt, arg in opts:\n if opt in (\"-d\", \"--inputDataset\"):\n inputDataset = arg\n elif opt in (\"-o\", \"--outputDir\"):\n outputDir = arg\n else:\n assert False, \"Unknown option.\"\n if inputDataset == \"undefined\":\n sys.exit(\"Input dataset, the directory that contains the articles XML file, is undefined. Use option -d or --inputDataset.\")\n elif not os.path.exists(inputDataset):\n sys.exit(\"The input dataset folder does not exist (%s).\" % inputDataset)\n\n if outputDir == \"undefined\":\n sys.exit(\"Output path, the directory into which the predictions should be written, is undefined. Use option -o or --outputDir.\")\n elif not os.path.exists(outputDir):\n os.mkdir(outputDir)\n\n return (inputDataset, outputDir)\n\n\n########## SAX ##########\n\nclass HyperpartisanNewsRandomPredictor(xml.sax.ContentHandler):\n def __init__(self, outFile):\n xml.sax.ContentHandler.__init__(self)\n self.outFile = outFile\n\n def startElement(self, name, attrs):\n self.current_element = name\n if name == \"article\":\n\n articleId = attrs.getValue(\"id\")\n\n if attrs.getValue(\"hyperpartisan\") == 'true':\n hyperpartisan = 1\n else:\n hyperpartisan = 0\n bias = attrs.getValue('bias')\n orientation = None\n\n if bias == 'least':\n orientation = 0\n elif bias == 'left':\n orientation = -10\n elif bias == 'right':\n orientation = 10\n elif bias == 'left-center':\n orientation = -5\n elif bias == 'right-center':\n orientation = 5\n\n self.outFile.write(str(articleId) + \", \" + str(hyperpartisan) + \", \" + str(orientation) + \"\\n\")\n\n # output format per line: \"<article id> <prediction>[ <confidence>]\"\n # - prediction is either \"true\" (hyperpartisan) or \"false\" (not hyperpartisan)\n # - confidence is an optional value to describe the confidence of the predictor in the prediction---the higher, the more confident\n\n########## MAIN ##########\n\n\ndef main(inputDataset, outputDir):\n \"\"\"Main method of this module.\"\"\"\n\n with open(outputDir + \"/\" + runOutputFileName, 'w') as outFile:\n outFile.write('articleId' + \",\" + 'hyperpartisan' + \",\" + 'orientation' + \"\\n\")\n for file in os.listdir(inputDataset):\n if file.endswith(\".xml\"):\n with open(inputDataset + \"/\" + file) as inputRunFile:\n xml.sax.parse(inputRunFile, HyperpartisanNewsRandomPredictor(outFile))\n print(file, 'done.')\n\n print(\"The predictions have been written to the output folder.\")\n\n\nif __name__ == '__main__':\n main(*parse_options())\n\n"
},
{
"alpha_fraction": 0.6772486567497253,
"alphanum_fraction": 0.6984127163887024,
"avg_line_length": 26,
"blob_id": "0c7d95cc2a1059d85d34e6fd062131910fffc18c",
"content_id": "8477a054e75b7e25874d7330ed1065f620042605",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/old_stuff/consolidate.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndf1 = pd.read_csv('features/prediction.txt')\ndf2 = pd.read_csv('output/truth.txt')\n\ndf = pd.merge(df1, df2, on=['articleId'])\ndf.to_csv('consolidated.csv', index=None)\n"
},
{
"alpha_fraction": 0.7654638886451721,
"alphanum_fraction": 0.7680412530899048,
"avg_line_length": 21.823530197143555,
"blob_id": "c3a2044eef25b0906fdf1565e73f47fbba01bc53",
"content_id": "a8344b4df7a76369bf65b90928cfc633b5048039",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 17,
"path": "/old_stuff/buzz/use_model.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom nltk import word_tokenize\nimport pickle\nimport json\n\nclassifier = None\nfeature_extractor = None\n\nwith open('xbg_model.pkl', 'rb') as f:\n\tclassifier = pickle.load(f)\n\tfeature_extractor = pickle.load(f)\n\ndef predict_func(article):\n\tfeats = feature_extractor.transform(article_text)\n\tpredictions = classifier.predict(testX)\n\treturn predictions[0]\n"
},
{
"alpha_fraction": 0.7477272748947144,
"alphanum_fraction": 0.75,
"avg_line_length": 21,
"blob_id": "9b7321b307e6f214996afbd267dc870197493bbd",
"content_id": "b206b4f8ac145188edf413bfdff5809a7263cadf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 440,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 20,
"path": "/library/use_model.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom nltk import word_tokenize\nimport pickle\nimport json\n\nclassifier = None\nfeature_extractor = None\n\nwith open('library/xbg_model.pkl', 'rb') as f:\n\tclassifier = pickle.load(f)\n\tfeature_extractor = pickle.load(f)\n\ndef predict_func(article_text):\n\tfeats = feature_extractor.transform([article_text])\n\tpredictions = classifier.predict(feats)\n\tif predictions[0]:\n\t\treturn 'false'\n\telse:\n\t\treturn 'true'\n"
},
{
"alpha_fraction": 0.5573770403862,
"alphanum_fraction": 0.568306028842926,
"avg_line_length": 23.399999618530273,
"blob_id": "f8315649db9f221552aec5fa65f76757ccab8bf0",
"content_id": "a0d6d470f80cc7e5cccb541481de6fe6e00497e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 15,
"path": "/old_stuff/buzz/convert_to_fastText.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\nlabels = []\ntext = []\n\nwith open('test_data.txt', 'r') as data_file:\n for line in data_file:\n article_text = line[7:]\n label = int(line[5])\n article_id = line[:4]\n labels.append(label)\n text.append(article_text.replace('\\n',' '))\n\nfor x in range(0, len(labels)):\n\tprint('__label__'+str(labels[x]), text[x])\n"
},
{
"alpha_fraction": 0.6972111463546753,
"alphanum_fraction": 0.7051792740821838,
"avg_line_length": 27.961538314819336,
"blob_id": "f31f36262bce5e5949dc1cf1ec1af87367ae5d2d",
"content_id": "5c31918748bf05ac03b10eb8c7466ef25f08f3f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1506,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 52,
"path": "/save_model.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom nltk import word_tokenize\nimport pickle\nimport json\n\nwholeDF = pd.DataFrame()\nlabels = []\nids = []\ntext = []\n\nwith open('data/test_data.txt', 'r') as data_file:\n for line in data_file:\n article_text = line[7:]\n label = int(line[5])\n article_id = line[:4]\n labels.append(label)\n text.append(article_text)\n # text.append(word_tokenize(article_text))\n ids.append(article_id)\n\nwholeDF['label'] = labels\nwholeDF['text'] = text\nwholeDF['aid'] = ids\n\ndel labels, ids, text\n\n# from sklearn.model_selection import train_test_split\n\n# trainX, validX, trainY, validY = train_test_split(wholeDF['text'], wholeDF['label'], test_size=0.2, shuffle=False)\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\ntrainX = wholeDF['text']\nvalidX = wholeDF['label']\n\n# character level uni, bi and tri features\ntfidf_vect_ngram_chars = TfidfVectorizer(analyzer='char', token_pattern=r'\\w{1,}', ngram_range=(1,3), max_features=5000)\ntfidf_vect_ngram_chars.fit(wholeDF['text'])\nxtrain_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(trainX) \n# xvalid_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(validX) \n\ndel wholeDF\n\nfrom xgboost import XGBClassifier\nclassifier = XGBClassifier()\nclassifier.fit(xtrain_tfidf_ngram_chars, validX)\nfile_name = \"library/xbg_model.pkl\"\nwith open(file_name, 'wb') as f:\n pickle.dump(classifier, f)\n pickle.dump(tfidf_vect_ngram_chars, f)\nprint('Pickle Saved to ', file_name)\n"
},
{
"alpha_fraction": 0.6984127163887024,
"alphanum_fraction": 0.7153265476226807,
"avg_line_length": 43.6860466003418,
"blob_id": "9283b328411efc79f771db99ef489737941f17c0",
"content_id": "65e23c896bddffe46b71bd902f5731f26bb4f629",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3843,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 86,
"path": "/old_stuff/buzz/classification_accuracy.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfeatures = pd.read_csv('prediction.txt')\ntruth = pd.read_csv('../../../BuzzFeedData/overview.csv')\ntruth['XML'] = truth['XML'].apply(lambda x: int(x[:-4]))\ntruth = truth[['XML', 'orientation']]\ntruth['orientation'] = truth['orientation'].apply(lambda x: 0 if x == 'mainstream' else 1)\n\ndf = pd.merge(features, truth, left_on='articleId', right_on='XML').drop('XML', axis=1)\n\nX = df.drop(['articleId', 'orientation'], axis=1)\nY = df['orientation']\n\n\"\"\"\nThese models use features such as sentiment of article etc etc\n\"\"\"\n\nfrom sklearn.model_selection import train_test_split, KFold, cross_val_score\nfrom sklearn import metrics \nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import LinearSVC\nimport numpy as np\nimport json\n\ntrain_X, test_X, train_y, test_y = train_test_split(X, Y, test_size=0.20)\n\n# def get_accuracy(model, trainX=train_X, testX=test_X, trainY=train_y, testY=test_y):\n# \tmodel.fit(trainX, trainY)\n# \treturn model.score(testX, testY)\ndef get_accuracy(model, trainX=train_X, testX=test_X, trainY=train_y, testY=test_y):\n model.fit(trainX, trainY)\n predictions = model.predict(testX)\n accuracy = metrics.accuracy_score(predictions, testY)\n precision_micro = metrics.precision_score(testY, predictions, average='micro')\n precision_binary = metrics.precision_score(testY, predictions)\n precision_macro = metrics.precision_score(testY, predictions, average='macro') \n recall_micro = metrics.recall_score(testY, predictions, average='micro')\n recall_binary = metrics.recall_score(testY, predictions)\n recall_macro = metrics.recall_score(testY, predictions, average='macro')\n f1_micro = metrics.f1_score(testY, predictions, average='micro')\n f1_binary = metrics.f1_score(testY, predictions)\n f1_macro = metrics.f1_score(testY, predictions, average='macro')\n d = {\n 'accuracy': accuracy,\n 'precision_micro': precision_micro,\n 'precision_binary': precision_binary,\n 'precision_macro': precision_macro,\n 'recall_micro': recall_micro,\n 'recall_binary': recall_binary,\n 'recall_macro': recall_macro,\n 'f1_micro': f1_micro,\n 'f1_binary': f1_binary,\n 'f1_macro': f1_macro\n }\n return json.dumps(d, indent=4)\n\ndef cross_validate_kfold(model, X=X, Y=Y, k=3):\n\treturn cross_val_score(model, X, Y, cv=k)\n\n\n# KNN\nprint('KNN, k=50, Accuracy:', get_accuracy(KNeighborsClassifier(n_neighbors=50)))\ntemp_arr = cross_validate_kfold(KNeighborsClassifier(n_neighbors=50))\nprint('KNN, k=50, 3-Cross Fold Accuracy:', temp_arr, 'Accuracy Mean', np.mean(temp_arr))\n\n# NaiveBayes\nprint('Gaussian Naive Bayes, k=50, Accuracy:', get_accuracy(GaussianNB()))\ntemp_arr = cross_validate_kfold(GaussianNB())\nprint('Gaussian Naive Bayes, k=50, 3-Cross Fold Accuracy:', temp_arr, 'Accuracy Mean', np.mean(temp_arr))\n\n# Random Forest\nprint('Random Forest, k=50, Accuracy:', get_accuracy(RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)))\ntemp_arr = cross_validate_kfold(RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0))\nprint('Random Forest, k=50, 3-Cross Fold Accuracy:', temp_arr, 'Accuracy Mean', np.mean(temp_arr))\n\n# LogisticRegression\nprint('Logistic Regression, k=50, Accuracy:', get_accuracy(LogisticRegression()))\ntemp_arr = cross_validate_kfold(LogisticRegression())\nprint('Logistic Regression, k=50, 3-Cross Fold Accuracy:', temp_arr, 'Accuracy Mean', np.mean(temp_arr))\n\n# SVM\nprint('SVM (Linear SVC), k=50, Accuracy:', get_accuracy(LinearSVC(tol=1e-1)))\ntemp_arr = cross_validate_kfold(LinearSVC(tol=1e-1))\nprint('SVM (Linear SVC), k=50, 3-Cross Fold Accuracy:', temp_arr, 'Accuracy Mean', np.mean(temp_arr))\n"
},
{
"alpha_fraction": 0.7356584072113037,
"alphanum_fraction": 0.7455997467041016,
"avg_line_length": 52.35652160644531,
"blob_id": "ea0ac30c314914e1dffc2c9636f042e3420b4529",
"content_id": "8f7b8ed50880f0aa2f152ae10bc41df54d7e5b5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6136,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 115,
"path": "/old_stuff/buzz/frequency_models.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom nltk import word_tokenize\nimport json\n\nwholeDF = pd.DataFrame()\nlabels = []\nids = []\ntext = []\n\nwith open('test_data.txt', 'r') as data_file:\n for line in data_file:\n article_text = line[7:]\n label = int(line[5])\n article_id = line[:4]\n labels.append(label)\n text.append(article_text)\n # text.append(word_tokenize(article_text))\n ids.append(article_id)\n\nwholeDF['label'] = labels\nwholeDF['text'] = text\nwholeDF['aid'] = ids\n\ndel labels, ids, text\n\nfrom sklearn.model_selection import train_test_split\n\ntrainX, validX, trainY, validY = train_test_split(wholeDF['text'], wholeDF['label'], test_size=0.2, shuffle=False)\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer\n\n# count vector representation\ncount_vect = CountVectorizer(analyzer='word', token_pattern=r'\\w{1,}')\ncount_vect.fit(wholeDF['text'])\nxtrain_count = count_vect.transform(trainX)\nxvalid_count = count_vect.transform(validX)\n\n# unigram, bigram and trigram features\ntfidf_vect_ngram = TfidfVectorizer(analyzer='word', token_pattern=r'\\w{1,}', max_features=5000, ngram_range=(1,3))\ntfidf_vect_ngram.fit(wholeDF['text'])\nxtrain_tfidf = tfidf_vect_ngram.transform(trainX)\nxvalid_tfidf = tfidf_vect_ngram.transform(validX)\n\n# character level uni, bi and tri features\ntfidf_vect_ngram_chars = TfidfVectorizer(analyzer='char', token_pattern=r'\\w{1,}', ngram_range=(1,3), max_features=5000)\ntfidf_vect_ngram_chars.fit(wholeDF['text'])\nxtrain_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(trainX) \nxvalid_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(validX) \n\ndel wholeDF\n\nfrom sklearn import metrics\ndef get_accuracy(model, trainX=trainX, testX=validX, trainY=trainY, testY=validY, is_neural_net=False):\n model.fit(trainX, trainY)\n predictions = model.predict(testX)\n if is_neural_net:\n predictions = predictions.argmax(axis=-1)\n accuracy = metrics.accuracy_score(predictions, testY)\n precision_micro = metrics.precision_score(validY, predictions, average='micro')\n precision_binary = metrics.precision_score(validY, predictions)\n precision_macro = metrics.precision_score(validY, predictions, average='macro') \n recall_micro = metrics.recall_score(validY, predictions, average='micro')\n recall_binary = metrics.recall_score(validY, predictions)\n recall_macro = metrics.recall_score(validY, predictions, average='macro')\n f1_micro = metrics.f1_score(validY, predictions, average='micro')\n f1_binary = metrics.f1_score(validY, predictions)\n f1_macro = metrics.f1_score(validY, predictions, average='macro')\n d = {\n 'accuracy': accuracy,\n 'precision_micro': precision_micro,\n 'precision_binary': precision_binary,\n 'precision_macro': precision_macro,\n 'recall_micro': recall_micro,\n 'recall_binary': recall_binary,\n 'recall_macro': recall_macro,\n 'f1_micro': f1_micro,\n 'f1_binary': f1_binary,\n 'f1_macro': f1_macro\n }\n return json.dumps(d, indent=4)\n\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import LinearSVC\nfrom xgboost import XGBClassifier\n\nprint('Count Vectors:')\nprint('KNN, Count Vector Accuracy:', get_accuracy(KNeighborsClassifier(n_neighbors=50), trainX=xtrain_count, testX=xvalid_count))\nprint('Gaussian Naive Bayes, Count Vector Accuracy:', get_accuracy(GaussianNB(), trainX=xtrain_count.todense(), testX=xvalid_count.todense()))\nprint('Random Forest, Count Vector Accuracy:', get_accuracy(RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0), trainX=xtrain_count, testX=xvalid_count))\nprint('Logistic Regression, Count Vector Accuracy:', get_accuracy(LogisticRegression(solver='lbfgs'), trainX=xtrain_count, testX=xvalid_count))\nprint('SVM (Linear SVC), Count Vector Accuracy:', get_accuracy(LinearSVC(tol=1e-1), trainX=xtrain_count, testX=xvalid_count))\nprint('xgboost, Count Vector Accuracy:', get_accuracy(XGBClassifier(), trainX=xtrain_count.tocsc(), testX=xvalid_count.tocsc()))\nprint('\\n')\n\nprint('Word Vectors:')\nprint('KNN, Word Vectors Accuracy:', get_accuracy(KNeighborsClassifier(n_neighbors=50), trainX=xtrain_tfidf, testX=xvalid_tfidf))\nprint('Gaussian Naive Bayes, Word Vectors Accuracy:', get_accuracy(GaussianNB(), trainX=xtrain_tfidf.todense(), testX=xvalid_tfidf.todense()))\nprint('Random Forest, Word Vectors Accuracy:', get_accuracy(RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0), trainX=xtrain_tfidf, testX=xvalid_tfidf))\nprint('Logistic Regression, Word Vectors Accuracy:', get_accuracy(LogisticRegression(solver='lbfgs'), trainX=xtrain_tfidf, testX=xvalid_tfidf))\nprint('SVM (Linear SVC), Word Vectors Accuracy:', get_accuracy(LinearSVC(tol=1e-1), trainX=xtrain_tfidf, testX=xvalid_tfidf))\nprint('xgboost, Word Vectors Accuracy:', get_accuracy(XGBClassifier(), trainX=xtrain_tfidf, testX=xvalid_tfidf))\nprint('\\n')\n\nprint('Character Vectors:')\nprint('KNN, Character Vectors Accuracy:', get_accuracy(KNeighborsClassifier(n_neighbors=50), trainX=xtrain_tfidf_ngram_chars, testX=xvalid_tfidf_ngram_chars))\nprint('Gaussian Naive Bayes, Character Vectors Accuracy:', get_accuracy(GaussianNB(), trainX=xtrain_tfidf_ngram_chars.todense(), testX=xvalid_tfidf_ngram_chars.todense()))\nprint('Random Forest, Character Vectors Accuracy:', get_accuracy(RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0), trainX=xtrain_tfidf_ngram_chars, testX=xvalid_tfidf_ngram_chars))\nprint('Logistic Regression, Character Vectors Accuracy:', get_accuracy(LogisticRegression(solver='lbfgs'), trainX=xtrain_tfidf_ngram_chars, testX=xvalid_tfidf_ngram_chars))\nprint('SVM (Linear SVC), Character Vectors Accuracy:', get_accuracy(LinearSVC(tol=1e-1), trainX=xtrain_tfidf_ngram_chars, testX=xvalid_tfidf_ngram_chars))\nprint('xgboost, Character Vectors Accuracy:', get_accuracy(XGBClassifier(), trainX=xtrain_tfidf_ngram_chars, testX=xvalid_tfidf_ngram_chars))\nprint('\\n')\n"
},
{
"alpha_fraction": 0.7165001034736633,
"alphanum_fraction": 0.7279216647148132,
"avg_line_length": 36.71538543701172,
"blob_id": "900c92224e64b104ba85597727bde43f0e57d3d2",
"content_id": "cd92ac97e0d5541e2ca5d7a29fb9caaf83f50d9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4903,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 130,
"path": "/old_stuff/buzz/deep_models.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom nltk import word_tokenize\n\nwholeDF = pd.DataFrame()\nlabels = []\nids = []\ntext = []\n\nwith open('test_data.txt', 'r') as data_file:\n for line in data_file:\n article_text = line[7:]\n label = int(line[5])\n article_id = line[:4]\n labels.append(label)\n text.append(article_text)\n # text.append(word_tokenize(article_text))\n ids.append(article_id)\n\nwholeDF['label'] = labels\nwholeDF['text'] = text\nwholeDF['aid'] = ids\n\ndel labels, ids, text\n\nfrom sklearn.model_selection import train_test_split\n\ntrainX, validX, trainY, validY = train_test_split(wholeDF['text'], wholeDF['label'], test_size=0.2, shuffle=False)\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer\n\n# count vector representation\ncount_vect = CountVectorizer(analyzer='word', token_pattern=r'\\w{1,}')\ncount_vect.fit(wholeDF['text'])\nxtrain_count = count_vect.transform(trainX)\nxvalid_count = count_vect.transform(validX)\n\n# unigram, bigram and trigram features\ntfidf_vect_ngram = TfidfVectorizer(analyzer='word', token_pattern=r'\\w{1,}', max_features=5000, ngram_range=(1,3))\ntfidf_vect_ngram.fit(wholeDF['text'])\nxtrain_tfidf = tfidf_vect_ngram.transform(trainX)\nxvalid_tfidf = tfidf_vect_ngram.transform(validX)\n\n# character level uni, bi and tri features\ntfidf_vect_ngram_chars = TfidfVectorizer(analyzer='char', token_pattern=r'\\w{1,}', ngram_range=(1,3), max_features=5000)\ntfidf_vect_ngram_chars.fit(wholeDF['text'])\nxtrain_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(trainX) \nxvalid_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(validX) \n\nvocab_size = xtrain_count.shape[1]\n\nfrom keras.preprocessing.text import one_hot\nfrom keras.preprocessing.sequence import pad_sequences\n\nencoded_docs = [one_hot(d, vocab_size) for d in wholeDF['text']]\nencoded_docs = pad_sequences(encoded_docs, padding='post')\n\nenctrainX, encvalidX, enctrainY, encvalidY = train_test_split(encoded_docs, wholeDF['label'], test_size=0.2, shuffle=False)\n\ndel wholeDF\n\nfrom sklearn import metrics\ndef get_accuracy(model, trainX=trainX, testX=validX, trainY=trainY, testY=validY, is_neural_net=False, epochs=5):\n model.fit(trainX, trainY, epochs=epochs)\n predictions = model.predict(testX)\n if is_neural_net:\n predictions = list(predictions.argmax(axis=-1).astype(int))\n d = { 'accuracy': metrics.accuracy_score(predictions, testY),\n \t'precision': metrics.precision_score(predictions, testY, average='binary'),\n \t'recall': metrics.recall_score(predictions, testY, average='binary')\n }\n return d\n\nfrom keras import layers, models, optimizers\n\n# Shallow Feed Forward Neural Network\ndef create_model_architecture(input_size):\n # create input layer \n input_layer = layers.Input((input_size, ), sparse=True)\n \n # create hidden layer\n hidden_layer = layers.Dense(100, activation=\"tanh\")(input_layer)\n \n # create output layer\n output_layer = layers.Dense(1, activation=\"sigmoid\")(hidden_layer)\n\n classifier = models.Model(inputs = input_layer, outputs = output_layer)\n classifier.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy', metrics=['accuracy'])\n return classifier\n\n# Simple CNN\ndef create_cnn(inp_size):\n # Add an Input Layer\n input_layer = layers.Input((inp_size, ))\n\n # embedding layer learnt from above\n embedding_layer = layers.Embedding(vocab_size, 200)(input_layer)\n\n # add dropout on this layer\n embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)\n\n # Add the convolutional Layer\n conv_layer = layers.Convolution1D(100, 3, activation=\"tanh\")(embedding_layer)\n\n # Add the pooling Layer\n pooling_layer = layers.GlobalMaxPool1D()(conv_layer)\n\n # Add the output Layers\n output_layer1 = layers.Dense(50, activation=\"relu\")(pooling_layer)\n output_layer1 = layers.Dropout(0.25)(output_layer1)\n output_layer2 = layers.Dense(1, activation=\"sigmoid\")(output_layer1)\n\n # Compile the model\n model = models.Model(inputs=input_layer, outputs=output_layer2)\n model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy', metrics=['accuracy'])\n \n return model\n\nclassifier = create_cnn(enctrainX.shape[1])\naccuracy_CNN_countvectors = get_accuracy(classifier, trainX=enctrainX, trainY=enctrainY, testX=encvalidX, testY=encvalidY, is_neural_net=True)\n\nclassifier = create_model_architecture(xtrain_count.shape[1])\naccuracy_NN_countvectors = get_accuracy(classifier, trainX=xtrain_count, testX=xvalid_count, is_neural_net=True)\n\nclassifier = create_model_architecture(xtrain_tfidf.shape[1])\naccuracy_NN_tfidf = get_accuracy(classifier, trainX=xtrain_tfidf, testX=xvalid_tfidf, is_neural_net=True)\n\nprint(\"CNN, Word Embeddings\", accuracy_CNN_countvectors)\nprint(\"Simple NN, Count Vectors\", accuracy_NN_countvectors)\nprint(\"Simple NN, Ngram Level TF IDF Vectors\", accuracy_NN_tfidf)\n"
},
{
"alpha_fraction": 0.6198731660842896,
"alphanum_fraction": 0.624101459980011,
"avg_line_length": 33.27536392211914,
"blob_id": "8e8d6dd6304dd9668ea8a8a83a1837eebb874a12",
"content_id": "b227dd1ad026a76b89f719b7661cd2e2c9360c91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4730,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 138,
"path": "/data_extractor.py",
"repo_name": "virresh/hyperpartisan-semeval19-task4",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"Random baseline for the PAN19 hyperpartisan news detection task\"\"\"\n# Version: 2018-09-18\n\n# Parameters:\n# --inputDataset=<directory>\n# Directory that contains the articles XML file with the articles for which a prediction should be made.\n# --outputDir=<directory>\n# Directory to which the predictions will be written. Will be created if it does not exist.\n\nfrom __future__ import division\n\nimport os\nimport getopt\nimport sys\nimport xml.sax\nimport random\n\n# from library.sentiment import SentimentAnalysis\nimport pandas as pd\n\nrandom.seed(42)\nrunOutputFileName = \"test_data.txt\"\n\n\"\"\"Global Variables\"\"\"\nnum_articles = 0\nchar_len = 0\n\ndef parse_options():\n \"\"\"Parses the command line options.\"\"\"\n try:\n long_options = [\"inputDataset=\", \"outputDir=\", \"truthDir=\"]\n opts, _ = getopt.getopt(sys.argv[1:], \"d:o:t:\", long_options)\n except getopt.GetoptError as err:\n print(str(err))\n sys.exit(2)\n\n inputDataset = \"undefined\"\n outputDir = \"undefined\"\n truthDir = \"undefined\"\n\n for opt, arg in opts:\n if opt in (\"-d\", \"--inputDataset\"):\n inputDataset = arg\n elif opt in (\"-o\", \"--outputDir\"):\n outputDir = arg\n elif opt in (\"-t\", \"--truthDir\"):\n truthDir = arg\n else:\n assert False, \"Unknown option.\"\n if inputDataset == \"undefined\":\n sys.exit(\"Input dataset, the directory that contains the articles XML file, is undefined. Use option -d or --inputDataset.\")\n elif not os.path.exists(inputDataset):\n sys.exit(\"The input dataset folder does not exist (%s).\" % inputDataset)\n\n if truthDir == \"undefined\":\n sys.exit(\"Ground Truth , the directory that contains the ground truth XML file, is undefined. Use option -d or --inputDataset.\")\n elif not os.path.exists(inputDataset):\n sys.exit(\"The ground truth folder does not exist (%s).\" % inputDataset)\n\n if outputDir == \"undefined\":\n sys.exit(\"Output path, the directory into which the predictions should be written, is undefined. Use option -o or --outputDir.\")\n elif not os.path.exists(outputDir):\n os.mkdir(outputDir)\n\n return (inputDataset, outputDir, truthDir)\n\n\n####### Ground Truth Parser #######\n\ngroundTruth = {}\nclass HyperpartisanNewsGroundTruthHandler(xml.sax.ContentHandler):\n def __init__(self):\n xml.sax.ContentHandler.__init__(self)\n\n def startElement(self, name, attrs):\n if name == \"article\":\n articleId = attrs.getValue(\"id\")\n hyperpartisan = attrs.getValue(\"hyperpartisan\")\n groundTruth[articleId] = hyperpartisan\n\n########## SAX ##########\n\nclass HyperpartisanNewsDataExtractor(xml.sax.ContentHandler):\n def __init__(self, outFile, labels):\n xml.sax.ContentHandler.__init__(self)\n self.outFile = outFile\n self.articleId = None\n self.article_title = ''\n self.article_content = ''\n self.labels = labels\n # self.outFile.write('articleId' + \",\" + 'hyperpartisan' + \",\" + 'text' + \"\\n\")\n\n def startElement(self, name, attrs):\n if name=='article':\n self.current_element = name\n self.articleId = attrs.getValue(\"id\")\n self.label = 1 if self.labels[self.articleId] == 'true' else 0\n self.article_title = attrs.getValue(\"title\")\n self.article_content = ''\n\n def endElement(self, name):\n global num_articles, char_len\n if name=='article':\n num_articles += 1\n self.article_content = (self.article_content+\" \"+self.article_title).lower().replace('\\n',' ')\n # print(self.article_content)\n self.outFile.write(self.articleId + \" \" + str(self.label) + \" \" + self.article_content + \"\\n\")\n\n def characters(self, content):\n self.article_content += content\n\n\n########## MAIN ##########\n\n\ndef main(inputDataset, outputDir, truthDir):\n \"\"\"Main method of this module.\"\"\"\n global num_articles, char_len\n\n for file in os.listdir(truthDir):\n if file.endswith(\".xml\"):\n with open(truthDir + \"/\" + file) as inputRunFile:\n xml.sax.parse(inputRunFile, HyperpartisanNewsGroundTruthHandler())\n\n with open(outputDir + \"/\" + runOutputFileName, 'w') as outFile:\n num_articles=0\n for file in os.listdir(inputDataset):\n if file.endswith(\".xml\"):\n print('Processing', file)\n with open(inputDataset + \"/\" + file) as inputRunFile:\n xml.sax.parse(inputRunFile, HyperpartisanNewsDataExtractor(outFile, groundTruth))\n\n print(\"The predictions have been written to the output folder.\")\n\nif __name__ == '__main__':\n main(*parse_options())\n"
}
] | 15 |
dongliu/traveler
|
https://github.com/dongliu/traveler
|
842390b66d6f6752bbe2296a11159ffba3e38e1c
|
234f81f9842b320998360c65d07193f7bc8c9d1e
|
e0c84f82e8d6cf539e8d2efacbb853d73633eb66
|
refs/heads/master
| 2023-08-29T12:42:59.655974 | 2023-08-12T19:46:34 | 2023-08-12T19:46:34 | 9,632,065 | 8 | 7 |
MIT
| 2013-04-23T20:00:13 | 2023-07-24T08:11:24 | 2023-09-11T01:20:41 |
JavaScript
|
[
{
"alpha_fraction": 0.7838179469108582,
"alphanum_fraction": 0.8053097128868103,
"avg_line_length": 36.66666793823242,
"blob_id": "c37a8948e470d0ee833f8140049a21cf1a5810fc",
"content_id": "34809498982cf040b254b26750c4cd45099d10d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 791,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 21,
"path": "/etc/mongo-configuration.default.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $BASH_SOURCE`\n\n# Run source setup.sh before running this script.\n\nexport MONGO_DIR_NAME=mongodb\nexport MONGO_BIN_DIRECTORY=$TRAVELER_SUPPORT_DIR/$MONGO_DIR_NAME/$HOST_ARCH/bin\nexport MONGO_DATA_DIRECTORY=$TRAVELER_DATA_DIR/$MONGO_DIR_NAME\nexport MONGO_LOG_DIRECTORY=$TRAVELER_VAR_DIR/logs/$MONGO_DIR_NAME.log\nexport MONGO_PID_DIRECTORY=$TRAVELER_VAR_DIR/run/$MONGO_DIR_NAME.pid\nexport MONGO_BIND_IP=127.0.0.1\n\n# Configurations\nexport MONGO_SERVER_PORT=27017\nexport MONGO_SERVER_ADDRESS=127.0.0.1\nexport MONGO_ADMIN_USERNAME=admin\nexport MONGO_ADMIN_PASSWD_FILE=$TRAVELER_INSTALL_ETC_DIR/mongo-admin.passwd\nexport MONGO_TRAVELER_USERNAME=traveler\nexport MONGO_TRAVELER_PASSWD_FILE=$TRAVELER_INSTALL_ETC_DIR/mongo-traveler.passwd\nexport MONGO_TRAVELER_DB=traveler\n"
},
{
"alpha_fraction": 0.6412213444709778,
"alphanum_fraction": 0.6458015441894531,
"avg_line_length": 56.79411697387695,
"blob_id": "cf8565a4c78b6e9866b6801f02fc869c9e307779",
"content_id": "722a32b03e9de2e1cffe6f621e4159334d453ba9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1965,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 34,
"path": "/views/docs/basics/tab.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Tabs and tables\n\nThe templates, travelers, and binders pages use tabs to separate entities in\ndifferent statuses. In each tab, the entities are listed in a table. There are\ntwo places that a button can be placed on a tabbed page. On each list page, when\na button is located on top of the tabs, the button's action is applicable to all\nthe tabs and tables inside the tabs. When a button is located **inside** a tab,\nthen the button's action is only applicable to that tab and table.\n\nAround a table, there are 6 areas each of which either hold optional tools or\ndisplay information.\n\n| area | location | content |\n| ---- | ------------ | ------------------------------------------------------------------- |\n| 1 | top left | a select input to change the number of records shown per table page |\n| 2 | top middle | show a message when the data inside the table is in processing |\n| 3 | top right | a text input to filter all the columns in the table |\n| 4 | bottom row | text inputs to filter the corresponding table column |\n| 5 | bottom left | the numbers of entries out of the total number shown in the view |\n| 6 | bottom right | pagination controls |\n\n</br>\n<img src=\"../images/data-tables.png\" alt=\"the areas of a data table\">\n\nSome tables have extra tools that allow a user to copy, export, or print the\ntable. The traveler application uses\n[the datatables js library](https://datatables.net/) for the tables in web UI.\nMany pages in the application are still on an old version of the library, and\nthe tools are not supported by browsers due to the dependency on the flash\ntechnology. We are in the process of updating those pages to use the latest\nversion of the datatables library.\n\n</br>\n<img src=\"../images/data-table-tools.png\" alt=\"data table tools\" style=\"width:25%\">\n"
},
{
"alpha_fraction": 0.7042253613471985,
"alphanum_fraction": 0.7124413251876831,
"avg_line_length": 20.299999237060547,
"blob_id": "4f4ca1f91ef1b831f0804f2baec24d4868f1f9c5",
"content_id": "1768197d55e622ab39c3da502bf1d8afb04d9108",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 852,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 40,
"path": "/tools/openapi/generatePyClient.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#\n# Script used to generate the required API from the api definitions. \n#\n# Usage:\n#\n# $0\n#\n\nMY_DIR=`dirname $0` && cd $MY_DIR && MY_DIR=`pwd`\nROOT_DIR=$MY_DIR\n\nOPEN_API_VERSION=\"4.3.1\"\nOPEN_API_GENERATOR_JAR=\"openapi-generator-cli-$OPEN_API_VERSION.jar\"\nOPEN_API_GENERATOR_JAR_URL=\"https://repo1.maven.org/maven2/org/openapitools/openapi-generator-cli/$OPEN_API_VERSION/$OPEN_API_GENERATOR_JAR\" \n\nGEN_CONFIG_FILE_PATH=$MY_DIR/ClientApiConfig.yml\nGEN_OUT_DIR=\"pythonApi\"\n\n\nOPENAPI_YML_PATH=\"./openapi.yaml\"\n\ncd $ROOT_DIR\n\ncurl -O $OPEN_API_GENERATOR_JAR_URL\n\njava -jar $OPEN_API_GENERATOR_JAR generate -i \"$OPENAPI_YML_PATH\" -g python -o $GEN_OUT_DIR -c $GEN_CONFIG_FILE_PATH\n\n# Clean up\nrm travelerApi -rv\nrm $OPEN_API_GENERATOR_JAR\n\n# Fetch the generated Api\ncd $GEN_OUT_DIR\ncp -rv travelerApi ../\ncd ..\n\n# Clean up\nrm -rf $GEN_OUT_DIR\n"
},
{
"alpha_fraction": 0.7060931921005249,
"alphanum_fraction": 0.7144563794136047,
"avg_line_length": 22.577465057373047,
"blob_id": "7311315c53ff10a52fc523bd772c93a320588341",
"content_id": "6086726828c49fada2f2e0d03d79188382188c3e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1674,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 71,
"path": "/sbin/mongodb-backup.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\n\nsource $MY_DIR/configure_paths.sh\n\n# import local traveler-mongo settings\nmongoConfigurationFile=$TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\nif [ -f $mongoConfigurationFile ]; then\n source $mongoConfigurationFile\nelse\n >&2 echo \"ERROR $mongoConfigurationFile does not exist.\"\n exit 1\nfi\nif [ ! -f $MONGO_ADMIN_PASSWD_FILE ]; then\n >&2 echo \"ERROR $MONGO_ADMIN_PASSWD_FILE does not exist.\"\n exit 1\nfi\nif [ -z $MONGO_ADMIN_USERNAME ]; then\n >&2 echo \"ERROR: missing administration username in configuration - $mongoConfigurationFile.\"\n exit 1\nfi\nif [ -z $MONGO_SERVER_PORT ]; then\n >&2 echo \"ERROR: missing server port in configuration - $mongoConfigurationFile.\"\n exit 1\nfi\nif [ -z $MONGO_SERVER_ADDRESS ]; then\n >&2 echo \"ERROR: missing server address in configuration - $mongoConfigurationFile.\"\n exit 1\nfi\n\n# perform backup\nif [ ! -d $TRAVELER_BACKUP_DIRECTORY ]; then\n mkdir -p $TRAVELER_BACKUP_DIRECTORY\nfi\n\ncd $TRAVELER_BACKUP_DIRECTORY\n\ndatestamp=`date +%Y%m%d`\ntimestamp=`date +%H-%M`\n\nif [ ! -d $datestamp ]; then\n mkdir $datestamp\nfi\n\ncd $datestamp\n\nif [ ! -d $timestamp ]; then\n mkdir $timestamp\nfi\ncd $timestamp\n\necho \"Performing mongo dump for date: $datestamp - $timestamp\"\n\nadminPassword=`cat $MONGO_ADMIN_PASSWD_FILE`\n\noutput=$($MONGO_BIN_DIRECTORY/mongodump \\\n--host $MONGO_SERVER_ADDRESS \\\n--port $MONGO_SERVER_PORT \\\n--username $MONGO_ADMIN_USERNAME \\\n--password $adminPassword 2>&1)\n\n# All output from mongodump is stderr\nerror=`echo \"$output\" | grep -i error`\nif [ ! -z \"$error\" ]; then\n >&2 echo $output\n cd $TRAVELER_BACKUP_DIRECTORY/$datestamp\n rm -R $timestamp\nelse\n echo -e $output\nfi\n"
},
{
"alpha_fraction": 0.5815832018852234,
"alphanum_fraction": 0.5901992321014404,
"avg_line_length": 25.154930114746094,
"blob_id": "efc78f046cf0953b908c8457d543aff7a7877641",
"content_id": "e00f82733dbe184985db2b4c7efd2f738a8a7830",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1857,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 71,
"path": "/lib/tag.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "var auth = require('./auth');\nvar reqUtils = require('./req-utils');\n\n/**\n * add tag routine for model at uri\n * @param {Express} app the express app\n * @param {String} uri the uri for the route\n * @param {Model} model the model object\n * @return {undefined}\n */\nfunction addTag(app, uri, model) {\n app.post(\n uri,\n auth.ensureAuthenticated,\n reqUtils.exist('id', model),\n reqUtils.canWriteMw('id'),\n reqUtils.filter('body', ['newtag']),\n reqUtils.sanitize('body', ['newtag']),\n function(req, res) {\n var doc = req[req.params.id];\n var newtag = req.body.newtag;\n doc.updatedBy = req.session.userid;\n doc.updatedOn = Date.now();\n var added = doc.tags.addToSet(newtag);\n if (added.length === 0) {\n return res.status(204).send();\n }\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(200).json({ tag: newtag });\n });\n }\n );\n}\n\n/**\n * remove tag routine for model at uri\n * @param {Express} app the express app\n * @param {String} uri the uri for the route\n * @param {Model} model the model object\n * @return {undefined}\n */\nfunction removeTag(app, uri, model) {\n app.delete(\n uri,\n auth.ensureAuthenticated,\n reqUtils.exist('id', model),\n reqUtils.canWriteMw('id'),\n function(req, res) {\n var doc = req[req.params.id];\n doc.updatedBy = req.session.userid;\n doc.updatedOn = Date.now();\n doc.tags.pull(req.params.tag);\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(204).send();\n });\n }\n );\n}\n\nmodule.exports = {\n addTag: addTag,\n removeTag: removeTag,\n};\n"
},
{
"alpha_fraction": 0.6508047580718994,
"alphanum_fraction": 0.6581525802612305,
"avg_line_length": 27.86868667602539,
"blob_id": "8ea752f6905d3fd339e70b6de865ee0f71102f65",
"content_id": "789f8a3f78cc9510f33d9b441eaf3016db9dd96f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2858,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 99,
"path": "/sbin/mongodb-restore.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\n\nsource $MY_DIR/configure_paths.sh\n\n# import local traveler-mongo settings and perform error checking\nmongoConfigurationFile=$TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\nif [ -f $mongoConfigurationFile ]; then\n source $mongoConfigurationFile\nelse\n >&2 echo \"ERROR $mongoConfigurationFile does not exist.\"\n exit 1\nfi\nif [ ! -f $MONGO_ADMIN_PASSWD_FILE ]; then\n >&2 echo \"ERROR $MONGO_ADMIN_PASSWD_FILE does not exist.\"\n exit 1\nfi\nif [ -z $MONGO_ADMIN_USERNAME ]; then\n >&2 echo \"ERROR: missing administration username in configuration - $mongoConfigurationFile.\"\n exit 1\nfi\nif [ -z $MONGO_SERVER_PORT ]; then\n >&2 echo \"ERROR: missing server port in configuration - $mongoConfigurationFile.\"\n exit 1\nfi\nif [ -z $MONGO_SERVER_ADDRESS ]; then\n >&2 echo \"ERROR: missing server address in configuration - $mongoConfigurationFile.\"\n exit 1\nfi\nif [ -z $MONGO_TRAVELER_DB ]; then\n >&2 echo \"ERROR: missing traveler database in configuration - $MONGO_TRAVELER_DB.\"\n exit 1\nfi\n\n\n# perform restore\nif [ ! -d $TRAVELER_BACKUP_DIRECTORY ]; then\n >&2 echo \"ERROR: no backup directory $TRAVELER_BACKUP_DIRECTORY, nothing to restore\"\n exit 1\nfi\n\ncd $TRAVELER_BACKUP_DIRECTORY\n\nif [ -z `ls` ]; then\n >&2 echo \"ERROR: no backups exist in $TRAVELER_BACKUP_DIRECTORY\"\nfi\n\npromptUserForBackupDirectory(){\n latestBackup=`ls -t | head -1`\n echo \"Enter 'ls' to view a list of backups.\"\n read -p \"Please enter the backup you wish to restore [$latestBackup]: \" chosenBackupDate\n\n if [ -z $chosenBackupDate ]; then\n chosenBackupDate=$latestBackup\n else\n if [ \"$chosenBackupDate\" == \"ls\" ]; then\n echo '========================================================'\n ls -l\n echo '========================================================'\n promptUserForBackupDirectory\n elif [ ! -d $chosenBackupDate ]; then\n echo \"Backup not found (Follow date format: YYYYMMDD)\"\n promptUserForBackupDirectory\n fi\n fi\n}\n\npromptUserForBackupDirectory\n\ncd $chosenBackupDate\n\nadminPassword=`cat $MONGO_ADMIN_PASSWD_FILE`\n\nPS3=\"Select time of backup: \"\nselect backupTime in *;\ndo\n case $backupTime in\n *)\n if [ -z $backupTime ]; then\n >&2 echo \"Invalid option entered\"\n else\n cd $backupTime\n echo \"Restoring backup: $chosenBackupDate - $backupTime\"\n # Drop current traveler database\n dropCommand=\"use $MONGO_TRAVELER_DB; \\n db.dropDatabase();\"\n echo -e $dropCommand | $MONGO_BIN_DIRECTORY/mongo $MONGO_SERVER_ADDRESS:$MONGO_SERVER_PORT/admin --username $MONGO_ADMIN_USERNAME --password $adminPassword\n\n $MONGO_BIN_DIRECTORY/mongorestore \\\n --host $MONGO_SERVER_ADDRESS \\\n --port $MONGO_SERVER_PORT \\\n --username $MONGO_ADMIN_USERNAME \\\n --password $adminPassword \\\n\t--batchSize=10\n break;\n fi\n ;;\n esac\ndone\n"
},
{
"alpha_fraction": 0.8056206107139587,
"alphanum_fraction": 0.8056206107139587,
"avg_line_length": 52.375,
"blob_id": "e601e646a939b94088bf1cd7fa7379eeee44c5c1",
"content_id": "8becb34c797ceb2a21db95e650979b5fdc556c44",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 427,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 8,
"path": "/views/docs/template/normal.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Normal templates\n\nMost traveler use cases can be covered with normal templates. The user can\ndefine most common HTML input types, including numbers, date, short text, long\ntext, radio button, checkbox, and file upload in a normal template. The user can\nalso include instructive directions of text, diagrams, and formulas in a normal\ntemplate. A normal template supports numbered sections for easy navigation and\nreference.\n"
},
{
"alpha_fraction": 0.7267552018165588,
"alphanum_fraction": 0.7305502891540527,
"avg_line_length": 26.736841201782227,
"blob_id": "4e571459d5aab6c55abbb21667f311bec87869a5",
"content_id": "53602539c878ae5047b288ce8cba52928a4e6fc5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 527,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 19,
"path": "/sbin/mongo_dev.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash \n\nMY_DIR=`dirname $0`\n\nsource $MY_DIR/configuration.sh\nsource $MY_DIR/configure_paths.sh\n\n# import local traveler-mongo settings \n\nsource $TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\n# Check to see that mongo is installed\nif [ ! -f $MONGO_BIN_DIRECTORY/mongo ]; then \n echo \"MongoDB was not found in the local directory: $MONGO_BIN_DIRECTORY\" \n echo \"please run 'make support' from $TRAVELER_ROOT_DIR directory\" \n exit 1 \nfi \n\n# Connect to mongodb \n$MONGO_BIN_DIRECTORY/mongo --port $MONGO_SERVER_PORT\n"
},
{
"alpha_fraction": 0.8001086115837097,
"alphanum_fraction": 0.8001086115837097,
"avg_line_length": 53.14706039428711,
"blob_id": "903ebb69db5d5101e3e2a6c2e7994d037e678981",
"content_id": "882fcd053cd78201d804d0cb8add5c8e02f5db74",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 1841,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 34,
"path": "/views/docs/template/review.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Template review and release process\n\nA traveler can only be created from a released template. A released template is\ncreated when a draft template is approved by the reviewers and released after\nthat. When the owner finishes editing a template, s/he can request a template\nreview by click on the <button class=\"btn btn-primary\">Submit for\nreview</button> button.\n\nAll the submitted templates are listed on the under review templates tab. On the\ntemplate review page, the template owner can add or remove reviewers. A reviewer\nis a user with the reviewer role. When any reviewer requests change in the form,\nthe review process is stopped. All past review results and comments for specific\nversions are viewable for future reference. The review process restarts when the\nowner makes changes and submits for review again.\n\nWhen all the reviewers approve the template of the current version, the <button\nclass=\"btn btn-primary\">Release</button> button will appear on the template\npage. When the owner releases the approved template, a new released template is\ncreated. The approved template is listed on the approved and released template\ntable.\n\n#### Reviewer\n\n**Audience: admin and reviewer**\n\nA normal traveler user cannot review templates. The admin needs to add the\nreviewer role to the users who want to perform the task. A reviewer sees <a\nhref=\"/reviews/\">Reviews</a> link on top of the traveler page. The reviews page\nlists all the active templates under review. The reviewer can approve or request\nfor more works for a template. A template needs to be approved by all the\nreviewers before release. A single rework request from any reviewer will\nterminate the review process, and the template becomes editable again. A\nreviewer can request change for a template that s/he has approved before it is\nreleased by the template's owner.\n"
},
{
"alpha_fraction": 0.5496183037757874,
"alphanum_fraction": 0.5604325532913208,
"avg_line_length": 25.644067764282227,
"blob_id": "8b1db21ea9c658704a446da667a29b62c3abbe18",
"content_id": "d4dc5cd259e91229fbcf685608d9d10e8bd5b580",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1572,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 59,
"path": "/routes/review.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const debug = require('debug')('traveler:route:review');\nconst mongoose = require('mongoose');\nconst auth = require('../lib/auth');\nconst routesUtilities = require('../utilities/routes');\n\nconst { Reviewer } = require('../lib/role');\n\nconst User = mongoose.model('User');\nconst Form = mongoose.model('Form');\n\nmodule.exports = function(app) {\n app.get('/reviews/', auth.ensureAuthenticated, function(req, res) {\n if (\n req.session.roles === undefined ||\n req.session.roles.indexOf(Reviewer) === -1\n ) {\n return res.status(403).send('only reviewer allowed');\n }\n return res.render('reviews', routesUtilities.getRenderObject(req));\n });\n\n app.get('/reviews/forms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n if (\n req.session.roles === undefined ||\n req.session.roles.indexOf(Reviewer) === -1\n ) {\n return res.status(403).send('only reviewer allowed');\n }\n try {\n const me = await User.findOne(\n {\n _id: req.session.userid,\n },\n 'reviews'\n ).exec();\n if (!me) {\n return res.status(400).send('cannot identify the current user');\n }\n const forms = await Form.find(\n {\n _id: {\n $in: me.reviews,\n },\n archived: {\n $ne: true,\n },\n },\n 'title formType status tags _v __review'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n debug(`error: ${error}`);\n return res.status(500).send(error.message);\n }\n });\n};\n"
},
{
"alpha_fraction": 0.6184032559394836,
"alphanum_fraction": 0.6251691579818726,
"avg_line_length": 23.633333206176758,
"blob_id": "71f2cdb2ece931cde0a1b2f3de2dcd1b058b989a",
"content_id": "1321d7ae93c2bde21e846cfe7bc8c7acb52c6071",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 739,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 30,
"path": "/routes/report.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*eslint max-nested-callbacks: [2, 4], complexity: [2, 20]*/\n\nvar auth = require('../lib/auth');\nvar routesUtilities = require('../utilities/routes');\n\nrequire('../model/binder.js');\n\n/**\n * get the traveler id list from the binder\n * @param {Binder} binder [description]\n * @return {[String]} traveler id list\n */\nfunction getTid(binder) {\n var tid = [];\n binder.works.forEach(function(w) {\n if (w.refType === 'traveler') {\n tid.push(w._id);\n }\n });\n return tid;\n}\n\nmodule.exports = function(app) {\n app.post('/travelers/report/', auth.ensureAuthenticated, function(req, res) {\n return res.render(\n 'report-travelers',\n routesUtilities.getRenderObject(req, { tid: req.body.travelers })\n );\n });\n};\n"
},
{
"alpha_fraction": 0.5173631906509399,
"alphanum_fraction": 0.5274450778961182,
"avg_line_length": 24.01077651977539,
"blob_id": "6b4803a9248913f58eaa6997194c6cf2dbd4ee5f",
"content_id": "480e51a96139a6b1b6e7f9f0f634d65fd8c18317",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 11605,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 464,
"path": "/lib/share.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*jslint es5: true*/\n\nvar config = require('../config/config');\nvar ad = config.ad;\nvar ldapClient = require('./ldap-client');\n\nvar mongoose = require('mongoose');\n\nvar User = mongoose.model('User');\nvar Group = mongoose.model('Group');\n\nfunction addUserFromAD(req, res, doc) {\n var name = req.body.name;\n var nameFilter = ad.nameFilter.replace('_name', name);\n var opts = {\n filter: nameFilter,\n attributes: ad.objAttributes,\n scope: 'sub',\n };\n\n ldapClient.search(ad.searchBase, opts, false, function(err, result) {\n if (err) {\n console.error(err.name + ' : ' + err.message);\n return res.status(500).json(err);\n }\n\n if (result.length === 0) {\n return res.status(400).send(name + ' is not found in AD!');\n }\n\n if (result.length > 1) {\n return res.status(400).send(name + ' is not unique!');\n }\n\n var id = result[0].uid.toLowerCase();\n var access = 0;\n if (req.body.access && req.body.access === 'write') {\n access = 1;\n }\n doc.sharedWith.addToSet({\n _id: id,\n username: name,\n access: access,\n });\n doc.save(function(docErr) {\n if (docErr) {\n console.error(docErr);\n return res.status(500).send(docErr.message);\n }\n var user = new User({\n _id: result[0].uid.toLowerCase(),\n name: result[0].displayName,\n email: result[0].mail,\n office: result[0].physicalDeliveryOfficeName,\n phone: result[0].telephoneNumber.toString(),\n mobile: result[0].mobile,\n });\n switch (doc.constructor.modelName) {\n case 'Form':\n user.forms = [doc._id];\n break;\n case 'Traveler':\n user.travelers = [doc._id];\n break;\n case 'Binder':\n user.binders = [doc._id];\n break;\n default:\n console.error(\n 'Something is wrong with doc type ' + doc.constructor.modelName\n );\n }\n user.save(function(userErr) {\n if (userErr) {\n console.error(userErr);\n }\n });\n return res\n .status(201)\n .send('The user named ' + name + ' was added to the share list.');\n });\n });\n}\n\nfunction addGroupFromAD(req, res, doc) {\n if (!ad.groupSearchFilter) {\n return res.status(500).send('AD not set up for groups');\n }\n var id = req.body.id.toLowerCase();\n var filter = ad.groupSearchFilter.replace('_id', id);\n var opts = {\n filter: filter,\n attributes: ad.groupAttributes,\n scope: 'sub',\n };\n\n ldapClient.search(ad.groupSearchBase, opts, false, function(err, result) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n\n if (result.length === 0) {\n return res.status(400).send(id + ' is not found in AD!');\n }\n\n if (result.length > 1) {\n return res.status(400).send(id + ' is not unique!');\n }\n\n var name = result[0].displayName;\n var access = 0;\n if (req.body.access && req.body.access === 'write') {\n access = 1;\n }\n doc.sharedGroup.addToSet({\n _id: id,\n groupname: name,\n access: access,\n });\n doc.save(function(docErr) {\n if (docErr) {\n console.error(docErr);\n return res.status(500).send(docErr.message);\n }\n var group = new Group({\n _id: result[0].uid.toLowerCase(),\n name: result[0].displayName,\n email: result[0].mail,\n });\n switch (doc.constructor.modelName) {\n case 'Form':\n group.forms = [doc._id];\n break;\n case 'Traveler':\n group.travelers = [doc._id];\n break;\n case 'Binder':\n group.binders = [doc._id];\n break;\n default:\n console.error(\n 'Something is wrong with doc type ' + doc.constructor.modelName\n );\n }\n group.save(function(groupErr) {\n if (groupErr) {\n console.error(groupErr);\n }\n });\n return res\n .status(201)\n .send('The group ' + id + ' was added to the share list.');\n });\n });\n}\n\nfunction addUser(req, res, doc) {\n var name = req.body.name;\n // check local db first then try ad\n User.findOne(\n {\n name: name,\n },\n function(err, user) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n if (user) {\n var access = 0;\n if (req.body.access && req.body.access === 'write') {\n access = 1;\n }\n doc.sharedWith.addToSet({\n _id: user._id,\n username: name,\n access: access,\n });\n doc.save(function(docErr) {\n if (docErr) {\n console.error(docErr);\n return res.status(500).send(docErr.message);\n }\n return res\n .status(201)\n .send('The user named ' + name + ' was added to the share list.');\n });\n var addToSet = {};\n switch (doc.constructor.modelName) {\n case 'Form':\n addToSet.forms = doc._id;\n break;\n case 'Traveler':\n addToSet.travelers = doc._id;\n break;\n case 'Binder':\n addToSet.binders = doc._id;\n break;\n default:\n console.error(\n 'Something is wrong with doc type ' + doc.constructor.modelName\n );\n }\n user.update(\n {\n $addToSet: addToSet,\n },\n function(useErr) {\n if (useErr) {\n console.error(useErr);\n }\n }\n );\n } else {\n addUserFromAD(req, res, doc);\n }\n }\n );\n}\n\nfunction addGroup(req, res, doc) {\n var id = req.body.id.toLowerCase();\n // check local db first then try ad\n Group.findOne(\n {\n _id: id,\n },\n function(err, group) {\n if (err) {\n console.error(err);\n if (ad.groupSearchFilter) {\n return addGroupFromAD(req, res, doc);\n } else {\n return res.status(500).send(err.message);\n }\n }\n if (group) {\n var access = 0;\n if (req.body.access && req.body.access === 'write') {\n access = 1;\n }\n doc.sharedGroup.addToSet({\n _id: id,\n groupname: group.name,\n access: access,\n });\n doc.save(function(docErr) {\n if (docErr) {\n console.error(docErr);\n return res.status(500).send(docErr.message);\n }\n return res\n .status(201)\n .send('The group ' + id + ' was added to the share list.');\n });\n var addToSet = {};\n switch (doc.constructor.modelName) {\n case 'Form':\n addToSet.forms = doc._id;\n break;\n case 'Traveler':\n addToSet.travelers = doc._id;\n break;\n case 'Binder':\n addToSet.binders = doc._id;\n break;\n default:\n console.error(\n 'Something is wrong with doc type ' + doc.constructor.modelName\n );\n }\n group.update(\n {\n $addToSet: addToSet,\n },\n function(groupErr) {\n if (groupErr) {\n console.error(groupErr);\n }\n }\n );\n } else if (ad.groupSearchFilter) {\n addGroupFromAD(req, res, doc);\n } else {\n console.error('Group not found: ' + id);\n return res.status(403).send('Group not found: ' + id);\n }\n }\n );\n}\n\nfunction removeFromList(req, res, doc) {\n // var form = req[req.params.id];\n var list;\n var ids = req.params.shareid.split(',');\n var removed = [];\n\n if (req.params.list === 'users') {\n list = doc.sharedWith;\n }\n if (req.params.list === 'groups') {\n list = doc.sharedGroup;\n }\n\n ids.forEach(function(id) {\n var share = list.id(id);\n if (share) {\n removed.push(id);\n share.remove();\n }\n });\n\n if (removed.length === 0) {\n return res\n .status(400)\n .send('cannot find ' + req.params.shareid + ' in list.');\n }\n\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n // keep the consistency of user's form list\n var Target;\n if (req.params.list === 'users') {\n Target = User;\n }\n if (req.params.list === 'groups') {\n Target = Group;\n }\n\n var pull = {};\n switch (doc.constructor.modelName) {\n case 'Form':\n pull.forms = doc._id;\n break;\n case 'Traveler':\n pull.travelers = doc._id;\n break;\n case 'Binder':\n pull.binders = doc._id;\n break;\n default:\n console.error(\n 'Something is wrong with doc type ' + doc.constructor.modelName\n );\n }\n\n removed.forEach(function(id) {\n Target.findByIdAndUpdate(\n id,\n {\n $pull: pull,\n },\n function(updateErr, target) {\n if (updateErr) {\n console.error(updateErr);\n }\n if (!target) {\n console.error(\n 'The ' + req.params.list + ' ' + id + ' is not in the db'\n );\n }\n }\n );\n });\n\n return res.status(200).json(removed);\n });\n}\n\n/**\n * add a user or a group into a document's share list\n * @param {ClientRequest} req http request object\n * @param {ServerResponse} res http response object\n * @param {Documment} doc the document to share\n * @return {undefined}\n */\nfunction addShare(req, res, doc) {\n if (\n ['Form', 'Traveler', 'Binder'].indexOf(doc.constructor.modelName) === -1\n ) {\n return res\n .status(500)\n .send('cannot handle the document type ' + doc.constructor.modelName);\n }\n if (req.params.list === 'users') {\n addUser(req, res, doc);\n }\n\n if (req.params.list === 'groups') {\n addGroup(req, res, doc);\n }\n}\n\n/**\n * remove a list of users or groups from a document's share list\n * @param {ClientRequest} req http request object\n * @param {ServerResponse} res http response object\n * @param {Documment} doc the document to share\n * @return {undefined}\n */\nfunction removeShare(req, res, doc) {\n if (\n ['Form', 'Traveler', 'Binder'].indexOf(doc.constructor.modelName) === -1\n ) {\n return res\n .status(500)\n .send('cannot handle the document type ' + doc.constructor.modelName);\n }\n\n removeFromList(req, res, doc);\n}\n\nfunction changeOwner(req, res, doc) {\n // get user id from name here\n var name = req.body.name;\n var nameFilter = ad.nameFilter.replace('_name', name);\n var opts = {\n filter: nameFilter,\n attributes: ad.objAttributes,\n scope: 'sub',\n };\n\n ldapClient.search(ad.searchBase, opts, false, function(ldapErr, result) {\n if (ldapErr) {\n console.error(ldapErr.name + ' : ' + ldapErr.message);\n return res.status(500).send(ldapErr.message);\n }\n\n if (result.length === 0) {\n return res.status(400).send(name + ' is not found in AD!');\n }\n\n if (result.length > 1) {\n return res.status(400).send(name + ' is not unique!');\n }\n\n var id = result[0].uid.toLowerCase();\n\n if (doc.owner === id) {\n return res.status(204).send();\n }\n\n doc.owner = id;\n doc.transferredOn = Date.now();\n\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(200).send('Owner is changed to ' + id);\n });\n });\n}\n\nmodule.exports = {\n addShare: addShare,\n removeShare: removeShare,\n changeOwner: changeOwner,\n};\n"
},
{
"alpha_fraction": 0.6936488151550293,
"alphanum_fraction": 0.704856812953949,
"avg_line_length": 23.581632614135742,
"blob_id": "0a07d4caac34bebdffa072cec46ed6646c155ced",
"content_id": "0569dccc435f05589c985bf8eada24b96ec73ea2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2409,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 98,
"path": "/etc/init.d/traveler-mongo-express",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\nCUR_DIR=`pwd`\ncd $MY_DIR\nMY_DIR=`pwd`\ncd $CUR_DIR\n\nsource $MY_DIR/../../setup.sh\n\nMONGO_EXPRESS_CONFIGURATION=$TRAVELER_INSTALL_ETC_DIR/mongo-express-configuration.sh\necho $MONGO_EXPRESS_CONFIGURATION\nif [ ! -f $MONGO_EXPRESS_CONFIGURATION ]; then\n >&2 echo \"$MONGO_EXPRESS_CONFIGURATION is not defined\"\n >&2 echo \"Please use the default file to configure it.\"\n exit 1\nfi\nsource $MONGO_EXPRESS_CONFIGURATION\n\nMONGO_CONFIGURATION=$TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\nif [ ! -f $MONGO_CONFIGURATION ]; then\n >&2 echo \"$MONGO_CONFIGURATION is not defined\"\n >&2 echo \"Please use the default file to configure it.\"\n exit 1\nfi\nsource $MONGO_CONFIGURATION\n\nERR_RED='\\033[0;31m'\nERR_END='\\033[0m\\n'\n\nprintErr(){\n printf \"${ERR_RED}${1}${ERR_END}\"\n}\n\nstart(){\n echo $MONGO_EXPRESS_DAEMON_SOURCE_DIR\n if [ ! -d $MONGO_EXPRESS_DAEMON_SOURCE_DIR ]; then\n >&2 printErr \"ERROR: Make sure mongo-express is installed. It could be done by running 'make support' from $TRAVELER_ROOT_DIR\"\n exit 1\n fi\n\n if [[ -f $MONGO_ADMIN_PASSWD_FILE ]]; then\n adminPass=`cat $MONGO_ADMIN_PASSWD_FILE`\n else\n printErr \"No passwd file exists for mongodb admin. Location $MONGO_ADMIN_PASSWD_FILE\"\n fi\n\n if [[ -f $MONGO_EXPRESS_DAEMON_PASSWD_FILE ]]; then\n mongoExpressAdminPass=`cat $MONGO_EXPRESS_DAEMON_PASSWD_FILE`\n else\n printErr \"No passwd file exists for mongo-express basic-auth. Location $MONGO_EXPRESS_DAEMON_PASSWD_FILE\"\n exit 1\n fi\n\n ME_CONFIG_SITE_SSL_ENABLED=$MONGO_EXPRESS_SSL_ENABLED \\\n ME_CONFIG_SITE_SSL_CRT_PATH=$MONGO_EXPRESS_SSL_CRT \\\n ME_CONFIG_SITE_SSL_KEY_PATH=$MONGO_EXPRESS_SSL_KEY \\\n ME_CONFIG_MONGODB_PORT=$MONGO_SERVER_PORT \\\n ME_CONFIG_MONGODB_SERVER=$MONGO_SERVER_ADDRESS \\\n ME_CONFIG_MONGODB_ADMINUSERNAME=$MONGO_ADMIN_USERNAME \\\n ME_CONFIG_MONGODB_ADMINPASSWORD=$adminPass \\\n ME_CONFIG_MONGODB_ENABLE_ADMIN=true \\\n ME_CONFIG_BASICAUTH_USERNAME=$MONGO_EXPRESS_DAEMON_USERNAME \\\n ME_CONFIG_BASICAUTH_PASSWORD=$mongoExpressAdminPass \\\n pm2 restart $MONGO_EXPRESS_DAEMON_APP_DIR --update-env --name mongo-express\n}\n\nstop(){\n pm2 stop $MONGO_EXPRESS_DAEMON_APP_DIR\n}\n\nrestart(){\n stop\n start\n}\n\nstatus(){\n pm2 status $MONGO_EXPRESS_DAEMON_APP_DIR\n}\n\ncase \"$1\" in\n start)\n start\n ;;\n stop)\n stop\n ;;\n restart)\n restart\n ;;\n status)\n status\n ;;\n *)\n echo \"Usage: $0 {start|stop|restart|status}\"\n exit 1\n ;;\nesac\n"
},
{
"alpha_fraction": 0.5116764307022095,
"alphanum_fraction": 0.5223090648651123,
"avg_line_length": 24.682044982910156,
"blob_id": "7cb5c7859a495134d33667ba2af30db96b6f0753",
"content_id": "52f82a5377a4a2d24924155ff916a0a8477e5150",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 20597,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 802,
"path": "/routes/binder.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* eslint-disable no-underscore-dangle */\n/* eslint-disable func-names */\n/* eslint-disable consistent-return */\n/* eslint max-nested-callbacks: [2, 4], complexity: [2, 20] */\n\nconst mongoose = require('mongoose');\nconst _ = require('lodash');\nconst jade = require('jade');\nconst auth = require('../lib/auth');\nconst authConfig = require('../config/config').auth;\nconst reqUtils = require('../lib/req-utils');\nconst shareLib = require('../lib/share');\nconst routesUtilities = require('../utilities/routes');\n\nconst valueProgressHtml = jade.compileFile(\n `${__dirname}/../views/binder-value-progress.jade`\n);\nconst travelerProgressHtml = jade.compileFile(\n `${__dirname}/../views/binder-traveler-progress.jade`\n);\nconst inputProgressHtml = jade.compileFile(\n `${__dirname}/../views/binder-input-progress.jade`\n);\n\nconst User = mongoose.model('User');\nconst Group = mongoose.model('Group');\nconst Binder = mongoose.model('Binder');\nconst Traveler = mongoose.model('Traveler');\n\nmodule.exports = function(app) {\n app.get('/binders/', auth.ensureAuthenticated, function(req, res) {\n res.render('binders', routesUtilities.getRenderObject(req));\n });\n\n app.get('/binders/json', auth.ensureAuthenticated, function(req, res) {\n Binder.find({\n createdBy: req.session.userid,\n status: {\n $ne: 3,\n },\n owner: {\n $exists: false,\n },\n }).exec(function(err, docs) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(docs);\n });\n });\n\n app.get(\n '/binders/:id/config',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canWriteMw('id'),\n function(req, res) {\n return res.render(\n 'binder-config',\n routesUtilities.getRenderObject(req, {\n binder: req[req.params.id],\n })\n );\n }\n );\n\n app.post(\n '/binders/:id/tags/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canWriteMw('id'),\n reqUtils.filter('body', ['newtag']),\n reqUtils.sanitize('body', ['newtag']),\n function(req, res) {\n const doc = req[req.params.id];\n doc.updatedBy = req.session.userid;\n doc.updatedOn = Date.now();\n doc.tags.addToSet(req.body.newtag);\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(204).send();\n });\n }\n );\n\n app.delete(\n '/binders/:id/tags/:tag',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canWriteMw('id'),\n function(req, res) {\n const doc = req[req.params.id];\n doc.updatedBy = req.session.userid;\n doc.updatedOn = Date.now();\n doc.tags.pull(req.params.tag);\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(204).send();\n });\n }\n );\n\n app.put(\n '/binders/:id/config',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n reqUtils.status('id', [0, 1]),\n reqUtils.filter('body', ['title', 'description']),\n reqUtils.sanitize('body', ['title', 'description']),\n function(req, res) {\n const doc = req[req.params.id];\n Object.keys(req.body).forEach(k => {\n if (req.body[k] !== null) {\n doc[k] = req.body[k];\n }\n });\n doc.updatedBy = req.session.userid;\n doc.updatedOn = Date.now();\n doc.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(204).send();\n });\n }\n );\n\n app.get(\n '/binders/:id/share/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const binder = req[req.params.id];\n return res.render(\n 'share',\n routesUtilities.getRenderObject(req, {\n type: 'Binder',\n id: req.params.id,\n title: binder.title,\n access: String(binder.publicAccess),\n })\n );\n }\n );\n\n app.put(\n '/binders/:id/share/public',\n auth.ensureAuthenticated,\n reqUtils.filter('body', ['access']),\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const binder = req[req.params.id];\n let { access } = req.body;\n if (['-1', '0', '1'].indexOf(access) === -1) {\n return res.status(400).send('not valid value');\n }\n access = Number(access);\n if (binder.publicAccess === access) {\n return res.status(204).send();\n }\n binder.publicAccess = access;\n binder.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res\n .status(200)\n .send(`public access is set to ${req.body.access}`);\n });\n }\n );\n\n app.get(\n '/binders/:id/share/:list/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canReadMw('id'),\n function(req, res) {\n const binder = req[req.params.id];\n if (req.params.list === 'users') {\n return res.status(200).json(binder.sharedWith || []);\n }\n if (req.params.list === 'groups') {\n return res.status(200).json(binder.sharedGroup || []);\n }\n return res.status(400).send('unknown share list.');\n }\n );\n\n app.post(\n '/binders/:id/share/:list/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const binder = req[req.params.id];\n let share = -2;\n if (req.params.list === 'users') {\n if (req.body.name) {\n share = reqUtils.getSharedWith(binder.sharedWith, req.body.name);\n } else {\n return res.status(400).send('user name is empty.');\n }\n }\n if (req.params.list === 'groups') {\n if (req.body.id) {\n share = reqUtils.getSharedGroup(binder.sharedGroup, req.body.id);\n } else {\n return res.status(400).send('group id is empty.');\n }\n }\n\n if (share === -2) {\n return res.status(400).send('unknown share list.');\n }\n\n if (share >= 0) {\n return res\n .status(400)\n .send(\n req.body.name ||\n `${req.body.id} is already in the ${req.params.list} list.`\n );\n }\n\n if (share === -1) {\n // new user in the list\n shareLib.addShare(req, res, binder);\n }\n }\n );\n\n app.put(\n '/binders/:id/share/:list/:shareid',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const binder = req[req.params.id];\n let share;\n if (req.params.list === 'users') {\n share = binder.sharedWith.id(req.params.shareid);\n }\n if (req.params.list === 'groups') {\n share = binder.sharedGroup.id(req.params.shareid);\n }\n\n if (!share) {\n // the user should in the list\n return res\n .status(404)\n .send(`cannot find ${req.params.shareid} in the list.`);\n }\n\n // change the access\n if (req.body.access && req.body.access === 'write') {\n share.access = 1;\n } else {\n share.access = 0;\n }\n binder.save(function(saveErr) {\n if (saveErr) {\n console.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n // check consistency of user's traveler list\n let Target;\n if (req.params.list === 'users') {\n Target = User;\n }\n if (req.params.list === 'groups') {\n Target = Group;\n }\n Target.findByIdAndUpdate(\n req.params.shareid,\n {\n $addToSet: {\n binders: binder._id,\n },\n },\n function(updateErr, target) {\n if (updateErr) {\n console.error(updateErr);\n }\n if (!target) {\n console.error(\n `The user/group ${req.params.userid} is not in the db`\n );\n }\n }\n );\n return res.status(200).json(share);\n });\n }\n );\n\n app.delete(\n '/binders/:id/share/:list/:shareid',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const binder = req[req.params.id];\n shareLib.removeShare(req, res, binder);\n }\n );\n\n app.get('/binders/new', auth.ensureAuthenticated, function(req, res) {\n res.render('binder-new', routesUtilities.getRenderObject(req));\n });\n\n app.post(\n '/binders/',\n auth.ensureAuthenticated,\n reqUtils.filter('body', ['title', 'description']),\n reqUtils.hasAll('body', ['title']),\n reqUtils.sanitize('body', ['title', 'description']),\n function(req, res) {\n const binder = {};\n if (req.body.works && _.isArray(req.body.works)) {\n binder.works = req.body.works;\n } else {\n binder.works = [];\n }\n\n binder.title = req.body.title;\n if (req.body.description) {\n binder.description = req.body.description;\n }\n binder.createdBy = req.session.userid;\n binder.createdOn = Date.now();\n new Binder(binder).save(function(err, newPackage) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n const url = `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/binders/${newPackage.id}/`;\n\n res.set('Location', url);\n return res\n .status(201)\n .send(`You can access the new binder at <a href=\"${url}\">${url}</a>`);\n });\n }\n );\n\n app.get('/transferredbinders/json', auth.ensureAuthenticated, function(\n req,\n res\n ) {\n Binder.find({\n owner: req.session.userid,\n status: {\n $ne: 3,\n },\n }).exec(function(err, binders) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n res.status(200).json(binders);\n });\n });\n\n app.get('/writablebinders/json', auth.ensureAuthenticated, function(\n req,\n res\n ) {\n const search = {\n status: {\n $ne: 3,\n },\n $or: [\n {\n createdBy: req.session.userid,\n owner: {\n $exists: false,\n },\n },\n {\n owner: req.session.userid,\n },\n {\n publicAccess: 1,\n },\n {\n sharedWith: {\n $elemMatch: {\n _id: req.session.userid,\n access: 1,\n },\n },\n },\n {\n sharedGroup: {\n $elemMatch: {\n _id: { $in: req.session.memberOf },\n access: 1,\n },\n },\n },\n ],\n };\n\n Binder.find(search)\n .lean()\n .exec(function(err, binders) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(binders);\n });\n });\n\n app.get('/sharedbinders/json', auth.ensureAuthenticated, function(req, res) {\n User.findOne(\n {\n _id: req.session.userid,\n },\n 'binders'\n ).exec(function(err, me) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n if (!me) {\n return res.status(400).send('cannot identify the current user');\n }\n Binder.find({\n _id: {\n $in: me.binders,\n },\n status: {\n $ne: 3,\n },\n }).exec(function(pErr, binders) {\n if (pErr) {\n console.error(pErr);\n return res.status(500).send(pErr.message);\n }\n return res.status(200).json(binders);\n });\n });\n });\n\n app.get('/groupsharedbinders/json', auth.ensureAuthenticated, function(\n req,\n res\n ) {\n Group.find(\n {\n _id: {\n $in: req.session.memberOf,\n },\n },\n 'binders'\n ).exec(function(err, groups) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n const binderIds = [];\n let i;\n let j;\n // merge the binders arrays\n for (i = 0; i < groups.length; i += 1) {\n for (j = 0; j < groups[i].binders.length; j += 1) {\n if (binderIds.indexOf(groups[i].binders[j]) === -1) {\n binderIds.push(groups[i].binders[j]);\n }\n }\n }\n Binder.find({\n _id: {\n $in: binderIds,\n },\n }).exec(function(pErr, binders) {\n if (pErr) {\n console.error(pErr);\n return res.status(500).send(pErr.message);\n }\n res.status(200).json(binders);\n });\n });\n });\n\n app.get('/archivedbinders/json', auth.ensureAuthenticated, function(\n req,\n res\n ) {\n Binder.find({\n createdBy: req.session.userid,\n status: 3,\n }).exec(function(err, binders) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(binders);\n });\n });\n\n app.put(\n '/binders/:id/owner',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n reqUtils.status('id', [0, 1]),\n reqUtils.filter('body', ['name']),\n function(req, res) {\n const doc = req[req.params.id];\n shareLib.changeOwner(req, res, doc);\n }\n );\n\n app.get(\n '/binders/:id/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canReadMw('id'),\n function(req, res) {\n res.render(\n 'binder',\n routesUtilities.getRenderObject(req, {\n binder: req[req.params.id],\n })\n );\n }\n );\n\n app.get(\n '/binders/:id/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canReadMw('id'),\n reqUtils.exist('id', Binder),\n function(req, res) {\n res.status(200).json(req[req.params.id]);\n }\n );\n\n app.put(\n '/binders/:id/status',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.isOwnerMw('id'),\n reqUtils.filter('body', ['status']),\n reqUtils.hasAll('body', ['status']),\n function(req, res) {\n const p = req[req.params.id];\n const s = req.body.status;\n\n if ([1, 2, 3].indexOf(s) === -1) {\n return res.status(400).send('invalid status');\n }\n\n if (p.status === s) {\n return res.status(204).send();\n }\n\n if (s === 1) {\n if ([0, 2].indexOf(p.status) === -1) {\n return res.status(400).send('invalid status change');\n }\n }\n\n if (s === 2) {\n if ([1].indexOf(p.status) === -1) {\n return res.status(400).send('invalid status change');\n }\n }\n p.status = s;\n p.save(function(err) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).send(`status updated to ${s}`);\n });\n }\n );\n\n function sendMerged(t, p, res, merged, binder) {\n if (t && p) {\n if (binder.isModified()) {\n binder.updateProgress();\n }\n res.status(200).json({\n works: merged,\n inputProgress: inputProgressHtml({ binder }),\n travelerProgress: travelerProgressHtml({ binder }),\n valueProgress: valueProgressHtml({ binder }),\n });\n }\n }\n\n app.get(\n '/binders/:id/works/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canReadMw('id'),\n async function getWorks(req, res) {\n const binder = req[req.params.id];\n const { works } = binder;\n\n const tids = [];\n const pids = [];\n\n works.forEach(function(w) {\n if (w.refType === 'traveler') {\n tids.push(w._id);\n } else {\n pids.push(w._id);\n }\n });\n\n const merged = [];\n if (tids.length !== 0) {\n try {\n const travelers = await Traveler.find(\n {\n _id: {\n $in: tids,\n },\n },\n 'title mapping devices tags locations manPower status createdBy owner sharedWith finishedInput totalInput'\n )\n .lean()\n .exec();\n travelers.forEach(function(t) {\n // works has its own toJSON, therefore need to merge only the plain object\n _.extend(t, works.id(t._id).toJSON());\n merged.push(t);\n });\n } catch (error) {\n res.status(500).send(error.message);\n }\n }\n\n if (pids.length !== 0) {\n try {\n const binders = await Binder.find(\n {\n _id: {\n $in: pids,\n },\n },\n 'title tags status createdBy owner finishedValue inProgressValue totalValue finishedInput totalInput'\n )\n .lean()\n .exec();\n binders.forEach(function(b) {\n _.extend(b, works.id(b._id).toJSON());\n merged.push(b);\n });\n } catch (error) {\n res.status(500).send(error.message);\n }\n }\n\n return res.status(200).json({\n works: merged,\n inputProgress: inputProgressHtml({ binder }),\n travelerProgress: travelerProgressHtml({ binder }),\n valueProgress: valueProgressHtml({ binder }),\n });\n }\n );\n\n app.post(\n '/binders/:id/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canWriteMw('id'),\n reqUtils.status('id', [0, 1]),\n reqUtils.filter('body', ['ids', 'type']),\n reqUtils.hasAll('body', ['ids', 'type']),\n function(req, res) {\n routesUtilities.binder.addWork(\n req[req.params.id],\n req.session.userid,\n req,\n res\n );\n }\n );\n\n app.delete(\n '/binders/:id/works/:wid',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canWriteMw('id'),\n reqUtils.status('id', [0, 1]),\n function(req, res) {\n const p = req[req.params.id];\n const work = p.works.id(req.params.wid);\n\n if (!work) {\n return res\n .status(404)\n .send(`Work ${req.params.wid} not found in the binder.`);\n }\n\n work.remove();\n p.updatedBy = req.session.userid;\n p.updatedOn = Date.now();\n\n p.updateProgress(function(err, newPackage) {\n if (err) {\n console.log(err);\n return res.status(500).send(err.message);\n }\n return res.json(newPackage);\n });\n }\n );\n\n app.put(\n '/binders/:id/works/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Binder),\n reqUtils.canWriteMw('id'),\n reqUtils.status('id', [0, 1]),\n function(req, res) {\n const binder = req[req.params.id];\n const { works } = binder;\n const updates = req.body;\n let valueChanged = false;\n Object.keys(updates).forEach(wid => {\n const work = works.id(wid);\n if (!work) {\n return;\n }\n const u = updates[wid];\n Object.keys(u).forEach(p => {\n if (work[p] !== u[p]) {\n if (p === 'value') {\n valueChanged = true;\n }\n work[p] = u[p];\n }\n });\n });\n\n if (!binder.isModified()) {\n return res.status(204).send();\n }\n\n const cb = function(err, newWP) {\n if (err) {\n console.error(err);\n return res\n .status(500)\n .send(`cannot save the updates to binder ${binder._id}`);\n }\n res.status(200).json(newWP.works);\n };\n\n if (valueChanged) {\n binder.updateProgress(cb);\n } else {\n binder.save(cb);\n }\n }\n );\n\n app.get('/publicbinders/', auth.ensureAuthenticated, function(req, res) {\n res.render('public-binders', routesUtilities.getRenderObject(req));\n });\n\n app.get('/publicbinders/json', auth.ensureAuthenticated, function(req, res) {\n Binder.find({\n publicAccess: {\n $in: [0, 1],\n },\n status: {\n $ne: 3,\n },\n }).exec(function(err, binders) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n res.status(200).json(binders);\n });\n });\n};\n"
},
{
"alpha_fraction": 0.5458875894546509,
"alphanum_fraction": 0.5474753975868225,
"avg_line_length": 23.6015625,
"blob_id": "f6487834e8412c2dbb792d27abc52d4db40eefc4",
"content_id": "7f1c96ed3291cf8260ce8ee66e5d5232637c4ebc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3149,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 128,
"path": "/public/javascripts/form-explorer.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const FormExplorer = (function(parent, $) {\n let releasedFormTable = null;\n let myFormTable = null;\n let formDom = null;\n let html = null;\n\n function retrieveForm(resource, fid, cb) {\n $.ajax({\n url: `/${resource}/${fid}/json`,\n type: 'GET',\n dataType: 'json',\n success: function(json) {\n cb(json);\n },\n });\n }\n\n function selectEvent() {\n $('tbody').on('click', 'a.preview', function preview() {\n const row = $(this).closest('tr');\n if (row.hasClass('row-selected')) {\n return;\n }\n $('tr').removeClass('row-selected');\n row.addClass('row-selected');\n\n const fid = this.id;\n const table = $(this).closest('table');\n let resource = 'forms';\n if (table.hasClass('released-forms')) {\n resource = 'released-forms';\n }\n\n retrieveForm(resource, fid, function(json) {\n formDom.fadeTo('slow', 1);\n html = json.html || json.base.html;\n loadForm(html);\n });\n });\n }\n\n function init(released, my, form) {\n const releasedColumns = [\n formExploreColumn,\n titleColumn,\n formTypeColumn,\n releasedOnColumn,\n releasedFormColumn,\n ];\n fnAddFilterFoot(released, releasedColumns);\n releasedFormTable = $(released).dataTable({\n sAjaxSource: '/released-forms/json',\n sAjaxDataProp: '',\n bProcessing: true,\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n aoColumns: releasedColumns,\n aaSorting: [[2, 'desc']],\n sDom: sDomPage,\n });\n const columns = [\n formExploreColumn,\n titleColumn,\n formTypeColumn,\n updatedOnColumn,\n formColumn,\n ];\n fnAddFilterFoot(my, columns);\n myFormTable = $(my).dataTable({\n sAjaxSource: '/myforms/json',\n sAjaxDataProp: '',\n bProcessing: true,\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n aoColumns: columns,\n aaSorting: [[2, 'desc']],\n sDom: sDomPage,\n });\n formDom = $(form);\n filterEvent();\n selectEvent();\n }\n\n // temparary solution for the dirty forms\n function cleanForm() {\n $('.control-group-buttons', formDom).remove();\n }\n\n function renderImg() {\n formDom.find('img').each(function() {\n var $this = $(this);\n if ($this.attr('name')) {\n if ($this.attr('src') === undefined) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n if ($this.attr('src').indexOf('http') === 0) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n if (prefix && $this.attr('src').indexOf(prefix) !== 0) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n }\n });\n }\n\n function renderForm() {\n cleanForm();\n renderImg();\n }\n\n function loadForm() {\n formDom.html(html);\n renderForm();\n }\n\n function getHtml() {\n return html;\n }\n\n parent.init = init;\n parent.getHtml = getHtml;\n return parent;\n})({}, jQuery);\n"
},
{
"alpha_fraction": 0.5701106786727905,
"alphanum_fraction": 0.5804120302200317,
"avg_line_length": 26.67659568786621,
"blob_id": "fc75fe013c65e1e22bae388e819b2f36b9372a7b",
"content_id": "a7e3411254d0331d2c456babe8fc55bb437bb08a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6504,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 235,
"path": "/routes/form-management.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const mongoose = require('mongoose');\nconst debug = require('debug')('traveler:released-form');\nconst _ = require('lodash');\nconst auth = require('../lib/auth');\nconst routesUtilities = require('../utilities/routes');\n\nconst Form = mongoose.model('Form');\nconst ReleasedForm = mongoose.model('ReleasedForm');\nconst { statusMap } = require('../model/released-form');\nconst reqUtils = require('../lib/req-utils');\nconst logger = require('../lib/loggers').getLogger();\nconst config = require('../config/config');\nconst { stateTransition } = require('../model/released-form');\n\nconst authConfig = config.auth;\n\nmodule.exports = function(app) {\n app.get(\n '/form-management/',\n auth.ensureAuthenticated,\n auth.verifyRole('admin'),\n function(req, res) {\n res.render('form-management', routesUtilities.getRenderObject(req));\n }\n );\n\n app.get(\n '/submitted-forms/json',\n auth.ensureAuthenticated,\n auth.verifyRole('admin'),\n function(req, res) {\n Form.find(\n {\n status: 0.5,\n },\n 'title formType status tags mapping _v __review'\n ).exec(function(err, forms) {\n if (err) {\n logger.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(forms);\n });\n }\n );\n\n app.get('/released-forms/json', auth.ensureAuthenticated, function(req, res) {\n ReleasedForm.find(\n {\n status: 1,\n },\n 'title formType status tags ver releasedOn releasedBy'\n ).exec(function(err, forms) {\n if (err) {\n logger.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(forms);\n });\n });\n\n app.get('/archived-released-forms/json', auth.ensureAuthenticated, function(\n req,\n res\n ) {\n ReleasedForm.find(\n {\n status: 2,\n },\n 'title formType status tags ver archivedOn archivedBy'\n ).exec(function(err, forms) {\n if (err) {\n logger.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(forms);\n });\n });\n\n app.get(\n '/released-forms/:id/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', ReleasedForm),\n function(req, res) {\n const releasedForm = req[req.params.id];\n return res.render(\n 'released-form',\n routesUtilities.getRenderObject(req, {\n id: req.params.id,\n title: releasedForm.title,\n formType: releasedForm.formType,\n status: releasedForm.status,\n statusText: statusMap[`${releasedForm.status}`],\n ver: releasedForm.ver,\n base: releasedForm.base,\n discrepancy: releasedForm.discrepancy,\n })\n );\n }\n );\n\n app.put(\n '/released-forms/:id/status',\n auth.ensureAuthenticated,\n reqUtils.exist('id', ReleasedForm),\n reqUtils.isOwnerOrAdminMw('id'),\n reqUtils.filter('body', ['status', 'version']),\n reqUtils.hasAll('body', ['status', 'version']),\n async function updateStatus(req, res) {\n const f = req[req.params.id];\n const s = req.body.status;\n const v = req.body.version;\n\n if ([2].indexOf(s) === -1) {\n return res.status(400).send('invalid status');\n }\n\n if (v !== f.ver) {\n return res.status(400).send(`the current version is ${f.ver}`);\n }\n\n // no change\n if (f.status === s) {\n return res.status(204).send();\n }\n\n const target = _.find(stateTransition, function(t) {\n return t.from === f.status;\n });\n\n debug(target);\n if (target.to.indexOf(s) === -1) {\n return res.status(400).send('invalid status change');\n }\n\n f.status = s;\n if (s === 2) {\n f.archivedBy = req.session.userid;\n f.archivedOn = Date.now();\n }\n // check if we need to increment the version\n f.incrementVersion();\n try {\n await f.saveWithHistory(req.session.userid);\n return res\n .status(200)\n .send(`released form ${req.params.id} status updated to ${s}`);\n } catch (error) {\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.post(\n '/released-forms/:id/clone',\n auth.ensureAuthenticated,\n reqUtils.exist('id', ReleasedForm),\n function(req, res) {\n const releasedForm = req[req.params.id];\n const { base } = releasedForm;\n const clonedForm = {};\n clonedForm.html = reqUtils.sanitizeText(base.html);\n clonedForm.title = reqUtils.sanitizeText(req.body.title);\n clonedForm.createdBy = req.session.userid;\n clonedForm.createdOn = Date.now();\n clonedForm.updatedBy = req.session.userid;\n clonedForm.updatedOn = Date.now();\n clonedForm.clonedFrom = base._id;\n clonedForm.formType = base.formType;\n clonedForm.sharedWith = [];\n clonedForm.tags = releasedForm.tags;\n new Form(clonedForm).save(function(saveErr, newform) {\n if (saveErr) {\n logger.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n const url = `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/forms/${newform.id}/`;\n res.set('Location', url);\n return res\n .status(201)\n .send(`You can see the new form at <a href=\"${url}\">${url}</a>`);\n });\n }\n );\n\n app.get('/released-forms/normal/json', auth.ensureAuthenticated, function(\n req,\n res\n ) {\n ReleasedForm.find(\n {\n status: 1,\n formType: 'normal',\n },\n 'title formType status tags _v releasedOn releasedBy'\n ).exec(function(err, forms) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(forms);\n });\n });\n\n app.get(\n '/released-forms/discrepancy/json',\n auth.ensureAuthenticated,\n function(req, res) {\n ReleasedForm.find(\n {\n status: 1,\n formType: 'discrepancy',\n },\n 'title formType status tags _v releasedOn releasedBy'\n ).exec(function(err, forms) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n return res.status(200).json(forms);\n });\n }\n );\n\n app.get(\n '/released-forms/:id/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', ReleasedForm),\n function(req, res) {\n return res.status(200).json(req[req.params.id]);\n }\n );\n};\n"
},
{
"alpha_fraction": 0.5457943677902222,
"alphanum_fraction": 0.5925233364105225,
"avg_line_length": 21.29166603088379,
"blob_id": "11870243837598d518c45e07c79d895c59f0ed82",
"content_id": "cc11a6e4abfbe1740f22ab7cdcee27ae42ecaf24",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 535,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 24,
"path": "/docker-compose.yml",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "version: \"3\"\nnetworks:\n default:\n external: true\n name: traveler-dev\nservices:\n web:\n build: .\n volumes:\n - .:/app\n # comment next line to exclude the node_modules\n - /app/node_modules\n # comment next line to exclude the docker configuration\n # - /app/docker\n ports:\n - \"3001:3001\"\n - \"3002:3002\"\n # - \"3443:3443\"\n restart: unless-stopped\n command: nodemon app.js\n environment:\n - TRAVELER_CONFIG_REL_PATH=docker\n - DEBUG=traveler:*\n - DEBUG_COLORS=true\n"
},
{
"alpha_fraction": 0.5749086737632751,
"alphanum_fraction": 0.587088942527771,
"avg_line_length": 14.222222328186035,
"blob_id": "802e759d7142c40d858a2a60d5bece1d9fb67e9f",
"content_id": "ef06fe5fe130280a16ba463d93e152fd7b0fdac0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 821,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 54,
"path": "/etc/init.d/traveler-webapp",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\nCUR_DIR=`pwd`\ncd $MY_DIR\nMY_DIR=`pwd` \ncd $CUR_DIR \n\nsource $MY_DIR/../../setup.sh\n\nTRAVELERD_CONFIGURATION=$TRAVELER_INSTALL_ETC_DIR/travelerd_configuration.sh\nif [ ! -f $TRAVELERD_CONFIGURATION ]; then \n >&2 echo \"$TRAVELERD_CONFIGURATION is not defined\"\n >&2 echo \"Please use the default file to configure it.\"\n exit 1\nfi\n\nsource $TRAVELERD_CONFIGURATION\n\nstart(){ \n pm2 start $TRAVELER_APP_DIR --name traveler\n}\n\nstop(){\n pm2 stop $TRAVELER_APP_DIR\n}\n\nrestart(){\n stop\n start\n}\n\nstatus(){\n pm2 status $TRAVELER_APP_DIR\n}\n\ncase \"$1\" in\n start)\n start\n ;;\n stop)\n stop\n ;;\n restart)\n restart\n ;;\n status)\n status\n ;;\n *)\n echo \"Usage: $0 {start|stop|restart|status}\"\n exit 1\n ;;\nesac"
},
{
"alpha_fraction": 0.4935305118560791,
"alphanum_fraction": 0.49722737073898315,
"avg_line_length": 27.473684310913086,
"blob_id": "a584c78726782a9b7de6e78273e4468e926456c2",
"content_id": "7cd5aeecafacecd22755f1d5ce2e727382239bb5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1082,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 38,
"path": "/public/javascripts/form-viewer.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global prefix, createSideNav, validationMessage*/\n\n$(function() {\n $('#output')\n .find('img')\n .each(function() {\n var $this = $(this);\n if ($this.attr('name')) {\n if ($this.attr('src') === undefined) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n if ($this.attr('src').indexOf('http') === 0) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n if (prefix && $this.attr('src').indexOf(prefix) !== 0) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n }\n });\n\n $('input, textarea').removeAttr('disabled');\n createSideNav();\n $('#show-validation').click(function() {\n $('.validation').remove();\n $('#validation').html(\n '<h3>Summary</h3>' + validationMessage(document.getElementById('output'))\n );\n $('#validation').show();\n });\n\n $('#hide-validation').click(function() {\n $('#validation').hide();\n $('.validation').hide();\n });\n});\n"
},
{
"alpha_fraction": 0.789625346660614,
"alphanum_fraction": 0.789625346660614,
"avg_line_length": 56.83333206176758,
"blob_id": "a91bb34698b3b59a77e1c62f398ceb0310cc1907",
"content_id": "32b9eb1097d14cf6344b7bca611d4e6f318a0989",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 347,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 6,
"path": "/views/docs/traveler/manage-forms.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Manage templates in a traveler (deprecated)\n\nThis feature was **removed** after we implemented a template release process.\nThe rational is that we should not change the traveler specification (templates)\nonce it is executed in the field. If there is any change to the template, there\nshould be a new traveler based on a new released template.\n"
},
{
"alpha_fraction": 0.7282415628433228,
"alphanum_fraction": 0.7282415628433228,
"avg_line_length": 17.766666412353516,
"blob_id": "151a021daf0d56c578afa429e4aac94fd9ab8272",
"content_id": "604f631e616701fba43a540f424d5b69f6087da9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 563,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 30,
"path": "/Makefile",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "# The top level makefile. Targets like \"all\" and \"clean\"\n# are defined in the RULES file.\n\nTOP = .\nSUBDIRS = src\n\n.PHONY: support, certificates, dev-mongo, dev-config, update, db-backup, db-restore\n\ndefault:\n\nsupport:\n\t$(TOP)/sbin/traveler_install_support.sh\n\nupdate:\n\t$(TOP)/sbin/traveler_update_support.sh\n\ndb-backup:\n\t$(TOP)/sbin/mongodb-backup.sh\n\ndb-restore:\n\t$(TOP)/sbin/mongodb-restore.sh\n\ncertificates:\n\t$(TOP)/sbin/create_web_service_certificates.sh\n\ndev-mongo:\n\t$(TOP)/sbin/configure_mongo_dev.sh\n\ndefault-config:\n\t$(TOP)/sbin/create_traveler_config.sh\n"
},
{
"alpha_fraction": 0.5915428400039673,
"alphanum_fraction": 0.6025739312171936,
"avg_line_length": 19.396875381469727,
"blob_id": "063aa862998215bf48a589ed5f8f93a5a5430353",
"content_id": "aab5021b3954fd76810e6021f4c8244359b31303",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6527,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 320,
"path": "/model/binder.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* eslint-disable no-param-reassign */\nconst mongoose = require('mongoose');\nconst appConfig = require('../config/config').app;\n\nconst { Schema } = mongoose;\nconst { ObjectId } = Schema.Types;\n\nconst share = require('./share');\nconst logger = require('../lib/loggers').getLogger();\n\n/**\n * finished is the percentage of value that is completed.\n * inProgress is the percentage of value that is still in progress.\n * If status === 2, then finished = 100, and inProgress = 0;\n * If status === 0, then finished = 0, and inProgress = 0;\n * finished and inProgress are cached status.\n * totalSteps and finishedSteps are cached status.\n * They should be updated when the reference traveler is loaded.\n */\n\nconst work = new Schema({\n refType: {\n type: String,\n required: true,\n enum: ['traveler', 'binder'],\n },\n addedOn: Date,\n addedBy: String,\n status: Number,\n finished: {\n type: Number,\n default: 0,\n min: 0,\n },\n inProgress: {\n type: Number,\n default: 0,\n min: 0,\n },\n finishedInput: {\n type: Number,\n default: 0,\n min: 0,\n },\n totalInput: {\n type: Number,\n default: 0,\n min: 0,\n },\n priority: {\n type: Number,\n min: 1,\n max: 10,\n default: 5,\n },\n sequence: {\n type: Number,\n min: 1,\n default: 1,\n },\n value: {\n type: Number,\n min: 0,\n default: 10,\n },\n color: {\n type: String,\n default: 'blue',\n enum: ['green', 'yellow', 'red', 'blue', 'black'],\n },\n});\n\n/**\n * publicAccess := 0 // for read or\n * | 1 // for write or\n * | -1 // no access\n *\n */\n\n/**\n * totalValue = sum(work value)\n * finishedValue = sum(work value X finished)\n * inProgressValue = sum(work value X inProgress)\n */\n\n/**\n * status := 0 // new\n * | 1 // active\n * | 2 // completed\n * | 3 // archived\n */\n\nconst binder = new Schema({\n title: String,\n description: String,\n status: {\n type: Number,\n default: 0,\n },\n tags: [String],\n createdBy: String,\n createdOn: Date,\n clonedBy: String,\n clonedFrom: ObjectId,\n updatedBy: String,\n updatedOn: Date,\n owner: String,\n transferredOn: Date,\n deadline: Date,\n publicAccess: {\n type: Number,\n default: appConfig.default_binder_public_access,\n },\n sharedWith: [share.user],\n sharedGroup: [share.group],\n works: [work],\n finishedInput: {\n type: Number,\n default: 0,\n min: 0,\n },\n totalInput: {\n type: Number,\n default: 0,\n min: 0,\n },\n // the date that the progress was updated\n progressUpdatedOn: Date,\n finishedValue: {\n type: Number,\n default: 0,\n min: 0,\n },\n inProgressValue: {\n type: Number,\n default: 0,\n min: 0,\n },\n totalValue: {\n type: Number,\n default: 0,\n min: 0,\n },\n finishedWork: {\n type: Number,\n default: 0,\n min: 0,\n },\n inProgressWork: {\n type: Number,\n default: 0,\n min: 0,\n },\n totalWork: {\n type: Number,\n default: 0,\n min: 0,\n },\n});\n\nconst progressFields = [\n 'status',\n 'finishedInput',\n 'totalInput',\n 'finishedValue',\n 'inProgressValue',\n 'totalValue',\n 'finishedWork',\n 'inProgressWork',\n 'totalWork',\n];\n\nfunction updateInputProgress(w, spec) {\n w.totalInput = spec.totalInput;\n w.finishedInput = spec.finishedInput;\n}\n\n// update work status according to spec, but not saved\nbinder.methods.updateWorkProgress = function(spec) {\n const w = this.works.id(spec._id);\n if (!w) {\n logger.warn(`no work _id ${spec._id} in binder ${this._id}`);\n return;\n }\n updateInputProgress(w, spec);\n if (w.status !== spec.status) {\n w.status = spec.status;\n }\n // same for traveler or binder\n if (spec.status === 2) {\n w.finished = 1;\n w.inProgress = 0;\n return;\n }\n\n // only apply to traveler work\n if (spec.status === 0 && w.refType === 'traveler') {\n w.finished = 0;\n w.inProgress = 0;\n return;\n }\n\n // active traveler\n if (w.refType === 'traveler') {\n work.finished = 0;\n if (spec.totalInput === 0) {\n w.inProgress = 1;\n } else {\n w.inProgress = spec.finishedInput / spec.totalInput;\n }\n return;\n }\n // new or active binder\n if (spec.totalValue === 0) {\n w.finished = 0;\n w.inProgress = 1;\n } else {\n w.finished = spec.finishedValue / spec.totalValue;\n w.inProgress = spec.inProgressValue / spec.totalValue;\n }\n};\n\n// update binder status and save\nbinder.methods.updateProgress = function(cb) {\n const { works } = this;\n let totalValue = 0;\n let finishedValue = 0;\n let inProgressValue = 0;\n let totalWork = 0;\n let finishedWork = 0;\n let inProgressWork = 0;\n let totalInput = 0;\n let finishedInput = 0;\n works.forEach(function(w) {\n totalInput += w.totalInput;\n finishedInput += w.finishedInput;\n\n totalValue += w.value;\n finishedValue += w.value * w.finished;\n inProgressValue += w.value * w.inProgress;\n\n totalWork += 1;\n finishedWork += w.finished;\n inProgressWork += w.inProgress;\n });\n\n this.totalInput = totalInput;\n this.finishedInput = finishedInput;\n\n this.totalValue = totalValue;\n this.finishedValue = finishedValue;\n this.inProgressValue = inProgressValue;\n\n this.totalWork = totalWork;\n this.finishedWork = finishedWork;\n this.inProgressWork = inProgressWork;\n\n if (this.isModified()) {\n this.progressUpdatedOn = Date.now();\n this.save(function(err, newBinder) {\n if (cb) {\n cb(err, newBinder);\n }\n if (err) {\n logger.error(err);\n }\n });\n }\n};\n\n/**\n * update the progress of binders that include this binder\n * @param {Binder} child the binder document\n * @return {undefined}\n */\nfunction updateParentProgress(child) {\n Binder.find({\n status: {\n $ne: 3,\n },\n works: {\n $elemMatch: {\n _id: child._id,\n },\n },\n }).exec(function(err, binders) {\n if (err) {\n return logger.error(\n `cannot find binders for traveler ${child._id}, error: ${err.message}`\n );\n }\n binders.forEach(function(b) {\n b.updateWorkProgress(child);\n b.updateProgress();\n });\n });\n}\n\nbinder.pre('save', function(next) {\n const modifiedPaths = this.modifiedPaths();\n // keep it so that we can refer at post save\n this.wasModifiedPaths = modifiedPaths;\n next();\n});\n\nbinder.post('save', function(obj) {\n const modifiedPaths = this.wasModifiedPaths;\n const updateParent = modifiedPaths.some(\n m => progressFields.indexOf(m) !== -1\n );\n if (updateParent) {\n updateParentProgress(obj);\n }\n});\n\nconst Binder = mongoose.model('Binder', binder);\n\nmodule.exports = {\n Binder,\n};\n"
},
{
"alpha_fraction": 0.6003541350364685,
"alphanum_fraction": 0.6089943051338196,
"avg_line_length": 27.816326141357422,
"blob_id": "96dff8b8c8cb4a03a58c3c4c979623b54ec4f6d2",
"content_id": "cc947fb98e3e795c9a0b1e5517fe6126e8881f94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 14120,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 490,
"path": "/public/javascripts/travelers.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false,\nframes: false, history: false, Image: false, location: false, name: false,\nnavigator: false, Option: false, parent: false, screen: false, setInterval:\nfalse, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false,\nHistory: false*/\n/*global moment: false, ajax401: false, prefix: false, updateAjaxURL: false,\ndisableAjaxCache: false, travelerGlobal: false, Holder: false*/\n/*global selectColumn: false, titleColumn: false, createdOnColumn: false,\nupdatedOnColumn: false, filledByColumn: false, sharedWithColumn: false,\nsharedGroupColumn: false, fnAddFilterFoot: false, sDomNoTools: false,\ncreatedOnColumn: false, transferredOnColumn: false, travelerConfigLinkColumn:\nfalse, travelerShareLinkColumn: false, travelerLinkColumn: false, statusColumn:\nfalse, deviceColumn: false, fnGetSelected: false, selectEvent: false,\nfilterEvent: false, ownerColumn: false, deadlineColumn: false,\ntravelerProgressColumn: false, archivedOnColumn: false, binderLinkColumn: false,\ntagsColumn: false, sDomNoTNoR: false*/\n\n/*global archiveFromModal, transferFromModal, modalScroll*/\n\nimport * as AddBinder from './lib/binder.js';\nimport * as Modal from './lib/modal.js';\n\nfunction noneSelectedModal() {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No traveler has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n}\n\nfunction cloneFromModal(\n travelerTable,\n sharedTravelerTable,\n groupSharedTravelerTable\n) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n var number = $('#modal .modal-body div.target').length;\n $('#modal .modal-body div.target').each(function() {\n var that = this;\n var success = false;\n $.ajax({\n url: '/travelers/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n source: this.id,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n success = true;\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n $('#return').prop('disabled', false);\n if (success) {\n travelerTable.fnReloadAjax();\n sharedTravelerTable.fnReloadAjax();\n groupSharedTravelerTable.fnReloadAjax();\n }\n }\n });\n });\n}\n\nfunction showHash() {\n if (window.location.hash) {\n $('.nav-tabs a[href=' + window.location.hash + ']').tab('show');\n }\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n var travelerAoColumns = [\n selectColumn,\n travelerConfigLinkColumn,\n travelerShareLinkColumn,\n travelerLinkColumn,\n titleColumn,\n statusColumn,\n deviceColumn,\n tagsColumn,\n keysColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n deadlineColumn,\n filledByColumn,\n updatedOnColumn,\n travelerProgressColumn,\n ];\n fnAddFilterFoot('#traveler-table', travelerAoColumns);\n var travelerTable = $('#traveler-table').dataTable({\n sAjaxSource: '/travelers/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: travelerAoColumns,\n aaSorting: [\n [11, 'desc'],\n [14, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n /*transferred traveler table starts*/\n var transferredTravelerAoColumns = [\n selectColumn,\n travelerConfigLinkColumn,\n travelerShareLinkColumn,\n travelerLinkColumn,\n titleColumn,\n statusColumn,\n deviceColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n transferredOnColumn,\n deadlineColumn,\n filledByColumn,\n updatedOnColumn,\n travelerProgressColumn,\n ];\n var transferredTravelerTable = $('#transferred-traveler-table').dataTable({\n sAjaxSource: '/transferredtravelers/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: transferredTravelerAoColumns,\n aaSorting: [\n [10, 'desc'],\n [11, 'desc'],\n [14, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#transferred-traveler-table', transferredTravelerAoColumns);\n /*transferred traveler table ends*/\n\n var sharedTravelerAoColumns = [\n selectColumn,\n travelerLinkColumn,\n titleColumn,\n statusColumn,\n deviceColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ownerColumn,\n createdOnColumn,\n deadlineColumn,\n filledByColumn,\n updatedOnColumn,\n travelerProgressColumn,\n ];\n fnAddFilterFoot('#shared-traveler-table', sharedTravelerAoColumns);\n var sharedTravelerTable = $('#shared-traveler-table').dataTable({\n sAjaxSource: '/sharedtravelers/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: sharedTravelerAoColumns,\n aaSorting: [\n [12, 'desc'],\n [9, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n var groupSharedTravelerAoColumns = [\n selectColumn,\n travelerLinkColumn,\n titleColumn,\n statusColumn,\n deviceColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ownerColumn,\n createdOnColumn,\n deadlineColumn,\n filledByColumn,\n updatedOnColumn,\n travelerProgressColumn,\n ];\n fnAddFilterFoot('#group-shared-traveler-table', sharedTravelerAoColumns);\n var groupSharedTravelerTable = $('#group-shared-traveler-table').dataTable({\n sAjaxSource: '/groupsharedtravelers/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: groupSharedTravelerAoColumns,\n aaSorting: [\n [12, 'desc'],\n [9, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n var archivedTravelerAoColumns = [\n selectColumn,\n travelerLinkColumn,\n titleColumn,\n archivedOnColumn,\n statusColumn,\n deviceColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n deadlineColumn,\n filledByColumn,\n updatedOnColumn,\n travelerProgressColumn,\n ];\n fnAddFilterFoot('#archived-traveler-table', archivedTravelerAoColumns);\n var archivedTravelerTable = $('#archived-traveler-table').dataTable({\n sAjaxSource: '/archivedtravelers/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: archivedTravelerAoColumns,\n aaSorting: [\n [3, 'desc'],\n [11, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n // show the tab in hash when loaded\n showHash();\n\n // add state for tab changes\n $('.nav-tabs a').on('click', function() {\n if (\n !$(this)\n .parent()\n .hasClass('active')\n ) {\n window.history.pushState(\n null,\n 'FRIB traveler :: ' + this.text,\n this.href\n );\n }\n });\n\n // show the tab when back and forward\n window.onhashchange = function() {\n showHash();\n };\n\n $('button.select-all').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n fnSelectAll(activeTable, 'row-selected', 'select-row', true);\n });\n\n $('button.deselect-all').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n fnDeselect(activeTable, 'row-selected', 'select-row');\n });\n\n $('button.archive').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n modalScroll(false);\n if (selected.length === 0) {\n noneSelectedModal();\n } else {\n $('#modalLabel').html(\n 'Archive the following ' + selected.length + ' travelers? '\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(Modal.formatItemUpdate(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n updateStatusFromModal(\n 4,\n 'travelers',\n activeTable,\n archivedTravelerTable\n );\n });\n }\n });\n\n $('#report').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n noneSelectedModal();\n return;\n }\n $('#report-form').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#report-form').append(\n $('<input type=\"hidden\"/>').attr({\n name: 'travelers[]',\n value: data._id,\n })\n );\n });\n $('#report-form').submit();\n });\n\n $('#clone').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n modalScroll(false);\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No traveler has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n 'Clone the following ' + selected.length + ' travelers? '\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(Modal.formatItemUpdate(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n cloneFromModal(\n travelerTable,\n sharedTravelerTable,\n groupSharedTravelerTable\n );\n });\n }\n });\n\n $('#add-to-binder').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n AddBinder.addModal(activeTable);\n });\n\n $('button.transfer').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n modalScroll(false);\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No traveler has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n 'Transfer the following ' + selected.length + ' travelers? '\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(Modal.formatItemUpdate(data));\n });\n $('#modal .modal-body').append('<h5>to the following user</h5>');\n $('#modal .modal-body').append(\n '<form class=\"form-inline\"><input id=\"username\" type=\"text\" placeholder=\"Last, First\" name=\"name\" class=\"input\" required></form>'\n );\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n\n travelerGlobal.usernames.initialize();\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n $('#submit').click(function() {\n transferFromModal($('#username').val(), 'travelers', activeTable);\n });\n }\n });\n\n $('#reload').click(function() {\n travelerTable.fnReloadAjax();\n transferredTravelerTable.fnReloadAjax();\n sharedTravelerTable.fnReloadAjax();\n groupSharedTravelerTable.fnReloadAjax();\n archivedTravelerTable.fnReloadAjax();\n });\n // binding events\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.7032040357589722,
"alphanum_fraction": 0.7051714658737183,
"avg_line_length": 25.55223846435547,
"blob_id": "4f9ac596be553d7fd2a69f7fd028ce26530fae68",
"content_id": "c2799b023629132702143d8ae52a94466b844062",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3558,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 134,
"path": "/utilities/mqtt.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const config = require('../config/config.js');\nconst logger = require('../lib/loggers').getLogger();\n\nconst mqttConfig = config.mqtt;\n\nlet travelerDataChangedTopic = undefined;\nlet travelerStatusChangedTopic = undefined;\nlet travelerDiscrepancyLogAddedTopic = undefined;\n\nlet mqttClient = undefined;\n\nif (mqttConfig) {\n const mqtt = require('mqtt');\n\n travelerDataChangedTopic = mqttConfig.topics.traveler_data_changed;\n travelerStatusChangedTopic = mqttConfig.topics.traveler_status_changed;\n travelerDiscrepancyLogAddedTopic =\n mqttConfig.topics.traveler_discrepancy_log_added;\n let mqttServerIp = mqttConfig.server_address;\n let mqttPort = mqttConfig.server_port;\n let mqttProtocol = mqttConfig.server_protocol;\n let mqttAddress = mqttProtocol + '://' + mqttServerIp;\n if (mqttPort !== undefined) {\n mqttAddress += ':' + mqttPort;\n }\n\n // If disconnects try every minute\n options = { reconnectPeriod: 60 };\n\n mqttUser = mqttConfig.username;\n if (mqttUser !== undefined) {\n options.username = mqttUser;\n options.password = mqttConfig.password;\n }\n\n mqttClient = mqtt.connect(mqttAddress, options);\n\n mqttClient.on('packetsend', function(obj) {\n if (obj.cmd === 'connect') {\n logger.info(\n 'Connection error occurred, check credentials or MQTT server status, reconnecting to MQTT server...'\n );\n } else if (obj.cmd === 'publish') {\n logger.info('Sent MQTT message to: ' + obj.topic);\n }\n });\n}\n\nfunction postDataEnteredMessage(topic, data) {\n if (mqttConfig) {\n let mqttMessage = JSON.stringify(data);\n mqttClient.publish(topic, mqttMessage);\n }\n}\n\nfunction findUDKByMapping(mapping, inputId) {\n if (mapping != null) {\n let mappings = Object.entries(mapping);\n\n for (let i = 0; i < mappings.length; i++) {\n mapping = mappings[i];\n if (mapping[1] === inputId) {\n return mapping[0];\n }\n }\n }\n\n return null;\n}\n\nfunction postTravelerDataChangedMessage(documentData, document) {\n if (mqttConfig === undefined) {\n return;\n }\n\n let udk = null;\n let inputId = documentData.name;\n\n // Attempt fetching latest mapping from form\n if (document.forms.length == 1) {\n let form = document.forms[0];\n let mapping = form.mapping;\n udk = findUDKByMapping(mapping, inputId);\n }\n // Try to fetch traveler mapping\n if (udk == null) {\n let mapping = document.mapping;\n udk = findUDKByMapping(mapping, inputId);\n }\n\n let dataEntered = {\n _id: documentData._id,\n traveler: documentData.traveler,\n name: documentData.name,\n value: documentData.value,\n inputType: documentData.inputType,\n inputBy: documentData.inputBy,\n inputOn: documentData.inputOn,\n userDefinedKey: udk,\n };\n\n postDataEnteredMessage(travelerDataChangedTopic, dataEntered);\n}\n\nfunction postTravelerStatusChangedMessage(document) {\n if (!mqttConfig) {\n return;\n }\n let statusChanged = {\n traveler: document.id,\n status: document.status,\n updatedBy: document.updatedBy,\n updatedOn: document.updatedOn,\n };\n postDataEnteredMessage(travelerStatusChangedTopic, statusChanged);\n}\n\nfunction postDiscrepancyLogAddedMessage(travelerId, log) {\n if (!mqttConfig) {\n return;\n }\n let newDiscrepancy = {\n traveler: travelerId,\n log: log,\n };\n\n postDataEnteredMessage(travelerDiscrepancyLogAddedTopic, newDiscrepancy);\n}\n\nmodule.exports = {\n postTravelerDataChangedMessage: postTravelerDataChangedMessage,\n postTravelerStatusChangedMessage: postTravelerStatusChangedMessage,\n postDiscrepancyLogAddedMessage: postDiscrepancyLogAddedMessage,\n};\n"
},
{
"alpha_fraction": 0.7523398399353027,
"alphanum_fraction": 0.7523398399353027,
"avg_line_length": 46.89655303955078,
"blob_id": "553ec33642ffabb8109a4f5fc16e01514cbef530",
"content_id": "0b157998494826254d55cbd2eb40b6541d1a611f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1389,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 29,
"path": "/views/docs/traveler/update.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Update the data and notes in a traveler\n\n**Audience: traveler users with write permission**\n\nIn order to update the data and notes of a traveler, the user must have the\nwrite permission of the traveler.\n\nA traveler's data can be updated only when it is in the\n[active status](#traveler-status). When the traveler is in other statuses, all\nthe inputs are disabled on the traveler page. Note on the traveler view page,\nthe user cannot update data or notes on that page even if s/he has write\npermission.\n\nWhen the user inputs a new value in an input, two buttons will appear on the\nright side. Click the <button value=\"save\" class=\"btn btn-primary\">Save</button>\nbutton to submit the change to the traveler server. Or click the\n<button value=\"reset\" class=\"btn\">Reset</button> button to reset to the original\nvalue. All other inputs are disable when an input is touched. If the change is\nsaved on the server, there will be a\n\n<div class=\"alert alert-success\"><button class=\"close\">x</button>Success</div>\nmessage on the top of the page. If something is wrong, then an \n<div class=\"alert alert-error\"><button class=\"close\">x</button>Error</div>\nmessage will appear.\n\nIn order to add a new note, click the\n<a class=\"new-note\" data-toggle=\"tooltip\" title=\"new note\"><i class=\"fa fa-file-o fa-lg\"></i></a>\nicon. Click the <span class=\"badge badge-info\">n</span> icon to show/hide the\nnotes.\n"
},
{
"alpha_fraction": 0.8040123581886292,
"alphanum_fraction": 0.8040123581886292,
"avg_line_length": 53,
"blob_id": "5fd3b6be6f4aa986512dfb509139ba7e5c1bbb48",
"content_id": "bfc2a9d0f13434a147c6efe57c30f080bb5fbe53",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 12,
"path": "/views/docs/template/discrepancy.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Discrepancy template\n\nA discrepancy template can be used for a quality assurance (QA) like process. It\nis owned by the QA process owner, who has the responsibility to verify the\nresult of a traveler. When a traveler is ready for quality assurance, a QA\npersonal will check if the result meets the expectation. A discrepancy is logged\nif the work does not pass QA, which will be followed by a correction. The\ncorrection will be recorded in the traveler with data updates. Then a new QA\niteration can be triggered.\n\nA released discrepancy template cannot used solely without being attached to a\nreleased normal template when creating a traveler.\n"
},
{
"alpha_fraction": 0.7951263785362244,
"alphanum_fraction": 0.7951263785362244,
"avg_line_length": 60.55555725097656,
"blob_id": "96a898f90da2cdbc743d60c088ff97ab3f930d0c",
"content_id": "9756ae1a83736de4e2161d5a6a509f6f7677af20",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1108,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 18,
"path": "/views/docs/basics/binder.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### What is a binder?\n\nA binder is a collection of works that a user puts together for easy management.\nThe traveler is a typical type of work. It is like a virtual folder containing\nthe works related to a specific topic. For example, an engineer can put all the\ntravelers related to a specific device into one binder. A workshop manager can\nput all the travelers involved in the workshop into one binder. One traveler can\nbe put into multiple binders.\n\nA work has properties like Sequence, Priority, Value, and color. The sequence is\na counting number defining the order to perform the works. The priority is a\ncounting number defining the importance, and one is the highest priority level.\nThe value represents the planned cost or the earning that the work will\ncontribute to a project as that used in\n[earned value management](https://en.wikipedia.org/wiki/Earned_value_management).\nThe color defines a status flag with a color code. A binder can be put into\nanother binder. This is useful for higher management to oversee the progress of\nsub teams. For more details, see the [binders section](#binders).\n"
},
{
"alpha_fraction": 0.7447130084037781,
"alphanum_fraction": 0.7462235689163208,
"avg_line_length": 40.375,
"blob_id": "525226ace4229523e3de726c2fffd1182106aaf1",
"content_id": "63f7ccaa493980c714350878f3242c517b9f9122",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1324,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 32,
"path": "/sbin/add_admin_user.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# The script will make a user an admin.\n# Make sure the user has logged into the system before running this command.\nMY_DIR=`dirname $0`\n\nsource $MY_DIR/configuration.sh\nsource $MY_DIR/configure_paths.sh\n\n# import local traveler-mongo settings\n\nsource $TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\n# Check to see that mongo is installed\nif [ ! -f $MONGO_BIN_DIRECTORY/mongo ]; then\n echo \"MongoDB was not found in the local directory: $MONGO_BIN_DIRECTORY\"\n echo \"please run 'make support' from $TRAVELER_ROOT_DIR directory\"\n exit 1\nfi\n\n# Connect to mongodb\necho 'This script will make a user an admin; make sure the user has logged into the traveler module before running this script'\nread -p \"Enter the username to make admin: \" adminUsername\nif [[ -f $MONGO_TRAVELER_PASSWD_FILE ]]; then\n travelerPassword=`cat $MONGO_TRAVELER_PASSWD_FILE`\nelse\n read -s -p \"Enter the password for mongodb $MONGO_TRAVELER_USERNAME user: \" travelerPassword\n echo ''\nfi\n\nmongoCommands=\"db.users.update({'_id':'$adminUsername'}, { \\$push:{ 'roles':'admin'}})\"\nmongoCommands=\"$mongoCommands\\ndb.users.findOne({'_id':'$adminUsername'});\"\necho -e $mongoCommands | $MONGO_BIN_DIRECTORY/mongo $MONGO_SERVER_ADDRESS:$MONGO_SERVER_PORT/$MONGO_TRAVELER_DB --username $MONGO_TRAVELER_USERNAME --password $travelerPassword\n"
},
{
"alpha_fraction": 0.7139037251472473,
"alphanum_fraction": 0.7185828685760498,
"avg_line_length": 23.933332443237305,
"blob_id": "36019eabd8bf87550f92dedb9c8f4223ba6128f9",
"content_id": "59ff436d39f4eefad43ff299f9869d87ab1497e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1496,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 60,
"path": "/sbin/traveler_update_support.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\n\nsource $MY_DIR/configuration.sh\nsource $MY_DIR/configure_paths.sh\n\ncd $TRAVELER_INSTALL_ETC_DIR\nsource mongo-configuration.sh\nsource mongo-express-configuration.sh\nsource travelerd_configuration.sh\n\nexecute(){\n echo \"Executing: $@\"\n eval \"$@\"\n}\n\nif [ -d $TRAVELER_SUPPORT_DIR ]; then\n cd $TRAVELER_SUPPORT_DIR\n if [ $TRAVELER_VERSION_CONTROL_TYPE == \"git\" ]; then\n \texecute git pull\n fi\nelse\n echo \"Creating new traveler support directory $TRAVELER_SUPPORT_DIR.\"\n # Go to one level up from the support directory\n cd `dirname $TRAVELER_SUPPORT_DIR`\n if [ $TRAVELER_VERSION_CONTROL_TYPE == \"git\" ]; then\n\t\texecute \"git clone $TRAVELER_SUPPORT_GIT_URL `basename $TRAVELER_SUPPORT_DIR`\" || exit 1\n fi\nfi\n\n#Check if no programs are running\nrunInstall=1\n\nif [ -f $MONGO_PID_DIRECTORY ]; then\n\techo \"Mongo pid file exists: $MONGO_PID_DIRECTORY\"\n\techo \"Update cannot be completed.\"\n\trunInstall=0\nfi\nif [ -f $TRAVELERD_PID_FILE ]; then\n\techo \"Traveler pid file exists: $TRAVELERD_PID_FILE\"\n\techo \"Update cannot be completed.\"\n\trunInstall=0\nfi\nif [ -f $MONGO_EXPRESS_DAEMON_PID_FILE ]; then\n\techo \"Mongo-express pid file exists: $MONGO_EXPRESS_DAEMON_PID_FILE\"\n\techo \"Update cannot be completed.\"\n\trunInstall=0\nfi\n\nif [ $runInstall -eq 1 ]; then\n\texecute $TRAVELER_SUPPORT_DIR/bin/install_all.sh\n\tcd $TRAVELER_ROOT_DIR\n\tsource setup.sh\n\tnpm install\nelse\n\texecute $TRAVELER_SUPPORT_DIR/bin/install_all.sh --silent\nfi\n\ncd $TRAVELER_ROOT_DIR\n"
},
{
"alpha_fraction": 0.6411682963371277,
"alphanum_fraction": 0.6446453332901001,
"avg_line_length": 21.294572830200195,
"blob_id": "e3d56b7d7711316d9c67af662a52e61185e0a8a2",
"content_id": "85672817db1b7f4a6b22d71d1d7514a2b3ae9157",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2876,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 129,
"path": "/etc/init.d/traveler-mongodb",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\nCUR_DIR=`pwd`\ncd $MY_DIR\nMY_DIR=`pwd`\ncd $CUR_DIR\n\nsource $MY_DIR/../../setup.sh\n\nMONGO_CONFIGURATION=$TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\nif [ ! -f $MONGO_CONFIGURATION ]; then\n >&2 echo \"$MONGO_CONFIGURATION is not defined\"\n >&2 echo \"Please use the default file to configure it.\"\n exit 1\nfi\nsource $MONGO_CONFIGURATION\n\n# Should only be used for administrative configurations\nstartNoAuth(){\n echo \"Starting mongo deamon\"\n # Create the log file when it does not exist\n if [ ! -f $MONGO_LOG_DIRECTORY ]; then\n touch $MONGO_LOG_DIRECTORY\n fi\n\n $MONGO_BIN_DIRECTORY/mongod \\\n --port=$MONGO_SERVER_PORT \\\n --fork --logpath=$MONGO_LOG_DIRECTORY --logappend\\\n --dbpath=$MONGO_DATA_DIRECTORY \\\n --pidfilepath=$MONGO_PID_DIRECTORY \\\n --bind_ip $MONGO_BIND_IP\n}\nstart(){\n echo \"Starting mongo deamon\"\n # Create the log file when it does not exist\n if [ ! -f $MONGO_LOG_DIRECTORY ]; then\n touch $MONGO_LOG_DIRECTORY\n fi\n\n $MONGO_BIN_DIRECTORY/mongod \\\n --auth \\\n --port=$MONGO_SERVER_PORT \\\n --fork --logpath=$MONGO_LOG_DIRECTORY --logappend\\\n --dbpath=$MONGO_DATA_DIRECTORY \\\n --pidfilepath=$MONGO_PID_DIRECTORY \\\n --bind_ip $MONGO_BIND_IP\n}\n\nstop (){\n if [ ! -f $MONGO_PID_DIRECTORY ]; then\n echo \"$MONGO_PID_DIRECTORY does not exist\"\n exit 0\n fi\n if [ `uname` == \"Linux\" ]; then\n $MONGO_BIN_DIRECTORY/mongod --shutdown --dbpath=$MONGO_DATA_DIRECTORY\n elif [ `uname` == \"Darwin\" ]; then\n if [[ -f $MONGO_ADMIN_PASSWD_FILE ]]; then\n adminPass=`cat $MONGO_ADMIN_PASSWD_FILE`\n else\n printErr \"No passwd file exists for mongodb admin: $MONGO_ADMIN_PASSWD_FILE\"\n exit 1\n fi\n\n $MONGO_BIN_DIRECTORY/mongo \\\n $MONGO_SERVER_ADDRESS:$MONGO_SERVER_PORT/admin \\\n --username $MONGO_ADMIN_USERNAME \\\n --password $adminPass \\\n --eval \"db.shutdownServer();\"\n fi\n # Check if pid file should be removed\n sleep 2\n pid=`cat $MONGO_PID_DIRECTORY`\n processResult=`ps $pid | grep $pid`\n if [ -z \"$processResult\" ]; then\n rm $MONGO_PID_DIRECTORY\n else\n echo \"Mongo process couldn't be stopped\"\n stop\n fi\n\n}\n\nrestart(){\n stop\n start\n}\n\nstatus(){\n pid=`cat $MONGO_PID_DIRECTORY`\n processResult=`ps $pid | grep $pid`\n if [ ! -z \"$processResult\" ]; then\n echo \"The traveler-mongod is running\"\n ps $pid\n\n\n # adminPass=`cat $MONGO_ADMIN_PASSWD_FILE`\n # echo ''\n # $MONGO_BIN_DIRECTORY/mongo \\\n # \t $MONGO_SERVER_ADDRESS:$MONGO_SERVER_PORT/admin \\\n #\t--username $MONGO_ADMIN_USERNAME \\\n #\t--password $adminPass \\\n #\t--eval \"printjson(db.serverStatus())\"\n\n else\n echo \"The traveler-mongod is not running\"\n fi\n}\ncase \"$1\" in\n start)\n start\n ;;\n stop)\n stop\n ;;\n restart)\n restart\n ;;\n status)\n status\n ;;\n startNoAuth)\n startNoAuth\n ;;\n *)\n echo \"Usage: $0 {start|stop|restart|status}\"\n exit 1\n ;;\nesac\n"
},
{
"alpha_fraction": 0.5865641236305237,
"alphanum_fraction": 0.5922051072120667,
"avg_line_length": 30.25,
"blob_id": "3be695b2eea408a55af8ff04f1917842d25cba9d",
"content_id": "6635fd37bcb4fd4e2f1fe679eaa040cc39d77424",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 9750,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 312,
"path": "/public/javascripts/released-forms.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* global ajax401, disableAjaxCache, prefix, updateAjaxURL,\n travelerGlobal, Holder, selectColumn, formLinkColumn, formConfigLinkColumn, titleColumn, tagsColumn, keysColumn, createdOnColumn,\n updatedOnColumn, updatedByColumn, sharedWithColumn, sharedGroupColumn,\n fnAddFilterFoot, sDomNoTools, createdByColumn, createdOnColumn,\n fnGetSelected, selectEvent, filterEvent, formShareLinkColumn,\n transferredOnColumn, ownerColumn, formStatusColumn, formTypeColumn,\n versionColumn, releasedFormLinkColumn, releasedFormStatusColumn,\n releasedFormVersionColumn, releasedByColumn, releasedOnColumn,\n transferFromModal, archivedByColumn, archivedOnColumn, formReviewLinkColumn */\n\nfunction travelFromModal() {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n let number = $('#modal .modal-body div.target').length;\n $('#modal .modal-body div.target').each(function() {\n const that = this;\n $.ajax({\n url: '/travelers/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n form: this.id,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(` : ${jqXHR.responseText}`);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n $('#return').prop('disabled', false);\n }\n });\n });\n}\n\nfunction cloneFromModal(activeTable) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n let number = $('#modal .modal-body div.target').length;\n let base = activeTable.fnSettings().sAjaxSource.split('/')[1];\n if (\n base === 'archivedforms' ||\n base === 'sharedforms' ||\n base === 'groupsharedforms'\n ) {\n base = 'forms';\n }\n\n if (base === 'archived-released-forms') {\n base = 'released-forms';\n }\n $('#modal .modal-body div.target').each(function() {\n const that = this;\n let success = false;\n $.ajax({\n url: `/${base}/${that.id}/clone`,\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n title: $('input', $(that)).val(),\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n success = true;\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(` : ${jqXHR.responseText}`);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0 && success) {\n $('#return').prop('disabled', false);\n }\n });\n });\n}\n\nfunction showHash() {\n if (window.location.hash) {\n $(`.nav-tabs a[href=${window.location.hash}]`).tab('show');\n }\n}\n\nfunction formatItemUpdate(data) {\n return `<div class=\"target\" id=\"${data._id}\"><b>${data.title}</b> </div>`;\n}\n\nfunction cloneItem(data) {\n return `<div class=\"target\" id=\"${data._id}\">clone <b>${data.title}</b> <br> with new title: <input type=\"text\" value=\"${data.title} clone\"></div>`;\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n\n /* released form table starts */\n const releasedFormAoColumns = [\n selectColumn,\n releasedFormLinkColumn,\n titleColumn,\n releasedFormStatusColumn,\n formTypeColumn,\n releasedFormVersionColumn,\n tagsColumn,\n releasedByColumn,\n releasedOnColumn,\n ];\n const releasedFormTable = $('#released-form-table').dataTable({\n sAjaxSource: '/released-forms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: releasedFormAoColumns,\n aaSorting: [[8, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#released-form-table', releasedFormAoColumns);\n /* released form table ends */\n\n /* archived released form table starts */\n const archivedReleasedFormAoColumns = [\n selectColumn,\n releasedFormLinkColumn,\n titleColumn,\n formTypeColumn,\n tagsColumn,\n releasedFormVersionColumn,\n archivedByColumn,\n archivedOnColumn,\n ];\n const archivedReleasedFormTable = $(\n '#archived-released-form-table'\n ).dataTable({\n sAjaxSource: '/archived-released-forms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: archivedReleasedFormAoColumns,\n aaSorting: [[7, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot(\n '#archived-released-form-table',\n archivedReleasedFormAoColumns\n );\n /* archived released form table ends */\n\n // show the tab in hash\n showHash();\n\n // add state for tab changes\n $('.nav-tabs a').on('click', function() {\n window.history.pushState(null, `forms :: ${this.text}`, this.href);\n });\n\n // show the tab when back and forward\n window.onhashchange = function() {\n showHash();\n };\n\n $('#form-travel').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n `Create travelers from the following ${selected.length} forms? `\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n travelFromModal();\n });\n }\n });\n\n $('button.transfer').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n `Transfer the following ${selected.length} forms? `\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-body').append('<h5>to the following user</h5>');\n $('#modal .modal-body').append(\n '<form class=\"form-inline\"><input id=\"username\" type=\"text\" placeholder=\"Last, First\" name=\"name\" class=\"input\" required></form>'\n );\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n\n travelerGlobal.usernames.initialize();\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n $('#submit').click(function() {\n transferFromModal($('#username').val(), 'forms', activeTable);\n });\n }\n });\n\n $('#clone').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(`Clone the following ${selected.length} form(s)? `);\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(cloneItem(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n cloneFromModal(activeTable);\n });\n }\n });\n\n $('#reload').click(function() {\n releasedFormTable.fnReloadAjax();\n archivedReleasedFormTable.fnReloadAjax();\n });\n // binding events\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.6331775784492493,
"alphanum_fraction": 0.6331775784492493,
"avg_line_length": 27.53333282470703,
"blob_id": "b417f246fa47a5937772b8d65c1f0ebdb98c747a",
"content_id": "197f723b451929f5a526b662f98a76a50fcfaa68",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 428,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 15,
"path": "/public/javascripts/groupnames.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "if (shareGroups) {\n travelerGlobal.groupnames = new Bloodhound({\n datumTokenizer: function(group) {\n return Bloodhound.tokenizers.whitespace(group._id);\n },\n queryTokenizer: Bloodhound.tokenizers.whitespace,\n identify: function(group) {\n return group._id;\n },\n prefetch: {\n url: (prefix ? prefix + '/groupnames' : '/groupnames') + '?deleted=false',\n cacheKey: 'groupnames',\n },\n });\n}\n"
},
{
"alpha_fraction": 0.484198659658432,
"alphanum_fraction": 0.4895033836364746,
"avg_line_length": 28.04918098449707,
"blob_id": "68f0366733328291231c4bafa89400fe66028be7",
"content_id": "4fd5950a0008102e2d8fd701f9e9f7821e9f1aca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 8860,
"license_type": "permissive",
"max_line_length": 316,
"num_lines": 305,
"path": "/public/javascripts/traveler-config.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false */\n/*global moment: false, ajax401: false, Modernizr: false, prefix: false, updateAjaxURL: false, disableAjaxCache: false, Bloodhound: false*/\n\nimport * as Editable from './lib/editable.js';\n\nfunction cleanDeviceForm() {\n $('#newDevice')\n .closest('li')\n .remove();\n $('#add').removeAttr('disabled');\n}\n\nfunction cleanTagForm() {\n $('#new-tag')\n .closest('li')\n .remove();\n $('#add-tag').removeAttr('disabled');\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n $('span.time').each(function() {\n $(this).text(\n moment($(this).text()).format('dddd, MMMM Do YYYY, h:mm:ss a')\n );\n });\n if ($('#deadline').attr('value')) {\n $('#deadline').val(\n moment($('#deadline').attr('value')).format('YYYY-MM-DD')\n );\n }\n if (!Modernizr.inputtypes.date) {\n $('#deadline').datepicker({\n format: 'yyyy-mm-dd',\n });\n }\n var initValue = {\n title: $('#title').html(),\n description: $('#description').html(),\n };\n\n Editable.binding($, initValue);\n\n var deadline = $('#deadline').val();\n\n $('#deadline').change(function() {\n var $dl = $(this).parent();\n if ($dl.children('.buttons').length === 0) {\n $dl.append(\n '<span class=\"buttons\"><button value=\"save\" class=\"btn btn-primary\">Save</button> <button value=\"reset\" class=\"btn\">Reset</button></span>'\n );\n }\n });\n\n $('#deadline')\n .parent()\n .on('click', 'button[value=\"save\"]', function(e) {\n e.preventDefault();\n var $this = $(this);\n var $input = $this\n .closest('.form-inline')\n .children('input')\n .first();\n $.ajax({\n url: './config',\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({\n deadline: moment($input.val()).utc(),\n }),\n })\n .done(function() {\n deadline = $input.val();\n $this.parent().remove();\n })\n .fail(function(jqXHR) {\n $this.val(deadline);\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot update the traveler config : ' +\n jqXHR.responseText +\n '</div>'\n );\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n }\n });\n });\n\n $('#deadline')\n .parent()\n .on('click', 'button[value=\"reset\"]', function(e) {\n e.preventDefault();\n var $this = $(this);\n $this\n .closest('.form-inline')\n .children('input')\n .first()\n .val(deadline);\n $this.parent().remove();\n });\n\n var devices;\n\n $('#add').click(function(e) {\n e.preventDefault();\n // add an input and a button add\n $('#add').attr('disabled', true);\n $('#devices').append(\n '<li><form class=\"form-inline\"><input id=\"newDevice\" type=\"text\"> <button id=\"confirm\" class=\"btn btn-primary\">Confirm</button> <button id=\"cancel\" class=\"btn\">Cancel</button></form></li>'\n );\n $('#cancel').click(function(cancelE) {\n cancelE.preventDefault();\n cleanDeviceForm();\n });\n\n if (showCCDB) {\n if (!devices) {\n devices = new Bloodhound({\n datumTokenizer: function(device) {\n return Bloodhound.tokenizers.nonword(device.inventoryId);\n },\n queryTokenizer: Bloodhound.tokenizers.nonword,\n identify: function(device) {\n return device.inventoryId;\n },\n prefetch: {\n url: prefix + '/devices/json',\n cacheKey: 'devices',\n },\n });\n devices.initialize();\n }\n } else if (!devices) {\n devices = [];\n }\n\n $('#newDevice').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'devices',\n limit: 20,\n display: 'inventoryId',\n source: devices,\n }\n );\n\n $('#confirm').click(function(confirmE) {\n confirmE.preventDefault();\n if (\n $('#newDevice')\n .val()\n .trim()\n ) {\n $.ajax({\n url: './devices/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n newdevice: $('#newDevice')\n .val()\n .trim(),\n }),\n })\n .done(function(data, textStatus, jqXHR) {\n if (jqXHR.status === 204) {\n return;\n }\n if (jqXHR.status === 200) {\n $('#devices').append(\n '<li><span class=\"device\">' +\n data.device +\n '</span> <button class=\"btn btn-small btn-warning removeDevice\"><i class=\"fa fa-trash-o fa-lg\"></i></button></li>'\n );\n }\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot add the tag</div>'\n );\n $(window).scrollTop(\n $('#message div:last-child').offset().top - 40\n );\n }\n })\n .always(function() {\n cleanDeviceForm();\n });\n }\n });\n });\n\n $('#devices').on('click', '.removeDevice', function(e) {\n e.preventDefault();\n var $that = $(this);\n $.ajax({\n url:\n './devices/' + encodeURIComponent($that.siblings('span.device').text()),\n type: 'DELETE',\n })\n .done(function() {\n $that.closest('li').remove();\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot remove the device</div>'\n );\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n }\n })\n .always();\n });\n\n var tags;\n\n $('#add-tag').click(function(e) {\n e.preventDefault();\n // add an input and a button add\n $('#add-tag').attr('disabled', true);\n $('#tags').append(\n '<li><form class=\"form-inline\"><input id=\"new-tag\" type=\"text\"> <button id=\"tag-confirm\" class=\"btn btn-primary\">Confirm</button> <button id=\"cancel\" class=\"btn\">Cancel</button></form></li>'\n );\n $('#cancel').click(function(cancelE) {\n cancelE.preventDefault();\n cleanTagForm();\n });\n\n if (!tags) {\n tags = [];\n }\n\n $('#tag-confirm').click(function(confirmE) {\n confirmE.preventDefault();\n if (\n $('#new-tag')\n .val()\n .trim()\n ) {\n $.ajax({\n url: './tags/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n newtag: $('#new-tag')\n .val()\n .trim(),\n }),\n })\n .done(function(data, textStatus, jqXHR) {\n if (jqXHR.status === 204) {\n return;\n }\n if (jqXHR.status === 200) {\n $('#tags').append(\n '<li><span class=\"tag\">' +\n data.tag +\n '</span> <button class=\"btn btn-small btn-warning remove-tag\"><i class=\"fa fa-trash-o fa-lg\"></i></button></li>'\n );\n }\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot add the tag</div>'\n );\n $(window).scrollTop(\n $('#message div:last-child').offset().top - 40\n );\n }\n })\n .always(function() {\n cleanTagForm();\n });\n }\n });\n });\n\n $('#tags').on('click', '.remove-tag', function(e) {\n e.preventDefault();\n var $that = $(this);\n $.ajax({\n url: './tags/' + encodeURIComponent($that.siblings('span.tag').text()),\n type: 'DELETE',\n })\n .done(function() {\n $that.closest('li').remove();\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot remove the tag</div>'\n );\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n }\n })\n .always();\n });\n});\n"
},
{
"alpha_fraction": 0.5570470094680786,
"alphanum_fraction": 0.5659955143928528,
"avg_line_length": 25.81999969482422,
"blob_id": "2fb560fe8ed804a3952c3ddc86e8d20f4729c784",
"content_id": "8c43ac3d863f6ad121467ed8365691ce22fc5402",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1341,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 50,
"path": "/routes/profile.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "var mongoose = require('mongoose');\nvar User = mongoose.model('User');\nvar auth = require('../lib/auth');\nvar config = require('../config/config.js');\nvar routesUtilities = require('../utilities/routes.js');\n\nmodule.exports = function(app) {\n app.get('/profile', auth.ensureAuthenticated, function(req, res) {\n // render the profile page\n User.findOne({\n _id: req.session.userid,\n }).exec(function(err, user) {\n if (err) {\n console.error(err);\n return res.status(500).send('something is wrong with the DB.');\n }\n return res.render(\n 'profile',\n routesUtilities.getRenderObject(req, {\n user: user,\n })\n );\n });\n });\n\n // user update her/his profile. This is a little different from the admin update the user's roles.\n app.put('/profile', auth.ensureAuthenticated, function(req, res) {\n if (!req.is('json')) {\n return res.status(415).json({\n error: 'json request expected.',\n });\n }\n User.findOneAndUpdate(\n {\n _id: req.session.userid,\n },\n {\n subscribe: req.body.subscribe,\n }\n ).exec(function(err, user) {\n if (err) {\n console.error(err);\n return res.status(500).json({\n error: err.message,\n });\n }\n return res.status(204).send();\n });\n });\n};\n"
},
{
"alpha_fraction": 0.7283950448036194,
"alphanum_fraction": 0.7389770746231079,
"avg_line_length": 27.350000381469727,
"blob_id": "9be13fbd5aee22aae681ae0979e63fecc339569d",
"content_id": "df0896b44bcb32c963dd2dd592abd6dd1146eb46",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 567,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 20,
"path": "/utilities/devices/default.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/**\n * Created by djarosz on 11/24/15.\n */\n/**\n * The purpose of this file is to provide the behavior that would happen normally when no controller is specified for device_application.\n *\n * Service configuration contains the configuration below.\n * \"device_application\": \"device\"\n *\n * In order to implement special functionality for application, \"device\"; device.js must be specified in the same directory as this file.\n */\n\nfunction getDeviceValue(value, cb) {\n cb(value);\n}\n\nmodule.exports = {\n getDeviceValue: getDeviceValue,\n devicesRemovalAllowed: true,\n};\n"
},
{
"alpha_fraction": 0.6130227446556091,
"alphanum_fraction": 0.6248809099197388,
"avg_line_length": 26.456396102905273,
"blob_id": "40b9193127dd22b5124cb36664cc5a810aff30da",
"content_id": "8009fe2a55be21bb95549ae35990568aa94e87e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 9445,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 344,
"path": "/public/javascripts/binders.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false,\nframes: false, history: false, Image: false, location: false, name: false,\nnavigator: false, Option: false, parent: false, screen: false, setInterval:\nfalse, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false,\nHistory: false*/\n/*global ajax401: false, prefix: false, updateAjaxURL: false, disableAjaxCache:\nfalse, moment: false, travelerGlobal: false*/\n/*global selectColumn: false, titleColumn: false, createdOnColumn: false,\nupdatedOnColumn: false, updatedByColumn: false, sharedWithColumn: false,\nsharedGroupColumn: false, fnAddFilterFoot: false, sDomNoTools: false,\ncreatedByColumn: false, createdOnColumn: false, fnGetSelected: false,\nselectEvent: false, filterEvent: false, clonedByColumn: false, archivedOnColumn:\nfalse, binderConfigLinkColumn: false, binderShareLinkColumn: false,\nbinderLinkColumn: false, tagsColumn: false, binderWorkProgressColumn: false,\ntransferredOnColumn: false, ownerColumn: false*/\n/*global archiveFromModal, transferFromModal, modalScroll, Holder*/\n\nimport * as AddBinder from './lib/binder.js';\nimport * as Modal from './lib/modal.js';\n\nfunction formatItemUpdate(data) {\n return (\n '<div class=\"target\" id=\"' +\n data._id +\n '\"><b>' +\n data.title +\n '</b>, created ' +\n moment(data.createdOn).fromNow() +\n (data.updatedOn ? ', updated ' + moment(data.updatedOn).fromNow() : '') +\n '</div>'\n );\n}\n\nfunction showHash() {\n if (window.location.hash) {\n $('.nav-tabs a[href=' + window.location.hash + ']').tab('show');\n }\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n\n var binderAoColumns = [\n selectColumn,\n binderConfigLinkColumn,\n binderShareLinkColumn,\n binderLinkColumn,\n titleColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n updatedByColumn,\n updatedOnColumn,\n binderWorkProgressColumn,\n ];\n fnAddFilterFoot('#binder-table', binderAoColumns);\n var binderTable = $('#binder-table').dataTable({\n sAjaxSource: '/binders/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: binderAoColumns,\n aaSorting: [\n [10, 'desc'],\n [8, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n var transferredBinderAoColumns = [\n selectColumn,\n binderConfigLinkColumn,\n binderShareLinkColumn,\n binderLinkColumn,\n titleColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n transferredOnColumn,\n updatedByColumn,\n updatedOnColumn,\n binderWorkProgressColumn,\n ];\n fnAddFilterFoot('#transferred-binder-table', transferredBinderAoColumns);\n var transferredBinderTable = $('#transferred-binder-table').dataTable({\n sAjaxSource: '/transferredbinders/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: transferredBinderAoColumns,\n aaSorting: [\n [11, 'desc'],\n [9, 'desc'],\n [8, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n var sharedBinderAoColumns = [\n selectColumn,\n binderLinkColumn,\n titleColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ownerColumn,\n createdOnColumn,\n updatedByColumn,\n updatedOnColumn,\n binderWorkProgressColumn,\n ];\n fnAddFilterFoot('#shared-binder-table', sharedBinderAoColumns);\n var sharedBinderTable = $('#shared-binder-table').dataTable({\n sAjaxSource: '/sharedbinders/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: sharedBinderAoColumns,\n aaSorting: [\n [9, 'desc'],\n [7, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n var groupSharedBinderAoColumns = [\n selectColumn,\n binderLinkColumn,\n titleColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdByColumn,\n clonedByColumn,\n createdOnColumn,\n updatedByColumn,\n updatedOnColumn,\n binderWorkProgressColumn,\n ];\n fnAddFilterFoot('#group-shared-binder-table', groupSharedBinderAoColumns);\n var groupSharedBinderTable = $('#group-shared-binder-table').dataTable({\n sAjaxSource: '/groupsharedbinders/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: groupSharedBinderAoColumns,\n aaSorting: [\n [8, 'desc'],\n [10, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n var archivedBinderAoColumns = [\n selectColumn,\n binderLinkColumn,\n titleColumn,\n archivedOnColumn,\n tagsColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n updatedByColumn,\n updatedOnColumn,\n binderWorkProgressColumn,\n ];\n fnAddFilterFoot('#archived-binder-table', archivedBinderAoColumns);\n var archivedBinderTable = $('#archived-binder-table').dataTable({\n sAjaxSource: '/archivedbinders/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: archivedBinderAoColumns,\n aaSorting: [\n [3, 'desc'],\n [9, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n // show the tab in hash when loaded\n showHash();\n\n // add state for tab changes\n $('.nav-tabs a').on('click', function() {\n if (\n !$(this)\n .parent()\n .hasClass('active')\n ) {\n window.history.pushState(null, 'Traveler :: ' + this.text, this.href);\n }\n });\n\n // show the tab when back and forward\n window.onhashchange = function() {\n showHash();\n };\n\n $('#reload').click(function() {\n binderTable.fnReloadAjax();\n transferredBinderTable.fnReloadAjax();\n sharedBinderTable.fnReloadAjax();\n groupSharedBinderTable.fnReloadAjax();\n archivedBinderTable.fnReloadAjax();\n });\n\n $('button.transfer').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n modalScroll(false);\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No work binder has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n 'Transfer the following ' + selected.length + ' work binders? '\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-body').append('<h5>to the following user</h5>');\n $('#modal .modal-body').append(\n '<form class=\"form-inline\"><input id=\"username\" type=\"text\" placeholder=\"Last, First\" name=\"name\" class=\"input\" required></form>'\n );\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n\n travelerGlobal.usernames.initialize();\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n $('#submit').click(function() {\n transferFromModal($('#username').val(), 'binders', activeTable);\n });\n }\n });\n\n $('button.archive').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n Modal.archive('binder', 3, activeTable, archivedBinderTable);\n });\n\n $('#add-to-binder').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n AddBinder.addModal(activeTable, 'binder');\n });\n\n // binding events\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.7521058917045593,
"alphanum_fraction": 0.7521058917045593,
"avg_line_length": 35.130435943603516,
"blob_id": "7d9b07e5826c6af7fae5b4dad81eb52844dd9919",
"content_id": "bfa641f19173e2f6682aeea7b5976376be9cc3f3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 831,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 23,
"path": "/views/docs/traveler/config.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Configure a traveler\n\n**Audience: traveler owner**\n\nThe traveler owner has the permission to configure a traveler. The configuration\noptions include\n\n- traveler title\n- traveler description\n- deadline\n- tags\n- forms\n- status\n\nClick the\n<a data-toggle=\"tooltip\" title=\"config the traveler\"><i class=\"fa fa-gear fa-lg\"></i></a>\nicon in order to navigate to the traveler configuration page. On the\nconfiguration page, click on the <button class=\"btn btn-primary\">Edit</button>\nbutton to update the traveler title or description. The deadline is a date\npicker. Click the <button id=\"add\" class=\"btn btn-primary\">Add tags</button>\nbutton to add a tag. If the traveler has a list of tags, click the\n<button class=\"btn btn-small btn-warning removeDevice\"><i class=\"fa fa-trash-o fa-lg\"></i></button>\nbutton behind a tag to remove it.\n"
},
{
"alpha_fraction": 0.6312364339828491,
"alphanum_fraction": 0.6312364339828491,
"avg_line_length": 26.117647171020508,
"blob_id": "096f5cd780f57becea7e81e822db76de09b92950",
"content_id": "b0844bf1d01b776ee69ee32a24bfdca3f13c7a0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 461,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 17,
"path": "/public/javascripts/groupids.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "if (shareGroups) {\n travelerGlobal.groupids = new Bloodhound({\n datumTokenizer: function(group) {\n return Bloodhound.tokenizers.nonword(group.sAMAccountName);\n },\n queryTokenizer: Bloodhound.tokenizers.nonword,\n identify: function(group) {\n return group.sAMAccountName;\n },\n prefetch: {\n url: prefix\n ? prefix + '/adgroups?term=lab.frib.'\n : '/adgroups?term=lab.frib.',\n cacheKey: 'adgroups',\n },\n });\n}\n"
},
{
"alpha_fraction": 0.5700384378433228,
"alphanum_fraction": 0.5746479034423828,
"avg_line_length": 24.35714340209961,
"blob_id": "709228a86bf76eb5f756f9bfeb070633edac097d",
"content_id": "702f71cb73ceeaf3eb0b465eef1e5c3dc8e7b4d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3905,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 154,
"path": "/lib/ldap-client.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const ldap = require('ldapjs');\nconst fs = require('fs');\nconst util = require('util');\nconst debug = require('debug')('traveler:ldap-client');\nconst config = require('../config/config');\nconst logger = require('./loggers').getLogger();\n\nconst { configPath } = config;\n\nconst { ad } = config;\n\nconst clientOptions = {\n url: ad.url,\n maxConnections: 5,\n connectTimeout: 10 * 1000,\n timeout: 15 * 1000,\n bindDN: ad.adminDn,\n bindCredentials: ad.adminPassword,\n};\nif (ad.ldapsCA !== undefined) {\n clientOptions.tlsOptions = {\n ca: fs.readFileSync(`${configPath}/${ad.ldapsCA}`),\n rejectUnauthorized: ad.ldapsRejectUnauthorized,\n };\n}\n\nfunction getDefaultClient(cb) {\n getClient(clientOptions, cb);\n}\n\nfunction getClient(clientOpts, cb) {\n const client = ldap.createClient(clientOpts);\n client.on('connect', function() {\n cb(client, function cleanUp() {\n client.unbind();\n client.destroy();\n });\n });\n client.on('timeout', function(message) {\n logger.error(message);\n });\n client.on('error', function(error) {\n logger.error(error);\n });\n}\n\nfunction searchForUser(username, cb) {\n const searchFilter = ad.searchFilter.replace('_id', username);\n const opts = {\n filter: searchFilter,\n scope: 'sub',\n };\n\n getDefaultClient(function(client, cleanUp) {\n client.search(ad.searchBase, opts, function(err, result) {\n if (err) {\n return cb(err);\n }\n const results = [];\n\n result.on('searchEntry', function(entry) {\n results.push(entry.object);\n });\n result.on('error', function(error) {\n logger.error(JSON.stringify(error));\n cleanUp();\n return cb(error);\n });\n result.on('end', function() {\n cleanUp();\n switch (results.length) {\n case 0:\n cb(`No result for specified username: ${username}`);\n break;\n case 1:\n mapDefaultKeyNames(results, ad.defaultKeys, function(error, items) {\n cb(null, items[0]);\n });\n break;\n default:\n cb(`Non unique for specified username: ${username}`);\n break;\n }\n });\n return null;\n });\n });\n}\n\nfunction search(base, opts, raw, cb) {\n getDefaultClient(function(client, cleanUp) {\n client.search(base, opts, function(err, result) {\n if (err) {\n logger.error(JSON.stringify(err));\n cleanUp();\n return cb(err);\n }\n const items = [];\n result.on('searchEntry', function(entry) {\n if (raw) {\n items.push(entry.raw);\n } else {\n items.push(entry.object);\n }\n });\n result.on('error', function(error) {\n logger.error(JSON.stringify(error));\n cleanUp();\n return cb(error);\n });\n result.on('end', function(r) {\n cleanUp();\n if (r.status !== 0) {\n const error = `non-zero status from LDAP search: ${r.status}`;\n logger.error(JSON.stringify(error));\n return cb(error);\n }\n switch (items.length) {\n case 0:\n return cb(null, []);\n default:\n mapDefaultKeyNames(items, ad.defaultKeys, cb);\n }\n return null;\n });\n return null;\n });\n });\n}\n\nfunction mapDefaultKeyNames(items, defaultItems, cb) {\n debug(`before map: ${util.inspect(items)}`);\n const itemKeys = Object.keys(items);\n const defaultKeys = Object.keys(defaultItems);\n itemKeys.forEach(itemKey => {\n const item = items[itemKey];\n defaultKeys.forEach(defaultKey => {\n if (item[defaultItems[defaultKey]] !== undefined) {\n item[defaultKey] = item[defaultItems[defaultKey]];\n } else {\n item[defaultKey] = '';\n }\n });\n });\n debug(`after map: ${util.inspect(items)}`);\n return cb(null, items);\n}\n\nmodule.exports = {\n getDefaultClient,\n getClient,\n search,\n searchForUser,\n};\n"
},
{
"alpha_fraction": 0.5223420858383179,
"alphanum_fraction": 0.5281201601028442,
"avg_line_length": 29.186046600341797,
"blob_id": "de6653a03436336d157f20fcf149875e5a0d8527",
"content_id": "d794c35435dba6465ce8cd9033fc2a75d6f55fc9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2596,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 86,
"path": "/public/javascripts/form-version-mgmt.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global ajax401: false, prefix: false, updateAjaxURL: false, moment: false*/\n\nimport * as Table from './lib/table1.10.js';\n\n$(function() {\n ajax401(prefix);\n\n updateAjaxURL(prefix);\n\n const versionColumns = [\n Table.versionRadioColumn('L', 'left'),\n Table.versionRadioColumn('R', 'right'),\n Table.versionColumn,\n Table.longDateColumn('created', 'a'),\n ];\n\n let latest = 0;\n const htmlUpdates = [];\n const versionTable = $('#version-table').DataTable({\n ajax: {\n url: './versions/json',\n type: 'GET',\n dataSrc: function(response) {\n // filter all the changes with html and v change\n response.forEach(update => {\n const changes = update.c;\n const found = { a: update.a };\n for (let i = 0; i < changes.length; i += 1) {\n if (changes[i].p === 'html') {\n found.html = changes[i].v;\n continue;\n }\n if (changes[i].p === '_v') {\n found._v = changes[i].v;\n continue;\n }\n }\n if (found.html !== undefined) {\n htmlUpdates.push(found);\n }\n });\n latest = htmlUpdates?.[htmlUpdates.length - 1]?._v || latest;\n return htmlUpdates;\n },\n },\n columns: versionColumns,\n pageLength: -1,\n dom: Table.domI,\n sorting: [[2, 'desc']],\n });\n\n $('#version-table tbody').on('click', 'input.radio-row', function(e) {\n const that = $(this);\n const data = versionTable.row(that.parents('tr')).data();\n $(`#${that.prop('name')} span.version`).text(` version ${data._v}`);\n $(`#${that.prop('name')}-form`).html(data.html);\n if (data._v < latest) {\n $(`#${that.prop('name')} .btn.use`).prop('disabled', false);\n $(`#${that.prop('name')} .btn.use`).prop('_v', data._v);\n } else {\n $(`#${that.prop('name')} .btn.use`).prop('disabled', true);\n }\n });\n\n $('.btn.use').click(function() {\n // set the chosen version as the latest version\n const version = $(this).prop('_v');\n const html = htmlUpdates.find(u => u._v === version).html;\n $.ajax({\n url: './',\n type: 'PUT',\n async: true,\n data: JSON.stringify({ html }),\n contentType: 'application/json',\n processData: false,\n })\n .done(function(responseData, textStatus, request) {\n window.location.reload(true);\n })\n .fail(function() {\n $('#message').append(\n `<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>failed to set a new version</div>`\n );\n });\n });\n});\n"
},
{
"alpha_fraction": 0.7659137845039368,
"alphanum_fraction": 0.7659137845039368,
"avg_line_length": 50.26315689086914,
"blob_id": "ae6ada038b5ffc37c9b70031f0bff068618d2178",
"content_id": "ae92b1ad8b3e45e6c04f99372c55709627718863",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1950,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 38,
"path": "/views/docs/basics/ownership.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Ownership, roles, and access control\n\nThe traveler application supports **role based** and **attribute based** access\ncontrol. When a user requests to access a resource, both the user's roles in the\ncurrent session and the resource's access related attributes are considered. The\naccess is granted if either the role or the attribute allows.\n\nThere are three special roles, admin, manager, and reviewer. A user can be\nassociated with multiple roles. Only an admin can modify a user's roles. Only a\nreviewer can review a submitted template to release. An admin or a manager is\ncapable of reading and writing all resources in the application.\n\nThe traveler application has three important entity types: template, traveler,\nand binder. Each type has three attributes to control the access, the ownership,\nsharing, and public accessibility.\n\nThere are three levels of access privileges: no access, read, and write. The\ndetails are listed in the following table.\n\n<!-- prettier-ignore -->\n| access privilege | details | \n|----------|-----------------------------|\n| no access | rejected when requesting to access an entity |\n| read | view the representation of an entity, but will not be able to modify the entity | \n| write | be able to view and modify the entity |\n\nEvery entity has an owner. The **owner** is the user who creates the entity. An\nentity’s ownership can be transferred to a different user by its current owner.\nThe owner, by default, has the privilege to configure attributes of the entity\nincluding the sharing and public accessibility.\n\nThe owner user can share an entity with other individual users or groups with\nread or write permission. The shared entity will also appear in the _shared\nentity_ tab or the _group shared entity_ tab of a user.\n\nThe entity owner can configure an entity to be publicly readable or writable.\nAll the public available entities are listed on the _all public forms_ or _all\npublic travelers_ pages.\n"
},
{
"alpha_fraction": 0.5896041989326477,
"alphanum_fraction": 0.5999469757080078,
"avg_line_length": 27.245317459106445,
"blob_id": "90f74eb5038972ab6bec9b3228fff7f246898df9",
"content_id": "fbf243f979f070b16079806eec78780e45bc2bb7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 15083,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 534,
"path": "/public/javascripts/forms.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* global ajax401, disableAjaxCache, prefix, updateAjaxURL,\n travelerGlobal, Holder, selectColumn, formLinkColumn, formConfigLinkColumn, titleColumn, tagsColumn, keysColumn, createdOnColumn,\n updatedOnColumn, updatedByColumn, sharedWithColumn, sharedGroupColumn,\n fnAddFilterFoot, sDomNoTools, createdByColumn, createdOnColumn,\n fnGetSelected, selectEvent, filterEvent, formShareLinkColumn,\n transferredOnColumn, ownerColumn, formStatusColumn, formTypeColumn,\n versionColumn, releasedFormLinkColumn, releasedFormStatusColumn,\n releasedFormVersionColumn, releasedByColumn, releasedOnColumn,\n transferFromModal, archivedByColumn, archivedOnColumn, formReviewLinkColumn */\n\nfunction travelFromModal() {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n let number = $('#modal .modal-body div.target').length;\n $('#modal .modal-body div.target').each(function() {\n const that = this;\n $.ajax({\n url: '/travelers/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n form: this.id,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(` : ${jqXHR.responseText}`);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n $('#return').prop('disabled', false);\n }\n });\n });\n}\n\nfunction cloneFromModal(activeTable, formTable) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n let number = $('#modal .modal-body div.target').length;\n let base = activeTable.fnSettings().sAjaxSource.split('/')[1];\n if (\n base === 'archivedforms' ||\n base === 'sharedforms' ||\n base === 'transferredforms' ||\n base === 'groupsharedforms' ||\n base === 'closedforms'\n ) {\n base = 'forms';\n }\n\n if (base === 'archived-released-forms') {\n base = 'released-forms';\n }\n $('#modal .modal-body div.target').each(function() {\n const that = this;\n let success = false;\n $.ajax({\n url: `/${base}/${that.id}/clone`,\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n title: $('input', $(that)).val(),\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n success = true;\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(` : ${jqXHR.responseText}`);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0 && success) {\n $('#return').prop('disabled', false);\n formTable.fnReloadAjax();\n }\n });\n });\n}\n\nfunction showHash() {\n if (window.location.hash) {\n $(`.nav-tabs a[href=${window.location.hash}]`).tab('show');\n }\n}\n\nfunction formatItemUpdate(data) {\n return `<div class=\"target\" id=\"${data._id}\"><b>${data.title}</b> </div>`;\n}\n\nfunction cloneItem(data) {\n return `<div class=\"target\" id=\"${data._id}\">clone <b>${data.title}</b> <br> with new title: <input type=\"text\" value=\"${data.title} clone\"></div>`;\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n /* form table starts */\n const formAoColumns = [\n selectColumn,\n formLinkColumn,\n formConfigLinkColumn,\n formShareLinkColumn,\n titleColumn,\n formStatusColumn,\n formTypeColumn,\n versionColumn,\n tagsColumn,\n keysColumn,\n createdOnColumn,\n updatedOnColumn,\n updatedByColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ];\n const formTable = $('#form-table').dataTable({\n sAjaxSource: '/forms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: formAoColumns,\n aaSorting: [\n [11, 'desc'],\n [10, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#form-table', formAoColumns);\n /* form table ends */\n\n /* transferred form table starts */\n const transferredFormAoColumns = [\n selectColumn,\n formLinkColumn,\n formShareLinkColumn,\n titleColumn,\n formStatusColumn,\n formTypeColumn,\n versionColumn,\n tagsColumn,\n keysColumn,\n createdByColumn,\n createdOnColumn,\n transferredOnColumn,\n updatedOnColumn,\n updatedByColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ];\n const transferredFormTable = $('#transferred-form-table').dataTable({\n sAjaxSource: '/transferredforms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: transferredFormAoColumns,\n aaSorting: [\n [11, 'desc'],\n [12, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#transferred-form-table', transferredFormAoColumns);\n /* transferred form table ends */\n\n /* shared form table starts */\n const sharedFormAoColumns = [\n selectColumn,\n formLinkColumn,\n titleColumn,\n formStatusColumn,\n formTypeColumn,\n versionColumn,\n tagsColumn,\n keysColumn,\n ownerColumn,\n updatedByColumn,\n updatedOnColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ];\n const sharedFormTable = $('#shared-form-table').dataTable({\n sAjaxSource: '/sharedforms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: sharedFormAoColumns,\n aaSorting: [[10, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#shared-form-table', sharedFormAoColumns);\n /* shared form table ends */\n\n /* group shared form table starts */\n const groupSharedFormAoColumns = sharedFormAoColumns;\n const groupSharedFormTable = $('#group-shared-form-table').dataTable({\n sAjaxSource: '/groupsharedforms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: groupSharedFormAoColumns,\n aaSorting: [[9, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#group-shared-form-table', groupSharedFormAoColumns);\n /* group shared form table ends */\n\n /* submitted form table starts */\n const submittedFormAoColumns = [\n selectColumn,\n formLinkColumn,\n formConfigLinkColumn,\n formReviewLinkColumn,\n titleColumn,\n formStatusColumn,\n formTypeColumn,\n versionColumn,\n tagsColumn,\n keysColumn,\n createdOnColumn,\n updatedOnColumn,\n updatedByColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ];\n const submittedFormTable = $('#submitted-form-table').dataTable({\n sAjaxSource: '/submittedforms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: submittedFormAoColumns,\n aaSorting: [\n [11, 'desc'],\n [10, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#submitted-form-table', submittedFormAoColumns);\n /* submitted form table ends */\n\n /* closed form table starts */\n const closedFormAoColumns = [\n selectColumn,\n formLinkColumn,\n titleColumn,\n formStatusColumn,\n formTypeColumn,\n versionColumn,\n tagsColumn,\n keysColumn,\n createdOnColumn,\n updatedOnColumn,\n updatedByColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ];\n const closedFormTable = $('#closed-form-table').dataTable({\n sAjaxSource: '/closedforms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: closedFormAoColumns,\n aaSorting: [\n [9, 'desc'],\n [8, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#closed-form-table', closedFormAoColumns);\n /* submitted form table ends */\n\n /* archieved form table starts */\n const archivedFormAoColumns = [\n selectColumn,\n formLinkColumn,\n titleColumn,\n formTypeColumn,\n versionColumn,\n tagsColumn,\n keysColumn,\n updatedByColumn,\n updatedOnColumn,\n ];\n const archivedFormTable = $('#archived-form-table').dataTable({\n sAjaxSource: '/archivedforms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: archivedFormAoColumns,\n aaSorting: [[8, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#archived-form-table', archivedFormAoColumns);\n /* archived form table ends */\n\n // show the tab in hash\n showHash();\n\n // add state for tab changes\n $('.nav-tabs a').on('click', function() {\n window.history.pushState(null, `forms :: ${this.text}`, this.href);\n });\n\n // show the tab when back and forward\n window.onhashchange = function() {\n showHash();\n };\n\n $('#form-travel').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n `Create travelers from the following ${selected.length} forms? `\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n travelFromModal();\n });\n }\n });\n\n $('button.transfer').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n `Transfer the following ${selected.length} forms? `\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-body').append('<h5>to the following user</h5>');\n $('#modal .modal-body').append(\n '<form class=\"form-inline\"><input id=\"username\" type=\"text\" placeholder=\"Last, First\" name=\"name\" class=\"input\" required></form>'\n );\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n\n travelerGlobal.usernames.initialize();\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n $('#submit').click(function() {\n transferFromModal($('#username').val(), 'forms', activeTable);\n });\n }\n });\n\n $('#clone').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(`Clone the following ${selected.length} form(s)? `);\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(cloneItem(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n cloneFromModal(activeTable, formTable);\n });\n }\n });\n\n $('#reload').click(function() {\n formTable.fnReloadAjax();\n transferredFormTable.fnReloadAjax();\n sharedFormTable.fnReloadAjax();\n groupSharedFormTable.fnReloadAjax();\n submittedFormTable.fnReloadAjax();\n closedFormTable.fnReloadAjax();\n archivedFormTable.fnReloadAjax();\n });\n // binding events\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.49699559807777405,
"alphanum_fraction": 0.5010014772415161,
"avg_line_length": 28.484251022338867,
"blob_id": "291ebfead58505795746535b6a30ca3b9ad5f2c6",
"content_id": "2590c05a15ff26c53bde1c7b59fa0c02c2cfeba5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7489,
"license_type": "permissive",
"max_line_length": 316,
"num_lines": 254,
"path": "/public/javascripts/traveler-viewer.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false */\n/*global moment: false, Binder: false, prefix: false*/\n\n// temparary solution for the dirty forms\nfunction cleanForm() {\n $('.control-group-buttons').remove();\n}\n\nfunction fileHistory(found) {\n var i;\n var output = '';\n var link;\n if (found.length > 0) {\n for (i = 0; i < found.length; i += 1) {\n link = prefix + '/data/' + found[i]._id;\n output =\n output +\n '<strong><a href=' +\n link +\n ' target=\"' +\n linkTarget +\n '\">' +\n found[i].value +\n '</a></strong> uploaded by ' +\n found[i].inputBy +\n ' ' +\n livespan(found[i].inputOn, false) +\n '; ';\n }\n }\n return output;\n}\n\nfunction notes(found) {\n var i;\n var output = '<dl>';\n if (found.length > 0) {\n for (i = 0; i < found.length; i += 1) {\n output =\n output +\n '<dt><b>' +\n found[i].inputBy +\n ' noted ' +\n livespan(found[i].inputOn, false) +\n '</b>: </dt>';\n output = output + '<dd>' + found[i].value + '</dd>';\n }\n }\n return output + '</dl>';\n}\n\nfunction renderNotes() {\n $.ajax({\n url: './notes/',\n type: 'GET',\n dataType: 'json',\n })\n .done(function(data) {\n $('#form .controls').each(function(index, controlsElement) {\n var inputElements = $(controlsElement).find('input,textarea');\n if (inputElements.length) {\n var element = inputElements[0];\n var found = data.filter(function(e) {\n return e.name === element.name;\n });\n $(element)\n .closest('.controls')\n .append(\n '<div class=\"note-buttons\"><b>notes</b>: <a class=\"notes-number\" href=\"#\" data-toggle=\"tooltip\" title=\"show/hide notes\"><span class=\"badge badge-info\">' +\n found.length +\n '</span></a> <a class=\"new-note\" href=\"#\" data-toggle=\"tooltip\" title=\"new note\"><i class=\"fa fa-file-o fa-lg\"></i></a></div>'\n );\n if (found.length) {\n found.sort(function(a, b) {\n if (a.inputOn > b.inputOn) {\n return -1;\n }\n return 1;\n });\n $(element)\n .closest('.controls')\n .append(\n '<div class=\"input-notes\" style=\"display: none;\">' +\n notes(found) +\n '</div>'\n );\n }\n }\n });\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot get saved traveler data</div>'\n );\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n }\n })\n .always();\n}\n\nfunction loadDiscrepancyLog(discrepancyForm) {\n DiscrepancyFormLoader.setForm(discrepancyForm);\n DiscrepancyFormLoader.renderLogs();\n DiscrepancyFormLoader.retrieveLogs();\n}\n\n$(function() {\n ajax401(prefix);\n\n createSideNav();\n\n cleanForm();\n\n // load discrepancy table and data\n var discrepancyForm;\n if (traveler.activeDiscrepancyForm) {\n discrepancyForm = findById(\n traveler.discrepancyForms,\n traveler.activeDiscrepancyForm\n );\n DiscrepancyFormLoader.setLogTable('#discrepancy-log-table');\n DiscrepancyFormLoader.setTid(traveler._id);\n loadDiscrepancyLog(discrepancyForm);\n }\n\n $('span.time').each(function() {\n $(this).text(\n moment($(this).text()).format('dddd, MMMM Do YYYY, h:mm:ss a')\n );\n });\n\n // update img\n $('#form')\n .find('img')\n .each(function() {\n var $this = $(this);\n if ($this.attr('name')) {\n if ($this.attr('src') === undefined) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n if ($this.attr('src').indexOf('http') === 0) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n if (prefix && $this.attr('src').indexOf(prefix) !== 0) {\n $($this.attr('src', prefix + '/formfiles/' + $this.attr('name')));\n return;\n }\n }\n });\n\n var binder = new Binder.FormBinder(document.forms[0]);\n $.ajax({\n url: './data/',\n type: 'GET',\n dataType: 'json',\n })\n .done(function(data) {\n $('#form .controls').each(function(index, controlsElement) {\n var inputElements = $(controlsElement).find('input,textarea');\n if (inputElements.length) {\n var element = inputElements[0];\n var found = data.filter(function(e) {\n return e.name === element.name;\n });\n if (found.length) {\n found.sort(function(a, b) {\n if (a.inputOn > b.inputOn) {\n return -1;\n }\n return 1;\n });\n if (element.type === 'file') {\n $(element)\n .closest('.controls')\n .append(\n '<div class=\"input-history\"><b>history</b>: ' +\n fileHistory(found) +\n '</div>'\n );\n } else {\n var currentValue = found[0].value;\n if (found[0].inputType === 'radio') {\n // Update element to match the value\n for (var i = 0; i < inputElements.size(); i++) {\n var ittrInput = inputElements[i];\n if (ittrInput.value === currentValue) {\n element = ittrInput;\n break;\n }\n }\n }\n binder.deserializeFieldFromValue(element, currentValue);\n binder.accessor.set(element.name, currentValue);\n $(element)\n .closest('.controls')\n .append(\n '<div class=\"input-history\"><b>history</b>: ' +\n history(found) +\n '</div>'\n );\n }\n }\n }\n });\n\n markFormValidity(document.getElementById('form'));\n\n // load the notes here\n renderNotes();\n })\n .fail(function() {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot get saved traveler data</div>'\n );\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n })\n .always();\n\n $('#form').on('click', 'a.notes-number', function(e) {\n e.preventDefault();\n var $input_notes = $(this)\n .closest('.controls')\n .find('.input-notes');\n if ($input_notes.is(':visible')) {\n $input_notes.hide();\n } else {\n $input_notes.show();\n }\n });\n\n $('#show-validation').click(function() {\n $('.validation').remove();\n $('#validation').html(\n '<h3>Summary</h3>' + validationMessage(document.getElementById('form'))\n );\n $('#validation').show();\n });\n\n $('#hide-validation').click(function() {\n $('#validation').hide();\n $('.validation').hide();\n });\n\n $('#show-notes').click(function() {\n $('.input-notes').show();\n });\n\n $('#hide-notes').click(function() {\n $('.input-notes').hide();\n });\n});\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.625,
"avg_line_length": 17.363636016845703,
"blob_id": "6d978460613756927b74ea74464bf48a8f561c89",
"content_id": "a5e6149278a9b2681a076d17277139422c752fd5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 808,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 44,
"path": "/model/user.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const mongoose = require('mongoose');\n\nconst { Schema } = mongoose;\nconst { ObjectId } = Schema.Types;\n\nconst user = new Schema({\n _id: String,\n name: String,\n email: String,\n office: String,\n phone: String,\n mobile: String,\n roles: [String],\n lastVisitedOn: Date,\n forms: [ObjectId],\n travelers: [ObjectId],\n binders: [ObjectId],\n // form reviews\n reviews: [ObjectId],\n subscribe: {\n type: Boolean,\n default: false,\n },\n});\n\nconst group = new Schema({\n _id: String,\n name: String,\n deleted: {\n type: Boolean,\n default: false,\n },\n members: [{ type: String, ref: 'User' }],\n forms: [ObjectId],\n travelers: [ObjectId],\n binders: [ObjectId],\n});\n\nconst User = mongoose.model('User', user);\nconst Group = mongoose.model('Group', group);\nmodule.exports = {\n User,\n Group,\n};\n"
},
{
"alpha_fraction": 0.679990828037262,
"alphanum_fraction": 0.6811394691467285,
"avg_line_length": 32.229007720947266,
"blob_id": "a1a31a24363763a425dee05bfa447dd3324c222b",
"content_id": "f11ba662e6c7224d11b5227438fb962ab9b3ad49",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4353,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 131,
"path": "/config/config.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/**\n * Created by djarosz on 11/3/15.\n */\n/* The purpose of this file is to load the correct directories for various project files\n *\n * The desired directory structure is as follows\n * -> Project Root Directory\n * ----> Distribution (This traveler module)\n * ----> etc\n * -------->traveler-config (directory with edited config files)\n * ----> data\n * --------> uploads (directory with uploaded data by users)\n *\n * The default directory structure if the above directory structure is as follows\n * -> Project Root Directory\n * ----> Distribution (This traveler module)\n * --------> config (directory with edited config files)\n * --------> traveler-uploads (directory with uploaded data by users)\n *\n * Specifying environment variables could also set the directories:\n * --TRAVELER_CONFIG_DIRECTORY\n * --TRAVELER_UPLOAD_DIRECTORY\n *\n * */\n\nconst fs = require('fs');\nconst optionalRequire = require('optional-require')(require);\n\nmodule.exports.configPath = '';\nmodule.exports.uploadPath = '';\nmodule.exports.viewConfig = '';\nmodule.exports.ad = '';\nmodule.exports.api = '';\nmodule.exports.app = '';\nmodule.exports.auth = '';\nmodule.exports.alias = '';\nmodule.exports.mongo = '';\nmodule.exports.service = '';\nmodule.exports.travelerPackageFile = '';\nmodule.exports.ui = '';\n\nfunction getPath(desiredPath, defaultPath) {\n // Check to see that desired path exists.\n try {\n var stat = fs.statSync(desiredPath);\n if (stat !== null) {\n return desiredPath;\n }\n } catch (err) {\n // Desired path was not found -- default\n return defaultPath;\n }\n}\n\nmodule.exports.load = function() {\n // Load Paths\n if (process.env.TRAVELER_CONFIG_REL_PATH) {\n module.exports.configPath = process.env.TRAVELER_CONFIG_REL_PATH;\n } else {\n module.exports.configPath = getPath('../etc/traveler-config', 'config');\n }\n\n // Load configuration files\n var configPath = this.configPath;\n module.exports.ad = require('../' + configPath + '/ad.json');\n module.exports.api = require('../' + configPath + '/api.json');\n module.exports.app = require('../' + configPath + '/app.json');\n module.exports.auth = require('../' + configPath + '/auth.json');\n module.exports.alias = require('../' + configPath + '/alias.json');\n module.exports.mongo = require('../' + configPath + '/mongo.json');\n module.exports.service = require('../' + configPath + '/service.json');\n module.exports.ui = require('../' + configPath + '/ui.json');\n module.exports.mqtt = optionalRequire(\n '../' + configPath + '/mqtt.json',\n 'To configure copy and edit: `cp config/mqtt_optional-change.json ' +\n configPath +\n '/mqtt.json`'\n );\n module.exports.travelerPackageFile = require('../package.json');\n\n if (process.env.TRAVELER_UPLOAD_REL_PATH) {\n module.exports.uploadPath = process.env.TRAVELER_UPLOAD_REL_PATH;\n } else if (module.exports.app.upload_dir) {\n module.exports.uploadPath = module.exports.app.upload_dir;\n } else {\n module.exports.uploadPath = getPath('../data/traveler-uploads', 'uploads');\n }\n\n // Load view configuration\n var viewConfig = {};\n viewConfig.showDevice = false;\n viewConfig.shareUsers = true;\n viewConfig.shareGroups = true;\n viewConfig.transferOwnership = true;\n viewConfig.linkTarget = '_blank';\n viewConfig.showBinderValue = false;\n viewConfig.showCCDB = this.service.device_application === 'devices';\n\n if (this.service.device !== undefined) {\n viewConfig.showDevice = true;\n }\n if (this.ad.shareUsers !== undefined) {\n viewConfig.shareUsers = this.ad.shareUsers;\n }\n if (this.ad.shareGroups !== undefined) {\n viewConfig.shareGroups = this.ad.shareGroups;\n }\n if (this.ad.transferOwnership !== undefined) {\n viewConfig.transferOwnership = this.ad.transferOwnership;\n }\n if (this.app.top_bar_urls) {\n viewConfig.topBarUrls = this.app.top_bar_urls;\n }\n if (this.app.deployment_name) {\n viewConfig.deploymentName = this.app.deployment_name;\n }\n if (this.app.link_target) {\n viewConfig.linkTarget = this.app.link_target;\n }\n if (\n this.travelerPackageFile.repository &&\n this.travelerPackageFile.repository.release\n ) {\n viewConfig.appVersion = this.travelerPackageFile.repository.release;\n } else {\n viewConfig.appVersion = this.travelerPackageFile.version;\n }\n viewConfig.terminology = this.ui.terminology;\n\n module.exports.viewConfig = viewConfig;\n};\n"
},
{
"alpha_fraction": 0.5358592867851257,
"alphanum_fraction": 0.641407310962677,
"avg_line_length": 25.39285659790039,
"blob_id": "5f4d252c4d1244fc48173a9cae1ce37065ed03b4",
"content_id": "65f8c720cccef58926e4d60d73f5fad30cb5a5d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 739,
"license_type": "permissive",
"max_line_length": 208,
"num_lines": 28,
"path": "/views/docs/api/notes.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Notes in a traveler\n\n- Method: GET\n- URL: https://hostname:port/apis/travelers/:id/notes/\n where :id is the id of the traveler whose notes are retrieved\n- Sample response:\n\n```json\n[\n {\n \"name\": \"2f067ecd\",\n \"value\": \"first notes\",\n \"inputBy\": \"liud\",\n \"inputOn\": \"2014-08-06T14:13:32.233Z\",\n \"_id\": \"53e2380cd48af61751d91394\"\n },\n {\n \"name\": \"2f067ecd\",\n \"value\": \"live stamp\",\n \"inputBy\": \"liud\",\n \"inputOn\": \"2014-08-07T14:20:55.944Z\",\n \"_id\": \"53e38b47d48af61751d91395\"\n },\n ...\n]\n```\n\nSimilar to the data API, each note item in the list contains the input name in the form and the note text. Besides, it also records who input the note at what time, by which the note history can be generated.\n"
},
{
"alpha_fraction": 0.7016509175300598,
"alphanum_fraction": 0.7028301954269409,
"avg_line_length": 25.10769271850586,
"blob_id": "1006fe24fed2a290e38017a819b2ae0823595c2c",
"content_id": "8ae5177d0971732a1e4a9e16d7ef7529b9de34be",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1696,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 65,
"path": "/sbin/traveler_install_support.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0` \n\nsource $MY_DIR/configuration.sh\nsource $MY_DIR/configure_paths.sh\n\necho 'INFO: Ignore the path warning messages above. This script will create the directories' \n\nexecute(){\n echo \"Executing: $@\"\n eval \"$@\" \n}\n\nif [ -d $TRAVELER_SUPPORT_DIR ]; then\n cd $TRAVELER_SUPPORT_DIR\n if [ $TRAVELER_VERSION_CONTROL_TYPE == \"git\" ]; then \n \texecute git pull\n fi\nelse \n echo \"Creating new traveler support directory $TRAVELER_SUPPORT_DIR.\"\n # Go to one level up from the support directory \n cd `dirname $TRAVELER_SUPPORT_DIR` \n if [ $TRAVELER_VERSION_CONTROL_TYPE == \"git\" ]; then \n\t\texecute \"git clone $TRAVELER_SUPPORT_GIT_URL `basename $TRAVELER_SUPPORT_DIR`\" || exit 1\n fi\nfi\n\ncd $TRAVELER_SUPPORT_DIR\necho \"Building support in `pwd`\"\n\nexecute $TRAVELER_SUPPORT_DIR/bin/clean_all.sh\nexecute $TRAVELER_SUPPORT_DIR/bin/install_all.sh\n\nif [ ! -d $TRAVELER_DATA_DIR ]; then\n echo \"Creating data directories in $TRAVELER_DATA_DIR\" \n mkdir -p $TRAVELER_DATA_DIR/mongodb\n mkdir -p $TRAVELER_DATA_DIR/traveler-uploads\nfi\n\nif [ ! -d $TRAVELER_VAR_DIR ]; then \n echo \"Creating data directories in $TRAVELER_VAR_DIR\"\n mkdir -p $TRAVELER_VAR_DIR/logs\n mkdir -p $TRAVELER_VAR_DIR/run\nfi\n\nif [ ! -d $TRAVELER_INSTALL_ETC_DIR ]; then\n echo \"Creating data directories in $TRAVELER_INSTALL_ETC_DIRECTORY\"\n mkdir -p $TRAVELER_INSTALL_ETC_DIR\nfi\n\n# Higher directory must rerun source setup \ncd $TRAVELER_ROOT_DIR\nsource setup.sh\n\nif [ ! -d $TRAVELER_CONFIG_DIR ]; then\n\techo \"Creating data directories in $TRAVELER_CONFIG_DIR\"\n\tmkdir -p $TRAVELER_CONFIG_DIR\nfi \n\n# Install traveler dependecies \nnpm install\n\n\ncd $TRAVELER_ROOT_DIR"
},
{
"alpha_fraction": 0.7823240756988525,
"alphanum_fraction": 0.7823240756988525,
"avg_line_length": 39.733333587646484,
"blob_id": "70498c55c513c073daeb8b3c4ddb4b3dfc4eae56",
"content_id": "4ea951734266fa8a8c72e14cce4c5d1ec5ae9812",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 611,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 15,
"path": "/views/docs/basics/header.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "## Basics of the traveler application\n\n**Audience: all users**\n\nThe [travelers](#traveler) are electronic documents created from predefined\n[templates](#form). A traveler lists the tasks in order to finish the work\ndefined by the released work template. The user records data and notes when\nperforming the tasks. Travelers can be grouped into working packages named\n[binders](#binder).\n\nBesides web based user interface, the traveler application provides a simple\nHTTP [API](#api) for other applications to operate templates, travelers, and\nbinders.\n\n<img src=\"../images/traveler-flow.png\" alt=\"traveler flow\">\n"
},
{
"alpha_fraction": 0.7095363140106201,
"alphanum_fraction": 0.728783905506134,
"avg_line_length": 27.575000762939453,
"blob_id": "3a60c090463e23de256ab3eaa8558ca88bd7bd12",
"content_id": "a4223e250d0a065364d16b4c1deb942e1d581058",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1143,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 40,
"path": "/tools/openapi/traveler_api_factory.py",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "from travelerApi import Configuration, ApiClient, TravelerApi, DataApi, FormApi, BinderApi\n\n\nclass TravelerApiFactory:\n\n\tdef __init__(self, host, username, password):\n\t\tconfig = Configuration(host=host, username=username, password=password)\n\t\tclient = ApiClient(configuration=config)\n\t\tself.traveler_api = TravelerApi(api_client=client)\n\t\tself.data_api = DataApi(api_client=client)\n\t\tself.form_api = FormApi(api_client=client)\n\t\tself.binder_api = BinderApi(api_client=client)\n\n\tdef get_traveler_api(self):\n\t\treturn self.traveler_api\n\n\tdef get_date_api(self):\n\t\treturn self.data_api\n\n\tdef get_form_api(self):\n\t\treturn self.form_api\n\n\tdef get_binder_api(self):\n\t\treturn self.binder_api\n\n\nif __name__ == \"__main__\":\n\tfactory = TravelerApiFactory(host='http://traveler:3443', username='api_write', password='')\n\n\ttraveler_api = factory.get_traveler_api()\n\tprint(traveler_api.get_travelers()[0].id)\n\n\tdata_api = factory.get_date_api()\n\tprint(data_api.get_data_by_id('6081eb156ddf0c251849dca0').id)\n\n\tform_api = factory.get_form_api()\n\tprint(form_api.get_forms()[0].id)\n\n\tbinder_api = factory.get_binder_api()\n\tprint(binder_api.get_binders()[0].id)\n"
},
{
"alpha_fraction": 0.5506149530410767,
"alphanum_fraction": 0.5515609979629517,
"avg_line_length": 32.03125,
"blob_id": "d35c8bef07c1da20011d0689e5860d40df63bf17",
"content_id": "4e76ad80c62ab5e1820c548cc1fd1402d3b7838d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1057,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 32,
"path": "/test/lib/req-utils-test.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "var reqUtils = require('../../lib/req-utils');\nrequire('chai').should();\nvar sinon = require('sinon');\n\ndescribe('req-utils', function() {\n describe('#sanitize', function() {\n it('should sanitize a json object', function() {\n var req = {};\n var res = {};\n req.body = {\n a_string: 'has a <script>alert()</script>',\n a_function: function() {\n console.log('inside a function');\n },\n an_object: { deep: { deep: 'has a <script>alert()</script>' } },\n an_array: ['has a <script>alert()</script>', 'text'],\n };\n var nextSpy = sinon.spy();\n reqUtils.sanitize('body', [\n 'a_string',\n 'a_function',\n 'an_object',\n 'an_array',\n ])(req, res, nextSpy);\n nextSpy.calledOnce.should.be.true;\n req.body.a_string.includes('script').should.be.false;\n (req.body.a_function === null).should.be.true;\n req.body.an_object.deep.deep.includes('script').should.be.false;\n req.body.an_array[0].includes('script').should.be.false;\n });\n });\n});\n"
},
{
"alpha_fraction": 0.7030128836631775,
"alphanum_fraction": 0.7064040899276733,
"avg_line_length": 36.9554443359375,
"blob_id": "e80d6a35c9a8c3a5ba0ea80118086b187ed8ae4b",
"content_id": "0416b272f35286709ec6b49b2f30ca64245f648d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 7667,
"license_type": "permissive",
"max_line_length": 237,
"num_lines": 202,
"path": "/sbin/create_traveler_config.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\nCUR_DIR=`pwd`\n\nsource $MY_DIR/configure_paths.sh\n\necho \"The script will copy the default configuration files for daemons\"\nDAEMON_CONFIG_DIR=$TRAVELER_ROOT_DIR/etc\nif [ ! -f $TRAVELER_INSTALL_ETC_DIR/mongo-express-configuration.sh ]; then\n cp $DAEMON_CONFIG_DIR/mongo-express-configuration.default.sh $TRAVELER_INSTALL_ETC_DIR/mongo-express-configuration.sh\nfi\nif [ ! -f $TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh ]; then\n cp $DAEMON_CONFIG_DIR/mongo-configuration.default.sh $TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\nfi\nif [ ! -f $TRAVELER_INSTALL_ETC_DIR/travelerd_configuration.sh ]; then\n cp $DAEMON_CONFIG_DIR/travelerd_configuration.default.sh $TRAVELER_INSTALL_ETC_DIR/travelerd_configuration.sh\nfi\n\necho -e \"\\nConfiugre MongoDB\"\n$MY_DIR/configure_mongo_dev.sh\n\nread -p \"Would you like to run web application using ssl? (Y/n): \" appSSL\nread -p \"Would you like to run api using ssl? (Y/n): \" apiSSL\nread -p \"Would you like to configure traveler-mongo-express-daemon to use ssl? (Y/n): \" mongoExpressSSL\n\nif [[ -z $appSSL ]]; then\n appSSL=\"y\"\nfi\nif [[ -z $apiSSL ]]; then\n apiSSL=\"y\"\nfi\nif [[ -z $mongoExpressSSL ]]; then\n mongoExpressSSL=\"y\"\nfi\n\nif [ $appSSL == \"y\" -o $apiSSL == \"y\" -o $mongoExpressSSL == \"y\" \\\n -o $appSSL == \"Y\" -o $apiSSL == \"Y\" -o $mongoExpressSSL == \"Y\" ]; then\n if [ ! -d $TRAVELER_CONFIG_DIR/ssl ]; then\n mkdir -p $TRAVELER_CONFIG_DIR/ssl\n fi\n\n echo -e \"\\nThe configuration for ssl will include files ssl/node.key and ssl/node.pem within the config folder\"\n read -p \"Would you like to run script to create self signed certificates for the configuration? (Y/n): \" createCerts\n if [[ -z $createCerts ]]; then\n createCerts=\"y\"\n fi\n SSL_BASE_NAME=`hostname -f`\n if [ $createCerts == 'y' -o $createCerts == 'Y' ]; then\n \t$MY_DIR/create_web_service_certificates.sh\n else\n \techo -e \"\\nThe certificate and private key should be placed in: \"\n \techo \"$TRAVELER_CONFIG_DIR/ssl/\"\n \techo \"Please enter the name of your crt and key file without extension (ex: node for node.crt and node.key) \"\n \tread -p \"What would you like to store the configured name of crt and key without extension [$SSL_BASE_NAME]: \" SSL_BASE_NAME\n if [[ -z $SSL_BASE_NAME ]]; then\n SSL_BASE_NAME=`hostname -f`\n fi\n fi\nfi\n\nif [ $mongoExpressSSL == \"y\" -o $mongoExpressSSL == \"Y\" ]; then\n mongoExpressConfigFile=$TRAVELER_INSTALL_ETC_DIR/mongo-express-configuration.sh\n cmd=\"cat $mongoExpressConfigFile | sed 's?#export MONGO_EXPRESS_SSL_ENABLED=.*?export MONGO_EXPRESS_SSL_ENABLED=true?g' > $mongoExpressConfigFile.2 && mv $mongoExpressConfigFile.2 $mongoExpressConfigFile\"\n eval $cmd\n cmd=\"cat $mongoExpressConfigFile | sed 's?#export MONGO_EXPRESS_SSL_CRT=.*?export MONGO_EXPRESS_SSL_CRT=$TRAVELER_CONFIG_DIR/ssl/$SSL_BASE_NAME.crt?g' > $mongoExpressConfigFile.2 && mv $mongoExpressConfigFile.2 $mongoExpressConfigFile\"\n eval $cmd\n cmd=\"cat $mongoExpressConfigFile | sed 's?#export MONGO_EXPRESS_SSL_KEY=.*?export MONGO_EXPRESS_SSL_KEY=$TRAVELER_CONFIG_DIR/ssl/$SSL_BASE_NAME.key?g' > $mongoExpressConfigFile.2 && mv $mongoExpressConfigFile.2 $mongoExpressConfigFile\"\n eval $cmd\nfi\n\nsource $mongoExpressConfigFile\nif [[ ! -f $MONGO_EXPRESS_DAEMON_PASSWD_FILE ]]; then\n read -s -p \"Please enter password for mongo-express to create passwd file for user $MONGO_EXPRESS_DAEMON_USERNAME [admin]: \" mongoExpressAdminPass\n if [[ -z $mongoExpressAdminPass ]]; then\n mongoExpressAdminPass=\"admin\"\n fi\n echo $mongoExpressAdminPass > $MONGO_EXPRESS_DAEMON_PASSWD_FILE\n chmod 400 $MONGO_EXPRESS_DAEMON_PASSWD_FILE\nfi\n\necho \"Creating configuration files: \"\n\n# Create configuration files\n\n# Prompt user for api information\nread -s -p \"Please enter the password for the api readOnly access (it will be stored in a configuration file) [readOnly]: \" apiReadPass\necho ''\nread -s -p \"[OPTIONAL] Please enter the password for the api write access (it will be stored in a configuration file): \" apiWritePass\necho ''\nread -p \"Please enter the port for the api [3443]: \" apiPort\n\nif [[ -z $apiReadPass ]]; then\n apiReadPass=\"readOnly\"\nfi\nif [[ -z $apiPort ]]; then\n apiPort=3443\nfi\n\n# API config file\napiJson=\"{\"\napiJson=\"$apiJson\\n \\\"api_users\\\": {\"\napiJson=\"$apiJson\\n \\\"api_read\\\": \\\"$apiReadPass\\\"\"\nif [ ! -z $apiWritePass ]; then\n apiJson=\"$apiJson,\\n \\\"api_write\\\": \\\"$apiWritePass\\\"\"\nfi\napiJson=\"$apiJson\\n },\"\napiJson=\"$apiJson\\n \\\"app_port\\\": \\\"$apiPort\\\"\"\nif [ $apiSSL = \"y\" ]; then\n apiJson=\"$apiJson,\\n \\\"ssl_key\\\": \\\"ssl/$SSL_BASE_NAME.key\\\",\"\n apiJson=\"$apiJson\\n \\\"ssl_cert\\\": \\\"ssl/$SSL_BASE_NAME.crt\\\"\"\nfi\n\napiJson=\"$apiJson\\n}\"\n\necho \"Configuration for the api has been generated\"\necho -e $apiJson\n\n# Prompt user for web application information\nread -p \"Plase enter the port for the web application [3001]: \" appPort\nread -p \"[OPTIONAL] Please enter the deployment name of this traveler instance: \" deploymentName\nif [[ -z $appPort ]]; then\n appPort=3001\nfi\n\n# APP config file\nappJson=\"{\"\nappJson=\"$appJson\\n \\\"app_port\\\": \\\"$appPort\\\"\"\nif [ $appSSL = \"y\" -o $appSSL = \"Y\" ]; then\n appJson=\"$appJson,\\n \\\"ssl_key\\\": \\\"ssl/$SSL_BASE_NAME.key\\\",\"\n appJson=\"$appJson\\n \\\"ssl_cert\\\": \\\"ssl/$SSL_BASE_NAME.crt\\\"\"\nfi\nif [ ! -z $deploymentName ]; then\n appJson=\"$appJson,\\n \\\"deployment_name\\\": \\\"$deploymentName\\\"\"\nfi\nappJson=\"$appJson\\n}\"\n\necho \"Configuration for the web application has been generated\"\necho -e $appJson\n\n# Place the configuration files in the config directory\ncd $TRAVELER_CONFIG_DIR\necho -e $apiJson > api.json\necho -e $appJson > app.json\n\nread -p \"Would you like to create a simple auth file configured for ldap type authentication? (Y/n): \" createAuth\n\nif [[ -z $createAuth ]]; then\n createAuth=\"y\"\nfi\n\nif [ $createAuth == \"y\" -o $createAuth == \"Y\" ]; then\n authJson=\"{\"\n authJson=\"$authJson\\n \\\"type\\\": \\\"ldap\\\",\"\n authJson=\"$authJson\\n \\\"service\\\": \\\"\\\"\"\n authJson=\"$authJson\\n}\"\n echo -e $authJson > auth.json\nelse\n\tif [ -f \"$TRAVELER_ROOT_DIR/config/auth_change.json\" ]; then\n\t\techo -e \"\\nThe auth confiuration includes authentication and proxy information\"\n\t\techo -e \"The default configuration will be copied\"\n\t\tcp \"$TRAVELER_ROOT_DIR/config/auth_change.json\" auth.json\n\tfi\nfi\n\n\nif [ -f \"$TRAVELER_ROOT_DIR/config/service_change.json\" ]; then\n echo -e \"\\nThe service configuration includes urls to external services such as devices or Component Database (CDB)\"\n echo -e \"A blank configuration will be created\"\n\techo \"{}\" > service.json\nfi\n\nif [ -f \"$TRAVELER_ROOT_DIR/config/ad_change.json\" ]; then\n echo -e \"\\nThe ad configuration includes ldap configuration\"\n echo -e \"The default configuration will be copied\"\n\tcp \"$TRAVELER_ROOT_DIR/config/ad_change.json\" ad.json\nfi\n\nif [ -f \"$TRAVELER_ROOT_DIR/config/ui_change.json\" ]; then\n echo -e \"\\nThe ui configuration includes web UI configuration\"\n echo -e \"The default configuration will be copied\"\n cp \"$TRAVELER_ROOT_DIR/config/ui_change.json\" ui.json\nfi\n\nif [ -f \"$TRAVELER_ROOT_DIR/config/alias_change.json\" ]; then\n echo -e \"\\nThe alias configuration includes group naming configuration\"\n echo -e \"The default configuration will be copied\"\n cp \"$TRAVELER_ROOT_DIR/config/alias_change.json\" alias.json\nfi\n\necho -e \"\\nAll of the traveler configuration is located in $TRAVELER_CONFIG_DIR\"\n\necho -e \"\\nNOTE: The app.json config file could also contain a list of top bar urls\"\necho \" Please see $TRAVELER_ROOT_DIR/config/app_change.json.\"\n\necho -e \"\\nPlease edit the following configuration files before starting the application:\"\necho \"\tad.json\"\nif ! [ $createAuth == \"y\" -o $createAuth == \"Y\" ]; then\n\techo \"\tauth.json\"\nfi\n\ncd $CUR_DIR\n"
},
{
"alpha_fraction": 0.5705426931381226,
"alphanum_fraction": 0.575531542301178,
"avg_line_length": 27.597333908081055,
"blob_id": "59d4ece8dc59f0485bd1aca909daabd4d17cbf0b",
"content_id": "55e086a9f74e4cc627707a16c8fb986c06689726",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 21448,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 750,
"path": "/routes/api.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*eslint max-nested-callbacks: [1, 4], complexity: [2, 20]*/\n\nvar fs = require('fs');\nvar mongoose = require('mongoose');\nvar basic = require('basic-auth');\nvar routesUtilities = require('../utilities/routes.js');\nvar _ = require('lodash');\nvar form = require('../model/form');\nvar reqUtils = require('../lib/req-utils');\nvar logger = require('../lib/loggers').getLogger();\nconst mqttUtilities = require('../utilities/mqtt.js');\nconst DataError = require('../lib/error').DataError;\n\nvar Form = mongoose.model('Form');\nvar ReleasedForm = mongoose.model('ReleasedForm');\nvar Traveler = mongoose.model('Traveler');\nvar Binder = mongoose.model('Binder');\nvar TravelerData = mongoose.model('TravelerData');\nvar TravelerNote = mongoose.model('TravelerNote');\nvar Log = mongoose.model('Log');\n\nvar WRITE_API_USER = 'api_write';\n\n/**\n * Checks if the api user who is logged in has write access.\n *\n * @param {Request} req - Request object\n * @param {Response} res - Response object\n * @param {function} next - Callback to be called when successful\n * @returns {*|ServerResponse} error when no permissions exist for writing\n */\nfunction checkWritePermissions(req, res, next) {\n var credentials = basic(req);\n if (credentials.name !== WRITE_API_USER) {\n return res.status(401).json({\n error: 'Write permissions are needed to create a form',\n });\n } else {\n next();\n }\n}\n\n/**\n * Performs error checking, displays proper message back to user returns the data resulted from the mongo query\n * When successful, responds to user with the data or performs callback.\n *\n * @param err - Error from the mongo query\n * @param data - Data resulting from the mongo query\n * @param res - Response object\n * @param successCB - Optional call back variable will be executed when specified.\n * @returns {*} Error object or data object. Nothing when callback is performed\n */\nfunction performMongoResponse(err, data, res, successCB) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n if (!data) {\n return res.status(410).send('gone');\n }\n if (successCB === undefined) {\n return res.status(200).json(data);\n } else {\n successCB();\n }\n}\n\n/**\n * Performs a search of parent entity and search of child entity. Displays any error messages if applicable.\n * When successful, responds to user with content entit(y/ies) referenced in the parent entity.\n *\n * @param parentEntity The parent entity object in which the content entity is referenced\n * @param parentEntityKey The key of the parent entity which references the content entity\n * @param contentEntity The entity for which is being requested that is referenced from parent entity\n * @param contentEntityKeys The keys that will be fetched from the db of the contnet entity\n * @param res Response object\n */\nfunction performFindEntityReferencedContentsByParentEntityId(\n parentEntity,\n parentEntityId,\n parentEntityKey,\n contentEntity,\n contentEntityKeys,\n res\n) {\n parentEntity.findById(parentEntityId, function(parentErr, parentObj) {\n performMongoResponse(parentErr, parentObj, res, function() {\n contentEntity\n .find(\n {\n _id: {\n $in: parentObj[parentEntityKey],\n },\n },\n contentEntityKeys\n )\n .lean()\n .exec(function(contentErr, contentObj) {\n performMongoResponse(contentErr, contentObj, res);\n });\n });\n });\n}\n\nmodule.exports = function(app) {\n app.get('/apis/travelers/', function(req, res) {\n var search = {\n archived: {\n $ne: true,\n },\n };\n if (req.query.hasOwnProperty('device')) {\n search.devices = {\n $in: [req.query.device],\n };\n }\n if (req.query.hasOwnProperty('formid')) {\n search['forms._id'] = {\n $in: [req.query.formid],\n };\n }\n if (req.query.hasOwnProperty('tag')) {\n search.tags = {\n $in: [req.query.tag],\n };\n }\n if (req.query.hasOwnProperty('userkey')) {\n search['mapping.' + req.query.userkey] = {\n $exists: true,\n };\n }\n Traveler.find(\n search,\n 'title status devices tags mapping createdBy clonedBy createdOn deadline updatedBy updatedOn sharedWith finishedInput totalInput'\n )\n .lean()\n .exec(function(err, travelers) {\n performMongoResponse(err, travelers, res);\n });\n });\n\n app.get('/apis/tags/travelers/', function(req, res) {\n var search = {\n archived: {\n $ne: true,\n },\n };\n if (req.query.hasOwnProperty('device')) {\n search.devices = {\n $in: [req.query.device],\n };\n }\n Traveler.find(search, 'tags')\n .lean()\n .exec(function(err, travelers) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n var output = [];\n travelers.forEach(function(t) {\n output = _.union(output, t.tags);\n });\n res.status(200).json(output);\n });\n });\n\n app.get('/apis/keys/travelers/', function(req, res) {\n var search = {\n archived: {\n $ne: true,\n },\n };\n if (req.query.hasOwnProperty('device')) {\n search.devices = {\n $in: [req.query.device],\n };\n }\n Traveler.find(search, 'mapping')\n .lean()\n .exec(function(err, travelers) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n var output = [];\n travelers.forEach(function(t) {\n output = _.union(output, _.keys(t.mapping));\n });\n res.status(200).json(output);\n });\n });\n\n app.get('/apis/forms/', function(req, res) {\n var search = {\n archived: {\n $ne: true,\n },\n };\n if (req.query.hasOwnProperty('tag')) {\n search.tags = {\n $in: [req.query.tag],\n };\n }\n if (req.query.hasOwnProperty('userkey')) {\n search['mapping.' + req.query.userkey] = {\n $exists: true,\n };\n }\n Form.find(search, function(err, forms) {\n performMongoResponse(err, forms, res);\n });\n });\n\n app.get('/apis/forms/:id/', function(req, res) {\n Form.findById(req.params.id, function(err, forms) {\n performMongoResponse(err, forms, res);\n });\n });\n\n app.get('/apis/forms/:id/released/', function(req, res) {\n ReleasedForm.find({ 'base._id': req.params.id }).exec(function(err, forms) {\n performMongoResponse(err, forms, res);\n });\n });\n\n app.get('/apis/releasedForms/', function(req, res) {\n ReleasedForm.find({}, function(err, releasedForms) {\n performMongoResponse(err, releasedForms, res);\n });\n });\n\n app.get('/apis/releasedForms/:id/', function(req, res) {\n ReleasedForm.findById(req.params.id, function(err, releasedForms) {\n performMongoResponse(err, releasedForms, res);\n });\n });\n\n app.get('/apis/binders/', function(req, res) {\n Binder.find({}, function(err, binders) {\n performMongoResponse(err, binders, res);\n });\n });\n\n app.get('/apis/binders/:id/', function(req, res) {\n Binder.findById(req.params.id, function(err, binder) {\n performMongoResponse(err, binder, res);\n });\n });\n\n app.post(\n '/apis/create/binders/',\n routesUtilities.filterBody(\n ['binderTitle', 'description', 'userName'],\n true\n ),\n checkWritePermissions,\n function(req, res) {\n var binderTitle = req.body.binderTitle;\n var userName = req.body.userName;\n var description = req.body.description;\n\n routesUtilities.binder.createBinder(\n binderTitle,\n description,\n userName,\n function(err, newBinder) {\n performMongoResponse(err, newBinder, res, function() {\n return res.status(201).json(newBinder);\n });\n }\n );\n }\n );\n\n app.post(\n '/apis/addWork/binders/:id/',\n routesUtilities.filterBody(['travelerIds', 'userName'], true),\n checkWritePermissions,\n function(req, res) {\n Binder.findById(req.params.id, function(err, binder) {\n performMongoResponse(err, binder, res, function() {\n var userName = req.body.userName;\n routesUtilities.binder.addWork(binder, userName, req, res);\n });\n });\n }\n );\n\n app.post(\n '/apis/removeWork/binders/:id/',\n routesUtilities.filterBody(['workId', 'userName'], true),\n checkWritePermissions,\n function(req, res) {\n Binder.findById(req.params.id, function(err, binder) {\n performMongoResponse(err, binder, res, function() {\n var userName = req.body.userName;\n var workId = req.body.workId;\n routesUtilities.binder.deleteWork(binder, workId, userName, req, res);\n });\n });\n }\n );\n\n app.get('/apis/travelers/:id/', function(req, res) {\n Traveler.findById(req.params.id, function(travelerErr, traveler) {\n performMongoResponse(travelerErr, traveler, res);\n });\n });\n\n app.put(\n '/apis/travelers/:id/status/',\n reqUtils.exist('id', Traveler),\n reqUtils.archived('id', false),\n checkWritePermissions,\n function(req, res) {\n var doc = req[req.params.id];\n\n if ([1, 1.5, 2, 3, 4].indexOf(req.body.status) === -1) {\n return res.status(400).send('invalid status');\n }\n\n if (doc.status === req.body.status) {\n return res.status(204).send();\n }\n\n var stateTransition = require('../model/traveler').stateTransition;\n\n var target = _.find(stateTransition, function(t) {\n return t.from === doc.status;\n });\n\n if (target.to.indexOf(req.body.status) === -1) {\n return res.status(400).send('invalid status change');\n }\n\n doc.status = req.body.status;\n // user id\n doc.updatedBy = req.body.userId;\n doc.updatedOn = Date.now();\n mqttUtilities.postTravelerStatusChangedMessage(doc);\n doc.save(function(saveErr, newDoc) {\n if (saveErr) {\n logger.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(200).json(newDoc);\n });\n }\n );\n\n app.post(\n '/apis/travelers/:id/data/',\n reqUtils.exist('id', Traveler),\n reqUtils.archived('id', false),\n reqUtils.status('id', [1]),\n checkWritePermissions,\n reqUtils.filter('body', ['name', 'value', 'type', 'userId']),\n reqUtils.hasAll('body', ['name', 'value', 'type']),\n reqUtils.sanitize('body', ['name', 'value', 'type', 'userId']),\n function(req, res) {\n var doc = req[req.params.id];\n var data = new TravelerData({\n traveler: doc._id,\n name: req.body.name,\n value: req.body.value,\n inputType: req.body.type,\n inputBy: req.body.userId,\n inputOn: Date.now(),\n });\n data.save(function(dataErr) {\n if (dataErr) {\n logger.error(dataErr.message);\n if (dataErr instanceof DataError) {\n return res.status(dataErr.status).send(dataErr.message);\n }\n return res.status(500).send(dataErr.message);\n }\n doc.updatedBy = req.body.userId;\n doc.updatedOn = Date.now();\n mqttUtilities.postTravelerDataChangedMessage(data);\n doc.data.push(data._id);\n // update the finished input number by reset\n routesUtilities.traveler.resetTouched(doc, function() {\n // save doc anyway\n doc.save(function(saveErr) {\n if (saveErr) {\n logger.error(saveErr);\n return res.status(500).send(saveErr.message);\n }\n return res.status(204).send();\n });\n });\n });\n }\n );\n\n /**\n * get the latest value for the given name from the data list\n * @param {String} name input name\n * @param {Array} data an array of TravelerData\n * @return {Number|String|null} the value for the given name\n */\n function dataForName(name, data) {\n if (!name) {\n return null;\n }\n if (_.isEmpty(data)) {\n return null;\n }\n\n var found = data.filter(function(d) {\n return d.name === name;\n });\n // get the latest value from history\n if (found.length) {\n found.sort(function(a, b) {\n if (a.inputOn > b.inputOn) {\n return -1;\n }\n return 1;\n });\n return found[0].value;\n }\n return null;\n }\n\n /**\n * retrieve the json representation of the traveler including the properties\n * in the give list, and the key-value's in the mapping\n * @param {Traveler} traveler the traveler mongoose object\n * @param {Array} props the list of properties to be included\n * @param {Function} cb callback function\n * @return {Object} the json representation\n */\n function retrieveKeyvalue(traveler, props, cb) {\n var output = {};\n props.forEach(function(p) {\n output[p] = traveler[p];\n });\n var mapping = traveler.mapping;\n TravelerData.find(\n {\n _id: {\n $in: traveler.data,\n },\n },\n 'name value inputOn inputType'\n ).exec(function(dataErr, docs) {\n if (dataErr) {\n return cb(dataErr);\n }\n var userDefined = {};\n _.mapKeys(mapping, function(name, key) {\n userDefined[key] = dataForName(name, docs);\n });\n output.user_defined = userDefined;\n return cb(null, output);\n });\n }\n\n /**\n * retrieve the json representation of the traveler including the properties\n * in the give list, and the {key, label, value}'s in the mapping\n * @param {Traveler} traveler the traveler mongoose object\n * @param {Array} props the list of properties to be included\n * @param {Function} cb callback function\n * @return {Object} the json representation\n */\n function retrieveKeyLabelValue(traveler, props, cb) {\n var output = {};\n props.forEach(function(p) {\n output[p] = traveler[p];\n });\n var mapping = traveler.mapping;\n var labels = traveler.labels;\n TravelerData.find(\n {\n _id: {\n $in: traveler.data,\n },\n },\n 'name value inputOn inputType'\n ).exec(function(dataErr, docs) {\n if (dataErr) {\n return cb(dataErr);\n }\n var userDefined = {};\n _.mapKeys(mapping, function(name, key) {\n userDefined[key] = {};\n userDefined[key].value = dataForName(name, docs);\n if (_.isObject(labels)) {\n userDefined[key].label = labels[name];\n }\n });\n output.user_defined = userDefined;\n return cb(null, output);\n });\n }\n\n app.get('/apis/travelers/:id/keyvalue/', function(req, res) {\n Traveler.findById(req.params.id, function(travelerErr, traveler) {\n retrieveKeyvalue(\n traveler,\n ['id', 'title', 'status', 'tags', 'devices'],\n function(err, output) {\n if (err) {\n return res.status(500).send(err.message);\n }\n return res.status(200).json(output);\n }\n );\n });\n });\n\n app.get('/apis/travelers/:id/keylabelvalue/', function(req, res) {\n Traveler.findById(req.params.id, function(travelerErr, traveler) {\n retrieveKeyLabelValue(\n traveler,\n ['id', 'title', 'status', 'tags', 'devices'],\n function(err, output) {\n if (err) {\n return res.status(500).send(err.message);\n }\n return res.status(200).json(output);\n }\n );\n });\n });\n\n app.get('/apis/travelers/:id/data/', function(req, res) {\n var travelerId = req.params.id;\n var travelerDataKeys = 'name value inputType inputBy inputOn';\n performFindEntityReferencedContentsByParentEntityId(\n Traveler,\n travelerId,\n 'data',\n TravelerData,\n travelerDataKeys,\n res\n );\n });\n\n app.get('/apis/travelers/:id/notes/', function(req, res) {\n var travelerId = req.params.id;\n var noteDataKeys = 'name value inputBy inputOn';\n performFindEntityReferencedContentsByParentEntityId(\n Traveler,\n travelerId,\n 'notes',\n TravelerNote,\n noteDataKeys,\n res\n );\n });\n\n function retrieveLogs(traveler, cb) {\n if (_.isEmpty(traveler.discrepancyLogs)) {\n return cb(null, []);\n }\n\n // retrieve all log data in one find\n Log.find(\n {\n _id: {\n $in: traveler.discrepancyLogs,\n },\n referenceForm: traveler.referenceDiscrepancyForm,\n },\n 'referenceForm records inputBy inputOn'\n ).exec(function(dataErr, logs) {\n if (dataErr) {\n logger.error(dataErr);\n return cb(dataErr);\n }\n return cb(null, logs);\n });\n }\n\n app.post(\n '/apis/archived/traveler/:id/',\n routesUtilities.filterBody(['archived'], true),\n checkWritePermissions,\n function(req, res) {\n var archivedStatus = req.body.archived;\n\n Traveler.findById(req.params.id, function(travelerErr, traveler) {\n performMongoResponse(travelerErr, traveler, res, function() {\n routesUtilities.traveler.changeArchivedState(\n traveler,\n archivedStatus\n );\n traveler.save(function(err) {\n performMongoResponse(err, traveler, res, function() {\n return res.status(200).json(traveler);\n });\n });\n });\n });\n }\n );\n\n app.get('/apis/travelers/:id/log/', reqUtils.exist('id', Traveler), function(\n req,\n res\n ) {\n let traveler = req[req.params.id];\n retrieveLogs(traveler, function(err, output) {\n if (err) {\n return res.status(500).send(err.message);\n }\n return res.status(200).json({\n discrepancyForm: traveler.discrepancyForms.id(\n traveler.activeDiscrepancyForm\n ),\n discrepancyLogs: output,\n });\n });\n });\n\n app.get('/apis/data/:id/', function(req, res) {\n TravelerData.findById(req.params.id)\n .lean()\n .exec(function(err, data) {\n performMongoResponse(err, data, res, function() {\n if (data.inputType === 'file') {\n fs.exists(data.file.path, function(exists) {\n if (exists) {\n return res.sendFile(data.file.path);\n }\n return res.status(410).send('gone');\n });\n } else {\n res.status(200).json(data);\n }\n });\n });\n });\n\n app.post(\n '/apis/create/form/',\n routesUtilities.filterBody(['formName', 'userName', 'html'], true),\n checkWritePermissions,\n function(req, res) {\n var formName = req.body.formName;\n var userName = req.body.userName;\n var html = req.body.html;\n var formType = req.body.formType;\n form.createForm(\n {\n title: formName,\n createdBy: userName,\n html: html,\n formType: formType,\n },\n function(err, newForm) {\n performMongoResponse(err, newForm, res, function() {\n return res.status(201).json(newForm);\n });\n }\n );\n }\n );\n\n app.post(\n '/apis/update/traveler/:id/',\n routesUtilities.filterBodyWithOptional(\n ['userName', 'title', 'description', 'deadline', 'status'],\n true,\n ['devices']\n ),\n checkWritePermissions,\n function(req, res) {\n try {\n var status = parseFloat(req.body.status);\n } catch (ex) {\n return res.status(400).json({\n error: 'Status provided was of invalid type. Expected: Float.',\n });\n }\n\n Traveler.findById(req.params.id, function(travelerErr, traveler) {\n performMongoResponse(travelerErr, traveler, res, function() {\n routesUtilities.traveler.updateTravelerStatus(\n req,\n res,\n traveler,\n status,\n false,\n function() {\n var deadline = req.body.deadline;\n if (deadline === '') {\n traveler.deadline = undefined;\n } else {\n traveler.deadline = deadline;\n }\n traveler.title = req.body.title;\n traveler.description = req.body.description;\n traveler.updatedBy = req.body.userName;\n traveler.updatedOn = Date.now();\n if (req.body.devices) {\n traveler.devices = req.body.devices;\n }\n\n traveler.save(function(err) {\n performMongoResponse(err, traveler, res, function() {\n return res.status(200).json(traveler);\n });\n });\n }\n );\n });\n });\n }\n );\n\n app.post(\n '/apis/create/traveler/',\n routesUtilities.filterBody(\n ['formId', 'title', 'userName', 'devices'],\n true\n ),\n checkWritePermissions,\n function(req, res) {\n ReleasedForm.findById(req.body.formId, function(formErr, form) {\n performMongoResponse(formErr, form, res, function() {\n var title = req.body.title;\n var userName = req.body.userName;\n var devices = req.body.devices;\n routesUtilities.traveler.createTraveler(\n form,\n title,\n userName,\n devices,\n function(newTravelerErr, newTraveler) {\n performMongoResponse(\n newTravelerErr,\n newTraveler,\n res,\n function() {\n return res.status(201).json(newTraveler);\n }\n );\n }\n );\n });\n });\n }\n );\n};\n"
},
{
"alpha_fraction": 0.7992376089096069,
"alphanum_fraction": 0.7992376089096069,
"avg_line_length": 42.72222137451172,
"blob_id": "3111cb0bb087955e7e356249b114a3bd4fde0b6c",
"content_id": "a567d833fd718c52ff42ace718e3926f61b6745c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 1574,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 36,
"path": "/views/docs/template/lifecycle.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### States and life cycle of a template\n\nThe following diagram shows the state transition of a template and a released\ntemplate.\n\n<figure align=\"center\">\n<img src=\"../images/template-life.png\" alt=\"template life cycle\">\n<figcaption>\nStates and life cycle of templates\n</figcaption>\n</figure>\n\nThere are two groups of templates: draft and released. Only a released template\ncan be used to create a traveler. The traveler application supports the review\nand approval process of templates.\n\nA template is a draft and editable when created. When a draft template is not\nneeded any more, the owner can archive it. The owner can clone an archived\ntemplate to generate a new draft template if some work needs to be picked up\nlater.\n\nWhen a draft template is ready for review, its owner can request one or more\nreviewers to check if the template is good to release. A reviewer can either\napprove or request for change. When any reviewer requests a change, the review\nprocess ends and the form becomes editable. All the reviewers must approve\nbefore a template can be released.\n\nWhen a user releases a template after a successful review process, a new\nreleased template is created. The user can choose to archive previously released\ntemplates from the same draft template of different versions. If the draft\ntemplate is a normal template, the user can choose to attach a released\ndiscrepancy template with it.\n\nA released template can be archived. Travelers can be created from an archived\nreleased template. This happens when the process is obsoleted or a new process\nis available.\n"
},
{
"alpha_fraction": 0.7134004831314087,
"alphanum_fraction": 0.7134004831314087,
"avg_line_length": 31.274999618530273,
"blob_id": "bd310c728ce46cacc9e13c92a0db24bc0b2b3bc8",
"content_id": "501b485adf5ee05380040f635166ed3fdd2c3ddc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1291,
"license_type": "permissive",
"max_line_length": 412,
"num_lines": 40,
"path": "/model/README.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "# Models\n\nThere are two types of models, those for entities, and others for attachable features of entities.\n\n## Entity models\n\n### form\n\nThe forms are the templates on the basis of which the released forms are created. There are two type of forms, normal and discrepancy. The discrepancy forms are only for collection of discrepancy data.\n\nState transition of form\n\narchived <-------------------------------\\\n ^ | |\ndraft ----> submitted for review ----> closed\n^-----------------|\n\n### released form\n\nThe released forms are the forms that have been approved for release, and therefore can be used to create travelers. A released form has two components, the base form and an optional discrepancy form. There are three possible combinations of base and discrepancy: base only, discrepancy only, base plus discrepancy. Note that only previously released discrepancy forms can be used to create a base + discrepancy.\n\n### traveler\n\n### binder\n\n### user\n\n## Attachable feature models\n\n## share\n\n## history\n\n## review\n\nAn approval model represents the request and the result of a reviewing process. It contains\n\n- policy: all | majority | any\n- requested reviewers: admin or reviewer role required\n- review results: approval or not, optional review comments\n"
},
{
"alpha_fraction": 0.6151173114776611,
"alphanum_fraction": 0.6715899109840393,
"avg_line_length": 29.289474487304688,
"blob_id": "84d3fbd0ca21142f80f359c0f9a0e8766329156b",
"content_id": "910bc300fbbf25a3eb0d5d90bf1fa817230c2d0e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1151,
"license_type": "permissive",
"max_line_length": 355,
"num_lines": 38,
"path": "/views/docs/api/data.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Data collected in a traveler\n\n- Method: GET\n- URL: https://hostname:port/apis/travelers/:id/data/\n where :id is the id of the traveler whose data is retrieved\n- Sample response:\n\n```json\n[\n {\n \"name\": \"2f067ecd\",\n \"value\": true,\n \"inputType\": \"checkbox\",\n \"inputBy\": \"liud\",\n \"inputOn\": \"2014-07-08T13:48:37.972Z\",\n \"_id\": \"53bbf6b52ace2f7f111d76ca\"\n },\n {\n \"name\": \"d134f3cd\",\n \"value\": \"something\",\n \"inputType\": \"textarea\",\n \"inputBy\": \"liud\",\n \"inputOn\": \"2014-07-08T13:49:01.784Z\",\n \"_id\": \"53bbf6cd2ace2f7f111d76cb\"\n },\n ...\n]\n```\n\nEach data item in the list contains the input name in the form, the input type and the value. Besides, it also records who input the value at what time, by which the input history can be generated. For file input, the value is the file's original name when it was uploaded. In order to retrieve the content of the file, the following file API can be used.\n\n#### File uploaded in a traveler\n\nFiles are special data collected, and they can be retrieved by\n\n- Method: GET\n- URL: https://hostname:port/apis/data/:id/\n where :id is the id of the data whose type is file.\n"
},
{
"alpha_fraction": 0.7269514799118042,
"alphanum_fraction": 0.7340186238288879,
"avg_line_length": 37.432098388671875,
"blob_id": "85a9b3a96e8c3fc2ca74328d2274bd7b900509e9",
"content_id": "606f19bf4935033d2060981f81b8198af875b676",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3113,
"license_type": "permissive",
"max_line_length": 195,
"num_lines": 81,
"path": "/sbin/configure_mongo_dev.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\n\nsource $MY_DIR/configuration.sh\nsource $MY_DIR/configure_paths.sh\n\n# import local traveler-mongo settings\nsource $TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\n\n# Check to see that mongo is installed\nif [ ! -f $MONGO_BIN_DIRECTORY/mongo ]; then\n echo \"MongoDB was not found in the local directory: $MONGO_BIN_DIRECTORY\"\n echo \"please run 'make support' from $TRAVELER_ROOT_DIR directory\"\n exit 1\nfi\n\n# Check to make sure there is nothing in the mongo directory yet\nif [ \"$(ls -A \"$MONGO_DATA_DIRECTORY\")\" ]; then\n >&2 echo \"Aborting: MongoDB has data in the data directory: $MONGO_DATA_DIRECTORY\"\n exit 1\nfi\n\nread -p \"What port would you like mongodb to run on? [27017]: \" mongoPort\nif [[ -z $mongoPort ]]; then\n mongoPort=27017\nfi\nif [ ! -z $mongoPort ]; then\n mongoConfigurationFile=$TRAVELER_INSTALL_ETC_DIR/mongo-configuration.sh\n cmd=\"cat $mongoConfigurationFile | sed 's?export MONGO_SERVER_PORT=.*?export MONGO_SERVER_PORT=$mongoPort?g' > $mongoConfigurationFile.2 && mv $mongoConfigurationFile.2 $mongoConfigurationFile\"\n eval $cmd\n export MONGO_SERVER_PORT=$mongoPort\nfi\n\n# Start mongodb server\n$TRAVELER_ETC_INIT_DIRECTORY/traveler-mongodb startNoAuth\n\n# Get password for the users that will be created\necho \"Admin password will be stored in a passwd file: $MONGO_ADMIN_PASSWD_FILE\"\nread -s -p \"Enter admin password for mongodb(it will be stored in a config file) [admin]: \" adminPass\necho ''\nread -s -p \"Enter traveler db password for mongodb(it will be stored in a config file) [traveler]: \" travelerPass\necho ''\n\nif [[ -z $adminPass ]]; then\n adminPass=\"admin\"\nfi\nif [[ -z $travelerPass ]]; then\n travelerPass=\"traveler\"\nfi\n\necho $adminPass > $MONGO_ADMIN_PASSWD_FILE\nchmod 400 $MONGO_ADMIN_PASSWD_FILE\necho $travelerPass > $MONGO_TRAVELER_PASSWD_FILE\nchmod 400 $MONGO_TRAVELER_PASSWD_FILE\n\ncommandjs=\"use admin;\"\ncommandjs=\"$commandjs \\n db.createUser({ user: \\\"$MONGO_ADMIN_USERNAME\\\", pwd: \\\"$adminPass\\\", roles: [ \\\"root\\\" ] } )\"\ncommandjs=\"$commandjs \\n use $MONGO_TRAVELER_DB;\"\ncommandjs=\"$commandjs \\n db.createUser( { user: \\\"$MONGO_TRAVELER_USERNAME\\\", pwd: \\\"$travelerPass\\\", roles: [ { role: \\\"readWrite\\\", db: \\\"$MONGO_TRAVELER_DB\\\" } ] } )\"\n\necho -e $commandjs | $MONGO_BIN_DIRECTORY/mongo --port $MONGO_SERVER_PORT\n\n$TRAVELER_ETC_INIT_DIRECTORY/traveler-mongodb stop\n\n# Create a JSON database configuration file\ntravelerMongoConfig=\"{\"\ntravelerMongoConfig=\"$travelerMongoConfig \\n \\\"server_address\\\": \\\"$MONGO_SERVER_ADDRESS\\\",\"\ntravelerMongoConfig=\"$travelerMongoConfig \\n \\\"server_port\\\": \\\"$MONGO_SERVER_PORT\\\",\"\ntravelerMongoConfig=\"$travelerMongoConfig \\n \\\"traveler_db\\\": \\\"$MONGO_TRAVELER_DB\\\",\"\ntravelerMongoConfig=\"$travelerMongoConfig \\n \\\"username\\\": \\\"$MONGO_TRAVELER_USERNAME\\\",\"\ntravelerMongoConfig=\"$travelerMongoConfig \\n \\\"password\\\": \\\"$travelerPass\\\"\"\ntravelerMongoConfig=\"$travelerMongoConfig \\n}\"\n\necho \"Configuration for mongoDB has been generated\"\necho -e $travelerMongoConfig\n\n\n# Place the configuration files in the config directory\ncd $TRAVELER_CONFIG_DIR\necho -e $travelerMongoConfig > mongo.json\n"
},
{
"alpha_fraction": 0.6402438879013062,
"alphanum_fraction": 0.6539633870124817,
"avg_line_length": 27.521739959716797,
"blob_id": "feb8ea9f52c921587ecb507cfa9229e260cba722",
"content_id": "87c0631ca099ae6200a57ab8c7a881c37b6f06ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 656,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 23,
"path": "/tools/openapi/setup.py",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDEV NOTE: To publish API\n# Update version in this file\npython3 setup.py sdist\ntwine upload dist/(specific version file)\n\"\"\"\n\nfrom setuptools import setup\nfrom setuptools import find_packages\n\nsetup(name='Traveler-API',\n version='1.5.5',\n packages=find_packages(),\n py_modules=[\"traveler_api_factory\"],\n install_requires=['python-dateutil',\n 'urllib3',\n 'six'],\n license='Copyright (c) 2015 Dong Liu, Dariusz Jarosz',\n description='Python APIs used to communicate with traveler API.',\n maintainer='Dariusz Jarosz',\n maintainer_email='[email protected]',\n url='https://github.com/AdvancedPhotonSource/traveler'\n )\n"
},
{
"alpha_fraction": 0.7821393609046936,
"alphanum_fraction": 0.7821393609046936,
"avg_line_length": 55.61111068725586,
"blob_id": "c9aca3e408e4c1598c9cf785a1d1c2a137b57537",
"content_id": "225534be226da2648480825ee9b9837fc2260c09",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 1019,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 18,
"path": "/views/docs/template/version-control.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Template version control\n\nWhen a watched property of a template is updated on the server (the user clicks\nthe save button), the template version will be incremented. The watched\nproperties include the title, description, and HTML. The template viewer or\nbuilder always renders the latest version when refreshed.\n\nThe user can view the versions with HTML changes by clicking the\n<a data-toggle=\"tooltip\" title=\"Check and switch versions\" class=\"btn btn-primary\">Version\ncontrol</a> button. The user can choose any two versions to compare them side by\nside. Note that not all the details of template HTML are viewable when rendered,\ne.g. the input validation rules like min and max value of a number. The user can\n\"revert\" the template to an old version by clicking the\n<button data-toggle=\"tooltip\" title=\"Create a new version\" class=\"btn btn-primary use\">Use</button>\nbutton. In order to record the change, a new version is created for the\ntemplate.\n\n<img src=\"../images/version-control.png\" alt=\"version control\">\n"
},
{
"alpha_fraction": 0.628227174282074,
"alphanum_fraction": 0.6385542154312134,
"avg_line_length": 25.409090042114258,
"blob_id": "a5081debe391e2be404bc29d072f0b347bca6b23",
"content_id": "074afe570017b38543035f0ac2602d0074e19598",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 581,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 22,
"path": "/routes/ldaplogin.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/**\n * Created by djarosz on 10/13/15.\n */\nvar config = require('../config/config.js');\nvar auth = require('../lib/auth');\nvar routesUtilities = require('../utilities/routes.js');\n\nmodule.exports = function(app) {\n app.get('/ldaplogin/', function(req, res) {\n res.render('ldaplogin', routesUtilities.getRenderObject(req));\n });\n\n app.post('/ldaplogin/', auth.ensureAuthenticated, function(req, res) {\n res.render(\n 'ldaplogin',\n routesUtilities.getRenderObject(req, {\n errorMessage: res.locals.error,\n })\n );\n delete res.locals.error;\n });\n};\n"
},
{
"alpha_fraction": 0.7696675062179565,
"alphanum_fraction": 0.7696675062179565,
"avg_line_length": 46.42307662963867,
"blob_id": "ebfecdfa38112a564d5b967f91b44da0b1ab81ef",
"content_id": "b0fc8ce916381210616b3a800e7ce0432faa30bf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1233,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 26,
"path": "/views/docs/traveler/update-status.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Update a traveler's status\n\n**Audience: traveler owner and other users with write permission**\n\nA traveler's possible statuses and allowed transitions among statuses are\ndescribed in the [traveler status](#traveler-status) section.\n\nThe user can change an initial traveler's status to **active** by clicking on\nthe <button id=\"work\" class=\"btn btn-primary\">Start to work</button> button when\nthe traveler is ready to accept data.\n\nThe user can change an active traveler to **submitted for completion** by\nclicking on the <button id=\"complete\" class=\"btn btn-primary\">Submit for\ncompletion</button> button on the traveler page.\n\nThe user can change a submitted traveler to **complete** by clicking on the\n<button id=\"approve\" class=\"btn btn-primary\">Approve completion</button> button\nwhen the work is complete. If the work is not complete, click on the\n<button id=\"more\" class=\"btn btn-warning\">More work</button> button to reject\nthe submission.\n\nThe user can change an active traveler to **frozen** by clicking on the\n<button id=\"freeze\" class=\"btn btn-warning\">Freeze</button> button in order to\nstop accepting data in the traveler. Click the\n<button id=\"resume\" class=\"btn btn-primary\">Resume</button> button to resume\nwork.\n"
},
{
"alpha_fraction": 0.5585314035415649,
"alphanum_fraction": 0.5630932450294495,
"avg_line_length": 26.18199920654297,
"blob_id": "0839c0738cfdc9d1afbe8ec2c9c12ab4e7a67e4a",
"content_id": "8a8fa9d4bae7a190a979abb56fcb1aba7ca88c85",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 13591,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 500,
"path": "/lib/auth.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "// authentication and authorization functions\nvar url = require('url');\nvar mongoose = require('mongoose');\nvar ldapClient = require('../lib/ldap-client');\nvar _ = require('lodash');\n\nconst debug = require('debug')('traveler:auth');\nconst util = require('util');\n\n// Import configuration files\nvar config = require('../config/config.js');\nvar configPath = config.configPath;\n\nvar ad = config.ad;\nvar auth = config.auth;\nvar alias = config.alias;\n\nvar apiUsers = config.api.api_users;\n\n// Create CAS client\nvar Client = null;\nif (auth.type === 'cas') {\n Client = require('cas.js');\n // validation of ticket is with the lan, and therefore url does not need to be proxied.\n var cas = new Client({\n base_url: auth.cas,\n service: auth.login_service,\n version: 1.0,\n });\n} else if (auth.type === 'ldap' || auth.type === 'ldapWithDnLookup') {\n var ldapLoginService = '/ldaplogin/';\n var ldapLookup = auth.type === 'ldapWithDnLookup';\n var clientOptions = {\n url: ad.url,\n maxConnections: 5,\n connectTimeout: 10 * 1000,\n timeout: 15 * 1000,\n };\n if (ad.ldapsCA !== undefined) {\n var fs = require('fs');\n clientOptions.tlsOptions = {\n ca: fs.readFileSync(configPath + '/' + ad.ldapsCA),\n rejectUnauthorized: ad.ldapsRejectUnauthorized,\n };\n }\n}\n\nvar User = mongoose.model('User');\nvar Group = mongoose.model('Group');\n\nfunction proxied(req, res, next) {\n if (\n req.get('x-forwarded-host') &&\n req.get('x-forwarded-host') === auth.proxy\n ) {\n req.proxied = true;\n req.proxied_prefix = url.parse(auth.proxied_service).pathname;\n }\n next();\n}\n\nfunction cn(s) {\n var first = s.split(',', 1)[0];\n return first.substr(3).toLowerCase();\n}\n\nfunction filterGroup(a) {\n var output = [];\n var i;\n var group;\n for (i = 0; i < a.length; i += 1) {\n group = cn(a[i]);\n if (group.indexOf('lab.frib') === 0) {\n output.push(group);\n if (alias.hasOwnProperty(group) && output.indexOf(alias[group]) === -1) {\n output.push(alias[group]);\n }\n }\n }\n return output;\n}\n\nfunction ensureAuthenticated(req, res, next) {\n debug(util.inspect(req.session));\n if (auth.type === 'cas') {\n return casEnsureAuthenticated(req, res, next);\n } else if (auth.type.startsWith('ldap')) {\n return ldapEnsureAuthenticated(req, res, next);\n }\n}\n\nfunction ldapEnsureAuthenticated(req, res, next) {\n if (req.session.userid) {\n //logged in already\n debug('user already logged in');\n return next();\n } else if (req.originalUrl !== ldapLoginService) {\n //Not on the login page currently so redirect user to login page\n return redirectToLoginService(req, res);\n } else {\n //POST method once the user submits the login form.\n console.log('perform authentication');\n //Perform authentication\n var username = req.body.username;\n username = username.toLowerCase();\n var password = req.body.password;\n\n var baseDN = ad.searchBase;\n if (ldapLookup) {\n ldapClient.searchForUser(username, function(err, ldapUser) {\n if (err !== null) {\n console.log(err.message);\n res.locals.error = 'Invalid username or password was provided.';\n return next();\n } else {\n return authenticateUsingLdap(\n ldapUser.dn,\n username,\n password,\n req,\n res,\n next\n );\n }\n });\n } else {\n var bindDN = 'uid=' + username + ',' + baseDN;\n return authenticateUsingLdap(bindDN, username, password, req, res, next);\n }\n }\n}\n\nfunction authenticateUsingLdap(bindDN, username, password, req, res, next) {\n ldapClient.getClient(clientOptions, function(localLdapClient, cleanUp) {\n localLdapClient.bind(bindDN, password, function(err) {\n cleanUp();\n if (err === null) {\n authenticationSucceeded(username, req, res);\n } else {\n var error = '';\n //Do not notify the user if the username is valid\n if (\n err.name === 'NoSuchObjectError' ||\n err.name === 'InvalidCredentialsError'\n ) {\n error = 'Invalid username or password was provided.';\n } else {\n error = err.name;\n }\n res.locals.error = error;\n next();\n }\n });\n });\n}\n\nfunction authenticationSucceeded(username, req, res) {\n getCurrentUser(username, req, res, function() {\n req.session.userid = username;\n if (req.session.landing === undefined) {\n redirectService(res, req, '/');\n } else {\n var landing = req.session.landing;\n req.session.landing = undefined;\n redirectService(res, req, landing);\n }\n });\n}\n\nfunction casEnsureAuthenticated(req, res, next) {\n // console.log(req.session);\n var ticketUrl = url.parse(req.url, true);\n if (req.session.userid) {\n // logged in already\n if (req.query.ticket) {\n // remove the ticket query param\n delete ticketUrl.query.ticket;\n return res.redirect(\n 301,\n url.format({\n pathname: req.proxied\n ? url.resolve(auth.proxied_service + '/', '.' + ticketUrl.pathname)\n : ticketUrl.pathname,\n query: ticketUrl.query,\n })\n );\n }\n next();\n } else if (req.query.ticket) {\n // just kicked back by CAS\n // var halt = pause(req);\n if (req.proxied) {\n cas.service = auth.login_proxied_service;\n } else {\n cas.service = auth.login_service;\n }\n\n var cas_hostname = cas.hostname.split(':');\n if (cas_hostname.length === 2) {\n cas.hostname = cas_hostname[0];\n cas.port = cas_hostname[1];\n }\n\n // validate the ticket\n cas.validate(req.query.ticket, function(err, casresponse, result) {\n if (err) {\n console.error(err.message);\n return res.status(401).send(err.message);\n }\n if (result.validated) {\n var userid = result.username;\n // set userid in session\n req.session.userid = userid;\n\n getCurrentUser(userid, req, res, function() {\n if (req.session.landing && req.session.landing !== '/login') {\n res.redirect(\n req.proxied\n ? url.resolve(\n auth.proxied_service + '/',\n '.' + req.session.landing\n )\n : req.session.landing\n );\n } else {\n // has a ticket but not landed before, must copy the ticket from somewhere ...\n res.redirect(req.proxied ? auth.proxied_service : '/');\n }\n // halt.resume();\n });\n } else {\n console.error('CAS reject this ticket');\n return res.redirect(\n req.proxied ? auth.login_proxied_service : auth.login_service\n );\n }\n });\n } else {\n redirectToLoginService(req, res);\n }\n}\n\nfunction redirectToLoginService(req, res) {\n if (auth.type === 'cas') {\n // if this is ajax call, then send 401 without redirect\n if (req.xhr) {\n // TODO: might need to properly set the WWW-Authenticate header\n res.set(\n 'WWW-Authenticate',\n 'CAS realm=\"' +\n (req.proxied ? auth.proxied_service : auth.service) +\n '\"'\n );\n res.status(401).send('xhr cannot be authenticated');\n } else {\n // set the landing, the first unauthenticated url\n req.session.landing = req.url;\n if (req.proxied) {\n res.redirect(\n auth.proxied_cas +\n '/login?service=' +\n encodeURIComponent(auth.login_proxied_service)\n );\n } else {\n res.redirect(\n auth.cas + '/login?service=' + encodeURIComponent(auth.login_service)\n );\n }\n }\n } else if (auth.type.startsWith('ldap')) {\n //ldap\n if (req.xhr) {\n res.status(401).send('xhr cannot be authenticated');\n } else {\n req.session.landing = req.originalUrl;\n redirectService(res, req, ldapLoginService);\n }\n }\n}\n\nfunction redirectService(res, req, destination) {\n if (req.proxied) {\n res.redirect(auth.proxied_service + destination);\n } else {\n res.redirect(auth.service + destination);\n }\n}\n\nfunction getCurrentUser(userid, req, res, cb) {\n userid = userid.toLowerCase();\n // query ad about other attribute\n ldapClient.searchForUser(userid, function(err, result) {\n if (err) {\n if (err instanceof Error) {\n console.error(err.name + ' : ' + err.message);\n return res.status(500).send('something wrong with ad');\n } else {\n return res.status(500).send(err);\n }\n }\n\n // set username and memberof in session\n req.session.username = result.displayName;\n\n if (ad.groupSearchBase === undefined) {\n // Find all locally-stored groups with this user as a member\n Group.find({\"members\": userid}, function(err, result) {\n if (err) {\n req.session.memberOf = [];\n return;\n }\n\n let groups = [];\n result.forEach(function(g) {\n groups.push(g.id);\n });\n req.session.memberOf = groups;\n });\n } else if (result.memberOf) {\n if (result.memberOf instanceof Array) {\n req.session.memberOf = filterGroup(result.memberOf);\n } else {\n req.session.memberOf = [result.memberOf];\n }\n } else {\n req.session.memberOf = [];\n }\n\n // load others from db\n User.findOne({\n _id: userid,\n }).exec(function(err, user) {\n if (err) {\n console.error(err.message);\n }\n if (user) {\n req.session.roles = user.roles;\n // update user last visited on\n User.findByIdAndUpdate(\n user._id,\n {\n lastVisitedOn: Date.now(),\n },\n function(err) {\n if (err) {\n console.error(err.message);\n }\n }\n );\n } else {\n // create a new user\n // TODO: need to load the user properties using ad.objAttributes\n var default_roles = [];\n if (auth.default_roles !== undefined) {\n default_roles = auth.default_roles;\n }\n req.session.roles = default_roles;\n\n var first = new User({\n _id: userid,\n name: result.displayName,\n email: result.mail,\n office: result.physicalDeliveryOfficeName,\n phone: result.telephoneNumber.toString(),\n mobile: result.mobile,\n roles: default_roles,\n lastVisitedOn: Date.now(),\n });\n\n // Check if current group exists\n if (ad.groupSearchBase === undefined) {\n //Try using user info to add a new group if needed.\n Group.findOne({\n name: result.memberOf,\n })\n .lean()\n .exec(function(err, group) {\n if (err) {\n console.error(err.msg);\n } else if (group === undefined) {\n var newGroup = new Group({\n _id: [result.memberOf],\n name: result.memberOf,\n forms: [],\n travelers: [],\n });\n\n newGroup.save(function(err, createdGroup) {\n if (err) {\n console.error(err.msg);\n } else {\n console.info('A new group created: ' + createdGroup.name);\n }\n });\n }\n });\n }\n\n first.save(function(err, newUser) {\n if (err) {\n console.error(err);\n console.error(newUser.toJSON());\n return res\n .status(500)\n .send('Cannot log in. Please contact the admin. Thanks.');\n }\n console.info('A new user created : ' + newUser.name);\n });\n }\n cb();\n });\n });\n}\n\nfunction sessionLocals(req, res, next) {\n res.locals = {\n session: req.session,\n prefix: req.proxied ? req.proxied_prefix : '',\n };\n next();\n}\n\nfunction checkAuth(req, res, next) {\n if (req.query.ticket) {\n ensureAuthenticated(req, res, next);\n } else {\n next();\n }\n}\n\n/**\n * check if the user has any of the roles\n * if true next\n * else reject\n *\n * @param {...String} roles\n * @return Function|null\n */\nfunction verifyRole(...roles) {\n return function(req, res, next) {\n if (roles.length === 0) {\n return next();\n }\n var i;\n if (req.session.roles) {\n for (i = 0; i < roles.length; i += 1) {\n if (req.session.roles.indexOf(roles[i]) > -1) {\n return next();\n }\n }\n res.status(403).send('You are not authorized to access this resource. ');\n } else {\n console.log('Cannot identify your roles.');\n res.status(500).send('something wrong with your session');\n }\n };\n}\n\nfunction requireRoles(condition, ...roles) {\n return function(req, res, next) {\n let pre = true;\n if (_.isFunction(condition)) {\n pre = condition(req, res);\n }\n if (!pre) {\n return next();\n }\n return verifyRole(...roles)(req, res, next);\n };\n}\n\nvar basic = require('basic-auth');\n\nfunction notKnown(cred) {\n if (apiUsers.hasOwnProperty(cred.name)) {\n if (apiUsers[cred.name] === cred.pass) {\n return false;\n }\n }\n return true;\n}\n\nfunction basicAuth(req, res, next) {\n var cred = basic(req);\n if (!cred || notKnown(cred)) {\n res.set('WWW-Authenticate', 'Basic realm=\"api\"');\n return res.status(401).send();\n }\n next();\n}\n\nmodule.exports = {\n ensureAuthenticated: ensureAuthenticated,\n verifyRole: verifyRole,\n requireRoles: requireRoles,\n checkAuth: checkAuth,\n sessionLocals: sessionLocals,\n basicAuth: basicAuth,\n proxied: proxied,\n};\n"
},
{
"alpha_fraction": 0.7513635158538818,
"alphanum_fraction": 0.7526677846908569,
"avg_line_length": 51.061729431152344,
"blob_id": "07468afb3cc29957e9b64ec8d1446da23331a27a",
"content_id": "857d8d0cdcadb3f2c78f31de5a3f6c3c33286d92",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 8434,
"license_type": "permissive",
"max_line_length": 211,
"num_lines": 162,
"path": "/views/docs/template/builder.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Template builder\n\nThe template builder is a what-you-see-is-what-you-get editor. It is the\nstarting point to use the traveler application for most users.\n\n#### Template type\n\nLog in the traveler application, and navigate to the <a href=\"/forms/\">Forms or\nTemplates</a> page. Then click the <a id=\"new\" href=\"/forms/new\" target=\"_blank\"\ndata-toggle=\"tooltip\" title=\"create new empty forms\" class=\"btn btn-primary\"><i\nclass=\"fa fa-file-o fa-lg\"></i> New form</a> button.\n\nA new page will load the following page.\n\n<figure align=\"center\">\n<img src=\"../images/template-type.png\" alt=\"new template page\" style=\"width:50%\">\n<figcaption>\nNew template\n</figcaption>\n</figure>\n\nThe user needs to set the new template's name, and choose the type. The default\ntype is [normal](#normal). The [discrepancy](#discrepancy) type is for QA\nprocess in order to check the discrepancy of a work. Click <button\nclass=\"btn btn-primary\">Confirm</button> to go to next step. Always start with\nthe normal type for your first try.\n\n#### Template components\n\nA new template has no inputs inside. The user can add new components, update the\nattributes of an existing component, duplicate a component, and adjust the\nlocation of a component.\n\n##### Basic input components\n\nThe template builder support 8 basic inputs types:\n\n<!-- prettier-ignore -->\n| input name | usage | properties |\n| ----------- | ----------- | ----------- |\n| Checkbox | specify a boolean value, true or false | Label, User defined key, Text, Required |\n| Radio | choose one out of multiple available options | Label, User defined key, Text, Required, Radio button value |\n| Text | a single line text to record | Label, User defined key, Placeholder, Required, Help |\n| Figure | not a user input, a visual instruction for traveler user | Select an image, Image alternate text, Width, Figure caption |\n| Paragraph | multiple line text to record | Label, User defined key, Placeholder, Row Required, Help |\n| Number | either an integer or a float value | Label, User defined key, Placeholder, Help, Min, Max, Required |\n| Upload file | use upload file | Label, User defined key, Help, Required |\n| Other types | Text/Number/Date/Date Time/Email/Phone number/Time/URL HTML5 input types with validation support | Label, User defined key, Placeholder, Help, Required |\n\n<br>\nEach input is specified by a list of properties. Some properties control the input\npresentation, and some control its behavior, and some are for internal traveler\napplication. The details of the input properties are listed in the following\ntable. \n<br>\n\n<!-- prettier-ignore -->\n| property name | usage | notes |\n| ------- | ------ | -------- |\n| Label | appears in front of the input, short description | default as \"label\", SHOULD be short and unique in the template |\n| User defined key | does not render in the template, but used for report and API | MUST be unique within the template; **only** letter, number, and \"\\_\" allowed (Example: MagMeas_1) |\n| Radio button value | appears behind the radio button | the value will be recorded in DB; each radio button value MUST be unique within the radio group |\n| Required | whether the input is required | when an input is required, the value MUST be present to pass template validation; for checkbox, required means it MUST be checked |\n| Placeholder | appears inside the input before the user touches | a short hint to the user |\n| Select an image | upload an image for the figure | choose an image file from local file system and then click upload |\n| Image alternate text | the text appears in the place when the image is not loaded | meaningful text for the image |\n| Width | the width of image appearing in the template | when the image is too large, use this property to resize it. The unit is pixel, and the height will be adjusted accordingly to keep the original aspect. |\n| Figure caption | appears below the image | a long text to describe the image |\n| Row | the number of rows for the text box | provide enough space so that the user can input or view the text without scrolling |\n| Min | minimum allowed value for a number | useful for validation |\n| Max | minimum allowed value for a number | useful for validation |\n| Help | appear below the input | a long hint to the user for the input |\n\n#### Advanced components\n\nCurrently, the builder supports two advanced controls, section and rich\ninstruction. The section is for easy navigation and reference of a traveler.\nWhen a template has sections, a floating navigation will be generated on the\nright side of the traveler page. With the navigation, the user can jump to a\nsection with a click. This is helpful when a template is several pages long.\n\nWith rich instruction, a user can add math formulas, web links, images, and\nlists to the template. This is useful when the user needs a rich format editor\nto compose the paragraph. Note that the image added into the rich instruction\nneeds to be hosted on a location that a traveler viewer can access. It is\ndifferent from the figure in basic input, which accepts an uploaded image file\nfrom the user and saved on the traveler server storage.\n\n#### Update, delete, or duplicate a component\n\nWhen hovering on an existing template component, the component will be focused\nand a set of buttons shows on the top right corner of the component as follows.\n\n<div\nclass=\"btn-group\"><a data-toggle=\"tooltip\" title=\"edit\" class=\"btn btn-info\"><i\nclass=\"fa fa-edit fa-lg\"></i></a><a data-toggle=\"tooltip\" title=\"duplicate\"\nclass=\"btn btn-info\"><i class=\"fa fa-copy fa-lg\"></i></a><a\ndata-toggle=\"tooltip\" title=\"remove\" class=\"btn btn-warning\"><i class=\"fa\nfa-trash-o fa-lg\"></i></a></div>\n\nThe first button is to show or hide the attribute panel for the component. The\nsecond is to create a new component same to the current component. The third is\nto remove the current component from the template.\n\n#### Save changes\n\nWhenever you update the template by adding a new input, or updating an input's\nattributes, or adjusting the locations of the inputs, you can save the change to\nthe server by clicking the <button class=\"btn btn-primary\">Save</button> button.\n\nWhen the user tries to save a template, the builder checks if a component's\neditor is still open. If it is, then the user will see an alert to finish the\nedit first. The user can either commit the change by clicking the\n<button class=\"btn btn-primary\">Done</button> button, or cancel the change by\nclicking the <a data-toggle=\"tooltip\" title=\"edit\" class=\"btn btn-info\"><i\nclass=\"fa fa-edit fa-lg\"></i></a> button again.\n\n#### Sequence number\n\nSequence numbers are added automatically to the components. There are three\nlevels of numbers: the section is the top level, the second is the rich\ninstruction, and the third is the basic input.\n\n```\n1 Section name\n1.1 instruction for what to do\n1.1.1 some data to collect\n```\n\nWhen a new component is added, or a component's location is adjusted, the\nnumbers are updated automatically. For the templates created with an older\nversion of the builder, there might not be numbers. The user can generate the\nnumbers by clicking the <button class=\"btn btn-primary\">Generate\nnumbering</button> button.\n\n#### Adjust component location\n\nClick the <button class=\"btn\">Adjust location</button> to enter the location\nadjustment mode. The user can drag and drop a component to a different place.\nThe sequence number will be updated every time a component's location is\nchanged. Click the <button class=\"btn\">Done</button> to exit the location\nadjustment mode. Note that the changes will not be saved until clicking the\n<button class=\"btn btn-primary\">Save</button> button.\n\n#### Import other templates\n\nIn order to make the composition of a new template fast, the user can import the\ncomponents inside any draft template or released template into the current\nbuilder. After importing, the user can adjust the location or remove components.\n\n#### Preview and validation\n\nThe user can preview the saved template any time when clicking the <button\nclass=\"btn btn-info\">Preview</button> button. The preview page renders the\ntemplate and the validation logic specified in the builder. The user can see the\nvalidation result when clicking the <button class=\"btn btn-info\">Show\nvalidation</button> button.\n\n#### Save as a new template\n\nThe user can save the template in the builder as a new template. The new\ntemplate can be found in the my draft templates list.\n"
},
{
"alpha_fraction": 0.5601555109024048,
"alphanum_fraction": 0.5685794353485107,
"avg_line_length": 25.86460304260254,
"blob_id": "146a79d0d8f76c647ebe3eee5859eb8fbef73818",
"content_id": "8a208b808bcdae70f42ee81aa5706edd956b508a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 13889,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 517,
"path": "/utilities/routes.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/**\n * Created by djarosz on 11/6/15.\n */\n/**\n * The purpose of this file is to store all functions and utilities that are used by multiple routes.\n */\nvar config = require('../config/config.js');\n\nvar Traveler = require('../model/traveler').Traveler;\nconst TravelerData = require('../model/traveler').TravelerData;\nvar Binder = require('../model/binder').Binder;\nvar _ = require('lodash');\nvar cheer = require('cheerio');\nconst logger = require('../lib/loggers').getLogger();\n\nconst formStatusMap = require('../model/released-form').statusMap;\n\nvar TravelerError = require('../lib/error').TravelerError;\n\nvar devices = require('./devices/default.js');\n// Override devices for a specific component system.\nif (config.service.device_application === 'cdb') {\n devices = require('./devices/cdb.js');\n}\n\nfunction filterBody(strings, findAll) {\n return filterBodyWithOptional(strings, findAll, undefined);\n}\n\nfunction filterBodyWithOptional(requiredStrings, findAll, optionalStrings) {\n var strings = requiredStrings;\n if (optionalStrings !== undefined) {\n strings = requiredStrings.concat(optionalStrings);\n }\n\n return function(req, res, next) {\n var k;\n var foundCount = 0;\n for (k in req.body) {\n if (req.body.hasOwnProperty(k)) {\n var index = strings.indexOf(k);\n if (index !== -1) {\n foundCount = foundCount + 1;\n } else {\n req.body[k] = null;\n }\n }\n }\n if (!findAll && foundCount > 0) {\n next();\n } else if (findAll && foundCount >= requiredStrings.length) {\n next();\n } else {\n var error;\n if (findAll) {\n error = 'Cannot find all the required parameters: ' + strings;\n } else if (!findAll) {\n error = 'Cannot find any of the required parameters: ' + strings;\n }\n return res.send(500, error);\n }\n };\n}\n\nfunction checkUserRole(req, role) {\n if (\n req.session.roles !== undefined &&\n req.session.roles.indexOf(role) !== -1\n ) {\n return true;\n } else {\n return false;\n }\n}\n\nfunction getRenderObject(req, extraAttributes) {\n var renderObject = {\n prefix: req.proxied ? req.proxied_prefix : '',\n viewConfig: config.viewConfig,\n roles: req.session.roles,\n helper: {\n upperCaseFirstLetter: function(text) {\n return text.charAt(0).toUpperCase() + text.slice(1);\n },\n },\n };\n if (extraAttributes !== undefined) {\n for (var key in extraAttributes) {\n renderObject[key] = extraAttributes[key];\n }\n }\n return renderObject;\n}\n\nfunction getDeviceValue(value) {\n return new Promise(function(resolve) {\n var deviceIndex = 0;\n processNextDevice();\n\n function processNextDevice() {\n if (value.length > deviceIndex) {\n devices.getDeviceValue(value[deviceIndex], function(curDeviceValue) {\n value[deviceIndex] = curDeviceValue;\n deviceIndex++;\n processNextDevice();\n });\n } else {\n resolve(value);\n }\n }\n });\n}\n\nfunction deviceRemovalAllowed() {\n return devices.devicesRemovalAllowed;\n}\n\nfunction addInputName(name, list) {\n if (list.indexOf(name) === -1) {\n list.push(name);\n }\n}\n\nconst binderUtil = {\n createBinder: function(\n title,\n description,\n createdBy,\n newBinderResultCallback\n ) {\n var binderToCreate = {};\n binderToCreate.title = title;\n binderToCreate.description = description;\n binderToCreate.createdBy = createdBy;\n binderToCreate.createdOn = Date.now();\n new Binder(binderToCreate).save(newBinderResultCallback);\n },\n\n deleteWork: function(binder, workId, userId, req, res) {\n var work = binder.works.id(workId);\n\n if (!work) {\n return res\n .status(404)\n .send('Work ' + req.params.wid + ' not found in the binder.');\n }\n\n work.remove();\n binder.updatedBy = userId;\n binder.updatedOn = Date.now();\n\n binder.updateProgress(function(err, newPackage) {\n if (err) {\n console.log(err);\n return res.status(500).send(err.message);\n }\n return res.json(newPackage);\n });\n },\n addWork(binder, userId, req, res) {\n const { ids, type } = req.body;\n if (!(ids instanceof Array)) {\n return res.send(400, 'ids must be an array');\n }\n if (ids.length === 0) {\n return res.send(204);\n }\n let model;\n if (type === 'traveler') {\n model = Traveler;\n } else if (type === 'binder') {\n model = Binder;\n } else {\n return res.send(400, `cannot handle ${type}`);\n }\n\n const { works } = binder;\n const added = [];\n\n model\n .find({\n _id: {\n $in: ids,\n },\n })\n .exec(function(err, items) {\n if (err) {\n console.error(err);\n return res.send(500, err.message);\n }\n\n if (items.length === 0) {\n return res.status(400).send('nothing to be added');\n }\n\n items.forEach(function(item) {\n if (type === 'binder') {\n // skip the binder to be added into itself\n if (item.id === binder.id) {\n logger.warn(`binder ${item.id} cannot be added into itself`);\n return;\n }\n // skip the binder if it contains other binders already\n for (let i = 0; i < item.works.length; i += 1) {\n if (item.works[i].refType === 'binder') {\n logger.warn(`binder ${item.id} contains other binder`);\n return;\n }\n }\n }\n let newWork;\n if (!works.id(item._id)) {\n newWork = {\n _id: item._id,\n refType: type,\n addedOn: Date.now(),\n addedBy: userId,\n status: item.status || 0,\n value: item.value || 10,\n };\n works.push(newWork);\n added.push(item.id);\n binder.updateWorkProgress(item);\n }\n });\n\n if (added.length === 0) {\n return res.send(400, 'no item added');\n }\n\n binder.updatedOn = Date.now();\n binder.updatedBy = userId;\n // update the totalValue, finishedValue, and finishedValue\n return binder.updateProgress(function(saveErr, newBinder) {\n if (saveErr) {\n logger.error(saveErr);\n return res.send(500, saveErr.message);\n }\n return res.json(200, newBinder);\n });\n });\n },\n};\n\nfunction addDiscrepancy(discrepancy, traveler) {\n // migrate traveler without discrepancyForms\n if (!traveler.discrepancyForms) {\n traveler.discrepancyForms = [];\n }\n traveler.discrepancyForms.push(discrepancy);\n // set reference for compatibility, discrepancy._id is the same as the discrepancy form id\n traveler.discrepancyForms[0].reference = discrepancy._id;\n traveler.activeDiscrepancyForm = traveler.discrepancyForms[0]._id;\n traveler.referenceDiscrepancyForm = discrepancy._id;\n}\n\nfunction addBase(base, traveler) {\n traveler.forms.push(base);\n // set reference for compatibility, base._id is the same as the base form id\n traveler.forms[0].reference = base._id;\n traveler.activeForm = traveler.forms[0]._id;\n traveler.mapping = base.mapping;\n traveler.labels = base.labels;\n traveler.types = base.types;\n traveler.totalInput = _.size(base.labels);\n}\nvar traveler = {\n /**\n * get the map of input name -> label in the form\n * @param {String} html form html\n * @return {Object} the map of input name -> label\n */\n inputLabels: function(html) {\n var $ = cheer.load(html);\n var inputs = $('input, textarea');\n var lastInputName = '';\n var i;\n var input;\n var inputName = '';\n var label = '';\n var map = {};\n for (i = 0; i < inputs.length; i += 1) {\n input = $(inputs[i]);\n inputName = input.attr('name');\n label = input\n .closest('.control-group')\n .children('.control-label')\n .children('span')\n .text();\n if (inputName) {\n inputName = inputName.trim();\n }\n if (label) {\n label = label.trim();\n }\n if (!inputName) {\n continue;\n }\n if (lastInputName !== inputName) {\n map[inputName] = label;\n }\n lastInputName = inputName;\n }\n return map;\n },\n createTraveler: function(form, title, userId, devices, newTravelerCallBack) {\n if (\n form.formType &&\n form.formType !== 'normal' &&\n form.formType !== 'normal_discrepancy'\n ) {\n return newTravelerCallBack(\n new TravelerError(\n `cannot create a traveler from ${form.id} of non normal type`,\n 400\n )\n );\n }\n\n if (formStatusMap['' + form.status] !== 'released') {\n return newTravelerCallBack(\n new TravelerError(\n `cannot create a traveler from a non-released form ${form.id}`,\n 400\n )\n );\n }\n\n var traveler = new Traveler({\n title: title,\n description: '',\n devices: devices,\n tags: form.base.tags,\n status: 0,\n createdBy: userId,\n createdOn: Date.now(),\n sharedWith: [],\n referenceReleasedForm: form._id,\n referenceReleasedFormVer: form.ver,\n forms: [],\n data: [],\n comments: [],\n finishedInput: 0,\n touchedInputs: [],\n });\n\n // for old forms without lables\n // if (!(_.isObject(form.base.labels) && _.size(form.base.labels) > 0)) {\n // form.base.labels = this.inputLabels(form.base.html);\n // }\n addBase(form.base, traveler);\n if (form.discrepancy) {\n addDiscrepancy(form.discrepancy, traveler);\n }\n traveler.save(newTravelerCallBack);\n },\n changeArchivedState: function(traveler, archived) {\n traveler.archived = archived;\n\n if (traveler.archived) {\n traveler.archivedOn = Date.now();\n }\n },\n updateTravelerStatus: function(\n req,\n res,\n travelerDoc,\n status,\n isSession,\n onSuccess\n ) {\n if (isSession) {\n if (status === 1.5) {\n if (!traveler.canWriteActive(req, travelerDoc)) {\n return res.send(\n 403,\n 'You are not authorized to access this resource'\n );\n }\n } else {\n if (travelerDoc.createdBy !== req.session.userid) {\n return res.send(\n 403,\n 'You are not authorized to access this resource'\n );\n }\n }\n }\n\n if (travelerDoc.status == status) {\n // Nothing to update\n onSuccess();\n } else {\n switch (status) {\n case 1:\n if ([0, 1.5, 3].indexOf(travelerDoc.status) !== -1) {\n travelerDoc.status = status;\n } else {\n return res.send(\n 400,\n 'cannot start to work from the current status'\n );\n }\n break;\n case 1.5:\n if ([1].indexOf(travelerDoc.status) !== -1) {\n travelerDoc.status = status;\n } else {\n return res.send(400, 'cannot complete from the current status');\n }\n break;\n case 2:\n if ([1, 1.5].indexOf(travelerDoc.status) !== -1) {\n travelerDoc.status = 2;\n } else {\n return res.send(400, 'cannot complete from the current status');\n }\n break;\n case 3:\n if ([1].indexOf(travelerDoc.status) !== -1) {\n travelerDoc.status = 3;\n } else {\n return res.send(400, 'cannot freeze from the current status');\n }\n }\n onSuccess();\n }\n },\n canWriteActive: function(req, travelerDoc) {\n if (traveler.canWrite(req, travelerDoc)) {\n return true;\n } else if (checkUserRole(req, 'write_active_travelers')) {\n return true;\n }\n\n return false;\n },\n canWrite: function(req, travelerDoc) {\n if (req.session == undefined) {\n return false;\n }\n\n if (travelerDoc.createdBy === req.session.userid) {\n return true;\n }\n if (\n travelerDoc.sharedWith &&\n travelerDoc.sharedWith.id(req.session.userid) &&\n travelerDoc.sharedWith.id(req.session.userid).access === 1\n ) {\n return true;\n }\n var i;\n if (travelerDoc.sharedGroup) {\n for (i = 0; i < req.session.memberOf.length; i += 1) {\n if (\n travelerDoc.sharedGroup.id(req.session.memberOf[i]) &&\n travelerDoc.sharedGroup.id(req.session.memberOf[i]).access === 1\n ) {\n return true;\n }\n }\n }\n return false;\n },\n resetTouched: function(doc, cb) {\n TravelerData.find(\n {\n _id: {\n $in: doc.data,\n },\n },\n 'name'\n ).exec(function(dataErr, data) {\n if (dataErr) {\n logger.error(dataErr);\n return cb(dataErr);\n }\n // reset the touched input name list and the finished input number\n logger.info('reset the touched inputs for traveler ' + doc._id);\n var labels = {};\n var activeForm;\n if (doc.forms.length === 1) {\n activeForm = doc.forms[0];\n } else {\n activeForm = doc.forms.id(doc.activeForm);\n }\n\n if (!(activeForm.labels && _.size(activeForm.labels) > 0)) {\n activeForm.labels = traveler.inputLabels(activeForm.html);\n }\n labels = activeForm.labels;\n // empty the current touched input list\n doc.touchedInputs = [];\n data.forEach(function(d) {\n // check if the data is for the active form\n if (labels.hasOwnProperty(d.name)) {\n addInputName(d.name, doc.touchedInputs);\n }\n });\n // finished input\n doc.finishedInput = doc.touchedInputs.length;\n cb();\n });\n },\n};\n\nmodule.exports = {\n filterBody: filterBody,\n filterBodyWithOptional: filterBodyWithOptional,\n checkUserRole: checkUserRole,\n getRenderObject: getRenderObject,\n getDeviceValue: getDeviceValue,\n deviceRemovalAllowed: deviceRemovalAllowed,\n traveler: traveler,\n binder: binderUtil,\n};\n"
},
{
"alpha_fraction": 0.6308615207672119,
"alphanum_fraction": 0.634678304195404,
"avg_line_length": 18.720430374145508,
"blob_id": "9ffdc4530ba62b38bbc982df6a0c385cc3943a4a",
"content_id": "b04a6ba2fd2cfa89f6718c9fa3e519cffe114be3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1834,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 93,
"path": "/model/released-form.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const mongoose = require('mongoose');\n\nconst { Schema } = mongoose;\nconst { addHistory } = require('./history');\nconst { addVersion } = require('./history');\n\n/*\nstatus := 1 // released\n | 2 // archived\n*/\n\nconst stateTransition = [\n {\n from: 1,\n to: [2],\n },\n];\n\nconst statusMap = {\n '1': 'released',\n '2': 'archived',\n};\n\nconst formContent = new Schema({\n // _id is the form _id\n html: String,\n mapping: Schema.Types.Mixed,\n labels: Schema.Types.Mixed,\n types: Schema.Types.Mixed,\n formType: {\n type: String,\n default: 'normal',\n enum: ['normal', 'discrepancy'],\n },\n _v: Number,\n});\n\n/**\n * formType:\n * normal => has only base, base is a normal released form\n * discrepancy => has only base, base is a discrepancy released form\n * normal_discrepancy => has a base and a discrepancy form\n */\nconst releasedForm = new Schema({\n title: String,\n description: String,\n releasedBy: String,\n releasedOn: Date,\n tags: [String],\n status: {\n type: Number,\n default: 1,\n },\n formType: {\n type: String,\n default: 'normal',\n enum: ['normal', 'discrepancy', 'normal_discrepancy'],\n },\n archivedOn: Date,\n archivedBy: String,\n base: formContent,\n discrepancy: { type: formContent, default: null },\n // ver format: base_v[:discrepancy_v]\n ver: String,\n});\n\nreleasedForm.plugin(addVersion, {\n fieldsToVersion: ['title', 'description', 'base', 'discrepancy'],\n});\n\nreleasedForm.plugin(addHistory, {\n fieldsToWatch: [\n 'title',\n 'description',\n 'tags',\n 'status',\n 'base',\n 'discrepancy',\n '_v',\n ],\n});\n\nconst ReleasedForm = mongoose.model('ReleasedForm', releasedForm);\n\n// FormContent is not for persistence\nconst FormContent = mongoose.model('FormContent', formContent);\n\nmodule.exports = {\n ReleasedForm,\n stateTransition,\n FormContent,\n statusMap,\n};\n"
},
{
"alpha_fraction": 0.8012048006057739,
"alphanum_fraction": 0.8012048006057739,
"avg_line_length": 54.33333206176758,
"blob_id": "4c08df9d83e130639707b955f39ebe3798698968",
"content_id": "009378745353d4d2bda88702c91fc31237456b32",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 996,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 18,
"path": "/views/docs/basics/template.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### What is a template?\n\nA template is the documentation for a predefined process. A user can execute the\nprocess multiple times and collect data during the executions. A template can\ncontain multiple sequenced sections, and each section can contain instructions\nand inputs.\n\nA user can design a template in a WYSIWYG (what you see is what you get) editor.\nEach template has a life cycle, and can be managed by users with special roles.\nUsers can only create travelers from the released templates. The\n[templates section](#forms) describes the details of how to work with templates.\n\nThere are two types of templates --- normal templates and discrepancy templates.\nA normal template defines a sequence of actions and data points to collect. A\ndiscrepancy template is for the QA process, in which the data collected in a\nnormal process is examined and requested for correction. A normal template can\nbe used on its own, while a discrepancy template has to be used together with a\nnormal template.\n"
},
{
"alpha_fraction": 0.8006279468536377,
"alphanum_fraction": 0.8006279468536377,
"avg_line_length": 41.53333282470703,
"blob_id": "b41707aa26aac0d2496b9ef60031f272d4743054",
"content_id": "0a1cdb29c372838ba600e1dbe7e4107ade27e99a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 637,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 15,
"path": "/etc/mongo-express-configuration.default.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $BASH_SOURCE`\n\n# Run source setup.sh before running this script. \nexport MONGO_EXPRESS_DAEMON_SOURCE_DIR=$TRAVELER_SUPPORT_DIR/nodejs/node_modules/mongo-express\nexport MONGO_EXPRESS_DAEMON_APP_DIR=$MONGO_EXPRESS_DAEMON_SOURCE_DIR/app.js\n\nexport MONGO_EXPRESS_DAEMON_USERNAME=admin\nexport MONGO_EXPRESS_DAEMON_PASSWD_FILE=$TRAVELER_INSTALL_ETC_DIR/mongo-express.passwd\n\n# To configure SSL in mongo-express, set the variables below. \n#export MONGO_EXPRESS_SSL_ENABLED=true\n#export MONGO_EXPRESS_SSL_CRT=$TRAVELER_ROOT_DIR/config/ssl/node.crt\n#export MONGO_EXPRESS_SSL_KEY=$TRAVELER_ROOT_DIR/config/ssl/node.key"
},
{
"alpha_fraction": 0.7157990336418152,
"alphanum_fraction": 0.7173123359680176,
"avg_line_length": 31.39215660095215,
"blob_id": "9aad4d1ee979d838474c7485b00d1bd34e200f42",
"content_id": "42d3a46eebc8b9bf6e81ae90dd299d5b1954d3e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3304,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 102,
"path": "/setup.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Traveler setup script for Bourne-type shells\n# This file is typically sourced in user's .bashrc file\n\nif [ -n \"$BASH_SOURCE\" ]; then\n input_param=$BASH_SOURCE\nelif [ -n \"$ZSH_VERSION\" ]; then\n setopt function_argzero\n input_param=$0\nelse\n echo 1>&2 \"Unsupported shell. Please use bash or zsh.\"\n exit 2\nfi\nmyDir=`dirname $input_param`\ncurrentDir=`pwd` && cd $myDir\n\n# TRAVELER_ROOT_DIR is not empty and the different from current directory\nif [ ! -z \"$TRAVELER_ROOT_DIR\" -a \"$TRAVELER_ROOT_DIR\" != `pwd` ]; then\n echo \"WARNING: Resetting TRAVELER_ROOT_DIR environment variable (old value: $TRAVELER_ROOT_DIR)\"\nfi \nexport TRAVELER_ROOT_DIR=`pwd`\n\n\nexport TRAVELER_INSTALL_DIR=$TRAVELER_ROOT_DIR/..\n # it is an existant directory\nif [ -d $TRAVELER_INSTALL_DIR ]; then\n cd $TRAVELER_INSTALL_DIR\n export TRAVELER_INSTALL_DIR=`pwd`\nfi\n\n\n# TRAVELER_DATA_DIR is not set \nexport TRAVELER_DATA_DIR=$TRAVELER_INSTALL_DIR/data\nif [ -d $TRAVELER_DATA_DIR ]; then\n cd $TRAVELER_DATA_DIR\n export TRAVELER_DATA_DIR=`pwd`\nfi\n \n# TRAVELER_VAR_DIR is not set\nexport TRAVELER_VAR_DIR=$TRAVELER_INSTALL_DIR/var\nif [ -d $TRAVELER_VAR_DIR ]; then\n cd $TRAVELER_VAR_DIR; \n export TRAVELER_VAR_DIR=`pwd`\nfi\n\n# TRAVELER_SUPPORT_DIR is not set\nexport TRAVELER_SUPPORT_DIR=$TRAVELER_INSTALL_DIR/support\nif [ -d $TRAVELER_SUPPORT_DIR ]; then\n cd $TRAVELER_SUPPORT_DIR\n export TRAVELER_SUPPORT_DIR=`pwd`\nfi\n\n# TRAVELER_INSTALL_ETC_DIRECTORY is not set\nexport TRAVELER_INSTALL_ETC_DIR=$TRAVELER_INSTALL_DIR/etc\nif [ -d $TRAVELER_INSTALL_ETC_DIR ]; then \n cd $TRAVELER_INSTALL_ETC_DIR\n export TRAVELER_INSTALL_ETC_DIRECTORY=`pwd`\nfi\n\nexport TRAVELER_CONFIG_DIR=$TRAVELER_INSTALL_ETC_DIRECTORY/traveler-config\nif [ -d $TRAVELER_CONFIG_DIR ]; then \n cd $TRAVELER_CONFIG_DIR\n export TRAVELER_CONFIG_DIR=`pwd`\nfi\n\n#Notify user of nonexistatnt directories. \nif [ ! -d $TRAVELER_SUPPORT_DIR ]; then \n echo \"Warning: $TRAVELER_SUPPORT_DIR directory does not exist. Developers should point TRAVELER_SUPPORT_DIR to desired area.\"\nfi\nif [ ! -d $TRAVELER_DATA_DIR ]; then\n echo \"Warning: $TRAVELER_DATA_DIR directory does not exist. Developers should point TRAVELER_DATA_DIR to desired area.\"\nfi\nif [ ! -d $TRAVELER_VAR_DIR ]; then\n echo \"Warning: $TRAVELER_VAR_DIR directory does not exist. Developers should point TRAVELER_VAR_DIR to desired area.\"\nfi\nif [ ! -d $TRAVELER_INSTALL_ETC_DIR ]; then \n echo \"Warning: $TRAVELER_INSTALL_ETC_DIR directory does not exist. Developers should point TRAVELER_INSTALL_ETC_DIR to desired area.\"\nfi\nif [ ! -d $TRAVELER_CONFIG_DIR ]; then \n echo \"Warning: $TRAVELER_CONFIG_DIR directory does not exist. Developers should point TRAVELER_CONFIG_DIR to desired area.\"\n echo \"Specify env variable, TRAVELER_CONFIG_DIR when starting node to point to the correct directory\" \nfi\n\n# SET PATH variable \nHOST_ARCH=\"`uname | tr '[:upper:]' '[:lower:]'`-`uname -m`\"\n\n# Add to path only if directory exists.\nprependPathIfDirExists() {\n _dir=$1\n if [ -d ${_dir} ]; then\n PATH=${_dir}:$PATH\n else\n\techo \"Warning: PATH $_dir was not added. it does not exist.\" \n fi\n}\n\nprependPathIfDirExists $TRAVELER_SUPPORT_DIR/mongodb/$HOST_ARCH/bin\nprependPathIfDirExists $TRAVELER_SUPPORT_DIR/nodejs/$HOST_ARCH/bin\n\n# Done \ncd $currentDir\n"
},
{
"alpha_fraction": 0.7757201790809631,
"alphanum_fraction": 0.7757201790809631,
"avg_line_length": 37.880001068115234,
"blob_id": "619c975d8f0d3c5f23478f59f3f40c82968174fb",
"content_id": "fefcfbb566a908dd31a81263185c42bcd727c1ec",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 972,
"license_type": "permissive",
"max_line_length": 193,
"num_lines": 25,
"path": "/README.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "# Traveler\nThe traveler is a Web application to define work templates, create work instances from released templates, and organize the work. \n## Installation\n\n### Manual installation (recommended)\n\nPlease follow [this instruction](installation-step.md) to install the dependency and traveler application step by step. \n\n### With script on one box\n\nIf you want to install the traveler application and its MongoDB dependency in one Linus box, you can follow [this instruction](installation-script.md). \n\n### Local development and test\n\nYou can quickly set up a standalone environment for the traveler application [with docker](docker.md). This is the best approach for local development or try out before production deployment. \n\n## Development\n### Source style and Lint\nWe use `eslint` and `prettier` for style and linting. \n\n## User manual\nSee https://dongliu.github.io/traveler/ for details.\n# License\n\n[MIT](https://github.com/dongliu/traveler/blob/master/LICENSE.md)\n"
},
{
"alpha_fraction": 0.5297595858573914,
"alphanum_fraction": 0.53133624792099,
"avg_line_length": 29.202381134033203,
"blob_id": "38f07eb034d3ac925746d3fb8324206858b361e5",
"content_id": "95623b45bd339a8df73189bb6956cffcc422bf86",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2537,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 84,
"path": "/public/javascripts/table-action.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "function modalScroll(scroll) {\n if (scroll) {\n $('#modal .modal-body').removeClass('modal-body-visible');\n $('#modal .modal-body').addClass('modal-body-scroll');\n } else {\n $('#modal .modal-body').removeClass('modal-body-scroll');\n $('#modal .modal-body').addClass('modal-body-visible');\n }\n}\n\nfunction updateStatusFromModal(status, type, fromTable, toTable, otherTable) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n var number = $('#modal .modal-body div.target').length;\n $('#modal .modal-body div.target').each(function() {\n var that = this;\n $.ajax({\n url: '/' + type + '/' + that.id + '/status',\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({\n status: status,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n $('#return').prop('disabled', false);\n fromTable.fnReloadAjax();\n toTable.fnReloadAjax();\n if (otherTable) {\n otherTable.fnReloadAjax();\n }\n }\n });\n });\n}\n\nfunction transferFromModal(newOwnerName, type, table) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n var number = $('#modal .modal-body div.target').length;\n $('#modal .modal-body div.target').each(function() {\n var that = this;\n $.ajax({\n url: '/' + type + '/' + that.id + '/owner',\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({\n name: newOwnerName,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"fa fa-exclamation\"></i>');\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n $('#return').prop('disabled', false);\n table.fnReloadAjax();\n }\n });\n });\n}\n\n$('button.reload').click(function() {\n var activeTable = $('.tab-pane.active table').dataTable();\n activeTable.fnReloadAjax();\n});\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.6086956262588501,
"avg_line_length": 23.769229888916016,
"blob_id": "3aecedd488e72121e717472dbf0a9dfbb7f910f5",
"content_id": "fc4050701690bc598b1ae894a15c7abed94630e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 322,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 13,
"path": "/routes/main.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "var routesUtilities = require('../utilities/routes.js');\nvar auth = require('../lib/auth');\n\nmodule.exports = function(app) {\n app.get('/', auth.ensureAuthenticated, function(req, res) {\n res.render(\n 'main',\n routesUtilities.getRenderObject(req, {\n roles: req.session.roles,\n })\n );\n });\n};\n"
},
{
"alpha_fraction": 0.8053097128868103,
"alphanum_fraction": 0.8053097128868103,
"avg_line_length": 41.375,
"blob_id": "9460968f75bc3167d991ab2ea474f0fae7c50f39",
"content_id": "8b1787c477e409222365c76abc6865a7ba75b4e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 339,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 8,
"path": "/views/docs/template/header.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "## Templates\n\n**Audience: traveler users, especially process template owner**\n\nBefore creating travelers, a user needs to design a template and release it in\nthe traveler application. A traveler template mimics the paper traveler so that\na process owner defines the sequence of actions and specifies the data to be\ncollected in each step.\n"
},
{
"alpha_fraction": 0.6079896092414856,
"alphanum_fraction": 0.6183825731277466,
"avg_line_length": 27.11872100830078,
"blob_id": "f9b9b471f04c3b6d5ed6edbde3d4d3188b294864",
"content_id": "a842b0e5f2bcfc17adf51f5994031ea7c0f88f09",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6158,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 219,
"path": "/public/javascripts/form-management.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*\nglobal moment, ajax401, disableAjaxCache, prefix, updateAjaxURL, Holder,\nselectColumn, formLinkColumn, formConfigLinkColumn, titleColumn, tagsColumn,\nkeysColumn, fnAddFilterFoot, sDomNoTools, reviewersColumn, firstReviewRequestedOnColumn,\nfnGetSelected, selectEvent, filterEvent, formShareLinkColumn, formStatusColumn,\nformTypeColumn, versionColumn, releasedFormStatusColumn,\nreleasedFormVersionColumn, releasedByColumn, releasedOnColumn,\narchivedByColumn, archivedOnColumn, releasedFormLinkColumn\n*/\n\nfunction cloneFromModal(formTable) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n let number = $('#modal .modal-body div.target').length;\n $('#modal .modal-body div.target').each(function() {\n const that = this;\n let success = false;\n $.ajax({\n url: `/forms/${that.id}/clone`,\n type: 'POST',\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n success = true;\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(` : ${jqXHR.responseText}`);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0 && success) {\n $('#return').prop('disabled', false);\n formTable.fnReloadAjax();\n }\n });\n });\n}\n\nfunction showHash() {\n if (window.location.hash) {\n $(`.nav-tabs a[href=${window.location.hash}]`).tab('show');\n }\n}\n\nfunction formatItemUpdate(data) {\n return `<div class=\"target\" id=\"${data._id}\"><b>${\n data.title\n }</b>, created ${moment(data.createdOn).fromNow()}${\n data.updatedOn ? `, updated ${moment(data.updatedOn).fromNow()}` : ''\n }</div>`;\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n const formAoColumns = [\n selectColumn,\n formLinkColumn,\n formConfigLinkColumn,\n formShareLinkColumn,\n titleColumn,\n formTypeColumn,\n versionColumn,\n formStatusColumn,\n tagsColumn,\n keysColumn,\n reviewersColumn,\n firstReviewRequestedOnColumn,\n ];\n const formTable = $('#submitted-form-table').dataTable({\n sAjaxSource: '/submitted-forms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: formAoColumns,\n aaSorting: [[11, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#submitted-form-table', formAoColumns);\n\n const releasedFormAoColumns = [\n selectColumn,\n releasedFormLinkColumn,\n titleColumn,\n formTypeColumn,\n releasedFormStatusColumn,\n releasedFormVersionColumn,\n tagsColumn,\n releasedByColumn,\n releasedOnColumn,\n ];\n const releasedFormTable = $('#released-form-table').dataTable({\n sAjaxSource: '/released-forms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: releasedFormAoColumns,\n aaSorting: [[8, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#released-form-table', releasedFormAoColumns);\n\n const archivedFormAoColumns = [\n selectColumn,\n formLinkColumn,\n titleColumn,\n formTypeColumn,\n tagsColumn,\n releasedFormStatusColumn,\n releasedFormVersionColumn,\n archivedByColumn,\n archivedOnColumn,\n ];\n const archivedFormTable = $('#archived-form-table').dataTable({\n sAjaxSource: '/archived-released-forms/json',\n sAjaxDataProp: '',\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: archivedFormAoColumns,\n aaSorting: [[8, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#archived-form-table', archivedFormAoColumns);\n\n // show the tab in hash\n showHash();\n\n // add state for tab changes\n $('.nav-tabs a').on('click', function() {\n window.history.pushState(null, `forms :: ${this.text}`, this.href);\n });\n\n // show the tab when back and forward\n window.onhashchange = function() {\n showHash();\n };\n\n $('#clone').click(function() {\n const activeTable = $('.tab-pane.active table').dataTable();\n const selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No form has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(`Clone the following ${selected.length} forms? `);\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n cloneFromModal(formTable);\n });\n }\n });\n\n $('#reload').click(function() {\n formTable.fnReloadAjax();\n releasedFormTable.fnReloadAjax();\n archivedFormTable.fnReloadAjax();\n });\n // binding events\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.7181817889213562,
"alphanum_fraction": 0.7227272987365723,
"avg_line_length": 23.44444465637207,
"blob_id": "0edb81a5aa79870a2f434886d3b4c7e7d5358bc4",
"content_id": "4b61c4ea68f6a829c789e6c2182a6d0a74a86b75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 220,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 9,
"path": "/sbin/configure_paths.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0` && cd $MY_DIR && MY_DIR=`pwd`\n\nsource $MY_DIR/../setup.sh\n\nexport TRAVELER_ETC_INIT_DIRECTORY=$TRAVELER_ROOT_DIR/etc/init.d\n\nexport TRAVELER_BACKUP_DIRECTORY=$TRAVELER_INSTALL_DIR/backup\n"
},
{
"alpha_fraction": 0.7462813258171082,
"alphanum_fraction": 0.7526561617851257,
"avg_line_length": 32.140846252441406,
"blob_id": "691865c0af3704f202241cc3f84dd9bc0dbe246a",
"content_id": "6c303d832f18ca93f79e07072bc422cae1ae9bdb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2353,
"license_type": "permissive",
"max_line_length": 281,
"num_lines": 71,
"path": "/docker.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "# use docker to set up traveler development environment\n\n## install docker\n\nSee <https://docs.docker.com/get-docker/> for instructions.\n\nAfter installation finished, start the docker desktop, configure it for CPU, memory, and storage that you want it to use on your machine.\n\nCheck if the docker desktop has `docker-compose` installed on your machine. If not, you need to install docker compose, see <https://docs.docker.com/compose/install/>.\n\n## create development network\n\nClone this repo to your local environment. Make sure you have the `traveler-dev` network in the docker.\n\n```\ndocker network list\n```\n\nIf not, run the following in your console to create the network.\n\n```\ndocker network create -d bridge --subnet 172.18.1.0/24 traveler-dev\n```\n\n## get the dependencies\n\nSee <https://github.com/dongliu/traveler-mongo> for mongodb and mongo express.\n\nSee <https://github.com/dongliu/traveler-ldap> for open ldap and a php ldap admin web interface.\n\n## build and run the application\n\nThe traveler application can be run by running\n\n```\ndocker-compose up\n```\n\nThe traveler application can be accessed at <http://localhost:3001>\n\nIf you want to server the application or the api on https, add `ssl_key` and `ssl_cert` configurations in the `app.json` and `api.json` files. You will need valid key and cert files in the `docker` directory, and set the values of `ssl_key` and `ssl_cert` to the name of the files.\n\nWhen you run for the first time, docker will build the image for you. If the application does not start successfully, try\n\n```\ndocker-compose --verbose up\n```\n\nfor detailed information. You should also check the logs of mongodb and open ldap service to see if there is an issue with those services. You can ssh into the running container with `docker exec -it traveler_web_1 /bin/sh`, where `traveler_web_1` is the running container name.\n\n`docker container list` shows all the containers running on your local.\n\nRun\n\n```\ndocker-compose down\n```\n\nto stop the appplication.\n\nYou can run with `docker-compose up -d` in a detached mode. Then you can run `docker-compose logs -f` to check the application log.\n\n## rebulid without cache\n\n```\ndocker-compose build --no-cache\n```\n\n## clean the traveler docker image\n\nRun `docker image list` to see the images on your local. `docker image remove image_name` to clean the image from yoru local.\n"
},
{
"alpha_fraction": 0.4825597405433655,
"alphanum_fraction": 0.4836583435535431,
"avg_line_length": 20.80239486694336,
"blob_id": "db52bed21b5e4fab12d1e815f811765303699d65",
"content_id": "5f398bd6a73a789dbae2aaa3fd60a01bdd5a1a25",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3641,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 167,
"path": "/public/javascripts/traveler-discrepancy-form-loader.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* global sDomClean, _, personColumn, dateColumn, Holder, traveler\n */\nvar DiscrepancyFormLoader = (function(parent, $, _) {\n var logs = [];\n var form = null;\n var tid = null;\n var table = null;\n var logTable = null;\n\n function discrepancyTableTitle(label, name, withKey = false) {\n var key = withKey\n ? '(' +\n (_.findKey(form.mapping, function(n) {\n return n === name;\n }) || '') +\n ')'\n : '';\n return label + key;\n }\n\n function logColumns(form) {\n var cols = [];\n cols.push({\n sTitle: 'sequence',\n mData: 'sequence',\n });\n _.mapKeys(form.labels, function(label, name) {\n cols.push({\n sTitle: discrepancyTableTitle(label, name),\n mData: name,\n sDefaultContent: '',\n bSortable: false,\n });\n });\n cols.push(\n personColumn('Documented by', 'inputBy'),\n dateColumn('On', 'inputOn')\n );\n return cols;\n }\n\n function renderLogs() {\n if (table === 'null' || form === 'null') {\n return;\n }\n if (logTable) {\n logTable.fnDestroy();\n $(table).empty();\n logTable = null;\n }\n var cols = logColumns(form);\n logTable = $(table).dataTable({\n aaData: [],\n bAutoWidth: true,\n // allow destroy and reinit\n bDestroy: true,\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n aoColumns: cols,\n iDisplayLength: -1,\n sDom: sDomClean,\n });\n }\n\n function fileLink(log, record) {\n return (\n '<a target=\"_blank\" href=\"./logs/' +\n log._id +\n '/records/' +\n record._id +\n '\">' +\n record.value +\n '</a>'\n );\n }\n\n function retrieveLogs(cb) {\n if (tid === null) {\n return;\n }\n $.ajax({\n url: '/travelers/' + tid + '/logs/',\n type: 'GET',\n dataType: 'json',\n }).done(function(json) {\n logs = json;\n if (logs.length > 0) {\n var data = [];\n logs.forEach(function(l) {\n var logData = {};\n if (\n l.referenceForm &&\n l.referenceForm === traveler.referenceDiscrepancyForm &&\n l.inputBy &&\n l.inputOn &&\n l.records.length > 0\n ) {\n logData.inputBy = l.inputBy;\n logData.inputOn = l.inputOn;\n l.records.forEach(function(r) {\n if (r.name) {\n logData[r.name] = r.value;\n }\n if (r.file) {\n logData[r.name] = fileLink(l, r);\n }\n });\n data.push(logData);\n }\n });\n // sort logData\n data.sort(function(a, b) {\n return a.inputOn - b.inputOn;\n });\n data.forEach(function(d, i) {\n d.sequence = i + 1;\n });\n logTable.fnAddData(data);\n }\n if (cb) {\n cb();\n }\n });\n }\n\n /**\n * @param {String} fid The form id to retrieve.\n * @return {undefined}\n */\n function retrieveForm(fid, cb) {\n $.ajax({\n url: '/forms/' + fid + '/json',\n type: 'GET',\n dataType: 'json',\n success: function(json) {\n form = json;\n if (cb) {\n cb(json);\n }\n },\n });\n }\n\n function setForm(f) {\n form = f;\n }\n\n function setTid(t) {\n tid = t;\n }\n\n function setLogTable(t) {\n table = t;\n }\n\n parent.renderLogs = renderLogs;\n parent.setLogTable = setLogTable;\n parent.retrieveLogs = retrieveLogs;\n parent.retrieveForm = retrieveForm;\n parent.setForm = setForm;\n parent.setTid = setTid;\n\n return parent;\n})(DiscrepancyFormLoader || {}, jQuery, _);\n"
},
{
"alpha_fraction": 0.6718403697013855,
"alphanum_fraction": 0.6962305903434753,
"avg_line_length": 21.549999237060547,
"blob_id": "cb356b86fee892a1600f1660e15e6949a5f4bbb7",
"content_id": "63ea5855fad1c6a531a9421f64ef2381d3f86fe5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 451,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 20,
"path": "/Dockerfile",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "FROM node:14-alpine\nWORKDIR /app\nCOPY package.json .\nCOPY package-lock.json .\n# RUN apk update && \\\n# apk add openssl\n\n# Add Tini, see https://github.com/krallin/tini for why\nRUN apk add --no-cache tini\n# Tini is now available at /sbin/tini\nENTRYPOINT [\"/sbin/tini\", \"--\"]\n# web port\nEXPOSE 3001\n# api port if https enabled\n# EXPOSE 3443\nRUN npm install --only=prod\nRUN npm install -g nodemon@2\nCOPY . .\n# RUN bower install\nCMD [\"node\", \"app.js\"]\n"
},
{
"alpha_fraction": 0.4887335002422333,
"alphanum_fraction": 0.4887335002422333,
"avg_line_length": 57.5,
"blob_id": "259c98919b810f58d68987ed56273517922f21f1",
"content_id": "9b3113280a50dd615b1f2243d3ec3783b19aad2b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1287,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 22,
"path": "/views/docs/traveler/status.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Traveler status\n\n**Audience: traveler owners and others with write permission**\n\nThe allowed access of a traveler changes with its status. The transitions\nbetween statuses, and the allowed access at each status are shown in the\nfollowing diagram, where **r** for read and **w** for write.\n<img src=\"../images/traveler-status.png\" alt=\"the statues of a traveler\">\n\nThe following table lists the status and corresponding allowed access for\ntraveler data and traveler notes.\n\n| status | artifact | allowed access |\n| --------------------------------------------- | -------- | ----------------- |\n| new | data | no data available |\n| new | notes | read and write |\n| active | data | read and write |\n| active | notes | read and write |\n| frozen, submitted for completion, or complete | data | read only |\n| frozen, submitted for completion, or complete | notes | read and write |\n| archived | data | read only |\n| archived | notes | read only |\n"
},
{
"alpha_fraction": 0.522962212562561,
"alphanum_fraction": 0.5266903638839722,
"avg_line_length": 28.35820960998535,
"blob_id": "c8e0d870864b70432bbc82c4e27c00ba2c8e4afa",
"content_id": "05e18152445827fc3c65e0ea9325410777de1a27",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5901,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 201,
"path": "/public/javascripts/groupmembers.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "function formatItemUpdate(data) {\n return (\n '<div class=\"target\" id=\"' +\n data._id +\n '\"><b>' +\n data.name +\n '</b>' +\n '</div>'\n );\n}\n\nfunction removeMembersFromModal(group, table) {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n let data = [];\n $('#modal .modal-body div.target').each(function() {\n data.push({_id: this.id});\n });\n $.ajax({\n url: '/groups/' + group + '/removeMembers',\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify(data),\n })\n .done(function() {\n $('#modal .modal-body div.target').each(function() {\n $(this).prepend('<i class=\"fa fa-check\"></i>');\n $(this).addClass('text-success');\n });\n })\n .fail(function(jqXHR) {\n $('#modal .modal-body div.target').each(function() {\n $(this).prepend('<i class=\"fa fa-exclamation\"></i>');\n $(this).append(' : ' + jqXHR.responseText);\n $(this).addClass('text-error');\n });\n })\n .always(function() {\n $('#return').prop('disabled', false);\n table.fnReloadAjax();\n });\n}\n\n$(function() {\n updateAjaxURL(prefix);\n\n travelerGlobal.usernames.initialize();\n\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n\n var memberColumns = [selectColumn, userIdColumn, fullNameNoLinkColumn];\n\n var memberTable = $('#members-table').dataTable({\n sAjaxSource: '/groups/' + group._id + '/members/json',\n sAjaxDataProp: '',\n /*fnInitComplete: function () {\n Holder.run({\n images: 'img.group',\n });\n },*/\n bAutoWidth: false,\n iDisplayLength: 10,\n aLengthMenu: [[10, 50, 100, -1], [10, 50, 100, 'All']],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: memberColumns,\n aaSorting: [[2, 'asc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#members-table', memberColumns);\n\n selectEvent();\n filterEvent();\n\n $('#addusertogroup').click(function(e) {\n e.preventDefault();\n var that = this;\n var displayName = $('#username').val();\n $.ajax({\n url: '/groups/' + group._id + '/addmember/' + displayName,\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({}),\n })\n .success(function(data, status, jqXHR) {\n $('#message').append(\n '<div class=\"alert alert-success\"><button class=\"close\" data-dismiss=\"alert\">x</button>' +\n 'User ' +\n displayName +\n ' has been added to this group.' +\n '</div>'\n );\n $(that).addClass('text-success');\n memberTable.fnReloadAjax();\n })\n .fail(function(jqXHR) {\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {});\n });\n\n $('button#btnRemoveMembers').click(function() {\n var activeTable = $('#members-table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No user(s) have been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html(\n 'Remove the following ' + selected.length + ' users? '\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#modal .modal-body').append(formatItemUpdate(data));\n });\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n\n $('#submit').click(function() {\n removeMembersFromModal(group._id, activeTable);\n });\n }\n });\n\n /*$('#btnRemoveMembers').click(function(e) {\n e.preventDefault();\n var that = this;\n $.ajax({\n url: '/groups/' + group._id + '/addmember/' + displayName,\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({}),\n })\n .success(function(data, status, jqXHR) {\n $('#message').append(\n '<div class=\"alert alert-success\"><button class=\"close\" data-dismiss=\"alert\">x</button>' +\n 'User ' +\n displayName +\n ' has been added to this group.' +\n '</div>'\n );\n $(that).addClass('text-success');\n memberTable.fnReloadAjax();\n })\n .fail(function(jqXHR) {\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {});\n });*/\n\n $('#btnDisplayName').click(function(e) {\n e.preventDefault();\n var that = this;\n $.ajax({\n url: '/groups/' + group._id,\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({ name: $('#displayName').val() }),\n })\n .success(function(data, status, jqXHR) {\n $('#message').append(\n '<div class=\"alert alert-success\"><button class=\"close\" data-dismiss=\"alert\">x</button>' +\n 'Display Name updated to \"' +\n $('#displayName').val() +\n '\"' +\n '</div>'\n );\n })\n .fail(function(jqXHR) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>' +\n 'Error: ' +\n jqXHR.responseText +\n '</div>'\n );\n });\n });\n});\n"
},
{
"alpha_fraction": 0.5318825840950012,
"alphanum_fraction": 0.5355516076087952,
"avg_line_length": 29.635658264160156,
"blob_id": "6ae957587a0c54bb3146abdca3e42f68982c0544",
"content_id": "87dc8ae6c6bf18c3eba3618db854d3eb8fdaf528",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7904,
"license_type": "permissive",
"max_line_length": 234,
"num_lines": 258,
"path": "/public/javascripts/users.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global selectColumn: false, useridColumn: false, fullNameNoLinkColumn: false, rolesColumn: false, lastVisitedOnColumn: false, fnGetSelected: false, selectEvent: false, filterEvent: false, sDomNoTools: false, fnAddFilterFoot: false*/\n/*global updateAjaxURL: false, prefix: false, Holder: false*/\n/*global travelerGlobal: false*/\n\nfunction inArray(name, ao) {\n var i;\n for (i = 0; i < ao.length; i += 1) {\n if (ao[i].name === name) {\n return true;\n }\n }\n return false;\n}\n\nfunction updateFromModal(cb) {\n $('#remove').prop('disabled', true);\n var number = $('#modal .modal-body div').length;\n $('#modal .modal-body div').each(function() {\n var that = this;\n $.ajax({\n url: '/users/' + that.id + '/refresh',\n type: 'GET',\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n })\n .fail(function(jqXHR) {\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n if (cb) {\n cb();\n }\n }\n });\n });\n}\n\nfunction modifyRolesFromModal(cb) {\n $('#remove').prop('disabled', true);\n var number = $('#modal .modal-body div').length;\n var roles = [];\n $('#modal-roles input:checked').each(function() {\n roles.push($(this).val());\n });\n $('#modal .modal-body div').each(function() {\n var that = this;\n $.ajax({\n url: '/users/' + that.id,\n type: 'PUT',\n contentType: 'application/json',\n data: JSON.stringify({\n roles: roles,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n })\n .fail(function(jqXHR) {\n $(that).append(' : ' + jqXHR.responseText);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n if (cb) {\n cb();\n }\n }\n });\n });\n}\n\n$(function() {\n updateAjaxURL(prefix);\n\n travelerGlobal.usernames.initialize();\n\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n\n var userColumns = [\n selectColumn,\n useridColumn,\n fullNameNoLinkColumn,\n rolesColumn,\n lastVisitedOnColumn,\n ];\n\n var userTable = $('#users-table').dataTable({\n sAjaxSource: '/users/json',\n sAjaxDataProp: '',\n fnInitComplete: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: userColumns,\n aaSorting: [[4, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#users-table', userColumns);\n selectEvent();\n filterEvent();\n\n $('#add').click(function(e) {\n e.preventDefault();\n var name = $('#username').val();\n if (inArray(name, userTable.fnGetData())) {\n //show message\n $('#message').append(\n '<div class=\"alert alert-info\"><button class=\"close\" data-dismiss=\"alert\">x</button>The user named <strong>' +\n name +\n '</strong> is already in the user list. </div>'\n );\n } else {\n let user = travelerGlobal.usernames.get(name);\n if (user === null) {\n console.error(\n 'Unknown user ' + name + '. Please select from the list.'\n );\n return;\n }\n let uid = user[0].sAMAccountName;\n $.ajax({\n url: '/users/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n name: uid,\n manager: $('#manager').prop('checked'),\n admin: $('#admin').prop('checked'),\n }),\n success: function(data, status, jqXHR) {\n $('#message').append(\n '<div class=\"alert alert-success\"><button class=\"close\" data-dismiss=\"alert\">x</button>' +\n jqXHR.responseText +\n '</div>'\n );\n userTable.fnReloadAjax();\n },\n error: function(jqXHR) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot update the share list : ' +\n jqXHR.responseText +\n '</div>'\n );\n },\n });\n }\n document.forms[0].reset();\n });\n\n $('#user-update').click(function() {\n var selected = fnGetSelected(userTable, 'row-selected');\n if (selected.length) {\n $('#modalLabel').html(\n 'Update the following ' +\n selected.length +\n ' users from the application? '\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n var data = userTable.fnGetData(row);\n $('#modal .modal-body').append(\n '<div id=\"' + data._id + '\">' + data.name + '</div>'\n );\n });\n $('#modal .modal-footer').html(\n '<button id=\"update\" class=\"btn btn-primary\">Confirm</button><button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#update').click(function(e) {\n e.preventDefault();\n $('#update').prop('disabled', true);\n updateFromModal(function() {\n userTable.fnReloadAjax();\n });\n });\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No users has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n }\n });\n\n $('#user-modify').click(function() {\n var selected = fnGetSelected(userTable, 'row-selected');\n if (selected.length) {\n $('#modalLabel').html(\n 'Modify the following ' + selected.length + \" users' role? \"\n );\n $('#modal .modal-body').empty();\n $('#modal .modal-body').append(\n '<form id=\"modal-roles\" class=\"form-inline\">' +\n '<label class=\"checkbox\"><input id=\"modal-manager\" type=\"checkbox\" value=\"manager\">manager</label> ' +\n '<label class=\"checkbox\"><input id=\"modal-reviewer\" type=\"checkbox\" value=\"reviewer\">reviewer</label> ' +\n '<label class=\"checkbox\"><input id=\"modal-admin\" type=\"checkbox\" value=\"admin\">admin</label> ' +\n '<label class=\"checkbox\"><input id=\"read_all_forms\" type=\"checkbox\" value=\"read_all_forms\">read_all_forms</label> ' +\n '<label class=\"checkbox\"><input id=\"write_active_travelers\" type=\"checkbox\" value=\"write_active_travelers\">write_active_travelers</label> ' +\n '</form>'\n );\n selected.forEach(function(row) {\n var data = userTable.fnGetData(row);\n $('#modal .modal-body').append(\n '<div id=\"' + data._id + '\">' + data.name + '</div>'\n );\n });\n $('#modal .modal-footer').html(\n '<button id=\"modify\" class=\"btn btn-primary\">Confirm</button><button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modify').click(function(e) {\n e.preventDefault();\n $('#modify').prop('disabled', true);\n modifyRolesFromModal(function() {\n userTable.fnReloadAjax();\n });\n });\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No users has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n }\n });\n});\n"
},
{
"alpha_fraction": 0.7128713130950928,
"alphanum_fraction": 0.7128713130950928,
"avg_line_length": 22.764705657958984,
"blob_id": "b853ba4c8e17d5c96ccfbded08fdffa1a2c1ba1f",
"content_id": "32530791ac1369123428b2cecbb2ac3517a8a163",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 404,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 17,
"path": "/lib/role.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const Manager = 'manager';\nconst Admin = 'admin';\nconst Reviewer = 'reviewer';\nconst Read_all_forms = 'read_all_forms';\nconst Write_active_travelers = 'write_active_travelers';\nconst Roles = [Manager, Admin, Reviewer];\nconst Permissions = [Read_all_forms, Write_active_travelers];\n\nmodule.exports = {\n Manager,\n Admin,\n Reviewer,\n Read_all_forms,\n Write_active_travelers,\n Roles,\n Permissions,\n};\n"
},
{
"alpha_fraction": 0.6215609312057495,
"alphanum_fraction": 0.6361594796180725,
"avg_line_length": 28.683332443237305,
"blob_id": "4f6514499f4242907ce05161b5ec6de007520a75",
"content_id": "756120c18de42b7861c6d6bdc3f65abb7da4d80d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1781,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 60,
"path": "/lib/review.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const mongoose = require('mongoose');\n\nconst { Reviewer } = require('./role');\n\nconst User = mongoose.model('User');\nconst logger = require('./loggers').getLogger();\n\nasync function addReviewRequest(req, res, doc) {\n const { name } = req.body;\n try {\n const reviewer = await User.findOne({\n name,\n }).exec();\n if (!reviewer) {\n return res\n .status(400)\n .send(\n `please add ${name} to etraveler user list and assign reviewer role to the user.`\n );\n }\n if (!reviewer.roles.includes(Reviewer)) {\n return res\n .status(400)\n .send(`User ${name} needs to have reviewer role in order to review.`);\n }\n await doc.requestReview(req.session.userid, reviewer);\n return res.status(201).send(`review request added for user ${name} .`);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n}\n\nasync function removeReviewRequest(req, res, doc) {\n const { requestId } = req.params;\n const ids = requestId.split(',');\n try {\n logger.info(`review request of ${ids} removed from ${doc._id}`);\n await doc.removeReviewRequest(ids[0]);\n return res.status(200).json(ids);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n}\n\nasync function addReviewResult(req, res, doc) {\n const { result = '2', comment, v } = req.body;\n try {\n await doc.addReviewResult(req.session.userid, result, comment, v);\n return res\n .status(201)\n .send(`review result from user ${req.session.userid} added.`);\n } catch (error) {\n logger.error(`failed to add review result, ${error}`);\n return res.status(500).send(error.message);\n }\n}\n\nmodule.exports = { addReviewRequest, removeReviewRequest, addReviewResult };\n"
},
{
"alpha_fraction": 0.559495210647583,
"alphanum_fraction": 0.653245210647583,
"avg_line_length": 30.39622688293457,
"blob_id": "147c25eb85d6d835f2fb6d365a7866df73b3d4e2",
"content_id": "6bb14b34c180a0384a869010932880727e423547",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1664,
"license_type": "permissive",
"max_line_length": 493,
"num_lines": 53,
"path": "/views/docs/api/travelers.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### The list of travelers\n\n- Method: GET\n- URL: https://hostname:port/apis/travelers/\n- Sample response:\n\n```json\n[\n {\n \"_id\": \"52f3f98a87d4808008000002\",\n \"createdBy\": \"liud\",\n \"createdOn\": \"2014-02-06T21:07:22.730Z\",\n \"devices\": [],\n \"sharedWith\": [],\n \"status\": 0,\n \"title\": \"update me\"\n },\n {\n \"_id\": \"52f8ed88f029d24d2b000002\",\n \"createdBy\": \"liud\",\n \"createdOn\": \"2014-02-10T15:17:28.849Z\",\n \"deadline\": \"2014-02-28T05:00:00.000Z\",\n \"devices\": [],\n \"finishedInput\": 4,\n \"sharedWith\": [],\n \"status\": 1.5,\n \"title\": \"a long traveler\",\n \"totalInput\": 36,\n \"updatedBy\": \"liud\",\n \"updatedOn\": \"2014-03-18T19:12:25.739Z\"\n },\n {\n \"title\": \"test77 update\",\n \"status\": 0,\n \"createdBy\": \"liud\",\n \"createdOn\": \"2014-03-31T15:34:27.947Z\",\n \"totalInput\": 34,\n \"finishedInput\": 0,\n \"_id\": \"53398b03951887482f000002\",\n \"sharedWith\": [],\n \"devices\": []\n },\n ...\n]\n```\n\nThe response will be a JSON array containing the list of travelers. Each traveler in the list is represented by a JSON object with traveler id, title, status, devices, createdBy, clonedBy, createdOn, deadline, updatedBy, updatedOn, sharedWith, finishedInput, and totalInput information. The traveler id can be used to retrieve more details of a traveler, https://hostname:port/apis/travelers/:id/ for the JSON representation and http://hostname:port/travelers/:id/ for the HTML representation.\n\nThe travler list can also be retrieved by a device name.\n\n- URL: https://hostname:port/apis/travelers/?device=:devicename\n where :devicename is the name of device that was assigned to the travelers.\n section#traveler\n"
},
{
"alpha_fraction": 0.41908714175224304,
"alphanum_fraction": 0.4564315378665924,
"avg_line_length": 19.08333396911621,
"blob_id": "ecdac617056ea523e263621415d45ae441b04984",
"content_id": "e9af653d11bd9df6f0a06bd3195693b0dc52ace6",
"detected_licenses": [
"OFL-1.1",
"MIT",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 241,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 12,
"path": "/docs/index_files/docs.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "$(function() {\n $('body').attr('data-spy', 'scroll');\n $('body').attr('data-target', '.sidebar');\n setTimeout(function() {\n $('#affixlist').affix({\n offset: {\n top: 270,\n bottom: 270,\n },\n });\n }, 100);\n});\n"
},
{
"alpha_fraction": 0.7882152199745178,
"alphanum_fraction": 0.7882152199745178,
"avg_line_length": 31.55555534362793,
"blob_id": "81cf0189e72f6271305c17091efdfe9c04486570",
"content_id": "c6d6fff4539f744ea5b9772cfada97ec051b1ac6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1171,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 36,
"path": "/installation-script.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "# Instalation - the one box Linux script way\n\nFor detailed deployment instructions please see https://confluence.aps.anl.gov/display/APSUCMS/Developer+Guide+for+the+Traveler+Module\n\n**Deployment of the traveler module:**\n\n```shell\n# Make a new directory to hold the traveler module and its support\nmkdir traveler\ncd traveler\ngit clone https://github.com/AdvancedPhotonSource/traveler.git distribution\ncd distribution\n# Install all of the support software\nmake support\n# Automate configuration of the application\nmake default-config\n# Navigate to configuration directory\ncd ../etc/traveler-config\n# End of output from make dev-config has a list of file(s) that need to be edited\nnano ad.json\n```\n\n**Starting the traveler module:**\n\n```shell\n# Navigate to the distirbution of the traveler module\n# When using the support mongodb, start the mongodb part of support\n./etc/init.d/traveler-mongodb start\n# It is good to start the project using node to make sure everything works properly.\nsource setup.sh\nnode app.js\n# When everything works, start traveler as daemon\n./etc/init.d/traveler-webapp start\n# Check progress of traveler-webapp\n./etc/init.d/traveler-webapp status\n```"
},
{
"alpha_fraction": 0.6042653918266296,
"alphanum_fraction": 0.6113743782043457,
"avg_line_length": 16.58333396911621,
"blob_id": "5ec6caa4e6d99c8b9300ab98448159cca52fd74e",
"content_id": "d698ca06e1655fb517bbac615712d7949a1703c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 422,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 24,
"path": "/model/share.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "var mongoose = require('mongoose');\nvar Schema = mongoose.Schema;\n\n/******\naccess := 0 // for read or\n | 1 // for write or\n | -1 // no access\n******/\nvar sharedWithUser = new Schema({\n _id: String,\n username: String,\n access: Number,\n});\n\nvar sharedWithGroup = new Schema({\n _id: String,\n groupname: String,\n access: Number,\n});\n\nmodule.exports = {\n user: sharedWithUser,\n group: sharedWithGroup,\n};\n"
},
{
"alpha_fraction": 0.785632848739624,
"alphanum_fraction": 0.785632848739624,
"avg_line_length": 57.46666717529297,
"blob_id": "8155bf57f2d7e9b08b99af8f70cbeb4f1e8de04b",
"content_id": "802a725b1a31a7e54bfb82af84b8ae72d1330e3c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 877,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 15,
"path": "/views/docs/basics/login.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Log in and out\n\nBesides this document page and the main page, all other resources are only\naccessible to **authenticated** users. Users can use their organization username\nand password to log in. Users are encouraged to log out when they do not work\nwith the application. If not log out, a user's session will expire after a\nperiod. When a user tries to access a resource URL on a browser with an expired\nsession, the user will be directed to the login page, and be redirected back to\nthe requested URL if login succeeds.\n\nWhen a page contains unsaved content and the session has expired, an error\nmessage will appear on the top of the page when the user tries to save. Log in\nthe application in a **new** tab or page, and then save the change again. Do not\nclose or navigate away from the page that contains the unsaved changes,\notherwise the unsaved changes will be lost\n"
},
{
"alpha_fraction": 0.6754098534584045,
"alphanum_fraction": 0.6761384606361389,
"avg_line_length": 25.91176414489746,
"blob_id": "2578a5bb789085189219df655226aae23b999e3d",
"content_id": "d2ebc36a5744e1446de4c9271c478790c984410d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2745,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 102,
"path": "/sbin/update_keys_on_travelers.py",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nUtility that allows updating existing traveler instances with keys that are now defined in the form.\n\nRequires a python environment with pymongo installed.\n\"\"\"\n\nimport os\nimport pprint\n\nfrom pymongo import MongoClient\n\ntry:\n\tmongo_host = os.environ['MONGO_SERVER_ADDRESS']\n\tmongo_port = os.environ['MONGO_SERVER_PORT']\n\tmongo_port = int(mongo_port)\n\tmongo_user = os.environ['MONGO_TRAVELER_USERNAME']\n\tmongo_pass_dir = os.environ['MONGO_TRAVELER_PASSWD_FILE']\nexcept KeyError, er:\n\tprint 'Missing Keys Error: %s' % er\n\tprint 'Please define environment variables: MONGO_SERVER_ADDRESS, MONGO_SERVER_PORT, MONGO_TRAVELER_USERNAME, MONGO_TRAVELER_PASSWD_FILE'\n\tprint 'Alternatively if you use traveler support mongo db, you can source etc/mongo-configuration.sh'\n\n\texit(1)\n\n\nf = open(mongo_pass_dir, 'r')\nmongo_pass = f.readline()\nmongo_pass = mongo_pass.rstrip('\\n')\n\nmongo_url = \"mongodb://%s:%s@%s:%s\" % (mongo_user, mongo_pass, mongo_host, mongo_port)\n\nclient = MongoClient(host=mongo_host, port=mongo_port, username=mongo_user, password=mongo_pass, authSource=\"traveler\")\n\ntraveler_db = client['traveler']\nforms_col = traveler_db['forms']\ntravelers_col = traveler_db['travelers']\n\n\nforms = forms_col.find()\n\nfor form in forms:\n\tprint '\\n**************************************************************\\n'\n\tsummary_information = {}\n\n\tform_id = form['_id']\n\n\tsummary_information['form'] = form_id\n\tsummary_information['travelers'] = []\n\n\ttravelers = travelers_col.find({'referenceForm': form_id})\n\n\tlabels = None\n\tkey_map = None\n\n\tif 'labels' in form:\n\t\tlabels = form['labels']\n\tif 'mapping' in form:\n\t\tkey_map = form['mapping']\n\n\tfor traveler in travelers:\n\t\tsummary_traveler = {}\n\n\t\ttraveler_id = traveler['_id']\n\t\tsummary_traveler['traveler'] = traveler_id\n\t\tsummary_traveler['adding_keys'] = False\n\t\tsummary_traveler['adding_labels'] = False\n\n\t\thtml = traveler['forms'][0]['html']\n\n\t\tnew_key_map = {}\n\t\tnew_labels = {}\n\n\t\tif key_map is not None:\n\t\t\tif 'mapping' not in traveler:\n\t\t\t\tfor key in key_map:\n\t\t\t\t\tinput_id = key_map[key]\n\n\t\t\t\t\tif html.__contains__(input_id):\n\t\t\t\t\t\tnew_key_map[key] = input_id\n\n\t\tif labels is not None:\n\t\t\tif 'labels' not in traveler:\n\t\t\t\tfor input_id in labels:\n\t\t\t\t\tif html.__contains__(input_id):\n\t\t\t\t\t\tnew_labels[input_id] = labels[input_id]\n\n\t\tif new_key_map or new_labels:\n\t\t\tupdate_fields = {}\n\t\t\tif new_key_map:\n\t\t\t\tsummary_traveler['adding_keys'] = True\n\t\t\t\tupdate_fields['mapping'] = new_key_map\n\n\t\t\tif new_labels:\n\t\t\t\tsummary_traveler['adding_labels'] = True\n\t\t\t\tupdate_fields['labels'] = new_labels\n\n\t\t\tupdate_doc = {'$set': update_fields}\n\t\t\ttravelers_col.update_one({'_id': traveler_id}, update_doc)\n\n\t\tsummary_information['travelers'].append(summary_traveler)\n\n\tpprint.pprint(summary_information)\n"
},
{
"alpha_fraction": 0.5213959217071533,
"alphanum_fraction": 0.5274200439453125,
"avg_line_length": 23.687179565429688,
"blob_id": "bfd85830887d8108b2610d108bea8e3bddadbcab",
"content_id": "163ad197942b6d5ef8c7b7f89b967771f6d7b306",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4814,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 195,
"path": "/public/javascripts/validation.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "function customCheckValidity(element) {\n var $element = $(element);\n if ($element.prop('type') === 'file' && $element.prop('required')) {\n // check history for required, only required is available for file input\n if ($element.closest('.controls').find('.input-history').length) {\n return true;\n }\n }\n return element.checkValidity();\n}\n\nfunction isValid(form) {\n var disabled = $('input,textarea', form)\n .first()\n .prop('disabled');\n if (disabled) {\n $('input,textarea', form).prop('disabled', false);\n }\n var i = 0;\n var input;\n for (i = 0; i < form.elements.length; i += 1) {\n input = form.elements[i];\n if (!customCheckValidity(input)) {\n if (disabled) {\n $('input,textarea', form).prop('disabled', true);\n }\n return false;\n }\n }\n return true;\n}\n\nfunction markValidity(element) {\n // if (element.checkValidity()) {\n if (customCheckValidity(element)) {\n $(element).removeClass('invalid');\n } else {\n $(element).addClass('invalid');\n }\n}\n\nfunction markFormValidity(form) {\n // set validity\n $('input,textarea', form).each(function() {\n var disabled = $(this).prop('disabled');\n if (disabled) {\n $(this).prop('disabled', false);\n }\n markValidity(this);\n if (disabled) {\n $(this).prop('disabled', true);\n }\n });\n}\n\nfunction validationMessage(form) {\n var disabled = $('input,textarea', form)\n .first()\n .prop('disabled');\n if (disabled) {\n $('input,textarea', form).prop('disabled', false);\n }\n let output = $('<div>');\n let last_input_name = '';\n for (let i = 0; i < form.elements.length; i += 1) {\n let p;\n let value;\n let help;\n let input = form.elements[i];\n let $input;\n let span;\n let label = [];\n let input_name = input.name;\n if (input_name === last_input_name) {\n continue;\n }\n last_input_name = input_name;\n\n p = $('<p>');\n span = $('<span class=\"validation\">');\n if (customCheckValidity(input)) {\n p.css('color', '#468847');\n span.css('color', '#468847');\n } else {\n p.css('color', '#b94a48');\n span.css('color', '#b94a48');\n }\n if (input.type === 'checkbox') {\n value = input.checked ? 'checked' : 'not checked';\n } else if (input.type === 'radio') {\n var radio_ittr = i;\n var ittr_input = input;\n value = '';\n while (ittr_input !== undefined && input_name === ittr_input.name) {\n if (value !== '') {\n value += ' / ';\n }\n if (ittr_input.checked) {\n value = ittr_input.value;\n break;\n }\n value += ittr_input.value;\n\n radio_ittr++;\n ittr_input = form.elements[radio_ittr];\n }\n } else if (input.type === 'file') {\n $input = $(input);\n if ($input.closest('.controls').find('.input-history').length) {\n value = $input\n .closest('.controls')\n .find('.input-history a')\n .text();\n } else {\n value = 'no file uploaded';\n }\n } else if (input.value === '') {\n value = 'no input from user';\n } else {\n value = input.value;\n }\n label.push(\n $(input)\n .closest('.control-group')\n .children('.control-label')\n .text()\n );\n if (input.type === 'checkbox') {\n label.push(\n $(input)\n .next()\n .text()\n );\n }\n help = $(input)\n .closest('.controls')\n .children('.help-block')\n .text();\n label.push(help);\n label = label.filter(e => e.length > 0).join(' ');\n if (customCheckValidity(input)) {\n p.html('<b>' + label + '</b>: ' + value);\n span.text('validation passed');\n } else {\n p.html(\n '<b>' +\n label +\n '</b>: ' +\n value +\n ' | Message: ' +\n input.validationMessage\n );\n span.text(input.validationMessage);\n }\n $(input)\n .closest('.controls')\n .append(span);\n output.append(p);\n }\n if (disabled) {\n $('input,textarea', form).prop('disabled', true);\n }\n return output.html();\n}\n\n/**\n * validate the discrepancy log form and show validation message for invalid input\n *\n * @param {Element} form - form HTML element\n *\n * @return {boolean} - true if the form is valid\n */\nfunction validateLog(form) {\n var i = 0;\n var input;\n var valid = true;\n for (i = 0; i < form.elements.length; i += 1) {\n input = form.elements[i];\n $(input).removeClass('invalid');\n $(input)\n .closest('.controls')\n .find('span.validation')\n .remove();\n if (!input.checkValidity()) {\n valid = false;\n $(input).addClass('invalid');\n $(input)\n .closest('.controls')\n .append(\n '<span class=\"validation\">' + input.validationMessage + '</span>'\n );\n }\n }\n return valid;\n}\n"
},
{
"alpha_fraction": 0.6104668378829956,
"alphanum_fraction": 0.6164138913154602,
"avg_line_length": 27.2605037689209,
"blob_id": "eac1e9cd7bff291894ed84c1a841bbc1fa51b540",
"content_id": "c6033677516154b61836b088a4b2eb842ef0a2ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3363,
"license_type": "permissive",
"max_line_length": 324,
"num_lines": 119,
"path": "/public/javascripts/binder-viewer.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*eslint max-nested-callbacks: [2, 4]*/\n\n/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false, moment */\n/*global sColumn, pColumn, vColumn, cColumn, travelerLinkColumn, aliasColumn, travelerProgressColumn, ownerColumn, deviceColumn, tagsColumn, manPowerColumn, sDomNoTools, fnAddFilterFoot, selectColumn, fnSelectAll, fnDeselect, fnGetSelected, selectEvent, filterEvent, keysColumn*/\n/*global ajax401: false, updateAjaxURL: false, disableAjaxCache: false, prefix: false, Holder*/\n\nfunction noneSelectedModal() {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No traveler has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n}\n\n$(function() {\n updateAjaxURL(prefix);\n ajax401(prefix);\n disableAjaxCache();\n\n var workAoColumns = [\n selectColumn,\n workLinkColumn,\n sColumn,\n cColumn,\n titleColumn,\n ownerColumn,\n deviceColumn,\n tagsColumn,\n keysColumn,\n manPowerColumn,\n travelerProgressColumn,\n ];\n fnAddFilterFoot('#work-table', workAoColumns);\n var worksTable = $('#work-table').dataTable({\n bAutoWidth: false,\n bPaginate: false,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, -1],\n [10, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: workAoColumns,\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n aaSorting: [\n [2, 'asc'],\n [3, 'asc'],\n ],\n sDom: sDomNoTools,\n });\n\n $.ajax({\n url: './works/json',\n type: 'GET',\n dataType: 'json',\n })\n .done(function(data) {\n worksTable.fnAddData(data.works);\n worksTable.fnDraw();\n $('#value-progress').html(data.valueProgress);\n $('#traveler-progress').html(data.travelerProgress);\n $('#input-progress').html(data.inputProgress);\n })\n .always();\n\n $('#sort').click(function() {\n worksTable.fnSort([\n [1, 'asc'],\n [2, 'asc'],\n ]);\n });\n\n $('span.time').each(function() {\n $(this).text(\n moment($(this).text()).format('dddd, MMMM Do YYYY, h:mm:ss a')\n );\n });\n\n $('button.select-all').click(function() {\n var activeTable = worksTable;\n fnSelectAll(activeTable, 'row-selected', 'select-row', true);\n });\n\n $('button.deselect-all').click(function() {\n var activeTable = worksTable;\n fnDeselect(activeTable, 'row-selected', 'select-row');\n });\n\n $('#report').click(function() {\n var activeTable = worksTable;\n var selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n noneSelectedModal();\n return;\n }\n $('#report-form').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#report-form').append(\n $('<input type=\"hidden\"/>').attr({\n name: 'travelers[]',\n value: data._id,\n })\n );\n });\n $('#report-form').submit();\n });\n\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.5291828513145447,
"alphanum_fraction": 0.6575875282287598,
"avg_line_length": 26.934782028198242,
"blob_id": "2281d55cf38519c2efa0d4463e9b51d3d5067b97",
"content_id": "dffd1a6b75599dc4f3de8d959a615cfb376a9d84",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1285,
"license_type": "permissive",
"max_line_length": 385,
"num_lines": 46,
"path": "/views/docs/api/traveler.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### The details of a traveler\n\n- Method: GET\n- URL: https://hostname:port/apis/travelers/:id/\n where :id is the id of the traveler to be retrieved\n- Sample response:\n\n```json\n{\n \"__v\": 26,\n \"_id\": \"53bbf46e2ace2f7f111d76c8\",\n \"createdBy\": \"liud\",\n \"createdOn\": \"2014-07-08T13:38:54.529Z\",\n \"description\": \"\",\n \"finishedInput\": 2,\n \"referenceForm\": \"5283aa947185189f61000001\",\n \"status\": 1,\n \"title\": \"test validation\",\n \"totalInput\": 7,\n \"updatedBy\": \"liud\",\n \"updatedOn\": \"2014-08-12T13:56:02.090Z\",\n \"archived\": false,\n \"notes\": [\n \"53e2380cd48af61751d91394\",\n \"53e38b47d48af61751d91395\",\n \"53e39121d48af61751d91396\",\n ...\n ],\n \"data\": [\n \"53bbf6b52ace2f7f111d76ca\",\n \"53bbf6cd2ace2f7f111d76cb\",\n ...\n ],\n \"activeForm\": 0,\n \"forms\": [\n {\n \"html\": \"...\",\n \"_id\": \"53bbf46e2ace2f7f111d76c9\"\n }\n ],\n \"sharedWith\": [],\n \"devices\": []\n}\n```\n\nThe traveler details JSON object contains more information than the object in a traveler list. The \"forms\" property contains a list of the forms that were used in this traveler. Currently, only one form is allowed for a traveler. The \"data\" property contains the data id's that were collected in the traveler. The \"notes\" property holds the note id's that were inputed in the traveler.\n"
},
{
"alpha_fraction": 0.7002341747283936,
"alphanum_fraction": 0.7002341747283936,
"avg_line_length": 41.70000076293945,
"blob_id": "b8958ef2f1b33e1ca09d7b7de8d1a065cb3fe65b",
"content_id": "0842e58124d8f89da53734d6e25af99646e9dfb9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 427,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 10,
"path": "/template.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*****\n * update root.templatizer to root.spec in spec.js,\n * update root.templatizer to root.input in input.js,\n * every time you update the jade files in /builderview or /inputview and\n * generate the js lib files.\n *****/\n\nvar templatizer = require('templatizer');\ntemplatizer(__dirname + '/builderview', __dirname + '/public/builder/spec.js');\ntemplatizer(__dirname + '/inputview', __dirname + '/public/builder/input.js');\n"
},
{
"alpha_fraction": 0.581039309501648,
"alphanum_fraction": 0.5875867009162903,
"avg_line_length": 23.930217742919922,
"blob_id": "7b6c48f4bbe8c92f30561f40445139aa764eaae1",
"content_id": "d8ed2137b687c2a5be3e6dd2b1add7fdd63db999",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 41085,
"license_type": "permissive",
"max_line_length": 331,
"num_lines": 1648,
"path": "/public/javascripts/table.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* global moment: false */\n/* global prefix: false, linkTarget: false, userid */\n\nfunction formatDate(date) {\n return date ? moment(date).fromNow() : '';\n}\n\nfunction formatDateLong(date) {\n return date ? moment(date).format('YYYY-MM-DD HH:mm:ss') : '';\n}\n\nfunction selectEvent() {\n $('tbody').on('click', 'input.select-row', function(e) {\n if ($(this).prop('checked')) {\n $(e.target)\n .closest('tr')\n .addClass('row-selected');\n } else {\n $(e.target)\n .closest('tr')\n .removeClass('row-selected');\n }\n });\n}\n\nfunction selectMultiEvent(table) {\n $(`${table} tbody`).on('click', 'input.select-row', function(e) {\n const tr = $(e.target).closest('tr');\n if ($(tr).hasClass('row-selected')) {\n $(tr).removeClass('row-selected');\n } else {\n $(tr).addClass('row-selected');\n }\n });\n}\n\nfunction selectOneEvent(table) {\n $(`${table} tbody`).on('click', 'input.select-row', function(e) {\n if ($(this).prop('checked')) {\n $(`${table} tr.row-selected`).removeClass('row-selected');\n $(`${table} input.select-row`)\n .not(this)\n .prop('checked', false);\n $(e.target)\n .closest('tr')\n .addClass('row-selected');\n } else {\n $(e.target)\n .closest('tr')\n .removeClass('row-selected');\n }\n });\n}\n\nfunction filterEvent() {\n $('.filter').on('keyup', 'input', function(e) {\n const table = $(this).closest('table');\n const th = $(this).closest('th');\n const filter = $(this).closest('.filter');\n let index;\n if (filter.is('thead')) {\n index = $('thead.filter th', table).index(th);\n $(`tfoot.filter th:nth-child(${index + 1}) input`, table).val(this.value);\n } else {\n index = $('tfoot.filter th', table).index(th);\n $(`thead.filter th:nth-child(${index + 1}) input`, table).val(this.value);\n }\n table.dataTable().fnFilter(this.value, index);\n });\n}\n\nfunction dateColumn(title, key) {\n return {\n sTitle: title,\n mData(source, type, val) {\n if (type === 'sort') {\n return source[key];\n }\n return formatDate(source[key]);\n },\n sDefaultContent: '',\n };\n}\n\nfunction longDateColumn(title, key) {\n return {\n sTitle: title,\n mData(source, type, val) {\n if (type === 'sort') {\n return source[key];\n }\n return formatDateLong(source[key]);\n },\n sDefaultContent: '',\n bFilter: true,\n };\n}\n\nfunction personColumn(title, key) {\n return {\n sTitle: title,\n mData: key,\n sDefaultContent: '',\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data;\n }\n if (data) {\n return `<img class=\"user\" data-src=\"holder.js/27x40?size=20&text=${data\n .substr(0, 1)\n .toUpperCase()}\">`;\n }\n return '';\n },\n bFilter: true,\n };\n}\n\nfunction keyValueColumn(collection, key) {\n return {\n sTitle: key,\n mData: `${collection}.${key}.value`,\n sDefaultContent: '',\n bFilter: true,\n };\n}\n\nfunction keyLabelColumn(key) {\n return {\n sTitle: 'label',\n mData: `user_defined.${key}.label`,\n sDefaultContent: '',\n bFilter: true,\n };\n}\n\nfunction valueLabel(data) {\n let output = '';\n if (data.value) {\n output += `<span class=\"input-value\">${data.value}</span>`;\n if (data.label) {\n output += `<span class=\"input-label\"> (${data.label})</span>`;\n }\n }\n return output;\n}\n\nfunction keyValueLableColumn(key) {\n return {\n sTitle: key,\n mData: `user_defined.${key}`,\n sDefaultContent: '',\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data.value;\n }\n if (data) {\n return valueLabel(data);\n }\n return '';\n },\n bFilter: true,\n };\n}\n\nfunction personNameColumn(title, key) {\n return {\n sTitle: title,\n mData: key,\n sDefaultContent: '',\n mRender(data, type, full) {\n return `<a href = \"/usernames/${data}\" target=\"${linkTarget}\" >${data}</a>`;\n },\n bFilter: true,\n };\n}\n\nfunction fnWrap(oTableLocal) {\n $(oTableLocal.fnSettings().aoData).each(function() {\n $(this.nTr).removeClass('nowrap');\n });\n oTableLocal.fnAdjustColumnSizing();\n}\n\nfunction fnUnwrap(oTableLocal) {\n $(oTableLocal.fnSettings().aoData).each(function() {\n $(this.nTr).addClass('nowrap');\n });\n oTableLocal.fnAdjustColumnSizing();\n}\n\nfunction fnGetSelected(oTableLocal, selectedClass) {\n const aReturn = [];\n let i;\n const aTrs = oTableLocal.fnGetNodes();\n\n for (i = 0; i < aTrs.length; i += 1) {\n if ($(aTrs[i]).hasClass(selectedClass)) {\n aReturn.push(aTrs[i]);\n }\n }\n return aReturn;\n}\n\nfunction fnGetSelectedInPage(oTableLocal, selectedClass, current) {\n if (current) {\n return oTableLocal.$(`tr.${selectedClass}`, {\n page: 'current',\n });\n }\n return oTableLocal.$(`tr.${selectedClass}`);\n}\n\nfunction fnDeselect(oTableLocal, selectedClass, checkboxClass) {\n const aTrs = oTableLocal.fnGetNodes();\n let i;\n\n for (i = 0; i < aTrs.length; i += 1) {\n if ($(aTrs[i]).hasClass(selectedClass)) {\n $(aTrs[i]).removeClass(selectedClass);\n $(aTrs[i])\n .find(`input.${checkboxClass}:checked`)\n .prop('checked', false);\n }\n }\n}\n\nfunction fnSelectAll(oTableLocal, selectedClass, checkboxClass, current) {\n fnDeselect(oTableLocal, selectedClass, checkboxClass);\n let rows;\n let i;\n if (current) {\n rows = oTableLocal.$('tr', {\n page: 'current',\n // When page is 'current', the following two options are forced:\n // 'filter':'applied' and 'order':'current'\n });\n } else {\n rows = oTableLocal.$('tr');\n }\n\n for (i = 0; i < rows.length; i += 1) {\n $(rows[i]).addClass(selectedClass);\n $(rows[i])\n .find(`input.${checkboxClass}`)\n .prop('checked', true);\n }\n}\n\nfunction fnSetDeselect(nTr, selectedClass, checkboxClass) {\n if ($(nTr).hasClass(selectedClass)) {\n $(nTr).removeClass(selectedClass);\n $(nTr)\n .find(`input.${checkboxClass}:checked`)\n .prop('checked', false);\n }\n}\n\nfunction fnSetColumnsVis(oTableLocal, columns, show) {\n columns.forEach(function(e, i, a) {\n oTableLocal.fnSetColumnVis(e, show);\n });\n}\n\nfunction fnAddFilterFoot(sTable, aoColumns) {\n const tr = $('<tr role=\"row\">');\n aoColumns.forEach(function(c) {\n if (c.bFilter) {\n tr.append(\n `<th><input type=\"text\" placeholder=\"${c.sTitle}\" style=\"width:80%;\" autocomplete=\"off\"></th>`\n );\n } else {\n tr.append('<th></th>');\n }\n });\n $(sTable).append($('<tfoot class=\"filter\">').append(tr));\n}\n\nfunction fnAddFilterHead(sTable, aoColumns) {\n const tr = $('<tr role=\"row\">');\n aoColumns.forEach(function(c) {\n if (c.bFilter) {\n tr.append(\n `<th><input type=\"text\" placeholder=\"${c.sTitle}\" style=\"width:80%;\" autocomplete=\"off\"></th>`\n );\n } else {\n tr.append('<th></th>');\n }\n });\n $(sTable).append($('<thead class=\"filter\">').append(tr));\n}\n\nfunction formatTravelerStatus(s) {\n const status = {\n '1': 'active',\n '1.5': 'submitted for completion',\n '2': 'completed',\n '3': 'frozen',\n '4': 'archived',\n '0': 'initialized',\n };\n if (status[s.toString()]) {\n return status[s.toString()];\n }\n return 'unknown';\n}\n\n$.fn.dataTableExt.oApi.fnAddDataAndDisplay = function(oSettings, aData) {\n /* Add the data */\n const iAdded = this.oApi._fnAddData(oSettings, aData);\n const nAdded = oSettings.aoData[iAdded].nTr;\n\n /* Need to re-filter and re-sort the table to get positioning correct, not perfect\n * as this will actually redraw the table on screen, but the update should be so fast (and\n * possibly not alter what is already on display) that the user will not notice\n */\n this.oApi._fnReDraw(oSettings);\n\n /* Find it's position in the table */\n let iPos = -1;\n let i;\n let iLen;\n\n for (i = 0, iLen = oSettings.aiDisplay.length; i < iLen; i += 1) {\n if (oSettings.aoData[oSettings.aiDisplay[i]].nTr === nAdded) {\n iPos = i;\n break;\n }\n }\n\n /* Get starting point, taking account of paging */\n if (iPos >= 0) {\n oSettings._iDisplayStart =\n Math.floor(i / oSettings._iDisplayLength) * oSettings._iDisplayLength;\n this.oApi._fnCalculateEnd(oSettings);\n }\n\n this.oApi._fnDraw(oSettings);\n return {\n nTr: nAdded,\n iPos: iAdded,\n };\n};\n\n$.fn.dataTableExt.oApi.fnDisplayRow = function(oSettings, nRow) {\n // Account for the \"display\" all case - row is already displayed\n if (oSettings._iDisplayLength === -1) {\n return;\n }\n\n // Find the node in the table\n let iPos = -1;\n let i;\n let iLen;\n for (i = 0, iLen = oSettings.aiDisplay.length; i < iLen; i += 1) {\n if (oSettings.aoData[oSettings.aiDisplay[i]].nTr === nRow) {\n iPos = i;\n break;\n }\n }\n\n // Alter the start point of the paging display\n if (iPos >= 0) {\n oSettings._iDisplayStart =\n Math.floor(i / oSettings._iDisplayLength) * oSettings._iDisplayLength;\n this.oApi._fnCalculateEnd(oSettings);\n }\n\n this.oApi._fnDraw(oSettings);\n};\n\nconst selectColumn = {\n sTitle: '',\n sDefaultContent:\n '<label class=\"checkbox\"><input type=\"checkbox\" class=\"select-row\"></label>',\n sSortDataType: 'dom-checkbox',\n asSorting: ['desc', 'asc'],\n};\n\nconst userIdColumn = {\n sTitle: 'User Id',\n mRender(data) {\n return `<label>${data}</label>`;\n },\n mData: '_id',\n bSortable: true,\n sWidth: '30px',\n};\n\nconst previewColumn = {\n sTitle: '',\n mData: '_id',\n bSortable: false,\n mRender(data) {\n return `<a data-toggle=\"tooltip\" title=\"preview the traveler with this form\" class=\"preview\" id=\"${data}\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n },\n sWidth: '25px',\n};\n\nconst formExploreColumn = {\n sTitle: '',\n mData: '_id',\n bSortable: false,\n mRender(data) {\n return `<a data-toggle=\"tooltip\" title=\"show the form\" class=\"preview\" id=\"${data}\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n },\n sWidth: '25px',\n};\n\nconst removeColumn = {\n sTitle: '',\n mData: '_id',\n bSortable: false,\n mRender(data) {\n return `<a data-toggle=\"tooltip\" title=\"remove the item\" class=\"remove text-warning\" id=\"${data}\"><i class=\"fa fa-trash fa-lg\"></i></a>`;\n },\n};\n\nconst referenceFormLinkColumn = {\n sTitle: 'Ref',\n mData: 'reference',\n mRender(data) {\n return `<a href=\"${prefix}/forms/${data}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the form\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n },\n bSortable: false,\n sWidth: '45px',\n};\n\nconst formColumn = {\n sTitle: 'Link',\n mData: '_id',\n mRender(data) {\n return `<a href=\"${prefix}/forms/${data}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the form\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n },\n bSortable: false,\n sWidth: '45px',\n};\n\nconst releasedFormColumn = {\n sTitle: 'Link',\n mData: '_id',\n mRender(data) {\n return `<a href=\"${prefix}/released-forms/${data}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the released form\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n },\n bSortable: false,\n sWidth: '45px',\n};\n\nconst aliasColumn = {\n sTitle: 'Alias',\n mData: 'alias',\n bFilter: true,\n};\n\nconst activatedOnColumn = {\n sTitle: 'Activated',\n mData(source, type) {\n const a = source.activatedOn;\n if (type === 'sort') {\n return a[a.length - 1];\n }\n return formatDate(a[a.length - 1]);\n },\n sDefaultContent: '',\n};\n\nconst idColumn = {\n sTitle: '',\n mData: '_id',\n bVisible: false,\n};\n\nconst formLinkColumn = {\n sTitle: '',\n mData: '_id',\n mRender(data) {\n return `<a href=\"${prefix}/forms/${data}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the form\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst releasedFormLinkColumn = {\n sTitle: '',\n mData: '_id',\n mRender(data) {\n return `<a href=\"${prefix}/released-forms/${data}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the form\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst formConfigLinkColumn = {\n sTitle: '',\n mData: '_id',\n mRender(data, type, full) {\n return `<a href=\"${prefix}/forms/${data}/config\" data-toggle=\"tooltip\" title=\"config the form\"><i class=\"fa fa-gear fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nfunction cloneForm(id, type, title) {\n $.ajax({\n url: `/${type}/${id}/clone`,\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n title,\n }),\n })\n .done(function(d) {\n $('#message').append(\n `${'<div class=\"alert alert-success\">' +\n '<button class=\"close\" data-dismiss=\"alert\">x</button>The form was cloned. '}${d}</div>`\n );\n })\n .fail(function(jqXHR) {\n $('#message').append(\n `${'<div class=\"alert alert-error\">' +\n '<button class=\"close\" data-dismiss=\"alert\">x</button>'}${\n jqXHR.responseText\n }.</div>`\n );\n });\n}\n\nfunction cloneModal(id, type) {\n $('#modalLabel').html('Specify the title');\n $('#modal .modal-body').empty();\n\n $('#modal .modal-body').append(\n '<div><input type=\"text\" value=\"clone\"></div>'\n );\n\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n cloneForm(id, type, $('#modal input').val());\n });\n}\n\nfunction cloneColumn(type) {\n return {\n sTitle: 'Clone',\n mData: '_id',\n mRender(data) {\n return `<a href=\"#\" onclick=\"cloneModal('${data}', '${type}');\" data-toggle=\"tooltip\" title=\"clone the form\"><i class=\"fa fa-copy fa-lg\"></i></a>`;\n },\n bSortable: false,\n };\n}\n\nconst formCloneColumn = cloneColumn('forms');\n\nconst releasedFormCloneColumn = cloneColumn('released-forms');\n\nconst formShareLinkColumn = {\n sTitle: '',\n mData(source) {\n if (source.publicAccess >= 0) {\n return `<a href=\"${prefix}/forms/${source._id}/share/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"share the form\" class=\"text-success\"><i class=\"fa fa-users fa-lg\"></i></a>`;\n }\n return `<a href=\"${prefix}/forms/${source._id}/share/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"share the form\"><i class=\"fa fa-users fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst formReviewLinkColumn = {\n sTitle: '',\n mData(source) {\n return `<a href=\"${prefix}/forms/${source._id}/review/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"reviews for the form\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst reviewerIdColumn = personColumn('Reviewer', '_id');\n\nconst requestedOnColumn = dateColumn('Requested on', 'requestedOn');\n\nconst reviewRequestedOnColumn = {\n sTitle: 'Requested on',\n mData(source, type) {\n if (!source.__review) {\n return '';\n }\n const requests = source.__review.reviewRequests;\n if (!requests) {\n return '';\n }\n const request = requests.find(function(r) {\n return r._id === userid;\n });\n if (!request) {\n return '';\n }\n return formatDate(request.requestedOn);\n },\n bFilter: true,\n};\n\nconst reviewRequestedByColumn = {\n sTitle: 'Requested by',\n mData(source, type) {\n if (!source.__review) {\n return '';\n }\n const requests = source.__review.reviewRequests;\n if (!requests) {\n return '';\n }\n const request = requests.find(function(r) {\n return r._id === userid;\n });\n if (!request) {\n return '';\n }\n return `<a target=\"${linkTarget}\" href=\"/users/${\n request.requestedBy\n }\"><img class=\"user\" data-src=\"holder.js/27x40?size=20&text=${request.requestedBy\n .substr(0, 1)\n .toUpperCase()}\" title=\"${request.requestedBy}\"></a>`;\n },\n bFilter: true,\n};\n\nconst reviewersColumn = {\n sTitle: 'Reviewers',\n mData(source, type) {\n if (source.__review) {\n const requests = source.__review.reviewRequests;\n if (!requests) {\n return '';\n }\n if (requests.length === 0) {\n return '';\n }\n const reviews = requests.map(function(r) {\n if (type === 'filter' || type === 'sort') {\n return r._id;\n }\n return `<a target=\"${linkTarget}\" href=\"/users/${r._id}\"><img class=\"user\" data-src=\"holder.js/27x40?size=20&text=${r._id.substr(0, 1).toUpperCase()}\" title=\"${r._id}\"></a>`;\n });\n if (type === 'filter' || type === 'sort') {\n return reviews.join('; ');\n }\n return reviews.join(' ');\n }\n return '';\n },\n bFilter: true,\n};\n\nconst firstReviewRequestedOnColumn = {\n sTitle: 'Requested on',\n mData(source, type) {\n if (source.__review) {\n const requests = source.__review.reviewRequests;\n if (!requests) {\n return '';\n }\n if (requests.length === 0) {\n return '';\n }\n const first = requests[0];\n if (type === 'sort') {\n return first.requestedOn;\n }\n return formatDate(first.requestedOn);\n }\n return '';\n },\n};\n\nconst createdOnColumn = dateColumn('Created', 'createdOn');\nconst createdByColumn = personColumn('Created by', 'createdBy');\nconst ownerColumn = {\n sTitle: 'Owner',\n sDefaultContent: '',\n mData(source, type) {\n const owner = source.owner || source.createdBy;\n if (type === 'sort' || type === 'filter') {\n return owner;\n }\n if (owner) {\n return `<a target=\"${linkTarget}\" href=\"/users/${owner}\"><img class=\"user\" data-src=\"holder.js/27x40?size=20&text=${owner\n .substr(0, 1)\n .toUpperCase()}\" title=\"${owner}\"></a>`;\n }\n return '';\n },\n bFilter: true,\n};\n\nconst clonedByColumn = personColumn('Cloned by', 'clonedBy');\n\nconst updatedOnColumn = dateColumn('Updated', 'updatedOn');\nconst updatedByColumn = personColumn('Updated by', 'updatedBy');\n\nconst releasedOnColumn = longDateColumn('Released', 'releasedOn');\nconst releasedByColumn = personColumn('Released by', 'releasedBy');\n\nconst transferredOnColumn = dateColumn('transferred', 'transferredOn');\n\nconst archivedOnColumn = dateColumn('Archived', 'archivedOn');\nconst archivedByColumn = personColumn('Archived by', 'archivedBy');\n\nconst deadlineColumn = dateColumn('Deadline', 'deadline');\n\nconst tagsColumn = {\n sTitle: 'Tags',\n sDefaultContent: '',\n mData(source, type, val) {\n return source.tags || [];\n },\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data.join(' ');\n }\n return data.join('; ');\n },\n bFilter: true,\n};\n\nconst keysColumn = {\n sTitle: 'Reporting IDs',\n sDefaultContent: '',\n mData(source, type, val) {\n if (source.mapping) {\n return Object.keys(source.mapping);\n }\n return [];\n },\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data.join(' ');\n }\n return data.join('; ');\n },\n bAutoWidth: false,\n sWidth: '210px',\n bFilter: true,\n};\n\nconst reviewResultColumn = {\n sTitle: 'Latest review result',\n sDefaultContent: '',\n mData: 'result',\n mRender(data) {\n if (!data) {\n return 'not reported';\n }\n if (data.result === '1') {\n return 'approved';\n }\n if (data.result === '2') {\n return 'comment';\n }\n return '';\n },\n bFilter: true,\n};\n\nconst commentColumn = {\n sTitle: 'Comment',\n sDefaultContent: '',\n mData: 'comment',\n bFilter: true,\n};\n\nconst titleColumn = {\n sTitle: 'Title',\n sDefaultContent: '',\n mData: 'title',\n bFilter: true,\n};\n\nconst versionColumn = {\n sTitle: 'Ver',\n mData: '_v',\n sDefaultContent: '',\n bFilter: true,\n sWidth: '45px',\n};\n\nconst releasedFormVersionColumn = {\n sTitle: 'Ver',\n mData: 'ver',\n sDefaultContent: '',\n bFilter: true,\n sWidth: '45px',\n};\n\nconst formTypeColumn = {\n sTitle: 'Type',\n mData: 'formType',\n sDefaultContent: 'normal',\n bFilter: true,\n};\n\nfunction formatFormStatus(s) {\n const status = {\n '0': 'draft',\n '0.5': 'under review',\n '1': 'closed',\n '2': 'archived',\n };\n if (status[s.toString()]) {\n return status[s.toString()];\n }\n return 'unknown';\n}\n\nconst formStatusColumn = {\n sTitle: 'Status',\n mData(source, type, val) {\n return formatFormStatus(source.status);\n },\n bFilter: true,\n};\n\nfunction formatReleasedFormStatus(s) {\n const status = {\n '1': 'released',\n '2': 'archived',\n };\n if (status[s.toString()]) {\n return status[s.toString()];\n }\n return 'unknown';\n}\n\nconst releasedFormStatusColumn = {\n sTitle: 'Status',\n mData(source, type, val) {\n return formatReleasedFormStatus(source.status);\n },\n bFilter: true,\n};\n\nconst travelerLinkColumn = {\n sTitle: '',\n mData(source, type, val) {\n if (source.hasOwnProperty('url')) {\n return `<a href=\"${source.url}\" data-toggle=\"tooltip\" title=\"go to the traveler\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n }\n if (source.hasOwnProperty('_id')) {\n return `<a href=\"${prefix}/travelers/${source._id}/\" data-toggle=\"tooltip\" title=\"go to the traveler\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n }\n return 'unknown';\n },\n bSortable: false,\n};\n\nconst travelerConfigLinkColumn = {\n sTitle: '',\n mData: '_id',\n mRender(data, type, full) {\n return `<a href=\"${prefix}/travelers/${data}/config\" data-toggle=\"tooltip\" title=\"config the traveler\"><i class=\"fa fa-gear fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst travelerShareLinkColumn = {\n sTitle: '',\n mData(source) {\n if (source.publicAccess >= 0) {\n return `<a href=\"${prefix}/travelers/${source._id}/share/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"share the traveler\" class=\"text-success\"><i class=\"fa fa-users fa-lg\"></i></a>`;\n }\n return `<a href=\"${prefix}/travelers/${source._id}/share/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"share the traveler\"><i class=\"fa fa-users fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst binderLinkColumn = {\n sTitle: '',\n mData(source, type, val) {\n if (source.hasOwnProperty('url')) {\n return `<a href=\"${source.url}\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the binder\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n }\n if (source.hasOwnProperty('_id')) {\n return `<a href=\"${prefix}/binders/${source._id}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the binder\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n }\n return 'unknown';\n },\n bSortable: false,\n};\n\nconst binderConfigLinkColumn = {\n sTitle: '',\n mData: '_id',\n mRender(data, type, full) {\n return `<a href=\"${prefix}/binders/${data}/config\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"config the binder\"><i class=\"fa fa-gear fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst binderShareLinkColumn = {\n sTitle: '',\n mData(source) {\n if (source.publicAccess >= 0) {\n return `<a href=\"${prefix}/binders/${source._id}/share/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"share the binder\" class=\"text-success\"><i class=\"fa fa-users fa-lg\"></i></a>`;\n }\n return `<a href=\"${prefix}/binders/${source._id}/share/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"share the binder\"><i class=\"fa fa-users fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nconst workLinkColumn = {\n sTitle: '',\n mData(source, type, val) {\n if (source.hasOwnProperty('url')) {\n return `<a href=\"${source.url}\" data-toggle=\"tooltip\" title=\"go to the work\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n }\n if (source.hasOwnProperty('_id')) {\n if (source.refType === 'traveler') {\n return `<a href=\"${prefix}/travelers/${source._id}/\" data-toggle=\"tooltip\" title=\"go to the traveler\"><i class=\"fa fa-edit fa-lg\"></i></a>`;\n }\n if (source.refType === 'binder') {\n return `<a href=\"${prefix}/binders/${source._id}/\" target=\"${linkTarget}\" data-toggle=\"tooltip\" title=\"go to the binder\"><i class=\"fa fa-eye fa-lg\"></i></a>`;\n }\n }\n return 'unknown';\n },\n bSortable: false,\n};\n\nconst deviceTravelerLinkColumn = {\n sTitle: '',\n mData: 'inventoryId',\n mRender(data, type, full) {\n return `<a href=\"${prefix}/currenttravelers/?device=${data}\" data-toggle=\"tooltip\" title=\"travelers for this device\"><i class=\"fa fa-search fa-lg\"></i></a>`;\n },\n bSortable: false,\n};\n\nfunction progressBar(active, finished, inProgress, text, width) {\n const w = width || '100px';\n const t = text || '';\n const bar = $(\n `<div class=\"progress\" style=\"width: ${w};\"><div class=\"bar bar-success\" style=\"width:${finished}%;\"></div><div class=\"bar bar-info\" style=\"width:${inProgress}%;\"></div><div class=\"progress-value\">${t}</div></div>`\n );\n if (active) {\n bar.addClass('active').addClass('progress-striped');\n }\n return bar[0].outerHTML;\n}\n\nconst travelerProgressColumn = {\n sTitle: 'Estimated progress',\n bSortable: true,\n sType: 'numeric',\n bAutoWidth: false,\n sWidth: '105px',\n mData(source, type) {\n if (source.status === 2) {\n if (type === 'sort') {\n return 1;\n }\n return progressBar(false, 100, 0);\n }\n\n if (!source.hasOwnProperty('totalInput')) {\n if (type === 'sort') {\n return 0;\n }\n return 'unknown';\n }\n\n if (source.totalInput === 0) {\n if (type === 'sort') {\n return 0;\n }\n return progressBar(source.status === 1, 0, 0);\n }\n\n if (!source.hasOwnProperty('finishedInput')) {\n if (type === 'sort') {\n return 0;\n }\n return 'unknown';\n }\n\n const inProgress = Math.floor(\n (source.finishedInput / source.totalInput) * 100\n );\n\n return progressBar(\n source.status === 1,\n 0,\n inProgress,\n `${source.finishedInput} / ${source.totalInput}`\n );\n },\n};\n\nconst workProgressColumn = {\n sTitle: 'Estimated progress',\n bSortable: true,\n sType: 'numeric',\n bAutoWidth: false,\n sWidth: '210px',\n mData(source, type) {\n const w = '200px';\n if (source.status === 2) {\n if (type === 'sort') {\n return 1;\n }\n return progressBar(\n false,\n 100,\n 0,\n `${source.value} + 0 / ${source.value}`,\n w\n );\n }\n\n const { inProgress } = source;\n let finished = 0;\n\n if (source.hasOwnProperty('finished')) {\n finished = source.finished;\n }\n\n if (type === 'sort') {\n return finished + inProgress;\n }\n\n return progressBar(\n source.status === 1,\n finished * 100,\n inProgress * 100,\n `${Math.round(finished * source.value)} + ${Math.round(\n inProgress * source.value\n )} / ${Math.round(source.value)}`,\n w\n );\n },\n};\n\nconst binderWorkProgressColumn = {\n sTitle: 'Work progress',\n bSortable: true,\n sType: 'numeric',\n bAutoWidth: false,\n sWidth: '105px',\n mData(source, type, val) {\n if (source.status === 2) {\n if (type === 'sort') {\n return 1;\n }\n return progressBar(false, 100, 0);\n }\n\n if (source.totalWork === 0) {\n if (type === 'sort') {\n return 0;\n }\n return progressBar(false, 0, 0);\n }\n\n const inProgress = source.inProgressWork / source.totalWork;\n const finished = source.finishedWork / source.totalWork;\n\n if (type === 'sort') {\n return finished + inProgress;\n }\n\n return progressBar(\n source.status === 1,\n finished * 100,\n inProgress * 100,\n `${source.finishedWork} / ${source.totalWork} + ${source.finishedInput} / ${source.totalInput}`\n );\n },\n};\n\nconst binderValueProgressColumn = {\n sTitle: 'Value progress',\n bSortable: true,\n sType: 'numeric',\n bAutoWidth: false,\n sWidth: '105px',\n mData(source, type, val) {\n if (source.status === 2) {\n if (type === 'sort') {\n return 1;\n }\n return progressBar(false, 100, 0);\n }\n\n if (source.totalValue === 0) {\n if (type === 'sort') {\n return 0;\n }\n return progressBar(false, 0, 0);\n }\n\n const inProgress = source.inProgressValue / source.totalValue;\n const finished = source.finishedValue / source.totalValue;\n\n if (type === 'sort') {\n return finished + inProgress;\n }\n\n return progressBar(\n source.status === 1,\n finished * 100,\n inProgress * 100,\n `${Math.round(source.finishedValue)} + ${Math.round(\n source.inProgressValue\n )} / ${Math.round(source.totalValue)}`\n );\n },\n};\n\nconst deviceColumn = {\n sTitle: 'Devices',\n mData(source, type, val) {\n return source.devices || [];\n },\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data.join(' ');\n }\n return data.join('; ');\n },\n bFilter: true,\n};\n\nfunction usersColumn(title, prop) {\n return {\n sTitle: title,\n mData(source, type) {\n if (source[prop]) {\n if (source[prop].length === 0) {\n return '';\n }\n const names = source[prop].map(function(u) {\n if (!u._id) {\n return u;\n }\n if (type === 'filter' || type === 'sort') {\n return u.username;\n }\n return `<a target=\"${linkTarget}\" href=\"/users/${u._id}\"><img class=\"user\" data-src=\"holder.js/27x40?size=20&text=${u._id.substr(0, 1).toUpperCase()}\"></a>`;\n });\n if (type === 'filter' || type === 'sort') {\n return names.join('; ');\n }\n return names.join(' ');\n }\n return '';\n },\n bFilter: true,\n };\n}\n\nfunction usersFilteredColumn(title, filter) {\n return {\n sTitle: title,\n mData(source, type) {\n const users = filter(source);\n if (users.length === 0) {\n return '';\n }\n const names = users.map(function(u) {\n if (!u._id) {\n return u;\n }\n if (type === 'filter' || type === 'sort') {\n return u.username;\n }\n return `<a target=\"${linkTarget}\" href=\"/users/${u._id}\"><img class=\"user\" data-src=\"holder.js/27x40?size=20&text=${u._id.substr(0, 1).toUpperCase()}\"></a>`;\n });\n if (type === 'filter' || type === 'sort') {\n return names.join('; ');\n }\n return names.join(' ');\n },\n bFilter: true,\n };\n}\n\nconst sharedWithColumn = usersColumn('Shared with', 'sharedWith');\n\nfunction notIn(user, users) {\n let i;\n for (i = 0; i < users.length; i += 1) {\n if (users[i]._id === user._id) {\n return false;\n }\n }\n return true;\n}\n\nconst manPowerColumn = usersFilteredColumn('Powered by', function(source) {\n const out = [];\n if (source.manPower) {\n source.manPower.forEach(function(m) {\n if (notIn(m, out)) {\n out.push(m);\n }\n });\n }\n\n if (source.sharedWith) {\n source.sharedWith.forEach(function(s) {\n if (s.access === 1) {\n if (notIn(s, out)) {\n out.push(s);\n }\n }\n });\n }\n return out;\n});\n\nconst filledByColumn = usersColumn('Filled by', 'manPower');\n\nconst sharedGroupColumn = {\n sTitle: 'Shared groups',\n mData(source, type, val) {\n if (source.sharedGroup) {\n if (source.sharedGroup.length === 0) {\n return '';\n }\n const names = source.sharedGroup.map(function(g) {\n return g.groupname;\n });\n return names.join('; ');\n }\n return '';\n },\n bFilter: true,\n};\n\nconst statusColumn = {\n sTitle: 'Status',\n mData: 'status',\n mRender(data, type, full) {\n return formatTravelerStatus(data);\n },\n bFilter: true,\n};\n\n/* shared user columns */\nconst useridColumn = personColumn('User', '_id');\n\nconst useridNoLinkColumn = {\n sTitle: 'User id',\n mData: '_id',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst userNameColumn = {\n sTitle: 'Full name',\n mData: 'username',\n sDefaultContent: '',\n mRender(data, type, full) {\n return `<a href = \"${prefix}/users?name=${data}\">${data}</a>`;\n },\n bFilter: true,\n};\n\nconst userNameNoLinkColumn = {\n sTitle: 'Full name',\n mData: 'username',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst fullNameNoLinkColumn = {\n sTitle: 'Full name',\n mData: 'name',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst groupIdColumn = {\n sTitle: 'Group id',\n mData: '_id',\n sDefaultContent: '',\n bFilter: true,\n mRender(data) {\n return `<a href=\"${prefix}/groups/${data}\">${data}</a>`;\n },\n};\n\nconst displayNameColumn = {\n sTitle: 'Display Name',\n mData: 'name',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst groupNameColumn = {\n sTitle: 'Group Name',\n mData: 'groupname',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst membersColumn = {\n sTitle: 'Member(s)',\n mData: 'members',\n sDefaultContent: '',\n bFilter: false,\n mRender(data) {\n data.sort(function(a, b) {\n if (a.name < b.name) {\n return -1;\n }\n if (a.name > b.name) {\n return 1;\n }\n return 0;\n });\n const result = data.map(function(d) {\n return `<li>${d.name}</li>`;\n });\n return `<ul>${result.join('')}</ul>`;\n },\n};\n\nconst accessColumn = {\n sTitle: 'Privilege',\n mData: 'access',\n sDefaultContent: '',\n mRender(data, type, full) {\n if (data === 0) {\n return 'read';\n }\n if (data === 1) {\n return 'write';\n }\n return 'unknown';\n },\n bFilter: true,\n};\n\n/* user columns */\nconst rolesColumn = {\n sTitle: 'Roles',\n mData: 'roles',\n sDefaultContent: '',\n mRender(data, type, full) {\n return data.join();\n },\n bFilter: true,\n};\n\nconst lastVisitedOnColumn = dateColumn('Last visited', 'lastVisitedOn');\n\n/* device columns */\n\nconst serialColumn = {\n sTitle: 'Serial',\n mData: 'inventoryId',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst typeColumn = {\n sTitle: 'Type',\n mData: 'deviceType.name',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst descriptionColumn = {\n sTitle: 'Description',\n mData: 'deviceType.description',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst modifiedOnColumn = dateColumn('Modified', 'dateModified');\n\nconst modifiedByColumn = {\n sTitle: 'Modified by',\n mData: 'modifiedBy',\n sDefaultContent: '',\n bFilter: true,\n};\n\nconst addedByColumn = personColumn('Added by', 'addedBy');\n\nconst addedOnColumn = dateColumn('Added on', 'addedOn');\n\nconst sequenceColumn = {\n sTitle: 'Sequence',\n mData: 'sequence',\n sClass: 'editable',\n sType: 'numeric',\n bFilter: true,\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data;\n }\n return `<input type=\"number\" min=1 step=1 class=\"input-mini config\" value=\"${data}\">`;\n },\n};\n\nconst sColumn = {\n sTitle: 'S',\n mData: 'sequence',\n bFilter: true,\n};\n\nconst priorityColumn = {\n sTitle: 'Priority',\n mData: 'priority',\n sClass: 'editable',\n sType: 'numeric',\n bFilter: true,\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data;\n }\n return `<input type=\"number\" min=1 step=1 class=\"input-mini config\" value=\"${data}\">`;\n },\n};\n\nconst pColumn = {\n sTitle: 'P',\n mData: 'priority',\n bFilter: true,\n};\n\nconst valueColumn = {\n sTitle: 'Value',\n mData: 'value',\n sClass: 'editable',\n sType: 'numeric',\n bFilter: true,\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data;\n }\n return `<input type=\"number\" min=0 class=\"input-mini config\" value=\"${data}\">`;\n },\n};\n\nconst vColumn = {\n sTitle: 'V',\n mData: 'value',\n bFilter: true,\n};\n\nconst colorColumn = {\n sTitle: 'Color',\n mData: 'color',\n sClass: 'editable',\n mRender(data, type) {\n if (type === 'sort' || type === 'filter') {\n return data;\n }\n const snippet = $(\n '<select name=\"select\" class=\"input-small config\"><option value = \"blue\" class=\"text-info\">blue</option><option value = \"green\" class=\"text-success\">green</option><option value = \"yellow\" class=\"text-warning\">yellow</option><option value = \"red\" class=\"text-error\">red</option><option value = \"black\">black</option></select>'\n );\n $(`option[value=\"${data}\"]`, snippet).attr('selected', 'selected');\n return snippet[0].outerHTML;\n },\n};\n\nconst cColumn = {\n sTitle: 'C',\n mData: 'color',\n mRender(data, type) {\n const snippet = $('<i class=\"fa fa-flag fa-lg\"></i>');\n if (type === 'sort' || type === 'filter') {\n return data;\n }\n switch (data) {\n case 'blue':\n snippet.addClass('text-info');\n break;\n case 'green':\n snippet.addClass('text-success');\n break;\n case 'yellow':\n snippet.addClass('text-warning');\n break;\n case 'red':\n snippet.addClass('text-error');\n break;\n default:\n }\n return snippet[0].outerHTML;\n },\n};\n\n/**\n * get a button config that exports only the visible, default all\n * @param {Sting} tool the tool name to extend\n * @return {Object} tool defination\n */\nfunction exportVisible(tool) {\n return {\n sExtends: tool,\n mColumns: 'visible',\n };\n}\n\nconst oTableTools = {\n sSwfPath: prefix\n ? `${prefix}/datatables/swf/copy_csv_xls_pdf.swf`\n : '/datatables/swf/copy_csv_xls_pdf.swf',\n aButtons: [\n exportVisible('copy'),\n 'print',\n {\n sExtends: 'collection',\n sButtonText: 'Save <span class=\"caret\" />',\n aButtons: [\n exportVisible('csv'),\n exportVisible('xls'),\n exportVisible('pdf'),\n ],\n },\n ],\n};\n\nconst sDom =\n \"<'row-fluid'<'span6'<'control-group'T>>><'row-fluid'<'span6'l><'span6'f>r>t<'row-fluid'<'span6'i><'span6'p>>\";\nconst Dom =\n \"<'row-fluid'<'span6'<'control-group'B>>><'row-fluid'<'span6'l><'span6'f>r>t<'row-fluid'<'span6'i><'span6'p>>\";\nconst sDom2i =\n \"<'row-fluid'<'span6'<'control-group'T>>><'row-fluid'<'span3'l><'span3'i><'span6'f>r>t<'row-fluid'<'span6'i><'span6'p>>\";\nconst sDom2i1p =\n \"<'row-fluid'<'span6'<'control-group'T>>><'row-fluid'<'span3'l><'span3'i><'span3'r><'span3'f>>t<'row-fluid'<'span6'i><'span6'p>>\";\nconst sDomNoTools =\n \"<'row-fluid'<'span4'l><'span4'<'text-center'r>><'span4'f>>t<'row-fluid'<'span6'i><'span6'p>>\";\nconst sDomNoTNoR = \"t<'row-fluid'<'span6'i><'span6'p>>\";\nconst sDomClean = 't';\nconst sDomPage = \"<'row-fluid'r>t<'row-fluid'<'span6'i><'span6'p>>\";\n\n/**\n * By default DataTables only uses the sAjaxSource variable at initialisation\n * time, however it can be useful to re-read an Ajax source and have the table\n * update. Typically you would need to use the `fnClearTable()` and\n * `fnAddData()` functions, however this wraps it all up in a single function\n * call.\n *\n * DataTables 1.10 provides the `dt-api ajax.url()` and `dt-api ajax.reload()`\n * methods, built-in, to give the same functionality as this plug-in. As such\n * this method is marked deprecated, but is available for use with legacy\n * version of DataTables. Please use the new API if you are used DataTables 1.10\n * or newer.\n *\n * @name fnReloadAjax\n * @summary Reload the table's data from the Ajax source\n * @author [Allan Jardine](http://sprymedia.co.uk)\n * @deprecated\n *\n * @param {string} [sNewSource] URL to get the data from. If not give, the\n * previously used URL is used.\n * @param {function} [fnCallback] Callback that is executed when the table has\n * redrawn with the new data\n * @param {boolean} [bStandingRedraw=false] Standing redraw (don't changing the\n * paging)\n *\n * @example\n * var table = $('#example').dataTable();\n *\n * // Example call to load a new file\n * table.fnReloadAjax( 'media/examples_support/json_source2.txt' );\n *\n * // Example call to reload from original file\n * table.fnReloadAjax();\n */\n\njQuery.fn.dataTableExt.oApi.fnReloadAjax = function(\n oSettings,\n sNewSource,\n fnCallback,\n bStandingRedraw\n) {\n // DataTables 1.10 compatibility - if 1.10 then `versionCheck` exists.\n // 1.10's API has ajax reloading built in, so we use those abilities\n // directly.\n if (jQuery.fn.dataTable.versionCheck) {\n const api = new jQuery.fn.dataTable.Api(oSettings);\n\n if (sNewSource) {\n api.ajax.url(sNewSource).load(fnCallback, !bStandingRedraw);\n } else {\n api.ajax.reload(fnCallback, !bStandingRedraw);\n }\n return;\n }\n\n if (sNewSource !== undefined && sNewSource !== null) {\n oSettings.sAjaxSource = sNewSource;\n }\n\n // Server-side processing should just call fnDraw\n if (oSettings.oFeatures.bServerSide) {\n this.fnDraw();\n return;\n }\n\n this.oApi._fnProcessingDisplay(oSettings, true);\n const that = this;\n const iStart = oSettings._iDisplayStart;\n const aData = [];\n\n this.oApi._fnServerParams(oSettings, aData);\n\n oSettings.fnServerData.call(\n oSettings.oInstance,\n oSettings.sAjaxSource,\n aData,\n function(json) {\n /* Clear the old information from the table */\n that.oApi._fnClearTable(oSettings);\n\n /* Got the data - add it to the table */\n const dataArray =\n oSettings.sAjaxDataProp !== ''\n ? that.oApi._fnGetObjectDataFn(oSettings.sAjaxDataProp)(json)\n : json;\n let i;\n for (i = 0; i < dataArray.length; i += 1) {\n that.oApi._fnAddData(oSettings, dataArray[i]);\n }\n\n oSettings.aiDisplay = oSettings.aiDisplayMaster.slice();\n\n that.fnDraw();\n\n if (bStandingRedraw === true) {\n oSettings._iDisplayStart = iStart;\n that.oApi._fnCalculateEnd(oSettings);\n that.fnDraw(false);\n }\n\n that.oApi._fnProcessingDisplay(oSettings, false);\n\n /* Callback user function - for event handlers etc */\n if (typeof fnCallback === 'function' && fnCallback !== null) {\n fnCallback(oSettings);\n }\n },\n oSettings\n );\n};\n"
},
{
"alpha_fraction": 0.7783816456794739,
"alphanum_fraction": 0.7783816456794739,
"avg_line_length": 56.10344696044922,
"blob_id": "56b10ac5ce79ca9d02d0064bd8d26de4e94f537a",
"content_id": "d78066181a6981088e62f647ecf613e2bfd3f072",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1656,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 29,
"path": "/views/docs/basics/traveler.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### What is a traveler?\n\nA traveler is an electrical document that supports the execution of a predefined\nprocess in a normal template and to collect user input data and notes in the\nprocess. It also supports collections of discrepancy QA logs with a discrepancy\ntemplate.\n\nA traveler has properties like title, description, deadline, locations, devices,\nand tags. The user can add/remove multiple tags into the tag list. Tags can be\nused to group and find travelers. A device is a special type of tag that\nrepresents a physical entity related to the traveler. The user creates a new\ntraveler when **initializing** it from a **released** template. Its state can be\nchanged to **active**, **submitted for completion**, **completed**, and\n**frozen**. A traveler, either finished or not, can be **archived** when it\nneeds no more attention from users. Only the traveler owner can access the\ntraveler when it is archived. A traveler owner can [share](#ownership) her/his\ntraveler with other users/groups. A user can also [transfer](#ownership) the\nownership of a traveler to another user.\n\nThe users with written permission to a traveler can input values into an\n**active** traveler. The input **history** is kept with the traveler. Each input\ncan also have user notes attached to it. Optionally, a traveler can contain the\nhistory of discrepancies. A traveler can be considered as the composition of a\nreleased form/template, the input data, the notes, and discrepancy logs:\n\n**traveler = template + data + notes [+ discrepancy logs]**\n\nThe [travelers section](#travelers) provides more detailed information about how\nto create, update, and manage travelers.\n"
},
{
"alpha_fraction": 0.8062015771865845,
"alphanum_fraction": 0.8062015771865845,
"avg_line_length": 63,
"blob_id": "3ba4761c7c3208ce82b29ea6d66fd264b053e17c",
"content_id": "9707ba22409916db2a79e64deb3a8cce2927e331",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 129,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 2,
"path": "/sbin/configuration.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "export TRAVELER_VERSION_CONTROL_TYPE=\"git\"\nexport TRAVELER_SUPPORT_GIT_URL=\"https://github.com/iTerminate/traveler-support.git\" \n"
},
{
"alpha_fraction": 0.6831989884376526,
"alphanum_fraction": 0.6980780959129333,
"avg_line_length": 38.34146499633789,
"blob_id": "86ec96c605f49f70386695a8fe35765330f1d876",
"content_id": "8b618f206c2432ec168456ec66995315ce4fae02",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1613,
"license_type": "permissive",
"max_line_length": 316,
"num_lines": 41,
"path": "/public/javascripts/public-binders.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false */\n/*global prefix: false, ajax401: false, updateAjaxURL: false, disableAjaxCache: false*/\n/*global titleColumn: false, createdOnColumn: false, updatedOnColumn: false, updatedByColumn: false, fnAddFilterFoot: false, sDomNoTools: false, createdOnColumn: false, filterEvent: false, binderLinkColumn: false, tagsColumn: false, binderWorkProgressColumn: false, ownerColumn: false*/\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n var publicBindersAoColumns = [\n binderLinkColumn,\n titleColumn,\n tagsColumn,\n ownerColumn,\n createdOnColumn,\n updatedByColumn,\n updatedOnColumn,\n binderWorkProgressColumn,\n ];\n fnAddFilterFoot('#public-binders-table', publicBindersAoColumns);\n $('#public-binders-table').dataTable({\n sAjaxSource: '/publicbinders/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n iDisplayLength: 10,\n aLengthMenu: [[10, 50, 100, -1], [10, 50, 100, 'All']],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: publicBindersAoColumns,\n aaSorting: [[5, 'desc']],\n sDom: sDomNoTools,\n });\n // binding events\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 39,
"blob_id": "af9d757485e819ca0864cebba7cbab0abc7de997",
"content_id": "4415e68905d1e5d3f1d77e03d80c06b623ebd804",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 40,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 1,
"path": "/logs/readme",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "This directory is created to keep logs.\n"
},
{
"alpha_fraction": 0.7276349067687988,
"alphanum_fraction": 0.739587128162384,
"avg_line_length": 22,
"blob_id": "88dec15749d9ae299656312961e8f41544cabd97",
"content_id": "a07f84cf602091ebffb34d572bee817829757255",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2761,
"license_type": "permissive",
"max_line_length": 187,
"num_lines": 120,
"path": "/installation-step.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "This document describes the steps to install the traveler application. These steps can be automated in a puppet or docker platform. \n\n## Install node.js LTS\n\nCheck OS release\n```shell\ncat /etc/os-release\n```\n\nCheck if yum is available. Install if not.\n\n```shell\nwhich yum\n```\nCheck available node.js from the default yum repo. \n\n```shell\nyum list nodejs\n```\nCheck https://nodejs.org/en/about/releases/ for the current LTS node version. \n\nYou will need `curl` to install. \n```shell\nwhich curl\n```\n\nE.g. in order to install node v14. \n```shell\ncurl -sL https://rpm.nodesource.com/setup_14.x | sudo bash -\nsudo yum install -y nodejs\n```\n\nCheck https://github.com/nodesource/distributions for the current LTS. \n\nAfter install, verify the `node` and `npm` version. \n```shell\nwhich node\nnode --version\nwhich npm\nnpm --version\n```\n\n## Install mongodb 3.4 \n\nFollowing https://www.digitalocean.com/community/tutorials/how-to-install-mongodb-on-centos-7 to install on centos 7. \n```shell\nsudo nano /etc/yum.repos.d/mongodb-org.repo\n```\nAdd the following\n```\n[mongodb-org-3.4]\nname=MongoDB Repository\nbaseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/\ngpgcheck=1\nenabled=1\ngpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc\n```\n```shell\nyum repolist\nsudo yum install mongodb-org\n```\nCheck `mongod` with `systemctl` after installation. \n```shell\nsudo systemctl stop mongod\nsudo systemctl status mongod\n```\n### Optimize mongodb\n\nSee https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/ for how to disable THP. \n\n\n## Install the traveler application and config\n\nAdd a `traveler` user to run the application on the box with node.js. \n```shell\nuseradd -m -d /home/traveler traveler\nsudo passwd traveler\n```\n\nAt `/home/traveler`,\n```shell\ngit clone https://github.com/dongliu/traveler.git \n```\n\nCopy the `config` directory from the repo root to `/home/traveler/traveler-config/`. Update the configuration files according to the installation. See the `docker` directory for example. \n\n## Install PM2 and config\n\nAs an admin user\n```shell\nsudo npm install pm2@latest -g\nwhich pm2\n```\n\nAs the `traveler` user\n```shell\npm2 install pm2-logrotate\n```\n\nStart the traveler application with pm2. This requires the application is properly configured. \n```shell\nNODE_ENV=production TRAVELER_CONFIG_REL_PATH=../traveler-config/ pm2 start --name traveler app.js\n```\n\n### Save the pm2 script \n```shell\npm2 save\n```\npm2 files will be created at `/home/traveler/.pm2`.\n\nAs the admin user\n```shell\nsudo env PATH=$PATH:/usr/bin pm2 startup centos -u traveler --hp /home/traveler\n```\n\nCheck if traveler script is properly created by\n```shell\ncat /etc/systemd/system/pm2-traveler.service\n```\nReboot the box and the traveler application should start. \n"
},
{
"alpha_fraction": 0.6402877569198608,
"alphanum_fraction": 0.6575539708137512,
"avg_line_length": 48.64285659790039,
"blob_id": "86c1a6ef7c02d31d2aeac748ba33f92cb2ed03ad",
"content_id": "55fb98c04a74f4adcb2dc728a83d85c1369c9546",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 695,
"license_type": "permissive",
"max_line_length": 332,
"num_lines": 14,
"path": "/public/javascripts/main.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false, History: false */\n$(function() {\n function updateH1m(start, messages) {\n return function() {\n $('#h1m').text(messages[start]);\n start += 1;\n if (start > messages.length - 1) {\n start = start % messages.length;\n }\n };\n }\n var messages = ['Work', 'Design', 'Organize', 'Collaborate'];\n window.setInterval(updateH1m(0, messages), 10 * 1000);\n});\n"
},
{
"alpha_fraction": 0.8136986494064331,
"alphanum_fraction": 0.8136986494064331,
"avg_line_length": 39.55555725097656,
"blob_id": "7745ca3b6c2bc6fa5c76d532d7516ab33ca29921",
"content_id": "ee542e2d81dfe18db5d9b3fff7fced43ccb0e0e3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 365,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 9,
"path": "/views/docs/api/header.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "## Application programming interface\n\n**Audience: developers**\n\nThe traveler application provides a limited API (application programming\ninterface) besides the Web interface. The API is designed in a\n[RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) style.\nCurrently, other applications can read the information of travelers through the\nAPI.\n"
},
{
"alpha_fraction": 0.5311111211776733,
"alphanum_fraction": 0.5311111211776733,
"avg_line_length": 33.61538314819336,
"blob_id": "f83e8d512818fdc5f1bf1547a08b0939f50a7df6",
"content_id": "e4b9265cedb5982812486b3b093241c8dd3bb5a6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1350,
"license_type": "permissive",
"max_line_length": 185,
"num_lines": 39,
"path": "/public/javascripts/profile.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global moment: false*/\n\n$(function() {\n var sub = $('#sub').prop('checked');\n $('#modify').click(function(e) {\n if ($('#sub').prop('checked') === sub) {\n $('#message').append(\n '<div class=\"alert alert-info\"><button class=\"close\" data-dismiss=\"alert\">x</button>The subscription state was not changed.</div>'\n );\n } else {\n sub = $('#sub').prop('checked');\n var request = $.ajax({\n type: 'PUT',\n async: true,\n data: JSON.stringify({\n subscribe: sub,\n }),\n contentType: 'application/json',\n processData: false,\n dataType: 'json',\n })\n .done(function(json) {\n var timestamp = request.getResponseHeader('Date');\n var dateObj = moment(timestamp);\n $('#message').append(\n '<div class=\"alert alert-info\"><button class=\"close\" data-dismiss=\"alert\">x</button>The modification was saved at ' +\n dateObj.format('HH:mm:ss') +\n '.</div>'\n );\n })\n .fail(function(jqXHR, status, error) {\n $('#message').append(\n '<div class=\"alert alert-info\"><button class=\"close\" data-dismiss=\"alert\">x</button>The modification request failed. You might need to try again or contact the admin.</div>'\n );\n });\n }\n e.preventDefault();\n });\n});\n"
},
{
"alpha_fraction": 0.752293586730957,
"alphanum_fraction": 0.752293586730957,
"avg_line_length": 35.33333206176758,
"blob_id": "4428147d8caf859951671c5b5d34f675ba032236",
"content_id": "62e6ef6da37e3980768b96a8a3415f7c39f871d6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 3,
"path": "/views/docs/contact.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "## Contact\n\nPlease contact Dong Liu (https://github.com/dongliu) if you have questions and need more supports.\n"
},
{
"alpha_fraction": 0.7772701382637024,
"alphanum_fraction": 0.7772701382637024,
"avg_line_length": 55.48387145996094,
"blob_id": "353f97aec26bd92749c3d841acedca87e9b705f5",
"content_id": "f99fe4e59d5fb7323b40aa4758946c2e6e042a8b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1751,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 31,
"path": "/views/docs/traveler/header.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "## Travelers\n\n**Audience: traveler users**\n\nThe start page for working with travelers is [/travelers/](/travelers/). There\nare five tabs on the page: [My travelers](/travelers/#travelers),\n[Transferred travelers](/travelers/#transferredtravelers),\n[Shared travelers](/travelers/#sharedtravelers),\n[Group shared travelers](/travelers/#groupsharedtravelers), and\n[Archived travelers](/travelers/#archivedtravelers). The\n[My travelers](/travelers/#travelers) tab contains a table of the travelers\n**created** by you. The\n[Transferred travelers](/travelers/#transferredtravelers) tab contains a table\nof the travelers **transferred** to you by other users. The\n[Shared travelers](/travelers/#sharedtravelers) tab contains a table of the\ntravelers **shared** with you by other users. The\n[Group shared travelers](/travelers/#groupsharedtravelers) tab contains a table\nof the travelers **shared** with **your groups** by other users. The\n[Archived travelers](/travelers/#archivedtravelers) tab contains a table of the\ntravelers **archived** by you. You are the **owner** of all the travelers in\n[My travelers](/travelers/#travelers) tab,\n[Transferred travelers](/travelers/#transferredtravelers) tab, and\n[Archived travelers](/travelers/#archivedtravelers) tab. The owner is\nresponsible to [configure](#config-traveler), [share](#share-traveler),\n[active and approve the completion](#traveler-status) of a traveler.\n\nA traveler can be located by its URL. The URL is like `/travelers/longstringid/`\nwhere the `longstringid` is the traveler's unique identity. The user can\nbookmark the traveler's URL or send it to other users. A user needs to have at\nleast read permission to view a traveler. See the\n[sharing traveler](#share-traveler) section for details.\n"
},
{
"alpha_fraction": 0.6333808898925781,
"alphanum_fraction": 0.667617678642273,
"avg_line_length": 25.961538314819336,
"blob_id": "b6b2f52a222645d4a8dc47e5e4e4b6310e4fa6b4",
"content_id": "64a6cac06737a3e2f27b06d52a600f6d77d4872d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 701,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 26,
"path": "/sbin/create_web_service_certificates.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $0`\nCUR_DIR=`pwd`\n\nsource $MY_DIR/configure_paths.sh\n\nif [ -d $TRAVELER_CONFIG_DIR ]; then\n\tif [ ! -d $TRAVELER_CONFIG_DIR/ssl ]; then\n\t\tmkdir -p $TRAVELER_CONFIG_DIR/ssl\n\tfi\n cd $TRAVELER_CONFIG_DIR/ssl\n echo \"Create a self signed certifcate for the traveler web service\"\n read -p \"Enter key bit length [1024]: \" keysize\n\n\t\texport CN=`hostname -f`\n openssl genrsa -out $CN.key $keysize || exit 1\n openssl req -config $TRAVELER_ROOT_DIR/etc/openssl.default.cnf -new -key $CN.key -out $CN.csr\n openssl x509 -sha512 -req -days 365 -in $CN.csr -signkey $CN.key -out $CN.crt\n\n\t\tchmod 400 ./$CN.key\n\t\tchmod 400 ./$CN.csr\n\t\tchmod 400 ./$CN.crt\nfi\n\ncd $CUR_DIR\n"
},
{
"alpha_fraction": 0.6199585199356079,
"alphanum_fraction": 0.6268725395202637,
"avg_line_length": 26.63694190979004,
"blob_id": "54865c6e3b04215a6c509b06474593b4c259638e",
"content_id": "bd1a0e37ae8654412e2b613d2a075912d87170c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4339,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 157,
"path": "/public/javascripts/report.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*eslint max-nested-callbacks: [2, 5]*/\n\n/* global deviceColumn, titleColumn, statusColumn, sDom, keyValueColumn,\n keyLabelColumn, oTableTools*/\n/* global ajax401: false, updateAjaxURL: false, disableAjaxCache: false, prefix:\n false, _, moment*/\n\n/**\n * generate the control checkbox to show/hide the column\n * @param {Object} col report table column defination\n * @return {String} a checkbox input\n */\nfunction colControl(col) {\n return (\n '<label class=\"checkbox inline-checkbox\"><input type=\"checkbox\" class=\"userkey\" checked data-toggle=\"' +\n (col.sTitle || col.mData || col) +\n '\">' +\n (col.sTitle || col.mData || col) +\n '</label>'\n );\n}\n\n/**\n * append the checkbox controls for the report table into target\n * @param {String} target Selector of the target\n * @param {Array} columns defination of the columns to control\n * @return {undefined}\n */\nfunction constructControl(target, columns) {\n columns.forEach(function(col) {\n $(target).append(colControl(col));\n });\n}\n\nfunction constructTable(table, travelers, colMap) {\n var systemColumns = [titleColumn, deviceColumn, statusColumn];\n var discrepancyColumns = [];\n var userColumns = [];\n var labelColIndex = [];\n systemColumns.forEach(function(col, index) {\n colMap[col.sTitle || col.mData] = [index];\n });\n var userKeys = [];\n var discrepancyKeys = [];\n var rows = [];\n var id;\n // get all user defined keys\n for (id in travelers) {\n userKeys = _.union(userKeys, _.keys(travelers[id].user_defined)).sort();\n discrepancyKeys = _.union(\n discrepancyKeys,\n _.keys(travelers[id].discrepancy)\n ).sort();\n }\n // add discrepancy keys to discrepancyColumns and colMap\n discrepancyKeys.forEach(function(key, index) {\n discrepancyColumns.push(keyValueColumn('discrepancy', key));\n colMap[key] = [systemColumns.length + index];\n });\n\n // add user defined keys to userColumns and colMap\n userKeys.forEach(function(key, index) {\n userColumns.push(keyLabelColumn(key));\n userColumns.push(keyValueColumn('user_defined', key));\n colMap[key] = [\n systemColumns.length + discrepancyColumns.length + 2 * index,\n systemColumns.length + discrepancyColumns.length + 2 * index + 1,\n ];\n labelColIndex.push(\n systemColumns.length + discrepancyColumns.length + 2 * index\n );\n });\n\n // get all the data\n for (id in travelers) {\n rows.push(travelers[id]);\n }\n\n constructControl('#system-keys', systemColumns);\n constructControl('#discrepancy-keys', discrepancyKeys);\n constructControl('#user-keys', userKeys);\n\n // draw the table\n var report = $(table).DataTable({\n data: rows,\n columns: systemColumns.concat(discrepancyColumns).concat(userColumns),\n pageLength: -1,\n lengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n pagingType: 'simple_numbers',\n dom: Dom,\n });\n\n // register column event handler\n $('.inline-checkbox input.userkey').on('input', function() {\n var show = $(this).prop('checked');\n colMap[$(this).data('toggle')].forEach(function(c) {\n report.column(c).visible(show);\n });\n });\n\n // register lable event hander\n $('.inline-checkbox input.labels').on('input', function() {\n var show = $(this).prop('checked');\n labelColIndex.forEach(function(c) {\n report.column(c).visible(show);\n });\n });\n\n return report;\n}\n\n$(function() {\n updateAjaxURL(prefix);\n ajax401(prefix);\n disableAjaxCache();\n\n var colMap = {};\n\n var tid = $('#report-table').data('travelers');\n var rowN = tid.length;\n var travelers = {};\n var finishedT = 0;\n\n $.each(tid, function(index, t) {\n $.ajax({\n url: '/travelers/' + t + '/keylabelvalue/json',\n type: 'GET',\n dataType: 'json',\n })\n .done(function(data) {\n travelers[t] = data;\n })\n .always(function() {\n finishedT += 1;\n if (finishedT >= rowN) {\n constructTable('#report-table', travelers, colMap);\n }\n });\n });\n\n $('input.group').on('input', function() {\n var value = $(this).prop('checked');\n var target = $(this).data('toggle');\n $(target + ' input[type=\"checkbox\"]')\n .prop('checked', value)\n .trigger('input');\n });\n\n $('span.time').each(function() {\n $(this).text(\n moment($(this).text()).format('dddd, MMMM Do YYYY, h:mm:ss a')\n );\n });\n});\n"
},
{
"alpha_fraction": 0.579996645450592,
"alphanum_fraction": 0.5867545008659363,
"avg_line_length": 22.86693572998047,
"blob_id": "6d65ac9c4f668c0ac385babb0d3c265ebb98ac68",
"content_id": "8a74ec16eeb0d9df42b76fee2d1463ca9c4a681f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5919,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 248,
"path": "/model/form.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const mongoose = require('mongoose');\nconst cheerio = require('cheerio');\nconst appConfig = require('../config/config').app;\n\nconst { Schema } = mongoose;\nconst { ObjectId } = Schema.Types;\nconst share = require('./share');\nconst { FormError } = require('../lib/error');\nconst { addHistory } = require('./history');\nconst { addVersion } = require('./history');\nconst { addReview } = require('./review');\n\n/** ****\npublicAccess := 0 // for read or\n | 1 // for write or\n | -1 // no access\n***** */\n/** ****\nstatus := 0 // editable draft\n | 0.5 // submitted for reviewing\n | 1 // review finished and all approved and released\n | 2 // archived\n***** */\n// mapping : user-key -> name\n// labels : name -> label\n// types: name -> input type\n\nconst stateTransition = [\n {\n from: 0,\n to: [0.5, 2],\n },\n {\n from: 0.5,\n to: [0, 1, 2],\n },\n {\n from: 1,\n to: [2],\n },\n];\n\nconst statusMap = {\n '0': 'draft',\n '0.5': 'submitted for review',\n '1': 'approved and released',\n '2': 'archived',\n};\n\nconst form = new Schema({\n title: String,\n description: String,\n createdBy: String,\n createdOn: Date,\n clonedFrom: ObjectId,\n updatedBy: String,\n updatedOn: Date,\n owner: String,\n tags: [String],\n status: {\n type: Number,\n default: 0,\n },\n transferredOn: Date,\n archivedOn: Date,\n archived: {\n type: Boolean,\n default: false,\n },\n publicAccess: {\n type: Number,\n default: appConfig.default_form_public_access,\n },\n sharedWith: [share.user],\n sharedGroup: [share.group],\n mapping: Schema.Types.Mixed,\n labels: Schema.Types.Mixed,\n types: Schema.Types.Mixed,\n html: String,\n formType: {\n type: String,\n default: 'normal',\n enum: ['normal', 'discrepancy'],\n },\n});\n\n/**\n * pre save middleware to add or update the mapping\n * and validate unique input name and data-userkey\n */\nform.pre('save', function(next) {\n const doc = this;\n if (doc.isNew || doc.isModified('html')) {\n const mapping = {};\n const labels = {};\n const types = {};\n const $ = cheerio.load(doc.html);\n const inputs = $('input, textarea');\n let lastInputName = '';\n let lastUserkey = '';\n let inputName = '';\n let label = '';\n let userkey = '';\n let inputType = '';\n for (let i = 0; i < inputs.length; i += 1) {\n const input = $(inputs[i]);\n inputName = input.attr('name');\n inputType = input.attr('type');\n label = input\n .closest('.control-group')\n .children('.control-label')\n .children('span.model-label')\n .text();\n userkey = input.attr('data-userkey');\n if (inputName) {\n inputName = inputName.trim();\n }\n if (label) {\n label = label.trim();\n }\n if (userkey) {\n userkey = userkey.trim();\n }\n\n if (!inputName) {\n continue;\n }\n // seen the same input name already\n if (lastInputName === inputName) {\n // only radio inputs share the same input name\n if (input.attr('type') === 'radio') {\n // consistent name -> userkey\n if (userkey === lastUserkey) {\n continue;\n } else {\n return next(\n new FormError(\n `inconsistent usekey \"${userkey}\"found for the same input name`,\n 400\n )\n );\n }\n } else {\n return next(\n new FormError(`duplicated input name \"${inputName}\"`, 400)\n );\n }\n } else {\n labels[inputName] = label;\n types[inputName] = inputType;\n // add user key mapping if userkey is not null or empty\n if (userkey) {\n if (mapping.hasOwnProperty(userkey)) {\n return next(\n new FormError(`duplicated input userkey \"${userkey}\"`, 400)\n );\n }\n mapping[userkey] = inputName;\n }\n }\n lastInputName = inputName;\n lastUserkey = userkey;\n }\n doc.mapping = mapping;\n doc.labels = labels;\n doc.types = types;\n }\n return next();\n});\n\n/**\n * Check if a form should be rendered in builder\n * @returns true if rendered in builder view, other wise false\n */\nform.methods.isBuilder = function() {\n const doc = this;\n return [0, 0.5, 1].includes(doc.status);\n};\n\nform.plugin(addVersion, {\n fieldsToVersion: ['title', 'description', 'html'],\n});\n\nform.plugin(addHistory, {\n fieldsToWatch: [\n 'title',\n 'description',\n 'owner',\n 'status',\n 'createdBy',\n 'publicAccess',\n 'html',\n '_v',\n ],\n});\n\nform.plugin(addReview);\n\nconst formFile = new Schema({\n form: ObjectId,\n value: String,\n inputType: String,\n file: {\n path: String,\n encoding: String,\n mimetype: String,\n },\n uploadedBy: String,\n uploadedOn: Date,\n});\n\nconst Form = mongoose.model('Form', form);\nconst FormFile = mongoose.model('FormFile', formFile);\n\nconst createForm = function(json, newFormResultCallBack) {\n const formToCreate = {};\n formToCreate.title = json.title;\n formToCreate.createdBy = json.createdBy;\n formToCreate.createdOn = Date.now();\n formToCreate.updatedBy = json.createdBy;\n formToCreate.updatedOn = Date.now();\n formToCreate.html = json.html || '';\n formToCreate.formType = json.formType || 'normal';\n formToCreate.sharedWith = [];\n new Form(formToCreate).save(newFormResultCallBack);\n};\n\nconst createFormWithHistory = function(uid, json) {\n const formToCreate = {};\n formToCreate.title = json.title;\n formToCreate.createdBy = json.createdBy;\n formToCreate.createdOn = Date.now();\n formToCreate.updatedBy = json.createdBy;\n formToCreate.updatedOn = Date.now();\n formToCreate.html = json.html || '';\n formToCreate.formType = json.formType || 'normal';\n formToCreate.sharedWith = [];\n return new Form(formToCreate).saveWithHistory(uid);\n};\n\nmodule.exports = {\n Form,\n FormFile,\n stateTransition,\n statusMap,\n createForm,\n createFormWithHistory,\n};\n"
},
{
"alpha_fraction": 0.6490984559059143,
"alphanum_fraction": 0.665742039680481,
"avg_line_length": 61.69565200805664,
"blob_id": "242d0ef73fc2c35d42150e3d01307e562c46b024",
"content_id": "571106370dca81dc00be52604e7f02f974fbaa8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2884,
"license_type": "permissive",
"max_line_length": 308,
"num_lines": 46,
"path": "/views/docs/basics/color.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Colors and graphical design\n\nThe traveler application uses a color convention in the interface design. The\nbuttons are colored according to the possible impact of the actions.\n\n<div><button class=\"btn btn-primary\">primary</button></div>\n<div><button class=\"btn btn-info\">information</button></div>\n<div><button class=\"btn btn-success\">success</button></div>\n<div><button class=\"btn btn-warning\">warning</button></div>\n<div><button class=\"btn btn-danger\">danger</button></div>\n\nEach traveler or binder has an estimated progress. The progress is visualized by\na bar. The bar color and corresponding entity status is listed in the following\ntable.\n\n<!-- prettier-ignore -->\n| progress bar | status |\n| -------------| -----------|\n| <div class=\"progress\" style=\"width: 100px;\"><div class=\"bar bar-success\" style=\"width:0%;\"></div><div class=\"bar bar-info\" style=\"width:0%;\"></div><div class=\"progress-value\">0 / 7</div></div> | initialized |\n| <div class=\"progress active progress-striped\" style=\"width: 100px;\"><div class=\"bar bar-success\" style=\"width:0%;\"></div><div class=\"bar bar-info\" style=\"width:28%;\"></div><div class=\"progress-value\">2 / 7</div></div> | active |\n| <div class=\"progress\" style=\"width: 100px;\"><div class=\"bar bar-success\" style=\"width:0%;\"></div><div class=\"bar bar-info\" style=\"width:85%;\"></div><div class=\"progress-value\">6 / 7</div></div> | submitted for completion approval or frozen |\n| <div class=\"progress\" style=\"width: 100px;\"><div class=\"bar bar-success\" style=\"width:100%;\"></div><div class=\"bar bar-info\" style=\"width:0%;\"></div><div class=\"progress-value\"></div></div> | approved completion |\n\n<br/>\n\nSome progress bars have values on it. The formats of the value notations are\nlisted in the following table.\n\n<!-- prettier-ignore -->\n| entity type | progress bar | values |\n| ----------- | ------------ | ------ |\n| traveler | <div class=\"progress active progress-striped\" style=\"width: 100px;\"><div class=\"bar bar-success\" style=\"width:0%;\"></div><div class=\"bar bar-info\" style=\"width:28%;\"></div><div class=\"progress-value\">2 / 7</div></div> | updated input number / total input number |\n| binder or entity in a binder | <div class=\"progress active progress-striped\" style=\"width: 100px;\"><div class=\"bar bar-success\" style=\"width:0%;\"></div><div class=\"bar bar-info\" style=\"width:25%;\"></div><div class=\"progress-value\">0 + 3 / 10</div></div> | finished value + in-progress value / total value |\n\n<br/>\n\nIn a binder, a colored flag denotes the status of a work.\n\n<!-- prettier-ignore -->\n| flag | status |\n| -------------| -----------|\n| <i class=\"fa fa-flag fa-lg text-info\"></i> | going well |\n| <i class=\"fa fa-flag fa-lg text-warning\"></i> | not going well |\n| <i class=\"fa fa-flag fa-lg text-success\"></i> | completed |\n| <i class=\"fa fa-flag fa-lg text-error\"></i> | failure |\n| <i class=\"fa fa-flag fa-lg black\"></i> | not active |\n"
},
{
"alpha_fraction": 0.7448275685310364,
"alphanum_fraction": 0.7448275685310364,
"avg_line_length": 19.85714340209961,
"blob_id": "ef9d6de91a0fae60944e254a6cd707d5d950365e",
"content_id": "1a4ccc603c63db45d592d0ae68a9ebf7b5e5fa54",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 145,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 7,
"path": "/etc/travelerd_configuration.default.sh",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nMY_DIR=`dirname $BASH_SOURCE`\n\n# Run source setup.sh before running this script. \n\nexport TRAVELER_APP_DIR=$TRAVELER_ROOT_DIR/app.js"
},
{
"alpha_fraction": 0.7783171534538269,
"alphanum_fraction": 0.7783171534538269,
"avg_line_length": 50.5,
"blob_id": "689745575527f481322596bfdba08040de634995",
"content_id": "7be28e897cab2f0a4a84b731f300b90115f6ce1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 618,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 12,
"path": "/views/docs/basics/print.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### Print\n\nIn most cases, the user can print the page to either PDF or a real printer with\nthe browser's print function. The traveler pages have a dedicated view to be\nprint format friendly. On a traveler page, clicking on the\n<button class=\"btn btn-primary\">Create PDF</button> button will open a new tab\nof the print view. On the print view, the user can use the top toggles to show\nor hide the validation, notes, and details information.\n\nThe traveler report page loads the table view of the data inside a group of\ntravelers. The user can generate a PDF file or print the table with the tools on\nthe page directly.\n"
},
{
"alpha_fraction": 0.4657767713069916,
"alphanum_fraction": 0.4717409908771515,
"avg_line_length": 23.116437911987305,
"blob_id": "8947df5d4a156a748e5c0f45fc76f9d79166f28f",
"content_id": "48f473705acb214aef6cf80f57113f2b98ef1d85",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3521,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 146,
"path": "/public/javascripts/util.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global moment: false*/\n\nfunction json2List(json) {\n var output = '<dl>';\n for (var k in json) {\n if (json.hasOwnProperty(k)) {\n if (typeof json[k] == 'object') {\n output =\n output +\n '<dl>' +\n '<dt>' +\n k +\n '</dt>' +\n '<dd>' +\n json2List(json[k]) +\n '</dd>' +\n '</dl>';\n } else {\n output = output + '<p><strong>' + k + '</strong> : ' + json[k] + '</p>';\n }\n }\n }\n output = output + '</dl>';\n return output;\n}\n\nfunction createSideNav() {\n $('.sidebar').empty();\n var $legend = $('legend');\n var $affix = $(\n '<ul class=\"nav nav-list nav-stacked affix bs-docs-sidenav\" data-offset-top=\"0\"></ul>'\n );\n var i;\n if ($legend.length > 1) {\n $affix.append('<li><h4>' + title + '</h4></li>');\n for (i = 0; i < $legend.length; i += 1) {\n $affix.append(\n '<li><a href=\"#' +\n $legend[i].id +\n '\">' +\n $legend[i].textContent +\n '</a></li>'\n );\n }\n $('.sidebar').append($('<div id=\"affixlist\"></div>').append($affix));\n $('body').attr('data-spy', 'scroll');\n $('body').attr('data-target', '#affixlist');\n }\n}\n\nfunction history(found) {\n var i;\n var output = '';\n if (found.length > 0) {\n for (i = 0; i < found.length; i += 1) {\n var inputType = found[i].inputType;\n var historyValue = found[i].value;\n var inputBy = found[i].inputBy;\n var inputOn = found[i].inputOn;\n output =\n output +\n generateHistoryRecordHtml(inputType, historyValue, inputBy, inputOn);\n }\n }\n return output;\n}\n\nfunction generateHistoryRecordHtml(\n type,\n historyValue,\n inputBy,\n inputOn,\n live = false\n) {\n if (type === 'url') {\n if (historyValue !== null) {\n if (historyValue.startsWith('http') === false) {\n historyValue = 'http://' + historyValue;\n }\n historyValue =\n '<a target=\"_blank\" href=' + historyValue + '>' + historyValue + '</a>';\n }\n }\n return (\n 'changed to <strong>' +\n historyValue +\n '</strong> by ' +\n inputBy +\n ' ' +\n livespan(inputOn, live) +\n '; '\n );\n}\n\nfunction livespan(stamp, live = true) {\n if (live) {\n return '<span data-livestamp=\"' + stamp + '\"></span>';\n } else {\n return (\n '<span>' + moment(stamp).format('MMM D YYYY, HH:mm:ss ZZ') + '</span>'\n );\n }\n}\n\nfunction findById(a, id) {\n var i;\n for (i = 0; i < a.length; i += 1) {\n if (a[i]._id === id) {\n return a[i];\n }\n }\n return null;\n}\n\n// function nameAuto(input, nameCache){\n// return {\n// minLength: 3,\n// source: function(req, res) {\n// var term = req.term.toLowerCase();\n// var output = [];\n// var key = term.charAt(0);\n// if (key in nameCache) {\n// for (var i = 0; i < nameCache[key].length; i += 1) {\n// if (nameCache[key][i].toLowerCase().indexOf(term) === 0) {\n// output.push(nameCache[key][i]);\n// }\n// }\n// res(output);\n// return;\n// }\n// $.getJSON('/adusernames', {term: key}, function(data, status, xhr) {\n// var names = [];\n// for (var i = 0; i < data.length; i += 1) {\n// if (data[i].displayName.indexOf(',') !== -1) {\n// names.push(data[i].displayName);\n// }\n// }\n// nameCache[term] = names;\n// res(names);\n// });\n// },\n// select: function(event, ui) {\n// $(input).val(ui.item.value);\n// }\n// };\n// }\n"
},
{
"alpha_fraction": 0.5914489030838013,
"alphanum_fraction": 0.5938242077827454,
"avg_line_length": 30.840335845947266,
"blob_id": "e447c3b73f295dd3651f45ae2347c9f0bbb83806",
"content_id": "6f175b4890862d03cc48a7f5a546e5cc22b65c9b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3789,
"license_type": "permissive",
"max_line_length": 153,
"num_lines": 119,
"path": "/public/javascripts/lib/binder.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* eslint-disable import/extensions */\n/* global fnGetSelected, selectColumn, binderLinkColumn, \n titleColumn, tagsColumn, createdOnColumn, updatedOnColumn, fnAddFilterFoot, \n sDomNoTNoR, selectEvent, filterEvent */\n\nimport * as Modal from './modal.js';\n\nexport function addItems(items, binders, type = 'traveler') {\n let number = $('#modal #progress div.target').length;\n $('#modal #progress div.target').each(function() {\n const that = this;\n let success = false;\n $.ajax({\n url: `/binders/${that.id}/`,\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n ids: items,\n type,\n }),\n })\n .done(function() {\n $(that).prepend('<i class=\"fa fa-check\"></i>');\n $(that).addClass('text-success');\n success = true;\n })\n .fail(function(jqXHR) {\n $(that).prepend('<i class=\"icon-question\"></i>');\n $(that).append(` : ${jqXHR.responseText}`);\n $(that).addClass('text-error');\n })\n .always(function() {\n number = number - 1;\n if (number === 0) {\n $('#return').prop('disabled', false);\n }\n });\n });\n}\n\nexport function addModal(fromTable, type = 'traveler') {\n const selected = fnGetSelected(fromTable, 'row-selected');\n const items = [];\n if (selected.length === 0) {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No item has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n return;\n }\n $('#modalLabel').html(`Add the ${selected.length} ${type}(s)`);\n $('#modal .modal-body').empty();\n Modal.modalScroll(true);\n selected.forEach(function(row) {\n const data = fromTable.fnGetData(row);\n items.push(data._id);\n $('#modal .modal-body').append(Modal.formatItemUpdate(data));\n });\n $('#modal .modal-body').append(\n '<h3 id=\"select\"> into following binders </h3>'\n );\n $('#modal .modal-body').append('<div id=\"progress\"></div>');\n $('#modal .modal-body').append(\n '<table id=\"owned-binder-table\" class=\"table table-bordered table-hover\"></table>'\n );\n const binderAoColumns = [\n selectColumn,\n binderLinkColumn,\n titleColumn,\n tagsColumn,\n createdOnColumn,\n updatedOnColumn,\n ];\n fnAddFilterFoot('#owned-binder-table', binderAoColumns);\n const ownedBinderTable = $('#owned-binder-table').dataTable({\n sAjaxSource: '/writablebinders/json',\n sAjaxDataProp: '',\n bAutoWidth: false,\n iDisplayLength: 5,\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: binderAoColumns,\n aaSorting: [\n [4, 'desc'],\n [5, 'desc'],\n ],\n sDom: sDomNoTNoR,\n });\n selectEvent();\n filterEvent();\n $('#modal .modal-footer').html(\n '<button id=\"submit\" class=\"btn btn-primary\">Confirm</button><button id=\"return\" data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n $('#submit').click(function() {\n $('#submit').prop('disabled', true);\n $('#return').prop('disabled', true);\n const binders = [];\n const selectedRow = fnGetSelected(ownedBinderTable, 'row-selected');\n if (selectedRow.length === 0) {\n $('#modal #select')\n .text('Please select binder!')\n .addClass('text-warning');\n $('#submit').prop('disabled', false);\n $('#return').prop('disabled', false);\n } else {\n selectedRow.forEach(function(row) {\n const data = ownedBinderTable.fnGetData(row);\n binders.push(data._id);\n $('#modal #progress').append(Modal.formatItemUpdate(data));\n });\n addItems(items, binders, type);\n }\n });\n}\n"
},
{
"alpha_fraction": 0.8032258152961731,
"alphanum_fraction": 0.8129032254219055,
"avg_line_length": 102.33333587646484,
"blob_id": "986ca419c1510bfd5a4f67f473f1ffd2b9e79558",
"content_id": "5c88209fbfa1059495a43c2640a10fdc33ffa2bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 310,
"license_type": "permissive",
"max_line_length": 285,
"num_lines": 3,
"path": "/views/docs/api/auth.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### API authentication\n\nThe API's are protected by basic authentication. If a client gets 401 response with \"api\" realm challenge, then the client either did not present the credential in the request or the presented credential was not right. Please contact the application operator for available credentials.\n"
},
{
"alpha_fraction": 0.6664112210273743,
"alphanum_fraction": 0.6735632419586182,
"avg_line_length": 36.644229888916016,
"blob_id": "23a1b444c317900d0eb804943feb2402717158e5",
"content_id": "5eab3fcd1efc7e9b7c609e5af864d314331c7666",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3915,
"license_type": "permissive",
"max_line_length": 799,
"num_lines": 104,
"path": "/public/javascripts/public-travelers.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false */\n/*global prefix: false, ajax401: false, updateAjaxURL: false, disableAjaxCache: false*/\n/*global selectColumn: false, titleColumn: false, createdOnColumn: false, updatedOnColumn: false, filledByColumn: false, sharedWithColumn: false, sharedGroupColumn: false, fnAddFilterFoot: false, sDomNoTools: false, createdOnColumn: false, transferredOnColumn: false, travelerConfigLinkColumn: false, travelerShareLinkColumn: false, travelerLinkColumn: false, statusColumn: false, deviceColumn: false, fnGetSelected: false, selectEvent: false, filterEvent: false, ownerColumn: false, deadlineColumn: /*global travelerLinkColumn: false, titleColumn: false, ownerColumn: false, deviceColumn: false, createdOnColumn: false, sharedWithColumn: false, sharedGroupColumn: false, fnAddFilterFoot: false, createdByColumn: false, createdOnColumn: false, sDomNoTools: false, filterEvent: false, Holder: false*/\n\nimport * as AddBinder from './lib/binder.js';\n\nfunction noneSelectedModal() {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No traveler has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n // var publicTravelersAoColumns = [travelerLinkColumn, titleColumn, createdByColumn, createdOnColumn, ownerColumn, deviceColumn, sharedWithColumn, sharedGroupColumn];\n var publicTravelersAoColumns = [\n selectColumn,\n travelerLinkColumn,\n titleColumn,\n statusColumn,\n deviceColumn,\n tagsColumn,\n keysColumn,\n sharedWithColumn,\n sharedGroupColumn,\n createdOnColumn,\n deadlineColumn,\n filledByColumn,\n updatedOnColumn,\n travelerProgressColumn,\n ];\n fnAddFilterFoot('#public-travelers-table', publicTravelersAoColumns);\n $('#public-travelers-table').dataTable({\n sAjaxSource: '/publictravelers/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [\n [10, 50, 100, -1],\n [10, 50, 100, 'All'],\n ],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: publicTravelersAoColumns,\n aaSorting: [\n // [3, 'desc']\n [12, 'desc'],\n [9, 'desc'],\n ],\n sDom: sDomNoTools,\n });\n\n $('#report').click(function() {\n var activeTable = $('.table.active table').dataTable();\n var selected = fnGetSelected(activeTable, 'row-selected');\n if (selected.length === 0) {\n noneSelectedModal();\n return;\n }\n $('#report-form').empty();\n selected.forEach(function(row) {\n var data = activeTable.fnGetData(row);\n $('#report-form').append(\n $('<input type=\"hidden\"/>').attr({\n name: 'travelers[]',\n value: data._id,\n })\n );\n });\n $('#report-form').submit();\n });\n\n $('button.select-all').click(function() {\n var activeTable = $('.table.active table').dataTable();\n fnSelectAll(activeTable, 'row-selected', 'select-row', true);\n });\n\n $('button.deselect-all').click(function() {\n var activeTable = $('.table.active table').dataTable();\n fnDeselect(activeTable, 'row-selected', 'select-row');\n });\n\n $('#add-to-binder').click(function() {\n const fromTable = $('#public-travelers-table').dataTable();\n AddBinder.addModal(fromTable);\n });\n\n // binding events\n selectEvent();\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.7490565776824951,
"alphanum_fraction": 0.7490565776824951,
"avg_line_length": 40.842105865478516,
"blob_id": "5ef244da110705c3f32eb1324eb2f29d11e4178a",
"content_id": "3be319ae447192e227ac49d767cfd27d6b6f1f4c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1590,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 38,
"path": "/views/docs/faq.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "## FAQ\n\n**Audience: all users**\n\n_Q: I cannot save the updates and I have the write permission._\n\nA: If you see warning messages on the top of the traveler page when you made\nupdates, then the warning message should include the reason. If your session is\ntimed out, you can log in in a new browser tab or windows, and come back the\ncurrent tab and continue.\n\n_Q: My browser cannot find the traveler server._\n\nA: Please connect to VPN and load the traveler application URL.\n\n_Q: How to delete a template, a traveler or a binder?_\n\nA: You **cannot** delete an entity (a form, a traveler, or a binder) in the\ntraveler application once it is created. You can **archive** them. You can\nalways **de-archive** an entity from your \"archived\" tab, to work on them again.\n\n_Q: How to correct the data or note in a traveler?_\n\nA: You **cannot** \"revise\" the input data in a traveler. You can always input a\nnew value into the input where you want to correct. You might also want to add a\nnote to the input in order to explain the reason for the update.\n\n_Q: I cannot update the data in a traveler._\n\nA: If you cannot load the traveler page, then you do not have permission to view\nthe traveler, or the traveler does not exist, or the owner of the traveler has\narchived it. If you can load the traveler page, but the inputs are disabled,\nthen you do not have the write permission, or the traveler is not active.\n\n_Q: How to let other users contribute to a traveler?_\n\nA: You need to **share** your traveler with them. Please see the\n[ownership and access control section](#ownership) for more details.\n"
},
{
"alpha_fraction": 0.8031495809555054,
"alphanum_fraction": 0.8031495809555054,
"avg_line_length": 41.66666793823242,
"blob_id": "e7f6874c2baa3bb5f9062b0522eae2f99c144c75",
"content_id": "ae5e14d927cdbf4f34d0842166a8364e8da68026",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 127,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 3,
"path": "/views/docs/hero.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "# Traveler\n\n## A Web application to define work templates, create work instances from released templates, and organize the work"
},
{
"alpha_fraction": 0.6621564626693726,
"alphanum_fraction": 0.6799154281616211,
"avg_line_length": 26.823530197143555,
"blob_id": "ef8b25ed0bab2874e44b67c97e74cb9a05b64f98",
"content_id": "524f601a58d5d70f88e42f539723adaa45c43b04",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2365,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 85,
"path": "/public/javascripts/public-forms.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*\n global prefix, ajax401, updateAjaxURL, disableAjaxCache: false formLinkColumn,\n titleColumn, ownerColumn, createdOnColumn, sharedWithColumn, sharedGroupColumn,\n fnAddFilterFoot, createdByColumn, createdOnColumn, sDomNoTools, filterEvent,\n formCloneColumn, formStatusColumn, tagsColumn, keysColumn, Holder,\n releasedFormLinkColumn, releasedFormCloneColumn, releasedFormStatusColumn,\n formTypeColumn, releasedFormVersionColumn, releasedByColumn, releasedOnColumn,\n */\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n var publicFormsAoColumns = [\n formLinkColumn,\n formCloneColumn,\n titleColumn,\n formStatusColumn,\n tagsColumn,\n keysColumn,\n createdByColumn,\n createdOnColumn,\n ownerColumn,\n sharedWithColumn,\n sharedGroupColumn,\n ];\n fnAddFilterFoot('#public-forms-table', publicFormsAoColumns);\n $('#public-forms-table').dataTable({\n sAjaxSource: '/publicforms/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n iDisplayLength: 10,\n aLengthMenu: [[10, 50, 100, -1], [10, 50, 100, 'All']],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: publicFormsAoColumns,\n aaSorting: [[3, 'desc']],\n sDom: sDomNoTools,\n });\n\n /*released form table starts*/\n var releasedFormAoColumns = [\n releasedFormLinkColumn,\n releasedFormCloneColumn,\n titleColumn,\n releasedFormStatusColumn,\n formTypeColumn,\n releasedFormVersionColumn,\n tagsColumn,\n releasedByColumn,\n releasedOnColumn,\n ];\n $('#released-forms-table').dataTable({\n sAjaxSource: '/released-forms/json',\n sAjaxDataProp: '',\n fnDrawCallback: function() {\n Holder.run({\n images: 'img.user',\n });\n },\n bAutoWidth: false,\n bProcessing: true,\n iDisplayLength: 10,\n aLengthMenu: [[10, 50, 100, -1], [10, 50, 100, 'All']],\n oLanguage: {\n sLoadingRecords: 'Please wait - loading data from the server ...',\n },\n bDeferRender: true,\n aoColumns: releasedFormAoColumns,\n aaSorting: [[8, 'desc']],\n sDom: sDomNoTools,\n });\n fnAddFilterFoot('#released-forms-table', releasedFormAoColumns);\n /*released form table ends*/\n\n // binding events\n filterEvent();\n});\n"
},
{
"alpha_fraction": 0.6722221970558167,
"alphanum_fraction": 0.6722221970558167,
"avg_line_length": 22.478260040283203,
"blob_id": "67292c0ce8539080818c0806e64d8e24d7ecd165",
"content_id": "7b956a77a7d23fa0540957fd9c25cd54fed3fbc3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 540,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 23,
"path": "/lib/loggers.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const winston = require('winston');\n\nconst { format } = winston;\n\nwinston.loggers.add('production', {\n format: format.json(),\n level: 'info',\n transports: [new winston.transports.Console()],\n});\n\nwinston.loggers.add('development', {\n format: format.simple(),\n level: 'debug',\n transports: [new winston.transports.Console()],\n});\n\nmodule.exports.getLogger = function() {\n const env = process.env.NODE_ENV;\n if (env === 'production') {\n return winston.loggers.get('production');\n }\n return winston.loggers.get('development');\n};\n"
},
{
"alpha_fraction": 0.5739411115646362,
"alphanum_fraction": 0.5811198949813843,
"avg_line_length": 22.265134811401367,
"blob_id": "5b99ba64452de50121066d12f17922fc04a8563b",
"content_id": "4745da2ce7c97b6fb3947e13f6ac149f00e85dc3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 11144,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 479,
"path": "/lib/req-utils.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const sanitize = require('sanitize-html');\nconst _ = require('lodash');\nconst debug = require('debug')('traveler:req-utils');\nconst routesUtilities = require('../utilities/routes');\nconst {\n Manager,\n Admin,\n Read_all_forms,\n Write_active_travelers,\n} = require('./role');\n\nconst htmlSanitizeConfiguration = {\n allowedTags: [\n 'div',\n 'a',\n 'legend',\n 'span',\n 'label',\n 'input',\n 'figure',\n 'figcaption',\n 'img',\n 'textarea',\n 'p',\n 'ul',\n 'ol',\n 'li',\n 'pre',\n 'strong',\n 'em',\n 'h1',\n 'h2',\n 'h3',\n 'h4',\n 'h5',\n 'h6',\n ],\n allowedAttributes: {\n div: ['class'],\n span: ['class', 'style'],\n legend: ['id'],\n label: ['class'],\n input: [\n 'type',\n 'disabled',\n 'name',\n 'placeholder',\n 'required',\n 'data-userkey',\n 'data-filetype',\n 'value',\n 'min',\n 'max',\n ],\n img: ['name', 'alt', 'width', 'src'],\n textarea: [\n 'disabled',\n 'name',\n 'placeholder',\n 'rows',\n 'required',\n 'data-userkey',\n ],\n a: ['href', 'title', 'target'],\n },\n};\n\n/**\n * Check the property list of http request. Set the property to null if it is\n * not in the give names list. Go next() if at least one in the give names\n * list, otherwise respond 400\n * @param {String} list 'body'|'params'|'query'\n * @param {[String]} names The property list to check against\n * @return {Function} The middleware\n */\nfunction filter(list, names) {\n return function(req, res, next) {\n let found = false;\n const keys = Object.keys(req[list]);\n keys.forEach(key => {\n if (names.includes(key)) {\n found = true;\n } else {\n req[list][key] = null;\n }\n });\n if (found) {\n return next();\n }\n return res.status(400).send(`cannot find any of ${names} in ${list}`);\n };\n}\n\nconst sanitizeValue = function(val) {\n if (_.isString(val)) {\n return sanitizeText(val);\n }\n if (_.isFunction(val)) {\n // clean out function\n return null;\n }\n if (_.isPlainObject(val)) {\n return _.mapValues(val, function(input) {\n return sanitizeValue(input);\n });\n }\n if (_.isArray(val)) {\n return val.map(function(input) {\n return sanitizeValue(input);\n });\n }\n\n // let other types of value go through\n return val;\n};\n\n/**\n * Uses the sanitize along with the configuration to return sanitized text\n *\n * @param textToSanitize\n * @returns {string}\n */\nfunction sanitizeText(textToSanitize) {\n return sanitize(textToSanitize, htmlSanitizeConfiguration);\n}\n\n/**\n * Sanitize the property list of http request against the give name list.\n * @param {String} list 'body'|'params'|'query'\n * @param {[String]} names The list to sanitize\n * @return {Function} The middleware\n */\nfunction sanitizeMw(list, names) {\n return function(req, res, next) {\n if (!names || names.length === 0) {\n debug(req[list]);\n req[list] = sanitizeValue(req[list]);\n debug(req[list]);\n } else {\n names.forEach(function(n) {\n if (req[list].hasOwnProperty(n)) {\n if (_.isString(req[list][n])) {\n req[list][n] = sanitizeText(req[list][n]);\n }\n\n if (_.isObject(req[list][n]) || _.isArray(req[list][n])) {\n req[list][n] = sanitizeValue(req[list][n]);\n }\n }\n });\n }\n next();\n };\n}\n\n/**\n * Check if the request[list] has all the properties in the names list\n * @param {String} list 'body'|'params'|'query'\n * @param {[String]} names The property list to check\n * @return {Function} The middleware\n */\nfunction hasAll(list, names) {\n return function(req, res, next) {\n let i;\n let miss = false;\n let missed;\n for (i = 0; i < names.length; i += 1) {\n if (!req[list].hasOwnProperty(names[i])) {\n miss = true;\n missed = names[i];\n break;\n }\n }\n if (miss) {\n return res.status(400).send(`cannot find ${missed} in ${list}`);\n }\n return next();\n };\n}\n\n/**\n * Check if id in the given source exists in collection\n * @param {String} pName the parameter name of item id in req source\n * @param {String} source the source of pName: params | body | query\n * @param {Model} collection the collection model\n * @return {Function} the middleware\n */\nfunction existSource(pName, source, collection) {\n return function(req, res, next) {\n debug(pName);\n debug(source);\n collection.findById(req[source][pName]).exec(function(err, item) {\n if (err) {\n console.error(err);\n return res.status(500).send(err.message);\n }\n\n if (!item) {\n return res.status(404).send(`item ${req[source][pName]} not found`);\n }\n\n req[req[source][pName]] = item;\n return next();\n });\n };\n}\n\n/**\n * Check if id from params exists in collection\n * @param {String} pName the parameter name of item id in req object\n * @param {Model} collection the collection model\n * @return {Function} the middleware\n */\nfunction exist(pName, collection) {\n return existSource(pName, 'params', collection);\n}\n\n/**\n * check if the document in a certain status (list)\n * @param {String} pName the parameter name of item id in req object\n * @param {[Number]} sList the allowed status list\n * @return {Function} the middleware\n */\nfunction status(pName, sList) {\n return function(req, res, next) {\n const s = req[req.params[pName]].status;\n if (sList.indexOf(s) === -1) {\n return res\n .status(400)\n .send(\n `request is not allowed for item ${req.params[pName]} status ${s}`\n );\n }\n return next();\n };\n}\n\n/**\n * check if the document is archived\n * @param {String} pName the parameter name of item id in req object\n * @param {Boolean} a true or false\n * @return {Function} the middleware\n */\nfunction archived(pName, a) {\n return function(req, res, next) {\n const arch = req[req.params[pName]].archived;\n if (a !== arch) {\n return res\n .status(400)\n .send(\n `request is not allowed for item ${req.params[pName]} archived ${arch}`\n );\n }\n return next();\n };\n}\n\n/** ***\naccess := -1 // no access\n | 0 // read\n | 1 // write\n**** */\n\nfunction getAccess(req, doc) {\n if (doc.publicAccess === 1) {\n return 1;\n }\n if (doc.createdBy === req.session.userid && !doc.owner) {\n return 1;\n }\n if (doc.owner === req.session.userid) {\n return 1;\n }\n if (routesUtilities.checkUserRole(req, Manager)) {\n return 1;\n }\n if (routesUtilities.checkUserRole(req, Admin)) {\n return 1;\n }\n if (\n doc.constructor.modelName === 'Form' &&\n doc.__review &&\n doc.__review.reviewRequests &&\n doc.__review.reviewRequests.id(req.session.userid)\n ) {\n return 1;\n }\n if (doc.sharedWith && doc.sharedWith.id(req.session.userid)) {\n return doc.sharedWith.id(req.session.userid).access;\n }\n let i;\n if (doc.sharedGroup && req.session.memberOf) {\n for (i = 0; i < req.session.memberOf.length; i += 1) {\n if (\n doc.sharedGroup.id(req.session.memberOf[i]) &&\n doc.sharedGroup.id(req.session.memberOf[i]).access === 1\n ) {\n return 1;\n }\n }\n for (i = 0; i < req.session.memberOf.length; i += 1) {\n if (doc.sharedGroup.id(req.session.memberOf[i])) {\n return 0;\n }\n }\n }\n if (\n doc.constructor.modelName === 'Traveler' &&\n routesUtilities.checkUserRole(req, Write_active_travelers)\n ) {\n return 1;\n }\n if (\n doc.constructor.modelName === 'Form' &&\n routesUtilities.checkUserRole(req, Read_all_forms)\n ) {\n return 0;\n }\n if (doc.publicAccess === 0) {\n return 0;\n }\n return -1;\n}\n\nfunction canWrite(req, doc) {\n return getAccess(req, doc) === 1;\n}\n\n/**\n * check if the user can write the document, and go next if yes\n * @param {String} pName the document to check\n * @return {Function} the middleware\n */\nfunction canWriteMw(pName) {\n return function(req, res, next) {\n if (!canWrite(req, req[req.params[pName]])) {\n return res\n .status(403)\n .send('you are not authorized to access this resource');\n }\n return next();\n };\n}\n\nfunction canRead(req, doc) {\n return getAccess(req, doc) >= 0;\n}\n\n/**\n * check if the user can read the document, and go next if yes\n * @param {String} pName the parameter name identifying the object\n * @param {String} source the source of pname in request, default params\n * @return {Function} the middleware\n */\nfunction canReadMw(pName, source = 'params') {\n return function(req, res, next) {\n if (!canRead(req, req[req[source][pName]])) {\n return res\n .status(403)\n .send('you are not authorized to access this resource');\n }\n return next();\n };\n}\n\nfunction isOwner(req, doc) {\n if (\n (doc.createdBy === req.session.userid ||\n doc.releasedBy === req.session.userid) &&\n !doc.owner\n ) {\n return true;\n }\n if (doc.owner === req.session.userid) {\n return true;\n }\n return false;\n}\n\n/**\n * check if the user is the owner of the document, if yes next()\n * @param {String} pName the object's id to check\n * @return {Function} the middleware\n */\nfunction isOwnerMw(pName) {\n return function(req, res, next) {\n if (!isOwner(req, req[req.params[pName]])) {\n return res\n .status(403)\n .send('you are not authorized to access this resource');\n }\n return next();\n };\n}\n\n/**\n * check if the user is the owner of the document, or is admin, if yes next()\n * @param {String} pName the object's id to check\n * @return {Function} the middleware\n */\nfunction isOwnerOrAdminMw(pName) {\n return function(req, res, next) {\n if (\n isOwner(req, req[req.params[pName]]) ||\n routesUtilities.checkUserRole(req, 'admin')\n ) {\n return next();\n }\n return res\n .status(403)\n .send('you are not authorized to access this resource');\n };\n}\n\nfunction requireOwner(condition, pName) {\n return function(req, res, next) {\n let pre = true;\n if (_.isFunction(condition)) {\n pre = condition(req, res);\n }\n if (!pre) {\n return next();\n }\n if (!isOwner(req, req[req.params[pName]])) {\n return res\n .status(403)\n .send('you are not authorized to access this resource');\n }\n return next();\n };\n}\n\nfunction getSharedWith(sharedWith, name) {\n let i;\n if (sharedWith.length === 0) {\n return -1;\n }\n for (i = 0; i < sharedWith.length; i += 1) {\n if (sharedWith[i].username === name) {\n return i;\n }\n }\n return -1;\n}\n\nfunction getSharedGroup(sharedGroup, id) {\n let i;\n if (sharedGroup.length === 0) {\n return -1;\n }\n for (i = 0; i < sharedGroup.length; i += 1) {\n if (sharedGroup[i]._id === id) {\n return i;\n }\n }\n return -1;\n}\n\nmodule.exports = {\n filter,\n hasAll,\n sanitize: sanitizeMw,\n sanitizeText,\n exist,\n existSource,\n status,\n archived,\n canRead,\n canReadMw,\n canWrite,\n canWriteMw,\n isOwner,\n isOwnerMw,\n isOwnerOrAdminMw,\n getAccess,\n getSharedWith,\n getSharedGroup,\n requireOwner,\n};\n"
},
{
"alpha_fraction": 0.5285961627960205,
"alphanum_fraction": 0.5398613810539246,
"avg_line_length": 27.14634132385254,
"blob_id": "08aa6b5b1ea0ea32d2f4bebac273b14d36f6af8e",
"content_id": "80cbe6b0fa64ca3f5f44420fe70ffb841a8f296a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1154,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 41,
"path": "/public/javascripts/ajax-helper.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global window: false*/\n\nfunction updateAjaxURL(prefix) {\n if (prefix) {\n $.ajaxPrefilter(function(options) {\n var target = options.url;\n if (target.indexOf('/') === 0) {\n if (target.indexOf(prefix + '/') !== 0) {\n options.url = prefix + target;\n }\n }\n });\n }\n}\n\nfunction ajax401(prefix) {\n $(document).ajaxError(function(event, jqXHR) {\n if (jqXHR.status >= 400) {\n if (jqXHR.status === 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Please click <a href=\"' +\n prefix +\n '/login\" target=\"\" + linkTarget>traveler log in</a>, and then save the changes on this page.</div>'\n );\n } else {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>HTTP request failed. Reason: ' +\n jqXHR.responseText +\n '</div>'\n );\n }\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n }\n });\n}\n\nfunction disableAjaxCache() {\n $.ajaxSetup({\n cache: false,\n });\n}\n"
},
{
"alpha_fraction": 0.5661040544509888,
"alphanum_fraction": 0.5808719992637634,
"avg_line_length": 29.255319595336914,
"blob_id": "bb7bdbf06669e59c0d02027818e20413e45eecaf",
"content_id": "d699910b4b192984ec01b2df8385a1b4fae72856",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1422,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 47,
"path": "/routes/device.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "var config = require('../config/config.js');\nvar auth = require('../lib/auth');\nvar service = config.service;\nvar request = require('request');\nvar routesUtilities = require('../utilities/routes.js');\n\nmodule.exports = function(app) {\n app.get('/devices/', function(req, res) {\n switch (service.device_application) {\n case 'devices':\n return res.render('devices', routesUtilities.getRenderObject(req));\n case 'cdb':\n return res.redirect(service.cdb.web_portal_url);\n default:\n return res.status(404).send('No valid devices setting has been found');\n }\n });\n\n app.get('/devices/json', auth.ensureAuthenticated, function(req, res) {\n if (!(service && service.device && service.device.url)) {\n return res.status(500).send('do not know device service url');\n }\n request(\n {\n url: service.device.url,\n timeout: 30 * 1000,\n strictSSL: false,\n headers: {\n Accept: 'application/json',\n },\n },\n function(err, response, resBody) {\n if (err) {\n console.log(err);\n return res\n .status(503)\n .send('cannot retrieve device list from' + service.device.url);\n }\n res.status(response.statusCode);\n if (response.statusCode === 200) {\n res.type('application/json');\n }\n return res.status(200).send(resBody);\n }\n );\n });\n};\n"
},
{
"alpha_fraction": 0.5070537328720093,
"alphanum_fraction": 0.5132935643196106,
"avg_line_length": 30.237287521362305,
"blob_id": "a585f0a8582038d5dcac3b389740fd71bade5d82",
"content_id": "c1d688c1c3fb0623f7959c70a169dc781566a0ab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3686,
"license_type": "permissive",
"max_line_length": 316,
"num_lines": 118,
"path": "/public/javascripts/form-config.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/*global clearInterval: false, clearTimeout: false, document: false, event: false, frames: false, history: false, Image: false, location: false, name: false, navigator: false, Option: false, parent: false, screen: false, setInterval: false, setTimeout: false, window: false, XMLHttpRequest: false, FormData: false */\n/*global moment: false, ajax401: false, prefix: false, updateAjaxURL: false, disableAjaxCache: false*/\n\nimport * as Editable from './lib/editable.js';\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n\n function cleanTagForm() {\n $('#new-tag')\n .closest('li')\n .remove();\n $('#add-tag').removeAttr('disabled');\n }\n\n $('span.time').each(function() {\n $(this).text(\n moment($(this).text()).format('dddd, MMMM Do YYYY, h:mm:ss a')\n );\n });\n var initValue = {\n title: $('#title').text(),\n description: $('#description').text(),\n };\n\n // url is the form without config part\n const targetPath = window.location.pathname.split('/');\n targetPath[targetPath.length - 1] = '';\n Editable.binding($, initValue, targetPath.join('/'));\n\n var tags;\n\n $('#add-tag').click(function(e) {\n e.preventDefault();\n // add an input and a button add\n $('#add-tag').attr('disabled', true);\n $('#tags').append(\n '<li><form class=\"form-inline\"><input id=\"new-tag\" type=\"text\"> <button id=\"confirm\" class=\"btn btn-primary\">Confirm</button> <button id=\"cancel\" class=\"btn\">Cancel</button></form></li>'\n );\n $('#cancel').click(function(cancelE) {\n cancelE.preventDefault();\n cleanTagForm();\n });\n\n if (!tags) {\n tags = [];\n }\n\n $('#confirm').click(function(confirmE) {\n confirmE.preventDefault();\n if (\n $('#new-tag')\n .val()\n .trim()\n ) {\n $.ajax({\n url: './tags/',\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify({\n newtag: $('#new-tag')\n .val()\n .trim(),\n }),\n })\n .done(function(data, textStatus, jqXHR) {\n if (jqXHR.status === 204) {\n return;\n }\n if (jqXHR.status === 200) {\n $('#tags').append(\n '<li><span class=\"tag\">' +\n data.tag +\n '</span> <button class=\"btn btn-small btn-warning remove-tag\"><i class=\"fa fa-trash-o fa-lg\"></i></button></li>'\n );\n }\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot add the tag</div>'\n );\n $(window).scrollTop(\n $('#message div:last-child').offset().top - 40\n );\n }\n })\n .always(function() {\n cleanTagForm();\n $('#add-tag').removeAttr('disabled');\n });\n }\n });\n });\n\n $('#tags').on('click', '.remove-tag', function(e) {\n e.preventDefault();\n var $that = $(this);\n $.ajax({\n url: './tags/' + encodeURIComponent($that.siblings('span.tag').text()),\n type: 'DELETE',\n })\n .done(function() {\n $that.closest('li').remove();\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot remove the tag</div>'\n );\n $(window).scrollTop($('#message div:last-child').offset().top - 40);\n }\n })\n .always();\n });\n});\n"
},
{
"alpha_fraction": 0.4948311448097229,
"alphanum_fraction": 0.5354927778244019,
"avg_line_length": 20.33823585510254,
"blob_id": "b71fb6f64aa9b3fc1c8d89b6fde66c613c30c650",
"content_id": "c0cd2d7204a4bdfe207c1978551d07316e8ed8b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1451,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 68,
"path": "/public/javascripts/uid.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/**\n * UID.core.js\n *\n * @author liud\n */\n\n/** @constructor */\nfunction UID() {}\n\n/**\n * The simplest function to get an UID string.\n * @returns {string} A version 4 UID string.\n */\nUID.generate = function() {\n var rand = UID._gri,\n hex = UID._ha;\n return (\n hex(rand(32), 8) + // time_low\n hex(rand(16), 4) + // time_mid\n hex(0x4000 | rand(12), 4) + // time_hi_and_version\n hex(0x8000 | rand(14), 4) + // clock_seq_hi_and_reserved clock_seq_low\n hex(rand(48), 12)\n ); // node\n};\n\n/**\n * Returns an unsigned x-bit random integer.\n * @param {int} x A positive integer ranging from 0 to 53, inclusive.\n * @returns {int} An unsigned x-bit random integer (0 <= f(x) < 2^x).\n */\nUID._gri = function(x) {\n // _getRandomInt\n if (x < 0) return NaN;\n if (x <= 30) return 0 | (Math.random() * (1 << x));\n if (x <= 53)\n return (\n (0 | (Math.random() * (1 << 30))) +\n (0 | (Math.random() * (1 << (x - 30)))) * (1 << 30)\n );\n return NaN;\n};\n\n/**\n * Converts an integer to a zero-filled hexadecimal string.\n * @param {int} num\n * @param {int} length\n * @returns {string}\n */\nUID._ha = function(num, length) {\n // _hexAligner\n var str = num.toString(16),\n i = length - str.length,\n z = '0';\n for (; i > 0; i >>>= 1, z += z) {\n if (i & 1) {\n str = z + str;\n }\n }\n return str;\n};\n\n/*a short uid*/\n\nUID.generateShort = function() {\n var rand = UID._gri,\n hex = UID._ha;\n return hex(rand(32), 8);\n};\n"
},
{
"alpha_fraction": 0.5349352955818176,
"alphanum_fraction": 0.5436847805976868,
"avg_line_length": 26.352136611938477,
"blob_id": "40be460086c28b758d9eaf3676e2e4e873d4dd8b",
"content_id": "e8ebbabec6fa55f3af451118e280e349a9294936",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 32002,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 1170,
"path": "/routes/form.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "const debug = require('debug')('traveler:route:form');\nconst _ = require('lodash');\nconst mongoose = require('mongoose');\nconst path = require('path');\nconst config = require('../config/config');\nconst auth = require('../lib/auth');\n\nconst authConfig = config.auth;\n\nconst routesUtilities = require('../utilities/routes');\nconst reqUtils = require('../lib/req-utils');\nconst shareLib = require('../lib/share');\nconst tag = require('../lib/tag');\nconst formModel = require('../model/form');\nconst reviewLib = require('../lib/review');\n\nconst Form = mongoose.model('Form');\nconst FormFile = mongoose.model('FormFile');\nconst ReleasedForm = mongoose.model('ReleasedForm');\nconst FormContent = mongoose.model('FormContent');\nconst User = mongoose.model('User');\nconst Group = mongoose.model('Group');\nconst History = mongoose.model('History');\nconst { stateTransition } = require('../model/form');\n\nconst logger = require('../lib/loggers').getLogger();\n\nfunction checkReviewer(form, userid) {\n return (\n form.__review &&\n form.__review.reviewRequests &&\n form.__review.reviewRequests.id(userid)\n );\n}\n\nmodule.exports = function(app) {\n app.get('/forms/', auth.ensureAuthenticated, function(req, res) {\n res.render('forms', routesUtilities.getRenderObject(req));\n });\n\n app.get('/releasedforms/', auth.ensureAuthenticated, function(req, res) {\n res.render('released-forms', routesUtilities.getRenderObject(req));\n });\n\n app.get('/forms/json', auth.ensureAuthenticated, async function(req, res) {\n try {\n const forms = await Form.find(\n {\n createdBy: req.session.userid,\n archived: {\n $ne: true,\n },\n status: 0,\n owner: {\n $exists: false,\n },\n },\n 'title formType status tags mapping createdBy createdOn updatedBy updatedOn publicAccess sharedWith sharedGroup _v'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/myforms/json', auth.ensureAuthenticated, async function(req, res) {\n try {\n const me = await User.findOne(\n {\n _id: req.session.userid,\n },\n 'forms'\n ).exec();\n if (!me) {\n return res.status(400).send('cannot identify the current user');\n }\n const forms = await Form.find(\n {\n $or: [\n {\n createdBy: req.session.userid,\n },\n {\n owner: req.session.userid,\n },\n {\n _id: {\n $in: me.forms,\n },\n },\n ],\n },\n 'title formType status updatedOn'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n // forms owned by the user that are under review\n app.get('/submittedforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n try {\n const forms = await Form.find(\n {\n $or: [\n {\n createdBy: req.session.userid,\n owner: {\n $exists: false,\n },\n },\n {\n owner: req.session.userid,\n },\n ],\n archived: {\n $ne: true,\n },\n status: {\n $in: [0.5],\n },\n },\n 'title formType status tags mapping createdBy createdOn updatedBy updatedOn publicAccess sharedWith sharedGroup _v'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n // forms owned by the user that are under review\n app.get('/closedforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n try {\n const forms = await Form.find(\n {\n createdBy: req.session.userid,\n archived: {\n $ne: true,\n },\n status: {\n $in: [1],\n },\n owner: {\n $exists: false,\n },\n },\n 'title formType status tags mapping createdBy createdOn updatedBy updatedOn publicAccess sharedWith sharedGroup _v'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/transferredforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n try {\n const forms = await Form.find(\n {\n owner: req.session.userid,\n status: 0,\n archived: {\n $ne: true,\n },\n },\n 'title formType status tags createdBy createdOn updatedBy updatedOn transferredOn publicAccess sharedWith sharedGroup'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/allforms/json', auth.ensureAuthenticated, async function(req, res) {\n if (!routesUtilities.checkUserRole(req, 'read_all_forms')) {\n return res.status(401).json('You are not authorized to view all forms.');\n }\n try {\n const forms = await Form.find(\n {},\n 'title formType status tags createdBy createdOn updatedBy updatedOn sharedWith sharedGroup'\n )\n .lean()\n .exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/sharedforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n try {\n const me = await User.findOne(\n {\n _id: req.session.userid,\n },\n 'forms'\n ).exec();\n if (!me) {\n return res.status(400).send('cannot identify the current user');\n }\n const forms = await Form.find(\n {\n _id: {\n $in: me.forms,\n },\n archived: {\n $ne: true,\n },\n },\n 'title formType status tags owner updatedBy updatedOn publicAccess sharedWith sharedGroup'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n debug(`error: ${error}`);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/groupsharedforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n try {\n const groups = await Group.find(\n {\n _id: {\n $in: req.session.memberOf,\n },\n },\n 'forms'\n ).exec();\n const formids = [];\n let i;\n let j;\n // merge the forms arrays\n for (i = 0; i < groups.length; i += 1) {\n for (j = 0; j < groups[i].forms.length; j += 1) {\n if (formids.indexOf(groups[i].forms[j]) === -1) {\n formids.push(groups[i].forms[j]);\n }\n }\n }\n const forms = await Form.find(\n {\n _id: {\n $in: formids,\n },\n archived: {\n $ne: true,\n },\n },\n 'title formType status tags owner updatedBy updatedOn publicAccess sharedWith sharedGroup'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/archivedforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n const search = {\n $and: [\n {\n $or: [\n {\n createdBy: req.session.userid,\n owner: {\n $exists: false,\n },\n },\n {\n owner: req.session.userid,\n },\n ],\n },\n {\n $or: [\n {\n archived: true,\n },\n {\n status: 2,\n },\n ],\n },\n ],\n };\n try {\n const forms = await Form.find(\n search,\n 'title formType status tags updatedBy updatedOn _v'\n ).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/publicforms/', auth.ensureAuthenticated, function(req, res) {\n res.render('public-forms', routesUtilities.getRenderObject(req));\n });\n\n app.get('/publicforms/json', auth.ensureAuthenticated, async function(\n req,\n res\n ) {\n try {\n const forms = await Form.find({\n publicAccess: {\n $in: [0, 1],\n },\n archived: {\n $ne: true,\n },\n }).exec();\n return res.status(200).json(forms);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n });\n\n app.get('/forms/new', auth.ensureAuthenticated, function(req, res) {\n return res.render('form-new', routesUtilities.getRenderObject(req));\n });\n\n app.get(\n '/forms/:id/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n function formBuilder(req, res) {\n const form = req[req.params.id];\n const access = reqUtils.getAccess(req, form);\n\n if (access === -1) {\n return res\n .status(403)\n .send('you are not authorized to access this resource');\n }\n\n if (form.archived) {\n return res.redirect(\n `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/forms/${req.params.id}/preview`\n );\n }\n\n const isReviewer = checkReviewer(form, req.session.userid);\n const allApproved = form.allApproved();\n debug(`all approved: ${allApproved}`);\n\n if (access === 1 && form.isBuilder()) {\n return res.render(\n 'form-builder',\n routesUtilities.getRenderObject(req, {\n id: req.params.id,\n title: form.title,\n html: form.html,\n status: form.status,\n statusText: formModel.statusMap[`${form.status}`],\n _v: form._v,\n formType: form.formType,\n prefix: req.proxied ? req.proxied_prefix : '',\n isReviewer,\n allApproved,\n review: form.__review,\n released_form_version_mgmt: config.app.released_form_version_mgmt,\n })\n );\n }\n\n return res.redirect(\n `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/forms/${req.params.id}/preview`\n );\n }\n );\n\n app.get(\n '/forms/:id/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canReadMw('id'),\n function(req, res) {\n return res.status(200).json(req[req.params.id]);\n }\n );\n\n app.get(\n '/forms/:id/released/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canReadMw('id'),\n async function(req, res) {\n const baseIds = [req.params.id];\n const parentFormId = req[req.params.id].clonedFrom;\n if (parentFormId) {\n baseIds.push(parentFormId);\n }\n\n try {\n const forms = await ReleasedForm.find({\n 'base._id': {\n $in: baseIds,\n },\n status: 1, // released\n }).exec();\n return res.status(200).json(forms);\n } catch (error) {\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.post(\n '/forms/:id/uploads/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canWriteMw('id'),\n async function(req, res) {\n const doc = req[req.params.id];\n if (_.isEmpty(req.files)) {\n return res.status(400).send('Expect One uploaded file');\n }\n\n if (!req.body.name) {\n return res.status(400).send('Expect input name');\n }\n\n const file = new FormFile({\n form: doc._id,\n value: req.files[req.body.name].originalname,\n file: {\n path: req.files[req.body.name].path,\n encoding: req.files[req.body.name].encoding,\n mimetype: req.files[req.body.name].mimetype,\n },\n inputType: req.body.type,\n uploadedBy: req.session.userid,\n uploadedOn: Date.now(),\n });\n try {\n const newFile = await file.save();\n const url = `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/formfiles/${newFile.id}`;\n res.set('Location', url);\n return res\n .status(201)\n .send(\n `The uploaded file is at <a target=\"_blank\" href=\"${url}\">${url}</a>`\n );\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.get(\n '/formfiles/:id',\n auth.ensureAuthenticated,\n reqUtils.exist('id', FormFile),\n function(req, res) {\n const data = req[req.params.id];\n if (data.inputType === 'file') {\n return res.sendFile(path.resolve(data.file.path));\n }\n return res.status(500).send('it is not a file');\n }\n );\n\n app.get(\n '/forms/:id/preview',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canReadMw('id'),\n function(req, res) {\n const form = req[req.params.id];\n return res.render(\n 'form-viewer',\n routesUtilities.getRenderObject(req, {\n id: req.params.id,\n title: form.title,\n html: form.html,\n })\n );\n }\n );\n\n app.get(\n '/forms/:id/config',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n reqUtils.archived('id', false),\n function(req, res) {\n const doc = req[req.params.id];\n return res.render(\n 'form-config',\n routesUtilities.getRenderObject(req, {\n form: doc,\n isOwner: reqUtils.isOwner(req, doc),\n })\n );\n }\n );\n\n app.get(\n '/forms/:id/share/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const form = req[req.params.id];\n return res.render(\n 'share',\n routesUtilities.getRenderObject(req, {\n type: 'form',\n id: req.params.id,\n title: form.title,\n access: String(form.publicAccess),\n })\n );\n }\n );\n\n app.get(\n '/forms/:id/version-mgmt',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canWriteMw('id'),\n reqUtils.status('id', [0, 0.5, 1, 2]),\n function(req, res) {\n const form = req[req.params.id];\n return res.render(\n 'form-version-mgmt',\n routesUtilities.getRenderObject(req, {\n type: 'form',\n id: req.params.id,\n title: form.title,\n })\n );\n }\n );\n\n app.get(\n '/forms/:id/versions/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canWriteMw('id'),\n async function(req, res) {\n const form = req[req.params.id];\n const updates = form.__updates;\n try {\n const result = await History.find({\n _id: {\n $in: updates,\n },\n }).exec();\n res.status(200).json(result);\n } catch (error) {\n logger.error(error);\n res.status(500).send(error.message);\n }\n }\n );\n\n app.get(\n '/forms/:id/review/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n // only available when under review\n reqUtils.status('id', [0.5]),\n function(req, res) {\n const form = req[req.params.id];\n return res.render(\n 'review',\n routesUtilities.getRenderObject(req, {\n type: 'form',\n id: req.params.id,\n title: form.title,\n })\n );\n }\n );\n\n app.get(\n '/forms/:id/review/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const form = req[req.params.id];\n return res.status(200).json(form.__review || {});\n }\n );\n\n // add a new review request\n app.post(\n '/forms/:id/review/requests',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n // only available when under review\n reqUtils.status('id', [0.5]),\n async function(req, res) {\n const form = req[req.params.id];\n await reviewLib.addReviewRequest(req, res, form);\n }\n );\n\n // remove a review request\n app.delete(\n '/forms/:id/review/requests/:requestId',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n // only available when under review\n reqUtils.status('id', [0.5]),\n async function(req, res) {\n const form = req[req.params.id];\n await reviewLib.removeReviewRequest(req, res, form);\n }\n );\n\n // add a new review request\n app.post(\n '/forms/:id/review/results',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n // only available when under review\n reqUtils.status('id', [0.5]),\n function(req, res, next) {\n const isReviewer = checkReviewer(req[req.params.id], req.session.userid);\n if (!isReviewer) {\n return res.status(401).send('only reviewer can submit');\n }\n return next();\n },\n async function(req, res) {\n const form = req[req.params.id];\n await reviewLib.addReviewResult(req, res, form);\n }\n );\n\n app.put(\n '/forms/:id/share/public',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n reqUtils.filter('body', ['access']),\n async function(req, res) {\n const form = req[req.params.id];\n let { access } = req.body;\n if (['-1', '0', '1'].indexOf(access) === -1) {\n return res.status(400).send('not valid value');\n }\n access = Number(access);\n if (form.publicAccess === access) {\n return res.status(204).send();\n }\n form.publicAccess = access;\n try {\n await form.save();\n return res\n .status(200)\n .send(`public access is set to ${req.body.access}`);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.get(\n '/forms/:id/share/:list/json',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const form = req[req.params.id];\n if (req.params.list === 'users') {\n return res.status(200).json(form.sharedWith || []);\n }\n if (req.params.list === 'groups') {\n return res.status(200).json(form.sharedGroup || []);\n }\n return res.status(400).send('unknown share list.');\n }\n );\n\n app.post(\n '/forms/:id/share/:list/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n function(req, res) {\n const form = req[req.params.id];\n let share = -2;\n if (req.params.list === 'users') {\n if (req.body.name) {\n share = reqUtils.getSharedWith(form.sharedWith, req.body.name);\n } else {\n return res.status(400).send('user name is empty.');\n }\n }\n if (req.params.list === 'groups') {\n if (req.body.id) {\n share = reqUtils.getSharedGroup(form.sharedGroup, req.body.id);\n } else {\n return res.status(400).send('group id is empty.');\n }\n }\n\n if (share === -2) {\n return res.status(400).send('unknown share list.');\n }\n\n if (share >= 0) {\n return res\n .status(400)\n .send(\n req.body.name ||\n `${req.body.id} is already in the ${req.params.list} list.`\n );\n }\n\n // share === -1\n return shareLib.addShare(req, res, form);\n }\n );\n\n app.put(\n '/forms/:id/share/:list/:shareid',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n reqUtils.filter('body', ['access']),\n async function(req, res) {\n const form = req[req.params.id];\n let share;\n if (req.params.list === 'users') {\n share = form.sharedWith.id(req.params.shareid);\n }\n if (req.params.list === 'groups') {\n share = form.sharedGroup.id(req.params.shareid);\n }\n if (!share) {\n return res\n .status(400)\n .send(`cannot find ${req.params.shareid} in the list.`);\n }\n // change the access\n if (req.body.access === 'write') {\n share.access = 1;\n } else if (req.body.access === 'read') {\n share.access = 0;\n } else {\n return res\n .status(400)\n .send(`cannot take the access ${req.body.access}`);\n }\n try {\n await form.save();\n // check consistency of user's form list\n let Target;\n if (req.params.list === 'users') {\n Target = User;\n }\n if (req.params.list === 'groups') {\n Target = Group;\n }\n const newTarget = await Target.findByIdAndUpdate(req.params.shareid, {\n $addToSet: {\n forms: form._id,\n },\n });\n if (!newTarget) {\n logger.error(`The user/group ${req.params.shareid} is not in the db`);\n return res\n .status(404)\n .send(`user/group ${req.params.shareid} not found`);\n }\n return res.status(200).json(share);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.delete(\n '/forms/:id/share/:list/:shareid',\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n auth.ensureAuthenticated,\n function(req, res) {\n const form = req[req.params.id];\n shareLib.removeShare(req, res, form);\n }\n );\n\n app.post(\n '/forms/',\n auth.ensureAuthenticated,\n reqUtils.filter('body', ['title', 'formType', 'html']),\n reqUtils.hasAll('body', ['title']),\n auth.requireRoles(req => {\n return (\n req.body.hasOwnProperty('formType') &&\n req.body.formType === 'discrepancy'\n );\n }, 'admin'),\n reqUtils.sanitize('body', ['html']),\n async function(req, res) {\n const html = req.body.html || '';\n try {\n const newForm = await formModel.createFormWithHistory(\n req.session.userid,\n {\n title: req.body.title,\n formType: req.body.formType,\n createdBy: req.session.userid,\n html,\n }\n );\n const url = `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/forms/${newForm.id}/`;\n\n res.set('Location', url);\n return res.status(303).json({\n location: url,\n });\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.post(\n '/forms/:id/clone',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canReadMw('id'),\n async function(req, res) {\n const doc = req[req.params.id];\n const form = {};\n form.html = reqUtils.sanitizeText(doc.html);\n form.title = reqUtils.sanitizeText(req.body.title);\n form.createdBy = req.session.userid;\n form.createdOn = Date.now();\n form.updatedBy = req.session.userid;\n form.updatedOn = Date.now();\n form.clonedFrom = doc._id;\n form.formType = doc.formType;\n form.sharedWith = [];\n form.tags = doc.tags;\n\n try {\n const newForm = await new Form(form).saveWithHistory(\n req.session.userid\n );\n const url = `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/forms/${newForm.id}/`;\n res.set('Location', url);\n return res\n .status(201)\n .send(`You can see the new form at <a href=\"${url}\">${url}</a>`);\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.put(\n '/forms/:id/archived',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n reqUtils.filter('body', ['archived']),\n async function(req, res) {\n const doc = req[req.params.id];\n if (doc.archived === req.body.archived) {\n return res.status(204).send();\n }\n\n doc.archived = req.body.archived;\n if (doc.archived) {\n doc.archivedOn = Date.now();\n }\n try {\n const newDoc = await doc.save();\n return res\n .status(200)\n .send(\n `Form ${req.params.id} archived state set to ${newDoc.archived}`\n );\n } catch (error) {\n logger.error(error);\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.put(\n '/forms/:id/owner',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.isOwnerMw('id'),\n reqUtils.filter('body', ['name']),\n function(req, res) {\n const doc = req[req.params.id];\n shareLib.changeOwner(req, res, doc);\n }\n );\n\n app.put(\n '/forms/:id/',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.canWriteMw('id'),\n reqUtils.status('id', [0]),\n reqUtils.filter('body', ['html', 'title', 'description']),\n reqUtils.sanitize('body', ['html', 'title', 'description']),\n async function(req, res) {\n if (!req.is('json')) {\n return res.status(415).send('json request expected');\n }\n const doc = req[req.params.id];\n if (req.body.hasOwnProperty('html')) {\n doc.html = req.body.html;\n }\n if (req.body.hasOwnProperty('title')) {\n if (reqUtils.isOwner(req, doc)) {\n doc.title = req.body.title;\n } else {\n req.send(403, 'not authorized to access this resource');\n }\n }\n\n if (req.body.hasOwnProperty('description')) {\n if (reqUtils.isOwner(req, doc)) {\n doc.description = req.body.description;\n } else {\n req.send(403, 'not authorized to access this resource');\n }\n }\n\n doc.updatedBy = req.session.userid;\n doc.updatedOn = Date.now();\n doc.incrementVersion();\n try {\n const newDoc = await doc.saveWithHistory(req.session.userid);\n return res.json(newDoc);\n } catch (error) {\n return res.status(500).send(error.message);\n }\n }\n );\n\n // add tag routines\n tag.addTag(app, '/forms/:id/tags/', Form);\n tag.removeTag(app, '/forms/:id/tags/:tag', Form);\n\n app.put(\n '/forms/:id/released',\n auth.ensureAuthenticated,\n // find the unreleased form\n reqUtils.exist('id', Form),\n // owner decide if release\n reqUtils.isOwnerMw('id'),\n function(req, res, next) {\n if (req[req.params.id].status !== 0.5) {\n return res\n .status(400)\n .send(`${req[req.params.id].id} has not been submitted for review`);\n }\n return next();\n },\n function(req, res, next) {\n if (!req[req.params.id].allApproved) {\n return res\n .status(400)\n .send(`${req[req.params.id].id} was not approved by all reviewers`);\n }\n return next();\n },\n // if the base form is normal then load the released discrepancy form\n function(req, res, next) {\n debug(req.body.discrepancyFormId);\n debug(req[req.params.id].formType);\n if (\n req[req.params.id].formType === 'normal' &&\n req.body.discrepancyFormId\n ) {\n reqUtils.existSource('discrepancyFormId', 'body', ReleasedForm)(\n req,\n res,\n next\n );\n } else {\n next();\n }\n },\n // check the discrepancy form type\n function(req, res, next) {\n debug(req[req.body.discrepancyFormId]);\n if (\n req[req.body.discrepancyFormId] &&\n req[req.body.discrepancyFormId].formType !== 'discrepancy'\n ) {\n return res\n .status(400)\n .send(\n `${req[req.body.discrepancyFormId].id} is not a discrepancy form`\n );\n }\n\n if (\n req[req.body.discrepancyFormId] &&\n req[req.body.discrepancyFormId].status !== 1\n ) {\n return res\n .status(400)\n .send(`${req[req.body.discrepancyFormId].id} is not released`);\n }\n return next();\n },\n async function releaseForm(req, res) {\n const releasedForm = {};\n const form = req[req.params.id];\n const discrepancyForm = req[req.body.discrepancyFormId];\n releasedForm.title = req.body.title || form.title;\n releasedForm.description = req.body.description || form.description;\n releasedForm.tags = form.tags;\n releasedForm.formType = form.formType;\n releasedForm.base = new FormContent(form);\n releasedForm.ver = `${releasedForm.base._v}`;\n if (discrepancyForm) {\n // update formType\n releasedForm.formType = 'normal_discrepancy';\n releasedForm.discrepancy = discrepancyForm.base;\n releasedForm.ver += `:${discrepancyForm.base._v}`;\n }\n releasedForm.releasedBy = req.session.userid;\n releasedForm.releasedOn = Date.now();\n\n // check if there is already a released form with the same name and\n // version\n try {\n const existingForm = await ReleasedForm.findOne({\n title: releasedForm.title,\n formType: releasedForm.formType,\n ver: releasedForm.ver,\n // only search the active released form, not archived\n // remove this condition if including the archive released form\n status: 1,\n });\n debug(`find existing form: ${existingForm}`);\n if (existingForm) {\n return res\n .status(400)\n .send(\n `A form with same title, type, and version was already released in ${existingForm._id}.`\n );\n }\n const saveForm = await new ReleasedForm(releasedForm).saveWithHistory(\n req.session.userid\n );\n\n // update the form status\n form.status = 1;\n form.updatedBy = req.session.userid;\n form.updatedOn = Date.now();\n await form.save();\n\n // close the review requests\n await form.closeReviewRequests();\n const url = `${\n req.proxied ? authConfig.proxied_service : authConfig.service\n }/released-forms/${saveForm._id}/`;\n return res.status(201).json({\n location: url,\n });\n } catch (error) {\n return res.status(500).send(error.message);\n }\n }\n );\n\n app.put(\n '/forms/:id/status',\n auth.ensureAuthenticated,\n reqUtils.exist('id', Form),\n reqUtils.filter('body', ['status', 'version']),\n reqUtils.hasAll('body', ['status', 'version']),\n reqUtils.canWriteMw('id'),\n async function updateStatus(req, res) {\n const f = req[req.params.id];\n const s = req.body.status;\n const v = req.body.version;\n\n if ([0, 0.5, 1, 2].indexOf(s) === -1) {\n return res.status(400).send('invalid status');\n }\n\n if (v !== f._v) {\n return res.status(400).send(`the current version is ${f._v}`);\n }\n\n // no change\n if (f.status === s) {\n return res.status(204).send();\n }\n\n const target = _.find(stateTransition, function(t) {\n return t.from === f.status;\n });\n\n debug(target);\n if (target === undefined || target.to.indexOf(s) === -1) {\n return res.status(400).send('invalid status change');\n }\n\n f.status = s;\n f.updatedBy = req.session.userid;\n f.updatedOn = Date.now();\n // check if we need to increment the version\n f.incrementVersion();\n try {\n await f.saveWithHistory(req.session.userid);\n return res.status(200).send(`status updated to ${s}`);\n } catch (error) {\n return res.status(500).send(error.message);\n }\n }\n );\n};\n"
},
{
"alpha_fraction": 0.5733653903007507,
"alphanum_fraction": 0.5766260623931885,
"avg_line_length": 25.36651611328125,
"blob_id": "131a85b08b890466ca20d2318488dbc157f62438",
"content_id": "76c83e610a31f19a48e6f577cfa5e01cf85b54dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5827,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 221,
"path": "/public/javascripts/review.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* global prefix: false, ajax401: false, updateAjaxURL: false, disableAjaxCache: false, travelerGlobal: false, Holder, moment */\n/* global selectColumn: false, reviewerIdColumn, fnGetSelected: false, selectEvent: false, filterEvent: false, sDomNoTools: false, reviewResultColumn, requestedOnColumn */\n\nconst path = window.location.pathname;\n\nfunction transformReview(review) {\n const reviews = [];\n const { reviewRequests = [], reviewResults = [] } = review;\n reviewRequests.forEach(reviewRequest => {\n const transformed = {\n _id: reviewRequest._id,\n requestedOn: reviewRequest.requestedOn,\n requestedBy: reviewRequest.requestedBy,\n result: reviewResults.reverse().find(reviewResult => {\n return reviewResult.reviewerId === reviewRequest._id;\n }),\n };\n reviews.push(transformed);\n });\n return reviews;\n}\n\nfunction initTable(oTable) {\n $.ajax({\n url: `${path}json`,\n type: 'GET',\n dataType: 'json',\n })\n .done(function(json) {\n oTable.fnClearTable();\n const reviews = transformReview(json);\n oTable.fnAddData(reviews);\n oTable.fnDraw();\n })\n .fail(function(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n '<div class=\"alert alert-info\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot reach the server for review information.</div>'\n );\n }\n });\n}\n\nfunction removeFromModal(cb) {\n const ids = [];\n $('#modal .modal-body .target').each(function() {\n ids.push(this.id);\n });\n $.ajax({\n url: `${path}requests/${ids.join()}`,\n type: 'DELETE',\n dataType: 'json',\n })\n .done(function(json) {\n json.forEach(function(id) {\n const item = $(`#${id}`);\n item.wrap('<del></del>');\n item.addClass('text-success');\n });\n })\n .fail(function(jqXHR) {\n $('.modal-body').append(`Error : ${jqXHR.responseText}`);\n })\n .always(function() {\n cb();\n });\n}\n\nfunction remove(oTable) {\n const selected = fnGetSelected(oTable, 'row-selected');\n if (selected.length) {\n $('#modalLabel').html(\n `Remove the following ${selected.length} review requests? `\n );\n $('#modal .modal-body').empty();\n selected.forEach(function(row) {\n const data = oTable.fnGetData(row);\n $('#modal .modal-body').append(\n `<div class=\"target\" id=\"${data._id}\">${data._id}</div>`\n );\n });\n $('#modal .modal-footer').html(\n '<button id=\"remove\" class=\"btn btn-primary\">Confirm</button><button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#remove').click(function(e) {\n e.preventDefault();\n $('#remove').prop('disabled', true);\n removeFromModal(function() {\n initTable(oTable);\n });\n });\n $('#modal').modal('show');\n } else {\n $('#modalLabel').html('Alert');\n $('#modal .modal-body').html('No item has been selected!');\n $('#modal .modal-footer').html(\n '<button data-dismiss=\"modal\" aria-hidden=\"true\" class=\"btn\">Return</button>'\n );\n $('#modal').modal('show');\n }\n}\n\nfunction inArray(name, ao) {\n let i;\n for (i = 0; i < ao.length; i += 1) {\n if ((ao[i].username || ao[i]._id) === name) {\n return true;\n }\n }\n return false;\n}\n\nfunction addTo(data, table, list) {\n if (!data.name) {\n $('#message').append(\n `<div class=\"alert\"><button class=\"close\" data-dismiss=\"alert\">x</button>${list} name is empty. </div>`\n );\n return;\n }\n if (inArray(data.name, table.fnGetData())) {\n const { name } = data;\n // show message\n $('#message').append(\n `<div class=\"alert alert-info\"><button class=\"close\" data-dismiss=\"alert\">x</button><strong>${name}</strong> is already in the review list. </div>`\n );\n return;\n }\n $.ajax({\n url: `${path}requests`,\n type: 'POST',\n contentType: 'application/json',\n data: JSON.stringify(data),\n processData: false,\n success(res, status, jqXHR) {\n $('#message').append(\n `<div class=\"alert alert-success\"><button class=\"close\" data-dismiss=\"alert\">x</button>${jqXHR.responseText}</div>`\n );\n initTable(table);\n },\n error(jqXHR) {\n if (jqXHR.status !== 401) {\n $('#message').append(\n `<div class=\"alert alert-error\"><button class=\"close\" data-dismiss=\"alert\">x</button>Cannot update the review list : ${jqXHR.responseText}</div>`\n );\n }\n },\n });\n}\n\n$(function() {\n ajax401(prefix);\n updateAjaxURL(prefix);\n disableAjaxCache();\n\n $('span.time').each(function() {\n if ($(this).text()) {\n $(this).text(\n moment($(this).text()).format('dddd, MMMM Do YYYY, h:mm:ss a')\n );\n }\n });\n\n if ($('#username').length) {\n travelerGlobal.usernames.initialize();\n }\n\n $('#username').typeahead(\n {\n minLength: 1,\n highlight: true,\n hint: true,\n },\n {\n name: 'usernames',\n display: 'displayName',\n limit: 20,\n source: travelerGlobal.usernames,\n }\n );\n\n $('#username').on('typeahead:select', function() {\n $('#add').attr('disabled', false);\n });\n\n const reviewAoColumns = [\n selectColumn,\n reviewerIdColumn,\n requestedOnColumn,\n reviewResultColumn,\n ];\n const reviewTable = $('#review-table').dataTable({\n aaData: [],\n aoColumns: reviewAoColumns,\n fnDrawCallback() {\n Holder.run({\n images: 'img.user',\n });\n },\n aaSorting: [[2, 'desc']],\n sDom: sDomNoTools,\n });\n\n selectEvent();\n filterEvent();\n\n $('#add').click(function(e) {\n e.preventDefault();\n const data = {};\n data.name = $('#username').val();\n addTo(data, reviewTable, 'users');\n $('form[name=\"user\"]')[0].reset();\n });\n\n $('#review-remove').click(function() {\n remove(reviewTable);\n });\n\n if ($('#username').length) {\n initTable(reviewTable);\n }\n});\n"
},
{
"alpha_fraction": 0.6010295748710632,
"alphanum_fraction": 0.6138995885848999,
"avg_line_length": 21.852941513061523,
"blob_id": "9b8180f44c5c3b06b6035f9ba3752fd0a1649ac7",
"content_id": "293d71c348735d64845c2fa5fe4ee85b58c78e3e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 777,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 34,
"path": "/public/javascripts/lib/table1.10.js",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "/* global moment: false */\nexport const versionColumn = {\n title: 'V',\n data: '_v',\n defaultContent: '',\n width: '25px',\n};\n\nexport function versionRadioColumn(title, name) {\n return {\n title,\n defaultContent: `<label class=\"radio\"><input type=\"radio\" name=\"${name}\" class=\"radio-row\"></label>`,\n width: '25px',\n };\n}\n\nfunction formatDateLong(date) {\n return date ? moment(date).format('YYYY-MM-DD HH:mm:ss') : '';\n}\n\nexport function longDateColumn(title, key) {\n return {\n title,\n data(row) {\n return formatDateLong(row[key]);\n },\n defaultContent: '',\n };\n}\n\nexport const dom =\n \"<'row-fluid'<'span6'<'control-group'B>>><'row-fluid'<'span6'l><'span6'f>r>t<'row-fluid'<'span6'i><'span6'p>>\";\n\nexport const domI = \"t<'row-fluid'<'span6'i>>\";\n"
},
{
"alpha_fraction": 0.7801547646522522,
"alphanum_fraction": 0.7801547646522522,
"avg_line_length": 50.093021392822266,
"blob_id": "1d862b3cfefdf20963f3660c7efd99d1f39323da",
"content_id": "58352eb66e4e0ce277c8bff88da215f058288f96",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2197,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 43,
"path": "/views/docs/traveler/view.md",
"repo_name": "dongliu/traveler",
"src_encoding": "UTF-8",
"text": "### View a traveler\n\n**Audience: traveler users**\n\nThe user can directly load the traveler in the browser with a traveler's URL. If\nthe user has only read permission of the traveler, the browser will redirect to\na read-only view. On the travelers page, click on the\n<a data-toggle=\"tooltip\" title=\"go to the traveler\"><i class=\"fa fa-edit fa-lg\"></i></a>\nicon in order to the traveler page.\n\nIn a traveler page, the top line is the traveler's title. Below the title is the\ntraveler status, and progress. The progress tells the number of inputs updated\nout of the total inputs. The numbers represent only rough progress\n**estimation** of the traveler. A traveler can be complete when some inputs have\nnot be updated.\n\nThe <button class=\"btn btn-info collapsed\">Details</button> button shows/hides\nsome detailed information of the traveler including the description, creation\nuser/time and last update user/time. The details information is hidden by\ndefault.\n\nThe\n<span data-toggle=\"buttons-radio\" class=\"btn-group\"><button id=\"show-validation\" class=\"btn btn-info\">Show\nvalidation</button><button id=\"hide-validation\" class=\"btn btn-info active\">Hide\nvalidation</button></span> buttons show/hide the validation information for the\ntraveler inputs. The validation information include a summary section shown\nunder the buttons, and a validation message under each input. The\n[validation rules](#builder) are defined in the form that is used as the active\nform.\n\nThe\n<span data-toggle=\"buttons-radio\" class=\"btn-group\"><button id=\"show-notes\" class=\"btn btn-info\">Show\nnotes</button><button id=\"hide-notes\" class=\"btn btn-info active\">Hide\nnotes</button></span> buttons show/hide the notes under each input. The\n<span class=\"badge badge-info\">n</span> icon shows the number of notes.\n\nThe value displayed in an input is the latest value saved on the server. The\nhistory of changes is shown under each input including the submitted value,\nsubmitter id and submission time.\n\nWhen a traveler has several sections, a side navigation menu is created on the\nright side. When scrolling up and down the page, the section corresponding to\nthe content in the current view is highlighted in the navigation menu.\n"
}
] | 125 |
mirmozavr/weather_analysis
|
https://github.com/mirmozavr/weather_analysis
|
91f5ceb7fbc8ba582548930361bd662f0ebc64b9
|
542054922facc39d6fd5b62062dc0e2f55939816
|
333617c0813efc001252cee8336de612d9ed353b
|
refs/heads/master
| 2023-04-20T10:57:07.596589 | 2021-06-01T16:14:30 | 2021-06-01T16:14:30 | 367,987,906 | 1 | 0 | null | 2021-05-16T21:23:21 | 2021-05-20T15:26:30 | 2021-06-01T16:14:30 |
Python
|
[
{
"alpha_fraction": 0.4155467748641968,
"alphanum_fraction": 0.5035573244094849,
"avg_line_length": 28.418603897094727,
"blob_id": "63e24afe8d827fb01939869aa625e04b98f203e3",
"content_id": "cd376ad9fa88aecc85444a5c035e91ffe38e5185",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3795,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 129,
"path": "/WA/tests/test_weather_analysis.py",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "import os\n\nimport pandas as pd\n\nfrom WA.analysis_methods import (\n get_city_and_day_with_max_temp,\n get_city_and_day_with_min_temp,\n get_city_with_biggest_max_temp_change,\n get_max_daily_temp_change,\n)\nfrom WA.data_structures import CityCentres, Hotels\n\npath = os.path.dirname(__file__)\n\n\ndef test_hotels_class_filters_data():\n hotels = Hotels(path + \"/test_hotels_class\")\n correct_hotels = {\n \"Name\": [\"Hotel Spa Villa Olimpica Suites\"],\n \"Country\": [\"ES\"],\n \"City\": [\"Barcelona\"],\n \"Latitude\": [41.3971434],\n \"Longitude\": [2.1921947],\n \"Address\": [\"41.3971434, 2.1921947\"],\n }\n correct_hotels_df = pd.DataFrame(correct_hotels)\n assert hotels.df.equals(correct_hotels_df)\n\n\ndef test_calc_city_centres():\n hotels = Hotels(path + \"/test_calc_city_centres\")\n centres = CityCentres(hotels)\n correct_centre_coordinates = {\n \"min_lat\": {(\"UK\", \"Sallisaw\"): 30.0, (\"US\", \"Coalville\"): 20.0},\n \"min_lon\": {(\"UK\", \"Sallisaw\"): -160.0, (\"US\", \"Coalville\"): -120.0},\n \"max_lat\": {(\"UK\", \"Sallisaw\"): 50.0, (\"US\", \"Coalville\"): 80.0},\n \"max_lon\": {(\"UK\", \"Sallisaw\"): -40.0, (\"US\", \"Coalville\"): -60.0},\n \"center_lat\": {(\"UK\", \"Sallisaw\"): 40.0, (\"US\", \"Coalville\"): 50.0},\n \"center_lon\": {(\"UK\", \"Sallisaw\"): -100.0, (\"US\", \"Coalville\"): -90.0},\n }\n correct_centre_coordinates_df = pd.DataFrame(correct_centre_coordinates)\n assert centres.df.equals(correct_centre_coordinates_df)\n\n\ntest_data = {\n \"Unnamed: 0\": [0, 1, 2, 3, 4, 5, 6, 7, 8],\n \"city\": [\n \"('AT', 'Vienna')\",\n \"('AT', 'Vienna')\",\n \"('AT', 'Vienna')\",\n \"('FR', 'Paris')\",\n \"('FR', 'Paris')\",\n \"('FR', 'Paris')\",\n \"('IT', 'Milan')\",\n \"('IT', 'Milan')\",\n \"('IT', 'Milan')\",\n ],\n \"day\": [\n \"2021-05-25\",\n \"2021-05-26\",\n \"2021-05-27\",\n \"2021-05-25\",\n \"2021-05-26\",\n \"2021-05-27\",\n \"2021-05-25\",\n \"2021-05-26\",\n \"2021-05-27\",\n ],\n \"temp\": [12.99, 18.66, 13.5, 13.12, 12.36, 15.08, 18.09, 17.6, 20.61],\n \"temp_min\": [6.58, 5.02, 11.13, 7.36, 9.47, 6.69, 12.2, 11.16, 12.05],\n \"temp_max\": [13.24, 20.75, 15.97, 14.84, 14.84, 19.53, 22.89, 22.24, 25.07],\n}\nweather_df = pd.DataFrame(test_data)\n\n\ndef test_get_city_and_day_with_max_temp():\n correct_series = pd.Series(\n {\n \"Unnamed: 0\": 8,\n \"city\": \"('IT', 'Milan')\",\n \"day\": \"2021-05-27\",\n \"temp\": 20.61,\n \"temp_min\": 12.05,\n \"temp_max\": 25.07,\n }\n )\n assert get_city_and_day_with_max_temp(weather_df).equals(correct_series)\n\n\ndef test_get_city_and_day_with_min_temp():\n correct_series = pd.Series(\n {\n \"Unnamed: 0\": 4,\n \"city\": \"('FR', 'Paris')\",\n \"day\": \"2021-05-26\",\n \"temp\": 12.36,\n \"temp_min\": 9.47,\n \"temp_max\": 14.84,\n }\n )\n\n assert get_city_and_day_with_min_temp(weather_df).equals(correct_series)\n\n\ndef test_get_max_daily_temp_change():\n correct_series = pd.Series(\n {\n \"Unnamed: 0\": 1,\n \"city\": \"('AT', 'Vienna')\",\n \"day\": \"2021-05-26\",\n \"temp\": 18.66,\n \"temp_min\": 5.02,\n \"temp_max\": 20.75,\n \"day_temp_delta\": 15.73,\n }\n )\n assert get_max_daily_temp_change(weather_df).equals(correct_series)\n\n\ndef test_get_city_with_biggest_max_temp_change():\n correct_series = pd.Series(\n {\n \"city\": \"('AT', 'Vienna')\",\n \"max_temp_low\": 13.24,\n \"max_temp_high\": 20.75,\n \"max_temp_delta\": 7.51,\n }\n )\n assert get_city_with_biggest_max_temp_change(weather_df).equals(correct_series)\n"
},
{
"alpha_fraction": 0.6715632081031799,
"alphanum_fraction": 0.6715632081031799,
"avg_line_length": 31.799999237060547,
"blob_id": "dc755773dd6205204854772ac156c2dcc98cd571",
"content_id": "69a23f9087cb0b35f20c41a208f2f8806706a9ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3608,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 110,
"path": "/WA/analysis_methods.py",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom data_structures import Weather\n\n\ndef analysis_tasks(weather: Weather, output_folder: str) -> None:\n \"\"\"Post processing analysis.\n\n Calculate:\n - city and observation day with the maximum temperature for the period under review;\n - city and day of observation with minimal temperature for the period under review;\n - city and day with a maximum difference between the maximum and minimum temperature.\n - city with maximum change in maximum temperature;\n\n Args:\n weather (Weather): Weather class object.\n output_folder (str): The path to desired folder for data export.\n \"\"\"\n weather_df = weather.df\n # city/day with max and min temp\n get_city_and_day_with_min_temp(weather_df).to_csv(\n path_or_buf=(output_folder + r\"\\coldest_city_and_day.csv\")\n )\n get_city_and_day_with_max_temp(weather_df).to_csv(\n path_or_buf=(output_folder + r\"\\hottest_city_and_day.csv\")\n )\n\n # city with max temp change during the day\n get_max_daily_temp_change(weather_df).to_csv(\n path_or_buf=(output_folder + r\"\\biggest_daily_temp_change_city_and_day.csv\")\n )\n\n # city with biggest max temp change\n get_city_with_biggest_max_temp_change(weather_df).to_csv(\n path_or_buf=(output_folder + r\"\\biggest_max_temp_change_city_and_day.csv\")\n )\n\n\ndef get_city_and_day_with_max_temp(weather_df: pd.DataFrame):\n \"\"\"Post processing analysis task.\n\n Calculates:\n - city and observation day with the maximum temperature for the period under review.\n\n Args:\n weather_df (pd.DataFrame) Dataframe from Weather class object.\n\n Returns:\n Dataframe with single city/day data.\n \"\"\"\n temp_column = weather_df[\"temp\"]\n max_temp_index = temp_column.idxmax()\n return weather_df.loc[max_temp_index]\n\n\ndef get_city_and_day_with_min_temp(weather_df: pd.DataFrame):\n \"\"\"Post processing analysis task.\n\n Calculates:\n - city and day of observation with minimal temperature for the period under review.\n\n Args:\n weather_df (pd.DataFrame) Dataframe from Weather class object.\n\n Returns:\n Dataframe with single city/day data.\n \"\"\"\n temp_column = weather_df[\"temp\"]\n min_temp_index = temp_column.idxmin()\n return weather_df.loc[min_temp_index]\n\n\ndef get_max_daily_temp_change(weather_df: pd.DataFrame):\n \"\"\"Post processing analysis task.\n\n Calculates:\n - city and day with a maximum difference between the maximum and minimum temperature.\n\n Args:\n weather_df (pd.DataFrame) Dataframe from Weather class object.\n\n Returns:\n Dataframe with single city/day data.\n \"\"\"\n weather_df[\"day_temp_delta\"] = weather_df[\"temp_max\"] - weather_df[\"temp_min\"]\n max_change_of_day_temp_index = weather_df[\"day_temp_delta\"].idxmax()\n return weather_df.loc[max_change_of_day_temp_index]\n\n\ndef get_city_with_biggest_max_temp_change(weather_df: pd.DataFrame):\n \"\"\"Post processing analysis task.\n\n Calculates:\n - city with maximum change in maximum temperature.\n\n Args:\n weather_df (pd.DataFrame) Dataframe from Weather class object.\n\n Returns:\n Dataframe with single city/day data.\n \"\"\"\n grouped = weather_df.groupby([\"city\"])\n\n max_temps = grouped.agg(\n max_temp_low=(\"temp_max\", \"min\"),\n max_temp_high=(\"temp_max\", \"max\"),\n )\n max_temps[\"max_temp_delta\"] = max_temps[\"max_temp_high\"] - max_temps[\"max_temp_low\"]\n max_temps.reset_index(inplace=True)\n max_temp_delta_index = max_temps[\"max_temp_delta\"].idxmax()\n return max_temps.loc[max_temp_delta_index]\n"
},
{
"alpha_fraction": 0.5930265784263611,
"alphanum_fraction": 0.5987905263900757,
"avg_line_length": 30.972808837890625,
"blob_id": "a2aa06a037ec0113f54b0b6825a8984781c2bec8",
"content_id": "8008768a21f74d651c329105a7e638467d1a8b2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10583,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 331,
"path": "/WA/data_structures.py",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "import asyncio\nimport zipfile\nfrom datetime import datetime, timedelta\nfrom functools import partial\nfrom multiprocessing import Pool\nfrom typing import List, Tuple\n\nimport aiohttp\nimport pandas as pd\nfrom geopy.exc import GeocoderServiceError\nfrom geopy.geocoders import Nominatim\nfrom keys import API_OW\n\npd.set_option(\"isplay.max_rows\", None)\npd.set_option(\"display.max_columns\", 10)\npd.set_option(\"display.width\", 1600)\n\n# prep geolocator\ngeolocator = Nominatim(user_agent=\"nvm\")\nreverse_coords = partial(geolocator.reverse, language=\"en\", timeout=5)\n\now_url_forecast = \"http://api.openweathermap.org/data/2.5/forecast\"\now_url_historical = \"http://api.openweathermap.org/data/2.5/onecall/timemachine\"\n\n\nclass Hotels:\n \"\"\"Data structure with information about hotels.\n\n Data will be gathered from archived csv files from provided folder.\n\n Attributes:\n df (pd.DataFrame): Dataframe, formed from provided data.\n \"\"\"\n\n def __init__(self, path: str):\n \"\"\"Form main dataframe.\n\n Args:\n path (str): The path to `hotels.zip` file.\n \"\"\"\n self.df = prepare_data(path)\n\n def fill_address(self, processes: int) -> None:\n \"\"\"Fill addresses in given dataframe.\n\n Incorrect country and city data will be fixed at the process.\n\n Args:\n processes (int): Number of processes to run.\n \"\"\"\n try:\n result = run_pool_of_address_workers(self.df, processes)\n self.df[\"Address\"] = [item[0] for item in result]\n self.df[\"Country\"] = [item[1] for item in result]\n self.df[\"City\"] = [item[2] for item in result]\n except GeocoderServiceError:\n quit()\n\n def __str__(self):\n return str(self.df)\n\n\ndef prepare_data(base: str) -> pd.DataFrame:\n \"\"\"Form a dataframe from csv data in `hotels.zip` file at given folder.\n\n Lines without one of the coordinates and\n lines with invalid coordinates (not numeric, latitude more than 90 or less\n than -90, longitude more than 180 or less than -180),\n will be skipped.\n\n Args:\n base (str): The path to `hotels.zip` file.\n\n Returns:\n Dataframe with valid coordinates.\n \"\"\"\n # read zip\n try:\n with zipfile.ZipFile(base + \"/hotels.zip\") as myzip:\n files = [\n item.filename\n for item in myzip.infolist()\n if item.filename.endswith(\".csv\")\n ]\n if not files:\n quit()\n df = pd.concat([pd.read_csv(myzip.open(file)) for file in files])\n except FileNotFoundError:\n quit()\n\n # preprocess dataset\n try:\n df[\"Latitude\"] = pd.to_numeric(df[\"Latitude\"], errors=\"coerce\")\n df[\"Longitude\"] = pd.to_numeric(df[\"Longitude\"], errors=\"coerce\")\n df = df[(abs(df[\"Latitude\"]) < 90) & (abs(df[\"Longitude\"]) < 180)]\n\n df[\"Address\"] = (\n df[\"Latitude\"].astype(\"str\") + \", \" + df[\"Longitude\"].astype(\"str\")\n )\n df.reset_index(inplace=True)\n df.drop([\"Id\", \"index\"], axis=1, inplace=True)\n except KeyError:\n quit()\n return df # [300:310] # SHORTENED!!!!\n\n\ndef run_pool_of_address_workers(df: pd.DataFrame, processes: int) -> List:\n \"\"\"Run address_worker method in the multiprocessing pool.\n\n Form a list of correct addresses, country codes and cities for given dataframe\n in multiprocessing mode.\n\n Args:\n df (pd.DataFrame): Dataframe to process.\n processes (int): Number of processes to run.\n\n Returns:\n List of tuples with address, county code and city for every line in dataframe.\n \"\"\"\n with Pool(processes=processes) as pool:\n return pool.map(address_worker, zip(df[\"Address\"], df[\"City\"]))\n\n\ndef address_worker(data: Tuple) -> Tuple:\n \"\"\"Get the address, country code and city for given coordinates.\n\n Args:\n data (Tuple): Tuple of coordinates concatenated as strings and original `City`\n\n Returns:\n Tuple with valid address, country code and city for given coordinates.\n \"\"\"\n coordinates_as_string = data[0]\n original_city = data[1]\n location = reverse_coords(coordinates_as_string)\n country_code = location.raw[\"address\"][\"country_code\"].upper()\n\n if \"city\" in location.raw[\"address\"]:\n city = location.raw[\"address\"][\"city\"]\n elif \"town\" in location.raw[\"address\"]:\n city = location.raw[\"address\"][\"town\"]\n elif \"village\" in location.raw[\"address\"]:\n city = location.raw[\"address\"][\"village\"]\n else:\n city = original_city\n return location.address, country_code, city\n\n\nclass CityCentres:\n \"\"\"Data structure with information about every city centre.\n\n Data will be calculated from Hotels class object.\n\n Attributes:\n df (pd.DataFrame): Dataframe, formed from provided object.\n \"\"\"\n\n def __init__(self, hotels: Hotels):\n \"\"\"Form main dataframe with city centres from Hotels class object.\n\n Args:\n hotels (Hotels): Hotels class object.\n \"\"\"\n self.df = calc_city_centres(hotels)\n\n def __str__(self):\n return str(self.df)\n\n\ndef calc_city_centres(hotels: Hotels) -> pd.DataFrame:\n \"\"\"Form the dataframe with calculated coordinates for city centre.\n\n City centre coordinates are average of one maximum and one minimum latitude and longitude\n for the hotels in this city.\n\n Args:\n hotels (Hotels): Hotels class object.\n\n Returns:\n Dataframe grouped by Country and City with coordinates of city centre.\n \"\"\"\n # find max and min city center coordinates\n city_group = hotels.df.groupby([\"Country\", \"City\"])\n min_lat_and_lon = city_group.min()\n min_lat_and_lon.rename(\n columns={\"Latitude\": \"min_lat\", \"Longitude\": \"min_lon\"}, inplace=True\n )\n max_lat_and_lon = city_group.max()\n max_lat_and_lon.rename(\n columns={\"Latitude\": \"max_lat\", \"Longitude\": \"max_lon\"}, inplace=True\n )\n city_centres = pd.concat(\n [\n min_lat_and_lon.loc[:, [\"min_lat\", \"min_lon\"]],\n max_lat_and_lon.loc[:, [\"max_lat\", \"max_lon\"]],\n ],\n axis=1,\n )\n # calculate average of max and min city centre coordinates\n city_centres[\"center_lat\"] = (\n city_centres[\"min_lat\"] + city_centres[\"max_lat\"]\n ) * 0.5\n city_centres[\"center_lon\"] = (\n city_centres[\"min_lon\"] + city_centres[\"max_lon\"]\n ) * 0.5\n return city_centres\n\n\nclass Weather:\n \"\"\"Data structure with weather information for every city centre.\n\n Data will be gathered from CityCentres class object and `openweathermap.org`\n\n Attributes:\n df (pd.DataFrame): Dataframe with city and weather information.\n \"\"\"\n\n def __init__(self, city_centres: CityCentres):\n \"\"\"Form main dataframe with weather information for every city centre.\n\n Args:\n city_centres (CityCentres): CityCentres class object.\n \"\"\"\n self.df = asyncio.run(get_weather(city_centres))\n\n def __str__(self):\n return str(self.df)\n\n\nasync def get_weather(city_centres: CityCentres) -> pd.DataFrame:\n \"\"\"Collect 11 days weather data for every city centre.\n\n Weather data will be asynchronously gathered from `openweathermap.org`\n\n Args:\n city_centres (CityCentres): CityCentres class object\n\n Returns:\n Dataframe with city, day and temperature data.\n \"\"\"\n tasks = []\n async with aiohttp.ClientSession() as session:\n for row in city_centres.df.itertuples():\n tasks.append(asyncio.create_task(get_historical_weather(session, row)))\n tasks.append(asyncio.create_task(get_forecast(session, row)))\n result = await asyncio.gather(*tasks)\n weather = [row for item in result for row in item]\n return pd.DataFrame(weather)\n\n\nasync def get_forecast(\n session: aiohttp.ClientSession, row: \"pd.core.frame.Pandas\"\n) -> List:\n \"\"\"Collect current weather and 5 days weather forecast.\n\n Args:\n session (aiohttp.ClientSession): Shared aiohttp.ClientSession.\n row (pd.core.frame.Pandas): Line from dataframe.\n\n Returns:\n List of dicts with city, day, and current, min, and max temperature.\n \"\"\"\n async with session.get(\n ow_url_forecast,\n params=[\n (\"lat\", row.center_lat),\n (\"lon\", row.center_lon),\n (\"appid\", API_OW),\n (\"units\", \"metric\"),\n ],\n ) as resp:\n city_weather = []\n forecast = await resp.json()\n for item in (forecast[\"list\"][index] for index in (0, 8, 16, 24, 32, 39)):\n city_weather.append(\n {\n \"city\": row.Index,\n \"day\": datetime.fromtimestamp(item[\"dt\"]).date(),\n \"temp\": item[\"main\"][\"temp\"],\n \"temp_min\": item[\"main\"][\"temp_min\"],\n \"temp_max\": item[\"main\"][\"temp_max\"],\n }\n )\n return city_weather\n\n\nasync def get_historical_weather(\n session: aiohttp.ClientSession, row: \"pd.core.frame.Pandas\"\n) -> List:\n \"\"\"Collect 5 days historical weather data.\n\n By the limitations from `openweathermap.org` 5 separate requests have to be done.\n https://openweathermap.org/api/one-call-api#history\n\n Args:\n session (aiohttp.ClientSession): Shared aiohttp.ClientSession.\n row (pd.core.frame.Pandas): Line from dataframe.\n\n Returns:\n List of dicts with city, day, and current, min, and max temperature.\n \"\"\"\n date_stamps = [\n int(datetime.timestamp(datetime.today() - timedelta(days=i)))\n for i in range(5, 0, -1)\n ]\n city_weather = []\n for date in date_stamps:\n async with session.get(\n ow_url_historical,\n params=[\n (\"lat\", row.center_lat),\n (\"lon\", row.center_lon),\n (\"dt\", date),\n (\"appid\", API_OW),\n (\"units\", \"metric\"),\n ],\n ) as resp:\n forecast = await resp.json()\n temp = forecast[\"current\"][\"temp\"]\n temp_min = min(item[\"temp\"] for item in forecast[\"hourly\"])\n temp_max = max(item[\"temp\"] for item in forecast[\"hourly\"])\n city_weather.append(\n {\n \"city\": row.Index,\n \"day\": datetime.fromtimestamp(forecast[\"current\"][\"dt\"]).date(),\n \"temp\": temp,\n \"temp_min\": temp_min,\n \"temp_max\": temp_max,\n }\n )\n return city_weather\n"
},
{
"alpha_fraction": 0.7340534925460815,
"alphanum_fraction": 0.7355967164039612,
"avg_line_length": 48.79487228393555,
"blob_id": "83b7c14f16e194705de0613b813a749e7f6e04ab",
"content_id": "2312c8f0fc0c661e99e860f513c1c9fa0dfbca77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1944,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 39,
"path": "/README.md",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": " ## Weather analysis.\n\nThe purpose of this programm is to process provided data, clear corrupted\ndata, add full addresses using `geopy` module, calculate coordinates for\ncity centres and gather weather data for 11 days period from\nopenweathermap.org, calculate:\n\n - city and observation day with the maximum temperature for the period under review;\n - city with maximum change in maximum temperature;\n - city and day of observation with minimal temperature for the period under review;\n - city and day with a maximum difference between the maximum and minimum temperature.\n\ndraw plots for max and min temperatures for every\n city centre. All gathered and calculated data will be saved at the output\n folder and will have following structure: `output_folder\\country\\city\\`\n\n###Options:\n * -if, --input-folder TEXT: Enter a path to 'Hotels.zip'. Current working\n directory is used by default\n * -of, --output-folder TEXT: Enter a path to the output data. Current working\n directory is used by default\n * -p, --processes INTEGER: Number of processes to run\n\n * --help Show this message and exit.\n\n### Requirements\nRequirements for interpreter are in `requirements-def.txt` file.\nProcessed archive must be `hotels.zip`.\nArchived `CSV` files must have following columns: Id, Name, Country, City, Latitude, Longitude.\n\n### Implementation for Windows\nTo run script simply type command: `python weather_analysis.py` Default parameters will be used.\nTo specify input folder, output folder and number of processes type:\n`python weather_analysis.py -if '\\your\\desired\\input_folder' -of '\\your\\desired\\output_folder' -p 4`\n\n### Testing\nTests are prepared with Pytest module. To run tests type `pytest` at the command line. More information at [docs.pytest.org](https://docs.pytest.org)\nTo run tests and get coverage report type `pytest --cov=WA --cov-report=html\n`.\n"
},
{
"alpha_fraction": 0.5266159772872925,
"alphanum_fraction": 0.7129277586936951,
"avg_line_length": 17.13793182373047,
"blob_id": "babedda0af02b81d4671adee1248f070ad8f54d4",
"content_id": "6b810521e76d60613c532eda14e2f85bb7460e57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 29,
"path": "/requirements-dev.txt",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "flake8==3.9.0\nflake8-annotations==2.6.2\nflake8-bandit==2.1.2\nflake8-bugbear==21.4.3\nflake8-builtins==1.5.3\nflake8-cognitive-complexity==0.1.0\nflake8-comprehensions==3.4.0\nflake8-docstrings==1.6.0\nflake8-eradicate==1.0.0\nflake8-mutable==1.2.0\nflake8-print==4.0.0\nflake8-pytest-style==1.4.1\nflake8-return==1.1.2\npep8-naming==0.11.1\n\nblack==20.8b1\npre-commit==2.12.0\n\npytest>=6.2.3\npytest-cov>=2.10.1\nisort==5.8.0\n\ngeopy==2.1.0\npandas==1.2.4\naiohttp==3.7.4.post0\nasync-timeout==3.0.1\nmatplotlib==3.4.2\nclick==8.0.1\npytest==6.2.4\n"
},
{
"alpha_fraction": 0.616126537322998,
"alphanum_fraction": 0.6219135522842407,
"avg_line_length": 35,
"blob_id": "c68d604dada52b415729757b78f0c2b5a77a1ac9",
"content_id": "ded4a3b98f515ce712b400b6396be1962841aecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2592,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 72,
"path": "/WA/export_utility.py",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "import os\nfrom typing import Tuple\n\nimport pandas as pd\nfrom data_structures import Hotels, Weather\nfrom matplotlib import pyplot as plt\n\n\ndef export_address_data(hotels: Hotels, output_folder: str) -> None:\n r\"\"\"Write hotels data from Hotels class object.\n\n Hotels data will be grouped by city and written to `CSV` files with 100 records or less.\n Files will be structured as followed `output_folder\\country\\city\\`.\n\n Args:\n hotels (Hotels): Hotels class object.\n output_folder (str): The path to desired folder for data export.\n \"\"\"\n grouped = hotels.df.groupby([\"Country\", \"City\"])\n chunk_size = 100\n for label, group in grouped:\n country, city = label[0], label[1]\n path = f\"{output_folder}\\\\{country}\\\\{city}\"\n os.makedirs(path, exist_ok=True)\n\n list_of_chunks = (\n group.iloc[i : i + chunk_size] for i in range(0, len(group), chunk_size)\n )\n for num, chunk in enumerate(list_of_chunks):\n file_name = f\"{path}\\\\{country}_{city}_hotels_p{num:03d}.csv\"\n chunk.to_csv(\n path_or_buf=file_name,\n columns=[\"Name\", \"Country\", \"City\", \"Address\", \"Latitude\", \"Longitude\"],\n )\n\n\ndef save_plots(weather: Weather, output_folder: str) -> None:\n \"\"\"Save min and max temperature diagram for every city in Weather class object.\n\n Args:\n weather (Weather): Weather class object.\n output_folder (str): The path to desired folder for data export.\n \"\"\"\n grouped = weather.df.groupby([\"city\"])\n for label, group in grouped:\n country, city = label[0], label[1]\n file_path = (\n f\"{output_folder}\\\\{country}\\\\{city}\\\\{country}_{city}_temp_plot.png\"\n )\n save_plot(label, group, file_path)\n\n\ndef save_plot(label: Tuple, group: \"pd.DataFrame\", file_path: str) -> None:\n r\"\"\"Form and save the weather diagram for single city.\n\n Args:\n label (tuple): Country and city.\n group (pd.DataFrame): Dataframe with weather data for 11 days for single city.\n file_path (str): The path formed as `output_folder\\country\\city\\country_city_temp_plot.png`\n \"\"\"\n plt.xlabel(\"Day\")\n plt.ylabel(\"Temperature\")\n plt.title(f\"{label}: daily min and max temperature\")\n plt.grid(True, which=\"both\")\n days = group[\"day\"]\n temp_min = group[\"temp_min\"]\n temp_max = group[\"temp_max\"]\n plt.plot(days, temp_min, label=\"Daily min temp.\", c=\"blue\")\n plt.plot(days, temp_max, label=\"Daily max temp.\", c=\"red\")\n plt.legend()\n plt.savefig(file_path)\n plt.clf()\n"
},
{
"alpha_fraction": 0.7446808218955994,
"alphanum_fraction": 0.7446808218955994,
"avg_line_length": 46,
"blob_id": "53ebc9971b5080940d180b3a8222db4b22805468",
"content_id": "505dd673601a881bd21d4c7ba71fde3015fec24a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 1,
"path": "/WA/keys.py",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "API_OW = \"your_api_key_for_openweathermap.org\"\n"
},
{
"alpha_fraction": 0.7526577115058899,
"alphanum_fraction": 0.7564375400543213,
"avg_line_length": 45.52747344970703,
"blob_id": "18b01ca18f897e16d5acc2b273dd2c5bc84864f8",
"content_id": "e66fe8750524e50a50842eaecfb01a3d16a905f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7145,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 91,
"path": "/TASK.md",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "# PythonLab - December 2020\n# Final course project\n\nНеобходимо написать консольную утилиту для многопоточной обработки данных, аккумулирования результатов через API из Интернета и их дальнейшего представления на графиках.\n\n## Входные данные\nВходные данные находятся в каталоге **/data** в данном репозитории в упакованном виде в файле **hotels.zip**.\n\nВнутри данного архива расположено несколько файлов в формате _.CSV_, содержащих множество строк с информацией по отелям. В том числе, среди информации вы найдете:\n\n- название отеля;\n- широту и долготу отеля;\n- страну и город, где расположен объект.\n\n## Выходные данные\nВсе полученные результаты должны быть расположены в выходном каталоге со следующей структурой:\n\n`{output_folder}\\{country}\\{city}\\`\n\n## Задание\n\nЗадание состоит из нескольких блоков и требований, которые перечислены ниже:\n\n1. Приложение должно представлять собой консольную утилиту, которая принимает на вход следующие параметры:\n\n - путь к каталогу с входными данными;\n - путь к каталогу для выходных данных;\n - количество потоков для параллельной обработки данных;\n - возможно другие параметры, необходимые для функционирования приложения.\n \n2. Первичная подготовка входных данных для использования:\n\n - распаковать архив с данными;\n - очистить данные от невалидных записей (содержащих заведомо ложные значения или отсутствующие необходимые элементы);\n - произвести группировку: для каждой страны выбрать город, содержащий максимальное количество отелей.\n \n3. Обработка данных:\n \n - Обогатить данные по каждому из отелей в выбранных городах в **многопоточном режиме** его географическим адресом, полученным при помощи пакета **geopy**;\n - Вычислить географический центр области города, равноудаленный от крайних отелей. \n - Для центра области при помощи стороннего сервиса (например, _openweathermap.org_) получить погодные данные:\n \n - исторические: за предыдущие 5 дней;\n - прогноз: на последующие 5 дней;\n - текущие значения.\n - Построить графики (например, при помощи пакета **matplotlib**), содержащие зависимости от дня:\n \n - минимальной температуры;\n - максимальной температуры.\n \n4. Пост-процессинг:\n\n - Среди всех центров (городов) найти:\n \n - город и день наблюдения с максимальной температурой за рассматриваемый период;\n - город с максимальным изменением максимальной температуры; \n - город и день наблюдения с минимальной температурой за рассматриваемый период;\n - город и день с максимальной разницей между максимальной и минимальной температурой.\n \n5. Сохранение результатов:\n\n - В каталоге с указанной структурой для каждого города сохранить:\n \n - все полученные графики;\n - список отелей (название, адрес, широта, долгота) в формате CSV в файлах, содержащих не более 100 записей в каждом;\n - полученную информацию по центру в произвольном формате, удобном для последующего использования.\n \n# Требования к проекту\n\nТребования достаточно либеральные:\n- Версия интерпретатора не ниже 3.7;\n- Заполненные _requirements.txt_ или _poetry.toml_;\n- Заполненный _.gitignore_;\n- Выбор конечного инструментария для выполнения задания во многом остается за исполнителем, например:\n \n - argparser - для обработки параметров командной строки;\n - geopy - для получения адреса по координатам;\n - matplotlib - для построения графиков;\n - zipfile - для работы с архивам;\n - requests, urllib, aiohttp-клиент, etc - для осуществления запросов к внешнему API;\n - threading, multiprocessing, asyncio, etc - для \"распараллеливания\" задач;\n - pytest, unittest - для создания тестов;\n - pandas - для представления данных в виде дата-фреймов;\n - csv - для работы с CSV-файлами;\n - и многие другие - как из комплекта поставки python, так и сторонние пакеты.\n- Ключевые фрагменты кода должны быть покрыты unit-тестами;\n- Код должен быть оформлен в соответствии с рекомендациями, данными вам при обучении на курсе; \n- Должна присутствовать документация, позволяющая незнакомому человеку начать использование приложения.\n\n\n**Оценивается общее качество кода, примененные решения, расширенная функциональность, оптимизации, улучшения и т.д.**"
},
{
"alpha_fraction": 0.7023255825042725,
"alphanum_fraction": 0.7034883499145508,
"avg_line_length": 28.152542114257812,
"blob_id": "56a64d574e76d54ae9fa0a64ce056b5a8d77fe1c",
"content_id": "041389a9d7dd6e481861b8bc3c12b56e3d9c0884",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1720,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 59,
"path": "/WA/weather_analysis.py",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "import os\n\nimport click\nfrom analysis_methods import analysis_tasks\nfrom data_structures import CityCentres, Hotels, Weather\nfrom export_utility import export_address_data, save_plots\n\n\[email protected]()\[email protected](\n \"--input-folder\",\n \"-if\",\n default=lambda: os.getcwd(),\n help=\"Enter a path to 'Hotels.zip'. Current working directory is used by default\",\n)\[email protected](\n \"--output-folder\",\n \"-of\",\n default=lambda: os.getcwd(),\n help=\"Enter a path to the output data. Current working directory is used by default\",\n)\[email protected](\n \"--processes\",\n \"-p\",\n type=int,\n default=lambda: os.cpu_count(),\n help=\"Number of processes to run\",\n)\ndef main(input_folder, output_folder, processes):\n r\"\"\"Weather analysis.\n\n The purpose of this programm is to process provided data (`hotels.zip`),\n clear corrupted data, add full addresses using `geopy` module,\n calculate coordinates for city centres and gather weather data\n for 11 days period from openweathermap.org,\n calculate: hottest day and city, coldest day and city,\n city with largest max temperature change, city and day with largest\n min and max temperature change, draw plots for max and min temperatures for\n every city centre.\n All gathered and calculated data will be saved at the output folder and will\n have following structure: `output_folder\\country\\city\\`\n \"\"\"\n hotels = Hotels(input_folder)\n\n hotels.fill_address(processes)\n\n export_address_data(hotels, output_folder)\n\n city_centres = CityCentres(hotels)\n\n weather = Weather(city_centres)\n\n analysis_tasks(weather, output_folder)\n\n save_plots(weather, output_folder)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.4968847334384918,
"alphanum_fraction": 0.5934579372406006,
"avg_line_length": 25.75,
"blob_id": "1cd10de0e0be463905efeebb31bd93f81aafb849",
"content_id": "2e948245954197728d61a589797480cfd7ae70f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 24,
"path": "/.flake8",
"repo_name": "mirmozavr/weather_analysis",
"src_encoding": "UTF-8",
"text": "[flake8]\nignore = E203, E501, W503, # handled by black\n ANN101, ANN204, ANN001, ANN201,\n D100,\n D101,\n D102,\n D103,\n D104, # no docstring in public package\n D105, # Missing docstring in magic method\n D200, # One-line docstring should fit on one line with quotes\n D107, # Missing docstring in __init__\n\nexclude =\n *_venv\n venv_*\n venv\nmax-cognitive-complexity = 10\nper-file-ignores =\n # No docs and annotation required for tests\n test*.py: D10, D101, D103, S101, ANN\n # Skip unused imports in __init__ files\n __init__.py: F401\n\ndoctests = True\n"
}
] | 10 |
tokssa/test
|
https://github.com/tokssa/test
|
12ac2cdccbc599d3742c64672538172958b5de83
|
e636fdde28d22bd77073b4cd4688d242cce35e7f
|
08f13b96c2a49a25db651e64dd10026f7065a5ee
|
refs/heads/master
| 2022-12-06T03:48:24.883302 | 2022-11-28T09:05:59 | 2022-11-28T09:05:59 | 183,459,392 | 2 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.578220009803772,
"alphanum_fraction": 0.6058595776557922,
"avg_line_length": 32.132076263427734,
"blob_id": "0b4a7a5f4fab0da118808730053064a0bbba7d9b",
"content_id": "0acb1e507660c742f252abdfdcecc4feb6b7443a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1913,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 53,
"path": "/Auto-Delete-Client",
"repo_name": "tokssa/test",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\r\n\r\nGRAY='\\033[1;33m'\r\nNC='\\033[0m'\r\n\r\ncat /etc/shadow | cut -d: -f1,8 | sed /:$/d > /usr/local/bin/Expire-List\r\nTOTALACCOUNTS=`cat /usr/local/bin/Expire-List | wc -l`\r\nfor((i=1; i<=$TOTALACCOUNTS; i++ ))\r\n\tdo\r\n\tTCLIENTVAL=`head -n $i /usr/local/bin/Expire-List | tail -n 1`\r\n\tCLIENT=`echo $TCLIENTVAL | cut -f1 -d:`\r\n\tCLIENTEXP=`echo $TCLIENTVAL | cut -f2 -d:`\r\n\tCLIENTEXPIREINSECONDS=$(( $CLIENTEXP * 86400 ))\r\n\tTODAYSTIME=`date +%s`\r\n\r\n\tif [ $CLIENTEXPIREINSECONDS -ge $TODAYSTIME ] ; then\r\n\t\tTIMETO1DAYS=$(( $TODAYSTIME + 86400 ))\r\n\t\tTIMETO2DAYS=$(( $TODAYSTIME + 172800 ))\r\n\t\t\tif [ $CLIENTEXPIREINSECONDS -le $TIMETO1DAYS ]; then\r\n\t\t\t\tif [[ -e /usr/local/bin/Check-Thai ]]; then\r\n\t\t\t\t\techo -e \" ${GRAY}$CLIENT${NC} จะหมดอายุอีกไม่เกิน 24 ชั่วโมง\"\r\n\t\t\t\telif [[ ! -e /usr/local/bin/Check-Thai ]]; then\r\n\t\t\t\t\techo -e \" ${GRAY}$CLIENT${NC} Will expire less more in 24 Hr.\"\r\n\t\t\t\tfi\r\n\t\t\telif [ $CLIENTEXPIREINSECONDS -le $TIMETO2DAYS ]; then\r\n\t\t\t\tif [[ -e /usr/local/bin/Check-Thai ]]; then\r\n\t\t\t\t\techo -e \" ${GRAY}$CLIENT${NC} จะหมดอายุอีกไม่เกิน 48 ชั่วโมง\"\r\n\t\t\t\telif [[ ! -e /usr/local/bin/Check-Thai ]]; then\r\n\t\t\t\t\techo -e \" ${GRAY}$CLIENT${NC} Will expire less more in 48 Hr.\"\r\n\t\t\t\tfi\r\n\t\t\tfi\r\n\telse\r\n\t\tif [[ $CHECKSYSTEM ]]; then\r\n\t\t\tuserdel $CLIENT\r\n\t\t\tmenu\r\n\t\t\texit\r\n\t\telse\r\n\t\t\t$CLIENT=$(tail -n +2 /etc/openvpn/easy-rsa/pki/index.txt | grep \"^V\" | cut -d '=' -f 2)\r\n\t\t\tcd /etc/openvpn/easy-rsa/\r\n\t\t\t./easyrsa --batch revoke $CLIENT\r\n\t\t\tEASYRSA_CRL_DAYS=3650 ./easyrsa gen-crl\r\n\t\t\trm -rf pki/reqs/$CLIENT.req\r\n\t\t\trm -rf pki/private/$CLIENT.key\r\n\t\t\trm -rf pki/issued/$CLIENT.crt\r\n\t\t\trm -rf /etc/openvpn/crl.pem\r\n\t\t\tcp /etc/openvpn/easy-rsa/pki/crl.pem /etc/openvpn/crl.pem\r\n\t\t\tchown nobody:$GROUPNAME /etc/openvpn/crl.pem\r\n\t\t\tuserdel $CLIENT\r\n\t\t\tmenu\r\n\t\t\texit\r\n\t\tfi\r\n\tfi\r\ndone\r\n"
},
{
"alpha_fraction": 0.762499988079071,
"alphanum_fraction": 0.762499988079071,
"avg_line_length": 25.66666603088379,
"blob_id": "d15f5b851eb35525d610f33fc94cb436438c9576",
"content_id": "49bab08d281710a399ac142d404dfa60e9410545",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 160,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 6,
"path": "/OpenSSH.sh",
"repo_name": "tokssa/test",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#script OpenSSH by Pirakit Khawpleum\n\nwget -O /etc/ssh/sshd_config 'https://raw.githubusercontent.com/MyGatherBk/PURE/master/sshd_config'\n\nservice ssh restart\n"
},
{
"alpha_fraction": 0.447826087474823,
"alphanum_fraction": 0.47826087474823,
"avg_line_length": 26.04878044128418,
"blob_id": "078efc5cf34d42cef0a8a0faea4dcaa4797a4fed",
"content_id": "a41074a6680f1ee1ecfbbf8cd43be3851713747e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1150,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 41,
"path": "/Banwidth-Per-Client",
"repo_name": "tokssa/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n\r\nSTATUS = \"/etc/openvpn/openvpn-status.log\"\r\nstatus_file = open(STATUS, 'r') \r\nstats = status_file.readlines() \r\nstatus_file.close()\r\nhosts = []\r\nheaders = { \r\n 'cn': 'CLIENT', \r\n 'virt': 'CLIENT IP',\r\n 'sent': 'DOWNLOAD', \r\n 'recv': 'UPLOAD',\r\n}\r\nsizes = [ \r\n (1<<50L, 'PB'),\r\n (1<<40L, 'TB'),\r\n (1<<30L, 'GB'),\r\n (1<<20L, 'MB'),\r\n (1<<10L, 'KB'),\r\n (1, 'B')\r\n]\r\ndef byte2str(size): \r\n for f, suf in sizes:\r\n if size >= f:\r\n break\r\n return \"%.2f %s\" % (size / float(f), suf)\r\nfor line in stats: \r\n cols = line.split(',')\r\n if len(cols) == 5 and not line.startswith('Common Name'):\r\n host = {}\r\n host['cn'] = cols[0]\r\n host['recv'] = byte2str(int(cols[2]))\r\n host['sent'] = byte2str(int(cols[3]))\r\n hosts.append(host)\r\n if len(cols) == 4 and not line.startswith('Virtual Address'):\r\n for h in hosts:\r\n if h['cn'] == cols[1]:\r\n h['virt'] = cols[0]\r\nfmt = \" %(cn)-16s %(virt)-16s %(sent)14s %(recv)15s \"\r\nprint fmt % headers \r\nprint \"\\n\".join([fmt % h for h in hosts])\r\n"
},
{
"alpha_fraction": 0.5982998013496399,
"alphanum_fraction": 0.648232638835907,
"avg_line_length": 28.563491821289062,
"blob_id": "0c99f8445881c639d178696567f2183dcf9bae81",
"content_id": "b1cc7a84ad382b334506888c138c97af0d184dae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 11987,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 378,
"path": "/l",
"repo_name": "tokssa/test",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n IP=$(wget -4qO- \"http://whatismyip.akamai.com/\")\n\tRCLOCAL='/etc/rc.local'\n\tGROUPNAME=nogroup\n\tOS=debian\n\tVERSION_ID=$(cat /etc/os-release | grep \"VERSION_ID\")\n\n\tclear\n\techo \"\"\n\tread -p \"IP Server : \" -e -i $IP IP\n\tread -p \"Port Server : \" -e -i 1194 PORT\n\tread -p \"Port Proxy : \" -e -i 8080 PROXY\n\techo \"\"\n\techo -e \" |${GRAY}1${NC}| UDP\"\n\techo -e \" |${GRAY}2${NC}| TCP\"\n\techo \"\"\n\tread -p \"Protocol : \" -e -i 2 PROTOCOL\n\tcase $PROTOCOL in\n\t\t1) \n\t\tPROTOCOL=udp\n\t\t;;\n\t\t2) \n\t\tPROTOCOL=tcp\n\t\t;;\n\tesac\n\techo \"\"\n\techo -e \" |${GRAY}1${NC}| DNS Current System\"\n\techo -e \" |${GRAY}2${NC}| DNS Google\"\n\techo \"\"\n\tread -p \"DNS : \" -e -i 1 DNS\n\techo \"\"\n\techo -e \" |${GRAY}1${NC}| 1 ไฟล์เชื่อมต่อได้ 1 เครื่องเท่านั้น แต่สามารถสร้างไฟล์เพิ่มได้\"\n\techo -e \" |${GRAY}2${NC}| 1 ไฟล์เชื่อมต่อได้หลายเครื่อง แต่ต้องใช้ชื่อบัญชีและรหัสผ่านเพื่อใช้เชื่อมต่อ\"\n\techo -e \" |${GRAY}3${NC}| 1 ไฟล์เชื่อมต่อได้ไม่จำกัดจำนวนเครื่อง\"\n\techo \"\"\n\tread -p \"Server System : \" -e OPENVPNSYSTEM\n\techo \"\"\n\tread -p \"Server Name: \" -e CLIENT\n\techo \"\"\n\tcase $OPENVPNSYSTEM in\n\t\t2)\n\t\tread -p \"Your Username : \" -e Usernames\n\t\tread -p \"Your Password : \" -e Passwords\n\t\t;;\n\tesac\n\techo \"\"\n\tread -n1 -r -p \"กด Enter 1 ครั้งเพื่อเริ่มทำการติดตั้ง หรือกด CTRL+C เพื่อยกเลิก\"\n\n\tapt-get update\n\tapt-get install iptables openssl ca-certificates -y\nchown -R root:root /etc/openvpn/easy-rsa/\nchown nobody:$GROUPNAME /etc/openvpn/crl.pem\nopenvpn --genkey --secret /etc/openvpn/ta.key\ncd /etc/openvpn/easy-rsa/\ncd\n\trm -rf /etc/openvpn/server.conf\n\trm -rf /etc/openvpn/client-common.txt\n\n\techo \"port $PORT\nproto $PROTOCOL\ndev tun\nsndbuf 0\nrcvbuf 0\nca ca.crt\ncert server.crt\nkey server.key\ndh dh.pem\nauth SHA512\ntls-auth ta.key 0\ntopology subnet\nserver 10.8.0.0 255.255.255.0\nifconfig-pool-persist ipp.txt\" > /etc/openvpn/server.conf\n\techo 'push \"redirect-gateway def1 bypass-dhcp\"' >> /etc/openvpn/server.conf\n\tcase $DNS in\n\t\t1)\n\t\tif grep -q \"127.0.0.53\" \"/etc/resolv.conf\"; then\n\t\t\tRESOLVCONF='/run/systemd/resolve/resolv.conf'\n\t\telse\n\t\t\tRESOLVCONF='/etc/resolv.conf'\n\t\tfi\n\t\t# Obtain the resolvers from resolv.conf and use them for OpenVPN\n\t\tgrep -v '#' $RESOLVCONF | grep 'nameserver' | grep -E -o '[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}' | while read line; do\n\t\t\techo \"push \\\"dhcp-option DNS $line\\\"\" >> /etc/openvpn/server.conf\n\t\tdone\n\t\t;;\n\t\t2)\n\t\techo 'push \"dhcp-option DNS 8.8.8.8\"' >> /etc/openvpn/server.conf\n\t\techo 'push \"dhcp-option DNS 8.8.4.4\"' >> /etc/openvpn/server.conf\n\t\t;;\n\tesac\n\techo \"keepalive 10 120\ncipher AES-256-CBC\ncomp-lzo\nuser nobody\ngroup $GROUPNAME\npersist-key\npersist-tun\nstatus openvpn-status.log\nverb 3\ncrl-verify crl.pem\" >> /etc/openvpn/server.conf\n\tcase $OPENVPNSYSTEM in\n\t\t1)\n\t\techo \"client-to-client\" >> /etc/openvpn/server.conf\n\t\t;;\n\t\t2)\n\t\tif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' ]]; then\n\t\t\techo \"plugin /usr/lib/openvpn/openvpn-auth-pam.so /etc/pam.d/login\" >> /etc/openvpn/server.conf\n\t\t\techo \"client-cert-not-required\" >> /etc/openvpn/server.conf\n\t\t\techo \"username-as-common-name\" >> /etc/openvpn/server.conf\n\t\telse\n\t\t\techo \"plugin /usr/lib/openvpn/openvpn-plugin-auth-pam.so /etc/pam.d/login\" >> /etc/openvpn/server.conf\n\t\t\techo \"client-cert-not-required\" >> /etc/openvpn/server.conf\n\t\t\techo \"username-as-common-name\" >> /etc/openvpn/server.conf\n\t\tfi\n\t\t;;\n\t\t3)\n\t\techo \"duplicate-cn\" >> /etc/openvpn/server.conf\n\t\t;;\n\tesac\n\n\tsed -i '/\\<net.ipv4.ip_forward\\>/c\\net.ipv4.ip_forward=1' /etc/sysctl.conf\n\tif ! grep -q \"\\<net.ipv4.ip_forward\\>\" /etc/sysctl.conf; then\n\t\techo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf\n\tfi\n\n\techo 1 > /proc/sys/net/ipv4/ip_forward\n\tif pgrep firewalld; then\n\t\tfirewall-cmd --zone=public --add-port=$PORT/$PROTOCOL\n\t\tfirewall-cmd --zone=trusted --add-source=10.8.0.0/24\n\t\tfirewall-cmd --permanent --zone=public --add-port=$PORT/$PROTOCOL\n\t\tfirewall-cmd --permanent --zone=trusted --add-source=10.8.0.0/24\n\t\tfirewall-cmd --direct --add-rule ipv4 nat POSTROUTING 0 -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP\n\t\tfirewall-cmd --permanent --direct --add-rule ipv4 nat POSTROUTING 0 -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP\n\telse\n\t\tif [[ \"$OS\" = 'debian' && ! -e $RCLOCAL ]]; then\n\t\t\techo '#!/bin/sh -e\nexit 0' > $RCLOCAL\n\t\tfi\n\t\tchmod +x $RCLOCAL\n\n\t\tiptables -t nat -A POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP\n\t\tsed -i \"1 a\\iptables -t nat -A POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP\" $RCLOCAL\n\t\tif iptables -L -n | grep -qE '^(REJECT|DROP)'; then\n\t\t\tiptables -I INPUT -p $PROTOCOL --dport $PORT -j ACCEPT\n\t\t\tiptables -I FORWARD -s 10.8.0.0/24 -j ACCEPT\n\t\t\tiptables -I FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT\n\t\t\tsed -i \"1 a\\iptables -I INPUT -p $PROTOCOL --dport $PORT -j ACCEPT\" $RCLOCAL\n\t\t\tsed -i \"1 a\\iptables -I FORWARD -s 10.8.0.0/24 -j ACCEPT\" $RCLOCAL\n\t\t\tsed -i \"1 a\\iptables -I FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT\" $RCLOCAL\n\t\tfi\n\tfi\n\n\tif hash sestatus 2>/dev/null; then\n\t\tif sestatus | grep \"Current mode\" | grep -qs \"enforcing\"; then\n\t\t\tif [[ \"$PORT\" != '1194' || \"$PROTOCOL\" = 'tcp' ]]; then\n\t\t\t\tsemanage port -a -t openvpn_port_t -p $PROTOCOL $PORT\n\t\t\tfi\n\t\tfi\n\tfi\n\n\n\tEXTERNALIP=$(wget -4qO- \"http://whatismyip.akamai.com/\")\n\tif [[ \"$IP\" != \"$EXTERNALIP\" ]]; then\n\t\techo \"\"\n\t\techo \"ตรวจพบเบื้องหลังเซิฟเวอร์ของคุณเป็น Network Addrsss Translation (NAT)\"\n\t\techo \"NAT คืออะไร ? : http://www.greatinfonet.co.th/15396685/nat\"\n\t\techo \"\"\n\t\techo \"หากเซิฟเวอร์ของคุณเป็น (NAT) คุณจำเป็นต้องระบุ IP ภายนอกของคุณ\"\n\t\techo \"หากไม่ใช่ กรุณาเว้นว่างไว้\"\n\t\techo \"หรือหากไม่แน่ใจ กรุณาเปิดดูลิ้งค์ด้านบนเพื่อศึกษาข้อมูลเกี่ยวกับ (NAT)\"\n\t\techo \"\"\n\t\tread -p \"External IP: \" -e USEREXTERNALIP\n\t\tif [[ \"$USEREXTERNALIP\" != \"\" ]]; then\n\t\t\tIP=$USEREXTERNALIP\n\t\tfi\n\tfi\n\n\techo \"client\ndev tun\nproto $PROTOCOL\nsndbuf 0\nrcvbuf 0\nremote $CLIENT 999 udp\nremote $IP:[email protected] $PORT\nhttp-proxy $IP $PROXY\nresolv-retry infinite\nnobind\npersist-key\npersist-tun\nremote-cert-tls server\nauth SHA512\ncipher AES-256-CBC\ncomp-lzo\nsetenv opt block-outside-dns\nkey-direction 1\nverb 3\" > /etc/openvpn/client-common.txt\n\n\tcase $OPENVPNSYSTEM in\n\t\t2)\n\t\techo \"auth-user-pass\" >> /etc/openvpn/client-common.txt\n\t\t;;\n\tesac\n\n\tcd\n\tapt-get -y install nginx\n\tcat > /etc/nginx/nginx.conf <<END\nuser www-data;\nworker_processes 2;\npid /var/run/nginx.pid;\nevents {\n\tmulti_accept on;\n worker_connections 1024;\n}\nhttp {\n\tautoindex on;\n sendfile on;\n tcp_nopush on;\n tcp_nodelay on;\n keepalive_timeout 65;\n types_hash_max_size 2048;\n server_tokens off;\n include /etc/nginx/mime.types;\n default_type application/octet-stream;\n access_log /var/log/nginx/access.log;\n error_log /var/log/nginx/error.log;\n client_max_body_size 32M;\n\tclient_header_buffer_size 8m;\n\tlarge_client_header_buffers 8 8m;\n\tfastcgi_buffer_size 8m;\n\tfastcgi_buffers 8 8m;\n\tfastcgi_read_timeout 600;\n include /etc/nginx/conf.d/*.conf;\n}\nEND\n\tmkdir -p /home/vps/public_html\n\techo \"<pre>BY FB : Ekkachai Chompoowiset | Donate : TrueWallet : 097-206-5255</pre>\" > /home/vps/public_html/index.html\n\techo \"<?phpinfo(); ?>\" > /home/vps/public_html/info.php\n\targs='$args'\n\turi='$uri'\n\tdocument_root='$document_root'\n\tfastcgi_script_name='$fastcgi_script_name'\n\tcat > /etc/nginx/conf.d/vps.conf <<END\nserver {\n listen 85;\n server_name 127.0.0.1 localhost;\n access_log /var/log/nginx/vps-access.log;\n error_log /var/log/nginx/vps-error.log error;\n root /home/vps/public_html;\n location / {\n index index.html index.htm index.php;\n\ttry_files $uri $uri/ /index.php?$args;\n }\n location ~ \\.php$ {\n include /etc/nginx/fastcgi_params;\n fastcgi_pass 127.0.0.1:9000;\n fastcgi_index index.php;\n fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;\n }\n}\nEND\n\n\tif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' || \"$VERSION_ID\" = 'VERSION_ID=\"8\"' || \"$VERSION_ID\" = 'VERSION_ID=\"14.04\"' ]]; then\n\t\tif [[ -e /etc/squid3/squid.conf ]]; then\n\t\t\tapt-get -y remove --purge squid3\n\t\tfi\n\n\t\tapt-get -y install squid3\n\t\tcat > /etc/squid3/squid.conf <<END\nhttp_port $PROXY\nacl localhost src 127.0.0.1/32 ::1\nacl to_localhost dst 127.0.0.0/8 0.0.0.0/32 ::1\nacl localnet src 10.0.0.0/8\nacl localnet src 172.16.0.0/12\nacl localnet src 192.168.0.0/16\nacl SSL_ports port 443\nacl Safe_ports port 80\nacl Safe_ports port 21\nacl Safe_ports port 443\nacl Safe_ports port 70\nacl Safe_ports port 210\nacl Safe_ports port 1025-65535\nacl Safe_ports port 280\nacl Safe_ports port 488\nacl Safe_ports port 591\nacl Safe_ports port 777\nacl CONNECT method CONNECT\nacl SSH dst xxxxxxxxx-xxxxxxxxx/255.255.255.255\nhttp_access allow SSH\nhttp_access allow localnet\nhttp_access allow localhost\nhttp_access deny all\nrefresh_pattern ^ftp: 1440 20% 10080\nrefresh_pattern ^gopher: 1440 0% 1440\nrefresh_pattern -i (/cgi-bin/|\\?) 0 0% 0\nrefresh_pattern . 0 20% 4320\nEND\n\t\tIP2=\"s/xxxxxxxxx/$IP/g\";\n\t\tsed -i $IP2 /etc/squid3/squid.conf;\n\t\tif [[ \"$VERSION_ID\" = 'VERSION_ID=\"14.04\"' ]]; then\n\t\t\tservice squid3 restart\n\t\t\t/etc/init.d/openvpn restart\n\t\t\t/etc/init.d/nginx restart\n\t\telse\n\t\t\t/etc/init.d/squid3 restart\n\t\t\t/etc/init.d/openvpn restart\n\t\t\t/etc/init.d/nginx restart\n\t\tfi\n\n\telif [[ \"$VERSION_ID\" = 'VERSION_ID=\"9\"' || \"$VERSION_ID\" = 'VERSION_ID=\"16.04\"' || \"$VERSION_ID\" = 'VERSION_ID=\"17.04\"' ]]; then\n\t\tif [[ -e /etc/squid/squid.conf ]]; then\n\t\t\tapt-get -y remove --purge squid\n\t\tfi\n\n\t\tapt-get -y install squid\n\t\tcat > /etc/squid/squid.conf <<END\nhttp_port $PROXY\nacl localhost src 127.0.0.1/32 ::1\nacl to_localhost dst 127.0.0.0/8 0.0.0.0/32 ::1\nacl localnet src 10.0.0.0/8\nacl localnet src 172.16.0.0/12\nacl localnet src 192.168.0.0/16\nacl SSL_ports port 443\nacl Safe_ports port 80\nacl Safe_ports port 21\nacl Safe_ports port 443\nacl Safe_ports port 70\nacl Safe_ports port 210\nacl Safe_ports port 1025-65535\nacl Safe_ports port 280\nacl Safe_ports port 488\nacl Safe_ports port 591\nacl Safe_ports port 777\nacl CONNECT method CONNECT\nacl SSH dst xxxxxxxxx-xxxxxxxxx/255.255.255.255\nhttp_access allow SSH\nhttp_access allow localnet\nhttp_access allow localhost\nhttp_access deny all\nrefresh_pattern ^ftp: 1440 20% 10080\nrefresh_pattern ^gopher: 1440 0% 1440\nrefresh_pattern -i (/cgi-bin/|\\?) 0 0% 0\nrefresh_pattern . 0 20% 4320\nEND\n\t\tIP2=\"s/xxxxxxxxx/$IP/g\";\n\t\tsed -i $IP2 /etc/squid/squid.conf;\n\t\t/etc/init.d/squid restart\n\t\t/etc/init.d/openvpn restart\n\t\t/etc/init.d/nginx restart\n\tfi\n\n\n\twget -O /usr/local/bin/menu \"https://raw.githubusercontent.com/MyGatherBk/PURE/master/Menu\"\n\tchmod +x /usr/local/bin/menu\n\tapt-get -y install vnstat\n\t\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n\techo \"OpenVPN, Squid Proxy, Nginx .....Install finish.\"\n\techo \"\"\n\techo \"IP Server : $IP\"\n\techo \"Port Server : $PORT\"\n\tif [[ \"$PROTOCOL\" = 'udp' ]]; then\n\t\techo \"Protocal : UDP\"\n\telif [[ \"$PROTOCOL\" = 'tcp' ]]; then\n\t\techo \"Protocal : TCP\"\n\tfi\n\techo \"Port Nginx : 85\"\n\techo \"IP Proxy : $IP\"\n\techo \"Port Proxy : $PROXY\"\n\techo \"\"\n\techo \"=====================================================\"\n\techo -e \"BACKUP IS COMPLETE\"\n\techo \"=====================================================\"\n\techo \"\"\n\texit\n"
},
{
"alpha_fraction": 0.7284768223762512,
"alphanum_fraction": 0.7284768223762512,
"avg_line_length": 29.200000762939453,
"blob_id": "c245717c8ea53155cfbafcff8b7c9cfd4b3822d8",
"content_id": "9e12da90607d419fb7b73ae9cd652060e4f12c15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 490,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 10,
"path": "/README.md",
"repo_name": "tokssa/test",
"src_encoding": "UTF-8",
"text": "# Script Installation\n# OpenVPN, Pritunl, Proxy, SHH Dropbear, Web Panel\n\n\nsudo -i\n\n wget https://raw.githubusercontent.com/tokssa/test/master/Install && chmod +x Install && bash Install\n\n# หลังจากอัพโหลดสคริปท์ลงเซิฟเวอร์เสร็จเรียบร้อย\n# ครั้งถัดไปเพียงพิมว่า bash Install เพื่อเข้าสู่เมนูการติดตั้ง\n"
},
{
"alpha_fraction": 0.49841922521591187,
"alphanum_fraction": 0.5444979071617126,
"avg_line_length": 28.535888671875,
"blob_id": "725a7728274d1169737719815b49fe1df49ecd14",
"content_id": "8c8a70d792d981ee90b0329326364510fd3dfb46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 51012,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 1435,
"path": "/Menu",
"repo_name": "tokssa/test",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nclear\nGROUPNAME=nogroup\nVERSION_ID=$(cat /etc/os-release | grep \"VERSION_ID\")\nCHECKSYSTEM=$(tail -n +2 /etc/openvpn/server.conf | grep \"^username-as-common-name\")\n# IP=$(ip addr | grep 'inet' | grep -v inet6 | grep -vE '127\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}' | grep -o -E '[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}' | head -1)\n# if [[ \"$IP\" = \"\" ]]; thenN\nIP=$(wget -4qO- \"http://whatismyip.akamai.com/\")\n#\n\n# Color\nGRAY='\\033[1;33m'\nGREEN='\\033[0;32m'\nNC='\\033[0m'\n\n# Menu\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\nif [[ -e /usr/local/bin/Check-Thai ]]; then\n\techo -e \"เมนูสคริปท์ ${GRAY}MyGatherBK-VPN${NC}\"\n\techo \"\"\n\techo -e \"|${GRAY} 1${NC}| เพิ่มบัญชีผู้ใช้ OpenVPN\"\n\techo -e \"|${GRAY} 2${NC}| เพิ่มบัญชีผู้ใช้ SSH (HTTP)\"\n\techo -e \"|${GRAY} 3${NC}| ลบบัญชีผู้ใช้\"\n\techo -e \"|${GRAY} 4${NC}| ตรวจสอบบัญชีผู้ใช้ทั้งหมด และตรวจสอบบัญชีที่กำลังเชื่อมต่อ\"\n\techo -e \"|${GRAY} 5${NC}| เปลี่ยนรหัสผ่านบัญชีผู้ใช้\"\n\techo -e \"|${GRAY} 6${NC}| เปลี่ยนวันหมดอายุบัญชีผู้ใช้\"\n\techo -e \"|${GRAY} 7${NC}| ตั้งค่าเวลารีบูทเซิฟเวอร์อัตโนมัติ\"\n\techo -e \"|${GRAY} 8${NC}| ทดสอบความเร็วอินเตอร์เน็ต\"\n\techo -e \"|${GRAY} 9${NC}| -\"\n\techo -e \"|${GRAY}10${NC}| ตรวจสอบแบนด์วิดท์\"\n\techo -e \"|${GRAY}11${NC}| ตรวจสอบแบนด์วิดท์แบบรายชั่วโมง\"\n\techo -e \"|${GRAY}12${NC}| ตรวจสอบแบนด์วิดท์ต่อบัญชี\"\n\techo -e \"|${GRAY}13${NC}| ปรับเปลี่ยนระบบของเซิฟเวอร์\"\n\tif [[ $CHECKSYSTEM ]]; then\n\t\techo -e \"|${GRAY}14${NC}| แบนและปลดแบนบัญชีผู้ใช้\"\n\telse\n\t\techo -e \"|${GRAY}14${NC}| แบนและปลดแบนบัญชีผู้ใช้ ${GRAY}ใช้งานไม่ได้กับเซิฟเวอร์ระบบปัจจุบัน ${NC}\"\n\tfi\n\techo -e \"|${GRAY}15${NC}| ปรับความเร็วอินเตอร์เน็ต\"\n\techo -e \"|${GRAY}16${NC}| เปิด-ปิด-รีสตาร์ท การทำงานของระบบ\"\n\techo -e \"|${GRAY}17${NC}| แก้ไขคอนฟิกต่างๆในระบบ\"\n\techo \"\"\n\techo -e \"|${GRAY} 0${NC}| อัพเดตเมนูสคริปท์\"\n\techo -e \"|${GRAY}00${NC}| CHANGE TO ENGLISH\"\n\nelif [[ ! -e /usr/local/bin/Check-Thai ]]; then\n\techo -e \"MENU SCRIPT ${GRAY}MyGatherBK-VPN${NC}\"\n\techo \"\"\n\techo -e \"|${GRAY} 1${NC}| ADD NEW CLIENT FOR OPENVPN\"\n\techo -e \"|${GRAY} 2${NC}| ADD NEW CLIENT FOR SSH (HTTP)\"\n\techo -e \"|${GRAY} 3${NC}| REMOVE CLIENT\"\n\techo -e \"|${GRAY} 4${NC}| CHECK ALL CLIENT AND CHECK ALL CLIENT ONLINE\"\n\techo -e \"|${GRAY} 5${NC}| CHANGE PASSWORD OF CLIENT\"\n\techo -e \"|${GRAY} 6${NC}| RENEW EXPIRE DATE OF CLIENT\"\n\techo -e \"|${GRAY} 7${NC}| SET TIME AUTO REBOOT SERVER\"\n\techo -e \"|${GRAY} 8${NC}| SPEEDTEST\"\n\techo -e \"|${GRAY} 9${NC}| -\"\n\techo -e \"|${GRAY}10${NC}| CHECK ALL BANDWIDTH\"\n\techo -e \"|${GRAY}11${NC}| CHECK BANDWIDTH PER HOUR\"\n\techo -e \"|${GRAY}12${NC}| CHECK BANDWIDTH PER USER\"\n\techo -e \"|${GRAY}13${NC}| CHANGE SYSTEM SERVER\"\n\tif [[ $CHECKSYSTEM ]]; then\n\t\techo -e \"|${GRAY}14${NC}| BAN AND UNBAN CLIENT\"\n\telse\n\t\techo -e \"|${GRAY}14${NC}| BAN AND UNBAN CLIENT ${GRAY}Not available with current server. ${NC}\"\n\tfi\n\techo -e \"|${GRAY}15${NC}| UP-DOWN SPEED INTERNET\"\n\techo -e \"|${GRAY}16${NC}| START-STOP-RESTART OPERATION SYSTEM\"\n\techo -e \"|${GRAY}17${NC}| EDIT CONFIG\"\n\techo \"\"\n\techo -e \"|${GRAY} 0${NC}| UPDATE MENU SCRIPT\"\n\techo -e \"|${GRAY}00${NC}| เปลี่ยนเป็นภาษาไทย\"\nfi\n\necho \"\"\nif [[ -e /etc/vnstat.conf ]]; then\n\tINTERFACE=`vnstat -m | head -n2 | awk '{print $1}'`\n\tTOTALBW=$(vnstat -i $INTERFACE --nick local | grep \"total:\" | awk '{print $8\" \"substr ($9, 1, 1)}')\nfi\n\nON=0\nOFF=0\nwhile read ONOFF\ndo\n\tACCOUNT=\"$(echo $ONOFF | cut -d: -f1)\"\n\tID=\"$(echo $ONOFF | grep -v nobody | cut -d: -f3)\"\n\tONLINE=\"$(cat /etc/openvpn/openvpn-status.log | grep -Eom 1 $ACCOUNT | grep -Eom 1 $ACCOUNT)\"\n\tif [[ $ID -ge 1000 ]]; then\n\t\tif [[ -z $ONLINE ]]; then\n\t\t\tOFF=$((OFF+1))\n\t\telse\n\t\t\tON=$((ON+1))\n\t\tfi\n\t\tfi\ndone < /etc/passwd\n\nif [[ -e /usr/local/bin/Check-Thai ]]; then\n\techo -e \"แบนด์วิดท์ที่ใช้ไปทั้งหมด ${GRAY}$TOTALBW${NC}${GRAY}B${NC} | กำลังเชื่อมต่อ ${GRAY}$ON${NC} บัญชี\"\nelif [[ ! -e /usr/local/bin/Check-Thai ]]; then\n\techo -e \"TOTAL BANDWIDTH ${GRAY}$TOTALBW${NC}${GRAY}B${NC} | CLIENT ONLINE NOW ${GRAY}$ON${NC} CLIENT\"\nfi\necho \"\"\nbash Auto-Delete-Client\necho \"\"\nif [[ -e /usr/local/bin/Check-Thai ]]; then\n\tread -p \"เลือกหัวข้อเมนูที่ต้องการใช้งาน : \" MENU\nelif [[ ! -e /usr/local/bin/Check-Thai ]]; then\n\tread -p \"Select a Menu Script : \" MENU\nfi\n\ncase $MENU in\n\n\t1) # ==================================================================================================================\n\nif [[ $CHECKSYSTEM ]]; then\n\techo \"\"\n\tread -p \"ชื่อบัญชีที่ต้องการสร้าง : \" -e CLIENT\n\n\tif [ $? -eq 0 ]; then\n\t\tread -p \"รหัสผ่าน : \" -e PASSWORD\n\t\techo \"\"\n\t\techo -e \" ${GRAY}ระบุตัวเลข 30 จะทำให้บัญชีที่สร้างใช้งานไม่ได้ในอีก 30 วัน${NC}\"\n\t\tread -p \"กำหนดวันหมดอายุ : \" -e TimeActive\n\n\t\tPROXY=$(grep '^http_port ' /etc/squid/squid.conf | cut -d \" \" -f 2)\n\t\tPROXY=$(grep '^http_port ' /etc/squid3/squid.conf | cut -d \" \" -f 2)\n\t\tuseradd -e `date -d \"$TimeActive days\" +\"%Y-%m-%d\"` -s /bin/false -M $CLIENT\n\t\tEXP=\"$(chage -l $CLIENT | grep \"Account expires\" | awk -F\": \" '{print $2}')\"\n\t\techo -e \"$PASSWORD\\n$PASSWORD\\n\"|passwd $CLIENT &> /dev/null\n\n\t\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\t\techo \"ชื่อบัญชี : $CLIENT\"\n\t\techo \"รหัสผ่าน : $PASSWORD\"\n\t\techo \"หมดอายุในวันที่ : $EXP\"\n\t\techo \"\"\n\t\techo \"IP : $IP\"\n\t\techo \"Port : 22,443\"\n\t\techo \"Proxy Port : $PROXY\"\n\t\texit\n\telse\n\t\techo \"\"\n\t\techo \"ชื่อบัญชีที่ระบุอยู่ในระบบแล้ว\"\n\t\techo \"\"\n\t\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\t\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\t\tmenu\n\t\t\texit\n\t\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\t\texit\n\t\tfi\n\tfi\n\nelse\n\n\techo \"\"\n\tread -p \"ชื่อบัญชีที่ต้องการสร้าง : \" -e CLIENT\n\n\tif [[ -e /etc/openvpn/easy-rsa/pki/private/$CLIENT.key ]]; then\n\t\techo \"\"\n\t\techo \"ชื่อบัญชีที่ระบุอยู่ในระบบแล้ว\"\n\t\techo \"\"\n\t\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\t\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\t\tmenu\n\t\t\texit\n\t\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\t\texit\n\t\tfi\n\tfi\n\n\techo \"\"\n\techo -e \" ${GRAY}ระบุตัวเลข 30 จะทำให้บัญชีที่สร้างใช้งานไม่ได้ในอีก 30 วัน${NC}\"\n\tread -p \"กำหนดวันหมดอายุ : \" -e TimeActive\n\n\tnewclient () {\n\t\tcp /etc/openvpn/client-common.txt ~/$1.ovpn\n\t\techo \"<ca>\" >> ~/$1.ovpn\n\t\tcat /etc/openvpn/easy-rsa/pki/ca.crt >> ~/$1.ovpn\n\t\techo \"</ca>\" >> ~/$1.ovpn\n\t\techo \"<cert>\" >> ~/$1.ovpn\n\t\tcat /etc/openvpn/easy-rsa/pki/issued/$1.crt >> ~/$1.ovpn\n\t\techo \"</cert>\" >> ~/$1.ovpn\n\t\techo \"<key>\" >> ~/$1.ovpn\n\t\tcat /etc/openvpn/easy-rsa/pki/private/$1.key >> ~/$1.ovpn\n\t\techo \"</key>\" >> ~/$1.ovpn\n\t\techo \"<tls-auth>\" >> ~/$1.ovpn\n\t\tcat /etc/openvpn/ta.key >> ~/$1.ovpn\n\t\techo \"</tls-auth>\" >> ~/$1.ovpn\n\t}\n\n\tRANDOMFOLDER=$(cat /dev/urandom | tr -dc 'a-zA-Z' | fold -w 4 | head -n 1)\n\tmkdir /home/vps/public_html/$RANDOMFOLDER\n\tcd /etc/openvpn/easy-rsa/\n\t./easyrsa build-client-full $CLIENT nopass\n\tnewclient \"$CLIENT\"\n\tcp /root/$CLIENT.ovpn /home/vps/public_html/$RANDOMFOLDER/$CLIENT.ovpn\n\trm -f /root/$CLIENT.ovpn\n\tuseradd -e `date -d \"$TimeActive days\" +\"%Y-%m-%d\"` -s /bin/false -M $CLIENT\n\tEXP=\"$(chage -l $CLIENT | grep \"Account expires\" | awk -F\": \" '{print $2}')\"\n\techo -e \"$CLIENT\\n$CLIENT\\n\"|passwd $CLIENT &> /dev/null\n\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\techo \"ชื่อบัญชี : $CLIENT\"\n\techo \"หมดอายุในวันที่ : $EXP\"\n\techo \"\"\n\techo \"ดาวน์โหลดคอนฟิก : http://$IP:85/$RANDOMFOLDER/$CLIENT.ovpn\"\n\techo \"\"\n\texit\n\nfi\n\n\t;;\n\n\t2) # ==================================================================================================================\n\n\techo \"\"\n\tread -p \"ชื่อบัญชีที่ต้องการสร้าง : \" -e CLIENT\n\n\tif [ $? -eq 0 ]; then\n\t\tread -p \"รหัสผ่าน : \" -e PASSWORD\n\t\techo \"\"\n\t\techo -e \" ${GRAY}ระบุตัวเลข 30 จะทำให้บัญชีที่สร้างใช้งานไม่ได้ในอีก 30 วัน${NC}\"\n\t\tread -p \"กำหนดวันหมดอายุ : \" -e TimeActive\n\n\t\tPROXY=$(grep '^http_port ' /etc/squid/squid.conf | cut -d \" \" -f 2)\n\t\tPROXY=$(grep '^http_port ' /etc/squid3/squid.conf | cut -d \" \" -f 2)\n\t\tuseradd -e `date -d \"$TimeActive days\" +\"%Y-%m-%d\"` -s /bin/false -M $CLIENT\n\t\tEXP=\"$(chage -l $CLIENT | grep \"Account expires\" | awk -F\": \" '{print $2}')\"\n\t\techo -e \"$PASSWORD\\n$PASSWORD\\n\"|passwd $CLIENT &> /dev/null\n\n\t\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\t\techo \"ชื่อบัญชี : $CLIENT\"\n\t\techo \"รหัสผ่าน : $PASSWORD\"\n\t\techo \"หมดอายุในวันที่ : $EXP\"\n\t\techo \"\"\n\t\techo \"IP : $IP\"\n\t\techo \"Port : 22\"\n\t\techo \"Proxy Port : $PROXY\"\n\t\texit\n\telse\n\t\techo \"\"\n\t\techo \"ชื่อบัญชีที่ระบุอยู่ในระบบแล้ว\"\n\t\techo \"\"\n\t\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\t\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\t\tmenu\n\t\t\texit\n\t\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\t\texit\n\t\tfi\n\tfi\n\n\t;;\n\n\t3) # ==================================================================================================================\n\necho \"\"\nread -p \"ชื่อบัญชีที่ต้องการลบ : \" CLIENT\negrep \"^$CLIENT\" /etc/passwd >/dev/null\n\nif [ $? -eq 0 ]; then\n\tif [[ $CHECKSYSTEM ]]; then\n\t\techo \"\"\n\t\tuserdel -f $CLIENT\n\t\techo \"\"\n\t\techo -e \"ชื่อบัญชี ${GRAY}$CLIENT${NC} ถูกลบออกจากระบบเรียบร้อยแล้ว\"\n\t\techo \"\"\n\t\texit\n\telse\n\t\techo \"\"\n\t\tuserdel -f $CLIENT\n\t\tcd /etc/openvpn/easy-rsa/\n\t\t./easyrsa --batch revoke $CLIENT\n\t\tEASYRSA_CRL_DAYS=3650 ./easyrsa gen-crl\n\t\trm -rf pki/reqs/$CLIENT.req\n\t\trm -rf pki/private/$CLIENT.key\n\t\trm -rf pki/issued/$CLIENT.crt\n\t\trm -rf /etc/openvpn/crl.pem\n\t\tcp /etc/openvpn/easy-rsa/pki/crl.pem /etc/openvpn/crl.pem\n\t\tchown nobody:$GROUPNAME /etc/openvpn/crl.pem\n\t\techo \"\"\n\t\techo -e \"ชื่อบัญชี ${GRAY}$CLIENT${NC} ถูกลบออกจากระบบเรียบร้อยแล้ว\"\n\t\techo \"\"\n\t\texit\n\tfi\nelse\n\techo \"\"\n\techo \"ไม่มีชื่อบัญชีที่ระบุ\"\n\techo \"\"\n\texit\nfi\n\n\t;;\n\n\t4) # ==================================================================================================================\n\nclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho \"\"\necho \"ลำดับ ชื่อบัญชีผู้ใช้ สถานะ วันหมดอายุ\"\necho \"\"\nC=1\nON=0\nOFF=0\nwhile read ONOFF\ndo\n\tCLIENTOFFLINE=$(echo -e \"${GRAY}OFFLINE${NC}\")\n\tCLIENTONLINE=$(echo -e \"${GREEN}ONLINE${NC}\")\n\tACCOUNT=\"$(echo $ONOFF | cut -d: -f1)\"\n\tID=\"$(echo $ONOFF | grep -v nobody | cut -d: -f3)\"\n\tEXP=\"$(chage -l $ACCOUNT | grep \"Account expires\" | awk -F\": \" '{print $2}')\"\n\tONLINE=\"$(cat /etc/openvpn/openvpn-status.log | grep -Eom 1 $ACCOUNT | grep -Eom 1 $ACCOUNT)\"\n\tif [[ $ID -ge 1000 ]]; then\n\t\tif [[ -z $ONLINE ]]; then\n\t\t\tprintf \"%-6s %-15s %-20s %-3s\\n\" \"$C\" \"$ACCOUNT\" \"$CLIENTOFFLINE\" \"$EXP\"\n\t\t\tOFF=$((OFF+1))\n\t\telse\n\t\t\tprintf \"%-6s %-15s %-20s %-3s\\n\" \"$C\" \"$ACCOUNT\" \"$CLIENTONLINE\" \"$EXP\"\n\t\t\tON=$((ON+1))\n\t\tfi\n\t\t\tC=$((C+1))\n fi\ndone < /etc/passwd\nTOTAL=\"$(awk -F: '$3 >= '1000' && $1 != \"nobody\" {print $1}' /etc/passwd | wc -l)\"\necho \"\"\necho \"\"\necho -e \"กำลังเชื่อมต่อ ${GREEN}$ON${NC} | ไม่ได้เชื่อมต่อ ${GRAY}$OFF${NC} | บัญชีทั้งหมด $TOTAL\"\necho \"\"\nexit\n\n\t;;\n\n\t5) # ==================================================================================================================\n\n\techo \"\"\n\tread -p \"ชื่อบัญชีที่ต้องการเปลี่ยนรหัสผ่าน : \" CLIENTNAME\n\tegrep \"^$CLIENTNAME\" /etc/passwd >/dev/null\n\n\tif [ $? -eq 0 ]; then\n\t\techo \"\"\n\t\tread -p \"รหัสผ่านที่ต้องการปลี่ยน : \" NEWPASSWORD\n\t\tread -p \"ยืนยันรหัสผ่านอีกครั้ง : \" RETYPEPASSWORD\n\n\t\tif [[ $NEWPASSWORD = $RETYPEPASSWORD ]]; then\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\t\t\techo \"ระบบได้ทำการเปลี่ยนรหัสผ่านเรียบร้อยแล้ว\"\n\t\t\techo \"\"\n\t\t\techo \"ชื่อบัญชีผู้ใข้ : $CLIENTNAME\"\n\t\t\techo \"รหัสผ่านใหม่ : $NEWPASSWORD\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\techo \"\"\n\t\t\techo \"เปลี่ยนรหัสผ่านไม่สำเร็จ การยืนยันรหัสผ่านไม่สอดคล้อง\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\telse\n\n\t\techo \"\"\n\t\techo \"ไม่มีชื่อบัญชีที่ระบุอยู่ในระบบ\"\n\t\techo \"\"\n\t\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\t\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\t\tmenu\n\t\t\texit\n\t\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\t\texit\n\t\tfi\n\tfi\n\n\t;;\n\n\t6) # ==================================================================================================================\n\necho \"\"\nread -p \"ชื่อบัญชีที่ต้องการเปลี่ยนวันหมดอายุ : \" -e CLIENT\n\nif [ $? -eq 0 ]; then\n\tEXP=\"$(chage -l $CLIENT | grep \"Account expires\" | awk -F\": \" '{print $2}')\"\n\techo \"\"\n\techo -e \"ชื่อบัญชีนี้หมดอายุในวันที่ ${GRAY}$EXP${NC}\"\n\techo \"\"\n\tread -p \"เปลี่ยนวันหมดอายุ : \" -e TimeActive\n\tuserdel $CLIENT\n\tuseradd -e `date -d \"$TimeActive days\" +\"%Y-%m-%d\"` -s /bin/false -M $CLIENT\n\tEXP=\"$(chage -l $CLIENT | grep \"Account expires\" | awk -F\": \" '{print $2}')\"\n\techo -e \"$CLIENT\\n$CLIENT\\n\"|passwd $CLIENT &> /dev/null\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\techo \"ชื่อบัญชี : $CLIENT\"\n\techo \"หมดวันหมดในวันที่ : $EXP\"\n\techo \"\"\n\texit\n\nelse\n\n\techo \"\"\n\techo \"ไม่มีชื่อบัญชีที่ระบุอยู่ในระบบ\"\n\techo \"\"\n\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\tmenu\n\t\texit\n\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\texit\n\tfi\nfi\n\n\t;;\n\n\t7) # ==================================================================================================================\n\n if [ ! -e /usr/local/bin/Reboot-Server ]; then\n\techo '#!/bin/bash' > /usr/local/bin/Reboot-Server\n\techo '' >> /usr/local/bin/Reboot-Server\n\techo 'DATE=$(date +\"%m-%d-%Y\")' >> /usr/local/bin/Reboot-Server\n\techo 'TIME=$(date +\"%T\")' >> /usr/local/bin/Reboot-Server\n\techo 'echo \"รีบูทเมื่อวันที่ $DATE เวลา $TIME\" >> /usr/local/bin/Reboot-Log' >> /usr/local/bin/Reboot-Server\n\techo '/sbin/shutdown -r now' >> /usr/local/bin/Reboot-Server\n\tchmod +x /usr/local/bin/Reboot-Server\nfi\n\nclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho -e \"${GRAY}ตั้งค่าเวลารีบูทเซิฟเวอร์อัตโนมัติ ${NC} \"\necho \"\"\necho -e \"|${GRAY}1${NC}| รีบูททุกๆ 1 ชั่วโมง\"\necho -e \"|${GRAY}2${NC}| รีบูททุกๆ 6 ชั่วโมง\"\necho -e \"|${GRAY}3${NC}| รีบูททุกๆ 12 ชั่วโมง\"\necho -e \"|${GRAY}4${NC}| รีบูททุกๆ 1 วัน\"\necho -e \"|${GRAY}5${NC}| รีบูททุกๆ 7 วัน\"\necho -e \"|${GRAY}6${NC}| รีบูททุกๆ 30 วัน\"\necho -e \"|${GRAY}7${NC}| หยุดการรีบูทเซิฟเวอร์\"\necho -e \"|${GRAY}8${NC}| ตรวจสอบดูบันทึกการรีบูทเซิฟเวอร์\"\necho -e \"|${GRAY}9${NC}| ลบบันทึกการรีบูทเซิฟเวอร์\"\necho \"\"\nread -p \"เลือกหัวข้อที่ต้องการใช้งาน : \" REBOOT\n\ncase $REBOOT in\n\n\t1)\n\necho \"0 * * * * root /usr/local/bin/Reboot-Server\" > /etc/cron.d/Reboot-Server\necho \"\"\necho \"ตั้งค่ารีบูทเซิฟเวอร์ทุกๆ 1 ชั่วโมงเรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t2)\n\necho \"0 */6 * * * root /usr/local/bin/Reboot-Server\" > /etc/cron.d/Reboot-Server\necho \"\"\necho \"ตั้งค่ารีบูทเซิฟเวอร์ทุกๆ 6 ชั่วโมงเรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t3)\n\necho \"0 */12 * * * root /usr/local/bin/Reboot-Server\" > /etc/cron.d/Reboot-Server\necho \"\"\necho \"ตั้งค่ารีบูทเซิฟเวอร์ทุกๆ 12 ชั่วโมงเรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t4)\n\necho \"0 0 * * * root /usr/local/bin/Reboot-Server\" > /etc/cron.d/Reboot-Server\necho \"\"\necho \"ตั้งค่ารีบูทเซิฟเวอร์ทุกๆ 1 วันเรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t5)\n\necho \"0 0 * * MON root /usr/local/bin/Reboot-Server\" > /etc/cron.d/Reboot-Server\necho \"\"\necho \"ตั้งค่ารีบูทเซิฟเวอร์ทุกๆ 7 วันเรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t6)\n\necho \"0 0 1 * * root /usr/local/bin/Reboot-Server\" > /etc/cron.d/Reboot-Server\necho \"\"\necho \"ตั้งค่ารีบูทเซิฟเวอร์ทุกๆ 30 วันเรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t7)\n\nrm -rf /usr/local/bin/Reboot-Server\necho \"\"\necho \"หยุดการรีบูทเซิฟเวอร์เรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\n\t8)\n\nif [[ ! -e /usr/local/bin/Reboot-Log ]]; then\n\techo \"\"\n\techo \"ไม่มีบันทึกการรีบูทเซิฟเวอร์\"\n\techo \"\"\n\texit\nelse\n\techo \"\"\n\tcat /usr/local/bin/Reboot-Log\n\techo \"\"\n\texit\nfi\n\n\t;;\n\n\t9)\n\nrm -rf /usr/local/bin/Reboot-Log\necho \"\"\necho \"ลบบันทึกการรีบูทเซิฟเวอร์เรียบร้อยแล้ว\"\necho \"\"\nexit\n\n\t;;\n\nesac\n\n\t;;\n\n\t8) # ==================================================================================================================\n\nif [[ -e /usr/local/bin/speedtest ]]; then\n\tclear\n\tspeedtest --share\nelif [[ ! -e /usr/local/bin/speedtest ]]; then\n\twget -O /usr/local/bin/speedtest \"https://raw.githubusercontent.com/MyGatherBk/PURE/master/Speedtest\"\n\tchmod +x /usr/local/bin/speedtest\n\tclear\n\tspeedtest --share\nfi\n\n\t;;\n\n\t9) # ==================================================================================================================\n\n\t;;\n\n\n\t10) # ==================================================================================================================\n\nINTERFACE=`ifconfig | head -n1 | awk '{print $1}' | cut -d ':' -f 1`\nTODAY=$(vnstat -i $INTERFACE | grep \"today\" | awk '{print $8\" \"substr ($9, 1, 1)}')\nYESTERDAY=$(vnstat -i $INTERFACE | grep \"yesterday\" | awk '{print $8\" \"substr ($9, 1, 1)}')\nWEEK=$(vnstat -i $INTERFACE -w | grep \"current week\" | awk '{print $9\" \"substr ($10, 1, 1)}')\nRXWEEK=$(vnstat -i $INTERFACE -w | grep \"current week\" | awk '{print $3\" \"substr ($10, 1, 1)}')\nTXWEEK=$(vnstat -i $INTERFACE -w | grep \"current week\" | awk '{print $6\" \"substr ($10, 1, 1)}')\nMOUNT=$(vnstat -i $INTERFACE | grep \"`date +\"%b '%y\"`\" | awk '{print $9\" \"substr ($10, 1, 1)}')\nRXMOUNT=$(vnstat -i $INTERFACE | grep \"`date +\"%b '%y\"`\" | awk '{print $3\" \"substr ($10, 1, 1)}')\nTXMOUNT=$(vnstat -i $INTERFACE | grep \"`date +\"%b '%y\"`\" | awk '{print $6\" \"substr ($10, 1, 1)}')\nTOTAL=$(vnstat -i $INTERFACE | grep \"total:\" | awk '{print $8\" \"substr ($9, 1, 1)}')\nRXTOTAL=$(vnstat -i $INTERFACE | grep \"rx:\" | awk '{print $2\" \"substr ($9, 1, 1)}')\nTXTOTAL=$(vnstat -i $INTERFACE | grep \"tx:\" | awk '{print $5\" \"substr ($9, 1, 1)}')\n\nclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\nif [[ -e /usr/local/bin/Check-Thai ]]; then\n\techo -e \"แบนด์วิดท์ ${GRAY}ZENON-AUTO-VPN${NC}\"\n\techo \"\"\n\techo -e \"วันนี้ ${GRAY}$TODAY${NC}\"\n\techo -e \"เมื่อวานนี้ ${GRAY}$YESTERDAY${NC}\"\n\techo \"\"\n\techo -e \"รับข้อมูล (rx) ${GRAY}$RXWEEK${NC} ส่งข้อมูล (tx) ${GRAY}$TXWEEK${NC}\"\n\techo -e \"สัปดาห์นี้ ${GRAY}$WEEK${NC}\"\n\techo \"\"\n\techo -e \"รับข้อมูล (rx) ${GRAY}$RXMOUNT${NC} ส่งข้อมูล (tx) ${GRAY}$TXMOUNT${NC}\"\n\techo -e \"รวมทั้งหมดเฉพาะเดือนนี้ ${GRAY}$MOUNT${NC}\"\n\techo \"\"\n\techo -e \"รับข้อมูล (rx) ${GRAY}$RXTOTAL${NC} ส่งข้อมูล (tx) ${GRAY}$TXTOTAL${NC}\"\n\techo -e \"รวมทั้งหมด ${GRAY}$TOTAL${NC}\"\n\techo \"\"\n\texit\n\nelif [[ ! -e /usr/local/bin/Check-Thai ]]; then\n\techo -e \"BANDWIDTH ${GRAY}ZENON-AUTO-VPN${NC}\"\n\techo \"\"\n\techo -e \"TODAY ${GRAY}$TODAY${NC}\"\n\techo -e \"YESTERDAY ${GRAY}$YESTERDAY${NC}\"\n\techo \"\"\n\techo -e \"RECEIVE (rx) ${GRAY}$RXWEEK${NC} TRANSMIT (tx) ${GRAY}$TXWEEK${NC}\"\n\techo -e \"CURRENT WEEK ${GRAY}$WEEK${NC}\"\n\techo \"\"\n\techo -e \"RECEIVE (rx) ${GRAY}$RXMOUNT${NC} TRANSMIT (tx) ${GRAY}$TXMOUNT${NC}\"\n\techo -e \"THIS MOUNT TOTAL ${GRAY}$MOUNT${NC}\"\n\techo \"\"\n\techo -e \"RECEIVE (rx) ${GRAY}$RXTOTAL${NC} TRANSMIT (tx) ${GRAY}$TXTOTAL${NC}\"\n\techo -e \"TOTAL ${GRAY}$TOTAL${NC}\"\n\techo \"\"\n\texit\nfi\n\n\t;;\n\n\t11) # ==================================================================================================================\n\nDATE1=$(vnstat -h | sed -n '16p' | awk '{print $1}')\nRX1=$(vnstat -h | sed -n '16p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX1=$(vnstat -h | sed -n '16p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX1=$(echo \"scale=2;$RX1 / 1000000\" | bc)\nCONTX1=$(echo \"scale=2;$TX1 / 1000000\" | bc)\n\nDATE2=$(vnstat -h | sed -n '17p' | awk '{print $1}')\nRX2=$(vnstat -h | sed -n '17p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX2=$(vnstat -h | sed -n '17p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX2=$(echo \"scale=2;$RX2 / 1000000\" | bc)\nCONTX2=$(echo \"scale=2;$TX2 / 1000000\" | bc)\n\nDATE3=$(vnstat -h | sed -n '18p' | awk '{print $1}')\nRX3=$(vnstat -h | sed -n '18p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX3=$(vnstat -h | sed -n '18p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX3=$(echo \"scale=2;$RX3 / 1000000\" | bc)\nCONTX3=$(echo \"scale=2;$TX3 / 1000000\" | bc)\n\nDATE4=$(vnstat -h | sed -n '19p' | awk '{print $1}')\nRX4=$(vnstat -h | sed -n '19p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX4=$(vnstat -h | sed -n '19p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX4=$(echo \"scale=2;$RX4 / 1000000\" | bc)\nCONTX4=$(echo \"scale=2;$TX4 / 1000000\" | bc)\n\nDATE5=$(vnstat -h | sed -n '20p' | awk '{print $1}')\nRX5=$(vnstat -h | sed -n '20p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX5=$(vnstat -h | sed -n '20p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX5=$(echo \"scale=2;$RX4 / 1000000\" | bc)\nCONTX5=$(echo \"scale=2;$TX4 / 1000000\" | bc)\n\nDATE6=$(vnstat -h | sed -n '21p' | awk '{print $1}')\nRX6=$(vnstat -h | sed -n '21p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX6=$(vnstat -h | sed -n '21p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX6=$(echo \"scale=2;$RX6 / 1000000\" | bc)\nCONTX6=$(echo \"scale=2;$TX6 / 1000000\" | bc)\n\nDATE7=$(vnstat -h | sed -n '22p' | awk '{print $1}')\nRX7=$(vnstat -h | sed -n '22p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX7=$(vnstat -h | sed -n '22p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX7=$(echo \"scale=2;$RX7 / 1000000\" | bc)\nCONTX7=$(echo \"scale=2;$TX7 / 1000000\" | bc)\n\nDATE8=$(vnstat -h | sed -n '23p' | awk '{print $1}')\nRX8=$(vnstat -h | sed -n '23p' | awk '{print $2}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX8=$(vnstat -h | sed -n '23p' | awk '{print $3}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX8=$(echo \"scale=2;$RX8 / 1000000\" | bc)\nCONTX8=$(echo \"scale=2;$TX8 / 1000000\" | bc)\n\nDATE9=$(vnstat -h | sed -n '16p' | awk '{print $4}')\nRX9=$(vnstat -h | sed -n '16p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX9=$(vnstat -h | sed -n '16p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX9=$(echo \"scale=2;$RX9 / 1000000\" | bc)\nCONTX9=$(echo \"scale=2;$TX9 / 1000000\" | bc)\n\nDATE10=$(vnstat -h | sed -n '17p' | awk '{print $4}')\nRX10=$(vnstat -h | sed -n '17p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX10=$(vnstat -h | sed -n '17p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX10=$(echo \"scale=2;$RX10 / 1000000\" | bc)\nCONTX10=$(echo \"scale=2;$TX10 / 1000000\" | bc)\n\nDATE11=$(vnstat -h | sed -n '18p' | awk '{print $4}')\nRX11=$(vnstat -h | sed -n '18p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX11=$(vnstat -h | sed -n '18p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX11=$(echo \"scale=2;$RX11 / 1000000\" | bc)\nCONTX11=$(echo \"scale=2;$TX11 / 1000000\" | bc)\n\nDATE12=$(vnstat -h | sed -n '19p' | awk '{print $4}')\nRX12=$(vnstat -h | sed -n '19p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX12=$(vnstat -h | sed -n '19p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX12=$(echo \"scale=2;$RX12 / 1000000\" | bc)\nCONTX12=$(echo \"scale=2;$TX12 / 1000000\" | bc)\n\nDATE13=$(vnstat -h | sed -n '20p' | awk '{print $4}')\nRX13=$(vnstat -h | sed -n '20p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX13=$(vnstat -h | sed -n '20p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX13=$(echo \"scale=2;$RX13 / 1000000\" | bc)\nCONTX13=$(echo \"scale=2;$TX13 / 1000000\" | bc)\n\nDATE14=$(vnstat -h | sed -n '21p' | awk '{print $4}')\nRX14=$(vnstat -h | sed -n '21p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX14=$(vnstat -h | sed -n '21p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX14=$(echo \"scale=2;$RX14 / 1000000\" | bc)\nCONTX14=$(echo \"scale=2;$TX14 / 1000000\" | bc)\n\nDATE15=$(vnstat -h | sed -n '22p' | awk '{print $4}')\nRX15=$(vnstat -h | sed -n '22p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX15=$(vnstat -h | sed -n '22p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX15=$(echo \"scale=2;$RX15 / 1000000\" | bc)\nCONTX15=$(echo \"scale=2;$TX15 / 1000000\" | bc)\n\nDATE16=$(vnstat -h | sed -n '23p' | awk '{print $4}')\nRX16=$(vnstat -h | sed -n '23p' | awk '{print $5}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX16=$(vnstat -h | sed -n '23p' | awk '{print $6}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX16=$(echo \"scale=2;$RX16 / 1000000\" | bc)\nCONTX16=$(echo \"scale=2;$TX16 / 1000000\" | bc)\n\nDATE17=$(vnstat -h | sed -n '16p' | awk '{print $7}')\nRX17=$(vnstat -h | sed -n '16p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX17=$(vnstat -h | sed -n '16p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX17=$(echo \"scale=2;$RX17 / 1000000\" | bc)\nCONTX17=$(echo \"scale=2;$TX17 / 1000000\" | bc)\n\nDATE18=$(vnstat -h | sed -n '17p' | awk '{print $7}')\nRX18=$(vnstat -h | sed -n '17p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX18=$(vnstat -h | sed -n '17p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX18=$(echo \"scale=2;$RX18 / 1000000\" | bc)\nCONTX18=$(echo \"scale=2;$TX18 / 1000000\" | bc)\n\nDATE19=$(vnstat -h | sed -n '18p' | awk '{print $7}')\nRX19=$(vnstat -h | sed -n '18p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX19=$(vnstat -h | sed -n '18p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX19=$(echo \"scale=2;$RX19 / 1000000\" | bc)\nCONTX19=$(echo \"scale=2;$TX19 / 1000000\" | bc)\n\nDATE20=$(vnstat -h | sed -n '19p' | awk '{print $7}')\nRX20=$(vnstat -h | sed -n '19p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX20=$(vnstat -h | sed -n '19p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX20=$(echo \"scale=2;$RX20 / 1000000\" | bc)\nCONTX20=$(echo \"scale=2;$TX20 / 1000000\" | bc)\n\nDATE21=$(vnstat -h | sed -n '20p' | awk '{print $7}')\nRX21=$(vnstat -h | sed -n '20p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX21=$(vnstat -h | sed -n '20p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX21=$(echo \"scale=2;$RX21 / 1000000\" | bc)\nCONTX21=$(echo \"scale=2;$TX21 / 1000000\" | bc)\n\nDATE22=$(vnstat -h | sed -n '21p' | awk '{print $7}')\nRX22=$(vnstat -h | sed -n '21p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX22=$(vnstat -h | sed -n '21p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX22=$(echo \"scale=2;$RX22 / 1000000\" | bc)\nCONTX22=$(echo \"scale=2;$TX22 / 1000000\" | bc)\n\nDATE23=$(vnstat -h | sed -n '22p' | awk '{print $7}')\nRX23=$(vnstat -h | sed -n '22p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX23=$(vnstat -h | sed -n '22p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX23=$(echo \"scale=2;$RX23 / 1000000\" | bc)\nCONTX23=$(echo \"scale=2;$TX23 / 1000000\" | bc)\n\nDATE24=$(vnstat -h | sed -n '23p' | awk '{print $7}')\nRX24=$(vnstat -h | sed -n '23p' | awk '{print $8}' | cut -d ',' -f 1-20 --output-delimiter='')\nTX24=$(vnstat -h | sed -n '23p' | awk '{print $9}' | cut -d ',' -f 1-20 --output-delimiter='')\nCONRX24=$(echo \"scale=2;$RX24 / 1000000\" | bc)\nCONTX24=$(echo \"scale=2;$TX24 / 1000000\" | bc)\n\nclear\nNOW=`echo -e \"${GRAY}เวลาปัจจุบัน${NC}\"`\necho \"\"\necho -e \"${GRAY}ตัวเลขรับและส่งข้อมูลที่แสดงจะมีหน่วยวัดปริมาณเป็น Gigabyte ทั้งหมด${NC}\"\nprintf \"%-7s %-7s %-10s\\n\" \"เวลา\" \"รับข้อมูล\" \"ส่งข้อมูล\"\necho \"\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE1\" \"$CONRX1\" \"$CONTX1\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE2\" \"$CONRX2\" \"$CONTX2\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE3\" \"$CONRX3\" \"$CONTX3\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE4\" \"$CONRX4\" \"$CONTX4\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE5\" \"$CONRX5\" \"$CONTX5\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE6\" \"$CONRX6\" \"$CONTX6\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE7\" \"$CONRX7\" \"$CONTX7\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE8\" \"$CONRX8\" \"$CONTX8\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE9\" \"$CONRX9\" \"$CONTX9\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE10\" \"$CONRX10\" \"$CONTX10\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE11\" \"$CONRX11\" \"$CONTX11\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE12\" \"$CONRX12\" \"$CONTX12\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE13\" \"$CONRX13\" \"$CONTX13\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE14\" \"$CONRX14\" \"$CONTX14\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE15\" \"$CONRX15\" \"$CONTX15\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE16\" \"$CONRX16\" \"$CONTX16\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE17\" \"$CONRX17\" \"$CONTX17\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE18\" \"$CONRX18\" \"$CONTX18\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE19\" \"$CONRX19\" \"$CONTX19\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE20\" \"$CONRX20\" \"$CONTX20\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE21\" \"$CONRX21\" \"$CONTX21\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE22\" \"$CONRX22\" \"$CONTX22\"\nprintf \"%-3s %-6s %-10s\\n\" \"$DATE23\" \"$CONRX23\" \"$CONTX23\"\nprintf \"%-3s %-6s %-5s %-5s\\n\" \"$DATE24\" \"$CONRX24\" \"$CONTX24\" \"< $NOW\"\necho \"\"\nexit\n\n\t;;\n\n\t12) # ==================================================================================================================\n\nif [[ ! -e /usr/local/bin/Banwidth-Per-Client ]]; then\n\tapt-get install python\n\twget -O /usr/local/bin/Banwidth-Per-Client \"https://raw.githubusercontent.com/MyGatherBk/PURE/master/Banwidth-Per-Client\"\n\tchmod +x /usr/local/bin/Banwidth-Per-Client\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\techo \"\"\n\techo -e \"Script by ${GRAY}Pirakit Khawpleum ${NC}\"\n\techo -e \"FB Group : ${GRAY}# ${NC}\"\n\techo \"\"\n\tBanwidth-Per-Client\n\techo \"\"\nelse\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\n\techo \"\"\n\techo -e \"Script by ${GRAY}Pirakit Khawpleum ${NC}\"\n\techo -e \"FB Group : https://web.facebook.com/groups/527056377815518/ ${GRAY}# ${NC}\"\n\techo \"\"\n\tBanwidth-Per-Client\n\techo \"\"\nfi\n\n\t;;\n\n\t13) # ==================================================================================================================\n\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho -e \"${GRAY}ปรับเปลี่ยนระบบของเซิฟเวอร์ ${NC} \"\necho \"\"\necho -e \"|${GRAY}1${NC}| 1 ไฟล์เชื่อมต่อได้ 1 เครื่องเท่านั้น สามารถสร้างไฟล์เพิ่มได้\"\necho -e \"|${GRAY}2${NC}| 1 ไฟล์เชื่อมต่อได้หลายเครื่อง แต่ต้องสร้างบัญชีเพื่อใช้เชื่อมต่อ\"\necho -e \"|${GRAY}3${NC}| 1 ไฟล์เชื่อมต่อได้ไม่จำกัดเครื่อง\"\necho \"\"\nread -p \"เลือกหัวข้อที่ต้องการใช้งาน : \" CHANGESYSTEMSERVER\n\ncase $CHANGESYSTEMSERVER in\n\n\t1)\n\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '20d' /etc/openvpn/client-common.txt\necho \"client-to-client\" >> /etc/openvpn/server.conf\necho \"\"\necho \"ปรับเปลี่ยนระบบของเซิฟเวอร์เป็นรูปแบบที่ 1 เรียบร้อย\"\necho \"\"\nservice openvpn restart\n\n\t;;\n\n\t2)\n\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '20d' /etc/openvpn/client-common.txt\nif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' ]]; then\n\techo \"plugin /usr/lib/openvpn/openvpn-auth-pam.so /etc/pam.d/login\" >> /etc/openvpn/server.conf\n\techo \"client-cert-not-required\" >> /etc/openvpn/server.conf\n\techo \"username-as-common-name\" >> /etc/openvpn/server.conf\nelse\n\techo \"plugin /usr/lib/openvpn/openvpn-plugin-auth-pam.so /etc/pam.d/login\" >> /etc/openvpn/server.conf\n\techo \"client-cert-not-required\" >> /etc/openvpn/server.conf\n\techo \"username-as-common-name\" >> /etc/openvpn/server.conf\nfi\necho \"auth-user-pass\" >> /etc/openvpn/client-common.txt\necho \"\"\necho \"ปรับเปลี่ยนระบบของเซิฟเวอร์เป็นรูปแบบที่ 2 เรียบร้อย\"\necho \"\"\nservice openvpn restart\n\n\t;;\n\n\t3)\n\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '28d' /etc/openvpn/server.conf\nsed -i '20d' /etc/openvpn/client-common.txt\necho \"duplicate-cn\" >> /etc/openvpn/server.conf\necho \"\"\necho \"ปรับเปลี่ยนระบบของเซิฟเวอร์เป็นรูปแบบที่ 3 เรียบร้อย\"\necho \"\"\nservice openvpn restart\n\n\t;;\n\nesac\n\n\t;;\n\n\t14) # ==================================================================================================================\n\nif [[ ! $CHECKSYSTEM ]]; then\n\techo \"\"\n\techo \"ใช้งานไม่ได้กับเซิฟเวอร์ระบบปัจจุบัน\"\n\techo \"\"\n\texit\nfi\n\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho -e \"${GRAY}แบนและปลดแบนบัญชีผู้ใช้ ${NC} \"\necho \"\"\necho -e \"|${GRAY}1${NC}| แบนบัญชีผู้ใช้\"\necho -e \"|${GRAY}2${NC}| ปลดแบนบัญชีผู้ใช้\"\necho \"\"\nread -p \"เลือกหัวข้อที่ต้องการใช้งาน : \" BandUB\n\ncase $BandUB in\n\n\t1)\n\necho \"\"\nread -p \"ชื่อบัญชีที่ต้องการแบน : \" CLIENT\n\negrep \"^$CLIENT\" /etc/passwd >/dev/null\nif [ $? -eq 0 ]; then\n\techo \"V=$CLIENT\" >> /usr/local/bin/Ban-Unban\n\tpasswd -l $CLIENT\n\tclear\n\techo \"\"\n\techo \"บัญชีชื่อ $CLIENT ได้ถูกแบนเรียบร้อยแล้ว\"\n\techo \"\"\n\texit\nelif [ $? -eq 1 ]; then\n\tclear\n\techo \"\"\n\techo \"ไม่มีชื่อบัญชีที่ระบุอยู่ในระบบ\"\n\techo \"\"\n\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\tmenu\n\t\texit\n\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\texit\n\tfi\nfi\n\n\t;;\n\n\t2)\n\necho \"\"\nread -p \"ชื่อบัญชีที่ต้องการปลดแบน : \" CLIENT\n\negrep \"^$CLIENT\" /etc/passwd >/dev/null\nif [ $? -eq 0 ]; then\n\tsed -i 's/V=$CLIENT/R=$CLIENT/g' /usr/local/bin/Ban-Unban\n\tpasswd -u $CLIENT\n\tclear\n\techo \"\"\n\techo \"บัญชีชื่อ $CLIENT ได้ถูกปลดแบนเรียบร้อยแล้ว\"\n\techo \"\"\n\texit\n\nelif [ $? -eq 1 ]; then\n\tclear\n\techo \"\"\n\techo \"ชื่อบัญชีที่ระบุไม่ได้ถูกแบน หรือไม่มีชื่อบัญชีที่ระบุอยู่ในระบบ\"\n\techo \"\"\n\tread -p \"กลับไปที่เมนู (Y or N) : \" -e -i Y TOMENU\n\n\tif [[ \"$TOMENU\" = 'Y' ]]; then\n\t\tmenu\n\t\texit\n\telif [[ \"$TOMENU\" = 'N' ]]; then\n\t\texit\n\tfi\nfi\n\n\t;;\n\nesac\n\n\t;;\n\n\t15) # ==================================================================================================================\n\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho -e \"${GRAY}ปรับความเร็วอินเตอร์เน็ต ${NC} \"\necho \"\"\necho -e \"|${GRAY}1${NC}| เปิดใช้งานการปรับแต่งความเร็วอินเทอร์เน็ต\"\necho -e \"|${GRAY}2${NC}| ปิดใช้งานการปรับแต่งความเร็วอินเทอร์เน็ต\"\necho \"\"\nread -p \"เลือกหัวข้อที่ต้องการใช้งาน : \" LIMITINTERNET\n\ncase $LIMITINTERNET in\n\n\t1)\n\necho \"\"\necho -e \"|${GRAY}1${NC}| Megabyte (Mbps)\"\necho -e \"|${GRAY}2${NC}| Kilobyte (Kbps)\"\necho \"\"\nread -p \"กรุณาเลือกหน่วยวัดความเร็วอินเทอร์เน็ต : \" -e PERSECOND\ncase $PERSECOND in\n\t1)\n\tPERSECOND=mbit\n\t;;\n\t2)\n\tPERSECOND=kbit\n\t;;\nesac\n\necho \"\"\necho \"\"\necho -e \"วิธีการใส่ : เช่นต้องการให้มีความเร็ว 10Mbps ให้ใส่เลข ${GRAY}10${NC}\"\necho -e \" หากต้องการให้มีความเร็ว 512Kbps ให้ใส่เลข ${GRAY}512${NC}\"\necho \"\"\nread -p \"ใส่จำนวนความเร็วการดาวน์โหลด : \" -e CHDL\nread -p \"ใส่จำนวนความเร็วการอัพโหลด : \" -e CHUL\n\nDNLD=$CHDL$PERSECOND\nUPLD=$CHUL$PERSECOND\n\nTC=/sbin/tc\n\nIF=\"$(ip ro | awk '$1 == \"default\" { print $5 }')\"\nIP=\"$(ip -o ro get $(ip ro | awk '$1 == \"default\" { print $3 }') | awk '{print $5}')/32\" # Host IP\n\nU32=\"$TC filter add dev $IF protocol ip parent 1: prio 1 u32\"\n\n $TC qdisc add dev $IF root handle 1: htb default 30\n $TC class add dev $IF parent 1: classid 1:1 htb rate $DNLD\n $TC class add dev $IF parent 1: classid 1:2 htb rate $UPLD\n $U32 match ip dst $IP flowid 1:1\n $U32 match ip src $IP flowid 1:2\n echo \"\"\n echo -e \"ความเร็วดาวน์โหลด ${GRAY}$CHDL $PERSECOND${NC}\"\n echo -e \"ความเร็วอัพโหลด ${GRAY}$CHUL $PERSECOND${NC}\"\n echo \"\"\n echo \"เปิดใช้งานการปรับแต่งความเร็วอินเทอร์เน็ต\"\n echo \"\"\n exit\n\n\t;;\n\n\t2)\n\nTC=/sbin/tc\nIF=\"$(ip ro | awk '$1 == \"default\" { print $5 }')\"\n\n $TC qdisc del dev $IF root\n echo \"\"\n echo \"ปิดใช้งานการปรับแต่งความเร็วอินเทอร์เน็ต\"\n echo \"\"\n exit\n\n\t;;\n\nesac\n\n\t;;\n\n\t16) # ==================================================================================================================\n\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho -e \"เปิด-ปิด-รีสตาร์ท การทำงานของระบบ ${GRAY}MyGatherBK-VPN${NC}\"\necho \"\"\necho -e \"|${GRAY}1${NC}| OPENVPN\"\necho -e \"|${GRAY}2${NC}| SSH DROPBEAR\"\necho -e \"|${GRAY}3${NC}| SQUID PROXY\"\necho \"\"\nread -p \"เลือกหัวข้อที่ต้องการใช้งาน : \" SERVICE\n\ncase $SERVICE in\n\n\t1)\n\n\techo \"\"\n\techo -e \"\t|${GRAY}1${NC}| เปิด\"\n\techo -e \"\t|${GRAY}2${NC}| ปิด\"\n\techo -e \"\t|${GRAY}3${NC}| รีสตาร์ท\"\n\techo \"\"\n\tread -p \"\tเลือกหัวข้อที่ต้องการใช้งาน : \" SERVICEOPENVPN\n\n\tcase $SERVICEOPENVPN in\n\n\t\t1)\n\tservice openvpn start\n\techo \"\"\n\techo -e \"\tOpenVPN ${GRAY}STARTED${NC}\"\n\techo \"\"\n\texit\n\t\t;;\n\n\t\t2)\n\tservice openvpn stop\n\techo \"\"\n\techo -e \"\tOpenVPN ${GRAY}STOPPED${NC}\"\n\techo \"\"\n\texit\n\t\t;;\n\n\t\t3)\n\tservice openvpn restart\n\techo \"\"\n\techo -e \"\tOpenVPN ${GRAY}RESTARTED${NC}\"\n\techo \"\"\n\texit\n\t\t;;\n\n\tesac\n\n\t;;\n\n\t2)\n\n\techo \"\"\n\techo -e \"\t|${GRAY}1${NC}| เปิด\"\n\techo -e \"\t|${GRAY}2${NC}| ปิด ${GRAY}หากปิดการทำงานจะไม่สามารถเข้าสู่เทอมินอลได้ ${NC} \"\n\techo -e \"\t|${GRAY}3${NC}| รีสตาร์ท\"\n\techo \"\"\n\tread -p \"\tเลือกหัวข้อที่ต้องการใช้งาน : \" SERVICEDROPBEAR\n\n\tcase $SERVICEDROPBEAR in\n\n\t\t1)\n\n\tif [[ -e /etc/default/dropbear ]]; then\n\t\tservice ssh start\n\t\techo \"\"\n\t\techo -e \"\tSSH Dropbear ${GRAY}STARTED${NC}\"\n\t\techo \"\"\n\t\texit\n\telif [[ ! -e /etc/default/dropbear ]]; then\n\t\techo \"\"\n\t\techo \"\tยังไม่ได้ติดตั้ง SSH Dropbear\"\n\t\techo \"\"\n\t\texit\n\tfi\n\t\t;;\n\n\t\t2)\n\tif [[ -e /etc/default/dropbear ]]; then\n\t\tservice ssh stop\n\t\techo \"\"\n\t\techo -e \"\tSSH Dropbear ${GRAY}STOPPED${NC}\"\n\t\techo \"\"\n\t\texit\n\telif [[ ! -e /etc/default/dropbear ]]; then\n\t\techo \"\"\n\t\techo \"\tยังไม่ได้ติดตั้ง SSH Dropbear\"\n\t\techo \"\"\n\t\texit\n\tfi\n\t\t;;\n\n\t\t3)\n\tif [[ -e /etc/default/dropbear ]]; then\n\t\tservice ssh restart\n\t\techo \"\"\n\t\techo -e \"\tSSH Dropbear ${GRAY}RESTARTED${NC}\"\n\t\techo \"\"\n\t\texit\n\telif [[ ! -e /etc/default/dropbear ]]; then\n\t\techo \"\"\n\t\techo \"\tยังไม่ได้ติดตั้ง SSH Dropbear\"\n\t\techo \"\"\n\t\texit\n\tfi\n\t\t;;\n\n\tesac\n\n\t;;\n\n\t3)\n\n\techo \"\"\n\techo -e \"\t|${GRAY}1${NC}| เปิด\"\n\techo -e \"\t|${GRAY}2${NC}| ปิด\"\n\techo -e \"\t|${GRAY}3${NC}| รีสตาร์ท\"\n\techo \"\"\n\tread -p \"\tเลือกหัวข้อที่ต้องการใช้งาน : \" SERVICEPROXY\n\n\tcase $SERVICEPROXY in\n\n\t\t1)\n\tif [[ \"$VERSION_ID\" = 'VERSION_ID=\"9\"' || \"$VERSION_ID\" = 'VERSION_ID=\"16.04\"' || \"$VERSION_ID\" = 'VERSION_ID=\"17.04\"' ]]; then\n\t\tif [[ ! -e /etc/squid/squid.conf ]]; then\n\t\t\techo \"\"\n\t\t\techo \"\tยังไม่ได้ติดตั้ง Squid Proxy\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\tservice squid start\n\t\t\techo \"\"\n\t\t\techo -e \"\tSquid Proxy ${GRAY}STARTED${NC}\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\telif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' || \"$VERSION_ID\" = 'VERSION_ID=\"8\"' || \"$VERSION_ID\" = 'VERSION_ID=\"14.04\"' ]]; then\n\t\tif [[ ! -e /etc/squid3/squid.conf ]]; then\n\t\t\techo \"\"\n\t\t\techo \"\tยังไม่ได้ติดตั้ง Squid Proxy\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\tservice squid3 start\n\t\t\techo \"\"\n\t\t\techo -e \"\tSquid Proxy ${GRAY}STARTED${NC}\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\tfi\n\t\t;;\n\n\t\t2)\n\tif [[ \"$VERSION_ID\" = 'VERSION_ID=\"9\"' || \"$VERSION_ID\" = 'VERSION_ID=\"16.04\"' || \"$VERSION_ID\" = 'VERSION_ID=\"17.04\"' ]]; then\n\t\tif [[ ! -e /etc/squid/squid.conf ]]; then\n\t\t\techo \"\"\n\t\t\techo \"\tยังไม่ได้ติดตั้ง Squid Proxy\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\tservice squid stop\n\t\t\techo \"\"\n\t\t\techo -e \"\tSquid Proxy ${GRAY}STOPPED${NC}\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\telif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' || \"$VERSION_ID\" = 'VERSION_ID=\"8\"' || \"$VERSION_ID\" = 'VERSION_ID=\"14.04\"' ]]; then\n\t\tif [[ ! -e /etc/squid3/squid.conf ]]; then\n\t\t\techo \"\"\n\t\t\techo \"\tยังไม่ได้ติดตั้ง Squid Proxy\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\tservice squid3 stop\n\t\t\techo \"\"\n\t\t\techo -e \"\tSquid Proxy ${GRAY}STOPPED${NC}\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\tfi\n\t\t;;\n\n\t\t3)\n\tif [[ \"$VERSION_ID\" = 'VERSION_ID=\"9\"' || \"$VERSION_ID\" = 'VERSION_ID=\"16.04\"' || \"$VERSION_ID\" = 'VERSION_ID=\"17.04\"' ]]; then\n\t\tif [[ ! -e /etc/squid/squid.conf ]]; then\n\t\t\techo \"\"\n\t\t\techo \"\tยังไม่ได้ติดตั้ง Squid Proxy\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\tservice squid restart\n\t\t\techo \"\"\n\t\t\techo -e \"\tSquid Proxy ${GRAY}RESTARTED${NC}\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\telif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' || \"$VERSION_ID\" = 'VERSION_ID=\"8\"' || \"$VERSION_ID\" = 'VERSION_ID=\"14.04\"' ]]; then\n\t\tif [[ ! -e /etc/squid3/squid.conf ]]; then\n\t\t\techo \"\"\n\t\t\techo \"\tยังไม่ได้ติดตั้ง Squid Proxy\"\n\t\t\techo \"\"\n\t\t\texit\n\t\telse\n\t\t\tservice squid3 restart\n\t\t\techo \"\"\n\t\t\techo -e \"\tSquid Proxy ${GRAY}RESTARTED${NC}\"\n\t\t\techo \"\"\n\t\t\texit\n\t\tfi\n\tfi\n\t\t;;\n\n\tesac\n\n\t;;\n\nesac\n\n\t;;\n\n\t17) # ==================================================================================================================\n\n\tclear\necho \"\"\necho \"~¤~ ๏[-ิ_•ิ]๏ ~¤~ Admin MyGatherBK ~¤~ ๏[-ิ_•ิ]๏ ~¤~\"\necho \"\"\n echo \"#BY FB : Pirakit Khawpleum\"\n echo \"#Donate : TrueWallet : 096-746-2978\"\n echo \"\"\necho -e \"แก้ไขคอนฟิกต่างๆในระบบ ${GRAY}MyGatherBK-VPN${NC}\"\necho \"\"\necho -e \"|${GRAY}1${NC}| OPENVPN ไฟล์ต้นแบบการสร้างคอนฟิก\"\necho -e \"|${GRAY}2${NC}| OPENVPN ไฟล์ข้อมูลเซิฟเวอร์\"\necho -e \"|${GRAY}3${NC}| SQUID PROXY ไฟล์รายละเอียดของพร็อกซี่\"\necho -e \"|${GRAY}4${NC}| MENU ไฟล์สคริปท์ของเมนู\"\necho \"\"\necho \"\"\nread -p \"เลือกหัวข้อที่ต้องการใช้งาน : \" EDIT\n\ncase $EDIT in\n\n\t1)\nnano /etc/openvpn/client-common.txt\nexit\n\t;;\n\t2)\nnano /etc/openvpn/server.conf\nexit\n\t;;\n\t3)\nif [[ \"$VERSION_ID\" = 'VERSION_ID=\"9\"' || \"$VERSION_ID\" = 'VERSION_ID=\"16.04\"' || \"$VERSION_ID\" = 'VERSION_ID=\"17.04\"' ]]; then\n\tnano /etc/squid/squid.conf\n\texit\nelif [[ \"$VERSION_ID\" = 'VERSION_ID=\"7\"' || \"$VERSION_ID\" = 'VERSION_ID=\"8\"' || \"$VERSION_ID\" = 'VERSION_ID=\"14.04\"' ]]; then\n\tnano /etc/squid3/squid.conf\n\texit\nfi\n\t;;\n\t4)\nnano /usr/local/bin/menu\nexit\n\t;;\n\nesac\n\n\t;;\n\n\t0) # ==================================================================================================================\n\nrm -f /usr/local/bin/menu\nwget -O /usr/local/bin/menu \"https://raw.githubusercontent.com/MyGatherBk/PURE/master/Menu\"\nchmod +x /usr/local/bin/menu\nrm -f /usr/local/bin/Auto-Delete-Client \nwget -O /usr/local/bin/Auto-Delete-Client \"https://raw.githubusercontent.com/MyGatherBk/PURE/master/Auto-Delete-Client\"\nchmod +x /usr/local/bin/Auto-Delete-Client\nmenu\n\n\t;;\n\n\t00) # ==================================================================================================================\n\nif [[ -e /usr/local/bin/Check-Thai ]]; then\n\trm -f /usr/local/bin/Check-Thai\n\tmenu\nelif [[ ! -e /usr/local/bin/Check-Thai ]]; then\n\techo \"Check Thai\" >> /usr/local/bin/Check-Thai\n\tmenu\nfi\n\n\t;;\n\nesac\n"
}
] | 6 |
lu-mac-admins/lumi-firefox-cck-customized
|
https://github.com/lu-mac-admins/lumi-firefox-cck-customized
|
913ae4452387d7090a97c0b3ac234d802723b7d6
|
106685f970e13c4d07105be67fd24ea62b534245
|
f490eea1c416471ecb7f2d1eb876816a75b3d659
|
refs/heads/master
| 2016-08-03T14:31:26.685900 | 2016-01-05T14:04:55 | 2016-01-05T14:04:55 | 24,060,199 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6539968848228455,
"alphanum_fraction": 0.6583071947097778,
"avg_line_length": 41.53333282470703,
"blob_id": "e753aa2614f4f34d944b9c4aa67533323ba7c4d7",
"content_id": "e6bdcaa35cbf5ee1ad341f0cd58ba648b8a7a215",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2552,
"license_type": "no_license",
"max_line_length": 537,
"num_lines": 60,
"path": "/Makefile",
"repo_name": "lu-mac-admins/lumi-firefox-cck-customized",
"src_encoding": "UTF-8",
"text": "USE_PKGBUILD=1\ninclude\t/usr/local/share/luggage/luggage.make\n\n.PHONY: get-latest prep-dmg customize-% cleanup munkiimport\n\nTITLE=firefox-customized\nREVERSE_DOMAIN=edu.lehigh.wilbur\nSIGNING_KEY=Developer ID Installer: First Last (XXXXXXXXXX)\n\nAPP=Firefox.app\nAUTOCONFIG=autoconfig.zip\n\nMUNKI_SUBDIR=apps/${TITLE}\n\nPAYLOAD=\\\n\tdownload-autoconfigzip \\\n\tprep-dmg \\\n\tpack-applications-${APP} \\\n\tcustomize-${APP} \n\ndownload-autoconfigzip: \n\tcurl -Lf -O https://github.com/lu-mac-admins/firefox-cck2/raw/master/LehighUniversityPSMacs/autoconfig.zip\n\t\nget-latest:\n\t$(eval DMG := $(shell ./get_latest_firefox.sh))\n\t@echo \"${@}: DMG = '$(DMG)'\"\n\t\n$(APP): get-latest\n\nprep-dmg: $(APP)\nifeq (,$(wildcard \"${DMG}\"))\n\t$(eval DMG_MNTPT := $(shell mktemp -d /tmp/firefox.XXXX))\n\thdiutil attach -quiet -readonly -nobrowse -mountpoint $(DMG_MNTPT) \"$(DMG)\"\n\tditto --noqtn -v $(DMG_MNTPT)/${APP} ${APP}\n\thdiutil detach $(DMG_MNTPT)\n\trmdir $(DMG_MNTPT)\nelse\n\t@echo \"*** Could not locate downloaded DMG file. ??? ***\"\nendif\n\ncustomize-%: %\n\t#sudo mv -v \"${WORK_D}/Applications/${<}/Contents/MacOS/defaults/pref\" \"${WORK_D}/Applications/${<}/Contents/MacOS/defaults/preferences\"\n\tsudo unzip ${AUTOCONFIG} -d \"${WORK_D}/Applications/${<}/Contents/Resources/\"\n\ncleanup: clean\n\trm -fr ./Firefox.app\n\trm -f Firefox*.dmg autoconfig.zip ${TITLE}-*{,signed-}*.{pkg,plist} \n\trm -f SHA512SUMS* KEY\n\nsign_pkg: pkg\n\t/usr/bin/productsign --sign \"${SIGNING_KEY}\" ${TITLE}-${PACKAGE_VERSION}.pkg ${TITLE}-signed-${PACKAGE_VERSION}.pkg\n\nmunkiimport: sign_pkg\n\t/usr/local/munki/makepkginfo ${TITLE}-signed-${PACKAGE_VERSION}.pkg -f \"${APP}\" --name=\"Firefox\" --displayname=\"${TITLE}-${PACKAGE_VERSION}\" --minimum-os-version=\"10.6\" --unattended_install -b \"${APP}\" | xml ed --net -u \"//key[text()='installs']/following-sibling::array[1]/dict/key[text()='path']/following-sibling::string[1]\" -x \"concat('/Applications/',text())\" -u \"/plist/dict/key[text()='installer_item_location']/following-sibling::string[1]\" -x \"concat('${MUNKI_SUBDIR}/',text())\" | tee \"${TITLE}-signed-${PACKAGE_VERSION}.plist\"\n\t$(eval MUNKI_REPO_PATH := $(shell /usr/bin/defaults read com.googlecode.munki.munkiimport repo_path))\n\tcp -v \"${TITLE}-signed-${PACKAGE_VERSION}.plist\" \"${MUNKI_REPO_PATH}/pkgsinfo/${MUNKI_SUBDIR}/\"\n\tcp -v \"${TITLE}-signed-${PACKAGE_VERSION}.pkg\" \"${MUNKI_REPO_PATH}/pkgs/${MUNKI_SUBDIR}/\"\n\t@echo \"*********************************************************\"\n\t@echo \"*** Do not forget to run munki's makecatalogs command ***\"\n\t@echo \"*********************************************************\"\n"
},
{
"alpha_fraction": 0.560291051864624,
"alphanum_fraction": 0.5764033198356628,
"avg_line_length": 26.884057998657227,
"blob_id": "addf2600db57c554686577c341cec631d403cb96",
"content_id": "162ab13d71dce6bca7fe8ed3e8e98ccde5f16139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1926,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 69,
"path": "/download_latest_ff.py",
"repo_name": "lu-mac-admins/lumi-firefox-cck-customized",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport requests\nimport hashlib\nimport pyprind\nimport regex\n\nBASE_URL_STUB = 'https://ftp.mozilla.org/pub/firefox/releases/latest'\nPGP_KEY = '{s}/KEY'.format(s=BASE_URL_STUB)\nSHA512SUMS = '{s}/SHA512SUMS'.format(s=BASE_URL_STUB)\nSHA512SUMS_ASC = '{u}.asc'.format(u=SHA512SUMS)\nLOCALE = \"en-US\"\nDMG_RGX = regex.compile(\n '^([A-Za-z0-9]{128})\\s+(mac/{locale}/Firefox\\s*[\\d\\.]*\\.dmg$')\n\n\ndef verify_pgp_signature_for_file(f):\n pass\n\ndef verify_digest_for_downloaded_installer_file(dgst, f):\n\ndef grep_for_mac_dmg_for_locale():\n pass\n\n\ndef # download_file(url):\n try:\n response = requests.get(url, stream=True)\n assert response.ok\n total_length = response.headers.get('content-length')\n assert 0 < int(total_length)\n except AssertionError as ae:\n print(ae)\n return None\n\n file_name = response.request.path_url.split('/')[-1]\n try:\n with open(file_name, \"xb\") as f:\n if total_length is None:\n f.write(response.content)\n else:\n dl = 0\n total_length = int(total_length)\n bar = pyprind.ProgBar(\n total_length, bar_char='█', title=file_name)\n for data in response.iter_content():\n dl += len(data)\n bar.update()\n f.write(data)\n print(\"\")\n except FileExistsError:\n print(\n \"File '{f}' already exists. Will not overwrite.\".format(f=file_name))\n except FileNotFoundError:\n print(\n \"File '{f}' does not exist (or is a bad/empty filename).\".format(f=file_name))\n\n\ndef main():\n # download_file(SHA512SUMS)\n # download_file(SHA512SUMS_ASC)\n # download_file(PGP_KEY)\n # download_file('{s}/mac/en-US/Firefox 39.0.dmg'.format(s=BASE_URL_STUB))\n pass\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5285171270370483,
"alphanum_fraction": 0.5373890995979309,
"avg_line_length": 31.875,
"blob_id": "89977130f422370d927f6b8ac5d902e736c07ae1",
"content_id": "d5d2d8f544a596bf67db4e957c47004dd7faf783",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 789,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 24,
"path": "/get_latest_firefox.sh",
"repo_name": "lu-mac-admins/lumi-firefox-cck-customized",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nPATH=/usr/local/bin:/usr/bin\n\nset -e\n\n#URL=\"https://ftp.mozilla.org/pub/firefox/releases/latest/mac/en-US\"\nOS=\"osx\"\nLANG=\"en-US\"\nURL=\"https://download.mozilla.org/?product=firefox-latest&os=${OS}&lang=${LANG}\"\nDMG=\"Firefox.dmg\"\n\n#echo \">>> Lookup up latest version's filename ... \" 1>&2\n#file=\"$(curl -s -l https://ftp.mozilla.org/pub/firefox/releases/latest/mac/en-US/ | egrep -o '(?:\")Firefox[^\"]+\\.dmg(?:\")' | tr -d '\"')\"\n#href=\"$(curl -s -l \"${URL}/\" | egrep -o '(?: *)href=\"[^\"]*[Ff]irefox[^\"]+\\.dmg\"' | sed -e 's/^ *href=\"//' -e 's/\" *$//' | tail -n 1)\"\n#file=\"$(basename \"${href}\")\"\n#echo \" '${file}'\" 1>&2\n\n#if [[ -n \"${file}\" ]]; then\n echo \">>> Downloading ${URL} ...\" 1>&2\n #curl -LO \"${URL}/${file}\"\n curl -L -o \"${DMG}\" \"${URL}\"\n echo \"${DMG}\"\n#fi\n"
},
{
"alpha_fraction": 0.7954545617103577,
"alphanum_fraction": 0.7954545617103577,
"avg_line_length": 72.33333587646484,
"blob_id": "6230b4ae3826a710bf4e8d9f902bf70c0226781e",
"content_id": "0b37346576e052cec8c36a59a8ebc294f2ccde7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 220,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 3,
"path": "/README.md",
"repo_name": "lu-mac-admins/lumi-firefox-cck-customized",
"src_encoding": "UTF-8",
"text": "Need to change how this is done, as it only really supports one lab, not easy to deploy\n\"versions\" to different sites with different configuration needs. (End up with multiple\nmunki pkginfo files and payloads per site.)\n"
}
] | 4 |
jamessorsona/learning-machine-learning
|
https://github.com/jamessorsona/learning-machine-learning
|
efaf1beb7c266f907ff75c9b81648b549fb5a1e2
|
0b3168403471e4bfaa2bbcb66aae405bd21640f8
|
05e9ce8eaf075edd9105e7316d52b6368a486e31
|
refs/heads/main
| 2023-06-27T22:00:09.464322 | 2021-07-30T11:48:28 | 2021-07-30T11:48:28 | 353,000,743 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7775423526763916,
"alphanum_fraction": 0.7888417840003967,
"avg_line_length": 31.18181800842285,
"blob_id": "2d05b453186302f92b4916eb70cce23f1cb1acf9",
"content_id": "b8749ee6dd8ee01c136d47a10dc14766fad16d4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1416,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 44,
"path": "/a0.py",
"repo_name": "jamessorsona/learning-machine-learning",
"src_encoding": "UTF-8",
"text": "# Author: James Carlo Sorsona\n\n\"\"\" Machine Learning Tutorial\nWebsite: https://machinelearningmastery.com/machine-learning-in-python-step-by-step/ \"\"\"\n\n# 2.1 Load libraries\nfrom pandas import read_csv\nfrom pandas.plotting import scatter_matrix\nfrom matplotlib import pyplot\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.model_selection import StratifiedKFold\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.svm import SVC\n\n\n# 2.2 Load dataset\nurl = \"https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv\"\nnames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']\ndataset = read_csv(url, names=names)\n# print(dataset)\n\n\n# # 3.1 Dimenstions of the dataset\n# print(dataset.shape)\n\n# # 3.2 Peeking at the data\n# print(dataset.head(20))\n\n# # 3.3 Statistical Summary\n# print(dataset.describe())\n\n# # 3.4 Class Distribution\n# print(dataset.groupby('class').size())\n\ndataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)\npyplot.show()\n"
},
{
"alpha_fraction": 0.8484848737716675,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 32,
"blob_id": "39402f79ae4da15c8ce91e022c39c364e99b71f7",
"content_id": "ddb8061bae52e606b851bf1bff536607989d765e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 2,
"path": "/README.md",
"repo_name": "jamessorsona/learning-machine-learning",
"src_encoding": "UTF-8",
"text": "# learning-machine-learning\nLearning machine learning with Python\n"
}
] | 2 |
inkytonik/skink-dashboard
|
https://github.com/inkytonik/skink-dashboard
|
15fb5085389e78762982f218f9d8139e877dbfa2
|
fe74ea9b1e888e81e4952f75a3fd5196f922824c
|
e4325b445ac6f3681aa2a34dc456334ad02dbe33
|
refs/heads/master
| 2022-10-23T07:25:11.657352 | 2017-11-18T08:04:50 | 2017-11-18T08:04:50 | 272,110,762 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7257601618766785,
"alphanum_fraction": 0.7446930408477783,
"avg_line_length": 33.86000061035156,
"blob_id": "87ca28aeec31e22a69a50649098f1e78aa1d4b4b",
"content_id": "01831d3fd5163f54fe3b5b58d093f9cd7991cc8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1743,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 50,
"path": "/README.md",
"repo_name": "inkytonik/skink-dashboard",
"src_encoding": "UTF-8",
"text": "#### Running grafana using docker\n\n ./grafana\n\n http://localhost:80 Grafana web interface\n http://localhost:81 Graphite web interface\n\n Grafana username: admin\n Grafana password: admin\n\n#### Generating data\n\nUse Skink bench setup to conduct a run. You should get a 'results-verified'\ndirectory containing a CSV file such as\n\n skink.2017-09-19_0356.results.sv-comp17.Test.xml.bz2.merged.csv\n\n#### Converting data to Graphite triples\n\n csvtodata <CSV file>\n\n#### Importing data to your local instance of Grafana\n\n csvtodata <CSV file> | import localhost\n\n#### Archived data\n\nAs we generate useful data sets we will commit them to this repository in the `data` directory.\nThus, we can recreate the dashboards from scratch if we need to, or you can create a local instance with all of the same data.\n\n#### Viewing data\n\n* Create a new dashboard in Grafana via drop-down menu near top-left corner.\n* Click on title of dashboard and select edit.\n* In metrics tab, select metric such as `skink.*.*.*.*.result`.\n* In display tab, specify display style. Points style is good for checking the data.\n* Select \"Back to dashboard\" in top tool bar.\n\n#### Matt's server\n\nMatt is running a Grafana instance at MQ internal address 10.46.35.0.\nWe are importing data to that instance when we have it.\n\n csvtodata <CSV file> | import 10.46.35.0\n\n#### Dashboard definitions\n\nGrafana can export dashboard definitions as JSON.\nWe will be putting useful ones in the dashboards folder of this repository so you can import them into your Grafana instances if you want.\nFor example, `dashboards/ReachSafety-Loops.json` contains a dashboard that can be used to visualise the data for the ReachSafety-Loops category of the SV-COMP.\n"
},
{
"alpha_fraction": 0.5381916761398315,
"alphanum_fraction": 0.5727953910827637,
"avg_line_length": 35.45930099487305,
"blob_id": "3bb0764d2d566536b92df712298c34539e76135e",
"content_id": "821c2f1e58b3d62196f564341ef511803e4ab3ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6271,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 172,
"path": "/csvtodata",
"repo_name": "inkytonik/skink-dashboard",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python3\n# csvtodata skink.2017-09-19_0356.results.sv-comp17.Test.xml.bz2.merged.csv ...\n# Convert a CSV from a merged benchexec run into data that can be imported\n# into Graphite.\n#\n# Filename must be in shown format so that time of run and run set name can be extracted.\n#\n# Expected CSV input format:\n# tool\t...\n# run set\t...\n# /sv-benchmarks/c/loops/\tstatus\tcputime (s)\twalltime (s)\tmemUsage\twit1_status\twit1_cputime (s)\twit1_walltime (s)\twit1_memUsage\twit2_status\twit2_cputime (s)\twit2_walltime (s)\twit2_memUsage\n# array_false-unreach-call_true-termination.i\tfalse(unreach-call)\t7.92938506\t9.296900265006116\t168075264\tfalse(unreach-call)\t3.991594749\t4.071597172995098\t98922496\n# <and more data lines>\n#\n# Update: sometime around November 2017, benchexec changed and the columns are now in a slightly different order:\n# /sv-benchmarks/c/\tstatus\tcputime (s)\twalltime (s)\tmemUsage\twit1_cputime (s)\twit1_memUsage\twit1_status\twit1_walltime (s)\twit2_cputime (s)\twit2_memUsage\twit2_status\twit2_walltime (s)\n# The script uses the header line to decide which of these two formats is being used.\n#\n# It is also possible to work with\n# /sv-benchmarks/c/ ...\n# loops/array_false-unreach-call_true-termination.i ...\n#\n# Uses the base key path: skink.svcomp.c.<set>.loops.<base file name> such as\n# skink.svcomp.c.Test.loops.array_false-unreach-call_true-termination\n# with data:\n# .result -1 (wrong) 0 (unknown) 1 (right)\n# .score points scored for this file based on SV-COMP 2018 scoring system\n# .witness -1 (wrong) 0 (unknown) 1 (right)\n# .cputime CPU time for the tool run (seconds)\n# .walltime wall clock time (seconds)\n# .memusage memory usage\n\nimport csv\nimport datetime\nimport getopt\nfrom pathlib import Path\nimport re\nimport sys\n\n# Main program\n\ndef main():\n try:\n opts, args = getopt.getopt(sys.argv[1:], 'h', ['help'])\n except getopt.GetoptError as err:\n montolib.error(err)\n usage()\n sys.exit(2)\n for o, a in opts:\n if o in ('-h', '--help'):\n usage()\n sys.exit()\n else:\n assert False, 'unhandled option'\n numargs = len(args)\n if numargs == 0:\n usage()\n else:\n for arg in args:\n process(arg)\n\ndef usage():\n print('usage: csvtodata file.csv...')\n\ndef process(filename):\n with open(filename, newline='') as csvfile:\n reader = csv.reader(csvfile, delimiter='\\t')\n basekey = 'dummy'\n format = 'new'\n for row in reader:\n if row[0] != 'tool' and row[0] != 'run set':\n if row[0].startswith('/'):\n basekey = 'skink.svcomp.c'\n dirparts = Path(row[0]).parts[3:]\n runset = getRunset(filename)\n basekey = basekey + '.' + runset\n if dirparts != ():\n basekey = basekey + '.' + '.'.join(dirparts)\n if row[5] == 'wit1_status':\n format = \"old\"\n else:\n key = basekey\n path = Path(row[0])\n testfilepath = path.parent\n if testfilepath.parts != ():\n key = key + '.' + '.'.join(testfilepath.parts)\n testfilebase = path.stem.replace('.','_')\n filekey = key + '.' + testfilebase\n timestamp = getTimestamp(filename)\n (toolok, score, witok) = getResults(testfilebase, row, format)\n printVal(filekey, 'result', str(toolok), timestamp)\n printVal(filekey, 'score', str(score), timestamp)\n printVal(filekey, 'witness', str(witok), timestamp)\n printVal(filekey, 'cputime', row[2], timestamp)\n printVal(filekey, 'walltime', row[3], timestamp)\n printVal(filekey, 'memusage', row[4], timestamp)\n\ndef printVal(filekey, field, value, timestamp):\n print(filekey + '.' + field + ' ' + value + ' ' + timestamp)\n\n# getScores\n# Returns (prog ok, score, witness ok)\n\ndef getResults(filename, row, format):\n toolResult = row[1]\n if format == 'old':\n violWitResult = row[5]\n corrWitResult = row[9]\n else:\n violWitResult = row[7]\n corrWitResult = row[11]\n isCorrect = 'true-unreach-call' in filename\n if toolResult == 'false(unreach-call)':\n if isCorrect:\n return (-1, -16, 0)\n else:\n if violWitResult == 'false(unreach-call)':\n return (1, 1, 1)\n else:\n return (1, 0, -1)\n elif toolResult == 'true':\n if isCorrect:\n if corrWitResult == 'true':\n return (1, 2, 1)\n else:\n return (1, 1, -1)\n else:\n return (-1, -32, 0)\n else:\n return (0, 0, 0)\n\n# getRunset\n# Return run set name for this benchexec run\n# Filename has this format:\n# skink.2017-09-19_0356.results.sv-comp17.Test.xml.bz2.merged.csv\n# Run set:\n# Test\n\ndef getRunset(filename):\n parts = filename.split('.')\n if '-' in parts[4]:\n parts = parts[4].split('-')\n return parts[0] + '.' + parts[1]\n else:\n return parts[4]\n\n# getTimestamp\n# Return timestamp for this benchexec run\n# Filename has this format:\n# skink.2017-09-19_0356.results.sv-comp17.Test.xml.bz2.merged.csv\n# Time section of filename is printed by benchexec using:\n# time.strftime(\"%Y-%m-%d_%H%M\", time.localtime())\n\ndef getTimestamp(filename):\n parts = filename.split('.')\n match = re.match('([0-9]{4})-([0-9]{2})-([0-9]{2})_([0-9]{2})([0-9]{2})', parts[1])\n if match:\n year = int(match.group(1))\n month = int(match.group(2))\n day = int(match.group(3))\n hour = int(match.group(4))\n minute = int(match.group(5))\n dt = datetime.datetime(year, month, day, hour, minute, tzinfo = datetime.timezone.utc)\n return str(int(dt.timestamp()))\n else:\n print('csvtodata: CSV filename is not in standard benchexec format skink.<date time>.results.sv-comp17.<set>.xml.bz2.merged.csv')\n exit(1)\n\n# Startup\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 11,
"blob_id": "5a5e8521483b61d661db33d908a0b7498a569b61",
"content_id": "317fb78b95d8dff07593f7e6db51aa9f6358d931",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 2,
"path": "/import",
"repo_name": "inkytonik/skink-dashboard",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nnc -c $1 2003\n"
},
{
"alpha_fraction": 0.45967742800712585,
"alphanum_fraction": 0.7338709831237793,
"avg_line_length": 61,
"blob_id": "1d0cbf09432e75078e2d8b51d481b26f791e1255",
"content_id": "d7a17f6abc59a1c648bb9cc397ce9661d2bfd1ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 2,
"path": "/grafana",
"repo_name": "inkytonik/skink-dashboard",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\ndocker run -p 80:3000 -p 81:81 -p 2003:2003 -p 8125:8125/udp -p 8126:8126 inkytonik/docker-grafana-graphite-skink\n"
}
] | 4 |
BlackFurryy/Logistic_regression
|
https://github.com/BlackFurryy/Logistic_regression
|
f2b13a34932399b5088eb21dd8258e902a93ab86
|
9231ea72b95e61babe5985f6d5f08e203eff684e
|
5f7efeeb8d267221df5cd7c53fea690d39b98313
|
refs/heads/master
| 2020-04-03T07:14:29.096578 | 2018-10-28T17:28:15 | 2018-10-28T17:28:15 | 155,096,754 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6292756795883179,
"alphanum_fraction": 0.6524145007133484,
"avg_line_length": 22.875,
"blob_id": "7dfb86e314a12b1f327ff6a55fb9a3cba39f46fc",
"content_id": "0a1399e2a7693a9e99e06b0135db5567648cc747",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1988,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 80,
"path": "/logistic_microchip.py",
"repo_name": "BlackFurryy/Logistic_regression",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jun 28 06:41:33 2018\r\n\r\n@author: vishawar\r\n\"\"\"\r\n\r\nimport pandas as pd\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\n\r\ndataset = pd.read_excel(\"microchip_QA.xlsx\")\r\n\r\ndataset = dataset.sample(frac=1)\r\n\r\n#from sklearn.utils import shuffle\r\n#dataset = shuffle(dataset)\r\n\r\nX = dataset.iloc[:,:-1].values\r\ny = dataset.iloc[:,2].values\r\n\r\nfrom sklearn.cross_validation import train_test_split\r\nX_train,X_test,y_train,y_test = train_test_split(X,y)\r\n\r\n\r\n#feature scaling - no need\r\n\r\n#fit the model\r\n#from sklearn.linear_model import LogisticRegression\r\n#classifier = LogisticRegression()\r\n\r\nfrom sklearn.svm import SVC\r\n\r\nclassifier = SVC(kernel=\"rbf\")\r\nclassifier.fit(X_train,y_train,)\r\n\r\ny_predict = classifier.predict(X_test)\r\n\r\n#calculate sucess percentage\r\nresult = np.mean(y_predict==y_test)*100\r\n\r\nfrom sklearn.metrics import confusion_matrix\r\nconf = np.float64(confusion_matrix(y_test,y_predict))\r\n\r\nprecision = conf[0,0]/(np.sum(conf[0,:]))\r\nrecall = conf[0,0]/(np.sum(conf[:,0]))\r\n\r\nF_score = (2*precision*recall)/(precision+recall)\r\n\r\n\r\n#from matplotlib.pyplot import ListedColormap\r\npos_idx = np.where(y==1)\r\nneg_idx = np.where(y==0)\r\n\r\nplt.scatter(X[pos_idx,0],X[pos_idx,1],marker =\"+\",color=\"blue\")\r\nplt.scatter(X[neg_idx,0],X[neg_idx,1],marker =\"x\",color=\"red\")\r\n\r\n\r\nh = .02 # step size in the mesh\r\n# create a mesh to plot in\r\nx_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1\r\ny_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1\r\nxx, yy = np.meshgrid(np.arange(x_min, x_max, h),\r\n np.arange(y_min, y_max, h))\r\n\r\n\r\n# Plot the decision boundary. For that, we will assign a color to each\r\n# point in the mesh [x_min, m_max]x[y_min, y_max].\r\nZ = classifier.predict(np.c_[xx.ravel(), yy.ravel()])\r\n\r\n# Put the result into a color plot\r\nZ = Z.reshape(xx.shape)\r\nplt.contour(xx, yy, Z, cmap=plt.cm.Paired)\r\n\r\nplt.title(\"SVM \")\r\nplt.xlabel(\"Test1 Score\")\r\nplt.ylabel(\"Test2 Score\")\r\nplt.legend()\r\nplt.show()"
},
{
"alpha_fraction": 0.6449416279792786,
"alphanum_fraction": 0.6639105081558228,
"avg_line_length": 25.810810089111328,
"blob_id": "18d930e120dfdefb235d5be31020001952cfe2b1",
"content_id": "af665449014adb621de97694a743ace0a77f50a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2056,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 74,
"path": "/logistic_regression.py",
"repo_name": "BlackFurryy/Logistic_regression",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jun 26 11:33:11 2018\r\n\r\n@author: vishawar\r\n\"\"\"\r\nimport numpy as np\r\nimport pandas as pd\r\nimport matplotlib.pyplot as plt\r\n\r\n#load data set\r\n\r\ndataset = pd.read_excel(\"university_exam.xlsx\")\r\nX = dataset.iloc[:,:-1].values\r\ny = dataset.iloc[:,2].values\r\n\r\n#separate train & test data\r\n\r\nfrom sklearn.cross_validation import train_test_split\r\nX_train,X_test,y_train,y_test = train_test_split(X,y)\r\n\r\n\r\n#feature scaling \r\n\r\nfrom sklearn.preprocessing import StandardScaler\r\nstd_scaler = StandardScaler()\r\nX_train = std_scaler.fit_transform(X_train)\r\nX_test = std_scaler.transform(X_test)\r\n\r\n#fit a logistic regression model over dataset\r\n\r\nfrom sklearn.linear_model import LogisticRegression\r\nclassifier = LogisticRegression()\r\n\r\n#from sklearn.svm import SVC\r\n#classifier = SVC()\r\n\r\nclassifier.fit(X_train,y_train)\r\n\r\n#predict\r\ny_predict = classifier.predict(X_test)\r\nresult_percentage = np.mean(y_predict==y_test)*100\r\n\r\n#confusion matrix\r\nfrom sklearn.metrics import confusion_matrix\r\nconf_matrix = confusion_matrix(y_test,y_predict)\r\n\r\n#from matplotlib.pyplot import ListedColormap\r\n#pos_idx = np.where(y==1)\r\n#neg_idx = np.where(y==0)\r\n\r\n#plt.scatter(X[pos_idx,0],X[pos_idx,1],marker =\"+\",color=\"blue\")\r\n#plt.scatter(X[neg_idx,0],X[neg_idx,1],marker =\"x\",color=\"red\")\r\n\r\nfrom matplotlib.colors import ListedColormap\r\nh = .02 # step size in the mesh\r\n# create a mesh to plot in\r\nX_set=X_train\r\ny_set = y_train\r\nx_min, x_max = X_set[:, 0].min() - 1, X_set[:, 0].max() + 1\r\ny_min, y_max = X_set[:, 1].min() - 1, X_set[:, 1].max() + 1\r\nxx, yy = np.meshgrid(np.arange(x_min, x_max, h),\r\n np.arange(y_min, y_max, h))\r\n\r\nplt.contourf(xx,yy,classifier.predict(np.array([xx.ravel(),yy.ravel()]).T).reshape(xx.shape),alpha=0.75,cmap=ListedColormap((\"red\",\"green\")))\r\nplt.xlim(xx.min(),xx.max())\r\nplt.ylim(xx.min(),xx.max())\r\n\r\n\r\nfor i,j in enumerate(np.unique(y_set)):\r\n plt.scatter(X_set[y_set == j,0],X_set[y_set == j,1],c= ListedColormap((\"Green\",\"red\"))(i),label =j)\r\n \r\n \r\nplt.legend()"
}
] | 2 |
shyzik93/big_data_collector2
|
https://github.com/shyzik93/big_data_collector2
|
47d8803dad51d0b15f542483c2f31f5f7339d9d6
|
599a8a2b138866bcc548be9ff2e1f5fc70fb1576
|
ff3d0170c55d53dd375c36b1ec4f54c92f9d7398
|
refs/heads/master
| 2020-08-06T20:02:25.237711 | 2019-10-06T07:54:07 | 2019-10-06T07:54:07 | 213,135,090 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6555555462837219,
"alphanum_fraction": 0.6555555462837219,
"avg_line_length": 21.5,
"blob_id": "d0cd7fc78260c6cde571acf2a53eb9dfc2351648",
"content_id": "0e347743d3e0dc9d99346e6a414be745627aaac4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 8,
"path": "/parsers/__init__.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import os, sys\n\n_path = os.path.dirname(__file__)\nsys.path.append(_path)\n\ndef get(module_name, cfg):\n module = __import__(module_name)\n return getattr(module, 'Parser')(cfg)\n"
},
{
"alpha_fraction": 0.5581216216087341,
"alphanum_fraction": 0.5615858435630798,
"avg_line_length": 28.202247619628906,
"blob_id": "01d90393c091fda6adf6f9beef9dda6bce61d733",
"content_id": "522670d866fac07bc3aeb60a7353585d3dc6eae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2689,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 89,
"path": "/pydb/sql_multitable.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "from . import sql_table\n\nclass Multitable:\n\n def __init__(self, db, tables, table_prefix, show_log, uniq_keys):\n self.db = db\n\n self.show_log = show_log\n\n self.tables = {}\n for table in tables:\n _table = sql_table.Table(self.db, table['name'], table['fields'])\n self.tables[table['name']] = _table\n _table.create()\n self.db.commit()\n\n def __getitem__(self, tname):\n return self.tables[tname]\n\n def select(self, tname, keys, where):\n\n where2 = []\n\n #print('orig:', where)\n\n for cond in where:\n fname = cond[0]\n if self.tables[tname].is_field_foreign(fname):\n foreign_table, foreign_field = self.tables[tname].get_foreign_field(fname)\n r = self.tables[foreign_table].select('id', [[foreign_field, '=', cond[2]]])\n _r = r.fetchone()\n if not _r: return r\n #r = r.fetchall()\n where2.append([fname, cond[1], _r[self.tables[foreign_table]['id']]])\n else:\n where2.append(cond)\n\n #print('new:', where2)\n\n return self.tables[tname].select(keys, where2)\n\n def insert(self, tname, fields):\n\n # Заменяем значения на id\n\n for fname, v in fields.items():\n if not self.tables[tname].is_field_foreign(fname): continue\n foreign_table, foreign_field = self.tables[tname].get_foreign_field(fname)\n\n fields[fname] = self.tables[foreign_table].insert({foreign_field:v})\n\n #print(foreign_table, foreign_field, v_id)\n\n # Вставляем строку\n\n return self.tables[tname].insert(fields)\n\n def insert_unique(self, tname, fields, unique_keys=None):\n\n if unique_keys is None:\n unique_keys = fields.keys()\n\n # Заменяем значения на id\n\n for fname, v in fields.items():\n if not self.tables[tname].is_field_foreign(fname): continue\n foreign_table, foreign_field = self.tables[tname].get_foreign_field(fname)\n\n fields[fname] = self.tables[foreign_table].insert({foreign_field:v})\n\n #print(foreign_table, foreign_field, v_id)\n\n # Проверяем наличие дубликата\n\n where = []\n for key in unique_keys:\n where.append([key, '=', fields[key]])\n\n kid = self.tables[tname]['id']\n r = self.tables[tname].select('id', where).fetchall()\n if r: return r[0][kid]\n\n # Вставляем строку\n\n return self.tables[tname].insert(fields)\n\n def commit(self):\n\n self.db.commit()"
},
{
"alpha_fraction": 0.44273504614830017,
"alphanum_fraction": 0.44786325097084045,
"avg_line_length": 21.461538314819336,
"blob_id": "3f2c516198498575e123a20b57d897c8d3ff8cb9",
"content_id": "d0c4380f903f275ea8fe5a11365c28a263ad0da4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 26,
"path": "/init.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import os.path\n\n# указываем пути\n\ncdir = os.path.dirname(__file__)\n\nsets = {\n 'db_table_prefix': 'parser_',\n 'db_dump_to': os.path.join(cdir, 'dump.sql'),\n 'db_type': 'sqlite3',\n 'db_sets': {\n 'sqlite3': {\n 'path': os.path.join(cdir, 'main.db'),\n },\n 'mysql': {\n 'host': '',\n 'name': '',\n 'user': '',\n 'password': '',\n 'port': 0\n }\n },\n 'path_row_data': os.path.join(cdir, 'data_loaded'),\n 'path_export_data': os.path.join(cdir, 'data_export'),\n 'show_log': True,\n}\n\n"
},
{
"alpha_fraction": 0.6206896305084229,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 24.827587127685547,
"blob_id": "d37bb7445bfdc1dab707d1e9a8ba96b2965af35e",
"content_id": "bf10c23430b3a6706910fdb074462aa218c1d261",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 29,
"path": "/configs/tables.ini",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "[url_scheme]\n name = VAR(255) NOT NULL UNIQUE\n[url_domain]\n name = VAR(255) NOT NULL UNIQUE\n[url_title]\n name = VAR(255) NOT NULL UNIQUE\n[url]\n scheme = INTEGER NOT NULL REF(url_scheme.name)\n domain = INTEGER NOT NULL REF(url_domain.name)\n path = VAR(255) NOT NULL\n title = INTEGER NOT NULL REF(url_title.name)\n\n\n[human_fname]\n name = VAR(255) NOT NULL\n[human_sname]\n name = VAR(255) NOT NULL\n[human_tname]\n name = VAR(255)\n[human]\n fname = INTEGER NOT NULL REF(human_fname.name)\n sname = INTEGER NOT NULL REF(human_sname.name)\n tname = INTEGER REF(human_tname.name)\n date_birth = DATETIME\n date_death = DATETIME\n\n[political_party]\n name = VAR(255) NOT NULL UNIQUE\n ogrn = VAR(13) NOT NULL UNIQUE\n \n"
},
{
"alpha_fraction": 0.48152002692222595,
"alphanum_fraction": 0.4844698905944824,
"avg_line_length": 28.865285873413086,
"blob_id": "06ef5cc71477f47526e71b26021022e02a66c283",
"content_id": "581ed7f7af255f4adc5aed6a289366e1cdd9fbc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5874,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 193,
"path": "/pydb/sql_table.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "from . import sqltools\nimport copy\n\nclass Table:\n\n def __init__(self, db, tname, tfields, tname_prefix=''):\n\n self.db = db\n self.sqltools = sqltools.SQLTools(self.db)\n\n self.tname = tname\n self.tname_prefix = tname_prefix\n\n self.name = tname_prefix + tname\n\n #self.tfields = copy.deepcopy(tfields)\n tfields['id'] = 'INTEGER PRIMARY KEY AUTOINCREMENT'\n tfields['is_deleted'] = 'INTEGER NOT NULL DEFAULT \\'0\\' '\n tfields['date_add'] = 'DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP'\n\n self.tfs = {}\n for fname, v in tfields.items():\n tf = {\n 'name': None,\n 'type': None,\n 'notnull': False,\n 'unique': False,\n 'foreign':False,\n 'foreign_table': None,\n 'foreign_field': None,\n 'autoincr': False,\n 'default': None,\n 'primary_key': False,\n }\n\n fmeta = v.lower().split()\n while len(fmeta) != 1:\n e = fmeta.pop()\n\n if e.startswith('ref('):\n foreign_table = e[4:-1].strip()\n #if '.' in foreign_table:\n foreign_table, foreign_field = foreign_table.split('.')\n #else:\n # foreign_field = 'id'\n tf['foreign'] = True\n tf['foreign_table'] = foreign_table\n tf['foreign_field'] = foreign_field # псевдоним\n elif e == 'unique':\n tf['unique'] = True\n elif e == 'null':\n fmeta.pop()\n tf['notnull'] = True\n elif e == 'autoincrement':\n tf['autoincr'] = True\n elif len(fmeta) > 1 and fmeta[-1] == 'default':\n tf['default'] = e\n elif fmeta[-1] == 'primary' and e == 'key':\n fmeta.pop()\n tf['primary_key'] = True\n\n tf['type'] = fmeta.pop()\n\n orig_name = self.tname+'_'+fname\n if tf['foreign']: orig_name += '_id'\n tf['name'] = orig_name\n\n #print(' ', tf)\n\n self.tfs[fname] = tf\n\n self.foreigns = []\n\n def __getitem__(self, fname):\n return self.tfs[fname]['name']\n\n def is_field_foreign(self, fname):\n\n return self.tfs[fname]['foreign']\n\n def is_field_unique(self, fname):\n\n return self.tfs[fname]['unique']\n\n def get_foreign_field(self, fname):\n ''' Только, если мы уверены в наличии внешнего ключа '''\n\n return self.tfs[fname]['foreign_table'], self.tfs[fname]['foreign_field']\n\n def build_field(self, fname):\n\n fmeta = []\n\n if self.tfs[fname]['notnull']:\n fmeta.append('not null')\n if self.tfs[fname]['unique']:\n fmeta.append('unique')\n if self.tfs[fname]['primary_key']:\n fmeta.append('primary key')\n if self.tfs[fname]['autoincr']:\n fmeta.append('autoincrement')\n if self.tfs[fname]['default'] is not None:\n fmeta.append('default '+self.tfs[fname]['default'])\n\n if self.tfs[fname]['foreign']:\n self.foreigns.append(f\"foreign key({self.tfs[fname]['name']}) references {self.tfs[fname]['foreign_table']}({self.tfs[fname]['foreign_table']}_id)\")\n\n fmeta = ' '.join(fmeta)\n\n return f\"`{self.tfs[fname]['name']}` {self.tfs[fname]['type']} {fmeta}\"\n\n def build_create(self):\n\n fields = []\n self.foreigns = []\n\n for fname in self.tfs:\n fields.append(self.build_field(fname))\n\n fields += self.foreigns\n\n fields = ',\\n '.join(fields)\n\n return f\"CREATE TABLE IF NOT EXISTS `{self.name}` (\\n {fields}\\n);\"\n\n def build_drop(self):\n\n return f\"DROP TABLE IF EXISTS `{self.name}`;\"\n\n def create(self):\n\n #print(self.build_create())\n self.db.execute(self.build_create())\n\n def select(self, keys, where):\n\n #print(' ', self.tname, keys, where)\n\n return self.sqltools.select(self.name, keys, where, self)\n\n def insert(self, fields):\n\n if len(fields) == 1:\n\n k, v = [i for i in fields.items()][0]\n\n kid = self.tfs['id']['name']#f'{self.tname}_id'\n if self.is_field_unique(k):\n k = self.tfs[k]['name']#f'{self.tname}_{k}'\n r = self.sqltools.select(self.name, kid, [[k, '=', v]]).fetchall()\n if r: return r[0][kid]\n\n return self.sqltools.insert(self.name, fields, None, self)\n\n def insert2(self, keys, values=None):\n ''' проверка на уникальность работает лишь для одного поля и одного значения '''\n\n if len(keys) == 1:\n\n if values is None:\n k, v = [i for i in keys.items()][0]\n else:\n k, v = (keys[0], values[0][0])\n\n kid = f'{self.tname}_id'\n if self.is_field_unique(k):\n k = f'{self.tname}_{k}'\n r = self.sqltools.select(self.name, kid, [[k, '=', v]]).fetchall()\n if r: return r[0][kid]\n\n '''if values is None:\n for k, v in keys.items():\n if not self.is_field_unique(k): continue\n r = self.sqltools.select(self.name, k, [[k, '=', v]]).fetchall()\n if r:\n '''\n\n '''if add_field_prefix:\n if values is None:\n pass\n else:\n pass\n '''\n\n return self.sqltools.insert(self.name, keys, values, self)\n\n def drop(self):\n\n self.db.execute(self.build_drop())\n\n def commit(self):\n\n self.db.commit()"
},
{
"alpha_fraction": 0.5294374227523804,
"alphanum_fraction": 0.5316179394721985,
"avg_line_length": 29.453332901000977,
"blob_id": "65cbcedb4522d3a4b9ac3dc91e7097c9b98a7f2d",
"content_id": "0525f2ba61250a2f85b9d2ce13b722d7a2195851",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2293,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 75,
"path": "/pyloader/saver_base.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import os.path\nimport os\nimport datetime\nimport urllib.parse\n \nclass SaverSQL():\n\n def __init__(self, mtables, path_to_save):\n\n self.mtables = mtables\n self.path_to_save = path_to_save\n \n def get_timemark(self):\n return datetime.datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")\n\n def exists(self, url):\n\n url = urllib.parse.urlparse(url)\n\n r = self.mtables.select('url', ['id', 'domain'], [\n ['scheme', '=', url.scheme],\n ['domain', '=', url.netloc],\n ['path', '=', url.path + url.query]\n ]).fetchall()\n\n if r:\n return r[0][self.mtables['url']['domain']], r[0][self.mtables['url']['id']]\n return False\n \n def open(self, url_index):\n\n domain_field_id = self.mtables['url_domain']['id']\n domain_index = self.mtables['url'].select('domain', [['id', '=', url_index]]).fetchall()[0][domain_field_id]\n\n path_file = os.path.join(self.path_to_save, str(domain_index), str(url_index))\n with open(path_file, \"r\") as f:\n return f.read()\n \n def save(self, content, url, title, encoding='utf-8'):\n\n # save meta on base\n\n url = urllib.parse.urlparse(url)\n\n fields = {\n 'scheme': url.scheme,\n 'domain': url.netloc,\n 'path': url.path + url.query,\n 'title': title,\n }\n \n max_index = self.mtables.insert_unique('url', fields)\n\n # save file on disk\n\n domain_field_id = self.mtables['url_domain']['id']\n domain_index = self.mtables['url_domain'].select('id', [['name', '=', url.netloc]]).fetchall()[0][domain_field_id]\n \n path_to_save = os.path.join(self.path_to_save, str(domain_index))\n if not os.path.exists(path_to_save):\n os.makedirs(path_to_save)\n path_file = os.path.join(path_to_save, str(max_index))\n\n if isinstance(content, (bytes, bytearray)):\n with open(path_file, 'wb') as f:\n f.write(content)\n elif isinstance(content, str):\n with open(path_file, 'w', encoding=encoding) as f:\n f.write(content)\n\n # commit if file was saved\n \n self.mtables.commit()\n \n return max_index\n\n "
},
{
"alpha_fraction": 0.5210628509521484,
"alphanum_fraction": 0.5294880270957947,
"avg_line_length": 31.82978630065918,
"blob_id": "f772fcd884e84f61f71669efa8c666c5309962be",
"content_id": "5c26e701032abb8a03f5ae11a662ee457e4b86f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1564,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 47,
"path": "/parsers/news_del_yeysk.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import requests\n\nclass Parser:\n\n def __init__(self, cfg):\n self.cfg = cfg\n\n def run(self):\n\n domain = \"http://m.deleysk.ru\"\n ses = requests.Session()\n bad_selectors = ['noscript', 'h4', 'footer', 'nav', 'form', 'script', 'h1', 'head', 'div.stat_box', 'div.social', 'div.comments']\n saver = self.cfg['saver']\n\n r = ses.get(domain)\n index, d = saver.save(r, domain, bad_selectors)\n\n max_count = d.cssselect('.lines_in .block_item a')\n if len(max_count) == 0:\n print('Блок с новостью не найден')\n return\n max_count = int(max_count[0].attrib['href'].split('/')[-1])\n\n start_count = 0\n sql = \"SELECT MAX(CAST(SUBSTR(`url_path`, 7) AS 'INTEGER')) AS start_count FROM `url`, `url_domain` WHERE `url`.`url_domain_id`=`url_domain`.`url_domain_id` AND `url_domain`.`url_domain_name`=?\"\n\n r = self.cfg['db'].execute(sql, (domain.split('/')[-1],)).fetchall()\n if len(r) != 0:\n #print(dict(r[0]))\n start_count = r[0]['start_count']\n if start_count is None: start_count = 0\n\n print(start_count, max_count)\n\n for inew in range(start_count, max_count+1):\n \n url = domain +'/news/'+ str(inew)\n\n indexes = saver.exists(url)\n if indexes: continue\n\n r = ses.get(url, allow_redirects=False)\n if 'Location' in r.headers:\n print('not find:', url)\n continue\n\n saver.save(r, url, bad_selectors)\n"
},
{
"alpha_fraction": 0.6798029541969299,
"alphanum_fraction": 0.6798029541969299,
"avg_line_length": 24.5,
"blob_id": "f574ffa441f37f7253fc29f4c297bd4912420a35",
"content_id": "e3c8b69fe22bb70e7fff5d878d069180bbf8c029",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 8,
"path": "/pydb/db_binders/__init__.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\n\nsys.path.append(os.path.dirname(__file__))\n\ndef get_db_binder(db_type_name, sets_db):\n module = __import__('binder_'+db_type_name)\n return getattr(module, 'DBBinder')(sets_db)"
},
{
"alpha_fraction": 0.48328936100006104,
"alphanum_fraction": 0.4898856580257416,
"avg_line_length": 36.295082092285156,
"blob_id": "468927d0163e4c7501b4de2723ddef0835e3e0a3",
"content_id": "c0a134a722baf9c467e905908c0ca7d33e4a7b80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2415,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 61,
"path": "/parsers/political_parties.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import re\nimport requests\n\nclass Parser:\n\n def __init__(self, cfg):\n self.cfg = cfg\n\n def run(self):\n\n domain = \"https://minjust.ru\"\n ses = requests.Session()\n bad_selectors = ['noscript', 'footer', 'nav', 'form', 'script', 'head', '#mobile-header', '#footer', '#typo-report-wrapper', '.breadcrumb']\n saver = self.cfg['saver']\n tbls = self.cfg['tbls']\n\n # всегда загружаем свежий список\n url = domain + '/mobile/ru/nko/gosreg/partii/spisok'\n r = ses.get(url)\n index, d = saver.save(r, url, bad_selectors)\n\n links = d.cssselect('#content .content .content a')\n for link in links:\n fparty = {\n 'name': link.text_content()\n }\n fparty['name'] = re.sub(r'^[\\d]*\\.?', '', fparty['name']).strip()\n fparty['name'] = fparty['name'].replace('\\xa0', ' ')\n fparty['name'] = fparty['name'].replace('«', '\"')\n fparty['name'] = fparty['name'].replace('»', '\"')\n if len(fparty['name']) < 3:\n print('пустое название партии', index, url)\n continue\n\n # а здесь можем брать и сохранённую страничку\n url = link.attrib['href']\n indexes = saver.exists(url)\n if indexes:\n index, d = (indexes[1], saver.open(indexes[1]))\n else:\n r = ses.get(url)\n index, d = saver.save(r, url, bad_selectors)\n\n descr = d.cssselect('.content')\n if not descr:\n print('Описание партии не найдено:', index, url)\n continue\n descr = descr[0].text_content().strip()#.split('\\n')\n descr = descr.replace('«', '\"')\n descr = descr.replace('»', '\"')\n descr = descr.replace('\\xa0', ' ')\n\n fparty['ogrn'] = re.findall(r'ОГРН[\\s.ёЁа-яА-Я0-9]*:[\\s\\xa0№.,ёЁа-яА-Я0-9]*(\\d{13})', descr)\n if not fparty['ogrn']: print('ОГРН не найден:', index, url)\n else: fparty['ogrn'] = fparty['ogrn'][0]\n #print(url, '\\n', fparty)\n #print(descr, '\\n\\n')\n #exit(0)\n\n new_index = tbls.insert_unique('political_party', fparty, ['ogrn'])\n print(new_index)"
},
{
"alpha_fraction": 0.5225133299827576,
"alphanum_fraction": 0.5253116488456726,
"avg_line_length": 30.70967674255371,
"blob_id": "de70b02f0de48eedeae7f1bc8330f68aa110d1e8",
"content_id": "22e01fcb162b3d7405d89de7132d0ca6afa815cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3966,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 124,
"path": "/pydb/sqltools.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "class SQLTools():\n\n def __init__(self, db):\n self.db = db\n\n def glue_fields(self, fields):\n ks = []\n vs = []\n for k, v in fields.items():\n ks.append(f\"`{k}`=?\")\n vs.append(v)\n return ', '.join(ks), vs\n\n def process_key(self, key, repl=None):\n if key == '*' or '(' in key or ' as ' in key.lower(): return key\n\n if repl and not key.startswith('`') and not key.endswith('`'): key = repl[key]\n\n if not key.startswith('`'): key = '`'+key\n if not key.endswith('`'): key = key+'`'\n return key\n\n def process_keys(self, keys, repl=None):\n if isinstance(keys, str):\n keys = [keys]\n for i, key in enumerate(keys):\n keys[i] = self.process_key(key, repl)\n return ','.join(keys)\n\n def process_cond(self, cond, repl=None):\n #print(' cond2:', cond)\n key, op, value = cond\n if value is None:\n if op == '=': op = ' IS '\n elif op == '!=': op = ' is not '\n key = self.process_key(key, repl)\n #print(' cond:', f'{key}{op}?', value)\n return f'{key}{op}?', value\n\n def process_where(self, where, main_op='AND', repl=None):\n #print(' where2:', where)\n if isinstance(where, tuple): # уже конвертированное\n return where[0], where[1]\n where_v = []\n for i, cond in enumerate(where):\n if isinstance(cond, str):\n continue # для выражений типа \"`tbl1`.`field1`=`tbl2`.`field1`\"\n cond, value = self.process_cond(cond, repl)\n where[i] = cond\n where_v.append(value)\n #print('where:', f' {main_op} '.join(where), where_v)\n return f' {main_op} '.join(where), where_v\n\n def AND(self, where):\n return self.process_where(where, 'AND')\n\n def OR(self, where):\n return self.process_where(where, 'OR')\n\n def update(self, table, fields, where):\n\n table = self.process_key(table)\n\n where, where_v = self.process_where(where)#' AND '.join(where)\n\n ks, vs = self.glue_fields(fields)\n vs += where_v\n\n sql = f\"UPDATE {table} SET {ks} WHERE {where}\"\n self.db.execute(sql, tuple(vs))\n\n def insert(self, table, keys, values=None, repl=None):\n\n table = self.process_key(table)\n\n if isinstance(keys, dict):\n values = [list(keys.values())]\n keys = list(keys.keys())\n\n ks = self.process_keys(keys, repl)\n\n indexes = []\n\n for vs in values:\n _vs = ','.join(['?']*len(vs))\n sql = f\"INSERT INTO {table} ({ks}) VALUES ({_vs})\"\n #print(sql, '\\n', tuple(vs))\n self.db.execute(sql, tuple(vs))\n indexes.append(self.db.lastrowid)\n\n return indexes[0] if len(indexes)==1 else indexes\n\n def select(self, tables, keys, where, repl=None):\n\n tables = self.process_keys(tables)\n keys = self.process_keys(keys, repl)\n where, where_v = self.process_where(where, 'AND', repl)#' AND '.join(where)\n\n sql = f\"SELECT {keys} FROM {tables} WHERE {where}\"\n #print(sql, '\\n', where_v)\n \n if not isinstance(where_v, tuple): where_v = tuple(where_v)\n return self.db.execute(sql, where_v)\n\n def insert_uniq(self, table, keys, keys_uniq, primary_key, values=None):\n\n keys_uniq = self.process_keys(keys_uniq)\n\n if isinstance(keys, dict):\n values = list(keys.values())\n keys = list(keys.keys())\n\n where = []\n #where_v = []\n for i, key in enumerate(keys):\n if key not in keys_uniq: continue\n where.append([key, '=', values[i]])#(f'{key}=?')\n #where_v.append(values[i])\n\n r = self.select(table, primary_key, where).fetchall()\n if not r:\n return self.insert(table, keys, [values])\n else:\n return r[0][primary_key]"
},
{
"alpha_fraction": 0.5849802494049072,
"alphanum_fraction": 0.5869565010070801,
"avg_line_length": 28.784313201904297,
"blob_id": "e3612e65abdf011cb6abbc71d0023348c3ff958f",
"content_id": "1936deae29ef35a086bb2fc352417efe5ba89a8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1518,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 51,
"path": "/pyloader/saver.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import lxml.html as html\nfrom lxml.html.clean import Cleaner\nfrom . import saver_base\n\nclass SaverSQL(saver_base.SaverSQL):\n\n def __init__(self, mtables, path_to_save):\n\n saver_base.SaverSQL.__init__(self, mtables, path_to_save)\n self.cleaner_cls = Cleaner(\n scripts=True,\n javascript=True,\n style=True,\n comments=True,\n inline_style=True,\n links=True,\n forms=True,\n meta=True,\n page_structure=False,\n kill_tags=['header', 'h1', 'noscript', 'h4', 'footer', 'nav']\n )\n\n def cleaner(self, d, selectors):\n\n for selector in selectors:\n els = d.cssselect(selector)\n for el in els:\n el.getparent().remove(el)\n\n def open(self, url_index):\n d = saver_base.SaverSQL.open(self, url_index)\n return html.document_fromstring(d)\n\n def save(self, req, url, selectors=None):\n\n if req.headers['Content-Type'].startswith(\"text/\"):\n content = req.text\n else:\n content = req.content\n\n document = html.document_fromstring(content)\n title = document.cssselect('title')[0].text_content()\n\n document = self.cleaner_cls.clean_html(document)\n if selectors: self.cleaner(document, selectors)\n\n document.make_links_absolute(base_url=url)\n\n index = saver_base.SaverSQL.save(self, html.tostring(document, encoding='unicode'), url, title)\n\n return index, document"
},
{
"alpha_fraction": 0.5380875468254089,
"alphanum_fraction": 0.5429497361183167,
"avg_line_length": 18.935483932495117,
"blob_id": "d6128573697d1deaf32a79fefa38533c2162e456",
"content_id": "1f925ed197f619bbd140d11ec05d504e71100a73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 31,
"path": "/pydb/db_binders/binder_sqlite3.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import sqlite3\n\nclass DBBinder:\n\n def __init__(self, sets_db):\n\n self.c = sqlite3.connect(sets_db['path'])\n self.c.row_factory = sqlite3.Row\n self.cu = self.c.cursor()\n\n self.lastrowid = None\n\n def execute(self, sql, values=()):\n\n r = self.cu.execute(sql, values)\n self.lastrowid = self.cu.lastrowid\n return r\n\n def export(self, to_file):\n\n with open(to_file, \"w\") as f:\n for line in self.c.iterdump():\n f.write(\"%s\\n\" % line)\n\n def commit(self):\n\n self.c.commit()\n\n def rollback(self):\n\n self.c.rollback()"
},
{
"alpha_fraction": 0.4955856502056122,
"alphanum_fraction": 0.5061801075935364,
"avg_line_length": 28.29310417175293,
"blob_id": "0f3a2ce4b98d684afe7168cf413b6c698c67b71a",
"content_id": "af84695f4f4738dfd626b89c11b1e49130c5325b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3537,
"license_type": "no_license",
"max_line_length": 203,
"num_lines": 116,
"path": "/parsers/loader0007.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import requests\nimport lxml.html as html\n\ndef get_contents(d, selectors):\n\n for k, v in selectors.items():\n v = d.cssselect(v)\n if v: v[0].text_content().strip()\n else: v = None\n\n selectors[k] = v\n\nclass Parser:\n\n def __init__(self, cfg):\n self.cfg = cfg\n\n def run(self):\n\n domain = \"https://pg.er.ru\"\n ses = requests.Session()\n bad_selectors = ['noscript', 'footer', 'nav', 'div.modal']\n saver = self.cfg['saver']\n\n max_count = 20000\n\n start_count = 10000\n sql = \"SELECT MAX(CAST(SUBSTR(`url_path`, 16) AS 'INTEGER')) AS start_count FROM `url`, `url_domain` WHERE `url`.`url_domain_id`=`url_domain`.`url_domain_id` AND `url_domain`.`url_domain_name`=?\"\n r = self.cfg['db'].execute(sql, (domain.split('/')[-1],)).fetchall()\n if len(r) != 0:\n print(dict(r[0]))\n start_count = r[0]['start_count']\n if start_count is None: start_count = 10000\n\n print(r, start_count, max_count)\n\n for inew in range(start_count, max_count+1):\n \n url = domain +'/pub/candidate/'+ str(inew)\n \n indexes = saver.exists(url)\n if indexes: continue\n \n r = ses.get(url, allow_redirects=False)\n if 'Location' in r.headers: continue\n\n index, d = saver.save(r, url, bad_selectors)\n\n # вынимаем данные\n\n fcand = get_contents(d, {\n 'name': 'div.candidate-name',\n 'region': 'div.candidate-region span.reg',\n 'el_distr': 'div.candidate-region span.type',\n 'politicy_party': 'div.candidate-party-status',\n })\n\n #fcand['about'] = html.tostring(d.cssselect('div.candidate-about-body')[0])\n\n name = fcand['name']\n if len(name) == 2: name.append(None)\n\n print(name)\n\n fcand = {}\n\n for row in d.cssselect('div.bio div.bio-row'):\n key = row.getchildren()[0].text_content().strip()\n #if key in ['О себе:']: value = html.tostring(row.getchildren()[1])\n #else: value = row.getchildren()[1].text_content().strip()\n \n '''if key == 'Дата и место рождения:':\n bdate, bplace = value.split(' ', 1)\n bdate = bdate.split('.')\n bdate.reverse()\n fcand['cand_bdate'] = '-'.join(bdate)\n fcand['cand_bplace'] = bplace[2:] if bplace.startswith('в ') else bplace\n continue\n '''\n \n fcand[key] = value\n print(key, ':', value)\n\n #print(fcand)\n print()\n\n'''\n\n\n d = html.document_fromstring(bytes(text, 'utf-8')) # before of ucs4\n \n\nkeys = {\n 'Сфера деятельности:': 'cand_job_type',\n 'Место работы:': 'cand_job_general',\n 'Должность:': 'cand_job_position',\n 'Образование:': 'cand_education',\n 'Учебные заведения:': 'cand_study_buildings',\n 'Депутатство:': 'cand_is_deputy',\n 'О себе:': 'cand_about_self',\n 'Сайт:': 'cand_website',\n 'Страницы в соцсетях:': 'cand_socnets',\n}\n \n fcand = {\n 'cand_fname': name[1],\n 'cand_sname': name[0],\n 'cand_tname': name[2],\n }\n \n db.add_row(fcand, url[len(domain)-1:])\n saver.c.commit()\n\nsaver.c.commit()\n\n'''\n"
},
{
"alpha_fraction": 0.5989679098129272,
"alphanum_fraction": 0.6100258231163025,
"avg_line_length": 26.31313133239746,
"blob_id": "091fca0d2e0da072766bcbec7b75377ee088a1b2",
"content_id": "1ff552ffbf04a0c5d8803546221a42ce821292fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2805,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 99,
"path": "/main.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import requests\nfrom init import sets\n\nfrom pydb import sql_multitable\nfrom pydb import db_binders\nfrom pydb import sql_table\n#from pydb import sqltools\nfrom pyloader import saver_base\nfrom pyloader import saver\nimport parsers\n\nimport configparser\nimport os.path\n\n'''\nimport math\nt = 0.118\na = 12.25\nprint(' ', (0.7276/t)*math.sin((a/2)*math.pi/180))\n'''\n#exit()\n\ndef ini2tables(tables_file):\n config = configparser.ConfigParser()\n config.read(os.path.join('configs', tables_file))\n \n tables = []\n for section_name in config:\n if section_name == 'DEFAULT': continue\n table = {'name': section_name, 'fields':{}}\n \n #print(section_name)\n \n for k, v in config[section_name].items():\n #print(' ', k, v)\n table['fields'][k] = v\n \n tables.append(table)\n \n return tables\n\n'''\nДля командной строки:\n+ экспорт/импорт базы\n+ запуск парсера\n'''\n\ndb = db_binders.get_db_binder(sets['db_type'], sets['db_sets'][sets['db_type']])\ntables = ini2tables('tables.ini')\nmtable = sql_multitable.Multitable(db, tables, sets['db_table_prefix'], sets['show_log'], None)\nsaver2 = saver_base.SaverSQL(mtable, sets['path_row_data'])\nsaver = saver.SaverSQL(mtable, sets['path_row_data'])\n\ncfg = {\n 'saver': saver,\n 'tbls': mtable,\n 'db': db,\n}\n\nparser = parsers.get('news_del_yeysk', cfg)\nparser = parsers.get('loader0007', cfg)\nparser = parsers.get('political_parties', cfg)\nparser.run()\n\nexit()\n\nif __name__ == '__main__':\n \n db.export(sets['db_dump_to'])\n print(db)\n print(mtable.tables)\n \n print(mtable.tables['url'].build_drop())\n print(mtable.tables['url'].build_create())\n print(mtable.tables['url_title'].insert({'name':'ыыввв'}))\n #print(mtable.tables['url_title'].insert(['name'], [['длрв ег впл'], ['оооооо']]))\n print(mtable.tables['url_title'].insert({'name': 'длрв ег впл'}))\n print(mtable.tables['url_title'].insert({'name': 'оооооо'}))\n \n print(mtable.insert('url', {'scheme': 'https', 'domain': 'mail.ru', 'path': 'user/inbox.cgi', 'title': 'Ваша почта'}))\n \n print(saver2.save('my text', 'https://vk.com/user1/profile?audio=6', 'mytitle'))\n \n url = 'http://m.deleysk.ru'\n r = requests.get(url)\n print(saver.save(r, url))\n \n print(saver.exists( 'https://vk.com/user1/profile?audio=6'))\n r = saver.exists('http://m.deleysk.ru')\n print(r)\n if r:\n print(saver.open(r[1]))\n \n #a = 'bhuijb'\n #sql = \"INSERT INTO `url_title` ('url_title_name') VALUES (?) WHERE NOT EXISTS (SELECT * FROM `url_title` WHERE `url_title_name` = ?)\"\n #db.execute(sql, (a,a))\n \n #stable.tables['source_url'].drop()\n db.commit()\n \n "
},
{
"alpha_fraction": 0.559556782245636,
"alphanum_fraction": 0.559556782245636,
"avg_line_length": 21.59375,
"blob_id": "44df770425d9ab795a0248f50e6b1917f7fc04ff",
"content_id": "0341b10966d60e69803c0d9fdccf76d897670692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 722,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 32,
"path": "/pydb/db_binders/binder_mysql.py",
"repo_name": "shyzik93/big_data_collector2",
"src_encoding": "UTF-8",
"text": "import pymysql\n\nclass DBBinder:\n\n def __init__(self, sets_db):\n\n self.c = pymysql.connect(db=sets_db['name'], user=sets_db['user'], passwd=sets_db['password'], host=sets_db['host'], port=sets_db['port'])\n self.cu = self.c.cursor()\n\n self.lastrowid = None\n\n def execute(self, sql, values=None):\n\n r = self.cu.execute(sql, values)\n self.lastrowid = self.cu.lastrowid\n return r\n\n def export(self, to_file):\n\n print(self.cu.execute('.dump t.sql'))\n\n with open(to_file, \"w\") as f:\n for line in self.c.iterdump():\n f.write(\"%s\\n\" % line)\n\n def commit(self):\n\n self.c.commit()\n\n def rollback(self):\n\n self.c.rollback()"
}
] | 15 |
Vonny1/Diplom-Django
|
https://github.com/Vonny1/Diplom-Django
|
21ed2a24a3837d8663796ae030dd0b3391f95385
|
b202255cc171b6619ab120631d758f8907fecce8
|
6ce377612eaed954b6950ccaec27b11ec7c02477
|
refs/heads/master
| 2022-12-14T13:12:17.274739 | 2020-09-18T10:10:56 | 2020-09-18T10:10:56 | 296,524,173 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7582417726516724,
"alphanum_fraction": 0.7582417726516724,
"avg_line_length": 17.200000762939453,
"blob_id": "d2438c8d3b535470d7dd1fe3a61aff379d61d9c2",
"content_id": "287af30f1e9048363b05e349d985f5f79e745066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/sqltable/apps.py",
"repo_name": "Vonny1/Diplom-Django",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass SqltableConfig(AppConfig):\n name = 'sqltable'\n"
},
{
"alpha_fraction": 0.707317054271698,
"alphanum_fraction": 0.707317054271698,
"avg_line_length": 28.909090042114258,
"blob_id": "6ea3fbebd3f8145ee0434429f8c99141eb3c3e7e",
"content_id": "f56379e5703494e6e169d4f42e42c269cb6d474c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 328,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 11,
"path": "/sqltable/urls.py",
"repo_name": "Vonny1/Diplom-Django",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom . import views\n\nurlpatterns = [\n path('', views.index, name='index'),\n path('workertable', views.workertable, name = 'workertable'),\n path('workerfullinfotable',views.workerfullinfotable, name = 'workerfullinfotable'),\n\n #path ('workertest',views.workertest, name = 'workertest')\n]"
},
{
"alpha_fraction": 0.8035264611244202,
"alphanum_fraction": 0.8035264611244202,
"avg_line_length": 27.214284896850586,
"blob_id": "705471bffc36bec54319751963f2c67ebcbc6ac1",
"content_id": "315a828df92df09025df202bbc1f0b1b811d4b96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 397,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 14,
"path": "/sqltable/views.py",
"repo_name": "Vonny1/Diplom-Django",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n# Create your views here.\nfrom django.http import HttpResponse\nfrom sqltable.models import WorkerResponse, WorkerfullinfoResponse, jsontext\n\n\n\ndef index(request):\n return HttpResponse(WorkerResponse)\ndef workertable(request):\n return HttpResponse(WorkerResponse)\ndef workerfullinfotable(request):\n return HttpResponse(WorkerfullinfoResponse)\n\n\n"
},
{
"alpha_fraction": 0.4991134703159332,
"alphanum_fraction": 0.5159574747085571,
"avg_line_length": 30.33333396911621,
"blob_id": "759c2031623caff3192c2fab28c795427fa0ca4a",
"content_id": "e823d43483d4f297d8665556f02fa7dcf4f37db9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1128,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 36,
"path": "/sqltable/migrations/0003_workerdepart_workerefftime.py",
"repo_name": "Vonny1/Diplom-Django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-06-18 20:34\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sqltable', '0002_workerarrive'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Workerdepart',\n fields=[\n ('workerdepart_id', models.AutoField(db_column='Workerdepart_id', primary_key=True, serialize=False)),\n ('time', models.TimeField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'workerdepart',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Workerefftime',\n fields=[\n ('workerefftime_id', models.AutoField(db_column='Workerefftime_id', primary_key=True, serialize=False)),\n ('date', models.DateField(blank=True, null=True)),\n ('efftime', models.TimeField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'workerefftime',\n 'managed': False,\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.47959116101264954,
"alphanum_fraction": 0.48545995354652405,
"avg_line_length": 37.88461685180664,
"blob_id": "eb365e803e38579f27089230f0bf533c9342d843",
"content_id": "20030842123b86eed9c7062b74bfb6f0eb08ba1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15165,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 390,
"path": "/sqltable/migrations/0001_initial.py",
"repo_name": "Vonny1/Diplom-Django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-06-12 19:34\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='AuthGroup',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=150, unique=True)),\n ],\n options={\n 'db_table': 'auth_group',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='AuthGroupPermissions',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n options={\n 'db_table': 'auth_group_permissions',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='AuthPermission',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=255)),\n ('codename', models.CharField(max_length=100)),\n ],\n options={\n 'db_table': 'auth_permission',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='AuthUser',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('password', models.CharField(max_length=128)),\n ('last_login', models.DateTimeField(blank=True, null=True)),\n ('is_superuser', models.IntegerField()),\n ('username', models.CharField(max_length=150, unique=True)),\n ('first_name', models.CharField(max_length=30)),\n ('last_name', models.CharField(max_length=150)),\n ('email', models.CharField(max_length=254)),\n ('is_staff', models.IntegerField()),\n ('is_active', models.IntegerField()),\n ('date_joined', models.DateTimeField()),\n ],\n options={\n 'db_table': 'auth_user',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='AuthUserGroups',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n options={\n 'db_table': 'auth_user_groups',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='AuthUserUserPermissions',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n options={\n 'db_table': 'auth_user_user_permissions',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Bankaccount',\n fields=[\n ('bankaccount_id', models.AutoField(db_column='Bankaccount_id', primary_key=True, serialize=False)),\n ('account', models.BigIntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'bankaccount',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Brigade',\n fields=[\n ('brigade_id', models.AutoField(db_column='Brigade_id', primary_key=True, serialize=False)),\n ],\n options={\n 'db_table': 'brigade',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Brigadeleader',\n fields=[\n ('brigadeleader_id', models.AutoField(db_column='Brigadeleader_id', primary_key=True, serialize=False)),\n ('first_name', models.CharField(blank=True, max_length=255, null=True)),\n ('last_name', models.CharField(blank=True, max_length=255, null=True)),\n ('patronym', models.CharField(blank=True, max_length=255, null=True)),\n ],\n options={\n 'db_table': 'brigadeleader',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Brigadeworker',\n fields=[\n ('brigadeworker_id', models.AutoField(db_column='Brigadeworker_id', primary_key=True, serialize=False)),\n ],\n options={\n 'db_table': 'brigadeworker',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Customer',\n fields=[\n ('customer_id', models.AutoField(db_column='Customer_id', primary_key=True, serialize=False)),\n ('name', models.CharField(blank=True, max_length=50, null=True)),\n ('address', models.CharField(blank=True, max_length=255, null=True)),\n ],\n options={\n 'db_table': 'customer',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Department',\n fields=[\n ('department_id', models.AutoField(db_column='Department_id', primary_key=True, serialize=False)),\n ('department', models.CharField(blank=True, max_length=255, null=True)),\n ],\n options={\n 'db_table': 'department',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='DjangoAdminLog',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('action_time', models.DateTimeField()),\n ('object_id', models.TextField(blank=True, null=True)),\n ('object_repr', models.CharField(max_length=200)),\n ('action_flag', models.PositiveSmallIntegerField()),\n ('change_message', models.TextField()),\n ],\n options={\n 'db_table': 'django_admin_log',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='DjangoContentType',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('app_label', models.CharField(max_length=100)),\n ('model', models.CharField(max_length=100)),\n ],\n options={\n 'db_table': 'django_content_type',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='DjangoMigrations',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('app', models.CharField(max_length=255)),\n ('name', models.CharField(max_length=255)),\n ('applied', models.DateTimeField()),\n ],\n options={\n 'db_table': 'django_migrations',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='DjangoSession',\n fields=[\n ('session_key', models.CharField(max_length=40, primary_key=True, serialize=False)),\n ('session_data', models.TextField()),\n ('expire_date', models.DateTimeField()),\n ],\n options={\n 'db_table': 'django_session',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Ordercustomer',\n fields=[\n ('ordercustomer_id', models.AutoField(db_column='Ordercustomer_id', primary_key=True, serialize=False)),\n ],\n options={\n 'db_table': 'ordercustomer',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Orderproduct',\n fields=[\n ('orderproduct_id', models.AutoField(db_column='Orderproduct_id', primary_key=True, serialize=False)),\n ('date', models.DateTimeField(blank=True, null=True)),\n ('quantity', models.IntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'orderproduct',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Premium',\n fields=[\n ('premium_id', models.AutoField(db_column='Premium_id', primary_key=True, serialize=False)),\n ('premium', models.FloatField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'premium',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Premiumbudget',\n fields=[\n ('premiumbudget_id', models.AutoField(db_column='Premiumbudget_id', primary_key=True, serialize=False)),\n ('month', models.CharField(blank=True, max_length=255, null=True)),\n ('budget', models.FloatField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'premiumbudget',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Product',\n fields=[\n ('product_id', models.AutoField(db_column='Product_id', primary_key=True, serialize=False)),\n ('name', models.CharField(blank=True, max_length=50, null=True)),\n ],\n options={\n 'db_table': 'product',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Productionjournal',\n fields=[\n ('productionjournal_id', models.AutoField(db_column='Productionjournal_id', primary_key=True, serialize=False)),\n ('quantity', models.SmallIntegerField(blank=True, null=True)),\n ('date', models.DateTimeField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'productionjournal',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Productionplan',\n fields=[\n ('productionplan_id', models.AutoField(db_column='Productionplan_id', primary_key=True, serialize=False)),\n ('quantity', models.SmallIntegerField(blank=True, null=True)),\n ('date', models.DateTimeField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'productionplan',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Rack',\n fields=[\n ('rack_id', models.AutoField(db_column='Rack_id', primary_key=True, serialize=False)),\n ('quantity', models.IntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'rack',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Rackfreesize',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('freesize', models.IntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'rackfreesize',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Rackoccupiedsize',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('occupiedsize', models.IntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'rackoccupiedsize',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Racksize',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('size', models.IntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'racksize',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Vacationcalendar',\n fields=[\n ('vacationcalendar_id', models.AutoField(db_column='Vacationcalendar_id', primary_key=True, serialize=False)),\n ('firstdate', models.DateField(blank=True, null=True)),\n ('lastdate', models.DateField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'vacationcalendar',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Wage',\n fields=[\n ('wage_id', models.AutoField(db_column='Wage_id', primary_key=True, serialize=False)),\n ('wage', models.FloatField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'wage',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Worker',\n fields=[\n ('worker_id', models.AutoField(db_column='Worker_id', primary_key=True, serialize=False)),\n ('firstname', models.CharField(blank=True, max_length=255, null=True)),\n ('lastname', models.CharField(blank=True, max_length=255, null=True)),\n ('patronymic', models.CharField(blank=True, max_length=255, null=True)),\n ],\n options={\n 'db_table': 'worker',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Workerexperience',\n fields=[\n ('workerexperience_id', models.AutoField(db_column='Workerexperience_id', primary_key=True, serialize=False)),\n ('firstdate', models.DateField(blank=True, null=True)),\n ('expdate', models.DateField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'workerexperience',\n 'managed': False,\n },\n ),\n migrations.CreateModel(\n name='Workerfullinfo',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('address', models.CharField(blank=True, max_length=255, null=True)),\n ('phonenumber', models.IntegerField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'workerfullinfo',\n 'managed': False,\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5049786567687988,
"alphanum_fraction": 0.5320056676864624,
"avg_line_length": 27.1200008392334,
"blob_id": "db0657f5f2c2d85bd42b742d43d28a72b993969a",
"content_id": "330c285fd51ed2010a6dc781eb37d0373f294a3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 703,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 25,
"path": "/sqltable/migrations/0002_workerarrive.py",
"repo_name": "Vonny1/Diplom-Django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-06-18 18:01\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sqltable', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Workerarrive',\n fields=[\n ('workerarrive_id', models.AutoField(db_column='Workerarrive_id', primary_key=True, serialize=False)),\n ('date', models.DateField(blank=True, null=True)),\n ('time', models.TimeField(blank=True, null=True)),\n ],\n options={\n 'db_table': 'workerarrive',\n 'managed': False,\n },\n ),\n ]\n"
}
] | 6 |
niragkadakia/varanneal
|
https://github.com/niragkadakia/varanneal
|
b95572268da9987c1bb5af81fc7a9c8abe183169
|
30541b2a9290e089f23efb34b68456e10abd17a3
|
dba55af3f2f20a7c5e02e196e7c7c7822b570473
|
refs/heads/master
| 2021-05-15T14:16:28.938003 | 2020-04-07T20:05:34 | 2020-04-07T20:05:34 | 107,182,839 | 1 | 0 | null | 2017-10-16T21:04:10 | 2017-08-26T01:23:36 | 2017-09-14T03:46:02 | null |
[
{
"alpha_fraction": 0.6282722353935242,
"alphanum_fraction": 0.6361256837844849,
"avg_line_length": 30.83333396911621,
"blob_id": "e7a09cb509c0c20f7b8b7fa9e2c483322ec13a5b",
"content_id": "bc694b16a0e39f21bac8ac68f7f605dd008cc92e",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 12,
"path": "/setup.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(name='varanneal',\n version='0.1.4',\n description='Variational annealing (VA) for state and parameter ' +\\\n 'estimation in partially observed systems.',\n url='http://github.com/paulrozdeba/varanneal',\n author='Paul Rozdeba',\n author_email='[email protected]',\n license='MIT',\n packages=['varanneal'],\n zip_safe=False)\n"
},
{
"alpha_fraction": 0.5264654159545898,
"alphanum_fraction": 0.5623359680175781,
"avg_line_length": 33.90076446533203,
"blob_id": "1130fe5887cd8c70a9ab1357d4b73e7695711e57",
"content_id": "53f1e5c71c9927f4e0e26f06c91f5b979f32345e",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4572,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 131,
"path": "/examples/nnet_barimages/bardata_anneal.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nExample deep neural network annealing with Sasha's rotated bar images.\n\"\"\"\n\nimport numpy as np\nfrom varanneal import va_nnet\nimport sys, time\n\nM = 10 # number of training examples\n# Next is the ADOLC tape ID. This only needs to be changed if you're\n# running multiple instances simultaneously (to avoid using the tape from \n# another instance with the same ID, although I'm not sure even this will \n# happen if you re-use an ID).\nadolcID = 0\n\n# Define the transfer function\ndef sigmoid(x, W, b):\n linpart = np.dot(W, x) + b\n return 1.0 / (1.0 + np.exp(-linpart))\n\n# Network structure\nN = 3 # Total number of layers\nD_in = 25 # Number of neurons in the input layer\nD_out = 4 # Number of neurons in the output layer\nD_hidden = 30 # Number of neurons in the hidden layers\n\n# Don't need to touch the next few lines, unless you want to manually alter \n# the network structure.\nstructure = np.zeros(N, dtype='int')\nstructure[0] = D_in # 3 neurons in the input layer\nstructure[N-1] = D_out # 2 neurons in the output layer\nfor i in range(1, N-1):\n structure[i] = D_hidden # 5 neurons in the hidden layers\n\n# Indices of measured components. Next line also doesn't need to be touched \n# unless you want to manually alter them.\nLidx = [np.linspace(0, D_in-1, D_in, dtype='int'), np.linspace(0, D_out-1, D_out, dtype='int')]\n\n################################################################################\n# Action/annealing parameters\n################################################################################\n# RM, RF0\nRM = 1.0\nRF0 = 1.0e-8 * RM * float(np.sum(structure) - structure[0]) / float(structure[0] + structure[-1])\n# alpha, and beta ladder\nalpha = 1.1\nbeta_array = np.linspace(0, 435, 436)\n\n################################################################################\n# Input and output data\n################################################################################\ndata_in = np.load(\"data/training_data.npy\")[:M, :]\ndata_out = np.load(\"data/training_label.npy\")[:M, :]\n\n################################################################################\n# Initial path/parameter guesses\n################################################################################\nnp.random.seed(43759436)\n# Neuron states\nXin = np.random.randn(D_in)\nXin = (Xin - np.average(Xin)) / np.std(Xin)\nX0 = np.copy(Xin)\n\nfor n in xrange(N-2):\n X0 = np.append(X0, 0.2*np.random.rand(D_hidden) + 0.4)\nX0 = np.append(X0, 0.2*np.random.rand(D_out) + 0.4)\n\nfor m in xrange(M - 1):\n Xin = np.random.randn(D_in)\n Xin = (Xin - np.average(Xin)) / np.std(Xin)\n X0 = np.append(X0, Xin)\n for n in xrange(N-2):\n X0 = np.append(X0, 0.2*np.random.rand(D_hidden) + 0.4)\n X0 = np.append(X0, 0.2*np.random.rand(D_out) + 0.4)\n\nX0 = np.array(X0).flatten()\n\n# Parameters\nNP = np.sum(structure[1:]*structure[:-1] + structure[1:])\n#Pidx = []\nP0 = np.array([], dtype=np.float64)\n\nW_i0 = 0\nW_if = structure[0]*structure[1]\nb_i0 = W_if\nb_if = b_i0 + structure[1]\n\nfor n in xrange(N - 1):\n if n == 0:\n Pidx = np.arange(W_i0, W_if, 1, dtype='int')\n else:\n Pidx = np.append(Pidx, np.arange(W_i0, W_if, 1, dtype='int'))\n if n == 0:\n P0 = np.append(P0, (2.0*np.random.rand(structure[n]*structure[n+1]) - 1.0) / D_in)\n else:\n P0 = np.append(P0, (2.0*np.random.rand(structure[n]*structure[n+1]) - 1.0) / D_hidden)\n P0 = np.append(P0, np.zeros(structure[n+1]))\n\n if n < N - 2:\n W_i0 = b_if\n W_if = W_i0 + structure[n+1]*structure[n+2]\n b_i0 = W_if\n b_if = b_i0 + structure[n+2]\n\nP0 = np.array(P0).flatten()\nPidx = np.array(Pidx).flatten().tolist()\n\n################################################################################\n# Annealing\n################################################################################\n# Initialize Annealer\nanneal1 = va_nnet.Annealer()\n# Set the network structure\nanneal1.set_structure(structure)\n# Set the activation function\nanneal1.set_activation(sigmoid)\n# Set the input and output data\nanneal1.set_input_data(data_in)\nanneal1.set_output_data(data_out)\n\n# Run the annealing using L-BFGS-B\nBFGS_options = {'gtol':1.0e-12, 'ftol':1.0e-12, 'maxfun':1000000, 'maxiter':1000000}\ntstart = time.time()\nanneal1.anneal(X0, P0, alpha, beta_array, RM, RF0, Pidx, Lidx=Lidx,\n method='L-BFGS-B', opt_args=BFGS_options, adolcID=adolcID)\nprint(\"\\nADOL-C annealing completed in %f s.\"%(time.time() - tstart))\n\n# Save the results of annealing\nanneal1.save_io(\"io.npy\")\nanneal1.save_Wb(\"W.npy\", \"b.npy\")\nanneal1.save_action_errors(\"action_errors.npy\")\n"
},
{
"alpha_fraction": 0.6039250493049622,
"alphanum_fraction": 0.6382694244384766,
"avg_line_length": 33.4923095703125,
"blob_id": "562fd7fc52c41d1faa821b4e856b31405878d3d9",
"content_id": "559d6605e7b66a1002e0df2a6f80e815b08249e2",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2242,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 65,
"path": "/examples/nnet_twin/data/gen_io_pairs.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGenerate lots of input/output pairs from the data-generating network.\n\"\"\"\n\nimport numpy as np\nimport os\n\n# Define the network activations\ndef activation(x, W, b):\n linpart = np.dot(W, x) + b\n return 1.0 / (1.0 + np.exp(-linpart))\n\n# Set up network structure\nD_in = 10\nD_out = 10\nD_hidden = 10\nN = 100 # number of layers, including input and output\n\n# Noise level in input/output data\nsigma = 0.005 # standard deviation of Gaussian noise\nsuffix = \"sm0p005\" # optional suffix to append to filenames\n\n# Generate lots of random input/output pairs\nNparam = 2 # number of different network parametrizations to generate data with\nNexamples = 10000 # number of examples to generate\n# Uncomment corresponding two lines to generate training, validation, or\n# test data.\nfolder = \"training\"\nnp.random.seed(43650832) # training\n#folder = \"validation\"\n#np.random.seed(69856438) # validation\n#folder = \"test\"\n#np.random.seed(78943689) # test\n\n# Create folders to contain data, if they don't exist yet\nif not os.path.exists(folder):\n os.makedirs(folder)\n\nfor i in xrange(Nparam): # parameter index\n # Make folder for this parametrization if it doesn't exist yet\n if not os.path.exists(folder + \"/param%d\"%(i+1,)):\n os.makedirs(folder + \"/param%d\"%(i+1,))\n\n # Load in parameters\n W = np.load(\"params/W_%d.npy\"%(i+1,))\n b = np.load(\"params/b_%d.npy\"%(i+1,))\n\n for j in xrange(Nexamples):\n y = []\n # Draw random input from N(0, sigma^2)\n yin = np.random.randn(D_in)\n # Normalize to have mean 0 and sigma=1\n yin = (yin - np.average(yin)) / np.std(yin)\n y.append(yin)\n for n in xrange(N - 1):\n y.append(activation(y[n], W[n], b[n]))\n np.save(\"%s/param%d/truestates_%d.npy\"%(folder, i+1, j+1), y)\n\n if sigma > 0:\n # Add noise to input and output to simulate observation noise\n noisy_input = y[0] + sigma*np.random.randn(D_in)\n # Output is clipped to valid sigmoid range\n noisy_output = np.clip(y[-1] + sigma*np.random.randn(D_out), 0.0001, 0.9999)\n noisy_io = np.array([noisy_input, noisy_output])\n np.save(\"%s/param%d/noisyio_%s_%d.npy\"%(folder, i+1, suffix, j+1), noisy_io)\n"
},
{
"alpha_fraction": 0.5901015400886536,
"alphanum_fraction": 0.624365508556366,
"avg_line_length": 25.266666412353516,
"blob_id": "ec0fb390a131d59cd5f2185de4a3b00ee8980a65",
"content_id": "fc8b89f0fd40010857376c32bbb103f903c2f50e",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 788,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 30,
"path": "/examples/nnet_barimages/SGEcluster/submit_multiM.sh",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "#!/share/apps/opt/python/2.7.9/bin/python2\n#$ -S /share/apps/opt/python/2.7.9/bin/python2\n#$ -V\n#$ -cwd\n#$ -j y\n#$ -M [email protected]\n#$ -o ./output\n#$ -e ./error\n#$ -q batch.q\n\nimport os\n\nM = [1, 2, 10, 100] # M values to loop through\nNinit = 100 # Number of initializations for annealing\n\n# Here we fetch the SGE task ID, which is important for deciding on which \n# M value to use, which initialization, etc.\nSGE_TASK_ID = int(os.getenv(\"SGE_TASK_ID\", 0))\n\ni_M = (int(SGE_TASK_ID - 1) / int(Ninit)) % int(len(M))\ninitID = int(SGE_TASK_ID - 1) % Ninit + 1\nadolcID = SGE_TASK_ID % 2000\n\nprint(\"M = %d\"%(M[i_M],))\nprint(\"initID = %d\"%(initID,))\nprint(\"SGE_TASK_ID = %d\"%(SGE_TASK_ID,))\n\nprint(os.system(\"uname -n\"))\n\nos.system(\"python2 SGE_bardata_anneal.py %d %d %d\"%(initID, M[i_M], adolcID))\n"
},
{
"alpha_fraction": 0.505649745464325,
"alphanum_fraction": 0.5461393594741821,
"avg_line_length": 33.630435943603516,
"blob_id": "925d141b312bb000df48329267ae6625a02e7f40",
"content_id": "c0c11c48a54cd9668842073f40ce0fe3e8c19b53",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3186,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 92,
"path": "/examples/Lorenz96_D20/Lorenz96_anneal.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nExample file for carrying out state and parameter estimation in the Lorenz 96\nsystem using the weak-constrained variational method.\n\nVaranneal implements the variational annealing algorithm and uses automatic\ndifferentiation to do the action minimization at each step.\n\"\"\"\n\nimport numpy as np\n#import varanneal\nfrom varanneal import va_ode\nimport sys, time\n\n# Define the model\ndef l96(t, x, k):\n return np.roll(x,1,1) * (np.roll(x,-1,1) - np.roll(x,2,1)) - x + k\n\nD = 20\n\n################################################################################\n# Action/annealing parameters\n################################################################################\n# Measured variable indices\nLidx = [0, 2, 4, 6, 8, 10, 14, 16]\n# RM, RF0\nRM = 1.0 / (0.5**2)\nRF0 = 4.0e-6\n# alpha, and beta ladder\nalpha = 1.5\nbeta_array = np.linspace(0, 100, 101)\n\n################################################################################\n# Load observed data\n################################################################################\ndata = np.load(\"l96_D20_dt0p025_N161_sm0p5_sec1_mem1.npy\")\ntimes_data = data[:, 0]\n#t0 = times_data[0]\n#tf = times_data[-1]\ndt_data = times_data[1] - times_data[0]\nN_data = len(times_data)\n\ndata = data[:, 1:]\ndata = data[:, Lidx]\n\n################################################################################\n# Initial path/parameter guesses\n################################################################################\n# Same sampling rate for data and forward mapping\ndt_model = dt_data\nN_model = N_data\nX0 = (20.0*np.random.rand(N_model * D) - 10.0).reshape((N_model, D))\n\n# Sample forward mapping twice as f\n#dt_model = dt_data / 2.0\n#meas_nskip = 2\n#N_model = (N_data - 1) * meas_nskip + 1\n#X0 = (20.0*np.random.rand(N_model * D) - 10.0).reshape((N_model, D))\n\n# Below lines are for initializing measured components to data; instead, we\n# use the convenience option \"init_to_data=True\" in the anneal() function below.\n#for i,l in enumerate(Lidx):\n# Xinit[:, l] = data[:, i]\n#Xinit = Xinit.flatten()\n\n# Parameters\nPidx = [0] # indices of estimated parameters\n# Initial guess\nP0 = np.array([4.0 * np.random.rand() + 6.0]) # Static parameter\n#Pinit = 4.0 * np.random.rand(N_model, 1) + 6.0 # Time-dependent parameter\n\n################################################################################\n# Annealing\n################################################################################\n# Initialize Annealer\nanneal1 = va_ode.Annealer()\n# Set the Lorenz 96 model\nanneal1.set_model(l96, D)\n# Load the data into the Annealer object\nanneal1.set_data(data, t=times_data)\n\n# Run the annealing using L-BFGS-B\nBFGS_options = {'gtol':1.0e-8, 'ftol':1.0e-8, 'maxfun':1000000, 'maxiter':1000000}\ntstart = time.time()\nanneal1.anneal(X0, P0, alpha, beta_array, RM, RF0, Lidx, Pidx, dt_model=dt_model,\n init_to_data=True, disc='SimpsonHermite', method='L-BFGS-B',\n opt_args=BFGS_options, adolcID=0)\nprint(\"\\nADOL-C annealing completed in %f s.\"%(time.time() - tstart))\n\n# Save the results of annealing\nanneal1.save_paths(\"paths.npy\")\nanneal1.save_params(\"params.npy\")\nanneal1.save_action_errors(\"action_errors.npy\")\n"
},
{
"alpha_fraction": 0.824355959892273,
"alphanum_fraction": 0.824355959892273,
"avg_line_length": 60,
"blob_id": "b1056e124bb6f04a788b21c00a711b251911963a",
"content_id": "d216c63c48bdd18c47a4a772404425c345d419b3",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 427,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 7,
"path": "/examples/nnet_barimages/SGEcluster/README.txt",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "This directory contains some code for running Sasha's bar data example on an \nSGE cluster, where multiple annealing runs are launched simultaneously with \ndifferent initializations of network state and parameter guesses.\n\nThe submission script is specifically tailored for our research group's cluster, \nso you should modify your options accordingly. One important thing in our \nscript is calling the right version of python.\n"
},
{
"alpha_fraction": 0.5392472147941589,
"alphanum_fraction": 0.5717798471450806,
"avg_line_length": 40.3046875,
"blob_id": "b7a7d11ae0ce37dfc384b2770e63c10487247243",
"content_id": "485887dd95309c6caf6d9b53a2ab69d91ede2848",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5287,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 128,
"path": "/examples/nnet_barimages/data/bardata_gen.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGenerate training or test data for Sasha's bar image example.\n\nThis script generates M labeled examples of noisy images of solid bars, oriented\neither horizontally, vertically, or diagonally at a 45-degree angle. You have \nthe choice of generating only centered bars, or bars centered on any/all pixels\nwithin the image field. This is done by setting the \"imagetype\" flag.\n\nAll data will be generated by adding noise to the image such that the values of \nthe pixels are no longer either zero or one.\n\"\"\"\n\nimport numpy as np\n\n################################################################################\n# You can set the options for the data in this section. You don't need to\n# change anything in beyond here, unless you want to manually alter the data\n# generation procedures for some reason\n################################################################################\n\n# Set the type of images you'd like to generate\nimagetype = \"centered\" # bars all centered in middle of image\n#imagetype = \"allpositions\" # bars centered on all pixels\n\n# Set dimension of images (must be odd!), i.e. images will be square and dim X dim pixels\ndim = 5\n\n# Number of training example *sets*, meaning Nsets output sets containing one of \n# every possible bar location.\nNsets = 1000\n\n# Image noise seed\nnp.random.seed(85964309)\n\n# Ouptut data file names\n# Make sure both of them end with the same file extension, either .npy or .dat\ndata_fname = \"training_data.npy\"\nlabel_fname = \"training_label.npy\"\n\n################################################################################\n# Don't need to touch any code beyond this point, unless you want to manually\n# alter the data-generating procedure for some reason.\n################################################################################\n\n# Check for valid image dimension\nif dim < 3:\n print(\"ERROR: Desired image dimension dim = %d is too small. Must be 3 or greater. Exiting!\")\n sys.exit(1)\nif dim%2 == 0:\n print(\"ERROR: Image dimension must be odd. Exiting!\")\n sys.exit(1)\n\nsize = (dim, dim) # size tuple for the image arrays\n\n# These arrays define the canonical noiseless images. All angled bars here are\n# either h_i (at zero or 180 degrees) d1_i (pi/4 or 5pi/4), v_i, (+/- pi/2), or\n# d2_i (3pi/4 or -pi/4) where the angle is measured from the left horizontal.\n\n# Vertical and horizontal images\nfor i in xrange(dim):\n exec \"v%d = np.zeros((dim, dim), dtype='int')\"%(i+1,)\n exec \"v%d[:, i] = 1\"%(i+1,)\n exec \"h%d = np.zeros((dim, dim), dtype='int')\"%(i+1,)\n exec \"h%d[i, :] = 1\"%(i+1,)\n\n# Diagonal images\nNdiag = 2*dim - 3 # number of possible diagonals\nfor i in xrange(Ndiag):\n if i <= Ndiag/2:\n v = np.ones(i + 2)\n else:\n v = np.ones(Ndiag - i + 1)\n exec \"d1%d = np.diag(v, -(Ndiag/2) + i)\"%(i+1,)\n exec \"d2%d = np.fliplr(d1%d)\"%(i+1, i+1)\n\n# Generates centered data\nif imagetype == \"centered\":\n data = np.zeros((4*Nsets, dim*dim), dtype=np.float64)\n labels = np.zeros((4*Nsets, 4), dtype=np.int8)\n hvidx = dim/2 + 1\n diagidx = Ndiag/2 + 1\n for m in xrange(Nsets):\n exec \"data[4*m, :] = (h%d + 0.35*(0.5 - np.random.random_sample(size))).flatten()\"%(hvidx,)\n exec \"data[4*m+1, :] = (v%d + 0.35*(0.5 - np.random.random_sample(size))).flatten()\"%(hvidx,)\n exec \"data[4*m+2, :] = (d1%d + 0.35*(0.5 - np.random.random_sample(size))).flatten()\"%(diagidx,)\n exec \"data[4*m+3, :] = (d2%d + 0.35*(0.5 - np.random.random_sample(size))).flatten()\"%(diagidx,)\n labels[4*m, :] = np.array([1,0,0,0]) # horizontal label\n labels[4*m+1, :] = np.array([0,0,1,0]) # vertical label\n labels[4*m+2, :] = np.array([0,1,0,0]) # diag label\n labels[4*m+3, :] = np.array([0,0,0,1]) # flipped diag label\n\n if data_fname.endswith(\".npy\"):\n np.save(data_fname, data)\n np.save(label_fname, labels)\n else:\n np.savetxt(data_fname, data, fmt=\"%.8e\")\n np.savetxt(label_fname, labels, fmt=\"%d\")\n\nif imagetype == \"allpositions\": \n # Generates images centered on all pixels\n M = Nsets*(2*dim + 2*Ndiag)\n data = np.zeros((M, dim*dim), dtype=np.float64)\n labels = np.zeros((M, 4), dtype=np.int8)\n idx = 0\n for m in xrange(Nsets):\n for j in xrange(1, dim+1):\n exec \"data[idx, :] = (h%d + 0.35 * (0.5 - np.random.random_sample(size))).flatten()\"%(j,)\n labels[idx, :] = np.array([1,0,0,0])\n idx += 1\n for j in xrange(1, dim+1):\n exec \"data[idx, :] = (v%d + 0.35 * (0.5 - np.random.random_sample(size))).flatten()\"%(j,)\n labels[idx, :] = np.array([0,0,1,0])\n idx += 1\n for j in xrange(1, Ndiag+1):\n exec \"data[idx, :] = (d1%d + 0.35 * (0.5 - np.random.random_sample(size))).flatten()\"%(j,)\n labels[idx, :] = np.array([0,1,0,0])\n idx += 1\n for j in xrange(1, Ndiag+1):\n exec \"data[idx, :] = (d2%d + 0.35 * (0.5 - np.random.random_sample(size))).flatten()\"%(j,)\n labels[idx, :] = np.array([0,0,0,1])\n idx += 1\n\n if data_fname.endswith(\".npy\"):\n np.save(data_fname, data)\n np.save(label_fname, labels)\n else:\n np.savetxt(data_fname, data, fmt=\"%.8e\")\n np.savetxt(label_fname, labels, fmt=\"%d\")\n"
},
{
"alpha_fraction": 0.5548698306083679,
"alphanum_fraction": 0.587270975112915,
"avg_line_length": 34.033782958984375,
"blob_id": "23448cfb22bdd93d49b86f18932960b2955ace80",
"content_id": "81832760920a8b239a8f2945566b22684b371141",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5185,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 148,
"path": "/examples/nnet_twin/nnet_twin_anneal.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\"Twin\" neural network training example.\n\"\"\"\n\nimport numpy as np\n#import varanneal\nfrom varanneal import va_nnet\nimport sys, time\n\nL = 10 # number of observed components\nM = 2 # number of training examples\nsuffix = \"sm0p005\" # suffix to specify \n# Next is the ADOLC tape ID. This only needs to be changed if you're\n# running multiple instances simultaneously (to avoid using the tape from \n# another instance with the same ID, although I'm not sure even this will \n# happen if you re-use an ID).\nadolcID = 0\n\n# Define the transfer function\ndef sigmoid(x, W, b):\n linpart = np.dot(W, x) + b\n return 1.0 / (1.0 + np.exp(-linpart))\n\n# Network structure\nN = 20 # Total number of layers\nD_in = 10 # Number of neurons in the input layer\nD_out = 10 # Number of neurons in the output layer\nD_hidden = 10 # Number of neurons in the hidden layers\n\n# Don't need to touch the next few lines, unless you want to manually alter \n# the network structure.\nstructure = np.zeros(N, dtype='int')\nstructure[0] = D_in # 3 neurons in the input layer\nstructure[N-1] = D_out # 2 neurons in the output layer\nfor i in range(1, N-1):\n structure[i] = D_hidden # 5 neurons in the hidden layers\n\n# Indices of measured components. Next line also doesn't need to be touched \n# unless you want to manually alter them.\nLidx = [np.linspace(0, L-1, L, dtype='int'), np.linspace(0, L-1, L, dtype='int')]\n\n################################################################################\n# Action/annealing parameters\n################################################################################\n# RM, RF0\nRM = 1.0 / (.005**2)\nRF0 = 1.0e-8 * RM * float(np.sum(structure) - structure[0]) / float(structure[0] + structure[-1]) # Initial RF value\n# alpha, and beta \"ladder\"\nalpha = 1.1\nbeta_array = np.linspace(0, 435, 436)\n\n################################################################################\n# Input and output data\n################################################################################\ndata_dir = \"data/training/param1/\"\ndata_in = []\ndata_out = []\n\n# Load all examples into an array\nfor n in range(M):\n data = np.load(data_dir + \"noisyio_sm0p005_%d.npy\"%(n+1,))\n data_in.append(data[0][Lidx[0]])\n data_out.append(data[-1][Lidx[1]])\n\ndata_in = np.array(data_in)\ndata_out = np.array(data_out)\n\n################################################################################\n# Initial path/parameter guesses\n################################################################################\nnp.random.seed(89072545)\n# Neuron states\n# First example\nXin = np.random.randn(D_in)\nXin = (Xin - np.average(Xin)) / np.std(Xin)\nX0 = [Xin]\nfor n in xrange(N-1):\n X0.append(0.2*np.random.rand(D_hidden) + 0.4)\n\n# Now the rest of the M-1 examples\nfor m in xrange(M - 1):\n Xin = np.random.randn(D_in)\n Xin = (Xin - np.average(Xin)) / np.std(Xin)\n X0.append(Xin)\n for n in xrange(N-1):\n X0.append(0.2*np.random.rand(D_hidden) + 0.4)\n\nX0 = np.array(X0).flatten()\n\n# Parameters\nNP = np.sum(structure[1:]*structure[:-1] + structure[1:]) # total number of parameters\nPidx = [] # array for storing estimated parameter indices\nP0 = np.array([], dtype=np.float64) # array for initial parameter\n\n# Next four lines are index initializations, don't need to touch\nW_i0 = 0\nW_if = structure[0]*structure[1]\nb_i0 = W_if\nb_if = b_i0 + structure[1]\n\nfor n in xrange(N - 1):\n # Only weights are estimated. Thus, Pidx will contain only weight indices,\n # and biases will be set to zero.\n Pidx.append(range(W_i0, W_if)[:])\n if n == 0:\n P0 = np.append(P0, (2.0*np.random.rand(structure[n]*structure[n+1]) - 1.0) / D_in)\n else:\n P0 = np.append(P0, (2.0*np.random.rand(structure[n]*structure[n+1]) - 1.0) / D_hidden)\n P0 = np.append(P0, np.zeros(structure[n+1]))\n\n # Update indices, also don't need to touch.\n if n < N - 2:\n W_i0 = b_if\n W_if = W_i0 + structure[n+1]*structure[n+2]\n b_i0 = W_if\n b_if = b_i0 + structure[n+2]\n\nP0 = np.array(P0).flatten()\nPidx = np.array(Pidx).flatten().tolist()\n\n################################################################################\n# Annealing\n################################################################################\n# Initialize Annealer\nanneal1 = va_nnet.Annealer()\n# Set the network structure\nanneal1.set_structure(structure)\n# Set the activation function\nanneal1.set_activation(sigmoid)\n# Set the input and output data\nanneal1.set_input_data(data_in)\nanneal1.set_output_data(data_out)\n\n# Run the annealing using L-BFGS-B\nBFGS_options = {'gtol':1.0e-12, 'ftol':1.0e-12, 'maxfun':1000000, 'maxiter':1000000}\ntstart = time.time()\nanneal1.anneal(X0, P0, alpha, beta_array, RM, RF0, Pidx, Lidx=Lidx,\n method='L-BFGS-B', opt_args=BFGS_options, adolcID=adolcID)\nprint(\"\\nADOL-C annealing completed in %f s.\"%(time.time() - tstart))\n\n# Save the *entire* estimated state, warning: big array!!\n#anneal1.save_states(\"states.npy\")\n# Save estimates of input/output pairs only.\nanneal1.save_io(\"io.npy\")\n# Save estimated weights and biases.\nanneal1.save_Wb(\"W.npy\", \"b.npy\")\n# Save action and constituent error terms.\nanneal1.save_action_errors(\"aerr.npy\")\n"
},
{
"alpha_fraction": 0.770605742931366,
"alphanum_fraction": 0.7785501480102539,
"avg_line_length": 52,
"blob_id": "f59b83481810cfe7c2b2114b8d779e1d7f50e927",
"content_id": "bbf3c08a61ba1eedd2751c886b29163413411f81",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1007,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 19,
"path": "/examples/nnet_twin/README.txt",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "In this example, variational annealing (VA) is used to train a \"rectangular\" \nneural network on input/output examples from *another* rectangular network. \nHere, rectangular is taken to mean that the input, output, and hidden layers \nall have the same number of neurons.\n\nThe data-generating network has 100 layers, and 10 neurons per layer (by default). \nTo run this example, you should first generate this data. Go in to the \"data\" \nfolder here, and run\n python2 gen_params.py\n python2 gen_io_pairs.py\nTo change the number of parametrizations, examples, etc., as well as how the \nparameters and examples are generated, you can edit these two files to your \nliking.\n\nOnce you've generated the training data, go back up one directory and run \n python2 nnet_twin_anneal.py\nThis will carry out VA for network state and parameter estimation. To change \nvarious parameters for the *estimated* network, edit nnet_twin_anneal.py to \nalter the estimated network structure, number of training examples, etc.\n"
},
{
"alpha_fraction": 0.49103420972824097,
"alphanum_fraction": 0.504328727722168,
"avg_line_length": 39.381473541259766,
"blob_id": "8bc3cff62e527ef0a775837b4fa88ee21278a199",
"content_id": "700d10f27b492c1657ecc3987768d2eaf6e47406",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 40543,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 1004,
"path": "/varanneal/va_ode.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nPaul Rozdeba ([email protected])\nDepartment of Physics\nUniversity of California, San Diego\nMay 23, 2017\n\nVarAnneal\n\nCarry out the variational annealing algorithm (VA) for estimating unobserved\ndynamical model states and parameters from time series data.\n\nVA is a form of variational data assimilation that uses numerical continuation\nto regularize the variational cost function, or \"action\", in a controlled way.\nVA was first proposed by Jack C. Quinn in his Ph.D. thesis (2010) [1], and is\ndescribed by J. Ye et al. (2015) in detail in [2].\n\nThis code uses automatic differentiation to evaluate derivatives of the\naction for optimization as implemented in ADOL-C, wrapped in Python code in a\npackage called PYADOLC (installation required for usage of VarAnneal).\nPYADOLC is available at https://github.com/b45ch1/pyadolc.\n\nTo run the annealing algorithm using this code, instantiate an Annealer object\nin your code using this module. This object allows you to load in observation\ndata, set a model for the system, initial guesses for the states and parameters,\netc. To get a good sense of how to use the code, follow along with the examples\nincluded with this package, and the user guide (coming soon).\n\nReferences:\n[1] J.C. Quinn, \"A path integral approach to data assimilation in stochastic\n nonlinear systems.\" Ph.D. thesis in physics, UC San Diego (2010).\n Available at: https://escholarship.org/uc/item/0bm253qk\n\n[2] J. Ye et al., \"Improved variational methods in statistical data assimilation.\"\n Nonlin. Proc. in Geophys., 22, 205-213 (2015).\n\"\"\"\n\nimport numpy as np\nimport adolc\nimport time\nimport sys\nfrom _autodiffmin import ADmin\n\nclass Annealer(ADmin):\n \"\"\"\n Annealer is the main object type for performing variational data\n assimilation using VA. It inherits the function minimization routines\n from ADmin, which uses automatic differentiation.\n \"\"\"\n def __init__(self):\n \"\"\"\n Constructor for the Annealer class.\n \"\"\"\n self.taped = False\n self.annealing_initialized = False\n\n def set_model(self, f, D):\n \"\"\"\n Set the D-dimensional dynamical model for the estimated system.\n The model function, f, must take arguments in the following order:\n t, x, p\n or, if there is a time-dependent stimulus for f (nonautonomous term):\n t, x, (p, stim)\n where x and stim are at the \"current\" time t. Thus, x should be a\n D-dimensional vector, and stim similarly a D_stim-dimensional vector.\n \"\"\"\n self.f = f\n self.D = D\n\n def set_data_fromfile(self, data_file, stim_file=None, nstart=0, N=None):\n \"\"\"\n Load data & stimulus time series from file.\n If data is a text file, must be in multi-column format with L+1 columns:\n t y_1 y_2 ... y_L\n If a .npy archive, should contain an N X (L+1) array with times in the\n zeroth element of each entry.\n Column/array formats should also be in the form t s_1 s_2 ...\n \"\"\"\n if data_file.endswith('npy'):\n data = np.load(data_file)\n else:\n data = np.loadtxt(data_file)\n\n self.t_data = data[:, 0]\n self.dt_data = self.t_data[1] - self.t_data[0]\n self.Y = data[:, 1:]\n\n if stim_file is not None:\n if stim_file.endswith('npy'):\n s = np.load(stim_file)\n else:\n s = np.loadtxt(stim_file)\n self.stim = s[:, 1:]\n else:\n self.stim = None\n\n self.dt_data = dt_data\n\n def set_data(self, data, stim=None, t=None, nstart=0, N=None):\n \"\"\"\n Directly pass in data and stim arrays\n If you pass in t, it's assumed y/stim does not contain time. Otherwise,\n it has to contain time in the zeroth element of each sample.\n \"\"\"\n if N is None:\n self.N_data = data.shape[0]\n else:\n self.N_data = N\n\n if t is None:\n self.t_data = data[nstart:(nstart + self.N_data), 0]\n self.dt_data = self.t_data[1] - self.t_data[0]\n self.Y = data[nstart:(nstart + self.N_data), 1:]\n if stim is not None:\n self.stim = stim[nstart:(nstart + self.N_data), 1:]\n else:\n self.stim = None\n else:\n self.t_data = t[nstart:(nstart + self.N_data)]\n self.dt_data = self.t_data[1] - self.t_data[0]\n self.Y = data[nstart:(nstart + self.N_data)]\n if stim is not None:\n self.stim = stim[nstart:(nstart + self.N_data)]\n else:\n self.stim = None\n\n\n ############################################################################\n # Gaussian action\n ############################################################################\n def A_gaussian(self, XP):\n \"\"\"\n Calculate the value of the Gaussian action.\n \"\"\"\n merr = self.me_gaussian(XP[:self.N_model*self.D])\n ferr = self.fe_gaussian(XP)\n return merr + ferr\n\n def A_gaussian_quad_control(self, XP):\n \"\"\"\n Calculate the value of the Gaussian action.\n \"\"\"\n merr = self.me_gaussian(XP[:self.N_model*self.D])\n ferr = self.fe_gaussian(XP)\n cerr = self.ce_quad(XP)\n return merr + ferr + cerr\n\n def A_gaussian_adjoint(self, XP):\n \"\"\"\n Calculate the value of the Gaussian action in the adjoint space\n defined by the optimally controlled system.\n \"\"\"\n XP[:self.N_model*self.D] /= self.adj_var_scaling\n merr = self.me_gaussian_adjoint(XP[:self.N_model*self.D])\n ferr = self.fe_gaussian(XP)\n return merr + ferr\n\n def A_least_squares(self, XP):\n \"\"\"\n Calculate the value of least squares on the data terms\n \"\"\"\n merr = self.me_gaussian(XP[:self.N_model*self.D])\n return merr\n\n def me_gaussian(self, X):\n \"\"\"\n Gaussian measurement error.\n \"\"\"\n x = np.reshape(X, (self.N_model, self.D))\n diff = x[::self.merr_nskip, self.Lidx] - self.Y\n\n if type(self.RM) == np.ndarray:\n # Contract RM with error\n if self.RM.shape == (self.N_data, self.L):\n merr = np.sum(self.RM * diff * diff)\n elif self.RM.shape == (self.N_data, self.L, self.L):\n merr = 0.0\n for i in xrange(self.N_data):\n merr += np.dot(diff[i], np.dot(self.RM[i], diff[i]))\n else:\n print(\"ERROR: RM is in an invalid shape.\")\n else:\n merr = self.RM * np.sum(diff * diff)\n\n return merr / (self.L * self.N_data)\n\n def fe_gaussian(self, XP):\n \"\"\"\n Gaussian model error.\n \"\"\"\n # Extract state and parameters from XP.\n if self.NPest == 0:\n x = np.reshape(XP, (self.N_model, self.D))\n p = self.P\n else:\n x = np.reshape(XP[:self.N_model*self.D], (self.N_model, self.D))\n p = np.array(self.P, dtype=XP.dtype)\n p[self.Pestidx] = XP[self.N_model*self.D:]\n \n # Start calculating the model error.\n # First compute time series of error terms.\n if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n disc_vec1, disc_vec2 = self.disc(x, p)\n diff1 = x[2::2] - x[:-2:2] - disc_vec1\n diff2 = x[1::2] - disc_vec2\n elif self.disc.im_func.__name__ == 'disc_forwardmap':\n diff = x[1:] - self.disc(x, p)\n else:\n diff = x[1:] - x[:-1] - self.disc(x, p)\n\n # Contract errors quadratically with RF.\n if type(self.RF) == np.ndarray:\n if self.RF.shape == (self.N_model - 1, self.D):\n if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n ferr1 = np.sum(self.RF[::2] * diff1 * diff1)\n ferr2 = np.sum(self.RF[1::2] * diff2 * diff2)\n ferr = ferr1 + ferr2\n else:\n ferr = np.sum(self.RF * diff * diff)\n\n elif self.RF.shape == (self.N_model - 1, self.D, self.D):\n if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n ferr1 = 0.0\n ferr2 = 0.0\n for i in xrange((self.N_model - 1) / 2):\n ferr1 = ferr1 + np.dot(diff1[i], np.dot(self.RF[2*i], diff1[i]))\n ferr2 = ferr2 + np.dot(diff2[i], np.dot(self.RF[2*i+1], diff2[i]))\n ferr = ferr1 + ferr2\n else:\n ferr = 0.0\n for i in xrange(self.N_model - 1):\n ferr = ferr + np.dot(diff[i], np.dot(self.RF[i], diff))\n\n else:\n print(\"ERROR: RF is in an invalid shape. Exiting.\")\n sys.exit(1)\n\n else:\n if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n ferr = self.RF * np.sum(diff1 * diff1 + diff2 * diff2)\n else:\n ferr = self.RF * np.sum(diff * diff)\n\n return ferr / (self.D * (self.N_model - 1))\n\n def fe_equality_constraints(self, XP):\n \"\"\"\n Model errors to serve as equality constraints, Rf is ignored.\n \"\"\"\n # Extract state and parameters from XP.\n if self.NPest == 0:\n x = np.reshape(XP, (self.N_model, self.D))\n p = self.P\n else:\n x = np.reshape(XP[:self.N_model*self.D], (self.N_model, self.D))\n p = np.array(self.P, dtype=XP.dtype)\n p[self.Pestidx] = XP[self.N_model*self.D:]\n \n # Start calculating the model error.\n # First compute time series of error terms.\n if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n disc_vec1, disc_vec2 = self.disc(x, p)\n diff1 = x[2::2] - x[:-2:2] - disc_vec1\n diff2 = x[1::2] - disc_vec2\n diff = np.vstack((diff1, diff2)).flatten() ## TODO Correct??\n elif self.disc.im_func.__name__ == 'disc_forwardmap':\n diff = x[1:] - self.disc(x, p)\n else:\n diff = x[1:] - x[:-1] - self.disc(x, p)\n \n return diff\n\n def me_gaussian_adjoint(self, X):\n \"\"\"\n Lagrangian error term for adjoint model / optimal control.\n \"\"\"\n \n xp = np.reshape(X, (self.N_model, self.D))\n x = xp[:, :self.D/2]\n p = xp[:, self.D/2:]\n diff = x[::self.merr_nskip, self.Lidx] - self.Y\n adj_term = 1 + p[::self.merr_nskip, self.Lidx]**2.0\n \n if type(self.RM) == np.ndarray:\n # Contract RM with error\n if self.RM.shape == (self.N_data, self.L):\n merr = np.sum(self.RM * diff * diff * adj_term)\n elif self.RM.shape == (self.N_data, self.L, self.L):\n print (\"ERROR: matrix RM not coded for adjoint action\")\n quit()\n else:\n print(\"ERROR: RM is in an invalid shape.\")\n else:\n merr = self.RM * np.sum(diff * diff * adj_term)\n\n return merr / (self.L * self.N_data)\n \n def ce_quad(self, XP):\n \"\"\"\n Quadratic control cost\n \"\"\"\n if self.NPest == 0:\n p = self.P\n u = p[self.Pdynidx]\n else:\n p = np.array(self.P, dtype=XP.dtype)\n p[self.Pestidx] = XP[self.N_model*self.D:]\n u = p[self.Pdynidx]\n\n ferr = np.sum(u * u)\n\n return ferr / (self.D * (self.N_model - 1))\n\n #def vecA_gaussian(self, XP):\n # \"\"\"\n # Vector-like terms of the Gaussian action.\n # This is here primarily for Levenberg-Marquardt.\n # \"\"\"\n # if self.NPest == 0:\n # x = np.reshape(XP, (self.N_model, self.D))\n # p = self.P\n # elif self.NPest == self.NP:\n # x = np.reshape(XP[:self.N_model*self.D], (self.N_model, self.D))\n # if self.P.ndim == 1:\n # p = XP[self.N_model*self.D:]\n # else:\n # p = np.reshape(XP[self.N_model*self.D:], (self.N_model, self.NPest))\n # else:\n # x = np.reshape(XP[:self.N_model*self.D], (self.N_model, self.D))\n # p = []\n # if self.P.ndim == 1:\n # j = self.NPest\n # for i in xrange(self.NP):\n # if i in self.Pidx:\n # p.append(XP[-j])\n # j -= 1\n # else:\n # p.append(self.P[i])\n # else:\n # j = self.N_model * self.NPest\n # for n in xrange(self.N_model):\n # pn = []\n # for i in xrange(self.NP):\n # if i in self.Pidx:\n # pn.append(XP[-j])\n # j -= 1\n # else:\n # pn.append(self.P[n, i])\n # p.append(pn)\n # p = np.array(p)\n #\n # # Evaluate the vector-like terms of the action.\n # # Measurement error\n # diff = x[::self.merr_nskip, self.Lidx] - self.Y\n #\n # if type(self.RM) == np.ndarray:\n # # Contract RM with error\n # if self.RM.shape == (self.N, self.L):\n # merr = self.RM * diff\n # elif self.RM.shape == (self.N, self.L, self.L):\n # merr = np.zeros_like(diff)\n # for i in xrange(self.N):\n # merr[i] = np.dot(self.RM[i], diff[i])\n # else:\n # print(\"ERROR: RM is in an invalid shape.\")\n # else:\n # merr = self.RM * diff\n #\n # # Model error\n # if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n # #disc_vec = self.disc(x, p)\n # disc_vec1, disc_vec2 = self.disc(x, p)\n # diff1 = x[2::2] - x[:-2:2] - disc_vec1\n # diff2 = x[1::2] - disc_vec2\n # elif self.disc.im_func.__name__ == 'disc_forwardmap':\n # diff = x[1:] - self.disc(x, p)\n # else:\n # diff = x[1:] - x[:-1] - self.disc(x, p)\n #\n # if type(self.RF) == np.ndarray:\n # # Contract RF with the model error time series terms\n # if self.RF.shape == (self.N - 1, self.D):\n # if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n # ferr1 = self.RF[::2] * diff1\n # ferr2 = self.RF[1::2] * diff2\n # ferr = np.append(ferr1, ferr2)\n # else:\n # ferr = self.RF * diff\n #\n # elif self.RF.shape == (self.N - 1, self.D, self.D):\n # if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n # ferr1 = np.zeros_like(diff1)\n # ferr2 = np.zeros_like(diff2)\n # for i in xrange((self.N - 1) / 2):\n # ferr1[i] = self.RF[2*i] * diff1[i]\n # ferr2[i] = self.RF[2*i + 1] * diff2[i]\n # ferr = np.append(ferr1, ferr2)\n # else:\n # ferr = np.zeros_like(diff)\n # for i in xrange(self.N - 1):\n # ferr[i] = np.dot(self.RF[i], diff)\n #\n # else:\n # print(\"ERROR: RF is in an invalid shape.\")\n #\n # else:\n # if self.disc.im_func.__name__ == \"disc_SimpsonHermite\":\n # ferr1 = self.RF * diff1\n # ferr2 = self.RF * diff2\n # ferr = np.append(ferr1, ferr2)\n # else:\n # ferr = self.RF * diff\n #\n # return np.append(merr/(self.N * self.L), ferr/((self.N - 1) * self.D))\n\n ############################################################################\n # Discretization routines\n ############################################################################\n def disc_euler(self, x, p):\n \"\"\"\n Euler's method for time discretization of f.\n \"\"\"\n # repeat static params to all timepoints, concatenate with time-dep params\n # p_arr has shape (timepoints, number of static + dyn params)\n if (self.NP) > 0:\n repeat_idxs = np.ones(self.NP_flat)\n repeat_idxs[self.Pfixidx] = self.NPdynmax\n p_expand = np.repeat(p, repeat_idxs.astype(int))\n p_arr = np.reshape(p_expand, (-1, self.NP), order='F')\n else:\n p_arr = []\n if self.stim is None:\n pn = p_arr[:-1]\n else:\n pn = (p_arr[:-1], self.stim[:-1])\n\n return self.dt_model * self.f(self.t_model[:-1], x[:-1], pn)\n\n def disc_midpoint(self, x, p):\n \"\"\"\n Time discretization for the action using the midpoint rule.\n \"\"\"\n # repeat static params to all timepoints, concatenate with time-dep params\n # p_arr has shape (timepoints, number of static + dyn params)\n if (self.NP) > 0:\n repeat_idxs = np.ones(self.NP_flat)\n repeat_idxs[self.Pfixidx] = self.NPdynmax\n p_expand = np.repeat(p, repeat_idxs.astype(int))\n p_arr = np.reshape(p_expand, (-1, self.NP), order='F')\n else:\n p_arr = []\n if self.stim is None:\n pmid = (p_arr[:-1] + p_arr[1:]) / 2.0\n else:\n pmid = ((p_arr[:-1] + p_arr[1:]) / 2.0, \n (self.stim[:-1] + self.stim[1:]) / 2.0)\n \n tmid = (self.t_model[:-1] + self.t_model[1:]) / 2.0\n xmid = (x[:1] + x[:-1]) / 2.0\n\n return self.dt_model * self.f(tmid, xmid, pmid)\n \n def disc_trapezoid(self, x, p):\n \"\"\"\n Time discretization for the action using the trapezoid rule.\n \"\"\"\n # repeat static params to all timepoints, concatenate with time-dep params\n # p_arr has shape (timepoints, number of static + dyn params)\n if (self.NP) > 0:\n repeat_idxs = np.ones(self.NP_flat)\n repeat_idxs[self.Pfixidx] = self.NPdynmax\n p_expand = np.repeat(p, repeat_idxs.astype(int))\n p_arr = np.reshape(p_expand, (-1, self.NP), order='F')\n else:\n p_arr = []\n if self.stim is None:\n pn = p_arr[:-1]\n pnp1 = p_arr[1:]\n else:\n pn = (p_arr[:-1], self.stim[:-1])\n pnp1 = (p_arr[1:], self.stim[1:])\n\n fn = self.f(self.t_model[:-1], x[:-1], pn)\n fnp1 = self.f(self.t_model[1:], x[1:], pnp1)\n\n return self.dt_model * (fn + fnp1) / 2.0\n\n #Don't use RK4 yet, still trying to decide how to implement with a stimulus.\n #def disc_rk4(self, x, p):\n # \"\"\"\n # RK4 time discretization for the action.\n # \"\"\"\n # if self.stim is None:\n # pn = p\n # pmid = p\n # pnp1 = p\n # else:\n # pn = (p, self.stim[:-2:2])\n # pmid = (p, self.stim[1:-1:2])\n # pnp1 = (p, self.stim[2::2])\n #\n # xn = x[:-1]\n # tn = np.tile(self.t[:-1], (self.D, 1)).T\n # k1 = self.f(tn, xn, pn)\n # k2 = self.f(tn + self.dt/2.0, xn + k1*self.dt/2.0, pmid)\n # k3 = self.f(tn + self.dt/2.0, xn + k2*self.dt/2.0, pmid)\n # k4 = self.f(tn + self.dt, xn + k3*self.dt, pnp1)\n # return self.dt * (k1 + 2.0*k2 + 2.0*k3 + k4)/6.0\n\n def disc_SimpsonHermite(self, x, p):\n \"\"\"\n Simpson-Hermite time discretization for the action.\n This discretization applies Simpson's rule to all the even-index time\n points, and a Hermite polynomial interpolation for the odd-index points\n in between.\n \"\"\"\n # repeat static params to all timepoints, concatenate with time-dep params\n # p_arr has shape (timepoints, number of static + dyn params)\n if (self.NP) > 0:\n repeat_idxs = np.ones(self.NP_flat)\n repeat_idxs[self.Pfixidx] = self.NPdynmax\n p_expand = np.repeat(p, repeat_idxs.astype(int))\n p_arr = np.reshape(p_expand, (-1, self.NP), order='F')\n else:\n p_arr = []\n if self.stim is None:\n pn = p_arr[:-2:2]\n pmid = p_arr[1:-1:2]\n pnp1 = p_arr[2::2]\n else:\n pn = (p_arr[:-2:2], self.stim[:-2:2])\n pmid = (p_arr[1:-1:2], self.stim[1:-1:2])\n pnp1 = (p_arr[2::2], self.stim[2::2])\n \n fn = self.f(self.t_model[:-2:2], x[:-2:2], pn)\n fmid = self.f(self.t_model[1:-1:2], x[1:-1:2], pmid)\n fnp1 = self.f(self.t_model[2::2], x[2::2], pnp1)\n\n disc_vec1 = (fn + 4.0*fmid + fnp1) * (2.0*self.dt_model)/6.0\n disc_vec2 = (x[:-2:2] + x[2::2])/2.0 + (fn - fnp1) * (2.0*self.dt_model)/8.0\n\n return disc_vec1, disc_vec2\n\n def disc_forwardmap(self, x, p):\n \"\"\"\n \"Discretization\" when f is a forward mapping, not an ODE.\n \"\"\"\n # repeat static params to all timepoints, concatenate with time-dep params\n # p_arr has shape (timepoints, number of static + dyn params)\n if (self.NP) > 0:\n repeat_idxs = np.ones(self.NP_flat)\n repeat_idxs[self.Pfixidx] = self.NPdynmax\n p_expand = np.repeat(p, repeat_idxs.astype(int))\n p_arr = np.reshape(p_expand, (-1, self.NP), order='F')\n else:\n p_arr = []\n if self.stim is None:\n pn = p_arr[:-1]\n else:\n pn = (p_arr[:-1], self.stim[:-1])\n\n return self.f(self.t_model[:-1], x[:-1], pn)\n\n \n ############################################################################\n # Annealing functions\n ############################################################################\n def anneal(self, X0, P0, alpha, beta_array, RM, RF0, Lidx, Pidx, Uidx, \n dt_model=None,\n init_to_data=True, action='A_gaussian', disc='trapezoid', \n method='L-BFGS-B', bounds=None, opt_args=None, adolcID=0,\n track_paths=None, track_params=None, track_action_errors=None,\n enforce_model=False, adj_var_scaling=None):\n \"\"\"\n Convenience function to carry out a full annealing run over all values\n of beta in beta_array.\n \"\"\"\n # Initialize the annealing procedure, if not already done.\n if self.annealing_initialized == False:\n self.anneal_init(X0, P0, alpha, beta_array, RM, RF0, Lidx, Pidx, \n Uidx, dt_model,\n init_to_data, action, disc, method, bounds,\n opt_args, adolcID, enforce_model, adj_var_scaling)\n\n # Loop through all beta values for annealing.\n for i in beta_array:\n print('------------------------------')\n print('Step %d of %d'%(self.betaidx+1, len(self.beta_array)))\n # Print RF\n if type(self.RF) == np.ndarray:\n if self.RF.shape == (self.N_model - 1, self.D):\n print('beta = %d, RF[n=0, i=0] = %.8e'%(self.beta, self.RF[0, 0]))\n elif self.RF.shape == (self.N_model - 1, self.D, self.D):\n print('beta = %d, RF[n=0, i=0, j=0] = %.8e'%(self.beta, self.RF[0, 0, 0]))\n else:\n print(\"Error: RF has an invalid shape. You really shouldn't be here...\")\n sys.exit(1)\n else:\n print('beta = %d, RF = %.8e'%(self.beta, self.RF))\n print('')\n\n self.anneal_step()\n\n # Track progress by saving to file after every step\n if track_paths is not None:\n try:\n dtype = track_paths['dtype']\n except:\n dtype = np.float64\n try:\n fmt = track_paths['fmt']\n except:\n fmt = \"%.8e\"\n self.save_paths(track_paths['filename'], dtype, fmt)\n\n if track_params is not None:\n try:\n dtype = track_params['dtype']\n except:\n dtype = np.float64\n try:\n fmt = track_params['fmt']\n except:\n fmt = \"%.8e\"\n self.save_params(track_params['filename'], dtype, fmt)\n\n if track_action_errors is not None:\n try:\n cmpt = track_action_errors['cmpt']\n except:\n cmpt = 0\n try:\n dtype = track_action_errors['dtype']\n except:\n dtype = np.float64\n try:\n fmt = track_action_errors['fmt']\n except:\n fmt = \"%.8e\"\n self.save_action_errors(track_action_errors['filename'], cmpt, dtype, fmt)\n \n\n def anneal_init(self, X0, P0, alpha, beta_array, RM, RF0, Lidx, Pidx, Uidx, \n dt_model=None, init_to_data=True, action='A_gaussian', \n disc='trapezoid', method='L-BFGS-B', bounds=None, \n opt_args=None, adolcID=0, enforce_model=False, \n adj_var_scaling=False):\n \"\"\"\n Initialize the annealing procedure.\n \"\"\"\n if method not in ('SLSQP', 'L-BFGS-B', 'NCG', 'LM', 'TNC'):\n print(\"ERROR: Optimization routine not recognized. Annealing not initialized.\")\n return None\n else:\n self.method = method\n\n # Separate dt_data and dt_model not supported yet if there is an external stimulus.\n if dt_model is not None and dt_model != self.dt_data and self.stim is not None:\n print(\"Error! Separate dt_data and dt_model currently not supported with an \" +\\\n \"external stimulus. Exiting.\")\n sys.exit(1)\n else:\n if dt_model is None:\n self.dt_model = self.dt_data\n self.N_model = self.N_data\n self.merr_nskip = 1\n self.t_model = np.copy(self.t_data)\n else:\n self.dt_model = dt_model\n self.merr_nskip = int(self.dt_data / self.dt_model)\n self.N_model = (self.N_data - 1) * self.merr_nskip + 1\n self.t_model = np.linspace(self.t_data[0], self.t_data[-1], self.N_model)\n\n # get optimization extra arguments\n self.opt_args = opt_args\n\n # set the discretization scheme and number of timepoints for t-dependent params\n exec ('self.disc = self.disc_%s'%(disc,))\n self.NPdynmax = self.N_model\n\n # set up static and time-dep parameters\n assert len(np.intersect1d(Uidx, Pidx)) == 0, \"Pidx and Uidx must be distinct\"\n if len(Uidx)*len(Pidx) > 0:\n assert max(np.hstack((Uidx, Pidx))) < len(P0), \"P0 has length %s, but \"\\\n \"Pidx or Uidx contains indices greater than this\" % len(P0)\n\n # Add bounds on states. Will only be used if optimization routine\n # supports it.\n if bounds is not None:\n self.bounds = []\n state_b = bounds[:self.D]\n for n in xrange(self.N_model):\n for i in xrange(self.D):\n self.bounds.append(state_b[i])\n param_b = bounds[self.D:]\n else:\n self.bounds = None\n \n # Fix momenta at endpoints to zero\n if action == 'A_gaussian_adjoint':\n for i in xrange(self.D/2):\n self.bounds[self.D/2 + i] = [0., 0.]\n self.bounds[len(self.bounds) - 1 - i] = [0., 0.]\n \n # Aggregate parameters: initial values, measured indices, and bounds, for\n # both static (Pfix) and time-dependent (Pdyn) parameters\n self.P = []\n self.Pfixidx = []\n self.Pdynidx = []\n self.Pestidx = []\n cumidx = 0\n boundsidx = 0\n for i, P in enumerate(P0):\n assert (len(P) == 1) or (len(P) == self.NPdynmax),\\\n 'P0 entries must be length 1 or # of timepoints (time-dep); for '\\\n 'euler or forwardmap use timepoints = N_model - 1, '\\\n 'otherwise use N_model'\n if len(P) == 1:\n # parameter is static\n assert i not in Uidx, \"[%s] in Uidx but initalized as static\" % i\n self.Pfixidx.append(cumidx)\n if i in Pidx:\n self.Pestidx.append(cumidx)\n if bounds is not None:\n self.bounds.append(param_b[boundsidx])\n boundsidx += 1\n cumidx += 1\n elif len(P) == self.NPdynmax:\n # parameter is dyanmic\n assert i not in Pidx, \"[%s] in Pidx but initalized as time-dep\" % i\n self.Pdynidx.extend(range(cumidx, cumidx + self.NPdynmax))\n if i in Uidx:\n self.Pestidx.extend(range(cumidx, cumidx + self.NPdynmax))\n if bounds is not None:\n self.bounds.extend([param_b[boundsidx]]*self.NPdynmax)\n boundsidx += 1\n cumidx += self.NPdynmax\n self.P.extend(P.tolist())\n \n # Numbers of unique parameters (all and to be estimated)\n self.NP = len(P0)\n self.NPest = len(Pidx) + len(Uidx)\n\n # All parameters, with time-dependent ones expanded out\n self.P = np.array(self.P)\n self.NP_flat = len(self.P)\n\n # Parameters to be estimated\n self.Pestidx = np.array(self.Pestidx)\n self.NPest_flat = len(self.Pestidx)\n\n # Get indices of measured components of f\n self.Lidx = Lidx\n self.L = len(Lidx)\n \n # Variable scaling allows the estimation of scaled costates\n if action == 'A_gaussian_adjoint':\n if adj_var_scaling is not None:\n assert len(adj_var_scaling) == self.D/2, \"adj_var_scaling should be\"\\\n \" np array of length D/2\"\n var_scaling = np.hstack((np.ones(self.D/2), adj_var_scaling))\n self.adj_var_scaling = np.tile(var_scaling, self.N_model)\n else:\n self.adj_var_scaling = np.ones(self.N_model*self.D)\n\n\n # Reshape RM and RF so that they span the whole time series, if they\n # are passed in as vectors or matrices. This is done because in the\n # action evaluation, it is more efficient to let numpy handle\n # multiplication over time rather than using python loops.\n # If RM or RF is already passed in as a time series, move on!\n if type(RM) == list:\n RM = np.array(RM)\n if type(RM) == np.ndarray:\n if RM.shape == (self.L,):\n self.RM = np.resize(RM, (self.N_data, self.L))\n elif RM.shape == (self.L, self.L):\n self.RM = np.resize(RM, (self.N_data, self.L, self.L))\n elif RM.shape in [(self.N_data, self.L), (self.N_data, self.L, self.L)]:\n self.RM = RM\n else:\n print(\"ERROR: RM has an invalid shape. Exiting.\")\n sys.exit(1)\n else:\n self.RM = RM\n\n if type(RF0) == list:\n RF0 = np.array(RF0)\n if type(RF0) == np.ndarray:\n if RF0.shape == (self.D,):\n self.RF0 = np.resize(RF0, (self.N_model - 1, self.D))\n elif RF0.shape == (self.D, self.D):\n self.RF0 = np.resize(RF0, (self.N_model - 1, self.D, self.D))\n elif RF0.shape in [(self.N_model - 1, self.D), (self.N_model - 1, self.D, self.D)]:\n self.RF0 = RF0\n else:\n print(\"ERROR: RF0 has an invalid shape. Exiting.\")\n sys.exit(1)\n else:\n self.RF0 = RF0\n\n # set up beta array in RF = RF0 * alpha**beta\n self.alpha = alpha\n self.beta_array = np.array(beta_array, dtype=np.uint16)\n self.Nbeta = len(self.beta_array)\n\n # set initial RF\n self.betaidx = 0\n self.beta = self.beta_array[self.betaidx]\n self.RF = self.RF0 * self.alpha**self.beta\n\n # set the desired action\n #if self.method == 'LM':\n # # Levenberg-Marquardt requires a \"vector action\"\n # self.A = self.vecA_gaussian\n if type(action) == str:\n exec ('self.A = self.%s'%(action))\n else:\n # Assumption: user has passed a function pointer\n self.A = action\n\n # Set equality constraints if model equations are to be enforced exactly.\n if enforce_model == True:\n self.constraints = self.fe_equality_constraints\n else:\n self.constraints = None\n\n # array to store minimizing paths\n self.minpaths = np.zeros((self.Nbeta, self.N_model*self.D + self.NP_flat),\n dtype=np.float64)\n \n # initialize observed state components to data if desired\n if init_to_data == True:\n X0[::self.merr_nskip, self.Lidx] = self.Y[:]\n \n # Flatten X0 and P0 into extended XP0 path vector. minpaths olds \n # all parameters and states whether or not being estimated.\n XP0 = np.append(X0.flatten(), self.P)\n self.minpaths[0] = XP0\n \n # array to store optimization results\n self.A_array = np.zeros(self.Nbeta, dtype=np.float64)\n self.me_array = np.zeros(self.Nbeta, dtype=np.float64)\n self.fe_array = np.zeros(self.Nbeta, dtype=np.float64)\n self.exitflags = np.empty(self.Nbeta, dtype=np.int8)\n\n # set the adolcID\n self.adolcID = adolcID\n\n # Initialization successful, we're at the beta = beta_0 step now.\n self.initalized = True\n\n def anneal_step(self):\n \"\"\"\n Perform a single annealing step. The cost function is minimized starting\n from the previous minimum (or the initial guess, if this is the first\n step). Then, RF is increased to prepare for the next annealing step.\n \"\"\"\n # minimize A using the chosen method\n if self.method in ['SLSQP', 'L-BFGS-B', 'NCG', 'TNC', 'LM']:\n idx = (self.betaidx > 0)*(self.betaidx - 1)\n if self.NPest == 0:\n XP0 = np.copy(self.minpaths[idx][:self.N_model*self.D])\n else:\n X0 = self.minpaths[idx][:self.N_model*self.D]\n P0 = self.minpaths[idx][self.N_model*self.D:][self.Pestidx]\n XP0 = np.append(X0, P0)\n if self.method == 'SLSQP':\n XPmin, Amin, exitflag = self.min_slsqp_scipy(XP0, self.gen_xtrace())\n elif self.method == 'L-BFGS-B':\n XPmin, Amin, exitflag = self.min_lbfgs_scipy(XP0, self.gen_xtrace())\n elif self.method == 'NCG':\n XPmin, Amin, exitflag = self.min_cg_scipy(XP0, self.gen_xtrace())\n elif self.method == 'TNC':\n XPmin, Amin, exitflag = self.min_tnc_scipy(XP0, self.gen_xtrace())\n #elif self.method == 'LM':\n # XPmin, Amin, exitflag = self.min_lm_scipy(XP0)\n else:\n print(\"You really shouldn't be here. Exiting.\")\n sys.exit(1)\n else:\n print(\"ERROR: Optimization routine not implemented or recognized.\")\n sys.exit(1)\n \n # update optimal parameter values if there are parameters being estimated\n if self.NPest_flat > 0:\n if isinstance(XPmin[0], adolc._adolc.adouble):\n self.P[self.Pestidx] = np.array([XPmin[self.N_model*self.D + i].val \\\n for i in self.Pestidx])\n else:\n self.P[self.Pestidx] = np.copy(XPmin[-self.NPest_flat + self.Pestidx])\n \n # store A_min and the minimizing path\n self.A_array[self.betaidx] = Amin\n self.me_array[self.betaidx] = self.me_gaussian(np.array(XPmin[:self.N_model*self.D]))\n self.fe_array[self.betaidx] = self.fe_gaussian(np.array(XPmin))\n self.minpaths[self.betaidx] = np.array(np.append(XPmin[:self.N_model*self.D], self.P))\n\n # increase RF\n if self.betaidx < len(self.beta_array) - 1:\n self.betaidx += 1\n self.beta = self.beta_array[self.betaidx]\n self.RF = self.RF0 * self.alpha**self.beta\n \n # set flags indicating that A needs to be retaped, and that we're no\n # longer at the beginning of the annealing procedure\n self.taped = False\n if self.annealing_initialized:\n # Indicate no longer at beta_0\n self.initialized = False\n\n ################################################################################\n # Routines to save annealing results.\n ################################################################################\n def save_paths(self, filename, dtype=np.float64, fmt=\"%.8e\"):\n \"\"\"\n Save minimizing paths (not including parameters).\n \"\"\"\n savearray = np.reshape(self.minpaths[:, :self.N_model*self.D], \\\n (self.Nbeta, self.N_model, self.D))\n\n # append time\n tsave = np.reshape(self.t_model, (self.N_model, 1))\n tsave = np.resize(tsave, (self.Nbeta, self.N_model, 1))\n savearray = np.dstack((tsave, savearray))\n\n if filename.endswith('.npy'):\n np.save(filename, savearray.astype(dtype))\n else:\n np.savetxt(filename, savearray, fmt=fmt)\n\n def save_params(self, filename, dtype=np.float64, fmt=\"%.8e\"):\n \"\"\"\n Save minimum action parameter values.\n \"\"\"\n if self.NPest == 0:\n print(\"WARNING: You did not estimate any parameters. Writing fixed \" \\\n + \"parameter values to file anyway.\")\n\n # first write fixed parameters to array\n savearray = np.resize(self.P, (self.Nbeta, self.NP_flat))\n \n # then overwrite values of estimated parameters \n if self.NPest > 0:\n est_param_array = self.minpaths[:, self.N_model*self.D:]\n savearray[:, self.Pestidx] = est_param_array[:, self.Pestidx]\n \n if filename.endswith('.npy'):\n np.save(filename, savearray.astype(dtype))\n else:\n np.savetxt(filename, savearray, fmt=fmt)\n\n def save_action_errors(self, filename, cmpt=0, dtype=np.float64, fmt=\"%.8e\"):\n \"\"\"\n Save beta values, action, and errors (with/without RM and RF) to file.\n cmpt sets which component of RF0 to normalize by.\n \"\"\"\n savearray = np.zeros((self.Nbeta, 5))\n savearray[:, 0] = self.beta_array\n savearray[:, 1] = self.A_array\n savearray[:, 2] = self.me_array\n savearray[:, 3] = self.fe_array\n\n # Save model error / RF\n if type(self.RF) == np.ndarray:\n if self.RF0.shape == (self.N_model - 1, self.D):\n savearray[:, 4] = self.fe_array / (self.RF0[0, 0] * self.alpha**self.beta_array)\n elif self.RF0.shape == (self.N_model - 1, self.D, self.D):\n savearray[:, 4] = self.fe_array / (self.RF0[0, 0, 0] * self.alpha**self.beta_array)\n else:\n print(\"RF shape currently not supported for saving.\")\n return 1\n else:\n savearray[:, 4] = self.fe_array / (self.RF0 * self.alpha**self.beta_array)\n\n if filename.endswith('.npy'):\n np.save(filename, savearray.astype(dtype))\n else:\n np.savetxt(filename, savearray, fmt=fmt)\n\n def save_as_minAone(self, savedir='', savefile=None):\n \"\"\"\n Save the result of this annealing in minAone data file style.\n \"\"\"\n if savedir.endswith('/') == False:\n savedir += '/'\n if savefile is None:\n savefile = savedir + 'D%d_M%d_PATH%d.dat'%(self.D, self.L, self.adolcID)\n else:\n savefile = savedir + savefile\n betaR = self.beta_array.reshape((self.Nbeta,1))\n exitR = self.exitflags.reshape((self.Nbeta,1))\n AR = self.A_array.reshape((self.Nbeta,1))\n savearray = np.hstack((betaR, exitR, AR, self.minpaths))\n np.savetxt(savefile, savearray)\n\n ############################################################################\n # AD taping & derivatives\n ############################################################################\n def gen_xtrace(self):\n \"\"\"\n Define a random state vector for the AD trace.\n \"\"\"\n xtrace = np.random.rand(self.N_model*self.D + self.NPest_flat)\n return xtrace\n"
},
{
"alpha_fraction": 0.36307692527770996,
"alphanum_fraction": 0.5784615278244019,
"avg_line_length": 28.545454025268555,
"blob_id": "b7ea5b4b5fd683067aa11fad55c9aa259d46a0c6",
"content_id": "9c1173e63bb2c94d28671926420bfe69b16f0c36",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 11,
"path": "/examples/jupyter-tutorial/NaKL/data/NaKL_trueparam_dt0p02_N6001.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "# True parameter values\n# Listed in the same order as defined in the NaKL ode\n\nimport numpy as np\n\nptrue = [120.0, 20.0, 0.3, 50.0, -77.0, -54.0,\n -40.0, 1.0/0.06667, 0.1, 0.4,\n -60.0, -1.0/0.06667, 1.0, 7.0,\n -55.0, 1.0/0.03333, 1.0, 5.0]\n\nnp.save(\"NaKL_trueparam_dt0p02_N6001.npy\", np.array(ptrue))\n"
},
{
"alpha_fraction": 0.7608535885810852,
"alphanum_fraction": 0.7652685642242432,
"avg_line_length": 60.772727966308594,
"blob_id": "409d5c02754e2e787b548e7665fc4b460ee0e8ed",
"content_id": "574d7eff432cd2f5d9000a90b5edacb957a0f1d3",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1359,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 22,
"path": "/examples/nnet_barimages/README.txt",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "In this example, variational annealing (VA) is used to train a neural network \nwith a single hidden layer on Sasha's bar image data. This data consists of\n\"images\" of vertical, horizontal, or diagonal white bars on a black \nbackground. These images are also noisy, where (for now) the noise is i.i.d. \nfor every pixel.\n\nThe data can be generated by running the \"bardata_gen.py\" script in the\ndata folder. Modify the options at the top of the script to change the \nresolution of the images, what kinds of images to generate, etc. You can, of \ncourse, go into the script and change the data at a lower level. \nAlternatively, you can use Sasha's iPython notebook in the data folder, which \nalso has some code for viewing the images.\n\nThe network has three layers. The input layer has dim*dim neurons, where dim \nis the side length (in pixels) of the input image. The number of hidden \nlayer neurons can be set by the user (default is 30). The output layer has N_C \nneurons for the N_C classes. By default, N_C = 4 (images are labeled as being \neither horizontal, vertical, or diagonal at 45 degrees in either direction).\n\nTo change the structure of the network, as well as other training/annealing \nparameters, edit the annealing script in this folder (bardata_anneal.py). This \nis also the script that should be run with python2 to train the network.\n"
},
{
"alpha_fraction": 0.6187050342559814,
"alphanum_fraction": 0.7194244861602783,
"avg_line_length": 16.375,
"blob_id": "d95ac21717c7baa43d7c716b6c9e0f203b0bfc5f",
"content_id": "60198c36a07d6225fe30607fae4cedc90c34a250",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 139,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 8,
"path": "/examples/nnet_barimages/SGEcluster/qsub_command.sh",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "mkdir -p 1ex\nmkdir -p 2ex\nmkdir -p 10ex\nmkdir -p 100ex\nmkdir -p output\nmkdir -p error\n\nqsub -t 1-400 -tc 100 -N barmultiM submit_multiM.sh\n"
},
{
"alpha_fraction": 0.5957909822463989,
"alphanum_fraction": 0.623367190361023,
"avg_line_length": 24.518518447875977,
"blob_id": "e0b651d7fd87e20b0e981aafb6d3c5d827bb4b25",
"content_id": "df145babde46cd0c8cecce931b51186364b6e473",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1378,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 54,
"path": "/examples/nnet_twin/data/gen_params.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGenerate random parameters for the data-generating network.\n\nThe weights are drawn from a normal distribution ~N(0,1).\nThe biases are all set to zero.\n\"\"\"\n\nimport numpy as np\nimport os\n\n# Set up network structure\nD_in = 10\nD_out = 10\nD_hidden = 10\nN = 100 # number of layers, including input and output\n\nNparamsets = 10 # number of different parameter sets to generate\n\nnp.random.seed(17439860) # change the seed to get different parameters\n\n# Create directory to store parameters, if it doesn't exist\nif not os.path.exists(\"params\"):\n os.makedirs(\"params\")\n\nfor i in xrange(Nparamsets):\n # Generate parameter set i\n W = [] # weights\n b = [] # biases\n\n # First layer\n Wn = (2.0*np.random.rand(D_hidden, D_in) - 1.0) / float(D_in)\n bn = np.zeros(D_hidden)\n W.append(Wn)\n b.append(bn)\n\n for n in xrange(1, N - 1):\n # Loop through layers and generate weights from n to n+1\n Wn = (2.0*np.random.rand(D_hidden, D_hidden) - 1.0) / float(D_hidden)\n bn = np.zeros(D_hidden)\n W.append(Wn)\n b.append(bn)\n\n # Last layer\n Wn = (2.0*np.random.rand(D_out, D_hidden) - 1.0) / float(D_hidden)\n bn = np.zeros(D_out)\n W.append(Wn)\n b.append(bn)\n\n W = np.array(W)\n b = np.array(b)\n\n # Save this parameter set to file\n np.save(\"params/W_%d.npy\"%(i+1,), W)\n np.save(\"params/b_%d.npy\"%(i+1,), b)\n"
},
{
"alpha_fraction": 0.717605710029602,
"alphanum_fraction": 0.7377848029136658,
"avg_line_length": 52.450618743896484,
"blob_id": "2505a76b4eda1f96a8bb579fce851dcc53446eb2",
"content_id": "fadfc224d656beb33ea4befd71e311871750c0e6",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8827,
"license_type": "permissive",
"max_line_length": 297,
"num_lines": 162,
"path": "/README.md",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "# VarAnneal\r\nVarAnneal is a Python module that uses the variational annealing (VA) algorithm first proposed by J.C. Quinn<sup>[1]</sup>\r\nand described in detail in Ye et. al.<sup>[2]</sup> to \r\nperform state and parameter estimation in partially observed dynamical systems. This method requires optimization \r\nof a cost function called the \"action\" that balances measurement error (deviations of state estimates from observations) \r\nand model error (deviations of trajectories from the assumed dynamical behavior given a state and parameter estimate). \r\nDerivatives of the cost function are computed using automatic differentiation (AD) as implemented in \r\n[PYADOLC](https://github.com/b45ch1/pyadolc), a Python wrapper around [ADOL-C](https://projects.coin-or.org/ADOL-C). \r\n\r\n### Get VarAnneal\r\nVarAnneal is under constant development. When you clone this repository, the master branch is the most up-to-date with the most bug fixes, new features, and (hopefully) the fewest bugs; while tags represent previous versions of the code. You can clone VarAnneal to your computer with the command\r\n```bash\r\n$ git clone https://github.com/paulrozdeba/varanneal\r\n```\r\nwhich, when you open the directory, will automatically have the master branch checked out. You can check out other tags by entering this directory and executing\r\n```bash\r\n$ git pull\r\n$ git fetch --tags\r\n$ git checkout tags/<tagname>\r\n```\r\nwhere the various tags can be found with `git tags --list`, or in \"Branch\" dropdown menu near the top of this page.\r\n\r\n### Install\r\nVarAnneal requires you have the following software installed on your computer:\r\n1. Python 2 (tested on 2.7.9, probably will work on anything ≥ 2.7).\r\n2. NumPy (tested on ≥ 1.12.0).\r\n3. SciPy (tested on ≥ 0.18.1).\r\n4. [PYADOLC](https://github.com/b45ch1/pyadolc) \r\n\r\nYou should follow the installation instructions for PYADOLC in the readme page linked to above.\r\nIf you're running any Linux \r\ndistribution you should be able to follow the Ubuntu installation instructions with some minor \r\nmodifications (mostly finding the right packages in your distribution's repository, which may have \r\nslightly different names from the Ubuntu repo).\r\n\r\n**Caveat:** Building PYADOLC currently fails with boost 1.65.1. Currently (as of 10/23/17), the newest version \r\nof boost available for Ubuntu 17.10 (Artful Aardvark) is 1.62.0.1, so Ubuntu users should not have this \r\nproblem. If you are running some other distribution with more up-to-date libraries, like Fedora or \r\nArch Linux, make sure to hold back boost to 1.64.0 at the latest while this issue is resolved. \r\nIf you are installing in Mac OS with homebrew, you should similarly hold back boost to \r\nan older version. Use these commands to install boost 1.59, and to get your system to properly link to them:\r\n```bash\r\n$ brew install [email protected]\r\n$ brew install [email protected]\r\n$ brew link [email protected] --force\r\n$ brew link [email protected] --force\r\n```\r\n\r\nOnce you have this all installed, clone this git repo somewhere on your computer; I usually like putting \r\ncloned repos in `~/.local/src`. There is a setup.py file in the repo so, if you use Anaconda for example, \r\nthen follow the usual procedure for installation. If you don't, you can easily install the package with \r\nsetuptools (comes automatically with [pip](https://pip.pypa.io/en/stable/installing/)). Install it locally \r\nwith the following steps:\r\n```bash\r\npython2 setup.py build\r\npython2 setup.py install --user\r\n```\r\nand now you should be able to import varanneal from anywhere (repeat this procedure for additional users \r\non the same machine). Note: I plan to get VarAnneal up on PyPI eventually...\r\n\r\n### Usage\r\n(This example loosely follows the code found in the examples folder in this repository, for the case of \r\nstate and parameter estimation in an ODE dynamical system. Check out the neural network examples too to \r\nsee how that works; eventually I'll update this README with instructions for neural networks too).\r\nStart by importing VarAnneal, as well as NumPy which we'll need too, then instantiate an Annealer object:\r\n```python\r\nimport numpy as np\r\nfrom varanneal import va_ode\r\n\r\nmyannealer = va_ode.Annealer()\r\n```\r\nAlternatively the following syntax for importing/using varanneal (ODE version) works too:\r\n```python\r\nimport varanneal\r\nmyannealer = varanneal.va_ode.Annealer()\r\n```\r\nNow define a dynamical model for the observed system (here we're going to use Lorenz 96 as an example):\r\n```python\r\ndef l96(t, x, k):\r\n return np.roll(x, 1, 1) * (np.roll(x, -1, 1) - np.roll(x, 2, 1)) - x + k\r\nD = 20 # dimensionality of the Lorenz model\r\n\r\nmyannealer.set_model(l96, D)\r\n```\r\nImport the observed data. This file should be plain-text file in the following format:\r\n\r\n`t, y_1, y_2, ..., y_L`\r\n\r\nor a Numpy .npy archive with shape (*N*, *L+1*) where the 0th element of each time step is the time, and the rest are \r\nthe observed values of the L observed variables. Use the built-in convenience function to do this:\r\n```python\r\nmyannealer.set_data_fromfile(\"datafile.npy\")\r\nN_data = myannealer.N_data # Number of data time points, we're going to use this in a bit\r\n```\r\nYour other option is to just pass myannealer a NumPy array containing the data directly, using myannealer.set_data. \r\nThis is up to you and your coding preferences. An example of how to use this other function is in the Lorenz96 \r\nexample in the examples folder.\r\n\r\nFinally, we need to set a few other important quantities like the model indices of the observed variables; the \r\nindices of the estimated parameters (all other parameters remain fixed); the annealing hyperparameters \r\n(measurement and model error coefficients RM and RF, respectively); the \"exponential ladder\" for annealing RF; \r\nthe desired optimization routine (and options for the routine); and last but not least the initial state and \r\nparameter guesses:\r\n```python\r\nLidx = [0, 2, 4, 8, 10, 14, 16] # measured variable indices\r\nRM = 1.0 / (0.5**2)\r\nRF0 = 4.0e-6 # initial RF value for annealing\r\n\r\n# Now define the \"exponential ladder\" for anealing\r\nalpha = 1.5\r\nbeta = np.linspace(0, 100, 101)\r\n\r\n# Initial state and parameter guesses\r\n# We're going to use the init_to_data option later to automatically set the observed variables to \r\n# their observed values in the data.\r\nN_model = N_data # Want to evaluate the model at the observation times\r\nX0 = (20.0 * np.random.rand(N_model * D) - 10.0).reshape((N_model, D))\r\n\r\nPidx = [0] # indices of estimated parameters\r\n# The initial parameter guess can either be a list of values, or an array with N entries of guesses \r\n# which VarAnneal interprets as the parameters being time-dependent. Here we're sticking with a \r\n# static parameter:\r\nP0 = np.array([4.0 * np.random.rand() + 6.0])\r\n\r\n# Options for L-BFGS-B in scipy. These set the tolerance levels for termination in f and its \r\n# gradient, as well as the maximum number of iterations before moving on. See the manpage for \r\n# L-BFGS-B in scipy.optimize.minimize at \r\n# https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb \r\n# for more information.\r\nBFGS_options = {'gtol':1.0e-8, 'ftol':1.0e-8, 'maxfun':1000000, 'maxiter':1000000}\r\n\r\nmyannealer.anneal(X0, P0, alpha, beta, RM, RF0, Lidx, Pidx, dt_model=dt_model, \r\n init_to_data=True, disc='SimpsonHermite', method='L-BFGS-B', \r\n opt_args=BFGS_options, adolcID=0)\r\n```\r\nThat's it! Let the annealer run, and at the end save the results. VarAnneal saves to NumPy .npy archives, which \r\nare far more efficient for storing multi-dimensional arrays (which is the case here), and use compression so the \r\nresulting files are far smaller than plain-text with much greater precision. They are all saved over the whole annealing \r\nrun, meaning that each array is structured like (N_beta, ...) where N_beta is the number of beta values visited \r\nduring the annealing. The ... represents the appropriate dimensions for whatever data is being saved.\r\n```python\r\nmyannealer.save_paths(\"paths.npy\") # Path estimates\r\nmyannealer.save_params(\"params.npy\") # Parameter estimates\r\nmyannealer.save_action_errors(\"action_errors.npy\") # Action and individual error terms\r\n```\r\n\r\n### References\r\n[1] J.C. Quinn, *A path integral approach to data assimilation in stochastic nonlinear systems.* Ph.D. \r\nthesis in physics, UC San Diego, https://escholarship.org/uc/item/obm253qk (2010).\r\n\r\n[2] J. Ye, N. Kadakia, P. Rozdeba, H.D.I. Abarbanel, and J.C. Quinn. *Improved variational methods in \r\nstatistical data assimilation.* Nonlin. Proc. Geophys. **22**, 205-213 (2015).\r\n\r\n### Author\r\nPaul Rozdeba \r\nMay 23, 2017\r\n\r\n### Contributors\r\nThanks to Nirag Kadakia and Uriel I. Morone for their contributions to this project.\r\n\r\n### License\r\nThis project is licensed under the MIT license. See LICENSE for more details.\r\n"
},
{
"alpha_fraction": 0.6331152319908142,
"alphanum_fraction": 0.689984917640686,
"avg_line_length": 27.797101974487305,
"blob_id": "b4baaebf38e81f82b968a9d5f89fa4cf5dda9939",
"content_id": "220f64a3421626e865e970dd7e21ea4d055d34a1",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1987,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 69,
"path": "/examples/Lorenz96_D20/Lorenz96_anneal_autograd.py",
"repo_name": "niragkadakia/varanneal",
"src_encoding": "UTF-8",
"text": "\"\"\"\nExample file for carrying out state and parameter estimation in the Lorenz 96\nsystem using the weak-constrained variational method.\n\nVaranneal implements the variational annealing algorithm and uses automatic\ndifferentiation to do the action minimization at each step.\n\"\"\"\n\nimport autograd.numpy as np\nimport varanneal_autograd\nimport sys, time\n\n# Define the model\ndef l96(t, x, k):\n return np.roll(x,1,1) * (np.roll(x,-1,1) - np.roll(x,2,1)) - x + k\n\nD = 20\n\n# Action/annealing parameters\nLidx = [0, 2, 4, 8, 10, 12, 14, 16]\nL = len(Lidx)\n# RM, RF\nRM = 1.0 / (0.5**2)\nRF0 = 4.0e-6\n# set alpha and beta values\nalpha = 1.5\nbeta_array = np.linspace(0.0, 100.0, 101)\n\n# Load observed data\ndata = np.load(\"l96_D20_dt0p025_N161_sm0p5_sec1_mem1.npy\")\ntimes = data[:, 0]\nt0 = times[0]\ntf = times[-1]\ndt = times[1] - times[0]\nN = len(times)\n\n# Initial path/parameter guessees\ndata = data[:, 1:]\ndata = data[:, Lidx]\nXinit = (20.0*np.random.rand(N*D) - 10.0).reshape((N,D))\nfor i,l in enumerate(Lidx):\n Xinit[:, l] = data[:, i]\nXinit = Xinit.flatten()\n\n# Parameters\n# For P, we just need something; we'll fill in the initial guess below\nP = np.array([0.0])\nPidx = [0] # indices of estimated parameters\nPinit = 4.0 * np.random.rand() + 6.0 # initial parameter guess\nXP0 = np.append(Xinit, Pinit)\n\n# Initialize Annealer\nanneal1 = varanneal_autograd.Annealer()\n# Define the model\nanneal1.set_model(l96, P, D)\n# Load the data into the Annealer object\nanneal1.set_data(data, dt, t=times)\n# Run the annealing using L-BFGS-B\nBFGS_options = {'gtol':1.0e-12, 'ftol':1.0e-12, 'maxfun':1000000, 'maxiter':1000000}\n\ntstart = time.time()\nanneal1.anneal(XP0, alpha, beta_array, RM, RF0, Lidx, Pidx,\n disc='SimpsonHermite', method='L-BFGS-B', opt_args=BFGS_options)\nprint(\"\\nAutograd annealing completed in %f s.\"%(time.time() - tstart))\n\n# Save the results of annealing\nanneal1.save_paths(\"paths.npy\")\nanneal1.save_params(\"params.npy\")\nanneal1.save_action_errors(\"action_errors.npy\")\n"
}
] | 16 |
JuHyang/EmptyRoom
|
https://github.com/JuHyang/EmptyRoom
|
65202f7ad01a1982f65cd5e8bc591aeab875fda3
|
17dd9789779a573e110c9e8c30ad4f28421b618a
|
c4a03f3461ca9f089d5f40bc8b03c2b9cae54375
|
refs/heads/master
| 2020-03-19T06:31:40.014898 | 2018-06-04T13:30:26 | 2018-06-04T13:30:26 | 136,029,036 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.682539701461792,
"alphanum_fraction": 0.7063491940498352,
"avg_line_length": 18.894737243652344,
"blob_id": "f3b8209b1d25f3a9cccf955b370240e4a8390931",
"content_id": "0fa6a0de652806c9b07fa49f0d5c2ffa459e9b40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/frontend/Empty_room/app/src/main/java/com/juhyang/android/empty_room/RoomPresenter.java",
"repo_name": "JuHyang/EmptyRoom",
"src_encoding": "UTF-8",
"text": "package com.juhyang.android.empty_room;\n\nimport java.util.ArrayList;\n\n/**\n * Created by kkss2 on 2017-04-16.\n */\n\npublic interface RoomPresenter {\n void setView (RoomPresenter.View view);\n\n int getRoomTotal (int day, int index);\n ArrayList<RoomData> onGetRoom (int buildingNum, int time);\n void changeBuilding(int buildingNum);\n\n public interface View {\n }\n\n}\n"
},
{
"alpha_fraction": 0.5679912567138672,
"alphanum_fraction": 0.5733568072319031,
"avg_line_length": 31.413043975830078,
"blob_id": "93c2f9207e71fe0ca4a90a648247adfe727eb80d",
"content_id": "2c19c48434d3805867ce9bec99f94542700a995d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 12030,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 368,
"path": "/frontend/Empty_room/app/src/main/java/com/juhyang/android/empty_room/RoomActivity.java",
"repo_name": "JuHyang/EmptyRoom",
"src_encoding": "UTF-8",
"text": "package com.juhyang.android.empty_room;\n\nimport android.app.Activity;\nimport android.app.AlertDialog;\nimport android.content.DialogInterface;\nimport android.content.SharedPreferences;\nimport android.os.Bundle;\nimport android.support.annotation.IdRes;\nimport android.support.design.widget.NavigationView;\nimport android.support.v4.widget.DrawerLayout;\nimport android.support.v7.app.ActionBar;\nimport android.support.v7.app.AppCompatActivity;\nimport android.support.v7.widget.Toolbar;\nimport android.util.Log;\nimport android.view.Gravity;\nimport android.view.LayoutInflater;\nimport android.view.MenuItem;\nimport android.view.View;\nimport android.widget.Button;\nimport android.widget.ImageButton;\nimport android.widget.ListView;\nimport android.widget.RadioGroup;\nimport android.widget.TextView;\nimport android.widget.Toast;\n\nimport java.util.ArrayList;\nimport java.util.Calendar;\n\npublic class RoomActivity extends AppCompatActivity implements RoomPresenter.View{\n private TextView textViewDay;\n private RoomAdapter roomAdapter;\n private RoomPresenter roomPresenter;\n private ArrayList<RoomData> roomDatas = null;\n private ListView listView;\n private Button btn_all, btn_eb, btn_sb, btn_nb;\n private ImageButton btn_menu, btn_setting, btn_back;\n private RadioGroup radioGroup_d;\n\n private Toolbar toolbar;\n private DrawerLayout drawerLayout;\n private NavigationView navigationView;\n\n\n\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_room);\n setCustomActionBar();\n\n roomPresenter = new RoomPresenterImp(RoomActivity.this);\n roomPresenter.setView(this);\n\n initView();\n\n SharedPreferences mPref = getSharedPreferences(\"isFirst\", Activity.MODE_PRIVATE);\n Boolean bFirst = mPref.getBoolean(\"isFirst\", false);\n if (bFirst == false) {\n Log.d(\"version\", \"first\");\n SharedPreferences.Editor editor = mPref.edit();\n editor.putBoolean(\"isFirst\", true);\n editor.commit();\n BuildingNum temp = new BuildingNum(99);\n temp.save();\n openDialog();\n }\n if (bFirst == true) {\n Log.d(\"version\", \"not first\");\n }\n\n getOpenData();\n\n initModel();\n makeList();\n aboutView();\n\n\n\n\n }\n\n public void initView () {\n listView = (ListView) findViewById(R.id.listView);\n btn_all = (Button) findViewById(R.id.btn_all);\n btn_eb = (Button) findViewById(R.id.btn_eb);\n btn_sb = (Button) findViewById(R.id.btn_sb);\n btn_nb = (Button) findViewById(R.id.btn_nb);\n }\n\n public void aboutView() {\n\n ArrayList<Integer> presentTime;\n presentTime = getPresentTime();\n int time = presentTime.get(1);\n int index = (time - 9) * 2;\n if (presentTime.get(2) >= 30) {\n index += 1;\n }\n\n BuildingNum temp = BuildingNum.findById(BuildingNum.class, 1);\n ArrayList<RoomData> roomData_temp;\n roomData_temp = roomPresenter.onGetRoom(temp.buildingnum, index);\n roomDatas.addAll(roomData_temp);\n roomAdapter.notifyDataSetChanged();\n\n final int finalIndex = index;\n btn_all.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n ArrayList<RoomData> roomData_temp;\n roomData_temp = roomPresenter.onGetRoom(0, finalIndex);\n roomDatas.clear();\n roomDatas.addAll(roomData_temp);\n roomAdapter.notifyDataSetChanged();\n }\n });\n btn_eb.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n ArrayList<RoomData> roomData_temp;\n roomData_temp = roomPresenter.onGetRoom(1, finalIndex);\n roomDatas.clear();\n roomDatas.addAll(roomData_temp);\n Log.v(\"태그\", roomDatas.get(0).room);\n roomAdapter.notifyDataSetChanged();\n }\n });\n btn_sb.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n ArrayList<RoomData> roomData_temp;\n roomData_temp = roomPresenter.onGetRoom(2, finalIndex);\n roomDatas.clear();\n roomDatas.addAll(roomData_temp);\n roomAdapter.notifyDataSetChanged();\n }\n });\n btn_nb.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n ArrayList<RoomData> roomData_temp;\n roomData_temp = roomPresenter.onGetRoom(3, finalIndex);\n roomDatas.clear();\n roomDatas.addAll(roomData_temp);\n roomAdapter.notifyDataSetChanged();\n }\n });\n\n }\n\n public ArrayList<Integer> getPresentTime () {\n ArrayList<Integer> presentTime;\n presentTime = new ArrayList<Integer>();\n\n Calendar calendar = Calendar.getInstance();\n int day = calendar.get(Calendar.DAY_OF_WEEK);\n int time = calendar.get(Calendar.HOUR_OF_DAY);\n int min = calendar.get(Calendar.MINUTE);\n\n if (time < 9) {\n time = 9;\n min = 0;\n } else if ( time > 18) {\n day += 1;\n time = 9;\n min = 0;\n }\n if (day < 2 || day > 6) {\n day = 2;\n }\n day = day - 1;\n presentTime.add(day);\n presentTime.add(time);\n presentTime.add(min);\n\n return presentTime;\n }\n\n public void getOpenData () {\n\n ArrayList<Integer> presentTime;\n presentTime = getPresentTime();\n int day = presentTime.get(0);\n int time = presentTime.get(1);\n int index = (time - 9) * 2;\n if (presentTime.get(2) >= 30) {\n index += 1;\n }\n int success = roomPresenter.getRoomTotal(day, index);\n\n changeDayText(day);\n\n if (success == 0) {\n Toast.makeText(this, \"서버에 문제가 있습니다. 잠시 후 다시 시도해 주세요\", Toast.LENGTH_SHORT).show();\n }\n }\n\n public void openDialog () {\n final int[] temp = new int[1];\n LayoutInflater layoutInflater = (LayoutInflater)getLayoutInflater();\n View dialogLayout = layoutInflater.inflate(R.layout.first_dialog, null);\n\n radioGroup_d = (RadioGroup) dialogLayout.findViewById(R.id.radio_building);\n\n radioGroup_d.setOnCheckedChangeListener(new RadioGroup.OnCheckedChangeListener() {\n @Override\n public void onCheckedChanged(RadioGroup group, @IdRes int checkedId) {\n switch (checkedId) {\n case R.id.radio_eb_d :\n temp[0] = 1;\n break;\n case R.id.radio_sb_d :\n temp[0] = 2;\n break;\n case R.id.radio_nb_d :\n temp[0] = 3;\n break;\n }\n }\n });\n\n AlertDialog.Builder builder = new AlertDialog.Builder(RoomActivity.this);\n builder.setPositiveButton(\"확인\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialog, int which) {\n roomPresenter.changeBuilding(temp[0]);\n }\n });\n\n builder.setTitle(\"주로 가는 건물\");\n builder.setView(dialogLayout);\n\n\n AlertDialog alertDialog = builder.create();\n alertDialog.show();\n }\n\n private void initModel () {\n roomDatas = new ArrayList<RoomData> ();\n }\n\n private void makeList() {\n roomAdapter = new RoomAdapter(roomDatas,getApplicationContext());\n listView.setAdapter(roomAdapter);\n }\n\n private void setCustomActionBar () {\n\n drawerLayout = (DrawerLayout) findViewById(R.id.dl_room_activity);\n navigationView = (NavigationView) findViewById(R.id.navigation);\n\n navigationView.setNavigationItemSelectedListener(new NavigationView.OnNavigationItemSelectedListener() {\n @Override\n public boolean onNavigationItemSelected(MenuItem item) {\n String day = (String) item.getTitle();\n char temp = day.charAt(4);\n switch (temp) {\n case '월' :\n changeDay(0);\n break;\n case '화' :\n changeDay(1);\n break;\n case '수' :\n changeDay(2);\n break;\n case '목' :\n changeDay(3);\n break;\n case '금' :\n changeDay(4);\n break;\n }\n btn_menu.setVisibility(View.VISIBLE);\n btn_back.setVisibility(View.GONE);\n drawerLayout.closeDrawer(Gravity.LEFT);\n return false;\n }\n\n });\n\n\n\n\n ActionBar actionBar = getSupportActionBar();\n\n actionBar.setDisplayShowCustomEnabled(true);\n actionBar.setDisplayHomeAsUpEnabled(false);\n actionBar.setDisplayShowTitleEnabled(false);\n\n View actionBarView = LayoutInflater.from(this).inflate(R.layout.layout_actionbar, null);\n\n btn_menu = (ImageButton) actionBarView.findViewById(R.id.btn_menu);\n btn_setting = (ImageButton) actionBarView.findViewById(R.id.btn_setting);\n btn_back = (ImageButton) actionBarView.findViewById(R.id.btn_back);\n textViewDay = (TextView) actionBarView.findViewById(R.id.textView_day);\n\n btn_menu.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n drawerLayout.openDrawer(Gravity.LEFT);\n btn_menu.setVisibility(View.GONE);\n btn_back.setVisibility(View.VISIBLE);\n }\n });\n btn_back.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n drawerLayout.closeDrawer(Gravity.LEFT);\n btn_menu.setVisibility(View.VISIBLE);\n btn_back.setVisibility(View.GONE);\n }\n });\n\n btn_setting.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n openDialog();\n }\n });\n\n\n actionBar.setCustomView(actionBarView);\n\n toolbar = (Toolbar) actionBarView.getParent();\n toolbar.setContentInsetsAbsolute(0,0);\n\n ActionBar.LayoutParams params = new ActionBar.LayoutParams(ActionBar.LayoutParams.MATCH_PARENT, ActionBar.LayoutParams.MATCH_PARENT);\n actionBar.setCustomView(actionBarView, params);\n }\n\n public void changeDay(int order) {\n roomPresenter.getRoomTotal(order,0);\n BuildingNum temp = BuildingNum.findById(BuildingNum.class, 1);\n ArrayList<RoomData> roomData_temp;\n roomData_temp = roomPresenter.onGetRoom(temp.buildingnum, 0);\n roomDatas.clear();\n roomDatas.addAll(roomData_temp);\n roomAdapter.notifyDataSetChanged();\n changeDayText(order);\n\n }\n\n public void changeDayText (int day) {\n switch (day) {\n case 0:\n textViewDay.setText(\"월요일\");\n break;\n case 1:\n textViewDay.setText(\"화요일\");\n break;\n case 2:\n textViewDay.setText(\"수요일\");\n break;\n case 3:\n textViewDay.setText(\"목요일\");\n break;\n case 4:\n textViewDay.setText(\"금요일\");\n break;\n\n }\n }\n\n\n\n}\n"
},
{
"alpha_fraction": 0.47588035464286804,
"alphanum_fraction": 0.4908345341682434,
"avg_line_length": 33.264461517333984,
"blob_id": "b1ca139887f935e1f8348f50380c96d99bc1b572",
"content_id": "43032a4f35cb27f5ae7c11b28f24688f5c18531f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4200,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 121,
"path": "/frontend/Empty_room/app/src/main/java/com/juhyang/android/empty_room/RoomModel.java",
"repo_name": "JuHyang/EmptyRoom",
"src_encoding": "UTF-8",
"text": "package com.juhyang.android.empty_room;\n\nimport java.io.IOException;\nimport java.util.ArrayList;\n\nimport retrofit2.Call;\nimport retrofit2.Retrofit;\nimport retrofit2.converter.gson.GsonConverterFactory;\n\n/**\n * Created by kkss2 on 2017-04-16.\n */\n\npublic class RoomModel {\n\n public RoomTotalData getRoomTotal (int day, int time) {\n final RoomTotalData roomTotalData = new RoomTotalData();\n roomTotalData.roomTotalData = new ArrayList<>();\n\n roomTotalData.success = 0;\n roomTotalData.roomTotalData = new ArrayList<>();\n Retrofit retrofit = new Retrofit.Builder()\n .baseUrl(\"http://175.201.94.92:3000\")\n .addConverterFactory(GsonConverterFactory.create())\n .build();\n\n ServerInterface service = retrofit.create(ServerInterface.class);\n final Call<RoomTotalData> call = service.getData(day, time);\n new Thread (new Runnable ()\n {\n\n @Override\n public void run() {\n try {\n roomTotalData.roomTotalData.addAll(call.execute().body().roomTotalData);\n roomTotalData.success = 1;\n } catch (IOException e) {\n roomTotalData.success = 0;\n }\n }\n }).start();\n\n try {\n Thread.sleep(1000);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n return roomTotalData;\n }\n\n public String makeText(int realtime, int status) {\n String result = \"\";\n if (status == 0 ) {\n result += Integer.toString(realtime) + \" : 00 ~ \" + Integer.toString(realtime) + \" : 30\";\n }\n else if (status == 1) {\n result += Integer.toString(realtime) + \" : 30 ~ \" + Integer.toString(realtime + 1) + \" : 00\";\n }\n return result;\n }\n\n public ArrayList<RoomData> makeArray (int buildingNum, int realtime, int status, RoomTotalData totalData) {\n ArrayList<RoomData> roomDatas = new ArrayList<RoomData>();\n\n int realtime_t = realtime;\n int status_t = status;\n int roop = totalData.roomTotalData.size();\n if (roop == 0) {\n RoomData roomData_temp = new RoomData(\"\", \"비어있는 강의실이 없습니다.\");\n roomDatas.add(roomData_temp);\n return roomDatas;\n }\n\n for (int i = 0; i < roop; i++) {\n RoomData roomData_temp = new RoomData();\n roomData_temp.time = makeText(realtime_t, status_t);\n if (status_t == 0) {\n status_t = 1;\n } else if (status_t == 1) {\n status_t = 0;\n realtime_t += 1;\n }\n int roop_2 = totalData.roomTotalData.get(i).size();\n if (roop_2 == 0) {\n roomData_temp.room = \"비어있는 강의실이 없습니다.\";\n roomDatas.add(roomData_temp);\n continue;\n }\n String temp = \"\";\n\n for (int j = 0; j < roop_2; j ++) {\n if (buildingNum == 0) {\n temp += totalData.roomTotalData.get(i).get(j) + \" \";\n } else if (buildingNum == 1) {\n if (totalData.roomTotalData.get(i).get(j).charAt(0) == '전') {\n temp += totalData.roomTotalData.get(i).get(j) + \" \";\n } else {\n continue;\n }\n } else if (buildingNum == 2) {\n if (totalData.roomTotalData.get(i).get(j).charAt(0) == '과') {\n temp += totalData.roomTotalData.get(i).get(j) + \" \";\n } else {\n continue;\n }\n } else if (buildingNum == 3) {\n if (totalData.roomTotalData.get(i).get(j).charAt(0) == '강') {\n temp += totalData.roomTotalData.get(i).get(j) + \" \";\n } else {\n continue;\n }\n }\n }\n roomData_temp.room = temp;\n roomDatas.add(roomData_temp);\n }\n return roomDatas;\n }\n\n}\n"
},
{
"alpha_fraction": 0.5955414175987244,
"alphanum_fraction": 0.6019108295440674,
"avg_line_length": 19.933332443237305,
"blob_id": "f0bbe2f703e4f502efc894f31b68f2b365cb8cf0",
"content_id": "b9e2be652b095ceb11042d22cc8b21f07b92e1d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 15,
"path": "/backend/test.py",
"repo_name": "JuHyang/EmptyRoom",
"src_encoding": "UTF-8",
"text": "#-*- coding: utf-8 -*-\n\nimport pymysql\n\nconn = pymysql.connect(host='localhost', user='root', password='dlwngid1',\n db='empty_room', charset='utf8')\n\ncurs = conn.cursor()\n\nsql = \"\"\"INSERT INTO empty_room (mon) VALUES (%s)\"\"\"\n\ncurs.execute(sql, ( 'hello world'))\nconn.commit()\n\nconn.close()\n"
},
{
"alpha_fraction": 0.4709879755973816,
"alphanum_fraction": 0.6445373892784119,
"avg_line_length": 67.32142639160156,
"blob_id": "8ca6b1ad49f355d9a0c87cbfbe90e1f1b6cdb258",
"content_id": "9eb067b52a0dc91044caadd35e83dc604cc66e21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2175,
"license_type": "no_license",
"max_line_length": 791,
"num_lines": 28,
"path": "/backend/get_room_inform.py",
"repo_name": "JuHyang/EmptyRoom",
"src_encoding": "UTF-8",
"text": "#-*- coding: utf-8 -*-\n\n##웹 크롤러를 이용한 소스코드 스크래핑 Selenium 을 이용함\n##Selenium 은 웹 테스팅 모듈\n\nfrom selenium import webdriver\nfrom bs4 import BeautifulSoup\n\nroom_list = ['EB0102', 'EB0103', 'EB0104', 'EB0105', 'EB0106', 'EB0225', 'EB0401', 'EB0402', 'EB0418', 'EB0420', 'SB0101', 'SB0102', 'SB0103', 'SB0104', 'SB0107', 'SB0108', 'SB0109', 'SB0110', 'SB0111', 'SB0112', 'SB0114', 'SB0115', 'SB0116', 'SB0117', 'SB0201', 'SB0202', 'SB0203', 'SB0206', 'SB0208', 'SB0211', 'SB0218', 'SB0219', 'SB0220', 'SB0221', 'SB0222', 'SB0232', 'SB0233', 'SB0234', 'SB0235', 'SB0301', 'SB0304', 'SB0306', 'SB0308', 'SB0311', 'SB0326', 'SB0327', 'SB0332', 'SB0407', 'SB0409', 'SB0412', 'SB0415', 'SB0418', 'SB0401', 'SB0403', 'SB0405', 'SB0406', 'SB0422', 'SB0424', 'SB0432', 'NB101', 'NB102', 'NB104', 'NB105', 'NB107', 'NB108', 'NB201', 'NB202', 'NB203', 'NB204', 'NB205', 'NB206', 'NB207', 'NB208', 'NB209', 'NB210', 'NB211', 'NB213', 'NB214', 'NB309', 'NB310']\n\ndriver = webdriver.Chrome () ##selenium 사용을 위한 crhome driver 연결\n\ndriver.implicitly_wait(3) ##암묵적으로 3초 기다림 (서버 안정화를 위함)\n\ndriver.get('https://www.kau.ac.kr/page/login.jsp?ppage=&target_page=act_Portal_Check.jsp@chk1-1') ##로그인 페이지에 접속\n\ndriver.find_element_by_name('p_id').send_keys('2015125061') ##소스코드중에 p_id 를 찾아서 입력\ndriver.find_element_by_name('p_pwd').send_keys('01040562889z!') ##소스코드중에 P_pwd를 찾아서 입력\ndriver.find_element_by_xpath('/html/body/div[2]/div[2]/table[2]/tbody/tr[3]/td/form/table/tbody/tr[3]/td/table/tbody/tr/td[2]/table/tbody/tr/td[2]/a/img').click() ##login 버튼 클릭\n\nfor room in room_list :\n url = 'https://portal.kau.ac.kr/sugang/LectSpaceRoomSchView.jsp?year=2017&hakgi=10&room_name=102&room_no=' + room ##url 생성 마지막에 i 는 강의실 코드\n driver.get(url) ##url 에 접속\n html = driver.page_source ##html 에 url에 있는 모든 소스코드를 담음\n fname = \"room/\" + room + \".txt\"\n f = open(fname, \"w\", encoding=\"utf-8\") ## 강의실코드.txt 파일에 소스코드를 저장\n f.write(html)\n f.close()\n"
},
{
"alpha_fraction": 0.6750713586807251,
"alphanum_fraction": 0.6812559366226196,
"avg_line_length": 28.605634689331055,
"blob_id": "d840a77646969ee4580fa931004ab64b5126c5e4",
"content_id": "c96e7dab4bcefcccb0e1cde855f39af937bcc329",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2102,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 71,
"path": "/frontend/Empty_room/app/src/main/java/com/juhyang/android/empty_room/RoomAdapter.java",
"repo_name": "JuHyang/EmptyRoom",
"src_encoding": "UTF-8",
"text": "package com.juhyang.android.empty_room;\n\nimport android.content.Context;\nimport android.view.LayoutInflater;\nimport android.view.View;\nimport android.view.ViewGroup;\nimport android.widget.BaseAdapter;\nimport android.widget.TextView;\n\nimport java.util.ArrayList;\n\n/**\n * Created by kkss2 on 2017-04-15.\n */\n\npublic class RoomAdapter extends BaseAdapter{\n private ArrayList<RoomData> roomDatas = null;\n private LayoutInflater layoutInflater = null;\n\n public RoomAdapter(ArrayList<RoomData> roomDatas, Context ctx){\n\n this.roomDatas = roomDatas;\n layoutInflater = (LayoutInflater)ctx.getSystemService(Context.LAYOUT_INFLATER_SERVICE);\n }\n\n public void setRoomDatas(ArrayList<RoomData> roomDatas){\n this.roomDatas = roomDatas;\n this.notifyDataSetChanged();\n }\n\n @Override\n public int getCount() {\n return roomDatas !=null ? roomDatas.size():0;\n }\n\n @Override\n public Object getItem(int position) {\n return (roomDatas !=null && (position >= 0 && position < roomDatas.size()) ? roomDatas.get(position) : null );\n }\n\n @Override\n public long getItemId(int position) {\n return (roomDatas !=null && (position >= 0 && position < roomDatas.size()) ? position : 0 );\n }\n\n @Override\n public View getView(int position, View convertView, ViewGroup parent) {\n\n\n RoomViewHolder roomViewHolder = new RoomViewHolder();\n if(convertView ==null){\n convertView = layoutInflater.inflate(R.layout.list_item,parent,false);\n\n roomViewHolder.textView_time = (TextView) convertView.findViewById(R.id.textView_time);\n roomViewHolder.textView_room = (TextView) convertView.findViewById(R.id.textView_room);\n\n\n convertView.setTag(roomViewHolder);\n }\n\n else{\n roomViewHolder = (RoomViewHolder)convertView.getTag();\n }\n\n RoomData roomData_temp = roomDatas.get(position);\n roomViewHolder.textView_time.setText(roomData_temp.time);\n roomViewHolder.textView_room.setText(roomData_temp.room);\n\n return convertView;\n }\n}\n"
}
] | 6 |
BrianMichell/security-camera
|
https://github.com/BrianMichell/security-camera
|
b4202ceff052ae4cf8e4771dbb9889b70ee464ba
|
43b84ad9fec01b05973e906c686e8441ac3d3985
|
323e94031e201f1cc5f25800dc4b907235191182
|
refs/heads/master
| 2020-03-23T06:32:35.164909 | 2018-07-17T01:36:06 | 2018-07-17T01:36:06 | 141,214,964 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4834478497505188,
"alphanum_fraction": 0.5409119129180908,
"avg_line_length": 24.015625,
"blob_id": "b45a1b0dde6c8598b15ce2e0b62b93b9229f9cd7",
"content_id": "f4093fe63c09bde6a652ae6502cb756a7e4e1ec4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1601,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 64,
"path": "/testing.py",
"repo_name": "BrianMichell/security-camera",
"src_encoding": "UTF-8",
"text": "import cv2 as cv\nimport time\n\ndef recordingTime(times):\n #Set localTime subscript back to 3\n localTime = time.localtime()\n for timeslot in times:\n if localTime[5] > timeslot[0] and localTime[5] < timeslot[1]:\n return True\n \n\ncap = cv.VideoCapture(0)\n\nfourcc = cv.VideoWriter_fourcc(*'DIVX')\nout = cv.VideoWriter('output.avi', fourcc, 7.0, (640, 480))\n\nintensity = 255\np_time = time.time()\ndescending = True\n\nwhile True:\n _, frame = cap.read()\n \n save = recordingTime(((15,45),(17,20)))\n \n if(save):\n delta = time.time() - p_time\n if(intensity >= 0 and descending):\n tmp = intensity - delta * 255\n intensity = max(0, tmp)\n else:\n tmp = intensity + delta * 255\n intensity = min(255, tmp)\n \n if(intensity == 0):\n descending = False\n if(intensity == 255):\n descending = True\n else:\n intensity = 0\n \n t = time.localtime()\n \n datestamp = \"Date: {}/{}/{}\".format(t[1], t[2], t[0])\n timestamp = \"{}:{}:{}\".format(t[3], t[4], t[5])\n \n cv.putText(frame, datestamp, (20, 20), cv.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv.LINE_AA)\n cv.putText(frame, timestamp, (20, 40), cv.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv.LINE_AA)\n cv.circle(frame, (600, 30), 20, (0, 0, intensity), -1)\n \n if(save):\n out.write(frame)\n cv.imshow('frame', frame)\n \n p_time = time.time()\n \n k = cv.waitKey(5) & 0xFF\n if(k == 27):\n break\n \nout.release()\n\ncv.destroyAllWindows()\ncap.release()\n"
}
] | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.