
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
10.2k
| golden_diff
stringlengths 151
4.94k
| verification_info
stringlengths 582
21k
| num_tokens
int64 271
2.05k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_36882
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-5963
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Problems when displaying multiple views of ContainerWidget.
`ContainerView.render` registers anonymous functions to `this.model.on('displayed')` . This is a problem because when rendering multiple views of the same widget container, multiple instances of this anonymous function get registered to this event.
PS: This is also related to #5958
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/html/widgets/widget_container.py`
Content:
```
1 """ContainerWidget class.
2
3 Represents a container that can be used to group other widgets.
4 """
5 #-----------------------------------------------------------------------------
6 # Copyright (c) 2013, the IPython Development Team.
7 #
8 # Distributed under the terms of the Modified BSD License.
9 #
10 # The full license is in the file COPYING.txt, distributed with this software.
11 #-----------------------------------------------------------------------------
12
13 #-----------------------------------------------------------------------------
14 # Imports
15 #-----------------------------------------------------------------------------
16 from .widget import DOMWidget
17 from IPython.utils.traitlets import Unicode, Tuple, TraitError
18
19 #-----------------------------------------------------------------------------
20 # Classes
21 #-----------------------------------------------------------------------------
22
23 class ContainerWidget(DOMWidget):
24 _view_name = Unicode('ContainerView', sync=True)
25
26 # Child widgets in the container.
27 # Using a tuple here to force reassignment to update the list.
28 # When a proper notifying-list trait exists, that is what should be used here.
29 children = Tuple()
30 _children = Tuple(sync=True)
31
32
33 def __init__(self, **kwargs):
34 super(ContainerWidget, self).__init__(**kwargs)
35 self.on_displayed(ContainerWidget._fire_children_displayed)
36
37 def _fire_children_displayed(self):
38 for child in self._children:
39 child._handle_displayed()
40
41 def _children_changed(self, name, old, new):
42 """Validate children list.
43
44 Makes sure only one instance of any given model can exist in the
45 children list.
46 An excellent post on uniqifiers is available at
47 http://www.peterbe.com/plog/uniqifiers-benchmark
48 which provides the inspiration for using this implementation. Below
49 I've implemented the `f5` algorithm using Python comprehensions."""
50 if new is not None:
51 seen = {}
52 def add_item(i):
53 seen[i.model_id] = True
54 return i
55 self._children = [add_item(i) for i in new if not i.model_id in seen]
56
57
58 class PopupWidget(ContainerWidget):
59 _view_name = Unicode('PopupView', sync=True)
60
61 description = Unicode(sync=True)
62 button_text = Unicode(sync=True)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/html/widgets/widget_container.py b/IPython/html/widgets/widget_container.py
--- a/IPython/html/widgets/widget_container.py
+++ b/IPython/html/widgets/widget_container.py
@@ -2,58 +2,29 @@
Represents a container that can be used to group other widgets.
"""
-#-----------------------------------------------------------------------------
-# Copyright (c) 2013, the IPython Development Team.
-#
+
+# Copyright (c) IPython Development Team.
# Distributed under the terms of the Modified BSD License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#-----------------------------------------------------------------------------
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
from .widget import DOMWidget
from IPython.utils.traitlets import Unicode, Tuple, TraitError
-#-----------------------------------------------------------------------------
-# Classes
-#-----------------------------------------------------------------------------
-
class ContainerWidget(DOMWidget):
_view_name = Unicode('ContainerView', sync=True)
# Child widgets in the container.
# Using a tuple here to force reassignment to update the list.
# When a proper notifying-list trait exists, that is what should be used here.
- children = Tuple()
- _children = Tuple(sync=True)
-
+ children = Tuple(sync=True)
def __init__(self, **kwargs):
super(ContainerWidget, self).__init__(**kwargs)
self.on_displayed(ContainerWidget._fire_children_displayed)
def _fire_children_displayed(self):
- for child in self._children:
+ for child in self.children:
child._handle_displayed()
- def _children_changed(self, name, old, new):
- """Validate children list.
-
- Makes sure only one instance of any given model can exist in the
- children list.
- An excellent post on uniqifiers is available at
- http://www.peterbe.com/plog/uniqifiers-benchmark
- which provides the inspiration for using this implementation. Below
- I've implemented the `f5` algorithm using Python comprehensions."""
- if new is not None:
- seen = {}
- def add_item(i):
- seen[i.model_id] = True
- return i
- self._children = [add_item(i) for i in new if not i.model_id in seen]
-
class PopupWidget(ContainerWidget):
_view_name = Unicode('PopupView', sync=True)
|
{"golden_diff": "diff --git a/IPython/html/widgets/widget_container.py b/IPython/html/widgets/widget_container.py\n--- a/IPython/html/widgets/widget_container.py\n+++ b/IPython/html/widgets/widget_container.py\n@@ -2,58 +2,29 @@\n \n Represents a container that can be used to group other widgets.\n \"\"\"\n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2013, the IPython Development Team.\n-#\n+\n+# Copyright (c) IPython Development Team.\n # Distributed under the terms of the Modified BSD License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#-----------------------------------------------------------------------------\n \n-#-----------------------------------------------------------------------------\n-# Imports\n-#-----------------------------------------------------------------------------\n from .widget import DOMWidget\n from IPython.utils.traitlets import Unicode, Tuple, TraitError\n \n-#-----------------------------------------------------------------------------\n-# Classes\n-#-----------------------------------------------------------------------------\n-\n class ContainerWidget(DOMWidget):\n _view_name = Unicode('ContainerView', sync=True)\n \n # Child widgets in the container.\n # Using a tuple here to force reassignment to update the list.\n # When a proper notifying-list trait exists, that is what should be used here.\n- children = Tuple()\n- _children = Tuple(sync=True)\n-\n+ children = Tuple(sync=True)\n \n def __init__(self, **kwargs):\n super(ContainerWidget, self).__init__(**kwargs)\n self.on_displayed(ContainerWidget._fire_children_displayed)\n \n def _fire_children_displayed(self):\n- for child in self._children:\n+ for child in self.children:\n child._handle_displayed()\n \n- def _children_changed(self, name, old, new):\n- \"\"\"Validate children list.\n-\n- Makes sure only one instance of any given model can exist in the \n- children list.\n- An excellent post on uniqifiers is available at \n- http://www.peterbe.com/plog/uniqifiers-benchmark\n- which provides the inspiration for using this implementation. Below\n- I've implemented the `f5` algorithm using Python comprehensions.\"\"\"\n- if new is not None:\n- seen = {}\n- def add_item(i):\n- seen[i.model_id] = True\n- return i\n- self._children = [add_item(i) for i in new if not i.model_id in seen]\n-\n \n class PopupWidget(ContainerWidget):\n _view_name = Unicode('PopupView', sync=True)\n", "issue": "Problems when displaying multiple views of ContainerWidget. \n`ContainerView.render` registers anonymous functions to `this.model.on('displayed')` . This is a problem because when rendering multiple views of the same widget container, multiple instances of this anonymous function get registered to this event. \n\nPS: This is also related to #5958\n\n", "before_files": [{"content": "\"\"\"ContainerWidget class. \n\nRepresents a container that can be used to group other widgets.\n\"\"\"\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, the IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\nfrom .widget import DOMWidget\nfrom IPython.utils.traitlets import Unicode, Tuple, TraitError\n\n#-----------------------------------------------------------------------------\n# Classes\n#-----------------------------------------------------------------------------\n\nclass ContainerWidget(DOMWidget):\n _view_name = Unicode('ContainerView', sync=True)\n\n # Child widgets in the container.\n # Using a tuple here to force reassignment to update the list.\n # When a proper notifying-list trait exists, that is what should be used here.\n children = Tuple()\n _children = Tuple(sync=True)\n\n\n def __init__(self, **kwargs):\n super(ContainerWidget, self).__init__(**kwargs)\n self.on_displayed(ContainerWidget._fire_children_displayed)\n\n def _fire_children_displayed(self):\n for child in self._children:\n child._handle_displayed()\n\n def _children_changed(self, name, old, new):\n \"\"\"Validate children list.\n\n Makes sure only one instance of any given model can exist in the \n children list.\n An excellent post on uniqifiers is available at \n http://www.peterbe.com/plog/uniqifiers-benchmark\n which provides the inspiration for using this implementation. Below\n I've implemented the `f5` algorithm using Python comprehensions.\"\"\"\n if new is not None:\n seen = {}\n def add_item(i):\n seen[i.model_id] = True\n return i\n self._children = [add_item(i) for i in new if not i.model_id in seen]\n\n\nclass PopupWidget(ContainerWidget):\n _view_name = Unicode('PopupView', sync=True)\n \n description = Unicode(sync=True)\n button_text = Unicode(sync=True)\n", "path": "IPython/html/widgets/widget_container.py"}], "after_files": [{"content": "\"\"\"ContainerWidget class. \n\nRepresents a container that can be used to group other widgets.\n\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nfrom .widget import DOMWidget\nfrom IPython.utils.traitlets import Unicode, Tuple, TraitError\n\nclass ContainerWidget(DOMWidget):\n _view_name = Unicode('ContainerView', sync=True)\n\n # Child widgets in the container.\n # Using a tuple here to force reassignment to update the list.\n # When a proper notifying-list trait exists, that is what should be used here.\n children = Tuple(sync=True)\n\n def __init__(self, **kwargs):\n super(ContainerWidget, self).__init__(**kwargs)\n self.on_displayed(ContainerWidget._fire_children_displayed)\n\n def _fire_children_displayed(self):\n for child in self.children:\n child._handle_displayed()\n\n\nclass PopupWidget(ContainerWidget):\n _view_name = Unicode('PopupView', sync=True)\n \n description = Unicode(sync=True)\n button_text = Unicode(sync=True)\n", "path": "IPython/html/widgets/widget_container.py"}]}
| 886 | 516 |
gh_patches_debug_2794
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5468
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[CKV_DOCKER_7] Erroneous failed check when --platform flag is used in multistage Dockerfile
**Describe the issue**
In the `CKV_DOCKER_7` check, when the `--platform` flag is used in a multistage Dockerfile, the check fails erroneously for images that have been created within the current Dockerfile and thus no version pegging should be required.
**Examples**
The Dockerfile below is green
```
FROM golang:1.20-bullseye AS base
FROM base AS build
```
but as soon as a `--platform` flag is added, the check fails:
```
FROM --platform=$BUILDPLATFORM golang:1.20-bullseye AS base
FROM base AS build
```
**Version (please complete the following information):**
- Checkov Version 2.4.4
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/dockerfile/checks/ReferenceLatestTag.py`
Content:
```
1 from __future__ import annotations
2
3 import re
4 from typing import TYPE_CHECKING
5
6 from checkov.common.models.enums import CheckCategories, CheckResult
7 from checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck
8
9 if TYPE_CHECKING:
10 from dockerfile_parse.parser import _Instruction
11
12 MULTI_STAGE_PATTERN = re.compile(r"(\S+)\s+as\s+(\S+)", re.IGNORECASE)
13
14
15 class ReferenceLatestTag(BaseDockerfileCheck):
16 def __init__(self) -> None:
17 name = "Ensure the base image uses a non latest version tag"
18 id = "CKV_DOCKER_7"
19 supported_instructions = ("FROM",)
20 categories = (CheckCategories.CONVENTION,)
21 super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)
22
23 def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:
24 stages = []
25
26 for content in conf:
27 base_image = content["value"]
28 if " as " in base_image.lower():
29 # do an initial lookup before using the regex
30 multi_stage = re.match(MULTI_STAGE_PATTERN, base_image)
31 if multi_stage:
32 base_image = multi_stage[1]
33 stages.append(multi_stage[2])
34
35 if ":" not in base_image and base_image not in stages and base_image != "scratch":
36 return CheckResult.FAILED, [content]
37 elif base_image.endswith(":latest"):
38 return CheckResult.FAILED, [content]
39 return CheckResult.PASSED, [content]
40
41
42 check = ReferenceLatestTag()
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/dockerfile/checks/ReferenceLatestTag.py b/checkov/dockerfile/checks/ReferenceLatestTag.py
--- a/checkov/dockerfile/checks/ReferenceLatestTag.py
+++ b/checkov/dockerfile/checks/ReferenceLatestTag.py
@@ -9,7 +9,7 @@
if TYPE_CHECKING:
from dockerfile_parse.parser import _Instruction
-MULTI_STAGE_PATTERN = re.compile(r"(\S+)\s+as\s+(\S+)", re.IGNORECASE)
+MULTI_STAGE_PATTERN = re.compile(r"(?:--platform=\S+\s+)?(\S+)\s+as\s+(\S+)", re.IGNORECASE)
class ReferenceLatestTag(BaseDockerfileCheck):
|
{"golden_diff": "diff --git a/checkov/dockerfile/checks/ReferenceLatestTag.py b/checkov/dockerfile/checks/ReferenceLatestTag.py\n--- a/checkov/dockerfile/checks/ReferenceLatestTag.py\n+++ b/checkov/dockerfile/checks/ReferenceLatestTag.py\n@@ -9,7 +9,7 @@\n if TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n \n-MULTI_STAGE_PATTERN = re.compile(r\"(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n+MULTI_STAGE_PATTERN = re.compile(r\"(?:--platform=\\S+\\s+)?(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n \n \n class ReferenceLatestTag(BaseDockerfileCheck):\n", "issue": "[CKV_DOCKER_7] Erroneous failed check when --platform flag is used in multistage Dockerfile\n**Describe the issue**\r\nIn the `CKV_DOCKER_7` check, when the `--platform` flag is used in a multistage Dockerfile, the check fails erroneously for images that have been created within the current Dockerfile and thus no version pegging should be required.\r\n\r\n**Examples**\r\nThe Dockerfile below is green\r\n\r\n```\r\nFROM golang:1.20-bullseye AS base\r\n\r\nFROM base AS build\r\n```\r\n\r\nbut as soon as a `--platform` flag is added, the check fails:\r\n\r\n```\r\nFROM --platform=$BUILDPLATFORM golang:1.20-bullseye AS base\r\n\r\nFROM base AS build\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.4.4\n", "before_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom typing import TYPE_CHECKING\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck\n\nif TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n\nMULTI_STAGE_PATTERN = re.compile(r\"(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n\n\nclass ReferenceLatestTag(BaseDockerfileCheck):\n def __init__(self) -> None:\n name = \"Ensure the base image uses a non latest version tag\"\n id = \"CKV_DOCKER_7\"\n supported_instructions = (\"FROM\",)\n categories = (CheckCategories.CONVENTION,)\n super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)\n\n def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:\n stages = []\n\n for content in conf:\n base_image = content[\"value\"]\n if \" as \" in base_image.lower():\n # do an initial lookup before using the regex\n multi_stage = re.match(MULTI_STAGE_PATTERN, base_image)\n if multi_stage:\n base_image = multi_stage[1]\n stages.append(multi_stage[2])\n\n if \":\" not in base_image and base_image not in stages and base_image != \"scratch\":\n return CheckResult.FAILED, [content]\n elif base_image.endswith(\":latest\"):\n return CheckResult.FAILED, [content]\n return CheckResult.PASSED, [content]\n\n\ncheck = ReferenceLatestTag()\n", "path": "checkov/dockerfile/checks/ReferenceLatestTag.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom typing import TYPE_CHECKING\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck\n\nif TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n\nMULTI_STAGE_PATTERN = re.compile(r\"(?:--platform=\\S+\\s+)?(\\S+)\\s+as\\s+(\\S+)\", re.IGNORECASE)\n\n\nclass ReferenceLatestTag(BaseDockerfileCheck):\n def __init__(self) -> None:\n name = \"Ensure the base image uses a non latest version tag\"\n id = \"CKV_DOCKER_7\"\n supported_instructions = (\"FROM\",)\n categories = (CheckCategories.CONVENTION,)\n super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)\n\n def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:\n stages = []\n\n for content in conf:\n base_image = content[\"value\"]\n if \" as \" in base_image.lower():\n # do an initial lookup before using the regex\n multi_stage = re.match(MULTI_STAGE_PATTERN, base_image)\n if multi_stage:\n base_image = multi_stage[1]\n stages.append(multi_stage[2])\n\n if \":\" not in base_image and base_image not in stages and base_image != \"scratch\":\n return CheckResult.FAILED, [content]\n elif base_image.endswith(\":latest\"):\n return CheckResult.FAILED, [content]\n return CheckResult.PASSED, [content]\n\n\ncheck = ReferenceLatestTag()\n", "path": "checkov/dockerfile/checks/ReferenceLatestTag.py"}]}
| 883 | 151 |
gh_patches_debug_31303
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider anytime_fitness is broken
During the global build at 2021-09-29-14-42-48, spider **anytime_fitness** failed with **0 features** and **0 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/logs/anytime_fitness.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/anytime_fitness.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from locations.items import GeojsonPointItem
4 import json
5 import html
6
7
8 class AnytimeFitnessSpider(scrapy.Spider):
9 name = 'anytime_fitness'
10 item_attributes = { 'brand': "Anytime Fitness" }
11 allowed_domains = ['www.anytimefitness.com']
12
13 def start_requests(self):
14 url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'
15 yield scrapy.Request(url, callback=self.parse)
16
17 def parse(self, response):
18 gyms = json.loads(response.body_as_unicode())
19
20 for gym in gyms:
21 yield GeojsonPointItem(
22 lat = gym['latitude'],
23 lon = gym['longitude'],
24 addr_full = ", ".join(filter(None, [gym['content']['address'], gym['content']['address2']])),
25 city = gym['content']['city'],
26 phone = gym['content']['phone'],
27 state = gym['content']['state_abbr'],
28 postcode = gym['content']['zip'],
29 ref = gym['content']['url'],
30 country = gym['content']['country'],
31 name = html.unescape(gym['content']['title']),
32 extras = {"number": gym['content']['number']}
33 )
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/anytime_fitness.py b/locations/spiders/anytime_fitness.py
--- a/locations/spiders/anytime_fitness.py
+++ b/locations/spiders/anytime_fitness.py
@@ -7,27 +7,27 @@
class AnytimeFitnessSpider(scrapy.Spider):
name = 'anytime_fitness'
- item_attributes = { 'brand': "Anytime Fitness" }
+ item_attributes = {'brand': "Anytime Fitness", 'brand_wikidata': "Q4778364"}
allowed_domains = ['www.anytimefitness.com']
def start_requests(self):
- url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'
+ url = 'https://www.anytimefitness.com/wp-content/uploads/locations.json'
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
- gyms = json.loads(response.body_as_unicode())
+ gyms = json.loads(response.text)
for gym in gyms:
yield GeojsonPointItem(
- lat = gym['latitude'],
- lon = gym['longitude'],
- addr_full = ", ".join(filter(None, [gym['content']['address'], gym['content']['address2']])),
- city = gym['content']['city'],
- phone = gym['content']['phone'],
- state = gym['content']['state_abbr'],
- postcode = gym['content']['zip'],
- ref = gym['content']['url'],
- country = gym['content']['country'],
- name = html.unescape(gym['content']['title']),
- extras = {"number": gym['content']['number']}
- )
+ lat=gym['latitude'],
+ lon=gym['longitude'],
+ addr_full=", ".join(filter(None, [gym['content']['address'], gym['content']['address2']])),
+ city=gym['content']['city'],
+ phone=gym['content']['phone'],
+ state=gym['content']['state_abbr'],
+ postcode=gym['content']['zip'],
+ ref=gym['content']['url'],
+ country=gym['content']['country'],
+ name=html.unescape(gym['content']['title']),
+ extras={"number": gym['content']['number']}
+ )
|
{"golden_diff": "diff --git a/locations/spiders/anytime_fitness.py b/locations/spiders/anytime_fitness.py\n--- a/locations/spiders/anytime_fitness.py\n+++ b/locations/spiders/anytime_fitness.py\n@@ -7,27 +7,27 @@\n \n class AnytimeFitnessSpider(scrapy.Spider):\n name = 'anytime_fitness'\n- item_attributes = { 'brand': \"Anytime Fitness\" }\n+ item_attributes = {'brand': \"Anytime Fitness\", 'brand_wikidata': \"Q4778364\"}\n allowed_domains = ['www.anytimefitness.com']\n \n def start_requests(self):\n- url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'\n+ url = 'https://www.anytimefitness.com/wp-content/uploads/locations.json'\n yield scrapy.Request(url, callback=self.parse)\n \n def parse(self, response):\n- gyms = json.loads(response.body_as_unicode())\n+ gyms = json.loads(response.text)\n \n for gym in gyms:\n yield GeojsonPointItem(\n- lat = gym['latitude'],\n- lon = gym['longitude'],\n- addr_full = \", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n- city = gym['content']['city'],\n- phone = gym['content']['phone'],\n- state = gym['content']['state_abbr'],\n- postcode = gym['content']['zip'],\n- ref = gym['content']['url'],\n- country = gym['content']['country'],\n- name = html.unescape(gym['content']['title']),\n- extras = {\"number\": gym['content']['number']}\n- )\n+ lat=gym['latitude'],\n+ lon=gym['longitude'],\n+ addr_full=\", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n+ city=gym['content']['city'],\n+ phone=gym['content']['phone'],\n+ state=gym['content']['state_abbr'],\n+ postcode=gym['content']['zip'],\n+ ref=gym['content']['url'],\n+ country=gym['content']['country'],\n+ name=html.unescape(gym['content']['title']),\n+ extras={\"number\": gym['content']['number']}\n+ )\n", "issue": "Spider anytime_fitness is broken\nDuring the global build at 2021-09-29-14-42-48, spider **anytime_fitness** failed with **0 features** and **0 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/logs/anytime_fitness.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-09-29-14-42-48/output/anytime_fitness.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom locations.items import GeojsonPointItem\nimport json\nimport html\n\n\nclass AnytimeFitnessSpider(scrapy.Spider):\n name = 'anytime_fitness'\n item_attributes = { 'brand': \"Anytime Fitness\" }\n allowed_domains = ['www.anytimefitness.com']\n\n def start_requests(self):\n url = 'https://www.anytimefitness.com/wp-content/uploads/gyms.json'\n yield scrapy.Request(url, callback=self.parse)\n\n def parse(self, response):\n gyms = json.loads(response.body_as_unicode())\n\n for gym in gyms:\n yield GeojsonPointItem(\n lat = gym['latitude'],\n lon = gym['longitude'],\n addr_full = \", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n city = gym['content']['city'],\n phone = gym['content']['phone'],\n state = gym['content']['state_abbr'],\n postcode = gym['content']['zip'],\n ref = gym['content']['url'],\n country = gym['content']['country'],\n name = html.unescape(gym['content']['title']),\n extras = {\"number\": gym['content']['number']}\n )\n", "path": "locations/spiders/anytime_fitness.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom locations.items import GeojsonPointItem\nimport json\nimport html\n\n\nclass AnytimeFitnessSpider(scrapy.Spider):\n name = 'anytime_fitness'\n item_attributes = {'brand': \"Anytime Fitness\", 'brand_wikidata': \"Q4778364\"}\n allowed_domains = ['www.anytimefitness.com']\n\n def start_requests(self):\n url = 'https://www.anytimefitness.com/wp-content/uploads/locations.json'\n yield scrapy.Request(url, callback=self.parse)\n\n def parse(self, response):\n gyms = json.loads(response.text)\n\n for gym in gyms:\n yield GeojsonPointItem(\n lat=gym['latitude'],\n lon=gym['longitude'],\n addr_full=\", \".join(filter(None, [gym['content']['address'], gym['content']['address2']])),\n city=gym['content']['city'],\n phone=gym['content']['phone'],\n state=gym['content']['state_abbr'],\n postcode=gym['content']['zip'],\n ref=gym['content']['url'],\n country=gym['content']['country'],\n name=html.unescape(gym['content']['title']),\n extras={\"number\": gym['content']['number']}\n )\n", "path": "locations/spiders/anytime_fitness.py"}]}
| 772 | 503 |
gh_patches_debug_29620
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-core-3251
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
apache2_module hangs with "WARNING: The following essential module will be disabled."
I have this code in my playbook:
```
- apache2_module: name={{item}} state=absent
with_items:
- autoindex
- negotiation
```
However someone decided that autoindex and negotiation both are "essential", so when I try to disable them I get this warning:
```
# a2dismod autoindex
WARNING: The following essential module will be disabled.
This might result in unexpected behavior and should NOT be done
unless you know exactly what you are doing!
autoindex
To continue type in the phrase 'Yes, do as I say!' or retry by passing '-f':
```
and expects me to actually type "Yes, do as I say!" (WTF?!?) if I don't provide "-f". The ansible module does not provide that -f parameter, so it locks up.
As weird as that is, I think there _at least_ should be a "force=true" option in apache2_module - or -f should be default.
(Not sure if that's true for all "a2dismod" instances because there is a suspiciously low amount of Google results (none). It is at least there for apache2 currently installed from dotdeb.org)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web_infrastructure/apache2_module.py`
Content:
```
1 #!/usr/bin/python
2 #coding: utf-8 -*-
3
4 # (c) 2013-2014, Christian Berendt <[email protected]>
5 #
6 # This module is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This software is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this software. If not, see <http://www.gnu.org/licenses/>.
18
19 DOCUMENTATION = '''
20 ---
21 module: apache2_module
22 version_added: 1.6
23 author: "Christian Berendt (@berendt)"
24 short_description: enables/disables a module of the Apache2 webserver
25 description:
26 - Enables or disables a specified module of the Apache2 webserver.
27 options:
28 name:
29 description:
30 - name of the module to enable/disable
31 required: true
32 state:
33 description:
34 - indicate the desired state of the resource
35 choices: ['present', 'absent']
36 default: present
37
38 requirements: ["a2enmod","a2dismod"]
39 '''
40
41 EXAMPLES = '''
42 # enables the Apache2 module "wsgi"
43 - apache2_module: state=present name=wsgi
44
45 # disables the Apache2 module "wsgi"
46 - apache2_module: state=absent name=wsgi
47 '''
48
49 import re
50
51 def _disable_module(module):
52 name = module.params['name']
53 a2dismod_binary = module.get_bin_path("a2dismod")
54 if a2dismod_binary is None:
55 module.fail_json(msg="a2dismod not found. Perhaps this system does not use a2dismod to manage apache")
56
57 result, stdout, stderr = module.run_command("%s %s" % (a2dismod_binary, name))
58
59 if re.match(r'.*\b' + name + r' already disabled', stdout, re.S|re.M):
60 module.exit_json(changed = False, result = "Success")
61 elif result != 0:
62 module.fail_json(msg="Failed to disable module %s: %s" % (name, stdout))
63 else:
64 module.exit_json(changed = True, result = "Disabled")
65
66 def _enable_module(module):
67 name = module.params['name']
68 a2enmod_binary = module.get_bin_path("a2enmod")
69 if a2enmod_binary is None:
70 module.fail_json(msg="a2enmod not found. Perhaps this system does not use a2enmod to manage apache")
71
72 result, stdout, stderr = module.run_command("%s %s" % (a2enmod_binary, name))
73
74 if re.match(r'.*\b' + name + r' already enabled', stdout, re.S|re.M):
75 module.exit_json(changed = False, result = "Success")
76 elif result != 0:
77 module.fail_json(msg="Failed to enable module %s: %s" % (name, stdout))
78 else:
79 module.exit_json(changed = True, result = "Enabled")
80
81 def main():
82 module = AnsibleModule(
83 argument_spec = dict(
84 name = dict(required=True),
85 state = dict(default='present', choices=['absent', 'present'])
86 ),
87 )
88
89 if module.params['state'] == 'present':
90 _enable_module(module)
91
92 if module.params['state'] == 'absent':
93 _disable_module(module)
94
95 # import module snippets
96 from ansible.module_utils.basic import *
97 if __name__ == '__main__':
98 main()
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web_infrastructure/apache2_module.py b/web_infrastructure/apache2_module.py
--- a/web_infrastructure/apache2_module.py
+++ b/web_infrastructure/apache2_module.py
@@ -29,6 +29,12 @@
description:
- name of the module to enable/disable
required: true
+ force:
+ description:
+ - force disabling of default modules and override Debian warnings
+ required: false
+ choices: ['yes', 'no']
+ default: no
state:
description:
- indicate the desired state of the resource
@@ -50,10 +56,14 @@
def _disable_module(module):
name = module.params['name']
+ force = module.params['force']
a2dismod_binary = module.get_bin_path("a2dismod")
if a2dismod_binary is None:
module.fail_json(msg="a2dismod not found. Perhaps this system does not use a2dismod to manage apache")
+ if force:
+ a2dismod_binary += ' -f'
+
result, stdout, stderr = module.run_command("%s %s" % (a2dismod_binary, name))
if re.match(r'.*\b' + name + r' already disabled', stdout, re.S|re.M):
@@ -82,6 +92,7 @@
module = AnsibleModule(
argument_spec = dict(
name = dict(required=True),
+ force = dict(required=False, type='bool', default=False),
state = dict(default='present', choices=['absent', 'present'])
),
)
|
{"golden_diff": "diff --git a/web_infrastructure/apache2_module.py b/web_infrastructure/apache2_module.py\n--- a/web_infrastructure/apache2_module.py\n+++ b/web_infrastructure/apache2_module.py\n@@ -29,6 +29,12 @@\n description:\n - name of the module to enable/disable\n required: true\n+ force:\n+ description:\n+ - force disabling of default modules and override Debian warnings\n+ required: false\n+ choices: ['yes', 'no']\n+ default: no\n state:\n description:\n - indicate the desired state of the resource\n@@ -50,10 +56,14 @@\n \n def _disable_module(module):\n name = module.params['name']\n+ force = module.params['force']\n a2dismod_binary = module.get_bin_path(\"a2dismod\")\n if a2dismod_binary is None:\n module.fail_json(msg=\"a2dismod not found. Perhaps this system does not use a2dismod to manage apache\")\n \n+ if force:\n+ a2dismod_binary += ' -f'\n+\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2dismod_binary, name))\n \n if re.match(r'.*\\b' + name + r' already disabled', stdout, re.S|re.M):\n@@ -82,6 +92,7 @@\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n+ force = dict(required=False, type='bool', default=False),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n )\n", "issue": "apache2_module hangs with \"WARNING: The following essential module will be disabled.\"\nI have this code in my playbook:\n\n```\n- apache2_module: name={{item}} state=absent\n with_items:\n - autoindex\n - negotiation\n```\n\nHowever someone decided that autoindex and negotiation both are \"essential\", so when I try to disable them I get this warning:\n\n```\n# a2dismod autoindex\nWARNING: The following essential module will be disabled.\nThis might result in unexpected behavior and should NOT be done\nunless you know exactly what you are doing!\n autoindex\n\nTo continue type in the phrase 'Yes, do as I say!' or retry by passing '-f':\n```\n\nand expects me to actually type \"Yes, do as I say!\" (WTF?!?) if I don't provide \"-f\". The ansible module does not provide that -f parameter, so it locks up.\n\nAs weird as that is, I think there _at least_ should be a \"force=true\" option in apache2_module - or -f should be default.\n\n(Not sure if that's true for all \"a2dismod\" instances because there is a suspiciously low amount of Google results (none). It is at least there for apache2 currently installed from dotdeb.org)\n\n", "before_files": [{"content": "#!/usr/bin/python\n#coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nversion_added: 1.6\nauthor: \"Christian Berendt (@berendt)\"\nshort_description: enables/disables a module of the Apache2 webserver\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n description:\n - name of the module to enable/disable\n required: true\n state:\n description:\n - indicate the desired state of the resource\n choices: ['present', 'absent']\n default: present\n\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n# enables the Apache2 module \"wsgi\"\n- apache2_module: state=present name=wsgi\n\n# disables the Apache2 module \"wsgi\"\n- apache2_module: state=absent name=wsgi\n'''\n\nimport re\n\ndef _disable_module(module):\n name = module.params['name']\n a2dismod_binary = module.get_bin_path(\"a2dismod\")\n if a2dismod_binary is None:\n module.fail_json(msg=\"a2dismod not found. Perhaps this system does not use a2dismod to manage apache\")\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2dismod_binary, name))\n\n if re.match(r'.*\\b' + name + r' already disabled', stdout, re.S|re.M):\n module.exit_json(changed = False, result = \"Success\")\n elif result != 0:\n module.fail_json(msg=\"Failed to disable module %s: %s\" % (name, stdout))\n else:\n module.exit_json(changed = True, result = \"Disabled\")\n\ndef _enable_module(module):\n name = module.params['name']\n a2enmod_binary = module.get_bin_path(\"a2enmod\")\n if a2enmod_binary is None:\n module.fail_json(msg=\"a2enmod not found. Perhaps this system does not use a2enmod to manage apache\")\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2enmod_binary, name))\n\n if re.match(r'.*\\b' + name + r' already enabled', stdout, re.S|re.M):\n module.exit_json(changed = False, result = \"Success\")\n elif result != 0:\n module.fail_json(msg=\"Failed to enable module %s: %s\" % (name, stdout))\n else:\n module.exit_json(changed = True, result = \"Enabled\")\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n )\n\n if module.params['state'] == 'present':\n _enable_module(module)\n\n if module.params['state'] == 'absent':\n _disable_module(module)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nif __name__ == '__main__':\n main()\n", "path": "web_infrastructure/apache2_module.py"}], "after_files": [{"content": "#!/usr/bin/python\n#coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nversion_added: 1.6\nauthor: \"Christian Berendt (@berendt)\"\nshort_description: enables/disables a module of the Apache2 webserver\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n description:\n - name of the module to enable/disable\n required: true\n force:\n description:\n - force disabling of default modules and override Debian warnings\n required: false\n choices: ['yes', 'no']\n default: no\n state:\n description:\n - indicate the desired state of the resource\n choices: ['present', 'absent']\n default: present\n\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n# enables the Apache2 module \"wsgi\"\n- apache2_module: state=present name=wsgi\n\n# disables the Apache2 module \"wsgi\"\n- apache2_module: state=absent name=wsgi\n'''\n\nimport re\n\ndef _disable_module(module):\n name = module.params['name']\n force = module.params['force']\n a2dismod_binary = module.get_bin_path(\"a2dismod\")\n if a2dismod_binary is None:\n module.fail_json(msg=\"a2dismod not found. Perhaps this system does not use a2dismod to manage apache\")\n\n if force:\n a2dismod_binary += ' -f'\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2dismod_binary, name))\n\n if re.match(r'.*\\b' + name + r' already disabled', stdout, re.S|re.M):\n module.exit_json(changed = False, result = \"Success\")\n elif result != 0:\n module.fail_json(msg=\"Failed to disable module %s: %s\" % (name, stdout))\n else:\n module.exit_json(changed = True, result = \"Disabled\")\n\ndef _enable_module(module):\n name = module.params['name']\n a2enmod_binary = module.get_bin_path(\"a2enmod\")\n if a2enmod_binary is None:\n module.fail_json(msg=\"a2enmod not found. Perhaps this system does not use a2enmod to manage apache\")\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2enmod_binary, name))\n\n if re.match(r'.*\\b' + name + r' already enabled', stdout, re.S|re.M):\n module.exit_json(changed = False, result = \"Success\")\n elif result != 0:\n module.fail_json(msg=\"Failed to enable module %s: %s\" % (name, stdout))\n else:\n module.exit_json(changed = True, result = \"Enabled\")\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n force = dict(required=False, type='bool', default=False),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n )\n\n if module.params['state'] == 'present':\n _enable_module(module)\n\n if module.params['state'] == 'absent':\n _disable_module(module)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nif __name__ == '__main__':\n main()\n", "path": "web_infrastructure/apache2_module.py"}]}
| 1,571 | 368 |
gh_patches_debug_21796
|
rasdani/github-patches
|
git_diff
|
psychopy__psychopy-4625
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
404 errors on some of the page in the HELP menus
Version used
- psychopy: 2021.2.3
https://www.psychopy.org/builder/builder.html
https://www.psychopy.org/api/api.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `psychopy/app/urls.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """A central location to store information about urls
5 """
6 urls = dict()
7
8 # links based on string names
9 urls['builder'] = "https://www.psychopy.org/builder/builder.html"
10 urls['builder.loops'] = "https://www.psychopy.org/builder/flow.html#loops"
11 # NB. builder components get their urls defined by the component code
12 # (so a custom component can have a url)
13
14 urls['downloads'] = "https://github.com/psychopy/psychopy/releases"
15 urls['changelog'] = "https://www.psychopy.org/changelog.html"
16
17 general = "https://www.psychopy.org/general/"
18 urls['prefs'] = general + "prefs.html"
19 urls['prefs.general'] = general + "prefs.html#general-settings"
20 urls['prefs.app'] = general + "prefs.html#application-settings"
21 urls['prefs.coder'] = general + "prefs.html#coder-settings"
22 urls['prefs.builder'] = general + "prefs.html#builder-settings"
23 urls['prefs.connections'] = general + "prefs.html#connection-settings"
24
25 # links keyed by wxIDs (e.g. menu item IDs)
26 urls['psychopyHome'] = "https://www.psychopy.org/"
27 urls['psychopyReference'] = "https://www.psychopy.org/api/api.html"
28 urls['coderTutorial'] = "https://www.psychopy.org/coder/tutorial1.html"
29 urls['builderHelp'] = urls['builder']
30 urls['builderDemos'] = "http://code.google.com/p/psychopy/downloads/list?can=2&q=demos"
31 urls['projsAbout'] = "https://www.psychopy.org/general/projects.html"
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/psychopy/app/urls.py b/psychopy/app/urls.py
--- a/psychopy/app/urls.py
+++ b/psychopy/app/urls.py
@@ -6,7 +6,7 @@
urls = dict()
# links based on string names
-urls['builder'] = "https://www.psychopy.org/builder/builder.html"
+urls['builder'] = "https://www.psychopy.org/builder"
urls['builder.loops'] = "https://www.psychopy.org/builder/flow.html#loops"
# NB. builder components get their urls defined by the component code
# (so a custom component can have a url)
@@ -24,7 +24,7 @@
# links keyed by wxIDs (e.g. menu item IDs)
urls['psychopyHome'] = "https://www.psychopy.org/"
-urls['psychopyReference'] = "https://www.psychopy.org/api/api.html"
+urls['psychopyReference'] = "https://www.psychopy.org/api"
urls['coderTutorial'] = "https://www.psychopy.org/coder/tutorial1.html"
urls['builderHelp'] = urls['builder']
urls['builderDemos'] = "http://code.google.com/p/psychopy/downloads/list?can=2&q=demos"
|
{"golden_diff": "diff --git a/psychopy/app/urls.py b/psychopy/app/urls.py\n--- a/psychopy/app/urls.py\n+++ b/psychopy/app/urls.py\n@@ -6,7 +6,7 @@\n urls = dict()\n \n # links based on string names\n-urls['builder'] = \"https://www.psychopy.org/builder/builder.html\"\n+urls['builder'] = \"https://www.psychopy.org/builder\"\n urls['builder.loops'] = \"https://www.psychopy.org/builder/flow.html#loops\"\n # NB. builder components get their urls defined by the component code\n # (so a custom component can have a url)\n@@ -24,7 +24,7 @@\n \n # links keyed by wxIDs (e.g. menu item IDs)\n urls['psychopyHome'] = \"https://www.psychopy.org/\"\n-urls['psychopyReference'] = \"https://www.psychopy.org/api/api.html\"\n+urls['psychopyReference'] = \"https://www.psychopy.org/api\"\n urls['coderTutorial'] = \"https://www.psychopy.org/coder/tutorial1.html\"\n urls['builderHelp'] = urls['builder']\n urls['builderDemos'] = \"http://code.google.com/p/psychopy/downloads/list?can=2&q=demos\"\n", "issue": "404 errors on some of the page in the HELP menus\nVersion used\r\n- psychopy: 2021.2.3\r\n\r\nhttps://www.psychopy.org/builder/builder.html\r\nhttps://www.psychopy.org/api/api.html\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"A central location to store information about urls\n\"\"\"\nurls = dict()\n\n# links based on string names\nurls['builder'] = \"https://www.psychopy.org/builder/builder.html\"\nurls['builder.loops'] = \"https://www.psychopy.org/builder/flow.html#loops\"\n# NB. builder components get their urls defined by the component code\n# (so a custom component can have a url)\n\nurls['downloads'] = \"https://github.com/psychopy/psychopy/releases\"\nurls['changelog'] = \"https://www.psychopy.org/changelog.html\"\n\ngeneral = \"https://www.psychopy.org/general/\"\nurls['prefs'] = general + \"prefs.html\"\nurls['prefs.general'] = general + \"prefs.html#general-settings\"\nurls['prefs.app'] = general + \"prefs.html#application-settings\"\nurls['prefs.coder'] = general + \"prefs.html#coder-settings\"\nurls['prefs.builder'] = general + \"prefs.html#builder-settings\"\nurls['prefs.connections'] = general + \"prefs.html#connection-settings\"\n\n# links keyed by wxIDs (e.g. menu item IDs)\nurls['psychopyHome'] = \"https://www.psychopy.org/\"\nurls['psychopyReference'] = \"https://www.psychopy.org/api/api.html\"\nurls['coderTutorial'] = \"https://www.psychopy.org/coder/tutorial1.html\"\nurls['builderHelp'] = urls['builder']\nurls['builderDemos'] = \"http://code.google.com/p/psychopy/downloads/list?can=2&q=demos\"\nurls['projsAbout'] = \"https://www.psychopy.org/general/projects.html\"\n", "path": "psychopy/app/urls.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"A central location to store information about urls\n\"\"\"\nurls = dict()\n\n# links based on string names\nurls['builder'] = \"https://www.psychopy.org/builder\"\nurls['builder.loops'] = \"https://www.psychopy.org/builder/flow.html#loops\"\n# NB. builder components get their urls defined by the component code\n# (so a custom component can have a url)\n\nurls['downloads'] = \"https://github.com/psychopy/psychopy/releases\"\nurls['changelog'] = \"https://www.psychopy.org/changelog.html\"\n\ngeneral = \"https://www.psychopy.org/general/\"\nurls['prefs'] = general + \"prefs.html\"\nurls['prefs.general'] = general + \"prefs.html#general-settings\"\nurls['prefs.app'] = general + \"prefs.html#application-settings\"\nurls['prefs.coder'] = general + \"prefs.html#coder-settings\"\nurls['prefs.builder'] = general + \"prefs.html#builder-settings\"\nurls['prefs.connections'] = general + \"prefs.html#connection-settings\"\n\n# links keyed by wxIDs (e.g. menu item IDs)\nurls['psychopyHome'] = \"https://www.psychopy.org/\"\nurls['psychopyReference'] = \"https://www.psychopy.org/api\"\nurls['coderTutorial'] = \"https://www.psychopy.org/coder/tutorial1.html\"\nurls['builderHelp'] = urls['builder']\nurls['builderDemos'] = \"http://code.google.com/p/psychopy/downloads/list?can=2&q=demos\"\nurls['projsAbout'] = \"https://www.psychopy.org/general/projects.html\"\n", "path": "psychopy/app/urls.py"}]}
| 739 | 285 |
gh_patches_debug_36007
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-414
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
arviz-darkgrid not working in example from quickstart
This command is not being recognized.
I installed the program from github on Mac OS 10.13 using macports Python3.5
az.style.use('arviz-darkgrid')
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import codecs
2 import shutil
3 import os
4 import re
5
6 import setuptools
7 from setuptools import setup, find_packages
8 from setuptools.command.install import install
9 from setuptools.command.develop import develop
10
11
12 PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))
13 REQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, 'requirements.txt')
14 README_FILE = os.path.join(PROJECT_ROOT, 'README.md')
15 VERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')
16
17
18 # Ensure matplotlib dependencies are available to copy
19 # styles over
20 setuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])
21
22 def get_requirements():
23 with codecs.open(REQUIREMENTS_FILE) as buff:
24 return buff.read().splitlines()
25
26
27 def get_long_description():
28 with codecs.open(README_FILE, 'rt') as buff:
29 return buff.read()
30
31
32 def copy_styles():
33 from matplotlib import get_configdir
34 sd = os.path.join(get_configdir(), "stylelib")
35 source = os.path.dirname(os.path.realpath(__file__))
36 lsd = os.path.join(source, 'arviz', 'plots', 'styles')
37 styles = [f for f in os.listdir(lsd)]
38 if not os.path.isdir(sd):
39 os.makedirs(sd)
40 for s in styles:
41 shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))
42
43
44 class DevelopStyles(develop):
45 def run(self):
46 copy_styles()
47 develop.run(self)
48
49 class InstallStyles(install):
50 def run(self):
51 copy_styles()
52 install.run(self)
53
54 def get_version():
55 lines = open(VERSION_FILE, 'rt').readlines()
56 version_regex = r"^__version__ = ['\"]([^'\"]*)['\"]"
57 for line in lines:
58 mo = re.search(version_regex, line, re.M)
59 if mo:
60 return mo.group(1)
61 raise RuntimeError('Unable to find version in %s.' % (VERSION_FILE,))
62
63 setup(
64 name='arviz',
65 version=get_version(),
66 description='Exploratory analysis of Bayesian models',
67 author='ArviZ Developers',
68 url="http://github.com/arviz-devs/arviz",
69 packages=find_packages(),
70 install_requires=get_requirements(),
71 long_description=get_long_description(),
72 long_description_content_type='text/markdown',
73 include_package_data=True,
74 cmdclass={
75 'develop': DevelopStyles,
76 'install': InstallStyles,
77 },
78 )
79
```
Path: `arviz/__init__.py`
Content:
```
1 # pylint: disable=wildcard-import,invalid-name,wrong-import-position
2 """ArviZ is a library for exploratory analysis of Bayesian models."""
3 __version__ = "0.2.1"
4
5 import logging
6 from matplotlib.pyplot import style
7
8 # Configure logging before importing arviz internals
9 _log = logging.getLogger("arviz")
10
11 if not logging.root.handlers:
12 handler = logging.StreamHandler()
13 _log.setLevel(logging.INFO)
14 _log.addHandler(handler)
15
16 from .data import *
17 from .plots import *
18 from .stats import *
19
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/__init__.py b/arviz/__init__.py
--- a/arviz/__init__.py
+++ b/arviz/__init__.py
@@ -2,9 +2,15 @@
"""ArviZ is a library for exploratory analysis of Bayesian models."""
__version__ = "0.2.1"
+import os
import logging
from matplotlib.pyplot import style
+# add ArviZ's styles to matplotlib's styles
+arviz_style_path = os.path.join(os.path.dirname(__file__), "plots", "styles")
+style.core.USER_LIBRARY_PATHS.append(arviz_style_path)
+style.core.reload_library()
+
# Configure logging before importing arviz internals
_log = logging.getLogger("arviz")
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,5 +1,4 @@
import codecs
-import shutil
import os
import re
@@ -15,10 +14,6 @@
VERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')
-# Ensure matplotlib dependencies are available to copy
-# styles over
-setuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])
-
def get_requirements():
with codecs.open(REQUIREMENTS_FILE) as buff:
return buff.read().splitlines()
@@ -28,29 +23,6 @@
with codecs.open(README_FILE, 'rt') as buff:
return buff.read()
-
-def copy_styles():
- from matplotlib import get_configdir
- sd = os.path.join(get_configdir(), "stylelib")
- source = os.path.dirname(os.path.realpath(__file__))
- lsd = os.path.join(source, 'arviz', 'plots', 'styles')
- styles = [f for f in os.listdir(lsd)]
- if not os.path.isdir(sd):
- os.makedirs(sd)
- for s in styles:
- shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))
-
-
-class DevelopStyles(develop):
- def run(self):
- copy_styles()
- develop.run(self)
-
-class InstallStyles(install):
- def run(self):
- copy_styles()
- install.run(self)
-
def get_version():
lines = open(VERSION_FILE, 'rt').readlines()
version_regex = r"^__version__ = ['\"]([^'\"]*)['\"]"
@@ -71,8 +43,4 @@
long_description=get_long_description(),
long_description_content_type='text/markdown',
include_package_data=True,
- cmdclass={
- 'develop': DevelopStyles,
- 'install': InstallStyles,
- },
)
|
{"golden_diff": "diff --git a/arviz/__init__.py b/arviz/__init__.py\n--- a/arviz/__init__.py\n+++ b/arviz/__init__.py\n@@ -2,9 +2,15 @@\n \"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n __version__ = \"0.2.1\"\n \n+import os\n import logging\n from matplotlib.pyplot import style\n \n+# add ArviZ's styles to matplotlib's styles\n+arviz_style_path = os.path.join(os.path.dirname(__file__), \"plots\", \"styles\")\n+style.core.USER_LIBRARY_PATHS.append(arviz_style_path)\n+style.core.reload_library()\n+\n # Configure logging before importing arviz internals\n _log = logging.getLogger(\"arviz\")\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,5 +1,4 @@\n import codecs\n-import shutil\n import os\n import re\n \n@@ -15,10 +14,6 @@\n VERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')\n \n \n-# Ensure matplotlib dependencies are available to copy\n-# styles over\n-setuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])\n-\n def get_requirements():\n with codecs.open(REQUIREMENTS_FILE) as buff:\n return buff.read().splitlines()\n@@ -28,29 +23,6 @@\n with codecs.open(README_FILE, 'rt') as buff:\n return buff.read()\n \n-\n-def copy_styles():\n- from matplotlib import get_configdir\n- sd = os.path.join(get_configdir(), \"stylelib\")\n- source = os.path.dirname(os.path.realpath(__file__))\n- lsd = os.path.join(source, 'arviz', 'plots', 'styles')\n- styles = [f for f in os.listdir(lsd)]\n- if not os.path.isdir(sd):\n- os.makedirs(sd)\n- for s in styles:\n- shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))\n-\n-\n-class DevelopStyles(develop):\n- def run(self):\n- copy_styles()\n- develop.run(self)\n-\n-class InstallStyles(install):\n- def run(self):\n- copy_styles()\n- install.run(self)\n-\n def get_version():\n lines = open(VERSION_FILE, 'rt').readlines()\n version_regex = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\n@@ -71,8 +43,4 @@\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n include_package_data=True,\n- cmdclass={\n- 'develop': DevelopStyles,\n- 'install': InstallStyles,\n- },\n )\n", "issue": "arviz-darkgrid not working in example from quickstart\nThis command is not being recognized.\r\nI installed the program from github on Mac OS 10.13 using macports Python3.5 \r\n\r\naz.style.use('arviz-darkgrid')\n", "before_files": [{"content": "import codecs\nimport shutil\nimport os\nimport re\n\nimport setuptools\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\n\n\nPROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))\nREQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, 'requirements.txt')\nREADME_FILE = os.path.join(PROJECT_ROOT, 'README.md')\nVERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')\n\n\n# Ensure matplotlib dependencies are available to copy\n# styles over\nsetuptools.dist.Distribution().fetch_build_eggs(['matplotlib>=3.0'])\n\ndef get_requirements():\n with codecs.open(REQUIREMENTS_FILE) as buff:\n return buff.read().splitlines()\n\n\ndef get_long_description():\n with codecs.open(README_FILE, 'rt') as buff:\n return buff.read()\n\n\ndef copy_styles():\n from matplotlib import get_configdir\n sd = os.path.join(get_configdir(), \"stylelib\")\n source = os.path.dirname(os.path.realpath(__file__))\n lsd = os.path.join(source, 'arviz', 'plots', 'styles')\n styles = [f for f in os.listdir(lsd)]\n if not os.path.isdir(sd):\n os.makedirs(sd)\n for s in styles:\n shutil.copy(os.path.join(lsd, s), os.path.join(sd, s))\n\n\nclass DevelopStyles(develop):\n def run(self):\n copy_styles()\n develop.run(self)\n\nclass InstallStyles(install):\n def run(self):\n copy_styles()\n install.run(self)\n\ndef get_version():\n lines = open(VERSION_FILE, 'rt').readlines()\n version_regex = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\n for line in lines:\n mo = re.search(version_regex, line, re.M)\n if mo:\n return mo.group(1)\n raise RuntimeError('Unable to find version in %s.' % (VERSION_FILE,))\n\nsetup(\n name='arviz',\n version=get_version(),\n description='Exploratory analysis of Bayesian models',\n author='ArviZ Developers',\n url=\"http://github.com/arviz-devs/arviz\",\n packages=find_packages(),\n install_requires=get_requirements(),\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n include_package_data=True,\n cmdclass={\n 'develop': DevelopStyles,\n 'install': InstallStyles,\n },\n)\n", "path": "setup.py"}, {"content": "# pylint: disable=wildcard-import,invalid-name,wrong-import-position\n\"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n__version__ = \"0.2.1\"\n\nimport logging\nfrom matplotlib.pyplot import style\n\n# Configure logging before importing arviz internals\n_log = logging.getLogger(\"arviz\")\n\nif not logging.root.handlers:\n handler = logging.StreamHandler()\n _log.setLevel(logging.INFO)\n _log.addHandler(handler)\n\nfrom .data import *\nfrom .plots import *\nfrom .stats import *\n", "path": "arviz/__init__.py"}], "after_files": [{"content": "import codecs\nimport os\nimport re\n\nimport setuptools\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\n\n\nPROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))\nREQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, 'requirements.txt')\nREADME_FILE = os.path.join(PROJECT_ROOT, 'README.md')\nVERSION_FILE = os.path.join(PROJECT_ROOT, 'arviz', '__init__.py')\n\n\ndef get_requirements():\n with codecs.open(REQUIREMENTS_FILE) as buff:\n return buff.read().splitlines()\n\n\ndef get_long_description():\n with codecs.open(README_FILE, 'rt') as buff:\n return buff.read()\n\ndef get_version():\n lines = open(VERSION_FILE, 'rt').readlines()\n version_regex = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\n for line in lines:\n mo = re.search(version_regex, line, re.M)\n if mo:\n return mo.group(1)\n raise RuntimeError('Unable to find version in %s.' % (VERSION_FILE,))\n\nsetup(\n name='arviz',\n version=get_version(),\n description='Exploratory analysis of Bayesian models',\n author='ArviZ Developers',\n url=\"http://github.com/arviz-devs/arviz\",\n packages=find_packages(),\n install_requires=get_requirements(),\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n include_package_data=True,\n)\n", "path": "setup.py"}, {"content": "# pylint: disable=wildcard-import,invalid-name,wrong-import-position\n\"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n__version__ = \"0.2.1\"\n\nimport os\nimport logging\nfrom matplotlib.pyplot import style\n\n# add ArviZ's styles to matplotlib's styles\narviz_style_path = os.path.join(os.path.dirname(__file__), \"plots\", \"styles\")\nstyle.core.USER_LIBRARY_PATHS.append(arviz_style_path)\nstyle.core.reload_library()\n\n# Configure logging before importing arviz internals\n_log = logging.getLogger(\"arviz\")\n\nif not logging.root.handlers:\n handler = logging.StreamHandler()\n _log.setLevel(logging.INFO)\n _log.addHandler(handler)\n\nfrom .data import *\nfrom .plots import *\nfrom .stats import *\n", "path": "arviz/__init__.py"}]}
| 1,138 | 588 |
gh_patches_debug_30651
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-8481
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Firestore: sync shim module with 'firestore_v1' package.
See https://github.com/googleapis/google-cloud-python/issues/7533#issuecomment-495917295 &ff.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `firestore/google/cloud/firestore.py`
Content:
```
1 # Copyright 2017 Google LLC All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Python idiomatic client for Google Cloud Firestore."""
16
17
18 from google.cloud.firestore_v1 import __version__
19 from google.cloud.firestore_v1 import Client
20 from google.cloud.firestore_v1 import CollectionReference
21 from google.cloud.firestore_v1 import DELETE_FIELD
22 from google.cloud.firestore_v1 import DocumentReference
23 from google.cloud.firestore_v1 import DocumentSnapshot
24 from google.cloud.firestore_v1 import enums
25 from google.cloud.firestore_v1 import ExistsOption
26 from google.cloud.firestore_v1 import GeoPoint
27 from google.cloud.firestore_v1 import LastUpdateOption
28 from google.cloud.firestore_v1 import Query
29 from google.cloud.firestore_v1 import ReadAfterWriteError
30 from google.cloud.firestore_v1 import SERVER_TIMESTAMP
31 from google.cloud.firestore_v1 import Transaction
32 from google.cloud.firestore_v1 import transactional
33 from google.cloud.firestore_v1 import types
34 from google.cloud.firestore_v1 import Watch
35 from google.cloud.firestore_v1 import WriteBatch
36 from google.cloud.firestore_v1 import WriteOption
37
38
39 __all__ = [
40 "__version__",
41 "Client",
42 "CollectionReference",
43 "DELETE_FIELD",
44 "DocumentReference",
45 "DocumentSnapshot",
46 "enums",
47 "ExistsOption",
48 "GeoPoint",
49 "LastUpdateOption",
50 "Query",
51 "ReadAfterWriteError",
52 "SERVER_TIMESTAMP",
53 "Transaction",
54 "transactional",
55 "types",
56 "Watch",
57 "WriteBatch",
58 "WriteOption",
59 ]
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/firestore/google/cloud/firestore.py b/firestore/google/cloud/firestore.py
--- a/firestore/google/cloud/firestore.py
+++ b/firestore/google/cloud/firestore.py
@@ -16,6 +16,8 @@
from google.cloud.firestore_v1 import __version__
+from google.cloud.firestore_v1 import ArrayRemove
+from google.cloud.firestore_v1 import ArrayUnion
from google.cloud.firestore_v1 import Client
from google.cloud.firestore_v1 import CollectionReference
from google.cloud.firestore_v1 import DELETE_FIELD
@@ -24,7 +26,10 @@
from google.cloud.firestore_v1 import enums
from google.cloud.firestore_v1 import ExistsOption
from google.cloud.firestore_v1 import GeoPoint
+from google.cloud.firestore_v1 import Increment
from google.cloud.firestore_v1 import LastUpdateOption
+from google.cloud.firestore_v1 import Maximum
+from google.cloud.firestore_v1 import Minimum
from google.cloud.firestore_v1 import Query
from google.cloud.firestore_v1 import ReadAfterWriteError
from google.cloud.firestore_v1 import SERVER_TIMESTAMP
@@ -38,6 +43,8 @@
__all__ = [
"__version__",
+ "ArrayRemove",
+ "ArrayUnion",
"Client",
"CollectionReference",
"DELETE_FIELD",
@@ -46,7 +53,10 @@
"enums",
"ExistsOption",
"GeoPoint",
+ "Increment",
"LastUpdateOption",
+ "Maximum",
+ "Minimum",
"Query",
"ReadAfterWriteError",
"SERVER_TIMESTAMP",
|
{"golden_diff": "diff --git a/firestore/google/cloud/firestore.py b/firestore/google/cloud/firestore.py\n--- a/firestore/google/cloud/firestore.py\n+++ b/firestore/google/cloud/firestore.py\n@@ -16,6 +16,8 @@\n \n \n from google.cloud.firestore_v1 import __version__\n+from google.cloud.firestore_v1 import ArrayRemove\n+from google.cloud.firestore_v1 import ArrayUnion\n from google.cloud.firestore_v1 import Client\n from google.cloud.firestore_v1 import CollectionReference\n from google.cloud.firestore_v1 import DELETE_FIELD\n@@ -24,7 +26,10 @@\n from google.cloud.firestore_v1 import enums\n from google.cloud.firestore_v1 import ExistsOption\n from google.cloud.firestore_v1 import GeoPoint\n+from google.cloud.firestore_v1 import Increment\n from google.cloud.firestore_v1 import LastUpdateOption\n+from google.cloud.firestore_v1 import Maximum\n+from google.cloud.firestore_v1 import Minimum\n from google.cloud.firestore_v1 import Query\n from google.cloud.firestore_v1 import ReadAfterWriteError\n from google.cloud.firestore_v1 import SERVER_TIMESTAMP\n@@ -38,6 +43,8 @@\n \n __all__ = [\n \"__version__\",\n+ \"ArrayRemove\",\n+ \"ArrayUnion\",\n \"Client\",\n \"CollectionReference\",\n \"DELETE_FIELD\",\n@@ -46,7 +53,10 @@\n \"enums\",\n \"ExistsOption\",\n \"GeoPoint\",\n+ \"Increment\",\n \"LastUpdateOption\",\n+ \"Maximum\",\n+ \"Minimum\",\n \"Query\",\n \"ReadAfterWriteError\",\n \"SERVER_TIMESTAMP\",\n", "issue": "Firestore: sync shim module with 'firestore_v1' package.\nSee https://github.com/googleapis/google-cloud-python/issues/7533#issuecomment-495917295 &ff.\n", "before_files": [{"content": "# Copyright 2017 Google LLC All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Python idiomatic client for Google Cloud Firestore.\"\"\"\n\n\nfrom google.cloud.firestore_v1 import __version__\nfrom google.cloud.firestore_v1 import Client\nfrom google.cloud.firestore_v1 import CollectionReference\nfrom google.cloud.firestore_v1 import DELETE_FIELD\nfrom google.cloud.firestore_v1 import DocumentReference\nfrom google.cloud.firestore_v1 import DocumentSnapshot\nfrom google.cloud.firestore_v1 import enums\nfrom google.cloud.firestore_v1 import ExistsOption\nfrom google.cloud.firestore_v1 import GeoPoint\nfrom google.cloud.firestore_v1 import LastUpdateOption\nfrom google.cloud.firestore_v1 import Query\nfrom google.cloud.firestore_v1 import ReadAfterWriteError\nfrom google.cloud.firestore_v1 import SERVER_TIMESTAMP\nfrom google.cloud.firestore_v1 import Transaction\nfrom google.cloud.firestore_v1 import transactional\nfrom google.cloud.firestore_v1 import types\nfrom google.cloud.firestore_v1 import Watch\nfrom google.cloud.firestore_v1 import WriteBatch\nfrom google.cloud.firestore_v1 import WriteOption\n\n\n__all__ = [\n \"__version__\",\n \"Client\",\n \"CollectionReference\",\n \"DELETE_FIELD\",\n \"DocumentReference\",\n \"DocumentSnapshot\",\n \"enums\",\n \"ExistsOption\",\n \"GeoPoint\",\n \"LastUpdateOption\",\n \"Query\",\n \"ReadAfterWriteError\",\n \"SERVER_TIMESTAMP\",\n \"Transaction\",\n \"transactional\",\n \"types\",\n \"Watch\",\n \"WriteBatch\",\n \"WriteOption\",\n]\n", "path": "firestore/google/cloud/firestore.py"}], "after_files": [{"content": "# Copyright 2017 Google LLC All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Python idiomatic client for Google Cloud Firestore.\"\"\"\n\n\nfrom google.cloud.firestore_v1 import __version__\nfrom google.cloud.firestore_v1 import ArrayRemove\nfrom google.cloud.firestore_v1 import ArrayUnion\nfrom google.cloud.firestore_v1 import Client\nfrom google.cloud.firestore_v1 import CollectionReference\nfrom google.cloud.firestore_v1 import DELETE_FIELD\nfrom google.cloud.firestore_v1 import DocumentReference\nfrom google.cloud.firestore_v1 import DocumentSnapshot\nfrom google.cloud.firestore_v1 import enums\nfrom google.cloud.firestore_v1 import ExistsOption\nfrom google.cloud.firestore_v1 import GeoPoint\nfrom google.cloud.firestore_v1 import Increment\nfrom google.cloud.firestore_v1 import LastUpdateOption\nfrom google.cloud.firestore_v1 import Maximum\nfrom google.cloud.firestore_v1 import Minimum\nfrom google.cloud.firestore_v1 import Query\nfrom google.cloud.firestore_v1 import ReadAfterWriteError\nfrom google.cloud.firestore_v1 import SERVER_TIMESTAMP\nfrom google.cloud.firestore_v1 import Transaction\nfrom google.cloud.firestore_v1 import transactional\nfrom google.cloud.firestore_v1 import types\nfrom google.cloud.firestore_v1 import Watch\nfrom google.cloud.firestore_v1 import WriteBatch\nfrom google.cloud.firestore_v1 import WriteOption\n\n\n__all__ = [\n \"__version__\",\n \"ArrayRemove\",\n \"ArrayUnion\",\n \"Client\",\n \"CollectionReference\",\n \"DELETE_FIELD\",\n \"DocumentReference\",\n \"DocumentSnapshot\",\n \"enums\",\n \"ExistsOption\",\n \"GeoPoint\",\n \"Increment\",\n \"LastUpdateOption\",\n \"Maximum\",\n \"Minimum\",\n \"Query\",\n \"ReadAfterWriteError\",\n \"SERVER_TIMESTAMP\",\n \"Transaction\",\n \"transactional\",\n \"types\",\n \"Watch\",\n \"WriteBatch\",\n \"WriteOption\",\n]\n", "path": "firestore/google/cloud/firestore.py"}]}
| 851 | 341 |
gh_patches_debug_3660
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-3320
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
python-magic dependency conflicts with file-magic (official python bindings for libmagic)
**Describe the bug**
I'm the Lutris packager for Mageia.
Lutris 0.5.8 added a dependency on `python-magic`, which is https://github.com/ahupp/python-magic
`python-magic` provides the `magic.py` module, which conflicts with the official Python bindings for libmagic provided by the `file` package (`python3-file-magic` on Mageia - previously `python3-magic` but I renamed it to make room for the conflicting `python-magic` package).
Long story short, those seem to be two competing implementations for the `magic` module and they can't be installed next to each other. Which means that once packaged in a distro, you can't install packaged software which independently require `file-magic` and `python-magic`.
Downstream issue (`rpmlint` and `lutris` can't be installed together): https://bugs.mageia.org/show_bug.cgi?id=27619
Upstream issue (8 years old, made some progress 2 years ago but still not resolved): https://github.com/ahupp/python-magic/issues/21
That's an unfortunate upstream issue and not directly related to Lutris but it does make packaging trickier. I'm not sure what the best solution would be here, but it might be worth checking if Lutris could use `python-magic` OR `file-magic`, whichever is installed? This would let distros settle on one fork as the main dependency for their packages.
**Steps to reproduce**
- Try to install a package that depends on `file`'s libmagic Python bindings together with Lutris that requires https://github.com/ahupp/python-magic
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/util/game_finder.py`
Content:
```
1 """Automatically detects game executables in a folder"""
2 import os
3
4 from lutris.util import system
5 from lutris.util.log import logger
6
7 try:
8 import magic
9 MAGIC_AVAILABLE = True
10 except ImportError:
11 MAGIC_AVAILABLE = False
12 magic = None
13
14
15 if not hasattr(magic, "from_file"):
16 logger.error("Your version of python-magic is too old.")
17 MAGIC_AVAILABLE = False
18
19
20 def is_excluded_elf(filename):
21 excluded = (
22 "xdg-open",
23 "uninstall"
24 )
25 _fn = filename.lower()
26 for exclude in excluded:
27 if exclude in _fn:
28 return True
29 return False
30
31
32 def find_linux_game_executable(path, make_executable=False):
33 """Looks for a binary or shell script that launches the game in a directory"""
34 if not MAGIC_AVAILABLE:
35 logger.warning("Magic not available. Not finding Linux executables")
36 return ""
37
38 for base, _dirs, files in os.walk(path):
39 candidates = {}
40 for _file in files:
41 if is_excluded_elf(_file):
42 continue
43 abspath = os.path.join(base, _file)
44 file_type = magic.from_file(abspath)
45 if "ASCII text executable" in file_type:
46 candidates["shell"] = abspath
47 if "Bourne-Again shell script" in file_type:
48 candidates["bash"] = abspath
49 if "64-bit LSB executable" in file_type:
50 candidates["64bit"] = abspath
51 if "32-bit LSB executable" in file_type:
52 candidates["32bit"] = abspath
53 if candidates:
54 if make_executable:
55 for file_type in candidates:
56 system.make_executable(candidates[file_type])
57 return (
58 candidates.get("shell")
59 or candidates.get("bash")
60 or candidates.get("64bit")
61 or candidates.get("32bit")
62 )
63 logger.error("Couldn't find a Linux executable in %s", path)
64 return ""
65
66
67 def is_excluded_dir(path):
68 excluded = (
69 "Internet Explorer",
70 "Windows NT",
71 "Common Files",
72 "Windows Media Player",
73 "windows",
74 "ProgramData",
75 "users",
76 "GameSpy Arcade"
77 )
78 skip = False
79 for dir_name in path.split("/"):
80 if dir_name in excluded:
81 skip = True
82 return skip
83
84
85 def is_excluded_exe(filename):
86 excluded = (
87 "unins000",
88 "uninstal",
89 "update",
90 "config.exe",
91 "gsarcade.exe",
92 "dosbox.exe",
93 )
94 _fn = filename.lower()
95 for exclude in excluded:
96 if exclude in _fn:
97 return True
98 return False
99
100
101 def find_windows_game_executable(path):
102 if not MAGIC_AVAILABLE:
103 logger.warning("Magic not available. Not finding Windows executables")
104 return ""
105
106 for base, _dirs, files in os.walk(path):
107 candidates = {}
108 if is_excluded_dir(base):
109 continue
110 for _file in files:
111 if is_excluded_exe(_file):
112 continue
113 abspath = os.path.join(base, _file)
114 if os.path.islink(abspath):
115 continue
116 file_type = magic.from_file(abspath)
117 if "MS Windows shortcut" in file_type:
118 candidates["link"] = abspath
119 elif "PE32+ executable (GUI) x86-64" in file_type:
120 candidates["64bit"] = abspath
121 elif "PE32 executable (GUI) Intel 80386" in file_type:
122 candidates["32bit"] = abspath
123 if candidates:
124 return (
125 candidates.get("link")
126 or candidates.get("64bit")
127 or candidates.get("32bit")
128 )
129 logger.error("Couldn't find a Windows executable in %s", path)
130 return ""
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/util/game_finder.py b/lutris/util/game_finder.py
--- a/lutris/util/game_finder.py
+++ b/lutris/util/game_finder.py
@@ -13,8 +13,12 @@
if not hasattr(magic, "from_file"):
- logger.error("Your version of python-magic is too old.")
- MAGIC_AVAILABLE = False
+ if hasattr(magic, "detect_from_filename"):
+ magic.from_file = magic.detect_from_filename
+ MAGIC_AVAILABLE = True
+ else:
+ logger.error("Your version of python-magic is too old.")
+ MAGIC_AVAILABLE = False
def is_excluded_elf(filename):
|
{"golden_diff": "diff --git a/lutris/util/game_finder.py b/lutris/util/game_finder.py\n--- a/lutris/util/game_finder.py\n+++ b/lutris/util/game_finder.py\n@@ -13,8 +13,12 @@\n \n \n if not hasattr(magic, \"from_file\"):\n- logger.error(\"Your version of python-magic is too old.\")\n- MAGIC_AVAILABLE = False\n+ if hasattr(magic, \"detect_from_filename\"):\n+ magic.from_file = magic.detect_from_filename\n+ MAGIC_AVAILABLE = True\n+ else:\n+ logger.error(\"Your version of python-magic is too old.\")\n+ MAGIC_AVAILABLE = False\n \n \n def is_excluded_elf(filename):\n", "issue": "python-magic dependency conflicts with file-magic (official python bindings for libmagic)\n**Describe the bug**\r\n\r\nI'm the Lutris packager for Mageia.\r\n\r\nLutris 0.5.8 added a dependency on `python-magic`, which is https://github.com/ahupp/python-magic\r\n\r\n`python-magic` provides the `magic.py` module, which conflicts with the official Python bindings for libmagic provided by the `file` package (`python3-file-magic` on Mageia - previously `python3-magic` but I renamed it to make room for the conflicting `python-magic` package).\r\n\r\nLong story short, those seem to be two competing implementations for the `magic` module and they can't be installed next to each other. Which means that once packaged in a distro, you can't install packaged software which independently require `file-magic` and `python-magic`.\r\nDownstream issue (`rpmlint` and `lutris` can't be installed together): https://bugs.mageia.org/show_bug.cgi?id=27619\r\n\r\nUpstream issue (8 years old, made some progress 2 years ago but still not resolved): https://github.com/ahupp/python-magic/issues/21\r\n\r\nThat's an unfortunate upstream issue and not directly related to Lutris but it does make packaging trickier. I'm not sure what the best solution would be here, but it might be worth checking if Lutris could use `python-magic` OR `file-magic`, whichever is installed? This would let distros settle on one fork as the main dependency for their packages.\r\n\r\n**Steps to reproduce**\r\n\r\n- Try to install a package that depends on `file`'s libmagic Python bindings together with Lutris that requires https://github.com/ahupp/python-magic\n", "before_files": [{"content": "\"\"\"Automatically detects game executables in a folder\"\"\"\nimport os\n\nfrom lutris.util import system\nfrom lutris.util.log import logger\n\ntry:\n import magic\n MAGIC_AVAILABLE = True\nexcept ImportError:\n MAGIC_AVAILABLE = False\n magic = None\n\n\nif not hasattr(magic, \"from_file\"):\n logger.error(\"Your version of python-magic is too old.\")\n MAGIC_AVAILABLE = False\n\n\ndef is_excluded_elf(filename):\n excluded = (\n \"xdg-open\",\n \"uninstall\"\n )\n _fn = filename.lower()\n for exclude in excluded:\n if exclude in _fn:\n return True\n return False\n\n\ndef find_linux_game_executable(path, make_executable=False):\n \"\"\"Looks for a binary or shell script that launches the game in a directory\"\"\"\n if not MAGIC_AVAILABLE:\n logger.warning(\"Magic not available. Not finding Linux executables\")\n return \"\"\n\n for base, _dirs, files in os.walk(path):\n candidates = {}\n for _file in files:\n if is_excluded_elf(_file):\n continue\n abspath = os.path.join(base, _file)\n file_type = magic.from_file(abspath)\n if \"ASCII text executable\" in file_type:\n candidates[\"shell\"] = abspath\n if \"Bourne-Again shell script\" in file_type:\n candidates[\"bash\"] = abspath\n if \"64-bit LSB executable\" in file_type:\n candidates[\"64bit\"] = abspath\n if \"32-bit LSB executable\" in file_type:\n candidates[\"32bit\"] = abspath\n if candidates:\n if make_executable:\n for file_type in candidates:\n system.make_executable(candidates[file_type])\n return (\n candidates.get(\"shell\")\n or candidates.get(\"bash\")\n or candidates.get(\"64bit\")\n or candidates.get(\"32bit\")\n )\n logger.error(\"Couldn't find a Linux executable in %s\", path)\n return \"\"\n\n\ndef is_excluded_dir(path):\n excluded = (\n \"Internet Explorer\",\n \"Windows NT\",\n \"Common Files\",\n \"Windows Media Player\",\n \"windows\",\n \"ProgramData\",\n \"users\",\n \"GameSpy Arcade\"\n )\n skip = False\n for dir_name in path.split(\"/\"):\n if dir_name in excluded:\n skip = True\n return skip\n\n\ndef is_excluded_exe(filename):\n excluded = (\n \"unins000\",\n \"uninstal\",\n \"update\",\n \"config.exe\",\n \"gsarcade.exe\",\n \"dosbox.exe\",\n )\n _fn = filename.lower()\n for exclude in excluded:\n if exclude in _fn:\n return True\n return False\n\n\ndef find_windows_game_executable(path):\n if not MAGIC_AVAILABLE:\n logger.warning(\"Magic not available. Not finding Windows executables\")\n return \"\"\n\n for base, _dirs, files in os.walk(path):\n candidates = {}\n if is_excluded_dir(base):\n continue\n for _file in files:\n if is_excluded_exe(_file):\n continue\n abspath = os.path.join(base, _file)\n if os.path.islink(abspath):\n continue\n file_type = magic.from_file(abspath)\n if \"MS Windows shortcut\" in file_type:\n candidates[\"link\"] = abspath\n elif \"PE32+ executable (GUI) x86-64\" in file_type:\n candidates[\"64bit\"] = abspath\n elif \"PE32 executable (GUI) Intel 80386\" in file_type:\n candidates[\"32bit\"] = abspath\n if candidates:\n return (\n candidates.get(\"link\")\n or candidates.get(\"64bit\")\n or candidates.get(\"32bit\")\n )\n logger.error(\"Couldn't find a Windows executable in %s\", path)\n return \"\"\n", "path": "lutris/util/game_finder.py"}], "after_files": [{"content": "\"\"\"Automatically detects game executables in a folder\"\"\"\nimport os\n\nfrom lutris.util import system\nfrom lutris.util.log import logger\n\ntry:\n import magic\n MAGIC_AVAILABLE = True\nexcept ImportError:\n MAGIC_AVAILABLE = False\n magic = None\n\n\nif not hasattr(magic, \"from_file\"):\n if hasattr(magic, \"detect_from_filename\"):\n magic.from_file = magic.detect_from_filename\n MAGIC_AVAILABLE = True\n else:\n logger.error(\"Your version of python-magic is too old.\")\n MAGIC_AVAILABLE = False\n\n\ndef is_excluded_elf(filename):\n excluded = (\n \"xdg-open\",\n \"uninstall\"\n )\n _fn = filename.lower()\n for exclude in excluded:\n if exclude in _fn:\n return True\n return False\n\n\ndef find_linux_game_executable(path, make_executable=False):\n \"\"\"Looks for a binary or shell script that launches the game in a directory\"\"\"\n if not MAGIC_AVAILABLE:\n logger.warning(\"Magic not available. Not finding Linux executables\")\n return \"\"\n\n for base, _dirs, files in os.walk(path):\n candidates = {}\n for _file in files:\n if is_excluded_elf(_file):\n continue\n abspath = os.path.join(base, _file)\n file_type = magic.from_file(abspath)\n if \"ASCII text executable\" in file_type:\n candidates[\"shell\"] = abspath\n if \"Bourne-Again shell script\" in file_type:\n candidates[\"bash\"] = abspath\n if \"64-bit LSB executable\" in file_type:\n candidates[\"64bit\"] = abspath\n if \"32-bit LSB executable\" in file_type:\n candidates[\"32bit\"] = abspath\n if candidates:\n if make_executable:\n for file_type in candidates:\n system.make_executable(candidates[file_type])\n return (\n candidates.get(\"shell\")\n or candidates.get(\"bash\")\n or candidates.get(\"64bit\")\n or candidates.get(\"32bit\")\n )\n logger.error(\"Couldn't find a Linux executable in %s\", path)\n return \"\"\n\n\ndef is_excluded_dir(path):\n excluded = (\n \"Internet Explorer\",\n \"Windows NT\",\n \"Common Files\",\n \"Windows Media Player\",\n \"windows\",\n \"ProgramData\",\n \"users\",\n \"GameSpy Arcade\"\n )\n skip = False\n for dir_name in path.split(\"/\"):\n if dir_name in excluded:\n skip = True\n return skip\n\n\ndef is_excluded_exe(filename):\n excluded = (\n \"unins000\",\n \"uninstal\",\n \"update\",\n \"config.exe\",\n \"gsarcade.exe\",\n \"dosbox.exe\",\n )\n _fn = filename.lower()\n for exclude in excluded:\n if exclude in _fn:\n return True\n return False\n\n\ndef find_windows_game_executable(path):\n if not MAGIC_AVAILABLE:\n logger.warning(\"Magic not available. Not finding Windows executables\")\n return \"\"\n\n for base, _dirs, files in os.walk(path):\n candidates = {}\n if is_excluded_dir(base):\n continue\n for _file in files:\n if is_excluded_exe(_file):\n continue\n abspath = os.path.join(base, _file)\n if os.path.islink(abspath):\n continue\n file_type = magic.from_file(abspath)\n if \"MS Windows shortcut\" in file_type:\n candidates[\"link\"] = abspath\n elif \"PE32+ executable (GUI) x86-64\" in file_type:\n candidates[\"64bit\"] = abspath\n elif \"PE32 executable (GUI) Intel 80386\" in file_type:\n candidates[\"32bit\"] = abspath\n if candidates:\n return (\n candidates.get(\"link\")\n or candidates.get(\"64bit\")\n or candidates.get(\"32bit\")\n )\n logger.error(\"Couldn't find a Windows executable in %s\", path)\n return \"\"\n", "path": "lutris/util/game_finder.py"}]}
| 1,778 | 151 |
gh_patches_debug_36275
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-1848
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API docs list duplicate attributes
Looks like all the attributes in the API docs are listed twice:
https://jupyterhub.readthedocs.io/en/latest/api/proxy.html#module-jupyterhub.proxy
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 import sys
4 import os
5 import shlex
6
7 # For conversion from markdown to html
8 import recommonmark.parser
9
10 # Set paths
11 sys.path.insert(0, os.path.abspath('.'))
12
13 # -- General configuration ------------------------------------------------
14
15 # Minimal Sphinx version
16 needs_sphinx = '1.4'
17
18 # Sphinx extension modules
19 extensions = [
20 'sphinx.ext.autodoc',
21 'sphinx.ext.intersphinx',
22 'sphinx.ext.napoleon',
23 'autodoc_traits',
24 'jupyter_alabaster_theme',
25 ]
26
27 templates_path = ['_templates']
28
29 # The master toctree document.
30 master_doc = 'index'
31
32 # General information about the project.
33 project = u'JupyterHub'
34 copyright = u'2016, Project Jupyter team'
35 author = u'Project Jupyter team'
36
37 # Autopopulate version
38 from os.path import dirname
39 docs = dirname(dirname(__file__))
40 root = dirname(docs)
41 sys.path.insert(0, root)
42 sys.path.insert(0, os.path.join(docs, 'sphinxext'))
43
44 import jupyterhub
45 # The short X.Y version.
46 version = '%i.%i' % jupyterhub.version_info[:2]
47 # The full version, including alpha/beta/rc tags.
48 release = jupyterhub.__version__
49
50 language = None
51 exclude_patterns = []
52 pygments_style = 'sphinx'
53 todo_include_todos = False
54
55 # Set the default role so we can use `foo` instead of ``foo``
56 default_role = 'literal'
57
58 # -- Source -------------------------------------------------------------
59
60 source_parsers = {
61 '.md': 'recommonmark.parser.CommonMarkParser',
62 }
63
64 source_suffix = ['.rst', '.md']
65 #source_encoding = 'utf-8-sig'
66
67 # -- Options for HTML output ----------------------------------------------
68
69 # The theme to use for HTML and HTML Help pages.
70 html_theme = 'jupyter_alabaster_theme'
71
72 #html_theme_options = {}
73 #html_theme_path = []
74 #html_title = None
75 #html_short_title = None
76 #html_logo = None
77 #html_favicon = None
78
79 # Paths that contain custom static files (such as style sheets)
80 html_static_path = ['_static']
81
82 #html_extra_path = []
83 #html_last_updated_fmt = '%b %d, %Y'
84 #html_use_smartypants = True
85 #html_sidebars = {}
86 #html_additional_pages = {}
87 #html_domain_indices = True
88 #html_use_index = True
89 #html_split_index = False
90 #html_show_sourcelink = True
91 #html_show_sphinx = True
92 #html_show_copyright = True
93 #html_use_opensearch = ''
94 #html_file_suffix = None
95 #html_search_language = 'en'
96 #html_search_options = {'type': 'default'}
97 #html_search_scorer = 'scorer.js'
98 htmlhelp_basename = 'JupyterHubdoc'
99
100 # -- Options for LaTeX output ---------------------------------------------
101
102 latex_elements = {
103 #'papersize': 'letterpaper',
104 #'pointsize': '10pt',
105 #'preamble': '',
106 #'figure_align': 'htbp',
107 }
108
109 # Grouping the document tree into LaTeX files. List of tuples
110 # (source start file, target name, title,
111 # author, documentclass [howto, manual, or own class]).
112 latex_documents = [
113 (master_doc, 'JupyterHub.tex', u'JupyterHub Documentation',
114 u'Project Jupyter team', 'manual'),
115 ]
116
117 #latex_logo = None
118 #latex_use_parts = False
119 #latex_show_pagerefs = False
120 #latex_show_urls = False
121 #latex_appendices = []
122 #latex_domain_indices = True
123
124
125 # -- manual page output -------------------------------------------------
126
127 # One entry per manual page. List of tuples
128 # (source start file, name, description, authors, manual section).
129 man_pages = [
130 (master_doc, 'jupyterhub', u'JupyterHub Documentation',
131 [author], 1)
132 ]
133
134 #man_show_urls = False
135
136
137 # -- Texinfo output -----------------------------------------------------
138
139 # Grouping the document tree into Texinfo files. List of tuples
140 # (source start file, target name, title, author,
141 # dir menu entry, description, category)
142 texinfo_documents = [
143 (master_doc, 'JupyterHub', u'JupyterHub Documentation',
144 author, 'JupyterHub', 'One line description of project.',
145 'Miscellaneous'),
146 ]
147
148 #texinfo_appendices = []
149 #texinfo_domain_indices = True
150 #texinfo_show_urls = 'footnote'
151 #texinfo_no_detailmenu = False
152
153
154 # -- Epub output --------------------------------------------------------
155
156 # Bibliographic Dublin Core info.
157 epub_title = project
158 epub_author = author
159 epub_publisher = author
160 epub_copyright = copyright
161
162 # A list of files that should not be packed into the epub file.
163 epub_exclude_files = ['search.html']
164
165 # -- Intersphinx ----------------------------------------------------------
166
167 intersphinx_mapping = {'https://docs.python.org/3/': None}
168
169 # -- Read The Docs --------------------------------------------------------
170
171 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
172 if not on_rtd:
173 import jupyter_alabaster_theme
174 html_theme = 'jupyter_alabaster_theme'
175 html_theme_path = [jupyter_alabaster_theme.get_path()]
176 else:
177 # readthedocs.org uses their theme by default, so no need to specify it
178 # build rest-api, since RTD doesn't run make
179 from subprocess import check_call as sh
180 sh(['make', 'rest-api'], cwd=docs)
181
182 # -- Spell checking -------------------------------------------------------
183
184 try:
185 import sphinxcontrib.spelling
186 except ImportError:
187 pass
188 else:
189 extensions.append("sphinxcontrib.spelling")
190
191 spelling_word_list_filename='spelling_wordlist.txt'
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -21,7 +21,6 @@
'sphinx.ext.intersphinx',
'sphinx.ext.napoleon',
'autodoc_traits',
- 'jupyter_alabaster_theme',
]
templates_path = ['_templates']
@@ -67,34 +66,39 @@
# -- Options for HTML output ----------------------------------------------
# The theme to use for HTML and HTML Help pages.
-html_theme = 'jupyter_alabaster_theme'
+html_theme = 'alabaster'
-#html_theme_options = {}
-#html_theme_path = []
-#html_title = None
-#html_short_title = None
-#html_logo = None
-#html_favicon = None
+html_logo = '_static/images/logo/logo.png'
+html_favicon = '_static/images/logo/favicon.ico'
# Paths that contain custom static files (such as style sheets)
html_static_path = ['_static']
-#html_extra_path = []
-#html_last_updated_fmt = '%b %d, %Y'
-#html_use_smartypants = True
-#html_sidebars = {}
-#html_additional_pages = {}
-#html_domain_indices = True
-#html_use_index = True
-#html_split_index = False
-#html_show_sourcelink = True
-#html_show_sphinx = True
-#html_show_copyright = True
-#html_use_opensearch = ''
-#html_file_suffix = None
-#html_search_language = 'en'
-#html_search_options = {'type': 'default'}
-#html_search_scorer = 'scorer.js'
+html_theme_options = {
+ 'show_related': True,
+ 'description': 'Documentation for JupyterHub',
+ 'github_user': 'jupyterhub',
+ 'github_repo': 'jupyterhub',
+ 'github_banner': False,
+ 'github_button': True,
+ 'github_type': 'star',
+ 'show_powered_by': False,
+ 'extra_nav_links': {
+ 'GitHub Repo': 'http://github.com/jupyterhub/jupyterhub',
+ 'Issue Tracker': 'http://github.com/jupyterhub/jupyterhub/issues',
+ },
+}
+
+html_sidebars = {
+ '**': [
+ 'about.html',
+ 'searchbox.html',
+ 'navigation.html',
+ 'relations.html',
+ 'sourcelink.html',
+ ],
+}
+
htmlhelp_basename = 'JupyterHubdoc'
# -- Options for LaTeX output ---------------------------------------------
@@ -170,9 +174,7 @@
on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
if not on_rtd:
- import jupyter_alabaster_theme
- html_theme = 'jupyter_alabaster_theme'
- html_theme_path = [jupyter_alabaster_theme.get_path()]
+ html_theme = 'alabaster'
else:
# readthedocs.org uses their theme by default, so no need to specify it
# build rest-api, since RTD doesn't run make
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -21,7 +21,6 @@\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.napoleon',\n 'autodoc_traits',\n- 'jupyter_alabaster_theme',\n ]\n \n templates_path = ['_templates']\n@@ -67,34 +66,39 @@\n # -- Options for HTML output ----------------------------------------------\n \n # The theme to use for HTML and HTML Help pages.\n-html_theme = 'jupyter_alabaster_theme'\n+html_theme = 'alabaster'\n \n-#html_theme_options = {}\n-#html_theme_path = []\n-#html_title = None\n-#html_short_title = None\n-#html_logo = None\n-#html_favicon = None\n+html_logo = '_static/images/logo/logo.png'\n+html_favicon = '_static/images/logo/favicon.ico'\n \n # Paths that contain custom static files (such as style sheets)\n html_static_path = ['_static']\n \n-#html_extra_path = []\n-#html_last_updated_fmt = '%b %d, %Y'\n-#html_use_smartypants = True\n-#html_sidebars = {}\n-#html_additional_pages = {}\n-#html_domain_indices = True\n-#html_use_index = True\n-#html_split_index = False\n-#html_show_sourcelink = True\n-#html_show_sphinx = True\n-#html_show_copyright = True\n-#html_use_opensearch = ''\n-#html_file_suffix = None\n-#html_search_language = 'en'\n-#html_search_options = {'type': 'default'}\n-#html_search_scorer = 'scorer.js'\n+html_theme_options = {\n+ 'show_related': True,\n+ 'description': 'Documentation for JupyterHub',\n+ 'github_user': 'jupyterhub',\n+ 'github_repo': 'jupyterhub',\n+ 'github_banner': False,\n+ 'github_button': True,\n+ 'github_type': 'star',\n+ 'show_powered_by': False,\n+ 'extra_nav_links': {\n+ 'GitHub Repo': 'http://github.com/jupyterhub/jupyterhub',\n+ 'Issue Tracker': 'http://github.com/jupyterhub/jupyterhub/issues',\n+ },\n+}\n+\n+html_sidebars = {\n+ '**': [\n+ 'about.html',\n+ 'searchbox.html',\n+ 'navigation.html',\n+ 'relations.html',\n+ 'sourcelink.html',\n+ ],\n+}\n+\n htmlhelp_basename = 'JupyterHubdoc'\n \n # -- Options for LaTeX output ---------------------------------------------\n@@ -170,9 +174,7 @@\n \n on_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n if not on_rtd:\n- import jupyter_alabaster_theme\n- html_theme = 'jupyter_alabaster_theme'\n- html_theme_path = [jupyter_alabaster_theme.get_path()]\n+ html_theme = 'alabaster'\n else:\n # readthedocs.org uses their theme by default, so no need to specify it\n # build rest-api, since RTD doesn't run make\n", "issue": "API docs list duplicate attributes\nLooks like all the attributes in the API docs are listed twice:\r\n\r\nhttps://jupyterhub.readthedocs.io/en/latest/api/proxy.html#module-jupyterhub.proxy\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\nimport sys\nimport os\nimport shlex\n\n# For conversion from markdown to html\nimport recommonmark.parser\n\n# Set paths\nsys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# Minimal Sphinx version\nneeds_sphinx = '1.4'\n\n# Sphinx extension modules\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.napoleon',\n 'autodoc_traits',\n 'jupyter_alabaster_theme',\n]\n\ntemplates_path = ['_templates']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'JupyterHub'\ncopyright = u'2016, Project Jupyter team'\nauthor = u'Project Jupyter team'\n\n# Autopopulate version\nfrom os.path import dirname\ndocs = dirname(dirname(__file__))\nroot = dirname(docs)\nsys.path.insert(0, root)\nsys.path.insert(0, os.path.join(docs, 'sphinxext'))\n\nimport jupyterhub\n# The short X.Y version.\nversion = '%i.%i' % jupyterhub.version_info[:2]\n# The full version, including alpha/beta/rc tags.\nrelease = jupyterhub.__version__\n\nlanguage = None\nexclude_patterns = []\npygments_style = 'sphinx'\ntodo_include_todos = False\n\n# Set the default role so we can use `foo` instead of ``foo``\ndefault_role = 'literal'\n\n# -- Source -------------------------------------------------------------\n\nsource_parsers = {\n '.md': 'recommonmark.parser.CommonMarkParser',\n}\n\nsource_suffix = ['.rst', '.md']\n#source_encoding = 'utf-8-sig'\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages.\nhtml_theme = 'jupyter_alabaster_theme'\n\n#html_theme_options = {}\n#html_theme_path = []\n#html_title = None\n#html_short_title = None\n#html_logo = None\n#html_favicon = None\n\n# Paths that contain custom static files (such as style sheets)\nhtml_static_path = ['_static']\n\n#html_extra_path = []\n#html_last_updated_fmt = '%b %d, %Y'\n#html_use_smartypants = True\n#html_sidebars = {}\n#html_additional_pages = {}\n#html_domain_indices = True\n#html_use_index = True\n#html_split_index = False\n#html_show_sourcelink = True\n#html_show_sphinx = True\n#html_show_copyright = True\n#html_use_opensearch = ''\n#html_file_suffix = None\n#html_search_language = 'en'\n#html_search_options = {'type': 'default'}\n#html_search_scorer = 'scorer.js'\nhtmlhelp_basename = 'JupyterHubdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n#'papersize': 'letterpaper',\n#'pointsize': '10pt',\n#'preamble': '',\n#'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'JupyterHub.tex', u'JupyterHub Documentation',\n u'Project Jupyter team', 'manual'),\n]\n\n#latex_logo = None\n#latex_use_parts = False\n#latex_show_pagerefs = False\n#latex_show_urls = False\n#latex_appendices = []\n#latex_domain_indices = True\n\n\n# -- manual page output -------------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'jupyterhub', u'JupyterHub Documentation',\n [author], 1)\n]\n\n#man_show_urls = False\n\n\n# -- Texinfo output -----------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'JupyterHub', u'JupyterHub Documentation',\n author, 'JupyterHub', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n#texinfo_appendices = []\n#texinfo_domain_indices = True\n#texinfo_show_urls = 'footnote'\n#texinfo_no_detailmenu = False\n\n\n# -- Epub output --------------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = ['search.html']\n\n# -- Intersphinx ----------------------------------------------------------\n\nintersphinx_mapping = {'https://docs.python.org/3/': None}\n\n# -- Read The Docs --------------------------------------------------------\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\nif not on_rtd:\n import jupyter_alabaster_theme\n html_theme = 'jupyter_alabaster_theme'\n html_theme_path = [jupyter_alabaster_theme.get_path()]\nelse:\n # readthedocs.org uses their theme by default, so no need to specify it\n # build rest-api, since RTD doesn't run make\n from subprocess import check_call as sh\n sh(['make', 'rest-api'], cwd=docs)\n\n# -- Spell checking -------------------------------------------------------\n\ntry:\n import sphinxcontrib.spelling\nexcept ImportError:\n pass\nelse:\n extensions.append(\"sphinxcontrib.spelling\")\n\nspelling_word_list_filename='spelling_wordlist.txt'\n", "path": "docs/source/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\nimport sys\nimport os\nimport shlex\n\n# For conversion from markdown to html\nimport recommonmark.parser\n\n# Set paths\nsys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# Minimal Sphinx version\nneeds_sphinx = '1.4'\n\n# Sphinx extension modules\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.napoleon',\n 'autodoc_traits',\n]\n\ntemplates_path = ['_templates']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'JupyterHub'\ncopyright = u'2016, Project Jupyter team'\nauthor = u'Project Jupyter team'\n\n# Autopopulate version\nfrom os.path import dirname\ndocs = dirname(dirname(__file__))\nroot = dirname(docs)\nsys.path.insert(0, root)\nsys.path.insert(0, os.path.join(docs, 'sphinxext'))\n\nimport jupyterhub\n# The short X.Y version.\nversion = '%i.%i' % jupyterhub.version_info[:2]\n# The full version, including alpha/beta/rc tags.\nrelease = jupyterhub.__version__\n\nlanguage = None\nexclude_patterns = []\npygments_style = 'sphinx'\ntodo_include_todos = False\n\n# Set the default role so we can use `foo` instead of ``foo``\ndefault_role = 'literal'\n\n# -- Source -------------------------------------------------------------\n\nsource_parsers = {\n '.md': 'recommonmark.parser.CommonMarkParser',\n}\n\nsource_suffix = ['.rst', '.md']\n#source_encoding = 'utf-8-sig'\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages.\nhtml_theme = 'alabaster'\n\nhtml_logo = '_static/images/logo/logo.png'\nhtml_favicon = '_static/images/logo/favicon.ico'\n\n# Paths that contain custom static files (such as style sheets)\nhtml_static_path = ['_static']\n\nhtml_theme_options = {\n 'show_related': True,\n 'description': 'Documentation for JupyterHub',\n 'github_user': 'jupyterhub',\n 'github_repo': 'jupyterhub',\n 'github_banner': False,\n 'github_button': True,\n 'github_type': 'star',\n 'show_powered_by': False,\n 'extra_nav_links': {\n 'GitHub Repo': 'http://github.com/jupyterhub/jupyterhub',\n 'Issue Tracker': 'http://github.com/jupyterhub/jupyterhub/issues',\n },\n}\n\nhtml_sidebars = {\n '**': [\n 'about.html',\n 'searchbox.html',\n 'navigation.html',\n 'relations.html',\n 'sourcelink.html',\n ],\n}\n\nhtmlhelp_basename = 'JupyterHubdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n#'papersize': 'letterpaper',\n#'pointsize': '10pt',\n#'preamble': '',\n#'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'JupyterHub.tex', u'JupyterHub Documentation',\n u'Project Jupyter team', 'manual'),\n]\n\n#latex_logo = None\n#latex_use_parts = False\n#latex_show_pagerefs = False\n#latex_show_urls = False\n#latex_appendices = []\n#latex_domain_indices = True\n\n\n# -- manual page output -------------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'jupyterhub', u'JupyterHub Documentation',\n [author], 1)\n]\n\n#man_show_urls = False\n\n\n# -- Texinfo output -----------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'JupyterHub', u'JupyterHub Documentation',\n author, 'JupyterHub', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n#texinfo_appendices = []\n#texinfo_domain_indices = True\n#texinfo_show_urls = 'footnote'\n#texinfo_no_detailmenu = False\n\n\n# -- Epub output --------------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = ['search.html']\n\n# -- Intersphinx ----------------------------------------------------------\n\nintersphinx_mapping = {'https://docs.python.org/3/': None}\n\n# -- Read The Docs --------------------------------------------------------\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\nif not on_rtd:\n html_theme = 'alabaster'\nelse:\n # readthedocs.org uses their theme by default, so no need to specify it\n # build rest-api, since RTD doesn't run make\n from subprocess import check_call as sh\n sh(['make', 'rest-api'], cwd=docs)\n\n# -- Spell checking -------------------------------------------------------\n\ntry:\n import sphinxcontrib.spelling\nexcept ImportError:\n pass\nelse:\n extensions.append(\"sphinxcontrib.spelling\")\n\nspelling_word_list_filename='spelling_wordlist.txt'\n", "path": "docs/source/conf.py"}]}
| 2,015 | 709 |
gh_patches_debug_20390
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-1488
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
unicode literrals
based on irc discussion with @rjarry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/util/lineboundaries.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from twisted.internet import defer
17
18
19 class LineBoundaryFinder(object):
20
21 __slots__ = ['partialLine', 'callback']
22
23 def __init__(self, callback):
24 self.partialLine = None
25 self.callback = callback
26
27 def append(self, text):
28 if self.partialLine:
29 text = self.partialLine + text
30 self.partialLine = None
31 if text:
32 if text[-1] != '\n':
33 i = text.rfind('\n')
34 if i >= 0:
35 i = i + 1
36 text, self.partialLine = text[:i], text[i:]
37 else:
38 self.partialLine = text
39 return defer.succeed(None)
40 return self.callback(text)
41
42 def flush(self):
43 if self.partialLine:
44 return self.append('\n')
45 else:
46 return defer.succeed(None)
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/util/lineboundaries.py b/master/buildbot/util/lineboundaries.py
--- a/master/buildbot/util/lineboundaries.py
+++ b/master/buildbot/util/lineboundaries.py
@@ -13,6 +13,8 @@
#
# Copyright Buildbot Team Members
+import re
+
from twisted.internet import defer
@@ -20,6 +22,10 @@
__slots__ = ['partialLine', 'callback']
+ # the lookahead here (`(?=.)`) ensures that `\r` doesn't match at the end
+ # of the buffer
+ newline_re = re.compile(r'(\r\n|\r(?=.)|\n)')
+
def __init__(self, callback):
self.partialLine = None
self.callback = callback
@@ -28,6 +34,7 @@
if self.partialLine:
text = self.partialLine + text
self.partialLine = None
+ text = self.newline_re.sub('\n', text)
if text:
if text[-1] != '\n':
i = text.rfind('\n')
|
{"golden_diff": "diff --git a/master/buildbot/util/lineboundaries.py b/master/buildbot/util/lineboundaries.py\n--- a/master/buildbot/util/lineboundaries.py\n+++ b/master/buildbot/util/lineboundaries.py\n@@ -13,6 +13,8 @@\n #\n # Copyright Buildbot Team Members\n \n+import re\n+\n from twisted.internet import defer\n \n \n@@ -20,6 +22,10 @@\n \n __slots__ = ['partialLine', 'callback']\n \n+ # the lookahead here (`(?=.)`) ensures that `\\r` doesn't match at the end\n+ # of the buffer\n+ newline_re = re.compile(r'(\\r\\n|\\r(?=.)|\\n)')\n+\n def __init__(self, callback):\n self.partialLine = None\n self.callback = callback\n@@ -28,6 +34,7 @@\n if self.partialLine:\n text = self.partialLine + text\n self.partialLine = None\n+ text = self.newline_re.sub('\\n', text)\n if text:\n if text[-1] != '\\n':\n i = text.rfind('\\n')\n", "issue": "unicode literrals\nbased on irc discussion with @rjarry \n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom twisted.internet import defer\n\n\nclass LineBoundaryFinder(object):\n\n __slots__ = ['partialLine', 'callback']\n\n def __init__(self, callback):\n self.partialLine = None\n self.callback = callback\n\n def append(self, text):\n if self.partialLine:\n text = self.partialLine + text\n self.partialLine = None\n if text:\n if text[-1] != '\\n':\n i = text.rfind('\\n')\n if i >= 0:\n i = i + 1\n text, self.partialLine = text[:i], text[i:]\n else:\n self.partialLine = text\n return defer.succeed(None)\n return self.callback(text)\n\n def flush(self):\n if self.partialLine:\n return self.append('\\n')\n else:\n return defer.succeed(None)\n", "path": "master/buildbot/util/lineboundaries.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport re\n\nfrom twisted.internet import defer\n\n\nclass LineBoundaryFinder(object):\n\n __slots__ = ['partialLine', 'callback']\n\n # the lookahead here (`(?=.)`) ensures that `\\r` doesn't match at the end\n # of the buffer\n newline_re = re.compile(r'(\\r\\n|\\r(?=.)|\\n)')\n\n def __init__(self, callback):\n self.partialLine = None\n self.callback = callback\n\n def append(self, text):\n if self.partialLine:\n text = self.partialLine + text\n self.partialLine = None\n text = self.newline_re.sub('\\n', text)\n if text:\n if text[-1] != '\\n':\n i = text.rfind('\\n')\n if i >= 0:\n i = i + 1\n text, self.partialLine = text[:i], text[i:]\n else:\n self.partialLine = text\n return defer.succeed(None)\n return self.callback(text)\n\n def flush(self):\n if self.partialLine:\n return self.append('\\n')\n else:\n return defer.succeed(None)\n", "path": "master/buildbot/util/lineboundaries.py"}]}
| 715 | 251 |
gh_patches_debug_4739
|
rasdani/github-patches
|
git_diff
|
searx__searx-2232
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[fix] Sphinx 3.2.1 build: add missing "engines" variable in the jinja context
## What does this PR do?
Fix PR #2210 which upgrade Sphinx version to 3.2.1.
The admin/engines.html page is empty.
## Why is this change important?
Fix the admin/engines.html page.
## How to test this PR locally?
Check the admin/engines.html page.
## Author's checklist
<!-- additional notes for reviewiers -->
## Related issues
#2210
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import sys, os
4 from sphinx_build_tools import load_sphinx_config
5 from searx.version import VERSION_STRING
6 from pallets_sphinx_themes import ProjectLink
7
8 from searx.brand import GIT_URL
9 GIT_BRANCH = os.environ.get("GIT_BRANCH", "master")
10 from searx.brand import SEARX_URL
11 from searx.brand import DOCS_URL
12
13
14 # Project --------------------------------------------------------------
15
16 project = u'searx'
17 copyright = u'2015-2020, Adam Tauber, Noémi Ványi'
18 author = u'Adam Tauber'
19 release, version = VERSION_STRING, VERSION_STRING
20 highlight_language = 'none'
21
22 # General --------------------------------------------------------------
23
24 master_doc = "index"
25 source_suffix = '.rst'
26 numfig = True
27
28 exclude_patterns = ['build-templates/*.rst']
29
30 from searx import webapp
31 from searx.engines import engines
32 jinja_contexts = {
33 'webapp': dict(**webapp.__dict__),
34 'engines': engines
35 }
36
37 # usage:: lorem :patch:`f373169` ipsum
38 extlinks = {}
39
40 # upstream links
41 extlinks['wiki'] = ('https://github.com/searx/searx/wiki/%s', ' ')
42 extlinks['pull'] = ('https://github.com/searx/searx/pull/%s', 'PR ')
43
44 # links to custom brand
45 extlinks['origin'] = (GIT_URL + '/blob/' + GIT_BRANCH + '/%s', 'git://')
46 extlinks['patch'] = (GIT_URL + '/commit/%s', '#')
47 extlinks['search'] = (SEARX_URL + '/%s', '#')
48 extlinks['docs'] = (DOCS_URL + '/%s', 'docs: ')
49 extlinks['pypi'] = ('https://pypi.org/project/%s', 'PyPi: ')
50 extlinks['man'] = ('https://manpages.debian.org/jump?q=%s', '')
51 #extlinks['role'] = (
52 # 'https://www.sphinx-doc.org/en/master/usage/restructuredtext/roles.html#role-%s', '')
53 extlinks['duref'] = (
54 'http://docutils.sourceforge.net/docs/ref/rst/restructuredtext.html#%s', '')
55 extlinks['durole'] = (
56 'http://docutils.sourceforge.net/docs/ref/rst/roles.html#%s', '')
57 extlinks['dudir'] = (
58 'http://docutils.sourceforge.net/docs/ref/rst/directives.html#%s', '')
59 extlinks['ctan'] = (
60 'https://ctan.org/pkg/%s', 'CTAN: ')
61
62 extensions = [
63 'sphinx.ext.imgmath',
64 'sphinx.ext.extlinks',
65 'sphinx.ext.viewcode',
66 "sphinx.ext.autodoc",
67 "sphinx.ext.intersphinx",
68 "pallets_sphinx_themes",
69 "sphinx_issues", # https://github.com/sloria/sphinx-issues/blob/master/README.rst
70 "sphinxcontrib.jinja", # https://github.com/tardyp/sphinx-jinja
71 "sphinxcontrib.programoutput", # https://github.com/NextThought/sphinxcontrib-programoutput
72 'linuxdoc.kernel_include', # Implementation of the 'kernel-include' reST-directive.
73 'linuxdoc.rstFlatTable', # Implementation of the 'flat-table' reST-directive.
74 'linuxdoc.kfigure', # Sphinx extension which implements scalable image handling.
75 "sphinx_tabs.tabs", # https://github.com/djungelorm/sphinx-tabs
76 ]
77
78 intersphinx_mapping = {
79 "python": ("https://docs.python.org/3/", None),
80 "flask": ("https://flask.palletsprojects.com/", None),
81 # "werkzeug": ("https://werkzeug.palletsprojects.com/", None),
82 "jinja": ("https://jinja.palletsprojects.com/", None),
83 "linuxdoc" : ("https://return42.github.io/linuxdoc/", None),
84 "sphinx" : ("https://www.sphinx-doc.org/en/master/", None),
85 }
86
87 issues_github_path = "searx/searx"
88
89 # HTML -----------------------------------------------------------------
90
91 sys.path.append(os.path.abspath('_themes'))
92 html_theme_path = ['_themes']
93 html_theme = "searx"
94
95 # sphinx.ext.imgmath setup
96 html_math_renderer = 'imgmath'
97 imgmath_image_format = 'svg'
98 imgmath_font_size = 14
99 # sphinx.ext.imgmath setup END
100
101 html_theme_options = {"index_sidebar_logo": True}
102 html_context = {
103 "project_links": [
104 ProjectLink("Source", GIT_URL),
105 ProjectLink("Wiki", "https://github.com/searx/searx/wiki"),
106 ProjectLink("Public instances", "https://searx.space/"),
107 ProjectLink("Twitter", "https://twitter.com/Searx_engine"),
108 ]
109 }
110 html_sidebars = {
111 "**": ["project.html", "relations.html", "searchbox.html"],
112 }
113 singlehtml_sidebars = {"index": ["project.html", "localtoc.html"]}
114 html_static_path = ["static"]
115 html_logo = "static/img/searx_logo_small.png"
116 html_title = "Searx Documentation ({})".format("Searx-{}.tex".format(VERSION_STRING))
117 html_show_sourcelink = False
118
119 # LaTeX ----------------------------------------------------------------
120
121 latex_documents = [
122 (master_doc, "searx-{}.tex".format(VERSION_STRING), html_title, author, "manual")
123 ]
124
125 # ------------------------------------------------------------------------------
126 # Since loadConfig overwrites settings from the global namespace, it has to be
127 # the last statement in the conf.py file
128 # ------------------------------------------------------------------------------
129 load_sphinx_config(globals())
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -28,10 +28,11 @@
exclude_patterns = ['build-templates/*.rst']
from searx import webapp
-from searx.engines import engines
+import searx.engines
+searx.engines.initialize_engines(searx.settings['engines'])
jinja_contexts = {
'webapp': dict(**webapp.__dict__),
- 'engines': engines
+ 'engines': searx.engines.engines
}
# usage:: lorem :patch:`f373169` ipsum
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -28,10 +28,11 @@\n exclude_patterns = ['build-templates/*.rst']\n \n from searx import webapp\n-from searx.engines import engines\n+import searx.engines\n+searx.engines.initialize_engines(searx.settings['engines'])\n jinja_contexts = {\n 'webapp': dict(**webapp.__dict__),\n- 'engines': engines\n+ 'engines': searx.engines.engines\n }\n \n # usage:: lorem :patch:`f373169` ipsum\n", "issue": "[fix] Sphinx 3.2.1 build: add missing \"engines\" variable in the jinja context\n## What does this PR do?\r\n\r\nFix PR #2210 which upgrade Sphinx version to 3.2.1.\r\n\r\nThe admin/engines.html page is empty.\r\n\r\n## Why is this change important?\r\n\r\nFix the admin/engines.html page.\r\n\r\n## How to test this PR locally?\r\n\r\nCheck the admin/engines.html page.\r\n\r\n## Author's checklist\r\n\r\n<!-- additional notes for reviewiers -->\r\n\r\n## Related issues\r\n\r\n#2210\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport sys, os\nfrom sphinx_build_tools import load_sphinx_config\nfrom searx.version import VERSION_STRING\nfrom pallets_sphinx_themes import ProjectLink\n\nfrom searx.brand import GIT_URL\nGIT_BRANCH = os.environ.get(\"GIT_BRANCH\", \"master\")\nfrom searx.brand import SEARX_URL\nfrom searx.brand import DOCS_URL\n\n\n# Project --------------------------------------------------------------\n\nproject = u'searx'\ncopyright = u'2015-2020, Adam Tauber, No\u00e9mi V\u00e1nyi'\nauthor = u'Adam Tauber'\nrelease, version = VERSION_STRING, VERSION_STRING\nhighlight_language = 'none'\n\n# General --------------------------------------------------------------\n\nmaster_doc = \"index\"\nsource_suffix = '.rst'\nnumfig = True\n\nexclude_patterns = ['build-templates/*.rst']\n\nfrom searx import webapp\nfrom searx.engines import engines\njinja_contexts = {\n 'webapp': dict(**webapp.__dict__),\n 'engines': engines\n}\n\n# usage:: lorem :patch:`f373169` ipsum\nextlinks = {}\n\n# upstream links\nextlinks['wiki'] = ('https://github.com/searx/searx/wiki/%s', ' ')\nextlinks['pull'] = ('https://github.com/searx/searx/pull/%s', 'PR ')\n\n# links to custom brand\nextlinks['origin'] = (GIT_URL + '/blob/' + GIT_BRANCH + '/%s', 'git://')\nextlinks['patch'] = (GIT_URL + '/commit/%s', '#')\nextlinks['search'] = (SEARX_URL + '/%s', '#')\nextlinks['docs'] = (DOCS_URL + '/%s', 'docs: ')\nextlinks['pypi'] = ('https://pypi.org/project/%s', 'PyPi: ')\nextlinks['man'] = ('https://manpages.debian.org/jump?q=%s', '')\n#extlinks['role'] = (\n# 'https://www.sphinx-doc.org/en/master/usage/restructuredtext/roles.html#role-%s', '')\nextlinks['duref'] = (\n 'http://docutils.sourceforge.net/docs/ref/rst/restructuredtext.html#%s', '')\nextlinks['durole'] = (\n 'http://docutils.sourceforge.net/docs/ref/rst/roles.html#%s', '')\nextlinks['dudir'] = (\n 'http://docutils.sourceforge.net/docs/ref/rst/directives.html#%s', '')\nextlinks['ctan'] = (\n 'https://ctan.org/pkg/%s', 'CTAN: ')\n\nextensions = [\n 'sphinx.ext.imgmath',\n 'sphinx.ext.extlinks',\n 'sphinx.ext.viewcode',\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"pallets_sphinx_themes\",\n \"sphinx_issues\", # https://github.com/sloria/sphinx-issues/blob/master/README.rst\n \"sphinxcontrib.jinja\", # https://github.com/tardyp/sphinx-jinja\n \"sphinxcontrib.programoutput\", # https://github.com/NextThought/sphinxcontrib-programoutput\n 'linuxdoc.kernel_include', # Implementation of the 'kernel-include' reST-directive.\n 'linuxdoc.rstFlatTable', # Implementation of the 'flat-table' reST-directive.\n 'linuxdoc.kfigure', # Sphinx extension which implements scalable image handling.\n \"sphinx_tabs.tabs\", # https://github.com/djungelorm/sphinx-tabs\n]\n\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"flask\": (\"https://flask.palletsprojects.com/\", None),\n # \"werkzeug\": (\"https://werkzeug.palletsprojects.com/\", None),\n \"jinja\": (\"https://jinja.palletsprojects.com/\", None),\n \"linuxdoc\" : (\"https://return42.github.io/linuxdoc/\", None),\n \"sphinx\" : (\"https://www.sphinx-doc.org/en/master/\", None),\n}\n\nissues_github_path = \"searx/searx\"\n\n# HTML -----------------------------------------------------------------\n\nsys.path.append(os.path.abspath('_themes'))\nhtml_theme_path = ['_themes']\nhtml_theme = \"searx\"\n\n# sphinx.ext.imgmath setup\nhtml_math_renderer = 'imgmath'\nimgmath_image_format = 'svg'\nimgmath_font_size = 14\n# sphinx.ext.imgmath setup END\n\nhtml_theme_options = {\"index_sidebar_logo\": True}\nhtml_context = {\n \"project_links\": [\n ProjectLink(\"Source\", GIT_URL),\n ProjectLink(\"Wiki\", \"https://github.com/searx/searx/wiki\"),\n ProjectLink(\"Public instances\", \"https://searx.space/\"),\n ProjectLink(\"Twitter\", \"https://twitter.com/Searx_engine\"),\n ]\n}\nhtml_sidebars = {\n \"**\": [\"project.html\", \"relations.html\", \"searchbox.html\"],\n}\nsinglehtml_sidebars = {\"index\": [\"project.html\", \"localtoc.html\"]}\nhtml_static_path = [\"static\"]\nhtml_logo = \"static/img/searx_logo_small.png\"\nhtml_title = \"Searx Documentation ({})\".format(\"Searx-{}.tex\".format(VERSION_STRING))\nhtml_show_sourcelink = False\n\n# LaTeX ----------------------------------------------------------------\n\nlatex_documents = [\n (master_doc, \"searx-{}.tex\".format(VERSION_STRING), html_title, author, \"manual\")\n]\n\n# ------------------------------------------------------------------------------\n# Since loadConfig overwrites settings from the global namespace, it has to be\n# the last statement in the conf.py file\n# ------------------------------------------------------------------------------\nload_sphinx_config(globals())\n", "path": "docs/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport sys, os\nfrom sphinx_build_tools import load_sphinx_config\nfrom searx.version import VERSION_STRING\nfrom pallets_sphinx_themes import ProjectLink\n\nfrom searx.brand import GIT_URL\nGIT_BRANCH = os.environ.get(\"GIT_BRANCH\", \"master\")\nfrom searx.brand import SEARX_URL\nfrom searx.brand import DOCS_URL\n\n\n# Project --------------------------------------------------------------\n\nproject = u'searx'\ncopyright = u'2015-2020, Adam Tauber, No\u00e9mi V\u00e1nyi'\nauthor = u'Adam Tauber'\nrelease, version = VERSION_STRING, VERSION_STRING\nhighlight_language = 'none'\n\n# General --------------------------------------------------------------\n\nmaster_doc = \"index\"\nsource_suffix = '.rst'\nnumfig = True\n\nexclude_patterns = ['build-templates/*.rst']\n\nfrom searx import webapp\nimport searx.engines\nsearx.engines.initialize_engines(searx.settings['engines'])\njinja_contexts = {\n 'webapp': dict(**webapp.__dict__),\n 'engines': searx.engines.engines\n}\n\n# usage:: lorem :patch:`f373169` ipsum\nextlinks = {}\n\n# upstream links\nextlinks['wiki'] = ('https://github.com/searx/searx/wiki/%s', ' ')\nextlinks['pull'] = ('https://github.com/searx/searx/pull/%s', 'PR ')\n\n# links to custom brand\nextlinks['origin'] = (GIT_URL + '/blob/' + GIT_BRANCH + '/%s', 'git://')\nextlinks['patch'] = (GIT_URL + '/commit/%s', '#')\nextlinks['search'] = (SEARX_URL + '/%s', '#')\nextlinks['docs'] = (DOCS_URL + '/%s', 'docs: ')\nextlinks['pypi'] = ('https://pypi.org/project/%s', 'PyPi: ')\nextlinks['man'] = ('https://manpages.debian.org/jump?q=%s', '')\n#extlinks['role'] = (\n# 'https://www.sphinx-doc.org/en/master/usage/restructuredtext/roles.html#role-%s', '')\nextlinks['duref'] = (\n 'http://docutils.sourceforge.net/docs/ref/rst/restructuredtext.html#%s', '')\nextlinks['durole'] = (\n 'http://docutils.sourceforge.net/docs/ref/rst/roles.html#%s', '')\nextlinks['dudir'] = (\n 'http://docutils.sourceforge.net/docs/ref/rst/directives.html#%s', '')\nextlinks['ctan'] = (\n 'https://ctan.org/pkg/%s', 'CTAN: ')\n\nextensions = [\n 'sphinx.ext.imgmath',\n 'sphinx.ext.extlinks',\n 'sphinx.ext.viewcode',\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"pallets_sphinx_themes\",\n \"sphinx_issues\", # https://github.com/sloria/sphinx-issues/blob/master/README.rst\n \"sphinxcontrib.jinja\", # https://github.com/tardyp/sphinx-jinja\n \"sphinxcontrib.programoutput\", # https://github.com/NextThought/sphinxcontrib-programoutput\n 'linuxdoc.kernel_include', # Implementation of the 'kernel-include' reST-directive.\n 'linuxdoc.rstFlatTable', # Implementation of the 'flat-table' reST-directive.\n 'linuxdoc.kfigure', # Sphinx extension which implements scalable image handling.\n \"sphinx_tabs.tabs\", # https://github.com/djungelorm/sphinx-tabs\n]\n\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"flask\": (\"https://flask.palletsprojects.com/\", None),\n # \"werkzeug\": (\"https://werkzeug.palletsprojects.com/\", None),\n \"jinja\": (\"https://jinja.palletsprojects.com/\", None),\n \"linuxdoc\" : (\"https://return42.github.io/linuxdoc/\", None),\n \"sphinx\" : (\"https://www.sphinx-doc.org/en/master/\", None),\n}\n\nissues_github_path = \"searx/searx\"\n\n# HTML -----------------------------------------------------------------\n\nsys.path.append(os.path.abspath('_themes'))\nhtml_theme_path = ['_themes']\nhtml_theme = \"searx\"\n\n# sphinx.ext.imgmath setup\nhtml_math_renderer = 'imgmath'\nimgmath_image_format = 'svg'\nimgmath_font_size = 14\n# sphinx.ext.imgmath setup END\n\nhtml_theme_options = {\"index_sidebar_logo\": True}\nhtml_context = {\n \"project_links\": [\n ProjectLink(\"Source\", GIT_URL),\n ProjectLink(\"Wiki\", \"https://github.com/searx/searx/wiki\"),\n ProjectLink(\"Public instances\", \"https://searx.space/\"),\n ProjectLink(\"Twitter\", \"https://twitter.com/Searx_engine\"),\n ]\n}\nhtml_sidebars = {\n \"**\": [\"project.html\", \"relations.html\", \"searchbox.html\"],\n}\nsinglehtml_sidebars = {\"index\": [\"project.html\", \"localtoc.html\"]}\nhtml_static_path = [\"static\"]\nhtml_logo = \"static/img/searx_logo_small.png\"\nhtml_title = \"Searx Documentation ({})\".format(\"Searx-{}.tex\".format(VERSION_STRING))\nhtml_show_sourcelink = False\n\n# LaTeX ----------------------------------------------------------------\n\nlatex_documents = [\n (master_doc, \"searx-{}.tex\".format(VERSION_STRING), html_title, author, \"manual\")\n]\n\n# ------------------------------------------------------------------------------\n# Since loadConfig overwrites settings from the global namespace, it has to be\n# the last statement in the conf.py file\n# ------------------------------------------------------------------------------\nload_sphinx_config(globals())\n", "path": "docs/conf.py"}]}
| 1,912 | 152 |
gh_patches_debug_7
|
rasdani/github-patches
|
git_diff
|
microsoft__Qcodes-4248
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Filename collision due to case-sensitivity in Keysight folder
When pulling the qcodes repository on Windows, there is a filename collision between the uppercase and lowercase Keysight folders.
The error message is as follows:
```bash
$ git clone https://github.com/QCoDeS/Qcodes.git
Cloning into 'Qcodes'...
remote: Enumerating objects: 1522, done.
remote: Counting objects: 100% (1522/1522), done.
remote: Compressing objects: 100% (655/655), done.
Receiving objects: 100% (112398/112398), 242.65 MiB | 2.58 MiB/s, done.
Resolving deltas: 100% (87395/87395), done.
warning: the following paths have collided (e.g. case-sensitive paths
on a case-insensitive filesystem) and only one from the same
colliding group is in the working tree:
'qcodes/instrument_drivers/Keysight/__init__.py'
'qcodes/instrument_drivers/keysight/__init__.py'
```
I propose we remove the lowercase keysight folder as it has now been deprecated for over 2 years.
### System
Windows/OSX and other OS's with case insensitive file systems.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qcodes/instrument_drivers/Keysight/__init__.py`
Content:
```
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qcodes/instrument_drivers/Keysight/__init__.py b/qcodes/instrument_drivers/Keysight/__init__.py
--- a/qcodes/instrument_drivers/Keysight/__init__.py
+++ b/qcodes/instrument_drivers/Keysight/__init__.py
@@ -0,0 +1 @@
+# Intentionally left blank
|
{"golden_diff": "diff --git a/qcodes/instrument_drivers/Keysight/__init__.py b/qcodes/instrument_drivers/Keysight/__init__.py\n--- a/qcodes/instrument_drivers/Keysight/__init__.py\n+++ b/qcodes/instrument_drivers/Keysight/__init__.py\n@@ -0,0 +1 @@\n+# Intentionally left blank\n", "issue": "Filename collision due to case-sensitivity in Keysight folder\nWhen pulling the qcodes repository on Windows, there is a filename collision between the uppercase and lowercase Keysight folders.\r\n\r\nThe error message is as follows:\r\n```bash\r\n$ git clone https://github.com/QCoDeS/Qcodes.git\r\nCloning into 'Qcodes'...\r\nremote: Enumerating objects: 1522, done.\r\nremote: Counting objects: 100% (1522/1522), done.\r\nremote: Compressing objects: 100% (655/655), done.\r\n\r\nReceiving objects: 100% (112398/112398), 242.65 MiB | 2.58 MiB/s, done.\r\nResolving deltas: 100% (87395/87395), done.\r\nwarning: the following paths have collided (e.g. case-sensitive paths\r\non a case-insensitive filesystem) and only one from the same\r\ncolliding group is in the working tree:\r\n\r\n 'qcodes/instrument_drivers/Keysight/__init__.py'\r\n 'qcodes/instrument_drivers/keysight/__init__.py'\r\n```\r\n\r\nI propose we remove the lowercase keysight folder as it has now been deprecated for over 2 years.\r\n\r\n### System\r\nWindows/OSX and other OS's with case insensitive file systems.\n", "before_files": [{"content": "", "path": "qcodes/instrument_drivers/Keysight/__init__.py"}], "after_files": [{"content": "# Intentionally left blank\n", "path": "qcodes/instrument_drivers/Keysight/__init__.py"}]}
| 575 | 79 |
gh_patches_debug_9066
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-3062
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
general_create performes one unnecessary db lookup
`Serializer.save()` returns the instance we want already. No need to fetch it again from the db.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/tasks/base.py`
Content:
```
1 from django.db import transaction
2
3 from pulpcore.app.apps import get_plugin_config
4 from pulpcore.app.models import CreatedResource, PulpTemporaryFile
5 from pulpcore.app.files import PulpTemporaryUploadedFile
6 from pulpcore.plugin.models import MasterModel
7
8
9 def general_create_from_temp_file(app_label, serializer_name, temp_file_pk, *args, **kwargs):
10 """
11 Create a model instance from contents stored in a temporary file.
12
13 A task which executes this function takes the ownership of a temporary file and deletes it
14 afterwards. This function calls the function general_create() to create a model instance.
15 """
16 temp_file = PulpTemporaryFile.objects.get(pk=temp_file_pk)
17
18 data = kwargs.pop("data", {})
19 data["file"] = PulpTemporaryUploadedFile.from_file(temp_file.file)
20
21 general_create(app_label, serializer_name, data=data, *args, **kwargs)
22 temp_file.delete()
23
24
25 def general_create(app_label, serializer_name, *args, **kwargs):
26 """
27 Create a model instance.
28
29 Raises:
30 ValidationError: If the serializer is not valid
31
32 """
33 data = kwargs.pop("data", None)
34 context = kwargs.pop("context", {})
35 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
36 serializer = serializer_class(data=data, context=context)
37 serializer.is_valid(raise_exception=True)
38 serializer.save()
39 instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()
40 resource = CreatedResource(content_object=instance)
41 resource.save()
42
43
44 def general_update(instance_id, app_label, serializer_name, *args, **kwargs):
45 """
46 Update a model
47
48 The model instance is identified using the app_label, id, and serializer name. The serializer is
49 used to perform validation.
50
51 Args:
52 id (str): the id of the model
53 app_label (str): the Django app label of the plugin that provides the model
54 serializer_name (str): name of the serializer class for the model
55 data (dict): dictionary whose keys represent the fields of the model and their corresponding
56 values.
57 partial (bool): When true, only the fields specified in the data dictionary are updated.
58 When false, any fields missing from the data dictionary are assumed to be None and
59 their values are updated as such.
60
61 Raises:
62 :class:`rest_framework.exceptions.ValidationError`: When serializer instance can't be saved
63 due to validation error. This theoretically should never occur since validation is
64 performed before the task is dispatched.
65 """
66 data = kwargs.pop("data", None)
67 partial = kwargs.pop("partial", False)
68 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
69 instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()
70 serializer = serializer_class(instance, data=data, partial=partial)
71 serializer.is_valid(raise_exception=True)
72 serializer.save()
73
74
75 def general_delete(instance_id, app_label, serializer_name):
76 """
77 Delete a model
78
79 The model instance is identified using the app_label, id, and serializer name.
80
81 Args:
82 id (str): the id of the model
83 app_label (str): the Django app label of the plugin that provides the model
84 serializer_name (str): name of the serializer class for the model
85 """
86 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
87 instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()
88 instance.delete()
89
90
91 def general_multi_delete(instance_ids):
92 """
93 Delete a list of model instances in a transaction
94
95 The model instances are identified using the id, app_label, and serializer_name.
96
97 Args:
98 instance_ids (list): List of tupels of id, app_label, serializer_name
99 """
100 instances = []
101 for instance_id, app_label, serializer_name in instance_ids:
102 serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
103 instance = serializer_class.Meta.model.objects.get(pk=instance_id)
104 if isinstance(instance, MasterModel):
105 instance = instance.cast()
106 instances.append(instance)
107 with transaction.atomic():
108 for instance in instances:
109 instance.delete()
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/tasks/base.py b/pulpcore/app/tasks/base.py
--- a/pulpcore/app/tasks/base.py
+++ b/pulpcore/app/tasks/base.py
@@ -35,8 +35,7 @@
serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]
serializer = serializer_class(data=data, context=context)
serializer.is_valid(raise_exception=True)
- serializer.save()
- instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()
+ instance = serializer.save().cast()
resource = CreatedResource(content_object=instance)
resource.save()
|
{"golden_diff": "diff --git a/pulpcore/app/tasks/base.py b/pulpcore/app/tasks/base.py\n--- a/pulpcore/app/tasks/base.py\n+++ b/pulpcore/app/tasks/base.py\n@@ -35,8 +35,7 @@\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n serializer = serializer_class(data=data, context=context)\n serializer.is_valid(raise_exception=True)\n- serializer.save()\n- instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()\n+ instance = serializer.save().cast()\n resource = CreatedResource(content_object=instance)\n resource.save()\n", "issue": "general_create performes one unnecessary db lookup\n`Serializer.save()` returns the instance we want already. No need to fetch it again from the db.\n", "before_files": [{"content": "from django.db import transaction\n\nfrom pulpcore.app.apps import get_plugin_config\nfrom pulpcore.app.models import CreatedResource, PulpTemporaryFile\nfrom pulpcore.app.files import PulpTemporaryUploadedFile\nfrom pulpcore.plugin.models import MasterModel\n\n\ndef general_create_from_temp_file(app_label, serializer_name, temp_file_pk, *args, **kwargs):\n \"\"\"\n Create a model instance from contents stored in a temporary file.\n\n A task which executes this function takes the ownership of a temporary file and deletes it\n afterwards. This function calls the function general_create() to create a model instance.\n \"\"\"\n temp_file = PulpTemporaryFile.objects.get(pk=temp_file_pk)\n\n data = kwargs.pop(\"data\", {})\n data[\"file\"] = PulpTemporaryUploadedFile.from_file(temp_file.file)\n\n general_create(app_label, serializer_name, data=data, *args, **kwargs)\n temp_file.delete()\n\n\ndef general_create(app_label, serializer_name, *args, **kwargs):\n \"\"\"\n Create a model instance.\n\n Raises:\n ValidationError: If the serializer is not valid\n\n \"\"\"\n data = kwargs.pop(\"data\", None)\n context = kwargs.pop(\"context\", {})\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n serializer = serializer_class(data=data, context=context)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n instance = serializer_class.Meta.model.objects.get(pk=serializer.instance.pk).cast()\n resource = CreatedResource(content_object=instance)\n resource.save()\n\n\ndef general_update(instance_id, app_label, serializer_name, *args, **kwargs):\n \"\"\"\n Update a model\n\n The model instance is identified using the app_label, id, and serializer name. The serializer is\n used to perform validation.\n\n Args:\n id (str): the id of the model\n app_label (str): the Django app label of the plugin that provides the model\n serializer_name (str): name of the serializer class for the model\n data (dict): dictionary whose keys represent the fields of the model and their corresponding\n values.\n partial (bool): When true, only the fields specified in the data dictionary are updated.\n When false, any fields missing from the data dictionary are assumed to be None and\n their values are updated as such.\n\n Raises:\n :class:`rest_framework.exceptions.ValidationError`: When serializer instance can't be saved\n due to validation error. This theoretically should never occur since validation is\n performed before the task is dispatched.\n \"\"\"\n data = kwargs.pop(\"data\", None)\n partial = kwargs.pop(\"partial\", False)\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()\n serializer = serializer_class(instance, data=data, partial=partial)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n\ndef general_delete(instance_id, app_label, serializer_name):\n \"\"\"\n Delete a model\n\n The model instance is identified using the app_label, id, and serializer name.\n\n Args:\n id (str): the id of the model\n app_label (str): the Django app label of the plugin that provides the model\n serializer_name (str): name of the serializer class for the model\n \"\"\"\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()\n instance.delete()\n\n\ndef general_multi_delete(instance_ids):\n \"\"\"\n Delete a list of model instances in a transaction\n\n The model instances are identified using the id, app_label, and serializer_name.\n\n Args:\n instance_ids (list): List of tupels of id, app_label, serializer_name\n \"\"\"\n instances = []\n for instance_id, app_label, serializer_name in instance_ids:\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id)\n if isinstance(instance, MasterModel):\n instance = instance.cast()\n instances.append(instance)\n with transaction.atomic():\n for instance in instances:\n instance.delete()\n", "path": "pulpcore/app/tasks/base.py"}], "after_files": [{"content": "from django.db import transaction\n\nfrom pulpcore.app.apps import get_plugin_config\nfrom pulpcore.app.models import CreatedResource, PulpTemporaryFile\nfrom pulpcore.app.files import PulpTemporaryUploadedFile\nfrom pulpcore.plugin.models import MasterModel\n\n\ndef general_create_from_temp_file(app_label, serializer_name, temp_file_pk, *args, **kwargs):\n \"\"\"\n Create a model instance from contents stored in a temporary file.\n\n A task which executes this function takes the ownership of a temporary file and deletes it\n afterwards. This function calls the function general_create() to create a model instance.\n \"\"\"\n temp_file = PulpTemporaryFile.objects.get(pk=temp_file_pk)\n\n data = kwargs.pop(\"data\", {})\n data[\"file\"] = PulpTemporaryUploadedFile.from_file(temp_file.file)\n\n general_create(app_label, serializer_name, data=data, *args, **kwargs)\n temp_file.delete()\n\n\ndef general_create(app_label, serializer_name, *args, **kwargs):\n \"\"\"\n Create a model instance.\n\n Raises:\n ValidationError: If the serializer is not valid\n\n \"\"\"\n data = kwargs.pop(\"data\", None)\n context = kwargs.pop(\"context\", {})\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n serializer = serializer_class(data=data, context=context)\n serializer.is_valid(raise_exception=True)\n instance = serializer.save().cast()\n resource = CreatedResource(content_object=instance)\n resource.save()\n\n\ndef general_update(instance_id, app_label, serializer_name, *args, **kwargs):\n \"\"\"\n Update a model\n\n The model instance is identified using the app_label, id, and serializer name. The serializer is\n used to perform validation.\n\n Args:\n id (str): the id of the model\n app_label (str): the Django app label of the plugin that provides the model\n serializer_name (str): name of the serializer class for the model\n data (dict): dictionary whose keys represent the fields of the model and their corresponding\n values.\n partial (bool): When true, only the fields specified in the data dictionary are updated.\n When false, any fields missing from the data dictionary are assumed to be None and\n their values are updated as such.\n\n Raises:\n :class:`rest_framework.exceptions.ValidationError`: When serializer instance can't be saved\n due to validation error. This theoretically should never occur since validation is\n performed before the task is dispatched.\n \"\"\"\n data = kwargs.pop(\"data\", None)\n partial = kwargs.pop(\"partial\", False)\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()\n serializer = serializer_class(instance, data=data, partial=partial)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n\ndef general_delete(instance_id, app_label, serializer_name):\n \"\"\"\n Delete a model\n\n The model instance is identified using the app_label, id, and serializer name.\n\n Args:\n id (str): the id of the model\n app_label (str): the Django app label of the plugin that provides the model\n serializer_name (str): name of the serializer class for the model\n \"\"\"\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id).cast()\n instance.delete()\n\n\ndef general_multi_delete(instance_ids):\n \"\"\"\n Delete a list of model instances in a transaction\n\n The model instances are identified using the id, app_label, and serializer_name.\n\n Args:\n instance_ids (list): List of tupels of id, app_label, serializer_name\n \"\"\"\n instances = []\n for instance_id, app_label, serializer_name in instance_ids:\n serializer_class = get_plugin_config(app_label).named_serializers[serializer_name]\n instance = serializer_class.Meta.model.objects.get(pk=instance_id)\n if isinstance(instance, MasterModel):\n instance = instance.cast()\n instances.append(instance)\n with transaction.atomic():\n for instance in instances:\n instance.delete()\n", "path": "pulpcore/app/tasks/base.py"}]}
| 1,410 | 135 |
gh_patches_debug_17239
|
rasdani/github-patches
|
git_diff
|
OCA__server-tools-18
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] mass_editing - Search in ir.model.fields not working
I setup the mass_editing for res.partner then i go to:
Settings -> Technical -> Database Structure -> Fields
and go to the Filter with ('model_id','=',61) where 61 is the id of res.partner in res.model. By typ "res.partner" and select "Partner" from the suggestion.
Then i get the following error:
File "[..]/mass_editing/mass_editing.py", line 34, in search
model_domain += [('model_id', 'in', map(int, domain[2][1:-1].split(',')))]
TypeError: 'int' object has no attribute '**getitem**'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mass_editing/models/ir_model_fields.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 ##############################################################################
3 #
4 # This module uses OpenERP, Open Source Management Solution Framework.
5 # Copyright (C):
6 # 2012-Today Serpent Consulting Services (<http://www.serpentcs.com>)
7 #
8 # This program is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with this program. If not, see <http://www.gnu.org/licenses/>
20 #
21 ##############################################################################
22
23 from openerp.osv import orm
24
25
26 class IrModelFields(orm.Model):
27 _inherit = 'ir.model.fields'
28
29 def search(
30 self, cr, uid, args, offset=0, limit=0, order=None, context=None,
31 count=False):
32 model_domain = []
33 for domain in args:
34 if domain[0] == 'model_id' and domain[2]\
35 and type(domain[2]) != list:
36 model_domain += [(
37 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]
38 else:
39 model_domain.append(domain)
40 return super(IrModelFields, self).search(
41 cr, uid, model_domain, offset=offset, limit=limit, order=order,
42 context=context, count=count)
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mass_editing/models/ir_model_fields.py b/mass_editing/models/ir_model_fields.py
--- a/mass_editing/models/ir_model_fields.py
+++ b/mass_editing/models/ir_model_fields.py
@@ -31,12 +31,14 @@
count=False):
model_domain = []
for domain in args:
- if domain[0] == 'model_id' and domain[2]\
- and type(domain[2]) != list:
- model_domain += [(
- 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]
+ if (len(domain) > 2 and domain[0] == 'model_id'
+ and isinstance(domain[2], basestring)):
+ model_domain += [
+ ('model_id', 'in', map(int, domain[2][1:-1].split(',')))
+ ]
else:
model_domain.append(domain)
return super(IrModelFields, self).search(
cr, uid, model_domain, offset=offset, limit=limit, order=order,
- context=context, count=count)
+ context=context, count=count
+ )
|
{"golden_diff": "diff --git a/mass_editing/models/ir_model_fields.py b/mass_editing/models/ir_model_fields.py\n--- a/mass_editing/models/ir_model_fields.py\n+++ b/mass_editing/models/ir_model_fields.py\n@@ -31,12 +31,14 @@\n count=False):\n model_domain = []\n for domain in args:\n- if domain[0] == 'model_id' and domain[2]\\\n- and type(domain[2]) != list:\n- model_domain += [(\n- 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]\n+ if (len(domain) > 2 and domain[0] == 'model_id'\n+ and isinstance(domain[2], basestring)):\n+ model_domain += [\n+ ('model_id', 'in', map(int, domain[2][1:-1].split(',')))\n+ ]\n else:\n model_domain.append(domain)\n return super(IrModelFields, self).search(\n cr, uid, model_domain, offset=offset, limit=limit, order=order,\n- context=context, count=count)\n+ context=context, count=count\n+ )\n", "issue": "[Bug] mass_editing - Search in ir.model.fields not working\nI setup the mass_editing for res.partner then i go to:\nSettings -> Technical -> Database Structure -> Fields\nand go to the Filter with ('model_id','=',61) where 61 is the id of res.partner in res.model. By typ \"res.partner\" and select \"Partner\" from the suggestion.\n\nThen i get the following error:\nFile \"[..]/mass_editing/mass_editing.py\", line 34, in search\n model_domain += [('model_id', 'in', map(int, domain[2][1:-1].split(',')))]\nTypeError: 'int' object has no attribute '**getitem**'\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n##############################################################################\n#\n# This module uses OpenERP, Open Source Management Solution Framework.\n# Copyright (C):\n# 2012-Today Serpent Consulting Services (<http://www.serpentcs.com>)\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>\n#\n##############################################################################\n\nfrom openerp.osv import orm\n\n\nclass IrModelFields(orm.Model):\n _inherit = 'ir.model.fields'\n\n def search(\n self, cr, uid, args, offset=0, limit=0, order=None, context=None,\n count=False):\n model_domain = []\n for domain in args:\n if domain[0] == 'model_id' and domain[2]\\\n and type(domain[2]) != list:\n model_domain += [(\n 'model_id', 'in', map(int, domain[2][1:-1].split(',')))]\n else:\n model_domain.append(domain)\n return super(IrModelFields, self).search(\n cr, uid, model_domain, offset=offset, limit=limit, order=order,\n context=context, count=count)\n", "path": "mass_editing/models/ir_model_fields.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n##############################################################################\n#\n# This module uses OpenERP, Open Source Management Solution Framework.\n# Copyright (C):\n# 2012-Today Serpent Consulting Services (<http://www.serpentcs.com>)\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>\n#\n##############################################################################\n\nfrom openerp.osv import orm\n\n\nclass IrModelFields(orm.Model):\n _inherit = 'ir.model.fields'\n\n def search(\n self, cr, uid, args, offset=0, limit=0, order=None, context=None,\n count=False):\n model_domain = []\n for domain in args:\n if (len(domain) > 2 and domain[0] == 'model_id'\n and isinstance(domain[2], basestring)):\n model_domain += [\n ('model_id', 'in', map(int, domain[2][1:-1].split(',')))\n ]\n else:\n model_domain.append(domain)\n return super(IrModelFields, self).search(\n cr, uid, model_domain, offset=offset, limit=limit, order=order,\n context=context, count=count\n )\n", "path": "mass_editing/models/ir_model_fields.py"}]}
| 870 | 264 |
gh_patches_debug_27276
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1393
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[PS-1] RPC service `pull_variable` implementation
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/ps/servicer.py`
Content:
```
1 import threading
2
3 from google.protobuf import empty_pb2
4
5 from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
6
7
8 class PserverServicer(elasticdl_pb2_grpc.PserverServicer):
9 """PS service implementation"""
10
11 def __init__(
12 self,
13 parameters,
14 grads_to_wait,
15 optimizer,
16 lr_staleness_modulation=False,
17 use_async=False,
18 ):
19 self._parameters = parameters
20 self._grads_to_wait = grads_to_wait
21 self._optimizer = optimizer
22 self._lr_staleness_modulation = lr_staleness_modulation
23 self._use_async = use_async
24 self._version = 0
25 self._lock = threading.Lock()
26
27 def pull_variable(self, request, _):
28 # TODO: implement this RPC service
29 return elasticdl_pb2.PullVariableResponse()
30
31 def pull_embedding_vector(self, request, _):
32 # TODO: implement this RPC service
33 return elasticdl_pb2.Tensor()
34
35 def push_model(self, request, _):
36 with self._lock:
37 self._parameters.init_from_model_pb(request)
38 return empty_pb2.Empty()
39
40 def push_gradient(self, request, _):
41 # TODO: implement this RPC service
42 return elasticdl_pb2.PushGradientResponse()
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py
--- a/elasticdl/python/ps/servicer.py
+++ b/elasticdl/python/ps/servicer.py
@@ -3,6 +3,7 @@
from google.protobuf import empty_pb2
from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
+from elasticdl.python.common.dtypes import dtype_numpy_to_tensor
class PserverServicer(elasticdl_pb2_grpc.PserverServicer):
@@ -25,8 +26,30 @@
self._lock = threading.Lock()
def pull_variable(self, request, _):
- # TODO: implement this RPC service
- return elasticdl_pb2.PullVariableResponse()
+ """
+ Response with all non-embedding parameters if initialized.
+ """
+ res = elasticdl_pb2.PullVariableResponse()
+ if not self._parameters.init_status:
+ res.model_init_status = False
+ return res
+
+ # Only sync-SGD needs lock
+ # TODO: use a read-write lock to support multiple concurrent reads
+ if not self._use_async:
+ self._lock.acquire()
+ res.model.version = self._parameters.version
+ for name, var in self._parameters.non_embedding_params.items():
+ tensor = res.model.param.add()
+ tensor.name = name
+ tensor.dim.extend(var.shape.as_list())
+ var_values = var.numpy()
+ tensor.content = var_values.tobytes()
+ tensor.dtype = dtype_numpy_to_tensor(var_values.dtype)
+ if not self._use_async:
+ self._lock.release()
+ res.model_init_status = True
+ return res
def pull_embedding_vector(self, request, _):
# TODO: implement this RPC service
|
{"golden_diff": "diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py\n--- a/elasticdl/python/ps/servicer.py\n+++ b/elasticdl/python/ps/servicer.py\n@@ -3,6 +3,7 @@\n from google.protobuf import empty_pb2\n \n from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\n+from elasticdl.python.common.dtypes import dtype_numpy_to_tensor\n \n \n class PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n@@ -25,8 +26,30 @@\n self._lock = threading.Lock()\n \n def pull_variable(self, request, _):\n- # TODO: implement this RPC service\n- return elasticdl_pb2.PullVariableResponse()\n+ \"\"\"\n+ Response with all non-embedding parameters if initialized.\n+ \"\"\"\n+ res = elasticdl_pb2.PullVariableResponse()\n+ if not self._parameters.init_status:\n+ res.model_init_status = False\n+ return res\n+\n+ # Only sync-SGD needs lock\n+ # TODO: use a read-write lock to support multiple concurrent reads\n+ if not self._use_async:\n+ self._lock.acquire()\n+ res.model.version = self._parameters.version\n+ for name, var in self._parameters.non_embedding_params.items():\n+ tensor = res.model.param.add()\n+ tensor.name = name\n+ tensor.dim.extend(var.shape.as_list())\n+ var_values = var.numpy()\n+ tensor.content = var_values.tobytes()\n+ tensor.dtype = dtype_numpy_to_tensor(var_values.dtype)\n+ if not self._use_async:\n+ self._lock.release()\n+ res.model_init_status = True\n+ return res\n \n def pull_embedding_vector(self, request, _):\n # TODO: implement this RPC service\n", "issue": "[PS-1] RPC service `pull_variable` implementation\n\n", "before_files": [{"content": "import threading\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\n\n\nclass PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n \"\"\"PS service implementation\"\"\"\n\n def __init__(\n self,\n parameters,\n grads_to_wait,\n optimizer,\n lr_staleness_modulation=False,\n use_async=False,\n ):\n self._parameters = parameters\n self._grads_to_wait = grads_to_wait\n self._optimizer = optimizer\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._version = 0\n self._lock = threading.Lock()\n\n def pull_variable(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PullVariableResponse()\n\n def pull_embedding_vector(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.Tensor()\n\n def push_model(self, request, _):\n with self._lock:\n self._parameters.init_from_model_pb(request)\n return empty_pb2.Empty()\n\n def push_gradient(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PushGradientResponse()\n", "path": "elasticdl/python/ps/servicer.py"}], "after_files": [{"content": "import threading\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\nfrom elasticdl.python.common.dtypes import dtype_numpy_to_tensor\n\n\nclass PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n \"\"\"PS service implementation\"\"\"\n\n def __init__(\n self,\n parameters,\n grads_to_wait,\n optimizer,\n lr_staleness_modulation=False,\n use_async=False,\n ):\n self._parameters = parameters\n self._grads_to_wait = grads_to_wait\n self._optimizer = optimizer\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._version = 0\n self._lock = threading.Lock()\n\n def pull_variable(self, request, _):\n \"\"\"\n Response with all non-embedding parameters if initialized.\n \"\"\"\n res = elasticdl_pb2.PullVariableResponse()\n if not self._parameters.init_status:\n res.model_init_status = False\n return res\n\n # Only sync-SGD needs lock\n # TODO: use a read-write lock to support multiple concurrent reads\n if not self._use_async:\n self._lock.acquire()\n res.model.version = self._parameters.version\n for name, var in self._parameters.non_embedding_params.items():\n tensor = res.model.param.add()\n tensor.name = name\n tensor.dim.extend(var.shape.as_list())\n var_values = var.numpy()\n tensor.content = var_values.tobytes()\n tensor.dtype = dtype_numpy_to_tensor(var_values.dtype)\n if not self._use_async:\n self._lock.release()\n res.model_init_status = True\n return res\n\n def pull_embedding_vector(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.Tensor()\n\n def push_model(self, request, _):\n with self._lock:\n self._parameters.init_from_model_pb(request)\n return empty_pb2.Empty()\n\n def push_gradient(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PushGradientResponse()\n", "path": "elasticdl/python/ps/servicer.py"}]}
| 635 | 403 |
gh_patches_debug_2146
|
rasdani/github-patches
|
git_diff
|
sktime__sktime-5368
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] `numba` related failures on main from `tslearn` `lcss`
On main, it seems we have the following `numba` related failures:
```
During: resolving callee type: type(CPUDispatcher(<function _local_squared_dist at 0x14fc267a0>))
During: typing of call at /Users/runner/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/tslearn/metrics/dtw_variants.py (1421)
```
This is not related to the recent newer `numba` release as we did not upgrade yet.
For test runs with the failures, see here: https://github.com/sktime/sktime/actions/runs/6424459407/job/17445296470?pr=5083
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sktime/dists_kernels/base/adapters/_tslearn.py`
Content:
```
1 # copyright: sktime developers, BSD-3-Clause License (see LICENSE file)
2 """Implements adapter for tslearn distances and kernels."""
3 import numpy as np
4
5 __all__ = ["_TslearnPwTrafoAdapter"]
6 __author__ = ["fkiraly"]
7
8
9 def _subset_dict(d, keys):
10 """Subsets dictionary to keys in iterable keys.
11
12 Parameters
13 ----------
14 d : dict
15 dictionary to subset
16 keys : iterable
17 keys to subset to
18
19 Returns
20 -------
21 dict
22 subsetted dictionary
23 """
24 return {key: d[key] for key in keys if key in d}
25
26
27 class _TslearnPwTrafoAdapter:
28 """Base adapter mixin for tslearn distances and kernels."""
29
30 _tags = {
31 "symmetric": False, # is the transformer symmetric, i.e., t(x,y)=t(y,x) always?
32 "X_inner_mtype": "df-list",
33 # which mtype is used internally in _transform?
34 "fit_is_empty": True, # is "fit" empty? Yes, for all pairwise transforms
35 "capability:missing_values": True, # can estimator handle missing data?
36 "capability:multivariate": True, # can estimator handle multivariate data?
37 "pwtrafo_type": "distance", # type of pw. transformer, "kernel" or "distance"
38 "python_dependencies": ["tslearn"],
39 }
40
41 # parameters to pass to the inner tslearn estimator, list of str
42 # if None, will pass all of self.get_params()
43 # otherwise, passes only the parameters in the list of str _inner_params
44 _inner_params = None
45
46 # controls whether vectorization is applied to the tslearn pwtrafo
47 # True: the adapted function is cdist-like, it can take Panel data directly
48 # False: the adapted function takes two time series and needs to be vectorized
49 _is_cdist = True
50
51 def _get_tslearn_pwtrafo(self):
52 """Abstract method to get tslearn pwtrafo.
53
54 should import and return tslearn pwtrafo
55 """
56 # from tslearn import pwtrafo
57 #
58 # return pwtrafo
59 raise NotImplementedError("abstract method")
60
61 def _eval_tslearn_pwtrafo(self, X, X2=None):
62 """Evaluate tslearn pwtrafo on two time series.
63
64 The default returns of _get_tslearn_pwtrafo
65 evaluated at X1, X2 and self.get_params
66
67 Parameters
68 ----------
69 X, X2: 2D np.ndarrays of format (n_variables, n_timepoints)
70 two time series to compute the pairwise transform on
71
72 Returns
73 -------
74 float
75 _get_tslearn_pwtrafo result evaluated at X1, X2, and self.get_params()
76 """
77 if X2 is None:
78 X2 = X
79
80 pwtrafo = self._get_tslearn_pwtrafo()
81 params = self.get_params()
82 if self._inner_params is not None:
83 params = _subset_dict(params, self._inner_params)
84
85 return pwtrafo(X, X2, **params)
86
87 def _coerce_df_list_to_list_of_arr(self, X):
88 return [df.values for df in X]
89
90 def _eval_tslearn_pwtrafo_vectorized(self, X, X2=None):
91 """Evaluate tslearn pwtrafo on two time series panels.
92
93 Vectorizes _eval_tslearn_pwtrafo over the first dimensions.
94
95 Parameters
96 ----------
97 X, X2: 3D np.ndarrays of format (n_instances n_variables, n_timepoints)
98 two time series panels to compute the pairwise transform on
99
100 Returns
101 -------
102 2D np.ndarray
103 (i, j)-th entry is _eval_tslearn_pwtrafo(self, X1[i], X2[j])
104 """
105 if X2 is None:
106 X2 = X
107
108 m = len(X)
109 n = len(X2)
110 res = np.zeros((m, n))
111 for i in range(m):
112 for j in range(n):
113 res[i, j] = self._eval_tslearn_pwtrafo(X[i], X2[j])
114 return res
115
116 def _transform(self, X, X2=None):
117 """Compute distance/kernel matrix.
118
119 Core logic
120
121 Behaviour: returns pairwise distance/kernel matrix
122 between samples in X and X2
123 if X2 is not passed, is equal to X
124 if X/X2 is a pd.DataFrame and contains non-numeric columns,
125 these are removed before computation
126
127 Parameters
128 ----------
129 X: 3D np.array of shape [num_instances, num_vars, num_time_points]
130 X2: 3D np.array of shape [num_instances, num_vars, num_time_points], optional
131 default X2 = X
132
133 Returns
134 -------
135 distmat: np.array of shape [n, m]
136 (i,j)-th entry contains distance/kernel between X[i] and X2[j]
137 """
138 if isinstance(X, list):
139 X = self._coerce_df_list_to_list_of_arr(X)
140 if isinstance(X2, list):
141 X2 = self._coerce_df_list_to_list_of_arr(X2)
142
143 return self._eval_tslearn_pwtrafo(X, X2)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sktime/dists_kernels/base/adapters/_tslearn.py b/sktime/dists_kernels/base/adapters/_tslearn.py
--- a/sktime/dists_kernels/base/adapters/_tslearn.py
+++ b/sktime/dists_kernels/base/adapters/_tslearn.py
@@ -140,4 +140,7 @@
if isinstance(X2, list):
X2 = self._coerce_df_list_to_list_of_arr(X2)
- return self._eval_tslearn_pwtrafo(X, X2)
+ if self._is_cdist:
+ return self._eval_tslearn_pwtrafo(X, X2)
+ else:
+ return self._eval_tslearn_pwtrafo_vectorized(X, X2)
|
{"golden_diff": "diff --git a/sktime/dists_kernels/base/adapters/_tslearn.py b/sktime/dists_kernels/base/adapters/_tslearn.py\n--- a/sktime/dists_kernels/base/adapters/_tslearn.py\n+++ b/sktime/dists_kernels/base/adapters/_tslearn.py\n@@ -140,4 +140,7 @@\n if isinstance(X2, list):\n X2 = self._coerce_df_list_to_list_of_arr(X2)\n \n- return self._eval_tslearn_pwtrafo(X, X2)\n+ if self._is_cdist:\n+ return self._eval_tslearn_pwtrafo(X, X2)\n+ else:\n+ return self._eval_tslearn_pwtrafo_vectorized(X, X2)\n", "issue": "[BUG] `numba` related failures on main from `tslearn` `lcss`\nOn main, it seems we have the following `numba` related failures:\r\n\r\n```\r\nDuring: resolving callee type: type(CPUDispatcher(<function _local_squared_dist at 0x14fc267a0>))\r\nDuring: typing of call at /Users/runner/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/tslearn/metrics/dtw_variants.py (1421)\r\n```\r\n\r\nThis is not related to the recent newer `numba` release as we did not upgrade yet.\r\n\r\nFor test runs with the failures, see here: https://github.com/sktime/sktime/actions/runs/6424459407/job/17445296470?pr=5083\r\n\n", "before_files": [{"content": "# copyright: sktime developers, BSD-3-Clause License (see LICENSE file)\n\"\"\"Implements adapter for tslearn distances and kernels.\"\"\"\nimport numpy as np\n\n__all__ = [\"_TslearnPwTrafoAdapter\"]\n__author__ = [\"fkiraly\"]\n\n\ndef _subset_dict(d, keys):\n \"\"\"Subsets dictionary to keys in iterable keys.\n\n Parameters\n ----------\n d : dict\n dictionary to subset\n keys : iterable\n keys to subset to\n\n Returns\n -------\n dict\n subsetted dictionary\n \"\"\"\n return {key: d[key] for key in keys if key in d}\n\n\nclass _TslearnPwTrafoAdapter:\n \"\"\"Base adapter mixin for tslearn distances and kernels.\"\"\"\n\n _tags = {\n \"symmetric\": False, # is the transformer symmetric, i.e., t(x,y)=t(y,x) always?\n \"X_inner_mtype\": \"df-list\",\n # which mtype is used internally in _transform?\n \"fit_is_empty\": True, # is \"fit\" empty? Yes, for all pairwise transforms\n \"capability:missing_values\": True, # can estimator handle missing data?\n \"capability:multivariate\": True, # can estimator handle multivariate data?\n \"pwtrafo_type\": \"distance\", # type of pw. transformer, \"kernel\" or \"distance\"\n \"python_dependencies\": [\"tslearn\"],\n }\n\n # parameters to pass to the inner tslearn estimator, list of str\n # if None, will pass all of self.get_params()\n # otherwise, passes only the parameters in the list of str _inner_params\n _inner_params = None\n\n # controls whether vectorization is applied to the tslearn pwtrafo\n # True: the adapted function is cdist-like, it can take Panel data directly\n # False: the adapted function takes two time series and needs to be vectorized\n _is_cdist = True\n\n def _get_tslearn_pwtrafo(self):\n \"\"\"Abstract method to get tslearn pwtrafo.\n\n should import and return tslearn pwtrafo\n \"\"\"\n # from tslearn import pwtrafo\n #\n # return pwtrafo\n raise NotImplementedError(\"abstract method\")\n\n def _eval_tslearn_pwtrafo(self, X, X2=None):\n \"\"\"Evaluate tslearn pwtrafo on two time series.\n\n The default returns of _get_tslearn_pwtrafo\n evaluated at X1, X2 and self.get_params\n\n Parameters\n ----------\n X, X2: 2D np.ndarrays of format (n_variables, n_timepoints)\n two time series to compute the pairwise transform on\n\n Returns\n -------\n float\n _get_tslearn_pwtrafo result evaluated at X1, X2, and self.get_params()\n \"\"\"\n if X2 is None:\n X2 = X\n\n pwtrafo = self._get_tslearn_pwtrafo()\n params = self.get_params()\n if self._inner_params is not None:\n params = _subset_dict(params, self._inner_params)\n\n return pwtrafo(X, X2, **params)\n\n def _coerce_df_list_to_list_of_arr(self, X):\n return [df.values for df in X]\n\n def _eval_tslearn_pwtrafo_vectorized(self, X, X2=None):\n \"\"\"Evaluate tslearn pwtrafo on two time series panels.\n\n Vectorizes _eval_tslearn_pwtrafo over the first dimensions.\n\n Parameters\n ----------\n X, X2: 3D np.ndarrays of format (n_instances n_variables, n_timepoints)\n two time series panels to compute the pairwise transform on\n\n Returns\n -------\n 2D np.ndarray\n (i, j)-th entry is _eval_tslearn_pwtrafo(self, X1[i], X2[j])\n \"\"\"\n if X2 is None:\n X2 = X\n\n m = len(X)\n n = len(X2)\n res = np.zeros((m, n))\n for i in range(m):\n for j in range(n):\n res[i, j] = self._eval_tslearn_pwtrafo(X[i], X2[j])\n return res\n\n def _transform(self, X, X2=None):\n \"\"\"Compute distance/kernel matrix.\n\n Core logic\n\n Behaviour: returns pairwise distance/kernel matrix\n between samples in X and X2\n if X2 is not passed, is equal to X\n if X/X2 is a pd.DataFrame and contains non-numeric columns,\n these are removed before computation\n\n Parameters\n ----------\n X: 3D np.array of shape [num_instances, num_vars, num_time_points]\n X2: 3D np.array of shape [num_instances, num_vars, num_time_points], optional\n default X2 = X\n\n Returns\n -------\n distmat: np.array of shape [n, m]\n (i,j)-th entry contains distance/kernel between X[i] and X2[j]\n \"\"\"\n if isinstance(X, list):\n X = self._coerce_df_list_to_list_of_arr(X)\n if isinstance(X2, list):\n X2 = self._coerce_df_list_to_list_of_arr(X2)\n\n return self._eval_tslearn_pwtrafo(X, X2)\n", "path": "sktime/dists_kernels/base/adapters/_tslearn.py"}], "after_files": [{"content": "# copyright: sktime developers, BSD-3-Clause License (see LICENSE file)\n\"\"\"Implements adapter for tslearn distances and kernels.\"\"\"\nimport numpy as np\n\n__all__ = [\"_TslearnPwTrafoAdapter\"]\n__author__ = [\"fkiraly\"]\n\n\ndef _subset_dict(d, keys):\n \"\"\"Subsets dictionary to keys in iterable keys.\n\n Parameters\n ----------\n d : dict\n dictionary to subset\n keys : iterable\n keys to subset to\n\n Returns\n -------\n dict\n subsetted dictionary\n \"\"\"\n return {key: d[key] for key in keys if key in d}\n\n\nclass _TslearnPwTrafoAdapter:\n \"\"\"Base adapter mixin for tslearn distances and kernels.\"\"\"\n\n _tags = {\n \"symmetric\": False, # is the transformer symmetric, i.e., t(x,y)=t(y,x) always?\n \"X_inner_mtype\": \"df-list\",\n # which mtype is used internally in _transform?\n \"fit_is_empty\": True, # is \"fit\" empty? Yes, for all pairwise transforms\n \"capability:missing_values\": True, # can estimator handle missing data?\n \"capability:multivariate\": True, # can estimator handle multivariate data?\n \"pwtrafo_type\": \"distance\", # type of pw. transformer, \"kernel\" or \"distance\"\n \"python_dependencies\": [\"tslearn\"],\n }\n\n # parameters to pass to the inner tslearn estimator, list of str\n # if None, will pass all of self.get_params()\n # otherwise, passes only the parameters in the list of str _inner_params\n _inner_params = None\n\n # controls whether vectorization is applied to the tslearn pwtrafo\n # True: the adapted function is cdist-like, it can take Panel data directly\n # False: the adapted function takes two time series and needs to be vectorized\n _is_cdist = True\n\n def _get_tslearn_pwtrafo(self):\n \"\"\"Abstract method to get tslearn pwtrafo.\n\n should import and return tslearn pwtrafo\n \"\"\"\n # from tslearn import pwtrafo\n #\n # return pwtrafo\n raise NotImplementedError(\"abstract method\")\n\n def _eval_tslearn_pwtrafo(self, X, X2=None):\n \"\"\"Evaluate tslearn pwtrafo on two time series.\n\n The default returns of _get_tslearn_pwtrafo\n evaluated at X1, X2 and self.get_params\n\n Parameters\n ----------\n X, X2: 2D np.ndarrays of format (n_variables, n_timepoints)\n two time series to compute the pairwise transform on\n\n Returns\n -------\n float\n _get_tslearn_pwtrafo result evaluated at X1, X2, and self.get_params()\n \"\"\"\n if X2 is None:\n X2 = X\n\n pwtrafo = self._get_tslearn_pwtrafo()\n params = self.get_params()\n if self._inner_params is not None:\n params = _subset_dict(params, self._inner_params)\n\n return pwtrafo(X, X2, **params)\n\n def _coerce_df_list_to_list_of_arr(self, X):\n return [df.values for df in X]\n\n def _eval_tslearn_pwtrafo_vectorized(self, X, X2=None):\n \"\"\"Evaluate tslearn pwtrafo on two time series panels.\n\n Vectorizes _eval_tslearn_pwtrafo over the first dimensions.\n\n Parameters\n ----------\n X, X2: 3D np.ndarrays of format (n_instances n_variables, n_timepoints)\n two time series panels to compute the pairwise transform on\n\n Returns\n -------\n 2D np.ndarray\n (i, j)-th entry is _eval_tslearn_pwtrafo(self, X1[i], X2[j])\n \"\"\"\n if X2 is None:\n X2 = X\n\n m = len(X)\n n = len(X2)\n res = np.zeros((m, n))\n for i in range(m):\n for j in range(n):\n res[i, j] = self._eval_tslearn_pwtrafo(X[i], X2[j])\n return res\n\n def _transform(self, X, X2=None):\n \"\"\"Compute distance/kernel matrix.\n\n Core logic\n\n Behaviour: returns pairwise distance/kernel matrix\n between samples in X and X2\n if X2 is not passed, is equal to X\n if X/X2 is a pd.DataFrame and contains non-numeric columns,\n these are removed before computation\n\n Parameters\n ----------\n X: 3D np.array of shape [num_instances, num_vars, num_time_points]\n X2: 3D np.array of shape [num_instances, num_vars, num_time_points], optional\n default X2 = X\n\n Returns\n -------\n distmat: np.array of shape [n, m]\n (i,j)-th entry contains distance/kernel between X[i] and X2[j]\n \"\"\"\n if isinstance(X, list):\n X = self._coerce_df_list_to_list_of_arr(X)\n if isinstance(X2, list):\n X2 = self._coerce_df_list_to_list_of_arr(X2)\n\n if self._is_cdist:\n return self._eval_tslearn_pwtrafo(X, X2)\n else:\n return self._eval_tslearn_pwtrafo_vectorized(X, X2)\n", "path": "sktime/dists_kernels/base/adapters/_tslearn.py"}]}
| 1,961 | 171 |
gh_patches_debug_1441
|
rasdani/github-patches
|
git_diff
|
Uberspace__lab-1000
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
link to "view changelog" no longer works
"view changelog" on each page will lead to the old master branch which now should be `main`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `source/conf.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # Uberspace 7 lab documentation build configuration file, created by
5 # sphinx-quickstart on Tue Feb 13 12:19:29 2018.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 # import os
21 # import sys
22 # sys.path.insert(0, os.path.abspath('.'))
23
24 import sphinx_rtd_theme
25
26 # -- General configuration ------------------------------------------------
27
28 # If your documentation needs a minimal Sphinx version, state it here.
29 #
30 # needs_sphinx = '1.0'
31
32 # Add any Sphinx extension module names here, as strings. They can be
33 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
34 # ones.
35 extensions = [
36 "authorship",
37 "sphinx.ext.extlinks",
38 "notfound.extension",
39 "sphinxcontrib.spelling",
40 ]
41
42 # Add spelling settings
43 tokenizer_lang = "en_GB"
44 spelling_word_list_filename = "dict.txt"
45
46 # Add any paths that contain templates here, relative to this directory.
47 templates_path = ["_templates"]
48
49 # The suffix(es) of source filenames.
50 # You can specify multiple suffix as a list of string:
51 #
52 # source_suffix = ['.rst', '.md']
53 source_suffix = ".rst"
54
55 # The master toctree document.
56 master_doc = "index"
57
58 # General information about the project.
59 project = "UberLab"
60 copyright = "2018, uberspace.de"
61 author = "uberspace.de"
62
63 # The version info for the project you're documenting, acts as replacement for
64 # |version| and |release|, also used in various other places throughout the
65 # built documents.
66 #
67 # The short X.Y version.
68 release = version = "7"
69
70 # The language for content autogenerated by Sphinx. Refer to documentation
71 # for a list of supported languages.
72 #
73 # This is also used if you do content translation via gettext catalogs.
74 # Usually you set "language" from the command line for these cases.
75 language = None
76
77 # List of patterns, relative to source directory, that match files and
78 # directories to ignore when looking for source files.
79 # This patterns also effect to html_static_path and html_extra_path
80 exclude_patterns = []
81
82 # The name of the Pygments (syntax highlighting) style to use.
83 pygments_style = "sphinx"
84
85 # If true, `todo` and `todoList` produce output, else they produce nothing.
86 todo_include_todos = False
87
88 # Configure the `extlinks` extension to handle the `manual` and `lab`
89 # directives.
90 # By setting an empty string as the second tuple element, the display text
91 # is the same as the target by default.
92 extlinks = {
93 "manual": ("https://manual.uberspace.de/%s.html", ""),
94 "manual_anchor": ("https://manual.uberspace.de/%s", ""),
95 "lab": ("%s.html", ""),
96 "lab_anchor": ("%s", ""),
97 }
98
99
100 # -- Options for HTML output ----------------------------------------------
101
102 html_theme = "sphinx_rtd_theme"
103 html_theme_options = {
104 "display_version": False,
105 "navigation_depth": 2,
106 "collapse_navigation": True,
107 }
108 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
109 html_last_updated_fmt = "%b %d, %Y"
110 html_context = {
111 "css_files": ["_static/css/custom.css"],
112 "display_github": True,
113 "github_user": "Uberspace",
114 "github_repo": "lab",
115 "github_version": "master",
116 "conf_py_path": "/source/",
117 }
118 html_show_copyright = False
119 html_favicon = "_static/favicon.ico"
120
121
122 # Theme options are theme-specific and customize the look and feel of a theme
123 # further. For a list of options available for each theme, see the
124 # documentation.
125 #
126 # html_theme_options = {}
127
128 # Add any paths that contain custom static files (such as style sheets) here,
129 # relative to this directory. They are copied after the builtin static files,
130 # so a file named "default.css" will overwrite the builtin "default.css".
131 html_static_path = ["_static"]
132 html_extra_path = ["_redirects"]
133
134 # Custom sidebar templates, must be a dictionary that maps document names
135 # to template names.
136 #
137 # This is required for the alabaster theme
138 # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
139 html_sidebars = {
140 "**": [
141 "relations.html", # needs 'show_related': True theme option to display
142 "searchbox.html",
143 ]
144 }
145
146 # sphinx-notfound-page
147 # https://github.com/rtfd/sphinx-notfound-page
148 notfound_no_urls_prefix = True
149
150 # -- Options for HTMLHelp output ------------------------------------------
151
152 # Output file base name for HTML help builder.
153 htmlhelp_basename = "Uberspace7labdoc"
154
155
156 exclude_patterns = ["404.rst", "includes/proxy-rewrite-static.rst"]
157
158
159 def setup(app):
160 app.add_js_file("js/custom.js")
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/source/conf.py b/source/conf.py
--- a/source/conf.py
+++ b/source/conf.py
@@ -112,7 +112,7 @@
"display_github": True,
"github_user": "Uberspace",
"github_repo": "lab",
- "github_version": "master",
+ "github_version": "main",
"conf_py_path": "/source/",
}
html_show_copyright = False
|
{"golden_diff": "diff --git a/source/conf.py b/source/conf.py\n--- a/source/conf.py\n+++ b/source/conf.py\n@@ -112,7 +112,7 @@\n \"display_github\": True,\n \"github_user\": \"Uberspace\",\n \"github_repo\": \"lab\",\n- \"github_version\": \"master\",\n+ \"github_version\": \"main\",\n \"conf_py_path\": \"/source/\",\n }\n html_show_copyright = False\n", "issue": "link to \"view changelog\" no longer works\n\"view changelog\" on each page will lead to the old master branch which now should be `main`\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Uberspace 7 lab documentation build configuration file, created by\n# sphinx-quickstart on Tue Feb 13 12:19:29 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nimport sphinx_rtd_theme\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"authorship\",\n \"sphinx.ext.extlinks\",\n \"notfound.extension\",\n \"sphinxcontrib.spelling\",\n]\n\n# Add spelling settings\ntokenizer_lang = \"en_GB\"\nspelling_word_list_filename = \"dict.txt\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# General information about the project.\nproject = \"UberLab\"\ncopyright = \"2018, uberspace.de\"\nauthor = \"uberspace.de\"\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nrelease = version = \"7\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n# Configure the `extlinks` extension to handle the `manual` and `lab`\n# directives.\n# By setting an empty string as the second tuple element, the display text\n# is the same as the target by default.\nextlinks = {\n \"manual\": (\"https://manual.uberspace.de/%s.html\", \"\"),\n \"manual_anchor\": (\"https://manual.uberspace.de/%s\", \"\"),\n \"lab\": (\"%s.html\", \"\"),\n \"lab_anchor\": (\"%s\", \"\"),\n}\n\n\n# -- Options for HTML output ----------------------------------------------\n\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_options = {\n \"display_version\": False,\n \"navigation_depth\": 2,\n \"collapse_navigation\": True,\n}\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\nhtml_last_updated_fmt = \"%b %d, %Y\"\nhtml_context = {\n \"css_files\": [\"_static/css/custom.css\"],\n \"display_github\": True,\n \"github_user\": \"Uberspace\",\n \"github_repo\": \"lab\",\n \"github_version\": \"master\",\n \"conf_py_path\": \"/source/\",\n}\nhtml_show_copyright = False\nhtml_favicon = \"_static/favicon.ico\"\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\nhtml_extra_path = [\"_redirects\"]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n \"**\": [\n \"relations.html\", # needs 'show_related': True theme option to display\n \"searchbox.html\",\n ]\n}\n\n# sphinx-notfound-page\n# https://github.com/rtfd/sphinx-notfound-page\nnotfound_no_urls_prefix = True\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Uberspace7labdoc\"\n\n\nexclude_patterns = [\"404.rst\", \"includes/proxy-rewrite-static.rst\"]\n\n\ndef setup(app):\n app.add_js_file(\"js/custom.js\")\n", "path": "source/conf.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Uberspace 7 lab documentation build configuration file, created by\n# sphinx-quickstart on Tue Feb 13 12:19:29 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nimport sphinx_rtd_theme\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"authorship\",\n \"sphinx.ext.extlinks\",\n \"notfound.extension\",\n \"sphinxcontrib.spelling\",\n]\n\n# Add spelling settings\ntokenizer_lang = \"en_GB\"\nspelling_word_list_filename = \"dict.txt\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# General information about the project.\nproject = \"UberLab\"\ncopyright = \"2018, uberspace.de\"\nauthor = \"uberspace.de\"\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nrelease = version = \"7\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n# Configure the `extlinks` extension to handle the `manual` and `lab`\n# directives.\n# By setting an empty string as the second tuple element, the display text\n# is the same as the target by default.\nextlinks = {\n \"manual\": (\"https://manual.uberspace.de/%s.html\", \"\"),\n \"manual_anchor\": (\"https://manual.uberspace.de/%s\", \"\"),\n \"lab\": (\"%s.html\", \"\"),\n \"lab_anchor\": (\"%s\", \"\"),\n}\n\n\n# -- Options for HTML output ----------------------------------------------\n\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_options = {\n \"display_version\": False,\n \"navigation_depth\": 2,\n \"collapse_navigation\": True,\n}\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\nhtml_last_updated_fmt = \"%b %d, %Y\"\nhtml_context = {\n \"css_files\": [\"_static/css/custom.css\"],\n \"display_github\": True,\n \"github_user\": \"Uberspace\",\n \"github_repo\": \"lab\",\n \"github_version\": \"main\",\n \"conf_py_path\": \"/source/\",\n}\nhtml_show_copyright = False\nhtml_favicon = \"_static/favicon.ico\"\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\nhtml_extra_path = [\"_redirects\"]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n \"**\": [\n \"relations.html\", # needs 'show_related': True theme option to display\n \"searchbox.html\",\n ]\n}\n\n# sphinx-notfound-page\n# https://github.com/rtfd/sphinx-notfound-page\nnotfound_no_urls_prefix = True\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Uberspace7labdoc\"\n\n\nexclude_patterns = [\"404.rst\", \"includes/proxy-rewrite-static.rst\"]\n\n\ndef setup(app):\n app.add_js_file(\"js/custom.js\")\n", "path": "source/conf.py"}]}
| 1,869 | 99 |
gh_patches_debug_26256
|
rasdani/github-patches
|
git_diff
|
koxudaxi__datamodel-code-generator-8
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use `Optional` for nullable fields?
If a field is `nullable` (https://swagger.io/docs/specification/data-models/data-types/#null) use the `Optional` type hint (https://pydantic-docs.helpmanual.io/#pep-484-types)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `datamodel_code_generator/__main__.py`
Content:
```
1 #! /usr/bin/env python
2
3 """
4 Main function.
5 """
6
7 import os
8 import sys
9 from argparse import ArgumentParser, FileType
10 from enum import IntEnum
11 from typing import Optional, Sequence
12
13 import argcomplete
14
15 from datamodel_code_generator.model import BaseModel, DataModelField
16 from datamodel_code_generator.parser.openapi import Parser
17
18
19 class Exit(IntEnum):
20 """Exit reasons."""
21
22 OK = 0
23 ERROR = 1
24
25
26 arg_parser = ArgumentParser()
27 arg_parser.add_argument("--input", help="Open API YAML file")
28 arg_parser.add_argument("--output", help="Output file", type=FileType("wt"), default=sys.stdout)
29
30
31 def main(args: Optional[Sequence[str]] = None) -> Exit:
32 """Main function."""
33
34 # add cli completion support
35 argcomplete.autocomplete(arg_parser)
36
37 if args is None:
38 args = sys.argv[1:]
39
40 args = arg_parser.parse_args(args)
41
42 input_filename = os.path.abspath(os.path.expanduser(args.input))
43 parser = Parser(BaseModel, DataModelField, filename=input_filename)
44 with args.output as file:
45 parser.parse(file)
46 print(parser.parse(), file=file)
47
48 return Exit.OK
49
50
51 if __name__ == "__main__":
52 sys.exit(main())
53
```
Path: `datamodel_code_generator/parser/openapi.py`
Content:
```
1 from dataclasses import Field, dataclass
2 from typing import Dict, List, Optional, Set, Type, Union
3
4 from prance import BaseParser, ResolvingParser
5
6 from ..model import CustomRootType, DataModel, DataModelField
7 from ..model.base import TemplateBase
8
9
10 @dataclass
11 class DataType:
12 type_hint: str
13 format: Optional[str] = None
14 default: Optional[Field] = None
15
16
17 data_types: Dict[str, Dict[str, DataType]] = {
18 # https://docs.python.org/3.7/library/json.html#encoders-and-decoders
19 'integer':
20 {
21 'int32': DataType(type_hint='int'),
22 'int64': DataType(type_hint='int')
23 },
24 'number':
25 {
26 'float': DataType(type_hint='float'),
27 'double': DataType(type_hint='float')
28 },
29 'string':
30 {'default': DataType(type_hint='str'),
31 'byte': DataType(type_hint='str'),
32 'binary': DataType(type_hint='bytes')
33 },
34 # 'data': date,}, #As defined by full-date - RFC3339
35 'boolean': {'default': DataType(type_hint='bool')}
36 }
37
38
39 def get_data_type(_type, format =None) -> DataType:
40 _format: str = format or 'default'
41 return data_types[_type][_format]
42
43
44 def dump_templates(templates: Union[TemplateBase, List[TemplateBase]]) -> str:
45 if isinstance(templates, TemplateBase):
46 templates = [templates]
47 return '\n\n'.join(str(m) for m in templates)
48
49
50 class Parser:
51 def __init__(self, data_model_type: Type[DataModel], data_model_field_type: Type[DataModelField],
52 filename: str = "api.yaml"):
53 self.base_parser = BaseParser(filename, backend='openapi-spec-validator')
54 self.resolving_parser = ResolvingParser(filename, backend='openapi-spec-validator')
55
56 self.data_model_type: Type[DataModel] = data_model_type
57 self.data_model_field_type: Type[DataModelField] = data_model_field_type
58 self.models = []
59
60 def parse_object(self, name: str, obj: Dict) -> str:
61 requires: Set[str] = set(obj.get('required', []))
62 d_list: List[DataModelField] = []
63 for field_name, filed in obj['properties'].items():
64 # object
65 d_list.append(self.data_model_field_type(
66 name=field_name, type_hint=get_data_type(filed["type"],
67 filed.get("format")).type_hint,
68 required=field_name in requires))
69 return dump_templates(self.data_model_type(name, fields=d_list))
70
71 def parse_array(self, name: str, obj: Dict) -> str:
72 templates: List[TemplateBase] = []
73 # continue
74 if '$ref' in obj['items']:
75 _type: str = f"List[{obj['items']['$ref'].split('/')[-1]}]"
76 templates.append(CustomRootType(name, _type))
77 elif 'properties' in obj['items']:
78 self.parse_object(name[:-1], obj['items'])
79 templates.append(CustomRootType(name, f'List[{name[:-1]}]'))
80 return dump_templates(templates)
81
82 def parse(self) -> str:
83 parsed_objects: List[str] = []
84 for obj_name, obj in self.base_parser.specification['components']['schemas'].items():
85 if 'properties' in obj:
86 parsed_objects.append(self.parse_object(obj_name, obj))
87 elif 'items' in obj:
88 parsed_objects.append(self.parse_array(obj_name, obj))
89
90 return '\n\n\n'.join(parsed_objects)
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/datamodel_code_generator/__main__.py b/datamodel_code_generator/__main__.py
--- a/datamodel_code_generator/__main__.py
+++ b/datamodel_code_generator/__main__.py
@@ -7,6 +7,7 @@
import os
import sys
from argparse import ArgumentParser, FileType
+from datetime import datetime, timezone
from enum import IntEnum
from typing import Optional, Sequence
@@ -41,8 +42,20 @@
input_filename = os.path.abspath(os.path.expanduser(args.input))
parser = Parser(BaseModel, DataModelField, filename=input_filename)
+ timestamp = datetime.now(timezone.utc).replace(microsecond=0).isoformat()
+ header = f"""\
+# generated by datamodel-codegen:
+# filename: {os.path.split(input_filename)[1]}
+# timestamp: {timestamp}
+
+from typing import List, Optional
+
+from pydantic import BaseModel
+
+
+"""
with args.output as file:
- parser.parse(file)
+ print(header, file=file)
print(parser.parse(), file=file)
return Exit.OK
diff --git a/datamodel_code_generator/parser/openapi.py b/datamodel_code_generator/parser/openapi.py
--- a/datamodel_code_generator/parser/openapi.py
+++ b/datamodel_code_generator/parser/openapi.py
@@ -1,6 +1,6 @@
-from dataclasses import Field, dataclass
from typing import Dict, List, Optional, Set, Type, Union
+from dataclasses import Field, dataclass
from prance import BaseParser, ResolvingParser
from ..model import CustomRootType, DataModel, DataModelField
|
{"golden_diff": "diff --git a/datamodel_code_generator/__main__.py b/datamodel_code_generator/__main__.py\n--- a/datamodel_code_generator/__main__.py\n+++ b/datamodel_code_generator/__main__.py\n@@ -7,6 +7,7 @@\n import os\n import sys\n from argparse import ArgumentParser, FileType\n+from datetime import datetime, timezone\n from enum import IntEnum\n from typing import Optional, Sequence\n \n@@ -41,8 +42,20 @@\n \n input_filename = os.path.abspath(os.path.expanduser(args.input))\n parser = Parser(BaseModel, DataModelField, filename=input_filename)\n+ timestamp = datetime.now(timezone.utc).replace(microsecond=0).isoformat()\n+ header = f\"\"\"\\\n+# generated by datamodel-codegen:\n+# filename: {os.path.split(input_filename)[1]}\n+# timestamp: {timestamp}\n+\n+from typing import List, Optional\n+\n+from pydantic import BaseModel\n+\n+\n+\"\"\"\n with args.output as file:\n- parser.parse(file)\n+ print(header, file=file)\n print(parser.parse(), file=file)\n \n return Exit.OK\ndiff --git a/datamodel_code_generator/parser/openapi.py b/datamodel_code_generator/parser/openapi.py\n--- a/datamodel_code_generator/parser/openapi.py\n+++ b/datamodel_code_generator/parser/openapi.py\n@@ -1,6 +1,6 @@\n-from dataclasses import Field, dataclass\n from typing import Dict, List, Optional, Set, Type, Union\n \n+from dataclasses import Field, dataclass\n from prance import BaseParser, ResolvingParser\n \n from ..model import CustomRootType, DataModel, DataModelField\n", "issue": "Use `Optional` for nullable fields?\nIf a field is `nullable` (https://swagger.io/docs/specification/data-models/data-types/#null) use the `Optional` type hint (https://pydantic-docs.helpmanual.io/#pep-484-types)\n", "before_files": [{"content": "#! /usr/bin/env python\n\n\"\"\"\nMain function.\n\"\"\"\n\nimport os\nimport sys\nfrom argparse import ArgumentParser, FileType\nfrom enum import IntEnum\nfrom typing import Optional, Sequence\n\nimport argcomplete\n\nfrom datamodel_code_generator.model import BaseModel, DataModelField\nfrom datamodel_code_generator.parser.openapi import Parser\n\n\nclass Exit(IntEnum):\n \"\"\"Exit reasons.\"\"\"\n\n OK = 0\n ERROR = 1\n\n\narg_parser = ArgumentParser()\narg_parser.add_argument(\"--input\", help=\"Open API YAML file\")\narg_parser.add_argument(\"--output\", help=\"Output file\", type=FileType(\"wt\"), default=sys.stdout)\n\n\ndef main(args: Optional[Sequence[str]] = None) -> Exit:\n \"\"\"Main function.\"\"\"\n\n # add cli completion support\n argcomplete.autocomplete(arg_parser)\n\n if args is None:\n args = sys.argv[1:]\n\n args = arg_parser.parse_args(args)\n\n input_filename = os.path.abspath(os.path.expanduser(args.input))\n parser = Parser(BaseModel, DataModelField, filename=input_filename)\n with args.output as file:\n parser.parse(file)\n print(parser.parse(), file=file)\n\n return Exit.OK\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "datamodel_code_generator/__main__.py"}, {"content": "from dataclasses import Field, dataclass\nfrom typing import Dict, List, Optional, Set, Type, Union\n\nfrom prance import BaseParser, ResolvingParser\n\nfrom ..model import CustomRootType, DataModel, DataModelField\nfrom ..model.base import TemplateBase\n\n\n@dataclass\nclass DataType:\n type_hint: str\n format: Optional[str] = None\n default: Optional[Field] = None\n\n\ndata_types: Dict[str, Dict[str, DataType]] = {\n # https://docs.python.org/3.7/library/json.html#encoders-and-decoders\n 'integer':\n {\n 'int32': DataType(type_hint='int'),\n 'int64': DataType(type_hint='int')\n },\n 'number':\n {\n 'float': DataType(type_hint='float'),\n 'double': DataType(type_hint='float')\n },\n 'string':\n {'default': DataType(type_hint='str'),\n 'byte': DataType(type_hint='str'),\n 'binary': DataType(type_hint='bytes')\n },\n # 'data': date,}, #As defined by full-date - RFC3339\n 'boolean': {'default': DataType(type_hint='bool')}\n}\n\n\ndef get_data_type(_type, format =None) -> DataType:\n _format: str = format or 'default'\n return data_types[_type][_format]\n\n\ndef dump_templates(templates: Union[TemplateBase, List[TemplateBase]]) -> str:\n if isinstance(templates, TemplateBase):\n templates = [templates]\n return '\\n\\n'.join(str(m) for m in templates)\n\n\nclass Parser:\n def __init__(self, data_model_type: Type[DataModel], data_model_field_type: Type[DataModelField],\n filename: str = \"api.yaml\"):\n self.base_parser = BaseParser(filename, backend='openapi-spec-validator')\n self.resolving_parser = ResolvingParser(filename, backend='openapi-spec-validator')\n\n self.data_model_type: Type[DataModel] = data_model_type\n self.data_model_field_type: Type[DataModelField] = data_model_field_type\n self.models = []\n\n def parse_object(self, name: str, obj: Dict) -> str:\n requires: Set[str] = set(obj.get('required', []))\n d_list: List[DataModelField] = []\n for field_name, filed in obj['properties'].items():\n # object\n d_list.append(self.data_model_field_type(\n name=field_name, type_hint=get_data_type(filed[\"type\"],\n filed.get(\"format\")).type_hint,\n required=field_name in requires))\n return dump_templates(self.data_model_type(name, fields=d_list))\n\n def parse_array(self, name: str, obj: Dict) -> str:\n templates: List[TemplateBase] = []\n # continue\n if '$ref' in obj['items']:\n _type: str = f\"List[{obj['items']['$ref'].split('/')[-1]}]\"\n templates.append(CustomRootType(name, _type))\n elif 'properties' in obj['items']:\n self.parse_object(name[:-1], obj['items'])\n templates.append(CustomRootType(name, f'List[{name[:-1]}]'))\n return dump_templates(templates)\n\n def parse(self) -> str:\n parsed_objects: List[str] = []\n for obj_name, obj in self.base_parser.specification['components']['schemas'].items():\n if 'properties' in obj:\n parsed_objects.append(self.parse_object(obj_name, obj))\n elif 'items' in obj:\n parsed_objects.append(self.parse_array(obj_name, obj))\n\n return '\\n\\n\\n'.join(parsed_objects)\n", "path": "datamodel_code_generator/parser/openapi.py"}], "after_files": [{"content": "#! /usr/bin/env python\n\n\"\"\"\nMain function.\n\"\"\"\n\nimport os\nimport sys\nfrom argparse import ArgumentParser, FileType\nfrom datetime import datetime, timezone\nfrom enum import IntEnum\nfrom typing import Optional, Sequence\n\nimport argcomplete\n\nfrom datamodel_code_generator.model import BaseModel, DataModelField\nfrom datamodel_code_generator.parser.openapi import Parser\n\n\nclass Exit(IntEnum):\n \"\"\"Exit reasons.\"\"\"\n\n OK = 0\n ERROR = 1\n\n\narg_parser = ArgumentParser()\narg_parser.add_argument(\"--input\", help=\"Open API YAML file\")\narg_parser.add_argument(\"--output\", help=\"Output file\", type=FileType(\"wt\"), default=sys.stdout)\n\n\ndef main(args: Optional[Sequence[str]] = None) -> Exit:\n \"\"\"Main function.\"\"\"\n\n # add cli completion support\n argcomplete.autocomplete(arg_parser)\n\n if args is None:\n args = sys.argv[1:]\n\n args = arg_parser.parse_args(args)\n\n input_filename = os.path.abspath(os.path.expanduser(args.input))\n parser = Parser(BaseModel, DataModelField, filename=input_filename)\n timestamp = datetime.now(timezone.utc).replace(microsecond=0).isoformat()\n header = f\"\"\"\\\n# generated by datamodel-codegen:\n# filename: {os.path.split(input_filename)[1]}\n# timestamp: {timestamp}\n\nfrom typing import List, Optional\n\nfrom pydantic import BaseModel\n\n\n\"\"\"\n with args.output as file:\n print(header, file=file)\n print(parser.parse(), file=file)\n\n return Exit.OK\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "datamodel_code_generator/__main__.py"}, {"content": "from typing import Dict, List, Optional, Set, Type, Union\n\nfrom dataclasses import Field, dataclass\nfrom prance import BaseParser, ResolvingParser\n\nfrom ..model import CustomRootType, DataModel, DataModelField\nfrom ..model.base import TemplateBase\n\n\n@dataclass\nclass DataType:\n type_hint: str\n format: Optional[str] = None\n default: Optional[Field] = None\n\n\ndata_types: Dict[str, Dict[str, DataType]] = {\n # https://docs.python.org/3.7/library/json.html#encoders-and-decoders\n 'integer':\n {\n 'int32': DataType(type_hint='int'),\n 'int64': DataType(type_hint='int')\n },\n 'number':\n {\n 'float': DataType(type_hint='float'),\n 'double': DataType(type_hint='float')\n },\n 'string':\n {'default': DataType(type_hint='str'),\n 'byte': DataType(type_hint='str'),\n 'binary': DataType(type_hint='bytes')\n },\n # 'data': date,}, #As defined by full-date - RFC3339\n 'boolean': {'default': DataType(type_hint='bool')}\n}\n\n\ndef get_data_type(_type, format =None) -> DataType:\n _format: str = format or 'default'\n return data_types[_type][_format]\n\n\ndef dump_templates(templates: Union[TemplateBase, List[TemplateBase]]) -> str:\n if isinstance(templates, TemplateBase):\n templates = [templates]\n return '\\n\\n'.join(str(m) for m in templates)\n\n\nclass Parser:\n def __init__(self, data_model_type: Type[DataModel], data_model_field_type: Type[DataModelField],\n filename: str = \"api.yaml\"):\n self.base_parser = BaseParser(filename, backend='openapi-spec-validator')\n self.resolving_parser = ResolvingParser(filename, backend='openapi-spec-validator')\n\n self.data_model_type: Type[DataModel] = data_model_type\n self.data_model_field_type: Type[DataModelField] = data_model_field_type\n self.models = []\n\n def parse_object(self, name: str, obj: Dict) -> str:\n requires: Set[str] = set(obj.get('required', []))\n d_list: List[DataModelField] = []\n for field_name, filed in obj['properties'].items():\n # object\n d_list.append(self.data_model_field_type(\n name=field_name, type_hint=get_data_type(filed[\"type\"],\n filed.get(\"format\")).type_hint,\n required=field_name in requires))\n return dump_templates(self.data_model_type(name, fields=d_list))\n\n def parse_array(self, name: str, obj: Dict) -> str:\n templates: List[TemplateBase] = []\n # continue\n if '$ref' in obj['items']:\n _type: str = f\"List[{obj['items']['$ref'].split('/')[-1]}]\"\n templates.append(CustomRootType(name, _type))\n elif 'properties' in obj['items']:\n self.parse_object(name[:-1], obj['items'])\n templates.append(CustomRootType(name, f'List[{name[:-1]}]'))\n return dump_templates(templates)\n\n def parse(self) -> str:\n parsed_objects: List[str] = []\n for obj_name, obj in self.base_parser.specification['components']['schemas'].items():\n if 'properties' in obj:\n parsed_objects.append(self.parse_object(obj_name, obj))\n elif 'items' in obj:\n parsed_objects.append(self.parse_array(obj_name, obj))\n\n return '\\n\\n\\n'.join(parsed_objects)\n", "path": "datamodel_code_generator/parser/openapi.py"}]}
| 1,681 | 359 |
gh_patches_debug_25820
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-537
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add tests for evaluation metrics reporting service
We previously added service to report evaluation metrics in #510. However, there isn't any test coverage for the added code yet. We should add some tests to cover `MasterServicer.ReportEvaluationMetrics`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/elasticdl/master/servicer.py`
Content:
```
1 import logging
2 import threading
3 import numpy as np
4
5 import tensorflow as tf
6
7 assert tf.executing_eagerly()
8
9 from google.protobuf import empty_pb2
10
11 from elasticdl.proto import elasticdl_pb2
12 from elasticdl.proto import elasticdl_pb2_grpc
13 from elasticdl.python.elasticdl.common.ndarray import ndarray_to_tensor, tensor_to_ndarray
14
15
16 class MasterServicer(elasticdl_pb2_grpc.MasterServicer):
17 """Master service implementation"""
18
19 def __init__(
20 self,
21 grads_to_wait,
22 minibatch_size,
23 optimizer,
24 task_q,
25 *,
26 init_var=[]
27 ):
28 # TODO: group params together into a single object.
29 self._logger = logging.getLogger(__name__)
30 self._opt = optimizer
31 self._task_q = task_q
32 self._lock = threading.Lock()
33 # A <string, tf.ResourceVariable> map. We use tf.ResourceVariable
34 # instead ndarray to avoid copying and conversion when calling
35 # optimizer's apply_gradients() function.
36 self._model = {}
37 self._version = 0
38 self._gradient_sum = {}
39 self._grad_to_wait = grads_to_wait
40 self._grad_n = 0
41 self._minibatch_size = minibatch_size
42 self._evaluation_metrics = {}
43 for var in init_var:
44 self.set_model_var(var.name, var.numpy())
45
46 def set_model_var(self, name, value):
47 """Add or set model variable. Value should be a float32 ndarray"""
48 if value.dtype != np.float32:
49 raise ValueError("Value should be a float32 numpy array")
50 self._model[name] = tf.Variable(
51 value, name=MasterServicer.var_name_encode(name)
52 )
53
54 @staticmethod
55 def var_name_encode(name):
56 return name.replace(":", "-")
57
58 def GetTask(self, request, _):
59 res = elasticdl_pb2.Task()
60 res.model_version = self._version
61 res.minibatch_size = self._minibatch_size
62 task_id, task = self._task_q.get(request.worker_id)
63 if task:
64 res.task_id = task_id
65 res.shard_file_name = task.file_name
66 res.start = task.start
67 res.end = task.end
68 return res
69
70 def GetModel(self, request, _):
71 _ = self._validate_model_version(request.min_version)
72
73 res = elasticdl_pb2.Model()
74 with self._lock:
75 res.version = self._version
76 for k, v in self._model.items():
77 res.param[k].CopyFrom(ndarray_to_tensor(v.numpy()))
78 return res
79
80 def _update_model(self):
81 assert self._lock.locked()
82 grad_var = []
83 for k in self._gradient_sum:
84 self._gradient_sum[k] = self._gradient_sum[k] / self._grad_to_wait
85 grad_var.append((self._gradient_sum[k], self._model[k]))
86 self._opt.apply_gradients(grad_var)
87 self._version += 1
88 self._gradient_sum.clear()
89 self._grad_n = 0
90
91 def _validate_model_version(self, request_model_version):
92 if request_model_version > self._version:
93 err_msg = "Model version %d not available yet, current version: %d" % (
94 request_model_version,
95 self._version,
96 )
97 self._logger.warning(err_msg)
98 raise ValueError(err_msg)
99
100 invalid_model_version = request_model_version < self._version
101 if invalid_model_version:
102 self._logger.warning(
103 "Task result for outdated version %d dropped",
104 request_model_version,
105 )
106 return invalid_model_version
107
108 def ReportGradient(self, request, _):
109 invalid_model_version = self._validate_model_version(request.model_version)
110
111 res = elasticdl_pb2.ReportGradientResponse()
112 if invalid_model_version:
113 res.accepted = False
114 res.model_version = self._version
115 return res
116
117 # TODO: Update task queue with task_id
118 with self._lock:
119 tmp = {}
120 # Do sanity check before accumulating gradients.
121 for k, v in request.gradient.items():
122 if k not in self._model:
123 raise ValueError(
124 "Gradient key: %s is not part of model", k
125 )
126 arr = tensor_to_ndarray(v)
127 if arr.shape != self._model[k].numpy().shape:
128 raise ValueError(
129 "Gradient key: %s has incompatible dimension", k
130 )
131 tmp[k] = arr
132
133 for k, v in tmp.items():
134 if k in self._gradient_sum:
135 self._gradient_sum[k] = self._gradient_sum[k] + v
136 else:
137 self._gradient_sum[k] = v
138
139 self._grad_n += 1
140 if self._grad_n >= self._grad_to_wait:
141 self._update_model()
142 res.accepted = True
143 res.model_version = self._version
144 return res
145
146 def ReportTaskResult(self, request, _):
147 if request.err_message:
148 self._logger.warning(
149 "Worker reported error: " + request.err_message
150 )
151 self._task_q.report(request.task_id, False)
152 else:
153 self._task_q.report(request.task_id, True)
154 return empty_pb2.Empty()
155
156 def ReportEvaluationMetrics(self, request, _):
157 invalid_model_version = self._validate_model_version(request.model_version)
158
159 res = elasticdl_pb2.ReportEvaluationMetricsResponse()
160 if invalid_model_version:
161 res.accepted = False
162 res.model_version = self._version
163 return res
164
165 with self._lock:
166 for k, v in request.evaluation_metrics.items():
167 arr = tensor_to_ndarray(v)
168 self._evaluation_metrics[k] = arr
169
170 self._update_model()
171 res.accepted = True
172 res.model_version = self._version
173 return res
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/elasticdl/master/servicer.py b/elasticdl/python/elasticdl/master/servicer.py
--- a/elasticdl/python/elasticdl/master/servicer.py
+++ b/elasticdl/python/elasticdl/master/servicer.py
@@ -77,6 +77,10 @@
res.param[k].CopyFrom(ndarray_to_tensor(v.numpy()))
return res
+ def _update_model_version(self):
+ assert self._lock.locked()
+ self._version += 1
+
def _update_model(self):
assert self._lock.locked()
grad_var = []
@@ -84,7 +88,7 @@
self._gradient_sum[k] = self._gradient_sum[k] / self._grad_to_wait
grad_var.append((self._gradient_sum[k], self._model[k]))
self._opt.apply_gradients(grad_var)
- self._version += 1
+ self._update_model_version()
self._gradient_sum.clear()
self._grad_n = 0
@@ -167,7 +171,7 @@
arr = tensor_to_ndarray(v)
self._evaluation_metrics[k] = arr
- self._update_model()
+ self._update_model_version()
res.accepted = True
res.model_version = self._version
return res
|
{"golden_diff": "diff --git a/elasticdl/python/elasticdl/master/servicer.py b/elasticdl/python/elasticdl/master/servicer.py\n--- a/elasticdl/python/elasticdl/master/servicer.py\n+++ b/elasticdl/python/elasticdl/master/servicer.py\n@@ -77,6 +77,10 @@\n res.param[k].CopyFrom(ndarray_to_tensor(v.numpy()))\n return res\n \n+ def _update_model_version(self):\n+ assert self._lock.locked()\n+ self._version += 1\n+\n def _update_model(self):\n assert self._lock.locked()\n grad_var = []\n@@ -84,7 +88,7 @@\n self._gradient_sum[k] = self._gradient_sum[k] / self._grad_to_wait\n grad_var.append((self._gradient_sum[k], self._model[k]))\n self._opt.apply_gradients(grad_var)\n- self._version += 1\n+ self._update_model_version()\n self._gradient_sum.clear()\n self._grad_n = 0\n \n@@ -167,7 +171,7 @@\n arr = tensor_to_ndarray(v)\n self._evaluation_metrics[k] = arr\n \n- self._update_model()\n+ self._update_model_version()\n res.accepted = True\n res.model_version = self._version\n return res\n", "issue": "Add tests for evaluation metrics reporting service\nWe previously added service to report evaluation metrics in #510. However, there isn't any test coverage for the added code yet. We should add some tests to cover `MasterServicer.ReportEvaluationMetrics`.\n", "before_files": [{"content": "import logging\nimport threading\nimport numpy as np\n\nimport tensorflow as tf\n\nassert tf.executing_eagerly()\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2\nfrom elasticdl.proto import elasticdl_pb2_grpc\nfrom elasticdl.python.elasticdl.common.ndarray import ndarray_to_tensor, tensor_to_ndarray\n\n\nclass MasterServicer(elasticdl_pb2_grpc.MasterServicer):\n \"\"\"Master service implementation\"\"\"\n\n def __init__(\n self,\n grads_to_wait,\n minibatch_size,\n optimizer,\n task_q,\n *,\n init_var=[]\n ):\n # TODO: group params together into a single object.\n self._logger = logging.getLogger(__name__)\n self._opt = optimizer\n self._task_q = task_q\n self._lock = threading.Lock()\n # A <string, tf.ResourceVariable> map. We use tf.ResourceVariable\n # instead ndarray to avoid copying and conversion when calling\n # optimizer's apply_gradients() function.\n self._model = {}\n self._version = 0\n self._gradient_sum = {}\n self._grad_to_wait = grads_to_wait\n self._grad_n = 0\n self._minibatch_size = minibatch_size\n self._evaluation_metrics = {}\n for var in init_var:\n self.set_model_var(var.name, var.numpy())\n\n def set_model_var(self, name, value):\n \"\"\"Add or set model variable. Value should be a float32 ndarray\"\"\"\n if value.dtype != np.float32:\n raise ValueError(\"Value should be a float32 numpy array\")\n self._model[name] = tf.Variable(\n value, name=MasterServicer.var_name_encode(name)\n )\n\n @staticmethod\n def var_name_encode(name):\n return name.replace(\":\", \"-\")\n\n def GetTask(self, request, _):\n res = elasticdl_pb2.Task()\n res.model_version = self._version\n res.minibatch_size = self._minibatch_size\n task_id, task = self._task_q.get(request.worker_id)\n if task:\n res.task_id = task_id\n res.shard_file_name = task.file_name\n res.start = task.start\n res.end = task.end\n return res\n\n def GetModel(self, request, _):\n _ = self._validate_model_version(request.min_version)\n\n res = elasticdl_pb2.Model()\n with self._lock:\n res.version = self._version\n for k, v in self._model.items():\n res.param[k].CopyFrom(ndarray_to_tensor(v.numpy()))\n return res\n\n def _update_model(self):\n assert self._lock.locked()\n grad_var = []\n for k in self._gradient_sum:\n self._gradient_sum[k] = self._gradient_sum[k] / self._grad_to_wait\n grad_var.append((self._gradient_sum[k], self._model[k]))\n self._opt.apply_gradients(grad_var)\n self._version += 1\n self._gradient_sum.clear()\n self._grad_n = 0\n\n def _validate_model_version(self, request_model_version):\n if request_model_version > self._version:\n err_msg = \"Model version %d not available yet, current version: %d\" % (\n request_model_version,\n self._version,\n )\n self._logger.warning(err_msg)\n raise ValueError(err_msg)\n\n invalid_model_version = request_model_version < self._version\n if invalid_model_version:\n self._logger.warning(\n \"Task result for outdated version %d dropped\",\n request_model_version,\n )\n return invalid_model_version\n\n def ReportGradient(self, request, _):\n invalid_model_version = self._validate_model_version(request.model_version)\n\n res = elasticdl_pb2.ReportGradientResponse()\n if invalid_model_version:\n res.accepted = False\n res.model_version = self._version\n return res\n\n # TODO: Update task queue with task_id\n with self._lock:\n tmp = {}\n # Do sanity check before accumulating gradients.\n for k, v in request.gradient.items():\n if k not in self._model:\n raise ValueError(\n \"Gradient key: %s is not part of model\", k\n )\n arr = tensor_to_ndarray(v)\n if arr.shape != self._model[k].numpy().shape:\n raise ValueError(\n \"Gradient key: %s has incompatible dimension\", k\n )\n tmp[k] = arr\n\n for k, v in tmp.items():\n if k in self._gradient_sum:\n self._gradient_sum[k] = self._gradient_sum[k] + v\n else:\n self._gradient_sum[k] = v\n\n self._grad_n += 1\n if self._grad_n >= self._grad_to_wait:\n self._update_model()\n res.accepted = True\n res.model_version = self._version\n return res\n\n def ReportTaskResult(self, request, _):\n if request.err_message:\n self._logger.warning(\n \"Worker reported error: \" + request.err_message\n )\n self._task_q.report(request.task_id, False)\n else:\n self._task_q.report(request.task_id, True)\n return empty_pb2.Empty()\n\n def ReportEvaluationMetrics(self, request, _):\n invalid_model_version = self._validate_model_version(request.model_version)\n\n res = elasticdl_pb2.ReportEvaluationMetricsResponse()\n if invalid_model_version:\n res.accepted = False\n res.model_version = self._version\n return res\n\n with self._lock:\n for k, v in request.evaluation_metrics.items():\n arr = tensor_to_ndarray(v)\n self._evaluation_metrics[k] = arr\n\n self._update_model()\n res.accepted = True\n res.model_version = self._version\n return res\n", "path": "elasticdl/python/elasticdl/master/servicer.py"}], "after_files": [{"content": "import logging\nimport threading\nimport numpy as np\n\nimport tensorflow as tf\n\nassert tf.executing_eagerly()\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2\nfrom elasticdl.proto import elasticdl_pb2_grpc\nfrom elasticdl.python.elasticdl.common.ndarray import ndarray_to_tensor, tensor_to_ndarray\n\n\nclass MasterServicer(elasticdl_pb2_grpc.MasterServicer):\n \"\"\"Master service implementation\"\"\"\n\n def __init__(\n self,\n grads_to_wait,\n minibatch_size,\n optimizer,\n task_q,\n *,\n init_var=[]\n ):\n # TODO: group params together into a single object.\n self._logger = logging.getLogger(__name__)\n self._opt = optimizer\n self._task_q = task_q\n self._lock = threading.Lock()\n # A <string, tf.ResourceVariable> map. We use tf.ResourceVariable\n # instead ndarray to avoid copying and conversion when calling\n # optimizer's apply_gradients() function.\n self._model = {}\n self._version = 0\n self._gradient_sum = {}\n self._grad_to_wait = grads_to_wait\n self._grad_n = 0\n self._minibatch_size = minibatch_size\n self._evaluation_metrics = {}\n for var in init_var:\n self.set_model_var(var.name, var.numpy())\n\n def set_model_var(self, name, value):\n \"\"\"Add or set model variable. Value should be a float32 ndarray\"\"\"\n if value.dtype != np.float32:\n raise ValueError(\"Value should be a float32 numpy array\")\n self._model[name] = tf.Variable(\n value, name=MasterServicer.var_name_encode(name)\n )\n\n @staticmethod\n def var_name_encode(name):\n return name.replace(\":\", \"-\")\n\n def GetTask(self, request, _):\n res = elasticdl_pb2.Task()\n res.model_version = self._version\n res.minibatch_size = self._minibatch_size\n task_id, task = self._task_q.get(request.worker_id)\n if task:\n res.task_id = task_id\n res.shard_file_name = task.file_name\n res.start = task.start\n res.end = task.end\n return res\n\n def GetModel(self, request, _):\n _ = self._validate_model_version(request.min_version)\n\n res = elasticdl_pb2.Model()\n with self._lock:\n res.version = self._version\n for k, v in self._model.items():\n res.param[k].CopyFrom(ndarray_to_tensor(v.numpy()))\n return res\n\n def _update_model_version(self):\n assert self._lock.locked()\n self._version += 1\n\n def _update_model(self):\n assert self._lock.locked()\n grad_var = []\n for k in self._gradient_sum:\n self._gradient_sum[k] = self._gradient_sum[k] / self._grad_to_wait\n grad_var.append((self._gradient_sum[k], self._model[k]))\n self._opt.apply_gradients(grad_var)\n self._update_model_version()\n self._gradient_sum.clear()\n self._grad_n = 0\n\n def _validate_model_version(self, request_model_version):\n if request_model_version > self._version:\n err_msg = \"Model version %d not available yet, current version: %d\" % (\n request_model_version,\n self._version,\n )\n self._logger.warning(err_msg)\n raise ValueError(err_msg)\n\n invalid_model_version = request_model_version < self._version\n if invalid_model_version:\n self._logger.warning(\n \"Task result for outdated version %d dropped\",\n request_model_version,\n )\n return invalid_model_version\n\n def ReportGradient(self, request, _):\n invalid_model_version = self._validate_model_version(request.model_version)\n\n res = elasticdl_pb2.ReportGradientResponse()\n if invalid_model_version:\n res.accepted = False\n res.model_version = self._version\n return res\n\n # TODO: Update task queue with task_id\n with self._lock:\n tmp = {}\n # Do sanity check before accumulating gradients.\n for k, v in request.gradient.items():\n if k not in self._model:\n raise ValueError(\n \"Gradient key: %s is not part of model\", k\n )\n arr = tensor_to_ndarray(v)\n if arr.shape != self._model[k].numpy().shape:\n raise ValueError(\n \"Gradient key: %s has incompatible dimension\", k\n )\n tmp[k] = arr\n\n for k, v in tmp.items():\n if k in self._gradient_sum:\n self._gradient_sum[k] = self._gradient_sum[k] + v\n else:\n self._gradient_sum[k] = v\n\n self._grad_n += 1\n if self._grad_n >= self._grad_to_wait:\n self._update_model()\n res.accepted = True\n res.model_version = self._version\n return res\n\n def ReportTaskResult(self, request, _):\n if request.err_message:\n self._logger.warning(\n \"Worker reported error: \" + request.err_message\n )\n self._task_q.report(request.task_id, False)\n else:\n self._task_q.report(request.task_id, True)\n return empty_pb2.Empty()\n\n def ReportEvaluationMetrics(self, request, _):\n invalid_model_version = self._validate_model_version(request.model_version)\n\n res = elasticdl_pb2.ReportEvaluationMetricsResponse()\n if invalid_model_version:\n res.accepted = False\n res.model_version = self._version\n return res\n\n with self._lock:\n for k, v in request.evaluation_metrics.items():\n arr = tensor_to_ndarray(v)\n self._evaluation_metrics[k] = arr\n\n self._update_model_version()\n res.accepted = True\n res.model_version = self._version\n return res\n", "path": "elasticdl/python/elasticdl/master/servicer.py"}]}
| 2,003 | 298 |
gh_patches_debug_14198
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-926
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add default field in test_annotation field of ChallengePhase model.
Please add `default=False` in the test_annotation field of ChallengePhase model.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/challenges/models.py`
Content:
```
1 from __future__ import unicode_literals
2
3 from django.utils import timezone
4 from django.contrib.postgres.fields import JSONField
5 from django.db import models
6
7 from base.models import (TimeStampedModel, )
8 from base.utils import RandomFileName
9 from participants.models import (ParticipantTeam, )
10
11
12 class Challenge(TimeStampedModel):
13
14 """Model representing a hosted Challenge"""
15 title = models.CharField(max_length=100)
16 short_description = models.TextField(null=True, blank=True)
17 description = models.TextField(null=True, blank=True)
18 terms_and_conditions = models.TextField(null=True, blank=True)
19 submission_guidelines = models.TextField(null=True, blank=True)
20 evaluation_details = models.TextField(null=True, blank=True)
21 image = models.ImageField(
22 upload_to='logos', null=True, blank=True, verbose_name="Logo")
23 start_date = models.DateTimeField(
24 null=True, blank=True, verbose_name="Start Date (UTC)")
25 end_date = models.DateTimeField(
26 null=True, blank=True, verbose_name="End Date (UTC)")
27 creator = models.ForeignKey(
28 'hosts.ChallengeHostTeam', related_name='challenge_creator')
29 published = models.BooleanField(
30 default=False, verbose_name="Publicly Available")
31 enable_forum = models.BooleanField(default=True)
32 anonymous_leaderboard = models.BooleanField(default=False)
33 participant_teams = models.ManyToManyField(ParticipantTeam, blank=True)
34 is_disabled = models.BooleanField(default=False)
35 evaluation_script = models.FileField(
36 default=False, upload_to=RandomFileName("evaluation_scripts")) # should be zip format
37 approved_by_admin = models.BooleanField(
38 default=False, verbose_name="Approved By Admin")
39
40 class Meta:
41 app_label = 'challenges'
42 db_table = 'challenge'
43
44 def __str__(self):
45 """Returns the title of Challenge"""
46 return self.title
47
48 def get_image_url(self):
49 """Returns the url of logo of Challenge"""
50 if self.image:
51 return self.image.url
52 return None
53
54 def get_evaluation_script_path(self):
55 """Returns the path of evaluation script"""
56 if self.evaluation_script:
57 return self.evaluation_script.url
58 return None
59
60 def get_start_date(self):
61 """Returns the start date of Challenge"""
62 return self.start_date
63
64 def get_end_date(self):
65 """Returns the end date of Challenge"""
66 return self.end_date
67
68 @property
69 def is_active(self):
70 """Returns if the challenge is active or not"""
71 if self.start_date < timezone.now() and self.end_date > timezone.now():
72 return True
73 return False
74
75
76 class DatasetSplit(TimeStampedModel):
77 name = models.CharField(max_length=100)
78 codename = models.CharField(max_length=100)
79
80 def __unicode__(self):
81 return self.name
82
83 class Meta:
84 app_label = 'challenges'
85 db_table = 'dataset_split'
86
87
88 class ChallengePhase(TimeStampedModel):
89
90 """Model representing a Challenge Phase"""
91 name = models.CharField(max_length=100)
92 description = models.TextField()
93 leaderboard_public = models.BooleanField(default=False)
94 start_date = models.DateTimeField(
95 null=True, blank=True, verbose_name="Start Date (UTC)")
96 end_date = models.DateTimeField(
97 null=True, blank=True, verbose_name="End Date (UTC)")
98 challenge = models.ForeignKey('Challenge')
99 is_public = models.BooleanField(default=False)
100 is_submission_public = models.BooleanField(default=False)
101 test_annotation = models.FileField(upload_to=RandomFileName("test_annotations"))
102 max_submissions_per_day = models.PositiveIntegerField(default=100000)
103 max_submissions = models.PositiveIntegerField(default=100000)
104 codename = models.CharField(max_length=100, default="Phase Code Name")
105 dataset_split = models.ManyToManyField(DatasetSplit, blank=True, through='ChallengePhaseSplit')
106
107 class Meta:
108 app_label = 'challenges'
109 db_table = 'challenge_phase'
110 unique_together = (('codename', 'challenge'),)
111
112 def __str__(self):
113 """Returns the name of Phase"""
114 return self.name
115
116 def get_start_date(self):
117 """Returns the start date of Phase"""
118 return self.start_date
119
120 def get_end_date(self):
121 """Returns the end date of Challenge"""
122 return self.end_date
123
124 @property
125 def is_active(self):
126 """Returns if the challenge is active or not"""
127 if self.start_date < timezone.now() and self.end_date > timezone.now():
128 return True
129 return False
130
131
132 class Leaderboard(TimeStampedModel):
133
134 schema = JSONField()
135
136 def __unicode__(self):
137 return "%s" % (self.id)
138
139 class Meta:
140 app_label = 'challenges'
141 db_table = 'leaderboard'
142
143
144 class ChallengePhaseSplit(TimeStampedModel):
145
146 # visibility options
147 HOST = 1
148 OWNER_AND_HOST = 2
149 PUBLIC = 3
150
151 VISIBILITY_OPTIONS = (
152 (HOST, 'host'),
153 (OWNER_AND_HOST, 'owner and host'),
154 (PUBLIC, 'public'),
155 )
156
157 challenge_phase = models.ForeignKey('ChallengePhase')
158 dataset_split = models.ForeignKey('DatasetSplit')
159 leaderboard = models.ForeignKey('Leaderboard')
160 visibility = models.PositiveSmallIntegerField(
161 choices=VISIBILITY_OPTIONS,
162 default=PUBLIC
163 )
164
165 def __unicode__(self):
166 return "%s : %s" % (self.challenge_phase.name, self.dataset_split.name)
167
168 class Meta:
169 app_label = 'challenges'
170 db_table = 'challenge_phase_split'
171
172
173 class LeaderboardData(TimeStampedModel):
174
175 challenge_phase_split = models.ForeignKey('ChallengePhaseSplit')
176 submission = models.ForeignKey('jobs.Submission')
177 leaderboard = models.ForeignKey('Leaderboard')
178 result = JSONField()
179
180 def __unicode__(self):
181 return "%s : %s" % (self.challenge_phase_split, self.submission)
182
183 class Meta:
184 app_label = 'challenges'
185 db_table = 'leaderboard_data'
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/challenges/models.py b/apps/challenges/models.py
--- a/apps/challenges/models.py
+++ b/apps/challenges/models.py
@@ -98,7 +98,7 @@
challenge = models.ForeignKey('Challenge')
is_public = models.BooleanField(default=False)
is_submission_public = models.BooleanField(default=False)
- test_annotation = models.FileField(upload_to=RandomFileName("test_annotations"))
+ test_annotation = models.FileField(upload_to=RandomFileName("test_annotations"), default=False)
max_submissions_per_day = models.PositiveIntegerField(default=100000)
max_submissions = models.PositiveIntegerField(default=100000)
codename = models.CharField(max_length=100, default="Phase Code Name")
|
{"golden_diff": "diff --git a/apps/challenges/models.py b/apps/challenges/models.py\n--- a/apps/challenges/models.py\n+++ b/apps/challenges/models.py\n@@ -98,7 +98,7 @@\n challenge = models.ForeignKey('Challenge')\n is_public = models.BooleanField(default=False)\n is_submission_public = models.BooleanField(default=False)\n- test_annotation = models.FileField(upload_to=RandomFileName(\"test_annotations\"))\n+ test_annotation = models.FileField(upload_to=RandomFileName(\"test_annotations\"), default=False)\n max_submissions_per_day = models.PositiveIntegerField(default=100000)\n max_submissions = models.PositiveIntegerField(default=100000)\n codename = models.CharField(max_length=100, default=\"Phase Code Name\")\n", "issue": "Add default field in test_annotation field of ChallengePhase model.\nPlease add `default=False` in the test_annotation field of ChallengePhase model.\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nfrom django.utils import timezone\nfrom django.contrib.postgres.fields import JSONField\nfrom django.db import models\n\nfrom base.models import (TimeStampedModel, )\nfrom base.utils import RandomFileName\nfrom participants.models import (ParticipantTeam, )\n\n\nclass Challenge(TimeStampedModel):\n\n \"\"\"Model representing a hosted Challenge\"\"\"\n title = models.CharField(max_length=100)\n short_description = models.TextField(null=True, blank=True)\n description = models.TextField(null=True, blank=True)\n terms_and_conditions = models.TextField(null=True, blank=True)\n submission_guidelines = models.TextField(null=True, blank=True)\n evaluation_details = models.TextField(null=True, blank=True)\n image = models.ImageField(\n upload_to='logos', null=True, blank=True, verbose_name=\"Logo\")\n start_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"Start Date (UTC)\")\n end_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"End Date (UTC)\")\n creator = models.ForeignKey(\n 'hosts.ChallengeHostTeam', related_name='challenge_creator')\n published = models.BooleanField(\n default=False, verbose_name=\"Publicly Available\")\n enable_forum = models.BooleanField(default=True)\n anonymous_leaderboard = models.BooleanField(default=False)\n participant_teams = models.ManyToManyField(ParticipantTeam, blank=True)\n is_disabled = models.BooleanField(default=False)\n evaluation_script = models.FileField(\n default=False, upload_to=RandomFileName(\"evaluation_scripts\")) # should be zip format\n approved_by_admin = models.BooleanField(\n default=False, verbose_name=\"Approved By Admin\")\n\n class Meta:\n app_label = 'challenges'\n db_table = 'challenge'\n\n def __str__(self):\n \"\"\"Returns the title of Challenge\"\"\"\n return self.title\n\n def get_image_url(self):\n \"\"\"Returns the url of logo of Challenge\"\"\"\n if self.image:\n return self.image.url\n return None\n\n def get_evaluation_script_path(self):\n \"\"\"Returns the path of evaluation script\"\"\"\n if self.evaluation_script:\n return self.evaluation_script.url\n return None\n\n def get_start_date(self):\n \"\"\"Returns the start date of Challenge\"\"\"\n return self.start_date\n\n def get_end_date(self):\n \"\"\"Returns the end date of Challenge\"\"\"\n return self.end_date\n\n @property\n def is_active(self):\n \"\"\"Returns if the challenge is active or not\"\"\"\n if self.start_date < timezone.now() and self.end_date > timezone.now():\n return True\n return False\n\n\nclass DatasetSplit(TimeStampedModel):\n name = models.CharField(max_length=100)\n codename = models.CharField(max_length=100)\n\n def __unicode__(self):\n return self.name\n\n class Meta:\n app_label = 'challenges'\n db_table = 'dataset_split'\n\n\nclass ChallengePhase(TimeStampedModel):\n\n \"\"\"Model representing a Challenge Phase\"\"\"\n name = models.CharField(max_length=100)\n description = models.TextField()\n leaderboard_public = models.BooleanField(default=False)\n start_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"Start Date (UTC)\")\n end_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"End Date (UTC)\")\n challenge = models.ForeignKey('Challenge')\n is_public = models.BooleanField(default=False)\n is_submission_public = models.BooleanField(default=False)\n test_annotation = models.FileField(upload_to=RandomFileName(\"test_annotations\"))\n max_submissions_per_day = models.PositiveIntegerField(default=100000)\n max_submissions = models.PositiveIntegerField(default=100000)\n codename = models.CharField(max_length=100, default=\"Phase Code Name\")\n dataset_split = models.ManyToManyField(DatasetSplit, blank=True, through='ChallengePhaseSplit')\n\n class Meta:\n app_label = 'challenges'\n db_table = 'challenge_phase'\n unique_together = (('codename', 'challenge'),)\n\n def __str__(self):\n \"\"\"Returns the name of Phase\"\"\"\n return self.name\n\n def get_start_date(self):\n \"\"\"Returns the start date of Phase\"\"\"\n return self.start_date\n\n def get_end_date(self):\n \"\"\"Returns the end date of Challenge\"\"\"\n return self.end_date\n\n @property\n def is_active(self):\n \"\"\"Returns if the challenge is active or not\"\"\"\n if self.start_date < timezone.now() and self.end_date > timezone.now():\n return True\n return False\n\n\nclass Leaderboard(TimeStampedModel):\n\n schema = JSONField()\n\n def __unicode__(self):\n return \"%s\" % (self.id)\n\n class Meta:\n app_label = 'challenges'\n db_table = 'leaderboard'\n\n\nclass ChallengePhaseSplit(TimeStampedModel):\n\n # visibility options\n HOST = 1\n OWNER_AND_HOST = 2\n PUBLIC = 3\n\n VISIBILITY_OPTIONS = (\n (HOST, 'host'),\n (OWNER_AND_HOST, 'owner and host'),\n (PUBLIC, 'public'),\n )\n\n challenge_phase = models.ForeignKey('ChallengePhase')\n dataset_split = models.ForeignKey('DatasetSplit')\n leaderboard = models.ForeignKey('Leaderboard')\n visibility = models.PositiveSmallIntegerField(\n choices=VISIBILITY_OPTIONS,\n default=PUBLIC\n )\n\n def __unicode__(self):\n return \"%s : %s\" % (self.challenge_phase.name, self.dataset_split.name)\n\n class Meta:\n app_label = 'challenges'\n db_table = 'challenge_phase_split'\n\n\nclass LeaderboardData(TimeStampedModel):\n\n challenge_phase_split = models.ForeignKey('ChallengePhaseSplit')\n submission = models.ForeignKey('jobs.Submission')\n leaderboard = models.ForeignKey('Leaderboard')\n result = JSONField()\n\n def __unicode__(self):\n return \"%s : %s\" % (self.challenge_phase_split, self.submission)\n\n class Meta:\n app_label = 'challenges'\n db_table = 'leaderboard_data'\n", "path": "apps/challenges/models.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nfrom django.utils import timezone\nfrom django.contrib.postgres.fields import JSONField\nfrom django.db import models\n\nfrom base.models import (TimeStampedModel, )\nfrom base.utils import RandomFileName\nfrom participants.models import (ParticipantTeam, )\n\n\nclass Challenge(TimeStampedModel):\n\n \"\"\"Model representing a hosted Challenge\"\"\"\n title = models.CharField(max_length=100)\n short_description = models.TextField(null=True, blank=True)\n description = models.TextField(null=True, blank=True)\n terms_and_conditions = models.TextField(null=True, blank=True)\n submission_guidelines = models.TextField(null=True, blank=True)\n evaluation_details = models.TextField(null=True, blank=True)\n image = models.ImageField(\n upload_to='logos', null=True, blank=True, verbose_name=\"Logo\")\n start_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"Start Date (UTC)\")\n end_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"End Date (UTC)\")\n creator = models.ForeignKey(\n 'hosts.ChallengeHostTeam', related_name='challenge_creator')\n published = models.BooleanField(\n default=False, verbose_name=\"Publicly Available\")\n enable_forum = models.BooleanField(default=True)\n anonymous_leaderboard = models.BooleanField(default=False)\n participant_teams = models.ManyToManyField(ParticipantTeam, blank=True)\n is_disabled = models.BooleanField(default=False)\n evaluation_script = models.FileField(\n default=False, upload_to=RandomFileName(\"evaluation_scripts\")) # should be zip format\n approved_by_admin = models.BooleanField(\n default=False, verbose_name=\"Approved By Admin\")\n\n class Meta:\n app_label = 'challenges'\n db_table = 'challenge'\n\n def __str__(self):\n \"\"\"Returns the title of Challenge\"\"\"\n return self.title\n\n def get_image_url(self):\n \"\"\"Returns the url of logo of Challenge\"\"\"\n if self.image:\n return self.image.url\n return None\n\n def get_evaluation_script_path(self):\n \"\"\"Returns the path of evaluation script\"\"\"\n if self.evaluation_script:\n return self.evaluation_script.url\n return None\n\n def get_start_date(self):\n \"\"\"Returns the start date of Challenge\"\"\"\n return self.start_date\n\n def get_end_date(self):\n \"\"\"Returns the end date of Challenge\"\"\"\n return self.end_date\n\n @property\n def is_active(self):\n \"\"\"Returns if the challenge is active or not\"\"\"\n if self.start_date < timezone.now() and self.end_date > timezone.now():\n return True\n return False\n\n\nclass DatasetSplit(TimeStampedModel):\n name = models.CharField(max_length=100)\n codename = models.CharField(max_length=100)\n\n def __unicode__(self):\n return self.name\n\n class Meta:\n app_label = 'challenges'\n db_table = 'dataset_split'\n\n\nclass ChallengePhase(TimeStampedModel):\n\n \"\"\"Model representing a Challenge Phase\"\"\"\n name = models.CharField(max_length=100)\n description = models.TextField()\n leaderboard_public = models.BooleanField(default=False)\n start_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"Start Date (UTC)\")\n end_date = models.DateTimeField(\n null=True, blank=True, verbose_name=\"End Date (UTC)\")\n challenge = models.ForeignKey('Challenge')\n is_public = models.BooleanField(default=False)\n is_submission_public = models.BooleanField(default=False)\n test_annotation = models.FileField(upload_to=RandomFileName(\"test_annotations\"), default=False)\n max_submissions_per_day = models.PositiveIntegerField(default=100000)\n max_submissions = models.PositiveIntegerField(default=100000)\n codename = models.CharField(max_length=100, default=\"Phase Code Name\")\n dataset_split = models.ManyToManyField(DatasetSplit, blank=True, through='ChallengePhaseSplit')\n\n class Meta:\n app_label = 'challenges'\n db_table = 'challenge_phase'\n unique_together = (('codename', 'challenge'),)\n\n def __str__(self):\n \"\"\"Returns the name of Phase\"\"\"\n return self.name\n\n def get_start_date(self):\n \"\"\"Returns the start date of Phase\"\"\"\n return self.start_date\n\n def get_end_date(self):\n \"\"\"Returns the end date of Challenge\"\"\"\n return self.end_date\n\n @property\n def is_active(self):\n \"\"\"Returns if the challenge is active or not\"\"\"\n if self.start_date < timezone.now() and self.end_date > timezone.now():\n return True\n return False\n\n\nclass Leaderboard(TimeStampedModel):\n\n schema = JSONField()\n\n def __unicode__(self):\n return \"%s\" % (self.id)\n\n class Meta:\n app_label = 'challenges'\n db_table = 'leaderboard'\n\n\nclass ChallengePhaseSplit(TimeStampedModel):\n\n # visibility options\n HOST = 1\n OWNER_AND_HOST = 2\n PUBLIC = 3\n\n VISIBILITY_OPTIONS = (\n (HOST, 'host'),\n (OWNER_AND_HOST, 'owner and host'),\n (PUBLIC, 'public'),\n )\n\n challenge_phase = models.ForeignKey('ChallengePhase')\n dataset_split = models.ForeignKey('DatasetSplit')\n leaderboard = models.ForeignKey('Leaderboard')\n visibility = models.PositiveSmallIntegerField(\n choices=VISIBILITY_OPTIONS,\n default=PUBLIC\n )\n\n def __unicode__(self):\n return \"%s : %s\" % (self.challenge_phase.name, self.dataset_split.name)\n\n class Meta:\n app_label = 'challenges'\n db_table = 'challenge_phase_split'\n\n\nclass LeaderboardData(TimeStampedModel):\n\n challenge_phase_split = models.ForeignKey('ChallengePhaseSplit')\n submission = models.ForeignKey('jobs.Submission')\n leaderboard = models.ForeignKey('Leaderboard')\n result = JSONField()\n\n def __unicode__(self):\n return \"%s : %s\" % (self.challenge_phase_split, self.submission)\n\n class Meta:\n app_label = 'challenges'\n db_table = 'leaderboard_data'\n", "path": "apps/challenges/models.py"}]}
| 2,031 | 163 |
gh_patches_debug_39482
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-1773
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] date/2.4.1: header_only option
Please add a header_only option to 'date' recipe.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/date/all/conanfile.py`
Content:
```
1 import os
2 from conans import ConanFile, CMake, tools
3
4
5 class DateConan(ConanFile):
6 name = "date"
7 url = "https://github.com/conan-io/conan-center-index"
8 homepage = "https://github.com/HowardHinnant/date"
9 description = "A date and time library based on the C++11/14/17 <chrono> header"
10 topics = ("date", "datetime", "timezone",
11 "calendar", "time", "iana-database")
12 license = "MIT"
13 exports_sources = ["patches/*", "CMakeLists.txt"]
14 settings = "os", "arch", "compiler", "build_type"
15 generators = "cmake",
16 options = {"shared": [True, False],
17 "fPIC": [True, False],
18 "use_system_tz_db": [True, False],
19 "use_tz_db_in_dot": [True, False]}
20 default_options = {"shared": False,
21 "fPIC": True,
22 "use_system_tz_db": False,
23 "use_tz_db_in_dot": False}
24
25 _cmake = None
26
27 @property
28 def _source_subfolder(self):
29 return "source_subfolder"
30 @property
31 def _build_subfolder(self):
32 return "build_subfolder"
33
34 def _configure_cmake(self):
35 if self._cmake:
36 return self._cmake
37 cmake = CMake(self)
38 cmake.definitions["ENABLE_DATE_TESTING"] = False
39 cmake.definitions["USE_SYSTEM_TZ_DB"] = self.options.use_system_tz_db
40 cmake.definitions["USE_TZ_DB_IN_DOT"] = self.options.use_tz_db_in_dot
41 cmake.configure()
42
43 self._cmake = cmake
44 return self._cmake
45
46 def config_options(self):
47 if self.settings.os == "Windows":
48 del self.options.fPIC
49
50 def configure(self):
51 if self.settings.compiler.cppstd:
52 tools.check_min_cppstd(self, "11")
53
54 def requirements(self):
55 if not self.options.use_system_tz_db:
56 self.requires("libcurl/7.69.1")
57
58 def source(self):
59 tools.get(**self.conan_data["sources"][self.version])
60 extracted_dir = self.name + "-" + self.version
61 os.rename(extracted_dir, self._source_subfolder)
62
63 def build(self):
64 for patch in self.conan_data["patches"][self.version]:
65 tools.patch(**patch)
66 cmake = self._configure_cmake()
67 cmake.build()
68
69 def package(self):
70 self.copy(pattern="LICENSE.txt", dst="licenses",
71 src=self._source_subfolder)
72 cmake = self._configure_cmake()
73 cmake.install()
74 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
75 tools.rmdir(os.path.join(self.package_folder, "CMake"))
76
77 def package_info(self):
78 self.cpp_info.libs = tools.collect_libs(self)
79 if self.settings.os == "Linux":
80 self.cpp_info.system_libs.append("pthread")
81
82 if self.options.use_system_tz_db and not self.settings.os == "Windows":
83 use_os_tzdb = 1
84 else:
85 use_os_tzdb = 0
86
87 defines = ["USE_OS_TZDB={}".format(use_os_tzdb)]
88 if self.settings.os == "Windows" and self.options.shared:
89 defines.append("DATE_USE_DLL=1")
90
91 self.cpp_info.defines.extend(defines)
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/date/all/conanfile.py b/recipes/date/all/conanfile.py
--- a/recipes/date/all/conanfile.py
+++ b/recipes/date/all/conanfile.py
@@ -15,10 +15,12 @@
generators = "cmake",
options = {"shared": [True, False],
"fPIC": [True, False],
+ "header_only": [True, False],
"use_system_tz_db": [True, False],
"use_tz_db_in_dot": [True, False]}
default_options = {"shared": False,
"fPIC": True,
+ "header_only": False,
"use_system_tz_db": False,
"use_tz_db_in_dot": False}
@@ -52,6 +54,8 @@
tools.check_min_cppstd(self, "11")
def requirements(self):
+ if self.options.header_only:
+ return
if not self.options.use_system_tz_db:
self.requires("libcurl/7.69.1")
@@ -63,18 +67,34 @@
def build(self):
for patch in self.conan_data["patches"][self.version]:
tools.patch(**patch)
+ if self.options.header_only:
+ self.output.info("Header only package, skipping build")
+ return
cmake = self._configure_cmake()
cmake.build()
def package(self):
self.copy(pattern="LICENSE.txt", dst="licenses",
src=self._source_subfolder)
+ if self.options.header_only:
+ src = os.path.join(self._source_subfolder, "include", "date")
+ dst = os.path.join("include", "date")
+ self.copy(pattern="date.h", dst=dst, src=src)
+ self.copy(pattern="tz.h", dst=dst, src=src)
+ self.copy(pattern="iso_week.h", dst=dst, src=src)
+ self.copy(pattern="julian.h", dst=dst, src=src)
+ self.copy(pattern="islamic.h", dst=dst, src=src)
+ return
+
cmake = self._configure_cmake()
cmake.install()
tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
tools.rmdir(os.path.join(self.package_folder, "CMake"))
def package_info(self):
+ if self.options.header_only:
+ return
+
self.cpp_info.libs = tools.collect_libs(self)
if self.settings.os == "Linux":
self.cpp_info.system_libs.append("pthread")
@@ -89,3 +109,7 @@
defines.append("DATE_USE_DLL=1")
self.cpp_info.defines.extend(defines)
+
+ def package_id(self):
+ if self.options.header_only:
+ self.info.header_only()
|
{"golden_diff": "diff --git a/recipes/date/all/conanfile.py b/recipes/date/all/conanfile.py\n--- a/recipes/date/all/conanfile.py\n+++ b/recipes/date/all/conanfile.py\n@@ -15,10 +15,12 @@\n generators = \"cmake\",\n options = {\"shared\": [True, False],\n \"fPIC\": [True, False],\n+ \"header_only\": [True, False],\n \"use_system_tz_db\": [True, False],\n \"use_tz_db_in_dot\": [True, False]}\n default_options = {\"shared\": False,\n \"fPIC\": True,\n+ \"header_only\": False,\n \"use_system_tz_db\": False,\n \"use_tz_db_in_dot\": False}\n \n@@ -52,6 +54,8 @@\n tools.check_min_cppstd(self, \"11\")\n \n def requirements(self):\n+ if self.options.header_only:\n+ return\n if not self.options.use_system_tz_db:\n self.requires(\"libcurl/7.69.1\")\n \n@@ -63,18 +67,34 @@\n def build(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n+ if self.options.header_only:\n+ self.output.info(\"Header only package, skipping build\")\n+ return\n cmake = self._configure_cmake()\n cmake.build()\n \n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\",\n src=self._source_subfolder)\n+ if self.options.header_only:\n+ src = os.path.join(self._source_subfolder, \"include\", \"date\")\n+ dst = os.path.join(\"include\", \"date\")\n+ self.copy(pattern=\"date.h\", dst=dst, src=src)\n+ self.copy(pattern=\"tz.h\", dst=dst, src=src)\n+ self.copy(pattern=\"iso_week.h\", dst=dst, src=src)\n+ self.copy(pattern=\"julian.h\", dst=dst, src=src)\n+ self.copy(pattern=\"islamic.h\", dst=dst, src=src)\n+ return\n+\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"CMake\"))\n \n def package_info(self):\n+ if self.options.header_only:\n+ return\n+\n self.cpp_info.libs = tools.collect_libs(self)\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n@@ -89,3 +109,7 @@\n defines.append(\"DATE_USE_DLL=1\")\n \n self.cpp_info.defines.extend(defines)\n+\n+ def package_id(self):\n+ if self.options.header_only:\n+ self.info.header_only()\n", "issue": "[package] date/2.4.1: header_only option\nPlease add a header_only option to 'date' recipe.\n", "before_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\n\n\nclass DateConan(ConanFile):\n name = \"date\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/HowardHinnant/date\"\n description = \"A date and time library based on the C++11/14/17 <chrono> header\"\n topics = (\"date\", \"datetime\", \"timezone\",\n \"calendar\", \"time\", \"iana-database\")\n license = \"MIT\"\n exports_sources = [\"patches/*\", \"CMakeLists.txt\"]\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n generators = \"cmake\",\n options = {\"shared\": [True, False],\n \"fPIC\": [True, False],\n \"use_system_tz_db\": [True, False],\n \"use_tz_db_in_dot\": [True, False]}\n default_options = {\"shared\": False,\n \"fPIC\": True,\n \"use_system_tz_db\": False,\n \"use_tz_db_in_dot\": False}\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n cmake = CMake(self)\n cmake.definitions[\"ENABLE_DATE_TESTING\"] = False\n cmake.definitions[\"USE_SYSTEM_TZ_DB\"] = self.options.use_system_tz_db\n cmake.definitions[\"USE_TZ_DB_IN_DOT\"] = self.options.use_tz_db_in_dot\n cmake.configure()\n\n self._cmake = cmake\n return self._cmake\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, \"11\")\n\n def requirements(self):\n if not self.options.use_system_tz_db:\n self.requires(\"libcurl/7.69.1\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def build(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\",\n src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"CMake\"))\n\n def package_info(self):\n self.cpp_info.libs = tools.collect_libs(self)\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n\n if self.options.use_system_tz_db and not self.settings.os == \"Windows\":\n use_os_tzdb = 1\n else:\n use_os_tzdb = 0\n\n defines = [\"USE_OS_TZDB={}\".format(use_os_tzdb)]\n if self.settings.os == \"Windows\" and self.options.shared:\n defines.append(\"DATE_USE_DLL=1\")\n\n self.cpp_info.defines.extend(defines)\n", "path": "recipes/date/all/conanfile.py"}], "after_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\n\n\nclass DateConan(ConanFile):\n name = \"date\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/HowardHinnant/date\"\n description = \"A date and time library based on the C++11/14/17 <chrono> header\"\n topics = (\"date\", \"datetime\", \"timezone\",\n \"calendar\", \"time\", \"iana-database\")\n license = \"MIT\"\n exports_sources = [\"patches/*\", \"CMakeLists.txt\"]\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n generators = \"cmake\",\n options = {\"shared\": [True, False],\n \"fPIC\": [True, False],\n \"header_only\": [True, False],\n \"use_system_tz_db\": [True, False],\n \"use_tz_db_in_dot\": [True, False]}\n default_options = {\"shared\": False,\n \"fPIC\": True,\n \"header_only\": False,\n \"use_system_tz_db\": False,\n \"use_tz_db_in_dot\": False}\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n cmake = CMake(self)\n cmake.definitions[\"ENABLE_DATE_TESTING\"] = False\n cmake.definitions[\"USE_SYSTEM_TZ_DB\"] = self.options.use_system_tz_db\n cmake.definitions[\"USE_TZ_DB_IN_DOT\"] = self.options.use_tz_db_in_dot\n cmake.configure()\n\n self._cmake = cmake\n return self._cmake\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, \"11\")\n\n def requirements(self):\n if self.options.header_only:\n return\n if not self.options.use_system_tz_db:\n self.requires(\"libcurl/7.69.1\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = self.name + \"-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def build(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n if self.options.header_only:\n self.output.info(\"Header only package, skipping build\")\n return\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE.txt\", dst=\"licenses\",\n src=self._source_subfolder)\n if self.options.header_only:\n src = os.path.join(self._source_subfolder, \"include\", \"date\")\n dst = os.path.join(\"include\", \"date\")\n self.copy(pattern=\"date.h\", dst=dst, src=src)\n self.copy(pattern=\"tz.h\", dst=dst, src=src)\n self.copy(pattern=\"iso_week.h\", dst=dst, src=src)\n self.copy(pattern=\"julian.h\", dst=dst, src=src)\n self.copy(pattern=\"islamic.h\", dst=dst, src=src)\n return\n\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"CMake\"))\n\n def package_info(self):\n if self.options.header_only:\n return\n\n self.cpp_info.libs = tools.collect_libs(self)\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.append(\"pthread\")\n\n if self.options.use_system_tz_db and not self.settings.os == \"Windows\":\n use_os_tzdb = 1\n else:\n use_os_tzdb = 0\n\n defines = [\"USE_OS_TZDB={}\".format(use_os_tzdb)]\n if self.settings.os == \"Windows\" and self.options.shared:\n defines.append(\"DATE_USE_DLL=1\")\n\n self.cpp_info.defines.extend(defines)\n\n def package_id(self):\n if self.options.header_only:\n self.info.header_only()\n", "path": "recipes/date/all/conanfile.py"}]}
| 1,228 | 630 |
gh_patches_debug_42660
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-2179
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[GHA] Better handling of environment variables and change detection
This should help reduce the number of times that Android AVD tests have to be run, along with consolidating some of the environment variable logic.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 from __future__ import print_function
3
4 import glob
5 import os
6 import platform
7 import subprocess
8 import sys
9 import traceback
10 from distutils.command.install import INSTALL_SCHEMES
11 from distutils.sysconfig import get_python_inc
12 from distutils.util import convert_path
13
14 from setuptools import find_packages
15 from setuptools import setup
16
17 # Get all template files
18 templates = []
19 for dirpath, dirnames, filenames in os.walk(convert_path('pwnlib/shellcraft/templates'), followlinks=True):
20 for f in filenames:
21 templates.append(os.path.relpath(os.path.join(dirpath, f), 'pwnlib'))
22
23 # This makes pwntools-LICENSE.txt appear with the package folders
24 for scheme in INSTALL_SCHEMES.values():
25 scheme['data'] = scheme['purelib']
26
27 console_scripts = ['pwn=pwnlib.commandline.main:main']
28
29 # Find all of the ancillary console scripts
30 # We have a magic flag --include-all-scripts
31 flag = '--only-use-pwn-command'
32 if flag in sys.argv:
33 sys.argv.remove(flag)
34 else:
35 flag = False
36
37 for filename in glob.glob('pwnlib/commandline/*'):
38 filename = os.path.basename(filename)
39 filename, ext = os.path.splitext(filename)
40
41 if ext != '.py' or '__init__' in filename:
42 continue
43
44 script = '%s=pwnlib.commandline.common:main' % filename
45 if not flag:
46 console_scripts.append(script)
47
48 install_requires = ['paramiko>=1.15.2',
49 'mako>=1.0.0',
50 'pyelftools>=0.2.4',
51 'capstone>=3.0.5rc2', # See Gallopsled/pwntools#971, Gallopsled/pwntools#1160
52 'ropgadget>=5.3',
53 'pyserial>=2.7',
54 'requests>=2.0',
55 'pip>=6.0.8',
56 'pygments>=2.0',
57 'pysocks',
58 'python-dateutil',
59 'packaging',
60 'psutil>=3.3.0',
61 'intervaltree>=3.0',
62 'sortedcontainers',
63 # see unicorn-engine/unicorn#1100 and #1170
64 'unicorn>=1.0.2rc1',
65 'six>=1.12.0',
66 'rpyc',
67 'colored_traceback',
68 ]
69
70 if platform.python_version_tuple()[0] == '2':
71 install_requires += ['pathlib2']
72
73 # Check that the user has installed the Python development headers
74 PythonH = os.path.join(get_python_inc(), 'Python.h')
75 if not os.path.exists(PythonH):
76 print("You must install the Python development headers!", file=sys.stderr)
77 print("$ apt-get install python-dev", file=sys.stderr)
78 sys.exit(-1)
79
80 # Convert README.md to reStructuredText for PyPI
81 long_description = ''
82 try:
83 long_description = subprocess.check_output(['pandoc', 'README.md', '--to=rst'], universal_newlines=True)
84 except Exception as e:
85 print("Failed to convert README.md through pandoc, proceeding anyway", file=sys.stderr)
86 traceback.print_exc()
87
88 setup(
89 name = 'pwntools',
90 python_requires = '>=2.7',
91 packages = find_packages(),
92 version = '4.11.0dev',
93 data_files = [('pwntools-doc',
94 glob.glob('*.md') + glob.glob('*.txt')),
95 ],
96 package_data = {
97 'pwnlib': [
98 'data/crcsums.txt',
99 'data/useragents/useragents.txt',
100 'data/binutils/*',
101 'data/includes/*.h',
102 'data/includes/*/*.h',
103 'data/templates/*.mako',
104 ] + templates,
105 },
106 entry_points = {'console_scripts': console_scripts},
107 scripts = glob.glob("bin/*"),
108 description = "Pwntools CTF framework and exploit development library.",
109 long_description = long_description,
110 author = "Gallopsled et al.",
111 author_email = "[email protected]",
112 url = 'https://pwntools.com',
113 download_url = "https://github.com/Gallopsled/pwntools/releases",
114 install_requires = install_requires,
115 license = "Mostly MIT, some GPL/BSD, see LICENSE-pwntools.txt",
116 keywords = 'pwntools exploit ctf capture the flag binary wargame overflow stack heap defcon',
117 classifiers = [
118 'Development Status :: 5 - Production/Stable',
119 'Environment :: Console',
120 'Intended Audience :: Developers',
121 'Intended Audience :: Science/Research',
122 'Intended Audience :: System Administrators',
123 'License :: OSI Approved :: MIT License',
124 'Natural Language :: English',
125 'Operating System :: POSIX :: Linux',
126 'Programming Language :: Python :: 2.7',
127 'Programming Language :: Python :: 3',
128 'Topic :: Security',
129 'Topic :: Software Development :: Assemblers',
130 'Topic :: Software Development :: Debuggers',
131 'Topic :: Software Development :: Disassemblers',
132 'Topic :: Software Development :: Embedded Systems',
133 'Topic :: Software Development :: Libraries :: Python Modules',
134 'Topic :: System :: System Shells',
135 'Topic :: Utilities',
136 ]
137 )
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -11,7 +11,6 @@
from distutils.sysconfig import get_python_inc
from distutils.util import convert_path
-from setuptools import find_packages
from setuptools import setup
# Get all template files
@@ -45,30 +44,12 @@
if not flag:
console_scripts.append(script)
-install_requires = ['paramiko>=1.15.2',
- 'mako>=1.0.0',
- 'pyelftools>=0.2.4',
- 'capstone>=3.0.5rc2', # See Gallopsled/pwntools#971, Gallopsled/pwntools#1160
- 'ropgadget>=5.3',
- 'pyserial>=2.7',
- 'requests>=2.0',
- 'pip>=6.0.8',
- 'pygments>=2.0',
- 'pysocks',
- 'python-dateutil',
- 'packaging',
- 'psutil>=3.3.0',
- 'intervaltree>=3.0',
- 'sortedcontainers',
- # see unicorn-engine/unicorn#1100 and #1170
- 'unicorn>=1.0.2rc1',
- 'six>=1.12.0',
- 'rpyc',
- 'colored_traceback',
-]
-
-if platform.python_version_tuple()[0] == '2':
- install_requires += ['pathlib2']
+compat = {}
+if sys.version_info < (3, 4):
+ import toml
+ project = toml.load('pyproject.toml')['project']
+ compat['install_requires'] = project['dependencies']
+ compat['name'] = project['name']
# Check that the user has installed the Python development headers
PythonH = os.path.join(get_python_inc(), 'Python.h')
@@ -77,18 +58,7 @@
print("$ apt-get install python-dev", file=sys.stderr)
sys.exit(-1)
-# Convert README.md to reStructuredText for PyPI
-long_description = ''
-try:
- long_description = subprocess.check_output(['pandoc', 'README.md', '--to=rst'], universal_newlines=True)
-except Exception as e:
- print("Failed to convert README.md through pandoc, proceeding anyway", file=sys.stderr)
- traceback.print_exc()
-
setup(
- name = 'pwntools',
- python_requires = '>=2.7',
- packages = find_packages(),
version = '4.11.0dev',
data_files = [('pwntools-doc',
glob.glob('*.md') + glob.glob('*.txt')),
@@ -105,33 +75,5 @@
},
entry_points = {'console_scripts': console_scripts},
scripts = glob.glob("bin/*"),
- description = "Pwntools CTF framework and exploit development library.",
- long_description = long_description,
- author = "Gallopsled et al.",
- author_email = "[email protected]",
- url = 'https://pwntools.com',
- download_url = "https://github.com/Gallopsled/pwntools/releases",
- install_requires = install_requires,
- license = "Mostly MIT, some GPL/BSD, see LICENSE-pwntools.txt",
- keywords = 'pwntools exploit ctf capture the flag binary wargame overflow stack heap defcon',
- classifiers = [
- 'Development Status :: 5 - Production/Stable',
- 'Environment :: Console',
- 'Intended Audience :: Developers',
- 'Intended Audience :: Science/Research',
- 'Intended Audience :: System Administrators',
- 'License :: OSI Approved :: MIT License',
- 'Natural Language :: English',
- 'Operating System :: POSIX :: Linux',
- 'Programming Language :: Python :: 2.7',
- 'Programming Language :: Python :: 3',
- 'Topic :: Security',
- 'Topic :: Software Development :: Assemblers',
- 'Topic :: Software Development :: Debuggers',
- 'Topic :: Software Development :: Disassemblers',
- 'Topic :: Software Development :: Embedded Systems',
- 'Topic :: Software Development :: Libraries :: Python Modules',
- 'Topic :: System :: System Shells',
- 'Topic :: Utilities',
- ]
+ **compat
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -11,7 +11,6 @@\n from distutils.sysconfig import get_python_inc\n from distutils.util import convert_path\n \n-from setuptools import find_packages\n from setuptools import setup\n \n # Get all template files\n@@ -45,30 +44,12 @@\n if not flag:\n console_scripts.append(script)\n \n-install_requires = ['paramiko>=1.15.2',\n- 'mako>=1.0.0',\n- 'pyelftools>=0.2.4',\n- 'capstone>=3.0.5rc2', # See Gallopsled/pwntools#971, Gallopsled/pwntools#1160\n- 'ropgadget>=5.3',\n- 'pyserial>=2.7',\n- 'requests>=2.0',\n- 'pip>=6.0.8',\n- 'pygments>=2.0',\n- 'pysocks',\n- 'python-dateutil',\n- 'packaging',\n- 'psutil>=3.3.0',\n- 'intervaltree>=3.0',\n- 'sortedcontainers',\n- # see unicorn-engine/unicorn#1100 and #1170\n- 'unicorn>=1.0.2rc1',\n- 'six>=1.12.0',\n- 'rpyc',\n- 'colored_traceback',\n-]\n-\n-if platform.python_version_tuple()[0] == '2':\n- install_requires += ['pathlib2']\n+compat = {}\n+if sys.version_info < (3, 4):\n+ import toml\n+ project = toml.load('pyproject.toml')['project']\n+ compat['install_requires'] = project['dependencies']\n+ compat['name'] = project['name']\n \n # Check that the user has installed the Python development headers\n PythonH = os.path.join(get_python_inc(), 'Python.h')\n@@ -77,18 +58,7 @@\n print(\"$ apt-get install python-dev\", file=sys.stderr)\n sys.exit(-1)\n \n-# Convert README.md to reStructuredText for PyPI\n-long_description = ''\n-try:\n- long_description = subprocess.check_output(['pandoc', 'README.md', '--to=rst'], universal_newlines=True)\n-except Exception as e:\n- print(\"Failed to convert README.md through pandoc, proceeding anyway\", file=sys.stderr)\n- traceback.print_exc()\n-\n setup(\n- name = 'pwntools',\n- python_requires = '>=2.7',\n- packages = find_packages(),\n version = '4.11.0dev',\n data_files = [('pwntools-doc',\n glob.glob('*.md') + glob.glob('*.txt')),\n@@ -105,33 +75,5 @@\n },\n entry_points = {'console_scripts': console_scripts},\n scripts = glob.glob(\"bin/*\"),\n- description = \"Pwntools CTF framework and exploit development library.\",\n- long_description = long_description,\n- author = \"Gallopsled et al.\",\n- author_email = \"[email protected]\",\n- url = 'https://pwntools.com',\n- download_url = \"https://github.com/Gallopsled/pwntools/releases\",\n- install_requires = install_requires,\n- license = \"Mostly MIT, some GPL/BSD, see LICENSE-pwntools.txt\",\n- keywords = 'pwntools exploit ctf capture the flag binary wargame overflow stack heap defcon',\n- classifiers = [\n- 'Development Status :: 5 - Production/Stable',\n- 'Environment :: Console',\n- 'Intended Audience :: Developers',\n- 'Intended Audience :: Science/Research',\n- 'Intended Audience :: System Administrators',\n- 'License :: OSI Approved :: MIT License',\n- 'Natural Language :: English',\n- 'Operating System :: POSIX :: Linux',\n- 'Programming Language :: Python :: 2.7',\n- 'Programming Language :: Python :: 3',\n- 'Topic :: Security',\n- 'Topic :: Software Development :: Assemblers',\n- 'Topic :: Software Development :: Debuggers',\n- 'Topic :: Software Development :: Disassemblers',\n- 'Topic :: Software Development :: Embedded Systems',\n- 'Topic :: Software Development :: Libraries :: Python Modules',\n- 'Topic :: System :: System Shells',\n- 'Topic :: Utilities',\n- ]\n+ **compat\n )\n", "issue": "[GHA] Better handling of environment variables and change detection\nThis should help reduce the number of times that Android AVD tests have to be run, along with consolidating some of the environment variable logic.\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import print_function\n\nimport glob\nimport os\nimport platform\nimport subprocess\nimport sys\nimport traceback\nfrom distutils.command.install import INSTALL_SCHEMES\nfrom distutils.sysconfig import get_python_inc\nfrom distutils.util import convert_path\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n# Get all template files\ntemplates = []\nfor dirpath, dirnames, filenames in os.walk(convert_path('pwnlib/shellcraft/templates'), followlinks=True):\n for f in filenames:\n templates.append(os.path.relpath(os.path.join(dirpath, f), 'pwnlib'))\n\n# This makes pwntools-LICENSE.txt appear with the package folders\nfor scheme in INSTALL_SCHEMES.values():\n scheme['data'] = scheme['purelib']\n\nconsole_scripts = ['pwn=pwnlib.commandline.main:main']\n\n# Find all of the ancillary console scripts\n# We have a magic flag --include-all-scripts\nflag = '--only-use-pwn-command'\nif flag in sys.argv:\n sys.argv.remove(flag)\nelse:\n flag = False\n\nfor filename in glob.glob('pwnlib/commandline/*'):\n filename = os.path.basename(filename)\n filename, ext = os.path.splitext(filename)\n\n if ext != '.py' or '__init__' in filename:\n continue\n\n script = '%s=pwnlib.commandline.common:main' % filename\n if not flag:\n console_scripts.append(script)\n\ninstall_requires = ['paramiko>=1.15.2',\n 'mako>=1.0.0',\n 'pyelftools>=0.2.4',\n 'capstone>=3.0.5rc2', # See Gallopsled/pwntools#971, Gallopsled/pwntools#1160\n 'ropgadget>=5.3',\n 'pyserial>=2.7',\n 'requests>=2.0',\n 'pip>=6.0.8',\n 'pygments>=2.0',\n 'pysocks',\n 'python-dateutil',\n 'packaging',\n 'psutil>=3.3.0',\n 'intervaltree>=3.0',\n 'sortedcontainers',\n # see unicorn-engine/unicorn#1100 and #1170\n 'unicorn>=1.0.2rc1',\n 'six>=1.12.0',\n 'rpyc',\n 'colored_traceback',\n]\n\nif platform.python_version_tuple()[0] == '2':\n install_requires += ['pathlib2']\n\n# Check that the user has installed the Python development headers\nPythonH = os.path.join(get_python_inc(), 'Python.h')\nif not os.path.exists(PythonH):\n print(\"You must install the Python development headers!\", file=sys.stderr)\n print(\"$ apt-get install python-dev\", file=sys.stderr)\n sys.exit(-1)\n\n# Convert README.md to reStructuredText for PyPI\nlong_description = ''\ntry:\n long_description = subprocess.check_output(['pandoc', 'README.md', '--to=rst'], universal_newlines=True)\nexcept Exception as e:\n print(\"Failed to convert README.md through pandoc, proceeding anyway\", file=sys.stderr)\n traceback.print_exc()\n\nsetup(\n name = 'pwntools',\n python_requires = '>=2.7',\n packages = find_packages(),\n version = '4.11.0dev',\n data_files = [('pwntools-doc',\n glob.glob('*.md') + glob.glob('*.txt')),\n ],\n package_data = {\n 'pwnlib': [\n 'data/crcsums.txt',\n 'data/useragents/useragents.txt',\n 'data/binutils/*',\n 'data/includes/*.h',\n 'data/includes/*/*.h',\n 'data/templates/*.mako',\n ] + templates,\n },\n entry_points = {'console_scripts': console_scripts},\n scripts = glob.glob(\"bin/*\"),\n description = \"Pwntools CTF framework and exploit development library.\",\n long_description = long_description,\n author = \"Gallopsled et al.\",\n author_email = \"[email protected]\",\n url = 'https://pwntools.com',\n download_url = \"https://github.com/Gallopsled/pwntools/releases\",\n install_requires = install_requires,\n license = \"Mostly MIT, some GPL/BSD, see LICENSE-pwntools.txt\",\n keywords = 'pwntools exploit ctf capture the flag binary wargame overflow stack heap defcon',\n classifiers = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Topic :: Security',\n 'Topic :: Software Development :: Assemblers',\n 'Topic :: Software Development :: Debuggers',\n 'Topic :: Software Development :: Disassemblers',\n 'Topic :: Software Development :: Embedded Systems',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: System :: System Shells',\n 'Topic :: Utilities',\n ]\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import print_function\n\nimport glob\nimport os\nimport platform\nimport subprocess\nimport sys\nimport traceback\nfrom distutils.command.install import INSTALL_SCHEMES\nfrom distutils.sysconfig import get_python_inc\nfrom distutils.util import convert_path\n\nfrom setuptools import setup\n\n# Get all template files\ntemplates = []\nfor dirpath, dirnames, filenames in os.walk(convert_path('pwnlib/shellcraft/templates'), followlinks=True):\n for f in filenames:\n templates.append(os.path.relpath(os.path.join(dirpath, f), 'pwnlib'))\n\n# This makes pwntools-LICENSE.txt appear with the package folders\nfor scheme in INSTALL_SCHEMES.values():\n scheme['data'] = scheme['purelib']\n\nconsole_scripts = ['pwn=pwnlib.commandline.main:main']\n\n# Find all of the ancillary console scripts\n# We have a magic flag --include-all-scripts\nflag = '--only-use-pwn-command'\nif flag in sys.argv:\n sys.argv.remove(flag)\nelse:\n flag = False\n\nfor filename in glob.glob('pwnlib/commandline/*'):\n filename = os.path.basename(filename)\n filename, ext = os.path.splitext(filename)\n\n if ext != '.py' or '__init__' in filename:\n continue\n\n script = '%s=pwnlib.commandline.common:main' % filename\n if not flag:\n console_scripts.append(script)\n\ncompat = {}\nif sys.version_info < (3, 4):\n import toml\n project = toml.load('pyproject.toml')['project']\n compat['install_requires'] = project['dependencies']\n compat['name'] = project['name']\n\n# Check that the user has installed the Python development headers\nPythonH = os.path.join(get_python_inc(), 'Python.h')\nif not os.path.exists(PythonH):\n print(\"You must install the Python development headers!\", file=sys.stderr)\n print(\"$ apt-get install python-dev\", file=sys.stderr)\n sys.exit(-1)\n\nsetup(\n version = '4.11.0dev',\n data_files = [('pwntools-doc',\n glob.glob('*.md') + glob.glob('*.txt')),\n ],\n package_data = {\n 'pwnlib': [\n 'data/crcsums.txt',\n 'data/useragents/useragents.txt',\n 'data/binutils/*',\n 'data/includes/*.h',\n 'data/includes/*/*.h',\n 'data/templates/*.mako',\n ] + templates,\n },\n entry_points = {'console_scripts': console_scripts},\n scripts = glob.glob(\"bin/*\"),\n **compat\n)\n", "path": "setup.py"}]}
| 1,790 | 1,019 |
gh_patches_debug_7814
|
rasdani/github-patches
|
git_diff
|
angr__angr-1703
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unlink simprocedure missing errno behavior
<!--
*Disclaimer:
The angr suite is maintained by a small team of volunteers.
While we cannot guarantee any timeliness for fixes and enhancements, we will do our best.
For more real-time help with angr, from us and the community, join our [Slack.](http://angr.io/invite/)*
-->
---
**Is your feature request related to a problem? Please describe.**
The unlink() function/syscall can set a diverse range of errno values. The simprocedure version of unlink doesn't model any of them, which causes incorrect execution of programs that use this interface.
The problem I'm specifically having is distinguishing failure because an existing file can't be removed, and failure because there is no file to remove.
**Describe the solution you would like.**
Add relevant errno assignments to the simprocedure. I'm not sure if the simfs function gives enough data to decide which error to return on failure, so its return might need to be augmented, as well.
**Please include a sample of what *should* work if this feature is implemented.**
Currently, the marked branch in the following C code is unreachable:
```
int my_remove() {
if(remove("/foo/bar")) {
if(ERRNO == ENOENT) {
//UNREACHABLE D:
return 0
}
return 1
}
return 0
}
```
**Describe alternatives you have considered.**
Forcing the simfs remove() operation to succeed would make my problem go away, but it doesn't solve the general issue that code reading the errno values after a failure won't work properly.
**Additional context.**
<!--
Add any other context or screenshots about the feature request here.
-->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `angr/procedures/linux_kernel/unlink.py`
Content:
```
1 import angr
2
3 ######################################
4 # unlink
5 ######################################
6
7 class unlink(angr.SimProcedure): #pylint:disable=W0622
8 #pylint:disable=arguments-differ
9
10 def run(self, path_addr):
11 # This is a dummy for now
12 strlen = angr.SIM_PROCEDURES['libc']['strlen']
13
14 p_strlen = self.inline_call(strlen, path_addr)
15 str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')
16 str_val = self.state.solver.eval(str_expr, cast_to=bytes)
17
18 if self.state.fs.delete(str_val):
19 return 0
20 else:
21 return -1
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/angr/procedures/linux_kernel/unlink.py b/angr/procedures/linux_kernel/unlink.py
--- a/angr/procedures/linux_kernel/unlink.py
+++ b/angr/procedures/linux_kernel/unlink.py
@@ -15,6 +15,10 @@
str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')
str_val = self.state.solver.eval(str_expr, cast_to=bytes)
+ # Check if entity exists before attempting to unlink
+ if not self.state.fs.get(str_val):
+ return self.state.libc.ret_errno('ENOENT')
+
if self.state.fs.delete(str_val):
return 0
else:
|
{"golden_diff": "diff --git a/angr/procedures/linux_kernel/unlink.py b/angr/procedures/linux_kernel/unlink.py\n--- a/angr/procedures/linux_kernel/unlink.py\n+++ b/angr/procedures/linux_kernel/unlink.py\n@@ -15,6 +15,10 @@\n str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')\n str_val = self.state.solver.eval(str_expr, cast_to=bytes)\n \n+ # Check if entity exists before attempting to unlink\n+ if not self.state.fs.get(str_val):\n+ return self.state.libc.ret_errno('ENOENT')\n+\n if self.state.fs.delete(str_val):\n return 0\n else:\n", "issue": "Unlink simprocedure missing errno behavior\n<!--\r\n*Disclaimer:\r\nThe angr suite is maintained by a small team of volunteers.\r\nWhile we cannot guarantee any timeliness for fixes and enhancements, we will do our best.\r\nFor more real-time help with angr, from us and the community, join our [Slack.](http://angr.io/invite/)*\r\n-->\r\n\r\n---\r\n\r\n**Is your feature request related to a problem? Please describe.**\r\nThe unlink() function/syscall can set a diverse range of errno values. The simprocedure version of unlink doesn't model any of them, which causes incorrect execution of programs that use this interface.\r\n\r\nThe problem I'm specifically having is distinguishing failure because an existing file can't be removed, and failure because there is no file to remove.\r\n\r\n**Describe the solution you would like.**\r\nAdd relevant errno assignments to the simprocedure. I'm not sure if the simfs function gives enough data to decide which error to return on failure, so its return might need to be augmented, as well.\r\n\r\n**Please include a sample of what *should* work if this feature is implemented.**\r\nCurrently, the marked branch in the following C code is unreachable:\r\n\r\n```\r\nint my_remove() {\r\n if(remove(\"/foo/bar\")) {\r\n if(ERRNO == ENOENT) {\r\n //UNREACHABLE D:\r\n return 0\r\n }\r\n return 1\r\n }\r\n return 0\r\n}\r\n```\r\n\r\n**Describe alternatives you have considered.**\r\nForcing the simfs remove() operation to succeed would make my problem go away, but it doesn't solve the general issue that code reading the errno values after a failure won't work properly.\r\n\r\n**Additional context.**\r\n<!--\r\nAdd any other context or screenshots about the feature request here.\r\n-->\r\n\n", "before_files": [{"content": "import angr\n\n######################################\n# unlink\n######################################\n\nclass unlink(angr.SimProcedure): #pylint:disable=W0622\n #pylint:disable=arguments-differ\n\n def run(self, path_addr):\n # This is a dummy for now\n strlen = angr.SIM_PROCEDURES['libc']['strlen']\n\n p_strlen = self.inline_call(strlen, path_addr)\n str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')\n str_val = self.state.solver.eval(str_expr, cast_to=bytes)\n\n if self.state.fs.delete(str_val):\n return 0\n else:\n return -1\n", "path": "angr/procedures/linux_kernel/unlink.py"}], "after_files": [{"content": "import angr\n\n######################################\n# unlink\n######################################\n\nclass unlink(angr.SimProcedure): #pylint:disable=W0622\n #pylint:disable=arguments-differ\n\n def run(self, path_addr):\n # This is a dummy for now\n strlen = angr.SIM_PROCEDURES['libc']['strlen']\n\n p_strlen = self.inline_call(strlen, path_addr)\n str_expr = self.state.memory.load(path_addr, p_strlen.max_null_index, endness='Iend_BE')\n str_val = self.state.solver.eval(str_expr, cast_to=bytes)\n\n # Check if entity exists before attempting to unlink\n if not self.state.fs.get(str_val):\n return self.state.libc.ret_errno('ENOENT')\n\n if self.state.fs.delete(str_val):\n return 0\n else:\n return -1\n", "path": "angr/procedures/linux_kernel/unlink.py"}]}
| 817 | 161 |
gh_patches_debug_38409
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-447
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Enhancement: Support dictConfig in picologging
`picologging` will implement a `dictConfig` with the following PR: https://github.com/microsoft/picologging/issues/53
We should enhance our integration to call this method once it's officially released.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlite/logging/__init__.py`
Content:
```
1 from logging import config
2 from typing import Any, Dict, List, Optional, Union
3
4 from pydantic import BaseModel
5 from typing_extensions import Literal
6
7 from starlite.logging.standard import QueueListenerHandler
8
9 __all__ = ["LoggingConfig", "QueueListenerHandler"]
10
11
12 class LoggingConfig(BaseModel):
13 """Convenience `pydantic` model for configuring logging.
14
15 For detailed instructions consult [standard library docs](https://docs.python.org/3/library/logging.config.html).
16 """
17
18 version: Literal[1] = 1
19 """The only valid value at present is 1."""
20 incremental: bool = False
21 """Whether the configuration is to be interpreted as incremental to the existing configuration. """
22 disable_existing_loggers: bool = False
23 """Whether any existing non-root loggers are to be disabled."""
24 filters: Optional[Dict[str, Dict[str, Any]]] = None
25 """A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance."""
26 propagate: bool = True
27 """If messages must propagate to handlers higher up the logger hierarchy from this logger."""
28 formatters: Dict[str, Dict[str, Any]] = {
29 "standard": {"format": "%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s"}
30 }
31 handlers: Dict[str, Dict[str, Any]] = {
32 "console": {
33 "class": "logging.StreamHandler",
34 "level": "DEBUG",
35 "formatter": "standard",
36 },
37 "queue_listener": {"class": "starlite.QueueListenerHandler", "handlers": ["cfg://handlers.console"]},
38 }
39 """A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance."""
40 loggers: Dict[str, Dict[str, Any]] = {
41 "starlite": {
42 "level": "INFO",
43 "handlers": ["queue_listener"],
44 },
45 }
46 """A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance."""
47 root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {"handlers": ["queue_listener"], "level": "INFO"}
48 """This will be the configuration for the root logger. Processing of the configuration will be as for any logger,
49 except that the propagate setting will not be applicable."""
50
51 def configure(self) -> None:
52 """Configured logger with the given configuration."""
53 config.dictConfig(self.dict(exclude_none=True))
54
```
Path: `starlite/logging/picologging.py`
Content:
```
1 from queue import Queue
2 from typing import Any, List
3
4 from picologging.handlers import QueueHandler, QueueListener
5
6 from starlite.logging.standard import resolve_handlers
7
8
9 class QueueListenerHandler(QueueHandler): # type: ignore
10 def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):
11 """Configures queue listener and handler to support non-blocking
12 logging configuration.
13
14 Requires `picologging`, install with:
15 ```shell
16 $ pip install starlite[picologging]
17 ```
18
19 Args:
20 handlers (list): list of handler names.
21 respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
22 deciding whether to pass messages to that handler.
23 """
24 super().__init__(queue)
25 self.handlers = resolve_handlers(handlers)
26 self._listener: QueueListener = QueueListener(
27 self.queue, *self.handlers, respect_handler_level=respect_handler_level
28 )
29 self._listener.start()
30
```
Path: `starlite/logging/standard.py`
Content:
```
1 from logging.handlers import QueueHandler, QueueListener
2 from queue import Queue
3 from typing import Any, List
4
5
6 class QueueListenerHandler(QueueHandler):
7 """Configures queue listener and handler to support non-blocking logging
8 configuration."""
9
10 def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):
11 """Configures queue listener and handler to support non-blocking
12 logging configuration.
13
14 Args:
15 handlers (list): list of handler names.
16 respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
17 deciding whether to pass messages to that handler.
18 """
19 super().__init__(queue)
20 self.handlers = resolve_handlers(handlers)
21 self._listener: QueueListener = QueueListener(
22 self.queue, *self.handlers, respect_handler_level=respect_handler_level
23 )
24 self._listener.start()
25
26
27 def resolve_handlers(handlers: List[Any]) -> List[Any]:
28 """Converts list of string of handlers to the object of respective handler.
29
30 Indexing the list performs the evaluation of the object.
31 """
32 return [handlers[i] for i in range(len(handlers))]
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/starlite/logging/__init__.py b/starlite/logging/__init__.py
--- a/starlite/logging/__init__.py
+++ b/starlite/logging/__init__.py
@@ -1,11 +1,16 @@
from logging import config
-from typing import Any, Dict, List, Optional, Union
+from typing import Any, Dict, Generator, Iterable, List, Optional, Union
from pydantic import BaseModel
from typing_extensions import Literal
from starlite.logging.standard import QueueListenerHandler
+try:
+ from picologging import config as picologging_config
+except ImportError:
+ picologging_config = None
+
__all__ = ["LoggingConfig", "QueueListenerHandler"]
@@ -49,5 +54,33 @@
except that the propagate setting will not be applicable."""
def configure(self) -> None:
- """Configured logger with the given configuration."""
+ """Configured logger with the given configuration.
+
+ If the logger class contains the word `picologging`, we try to
+ import and set the dictConfig
+ """
+ for logging_class in find_keys(self.handlers, "class"):
+ if "picologging" in logging_class and picologging_config:
+ picologging_config.dictConfig(self.dict(exclude_none=True))
+ break
config.dictConfig(self.dict(exclude_none=True))
+
+
+def find_keys(node: Union[List, Dict], key: str) -> Generator[Iterable, None, None]:
+ """Find Nested Keys with name
+ Search a dictionary for the presence of key
+ Args:
+ node (Union[List, Dict]): a dictionary to search
+ key (str): the dictionary key to find
+
+ Yields:
+ Generator[Iterable, None, None]: Value of dictionary key
+ """
+ if isinstance(node, list):
+ for list_entry in node:
+ yield from find_keys(list_entry, key)
+ elif isinstance(node, dict):
+ if key in node:
+ yield node[key]
+ for dict_entry in node.values():
+ yield from find_keys(dict_entry, key)
diff --git a/starlite/logging/picologging.py b/starlite/logging/picologging.py
--- a/starlite/logging/picologging.py
+++ b/starlite/logging/picologging.py
@@ -18,7 +18,7 @@
Args:
handlers (list): list of handler names.
- respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when
deciding whether to pass messages to that handler.
"""
super().__init__(queue)
diff --git a/starlite/logging/standard.py b/starlite/logging/standard.py
--- a/starlite/logging/standard.py
+++ b/starlite/logging/standard.py
@@ -13,7 +13,7 @@
Args:
handlers (list): list of handler names.
- respect_handler_level (bool): A handler’s level is respected (compared with the level for the message) when
+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when
deciding whether to pass messages to that handler.
"""
super().__init__(queue)
|
{"golden_diff": "diff --git a/starlite/logging/__init__.py b/starlite/logging/__init__.py\n--- a/starlite/logging/__init__.py\n+++ b/starlite/logging/__init__.py\n@@ -1,11 +1,16 @@\n from logging import config\n-from typing import Any, Dict, List, Optional, Union\n+from typing import Any, Dict, Generator, Iterable, List, Optional, Union\n \n from pydantic import BaseModel\n from typing_extensions import Literal\n \n from starlite.logging.standard import QueueListenerHandler\n \n+try:\n+ from picologging import config as picologging_config\n+except ImportError:\n+ picologging_config = None\n+\n __all__ = [\"LoggingConfig\", \"QueueListenerHandler\"]\n \n \n@@ -49,5 +54,33 @@\n except that the propagate setting will not be applicable.\"\"\"\n \n def configure(self) -> None:\n- \"\"\"Configured logger with the given configuration.\"\"\"\n+ \"\"\"Configured logger with the given configuration.\n+\n+ If the logger class contains the word `picologging`, we try to\n+ import and set the dictConfig\n+ \"\"\"\n+ for logging_class in find_keys(self.handlers, \"class\"):\n+ if \"picologging\" in logging_class and picologging_config:\n+ picologging_config.dictConfig(self.dict(exclude_none=True))\n+ break\n config.dictConfig(self.dict(exclude_none=True))\n+\n+\n+def find_keys(node: Union[List, Dict], key: str) -> Generator[Iterable, None, None]:\n+ \"\"\"Find Nested Keys with name\n+ Search a dictionary for the presence of key\n+ Args:\n+ node (Union[List, Dict]): a dictionary to search\n+ key (str): the dictionary key to find\n+\n+ Yields:\n+ Generator[Iterable, None, None]: Value of dictionary key\n+ \"\"\"\n+ if isinstance(node, list):\n+ for list_entry in node:\n+ yield from find_keys(list_entry, key)\n+ elif isinstance(node, dict):\n+ if key in node:\n+ yield node[key]\n+ for dict_entry in node.values():\n+ yield from find_keys(dict_entry, key)\ndiff --git a/starlite/logging/picologging.py b/starlite/logging/picologging.py\n--- a/starlite/logging/picologging.py\n+++ b/starlite/logging/picologging.py\n@@ -18,7 +18,7 @@\n \n Args:\n handlers (list): list of handler names.\n- respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\ndiff --git a/starlite/logging/standard.py b/starlite/logging/standard.py\n--- a/starlite/logging/standard.py\n+++ b/starlite/logging/standard.py\n@@ -13,7 +13,7 @@\n \n Args:\n handlers (list): list of handler names.\n- respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n+ respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n", "issue": "Enhancement: Support dictConfig in picologging\n`picologging` will implement a `dictConfig` with the following PR: https://github.com/microsoft/picologging/issues/53\r\n\r\nWe should enhance our integration to call this method once it's officially released.\r\n\n", "before_files": [{"content": "from logging import config\nfrom typing import Any, Dict, List, Optional, Union\n\nfrom pydantic import BaseModel\nfrom typing_extensions import Literal\n\nfrom starlite.logging.standard import QueueListenerHandler\n\n__all__ = [\"LoggingConfig\", \"QueueListenerHandler\"]\n\n\nclass LoggingConfig(BaseModel):\n \"\"\"Convenience `pydantic` model for configuring logging.\n\n For detailed instructions consult [standard library docs](https://docs.python.org/3/library/logging.config.html).\n \"\"\"\n\n version: Literal[1] = 1\n \"\"\"The only valid value at present is 1.\"\"\"\n incremental: bool = False\n \"\"\"Whether the configuration is to be interpreted as incremental to the existing configuration. \"\"\"\n disable_existing_loggers: bool = False\n \"\"\"Whether any existing non-root loggers are to be disabled.\"\"\"\n filters: Optional[Dict[str, Dict[str, Any]]] = None\n \"\"\"A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance.\"\"\"\n propagate: bool = True\n \"\"\"If messages must propagate to handlers higher up the logger hierarchy from this logger.\"\"\"\n formatters: Dict[str, Dict[str, Any]] = {\n \"standard\": {\"format\": \"%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s\"}\n }\n handlers: Dict[str, Dict[str, Any]] = {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n \"queue_listener\": {\"class\": \"starlite.QueueListenerHandler\", \"handlers\": [\"cfg://handlers.console\"]},\n }\n \"\"\"A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance.\"\"\"\n loggers: Dict[str, Dict[str, Any]] = {\n \"starlite\": {\n \"level\": \"INFO\",\n \"handlers\": [\"queue_listener\"],\n },\n }\n \"\"\"A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance.\"\"\"\n root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {\"handlers\": [\"queue_listener\"], \"level\": \"INFO\"}\n \"\"\"This will be the configuration for the root logger. Processing of the configuration will be as for any logger,\n except that the propagate setting will not be applicable.\"\"\"\n\n def configure(self) -> None:\n \"\"\"Configured logger with the given configuration.\"\"\"\n config.dictConfig(self.dict(exclude_none=True))\n", "path": "starlite/logging/__init__.py"}, {"content": "from queue import Queue\nfrom typing import Any, List\n\nfrom picologging.handlers import QueueHandler, QueueListener\n\nfrom starlite.logging.standard import resolve_handlers\n\n\nclass QueueListenerHandler(QueueHandler): # type: ignore\n def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Requires `picologging`, install with:\n ```shell\n $ pip install starlite[picologging]\n ```\n\n Args:\n handlers (list): list of handler names.\n respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n self.handlers = resolve_handlers(handlers)\n self._listener: QueueListener = QueueListener(\n self.queue, *self.handlers, respect_handler_level=respect_handler_level\n )\n self._listener.start()\n", "path": "starlite/logging/picologging.py"}, {"content": "from logging.handlers import QueueHandler, QueueListener\nfrom queue import Queue\nfrom typing import Any, List\n\n\nclass QueueListenerHandler(QueueHandler):\n \"\"\"Configures queue listener and handler to support non-blocking logging\n configuration.\"\"\"\n\n def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Args:\n handlers (list): list of handler names.\n respect_handler_level (bool): A handler\u2019s level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n self.handlers = resolve_handlers(handlers)\n self._listener: QueueListener = QueueListener(\n self.queue, *self.handlers, respect_handler_level=respect_handler_level\n )\n self._listener.start()\n\n\ndef resolve_handlers(handlers: List[Any]) -> List[Any]:\n \"\"\"Converts list of string of handlers to the object of respective handler.\n\n Indexing the list performs the evaluation of the object.\n \"\"\"\n return [handlers[i] for i in range(len(handlers))]\n", "path": "starlite/logging/standard.py"}], "after_files": [{"content": "from logging import config\nfrom typing import Any, Dict, Generator, Iterable, List, Optional, Union\n\nfrom pydantic import BaseModel\nfrom typing_extensions import Literal\n\nfrom starlite.logging.standard import QueueListenerHandler\n\ntry:\n from picologging import config as picologging_config\nexcept ImportError:\n picologging_config = None\n\n__all__ = [\"LoggingConfig\", \"QueueListenerHandler\"]\n\n\nclass LoggingConfig(BaseModel):\n \"\"\"Convenience `pydantic` model for configuring logging.\n\n For detailed instructions consult [standard library docs](https://docs.python.org/3/library/logging.config.html).\n \"\"\"\n\n version: Literal[1] = 1\n \"\"\"The only valid value at present is 1.\"\"\"\n incremental: bool = False\n \"\"\"Whether the configuration is to be interpreted as incremental to the existing configuration. \"\"\"\n disable_existing_loggers: bool = False\n \"\"\"Whether any existing non-root loggers are to be disabled.\"\"\"\n filters: Optional[Dict[str, Dict[str, Any]]] = None\n \"\"\"A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance.\"\"\"\n propagate: bool = True\n \"\"\"If messages must propagate to handlers higher up the logger hierarchy from this logger.\"\"\"\n formatters: Dict[str, Dict[str, Any]] = {\n \"standard\": {\"format\": \"%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s\"}\n }\n handlers: Dict[str, Dict[str, Any]] = {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n \"queue_listener\": {\"class\": \"starlite.QueueListenerHandler\", \"handlers\": [\"cfg://handlers.console\"]},\n }\n \"\"\"A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance.\"\"\"\n loggers: Dict[str, Dict[str, Any]] = {\n \"starlite\": {\n \"level\": \"INFO\",\n \"handlers\": [\"queue_listener\"],\n },\n }\n \"\"\"A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance.\"\"\"\n root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {\"handlers\": [\"queue_listener\"], \"level\": \"INFO\"}\n \"\"\"This will be the configuration for the root logger. Processing of the configuration will be as for any logger,\n except that the propagate setting will not be applicable.\"\"\"\n\n def configure(self) -> None:\n \"\"\"Configured logger with the given configuration.\n\n If the logger class contains the word `picologging`, we try to\n import and set the dictConfig\n \"\"\"\n for logging_class in find_keys(self.handlers, \"class\"):\n if \"picologging\" in logging_class and picologging_config:\n picologging_config.dictConfig(self.dict(exclude_none=True))\n break\n config.dictConfig(self.dict(exclude_none=True))\n\n\ndef find_keys(node: Union[List, Dict], key: str) -> Generator[Iterable, None, None]:\n \"\"\"Find Nested Keys with name\n Search a dictionary for the presence of key\n Args:\n node (Union[List, Dict]): a dictionary to search\n key (str): the dictionary key to find\n\n Yields:\n Generator[Iterable, None, None]: Value of dictionary key\n \"\"\"\n if isinstance(node, list):\n for list_entry in node:\n yield from find_keys(list_entry, key)\n elif isinstance(node, dict):\n if key in node:\n yield node[key]\n for dict_entry in node.values():\n yield from find_keys(dict_entry, key)\n", "path": "starlite/logging/__init__.py"}, {"content": "from queue import Queue\nfrom typing import Any, List\n\nfrom picologging.handlers import QueueHandler, QueueListener\n\nfrom starlite.logging.standard import resolve_handlers\n\n\nclass QueueListenerHandler(QueueHandler): # type: ignore\n def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Requires `picologging`, install with:\n ```shell\n $ pip install starlite[picologging]\n ```\n\n Args:\n handlers (list): list of handler names.\n respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n self.handlers = resolve_handlers(handlers)\n self._listener: QueueListener = QueueListener(\n self.queue, *self.handlers, respect_handler_level=respect_handler_level\n )\n self._listener.start()\n", "path": "starlite/logging/picologging.py"}, {"content": "from logging.handlers import QueueHandler, QueueListener\nfrom queue import Queue\nfrom typing import Any, List\n\n\nclass QueueListenerHandler(QueueHandler):\n \"\"\"Configures queue listener and handler to support non-blocking logging\n configuration.\"\"\"\n\n def __init__(self, handlers: List[Any], respect_handler_level: bool = False, queue: Queue = Queue(-1)):\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Args:\n handlers (list): list of handler names.\n respect_handler_level (bool): A handler's level is respected (compared with the level for the message) when\n deciding whether to pass messages to that handler.\n \"\"\"\n super().__init__(queue)\n self.handlers = resolve_handlers(handlers)\n self._listener: QueueListener = QueueListener(\n self.queue, *self.handlers, respect_handler_level=respect_handler_level\n )\n self._listener.start()\n\n\ndef resolve_handlers(handlers: List[Any]) -> List[Any]:\n \"\"\"Converts list of string of handlers to the object of respective handler.\n\n Indexing the list performs the evaluation of the object.\n \"\"\"\n return [handlers[i] for i in range(len(handlers))]\n", "path": "starlite/logging/standard.py"}]}
| 1,594 | 745 |
gh_patches_debug_61002
|
rasdani/github-patches
|
git_diff
|
ourownstory__neural_prophet-1254
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Static Trend does not follow required forecasting pattern
**Source Code:**
```
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level, set_random_seed
set_log_level("ERROR")
data_location = "https://raw.githubusercontent.com/ourownstory/neuralprophet-data/main/datasets/"
file = "energy/SF_hospital_load.csv"
data_df = pd.read_csv(data_location + file)
m = NeuralProphet()
train_df, test_df = m.split_df(data_df, freq="H", valid_p=1.0 / 5)
quantile_lo, quantile_hi = 0.05, 0.95
quantiles = [quantile_lo, quantile_hi]
n_lags = 3 * 24
n_forecasts = 24
m = NeuralProphet(
growth="off",
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
n_forecasts = n_forecasts,
n_lags=n_lags,
ar_reg=1,
learning_rate=0.01,
quantiles=quantiles,
)
random_seed = 0
set_random_seed(random_seed)
metrics = m.fit(train_df, freq="H")
forecast = m.predict(test_df)
```
**Error:**
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [1], in <cell line: 34>()
31 metrics = m.fit(train_df, freq="H")
32 metrics.tail(1)
---> 34 forecast = m.predict(test_df)
File ~.../neuralprophet/forecaster.py:940, in NeuralProphet.predict(self, df, decompose, raw)
938 fcst = fcst[:-1]
939 else:
--> 940 fcst = self._reshape_raw_predictions_to_forecst_df(df_i, predicted, components)
941 if periods_added[df_name] > 0:
942 fcst = fcst[: -periods_added[df_name]]
File ~.../neuralprophet/forecaster.py:3169, in NeuralProphet._reshape_raw_predictions_to_forecst_df(self, df, predicted, components)
3167 for j in range(len(self.config_train.quantiles)):
3168 forecast_0 = components[comp][0, :, j]
-> 3169 forecast_rest = components[comp][1:, self.n_forecasts - 1, j]
3170 yhat = np.concatenate(([np.NaN] * self.max_lags, forecast_0, forecast_rest))
3171 if j == 0: # temporary condition to add only the median component
3172 # add yhat into dataframe, using df_forecast indexing
IndexError: index 23 is out of bounds for axis 1 with size 1
```
Is it because I used the empty `m = NeuralProphet()` to split to data to train/test?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `neuralprophet/components/trend/static.py`
Content:
```
1 from neuralprophet.components.trend import Trend
2
3
4 class StaticTrend(Trend):
5 def __init__(self, config, id_list, quantiles, num_trends_modelled, n_forecasts, device):
6 super().__init__(
7 config=config,
8 n_forecasts=n_forecasts,
9 num_trends_modelled=num_trends_modelled,
10 quantiles=quantiles,
11 id_list=id_list,
12 device=device,
13 )
14
15 def forward(self, t, meta):
16 """
17 Computes trend based on model configuration.
18
19 Parameters
20 ----------
21 t : torch.Tensor float
22 normalized time, dim: (batch, n_forecasts)
23 meta: dict
24 Metadata about the all the samples of the model input batch. Contains the following:
25 * ``df_name`` (list, str), time series ID corresponding to each sample of the input batch.
26 Returns
27 -------
28 torch.Tensor
29 Trend component, same dimensions as input t
30 """
31 return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)
32
33 @property
34 def get_trend_deltas(self):
35 pass
36
37 def add_regularization(self):
38 pass
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/neuralprophet/components/trend/static.py b/neuralprophet/components/trend/static.py
--- a/neuralprophet/components/trend/static.py
+++ b/neuralprophet/components/trend/static.py
@@ -28,7 +28,7 @@
torch.Tensor
Trend component, same dimensions as input t
"""
- return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)
+ return self.bias.unsqueeze(dim=0).repeat(t.shape[0], self.n_forecasts, 1)
@property
def get_trend_deltas(self):
|
{"golden_diff": "diff --git a/neuralprophet/components/trend/static.py b/neuralprophet/components/trend/static.py\n--- a/neuralprophet/components/trend/static.py\n+++ b/neuralprophet/components/trend/static.py\n@@ -28,7 +28,7 @@\n torch.Tensor\n Trend component, same dimensions as input t\n \"\"\"\n- return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)\n+ return self.bias.unsqueeze(dim=0).repeat(t.shape[0], self.n_forecasts, 1)\n \n @property\n def get_trend_deltas(self):\n", "issue": "Static Trend does not follow required forecasting pattern\n**Source Code:**\r\n\r\n```\r\nimport pandas as pd\r\nfrom neuralprophet import NeuralProphet, set_log_level, set_random_seed\r\nset_log_level(\"ERROR\")\r\n\r\ndata_location = \"https://raw.githubusercontent.com/ourownstory/neuralprophet-data/main/datasets/\"\r\nfile = \"energy/SF_hospital_load.csv\"\r\ndata_df = pd.read_csv(data_location + file)\r\n\r\nm = NeuralProphet()\r\ntrain_df, test_df = m.split_df(data_df, freq=\"H\", valid_p=1.0 / 5)\r\n\r\nquantile_lo, quantile_hi = 0.05, 0.95\r\nquantiles = [quantile_lo, quantile_hi]\r\nn_lags = 3 * 24\r\nn_forecasts = 24\r\n\r\nm = NeuralProphet(\r\n growth=\"off\",\r\n yearly_seasonality=False,\r\n weekly_seasonality=False,\r\n daily_seasonality=False,\r\n n_forecasts = n_forecasts,\r\n n_lags=n_lags,\r\n ar_reg=1,\r\n learning_rate=0.01,\r\n quantiles=quantiles,\r\n)\r\n\r\nrandom_seed = 0\r\nset_random_seed(random_seed)\r\nmetrics = m.fit(train_df, freq=\"H\")\r\n\r\nforecast = m.predict(test_df)\r\n```\r\n\r\n**Error:**\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nIndexError Traceback (most recent call last)\r\nInput In [1], in <cell line: 34>()\r\n 31 metrics = m.fit(train_df, freq=\"H\")\r\n 32 metrics.tail(1)\r\n---> 34 forecast = m.predict(test_df)\r\n\r\nFile ~.../neuralprophet/forecaster.py:940, in NeuralProphet.predict(self, df, decompose, raw)\r\n 938 fcst = fcst[:-1]\r\n 939 else:\r\n--> 940 fcst = self._reshape_raw_predictions_to_forecst_df(df_i, predicted, components)\r\n 941 if periods_added[df_name] > 0:\r\n 942 fcst = fcst[: -periods_added[df_name]]\r\n\r\nFile ~.../neuralprophet/forecaster.py:3169, in NeuralProphet._reshape_raw_predictions_to_forecst_df(self, df, predicted, components)\r\n 3167 for j in range(len(self.config_train.quantiles)):\r\n 3168 forecast_0 = components[comp][0, :, j]\r\n-> 3169 forecast_rest = components[comp][1:, self.n_forecasts - 1, j]\r\n 3170 yhat = np.concatenate(([np.NaN] * self.max_lags, forecast_0, forecast_rest))\r\n 3171 if j == 0: # temporary condition to add only the median component\r\n 3172 # add yhat into dataframe, using df_forecast indexing\r\n\r\nIndexError: index 23 is out of bounds for axis 1 with size 1\r\n```\r\n\r\nIs it because I used the empty `m = NeuralProphet()` to split to data to train/test?\n", "before_files": [{"content": "from neuralprophet.components.trend import Trend\n\n\nclass StaticTrend(Trend):\n def __init__(self, config, id_list, quantiles, num_trends_modelled, n_forecasts, device):\n super().__init__(\n config=config,\n n_forecasts=n_forecasts,\n num_trends_modelled=num_trends_modelled,\n quantiles=quantiles,\n id_list=id_list,\n device=device,\n )\n\n def forward(self, t, meta):\n \"\"\"\n Computes trend based on model configuration.\n\n Parameters\n ----------\n t : torch.Tensor float\n normalized time, dim: (batch, n_forecasts)\n meta: dict\n Metadata about the all the samples of the model input batch. Contains the following:\n * ``df_name`` (list, str), time series ID corresponding to each sample of the input batch.\n Returns\n -------\n torch.Tensor\n Trend component, same dimensions as input t\n \"\"\"\n return self.bias.unsqueeze(dim=0).repeat(t.shape[0], 1, 1)\n\n @property\n def get_trend_deltas(self):\n pass\n\n def add_regularization(self):\n pass\n", "path": "neuralprophet/components/trend/static.py"}], "after_files": [{"content": "from neuralprophet.components.trend import Trend\n\n\nclass StaticTrend(Trend):\n def __init__(self, config, id_list, quantiles, num_trends_modelled, n_forecasts, device):\n super().__init__(\n config=config,\n n_forecasts=n_forecasts,\n num_trends_modelled=num_trends_modelled,\n quantiles=quantiles,\n id_list=id_list,\n device=device,\n )\n\n def forward(self, t, meta):\n \"\"\"\n Computes trend based on model configuration.\n\n Parameters\n ----------\n t : torch.Tensor float\n normalized time, dim: (batch, n_forecasts)\n meta: dict\n Metadata about the all the samples of the model input batch. Contains the following:\n * ``df_name`` (list, str), time series ID corresponding to each sample of the input batch.\n Returns\n -------\n torch.Tensor\n Trend component, same dimensions as input t\n \"\"\"\n return self.bias.unsqueeze(dim=0).repeat(t.shape[0], self.n_forecasts, 1)\n\n @property\n def get_trend_deltas(self):\n pass\n\n def add_regularization(self):\n pass\n", "path": "neuralprophet/components/trend/static.py"}]}
| 1,263 | 136 |
gh_patches_debug_10878
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmsegmentation-1463
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
STDC training on fp16: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same
在stdc1_512x1024_80k_cityscapes.py中添加了
```
optimizer_config = dict(type='Fp16OptimizerHook', loss_scale='dynamic')
fp16 = dict()
```
后再次进行训练则出现了以下报错
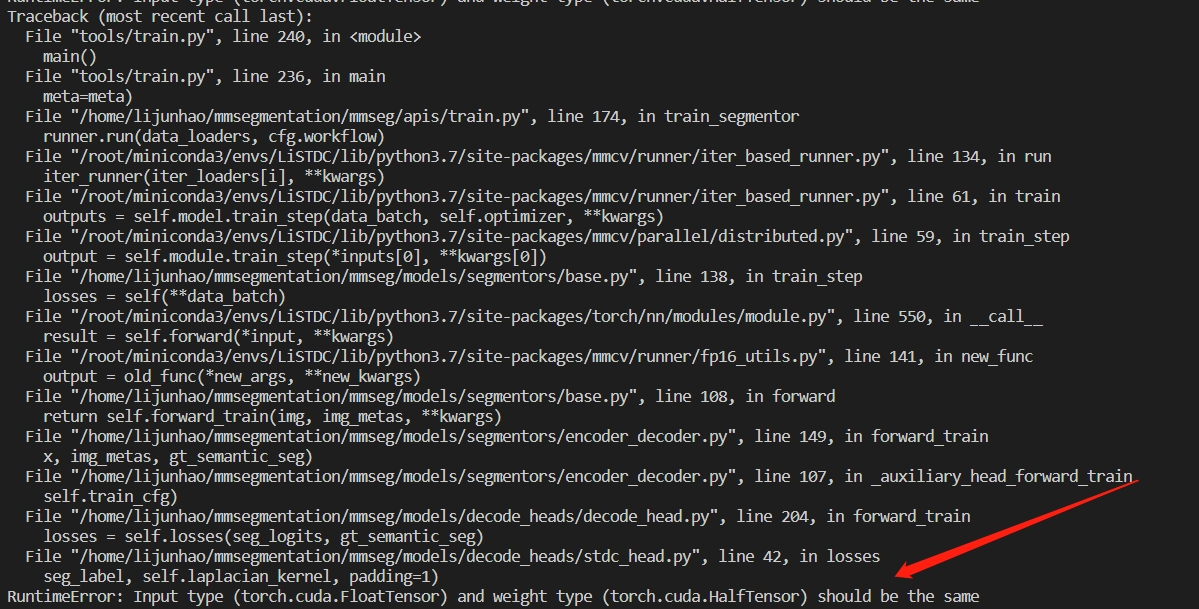
请问该如何修改
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmseg/models/decode_heads/stdc_head.py`
Content:
```
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import torch
3 import torch.nn.functional as F
4
5 from ..builder import HEADS
6 from .fcn_head import FCNHead
7
8
9 @HEADS.register_module()
10 class STDCHead(FCNHead):
11 """This head is the implementation of `Rethinking BiSeNet For Real-time
12 Semantic Segmentation <https://arxiv.org/abs/2104.13188>`_.
13
14 Args:
15 boundary_threshold (float): The threshold of calculating boundary.
16 Default: 0.1.
17 """
18
19 def __init__(self, boundary_threshold=0.1, **kwargs):
20 super(STDCHead, self).__init__(**kwargs)
21 self.boundary_threshold = boundary_threshold
22 # Using register buffer to make laplacian kernel on the same
23 # device of `seg_label`.
24 self.register_buffer(
25 'laplacian_kernel',
26 torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],
27 dtype=torch.float32,
28 requires_grad=False).reshape((1, 1, 3, 3)))
29 self.fusion_kernel = torch.nn.Parameter(
30 torch.tensor([[6. / 10], [3. / 10], [1. / 10]],
31 dtype=torch.float32).reshape(1, 3, 1, 1),
32 requires_grad=False)
33
34 def losses(self, seg_logit, seg_label):
35 """Compute Detail Aggregation Loss."""
36 # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv
37 # parameters. However, it is a constant in original repo and other
38 # codebase because it would not be added into computation graph
39 # after threshold operation.
40 seg_label = seg_label.float()
41 boundary_targets = F.conv2d(
42 seg_label, self.laplacian_kernel, padding=1)
43 boundary_targets = boundary_targets.clamp(min=0)
44 boundary_targets[boundary_targets > self.boundary_threshold] = 1
45 boundary_targets[boundary_targets <= self.boundary_threshold] = 0
46
47 boundary_targets_x2 = F.conv2d(
48 seg_label, self.laplacian_kernel, stride=2, padding=1)
49 boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
50
51 boundary_targets_x4 = F.conv2d(
52 seg_label, self.laplacian_kernel, stride=4, padding=1)
53 boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
54
55 boundary_targets_x4_up = F.interpolate(
56 boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
57 boundary_targets_x2_up = F.interpolate(
58 boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
59
60 boundary_targets_x2_up[
61 boundary_targets_x2_up > self.boundary_threshold] = 1
62 boundary_targets_x2_up[
63 boundary_targets_x2_up <= self.boundary_threshold] = 0
64
65 boundary_targets_x4_up[
66 boundary_targets_x4_up > self.boundary_threshold] = 1
67 boundary_targets_x4_up[
68 boundary_targets_x4_up <= self.boundary_threshold] = 0
69
70 boudary_targets_pyramids = torch.stack(
71 (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),
72 dim=1)
73
74 boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
75 boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,
76 self.fusion_kernel)
77
78 boudary_targets_pyramid[
79 boudary_targets_pyramid > self.boundary_threshold] = 1
80 boudary_targets_pyramid[
81 boudary_targets_pyramid <= self.boundary_threshold] = 0
82
83 loss = super(STDCHead, self).losses(seg_logit,
84 boudary_targets_pyramid.long())
85 return loss
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py
--- a/mmseg/models/decode_heads/stdc_head.py
+++ b/mmseg/models/decode_heads/stdc_head.py
@@ -37,7 +37,7 @@
# parameters. However, it is a constant in original repo and other
# codebase because it would not be added into computation graph
# after threshold operation.
- seg_label = seg_label.float()
+ seg_label = seg_label.to(self.laplacian_kernel)
boundary_targets = F.conv2d(
seg_label, self.laplacian_kernel, padding=1)
boundary_targets = boundary_targets.clamp(min=0)
|
{"golden_diff": "diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py\n--- a/mmseg/models/decode_heads/stdc_head.py\n+++ b/mmseg/models/decode_heads/stdc_head.py\n@@ -37,7 +37,7 @@\n # parameters. However, it is a constant in original repo and other\n # codebase because it would not be added into computation graph\n # after threshold operation.\n- seg_label = seg_label.float()\n+ seg_label = seg_label.to(self.laplacian_kernel)\n boundary_targets = F.conv2d(\n seg_label, self.laplacian_kernel, padding=1)\n boundary_targets = boundary_targets.clamp(min=0)\n", "issue": "STDC training on fp16: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same\n\u5728stdc1_512x1024_80k_cityscapes.py\u4e2d\u6dfb\u52a0\u4e86\r\n```\r\noptimizer_config = dict(type='Fp16OptimizerHook', loss_scale='dynamic')\r\nfp16 = dict()\r\n```\r\n\u540e\u518d\u6b21\u8fdb\u884c\u8bad\u7ec3\u5219\u51fa\u73b0\u4e86\u4ee5\u4e0b\u62a5\u9519\r\n\r\n\r\n\u8bf7\u95ee\u8be5\u5982\u4f55\u4fee\u6539\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport torch\nimport torch.nn.functional as F\n\nfrom ..builder import HEADS\nfrom .fcn_head import FCNHead\n\n\[email protected]_module()\nclass STDCHead(FCNHead):\n \"\"\"This head is the implementation of `Rethinking BiSeNet For Real-time\n Semantic Segmentation <https://arxiv.org/abs/2104.13188>`_.\n\n Args:\n boundary_threshold (float): The threshold of calculating boundary.\n Default: 0.1.\n \"\"\"\n\n def __init__(self, boundary_threshold=0.1, **kwargs):\n super(STDCHead, self).__init__(**kwargs)\n self.boundary_threshold = boundary_threshold\n # Using register buffer to make laplacian kernel on the same\n # device of `seg_label`.\n self.register_buffer(\n 'laplacian_kernel',\n torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],\n dtype=torch.float32,\n requires_grad=False).reshape((1, 1, 3, 3)))\n self.fusion_kernel = torch.nn.Parameter(\n torch.tensor([[6. / 10], [3. / 10], [1. / 10]],\n dtype=torch.float32).reshape(1, 3, 1, 1),\n requires_grad=False)\n\n def losses(self, seg_logit, seg_label):\n \"\"\"Compute Detail Aggregation Loss.\"\"\"\n # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv\n # parameters. However, it is a constant in original repo and other\n # codebase because it would not be added into computation graph\n # after threshold operation.\n seg_label = seg_label.float()\n boundary_targets = F.conv2d(\n seg_label, self.laplacian_kernel, padding=1)\n boundary_targets = boundary_targets.clamp(min=0)\n boundary_targets[boundary_targets > self.boundary_threshold] = 1\n boundary_targets[boundary_targets <= self.boundary_threshold] = 0\n\n boundary_targets_x2 = F.conv2d(\n seg_label, self.laplacian_kernel, stride=2, padding=1)\n boundary_targets_x2 = boundary_targets_x2.clamp(min=0)\n\n boundary_targets_x4 = F.conv2d(\n seg_label, self.laplacian_kernel, stride=4, padding=1)\n boundary_targets_x4 = boundary_targets_x4.clamp(min=0)\n\n boundary_targets_x4_up = F.interpolate(\n boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')\n boundary_targets_x2_up = F.interpolate(\n boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')\n\n boundary_targets_x2_up[\n boundary_targets_x2_up > self.boundary_threshold] = 1\n boundary_targets_x2_up[\n boundary_targets_x2_up <= self.boundary_threshold] = 0\n\n boundary_targets_x4_up[\n boundary_targets_x4_up > self.boundary_threshold] = 1\n boundary_targets_x4_up[\n boundary_targets_x4_up <= self.boundary_threshold] = 0\n\n boudary_targets_pyramids = torch.stack(\n (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),\n dim=1)\n\n boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)\n boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,\n self.fusion_kernel)\n\n boudary_targets_pyramid[\n boudary_targets_pyramid > self.boundary_threshold] = 1\n boudary_targets_pyramid[\n boudary_targets_pyramid <= self.boundary_threshold] = 0\n\n loss = super(STDCHead, self).losses(seg_logit,\n boudary_targets_pyramid.long())\n return loss\n", "path": "mmseg/models/decode_heads/stdc_head.py"}], "after_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport torch\nimport torch.nn.functional as F\n\nfrom ..builder import HEADS\nfrom .fcn_head import FCNHead\n\n\[email protected]_module()\nclass STDCHead(FCNHead):\n \"\"\"This head is the implementation of `Rethinking BiSeNet For Real-time\n Semantic Segmentation <https://arxiv.org/abs/2104.13188>`_.\n\n Args:\n boundary_threshold (float): The threshold of calculating boundary.\n Default: 0.1.\n \"\"\"\n\n def __init__(self, boundary_threshold=0.1, **kwargs):\n super(STDCHead, self).__init__(**kwargs)\n self.boundary_threshold = boundary_threshold\n # Using register buffer to make laplacian kernel on the same\n # device of `seg_label`.\n self.register_buffer(\n 'laplacian_kernel',\n torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],\n dtype=torch.float32,\n requires_grad=False).reshape((1, 1, 3, 3)))\n self.fusion_kernel = torch.nn.Parameter(\n torch.tensor([[6. / 10], [3. / 10], [1. / 10]],\n dtype=torch.float32).reshape(1, 3, 1, 1),\n requires_grad=False)\n\n def losses(self, seg_logit, seg_label):\n \"\"\"Compute Detail Aggregation Loss.\"\"\"\n # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv\n # parameters. However, it is a constant in original repo and other\n # codebase because it would not be added into computation graph\n # after threshold operation.\n seg_label = seg_label.to(self.laplacian_kernel)\n boundary_targets = F.conv2d(\n seg_label, self.laplacian_kernel, padding=1)\n boundary_targets = boundary_targets.clamp(min=0)\n boundary_targets[boundary_targets > self.boundary_threshold] = 1\n boundary_targets[boundary_targets <= self.boundary_threshold] = 0\n\n boundary_targets_x2 = F.conv2d(\n seg_label, self.laplacian_kernel, stride=2, padding=1)\n boundary_targets_x2 = boundary_targets_x2.clamp(min=0)\n\n boundary_targets_x4 = F.conv2d(\n seg_label, self.laplacian_kernel, stride=4, padding=1)\n boundary_targets_x4 = boundary_targets_x4.clamp(min=0)\n\n boundary_targets_x4_up = F.interpolate(\n boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')\n boundary_targets_x2_up = F.interpolate(\n boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')\n\n boundary_targets_x2_up[\n boundary_targets_x2_up > self.boundary_threshold] = 1\n boundary_targets_x2_up[\n boundary_targets_x2_up <= self.boundary_threshold] = 0\n\n boundary_targets_x4_up[\n boundary_targets_x4_up > self.boundary_threshold] = 1\n boundary_targets_x4_up[\n boundary_targets_x4_up <= self.boundary_threshold] = 0\n\n boudary_targets_pyramids = torch.stack(\n (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),\n dim=1)\n\n boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)\n boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,\n self.fusion_kernel)\n\n boudary_targets_pyramid[\n boudary_targets_pyramid > self.boundary_threshold] = 1\n boudary_targets_pyramid[\n boudary_targets_pyramid <= self.boundary_threshold] = 0\n\n loss = super(STDCHead, self).losses(seg_logit,\n boudary_targets_pyramid.long())\n return loss\n", "path": "mmseg/models/decode_heads/stdc_head.py"}]}
| 1,445 | 156 |
gh_patches_debug_31467
|
rasdani/github-patches
|
git_diff
|
pfnet__pytorch-pfn-extras-15
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in sequential repeat when the layer has no parameters
**problems Statement**
In `init` mode, the repeated layer will be reset. In `Pytorch`, we used `reset_parameters` function to reset the parameters of layers, as here:
https://github.com/pfnet/pytorch-pfn-extras/blob/92dad97e3a3eaafb9eb2b2b804266b5ef922e4c7/pytorch_pfn_extras/nn/modules/extended_sequential.py#L15
However, there are layers have no parameters nor `reset_parameters`, such as `torch.nn.ReLU`. An error is raised when the model contains such layer.
**Error Message**
```
pytorch_pfn_extras/nn/modules/extended_sequential.py:68: in repeat
model_list.append(self._copy_model(mode))
pytorch_pfn_extras/nn/modules/extended_sequential.py:27: in _copy_model
return _reset_parameters(copy.deepcopy(self))
pytorch_pfn_extras/nn/modules/extended_sequential.py:9: in _reset_parameters
_reset_parameters(submodel)
pytorch_pfn_extras/nn/modules/extended_sequential.py:17: in _reset_parameters
model.reset_parameters()
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = ReLU(), name = 'reset_parameters'
def __getattr__(self, name):
if '_parameters' in self.__dict__:
_parameters = self.__dict__['_parameters']
if name in _parameters:
return _parameters[name]
if '_buffers' in self.__dict__:
_buffers = self.__dict__['_buffers']
if name in _buffers:
return _buffers[name]
if '_modules' in self.__dict__:
modules = self.__dict__['_modules']
if name in modules:
return modules[name]
raise AttributeError("'{}' object has no attribute '{}'".format(
> type(self).__name__, name))
E AttributeError: 'ReLU' object has no attribute 'reset_parameters'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_pfn_extras/nn/modules/extended_sequential.py`
Content:
```
1 import torch
2 import copy
3
4
5 def _reset_parameters(model):
6 if isinstance(model, torch.nn.Sequential) or \
7 isinstance(model, torch.nn.ModuleList):
8 for submodel in model:
9 _reset_parameters(submodel)
10 elif isinstance(model, torch.nn.ModuleDict):
11 for submodel in model.values():
12 _reset_parameters(submodel)
13 else:
14 if isinstance(model, torch.nn.Module):
15 model.reset_parameters()
16 return model
17
18
19 class ExtendedSequential(torch.nn.Sequential):
20 """Sequential module with extended features from chainer.
21
22 """
23 def _copy_model(self, mode):
24 if mode == 'init':
25 return _reset_parameters(copy.deepcopy(self))
26 elif mode == 'copy':
27 return copy.deepcopy(self)
28 else:
29 # mode == share
30 return copy.copy(self)
31
32 def repeat(self, n_repeat: int, mode: 'str' = 'init'):
33 """Repeats this Sequential multiple times.
34
35 This method returns a :class:`~torch.nn.Sequential` object which has
36 original `Sequential` multiple times repeatedly. The ``mode``
37 argument means how to copy this sequential to repeat.
38
39 The functions is supposed to behave the same way as `repeat`
40 in `chainer`.
41
42 Args:
43 n_repeat (int): Number of times to repeat.
44 mode (str): It should be either ``init``, ``copy``, or ``share``.
45 ``init`` means parameters of each repeated element in the
46 returned :class:`~torch.nn.Sequential` will be re-initialized,
47 so that all elements have different initial parameters.
48 ``copy`` means that the parameters will not be re-initialized
49 but object itself will be deep-copied, so that all elements
50 have same initial parameters but can be changed independently.
51 ``share`` means all the elements which consist the resulting
52 :class:`~torch.nn.Sequential` object are same object because
53 they are shallow-copied, so that all parameters of elements
54 are shared with each other.
55 """
56 if n_repeat <= 0:
57 return ExtendedSequential()
58
59 if mode not in ['copy', 'share', 'init']:
60 raise ValueError(
61 'The \'mode\' argument should be either \'init\','
62 '\'copy\', or \'share\'. But {} was given.'.format(mode))
63
64 model_list = []
65 for _ in range(n_repeat):
66 model_list.append(self._copy_model(mode))
67 return ExtendedSequential(*model_list)
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytorch_pfn_extras/nn/modules/extended_sequential.py b/pytorch_pfn_extras/nn/modules/extended_sequential.py
--- a/pytorch_pfn_extras/nn/modules/extended_sequential.py
+++ b/pytorch_pfn_extras/nn/modules/extended_sequential.py
@@ -1,5 +1,6 @@
import torch
import copy
+import warnings
def _reset_parameters(model):
@@ -11,8 +12,19 @@
for submodel in model.values():
_reset_parameters(submodel)
else:
- if isinstance(model, torch.nn.Module):
+ if hasattr(model, 'reset_parameters'):
model.reset_parameters()
+ elif hasattr(model, '_reset_parameters'):
+ model._reset_parameters()
+ else:
+ if (len(list(model.parameters())) != 0 or
+ len(list(model.buffers())) != 0):
+ warnings.warn('Cannot reset the parameters of module {}. '
+ 'Consider adding `reset_parameters` or '
+ '`_reset_parameters` '
+ 'functions to the module'.format(model),
+ UserWarning)
+
return model
@@ -39,6 +51,18 @@
The functions is supposed to behave the same way as `repeat`
in `chainer`.
+ When the mode is set to ``init``, the default value,
+ modules will be copied and reinitialized by calling
+ ``reset_parameters`` (or ``_reset_parameters``) method.
+
+ To repeat user-defined modules, which have parameters or buffers,
+ with mode=``init`` in this Sequential,
+ you need to implement the ``reset_parameters`` or ``_reset_parameters``
+ method to the module to reinitialize parameters
+ and (if necessary) buffers;
+ otherwise the initialization cannot be performed
+ and a warning message will be shown.
+
Args:
n_repeat (int): Number of times to repeat.
mode (str): It should be either ``init``, ``copy``, or ``share``.
|
{"golden_diff": "diff --git a/pytorch_pfn_extras/nn/modules/extended_sequential.py b/pytorch_pfn_extras/nn/modules/extended_sequential.py\n--- a/pytorch_pfn_extras/nn/modules/extended_sequential.py\n+++ b/pytorch_pfn_extras/nn/modules/extended_sequential.py\n@@ -1,5 +1,6 @@\n import torch\n import copy\n+import warnings\n \n \n def _reset_parameters(model):\n@@ -11,8 +12,19 @@\n for submodel in model.values():\n _reset_parameters(submodel)\n else:\n- if isinstance(model, torch.nn.Module):\n+ if hasattr(model, 'reset_parameters'):\n model.reset_parameters()\n+ elif hasattr(model, '_reset_parameters'):\n+ model._reset_parameters()\n+ else:\n+ if (len(list(model.parameters())) != 0 or\n+ len(list(model.buffers())) != 0):\n+ warnings.warn('Cannot reset the parameters of module {}. '\n+ 'Consider adding `reset_parameters` or '\n+ '`_reset_parameters` '\n+ 'functions to the module'.format(model),\n+ UserWarning)\n+\n return model\n \n \n@@ -39,6 +51,18 @@\n The functions is supposed to behave the same way as `repeat`\n in `chainer`.\n \n+ When the mode is set to ``init``, the default value,\n+ modules will be copied and reinitialized by calling\n+ ``reset_parameters`` (or ``_reset_parameters``) method.\n+\n+ To repeat user-defined modules, which have parameters or buffers,\n+ with mode=``init`` in this Sequential,\n+ you need to implement the ``reset_parameters`` or ``_reset_parameters``\n+ method to the module to reinitialize parameters\n+ and (if necessary) buffers;\n+ otherwise the initialization cannot be performed\n+ and a warning message will be shown.\n+\n Args:\n n_repeat (int): Number of times to repeat.\n mode (str): It should be either ``init``, ``copy``, or ``share``.\n", "issue": "Bug in sequential repeat when the layer has no parameters\n**problems Statement**\r\nIn `init` mode, the repeated layer will be reset. In `Pytorch`, we used `reset_parameters` function to reset the parameters of layers, as here:\r\nhttps://github.com/pfnet/pytorch-pfn-extras/blob/92dad97e3a3eaafb9eb2b2b804266b5ef922e4c7/pytorch_pfn_extras/nn/modules/extended_sequential.py#L15\r\n\r\nHowever, there are layers have no parameters nor `reset_parameters`, such as `torch.nn.ReLU`. An error is raised when the model contains such layer.\r\n\r\n**Error Message**\r\n```\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:68: in repeat\r\n model_list.append(self._copy_model(mode))\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:27: in _copy_model\r\n return _reset_parameters(copy.deepcopy(self))\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:9: in _reset_parameters\r\n _reset_parameters(submodel)\r\npytorch_pfn_extras/nn/modules/extended_sequential.py:17: in _reset_parameters\r\n model.reset_parameters()\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\nself = ReLU(), name = 'reset_parameters'\r\n\r\n def __getattr__(self, name):\r\n if '_parameters' in self.__dict__:\r\n _parameters = self.__dict__['_parameters']\r\n if name in _parameters:\r\n return _parameters[name]\r\n if '_buffers' in self.__dict__:\r\n _buffers = self.__dict__['_buffers']\r\n if name in _buffers:\r\n return _buffers[name]\r\n if '_modules' in self.__dict__:\r\n modules = self.__dict__['_modules']\r\n if name in modules:\r\n return modules[name]\r\n raise AttributeError(\"'{}' object has no attribute '{}'\".format(\r\n> type(self).__name__, name))\r\nE AttributeError: 'ReLU' object has no attribute 'reset_parameters'\r\n```\n", "before_files": [{"content": "import torch\nimport copy\n\n\ndef _reset_parameters(model):\n if isinstance(model, torch.nn.Sequential) or \\\n isinstance(model, torch.nn.ModuleList):\n for submodel in model:\n _reset_parameters(submodel)\n elif isinstance(model, torch.nn.ModuleDict):\n for submodel in model.values():\n _reset_parameters(submodel)\n else:\n if isinstance(model, torch.nn.Module):\n model.reset_parameters()\n return model\n\n\nclass ExtendedSequential(torch.nn.Sequential):\n \"\"\"Sequential module with extended features from chainer.\n\n \"\"\"\n def _copy_model(self, mode):\n if mode == 'init':\n return _reset_parameters(copy.deepcopy(self))\n elif mode == 'copy':\n return copy.deepcopy(self)\n else:\n # mode == share\n return copy.copy(self)\n\n def repeat(self, n_repeat: int, mode: 'str' = 'init'):\n \"\"\"Repeats this Sequential multiple times.\n\n This method returns a :class:`~torch.nn.Sequential` object which has\n original `Sequential` multiple times repeatedly. The ``mode``\n argument means how to copy this sequential to repeat.\n\n The functions is supposed to behave the same way as `repeat`\n in `chainer`.\n\n Args:\n n_repeat (int): Number of times to repeat.\n mode (str): It should be either ``init``, ``copy``, or ``share``.\n ``init`` means parameters of each repeated element in the\n returned :class:`~torch.nn.Sequential` will be re-initialized,\n so that all elements have different initial parameters.\n ``copy`` means that the parameters will not be re-initialized\n but object itself will be deep-copied, so that all elements\n have same initial parameters but can be changed independently.\n ``share`` means all the elements which consist the resulting\n :class:`~torch.nn.Sequential` object are same object because\n they are shallow-copied, so that all parameters of elements\n are shared with each other.\n \"\"\"\n if n_repeat <= 0:\n return ExtendedSequential()\n\n if mode not in ['copy', 'share', 'init']:\n raise ValueError(\n 'The \\'mode\\' argument should be either \\'init\\','\n '\\'copy\\', or \\'share\\'. But {} was given.'.format(mode))\n\n model_list = []\n for _ in range(n_repeat):\n model_list.append(self._copy_model(mode))\n return ExtendedSequential(*model_list)\n", "path": "pytorch_pfn_extras/nn/modules/extended_sequential.py"}], "after_files": [{"content": "import torch\nimport copy\nimport warnings\n\n\ndef _reset_parameters(model):\n if isinstance(model, torch.nn.Sequential) or \\\n isinstance(model, torch.nn.ModuleList):\n for submodel in model:\n _reset_parameters(submodel)\n elif isinstance(model, torch.nn.ModuleDict):\n for submodel in model.values():\n _reset_parameters(submodel)\n else:\n if hasattr(model, 'reset_parameters'):\n model.reset_parameters()\n elif hasattr(model, '_reset_parameters'):\n model._reset_parameters()\n else:\n if (len(list(model.parameters())) != 0 or\n len(list(model.buffers())) != 0):\n warnings.warn('Cannot reset the parameters of module {}. '\n 'Consider adding `reset_parameters` or '\n '`_reset_parameters` '\n 'functions to the module'.format(model),\n UserWarning)\n\n return model\n\n\nclass ExtendedSequential(torch.nn.Sequential):\n \"\"\"Sequential module with extended features from chainer.\n\n \"\"\"\n def _copy_model(self, mode):\n if mode == 'init':\n return _reset_parameters(copy.deepcopy(self))\n elif mode == 'copy':\n return copy.deepcopy(self)\n else:\n # mode == share\n return copy.copy(self)\n\n def repeat(self, n_repeat: int, mode: 'str' = 'init'):\n \"\"\"Repeats this Sequential multiple times.\n\n This method returns a :class:`~torch.nn.Sequential` object which has\n original `Sequential` multiple times repeatedly. The ``mode``\n argument means how to copy this sequential to repeat.\n\n The functions is supposed to behave the same way as `repeat`\n in `chainer`.\n\n When the mode is set to ``init``, the default value,\n modules will be copied and reinitialized by calling\n ``reset_parameters`` (or ``_reset_parameters``) method.\n\n To repeat user-defined modules, which have parameters or buffers,\n with mode=``init`` in this Sequential,\n you need to implement the ``reset_parameters`` or ``_reset_parameters``\n method to the module to reinitialize parameters\n and (if necessary) buffers;\n otherwise the initialization cannot be performed\n and a warning message will be shown.\n\n Args:\n n_repeat (int): Number of times to repeat.\n mode (str): It should be either ``init``, ``copy``, or ``share``.\n ``init`` means parameters of each repeated element in the\n returned :class:`~torch.nn.Sequential` will be re-initialized,\n so that all elements have different initial parameters.\n ``copy`` means that the parameters will not be re-initialized\n but object itself will be deep-copied, so that all elements\n have same initial parameters but can be changed independently.\n ``share`` means all the elements which consist the resulting\n :class:`~torch.nn.Sequential` object are same object because\n they are shallow-copied, so that all parameters of elements\n are shared with each other.\n \"\"\"\n if n_repeat <= 0:\n return ExtendedSequential()\n\n if mode not in ['copy', 'share', 'init']:\n raise ValueError(\n 'The \\'mode\\' argument should be either \\'init\\','\n '\\'copy\\', or \\'share\\'. But {} was given.'.format(mode))\n\n model_list = []\n for _ in range(n_repeat):\n model_list.append(self._copy_model(mode))\n return ExtendedSequential(*model_list)\n", "path": "pytorch_pfn_extras/nn/modules/extended_sequential.py"}]}
| 1,466 | 448 |
gh_patches_debug_20459
|
rasdani/github-patches
|
git_diff
|
pytorch__text-1805
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make TorchText installable from direct reference
In order to make `pip install https://github.com/pytorch/text` succeed
`setup.py` should have logic to initialize submodules
Add `check_submodules()` routine to setup.py to check if
'third_party/re2/CMakeLists.txt' is present on the filesystem and
attempt to initialize submodules if it is not
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 import distutils.command.clean
3 import io
4 import os
5 import shutil
6 import subprocess
7 from pathlib import Path
8
9 from build_tools import setup_helpers
10 from setuptools import find_packages, setup
11
12 ROOT_DIR = Path(__file__).parent.resolve()
13
14
15 def read(*names, **kwargs):
16 with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get("encoding", "utf8")) as fp:
17 return fp.read()
18
19
20 def _get_version():
21 try:
22 cmd = ["git", "rev-parse", "HEAD"]
23 sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode("ascii").strip()
24 except Exception:
25 sha = None
26
27 if "BUILD_VERSION" in os.environ:
28 version = os.environ["BUILD_VERSION"]
29 else:
30 with open(os.path.join(ROOT_DIR, "version.txt"), "r") as f:
31 version = f.readline().strip()
32 if sha is not None:
33 version += "+" + sha[:7]
34
35 if sha is None:
36 sha = "Unknown"
37 return version, sha
38
39
40 def _export_version(version, sha):
41 version_path = ROOT_DIR / "torchtext" / "version.py"
42 with open(version_path, "w") as fileobj:
43 fileobj.write("__version__ = '{}'\n".format(version))
44 fileobj.write("git_version = {}\n".format(repr(sha)))
45
46
47 VERSION, SHA = _get_version()
48 _export_version(VERSION, SHA)
49
50 print("-- Building version " + VERSION)
51
52 pytorch_package_version = os.getenv("PYTORCH_VERSION")
53
54 pytorch_package_dep = "torch"
55 if pytorch_package_version is not None:
56 pytorch_package_dep += "==" + pytorch_package_version
57
58
59 class clean(distutils.command.clean.clean):
60 def run(self):
61 # Run default behavior first
62 distutils.command.clean.clean.run(self)
63
64 # Remove torchtext extension
65 for path in (ROOT_DIR / "torchtext").glob("**/*.so"):
66 print(f"removing '{path}'")
67 path.unlink()
68 # Remove build directory
69 build_dirs = [
70 ROOT_DIR / "build",
71 ROOT_DIR / "third_party" / "build",
72 ]
73 for path in build_dirs:
74 if path.exists():
75 print(f"removing '{path}' (and everything under it)")
76 shutil.rmtree(str(path), ignore_errors=True)
77
78
79 setup_info = dict(
80 # Metadata
81 name="torchtext",
82 version=VERSION,
83 author="PyTorch core devs and James Bradbury",
84 author_email="[email protected]",
85 url="https://github.com/pytorch/text",
86 description="Text utilities and datasets for PyTorch",
87 long_description=read("README.rst"),
88 license="BSD",
89 install_requires=["tqdm", "requests", pytorch_package_dep, "numpy"],
90 python_requires=">=3.7",
91 classifiers=[
92 "Programming Language :: Python :: 3.7",
93 "Programming Language :: Python :: 3.8",
94 "Programming Language :: Python :: 3.9",
95 ],
96 # Package info
97 packages=find_packages(exclude=("test*", "build_tools*")),
98 zip_safe=False,
99 # Extension info
100 # If you are trying to use torchtext.so and see no registered op.
101 # See here: https://github.com/pytorch/vision/issues/2134"
102 ext_modules=setup_helpers.get_ext_modules(),
103 cmdclass={
104 "build_ext": setup_helpers.CMakeBuild,
105 "clean": clean,
106 },
107 )
108
109 setup(**setup_info)
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -4,6 +4,7 @@
import os
import shutil
import subprocess
+import sys
from pathlib import Path
from build_tools import setup_helpers
@@ -44,6 +45,18 @@
fileobj.write("git_version = {}\n".format(repr(sha)))
+def _init_submodule():
+ print(" --- Initializing submodules")
+ try:
+ subprocess.check_call(["git", "submodule", "init"])
+ subprocess.check_call(["git", "submodule", "update"])
+ except Exception:
+ print(" --- Submodule initalization failed")
+ print("Please run:\n\tgit submodule update --init --recursive")
+ sys.exit(1)
+ print(" --- Initialized submodule")
+
+
VERSION, SHA = _get_version()
_export_version(VERSION, SHA)
@@ -76,6 +89,7 @@
shutil.rmtree(str(path), ignore_errors=True)
+_init_submodule()
setup_info = dict(
# Metadata
name="torchtext",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -4,6 +4,7 @@\n import os\n import shutil\n import subprocess\n+import sys\n from pathlib import Path\n \n from build_tools import setup_helpers\n@@ -44,6 +45,18 @@\n fileobj.write(\"git_version = {}\\n\".format(repr(sha)))\n \n \n+def _init_submodule():\n+ print(\" --- Initializing submodules\")\n+ try:\n+ subprocess.check_call([\"git\", \"submodule\", \"init\"])\n+ subprocess.check_call([\"git\", \"submodule\", \"update\"])\n+ except Exception:\n+ print(\" --- Submodule initalization failed\")\n+ print(\"Please run:\\n\\tgit submodule update --init --recursive\")\n+ sys.exit(1)\n+ print(\" --- Initialized submodule\")\n+\n+\n VERSION, SHA = _get_version()\n _export_version(VERSION, SHA)\n \n@@ -76,6 +89,7 @@\n shutil.rmtree(str(path), ignore_errors=True)\n \n \n+_init_submodule()\n setup_info = dict(\n # Metadata\n name=\"torchtext\",\n", "issue": "Make TorchText installable from direct reference\nIn order to make `pip install https://github.com/pytorch/text` succeed\r\n`setup.py` should have logic to initialize submodules\r\n\r\nAdd `check_submodules()` routine to setup.py to check if\r\n'third_party/re2/CMakeLists.txt' is present on the filesystem and\r\nattempt to initialize submodules if it is not\n", "before_files": [{"content": "#!/usr/bin/env python\nimport distutils.command.clean\nimport io\nimport os\nimport shutil\nimport subprocess\nfrom pathlib import Path\n\nfrom build_tools import setup_helpers\nfrom setuptools import find_packages, setup\n\nROOT_DIR = Path(__file__).parent.resolve()\n\n\ndef read(*names, **kwargs):\n with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get(\"encoding\", \"utf8\")) as fp:\n return fp.read()\n\n\ndef _get_version():\n try:\n cmd = [\"git\", \"rev-parse\", \"HEAD\"]\n sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode(\"ascii\").strip()\n except Exception:\n sha = None\n\n if \"BUILD_VERSION\" in os.environ:\n version = os.environ[\"BUILD_VERSION\"]\n else:\n with open(os.path.join(ROOT_DIR, \"version.txt\"), \"r\") as f:\n version = f.readline().strip()\n if sha is not None:\n version += \"+\" + sha[:7]\n\n if sha is None:\n sha = \"Unknown\"\n return version, sha\n\n\ndef _export_version(version, sha):\n version_path = ROOT_DIR / \"torchtext\" / \"version.py\"\n with open(version_path, \"w\") as fileobj:\n fileobj.write(\"__version__ = '{}'\\n\".format(version))\n fileobj.write(\"git_version = {}\\n\".format(repr(sha)))\n\n\nVERSION, SHA = _get_version()\n_export_version(VERSION, SHA)\n\nprint(\"-- Building version \" + VERSION)\n\npytorch_package_version = os.getenv(\"PYTORCH_VERSION\")\n\npytorch_package_dep = \"torch\"\nif pytorch_package_version is not None:\n pytorch_package_dep += \"==\" + pytorch_package_version\n\n\nclass clean(distutils.command.clean.clean):\n def run(self):\n # Run default behavior first\n distutils.command.clean.clean.run(self)\n\n # Remove torchtext extension\n for path in (ROOT_DIR / \"torchtext\").glob(\"**/*.so\"):\n print(f\"removing '{path}'\")\n path.unlink()\n # Remove build directory\n build_dirs = [\n ROOT_DIR / \"build\",\n ROOT_DIR / \"third_party\" / \"build\",\n ]\n for path in build_dirs:\n if path.exists():\n print(f\"removing '{path}' (and everything under it)\")\n shutil.rmtree(str(path), ignore_errors=True)\n\n\nsetup_info = dict(\n # Metadata\n name=\"torchtext\",\n version=VERSION,\n author=\"PyTorch core devs and James Bradbury\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pytorch/text\",\n description=\"Text utilities and datasets for PyTorch\",\n long_description=read(\"README.rst\"),\n license=\"BSD\",\n install_requires=[\"tqdm\", \"requests\", pytorch_package_dep, \"numpy\"],\n python_requires=\">=3.7\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n # Package info\n packages=find_packages(exclude=(\"test*\", \"build_tools*\")),\n zip_safe=False,\n # Extension info\n # If you are trying to use torchtext.so and see no registered op.\n # See here: https://github.com/pytorch/vision/issues/2134\"\n ext_modules=setup_helpers.get_ext_modules(),\n cmdclass={\n \"build_ext\": setup_helpers.CMakeBuild,\n \"clean\": clean,\n },\n)\n\nsetup(**setup_info)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport distutils.command.clean\nimport io\nimport os\nimport shutil\nimport subprocess\nimport sys\nfrom pathlib import Path\n\nfrom build_tools import setup_helpers\nfrom setuptools import find_packages, setup\n\nROOT_DIR = Path(__file__).parent.resolve()\n\n\ndef read(*names, **kwargs):\n with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get(\"encoding\", \"utf8\")) as fp:\n return fp.read()\n\n\ndef _get_version():\n try:\n cmd = [\"git\", \"rev-parse\", \"HEAD\"]\n sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode(\"ascii\").strip()\n except Exception:\n sha = None\n\n if \"BUILD_VERSION\" in os.environ:\n version = os.environ[\"BUILD_VERSION\"]\n else:\n with open(os.path.join(ROOT_DIR, \"version.txt\"), \"r\") as f:\n version = f.readline().strip()\n if sha is not None:\n version += \"+\" + sha[:7]\n\n if sha is None:\n sha = \"Unknown\"\n return version, sha\n\n\ndef _export_version(version, sha):\n version_path = ROOT_DIR / \"torchtext\" / \"version.py\"\n with open(version_path, \"w\") as fileobj:\n fileobj.write(\"__version__ = '{}'\\n\".format(version))\n fileobj.write(\"git_version = {}\\n\".format(repr(sha)))\n\n\ndef _init_submodule():\n print(\" --- Initializing submodules\")\n try:\n subprocess.check_call([\"git\", \"submodule\", \"init\"])\n subprocess.check_call([\"git\", \"submodule\", \"update\"])\n except Exception:\n print(\" --- Submodule initalization failed\")\n print(\"Please run:\\n\\tgit submodule update --init --recursive\")\n sys.exit(1)\n print(\" --- Initialized submodule\")\n\n\nVERSION, SHA = _get_version()\n_export_version(VERSION, SHA)\n\nprint(\"-- Building version \" + VERSION)\n\npytorch_package_version = os.getenv(\"PYTORCH_VERSION\")\n\npytorch_package_dep = \"torch\"\nif pytorch_package_version is not None:\n pytorch_package_dep += \"==\" + pytorch_package_version\n\n\nclass clean(distutils.command.clean.clean):\n def run(self):\n # Run default behavior first\n distutils.command.clean.clean.run(self)\n\n # Remove torchtext extension\n for path in (ROOT_DIR / \"torchtext\").glob(\"**/*.so\"):\n print(f\"removing '{path}'\")\n path.unlink()\n # Remove build directory\n build_dirs = [\n ROOT_DIR / \"build\",\n ROOT_DIR / \"third_party\" / \"build\",\n ]\n for path in build_dirs:\n if path.exists():\n print(f\"removing '{path}' (and everything under it)\")\n shutil.rmtree(str(path), ignore_errors=True)\n\n\n_init_submodule()\nsetup_info = dict(\n # Metadata\n name=\"torchtext\",\n version=VERSION,\n author=\"PyTorch core devs and James Bradbury\",\n author_email=\"[email protected]\",\n url=\"https://github.com/pytorch/text\",\n description=\"Text utilities and datasets for PyTorch\",\n long_description=read(\"README.rst\"),\n license=\"BSD\",\n install_requires=[\"tqdm\", \"requests\", pytorch_package_dep, \"numpy\"],\n python_requires=\">=3.7\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n # Package info\n packages=find_packages(exclude=(\"test*\", \"build_tools*\")),\n zip_safe=False,\n # Extension info\n # If you are trying to use torchtext.so and see no registered op.\n # See here: https://github.com/pytorch/vision/issues/2134\"\n ext_modules=setup_helpers.get_ext_modules(),\n cmdclass={\n \"build_ext\": setup_helpers.CMakeBuild,\n \"clean\": clean,\n },\n)\n\nsetup(**setup_info)\n", "path": "setup.py"}]}
| 1,333 | 247 |
gh_patches_debug_36718
|
rasdani/github-patches
|
git_diff
|
prowler-cloud__prowler-2726
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: Context name on conditions are case-insensitive
### Steps to Reproduce
As yo can see here https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html, context name on conditions are case-insensitive. Some default aws policies are "AWS:xxxx" instead of "aws:xxxx", so prowler fails to detect it. Also can happen with manual policies, if someone put "aws:sourceaccount" inseat of "aws:SourceAccount". So is_account_only_allowed_in_condition must be case-insensitive to work.
I found it on SNS default policy, which look like this:
```
{
"Version": "2008-10-17",
"Id": "__default_policy_ID",
"Statement": [
{
"Sid": "__default_statement_ID",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": [
"SNS:GetTopicAttributes",
"SNS:SetTopicAttributes",
"SNS:AddPermission",
"SNS:RemovePermission",
"SNS:DeleteTopic",
"SNS:Subscribe",
"SNS:ListSubscriptionsByTopic",
"SNS:Publish",
"SNS:Receive"
],
"Resource": "arn:aws:sns:eu-west-1:XXXXXXXX:config-topic",
"Condition": {
"StringEquals": {
"AWS:SourceOwner": "XXXXXXXX"
}
}
}
]
}
```
### Expected behavior
It should pass when found a condition like "AWS:SourceOwner" with a valid value.
### Actual Result with Screenshots or Logs
It can't detect correctly the condition, so the test fails.
╭────────────┬───────────┬───────────┬────────────┬────────┬──────────┬───────╮
│ Provider │ Service │ Status │ Critical │ High │ Medium │ Low │
├────────────┼───────────┼───────────┼────────────┼────────┼──────────┼───────┤
│ aws │ sns │ FAIL (13) │ 0 │ 13 │ 0 │ 0 │
╰────────────┴───────────┴───────────┴────────────┴────────┴──────────┴───────╯
### How did you install Prowler?
Cloning the repository from github.com (git clone)
### Environment Resource
8. SNS
### OS used
5. Ubuntu
### Prowler version
Prowler 3.8.2
### Pip version
pip 23.2.1
### Context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py`
Content:
```
1 # lista de cuentas y te devuelva las válidas
2 def is_account_only_allowed_in_condition(
3 condition_statement: dict, source_account: str
4 ):
5 is_condition_valid = False
6 valid_condition_options = {
7 "StringEquals": [
8 "aws:SourceAccount",
9 "aws:SourceOwner",
10 "s3:ResourceAccount",
11 "aws:PrincipalAccount",
12 "aws:ResourceAccount",
13 ],
14 "StringLike": [
15 "aws:SourceAccount",
16 "aws:SourceOwner",
17 "aws:SourceArn",
18 "aws:PrincipalArn",
19 "aws:ResourceAccount",
20 "aws:PrincipalAccount",
21 ],
22 "ArnLike": ["aws:SourceArn", "aws:PrincipalArn"],
23 "ArnEquals": ["aws:SourceArn", "aws:PrincipalArn"],
24 }
25
26 for condition_operator, condition_operator_key in valid_condition_options.items():
27 if condition_operator in condition_statement:
28 for value in condition_operator_key:
29 if value in condition_statement[condition_operator]:
30 # values are a list
31 if isinstance(
32 condition_statement[condition_operator][value],
33 list,
34 ):
35 # if there is an arn/account without the source account -> we do not consider it safe
36 # here by default we assume is true and look for false entries
37 is_condition_valid = True
38 for item in condition_statement[condition_operator][value]:
39 if source_account not in item:
40 is_condition_valid = False
41 break
42
43 # value is a string
44 elif isinstance(
45 condition_statement[condition_operator][value],
46 str,
47 ):
48 if (
49 source_account
50 in condition_statement[condition_operator][value]
51 ):
52 is_condition_valid = True
53
54 return is_condition_valid
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py
--- a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py
+++ b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py
@@ -1,31 +1,52 @@
-# lista de cuentas y te devuelva las válidas
def is_account_only_allowed_in_condition(
condition_statement: dict, source_account: str
):
+ """
+ is_account_only_allowed_in_condition parses the IAM Condition policy block and returns True if the source_account passed as argument is within, False if not.
+
+ @param condition_statement: dict with an IAM Condition block, e.g.:
+ {
+ "StringLike": {
+ "AWS:SourceAccount": 111122223333
+ }
+ }
+
+ @param source_account: str with a 12-digit AWS Account number, e.g.: 111122223333
+ """
is_condition_valid = False
+
+ # The conditions must be defined in lowercase since the context key names are not case-sensitive.
+ # For example, including the aws:SourceAccount context key is equivalent to testing for AWS:SourceAccount
+ # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html
valid_condition_options = {
"StringEquals": [
- "aws:SourceAccount",
- "aws:SourceOwner",
- "s3:ResourceAccount",
- "aws:PrincipalAccount",
- "aws:ResourceAccount",
+ "aws:sourceaccount",
+ "aws:sourceowner",
+ "s3:resourceaccount",
+ "aws:principalaccount",
+ "aws:resourceaccount",
],
"StringLike": [
- "aws:SourceAccount",
- "aws:SourceOwner",
- "aws:SourceArn",
- "aws:PrincipalArn",
- "aws:ResourceAccount",
- "aws:PrincipalAccount",
+ "aws:sourceaccount",
+ "aws:sourceowner",
+ "aws:sourcearn",
+ "aws:principalarn",
+ "aws:resourceaccount",
+ "aws:principalaccount",
],
- "ArnLike": ["aws:SourceArn", "aws:PrincipalArn"],
- "ArnEquals": ["aws:SourceArn", "aws:PrincipalArn"],
+ "ArnLike": ["aws:sourcearn", "aws:principalarn"],
+ "ArnEquals": ["aws:sourcearn", "aws:principalarn"],
}
for condition_operator, condition_operator_key in valid_condition_options.items():
if condition_operator in condition_statement:
for value in condition_operator_key:
+ # We need to transform the condition_statement into lowercase
+ condition_statement[condition_operator] = {
+ k.lower(): v
+ for k, v in condition_statement[condition_operator].items()
+ }
+
if value in condition_statement[condition_operator]:
# values are a list
if isinstance(
|
{"golden_diff": "diff --git a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py\n--- a/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py\n+++ b/prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py\n@@ -1,31 +1,52 @@\n-# lista de cuentas y te devuelva las v\u00e1lidas\n def is_account_only_allowed_in_condition(\n condition_statement: dict, source_account: str\n ):\n+ \"\"\"\n+ is_account_only_allowed_in_condition parses the IAM Condition policy block and returns True if the source_account passed as argument is within, False if not.\n+\n+ @param condition_statement: dict with an IAM Condition block, e.g.:\n+ {\n+ \"StringLike\": {\n+ \"AWS:SourceAccount\": 111122223333\n+ }\n+ }\n+\n+ @param source_account: str with a 12-digit AWS Account number, e.g.: 111122223333\n+ \"\"\"\n is_condition_valid = False\n+\n+ # The conditions must be defined in lowercase since the context key names are not case-sensitive.\n+ # For example, including the aws:SourceAccount context key is equivalent to testing for AWS:SourceAccount\n+ # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html\n valid_condition_options = {\n \"StringEquals\": [\n- \"aws:SourceAccount\",\n- \"aws:SourceOwner\",\n- \"s3:ResourceAccount\",\n- \"aws:PrincipalAccount\",\n- \"aws:ResourceAccount\",\n+ \"aws:sourceaccount\",\n+ \"aws:sourceowner\",\n+ \"s3:resourceaccount\",\n+ \"aws:principalaccount\",\n+ \"aws:resourceaccount\",\n ],\n \"StringLike\": [\n- \"aws:SourceAccount\",\n- \"aws:SourceOwner\",\n- \"aws:SourceArn\",\n- \"aws:PrincipalArn\",\n- \"aws:ResourceAccount\",\n- \"aws:PrincipalAccount\",\n+ \"aws:sourceaccount\",\n+ \"aws:sourceowner\",\n+ \"aws:sourcearn\",\n+ \"aws:principalarn\",\n+ \"aws:resourceaccount\",\n+ \"aws:principalaccount\",\n ],\n- \"ArnLike\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n- \"ArnEquals\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n+ \"ArnLike\": [\"aws:sourcearn\", \"aws:principalarn\"],\n+ \"ArnEquals\": [\"aws:sourcearn\", \"aws:principalarn\"],\n }\n \n for condition_operator, condition_operator_key in valid_condition_options.items():\n if condition_operator in condition_statement:\n for value in condition_operator_key:\n+ # We need to transform the condition_statement into lowercase\n+ condition_statement[condition_operator] = {\n+ k.lower(): v\n+ for k, v in condition_statement[condition_operator].items()\n+ }\n+\n if value in condition_statement[condition_operator]:\n # values are a list\n if isinstance(\n", "issue": "[Bug]: Context name on conditions are case-insensitive\n### Steps to Reproduce\n\nAs yo can see here https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html, context name on conditions are case-insensitive. Some default aws policies are \"AWS:xxxx\" instead of \"aws:xxxx\", so prowler fails to detect it. Also can happen with manual policies, if someone put \"aws:sourceaccount\" inseat of \"aws:SourceAccount\". So is_account_only_allowed_in_condition must be case-insensitive to work.\r\n\r\nI found it on SNS default policy, which look like this:\r\n\r\n```\r\n{\r\n \"Version\": \"2008-10-17\",\r\n \"Id\": \"__default_policy_ID\",\r\n \"Statement\": [\r\n {\r\n \"Sid\": \"__default_statement_ID\",\r\n \"Effect\": \"Allow\",\r\n \"Principal\": {\r\n \"AWS\": \"*\"\r\n },\r\n \"Action\": [\r\n \"SNS:GetTopicAttributes\",\r\n \"SNS:SetTopicAttributes\",\r\n \"SNS:AddPermission\",\r\n \"SNS:RemovePermission\",\r\n \"SNS:DeleteTopic\",\r\n \"SNS:Subscribe\",\r\n \"SNS:ListSubscriptionsByTopic\",\r\n \"SNS:Publish\",\r\n \"SNS:Receive\"\r\n ],\r\n \"Resource\": \"arn:aws:sns:eu-west-1:XXXXXXXX:config-topic\",\r\n \"Condition\": {\r\n \"StringEquals\": {\r\n \"AWS:SourceOwner\": \"XXXXXXXX\"\r\n }\r\n }\r\n }\r\n ]\r\n}\r\n```\r\n\r\n\n\n### Expected behavior\n\nIt should pass when found a condition like \"AWS:SourceOwner\" with a valid value. \n\n### Actual Result with Screenshots or Logs\n\nIt can't detect correctly the condition, so the test fails.\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 Provider \u2502 Service \u2502 Status \u2502 Critical \u2502 High \u2502 Medium \u2502 Low \u2502\r\n\u251c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u253c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2524\r\n\u2502 aws \u2502 sns \u2502 FAIL (13) \u2502 0 \u2502 13 \u2502 0 \u2502 0 \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2534\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\n\n### How did you install Prowler?\n\nCloning the repository from github.com (git clone)\n\n### Environment Resource\n\n8. SNS\n\n### OS used\n\n5. Ubuntu\n\n### Prowler version\n\nProwler 3.8.2\n\n### Pip version\n\npip 23.2.1\n\n### Context\n\n_No response_\n", "before_files": [{"content": "# lista de cuentas y te devuelva las v\u00e1lidas\ndef is_account_only_allowed_in_condition(\n condition_statement: dict, source_account: str\n):\n is_condition_valid = False\n valid_condition_options = {\n \"StringEquals\": [\n \"aws:SourceAccount\",\n \"aws:SourceOwner\",\n \"s3:ResourceAccount\",\n \"aws:PrincipalAccount\",\n \"aws:ResourceAccount\",\n ],\n \"StringLike\": [\n \"aws:SourceAccount\",\n \"aws:SourceOwner\",\n \"aws:SourceArn\",\n \"aws:PrincipalArn\",\n \"aws:ResourceAccount\",\n \"aws:PrincipalAccount\",\n ],\n \"ArnLike\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n \"ArnEquals\": [\"aws:SourceArn\", \"aws:PrincipalArn\"],\n }\n\n for condition_operator, condition_operator_key in valid_condition_options.items():\n if condition_operator in condition_statement:\n for value in condition_operator_key:\n if value in condition_statement[condition_operator]:\n # values are a list\n if isinstance(\n condition_statement[condition_operator][value],\n list,\n ):\n # if there is an arn/account without the source account -> we do not consider it safe\n # here by default we assume is true and look for false entries\n is_condition_valid = True\n for item in condition_statement[condition_operator][value]:\n if source_account not in item:\n is_condition_valid = False\n break\n\n # value is a string\n elif isinstance(\n condition_statement[condition_operator][value],\n str,\n ):\n if (\n source_account\n in condition_statement[condition_operator][value]\n ):\n is_condition_valid = True\n\n return is_condition_valid\n", "path": "prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py"}], "after_files": [{"content": "def is_account_only_allowed_in_condition(\n condition_statement: dict, source_account: str\n):\n \"\"\"\n is_account_only_allowed_in_condition parses the IAM Condition policy block and returns True if the source_account passed as argument is within, False if not.\n\n @param condition_statement: dict with an IAM Condition block, e.g.:\n {\n \"StringLike\": {\n \"AWS:SourceAccount\": 111122223333\n }\n }\n\n @param source_account: str with a 12-digit AWS Account number, e.g.: 111122223333\n \"\"\"\n is_condition_valid = False\n\n # The conditions must be defined in lowercase since the context key names are not case-sensitive.\n # For example, including the aws:SourceAccount context key is equivalent to testing for AWS:SourceAccount\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_condition.html\n valid_condition_options = {\n \"StringEquals\": [\n \"aws:sourceaccount\",\n \"aws:sourceowner\",\n \"s3:resourceaccount\",\n \"aws:principalaccount\",\n \"aws:resourceaccount\",\n ],\n \"StringLike\": [\n \"aws:sourceaccount\",\n \"aws:sourceowner\",\n \"aws:sourcearn\",\n \"aws:principalarn\",\n \"aws:resourceaccount\",\n \"aws:principalaccount\",\n ],\n \"ArnLike\": [\"aws:sourcearn\", \"aws:principalarn\"],\n \"ArnEquals\": [\"aws:sourcearn\", \"aws:principalarn\"],\n }\n\n for condition_operator, condition_operator_key in valid_condition_options.items():\n if condition_operator in condition_statement:\n for value in condition_operator_key:\n # We need to transform the condition_statement into lowercase\n condition_statement[condition_operator] = {\n k.lower(): v\n for k, v in condition_statement[condition_operator].items()\n }\n\n if value in condition_statement[condition_operator]:\n # values are a list\n if isinstance(\n condition_statement[condition_operator][value],\n list,\n ):\n # if there is an arn/account without the source account -> we do not consider it safe\n # here by default we assume is true and look for false entries\n is_condition_valid = True\n for item in condition_statement[condition_operator][value]:\n if source_account not in item:\n is_condition_valid = False\n break\n\n # value is a string\n elif isinstance(\n condition_statement[condition_operator][value],\n str,\n ):\n if (\n source_account\n in condition_statement[condition_operator][value]\n ):\n is_condition_valid = True\n\n return is_condition_valid\n", "path": "prowler/providers/aws/lib/policy_condition_parser/policy_condition_parser.py"}]}
| 1,318 | 697 |
gh_patches_debug_6499
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-481
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Warn about ignored buildHorizon and logHorizion.
These aren't currently used, but they could be supported in the database. Either we should get rid of them, or open a ticket to add back support (and probably document that they aren't currently working).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/status/web/logs.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16
17 from zope.interface import implements
18 from twisted.python import components
19 from twisted.spread import pb
20 from twisted.web import server
21 from twisted.web.resource import Resource
22 from twisted.web.error import NoResource
23
24 from buildbot import interfaces
25 from buildbot.status import logfile
26 from buildbot.status.web.base import IHTMLLog, HtmlResource, path_to_root
27
28 class ChunkConsumer:
29 implements(interfaces.IStatusLogConsumer)
30
31 def __init__(self, original, textlog):
32 self.original = original
33 self.textlog = textlog
34 def registerProducer(self, producer, streaming):
35 self.producer = producer
36 self.original.registerProducer(producer, streaming)
37 def unregisterProducer(self):
38 self.original.unregisterProducer()
39 def writeChunk(self, chunk):
40 formatted = self.textlog.content([chunk])
41 try:
42 if isinstance(formatted, unicode):
43 formatted = formatted.encode('utf-8')
44 self.original.write(formatted)
45 except pb.DeadReferenceError:
46 self.producing.stopProducing()
47 def finish(self):
48 self.textlog.finished()
49
50
51 # /builders/$builder/builds/$buildnum/steps/$stepname/logs/$logname
52 class TextLog(Resource):
53 # a new instance of this Resource is created for each client who views
54 # it, so we can afford to track the request in the Resource.
55 implements(IHTMLLog)
56
57 asText = False
58 subscribed = False
59
60 def __init__(self, original):
61 Resource.__init__(self)
62 self.original = original
63
64 def getChild(self, path, req):
65 if path == "text":
66 self.asText = True
67 return self
68 return Resource.getChild(self, path, req)
69
70 def content(self, entries):
71 html_entries = []
72 text_data = ''
73 for type, entry in entries:
74 if type >= len(logfile.ChunkTypes) or type < 0:
75 # non-std channel, don't display
76 continue
77
78 is_header = type == logfile.HEADER
79
80 if not self.asText:
81 # jinja only works with unicode, or pure ascii, so assume utf-8 in logs
82 if not isinstance(entry, unicode):
83 entry = unicode(entry, 'utf-8', 'replace')
84 html_entries.append(dict(type = logfile.ChunkTypes[type],
85 text = entry,
86 is_header = is_header))
87 elif not is_header:
88 text_data += entry
89
90 if self.asText:
91 return text_data
92 else:
93 return self.template.module.chunks(html_entries)
94
95 def render_HEAD(self, req):
96 self._setContentType(req)
97
98 # vague approximation, ignores markup
99 req.setHeader("content-length", self.original.length)
100 return ''
101
102 def render_GET(self, req):
103 self._setContentType(req)
104 self.req = req
105
106 if not self.asText:
107 self.template = req.site.buildbot_service.templates.get_template("logs.html")
108
109 data = self.template.module.page_header(
110 pageTitle = "Log File contents",
111 texturl = req.childLink("text"),
112 path_to_root = path_to_root(req))
113 data = data.encode('utf-8')
114 req.write(data)
115
116 self.original.subscribeConsumer(ChunkConsumer(req, self))
117 return server.NOT_DONE_YET
118
119 def _setContentType(self, req):
120 if self.asText:
121 req.setHeader("content-type", "text/plain; charset=utf-8")
122 else:
123 req.setHeader("content-type", "text/html; charset=utf-8")
124
125 def finished(self):
126 if not self.req:
127 return
128 try:
129 if not self.asText:
130 data = self.template.module.page_footer()
131 data = data.encode('utf-8')
132 self.req.write(data)
133 self.req.finish()
134 except pb.DeadReferenceError:
135 pass
136 # break the cycle, the Request's .notifications list includes the
137 # Deferred (from req.notifyFinish) that's pointing at us.
138 self.req = None
139
140 # release template
141 self.template = None
142
143 components.registerAdapter(TextLog, interfaces.IStatusLog, IHTMLLog)
144
145
146 class HTMLLog(Resource):
147 implements(IHTMLLog)
148
149 def __init__(self, original):
150 Resource.__init__(self)
151 self.original = original
152
153 def render(self, request):
154 request.setHeader("content-type", "text/html")
155 return self.original.html
156
157 components.registerAdapter(HTMLLog, logfile.HTMLLogFile, IHTMLLog)
158
159
160 class LogsResource(HtmlResource):
161 addSlash = True
162
163 def __init__(self, step_status):
164 HtmlResource.__init__(self)
165 self.step_status = step_status
166
167 def getChild(self, path, req):
168 for log in self.step_status.getLogs():
169 if path == log.getName():
170 if log.hasContents():
171 return IHTMLLog(interfaces.IStatusLog(log))
172 return NoResource("Empty Log '%s'" % path)
173 return HtmlResource.getChild(self, path, req)
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/status/web/logs.py b/master/buildbot/status/web/logs.py
--- a/master/buildbot/status/web/logs.py
+++ b/master/buildbot/status/web/logs.py
@@ -103,6 +103,11 @@
self._setContentType(req)
self.req = req
+ if (self.original.isFinished()):
+ req.setHeader("Cache-Control", "max-age=604800")
+ else:
+ req.setHeader("Cache-Control", "no-cache")
+
if not self.asText:
self.template = req.site.buildbot_service.templates.get_template("logs.html")
|
{"golden_diff": "diff --git a/master/buildbot/status/web/logs.py b/master/buildbot/status/web/logs.py\n--- a/master/buildbot/status/web/logs.py\n+++ b/master/buildbot/status/web/logs.py\n@@ -103,6 +103,11 @@\n self._setContentType(req)\n self.req = req\n \n+ if (self.original.isFinished()):\n+ req.setHeader(\"Cache-Control\", \"max-age=604800\")\n+ else:\n+ req.setHeader(\"Cache-Control\", \"no-cache\")\n+\n if not self.asText:\n self.template = req.site.buildbot_service.templates.get_template(\"logs.html\")\n", "issue": "Warn about ignored buildHorizon and logHorizion.\nThese aren't currently used, but they could be supported in the database. Either we should get rid of them, or open a ticket to add back support (and probably document that they aren't currently working).\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\nfrom zope.interface import implements\nfrom twisted.python import components\nfrom twisted.spread import pb\nfrom twisted.web import server\nfrom twisted.web.resource import Resource\nfrom twisted.web.error import NoResource\n\nfrom buildbot import interfaces\nfrom buildbot.status import logfile\nfrom buildbot.status.web.base import IHTMLLog, HtmlResource, path_to_root\n\nclass ChunkConsumer:\n implements(interfaces.IStatusLogConsumer)\n\n def __init__(self, original, textlog):\n self.original = original\n self.textlog = textlog\n def registerProducer(self, producer, streaming):\n self.producer = producer\n self.original.registerProducer(producer, streaming)\n def unregisterProducer(self):\n self.original.unregisterProducer()\n def writeChunk(self, chunk):\n formatted = self.textlog.content([chunk])\n try:\n if isinstance(formatted, unicode):\n formatted = formatted.encode('utf-8')\n self.original.write(formatted)\n except pb.DeadReferenceError:\n self.producing.stopProducing()\n def finish(self):\n self.textlog.finished()\n\n\n# /builders/$builder/builds/$buildnum/steps/$stepname/logs/$logname\nclass TextLog(Resource):\n # a new instance of this Resource is created for each client who views\n # it, so we can afford to track the request in the Resource.\n implements(IHTMLLog)\n\n asText = False\n subscribed = False\n\n def __init__(self, original):\n Resource.__init__(self)\n self.original = original\n\n def getChild(self, path, req):\n if path == \"text\":\n self.asText = True\n return self\n return Resource.getChild(self, path, req)\n\n def content(self, entries):\n html_entries = []\n text_data = ''\n for type, entry in entries:\n if type >= len(logfile.ChunkTypes) or type < 0:\n # non-std channel, don't display\n continue\n \n is_header = type == logfile.HEADER\n\n if not self.asText:\n # jinja only works with unicode, or pure ascii, so assume utf-8 in logs\n if not isinstance(entry, unicode):\n entry = unicode(entry, 'utf-8', 'replace')\n html_entries.append(dict(type = logfile.ChunkTypes[type], \n text = entry,\n is_header = is_header))\n elif not is_header:\n text_data += entry\n\n if self.asText:\n return text_data\n else:\n return self.template.module.chunks(html_entries)\n\n def render_HEAD(self, req):\n self._setContentType(req)\n\n # vague approximation, ignores markup\n req.setHeader(\"content-length\", self.original.length)\n return ''\n\n def render_GET(self, req):\n self._setContentType(req)\n self.req = req\n\n if not self.asText:\n self.template = req.site.buildbot_service.templates.get_template(\"logs.html\") \n \n data = self.template.module.page_header(\n pageTitle = \"Log File contents\",\n texturl = req.childLink(\"text\"),\n path_to_root = path_to_root(req))\n data = data.encode('utf-8') \n req.write(data)\n\n self.original.subscribeConsumer(ChunkConsumer(req, self))\n return server.NOT_DONE_YET\n\n def _setContentType(self, req):\n if self.asText:\n req.setHeader(\"content-type\", \"text/plain; charset=utf-8\")\n else:\n req.setHeader(\"content-type\", \"text/html; charset=utf-8\")\n \n def finished(self):\n if not self.req:\n return\n try:\n if not self.asText:\n data = self.template.module.page_footer()\n data = data.encode('utf-8')\n self.req.write(data)\n self.req.finish()\n except pb.DeadReferenceError:\n pass\n # break the cycle, the Request's .notifications list includes the\n # Deferred (from req.notifyFinish) that's pointing at us.\n self.req = None\n \n # release template\n self.template = None\n\ncomponents.registerAdapter(TextLog, interfaces.IStatusLog, IHTMLLog)\n\n\nclass HTMLLog(Resource):\n implements(IHTMLLog)\n\n def __init__(self, original):\n Resource.__init__(self)\n self.original = original\n\n def render(self, request):\n request.setHeader(\"content-type\", \"text/html\")\n return self.original.html\n\ncomponents.registerAdapter(HTMLLog, logfile.HTMLLogFile, IHTMLLog)\n\n\nclass LogsResource(HtmlResource):\n addSlash = True\n\n def __init__(self, step_status):\n HtmlResource.__init__(self)\n self.step_status = step_status\n\n def getChild(self, path, req):\n for log in self.step_status.getLogs():\n if path == log.getName():\n if log.hasContents():\n return IHTMLLog(interfaces.IStatusLog(log))\n return NoResource(\"Empty Log '%s'\" % path)\n return HtmlResource.getChild(self, path, req)\n", "path": "master/buildbot/status/web/logs.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\nfrom zope.interface import implements\nfrom twisted.python import components\nfrom twisted.spread import pb\nfrom twisted.web import server\nfrom twisted.web.resource import Resource\nfrom twisted.web.error import NoResource\n\nfrom buildbot import interfaces\nfrom buildbot.status import logfile\nfrom buildbot.status.web.base import IHTMLLog, HtmlResource, path_to_root\n\nclass ChunkConsumer:\n implements(interfaces.IStatusLogConsumer)\n\n def __init__(self, original, textlog):\n self.original = original\n self.textlog = textlog\n def registerProducer(self, producer, streaming):\n self.producer = producer\n self.original.registerProducer(producer, streaming)\n def unregisterProducer(self):\n self.original.unregisterProducer()\n def writeChunk(self, chunk):\n formatted = self.textlog.content([chunk])\n try:\n if isinstance(formatted, unicode):\n formatted = formatted.encode('utf-8')\n self.original.write(formatted)\n except pb.DeadReferenceError:\n self.producing.stopProducing()\n def finish(self):\n self.textlog.finished()\n\n\n# /builders/$builder/builds/$buildnum/steps/$stepname/logs/$logname\nclass TextLog(Resource):\n # a new instance of this Resource is created for each client who views\n # it, so we can afford to track the request in the Resource.\n implements(IHTMLLog)\n\n asText = False\n subscribed = False\n\n def __init__(self, original):\n Resource.__init__(self)\n self.original = original\n\n def getChild(self, path, req):\n if path == \"text\":\n self.asText = True\n return self\n return Resource.getChild(self, path, req)\n\n def content(self, entries):\n html_entries = []\n text_data = ''\n for type, entry in entries:\n if type >= len(logfile.ChunkTypes) or type < 0:\n # non-std channel, don't display\n continue\n \n is_header = type == logfile.HEADER\n\n if not self.asText:\n # jinja only works with unicode, or pure ascii, so assume utf-8 in logs\n if not isinstance(entry, unicode):\n entry = unicode(entry, 'utf-8', 'replace')\n html_entries.append(dict(type = logfile.ChunkTypes[type], \n text = entry,\n is_header = is_header))\n elif not is_header:\n text_data += entry\n\n if self.asText:\n return text_data\n else:\n return self.template.module.chunks(html_entries)\n\n def render_HEAD(self, req):\n self._setContentType(req)\n\n # vague approximation, ignores markup\n req.setHeader(\"content-length\", self.original.length)\n return ''\n\n def render_GET(self, req):\n self._setContentType(req)\n self.req = req\n\n if (self.original.isFinished()):\n req.setHeader(\"Cache-Control\", \"max-age=604800\")\n else:\n req.setHeader(\"Cache-Control\", \"no-cache\")\n\n if not self.asText:\n self.template = req.site.buildbot_service.templates.get_template(\"logs.html\") \n \n data = self.template.module.page_header(\n pageTitle = \"Log File contents\",\n texturl = req.childLink(\"text\"),\n path_to_root = path_to_root(req))\n data = data.encode('utf-8') \n req.write(data)\n\n self.original.subscribeConsumer(ChunkConsumer(req, self))\n return server.NOT_DONE_YET\n\n def _setContentType(self, req):\n if self.asText:\n req.setHeader(\"content-type\", \"text/plain; charset=utf-8\")\n else:\n req.setHeader(\"content-type\", \"text/html; charset=utf-8\")\n \n def finished(self):\n if not self.req:\n return\n try:\n if not self.asText:\n data = self.template.module.page_footer()\n data = data.encode('utf-8')\n self.req.write(data)\n self.req.finish()\n except pb.DeadReferenceError:\n pass\n # break the cycle, the Request's .notifications list includes the\n # Deferred (from req.notifyFinish) that's pointing at us.\n self.req = None\n \n # release template\n self.template = None\n\ncomponents.registerAdapter(TextLog, interfaces.IStatusLog, IHTMLLog)\n\n\nclass HTMLLog(Resource):\n implements(IHTMLLog)\n\n def __init__(self, original):\n Resource.__init__(self)\n self.original = original\n\n def render(self, request):\n request.setHeader(\"content-type\", \"text/html\")\n return self.original.html\n\ncomponents.registerAdapter(HTMLLog, logfile.HTMLLogFile, IHTMLLog)\n\n\nclass LogsResource(HtmlResource):\n addSlash = True\n\n def __init__(self, step_status):\n HtmlResource.__init__(self)\n self.step_status = step_status\n\n def getChild(self, path, req):\n for log in self.step_status.getLogs():\n if path == log.getName():\n if log.hasContents():\n return IHTMLLog(interfaces.IStatusLog(log))\n return NoResource(\"Empty Log '%s'\" % path)\n return HtmlResource.getChild(self, path, req)\n", "path": "master/buildbot/status/web/logs.py"}]}
| 1,975 | 136 |
gh_patches_debug_28421
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3015
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Plone does not redirect ajax calls
## BUG/PROBLEM REPORT (OR OTHER COMMON ISSUE)
### What I did:
1. Create a document with id "a"
2. Rename it to "b"
3. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: text/html'`: you will get a redirect (301) + some not useful text ignored by the browser
4. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: application/json'` you will get a not found json text (status 404)
Note that the two commands differ only for the `Accept` header.
### What I expect to happen:
I expect a 301 when I browse to http://localhost:8080/Plone/a/@@getVocabulary for both the values of the Accept header
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/browser/exceptions.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from AccessControl import getSecurityManager
3 from Products.Five import BrowserView
4 from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
5 from zExceptions.ExceptionFormatter import format_exception
6
7 import json
8 import sys
9
10
11 class ExceptionView(BrowserView):
12 basic_template = ViewPageTemplateFile('templates/basic_error_message.pt')
13
14 def is_manager(self):
15 return getSecurityManager().checkPermission(
16 'Manage portal', self.context)
17
18 def __call__(self):
19 exception = self.context
20 self.context = self.__parent__
21 request = self.request
22
23 error_type = exception.__class__.__name__
24 exc_type, value, traceback = sys.exc_info()
25 error_tb = ''.join(
26 format_exception(exc_type, value, traceback, as_html=False))
27 request.response.setStatus(exc_type)
28
29 # Indicate exception as JSON
30 if "text/html" not in request.getHeader('Accept', ''):
31 request.response.setHeader("Content-Type", "application/json")
32 return json.dumps({
33 'error_type': error_type,
34 })
35
36 # Render page with user-facing error notice
37 request.set('disable_border', True)
38 request.set('disable_plone.leftcolumn', True)
39 request.set('disable_plone.rightcolumn', True)
40
41 try:
42 return self.index(
43 error_type=error_type,
44 error_tb=error_tb)
45 except:
46 return self.basic_template(
47 error_type=error_type,
48 error_tb=error_tb)
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/browser/exceptions.py b/Products/CMFPlone/browser/exceptions.py
--- a/Products/CMFPlone/browser/exceptions.py
+++ b/Products/CMFPlone/browser/exceptions.py
@@ -1,8 +1,10 @@
# -*- coding: utf-8 -*-
from AccessControl import getSecurityManager
+from plone.memoize.view import memoize
from Products.Five import BrowserView
from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
from zExceptions.ExceptionFormatter import format_exception
+from zope.component import getMultiAdapter
import json
import sys
@@ -15,12 +17,24 @@
return getSecurityManager().checkPermission(
'Manage portal', self.context)
+ @property
+ @memoize
+ def plone_redirector_view(self):
+ return getMultiAdapter(
+ (self.__parent__, self.request), name="plone_redirector_view"
+ )
+
def __call__(self):
exception = self.context
+ error_type = exception.__class__.__name__
+ if error_type == "NotFound" and self.plone_redirector_view.attempt_redirect():
+ # if a redirect is possible attempt_redirect returns True
+ # and sets the proper location header
+ return
+
self.context = self.__parent__
request = self.request
- error_type = exception.__class__.__name__
exc_type, value, traceback = sys.exc_info()
error_tb = ''.join(
format_exception(exc_type, value, traceback, as_html=False))
|
{"golden_diff": "diff --git a/Products/CMFPlone/browser/exceptions.py b/Products/CMFPlone/browser/exceptions.py\n--- a/Products/CMFPlone/browser/exceptions.py\n+++ b/Products/CMFPlone/browser/exceptions.py\n@@ -1,8 +1,10 @@\n # -*- coding: utf-8 -*-\n from AccessControl import getSecurityManager\n+from plone.memoize.view import memoize\n from Products.Five import BrowserView\n from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\n from zExceptions.ExceptionFormatter import format_exception\n+from zope.component import getMultiAdapter\n \n import json\n import sys\n@@ -15,12 +17,24 @@\n return getSecurityManager().checkPermission(\n 'Manage portal', self.context)\n \n+ @property\n+ @memoize\n+ def plone_redirector_view(self):\n+ return getMultiAdapter(\n+ (self.__parent__, self.request), name=\"plone_redirector_view\"\n+ )\n+\n def __call__(self):\n exception = self.context\n+ error_type = exception.__class__.__name__\n+ if error_type == \"NotFound\" and self.plone_redirector_view.attempt_redirect():\n+ # if a redirect is possible attempt_redirect returns True\n+ # and sets the proper location header\n+ return\n+\n self.context = self.__parent__\n request = self.request\n \n- error_type = exception.__class__.__name__\n exc_type, value, traceback = sys.exc_info()\n error_tb = ''.join(\n format_exception(exc_type, value, traceback, as_html=False))\n", "issue": "Plone does not redirect ajax calls\n## BUG/PROBLEM REPORT (OR OTHER COMMON ISSUE)\r\n\r\n### What I did:\r\n\r\n1. Create a document with id \"a\"\r\n2. Rename it to \"b\"\r\n3. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: text/html'`: you will get a redirect (301) + some not useful text ignored by the browser\r\n4. Run `curl -sI 'http://localhost:8080/Plone/a/@@getVocabulary' -H 'Authorization: Basic YOURB64' -H 'Accept: application/json'` you will get a not found json text (status 404)\r\n\r\nNote that the two commands differ only for the `Accept` header.\r\n\r\n### What I expect to happen:\r\n\r\nI expect a 301 when I browse to http://localhost:8080/Plone/a/@@getVocabulary for both the values of the Accept header\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl import getSecurityManager\nfrom Products.Five import BrowserView\nfrom Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\nfrom zExceptions.ExceptionFormatter import format_exception\n\nimport json\nimport sys\n\n\nclass ExceptionView(BrowserView):\n basic_template = ViewPageTemplateFile('templates/basic_error_message.pt')\n\n def is_manager(self):\n return getSecurityManager().checkPermission(\n 'Manage portal', self.context)\n\n def __call__(self):\n exception = self.context\n self.context = self.__parent__\n request = self.request\n\n error_type = exception.__class__.__name__\n exc_type, value, traceback = sys.exc_info()\n error_tb = ''.join(\n format_exception(exc_type, value, traceback, as_html=False))\n request.response.setStatus(exc_type)\n\n # Indicate exception as JSON\n if \"text/html\" not in request.getHeader('Accept', ''):\n request.response.setHeader(\"Content-Type\", \"application/json\")\n return json.dumps({\n 'error_type': error_type,\n })\n\n # Render page with user-facing error notice\n request.set('disable_border', True)\n request.set('disable_plone.leftcolumn', True)\n request.set('disable_plone.rightcolumn', True)\n\n try:\n return self.index(\n error_type=error_type,\n error_tb=error_tb)\n except:\n return self.basic_template(\n error_type=error_type,\n error_tb=error_tb)\n", "path": "Products/CMFPlone/browser/exceptions.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl import getSecurityManager\nfrom plone.memoize.view import memoize\nfrom Products.Five import BrowserView\nfrom Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\nfrom zExceptions.ExceptionFormatter import format_exception\nfrom zope.component import getMultiAdapter\n\nimport json\nimport sys\n\n\nclass ExceptionView(BrowserView):\n basic_template = ViewPageTemplateFile('templates/basic_error_message.pt')\n\n def is_manager(self):\n return getSecurityManager().checkPermission(\n 'Manage portal', self.context)\n\n @property\n @memoize\n def plone_redirector_view(self):\n return getMultiAdapter(\n (self.__parent__, self.request), name=\"plone_redirector_view\"\n )\n\n def __call__(self):\n exception = self.context\n error_type = exception.__class__.__name__\n if error_type == \"NotFound\" and self.plone_redirector_view.attempt_redirect():\n # if a redirect is possible attempt_redirect returns True\n # and sets the proper location header\n return\n\n self.context = self.__parent__\n request = self.request\n\n exc_type, value, traceback = sys.exc_info()\n error_tb = ''.join(\n format_exception(exc_type, value, traceback, as_html=False))\n request.response.setStatus(exc_type)\n\n # Indicate exception as JSON\n if \"text/html\" not in request.getHeader('Accept', ''):\n request.response.setHeader(\"Content-Type\", \"application/json\")\n return json.dumps({\n 'error_type': error_type,\n })\n\n # Render page with user-facing error notice\n request.set('disable_border', True)\n request.set('disable_plone.leftcolumn', True)\n request.set('disable_plone.rightcolumn', True)\n\n try:\n return self.index(\n error_type=error_type,\n error_tb=error_tb)\n except:\n return self.basic_template(\n error_type=error_type,\n error_tb=error_tb)\n", "path": "Products/CMFPlone/browser/exceptions.py"}]}
| 911 | 354 |
gh_patches_debug_44184
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-2899
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add the example of super_resolution
Related to #2878
Description: I have added the example for the super resolution in the `PyTorch/examples`
Check list:
- [x] New tests are added (if a new feature is added)
- [ ] New doc strings: description and/or example code are in RST format
- [ ] Documentation is updated (if required)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/super_resolution/main.py`
Content:
```
1 import argparse
2
3 import torch
4 import torch.nn as nn
5 import torch.optim as optim
6 import torchvision
7 from model import Net
8 from torch.utils.data import DataLoader
9 from torchvision.transforms.functional import center_crop, resize, to_tensor
10
11 from ignite.engine import Engine, Events
12 from ignite.metrics import PSNR
13
14 # Training settings
15 parser = argparse.ArgumentParser(description="PyTorch Super Res Example")
16 parser.add_argument("--upscale_factor", type=int, required=True, help="super resolution upscale factor")
17 parser.add_argument("--batch_size", type=int, default=64, help="training batch size")
18 parser.add_argument("--test_batch_size", type=int, default=10, help="testing batch size")
19 parser.add_argument("--n_epochs", type=int, default=2, help="number of epochs to train for")
20 parser.add_argument("--lr", type=float, default=0.01, help="Learning Rate. Default=0.01")
21 parser.add_argument("--cuda", action="store_true", help="use cuda?")
22 parser.add_argument("--mps", action="store_true", default=False, help="enables macOS GPU training")
23 parser.add_argument("--threads", type=int, default=4, help="number of threads for data loader to use")
24 parser.add_argument("--seed", type=int, default=123, help="random seed to use. Default=123")
25 opt = parser.parse_args()
26
27 print(opt)
28
29 if opt.cuda and not torch.cuda.is_available():
30 raise Exception("No GPU found, please run without --cuda")
31 if not opt.mps and torch.backends.mps.is_available():
32 raise Exception("Found mps device, please run with --mps to enable macOS GPU")
33
34 torch.manual_seed(opt.seed)
35 use_mps = opt.mps and torch.backends.mps.is_available()
36
37 if opt.cuda:
38 device = torch.device("cuda")
39 elif use_mps:
40 device = torch.device("mps")
41 else:
42 device = torch.device("cpu")
43
44 print("===> Loading datasets")
45
46
47 class SRDataset(torch.utils.data.Dataset):
48 def __init__(self, dataset, scale_factor, crop_size=256):
49 self.dataset = dataset
50 self.scale_factor = scale_factor
51 self.crop_size = crop_size
52
53 def __getitem__(self, index):
54 image, _ = self.dataset[index]
55 img = image.convert("YCbCr")
56 hr_image, _, _ = img.split()
57 hr_image = center_crop(hr_image, self.crop_size)
58 lr_image = hr_image.copy()
59 if self.scale_factor != 1:
60 size = self.crop_size // self.scale_factor
61 lr_image = resize(lr_image, [size, size])
62 hr_image = to_tensor(hr_image)
63 lr_image = to_tensor(lr_image)
64 return lr_image, hr_image
65
66 def __len__(self):
67 return len(self.dataset)
68
69
70 trainset = torchvision.datasets.Caltech101(root="./data", download=True)
71 testset = torchvision.datasets.Caltech101(root="./data", download=False)
72
73 trainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor)
74 testset_sr = SRDataset(testset, scale_factor=opt.upscale_factor)
75
76 training_data_loader = DataLoader(dataset=trainset_sr, num_workers=opt.threads, batch_size=opt.batch_size, shuffle=True)
77 testing_data_loader = DataLoader(dataset=testset_sr, num_workers=opt.threads, batch_size=opt.test_batch_size)
78
79 print("===> Building model")
80 model = Net(upscale_factor=opt.upscale_factor).to(device)
81 criterion = nn.MSELoss()
82
83 optimizer = optim.Adam(model.parameters(), lr=opt.lr)
84
85
86 def train_step(engine, batch):
87 model.train()
88 input, target = batch[0].to(device), batch[1].to(device)
89
90 optimizer.zero_grad()
91 loss = criterion(model(input), target)
92 loss.backward()
93 optimizer.step()
94
95 return loss.item()
96
97
98 def validation_step(engine, batch):
99 model.eval()
100 with torch.no_grad():
101 x, y = batch[0].to(device), batch[1].to(device)
102 y_pred = model(x)
103
104 return y_pred, y
105
106
107 trainer = Engine(train_step)
108 evaluator = Engine(validation_step)
109 psnr = PSNR(data_range=1)
110 psnr.attach(evaluator, "psnr")
111 validate_every = 1
112 log_interval = 100
113
114
115 @trainer.on(Events.ITERATION_COMPLETED(every=log_interval))
116 def log_training_loss(engine):
117 print(
118 "===> Epoch[{}]({}/{}): Loss: {:.4f}".format(
119 engine.state.epoch, engine.state.iteration, len(training_data_loader), engine.state.output
120 )
121 )
122
123
124 @trainer.on(Events.EPOCH_COMPLETED(every=validate_every))
125 def log_validation():
126 evaluator.run(testing_data_loader)
127 metrics = evaluator.state.metrics
128 print(f"Epoch: {trainer.state.epoch}, Avg. PSNR: {metrics['psnr']} dB")
129
130
131 @trainer.on(Events.EPOCH_COMPLETED)
132 def log_epoch_time():
133 print(f"Epoch {trainer.state.epoch}, Time Taken : {trainer.state.times['EPOCH_COMPLETED']}")
134
135
136 @trainer.on(Events.COMPLETED)
137 def log_total_time():
138 print(f"Total Time: {trainer.state.times['COMPLETED']}")
139
140
141 @trainer.on(Events.EPOCH_COMPLETED)
142 def checkpoint():
143 model_out_path = "model_epoch_{}.pth".format(trainer.state.epoch)
144 torch.save(model, model_out_path)
145 print("Checkpoint saved to {}".format(model_out_path))
146
147
148 trainer.run(training_data_loader, opt.n_epochs)
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/super_resolution/main.py b/examples/super_resolution/main.py
--- a/examples/super_resolution/main.py
+++ b/examples/super_resolution/main.py
@@ -8,11 +8,15 @@
from torch.utils.data import DataLoader
from torchvision.transforms.functional import center_crop, resize, to_tensor
+from ignite.contrib.handlers import ProgressBar
+
from ignite.engine import Engine, Events
+from ignite.handlers import BasicTimeProfiler
from ignite.metrics import PSNR
# Training settings
parser = argparse.ArgumentParser(description="PyTorch Super Res Example")
+parser.add_argument("--crop_size", type=int, default=256, help="cropped size of the images for training")
parser.add_argument("--upscale_factor", type=int, required=True, help="super resolution upscale factor")
parser.add_argument("--batch_size", type=int, default=64, help="training batch size")
parser.add_argument("--test_batch_size", type=int, default=10, help="testing batch size")
@@ -22,6 +26,8 @@
parser.add_argument("--mps", action="store_true", default=False, help="enables macOS GPU training")
parser.add_argument("--threads", type=int, default=4, help="number of threads for data loader to use")
parser.add_argument("--seed", type=int, default=123, help="random seed to use. Default=123")
+parser.add_argument("--debug", action="store_true", help="use debug")
+
opt = parser.parse_args()
print(opt)
@@ -70,8 +76,8 @@
trainset = torchvision.datasets.Caltech101(root="./data", download=True)
testset = torchvision.datasets.Caltech101(root="./data", download=False)
-trainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor)
-testset_sr = SRDataset(testset, scale_factor=opt.upscale_factor)
+trainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor, crop_size=opt.crop_size)
+testset_sr = SRDataset(testset, scale_factor=opt.upscale_factor, crop_size=opt.crop_size)
training_data_loader = DataLoader(dataset=trainset_sr, num_workers=opt.threads, batch_size=opt.batch_size, shuffle=True)
testing_data_loader = DataLoader(dataset=testset_sr, num_workers=opt.threads, batch_size=opt.test_batch_size)
@@ -109,35 +115,22 @@
psnr = PSNR(data_range=1)
psnr.attach(evaluator, "psnr")
validate_every = 1
-log_interval = 100
-
[email protected](Events.ITERATION_COMPLETED(every=log_interval))
-def log_training_loss(engine):
- print(
- "===> Epoch[{}]({}/{}): Loss: {:.4f}".format(
- engine.state.epoch, engine.state.iteration, len(training_data_loader), engine.state.output
- )
- )
+if opt.debug:
+ epoch_length = 10
+ validate_epoch_length = 1
+else:
+ epoch_length = len(training_data_loader)
+ validate_epoch_length = len(testing_data_loader)
@trainer.on(Events.EPOCH_COMPLETED(every=validate_every))
def log_validation():
- evaluator.run(testing_data_loader)
+ evaluator.run(testing_data_loader, epoch_length=validate_epoch_length)
metrics = evaluator.state.metrics
print(f"Epoch: {trainer.state.epoch}, Avg. PSNR: {metrics['psnr']} dB")
[email protected](Events.EPOCH_COMPLETED)
-def log_epoch_time():
- print(f"Epoch {trainer.state.epoch}, Time Taken : {trainer.state.times['EPOCH_COMPLETED']}")
-
-
[email protected](Events.COMPLETED)
-def log_total_time():
- print(f"Total Time: {trainer.state.times['COMPLETED']}")
-
-
@trainer.on(Events.EPOCH_COMPLETED)
def checkpoint():
model_out_path = "model_epoch_{}.pth".format(trainer.state.epoch)
@@ -145,4 +138,13 @@
print("Checkpoint saved to {}".format(model_out_path))
-trainer.run(training_data_loader, opt.n_epochs)
+# Attach basic profiler
+basic_profiler = BasicTimeProfiler()
+basic_profiler.attach(trainer)
+
+ProgressBar().attach(trainer, output_transform=lambda x: {"loss": x})
+
+trainer.run(training_data_loader, opt.n_epochs, epoch_length=epoch_length)
+
+results = basic_profiler.get_results()
+basic_profiler.print_results(results)
|
{"golden_diff": "diff --git a/examples/super_resolution/main.py b/examples/super_resolution/main.py\n--- a/examples/super_resolution/main.py\n+++ b/examples/super_resolution/main.py\n@@ -8,11 +8,15 @@\n from torch.utils.data import DataLoader\n from torchvision.transforms.functional import center_crop, resize, to_tensor\n \n+from ignite.contrib.handlers import ProgressBar\n+\n from ignite.engine import Engine, Events\n+from ignite.handlers import BasicTimeProfiler\n from ignite.metrics import PSNR\n \n # Training settings\n parser = argparse.ArgumentParser(description=\"PyTorch Super Res Example\")\n+parser.add_argument(\"--crop_size\", type=int, default=256, help=\"cropped size of the images for training\")\n parser.add_argument(\"--upscale_factor\", type=int, required=True, help=\"super resolution upscale factor\")\n parser.add_argument(\"--batch_size\", type=int, default=64, help=\"training batch size\")\n parser.add_argument(\"--test_batch_size\", type=int, default=10, help=\"testing batch size\")\n@@ -22,6 +26,8 @@\n parser.add_argument(\"--mps\", action=\"store_true\", default=False, help=\"enables macOS GPU training\")\n parser.add_argument(\"--threads\", type=int, default=4, help=\"number of threads for data loader to use\")\n parser.add_argument(\"--seed\", type=int, default=123, help=\"random seed to use. Default=123\")\n+parser.add_argument(\"--debug\", action=\"store_true\", help=\"use debug\")\n+\n opt = parser.parse_args()\n \n print(opt)\n@@ -70,8 +76,8 @@\n trainset = torchvision.datasets.Caltech101(root=\"./data\", download=True)\n testset = torchvision.datasets.Caltech101(root=\"./data\", download=False)\n \n-trainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor)\n-testset_sr = SRDataset(testset, scale_factor=opt.upscale_factor)\n+trainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor, crop_size=opt.crop_size)\n+testset_sr = SRDataset(testset, scale_factor=opt.upscale_factor, crop_size=opt.crop_size)\n \n training_data_loader = DataLoader(dataset=trainset_sr, num_workers=opt.threads, batch_size=opt.batch_size, shuffle=True)\n testing_data_loader = DataLoader(dataset=testset_sr, num_workers=opt.threads, batch_size=opt.test_batch_size)\n@@ -109,35 +115,22 @@\n psnr = PSNR(data_range=1)\n psnr.attach(evaluator, \"psnr\")\n validate_every = 1\n-log_interval = 100\n-\n \[email protected](Events.ITERATION_COMPLETED(every=log_interval))\n-def log_training_loss(engine):\n- print(\n- \"===> Epoch[{}]({}/{}): Loss: {:.4f}\".format(\n- engine.state.epoch, engine.state.iteration, len(training_data_loader), engine.state.output\n- )\n- )\n+if opt.debug:\n+ epoch_length = 10\n+ validate_epoch_length = 1\n+else:\n+ epoch_length = len(training_data_loader)\n+ validate_epoch_length = len(testing_data_loader)\n \n \n @trainer.on(Events.EPOCH_COMPLETED(every=validate_every))\n def log_validation():\n- evaluator.run(testing_data_loader)\n+ evaluator.run(testing_data_loader, epoch_length=validate_epoch_length)\n metrics = evaluator.state.metrics\n print(f\"Epoch: {trainer.state.epoch}, Avg. PSNR: {metrics['psnr']} dB\")\n \n \[email protected](Events.EPOCH_COMPLETED)\n-def log_epoch_time():\n- print(f\"Epoch {trainer.state.epoch}, Time Taken : {trainer.state.times['EPOCH_COMPLETED']}\")\n-\n-\[email protected](Events.COMPLETED)\n-def log_total_time():\n- print(f\"Total Time: {trainer.state.times['COMPLETED']}\")\n-\n-\n @trainer.on(Events.EPOCH_COMPLETED)\n def checkpoint():\n model_out_path = \"model_epoch_{}.pth\".format(trainer.state.epoch)\n@@ -145,4 +138,13 @@\n print(\"Checkpoint saved to {}\".format(model_out_path))\n \n \n-trainer.run(training_data_loader, opt.n_epochs)\n+# Attach basic profiler\n+basic_profiler = BasicTimeProfiler()\n+basic_profiler.attach(trainer)\n+\n+ProgressBar().attach(trainer, output_transform=lambda x: {\"loss\": x})\n+\n+trainer.run(training_data_loader, opt.n_epochs, epoch_length=epoch_length)\n+\n+results = basic_profiler.get_results()\n+basic_profiler.print_results(results)\n", "issue": "Add the example of super_resolution\nRelated to #2878 \r\n\r\nDescription: I have added the example for the super resolution in the `PyTorch/examples`\r\n\r\nCheck list:\r\n\r\n- [x] New tests are added (if a new feature is added)\r\n- [ ] New doc strings: description and/or example code are in RST format\r\n- [ ] Documentation is updated (if required)\r\n\n", "before_files": [{"content": "import argparse\n\nimport torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torchvision\nfrom model import Net\nfrom torch.utils.data import DataLoader\nfrom torchvision.transforms.functional import center_crop, resize, to_tensor\n\nfrom ignite.engine import Engine, Events\nfrom ignite.metrics import PSNR\n\n# Training settings\nparser = argparse.ArgumentParser(description=\"PyTorch Super Res Example\")\nparser.add_argument(\"--upscale_factor\", type=int, required=True, help=\"super resolution upscale factor\")\nparser.add_argument(\"--batch_size\", type=int, default=64, help=\"training batch size\")\nparser.add_argument(\"--test_batch_size\", type=int, default=10, help=\"testing batch size\")\nparser.add_argument(\"--n_epochs\", type=int, default=2, help=\"number of epochs to train for\")\nparser.add_argument(\"--lr\", type=float, default=0.01, help=\"Learning Rate. Default=0.01\")\nparser.add_argument(\"--cuda\", action=\"store_true\", help=\"use cuda?\")\nparser.add_argument(\"--mps\", action=\"store_true\", default=False, help=\"enables macOS GPU training\")\nparser.add_argument(\"--threads\", type=int, default=4, help=\"number of threads for data loader to use\")\nparser.add_argument(\"--seed\", type=int, default=123, help=\"random seed to use. Default=123\")\nopt = parser.parse_args()\n\nprint(opt)\n\nif opt.cuda and not torch.cuda.is_available():\n raise Exception(\"No GPU found, please run without --cuda\")\nif not opt.mps and torch.backends.mps.is_available():\n raise Exception(\"Found mps device, please run with --mps to enable macOS GPU\")\n\ntorch.manual_seed(opt.seed)\nuse_mps = opt.mps and torch.backends.mps.is_available()\n\nif opt.cuda:\n device = torch.device(\"cuda\")\nelif use_mps:\n device = torch.device(\"mps\")\nelse:\n device = torch.device(\"cpu\")\n\nprint(\"===> Loading datasets\")\n\n\nclass SRDataset(torch.utils.data.Dataset):\n def __init__(self, dataset, scale_factor, crop_size=256):\n self.dataset = dataset\n self.scale_factor = scale_factor\n self.crop_size = crop_size\n\n def __getitem__(self, index):\n image, _ = self.dataset[index]\n img = image.convert(\"YCbCr\")\n hr_image, _, _ = img.split()\n hr_image = center_crop(hr_image, self.crop_size)\n lr_image = hr_image.copy()\n if self.scale_factor != 1:\n size = self.crop_size // self.scale_factor\n lr_image = resize(lr_image, [size, size])\n hr_image = to_tensor(hr_image)\n lr_image = to_tensor(lr_image)\n return lr_image, hr_image\n\n def __len__(self):\n return len(self.dataset)\n\n\ntrainset = torchvision.datasets.Caltech101(root=\"./data\", download=True)\ntestset = torchvision.datasets.Caltech101(root=\"./data\", download=False)\n\ntrainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor)\ntestset_sr = SRDataset(testset, scale_factor=opt.upscale_factor)\n\ntraining_data_loader = DataLoader(dataset=trainset_sr, num_workers=opt.threads, batch_size=opt.batch_size, shuffle=True)\ntesting_data_loader = DataLoader(dataset=testset_sr, num_workers=opt.threads, batch_size=opt.test_batch_size)\n\nprint(\"===> Building model\")\nmodel = Net(upscale_factor=opt.upscale_factor).to(device)\ncriterion = nn.MSELoss()\n\noptimizer = optim.Adam(model.parameters(), lr=opt.lr)\n\n\ndef train_step(engine, batch):\n model.train()\n input, target = batch[0].to(device), batch[1].to(device)\n\n optimizer.zero_grad()\n loss = criterion(model(input), target)\n loss.backward()\n optimizer.step()\n\n return loss.item()\n\n\ndef validation_step(engine, batch):\n model.eval()\n with torch.no_grad():\n x, y = batch[0].to(device), batch[1].to(device)\n y_pred = model(x)\n\n return y_pred, y\n\n\ntrainer = Engine(train_step)\nevaluator = Engine(validation_step)\npsnr = PSNR(data_range=1)\npsnr.attach(evaluator, \"psnr\")\nvalidate_every = 1\nlog_interval = 100\n\n\[email protected](Events.ITERATION_COMPLETED(every=log_interval))\ndef log_training_loss(engine):\n print(\n \"===> Epoch[{}]({}/{}): Loss: {:.4f}\".format(\n engine.state.epoch, engine.state.iteration, len(training_data_loader), engine.state.output\n )\n )\n\n\[email protected](Events.EPOCH_COMPLETED(every=validate_every))\ndef log_validation():\n evaluator.run(testing_data_loader)\n metrics = evaluator.state.metrics\n print(f\"Epoch: {trainer.state.epoch}, Avg. PSNR: {metrics['psnr']} dB\")\n\n\[email protected](Events.EPOCH_COMPLETED)\ndef log_epoch_time():\n print(f\"Epoch {trainer.state.epoch}, Time Taken : {trainer.state.times['EPOCH_COMPLETED']}\")\n\n\[email protected](Events.COMPLETED)\ndef log_total_time():\n print(f\"Total Time: {trainer.state.times['COMPLETED']}\")\n\n\[email protected](Events.EPOCH_COMPLETED)\ndef checkpoint():\n model_out_path = \"model_epoch_{}.pth\".format(trainer.state.epoch)\n torch.save(model, model_out_path)\n print(\"Checkpoint saved to {}\".format(model_out_path))\n\n\ntrainer.run(training_data_loader, opt.n_epochs)\n", "path": "examples/super_resolution/main.py"}], "after_files": [{"content": "import argparse\n\nimport torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torchvision\nfrom model import Net\nfrom torch.utils.data import DataLoader\nfrom torchvision.transforms.functional import center_crop, resize, to_tensor\n\nfrom ignite.contrib.handlers import ProgressBar\n\nfrom ignite.engine import Engine, Events\nfrom ignite.handlers import BasicTimeProfiler\nfrom ignite.metrics import PSNR\n\n# Training settings\nparser = argparse.ArgumentParser(description=\"PyTorch Super Res Example\")\nparser.add_argument(\"--crop_size\", type=int, default=256, help=\"cropped size of the images for training\")\nparser.add_argument(\"--upscale_factor\", type=int, required=True, help=\"super resolution upscale factor\")\nparser.add_argument(\"--batch_size\", type=int, default=64, help=\"training batch size\")\nparser.add_argument(\"--test_batch_size\", type=int, default=10, help=\"testing batch size\")\nparser.add_argument(\"--n_epochs\", type=int, default=2, help=\"number of epochs to train for\")\nparser.add_argument(\"--lr\", type=float, default=0.01, help=\"Learning Rate. Default=0.01\")\nparser.add_argument(\"--cuda\", action=\"store_true\", help=\"use cuda?\")\nparser.add_argument(\"--mps\", action=\"store_true\", default=False, help=\"enables macOS GPU training\")\nparser.add_argument(\"--threads\", type=int, default=4, help=\"number of threads for data loader to use\")\nparser.add_argument(\"--seed\", type=int, default=123, help=\"random seed to use. Default=123\")\nparser.add_argument(\"--debug\", action=\"store_true\", help=\"use debug\")\n\nopt = parser.parse_args()\n\nprint(opt)\n\nif opt.cuda and not torch.cuda.is_available():\n raise Exception(\"No GPU found, please run without --cuda\")\nif not opt.mps and torch.backends.mps.is_available():\n raise Exception(\"Found mps device, please run with --mps to enable macOS GPU\")\n\ntorch.manual_seed(opt.seed)\nuse_mps = opt.mps and torch.backends.mps.is_available()\n\nif opt.cuda:\n device = torch.device(\"cuda\")\nelif use_mps:\n device = torch.device(\"mps\")\nelse:\n device = torch.device(\"cpu\")\n\nprint(\"===> Loading datasets\")\n\n\nclass SRDataset(torch.utils.data.Dataset):\n def __init__(self, dataset, scale_factor, crop_size=256):\n self.dataset = dataset\n self.scale_factor = scale_factor\n self.crop_size = crop_size\n\n def __getitem__(self, index):\n image, _ = self.dataset[index]\n img = image.convert(\"YCbCr\")\n hr_image, _, _ = img.split()\n hr_image = center_crop(hr_image, self.crop_size)\n lr_image = hr_image.copy()\n if self.scale_factor != 1:\n size = self.crop_size // self.scale_factor\n lr_image = resize(lr_image, [size, size])\n hr_image = to_tensor(hr_image)\n lr_image = to_tensor(lr_image)\n return lr_image, hr_image\n\n def __len__(self):\n return len(self.dataset)\n\n\ntrainset = torchvision.datasets.Caltech101(root=\"./data\", download=True)\ntestset = torchvision.datasets.Caltech101(root=\"./data\", download=False)\n\ntrainset_sr = SRDataset(trainset, scale_factor=opt.upscale_factor, crop_size=opt.crop_size)\ntestset_sr = SRDataset(testset, scale_factor=opt.upscale_factor, crop_size=opt.crop_size)\n\ntraining_data_loader = DataLoader(dataset=trainset_sr, num_workers=opt.threads, batch_size=opt.batch_size, shuffle=True)\ntesting_data_loader = DataLoader(dataset=testset_sr, num_workers=opt.threads, batch_size=opt.test_batch_size)\n\nprint(\"===> Building model\")\nmodel = Net(upscale_factor=opt.upscale_factor).to(device)\ncriterion = nn.MSELoss()\n\noptimizer = optim.Adam(model.parameters(), lr=opt.lr)\n\n\ndef train_step(engine, batch):\n model.train()\n input, target = batch[0].to(device), batch[1].to(device)\n\n optimizer.zero_grad()\n loss = criterion(model(input), target)\n loss.backward()\n optimizer.step()\n\n return loss.item()\n\n\ndef validation_step(engine, batch):\n model.eval()\n with torch.no_grad():\n x, y = batch[0].to(device), batch[1].to(device)\n y_pred = model(x)\n\n return y_pred, y\n\n\ntrainer = Engine(train_step)\nevaluator = Engine(validation_step)\npsnr = PSNR(data_range=1)\npsnr.attach(evaluator, \"psnr\")\nvalidate_every = 1\n\nif opt.debug:\n epoch_length = 10\n validate_epoch_length = 1\nelse:\n epoch_length = len(training_data_loader)\n validate_epoch_length = len(testing_data_loader)\n\n\[email protected](Events.EPOCH_COMPLETED(every=validate_every))\ndef log_validation():\n evaluator.run(testing_data_loader, epoch_length=validate_epoch_length)\n metrics = evaluator.state.metrics\n print(f\"Epoch: {trainer.state.epoch}, Avg. PSNR: {metrics['psnr']} dB\")\n\n\[email protected](Events.EPOCH_COMPLETED)\ndef checkpoint():\n model_out_path = \"model_epoch_{}.pth\".format(trainer.state.epoch)\n torch.save(model, model_out_path)\n print(\"Checkpoint saved to {}\".format(model_out_path))\n\n\n# Attach basic profiler\nbasic_profiler = BasicTimeProfiler()\nbasic_profiler.attach(trainer)\n\nProgressBar().attach(trainer, output_transform=lambda x: {\"loss\": x})\n\ntrainer.run(training_data_loader, opt.n_epochs, epoch_length=epoch_length)\n\nresults = basic_profiler.get_results()\nbasic_profiler.print_results(results)\n", "path": "examples/super_resolution/main.py"}]}
| 1,881 | 980 |
gh_patches_debug_36768
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1309
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python `bigquery_create_job` sample is inconsistent with other code samples
The https://github.com/googleapis/python-bigquery/blob/main/samples/create_job.py code sample appears here: https://cloud.google.com/bigquery/docs/running-jobs#running_jobs_using_client_libraries
This sample requires two improvements:
* [ ] That section is about any kind of job, not just queries. As such, it should use the [create_job](https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job) method instead of the more specific `query` method. There should be comments that it is recommended to use the corresponding method for query/copy/load/extract.
* [ ] Remove `job_id_prefix` logic, as labels cover similar functionality and are recommended over custom job IDs.
* [ ] Move the sample to the `samples/snippets` directory. Needs to be done in 2 separate PRs so that the existing samples in the docs don't 404.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `samples/create_job.py`
Content:
```
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import typing
16
17 if typing.TYPE_CHECKING:
18 from google.cloud import bigquery
19
20
21 def create_job() -> "bigquery.QueryJob":
22
23 # [START bigquery_create_job]
24 from google.cloud import bigquery
25
26 # Construct a BigQuery client object.
27 client = bigquery.Client()
28
29 query_job = client.query(
30 "SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`",
31 # Explicitly force job execution to be routed to a specific processing
32 # location.
33 location="US",
34 # Specify a job configuration to set optional job resource properties.
35 job_config=bigquery.QueryJobConfig(
36 labels={"example-label": "example-value"}, maximum_bytes_billed=1000000
37 ),
38 # The client libraries automatically generate a job ID. Override the
39 # generated ID with either the job_id_prefix or job_id parameters.
40 job_id_prefix="code_sample_",
41 ) # Make an API request.
42
43 print("Started job: {}".format(query_job.job_id))
44 # [END bigquery_create_job]
45 return query_job
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/samples/create_job.py b/samples/create_job.py
--- a/samples/create_job.py
+++ b/samples/create_job.py
@@ -13,12 +13,13 @@
# limitations under the License.
import typing
+from typing import Union
if typing.TYPE_CHECKING:
- from google.cloud import bigquery
+ from google.cloud.bigquery import LoadJob, CopyJob, ExtractJob, QueryJob
-def create_job() -> "bigquery.QueryJob":
+def create_job() -> "Union[LoadJob, CopyJob, ExtractJob, QueryJob]":
# [START bigquery_create_job]
from google.cloud import bigquery
@@ -26,20 +27,41 @@
# Construct a BigQuery client object.
client = bigquery.Client()
- query_job = client.query(
- "SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`",
- # Explicitly force job execution to be routed to a specific processing
- # location.
- location="US",
- # Specify a job configuration to set optional job resource properties.
- job_config=bigquery.QueryJobConfig(
- labels={"example-label": "example-value"}, maximum_bytes_billed=1000000
- ),
- # The client libraries automatically generate a job ID. Override the
- # generated ID with either the job_id_prefix or job_id parameters.
- job_id_prefix="code_sample_",
+ query_job = client.create_job(
+ # Specify a job configuration, providing a query
+ # and/or optional job resource properties, as needed.
+ # The job instance can be a LoadJob, CopyJob, ExtractJob, QueryJob
+ # Here, we demonstrate a "query" job.
+ # References:
+ # https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job
+ # https://cloud.google.com/bigquery/docs/reference/rest/v2/Job
+ #
+ # Example use cases for .create_job() include:
+ # * to retry failed jobs
+ # * to generate jobs with an experimental API property that hasn't
+ # been added to one of the manually written job configuration
+ # classes yet
+ #
+ # NOTE: unless it is necessary to create a job in this way, the
+ # preferred approach is to use one of the dedicated API calls:
+ # client.query()
+ # client.extract_table()
+ # client.copy_table()
+ # client.load_table_file(), client.load_table_from_dataframe(), etc
+ job_config={
+ "query": {
+ "query": """
+ SELECT country_name
+ FROM `bigquery-public-data.utility_us.country_code_iso`
+ LIMIT 5
+ """,
+ },
+ "labels": {"example-label": "example-value"},
+ "maximum_bytes_billed": 10000000,
+ }
) # Make an API request.
- print("Started job: {}".format(query_job.job_id))
+ print(f"Started job: {query_job.job_id}")
# [END bigquery_create_job]
+
return query_job
|
{"golden_diff": "diff --git a/samples/create_job.py b/samples/create_job.py\n--- a/samples/create_job.py\n+++ b/samples/create_job.py\n@@ -13,12 +13,13 @@\n # limitations under the License.\n \n import typing\n+from typing import Union\n \n if typing.TYPE_CHECKING:\n- from google.cloud import bigquery\n+ from google.cloud.bigquery import LoadJob, CopyJob, ExtractJob, QueryJob\n \n \n-def create_job() -> \"bigquery.QueryJob\":\n+def create_job() -> \"Union[LoadJob, CopyJob, ExtractJob, QueryJob]\":\n \n # [START bigquery_create_job]\n from google.cloud import bigquery\n@@ -26,20 +27,41 @@\n # Construct a BigQuery client object.\n client = bigquery.Client()\n \n- query_job = client.query(\n- \"SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`\",\n- # Explicitly force job execution to be routed to a specific processing\n- # location.\n- location=\"US\",\n- # Specify a job configuration to set optional job resource properties.\n- job_config=bigquery.QueryJobConfig(\n- labels={\"example-label\": \"example-value\"}, maximum_bytes_billed=1000000\n- ),\n- # The client libraries automatically generate a job ID. Override the\n- # generated ID with either the job_id_prefix or job_id parameters.\n- job_id_prefix=\"code_sample_\",\n+ query_job = client.create_job(\n+ # Specify a job configuration, providing a query\n+ # and/or optional job resource properties, as needed.\n+ # The job instance can be a LoadJob, CopyJob, ExtractJob, QueryJob\n+ # Here, we demonstrate a \"query\" job.\n+ # References:\n+ # https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job\n+ # https://cloud.google.com/bigquery/docs/reference/rest/v2/Job\n+ #\n+ # Example use cases for .create_job() include:\n+ # * to retry failed jobs\n+ # * to generate jobs with an experimental API property that hasn't\n+ # been added to one of the manually written job configuration\n+ # classes yet\n+ #\n+ # NOTE: unless it is necessary to create a job in this way, the\n+ # preferred approach is to use one of the dedicated API calls:\n+ # client.query()\n+ # client.extract_table()\n+ # client.copy_table()\n+ # client.load_table_file(), client.load_table_from_dataframe(), etc\n+ job_config={\n+ \"query\": {\n+ \"query\": \"\"\"\n+ SELECT country_name\n+ FROM `bigquery-public-data.utility_us.country_code_iso`\n+ LIMIT 5\n+ \"\"\",\n+ },\n+ \"labels\": {\"example-label\": \"example-value\"},\n+ \"maximum_bytes_billed\": 10000000,\n+ }\n ) # Make an API request.\n \n- print(\"Started job: {}\".format(query_job.job_id))\n+ print(f\"Started job: {query_job.job_id}\")\n # [END bigquery_create_job]\n+\n return query_job\n", "issue": "Python `bigquery_create_job` sample is inconsistent with other code samples\nThe https://github.com/googleapis/python-bigquery/blob/main/samples/create_job.py code sample appears here: https://cloud.google.com/bigquery/docs/running-jobs#running_jobs_using_client_libraries\r\n\r\nThis sample requires two improvements:\r\n\r\n* [ ] That section is about any kind of job, not just queries. As such, it should use the [create_job](https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job) method instead of the more specific `query` method. There should be comments that it is recommended to use the corresponding method for query/copy/load/extract.\r\n* [ ] Remove `job_id_prefix` logic, as labels cover similar functionality and are recommended over custom job IDs.\r\n* [ ] Move the sample to the `samples/snippets` directory. Needs to be done in 2 separate PRs so that the existing samples in the docs don't 404.\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\n\nif typing.TYPE_CHECKING:\n from google.cloud import bigquery\n\n\ndef create_job() -> \"bigquery.QueryJob\":\n\n # [START bigquery_create_job]\n from google.cloud import bigquery\n\n # Construct a BigQuery client object.\n client = bigquery.Client()\n\n query_job = client.query(\n \"SELECT country_name from `bigquery-public-data.utility_us.country_code_iso`\",\n # Explicitly force job execution to be routed to a specific processing\n # location.\n location=\"US\",\n # Specify a job configuration to set optional job resource properties.\n job_config=bigquery.QueryJobConfig(\n labels={\"example-label\": \"example-value\"}, maximum_bytes_billed=1000000\n ),\n # The client libraries automatically generate a job ID. Override the\n # generated ID with either the job_id_prefix or job_id parameters.\n job_id_prefix=\"code_sample_\",\n ) # Make an API request.\n\n print(\"Started job: {}\".format(query_job.job_id))\n # [END bigquery_create_job]\n return query_job\n", "path": "samples/create_job.py"}], "after_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\nfrom typing import Union\n\nif typing.TYPE_CHECKING:\n from google.cloud.bigquery import LoadJob, CopyJob, ExtractJob, QueryJob\n\n\ndef create_job() -> \"Union[LoadJob, CopyJob, ExtractJob, QueryJob]\":\n\n # [START bigquery_create_job]\n from google.cloud import bigquery\n\n # Construct a BigQuery client object.\n client = bigquery.Client()\n\n query_job = client.create_job(\n # Specify a job configuration, providing a query\n # and/or optional job resource properties, as needed.\n # The job instance can be a LoadJob, CopyJob, ExtractJob, QueryJob\n # Here, we demonstrate a \"query\" job.\n # References:\n # https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.create_job\n # https://cloud.google.com/bigquery/docs/reference/rest/v2/Job\n #\n # Example use cases for .create_job() include:\n # * to retry failed jobs\n # * to generate jobs with an experimental API property that hasn't\n # been added to one of the manually written job configuration\n # classes yet\n #\n # NOTE: unless it is necessary to create a job in this way, the\n # preferred approach is to use one of the dedicated API calls:\n # client.query()\n # client.extract_table()\n # client.copy_table()\n # client.load_table_file(), client.load_table_from_dataframe(), etc\n job_config={\n \"query\": {\n \"query\": \"\"\"\n SELECT country_name\n FROM `bigquery-public-data.utility_us.country_code_iso`\n LIMIT 5\n \"\"\",\n },\n \"labels\": {\"example-label\": \"example-value\"},\n \"maximum_bytes_billed\": 10000000,\n }\n ) # Make an API request.\n\n print(f\"Started job: {query_job.job_id}\")\n # [END bigquery_create_job]\n\n return query_job\n", "path": "samples/create_job.py"}]}
| 924 | 729 |
gh_patches_debug_29619
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-4115
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add facility setting to disable 'guest' browsing
### Observed behavior
Some organizations prefer that their users always be logged in
### Expected behavior
A facility setting can be added, e.g. "Disable guest access".
When this setting is active:
* "Access as guest" is hidden on the log-in page
* When a user visits a page without an active session, they are redirected to the log-in page
### User-facing consequences
Sometimes students are accessing as a guest because it's easier than dealing with a log-in
### Context
k0.10.0
----
cc @jtamiace @rtibbles this seem reasonable?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/core/device/serializers.py`
Content:
```
1 from django.db import transaction
2 from django.utils.translation import check_for_language
3 from django.utils.translation import ugettext_lazy as _
4 from rest_framework import serializers
5
6 from .models import DevicePermissions
7 from .models import DeviceSettings
8 from kolibri.core.auth.constants.facility_presets import choices
9 from kolibri.core.auth.constants.facility_presets import mappings
10 from kolibri.core.auth.constants.role_kinds import ADMIN
11 from kolibri.core.auth.models import Facility
12 from kolibri.core.auth.models import FacilityUser
13 from kolibri.core.auth.serializers import FacilitySerializer
14 from kolibri.core.auth.serializers import FacilityUserSerializer
15
16
17 class DevicePermissionsSerializer(serializers.ModelSerializer):
18
19 user = serializers.PrimaryKeyRelatedField(queryset=FacilityUser.objects.all())
20
21 class Meta:
22 model = DevicePermissions
23 fields = (
24 'user', 'is_superuser', 'can_manage_content',
25 )
26
27
28 class NoFacilityFacilityUserSerializer(FacilityUserSerializer):
29
30 class Meta:
31 model = FacilityUser
32 fields = ('id', 'username', 'full_name', 'password', )
33
34
35 class DeviceProvisionSerializer(serializers.Serializer):
36 facility = FacilitySerializer()
37 preset = serializers.ChoiceField(choices=choices)
38 superuser = NoFacilityFacilityUserSerializer()
39 language_id = serializers.CharField(max_length=15)
40
41 class Meta:
42 fields = ('facility', 'dataset', 'superuser', 'language_id')
43
44 def validate_language_id(self, language_id):
45 """
46 Check that the language_id is supported by Kolibri
47 """
48 if not check_for_language(language_id):
49 raise serializers.ValidationError(_("Language is not supported by Kolibri"))
50 return language_id
51
52 def create(self, validated_data):
53 """
54 Endpoint for initial setup of a device.
55 Expects a value for:
56 default language - the default language of this Kolibri device
57 facility - the required fields for setting up a facility
58 facilitydataset - facility configuration options
59 superuser - the required fields for a facilityuser who will be set as the super user for this device
60 """
61 with transaction.atomic():
62 facility = Facility.objects.create(**validated_data.pop('facility'))
63 preset = validated_data.pop('preset')
64 dataset_data = mappings[preset]
65 for key, value in dataset_data.items():
66 setattr(facility.dataset, key, value)
67 facility.dataset.save()
68 superuser_data = validated_data.pop('superuser')
69 superuser_data['facility'] = facility
70 superuser = FacilityUserSerializer(data=superuser_data).create(superuser_data)
71 superuser.set_password(superuser_data["password"])
72 superuser.save()
73 facility.add_role(superuser, ADMIN)
74 DevicePermissions.objects.create(user=superuser, is_superuser=True)
75 language_id = validated_data.pop('language_id')
76 device_settings, created = DeviceSettings.objects.get_or_create()
77 device_settings.is_provisioned = True
78 device_settings.language_id = language_id
79 device_settings.default_facility = facility
80 device_settings.save()
81 return {
82 "facility": facility,
83 "preset": preset,
84 "superuser": superuser,
85 "language_id": language_id
86 }
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/core/device/serializers.py b/kolibri/core/device/serializers.py
--- a/kolibri/core/device/serializers.py
+++ b/kolibri/core/device/serializers.py
@@ -37,9 +37,10 @@
preset = serializers.ChoiceField(choices=choices)
superuser = NoFacilityFacilityUserSerializer()
language_id = serializers.CharField(max_length=15)
+ settings = serializers.JSONField()
class Meta:
- fields = ('facility', 'dataset', 'superuser', 'language_id')
+ fields = ('facility', 'dataset', 'superuser', 'language_id', 'settings',)
def validate_language_id(self, language_id):
"""
@@ -64,6 +65,10 @@
dataset_data = mappings[preset]
for key, value in dataset_data.items():
setattr(facility.dataset, key, value)
+ # overwrite the settings in dataset_data with validated_data.settings
+ custom_settings = validated_data.pop('settings')
+ for key, value in custom_settings.items():
+ setattr(facility.dataset, key, value)
facility.dataset.save()
superuser_data = validated_data.pop('superuser')
superuser_data['facility'] = facility
@@ -82,5 +87,6 @@
"facility": facility,
"preset": preset,
"superuser": superuser,
- "language_id": language_id
+ "language_id": language_id,
+ "settings": custom_settings,
}
|
{"golden_diff": "diff --git a/kolibri/core/device/serializers.py b/kolibri/core/device/serializers.py\n--- a/kolibri/core/device/serializers.py\n+++ b/kolibri/core/device/serializers.py\n@@ -37,9 +37,10 @@\n preset = serializers.ChoiceField(choices=choices)\n superuser = NoFacilityFacilityUserSerializer()\n language_id = serializers.CharField(max_length=15)\n+ settings = serializers.JSONField()\n \n class Meta:\n- fields = ('facility', 'dataset', 'superuser', 'language_id')\n+ fields = ('facility', 'dataset', 'superuser', 'language_id', 'settings',)\n \n def validate_language_id(self, language_id):\n \"\"\"\n@@ -64,6 +65,10 @@\n dataset_data = mappings[preset]\n for key, value in dataset_data.items():\n setattr(facility.dataset, key, value)\n+ # overwrite the settings in dataset_data with validated_data.settings\n+ custom_settings = validated_data.pop('settings')\n+ for key, value in custom_settings.items():\n+ setattr(facility.dataset, key, value)\n facility.dataset.save()\n superuser_data = validated_data.pop('superuser')\n superuser_data['facility'] = facility\n@@ -82,5 +87,6 @@\n \"facility\": facility,\n \"preset\": preset,\n \"superuser\": superuser,\n- \"language_id\": language_id\n+ \"language_id\": language_id,\n+ \"settings\": custom_settings,\n }\n", "issue": "add facility setting to disable 'guest' browsing\n\r\n### Observed behavior\r\n\r\nSome organizations prefer that their users always be logged in\r\n\r\n### Expected behavior\r\n\r\nA facility setting can be added, e.g. \"Disable guest access\".\r\n\r\nWhen this setting is active:\r\n\r\n* \"Access as guest\" is hidden on the log-in page\r\n* When a user visits a page without an active session, they are redirected to the log-in page\r\n\r\n### User-facing consequences\r\n\r\nSometimes students are accessing as a guest because it's easier than dealing with a log-in\r\n\r\n### Context\r\n\r\nk0.10.0\r\n\r\n\r\n----\r\n\r\ncc @jtamiace @rtibbles this seem reasonable?\r\n\r\n\n", "before_files": [{"content": "from django.db import transaction\nfrom django.utils.translation import check_for_language\nfrom django.utils.translation import ugettext_lazy as _\nfrom rest_framework import serializers\n\nfrom .models import DevicePermissions\nfrom .models import DeviceSettings\nfrom kolibri.core.auth.constants.facility_presets import choices\nfrom kolibri.core.auth.constants.facility_presets import mappings\nfrom kolibri.core.auth.constants.role_kinds import ADMIN\nfrom kolibri.core.auth.models import Facility\nfrom kolibri.core.auth.models import FacilityUser\nfrom kolibri.core.auth.serializers import FacilitySerializer\nfrom kolibri.core.auth.serializers import FacilityUserSerializer\n\n\nclass DevicePermissionsSerializer(serializers.ModelSerializer):\n\n user = serializers.PrimaryKeyRelatedField(queryset=FacilityUser.objects.all())\n\n class Meta:\n model = DevicePermissions\n fields = (\n 'user', 'is_superuser', 'can_manage_content',\n )\n\n\nclass NoFacilityFacilityUserSerializer(FacilityUserSerializer):\n\n class Meta:\n model = FacilityUser\n fields = ('id', 'username', 'full_name', 'password', )\n\n\nclass DeviceProvisionSerializer(serializers.Serializer):\n facility = FacilitySerializer()\n preset = serializers.ChoiceField(choices=choices)\n superuser = NoFacilityFacilityUserSerializer()\n language_id = serializers.CharField(max_length=15)\n\n class Meta:\n fields = ('facility', 'dataset', 'superuser', 'language_id')\n\n def validate_language_id(self, language_id):\n \"\"\"\n Check that the language_id is supported by Kolibri\n \"\"\"\n if not check_for_language(language_id):\n raise serializers.ValidationError(_(\"Language is not supported by Kolibri\"))\n return language_id\n\n def create(self, validated_data):\n \"\"\"\n Endpoint for initial setup of a device.\n Expects a value for:\n default language - the default language of this Kolibri device\n facility - the required fields for setting up a facility\n facilitydataset - facility configuration options\n superuser - the required fields for a facilityuser who will be set as the super user for this device\n \"\"\"\n with transaction.atomic():\n facility = Facility.objects.create(**validated_data.pop('facility'))\n preset = validated_data.pop('preset')\n dataset_data = mappings[preset]\n for key, value in dataset_data.items():\n setattr(facility.dataset, key, value)\n facility.dataset.save()\n superuser_data = validated_data.pop('superuser')\n superuser_data['facility'] = facility\n superuser = FacilityUserSerializer(data=superuser_data).create(superuser_data)\n superuser.set_password(superuser_data[\"password\"])\n superuser.save()\n facility.add_role(superuser, ADMIN)\n DevicePermissions.objects.create(user=superuser, is_superuser=True)\n language_id = validated_data.pop('language_id')\n device_settings, created = DeviceSettings.objects.get_or_create()\n device_settings.is_provisioned = True\n device_settings.language_id = language_id\n device_settings.default_facility = facility\n device_settings.save()\n return {\n \"facility\": facility,\n \"preset\": preset,\n \"superuser\": superuser,\n \"language_id\": language_id\n }\n", "path": "kolibri/core/device/serializers.py"}], "after_files": [{"content": "from django.db import transaction\nfrom django.utils.translation import check_for_language\nfrom django.utils.translation import ugettext_lazy as _\nfrom rest_framework import serializers\n\nfrom .models import DevicePermissions\nfrom .models import DeviceSettings\nfrom kolibri.core.auth.constants.facility_presets import choices\nfrom kolibri.core.auth.constants.facility_presets import mappings\nfrom kolibri.core.auth.constants.role_kinds import ADMIN\nfrom kolibri.core.auth.models import Facility\nfrom kolibri.core.auth.models import FacilityUser\nfrom kolibri.core.auth.serializers import FacilitySerializer\nfrom kolibri.core.auth.serializers import FacilityUserSerializer\n\n\nclass DevicePermissionsSerializer(serializers.ModelSerializer):\n\n user = serializers.PrimaryKeyRelatedField(queryset=FacilityUser.objects.all())\n\n class Meta:\n model = DevicePermissions\n fields = (\n 'user', 'is_superuser', 'can_manage_content',\n )\n\n\nclass NoFacilityFacilityUserSerializer(FacilityUserSerializer):\n\n class Meta:\n model = FacilityUser\n fields = ('id', 'username', 'full_name', 'password', )\n\n\nclass DeviceProvisionSerializer(serializers.Serializer):\n facility = FacilitySerializer()\n preset = serializers.ChoiceField(choices=choices)\n superuser = NoFacilityFacilityUserSerializer()\n language_id = serializers.CharField(max_length=15)\n settings = serializers.JSONField()\n\n class Meta:\n fields = ('facility', 'dataset', 'superuser', 'language_id', 'settings',)\n\n def validate_language_id(self, language_id):\n \"\"\"\n Check that the language_id is supported by Kolibri\n \"\"\"\n if not check_for_language(language_id):\n raise serializers.ValidationError(_(\"Language is not supported by Kolibri\"))\n return language_id\n\n def create(self, validated_data):\n \"\"\"\n Endpoint for initial setup of a device.\n Expects a value for:\n default language - the default language of this Kolibri device\n facility - the required fields for setting up a facility\n facilitydataset - facility configuration options\n superuser - the required fields for a facilityuser who will be set as the super user for this device\n \"\"\"\n with transaction.atomic():\n facility = Facility.objects.create(**validated_data.pop('facility'))\n preset = validated_data.pop('preset')\n dataset_data = mappings[preset]\n for key, value in dataset_data.items():\n setattr(facility.dataset, key, value)\n # overwrite the settings in dataset_data with validated_data.settings\n custom_settings = validated_data.pop('settings')\n for key, value in custom_settings.items():\n setattr(facility.dataset, key, value)\n facility.dataset.save()\n superuser_data = validated_data.pop('superuser')\n superuser_data['facility'] = facility\n superuser = FacilityUserSerializer(data=superuser_data).create(superuser_data)\n superuser.set_password(superuser_data[\"password\"])\n superuser.save()\n facility.add_role(superuser, ADMIN)\n DevicePermissions.objects.create(user=superuser, is_superuser=True)\n language_id = validated_data.pop('language_id')\n device_settings, created = DeviceSettings.objects.get_or_create()\n device_settings.is_provisioned = True\n device_settings.language_id = language_id\n device_settings.default_facility = facility\n device_settings.save()\n return {\n \"facility\": facility,\n \"preset\": preset,\n \"superuser\": superuser,\n \"language_id\": language_id,\n \"settings\": custom_settings,\n }\n", "path": "kolibri/core/device/serializers.py"}]}
| 1,234 | 338 |
gh_patches_debug_29342
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-4614
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support "device" keyword argument
Adds the optional "device" keyword argument to Tensor and Storage
constructors and .new methods.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/distributions/categorical.py`
Content:
```
1 import torch
2 from torch.autograd import Variable
3 from torch.distributions import constraints
4 from torch.distributions.distribution import Distribution
5 from torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property
6
7
8 class Categorical(Distribution):
9 r"""
10 Creates a categorical distribution parameterized by `probs`.
11
12 .. note::
13 It is equivalent to the distribution that ``multinomial()`` samples from.
14
15 Samples are integers from `0 ... K-1` where `K` is probs.size(-1).
16
17 If `probs` is 1D with length-`K`, each element is the relative probability
18 of sampling the class at that index.
19
20 If `probs` is 2D, it is treated as a batch of probability vectors.
21
22 See also: :func:`torch.multinomial`
23
24 Example::
25
26 >>> m = Categorical(torch.Tensor([ 0.25, 0.25, 0.25, 0.25 ]))
27 >>> m.sample() # equal probability of 0, 1, 2, 3
28 3
29 [torch.LongTensor of size 1]
30
31 Args:
32 probs (Tensor or Variable): event probabilities
33 """
34 params = {'probs': constraints.simplex}
35 has_enumerate_support = True
36
37 def __init__(self, probs=None, logits=None):
38 if (probs is None) == (logits is None):
39 raise ValueError("Either `probs` or `logits` must be specified, but not both.")
40 if probs is not None:
41 self.probs = probs / probs.sum(-1, keepdim=True)
42 else:
43 self.logits = logits - log_sum_exp(logits)
44 batch_shape = self.probs.size()[:-1] if probs is not None else self.logits.size()[:-1]
45 super(Categorical, self).__init__(batch_shape)
46
47 @constraints.dependent_property
48 def support(self):
49 return constraints.integer_interval(0, self.probs.size()[-1] - 1)
50
51 @lazy_property
52 def logits(self):
53 return probs_to_logits(self.probs)
54
55 @lazy_property
56 def probs(self):
57 return logits_to_probs(self.logits)
58
59 def sample(self, sample_shape=torch.Size()):
60 num_events = self.probs.size()[-1]
61 sample_shape = self._extended_shape(sample_shape)
62 param_shape = sample_shape + self.probs.size()[-1:]
63 probs = self.probs.expand(param_shape)
64 probs_2d = probs.contiguous().view(-1, num_events)
65 sample_2d = torch.multinomial(probs_2d, 1, True)
66 return sample_2d.contiguous().view(sample_shape)
67
68 def log_prob(self, value):
69 self._validate_log_prob_arg(value)
70 param_shape = value.size() + self.probs.size()[-1:]
71 log_pmf = self.logits.expand(param_shape)
72 return log_pmf.gather(-1, value.unsqueeze(-1).long()).squeeze(-1)
73
74 def entropy(self):
75 p_log_p = self.logits * self.probs
76 return -p_log_p.sum(-1)
77
78 def enumerate_support(self):
79 num_events = self.probs.size()[-1]
80 values = torch.arange(num_events).long()
81 values = values.view((-1,) + (1,) * len(self._batch_shape))
82 values = values.expand((-1,) + self._batch_shape)
83 if self.probs.is_cuda:
84 values = values.cuda(self.probs.get_device())
85 if isinstance(self.probs, Variable):
86 values = Variable(values)
87 return values
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch/distributions/categorical.py b/torch/distributions/categorical.py
--- a/torch/distributions/categorical.py
+++ b/torch/distributions/categorical.py
@@ -2,7 +2,7 @@
from torch.autograd import Variable
from torch.distributions import constraints
from torch.distributions.distribution import Distribution
-from torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property
+from torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property, broadcast_all
class Categorical(Distribution):
@@ -41,6 +41,7 @@
self.probs = probs / probs.sum(-1, keepdim=True)
else:
self.logits = logits - log_sum_exp(logits)
+ self._num_events = self.probs.size()[-1] if self.probs is not None else self.logits.size()[-1]
batch_shape = self.probs.size()[:-1] if probs is not None else self.logits.size()[:-1]
super(Categorical, self).__init__(batch_shape)
@@ -67,7 +68,9 @@
def log_prob(self, value):
self._validate_log_prob_arg(value)
- param_shape = value.size() + self.probs.size()[-1:]
+ value_shape = torch._C._infer_size(value.size(), self.batch_shape) if self.batch_shape else value.size()
+ param_shape = value_shape + (self._num_events,)
+ value = value.expand(value_shape)
log_pmf = self.logits.expand(param_shape)
return log_pmf.gather(-1, value.unsqueeze(-1).long()).squeeze(-1)
|
{"golden_diff": "diff --git a/torch/distributions/categorical.py b/torch/distributions/categorical.py\n--- a/torch/distributions/categorical.py\n+++ b/torch/distributions/categorical.py\n@@ -2,7 +2,7 @@\n from torch.autograd import Variable\n from torch.distributions import constraints\n from torch.distributions.distribution import Distribution\n-from torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property\n+from torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property, broadcast_all\n \n \n class Categorical(Distribution):\n@@ -41,6 +41,7 @@\n self.probs = probs / probs.sum(-1, keepdim=True)\n else:\n self.logits = logits - log_sum_exp(logits)\n+ self._num_events = self.probs.size()[-1] if self.probs is not None else self.logits.size()[-1]\n batch_shape = self.probs.size()[:-1] if probs is not None else self.logits.size()[:-1]\n super(Categorical, self).__init__(batch_shape)\n \n@@ -67,7 +68,9 @@\n \n def log_prob(self, value):\n self._validate_log_prob_arg(value)\n- param_shape = value.size() + self.probs.size()[-1:]\n+ value_shape = torch._C._infer_size(value.size(), self.batch_shape) if self.batch_shape else value.size()\n+ param_shape = value_shape + (self._num_events,)\n+ value = value.expand(value_shape)\n log_pmf = self.logits.expand(param_shape)\n return log_pmf.gather(-1, value.unsqueeze(-1).long()).squeeze(-1)\n", "issue": "Support \"device\" keyword argument\nAdds the optional \"device\" keyword argument to Tensor and Storage\nconstructors and .new methods.\n\n", "before_files": [{"content": "import torch\nfrom torch.autograd import Variable\nfrom torch.distributions import constraints\nfrom torch.distributions.distribution import Distribution\nfrom torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property\n\n\nclass Categorical(Distribution):\n r\"\"\"\n Creates a categorical distribution parameterized by `probs`.\n\n .. note::\n It is equivalent to the distribution that ``multinomial()`` samples from.\n\n Samples are integers from `0 ... K-1` where `K` is probs.size(-1).\n\n If `probs` is 1D with length-`K`, each element is the relative probability\n of sampling the class at that index.\n\n If `probs` is 2D, it is treated as a batch of probability vectors.\n\n See also: :func:`torch.multinomial`\n\n Example::\n\n >>> m = Categorical(torch.Tensor([ 0.25, 0.25, 0.25, 0.25 ]))\n >>> m.sample() # equal probability of 0, 1, 2, 3\n 3\n [torch.LongTensor of size 1]\n\n Args:\n probs (Tensor or Variable): event probabilities\n \"\"\"\n params = {'probs': constraints.simplex}\n has_enumerate_support = True\n\n def __init__(self, probs=None, logits=None):\n if (probs is None) == (logits is None):\n raise ValueError(\"Either `probs` or `logits` must be specified, but not both.\")\n if probs is not None:\n self.probs = probs / probs.sum(-1, keepdim=True)\n else:\n self.logits = logits - log_sum_exp(logits)\n batch_shape = self.probs.size()[:-1] if probs is not None else self.logits.size()[:-1]\n super(Categorical, self).__init__(batch_shape)\n\n @constraints.dependent_property\n def support(self):\n return constraints.integer_interval(0, self.probs.size()[-1] - 1)\n\n @lazy_property\n def logits(self):\n return probs_to_logits(self.probs)\n\n @lazy_property\n def probs(self):\n return logits_to_probs(self.logits)\n\n def sample(self, sample_shape=torch.Size()):\n num_events = self.probs.size()[-1]\n sample_shape = self._extended_shape(sample_shape)\n param_shape = sample_shape + self.probs.size()[-1:]\n probs = self.probs.expand(param_shape)\n probs_2d = probs.contiguous().view(-1, num_events)\n sample_2d = torch.multinomial(probs_2d, 1, True)\n return sample_2d.contiguous().view(sample_shape)\n\n def log_prob(self, value):\n self._validate_log_prob_arg(value)\n param_shape = value.size() + self.probs.size()[-1:]\n log_pmf = self.logits.expand(param_shape)\n return log_pmf.gather(-1, value.unsqueeze(-1).long()).squeeze(-1)\n\n def entropy(self):\n p_log_p = self.logits * self.probs\n return -p_log_p.sum(-1)\n\n def enumerate_support(self):\n num_events = self.probs.size()[-1]\n values = torch.arange(num_events).long()\n values = values.view((-1,) + (1,) * len(self._batch_shape))\n values = values.expand((-1,) + self._batch_shape)\n if self.probs.is_cuda:\n values = values.cuda(self.probs.get_device())\n if isinstance(self.probs, Variable):\n values = Variable(values)\n return values\n", "path": "torch/distributions/categorical.py"}], "after_files": [{"content": "import torch\nfrom torch.autograd import Variable\nfrom torch.distributions import constraints\nfrom torch.distributions.distribution import Distribution\nfrom torch.distributions.utils import probs_to_logits, logits_to_probs, log_sum_exp, lazy_property, broadcast_all\n\n\nclass Categorical(Distribution):\n r\"\"\"\n Creates a categorical distribution parameterized by `probs`.\n\n .. note::\n It is equivalent to the distribution that ``multinomial()`` samples from.\n\n Samples are integers from `0 ... K-1` where `K` is probs.size(-1).\n\n If `probs` is 1D with length-`K`, each element is the relative probability\n of sampling the class at that index.\n\n If `probs` is 2D, it is treated as a batch of probability vectors.\n\n See also: :func:`torch.multinomial`\n\n Example::\n\n >>> m = Categorical(torch.Tensor([ 0.25, 0.25, 0.25, 0.25 ]))\n >>> m.sample() # equal probability of 0, 1, 2, 3\n 3\n [torch.LongTensor of size 1]\n\n Args:\n probs (Tensor or Variable): event probabilities\n \"\"\"\n params = {'probs': constraints.simplex}\n has_enumerate_support = True\n\n def __init__(self, probs=None, logits=None):\n if (probs is None) == (logits is None):\n raise ValueError(\"Either `probs` or `logits` must be specified, but not both.\")\n if probs is not None:\n self.probs = probs / probs.sum(-1, keepdim=True)\n else:\n self.logits = logits - log_sum_exp(logits)\n self._num_events = self.probs.size()[-1] if self.probs is not None else self.logits.size()[-1]\n batch_shape = self.probs.size()[:-1] if probs is not None else self.logits.size()[:-1]\n super(Categorical, self).__init__(batch_shape)\n\n @constraints.dependent_property\n def support(self):\n return constraints.integer_interval(0, self.probs.size()[-1] - 1)\n\n @lazy_property\n def logits(self):\n return probs_to_logits(self.probs)\n\n @lazy_property\n def probs(self):\n return logits_to_probs(self.logits)\n\n def sample(self, sample_shape=torch.Size()):\n num_events = self.probs.size()[-1]\n sample_shape = self._extended_shape(sample_shape)\n param_shape = sample_shape + self.probs.size()[-1:]\n probs = self.probs.expand(param_shape)\n probs_2d = probs.contiguous().view(-1, num_events)\n sample_2d = torch.multinomial(probs_2d, 1, True)\n return sample_2d.contiguous().view(sample_shape)\n\n def log_prob(self, value):\n self._validate_log_prob_arg(value)\n value_shape = torch._C._infer_size(value.size(), self.batch_shape) if self.batch_shape else value.size()\n param_shape = value_shape + (self._num_events,)\n value = value.expand(value_shape)\n log_pmf = self.logits.expand(param_shape)\n return log_pmf.gather(-1, value.unsqueeze(-1).long()).squeeze(-1)\n\n def entropy(self):\n p_log_p = self.logits * self.probs\n return -p_log_p.sum(-1)\n\n def enumerate_support(self):\n num_events = self.probs.size()[-1]\n values = torch.arange(num_events).long()\n values = values.view((-1,) + (1,) * len(self._batch_shape))\n values = values.expand((-1,) + self._batch_shape)\n if self.probs.is_cuda:\n values = values.cuda(self.probs.get_device())\n if isinstance(self.probs, Variable):\n values = Variable(values)\n return values\n", "path": "torch/distributions/categorical.py"}]}
| 1,254 | 368 |
gh_patches_debug_24879
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-242
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add assignee model to run.py
See also #61.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `run.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import argparse
7 import csv
8 import os
9 from datetime import datetime
10 from datetime import timedelta
11
12 import numpy as np
13
14 from bugbug import bugzilla
15 from bugbug import db
16 from bugbug import repository # noqa
17
18 if __name__ == '__main__':
19 parser = argparse.ArgumentParser()
20 parser.add_argument('--lemmatization', help='Perform lemmatization (using spaCy)', action='store_true')
21 parser.add_argument('--train', help='Perform training', action='store_true')
22 parser.add_argument('--goal',
23 help='Goal of the classifier',
24 choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask'],
25 default='bug')
26 parser.add_argument('--classifier', help='Type of the classifier', choices=['default', 'nn'], default='default')
27 parser.add_argument('--classify', help='Perform evaluation', action='store_true')
28 parser.add_argument('--generate-sheet', help='Perform evaluation on bugs from last week and generate a csv file', action='store_true')
29 args = parser.parse_args()
30
31 model_file_name = '{}{}model'.format(
32 args.goal,
33 '' if args.classifier == 'default' else args.classifier
34 )
35
36 if args.goal == 'bug':
37 from bugbug.models.bug import BugModel
38 model_class = BugModel
39 elif args.goal == 'defectfeaturetask':
40 from bugbug.models.defect_feature_task import DefectFeatureTaskModel
41 model_class = DefectFeatureTaskModel
42 elif args.goal == 'regression':
43 from bugbug.models.regression import RegressionModel
44 model_class = RegressionModel
45 elif args.goal == 'tracking':
46 from bugbug.models.tracking import TrackingModel
47 model_class = TrackingModel
48 elif args.goal == 'qaneeded':
49 from bugbug.models.qaneeded import QANeededModel
50 model_class = QANeededModel
51 elif args.goal == 'uplift':
52 from bugbug.models.uplift import UpliftModel
53 model_class = UpliftModel
54 elif args.goal == 'component':
55 if args.classifier == 'default':
56 from bugbug.models.component import ComponentModel
57 model_class = ComponentModel
58 elif args.classifier == 'nn':
59 from bugbug.models.component_nn import ComponentNNModel
60 model_class = ComponentNNModel
61 elif args.goal == 'devdocneeded':
62 from bugbug.models.devdocneeded import DevDocNeededModel
63 model_class = DevDocNeededModel
64
65 if args.train:
66 db.download()
67
68 model = model_class(args.lemmatization)
69 model.train()
70 else:
71 model = model_class.load(model_file_name)
72
73 if args.classify:
74 for bug in bugzilla.get_bugs():
75 print(f'https://bugzilla.mozilla.org/show_bug.cgi?id={ bug["id"] } - { bug["summary"]} ')
76
77 if model.calculate_importance:
78 probas, importances = model.classify(bug, probabilities=True, importances=True)
79
80 feature_names = model.get_feature_names()
81 for i, (importance, index, is_positive) in enumerate(importances):
82 print(f'{i + 1}. \'{feature_names[int(index)]}\' ({"+" if (is_positive) else "-"}{importance})')
83 else:
84 probas = model.classify(bug, probabilities=True, importances=False)
85
86 if np.argmax(probas) == 1:
87 print(f'Positive! {probas}')
88 else:
89 print(f'Negative! {probas}')
90 input()
91
92 if args.generate_sheet:
93 today = datetime.utcnow()
94 a_week_ago = today - timedelta(7)
95 bugs = bugzilla.download_bugs_between(a_week_ago, today)
96
97 print(f'Classifying {len(bugs)} bugs...')
98
99 rows = [
100 ['Bug', f'{args.goal}(model)', args.goal, 'Title']
101 ]
102
103 for bug in bugs:
104 p = model.classify(bug, probabilities=True)
105 rows.append([f'https://bugzilla.mozilla.org/show_bug.cgi?id={bug["id"]}', 'y' if p[0][1] >= 0.7 else 'n', '', bug['summary']])
106
107 os.makedirs('sheets', exist_ok=True)
108 with open(os.path.join('sheets', f'{args.goal}-{datetime.utcnow().strftime("%Y-%m-%d")}-labels.csv'), 'w') as f:
109 writer = csv.writer(f)
110 writer.writerows(rows)
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/run.py b/run.py
--- a/run.py
+++ b/run.py
@@ -21,7 +21,7 @@
parser.add_argument('--train', help='Perform training', action='store_true')
parser.add_argument('--goal',
help='Goal of the classifier',
- choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask'],
+ choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask', 'assignee'],
default='bug')
parser.add_argument('--classifier', help='Type of the classifier', choices=['default', 'nn'], default='default')
parser.add_argument('--classify', help='Perform evaluation', action='store_true')
@@ -61,6 +61,9 @@
elif args.goal == 'devdocneeded':
from bugbug.models.devdocneeded import DevDocNeededModel
model_class = DevDocNeededModel
+ elif args.goal == 'assignee':
+ from bugbug.models.assignee import AssigneeModel
+ model_class = AssigneeModel
if args.train:
db.download()
|
{"golden_diff": "diff --git a/run.py b/run.py\n--- a/run.py\n+++ b/run.py\n@@ -21,7 +21,7 @@\n parser.add_argument('--train', help='Perform training', action='store_true')\n parser.add_argument('--goal',\n help='Goal of the classifier',\n- choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask'],\n+ choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask', 'assignee'],\n default='bug')\n parser.add_argument('--classifier', help='Type of the classifier', choices=['default', 'nn'], default='default')\n parser.add_argument('--classify', help='Perform evaluation', action='store_true')\n@@ -61,6 +61,9 @@\n elif args.goal == 'devdocneeded':\n from bugbug.models.devdocneeded import DevDocNeededModel\n model_class = DevDocNeededModel\n+ elif args.goal == 'assignee':\n+ from bugbug.models.assignee import AssigneeModel\n+ model_class = AssigneeModel\n \n if args.train:\n db.download()\n", "issue": "Add assignee model to run.py\nSee also #61.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport argparse\nimport csv\nimport os\nfrom datetime import datetime\nfrom datetime import timedelta\n\nimport numpy as np\n\nfrom bugbug import bugzilla\nfrom bugbug import db\nfrom bugbug import repository # noqa\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--lemmatization', help='Perform lemmatization (using spaCy)', action='store_true')\n parser.add_argument('--train', help='Perform training', action='store_true')\n parser.add_argument('--goal',\n help='Goal of the classifier',\n choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask'],\n default='bug')\n parser.add_argument('--classifier', help='Type of the classifier', choices=['default', 'nn'], default='default')\n parser.add_argument('--classify', help='Perform evaluation', action='store_true')\n parser.add_argument('--generate-sheet', help='Perform evaluation on bugs from last week and generate a csv file', action='store_true')\n args = parser.parse_args()\n\n model_file_name = '{}{}model'.format(\n args.goal,\n '' if args.classifier == 'default' else args.classifier\n )\n\n if args.goal == 'bug':\n from bugbug.models.bug import BugModel\n model_class = BugModel\n elif args.goal == 'defectfeaturetask':\n from bugbug.models.defect_feature_task import DefectFeatureTaskModel\n model_class = DefectFeatureTaskModel\n elif args.goal == 'regression':\n from bugbug.models.regression import RegressionModel\n model_class = RegressionModel\n elif args.goal == 'tracking':\n from bugbug.models.tracking import TrackingModel\n model_class = TrackingModel\n elif args.goal == 'qaneeded':\n from bugbug.models.qaneeded import QANeededModel\n model_class = QANeededModel\n elif args.goal == 'uplift':\n from bugbug.models.uplift import UpliftModel\n model_class = UpliftModel\n elif args.goal == 'component':\n if args.classifier == 'default':\n from bugbug.models.component import ComponentModel\n model_class = ComponentModel\n elif args.classifier == 'nn':\n from bugbug.models.component_nn import ComponentNNModel\n model_class = ComponentNNModel\n elif args.goal == 'devdocneeded':\n from bugbug.models.devdocneeded import DevDocNeededModel\n model_class = DevDocNeededModel\n\n if args.train:\n db.download()\n\n model = model_class(args.lemmatization)\n model.train()\n else:\n model = model_class.load(model_file_name)\n\n if args.classify:\n for bug in bugzilla.get_bugs():\n print(f'https://bugzilla.mozilla.org/show_bug.cgi?id={ bug[\"id\"] } - { bug[\"summary\"]} ')\n\n if model.calculate_importance:\n probas, importances = model.classify(bug, probabilities=True, importances=True)\n\n feature_names = model.get_feature_names()\n for i, (importance, index, is_positive) in enumerate(importances):\n print(f'{i + 1}. \\'{feature_names[int(index)]}\\' ({\"+\" if (is_positive) else \"-\"}{importance})')\n else:\n probas = model.classify(bug, probabilities=True, importances=False)\n\n if np.argmax(probas) == 1:\n print(f'Positive! {probas}')\n else:\n print(f'Negative! {probas}')\n input()\n\n if args.generate_sheet:\n today = datetime.utcnow()\n a_week_ago = today - timedelta(7)\n bugs = bugzilla.download_bugs_between(a_week_ago, today)\n\n print(f'Classifying {len(bugs)} bugs...')\n\n rows = [\n ['Bug', f'{args.goal}(model)', args.goal, 'Title']\n ]\n\n for bug in bugs:\n p = model.classify(bug, probabilities=True)\n rows.append([f'https://bugzilla.mozilla.org/show_bug.cgi?id={bug[\"id\"]}', 'y' if p[0][1] >= 0.7 else 'n', '', bug['summary']])\n\n os.makedirs('sheets', exist_ok=True)\n with open(os.path.join('sheets', f'{args.goal}-{datetime.utcnow().strftime(\"%Y-%m-%d\")}-labels.csv'), 'w') as f:\n writer = csv.writer(f)\n writer.writerows(rows)\n", "path": "run.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport argparse\nimport csv\nimport os\nfrom datetime import datetime\nfrom datetime import timedelta\n\nimport numpy as np\n\nfrom bugbug import bugzilla\nfrom bugbug import db\nfrom bugbug import repository # noqa\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--lemmatization', help='Perform lemmatization (using spaCy)', action='store_true')\n parser.add_argument('--train', help='Perform training', action='store_true')\n parser.add_argument('--goal',\n help='Goal of the classifier',\n choices=['bug', 'regression', 'tracking', 'qaneeded', 'uplift', 'component', 'devdocneeded', 'defectfeaturetask', 'assignee'],\n default='bug')\n parser.add_argument('--classifier', help='Type of the classifier', choices=['default', 'nn'], default='default')\n parser.add_argument('--classify', help='Perform evaluation', action='store_true')\n parser.add_argument('--generate-sheet', help='Perform evaluation on bugs from last week and generate a csv file', action='store_true')\n args = parser.parse_args()\n\n model_file_name = '{}{}model'.format(\n args.goal,\n '' if args.classifier == 'default' else args.classifier\n )\n\n if args.goal == 'bug':\n from bugbug.models.bug import BugModel\n model_class = BugModel\n elif args.goal == 'defectfeaturetask':\n from bugbug.models.defect_feature_task import DefectFeatureTaskModel\n model_class = DefectFeatureTaskModel\n elif args.goal == 'regression':\n from bugbug.models.regression import RegressionModel\n model_class = RegressionModel\n elif args.goal == 'tracking':\n from bugbug.models.tracking import TrackingModel\n model_class = TrackingModel\n elif args.goal == 'qaneeded':\n from bugbug.models.qaneeded import QANeededModel\n model_class = QANeededModel\n elif args.goal == 'uplift':\n from bugbug.models.uplift import UpliftModel\n model_class = UpliftModel\n elif args.goal == 'component':\n if args.classifier == 'default':\n from bugbug.models.component import ComponentModel\n model_class = ComponentModel\n elif args.classifier == 'nn':\n from bugbug.models.component_nn import ComponentNNModel\n model_class = ComponentNNModel\n elif args.goal == 'devdocneeded':\n from bugbug.models.devdocneeded import DevDocNeededModel\n model_class = DevDocNeededModel\n elif args.goal == 'assignee':\n from bugbug.models.assignee import AssigneeModel\n model_class = AssigneeModel\n\n if args.train:\n db.download()\n\n model = model_class(args.lemmatization)\n model.train()\n else:\n model = model_class.load(model_file_name)\n\n if args.classify:\n for bug in bugzilla.get_bugs():\n print(f'https://bugzilla.mozilla.org/show_bug.cgi?id={ bug[\"id\"] } - { bug[\"summary\"]} ')\n\n if model.calculate_importance:\n probas, importances = model.classify(bug, probabilities=True, importances=True)\n\n feature_names = model.get_feature_names()\n for i, (importance, index, is_positive) in enumerate(importances):\n print(f'{i + 1}. \\'{feature_names[int(index)]}\\' ({\"+\" if (is_positive) else \"-\"}{importance})')\n else:\n probas = model.classify(bug, probabilities=True, importances=False)\n\n if np.argmax(probas) == 1:\n print(f'Positive! {probas}')\n else:\n print(f'Negative! {probas}')\n input()\n\n if args.generate_sheet:\n today = datetime.utcnow()\n a_week_ago = today - timedelta(7)\n bugs = bugzilla.download_bugs_between(a_week_ago, today)\n\n print(f'Classifying {len(bugs)} bugs...')\n\n rows = [\n ['Bug', f'{args.goal}(model)', args.goal, 'Title']\n ]\n\n for bug in bugs:\n p = model.classify(bug, probabilities=True)\n rows.append([f'https://bugzilla.mozilla.org/show_bug.cgi?id={bug[\"id\"]}', 'y' if p[0][1] >= 0.7 else 'n', '', bug['summary']])\n\n os.makedirs('sheets', exist_ok=True)\n with open(os.path.join('sheets', f'{args.goal}-{datetime.utcnow().strftime(\"%Y-%m-%d\")}-labels.csv'), 'w') as f:\n writer = csv.writer(f)\n writer.writerows(rows)\n", "path": "run.py"}]}
| 1,540 | 273 |
gh_patches_debug_19434
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-3456
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pyramid.exceptions.ConfigurationConflictError: <exception str() failed>
**Describe the bug**
While building an app I caused an error who's traceback ending the the following line:
```
pyramid.exceptions.ConfigurationConflictError: <exception str() failed>
```
What caused the error in the first place was that I copied a python package containing my views to a new package called controllers and forgot to delete the original views package. I assume that the configurator failed while trying to commit the config.scan(). Since I couldn't find any information online about the above traceback message I assume that this is probably just some internal problem with Pyramid.
**To Reproduce**
download from: https://github.com/benkawecki/pypi/tree/error
after setting up run
```
pserve development.ini
```
**Expected behavior**
I expect there to be an error message.
**Screenshots**
Screenshot of the error message:
<img width="489" alt="screen shot 2019-01-15 at 10 02 44 pm" src="https://user-images.githubusercontent.com/39999125/51224413-c57eb800-1913-11e9-9e0f-b25878a479f5.png">
Screenshot of installed packages:
<img width="488" alt="screen shot 2019-01-15 at 10 24 42 pm" src="https://user-images.githubusercontent.com/39999125/51224563-8b61e600-1914-11e9-9b04-42936f94d4bd.png">
**Additional context**
I'm looking to help out in open-source more this year so if this is an easy fix I would love to see if I can do it!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyramid/exceptions.py`
Content:
```
1 from pyramid.httpexceptions import HTTPBadRequest, HTTPNotFound, HTTPForbidden
2
3 NotFound = HTTPNotFound # bw compat
4 Forbidden = HTTPForbidden # bw compat
5
6 CR = '\n'
7
8
9 class BadCSRFOrigin(HTTPBadRequest):
10 """
11 This exception indicates the request has failed cross-site request forgery
12 origin validation.
13 """
14
15 title = "Bad CSRF Origin"
16 explanation = (
17 "Access is denied. This server can not verify that the origin or "
18 "referrer of your request matches the current site. Either your "
19 "browser supplied the wrong Origin or Referrer or it did not supply "
20 "one at all."
21 )
22
23
24 class BadCSRFToken(HTTPBadRequest):
25 """
26 This exception indicates the request has failed cross-site request
27 forgery token validation.
28 """
29
30 title = 'Bad CSRF Token'
31 explanation = (
32 'Access is denied. This server can not verify that your cross-site '
33 'request forgery token belongs to your login session. Either you '
34 'supplied the wrong cross-site request forgery token or your session '
35 'no longer exists. This may be due to session timeout or because '
36 'browser is not supplying the credentials required, as can happen '
37 'when the browser has cookies turned off.'
38 )
39
40
41 class PredicateMismatch(HTTPNotFound):
42 """
43 This exception is raised by multiviews when no view matches
44 all given predicates.
45
46 This exception subclasses the :class:`HTTPNotFound` exception for a
47 specific reason: if it reaches the main exception handler, it should
48 be treated as :class:`HTTPNotFound`` by any exception view
49 registrations. Thus, typically, this exception will not be seen
50 publicly.
51
52 However, this exception will be raised if the predicates of all
53 views configured to handle another exception context cannot be
54 successfully matched. For instance, if a view is configured to
55 handle a context of ``HTTPForbidden`` and the configured with
56 additional predicates, then :class:`PredicateMismatch` will be
57 raised if:
58
59 * An original view callable has raised :class:`HTTPForbidden` (thus
60 invoking an exception view); and
61 * The given request fails to match all predicates for said
62 exception view associated with :class:`HTTPForbidden`.
63
64 The same applies to any type of exception being handled by an
65 exception view.
66 """
67
68
69 class URLDecodeError(UnicodeDecodeError):
70 """
71 This exception is raised when :app:`Pyramid` cannot
72 successfully decode a URL or a URL path segment. This exception
73 behaves just like the Python builtin
74 :exc:`UnicodeDecodeError`. It is a subclass of the builtin
75 :exc:`UnicodeDecodeError` exception only for identity purposes,
76 mostly so an exception view can be registered when a URL cannot be
77 decoded.
78 """
79
80
81 class ConfigurationError(Exception):
82 """ Raised when inappropriate input values are supplied to an API
83 method of a :term:`Configurator`"""
84
85
86 class ConfigurationConflictError(ConfigurationError):
87 """ Raised when a configuration conflict is detected during action
88 processing"""
89
90 def __init__(self, conflicts):
91 self._conflicts = conflicts
92
93 def __str__(self):
94 r = ["Conflicting configuration actions"]
95 items = sorted(self._conflicts.items())
96 for discriminator, infos in items:
97 r.append(" For: %s" % (discriminator,))
98 for info in infos:
99 for line in str(info).rstrip().split(CR):
100 r.append(" " + line)
101
102 return CR.join(r)
103
104
105 class ConfigurationExecutionError(ConfigurationError):
106 """An error occurred during execution of a configuration action
107 """
108
109 def __init__(self, etype, evalue, info):
110 self.etype, self.evalue, self.info = etype, evalue, info
111
112 def __str__(self):
113 return "%s: %s\n in:\n %s" % (self.etype, self.evalue, self.info)
114
115
116 class CyclicDependencyError(Exception):
117 """ The exception raised when the Pyramid topological sorter detects a
118 cyclic dependency."""
119
120 def __init__(self, cycles):
121 self.cycles = cycles
122
123 def __str__(self):
124 L = []
125 cycles = self.cycles
126 for cycle in cycles:
127 dependent = cycle
128 dependees = cycles[cycle]
129 L.append('%r sorts before %r' % (dependent, dependees))
130 msg = 'Implicit ordering cycle:' + '; '.join(L)
131 return msg
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyramid/exceptions.py b/src/pyramid/exceptions.py
--- a/src/pyramid/exceptions.py
+++ b/src/pyramid/exceptions.py
@@ -3,8 +3,6 @@
NotFound = HTTPNotFound # bw compat
Forbidden = HTTPForbidden # bw compat
-CR = '\n'
-
class BadCSRFOrigin(HTTPBadRequest):
"""
@@ -92,14 +90,13 @@
def __str__(self):
r = ["Conflicting configuration actions"]
- items = sorted(self._conflicts.items())
- for discriminator, infos in items:
+ for discriminator, infos in self._conflicts.items():
r.append(" For: %s" % (discriminator,))
for info in infos:
- for line in str(info).rstrip().split(CR):
+ for line in str(info).rstrip().split('\n'):
r.append(" " + line)
- return CR.join(r)
+ return '\n'.join(r)
class ConfigurationExecutionError(ConfigurationError):
|
{"golden_diff": "diff --git a/src/pyramid/exceptions.py b/src/pyramid/exceptions.py\n--- a/src/pyramid/exceptions.py\n+++ b/src/pyramid/exceptions.py\n@@ -3,8 +3,6 @@\n NotFound = HTTPNotFound # bw compat\n Forbidden = HTTPForbidden # bw compat\n \n-CR = '\\n'\n-\n \n class BadCSRFOrigin(HTTPBadRequest):\n \"\"\"\n@@ -92,14 +90,13 @@\n \n def __str__(self):\n r = [\"Conflicting configuration actions\"]\n- items = sorted(self._conflicts.items())\n- for discriminator, infos in items:\n+ for discriminator, infos in self._conflicts.items():\n r.append(\" For: %s\" % (discriminator,))\n for info in infos:\n- for line in str(info).rstrip().split(CR):\n+ for line in str(info).rstrip().split('\\n'):\n r.append(\" \" + line)\n \n- return CR.join(r)\n+ return '\\n'.join(r)\n \n \n class ConfigurationExecutionError(ConfigurationError):\n", "issue": "pyramid.exceptions.ConfigurationConflictError: <exception str() failed>\n**Describe the bug**\r\nWhile building an app I caused an error who's traceback ending the the following line:\r\n```\r\npyramid.exceptions.ConfigurationConflictError: <exception str() failed>\r\n```\r\nWhat caused the error in the first place was that I copied a python package containing my views to a new package called controllers and forgot to delete the original views package. I assume that the configurator failed while trying to commit the config.scan(). Since I couldn't find any information online about the above traceback message I assume that this is probably just some internal problem with Pyramid. \r\n**To Reproduce**\r\ndownload from: https://github.com/benkawecki/pypi/tree/error\r\nafter setting up run \r\n``` \r\npserve development.ini\r\n```\r\n\r\n**Expected behavior**\r\nI expect there to be an error message. \r\n\r\n**Screenshots**\r\nScreenshot of the error message:\r\n<img width=\"489\" alt=\"screen shot 2019-01-15 at 10 02 44 pm\" src=\"https://user-images.githubusercontent.com/39999125/51224413-c57eb800-1913-11e9-9e0f-b25878a479f5.png\">\r\nScreenshot of installed packages:\r\n<img width=\"488\" alt=\"screen shot 2019-01-15 at 10 24 42 pm\" src=\"https://user-images.githubusercontent.com/39999125/51224563-8b61e600-1914-11e9-9b04-42936f94d4bd.png\">\r\n\r\n\r\n\r\n**Additional context**\r\nI'm looking to help out in open-source more this year so if this is an easy fix I would love to see if I can do it!\r\n\n", "before_files": [{"content": "from pyramid.httpexceptions import HTTPBadRequest, HTTPNotFound, HTTPForbidden\n\nNotFound = HTTPNotFound # bw compat\nForbidden = HTTPForbidden # bw compat\n\nCR = '\\n'\n\n\nclass BadCSRFOrigin(HTTPBadRequest):\n \"\"\"\n This exception indicates the request has failed cross-site request forgery\n origin validation.\n \"\"\"\n\n title = \"Bad CSRF Origin\"\n explanation = (\n \"Access is denied. This server can not verify that the origin or \"\n \"referrer of your request matches the current site. Either your \"\n \"browser supplied the wrong Origin or Referrer or it did not supply \"\n \"one at all.\"\n )\n\n\nclass BadCSRFToken(HTTPBadRequest):\n \"\"\"\n This exception indicates the request has failed cross-site request\n forgery token validation.\n \"\"\"\n\n title = 'Bad CSRF Token'\n explanation = (\n 'Access is denied. This server can not verify that your cross-site '\n 'request forgery token belongs to your login session. Either you '\n 'supplied the wrong cross-site request forgery token or your session '\n 'no longer exists. This may be due to session timeout or because '\n 'browser is not supplying the credentials required, as can happen '\n 'when the browser has cookies turned off.'\n )\n\n\nclass PredicateMismatch(HTTPNotFound):\n \"\"\"\n This exception is raised by multiviews when no view matches\n all given predicates.\n\n This exception subclasses the :class:`HTTPNotFound` exception for a\n specific reason: if it reaches the main exception handler, it should\n be treated as :class:`HTTPNotFound`` by any exception view\n registrations. Thus, typically, this exception will not be seen\n publicly.\n\n However, this exception will be raised if the predicates of all\n views configured to handle another exception context cannot be\n successfully matched. For instance, if a view is configured to\n handle a context of ``HTTPForbidden`` and the configured with\n additional predicates, then :class:`PredicateMismatch` will be\n raised if:\n\n * An original view callable has raised :class:`HTTPForbidden` (thus\n invoking an exception view); and\n * The given request fails to match all predicates for said\n exception view associated with :class:`HTTPForbidden`.\n\n The same applies to any type of exception being handled by an\n exception view.\n \"\"\"\n\n\nclass URLDecodeError(UnicodeDecodeError):\n \"\"\"\n This exception is raised when :app:`Pyramid` cannot\n successfully decode a URL or a URL path segment. This exception\n behaves just like the Python builtin\n :exc:`UnicodeDecodeError`. It is a subclass of the builtin\n :exc:`UnicodeDecodeError` exception only for identity purposes,\n mostly so an exception view can be registered when a URL cannot be\n decoded.\n \"\"\"\n\n\nclass ConfigurationError(Exception):\n \"\"\" Raised when inappropriate input values are supplied to an API\n method of a :term:`Configurator`\"\"\"\n\n\nclass ConfigurationConflictError(ConfigurationError):\n \"\"\" Raised when a configuration conflict is detected during action\n processing\"\"\"\n\n def __init__(self, conflicts):\n self._conflicts = conflicts\n\n def __str__(self):\n r = [\"Conflicting configuration actions\"]\n items = sorted(self._conflicts.items())\n for discriminator, infos in items:\n r.append(\" For: %s\" % (discriminator,))\n for info in infos:\n for line in str(info).rstrip().split(CR):\n r.append(\" \" + line)\n\n return CR.join(r)\n\n\nclass ConfigurationExecutionError(ConfigurationError):\n \"\"\"An error occurred during execution of a configuration action\n \"\"\"\n\n def __init__(self, etype, evalue, info):\n self.etype, self.evalue, self.info = etype, evalue, info\n\n def __str__(self):\n return \"%s: %s\\n in:\\n %s\" % (self.etype, self.evalue, self.info)\n\n\nclass CyclicDependencyError(Exception):\n \"\"\" The exception raised when the Pyramid topological sorter detects a\n cyclic dependency.\"\"\"\n\n def __init__(self, cycles):\n self.cycles = cycles\n\n def __str__(self):\n L = []\n cycles = self.cycles\n for cycle in cycles:\n dependent = cycle\n dependees = cycles[cycle]\n L.append('%r sorts before %r' % (dependent, dependees))\n msg = 'Implicit ordering cycle:' + '; '.join(L)\n return msg\n", "path": "src/pyramid/exceptions.py"}], "after_files": [{"content": "from pyramid.httpexceptions import HTTPBadRequest, HTTPNotFound, HTTPForbidden\n\nNotFound = HTTPNotFound # bw compat\nForbidden = HTTPForbidden # bw compat\n\n\nclass BadCSRFOrigin(HTTPBadRequest):\n \"\"\"\n This exception indicates the request has failed cross-site request forgery\n origin validation.\n \"\"\"\n\n title = \"Bad CSRF Origin\"\n explanation = (\n \"Access is denied. This server can not verify that the origin or \"\n \"referrer of your request matches the current site. Either your \"\n \"browser supplied the wrong Origin or Referrer or it did not supply \"\n \"one at all.\"\n )\n\n\nclass BadCSRFToken(HTTPBadRequest):\n \"\"\"\n This exception indicates the request has failed cross-site request\n forgery token validation.\n \"\"\"\n\n title = 'Bad CSRF Token'\n explanation = (\n 'Access is denied. This server can not verify that your cross-site '\n 'request forgery token belongs to your login session. Either you '\n 'supplied the wrong cross-site request forgery token or your session '\n 'no longer exists. This may be due to session timeout or because '\n 'browser is not supplying the credentials required, as can happen '\n 'when the browser has cookies turned off.'\n )\n\n\nclass PredicateMismatch(HTTPNotFound):\n \"\"\"\n This exception is raised by multiviews when no view matches\n all given predicates.\n\n This exception subclasses the :class:`HTTPNotFound` exception for a\n specific reason: if it reaches the main exception handler, it should\n be treated as :class:`HTTPNotFound`` by any exception view\n registrations. Thus, typically, this exception will not be seen\n publicly.\n\n However, this exception will be raised if the predicates of all\n views configured to handle another exception context cannot be\n successfully matched. For instance, if a view is configured to\n handle a context of ``HTTPForbidden`` and the configured with\n additional predicates, then :class:`PredicateMismatch` will be\n raised if:\n\n * An original view callable has raised :class:`HTTPForbidden` (thus\n invoking an exception view); and\n * The given request fails to match all predicates for said\n exception view associated with :class:`HTTPForbidden`.\n\n The same applies to any type of exception being handled by an\n exception view.\n \"\"\"\n\n\nclass URLDecodeError(UnicodeDecodeError):\n \"\"\"\n This exception is raised when :app:`Pyramid` cannot\n successfully decode a URL or a URL path segment. This exception\n behaves just like the Python builtin\n :exc:`UnicodeDecodeError`. It is a subclass of the builtin\n :exc:`UnicodeDecodeError` exception only for identity purposes,\n mostly so an exception view can be registered when a URL cannot be\n decoded.\n \"\"\"\n\n\nclass ConfigurationError(Exception):\n \"\"\" Raised when inappropriate input values are supplied to an API\n method of a :term:`Configurator`\"\"\"\n\n\nclass ConfigurationConflictError(ConfigurationError):\n \"\"\" Raised when a configuration conflict is detected during action\n processing\"\"\"\n\n def __init__(self, conflicts):\n self._conflicts = conflicts\n\n def __str__(self):\n r = [\"Conflicting configuration actions\"]\n for discriminator, infos in self._conflicts.items():\n r.append(\" For: %s\" % (discriminator,))\n for info in infos:\n for line in str(info).rstrip().split('\\n'):\n r.append(\" \" + line)\n\n return '\\n'.join(r)\n\n\nclass ConfigurationExecutionError(ConfigurationError):\n \"\"\"An error occurred during execution of a configuration action\n \"\"\"\n\n def __init__(self, etype, evalue, info):\n self.etype, self.evalue, self.info = etype, evalue, info\n\n def __str__(self):\n return \"%s: %s\\n in:\\n %s\" % (self.etype, self.evalue, self.info)\n\n\nclass CyclicDependencyError(Exception):\n \"\"\" The exception raised when the Pyramid topological sorter detects a\n cyclic dependency.\"\"\"\n\n def __init__(self, cycles):\n self.cycles = cycles\n\n def __str__(self):\n L = []\n cycles = self.cycles\n for cycle in cycles:\n dependent = cycle\n dependees = cycles[cycle]\n L.append('%r sorts before %r' % (dependent, dependees))\n msg = 'Implicit ordering cycle:' + '; '.join(L)\n return msg\n", "path": "src/pyramid/exceptions.py"}]}
| 1,953 | 229 |
gh_patches_debug_10317
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-6153
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
spurious testinfra failures when servers have non-default hostnames
## Description
If a production instance is configured with hostnames other than the recommended `app` and `mon`, `securedrop-admin verify` will report spurious testinfra failures.
First noticed in <https://github.com/freedomofpress/securedrop/issues/6127#issuecomment-938342242>.
## Steps to Reproduce
1. `securedrop-admin sdconfig` with non-default hostnames, e.g. those provisioned by `molecule create -s libvirt-prod-focal`:
```yaml
app_hostname: app-prod
monitor_hostname: mon-prod
```
2. `securedrop-admin install`
3. `securedrop-admin setup -t`
4. `securedrop-admin verify`
## Expected Behavior
All testinfra tests pass.
## Actual Behavior
Hostname-dependent testinfra tests fail, including:
* `app/test_ossec_agent.py::test_hosts_files`
* `mon/test_ossec_server.py::test_ossec_connectivity`
* `mon/test_ossec_server.py::test_hosts_files`
* `mon/test_postfix.py::test_postfix_generic_maps`
## Comments
_Originally posted by @zenmonkeykstop in <https://github.com/freedomofpress/securedrop/issues/6103#issuecomment-946018659>:_
> testinfra tests take their expected values from a bunch of variables in a yaml file, with some of said values (like server IPs) in prod runs being overridden from the `install_files/ansible-base/group_vars/all/site-specific` file created by `./securedrop-admin sdconfig`. Looks like the server hostnames are *not* being overridden. So if they're not named according to the reccos in the docs I'd expect to see this error. Would be an easy fix to override them too methinks - check `molecule/testinfra/conftest.py`.
https://github.com/freedomofpress/securedrop/blob/2882d1ea39175bd98c302000bb506e9b88a18a1f/molecule/testinfra/conftest.py#L49-L50
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `molecule/testinfra/conftest.py`
Content:
```
1 """
2 Configuration for TestInfra test suite for SecureDrop.
3 Handles importing host-specific test vars, so test functions
4 can be reused across multiple hosts, with varied targets.
5
6 Vars should be placed in `testinfra/vars/<hostname>.yml`.
7 """
8
9 import io
10 import os
11 import yaml
12 from typing import Any, Dict
13
14 import testutils
15
16
17 # The config tests target staging by default.
18 target_host = os.environ.get('SECUREDROP_TESTINFRA_TARGET_HOST', 'staging')
19
20
21 def securedrop_import_testinfra_vars(hostname, with_header=False):
22 """
23 Import vars from a YAML file to populate tests with host-specific
24 values used in checks. For instance, the SecureDrop docroot will
25 be under /vagrant in development, but /var/www/securedrop in staging.
26
27 Vars must be stored in `testinfra/vars/<hostname>.yml`.
28 """
29 filepath = os.path.join(os.path.dirname(__file__), "vars", hostname+".yml")
30 with io.open(filepath, 'r') as f:
31 hostvars = yaml.safe_load(f)
32
33 hostvars['securedrop_venv_site_packages'] = hostvars["securedrop_venv_site_packages"].format("3.8") # noqa: E501
34 hostvars['python_version'] = "3.8"
35 hostvars['apparmor_enforce_actual'] = hostvars['apparmor_enforce']['focal']
36
37 # If the tests are run against a production environment, check local config
38 # and override as necessary.
39 prod_filepath = os.path.join(os.path.dirname(__file__),
40 "../../install_files/ansible-base/group_vars/all/site-specific")
41 if os.path.isfile(prod_filepath):
42 with io.open(prod_filepath, 'r') as f:
43 prodvars = yaml.safe_load(f)
44
45 def _prod_override(vars_key, prod_key):
46 if prod_key in prodvars:
47 hostvars[vars_key] = prodvars[prod_key]
48
49 _prod_override('app_ip', 'app_ip')
50 _prod_override('mon_ip', 'monitor_ip')
51 _prod_override('sasl_domain', 'sasl_domain')
52 _prod_override('sasl_username', 'sasl_username')
53 _prod_override('sasl_password', 'sasl_password')
54 _prod_override('daily_reboot_time', 'daily_reboot_time')
55
56 # Check repo targeting, and update vars
57 repo_filepath = os.path.join(os.path.dirname(__file__),
58 "../../install_files/ansible-base/roles/install-fpf-repo/defaults/main.yml") # noqa: E501
59 if os.path.isfile(repo_filepath):
60 with io.open(repo_filepath, 'r') as f:
61 repovars = yaml.safe_load(f)
62 if 'apt_repo_url' in repovars:
63 hostvars['fpf_apt_repo_url'] = repovars['apt_repo_url']
64
65 if with_header:
66 hostvars = dict(securedrop_test_vars=hostvars)
67
68 return hostvars
69
70
71 class TestVars(dict):
72 managed_attrs = {} # type: Dict[str, Any]
73
74 def __init__(self, initial: Dict[str, Any]) -> None:
75 self.securedrop_target_distribution = os.environ.get("SECUREDROP_TARGET_DISTRIBUTION")
76 self.managed_attrs.update(initial)
77
78 def __getattr__(self, name: str) -> Any:
79 """
80 If the requested attribute names a dict in managed_attrs and that
81 contains a key with the name of the target distribution,
82 e.g. "focal", return that. Otherwise return the entire item
83 under the requested name.
84 """
85 try:
86 attr = self.managed_attrs[name]
87 if isinstance(attr, dict) and self.securedrop_target_distribution in attr:
88 return attr[self.securedrop_target_distribution]
89 return attr
90 except KeyError:
91 raise AttributeError(name)
92
93 def __str__(self) -> str:
94 return str(self.managed_attrs)
95
96
97 testutils.securedrop_test_vars = TestVars(securedrop_import_testinfra_vars(target_host))
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/molecule/testinfra/conftest.py b/molecule/testinfra/conftest.py
--- a/molecule/testinfra/conftest.py
+++ b/molecule/testinfra/conftest.py
@@ -47,7 +47,9 @@
hostvars[vars_key] = prodvars[prod_key]
_prod_override('app_ip', 'app_ip')
+ _prod_override('app_hostname', 'app_hostname')
_prod_override('mon_ip', 'monitor_ip')
+ _prod_override('monitor_hostname', 'monitor_hostname')
_prod_override('sasl_domain', 'sasl_domain')
_prod_override('sasl_username', 'sasl_username')
_prod_override('sasl_password', 'sasl_password')
|
{"golden_diff": "diff --git a/molecule/testinfra/conftest.py b/molecule/testinfra/conftest.py\n--- a/molecule/testinfra/conftest.py\n+++ b/molecule/testinfra/conftest.py\n@@ -47,7 +47,9 @@\n hostvars[vars_key] = prodvars[prod_key]\n \n _prod_override('app_ip', 'app_ip')\n+ _prod_override('app_hostname', 'app_hostname')\n _prod_override('mon_ip', 'monitor_ip')\n+ _prod_override('monitor_hostname', 'monitor_hostname')\n _prod_override('sasl_domain', 'sasl_domain')\n _prod_override('sasl_username', 'sasl_username')\n _prod_override('sasl_password', 'sasl_password')\n", "issue": "spurious testinfra failures when servers have non-default hostnames\n## Description\r\n\r\nIf a production instance is configured with hostnames other than the recommended `app` and `mon`, `securedrop-admin verify` will report spurious testinfra failures.\r\n\r\nFirst noticed in <https://github.com/freedomofpress/securedrop/issues/6127#issuecomment-938342242>.\r\n\r\n## Steps to Reproduce\r\n\r\n1. `securedrop-admin sdconfig` with non-default hostnames, e.g. those provisioned by `molecule create -s libvirt-prod-focal`:\r\n ```yaml\r\n app_hostname: app-prod\r\n monitor_hostname: mon-prod\r\n ```\r\n2. `securedrop-admin install`\r\n3. `securedrop-admin setup -t`\r\n4. `securedrop-admin verify`\r\n\r\n## Expected Behavior\r\n\r\nAll testinfra tests pass.\r\n\r\n## Actual Behavior\r\n\r\nHostname-dependent testinfra tests fail, including:\r\n\r\n* `app/test_ossec_agent.py::test_hosts_files`\r\n* `mon/test_ossec_server.py::test_ossec_connectivity`\r\n* `mon/test_ossec_server.py::test_hosts_files`\r\n* `mon/test_postfix.py::test_postfix_generic_maps`\r\n\r\n## Comments\r\n\r\n_Originally posted by @zenmonkeykstop in <https://github.com/freedomofpress/securedrop/issues/6103#issuecomment-946018659>:_\r\n\r\n> testinfra tests take their expected values from a bunch of variables in a yaml file, with some of said values (like server IPs) in prod runs being overridden from the `install_files/ansible-base/group_vars/all/site-specific` file created by `./securedrop-admin sdconfig`. Looks like the server hostnames are *not* being overridden. So if they're not named according to the reccos in the docs I'd expect to see this error. Would be an easy fix to override them too methinks - check `molecule/testinfra/conftest.py`.\r\n\r\nhttps://github.com/freedomofpress/securedrop/blob/2882d1ea39175bd98c302000bb506e9b88a18a1f/molecule/testinfra/conftest.py#L49-L50\n", "before_files": [{"content": "\"\"\"\nConfiguration for TestInfra test suite for SecureDrop.\nHandles importing host-specific test vars, so test functions\ncan be reused across multiple hosts, with varied targets.\n\nVars should be placed in `testinfra/vars/<hostname>.yml`.\n\"\"\"\n\nimport io\nimport os\nimport yaml\nfrom typing import Any, Dict\n\nimport testutils\n\n\n# The config tests target staging by default.\ntarget_host = os.environ.get('SECUREDROP_TESTINFRA_TARGET_HOST', 'staging')\n\n\ndef securedrop_import_testinfra_vars(hostname, with_header=False):\n \"\"\"\n Import vars from a YAML file to populate tests with host-specific\n values used in checks. For instance, the SecureDrop docroot will\n be under /vagrant in development, but /var/www/securedrop in staging.\n\n Vars must be stored in `testinfra/vars/<hostname>.yml`.\n \"\"\"\n filepath = os.path.join(os.path.dirname(__file__), \"vars\", hostname+\".yml\")\n with io.open(filepath, 'r') as f:\n hostvars = yaml.safe_load(f)\n\n hostvars['securedrop_venv_site_packages'] = hostvars[\"securedrop_venv_site_packages\"].format(\"3.8\") # noqa: E501\n hostvars['python_version'] = \"3.8\"\n hostvars['apparmor_enforce_actual'] = hostvars['apparmor_enforce']['focal']\n\n # If the tests are run against a production environment, check local config\n # and override as necessary.\n prod_filepath = os.path.join(os.path.dirname(__file__),\n \"../../install_files/ansible-base/group_vars/all/site-specific\")\n if os.path.isfile(prod_filepath):\n with io.open(prod_filepath, 'r') as f:\n prodvars = yaml.safe_load(f)\n\n def _prod_override(vars_key, prod_key):\n if prod_key in prodvars:\n hostvars[vars_key] = prodvars[prod_key]\n\n _prod_override('app_ip', 'app_ip')\n _prod_override('mon_ip', 'monitor_ip')\n _prod_override('sasl_domain', 'sasl_domain')\n _prod_override('sasl_username', 'sasl_username')\n _prod_override('sasl_password', 'sasl_password')\n _prod_override('daily_reboot_time', 'daily_reboot_time')\n\n # Check repo targeting, and update vars\n repo_filepath = os.path.join(os.path.dirname(__file__),\n \"../../install_files/ansible-base/roles/install-fpf-repo/defaults/main.yml\") # noqa: E501\n if os.path.isfile(repo_filepath):\n with io.open(repo_filepath, 'r') as f:\n repovars = yaml.safe_load(f)\n if 'apt_repo_url' in repovars:\n hostvars['fpf_apt_repo_url'] = repovars['apt_repo_url']\n\n if with_header:\n hostvars = dict(securedrop_test_vars=hostvars)\n\n return hostvars\n\n\nclass TestVars(dict):\n managed_attrs = {} # type: Dict[str, Any]\n\n def __init__(self, initial: Dict[str, Any]) -> None:\n self.securedrop_target_distribution = os.environ.get(\"SECUREDROP_TARGET_DISTRIBUTION\")\n self.managed_attrs.update(initial)\n\n def __getattr__(self, name: str) -> Any:\n \"\"\"\n If the requested attribute names a dict in managed_attrs and that\n contains a key with the name of the target distribution,\n e.g. \"focal\", return that. Otherwise return the entire item\n under the requested name.\n \"\"\"\n try:\n attr = self.managed_attrs[name]\n if isinstance(attr, dict) and self.securedrop_target_distribution in attr:\n return attr[self.securedrop_target_distribution]\n return attr\n except KeyError:\n raise AttributeError(name)\n\n def __str__(self) -> str:\n return str(self.managed_attrs)\n\n\ntestutils.securedrop_test_vars = TestVars(securedrop_import_testinfra_vars(target_host))\n", "path": "molecule/testinfra/conftest.py"}], "after_files": [{"content": "\"\"\"\nConfiguration for TestInfra test suite for SecureDrop.\nHandles importing host-specific test vars, so test functions\ncan be reused across multiple hosts, with varied targets.\n\nVars should be placed in `testinfra/vars/<hostname>.yml`.\n\"\"\"\n\nimport io\nimport os\nimport yaml\nfrom typing import Any, Dict\n\nimport testutils\n\n\n# The config tests target staging by default.\ntarget_host = os.environ.get('SECUREDROP_TESTINFRA_TARGET_HOST', 'staging')\n\n\ndef securedrop_import_testinfra_vars(hostname, with_header=False):\n \"\"\"\n Import vars from a YAML file to populate tests with host-specific\n values used in checks. For instance, the SecureDrop docroot will\n be under /vagrant in development, but /var/www/securedrop in staging.\n\n Vars must be stored in `testinfra/vars/<hostname>.yml`.\n \"\"\"\n filepath = os.path.join(os.path.dirname(__file__), \"vars\", hostname+\".yml\")\n with io.open(filepath, 'r') as f:\n hostvars = yaml.safe_load(f)\n\n hostvars['securedrop_venv_site_packages'] = hostvars[\"securedrop_venv_site_packages\"].format(\"3.8\") # noqa: E501\n hostvars['python_version'] = \"3.8\"\n hostvars['apparmor_enforce_actual'] = hostvars['apparmor_enforce']['focal']\n\n # If the tests are run against a production environment, check local config\n # and override as necessary.\n prod_filepath = os.path.join(os.path.dirname(__file__),\n \"../../install_files/ansible-base/group_vars/all/site-specific\")\n if os.path.isfile(prod_filepath):\n with io.open(prod_filepath, 'r') as f:\n prodvars = yaml.safe_load(f)\n\n def _prod_override(vars_key, prod_key):\n if prod_key in prodvars:\n hostvars[vars_key] = prodvars[prod_key]\n\n _prod_override('app_ip', 'app_ip')\n _prod_override('app_hostname', 'app_hostname')\n _prod_override('mon_ip', 'monitor_ip')\n _prod_override('monitor_hostname', 'monitor_hostname')\n _prod_override('sasl_domain', 'sasl_domain')\n _prod_override('sasl_username', 'sasl_username')\n _prod_override('sasl_password', 'sasl_password')\n _prod_override('daily_reboot_time', 'daily_reboot_time')\n\n # Check repo targeting, and update vars\n repo_filepath = os.path.join(os.path.dirname(__file__),\n \"../../install_files/ansible-base/roles/install-fpf-repo/defaults/main.yml\") # noqa: E501\n if os.path.isfile(repo_filepath):\n with io.open(repo_filepath, 'r') as f:\n repovars = yaml.safe_load(f)\n if 'apt_repo_url' in repovars:\n hostvars['fpf_apt_repo_url'] = repovars['apt_repo_url']\n\n if with_header:\n hostvars = dict(securedrop_test_vars=hostvars)\n\n return hostvars\n\n\nclass TestVars(dict):\n managed_attrs = {} # type: Dict[str, Any]\n\n def __init__(self, initial: Dict[str, Any]) -> None:\n self.securedrop_target_distribution = os.environ.get(\"SECUREDROP_TARGET_DISTRIBUTION\")\n self.managed_attrs.update(initial)\n\n def __getattr__(self, name: str) -> Any:\n \"\"\"\n If the requested attribute names a dict in managed_attrs and that\n contains a key with the name of the target distribution,\n e.g. \"focal\", return that. Otherwise return the entire item\n under the requested name.\n \"\"\"\n try:\n attr = self.managed_attrs[name]\n if isinstance(attr, dict) and self.securedrop_target_distribution in attr:\n return attr[self.securedrop_target_distribution]\n return attr\n except KeyError:\n raise AttributeError(name)\n\n def __str__(self) -> str:\n return str(self.managed_attrs)\n\n\ntestutils.securedrop_test_vars = TestVars(securedrop_import_testinfra_vars(target_host))\n", "path": "molecule/testinfra/conftest.py"}]}
| 1,814 | 163 |
gh_patches_debug_99
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-6663
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
st.json replaces multiple spaces with single space
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
When using st.json, multiple spaces in strings are replaced with a single space.
### Reproducible Code Example
```Python
import streamlit as st
st.json({"Hello World": "Hello James"})
```
### Steps To Reproduce
_No response_
### Expected Behavior
_No response_
### Current Behavior
_No response_
### Is this a regression?
- [ ] Yes, this used to work in a previous version.
### Debug info
- Streamlit version:
- Python version:
- Operating System:
- Browser:
- Virtual environment:
### Additional Information
_No response_
### Are you willing to submit a PR?
- [ ] Yes, I am willing to submit a PR!
st.json replaces multiple spaces with single space
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
When using st.json, multiple spaces in strings are replaced with a single space.
### Reproducible Code Example
```Python
import streamlit as st
st.json({"Hello World": "Hello James"})
```
### Steps To Reproduce
_No response_
### Expected Behavior
_No response_
### Current Behavior
_No response_
### Is this a regression?
- [ ] Yes, this used to work in a previous version.
### Debug info
- Streamlit version:
- Python version:
- Operating System:
- Browser:
- Virtual environment:
### Additional Information
_No response_
### Are you willing to submit a PR?
- [ ] Yes, I am willing to submit a PR!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `e2e/scripts/st_json.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import streamlit as st
16
17 data = {"foo": "bar"}
18 st.json(data)
19 st.json(data, expanded=False)
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/e2e/scripts/st_json.py b/e2e/scripts/st_json.py
--- a/e2e/scripts/st_json.py
+++ b/e2e/scripts/st_json.py
@@ -17,3 +17,5 @@
data = {"foo": "bar"}
st.json(data)
st.json(data, expanded=False)
+data = {"Hello World": "Foo Bar"}
+st.json(data)
|
{"golden_diff": "diff --git a/e2e/scripts/st_json.py b/e2e/scripts/st_json.py\n--- a/e2e/scripts/st_json.py\n+++ b/e2e/scripts/st_json.py\n@@ -17,3 +17,5 @@\n data = {\"foo\": \"bar\"}\n st.json(data)\n st.json(data, expanded=False)\n+data = {\"Hello World\": \"Foo Bar\"}\n+st.json(data)\n", "issue": "st.json replaces multiple spaces with single space\n### Checklist\n\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\n- [X] I added a very descriptive title to this issue.\n- [X] I have provided sufficient information below to help reproduce this issue.\n\n### Summary\n\nWhen using st.json, multiple spaces in strings are replaced with a single space.\n\n### Reproducible Code Example\n\n```Python\nimport streamlit as st\r\n\r\nst.json({\"Hello World\": \"Hello James\"})\n```\n\n\n### Steps To Reproduce\n\n_No response_\n\n### Expected Behavior\n\n_No response_\n\n### Current Behavior\n\n_No response_\n\n### Is this a regression?\n\n- [ ] Yes, this used to work in a previous version.\n\n### Debug info\n\n- Streamlit version:\r\n- Python version:\r\n- Operating System:\r\n- Browser:\r\n- Virtual environment:\r\n\n\n### Additional Information\n\n_No response_\n\n### Are you willing to submit a PR?\n\n- [ ] Yes, I am willing to submit a PR!\nst.json replaces multiple spaces with single space\n### Checklist\n\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\n- [X] I added a very descriptive title to this issue.\n- [X] I have provided sufficient information below to help reproduce this issue.\n\n### Summary\n\nWhen using st.json, multiple spaces in strings are replaced with a single space.\n\n### Reproducible Code Example\n\n```Python\nimport streamlit as st\r\n\r\nst.json({\"Hello World\": \"Hello James\"})\n```\n\n\n### Steps To Reproduce\n\n_No response_\n\n### Expected Behavior\n\n_No response_\n\n### Current Behavior\n\n_No response_\n\n### Is this a regression?\n\n- [ ] Yes, this used to work in a previous version.\n\n### Debug info\n\n- Streamlit version:\r\n- Python version:\r\n- Operating System:\r\n- Browser:\r\n- Virtual environment:\r\n\n\n### Additional Information\n\n_No response_\n\n### Are you willing to submit a PR?\n\n- [ ] Yes, I am willing to submit a PR!\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\ndata = {\"foo\": \"bar\"}\nst.json(data)\nst.json(data, expanded=False)\n", "path": "e2e/scripts/st_json.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\ndata = {\"foo\": \"bar\"}\nst.json(data)\nst.json(data, expanded=False)\ndata = {\"Hello World\": \"Foo Bar\"}\nst.json(data)\n", "path": "e2e/scripts/st_json.py"}]}
| 901 | 89 |
gh_patches_debug_667
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6901
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ci: PyPi publish job fails in "Build distribution" step with error `module 'sqlalchemy' has no attribute 'orm'`
https://github.com/meltano/meltano/actions/runs/3267990463/jobs/5373871668
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py`
Content:
```
1 """add resource type to embed token
2
3 Revision ID: 23ea52e6d784
4 Revises: ceb00d7ff3bd
5 Create Date: 2020-02-12 09:29:31.592426
6
7 """
8 import sqlalchemy as sa
9 from alembic import op
10
11 from meltano.migrations.utils.dialect_typing import (
12 get_dialect_name,
13 max_string_length_for_dialect,
14 )
15
16 # revision identifiers, used by Alembic.
17 revision = "23ea52e6d784"
18 down_revision = "ceb00d7ff3bd"
19 branch_labels = None
20 depends_on = None
21
22 Session = sa.orm.sessionmaker()
23
24
25 def upgrade():
26 dialect_name = get_dialect_name()
27 max_string_length = max_string_length_for_dialect(dialect_name)
28
29 op.add_column(
30 "embed_tokens", sa.Column("resource_type", sa.String(max_string_length))
31 )
32
33 metadata = sa.MetaData(bind=op.get_bind())
34 Embed_Tokens = sa.Table("embed_tokens", metadata, autoload=True)
35 op.execute(Embed_Tokens.update().values({"resource_type": "report"}))
36
37
38 def downgrade():
39 op.drop_column("embed_tokens", "resource_type")
40
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py b/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py
--- a/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py
+++ b/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py
@@ -6,6 +6,7 @@
"""
import sqlalchemy as sa
+import sqlalchemy.orm
from alembic import op
from meltano.migrations.utils.dialect_typing import (
|
{"golden_diff": "diff --git a/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py b/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py\n--- a/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py\n+++ b/src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py\n@@ -6,6 +6,7 @@\n \n \"\"\"\n import sqlalchemy as sa\n+import sqlalchemy.orm\n from alembic import op\n \n from meltano.migrations.utils.dialect_typing import (\n", "issue": "ci: PyPi publish job fails in \"Build distribution\" step with error `module 'sqlalchemy' has no attribute 'orm'`\nhttps://github.com/meltano/meltano/actions/runs/3267990463/jobs/5373871668\n", "before_files": [{"content": "\"\"\"add resource type to embed token\n\nRevision ID: 23ea52e6d784\nRevises: ceb00d7ff3bd\nCreate Date: 2020-02-12 09:29:31.592426\n\n\"\"\"\nimport sqlalchemy as sa\nfrom alembic import op\n\nfrom meltano.migrations.utils.dialect_typing import (\n get_dialect_name,\n max_string_length_for_dialect,\n)\n\n# revision identifiers, used by Alembic.\nrevision = \"23ea52e6d784\"\ndown_revision = \"ceb00d7ff3bd\"\nbranch_labels = None\ndepends_on = None\n\nSession = sa.orm.sessionmaker()\n\n\ndef upgrade():\n dialect_name = get_dialect_name()\n max_string_length = max_string_length_for_dialect(dialect_name)\n\n op.add_column(\n \"embed_tokens\", sa.Column(\"resource_type\", sa.String(max_string_length))\n )\n\n metadata = sa.MetaData(bind=op.get_bind())\n Embed_Tokens = sa.Table(\"embed_tokens\", metadata, autoload=True)\n op.execute(Embed_Tokens.update().values({\"resource_type\": \"report\"}))\n\n\ndef downgrade():\n op.drop_column(\"embed_tokens\", \"resource_type\")\n", "path": "src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py"}], "after_files": [{"content": "\"\"\"add resource type to embed token\n\nRevision ID: 23ea52e6d784\nRevises: ceb00d7ff3bd\nCreate Date: 2020-02-12 09:29:31.592426\n\n\"\"\"\nimport sqlalchemy as sa\nimport sqlalchemy.orm\nfrom alembic import op\n\nfrom meltano.migrations.utils.dialect_typing import (\n get_dialect_name,\n max_string_length_for_dialect,\n)\n\n# revision identifiers, used by Alembic.\nrevision = \"23ea52e6d784\"\ndown_revision = \"ceb00d7ff3bd\"\nbranch_labels = None\ndepends_on = None\n\nSession = sa.orm.sessionmaker()\n\n\ndef upgrade():\n dialect_name = get_dialect_name()\n max_string_length = max_string_length_for_dialect(dialect_name)\n\n op.add_column(\n \"embed_tokens\", sa.Column(\"resource_type\", sa.String(max_string_length))\n )\n\n metadata = sa.MetaData(bind=op.get_bind())\n Embed_Tokens = sa.Table(\"embed_tokens\", metadata, autoload=True)\n op.execute(Embed_Tokens.update().values({\"resource_type\": \"report\"}))\n\n\ndef downgrade():\n op.drop_column(\"embed_tokens\", \"resource_type\")\n", "path": "src/meltano/migrations/versions/23ea52e6d784_add_resource_type_to_embed_token.py"}]}
| 705 | 161 |
gh_patches_debug_40162
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3398
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider lululemon is broken
During the global build at 2021-06-02-14-42-40, spider **lululemon** failed with **0 features** and **0 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-02-14-42-40/logs/lululemon.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-02-14-42-40/output/lululemon.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-02-14-42-40/output/lululemon.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/lululemon.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import json
3 import scrapy
4
5 from locations.items import GeojsonPointItem
6 from locations.hours import OpeningHours
7
8 WEEKDAYS = ["Mo", "Tu", "We", "Th", "Fr", "Sa", "Su"]
9
10
11 class LuLuLemonSpider(scrapy.Spider):
12 download_delay = 0.1
13 name = "lululemon"
14 item_attributes = {"brand": "LuLuLemon", "brand_wikidata": "Q6702957"}
15 allowed_domains = ["shop.lululemon.com"]
16 start_urls = ("https://shop.lululemon.com/stores/all-lululemon-stores",)
17
18 def parse(self, response):
19 urls = response.xpath('//a[@class="store-link basic"]/@href').extract()
20 for path in urls:
21 yield scrapy.Request(response.urljoin(path), callback=self.parse_store)
22
23 def parse_store(self, response):
24 address = {}
25 geo = {}
26 data = json.loads(
27 response.xpath('//script[@type="application/ld+json"]/text()').extract_first()
28 )
29
30 ref = response.xpath('//h1[@class="lll-stack-lvl4"]/text()').extract_first()
31
32 if data.get("address"):
33 address["full"] = data["address"].get("streetAddress")
34 address["zip"] = data["address"].get("postalCode")
35 address["state"] = data["address"].get("addressRegion")
36 address["city"] = data["address"].get("addressLocality")
37 address["country"] = data["address"].get("addressCountry")
38 if data.get("geo"):
39 geo["lat"] = data["geo"].get("latitude")
40 geo["lon"] = data["geo"].get("longitude")
41 oh = self.parse_hours(data.get("openingHours"))
42 if not oh:
43 ref = "CLOSED - {}".format(ref)
44
45 properties = {
46 "addr_full": address.get("full"),
47 "phone": data.get("telephone"),
48 "city": address.get("city"),
49 "state": address.get("state"),
50 "postcode": address.get("zip"),
51 "ref": ref,
52 "website": response.url,
53 "lat": geo.get("lat"),
54 "lon": geo.get("lon"),
55 "opening_hours": oh,
56 }
57 yield GeojsonPointItem(**properties)
58
59 def parse_hours(self, hours):
60 oh = OpeningHours()
61
62 for h in hours:
63 t = h.replace(" - ", "-")
64 d, h = t.split()
65 ot, ct = h.split("-")
66 # Some stores are permanently closed, thus no time is defined
67 if ot == "null" or ct == "null":
68 continue
69 days = self.parse_days(d)
70 for day in days:
71 oh.add_range(day=day, open_time=ot, close_time=ct, time_format="%H:%M")
72
73 return oh.as_opening_hours()
74
75 def parse_days(self, days):
76 """Parse day ranges and returns a list of days it represent
77 The following formats are considered:
78 - Single day, e.g. "Mon", "Monday"
79 - Range, e.g. "Mon-Fri", "Tue-Sund", "Sat-Sunday"
80 - Two days, e.g. "Sat & Sun", "Friday & Su"
81
82 Returns a list with the weekdays
83 """
84 # Produce a list of weekdays between two days e.g. su-sa, mo-th, etc.
85 if "-" in days:
86 d = days.split("-")
87 r = [i.strip()[:2] for i in d]
88 s = WEEKDAYS.index(r[0].title())
89 e = WEEKDAYS.index(r[1].title())
90 if s <= e:
91 return WEEKDAYS[s : e + 1]
92 else:
93 return WEEKDAYS[s:] + WEEKDAYS[: e + 1]
94 # Two days
95 if "&" in days:
96 d = days.split("&")
97 return [i.strip()[:2].title() for i in d]
98 # Single days
99 else:
100 return [days.strip()[:2].title()]
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/lululemon.py b/locations/spiders/lululemon.py
--- a/locations/spiders/lululemon.py
+++ b/locations/spiders/lululemon.py
@@ -16,35 +16,39 @@
start_urls = ("https://shop.lululemon.com/stores/all-lululemon-stores",)
def parse(self, response):
- urls = response.xpath('//a[@class="store-link basic"]/@href').extract()
+ urls = response.xpath('//a[@class="store-list_storeLink__3krLG"]/@href').extract()
for path in urls:
yield scrapy.Request(response.urljoin(path), callback=self.parse_store)
def parse_store(self, response):
address = {}
geo = {}
+ hours = {}
+ status = "CLOSED"
data = json.loads(
- response.xpath('//script[@type="application/ld+json"]/text()').extract_first()
+ response.xpath('//script[@type="application/json"]/text()').extract_first()
)
- ref = response.xpath('//h1[@class="lll-stack-lvl4"]/text()').extract_first()
+ ref = data["props"]["pageProps"]["storeData"]["name"]
+ address["full"] = data["props"]["pageProps"]["storeData"].get("fullAddress")
+ address["zip"] = address["full"].split(",")[-1].strip()
+ address["state"] = data["props"]["pageProps"]["storeData"].get("state")
+ address["city"] = data["props"]["pageProps"]["storeData"].get("city")
+ address["country"] = data["props"]["pageProps"]["storeData"].get("country")
+ address["phone"] = data["props"]["pageProps"]["storeData"].get("phone")
+ geo["lat"] = data["props"]["pageProps"]["storeData"].get("latitude")
+ geo["lon"] = data["props"]["pageProps"]["storeData"].get("longitude")
+ hours = data["props"]["pageProps"]["storeData"].get("hours")
+ if data["props"]["pageProps"]["storeData"].get("status") == "active_soon":
+ status = "Opening soon"
- if data.get("address"):
- address["full"] = data["address"].get("streetAddress")
- address["zip"] = data["address"].get("postalCode")
- address["state"] = data["address"].get("addressRegion")
- address["city"] = data["address"].get("addressLocality")
- address["country"] = data["address"].get("addressCountry")
- if data.get("geo"):
- geo["lat"] = data["geo"].get("latitude")
- geo["lon"] = data["geo"].get("longitude")
- oh = self.parse_hours(data.get("openingHours"))
+ oh = self.parse_hours(hours)
if not oh:
- ref = "CLOSED - {}".format(ref)
+ ref = "{} - {}".format(status, ref)
properties = {
"addr_full": address.get("full"),
- "phone": data.get("telephone"),
+ "phone": address.get("phone"),
"city": address.get("city"),
"state": address.get("state"),
"postcode": address.get("zip"),
@@ -60,11 +64,11 @@
oh = OpeningHours()
for h in hours:
- t = h.replace(" - ", "-")
- d, h = t.split()
- ot, ct = h.split("-")
+ d = h.get("name")
+ ot = h.get("openHour")
+ ct = h.get("closeHour")
# Some stores are permanently closed, thus no time is defined
- if ot == "null" or ct == "null":
+ if not ot or not ct:
continue
days = self.parse_days(d)
for day in days:
|
{"golden_diff": "diff --git a/locations/spiders/lululemon.py b/locations/spiders/lululemon.py\n--- a/locations/spiders/lululemon.py\n+++ b/locations/spiders/lululemon.py\n@@ -16,35 +16,39 @@\n start_urls = (\"https://shop.lululemon.com/stores/all-lululemon-stores\",)\n \n def parse(self, response):\n- urls = response.xpath('//a[@class=\"store-link basic\"]/@href').extract()\n+ urls = response.xpath('//a[@class=\"store-list_storeLink__3krLG\"]/@href').extract()\n for path in urls:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_store)\n \n def parse_store(self, response):\n address = {}\n geo = {}\n+ hours = {}\n+ status = \"CLOSED\"\n data = json.loads(\n- response.xpath('//script[@type=\"application/ld+json\"]/text()').extract_first()\n+ response.xpath('//script[@type=\"application/json\"]/text()').extract_first()\n )\n \n- ref = response.xpath('//h1[@class=\"lll-stack-lvl4\"]/text()').extract_first()\n+ ref = data[\"props\"][\"pageProps\"][\"storeData\"][\"name\"]\n+ address[\"full\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"fullAddress\")\n+ address[\"zip\"] = address[\"full\"].split(\",\")[-1].strip()\n+ address[\"state\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"state\")\n+ address[\"city\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"city\")\n+ address[\"country\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"country\")\n+ address[\"phone\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"phone\")\n+ geo[\"lat\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"latitude\")\n+ geo[\"lon\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"longitude\")\n+ hours = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"hours\")\n+ if data[\"props\"][\"pageProps\"][\"storeData\"].get(\"status\") == \"active_soon\":\n+ status = \"Opening soon\"\n \n- if data.get(\"address\"):\n- address[\"full\"] = data[\"address\"].get(\"streetAddress\")\n- address[\"zip\"] = data[\"address\"].get(\"postalCode\")\n- address[\"state\"] = data[\"address\"].get(\"addressRegion\")\n- address[\"city\"] = data[\"address\"].get(\"addressLocality\")\n- address[\"country\"] = data[\"address\"].get(\"addressCountry\")\n- if data.get(\"geo\"):\n- geo[\"lat\"] = data[\"geo\"].get(\"latitude\")\n- geo[\"lon\"] = data[\"geo\"].get(\"longitude\")\n- oh = self.parse_hours(data.get(\"openingHours\"))\n+ oh = self.parse_hours(hours)\n if not oh:\n- ref = \"CLOSED - {}\".format(ref)\n+ ref = \"{} - {}\".format(status, ref)\n \n properties = {\n \"addr_full\": address.get(\"full\"),\n- \"phone\": data.get(\"telephone\"),\n+ \"phone\": address.get(\"phone\"),\n \"city\": address.get(\"city\"),\n \"state\": address.get(\"state\"),\n \"postcode\": address.get(\"zip\"),\n@@ -60,11 +64,11 @@\n oh = OpeningHours()\n \n for h in hours:\n- t = h.replace(\" - \", \"-\")\n- d, h = t.split()\n- ot, ct = h.split(\"-\")\n+ d = h.get(\"name\")\n+ ot = h.get(\"openHour\")\n+ ct = h.get(\"closeHour\")\n # Some stores are permanently closed, thus no time is defined\n- if ot == \"null\" or ct == \"null\":\n+ if not ot or not ct:\n continue\n days = self.parse_days(d)\n for day in days:\n", "issue": "Spider lululemon is broken\nDuring the global build at 2021-06-02-14-42-40, spider **lululemon** failed with **0 features** and **0 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-02-14-42-40/logs/lululemon.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-02-14-42-40/output/lululemon.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-02-14-42-40/output/lululemon.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport json\nimport scrapy\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\nWEEKDAYS = [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\", \"Su\"]\n\n\nclass LuLuLemonSpider(scrapy.Spider):\n download_delay = 0.1\n name = \"lululemon\"\n item_attributes = {\"brand\": \"LuLuLemon\", \"brand_wikidata\": \"Q6702957\"}\n allowed_domains = [\"shop.lululemon.com\"]\n start_urls = (\"https://shop.lululemon.com/stores/all-lululemon-stores\",)\n\n def parse(self, response):\n urls = response.xpath('//a[@class=\"store-link basic\"]/@href').extract()\n for path in urls:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_store)\n\n def parse_store(self, response):\n address = {}\n geo = {}\n data = json.loads(\n response.xpath('//script[@type=\"application/ld+json\"]/text()').extract_first()\n )\n\n ref = response.xpath('//h1[@class=\"lll-stack-lvl4\"]/text()').extract_first()\n\n if data.get(\"address\"):\n address[\"full\"] = data[\"address\"].get(\"streetAddress\")\n address[\"zip\"] = data[\"address\"].get(\"postalCode\")\n address[\"state\"] = data[\"address\"].get(\"addressRegion\")\n address[\"city\"] = data[\"address\"].get(\"addressLocality\")\n address[\"country\"] = data[\"address\"].get(\"addressCountry\")\n if data.get(\"geo\"):\n geo[\"lat\"] = data[\"geo\"].get(\"latitude\")\n geo[\"lon\"] = data[\"geo\"].get(\"longitude\")\n oh = self.parse_hours(data.get(\"openingHours\"))\n if not oh:\n ref = \"CLOSED - {}\".format(ref)\n\n properties = {\n \"addr_full\": address.get(\"full\"),\n \"phone\": data.get(\"telephone\"),\n \"city\": address.get(\"city\"),\n \"state\": address.get(\"state\"),\n \"postcode\": address.get(\"zip\"),\n \"ref\": ref,\n \"website\": response.url,\n \"lat\": geo.get(\"lat\"),\n \"lon\": geo.get(\"lon\"),\n \"opening_hours\": oh,\n }\n yield GeojsonPointItem(**properties)\n\n def parse_hours(self, hours):\n oh = OpeningHours()\n\n for h in hours:\n t = h.replace(\" - \", \"-\")\n d, h = t.split()\n ot, ct = h.split(\"-\")\n # Some stores are permanently closed, thus no time is defined\n if ot == \"null\" or ct == \"null\":\n continue\n days = self.parse_days(d)\n for day in days:\n oh.add_range(day=day, open_time=ot, close_time=ct, time_format=\"%H:%M\")\n\n return oh.as_opening_hours()\n\n def parse_days(self, days):\n \"\"\"Parse day ranges and returns a list of days it represent\n The following formats are considered:\n - Single day, e.g. \"Mon\", \"Monday\"\n - Range, e.g. \"Mon-Fri\", \"Tue-Sund\", \"Sat-Sunday\"\n - Two days, e.g. \"Sat & Sun\", \"Friday & Su\"\n\n Returns a list with the weekdays\n \"\"\"\n # Produce a list of weekdays between two days e.g. su-sa, mo-th, etc.\n if \"-\" in days:\n d = days.split(\"-\")\n r = [i.strip()[:2] for i in d]\n s = WEEKDAYS.index(r[0].title())\n e = WEEKDAYS.index(r[1].title())\n if s <= e:\n return WEEKDAYS[s : e + 1]\n else:\n return WEEKDAYS[s:] + WEEKDAYS[: e + 1]\n # Two days\n if \"&\" in days:\n d = days.split(\"&\")\n return [i.strip()[:2].title() for i in d]\n # Single days\n else:\n return [days.strip()[:2].title()]\n", "path": "locations/spiders/lululemon.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport json\nimport scrapy\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\nWEEKDAYS = [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\", \"Su\"]\n\n\nclass LuLuLemonSpider(scrapy.Spider):\n download_delay = 0.1\n name = \"lululemon\"\n item_attributes = {\"brand\": \"LuLuLemon\", \"brand_wikidata\": \"Q6702957\"}\n allowed_domains = [\"shop.lululemon.com\"]\n start_urls = (\"https://shop.lululemon.com/stores/all-lululemon-stores\",)\n\n def parse(self, response):\n urls = response.xpath('//a[@class=\"store-list_storeLink__3krLG\"]/@href').extract()\n for path in urls:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_store)\n\n def parse_store(self, response):\n address = {}\n geo = {}\n hours = {}\n status = \"CLOSED\"\n data = json.loads(\n response.xpath('//script[@type=\"application/json\"]/text()').extract_first()\n )\n\n ref = data[\"props\"][\"pageProps\"][\"storeData\"][\"name\"]\n address[\"full\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"fullAddress\")\n address[\"zip\"] = address[\"full\"].split(\",\")[-1].strip()\n address[\"state\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"state\")\n address[\"city\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"city\")\n address[\"country\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"country\")\n address[\"phone\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"phone\")\n geo[\"lat\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"latitude\")\n geo[\"lon\"] = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"longitude\")\n hours = data[\"props\"][\"pageProps\"][\"storeData\"].get(\"hours\")\n if data[\"props\"][\"pageProps\"][\"storeData\"].get(\"status\") == \"active_soon\":\n status = \"Opening soon\"\n\n oh = self.parse_hours(hours)\n if not oh:\n ref = \"{} - {}\".format(status, ref)\n\n properties = {\n \"addr_full\": address.get(\"full\"),\n \"phone\": address.get(\"phone\"),\n \"city\": address.get(\"city\"),\n \"state\": address.get(\"state\"),\n \"postcode\": address.get(\"zip\"),\n \"ref\": ref,\n \"website\": response.url,\n \"lat\": geo.get(\"lat\"),\n \"lon\": geo.get(\"lon\"),\n \"opening_hours\": oh,\n }\n yield GeojsonPointItem(**properties)\n\n def parse_hours(self, hours):\n oh = OpeningHours()\n\n for h in hours:\n d = h.get(\"name\")\n ot = h.get(\"openHour\")\n ct = h.get(\"closeHour\")\n # Some stores are permanently closed, thus no time is defined\n if not ot or not ct:\n continue\n days = self.parse_days(d)\n for day in days:\n oh.add_range(day=day, open_time=ot, close_time=ct, time_format=\"%H:%M\")\n\n return oh.as_opening_hours()\n\n def parse_days(self, days):\n \"\"\"Parse day ranges and returns a list of days it represent\n The following formats are considered:\n - Single day, e.g. \"Mon\", \"Monday\"\n - Range, e.g. \"Mon-Fri\", \"Tue-Sund\", \"Sat-Sunday\"\n - Two days, e.g. \"Sat & Sun\", \"Friday & Su\"\n\n Returns a list with the weekdays\n \"\"\"\n # Produce a list of weekdays between two days e.g. su-sa, mo-th, etc.\n if \"-\" in days:\n d = days.split(\"-\")\n r = [i.strip()[:2] for i in d]\n s = WEEKDAYS.index(r[0].title())\n e = WEEKDAYS.index(r[1].title())\n if s <= e:\n return WEEKDAYS[s : e + 1]\n else:\n return WEEKDAYS[s:] + WEEKDAYS[: e + 1]\n # Two days\n if \"&\" in days:\n d = days.split(\"&\")\n return [i.strip()[:2].title() for i in d]\n # Single days\n else:\n return [days.strip()[:2].title()]\n", "path": "locations/spiders/lululemon.py"}]}
| 1,553 | 875 |
gh_patches_debug_43013
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-7599
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
feat: Add `page_number` to meta of Documents in `DocumentSplitter`
**Is your feature request related to a problem? Please describe.**
In Haystack v1 we had an option in the Preprocessor to add the original `page_number` to a Document's meta data when it was split into a chunk. This feature made down stream applications of visualizing the retrieved text from original files (e.g. PDFs) very easy and straightforward, so I'd like to see it in Haystack v2 as well.
**Describe the solution you'd like**
I would like to add the option to store the `page_number` in the meta info of the Document in the DocumentSplitter component. I believe we can use a similar/same implementation of calculating this like we did for the Preprocessor.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `haystack/components/preprocessors/document_splitter.py`
Content:
```
1 from copy import deepcopy
2 from typing import List, Literal
3
4 from more_itertools import windowed
5
6 from haystack import Document, component
7
8
9 @component
10 class DocumentSplitter:
11 """
12 Splits a list of text documents into a list of text documents with shorter texts.
13
14 Splitting documents with long texts is a common preprocessing step during indexing.
15 This allows Embedders to create significant semantic representations
16 and avoids exceeding the maximum context length of language models.
17 """
18
19 def __init__(
20 self,
21 split_by: Literal["word", "sentence", "page", "passage"] = "word",
22 split_length: int = 200,
23 split_overlap: int = 0,
24 ):
25 """
26 Initialize the DocumentSplitter.
27
28 :param split_by: The unit by which the document should be split. Choose from "word" for splitting by " ",
29 "sentence" for splitting by ".", "page" for splitting by "\\f" or "passage" for splitting by "\\n\\n".
30 :param split_length: The maximum number of units in each split.
31 :param split_overlap: The number of units that each split should overlap.
32 """
33
34 self.split_by = split_by
35 if split_by not in ["word", "sentence", "page", "passage"]:
36 raise ValueError("split_by must be one of 'word', 'sentence', 'page' or 'passage'.")
37 if split_length <= 0:
38 raise ValueError("split_length must be greater than 0.")
39 self.split_length = split_length
40 if split_overlap < 0:
41 raise ValueError("split_overlap must be greater than or equal to 0.")
42 self.split_overlap = split_overlap
43
44 @component.output_types(documents=List[Document])
45 def run(self, documents: List[Document]):
46 """
47 Split documents into smaller parts.
48
49 Splits documents by the unit expressed in `split_by`, with a length of `split_length`
50 and an overlap of `split_overlap`.
51
52 :param documents: The documents to split.
53
54 :returns: A dictionary with the following key:
55 - `documents`: List of documents with the split texts. A metadata field "source_id" is added to each
56 document to keep track of the original document that was split. Other metadata are copied from the original
57 document.
58
59 :raises TypeError: if the input is not a list of Documents.
60 :raises ValueError: if the content of a document is None.
61 """
62
63 if not isinstance(documents, list) or (documents and not isinstance(documents[0], Document)):
64 raise TypeError("DocumentSplitter expects a List of Documents as input.")
65
66 split_docs = []
67 for doc in documents:
68 if doc.content is None:
69 raise ValueError(
70 f"DocumentSplitter only works with text documents but document.content for document ID {doc.id} is None."
71 )
72 units = self._split_into_units(doc.content, self.split_by)
73 text_splits = self._concatenate_units(units, self.split_length, self.split_overlap)
74 metadata = deepcopy(doc.meta)
75 metadata["source_id"] = doc.id
76 split_docs += [Document(content=txt, meta=metadata) for txt in text_splits]
77 return {"documents": split_docs}
78
79 def _split_into_units(self, text: str, split_by: Literal["word", "sentence", "passage", "page"]) -> List[str]:
80 if split_by == "page":
81 split_at = "\f"
82 elif split_by == "passage":
83 split_at = "\n\n"
84 elif split_by == "sentence":
85 split_at = "."
86 elif split_by == "word":
87 split_at = " "
88 else:
89 raise NotImplementedError(
90 "DocumentSplitter only supports 'word', 'sentence', 'page' or 'passage' split_by options."
91 )
92 units = text.split(split_at)
93 # Add the delimiter back to all units except the last one
94 for i in range(len(units) - 1):
95 units[i] += split_at
96 return units
97
98 def _concatenate_units(self, elements: List[str], split_length: int, split_overlap: int) -> List[str]:
99 """
100 Concatenates the elements into parts of split_length units.
101 """
102 text_splits = []
103 segments = windowed(elements, n=split_length, step=split_length - split_overlap)
104 for seg in segments:
105 current_units = [unit for unit in seg if unit is not None]
106 txt = "".join(current_units)
107 if len(txt) > 0:
108 text_splits.append(txt)
109 return text_splits
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/haystack/components/preprocessors/document_splitter.py b/haystack/components/preprocessors/document_splitter.py
--- a/haystack/components/preprocessors/document_splitter.py
+++ b/haystack/components/preprocessors/document_splitter.py
@@ -1,5 +1,5 @@
from copy import deepcopy
-from typing import List, Literal
+from typing import Dict, List, Literal, Tuple
from more_itertools import windowed
@@ -53,7 +53,7 @@
:returns: A dictionary with the following key:
- `documents`: List of documents with the split texts. A metadata field "source_id" is added to each
- document to keep track of the original document that was split. Other metadata are copied from the original
+ document to keep track of the original document that was split. Another metadata field "page_number" is added to each number to keep track of the page it belonged to in the original document. Other metadata are copied from the original
document.
:raises TypeError: if the input is not a list of Documents.
@@ -70,10 +70,12 @@
f"DocumentSplitter only works with text documents but document.content for document ID {doc.id} is None."
)
units = self._split_into_units(doc.content, self.split_by)
- text_splits = self._concatenate_units(units, self.split_length, self.split_overlap)
+ text_splits, splits_pages = self._concatenate_units(units, self.split_length, self.split_overlap)
metadata = deepcopy(doc.meta)
metadata["source_id"] = doc.id
- split_docs += [Document(content=txt, meta=metadata) for txt in text_splits]
+ split_docs += self._create_docs_from_splits(
+ text_splits=text_splits, splits_pages=splits_pages, meta=metadata
+ )
return {"documents": split_docs}
def _split_into_units(self, text: str, split_by: Literal["word", "sentence", "passage", "page"]) -> List[str]:
@@ -95,15 +97,40 @@
units[i] += split_at
return units
- def _concatenate_units(self, elements: List[str], split_length: int, split_overlap: int) -> List[str]:
+ def _concatenate_units(
+ self, elements: List[str], split_length: int, split_overlap: int
+ ) -> Tuple[List[str], List[int]]:
"""
- Concatenates the elements into parts of split_length units.
+ Concatenates the elements into parts of split_length units keeping track of the original page number that each element belongs.
"""
text_splits = []
+ splits_pages = []
+ cur_page = 1
segments = windowed(elements, n=split_length, step=split_length - split_overlap)
for seg in segments:
current_units = [unit for unit in seg if unit is not None]
txt = "".join(current_units)
if len(txt) > 0:
text_splits.append(txt)
- return text_splits
+ splits_pages.append(cur_page)
+ processed_units = current_units[: split_length - split_overlap]
+ if self.split_by == "page":
+ num_page_breaks = len(processed_units)
+ else:
+ num_page_breaks = sum(processed_unit.count("\f") for processed_unit in processed_units)
+ cur_page += num_page_breaks
+ return text_splits, splits_pages
+
+ @staticmethod
+ def _create_docs_from_splits(text_splits: List[str], splits_pages: List[int], meta: Dict) -> List[Document]:
+ """
+ Creates Document objects from text splits enriching them with page number and the metadata of the original document.
+ """
+ documents: List[Document] = []
+
+ for i, txt in enumerate(text_splits):
+ meta = deepcopy(meta)
+ doc = Document(content=txt, meta=meta)
+ doc.meta["page_number"] = splits_pages[i]
+ documents.append(doc)
+ return documents
|
{"golden_diff": "diff --git a/haystack/components/preprocessors/document_splitter.py b/haystack/components/preprocessors/document_splitter.py\n--- a/haystack/components/preprocessors/document_splitter.py\n+++ b/haystack/components/preprocessors/document_splitter.py\n@@ -1,5 +1,5 @@\n from copy import deepcopy\n-from typing import List, Literal\n+from typing import Dict, List, Literal, Tuple\n \n from more_itertools import windowed\n \n@@ -53,7 +53,7 @@\n \n :returns: A dictionary with the following key:\n - `documents`: List of documents with the split texts. A metadata field \"source_id\" is added to each\n- document to keep track of the original document that was split. Other metadata are copied from the original\n+ document to keep track of the original document that was split. Another metadata field \"page_number\" is added to each number to keep track of the page it belonged to in the original document. Other metadata are copied from the original\n document.\n \n :raises TypeError: if the input is not a list of Documents.\n@@ -70,10 +70,12 @@\n f\"DocumentSplitter only works with text documents but document.content for document ID {doc.id} is None.\"\n )\n units = self._split_into_units(doc.content, self.split_by)\n- text_splits = self._concatenate_units(units, self.split_length, self.split_overlap)\n+ text_splits, splits_pages = self._concatenate_units(units, self.split_length, self.split_overlap)\n metadata = deepcopy(doc.meta)\n metadata[\"source_id\"] = doc.id\n- split_docs += [Document(content=txt, meta=metadata) for txt in text_splits]\n+ split_docs += self._create_docs_from_splits(\n+ text_splits=text_splits, splits_pages=splits_pages, meta=metadata\n+ )\n return {\"documents\": split_docs}\n \n def _split_into_units(self, text: str, split_by: Literal[\"word\", \"sentence\", \"passage\", \"page\"]) -> List[str]:\n@@ -95,15 +97,40 @@\n units[i] += split_at\n return units\n \n- def _concatenate_units(self, elements: List[str], split_length: int, split_overlap: int) -> List[str]:\n+ def _concatenate_units(\n+ self, elements: List[str], split_length: int, split_overlap: int\n+ ) -> Tuple[List[str], List[int]]:\n \"\"\"\n- Concatenates the elements into parts of split_length units.\n+ Concatenates the elements into parts of split_length units keeping track of the original page number that each element belongs.\n \"\"\"\n text_splits = []\n+ splits_pages = []\n+ cur_page = 1\n segments = windowed(elements, n=split_length, step=split_length - split_overlap)\n for seg in segments:\n current_units = [unit for unit in seg if unit is not None]\n txt = \"\".join(current_units)\n if len(txt) > 0:\n text_splits.append(txt)\n- return text_splits\n+ splits_pages.append(cur_page)\n+ processed_units = current_units[: split_length - split_overlap]\n+ if self.split_by == \"page\":\n+ num_page_breaks = len(processed_units)\n+ else:\n+ num_page_breaks = sum(processed_unit.count(\"\\f\") for processed_unit in processed_units)\n+ cur_page += num_page_breaks\n+ return text_splits, splits_pages\n+\n+ @staticmethod\n+ def _create_docs_from_splits(text_splits: List[str], splits_pages: List[int], meta: Dict) -> List[Document]:\n+ \"\"\"\n+ Creates Document objects from text splits enriching them with page number and the metadata of the original document.\n+ \"\"\"\n+ documents: List[Document] = []\n+\n+ for i, txt in enumerate(text_splits):\n+ meta = deepcopy(meta)\n+ doc = Document(content=txt, meta=meta)\n+ doc.meta[\"page_number\"] = splits_pages[i]\n+ documents.append(doc)\n+ return documents\n", "issue": "feat: Add `page_number` to meta of Documents in `DocumentSplitter`\n**Is your feature request related to a problem? Please describe.**\r\nIn Haystack v1 we had an option in the Preprocessor to add the original `page_number` to a Document's meta data when it was split into a chunk. This feature made down stream applications of visualizing the retrieved text from original files (e.g. PDFs) very easy and straightforward, so I'd like to see it in Haystack v2 as well. \r\n\r\n**Describe the solution you'd like**\r\nI would like to add the option to store the `page_number` in the meta info of the Document in the DocumentSplitter component. I believe we can use a similar/same implementation of calculating this like we did for the Preprocessor. \r\n\n", "before_files": [{"content": "from copy import deepcopy\nfrom typing import List, Literal\n\nfrom more_itertools import windowed\n\nfrom haystack import Document, component\n\n\n@component\nclass DocumentSplitter:\n \"\"\"\n Splits a list of text documents into a list of text documents with shorter texts.\n\n Splitting documents with long texts is a common preprocessing step during indexing.\n This allows Embedders to create significant semantic representations\n and avoids exceeding the maximum context length of language models.\n \"\"\"\n\n def __init__(\n self,\n split_by: Literal[\"word\", \"sentence\", \"page\", \"passage\"] = \"word\",\n split_length: int = 200,\n split_overlap: int = 0,\n ):\n \"\"\"\n Initialize the DocumentSplitter.\n\n :param split_by: The unit by which the document should be split. Choose from \"word\" for splitting by \" \",\n \"sentence\" for splitting by \".\", \"page\" for splitting by \"\\\\f\" or \"passage\" for splitting by \"\\\\n\\\\n\".\n :param split_length: The maximum number of units in each split.\n :param split_overlap: The number of units that each split should overlap.\n \"\"\"\n\n self.split_by = split_by\n if split_by not in [\"word\", \"sentence\", \"page\", \"passage\"]:\n raise ValueError(\"split_by must be one of 'word', 'sentence', 'page' or 'passage'.\")\n if split_length <= 0:\n raise ValueError(\"split_length must be greater than 0.\")\n self.split_length = split_length\n if split_overlap < 0:\n raise ValueError(\"split_overlap must be greater than or equal to 0.\")\n self.split_overlap = split_overlap\n\n @component.output_types(documents=List[Document])\n def run(self, documents: List[Document]):\n \"\"\"\n Split documents into smaller parts.\n\n Splits documents by the unit expressed in `split_by`, with a length of `split_length`\n and an overlap of `split_overlap`.\n\n :param documents: The documents to split.\n\n :returns: A dictionary with the following key:\n - `documents`: List of documents with the split texts. A metadata field \"source_id\" is added to each\n document to keep track of the original document that was split. Other metadata are copied from the original\n document.\n\n :raises TypeError: if the input is not a list of Documents.\n :raises ValueError: if the content of a document is None.\n \"\"\"\n\n if not isinstance(documents, list) or (documents and not isinstance(documents[0], Document)):\n raise TypeError(\"DocumentSplitter expects a List of Documents as input.\")\n\n split_docs = []\n for doc in documents:\n if doc.content is None:\n raise ValueError(\n f\"DocumentSplitter only works with text documents but document.content for document ID {doc.id} is None.\"\n )\n units = self._split_into_units(doc.content, self.split_by)\n text_splits = self._concatenate_units(units, self.split_length, self.split_overlap)\n metadata = deepcopy(doc.meta)\n metadata[\"source_id\"] = doc.id\n split_docs += [Document(content=txt, meta=metadata) for txt in text_splits]\n return {\"documents\": split_docs}\n\n def _split_into_units(self, text: str, split_by: Literal[\"word\", \"sentence\", \"passage\", \"page\"]) -> List[str]:\n if split_by == \"page\":\n split_at = \"\\f\"\n elif split_by == \"passage\":\n split_at = \"\\n\\n\"\n elif split_by == \"sentence\":\n split_at = \".\"\n elif split_by == \"word\":\n split_at = \" \"\n else:\n raise NotImplementedError(\n \"DocumentSplitter only supports 'word', 'sentence', 'page' or 'passage' split_by options.\"\n )\n units = text.split(split_at)\n # Add the delimiter back to all units except the last one\n for i in range(len(units) - 1):\n units[i] += split_at\n return units\n\n def _concatenate_units(self, elements: List[str], split_length: int, split_overlap: int) -> List[str]:\n \"\"\"\n Concatenates the elements into parts of split_length units.\n \"\"\"\n text_splits = []\n segments = windowed(elements, n=split_length, step=split_length - split_overlap)\n for seg in segments:\n current_units = [unit for unit in seg if unit is not None]\n txt = \"\".join(current_units)\n if len(txt) > 0:\n text_splits.append(txt)\n return text_splits\n", "path": "haystack/components/preprocessors/document_splitter.py"}], "after_files": [{"content": "from copy import deepcopy\nfrom typing import Dict, List, Literal, Tuple\n\nfrom more_itertools import windowed\n\nfrom haystack import Document, component\n\n\n@component\nclass DocumentSplitter:\n \"\"\"\n Splits a list of text documents into a list of text documents with shorter texts.\n\n Splitting documents with long texts is a common preprocessing step during indexing.\n This allows Embedders to create significant semantic representations\n and avoids exceeding the maximum context length of language models.\n \"\"\"\n\n def __init__(\n self,\n split_by: Literal[\"word\", \"sentence\", \"page\", \"passage\"] = \"word\",\n split_length: int = 200,\n split_overlap: int = 0,\n ):\n \"\"\"\n Initialize the DocumentSplitter.\n\n :param split_by: The unit by which the document should be split. Choose from \"word\" for splitting by \" \",\n \"sentence\" for splitting by \".\", \"page\" for splitting by \"\\\\f\" or \"passage\" for splitting by \"\\\\n\\\\n\".\n :param split_length: The maximum number of units in each split.\n :param split_overlap: The number of units that each split should overlap.\n \"\"\"\n\n self.split_by = split_by\n if split_by not in [\"word\", \"sentence\", \"page\", \"passage\"]:\n raise ValueError(\"split_by must be one of 'word', 'sentence', 'page' or 'passage'.\")\n if split_length <= 0:\n raise ValueError(\"split_length must be greater than 0.\")\n self.split_length = split_length\n if split_overlap < 0:\n raise ValueError(\"split_overlap must be greater than or equal to 0.\")\n self.split_overlap = split_overlap\n\n @component.output_types(documents=List[Document])\n def run(self, documents: List[Document]):\n \"\"\"\n Split documents into smaller parts.\n\n Splits documents by the unit expressed in `split_by`, with a length of `split_length`\n and an overlap of `split_overlap`.\n\n :param documents: The documents to split.\n\n :returns: A dictionary with the following key:\n - `documents`: List of documents with the split texts. A metadata field \"source_id\" is added to each\n document to keep track of the original document that was split. Another metadata field \"page_number\" is added to each number to keep track of the page it belonged to in the original document. Other metadata are copied from the original\n document.\n\n :raises TypeError: if the input is not a list of Documents.\n :raises ValueError: if the content of a document is None.\n \"\"\"\n\n if not isinstance(documents, list) or (documents and not isinstance(documents[0], Document)):\n raise TypeError(\"DocumentSplitter expects a List of Documents as input.\")\n\n split_docs = []\n for doc in documents:\n if doc.content is None:\n raise ValueError(\n f\"DocumentSplitter only works with text documents but document.content for document ID {doc.id} is None.\"\n )\n units = self._split_into_units(doc.content, self.split_by)\n text_splits, splits_pages = self._concatenate_units(units, self.split_length, self.split_overlap)\n metadata = deepcopy(doc.meta)\n metadata[\"source_id\"] = doc.id\n split_docs += self._create_docs_from_splits(\n text_splits=text_splits, splits_pages=splits_pages, meta=metadata\n )\n return {\"documents\": split_docs}\n\n def _split_into_units(self, text: str, split_by: Literal[\"word\", \"sentence\", \"passage\", \"page\"]) -> List[str]:\n if split_by == \"page\":\n split_at = \"\\f\"\n elif split_by == \"passage\":\n split_at = \"\\n\\n\"\n elif split_by == \"sentence\":\n split_at = \".\"\n elif split_by == \"word\":\n split_at = \" \"\n else:\n raise NotImplementedError(\n \"DocumentSplitter only supports 'word', 'sentence', 'page' or 'passage' split_by options.\"\n )\n units = text.split(split_at)\n # Add the delimiter back to all units except the last one\n for i in range(len(units) - 1):\n units[i] += split_at\n return units\n\n def _concatenate_units(\n self, elements: List[str], split_length: int, split_overlap: int\n ) -> Tuple[List[str], List[int]]:\n \"\"\"\n Concatenates the elements into parts of split_length units keeping track of the original page number that each element belongs.\n \"\"\"\n text_splits = []\n splits_pages = []\n cur_page = 1\n segments = windowed(elements, n=split_length, step=split_length - split_overlap)\n for seg in segments:\n current_units = [unit for unit in seg if unit is not None]\n txt = \"\".join(current_units)\n if len(txt) > 0:\n text_splits.append(txt)\n splits_pages.append(cur_page)\n processed_units = current_units[: split_length - split_overlap]\n if self.split_by == \"page\":\n num_page_breaks = len(processed_units)\n else:\n num_page_breaks = sum(processed_unit.count(\"\\f\") for processed_unit in processed_units)\n cur_page += num_page_breaks\n return text_splits, splits_pages\n\n @staticmethod\n def _create_docs_from_splits(text_splits: List[str], splits_pages: List[int], meta: Dict) -> List[Document]:\n \"\"\"\n Creates Document objects from text splits enriching them with page number and the metadata of the original document.\n \"\"\"\n documents: List[Document] = []\n\n for i, txt in enumerate(text_splits):\n meta = deepcopy(meta)\n doc = Document(content=txt, meta=meta)\n doc.meta[\"page_number\"] = splits_pages[i]\n documents.append(doc)\n return documents\n", "path": "haystack/components/preprocessors/document_splitter.py"}]}
| 1,648 | 885 |
gh_patches_debug_29498
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-5443
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: polars backend chokes on Categorical
### What happened?
Expected `ibis.polars.read_parquet` to succeed with a categorical dtype in the parquet file. Instead, we see a `KeyError: Categorical` exception.
It looks like the reverse direction is fine, but I believe `ibis.backends.polars.datatypes.py` needs the `dt.Category: pl.Categorical,` pair added into `_to_polars_types`
### What version of ibis are you using?
4.0.0 (still exists on main)
### What backend(s) are you using, if any?
polars
### Relevant log output
```sh
KeyError Traceback (most recent call last)
Cell In[3], line 1
----> 1 ibis.polars.read_parquet('data.parquet')
File ~/.conda/envs/modin/lib/python3.10/site-packages/ibis/backends/polars/__init__.py:211, in Backend.read_parquet(self, path, table_name, **kwargs)
209 table_name = table_name or f"ibis_read_parquet_{next(pa_n)}"
210 self._tables[table_name] = pl.scan_parquet(path, **kwargs)
--> 211 return self.table(table_name)
File ~/.conda/envs/modin/lib/python3.10/site-packages/ibis/backends/polars/__init__.py:61, in Backend.table(self, name, _schema)
60 def table(self, name: str, _schema: sch.Schema = None) -> ir.Table:
---> 61 schema = sch.infer(self._tables[name])
62 return self.table_class(name, schema, self).to_expr()
File ~/.conda/envs/modin/lib/python3.10/site-packages/multipledispatch/dispatcher.py:278, in Dispatcher.__call__(self, *args, **kwargs)
276 self._cache[types] = func
277 try:
--> 278 return func(*args, **kwargs)
280 except MDNotImplementedError:
281 funcs = self.dispatch_iter(*types)
File ~/.conda/envs/modin/lib/python3.10/site-packages/ibis/backends/polars/datatypes.py:104, in from_polars_schema(df)
102 @sch.infer.register(pl.LazyFrame)
103 def from_polars_schema(df: pl.LazyFrame) -> sch.Schema:
...
75 """Convert polars dtype to the ibis counterpart."""
---> 76 klass = _to_ibis_dtypes[typ]
77 return klass()
KeyError: Categorical
```
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ibis/backends/polars/datatypes.py`
Content:
```
1 from __future__ import annotations
2
3 import functools
4
5 import polars as pl
6
7 import ibis.expr.datatypes as dt
8 import ibis.expr.schema as sch
9
10 _to_polars_types = {
11 dt.Boolean: pl.Boolean,
12 dt.Null: pl.Null,
13 dt.Array: pl.List,
14 dt.String: pl.Utf8,
15 dt.Binary: pl.Binary,
16 dt.Date: pl.Date,
17 dt.Time: pl.Time,
18 dt.Int8: pl.Int8,
19 dt.Int16: pl.Int16,
20 dt.Int32: pl.Int32,
21 dt.Int64: pl.Int64,
22 dt.UInt8: pl.UInt8,
23 dt.UInt16: pl.UInt16,
24 dt.UInt32: pl.UInt32,
25 dt.UInt64: pl.UInt64,
26 dt.Float32: pl.Float32,
27 dt.Float64: pl.Float64,
28 }
29
30 _to_ibis_dtypes = {v: k for k, v in _to_polars_types.items()}
31
32
33 @functools.singledispatch
34 def to_polars_type(dtype):
35 """Convert ibis dtype to the polars counterpart."""
36 try:
37 return _to_polars_types[dtype.__class__] # else return pl.Object?
38 except KeyError:
39 raise NotImplementedError(
40 f"Translation to polars dtype not implemented for {dtype}"
41 )
42
43
44 @to_polars_type.register(dt.Timestamp)
45 def from_ibis_timestamp(dtype):
46 return pl.Datetime("ns", dtype.timezone)
47
48
49 @to_polars_type.register(dt.Interval)
50 def from_ibis_interval(dtype):
51 if dtype.unit in {'us', 'ns', 'ms'}:
52 return pl.Duration(dtype.unit)
53 else:
54 raise ValueError(f"Unsupported polars duration unit: {dtype.unit}")
55
56
57 @to_polars_type.register(dt.Struct)
58 def from_ibis_struct(dtype):
59 fields = [
60 pl.Field(name=name, dtype=to_polars_type(dtype))
61 for name, dtype in dtype.fields.items()
62 ]
63 return pl.Struct(fields)
64
65
66 @to_polars_type.register(dt.Category)
67 def from_ibis_category(dtype):
68 return pl.Categorical
69
70
71 @to_polars_type.register(dt.Array)
72 def from_ibis_array(dtype):
73 return pl.List(to_polars_type(dtype.value_type))
74
75
76 @functools.singledispatch
77 def to_ibis_dtype(typ):
78 """Convert polars dtype to the ibis counterpart."""
79 klass = _to_ibis_dtypes[typ]
80 return klass()
81
82
83 @to_ibis_dtype.register(pl.Datetime)
84 def from_polars_datetime(typ):
85 # TODO(kszucs): handle timezone?
86 return dt.Timestamp()
87
88
89 @to_ibis_dtype.register(pl.List)
90 def from_polars_list(typ):
91 return dt.Array(to_ibis_dtype(typ.inner))
92
93
94 @to_ibis_dtype.register(pl.Struct)
95 def from_polars_struct(typ):
96 return dt.Struct.from_tuples(
97 [(field.name, to_ibis_dtype(field.dtype)) for field in typ.fields]
98 )
99
100
101 # Can't register here since polars datatypes are classes
102 # @dt.dtype.register(pl.DataType)
103
104
105 @sch.infer.register(pl.LazyFrame)
106 def from_polars_schema(df: pl.LazyFrame) -> sch.Schema:
107 fields = [(name, to_ibis_dtype(typ)) for name, typ in df.schema.items()]
108 return sch.Schema.from_tuples(fields)
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ibis/backends/polars/datatypes.py b/ibis/backends/polars/datatypes.py
--- a/ibis/backends/polars/datatypes.py
+++ b/ibis/backends/polars/datatypes.py
@@ -10,7 +10,6 @@
_to_polars_types = {
dt.Boolean: pl.Boolean,
dt.Null: pl.Null,
- dt.Array: pl.List,
dt.String: pl.Utf8,
dt.Binary: pl.Binary,
dt.Date: pl.Date,
@@ -28,6 +27,7 @@
}
_to_ibis_dtypes = {v: k for k, v in _to_polars_types.items()}
+_to_ibis_dtypes[pl.Categorical] = dt.String
@functools.singledispatch
@@ -64,7 +64,7 @@
@to_polars_type.register(dt.Category)
-def from_ibis_category(dtype):
+def from_ibis_category(_):
return pl.Categorical
@@ -82,8 +82,12 @@
@to_ibis_dtype.register(pl.Datetime)
def from_polars_datetime(typ):
- # TODO(kszucs): handle timezone?
- return dt.Timestamp()
+ return dt.Timestamp(timezone=typ.tz)
+
+
+@to_ibis_dtype.register(pl.Duration)
+def from_polars_duration(typ):
+ return dt.Interval(unit=typ.tu)
@to_ibis_dtype.register(pl.List)
@@ -98,10 +102,6 @@
)
-# Can't register here since polars datatypes are classes
-# @dt.dtype.register(pl.DataType)
-
-
@sch.infer.register(pl.LazyFrame)
def from_polars_schema(df: pl.LazyFrame) -> sch.Schema:
fields = [(name, to_ibis_dtype(typ)) for name, typ in df.schema.items()]
|
{"golden_diff": "diff --git a/ibis/backends/polars/datatypes.py b/ibis/backends/polars/datatypes.py\n--- a/ibis/backends/polars/datatypes.py\n+++ b/ibis/backends/polars/datatypes.py\n@@ -10,7 +10,6 @@\n _to_polars_types = {\n dt.Boolean: pl.Boolean,\n dt.Null: pl.Null,\n- dt.Array: pl.List,\n dt.String: pl.Utf8,\n dt.Binary: pl.Binary,\n dt.Date: pl.Date,\n@@ -28,6 +27,7 @@\n }\n \n _to_ibis_dtypes = {v: k for k, v in _to_polars_types.items()}\n+_to_ibis_dtypes[pl.Categorical] = dt.String\n \n \n @functools.singledispatch\n@@ -64,7 +64,7 @@\n \n \n @to_polars_type.register(dt.Category)\n-def from_ibis_category(dtype):\n+def from_ibis_category(_):\n return pl.Categorical\n \n \n@@ -82,8 +82,12 @@\n \n @to_ibis_dtype.register(pl.Datetime)\n def from_polars_datetime(typ):\n- # TODO(kszucs): handle timezone?\n- return dt.Timestamp()\n+ return dt.Timestamp(timezone=typ.tz)\n+\n+\n+@to_ibis_dtype.register(pl.Duration)\n+def from_polars_duration(typ):\n+ return dt.Interval(unit=typ.tu)\n \n \n @to_ibis_dtype.register(pl.List)\n@@ -98,10 +102,6 @@\n )\n \n \n-# Can't register here since polars datatypes are classes\n-# @dt.dtype.register(pl.DataType)\n-\n-\n @sch.infer.register(pl.LazyFrame)\n def from_polars_schema(df: pl.LazyFrame) -> sch.Schema:\n fields = [(name, to_ibis_dtype(typ)) for name, typ in df.schema.items()]\n", "issue": "bug: polars backend chokes on Categorical\n### What happened?\n\nExpected `ibis.polars.read_parquet` to succeed with a categorical dtype in the parquet file. Instead, we see a `KeyError: Categorical` exception.\r\n\r\nIt looks like the reverse direction is fine, but I believe `ibis.backends.polars.datatypes.py` needs the `dt.Category: pl.Categorical,` pair added into `_to_polars_types`\n\n### What version of ibis are you using?\n\n4.0.0 (still exists on main)\n\n### What backend(s) are you using, if any?\n\npolars\n\n### Relevant log output\n\n```sh\nKeyError Traceback (most recent call last)\r\nCell In[3], line 1\r\n----> 1 ibis.polars.read_parquet('data.parquet')\r\n\r\nFile ~/.conda/envs/modin/lib/python3.10/site-packages/ibis/backends/polars/__init__.py:211, in Backend.read_parquet(self, path, table_name, **kwargs)\r\n 209 table_name = table_name or f\"ibis_read_parquet_{next(pa_n)}\"\r\n 210 self._tables[table_name] = pl.scan_parquet(path, **kwargs)\r\n--> 211 return self.table(table_name)\r\n\r\nFile ~/.conda/envs/modin/lib/python3.10/site-packages/ibis/backends/polars/__init__.py:61, in Backend.table(self, name, _schema)\r\n 60 def table(self, name: str, _schema: sch.Schema = None) -> ir.Table:\r\n---> 61 schema = sch.infer(self._tables[name])\r\n 62 return self.table_class(name, schema, self).to_expr()\r\n\r\nFile ~/.conda/envs/modin/lib/python3.10/site-packages/multipledispatch/dispatcher.py:278, in Dispatcher.__call__(self, *args, **kwargs)\r\n 276 self._cache[types] = func\r\n 277 try:\r\n--> 278 return func(*args, **kwargs)\r\n 280 except MDNotImplementedError:\r\n 281 funcs = self.dispatch_iter(*types)\r\n\r\nFile ~/.conda/envs/modin/lib/python3.10/site-packages/ibis/backends/polars/datatypes.py:104, in from_polars_schema(df)\r\n 102 @sch.infer.register(pl.LazyFrame)\r\n 103 def from_polars_schema(df: pl.LazyFrame) -> sch.Schema:\r\n...\r\n 75 \"\"\"Convert polars dtype to the ibis counterpart.\"\"\"\r\n---> 76 klass = _to_ibis_dtypes[typ]\r\n 77 return klass()\r\n\r\nKeyError: Categorical\n```\n\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "from __future__ import annotations\n\nimport functools\n\nimport polars as pl\n\nimport ibis.expr.datatypes as dt\nimport ibis.expr.schema as sch\n\n_to_polars_types = {\n dt.Boolean: pl.Boolean,\n dt.Null: pl.Null,\n dt.Array: pl.List,\n dt.String: pl.Utf8,\n dt.Binary: pl.Binary,\n dt.Date: pl.Date,\n dt.Time: pl.Time,\n dt.Int8: pl.Int8,\n dt.Int16: pl.Int16,\n dt.Int32: pl.Int32,\n dt.Int64: pl.Int64,\n dt.UInt8: pl.UInt8,\n dt.UInt16: pl.UInt16,\n dt.UInt32: pl.UInt32,\n dt.UInt64: pl.UInt64,\n dt.Float32: pl.Float32,\n dt.Float64: pl.Float64,\n}\n\n_to_ibis_dtypes = {v: k for k, v in _to_polars_types.items()}\n\n\[email protected]\ndef to_polars_type(dtype):\n \"\"\"Convert ibis dtype to the polars counterpart.\"\"\"\n try:\n return _to_polars_types[dtype.__class__] # else return pl.Object?\n except KeyError:\n raise NotImplementedError(\n f\"Translation to polars dtype not implemented for {dtype}\"\n )\n\n\n@to_polars_type.register(dt.Timestamp)\ndef from_ibis_timestamp(dtype):\n return pl.Datetime(\"ns\", dtype.timezone)\n\n\n@to_polars_type.register(dt.Interval)\ndef from_ibis_interval(dtype):\n if dtype.unit in {'us', 'ns', 'ms'}:\n return pl.Duration(dtype.unit)\n else:\n raise ValueError(f\"Unsupported polars duration unit: {dtype.unit}\")\n\n\n@to_polars_type.register(dt.Struct)\ndef from_ibis_struct(dtype):\n fields = [\n pl.Field(name=name, dtype=to_polars_type(dtype))\n for name, dtype in dtype.fields.items()\n ]\n return pl.Struct(fields)\n\n\n@to_polars_type.register(dt.Category)\ndef from_ibis_category(dtype):\n return pl.Categorical\n\n\n@to_polars_type.register(dt.Array)\ndef from_ibis_array(dtype):\n return pl.List(to_polars_type(dtype.value_type))\n\n\[email protected]\ndef to_ibis_dtype(typ):\n \"\"\"Convert polars dtype to the ibis counterpart.\"\"\"\n klass = _to_ibis_dtypes[typ]\n return klass()\n\n\n@to_ibis_dtype.register(pl.Datetime)\ndef from_polars_datetime(typ):\n # TODO(kszucs): handle timezone?\n return dt.Timestamp()\n\n\n@to_ibis_dtype.register(pl.List)\ndef from_polars_list(typ):\n return dt.Array(to_ibis_dtype(typ.inner))\n\n\n@to_ibis_dtype.register(pl.Struct)\ndef from_polars_struct(typ):\n return dt.Struct.from_tuples(\n [(field.name, to_ibis_dtype(field.dtype)) for field in typ.fields]\n )\n\n\n# Can't register here since polars datatypes are classes\n# @dt.dtype.register(pl.DataType)\n\n\[email protected](pl.LazyFrame)\ndef from_polars_schema(df: pl.LazyFrame) -> sch.Schema:\n fields = [(name, to_ibis_dtype(typ)) for name, typ in df.schema.items()]\n return sch.Schema.from_tuples(fields)\n", "path": "ibis/backends/polars/datatypes.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport functools\n\nimport polars as pl\n\nimport ibis.expr.datatypes as dt\nimport ibis.expr.schema as sch\n\n_to_polars_types = {\n dt.Boolean: pl.Boolean,\n dt.Null: pl.Null,\n dt.String: pl.Utf8,\n dt.Binary: pl.Binary,\n dt.Date: pl.Date,\n dt.Time: pl.Time,\n dt.Int8: pl.Int8,\n dt.Int16: pl.Int16,\n dt.Int32: pl.Int32,\n dt.Int64: pl.Int64,\n dt.UInt8: pl.UInt8,\n dt.UInt16: pl.UInt16,\n dt.UInt32: pl.UInt32,\n dt.UInt64: pl.UInt64,\n dt.Float32: pl.Float32,\n dt.Float64: pl.Float64,\n}\n\n_to_ibis_dtypes = {v: k for k, v in _to_polars_types.items()}\n_to_ibis_dtypes[pl.Categorical] = dt.String\n\n\[email protected]\ndef to_polars_type(dtype):\n \"\"\"Convert ibis dtype to the polars counterpart.\"\"\"\n try:\n return _to_polars_types[dtype.__class__] # else return pl.Object?\n except KeyError:\n raise NotImplementedError(\n f\"Translation to polars dtype not implemented for {dtype}\"\n )\n\n\n@to_polars_type.register(dt.Timestamp)\ndef from_ibis_timestamp(dtype):\n return pl.Datetime(\"ns\", dtype.timezone)\n\n\n@to_polars_type.register(dt.Interval)\ndef from_ibis_interval(dtype):\n if dtype.unit in {'us', 'ns', 'ms'}:\n return pl.Duration(dtype.unit)\n else:\n raise ValueError(f\"Unsupported polars duration unit: {dtype.unit}\")\n\n\n@to_polars_type.register(dt.Struct)\ndef from_ibis_struct(dtype):\n fields = [\n pl.Field(name=name, dtype=to_polars_type(dtype))\n for name, dtype in dtype.fields.items()\n ]\n return pl.Struct(fields)\n\n\n@to_polars_type.register(dt.Category)\ndef from_ibis_category(_):\n return pl.Categorical\n\n\n@to_polars_type.register(dt.Array)\ndef from_ibis_array(dtype):\n return pl.List(to_polars_type(dtype.value_type))\n\n\[email protected]\ndef to_ibis_dtype(typ):\n \"\"\"Convert polars dtype to the ibis counterpart.\"\"\"\n klass = _to_ibis_dtypes[typ]\n return klass()\n\n\n@to_ibis_dtype.register(pl.Datetime)\ndef from_polars_datetime(typ):\n return dt.Timestamp(timezone=typ.tz)\n\n\n@to_ibis_dtype.register(pl.Duration)\ndef from_polars_duration(typ):\n return dt.Interval(unit=typ.tu)\n\n\n@to_ibis_dtype.register(pl.List)\ndef from_polars_list(typ):\n return dt.Array(to_ibis_dtype(typ.inner))\n\n\n@to_ibis_dtype.register(pl.Struct)\ndef from_polars_struct(typ):\n return dt.Struct.from_tuples(\n [(field.name, to_ibis_dtype(field.dtype)) for field in typ.fields]\n )\n\n\[email protected](pl.LazyFrame)\ndef from_polars_schema(df: pl.LazyFrame) -> sch.Schema:\n fields = [(name, to_ibis_dtype(typ)) for name, typ in df.schema.items()]\n return sch.Schema.from_tuples(fields)\n", "path": "ibis/backends/polars/datatypes.py"}]}
| 1,837 | 413 |
gh_patches_debug_33719
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-1647
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a default Organsiation Logo image
- [x] Finalise image decision
- [x] Implement new image
## Test plan
GIVEN the organisation directory page
WHEN an organisation has no logo
THEN the image as shown below should be displayed
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/templatetags/rsr_utils.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Akvo RSR is covered by the GNU Affero General Public License.
3
4 See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6 """
7
8 from __future__ import absolute_import, print_function
9
10 from django import template
11 from django.contrib.auth import get_user_model
12 from akvo.rsr.models import Keyword, PartnerSite, Project, ProjectUpdate, Organisation
13 register = template.Library()
14
15
16 @register.inclusion_tag('rsr_utils/img.html', takes_context=True)
17 def img(context, obj, width, height, alt):
18 """Standard way to show image."""
19 geometry = '{}x{}'.format(width, height)
20
21 # Based on type get image
22 img = obj
23 if isinstance(obj, Project):
24 img = obj.current_image
25 elif isinstance(obj, ProjectUpdate):
26 img = obj.photo
27 elif isinstance(obj, Organisation):
28 img = obj.logo
29 elif isinstance(obj, get_user_model()):
30 img = obj.avatar
31 elif isinstance(obj, PartnerSite):
32 img = obj.logo
33 elif isinstance(obj, Keyword):
34 img = obj.logo
35
36 height = '{}.px'.format(height)
37
38 return {'alt': alt,
39 'height': height,
40 'img': img,
41 'geometry': geometry,
42 'width': width}
43
44
45 @register.inclusion_tag('rsr_utils/vid_img.html', takes_context=True)
46 def vid_img(context, obj, width, height, alt):
47 """Standard way to show video thumbnail."""
48 geometry = '{}x{}'.format(width, height)
49
50 # Based on type get video
51 vid = obj
52 if isinstance(obj, ProjectUpdate):
53 vid = obj.video
54
55 height = '{}.px'.format(height)
56
57 return {'alt': alt,
58 'height': height,
59 'vid': vid,
60 'geometry': geometry,
61 'width': width}
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rsr/templatetags/rsr_utils.py b/akvo/rsr/templatetags/rsr_utils.py
--- a/akvo/rsr/templatetags/rsr_utils.py
+++ b/akvo/rsr/templatetags/rsr_utils.py
@@ -8,6 +8,7 @@
from __future__ import absolute_import, print_function
from django import template
+from django.conf import settings
from django.contrib.auth import get_user_model
from akvo.rsr.models import Keyword, PartnerSite, Project, ProjectUpdate, Organisation
register = template.Library()
@@ -16,16 +17,22 @@
@register.inclusion_tag('rsr_utils/img.html', takes_context=True)
def img(context, obj, width, height, alt):
"""Standard way to show image."""
- geometry = '{}x{}'.format(width, height)
+ img = ""
+ geometry = "{}x{}".format(width, height)
+ default_img = "//placehold.it/{}".format(geometry)
- # Based on type get image
- img = obj
if isinstance(obj, Project):
img = obj.current_image
elif isinstance(obj, ProjectUpdate):
img = obj.photo
elif isinstance(obj, Organisation):
- img = obj.logo
+ if obj.logo:
+ img = obj.logo
+ else:
+ default_img = "//{}{}{}".format(
+ context["request"].get_host(),
+ getattr(settings, "STATIC_URL"),
+ "images/default-org-logo.jpg")
elif isinstance(obj, get_user_model()):
img = obj.avatar
elif isinstance(obj, PartnerSite):
@@ -33,13 +40,10 @@
elif isinstance(obj, Keyword):
img = obj.logo
- height = '{}.px'.format(height)
-
- return {'alt': alt,
- 'height': height,
- 'img': img,
- 'geometry': geometry,
- 'width': width}
+ return {"default_img": default_img,
+ "geometry": geometry,
+ "img": img,
+ "alt": alt}
@register.inclusion_tag('rsr_utils/vid_img.html', takes_context=True)
|
{"golden_diff": "diff --git a/akvo/rsr/templatetags/rsr_utils.py b/akvo/rsr/templatetags/rsr_utils.py\n--- a/akvo/rsr/templatetags/rsr_utils.py\n+++ b/akvo/rsr/templatetags/rsr_utils.py\n@@ -8,6 +8,7 @@\n from __future__ import absolute_import, print_function\n \n from django import template\n+from django.conf import settings\n from django.contrib.auth import get_user_model\n from akvo.rsr.models import Keyword, PartnerSite, Project, ProjectUpdate, Organisation\n register = template.Library()\n@@ -16,16 +17,22 @@\n @register.inclusion_tag('rsr_utils/img.html', takes_context=True)\n def img(context, obj, width, height, alt):\n \"\"\"Standard way to show image.\"\"\"\n- geometry = '{}x{}'.format(width, height)\n+ img = \"\"\n+ geometry = \"{}x{}\".format(width, height)\n+ default_img = \"//placehold.it/{}\".format(geometry)\n \n- # Based on type get image\n- img = obj\n if isinstance(obj, Project):\n img = obj.current_image\n elif isinstance(obj, ProjectUpdate):\n img = obj.photo\n elif isinstance(obj, Organisation):\n- img = obj.logo\n+ if obj.logo:\n+ img = obj.logo\n+ else:\n+ default_img = \"//{}{}{}\".format(\n+ context[\"request\"].get_host(),\n+ getattr(settings, \"STATIC_URL\"),\n+ \"images/default-org-logo.jpg\")\n elif isinstance(obj, get_user_model()):\n img = obj.avatar\n elif isinstance(obj, PartnerSite):\n@@ -33,13 +40,10 @@\n elif isinstance(obj, Keyword):\n img = obj.logo\n \n- height = '{}.px'.format(height)\n-\n- return {'alt': alt,\n- 'height': height,\n- 'img': img,\n- 'geometry': geometry,\n- 'width': width}\n+ return {\"default_img\": default_img,\n+ \"geometry\": geometry,\n+ \"img\": img,\n+ \"alt\": alt}\n \n \n @register.inclusion_tag('rsr_utils/vid_img.html', takes_context=True)\n", "issue": "Add a default Organsiation Logo image\n- [x] Finalise image decision\n- [x] Implement new image\n## Test plan\n\nGIVEN the organisation directory page\nWHEN an organisation has no logo\nTHEN the image as shown below should be displayed\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom __future__ import absolute_import, print_function\n\nfrom django import template\nfrom django.contrib.auth import get_user_model\nfrom akvo.rsr.models import Keyword, PartnerSite, Project, ProjectUpdate, Organisation\nregister = template.Library()\n\n\[email protected]_tag('rsr_utils/img.html', takes_context=True)\ndef img(context, obj, width, height, alt):\n \"\"\"Standard way to show image.\"\"\"\n geometry = '{}x{}'.format(width, height)\n\n # Based on type get image\n img = obj\n if isinstance(obj, Project):\n img = obj.current_image\n elif isinstance(obj, ProjectUpdate):\n img = obj.photo\n elif isinstance(obj, Organisation):\n img = obj.logo\n elif isinstance(obj, get_user_model()):\n img = obj.avatar\n elif isinstance(obj, PartnerSite):\n img = obj.logo\n elif isinstance(obj, Keyword):\n img = obj.logo\n\n height = '{}.px'.format(height)\n\n return {'alt': alt,\n 'height': height,\n 'img': img,\n 'geometry': geometry,\n 'width': width}\n\n\[email protected]_tag('rsr_utils/vid_img.html', takes_context=True)\ndef vid_img(context, obj, width, height, alt):\n \"\"\"Standard way to show video thumbnail.\"\"\"\n geometry = '{}x{}'.format(width, height)\n\n # Based on type get video\n vid = obj\n if isinstance(obj, ProjectUpdate):\n vid = obj.video\n\n height = '{}.px'.format(height)\n\n return {'alt': alt,\n 'height': height,\n 'vid': vid,\n 'geometry': geometry,\n 'width': width}\n", "path": "akvo/rsr/templatetags/rsr_utils.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom __future__ import absolute_import, print_function\n\nfrom django import template\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom akvo.rsr.models import Keyword, PartnerSite, Project, ProjectUpdate, Organisation\nregister = template.Library()\n\n\[email protected]_tag('rsr_utils/img.html', takes_context=True)\ndef img(context, obj, width, height, alt):\n \"\"\"Standard way to show image.\"\"\"\n img = \"\"\n geometry = \"{}x{}\".format(width, height)\n default_img = \"//placehold.it/{}\".format(geometry)\n\n if isinstance(obj, Project):\n img = obj.current_image\n elif isinstance(obj, ProjectUpdate):\n img = obj.photo\n elif isinstance(obj, Organisation):\n if obj.logo:\n img = obj.logo\n else:\n default_img = \"//{}{}{}\".format(\n context[\"request\"].get_host(),\n getattr(settings, \"STATIC_URL\"),\n \"images/default-org-logo.jpg\")\n elif isinstance(obj, get_user_model()):\n img = obj.avatar\n elif isinstance(obj, PartnerSite):\n img = obj.logo\n elif isinstance(obj, Keyword):\n img = obj.logo\n\n return {\"default_img\": default_img,\n \"geometry\": geometry,\n \"img\": img,\n \"alt\": alt}\n\n\[email protected]_tag('rsr_utils/vid_img.html', takes_context=True)\ndef vid_img(context, obj, width, height, alt):\n \"\"\"Standard way to show video thumbnail.\"\"\"\n geometry = '{}x{}'.format(width, height)\n\n # Based on type get video\n vid = obj\n if isinstance(obj, ProjectUpdate):\n vid = obj.video\n\n height = '{}.px'.format(height)\n\n return {'alt': alt,\n 'height': height,\n 'vid': vid,\n 'geometry': geometry,\n 'width': width}\n", "path": "akvo/rsr/templatetags/rsr_utils.py"}]}
| 868 | 488 |
gh_patches_debug_18945
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Extras not propagated into requirements.txt after insertion
Extras, in this context, are specific functional extensions to a particular package.
This is similar to #154 but differs because this triggers when adding an extra to an existing requirement.
The cached result appears to prevent appropriate detection that the extra was added.
##### Steps to replicate
1. Create a `requirements.in` as follows:
```text
pip-tools
hypothesis
```
2. Run `pip-compile` from the command line.
3. Edit the requirements.in file to the following:
```text
pip-tools
hypothesis[django]
```
4. Re-run `pip-compile` from the command line.
3. Examine `requirements.txt`
##### Expected result
```text
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile --output-file reqs.txt reqs.in
#
click==6.6 # via pip-tools
django==1.10.3 # via hypothesis
fake-factory==0.7.2 # via hypothesis
first==2.0.1 # via pip-tools
hypothesis[django]==3.6.0
pip-tools==1.7.0
python-dateutil==2.6.0 # via fake-factory
pytz==2016.7 # via hypothesis
six==1.10.0 # via fake-factory, pip-tools, python-dateutil
```
##### Actual result
```text
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile --output-file reqs.txt reqs.in
#
click==6.6 # via pip-tools
first==2.0.1 # via pip-tools
hypothesis==3.6.0
pip-tools==1.7.0
six==1.10.0 # via pip-tools
```
##### Workaround
Simply deleting the existing `requirements.txt` file and installing from scratch appears to work, but shouldn't be a necessary part of the pip-tools workflow.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `piptools/repositories/local.py`
Content:
```
1 # coding: utf-8
2 from __future__ import (absolute_import, division, print_function,
3 unicode_literals)
4
5 from piptools.utils import key_from_req
6 from .base import BaseRepository
7
8
9 def ireq_satisfied_by_existing_pin(ireq, existing_pin):
10 """
11 Return True if the given InstallationRequirement is satisfied by the
12 previously encountered version pin.
13 """
14 if hasattr(existing_pin.req, 'specs'):
15 # pip < 8.1.2
16 version = existing_pin.req.specs[0][1]
17 return version in ireq.req
18 else:
19 # pip >= 8.1.2
20 version = next(iter(existing_pin.req.specifier)).version
21 return version in ireq.req.specifier
22
23
24 class LocalRequirementsRepository(BaseRepository):
25 """
26 The LocalRequirementsRepository proxied the _real_ repository by first
27 checking if a requirement can be satisfied by existing pins (i.e. the
28 result of a previous compile step).
29
30 In effect, if a requirement can be satisfied with a version pinned in the
31 requirements file, we prefer that version over the best match found in
32 PyPI. This keeps updates to the requirements.txt down to a minimum.
33 """
34 def __init__(self, existing_pins, proxied_repository):
35 self.repository = proxied_repository
36 self.existing_pins = existing_pins
37
38 @property
39 def finder(self):
40 return self.repository.finder
41
42 @property
43 def session(self):
44 return self.repository.session
45
46 @property
47 def DEFAULT_INDEX_URL(self):
48 return self.repository.DEFAULT_INDEX_URL
49
50 def clear_caches(self):
51 self.repository.clear_caches()
52
53 def freshen_build_caches(self):
54 self.repository.freshen_build_caches()
55
56 def find_best_match(self, ireq, prereleases=None):
57 key = key_from_req(ireq.req)
58 existing_pin = self.existing_pins.get(key)
59 if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):
60 return existing_pin
61 else:
62 return self.repository.find_best_match(ireq, prereleases)
63
64 def get_dependencies(self, ireq):
65 return self.repository.get_dependencies(ireq)
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/piptools/repositories/local.py b/piptools/repositories/local.py
--- a/piptools/repositories/local.py
+++ b/piptools/repositories/local.py
@@ -2,7 +2,7 @@
from __future__ import (absolute_import, division, print_function,
unicode_literals)
-from piptools.utils import key_from_req
+from piptools.utils import as_tuple, key_from_req, make_install_requirement
from .base import BaseRepository
@@ -57,7 +57,10 @@
key = key_from_req(ireq.req)
existing_pin = self.existing_pins.get(key)
if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):
- return existing_pin
+ project, version, _ = as_tuple(existing_pin)
+ return make_install_requirement(
+ project, version, ireq.extras
+ )
else:
return self.repository.find_best_match(ireq, prereleases)
|
{"golden_diff": "diff --git a/piptools/repositories/local.py b/piptools/repositories/local.py\n--- a/piptools/repositories/local.py\n+++ b/piptools/repositories/local.py\n@@ -2,7 +2,7 @@\n from __future__ import (absolute_import, division, print_function,\n unicode_literals)\n \n-from piptools.utils import key_from_req\n+from piptools.utils import as_tuple, key_from_req, make_install_requirement\n from .base import BaseRepository\n \n \n@@ -57,7 +57,10 @@\n key = key_from_req(ireq.req)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n- return existing_pin\n+ project, version, _ = as_tuple(existing_pin)\n+ return make_install_requirement(\n+ project, version, ireq.extras\n+ )\n else:\n return self.repository.find_best_match(ireq, prereleases)\n", "issue": "Extras not propagated into requirements.txt after insertion\nExtras, in this context, are specific functional extensions to a particular package.\r\n\r\nThis is similar to #154 but differs because this triggers when adding an extra to an existing requirement.\r\n\r\nThe cached result appears to prevent appropriate detection that the extra was added.\r\n\r\n##### Steps to replicate\r\n\r\n1. Create a `requirements.in` as follows:\r\n ```text\r\npip-tools\r\nhypothesis\r\n ```\r\n2. Run `pip-compile` from the command line.\r\n3. Edit the requirements.in file to the following:\r\n ```text\r\npip-tools\r\nhypothesis[django]\r\n ```\r\n4. Re-run `pip-compile` from the command line.\r\n3. Examine `requirements.txt`\r\n\r\n##### Expected result\r\n\r\n```text\r\n#\r\n# This file is autogenerated by pip-compile\r\n# To update, run:\r\n#\r\n# pip-compile --output-file reqs.txt reqs.in\r\n#\r\nclick==6.6 # via pip-tools\r\ndjango==1.10.3 # via hypothesis\r\nfake-factory==0.7.2 # via hypothesis\r\nfirst==2.0.1 # via pip-tools\r\nhypothesis[django]==3.6.0\r\npip-tools==1.7.0\r\npython-dateutil==2.6.0 # via fake-factory\r\npytz==2016.7 # via hypothesis\r\nsix==1.10.0 # via fake-factory, pip-tools, python-dateutil\r\n```\r\n\r\n##### Actual result\r\n\r\n```text\r\n#\r\n# This file is autogenerated by pip-compile\r\n# To update, run:\r\n#\r\n# pip-compile --output-file reqs.txt reqs.in\r\n#\r\nclick==6.6 # via pip-tools\r\nfirst==2.0.1 # via pip-tools\r\nhypothesis==3.6.0\r\npip-tools==1.7.0\r\nsix==1.10.0 # via pip-tools\r\n```\r\n\r\n##### Workaround\r\n\r\nSimply deleting the existing `requirements.txt` file and installing from scratch appears to work, but shouldn't be a necessary part of the pip-tools workflow.\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nfrom piptools.utils import key_from_req\nfrom .base import BaseRepository\n\n\ndef ireq_satisfied_by_existing_pin(ireq, existing_pin):\n \"\"\"\n Return True if the given InstallationRequirement is satisfied by the\n previously encountered version pin.\n \"\"\"\n if hasattr(existing_pin.req, 'specs'):\n # pip < 8.1.2\n version = existing_pin.req.specs[0][1]\n return version in ireq.req\n else:\n # pip >= 8.1.2\n version = next(iter(existing_pin.req.specifier)).version\n return version in ireq.req.specifier\n\n\nclass LocalRequirementsRepository(BaseRepository):\n \"\"\"\n The LocalRequirementsRepository proxied the _real_ repository by first\n checking if a requirement can be satisfied by existing pins (i.e. the\n result of a previous compile step).\n\n In effect, if a requirement can be satisfied with a version pinned in the\n requirements file, we prefer that version over the best match found in\n PyPI. This keeps updates to the requirements.txt down to a minimum.\n \"\"\"\n def __init__(self, existing_pins, proxied_repository):\n self.repository = proxied_repository\n self.existing_pins = existing_pins\n\n @property\n def finder(self):\n return self.repository.finder\n\n @property\n def session(self):\n return self.repository.session\n\n @property\n def DEFAULT_INDEX_URL(self):\n return self.repository.DEFAULT_INDEX_URL\n\n def clear_caches(self):\n self.repository.clear_caches()\n\n def freshen_build_caches(self):\n self.repository.freshen_build_caches()\n\n def find_best_match(self, ireq, prereleases=None):\n key = key_from_req(ireq.req)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n return existing_pin\n else:\n return self.repository.find_best_match(ireq, prereleases)\n\n def get_dependencies(self, ireq):\n return self.repository.get_dependencies(ireq)\n", "path": "piptools/repositories/local.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nfrom piptools.utils import as_tuple, key_from_req, make_install_requirement\nfrom .base import BaseRepository\n\n\ndef ireq_satisfied_by_existing_pin(ireq, existing_pin):\n \"\"\"\n Return True if the given InstallationRequirement is satisfied by the\n previously encountered version pin.\n \"\"\"\n if hasattr(existing_pin.req, 'specs'):\n # pip < 8.1.2\n version = existing_pin.req.specs[0][1]\n return version in ireq.req\n else:\n # pip >= 8.1.2\n version = next(iter(existing_pin.req.specifier)).version\n return version in ireq.req.specifier\n\n\nclass LocalRequirementsRepository(BaseRepository):\n \"\"\"\n The LocalRequirementsRepository proxied the _real_ repository by first\n checking if a requirement can be satisfied by existing pins (i.e. the\n result of a previous compile step).\n\n In effect, if a requirement can be satisfied with a version pinned in the\n requirements file, we prefer that version over the best match found in\n PyPI. This keeps updates to the requirements.txt down to a minimum.\n \"\"\"\n def __init__(self, existing_pins, proxied_repository):\n self.repository = proxied_repository\n self.existing_pins = existing_pins\n\n @property\n def finder(self):\n return self.repository.finder\n\n @property\n def session(self):\n return self.repository.session\n\n @property\n def DEFAULT_INDEX_URL(self):\n return self.repository.DEFAULT_INDEX_URL\n\n def clear_caches(self):\n self.repository.clear_caches()\n\n def freshen_build_caches(self):\n self.repository.freshen_build_caches()\n\n def find_best_match(self, ireq, prereleases=None):\n key = key_from_req(ireq.req)\n existing_pin = self.existing_pins.get(key)\n if existing_pin and ireq_satisfied_by_existing_pin(ireq, existing_pin):\n project, version, _ = as_tuple(existing_pin)\n return make_install_requirement(\n project, version, ireq.extras\n )\n else:\n return self.repository.find_best_match(ireq, prereleases)\n\n def get_dependencies(self, ireq):\n return self.repository.get_dependencies(ireq)\n", "path": "piptools/repositories/local.py"}]}
| 1,320 | 218 |
gh_patches_debug_16295
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-2286
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
stderr: ERROR: Unable to locate a modulefile for 'PrgEnv-pgi'
I am installing CrayCCE on the a Cray XC40 and am recieving the error.
```
stderr: ERROR: Unable to locate a modulefile for 'PrgEnv-pgi'\n)")
```
Looking at the LOG I see...
```
module unload PrgEnv-gnu
module unload PrgEnv-intel
module unload PrgEnv-pgi
; stderr: ERROR: Unable to locate a modulefile for 'PrgEnv-pgi'
```
In our system we do not even have `PrgEnv-pgi` so it is natural that we get this error, but we are not using pgi either so
it should be checked if such a module exists prior of unloading it.
Also `PrgEnv-pgi` is not listed as a dependency in the config file.
We are using module.tcl Modules Release 4.1.3.1 (2018-11-29)
and I know that EasyBuild prefers Lmod, but still module.tcl is supported.
Cheers
Henric
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `easybuild/easyblocks/generic/craytoolchain.py`
Content:
```
1 ##
2 # Copyright 2015-2020 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for installing Cray toolchains, implemented as an easyblock
27
28 @author: Kenneth Hoste (Ghent University)
29 @author: Guilherme Peretti Pezzi (CSCS)
30 @author: Petar Forai (IMP/IMBA)
31 """
32
33 from easybuild.easyblocks.generic.bundle import Bundle
34 from easybuild.tools.build_log import EasyBuildError
35
36
37 KNOWN_PRGENVS = ['PrgEnv-cray', 'PrgEnv-gnu', 'PrgEnv-intel', 'PrgEnv-pgi']
38
39
40 class CrayToolchain(Bundle):
41 """
42 Compiler toolchain: generate module file only, nothing to build/install
43 """
44
45 def prepare_step(self, *args, **kwargs):
46 """Prepare build environment (skip loaded of dependencies)."""
47
48 kwargs['load_tc_deps_modules'] = False
49
50 super(CrayToolchain, self).prepare_step(*args, **kwargs)
51
52 def make_module_dep(self):
53 """
54 Generate load/swap statements for dependencies in the module file
55 """
56 prgenv_mod = None
57
58 # collect 'swap' statement for dependencies (except PrgEnv)
59 swap_deps = []
60 for dep in self.toolchain.dependencies:
61 mod_name = dep['full_mod_name']
62 # determine versionless module name, e.g. 'fftw/3.3.4.1' => 'fftw'
63 dep_name = '/'.join(mod_name.split('/')[:-1])
64
65 if mod_name.startswith('PrgEnv'):
66 prgenv_mod = mod_name
67 else:
68 swap_deps.append(self.module_generator.swap_module(dep_name, mod_name).lstrip())
69
70 self.log.debug("Swap statements for dependencies of %s: %s", self.full_mod_name, swap_deps)
71
72 if prgenv_mod is None:
73 raise EasyBuildError("Could not find a PrgEnv-* module listed as dependency: %s",
74 self.toolchain.dependencies)
75
76 # unload statements for other PrgEnv modules
77 prgenv_unloads = ['']
78 for prgenv in [prgenv for prgenv in KNOWN_PRGENVS if not prgenv_mod.startswith(prgenv)]:
79 prgenv_unloads.append(self.module_generator.unload_module(prgenv).strip())
80
81 # load statement for selected PrgEnv module (only when not loaded yet)
82 prgenv_load = self.module_generator.load_module(prgenv_mod, recursive_unload=False)
83
84 txt = '\n'.join(prgenv_unloads + [prgenv_load] + swap_deps)
85 return txt
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/easybuild/easyblocks/generic/craytoolchain.py b/easybuild/easyblocks/generic/craytoolchain.py
--- a/easybuild/easyblocks/generic/craytoolchain.py
+++ b/easybuild/easyblocks/generic/craytoolchain.py
@@ -76,7 +76,9 @@
# unload statements for other PrgEnv modules
prgenv_unloads = ['']
for prgenv in [prgenv for prgenv in KNOWN_PRGENVS if not prgenv_mod.startswith(prgenv)]:
- prgenv_unloads.append(self.module_generator.unload_module(prgenv).strip())
+ is_loaded_guard = self.module_generator.is_loaded(prgenv)
+ unload_stmt = self.module_generator.unload_module(prgenv).strip()
+ prgenv_unloads.append(self.module_generator.conditional_statement(is_loaded_guard, unload_stmt))
# load statement for selected PrgEnv module (only when not loaded yet)
prgenv_load = self.module_generator.load_module(prgenv_mod, recursive_unload=False)
|
{"golden_diff": "diff --git a/easybuild/easyblocks/generic/craytoolchain.py b/easybuild/easyblocks/generic/craytoolchain.py\n--- a/easybuild/easyblocks/generic/craytoolchain.py\n+++ b/easybuild/easyblocks/generic/craytoolchain.py\n@@ -76,7 +76,9 @@\n # unload statements for other PrgEnv modules\n prgenv_unloads = ['']\n for prgenv in [prgenv for prgenv in KNOWN_PRGENVS if not prgenv_mod.startswith(prgenv)]:\n- prgenv_unloads.append(self.module_generator.unload_module(prgenv).strip())\n+ is_loaded_guard = self.module_generator.is_loaded(prgenv)\n+ unload_stmt = self.module_generator.unload_module(prgenv).strip()\n+ prgenv_unloads.append(self.module_generator.conditional_statement(is_loaded_guard, unload_stmt))\n \n # load statement for selected PrgEnv module (only when not loaded yet)\n prgenv_load = self.module_generator.load_module(prgenv_mod, recursive_unload=False)\n", "issue": "stderr: ERROR: Unable to locate a modulefile for 'PrgEnv-pgi' \nI am installing CrayCCE on the a Cray XC40 and am recieving the error.\r\n\r\n```\r\nstderr: ERROR: Unable to locate a modulefile for 'PrgEnv-pgi'\\n)\") \r\n```\r\n\r\nLooking at the LOG I see...\r\n\r\n```\r\nmodule unload PrgEnv-gnu\r\nmodule unload PrgEnv-intel\r\nmodule unload PrgEnv-pgi\r\n\r\n; stderr: ERROR: Unable to locate a modulefile for 'PrgEnv-pgi' \r\n```\r\n\r\nIn our system we do not even have `PrgEnv-pgi` so it is natural that we get this error, but we are not using pgi either so\r\nit should be checked if such a module exists prior of unloading it.\r\nAlso `PrgEnv-pgi` is not listed as a dependency in the config file.\r\n\r\nWe are using module.tcl Modules Release 4.1.3.1 (2018-11-29)\r\nand I know that EasyBuild prefers Lmod, but still module.tcl is supported.\r\n\r\nCheers\r\nHenric\n", "before_files": [{"content": "##\n# Copyright 2015-2020 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for installing Cray toolchains, implemented as an easyblock\n\n@author: Kenneth Hoste (Ghent University)\n@author: Guilherme Peretti Pezzi (CSCS)\n@author: Petar Forai (IMP/IMBA)\n\"\"\"\n\nfrom easybuild.easyblocks.generic.bundle import Bundle\nfrom easybuild.tools.build_log import EasyBuildError\n\n\nKNOWN_PRGENVS = ['PrgEnv-cray', 'PrgEnv-gnu', 'PrgEnv-intel', 'PrgEnv-pgi']\n\n\nclass CrayToolchain(Bundle):\n \"\"\"\n Compiler toolchain: generate module file only, nothing to build/install\n \"\"\"\n\n def prepare_step(self, *args, **kwargs):\n \"\"\"Prepare build environment (skip loaded of dependencies).\"\"\"\n\n kwargs['load_tc_deps_modules'] = False\n\n super(CrayToolchain, self).prepare_step(*args, **kwargs)\n\n def make_module_dep(self):\n \"\"\"\n Generate load/swap statements for dependencies in the module file\n \"\"\"\n prgenv_mod = None\n\n # collect 'swap' statement for dependencies (except PrgEnv)\n swap_deps = []\n for dep in self.toolchain.dependencies:\n mod_name = dep['full_mod_name']\n # determine versionless module name, e.g. 'fftw/3.3.4.1' => 'fftw'\n dep_name = '/'.join(mod_name.split('/')[:-1])\n\n if mod_name.startswith('PrgEnv'):\n prgenv_mod = mod_name\n else:\n swap_deps.append(self.module_generator.swap_module(dep_name, mod_name).lstrip())\n\n self.log.debug(\"Swap statements for dependencies of %s: %s\", self.full_mod_name, swap_deps)\n\n if prgenv_mod is None:\n raise EasyBuildError(\"Could not find a PrgEnv-* module listed as dependency: %s\",\n self.toolchain.dependencies)\n\n # unload statements for other PrgEnv modules\n prgenv_unloads = ['']\n for prgenv in [prgenv for prgenv in KNOWN_PRGENVS if not prgenv_mod.startswith(prgenv)]:\n prgenv_unloads.append(self.module_generator.unload_module(prgenv).strip())\n\n # load statement for selected PrgEnv module (only when not loaded yet)\n prgenv_load = self.module_generator.load_module(prgenv_mod, recursive_unload=False)\n\n txt = '\\n'.join(prgenv_unloads + [prgenv_load] + swap_deps)\n return txt\n", "path": "easybuild/easyblocks/generic/craytoolchain.py"}], "after_files": [{"content": "##\n# Copyright 2015-2020 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for installing Cray toolchains, implemented as an easyblock\n\n@author: Kenneth Hoste (Ghent University)\n@author: Guilherme Peretti Pezzi (CSCS)\n@author: Petar Forai (IMP/IMBA)\n\"\"\"\n\nfrom easybuild.easyblocks.generic.bundle import Bundle\nfrom easybuild.tools.build_log import EasyBuildError\n\n\nKNOWN_PRGENVS = ['PrgEnv-cray', 'PrgEnv-gnu', 'PrgEnv-intel', 'PrgEnv-pgi']\n\n\nclass CrayToolchain(Bundle):\n \"\"\"\n Compiler toolchain: generate module file only, nothing to build/install\n \"\"\"\n\n def prepare_step(self, *args, **kwargs):\n \"\"\"Prepare build environment (skip loaded of dependencies).\"\"\"\n\n kwargs['load_tc_deps_modules'] = False\n\n super(CrayToolchain, self).prepare_step(*args, **kwargs)\n\n def make_module_dep(self):\n \"\"\"\n Generate load/swap statements for dependencies in the module file\n \"\"\"\n prgenv_mod = None\n\n # collect 'swap' statement for dependencies (except PrgEnv)\n swap_deps = []\n for dep in self.toolchain.dependencies:\n mod_name = dep['full_mod_name']\n # determine versionless module name, e.g. 'fftw/3.3.4.1' => 'fftw'\n dep_name = '/'.join(mod_name.split('/')[:-1])\n\n if mod_name.startswith('PrgEnv'):\n prgenv_mod = mod_name\n else:\n swap_deps.append(self.module_generator.swap_module(dep_name, mod_name).lstrip())\n\n self.log.debug(\"Swap statements for dependencies of %s: %s\", self.full_mod_name, swap_deps)\n\n if prgenv_mod is None:\n raise EasyBuildError(\"Could not find a PrgEnv-* module listed as dependency: %s\",\n self.toolchain.dependencies)\n\n # unload statements for other PrgEnv modules\n prgenv_unloads = ['']\n for prgenv in [prgenv for prgenv in KNOWN_PRGENVS if not prgenv_mod.startswith(prgenv)]:\n is_loaded_guard = self.module_generator.is_loaded(prgenv)\n unload_stmt = self.module_generator.unload_module(prgenv).strip()\n prgenv_unloads.append(self.module_generator.conditional_statement(is_loaded_guard, unload_stmt))\n\n # load statement for selected PrgEnv module (only when not loaded yet)\n prgenv_load = self.module_generator.load_module(prgenv_mod, recursive_unload=False)\n\n txt = '\\n'.join(prgenv_unloads + [prgenv_load] + swap_deps)\n return txt\n", "path": "easybuild/easyblocks/generic/craytoolchain.py"}]}
| 1,496 | 240 |
gh_patches_debug_13802
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-3260
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Conda generic easyblock doesn't recognise Miniforge
When using Miniforge3 instead of Miniconda3 (created via [https://github.com/easybuilders/easybuild-easyconfigs/pull/20227](https://github.com/easybuilders/easybuild-easyconfigs/pull/20227)) the block does not identify that this is a viable conda environment.
The reported error in the logs is:
```
EasyBuild crashed with an error (at easybuild/base/exceptions.py:126 in __init__): No conda/mamba/micromamba available. (at easybuild/easyblocks/generic/conda.py:72 in install_step)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `easybuild/easyblocks/generic/conda.py`
Content:
```
1 ##
2 # Copyright 2009-2023 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for installing software using 'conda', implemented as an easyblock.
27
28 @author: Jillian Rowe (New York University Abu Dhabi)
29 @author: Kenneth Hoste (HPC-UGent)
30 """
31
32 import os
33
34 from easybuild.easyblocks.generic.binary import Binary
35 from easybuild.framework.easyconfig import CUSTOM
36 from easybuild.tools.run import run_cmd
37 from easybuild.tools.modules import get_software_root
38 from easybuild.tools.build_log import EasyBuildError
39
40
41 class Conda(Binary):
42 """Support for installing software using 'conda'."""
43
44 @staticmethod
45 def extra_options(extra_vars=None):
46 """Extra easyconfig parameters specific to Conda easyblock."""
47 extra_vars = Binary.extra_options(extra_vars)
48 extra_vars.update({
49 'channels': [None, "List of conda channels to pass to 'conda install'", CUSTOM],
50 'environment_file': [None, "Conda environment.yml file to use with 'conda env create'", CUSTOM],
51 'remote_environment': [None, "Remote conda environment to use with 'conda env create'", CUSTOM],
52 'requirements': [None, "Requirements specification to pass to 'conda install'", CUSTOM],
53 })
54 return extra_vars
55
56 def extract_step(self):
57 """Copy sources via extract_step of parent, if any are specified."""
58 if self.src:
59 super(Conda, self).extract_step()
60
61 def install_step(self):
62 """Install software using 'conda env create' or 'conda create' & 'conda install'
63 (or the 'mamba', etc., equivalent)."""
64 if (get_software_root('anaconda2') or get_software_root('miniconda2') or
65 get_software_root('anaconda3') or get_software_root('miniconda3')):
66 conda_cmd = 'conda'
67 elif get_software_root('mamba'):
68 conda_cmd = 'mamba'
69 elif get_software_root('micromamba'):
70 conda_cmd = 'micromamba'
71 else:
72 raise EasyBuildError("No conda/mamba/micromamba available.")
73
74 # initialize conda environment
75 # setuptools is just a choice, but *something* needs to be there
76 cmd = "%s config --add create_default_packages setuptools" % conda_cmd
77 run_cmd(cmd, log_all=True, simple=True)
78
79 if self.cfg['environment_file'] or self.cfg['remote_environment']:
80
81 if self.cfg['environment_file']:
82 env_spec = '-f ' + self.cfg['environment_file']
83 else:
84 env_spec = self.cfg['remote_environment']
85
86 # use --force to ignore existing installation directory
87 cmd = "%s %s env create --force %s -p %s" % (self.cfg['preinstallopts'], conda_cmd,
88 env_spec, self.installdir)
89 run_cmd(cmd, log_all=True, simple=True)
90
91 else:
92
93 if self.cfg['requirements']:
94
95 install_args = "-y %s " % self.cfg['requirements']
96 if self.cfg['channels']:
97 install_args += ' '.join('-c ' + chan for chan in self.cfg['channels'])
98
99 self.log.info("Installed conda requirements")
100
101 cmd = "%s %s create --force -y -p %s %s" % (self.cfg['preinstallopts'], conda_cmd,
102 self.installdir, install_args)
103 run_cmd(cmd, log_all=True, simple=True)
104
105 # clean up
106 cmd = "%s clean -ya" % conda_cmd
107 run_cmd(cmd, log_all=True, simple=True)
108
109 def make_module_extra(self):
110 """Add the install directory to the PATH."""
111 txt = super(Conda, self).make_module_extra()
112 txt += self.module_generator.set_environment('CONDA_ENV', self.installdir)
113 txt += self.module_generator.set_environment('CONDA_PREFIX', self.installdir)
114 txt += self.module_generator.set_environment('CONDA_DEFAULT_ENV', self.installdir)
115 self.log.debug("make_module_extra added this: %s", txt)
116 return txt
117
118 def make_module_req_guess(self):
119 """
120 A dictionary of possible directories to look for.
121 """
122 # LD_LIBRARY_PATH issue discusses here
123 # http://superuser.com/questions/980250/environment-module-cannot-initialize-tcl
124 return {
125 'PATH': ['bin', 'sbin'],
126 'MANPATH': ['man', os.path.join('share', 'man')],
127 'PKG_CONFIG_PATH': [os.path.join(x, 'pkgconfig') for x in ['lib', 'lib32', 'lib64', 'share']],
128 }
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/easybuild/easyblocks/generic/conda.py b/easybuild/easyblocks/generic/conda.py
--- a/easybuild/easyblocks/generic/conda.py
+++ b/easybuild/easyblocks/generic/conda.py
@@ -62,7 +62,8 @@
"""Install software using 'conda env create' or 'conda create' & 'conda install'
(or the 'mamba', etc., equivalent)."""
if (get_software_root('anaconda2') or get_software_root('miniconda2') or
- get_software_root('anaconda3') or get_software_root('miniconda3')):
+ get_software_root('anaconda3') or get_software_root('miniconda3') or
+ get_software_root('miniforge3')):
conda_cmd = 'conda'
elif get_software_root('mamba'):
conda_cmd = 'mamba'
|
{"golden_diff": "diff --git a/easybuild/easyblocks/generic/conda.py b/easybuild/easyblocks/generic/conda.py\n--- a/easybuild/easyblocks/generic/conda.py\n+++ b/easybuild/easyblocks/generic/conda.py\n@@ -62,7 +62,8 @@\n \"\"\"Install software using 'conda env create' or 'conda create' & 'conda install'\n (or the 'mamba', etc., equivalent).\"\"\"\n if (get_software_root('anaconda2') or get_software_root('miniconda2') or\n- get_software_root('anaconda3') or get_software_root('miniconda3')):\n+ get_software_root('anaconda3') or get_software_root('miniconda3') or\n+ get_software_root('miniforge3')):\n conda_cmd = 'conda'\n elif get_software_root('mamba'):\n conda_cmd = 'mamba'\n", "issue": "Conda generic easyblock doesn't recognise Miniforge\nWhen using Miniforge3 instead of Miniconda3 (created via [https://github.com/easybuilders/easybuild-easyconfigs/pull/20227](https://github.com/easybuilders/easybuild-easyconfigs/pull/20227)) the block does not identify that this is a viable conda environment.\r\n\r\nThe reported error in the logs is:\r\n\r\n```\r\nEasyBuild crashed with an error (at easybuild/base/exceptions.py:126 in __init__): No conda/mamba/micromamba available. (at easybuild/easyblocks/generic/conda.py:72 in install_step)\r\n```\n", "before_files": [{"content": "##\n# Copyright 2009-2023 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for installing software using 'conda', implemented as an easyblock.\n\n@author: Jillian Rowe (New York University Abu Dhabi)\n@author: Kenneth Hoste (HPC-UGent)\n\"\"\"\n\nimport os\n\nfrom easybuild.easyblocks.generic.binary import Binary\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.run import run_cmd\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.build_log import EasyBuildError\n\n\nclass Conda(Binary):\n \"\"\"Support for installing software using 'conda'.\"\"\"\n\n @staticmethod\n def extra_options(extra_vars=None):\n \"\"\"Extra easyconfig parameters specific to Conda easyblock.\"\"\"\n extra_vars = Binary.extra_options(extra_vars)\n extra_vars.update({\n 'channels': [None, \"List of conda channels to pass to 'conda install'\", CUSTOM],\n 'environment_file': [None, \"Conda environment.yml file to use with 'conda env create'\", CUSTOM],\n 'remote_environment': [None, \"Remote conda environment to use with 'conda env create'\", CUSTOM],\n 'requirements': [None, \"Requirements specification to pass to 'conda install'\", CUSTOM],\n })\n return extra_vars\n\n def extract_step(self):\n \"\"\"Copy sources via extract_step of parent, if any are specified.\"\"\"\n if self.src:\n super(Conda, self).extract_step()\n\n def install_step(self):\n \"\"\"Install software using 'conda env create' or 'conda create' & 'conda install'\n (or the 'mamba', etc., equivalent).\"\"\"\n if (get_software_root('anaconda2') or get_software_root('miniconda2') or\n get_software_root('anaconda3') or get_software_root('miniconda3')):\n conda_cmd = 'conda'\n elif get_software_root('mamba'):\n conda_cmd = 'mamba'\n elif get_software_root('micromamba'):\n conda_cmd = 'micromamba'\n else:\n raise EasyBuildError(\"No conda/mamba/micromamba available.\")\n\n # initialize conda environment\n # setuptools is just a choice, but *something* needs to be there\n cmd = \"%s config --add create_default_packages setuptools\" % conda_cmd\n run_cmd(cmd, log_all=True, simple=True)\n\n if self.cfg['environment_file'] or self.cfg['remote_environment']:\n\n if self.cfg['environment_file']:\n env_spec = '-f ' + self.cfg['environment_file']\n else:\n env_spec = self.cfg['remote_environment']\n\n # use --force to ignore existing installation directory\n cmd = \"%s %s env create --force %s -p %s\" % (self.cfg['preinstallopts'], conda_cmd,\n env_spec, self.installdir)\n run_cmd(cmd, log_all=True, simple=True)\n\n else:\n\n if self.cfg['requirements']:\n\n install_args = \"-y %s \" % self.cfg['requirements']\n if self.cfg['channels']:\n install_args += ' '.join('-c ' + chan for chan in self.cfg['channels'])\n\n self.log.info(\"Installed conda requirements\")\n\n cmd = \"%s %s create --force -y -p %s %s\" % (self.cfg['preinstallopts'], conda_cmd,\n self.installdir, install_args)\n run_cmd(cmd, log_all=True, simple=True)\n\n # clean up\n cmd = \"%s clean -ya\" % conda_cmd\n run_cmd(cmd, log_all=True, simple=True)\n\n def make_module_extra(self):\n \"\"\"Add the install directory to the PATH.\"\"\"\n txt = super(Conda, self).make_module_extra()\n txt += self.module_generator.set_environment('CONDA_ENV', self.installdir)\n txt += self.module_generator.set_environment('CONDA_PREFIX', self.installdir)\n txt += self.module_generator.set_environment('CONDA_DEFAULT_ENV', self.installdir)\n self.log.debug(\"make_module_extra added this: %s\", txt)\n return txt\n\n def make_module_req_guess(self):\n \"\"\"\n A dictionary of possible directories to look for.\n \"\"\"\n # LD_LIBRARY_PATH issue discusses here\n # http://superuser.com/questions/980250/environment-module-cannot-initialize-tcl\n return {\n 'PATH': ['bin', 'sbin'],\n 'MANPATH': ['man', os.path.join('share', 'man')],\n 'PKG_CONFIG_PATH': [os.path.join(x, 'pkgconfig') for x in ['lib', 'lib32', 'lib64', 'share']],\n }\n", "path": "easybuild/easyblocks/generic/conda.py"}], "after_files": [{"content": "##\n# Copyright 2009-2023 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for installing software using 'conda', implemented as an easyblock.\n\n@author: Jillian Rowe (New York University Abu Dhabi)\n@author: Kenneth Hoste (HPC-UGent)\n\"\"\"\n\nimport os\n\nfrom easybuild.easyblocks.generic.binary import Binary\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.run import run_cmd\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.build_log import EasyBuildError\n\n\nclass Conda(Binary):\n \"\"\"Support for installing software using 'conda'.\"\"\"\n\n @staticmethod\n def extra_options(extra_vars=None):\n \"\"\"Extra easyconfig parameters specific to Conda easyblock.\"\"\"\n extra_vars = Binary.extra_options(extra_vars)\n extra_vars.update({\n 'channels': [None, \"List of conda channels to pass to 'conda install'\", CUSTOM],\n 'environment_file': [None, \"Conda environment.yml file to use with 'conda env create'\", CUSTOM],\n 'remote_environment': [None, \"Remote conda environment to use with 'conda env create'\", CUSTOM],\n 'requirements': [None, \"Requirements specification to pass to 'conda install'\", CUSTOM],\n })\n return extra_vars\n\n def extract_step(self):\n \"\"\"Copy sources via extract_step of parent, if any are specified.\"\"\"\n if self.src:\n super(Conda, self).extract_step()\n\n def install_step(self):\n \"\"\"Install software using 'conda env create' or 'conda create' & 'conda install'\n (or the 'mamba', etc., equivalent).\"\"\"\n if (get_software_root('anaconda2') or get_software_root('miniconda2') or\n get_software_root('anaconda3') or get_software_root('miniconda3') or\n get_software_root('miniforge3')):\n conda_cmd = 'conda'\n elif get_software_root('mamba'):\n conda_cmd = 'mamba'\n elif get_software_root('micromamba'):\n conda_cmd = 'micromamba'\n else:\n raise EasyBuildError(\"No conda/mamba/micromamba available.\")\n\n # initialize conda environment\n # setuptools is just a choice, but *something* needs to be there\n cmd = \"%s config --add create_default_packages setuptools\" % conda_cmd\n run_cmd(cmd, log_all=True, simple=True)\n\n if self.cfg['environment_file'] or self.cfg['remote_environment']:\n\n if self.cfg['environment_file']:\n env_spec = '-f ' + self.cfg['environment_file']\n else:\n env_spec = self.cfg['remote_environment']\n\n # use --force to ignore existing installation directory\n cmd = \"%s %s env create --force %s -p %s\" % (self.cfg['preinstallopts'], conda_cmd,\n env_spec, self.installdir)\n run_cmd(cmd, log_all=True, simple=True)\n\n else:\n\n if self.cfg['requirements']:\n\n install_args = \"-y %s \" % self.cfg['requirements']\n if self.cfg['channels']:\n install_args += ' '.join('-c ' + chan for chan in self.cfg['channels'])\n\n self.log.info(\"Installed conda requirements\")\n\n cmd = \"%s %s create --force -y -p %s %s\" % (self.cfg['preinstallopts'], conda_cmd,\n self.installdir, install_args)\n run_cmd(cmd, log_all=True, simple=True)\n\n # clean up\n cmd = \"%s clean -ya\" % conda_cmd\n run_cmd(cmd, log_all=True, simple=True)\n\n def make_module_extra(self):\n \"\"\"Add the install directory to the PATH.\"\"\"\n txt = super(Conda, self).make_module_extra()\n txt += self.module_generator.set_environment('CONDA_ENV', self.installdir)\n txt += self.module_generator.set_environment('CONDA_PREFIX', self.installdir)\n txt += self.module_generator.set_environment('CONDA_DEFAULT_ENV', self.installdir)\n self.log.debug(\"make_module_extra added this: %s\", txt)\n return txt\n\n def make_module_req_guess(self):\n \"\"\"\n A dictionary of possible directories to look for.\n \"\"\"\n # LD_LIBRARY_PATH issue discusses here\n # http://superuser.com/questions/980250/environment-module-cannot-initialize-tcl\n return {\n 'PATH': ['bin', 'sbin'],\n 'MANPATH': ['man', os.path.join('share', 'man')],\n 'PKG_CONFIG_PATH': [os.path.join(x, 'pkgconfig') for x in ['lib', 'lib32', 'lib64', 'share']],\n }\n", "path": "easybuild/easyblocks/generic/conda.py"}]}
| 1,968 | 211 |
gh_patches_debug_19559
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-584
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecated class inheritance check bug
``` python
>>> from scrapy.spider import BaseSpider
>>> class A(BaseSpider):
... pass
...
>>> class B(BaseSpider):
... pass
...
>>> isinstance(A('foo'), B)
True
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/utils/deprecate.py`
Content:
```
1 """Some helpers for deprecation messages"""
2
3 import warnings
4 import inspect
5 from scrapy.exceptions import ScrapyDeprecationWarning
6
7
8 def attribute(obj, oldattr, newattr, version='0.12'):
9 cname = obj.__class__.__name__
10 warnings.warn("%s.%s attribute is deprecated and will be no longer supported "
11 "in Scrapy %s, use %s.%s attribute instead" % \
12 (cname, oldattr, version, cname, newattr), ScrapyDeprecationWarning, stacklevel=3)
13
14
15 def create_deprecated_class(name, new_class, clsdict=None,
16 warn_category=ScrapyDeprecationWarning,
17 warn_once=True,
18 old_class_path=None,
19 new_class_path=None,
20 subclass_warn_message="{cls} inherits from "\
21 "deprecated class {old}, please inherit "\
22 "from {new}.",
23 instance_warn_message="{cls} is deprecated, "\
24 "instantiate {new} instead."):
25 """
26 Return a "deprecated" class that causes its subclasses to issue a warning.
27 Subclasses of ``new_class`` are considered subclasses of this class.
28 It also warns when the deprecated class is instantiated, but do not when
29 its subclasses are instantiated.
30
31 It can be used to rename a base class in a library. For example, if we
32 have
33
34 class OldName(SomeClass):
35 # ...
36
37 and we want to rename it to NewName, we can do the following::
38
39 class NewName(SomeClass):
40 # ...
41
42 OldName = create_deprecated_class('OldName', NewName)
43
44 Then, if user class inherits from OldName, warning is issued. Also, if
45 some code uses ``issubclass(sub, OldName)`` or ``isinstance(sub(), OldName)``
46 checks they'll still return True if sub is a subclass of NewName instead of
47 OldName.
48 """
49
50 class DeprecatedClass(new_class.__class__):
51
52 deprecated_class = None
53 warned_on_subclass = False
54
55 def __new__(metacls, name, bases, clsdict_):
56 cls = super(DeprecatedClass, metacls).__new__(metacls, name, bases, clsdict_)
57 if metacls.deprecated_class is None:
58 metacls.deprecated_class = cls
59 return cls
60
61 def __init__(cls, name, bases, clsdict_):
62 meta = cls.__class__
63 old = meta.deprecated_class
64 if old in bases and not (warn_once and meta.warned_on_subclass):
65 meta.warned_on_subclass = True
66 msg = subclass_warn_message.format(cls=_clspath(cls),
67 old=_clspath(old, old_class_path),
68 new=_clspath(new_class, new_class_path))
69 if warn_once:
70 msg += ' (warning only on first subclass, there may be others)'
71 warnings.warn(msg, warn_category, stacklevel=2)
72 super(DeprecatedClass, cls).__init__(name, bases, clsdict_)
73
74 # see http://www.python.org/dev/peps/pep-3119/#overloading-isinstance-and-issubclass
75 # and http://docs.python.org/2/reference/datamodel.html#customizing-instance-and-subclass-checks
76 # for implementation details
77 def __instancecheck__(cls, inst):
78 return any(cls.__subclasscheck__(c)
79 for c in {type(inst), inst.__class__})
80
81 def __subclasscheck__(cls, sub):
82 if not inspect.isclass(sub):
83 raise TypeError("issubclass() arg 1 must be a class")
84
85 mro = getattr(sub, '__mro__', ())
86 candidates = {cls, new_class}
87 return any(c in candidates for c in mro)
88
89 def __call__(cls, *args, **kwargs):
90 old = DeprecatedClass.deprecated_class
91 if cls is old:
92 msg = instance_warn_message.format(cls=_clspath(cls, old_class_path),
93 new=_clspath(new_class, new_class_path))
94 warnings.warn(msg, warn_category, stacklevel=2)
95 return super(DeprecatedClass, cls).__call__(*args, **kwargs)
96
97 deprecated_cls = DeprecatedClass(name, (new_class,), clsdict or {})
98 frm = inspect.stack()[1]
99 parent_module = inspect.getmodule(frm[0])
100 if parent_module is not None:
101 deprecated_cls.__module__ = parent_module.__name__
102
103 return deprecated_cls
104
105
106 def _clspath(cls, forced=None):
107 if forced is not None:
108 return forced
109 return '{}.{}'.format(cls.__module__, cls.__name__)
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/utils/deprecate.py b/scrapy/utils/deprecate.py
--- a/scrapy/utils/deprecate.py
+++ b/scrapy/utils/deprecate.py
@@ -79,12 +79,18 @@
for c in {type(inst), inst.__class__})
def __subclasscheck__(cls, sub):
+ if cls is not DeprecatedClass.deprecated_class:
+ # we should do the magic only if second `issubclass` argument
+ # is the deprecated class itself - subclasses of the
+ # deprecated class should not use custom `__subclasscheck__`
+ # method.
+ return super(DeprecatedClass, cls).__subclasscheck__(sub)
+
if not inspect.isclass(sub):
raise TypeError("issubclass() arg 1 must be a class")
mro = getattr(sub, '__mro__', ())
- candidates = {cls, new_class}
- return any(c in candidates for c in mro)
+ return any(c in {cls, new_class} for c in mro)
def __call__(cls, *args, **kwargs):
old = DeprecatedClass.deprecated_class
|
{"golden_diff": "diff --git a/scrapy/utils/deprecate.py b/scrapy/utils/deprecate.py\n--- a/scrapy/utils/deprecate.py\n+++ b/scrapy/utils/deprecate.py\n@@ -79,12 +79,18 @@\n for c in {type(inst), inst.__class__})\n \n def __subclasscheck__(cls, sub):\n+ if cls is not DeprecatedClass.deprecated_class:\n+ # we should do the magic only if second `issubclass` argument\n+ # is the deprecated class itself - subclasses of the\n+ # deprecated class should not use custom `__subclasscheck__`\n+ # method.\n+ return super(DeprecatedClass, cls).__subclasscheck__(sub)\n+\n if not inspect.isclass(sub):\n raise TypeError(\"issubclass() arg 1 must be a class\")\n \n mro = getattr(sub, '__mro__', ())\n- candidates = {cls, new_class}\n- return any(c in candidates for c in mro)\n+ return any(c in {cls, new_class} for c in mro)\n \n def __call__(cls, *args, **kwargs):\n old = DeprecatedClass.deprecated_class\n", "issue": "Deprecated class inheritance check bug\n``` python\n>>> from scrapy.spider import BaseSpider\n>>> class A(BaseSpider):\n... pass\n... \n>>> class B(BaseSpider):\n... pass\n... \n>>> isinstance(A('foo'), B)\nTrue\n```\n\n", "before_files": [{"content": "\"\"\"Some helpers for deprecation messages\"\"\"\n\nimport warnings\nimport inspect\nfrom scrapy.exceptions import ScrapyDeprecationWarning\n\n\ndef attribute(obj, oldattr, newattr, version='0.12'):\n cname = obj.__class__.__name__\n warnings.warn(\"%s.%s attribute is deprecated and will be no longer supported \"\n \"in Scrapy %s, use %s.%s attribute instead\" % \\\n (cname, oldattr, version, cname, newattr), ScrapyDeprecationWarning, stacklevel=3)\n\n\ndef create_deprecated_class(name, new_class, clsdict=None,\n warn_category=ScrapyDeprecationWarning,\n warn_once=True,\n old_class_path=None,\n new_class_path=None,\n subclass_warn_message=\"{cls} inherits from \"\\\n \"deprecated class {old}, please inherit \"\\\n \"from {new}.\",\n instance_warn_message=\"{cls} is deprecated, \"\\\n \"instantiate {new} instead.\"):\n \"\"\"\n Return a \"deprecated\" class that causes its subclasses to issue a warning.\n Subclasses of ``new_class`` are considered subclasses of this class.\n It also warns when the deprecated class is instantiated, but do not when\n its subclasses are instantiated.\n\n It can be used to rename a base class in a library. For example, if we\n have\n\n class OldName(SomeClass):\n # ...\n\n and we want to rename it to NewName, we can do the following::\n\n class NewName(SomeClass):\n # ...\n\n OldName = create_deprecated_class('OldName', NewName)\n\n Then, if user class inherits from OldName, warning is issued. Also, if\n some code uses ``issubclass(sub, OldName)`` or ``isinstance(sub(), OldName)``\n checks they'll still return True if sub is a subclass of NewName instead of\n OldName.\n \"\"\"\n\n class DeprecatedClass(new_class.__class__):\n\n deprecated_class = None\n warned_on_subclass = False\n\n def __new__(metacls, name, bases, clsdict_):\n cls = super(DeprecatedClass, metacls).__new__(metacls, name, bases, clsdict_)\n if metacls.deprecated_class is None:\n metacls.deprecated_class = cls\n return cls\n\n def __init__(cls, name, bases, clsdict_):\n meta = cls.__class__\n old = meta.deprecated_class\n if old in bases and not (warn_once and meta.warned_on_subclass):\n meta.warned_on_subclass = True\n msg = subclass_warn_message.format(cls=_clspath(cls),\n old=_clspath(old, old_class_path),\n new=_clspath(new_class, new_class_path))\n if warn_once:\n msg += ' (warning only on first subclass, there may be others)'\n warnings.warn(msg, warn_category, stacklevel=2)\n super(DeprecatedClass, cls).__init__(name, bases, clsdict_)\n\n # see http://www.python.org/dev/peps/pep-3119/#overloading-isinstance-and-issubclass\n # and http://docs.python.org/2/reference/datamodel.html#customizing-instance-and-subclass-checks\n # for implementation details\n def __instancecheck__(cls, inst):\n return any(cls.__subclasscheck__(c)\n for c in {type(inst), inst.__class__})\n\n def __subclasscheck__(cls, sub):\n if not inspect.isclass(sub):\n raise TypeError(\"issubclass() arg 1 must be a class\")\n\n mro = getattr(sub, '__mro__', ())\n candidates = {cls, new_class}\n return any(c in candidates for c in mro)\n\n def __call__(cls, *args, **kwargs):\n old = DeprecatedClass.deprecated_class\n if cls is old:\n msg = instance_warn_message.format(cls=_clspath(cls, old_class_path),\n new=_clspath(new_class, new_class_path))\n warnings.warn(msg, warn_category, stacklevel=2)\n return super(DeprecatedClass, cls).__call__(*args, **kwargs)\n\n deprecated_cls = DeprecatedClass(name, (new_class,), clsdict or {})\n frm = inspect.stack()[1]\n parent_module = inspect.getmodule(frm[0])\n if parent_module is not None:\n deprecated_cls.__module__ = parent_module.__name__\n\n return deprecated_cls\n\n\ndef _clspath(cls, forced=None):\n if forced is not None:\n return forced\n return '{}.{}'.format(cls.__module__, cls.__name__)\n", "path": "scrapy/utils/deprecate.py"}], "after_files": [{"content": "\"\"\"Some helpers for deprecation messages\"\"\"\n\nimport warnings\nimport inspect\nfrom scrapy.exceptions import ScrapyDeprecationWarning\n\n\ndef attribute(obj, oldattr, newattr, version='0.12'):\n cname = obj.__class__.__name__\n warnings.warn(\"%s.%s attribute is deprecated and will be no longer supported \"\n \"in Scrapy %s, use %s.%s attribute instead\" % \\\n (cname, oldattr, version, cname, newattr), ScrapyDeprecationWarning, stacklevel=3)\n\n\ndef create_deprecated_class(name, new_class, clsdict=None,\n warn_category=ScrapyDeprecationWarning,\n warn_once=True,\n old_class_path=None,\n new_class_path=None,\n subclass_warn_message=\"{cls} inherits from \"\\\n \"deprecated class {old}, please inherit \"\\\n \"from {new}.\",\n instance_warn_message=\"{cls} is deprecated, \"\\\n \"instantiate {new} instead.\"):\n \"\"\"\n Return a \"deprecated\" class that causes its subclasses to issue a warning.\n Subclasses of ``new_class`` are considered subclasses of this class.\n It also warns when the deprecated class is instantiated, but do not when\n its subclasses are instantiated.\n\n It can be used to rename a base class in a library. For example, if we\n have\n\n class OldName(SomeClass):\n # ...\n\n and we want to rename it to NewName, we can do the following::\n\n class NewName(SomeClass):\n # ...\n\n OldName = create_deprecated_class('OldName', NewName)\n\n Then, if user class inherits from OldName, warning is issued. Also, if\n some code uses ``issubclass(sub, OldName)`` or ``isinstance(sub(), OldName)``\n checks they'll still return True if sub is a subclass of NewName instead of\n OldName.\n \"\"\"\n\n class DeprecatedClass(new_class.__class__):\n\n deprecated_class = None\n warned_on_subclass = False\n\n def __new__(metacls, name, bases, clsdict_):\n cls = super(DeprecatedClass, metacls).__new__(metacls, name, bases, clsdict_)\n if metacls.deprecated_class is None:\n metacls.deprecated_class = cls\n return cls\n\n def __init__(cls, name, bases, clsdict_):\n meta = cls.__class__\n old = meta.deprecated_class\n if old in bases and not (warn_once and meta.warned_on_subclass):\n meta.warned_on_subclass = True\n msg = subclass_warn_message.format(cls=_clspath(cls),\n old=_clspath(old, old_class_path),\n new=_clspath(new_class, new_class_path))\n if warn_once:\n msg += ' (warning only on first subclass, there may be others)'\n warnings.warn(msg, warn_category, stacklevel=2)\n super(DeprecatedClass, cls).__init__(name, bases, clsdict_)\n\n # see http://www.python.org/dev/peps/pep-3119/#overloading-isinstance-and-issubclass\n # and http://docs.python.org/2/reference/datamodel.html#customizing-instance-and-subclass-checks\n # for implementation details\n def __instancecheck__(cls, inst):\n return any(cls.__subclasscheck__(c)\n for c in {type(inst), inst.__class__})\n\n def __subclasscheck__(cls, sub):\n if cls is not DeprecatedClass.deprecated_class:\n # we should do the magic only if second `issubclass` argument\n # is the deprecated class itself - subclasses of the\n # deprecated class should not use custom `__subclasscheck__`\n # method.\n return super(DeprecatedClass, cls).__subclasscheck__(sub)\n\n if not inspect.isclass(sub):\n raise TypeError(\"issubclass() arg 1 must be a class\")\n\n mro = getattr(sub, '__mro__', ())\n return any(c in {cls, new_class} for c in mro)\n\n def __call__(cls, *args, **kwargs):\n old = DeprecatedClass.deprecated_class\n if cls is old:\n msg = instance_warn_message.format(cls=_clspath(cls, old_class_path),\n new=_clspath(new_class, new_class_path))\n warnings.warn(msg, warn_category, stacklevel=2)\n return super(DeprecatedClass, cls).__call__(*args, **kwargs)\n\n deprecated_cls = DeprecatedClass(name, (new_class,), clsdict or {})\n frm = inspect.stack()[1]\n parent_module = inspect.getmodule(frm[0])\n if parent_module is not None:\n deprecated_cls.__module__ = parent_module.__name__\n\n return deprecated_cls\n\n\ndef _clspath(cls, forced=None):\n if forced is not None:\n return forced\n return '{}.{}'.format(cls.__module__, cls.__name__)\n", "path": "scrapy/utils/deprecate.py"}]}
| 1,535 | 259 |
gh_patches_debug_66278
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-4733
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incorrect requirements.txt formatting in poetry export
The `requirements.txt` format needs to put a space in front of the semicolon that specifies the package and the pyversion and platform constraints. Right now, without the space, the semicolon will be interpreted as part of a URL. See this issue in `packaging`:
https://github.com/pypa/packaging/issues/456
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `poetry/utils/exporter.py`
Content:
```
1 import urllib.parse
2
3 from pathlib import Path
4 from typing import Optional
5 from typing import Sequence
6 from typing import Union
7
8 from cleo.io.io import IO
9
10 from poetry.core.packages.utils.utils import path_to_url
11 from poetry.poetry import Poetry
12 from poetry.utils._compat import decode
13
14
15 class Exporter:
16 """
17 Exporter class to export a lock file to alternative formats.
18 """
19
20 FORMAT_REQUIREMENTS_TXT = "requirements.txt"
21 #: The names of the supported export formats.
22 ACCEPTED_FORMATS = (FORMAT_REQUIREMENTS_TXT,)
23 ALLOWED_HASH_ALGORITHMS = ("sha256", "sha384", "sha512")
24
25 def __init__(self, poetry: Poetry) -> None:
26 self._poetry = poetry
27
28 def export(
29 self,
30 fmt: str,
31 cwd: Path,
32 output: Union[IO, str],
33 with_hashes: bool = True,
34 dev: bool = False,
35 extras: Optional[Union[bool, Sequence[str]]] = None,
36 with_credentials: bool = False,
37 ) -> None:
38 if fmt not in self.ACCEPTED_FORMATS:
39 raise ValueError(f"Invalid export format: {fmt}")
40
41 getattr(self, "_export_{}".format(fmt.replace(".", "_")))(
42 cwd,
43 output,
44 with_hashes=with_hashes,
45 dev=dev,
46 extras=extras,
47 with_credentials=with_credentials,
48 )
49
50 def _export_requirements_txt(
51 self,
52 cwd: Path,
53 output: Union[IO, str],
54 with_hashes: bool = True,
55 dev: bool = False,
56 extras: Optional[Union[bool, Sequence[str]]] = None,
57 with_credentials: bool = False,
58 ) -> None:
59 indexes = set()
60 content = ""
61 dependency_lines = set()
62
63 for dependency_package in self._poetry.locker.get_project_dependency_packages(
64 project_requires=self._poetry.package.all_requires, dev=dev, extras=extras
65 ):
66 line = ""
67
68 dependency = dependency_package.dependency
69 package = dependency_package.package
70
71 if package.develop:
72 line += "-e "
73
74 requirement = dependency.to_pep_508(with_extras=False)
75 is_direct_local_reference = (
76 dependency.is_file() or dependency.is_directory()
77 )
78 is_direct_remote_reference = dependency.is_vcs() or dependency.is_url()
79
80 if is_direct_remote_reference:
81 line = requirement
82 elif is_direct_local_reference:
83 dependency_uri = path_to_url(dependency.source_url)
84 line = f"{dependency.name} @ {dependency_uri}"
85 else:
86 line = f"{package.name}=={package.version}"
87
88 if not is_direct_remote_reference:
89 if ";" in requirement:
90 markers = requirement.split(";", 1)[1].strip()
91 if markers:
92 line += f"; {markers}"
93
94 if (
95 not is_direct_remote_reference
96 and not is_direct_local_reference
97 and package.source_url
98 ):
99 indexes.add(package.source_url)
100
101 if package.files and with_hashes:
102 hashes = []
103 for f in package.files:
104 h = f["hash"]
105 algorithm = "sha256"
106 if ":" in h:
107 algorithm, h = h.split(":")
108
109 if algorithm not in self.ALLOWED_HASH_ALGORITHMS:
110 continue
111
112 hashes.append(f"{algorithm}:{h}")
113
114 if hashes:
115 line += " \\\n"
116 for i, h in enumerate(hashes):
117 line += " --hash={}{}".format(
118 h, " \\\n" if i < len(hashes) - 1 else ""
119 )
120 dependency_lines.add(line)
121
122 content += "\n".join(sorted(dependency_lines))
123 content += "\n"
124
125 if indexes:
126 # If we have extra indexes, we add them to the beginning of the output
127 indexes_header = ""
128 for index in sorted(indexes):
129 repositories = [
130 r
131 for r in self._poetry.pool.repositories
132 if r.url == index.rstrip("/")
133 ]
134 if not repositories:
135 continue
136 repository = repositories[0]
137 if (
138 self._poetry.pool.has_default()
139 and repository is self._poetry.pool.repositories[0]
140 ):
141 url = (
142 repository.authenticated_url
143 if with_credentials
144 else repository.url
145 )
146 indexes_header = f"--index-url {url}\n"
147 continue
148
149 url = (
150 repository.authenticated_url if with_credentials else repository.url
151 )
152 parsed_url = urllib.parse.urlsplit(url)
153 if parsed_url.scheme == "http":
154 indexes_header += f"--trusted-host {parsed_url.netloc}\n"
155 indexes_header += f"--extra-index-url {url}\n"
156
157 content = indexes_header + "\n" + content
158
159 self._output(content, cwd, output)
160
161 def _output(self, content: str, cwd: Path, output: Union[IO, str]) -> None:
162 decoded = decode(content)
163 try:
164 output.write(decoded)
165 except AttributeError:
166 filepath = cwd / output
167 with filepath.open("w", encoding="utf-8") as f:
168 f.write(decoded)
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/poetry/utils/exporter.py b/poetry/utils/exporter.py
--- a/poetry/utils/exporter.py
+++ b/poetry/utils/exporter.py
@@ -89,7 +89,7 @@
if ";" in requirement:
markers = requirement.split(";", 1)[1].strip()
if markers:
- line += f"; {markers}"
+ line += f" ; {markers}"
if (
not is_direct_remote_reference
|
{"golden_diff": "diff --git a/poetry/utils/exporter.py b/poetry/utils/exporter.py\n--- a/poetry/utils/exporter.py\n+++ b/poetry/utils/exporter.py\n@@ -89,7 +89,7 @@\n if \";\" in requirement:\n markers = requirement.split(\";\", 1)[1].strip()\n if markers:\n- line += f\"; {markers}\"\n+ line += f\" ; {markers}\"\n \n if (\n not is_direct_remote_reference\n", "issue": "Incorrect requirements.txt formatting in poetry export \nThe `requirements.txt` format needs to put a space in front of the semicolon that specifies the package and the pyversion and platform constraints. Right now, without the space, the semicolon will be interpreted as part of a URL. See this issue in `packaging`:\r\nhttps://github.com/pypa/packaging/issues/456\n", "before_files": [{"content": "import urllib.parse\n\nfrom pathlib import Path\nfrom typing import Optional\nfrom typing import Sequence\nfrom typing import Union\n\nfrom cleo.io.io import IO\n\nfrom poetry.core.packages.utils.utils import path_to_url\nfrom poetry.poetry import Poetry\nfrom poetry.utils._compat import decode\n\n\nclass Exporter:\n \"\"\"\n Exporter class to export a lock file to alternative formats.\n \"\"\"\n\n FORMAT_REQUIREMENTS_TXT = \"requirements.txt\"\n #: The names of the supported export formats.\n ACCEPTED_FORMATS = (FORMAT_REQUIREMENTS_TXT,)\n ALLOWED_HASH_ALGORITHMS = (\"sha256\", \"sha384\", \"sha512\")\n\n def __init__(self, poetry: Poetry) -> None:\n self._poetry = poetry\n\n def export(\n self,\n fmt: str,\n cwd: Path,\n output: Union[IO, str],\n with_hashes: bool = True,\n dev: bool = False,\n extras: Optional[Union[bool, Sequence[str]]] = None,\n with_credentials: bool = False,\n ) -> None:\n if fmt not in self.ACCEPTED_FORMATS:\n raise ValueError(f\"Invalid export format: {fmt}\")\n\n getattr(self, \"_export_{}\".format(fmt.replace(\".\", \"_\")))(\n cwd,\n output,\n with_hashes=with_hashes,\n dev=dev,\n extras=extras,\n with_credentials=with_credentials,\n )\n\n def _export_requirements_txt(\n self,\n cwd: Path,\n output: Union[IO, str],\n with_hashes: bool = True,\n dev: bool = False,\n extras: Optional[Union[bool, Sequence[str]]] = None,\n with_credentials: bool = False,\n ) -> None:\n indexes = set()\n content = \"\"\n dependency_lines = set()\n\n for dependency_package in self._poetry.locker.get_project_dependency_packages(\n project_requires=self._poetry.package.all_requires, dev=dev, extras=extras\n ):\n line = \"\"\n\n dependency = dependency_package.dependency\n package = dependency_package.package\n\n if package.develop:\n line += \"-e \"\n\n requirement = dependency.to_pep_508(with_extras=False)\n is_direct_local_reference = (\n dependency.is_file() or dependency.is_directory()\n )\n is_direct_remote_reference = dependency.is_vcs() or dependency.is_url()\n\n if is_direct_remote_reference:\n line = requirement\n elif is_direct_local_reference:\n dependency_uri = path_to_url(dependency.source_url)\n line = f\"{dependency.name} @ {dependency_uri}\"\n else:\n line = f\"{package.name}=={package.version}\"\n\n if not is_direct_remote_reference:\n if \";\" in requirement:\n markers = requirement.split(\";\", 1)[1].strip()\n if markers:\n line += f\"; {markers}\"\n\n if (\n not is_direct_remote_reference\n and not is_direct_local_reference\n and package.source_url\n ):\n indexes.add(package.source_url)\n\n if package.files and with_hashes:\n hashes = []\n for f in package.files:\n h = f[\"hash\"]\n algorithm = \"sha256\"\n if \":\" in h:\n algorithm, h = h.split(\":\")\n\n if algorithm not in self.ALLOWED_HASH_ALGORITHMS:\n continue\n\n hashes.append(f\"{algorithm}:{h}\")\n\n if hashes:\n line += \" \\\\\\n\"\n for i, h in enumerate(hashes):\n line += \" --hash={}{}\".format(\n h, \" \\\\\\n\" if i < len(hashes) - 1 else \"\"\n )\n dependency_lines.add(line)\n\n content += \"\\n\".join(sorted(dependency_lines))\n content += \"\\n\"\n\n if indexes:\n # If we have extra indexes, we add them to the beginning of the output\n indexes_header = \"\"\n for index in sorted(indexes):\n repositories = [\n r\n for r in self._poetry.pool.repositories\n if r.url == index.rstrip(\"/\")\n ]\n if not repositories:\n continue\n repository = repositories[0]\n if (\n self._poetry.pool.has_default()\n and repository is self._poetry.pool.repositories[0]\n ):\n url = (\n repository.authenticated_url\n if with_credentials\n else repository.url\n )\n indexes_header = f\"--index-url {url}\\n\"\n continue\n\n url = (\n repository.authenticated_url if with_credentials else repository.url\n )\n parsed_url = urllib.parse.urlsplit(url)\n if parsed_url.scheme == \"http\":\n indexes_header += f\"--trusted-host {parsed_url.netloc}\\n\"\n indexes_header += f\"--extra-index-url {url}\\n\"\n\n content = indexes_header + \"\\n\" + content\n\n self._output(content, cwd, output)\n\n def _output(self, content: str, cwd: Path, output: Union[IO, str]) -> None:\n decoded = decode(content)\n try:\n output.write(decoded)\n except AttributeError:\n filepath = cwd / output\n with filepath.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decoded)\n", "path": "poetry/utils/exporter.py"}], "after_files": [{"content": "import urllib.parse\n\nfrom pathlib import Path\nfrom typing import Optional\nfrom typing import Sequence\nfrom typing import Union\n\nfrom cleo.io.io import IO\n\nfrom poetry.core.packages.utils.utils import path_to_url\nfrom poetry.poetry import Poetry\nfrom poetry.utils._compat import decode\n\n\nclass Exporter:\n \"\"\"\n Exporter class to export a lock file to alternative formats.\n \"\"\"\n\n FORMAT_REQUIREMENTS_TXT = \"requirements.txt\"\n #: The names of the supported export formats.\n ACCEPTED_FORMATS = (FORMAT_REQUIREMENTS_TXT,)\n ALLOWED_HASH_ALGORITHMS = (\"sha256\", \"sha384\", \"sha512\")\n\n def __init__(self, poetry: Poetry) -> None:\n self._poetry = poetry\n\n def export(\n self,\n fmt: str,\n cwd: Path,\n output: Union[IO, str],\n with_hashes: bool = True,\n dev: bool = False,\n extras: Optional[Union[bool, Sequence[str]]] = None,\n with_credentials: bool = False,\n ) -> None:\n if fmt not in self.ACCEPTED_FORMATS:\n raise ValueError(f\"Invalid export format: {fmt}\")\n\n getattr(self, \"_export_{}\".format(fmt.replace(\".\", \"_\")))(\n cwd,\n output,\n with_hashes=with_hashes,\n dev=dev,\n extras=extras,\n with_credentials=with_credentials,\n )\n\n def _export_requirements_txt(\n self,\n cwd: Path,\n output: Union[IO, str],\n with_hashes: bool = True,\n dev: bool = False,\n extras: Optional[Union[bool, Sequence[str]]] = None,\n with_credentials: bool = False,\n ) -> None:\n indexes = set()\n content = \"\"\n dependency_lines = set()\n\n for dependency_package in self._poetry.locker.get_project_dependency_packages(\n project_requires=self._poetry.package.all_requires, dev=dev, extras=extras\n ):\n line = \"\"\n\n dependency = dependency_package.dependency\n package = dependency_package.package\n\n if package.develop:\n line += \"-e \"\n\n requirement = dependency.to_pep_508(with_extras=False)\n is_direct_local_reference = (\n dependency.is_file() or dependency.is_directory()\n )\n is_direct_remote_reference = dependency.is_vcs() or dependency.is_url()\n\n if is_direct_remote_reference:\n line = requirement\n elif is_direct_local_reference:\n dependency_uri = path_to_url(dependency.source_url)\n line = f\"{dependency.name} @ {dependency_uri}\"\n else:\n line = f\"{package.name}=={package.version}\"\n\n if not is_direct_remote_reference:\n if \";\" in requirement:\n markers = requirement.split(\";\", 1)[1].strip()\n if markers:\n line += f\" ; {markers}\"\n\n if (\n not is_direct_remote_reference\n and not is_direct_local_reference\n and package.source_url\n ):\n indexes.add(package.source_url)\n\n if package.files and with_hashes:\n hashes = []\n for f in package.files:\n h = f[\"hash\"]\n algorithm = \"sha256\"\n if \":\" in h:\n algorithm, h = h.split(\":\")\n\n if algorithm not in self.ALLOWED_HASH_ALGORITHMS:\n continue\n\n hashes.append(f\"{algorithm}:{h}\")\n\n if hashes:\n line += \" \\\\\\n\"\n for i, h in enumerate(hashes):\n line += \" --hash={}{}\".format(\n h, \" \\\\\\n\" if i < len(hashes) - 1 else \"\"\n )\n dependency_lines.add(line)\n\n content += \"\\n\".join(sorted(dependency_lines))\n content += \"\\n\"\n\n if indexes:\n # If we have extra indexes, we add them to the beginning of the output\n indexes_header = \"\"\n for index in sorted(indexes):\n repositories = [\n r\n for r in self._poetry.pool.repositories\n if r.url == index.rstrip(\"/\")\n ]\n if not repositories:\n continue\n repository = repositories[0]\n if (\n self._poetry.pool.has_default()\n and repository is self._poetry.pool.repositories[0]\n ):\n url = (\n repository.authenticated_url\n if with_credentials\n else repository.url\n )\n indexes_header = f\"--index-url {url}\\n\"\n continue\n\n url = (\n repository.authenticated_url if with_credentials else repository.url\n )\n parsed_url = urllib.parse.urlsplit(url)\n if parsed_url.scheme == \"http\":\n indexes_header += f\"--trusted-host {parsed_url.netloc}\\n\"\n indexes_header += f\"--extra-index-url {url}\\n\"\n\n content = indexes_header + \"\\n\" + content\n\n self._output(content, cwd, output)\n\n def _output(self, content: str, cwd: Path, output: Union[IO, str]) -> None:\n decoded = decode(content)\n try:\n output.write(decoded)\n except AttributeError:\n filepath = cwd / output\n with filepath.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decoded)\n", "path": "poetry/utils/exporter.py"}]}
| 1,863 | 106 |
gh_patches_debug_17388
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-816
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: CRS is missing
https://github.com/Zeroto521/my-data-toolkit/blob/93aaefa0193c1822af21c60d9edbbc9acff68815/dtoolkit/geoaccessor/series/to_geoframe.py#L86-L87
`np.asarray` will remove CRS information from GeoSeries.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/geoaccessor/series/to_geoframe.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 import geopandas as gpd
6 import numpy as np
7 import pandas as pd
8 from geopandas.base import is_geometry_type
9
10 from dtoolkit.accessor.register import register_series_method
11
12 if TYPE_CHECKING:
13 from pyproj import CRS
14
15
16 @register_series_method
17 def to_geoframe(
18 s: pd.Series,
19 /,
20 geometry: gpd.GeoSeries = None,
21 crs: CRS | str | int = None,
22 **kwargs,
23 ) -> gpd.GeoDataFrame | pd.DataFrame:
24 """
25 Transform an array of shapely scalars :class:`~pandas.Series` to
26 a :class:`~geopandas.GeoDataFrame`.
27
28 Parameters
29 ----------
30 geometry : GeoSeries, optional
31 It will be prior set as 'geometry' column on GeoDataFrame. If the input
32 is a GeoSeries, its index will be ignored.
33
34 crs : CRS, str, int, optional
35 Coordinate Reference System of the geometry objects. Can be anything
36 accepted by :meth:`~pyproj.crs.CRS.from_user_input`, such as an authority
37 string (eg "EPSG:4326" / 4326) or a WKT string.
38
39 **kwargs
40 See the documentation for :class:`~geopandas.GeoDataFrame` and for complete
41 details on the keyword arguments.
42
43 Returns
44 -------
45 DataFrame or GeoDataFrame
46 GeoDataFrame if the data is an array of shapely scalars or ``geometry`` is set.
47
48 See Also
49 --------
50 dtoolkit.geoaccessor.series.to_geoseries
51 dtoolkit.geoaccessor.dataframe.to_geoframe
52
53 Examples
54 --------
55 >>> import dtoolkit.geoaccessor
56 >>> import pandas as pd
57 >>> s = pd.Series(
58 ... pd.Series(
59 ... [
60 ... "POINT (1 1)",
61 ... "POINT (2 2)",
62 ... "POINT (3 3)",
63 ... ],
64 ... )
65 ... .from_wkt(drop=True, crs=4326)
66 ... )
67 >>> s
68 0 POINT (1.00000 1.00000)
69 1 POINT (2.00000 2.00000)
70 2 POINT (3.00000 3.00000)
71 dtype: geometry
72 >>> type(s)
73 <class 'pandas.core.series.Series'>
74 >>> gs = s.to_geoframe()
75 >>> gs
76 geometry
77 0 POINT (1.00000 1.00000)
78 1 POINT (2.00000 2.00000)
79 2 POINT (3.00000 3.00000)
80 >>> type(gs)
81 <class 'geopandas.geodataframe.GeoDataFrame'>
82 """
83
84 if geometry is not None:
85 # FIXME: https://github.com/geopandas/geopandas/issues/2660
86 if isinstance(geometry, gpd.GeoSeries):
87 geometry = np.asarray(geometry)
88 return gpd.GeoDataFrame(s, geometry=geometry, crs=crs, **kwargs)
89 elif is_geometry_type(s):
90 return gpd.GeoDataFrame(geometry=s, crs=crs, **kwargs)
91 else:
92 return s.to_frame()
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dtoolkit/geoaccessor/series/to_geoframe.py b/dtoolkit/geoaccessor/series/to_geoframe.py
--- a/dtoolkit/geoaccessor/series/to_geoframe.py
+++ b/dtoolkit/geoaccessor/series/to_geoframe.py
@@ -3,7 +3,6 @@
from typing import TYPE_CHECKING
import geopandas as gpd
-import numpy as np
import pandas as pd
from geopandas.base import is_geometry_type
@@ -84,7 +83,7 @@
if geometry is not None:
# FIXME: https://github.com/geopandas/geopandas/issues/2660
if isinstance(geometry, gpd.GeoSeries):
- geometry = np.asarray(geometry)
+ geometry = geometry.set_axis(s.index)
return gpd.GeoDataFrame(s, geometry=geometry, crs=crs, **kwargs)
elif is_geometry_type(s):
return gpd.GeoDataFrame(geometry=s, crs=crs, **kwargs)
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/series/to_geoframe.py b/dtoolkit/geoaccessor/series/to_geoframe.py\n--- a/dtoolkit/geoaccessor/series/to_geoframe.py\n+++ b/dtoolkit/geoaccessor/series/to_geoframe.py\n@@ -3,7 +3,6 @@\n from typing import TYPE_CHECKING\n \n import geopandas as gpd\n-import numpy as np\n import pandas as pd\n from geopandas.base import is_geometry_type\n \n@@ -84,7 +83,7 @@\n if geometry is not None:\n # FIXME: https://github.com/geopandas/geopandas/issues/2660\n if isinstance(geometry, gpd.GeoSeries):\n- geometry = np.asarray(geometry)\n+ geometry = geometry.set_axis(s.index)\n return gpd.GeoDataFrame(s, geometry=geometry, crs=crs, **kwargs)\n elif is_geometry_type(s):\n return gpd.GeoDataFrame(geometry=s, crs=crs, **kwargs)\n", "issue": "BUG: CRS is missing\nhttps://github.com/Zeroto521/my-data-toolkit/blob/93aaefa0193c1822af21c60d9edbbc9acff68815/dtoolkit/geoaccessor/series/to_geoframe.py#L86-L87\r\n\r\n`np.asarray` will remove CRS information from GeoSeries.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nimport geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom geopandas.base import is_geometry_type\n\nfrom dtoolkit.accessor.register import register_series_method\n\nif TYPE_CHECKING:\n from pyproj import CRS\n\n\n@register_series_method\ndef to_geoframe(\n s: pd.Series,\n /,\n geometry: gpd.GeoSeries = None,\n crs: CRS | str | int = None,\n **kwargs,\n) -> gpd.GeoDataFrame | pd.DataFrame:\n \"\"\"\n Transform an array of shapely scalars :class:`~pandas.Series` to\n a :class:`~geopandas.GeoDataFrame`.\n\n Parameters\n ----------\n geometry : GeoSeries, optional\n It will be prior set as 'geometry' column on GeoDataFrame. If the input\n is a GeoSeries, its index will be ignored.\n\n crs : CRS, str, int, optional\n Coordinate Reference System of the geometry objects. Can be anything\n accepted by :meth:`~pyproj.crs.CRS.from_user_input`, such as an authority\n string (eg \"EPSG:4326\" / 4326) or a WKT string.\n\n **kwargs\n See the documentation for :class:`~geopandas.GeoDataFrame` and for complete\n details on the keyword arguments.\n\n Returns\n -------\n DataFrame or GeoDataFrame\n GeoDataFrame if the data is an array of shapely scalars or ``geometry`` is set.\n\n See Also\n --------\n dtoolkit.geoaccessor.series.to_geoseries\n dtoolkit.geoaccessor.dataframe.to_geoframe\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import pandas as pd\n >>> s = pd.Series(\n ... pd.Series(\n ... [\n ... \"POINT (1 1)\",\n ... \"POINT (2 2)\",\n ... \"POINT (3 3)\",\n ... ],\n ... )\n ... .from_wkt(drop=True, crs=4326)\n ... )\n >>> s\n 0 POINT (1.00000 1.00000)\n 1 POINT (2.00000 2.00000)\n 2 POINT (3.00000 3.00000)\n dtype: geometry\n >>> type(s)\n <class 'pandas.core.series.Series'>\n >>> gs = s.to_geoframe()\n >>> gs\n geometry\n 0 POINT (1.00000 1.00000)\n 1 POINT (2.00000 2.00000)\n 2 POINT (3.00000 3.00000)\n >>> type(gs)\n <class 'geopandas.geodataframe.GeoDataFrame'>\n \"\"\"\n\n if geometry is not None:\n # FIXME: https://github.com/geopandas/geopandas/issues/2660\n if isinstance(geometry, gpd.GeoSeries):\n geometry = np.asarray(geometry)\n return gpd.GeoDataFrame(s, geometry=geometry, crs=crs, **kwargs)\n elif is_geometry_type(s):\n return gpd.GeoDataFrame(geometry=s, crs=crs, **kwargs)\n else:\n return s.to_frame()\n", "path": "dtoolkit/geoaccessor/series/to_geoframe.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nimport geopandas as gpd\nimport pandas as pd\nfrom geopandas.base import is_geometry_type\n\nfrom dtoolkit.accessor.register import register_series_method\n\nif TYPE_CHECKING:\n from pyproj import CRS\n\n\n@register_series_method\ndef to_geoframe(\n s: pd.Series,\n /,\n geometry: gpd.GeoSeries = None,\n crs: CRS | str | int = None,\n **kwargs,\n) -> gpd.GeoDataFrame | pd.DataFrame:\n \"\"\"\n Transform an array of shapely scalars :class:`~pandas.Series` to\n a :class:`~geopandas.GeoDataFrame`.\n\n Parameters\n ----------\n geometry : GeoSeries, optional\n It will be prior set as 'geometry' column on GeoDataFrame. If the input\n is a GeoSeries, its index will be ignored.\n\n crs : CRS, str, int, optional\n Coordinate Reference System of the geometry objects. Can be anything\n accepted by :meth:`~pyproj.crs.CRS.from_user_input`, such as an authority\n string (eg \"EPSG:4326\" / 4326) or a WKT string.\n\n **kwargs\n See the documentation for :class:`~geopandas.GeoDataFrame` and for complete\n details on the keyword arguments.\n\n Returns\n -------\n DataFrame or GeoDataFrame\n GeoDataFrame if the data is an array of shapely scalars or ``geometry`` is set.\n\n See Also\n --------\n dtoolkit.geoaccessor.series.to_geoseries\n dtoolkit.geoaccessor.dataframe.to_geoframe\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import pandas as pd\n >>> s = pd.Series(\n ... pd.Series(\n ... [\n ... \"POINT (1 1)\",\n ... \"POINT (2 2)\",\n ... \"POINT (3 3)\",\n ... ],\n ... )\n ... .from_wkt(drop=True, crs=4326)\n ... )\n >>> s\n 0 POINT (1.00000 1.00000)\n 1 POINT (2.00000 2.00000)\n 2 POINT (3.00000 3.00000)\n dtype: geometry\n >>> type(s)\n <class 'pandas.core.series.Series'>\n >>> gs = s.to_geoframe()\n >>> gs\n geometry\n 0 POINT (1.00000 1.00000)\n 1 POINT (2.00000 2.00000)\n 2 POINT (3.00000 3.00000)\n >>> type(gs)\n <class 'geopandas.geodataframe.GeoDataFrame'>\n \"\"\"\n\n if geometry is not None:\n # FIXME: https://github.com/geopandas/geopandas/issues/2660\n if isinstance(geometry, gpd.GeoSeries):\n geometry = geometry.set_axis(s.index)\n return gpd.GeoDataFrame(s, geometry=geometry, crs=crs, **kwargs)\n elif is_geometry_type(s):\n return gpd.GeoDataFrame(geometry=s, crs=crs, **kwargs)\n else:\n return s.to_frame()\n", "path": "dtoolkit/geoaccessor/series/to_geoframe.py"}]}
| 1,310 | 230 |
gh_patches_debug_17387
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-13132
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Gift card filter by `createdByEmail`
## Problem
Customer support needs to find customers giftcards to be able to resend code, correct balance or inquiry about balance
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/graphql/giftcard/filters.py`
Content:
```
1 from typing import List
2 from uuid import UUID
3
4 import django_filters
5 import graphene
6 from django.db.models import Exists, OuterRef, Q
7 from graphql.error import GraphQLError
8
9 from ...account import models as account_models
10 from ...giftcard import models
11 from ...order import models as order_models
12 from ...product import models as product_models
13 from ..core.doc_category import DOC_CATEGORY_GIFT_CARDS
14 from ..core.filters import (
15 GlobalIDMultipleChoiceFilter,
16 ListObjectTypeFilter,
17 MetadataFilterBase,
18 ObjectTypeFilter,
19 )
20 from ..core.types import (
21 BaseInputObjectType,
22 FilterInputObjectType,
23 NonNullList,
24 PriceRangeInput,
25 )
26 from ..utils import resolve_global_ids_to_primary_keys
27 from .enums import GiftCardEventsEnum
28
29
30 def filter_products(qs, _, value):
31 if value:
32 _, product_pks = resolve_global_ids_to_primary_keys(value, "Product")
33 qs = filter_gift_cards_by_products(qs, product_pks)
34 return qs
35
36
37 def filter_gift_cards_by_products(qs, product_ids):
38 products = product_models.Product.objects.filter(pk__in=product_ids)
39 return qs.filter(Exists(products.filter(pk=OuterRef("product_id"))))
40
41
42 def filter_used_by(qs, _, value):
43 if value:
44 _, user_pks = resolve_global_ids_to_primary_keys(value, "User")
45 qs = filter_gift_cards_by_used_by_user(qs, user_pks)
46 return qs
47
48
49 def filter_gift_cards_by_used_by_user(qs, user_pks):
50 users = account_models.User.objects.filter(pk__in=user_pks)
51 return qs.filter(Exists(users.filter(pk=OuterRef("used_by_id"))))
52
53
54 def filter_tags_list(qs, _, value):
55 if not value:
56 return qs
57 tags = models.GiftCardTag.objects.filter(name__in=value)
58 return qs.filter(Exists(tags.filter(pk=OuterRef("tags__id"))))
59
60
61 def filter_gift_card_used(qs, _, value):
62 if value is None:
63 return qs
64 return qs.filter(used_by_email__isnull=not value)
65
66
67 def filter_currency(qs, _, value):
68 if not value:
69 return qs
70 return qs.filter(currency=value)
71
72
73 def _filter_by_price(qs, field, value):
74 lookup = {}
75 if lte := value.get("lte"):
76 lookup[f"{field}_amount__lte"] = lte
77 if gte := value.get("gte"):
78 lookup[f"{field}_amount__gte"] = gte
79 return qs.filter(**lookup)
80
81
82 def filter_code(qs, _, value):
83 if not value:
84 return qs
85 return qs.filter(code=value)
86
87
88 class GiftCardFilter(MetadataFilterBase):
89 tags = ListObjectTypeFilter(input_class=graphene.String, method=filter_tags_list)
90 products = GlobalIDMultipleChoiceFilter(method=filter_products)
91 used_by = GlobalIDMultipleChoiceFilter(method=filter_used_by)
92 used = django_filters.BooleanFilter(method=filter_gift_card_used)
93 currency = django_filters.CharFilter(method=filter_currency)
94 current_balance = ObjectTypeFilter(
95 input_class=PriceRangeInput, method="filter_current_balance"
96 )
97 initial_balance = ObjectTypeFilter(
98 input_class=PriceRangeInput, method="filter_initial_balance"
99 )
100 is_active = django_filters.BooleanFilter()
101 code = django_filters.CharFilter(method=filter_code)
102
103 class Meta:
104 model = models.GiftCard
105 fields = ["is_active"]
106
107 def filter_current_balance(self, queryset, name, value):
108 check_currency_in_filter_data(self.data)
109 return _filter_by_price(queryset, "current_balance", value)
110
111 def filter_initial_balance(self, queryset, name, value):
112 check_currency_in_filter_data(self.data)
113 return _filter_by_price(queryset, "initial_balance", value)
114
115
116 def check_currency_in_filter_data(filter_data: dict):
117 currency = filter_data.get("currency")
118 if not currency:
119 raise GraphQLError(
120 "You must provide a `currency` filter parameter for filtering by price."
121 )
122
123
124 class GiftCardFilterInput(FilterInputObjectType):
125 class Meta:
126 doc_category = DOC_CATEGORY_GIFT_CARDS
127 filterset_class = GiftCardFilter
128
129
130 def filter_events_by_type(events: List[models.GiftCardEvent], type_value: str):
131 filtered_events = []
132 for event in events:
133 if event.type == type_value:
134 filtered_events.append(event)
135 return filtered_events
136
137
138 def filter_events_by_orders(events: List[models.GiftCardEvent], order_ids: List[str]):
139 order_pks = _get_order_pks(order_ids)
140
141 filtered_events = []
142 for event in events:
143 if event.order_id in order_pks:
144 filtered_events.append(event)
145 return filtered_events
146
147
148 def _get_order_pks(order_ids: List[str]):
149 _, order_pks = resolve_global_ids_to_primary_keys(order_ids, "Order")
150
151 pks = []
152 old_pks = []
153 for pk in order_pks:
154 try:
155 pks.append(UUID(pk))
156 except ValueError:
157 old_pks.append(pk)
158
159 return order_models.Order.objects.filter(
160 Q(id__in=pks) | (Q(use_old_id=True) & Q(number__in=old_pks))
161 ).values_list("id", flat=True)
162
163
164 class GiftCardEventFilterInput(BaseInputObjectType):
165 type = graphene.Argument(GiftCardEventsEnum)
166 orders = NonNullList(graphene.ID)
167
168 class Meta:
169 doc_category = DOC_CATEGORY_GIFT_CARDS
170
171
172 def filter_gift_card_tag_search(qs, _, value):
173 if not value:
174 return qs
175 return qs.filter(name__ilike=value)
176
177
178 class GiftCardTagFilter(django_filters.FilterSet):
179 search = django_filters.CharFilter(method=filter_gift_card_tag_search)
180
181
182 class GiftCardTagFilterInput(FilterInputObjectType):
183 class Meta:
184 doc_category = DOC_CATEGORY_GIFT_CARDS
185 filterset_class = GiftCardTagFilter
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/graphql/giftcard/filters.py b/saleor/graphql/giftcard/filters.py
--- a/saleor/graphql/giftcard/filters.py
+++ b/saleor/graphql/giftcard/filters.py
@@ -85,6 +85,12 @@
return qs.filter(code=value)
+def filter_created_by_email(qs, _, value):
+ if not value:
+ return qs
+ return qs.filter(created_by_email=value)
+
+
class GiftCardFilter(MetadataFilterBase):
tags = ListObjectTypeFilter(input_class=graphene.String, method=filter_tags_list)
products = GlobalIDMultipleChoiceFilter(method=filter_products)
@@ -99,6 +105,7 @@
)
is_active = django_filters.BooleanFilter()
code = django_filters.CharFilter(method=filter_code)
+ created_by_email = django_filters.CharFilter(method=filter_created_by_email)
class Meta:
model = models.GiftCard
|
{"golden_diff": "diff --git a/saleor/graphql/giftcard/filters.py b/saleor/graphql/giftcard/filters.py\n--- a/saleor/graphql/giftcard/filters.py\n+++ b/saleor/graphql/giftcard/filters.py\n@@ -85,6 +85,12 @@\n return qs.filter(code=value)\n \n \n+def filter_created_by_email(qs, _, value):\n+ if not value:\n+ return qs\n+ return qs.filter(created_by_email=value)\n+\n+\n class GiftCardFilter(MetadataFilterBase):\n tags = ListObjectTypeFilter(input_class=graphene.String, method=filter_tags_list)\n products = GlobalIDMultipleChoiceFilter(method=filter_products)\n@@ -99,6 +105,7 @@\n )\n is_active = django_filters.BooleanFilter()\n code = django_filters.CharFilter(method=filter_code)\n+ created_by_email = django_filters.CharFilter(method=filter_created_by_email)\n \n class Meta:\n model = models.GiftCard\n", "issue": "Gift card filter by `createdByEmail`\n## Problem\r\n\r\nCustomer support needs to find customers giftcards to be able to resend code, correct balance or inquiry about balance\r\n\n", "before_files": [{"content": "from typing import List\nfrom uuid import UUID\n\nimport django_filters\nimport graphene\nfrom django.db.models import Exists, OuterRef, Q\nfrom graphql.error import GraphQLError\n\nfrom ...account import models as account_models\nfrom ...giftcard import models\nfrom ...order import models as order_models\nfrom ...product import models as product_models\nfrom ..core.doc_category import DOC_CATEGORY_GIFT_CARDS\nfrom ..core.filters import (\n GlobalIDMultipleChoiceFilter,\n ListObjectTypeFilter,\n MetadataFilterBase,\n ObjectTypeFilter,\n)\nfrom ..core.types import (\n BaseInputObjectType,\n FilterInputObjectType,\n NonNullList,\n PriceRangeInput,\n)\nfrom ..utils import resolve_global_ids_to_primary_keys\nfrom .enums import GiftCardEventsEnum\n\n\ndef filter_products(qs, _, value):\n if value:\n _, product_pks = resolve_global_ids_to_primary_keys(value, \"Product\")\n qs = filter_gift_cards_by_products(qs, product_pks)\n return qs\n\n\ndef filter_gift_cards_by_products(qs, product_ids):\n products = product_models.Product.objects.filter(pk__in=product_ids)\n return qs.filter(Exists(products.filter(pk=OuterRef(\"product_id\"))))\n\n\ndef filter_used_by(qs, _, value):\n if value:\n _, user_pks = resolve_global_ids_to_primary_keys(value, \"User\")\n qs = filter_gift_cards_by_used_by_user(qs, user_pks)\n return qs\n\n\ndef filter_gift_cards_by_used_by_user(qs, user_pks):\n users = account_models.User.objects.filter(pk__in=user_pks)\n return qs.filter(Exists(users.filter(pk=OuterRef(\"used_by_id\"))))\n\n\ndef filter_tags_list(qs, _, value):\n if not value:\n return qs\n tags = models.GiftCardTag.objects.filter(name__in=value)\n return qs.filter(Exists(tags.filter(pk=OuterRef(\"tags__id\"))))\n\n\ndef filter_gift_card_used(qs, _, value):\n if value is None:\n return qs\n return qs.filter(used_by_email__isnull=not value)\n\n\ndef filter_currency(qs, _, value):\n if not value:\n return qs\n return qs.filter(currency=value)\n\n\ndef _filter_by_price(qs, field, value):\n lookup = {}\n if lte := value.get(\"lte\"):\n lookup[f\"{field}_amount__lte\"] = lte\n if gte := value.get(\"gte\"):\n lookup[f\"{field}_amount__gte\"] = gte\n return qs.filter(**lookup)\n\n\ndef filter_code(qs, _, value):\n if not value:\n return qs\n return qs.filter(code=value)\n\n\nclass GiftCardFilter(MetadataFilterBase):\n tags = ListObjectTypeFilter(input_class=graphene.String, method=filter_tags_list)\n products = GlobalIDMultipleChoiceFilter(method=filter_products)\n used_by = GlobalIDMultipleChoiceFilter(method=filter_used_by)\n used = django_filters.BooleanFilter(method=filter_gift_card_used)\n currency = django_filters.CharFilter(method=filter_currency)\n current_balance = ObjectTypeFilter(\n input_class=PriceRangeInput, method=\"filter_current_balance\"\n )\n initial_balance = ObjectTypeFilter(\n input_class=PriceRangeInput, method=\"filter_initial_balance\"\n )\n is_active = django_filters.BooleanFilter()\n code = django_filters.CharFilter(method=filter_code)\n\n class Meta:\n model = models.GiftCard\n fields = [\"is_active\"]\n\n def filter_current_balance(self, queryset, name, value):\n check_currency_in_filter_data(self.data)\n return _filter_by_price(queryset, \"current_balance\", value)\n\n def filter_initial_balance(self, queryset, name, value):\n check_currency_in_filter_data(self.data)\n return _filter_by_price(queryset, \"initial_balance\", value)\n\n\ndef check_currency_in_filter_data(filter_data: dict):\n currency = filter_data.get(\"currency\")\n if not currency:\n raise GraphQLError(\n \"You must provide a `currency` filter parameter for filtering by price.\"\n )\n\n\nclass GiftCardFilterInput(FilterInputObjectType):\n class Meta:\n doc_category = DOC_CATEGORY_GIFT_CARDS\n filterset_class = GiftCardFilter\n\n\ndef filter_events_by_type(events: List[models.GiftCardEvent], type_value: str):\n filtered_events = []\n for event in events:\n if event.type == type_value:\n filtered_events.append(event)\n return filtered_events\n\n\ndef filter_events_by_orders(events: List[models.GiftCardEvent], order_ids: List[str]):\n order_pks = _get_order_pks(order_ids)\n\n filtered_events = []\n for event in events:\n if event.order_id in order_pks:\n filtered_events.append(event)\n return filtered_events\n\n\ndef _get_order_pks(order_ids: List[str]):\n _, order_pks = resolve_global_ids_to_primary_keys(order_ids, \"Order\")\n\n pks = []\n old_pks = []\n for pk in order_pks:\n try:\n pks.append(UUID(pk))\n except ValueError:\n old_pks.append(pk)\n\n return order_models.Order.objects.filter(\n Q(id__in=pks) | (Q(use_old_id=True) & Q(number__in=old_pks))\n ).values_list(\"id\", flat=True)\n\n\nclass GiftCardEventFilterInput(BaseInputObjectType):\n type = graphene.Argument(GiftCardEventsEnum)\n orders = NonNullList(graphene.ID)\n\n class Meta:\n doc_category = DOC_CATEGORY_GIFT_CARDS\n\n\ndef filter_gift_card_tag_search(qs, _, value):\n if not value:\n return qs\n return qs.filter(name__ilike=value)\n\n\nclass GiftCardTagFilter(django_filters.FilterSet):\n search = django_filters.CharFilter(method=filter_gift_card_tag_search)\n\n\nclass GiftCardTagFilterInput(FilterInputObjectType):\n class Meta:\n doc_category = DOC_CATEGORY_GIFT_CARDS\n filterset_class = GiftCardTagFilter\n", "path": "saleor/graphql/giftcard/filters.py"}], "after_files": [{"content": "from typing import List\nfrom uuid import UUID\n\nimport django_filters\nimport graphene\nfrom django.db.models import Exists, OuterRef, Q\nfrom graphql.error import GraphQLError\n\nfrom ...account import models as account_models\nfrom ...giftcard import models\nfrom ...order import models as order_models\nfrom ...product import models as product_models\nfrom ..core.doc_category import DOC_CATEGORY_GIFT_CARDS\nfrom ..core.filters import (\n GlobalIDMultipleChoiceFilter,\n ListObjectTypeFilter,\n MetadataFilterBase,\n ObjectTypeFilter,\n)\nfrom ..core.types import (\n BaseInputObjectType,\n FilterInputObjectType,\n NonNullList,\n PriceRangeInput,\n)\nfrom ..utils import resolve_global_ids_to_primary_keys\nfrom .enums import GiftCardEventsEnum\n\n\ndef filter_products(qs, _, value):\n if value:\n _, product_pks = resolve_global_ids_to_primary_keys(value, \"Product\")\n qs = filter_gift_cards_by_products(qs, product_pks)\n return qs\n\n\ndef filter_gift_cards_by_products(qs, product_ids):\n products = product_models.Product.objects.filter(pk__in=product_ids)\n return qs.filter(Exists(products.filter(pk=OuterRef(\"product_id\"))))\n\n\ndef filter_used_by(qs, _, value):\n if value:\n _, user_pks = resolve_global_ids_to_primary_keys(value, \"User\")\n qs = filter_gift_cards_by_used_by_user(qs, user_pks)\n return qs\n\n\ndef filter_gift_cards_by_used_by_user(qs, user_pks):\n users = account_models.User.objects.filter(pk__in=user_pks)\n return qs.filter(Exists(users.filter(pk=OuterRef(\"used_by_id\"))))\n\n\ndef filter_tags_list(qs, _, value):\n if not value:\n return qs\n tags = models.GiftCardTag.objects.filter(name__in=value)\n return qs.filter(Exists(tags.filter(pk=OuterRef(\"tags__id\"))))\n\n\ndef filter_gift_card_used(qs, _, value):\n if value is None:\n return qs\n return qs.filter(used_by_email__isnull=not value)\n\n\ndef filter_currency(qs, _, value):\n if not value:\n return qs\n return qs.filter(currency=value)\n\n\ndef _filter_by_price(qs, field, value):\n lookup = {}\n if lte := value.get(\"lte\"):\n lookup[f\"{field}_amount__lte\"] = lte\n if gte := value.get(\"gte\"):\n lookup[f\"{field}_amount__gte\"] = gte\n return qs.filter(**lookup)\n\n\ndef filter_code(qs, _, value):\n if not value:\n return qs\n return qs.filter(code=value)\n\n\ndef filter_created_by_email(qs, _, value):\n if not value:\n return qs\n return qs.filter(created_by_email=value)\n\n\nclass GiftCardFilter(MetadataFilterBase):\n tags = ListObjectTypeFilter(input_class=graphene.String, method=filter_tags_list)\n products = GlobalIDMultipleChoiceFilter(method=filter_products)\n used_by = GlobalIDMultipleChoiceFilter(method=filter_used_by)\n used = django_filters.BooleanFilter(method=filter_gift_card_used)\n currency = django_filters.CharFilter(method=filter_currency)\n current_balance = ObjectTypeFilter(\n input_class=PriceRangeInput, method=\"filter_current_balance\"\n )\n initial_balance = ObjectTypeFilter(\n input_class=PriceRangeInput, method=\"filter_initial_balance\"\n )\n is_active = django_filters.BooleanFilter()\n code = django_filters.CharFilter(method=filter_code)\n created_by_email = django_filters.CharFilter(method=filter_created_by_email)\n\n class Meta:\n model = models.GiftCard\n fields = [\"is_active\"]\n\n def filter_current_balance(self, queryset, name, value):\n check_currency_in_filter_data(self.data)\n return _filter_by_price(queryset, \"current_balance\", value)\n\n def filter_initial_balance(self, queryset, name, value):\n check_currency_in_filter_data(self.data)\n return _filter_by_price(queryset, \"initial_balance\", value)\n\n\ndef check_currency_in_filter_data(filter_data: dict):\n currency = filter_data.get(\"currency\")\n if not currency:\n raise GraphQLError(\n \"You must provide a `currency` filter parameter for filtering by price.\"\n )\n\n\nclass GiftCardFilterInput(FilterInputObjectType):\n class Meta:\n doc_category = DOC_CATEGORY_GIFT_CARDS\n filterset_class = GiftCardFilter\n\n\ndef filter_events_by_type(events: List[models.GiftCardEvent], type_value: str):\n filtered_events = []\n for event in events:\n if event.type == type_value:\n filtered_events.append(event)\n return filtered_events\n\n\ndef filter_events_by_orders(events: List[models.GiftCardEvent], order_ids: List[str]):\n order_pks = _get_order_pks(order_ids)\n\n filtered_events = []\n for event in events:\n if event.order_id in order_pks:\n filtered_events.append(event)\n return filtered_events\n\n\ndef _get_order_pks(order_ids: List[str]):\n _, order_pks = resolve_global_ids_to_primary_keys(order_ids, \"Order\")\n\n pks = []\n old_pks = []\n for pk in order_pks:\n try:\n pks.append(UUID(pk))\n except ValueError:\n old_pks.append(pk)\n\n return order_models.Order.objects.filter(\n Q(id__in=pks) | (Q(use_old_id=True) & Q(number__in=old_pks))\n ).values_list(\"id\", flat=True)\n\n\nclass GiftCardEventFilterInput(BaseInputObjectType):\n type = graphene.Argument(GiftCardEventsEnum)\n orders = NonNullList(graphene.ID)\n\n class Meta:\n doc_category = DOC_CATEGORY_GIFT_CARDS\n\n\ndef filter_gift_card_tag_search(qs, _, value):\n if not value:\n return qs\n return qs.filter(name__ilike=value)\n\n\nclass GiftCardTagFilter(django_filters.FilterSet):\n search = django_filters.CharFilter(method=filter_gift_card_tag_search)\n\n\nclass GiftCardTagFilterInput(FilterInputObjectType):\n class Meta:\n doc_category = DOC_CATEGORY_GIFT_CARDS\n filterset_class = GiftCardTagFilter\n", "path": "saleor/graphql/giftcard/filters.py"}]}
| 2,044 | 215 |
gh_patches_debug_36434
|
rasdani/github-patches
|
git_diff
|
team-ocean__veros-70
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow for custom setup folders
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `veros/cli/veros_copy_setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os
4 import shutil
5 import pkg_resources
6 import functools
7
8 import click
9
10 SETUPDIR = pkg_resources.resource_filename('veros', 'setup')
11 SETUPS = sorted([
12 setup for setup in os.listdir(SETUPDIR)
13 if os.path.isdir(os.path.join(SETUPDIR, setup))
14 and not setup.startswith('_')
15 ])
16 IGNORE_PATTERNS = ['__init__.py', '*.pyc', '__pycache__/']
17
18
19 def copy_setup(setup, to=None):
20 """Copy a standard setup to another directory"""
21 if to is None:
22 to = os.path.join(os.getcwd(), setup)
23
24 parent = os.path.dirname(os.path.realpath(to))
25
26 if not os.path.exists(parent):
27 os.makedirs(parent)
28
29 ignore = shutil.ignore_patterns(*IGNORE_PATTERNS)
30 shutil.copytree(
31 os.path.join(SETUPDIR, setup), to, ignore=ignore
32 )
33
34
35 @click.command('veros-copy-setup')
36 @click.argument('setup', type=click.Choice(SETUPS), metavar='SETUP')
37 @click.option('--to', type=click.Path(dir_okay=False, file_okay=False), required=False,
38 default=None, help='Target directory (default: copy to current working directory)')
39 @functools.wraps(copy_setup)
40 def cli(*args, **kwargs):
41 copy_setup(*args, **kwargs)
42
43
44 if __name__ == '__main__':
45 cli()
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/veros/cli/veros_copy_setup.py b/veros/cli/veros_copy_setup.py
--- a/veros/cli/veros_copy_setup.py
+++ b/veros/cli/veros_copy_setup.py
@@ -7,35 +7,69 @@
import click
-SETUPDIR = pkg_resources.resource_filename('veros', 'setup')
-SETUPS = sorted([
- setup for setup in os.listdir(SETUPDIR)
- if os.path.isdir(os.path.join(SETUPDIR, setup))
- and not setup.startswith('_')
-])
+SETUPDIR_ENVVAR = 'VEROS_SETUP_DIR'
IGNORE_PATTERNS = ['__init__.py', '*.pyc', '__pycache__/']
+SETUPS = {}
+
+setup_dirs = [pkg_resources.resource_filename('veros', 'setup')]
+
+for setup_dir in os.environ.get(SETUPDIR_ENVVAR, '').split(';'):
+ if os.path.isdir(setup_dir):
+ setup_dirs.append(setup_dir)
+
+# populate {setup_name: path} mapping
+for setup_dir in setup_dirs:
+ for setup in os.listdir(setup_dir):
+ setup_path = os.path.join(setup_dir, setup)
+ if not os.path.isdir(setup_path):
+ continue
+ if setup.startswith(('_', '.')):
+ continue
+ SETUPS[setup] = setup_path
+
+SETUP_NAMES = sorted(SETUPS.keys())
def copy_setup(setup, to=None):
- """Copy a standard setup to another directory"""
+ """Copy a standard setup to another directory.
+
+ Argument must be one of: {setups}
+
+ Example:
+
+ $ veros copy-setup global_4deg --to ~/veros-setups/4deg-lowfric
+
+ Further directories containing setup templates can be added to this command
+ via the {setup_envvar} environment variable.
+ """
if to is None:
to = os.path.join(os.getcwd(), setup)
- parent = os.path.dirname(os.path.realpath(to))
+ if os.path.exists(to):
+ raise RuntimeError('Target directory must not exist')
+
+ to_parent = os.path.dirname(os.path.realpath(to))
- if not os.path.exists(parent):
- os.makedirs(parent)
+ if not os.path.exists(to_parent):
+ os.makedirs(to_parent)
ignore = shutil.ignore_patterns(*IGNORE_PATTERNS)
shutil.copytree(
- os.path.join(SETUPDIR, setup), to, ignore=ignore
+ SETUPS[setup], to, ignore=ignore
)
+copy_setup.__doc__ = copy_setup.__doc__.format(
+ setups=', '.join(SETUP_NAMES), setup_envvar=SETUPDIR_ENVVAR
+)
+
+
@click.command('veros-copy-setup')
[email protected]('setup', type=click.Choice(SETUPS), metavar='SETUP')
[email protected]('--to', type=click.Path(dir_okay=False, file_okay=False), required=False,
- default=None, help='Target directory (default: copy to current working directory)')
[email protected]('setup', type=click.Choice(SETUP_NAMES), metavar='SETUP')
[email protected]('--to', required=False, default=None,
+ type=click.Path(dir_okay=False, file_okay=False, writable=True),
+ help=('Target directory, must not exist '
+ '(default: copy to current working directory)'))
@functools.wraps(copy_setup)
def cli(*args, **kwargs):
copy_setup(*args, **kwargs)
|
{"golden_diff": "diff --git a/veros/cli/veros_copy_setup.py b/veros/cli/veros_copy_setup.py\n--- a/veros/cli/veros_copy_setup.py\n+++ b/veros/cli/veros_copy_setup.py\n@@ -7,35 +7,69 @@\n \n import click\n \n-SETUPDIR = pkg_resources.resource_filename('veros', 'setup')\n-SETUPS = sorted([\n- setup for setup in os.listdir(SETUPDIR)\n- if os.path.isdir(os.path.join(SETUPDIR, setup))\n- and not setup.startswith('_')\n-])\n+SETUPDIR_ENVVAR = 'VEROS_SETUP_DIR'\n IGNORE_PATTERNS = ['__init__.py', '*.pyc', '__pycache__/']\n+SETUPS = {}\n+\n+setup_dirs = [pkg_resources.resource_filename('veros', 'setup')]\n+\n+for setup_dir in os.environ.get(SETUPDIR_ENVVAR, '').split(';'):\n+ if os.path.isdir(setup_dir):\n+ setup_dirs.append(setup_dir)\n+\n+# populate {setup_name: path} mapping\n+for setup_dir in setup_dirs:\n+ for setup in os.listdir(setup_dir):\n+ setup_path = os.path.join(setup_dir, setup)\n+ if not os.path.isdir(setup_path):\n+ continue\n+ if setup.startswith(('_', '.')):\n+ continue\n+ SETUPS[setup] = setup_path\n+\n+SETUP_NAMES = sorted(SETUPS.keys())\n \n \n def copy_setup(setup, to=None):\n- \"\"\"Copy a standard setup to another directory\"\"\"\n+ \"\"\"Copy a standard setup to another directory.\n+\n+ Argument must be one of: {setups}\n+\n+ Example:\n+\n+ $ veros copy-setup global_4deg --to ~/veros-setups/4deg-lowfric\n+\n+ Further directories containing setup templates can be added to this command\n+ via the {setup_envvar} environment variable.\n+ \"\"\"\n if to is None:\n to = os.path.join(os.getcwd(), setup)\n \n- parent = os.path.dirname(os.path.realpath(to))\n+ if os.path.exists(to):\n+ raise RuntimeError('Target directory must not exist')\n+\n+ to_parent = os.path.dirname(os.path.realpath(to))\n \n- if not os.path.exists(parent):\n- os.makedirs(parent)\n+ if not os.path.exists(to_parent):\n+ os.makedirs(to_parent)\n \n ignore = shutil.ignore_patterns(*IGNORE_PATTERNS)\n shutil.copytree(\n- os.path.join(SETUPDIR, setup), to, ignore=ignore\n+ SETUPS[setup], to, ignore=ignore\n )\n \n \n+copy_setup.__doc__ = copy_setup.__doc__.format(\n+ setups=', '.join(SETUP_NAMES), setup_envvar=SETUPDIR_ENVVAR\n+)\n+\n+\n @click.command('veros-copy-setup')\[email protected]('setup', type=click.Choice(SETUPS), metavar='SETUP')\[email protected]('--to', type=click.Path(dir_okay=False, file_okay=False), required=False,\n- default=None, help='Target directory (default: copy to current working directory)')\[email protected]('setup', type=click.Choice(SETUP_NAMES), metavar='SETUP')\[email protected]('--to', required=False, default=None,\n+ type=click.Path(dir_okay=False, file_okay=False, writable=True),\n+ help=('Target directory, must not exist '\n+ '(default: copy to current working directory)'))\n @functools.wraps(copy_setup)\n def cli(*args, **kwargs):\n copy_setup(*args, **kwargs)\n", "issue": "Allow for custom setup folders\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport shutil\nimport pkg_resources\nimport functools\n\nimport click\n\nSETUPDIR = pkg_resources.resource_filename('veros', 'setup')\nSETUPS = sorted([\n setup for setup in os.listdir(SETUPDIR)\n if os.path.isdir(os.path.join(SETUPDIR, setup))\n and not setup.startswith('_')\n])\nIGNORE_PATTERNS = ['__init__.py', '*.pyc', '__pycache__/']\n\n\ndef copy_setup(setup, to=None):\n \"\"\"Copy a standard setup to another directory\"\"\"\n if to is None:\n to = os.path.join(os.getcwd(), setup)\n\n parent = os.path.dirname(os.path.realpath(to))\n\n if not os.path.exists(parent):\n os.makedirs(parent)\n\n ignore = shutil.ignore_patterns(*IGNORE_PATTERNS)\n shutil.copytree(\n os.path.join(SETUPDIR, setup), to, ignore=ignore\n )\n\n\[email protected]('veros-copy-setup')\[email protected]('setup', type=click.Choice(SETUPS), metavar='SETUP')\[email protected]('--to', type=click.Path(dir_okay=False, file_okay=False), required=False,\n default=None, help='Target directory (default: copy to current working directory)')\[email protected](copy_setup)\ndef cli(*args, **kwargs):\n copy_setup(*args, **kwargs)\n\n\nif __name__ == '__main__':\n cli()\n", "path": "veros/cli/veros_copy_setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport shutil\nimport pkg_resources\nimport functools\n\nimport click\n\nSETUPDIR_ENVVAR = 'VEROS_SETUP_DIR'\nIGNORE_PATTERNS = ['__init__.py', '*.pyc', '__pycache__/']\nSETUPS = {}\n\nsetup_dirs = [pkg_resources.resource_filename('veros', 'setup')]\n\nfor setup_dir in os.environ.get(SETUPDIR_ENVVAR, '').split(';'):\n if os.path.isdir(setup_dir):\n setup_dirs.append(setup_dir)\n\n# populate {setup_name: path} mapping\nfor setup_dir in setup_dirs:\n for setup in os.listdir(setup_dir):\n setup_path = os.path.join(setup_dir, setup)\n if not os.path.isdir(setup_path):\n continue\n if setup.startswith(('_', '.')):\n continue\n SETUPS[setup] = setup_path\n\nSETUP_NAMES = sorted(SETUPS.keys())\n\n\ndef copy_setup(setup, to=None):\n \"\"\"Copy a standard setup to another directory.\n\n Argument must be one of: {setups}\n\n Example:\n\n $ veros copy-setup global_4deg --to ~/veros-setups/4deg-lowfric\n\n Further directories containing setup templates can be added to this command\n via the {setup_envvar} environment variable.\n \"\"\"\n if to is None:\n to = os.path.join(os.getcwd(), setup)\n\n if os.path.exists(to):\n raise RuntimeError('Target directory must not exist')\n\n to_parent = os.path.dirname(os.path.realpath(to))\n\n if not os.path.exists(to_parent):\n os.makedirs(to_parent)\n\n ignore = shutil.ignore_patterns(*IGNORE_PATTERNS)\n shutil.copytree(\n SETUPS[setup], to, ignore=ignore\n )\n\n\ncopy_setup.__doc__ = copy_setup.__doc__.format(\n setups=', '.join(SETUP_NAMES), setup_envvar=SETUPDIR_ENVVAR\n)\n\n\[email protected]('veros-copy-setup')\[email protected]('setup', type=click.Choice(SETUP_NAMES), metavar='SETUP')\[email protected]('--to', required=False, default=None,\n type=click.Path(dir_okay=False, file_okay=False, writable=True),\n help=('Target directory, must not exist '\n '(default: copy to current working directory)'))\[email protected](copy_setup)\ndef cli(*args, **kwargs):\n copy_setup(*args, **kwargs)\n\n\nif __name__ == '__main__':\n cli()\n", "path": "veros/cli/veros_copy_setup.py"}]}
| 663 | 786 |
gh_patches_debug_3767
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-321
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
More menu navigation cleanups
<img width="834" alt="screen shot 2016-06-22 at 00 00 38" src="https://cloud.githubusercontent.com/assets/178003/16247917/6d784382-380c-11e6-91f6-29423d263b8c.png">
- [ ] Make project icon and name clickable - click should take you to e.g. /en/qgis/
- [ ] Changelogs -> Changelog
- [ ] Remove version entries item
- [ ] Remove version thumbnails item
- [ ] Remove add entry item
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django_project/base/templatetags/custom_markup.py`
Content:
```
1 import markdown
2 from django import template
3 from django.template.defaultfilters import stringfilter
4 from django.utils.encoding import force_unicode
5 from django.utils.safestring import mark_safe
6
7 register = template.Library()
8
9
10 @register.filter(name='base_markdown', is_safe=True)
11 @stringfilter
12 def base_markdown(value):
13 extensions = ["nl2br", ]
14
15 return mark_safe(markdown.markdown(force_unicode(value),
16 extensions,
17 safe_mode=True,
18 enable_attributes=False))
19
20
21 @register.filter(name='is_gif', is_safe=True)
22 @stringfilter
23 def is_gif(value):
24 return value[-4:] == '.gif'
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django_project/base/templatetags/custom_markup.py b/django_project/base/templatetags/custom_markup.py
--- a/django_project/base/templatetags/custom_markup.py
+++ b/django_project/base/templatetags/custom_markup.py
@@ -22,3 +22,17 @@
@stringfilter
def is_gif(value):
return value[-4:] == '.gif'
+
+
[email protected]_tag('button_span.html', takes_context=True)
+def show_button_icon(context, value):
+
+ context_icon = {
+ 'add': 'glyphicon glyphicon-asterisk',
+ 'update': 'glyphicon glyphicon-pencil',
+ 'delete': 'glyphicon glyphicon-minus'
+ }
+
+ return {
+ 'button_icon': context_icon[value]
+ }
|
{"golden_diff": "diff --git a/django_project/base/templatetags/custom_markup.py b/django_project/base/templatetags/custom_markup.py\n--- a/django_project/base/templatetags/custom_markup.py\n+++ b/django_project/base/templatetags/custom_markup.py\n@@ -22,3 +22,17 @@\n @stringfilter\n def is_gif(value):\n return value[-4:] == '.gif'\n+\n+\[email protected]_tag('button_span.html', takes_context=True)\n+def show_button_icon(context, value):\n+\n+ context_icon = {\n+ 'add': 'glyphicon glyphicon-asterisk',\n+ 'update': 'glyphicon glyphicon-pencil',\n+ 'delete': 'glyphicon glyphicon-minus'\n+ }\n+\n+ return {\n+ 'button_icon': context_icon[value]\n+ }\n", "issue": "More menu navigation cleanups\n<img width=\"834\" alt=\"screen shot 2016-06-22 at 00 00 38\" src=\"https://cloud.githubusercontent.com/assets/178003/16247917/6d784382-380c-11e6-91f6-29423d263b8c.png\">\n- [ ] Make project icon and name clickable - click should take you to e.g. /en/qgis/\n- [ ] Changelogs -> Changelog\n- [ ] Remove version entries item\n- [ ] Remove version thumbnails item\n- [ ] Remove add entry item\n\n", "before_files": [{"content": "import markdown\nfrom django import template\nfrom django.template.defaultfilters import stringfilter\nfrom django.utils.encoding import force_unicode\nfrom django.utils.safestring import mark_safe\n\nregister = template.Library()\n\n\[email protected](name='base_markdown', is_safe=True)\n@stringfilter\ndef base_markdown(value):\n extensions = [\"nl2br\", ]\n\n return mark_safe(markdown.markdown(force_unicode(value),\n extensions,\n safe_mode=True,\n enable_attributes=False))\n\n\[email protected](name='is_gif', is_safe=True)\n@stringfilter\ndef is_gif(value):\n return value[-4:] == '.gif'\n", "path": "django_project/base/templatetags/custom_markup.py"}], "after_files": [{"content": "import markdown\nfrom django import template\nfrom django.template.defaultfilters import stringfilter\nfrom django.utils.encoding import force_unicode\nfrom django.utils.safestring import mark_safe\n\nregister = template.Library()\n\n\[email protected](name='base_markdown', is_safe=True)\n@stringfilter\ndef base_markdown(value):\n extensions = [\"nl2br\", ]\n\n return mark_safe(markdown.markdown(force_unicode(value),\n extensions,\n safe_mode=True,\n enable_attributes=False))\n\n\[email protected](name='is_gif', is_safe=True)\n@stringfilter\ndef is_gif(value):\n return value[-4:] == '.gif'\n\n\[email protected]_tag('button_span.html', takes_context=True)\ndef show_button_icon(context, value):\n\n context_icon = {\n 'add': 'glyphicon glyphicon-asterisk',\n 'update': 'glyphicon glyphicon-pencil',\n 'delete': 'glyphicon glyphicon-minus'\n }\n\n return {\n 'button_icon': context_icon[value]\n }\n", "path": "django_project/base/templatetags/custom_markup.py"}]}
| 601 | 179 |
gh_patches_debug_30508
|
rasdani/github-patches
|
git_diff
|
vas3k__vas3k.club-709
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Баг: В посте ссылке, если ссылка на ютуб плейлист то он ресолвиться в первое видео, и теряеться информация о том что это плейлист
Пример https://vas3k.club/link/11936/ линк и эмбедд ведет на https://www.youtube.com/watch?v=CC71WyVLnnk вместо ожидаемого https://www.youtube.com/watch?v=CC71WyVLnnk&list=PLXOrZPAO2Ui021R3sKD5z0n9Qzeix9Kbj&index=2
Аналогично при вставке ссылки на плейлист в тело поста, она ресолвится в первое видео
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `common/regexp.py`
Content:
```
1 import re
2
3 USERNAME_RE = re.compile(r"(?:\s|\n|^)@([A-Za-z0-9_-]{3,})")
4 IMAGE_RE = re.compile(r"(http(s?):)([/|.|\w|\s|-])*\.(?:jpg|jpeg|gif|png)")
5 VIDEO_RE = re.compile(r"(http(s?):)([/|.|\w|\s|-])*\.(?:mov|mp4)")
6 YOUTUBE_RE = re.compile(
7 r"http(?:s?):\/\/(?:www\.)?youtu(?:be\.com\/watch\?v=|\.be\/)([\w\-\_]*)(&(amp;)?[\w\?=]*)?"
8 )
9 TWITTER_RE = re.compile(r"(https?:\/\/twitter.com\/[a-zA-Z0-9_]+\/status\/[\d]+)")
10 FAVICON_RE = re.compile(r"(http(s?):)([/|.|\w|\s|-])*\.(?:jpg|jpeg|gif|png|ico)")
11
```
Path: `common/markdown/club_renderer.py`
Content:
```
1 import html
2 import mistune
3 from urllib.parse import unquote
4 from mistune import escape_html
5 from slugify import slugify
6
7 from common.regexp import IMAGE_RE, VIDEO_RE, YOUTUBE_RE, TWITTER_RE, USERNAME_RE
8
9 IMAGE_CSS_CLASSES = {
10 "-": "text-body-image-full"
11 }
12
13
14 class ClubRenderer(mistune.HTMLRenderer):
15 def text(self, text):
16 text = escape_html(text)
17 text = USERNAME_RE.sub(r' <a href="/user/\1/">@\1</a>', text)
18 return text
19
20 def paragraph(self, text):
21 text = text.replace("\n", "<br>\n") # Mistune 2.0 broke newlines, let's hack it =/
22 return f"<p>{text}</p>\n"
23
24 def heading(self, text, level):
25 tag = f"h{level}"
26 anchor = slugify(text[:24])
27 return f"<{tag} id=\"{anchor}\"><a href=\"#{anchor}\">{text}</a></{tag}>\n"
28
29 def link(self, link, text=None, title=None):
30 if not text and not title:
31 # it's a pure link (without link tag) and we can try to parse it
32 embed = self.embed(link, text or "", title or "")
33 if embed:
34 return embed
35
36 if text is None:
37 text = link
38
39 # here's some magic of unescape->unquote->escape
40 # to fix cyrillic (and other non-latin) wikipedia URLs
41 return f'<a href="{self._safe_url(link)}">{html.escape(unquote(html.unescape(text or link)))}</a>'
42
43 def image(self, src, alt="", title=None):
44 embed = self.embed(src, alt, title)
45 if embed:
46 return embed
47
48 # users can try to "hack" our parser by using non-image urls
49 # so, if its not an image or video, display it as a link to avoid auto-loading
50 return f'<a href="{escape_html(src)}">{escape_html(src)}</a>'
51
52 def embed(self, src, alt="", title=None):
53 if IMAGE_RE.match(src):
54 return self.simple_image(src, alt, title)
55
56 if YOUTUBE_RE.match(src):
57 return self.youtube(src, alt, title)
58
59 if VIDEO_RE.match(src):
60 return self.video(src, alt, title)
61
62 if TWITTER_RE.match(src):
63 return self.tweet(src, alt, title)
64
65 return None
66
67 def simple_image(self, src, alt="", title=None):
68 css_classes = ""
69 title = title or alt
70 if title in IMAGE_CSS_CLASSES:
71 css_classes = IMAGE_CSS_CLASSES[title]
72
73 image_tag = f'<img loading="lazy" src="{escape_html(src)}" alt="{escape_html(title)}">'
74 caption = f"<figcaption>{escape_html(title)}</figcaption>" if title else ""
75 return f'<figure class="{css_classes}">{image_tag}{caption}</figure>'
76
77 def youtube(self, src, alt="", title=None):
78 youtube_match = YOUTUBE_RE.match(src)
79 video_tag = (
80 f'<span class="ratio-16-9">'
81 f'<iframe loading="lazy" src="https://www.youtube.com/embed/{escape_html(youtube_match.group(1))}'
82 f'?autoplay=0&controls=1&showinfo=1&vq=hd1080"'
83 f'allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; fullscreen"'
84 f'allowfullscreen></iframe>'
85 f"</span>"
86 )
87 caption = f"<figcaption>{escape_html(title)}</figcaption>" if title else ""
88 return f"<figure>{video_tag}{caption}</figure>"
89
90 def video(self, src, alt="", title=None):
91 video_tag = (
92 f'<video src="{escape_html(src)}" controls autoplay loop muted playsinline>{escape_html(alt)}</video>'
93 )
94 caption = f"<figcaption>{escape_html(title)}</figcaption>" if title else ""
95 return f"<figure>{video_tag}{caption}</figure>"
96
97 def tweet(self, src, alt="", title=None):
98 tweet_match = TWITTER_RE.match(src)
99 twitter_tag = f'<blockquote class="twitter-tweet" tw-align-center>' \
100 f'<a href="{tweet_match.group(1)}"></a></blockquote><br>' \
101 f'<a href="{src}" target="_blank">{src}</a>'
102 return twitter_tag
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/common/markdown/club_renderer.py b/common/markdown/club_renderer.py
--- a/common/markdown/club_renderer.py
+++ b/common/markdown/club_renderer.py
@@ -76,10 +76,13 @@
def youtube(self, src, alt="", title=None):
youtube_match = YOUTUBE_RE.match(src)
+ playlist = ""
+ if youtube_match.group(2):
+ playlist = f"list={escape_html(youtube_match.group(2))}&listType=playlist&"
video_tag = (
f'<span class="ratio-16-9">'
f'<iframe loading="lazy" src="https://www.youtube.com/embed/{escape_html(youtube_match.group(1))}'
- f'?autoplay=0&controls=1&showinfo=1&vq=hd1080"'
+ f'?{playlist}autoplay=0&controls=1&showinfo=1&vq=hd1080"'
f'allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; fullscreen"'
f'allowfullscreen></iframe>'
f"</span>"
diff --git a/common/regexp.py b/common/regexp.py
--- a/common/regexp.py
+++ b/common/regexp.py
@@ -4,7 +4,7 @@
IMAGE_RE = re.compile(r"(http(s?):)([/|.|\w|\s|-])*\.(?:jpg|jpeg|gif|png)")
VIDEO_RE = re.compile(r"(http(s?):)([/|.|\w|\s|-])*\.(?:mov|mp4)")
YOUTUBE_RE = re.compile(
- r"http(?:s?):\/\/(?:www\.)?youtu(?:be\.com\/watch\?v=|\.be\/)([\w\-\_]*)(&(amp;)?[\w\?=]*)?"
+ r"http(?:s?):\/\/(?:www\.)?youtu(?:be\.com\/watch\?v=|\.be\/)([\w\-\_]*)(?:.*list=(PL[\w\-\_]*))?"
)
TWITTER_RE = re.compile(r"(https?:\/\/twitter.com\/[a-zA-Z0-9_]+\/status\/[\d]+)")
FAVICON_RE = re.compile(r"(http(s?):)([/|.|\w|\s|-])*\.(?:jpg|jpeg|gif|png|ico)")
|
{"golden_diff": "diff --git a/common/markdown/club_renderer.py b/common/markdown/club_renderer.py\n--- a/common/markdown/club_renderer.py\n+++ b/common/markdown/club_renderer.py\n@@ -76,10 +76,13 @@\n \n def youtube(self, src, alt=\"\", title=None):\n youtube_match = YOUTUBE_RE.match(src)\n+ playlist = \"\"\n+ if youtube_match.group(2):\n+ playlist = f\"list={escape_html(youtube_match.group(2))}&listType=playlist&\"\n video_tag = (\n f'<span class=\"ratio-16-9\">'\n f'<iframe loading=\"lazy\" src=\"https://www.youtube.com/embed/{escape_html(youtube_match.group(1))}'\n- f'?autoplay=0&controls=1&showinfo=1&vq=hd1080\"'\n+ f'?{playlist}autoplay=0&controls=1&showinfo=1&vq=hd1080\"'\n f'allow=\"accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; fullscreen\"'\n f'allowfullscreen></iframe>'\n f\"</span>\"\ndiff --git a/common/regexp.py b/common/regexp.py\n--- a/common/regexp.py\n+++ b/common/regexp.py\n@@ -4,7 +4,7 @@\n IMAGE_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:jpg|jpeg|gif|png)\")\n VIDEO_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:mov|mp4)\")\n YOUTUBE_RE = re.compile(\n- r\"http(?:s?):\\/\\/(?:www\\.)?youtu(?:be\\.com\\/watch\\?v=|\\.be\\/)([\\w\\-\\_]*)(&(amp;)?\u200c\u200b[\\w\\?\u200c\u200b=]*)?\"\n+ r\"http(?:s?):\\/\\/(?:www\\.)?youtu(?:be\\.com\\/watch\\?v=|\\.be\\/)([\\w\\-\\_]*)(?:.*list=(PL[\\w\\-\\_]*))?\"\n )\n TWITTER_RE = re.compile(r\"(https?:\\/\\/twitter.com\\/[a-zA-Z0-9_]+\\/status\\/[\\d]+)\")\n FAVICON_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:jpg|jpeg|gif|png|ico)\")\n", "issue": "\u0411\u0430\u0433: \u0412 \u043f\u043e\u0441\u0442\u0435 \u0441\u0441\u044b\u043b\u043a\u0435, \u0435\u0441\u043b\u0438 \u0441\u0441\u044b\u043b\u043a\u0430 \u043d\u0430 \u044e\u0442\u0443\u0431 \u043f\u043b\u0435\u0439\u043b\u0438\u0441\u0442 \u0442\u043e \u043e\u043d \u0440\u0435\u0441\u043e\u043b\u0432\u0438\u0442\u044c\u0441\u044f \u0432 \u043f\u0435\u0440\u0432\u043e\u0435 \u0432\u0438\u0434\u0435\u043e, \u0438 \u0442\u0435\u0440\u044f\u0435\u0442\u044c\u0441\u044f \u0438\u043d\u0444\u043e\u0440\u043c\u0430\u0446\u0438\u044f \u043e \u0442\u043e\u043c \u0447\u0442\u043e \u044d\u0442\u043e \u043f\u043b\u0435\u0439\u043b\u0438\u0441\u0442 \n\u041f\u0440\u0438\u043c\u0435\u0440 https://vas3k.club/link/11936/ \u043b\u0438\u043d\u043a \u0438 \u044d\u043c\u0431\u0435\u0434\u0434 \u0432\u0435\u0434\u0435\u0442 \u043d\u0430 https://www.youtube.com/watch?v=CC71WyVLnnk \u0432\u043c\u0435\u0441\u0442\u043e \u043e\u0436\u0438\u0434\u0430\u0435\u043c\u043e\u0433\u043e https://www.youtube.com/watch?v=CC71WyVLnnk&list=PLXOrZPAO2Ui021R3sKD5z0n9Qzeix9Kbj&index=2 \r\n\r\n\u0410\u043d\u0430\u043b\u043e\u0433\u0438\u0447\u043d\u043e \u043f\u0440\u0438 \u0432\u0441\u0442\u0430\u0432\u043a\u0435 \u0441\u0441\u044b\u043b\u043a\u0438 \u043d\u0430 \u043f\u043b\u0435\u0439\u043b\u0438\u0441\u0442 \u0432 \u0442\u0435\u043b\u043e \u043f\u043e\u0441\u0442\u0430, \u043e\u043d\u0430 \u0440\u0435\u0441\u043e\u043b\u0432\u0438\u0442\u0441\u044f \u0432 \u043f\u0435\u0440\u0432\u043e\u0435 \u0432\u0438\u0434\u0435\u043e\n", "before_files": [{"content": "import re\n\nUSERNAME_RE = re.compile(r\"(?:\\s|\\n|^)@([A-Za-z0-9_-]{3,})\")\nIMAGE_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:jpg|jpeg|gif|png)\")\nVIDEO_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:mov|mp4)\")\nYOUTUBE_RE = re.compile(\n r\"http(?:s?):\\/\\/(?:www\\.)?youtu(?:be\\.com\\/watch\\?v=|\\.be\\/)([\\w\\-\\_]*)(&(amp;)?\u200c\u200b[\\w\\?\u200c\u200b=]*)?\"\n)\nTWITTER_RE = re.compile(r\"(https?:\\/\\/twitter.com\\/[a-zA-Z0-9_]+\\/status\\/[\\d]+)\")\nFAVICON_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:jpg|jpeg|gif|png|ico)\")\n", "path": "common/regexp.py"}, {"content": "import html\nimport mistune\nfrom urllib.parse import unquote\nfrom mistune import escape_html\nfrom slugify import slugify\n\nfrom common.regexp import IMAGE_RE, VIDEO_RE, YOUTUBE_RE, TWITTER_RE, USERNAME_RE\n\nIMAGE_CSS_CLASSES = {\n \"-\": \"text-body-image-full\"\n}\n\n\nclass ClubRenderer(mistune.HTMLRenderer):\n def text(self, text):\n text = escape_html(text)\n text = USERNAME_RE.sub(r' <a href=\"/user/\\1/\">@\\1</a>', text)\n return text\n\n def paragraph(self, text):\n text = text.replace(\"\\n\", \"<br>\\n\") # Mistune 2.0 broke newlines, let's hack it =/\n return f\"<p>{text}</p>\\n\"\n\n def heading(self, text, level):\n tag = f\"h{level}\"\n anchor = slugify(text[:24])\n return f\"<{tag} id=\\\"{anchor}\\\"><a href=\\\"#{anchor}\\\">{text}</a></{tag}>\\n\"\n\n def link(self, link, text=None, title=None):\n if not text and not title:\n # it's a pure link (without link tag) and we can try to parse it\n embed = self.embed(link, text or \"\", title or \"\")\n if embed:\n return embed\n\n if text is None:\n text = link\n\n # here's some magic of unescape->unquote->escape\n # to fix cyrillic (and other non-latin) wikipedia URLs\n return f'<a href=\"{self._safe_url(link)}\">{html.escape(unquote(html.unescape(text or link)))}</a>'\n\n def image(self, src, alt=\"\", title=None):\n embed = self.embed(src, alt, title)\n if embed:\n return embed\n\n # users can try to \"hack\" our parser by using non-image urls\n # so, if its not an image or video, display it as a link to avoid auto-loading\n return f'<a href=\"{escape_html(src)}\">{escape_html(src)}</a>'\n\n def embed(self, src, alt=\"\", title=None):\n if IMAGE_RE.match(src):\n return self.simple_image(src, alt, title)\n\n if YOUTUBE_RE.match(src):\n return self.youtube(src, alt, title)\n\n if VIDEO_RE.match(src):\n return self.video(src, alt, title)\n\n if TWITTER_RE.match(src):\n return self.tweet(src, alt, title)\n\n return None\n\n def simple_image(self, src, alt=\"\", title=None):\n css_classes = \"\"\n title = title or alt\n if title in IMAGE_CSS_CLASSES:\n css_classes = IMAGE_CSS_CLASSES[title]\n\n image_tag = f'<img loading=\"lazy\" src=\"{escape_html(src)}\" alt=\"{escape_html(title)}\">'\n caption = f\"<figcaption>{escape_html(title)}</figcaption>\" if title else \"\"\n return f'<figure class=\"{css_classes}\">{image_tag}{caption}</figure>'\n\n def youtube(self, src, alt=\"\", title=None):\n youtube_match = YOUTUBE_RE.match(src)\n video_tag = (\n f'<span class=\"ratio-16-9\">'\n f'<iframe loading=\"lazy\" src=\"https://www.youtube.com/embed/{escape_html(youtube_match.group(1))}'\n f'?autoplay=0&controls=1&showinfo=1&vq=hd1080\"'\n f'allow=\"accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; fullscreen\"'\n f'allowfullscreen></iframe>'\n f\"</span>\"\n )\n caption = f\"<figcaption>{escape_html(title)}</figcaption>\" if title else \"\"\n return f\"<figure>{video_tag}{caption}</figure>\"\n\n def video(self, src, alt=\"\", title=None):\n video_tag = (\n f'<video src=\"{escape_html(src)}\" controls autoplay loop muted playsinline>{escape_html(alt)}</video>'\n )\n caption = f\"<figcaption>{escape_html(title)}</figcaption>\" if title else \"\"\n return f\"<figure>{video_tag}{caption}</figure>\"\n\n def tweet(self, src, alt=\"\", title=None):\n tweet_match = TWITTER_RE.match(src)\n twitter_tag = f'<blockquote class=\"twitter-tweet\" tw-align-center>' \\\n f'<a href=\"{tweet_match.group(1)}\"></a></blockquote><br>' \\\n f'<a href=\"{src}\" target=\"_blank\">{src}</a>'\n return twitter_tag\n", "path": "common/markdown/club_renderer.py"}], "after_files": [{"content": "import re\n\nUSERNAME_RE = re.compile(r\"(?:\\s|\\n|^)@([A-Za-z0-9_-]{3,})\")\nIMAGE_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:jpg|jpeg|gif|png)\")\nVIDEO_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:mov|mp4)\")\nYOUTUBE_RE = re.compile(\n r\"http(?:s?):\\/\\/(?:www\\.)?youtu(?:be\\.com\\/watch\\?v=|\\.be\\/)([\\w\\-\\_]*)(?:.*list=(PL[\\w\\-\\_]*))?\"\n)\nTWITTER_RE = re.compile(r\"(https?:\\/\\/twitter.com\\/[a-zA-Z0-9_]+\\/status\\/[\\d]+)\")\nFAVICON_RE = re.compile(r\"(http(s?):)([/|.|\\w|\\s|-])*\\.(?:jpg|jpeg|gif|png|ico)\")\n", "path": "common/regexp.py"}, {"content": "import html\nimport mistune\nfrom urllib.parse import unquote\nfrom mistune import escape_html\nfrom slugify import slugify\n\nfrom common.regexp import IMAGE_RE, VIDEO_RE, YOUTUBE_RE, TWITTER_RE, USERNAME_RE\n\nIMAGE_CSS_CLASSES = {\n \"-\": \"text-body-image-full\"\n}\n\n\nclass ClubRenderer(mistune.HTMLRenderer):\n def text(self, text):\n text = escape_html(text)\n text = USERNAME_RE.sub(r' <a href=\"/user/\\1/\">@\\1</a>', text)\n return text\n\n def paragraph(self, text):\n text = text.replace(\"\\n\", \"<br>\\n\") # Mistune 2.0 broke newlines, let's hack it =/\n return f\"<p>{text}</p>\\n\"\n\n def heading(self, text, level):\n tag = f\"h{level}\"\n anchor = slugify(text[:24])\n return f\"<{tag} id=\\\"{anchor}\\\"><a href=\\\"#{anchor}\\\">{text}</a></{tag}>\\n\"\n\n def link(self, link, text=None, title=None):\n if not text and not title:\n # it's a pure link (without link tag) and we can try to parse it\n embed = self.embed(link, text or \"\", title or \"\")\n if embed:\n return embed\n\n if text is None:\n text = link\n\n # here's some magic of unescape->unquote->escape\n # to fix cyrillic (and other non-latin) wikipedia URLs\n return f'<a href=\"{self._safe_url(link)}\">{html.escape(unquote(html.unescape(text or link)))}</a>'\n\n def image(self, src, alt=\"\", title=None):\n embed = self.embed(src, alt, title)\n if embed:\n return embed\n\n # users can try to \"hack\" our parser by using non-image urls\n # so, if its not an image or video, display it as a link to avoid auto-loading\n return f'<a href=\"{escape_html(src)}\">{escape_html(src)}</a>'\n\n def embed(self, src, alt=\"\", title=None):\n if IMAGE_RE.match(src):\n return self.simple_image(src, alt, title)\n\n if YOUTUBE_RE.match(src):\n return self.youtube(src, alt, title)\n\n if VIDEO_RE.match(src):\n return self.video(src, alt, title)\n\n if TWITTER_RE.match(src):\n return self.tweet(src, alt, title)\n\n return None\n\n def simple_image(self, src, alt=\"\", title=None):\n css_classes = \"\"\n title = title or alt\n if title in IMAGE_CSS_CLASSES:\n css_classes = IMAGE_CSS_CLASSES[title]\n\n image_tag = f'<img loading=\"lazy\" src=\"{escape_html(src)}\" alt=\"{escape_html(title)}\">'\n caption = f\"<figcaption>{escape_html(title)}</figcaption>\" if title else \"\"\n return f'<figure class=\"{css_classes}\">{image_tag}{caption}</figure>'\n\n def youtube(self, src, alt=\"\", title=None):\n youtube_match = YOUTUBE_RE.match(src)\n playlist = \"\"\n if youtube_match.group(2):\n playlist = f\"list={escape_html(youtube_match.group(2))}&listType=playlist&\"\n video_tag = (\n f'<span class=\"ratio-16-9\">'\n f'<iframe loading=\"lazy\" src=\"https://www.youtube.com/embed/{escape_html(youtube_match.group(1))}'\n f'?{playlist}autoplay=0&controls=1&showinfo=1&vq=hd1080\"'\n f'allow=\"accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; fullscreen\"'\n f'allowfullscreen></iframe>'\n f\"</span>\"\n )\n caption = f\"<figcaption>{escape_html(title)}</figcaption>\" if title else \"\"\n return f\"<figure>{video_tag}{caption}</figure>\"\n\n def video(self, src, alt=\"\", title=None):\n video_tag = (\n f'<video src=\"{escape_html(src)}\" controls autoplay loop muted playsinline>{escape_html(alt)}</video>'\n )\n caption = f\"<figcaption>{escape_html(title)}</figcaption>\" if title else \"\"\n return f\"<figure>{video_tag}{caption}</figure>\"\n\n def tweet(self, src, alt=\"\", title=None):\n tweet_match = TWITTER_RE.match(src)\n twitter_tag = f'<blockquote class=\"twitter-tweet\" tw-align-center>' \\\n f'<a href=\"{tweet_match.group(1)}\"></a></blockquote><br>' \\\n f'<a href=\"{src}\" target=\"_blank\">{src}</a>'\n return twitter_tag\n", "path": "common/markdown/club_renderer.py"}]}
| 1,857 | 528 |
gh_patches_debug_67495
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-605
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RayWorker import error
When import `vllm` I got following error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/code/vllm/vllm/__init__.py", line 4, in <module>
from vllm.engine.async_llm_engine import AsyncLLMEngine
File "/code/vllm/vllm/engine/async_llm_engine.py", line 7, in <module>
from vllm.engine.llm_engine import LLMEngine
File "/code/vllm/vllm/engine/llm_engine.py", line 9, in <module>
from vllm.engine.ray_utils import initialize_cluster, ray, RayWorker
ImportError: cannot import name 'RayWorker' from 'vllm.engine.ray_utils'
```
It seems `ray` requires `pandas` I haven't installed it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vllm/engine/ray_utils.py`
Content:
```
1 import socket
2 from typing import Optional, Tuple, TYPE_CHECKING
3
4 from vllm.config import ParallelConfig
5
6 try:
7 import ray
8 from ray.air.util.torch_dist import TorchDistributedWorker
9
10 class RayWorker(TorchDistributedWorker):
11 """Ray wrapper for vllm.worker.Worker, allowing Worker to be
12 lazliy initialized after Ray sets CUDA_VISIBLE_DEVICES."""
13
14 def __init__(self) -> None:
15 self.worker = None
16
17 def init_worker(self, worker_init_fn):
18 self.worker = worker_init_fn()
19
20 def __getattr__(self, name):
21 return getattr(self.worker, name)
22
23 def execute_method(self, method, *args, **kwargs):
24 executor = getattr(self, method)
25 return executor(*args, **kwargs)
26
27 except ImportError:
28 ray = None
29 TorchDistributedWorker = None
30
31 if TYPE_CHECKING:
32 from ray.util.placement_group import PlacementGroup
33
34
35 def get_open_port():
36 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
37 s.bind(("", 0))
38 return s.getsockname()[1]
39
40
41 def initialize_cluster(
42 parallel_config: ParallelConfig,
43 engine_use_ray: bool = False,
44 ray_address: Optional[str] = None,
45 ) -> Tuple[str, Optional["PlacementGroup"]]:
46 """Initialize the distributed cluster probably with Ray.
47
48 Args:
49 parallel_config: The configurations for parallel execution.
50 engine_use_ray: Whether to use Ray for async engine.
51 ray_address: The address of the Ray cluster. If None, uses
52 the default Ray cluster address.
53
54 Returns:
55 A tuple of (`distributed_init_method`, `all_stage_devices`). The
56 `distributed_init_method` is the address for initializing the
57 distributed backend. `all_stage_devices` includes device IDs for
58 each worker in each pipeline stage. Each device ID is a tuple of
59 (rank, node resource, device id).
60 """
61 if parallel_config.worker_use_ray or engine_use_ray:
62 if ray is None:
63 raise ImportError(
64 "Ray is not installed. Please install Ray to use distributed "
65 "serving.")
66 # Connect to a ray cluster.
67 ray.init(address=ray_address, ignore_reinit_error=True)
68
69 if not parallel_config.worker_use_ray:
70 # Initialize cluster locally.
71 port = get_open_port()
72 # We need to setup the distributed init method to make sure
73 # the distributed megatron code (e.g., get world size) works correctly.
74 distributed_init_method = f"tcp://localhost:{port}"
75 return distributed_init_method, None
76
77 current_placement_group = ray.util.get_current_placement_group()
78 if current_placement_group:
79 # We are in a placement group
80 bundles = current_placement_group.bundle_specs
81 # Verify that we can use the placement group.
82 gpu_bundles = 0
83 for bundle in bundles:
84 bundle_gpus = bundle.get("GPU", 0)
85 if bundle_gpus > 1:
86 raise ValueError(
87 "Placement group bundle cannot have more than 1 GPU.")
88 if bundle_gpus:
89 gpu_bundles += 1
90 if parallel_config.world_size > gpu_bundles:
91 raise ValueError(
92 "The number of required GPUs exceeds the total number of "
93 "available GPUs in the placement group.")
94 else:
95 num_gpus_in_cluster = ray.cluster_resources().get("GPU", 0)
96 if parallel_config.world_size > num_gpus_in_cluster:
97 raise ValueError(
98 "The number of required GPUs exceeds the total number of "
99 "available GPUs in the cluster.")
100 # Create a new placement group
101 current_placement_group = ray.util.placement_group([{
102 "GPU": 1
103 }] * parallel_config.world_size)
104 # Wait until PG is ready - this will block until all
105 # requested resources are available, and will timeout
106 # if they cannot be provisioned.
107 ray.get(current_placement_group.ready(), timeout=1800)
108
109 return None, current_placement_group
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vllm/engine/ray_utils.py b/vllm/engine/ray_utils.py
--- a/vllm/engine/ray_utils.py
+++ b/vllm/engine/ray_utils.py
@@ -27,6 +27,7 @@
except ImportError:
ray = None
TorchDistributedWorker = None
+ RayWorker = None # pylint: disable=invalid-name
if TYPE_CHECKING:
from ray.util.placement_group import PlacementGroup
|
{"golden_diff": "diff --git a/vllm/engine/ray_utils.py b/vllm/engine/ray_utils.py\n--- a/vllm/engine/ray_utils.py\n+++ b/vllm/engine/ray_utils.py\n@@ -27,6 +27,7 @@\n except ImportError:\n ray = None\n TorchDistributedWorker = None\n+ RayWorker = None # pylint: disable=invalid-name\n \n if TYPE_CHECKING:\n from ray.util.placement_group import PlacementGroup\n", "issue": "RayWorker import error\nWhen import `vllm` I got following error\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/code/vllm/vllm/__init__.py\", line 4, in <module>\r\n from vllm.engine.async_llm_engine import AsyncLLMEngine\r\n File \"/code/vllm/vllm/engine/async_llm_engine.py\", line 7, in <module>\r\n from vllm.engine.llm_engine import LLMEngine\r\n File \"/code/vllm/vllm/engine/llm_engine.py\", line 9, in <module>\r\n from vllm.engine.ray_utils import initialize_cluster, ray, RayWorker\r\nImportError: cannot import name 'RayWorker' from 'vllm.engine.ray_utils' \r\n```\r\nIt seems `ray` requires `pandas` I haven't installed it.\r\n\n", "before_files": [{"content": "import socket\nfrom typing import Optional, Tuple, TYPE_CHECKING\n\nfrom vllm.config import ParallelConfig\n\ntry:\n import ray\n from ray.air.util.torch_dist import TorchDistributedWorker\n\n class RayWorker(TorchDistributedWorker):\n \"\"\"Ray wrapper for vllm.worker.Worker, allowing Worker to be\n lazliy initialized after Ray sets CUDA_VISIBLE_DEVICES.\"\"\"\n\n def __init__(self) -> None:\n self.worker = None\n\n def init_worker(self, worker_init_fn):\n self.worker = worker_init_fn()\n\n def __getattr__(self, name):\n return getattr(self.worker, name)\n\n def execute_method(self, method, *args, **kwargs):\n executor = getattr(self, method)\n return executor(*args, **kwargs)\n\nexcept ImportError:\n ray = None\n TorchDistributedWorker = None\n\nif TYPE_CHECKING:\n from ray.util.placement_group import PlacementGroup\n\n\ndef get_open_port():\n with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:\n s.bind((\"\", 0))\n return s.getsockname()[1]\n\n\ndef initialize_cluster(\n parallel_config: ParallelConfig,\n engine_use_ray: bool = False,\n ray_address: Optional[str] = None,\n) -> Tuple[str, Optional[\"PlacementGroup\"]]:\n \"\"\"Initialize the distributed cluster probably with Ray.\n\n Args:\n parallel_config: The configurations for parallel execution.\n engine_use_ray: Whether to use Ray for async engine.\n ray_address: The address of the Ray cluster. If None, uses\n the default Ray cluster address.\n\n Returns:\n A tuple of (`distributed_init_method`, `all_stage_devices`). The\n `distributed_init_method` is the address for initializing the\n distributed backend. `all_stage_devices` includes device IDs for\n each worker in each pipeline stage. Each device ID is a tuple of\n (rank, node resource, device id).\n \"\"\"\n if parallel_config.worker_use_ray or engine_use_ray:\n if ray is None:\n raise ImportError(\n \"Ray is not installed. Please install Ray to use distributed \"\n \"serving.\")\n # Connect to a ray cluster.\n ray.init(address=ray_address, ignore_reinit_error=True)\n\n if not parallel_config.worker_use_ray:\n # Initialize cluster locally.\n port = get_open_port()\n # We need to setup the distributed init method to make sure\n # the distributed megatron code (e.g., get world size) works correctly.\n distributed_init_method = f\"tcp://localhost:{port}\"\n return distributed_init_method, None\n\n current_placement_group = ray.util.get_current_placement_group()\n if current_placement_group:\n # We are in a placement group\n bundles = current_placement_group.bundle_specs\n # Verify that we can use the placement group.\n gpu_bundles = 0\n for bundle in bundles:\n bundle_gpus = bundle.get(\"GPU\", 0)\n if bundle_gpus > 1:\n raise ValueError(\n \"Placement group bundle cannot have more than 1 GPU.\")\n if bundle_gpus:\n gpu_bundles += 1\n if parallel_config.world_size > gpu_bundles:\n raise ValueError(\n \"The number of required GPUs exceeds the total number of \"\n \"available GPUs in the placement group.\")\n else:\n num_gpus_in_cluster = ray.cluster_resources().get(\"GPU\", 0)\n if parallel_config.world_size > num_gpus_in_cluster:\n raise ValueError(\n \"The number of required GPUs exceeds the total number of \"\n \"available GPUs in the cluster.\")\n # Create a new placement group\n current_placement_group = ray.util.placement_group([{\n \"GPU\": 1\n }] * parallel_config.world_size)\n # Wait until PG is ready - this will block until all\n # requested resources are available, and will timeout\n # if they cannot be provisioned.\n ray.get(current_placement_group.ready(), timeout=1800)\n\n return None, current_placement_group\n", "path": "vllm/engine/ray_utils.py"}], "after_files": [{"content": "import socket\nfrom typing import Optional, Tuple, TYPE_CHECKING\n\nfrom vllm.config import ParallelConfig\n\ntry:\n import ray\n from ray.air.util.torch_dist import TorchDistributedWorker\n\n class RayWorker(TorchDistributedWorker):\n \"\"\"Ray wrapper for vllm.worker.Worker, allowing Worker to be\n lazliy initialized after Ray sets CUDA_VISIBLE_DEVICES.\"\"\"\n\n def __init__(self) -> None:\n self.worker = None\n\n def init_worker(self, worker_init_fn):\n self.worker = worker_init_fn()\n\n def __getattr__(self, name):\n return getattr(self.worker, name)\n\n def execute_method(self, method, *args, **kwargs):\n executor = getattr(self, method)\n return executor(*args, **kwargs)\n\nexcept ImportError:\n ray = None\n TorchDistributedWorker = None\n RayWorker = None # pylint: disable=invalid-name\n\nif TYPE_CHECKING:\n from ray.util.placement_group import PlacementGroup\n\n\ndef get_open_port():\n with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:\n s.bind((\"\", 0))\n return s.getsockname()[1]\n\n\ndef initialize_cluster(\n parallel_config: ParallelConfig,\n engine_use_ray: bool = False,\n ray_address: Optional[str] = None,\n) -> Tuple[str, Optional[\"PlacementGroup\"]]:\n \"\"\"Initialize the distributed cluster probably with Ray.\n\n Args:\n parallel_config: The configurations for parallel execution.\n engine_use_ray: Whether to use Ray for async engine.\n ray_address: The address of the Ray cluster. If None, uses\n the default Ray cluster address.\n\n Returns:\n A tuple of (`distributed_init_method`, `all_stage_devices`). The\n `distributed_init_method` is the address for initializing the\n distributed backend. `all_stage_devices` includes device IDs for\n each worker in each pipeline stage. Each device ID is a tuple of\n (rank, node resource, device id).\n \"\"\"\n if parallel_config.worker_use_ray or engine_use_ray:\n if ray is None:\n raise ImportError(\n \"Ray is not installed. Please install Ray to use distributed \"\n \"serving.\")\n # Connect to a ray cluster.\n ray.init(address=ray_address, ignore_reinit_error=True)\n\n if not parallel_config.worker_use_ray:\n # Initialize cluster locally.\n port = get_open_port()\n # We need to setup the distributed init method to make sure\n # the distributed megatron code (e.g., get world size) works correctly.\n distributed_init_method = f\"tcp://localhost:{port}\"\n return distributed_init_method, None\n\n current_placement_group = ray.util.get_current_placement_group()\n if current_placement_group:\n # We are in a placement group\n bundles = current_placement_group.bundle_specs\n # Verify that we can use the placement group.\n gpu_bundles = 0\n for bundle in bundles:\n bundle_gpus = bundle.get(\"GPU\", 0)\n if bundle_gpus > 1:\n raise ValueError(\n \"Placement group bundle cannot have more than 1 GPU.\")\n if bundle_gpus:\n gpu_bundles += 1\n if parallel_config.world_size > gpu_bundles:\n raise ValueError(\n \"The number of required GPUs exceeds the total number of \"\n \"available GPUs in the placement group.\")\n else:\n num_gpus_in_cluster = ray.cluster_resources().get(\"GPU\", 0)\n if parallel_config.world_size > num_gpus_in_cluster:\n raise ValueError(\n \"The number of required GPUs exceeds the total number of \"\n \"available GPUs in the cluster.\")\n # Create a new placement group\n current_placement_group = ray.util.placement_group([{\n \"GPU\": 1\n }] * parallel_config.world_size)\n # Wait until PG is ready - this will block until all\n # requested resources are available, and will timeout\n # if they cannot be provisioned.\n ray.get(current_placement_group.ready(), timeout=1800)\n\n return None, current_placement_group\n", "path": "vllm/engine/ray_utils.py"}]}
| 1,552 | 103 |
gh_patches_debug_14593
|
rasdani/github-patches
|
git_diff
|
PlasmaPy__PlasmaPy-703
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create classes to represent ionization state distributions
My plan for this PR is to create classes to represent the ionization state distributions of one or more elements. I am going to add in a bunch of dunder methods like `__getitem__` and maybe `__call__` to help making access to the ionization states more straightfoward and intuitive. Any suggestions on the naming convention will be helpful so that we can maximize readability.
Eventually we'll need a way to calculate ionization state distributions assuming collisional ionization equilibrium, but that will be for a different PR. The purpose of this PR is to set up how to store and access the ionization distributions. This will be discussed in #352.
This will address some of #352. It will probably be best to wait until after the `0.1.0` release to merge this, since this PR is only for a partial implementation anyway.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plasmapy/classes/sources/plasma3d.py`
Content:
```
1 """
2 Defines the core Plasma class used by PlasmaPy to represent plasma properties.
3 """
4
5 import numpy as np
6 import astropy.units as u
7 import itertools
8
9 from plasmapy.formulary.magnetostatics import MagnetoStatics
10
11 from astropy.constants import mu0
12
13 from plasmapy.classes import GenericPlasma
14
15 __all__ = [
16 "Plasma3D"
17 ]
18
19
20 class Plasma3D(GenericPlasma):
21 """
22 Core class for describing and calculating plasma parameters with
23 spatial dimensions.
24
25 Attributes
26 ----------
27 x : `astropy.units.Quantity`
28 x-coordinates within the plasma domain. Equal to the
29 `domain_x` input parameter.
30 y : `astropy.units.Quantity`
31 y-coordinates within the plasma domain. Equal to the
32 `domain_y` input parameter.
33 z : `astropy.units.Quantity`
34 z-coordinates within the plasma domain. Equal to the
35 `domain_z` input parameter.
36 grid : `astropy.units.Quantity`
37 (3, x, y, z) array containing the values of each coordinate at
38 every point in the domain.
39 domain_shape : tuple
40 Shape of the plasma domain.
41 density : `astropy.units.Quantity`
42 (x, y, z) array of mass density at every point in the domain.
43 momentum : `astropy.units.Quantity`
44 (3, x, y, z) array of the momentum vector at every point in
45 the domain.
46 pressure : `astropy.units.Quantity`
47 (x, y, z) array of pressure at every point in the domain.
48 magnetic_field : `astropy.units.Quantity`
49 (3, x, y, z) array of the magnetic field vector at every point
50 in the domain.
51
52 Parameters
53 ----------
54 domain_x : `astropy.units.Quantity`
55 1D array of x-coordinates for the plasma domain. Must have
56 units convertable to length.
57 domain_y : `astropy.units.Quantity`
58 1D array of y-coordinates for the plasma domain. Must have
59 units convertable to length.
60 domain_z : `astropy.units.Quantity`
61 1D array of z-coordinates for the plasma domain. Must have
62 units convertable to length.
63
64 """
65 @u.quantity_input(domain_x=u.m, domain_y=u.m, domain_z=u.m)
66 def __init__(self, domain_x, domain_y, domain_z):
67 # Define domain sizes
68 self.x = domain_x
69 self.y = domain_y
70 self.z = domain_z
71
72 self.grid = np.array(np.meshgrid(self.x, self.y, self.z,
73 indexing='ij'))
74 self.domain_shape = (len(self.x), len(self.y), len(self.z))
75
76 # Initiate core plasma variables
77 self.density = np.zeros(self.domain_shape) * u.kg / u.m**3
78 self.momentum = np.zeros((3, *self.domain_shape)) * u.kg / (u.m ** 2 * u.s)
79 self.pressure = np.zeros(self.domain_shape) * u.Pa
80 self.magnetic_field = np.zeros((3, *self.domain_shape)) * u.T
81 self.electric_field = np.zeros((3, *self.domain_shape)) * u.V / u.m
82
83 @property
84 def velocity(self):
85 return self.momentum / self.density
86
87 @property
88 def magnetic_field_strength(self):
89 B = self.magnetic_field
90 return np.sqrt(np.sum(B * B, axis=0))
91
92 @property
93 def electric_field_strength(self):
94 E = self.electric_field
95 return np.sqrt(np.sum(E * E, axis=0))
96
97 @property
98 def alfven_speed(self):
99 B = self.magnetic_field
100 rho = self.density
101 return np.sqrt(np.sum(B * B, axis=0) / (mu0 * rho))
102
103 @classmethod
104 def is_datasource_for(cls, **kwargs):
105 if len(kwargs) == 3:
106 match = all(f'domain_{direction}' in kwargs.keys() for direction in 'xyz')
107 else:
108 match = False
109 return match
110
111 def add_magnetostatic(self, *mstats: MagnetoStatics):
112 # for each MagnetoStatic argument
113 for mstat in mstats:
114 # loop over 3D-index (ix,iy,iz)
115 for point_index in itertools.product(*[list(range(n)) for n in self.domain_shape]):
116 # get coordinate
117 p = self.grid[(slice(None),)+point_index] # function as [:, *index]
118 # calculate magnetic field at this point and add back
119 self.magnetic_field[(slice(None),)+point_index] += mstat.magnetic_field(p)
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plasmapy/classes/sources/plasma3d.py b/plasmapy/classes/sources/plasma3d.py
--- a/plasmapy/classes/sources/plasma3d.py
+++ b/plasmapy/classes/sources/plasma3d.py
@@ -110,9 +110,10 @@
def add_magnetostatic(self, *mstats: MagnetoStatics):
# for each MagnetoStatic argument
+ prod = itertools.product(*[list(range(n)) for n in self.domain_shape])
for mstat in mstats:
# loop over 3D-index (ix,iy,iz)
- for point_index in itertools.product(*[list(range(n)) for n in self.domain_shape]):
+ for point_index in prod:
# get coordinate
p = self.grid[(slice(None),)+point_index] # function as [:, *index]
# calculate magnetic field at this point and add back
|
{"golden_diff": "diff --git a/plasmapy/classes/sources/plasma3d.py b/plasmapy/classes/sources/plasma3d.py\n--- a/plasmapy/classes/sources/plasma3d.py\n+++ b/plasmapy/classes/sources/plasma3d.py\n@@ -110,9 +110,10 @@\n \n def add_magnetostatic(self, *mstats: MagnetoStatics):\n # for each MagnetoStatic argument\n+ prod = itertools.product(*[list(range(n)) for n in self.domain_shape])\n for mstat in mstats:\n # loop over 3D-index (ix,iy,iz)\n- for point_index in itertools.product(*[list(range(n)) for n in self.domain_shape]):\n+ for point_index in prod:\n # get coordinate\n p = self.grid[(slice(None),)+point_index] # function as [:, *index]\n # calculate magnetic field at this point and add back\n", "issue": "Create classes to represent ionization state distributions\nMy plan for this PR is to create classes to represent the ionization state distributions of one or more elements. I am going to add in a bunch of dunder methods like `__getitem__` and maybe `__call__` to help making access to the ionization states more straightfoward and intuitive. Any suggestions on the naming convention will be helpful so that we can maximize readability. \r\n\r\nEventually we'll need a way to calculate ionization state distributions assuming collisional ionization equilibrium, but that will be for a different PR. The purpose of this PR is to set up how to store and access the ionization distributions. This will be discussed in #352.\r\n\r\nThis will address some of #352. It will probably be best to wait until after the `0.1.0` release to merge this, since this PR is only for a partial implementation anyway.\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nDefines the core Plasma class used by PlasmaPy to represent plasma properties.\n\"\"\"\n\nimport numpy as np\nimport astropy.units as u\nimport itertools\n\nfrom plasmapy.formulary.magnetostatics import MagnetoStatics\n\nfrom astropy.constants import mu0\n\nfrom plasmapy.classes import GenericPlasma\n\n__all__ = [\n \"Plasma3D\"\n]\n\n\nclass Plasma3D(GenericPlasma):\n \"\"\"\n Core class for describing and calculating plasma parameters with\n spatial dimensions.\n\n Attributes\n ----------\n x : `astropy.units.Quantity`\n x-coordinates within the plasma domain. Equal to the\n `domain_x` input parameter.\n y : `astropy.units.Quantity`\n y-coordinates within the plasma domain. Equal to the\n `domain_y` input parameter.\n z : `astropy.units.Quantity`\n z-coordinates within the plasma domain. Equal to the\n `domain_z` input parameter.\n grid : `astropy.units.Quantity`\n (3, x, y, z) array containing the values of each coordinate at\n every point in the domain.\n domain_shape : tuple\n Shape of the plasma domain.\n density : `astropy.units.Quantity`\n (x, y, z) array of mass density at every point in the domain.\n momentum : `astropy.units.Quantity`\n (3, x, y, z) array of the momentum vector at every point in\n the domain.\n pressure : `astropy.units.Quantity`\n (x, y, z) array of pressure at every point in the domain.\n magnetic_field : `astropy.units.Quantity`\n (3, x, y, z) array of the magnetic field vector at every point\n in the domain.\n\n Parameters\n ----------\n domain_x : `astropy.units.Quantity`\n 1D array of x-coordinates for the plasma domain. Must have\n units convertable to length.\n domain_y : `astropy.units.Quantity`\n 1D array of y-coordinates for the plasma domain. Must have\n units convertable to length.\n domain_z : `astropy.units.Quantity`\n 1D array of z-coordinates for the plasma domain. Must have\n units convertable to length.\n\n \"\"\"\n @u.quantity_input(domain_x=u.m, domain_y=u.m, domain_z=u.m)\n def __init__(self, domain_x, domain_y, domain_z):\n # Define domain sizes\n self.x = domain_x\n self.y = domain_y\n self.z = domain_z\n\n self.grid = np.array(np.meshgrid(self.x, self.y, self.z,\n indexing='ij'))\n self.domain_shape = (len(self.x), len(self.y), len(self.z))\n\n # Initiate core plasma variables\n self.density = np.zeros(self.domain_shape) * u.kg / u.m**3\n self.momentum = np.zeros((3, *self.domain_shape)) * u.kg / (u.m ** 2 * u.s)\n self.pressure = np.zeros(self.domain_shape) * u.Pa\n self.magnetic_field = np.zeros((3, *self.domain_shape)) * u.T\n self.electric_field = np.zeros((3, *self.domain_shape)) * u.V / u.m\n\n @property\n def velocity(self):\n return self.momentum / self.density\n\n @property\n def magnetic_field_strength(self):\n B = self.magnetic_field\n return np.sqrt(np.sum(B * B, axis=0))\n\n @property\n def electric_field_strength(self):\n E = self.electric_field\n return np.sqrt(np.sum(E * E, axis=0))\n\n @property\n def alfven_speed(self):\n B = self.magnetic_field\n rho = self.density\n return np.sqrt(np.sum(B * B, axis=0) / (mu0 * rho))\n\n @classmethod\n def is_datasource_for(cls, **kwargs):\n if len(kwargs) == 3:\n match = all(f'domain_{direction}' in kwargs.keys() for direction in 'xyz')\n else:\n match = False\n return match\n\n def add_magnetostatic(self, *mstats: MagnetoStatics):\n # for each MagnetoStatic argument\n for mstat in mstats:\n # loop over 3D-index (ix,iy,iz)\n for point_index in itertools.product(*[list(range(n)) for n in self.domain_shape]):\n # get coordinate\n p = self.grid[(slice(None),)+point_index] # function as [:, *index]\n # calculate magnetic field at this point and add back\n self.magnetic_field[(slice(None),)+point_index] += mstat.magnetic_field(p)\n", "path": "plasmapy/classes/sources/plasma3d.py"}], "after_files": [{"content": "\"\"\"\nDefines the core Plasma class used by PlasmaPy to represent plasma properties.\n\"\"\"\n\nimport numpy as np\nimport astropy.units as u\nimport itertools\n\nfrom plasmapy.formulary.magnetostatics import MagnetoStatics\n\nfrom astropy.constants import mu0\n\nfrom plasmapy.classes import GenericPlasma\n\n__all__ = [\n \"Plasma3D\"\n]\n\n\nclass Plasma3D(GenericPlasma):\n \"\"\"\n Core class for describing and calculating plasma parameters with\n spatial dimensions.\n\n Attributes\n ----------\n x : `astropy.units.Quantity`\n x-coordinates within the plasma domain. Equal to the\n `domain_x` input parameter.\n y : `astropy.units.Quantity`\n y-coordinates within the plasma domain. Equal to the\n `domain_y` input parameter.\n z : `astropy.units.Quantity`\n z-coordinates within the plasma domain. Equal to the\n `domain_z` input parameter.\n grid : `astropy.units.Quantity`\n (3, x, y, z) array containing the values of each coordinate at\n every point in the domain.\n domain_shape : tuple\n Shape of the plasma domain.\n density : `astropy.units.Quantity`\n (x, y, z) array of mass density at every point in the domain.\n momentum : `astropy.units.Quantity`\n (3, x, y, z) array of the momentum vector at every point in\n the domain.\n pressure : `astropy.units.Quantity`\n (x, y, z) array of pressure at every point in the domain.\n magnetic_field : `astropy.units.Quantity`\n (3, x, y, z) array of the magnetic field vector at every point\n in the domain.\n\n Parameters\n ----------\n domain_x : `astropy.units.Quantity`\n 1D array of x-coordinates for the plasma domain. Must have\n units convertable to length.\n domain_y : `astropy.units.Quantity`\n 1D array of y-coordinates for the plasma domain. Must have\n units convertable to length.\n domain_z : `astropy.units.Quantity`\n 1D array of z-coordinates for the plasma domain. Must have\n units convertable to length.\n\n \"\"\"\n @u.quantity_input(domain_x=u.m, domain_y=u.m, domain_z=u.m)\n def __init__(self, domain_x, domain_y, domain_z):\n # Define domain sizes\n self.x = domain_x\n self.y = domain_y\n self.z = domain_z\n\n self.grid = np.array(np.meshgrid(self.x, self.y, self.z,\n indexing='ij'))\n self.domain_shape = (len(self.x), len(self.y), len(self.z))\n\n # Initiate core plasma variables\n self.density = np.zeros(self.domain_shape) * u.kg / u.m**3\n self.momentum = np.zeros((3, *self.domain_shape)) * u.kg / (u.m ** 2 * u.s)\n self.pressure = np.zeros(self.domain_shape) * u.Pa\n self.magnetic_field = np.zeros((3, *self.domain_shape)) * u.T\n self.electric_field = np.zeros((3, *self.domain_shape)) * u.V / u.m\n\n @property\n def velocity(self):\n return self.momentum / self.density\n\n @property\n def magnetic_field_strength(self):\n B = self.magnetic_field\n return np.sqrt(np.sum(B * B, axis=0))\n\n @property\n def electric_field_strength(self):\n E = self.electric_field\n return np.sqrt(np.sum(E * E, axis=0))\n\n @property\n def alfven_speed(self):\n B = self.magnetic_field\n rho = self.density\n return np.sqrt(np.sum(B * B, axis=0) / (mu0 * rho))\n\n @classmethod\n def is_datasource_for(cls, **kwargs):\n if len(kwargs) == 3:\n match = all(f'domain_{direction}' in kwargs.keys() for direction in 'xyz')\n else:\n match = False\n return match\n\n def add_magnetostatic(self, *mstats: MagnetoStatics):\n # for each MagnetoStatic argument\n prod = itertools.product(*[list(range(n)) for n in self.domain_shape])\n for mstat in mstats:\n # loop over 3D-index (ix,iy,iz)\n for point_index in prod:\n # get coordinate\n p = self.grid[(slice(None),)+point_index] # function as [:, *index]\n # calculate magnetic field at this point and add back\n self.magnetic_field[(slice(None),)+point_index] += mstat.magnetic_field(p)\n", "path": "plasmapy/classes/sources/plasma3d.py"}]}
| 1,750 | 208 |
gh_patches_debug_1994
|
rasdani/github-patches
|
git_diff
|
frappe__hrms-1526
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Organizational Chart: Total connections includes employees left
### Information about bug
<img width="329" alt="Screenshot 2024-03-08 at 11 20 37 AM" src="https://github.com/frappe/hrms/assets/20027965/b88248f8-502e-41fa-ba1a-87c0cd43165a">
The current system displays a total count of connections for each employee, including those who are no longer with the company. However, when viewing the connections, only active employees are shown.
**Expected Output:**
The count now reflects only active employees, ensuring consistency between the number displayed and the individuals visible upon selecting any employee.
### Module
HR
### Version
ERPNext: v14.x.x-develop () (develop)
Frappe Framework: v15.x.x-develop () (develop)
Frappe HR: v16.0.0-dev (develop)
### Installation method
manual install
### Relevant log output / Stack trace / Full Error Message.
_No response_
### Code of Conduct
- [x] I agree to follow this project's Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hrms/hr/page/organizational_chart/organizational_chart.py`
Content:
```
1 import frappe
2 from frappe.query_builder.functions import Count
3
4
5 @frappe.whitelist()
6 def get_children(parent=None, company=None, exclude_node=None):
7 filters = [["status", "=", "Active"]]
8 if company and company != "All Companies":
9 filters.append(["company", "=", company])
10
11 if parent and company and parent != company:
12 filters.append(["reports_to", "=", parent])
13 else:
14 filters.append(["reports_to", "=", ""])
15
16 if exclude_node:
17 filters.append(["name", "!=", exclude_node])
18
19 employees = frappe.get_all(
20 "Employee",
21 fields=[
22 "employee_name as name",
23 "name as id",
24 "lft",
25 "rgt",
26 "reports_to",
27 "image",
28 "designation as title",
29 ],
30 filters=filters,
31 order_by="name",
32 )
33
34 for employee in employees:
35 employee.connections = get_connections(employee.id, employee.lft, employee.rgt)
36 employee.expandable = bool(employee.connections)
37
38 return employees
39
40
41 def get_connections(employee: str, lft: int, rgt: int) -> int:
42 Employee = frappe.qb.DocType("Employee")
43 query = (
44 frappe.qb.from_(Employee)
45 .select(Count(Employee.name))
46 .where((Employee.lft > lft) & (Employee.rgt < rgt))
47 ).run()
48
49 return query[0][0]
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hrms/hr/page/organizational_chart/organizational_chart.py b/hrms/hr/page/organizational_chart/organizational_chart.py
--- a/hrms/hr/page/organizational_chart/organizational_chart.py
+++ b/hrms/hr/page/organizational_chart/organizational_chart.py
@@ -43,7 +43,7 @@
query = (
frappe.qb.from_(Employee)
.select(Count(Employee.name))
- .where((Employee.lft > lft) & (Employee.rgt < rgt))
+ .where((Employee.lft > lft) & (Employee.rgt < rgt) & (Employee.status == "Active"))
).run()
return query[0][0]
|
{"golden_diff": "diff --git a/hrms/hr/page/organizational_chart/organizational_chart.py b/hrms/hr/page/organizational_chart/organizational_chart.py\n--- a/hrms/hr/page/organizational_chart/organizational_chart.py\n+++ b/hrms/hr/page/organizational_chart/organizational_chart.py\n@@ -43,7 +43,7 @@\n \tquery = (\n \t\tfrappe.qb.from_(Employee)\n \t\t.select(Count(Employee.name))\n-\t\t.where((Employee.lft > lft) & (Employee.rgt < rgt))\n+\t\t.where((Employee.lft > lft) & (Employee.rgt < rgt) & (Employee.status == \"Active\"))\n \t).run()\n \n \treturn query[0][0]\n", "issue": "Organizational Chart: Total connections includes employees left\n### Information about bug\n\n<img width=\"329\" alt=\"Screenshot 2024-03-08 at 11 20 37\u202fAM\" src=\"https://github.com/frappe/hrms/assets/20027965/b88248f8-502e-41fa-ba1a-87c0cd43165a\">\r\n\r\nThe current system displays a total count of connections for each employee, including those who are no longer with the company. However, when viewing the connections, only active employees are shown.\r\n\r\n**Expected Output:**\r\nThe count now reflects only active employees, ensuring consistency between the number displayed and the individuals visible upon selecting any employee.\n\n### Module\n\nHR\n\n### Version\n\nERPNext: v14.x.x-develop () (develop)\r\n\r\nFrappe Framework: v15.x.x-develop () (develop)\r\n\r\nFrappe HR: v16.0.0-dev (develop)\n\n### Installation method\n\nmanual install\n\n### Relevant log output / Stack trace / Full Error Message.\n\n_No response_\n\n### Code of Conduct\n\n- [x] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "import frappe\nfrom frappe.query_builder.functions import Count\n\n\[email protected]()\ndef get_children(parent=None, company=None, exclude_node=None):\n\tfilters = [[\"status\", \"=\", \"Active\"]]\n\tif company and company != \"All Companies\":\n\t\tfilters.append([\"company\", \"=\", company])\n\n\tif parent and company and parent != company:\n\t\tfilters.append([\"reports_to\", \"=\", parent])\n\telse:\n\t\tfilters.append([\"reports_to\", \"=\", \"\"])\n\n\tif exclude_node:\n\t\tfilters.append([\"name\", \"!=\", exclude_node])\n\n\temployees = frappe.get_all(\n\t\t\"Employee\",\n\t\tfields=[\n\t\t\t\"employee_name as name\",\n\t\t\t\"name as id\",\n\t\t\t\"lft\",\n\t\t\t\"rgt\",\n\t\t\t\"reports_to\",\n\t\t\t\"image\",\n\t\t\t\"designation as title\",\n\t\t],\n\t\tfilters=filters,\n\t\torder_by=\"name\",\n\t)\n\n\tfor employee in employees:\n\t\temployee.connections = get_connections(employee.id, employee.lft, employee.rgt)\n\t\temployee.expandable = bool(employee.connections)\n\n\treturn employees\n\n\ndef get_connections(employee: str, lft: int, rgt: int) -> int:\n\tEmployee = frappe.qb.DocType(\"Employee\")\n\tquery = (\n\t\tfrappe.qb.from_(Employee)\n\t\t.select(Count(Employee.name))\n\t\t.where((Employee.lft > lft) & (Employee.rgt < rgt))\n\t).run()\n\n\treturn query[0][0]\n", "path": "hrms/hr/page/organizational_chart/organizational_chart.py"}], "after_files": [{"content": "import frappe\nfrom frappe.query_builder.functions import Count\n\n\[email protected]()\ndef get_children(parent=None, company=None, exclude_node=None):\n\tfilters = [[\"status\", \"=\", \"Active\"]]\n\tif company and company != \"All Companies\":\n\t\tfilters.append([\"company\", \"=\", company])\n\n\tif parent and company and parent != company:\n\t\tfilters.append([\"reports_to\", \"=\", parent])\n\telse:\n\t\tfilters.append([\"reports_to\", \"=\", \"\"])\n\n\tif exclude_node:\n\t\tfilters.append([\"name\", \"!=\", exclude_node])\n\n\temployees = frappe.get_all(\n\t\t\"Employee\",\n\t\tfields=[\n\t\t\t\"employee_name as name\",\n\t\t\t\"name as id\",\n\t\t\t\"lft\",\n\t\t\t\"rgt\",\n\t\t\t\"reports_to\",\n\t\t\t\"image\",\n\t\t\t\"designation as title\",\n\t\t],\n\t\tfilters=filters,\n\t\torder_by=\"name\",\n\t)\n\n\tfor employee in employees:\n\t\temployee.connections = get_connections(employee.id, employee.lft, employee.rgt)\n\t\temployee.expandable = bool(employee.connections)\n\n\treturn employees\n\n\ndef get_connections(employee: str, lft: int, rgt: int) -> int:\n\tEmployee = frappe.qb.DocType(\"Employee\")\n\tquery = (\n\t\tfrappe.qb.from_(Employee)\n\t\t.select(Count(Employee.name))\n\t\t.where((Employee.lft > lft) & (Employee.rgt < rgt) & (Employee.status == \"Active\"))\n\t).run()\n\n\treturn query[0][0]\n", "path": "hrms/hr/page/organizational_chart/organizational_chart.py"}]}
| 950 | 162 |
gh_patches_debug_11872
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-465
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bound the maximum supported Python version
Related: #462.
The BigQuery library does not support Python 3.9 yet, as the `bqstorage` and `pandas` extras are blocked by the `pyarrow` dependency. Pyarrow [added](https://issues.apache.org/jira/browse/ARROW-10224) the Python 3.9 support, but the change has not been released yet (awaiting `pyarrow==3.0.0`).
We need to reflect this in `setup.py`'s ``python_requires`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 "google-api-core[grpc] >= 1.23.0, < 2.0.0dev",
33 "proto-plus >= 1.10.0",
34 "google-cloud-core >= 1.4.1, < 2.0dev",
35 "google-resumable-media >= 0.6.0, < 2.0dev",
36 "six >=1.13.0,< 2.0.0dev",
37 "protobuf >= 3.12.0",
38 ]
39 extras = {
40 "bqstorage": [
41 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
42 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
43 # installed, even though `google-cloud-bigquery-storage` specifies it
44 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
45 # See: https://github.com/googleapis/python-bigquery/issues/83 The
46 # grpc.Channel.close() method isn't added until 1.32.0.
47 # https://github.com/grpc/grpc/pull/15254
48 "grpcio >= 1.32.0, < 2.0dev",
49 "pyarrow >= 1.0.0, < 3.0dev",
50 ],
51 "pandas": [
52 "pandas>=0.23.0",
53 # pyarrow 1.0.0 is required for the use of timestamp_as_object keyword.
54 "pyarrow >= 1.0.0, < 3.0dev",
55 ],
56 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
57 "opentelemetry": [
58 "opentelemetry-api==0.11b0",
59 "opentelemetry-sdk==0.11b0",
60 "opentelemetry-instrumentation==0.11b0",
61 ],
62 }
63
64 all_extras = []
65
66 for extra in extras:
67 all_extras.extend(extras[extra])
68
69 extras["all"] = all_extras
70
71 # Setup boilerplate below this line.
72
73 package_root = os.path.abspath(os.path.dirname(__file__))
74
75 readme_filename = os.path.join(package_root, "README.rst")
76 with io.open(readme_filename, encoding="utf-8") as readme_file:
77 readme = readme_file.read()
78
79 version = {}
80 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
81 exec(fp.read(), version)
82 version = version["__version__"]
83
84 # Only include packages under the 'google' namespace. Do not include tests,
85 # benchmarks, etc.
86 packages = [
87 package
88 for package in setuptools.PEP420PackageFinder.find()
89 if package.startswith("google")
90 ]
91
92 # Determine which namespaces are needed.
93 namespaces = ["google"]
94 if "google.cloud" in packages:
95 namespaces.append("google.cloud")
96
97
98 setuptools.setup(
99 name=name,
100 version=version,
101 description=description,
102 long_description=readme,
103 author="Google LLC",
104 author_email="[email protected]",
105 license="Apache 2.0",
106 url="https://github.com/googleapis/python-bigquery",
107 classifiers=[
108 release_status,
109 "Intended Audience :: Developers",
110 "License :: OSI Approved :: Apache Software License",
111 "Programming Language :: Python",
112 "Programming Language :: Python :: 3",
113 "Programming Language :: Python :: 3.6",
114 "Programming Language :: Python :: 3.7",
115 "Programming Language :: Python :: 3.8",
116 "Operating System :: OS Independent",
117 "Topic :: Internet",
118 ],
119 platforms="Posix; MacOS X; Windows",
120 packages=packages,
121 namespace_packages=namespaces,
122 install_requires=dependencies,
123 extras_require=extras,
124 python_requires=">=3.6",
125 include_package_data=True,
126 zip_safe=False,
127 )
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -33,7 +33,6 @@
"proto-plus >= 1.10.0",
"google-cloud-core >= 1.4.1, < 2.0dev",
"google-resumable-media >= 0.6.0, < 2.0dev",
- "six >=1.13.0,< 2.0.0dev",
"protobuf >= 3.12.0",
]
extras = {
@@ -121,7 +120,7 @@
namespace_packages=namespaces,
install_requires=dependencies,
extras_require=extras,
- python_requires=">=3.6",
+ python_requires=">=3.6, <3.9",
include_package_data=True,
zip_safe=False,
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -33,7 +33,6 @@\n \"proto-plus >= 1.10.0\",\n \"google-cloud-core >= 1.4.1, < 2.0dev\",\n \"google-resumable-media >= 0.6.0, < 2.0dev\",\n- \"six >=1.13.0,< 2.0.0dev\",\n \"protobuf >= 3.12.0\",\n ]\n extras = {\n@@ -121,7 +120,7 @@\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n- python_requires=\">=3.6\",\n+ python_requires=\">=3.6, <3.9\",\n include_package_data=True,\n zip_safe=False,\n )\n", "issue": "Bound the maximum supported Python version\nRelated: #462.\r\n\r\nThe BigQuery library does not support Python 3.9 yet, as the `bqstorage` and `pandas` extras are blocked by the `pyarrow` dependency. Pyarrow [added](https://issues.apache.org/jira/browse/ARROW-10224) the Python 3.9 support, but the change has not been released yet (awaiting `pyarrow==3.0.0`).\r\n\r\nWe need to reflect this in `setup.py`'s ``python_requires`.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"google-api-core[grpc] >= 1.23.0, < 2.0.0dev\",\n \"proto-plus >= 1.10.0\",\n \"google-cloud-core >= 1.4.1, < 2.0dev\",\n \"google-resumable-media >= 0.6.0, < 2.0dev\",\n \"six >=1.13.0,< 2.0.0dev\",\n \"protobuf >= 3.12.0\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.32.0, < 2.0dev\",\n \"pyarrow >= 1.0.0, < 3.0dev\",\n ],\n \"pandas\": [\n \"pandas>=0.23.0\",\n # pyarrow 1.0.0 is required for the use of timestamp_as_object keyword.\n \"pyarrow >= 1.0.0, < 3.0dev\",\n ],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api==0.11b0\",\n \"opentelemetry-sdk==0.11b0\",\n \"opentelemetry-instrumentation==0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"google-api-core[grpc] >= 1.23.0, < 2.0.0dev\",\n \"proto-plus >= 1.10.0\",\n \"google-cloud-core >= 1.4.1, < 2.0dev\",\n \"google-resumable-media >= 0.6.0, < 2.0dev\",\n \"protobuf >= 3.12.0\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.32.0, < 2.0dev\",\n \"pyarrow >= 1.0.0, < 3.0dev\",\n ],\n \"pandas\": [\n \"pandas>=0.23.0\",\n # pyarrow 1.0.0 is required for the use of timestamp_as_object keyword.\n \"pyarrow >= 1.0.0, < 3.0dev\",\n ],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api==0.11b0\",\n \"opentelemetry-sdk==0.11b0\",\n \"opentelemetry-instrumentation==0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.9\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,736 | 193 |
gh_patches_debug_10629
|
rasdani/github-patches
|
git_diff
|
jumpserver__jumpserver-138
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
change(version num) change jumpserver version
from 0.3.0 -> 0.3.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jperm/models.py`
Content:
```
1 import datetime
2
3 from django.db import models
4 from jasset.models import Asset, AssetGroup
5 from juser.models import User, UserGroup
6
7
8 class PermLog(models.Model):
9 datetime = models.DateTimeField(auto_now_add=True)
10 action = models.CharField(max_length=100, null=True, blank=True, default='')
11 results = models.CharField(max_length=1000, null=True, blank=True, default='')
12 is_success = models.BooleanField(default=False)
13 is_finish = models.BooleanField(default=False)
14
15
16 class PermSudo(models.Model):
17 name = models.CharField(max_length=100, unique=True)
18 date_added = models.DateTimeField(auto_now=True)
19 commands = models.TextField()
20 comment = models.CharField(max_length=100, null=True, blank=True, default='')
21
22 def __unicode__(self):
23 return self.name
24
25
26 class PermRole(models.Model):
27 name = models.CharField(max_length=100, unique=True)
28 comment = models.CharField(max_length=100, null=True, blank=True, default='')
29 password = models.CharField(max_length=100)
30 key_path = models.CharField(max_length=100)
31 date_added = models.DateTimeField(auto_now=True)
32 sudo = models.ManyToManyField(PermSudo, related_name='perm_role')
33
34 def __unicode__(self):
35 return self.name
36
37
38 class PermRule(models.Model):
39 date_added = models.DateTimeField(auto_now=True)
40 name = models.CharField(max_length=100, unique=True)
41 comment = models.CharField(max_length=100)
42 asset = models.ManyToManyField(Asset, related_name='perm_rule')
43 asset_group = models.ManyToManyField(AssetGroup, related_name='perm_rule')
44 user = models.ManyToManyField(User, related_name='perm_rule')
45 user_group = models.ManyToManyField(UserGroup, related_name='perm_rule')
46 role = models.ManyToManyField(PermRole, related_name='perm_rule')
47
48 def __unicode__(self):
49 return self.name
50
51
52 class PermPush(models.Model):
53 asset = models.ForeignKey(Asset, related_name='perm_push')
54 role = models.ForeignKey(PermRole, related_name='perm_push')
55 is_public_key = models.BooleanField(default=False)
56 is_password = models.BooleanField(default=False)
57 success = models.BooleanField(default=False)
58 result = models.TextField(default='')
59 date_added = models.DateTimeField(auto_now=True)
60
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jperm/models.py b/jperm/models.py
--- a/jperm/models.py
+++ b/jperm/models.py
@@ -26,7 +26,7 @@
class PermRole(models.Model):
name = models.CharField(max_length=100, unique=True)
comment = models.CharField(max_length=100, null=True, blank=True, default='')
- password = models.CharField(max_length=100)
+ password = models.CharField(max_length=128)
key_path = models.CharField(max_length=100)
date_added = models.DateTimeField(auto_now=True)
sudo = models.ManyToManyField(PermSudo, related_name='perm_role')
|
{"golden_diff": "diff --git a/jperm/models.py b/jperm/models.py\n--- a/jperm/models.py\n+++ b/jperm/models.py\n@@ -26,7 +26,7 @@\n class PermRole(models.Model):\n name = models.CharField(max_length=100, unique=True)\n comment = models.CharField(max_length=100, null=True, blank=True, default='')\n- password = models.CharField(max_length=100)\n+ password = models.CharField(max_length=128)\n key_path = models.CharField(max_length=100)\n date_added = models.DateTimeField(auto_now=True)\n sudo = models.ManyToManyField(PermSudo, related_name='perm_role')\n", "issue": "change(version num) change jumpserver version\nfrom 0.3.0 -> 0.3.1\n\n", "before_files": [{"content": "import datetime\n\nfrom django.db import models\nfrom jasset.models import Asset, AssetGroup\nfrom juser.models import User, UserGroup\n\n\nclass PermLog(models.Model):\n datetime = models.DateTimeField(auto_now_add=True)\n action = models.CharField(max_length=100, null=True, blank=True, default='')\n results = models.CharField(max_length=1000, null=True, blank=True, default='')\n is_success = models.BooleanField(default=False)\n is_finish = models.BooleanField(default=False)\n\n\nclass PermSudo(models.Model):\n name = models.CharField(max_length=100, unique=True)\n date_added = models.DateTimeField(auto_now=True)\n commands = models.TextField()\n comment = models.CharField(max_length=100, null=True, blank=True, default='')\n\n def __unicode__(self):\n return self.name\n\n\nclass PermRole(models.Model):\n name = models.CharField(max_length=100, unique=True)\n comment = models.CharField(max_length=100, null=True, blank=True, default='')\n password = models.CharField(max_length=100)\n key_path = models.CharField(max_length=100)\n date_added = models.DateTimeField(auto_now=True)\n sudo = models.ManyToManyField(PermSudo, related_name='perm_role')\n\n def __unicode__(self):\n return self.name\n\n\nclass PermRule(models.Model):\n date_added = models.DateTimeField(auto_now=True)\n name = models.CharField(max_length=100, unique=True)\n comment = models.CharField(max_length=100)\n asset = models.ManyToManyField(Asset, related_name='perm_rule')\n asset_group = models.ManyToManyField(AssetGroup, related_name='perm_rule')\n user = models.ManyToManyField(User, related_name='perm_rule')\n user_group = models.ManyToManyField(UserGroup, related_name='perm_rule')\n role = models.ManyToManyField(PermRole, related_name='perm_rule')\n\n def __unicode__(self):\n return self.name\n\n\nclass PermPush(models.Model):\n asset = models.ForeignKey(Asset, related_name='perm_push')\n role = models.ForeignKey(PermRole, related_name='perm_push')\n is_public_key = models.BooleanField(default=False)\n is_password = models.BooleanField(default=False)\n success = models.BooleanField(default=False)\n result = models.TextField(default='')\n date_added = models.DateTimeField(auto_now=True)\n\n", "path": "jperm/models.py"}], "after_files": [{"content": "import datetime\n\nfrom django.db import models\nfrom jasset.models import Asset, AssetGroup\nfrom juser.models import User, UserGroup\n\n\nclass PermLog(models.Model):\n datetime = models.DateTimeField(auto_now_add=True)\n action = models.CharField(max_length=100, null=True, blank=True, default='')\n results = models.CharField(max_length=1000, null=True, blank=True, default='')\n is_success = models.BooleanField(default=False)\n is_finish = models.BooleanField(default=False)\n\n\nclass PermSudo(models.Model):\n name = models.CharField(max_length=100, unique=True)\n date_added = models.DateTimeField(auto_now=True)\n commands = models.TextField()\n comment = models.CharField(max_length=100, null=True, blank=True, default='')\n\n def __unicode__(self):\n return self.name\n\n\nclass PermRole(models.Model):\n name = models.CharField(max_length=100, unique=True)\n comment = models.CharField(max_length=100, null=True, blank=True, default='')\n password = models.CharField(max_length=128)\n key_path = models.CharField(max_length=100)\n date_added = models.DateTimeField(auto_now=True)\n sudo = models.ManyToManyField(PermSudo, related_name='perm_role')\n\n def __unicode__(self):\n return self.name\n\n\nclass PermRule(models.Model):\n date_added = models.DateTimeField(auto_now=True)\n name = models.CharField(max_length=100, unique=True)\n comment = models.CharField(max_length=100)\n asset = models.ManyToManyField(Asset, related_name='perm_rule')\n asset_group = models.ManyToManyField(AssetGroup, related_name='perm_rule')\n user = models.ManyToManyField(User, related_name='perm_rule')\n user_group = models.ManyToManyField(UserGroup, related_name='perm_rule')\n role = models.ManyToManyField(PermRole, related_name='perm_rule')\n\n def __unicode__(self):\n return self.name\n\n\nclass PermPush(models.Model):\n asset = models.ForeignKey(Asset, related_name='perm_push')\n role = models.ForeignKey(PermRole, related_name='perm_push')\n is_public_key = models.BooleanField(default=False)\n is_password = models.BooleanField(default=False)\n success = models.BooleanField(default=False)\n result = models.TextField(default='')\n date_added = models.DateTimeField(auto_now=True)\n\n", "path": "jperm/models.py"}]}
| 895 | 146 |
gh_patches_debug_9067
|
rasdani/github-patches
|
git_diff
|
nautobot__nautobot-5190
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add support for an OS Model to define target OS image per device
### Proposed Functionality
Support a model to define OSs that should be used by each device and ensure there is also a relationship between vendor and platform.
### Use Case
As a user, I should be able to define the intended OS or list of supported OSs per device. I should preferably be able to run search queries within the UI using greater than and less than (<>) operators to verify if my devices.
### Database Changes
Yes, will require a new database model(s), as well as updates to Vendor and Platform models
### External Dependencies
Maybe - need to explore external library(ies) for parsing idiosyncratic vendor OS version strings.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nautobot/dcim/api/urls.py`
Content:
```
1 from nautobot.core.api.routers import OrderedDefaultRouter
2
3 from . import views
4
5 router = OrderedDefaultRouter()
6 router.APIRootView = views.DCIMRootView
7
8 # Locations
9 router.register("location-types", views.LocationTypeViewSet)
10 router.register("locations", views.LocationViewSet)
11
12 # Racks
13 router.register("rack-groups", views.RackGroupViewSet)
14 router.register("racks", views.RackViewSet)
15 router.register("rack-reservations", views.RackReservationViewSet)
16
17 # Device types
18 router.register("hardware-families", views.HardwareFamilyViewSet)
19 router.register("manufacturers", views.ManufacturerViewSet)
20 router.register("device-types", views.DeviceTypeViewSet)
21
22 # Device type components
23 router.register("console-port-templates", views.ConsolePortTemplateViewSet)
24 router.register("console-server-port-templates", views.ConsoleServerPortTemplateViewSet)
25 router.register("power-port-templates", views.PowerPortTemplateViewSet)
26 router.register("power-outlet-templates", views.PowerOutletTemplateViewSet)
27 router.register("interface-templates", views.InterfaceTemplateViewSet)
28 router.register("front-port-templates", views.FrontPortTemplateViewSet)
29 router.register("rear-port-templates", views.RearPortTemplateViewSet)
30 router.register("device-bay-templates", views.DeviceBayTemplateViewSet)
31
32 # Devices
33 router.register("platforms", views.PlatformViewSet)
34 router.register("devices", views.DeviceViewSet)
35
36 # Device components
37 router.register("console-ports", views.ConsolePortViewSet)
38 router.register("console-server-ports", views.ConsoleServerPortViewSet)
39 router.register("power-ports", views.PowerPortViewSet)
40 router.register("power-outlets", views.PowerOutletViewSet)
41 router.register("interfaces", views.InterfaceViewSet)
42 router.register("front-ports", views.FrontPortViewSet)
43 router.register("rear-ports", views.RearPortViewSet)
44 router.register("device-bays", views.DeviceBayViewSet)
45 router.register("inventory-items", views.InventoryItemViewSet)
46
47 # Connections
48 router.register("console-connections", views.ConsoleConnectionViewSet, basename="consoleconnections")
49 router.register("power-connections", views.PowerConnectionViewSet, basename="powerconnections")
50 router.register(
51 "interface-connections",
52 views.InterfaceConnectionViewSet,
53 basename="interfaceconnections",
54 )
55
56 # Cables
57 router.register("cables", views.CableViewSet)
58
59 # Interface Redundancy Group
60 router.register("interface-redundancy-groups", views.InterfaceRedundancyGroupViewSet)
61 router.register("interface-redundancy-group-associations", views.InterfaceRedundancyGroupAssociationViewSet)
62
63 # Virtual chassis
64 router.register("virtual-chassis", views.VirtualChassisViewSet)
65
66 # Power
67 router.register("power-panels", views.PowerPanelViewSet)
68 router.register("power-feeds", views.PowerFeedViewSet)
69
70 # Device Redundancy Group
71 router.register("device-redundancy-groups", views.DeviceRedundancyGroupViewSet)
72
73 # Software images
74 router.register("software-images", views.SoftwareImageViewSet)
75 router.register("software-versions", views.SoftwareVersionViewSet)
76 router.register("device-type-to-software-image", views.DeviceTypeToSoftwareImageViewSet)
77
78 # Miscellaneous
79 router.register("connected-device", views.ConnectedDeviceViewSet, basename="connected-device")
80
81 app_name = "dcim-api"
82 urlpatterns = router.urls
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nautobot/dcim/api/urls.py b/nautobot/dcim/api/urls.py
--- a/nautobot/dcim/api/urls.py
+++ b/nautobot/dcim/api/urls.py
@@ -73,7 +73,7 @@
# Software images
router.register("software-images", views.SoftwareImageViewSet)
router.register("software-versions", views.SoftwareVersionViewSet)
-router.register("device-type-to-software-image", views.DeviceTypeToSoftwareImageViewSet)
+router.register("device-types-to-software-images", views.DeviceTypeToSoftwareImageViewSet)
# Miscellaneous
router.register("connected-device", views.ConnectedDeviceViewSet, basename="connected-device")
|
{"golden_diff": "diff --git a/nautobot/dcim/api/urls.py b/nautobot/dcim/api/urls.py\n--- a/nautobot/dcim/api/urls.py\n+++ b/nautobot/dcim/api/urls.py\n@@ -73,7 +73,7 @@\n # Software images\n router.register(\"software-images\", views.SoftwareImageViewSet)\n router.register(\"software-versions\", views.SoftwareVersionViewSet)\n-router.register(\"device-type-to-software-image\", views.DeviceTypeToSoftwareImageViewSet)\n+router.register(\"device-types-to-software-images\", views.DeviceTypeToSoftwareImageViewSet)\n \n # Miscellaneous\n router.register(\"connected-device\", views.ConnectedDeviceViewSet, basename=\"connected-device\")\n", "issue": "Add support for an OS Model to define target OS image per device\n### Proposed Functionality\r\nSupport a model to define OSs that should be used by each device and ensure there is also a relationship between vendor and platform.\r\n\r\n### Use Case\r\nAs a user, I should be able to define the intended OS or list of supported OSs per device. I should preferably be able to run search queries within the UI using greater than and less than (<>) operators to verify if my devices.\r\n\r\n### Database Changes\r\nYes, will require a new database model(s), as well as updates to Vendor and Platform models\r\n\r\n### External Dependencies\r\nMaybe - need to explore external library(ies) for parsing idiosyncratic vendor OS version strings.\r\n\n", "before_files": [{"content": "from nautobot.core.api.routers import OrderedDefaultRouter\n\nfrom . import views\n\nrouter = OrderedDefaultRouter()\nrouter.APIRootView = views.DCIMRootView\n\n# Locations\nrouter.register(\"location-types\", views.LocationTypeViewSet)\nrouter.register(\"locations\", views.LocationViewSet)\n\n# Racks\nrouter.register(\"rack-groups\", views.RackGroupViewSet)\nrouter.register(\"racks\", views.RackViewSet)\nrouter.register(\"rack-reservations\", views.RackReservationViewSet)\n\n# Device types\nrouter.register(\"hardware-families\", views.HardwareFamilyViewSet)\nrouter.register(\"manufacturers\", views.ManufacturerViewSet)\nrouter.register(\"device-types\", views.DeviceTypeViewSet)\n\n# Device type components\nrouter.register(\"console-port-templates\", views.ConsolePortTemplateViewSet)\nrouter.register(\"console-server-port-templates\", views.ConsoleServerPortTemplateViewSet)\nrouter.register(\"power-port-templates\", views.PowerPortTemplateViewSet)\nrouter.register(\"power-outlet-templates\", views.PowerOutletTemplateViewSet)\nrouter.register(\"interface-templates\", views.InterfaceTemplateViewSet)\nrouter.register(\"front-port-templates\", views.FrontPortTemplateViewSet)\nrouter.register(\"rear-port-templates\", views.RearPortTemplateViewSet)\nrouter.register(\"device-bay-templates\", views.DeviceBayTemplateViewSet)\n\n# Devices\nrouter.register(\"platforms\", views.PlatformViewSet)\nrouter.register(\"devices\", views.DeviceViewSet)\n\n# Device components\nrouter.register(\"console-ports\", views.ConsolePortViewSet)\nrouter.register(\"console-server-ports\", views.ConsoleServerPortViewSet)\nrouter.register(\"power-ports\", views.PowerPortViewSet)\nrouter.register(\"power-outlets\", views.PowerOutletViewSet)\nrouter.register(\"interfaces\", views.InterfaceViewSet)\nrouter.register(\"front-ports\", views.FrontPortViewSet)\nrouter.register(\"rear-ports\", views.RearPortViewSet)\nrouter.register(\"device-bays\", views.DeviceBayViewSet)\nrouter.register(\"inventory-items\", views.InventoryItemViewSet)\n\n# Connections\nrouter.register(\"console-connections\", views.ConsoleConnectionViewSet, basename=\"consoleconnections\")\nrouter.register(\"power-connections\", views.PowerConnectionViewSet, basename=\"powerconnections\")\nrouter.register(\n \"interface-connections\",\n views.InterfaceConnectionViewSet,\n basename=\"interfaceconnections\",\n)\n\n# Cables\nrouter.register(\"cables\", views.CableViewSet)\n\n# Interface Redundancy Group\nrouter.register(\"interface-redundancy-groups\", views.InterfaceRedundancyGroupViewSet)\nrouter.register(\"interface-redundancy-group-associations\", views.InterfaceRedundancyGroupAssociationViewSet)\n\n# Virtual chassis\nrouter.register(\"virtual-chassis\", views.VirtualChassisViewSet)\n\n# Power\nrouter.register(\"power-panels\", views.PowerPanelViewSet)\nrouter.register(\"power-feeds\", views.PowerFeedViewSet)\n\n# Device Redundancy Group\nrouter.register(\"device-redundancy-groups\", views.DeviceRedundancyGroupViewSet)\n\n# Software images\nrouter.register(\"software-images\", views.SoftwareImageViewSet)\nrouter.register(\"software-versions\", views.SoftwareVersionViewSet)\nrouter.register(\"device-type-to-software-image\", views.DeviceTypeToSoftwareImageViewSet)\n\n# Miscellaneous\nrouter.register(\"connected-device\", views.ConnectedDeviceViewSet, basename=\"connected-device\")\n\napp_name = \"dcim-api\"\nurlpatterns = router.urls\n", "path": "nautobot/dcim/api/urls.py"}], "after_files": [{"content": "from nautobot.core.api.routers import OrderedDefaultRouter\n\nfrom . import views\n\nrouter = OrderedDefaultRouter()\nrouter.APIRootView = views.DCIMRootView\n\n# Locations\nrouter.register(\"location-types\", views.LocationTypeViewSet)\nrouter.register(\"locations\", views.LocationViewSet)\n\n# Racks\nrouter.register(\"rack-groups\", views.RackGroupViewSet)\nrouter.register(\"racks\", views.RackViewSet)\nrouter.register(\"rack-reservations\", views.RackReservationViewSet)\n\n# Device types\nrouter.register(\"hardware-families\", views.HardwareFamilyViewSet)\nrouter.register(\"manufacturers\", views.ManufacturerViewSet)\nrouter.register(\"device-types\", views.DeviceTypeViewSet)\n\n# Device type components\nrouter.register(\"console-port-templates\", views.ConsolePortTemplateViewSet)\nrouter.register(\"console-server-port-templates\", views.ConsoleServerPortTemplateViewSet)\nrouter.register(\"power-port-templates\", views.PowerPortTemplateViewSet)\nrouter.register(\"power-outlet-templates\", views.PowerOutletTemplateViewSet)\nrouter.register(\"interface-templates\", views.InterfaceTemplateViewSet)\nrouter.register(\"front-port-templates\", views.FrontPortTemplateViewSet)\nrouter.register(\"rear-port-templates\", views.RearPortTemplateViewSet)\nrouter.register(\"device-bay-templates\", views.DeviceBayTemplateViewSet)\n\n# Devices\nrouter.register(\"platforms\", views.PlatformViewSet)\nrouter.register(\"devices\", views.DeviceViewSet)\n\n# Device components\nrouter.register(\"console-ports\", views.ConsolePortViewSet)\nrouter.register(\"console-server-ports\", views.ConsoleServerPortViewSet)\nrouter.register(\"power-ports\", views.PowerPortViewSet)\nrouter.register(\"power-outlets\", views.PowerOutletViewSet)\nrouter.register(\"interfaces\", views.InterfaceViewSet)\nrouter.register(\"front-ports\", views.FrontPortViewSet)\nrouter.register(\"rear-ports\", views.RearPortViewSet)\nrouter.register(\"device-bays\", views.DeviceBayViewSet)\nrouter.register(\"inventory-items\", views.InventoryItemViewSet)\n\n# Connections\nrouter.register(\"console-connections\", views.ConsoleConnectionViewSet, basename=\"consoleconnections\")\nrouter.register(\"power-connections\", views.PowerConnectionViewSet, basename=\"powerconnections\")\nrouter.register(\n \"interface-connections\",\n views.InterfaceConnectionViewSet,\n basename=\"interfaceconnections\",\n)\n\n# Cables\nrouter.register(\"cables\", views.CableViewSet)\n\n# Interface Redundancy Group\nrouter.register(\"interface-redundancy-groups\", views.InterfaceRedundancyGroupViewSet)\nrouter.register(\"interface-redundancy-group-associations\", views.InterfaceRedundancyGroupAssociationViewSet)\n\n# Virtual chassis\nrouter.register(\"virtual-chassis\", views.VirtualChassisViewSet)\n\n# Power\nrouter.register(\"power-panels\", views.PowerPanelViewSet)\nrouter.register(\"power-feeds\", views.PowerFeedViewSet)\n\n# Device Redundancy Group\nrouter.register(\"device-redundancy-groups\", views.DeviceRedundancyGroupViewSet)\n\n# Software images\nrouter.register(\"software-images\", views.SoftwareImageViewSet)\nrouter.register(\"software-versions\", views.SoftwareVersionViewSet)\nrouter.register(\"device-types-to-software-images\", views.DeviceTypeToSoftwareImageViewSet)\n\n# Miscellaneous\nrouter.register(\"connected-device\", views.ConnectedDeviceViewSet, basename=\"connected-device\")\n\napp_name = \"dcim-api\"\nurlpatterns = router.urls\n", "path": "nautobot/dcim/api/urls.py"}]}
| 1,250 | 147 |
gh_patches_debug_1490
|
rasdani/github-patches
|
git_diff
|
coala__coala-bears-2811
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HgCommitBear: Make asciinema
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bears/vcs/mercurial/HgCommitBear.py`
Content:
```
1 import os
2 import shutil
3
4 from bears.vcs.CommitBear import _CommitBear
5 from coala_utils.ContextManagers import change_directory
6 from coalib.misc.Shell import run_shell_command
7
8
9 class HgCommitBear(_CommitBear):
10 LANGUAGES = {'Hg'}
11 CAN_DETECT = {'Formatting'}
12
13 @classmethod
14 def check_prerequisites(cls):
15 if shutil.which('hg') is None:
16 return 'hg is not installed.'
17 else:
18 return True
19
20 def get_remotes():
21 remotes, _ = run_shell_command('hg paths')
22 return remotes
23
24 def get_head_commit(self):
25 with change_directory(self.get_config_dir() or os.getcwd()):
26 return run_shell_command('hg log -l 1 --template "{desc}"')
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bears/vcs/mercurial/HgCommitBear.py b/bears/vcs/mercurial/HgCommitBear.py
--- a/bears/vcs/mercurial/HgCommitBear.py
+++ b/bears/vcs/mercurial/HgCommitBear.py
@@ -9,6 +9,7 @@
class HgCommitBear(_CommitBear):
LANGUAGES = {'Hg'}
CAN_DETECT = {'Formatting'}
+ ASCIINEMA_URL = 'https://asciinema.org/a/3Kfn2EDjYLmsbPoL7lRuLyhlN'
@classmethod
def check_prerequisites(cls):
|
{"golden_diff": "diff --git a/bears/vcs/mercurial/HgCommitBear.py b/bears/vcs/mercurial/HgCommitBear.py\n--- a/bears/vcs/mercurial/HgCommitBear.py\n+++ b/bears/vcs/mercurial/HgCommitBear.py\n@@ -9,6 +9,7 @@\n class HgCommitBear(_CommitBear):\n LANGUAGES = {'Hg'}\n CAN_DETECT = {'Formatting'}\n+ ASCIINEMA_URL = 'https://asciinema.org/a/3Kfn2EDjYLmsbPoL7lRuLyhlN'\n \n @classmethod\n def check_prerequisites(cls):\n", "issue": "HgCommitBear: Make asciinema\n\n", "before_files": [{"content": "import os\nimport shutil\n\nfrom bears.vcs.CommitBear import _CommitBear\nfrom coala_utils.ContextManagers import change_directory\nfrom coalib.misc.Shell import run_shell_command\n\n\nclass HgCommitBear(_CommitBear):\n LANGUAGES = {'Hg'}\n CAN_DETECT = {'Formatting'}\n\n @classmethod\n def check_prerequisites(cls):\n if shutil.which('hg') is None:\n return 'hg is not installed.'\n else:\n return True\n\n def get_remotes():\n remotes, _ = run_shell_command('hg paths')\n return remotes\n\n def get_head_commit(self):\n with change_directory(self.get_config_dir() or os.getcwd()):\n return run_shell_command('hg log -l 1 --template \"{desc}\"')\n", "path": "bears/vcs/mercurial/HgCommitBear.py"}], "after_files": [{"content": "import os\nimport shutil\n\nfrom bears.vcs.CommitBear import _CommitBear\nfrom coala_utils.ContextManagers import change_directory\nfrom coalib.misc.Shell import run_shell_command\n\n\nclass HgCommitBear(_CommitBear):\n LANGUAGES = {'Hg'}\n CAN_DETECT = {'Formatting'}\n ASCIINEMA_URL = 'https://asciinema.org/a/3Kfn2EDjYLmsbPoL7lRuLyhlN'\n\n @classmethod\n def check_prerequisites(cls):\n if shutil.which('hg') is None:\n return 'hg is not installed.'\n else:\n return True\n\n def get_remotes():\n remotes, _ = run_shell_command('hg paths')\n return remotes\n\n def get_head_commit(self):\n with change_directory(self.get_config_dir() or os.getcwd()):\n return run_shell_command('hg log -l 1 --template \"{desc}\"')\n", "path": "bears/vcs/mercurial/HgCommitBear.py"}]}
| 490 | 146 |
gh_patches_debug_2203
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-4145
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
v1 api crashes on some content when serializing to xml
See the very old ticket at https://github.com/django-tastypie/django-tastypie/issues/1107.
submission.first_two_pages can contain formfeeds. These break tastypie's xml serialization. Json serialization succeeds.
The quick fix is to stop exposing first_two_pages through the API.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/submit/resources.py`
Content:
```
1 # Copyright The IETF Trust 2014-2019, All Rights Reserved
2 # -*- coding: utf-8 -*-
3 # Autogenerated by the mkresources management command 2014-11-13 23:53
4
5
6 from ietf.api import ModelResource
7 from tastypie.fields import ToOneField, ToManyField
8 from tastypie.constants import ALL, ALL_WITH_RELATIONS
9 from tastypie.cache import SimpleCache
10
11 from ietf import api
12 from ietf.submit.models import ( Preapproval, SubmissionCheck, Submission,
13 SubmissionEmailEvent, SubmissionEvent, SubmissionExtResource )
14 from ietf.person.resources import PersonResource
15
16
17 class PreapprovalResource(ModelResource):
18 by = ToOneField(PersonResource, 'by')
19 class Meta:
20 cache = SimpleCache()
21 queryset = Preapproval.objects.all()
22 serializer = api.Serializer()
23 #resource_name = 'preapproval'
24 ordering = ['id', ]
25 filtering = {
26 "id": ALL,
27 "name": ALL,
28 "time": ALL,
29 "by": ALL_WITH_RELATIONS,
30 }
31 api.submit.register(PreapprovalResource())
32
33 from ietf.group.resources import GroupResource
34 from ietf.name.resources import DraftSubmissionStateNameResource
35 from ietf.doc.resources import DocumentResource
36 class SubmissionResource(ModelResource):
37 state = ToOneField(DraftSubmissionStateNameResource, 'state')
38 group = ToOneField(GroupResource, 'group', null=True)
39 draft = ToOneField(DocumentResource, 'draft', null=True)
40 checks = ToManyField('ietf.submit.resources.SubmissionCheckResource', 'checks', null=True)
41 class Meta:
42 cache = SimpleCache()
43 queryset = Submission.objects.all()
44 serializer = api.Serializer()
45 #resource_name = 'submission'
46 ordering = ['id', ]
47 filtering = {
48 "id": ALL,
49 "remote_ip": ALL,
50 "access_key": ALL,
51 "auth_key": ALL,
52 "name": ALL,
53 "title": ALL,
54 "abstract": ALL,
55 "rev": ALL,
56 "pages": ALL,
57 "authors": ALL,
58 "note": ALL,
59 "replaces": ALL,
60 "first_two_pages": ALL,
61 "file_types": ALL,
62 "file_size": ALL,
63 "document_date": ALL,
64 "submission_date": ALL,
65 "submitter": ALL,
66 "xml_version": ALL,
67 "state": ALL_WITH_RELATIONS,
68 "group": ALL_WITH_RELATIONS,
69 "draft": ALL_WITH_RELATIONS,
70 }
71 api.submit.register(SubmissionResource())
72
73 from ietf.person.resources import PersonResource
74 class SubmissionEventResource(ModelResource):
75 submission = ToOneField(SubmissionResource, 'submission')
76 by = ToOneField(PersonResource, 'by', null=True)
77 class Meta:
78 cache = SimpleCache()
79 queryset = SubmissionEvent.objects.all()
80 serializer = api.Serializer()
81 #resource_name = 'submissionevent'
82 ordering = ['id', ]
83 filtering = {
84 "id": ALL,
85 "time": ALL,
86 "desc": ALL,
87 "submission": ALL_WITH_RELATIONS,
88 "by": ALL_WITH_RELATIONS,
89 }
90 api.submit.register(SubmissionEventResource())
91
92 class SubmissionCheckResource(ModelResource):
93 submission = ToOneField(SubmissionResource, 'submission')
94 class Meta:
95 cache = SimpleCache()
96 queryset = SubmissionCheck.objects.all()
97 serializer = api.Serializer()
98 #resource_name = 'submissioncheck'
99 ordering = ['id', ]
100 filtering = {
101 "id": ALL,
102 "time": ALL,
103 "checker": ALL,
104 "passed": ALL,
105 "message": ALL,
106 "errors": ALL,
107 "warnings": ALL,
108 "items": ALL,
109 "submission": ALL_WITH_RELATIONS,
110 }
111 api.submit.register(SubmissionCheckResource())
112
113
114
115 from ietf.person.resources import PersonResource
116 from ietf.message.resources import MessageResource
117 class SubmissionEmailEventResource(ModelResource):
118 submission = ToOneField(SubmissionResource, 'submission')
119 by = ToOneField(PersonResource, 'by', null=True)
120 submissionevent_ptr = ToOneField(SubmissionEventResource, 'submissionevent_ptr')
121 message = ToOneField(MessageResource, 'message', null=True)
122 in_reply_to = ToOneField(MessageResource, 'in_reply_to', null=True)
123 class Meta:
124 queryset = SubmissionEmailEvent.objects.all()
125 serializer = api.Serializer()
126 cache = SimpleCache()
127 #resource_name = 'submissionemailevent'
128 ordering = ['id', ]
129 filtering = {
130 "id": ALL,
131 "time": ALL,
132 "desc": ALL,
133 "msgtype": ALL,
134 "submission": ALL_WITH_RELATIONS,
135 "by": ALL_WITH_RELATIONS,
136 "submissionevent_ptr": ALL_WITH_RELATIONS,
137 "message": ALL_WITH_RELATIONS,
138 "in_reply_to": ALL_WITH_RELATIONS,
139 }
140 api.submit.register(SubmissionEmailEventResource())
141
142
143
144 from ietf.name.resources import ExtResourceNameResource
145 class SubmissionExtResourceResource(ModelResource):
146 name = ToOneField(ExtResourceNameResource, 'name')
147 submission = ToOneField(SubmissionResource, 'submission')
148 class Meta:
149 queryset = SubmissionExtResource.objects.all()
150 serializer = api.Serializer()
151 cache = SimpleCache()
152 resource_name = 'submissionextresource'
153 ordering = ['id', ]
154 filtering = {
155 "id": ALL,
156 "display_name": ALL,
157 "value": ALL,
158 "name": ALL_WITH_RELATIONS,
159 "submission": ALL_WITH_RELATIONS,
160 }
161 api.submit.register(SubmissionExtResourceResource())
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/submit/resources.py b/ietf/submit/resources.py
--- a/ietf/submit/resources.py
+++ b/ietf/submit/resources.py
@@ -68,6 +68,7 @@
"group": ALL_WITH_RELATIONS,
"draft": ALL_WITH_RELATIONS,
}
+ excludes = ('first_two_pages',)
api.submit.register(SubmissionResource())
from ietf.person.resources import PersonResource
|
{"golden_diff": "diff --git a/ietf/submit/resources.py b/ietf/submit/resources.py\n--- a/ietf/submit/resources.py\n+++ b/ietf/submit/resources.py\n@@ -68,6 +68,7 @@\n \"group\": ALL_WITH_RELATIONS,\n \"draft\": ALL_WITH_RELATIONS,\n }\n+ excludes = ('first_two_pages',)\n api.submit.register(SubmissionResource())\n \n from ietf.person.resources import PersonResource\n", "issue": "v1 api crashes on some content when serializing to xml\nSee the very old ticket at https://github.com/django-tastypie/django-tastypie/issues/1107.\r\n\r\nsubmission.first_two_pages can contain formfeeds. These break tastypie's xml serialization. Json serialization succeeds.\r\n\r\nThe quick fix is to stop exposing first_two_pages through the API.\r\n\r\n\n", "before_files": [{"content": "# Copyright The IETF Trust 2014-2019, All Rights Reserved\n# -*- coding: utf-8 -*-\n# Autogenerated by the mkresources management command 2014-11-13 23:53\n\n\nfrom ietf.api import ModelResource\nfrom tastypie.fields import ToOneField, ToManyField\nfrom tastypie.constants import ALL, ALL_WITH_RELATIONS\nfrom tastypie.cache import SimpleCache\n\nfrom ietf import api\nfrom ietf.submit.models import ( Preapproval, SubmissionCheck, Submission,\n SubmissionEmailEvent, SubmissionEvent, SubmissionExtResource )\nfrom ietf.person.resources import PersonResource\n\n\nclass PreapprovalResource(ModelResource):\n by = ToOneField(PersonResource, 'by')\n class Meta:\n cache = SimpleCache()\n queryset = Preapproval.objects.all()\n serializer = api.Serializer()\n #resource_name = 'preapproval'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"name\": ALL,\n \"time\": ALL,\n \"by\": ALL_WITH_RELATIONS,\n }\napi.submit.register(PreapprovalResource())\n\nfrom ietf.group.resources import GroupResource\nfrom ietf.name.resources import DraftSubmissionStateNameResource\nfrom ietf.doc.resources import DocumentResource\nclass SubmissionResource(ModelResource):\n state = ToOneField(DraftSubmissionStateNameResource, 'state')\n group = ToOneField(GroupResource, 'group', null=True)\n draft = ToOneField(DocumentResource, 'draft', null=True)\n checks = ToManyField('ietf.submit.resources.SubmissionCheckResource', 'checks', null=True)\n class Meta:\n cache = SimpleCache()\n queryset = Submission.objects.all()\n serializer = api.Serializer()\n #resource_name = 'submission'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"remote_ip\": ALL,\n \"access_key\": ALL,\n \"auth_key\": ALL,\n \"name\": ALL,\n \"title\": ALL,\n \"abstract\": ALL,\n \"rev\": ALL,\n \"pages\": ALL,\n \"authors\": ALL,\n \"note\": ALL,\n \"replaces\": ALL,\n \"first_two_pages\": ALL,\n \"file_types\": ALL,\n \"file_size\": ALL,\n \"document_date\": ALL,\n \"submission_date\": ALL,\n \"submitter\": ALL,\n \"xml_version\": ALL,\n \"state\": ALL_WITH_RELATIONS,\n \"group\": ALL_WITH_RELATIONS,\n \"draft\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionResource())\n\nfrom ietf.person.resources import PersonResource\nclass SubmissionEventResource(ModelResource):\n submission = ToOneField(SubmissionResource, 'submission')\n by = ToOneField(PersonResource, 'by', null=True)\n class Meta:\n cache = SimpleCache()\n queryset = SubmissionEvent.objects.all()\n serializer = api.Serializer()\n #resource_name = 'submissionevent'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"time\": ALL,\n \"desc\": ALL,\n \"submission\": ALL_WITH_RELATIONS,\n \"by\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionEventResource())\n\nclass SubmissionCheckResource(ModelResource):\n submission = ToOneField(SubmissionResource, 'submission')\n class Meta:\n cache = SimpleCache()\n queryset = SubmissionCheck.objects.all()\n serializer = api.Serializer()\n #resource_name = 'submissioncheck'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"time\": ALL,\n \"checker\": ALL,\n \"passed\": ALL,\n \"message\": ALL,\n \"errors\": ALL,\n \"warnings\": ALL,\n \"items\": ALL,\n \"submission\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionCheckResource())\n\n\n\nfrom ietf.person.resources import PersonResource\nfrom ietf.message.resources import MessageResource\nclass SubmissionEmailEventResource(ModelResource):\n submission = ToOneField(SubmissionResource, 'submission')\n by = ToOneField(PersonResource, 'by', null=True)\n submissionevent_ptr = ToOneField(SubmissionEventResource, 'submissionevent_ptr')\n message = ToOneField(MessageResource, 'message', null=True)\n in_reply_to = ToOneField(MessageResource, 'in_reply_to', null=True)\n class Meta:\n queryset = SubmissionEmailEvent.objects.all()\n serializer = api.Serializer()\n cache = SimpleCache()\n #resource_name = 'submissionemailevent'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"time\": ALL,\n \"desc\": ALL,\n \"msgtype\": ALL,\n \"submission\": ALL_WITH_RELATIONS,\n \"by\": ALL_WITH_RELATIONS,\n \"submissionevent_ptr\": ALL_WITH_RELATIONS,\n \"message\": ALL_WITH_RELATIONS,\n \"in_reply_to\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionEmailEventResource())\n\n\n\nfrom ietf.name.resources import ExtResourceNameResource\nclass SubmissionExtResourceResource(ModelResource):\n name = ToOneField(ExtResourceNameResource, 'name')\n submission = ToOneField(SubmissionResource, 'submission')\n class Meta:\n queryset = SubmissionExtResource.objects.all()\n serializer = api.Serializer()\n cache = SimpleCache()\n resource_name = 'submissionextresource'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"display_name\": ALL,\n \"value\": ALL,\n \"name\": ALL_WITH_RELATIONS,\n \"submission\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionExtResourceResource())\n", "path": "ietf/submit/resources.py"}], "after_files": [{"content": "# Copyright The IETF Trust 2014-2019, All Rights Reserved\n# -*- coding: utf-8 -*-\n# Autogenerated by the mkresources management command 2014-11-13 23:53\n\n\nfrom ietf.api import ModelResource\nfrom tastypie.fields import ToOneField, ToManyField\nfrom tastypie.constants import ALL, ALL_WITH_RELATIONS\nfrom tastypie.cache import SimpleCache\n\nfrom ietf import api\nfrom ietf.submit.models import ( Preapproval, SubmissionCheck, Submission,\n SubmissionEmailEvent, SubmissionEvent, SubmissionExtResource )\nfrom ietf.person.resources import PersonResource\n\n\nclass PreapprovalResource(ModelResource):\n by = ToOneField(PersonResource, 'by')\n class Meta:\n cache = SimpleCache()\n queryset = Preapproval.objects.all()\n serializer = api.Serializer()\n #resource_name = 'preapproval'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"name\": ALL,\n \"time\": ALL,\n \"by\": ALL_WITH_RELATIONS,\n }\napi.submit.register(PreapprovalResource())\n\nfrom ietf.group.resources import GroupResource\nfrom ietf.name.resources import DraftSubmissionStateNameResource\nfrom ietf.doc.resources import DocumentResource\nclass SubmissionResource(ModelResource):\n state = ToOneField(DraftSubmissionStateNameResource, 'state')\n group = ToOneField(GroupResource, 'group', null=True)\n draft = ToOneField(DocumentResource, 'draft', null=True)\n checks = ToManyField('ietf.submit.resources.SubmissionCheckResource', 'checks', null=True)\n class Meta:\n cache = SimpleCache()\n queryset = Submission.objects.all()\n serializer = api.Serializer()\n #resource_name = 'submission'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"remote_ip\": ALL,\n \"access_key\": ALL,\n \"auth_key\": ALL,\n \"name\": ALL,\n \"title\": ALL,\n \"abstract\": ALL,\n \"rev\": ALL,\n \"pages\": ALL,\n \"authors\": ALL,\n \"note\": ALL,\n \"replaces\": ALL,\n \"first_two_pages\": ALL,\n \"file_types\": ALL,\n \"file_size\": ALL,\n \"document_date\": ALL,\n \"submission_date\": ALL,\n \"submitter\": ALL,\n \"xml_version\": ALL,\n \"state\": ALL_WITH_RELATIONS,\n \"group\": ALL_WITH_RELATIONS,\n \"draft\": ALL_WITH_RELATIONS,\n }\n excludes = ('first_two_pages',)\napi.submit.register(SubmissionResource())\n\nfrom ietf.person.resources import PersonResource\nclass SubmissionEventResource(ModelResource):\n submission = ToOneField(SubmissionResource, 'submission')\n by = ToOneField(PersonResource, 'by', null=True)\n class Meta:\n cache = SimpleCache()\n queryset = SubmissionEvent.objects.all()\n serializer = api.Serializer()\n #resource_name = 'submissionevent'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"time\": ALL,\n \"desc\": ALL,\n \"submission\": ALL_WITH_RELATIONS,\n \"by\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionEventResource())\n\nclass SubmissionCheckResource(ModelResource):\n submission = ToOneField(SubmissionResource, 'submission')\n class Meta:\n cache = SimpleCache()\n queryset = SubmissionCheck.objects.all()\n serializer = api.Serializer()\n #resource_name = 'submissioncheck'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"time\": ALL,\n \"checker\": ALL,\n \"passed\": ALL,\n \"message\": ALL,\n \"errors\": ALL,\n \"warnings\": ALL,\n \"items\": ALL,\n \"submission\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionCheckResource())\n\n\n\nfrom ietf.person.resources import PersonResource\nfrom ietf.message.resources import MessageResource\nclass SubmissionEmailEventResource(ModelResource):\n submission = ToOneField(SubmissionResource, 'submission')\n by = ToOneField(PersonResource, 'by', null=True)\n submissionevent_ptr = ToOneField(SubmissionEventResource, 'submissionevent_ptr')\n message = ToOneField(MessageResource, 'message', null=True)\n in_reply_to = ToOneField(MessageResource, 'in_reply_to', null=True)\n class Meta:\n queryset = SubmissionEmailEvent.objects.all()\n serializer = api.Serializer()\n cache = SimpleCache()\n #resource_name = 'submissionemailevent'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"time\": ALL,\n \"desc\": ALL,\n \"msgtype\": ALL,\n \"submission\": ALL_WITH_RELATIONS,\n \"by\": ALL_WITH_RELATIONS,\n \"submissionevent_ptr\": ALL_WITH_RELATIONS,\n \"message\": ALL_WITH_RELATIONS,\n \"in_reply_to\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionEmailEventResource())\n\n\n\nfrom ietf.name.resources import ExtResourceNameResource\nclass SubmissionExtResourceResource(ModelResource):\n name = ToOneField(ExtResourceNameResource, 'name')\n submission = ToOneField(SubmissionResource, 'submission')\n class Meta:\n queryset = SubmissionExtResource.objects.all()\n serializer = api.Serializer()\n cache = SimpleCache()\n resource_name = 'submissionextresource'\n ordering = ['id', ]\n filtering = { \n \"id\": ALL,\n \"display_name\": ALL,\n \"value\": ALL,\n \"name\": ALL_WITH_RELATIONS,\n \"submission\": ALL_WITH_RELATIONS,\n }\napi.submit.register(SubmissionExtResourceResource())\n", "path": "ietf/submit/resources.py"}]}
| 1,954 | 95 |
gh_patches_debug_26289
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-4506
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/expectations/regex_based_column_map_expectation_template.py`
Content:
```
1 """
2 This is a template for creating custom RegexBasedColumnMapExpectations.
3 For detailed instructions on how to use it, please see:
4 https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_regex_based_column_map_expectations
5 """
6
7 from typing import Dict, Optional
8
9 from great_expectations.core.expectation_configuration import ExpectationConfiguration
10 from great_expectations.exceptions.exceptions import (
11 InvalidExpectationConfigurationError,
12 )
13 from great_expectations.expectations.regex_based_column_map_expectation import (
14 RegexBasedColumnMapExpectation,
15 RegexColumnMapMetricProvider,
16 )
17
18
19 # <snippet>
20 # This class defines the Expectation itself
21 class ExpectColumnValuesToMatchSomeRegex(RegexBasedColumnMapExpectation):
22 """TODO: Add a docstring here"""
23
24 # These values will be used to configure the metric created by your expectation
25 regex_snake_name = "regex_name"
26 regex_camel_name = "RegexName"
27 regex = "regex pattern"
28 semantic_type_name_plural = None
29
30 # These examples will be shown in the public gallery.
31 # They will also be executed as unit tests for your Expectation.
32 examples = []
33
34 def validate_configuration(self, configuration: Optional[ExpectationConfiguration]):
35 """
36 Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that
37 necessary configuration arguments have been provided for the validation of the expectation.
38
39 Args:
40 configuration (OPTIONAL[ExpectationConfiguration]): \
41 An optional Expectation Configuration entry that will be used to configure the expectation
42 Returns:
43 True if the configuration has been validated successfully. Otherwise, raises an exception
44 """
45
46 super().validate_configuration(configuration)
47 if configuration is None:
48 configuration = self.configuration
49
50 # # Check other things in configuration.kwargs and raise Exceptions if needed
51 # try:
52 # assert (
53 # ...
54 # ), "message"
55 # assert (
56 # ...
57 # ), "message"
58 # except AssertionError as e:
59 # raise InvalidExpectationConfigurationError(str(e))
60
61 return True
62
63 # Here your regex is used to create a custom metric for this expectation
64 map_metric = RegexBasedColumnMapExpectation.register_metric(
65 regex_snake_name=regex_snake_name,
66 regex_camel_name=regex_camel_name,
67 regex_=regex,
68 )
69
70 # This object contains metadata for display in the public Gallery
71 library_metadata = {
72 "tags": [], # Tags for this Expectation in the Gallery
73 "contributors": [ # Github handles for all contributors to this Expectation.
74 "@your_name_here", # Don't forget to add your github handle here!
75 ],
76 }
77
78
79 # </snippet>
80 if __name__ == "__main__":
81 ExpectColumnValuesToMatchSomeRegex().print_diagnostic_checklist()
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/expectations/regex_based_column_map_expectation_template.py b/examples/expectations/regex_based_column_map_expectation_template.py
--- a/examples/expectations/regex_based_column_map_expectation_template.py
+++ b/examples/expectations/regex_based_column_map_expectation_template.py
@@ -31,35 +31,6 @@
# They will also be executed as unit tests for your Expectation.
examples = []
- def validate_configuration(self, configuration: Optional[ExpectationConfiguration]):
- """
- Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that
- necessary configuration arguments have been provided for the validation of the expectation.
-
- Args:
- configuration (OPTIONAL[ExpectationConfiguration]): \
- An optional Expectation Configuration entry that will be used to configure the expectation
- Returns:
- True if the configuration has been validated successfully. Otherwise, raises an exception
- """
-
- super().validate_configuration(configuration)
- if configuration is None:
- configuration = self.configuration
-
- # # Check other things in configuration.kwargs and raise Exceptions if needed
- # try:
- # assert (
- # ...
- # ), "message"
- # assert (
- # ...
- # ), "message"
- # except AssertionError as e:
- # raise InvalidExpectationConfigurationError(str(e))
-
- return True
-
# Here your regex is used to create a custom metric for this expectation
map_metric = RegexBasedColumnMapExpectation.register_metric(
regex_snake_name=regex_snake_name,
|
{"golden_diff": "diff --git a/examples/expectations/regex_based_column_map_expectation_template.py b/examples/expectations/regex_based_column_map_expectation_template.py\n--- a/examples/expectations/regex_based_column_map_expectation_template.py\n+++ b/examples/expectations/regex_based_column_map_expectation_template.py\n@@ -31,35 +31,6 @@\n # They will also be executed as unit tests for your Expectation.\n examples = []\n \n- def validate_configuration(self, configuration: Optional[ExpectationConfiguration]):\n- \"\"\"\n- Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that\n- necessary configuration arguments have been provided for the validation of the expectation.\n-\n- Args:\n- configuration (OPTIONAL[ExpectationConfiguration]): \\\n- An optional Expectation Configuration entry that will be used to configure the expectation\n- Returns:\n- True if the configuration has been validated successfully. Otherwise, raises an exception\n- \"\"\"\n-\n- super().validate_configuration(configuration)\n- if configuration is None:\n- configuration = self.configuration\n-\n- # # Check other things in configuration.kwargs and raise Exceptions if needed\n- # try:\n- # assert (\n- # ...\n- # ), \"message\"\n- # assert (\n- # ...\n- # ), \"message\"\n- # except AssertionError as e:\n- # raise InvalidExpectationConfigurationError(str(e))\n-\n- return True\n-\n # Here your regex is used to create a custom metric for this expectation\n map_metric = RegexBasedColumnMapExpectation.register_metric(\n regex_snake_name=regex_snake_name,\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "\"\"\"\nThis is a template for creating custom RegexBasedColumnMapExpectations.\nFor detailed instructions on how to use it, please see:\n https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_regex_based_column_map_expectations\n\"\"\"\n\nfrom typing import Dict, Optional\n\nfrom great_expectations.core.expectation_configuration import ExpectationConfiguration\nfrom great_expectations.exceptions.exceptions import (\n InvalidExpectationConfigurationError,\n)\nfrom great_expectations.expectations.regex_based_column_map_expectation import (\n RegexBasedColumnMapExpectation,\n RegexColumnMapMetricProvider,\n)\n\n\n# <snippet>\n# This class defines the Expectation itself\nclass ExpectColumnValuesToMatchSomeRegex(RegexBasedColumnMapExpectation):\n \"\"\"TODO: Add a docstring here\"\"\"\n\n # These values will be used to configure the metric created by your expectation\n regex_snake_name = \"regex_name\"\n regex_camel_name = \"RegexName\"\n regex = \"regex pattern\"\n semantic_type_name_plural = None\n\n # These examples will be shown in the public gallery.\n # They will also be executed as unit tests for your Expectation.\n examples = []\n\n def validate_configuration(self, configuration: Optional[ExpectationConfiguration]):\n \"\"\"\n Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that\n necessary configuration arguments have been provided for the validation of the expectation.\n\n Args:\n configuration (OPTIONAL[ExpectationConfiguration]): \\\n An optional Expectation Configuration entry that will be used to configure the expectation\n Returns:\n True if the configuration has been validated successfully. Otherwise, raises an exception\n \"\"\"\n\n super().validate_configuration(configuration)\n if configuration is None:\n configuration = self.configuration\n\n # # Check other things in configuration.kwargs and raise Exceptions if needed\n # try:\n # assert (\n # ...\n # ), \"message\"\n # assert (\n # ...\n # ), \"message\"\n # except AssertionError as e:\n # raise InvalidExpectationConfigurationError(str(e))\n\n return True\n\n # Here your regex is used to create a custom metric for this expectation\n map_metric = RegexBasedColumnMapExpectation.register_metric(\n regex_snake_name=regex_snake_name,\n regex_camel_name=regex_camel_name,\n regex_=regex,\n )\n\n # This object contains metadata for display in the public Gallery\n library_metadata = {\n \"tags\": [], # Tags for this Expectation in the Gallery\n \"contributors\": [ # Github handles for all contributors to this Expectation.\n \"@your_name_here\", # Don't forget to add your github handle here!\n ],\n }\n\n\n# </snippet>\nif __name__ == \"__main__\":\n ExpectColumnValuesToMatchSomeRegex().print_diagnostic_checklist()\n", "path": "examples/expectations/regex_based_column_map_expectation_template.py"}], "after_files": [{"content": "\"\"\"\nThis is a template for creating custom RegexBasedColumnMapExpectations.\nFor detailed instructions on how to use it, please see:\n https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_regex_based_column_map_expectations\n\"\"\"\n\nfrom typing import Dict, Optional\n\nfrom great_expectations.core.expectation_configuration import ExpectationConfiguration\nfrom great_expectations.exceptions.exceptions import (\n InvalidExpectationConfigurationError,\n)\nfrom great_expectations.expectations.regex_based_column_map_expectation import (\n RegexBasedColumnMapExpectation,\n RegexColumnMapMetricProvider,\n)\n\n\n# <snippet>\n# This class defines the Expectation itself\nclass ExpectColumnValuesToMatchSomeRegex(RegexBasedColumnMapExpectation):\n \"\"\"TODO: Add a docstring here\"\"\"\n\n # These values will be used to configure the metric created by your expectation\n regex_snake_name = \"regex_name\"\n regex_camel_name = \"RegexName\"\n regex = \"regex pattern\"\n semantic_type_name_plural = None\n\n # These examples will be shown in the public gallery.\n # They will also be executed as unit tests for your Expectation.\n examples = []\n\n # Here your regex is used to create a custom metric for this expectation\n map_metric = RegexBasedColumnMapExpectation.register_metric(\n regex_snake_name=regex_snake_name,\n regex_camel_name=regex_camel_name,\n regex_=regex,\n )\n\n # This object contains metadata for display in the public Gallery\n library_metadata = {\n \"tags\": [], # Tags for this Expectation in the Gallery\n \"contributors\": [ # Github handles for all contributors to this Expectation.\n \"@your_name_here\", # Don't forget to add your github handle here!\n ],\n }\n\n\n# </snippet>\nif __name__ == \"__main__\":\n ExpectColumnValuesToMatchSomeRegex().print_diagnostic_checklist()\n", "path": "examples/expectations/regex_based_column_map_expectation_template.py"}]}
| 1,072 | 365 |
gh_patches_debug_51093
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-16195
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
argmax
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/tensor.py`
Content:
```
1 # local
2 import ivy
3 import ivy.functional.frontends.paddle as paddle_frontend
4 from ivy.functional.frontends.paddle.func_wrapper import (
5 _to_ivy_array,
6 )
7 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
8
9
10 class Tensor:
11 def __init__(self, array, dtype=None, place="cpu", stop_gradient=True):
12 self._ivy_array = (
13 ivy.array(array, dtype=dtype, device=place)
14 if not isinstance(array, ivy.Array)
15 else array
16 )
17 self._dtype = dtype
18 self._place = place
19 self._stop_gradient = stop_gradient
20
21 def __repr__(self):
22 return (
23 str(self._ivy_array.__repr__())
24 .replace("ivy.array", "ivy.frontends.paddle.Tensor")
25 .replace("dev", "place")
26 )
27
28 # Properties #
29 # ---------- #
30
31 @property
32 def ivy_array(self):
33 return self._ivy_array
34
35 @property
36 def place(self):
37 return self.ivy_array.device
38
39 @property
40 def dtype(self):
41 return self._ivy_array.dtype
42
43 @property
44 def shape(self):
45 return self._ivy_array.shape
46
47 @property
48 def ndim(self):
49 return self.dim()
50
51 # Setters #
52 # --------#
53
54 @ivy_array.setter
55 def ivy_array(self, array):
56 self._ivy_array = (
57 ivy.array(array) if not isinstance(array, ivy.Array) else array
58 )
59
60 # Special Methods #
61 # -------------------#
62
63 def __getitem__(self, item):
64 ivy_args = ivy.nested_map([self, item], _to_ivy_array)
65 ret = ivy.get_item(*ivy_args)
66 return paddle_frontend.Tensor(ret)
67
68 def __setitem__(self, item, value):
69 item, value = ivy.nested_map([item, value], _to_ivy_array)
70 self.ivy_array[item] = value
71
72 def __iter__(self):
73 if self.ndim == 0:
74 raise TypeError("iteration over a 0-d tensor not supported")
75 for i in range(self.shape[0]):
76 yield self[i]
77
78 # Instance Methods #
79 # ---------------- #
80
81 def reshape(self, *args, shape=None):
82 if args and shape:
83 raise TypeError("reshape() got multiple values for argument 'shape'")
84 if shape is not None:
85 return paddle_frontend.reshape(self._ivy_array, shape)
86 if args:
87 if isinstance(args[0], (tuple, list)):
88 shape = args[0]
89 return paddle_frontend.reshape(self._ivy_array, shape)
90 else:
91 return paddle_frontend.reshape(self._ivy_array, args)
92 return paddle_frontend.reshape(self._ivy_array)
93
94 def dim(self):
95 return self.ivy_array.ndim
96
97 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
98 def abs(self):
99 return paddle_frontend.abs(self)
100
101 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
102 def asinh(self, name=None):
103 return ivy.asinh(self._ivy_array)
104
105 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
106 def asin(self, name=None):
107 return ivy.asin(self._ivy_array)
108
109 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
110 def log(self, name=None):
111 return ivy.log(self._ivy_array)
112
113 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
114 def sin(self, name=None):
115 return ivy.sin(self._ivy_array)
116
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/tensor.py b/ivy/functional/frontends/paddle/tensor/tensor.py
--- a/ivy/functional/frontends/paddle/tensor/tensor.py
+++ b/ivy/functional/frontends/paddle/tensor/tensor.py
@@ -114,3 +114,6 @@
def sin(self, name=None):
return ivy.sin(self._ivy_array)
+ @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
+ def argmax(self, axis=None, keepdim=False, dtype=None, name=None):
+ return ivy.argmax(self._ivy_array, axis=axis, keepdims=keepdim, dtype=dtype)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/tensor.py b/ivy/functional/frontends/paddle/tensor/tensor.py\n--- a/ivy/functional/frontends/paddle/tensor/tensor.py\n+++ b/ivy/functional/frontends/paddle/tensor/tensor.py\n@@ -114,3 +114,6 @@\n def sin(self, name=None):\r\n return ivy.sin(self._ivy_array)\r\n \r\n+ @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n+ def argmax(self, axis=None, keepdim=False, dtype=None, name=None):\r\n+ return ivy.argmax(self._ivy_array, axis=axis, keepdims=keepdim, dtype=dtype)\n", "issue": "argmax\n\n", "before_files": [{"content": "# local\r\nimport ivy\r\nimport ivy.functional.frontends.paddle as paddle_frontend\r\nfrom ivy.functional.frontends.paddle.func_wrapper import (\r\n _to_ivy_array,\r\n)\r\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\r\n\r\n\r\nclass Tensor:\r\n def __init__(self, array, dtype=None, place=\"cpu\", stop_gradient=True):\r\n self._ivy_array = (\r\n ivy.array(array, dtype=dtype, device=place)\r\n if not isinstance(array, ivy.Array)\r\n else array\r\n )\r\n self._dtype = dtype\r\n self._place = place\r\n self._stop_gradient = stop_gradient\r\n\r\n def __repr__(self):\r\n return (\r\n str(self._ivy_array.__repr__())\r\n .replace(\"ivy.array\", \"ivy.frontends.paddle.Tensor\")\r\n .replace(\"dev\", \"place\")\r\n )\r\n\r\n # Properties #\r\n # ---------- #\r\n\r\n @property\r\n def ivy_array(self):\r\n return self._ivy_array\r\n\r\n @property\r\n def place(self):\r\n return self.ivy_array.device\r\n\r\n @property\r\n def dtype(self):\r\n return self._ivy_array.dtype\r\n\r\n @property\r\n def shape(self):\r\n return self._ivy_array.shape\r\n\r\n @property\r\n def ndim(self):\r\n return self.dim()\r\n\r\n # Setters #\r\n # --------#\r\n\r\n @ivy_array.setter\r\n def ivy_array(self, array):\r\n self._ivy_array = (\r\n ivy.array(array) if not isinstance(array, ivy.Array) else array\r\n )\r\n\r\n # Special Methods #\r\n # -------------------#\r\n\r\n def __getitem__(self, item):\r\n ivy_args = ivy.nested_map([self, item], _to_ivy_array)\r\n ret = ivy.get_item(*ivy_args)\r\n return paddle_frontend.Tensor(ret)\r\n\r\n def __setitem__(self, item, value):\r\n item, value = ivy.nested_map([item, value], _to_ivy_array)\r\n self.ivy_array[item] = value\r\n\r\n def __iter__(self):\r\n if self.ndim == 0:\r\n raise TypeError(\"iteration over a 0-d tensor not supported\")\r\n for i in range(self.shape[0]):\r\n yield self[i]\r\n\r\n # Instance Methods #\r\n # ---------------- #\r\n\r\n def reshape(self, *args, shape=None):\r\n if args and shape:\r\n raise TypeError(\"reshape() got multiple values for argument 'shape'\")\r\n if shape is not None:\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n if args:\r\n if isinstance(args[0], (tuple, list)):\r\n shape = args[0]\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n else:\r\n return paddle_frontend.reshape(self._ivy_array, args)\r\n return paddle_frontend.reshape(self._ivy_array)\r\n\r\n def dim(self):\r\n return self.ivy_array.ndim\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def abs(self):\r\n return paddle_frontend.abs(self)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def asinh(self, name=None):\r\n return ivy.asinh(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def asin(self, name=None):\r\n return ivy.asin(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def log(self, name=None):\r\n return ivy.log(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def sin(self, name=None):\r\n return ivy.sin(self._ivy_array)\r\n\r\n", "path": "ivy/functional/frontends/paddle/tensor/tensor.py"}], "after_files": [{"content": "# local\r\nimport ivy\r\nimport ivy.functional.frontends.paddle as paddle_frontend\r\nfrom ivy.functional.frontends.paddle.func_wrapper import (\r\n _to_ivy_array,\r\n)\r\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\r\n\r\n\r\nclass Tensor:\r\n def __init__(self, array, dtype=None, place=\"cpu\", stop_gradient=True):\r\n self._ivy_array = (\r\n ivy.array(array, dtype=dtype, device=place)\r\n if not isinstance(array, ivy.Array)\r\n else array\r\n )\r\n self._dtype = dtype\r\n self._place = place\r\n self._stop_gradient = stop_gradient\r\n\r\n def __repr__(self):\r\n return (\r\n str(self._ivy_array.__repr__())\r\n .replace(\"ivy.array\", \"ivy.frontends.paddle.Tensor\")\r\n .replace(\"dev\", \"place\")\r\n )\r\n\r\n # Properties #\r\n # ---------- #\r\n\r\n @property\r\n def ivy_array(self):\r\n return self._ivy_array\r\n\r\n @property\r\n def place(self):\r\n return self.ivy_array.device\r\n\r\n @property\r\n def dtype(self):\r\n return self._ivy_array.dtype\r\n\r\n @property\r\n def shape(self):\r\n return self._ivy_array.shape\r\n\r\n @property\r\n def ndim(self):\r\n return self.dim()\r\n\r\n # Setters #\r\n # --------#\r\n\r\n @ivy_array.setter\r\n def ivy_array(self, array):\r\n self._ivy_array = (\r\n ivy.array(array) if not isinstance(array, ivy.Array) else array\r\n )\r\n\r\n # Special Methods #\r\n # -------------------#\r\n\r\n def __getitem__(self, item):\r\n ivy_args = ivy.nested_map([self, item], _to_ivy_array)\r\n ret = ivy.get_item(*ivy_args)\r\n return paddle_frontend.Tensor(ret)\r\n\r\n def __setitem__(self, item, value):\r\n item, value = ivy.nested_map([item, value], _to_ivy_array)\r\n self.ivy_array[item] = value\r\n\r\n def __iter__(self):\r\n if self.ndim == 0:\r\n raise TypeError(\"iteration over a 0-d tensor not supported\")\r\n for i in range(self.shape[0]):\r\n yield self[i]\r\n\r\n # Instance Methods #\r\n # ---------------- #\r\n\r\n def reshape(self, *args, shape=None):\r\n if args and shape:\r\n raise TypeError(\"reshape() got multiple values for argument 'shape'\")\r\n if shape is not None:\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n if args:\r\n if isinstance(args[0], (tuple, list)):\r\n shape = args[0]\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n else:\r\n return paddle_frontend.reshape(self._ivy_array, args)\r\n return paddle_frontend.reshape(self._ivy_array)\r\n\r\n def dim(self):\r\n return self.ivy_array.ndim\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def abs(self):\r\n return paddle_frontend.abs(self)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def asinh(self, name=None):\r\n return ivy.asinh(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def asin(self, name=None):\r\n return ivy.asin(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def log(self, name=None):\r\n return ivy.log(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def sin(self, name=None):\r\n return ivy.sin(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def argmax(self, axis=None, keepdim=False, dtype=None, name=None):\r\n return ivy.argmax(self._ivy_array, axis=axis, keepdims=keepdim, dtype=dtype)\r\n", "path": "ivy/functional/frontends/paddle/tensor/tensor.py"}]}
| 1,384 | 175 |
gh_patches_debug_10275
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-524
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`sktime` missing dependency
In requirements.txt
`sktime[arima] >= 0.5.0`
bat
`(mindsdb) C:\Users\User>pip install sktime[arima]>=0.5.0
WARNING: sktime 0.7.0 does not provide the extra 'arima'`
install
`(mindsdb) C:\Users\User>pip install sktime[arima]==0.5.0`
`sktime` missing dependency
In requirements.txt
`sktime[arima] >= 0.5.0`
bat
`(mindsdb) C:\Users\User>pip install sktime[arima]>=0.5.0
WARNING: sktime 0.7.0 does not provide the extra 'arima'`
install
`(mindsdb) C:\Users\User>pip install sktime[arima]==0.5.0`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightwood/model/sktime.py`
Content:
```
1 import numpy as np
2 import pandas as pd
3 from typing import Dict, List, Union
4 from sktime.forecasting.arima import AutoARIMA
5
6 from lightwood.api import dtype
7 from lightwood.helpers.log import log
8 from lightwood.model.base import BaseModel
9 from lightwood.encoder.time_series.helpers.common import get_group_matches
10 from lightwood.data.encoded_ds import EncodedDs, ConcatedEncodedDs
11
12
13 class SkTime(BaseModel):
14 forecaster: str
15 n_ts_predictions: int
16 target: str
17 supports_proba: bool
18
19 def __init__(
20 self, stop_after: int, target: str, dtype_dict: Dict[str, str],
21 n_ts_predictions: int, ts_analysis: Dict):
22 super().__init__(stop_after)
23 self.target = target
24 dtype_dict[target] = dtype.float
25 self.model_class = AutoARIMA
26 self.models = {}
27 self.n_ts_predictions = n_ts_predictions
28 self.ts_analysis = ts_analysis
29 self.forecasting_horizon = np.arange(1, self.n_ts_predictions)
30 self.cutoff_index = {} # marks index at which training data stops and forecasting window starts
31 self.grouped_by = ['__default'] if not ts_analysis['tss'].group_by else ts_analysis['tss'].group_by
32 self.supports_proba = False
33 self.stable = True
34
35 def fit(self, ds_arr: List[EncodedDs]) -> None:
36 log.info('Started fitting sktime forecaster for array prediction')
37
38 all_folds = ConcatedEncodedDs(ds_arr)
39 df = all_folds.data_frame.sort_values(by=f'__mdb_original_{self.ts_analysis["tss"].order_by[0]}')
40 data = {'data': df[self.target],
41 'group_info': {gcol: df[gcol].tolist()
42 for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}
43
44 for group in self.ts_analysis['group_combinations']:
45 self.models[group] = self.model_class()
46
47 if self.grouped_by == ['__default']:
48 series_idxs = data['data'].index
49 series_data = data['data'].values
50 else:
51 series_idxs, series_data = get_group_matches(data, group)
52
53 if series_data.size > 0:
54 series = pd.Series(series_data.squeeze(), index=series_idxs)
55 series = series.sort_index(ascending=True)
56 series = series.reset_index(drop=True)
57 try:
58 self.models[group].fit(series)
59 except ValueError:
60 self.models[group] = self.model_class(deseasonalize=False)
61 self.models[group].fit(series)
62
63 self.cutoff_index[group] = len(series)
64
65 if self.grouped_by == ['__default']:
66 break
67
68 def __call__(self, ds: Union[EncodedDs, ConcatedEncodedDs], predict_proba: bool = False) -> pd.DataFrame:
69 if predict_proba:
70 log.warning('This model does not output probability estimates')
71
72 length = sum(ds.encoded_ds_lenghts) if isinstance(ds, ConcatedEncodedDs) else len(ds)
73 ydf = pd.DataFrame(0, # zero-filled
74 index=np.arange(length),
75 columns=['prediction'],
76 dtype=object)
77
78 data = {'data': ds.data_frame[self.target].reset_index(drop=True),
79 'group_info': {gcol: ds.data_frame[gcol].tolist()
80 for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}
81
82 # all_idxs = list(range(length)) # @TODO: substract, and assign empty predictions to remainder
83
84 for group in self.ts_analysis['group_combinations']:
85
86 if self.grouped_by == ['__default']:
87 series_idxs = data['data'].index
88 series_data = data['data'].values
89 else:
90 series_idxs, series_data = get_group_matches(data, group)
91
92 if series_data.size > 0:
93 series = pd.Series(series_data.squeeze(), index=series_idxs)
94 series = series.sort_index(ascending=True)
95 series = series.reset_index(drop=True)
96
97 for idx, _ in enumerate(series.iteritems()):
98 ydf['prediction'].iloc[series_idxs[idx]] = self.models[group].predict(
99 np.arange(idx, # +cutoff
100 idx + self.n_ts_predictions)).tolist() # +cutoff
101
102 if self.grouped_by == ['__default']:
103 break
104
105 return ydf[['prediction']]
106
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightwood/model/sktime.py b/lightwood/model/sktime.py
--- a/lightwood/model/sktime.py
+++ b/lightwood/model/sktime.py
@@ -42,7 +42,8 @@
for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}
for group in self.ts_analysis['group_combinations']:
- self.models[group] = self.model_class()
+ # many warnings might be thrown inside of statsmodels during stepwise procedure
+ self.models[group] = self.model_class(suppress_warnings=True)
if self.grouped_by == ['__default']:
series_idxs = data['data'].index
|
{"golden_diff": "diff --git a/lightwood/model/sktime.py b/lightwood/model/sktime.py\n--- a/lightwood/model/sktime.py\n+++ b/lightwood/model/sktime.py\n@@ -42,7 +42,8 @@\n for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}\n \n for group in self.ts_analysis['group_combinations']:\n- self.models[group] = self.model_class()\n+ # many warnings might be thrown inside of statsmodels during stepwise procedure\n+ self.models[group] = self.model_class(suppress_warnings=True)\n \n if self.grouped_by == ['__default']:\n series_idxs = data['data'].index\n", "issue": "`sktime` missing dependency\nIn requirements.txt\r\n`sktime[arima] >= 0.5.0`\r\nbat \r\n`(mindsdb) C:\\Users\\User>pip install sktime[arima]>=0.5.0\r\nWARNING: sktime 0.7.0 does not provide the extra 'arima'`\r\ninstall\r\n`(mindsdb) C:\\Users\\User>pip install sktime[arima]==0.5.0`\n`sktime` missing dependency\nIn requirements.txt\r\n`sktime[arima] >= 0.5.0`\r\nbat \r\n`(mindsdb) C:\\Users\\User>pip install sktime[arima]>=0.5.0\r\nWARNING: sktime 0.7.0 does not provide the extra 'arima'`\r\ninstall\r\n`(mindsdb) C:\\Users\\User>pip install sktime[arima]==0.5.0`\n", "before_files": [{"content": "import numpy as np\nimport pandas as pd\nfrom typing import Dict, List, Union\nfrom sktime.forecasting.arima import AutoARIMA\n\nfrom lightwood.api import dtype\nfrom lightwood.helpers.log import log\nfrom lightwood.model.base import BaseModel\nfrom lightwood.encoder.time_series.helpers.common import get_group_matches\nfrom lightwood.data.encoded_ds import EncodedDs, ConcatedEncodedDs\n\n\nclass SkTime(BaseModel):\n forecaster: str\n n_ts_predictions: int\n target: str\n supports_proba: bool\n\n def __init__(\n self, stop_after: int, target: str, dtype_dict: Dict[str, str],\n n_ts_predictions: int, ts_analysis: Dict):\n super().__init__(stop_after)\n self.target = target\n dtype_dict[target] = dtype.float\n self.model_class = AutoARIMA\n self.models = {}\n self.n_ts_predictions = n_ts_predictions\n self.ts_analysis = ts_analysis\n self.forecasting_horizon = np.arange(1, self.n_ts_predictions)\n self.cutoff_index = {} # marks index at which training data stops and forecasting window starts\n self.grouped_by = ['__default'] if not ts_analysis['tss'].group_by else ts_analysis['tss'].group_by\n self.supports_proba = False\n self.stable = True\n\n def fit(self, ds_arr: List[EncodedDs]) -> None:\n log.info('Started fitting sktime forecaster for array prediction')\n\n all_folds = ConcatedEncodedDs(ds_arr)\n df = all_folds.data_frame.sort_values(by=f'__mdb_original_{self.ts_analysis[\"tss\"].order_by[0]}')\n data = {'data': df[self.target],\n 'group_info': {gcol: df[gcol].tolist()\n for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}\n\n for group in self.ts_analysis['group_combinations']:\n self.models[group] = self.model_class()\n\n if self.grouped_by == ['__default']:\n series_idxs = data['data'].index\n series_data = data['data'].values\n else:\n series_idxs, series_data = get_group_matches(data, group)\n\n if series_data.size > 0:\n series = pd.Series(series_data.squeeze(), index=series_idxs)\n series = series.sort_index(ascending=True)\n series = series.reset_index(drop=True)\n try:\n self.models[group].fit(series)\n except ValueError:\n self.models[group] = self.model_class(deseasonalize=False)\n self.models[group].fit(series)\n\n self.cutoff_index[group] = len(series)\n\n if self.grouped_by == ['__default']:\n break\n\n def __call__(self, ds: Union[EncodedDs, ConcatedEncodedDs], predict_proba: bool = False) -> pd.DataFrame:\n if predict_proba:\n log.warning('This model does not output probability estimates')\n\n length = sum(ds.encoded_ds_lenghts) if isinstance(ds, ConcatedEncodedDs) else len(ds)\n ydf = pd.DataFrame(0, # zero-filled\n index=np.arange(length),\n columns=['prediction'],\n dtype=object)\n\n data = {'data': ds.data_frame[self.target].reset_index(drop=True),\n 'group_info': {gcol: ds.data_frame[gcol].tolist()\n for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}\n\n # all_idxs = list(range(length)) # @TODO: substract, and assign empty predictions to remainder\n\n for group in self.ts_analysis['group_combinations']:\n\n if self.grouped_by == ['__default']:\n series_idxs = data['data'].index\n series_data = data['data'].values\n else:\n series_idxs, series_data = get_group_matches(data, group)\n\n if series_data.size > 0:\n series = pd.Series(series_data.squeeze(), index=series_idxs)\n series = series.sort_index(ascending=True)\n series = series.reset_index(drop=True)\n\n for idx, _ in enumerate(series.iteritems()):\n ydf['prediction'].iloc[series_idxs[idx]] = self.models[group].predict(\n np.arange(idx, # +cutoff\n idx + self.n_ts_predictions)).tolist() # +cutoff\n\n if self.grouped_by == ['__default']:\n break\n\n return ydf[['prediction']]\n", "path": "lightwood/model/sktime.py"}], "after_files": [{"content": "import numpy as np\nimport pandas as pd\nfrom typing import Dict, List, Union\nfrom sktime.forecasting.arima import AutoARIMA\n\nfrom lightwood.api import dtype\nfrom lightwood.helpers.log import log\nfrom lightwood.model.base import BaseModel\nfrom lightwood.encoder.time_series.helpers.common import get_group_matches\nfrom lightwood.data.encoded_ds import EncodedDs, ConcatedEncodedDs\n\n\nclass SkTime(BaseModel):\n forecaster: str\n n_ts_predictions: int\n target: str\n supports_proba: bool\n\n def __init__(\n self, stop_after: int, target: str, dtype_dict: Dict[str, str],\n n_ts_predictions: int, ts_analysis: Dict):\n super().__init__(stop_after)\n self.target = target\n dtype_dict[target] = dtype.float\n self.model_class = AutoARIMA\n self.models = {}\n self.n_ts_predictions = n_ts_predictions\n self.ts_analysis = ts_analysis\n self.forecasting_horizon = np.arange(1, self.n_ts_predictions)\n self.cutoff_index = {} # marks index at which training data stops and forecasting window starts\n self.grouped_by = ['__default'] if not ts_analysis['tss'].group_by else ts_analysis['tss'].group_by\n self.supports_proba = False\n self.stable = True\n\n def fit(self, ds_arr: List[EncodedDs]) -> None:\n log.info('Started fitting sktime forecaster for array prediction')\n\n all_folds = ConcatedEncodedDs(ds_arr)\n df = all_folds.data_frame.sort_values(by=f'__mdb_original_{self.ts_analysis[\"tss\"].order_by[0]}')\n data = {'data': df[self.target],\n 'group_info': {gcol: df[gcol].tolist()\n for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}\n\n for group in self.ts_analysis['group_combinations']:\n # many warnings might be thrown inside of statsmodels during stepwise procedure\n self.models[group] = self.model_class(suppress_warnings=True)\n\n if self.grouped_by == ['__default']:\n series_idxs = data['data'].index\n series_data = data['data'].values\n else:\n series_idxs, series_data = get_group_matches(data, group)\n\n if series_data.size > 0:\n series = pd.Series(series_data.squeeze(), index=series_idxs)\n series = series.sort_index(ascending=True)\n series = series.reset_index(drop=True)\n try:\n self.models[group].fit(series)\n except ValueError:\n self.models[group] = self.model_class(deseasonalize=False)\n self.models[group].fit(series)\n\n self.cutoff_index[group] = len(series)\n\n if self.grouped_by == ['__default']:\n break\n\n def __call__(self, ds: Union[EncodedDs, ConcatedEncodedDs], predict_proba: bool = False) -> pd.DataFrame:\n if predict_proba:\n log.warning('This model does not output probability estimates')\n\n length = sum(ds.encoded_ds_lenghts) if isinstance(ds, ConcatedEncodedDs) else len(ds)\n ydf = pd.DataFrame(0, # zero-filled\n index=np.arange(length),\n columns=['prediction'],\n dtype=object)\n\n data = {'data': ds.data_frame[self.target].reset_index(drop=True),\n 'group_info': {gcol: ds.data_frame[gcol].tolist()\n for gcol in self.grouped_by} if self.ts_analysis['tss'].group_by else {}}\n\n # all_idxs = list(range(length)) # @TODO: substract, and assign empty predictions to remainder\n\n for group in self.ts_analysis['group_combinations']:\n\n if self.grouped_by == ['__default']:\n series_idxs = data['data'].index\n series_data = data['data'].values\n else:\n series_idxs, series_data = get_group_matches(data, group)\n\n if series_data.size > 0:\n series = pd.Series(series_data.squeeze(), index=series_idxs)\n series = series.sort_index(ascending=True)\n series = series.reset_index(drop=True)\n\n for idx, _ in enumerate(series.iteritems()):\n ydf['prediction'].iloc[series_idxs[idx]] = self.models[group].predict(\n np.arange(idx, # +cutoff\n idx + self.n_ts_predictions)).tolist() # +cutoff\n\n if self.grouped_by == ['__default']:\n break\n\n return ydf[['prediction']]\n", "path": "lightwood/model/sktime.py"}]}
| 1,635 | 154 |
gh_patches_debug_26823
|
rasdani/github-patches
|
git_diff
|
ydataai__ydata-profiling-67
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add badges for "highly skewed", "zeros"
I enjoy the badges on the report and am happy to submit a PR for this if it isn't being worked on elsewhere.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pandas_profiling/templates.py`
Content:
```
1 # coding=UTF-8
2
3 '''This file contains all templates used for generating the HTML profile report'''
4
5 from jinja2 import Environment, PackageLoader
6
7 # Initializing Jinja
8 pl = PackageLoader('pandas_profiling', 'templates')
9 jinja2_env = Environment(lstrip_blocks=True, trim_blocks=True, loader=pl)
10
11 # Mapping between template name and file
12 templates = {'freq_table_row': 'freq_table_row.html',
13 'mini_freq_table_row': 'mini_freq_table_row.html',
14 'freq_table': 'freq_table.html',
15 'mini_freq_table': 'mini_freq_table.html',
16 'row_num': 'row_num.html',
17 'row_date': 'row_date.html',
18 'row_cat': 'row_cat.html',
19 'row_bool': 'row_bool.html',
20 'row_corr': 'row_corr.html',
21 'row_recoded': 'row_recoded.html',
22 'row_const': 'row_const.html',
23 'row_unique': 'row_unique.html',
24 'overview': 'overview.html',
25 'sample': 'sample.html',
26 'base': 'base.html',
27 'wrapper': 'wrapper.html'
28 }
29
30 # Mapping between row type and var type
31 var_type = {'NUM': 'Numeric',
32 'DATE': 'Date',
33 'CAT': 'Categorical',
34 'UNIQUE': 'Categorical, Unique',
35 'BOOL': 'Boolean',
36 'CONST': 'Constant',
37 'CORR': 'Highly correlated',
38 'RECODED': 'Recoded'
39 }
40
41
42 def template(template_name):
43 """Return a jinja template ready for rendering. If needed, global variables are initialized.
44
45 Parameters
46 ----------
47 template_name: str, the name of the template as defined in the templates mapping
48
49 Returns
50 -------
51 The Jinja template ready for rendering
52 """
53 globals = None
54 if template_name.startswith('row_'):
55 # This is a row template setting global variable
56 globals = dict()
57 globals['vartype'] = var_type[template_name.split('_')[1].upper()]
58 return jinja2_env.get_template(templates[template_name], globals=globals)
59
60
61 # mapping between row type and template name
62 row_templates_dict = {'NUM': template('row_num'),
63 'DATE': template('row_date'),
64 'DISCRETE': template('row_num'),
65 'CAT': template('row_cat'),
66 'BOOL': template('row_bool'),
67 'UNIQUE': template('row_unique'),
68 'CONST': template('row_const'),
69 'CORR': template('row_corr'),
70 'RECODED': template('row_recoded')
71 }
72
73 # The number of column to use in the display of the frequency table according to the category
74 mini_freq_table_nb_col = {'CAT': 6, 'BOOL': 3}
75
76 messages = dict()
77 messages['CONST'] = u'{0[varname]} has constant value {0[mode]} <span class="label label-primary">Rejected</span>'
78 messages['CORR'] = u'{0[varname]} is highly correlated with {0[correlation_var]} (ρ = {0[correlation]}) <span class="label label-primary">Rejected</span>'
79 messages['RECODED'] = u'{0[varname]} is a recoding of {0[correlation_var]} <span class="label label-primary">Rejected</span>'
80 messages['HIGH_CARDINALITY'] = u'{varname} has a high cardinality: {0[distinct_count]} distinct values <span class="label label-warning">Warning</span>'
81 messages['n_duplicates'] = u'Dataset has {0[n_duplicates]} duplicate rows <span class="label label-warning">Warning</span>'
82 messages['skewness'] = u'{varname} is highly skewed (γ1 = {0[skewness]})'
83 messages['p_missing'] = u'{varname} has {0[n_missing]} / {0[p_missing]} missing values <span class="label label-default">Missing</span>'
84 messages['p_infinite'] = u'{varname} has {0[n_infinite]} / {0[p_infinite]} infinite values <span class="label label-default">Infinite</span>'
85 messages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros'
86
87 message_row = u'<li>{message}</li>'
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pandas_profiling/templates.py b/pandas_profiling/templates.py
--- a/pandas_profiling/templates.py
+++ b/pandas_profiling/templates.py
@@ -79,9 +79,9 @@
messages['RECODED'] = u'{0[varname]} is a recoding of {0[correlation_var]} <span class="label label-primary">Rejected</span>'
messages['HIGH_CARDINALITY'] = u'{varname} has a high cardinality: {0[distinct_count]} distinct values <span class="label label-warning">Warning</span>'
messages['n_duplicates'] = u'Dataset has {0[n_duplicates]} duplicate rows <span class="label label-warning">Warning</span>'
-messages['skewness'] = u'{varname} is highly skewed (γ1 = {0[skewness]})'
+messages['skewness'] = u'{varname} is highly skewed (γ1 = {0[skewness]}) <span class="label label-info">Skewed</span>'
messages['p_missing'] = u'{varname} has {0[n_missing]} / {0[p_missing]} missing values <span class="label label-default">Missing</span>'
messages['p_infinite'] = u'{varname} has {0[n_infinite]} / {0[p_infinite]} infinite values <span class="label label-default">Infinite</span>'
-messages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros'
+messages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros <span class="label label-info">Zeros</span>'
message_row = u'<li>{message}</li>'
|
{"golden_diff": "diff --git a/pandas_profiling/templates.py b/pandas_profiling/templates.py\n--- a/pandas_profiling/templates.py\n+++ b/pandas_profiling/templates.py\n@@ -79,9 +79,9 @@\n messages['RECODED'] = u'{0[varname]} is a recoding of {0[correlation_var]} <span class=\"label label-primary\">Rejected</span>'\n messages['HIGH_CARDINALITY'] = u'{varname} has a high cardinality: {0[distinct_count]} distinct values <span class=\"label label-warning\">Warning</span>'\n messages['n_duplicates'] = u'Dataset has {0[n_duplicates]} duplicate rows <span class=\"label label-warning\">Warning</span>'\n-messages['skewness'] = u'{varname} is highly skewed (\u03b31 = {0[skewness]})'\n+messages['skewness'] = u'{varname} is highly skewed (\u03b31 = {0[skewness]}) <span class=\"label label-info\">Skewed</span>'\n messages['p_missing'] = u'{varname} has {0[n_missing]} / {0[p_missing]} missing values <span class=\"label label-default\">Missing</span>'\n messages['p_infinite'] = u'{varname} has {0[n_infinite]} / {0[p_infinite]} infinite values <span class=\"label label-default\">Infinite</span>'\n-messages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros'\n+messages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros <span class=\"label label-info\">Zeros</span>'\n \n message_row = u'<li>{message}</li>'\n", "issue": "Add badges for \"highly skewed\", \"zeros\"\nI enjoy the badges on the report and am happy to submit a PR for this if it isn't being worked on elsewhere.\n", "before_files": [{"content": "# coding=UTF-8\n\n'''This file contains all templates used for generating the HTML profile report'''\n\nfrom jinja2 import Environment, PackageLoader\n\n# Initializing Jinja\npl = PackageLoader('pandas_profiling', 'templates')\njinja2_env = Environment(lstrip_blocks=True, trim_blocks=True, loader=pl)\n\n# Mapping between template name and file\ntemplates = {'freq_table_row': 'freq_table_row.html',\n 'mini_freq_table_row': 'mini_freq_table_row.html',\n 'freq_table': 'freq_table.html',\n 'mini_freq_table': 'mini_freq_table.html',\n 'row_num': 'row_num.html',\n 'row_date': 'row_date.html',\n 'row_cat': 'row_cat.html',\n 'row_bool': 'row_bool.html',\n 'row_corr': 'row_corr.html',\n 'row_recoded': 'row_recoded.html',\n 'row_const': 'row_const.html',\n 'row_unique': 'row_unique.html',\n 'overview': 'overview.html',\n 'sample': 'sample.html',\n 'base': 'base.html',\n 'wrapper': 'wrapper.html'\n }\n\n# Mapping between row type and var type\nvar_type = {'NUM': 'Numeric',\n 'DATE': 'Date',\n 'CAT': 'Categorical',\n 'UNIQUE': 'Categorical, Unique',\n 'BOOL': 'Boolean',\n 'CONST': 'Constant',\n 'CORR': 'Highly correlated',\n 'RECODED': 'Recoded'\n }\n\n\ndef template(template_name):\n \"\"\"Return a jinja template ready for rendering. If needed, global variables are initialized.\n\n Parameters\n ----------\n template_name: str, the name of the template as defined in the templates mapping\n\n Returns\n -------\n The Jinja template ready for rendering\n \"\"\"\n globals = None\n if template_name.startswith('row_'):\n # This is a row template setting global variable\n globals = dict()\n globals['vartype'] = var_type[template_name.split('_')[1].upper()]\n return jinja2_env.get_template(templates[template_name], globals=globals)\n\n\n# mapping between row type and template name\nrow_templates_dict = {'NUM': template('row_num'),\n 'DATE': template('row_date'),\n 'DISCRETE': template('row_num'),\n 'CAT': template('row_cat'),\n 'BOOL': template('row_bool'),\n 'UNIQUE': template('row_unique'),\n 'CONST': template('row_const'),\n 'CORR': template('row_corr'),\n 'RECODED': template('row_recoded')\n }\n\n# The number of column to use in the display of the frequency table according to the category\nmini_freq_table_nb_col = {'CAT': 6, 'BOOL': 3}\n\nmessages = dict()\nmessages['CONST'] = u'{0[varname]} has constant value {0[mode]} <span class=\"label label-primary\">Rejected</span>'\nmessages['CORR'] = u'{0[varname]} is highly correlated with {0[correlation_var]} (\u03c1 = {0[correlation]}) <span class=\"label label-primary\">Rejected</span>'\nmessages['RECODED'] = u'{0[varname]} is a recoding of {0[correlation_var]} <span class=\"label label-primary\">Rejected</span>'\nmessages['HIGH_CARDINALITY'] = u'{varname} has a high cardinality: {0[distinct_count]} distinct values <span class=\"label label-warning\">Warning</span>'\nmessages['n_duplicates'] = u'Dataset has {0[n_duplicates]} duplicate rows <span class=\"label label-warning\">Warning</span>'\nmessages['skewness'] = u'{varname} is highly skewed (\u03b31 = {0[skewness]})'\nmessages['p_missing'] = u'{varname} has {0[n_missing]} / {0[p_missing]} missing values <span class=\"label label-default\">Missing</span>'\nmessages['p_infinite'] = u'{varname} has {0[n_infinite]} / {0[p_infinite]} infinite values <span class=\"label label-default\">Infinite</span>'\nmessages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros'\n\nmessage_row = u'<li>{message}</li>'\n", "path": "pandas_profiling/templates.py"}], "after_files": [{"content": "# coding=UTF-8\n\n'''This file contains all templates used for generating the HTML profile report'''\n\nfrom jinja2 import Environment, PackageLoader\n\n# Initializing Jinja\npl = PackageLoader('pandas_profiling', 'templates')\njinja2_env = Environment(lstrip_blocks=True, trim_blocks=True, loader=pl)\n\n# Mapping between template name and file\ntemplates = {'freq_table_row': 'freq_table_row.html',\n 'mini_freq_table_row': 'mini_freq_table_row.html',\n 'freq_table': 'freq_table.html',\n 'mini_freq_table': 'mini_freq_table.html',\n 'row_num': 'row_num.html',\n 'row_date': 'row_date.html',\n 'row_cat': 'row_cat.html',\n 'row_bool': 'row_bool.html',\n 'row_corr': 'row_corr.html',\n 'row_recoded': 'row_recoded.html',\n 'row_const': 'row_const.html',\n 'row_unique': 'row_unique.html',\n 'overview': 'overview.html',\n 'sample': 'sample.html',\n 'base': 'base.html',\n 'wrapper': 'wrapper.html'\n }\n\n# Mapping between row type and var type\nvar_type = {'NUM': 'Numeric',\n 'DATE': 'Date',\n 'CAT': 'Categorical',\n 'UNIQUE': 'Categorical, Unique',\n 'BOOL': 'Boolean',\n 'CONST': 'Constant',\n 'CORR': 'Highly correlated',\n 'RECODED': 'Recoded'\n }\n\n\ndef template(template_name):\n \"\"\"Return a jinja template ready for rendering. If needed, global variables are initialized.\n\n Parameters\n ----------\n template_name: str, the name of the template as defined in the templates mapping\n\n Returns\n -------\n The Jinja template ready for rendering\n \"\"\"\n globals = None\n if template_name.startswith('row_'):\n # This is a row template setting global variable\n globals = dict()\n globals['vartype'] = var_type[template_name.split('_')[1].upper()]\n return jinja2_env.get_template(templates[template_name], globals=globals)\n\n\n# mapping between row type and template name\nrow_templates_dict = {'NUM': template('row_num'),\n 'DATE': template('row_date'),\n 'DISCRETE': template('row_num'),\n 'CAT': template('row_cat'),\n 'BOOL': template('row_bool'),\n 'UNIQUE': template('row_unique'),\n 'CONST': template('row_const'),\n 'CORR': template('row_corr'),\n 'RECODED': template('row_recoded')\n }\n\n# The number of column to use in the display of the frequency table according to the category\nmini_freq_table_nb_col = {'CAT': 6, 'BOOL': 3}\n\nmessages = dict()\nmessages['CONST'] = u'{0[varname]} has constant value {0[mode]} <span class=\"label label-primary\">Rejected</span>'\nmessages['CORR'] = u'{0[varname]} is highly correlated with {0[correlation_var]} (\u03c1 = {0[correlation]}) <span class=\"label label-primary\">Rejected</span>'\nmessages['RECODED'] = u'{0[varname]} is a recoding of {0[correlation_var]} <span class=\"label label-primary\">Rejected</span>'\nmessages['HIGH_CARDINALITY'] = u'{varname} has a high cardinality: {0[distinct_count]} distinct values <span class=\"label label-warning\">Warning</span>'\nmessages['n_duplicates'] = u'Dataset has {0[n_duplicates]} duplicate rows <span class=\"label label-warning\">Warning</span>'\nmessages['skewness'] = u'{varname} is highly skewed (\u03b31 = {0[skewness]}) <span class=\"label label-info\">Skewed</span>'\nmessages['p_missing'] = u'{varname} has {0[n_missing]} / {0[p_missing]} missing values <span class=\"label label-default\">Missing</span>'\nmessages['p_infinite'] = u'{varname} has {0[n_infinite]} / {0[p_infinite]} infinite values <span class=\"label label-default\">Infinite</span>'\nmessages['p_zeros'] = u'{varname} has {0[n_zeros]} / {0[p_zeros]} zeros <span class=\"label label-info\">Zeros</span>'\n\nmessage_row = u'<li>{message}</li>'\n", "path": "pandas_profiling/templates.py"}]}
| 1,395 | 377 |
gh_patches_debug_13624
|
rasdani/github-patches
|
git_diff
|
encode__httpx-1391
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Path encoding broken for non-ASCII in WSGI mode
### Describe the bug
When using httpx to call into a WSGI application (my preferred way to test Flask app nowadays), the web view receives urlencoded paths.
I'm not sure where this really belongs to (is it a bug in httpx or Flask!?), but I've been working around it for months, so I guess I'll make myself unpopular and try it here first. If it turns out to be Flask's fault, I'l headl over and bother the Pallets folks.
### To reproduce
```python
from flask import Flask, request
import httpx
app = Flask(__name__)
@app.route('/<path>')
def hello_world(path):
return f"path: { path }, query: { request.args['a'] }, url: { request.url }"
if __name__ == "__main__":
with httpx.Client(app=app, base_url="http://testserver") as client:
resp = client.get("/ä", params={"a": "ä"})
print("httpx", resp.text)
with app.test_client() as client:
resp = client.get("/ä?a=%C3%A4")
print("flask", resp.get_data().decode("utf-8"))
```
### Expected behavior
```
httpx path: ä, query: ä, url: http://testserver/ä?a=ä
flask path: ä, query: ä, url: http://localhost/ä?a=ä
```
### Actual behavior
```
httpx path: %C3%A4, query: ä, url: http://testserver/%25C3%25A4?a=ä
flask path: ä, query: ä, url: http://localhost/ä?a=ä
```
NB
- it seems to handle query parameters just fine.
- `%25` is the ASCII code of the percent sign
### Environment
- OS: macOS
- Python version: 3.8.6
- HTTPX version: 0.16.1
- Async environment: n/a
- HTTP proxy: n/a
- Custom certificates: no
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `httpx/_transports/wsgi.py`
Content:
```
1 import io
2 import itertools
3 import typing
4
5 import httpcore
6
7
8 def _skip_leading_empty_chunks(body: typing.Iterable) -> typing.Iterable:
9 body = iter(body)
10 for chunk in body:
11 if chunk:
12 return itertools.chain([chunk], body)
13 return []
14
15
16 class WSGITransport(httpcore.SyncHTTPTransport):
17 """
18 A custom transport that handles sending requests directly to an WSGI app.
19 The simplest way to use this functionality is to use the `app` argument.
20
21 ```
22 client = httpx.Client(app=app)
23 ```
24
25 Alternatively, you can setup the transport instance explicitly.
26 This allows you to include any additional configuration arguments specific
27 to the WSGITransport class:
28
29 ```
30 transport = httpx.WSGITransport(
31 app=app,
32 script_name="/submount",
33 remote_addr="1.2.3.4"
34 )
35 client = httpx.Client(transport=transport)
36 ```
37
38 Arguments:
39
40 * `app` - The ASGI application.
41 * `raise_app_exceptions` - Boolean indicating if exceptions in the application
42 should be raised. Default to `True`. Can be set to `False` for use cases
43 such as testing the content of a client 500 response.
44 * `script_name` - The root path on which the ASGI application should be mounted.
45 * `remote_addr` - A string indicating the client IP of incoming requests.
46 ```
47 """
48
49 def __init__(
50 self,
51 app: typing.Callable,
52 raise_app_exceptions: bool = True,
53 script_name: str = "",
54 remote_addr: str = "127.0.0.1",
55 ) -> None:
56 self.app = app
57 self.raise_app_exceptions = raise_app_exceptions
58 self.script_name = script_name
59 self.remote_addr = remote_addr
60
61 def request(
62 self,
63 method: bytes,
64 url: typing.Tuple[bytes, bytes, typing.Optional[int], bytes],
65 headers: typing.List[typing.Tuple[bytes, bytes]] = None,
66 stream: httpcore.SyncByteStream = None,
67 ext: dict = None,
68 ) -> typing.Tuple[
69 int, typing.List[typing.Tuple[bytes, bytes]], httpcore.SyncByteStream, dict
70 ]:
71 headers = [] if headers is None else headers
72 stream = httpcore.PlainByteStream(content=b"") if stream is None else stream
73
74 scheme, host, port, full_path = url
75 path, _, query = full_path.partition(b"?")
76 environ = {
77 "wsgi.version": (1, 0),
78 "wsgi.url_scheme": scheme.decode("ascii"),
79 "wsgi.input": io.BytesIO(b"".join(stream)),
80 "wsgi.errors": io.BytesIO(),
81 "wsgi.multithread": True,
82 "wsgi.multiprocess": False,
83 "wsgi.run_once": False,
84 "REQUEST_METHOD": method.decode(),
85 "SCRIPT_NAME": self.script_name,
86 "PATH_INFO": path.decode("ascii"),
87 "QUERY_STRING": query.decode("ascii"),
88 "SERVER_NAME": host.decode("ascii"),
89 "SERVER_PORT": str(port),
90 "REMOTE_ADDR": self.remote_addr,
91 }
92 for header_key, header_value in headers:
93 key = header_key.decode("ascii").upper().replace("-", "_")
94 if key not in ("CONTENT_TYPE", "CONTENT_LENGTH"):
95 key = "HTTP_" + key
96 environ[key] = header_value.decode("ascii")
97
98 seen_status = None
99 seen_response_headers = None
100 seen_exc_info = None
101
102 def start_response(
103 status: str, response_headers: list, exc_info: typing.Any = None
104 ) -> None:
105 nonlocal seen_status, seen_response_headers, seen_exc_info
106 seen_status = status
107 seen_response_headers = response_headers
108 seen_exc_info = exc_info
109
110 result = self.app(environ, start_response)
111 # This is needed because the status returned by start_response
112 # shouldn't be used until the first non-empty chunk has been served.
113 result = _skip_leading_empty_chunks(result)
114
115 assert seen_status is not None
116 assert seen_response_headers is not None
117 if seen_exc_info and self.raise_app_exceptions:
118 raise seen_exc_info[1]
119
120 status_code = int(seen_status.split()[0])
121 headers = [
122 (key.encode("ascii"), value.encode("ascii"))
123 for key, value in seen_response_headers
124 ]
125 stream = httpcore.IteratorByteStream(iterator=result)
126 ext = {}
127
128 return (status_code, headers, stream, ext)
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/httpx/_transports/wsgi.py b/httpx/_transports/wsgi.py
--- a/httpx/_transports/wsgi.py
+++ b/httpx/_transports/wsgi.py
@@ -1,6 +1,7 @@
import io
import itertools
import typing
+from urllib.parse import unquote
import httpcore
@@ -83,7 +84,7 @@
"wsgi.run_once": False,
"REQUEST_METHOD": method.decode(),
"SCRIPT_NAME": self.script_name,
- "PATH_INFO": path.decode("ascii"),
+ "PATH_INFO": unquote(path.decode("ascii")),
"QUERY_STRING": query.decode("ascii"),
"SERVER_NAME": host.decode("ascii"),
"SERVER_PORT": str(port),
|
{"golden_diff": "diff --git a/httpx/_transports/wsgi.py b/httpx/_transports/wsgi.py\n--- a/httpx/_transports/wsgi.py\n+++ b/httpx/_transports/wsgi.py\n@@ -1,6 +1,7 @@\n import io\n import itertools\n import typing\n+from urllib.parse import unquote\n \n import httpcore\n \n@@ -83,7 +84,7 @@\n \"wsgi.run_once\": False,\n \"REQUEST_METHOD\": method.decode(),\n \"SCRIPT_NAME\": self.script_name,\n- \"PATH_INFO\": path.decode(\"ascii\"),\n+ \"PATH_INFO\": unquote(path.decode(\"ascii\")),\n \"QUERY_STRING\": query.decode(\"ascii\"),\n \"SERVER_NAME\": host.decode(\"ascii\"),\n \"SERVER_PORT\": str(port),\n", "issue": "Path encoding broken for non-ASCII in WSGI mode\n### Describe the bug\r\n\r\nWhen using httpx to call into a WSGI application (my preferred way to test Flask app nowadays), the web view receives urlencoded paths.\r\n\r\nI'm not sure where this really belongs to (is it a bug in httpx or Flask!?), but I've been working around it for months, so I guess I'll make myself unpopular and try it here first. If it turns out to be Flask's fault, I'l headl over and bother the Pallets folks.\r\n\r\n### To reproduce\r\n\r\n```python\r\nfrom flask import Flask, request\r\n\r\nimport httpx\r\n\r\n\r\napp = Flask(__name__)\r\n\r\[email protected]('/<path>')\r\ndef hello_world(path):\r\n return f\"path: { path }, query: { request.args['a'] }, url: { request.url }\"\r\n\r\n\r\nif __name__ == \"__main__\":\r\n with httpx.Client(app=app, base_url=\"http://testserver\") as client:\r\n resp = client.get(\"/\u00e4\", params={\"a\": \"\u00e4\"})\r\n\r\n print(\"httpx\", resp.text)\r\n\r\n with app.test_client() as client:\r\n resp = client.get(\"/\u00e4?a=%C3%A4\")\r\n\r\n print(\"flask\", resp.get_data().decode(\"utf-8\"))\r\n```\r\n\r\n### Expected behavior\r\n\r\n```\r\nhttpx path: \u00e4, query: \u00e4, url: http://testserver/\u00e4?a=\u00e4\r\nflask path: \u00e4, query: \u00e4, url: http://localhost/\u00e4?a=\u00e4\r\n```\r\n\r\n### Actual behavior\r\n\r\n```\r\nhttpx path: %C3%A4, query: \u00e4, url: http://testserver/%25C3%25A4?a=\u00e4\r\nflask path: \u00e4, query: \u00e4, url: http://localhost/\u00e4?a=\u00e4\r\n```\r\n\r\nNB\r\n\r\n- it seems to handle query parameters just fine.\r\n- `%25` is the ASCII code of the percent sign\r\n\r\n### Environment\r\n\r\n- OS: macOS\r\n- Python version: 3.8.6\r\n- HTTPX version: 0.16.1\r\n- Async environment: n/a\r\n- HTTP proxy: n/a\r\n- Custom certificates: no\r\n\n", "before_files": [{"content": "import io\nimport itertools\nimport typing\n\nimport httpcore\n\n\ndef _skip_leading_empty_chunks(body: typing.Iterable) -> typing.Iterable:\n body = iter(body)\n for chunk in body:\n if chunk:\n return itertools.chain([chunk], body)\n return []\n\n\nclass WSGITransport(httpcore.SyncHTTPTransport):\n \"\"\"\n A custom transport that handles sending requests directly to an WSGI app.\n The simplest way to use this functionality is to use the `app` argument.\n\n ```\n client = httpx.Client(app=app)\n ```\n\n Alternatively, you can setup the transport instance explicitly.\n This allows you to include any additional configuration arguments specific\n to the WSGITransport class:\n\n ```\n transport = httpx.WSGITransport(\n app=app,\n script_name=\"/submount\",\n remote_addr=\"1.2.3.4\"\n )\n client = httpx.Client(transport=transport)\n ```\n\n Arguments:\n\n * `app` - The ASGI application.\n * `raise_app_exceptions` - Boolean indicating if exceptions in the application\n should be raised. Default to `True`. Can be set to `False` for use cases\n such as testing the content of a client 500 response.\n * `script_name` - The root path on which the ASGI application should be mounted.\n * `remote_addr` - A string indicating the client IP of incoming requests.\n ```\n \"\"\"\n\n def __init__(\n self,\n app: typing.Callable,\n raise_app_exceptions: bool = True,\n script_name: str = \"\",\n remote_addr: str = \"127.0.0.1\",\n ) -> None:\n self.app = app\n self.raise_app_exceptions = raise_app_exceptions\n self.script_name = script_name\n self.remote_addr = remote_addr\n\n def request(\n self,\n method: bytes,\n url: typing.Tuple[bytes, bytes, typing.Optional[int], bytes],\n headers: typing.List[typing.Tuple[bytes, bytes]] = None,\n stream: httpcore.SyncByteStream = None,\n ext: dict = None,\n ) -> typing.Tuple[\n int, typing.List[typing.Tuple[bytes, bytes]], httpcore.SyncByteStream, dict\n ]:\n headers = [] if headers is None else headers\n stream = httpcore.PlainByteStream(content=b\"\") if stream is None else stream\n\n scheme, host, port, full_path = url\n path, _, query = full_path.partition(b\"?\")\n environ = {\n \"wsgi.version\": (1, 0),\n \"wsgi.url_scheme\": scheme.decode(\"ascii\"),\n \"wsgi.input\": io.BytesIO(b\"\".join(stream)),\n \"wsgi.errors\": io.BytesIO(),\n \"wsgi.multithread\": True,\n \"wsgi.multiprocess\": False,\n \"wsgi.run_once\": False,\n \"REQUEST_METHOD\": method.decode(),\n \"SCRIPT_NAME\": self.script_name,\n \"PATH_INFO\": path.decode(\"ascii\"),\n \"QUERY_STRING\": query.decode(\"ascii\"),\n \"SERVER_NAME\": host.decode(\"ascii\"),\n \"SERVER_PORT\": str(port),\n \"REMOTE_ADDR\": self.remote_addr,\n }\n for header_key, header_value in headers:\n key = header_key.decode(\"ascii\").upper().replace(\"-\", \"_\")\n if key not in (\"CONTENT_TYPE\", \"CONTENT_LENGTH\"):\n key = \"HTTP_\" + key\n environ[key] = header_value.decode(\"ascii\")\n\n seen_status = None\n seen_response_headers = None\n seen_exc_info = None\n\n def start_response(\n status: str, response_headers: list, exc_info: typing.Any = None\n ) -> None:\n nonlocal seen_status, seen_response_headers, seen_exc_info\n seen_status = status\n seen_response_headers = response_headers\n seen_exc_info = exc_info\n\n result = self.app(environ, start_response)\n # This is needed because the status returned by start_response\n # shouldn't be used until the first non-empty chunk has been served.\n result = _skip_leading_empty_chunks(result)\n\n assert seen_status is not None\n assert seen_response_headers is not None\n if seen_exc_info and self.raise_app_exceptions:\n raise seen_exc_info[1]\n\n status_code = int(seen_status.split()[0])\n headers = [\n (key.encode(\"ascii\"), value.encode(\"ascii\"))\n for key, value in seen_response_headers\n ]\n stream = httpcore.IteratorByteStream(iterator=result)\n ext = {}\n\n return (status_code, headers, stream, ext)\n", "path": "httpx/_transports/wsgi.py"}], "after_files": [{"content": "import io\nimport itertools\nimport typing\nfrom urllib.parse import unquote\n\nimport httpcore\n\n\ndef _skip_leading_empty_chunks(body: typing.Iterable) -> typing.Iterable:\n body = iter(body)\n for chunk in body:\n if chunk:\n return itertools.chain([chunk], body)\n return []\n\n\nclass WSGITransport(httpcore.SyncHTTPTransport):\n \"\"\"\n A custom transport that handles sending requests directly to an WSGI app.\n The simplest way to use this functionality is to use the `app` argument.\n\n ```\n client = httpx.Client(app=app)\n ```\n\n Alternatively, you can setup the transport instance explicitly.\n This allows you to include any additional configuration arguments specific\n to the WSGITransport class:\n\n ```\n transport = httpx.WSGITransport(\n app=app,\n script_name=\"/submount\",\n remote_addr=\"1.2.3.4\"\n )\n client = httpx.Client(transport=transport)\n ```\n\n Arguments:\n\n * `app` - The ASGI application.\n * `raise_app_exceptions` - Boolean indicating if exceptions in the application\n should be raised. Default to `True`. Can be set to `False` for use cases\n such as testing the content of a client 500 response.\n * `script_name` - The root path on which the ASGI application should be mounted.\n * `remote_addr` - A string indicating the client IP of incoming requests.\n ```\n \"\"\"\n\n def __init__(\n self,\n app: typing.Callable,\n raise_app_exceptions: bool = True,\n script_name: str = \"\",\n remote_addr: str = \"127.0.0.1\",\n ) -> None:\n self.app = app\n self.raise_app_exceptions = raise_app_exceptions\n self.script_name = script_name\n self.remote_addr = remote_addr\n\n def request(\n self,\n method: bytes,\n url: typing.Tuple[bytes, bytes, typing.Optional[int], bytes],\n headers: typing.List[typing.Tuple[bytes, bytes]] = None,\n stream: httpcore.SyncByteStream = None,\n ext: dict = None,\n ) -> typing.Tuple[\n int, typing.List[typing.Tuple[bytes, bytes]], httpcore.SyncByteStream, dict\n ]:\n headers = [] if headers is None else headers\n stream = httpcore.PlainByteStream(content=b\"\") if stream is None else stream\n\n scheme, host, port, full_path = url\n path, _, query = full_path.partition(b\"?\")\n environ = {\n \"wsgi.version\": (1, 0),\n \"wsgi.url_scheme\": scheme.decode(\"ascii\"),\n \"wsgi.input\": io.BytesIO(b\"\".join(stream)),\n \"wsgi.errors\": io.BytesIO(),\n \"wsgi.multithread\": True,\n \"wsgi.multiprocess\": False,\n \"wsgi.run_once\": False,\n \"REQUEST_METHOD\": method.decode(),\n \"SCRIPT_NAME\": self.script_name,\n \"PATH_INFO\": unquote(path.decode(\"ascii\")),\n \"QUERY_STRING\": query.decode(\"ascii\"),\n \"SERVER_NAME\": host.decode(\"ascii\"),\n \"SERVER_PORT\": str(port),\n \"REMOTE_ADDR\": self.remote_addr,\n }\n for header_key, header_value in headers:\n key = header_key.decode(\"ascii\").upper().replace(\"-\", \"_\")\n if key not in (\"CONTENT_TYPE\", \"CONTENT_LENGTH\"):\n key = \"HTTP_\" + key\n environ[key] = header_value.decode(\"ascii\")\n\n seen_status = None\n seen_response_headers = None\n seen_exc_info = None\n\n def start_response(\n status: str, response_headers: list, exc_info: typing.Any = None\n ) -> None:\n nonlocal seen_status, seen_response_headers, seen_exc_info\n seen_status = status\n seen_response_headers = response_headers\n seen_exc_info = exc_info\n\n result = self.app(environ, start_response)\n # This is needed because the status returned by start_response\n # shouldn't be used until the first non-empty chunk has been served.\n result = _skip_leading_empty_chunks(result)\n\n assert seen_status is not None\n assert seen_response_headers is not None\n if seen_exc_info and self.raise_app_exceptions:\n raise seen_exc_info[1]\n\n status_code = int(seen_status.split()[0])\n headers = [\n (key.encode(\"ascii\"), value.encode(\"ascii\"))\n for key, value in seen_response_headers\n ]\n stream = httpcore.IteratorByteStream(iterator=result)\n ext = {}\n\n return (status_code, headers, stream, ext)\n", "path": "httpx/_transports/wsgi.py"}]}
| 2,017 | 165 |
gh_patches_debug_29181
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
project_list in container add project form contains all projects
@CarolingerSeilchenspringer at the moment all projects (not only the ones belonging to the organisation) can be added to a container. Should that stay that way?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/projectcontainers/forms.py`
Content:
```
1 from django.db.models import Q
2 from django.utils.translation import ugettext_lazy as _
3
4 from adhocracy4.dashboard.forms import ProjectCreateForm
5 from adhocracy4.dashboard.forms import ProjectDashboardForm
6 from meinberlin.apps.contrib.widgets import Select2MultipleWidget
7
8 from . import models
9
10 LABELS = {
11 'name': _('Title of your container'),
12 'description': _('Short description of your container'),
13 'tile_image': _('Logo'),
14 }
15
16 HELP_TEXTS = {
17 'name': _('This title will appear on the '
18 'teaser card and on top of the container '
19 'detail page. It should be max. 120 characters long'),
20 'description': _('This short description will appear on '
21 'the header of the container and in the teaser. '
22 'It should briefly state the goal of the '
23 'projects in max. 250 chars.'),
24 'tile_image': _(
25 'The image will be shown in the container tile.'
26 ),
27 }
28
29
30 class ContainerCreateForm(ProjectCreateForm):
31
32 class Meta:
33 model = models.ProjectContainer
34 fields = ['name', 'description',
35 'tile_image', 'tile_image_copyright']
36 labels = LABELS
37 help_texts = HELP_TEXTS
38
39
40 class ContainerBasicForm(ProjectDashboardForm):
41
42 class Meta:
43 model = models.ProjectContainer
44 fields = ['name', 'description', 'tile_image',
45 'tile_image_copyright', 'is_archived']
46 required_for_project_publish = ['name', 'description']
47 labels = LABELS
48 help_texts = HELP_TEXTS
49
50
51 class ContainerInformationForm(ProjectDashboardForm):
52
53 class Meta:
54 model = models.ProjectContainer
55 fields = ['information']
56 required_for_project_publish = ['information']
57 labels = {
58 'information': _('Description of your container'),
59 }
60
61
62 class ContainerProjectsForm(ProjectDashboardForm):
63
64 def __init__(self, *args, **kwargs):
65 super().__init__(*args, **kwargs)
66
67 # We tried to find a good balance between a short list and
68 # all necessary projects. The details may change over time.
69 # Projects that are already selected should remain in the queryset.
70 self.fields['projects'].queryset = self.fields['projects'].queryset \
71 .filter(projectcontainer=None)\
72 .filter(Q(containers=self.instance) |
73 (Q(containers=None) &
74 Q(is_archived=False) &
75 Q(is_public=True)))\
76 .order_by('name')
77
78 class Meta:
79 model = models.ProjectContainer
80 fields = ['projects']
81 required_for_project_publish = ['projects']
82 widgets = {
83 'projects': Select2MultipleWidget,
84 }
85
```
Path: `meinberlin/apps/projectcontainers/views.py`
Content:
```
1 from django.utils.translation import ugettext_lazy as _
2 from django.views import generic
3
4 from adhocracy4.dashboard import mixins as dashboard_mixins
5 from adhocracy4.dashboard.blueprints import ProjectBlueprint
6 from adhocracy4.dashboard.components.forms.views import \
7 ProjectComponentFormView
8 from adhocracy4.dashboard.views import ProjectCreateView
9
10 from . import forms
11 from . import models
12
13
14 class ContainerCreateView(ProjectCreateView):
15 model = models.ProjectContainer
16 slug_url_kwarg = 'project_slug'
17 form_class = forms.ContainerCreateForm
18 template_name = 'meinberlin_projectcontainers/container_create_form.html'
19 success_message = _('Container successfully created.')
20
21 blueprint = ProjectBlueprint(
22 title=_('Container'),
23 description=_(
24 'A container contains multiple projects.'
25 ),
26 content=[],
27 image='',
28 settings_model=None,
29 )
30
31
32 class ContainerBasicFormView(ProjectComponentFormView):
33 model = models.ProjectContainer
34
35 @property
36 def project(self):
37 project = super().project
38 return project.projectcontainer
39
40 def get_object(self, queryset=None):
41 return self.project
42
43
44 class ContainerProjectsView(ProjectComponentFormView):
45 model = models.ProjectContainer
46
47 @property
48 def project(self):
49 project = super().project
50 return project.projectcontainer
51
52 def get_object(self, queryset=None):
53 return self.project
54
55
56 class ContainerListView(dashboard_mixins.DashboardBaseMixin,
57 generic.ListView):
58 model = models.ProjectContainer
59 paginate_by = 12
60 template_name = 'meinberlin_projectcontainers/container_list.html'
61 permission_required = 'a4projects.add_project'
62 menu_item = 'project'
63
64 def get_queryset(self):
65 return super().get_queryset().filter(
66 organisation=self.organisation
67 )
68
69 def get_permission_object(self):
70 return self.organisation
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/projectcontainers/forms.py b/meinberlin/apps/projectcontainers/forms.py
--- a/meinberlin/apps/projectcontainers/forms.py
+++ b/meinberlin/apps/projectcontainers/forms.py
@@ -62,12 +62,20 @@
class ContainerProjectsForm(ProjectDashboardForm):
def __init__(self, *args, **kwargs):
+ self.user = kwargs.pop('user')
+ self.organisation = kwargs.pop('organisation')
super().__init__(*args, **kwargs)
- # We tried to find a good balance between a short list and
- # all necessary projects. The details may change over time.
- # Projects that are already selected should remain in the queryset.
- self.fields['projects'].queryset = self.fields['projects'].queryset \
+ projects = self.fields['projects']\
+ .queryset.filter(organisation=self.organisation)
+ if not self.organisation.has_initiator(self.user):
+ user_groups = self.user.groups.all()
+ org_groups = self.organisation.groups.all()
+ shared_groups = user_groups & org_groups
+ group = shared_groups.distinct().first()
+ projects = projects.filter(group=group)
+
+ self.fields['projects'].queryset = projects \
.filter(projectcontainer=None)\
.filter(Q(containers=self.instance) |
(Q(containers=None) &
diff --git a/meinberlin/apps/projectcontainers/views.py b/meinberlin/apps/projectcontainers/views.py
--- a/meinberlin/apps/projectcontainers/views.py
+++ b/meinberlin/apps/projectcontainers/views.py
@@ -52,6 +52,12 @@
def get_object(self, queryset=None):
return self.project
+ def get_form_kwargs(self):
+ kwargs = super().get_form_kwargs()
+ kwargs['user'] = self.request.user
+ kwargs['organisation'] = self.project.organisation
+ return kwargs
+
class ContainerListView(dashboard_mixins.DashboardBaseMixin,
generic.ListView):
|
{"golden_diff": "diff --git a/meinberlin/apps/projectcontainers/forms.py b/meinberlin/apps/projectcontainers/forms.py\n--- a/meinberlin/apps/projectcontainers/forms.py\n+++ b/meinberlin/apps/projectcontainers/forms.py\n@@ -62,12 +62,20 @@\n class ContainerProjectsForm(ProjectDashboardForm):\n \n def __init__(self, *args, **kwargs):\n+ self.user = kwargs.pop('user')\n+ self.organisation = kwargs.pop('organisation')\n super().__init__(*args, **kwargs)\n \n- # We tried to find a good balance between a short list and\n- # all necessary projects. The details may change over time.\n- # Projects that are already selected should remain in the queryset.\n- self.fields['projects'].queryset = self.fields['projects'].queryset \\\n+ projects = self.fields['projects']\\\n+ .queryset.filter(organisation=self.organisation)\n+ if not self.organisation.has_initiator(self.user):\n+ user_groups = self.user.groups.all()\n+ org_groups = self.organisation.groups.all()\n+ shared_groups = user_groups & org_groups\n+ group = shared_groups.distinct().first()\n+ projects = projects.filter(group=group)\n+\n+ self.fields['projects'].queryset = projects \\\n .filter(projectcontainer=None)\\\n .filter(Q(containers=self.instance) |\n (Q(containers=None) &\ndiff --git a/meinberlin/apps/projectcontainers/views.py b/meinberlin/apps/projectcontainers/views.py\n--- a/meinberlin/apps/projectcontainers/views.py\n+++ b/meinberlin/apps/projectcontainers/views.py\n@@ -52,6 +52,12 @@\n def get_object(self, queryset=None):\n return self.project\n \n+ def get_form_kwargs(self):\n+ kwargs = super().get_form_kwargs()\n+ kwargs['user'] = self.request.user\n+ kwargs['organisation'] = self.project.organisation\n+ return kwargs\n+\n \n class ContainerListView(dashboard_mixins.DashboardBaseMixin,\n generic.ListView):\n", "issue": "project_list in container add project form contains all projects\n@CarolingerSeilchenspringer at the moment all projects (not only the ones belonging to the organisation) can be added to a container. Should that stay that way?\r\n\n", "before_files": [{"content": "from django.db.models import Q\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom adhocracy4.dashboard.forms import ProjectCreateForm\nfrom adhocracy4.dashboard.forms import ProjectDashboardForm\nfrom meinberlin.apps.contrib.widgets import Select2MultipleWidget\n\nfrom . import models\n\nLABELS = {\n 'name': _('Title of your container'),\n 'description': _('Short description of your container'),\n 'tile_image': _('Logo'),\n}\n\nHELP_TEXTS = {\n 'name': _('This title will appear on the '\n 'teaser card and on top of the container '\n 'detail page. It should be max. 120 characters long'),\n 'description': _('This short description will appear on '\n 'the header of the container and in the teaser. '\n 'It should briefly state the goal of the '\n 'projects in max. 250 chars.'),\n 'tile_image': _(\n 'The image will be shown in the container tile.'\n ),\n}\n\n\nclass ContainerCreateForm(ProjectCreateForm):\n\n class Meta:\n model = models.ProjectContainer\n fields = ['name', 'description',\n 'tile_image', 'tile_image_copyright']\n labels = LABELS\n help_texts = HELP_TEXTS\n\n\nclass ContainerBasicForm(ProjectDashboardForm):\n\n class Meta:\n model = models.ProjectContainer\n fields = ['name', 'description', 'tile_image',\n 'tile_image_copyright', 'is_archived']\n required_for_project_publish = ['name', 'description']\n labels = LABELS\n help_texts = HELP_TEXTS\n\n\nclass ContainerInformationForm(ProjectDashboardForm):\n\n class Meta:\n model = models.ProjectContainer\n fields = ['information']\n required_for_project_publish = ['information']\n labels = {\n 'information': _('Description of your container'),\n }\n\n\nclass ContainerProjectsForm(ProjectDashboardForm):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n # We tried to find a good balance between a short list and\n # all necessary projects. The details may change over time.\n # Projects that are already selected should remain in the queryset.\n self.fields['projects'].queryset = self.fields['projects'].queryset \\\n .filter(projectcontainer=None)\\\n .filter(Q(containers=self.instance) |\n (Q(containers=None) &\n Q(is_archived=False) &\n Q(is_public=True)))\\\n .order_by('name')\n\n class Meta:\n model = models.ProjectContainer\n fields = ['projects']\n required_for_project_publish = ['projects']\n widgets = {\n 'projects': Select2MultipleWidget,\n }\n", "path": "meinberlin/apps/projectcontainers/forms.py"}, {"content": "from django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.dashboard.blueprints import ProjectBlueprint\nfrom adhocracy4.dashboard.components.forms.views import \\\n ProjectComponentFormView\nfrom adhocracy4.dashboard.views import ProjectCreateView\n\nfrom . import forms\nfrom . import models\n\n\nclass ContainerCreateView(ProjectCreateView):\n model = models.ProjectContainer\n slug_url_kwarg = 'project_slug'\n form_class = forms.ContainerCreateForm\n template_name = 'meinberlin_projectcontainers/container_create_form.html'\n success_message = _('Container successfully created.')\n\n blueprint = ProjectBlueprint(\n title=_('Container'),\n description=_(\n 'A container contains multiple projects.'\n ),\n content=[],\n image='',\n settings_model=None,\n )\n\n\nclass ContainerBasicFormView(ProjectComponentFormView):\n model = models.ProjectContainer\n\n @property\n def project(self):\n project = super().project\n return project.projectcontainer\n\n def get_object(self, queryset=None):\n return self.project\n\n\nclass ContainerProjectsView(ProjectComponentFormView):\n model = models.ProjectContainer\n\n @property\n def project(self):\n project = super().project\n return project.projectcontainer\n\n def get_object(self, queryset=None):\n return self.project\n\n\nclass ContainerListView(dashboard_mixins.DashboardBaseMixin,\n generic.ListView):\n model = models.ProjectContainer\n paginate_by = 12\n template_name = 'meinberlin_projectcontainers/container_list.html'\n permission_required = 'a4projects.add_project'\n menu_item = 'project'\n\n def get_queryset(self):\n return super().get_queryset().filter(\n organisation=self.organisation\n )\n\n def get_permission_object(self):\n return self.organisation\n", "path": "meinberlin/apps/projectcontainers/views.py"}], "after_files": [{"content": "from django.db.models import Q\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom adhocracy4.dashboard.forms import ProjectCreateForm\nfrom adhocracy4.dashboard.forms import ProjectDashboardForm\nfrom meinberlin.apps.contrib.widgets import Select2MultipleWidget\n\nfrom . import models\n\nLABELS = {\n 'name': _('Title of your container'),\n 'description': _('Short description of your container'),\n 'tile_image': _('Logo'),\n}\n\nHELP_TEXTS = {\n 'name': _('This title will appear on the '\n 'teaser card and on top of the container '\n 'detail page. It should be max. 120 characters long'),\n 'description': _('This short description will appear on '\n 'the header of the container and in the teaser. '\n 'It should briefly state the goal of the '\n 'projects in max. 250 chars.'),\n 'tile_image': _(\n 'The image will be shown in the container tile.'\n ),\n}\n\n\nclass ContainerCreateForm(ProjectCreateForm):\n\n class Meta:\n model = models.ProjectContainer\n fields = ['name', 'description',\n 'tile_image', 'tile_image_copyright']\n labels = LABELS\n help_texts = HELP_TEXTS\n\n\nclass ContainerBasicForm(ProjectDashboardForm):\n\n class Meta:\n model = models.ProjectContainer\n fields = ['name', 'description', 'tile_image',\n 'tile_image_copyright', 'is_archived']\n required_for_project_publish = ['name', 'description']\n labels = LABELS\n help_texts = HELP_TEXTS\n\n\nclass ContainerInformationForm(ProjectDashboardForm):\n\n class Meta:\n model = models.ProjectContainer\n fields = ['information']\n required_for_project_publish = ['information']\n labels = {\n 'information': _('Description of your container'),\n }\n\n\nclass ContainerProjectsForm(ProjectDashboardForm):\n\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop('user')\n self.organisation = kwargs.pop('organisation')\n super().__init__(*args, **kwargs)\n\n projects = self.fields['projects']\\\n .queryset.filter(organisation=self.organisation)\n if not self.organisation.has_initiator(self.user):\n user_groups = self.user.groups.all()\n org_groups = self.organisation.groups.all()\n shared_groups = user_groups & org_groups\n group = shared_groups.distinct().first()\n projects = projects.filter(group=group)\n\n self.fields['projects'].queryset = projects \\\n .filter(projectcontainer=None)\\\n .filter(Q(containers=self.instance) |\n (Q(containers=None) &\n Q(is_archived=False) &\n Q(is_public=True)))\\\n .order_by('name')\n\n class Meta:\n model = models.ProjectContainer\n fields = ['projects']\n required_for_project_publish = ['projects']\n widgets = {\n 'projects': Select2MultipleWidget,\n }\n", "path": "meinberlin/apps/projectcontainers/forms.py"}, {"content": "from django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.dashboard.blueprints import ProjectBlueprint\nfrom adhocracy4.dashboard.components.forms.views import \\\n ProjectComponentFormView\nfrom adhocracy4.dashboard.views import ProjectCreateView\n\nfrom . import forms\nfrom . import models\n\n\nclass ContainerCreateView(ProjectCreateView):\n model = models.ProjectContainer\n slug_url_kwarg = 'project_slug'\n form_class = forms.ContainerCreateForm\n template_name = 'meinberlin_projectcontainers/container_create_form.html'\n success_message = _('Container successfully created.')\n\n blueprint = ProjectBlueprint(\n title=_('Container'),\n description=_(\n 'A container contains multiple projects.'\n ),\n content=[],\n image='',\n settings_model=None,\n )\n\n\nclass ContainerBasicFormView(ProjectComponentFormView):\n model = models.ProjectContainer\n\n @property\n def project(self):\n project = super().project\n return project.projectcontainer\n\n def get_object(self, queryset=None):\n return self.project\n\n\nclass ContainerProjectsView(ProjectComponentFormView):\n model = models.ProjectContainer\n\n @property\n def project(self):\n project = super().project\n return project.projectcontainer\n\n def get_object(self, queryset=None):\n return self.project\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['user'] = self.request.user\n kwargs['organisation'] = self.project.organisation\n return kwargs\n\n\nclass ContainerListView(dashboard_mixins.DashboardBaseMixin,\n generic.ListView):\n model = models.ProjectContainer\n paginate_by = 12\n template_name = 'meinberlin_projectcontainers/container_list.html'\n permission_required = 'a4projects.add_project'\n menu_item = 'project'\n\n def get_queryset(self):\n return super().get_queryset().filter(\n organisation=self.organisation\n )\n\n def get_permission_object(self):\n return self.organisation\n", "path": "meinberlin/apps/projectcontainers/views.py"}]}
| 1,604 | 443 |
gh_patches_debug_6613
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-2515
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Getting dynamic challenges by ID does not return decay function
When getting a dynamic challenge from `GET /api/v1/challenges/<challenge-id>`, the challenge does not return its decay function.
This seems to be caused by [this](https://github.com/CTFd/CTFd/blob/master/CTFd/plugins/dynamic_challenges/__init__.py#L60-L90) function which does not include `challenge.function`.
This seems be have been missed out when implementing different decay functions for dynamic challenges. This does not have any impact on normal usage of CTFd, but I see no reason not to include the function in the response.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/plugins/dynamic_challenges/__init__.py`
Content:
```
1 from flask import Blueprint
2
3 from CTFd.models import Challenges, db
4 from CTFd.plugins import register_plugin_assets_directory
5 from CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge
6 from CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic
7 from CTFd.plugins.migrations import upgrade
8
9
10 class DynamicChallenge(Challenges):
11 __mapper_args__ = {"polymorphic_identity": "dynamic"}
12 id = db.Column(
13 db.Integer, db.ForeignKey("challenges.id", ondelete="CASCADE"), primary_key=True
14 )
15 initial = db.Column(db.Integer, default=0)
16 minimum = db.Column(db.Integer, default=0)
17 decay = db.Column(db.Integer, default=0)
18 function = db.Column(db.String(32), default="logarithmic")
19
20 def __init__(self, *args, **kwargs):
21 super(DynamicChallenge, self).__init__(**kwargs)
22 self.value = kwargs["initial"]
23
24
25 class DynamicValueChallenge(BaseChallenge):
26 id = "dynamic" # Unique identifier used to register challenges
27 name = "dynamic" # Name of a challenge type
28 templates = (
29 { # Handlebars templates used for each aspect of challenge editing & viewing
30 "create": "/plugins/dynamic_challenges/assets/create.html",
31 "update": "/plugins/dynamic_challenges/assets/update.html",
32 "view": "/plugins/dynamic_challenges/assets/view.html",
33 }
34 )
35 scripts = { # Scripts that are loaded when a template is loaded
36 "create": "/plugins/dynamic_challenges/assets/create.js",
37 "update": "/plugins/dynamic_challenges/assets/update.js",
38 "view": "/plugins/dynamic_challenges/assets/view.js",
39 }
40 # Route at which files are accessible. This must be registered using register_plugin_assets_directory()
41 route = "/plugins/dynamic_challenges/assets/"
42 # Blueprint used to access the static_folder directory.
43 blueprint = Blueprint(
44 "dynamic_challenges",
45 __name__,
46 template_folder="templates",
47 static_folder="assets",
48 )
49 challenge_model = DynamicChallenge
50
51 @classmethod
52 def calculate_value(cls, challenge):
53 f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)
54 value = f(challenge)
55
56 challenge.value = value
57 db.session.commit()
58 return challenge
59
60 @classmethod
61 def read(cls, challenge):
62 """
63 This method is in used to access the data of a challenge in a format processable by the front end.
64
65 :param challenge:
66 :return: Challenge object, data dictionary to be returned to the user
67 """
68 challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()
69 data = {
70 "id": challenge.id,
71 "name": challenge.name,
72 "value": challenge.value,
73 "initial": challenge.initial,
74 "decay": challenge.decay,
75 "minimum": challenge.minimum,
76 "description": challenge.description,
77 "connection_info": challenge.connection_info,
78 "next_id": challenge.next_id,
79 "category": challenge.category,
80 "state": challenge.state,
81 "max_attempts": challenge.max_attempts,
82 "type": challenge.type,
83 "type_data": {
84 "id": cls.id,
85 "name": cls.name,
86 "templates": cls.templates,
87 "scripts": cls.scripts,
88 },
89 }
90 return data
91
92 @classmethod
93 def update(cls, challenge, request):
94 """
95 This method is used to update the information associated with a challenge. This should be kept strictly to the
96 Challenges table and any child tables.
97
98 :param challenge:
99 :param request:
100 :return:
101 """
102 data = request.form or request.get_json()
103
104 for attr, value in data.items():
105 # We need to set these to floats so that the next operations don't operate on strings
106 if attr in ("initial", "minimum", "decay"):
107 value = float(value)
108 setattr(challenge, attr, value)
109
110 return DynamicValueChallenge.calculate_value(challenge)
111
112 @classmethod
113 def solve(cls, user, team, challenge, request):
114 super().solve(user, team, challenge, request)
115
116 DynamicValueChallenge.calculate_value(challenge)
117
118
119 def load(app):
120 upgrade(plugin_name="dynamic_challenges")
121 CHALLENGE_CLASSES["dynamic"] = DynamicValueChallenge
122 register_plugin_assets_directory(
123 app, base_path="/plugins/dynamic_challenges/assets/"
124 )
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/plugins/dynamic_challenges/__init__.py b/CTFd/plugins/dynamic_challenges/__init__.py
--- a/CTFd/plugins/dynamic_challenges/__init__.py
+++ b/CTFd/plugins/dynamic_challenges/__init__.py
@@ -73,6 +73,7 @@
"initial": challenge.initial,
"decay": challenge.decay,
"minimum": challenge.minimum,
+ "function": challenge.function,
"description": challenge.description,
"connection_info": challenge.connection_info,
"next_id": challenge.next_id,
|
{"golden_diff": "diff --git a/CTFd/plugins/dynamic_challenges/__init__.py b/CTFd/plugins/dynamic_challenges/__init__.py\n--- a/CTFd/plugins/dynamic_challenges/__init__.py\n+++ b/CTFd/plugins/dynamic_challenges/__init__.py\n@@ -73,6 +73,7 @@\n \"initial\": challenge.initial,\n \"decay\": challenge.decay,\n \"minimum\": challenge.minimum,\n+ \"function\": challenge.function,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n \"next_id\": challenge.next_id,\n", "issue": "Getting dynamic challenges by ID does not return decay function\nWhen getting a dynamic challenge from `GET /api/v1/challenges/<challenge-id>`, the challenge does not return its decay function.\r\n\r\nThis seems to be caused by [this](https://github.com/CTFd/CTFd/blob/master/CTFd/plugins/dynamic_challenges/__init__.py#L60-L90) function which does not include `challenge.function`.\r\n\r\nThis seems be have been missed out when implementing different decay functions for dynamic challenges. This does not have any impact on normal usage of CTFd, but I see no reason not to include the function in the response.\r\n\n", "before_files": [{"content": "from flask import Blueprint\n\nfrom CTFd.models import Challenges, db\nfrom CTFd.plugins import register_plugin_assets_directory\nfrom CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge\nfrom CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic\nfrom CTFd.plugins.migrations import upgrade\n\n\nclass DynamicChallenge(Challenges):\n __mapper_args__ = {\"polymorphic_identity\": \"dynamic\"}\n id = db.Column(\n db.Integer, db.ForeignKey(\"challenges.id\", ondelete=\"CASCADE\"), primary_key=True\n )\n initial = db.Column(db.Integer, default=0)\n minimum = db.Column(db.Integer, default=0)\n decay = db.Column(db.Integer, default=0)\n function = db.Column(db.String(32), default=\"logarithmic\")\n\n def __init__(self, *args, **kwargs):\n super(DynamicChallenge, self).__init__(**kwargs)\n self.value = kwargs[\"initial\"]\n\n\nclass DynamicValueChallenge(BaseChallenge):\n id = \"dynamic\" # Unique identifier used to register challenges\n name = \"dynamic\" # Name of a challenge type\n templates = (\n { # Handlebars templates used for each aspect of challenge editing & viewing\n \"create\": \"/plugins/dynamic_challenges/assets/create.html\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.html\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.html\",\n }\n )\n scripts = { # Scripts that are loaded when a template is loaded\n \"create\": \"/plugins/dynamic_challenges/assets/create.js\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.js\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.js\",\n }\n # Route at which files are accessible. This must be registered using register_plugin_assets_directory()\n route = \"/plugins/dynamic_challenges/assets/\"\n # Blueprint used to access the static_folder directory.\n blueprint = Blueprint(\n \"dynamic_challenges\",\n __name__,\n template_folder=\"templates\",\n static_folder=\"assets\",\n )\n challenge_model = DynamicChallenge\n\n @classmethod\n def calculate_value(cls, challenge):\n f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)\n value = f(challenge)\n\n challenge.value = value\n db.session.commit()\n return challenge\n\n @classmethod\n def read(cls, challenge):\n \"\"\"\n This method is in used to access the data of a challenge in a format processable by the front end.\n\n :param challenge:\n :return: Challenge object, data dictionary to be returned to the user\n \"\"\"\n challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()\n data = {\n \"id\": challenge.id,\n \"name\": challenge.name,\n \"value\": challenge.value,\n \"initial\": challenge.initial,\n \"decay\": challenge.decay,\n \"minimum\": challenge.minimum,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n \"next_id\": challenge.next_id,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n \"type\": challenge.type,\n \"type_data\": {\n \"id\": cls.id,\n \"name\": cls.name,\n \"templates\": cls.templates,\n \"scripts\": cls.scripts,\n },\n }\n return data\n\n @classmethod\n def update(cls, challenge, request):\n \"\"\"\n This method is used to update the information associated with a challenge. This should be kept strictly to the\n Challenges table and any child tables.\n\n :param challenge:\n :param request:\n :return:\n \"\"\"\n data = request.form or request.get_json()\n\n for attr, value in data.items():\n # We need to set these to floats so that the next operations don't operate on strings\n if attr in (\"initial\", \"minimum\", \"decay\"):\n value = float(value)\n setattr(challenge, attr, value)\n\n return DynamicValueChallenge.calculate_value(challenge)\n\n @classmethod\n def solve(cls, user, team, challenge, request):\n super().solve(user, team, challenge, request)\n\n DynamicValueChallenge.calculate_value(challenge)\n\n\ndef load(app):\n upgrade(plugin_name=\"dynamic_challenges\")\n CHALLENGE_CLASSES[\"dynamic\"] = DynamicValueChallenge\n register_plugin_assets_directory(\n app, base_path=\"/plugins/dynamic_challenges/assets/\"\n )\n", "path": "CTFd/plugins/dynamic_challenges/__init__.py"}], "after_files": [{"content": "from flask import Blueprint\n\nfrom CTFd.models import Challenges, db\nfrom CTFd.plugins import register_plugin_assets_directory\nfrom CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge\nfrom CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic\nfrom CTFd.plugins.migrations import upgrade\n\n\nclass DynamicChallenge(Challenges):\n __mapper_args__ = {\"polymorphic_identity\": \"dynamic\"}\n id = db.Column(\n db.Integer, db.ForeignKey(\"challenges.id\", ondelete=\"CASCADE\"), primary_key=True\n )\n initial = db.Column(db.Integer, default=0)\n minimum = db.Column(db.Integer, default=0)\n decay = db.Column(db.Integer, default=0)\n function = db.Column(db.String(32), default=\"logarithmic\")\n\n def __init__(self, *args, **kwargs):\n super(DynamicChallenge, self).__init__(**kwargs)\n self.value = kwargs[\"initial\"]\n\n\nclass DynamicValueChallenge(BaseChallenge):\n id = \"dynamic\" # Unique identifier used to register challenges\n name = \"dynamic\" # Name of a challenge type\n templates = (\n { # Handlebars templates used for each aspect of challenge editing & viewing\n \"create\": \"/plugins/dynamic_challenges/assets/create.html\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.html\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.html\",\n }\n )\n scripts = { # Scripts that are loaded when a template is loaded\n \"create\": \"/plugins/dynamic_challenges/assets/create.js\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.js\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.js\",\n }\n # Route at which files are accessible. This must be registered using register_plugin_assets_directory()\n route = \"/plugins/dynamic_challenges/assets/\"\n # Blueprint used to access the static_folder directory.\n blueprint = Blueprint(\n \"dynamic_challenges\",\n __name__,\n template_folder=\"templates\",\n static_folder=\"assets\",\n )\n challenge_model = DynamicChallenge\n\n @classmethod\n def calculate_value(cls, challenge):\n f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)\n value = f(challenge)\n\n challenge.value = value\n db.session.commit()\n return challenge\n\n @classmethod\n def read(cls, challenge):\n \"\"\"\n This method is in used to access the data of a challenge in a format processable by the front end.\n\n :param challenge:\n :return: Challenge object, data dictionary to be returned to the user\n \"\"\"\n challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()\n data = {\n \"id\": challenge.id,\n \"name\": challenge.name,\n \"value\": challenge.value,\n \"initial\": challenge.initial,\n \"decay\": challenge.decay,\n \"minimum\": challenge.minimum,\n \"function\": challenge.function,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n \"next_id\": challenge.next_id,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n \"type\": challenge.type,\n \"type_data\": {\n \"id\": cls.id,\n \"name\": cls.name,\n \"templates\": cls.templates,\n \"scripts\": cls.scripts,\n },\n }\n return data\n\n @classmethod\n def update(cls, challenge, request):\n \"\"\"\n This method is used to update the information associated with a challenge. This should be kept strictly to the\n Challenges table and any child tables.\n\n :param challenge:\n :param request:\n :return:\n \"\"\"\n data = request.form or request.get_json()\n\n for attr, value in data.items():\n # We need to set these to floats so that the next operations don't operate on strings\n if attr in (\"initial\", \"minimum\", \"decay\"):\n value = float(value)\n setattr(challenge, attr, value)\n\n return DynamicValueChallenge.calculate_value(challenge)\n\n @classmethod\n def solve(cls, user, team, challenge, request):\n super().solve(user, team, challenge, request)\n\n DynamicValueChallenge.calculate_value(challenge)\n\n\ndef load(app):\n upgrade(plugin_name=\"dynamic_challenges\")\n CHALLENGE_CLASSES[\"dynamic\"] = DynamicValueChallenge\n register_plugin_assets_directory(\n app, base_path=\"/plugins/dynamic_challenges/assets/\"\n )\n", "path": "CTFd/plugins/dynamic_challenges/__init__.py"}]}
| 1,623 | 127 |
gh_patches_debug_9313
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1364
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Ax-Plugin] Add support for Python 3.9
Python 3.9 support pending on scikit 2.4.0 release. Relevant comment: https://github.com/scikit-learn/scikit-learn/issues/18621#issuecomment-733078676
Related to #1062
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/hydra_ax_sweeper/setup.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 # type: ignore
3 from setuptools import find_namespace_packages, setup
4
5 with open("README.md", "r") as fh:
6 LONG_DESC = fh.read()
7 setup(
8 name="hydra-ax-sweeper",
9 version="1.1.0rc1",
10 author="Omry Yadan, Shagun Sodhani",
11 author_email="[email protected], [email protected]",
12 description="Hydra Ax Sweeper plugin",
13 long_description=LONG_DESC,
14 long_description_content_type="text/markdown",
15 url="https://github.com/facebookresearch/hydra/",
16 packages=find_namespace_packages(include=["hydra_plugins.*"]),
17 classifiers=[
18 "License :: OSI Approved :: MIT License",
19 "Programming Language :: Python :: 3.7",
20 "Programming Language :: Python :: 3.8",
21 # "Programming Language :: Python :: 3.9",
22 "Operating System :: POSIX :: Linux",
23 "Operating System :: MacOS",
24 "Development Status :: 4 - Beta",
25 ],
26 install_requires=["hydra-core>=1.0.0", "ax-platform>=0.1.13"],
27 include_package_data=True,
28 )
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/hydra_ax_sweeper/setup.py b/plugins/hydra_ax_sweeper/setup.py
--- a/plugins/hydra_ax_sweeper/setup.py
+++ b/plugins/hydra_ax_sweeper/setup.py
@@ -18,7 +18,7 @@
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
- # "Programming Language :: Python :: 3.9",
+ "Programming Language :: Python :: 3.9",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Development Status :: 4 - Beta",
|
{"golden_diff": "diff --git a/plugins/hydra_ax_sweeper/setup.py b/plugins/hydra_ax_sweeper/setup.py\n--- a/plugins/hydra_ax_sweeper/setup.py\n+++ b/plugins/hydra_ax_sweeper/setup.py\n@@ -18,7 +18,7 @@\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n- # \"Programming Language :: Python :: 3.9\",\n+ \"Programming Language :: Python :: 3.9\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS\",\n \"Development Status :: 4 - Beta\",\n", "issue": "[Ax-Plugin] Add support for Python 3.9\nPython 3.9 support pending on scikit 2.4.0 release. Relevant comment: https://github.com/scikit-learn/scikit-learn/issues/18621#issuecomment-733078676\r\n\r\nRelated to #1062 \n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nfrom setuptools import find_namespace_packages, setup\n\nwith open(\"README.md\", \"r\") as fh:\n LONG_DESC = fh.read()\n setup(\n name=\"hydra-ax-sweeper\",\n version=\"1.1.0rc1\",\n author=\"Omry Yadan, Shagun Sodhani\",\n author_email=\"[email protected], [email protected]\",\n description=\"Hydra Ax Sweeper plugin\",\n long_description=LONG_DESC,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/facebookresearch/hydra/\",\n packages=find_namespace_packages(include=[\"hydra_plugins.*\"]),\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n # \"Programming Language :: Python :: 3.9\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS\",\n \"Development Status :: 4 - Beta\",\n ],\n install_requires=[\"hydra-core>=1.0.0\", \"ax-platform>=0.1.13\"],\n include_package_data=True,\n )\n", "path": "plugins/hydra_ax_sweeper/setup.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nfrom setuptools import find_namespace_packages, setup\n\nwith open(\"README.md\", \"r\") as fh:\n LONG_DESC = fh.read()\n setup(\n name=\"hydra-ax-sweeper\",\n version=\"1.1.0rc1\",\n author=\"Omry Yadan, Shagun Sodhani\",\n author_email=\"[email protected], [email protected]\",\n description=\"Hydra Ax Sweeper plugin\",\n long_description=LONG_DESC,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/facebookresearch/hydra/\",\n packages=find_namespace_packages(include=[\"hydra_plugins.*\"]),\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS\",\n \"Development Status :: 4 - Beta\",\n ],\n install_requires=[\"hydra-core>=1.0.0\", \"ax-platform>=0.1.13\"],\n include_package_data=True,\n )\n", "path": "plugins/hydra_ax_sweeper/setup.py"}]}
| 661 | 151 |
gh_patches_debug_34844
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-375
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[ENH] Naming conventions
I wanted to discuss naming conventions for the various functions and arguments for consistency. `expand_column` has a parameter `column` whereas `add_column` had `col_name`.
Also, is `_column` necessary in each function? Would it be ok to just have an `add()` or `transform()` method? In general I'm more on the side of more verbose function names, but just wanted to throw the idea out there.
Similarly, when following the format of `limit_column_characters` functions like `change_type` should probably be named `change_column_type`.
I'm not married to any of this (except the function arguments, those should be consistent) but wanted to get peoples' ideas.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `janitor/io.py`
Content:
```
1 import os
2 from glob import glob
3
4 import pandas as pd
5
6
7 def read_csvs(filespath: str, seperate_df: bool = False, **kwargs):
8 """
9 :param filespath: The filepath pattern matching the CSVs files.
10 Accepts regular expressions, with or without csv extension.
11 :param seperate_df: If False (default) returns a single Dataframe
12 with the concatenation of the csv files.
13 If True, returns a dictionary of seperate dataframes
14 for each CSV file.
15 :param kwargs: Keyword arguments to pass into the
16 original pandas `read_csv`.
17 """
18 # Sanitize input
19 assert filespath is not None
20 assert len(filespath) != 0
21
22 # Read the csv files
23 dfs = {
24 os.path.basename(f): pd.read_csv(f, **kwargs) for f in glob(filespath)
25 }
26 # Check if dataframes have been read
27 if len(dfs) == 0:
28 raise ValueError("No CSV files to read with the given filespath")
29 # Concatenate the dataframes if requested (default)
30 col_names = list(dfs.values())[0].columns
31 if not seperate_df:
32 # If columns do not match raise an error
33 for df in dfs.values():
34 if not all(df.columns == col_names):
35 raise ValueError(
36 "Columns in input CSV files do not match."
37 "Files cannot be concatenated"
38 )
39 return pd.concat(list(dfs.values()), ignore_index=True, sort=False)
40 else:
41 return dfs
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/janitor/io.py b/janitor/io.py
--- a/janitor/io.py
+++ b/janitor/io.py
@@ -1,34 +1,49 @@
import os
from glob import glob
+from typing import Iterable, Union
import pandas as pd
+from .utils import deprecated_alias
-def read_csvs(filespath: str, seperate_df: bool = False, **kwargs):
+
+@deprecated_alias(seperate_df="separate_df", filespath="files_path")
+def read_csvs(
+ files_path: Union[str, Iterable[str]], separate_df: bool = False, **kwargs
+) -> Union[pd.DataFrame, dict]:
"""
- :param filespath: The filepath pattern matching the CSVs files.
+ :param files_path: The filepath pattern matching the CSVs files.
Accepts regular expressions, with or without csv extension.
- :param seperate_df: If False (default) returns a single Dataframe
+ Also accepts iterable of file paths.
+ :param separate_df: If False (default) returns a single Dataframe
with the concatenation of the csv files.
- If True, returns a dictionary of seperate dataframes
+ If True, returns a dictionary of separate dataframes
for each CSV file.
:param kwargs: Keyword arguments to pass into the
original pandas `read_csv`.
"""
# Sanitize input
- assert filespath is not None
- assert len(filespath) != 0
+ assert files_path is not None
+ assert len(files_path) != 0
# Read the csv files
- dfs = {
- os.path.basename(f): pd.read_csv(f, **kwargs) for f in glob(filespath)
- }
+ # String to file/folder or file pattern provided
+ if isinstance(files_path, str):
+ dfs = {
+ os.path.basename(f): pd.read_csv(f, **kwargs)
+ for f in glob(files_path)
+ }
+ # Iterable of file paths provided
+ else:
+ dfs = {
+ os.path.basename(f): pd.read_csv(f, **kwargs) for f in files_path
+ }
# Check if dataframes have been read
if len(dfs) == 0:
- raise ValueError("No CSV files to read with the given filespath")
+ raise ValueError("No CSV files to read with the given `files_path`")
# Concatenate the dataframes if requested (default)
col_names = list(dfs.values())[0].columns
- if not seperate_df:
+ if not separate_df:
# If columns do not match raise an error
for df in dfs.values():
if not all(df.columns == col_names):
|
{"golden_diff": "diff --git a/janitor/io.py b/janitor/io.py\n--- a/janitor/io.py\n+++ b/janitor/io.py\n@@ -1,34 +1,49 @@\n import os\n from glob import glob\n+from typing import Iterable, Union\n \n import pandas as pd\n \n+from .utils import deprecated_alias\n \n-def read_csvs(filespath: str, seperate_df: bool = False, **kwargs):\n+\n+@deprecated_alias(seperate_df=\"separate_df\", filespath=\"files_path\")\n+def read_csvs(\n+ files_path: Union[str, Iterable[str]], separate_df: bool = False, **kwargs\n+) -> Union[pd.DataFrame, dict]:\n \"\"\"\n- :param filespath: The filepath pattern matching the CSVs files.\n+ :param files_path: The filepath pattern matching the CSVs files.\n Accepts regular expressions, with or without csv extension.\n- :param seperate_df: If False (default) returns a single Dataframe\n+ Also accepts iterable of file paths.\n+ :param separate_df: If False (default) returns a single Dataframe\n with the concatenation of the csv files.\n- If True, returns a dictionary of seperate dataframes\n+ If True, returns a dictionary of separate dataframes\n for each CSV file.\n :param kwargs: Keyword arguments to pass into the\n original pandas `read_csv`.\n \"\"\"\n # Sanitize input\n- assert filespath is not None\n- assert len(filespath) != 0\n+ assert files_path is not None\n+ assert len(files_path) != 0\n \n # Read the csv files\n- dfs = {\n- os.path.basename(f): pd.read_csv(f, **kwargs) for f in glob(filespath)\n- }\n+ # String to file/folder or file pattern provided\n+ if isinstance(files_path, str):\n+ dfs = {\n+ os.path.basename(f): pd.read_csv(f, **kwargs)\n+ for f in glob(files_path)\n+ }\n+ # Iterable of file paths provided\n+ else:\n+ dfs = {\n+ os.path.basename(f): pd.read_csv(f, **kwargs) for f in files_path\n+ }\n # Check if dataframes have been read\n if len(dfs) == 0:\n- raise ValueError(\"No CSV files to read with the given filespath\")\n+ raise ValueError(\"No CSV files to read with the given `files_path`\")\n # Concatenate the dataframes if requested (default)\n col_names = list(dfs.values())[0].columns\n- if not seperate_df:\n+ if not separate_df:\n # If columns do not match raise an error\n for df in dfs.values():\n if not all(df.columns == col_names):\n", "issue": "[ENH] Naming conventions\nI wanted to discuss naming conventions for the various functions and arguments for consistency. `expand_column` has a parameter `column` whereas `add_column` had `col_name`.\r\n\r\nAlso, is `_column` necessary in each function? Would it be ok to just have an `add()` or `transform()` method? In general I'm more on the side of more verbose function names, but just wanted to throw the idea out there.\r\n\r\nSimilarly, when following the format of `limit_column_characters` functions like `change_type` should probably be named `change_column_type`.\r\n\r\nI'm not married to any of this (except the function arguments, those should be consistent) but wanted to get peoples' ideas.\n", "before_files": [{"content": "import os\nfrom glob import glob\n\nimport pandas as pd\n\n\ndef read_csvs(filespath: str, seperate_df: bool = False, **kwargs):\n \"\"\"\n :param filespath: The filepath pattern matching the CSVs files.\n Accepts regular expressions, with or without csv extension.\n :param seperate_df: If False (default) returns a single Dataframe\n with the concatenation of the csv files.\n If True, returns a dictionary of seperate dataframes\n for each CSV file.\n :param kwargs: Keyword arguments to pass into the\n original pandas `read_csv`.\n \"\"\"\n # Sanitize input\n assert filespath is not None\n assert len(filespath) != 0\n\n # Read the csv files\n dfs = {\n os.path.basename(f): pd.read_csv(f, **kwargs) for f in glob(filespath)\n }\n # Check if dataframes have been read\n if len(dfs) == 0:\n raise ValueError(\"No CSV files to read with the given filespath\")\n # Concatenate the dataframes if requested (default)\n col_names = list(dfs.values())[0].columns\n if not seperate_df:\n # If columns do not match raise an error\n for df in dfs.values():\n if not all(df.columns == col_names):\n raise ValueError(\n \"Columns in input CSV files do not match.\"\n \"Files cannot be concatenated\"\n )\n return pd.concat(list(dfs.values()), ignore_index=True, sort=False)\n else:\n return dfs\n", "path": "janitor/io.py"}], "after_files": [{"content": "import os\nfrom glob import glob\nfrom typing import Iterable, Union\n\nimport pandas as pd\n\nfrom .utils import deprecated_alias\n\n\n@deprecated_alias(seperate_df=\"separate_df\", filespath=\"files_path\")\ndef read_csvs(\n files_path: Union[str, Iterable[str]], separate_df: bool = False, **kwargs\n) -> Union[pd.DataFrame, dict]:\n \"\"\"\n :param files_path: The filepath pattern matching the CSVs files.\n Accepts regular expressions, with or without csv extension.\n Also accepts iterable of file paths.\n :param separate_df: If False (default) returns a single Dataframe\n with the concatenation of the csv files.\n If True, returns a dictionary of separate dataframes\n for each CSV file.\n :param kwargs: Keyword arguments to pass into the\n original pandas `read_csv`.\n \"\"\"\n # Sanitize input\n assert files_path is not None\n assert len(files_path) != 0\n\n # Read the csv files\n # String to file/folder or file pattern provided\n if isinstance(files_path, str):\n dfs = {\n os.path.basename(f): pd.read_csv(f, **kwargs)\n for f in glob(files_path)\n }\n # Iterable of file paths provided\n else:\n dfs = {\n os.path.basename(f): pd.read_csv(f, **kwargs) for f in files_path\n }\n # Check if dataframes have been read\n if len(dfs) == 0:\n raise ValueError(\"No CSV files to read with the given `files_path`\")\n # Concatenate the dataframes if requested (default)\n col_names = list(dfs.values())[0].columns\n if not separate_df:\n # If columns do not match raise an error\n for df in dfs.values():\n if not all(df.columns == col_names):\n raise ValueError(\n \"Columns in input CSV files do not match.\"\n \"Files cannot be concatenated\"\n )\n return pd.concat(list(dfs.values()), ignore_index=True, sort=False)\n else:\n return dfs\n", "path": "janitor/io.py"}]}
| 813 | 601 |
gh_patches_debug_25000
|
rasdani/github-patches
|
git_diff
|
adfinis__timed-backend-938
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: remaining effort on initial report creation is buggy
## Scenario
Create a report and add an estimated remaining effort to it.
## Expected behavior
It updates the remaining effort of the certain task in the statistics view.
## Actual behavior
After submitting the report the remaining effort does **not** update in stats view. But after editing the rem. effort and saving the report again in the timesheet, it will update the values in the stats view.
The attributes are fine in both requests to the backend. I suspect that a the `POST` and `PATCH` requests have different handling of the remaining effort attribute. Maybe the `POST` does not properly trigger the update?

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `timed/tracking/signals.py`
Content:
```
1 from django.db.models import Sum
2 from django.db.models.signals import pre_save
3 from django.dispatch import receiver
4
5 from timed.tracking.models import Report
6
7
8 @receiver(pre_save, sender=Report)
9 def update_rejected_on_reports(sender, instance, **kwargs):
10 """Unreject report when the task changes."""
11 # Check if the report is being created or updated
12 if instance.pk and instance.rejected:
13 report = Report.objects.get(id=instance.id)
14 if report.task_id != instance.task_id:
15 instance.rejected = False
16
17
18 @receiver(pre_save, sender=Report)
19 def update_most_recent_remaining_effort(sender, instance, **kwargs):
20 """Update remaining effort on task, if remaining effort tracking is active.
21
22 Update most_recent_remaining_effort on task and total_remaining_effort on project
23 only if remaining effort on report has changed.
24 Any other change on report should not trigger this signal.
25 """
26 if kwargs.get("raw", False): # pragma: no cover
27 return
28
29 if not instance.pk:
30 return
31 if instance.task.project.remaining_effort_tracking is not True:
32 return
33
34 if instance.remaining_effort != Report.objects.get(id=instance.id).remaining_effort:
35 task = instance.task
36 task.most_recent_remaining_effort = instance.remaining_effort
37 task.save()
38
39 project = task.project
40 total_remaining_effort = (
41 project.tasks.all()
42 .aggregate(sum_remaining=Sum("most_recent_remaining_effort"))
43 .get("sum_remaining")
44 )
45 project.total_remaining_effort = total_remaining_effort
46 project.save()
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/timed/tracking/signals.py b/timed/tracking/signals.py
--- a/timed/tracking/signals.py
+++ b/timed/tracking/signals.py
@@ -26,21 +26,30 @@
if kwargs.get("raw", False): # pragma: no cover
return
- if not instance.pk:
- return
if instance.task.project.remaining_effort_tracking is not True:
return
+ # update most_recent_remaining_effort and total_remaining_effort on report creation
+ if not instance.pk:
+ update_remaining_effort(instance)
+ return
+
+ # check if remaining effort has changed on report update
if instance.remaining_effort != Report.objects.get(id=instance.id).remaining_effort:
- task = instance.task
- task.most_recent_remaining_effort = instance.remaining_effort
- task.save()
-
- project = task.project
- total_remaining_effort = (
- project.tasks.all()
- .aggregate(sum_remaining=Sum("most_recent_remaining_effort"))
- .get("sum_remaining")
- )
- project.total_remaining_effort = total_remaining_effort
- project.save()
+ update_remaining_effort(instance)
+
+
+def update_remaining_effort(report):
+ task = report.task
+ project = task.project
+
+ task.most_recent_remaining_effort = report.remaining_effort
+ task.save()
+
+ total_remaining_effort = (
+ task.project.tasks.all()
+ .aggregate(sum_remaining=Sum("most_recent_remaining_effort"))
+ .get("sum_remaining")
+ )
+ project.total_remaining_effort = total_remaining_effort
+ project.save()
|
{"golden_diff": "diff --git a/timed/tracking/signals.py b/timed/tracking/signals.py\n--- a/timed/tracking/signals.py\n+++ b/timed/tracking/signals.py\n@@ -26,21 +26,30 @@\n if kwargs.get(\"raw\", False): # pragma: no cover\n return\n \n- if not instance.pk:\n- return\n if instance.task.project.remaining_effort_tracking is not True:\n return\n \n+ # update most_recent_remaining_effort and total_remaining_effort on report creation\n+ if not instance.pk:\n+ update_remaining_effort(instance)\n+ return\n+\n+ # check if remaining effort has changed on report update\n if instance.remaining_effort != Report.objects.get(id=instance.id).remaining_effort:\n- task = instance.task\n- task.most_recent_remaining_effort = instance.remaining_effort\n- task.save()\n-\n- project = task.project\n- total_remaining_effort = (\n- project.tasks.all()\n- .aggregate(sum_remaining=Sum(\"most_recent_remaining_effort\"))\n- .get(\"sum_remaining\")\n- )\n- project.total_remaining_effort = total_remaining_effort\n- project.save()\n+ update_remaining_effort(instance)\n+\n+\n+def update_remaining_effort(report):\n+ task = report.task\n+ project = task.project\n+\n+ task.most_recent_remaining_effort = report.remaining_effort\n+ task.save()\n+\n+ total_remaining_effort = (\n+ task.project.tasks.all()\n+ .aggregate(sum_remaining=Sum(\"most_recent_remaining_effort\"))\n+ .get(\"sum_remaining\")\n+ )\n+ project.total_remaining_effort = total_remaining_effort\n+ project.save()\n", "issue": "bug: remaining effort on initial report creation is buggy\n## Scenario\r\nCreate a report and add an estimated remaining effort to it.\r\n\r\n## Expected behavior\r\nIt updates the remaining effort of the certain task in the statistics view.\r\n\r\n## Actual behavior\r\nAfter submitting the report the remaining effort does **not** update in stats view. But after editing the rem. effort and saving the report again in the timesheet, it will update the values in the stats view.\r\n\r\nThe attributes are fine in both requests to the backend. I suspect that a the `POST` and `PATCH` requests have different handling of the remaining effort attribute. Maybe the `POST` does not properly trigger the update?\r\n\r\n\n", "before_files": [{"content": "from django.db.models import Sum\nfrom django.db.models.signals import pre_save\nfrom django.dispatch import receiver\n\nfrom timed.tracking.models import Report\n\n\n@receiver(pre_save, sender=Report)\ndef update_rejected_on_reports(sender, instance, **kwargs):\n \"\"\"Unreject report when the task changes.\"\"\"\n # Check if the report is being created or updated\n if instance.pk and instance.rejected:\n report = Report.objects.get(id=instance.id)\n if report.task_id != instance.task_id:\n instance.rejected = False\n\n\n@receiver(pre_save, sender=Report)\ndef update_most_recent_remaining_effort(sender, instance, **kwargs):\n \"\"\"Update remaining effort on task, if remaining effort tracking is active.\n\n Update most_recent_remaining_effort on task and total_remaining_effort on project\n only if remaining effort on report has changed.\n Any other change on report should not trigger this signal.\n \"\"\"\n if kwargs.get(\"raw\", False): # pragma: no cover\n return\n\n if not instance.pk:\n return\n if instance.task.project.remaining_effort_tracking is not True:\n return\n\n if instance.remaining_effort != Report.objects.get(id=instance.id).remaining_effort:\n task = instance.task\n task.most_recent_remaining_effort = instance.remaining_effort\n task.save()\n\n project = task.project\n total_remaining_effort = (\n project.tasks.all()\n .aggregate(sum_remaining=Sum(\"most_recent_remaining_effort\"))\n .get(\"sum_remaining\")\n )\n project.total_remaining_effort = total_remaining_effort\n project.save()\n", "path": "timed/tracking/signals.py"}], "after_files": [{"content": "from django.db.models import Sum\nfrom django.db.models.signals import pre_save\nfrom django.dispatch import receiver\n\nfrom timed.tracking.models import Report\n\n\n@receiver(pre_save, sender=Report)\ndef update_rejected_on_reports(sender, instance, **kwargs):\n \"\"\"Unreject report when the task changes.\"\"\"\n # Check if the report is being created or updated\n if instance.pk and instance.rejected:\n report = Report.objects.get(id=instance.id)\n if report.task_id != instance.task_id:\n instance.rejected = False\n\n\n@receiver(pre_save, sender=Report)\ndef update_most_recent_remaining_effort(sender, instance, **kwargs):\n \"\"\"Update remaining effort on task, if remaining effort tracking is active.\n\n Update most_recent_remaining_effort on task and total_remaining_effort on project\n only if remaining effort on report has changed.\n Any other change on report should not trigger this signal.\n \"\"\"\n if kwargs.get(\"raw\", False): # pragma: no cover\n return\n\n if instance.task.project.remaining_effort_tracking is not True:\n return\n\n # update most_recent_remaining_effort and total_remaining_effort on report creation\n if not instance.pk:\n update_remaining_effort(instance)\n return\n\n # check if remaining effort has changed on report update\n if instance.remaining_effort != Report.objects.get(id=instance.id).remaining_effort:\n update_remaining_effort(instance)\n\n\ndef update_remaining_effort(report):\n task = report.task\n project = task.project\n\n task.most_recent_remaining_effort = report.remaining_effort\n task.save()\n\n total_remaining_effort = (\n task.project.tasks.all()\n .aggregate(sum_remaining=Sum(\"most_recent_remaining_effort\"))\n .get(\"sum_remaining\")\n )\n project.total_remaining_effort = total_remaining_effort\n project.save()\n", "path": "timed/tracking/signals.py"}]}
| 892 | 376 |
gh_patches_debug_34733
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-231
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: base manifest value for 'exclude' is always ignored
I stumbled upon this bug while working on #226: the culprit is [`Repository.hooks`](https://github.com/pre-commit/pre-commit/blob/master/pre_commit/repository.py#L48).
A quick fix for this would be to simply remove the default value from `pre_commit/clientlib/validate_config.py`, but the root cause is that any default value defined for a field in this file will make the corresponding manifest field useless.
Basically here is what happens in `Repository.hooks`:
- all the hooks defined in the current repository are enumerated
- at this stage, a `hook` is a dict closely matching the Yaml the config file content, **plus** default values for fields not defined in the Yaml but having a JSON schema 'default'
- when doing the dict merge, **every** (key,value) pair in `hook` overrides the corresponding manifest entry. This includes default config value like `exclude: '$^'` overriding a base manifest value like `exclude: '.bak$'`
Hence I suggest either adding a test ensuring there will never be any 'default' defined in `CONFIG_JSON_SCHEMA`, or improving the merge logic.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/clientlib/validate_config.py`
Content:
```
1 from __future__ import unicode_literals
2
3 from pre_commit.clientlib.validate_base import get_run_function
4 from pre_commit.clientlib.validate_base import get_validator
5 from pre_commit.clientlib.validate_base import is_regex_valid
6 from pre_commit.errors import FatalError
7
8
9 _LOCAL_HOOKS_MAGIC_REPO_STRING = 'local'
10
11
12 def is_local_hooks(repo_entry):
13 return repo_entry['repo'] == _LOCAL_HOOKS_MAGIC_REPO_STRING
14
15
16 class InvalidConfigError(FatalError):
17 pass
18
19
20 CONFIG_JSON_SCHEMA = {
21 'type': 'array',
22 'minItems': 1,
23 'items': {
24 'type': 'object',
25 'properties': {
26 'repo': {'type': 'string'},
27 'sha': {'type': 'string'},
28 'hooks': {
29 'type': 'array',
30 'minItems': 1,
31 'items': {
32 'type': 'object',
33 'properties': {
34 'id': {'type': 'string'},
35 'files': {'type': 'string'},
36 'exclude': {'type': 'string', 'default': '^$'},
37 'language_version': {'type': 'string'},
38 'args': {
39 'type': 'array',
40 'items': {'type': 'string'},
41 },
42 },
43 'required': ['id'],
44 }
45 }
46 },
47 'required': ['repo', 'hooks'],
48 }
49 }
50
51
52 def try_regex(repo, hook, value, field_name):
53 if not is_regex_valid(value):
54 raise InvalidConfigError(
55 'Invalid {0} regex at {1}, {2}: {3}'.format(
56 field_name, repo, hook, value,
57 )
58 )
59
60
61 def validate_config_extra(config):
62 for repo in config:
63 if is_local_hooks(repo):
64 if 'sha' in repo:
65 raise InvalidConfigError(
66 '"sha" property provided for local hooks'
67 )
68 elif 'sha' not in repo:
69 raise InvalidConfigError(
70 'Missing "sha" field for repository {0}'.format(repo['repo'])
71 )
72 for hook in repo['hooks']:
73 try_regex(repo, hook['id'], hook.get('files', ''), 'files')
74 try_regex(repo, hook['id'], hook['exclude'], 'exclude')
75
76
77 load_config = get_validator(
78 CONFIG_JSON_SCHEMA,
79 InvalidConfigError,
80 additional_validation_strategy=validate_config_extra,
81 )
82
83
84 run = get_run_function('Config filenames.', load_config, InvalidConfigError)
85
86
87 if __name__ == '__main__':
88 exit(run())
89
```
Path: `pre_commit/clientlib/validate_manifest.py`
Content:
```
1 from __future__ import unicode_literals
2
3 from pre_commit.clientlib.validate_base import get_run_function
4 from pre_commit.clientlib.validate_base import get_validator
5 from pre_commit.clientlib.validate_base import is_regex_valid
6 from pre_commit.languages.all import all_languages
7
8
9 class InvalidManifestError(ValueError):
10 pass
11
12
13 MANIFEST_JSON_SCHEMA = {
14 'type': 'array',
15 'minItems': 1,
16 'items': {
17 'type': 'object',
18 'properties': {
19 'id': {'type': 'string'},
20 'name': {'type': 'string'},
21 'description': {'type': 'string', 'default': ''},
22 'entry': {'type': 'string'},
23 'language': {'type': 'string'},
24 'language_version': {'type': 'string', 'default': 'default'},
25 'files': {'type': 'string'},
26 'expected_return_value': {'type': 'number', 'default': 0},
27 'args': {
28 'type': 'array',
29 'default': [],
30 'items': {
31 'type': 'string',
32 },
33 },
34 },
35 'required': ['id', 'name', 'entry', 'language', 'files'],
36 },
37 }
38
39
40 def validate_languages(hook_config):
41 if hook_config['language'] not in all_languages:
42 raise InvalidManifestError(
43 'Expected language {0} for {1} to be one of {2!r}'.format(
44 hook_config['id'],
45 hook_config['language'],
46 all_languages,
47 )
48 )
49
50
51 def validate_files(hook_config):
52 if not is_regex_valid(hook_config['files']):
53 raise InvalidManifestError(
54 'Invalid files regex at {0}: {1}'.format(
55 hook_config['id'],
56 hook_config['files'],
57 )
58 )
59
60
61 def additional_manifest_check(obj):
62 for hook_config in obj:
63 validate_languages(hook_config)
64 validate_files(hook_config)
65
66
67 load_manifest = get_validator(
68 MANIFEST_JSON_SCHEMA,
69 InvalidManifestError,
70 additional_manifest_check,
71 )
72
73
74 run = get_run_function(
75 'Manifest filenames.',
76 load_manifest,
77 InvalidManifestError,
78 )
79
80
81 if __name__ == '__main__':
82 exit(run())
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/clientlib/validate_config.py b/pre_commit/clientlib/validate_config.py
--- a/pre_commit/clientlib/validate_config.py
+++ b/pre_commit/clientlib/validate_config.py
@@ -33,7 +33,7 @@
'properties': {
'id': {'type': 'string'},
'files': {'type': 'string'},
- 'exclude': {'type': 'string', 'default': '^$'},
+ 'exclude': {'type': 'string'},
'language_version': {'type': 'string'},
'args': {
'type': 'array',
@@ -71,7 +71,7 @@
)
for hook in repo['hooks']:
try_regex(repo, hook['id'], hook.get('files', ''), 'files')
- try_regex(repo, hook['id'], hook['exclude'], 'exclude')
+ try_regex(repo, hook['id'], hook.get('exclude', ''), 'exclude')
load_config = get_validator(
diff --git a/pre_commit/clientlib/validate_manifest.py b/pre_commit/clientlib/validate_manifest.py
--- a/pre_commit/clientlib/validate_manifest.py
+++ b/pre_commit/clientlib/validate_manifest.py
@@ -20,6 +20,7 @@
'name': {'type': 'string'},
'description': {'type': 'string', 'default': ''},
'entry': {'type': 'string'},
+ 'exclude': {'type': 'string', 'default': '^$'},
'language': {'type': 'string'},
'language_version': {'type': 'string', 'default': 'default'},
'files': {'type': 'string'},
@@ -52,8 +53,14 @@
if not is_regex_valid(hook_config['files']):
raise InvalidManifestError(
'Invalid files regex at {0}: {1}'.format(
- hook_config['id'],
- hook_config['files'],
+ hook_config['id'], hook_config['files'],
+ )
+ )
+
+ if not is_regex_valid(hook_config.get('exclude', '')):
+ raise InvalidManifestError(
+ 'Invalid exclude regex at {0}: {1}'.format(
+ hook_config['id'], hook_config['exclude'],
)
)
|
{"golden_diff": "diff --git a/pre_commit/clientlib/validate_config.py b/pre_commit/clientlib/validate_config.py\n--- a/pre_commit/clientlib/validate_config.py\n+++ b/pre_commit/clientlib/validate_config.py\n@@ -33,7 +33,7 @@\n 'properties': {\n 'id': {'type': 'string'},\n 'files': {'type': 'string'},\n- 'exclude': {'type': 'string', 'default': '^$'},\n+ 'exclude': {'type': 'string'},\n 'language_version': {'type': 'string'},\n 'args': {\n 'type': 'array',\n@@ -71,7 +71,7 @@\n )\n for hook in repo['hooks']:\n try_regex(repo, hook['id'], hook.get('files', ''), 'files')\n- try_regex(repo, hook['id'], hook['exclude'], 'exclude')\n+ try_regex(repo, hook['id'], hook.get('exclude', ''), 'exclude')\n \n \n load_config = get_validator(\ndiff --git a/pre_commit/clientlib/validate_manifest.py b/pre_commit/clientlib/validate_manifest.py\n--- a/pre_commit/clientlib/validate_manifest.py\n+++ b/pre_commit/clientlib/validate_manifest.py\n@@ -20,6 +20,7 @@\n 'name': {'type': 'string'},\n 'description': {'type': 'string', 'default': ''},\n 'entry': {'type': 'string'},\n+ 'exclude': {'type': 'string', 'default': '^$'},\n 'language': {'type': 'string'},\n 'language_version': {'type': 'string', 'default': 'default'},\n 'files': {'type': 'string'},\n@@ -52,8 +53,14 @@\n if not is_regex_valid(hook_config['files']):\n raise InvalidManifestError(\n 'Invalid files regex at {0}: {1}'.format(\n- hook_config['id'],\n- hook_config['files'],\n+ hook_config['id'], hook_config['files'],\n+ )\n+ )\n+\n+ if not is_regex_valid(hook_config.get('exclude', '')):\n+ raise InvalidManifestError(\n+ 'Invalid exclude regex at {0}: {1}'.format(\n+ hook_config['id'], hook_config['exclude'],\n )\n )\n", "issue": "Bug: base manifest value for 'exclude' is always ignored\nI stumbled upon this bug while working on #226: the culprit is [`Repository.hooks`](https://github.com/pre-commit/pre-commit/blob/master/pre_commit/repository.py#L48).\n\nA quick fix for this would be to simply remove the default value from `pre_commit/clientlib/validate_config.py`, but the root cause is that any default value defined for a field in this file will make the corresponding manifest field useless.\n\nBasically here is what happens in `Repository.hooks`:\n- all the hooks defined in the current repository are enumerated\n- at this stage, a `hook` is a dict closely matching the Yaml the config file content, **plus** default values for fields not defined in the Yaml but having a JSON schema 'default'\n- when doing the dict merge, **every** (key,value) pair in `hook` overrides the corresponding manifest entry. This includes default config value like `exclude: '$^'` overriding a base manifest value like `exclude: '.bak$'`\n\nHence I suggest either adding a test ensuring there will never be any 'default' defined in `CONFIG_JSON_SCHEMA`, or improving the merge logic.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nfrom pre_commit.clientlib.validate_base import get_run_function\nfrom pre_commit.clientlib.validate_base import get_validator\nfrom pre_commit.clientlib.validate_base import is_regex_valid\nfrom pre_commit.errors import FatalError\n\n\n_LOCAL_HOOKS_MAGIC_REPO_STRING = 'local'\n\n\ndef is_local_hooks(repo_entry):\n return repo_entry['repo'] == _LOCAL_HOOKS_MAGIC_REPO_STRING\n\n\nclass InvalidConfigError(FatalError):\n pass\n\n\nCONFIG_JSON_SCHEMA = {\n 'type': 'array',\n 'minItems': 1,\n 'items': {\n 'type': 'object',\n 'properties': {\n 'repo': {'type': 'string'},\n 'sha': {'type': 'string'},\n 'hooks': {\n 'type': 'array',\n 'minItems': 1,\n 'items': {\n 'type': 'object',\n 'properties': {\n 'id': {'type': 'string'},\n 'files': {'type': 'string'},\n 'exclude': {'type': 'string', 'default': '^$'},\n 'language_version': {'type': 'string'},\n 'args': {\n 'type': 'array',\n 'items': {'type': 'string'},\n },\n },\n 'required': ['id'],\n }\n }\n },\n 'required': ['repo', 'hooks'],\n }\n}\n\n\ndef try_regex(repo, hook, value, field_name):\n if not is_regex_valid(value):\n raise InvalidConfigError(\n 'Invalid {0} regex at {1}, {2}: {3}'.format(\n field_name, repo, hook, value,\n )\n )\n\n\ndef validate_config_extra(config):\n for repo in config:\n if is_local_hooks(repo):\n if 'sha' in repo:\n raise InvalidConfigError(\n '\"sha\" property provided for local hooks'\n )\n elif 'sha' not in repo:\n raise InvalidConfigError(\n 'Missing \"sha\" field for repository {0}'.format(repo['repo'])\n )\n for hook in repo['hooks']:\n try_regex(repo, hook['id'], hook.get('files', ''), 'files')\n try_regex(repo, hook['id'], hook['exclude'], 'exclude')\n\n\nload_config = get_validator(\n CONFIG_JSON_SCHEMA,\n InvalidConfigError,\n additional_validation_strategy=validate_config_extra,\n)\n\n\nrun = get_run_function('Config filenames.', load_config, InvalidConfigError)\n\n\nif __name__ == '__main__':\n exit(run())\n", "path": "pre_commit/clientlib/validate_config.py"}, {"content": "from __future__ import unicode_literals\n\nfrom pre_commit.clientlib.validate_base import get_run_function\nfrom pre_commit.clientlib.validate_base import get_validator\nfrom pre_commit.clientlib.validate_base import is_regex_valid\nfrom pre_commit.languages.all import all_languages\n\n\nclass InvalidManifestError(ValueError):\n pass\n\n\nMANIFEST_JSON_SCHEMA = {\n 'type': 'array',\n 'minItems': 1,\n 'items': {\n 'type': 'object',\n 'properties': {\n 'id': {'type': 'string'},\n 'name': {'type': 'string'},\n 'description': {'type': 'string', 'default': ''},\n 'entry': {'type': 'string'},\n 'language': {'type': 'string'},\n 'language_version': {'type': 'string', 'default': 'default'},\n 'files': {'type': 'string'},\n 'expected_return_value': {'type': 'number', 'default': 0},\n 'args': {\n 'type': 'array',\n 'default': [],\n 'items': {\n 'type': 'string',\n },\n },\n },\n 'required': ['id', 'name', 'entry', 'language', 'files'],\n },\n}\n\n\ndef validate_languages(hook_config):\n if hook_config['language'] not in all_languages:\n raise InvalidManifestError(\n 'Expected language {0} for {1} to be one of {2!r}'.format(\n hook_config['id'],\n hook_config['language'],\n all_languages,\n )\n )\n\n\ndef validate_files(hook_config):\n if not is_regex_valid(hook_config['files']):\n raise InvalidManifestError(\n 'Invalid files regex at {0}: {1}'.format(\n hook_config['id'],\n hook_config['files'],\n )\n )\n\n\ndef additional_manifest_check(obj):\n for hook_config in obj:\n validate_languages(hook_config)\n validate_files(hook_config)\n\n\nload_manifest = get_validator(\n MANIFEST_JSON_SCHEMA,\n InvalidManifestError,\n additional_manifest_check,\n)\n\n\nrun = get_run_function(\n 'Manifest filenames.',\n load_manifest,\n InvalidManifestError,\n)\n\n\nif __name__ == '__main__':\n exit(run())\n", "path": "pre_commit/clientlib/validate_manifest.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nfrom pre_commit.clientlib.validate_base import get_run_function\nfrom pre_commit.clientlib.validate_base import get_validator\nfrom pre_commit.clientlib.validate_base import is_regex_valid\nfrom pre_commit.errors import FatalError\n\n\n_LOCAL_HOOKS_MAGIC_REPO_STRING = 'local'\n\n\ndef is_local_hooks(repo_entry):\n return repo_entry['repo'] == _LOCAL_HOOKS_MAGIC_REPO_STRING\n\n\nclass InvalidConfigError(FatalError):\n pass\n\n\nCONFIG_JSON_SCHEMA = {\n 'type': 'array',\n 'minItems': 1,\n 'items': {\n 'type': 'object',\n 'properties': {\n 'repo': {'type': 'string'},\n 'sha': {'type': 'string'},\n 'hooks': {\n 'type': 'array',\n 'minItems': 1,\n 'items': {\n 'type': 'object',\n 'properties': {\n 'id': {'type': 'string'},\n 'files': {'type': 'string'},\n 'exclude': {'type': 'string'},\n 'language_version': {'type': 'string'},\n 'args': {\n 'type': 'array',\n 'items': {'type': 'string'},\n },\n },\n 'required': ['id'],\n }\n }\n },\n 'required': ['repo', 'hooks'],\n }\n}\n\n\ndef try_regex(repo, hook, value, field_name):\n if not is_regex_valid(value):\n raise InvalidConfigError(\n 'Invalid {0} regex at {1}, {2}: {3}'.format(\n field_name, repo, hook, value,\n )\n )\n\n\ndef validate_config_extra(config):\n for repo in config:\n if is_local_hooks(repo):\n if 'sha' in repo:\n raise InvalidConfigError(\n '\"sha\" property provided for local hooks'\n )\n elif 'sha' not in repo:\n raise InvalidConfigError(\n 'Missing \"sha\" field for repository {0}'.format(repo['repo'])\n )\n for hook in repo['hooks']:\n try_regex(repo, hook['id'], hook.get('files', ''), 'files')\n try_regex(repo, hook['id'], hook.get('exclude', ''), 'exclude')\n\n\nload_config = get_validator(\n CONFIG_JSON_SCHEMA,\n InvalidConfigError,\n additional_validation_strategy=validate_config_extra,\n)\n\n\nrun = get_run_function('Config filenames.', load_config, InvalidConfigError)\n\n\nif __name__ == '__main__':\n exit(run())\n", "path": "pre_commit/clientlib/validate_config.py"}, {"content": "from __future__ import unicode_literals\n\nfrom pre_commit.clientlib.validate_base import get_run_function\nfrom pre_commit.clientlib.validate_base import get_validator\nfrom pre_commit.clientlib.validate_base import is_regex_valid\nfrom pre_commit.languages.all import all_languages\n\n\nclass InvalidManifestError(ValueError):\n pass\n\n\nMANIFEST_JSON_SCHEMA = {\n 'type': 'array',\n 'minItems': 1,\n 'items': {\n 'type': 'object',\n 'properties': {\n 'id': {'type': 'string'},\n 'name': {'type': 'string'},\n 'description': {'type': 'string', 'default': ''},\n 'entry': {'type': 'string'},\n 'exclude': {'type': 'string', 'default': '^$'},\n 'language': {'type': 'string'},\n 'language_version': {'type': 'string', 'default': 'default'},\n 'files': {'type': 'string'},\n 'expected_return_value': {'type': 'number', 'default': 0},\n 'args': {\n 'type': 'array',\n 'default': [],\n 'items': {\n 'type': 'string',\n },\n },\n },\n 'required': ['id', 'name', 'entry', 'language', 'files'],\n },\n}\n\n\ndef validate_languages(hook_config):\n if hook_config['language'] not in all_languages:\n raise InvalidManifestError(\n 'Expected language {0} for {1} to be one of {2!r}'.format(\n hook_config['id'],\n hook_config['language'],\n all_languages,\n )\n )\n\n\ndef validate_files(hook_config):\n if not is_regex_valid(hook_config['files']):\n raise InvalidManifestError(\n 'Invalid files regex at {0}: {1}'.format(\n hook_config['id'], hook_config['files'],\n )\n )\n\n if not is_regex_valid(hook_config.get('exclude', '')):\n raise InvalidManifestError(\n 'Invalid exclude regex at {0}: {1}'.format(\n hook_config['id'], hook_config['exclude'],\n )\n )\n\n\ndef additional_manifest_check(obj):\n for hook_config in obj:\n validate_languages(hook_config)\n validate_files(hook_config)\n\n\nload_manifest = get_validator(\n MANIFEST_JSON_SCHEMA,\n InvalidManifestError,\n additional_manifest_check,\n)\n\n\nrun = get_run_function(\n 'Manifest filenames.',\n load_manifest,\n InvalidManifestError,\n)\n\n\nif __name__ == '__main__':\n exit(run())\n", "path": "pre_commit/clientlib/validate_manifest.py"}]}
| 1,877 | 492 |
gh_patches_debug_964
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-1631
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] `Cannot find serializable class` raised when calling set_label
When calling DataFrame.columns=xxxx in distributed environment, a KeyError is raised with message `Cannot find serializable class for type_id 1517314310`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mars/dataframe/indexing/__init__.py`
Content:
```
1 # Copyright 1999-2020 Alibaba Group Holding Ltd.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 def _install():
17 from pandas.util import cache_readonly
18 from ..operands import DATAFRAME_TYPE, SERIES_TYPE, INDEX_TYPE
19 from .at import at
20 from .getitem import dataframe_getitem, series_getitem
21 from .iat import iat
22 from .iloc import iloc, head, tail
23 from .insert import df_insert
24 from .loc import loc
25 from .rename import df_rename, series_rename, index_rename
26 from .reset_index import df_reset_index, series_reset_index
27 from .set_index import set_index
28 from .setitem import dataframe_setitem
29 from .reindex import reindex
30 from .where import mask, where
31
32 for cls in DATAFRAME_TYPE + SERIES_TYPE:
33 setattr(cls, 'iloc', cache_readonly(iloc))
34 setattr(cls, 'loc', cache_readonly(loc))
35 setattr(cls, 'iat', cache_readonly(iat))
36 setattr(cls, 'at', cache_readonly(at))
37 setattr(cls, 'reindex', reindex)
38 setattr(cls, 'head', head)
39 setattr(cls, 'tail', tail)
40 setattr(cls, 'mask', mask)
41 setattr(cls, 'where', where)
42
43 for cls in DATAFRAME_TYPE:
44 setattr(cls, 'set_index', set_index)
45 setattr(cls, '__getitem__', dataframe_getitem)
46 setattr(cls, '__setitem__', dataframe_setitem)
47 setattr(cls, 'insert', df_insert)
48 setattr(cls, 'reset_index', df_reset_index)
49 setattr(cls, 'rename', df_rename)
50
51 for cls in SERIES_TYPE:
52 setattr(cls, '__getitem__', series_getitem)
53 setattr(cls, 'reset_index', series_reset_index)
54 setattr(cls, 'rename', series_rename)
55
56 for cls in INDEX_TYPE:
57 setattr(cls, 'rename', index_rename)
58
59
60 _install()
61 del _install
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mars/dataframe/indexing/__init__.py b/mars/dataframe/indexing/__init__.py
--- a/mars/dataframe/indexing/__init__.py
+++ b/mars/dataframe/indexing/__init__.py
@@ -56,6 +56,10 @@
for cls in INDEX_TYPE:
setattr(cls, 'rename', index_rename)
+ # make sure operand is registered
+ from .set_label import DataFrameSetLabel
+ del DataFrameSetLabel
+
_install()
del _install
|
{"golden_diff": "diff --git a/mars/dataframe/indexing/__init__.py b/mars/dataframe/indexing/__init__.py\n--- a/mars/dataframe/indexing/__init__.py\n+++ b/mars/dataframe/indexing/__init__.py\n@@ -56,6 +56,10 @@\n for cls in INDEX_TYPE:\n setattr(cls, 'rename', index_rename)\n \n+ # make sure operand is registered\n+ from .set_label import DataFrameSetLabel\n+ del DataFrameSetLabel\n+\n \n _install()\n del _install\n", "issue": "[BUG] `Cannot find serializable class` raised when calling set_label\nWhen calling DataFrame.columns=xxxx in distributed environment, a KeyError is raised with message `Cannot find serializable class for type_id 1517314310`.\n", "before_files": [{"content": "# Copyright 1999-2020 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\ndef _install():\n from pandas.util import cache_readonly\n from ..operands import DATAFRAME_TYPE, SERIES_TYPE, INDEX_TYPE\n from .at import at\n from .getitem import dataframe_getitem, series_getitem\n from .iat import iat\n from .iloc import iloc, head, tail\n from .insert import df_insert\n from .loc import loc\n from .rename import df_rename, series_rename, index_rename\n from .reset_index import df_reset_index, series_reset_index\n from .set_index import set_index\n from .setitem import dataframe_setitem\n from .reindex import reindex\n from .where import mask, where\n\n for cls in DATAFRAME_TYPE + SERIES_TYPE:\n setattr(cls, 'iloc', cache_readonly(iloc))\n setattr(cls, 'loc', cache_readonly(loc))\n setattr(cls, 'iat', cache_readonly(iat))\n setattr(cls, 'at', cache_readonly(at))\n setattr(cls, 'reindex', reindex)\n setattr(cls, 'head', head)\n setattr(cls, 'tail', tail)\n setattr(cls, 'mask', mask)\n setattr(cls, 'where', where)\n\n for cls in DATAFRAME_TYPE:\n setattr(cls, 'set_index', set_index)\n setattr(cls, '__getitem__', dataframe_getitem)\n setattr(cls, '__setitem__', dataframe_setitem)\n setattr(cls, 'insert', df_insert)\n setattr(cls, 'reset_index', df_reset_index)\n setattr(cls, 'rename', df_rename)\n\n for cls in SERIES_TYPE:\n setattr(cls, '__getitem__', series_getitem)\n setattr(cls, 'reset_index', series_reset_index)\n setattr(cls, 'rename', series_rename)\n\n for cls in INDEX_TYPE:\n setattr(cls, 'rename', index_rename)\n\n\n_install()\ndel _install\n", "path": "mars/dataframe/indexing/__init__.py"}], "after_files": [{"content": "# Copyright 1999-2020 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\ndef _install():\n from pandas.util import cache_readonly\n from ..operands import DATAFRAME_TYPE, SERIES_TYPE, INDEX_TYPE\n from .at import at\n from .getitem import dataframe_getitem, series_getitem\n from .iat import iat\n from .iloc import iloc, head, tail\n from .insert import df_insert\n from .loc import loc\n from .rename import df_rename, series_rename, index_rename\n from .reset_index import df_reset_index, series_reset_index\n from .set_index import set_index\n from .setitem import dataframe_setitem\n from .reindex import reindex\n from .where import mask, where\n\n for cls in DATAFRAME_TYPE + SERIES_TYPE:\n setattr(cls, 'iloc', cache_readonly(iloc))\n setattr(cls, 'loc', cache_readonly(loc))\n setattr(cls, 'iat', cache_readonly(iat))\n setattr(cls, 'at', cache_readonly(at))\n setattr(cls, 'reindex', reindex)\n setattr(cls, 'head', head)\n setattr(cls, 'tail', tail)\n setattr(cls, 'mask', mask)\n setattr(cls, 'where', where)\n\n for cls in DATAFRAME_TYPE:\n setattr(cls, 'set_index', set_index)\n setattr(cls, '__getitem__', dataframe_getitem)\n setattr(cls, '__setitem__', dataframe_setitem)\n setattr(cls, 'insert', df_insert)\n setattr(cls, 'reset_index', df_reset_index)\n setattr(cls, 'rename', df_rename)\n\n for cls in SERIES_TYPE:\n setattr(cls, '__getitem__', series_getitem)\n setattr(cls, 'reset_index', series_reset_index)\n setattr(cls, 'rename', series_rename)\n\n for cls in INDEX_TYPE:\n setattr(cls, 'rename', index_rename)\n\n # make sure operand is registered\n from .set_label import DataFrameSetLabel\n del DataFrameSetLabel\n\n\n_install()\ndel _install\n", "path": "mars/dataframe/indexing/__init__.py"}]}
| 970 | 119 |
gh_patches_debug_60446
|
rasdani/github-patches
|
git_diff
|
helmholtz-analytics__heat-471
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update lasso example
**Description**
The lasso example references heat.ml.regression.lasso
**To Reproduce**
Steps to reproduce the behavior:
1. Which module/class/function is affected?
examples/lasso/demo.py
2. What are the circumstances under which the bug appears?
run demo.py
3. What is the exact error-message/errorous behavious?
`Traceback (most recent call last):
File "demo.py", line 10, in <module>
import heat.ml.regression.lasso as lasso
ModuleNotFoundError: No module named 'heat.ml'`
**Expected behavior**
Should import heat.core.regression.lasso
**Version Info**
Which version are you using?
0.2.1
Update lasso example
**Description**
The lasso example references heat.ml.regression.lasso
**To Reproduce**
Steps to reproduce the behavior:
1. Which module/class/function is affected?
examples/lasso/demo.py
2. What are the circumstances under which the bug appears?
run demo.py
3. What is the exact error-message/errorous behavious?
`Traceback (most recent call last):
File "demo.py", line 10, in <module>
import heat.ml.regression.lasso as lasso
ModuleNotFoundError: No module named 'heat.ml'`
**Expected behavior**
Should import heat.core.regression.lasso
**Version Info**
Which version are you using?
0.2.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/lasso/demo.py`
Content:
```
1 import numpy as np
2 import torch
3 import sys
4
5 sys.path.append("../../")
6
7 import heat as ht
8 from matplotlib import pyplot as plt
9 from sklearn import datasets
10 import heat.ml.regression.lasso as lasso
11 import plotfkt
12
13 # read scikit diabetes data set
14 diabetes = datasets.load_diabetes()
15
16 # load diabetes dataset from hdf5 file
17 X = ht.load_hdf5("../../heat/datasets/data/diabetes.h5", dataset="x", split=0)
18 y = ht.load_hdf5("../../heat/datasets/data/diabetes.h5", dataset="y", split=0)
19
20 # normalize dataset #DoTO this goes into the lasso fit routine soon as issue #106 is solved
21 X = X / ht.sqrt((ht.mean(X ** 2, axis=0)))
22
23 # HeAT lasso instance
24 estimator = lasso.HeatLasso(max_iter=100)
25
26 # List lasso model parameters
27 theta_list = list()
28
29 # Range of lambda values
30 lamda = np.logspace(0, 4, 10) / 10
31
32 # compute the lasso path
33 for l in lamda:
34 estimator.lam = l
35 estimator.fit(X, y)
36 theta_list.append(estimator.theta.numpy().flatten())
37
38 # Stack estimated model parameters into one numpy array
39 theta_lasso = np.stack(theta_list).T
40
41 # Stack into numpy array
42 theta_lasso = np.stack(theta_list).T[1:, :]
43
44
45 # plot lasso paths
46 plt.subplot(3, 1, 1)
47 plotfkt.plot_lasso_path(
48 lamda, theta_lasso, diabetes.feature_names, title="Lasso Paths - HeAT implementation"
49 )
50
51 if X.is_distributed():
52 distributed = X.comm.rank
53 else:
54 distributed = False
55
56 # Now the same stuff in numpy
57 X = diabetes.data.astype("float32")
58 y = diabetes.target.astype("float32")
59
60 m, _ = X.shape
61 X = np.concatenate((np.ones((m, 1)).astype("float32"), X), axis=1)
62
63 # normalize dataset
64 X = X / np.sqrt((np.mean(X ** 2, axis=0)))
65
66 # Numpy lasso instance
67 estimator = lasso.NumpyLasso(max_iter=100)
68
69 # List lasso model parameters
70 theta_list = list()
71
72 # Range of lambda values
73 lamda = np.logspace(0, 4, 10) / 10
74
75 # compute the lasso path
76 for l in lamda:
77 estimator.lam = l
78 estimator.fit(X, y)
79 theta_list.append(estimator.theta.flatten())
80
81 # Stack estimated model parameters into one numpy array
82 theta_lasso = np.stack(theta_list).T
83
84 # Stack into numpy array
85 theta_lasso = np.stack(theta_list).T[1:, :]
86
87 # plot lasso paths
88 plt.subplot(3, 1, 2)
89 plotfkt.plot_lasso_path(
90 lamda, theta_lasso, diabetes.feature_names, title="Lasso Paths - Numpy implementation"
91 )
92
93 # Now the same stuff again in PyTorch
94 X = torch.tensor(X)
95 y = torch.tensor(y)
96
97 # HeAT lasso instance
98 estimator = lasso.PytorchLasso(max_iter=100)
99
100 # List lasso model parameters
101 theta_list = list()
102
103 # Range of lambda values
104 lamda = np.logspace(0, 4, 10) / 10
105
106 # compute the lasso path
107 for l in lamda:
108 estimator.lam = l
109 estimator.fit(X, y)
110 theta_list.append(estimator.theta.numpy().flatten())
111
112 # Stack estimated model parameters into one numpy array
113 theta_lasso = np.stack(theta_list).T
114
115 # Stack into numpy array
116 theta_lasso = np.stack(theta_list).T[1:, :]
117
118 # plot lasso paths
119 plt.subplot(3, 1, 3)
120 plotfkt.plot_lasso_path(
121 lamda, theta_lasso, diabetes.feature_names, title="Lasso Paths - PyTorch implementation"
122 )
123
124 # plot only with first rank
125 if distributed is False:
126 plt.show()
127 elif distributed == 0:
128 plt.show()
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/lasso/demo.py b/examples/lasso/demo.py
--- a/examples/lasso/demo.py
+++ b/examples/lasso/demo.py
@@ -7,7 +7,7 @@
import heat as ht
from matplotlib import pyplot as plt
from sklearn import datasets
-import heat.ml.regression.lasso as lasso
+import heat.core.regression.lasso as lasso
import plotfkt
# read scikit diabetes data set
|
{"golden_diff": "diff --git a/examples/lasso/demo.py b/examples/lasso/demo.py\n--- a/examples/lasso/demo.py\n+++ b/examples/lasso/demo.py\n@@ -7,7 +7,7 @@\n import heat as ht\n from matplotlib import pyplot as plt\n from sklearn import datasets\n-import heat.ml.regression.lasso as lasso\n+import heat.core.regression.lasso as lasso\n import plotfkt\n \n # read scikit diabetes data set\n", "issue": "Update lasso example\n**Description**\r\nThe lasso example references heat.ml.regression.lasso\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Which module/class/function is affected?\r\n examples/lasso/demo.py\r\n2. What are the circumstances under which the bug appears?\r\n run demo.py\r\n3. What is the exact error-message/errorous behavious?\r\n `Traceback (most recent call last):\r\n File \"demo.py\", line 10, in <module>\r\n import heat.ml.regression.lasso as lasso\r\nModuleNotFoundError: No module named 'heat.ml'`\r\n\r\n**Expected behavior**\r\nShould import heat.core.regression.lasso\r\n\r\n**Version Info**\r\n Which version are you using?\r\n0.2.1\r\n\nUpdate lasso example\n**Description**\r\nThe lasso example references heat.ml.regression.lasso\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Which module/class/function is affected?\r\n examples/lasso/demo.py\r\n2. What are the circumstances under which the bug appears?\r\n run demo.py\r\n3. What is the exact error-message/errorous behavious?\r\n `Traceback (most recent call last):\r\n File \"demo.py\", line 10, in <module>\r\n import heat.ml.regression.lasso as lasso\r\nModuleNotFoundError: No module named 'heat.ml'`\r\n\r\n**Expected behavior**\r\nShould import heat.core.regression.lasso\r\n\r\n**Version Info**\r\n Which version are you using?\r\n0.2.1\r\n\n", "before_files": [{"content": "import numpy as np\nimport torch\nimport sys\n\nsys.path.append(\"../../\")\n\nimport heat as ht\nfrom matplotlib import pyplot as plt\nfrom sklearn import datasets\nimport heat.ml.regression.lasso as lasso\nimport plotfkt\n\n# read scikit diabetes data set\ndiabetes = datasets.load_diabetes()\n\n# load diabetes dataset from hdf5 file\nX = ht.load_hdf5(\"../../heat/datasets/data/diabetes.h5\", dataset=\"x\", split=0)\ny = ht.load_hdf5(\"../../heat/datasets/data/diabetes.h5\", dataset=\"y\", split=0)\n\n# normalize dataset #DoTO this goes into the lasso fit routine soon as issue #106 is solved\nX = X / ht.sqrt((ht.mean(X ** 2, axis=0)))\n\n# HeAT lasso instance\nestimator = lasso.HeatLasso(max_iter=100)\n\n# List lasso model parameters\ntheta_list = list()\n\n# Range of lambda values\nlamda = np.logspace(0, 4, 10) / 10\n\n# compute the lasso path\nfor l in lamda:\n estimator.lam = l\n estimator.fit(X, y)\n theta_list.append(estimator.theta.numpy().flatten())\n\n# Stack estimated model parameters into one numpy array\ntheta_lasso = np.stack(theta_list).T\n\n# Stack into numpy array\ntheta_lasso = np.stack(theta_list).T[1:, :]\n\n\n# plot lasso paths\nplt.subplot(3, 1, 1)\nplotfkt.plot_lasso_path(\n lamda, theta_lasso, diabetes.feature_names, title=\"Lasso Paths - HeAT implementation\"\n)\n\nif X.is_distributed():\n distributed = X.comm.rank\nelse:\n distributed = False\n\n# Now the same stuff in numpy\nX = diabetes.data.astype(\"float32\")\ny = diabetes.target.astype(\"float32\")\n\nm, _ = X.shape\nX = np.concatenate((np.ones((m, 1)).astype(\"float32\"), X), axis=1)\n\n# normalize dataset\nX = X / np.sqrt((np.mean(X ** 2, axis=0)))\n\n# Numpy lasso instance\nestimator = lasso.NumpyLasso(max_iter=100)\n\n# List lasso model parameters\ntheta_list = list()\n\n# Range of lambda values\nlamda = np.logspace(0, 4, 10) / 10\n\n# compute the lasso path\nfor l in lamda:\n estimator.lam = l\n estimator.fit(X, y)\n theta_list.append(estimator.theta.flatten())\n\n# Stack estimated model parameters into one numpy array\ntheta_lasso = np.stack(theta_list).T\n\n# Stack into numpy array\ntheta_lasso = np.stack(theta_list).T[1:, :]\n\n# plot lasso paths\nplt.subplot(3, 1, 2)\nplotfkt.plot_lasso_path(\n lamda, theta_lasso, diabetes.feature_names, title=\"Lasso Paths - Numpy implementation\"\n)\n\n# Now the same stuff again in PyTorch\nX = torch.tensor(X)\ny = torch.tensor(y)\n\n# HeAT lasso instance\nestimator = lasso.PytorchLasso(max_iter=100)\n\n# List lasso model parameters\ntheta_list = list()\n\n# Range of lambda values\nlamda = np.logspace(0, 4, 10) / 10\n\n# compute the lasso path\nfor l in lamda:\n estimator.lam = l\n estimator.fit(X, y)\n theta_list.append(estimator.theta.numpy().flatten())\n\n# Stack estimated model parameters into one numpy array\ntheta_lasso = np.stack(theta_list).T\n\n# Stack into numpy array\ntheta_lasso = np.stack(theta_list).T[1:, :]\n\n# plot lasso paths\nplt.subplot(3, 1, 3)\nplotfkt.plot_lasso_path(\n lamda, theta_lasso, diabetes.feature_names, title=\"Lasso Paths - PyTorch implementation\"\n)\n\n# plot only with first rank\nif distributed is False:\n plt.show()\nelif distributed == 0:\n plt.show()\n", "path": "examples/lasso/demo.py"}], "after_files": [{"content": "import numpy as np\nimport torch\nimport sys\n\nsys.path.append(\"../../\")\n\nimport heat as ht\nfrom matplotlib import pyplot as plt\nfrom sklearn import datasets\nimport heat.core.regression.lasso as lasso\nimport plotfkt\n\n# read scikit diabetes data set\ndiabetes = datasets.load_diabetes()\n\n# load diabetes dataset from hdf5 file\nX = ht.load_hdf5(\"../../heat/datasets/data/diabetes.h5\", dataset=\"x\", split=0)\ny = ht.load_hdf5(\"../../heat/datasets/data/diabetes.h5\", dataset=\"y\", split=0)\n\n# normalize dataset #DoTO this goes into the lasso fit routine soon as issue #106 is solved\nX = X / ht.sqrt((ht.mean(X ** 2, axis=0)))\n\n# HeAT lasso instance\nestimator = lasso.HeatLasso(max_iter=100)\n\n# List lasso model parameters\ntheta_list = list()\n\n# Range of lambda values\nlamda = np.logspace(0, 4, 10) / 10\n\n# compute the lasso path\nfor l in lamda:\n estimator.lam = l\n estimator.fit(X, y)\n theta_list.append(estimator.theta.numpy().flatten())\n\n# Stack estimated model parameters into one numpy array\ntheta_lasso = np.stack(theta_list).T\n\n# Stack into numpy array\ntheta_lasso = np.stack(theta_list).T[1:, :]\n\n\n# plot lasso paths\nplt.subplot(3, 1, 1)\nplotfkt.plot_lasso_path(\n lamda, theta_lasso, diabetes.feature_names, title=\"Lasso Paths - HeAT implementation\"\n)\n\nif X.is_distributed():\n distributed = X.comm.rank\nelse:\n distributed = False\n\n# Now the same stuff in numpy\nX = diabetes.data.astype(\"float32\")\ny = diabetes.target.astype(\"float32\")\n\nm, _ = X.shape\nX = np.concatenate((np.ones((m, 1)).astype(\"float32\"), X), axis=1)\n\n# normalize dataset\nX = X / np.sqrt((np.mean(X ** 2, axis=0)))\n\n# Numpy lasso instance\nestimator = lasso.NumpyLasso(max_iter=100)\n\n# List lasso model parameters\ntheta_list = list()\n\n# Range of lambda values\nlamda = np.logspace(0, 4, 10) / 10\n\n# compute the lasso path\nfor l in lamda:\n estimator.lam = l\n estimator.fit(X, y)\n theta_list.append(estimator.theta.flatten())\n\n# Stack estimated model parameters into one numpy array\ntheta_lasso = np.stack(theta_list).T\n\n# Stack into numpy array\ntheta_lasso = np.stack(theta_list).T[1:, :]\n\n# plot lasso paths\nplt.subplot(3, 1, 2)\nplotfkt.plot_lasso_path(\n lamda, theta_lasso, diabetes.feature_names, title=\"Lasso Paths - Numpy implementation\"\n)\n\n# Now the same stuff again in PyTorch\nX = torch.tensor(X)\ny = torch.tensor(y)\n\n# HeAT lasso instance\nestimator = lasso.PytorchLasso(max_iter=100)\n\n# List lasso model parameters\ntheta_list = list()\n\n# Range of lambda values\nlamda = np.logspace(0, 4, 10) / 10\n\n# compute the lasso path\nfor l in lamda:\n estimator.lam = l\n estimator.fit(X, y)\n theta_list.append(estimator.theta.numpy().flatten())\n\n# Stack estimated model parameters into one numpy array\ntheta_lasso = np.stack(theta_list).T\n\n# Stack into numpy array\ntheta_lasso = np.stack(theta_list).T[1:, :]\n\n# plot lasso paths\nplt.subplot(3, 1, 3)\nplotfkt.plot_lasso_path(\n lamda, theta_lasso, diabetes.feature_names, title=\"Lasso Paths - PyTorch implementation\"\n)\n\n# plot only with first rank\nif distributed is False:\n plt.show()\nelif distributed == 0:\n plt.show()\n", "path": "examples/lasso/demo.py"}]}
| 1,790 | 101 |
gh_patches_debug_18021
|
rasdani/github-patches
|
git_diff
|
dj-stripe__dj-stripe-348
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Django 1.10 support
https://github.com/kavdev/dj-stripe/blob/master/djstripe/__init__.py#L19
`'1.10'` is less than `'1.7.x'`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `djstripe/__init__.py`
Content:
```
1 from __future__ import unicode_literals
2 import warnings
3
4 from django import get_version as get_django_version
5
6 __title__ = "dj-stripe"
7 __summary__ = "Django + Stripe Made Easy"
8 __uri__ = "https://github.com/kavdev/dj-stripe/"
9
10 __version__ = "0.9.0.dev0"
11
12 __author__ = "Alexander Kavanaugh"
13 __email__ = "[email protected]"
14
15 __license__ = "BSD"
16 __license__ = "License :: OSI Approved :: BSD License"
17 __copyright__ = "Copyright 2016 Alexander Kavanaugh"
18
19 if get_django_version() <= '1.7.x':
20 msg = "dj-stripe deprecation notice: Django 1.7 and lower are no longer\n" \
21 "supported. Please upgrade to Django 1.8 or higher.\n" \
22 "Reference: https://github.com/kavdev/dj-stripe/issues/275"
23 warnings.warn(msg)
24
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/djstripe/__init__.py b/djstripe/__init__.py
--- a/djstripe/__init__.py
+++ b/djstripe/__init__.py
@@ -1,7 +1,7 @@
from __future__ import unicode_literals
import warnings
-from django import get_version as get_django_version
+from django import VERSION as django_version
__title__ = "dj-stripe"
__summary__ = "Django + Stripe Made Easy"
@@ -16,7 +16,7 @@
__license__ = "License :: OSI Approved :: BSD License"
__copyright__ = "Copyright 2016 Alexander Kavanaugh"
-if get_django_version() <= '1.7.x':
+if django_version < (1, 8):
msg = "dj-stripe deprecation notice: Django 1.7 and lower are no longer\n" \
"supported. Please upgrade to Django 1.8 or higher.\n" \
"Reference: https://github.com/kavdev/dj-stripe/issues/275"
|
{"golden_diff": "diff --git a/djstripe/__init__.py b/djstripe/__init__.py\n--- a/djstripe/__init__.py\n+++ b/djstripe/__init__.py\n@@ -1,7 +1,7 @@\n from __future__ import unicode_literals\n import warnings\n \n-from django import get_version as get_django_version\n+from django import VERSION as django_version\n \n __title__ = \"dj-stripe\"\n __summary__ = \"Django + Stripe Made Easy\"\n@@ -16,7 +16,7 @@\n __license__ = \"License :: OSI Approved :: BSD License\"\n __copyright__ = \"Copyright 2016 Alexander Kavanaugh\"\n \n-if get_django_version() <= '1.7.x':\n+if django_version < (1, 8):\n msg = \"dj-stripe deprecation notice: Django 1.7 and lower are no longer\\n\" \\\n \"supported. Please upgrade to Django 1.8 or higher.\\n\" \\\n \"Reference: https://github.com/kavdev/dj-stripe/issues/275\"\n", "issue": "Django 1.10 support\nhttps://github.com/kavdev/dj-stripe/blob/master/djstripe/__init__.py#L19\n\n`'1.10'` is less than `'1.7.x'`\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nimport warnings\n\nfrom django import get_version as get_django_version\n\n__title__ = \"dj-stripe\"\n__summary__ = \"Django + Stripe Made Easy\"\n__uri__ = \"https://github.com/kavdev/dj-stripe/\"\n\n__version__ = \"0.9.0.dev0\"\n\n__author__ = \"Alexander Kavanaugh\"\n__email__ = \"[email protected]\"\n\n__license__ = \"BSD\"\n__license__ = \"License :: OSI Approved :: BSD License\"\n__copyright__ = \"Copyright 2016 Alexander Kavanaugh\"\n\nif get_django_version() <= '1.7.x':\n msg = \"dj-stripe deprecation notice: Django 1.7 and lower are no longer\\n\" \\\n \"supported. Please upgrade to Django 1.8 or higher.\\n\" \\\n \"Reference: https://github.com/kavdev/dj-stripe/issues/275\"\n warnings.warn(msg)\n", "path": "djstripe/__init__.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nimport warnings\n\nfrom django import VERSION as django_version\n\n__title__ = \"dj-stripe\"\n__summary__ = \"Django + Stripe Made Easy\"\n__uri__ = \"https://github.com/kavdev/dj-stripe/\"\n\n__version__ = \"0.9.0.dev0\"\n\n__author__ = \"Alexander Kavanaugh\"\n__email__ = \"[email protected]\"\n\n__license__ = \"BSD\"\n__license__ = \"License :: OSI Approved :: BSD License\"\n__copyright__ = \"Copyright 2016 Alexander Kavanaugh\"\n\nif django_version < (1, 8):\n msg = \"dj-stripe deprecation notice: Django 1.7 and lower are no longer\\n\" \\\n \"supported. Please upgrade to Django 1.8 or higher.\\n\" \\\n \"Reference: https://github.com/kavdev/dj-stripe/issues/275\"\n warnings.warn(msg)\n", "path": "djstripe/__init__.py"}]}
| 566 | 229 |
gh_patches_debug_4821
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-13306
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Indicate attempted allocation size when constructing an array gives a MemoryError
I've seen multiple questions now of the form "why does this give a MemoryError" when the reason is the user ended up allocating a bigger array than expected.
It would be helpful to include the shape and dtype in the error message.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numpy/core/_exceptions.py`
Content:
```
1 """
2 Various richly-typed exceptions, that also help us deal with string formatting
3 in python where it's easier.
4
5 By putting the formatting in `__str__`, we also avoid paying the cost for
6 users who silence the exceptions.
7 """
8 from numpy.core.overrides import set_module
9
10 def _unpack_tuple(tup):
11 if len(tup) == 1:
12 return tup[0]
13 else:
14 return tup
15
16
17 def _display_as_base(cls):
18 """
19 A decorator that makes an exception class look like its base.
20
21 We use this to hide subclasses that are implementation details - the user
22 should catch the base type, which is what the traceback will show them.
23
24 Classes decorated with this decorator are subject to removal without a
25 deprecation warning.
26 """
27 assert issubclass(cls, Exception)
28 cls.__name__ = cls.__base__.__name__
29 cls.__qualname__ = cls.__base__.__qualname__
30 return cls
31
32
33 class UFuncTypeError(TypeError):
34 """ Base class for all ufunc exceptions """
35 def __init__(self, ufunc):
36 self.ufunc = ufunc
37
38
39 @_display_as_base
40 class _UFuncNoLoopError(UFuncTypeError):
41 """ Thrown when a ufunc loop cannot be found """
42 def __init__(self, ufunc, dtypes):
43 super().__init__(ufunc)
44 self.dtypes = tuple(dtypes)
45
46 def __str__(self):
47 return (
48 "ufunc {!r} did not contain a loop with signature matching types "
49 "{!r} -> {!r}"
50 ).format(
51 self.ufunc.__name__,
52 _unpack_tuple(self.dtypes[:self.ufunc.nin]),
53 _unpack_tuple(self.dtypes[self.ufunc.nin:])
54 )
55
56
57 @_display_as_base
58 class _UFuncCastingError(UFuncTypeError):
59 def __init__(self, ufunc, casting, from_, to):
60 super().__init__(ufunc)
61 self.casting = casting
62 self.from_ = from_
63 self.to = to
64
65
66 @_display_as_base
67 class _UFuncInputCastingError(_UFuncCastingError):
68 """ Thrown when a ufunc input cannot be casted """
69 def __init__(self, ufunc, casting, from_, to, i):
70 super().__init__(ufunc, casting, from_, to)
71 self.in_i = i
72
73 def __str__(self):
74 # only show the number if more than one input exists
75 i_str = "{} ".format(self.in_i) if self.ufunc.nin != 1 else ""
76 return (
77 "Cannot cast ufunc {!r} input {}from {!r} to {!r} with casting "
78 "rule {!r}"
79 ).format(
80 self.ufunc.__name__, i_str, self.from_, self.to, self.casting
81 )
82
83
84 @_display_as_base
85 class _UFuncOutputCastingError(_UFuncCastingError):
86 """ Thrown when a ufunc output cannot be casted """
87 def __init__(self, ufunc, casting, from_, to, i):
88 super().__init__(ufunc, casting, from_, to)
89 self.out_i = i
90
91 def __str__(self):
92 # only show the number if more than one output exists
93 i_str = "{} ".format(self.out_i) if self.ufunc.nout != 1 else ""
94 return (
95 "Cannot cast ufunc {!r} output {}from {!r} to {!r} with casting "
96 "rule {!r}"
97 ).format(
98 self.ufunc.__name__, i_str, self.from_, self.to, self.casting
99 )
100
101
102 # Exception used in shares_memory()
103 @set_module('numpy')
104 class TooHardError(RuntimeError):
105 pass
106
107
108 @set_module('numpy')
109 class AxisError(ValueError, IndexError):
110 """ Axis supplied was invalid. """
111 def __init__(self, axis, ndim=None, msg_prefix=None):
112 # single-argument form just delegates to base class
113 if ndim is None and msg_prefix is None:
114 msg = axis
115
116 # do the string formatting here, to save work in the C code
117 else:
118 msg = ("axis {} is out of bounds for array of dimension {}"
119 .format(axis, ndim))
120 if msg_prefix is not None:
121 msg = "{}: {}".format(msg_prefix, msg)
122
123 super(AxisError, self).__init__(msg)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/numpy/core/_exceptions.py b/numpy/core/_exceptions.py
--- a/numpy/core/_exceptions.py
+++ b/numpy/core/_exceptions.py
@@ -121,3 +121,15 @@
msg = "{}: {}".format(msg_prefix, msg)
super(AxisError, self).__init__(msg)
+
+
+@_display_as_base
+class _ArrayMemoryError(MemoryError):
+ """ Thrown when an array cannot be allocated"""
+ def __init__(self, shape, dtype):
+ self.shape = shape
+ self.dtype = dtype
+
+ def __str__(self):
+ return "Unable to allocate array with shape {} and data type {}".format(self.shape, self.dtype)
+
|
{"golden_diff": "diff --git a/numpy/core/_exceptions.py b/numpy/core/_exceptions.py\n--- a/numpy/core/_exceptions.py\n+++ b/numpy/core/_exceptions.py\n@@ -121,3 +121,15 @@\n msg = \"{}: {}\".format(msg_prefix, msg)\n \n super(AxisError, self).__init__(msg)\n+\n+\n+@_display_as_base\n+class _ArrayMemoryError(MemoryError):\n+ \"\"\" Thrown when an array cannot be allocated\"\"\"\n+ def __init__(self, shape, dtype):\n+ self.shape = shape\n+ self.dtype = dtype\n+\n+ def __str__(self):\n+ return \"Unable to allocate array with shape {} and data type {}\".format(self.shape, self.dtype)\n+\n", "issue": "Indicate attempted allocation size when constructing an array gives a MemoryError\nI've seen multiple questions now of the form \"why does this give a MemoryError\" when the reason is the user ended up allocating a bigger array than expected.\r\n\r\nIt would be helpful to include the shape and dtype in the error message.\n", "before_files": [{"content": "\"\"\"\nVarious richly-typed exceptions, that also help us deal with string formatting\nin python where it's easier.\n\nBy putting the formatting in `__str__`, we also avoid paying the cost for\nusers who silence the exceptions.\n\"\"\"\nfrom numpy.core.overrides import set_module\n\ndef _unpack_tuple(tup):\n if len(tup) == 1:\n return tup[0]\n else:\n return tup\n\n\ndef _display_as_base(cls):\n \"\"\"\n A decorator that makes an exception class look like its base.\n\n We use this to hide subclasses that are implementation details - the user\n should catch the base type, which is what the traceback will show them.\n\n Classes decorated with this decorator are subject to removal without a\n deprecation warning.\n \"\"\"\n assert issubclass(cls, Exception)\n cls.__name__ = cls.__base__.__name__\n cls.__qualname__ = cls.__base__.__qualname__\n return cls\n\n\nclass UFuncTypeError(TypeError):\n \"\"\" Base class for all ufunc exceptions \"\"\"\n def __init__(self, ufunc):\n self.ufunc = ufunc\n\n\n@_display_as_base\nclass _UFuncNoLoopError(UFuncTypeError):\n \"\"\" Thrown when a ufunc loop cannot be found \"\"\"\n def __init__(self, ufunc, dtypes):\n super().__init__(ufunc)\n self.dtypes = tuple(dtypes)\n\n def __str__(self):\n return (\n \"ufunc {!r} did not contain a loop with signature matching types \"\n \"{!r} -> {!r}\"\n ).format(\n self.ufunc.__name__,\n _unpack_tuple(self.dtypes[:self.ufunc.nin]),\n _unpack_tuple(self.dtypes[self.ufunc.nin:])\n )\n\n\n@_display_as_base\nclass _UFuncCastingError(UFuncTypeError):\n def __init__(self, ufunc, casting, from_, to):\n super().__init__(ufunc)\n self.casting = casting\n self.from_ = from_\n self.to = to\n\n\n@_display_as_base\nclass _UFuncInputCastingError(_UFuncCastingError):\n \"\"\" Thrown when a ufunc input cannot be casted \"\"\"\n def __init__(self, ufunc, casting, from_, to, i):\n super().__init__(ufunc, casting, from_, to)\n self.in_i = i\n\n def __str__(self):\n # only show the number if more than one input exists\n i_str = \"{} \".format(self.in_i) if self.ufunc.nin != 1 else \"\"\n return (\n \"Cannot cast ufunc {!r} input {}from {!r} to {!r} with casting \"\n \"rule {!r}\"\n ).format(\n self.ufunc.__name__, i_str, self.from_, self.to, self.casting\n )\n\n\n@_display_as_base\nclass _UFuncOutputCastingError(_UFuncCastingError):\n \"\"\" Thrown when a ufunc output cannot be casted \"\"\"\n def __init__(self, ufunc, casting, from_, to, i):\n super().__init__(ufunc, casting, from_, to)\n self.out_i = i\n\n def __str__(self):\n # only show the number if more than one output exists\n i_str = \"{} \".format(self.out_i) if self.ufunc.nout != 1 else \"\"\n return (\n \"Cannot cast ufunc {!r} output {}from {!r} to {!r} with casting \"\n \"rule {!r}\"\n ).format(\n self.ufunc.__name__, i_str, self.from_, self.to, self.casting\n )\n\n\n# Exception used in shares_memory()\n@set_module('numpy')\nclass TooHardError(RuntimeError):\n pass\n\n\n@set_module('numpy')\nclass AxisError(ValueError, IndexError):\n \"\"\" Axis supplied was invalid. \"\"\"\n def __init__(self, axis, ndim=None, msg_prefix=None):\n # single-argument form just delegates to base class\n if ndim is None and msg_prefix is None:\n msg = axis\n\n # do the string formatting here, to save work in the C code\n else:\n msg = (\"axis {} is out of bounds for array of dimension {}\"\n .format(axis, ndim))\n if msg_prefix is not None:\n msg = \"{}: {}\".format(msg_prefix, msg)\n\n super(AxisError, self).__init__(msg)\n", "path": "numpy/core/_exceptions.py"}], "after_files": [{"content": "\"\"\"\nVarious richly-typed exceptions, that also help us deal with string formatting\nin python where it's easier.\n\nBy putting the formatting in `__str__`, we also avoid paying the cost for\nusers who silence the exceptions.\n\"\"\"\nfrom numpy.core.overrides import set_module\n\ndef _unpack_tuple(tup):\n if len(tup) == 1:\n return tup[0]\n else:\n return tup\n\n\ndef _display_as_base(cls):\n \"\"\"\n A decorator that makes an exception class look like its base.\n\n We use this to hide subclasses that are implementation details - the user\n should catch the base type, which is what the traceback will show them.\n\n Classes decorated with this decorator are subject to removal without a\n deprecation warning.\n \"\"\"\n assert issubclass(cls, Exception)\n cls.__name__ = cls.__base__.__name__\n cls.__qualname__ = cls.__base__.__qualname__\n return cls\n\n\nclass UFuncTypeError(TypeError):\n \"\"\" Base class for all ufunc exceptions \"\"\"\n def __init__(self, ufunc):\n self.ufunc = ufunc\n\n\n@_display_as_base\nclass _UFuncNoLoopError(UFuncTypeError):\n \"\"\" Thrown when a ufunc loop cannot be found \"\"\"\n def __init__(self, ufunc, dtypes):\n super().__init__(ufunc)\n self.dtypes = tuple(dtypes)\n\n def __str__(self):\n return (\n \"ufunc {!r} did not contain a loop with signature matching types \"\n \"{!r} -> {!r}\"\n ).format(\n self.ufunc.__name__,\n _unpack_tuple(self.dtypes[:self.ufunc.nin]),\n _unpack_tuple(self.dtypes[self.ufunc.nin:])\n )\n\n\n@_display_as_base\nclass _UFuncCastingError(UFuncTypeError):\n def __init__(self, ufunc, casting, from_, to):\n super().__init__(ufunc)\n self.casting = casting\n self.from_ = from_\n self.to = to\n\n\n@_display_as_base\nclass _UFuncInputCastingError(_UFuncCastingError):\n \"\"\" Thrown when a ufunc input cannot be casted \"\"\"\n def __init__(self, ufunc, casting, from_, to, i):\n super().__init__(ufunc, casting, from_, to)\n self.in_i = i\n\n def __str__(self):\n # only show the number if more than one input exists\n i_str = \"{} \".format(self.in_i) if self.ufunc.nin != 1 else \"\"\n return (\n \"Cannot cast ufunc {!r} input {}from {!r} to {!r} with casting \"\n \"rule {!r}\"\n ).format(\n self.ufunc.__name__, i_str, self.from_, self.to, self.casting\n )\n\n\n@_display_as_base\nclass _UFuncOutputCastingError(_UFuncCastingError):\n \"\"\" Thrown when a ufunc output cannot be casted \"\"\"\n def __init__(self, ufunc, casting, from_, to, i):\n super().__init__(ufunc, casting, from_, to)\n self.out_i = i\n\n def __str__(self):\n # only show the number if more than one output exists\n i_str = \"{} \".format(self.out_i) if self.ufunc.nout != 1 else \"\"\n return (\n \"Cannot cast ufunc {!r} output {}from {!r} to {!r} with casting \"\n \"rule {!r}\"\n ).format(\n self.ufunc.__name__, i_str, self.from_, self.to, self.casting\n )\n\n\n# Exception used in shares_memory()\n@set_module('numpy')\nclass TooHardError(RuntimeError):\n pass\n\n\n@set_module('numpy')\nclass AxisError(ValueError, IndexError):\n \"\"\" Axis supplied was invalid. \"\"\"\n def __init__(self, axis, ndim=None, msg_prefix=None):\n # single-argument form just delegates to base class\n if ndim is None and msg_prefix is None:\n msg = axis\n\n # do the string formatting here, to save work in the C code\n else:\n msg = (\"axis {} is out of bounds for array of dimension {}\"\n .format(axis, ndim))\n if msg_prefix is not None:\n msg = \"{}: {}\".format(msg_prefix, msg)\n\n super(AxisError, self).__init__(msg)\n\n\n@_display_as_base\nclass _ArrayMemoryError(MemoryError):\n \"\"\" Thrown when an array cannot be allocated\"\"\"\n def __init__(self, shape, dtype):\n self.shape = shape\n self.dtype = dtype\n\n def __str__(self):\n return \"Unable to allocate array with shape {} and data type {}\".format(self.shape, self.dtype)\n\n", "path": "numpy/core/_exceptions.py"}]}
| 1,547 | 165 |
gh_patches_debug_12594
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-1600
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update Kubernetes example of "simple" to avoid potential errors
https://github.com/optuna/optuna/blob/a5a55a6354b3c60dd7e3a08adcbc3818e90599f0/examples/kubernetes/simple/sklearn_distributed.py#L45-L54
Like https://github.com/optuna/optuna/pull/1536, we should create a study before running the script.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/kubernetes/simple/sklearn_distributed.py`
Content:
```
1 """
2 Optuna distributed optimization example that optimizes
3 an sklearn classifier for the Iris dataset on Kubernetes.
4
5 This example's code is mostly the same as the sklearn_simple.py example, except for two things:
6
7 1 - It gives a name to the study and sets load_if_exists to True
8 in order to avoid errors when the code is run from multiple workers.
9
10 2 - It sets the storage address to the postgres pod deployed with the workers.
11
12 """
13 import os
14
15 import sklearn.datasets
16 import sklearn.ensemble
17 import sklearn.model_selection
18 import sklearn.svm
19
20 import optuna
21
22
23 # FYI: Objective functions can take additional arguments
24 # (https://optuna.readthedocs.io/en/stable/faq.html#objective-func-additional-args).
25 def objective(trial):
26 iris = sklearn.datasets.load_iris()
27 x, y = iris.data, iris.target
28
29 classifier_name = trial.suggest_categorical("classifier", ["SVC", "RandomForest"])
30 if classifier_name == "SVC":
31 svc_c = trial.suggest_float("svc_c", 1e-10, 1e10, log=True)
32 classifier_obj = sklearn.svm.SVC(C=svc_c, gamma="auto")
33 else:
34 rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True)
35 classifier_obj = sklearn.ensemble.RandomForestClassifier(
36 max_depth=rf_max_depth, n_estimators=10
37 )
38
39 score = sklearn.model_selection.cross_val_score(classifier_obj, x, y, n_jobs=-1, cv=3)
40 accuracy = score.mean()
41 return accuracy
42
43
44 if __name__ == "__main__":
45 study = optuna.create_study(
46 direction="maximize",
47 study_name="kubernetes",
48 storage="postgresql://{}:{}@postgres:5432/{}".format(
49 os.environ["POSTGRES_USER"],
50 os.environ["POSTGRES_PASSWORD"],
51 os.environ["POSTGRES_DB"],
52 ),
53 load_if_exists=True,
54 )
55 study.optimize(objective, n_trials=20)
56 print(study.best_trial)
57
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/kubernetes/simple/sklearn_distributed.py b/examples/kubernetes/simple/sklearn_distributed.py
--- a/examples/kubernetes/simple/sklearn_distributed.py
+++ b/examples/kubernetes/simple/sklearn_distributed.py
@@ -42,15 +42,13 @@
if __name__ == "__main__":
- study = optuna.create_study(
- direction="maximize",
+ study = optuna.load_study(
study_name="kubernetes",
storage="postgresql://{}:{}@postgres:5432/{}".format(
os.environ["POSTGRES_USER"],
os.environ["POSTGRES_PASSWORD"],
os.environ["POSTGRES_DB"],
),
- load_if_exists=True,
)
study.optimize(objective, n_trials=20)
print(study.best_trial)
|
{"golden_diff": "diff --git a/examples/kubernetes/simple/sklearn_distributed.py b/examples/kubernetes/simple/sklearn_distributed.py\n--- a/examples/kubernetes/simple/sklearn_distributed.py\n+++ b/examples/kubernetes/simple/sklearn_distributed.py\n@@ -42,15 +42,13 @@\n \n \n if __name__ == \"__main__\":\n- study = optuna.create_study(\n- direction=\"maximize\",\n+ study = optuna.load_study(\n study_name=\"kubernetes\",\n storage=\"postgresql://{}:{}@postgres:5432/{}\".format(\n os.environ[\"POSTGRES_USER\"],\n os.environ[\"POSTGRES_PASSWORD\"],\n os.environ[\"POSTGRES_DB\"],\n ),\n- load_if_exists=True,\n )\n study.optimize(objective, n_trials=20)\n print(study.best_trial)\n", "issue": "Update Kubernetes example of \"simple\" to avoid potential errors\nhttps://github.com/optuna/optuna/blob/a5a55a6354b3c60dd7e3a08adcbc3818e90599f0/examples/kubernetes/simple/sklearn_distributed.py#L45-L54\r\n\r\nLike https://github.com/optuna/optuna/pull/1536, we should create a study before running the script.\n", "before_files": [{"content": "\"\"\"\nOptuna distributed optimization example that optimizes\nan sklearn classifier for the Iris dataset on Kubernetes.\n\nThis example's code is mostly the same as the sklearn_simple.py example, except for two things:\n\n1 - It gives a name to the study and sets load_if_exists to True\nin order to avoid errors when the code is run from multiple workers.\n\n2 - It sets the storage address to the postgres pod deployed with the workers.\n\n\"\"\"\nimport os\n\nimport sklearn.datasets\nimport sklearn.ensemble\nimport sklearn.model_selection\nimport sklearn.svm\n\nimport optuna\n\n\n# FYI: Objective functions can take additional arguments\n# (https://optuna.readthedocs.io/en/stable/faq.html#objective-func-additional-args).\ndef objective(trial):\n iris = sklearn.datasets.load_iris()\n x, y = iris.data, iris.target\n\n classifier_name = trial.suggest_categorical(\"classifier\", [\"SVC\", \"RandomForest\"])\n if classifier_name == \"SVC\":\n svc_c = trial.suggest_float(\"svc_c\", 1e-10, 1e10, log=True)\n classifier_obj = sklearn.svm.SVC(C=svc_c, gamma=\"auto\")\n else:\n rf_max_depth = trial.suggest_int(\"rf_max_depth\", 2, 32, log=True)\n classifier_obj = sklearn.ensemble.RandomForestClassifier(\n max_depth=rf_max_depth, n_estimators=10\n )\n\n score = sklearn.model_selection.cross_val_score(classifier_obj, x, y, n_jobs=-1, cv=3)\n accuracy = score.mean()\n return accuracy\n\n\nif __name__ == \"__main__\":\n study = optuna.create_study(\n direction=\"maximize\",\n study_name=\"kubernetes\",\n storage=\"postgresql://{}:{}@postgres:5432/{}\".format(\n os.environ[\"POSTGRES_USER\"],\n os.environ[\"POSTGRES_PASSWORD\"],\n os.environ[\"POSTGRES_DB\"],\n ),\n load_if_exists=True,\n )\n study.optimize(objective, n_trials=20)\n print(study.best_trial)\n", "path": "examples/kubernetes/simple/sklearn_distributed.py"}], "after_files": [{"content": "\"\"\"\nOptuna distributed optimization example that optimizes\nan sklearn classifier for the Iris dataset on Kubernetes.\n\nThis example's code is mostly the same as the sklearn_simple.py example, except for two things:\n\n1 - It gives a name to the study and sets load_if_exists to True\nin order to avoid errors when the code is run from multiple workers.\n\n2 - It sets the storage address to the postgres pod deployed with the workers.\n\n\"\"\"\nimport os\n\nimport sklearn.datasets\nimport sklearn.ensemble\nimport sklearn.model_selection\nimport sklearn.svm\n\nimport optuna\n\n\n# FYI: Objective functions can take additional arguments\n# (https://optuna.readthedocs.io/en/stable/faq.html#objective-func-additional-args).\ndef objective(trial):\n iris = sklearn.datasets.load_iris()\n x, y = iris.data, iris.target\n\n classifier_name = trial.suggest_categorical(\"classifier\", [\"SVC\", \"RandomForest\"])\n if classifier_name == \"SVC\":\n svc_c = trial.suggest_float(\"svc_c\", 1e-10, 1e10, log=True)\n classifier_obj = sklearn.svm.SVC(C=svc_c, gamma=\"auto\")\n else:\n rf_max_depth = trial.suggest_int(\"rf_max_depth\", 2, 32, log=True)\n classifier_obj = sklearn.ensemble.RandomForestClassifier(\n max_depth=rf_max_depth, n_estimators=10\n )\n\n score = sklearn.model_selection.cross_val_score(classifier_obj, x, y, n_jobs=-1, cv=3)\n accuracy = score.mean()\n return accuracy\n\n\nif __name__ == \"__main__\":\n study = optuna.load_study(\n study_name=\"kubernetes\",\n storage=\"postgresql://{}:{}@postgres:5432/{}\".format(\n os.environ[\"POSTGRES_USER\"],\n os.environ[\"POSTGRES_PASSWORD\"],\n os.environ[\"POSTGRES_DB\"],\n ),\n )\n study.optimize(objective, n_trials=20)\n print(study.best_trial)\n", "path": "examples/kubernetes/simple/sklearn_distributed.py"}]}
| 922 | 175 |
gh_patches_debug_27870
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-2427
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Undocumented behaviour of sni kwarg of remote()
In `remote()` 'server_hostname' ssl arg can be set like this:
```python
remote('172.22.0.2', 9090, ssl=True, sni='example.com')
```
This behaviour of `sni` kwarg is undocumented. Currently only behaviour of passing a bool in documented.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/tubes/remote.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import division
3
4 import socket
5 import socks
6
7 from pwnlib.log import getLogger
8 from pwnlib.timeout import Timeout
9 from pwnlib.tubes.sock import sock
10
11 log = getLogger(__name__)
12
13 class remote(sock):
14 r"""Creates a TCP or UDP-connection to a remote host. It supports
15 both IPv4 and IPv6.
16
17 The returned object supports all the methods from
18 :class:`pwnlib.tubes.sock` and :class:`pwnlib.tubes.tube`.
19
20 Arguments:
21 host(str): The host to connect to.
22 port(int): The port to connect to.
23 fam: The string "any", "ipv4" or "ipv6" or an integer to pass to :func:`socket.getaddrinfo`.
24 typ: The string "tcp" or "udp" or an integer to pass to :func:`socket.getaddrinfo`.
25 timeout: A positive number, None or the string "default".
26 ssl(bool): Wrap the socket with SSL
27 ssl_context(ssl.SSLContext): Specify SSLContext used to wrap the socket.
28 sni: Set 'server_hostname' in ssl_args based on the host parameter.
29 sock(socket.socket): Socket to inherit, rather than connecting
30 ssl_args(dict): Pass ssl.wrap_socket named arguments in a dictionary.
31
32 Examples:
33
34 >>> r = remote('google.com', 443, ssl=True)
35 >>> r.send(b'GET /\r\n\r\n')
36 >>> r.recvn(4)
37 b'HTTP'
38
39 If a connection cannot be made, an exception is raised.
40
41 >>> r = remote('127.0.0.1', 1)
42 Traceback (most recent call last):
43 ...
44 PwnlibException: Could not connect to 127.0.0.1 on port 1
45
46 You can also use :meth:`.remote.fromsocket` to wrap an existing socket.
47
48 >>> import socket
49 >>> s = socket.socket()
50 >>> s.connect(('google.com', 80))
51 >>> s.send(b'GET /' + b'\r\n'*2)
52 9
53 >>> r = remote.fromsocket(s)
54 >>> r.recvn(4)
55 b'HTTP'
56 """
57
58 def __init__(self, host, port,
59 fam = "any", typ = "tcp",
60 ssl=False, sock=None, ssl_context=None, ssl_args=None, sni=True,
61 *args, **kwargs):
62 super(remote, self).__init__(*args, **kwargs)
63
64 # convert port to string for sagemath support
65 self.rport = str(port)
66 self.rhost = host
67
68 if sock:
69 self.family = sock.family
70 self.type = sock.type
71 self.proto = sock.proto
72 self.sock = sock
73
74 else:
75 typ = self._get_type(typ)
76 fam = self._get_family(fam)
77 try:
78 self.sock = self._connect(fam, typ)
79 except socket.gaierror as e:
80 if e.errno != socket.EAI_NONAME:
81 raise
82 self.error('Could not resolve hostname: %r', host)
83 if self.sock:
84 self.settimeout(self.timeout)
85 self.lhost, self.lport = self.sock.getsockname()[:2]
86
87 if ssl:
88 # Deferred import to save startup time
89 import ssl as _ssl
90
91 ssl_args = ssl_args or {}
92 ssl_context = ssl_context or _ssl.SSLContext(_ssl.PROTOCOL_TLSv1_2)
93 if isinstance(sni, str):
94 ssl_args["server_hostname"] = sni
95 elif sni:
96 ssl_args["server_hostname"] = host
97 self.sock = ssl_context.wrap_socket(self.sock,**ssl_args)
98
99 def _connect(self, fam, typ):
100 sock = None
101 timeout = self.timeout
102
103 with self.waitfor('Opening connection to %s on port %s' % (self.rhost, self.rport)) as h:
104 for res in socket.getaddrinfo(self.rhost, self.rport, fam, typ, 0, socket.AI_PASSIVE):
105 self.family, self.type, self.proto, _canonname, sockaddr = res
106
107 if self.type not in [socket.SOCK_STREAM, socket.SOCK_DGRAM]:
108 continue
109
110 h.status("Trying %s", sockaddr[0])
111
112 sock = socket.socket(self.family, self.type, self.proto)
113
114 if timeout is not None and timeout <= 0:
115 sock.setblocking(0)
116 else:
117 sock.setblocking(1)
118 sock.settimeout(timeout)
119
120 try:
121 sock.connect(sockaddr)
122 return sock
123 except socks.ProxyError:
124 raise
125 except socket.error:
126 pass
127 self.error("Could not connect to %s on port %s", self.rhost, self.rport)
128
129 @classmethod
130 def fromsocket(cls, socket):
131 """
132 Helper method to wrap a standard python socket.socket with the
133 tube APIs.
134
135 Arguments:
136 socket: Instance of socket.socket
137
138 Returns:
139 Instance of pwnlib.tubes.remote.remote.
140 """
141 s = socket
142 host, port = s.getpeername()
143 return remote(host, port, fam=s.family, typ=s.type, sock=s)
144
145 class tcp(remote):
146 __doc__ = remote.__doc__
147 def __init__(self, host, port, *a, **kw):
148 return super(tcp, self).__init__(host, port, typ="tcp", *a, **kw)
149
150 class udp(remote):
151 __doc__ = remote.__doc__
152 def __init__(self, host, port, *a, **kw):
153 return super(udp, self).__init__(host, port, typ="udp", *a, **kw)
154
155 class connect(remote):
156 __doc__ = remote.__doc__
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/tubes/remote.py b/pwnlib/tubes/remote.py
--- a/pwnlib/tubes/remote.py
+++ b/pwnlib/tubes/remote.py
@@ -23,11 +23,11 @@
fam: The string "any", "ipv4" or "ipv6" or an integer to pass to :func:`socket.getaddrinfo`.
typ: The string "tcp" or "udp" or an integer to pass to :func:`socket.getaddrinfo`.
timeout: A positive number, None or the string "default".
+ sock(:class:`socket.socket`): Socket to inherit, rather than connecting
ssl(bool): Wrap the socket with SSL
ssl_context(ssl.SSLContext): Specify SSLContext used to wrap the socket.
- sni: Set 'server_hostname' in ssl_args based on the host parameter.
- sock(socket.socket): Socket to inherit, rather than connecting
- ssl_args(dict): Pass ssl.wrap_socket named arguments in a dictionary.
+ ssl_args(dict): Pass :func:`ssl.wrap_socket` named arguments in a dictionary.
+ sni(str,bool): Set 'server_hostname' in ssl_args. Set to True to set it based on the host argument. Set to False to not provide any value. Default is True.
Examples:
@@ -57,7 +57,7 @@
def __init__(self, host, port,
fam = "any", typ = "tcp",
- ssl=False, sock=None, ssl_context=None, ssl_args=None, sni=True,
+ sock=None, ssl=False, ssl_context=None, ssl_args=None, sni=True,
*args, **kwargs):
super(remote, self).__init__(*args, **kwargs)
|
{"golden_diff": "diff --git a/pwnlib/tubes/remote.py b/pwnlib/tubes/remote.py\n--- a/pwnlib/tubes/remote.py\n+++ b/pwnlib/tubes/remote.py\n@@ -23,11 +23,11 @@\n fam: The string \"any\", \"ipv4\" or \"ipv6\" or an integer to pass to :func:`socket.getaddrinfo`.\n typ: The string \"tcp\" or \"udp\" or an integer to pass to :func:`socket.getaddrinfo`.\n timeout: A positive number, None or the string \"default\".\n+ sock(:class:`socket.socket`): Socket to inherit, rather than connecting\n ssl(bool): Wrap the socket with SSL\n ssl_context(ssl.SSLContext): Specify SSLContext used to wrap the socket.\n- sni: Set 'server_hostname' in ssl_args based on the host parameter.\n- sock(socket.socket): Socket to inherit, rather than connecting\n- ssl_args(dict): Pass ssl.wrap_socket named arguments in a dictionary.\n+ ssl_args(dict): Pass :func:`ssl.wrap_socket` named arguments in a dictionary.\n+ sni(str,bool): Set 'server_hostname' in ssl_args. Set to True to set it based on the host argument. Set to False to not provide any value. Default is True.\n \n Examples:\n \n@@ -57,7 +57,7 @@\n \n def __init__(self, host, port,\n fam = \"any\", typ = \"tcp\",\n- ssl=False, sock=None, ssl_context=None, ssl_args=None, sni=True,\n+ sock=None, ssl=False, ssl_context=None, ssl_args=None, sni=True,\n *args, **kwargs):\n super(remote, self).__init__(*args, **kwargs)\n", "issue": "Undocumented behaviour of sni kwarg of remote()\nIn `remote()` 'server_hostname' ssl arg can be set like this:\r\n```python\r\nremote('172.22.0.2', 9090, ssl=True, sni='example.com')\r\n```\r\nThis behaviour of `sni` kwarg is undocumented. Currently only behaviour of passing a bool in documented.\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\n\nimport socket\nimport socks\n\nfrom pwnlib.log import getLogger\nfrom pwnlib.timeout import Timeout\nfrom pwnlib.tubes.sock import sock\n\nlog = getLogger(__name__)\n\nclass remote(sock):\n r\"\"\"Creates a TCP or UDP-connection to a remote host. It supports\n both IPv4 and IPv6.\n\n The returned object supports all the methods from\n :class:`pwnlib.tubes.sock` and :class:`pwnlib.tubes.tube`.\n\n Arguments:\n host(str): The host to connect to.\n port(int): The port to connect to.\n fam: The string \"any\", \"ipv4\" or \"ipv6\" or an integer to pass to :func:`socket.getaddrinfo`.\n typ: The string \"tcp\" or \"udp\" or an integer to pass to :func:`socket.getaddrinfo`.\n timeout: A positive number, None or the string \"default\".\n ssl(bool): Wrap the socket with SSL\n ssl_context(ssl.SSLContext): Specify SSLContext used to wrap the socket.\n sni: Set 'server_hostname' in ssl_args based on the host parameter.\n sock(socket.socket): Socket to inherit, rather than connecting\n ssl_args(dict): Pass ssl.wrap_socket named arguments in a dictionary.\n\n Examples:\n\n >>> r = remote('google.com', 443, ssl=True)\n >>> r.send(b'GET /\\r\\n\\r\\n')\n >>> r.recvn(4)\n b'HTTP'\n\n If a connection cannot be made, an exception is raised.\n\n >>> r = remote('127.0.0.1', 1)\n Traceback (most recent call last):\n ...\n PwnlibException: Could not connect to 127.0.0.1 on port 1\n\n You can also use :meth:`.remote.fromsocket` to wrap an existing socket.\n\n >>> import socket\n >>> s = socket.socket()\n >>> s.connect(('google.com', 80))\n >>> s.send(b'GET /' + b'\\r\\n'*2)\n 9\n >>> r = remote.fromsocket(s)\n >>> r.recvn(4)\n b'HTTP'\n \"\"\"\n\n def __init__(self, host, port,\n fam = \"any\", typ = \"tcp\",\n ssl=False, sock=None, ssl_context=None, ssl_args=None, sni=True,\n *args, **kwargs):\n super(remote, self).__init__(*args, **kwargs)\n\n # convert port to string for sagemath support\n self.rport = str(port)\n self.rhost = host\n\n if sock:\n self.family = sock.family\n self.type = sock.type\n self.proto = sock.proto\n self.sock = sock\n\n else:\n typ = self._get_type(typ)\n fam = self._get_family(fam)\n try:\n self.sock = self._connect(fam, typ)\n except socket.gaierror as e:\n if e.errno != socket.EAI_NONAME:\n raise\n self.error('Could not resolve hostname: %r', host)\n if self.sock:\n self.settimeout(self.timeout)\n self.lhost, self.lport = self.sock.getsockname()[:2]\n\n if ssl:\n # Deferred import to save startup time\n import ssl as _ssl\n\n ssl_args = ssl_args or {}\n ssl_context = ssl_context or _ssl.SSLContext(_ssl.PROTOCOL_TLSv1_2)\n if isinstance(sni, str):\n ssl_args[\"server_hostname\"] = sni\n elif sni:\n ssl_args[\"server_hostname\"] = host\n self.sock = ssl_context.wrap_socket(self.sock,**ssl_args)\n\n def _connect(self, fam, typ):\n sock = None\n timeout = self.timeout\n\n with self.waitfor('Opening connection to %s on port %s' % (self.rhost, self.rport)) as h:\n for res in socket.getaddrinfo(self.rhost, self.rport, fam, typ, 0, socket.AI_PASSIVE):\n self.family, self.type, self.proto, _canonname, sockaddr = res\n\n if self.type not in [socket.SOCK_STREAM, socket.SOCK_DGRAM]:\n continue\n\n h.status(\"Trying %s\", sockaddr[0])\n\n sock = socket.socket(self.family, self.type, self.proto)\n\n if timeout is not None and timeout <= 0:\n sock.setblocking(0)\n else:\n sock.setblocking(1)\n sock.settimeout(timeout)\n\n try:\n sock.connect(sockaddr)\n return sock\n except socks.ProxyError:\n raise\n except socket.error:\n pass\n self.error(\"Could not connect to %s on port %s\", self.rhost, self.rport)\n\n @classmethod\n def fromsocket(cls, socket):\n \"\"\"\n Helper method to wrap a standard python socket.socket with the\n tube APIs.\n\n Arguments:\n socket: Instance of socket.socket\n\n Returns:\n Instance of pwnlib.tubes.remote.remote.\n \"\"\"\n s = socket\n host, port = s.getpeername()\n return remote(host, port, fam=s.family, typ=s.type, sock=s)\n\nclass tcp(remote):\n __doc__ = remote.__doc__\n def __init__(self, host, port, *a, **kw):\n return super(tcp, self).__init__(host, port, typ=\"tcp\", *a, **kw)\n\nclass udp(remote):\n __doc__ = remote.__doc__\n def __init__(self, host, port, *a, **kw):\n return super(udp, self).__init__(host, port, typ=\"udp\", *a, **kw)\n\nclass connect(remote):\n __doc__ = remote.__doc__\n", "path": "pwnlib/tubes/remote.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\n\nimport socket\nimport socks\n\nfrom pwnlib.log import getLogger\nfrom pwnlib.timeout import Timeout\nfrom pwnlib.tubes.sock import sock\n\nlog = getLogger(__name__)\n\nclass remote(sock):\n r\"\"\"Creates a TCP or UDP-connection to a remote host. It supports\n both IPv4 and IPv6.\n\n The returned object supports all the methods from\n :class:`pwnlib.tubes.sock` and :class:`pwnlib.tubes.tube`.\n\n Arguments:\n host(str): The host to connect to.\n port(int): The port to connect to.\n fam: The string \"any\", \"ipv4\" or \"ipv6\" or an integer to pass to :func:`socket.getaddrinfo`.\n typ: The string \"tcp\" or \"udp\" or an integer to pass to :func:`socket.getaddrinfo`.\n timeout: A positive number, None or the string \"default\".\n sock(:class:`socket.socket`): Socket to inherit, rather than connecting\n ssl(bool): Wrap the socket with SSL\n ssl_context(ssl.SSLContext): Specify SSLContext used to wrap the socket.\n ssl_args(dict): Pass :func:`ssl.wrap_socket` named arguments in a dictionary.\n sni(str,bool): Set 'server_hostname' in ssl_args. Set to True to set it based on the host argument. Set to False to not provide any value. Default is True.\n\n Examples:\n\n >>> r = remote('google.com', 443, ssl=True)\n >>> r.send(b'GET /\\r\\n\\r\\n')\n >>> r.recvn(4)\n b'HTTP'\n\n If a connection cannot be made, an exception is raised.\n\n >>> r = remote('127.0.0.1', 1)\n Traceback (most recent call last):\n ...\n PwnlibException: Could not connect to 127.0.0.1 on port 1\n\n You can also use :meth:`.remote.fromsocket` to wrap an existing socket.\n\n >>> import socket\n >>> s = socket.socket()\n >>> s.connect(('google.com', 80))\n >>> s.send(b'GET /' + b'\\r\\n'*2)\n 9\n >>> r = remote.fromsocket(s)\n >>> r.recvn(4)\n b'HTTP'\n \"\"\"\n\n def __init__(self, host, port,\n fam = \"any\", typ = \"tcp\",\n sock=None, ssl=False, ssl_context=None, ssl_args=None, sni=True,\n *args, **kwargs):\n super(remote, self).__init__(*args, **kwargs)\n\n # convert port to string for sagemath support\n self.rport = str(port)\n self.rhost = host\n\n if sock:\n self.family = sock.family\n self.type = sock.type\n self.proto = sock.proto\n self.sock = sock\n\n else:\n typ = self._get_type(typ)\n fam = self._get_family(fam)\n try:\n self.sock = self._connect(fam, typ)\n except socket.gaierror as e:\n if e.errno != socket.EAI_NONAME:\n raise\n self.error('Could not resolve hostname: %r', host)\n if self.sock:\n self.settimeout(self.timeout)\n self.lhost, self.lport = self.sock.getsockname()[:2]\n\n if ssl:\n # Deferred import to save startup time\n import ssl as _ssl\n\n ssl_args = ssl_args or {}\n ssl_context = ssl_context or _ssl.SSLContext(_ssl.PROTOCOL_TLSv1_2)\n if isinstance(sni, str):\n ssl_args[\"server_hostname\"] = sni\n elif sni:\n ssl_args[\"server_hostname\"] = host\n self.sock = ssl_context.wrap_socket(self.sock,**ssl_args)\n\n def _connect(self, fam, typ):\n sock = None\n timeout = self.timeout\n\n with self.waitfor('Opening connection to %s on port %s' % (self.rhost, self.rport)) as h:\n for res in socket.getaddrinfo(self.rhost, self.rport, fam, typ, 0, socket.AI_PASSIVE):\n self.family, self.type, self.proto, _canonname, sockaddr = res\n\n if self.type not in [socket.SOCK_STREAM, socket.SOCK_DGRAM]:\n continue\n\n h.status(\"Trying %s\", sockaddr[0])\n\n sock = socket.socket(self.family, self.type, self.proto)\n\n if timeout is not None and timeout <= 0:\n sock.setblocking(0)\n else:\n sock.setblocking(1)\n sock.settimeout(timeout)\n\n try:\n sock.connect(sockaddr)\n return sock\n except socks.ProxyError:\n raise\n except socket.error:\n pass\n self.error(\"Could not connect to %s on port %s\", self.rhost, self.rport)\n\n @classmethod\n def fromsocket(cls, socket):\n \"\"\"\n Helper method to wrap a standard python socket.socket with the\n tube APIs.\n\n Arguments:\n socket: Instance of socket.socket\n\n Returns:\n Instance of pwnlib.tubes.remote.remote.\n \"\"\"\n s = socket\n host, port = s.getpeername()\n return remote(host, port, fam=s.family, typ=s.type, sock=s)\n\nclass tcp(remote):\n __doc__ = remote.__doc__\n def __init__(self, host, port, *a, **kw):\n return super(tcp, self).__init__(host, port, typ=\"tcp\", *a, **kw)\n\nclass udp(remote):\n __doc__ = remote.__doc__\n def __init__(self, host, port, *a, **kw):\n return super(udp, self).__init__(host, port, typ=\"udp\", *a, **kw)\n\nclass connect(remote):\n __doc__ = remote.__doc__\n", "path": "pwnlib/tubes/remote.py"}]}
| 1,993 | 385 |
gh_patches_debug_1285
|
rasdani/github-patches
|
git_diff
|
openai__gym-2633
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug Report] Empty print version warning
**Describe the bug**
When I import gym, there's an empty line printed.
It's because of this line: https://github.com/openai/gym/blob/master/gym/__init__.py#L30
Either it's a bug, because `notice` shouldn't be an empty string, or the check should be `if notice:` which is false for both `None` and `""` (empty string).
Currently it's cluttering the logs at best, or masking some other issue.
**Code example**
```python
import gym
```
**System Info**
Describe the characteristic of your environment:
Latest gym installed from pip, Ubuntu 20.04, Python 3.9.7
### Checklist
- [x] I have checked that there is no similar [issue](https://github.com/openai/gym/issues) in the repo (**required**)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gym/__init__.py`
Content:
```
1 from gym import error
2 from gym.version import VERSION as __version__
3
4 from gym.core import (
5 Env,
6 Wrapper,
7 ObservationWrapper,
8 ActionWrapper,
9 RewardWrapper,
10 )
11 from gym.spaces import Space
12 from gym.envs import make, spec, register
13 from gym import logger
14 from gym import vector
15 from gym import wrappers
16 import os
17
18
19 __all__ = ["Env", "Space", "Wrapper", "make", "spec", "register"]
20
21 os.environ["PYGAME_HIDE_SUPPORT_PROMPT"] = "hide"
22
23 try:
24 import gym_notices.notices as notices
25 import sys
26
27 # print version warning if necessary
28 notice = notices.notices.get(__version__)
29 if notice is not None:
30 print(notice, file=sys.stderr)
31
32 except Exception: # nosec
33 pass
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gym/__init__.py b/gym/__init__.py
--- a/gym/__init__.py
+++ b/gym/__init__.py
@@ -26,7 +26,7 @@
# print version warning if necessary
notice = notices.notices.get(__version__)
- if notice is not None:
+ if notice:
print(notice, file=sys.stderr)
except Exception: # nosec
|
{"golden_diff": "diff --git a/gym/__init__.py b/gym/__init__.py\n--- a/gym/__init__.py\n+++ b/gym/__init__.py\n@@ -26,7 +26,7 @@\n \n # print version warning if necessary\n notice = notices.notices.get(__version__)\n- if notice is not None:\n+ if notice:\n print(notice, file=sys.stderr)\n \n except Exception: # nosec\n", "issue": "[Bug Report] Empty print version warning \n**Describe the bug**\r\nWhen I import gym, there's an empty line printed.\r\nIt's because of this line: https://github.com/openai/gym/blob/master/gym/__init__.py#L30\r\n\r\nEither it's a bug, because `notice` shouldn't be an empty string, or the check should be `if notice:` which is false for both `None` and `\"\"` (empty string).\r\n\r\nCurrently it's cluttering the logs at best, or masking some other issue.\r\n\r\n**Code example**\r\n```python\r\nimport gym\r\n```\r\n\r\n**System Info**\r\nDescribe the characteristic of your environment:\r\nLatest gym installed from pip, Ubuntu 20.04, Python 3.9.7\r\n\r\n\r\n### Checklist\r\n\r\n- [x] I have checked that there is no similar [issue](https://github.com/openai/gym/issues) in the repo (**required**)\r\n\n", "before_files": [{"content": "from gym import error\nfrom gym.version import VERSION as __version__\n\nfrom gym.core import (\n Env,\n Wrapper,\n ObservationWrapper,\n ActionWrapper,\n RewardWrapper,\n)\nfrom gym.spaces import Space\nfrom gym.envs import make, spec, register\nfrom gym import logger\nfrom gym import vector\nfrom gym import wrappers\nimport os\n\n\n__all__ = [\"Env\", \"Space\", \"Wrapper\", \"make\", \"spec\", \"register\"]\n\nos.environ[\"PYGAME_HIDE_SUPPORT_PROMPT\"] = \"hide\"\n\ntry:\n import gym_notices.notices as notices\n import sys\n\n # print version warning if necessary\n notice = notices.notices.get(__version__)\n if notice is not None:\n print(notice, file=sys.stderr)\n\nexcept Exception: # nosec\n pass\n", "path": "gym/__init__.py"}], "after_files": [{"content": "from gym import error\nfrom gym.version import VERSION as __version__\n\nfrom gym.core import (\n Env,\n Wrapper,\n ObservationWrapper,\n ActionWrapper,\n RewardWrapper,\n)\nfrom gym.spaces import Space\nfrom gym.envs import make, spec, register\nfrom gym import logger\nfrom gym import vector\nfrom gym import wrappers\nimport os\n\n\n__all__ = [\"Env\", \"Space\", \"Wrapper\", \"make\", \"spec\", \"register\"]\n\nos.environ[\"PYGAME_HIDE_SUPPORT_PROMPT\"] = \"hide\"\n\ntry:\n import gym_notices.notices as notices\n import sys\n\n # print version warning if necessary\n notice = notices.notices.get(__version__)\n if notice:\n print(notice, file=sys.stderr)\n\nexcept Exception: # nosec\n pass\n", "path": "gym/__init__.py"}]}
| 691 | 98 |
gh_patches_debug_23023
|
rasdani/github-patches
|
git_diff
|
conda__conda-9464
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conda raises bogus NotWritableError exception for a bogus attempt to chown to root
This isn't a dupe (well it is a dupe of #7109) but the issue still persists.
#7180 fixed the problem in one section of code, but the same problematic snippet is present here:
https://github.com/conda/conda/blob/master/conda/gateways/disk/update.py#L121
conda raises bogus NotWritableError exception for a bogus attempt to chown to root
This isn't a dupe (well it is a dupe of #7109) but the issue still persists.
#7180 fixed the problem in one section of code, but the same problematic snippet is present here:
https://github.com/conda/conda/blob/master/conda/gateways/disk/update.py#L121
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/gateways/disk/update.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (C) 2012 Anaconda, Inc
3 # SPDX-License-Identifier: BSD-3-Clause
4 from __future__ import absolute_import, division, print_function, unicode_literals
5
6 from errno import EINVAL, EXDEV, EPERM
7 from logging import getLogger
8 import os
9 from os.path import dirname, isdir, split, basename, join, exists
10 import re
11 from shutil import move
12 from subprocess import Popen, PIPE
13
14 from . import exp_backoff_fn, mkdir_p, mkdir_p_sudo_safe
15 from .delete import rm_rf
16 from .link import lexists
17 from ...base.context import context
18 from ...common.compat import on_win
19 from ...common.path import expand
20 from ...exceptions import NotWritableError
21
22 log = getLogger(__name__)
23
24 SHEBANG_REGEX = re.compile(br'^(#!((?:\\ |[^ \n\r])+)(.*))')
25
26
27 class CancelOperation(Exception):
28 pass
29
30
31 def update_file_in_place_as_binary(file_full_path, callback):
32 # callback should be a callable that takes one positional argument, which is the
33 # content of the file before updating
34 # this method updates the file in-place, without releasing the file lock
35 fh = None
36 try:
37 fh = exp_backoff_fn(open, file_full_path, 'rb+')
38 log.trace("in-place update path locked for %s", file_full_path)
39 data = fh.read()
40 fh.seek(0)
41 try:
42 fh.write(callback(data))
43 fh.truncate()
44 except CancelOperation:
45 pass # NOQA
46 finally:
47 if fh:
48 fh.close()
49
50
51 def rename(source_path, destination_path, force=False):
52 if lexists(destination_path) and force:
53 rm_rf(destination_path)
54 if lexists(source_path):
55 log.trace("renaming %s => %s", source_path, destination_path)
56 try:
57 os.rename(source_path, destination_path)
58 except EnvironmentError as e:
59 if (on_win and dirname(source_path) == dirname(destination_path)
60 and os.path.isfile(source_path)):
61 condabin_dir = join(context.conda_prefix, "condabin")
62 rename_script = join(condabin_dir, 'rename_tmp.bat')
63 if exists(rename_script):
64 _dirname, _src_fn = split(source_path)
65 _dest_fn = basename(destination_path)
66 p = Popen(['cmd.exe', '/C', rename_script, _dirname,
67 _src_fn, _dest_fn], stdout=PIPE, stderr=PIPE)
68 stdout, stderr = p.communicate()
69 else:
70 log.debug("{} is missing. Conda was not installed correctly or has been "
71 "corrupted. Please file an issue on the conda github repo."
72 .format(rename_script))
73 elif e.errno in (EINVAL, EXDEV, EPERM):
74 # https://github.com/conda/conda/issues/6811
75 # https://github.com/conda/conda/issues/6711
76 log.trace("Could not rename %s => %s due to errno [%s]. Falling back"
77 " to copy/unlink", source_path, destination_path, e.errno)
78 # https://github.com/moby/moby/issues/25409#issuecomment-238537855
79 # shutil.move() falls back to copy+unlink
80 move(source_path, destination_path)
81 else:
82 raise
83 else:
84 log.trace("cannot rename; source path does not exist '%s'", source_path)
85
86
87 def backoff_rename(source_path, destination_path, force=False):
88 exp_backoff_fn(rename, source_path, destination_path, force)
89
90
91 def touch(path, mkdir=False, sudo_safe=False):
92 # sudo_safe: use any time `path` is within the user's home directory
93 # returns:
94 # True if the file did not exist but was created
95 # False if the file already existed
96 # raises: NotWritableError, which is also an OSError having attached errno
97 try:
98 path = expand(path)
99 log.trace("touching path %s", path)
100 if lexists(path):
101 os.utime(path, None)
102 return True
103 else:
104 dirpath = dirname(path)
105 if not isdir(dirpath) and mkdir:
106 if sudo_safe:
107 mkdir_p_sudo_safe(dirpath)
108 else:
109 mkdir_p(dirpath)
110 else:
111 assert isdir(dirname(path))
112 try:
113 fh = open(path, 'a')
114 except:
115 raise
116 else:
117 fh.close()
118 if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:
119 uid = int(os.environ['SUDO_UID'])
120 gid = int(os.environ.get('SUDO_GID', -1))
121 log.trace("chowning %s:%s %s", uid, gid, path)
122 os.chown(path, uid, gid)
123 return False
124 except (IOError, OSError) as e:
125 raise NotWritableError(path, e.errno, caused_by=e)
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/gateways/disk/update.py b/conda/gateways/disk/update.py
--- a/conda/gateways/disk/update.py
+++ b/conda/gateways/disk/update.py
@@ -109,17 +109,17 @@
mkdir_p(dirpath)
else:
assert isdir(dirname(path))
- try:
- fh = open(path, 'a')
- except:
- raise
- else:
- fh.close()
- if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:
- uid = int(os.environ['SUDO_UID'])
- gid = int(os.environ.get('SUDO_GID', -1))
- log.trace("chowning %s:%s %s", uid, gid, path)
- os.chown(path, uid, gid)
- return False
+ with open(path, 'a'):
+ pass
+ # This chown call causes a false positive PermissionError to be
+ # raised (similar to #7109) when called in an environment which
+ # comes from sudo -u.
+ #
+ # if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:
+ # uid = int(os.environ['SUDO_UID'])
+ # gid = int(os.environ.get('SUDO_GID', -1))
+ # log.trace("chowning %s:%s %s", uid, gid, path)
+ # os.chown(path, uid, gid)
+ return False
except (IOError, OSError) as e:
raise NotWritableError(path, e.errno, caused_by=e)
|
{"golden_diff": "diff --git a/conda/gateways/disk/update.py b/conda/gateways/disk/update.py\n--- a/conda/gateways/disk/update.py\n+++ b/conda/gateways/disk/update.py\n@@ -109,17 +109,17 @@\n mkdir_p(dirpath)\n else:\n assert isdir(dirname(path))\n- try:\n- fh = open(path, 'a')\n- except:\n- raise\n- else:\n- fh.close()\n- if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:\n- uid = int(os.environ['SUDO_UID'])\n- gid = int(os.environ.get('SUDO_GID', -1))\n- log.trace(\"chowning %s:%s %s\", uid, gid, path)\n- os.chown(path, uid, gid)\n- return False\n+ with open(path, 'a'):\n+ pass\n+ # This chown call causes a false positive PermissionError to be\n+ # raised (similar to #7109) when called in an environment which\n+ # comes from sudo -u.\n+ #\n+ # if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:\n+ # uid = int(os.environ['SUDO_UID'])\n+ # gid = int(os.environ.get('SUDO_GID', -1))\n+ # log.trace(\"chowning %s:%s %s\", uid, gid, path)\n+ # os.chown(path, uid, gid)\n+ return False\n except (IOError, OSError) as e:\n raise NotWritableError(path, e.errno, caused_by=e)\n", "issue": "conda raises bogus NotWritableError exception for a bogus attempt to chown to root\nThis isn't a dupe (well it is a dupe of #7109) but the issue still persists.\r\n\r\n#7180 fixed the problem in one section of code, but the same problematic snippet is present here:\r\n\r\nhttps://github.com/conda/conda/blob/master/conda/gateways/disk/update.py#L121\nconda raises bogus NotWritableError exception for a bogus attempt to chown to root\nThis isn't a dupe (well it is a dupe of #7109) but the issue still persists.\r\n\r\n#7180 fixed the problem in one section of code, but the same problematic snippet is present here:\r\n\r\nhttps://github.com/conda/conda/blob/master/conda/gateways/disk/update.py#L121\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (C) 2012 Anaconda, Inc\n# SPDX-License-Identifier: BSD-3-Clause\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom errno import EINVAL, EXDEV, EPERM\nfrom logging import getLogger\nimport os\nfrom os.path import dirname, isdir, split, basename, join, exists\nimport re\nfrom shutil import move\nfrom subprocess import Popen, PIPE\n\nfrom . import exp_backoff_fn, mkdir_p, mkdir_p_sudo_safe\nfrom .delete import rm_rf\nfrom .link import lexists\nfrom ...base.context import context\nfrom ...common.compat import on_win\nfrom ...common.path import expand\nfrom ...exceptions import NotWritableError\n\nlog = getLogger(__name__)\n\nSHEBANG_REGEX = re.compile(br'^(#!((?:\\\\ |[^ \\n\\r])+)(.*))')\n\n\nclass CancelOperation(Exception):\n pass\n\n\ndef update_file_in_place_as_binary(file_full_path, callback):\n # callback should be a callable that takes one positional argument, which is the\n # content of the file before updating\n # this method updates the file in-place, without releasing the file lock\n fh = None\n try:\n fh = exp_backoff_fn(open, file_full_path, 'rb+')\n log.trace(\"in-place update path locked for %s\", file_full_path)\n data = fh.read()\n fh.seek(0)\n try:\n fh.write(callback(data))\n fh.truncate()\n except CancelOperation:\n pass # NOQA\n finally:\n if fh:\n fh.close()\n\n\ndef rename(source_path, destination_path, force=False):\n if lexists(destination_path) and force:\n rm_rf(destination_path)\n if lexists(source_path):\n log.trace(\"renaming %s => %s\", source_path, destination_path)\n try:\n os.rename(source_path, destination_path)\n except EnvironmentError as e:\n if (on_win and dirname(source_path) == dirname(destination_path)\n and os.path.isfile(source_path)):\n condabin_dir = join(context.conda_prefix, \"condabin\")\n rename_script = join(condabin_dir, 'rename_tmp.bat')\n if exists(rename_script):\n _dirname, _src_fn = split(source_path)\n _dest_fn = basename(destination_path)\n p = Popen(['cmd.exe', '/C', rename_script, _dirname,\n _src_fn, _dest_fn], stdout=PIPE, stderr=PIPE)\n stdout, stderr = p.communicate()\n else:\n log.debug(\"{} is missing. Conda was not installed correctly or has been \"\n \"corrupted. Please file an issue on the conda github repo.\"\n .format(rename_script))\n elif e.errno in (EINVAL, EXDEV, EPERM):\n # https://github.com/conda/conda/issues/6811\n # https://github.com/conda/conda/issues/6711\n log.trace(\"Could not rename %s => %s due to errno [%s]. Falling back\"\n \" to copy/unlink\", source_path, destination_path, e.errno)\n # https://github.com/moby/moby/issues/25409#issuecomment-238537855\n # shutil.move() falls back to copy+unlink\n move(source_path, destination_path)\n else:\n raise\n else:\n log.trace(\"cannot rename; source path does not exist '%s'\", source_path)\n\n\ndef backoff_rename(source_path, destination_path, force=False):\n exp_backoff_fn(rename, source_path, destination_path, force)\n\n\ndef touch(path, mkdir=False, sudo_safe=False):\n # sudo_safe: use any time `path` is within the user's home directory\n # returns:\n # True if the file did not exist but was created\n # False if the file already existed\n # raises: NotWritableError, which is also an OSError having attached errno\n try:\n path = expand(path)\n log.trace(\"touching path %s\", path)\n if lexists(path):\n os.utime(path, None)\n return True\n else:\n dirpath = dirname(path)\n if not isdir(dirpath) and mkdir:\n if sudo_safe:\n mkdir_p_sudo_safe(dirpath)\n else:\n mkdir_p(dirpath)\n else:\n assert isdir(dirname(path))\n try:\n fh = open(path, 'a')\n except:\n raise\n else:\n fh.close()\n if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:\n uid = int(os.environ['SUDO_UID'])\n gid = int(os.environ.get('SUDO_GID', -1))\n log.trace(\"chowning %s:%s %s\", uid, gid, path)\n os.chown(path, uid, gid)\n return False\n except (IOError, OSError) as e:\n raise NotWritableError(path, e.errno, caused_by=e)\n", "path": "conda/gateways/disk/update.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (C) 2012 Anaconda, Inc\n# SPDX-License-Identifier: BSD-3-Clause\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom errno import EINVAL, EXDEV, EPERM\nfrom logging import getLogger\nimport os\nfrom os.path import dirname, isdir, split, basename, join, exists\nimport re\nfrom shutil import move\nfrom subprocess import Popen, PIPE\n\nfrom . import exp_backoff_fn, mkdir_p, mkdir_p_sudo_safe\nfrom .delete import rm_rf\nfrom .link import lexists\nfrom ...base.context import context\nfrom ...common.compat import on_win\nfrom ...common.path import expand\nfrom ...exceptions import NotWritableError\n\nlog = getLogger(__name__)\n\nSHEBANG_REGEX = re.compile(br'^(#!((?:\\\\ |[^ \\n\\r])+)(.*))')\n\n\nclass CancelOperation(Exception):\n pass\n\n\ndef update_file_in_place_as_binary(file_full_path, callback):\n # callback should be a callable that takes one positional argument, which is the\n # content of the file before updating\n # this method updates the file in-place, without releasing the file lock\n fh = None\n try:\n fh = exp_backoff_fn(open, file_full_path, 'rb+')\n log.trace(\"in-place update path locked for %s\", file_full_path)\n data = fh.read()\n fh.seek(0)\n try:\n fh.write(callback(data))\n fh.truncate()\n except CancelOperation:\n pass # NOQA\n finally:\n if fh:\n fh.close()\n\n\ndef rename(source_path, destination_path, force=False):\n if lexists(destination_path) and force:\n rm_rf(destination_path)\n if lexists(source_path):\n log.trace(\"renaming %s => %s\", source_path, destination_path)\n try:\n os.rename(source_path, destination_path)\n except EnvironmentError as e:\n if (on_win and dirname(source_path) == dirname(destination_path)\n and os.path.isfile(source_path)):\n condabin_dir = join(context.conda_prefix, \"condabin\")\n rename_script = join(condabin_dir, 'rename_tmp.bat')\n if exists(rename_script):\n _dirname, _src_fn = split(source_path)\n _dest_fn = basename(destination_path)\n p = Popen(['cmd.exe', '/C', rename_script, _dirname,\n _src_fn, _dest_fn], stdout=PIPE, stderr=PIPE)\n stdout, stderr = p.communicate()\n else:\n log.debug(\"{} is missing. Conda was not installed correctly or has been \"\n \"corrupted. Please file an issue on the conda github repo.\"\n .format(rename_script))\n elif e.errno in (EINVAL, EXDEV, EPERM):\n # https://github.com/conda/conda/issues/6811\n # https://github.com/conda/conda/issues/6711\n log.trace(\"Could not rename %s => %s due to errno [%s]. Falling back\"\n \" to copy/unlink\", source_path, destination_path, e.errno)\n # https://github.com/moby/moby/issues/25409#issuecomment-238537855\n # shutil.move() falls back to copy+unlink\n move(source_path, destination_path)\n else:\n raise\n else:\n log.trace(\"cannot rename; source path does not exist '%s'\", source_path)\n\n\ndef backoff_rename(source_path, destination_path, force=False):\n exp_backoff_fn(rename, source_path, destination_path, force)\n\n\ndef touch(path, mkdir=False, sudo_safe=False):\n # sudo_safe: use any time `path` is within the user's home directory\n # returns:\n # True if the file did not exist but was created\n # False if the file already existed\n # raises: NotWritableError, which is also an OSError having attached errno\n try:\n path = expand(path)\n log.trace(\"touching path %s\", path)\n if lexists(path):\n os.utime(path, None)\n return True\n else:\n dirpath = dirname(path)\n if not isdir(dirpath) and mkdir:\n if sudo_safe:\n mkdir_p_sudo_safe(dirpath)\n else:\n mkdir_p(dirpath)\n else:\n assert isdir(dirname(path))\n with open(path, 'a'):\n pass\n # This chown call causes a false positive PermissionError to be\n # raised (similar to #7109) when called in an environment which\n # comes from sudo -u.\n #\n # if sudo_safe and not on_win and os.environ.get('SUDO_UID') is not None:\n # uid = int(os.environ['SUDO_UID'])\n # gid = int(os.environ.get('SUDO_GID', -1))\n # log.trace(\"chowning %s:%s %s\", uid, gid, path)\n # os.chown(path, uid, gid)\n return False\n except (IOError, OSError) as e:\n raise NotWritableError(path, e.errno, caused_by=e)\n", "path": "conda/gateways/disk/update.py"}]}
| 1,809 | 383 |
gh_patches_debug_16882
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-1535
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Learn's Search is broken
## Summary
* Search within Learn is currently broken on Develop.
* See [triggerSearch()](https://github.com/learningequality/kolibri/blob/develop/kolibri/plugins/learn/assets/src/state/actions.js#L377)
## Exception
`Exception Value: 'list' object has no attribute 'values_list'`
## How to reproduce
1. Search for something within Learn
## Real-life consequences
:rage4:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/content/serializers.py`
Content:
```
1 from django.db.models import Manager
2 from django.db.models.query import RawQuerySet
3 from kolibri.content.models import AssessmentMetaData, ChannelMetadataCache, ContentNode, File
4 from rest_framework import serializers
5
6 from .content_db_router import default_database_is_attached, get_active_content_database
7
8
9 class ChannelMetadataCacheSerializer(serializers.ModelSerializer):
10
11 class Meta:
12 model = ChannelMetadataCache
13 fields = ('root_pk', 'id', 'name', 'description', 'author')
14
15
16 class FileSerializer(serializers.ModelSerializer):
17 storage_url = serializers.SerializerMethodField()
18 preset = serializers.SerializerMethodField()
19 download_url = serializers.SerializerMethodField()
20
21 def get_storage_url(self, target_node):
22 return target_node.get_storage_url()
23
24 def get_preset(self, target_node):
25 return target_node.get_preset()
26
27 def get_download_url(self, target_node):
28 return target_node.get_download_url()
29
30 class Meta:
31 model = File
32 fields = ('storage_url', 'id', 'priority', 'checksum', 'available', 'file_size', 'extension', 'preset', 'lang',
33 'supplementary', 'thumbnail', 'download_url')
34
35
36 class AssessmentMetaDataSerializer(serializers.ModelSerializer):
37
38 assessment_item_ids = serializers.JSONField(default='[]')
39 mastery_model = serializers.JSONField(default='{}')
40
41 class Meta:
42 model = AssessmentMetaData
43 fields = ('assessment_item_ids', 'number_of_assessments', 'mastery_model', 'randomize', 'is_manipulable', )
44
45
46 def get_progress_fraction(content_id, user):
47 from kolibri.logger.models import ContentSummaryLog
48 try:
49 # add up all the progress for the logs, and divide by the total number of content nodes to get overall progress
50 overall_progress = ContentSummaryLog.objects.get(user=user, content_id=content_id).progress
51 except ContentSummaryLog.DoesNotExist:
52 return None
53 return round(overall_progress, 4)
54
55
56 def get_progress_fractions(nodes, user):
57 from kolibri.logger.models import ContentSummaryLog
58 if isinstance(nodes, RawQuerySet):
59 leaf_ids = [datum.content_id for datum in nodes]
60 else:
61 leaf_ids = nodes.values_list("content_id", flat=True)
62
63 # get all summary logs for the current user that correspond to the descendant content nodes
64 if default_database_is_attached(): # if possible, do a direct join between the content and default databases
65 channel_alias = get_active_content_database()
66 summary_logs = ContentSummaryLog.objects.using(channel_alias).filter(user=user, content_id__in=leaf_ids)
67 else: # otherwise, convert the leaf queryset into a flat list of ids and use that
68 summary_logs = ContentSummaryLog.objects.filter(user=user, content_id__in=list(leaf_ids))
69
70 # make a lookup dict for all logs to allow mapping from content_id to current progress
71 overall_progress = {log['content_id']: round(log['progress'], 4) for log in summary_logs.values('content_id', 'progress')}
72 return overall_progress
73
74
75 class ContentNodeListSerializer(serializers.ListSerializer):
76
77 def to_representation(self, data):
78
79 if 'request' not in self.context or not self.context['request'].user.is_facility_user:
80 progress_dict = {}
81 else:
82 user = self.context["request"].user
83 progress_dict = get_progress_fractions(data, user)
84
85 # Dealing with nested relationships, data can be a Manager,
86 # so, first get a queryset from the Manager if needed
87 iterable = data.all() if isinstance(data, Manager) else data
88
89 return [
90 self.child.to_representation(item, progress_dict.get(item.content_id)) for item in iterable
91 ]
92
93
94 class ContentNodeSerializer(serializers.ModelSerializer):
95 parent = serializers.PrimaryKeyRelatedField(read_only=True)
96 files = FileSerializer(many=True, read_only=True)
97 assessmentmetadata = AssessmentMetaDataSerializer(read_only=True, allow_null=True, many=True)
98 license = serializers.StringRelatedField(many=False)
99 license_description = serializers.SerializerMethodField()
100
101 def __init__(self, *args, **kwargs):
102 # Instantiate the superclass normally
103 super(ContentNodeSerializer, self).__init__(*args, **kwargs)
104
105 # enable dynamic fields specification!
106 if 'request' in self.context and self.context['request'].GET.get('fields', None):
107 fields = self.context['request'].GET['fields'].split(',')
108 # Drop any fields that are not specified in the `fields` argument.
109 allowed = set(fields)
110 existing = set(self.fields.keys())
111 for field_name in existing - allowed:
112 self.fields.pop(field_name)
113
114 def to_representation(self, instance, progress_fraction=None):
115 if progress_fraction is None:
116 if 'request' not in self.context or not self.context['request'].user.is_facility_user:
117 progress_fraction = 0
118 else:
119 user = self.context["request"].user
120 progress_fraction = get_progress_fraction(instance.content_id, user)
121 value = super(ContentNodeSerializer, self).to_representation(instance)
122 value['progress_fraction'] = progress_fraction
123 return value
124
125 def get_license_description(self, target_node):
126 if target_node.license_id:
127 return target_node.license.license_description
128 return ''
129
130 class Meta:
131 model = ContentNode
132 fields = (
133 'pk', 'content_id', 'title', 'description', 'kind', 'available', 'sort_order', 'license_owner',
134 'license', 'license_description', 'files', 'parent', 'author',
135 'assessmentmetadata',
136 )
137
138 list_serializer_class = ContentNodeListSerializer
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/content/serializers.py b/kolibri/content/serializers.py
--- a/kolibri/content/serializers.py
+++ b/kolibri/content/serializers.py
@@ -55,7 +55,7 @@
def get_progress_fractions(nodes, user):
from kolibri.logger.models import ContentSummaryLog
- if isinstance(nodes, RawQuerySet):
+ if isinstance(nodes, RawQuerySet) or isinstance(nodes, list):
leaf_ids = [datum.content_id for datum in nodes]
else:
leaf_ids = nodes.values_list("content_id", flat=True)
@@ -76,6 +76,9 @@
def to_representation(self, data):
+ if not data:
+ return data
+
if 'request' not in self.context or not self.context['request'].user.is_facility_user:
progress_dict = {}
else:
|
{"golden_diff": "diff --git a/kolibri/content/serializers.py b/kolibri/content/serializers.py\n--- a/kolibri/content/serializers.py\n+++ b/kolibri/content/serializers.py\n@@ -55,7 +55,7 @@\n \n def get_progress_fractions(nodes, user):\n from kolibri.logger.models import ContentSummaryLog\n- if isinstance(nodes, RawQuerySet):\n+ if isinstance(nodes, RawQuerySet) or isinstance(nodes, list):\n leaf_ids = [datum.content_id for datum in nodes]\n else:\n leaf_ids = nodes.values_list(\"content_id\", flat=True)\n@@ -76,6 +76,9 @@\n \n def to_representation(self, data):\n \n+ if not data:\n+ return data\n+\n if 'request' not in self.context or not self.context['request'].user.is_facility_user:\n progress_dict = {}\n else:\n", "issue": "Learn's Search is broken\n## Summary\r\n\r\n* Search within Learn is currently broken on Develop.\r\n* See [triggerSearch()](https://github.com/learningequality/kolibri/blob/develop/kolibri/plugins/learn/assets/src/state/actions.js#L377)\r\n\r\n## Exception\r\n\r\n`Exception Value: 'list' object has no attribute 'values_list'`\r\n\r\n## How to reproduce\r\n\r\n1. Search for something within Learn\r\n\r\n## Real-life consequences\r\n\r\n:rage4: \n", "before_files": [{"content": "from django.db.models import Manager\nfrom django.db.models.query import RawQuerySet\nfrom kolibri.content.models import AssessmentMetaData, ChannelMetadataCache, ContentNode, File\nfrom rest_framework import serializers\n\nfrom .content_db_router import default_database_is_attached, get_active_content_database\n\n\nclass ChannelMetadataCacheSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = ChannelMetadataCache\n fields = ('root_pk', 'id', 'name', 'description', 'author')\n\n\nclass FileSerializer(serializers.ModelSerializer):\n storage_url = serializers.SerializerMethodField()\n preset = serializers.SerializerMethodField()\n download_url = serializers.SerializerMethodField()\n\n def get_storage_url(self, target_node):\n return target_node.get_storage_url()\n\n def get_preset(self, target_node):\n return target_node.get_preset()\n\n def get_download_url(self, target_node):\n return target_node.get_download_url()\n\n class Meta:\n model = File\n fields = ('storage_url', 'id', 'priority', 'checksum', 'available', 'file_size', 'extension', 'preset', 'lang',\n 'supplementary', 'thumbnail', 'download_url')\n\n\nclass AssessmentMetaDataSerializer(serializers.ModelSerializer):\n\n assessment_item_ids = serializers.JSONField(default='[]')\n mastery_model = serializers.JSONField(default='{}')\n\n class Meta:\n model = AssessmentMetaData\n fields = ('assessment_item_ids', 'number_of_assessments', 'mastery_model', 'randomize', 'is_manipulable', )\n\n\ndef get_progress_fraction(content_id, user):\n from kolibri.logger.models import ContentSummaryLog\n try:\n # add up all the progress for the logs, and divide by the total number of content nodes to get overall progress\n overall_progress = ContentSummaryLog.objects.get(user=user, content_id=content_id).progress\n except ContentSummaryLog.DoesNotExist:\n return None\n return round(overall_progress, 4)\n\n\ndef get_progress_fractions(nodes, user):\n from kolibri.logger.models import ContentSummaryLog\n if isinstance(nodes, RawQuerySet):\n leaf_ids = [datum.content_id for datum in nodes]\n else:\n leaf_ids = nodes.values_list(\"content_id\", flat=True)\n\n # get all summary logs for the current user that correspond to the descendant content nodes\n if default_database_is_attached(): # if possible, do a direct join between the content and default databases\n channel_alias = get_active_content_database()\n summary_logs = ContentSummaryLog.objects.using(channel_alias).filter(user=user, content_id__in=leaf_ids)\n else: # otherwise, convert the leaf queryset into a flat list of ids and use that\n summary_logs = ContentSummaryLog.objects.filter(user=user, content_id__in=list(leaf_ids))\n\n # make a lookup dict for all logs to allow mapping from content_id to current progress\n overall_progress = {log['content_id']: round(log['progress'], 4) for log in summary_logs.values('content_id', 'progress')}\n return overall_progress\n\n\nclass ContentNodeListSerializer(serializers.ListSerializer):\n\n def to_representation(self, data):\n\n if 'request' not in self.context or not self.context['request'].user.is_facility_user:\n progress_dict = {}\n else:\n user = self.context[\"request\"].user\n progress_dict = get_progress_fractions(data, user)\n\n # Dealing with nested relationships, data can be a Manager,\n # so, first get a queryset from the Manager if needed\n iterable = data.all() if isinstance(data, Manager) else data\n\n return [\n self.child.to_representation(item, progress_dict.get(item.content_id)) for item in iterable\n ]\n\n\nclass ContentNodeSerializer(serializers.ModelSerializer):\n parent = serializers.PrimaryKeyRelatedField(read_only=True)\n files = FileSerializer(many=True, read_only=True)\n assessmentmetadata = AssessmentMetaDataSerializer(read_only=True, allow_null=True, many=True)\n license = serializers.StringRelatedField(many=False)\n license_description = serializers.SerializerMethodField()\n\n def __init__(self, *args, **kwargs):\n # Instantiate the superclass normally\n super(ContentNodeSerializer, self).__init__(*args, **kwargs)\n\n # enable dynamic fields specification!\n if 'request' in self.context and self.context['request'].GET.get('fields', None):\n fields = self.context['request'].GET['fields'].split(',')\n # Drop any fields that are not specified in the `fields` argument.\n allowed = set(fields)\n existing = set(self.fields.keys())\n for field_name in existing - allowed:\n self.fields.pop(field_name)\n\n def to_representation(self, instance, progress_fraction=None):\n if progress_fraction is None:\n if 'request' not in self.context or not self.context['request'].user.is_facility_user:\n progress_fraction = 0\n else:\n user = self.context[\"request\"].user\n progress_fraction = get_progress_fraction(instance.content_id, user)\n value = super(ContentNodeSerializer, self).to_representation(instance)\n value['progress_fraction'] = progress_fraction\n return value\n\n def get_license_description(self, target_node):\n if target_node.license_id:\n return target_node.license.license_description\n return ''\n\n class Meta:\n model = ContentNode\n fields = (\n 'pk', 'content_id', 'title', 'description', 'kind', 'available', 'sort_order', 'license_owner',\n 'license', 'license_description', 'files', 'parent', 'author',\n 'assessmentmetadata',\n )\n\n list_serializer_class = ContentNodeListSerializer\n", "path": "kolibri/content/serializers.py"}], "after_files": [{"content": "from django.db.models import Manager\nfrom django.db.models.query import RawQuerySet\nfrom kolibri.content.models import AssessmentMetaData, ChannelMetadataCache, ContentNode, File\nfrom rest_framework import serializers\n\nfrom .content_db_router import default_database_is_attached, get_active_content_database\n\n\nclass ChannelMetadataCacheSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = ChannelMetadataCache\n fields = ('root_pk', 'id', 'name', 'description', 'author')\n\n\nclass FileSerializer(serializers.ModelSerializer):\n storage_url = serializers.SerializerMethodField()\n preset = serializers.SerializerMethodField()\n download_url = serializers.SerializerMethodField()\n\n def get_storage_url(self, target_node):\n return target_node.get_storage_url()\n\n def get_preset(self, target_node):\n return target_node.get_preset()\n\n def get_download_url(self, target_node):\n return target_node.get_download_url()\n\n class Meta:\n model = File\n fields = ('storage_url', 'id', 'priority', 'checksum', 'available', 'file_size', 'extension', 'preset', 'lang',\n 'supplementary', 'thumbnail', 'download_url')\n\n\nclass AssessmentMetaDataSerializer(serializers.ModelSerializer):\n\n assessment_item_ids = serializers.JSONField(default='[]')\n mastery_model = serializers.JSONField(default='{}')\n\n class Meta:\n model = AssessmentMetaData\n fields = ('assessment_item_ids', 'number_of_assessments', 'mastery_model', 'randomize', 'is_manipulable', )\n\n\ndef get_progress_fraction(content_id, user):\n from kolibri.logger.models import ContentSummaryLog\n try:\n # add up all the progress for the logs, and divide by the total number of content nodes to get overall progress\n overall_progress = ContentSummaryLog.objects.get(user=user, content_id=content_id).progress\n except ContentSummaryLog.DoesNotExist:\n return None\n return round(overall_progress, 4)\n\n\ndef get_progress_fractions(nodes, user):\n from kolibri.logger.models import ContentSummaryLog\n if isinstance(nodes, RawQuerySet) or isinstance(nodes, list):\n leaf_ids = [datum.content_id for datum in nodes]\n else:\n leaf_ids = nodes.values_list(\"content_id\", flat=True)\n\n # get all summary logs for the current user that correspond to the descendant content nodes\n if default_database_is_attached(): # if possible, do a direct join between the content and default databases\n channel_alias = get_active_content_database()\n summary_logs = ContentSummaryLog.objects.using(channel_alias).filter(user=user, content_id__in=leaf_ids)\n else: # otherwise, convert the leaf queryset into a flat list of ids and use that\n summary_logs = ContentSummaryLog.objects.filter(user=user, content_id__in=list(leaf_ids))\n\n # make a lookup dict for all logs to allow mapping from content_id to current progress\n overall_progress = {log['content_id']: round(log['progress'], 4) for log in summary_logs.values('content_id', 'progress')}\n return overall_progress\n\n\nclass ContentNodeListSerializer(serializers.ListSerializer):\n\n def to_representation(self, data):\n\n if not data:\n return data\n\n if 'request' not in self.context or not self.context['request'].user.is_facility_user:\n progress_dict = {}\n else:\n user = self.context[\"request\"].user\n progress_dict = get_progress_fractions(data, user)\n\n # Dealing with nested relationships, data can be a Manager,\n # so, first get a queryset from the Manager if needed\n iterable = data.all() if isinstance(data, Manager) else data\n\n return [\n self.child.to_representation(item, progress_dict.get(item.content_id)) for item in iterable\n ]\n\n\nclass ContentNodeSerializer(serializers.ModelSerializer):\n parent = serializers.PrimaryKeyRelatedField(read_only=True)\n files = FileSerializer(many=True, read_only=True)\n assessmentmetadata = AssessmentMetaDataSerializer(read_only=True, allow_null=True, many=True)\n license = serializers.StringRelatedField(many=False)\n license_description = serializers.SerializerMethodField()\n\n def __init__(self, *args, **kwargs):\n # Instantiate the superclass normally\n super(ContentNodeSerializer, self).__init__(*args, **kwargs)\n\n # enable dynamic fields specification!\n if 'request' in self.context and self.context['request'].GET.get('fields', None):\n fields = self.context['request'].GET['fields'].split(',')\n # Drop any fields that are not specified in the `fields` argument.\n allowed = set(fields)\n existing = set(self.fields.keys())\n for field_name in existing - allowed:\n self.fields.pop(field_name)\n\n def to_representation(self, instance, progress_fraction=None):\n if progress_fraction is None:\n if 'request' not in self.context or not self.context['request'].user.is_facility_user:\n progress_fraction = 0\n else:\n user = self.context[\"request\"].user\n progress_fraction = get_progress_fraction(instance.content_id, user)\n value = super(ContentNodeSerializer, self).to_representation(instance)\n value['progress_fraction'] = progress_fraction\n return value\n\n def get_license_description(self, target_node):\n if target_node.license_id:\n return target_node.license.license_description\n return ''\n\n class Meta:\n model = ContentNode\n fields = (\n 'pk', 'content_id', 'title', 'description', 'kind', 'available', 'sort_order', 'license_owner',\n 'license', 'license_description', 'files', 'parent', 'author',\n 'assessmentmetadata',\n )\n\n list_serializer_class = ContentNodeListSerializer\n", "path": "kolibri/content/serializers.py"}]}
| 1,868 | 198 |
gh_patches_debug_15758
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3133
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
mail_password form crashes if user is not found
Visiting /mali_password without providing a userid will simply crash. And if mail_password_form is submitted and a user is not found, or the user doesn't have an email configured, it will crash as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/browser/login/mail_password.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from AccessControl import Unauthorized
3 from Products.CMFPlone import PloneMessageFactory as _
4 from Products.Five import BrowserView
5 from Products.statusmessages.interfaces import IStatusMessage
6
7
8 class MailPasswordView(BrowserView):
9
10 def __call__(self):
11 try:
12 response = self.context.portal_registration.mailPassword(
13 self.request.form.get('userid', ''),
14 self.request,
15 )
16 except ValueError as e:
17 try:
18 msg = _(str(e))
19 except Unauthorized:
20 # If we are not allowed to tell the user, what is wrong, he
21 # should get an error message and contact the admins
22 raise e
23 IStatusMessage(self.request).add(msg)
24 self.request.response.redirect(
25 self.context.absolute_url() + 'mail_password_form'
26 )
27 return response
28
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/browser/login/mail_password.py b/Products/CMFPlone/browser/login/mail_password.py
--- a/Products/CMFPlone/browser/login/mail_password.py
+++ b/Products/CMFPlone/browser/login/mail_password.py
@@ -8,6 +8,7 @@
class MailPasswordView(BrowserView):
def __call__(self):
+ response = None
try:
response = self.context.portal_registration.mailPassword(
self.request.form.get('userid', ''),
@@ -22,6 +23,6 @@
raise e
IStatusMessage(self.request).add(msg)
self.request.response.redirect(
- self.context.absolute_url() + 'mail_password_form'
+ self.context.absolute_url() + '/mail_password_form'
)
return response
|
{"golden_diff": "diff --git a/Products/CMFPlone/browser/login/mail_password.py b/Products/CMFPlone/browser/login/mail_password.py\n--- a/Products/CMFPlone/browser/login/mail_password.py\n+++ b/Products/CMFPlone/browser/login/mail_password.py\n@@ -8,6 +8,7 @@\n class MailPasswordView(BrowserView):\n \n def __call__(self):\n+ response = None\n try:\n response = self.context.portal_registration.mailPassword(\n self.request.form.get('userid', ''),\n@@ -22,6 +23,6 @@\n raise e\n IStatusMessage(self.request).add(msg)\n self.request.response.redirect(\n- self.context.absolute_url() + 'mail_password_form'\n+ self.context.absolute_url() + '/mail_password_form'\n )\n return response\n", "issue": "mail_password form crashes if user is not found\nVisiting /mali_password without providing a userid will simply crash. And if mail_password_form is submitted and a user is not found, or the user doesn't have an email configured, it will crash as well.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl import Unauthorized\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.Five import BrowserView\nfrom Products.statusmessages.interfaces import IStatusMessage\n\n\nclass MailPasswordView(BrowserView):\n\n def __call__(self):\n try:\n response = self.context.portal_registration.mailPassword(\n self.request.form.get('userid', ''),\n self.request,\n )\n except ValueError as e:\n try:\n msg = _(str(e))\n except Unauthorized:\n # If we are not allowed to tell the user, what is wrong, he\n # should get an error message and contact the admins\n raise e\n IStatusMessage(self.request).add(msg)\n self.request.response.redirect(\n self.context.absolute_url() + 'mail_password_form'\n )\n return response\n", "path": "Products/CMFPlone/browser/login/mail_password.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl import Unauthorized\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.Five import BrowserView\nfrom Products.statusmessages.interfaces import IStatusMessage\n\n\nclass MailPasswordView(BrowserView):\n\n def __call__(self):\n response = None\n try:\n response = self.context.portal_registration.mailPassword(\n self.request.form.get('userid', ''),\n self.request,\n )\n except ValueError as e:\n try:\n msg = _(str(e))\n except Unauthorized:\n # If we are not allowed to tell the user, what is wrong, he\n # should get an error message and contact the admins\n raise e\n IStatusMessage(self.request).add(msg)\n self.request.response.redirect(\n self.context.absolute_url() + '/mail_password_form'\n )\n return response\n", "path": "Products/CMFPlone/browser/login/mail_password.py"}]}
| 545 | 178 |
gh_patches_debug_13309
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-1524
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
note should print when verbosity is set to at least verbose
We have the `note` function that prints its argument only on the final example, but actually it should probably print it for *every* example when `verbosity >= Verbosity.verbose`, so that people can actually see the tests as they run.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hypothesis-python/src/hypothesis/control.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2018 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 import traceback
21
22 from hypothesis.errors import CleanupFailed, InvalidArgument, \
23 UnsatisfiedAssumption
24 from hypothesis.reporting import report
25 from hypothesis.utils.dynamicvariables import DynamicVariable
26
27 if False:
28 from typing import Any, AnyStr # noqa
29
30
31 def reject():
32 raise UnsatisfiedAssumption()
33
34
35 def assume(condition):
36 # type: (Any) -> bool
37 """Calling ``assume`` is like an :ref:`assert <python:assert>` that marks
38 the example as bad, rather than failing the test.
39
40 This allows you to specify properties that you *assume* will be
41 true, and let Hypothesis try to avoid similar examples in future.
42 """
43 if not condition:
44 raise UnsatisfiedAssumption()
45 return True
46
47
48 _current_build_context = DynamicVariable(None)
49
50
51 def current_build_context():
52 context = _current_build_context.value
53 if context is None:
54 raise InvalidArgument(
55 u'No build context registered')
56 return context
57
58
59 class BuildContext(object):
60
61 def __init__(self, data, is_final=False, close_on_capture=True):
62 self.data = data
63 self.tasks = []
64 self.is_final = is_final
65 self.close_on_capture = close_on_capture
66 self.close_on_del = False
67 self.notes = []
68
69 def __enter__(self):
70 self.assign_variable = _current_build_context.with_value(self)
71 self.assign_variable.__enter__()
72 return self
73
74 def __exit__(self, exc_type, exc_value, tb):
75 self.assign_variable.__exit__(exc_type, exc_value, tb)
76 if self.close() and exc_type is None:
77 raise CleanupFailed()
78
79 def local(self):
80 return _current_build_context.with_value(self)
81
82 def close(self):
83 any_failed = False
84 for task in self.tasks:
85 try:
86 task()
87 except BaseException:
88 any_failed = True
89 report(traceback.format_exc())
90 return any_failed
91
92
93 def cleanup(teardown):
94 """Register a function to be called when the current test has finished
95 executing. Any exceptions thrown in teardown will be printed but not
96 rethrown.
97
98 Inside a test this isn't very interesting, because you can just use
99 a finally block, but note that you can use this inside map, flatmap,
100 etc. in order to e.g. insist that a value is closed at the end.
101 """
102 context = _current_build_context.value
103 if context is None:
104 raise InvalidArgument(
105 u'Cannot register cleanup outside of build context')
106 context.tasks.append(teardown)
107
108
109 def note(value):
110 # type: (AnyStr) -> None
111 """Report this value in the final execution."""
112 context = _current_build_context.value
113 if context is None:
114 raise InvalidArgument(
115 'Cannot make notes outside of a test')
116 context.notes.append(value)
117 if context.is_final:
118 report(value)
119
120
121 def event(value):
122 # type: (AnyStr) -> None
123 """Record an event that occurred this test. Statistics on number of test
124 runs with each event will be reported at the end if you run Hypothesis in
125 statistics reporting mode.
126
127 Events should be strings or convertible to them.
128 """
129 context = _current_build_context.value
130 if context is None:
131 raise InvalidArgument(
132 'Cannot make record events outside of a test')
133
134 if context.data is not None:
135 context.data.note_event(value)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hypothesis-python/src/hypothesis/control.py b/hypothesis-python/src/hypothesis/control.py
--- a/hypothesis-python/src/hypothesis/control.py
+++ b/hypothesis-python/src/hypothesis/control.py
@@ -19,6 +19,7 @@
import traceback
+from hypothesis import Verbosity, settings
from hypothesis.errors import CleanupFailed, InvalidArgument, \
UnsatisfiedAssumption
from hypothesis.reporting import report
@@ -114,7 +115,7 @@
raise InvalidArgument(
'Cannot make notes outside of a test')
context.notes.append(value)
- if context.is_final:
+ if context.is_final or settings.default.verbosity >= Verbosity.verbose:
report(value)
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/control.py b/hypothesis-python/src/hypothesis/control.py\n--- a/hypothesis-python/src/hypothesis/control.py\n+++ b/hypothesis-python/src/hypothesis/control.py\n@@ -19,6 +19,7 @@\n \n import traceback\n \n+from hypothesis import Verbosity, settings\n from hypothesis.errors import CleanupFailed, InvalidArgument, \\\n UnsatisfiedAssumption\n from hypothesis.reporting import report\n@@ -114,7 +115,7 @@\n raise InvalidArgument(\n 'Cannot make notes outside of a test')\n context.notes.append(value)\n- if context.is_final:\n+ if context.is_final or settings.default.verbosity >= Verbosity.verbose:\n report(value)\n", "issue": "note should print when verbosity is set to at least verbose \nWe have the `note` function that prints its argument only on the final example, but actually it should probably print it for *every* example when `verbosity >= Verbosity.verbose`, so that people can actually see the tests as they run. \n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2018 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport traceback\n\nfrom hypothesis.errors import CleanupFailed, InvalidArgument, \\\n UnsatisfiedAssumption\nfrom hypothesis.reporting import report\nfrom hypothesis.utils.dynamicvariables import DynamicVariable\n\nif False:\n from typing import Any, AnyStr # noqa\n\n\ndef reject():\n raise UnsatisfiedAssumption()\n\n\ndef assume(condition):\n # type: (Any) -> bool\n \"\"\"Calling ``assume`` is like an :ref:`assert <python:assert>` that marks\n the example as bad, rather than failing the test.\n\n This allows you to specify properties that you *assume* will be\n true, and let Hypothesis try to avoid similar examples in future.\n \"\"\"\n if not condition:\n raise UnsatisfiedAssumption()\n return True\n\n\n_current_build_context = DynamicVariable(None)\n\n\ndef current_build_context():\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n u'No build context registered')\n return context\n\n\nclass BuildContext(object):\n\n def __init__(self, data, is_final=False, close_on_capture=True):\n self.data = data\n self.tasks = []\n self.is_final = is_final\n self.close_on_capture = close_on_capture\n self.close_on_del = False\n self.notes = []\n\n def __enter__(self):\n self.assign_variable = _current_build_context.with_value(self)\n self.assign_variable.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_value, tb):\n self.assign_variable.__exit__(exc_type, exc_value, tb)\n if self.close() and exc_type is None:\n raise CleanupFailed()\n\n def local(self):\n return _current_build_context.with_value(self)\n\n def close(self):\n any_failed = False\n for task in self.tasks:\n try:\n task()\n except BaseException:\n any_failed = True\n report(traceback.format_exc())\n return any_failed\n\n\ndef cleanup(teardown):\n \"\"\"Register a function to be called when the current test has finished\n executing. Any exceptions thrown in teardown will be printed but not\n rethrown.\n\n Inside a test this isn't very interesting, because you can just use\n a finally block, but note that you can use this inside map, flatmap,\n etc. in order to e.g. insist that a value is closed at the end.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n u'Cannot register cleanup outside of build context')\n context.tasks.append(teardown)\n\n\ndef note(value):\n # type: (AnyStr) -> None\n \"\"\"Report this value in the final execution.\"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n 'Cannot make notes outside of a test')\n context.notes.append(value)\n if context.is_final:\n report(value)\n\n\ndef event(value):\n # type: (AnyStr) -> None\n \"\"\"Record an event that occurred this test. Statistics on number of test\n runs with each event will be reported at the end if you run Hypothesis in\n statistics reporting mode.\n\n Events should be strings or convertible to them.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n 'Cannot make record events outside of a test')\n\n if context.data is not None:\n context.data.note_event(value)\n", "path": "hypothesis-python/src/hypothesis/control.py"}], "after_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2018 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport traceback\n\nfrom hypothesis import Verbosity, settings\nfrom hypothesis.errors import CleanupFailed, InvalidArgument, \\\n UnsatisfiedAssumption\nfrom hypothesis.reporting import report\nfrom hypothesis.utils.dynamicvariables import DynamicVariable\n\nif False:\n from typing import Any, AnyStr # noqa\n\n\ndef reject():\n raise UnsatisfiedAssumption()\n\n\ndef assume(condition):\n # type: (Any) -> bool\n \"\"\"Calling ``assume`` is like an :ref:`assert <python:assert>` that marks\n the example as bad, rather than failing the test.\n\n This allows you to specify properties that you *assume* will be\n true, and let Hypothesis try to avoid similar examples in future.\n \"\"\"\n if not condition:\n raise UnsatisfiedAssumption()\n return True\n\n\n_current_build_context = DynamicVariable(None)\n\n\ndef current_build_context():\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n u'No build context registered')\n return context\n\n\nclass BuildContext(object):\n\n def __init__(self, data, is_final=False, close_on_capture=True):\n self.data = data\n self.tasks = []\n self.is_final = is_final\n self.close_on_capture = close_on_capture\n self.close_on_del = False\n self.notes = []\n\n def __enter__(self):\n self.assign_variable = _current_build_context.with_value(self)\n self.assign_variable.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_value, tb):\n self.assign_variable.__exit__(exc_type, exc_value, tb)\n if self.close() and exc_type is None:\n raise CleanupFailed()\n\n def local(self):\n return _current_build_context.with_value(self)\n\n def close(self):\n any_failed = False\n for task in self.tasks:\n try:\n task()\n except BaseException:\n any_failed = True\n report(traceback.format_exc())\n return any_failed\n\n\ndef cleanup(teardown):\n \"\"\"Register a function to be called when the current test has finished\n executing. Any exceptions thrown in teardown will be printed but not\n rethrown.\n\n Inside a test this isn't very interesting, because you can just use\n a finally block, but note that you can use this inside map, flatmap,\n etc. in order to e.g. insist that a value is closed at the end.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n u'Cannot register cleanup outside of build context')\n context.tasks.append(teardown)\n\n\ndef note(value):\n # type: (AnyStr) -> None\n \"\"\"Report this value in the final execution.\"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n 'Cannot make notes outside of a test')\n context.notes.append(value)\n if context.is_final or settings.default.verbosity >= Verbosity.verbose:\n report(value)\n\n\ndef event(value):\n # type: (AnyStr) -> None\n \"\"\"Record an event that occurred this test. Statistics on number of test\n runs with each event will be reported at the end if you run Hypothesis in\n statistics reporting mode.\n\n Events should be strings or convertible to them.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\n 'Cannot make record events outside of a test')\n\n if context.data is not None:\n context.data.note_event(value)\n", "path": "hypothesis-python/src/hypothesis/control.py"}]}
| 1,569 | 162 |
gh_patches_debug_6639
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2217
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Using typing-extensions 4 with web3.py and python < 3.8
Hey guys,
This is question on typing-extensions package. In setup.py https://github.com/ethereum/web3.py/blob/74fbcd1761407ee37808173b089d8e44e537fb99/setup.py#L88-L89
you require <4 and python <3.8. From what I understand that is since these extensions you use have made it into stdlib's typing module from 3.8 and on.
But from what I see this requirement creates a probem for projects like ours which are still in python 3.7, use web3.py and want to use typing-extensions 4. Is there any reason for the < 4 requirement?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 find_packages,
5 setup,
6 )
7
8 extras_require = {
9 'tester': [
10 "eth-tester[py-evm]==v0.6.0-beta.4",
11 "py-geth>=3.6.0,<4",
12 ],
13 'linter': [
14 "flake8==3.8.3",
15 "isort>=4.2.15,<4.3.5",
16 "mypy==0.812",
17 ],
18 'docs': [
19 "mock",
20 "sphinx-better-theme>=0.1.4",
21 "click>=5.1",
22 "configparser==3.5.0",
23 "contextlib2>=0.5.4",
24 "py-geth>=3.6.0,<4",
25 "py-solc>=0.4.0",
26 "pytest>=4.4.0,<5.0.0",
27 "sphinx>=3.0,<4",
28 "sphinx_rtd_theme>=0.1.9",
29 "toposort>=1.4",
30 "towncrier==18.5.0",
31 "urllib3",
32 "wheel"
33 ],
34 'dev': [
35 "bumpversion",
36 "flaky>=3.7.0,<4",
37 "hypothesis>=3.31.2,<6",
38 "pytest>=4.4.0,<5.0.0",
39 "pytest-asyncio>=0.10.0,<0.11",
40 "pytest-mock>=1.10,<2",
41 "pytest-pythonpath>=0.3",
42 "pytest-watch>=4.2,<5",
43 "pytest-xdist>=1.29,<2",
44 "setuptools>=38.6.0",
45 "tox>=1.8.0",
46 "tqdm>4.32,<5",
47 "twine>=1.13,<2",
48 "pluggy==0.13.1",
49 "when-changed>=0.3.0,<0.4"
50 ]
51 }
52
53 extras_require['dev'] = (
54 extras_require['tester']
55 + extras_require['linter']
56 + extras_require['docs']
57 + extras_require['dev']
58 )
59
60 with open('./README.md') as readme:
61 long_description = readme.read()
62
63 setup(
64 name='web3',
65 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
66 version='5.25.0',
67 description="""Web3.py""",
68 long_description_content_type='text/markdown',
69 long_description=long_description,
70 author='Piper Merriam',
71 author_email='[email protected]',
72 url='https://github.com/ethereum/web3.py',
73 include_package_data=True,
74 install_requires=[
75 "aiohttp>=3.7.4.post0,<4",
76 "eth-abi>=2.0.0b6,<3.0.0",
77 "eth-account>=0.5.6,<0.6.0",
78 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
79 "eth-typing>=2.0.0,<3.0.0",
80 "eth-utils>=1.9.5,<2.0.0",
81 "hexbytes>=0.1.0,<1.0.0",
82 "ipfshttpclient==0.8.0a2",
83 "jsonschema>=3.2.0,<4.0.0",
84 "lru-dict>=1.1.6,<2.0.0",
85 "protobuf>=3.10.0,<4",
86 "pywin32>=223;platform_system=='Windows'",
87 "requests>=2.16.0,<3.0.0",
88 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
89 "typing-extensions>=3.7.4.1,<4;python_version<'3.8'",
90 "websockets>=9.1,<10",
91 ],
92 python_requires='>=3.6,<4',
93 extras_require=extras_require,
94 py_modules=['web3', 'ens', 'ethpm'],
95 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
96 license="MIT",
97 zip_safe=False,
98 keywords='ethereum',
99 packages=find_packages(exclude=["tests", "tests.*"]),
100 package_data={"web3": ["py.typed"]},
101 classifiers=[
102 'Development Status :: 5 - Production/Stable',
103 'Intended Audience :: Developers',
104 'License :: OSI Approved :: MIT License',
105 'Natural Language :: English',
106 'Programming Language :: Python :: 3',
107 'Programming Language :: Python :: 3.6',
108 'Programming Language :: Python :: 3.7',
109 'Programming Language :: Python :: 3.8',
110 'Programming Language :: Python :: 3.9',
111 ],
112 )
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -86,7 +86,7 @@
"pywin32>=223;platform_system=='Windows'",
"requests>=2.16.0,<3.0.0",
# remove typing_extensions after python_requires>=3.8, see web3._utils.compat
- "typing-extensions>=3.7.4.1,<4;python_version<'3.8'",
+ "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
"websockets>=9.1,<10",
],
python_requires='>=3.6,<4',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -86,7 +86,7 @@\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n- \"typing-extensions>=3.7.4.1,<4;python_version<'3.8'\",\n+ \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n", "issue": "Using typing-extensions 4 with web3.py and python < 3.8\nHey guys,\r\n\r\nThis is question on typing-extensions package. In setup.py https://github.com/ethereum/web3.py/blob/74fbcd1761407ee37808173b089d8e44e537fb99/setup.py#L88-L89\r\n\r\nyou require <4 and python <3.8. From what I understand that is since these extensions you use have made it into stdlib's typing module from 3.8 and on.\r\n\r\nBut from what I see this requirement creates a probem for projects like ours which are still in python 3.7, use web3.py and want to use typing-extensions 4. Is there any reason for the < 4 requirement?\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.4\",\n \"py-geth>=3.6.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.812\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.25.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.6,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<4;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.4\",\n \"py-geth>=3.6.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.812\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.25.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.6,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}]}
| 1,786 | 158 |
gh_patches_debug_670
|
rasdani/github-patches
|
git_diff
|
pytorch__examples-182
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Division error
Training a model for `fast-neural-style` raises a RuntimeError from variable division during input normalization.
- python2.7
- torch==0.1.12.post2
- torchvision==0.1.8
````
Traceback (most recent call last):
File "neural_style/neural_style.py", line 226, in <module>
main()
File "neural_style/neural_style.py", line 220, in main
train(args)
File "neural_style/neural_style.py", line 65, in train
style_v = utils.normalize_batch(style_v)
File "/home/paperspace/embro/neural_style/utils.py", line 42, in normalize_batch
batch /= Variable(std)
File "/usr/local/lib/python2.7/dist-packages/torch/autograd/variable.py", line 793, in __idiv__
return self.div_(other)
File "/usr/local/lib/python2.7/dist-packages/torch/autograd/variable.py", line 323, in div_
raise RuntimeError("div_ only supports scalar multiplication")
````
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fast_neural_style/neural_style/utils.py`
Content:
```
1 import torch
2 from PIL import Image
3 from torch.autograd import Variable
4
5
6 def load_image(filename, size=None, scale=None):
7 img = Image.open(filename)
8 if size is not None:
9 img = img.resize((size, size), Image.ANTIALIAS)
10 elif scale is not None:
11 img = img.resize((int(img.size[0] / scale), int(img.size[1] / scale)), Image.ANTIALIAS)
12 return img
13
14
15 def save_image(filename, data):
16 img = data.clone().clamp(0, 255).numpy()
17 img = img.transpose(1, 2, 0).astype("uint8")
18 img = Image.fromarray(img)
19 img.save(filename)
20
21
22 def gram_matrix(y):
23 (b, ch, h, w) = y.size()
24 features = y.view(b, ch, w * h)
25 features_t = features.transpose(1, 2)
26 gram = features.bmm(features_t) / (ch * h * w)
27 return gram
28
29
30 def normalize_batch(batch):
31 # normalize using imagenet mean and std
32 mean = batch.data.new(batch.data.size())
33 std = batch.data.new(batch.data.size())
34 mean[:, 0, :, :] = 0.485
35 mean[:, 1, :, :] = 0.456
36 mean[:, 2, :, :] = 0.406
37 std[:, 0, :, :] = 0.229
38 std[:, 1, :, :] = 0.224
39 std[:, 2, :, :] = 0.225
40 batch = torch.div(batch, 255.0)
41 batch -= Variable(mean)
42 batch /= Variable(std)
43 return batch
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fast_neural_style/neural_style/utils.py b/fast_neural_style/neural_style/utils.py
--- a/fast_neural_style/neural_style/utils.py
+++ b/fast_neural_style/neural_style/utils.py
@@ -39,5 +39,5 @@
std[:, 2, :, :] = 0.225
batch = torch.div(batch, 255.0)
batch -= Variable(mean)
- batch /= Variable(std)
+ batch = batch / Variable(std)
return batch
|
{"golden_diff": "diff --git a/fast_neural_style/neural_style/utils.py b/fast_neural_style/neural_style/utils.py\n--- a/fast_neural_style/neural_style/utils.py\n+++ b/fast_neural_style/neural_style/utils.py\n@@ -39,5 +39,5 @@\n std[:, 2, :, :] = 0.225\n batch = torch.div(batch, 255.0)\n batch -= Variable(mean)\n- batch /= Variable(std)\n+ batch = batch / Variable(std)\n return batch\n", "issue": "Division error\nTraining a model for `fast-neural-style` raises a RuntimeError from variable division during input normalization. \r\n\r\n- python2.7\r\n- torch==0.1.12.post2\r\n- torchvision==0.1.8\r\n\r\n````\r\nTraceback (most recent call last):\r\n File \"neural_style/neural_style.py\", line 226, in <module>\r\n main()\r\n File \"neural_style/neural_style.py\", line 220, in main\r\n train(args)\r\n File \"neural_style/neural_style.py\", line 65, in train\r\n style_v = utils.normalize_batch(style_v)\r\n File \"/home/paperspace/embro/neural_style/utils.py\", line 42, in normalize_batch\r\n batch /= Variable(std)\r\n File \"/usr/local/lib/python2.7/dist-packages/torch/autograd/variable.py\", line 793, in __idiv__\r\n return self.div_(other)\r\n File \"/usr/local/lib/python2.7/dist-packages/torch/autograd/variable.py\", line 323, in div_\r\n raise RuntimeError(\"div_ only supports scalar multiplication\")\r\n````\r\n\r\n\r\n\n", "before_files": [{"content": "import torch\nfrom PIL import Image\nfrom torch.autograd import Variable\n\n\ndef load_image(filename, size=None, scale=None):\n img = Image.open(filename)\n if size is not None:\n img = img.resize((size, size), Image.ANTIALIAS)\n elif scale is not None:\n img = img.resize((int(img.size[0] / scale), int(img.size[1] / scale)), Image.ANTIALIAS)\n return img\n\n\ndef save_image(filename, data):\n img = data.clone().clamp(0, 255).numpy()\n img = img.transpose(1, 2, 0).astype(\"uint8\")\n img = Image.fromarray(img)\n img.save(filename)\n\n\ndef gram_matrix(y):\n (b, ch, h, w) = y.size()\n features = y.view(b, ch, w * h)\n features_t = features.transpose(1, 2)\n gram = features.bmm(features_t) / (ch * h * w)\n return gram\n\n\ndef normalize_batch(batch):\n # normalize using imagenet mean and std\n mean = batch.data.new(batch.data.size())\n std = batch.data.new(batch.data.size())\n mean[:, 0, :, :] = 0.485\n mean[:, 1, :, :] = 0.456\n mean[:, 2, :, :] = 0.406\n std[:, 0, :, :] = 0.229\n std[:, 1, :, :] = 0.224\n std[:, 2, :, :] = 0.225\n batch = torch.div(batch, 255.0)\n batch -= Variable(mean)\n batch /= Variable(std)\n return batch\n", "path": "fast_neural_style/neural_style/utils.py"}], "after_files": [{"content": "import torch\nfrom PIL import Image\nfrom torch.autograd import Variable\n\n\ndef load_image(filename, size=None, scale=None):\n img = Image.open(filename)\n if size is not None:\n img = img.resize((size, size), Image.ANTIALIAS)\n elif scale is not None:\n img = img.resize((int(img.size[0] / scale), int(img.size[1] / scale)), Image.ANTIALIAS)\n return img\n\n\ndef save_image(filename, data):\n img = data.clone().clamp(0, 255).numpy()\n img = img.transpose(1, 2, 0).astype(\"uint8\")\n img = Image.fromarray(img)\n img.save(filename)\n\n\ndef gram_matrix(y):\n (b, ch, h, w) = y.size()\n features = y.view(b, ch, w * h)\n features_t = features.transpose(1, 2)\n gram = features.bmm(features_t) / (ch * h * w)\n return gram\n\n\ndef normalize_batch(batch):\n # normalize using imagenet mean and std\n mean = batch.data.new(batch.data.size())\n std = batch.data.new(batch.data.size())\n mean[:, 0, :, :] = 0.485\n mean[:, 1, :, :] = 0.456\n mean[:, 2, :, :] = 0.406\n std[:, 0, :, :] = 0.229\n std[:, 1, :, :] = 0.224\n std[:, 2, :, :] = 0.225\n batch = torch.div(batch, 255.0)\n batch -= Variable(mean)\n batch = batch / Variable(std)\n return batch\n", "path": "fast_neural_style/neural_style/utils.py"}]}
| 983 | 116 |
gh_patches_debug_34378
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-3637
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CSVReader does not handle quoted fields or tsv files
### Summary
I want to add functionality to the CSVReader so it can handle tsv files. While checking that out, I noticed that we're just splitting on `,`, which is not ideal.
### Actual behavior
Parsing CSV files with fields that contain quoted text with ',' characters does not work correctly. TSV files are not supported.
### Expected behavior
Quoted fields should be correctly parsed if they contain the delimiter.
### How to replicate the behavior
Run the script below.
### Script/Workflow details
```
from nipype.interfaces import utility
reader = utility.CSVReader()
lines = ["foo,\"hello,world\",300.1\n"]
with open("testcsv.csv", "w") as fid:
fid.writelines(lines)
fid.flush()
reader.inputs.in_file = "testcsv.csv"
out = reader.run()
assert out.outputs.column_1 == ["hello, world"]
```
### Platform details:
<!-- Please run the following code from your shell and place the output between the triple ticks, below.
python -c "import nipype; from pprint import pprint; pprint(nipype.get_info())"
-->
```
{'commit_hash': 'c46a957bd',
'commit_source': 'repository',
'networkx_version': '3.2.1',
'nibabel_version': '5.2.1',
'nipype_version': '1.8.7.dev0',
'numpy_version': '1.26.4',
'pkg_path': '/home/USER/Desktop/nipype/nipype',
'scipy_version': '1.12.0',
'sys_executable': '/home/USER/Desktop/nipype/.venv/bin/python',
'sys_platform': 'linux',
'sys_version': '3.9.18 (main, Feb 1 2024, 11:48:51) \n[GCC 11.4.0]',
'traits_version': '6.3.2'}
```
### Execution environment
- My python environment outside container
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nipype/interfaces/utility/csv.py`
Content:
```
1 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-
2 # vi: set ft=python sts=4 ts=4 sw=4 et:
3 """CSV Handling utilities
4 """
5 from ..base import traits, TraitedSpec, DynamicTraitedSpec, File, BaseInterface
6 from ..io import add_traits
7
8
9 class CSVReaderInputSpec(DynamicTraitedSpec, TraitedSpec):
10 in_file = File(
11 exists=True, mandatory=True, desc="Input comma-seperated value (CSV) file"
12 )
13 header = traits.Bool(
14 False, usedefault=True, desc="True if the first line is a column header"
15 )
16
17
18 class CSVReader(BaseInterface):
19 """
20 Examples
21 --------
22
23 >>> reader = CSVReader() # doctest: +SKIP
24 >>> reader.inputs.in_file = 'noHeader.csv' # doctest: +SKIP
25 >>> out = reader.run() # doctest: +SKIP
26 >>> out.outputs.column_0 == ['foo', 'bar', 'baz'] # doctest: +SKIP
27 True
28 >>> out.outputs.column_1 == ['hello', 'world', 'goodbye'] # doctest: +SKIP
29 True
30 >>> out.outputs.column_2 == ['300.1', '5', '0.3'] # doctest: +SKIP
31 True
32
33 >>> reader = CSVReader() # doctest: +SKIP
34 >>> reader.inputs.in_file = 'header.csv' # doctest: +SKIP
35 >>> reader.inputs.header = True # doctest: +SKIP
36 >>> out = reader.run() # doctest: +SKIP
37 >>> out.outputs.files == ['foo', 'bar', 'baz'] # doctest: +SKIP
38 True
39 >>> out.outputs.labels == ['hello', 'world', 'goodbye'] # doctest: +SKIP
40 True
41 >>> out.outputs.erosion == ['300.1', '5', '0.3'] # doctest: +SKIP
42 True
43
44 """
45
46 input_spec = CSVReaderInputSpec
47 output_spec = DynamicTraitedSpec
48 _always_run = True
49
50 def _append_entry(self, outputs, entry):
51 for key, value in zip(self._outfields, entry):
52 outputs[key].append(value)
53 return outputs
54
55 def _parse_line(self, line):
56 line = line.replace("\n", "")
57 entry = [x.strip() for x in line.split(",")]
58 return entry
59
60 def _get_outfields(self):
61 with open(self.inputs.in_file) as fid:
62 entry = self._parse_line(fid.readline())
63 if self.inputs.header:
64 self._outfields = tuple(entry)
65 else:
66 self._outfields = tuple(["column_" + str(x) for x in range(len(entry))])
67 return self._outfields
68
69 def _run_interface(self, runtime):
70 self._get_outfields()
71 return runtime
72
73 def _outputs(self):
74 return self._add_output_traits(super()._outputs())
75
76 def _add_output_traits(self, base):
77 return add_traits(base, self._get_outfields())
78
79 def _list_outputs(self):
80 outputs = self.output_spec().get()
81 isHeader = True
82 for key in self._outfields:
83 outputs[key] = [] # initialize outfields
84 with open(self.inputs.in_file) as fid:
85 for line in fid.readlines():
86 if self.inputs.header and isHeader: # skip header line
87 isHeader = False
88 continue
89 entry = self._parse_line(line)
90 outputs = self._append_entry(outputs, entry)
91 return outputs
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nipype/interfaces/utility/csv.py b/nipype/interfaces/utility/csv.py
--- a/nipype/interfaces/utility/csv.py
+++ b/nipype/interfaces/utility/csv.py
@@ -2,6 +2,7 @@
# vi: set ft=python sts=4 ts=4 sw=4 et:
"""CSV Handling utilities
"""
+import csv
from ..base import traits, TraitedSpec, DynamicTraitedSpec, File, BaseInterface
from ..io import add_traits
@@ -13,6 +14,7 @@
header = traits.Bool(
False, usedefault=True, desc="True if the first line is a column header"
)
+ delimiter = traits.String(",", usedefault=True, desc="Delimiter to use.")
class CSVReader(BaseInterface):
@@ -52,14 +54,11 @@
outputs[key].append(value)
return outputs
- def _parse_line(self, line):
- line = line.replace("\n", "")
- entry = [x.strip() for x in line.split(",")]
- return entry
-
def _get_outfields(self):
with open(self.inputs.in_file) as fid:
- entry = self._parse_line(fid.readline())
+ reader = csv.reader(fid, delimiter=self.inputs.delimiter)
+
+ entry = next(reader)
if self.inputs.header:
self._outfields = tuple(entry)
else:
@@ -82,10 +81,10 @@
for key in self._outfields:
outputs[key] = [] # initialize outfields
with open(self.inputs.in_file) as fid:
- for line in fid.readlines():
+ reader = csv.reader(fid, delimiter=self.inputs.delimiter)
+ for entry in reader:
if self.inputs.header and isHeader: # skip header line
isHeader = False
continue
- entry = self._parse_line(line)
outputs = self._append_entry(outputs, entry)
return outputs
|
{"golden_diff": "diff --git a/nipype/interfaces/utility/csv.py b/nipype/interfaces/utility/csv.py\n--- a/nipype/interfaces/utility/csv.py\n+++ b/nipype/interfaces/utility/csv.py\n@@ -2,6 +2,7 @@\n # vi: set ft=python sts=4 ts=4 sw=4 et:\n \"\"\"CSV Handling utilities\n \"\"\"\n+import csv\n from ..base import traits, TraitedSpec, DynamicTraitedSpec, File, BaseInterface\n from ..io import add_traits\n \n@@ -13,6 +14,7 @@\n header = traits.Bool(\n False, usedefault=True, desc=\"True if the first line is a column header\"\n )\n+ delimiter = traits.String(\",\", usedefault=True, desc=\"Delimiter to use.\")\n \n \n class CSVReader(BaseInterface):\n@@ -52,14 +54,11 @@\n outputs[key].append(value)\n return outputs\n \n- def _parse_line(self, line):\n- line = line.replace(\"\\n\", \"\")\n- entry = [x.strip() for x in line.split(\",\")]\n- return entry\n-\n def _get_outfields(self):\n with open(self.inputs.in_file) as fid:\n- entry = self._parse_line(fid.readline())\n+ reader = csv.reader(fid, delimiter=self.inputs.delimiter)\n+\n+ entry = next(reader)\n if self.inputs.header:\n self._outfields = tuple(entry)\n else:\n@@ -82,10 +81,10 @@\n for key in self._outfields:\n outputs[key] = [] # initialize outfields\n with open(self.inputs.in_file) as fid:\n- for line in fid.readlines():\n+ reader = csv.reader(fid, delimiter=self.inputs.delimiter)\n+ for entry in reader:\n if self.inputs.header and isHeader: # skip header line\n isHeader = False\n continue\n- entry = self._parse_line(line)\n outputs = self._append_entry(outputs, entry)\n return outputs\n", "issue": "CSVReader does not handle quoted fields or tsv files\n### Summary\r\nI want to add functionality to the CSVReader so it can handle tsv files. While checking that out, I noticed that we're just splitting on `,`, which is not ideal.\r\n\r\n### Actual behavior\r\nParsing CSV files with fields that contain quoted text with ',' characters does not work correctly. TSV files are not supported.\r\n\r\n\r\n### Expected behavior\r\nQuoted fields should be correctly parsed if they contain the delimiter.\r\n\r\n### How to replicate the behavior\r\nRun the script below.\r\n\r\n### Script/Workflow details\r\n\r\n```\r\nfrom nipype.interfaces import utility\r\n\r\nreader = utility.CSVReader()\r\n\r\nlines = [\"foo,\\\"hello,world\\\",300.1\\n\"]\r\n\r\nwith open(\"testcsv.csv\", \"w\") as fid:\r\n fid.writelines(lines)\r\n fid.flush()\r\n\r\nreader.inputs.in_file = \"testcsv.csv\"\r\nout = reader.run()\r\n\r\nassert out.outputs.column_1 == [\"hello, world\"]\r\n```\r\n\r\n### Platform details:\r\n\r\n<!-- Please run the following code from your shell and place the output between the triple ticks, below.\r\npython -c \"import nipype; from pprint import pprint; pprint(nipype.get_info())\"\r\n-->\r\n\r\n```\r\n{'commit_hash': 'c46a957bd',\r\n 'commit_source': 'repository',\r\n 'networkx_version': '3.2.1',\r\n 'nibabel_version': '5.2.1',\r\n 'nipype_version': '1.8.7.dev0',\r\n 'numpy_version': '1.26.4',\r\n 'pkg_path': '/home/USER/Desktop/nipype/nipype',\r\n 'scipy_version': '1.12.0',\r\n 'sys_executable': '/home/USER/Desktop/nipype/.venv/bin/python',\r\n 'sys_platform': 'linux',\r\n 'sys_version': '3.9.18 (main, Feb 1 2024, 11:48:51) \\n[GCC 11.4.0]',\r\n 'traits_version': '6.3.2'}\r\n\r\n```\r\n\r\n### Execution environment\r\n- My python environment outside container\r\n\n", "before_files": [{"content": "# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"CSV Handling utilities\n\"\"\"\nfrom ..base import traits, TraitedSpec, DynamicTraitedSpec, File, BaseInterface\nfrom ..io import add_traits\n\n\nclass CSVReaderInputSpec(DynamicTraitedSpec, TraitedSpec):\n in_file = File(\n exists=True, mandatory=True, desc=\"Input comma-seperated value (CSV) file\"\n )\n header = traits.Bool(\n False, usedefault=True, desc=\"True if the first line is a column header\"\n )\n\n\nclass CSVReader(BaseInterface):\n \"\"\"\n Examples\n --------\n\n >>> reader = CSVReader() # doctest: +SKIP\n >>> reader.inputs.in_file = 'noHeader.csv' # doctest: +SKIP\n >>> out = reader.run() # doctest: +SKIP\n >>> out.outputs.column_0 == ['foo', 'bar', 'baz'] # doctest: +SKIP\n True\n >>> out.outputs.column_1 == ['hello', 'world', 'goodbye'] # doctest: +SKIP\n True\n >>> out.outputs.column_2 == ['300.1', '5', '0.3'] # doctest: +SKIP\n True\n\n >>> reader = CSVReader() # doctest: +SKIP\n >>> reader.inputs.in_file = 'header.csv' # doctest: +SKIP\n >>> reader.inputs.header = True # doctest: +SKIP\n >>> out = reader.run() # doctest: +SKIP\n >>> out.outputs.files == ['foo', 'bar', 'baz'] # doctest: +SKIP\n True\n >>> out.outputs.labels == ['hello', 'world', 'goodbye'] # doctest: +SKIP\n True\n >>> out.outputs.erosion == ['300.1', '5', '0.3'] # doctest: +SKIP\n True\n\n \"\"\"\n\n input_spec = CSVReaderInputSpec\n output_spec = DynamicTraitedSpec\n _always_run = True\n\n def _append_entry(self, outputs, entry):\n for key, value in zip(self._outfields, entry):\n outputs[key].append(value)\n return outputs\n\n def _parse_line(self, line):\n line = line.replace(\"\\n\", \"\")\n entry = [x.strip() for x in line.split(\",\")]\n return entry\n\n def _get_outfields(self):\n with open(self.inputs.in_file) as fid:\n entry = self._parse_line(fid.readline())\n if self.inputs.header:\n self._outfields = tuple(entry)\n else:\n self._outfields = tuple([\"column_\" + str(x) for x in range(len(entry))])\n return self._outfields\n\n def _run_interface(self, runtime):\n self._get_outfields()\n return runtime\n\n def _outputs(self):\n return self._add_output_traits(super()._outputs())\n\n def _add_output_traits(self, base):\n return add_traits(base, self._get_outfields())\n\n def _list_outputs(self):\n outputs = self.output_spec().get()\n isHeader = True\n for key in self._outfields:\n outputs[key] = [] # initialize outfields\n with open(self.inputs.in_file) as fid:\n for line in fid.readlines():\n if self.inputs.header and isHeader: # skip header line\n isHeader = False\n continue\n entry = self._parse_line(line)\n outputs = self._append_entry(outputs, entry)\n return outputs\n", "path": "nipype/interfaces/utility/csv.py"}], "after_files": [{"content": "# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"CSV Handling utilities\n\"\"\"\nimport csv\nfrom ..base import traits, TraitedSpec, DynamicTraitedSpec, File, BaseInterface\nfrom ..io import add_traits\n\n\nclass CSVReaderInputSpec(DynamicTraitedSpec, TraitedSpec):\n in_file = File(\n exists=True, mandatory=True, desc=\"Input comma-seperated value (CSV) file\"\n )\n header = traits.Bool(\n False, usedefault=True, desc=\"True if the first line is a column header\"\n )\n delimiter = traits.String(\",\", usedefault=True, desc=\"Delimiter to use.\")\n\n\nclass CSVReader(BaseInterface):\n \"\"\"\n Examples\n --------\n\n >>> reader = CSVReader() # doctest: +SKIP\n >>> reader.inputs.in_file = 'noHeader.csv' # doctest: +SKIP\n >>> out = reader.run() # doctest: +SKIP\n >>> out.outputs.column_0 == ['foo', 'bar', 'baz'] # doctest: +SKIP\n True\n >>> out.outputs.column_1 == ['hello', 'world', 'goodbye'] # doctest: +SKIP\n True\n >>> out.outputs.column_2 == ['300.1', '5', '0.3'] # doctest: +SKIP\n True\n\n >>> reader = CSVReader() # doctest: +SKIP\n >>> reader.inputs.in_file = 'header.csv' # doctest: +SKIP\n >>> reader.inputs.header = True # doctest: +SKIP\n >>> out = reader.run() # doctest: +SKIP\n >>> out.outputs.files == ['foo', 'bar', 'baz'] # doctest: +SKIP\n True\n >>> out.outputs.labels == ['hello', 'world', 'goodbye'] # doctest: +SKIP\n True\n >>> out.outputs.erosion == ['300.1', '5', '0.3'] # doctest: +SKIP\n True\n\n \"\"\"\n\n input_spec = CSVReaderInputSpec\n output_spec = DynamicTraitedSpec\n _always_run = True\n\n def _append_entry(self, outputs, entry):\n for key, value in zip(self._outfields, entry):\n outputs[key].append(value)\n return outputs\n\n def _get_outfields(self):\n with open(self.inputs.in_file) as fid:\n reader = csv.reader(fid, delimiter=self.inputs.delimiter)\n\n entry = next(reader)\n if self.inputs.header:\n self._outfields = tuple(entry)\n else:\n self._outfields = tuple([\"column_\" + str(x) for x in range(len(entry))])\n return self._outfields\n\n def _run_interface(self, runtime):\n self._get_outfields()\n return runtime\n\n def _outputs(self):\n return self._add_output_traits(super()._outputs())\n\n def _add_output_traits(self, base):\n return add_traits(base, self._get_outfields())\n\n def _list_outputs(self):\n outputs = self.output_spec().get()\n isHeader = True\n for key in self._outfields:\n outputs[key] = [] # initialize outfields\n with open(self.inputs.in_file) as fid:\n reader = csv.reader(fid, delimiter=self.inputs.delimiter)\n for entry in reader:\n if self.inputs.header and isHeader: # skip header line\n isHeader = False\n continue\n outputs = self._append_entry(outputs, entry)\n return outputs\n", "path": "nipype/interfaces/utility/csv.py"}]}
| 1,690 | 428 |
gh_patches_debug_22105
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-4902
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Protect against web/api 5xx responses
When a build is attempted, but a web/api instance throws a 5xx response, a number of strange behaviors can result:
- Builds will get stuck in triggered state
- Builds will fail randomly when updating the api fails
- 5xx responses will be returned from the web servers to users
Part of the resolution to this may be defensive protection around intermittent 5xx responses. This may take some operation changes as well though, as our load balancer should really assume a 5xx response is enough to dislodge the server from the lb group.
Raised from #2255
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/restapi/client.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Simple client to access our API with Slumber credentials."""
4
5 from __future__ import (
6 absolute_import,
7 division,
8 print_function,
9 unicode_literals,
10 )
11
12 import logging
13
14 import requests
15 from django.conf import settings
16 from requests_toolbelt.adapters import host_header_ssl
17 from rest_framework.renderers import JSONRenderer
18 from slumber import API, serialize
19
20 log = logging.getLogger(__name__)
21
22 PRODUCTION_DOMAIN = getattr(settings, 'PRODUCTION_DOMAIN', 'readthedocs.org')
23 API_HOST = getattr(settings, 'SLUMBER_API_HOST', 'https://readthedocs.org')
24 USER = getattr(settings, 'SLUMBER_USERNAME', None)
25 PASS = getattr(settings, 'SLUMBER_PASSWORD', None)
26
27
28 class DrfJsonSerializer(serialize.JsonSerializer):
29
30 """Additional serialization help from the DRF renderer"""
31
32 key = 'json-drf'
33
34 def dumps(self, data):
35 """Used to be able to render datetime objects."""
36 return JSONRenderer().render(data)
37
38
39 def setup_api():
40 session = requests.Session()
41 if API_HOST.startswith('https'):
42 # Only use the HostHeaderSSLAdapter for HTTPS connections
43 adapter_class = host_header_ssl.HostHeaderSSLAdapter
44 else:
45 adapter_class = requests.adapters.HTTPAdapter
46
47 session.mount(
48 API_HOST,
49 adapter_class(max_retries=3),
50 )
51 session.headers.update({'Host': PRODUCTION_DOMAIN})
52 api_config = {
53 'base_url': '%s/api/v2/' % API_HOST,
54 'serializer': serialize.Serializer(
55 default='json-drf',
56 serializers=[
57 serialize.JsonSerializer(),
58 DrfJsonSerializer(),
59 ],
60 ),
61 'session': session,
62 }
63 if USER and PASS:
64 log.debug(
65 'Using slumber v2 with user %s, pointed at %s',
66 USER,
67 API_HOST,
68 )
69 session.auth = (USER, PASS)
70 else:
71 log.warning('SLUMBER_USERNAME/PASSWORD settings are not set')
72 return API(**api_config)
73
74
75 api = setup_api()
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/restapi/client.py b/readthedocs/restapi/client.py
--- a/readthedocs/restapi/client.py
+++ b/readthedocs/restapi/client.py
@@ -13,6 +13,7 @@
import requests
from django.conf import settings
+from requests.packages.urllib3.util.retry import Retry # noqa
from requests_toolbelt.adapters import host_header_ssl
from rest_framework.renderers import JSONRenderer
from slumber import API, serialize
@@ -44,9 +45,21 @@
else:
adapter_class = requests.adapters.HTTPAdapter
+ # Define a retry mechanism trying to attempt to not fail in the first
+ # error. Builders hit this issue frequently because the webs are high loaded
+ retry = Retry(
+ total=3,
+ read=3,
+ connect=3,
+ status=3,
+ backoff_factor=0.5, # 0.5, 1, 2 seconds
+ method_whitelist=('GET', 'PUT', 'PATCH', 'POST'),
+ status_forcelist=(408, 413, 429, 500, 502, 503, 504),
+ )
+
session.mount(
API_HOST,
- adapter_class(max_retries=3),
+ adapter_class(max_retries=retry),
)
session.headers.update({'Host': PRODUCTION_DOMAIN})
api_config = {
|
{"golden_diff": "diff --git a/readthedocs/restapi/client.py b/readthedocs/restapi/client.py\n--- a/readthedocs/restapi/client.py\n+++ b/readthedocs/restapi/client.py\n@@ -13,6 +13,7 @@\n \n import requests\n from django.conf import settings\n+from requests.packages.urllib3.util.retry import Retry # noqa\n from requests_toolbelt.adapters import host_header_ssl\n from rest_framework.renderers import JSONRenderer\n from slumber import API, serialize\n@@ -44,9 +45,21 @@\n else:\n adapter_class = requests.adapters.HTTPAdapter\n \n+ # Define a retry mechanism trying to attempt to not fail in the first\n+ # error. Builders hit this issue frequently because the webs are high loaded\n+ retry = Retry(\n+ total=3,\n+ read=3,\n+ connect=3,\n+ status=3,\n+ backoff_factor=0.5, # 0.5, 1, 2 seconds\n+ method_whitelist=('GET', 'PUT', 'PATCH', 'POST'),\n+ status_forcelist=(408, 413, 429, 500, 502, 503, 504),\n+ )\n+\n session.mount(\n API_HOST,\n- adapter_class(max_retries=3),\n+ adapter_class(max_retries=retry),\n )\n session.headers.update({'Host': PRODUCTION_DOMAIN})\n api_config = {\n", "issue": "Protect against web/api 5xx responses\nWhen a build is attempted, but a web/api instance throws a 5xx response, a number of strange behaviors can result:\n- Builds will get stuck in triggered state\n- Builds will fail randomly when updating the api fails\n- 5xx responses will be returned from the web servers to users\n\nPart of the resolution to this may be defensive protection around intermittent 5xx responses. This may take some operation changes as well though, as our load balancer should really assume a 5xx response is enough to dislodge the server from the lb group.\n\nRaised from #2255 \n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Simple client to access our API with Slumber credentials.\"\"\"\n\nfrom __future__ import (\n absolute_import,\n division,\n print_function,\n unicode_literals,\n)\n\nimport logging\n\nimport requests\nfrom django.conf import settings\nfrom requests_toolbelt.adapters import host_header_ssl\nfrom rest_framework.renderers import JSONRenderer\nfrom slumber import API, serialize\n\nlog = logging.getLogger(__name__)\n\nPRODUCTION_DOMAIN = getattr(settings, 'PRODUCTION_DOMAIN', 'readthedocs.org')\nAPI_HOST = getattr(settings, 'SLUMBER_API_HOST', 'https://readthedocs.org')\nUSER = getattr(settings, 'SLUMBER_USERNAME', None)\nPASS = getattr(settings, 'SLUMBER_PASSWORD', None)\n\n\nclass DrfJsonSerializer(serialize.JsonSerializer):\n\n \"\"\"Additional serialization help from the DRF renderer\"\"\"\n\n key = 'json-drf'\n\n def dumps(self, data):\n \"\"\"Used to be able to render datetime objects.\"\"\"\n return JSONRenderer().render(data)\n\n\ndef setup_api():\n session = requests.Session()\n if API_HOST.startswith('https'):\n # Only use the HostHeaderSSLAdapter for HTTPS connections\n adapter_class = host_header_ssl.HostHeaderSSLAdapter\n else:\n adapter_class = requests.adapters.HTTPAdapter\n\n session.mount(\n API_HOST,\n adapter_class(max_retries=3),\n )\n session.headers.update({'Host': PRODUCTION_DOMAIN})\n api_config = {\n 'base_url': '%s/api/v2/' % API_HOST,\n 'serializer': serialize.Serializer(\n default='json-drf',\n serializers=[\n serialize.JsonSerializer(),\n DrfJsonSerializer(),\n ],\n ),\n 'session': session,\n }\n if USER and PASS:\n log.debug(\n 'Using slumber v2 with user %s, pointed at %s',\n USER,\n API_HOST,\n )\n session.auth = (USER, PASS)\n else:\n log.warning('SLUMBER_USERNAME/PASSWORD settings are not set')\n return API(**api_config)\n\n\napi = setup_api()\n", "path": "readthedocs/restapi/client.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Simple client to access our API with Slumber credentials.\"\"\"\n\nfrom __future__ import (\n absolute_import,\n division,\n print_function,\n unicode_literals,\n)\n\nimport logging\n\nimport requests\nfrom django.conf import settings\nfrom requests.packages.urllib3.util.retry import Retry # noqa\nfrom requests_toolbelt.adapters import host_header_ssl\nfrom rest_framework.renderers import JSONRenderer\nfrom slumber import API, serialize\n\nlog = logging.getLogger(__name__)\n\nPRODUCTION_DOMAIN = getattr(settings, 'PRODUCTION_DOMAIN', 'readthedocs.org')\nAPI_HOST = getattr(settings, 'SLUMBER_API_HOST', 'https://readthedocs.org')\nUSER = getattr(settings, 'SLUMBER_USERNAME', None)\nPASS = getattr(settings, 'SLUMBER_PASSWORD', None)\n\n\nclass DrfJsonSerializer(serialize.JsonSerializer):\n\n \"\"\"Additional serialization help from the DRF renderer\"\"\"\n\n key = 'json-drf'\n\n def dumps(self, data):\n \"\"\"Used to be able to render datetime objects.\"\"\"\n return JSONRenderer().render(data)\n\n\ndef setup_api():\n session = requests.Session()\n if API_HOST.startswith('https'):\n # Only use the HostHeaderSSLAdapter for HTTPS connections\n adapter_class = host_header_ssl.HostHeaderSSLAdapter\n else:\n adapter_class = requests.adapters.HTTPAdapter\n\n # Define a retry mechanism trying to attempt to not fail in the first\n # error. Builders hit this issue frequently because the webs are high loaded\n retry = Retry(\n total=3,\n read=3,\n connect=3,\n status=3,\n backoff_factor=0.5, # 0.5, 1, 2 seconds\n method_whitelist=('GET', 'PUT', 'PATCH', 'POST'),\n status_forcelist=(408, 413, 429, 500, 502, 503, 504),\n )\n\n session.mount(\n API_HOST,\n adapter_class(max_retries=retry),\n )\n session.headers.update({'Host': PRODUCTION_DOMAIN})\n api_config = {\n 'base_url': '%s/api/v2/' % API_HOST,\n 'serializer': serialize.Serializer(\n default='json-drf',\n serializers=[\n serialize.JsonSerializer(),\n DrfJsonSerializer(),\n ],\n ),\n 'session': session,\n }\n if USER and PASS:\n log.debug(\n 'Using slumber v2 with user %s, pointed at %s',\n USER,\n API_HOST,\n )\n session.auth = (USER, PASS)\n else:\n log.warning('SLUMBER_USERNAME/PASSWORD settings are not set')\n return API(**api_config)\n\n\napi = setup_api()\n", "path": "readthedocs/restapi/client.py"}]}
| 979 | 326 |
gh_patches_debug_6546
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2645
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider texas_roadhouse is broken
During the global build at 2021-08-11-14-42-19, spider **texas_roadhouse** failed with **0 features** and **0 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/logs/texas_roadhouse.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/texas_roadhouse.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/texas_roadhouse.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/texas_roadhouse.py`
Content:
```
1 import json
2 import scrapy
3 from locations.items import GeojsonPointItem
4 from locations.hours import OpeningHours
5
6
7 class TexasRoadhouseSpider(scrapy.Spider):
8 name = "texas_roadhouse"
9 item_attributes = { 'brand': "Texas Roadhouse", 'brand_wikidata': "Q7707945" }
10 allowed_domains = ["www.texasroadhouse.com"]
11 start_urls = (
12 'https://www.texasroadhouse.com/sitemap.xml',
13 )
14
15 def parse_hours(self, store_hours):
16 opening_hours = OpeningHours()
17
18 for weekday in store_hours:
19 # convert day from full Monday to Mo, etc
20 day = weekday.get('day')[:2]
21 open_time = weekday.get('hours').get('openTime')
22 close_time = weekday.get('hours').get('closeTime')
23 opening_hours.add_range(day=day,
24 open_time=open_time,
25 close_time=close_time,
26 time_format='%I:%M%p')
27
28 return opening_hours.as_opening_hours()
29
30 def parse(self, response):
31 response.selector.remove_namespaces()
32 city_urls = response.xpath('//url/loc/text()').extract()
33 for path in city_urls:
34 if path.startswith('https://www.texasroadhouse.com/locations/'):
35 yield scrapy.Request(
36 path.strip(),
37 callback=self.parse_store,
38 )
39
40 def parse_store(self, response):
41 data = json.loads(response.xpath('//script/text()').extract_first()[22:-1])
42
43 properties = {
44 'lat': data['latitude'],
45 'lon': data['longitude'],
46 'ref': data['url'],
47 'name': data['name'],
48 'addr_full': data['address1'],
49 'city': data['city'],
50 'state': data['state'],
51 'postcode': data['postalCode'],
52 'country': data['countryCode'],
53 'phone': data['telephone'],
54 'website': response.urljoin(data['url']),
55 'opening_hours': self.parse_hours(data['schedule']),
56 }
57
58 yield GeojsonPointItem(**properties)
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/texas_roadhouse.py b/locations/spiders/texas_roadhouse.py
--- a/locations/spiders/texas_roadhouse.py
+++ b/locations/spiders/texas_roadhouse.py
@@ -6,7 +6,10 @@
class TexasRoadhouseSpider(scrapy.Spider):
name = "texas_roadhouse"
- item_attributes = { 'brand': "Texas Roadhouse", 'brand_wikidata': "Q7707945" }
+ item_attributes = {
+ 'brand': "Texas Roadhouse",
+ 'brand_wikidata': "Q7707945",
+ }
allowed_domains = ["www.texasroadhouse.com"]
start_urls = (
'https://www.texasroadhouse.com/sitemap.xml',
|
{"golden_diff": "diff --git a/locations/spiders/texas_roadhouse.py b/locations/spiders/texas_roadhouse.py\n--- a/locations/spiders/texas_roadhouse.py\n+++ b/locations/spiders/texas_roadhouse.py\n@@ -6,7 +6,10 @@\n \n class TexasRoadhouseSpider(scrapy.Spider):\n name = \"texas_roadhouse\"\n- item_attributes = { 'brand': \"Texas Roadhouse\", 'brand_wikidata': \"Q7707945\" }\n+ item_attributes = {\n+ 'brand': \"Texas Roadhouse\",\n+ 'brand_wikidata': \"Q7707945\",\n+ }\n allowed_domains = [\"www.texasroadhouse.com\"]\n start_urls = (\n 'https://www.texasroadhouse.com/sitemap.xml',\n", "issue": "Spider texas_roadhouse is broken\nDuring the global build at 2021-08-11-14-42-19, spider **texas_roadhouse** failed with **0 features** and **0 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/logs/texas_roadhouse.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/texas_roadhouse.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/texas_roadhouse.geojson))\n", "before_files": [{"content": "import json\nimport scrapy\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass TexasRoadhouseSpider(scrapy.Spider):\n name = \"texas_roadhouse\"\n item_attributes = { 'brand': \"Texas Roadhouse\", 'brand_wikidata': \"Q7707945\" }\n allowed_domains = [\"www.texasroadhouse.com\"]\n start_urls = (\n 'https://www.texasroadhouse.com/sitemap.xml',\n )\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n\n for weekday in store_hours:\n # convert day from full Monday to Mo, etc\n day = weekday.get('day')[:2]\n open_time = weekday.get('hours').get('openTime')\n close_time = weekday.get('hours').get('closeTime')\n opening_hours.add_range(day=day,\n open_time=open_time,\n close_time=close_time,\n time_format='%I:%M%p')\n\n return opening_hours.as_opening_hours()\n\n def parse(self, response):\n response.selector.remove_namespaces()\n city_urls = response.xpath('//url/loc/text()').extract()\n for path in city_urls:\n if path.startswith('https://www.texasroadhouse.com/locations/'):\n yield scrapy.Request(\n path.strip(),\n callback=self.parse_store,\n )\n\n def parse_store(self, response):\n data = json.loads(response.xpath('//script/text()').extract_first()[22:-1])\n\n properties = {\n 'lat': data['latitude'],\n 'lon': data['longitude'],\n 'ref': data['url'],\n 'name': data['name'],\n 'addr_full': data['address1'],\n 'city': data['city'],\n 'state': data['state'],\n 'postcode': data['postalCode'],\n 'country': data['countryCode'],\n 'phone': data['telephone'],\n 'website': response.urljoin(data['url']),\n 'opening_hours': self.parse_hours(data['schedule']),\n }\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/texas_roadhouse.py"}], "after_files": [{"content": "import json\nimport scrapy\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass TexasRoadhouseSpider(scrapy.Spider):\n name = \"texas_roadhouse\"\n item_attributes = {\n 'brand': \"Texas Roadhouse\",\n 'brand_wikidata': \"Q7707945\",\n }\n allowed_domains = [\"www.texasroadhouse.com\"]\n start_urls = (\n 'https://www.texasroadhouse.com/sitemap.xml',\n )\n\n def parse_hours(self, store_hours):\n opening_hours = OpeningHours()\n\n for weekday in store_hours:\n # convert day from full Monday to Mo, etc\n day = weekday.get('day')[:2]\n open_time = weekday.get('hours').get('openTime')\n close_time = weekday.get('hours').get('closeTime')\n opening_hours.add_range(day=day,\n open_time=open_time,\n close_time=close_time,\n time_format='%I:%M%p')\n\n return opening_hours.as_opening_hours()\n\n def parse(self, response):\n response.selector.remove_namespaces()\n city_urls = response.xpath('//url/loc/text()').extract()\n for path in city_urls:\n if path.startswith('https://www.texasroadhouse.com/locations/'):\n yield scrapy.Request(\n path.strip(),\n callback=self.parse_store,\n )\n\n def parse_store(self, response):\n data = json.loads(response.xpath('//script/text()').extract_first()[22:-1])\n\n properties = {\n 'lat': data['latitude'],\n 'lon': data['longitude'],\n 'ref': data['url'],\n 'name': data['name'],\n 'addr_full': data['address1'],\n 'city': data['city'],\n 'state': data['state'],\n 'postcode': data['postalCode'],\n 'country': data['countryCode'],\n 'phone': data['telephone'],\n 'website': response.urljoin(data['url']),\n 'opening_hours': self.parse_hours(data['schedule']),\n }\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/texas_roadhouse.py"}]}
| 1,014 | 183 |
gh_patches_debug_4587
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-11722
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing ship numpy testing decorator
```
Traceback (most recent call last):
File "/Users/mbussonnier/dev/cpython/test/bin/iptest", line 6, in <module>
from IPython.testing.iptestcontroller import main
File "/Users/mbussonnier/dev/cpython/test/lib/python3.8/site-packages/IPython/testing/iptestcontroller.py", line 23, in <module>
from .iptest import (
File "/Users/mbussonnier/dev/cpython/test/lib/python3.8/site-packages/IPython/testing/iptest.py", line 40, in <module>
from IPython.external.decorators import KnownFailure, dec
ImportError: cannot import name 'dec' from 'IPython.external.decorators' (/Users/mbussonnier/dev/cpython/test/lib/python3.8/site-packages/IPython/external/decorators/__init__.py)
```
Seem like `dec` is not define ini out `_decorator.py`
Appologies for shortness boarding a plane
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/external/decorators/__init__.py`
Content:
```
1 try:
2 from numpy.testing import *
3 from numpy.testing import dec
4 from numpy.testing.noseclasses import KnownFailure
5 except ImportError:
6 from ._decorators import *
7 try:
8 from ._numpy_testing_noseclasses import KnownFailure
9 except ImportError:
10 pass
11
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/external/decorators/__init__.py b/IPython/external/decorators/__init__.py
--- a/IPython/external/decorators/__init__.py
+++ b/IPython/external/decorators/__init__.py
@@ -1,9 +1,7 @@
try:
- from numpy.testing import *
- from numpy.testing import dec
- from numpy.testing.noseclasses import KnownFailure
+ from numpy.testing.noseclasses import KnownFailure, knownfailureif
except ImportError:
- from ._decorators import *
+ from ._decorators import knownfailureif
try:
from ._numpy_testing_noseclasses import KnownFailure
except ImportError:
|
{"golden_diff": "diff --git a/IPython/external/decorators/__init__.py b/IPython/external/decorators/__init__.py\n--- a/IPython/external/decorators/__init__.py\n+++ b/IPython/external/decorators/__init__.py\n@@ -1,9 +1,7 @@\n try:\n- from numpy.testing import *\n- from numpy.testing import dec\n- from numpy.testing.noseclasses import KnownFailure\n+ from numpy.testing.noseclasses import KnownFailure, knownfailureif\n except ImportError:\n- from ._decorators import *\n+ from ._decorators import knownfailureif\n try:\n from ._numpy_testing_noseclasses import KnownFailure\n except ImportError:\n", "issue": "Missing ship numpy testing decorator\n```\r\nTraceback (most recent call last):\r\n File \"/Users/mbussonnier/dev/cpython/test/bin/iptest\", line 6, in <module>\r\n from IPython.testing.iptestcontroller import main\r\n File \"/Users/mbussonnier/dev/cpython/test/lib/python3.8/site-packages/IPython/testing/iptestcontroller.py\", line 23, in <module>\r\n from .iptest import (\r\n File \"/Users/mbussonnier/dev/cpython/test/lib/python3.8/site-packages/IPython/testing/iptest.py\", line 40, in <module>\r\n from IPython.external.decorators import KnownFailure, dec\r\nImportError: cannot import name 'dec' from 'IPython.external.decorators' (/Users/mbussonnier/dev/cpython/test/lib/python3.8/site-packages/IPython/external/decorators/__init__.py)\r\n```\r\n\r\nSeem like `dec` is not define ini out `_decorator.py` \r\n\r\n\r\nAppologies for shortness boarding a plane\n", "before_files": [{"content": "try:\n from numpy.testing import *\n from numpy.testing import dec\n from numpy.testing.noseclasses import KnownFailure\nexcept ImportError:\n from ._decorators import *\n try:\n from ._numpy_testing_noseclasses import KnownFailure\n except ImportError:\n pass\n", "path": "IPython/external/decorators/__init__.py"}], "after_files": [{"content": "try:\n from numpy.testing.noseclasses import KnownFailure, knownfailureif\nexcept ImportError:\n from ._decorators import knownfailureif\n try:\n from ._numpy_testing_noseclasses import KnownFailure\n except ImportError:\n pass\n", "path": "IPython/external/decorators/__init__.py"}]}
| 557 | 150 |
gh_patches_debug_17485
|
rasdani/github-patches
|
git_diff
|
kymatio__kymatio-183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[MAINT] AttributeError: module 'kymatio' has no attribute '__version__'
This came up in #172
PEP 396 has introduced the convention of exposing the constant `__version__` to the top-level module
At the moment this is in `kymatio.version.version` (so that `version.py` can be loaded in `setup.py` without importing the whole `kymatio` module)
https://www.python.org/dev/peps/pep-0396/
Will submit a PR later
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kymatio/__init__.py`
Content:
```
1 __all__ = [
2 'Scattering3D',
3 'Scattering2D',
4 'Scattering1D'
5 ]
6
7 from .scattering2d.scattering2d import Scattering2D
8 from .scattering1d.scattering1d import Scattering1D
9 from .scattering3d.scattering3d import Scattering3D
10
11 # Make sure that DeprecationWarning within this package always gets printed
12 ### Snippet copied from sklearn.__init__
13 import warnings
14 import re
15 warnings.filterwarnings('always', category=DeprecationWarning,
16 module=r'^{0}.*'.format(re.escape(__name__)))
17 ### End Snippet
18
19
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kymatio/__init__.py b/kymatio/__init__.py
--- a/kymatio/__init__.py
+++ b/kymatio/__init__.py
@@ -1,13 +1,3 @@
-__all__ = [
- 'Scattering3D',
- 'Scattering2D',
- 'Scattering1D'
- ]
-
-from .scattering2d.scattering2d import Scattering2D
-from .scattering1d.scattering1d import Scattering1D
-from .scattering3d.scattering3d import Scattering3D
-
# Make sure that DeprecationWarning within this package always gets printed
### Snippet copied from sklearn.__init__
import warnings
@@ -16,4 +6,14 @@
module=r'^{0}.*'.format(re.escape(__name__)))
### End Snippet
+__all__ = [
+ 'Scattering1D',
+ 'Scattering2D',
+ 'Scattering3D'
+ ]
+
+from .scattering1d.scattering1d import Scattering1D
+from .scattering2d.scattering2d import Scattering2D
+from .scattering3d.scattering3d import Scattering3D
+from .version import version as __version__
|
{"golden_diff": "diff --git a/kymatio/__init__.py b/kymatio/__init__.py\n--- a/kymatio/__init__.py\n+++ b/kymatio/__init__.py\n@@ -1,13 +1,3 @@\n-__all__ = [\n- 'Scattering3D',\n- 'Scattering2D',\n- 'Scattering1D'\n- ]\n-\n-from .scattering2d.scattering2d import Scattering2D\n-from .scattering1d.scattering1d import Scattering1D\n-from .scattering3d.scattering3d import Scattering3D\n-\n # Make sure that DeprecationWarning within this package always gets printed\n ### Snippet copied from sklearn.__init__\n import warnings\n@@ -16,4 +6,14 @@\n module=r'^{0}.*'.format(re.escape(__name__)))\n ### End Snippet\n \n+__all__ = [\n+ 'Scattering1D',\n+ 'Scattering2D',\n+ 'Scattering3D'\n+ ]\n+\n+from .scattering1d.scattering1d import Scattering1D\n+from .scattering2d.scattering2d import Scattering2D\n+from .scattering3d.scattering3d import Scattering3D\n \n+from .version import version as __version__\n", "issue": "[MAINT] AttributeError: module 'kymatio' has no attribute '__version__'\nThis came up in #172\r\n\r\nPEP 396 has introduced the convention of exposing the constant `__version__` to the top-level module\r\nAt the moment this is in `kymatio.version.version` (so that `version.py` can be loaded in `setup.py` without importing the whole `kymatio` module)\r\nhttps://www.python.org/dev/peps/pep-0396/\r\n\r\nWill submit a PR later\r\n\n", "before_files": [{"content": "__all__ = [\n 'Scattering3D',\n 'Scattering2D',\n 'Scattering1D'\n ]\n\nfrom .scattering2d.scattering2d import Scattering2D\nfrom .scattering1d.scattering1d import Scattering1D\nfrom .scattering3d.scattering3d import Scattering3D\n\n# Make sure that DeprecationWarning within this package always gets printed\n### Snippet copied from sklearn.__init__\nimport warnings\nimport re\nwarnings.filterwarnings('always', category=DeprecationWarning,\n module=r'^{0}.*'.format(re.escape(__name__)))\n### End Snippet\n\n\n", "path": "kymatio/__init__.py"}], "after_files": [{"content": "# Make sure that DeprecationWarning within this package always gets printed\n### Snippet copied from sklearn.__init__\nimport warnings\nimport re\nwarnings.filterwarnings('always', category=DeprecationWarning,\n module=r'^{0}.*'.format(re.escape(__name__)))\n### End Snippet\n\n__all__ = [\n 'Scattering1D',\n 'Scattering2D',\n 'Scattering3D'\n ]\n\nfrom .scattering1d.scattering1d import Scattering1D\nfrom .scattering2d.scattering2d import Scattering2D\nfrom .scattering3d.scattering3d import Scattering3D\n\nfrom .version import version as __version__\n", "path": "kymatio/__init__.py"}]}
| 553 | 289 |
gh_patches_debug_17251
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ASGI app broken with asyncio
Our ASGI app is currently broken with async io stuff. The implementation I made needs a bit of love :) We might have a look at how Ariadne is doing this :)
Here's a test that fails:
```python
import typing
import pytest
import strawberry
from starlette.testclient import TestClient
from strawberry.asgi import GraphQL
@pytest.fixture
def async_schema():
@strawberry.type
class Query:
@strawberry.field
async def hello(self, info, name: typing.Optional[str] = None) -> str:
return f"Hello {name or 'world'}"
return strawberry.Schema(Query)
@pytest.fixture
def test_client(async_schema):
app = GraphQL(async_schema)
return TestClient(app)
def test_simple_query(schema, test_client):
response = test_client.post("/", json={"query": "{ hello }"})
assert response.json() == {"data": {"hello": "Hello world"}}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/graphql.py`
Content:
```
1 import typing
2
3 from graphql import (
4 ExecutionResult,
5 GraphQLError,
6 GraphQLSchema,
7 execute as graphql_excute,
8 parse,
9 )
10 from graphql.subscription import subscribe as graphql_subscribe
11 from graphql.type import validate_schema
12 from graphql.validation import validate
13
14 from .middleware import DirectivesMiddleware
15
16
17 async def execute(
18 schema: GraphQLSchema,
19 query: str,
20 context_value: typing.Any = None,
21 variable_values: typing.Dict[str, typing.Any] = None,
22 operation_name: str = None,
23 ):
24 schema_validation_errors = validate_schema(schema)
25 if schema_validation_errors:
26 return ExecutionResult(data=None, errors=schema_validation_errors)
27
28 try:
29 document = parse(query)
30 except GraphQLError as error:
31 return ExecutionResult(data=None, errors=[error])
32 except Exception as error:
33 error = GraphQLError(str(error), original_error=error)
34 return ExecutionResult(data=None, errors=[error])
35
36 validation_errors = validate(schema, document)
37
38 if validation_errors:
39 return ExecutionResult(data=None, errors=validation_errors)
40
41 return graphql_excute(
42 schema,
43 parse(query),
44 middleware=[DirectivesMiddleware()],
45 variable_values=variable_values,
46 operation_name=operation_name,
47 context_value=context_value,
48 )
49
50
51 async def subscribe(
52 schema: GraphQLSchema,
53 query: str,
54 root_value: typing.Any = None,
55 context_value: typing.Any = None,
56 variable_values: typing.Dict[str, typing.Any] = None,
57 operation_name: str = None,
58 ) -> typing.Union[typing.AsyncIterator[ExecutionResult], ExecutionResult]:
59 document = parse(query)
60
61 return await graphql_subscribe(
62 schema=schema,
63 document=document,
64 root_value=root_value,
65 context_value=context_value,
66 variable_values=variable_values,
67 operation_name=operation_name,
68 )
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/graphql.py b/strawberry/graphql.py
--- a/strawberry/graphql.py
+++ b/strawberry/graphql.py
@@ -1,4 +1,5 @@
import typing
+from inspect import isawaitable
from graphql import (
ExecutionResult,
@@ -38,7 +39,7 @@
if validation_errors:
return ExecutionResult(data=None, errors=validation_errors)
- return graphql_excute(
+ result = graphql_excute(
schema,
parse(query),
middleware=[DirectivesMiddleware()],
@@ -46,6 +47,9 @@
operation_name=operation_name,
context_value=context_value,
)
+ if isawaitable(result):
+ result = await typing.cast(typing.Awaitable[ExecutionResult], result)
+ return result
async def subscribe(
|
{"golden_diff": "diff --git a/strawberry/graphql.py b/strawberry/graphql.py\n--- a/strawberry/graphql.py\n+++ b/strawberry/graphql.py\n@@ -1,4 +1,5 @@\n import typing\n+from inspect import isawaitable\n \n from graphql import (\n ExecutionResult,\n@@ -38,7 +39,7 @@\n if validation_errors:\n return ExecutionResult(data=None, errors=validation_errors)\n \n- return graphql_excute(\n+ result = graphql_excute(\n schema,\n parse(query),\n middleware=[DirectivesMiddleware()],\n@@ -46,6 +47,9 @@\n operation_name=operation_name,\n context_value=context_value,\n )\n+ if isawaitable(result):\n+ result = await typing.cast(typing.Awaitable[ExecutionResult], result)\n+ return result\n \n \n async def subscribe(\n", "issue": "ASGI app broken with asyncio\nOur ASGI app is currently broken with async io stuff. The implementation I made needs a bit of love :) We might have a look at how Ariadne is doing this :)\r\n\r\nHere's a test that fails:\r\n\r\n```python\r\nimport typing\r\n\r\nimport pytest\r\n\r\nimport strawberry\r\nfrom starlette.testclient import TestClient\r\nfrom strawberry.asgi import GraphQL\r\n\r\n\r\[email protected]\r\ndef async_schema():\r\n @strawberry.type\r\n class Query:\r\n @strawberry.field\r\n async def hello(self, info, name: typing.Optional[str] = None) -> str:\r\n return f\"Hello {name or 'world'}\"\r\n\r\n return strawberry.Schema(Query)\r\n\r\n\r\[email protected]\r\ndef test_client(async_schema):\r\n app = GraphQL(async_schema)\r\n\r\n return TestClient(app)\r\n\r\n\r\ndef test_simple_query(schema, test_client):\r\n response = test_client.post(\"/\", json={\"query\": \"{ hello }\"})\r\n\r\n assert response.json() == {\"data\": {\"hello\": \"Hello world\"}}\r\n```\n", "before_files": [{"content": "import typing\n\nfrom graphql import (\n ExecutionResult,\n GraphQLError,\n GraphQLSchema,\n execute as graphql_excute,\n parse,\n)\nfrom graphql.subscription import subscribe as graphql_subscribe\nfrom graphql.type import validate_schema\nfrom graphql.validation import validate\n\nfrom .middleware import DirectivesMiddleware\n\n\nasync def execute(\n schema: GraphQLSchema,\n query: str,\n context_value: typing.Any = None,\n variable_values: typing.Dict[str, typing.Any] = None,\n operation_name: str = None,\n):\n schema_validation_errors = validate_schema(schema)\n if schema_validation_errors:\n return ExecutionResult(data=None, errors=schema_validation_errors)\n\n try:\n document = parse(query)\n except GraphQLError as error:\n return ExecutionResult(data=None, errors=[error])\n except Exception as error:\n error = GraphQLError(str(error), original_error=error)\n return ExecutionResult(data=None, errors=[error])\n\n validation_errors = validate(schema, document)\n\n if validation_errors:\n return ExecutionResult(data=None, errors=validation_errors)\n\n return graphql_excute(\n schema,\n parse(query),\n middleware=[DirectivesMiddleware()],\n variable_values=variable_values,\n operation_name=operation_name,\n context_value=context_value,\n )\n\n\nasync def subscribe(\n schema: GraphQLSchema,\n query: str,\n root_value: typing.Any = None,\n context_value: typing.Any = None,\n variable_values: typing.Dict[str, typing.Any] = None,\n operation_name: str = None,\n) -> typing.Union[typing.AsyncIterator[ExecutionResult], ExecutionResult]:\n document = parse(query)\n\n return await graphql_subscribe(\n schema=schema,\n document=document,\n root_value=root_value,\n context_value=context_value,\n variable_values=variable_values,\n operation_name=operation_name,\n )\n", "path": "strawberry/graphql.py"}], "after_files": [{"content": "import typing\nfrom inspect import isawaitable\n\nfrom graphql import (\n ExecutionResult,\n GraphQLError,\n GraphQLSchema,\n execute as graphql_excute,\n parse,\n)\nfrom graphql.subscription import subscribe as graphql_subscribe\nfrom graphql.type import validate_schema\nfrom graphql.validation import validate\n\nfrom .middleware import DirectivesMiddleware\n\n\nasync def execute(\n schema: GraphQLSchema,\n query: str,\n context_value: typing.Any = None,\n variable_values: typing.Dict[str, typing.Any] = None,\n operation_name: str = None,\n):\n schema_validation_errors = validate_schema(schema)\n if schema_validation_errors:\n return ExecutionResult(data=None, errors=schema_validation_errors)\n\n try:\n document = parse(query)\n except GraphQLError as error:\n return ExecutionResult(data=None, errors=[error])\n except Exception as error:\n error = GraphQLError(str(error), original_error=error)\n return ExecutionResult(data=None, errors=[error])\n\n validation_errors = validate(schema, document)\n\n if validation_errors:\n return ExecutionResult(data=None, errors=validation_errors)\n\n result = graphql_excute(\n schema,\n parse(query),\n middleware=[DirectivesMiddleware()],\n variable_values=variable_values,\n operation_name=operation_name,\n context_value=context_value,\n )\n if isawaitable(result):\n result = await typing.cast(typing.Awaitable[ExecutionResult], result)\n return result\n\n\nasync def subscribe(\n schema: GraphQLSchema,\n query: str,\n root_value: typing.Any = None,\n context_value: typing.Any = None,\n variable_values: typing.Dict[str, typing.Any] = None,\n operation_name: str = None,\n) -> typing.Union[typing.AsyncIterator[ExecutionResult], ExecutionResult]:\n document = parse(query)\n\n return await graphql_subscribe(\n schema=schema,\n document=document,\n root_value=root_value,\n context_value=context_value,\n variable_values=variable_values,\n operation_name=operation_name,\n )\n", "path": "strawberry/graphql.py"}]}
| 990 | 187 |
gh_patches_debug_31569
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-74
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Honor Environment LANG
I am currently using a wrapper for fake-factory to be able to choose the output but it would be great it would become part of fake-factory core.
This is the script i have in my path: https://gist.github.com/makefu/9101269
usage:
$ LANG=de_DE.utf-8 faker address
Davide-Kaul-Weg 175
94892 Königs Wusterhausen
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/__main__.py`
Content:
```
1 from __future__ import unicode_literals
2 from __future__ import print_function
3 import sys
4
5 if sys.version < '3':
6 text_type = unicode
7 binary_type = str
8 else:
9 text_type = str
10 binary_type = bytes
11
12
13 def print_provider(doc, provider, formatters, excludes=None):
14 if excludes is None:
15 excludes = []
16
17 print()
18 print("### faker.providers.{0}".format(doc.get_provider_name(provider)))
19 print()
20
21 for signature, example in formatters.items():
22 if signature in excludes:
23 continue
24 try:
25 lines = text_type(example).expandtabs().splitlines()
26 except UnicodeEncodeError:
27 raise Exception('error on "{0}" with value "{1}"'.format(signature, example))
28 margin = max(30, doc.max_name_len+1)
29 remains = 150 - margin
30 separator = '#'
31 for line in lines:
32 for i in range(0, (len(line) // remains) + 1):
33 print("\t{fake:<{margin}}{separator} {example}".format(
34 fake=signature,
35 separator=separator,
36 example=line[i*remains:(i+1)*remains],
37 margin=margin
38 ))
39 signature = separator = ' '
40
41
42 def main(provider_or_field=None, *args):
43 from faker import Faker, Factory, documentor, DEFAULT_LOCALE, AVAILABLE_LOCALES
44 fake = Faker(locale=DEFAULT_LOCALE)
45
46 from faker.providers import BaseProvider
47 base_provider_formatters = [f for f in dir(BaseProvider)]
48
49 if provider_or_field:
50 if '.' in provider_or_field:
51 parts = provider_or_field.split('.')
52 locale = parts[-2] if parts[-2] in AVAILABLE_LOCALES else DEFAULT_LOCALE
53 fake = Factory.create(locale, providers=[parts[-1]])
54 doc = documentor.Documentor(fake)
55 doc.already_generated = base_provider_formatters
56 print_provider(doc, fake.get_providers()[0], doc.get_provider_formatters(fake.get_providers()[0]))
57 else:
58 try:
59 print(fake.format(provider_or_field, *args))
60 except AttributeError:
61 print('No faker found for "{0}({1})"'.format(provider_or_field, args))
62
63 else:
64 doc = documentor.Documentor(fake)
65
66 formatters = doc.get_formatters(with_args=True, with_defaults=True)
67
68 for provider, fakers in formatters:
69
70 print_provider(doc, provider, fakers)
71
72 for lang in AVAILABLE_LOCALES:
73 if lang == DEFAULT_LOCALE:
74 continue
75 print()
76 print('## LANGUAGE {0}'.format(lang))
77 fake = Faker(locale=lang)
78 d = documentor.Documentor(fake)
79
80 for p, fs in d.get_formatters(with_args=True, with_defaults=True, locale=lang,
81 excludes=base_provider_formatters):
82 print_provider(d, p, fs)
83
84
85 if __name__ == "__main__":
86 if sys.stdout.encoding is None:
87 print("please set python env PYTHONIOENCODING=UTF-8, example: "
88 "export PYTHONIOENCODING=UTF-8, when write to stdout", file=sys.stderr)
89 exit(1)
90 main(*sys.argv[1:])
```
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os
4 from setuptools import setup, find_packages
5
6 here = os.path.abspath(os.path.dirname(__file__))
7 README = open(os.path.join(here, 'README.md')).read()
8 NEWS = open(os.path.join(here, 'NEWS.txt')).read()
9
10
11 version = '0.3.2'
12
13 setup(name='fake-factory',
14 version=version,
15 description="Faker is a Python package that generates fake data for you.",
16 long_description=README + '\n\n' + NEWS,
17 classifiers=[
18 # Get strings from http://pypi.python.org/pypi?%3Aaction=list_classifiers
19 'Development Status :: 3 - Alpha',
20 'Environment :: Console',
21 'Intended Audience :: Developers',
22 'Programming Language :: Python',
23 'Programming Language :: Python :: 2',
24 'Programming Language :: Python :: 3',
25 'Topic :: Software Development :: Libraries :: Python Modules',
26 'Topic :: Software Development :: Testing',
27 'Topic :: Utilities',
28 'License :: OSI Approved :: MIT License'
29 ],
30 keywords='faker fixtures data test mock generator',
31 author='joke2k',
32 author_email='[email protected]',
33 url='http://github.com/joke2k/faker',
34 license='MIT License',
35 packages=find_packages(exclude=['*.tests']),
36 platforms=["any"],
37 test_suite='faker.tests',
38 )
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/__main__.py b/faker/__main__.py
--- a/faker/__main__.py
+++ b/faker/__main__.py
@@ -1,5 +1,9 @@
from __future__ import unicode_literals
from __future__ import print_function
+
+from faker import Faker, Factory, documentor, AVAILABLE_LOCALES, DEFAULT_LOCALE
+
+import os
import sys
if sys.version < '3':
@@ -40,7 +44,6 @@
def main(provider_or_field=None, *args):
- from faker import Faker, Factory, documentor, DEFAULT_LOCALE, AVAILABLE_LOCALES
fake = Faker(locale=DEFAULT_LOCALE)
from faker.providers import BaseProvider
@@ -82,6 +85,28 @@
print_provider(d, p, fs)
+def command(*args):
+ try:
+ f = args[0]
+ except IndexError:
+ f = '--help'
+
+ if f in ["--help", "-h"]:
+ main()
+ sys.exit()
+
+ locale = os.environ['LANG'].split('.')[0]
+
+ if locale not in AVAILABLE_LOCALES:
+ locale = DEFAULT_LOCALE
+ fake = Faker(locale=locale)
+
+ try:
+ print(fake.format(f, *args[1:]))
+ except AttributeError:
+ print('No faker found for "{0}"'.format(f))
+
+
if __name__ == "__main__":
if sys.stdout.encoding is None:
print("please set python env PYTHONIOENCODING=UTF-8, example: "
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -14,6 +14,7 @@
version=version,
description="Faker is a Python package that generates fake data for you.",
long_description=README + '\n\n' + NEWS,
+ scripts=['bin/faker'],
classifiers=[
# Get strings from http://pypi.python.org/pypi?%3Aaction=list_classifiers
'Development Status :: 3 - Alpha',
|
{"golden_diff": "diff --git a/faker/__main__.py b/faker/__main__.py\n--- a/faker/__main__.py\n+++ b/faker/__main__.py\n@@ -1,5 +1,9 @@\n from __future__ import unicode_literals\n from __future__ import print_function\n+\n+from faker import Faker, Factory, documentor, AVAILABLE_LOCALES, DEFAULT_LOCALE\n+\n+import os\n import sys\n \n if sys.version < '3':\n@@ -40,7 +44,6 @@\n \n \n def main(provider_or_field=None, *args):\n- from faker import Faker, Factory, documentor, DEFAULT_LOCALE, AVAILABLE_LOCALES\n fake = Faker(locale=DEFAULT_LOCALE)\n \n from faker.providers import BaseProvider\n@@ -82,6 +85,28 @@\n print_provider(d, p, fs)\n \n \n+def command(*args):\n+ try:\n+ f = args[0]\n+ except IndexError:\n+ f = '--help'\n+\n+ if f in [\"--help\", \"-h\"]:\n+ main()\n+ sys.exit()\n+\n+ locale = os.environ['LANG'].split('.')[0]\n+ \n+ if locale not in AVAILABLE_LOCALES:\n+ locale = DEFAULT_LOCALE\n+ fake = Faker(locale=locale)\n+\n+ try:\n+ print(fake.format(f, *args[1:]))\n+ except AttributeError:\n+ print('No faker found for \"{0}\"'.format(f))\n+\n+\n if __name__ == \"__main__\":\n if sys.stdout.encoding is None:\n print(\"please set python env PYTHONIOENCODING=UTF-8, example: \"\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -14,6 +14,7 @@\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README + '\\n\\n' + NEWS,\n+ scripts=['bin/faker'],\n classifiers=[\n # Get strings from http://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n", "issue": "Honor Environment LANG\nI am currently using a wrapper for fake-factory to be able to choose the output but it would be great it would become part of fake-factory core.\n\nThis is the script i have in my path: https://gist.github.com/makefu/9101269\n\nusage: \n$ LANG=de_DE.utf-8 faker address\n Davide-Kaul-Weg 175\n 94892 K\u00f6nigs Wusterhausen\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom __future__ import print_function\nimport sys\n\nif sys.version < '3':\n text_type = unicode\n binary_type = str\nelse:\n text_type = str\n binary_type = bytes\n\n\ndef print_provider(doc, provider, formatters, excludes=None):\n if excludes is None:\n excludes = []\n\n print()\n print(\"### faker.providers.{0}\".format(doc.get_provider_name(provider)))\n print()\n\n for signature, example in formatters.items():\n if signature in excludes:\n continue\n try:\n lines = text_type(example).expandtabs().splitlines()\n except UnicodeEncodeError:\n raise Exception('error on \"{0}\" with value \"{1}\"'.format(signature, example))\n margin = max(30, doc.max_name_len+1)\n remains = 150 - margin\n separator = '#'\n for line in lines:\n for i in range(0, (len(line) // remains) + 1):\n print(\"\\t{fake:<{margin}}{separator} {example}\".format(\n fake=signature,\n separator=separator,\n example=line[i*remains:(i+1)*remains],\n margin=margin\n ))\n signature = separator = ' '\n\n\ndef main(provider_or_field=None, *args):\n from faker import Faker, Factory, documentor, DEFAULT_LOCALE, AVAILABLE_LOCALES\n fake = Faker(locale=DEFAULT_LOCALE)\n\n from faker.providers import BaseProvider\n base_provider_formatters = [f for f in dir(BaseProvider)]\n\n if provider_or_field:\n if '.' in provider_or_field:\n parts = provider_or_field.split('.')\n locale = parts[-2] if parts[-2] in AVAILABLE_LOCALES else DEFAULT_LOCALE\n fake = Factory.create(locale, providers=[parts[-1]])\n doc = documentor.Documentor(fake)\n doc.already_generated = base_provider_formatters\n print_provider(doc, fake.get_providers()[0], doc.get_provider_formatters(fake.get_providers()[0]))\n else:\n try:\n print(fake.format(provider_or_field, *args))\n except AttributeError:\n print('No faker found for \"{0}({1})\"'.format(provider_or_field, args))\n\n else:\n doc = documentor.Documentor(fake)\n\n formatters = doc.get_formatters(with_args=True, with_defaults=True)\n\n for provider, fakers in formatters:\n\n print_provider(doc, provider, fakers)\n\n for lang in AVAILABLE_LOCALES:\n if lang == DEFAULT_LOCALE:\n continue\n print()\n print('## LANGUAGE {0}'.format(lang))\n fake = Faker(locale=lang)\n d = documentor.Documentor(fake)\n\n for p, fs in d.get_formatters(with_args=True, with_defaults=True, locale=lang,\n excludes=base_provider_formatters):\n print_provider(d, p, fs)\n\n\nif __name__ == \"__main__\":\n if sys.stdout.encoding is None:\n print(\"please set python env PYTHONIOENCODING=UTF-8, example: \"\n \"export PYTHONIOENCODING=UTF-8, when write to stdout\", file=sys.stderr)\n exit(1)\n main(*sys.argv[1:])", "path": "faker/__main__.py"}, {"content": "#!/usr/bin/env python\n\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = open(os.path.join(here, 'README.md')).read()\nNEWS = open(os.path.join(here, 'NEWS.txt')).read()\n\n\nversion = '0.3.2'\n\nsetup(name='fake-factory',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README + '\\n\\n' + NEWS,\n classifiers=[\n # Get strings from http://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='http://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=['*.tests']),\n platforms=[\"any\"],\n test_suite='faker.tests',\n )\n", "path": "setup.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nfrom __future__ import print_function\n\nfrom faker import Faker, Factory, documentor, AVAILABLE_LOCALES, DEFAULT_LOCALE\n\nimport os\nimport sys\n\nif sys.version < '3':\n text_type = unicode\n binary_type = str\nelse:\n text_type = str\n binary_type = bytes\n\n\ndef print_provider(doc, provider, formatters, excludes=None):\n if excludes is None:\n excludes = []\n\n print()\n print(\"### faker.providers.{0}\".format(doc.get_provider_name(provider)))\n print()\n\n for signature, example in formatters.items():\n if signature in excludes:\n continue\n try:\n lines = text_type(example).expandtabs().splitlines()\n except UnicodeEncodeError:\n raise Exception('error on \"{0}\" with value \"{1}\"'.format(signature, example))\n margin = max(30, doc.max_name_len+1)\n remains = 150 - margin\n separator = '#'\n for line in lines:\n for i in range(0, (len(line) // remains) + 1):\n print(\"\\t{fake:<{margin}}{separator} {example}\".format(\n fake=signature,\n separator=separator,\n example=line[i*remains:(i+1)*remains],\n margin=margin\n ))\n signature = separator = ' '\n\n\ndef main(provider_or_field=None, *args):\n fake = Faker(locale=DEFAULT_LOCALE)\n\n from faker.providers import BaseProvider\n base_provider_formatters = [f for f in dir(BaseProvider)]\n\n if provider_or_field:\n if '.' in provider_or_field:\n parts = provider_or_field.split('.')\n locale = parts[-2] if parts[-2] in AVAILABLE_LOCALES else DEFAULT_LOCALE\n fake = Factory.create(locale, providers=[parts[-1]])\n doc = documentor.Documentor(fake)\n doc.already_generated = base_provider_formatters\n print_provider(doc, fake.get_providers()[0], doc.get_provider_formatters(fake.get_providers()[0]))\n else:\n try:\n print(fake.format(provider_or_field, *args))\n except AttributeError:\n print('No faker found for \"{0}({1})\"'.format(provider_or_field, args))\n\n else:\n doc = documentor.Documentor(fake)\n\n formatters = doc.get_formatters(with_args=True, with_defaults=True)\n\n for provider, fakers in formatters:\n\n print_provider(doc, provider, fakers)\n\n for lang in AVAILABLE_LOCALES:\n if lang == DEFAULT_LOCALE:\n continue\n print()\n print('## LANGUAGE {0}'.format(lang))\n fake = Faker(locale=lang)\n d = documentor.Documentor(fake)\n\n for p, fs in d.get_formatters(with_args=True, with_defaults=True, locale=lang,\n excludes=base_provider_formatters):\n print_provider(d, p, fs)\n\n\ndef command(*args):\n try:\n f = args[0]\n except IndexError:\n f = '--help'\n\n if f in [\"--help\", \"-h\"]:\n main()\n sys.exit()\n\n locale = os.environ['LANG'].split('.')[0]\n \n if locale not in AVAILABLE_LOCALES:\n locale = DEFAULT_LOCALE\n fake = Faker(locale=locale)\n\n try:\n print(fake.format(f, *args[1:]))\n except AttributeError:\n print('No faker found for \"{0}\"'.format(f))\n\n\nif __name__ == \"__main__\":\n if sys.stdout.encoding is None:\n print(\"please set python env PYTHONIOENCODING=UTF-8, example: \"\n \"export PYTHONIOENCODING=UTF-8, when write to stdout\", file=sys.stderr)\n exit(1)\n main(*sys.argv[1:])", "path": "faker/__main__.py"}, {"content": "#!/usr/bin/env python\n\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = open(os.path.join(here, 'README.md')).read()\nNEWS = open(os.path.join(here, 'NEWS.txt')).read()\n\n\nversion = '0.3.2'\n\nsetup(name='fake-factory',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README + '\\n\\n' + NEWS,\n scripts=['bin/faker'],\n classifiers=[\n # Get strings from http://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='http://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=['*.tests']),\n platforms=[\"any\"],\n test_suite='faker.tests',\n )\n", "path": "setup.py"}]}
| 1,617 | 464 |
gh_patches_debug_35374
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-3156
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Language: support mention type in Entity.mentions.
[Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type.
Furthermore, this change should add mention_type information to the mention documentation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `language/google/cloud/language/entity.py`
Content:
```
1 # Copyright 2016-2017 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Definition for Google Cloud Natural Language API entities.
16
17 An entity is used to describe a proper name extracted from text.
18 """
19
20
21 class EntityType(object):
22 """List of possible entity types."""
23
24 UNKNOWN = 'UNKNOWN'
25 """Unknown entity type."""
26
27 PERSON = 'PERSON'
28 """Person entity type."""
29
30 LOCATION = 'LOCATION'
31 """Location entity type."""
32
33 ORGANIZATION = 'ORGANIZATION'
34 """Organization entity type."""
35
36 EVENT = 'EVENT'
37 """Event entity type."""
38
39 WORK_OF_ART = 'WORK_OF_ART'
40 """Work of art entity type."""
41
42 CONSUMER_GOOD = 'CONSUMER_GOOD'
43 """Consumer good entity type."""
44
45 OTHER = 'OTHER'
46 """Other entity type (i.e. known but not classified)."""
47
48
49 class Entity(object):
50 """A Google Cloud Natural Language API entity.
51
52 Represents a phrase in text that is a known entity, such as a person,
53 an organization, or location. The API associates information, such as
54 salience and mentions, with entities.
55
56 .. _Entity message: https://cloud.google.com/natural-language/\
57 reference/rest/v1/Entity
58 .. _EntityType enum: https://cloud.google.com/natural-language/\
59 reference/rest/v1/Entity#Type
60
61 See `Entity message`_.
62
63 :type name: str
64 :param name: The name / phrase identified as the entity.
65
66 :type entity_type: str
67 :param entity_type: The type of the entity. See `EntityType enum`_.
68
69 :type metadata: dict
70 :param metadata: The metadata associated with the entity.
71 Wikipedia URLs and Knowledge Graph MIDs are
72 provided, if available. The associated keys are
73 "wikipedia_url" and "mid", respectively.
74
75 :type salience: float
76 :param salience: The prominence of the entity / phrase within the text
77 containing it.
78
79 :type mentions: list
80 :param mentions: List of strings that mention the entity.
81 """
82
83 def __init__(self, name, entity_type, metadata, salience, mentions):
84 self.name = name
85 self.entity_type = entity_type
86 self.metadata = metadata
87 self.salience = salience
88 self.mentions = mentions
89
90 @classmethod
91 def from_api_repr(cls, payload):
92 """Convert an Entity from the JSON API into an :class:`Entity`.
93
94 :param payload: dict
95 :type payload: The value from the backend.
96
97 :rtype: :class:`Entity`
98 :returns: The entity parsed from the API representation.
99 """
100 name = payload['name']
101 entity_type = payload['type']
102 metadata = payload['metadata']
103 salience = payload['salience']
104 mentions = [value['text']['content']
105 for value in payload['mentions']]
106 return cls(name, entity_type, metadata, salience, mentions)
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/language/google/cloud/language/entity.py b/language/google/cloud/language/entity.py
--- a/language/google/cloud/language/entity.py
+++ b/language/google/cloud/language/entity.py
@@ -46,6 +46,80 @@
"""Other entity type (i.e. known but not classified)."""
+class MentionType(object):
+ """List of possible mention types."""
+
+ TYPE_UNKNOWN = 'TYPE_UNKNOWN'
+ """Unknown mention type"""
+
+ PROPER = 'PROPER'
+ """Proper name"""
+
+ COMMON = 'COMMON'
+ """Common noun (or noun compound)"""
+
+
+class Mention(object):
+ """A Google Cloud Natural Language API mention.
+
+ Represents a mention for an entity in the text. Currently, proper noun
+ mentions are supported.
+ """
+ def __init__(self, text, mention_type):
+ self.text = text
+ self.mention_type = mention_type
+
+ def __str__(self):
+ return str(self.text)
+
+ @classmethod
+ def from_api_repr(cls, payload):
+ """Convert a Mention from the JSON API into an :class:`Mention`.
+
+ :param payload: dict
+ :type payload: The value from the backend.
+
+ :rtype: :class:`Mention`
+ :returns: The mention parsed from the API representation.
+ """
+ text = TextSpan.from_api_repr(payload['text'])
+ mention_type = payload['type']
+ return cls(text, mention_type)
+
+
+class TextSpan(object):
+ """A span of text from Google Cloud Natural Language API.
+
+ Represents a word or phrase of text, as well as its offset
+ from the original document.
+ """
+ def __init__(self, content, begin_offset):
+ self.content = content
+ self.begin_offset = begin_offset
+
+ def __str__(self):
+ """Return the string representation of this TextSpan.
+
+ :rtype: str
+ :returns: The text content
+ """
+ return self.content
+
+ @classmethod
+ def from_api_repr(cls, payload):
+ """Convert a TextSpan from the JSON API into an :class:`TextSpan`.
+
+ :param payload: dict
+ :type payload: The value from the backend.
+
+ :rtype: :class:`TextSpan`
+ :returns: The text span parsed from the API representation.
+ """
+ content = payload['content']
+ begin_offset = payload['beginOffset']
+ return cls(content=content, begin_offset=begin_offset)
+
+
class Entity(object):
"""A Google Cloud Natural Language API entity.
@@ -101,6 +175,5 @@
entity_type = payload['type']
metadata = payload['metadata']
salience = payload['salience']
- mentions = [value['text']['content']
- for value in payload['mentions']]
+ mentions = [Mention.from_api_repr(val) for val in payload['mentions']]
return cls(name, entity_type, metadata, salience, mentions)
|
{"golden_diff": "diff --git a/language/google/cloud/language/entity.py b/language/google/cloud/language/entity.py\n--- a/language/google/cloud/language/entity.py\n+++ b/language/google/cloud/language/entity.py\n@@ -46,6 +46,80 @@\n \"\"\"Other entity type (i.e. known but not classified).\"\"\"\n \n \n+class MentionType(object):\n+ \"\"\"List of possible mention types.\"\"\"\n+\n+ TYPE_UNKNOWN = 'TYPE_UNKNOWN'\n+ \"\"\"Unknown mention type\"\"\"\n+\n+ PROPER = 'PROPER'\n+ \"\"\"Proper name\"\"\"\n+\n+ COMMON = 'COMMON'\n+ \"\"\"Common noun (or noun compound)\"\"\"\n+\n+\n+class Mention(object):\n+ \"\"\"A Google Cloud Natural Language API mention.\n+\n+ Represents a mention for an entity in the text. Currently, proper noun\n+ mentions are supported.\n+ \"\"\"\n+ def __init__(self, text, mention_type):\n+ self.text = text\n+ self.mention_type = mention_type\n+\n+ def __str__(self):\n+ return str(self.text)\n+\n+ @classmethod\n+ def from_api_repr(cls, payload):\n+ \"\"\"Convert a Mention from the JSON API into an :class:`Mention`.\n+\n+ :param payload: dict\n+ :type payload: The value from the backend.\n+\n+ :rtype: :class:`Mention`\n+ :returns: The mention parsed from the API representation.\n+ \"\"\"\n+ text = TextSpan.from_api_repr(payload['text'])\n+ mention_type = payload['type']\n+ return cls(text, mention_type)\n+\n+\n+class TextSpan(object):\n+ \"\"\"A span of text from Google Cloud Natural Language API.\n+\n+ Represents a word or phrase of text, as well as its offset\n+ from the original document.\n+ \"\"\"\n+ def __init__(self, content, begin_offset):\n+ self.content = content\n+ self.begin_offset = begin_offset\n+\n+ def __str__(self):\n+ \"\"\"Return the string representation of this TextSpan.\n+\n+ :rtype: str\n+ :returns: The text content\n+ \"\"\"\n+ return self.content\n+\n+ @classmethod\n+ def from_api_repr(cls, payload):\n+ \"\"\"Convert a TextSpan from the JSON API into an :class:`TextSpan`.\n+\n+ :param payload: dict\n+ :type payload: The value from the backend.\n+\n+ :rtype: :class:`TextSpan`\n+ :returns: The text span parsed from the API representation.\n+ \"\"\"\n+ content = payload['content']\n+ begin_offset = payload['beginOffset']\n+ return cls(content=content, begin_offset=begin_offset)\n+\n+\n class Entity(object):\n \"\"\"A Google Cloud Natural Language API entity.\n \n@@ -101,6 +175,5 @@\n entity_type = payload['type']\n metadata = payload['metadata']\n salience = payload['salience']\n- mentions = [value['text']['content']\n- for value in payload['mentions']]\n+ mentions = [Mention.from_api_repr(val) for val in payload['mentions']]\n return cls(name, entity_type, metadata, salience, mentions)\n", "issue": "Language: support mention type in Entity.mentions.\n[Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type.\r\n\r\nFurthermore, this change should add mention_type information to the mention documentation.\n", "before_files": [{"content": "# Copyright 2016-2017 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Definition for Google Cloud Natural Language API entities.\n\nAn entity is used to describe a proper name extracted from text.\n\"\"\"\n\n\nclass EntityType(object):\n \"\"\"List of possible entity types.\"\"\"\n\n UNKNOWN = 'UNKNOWN'\n \"\"\"Unknown entity type.\"\"\"\n\n PERSON = 'PERSON'\n \"\"\"Person entity type.\"\"\"\n\n LOCATION = 'LOCATION'\n \"\"\"Location entity type.\"\"\"\n\n ORGANIZATION = 'ORGANIZATION'\n \"\"\"Organization entity type.\"\"\"\n\n EVENT = 'EVENT'\n \"\"\"Event entity type.\"\"\"\n\n WORK_OF_ART = 'WORK_OF_ART'\n \"\"\"Work of art entity type.\"\"\"\n\n CONSUMER_GOOD = 'CONSUMER_GOOD'\n \"\"\"Consumer good entity type.\"\"\"\n\n OTHER = 'OTHER'\n \"\"\"Other entity type (i.e. known but not classified).\"\"\"\n\n\nclass Entity(object):\n \"\"\"A Google Cloud Natural Language API entity.\n\n Represents a phrase in text that is a known entity, such as a person,\n an organization, or location. The API associates information, such as\n salience and mentions, with entities.\n\n .. _Entity message: https://cloud.google.com/natural-language/\\\n reference/rest/v1/Entity\n .. _EntityType enum: https://cloud.google.com/natural-language/\\\n reference/rest/v1/Entity#Type\n\n See `Entity message`_.\n\n :type name: str\n :param name: The name / phrase identified as the entity.\n\n :type entity_type: str\n :param entity_type: The type of the entity. See `EntityType enum`_.\n\n :type metadata: dict\n :param metadata: The metadata associated with the entity.\n Wikipedia URLs and Knowledge Graph MIDs are\n provided, if available. The associated keys are\n \"wikipedia_url\" and \"mid\", respectively.\n\n :type salience: float\n :param salience: The prominence of the entity / phrase within the text\n containing it.\n\n :type mentions: list\n :param mentions: List of strings that mention the entity.\n \"\"\"\n\n def __init__(self, name, entity_type, metadata, salience, mentions):\n self.name = name\n self.entity_type = entity_type\n self.metadata = metadata\n self.salience = salience\n self.mentions = mentions\n\n @classmethod\n def from_api_repr(cls, payload):\n \"\"\"Convert an Entity from the JSON API into an :class:`Entity`.\n\n :param payload: dict\n :type payload: The value from the backend.\n\n :rtype: :class:`Entity`\n :returns: The entity parsed from the API representation.\n \"\"\"\n name = payload['name']\n entity_type = payload['type']\n metadata = payload['metadata']\n salience = payload['salience']\n mentions = [value['text']['content']\n for value in payload['mentions']]\n return cls(name, entity_type, metadata, salience, mentions)\n", "path": "language/google/cloud/language/entity.py"}], "after_files": [{"content": "# Copyright 2016-2017 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Definition for Google Cloud Natural Language API entities.\n\nAn entity is used to describe a proper name extracted from text.\n\"\"\"\n\n\nclass EntityType(object):\n \"\"\"List of possible entity types.\"\"\"\n\n UNKNOWN = 'UNKNOWN'\n \"\"\"Unknown entity type.\"\"\"\n\n PERSON = 'PERSON'\n \"\"\"Person entity type.\"\"\"\n\n LOCATION = 'LOCATION'\n \"\"\"Location entity type.\"\"\"\n\n ORGANIZATION = 'ORGANIZATION'\n \"\"\"Organization entity type.\"\"\"\n\n EVENT = 'EVENT'\n \"\"\"Event entity type.\"\"\"\n\n WORK_OF_ART = 'WORK_OF_ART'\n \"\"\"Work of art entity type.\"\"\"\n\n CONSUMER_GOOD = 'CONSUMER_GOOD'\n \"\"\"Consumer good entity type.\"\"\"\n\n OTHER = 'OTHER'\n \"\"\"Other entity type (i.e. known but not classified).\"\"\"\n\n\nclass MentionType(object):\n \"\"\"List of possible mention types.\"\"\"\n\n TYPE_UNKNOWN = 'TYPE_UNKNOWN'\n \"\"\"Unknown mention type\"\"\"\n\n PROPER = 'PROPER'\n \"\"\"Proper name\"\"\"\n\n COMMON = 'COMMON'\n \"\"\"Common noun (or noun compound)\"\"\"\n\n\nclass Mention(object):\n \"\"\"A Google Cloud Natural Language API mention.\n\n Represents a mention for an entity in the text. Currently, proper noun\n mentions are supported.\n \"\"\"\n def __init__(self, text, mention_type):\n self.text = text\n self.mention_type = mention_type\n\n def __str__(self):\n return str(self.text)\n\n @classmethod\n def from_api_repr(cls, payload):\n \"\"\"Convert a Mention from the JSON API into an :class:`Mention`.\n\n :param payload: dict\n :type payload: The value from the backend.\n\n :rtype: :class:`Mention`\n :returns: The mention parsed from the API representation.\n \"\"\"\n text = TextSpan.from_api_repr(payload['text'])\n mention_type = payload['type']\n return cls(text, mention_type)\n\n\nclass TextSpan(object):\n \"\"\"A span of text from Google Cloud Natural Language API.\n\n Represents a word or phrase of text, as well as its offset\n from the original document.\n \"\"\"\n def __init__(self, content, begin_offset):\n self.content = content\n self.begin_offset = begin_offset\n\n def __str__(self):\n \"\"\"Return the string representation of this TextSpan.\n\n :rtype: str\n :returns: The text content\n \"\"\"\n return self.content\n\n @classmethod\n def from_api_repr(cls, payload):\n \"\"\"Convert a TextSpan from the JSON API into an :class:`TextSpan`.\n\n :param payload: dict\n :type payload: The value from the backend.\n\n :rtype: :class:`TextSpan`\n :returns: The text span parsed from the API representation.\n \"\"\"\n content = payload['content']\n begin_offset = payload['beginOffset']\n return cls(content=content, begin_offset=begin_offset)\n\n\nclass Entity(object):\n \"\"\"A Google Cloud Natural Language API entity.\n\n Represents a phrase in text that is a known entity, such as a person,\n an organization, or location. The API associates information, such as\n salience and mentions, with entities.\n\n .. _Entity message: https://cloud.google.com/natural-language/\\\n reference/rest/v1/Entity\n .. _EntityType enum: https://cloud.google.com/natural-language/\\\n reference/rest/v1/Entity#Type\n\n See `Entity message`_.\n\n :type name: str\n :param name: The name / phrase identified as the entity.\n\n :type entity_type: str\n :param entity_type: The type of the entity. See `EntityType enum`_.\n\n :type metadata: dict\n :param metadata: The metadata associated with the entity.\n Wikipedia URLs and Knowledge Graph MIDs are\n provided, if available. The associated keys are\n \"wikipedia_url\" and \"mid\", respectively.\n\n :type salience: float\n :param salience: The prominence of the entity / phrase within the text\n containing it.\n\n :type mentions: list\n :param mentions: List of strings that mention the entity.\n \"\"\"\n\n def __init__(self, name, entity_type, metadata, salience, mentions):\n self.name = name\n self.entity_type = entity_type\n self.metadata = metadata\n self.salience = salience\n self.mentions = mentions\n\n @classmethod\n def from_api_repr(cls, payload):\n \"\"\"Convert an Entity from the JSON API into an :class:`Entity`.\n\n :param payload: dict\n :type payload: The value from the backend.\n\n :rtype: :class:`Entity`\n :returns: The entity parsed from the API representation.\n \"\"\"\n name = payload['name']\n entity_type = payload['type']\n metadata = payload['metadata']\n salience = payload['salience']\n mentions = [Mention.from_api_repr(val) for val in payload['mentions']]\n return cls(name, entity_type, metadata, salience, mentions)\n", "path": "language/google/cloud/language/entity.py"}]}
| 1,321 | 689 |
gh_patches_debug_1416
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-4871
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`Insufficient Permission for Chat Profile` on load
Use Case:
1. Create New User without System Manager Role
2. Log-in to System
3. Error Pops-up when system is trying to create Chat Profile.
I tried replicating it to a user that was once has a System Manager role and it was not popping up. It was because the user has already Chat Profile.
Here is the log. Hope this helps!

Any help is greatly appreciated. I will also try to create an issue for this here in discuss.
Thanks,
Dori
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `frappe/chat/doctype/chat_profile/chat_profile.py`
Content:
```
1 # imports - module imports
2 from frappe.model.document import Document
3 from frappe import _
4 import frappe
5
6 # imports - frappe module imports
7 from frappe.core.doctype.version.version import get_diff
8 from frappe.chat.doctype.chat_room import chat_room
9 from frappe.chat.util import (
10 safe_json_loads,
11 filter_dict,
12 dictify
13 )
14
15 session = frappe.session
16
17 class ChatProfile(Document):
18 def before_save(self):
19 if not self.is_new():
20 self.get_doc_before_save()
21
22 def on_update(self):
23 if not self.is_new():
24 b, a = self.get_doc_before_save(), self
25 diff = dictify(get_diff(a, b))
26 if diff:
27 user = session.user
28
29 fields = [changed[0] for changed in diff.changed]
30
31 if 'status' in fields:
32 rooms = chat_room.get(user, filters = ['Chat Room', 'type', '=', 'Direct'])
33 update = dict(user = user, data = dict(status = self.status))
34
35 for room in rooms:
36 frappe.publish_realtime('frappe.chat.profile:update', update, room = room.name, after_commit = True)
37
38 if 'enable_chat' in fields:
39 update = dict(user = user, data = dict(enable_chat = bool(self.enable_chat)))
40 frappe.publish_realtime('frappe.chat.profile:update', update, user = user, after_commit = True)
41
42 def authenticate(user):
43 if user != session.user:
44 frappe.throw(_("Sorry, you're not authorized."))
45
46 @frappe.whitelist()
47 def get(user, fields = None):
48 duser = frappe.get_doc('User', user)
49 dprof = frappe.get_doc('Chat Profile', user)
50
51 # If you're adding something here, make sure the client recieves it.
52 profile = dict(
53 # User
54 name = duser.name,
55 email = duser.email,
56 first_name = duser.first_name,
57 last_name = duser.last_name,
58 username = duser.username,
59 avatar = duser.user_image,
60 bio = duser.bio,
61 # Chat Profile
62 status = dprof.status,
63 chat_background = dprof.chat_background,
64 message_preview = bool(dprof.message_preview),
65 notification_tones = bool(dprof.notification_tones),
66 conversation_tones = bool(dprof.conversation_tones),
67 enable_chat = bool(dprof.enable_chat)
68 )
69 profile = filter_dict(profile, fields)
70
71 return dictify(profile)
72
73 @frappe.whitelist()
74 def create(user, exists_ok = False, fields = None):
75 authenticate(user)
76
77 exists_ok, fields = safe_json_loads(exists_ok, fields)
78
79 if frappe.db.exists('Chat Profile', user):
80 if not exists_ok:
81 frappe.throw(_('Chat Profile for User {user} exists.'.format(user = user)))
82 else:
83 dprof = frappe.new_doc('Chat Profile')
84 dprof.user = user
85 dprof.save()
86
87 profile = get(user, fields = fields)
88
89 return profile
90
91 @frappe.whitelist()
92 def update(user, data):
93 authenticate(user)
94
95 data = safe_json_loads(data)
96
97 dprof = frappe.get_doc('Chat Profile', user)
98 dprof.update(data)
99 dprof.save(ignore_permissions = True)
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/frappe/chat/doctype/chat_profile/chat_profile.py b/frappe/chat/doctype/chat_profile/chat_profile.py
--- a/frappe/chat/doctype/chat_profile/chat_profile.py
+++ b/frappe/chat/doctype/chat_profile/chat_profile.py
@@ -82,7 +82,7 @@
else:
dprof = frappe.new_doc('Chat Profile')
dprof.user = user
- dprof.save()
+ dprof.save(ignore_permissions = True)
profile = get(user, fields = fields)
|
{"golden_diff": "diff --git a/frappe/chat/doctype/chat_profile/chat_profile.py b/frappe/chat/doctype/chat_profile/chat_profile.py\n--- a/frappe/chat/doctype/chat_profile/chat_profile.py\n+++ b/frappe/chat/doctype/chat_profile/chat_profile.py\n@@ -82,7 +82,7 @@\n else:\n dprof = frappe.new_doc('Chat Profile')\n dprof.user = user\n- dprof.save()\n+ dprof.save(ignore_permissions = True)\n \n profile = get(user, fields = fields)\n", "issue": "`Insufficient Permission for Chat Profile` on load\nUse Case:\r\n\r\n1. Create New User without System Manager Role\r\n2. Log-in to System\r\n3. Error Pops-up when system is trying to create Chat Profile.\r\n\r\nI tried replicating it to a user that was once has a System Manager role and it was not popping up. It was because the user has already Chat Profile.\r\n\r\nHere is the log. Hope this helps!\r\n\r\n\r\n\r\n\r\nAny help is greatly appreciated. I will also try to create an issue for this here in discuss.\r\n\r\nThanks,\r\n\r\nDori\n", "before_files": [{"content": "# imports - module imports\nfrom frappe.model.document import Document\nfrom frappe import _\nimport frappe\n\n# imports - frappe module imports\nfrom frappe.core.doctype.version.version import get_diff\nfrom frappe.chat.doctype.chat_room import chat_room\nfrom frappe.chat.util import (\n safe_json_loads,\n filter_dict,\n dictify\n)\n\nsession = frappe.session\n\nclass ChatProfile(Document):\n def before_save(self):\n if not self.is_new():\n self.get_doc_before_save()\n\n def on_update(self):\n if not self.is_new():\n b, a = self.get_doc_before_save(), self\n diff = dictify(get_diff(a, b))\n if diff:\n user = session.user\n\n fields = [changed[0] for changed in diff.changed]\n\n if 'status' in fields:\n rooms = chat_room.get(user, filters = ['Chat Room', 'type', '=', 'Direct'])\n update = dict(user = user, data = dict(status = self.status))\n\n for room in rooms:\n frappe.publish_realtime('frappe.chat.profile:update', update, room = room.name, after_commit = True)\n\n if 'enable_chat' in fields:\n update = dict(user = user, data = dict(enable_chat = bool(self.enable_chat)))\n frappe.publish_realtime('frappe.chat.profile:update', update, user = user, after_commit = True)\n\ndef authenticate(user):\n if user != session.user:\n frappe.throw(_(\"Sorry, you're not authorized.\"))\n\[email protected]()\ndef get(user, fields = None):\n duser = frappe.get_doc('User', user)\n dprof = frappe.get_doc('Chat Profile', user)\n\n # If you're adding something here, make sure the client recieves it.\n profile = dict(\n # User\n name = duser.name,\n email = duser.email,\n first_name = duser.first_name,\n last_name = duser.last_name,\n username = duser.username,\n avatar = duser.user_image,\n bio = duser.bio,\n # Chat Profile\n status = dprof.status,\n chat_background = dprof.chat_background,\n message_preview = bool(dprof.message_preview),\n notification_tones = bool(dprof.notification_tones),\n conversation_tones = bool(dprof.conversation_tones),\n enable_chat = bool(dprof.enable_chat)\n )\n profile = filter_dict(profile, fields)\n\n return dictify(profile)\n\[email protected]()\ndef create(user, exists_ok = False, fields = None):\n authenticate(user)\n\n exists_ok, fields = safe_json_loads(exists_ok, fields)\n\n if frappe.db.exists('Chat Profile', user):\n if not exists_ok:\n frappe.throw(_('Chat Profile for User {user} exists.'.format(user = user)))\n else:\n dprof = frappe.new_doc('Chat Profile')\n dprof.user = user\n dprof.save()\n\n profile = get(user, fields = fields)\n\n return profile\n\[email protected]()\ndef update(user, data):\n authenticate(user)\n\n data = safe_json_loads(data)\n\n dprof = frappe.get_doc('Chat Profile', user)\n dprof.update(data)\n dprof.save(ignore_permissions = True)", "path": "frappe/chat/doctype/chat_profile/chat_profile.py"}], "after_files": [{"content": "# imports - module imports\nfrom frappe.model.document import Document\nfrom frappe import _\nimport frappe\n\n# imports - frappe module imports\nfrom frappe.core.doctype.version.version import get_diff\nfrom frappe.chat.doctype.chat_room import chat_room\nfrom frappe.chat.util import (\n safe_json_loads,\n filter_dict,\n dictify\n)\n\nsession = frappe.session\n\nclass ChatProfile(Document):\n def before_save(self):\n if not self.is_new():\n self.get_doc_before_save()\n\n def on_update(self):\n if not self.is_new():\n b, a = self.get_doc_before_save(), self\n diff = dictify(get_diff(a, b))\n if diff:\n user = session.user\n\n fields = [changed[0] for changed in diff.changed]\n\n if 'status' in fields:\n rooms = chat_room.get(user, filters = ['Chat Room', 'type', '=', 'Direct'])\n update = dict(user = user, data = dict(status = self.status))\n\n for room in rooms:\n frappe.publish_realtime('frappe.chat.profile:update', update, room = room.name, after_commit = True)\n\n if 'enable_chat' in fields:\n update = dict(user = user, data = dict(enable_chat = bool(self.enable_chat)))\n frappe.publish_realtime('frappe.chat.profile:update', update, user = user, after_commit = True)\n\ndef authenticate(user):\n if user != session.user:\n frappe.throw(_(\"Sorry, you're not authorized.\"))\n\[email protected]()\ndef get(user, fields = None):\n duser = frappe.get_doc('User', user)\n dprof = frappe.get_doc('Chat Profile', user)\n\n # If you're adding something here, make sure the client recieves it.\n profile = dict(\n # User\n name = duser.name,\n email = duser.email,\n first_name = duser.first_name,\n last_name = duser.last_name,\n username = duser.username,\n avatar = duser.user_image,\n bio = duser.bio,\n # Chat Profile\n status = dprof.status,\n chat_background = dprof.chat_background,\n message_preview = bool(dprof.message_preview),\n notification_tones = bool(dprof.notification_tones),\n conversation_tones = bool(dprof.conversation_tones),\n enable_chat = bool(dprof.enable_chat)\n )\n profile = filter_dict(profile, fields)\n\n return dictify(profile)\n\[email protected]()\ndef create(user, exists_ok = False, fields = None):\n authenticate(user)\n\n exists_ok, fields = safe_json_loads(exists_ok, fields)\n\n if frappe.db.exists('Chat Profile', user):\n if not exists_ok:\n frappe.throw(_('Chat Profile for User {user} exists.'.format(user = user)))\n else:\n dprof = frappe.new_doc('Chat Profile')\n dprof.user = user\n dprof.save(ignore_permissions = True)\n\n profile = get(user, fields = fields)\n\n return profile\n\[email protected]()\ndef update(user, data):\n authenticate(user)\n\n data = safe_json_loads(data)\n\n dprof = frappe.get_doc('Chat Profile', user)\n dprof.update(data)\n dprof.save(ignore_permissions = True)", "path": "frappe/chat/doctype/chat_profile/chat_profile.py"}]}
| 1,367 | 114 |
gh_patches_debug_23168
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-983
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Go SDK: go get by Version Tag Does Not Work
## Problem & Expected Behavour
`go get` to install the Feast Go SDK should work by version tag:
```
go get github.com/feast-dev/feast/sdk/[email protected]
```
Returns:
```
go get github.com/feast-dev/feast/sdk/[email protected]: module github.com/feast-dev/[email protected] found, but does not contain package github.com/feast-dev/feast/sdk/go
```
Instead of installing the Go SDK at release version tag v0.5.1.
## Proposed Solution
- Update [setup.py](https://github.com/feast-dev/feast/blob/89883d418b4935d595585689d63d246ad133cabe/sdk/python/setup.py#L86) to support non semver tags. (ie `sdk/go/v0.5.1`)
- Introduce additional tag `sdk/go/v<VERSION>` each release. This tag will allow us to pull the go module by a versioned tag. [Reference](https://github.com/golang/go/wiki/Modules#faqs--multi-module-repositories)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/setup.py`
Content:
```
1 # Copyright 2019 The Feast Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import subprocess
17
18 from setuptools import find_packages, setup
19
20 NAME = "feast"
21 DESCRIPTION = "Python SDK for Feast"
22 URL = "https://github.com/feast-dev/feast"
23 AUTHOR = "Feast"
24 REQUIRES_PYTHON = ">=3.6.0"
25
26 REQUIRED = [
27 "Click==7.*",
28 "google-api-core==1.20.*",
29 "google-auth<2.0dev,>=1.14.0",
30 "google-cloud-bigquery==1.18.*",
31 "google-cloud-storage==1.20.*",
32 "google-cloud-core==1.0.*",
33 "googleapis-common-protos==1.*",
34 "google-cloud-bigquery-storage==0.7.*",
35 "grpcio==1.*",
36 "pandas~=1.0.0",
37 "pandavro==1.5.*",
38 "protobuf>=3.10",
39 "PyYAML==5.1.*",
40 "fastavro>=0.22.11,<0.23",
41 "kafka-python==1.*",
42 "tabulate==0.8.*",
43 "toml==0.10.*",
44 "tqdm==4.*",
45 "pyarrow<0.16.0,>=0.15.1",
46 "numpy",
47 "google",
48 "confluent_kafka",
49 ]
50
51 # README file from Feast repo root directory
52 repo_root = (
53 subprocess.Popen(["git", "rev-parse", "--show-toplevel"], stdout=subprocess.PIPE)
54 .communicate()[0]
55 .rstrip()
56 .decode("utf-8")
57 )
58 README_FILE = os.path.join(repo_root, "README.md")
59 with open(os.path.join(README_FILE), "r") as f:
60 LONG_DESCRIPTION = f.read()
61
62 setup(
63 name=NAME,
64 author=AUTHOR,
65 description=DESCRIPTION,
66 long_description=LONG_DESCRIPTION,
67 long_description_content_type="text/markdown",
68 python_requires=REQUIRES_PYTHON,
69 url=URL,
70 packages=find_packages(exclude=("tests",)),
71 install_requires=REQUIRED,
72 # https://stackoverflow.com/questions/28509965/setuptools-development-requirements
73 # Install dev requirements with: pip install -e .[dev]
74 extras_require={"dev": ["mypy-protobuf==1.*", "grpcio-testing==1.*"]},
75 include_package_data=True,
76 license="Apache",
77 classifiers=[
78 # Trove classifiers
79 # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers
80 "License :: OSI Approved :: Apache Software License",
81 "Programming Language :: Python",
82 "Programming Language :: Python :: 3",
83 "Programming Language :: Python :: 3.6",
84 ],
85 entry_points={"console_scripts": ["feast=feast.cli:cli"]},
86 use_scm_version={"root": "../..", "relative_to": __file__},
87 setup_requires=["setuptools_scm"],
88 )
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/setup.py b/sdk/python/setup.py
--- a/sdk/python/setup.py
+++ b/sdk/python/setup.py
@@ -13,6 +13,7 @@
# limitations under the License.
import os
+import re
import subprocess
from setuptools import find_packages, setup
@@ -59,6 +60,13 @@
with open(os.path.join(README_FILE), "r") as f:
LONG_DESCRIPTION = f.read()
+# Add Support for parsing tags that have a prefix containing '/' (ie 'sdk/go') to setuptools_scm.
+# Regex modified from default tag regex in:
+# https://github.com/pypa/setuptools_scm/blob/2a1b46d38fb2b8aeac09853e660bcd0d7c1bc7be/src/setuptools_scm/config.py#L9
+TAG_REGEX = re.compile(
+ r"^(?:[\/\w-]+)?(?P<version>[vV]?\d+(?:\.\d+){0,2}[^\+]*)(?:\+.*)?$"
+)
+
setup(
name=NAME,
author=AUTHOR,
@@ -83,6 +91,6 @@
"Programming Language :: Python :: 3.6",
],
entry_points={"console_scripts": ["feast=feast.cli:cli"]},
- use_scm_version={"root": "../..", "relative_to": __file__},
+ use_scm_version={"root": "../..", "relative_to": __file__, "tag_regex": TAG_REGEX},
setup_requires=["setuptools_scm"],
)
|
{"golden_diff": "diff --git a/sdk/python/setup.py b/sdk/python/setup.py\n--- a/sdk/python/setup.py\n+++ b/sdk/python/setup.py\n@@ -13,6 +13,7 @@\n # limitations under the License.\n \n import os\n+import re\n import subprocess\n \n from setuptools import find_packages, setup\n@@ -59,6 +60,13 @@\n with open(os.path.join(README_FILE), \"r\") as f:\n LONG_DESCRIPTION = f.read()\n \n+# Add Support for parsing tags that have a prefix containing '/' (ie 'sdk/go') to setuptools_scm.\n+# Regex modified from default tag regex in:\n+# https://github.com/pypa/setuptools_scm/blob/2a1b46d38fb2b8aeac09853e660bcd0d7c1bc7be/src/setuptools_scm/config.py#L9\n+TAG_REGEX = re.compile(\n+ r\"^(?:[\\/\\w-]+)?(?P<version>[vV]?\\d+(?:\\.\\d+){0,2}[^\\+]*)(?:\\+.*)?$\"\n+)\n+\n setup(\n name=NAME,\n author=AUTHOR,\n@@ -83,6 +91,6 @@\n \"Programming Language :: Python :: 3.6\",\n ],\n entry_points={\"console_scripts\": [\"feast=feast.cli:cli\"]},\n- use_scm_version={\"root\": \"../..\", \"relative_to\": __file__},\n+ use_scm_version={\"root\": \"../..\", \"relative_to\": __file__, \"tag_regex\": TAG_REGEX},\n setup_requires=[\"setuptools_scm\"],\n )\n", "issue": "Go SDK: go get by Version Tag Does Not Work\n## Problem & Expected Behavour\r\n`go get` to install the Feast Go SDK should work by version tag:\r\n```\r\ngo get github.com/feast-dev/feast/sdk/[email protected]\r\n```\r\nReturns: \r\n```\r\ngo get github.com/feast-dev/feast/sdk/[email protected]: module github.com/feast-dev/[email protected] found, but does not contain package github.com/feast-dev/feast/sdk/go\r\n```\r\nInstead of installing the Go SDK at release version tag v0.5.1.\r\n\r\n## Proposed Solution\r\n- Update [setup.py](https://github.com/feast-dev/feast/blob/89883d418b4935d595585689d63d246ad133cabe/sdk/python/setup.py#L86) to support non semver tags. (ie `sdk/go/v0.5.1`)\r\n- Introduce additional tag `sdk/go/v<VERSION>` each release. This tag will allow us to pull the go module by a versioned tag. [Reference](https://github.com/golang/go/wiki/Modules#faqs--multi-module-repositories)\n", "before_files": [{"content": "# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\nNAME = \"feast\"\nDESCRIPTION = \"Python SDK for Feast\"\nURL = \"https://github.com/feast-dev/feast\"\nAUTHOR = \"Feast\"\nREQUIRES_PYTHON = \">=3.6.0\"\n\nREQUIRED = [\n \"Click==7.*\",\n \"google-api-core==1.20.*\",\n \"google-auth<2.0dev,>=1.14.0\",\n \"google-cloud-bigquery==1.18.*\",\n \"google-cloud-storage==1.20.*\",\n \"google-cloud-core==1.0.*\",\n \"googleapis-common-protos==1.*\",\n \"google-cloud-bigquery-storage==0.7.*\",\n \"grpcio==1.*\",\n \"pandas~=1.0.0\",\n \"pandavro==1.5.*\",\n \"protobuf>=3.10\",\n \"PyYAML==5.1.*\",\n \"fastavro>=0.22.11,<0.23\",\n \"kafka-python==1.*\",\n \"tabulate==0.8.*\",\n \"toml==0.10.*\",\n \"tqdm==4.*\",\n \"pyarrow<0.16.0,>=0.15.1\",\n \"numpy\",\n \"google\",\n \"confluent_kafka\",\n]\n\n# README file from Feast repo root directory\nrepo_root = (\n subprocess.Popen([\"git\", \"rev-parse\", \"--show-toplevel\"], stdout=subprocess.PIPE)\n .communicate()[0]\n .rstrip()\n .decode(\"utf-8\")\n)\nREADME_FILE = os.path.join(repo_root, \"README.md\")\nwith open(os.path.join(README_FILE), \"r\") as f:\n LONG_DESCRIPTION = f.read()\n\nsetup(\n name=NAME,\n author=AUTHOR,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n python_requires=REQUIRES_PYTHON,\n url=URL,\n packages=find_packages(exclude=(\"tests\",)),\n install_requires=REQUIRED,\n # https://stackoverflow.com/questions/28509965/setuptools-development-requirements\n # Install dev requirements with: pip install -e .[dev]\n extras_require={\"dev\": [\"mypy-protobuf==1.*\", \"grpcio-testing==1.*\"]},\n include_package_data=True,\n license=\"Apache\",\n classifiers=[\n # Trove classifiers\n # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n ],\n entry_points={\"console_scripts\": [\"feast=feast.cli:cli\"]},\n use_scm_version={\"root\": \"../..\", \"relative_to\": __file__},\n setup_requires=[\"setuptools_scm\"],\n)\n", "path": "sdk/python/setup.py"}], "after_files": [{"content": "# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport re\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\nNAME = \"feast\"\nDESCRIPTION = \"Python SDK for Feast\"\nURL = \"https://github.com/feast-dev/feast\"\nAUTHOR = \"Feast\"\nREQUIRES_PYTHON = \">=3.6.0\"\n\nREQUIRED = [\n \"Click==7.*\",\n \"google-api-core==1.20.*\",\n \"google-auth<2.0dev,>=1.14.0\",\n \"google-cloud-bigquery==1.18.*\",\n \"google-cloud-storage==1.20.*\",\n \"google-cloud-core==1.0.*\",\n \"googleapis-common-protos==1.*\",\n \"google-cloud-bigquery-storage==0.7.*\",\n \"grpcio==1.*\",\n \"pandas~=1.0.0\",\n \"pandavro==1.5.*\",\n \"protobuf>=3.10\",\n \"PyYAML==5.1.*\",\n \"fastavro>=0.22.11,<0.23\",\n \"kafka-python==1.*\",\n \"tabulate==0.8.*\",\n \"toml==0.10.*\",\n \"tqdm==4.*\",\n \"pyarrow<0.16.0,>=0.15.1\",\n \"numpy\",\n \"google\",\n \"confluent_kafka\",\n]\n\n# README file from Feast repo root directory\nrepo_root = (\n subprocess.Popen([\"git\", \"rev-parse\", \"--show-toplevel\"], stdout=subprocess.PIPE)\n .communicate()[0]\n .rstrip()\n .decode(\"utf-8\")\n)\nREADME_FILE = os.path.join(repo_root, \"README.md\")\nwith open(os.path.join(README_FILE), \"r\") as f:\n LONG_DESCRIPTION = f.read()\n\n# Add Support for parsing tags that have a prefix containing '/' (ie 'sdk/go') to setuptools_scm.\n# Regex modified from default tag regex in:\n# https://github.com/pypa/setuptools_scm/blob/2a1b46d38fb2b8aeac09853e660bcd0d7c1bc7be/src/setuptools_scm/config.py#L9\nTAG_REGEX = re.compile(\n r\"^(?:[\\/\\w-]+)?(?P<version>[vV]?\\d+(?:\\.\\d+){0,2}[^\\+]*)(?:\\+.*)?$\"\n)\n\nsetup(\n name=NAME,\n author=AUTHOR,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n python_requires=REQUIRES_PYTHON,\n url=URL,\n packages=find_packages(exclude=(\"tests\",)),\n install_requires=REQUIRED,\n # https://stackoverflow.com/questions/28509965/setuptools-development-requirements\n # Install dev requirements with: pip install -e .[dev]\n extras_require={\"dev\": [\"mypy-protobuf==1.*\", \"grpcio-testing==1.*\"]},\n include_package_data=True,\n license=\"Apache\",\n classifiers=[\n # Trove classifiers\n # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n ],\n entry_points={\"console_scripts\": [\"feast=feast.cli:cli\"]},\n use_scm_version={\"root\": \"../..\", \"relative_to\": __file__, \"tag_regex\": TAG_REGEX},\n setup_requires=[\"setuptools_scm\"],\n)\n", "path": "sdk/python/setup.py"}]}
| 1,500 | 358 |
gh_patches_debug_20222
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-3211
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
proxyauth option breaks flow state access in addons
##### Steps to reproduce the problem:
1. Create `test.py` addon
```py
from mitmproxy import ctx
class AuthTest:
def response(self, flow):
ctx.log.info('Getting flow state')
flow.get_state()
ctx.log.info('Got flow state')
addons = [
AuthTest()
]
```
2. Start `mitmdump`, navigate to example.com and observe the log
```bash
mitmdump -s server/test.py
Loading script server/test.py
Proxy server listening at http://*:8080
...
[::1]:56410: GET http://example.com/
<< 200 OK 606b
Getting flow state
Got flow state
```
3. Re-start `mitmdump` with proxyauth applied and navigate to example.com again
```bash
mitmdump -s server/test.py --set proxyauth=foo:bar
Loading script server/test.py
Proxy server listening at http://*:8080
...
[::1]:56290: GET http://example.com/
<< 200 OK 606b
Getting flow state
Addon error: Traceback (most recent call last):
File "server/test.py", line 5, in response
flow.get_state()
File "/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/flow.py", line 94, in get_state
d = super().get_state()
File "/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py", line 31, in get_state
state[attr] = get_state(cls, val)
File "/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py", line 94, in get_state
return _process(typeinfo, val, False)
File "/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py", line 77, in _process
for k, v in val.items()
File "/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py", line 77, in <dictcomp>
for k, v in val.items()
File "/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py", line 81, in _process
assert isinstance(val, (int, str, bool, bytes))
AssertionError
```
##### Any other comments? What have you tried so far?
There's a FIXME [right near the code that's breaking](https://github.com/mitmproxy/mitmproxy/blob/master/mitmproxy/stateobject.py#L80), but I think it's a red herring. My best guess is that proxy auth adds something to the flow state that isn't in the list of allowed types `int, str, bool, bytes`—possibly a `dict`.
##### System information
```bash
mitmdump --version
Mitmproxy: 4.0.1
Python: 3.6.5
OpenSSL: OpenSSL 1.0.2o 27 Mar 2018
Platform: Darwin-17.5.0-x86_64-i386-64bit
```
<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/stateobject.py`
Content:
```
1 import typing
2 from typing import Any # noqa
3 from typing import MutableMapping # noqa
4
5 from mitmproxy.coretypes import serializable
6 from mitmproxy.utils import typecheck
7
8
9 class StateObject(serializable.Serializable):
10 """
11 An object with serializable state.
12
13 State attributes can either be serializable types(str, tuple, bool, ...)
14 or StateObject instances themselves.
15 """
16
17 _stateobject_attributes: MutableMapping[str, Any] = None
18 """
19 An attribute-name -> class-or-type dict containing all attributes that
20 should be serialized. If the attribute is a class, it must implement the
21 Serializable protocol.
22 """
23
24 def get_state(self):
25 """
26 Retrieve object state.
27 """
28 state = {}
29 for attr, cls in self._stateobject_attributes.items():
30 val = getattr(self, attr)
31 state[attr] = get_state(cls, val)
32 return state
33
34 def set_state(self, state):
35 """
36 Load object state from data returned by a get_state call.
37 """
38 state = state.copy()
39 for attr, cls in self._stateobject_attributes.items():
40 val = state.pop(attr)
41 if val is None:
42 setattr(self, attr, val)
43 else:
44 curr = getattr(self, attr)
45 if hasattr(curr, "set_state"):
46 curr.set_state(val)
47 else:
48 setattr(self, attr, make_object(cls, val))
49 if state:
50 raise RuntimeWarning("Unexpected State in __setstate__: {}".format(state))
51
52
53 def _process(typeinfo: typecheck.Type, val: typing.Any, make: bool) -> typing.Any:
54 if val is None:
55 return None
56 elif make and hasattr(typeinfo, "from_state"):
57 return typeinfo.from_state(val)
58 elif not make and hasattr(val, "get_state"):
59 return val.get_state()
60
61 typename = str(typeinfo)
62
63 if typename.startswith("typing.List"):
64 T = typecheck.sequence_type(typeinfo)
65 return [_process(T, x, make) for x in val]
66 elif typename.startswith("typing.Tuple"):
67 Ts = typecheck.tuple_types(typeinfo)
68 if len(Ts) != len(val):
69 raise ValueError("Invalid data. Expected {}, got {}.".format(Ts, val))
70 return tuple(
71 _process(T, x, make) for T, x in zip(Ts, val)
72 )
73 elif typename.startswith("typing.Dict"):
74 k_cls, v_cls = typecheck.mapping_types(typeinfo)
75 return {
76 _process(k_cls, k, make): _process(v_cls, v, make)
77 for k, v in val.items()
78 }
79 elif typename.startswith("typing.Any"):
80 # FIXME: Remove this when we remove flow.metadata
81 assert isinstance(val, (int, str, bool, bytes))
82 return val
83 else:
84 return typeinfo(val)
85
86
87 def make_object(typeinfo: typecheck.Type, val: typing.Any) -> typing.Any:
88 """Create an object based on the state given in val."""
89 return _process(typeinfo, val, True)
90
91
92 def get_state(typeinfo: typecheck.Type, val: typing.Any) -> typing.Any:
93 """Get the state of the object given as val."""
94 return _process(typeinfo, val, False)
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/stateobject.py b/mitmproxy/stateobject.py
--- a/mitmproxy/stateobject.py
+++ b/mitmproxy/stateobject.py
@@ -1,6 +1,7 @@
import typing
from typing import Any # noqa
from typing import MutableMapping # noqa
+import json
from mitmproxy.coretypes import serializable
from mitmproxy.utils import typecheck
@@ -77,8 +78,14 @@
for k, v in val.items()
}
elif typename.startswith("typing.Any"):
- # FIXME: Remove this when we remove flow.metadata
- assert isinstance(val, (int, str, bool, bytes))
+ # This requires a bit of explanation. We can't import our IO layer here,
+ # because it causes a circular import. Rather than restructuring the
+ # code for this, we use JSON serialization, which has similar primitive
+ # type restrictions as tnetstring, to check for conformance.
+ try:
+ json.dumps(val)
+ except TypeError:
+ raise ValueError(f"Data not serializable: {val}")
return val
else:
return typeinfo(val)
|
{"golden_diff": "diff --git a/mitmproxy/stateobject.py b/mitmproxy/stateobject.py\n--- a/mitmproxy/stateobject.py\n+++ b/mitmproxy/stateobject.py\n@@ -1,6 +1,7 @@\n import typing\n from typing import Any # noqa\n from typing import MutableMapping # noqa\n+import json\n \n from mitmproxy.coretypes import serializable\n from mitmproxy.utils import typecheck\n@@ -77,8 +78,14 @@\n for k, v in val.items()\n }\n elif typename.startswith(\"typing.Any\"):\n- # FIXME: Remove this when we remove flow.metadata\n- assert isinstance(val, (int, str, bool, bytes))\n+ # This requires a bit of explanation. We can't import our IO layer here,\n+ # because it causes a circular import. Rather than restructuring the\n+ # code for this, we use JSON serialization, which has similar primitive\n+ # type restrictions as tnetstring, to check for conformance.\n+ try:\n+ json.dumps(val)\n+ except TypeError:\n+ raise ValueError(f\"Data not serializable: {val}\")\n return val\n else:\n return typeinfo(val)\n", "issue": "proxyauth option breaks flow state access in addons\n##### Steps to reproduce the problem:\r\n\r\n1. Create `test.py` addon\r\n```py\r\nfrom mitmproxy import ctx\r\nclass AuthTest:\r\n def response(self, flow):\r\n ctx.log.info('Getting flow state')\r\n flow.get_state()\r\n ctx.log.info('Got flow state')\r\n\r\naddons = [\r\n AuthTest()\r\n]\r\n```\r\n2. Start `mitmdump`, navigate to example.com and observe the log\r\n```bash\r\nmitmdump -s server/test.py\r\nLoading script server/test.py\r\nProxy server listening at http://*:8080\r\n...\r\n[::1]:56410: GET http://example.com/\r\n << 200 OK 606b\r\nGetting flow state\r\nGot flow state\r\n```\r\n3. Re-start `mitmdump` with proxyauth applied and navigate to example.com again\r\n```bash\r\nmitmdump -s server/test.py --set proxyauth=foo:bar\r\nLoading script server/test.py\r\nProxy server listening at http://*:8080\r\n...\r\n[::1]:56290: GET http://example.com/\r\n << 200 OK 606b\r\nGetting flow state\r\nAddon error: Traceback (most recent call last):\r\n File \"server/test.py\", line 5, in response\r\n flow.get_state()\r\n File \"/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/flow.py\", line 94, in get_state\r\n d = super().get_state()\r\n File \"/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py\", line 31, in get_state\r\n state[attr] = get_state(cls, val)\r\n File \"/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py\", line 94, in get_state\r\n return _process(typeinfo, val, False)\r\n File \"/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py\", line 77, in _process\r\n for k, v in val.items()\r\n File \"/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py\", line 77, in <dictcomp>\r\n for k, v in val.items()\r\n File \"/usr/local/Cellar/mitmproxy/4.0.1/libexec/lib/python3.6/site-packages/mitmproxy/stateobject.py\", line 81, in _process\r\n assert isinstance(val, (int, str, bool, bytes))\r\nAssertionError\r\n```\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\nThere's a FIXME [right near the code that's breaking](https://github.com/mitmproxy/mitmproxy/blob/master/mitmproxy/stateobject.py#L80), but I think it's a red herring. My best guess is that proxy auth adds something to the flow state that isn't in the list of allowed types `int, str, bool, bytes`\u2014possibly a `dict`.\r\n\r\n##### System information\r\n\r\n```bash\r\nmitmdump --version\r\nMitmproxy: 4.0.1\r\nPython: 3.6.5\r\nOpenSSL: OpenSSL 1.0.2o 27 Mar 2018\r\nPlatform: Darwin-17.5.0-x86_64-i386-64bit\r\n```\r\n\r\n<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->\r\n\n", "before_files": [{"content": "import typing\nfrom typing import Any # noqa\nfrom typing import MutableMapping # noqa\n\nfrom mitmproxy.coretypes import serializable\nfrom mitmproxy.utils import typecheck\n\n\nclass StateObject(serializable.Serializable):\n \"\"\"\n An object with serializable state.\n\n State attributes can either be serializable types(str, tuple, bool, ...)\n or StateObject instances themselves.\n \"\"\"\n\n _stateobject_attributes: MutableMapping[str, Any] = None\n \"\"\"\n An attribute-name -> class-or-type dict containing all attributes that\n should be serialized. If the attribute is a class, it must implement the\n Serializable protocol.\n \"\"\"\n\n def get_state(self):\n \"\"\"\n Retrieve object state.\n \"\"\"\n state = {}\n for attr, cls in self._stateobject_attributes.items():\n val = getattr(self, attr)\n state[attr] = get_state(cls, val)\n return state\n\n def set_state(self, state):\n \"\"\"\n Load object state from data returned by a get_state call.\n \"\"\"\n state = state.copy()\n for attr, cls in self._stateobject_attributes.items():\n val = state.pop(attr)\n if val is None:\n setattr(self, attr, val)\n else:\n curr = getattr(self, attr)\n if hasattr(curr, \"set_state\"):\n curr.set_state(val)\n else:\n setattr(self, attr, make_object(cls, val))\n if state:\n raise RuntimeWarning(\"Unexpected State in __setstate__: {}\".format(state))\n\n\ndef _process(typeinfo: typecheck.Type, val: typing.Any, make: bool) -> typing.Any:\n if val is None:\n return None\n elif make and hasattr(typeinfo, \"from_state\"):\n return typeinfo.from_state(val)\n elif not make and hasattr(val, \"get_state\"):\n return val.get_state()\n\n typename = str(typeinfo)\n\n if typename.startswith(\"typing.List\"):\n T = typecheck.sequence_type(typeinfo)\n return [_process(T, x, make) for x in val]\n elif typename.startswith(\"typing.Tuple\"):\n Ts = typecheck.tuple_types(typeinfo)\n if len(Ts) != len(val):\n raise ValueError(\"Invalid data. Expected {}, got {}.\".format(Ts, val))\n return tuple(\n _process(T, x, make) for T, x in zip(Ts, val)\n )\n elif typename.startswith(\"typing.Dict\"):\n k_cls, v_cls = typecheck.mapping_types(typeinfo)\n return {\n _process(k_cls, k, make): _process(v_cls, v, make)\n for k, v in val.items()\n }\n elif typename.startswith(\"typing.Any\"):\n # FIXME: Remove this when we remove flow.metadata\n assert isinstance(val, (int, str, bool, bytes))\n return val\n else:\n return typeinfo(val)\n\n\ndef make_object(typeinfo: typecheck.Type, val: typing.Any) -> typing.Any:\n \"\"\"Create an object based on the state given in val.\"\"\"\n return _process(typeinfo, val, True)\n\n\ndef get_state(typeinfo: typecheck.Type, val: typing.Any) -> typing.Any:\n \"\"\"Get the state of the object given as val.\"\"\"\n return _process(typeinfo, val, False)\n", "path": "mitmproxy/stateobject.py"}], "after_files": [{"content": "import typing\nfrom typing import Any # noqa\nfrom typing import MutableMapping # noqa\nimport json\n\nfrom mitmproxy.coretypes import serializable\nfrom mitmproxy.utils import typecheck\n\n\nclass StateObject(serializable.Serializable):\n \"\"\"\n An object with serializable state.\n\n State attributes can either be serializable types(str, tuple, bool, ...)\n or StateObject instances themselves.\n \"\"\"\n\n _stateobject_attributes: MutableMapping[str, Any] = None\n \"\"\"\n An attribute-name -> class-or-type dict containing all attributes that\n should be serialized. If the attribute is a class, it must implement the\n Serializable protocol.\n \"\"\"\n\n def get_state(self):\n \"\"\"\n Retrieve object state.\n \"\"\"\n state = {}\n for attr, cls in self._stateobject_attributes.items():\n val = getattr(self, attr)\n state[attr] = get_state(cls, val)\n return state\n\n def set_state(self, state):\n \"\"\"\n Load object state from data returned by a get_state call.\n \"\"\"\n state = state.copy()\n for attr, cls in self._stateobject_attributes.items():\n val = state.pop(attr)\n if val is None:\n setattr(self, attr, val)\n else:\n curr = getattr(self, attr)\n if hasattr(curr, \"set_state\"):\n curr.set_state(val)\n else:\n setattr(self, attr, make_object(cls, val))\n if state:\n raise RuntimeWarning(\"Unexpected State in __setstate__: {}\".format(state))\n\n\ndef _process(typeinfo: typecheck.Type, val: typing.Any, make: bool) -> typing.Any:\n if val is None:\n return None\n elif make and hasattr(typeinfo, \"from_state\"):\n return typeinfo.from_state(val)\n elif not make and hasattr(val, \"get_state\"):\n return val.get_state()\n\n typename = str(typeinfo)\n\n if typename.startswith(\"typing.List\"):\n T = typecheck.sequence_type(typeinfo)\n return [_process(T, x, make) for x in val]\n elif typename.startswith(\"typing.Tuple\"):\n Ts = typecheck.tuple_types(typeinfo)\n if len(Ts) != len(val):\n raise ValueError(\"Invalid data. Expected {}, got {}.\".format(Ts, val))\n return tuple(\n _process(T, x, make) for T, x in zip(Ts, val)\n )\n elif typename.startswith(\"typing.Dict\"):\n k_cls, v_cls = typecheck.mapping_types(typeinfo)\n return {\n _process(k_cls, k, make): _process(v_cls, v, make)\n for k, v in val.items()\n }\n elif typename.startswith(\"typing.Any\"):\n # This requires a bit of explanation. We can't import our IO layer here,\n # because it causes a circular import. Rather than restructuring the\n # code for this, we use JSON serialization, which has similar primitive\n # type restrictions as tnetstring, to check for conformance.\n try:\n json.dumps(val)\n except TypeError:\n raise ValueError(f\"Data not serializable: {val}\")\n return val\n else:\n return typeinfo(val)\n\n\ndef make_object(typeinfo: typecheck.Type, val: typing.Any) -> typing.Any:\n \"\"\"Create an object based on the state given in val.\"\"\"\n return _process(typeinfo, val, True)\n\n\ndef get_state(typeinfo: typecheck.Type, val: typing.Any) -> typing.Any:\n \"\"\"Get the state of the object given as val.\"\"\"\n return _process(typeinfo, val, False)\n", "path": "mitmproxy/stateobject.py"}]}
| 1,965 | 258 |
gh_patches_debug_506
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-765
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add test for email sending after moderator was added to project
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `euth/projects/emails.py`
Content:
```
1 from euth.contrib.emails import OpinEmail
2
3
4 class ModeratorAddedEmail(OpinEmail):
5 template_name = 'notify_new_moderator'
6
7 def get_recipients(self):
8 self.kwargs['user']
9
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/euth/projects/emails.py b/euth/projects/emails.py
--- a/euth/projects/emails.py
+++ b/euth/projects/emails.py
@@ -4,5 +4,5 @@
class ModeratorAddedEmail(OpinEmail):
template_name = 'notify_new_moderator'
- def get_recipients(self):
- self.kwargs['user']
+ def get_receivers(self):
+ return [self.kwargs['user']]
|
{"golden_diff": "diff --git a/euth/projects/emails.py b/euth/projects/emails.py\n--- a/euth/projects/emails.py\n+++ b/euth/projects/emails.py\n@@ -4,5 +4,5 @@\n class ModeratorAddedEmail(OpinEmail):\n template_name = 'notify_new_moderator'\n \n- def get_recipients(self):\n- self.kwargs['user']\n+ def get_receivers(self):\n+ return [self.kwargs['user']]\n", "issue": "add test for email sending after moderator was added to project\n\n", "before_files": [{"content": "from euth.contrib.emails import OpinEmail\n\n\nclass ModeratorAddedEmail(OpinEmail):\n template_name = 'notify_new_moderator'\n\n def get_recipients(self):\n self.kwargs['user']\n", "path": "euth/projects/emails.py"}], "after_files": [{"content": "from euth.contrib.emails import OpinEmail\n\n\nclass ModeratorAddedEmail(OpinEmail):\n template_name = 'notify_new_moderator'\n\n def get_receivers(self):\n return [self.kwargs['user']]\n", "path": "euth/projects/emails.py"}]}
| 326 | 99 |
gh_patches_debug_20006
|
rasdani/github-patches
|
git_diff
|
googleapis__google-api-python-client-1104
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create and populate folder for static discovery documents
`googleapiclient` downloads the discovery docs for a Google API service at runtime and then constructs a client. Issue #1063 captures the need to move to a static package where the discovery docs are not fetched at run time. An incremental step towards satisfying #1063 would be to create a folder with static Google API discovery documents in this repo. The [discoveries folder](https://github.com/googleapis/discovery-artifact-manager/tree/master/discoveries) in the googleapis/discovery-artifact-manager repo has an up to date copy of the discovery documents. One approach would be to modify [synth.py](https://github.com/googleapis/google-api-python-client/blob/master/synth.py) to copy the discovery documents from discovery-artifact-manager similar to how it is done [here](https://github.com/googleapis/python-api-common-protos/blob/master/synth.py#L38).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `synth.py`
Content:
```
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import synthtool as s
16 from synthtool import gcp
17
18 common = gcp.CommonTemplates()
19
20 # ----------------------------------------------------------------------------
21 # Add templated files
22 # ----------------------------------------------------------------------------
23 templated_files = common.py_library()
24
25 # Copy kokoro configs.
26 # Docs are excluded as repo docs cannot currently be generated using sphinx.
27 s.move(templated_files / '.kokoro', excludes=['**/docs/*', 'publish-docs.sh'])
28
29 # Also move issue templates
30 s.move(templated_files / '.github')
31
32 s.shell.run(["nox", "-s", "docs"], hide_output=False)
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/synth.py b/synth.py
--- a/synth.py
+++ b/synth.py
@@ -14,6 +14,9 @@
import synthtool as s
from synthtool import gcp
+from synthtool.sources import git
+
+DISCOVERY_ARTIFACT_MANAGER_REPO = "googleapis/discovery-artifact-manager"
common = gcp.CommonTemplates()
@@ -29,4 +32,20 @@
# Also move issue templates
s.move(templated_files / '.github')
-s.shell.run(["nox", "-s", "docs"], hide_output=False)
\ No newline at end of file
+# ----------------------------------------------------------------------------
+# Copy discoveries folder from discovery-artifact-manager repo
+# ----------------------------------------------------------------------------
+
+discovery_artifact_manager_url = git.make_repo_clone_url(DISCOVERY_ARTIFACT_MANAGER_REPO)
+discovery_artifacts = git.clone(discovery_artifact_manager_url) / "discoveries"
+
+excludes = [
+ "**/BUILD.bazel",
+]
+s.copy(discovery_artifacts,
+ "googleapiclient/discovery_cache/documents", excludes=excludes)
+
+# ----------------------------------------------------------------------------
+# Generate docs
+# ----------------------------------------------------------------------------
+s.shell.run(["nox", "-s", "docs"], hide_output=False)
|
{"golden_diff": "diff --git a/synth.py b/synth.py\n--- a/synth.py\n+++ b/synth.py\n@@ -14,6 +14,9 @@\n \n import synthtool as s\n from synthtool import gcp\n+from synthtool.sources import git\n+\n+DISCOVERY_ARTIFACT_MANAGER_REPO = \"googleapis/discovery-artifact-manager\"\n \n common = gcp.CommonTemplates()\n \n@@ -29,4 +32,20 @@\n # Also move issue templates\n s.move(templated_files / '.github')\n \n-s.shell.run([\"nox\", \"-s\", \"docs\"], hide_output=False)\n\\ No newline at end of file\n+# ----------------------------------------------------------------------------\n+# Copy discoveries folder from discovery-artifact-manager repo\n+# ----------------------------------------------------------------------------\n+\n+discovery_artifact_manager_url = git.make_repo_clone_url(DISCOVERY_ARTIFACT_MANAGER_REPO)\n+discovery_artifacts = git.clone(discovery_artifact_manager_url) / \"discoveries\"\n+\n+excludes = [\n+ \"**/BUILD.bazel\",\n+]\n+s.copy(discovery_artifacts,\n+ \"googleapiclient/discovery_cache/documents\", excludes=excludes)\n+\n+# ----------------------------------------------------------------------------\n+# Generate docs\n+# ----------------------------------------------------------------------------\n+s.shell.run([\"nox\", \"-s\", \"docs\"], hide_output=False)\n", "issue": "Create and populate folder for static discovery documents \n`googleapiclient` downloads the discovery docs for a Google API service at runtime and then constructs a client. Issue #1063 captures the need to move to a static package where the discovery docs are not fetched at run time. An incremental step towards satisfying #1063 would be to create a folder with static Google API discovery documents in this repo. The [discoveries folder](https://github.com/googleapis/discovery-artifact-manager/tree/master/discoveries) in the googleapis/discovery-artifact-manager repo has an up to date copy of the discovery documents. One approach would be to modify [synth.py](https://github.com/googleapis/google-api-python-client/blob/master/synth.py) to copy the discovery documents from discovery-artifact-manager similar to how it is done [here](https://github.com/googleapis/python-api-common-protos/blob/master/synth.py#L38).\n", "before_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport synthtool as s\nfrom synthtool import gcp\n\ncommon = gcp.CommonTemplates()\n\n# ----------------------------------------------------------------------------\n# Add templated files\n# ----------------------------------------------------------------------------\ntemplated_files = common.py_library()\n\n# Copy kokoro configs.\n# Docs are excluded as repo docs cannot currently be generated using sphinx.\ns.move(templated_files / '.kokoro', excludes=['**/docs/*', 'publish-docs.sh'])\n\n# Also move issue templates\ns.move(templated_files / '.github')\n\ns.shell.run([\"nox\", \"-s\", \"docs\"], hide_output=False)", "path": "synth.py"}], "after_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport synthtool as s\nfrom synthtool import gcp\nfrom synthtool.sources import git\n\nDISCOVERY_ARTIFACT_MANAGER_REPO = \"googleapis/discovery-artifact-manager\"\n\ncommon = gcp.CommonTemplates()\n\n# ----------------------------------------------------------------------------\n# Add templated files\n# ----------------------------------------------------------------------------\ntemplated_files = common.py_library()\n\n# Copy kokoro configs.\n# Docs are excluded as repo docs cannot currently be generated using sphinx.\ns.move(templated_files / '.kokoro', excludes=['**/docs/*', 'publish-docs.sh'])\n\n# Also move issue templates\ns.move(templated_files / '.github')\n\n# ----------------------------------------------------------------------------\n# Copy discoveries folder from discovery-artifact-manager repo\n# ----------------------------------------------------------------------------\n\ndiscovery_artifact_manager_url = git.make_repo_clone_url(DISCOVERY_ARTIFACT_MANAGER_REPO)\ndiscovery_artifacts = git.clone(discovery_artifact_manager_url) / \"discoveries\"\n\nexcludes = [\n \"**/BUILD.bazel\",\n]\ns.copy(discovery_artifacts,\n \"googleapiclient/discovery_cache/documents\", excludes=excludes)\n\n# ----------------------------------------------------------------------------\n# Generate docs\n# ----------------------------------------------------------------------------\ns.shell.run([\"nox\", \"-s\", \"docs\"], hide_output=False)\n", "path": "synth.py"}]}
| 758 | 262 |
gh_patches_debug_24701
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-6328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Migrate DocHistory objects for RFCs
### Describe the issue
`DocHistory` objects that pertain to the RFC rather than the I-D need to be migrated to hang off the new `type_id="rfc"` `Document`. The `name` and `rfc_number` fields should be updated to match.
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/doc/migrations/0017_move_dochistory.py`
Content:
```
1 # Generated by Django 4.2.5 on 2023-09-11 17:52
2
3 from django.db import migrations
4
5 from django.db.models import Subquery, OuterRef, F
6
7
8 def forward(apps, schema_editor):
9 DocHistory = apps.get_model("doc", "DocHistory")
10 RelatedDocument = apps.get_model("doc", "RelatedDocument")
11 DocHistory.objects.filter(type_id="draft", doc__type_id="rfc").update(type_id="rfc")
12 DocHistory.objects.filter(
13 type_id="draft", doc__type_id="draft", name__startswith="rfc"
14 ).annotate(
15 rfc_id=Subquery(
16 RelatedDocument.objects.filter(
17 source_id=OuterRef("doc_id"), relationship_id="became_rfc"
18 ).values_list("target_id", flat=True)[:1]
19 )
20 ).update(
21 doc_id=F("rfc_id"), type_id="rfc"
22 )
23 assert not DocHistory.objects.filter(
24 name__startswith="rfc", type_id="draft"
25 ).exists()
26
27
28 class Migration(migrations.Migration):
29 dependencies = [
30 ("doc", "0016_delete_docalias"),
31 ]
32
33 # There is no going back
34 operations = [migrations.RunPython(forward)]
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/doc/migrations/0017_move_dochistory.py b/ietf/doc/migrations/0017_move_dochistory.py
--- a/ietf/doc/migrations/0017_move_dochistory.py
+++ b/ietf/doc/migrations/0017_move_dochistory.py
@@ -8,6 +8,7 @@
def forward(apps, schema_editor):
DocHistory = apps.get_model("doc", "DocHistory")
RelatedDocument = apps.get_model("doc", "RelatedDocument")
+ Document = apps.get_model("doc", "Document")
DocHistory.objects.filter(type_id="draft", doc__type_id="rfc").update(type_id="rfc")
DocHistory.objects.filter(
type_id="draft", doc__type_id="draft", name__startswith="rfc"
@@ -20,9 +21,19 @@
).update(
doc_id=F("rfc_id"), type_id="rfc"
)
+ DocHistory.objects.filter(type_id="rfc").annotate(
+ rfcno=Subquery(
+ Document.objects.filter(pk=OuterRef("doc_id")).values_list(
+ "rfc_number", flat=True
+ )[:1]
+ )
+ ).update(rfc_number=F("rfcno"))
assert not DocHistory.objects.filter(
name__startswith="rfc", type_id="draft"
).exists()
+ assert not DocHistory.objects.filter(
+ type_id="rfc", rfc_number__isnull=True
+ ).exists()
class Migration(migrations.Migration):
|
{"golden_diff": "diff --git a/ietf/doc/migrations/0017_move_dochistory.py b/ietf/doc/migrations/0017_move_dochistory.py\n--- a/ietf/doc/migrations/0017_move_dochistory.py\n+++ b/ietf/doc/migrations/0017_move_dochistory.py\n@@ -8,6 +8,7 @@\n def forward(apps, schema_editor):\n DocHistory = apps.get_model(\"doc\", \"DocHistory\")\n RelatedDocument = apps.get_model(\"doc\", \"RelatedDocument\")\n+ Document = apps.get_model(\"doc\", \"Document\")\n DocHistory.objects.filter(type_id=\"draft\", doc__type_id=\"rfc\").update(type_id=\"rfc\")\n DocHistory.objects.filter(\n type_id=\"draft\", doc__type_id=\"draft\", name__startswith=\"rfc\"\n@@ -20,9 +21,19 @@\n ).update(\n doc_id=F(\"rfc_id\"), type_id=\"rfc\"\n )\n+ DocHistory.objects.filter(type_id=\"rfc\").annotate(\n+ rfcno=Subquery(\n+ Document.objects.filter(pk=OuterRef(\"doc_id\")).values_list(\n+ \"rfc_number\", flat=True\n+ )[:1]\n+ )\n+ ).update(rfc_number=F(\"rfcno\"))\n assert not DocHistory.objects.filter(\n name__startswith=\"rfc\", type_id=\"draft\"\n ).exists()\n+ assert not DocHistory.objects.filter(\n+ type_id=\"rfc\", rfc_number__isnull=True\n+ ).exists()\n \n \n class Migration(migrations.Migration):\n", "issue": "Migrate DocHistory objects for RFCs\n### Describe the issue\n\n`DocHistory` objects that pertain to the RFC rather than the I-D need to be migrated to hang off the new `type_id=\"rfc\"` `Document`. The `name` and `rfc_number` fields should be updated to match.\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "# Generated by Django 4.2.5 on 2023-09-11 17:52\n\nfrom django.db import migrations\n\nfrom django.db.models import Subquery, OuterRef, F\n\n\ndef forward(apps, schema_editor):\n DocHistory = apps.get_model(\"doc\", \"DocHistory\")\n RelatedDocument = apps.get_model(\"doc\", \"RelatedDocument\")\n DocHistory.objects.filter(type_id=\"draft\", doc__type_id=\"rfc\").update(type_id=\"rfc\")\n DocHistory.objects.filter(\n type_id=\"draft\", doc__type_id=\"draft\", name__startswith=\"rfc\"\n ).annotate(\n rfc_id=Subquery(\n RelatedDocument.objects.filter(\n source_id=OuterRef(\"doc_id\"), relationship_id=\"became_rfc\"\n ).values_list(\"target_id\", flat=True)[:1]\n )\n ).update(\n doc_id=F(\"rfc_id\"), type_id=\"rfc\"\n )\n assert not DocHistory.objects.filter(\n name__startswith=\"rfc\", type_id=\"draft\"\n ).exists()\n\n\nclass Migration(migrations.Migration):\n dependencies = [\n (\"doc\", \"0016_delete_docalias\"),\n ]\n\n # There is no going back\n operations = [migrations.RunPython(forward)]\n", "path": "ietf/doc/migrations/0017_move_dochistory.py"}], "after_files": [{"content": "# Generated by Django 4.2.5 on 2023-09-11 17:52\n\nfrom django.db import migrations\n\nfrom django.db.models import Subquery, OuterRef, F\n\n\ndef forward(apps, schema_editor):\n DocHistory = apps.get_model(\"doc\", \"DocHistory\")\n RelatedDocument = apps.get_model(\"doc\", \"RelatedDocument\")\n Document = apps.get_model(\"doc\", \"Document\")\n DocHistory.objects.filter(type_id=\"draft\", doc__type_id=\"rfc\").update(type_id=\"rfc\")\n DocHistory.objects.filter(\n type_id=\"draft\", doc__type_id=\"draft\", name__startswith=\"rfc\"\n ).annotate(\n rfc_id=Subquery(\n RelatedDocument.objects.filter(\n source_id=OuterRef(\"doc_id\"), relationship_id=\"became_rfc\"\n ).values_list(\"target_id\", flat=True)[:1]\n )\n ).update(\n doc_id=F(\"rfc_id\"), type_id=\"rfc\"\n )\n DocHistory.objects.filter(type_id=\"rfc\").annotate(\n rfcno=Subquery(\n Document.objects.filter(pk=OuterRef(\"doc_id\")).values_list(\n \"rfc_number\", flat=True\n )[:1]\n )\n ).update(rfc_number=F(\"rfcno\"))\n assert not DocHistory.objects.filter(\n name__startswith=\"rfc\", type_id=\"draft\"\n ).exists()\n assert not DocHistory.objects.filter(\n type_id=\"rfc\", rfc_number__isnull=True\n ).exists()\n\n\nclass Migration(migrations.Migration):\n dependencies = [\n (\"doc\", \"0016_delete_docalias\"),\n ]\n\n # There is no going back\n operations = [migrations.RunPython(forward)]\n", "path": "ietf/doc/migrations/0017_move_dochistory.py"}]}
| 720 | 350 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.