
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_5286
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-998
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Failure to check out revision pre-commit v1.15.1
```console
$ cat .pre-commit-config.yaml
repos:
- repo: https://github.com/asottile/pyupgrade
rev: v1.13.0
hooks:
- id: pyupgrade
$ pre-commit install-hooks
[INFO] Initializing environment for https://github.com/asottile/pyupgrade.
An unexpected error has occurred: CalledProcessError: Command: ('/usr/bin/git', 'checkout', 'v1.13.0')
Return code: 1
Expected return code: 0
Output: (none)
Errors:
error: pathspec 'v1.13.0' did not match any file(s) known to git.
Check the log at /code/.cache/pre-commit/pre-commit.log
lyftsvc@b780c05acb2e:/code/places$ cat ~/.cacp^C
lyftsvc@b780c05acb2e:/code/places$ cat /code/.cache/pre-commit/pre-commit.log
An unexpected error has occurred: CalledProcessError: Command: ('/usr/bin/git', 'checkout', 'v1.13.0')
Return code: 1
Expected return code: 0
Output: (none)
Errors:
error: pathspec 'v1.13.0' did not match any file(s) known to git.
Traceback (most recent call last):
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 172, in clone_strategy
self._shallow_clone(ref, _git_cmd)
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 149, in _shallow_clone
git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 166, in _git_cmd
cmd_output('git', *args, cwd=directory, env=env)
File "/venv/lib/python3.6/site-packages/pre_commit/util.py", line 153, in cmd_output
returncode, cmd, retcode, output=(stdout, stderr),
pre_commit.util.CalledProcessError: Command: ('/usr/bin/git', '-c', 'protocol.version=2', 'fetch', 'origin', 'v1.13.0', '--depth=1')
Return code: 128
Expected return code: 0
Output: (none)
Errors:
fatal: unknown value for config 'protocol.version': 2
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/venv/lib/python3.6/site-packages/pre_commit/error_handler.py", line 46, in error_handler
yield
File "/venv/lib/python3.6/site-packages/pre_commit/main.py", line 274, in main
return install_hooks(args.config, store)
File "/venv/lib/python3.6/site-packages/pre_commit/commands/install_uninstall.py", line 129, in install_hooks
install_hook_envs(all_hooks(load_config(config_file), store), store)
File "/venv/lib/python3.6/site-packages/pre_commit/repository.py", line 221, in all_hooks
for repo in root_config['repos']
File "/venv/lib/python3.6/site-packages/pre_commit/repository.py", line 222, in <genexpr>
for hook in _repository_hooks(repo, store, root_config)
File "/venv/lib/python3.6/site-packages/pre_commit/repository.py", line 197, in _repository_hooks
return _cloned_repository_hooks(repo_config, store, root_config)
File "/venv/lib/python3.6/site-packages/pre_commit/repository.py", line 166, in _cloned_repository_hooks
manifest_path = os.path.join(store.clone(repo, rev), C.MANIFEST_FILE)
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 176, in clone
return self._new_repo(repo, ref, deps, clone_strategy)
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 128, in _new_repo
make_strategy(directory)
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 174, in clone_strategy
self._complete_clone(ref, _git_cmd)
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 142, in _complete_clone
git_cmd('checkout', ref)
File "/venv/lib/python3.6/site-packages/pre_commit/store.py", line 166, in _git_cmd
cmd_output('git', *args, cwd=directory, env=env)
File "/venv/lib/python3.6/site-packages/pre_commit/util.py", line 153, in cmd_output
returncode, cmd, retcode, output=(stdout, stderr),
pre_commit.util.CalledProcessError: Command: ('/usr/bin/git', 'checkout', 'v1.13.0')
Return code: 1
Expected return code: 0
Output: (none)
Errors:
error: pathspec 'v1.13.0' did not match any file(s) known to git.
```
Perhaps related to the new clone strategy
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/store.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import contextlib
4 import io
5 import logging
6 import os.path
7 import sqlite3
8 import tempfile
9
10 import pre_commit.constants as C
11 from pre_commit import file_lock
12 from pre_commit import git
13 from pre_commit.util import CalledProcessError
14 from pre_commit.util import clean_path_on_failure
15 from pre_commit.util import cmd_output
16 from pre_commit.util import resource_text
17 from pre_commit.util import rmtree
18
19
20 logger = logging.getLogger('pre_commit')
21
22
23 def _get_default_directory():
24 """Returns the default directory for the Store. This is intentionally
25 underscored to indicate that `Store.get_default_directory` is the intended
26 way to get this information. This is also done so
27 `Store.get_default_directory` can be mocked in tests and
28 `_get_default_directory` can be tested.
29 """
30 return os.environ.get('PRE_COMMIT_HOME') or os.path.join(
31 os.environ.get('XDG_CACHE_HOME') or os.path.expanduser('~/.cache'),
32 'pre-commit',
33 )
34
35
36 class Store(object):
37 get_default_directory = staticmethod(_get_default_directory)
38
39 def __init__(self, directory=None):
40 self.directory = directory or Store.get_default_directory()
41 self.db_path = os.path.join(self.directory, 'db.db')
42
43 if not os.path.exists(self.directory):
44 os.makedirs(self.directory)
45 with io.open(os.path.join(self.directory, 'README'), 'w') as f:
46 f.write(
47 'This directory is maintained by the pre-commit project.\n'
48 'Learn more: https://github.com/pre-commit/pre-commit\n',
49 )
50
51 if os.path.exists(self.db_path):
52 return
53 with self.exclusive_lock():
54 # Another process may have already completed this work
55 if os.path.exists(self.db_path): # pragma: no cover (race)
56 return
57 # To avoid a race where someone ^Cs between db creation and
58 # execution of the CREATE TABLE statement
59 fd, tmpfile = tempfile.mkstemp(dir=self.directory)
60 # We'll be managing this file ourselves
61 os.close(fd)
62 with self.connect(db_path=tmpfile) as db:
63 db.executescript(
64 'CREATE TABLE repos ('
65 ' repo TEXT NOT NULL,'
66 ' ref TEXT NOT NULL,'
67 ' path TEXT NOT NULL,'
68 ' PRIMARY KEY (repo, ref)'
69 ');',
70 )
71 self._create_config_table_if_not_exists(db)
72
73 # Atomic file move
74 os.rename(tmpfile, self.db_path)
75
76 @contextlib.contextmanager
77 def exclusive_lock(self):
78 def blocked_cb(): # pragma: no cover (tests are single-process)
79 logger.info('Locking pre-commit directory')
80
81 with file_lock.lock(os.path.join(self.directory, '.lock'), blocked_cb):
82 yield
83
84 @contextlib.contextmanager
85 def connect(self, db_path=None):
86 db_path = db_path or self.db_path
87 # sqlite doesn't close its fd with its contextmanager >.<
88 # contextlib.closing fixes this.
89 # See: https://stackoverflow.com/a/28032829/812183
90 with contextlib.closing(sqlite3.connect(db_path)) as db:
91 # this creates a transaction
92 with db:
93 yield db
94
95 @classmethod
96 def db_repo_name(cls, repo, deps):
97 if deps:
98 return '{}:{}'.format(repo, ','.join(sorted(deps)))
99 else:
100 return repo
101
102 def _new_repo(self, repo, ref, deps, make_strategy):
103 repo = self.db_repo_name(repo, deps)
104
105 def _get_result():
106 # Check if we already exist
107 with self.connect() as db:
108 result = db.execute(
109 'SELECT path FROM repos WHERE repo = ? AND ref = ?',
110 (repo, ref),
111 ).fetchone()
112 if result:
113 return result[0]
114
115 result = _get_result()
116 if result:
117 return result
118 with self.exclusive_lock():
119 # Another process may have already completed this work
120 result = _get_result()
121 if result: # pragma: no cover (race)
122 return result
123
124 logger.info('Initializing environment for {}.'.format(repo))
125
126 directory = tempfile.mkdtemp(prefix='repo', dir=self.directory)
127 with clean_path_on_failure(directory):
128 make_strategy(directory)
129
130 # Update our db with the created repo
131 with self.connect() as db:
132 db.execute(
133 'INSERT INTO repos (repo, ref, path) VALUES (?, ?, ?)',
134 [repo, ref, directory],
135 )
136 return directory
137
138 def _complete_clone(self, ref, git_cmd):
139 """Perform a complete clone of a repository and its submodules """
140
141 git_cmd('fetch', 'origin')
142 git_cmd('checkout', ref)
143 git_cmd('submodule', 'update', '--init', '--recursive')
144
145 def _shallow_clone(self, ref, git_cmd): # pragma: windows no cover
146 """Perform a shallow clone of a repository and its submodules """
147
148 git_config = 'protocol.version=2'
149 git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')
150 git_cmd('checkout', ref)
151 git_cmd(
152 '-c', git_config, 'submodule', 'update', '--init',
153 '--recursive', '--depth=1',
154 )
155
156 def clone(self, repo, ref, deps=()):
157 """Clone the given url and checkout the specific ref."""
158
159 if os.path.isdir(repo):
160 repo = os.path.abspath(repo)
161
162 def clone_strategy(directory):
163 env = git.no_git_env()
164
165 def _git_cmd(*args):
166 cmd_output('git', *args, cwd=directory, env=env)
167
168 _git_cmd('init', '.')
169 _git_cmd('remote', 'add', 'origin', repo)
170
171 try:
172 self._shallow_clone(ref, _git_cmd)
173 except CalledProcessError:
174 self._complete_clone(ref, _git_cmd)
175
176 return self._new_repo(repo, ref, deps, clone_strategy)
177
178 LOCAL_RESOURCES = (
179 'Cargo.toml', 'main.go', 'main.rs', '.npmignore', 'package.json',
180 'pre_commit_dummy_package.gemspec', 'setup.py',
181 )
182
183 def make_local(self, deps):
184 def make_local_strategy(directory):
185 for resource in self.LOCAL_RESOURCES:
186 contents = resource_text('empty_template_{}'.format(resource))
187 with io.open(os.path.join(directory, resource), 'w') as f:
188 f.write(contents)
189
190 env = git.no_git_env()
191
192 # initialize the git repository so it looks more like cloned repos
193 def _git_cmd(*args):
194 cmd_output('git', *args, cwd=directory, env=env)
195
196 _git_cmd('init', '.')
197 _git_cmd('config', 'remote.origin.url', '<<unknown>>')
198 _git_cmd('add', '.')
199 git.commit(repo=directory)
200
201 return self._new_repo(
202 'local', C.LOCAL_REPO_VERSION, deps, make_local_strategy,
203 )
204
205 def _create_config_table_if_not_exists(self, db):
206 db.executescript(
207 'CREATE TABLE IF NOT EXISTS configs ('
208 ' path TEXT NOT NULL,'
209 ' PRIMARY KEY (path)'
210 ');',
211 )
212
213 def mark_config_used(self, path):
214 path = os.path.realpath(path)
215 # don't insert config files that do not exist
216 if not os.path.exists(path):
217 return
218 with self.connect() as db:
219 # TODO: eventually remove this and only create in _create
220 self._create_config_table_if_not_exists(db)
221 db.execute('INSERT OR IGNORE INTO configs VALUES (?)', (path,))
222
223 def select_all_configs(self):
224 with self.connect() as db:
225 self._create_config_table_if_not_exists(db)
226 rows = db.execute('SELECT path FROM configs').fetchall()
227 return [path for path, in rows]
228
229 def delete_configs(self, configs):
230 with self.connect() as db:
231 rows = [(path,) for path in configs]
232 db.executemany('DELETE FROM configs WHERE path = ?', rows)
233
234 def select_all_repos(self):
235 with self.connect() as db:
236 return db.execute('SELECT repo, ref, path from repos').fetchall()
237
238 def delete_repo(self, db_repo_name, ref, path):
239 with self.connect() as db:
240 db.execute(
241 'DELETE FROM repos WHERE repo = ? and ref = ?',
242 (db_repo_name, ref),
243 )
244 rmtree(path)
245
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/store.py b/pre_commit/store.py
--- a/pre_commit/store.py
+++ b/pre_commit/store.py
@@ -138,7 +138,7 @@
def _complete_clone(self, ref, git_cmd):
"""Perform a complete clone of a repository and its submodules """
- git_cmd('fetch', 'origin')
+ git_cmd('fetch', 'origin', '--tags')
git_cmd('checkout', ref)
git_cmd('submodule', 'update', '--init', '--recursive')
|
{"golden_diff": "diff --git a/pre_commit/store.py b/pre_commit/store.py\n--- a/pre_commit/store.py\n+++ b/pre_commit/store.py\n@@ -138,7 +138,7 @@\n def _complete_clone(self, ref, git_cmd):\n \"\"\"Perform a complete clone of a repository and its submodules \"\"\"\n \n- git_cmd('fetch', 'origin')\n+ git_cmd('fetch', 'origin', '--tags')\n git_cmd('checkout', ref)\n git_cmd('submodule', 'update', '--init', '--recursive')\n", "issue": "Failure to check out revision pre-commit v1.15.1\n```console\r\n$ cat .pre-commit-config.yaml \r\nrepos:\r\n- repo: https://github.com/asottile/pyupgrade\r\n rev: v1.13.0\r\n hooks:\r\n - id: pyupgrade\r\n$ pre-commit install-hooks\r\n[INFO] Initializing environment for https://github.com/asottile/pyupgrade.\r\nAn unexpected error has occurred: CalledProcessError: Command: ('/usr/bin/git', 'checkout', 'v1.13.0')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors: \r\n error: pathspec 'v1.13.0' did not match any file(s) known to git.\r\n \r\n\r\nCheck the log at /code/.cache/pre-commit/pre-commit.log\r\nlyftsvc@b780c05acb2e:/code/places$ cat ~/.cacp^C\r\nlyftsvc@b780c05acb2e:/code/places$ cat /code/.cache/pre-commit/pre-commit.log \r\nAn unexpected error has occurred: CalledProcessError: Command: ('/usr/bin/git', 'checkout', 'v1.13.0')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors: \r\n error: pathspec 'v1.13.0' did not match any file(s) known to git.\r\n \r\n\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 172, in clone_strategy\r\n self._shallow_clone(ref, _git_cmd)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 149, in _shallow_clone\r\n git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 166, in _git_cmd\r\n cmd_output('git', *args, cwd=directory, env=env)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/util.py\", line 153, in cmd_output\r\n returncode, cmd, retcode, output=(stdout, stderr),\r\npre_commit.util.CalledProcessError: Command: ('/usr/bin/git', '-c', 'protocol.version=2', 'fetch', 'origin', 'v1.13.0', '--depth=1')\r\nReturn code: 128\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors: \r\n fatal: unknown value for config 'protocol.version': 2\r\n \r\n\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/error_handler.py\", line 46, in error_handler\r\n yield\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/main.py\", line 274, in main\r\n return install_hooks(args.config, store)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/commands/install_uninstall.py\", line 129, in install_hooks\r\n install_hook_envs(all_hooks(load_config(config_file), store), store)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/repository.py\", line 221, in all_hooks\r\n for repo in root_config['repos']\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/repository.py\", line 222, in <genexpr>\r\n for hook in _repository_hooks(repo, store, root_config)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/repository.py\", line 197, in _repository_hooks\r\n return _cloned_repository_hooks(repo_config, store, root_config)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/repository.py\", line 166, in _cloned_repository_hooks\r\n manifest_path = os.path.join(store.clone(repo, rev), C.MANIFEST_FILE)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 176, in clone\r\n return self._new_repo(repo, ref, deps, clone_strategy)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 128, in _new_repo\r\n make_strategy(directory)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 174, in clone_strategy\r\n self._complete_clone(ref, _git_cmd)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 142, in _complete_clone\r\n git_cmd('checkout', ref)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/store.py\", line 166, in _git_cmd\r\n cmd_output('git', *args, cwd=directory, env=env)\r\n File \"/venv/lib/python3.6/site-packages/pre_commit/util.py\", line 153, in cmd_output\r\n returncode, cmd, retcode, output=(stdout, stderr),\r\npre_commit.util.CalledProcessError: Command: ('/usr/bin/git', 'checkout', 'v1.13.0')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors: \r\n error: pathspec 'v1.13.0' did not match any file(s) known to git.\r\n```\r\n\r\nPerhaps related to the new clone strategy\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport logging\nimport os.path\nimport sqlite3\nimport tempfile\n\nimport pre_commit.constants as C\nfrom pre_commit import file_lock\nfrom pre_commit import git\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import resource_text\nfrom pre_commit.util import rmtree\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ndef _get_default_directory():\n \"\"\"Returns the default directory for the Store. This is intentionally\n underscored to indicate that `Store.get_default_directory` is the intended\n way to get this information. This is also done so\n `Store.get_default_directory` can be mocked in tests and\n `_get_default_directory` can be tested.\n \"\"\"\n return os.environ.get('PRE_COMMIT_HOME') or os.path.join(\n os.environ.get('XDG_CACHE_HOME') or os.path.expanduser('~/.cache'),\n 'pre-commit',\n )\n\n\nclass Store(object):\n get_default_directory = staticmethod(_get_default_directory)\n\n def __init__(self, directory=None):\n self.directory = directory or Store.get_default_directory()\n self.db_path = os.path.join(self.directory, 'db.db')\n\n if not os.path.exists(self.directory):\n os.makedirs(self.directory)\n with io.open(os.path.join(self.directory, 'README'), 'w') as f:\n f.write(\n 'This directory is maintained by the pre-commit project.\\n'\n 'Learn more: https://github.com/pre-commit/pre-commit\\n',\n )\n\n if os.path.exists(self.db_path):\n return\n with self.exclusive_lock():\n # Another process may have already completed this work\n if os.path.exists(self.db_path): # pragma: no cover (race)\n return\n # To avoid a race where someone ^Cs between db creation and\n # execution of the CREATE TABLE statement\n fd, tmpfile = tempfile.mkstemp(dir=self.directory)\n # We'll be managing this file ourselves\n os.close(fd)\n with self.connect(db_path=tmpfile) as db:\n db.executescript(\n 'CREATE TABLE repos ('\n ' repo TEXT NOT NULL,'\n ' ref TEXT NOT NULL,'\n ' path TEXT NOT NULL,'\n ' PRIMARY KEY (repo, ref)'\n ');',\n )\n self._create_config_table_if_not_exists(db)\n\n # Atomic file move\n os.rename(tmpfile, self.db_path)\n\n @contextlib.contextmanager\n def exclusive_lock(self):\n def blocked_cb(): # pragma: no cover (tests are single-process)\n logger.info('Locking pre-commit directory')\n\n with file_lock.lock(os.path.join(self.directory, '.lock'), blocked_cb):\n yield\n\n @contextlib.contextmanager\n def connect(self, db_path=None):\n db_path = db_path or self.db_path\n # sqlite doesn't close its fd with its contextmanager >.<\n # contextlib.closing fixes this.\n # See: https://stackoverflow.com/a/28032829/812183\n with contextlib.closing(sqlite3.connect(db_path)) as db:\n # this creates a transaction\n with db:\n yield db\n\n @classmethod\n def db_repo_name(cls, repo, deps):\n if deps:\n return '{}:{}'.format(repo, ','.join(sorted(deps)))\n else:\n return repo\n\n def _new_repo(self, repo, ref, deps, make_strategy):\n repo = self.db_repo_name(repo, deps)\n\n def _get_result():\n # Check if we already exist\n with self.connect() as db:\n result = db.execute(\n 'SELECT path FROM repos WHERE repo = ? AND ref = ?',\n (repo, ref),\n ).fetchone()\n if result:\n return result[0]\n\n result = _get_result()\n if result:\n return result\n with self.exclusive_lock():\n # Another process may have already completed this work\n result = _get_result()\n if result: # pragma: no cover (race)\n return result\n\n logger.info('Initializing environment for {}.'.format(repo))\n\n directory = tempfile.mkdtemp(prefix='repo', dir=self.directory)\n with clean_path_on_failure(directory):\n make_strategy(directory)\n\n # Update our db with the created repo\n with self.connect() as db:\n db.execute(\n 'INSERT INTO repos (repo, ref, path) VALUES (?, ?, ?)',\n [repo, ref, directory],\n )\n return directory\n\n def _complete_clone(self, ref, git_cmd):\n \"\"\"Perform a complete clone of a repository and its submodules \"\"\"\n\n git_cmd('fetch', 'origin')\n git_cmd('checkout', ref)\n git_cmd('submodule', 'update', '--init', '--recursive')\n\n def _shallow_clone(self, ref, git_cmd): # pragma: windows no cover\n \"\"\"Perform a shallow clone of a repository and its submodules \"\"\"\n\n git_config = 'protocol.version=2'\n git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')\n git_cmd('checkout', ref)\n git_cmd(\n '-c', git_config, 'submodule', 'update', '--init',\n '--recursive', '--depth=1',\n )\n\n def clone(self, repo, ref, deps=()):\n \"\"\"Clone the given url and checkout the specific ref.\"\"\"\n\n if os.path.isdir(repo):\n repo = os.path.abspath(repo)\n\n def clone_strategy(directory):\n env = git.no_git_env()\n\n def _git_cmd(*args):\n cmd_output('git', *args, cwd=directory, env=env)\n\n _git_cmd('init', '.')\n _git_cmd('remote', 'add', 'origin', repo)\n\n try:\n self._shallow_clone(ref, _git_cmd)\n except CalledProcessError:\n self._complete_clone(ref, _git_cmd)\n\n return self._new_repo(repo, ref, deps, clone_strategy)\n\n LOCAL_RESOURCES = (\n 'Cargo.toml', 'main.go', 'main.rs', '.npmignore', 'package.json',\n 'pre_commit_dummy_package.gemspec', 'setup.py',\n )\n\n def make_local(self, deps):\n def make_local_strategy(directory):\n for resource in self.LOCAL_RESOURCES:\n contents = resource_text('empty_template_{}'.format(resource))\n with io.open(os.path.join(directory, resource), 'w') as f:\n f.write(contents)\n\n env = git.no_git_env()\n\n # initialize the git repository so it looks more like cloned repos\n def _git_cmd(*args):\n cmd_output('git', *args, cwd=directory, env=env)\n\n _git_cmd('init', '.')\n _git_cmd('config', 'remote.origin.url', '<<unknown>>')\n _git_cmd('add', '.')\n git.commit(repo=directory)\n\n return self._new_repo(\n 'local', C.LOCAL_REPO_VERSION, deps, make_local_strategy,\n )\n\n def _create_config_table_if_not_exists(self, db):\n db.executescript(\n 'CREATE TABLE IF NOT EXISTS configs ('\n ' path TEXT NOT NULL,'\n ' PRIMARY KEY (path)'\n ');',\n )\n\n def mark_config_used(self, path):\n path = os.path.realpath(path)\n # don't insert config files that do not exist\n if not os.path.exists(path):\n return\n with self.connect() as db:\n # TODO: eventually remove this and only create in _create\n self._create_config_table_if_not_exists(db)\n db.execute('INSERT OR IGNORE INTO configs VALUES (?)', (path,))\n\n def select_all_configs(self):\n with self.connect() as db:\n self._create_config_table_if_not_exists(db)\n rows = db.execute('SELECT path FROM configs').fetchall()\n return [path for path, in rows]\n\n def delete_configs(self, configs):\n with self.connect() as db:\n rows = [(path,) for path in configs]\n db.executemany('DELETE FROM configs WHERE path = ?', rows)\n\n def select_all_repos(self):\n with self.connect() as db:\n return db.execute('SELECT repo, ref, path from repos').fetchall()\n\n def delete_repo(self, db_repo_name, ref, path):\n with self.connect() as db:\n db.execute(\n 'DELETE FROM repos WHERE repo = ? and ref = ?',\n (db_repo_name, ref),\n )\n rmtree(path)\n", "path": "pre_commit/store.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport logging\nimport os.path\nimport sqlite3\nimport tempfile\n\nimport pre_commit.constants as C\nfrom pre_commit import file_lock\nfrom pre_commit import git\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import resource_text\nfrom pre_commit.util import rmtree\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ndef _get_default_directory():\n \"\"\"Returns the default directory for the Store. This is intentionally\n underscored to indicate that `Store.get_default_directory` is the intended\n way to get this information. This is also done so\n `Store.get_default_directory` can be mocked in tests and\n `_get_default_directory` can be tested.\n \"\"\"\n return os.environ.get('PRE_COMMIT_HOME') or os.path.join(\n os.environ.get('XDG_CACHE_HOME') or os.path.expanduser('~/.cache'),\n 'pre-commit',\n )\n\n\nclass Store(object):\n get_default_directory = staticmethod(_get_default_directory)\n\n def __init__(self, directory=None):\n self.directory = directory or Store.get_default_directory()\n self.db_path = os.path.join(self.directory, 'db.db')\n\n if not os.path.exists(self.directory):\n os.makedirs(self.directory)\n with io.open(os.path.join(self.directory, 'README'), 'w') as f:\n f.write(\n 'This directory is maintained by the pre-commit project.\\n'\n 'Learn more: https://github.com/pre-commit/pre-commit\\n',\n )\n\n if os.path.exists(self.db_path):\n return\n with self.exclusive_lock():\n # Another process may have already completed this work\n if os.path.exists(self.db_path): # pragma: no cover (race)\n return\n # To avoid a race where someone ^Cs between db creation and\n # execution of the CREATE TABLE statement\n fd, tmpfile = tempfile.mkstemp(dir=self.directory)\n # We'll be managing this file ourselves\n os.close(fd)\n with self.connect(db_path=tmpfile) as db:\n db.executescript(\n 'CREATE TABLE repos ('\n ' repo TEXT NOT NULL,'\n ' ref TEXT NOT NULL,'\n ' path TEXT NOT NULL,'\n ' PRIMARY KEY (repo, ref)'\n ');',\n )\n self._create_config_table_if_not_exists(db)\n\n # Atomic file move\n os.rename(tmpfile, self.db_path)\n\n @contextlib.contextmanager\n def exclusive_lock(self):\n def blocked_cb(): # pragma: no cover (tests are single-process)\n logger.info('Locking pre-commit directory')\n\n with file_lock.lock(os.path.join(self.directory, '.lock'), blocked_cb):\n yield\n\n @contextlib.contextmanager\n def connect(self, db_path=None):\n db_path = db_path or self.db_path\n # sqlite doesn't close its fd with its contextmanager >.<\n # contextlib.closing fixes this.\n # See: https://stackoverflow.com/a/28032829/812183\n with contextlib.closing(sqlite3.connect(db_path)) as db:\n # this creates a transaction\n with db:\n yield db\n\n @classmethod\n def db_repo_name(cls, repo, deps):\n if deps:\n return '{}:{}'.format(repo, ','.join(sorted(deps)))\n else:\n return repo\n\n def _new_repo(self, repo, ref, deps, make_strategy):\n repo = self.db_repo_name(repo, deps)\n\n def _get_result():\n # Check if we already exist\n with self.connect() as db:\n result = db.execute(\n 'SELECT path FROM repos WHERE repo = ? AND ref = ?',\n (repo, ref),\n ).fetchone()\n if result:\n return result[0]\n\n result = _get_result()\n if result:\n return result\n with self.exclusive_lock():\n # Another process may have already completed this work\n result = _get_result()\n if result: # pragma: no cover (race)\n return result\n\n logger.info('Initializing environment for {}.'.format(repo))\n\n directory = tempfile.mkdtemp(prefix='repo', dir=self.directory)\n with clean_path_on_failure(directory):\n make_strategy(directory)\n\n # Update our db with the created repo\n with self.connect() as db:\n db.execute(\n 'INSERT INTO repos (repo, ref, path) VALUES (?, ?, ?)',\n [repo, ref, directory],\n )\n return directory\n\n def _complete_clone(self, ref, git_cmd):\n \"\"\"Perform a complete clone of a repository and its submodules \"\"\"\n\n git_cmd('fetch', 'origin', '--tags')\n git_cmd('checkout', ref)\n git_cmd('submodule', 'update', '--init', '--recursive')\n\n def _shallow_clone(self, ref, git_cmd): # pragma: windows no cover\n \"\"\"Perform a shallow clone of a repository and its submodules \"\"\"\n\n git_config = 'protocol.version=2'\n git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')\n git_cmd('checkout', ref)\n git_cmd(\n '-c', git_config, 'submodule', 'update', '--init',\n '--recursive', '--depth=1',\n )\n\n def clone(self, repo, ref, deps=()):\n \"\"\"Clone the given url and checkout the specific ref.\"\"\"\n\n if os.path.isdir(repo):\n repo = os.path.abspath(repo)\n\n def clone_strategy(directory):\n env = git.no_git_env()\n\n def _git_cmd(*args):\n cmd_output('git', *args, cwd=directory, env=env)\n\n _git_cmd('init', '.')\n _git_cmd('remote', 'add', 'origin', repo)\n\n try:\n self._shallow_clone(ref, _git_cmd)\n except CalledProcessError:\n self._complete_clone(ref, _git_cmd)\n\n return self._new_repo(repo, ref, deps, clone_strategy)\n\n LOCAL_RESOURCES = (\n 'Cargo.toml', 'main.go', 'main.rs', '.npmignore', 'package.json',\n 'pre_commit_dummy_package.gemspec', 'setup.py',\n )\n\n def make_local(self, deps):\n def make_local_strategy(directory):\n for resource in self.LOCAL_RESOURCES:\n contents = resource_text('empty_template_{}'.format(resource))\n with io.open(os.path.join(directory, resource), 'w') as f:\n f.write(contents)\n\n env = git.no_git_env()\n\n # initialize the git repository so it looks more like cloned repos\n def _git_cmd(*args):\n cmd_output('git', *args, cwd=directory, env=env)\n\n _git_cmd('init', '.')\n _git_cmd('config', 'remote.origin.url', '<<unknown>>')\n _git_cmd('add', '.')\n git.commit(repo=directory)\n\n return self._new_repo(\n 'local', C.LOCAL_REPO_VERSION, deps, make_local_strategy,\n )\n\n def _create_config_table_if_not_exists(self, db):\n db.executescript(\n 'CREATE TABLE IF NOT EXISTS configs ('\n ' path TEXT NOT NULL,'\n ' PRIMARY KEY (path)'\n ');',\n )\n\n def mark_config_used(self, path):\n path = os.path.realpath(path)\n # don't insert config files that do not exist\n if not os.path.exists(path):\n return\n with self.connect() as db:\n # TODO: eventually remove this and only create in _create\n self._create_config_table_if_not_exists(db)\n db.execute('INSERT OR IGNORE INTO configs VALUES (?)', (path,))\n\n def select_all_configs(self):\n with self.connect() as db:\n self._create_config_table_if_not_exists(db)\n rows = db.execute('SELECT path FROM configs').fetchall()\n return [path for path, in rows]\n\n def delete_configs(self, configs):\n with self.connect() as db:\n rows = [(path,) for path in configs]\n db.executemany('DELETE FROM configs WHERE path = ?', rows)\n\n def select_all_repos(self):\n with self.connect() as db:\n return db.execute('SELECT repo, ref, path from repos').fetchall()\n\n def delete_repo(self, db_repo_name, ref, path):\n with self.connect() as db:\n db.execute(\n 'DELETE FROM repos WHERE repo = ? and ref = ?',\n (db_repo_name, ref),\n )\n rmtree(path)\n", "path": "pre_commit/store.py"}]}
| 3,966 | 116 |
gh_patches_debug_26644
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-293
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cliquet.storage.exceptions.BackendError: ConnectionError: Error 8 connecting to localhos:6379
The config wizard has typos:
https://github.com/Kinto/kinto/blob/master/kinto/config/__init__.py#L39
https://github.com/Kinto/kinto/blob/master/kinto/config/__init__.py#L41
https://github.com/Kinto/kinto/blob/master/kinto/config/__init__.py#L43
I am not sure how, but maybe we could have a way to test that the produced default config works
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/config/__init__.py`
Content:
```
1 import os
2 import binascii
3 import codecs
4 from six.moves import input
5
6 HERE = os.path.abspath(os.path.dirname(__file__))
7
8
9 def render_template(template, destination, **kwargs):
10 template = os.path.join(HERE, template)
11
12 with codecs.open(template, 'r', encoding='utf-8') as f:
13 raw_template = f.read()
14 rendered = raw_template.format(**kwargs)
15 with codecs.open(destination, 'w+', encoding='utf-8') as output:
16 output.write(rendered)
17
18
19 def init(config_file):
20 values = {}
21 values['secret'] = binascii.b2a_hex(os.urandom(32))
22
23 backend = input("Which backend to use? "
24 "(1 - postgresql, 2 - redis, default - memory) ").strip()
25
26 if backend == '1':
27 # Postgresql configuration
28 postgresql_url = "postgres://postgres:postgres@localhost/postgres"
29 values['storage_backend'] = "cliquet.storage.postgresql"
30 values['storage_url'] = postgresql_url
31 values['cache_backend'] = "cliquet.cache.postgresql"
32 values['cache_url'] = postgresql_url
33 values['permission_backend'] = "cliquet.permission.postgresql"
34 values['permission_url'] = postgresql_url
35
36 elif backend == '2':
37 # Redis configuration
38 values['storage_backend'] = "cliquet.storage.redis"
39 values['storage_url'] = "redis://localhos:6379/1"
40 values['cache_backend'] = "cliquet.cache.redis"
41 values['cache_url'] = "redis://localhos:6379/2"
42 values['permission_backend'] = "cliquet.permission.redis"
43 values['permission_url'] = "redis://localhos:6379/3"
44
45 else:
46 # Memory configuration / default backend
47 values['storage_backend'] = "cliquet.storage.memory"
48 values['storage_url'] = ""
49 values['cache_backend'] = "cliquet.cache.memory"
50 values['cache_url'] = ""
51 values['permission_backend'] = "cliquet.permission.memory"
52 values['permission_url'] = ""
53
54 render_template("kinto.tpl", config_file,
55 secret=values['secret'],
56 storage_backend=values['storage_backend'],
57 storage_url=values['storage_url'],
58 cache_backend=values['cache_backend'],
59 cache_url=values['cache_url'],
60 permission_backend=values['permission_backend'],
61 permission_url=values['permission_url'])
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/config/__init__.py b/kinto/config/__init__.py
--- a/kinto/config/__init__.py
+++ b/kinto/config/__init__.py
@@ -36,11 +36,11 @@
elif backend == '2':
# Redis configuration
values['storage_backend'] = "cliquet.storage.redis"
- values['storage_url'] = "redis://localhos:6379/1"
+ values['storage_url'] = "redis://localhost:6379/1"
values['cache_backend'] = "cliquet.cache.redis"
- values['cache_url'] = "redis://localhos:6379/2"
+ values['cache_url'] = "redis://localhost:6379/2"
values['permission_backend'] = "cliquet.permission.redis"
- values['permission_url'] = "redis://localhos:6379/3"
+ values['permission_url'] = "redis://localhost:6379/3"
else:
# Memory configuration / default backend
@@ -51,11 +51,4 @@
values['permission_backend'] = "cliquet.permission.memory"
values['permission_url'] = ""
- render_template("kinto.tpl", config_file,
- secret=values['secret'],
- storage_backend=values['storage_backend'],
- storage_url=values['storage_url'],
- cache_backend=values['cache_backend'],
- cache_url=values['cache_url'],
- permission_backend=values['permission_backend'],
- permission_url=values['permission_url'])
+ render_template("kinto.tpl", config_file, **values)
|
{"golden_diff": "diff --git a/kinto/config/__init__.py b/kinto/config/__init__.py\n--- a/kinto/config/__init__.py\n+++ b/kinto/config/__init__.py\n@@ -36,11 +36,11 @@\n elif backend == '2':\n # Redis configuration\n values['storage_backend'] = \"cliquet.storage.redis\"\n- values['storage_url'] = \"redis://localhos:6379/1\"\n+ values['storage_url'] = \"redis://localhost:6379/1\"\n values['cache_backend'] = \"cliquet.cache.redis\"\n- values['cache_url'] = \"redis://localhos:6379/2\"\n+ values['cache_url'] = \"redis://localhost:6379/2\"\n values['permission_backend'] = \"cliquet.permission.redis\"\n- values['permission_url'] = \"redis://localhos:6379/3\"\n+ values['permission_url'] = \"redis://localhost:6379/3\"\n \n else:\n # Memory configuration / default backend\n@@ -51,11 +51,4 @@\n values['permission_backend'] = \"cliquet.permission.memory\"\n values['permission_url'] = \"\"\n \n- render_template(\"kinto.tpl\", config_file,\n- secret=values['secret'],\n- storage_backend=values['storage_backend'],\n- storage_url=values['storage_url'],\n- cache_backend=values['cache_backend'],\n- cache_url=values['cache_url'],\n- permission_backend=values['permission_backend'],\n- permission_url=values['permission_url'])\n+ render_template(\"kinto.tpl\", config_file, **values)\n", "issue": "cliquet.storage.exceptions.BackendError: ConnectionError: Error 8 connecting to localhos:6379\nThe config wizard has typos:\n\nhttps://github.com/Kinto/kinto/blob/master/kinto/config/__init__.py#L39\nhttps://github.com/Kinto/kinto/blob/master/kinto/config/__init__.py#L41\nhttps://github.com/Kinto/kinto/blob/master/kinto/config/__init__.py#L43\n\nI am not sure how, but maybe we could have a way to test that the produced default config works\n\n", "before_files": [{"content": "import os\nimport binascii\nimport codecs\nfrom six.moves import input\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef render_template(template, destination, **kwargs):\n template = os.path.join(HERE, template)\n\n with codecs.open(template, 'r', encoding='utf-8') as f:\n raw_template = f.read()\n rendered = raw_template.format(**kwargs)\n with codecs.open(destination, 'w+', encoding='utf-8') as output:\n output.write(rendered)\n\n\ndef init(config_file):\n values = {}\n values['secret'] = binascii.b2a_hex(os.urandom(32))\n\n backend = input(\"Which backend to use? \"\n \"(1 - postgresql, 2 - redis, default - memory) \").strip()\n\n if backend == '1':\n # Postgresql configuration\n postgresql_url = \"postgres://postgres:postgres@localhost/postgres\"\n values['storage_backend'] = \"cliquet.storage.postgresql\"\n values['storage_url'] = postgresql_url\n values['cache_backend'] = \"cliquet.cache.postgresql\"\n values['cache_url'] = postgresql_url\n values['permission_backend'] = \"cliquet.permission.postgresql\"\n values['permission_url'] = postgresql_url\n\n elif backend == '2':\n # Redis configuration\n values['storage_backend'] = \"cliquet.storage.redis\"\n values['storage_url'] = \"redis://localhos:6379/1\"\n values['cache_backend'] = \"cliquet.cache.redis\"\n values['cache_url'] = \"redis://localhos:6379/2\"\n values['permission_backend'] = \"cliquet.permission.redis\"\n values['permission_url'] = \"redis://localhos:6379/3\"\n\n else:\n # Memory configuration / default backend\n values['storage_backend'] = \"cliquet.storage.memory\"\n values['storage_url'] = \"\"\n values['cache_backend'] = \"cliquet.cache.memory\"\n values['cache_url'] = \"\"\n values['permission_backend'] = \"cliquet.permission.memory\"\n values['permission_url'] = \"\"\n\n render_template(\"kinto.tpl\", config_file,\n secret=values['secret'],\n storage_backend=values['storage_backend'],\n storage_url=values['storage_url'],\n cache_backend=values['cache_backend'],\n cache_url=values['cache_url'],\n permission_backend=values['permission_backend'],\n permission_url=values['permission_url'])\n", "path": "kinto/config/__init__.py"}], "after_files": [{"content": "import os\nimport binascii\nimport codecs\nfrom six.moves import input\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef render_template(template, destination, **kwargs):\n template = os.path.join(HERE, template)\n\n with codecs.open(template, 'r', encoding='utf-8') as f:\n raw_template = f.read()\n rendered = raw_template.format(**kwargs)\n with codecs.open(destination, 'w+', encoding='utf-8') as output:\n output.write(rendered)\n\n\ndef init(config_file):\n values = {}\n values['secret'] = binascii.b2a_hex(os.urandom(32))\n\n backend = input(\"Which backend to use? \"\n \"(1 - postgresql, 2 - redis, default - memory) \").strip()\n\n if backend == '1':\n # Postgresql configuration\n postgresql_url = \"postgres://postgres:postgres@localhost/postgres\"\n values['storage_backend'] = \"cliquet.storage.postgresql\"\n values['storage_url'] = postgresql_url\n values['cache_backend'] = \"cliquet.cache.postgresql\"\n values['cache_url'] = postgresql_url\n values['permission_backend'] = \"cliquet.permission.postgresql\"\n values['permission_url'] = postgresql_url\n\n elif backend == '2':\n # Redis configuration\n values['storage_backend'] = \"cliquet.storage.redis\"\n values['storage_url'] = \"redis://localhost:6379/1\"\n values['cache_backend'] = \"cliquet.cache.redis\"\n values['cache_url'] = \"redis://localhost:6379/2\"\n values['permission_backend'] = \"cliquet.permission.redis\"\n values['permission_url'] = \"redis://localhost:6379/3\"\n\n else:\n # Memory configuration / default backend\n values['storage_backend'] = \"cliquet.storage.memory\"\n values['storage_url'] = \"\"\n values['cache_backend'] = \"cliquet.cache.memory\"\n values['cache_url'] = \"\"\n values['permission_backend'] = \"cliquet.permission.memory\"\n values['permission_url'] = \"\"\n\n render_template(\"kinto.tpl\", config_file, **values)\n", "path": "kinto/config/__init__.py"}]}
| 1,041 | 374 |
gh_patches_debug_41958
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-3860
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug - MSBuild helper should not force compiler flags such as `/o`
It seems that the `.props` file used to inject a few things implicitly into the build sometimes results in conflicts as seen here:
```
2>cl : Command line warning D9025: overriding '/O2' with '/Od' [path_to_my_project.vcxproj]
2>cl : Command line warning D9025: overriding '/Od' with '/O2' [path_to_my_project.vcxproj]
<..... above pair of message seen dozens of times.>
2>cl : Command line error D8016: '/RTC1' and '/O2' command-line options are incompatible
```
This can happen in very common circumstances, including any projects that have "Runtime checks" enabled, which I believe is the default for DLL projects.
Eventually, would be good to validate whatever flags are being injected.
- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/build/visual_environment.py`
Content:
```
1 import copy
2 import os
3
4 from conans.client.build.compiler_flags import build_type_define, build_type_flags, visual_runtime, format_defines, \
5 include_path_option, parallel_compiler_cl_flag
6 from conans.client.build.cppstd_flags import cppstd_flag
7
8
9 class VisualStudioBuildEnvironment(object):
10 """
11 - LIB: library paths with semicolon separator
12 - CL: /I (include paths)
13 - _LINK_: linker options and libraries
14
15 https://msdn.microsoft.com/en-us/library/19z1t1wy.aspx
16 https://msdn.microsoft.com/en-us/library/fwkeyyhe.aspx
17 https://msdn.microsoft.com/en-us/library/9s7c9wdw.aspx
18 https://msdn.microsoft.com/en-us/library/6y6t9esh.aspx
19
20 """
21 def __init__(self, conanfile):
22 """
23 :param conanfile: ConanFile instance
24 :param quote_paths: The path directories will be quoted. If you are using the vars together with
25 environment_append keep it to True, for virtualbuildenv quote_paths=False is required.
26 """
27 self._settings = conanfile.settings
28 self._deps_cpp_info = conanfile.deps_cpp_info
29 self._runtime = self._settings.get_safe("compiler.runtime")
30
31 self.include_paths = conanfile.deps_cpp_info.include_paths
32 self.lib_paths = conanfile.deps_cpp_info.lib_paths
33 self.defines = copy.copy(conanfile.deps_cpp_info.defines)
34 self.flags = self._configure_flags()
35 self.cxx_flags = copy.copy(self._deps_cpp_info.cppflags)
36 self.link_flags = self._configure_link_flags()
37 self.libs = conanfile.deps_cpp_info.libs
38 self.std = self._std_cpp()
39 self.parallel = False
40
41 def _configure_link_flags(self):
42 ret = copy.copy(self._deps_cpp_info.exelinkflags)
43 ret.extend(self._deps_cpp_info.sharedlinkflags)
44 return ret
45
46 def _configure_flags(self):
47 ret = copy.copy(self._deps_cpp_info.cflags)
48 ret.extend(vs_build_type_flags(self._settings))
49 return ret
50
51 def _get_cl_list(self, quotes=True):
52 # FIXME: It should be managed with the compiler_flags module
53 # But need further investigation about the quotes and so on, so better to not break anything
54 if quotes:
55 ret = ['%s"%s"' % (include_path_option, lib) for lib in self.include_paths]
56 else:
57 ret = ['%s%s' % (include_path_option, lib) for lib in self.include_paths]
58
59 runtime = visual_runtime(self._runtime)
60 if runtime:
61 ret.append(runtime)
62
63 ret.extend(format_defines(self.defines))
64 ret.extend(self.flags)
65 ret.extend(self.cxx_flags)
66
67 if self.parallel: # Build source in parallel
68 ret.append(parallel_compiler_cl_flag())
69
70 if self.std:
71 ret.append(self.std)
72
73 return ret
74
75 def _get_link_list(self):
76 def format_lib(lib):
77 return lib if lib.endswith('.lib') else '%s.lib' % lib
78
79 ret = [flag for flag in self.link_flags] # copy
80 ret.extend([format_lib(lib) for lib in self.libs])
81
82 return ret
83
84 @property
85 def vars(self):
86 """Used in conanfile with environment_append"""
87 flags = self._get_cl_list()
88 link_flags = self._get_link_list()
89
90 cl_args = " ".join(flags) + _environ_value_prefix("CL")
91 link_args = " ".join(link_flags)
92 lib_paths = ";".join(['%s' % lib for lib in self.lib_paths]) + _environ_value_prefix("LIB", ";")
93 return {"CL": cl_args,
94 "LIB": lib_paths,
95 "_LINK_": link_args}
96
97 @property
98 def vars_dict(self):
99 """Used in virtualbuildenvironment"""
100 # Here we do not quote the include paths, it's going to be used by virtual environment
101 cl = self._get_cl_list(quotes=False)
102 link = self._get_link_list()
103
104 lib = [lib for lib in self.lib_paths] # copy
105
106 if os.environ.get("CL", None):
107 cl.append(os.environ.get("CL"))
108
109 if os.environ.get("LIB", None):
110 lib.append(os.environ.get("LIB"))
111
112 if os.environ.get("_LINK_", None):
113 link.append(os.environ.get("_LINK_"))
114
115 ret = {"CL": cl,
116 "LIB": lib,
117 "_LINK_": link}
118 return ret
119
120 def _std_cpp(self):
121 return vs_std_cpp(self._settings)
122
123
124 def vs_build_type_flags(settings):
125 build_type = settings.get_safe("build_type")
126 ret = []
127 btd = build_type_define(build_type=build_type)
128 if btd:
129 ret.extend(format_defines([btd]))
130 btfs = build_type_flags("Visual Studio", build_type=build_type,
131 vs_toolset=settings.get_safe("compiler.toolset"))
132 if btfs:
133 ret.extend(btfs)
134
135 return ret
136
137
138 def vs_std_cpp(settings):
139 if settings.get_safe("compiler") == "Visual Studio" and \
140 settings.get_safe("cppstd"):
141 flag = cppstd_flag(settings.get_safe("compiler"),
142 settings.get_safe("compiler.version"),
143 settings.get_safe("cppstd"))
144 return flag
145 return None
146
147
148 def _environ_value_prefix(var_name, prefix=" "):
149 if os.environ.get(var_name, ""):
150 return "%s%s" % (prefix, os.environ.get(var_name, ""))
151 else:
152 return ""
153
```
Path: `conans/client/build/msbuild.py`
Content:
```
1 import copy
2 import re
3
4 from conans import tools
5 from conans.client.build.visual_environment import (VisualStudioBuildEnvironment,
6 vs_build_type_flags, vs_std_cpp)
7 from conans.client.tools.oss import cpu_count
8 from conans.client.tools.win import vcvars_command
9 from conans.errors import ConanException
10 from conans.util.env_reader import get_env
11 from conans.util.files import tmp_file
12 from conans.model.conan_file import ConanFile
13
14
15 class MSBuild(object):
16
17 def __init__(self, conanfile):
18 if isinstance(conanfile, ConanFile):
19 self._conanfile = conanfile
20 self._settings = self._conanfile.settings
21 self._output = self._conanfile.output
22 self.build_env = VisualStudioBuildEnvironment(self._conanfile)
23 else: # backwards compatible with build_sln_command
24 self._settings = conanfile
25 self.build_env = None
26
27 def build(self, project_file, targets=None, upgrade_project=True, build_type=None, arch=None,
28 parallel=True, force_vcvars=False, toolset=None, platforms=None, use_env=True,
29 vcvars_ver=None, winsdk_version=None, properties=None):
30
31 self.build_env.parallel = parallel
32
33 with tools.environment_append(self.build_env.vars):
34 # Path for custom properties file
35 props_file_contents = self._get_props_file_contents()
36 with tmp_file(props_file_contents) as props_file_path:
37 vcvars = vcvars_command(self._conanfile.settings, force=force_vcvars,
38 vcvars_ver=vcvars_ver, winsdk_version=winsdk_version)
39 command = self.get_command(project_file, props_file_path,
40 targets=targets, upgrade_project=upgrade_project,
41 build_type=build_type, arch=arch, parallel=parallel,
42 toolset=toolset, platforms=platforms,
43 use_env=use_env, properties=properties)
44 command = "%s && %s" % (vcvars, command)
45 return self._conanfile.run(command)
46
47 def get_command(self, project_file, props_file_path=None, targets=None, upgrade_project=True,
48 build_type=None, arch=None, parallel=True, toolset=None, platforms=None,
49 use_env=False, properties=None):
50
51 targets = targets or []
52 properties = properties or {}
53 command = []
54
55 if upgrade_project and not get_env("CONAN_SKIP_VS_PROJECTS_UPGRADE", False):
56 command.append('devenv "%s" /upgrade &&' % project_file)
57 else:
58 self._output.info("Skipped sln project upgrade")
59
60 build_type = build_type or self._settings.get_safe("build_type")
61 arch = arch or self._settings.get_safe("arch")
62 if not build_type:
63 raise ConanException("Cannot build_sln_command, build_type not defined")
64 if not arch:
65 raise ConanException("Cannot build_sln_command, arch not defined")
66
67 command.append('msbuild "%s" /p:Configuration="%s"' % (project_file, build_type))
68 msvc_arch = {'x86': 'x86',
69 'x86_64': 'x64',
70 'armv7': 'ARM',
71 'armv8': 'ARM64'}
72 if platforms:
73 msvc_arch.update(platforms)
74 msvc_arch = msvc_arch.get(str(arch))
75 try:
76 sln = tools.load(project_file)
77 pattern = re.compile(r"GlobalSection\(SolutionConfigurationPlatforms\)"
78 r"(.*?)EndGlobalSection", re.DOTALL)
79 solution_global = pattern.search(sln).group(1)
80 lines = solution_global.splitlines()
81 lines = [s.split("=")[0].strip() for s in lines]
82 except Exception:
83 pass
84 else:
85 config = "%s|%s" % (build_type, msvc_arch)
86 if config not in "".join(lines):
87 self._output.warn("***** The configuration %s does not exist in this solution *****" % config)
88 self._output.warn("Use 'platforms' argument to define your architectures")
89
90 if use_env:
91 command.append('/p:UseEnv=true')
92
93 if msvc_arch:
94 command.append('/p:Platform="%s"' % msvc_arch)
95
96 if parallel:
97 command.append('/m:%s' % cpu_count())
98
99 if targets:
100 command.append("/target:%s" % ";".join(targets))
101
102 if toolset:
103 command.append('/p:PlatformToolset="%s"' % toolset)
104
105 if props_file_path:
106 command.append('/p:ForceImportBeforeCppTargets="%s"' % props_file_path)
107
108 for name, value in properties.items():
109 command.append('/p:%s="%s"' % (name, value))
110
111 return " ".join(command)
112
113 def _get_props_file_contents(self):
114 # how to specify runtime in command line:
115 # https://stackoverflow.com/questions/38840332/msbuild-overrides-properties-while-building-vc-project
116 runtime_library = {"MT": "MultiThreaded",
117 "MTd": "MultiThreadedDebug",
118 "MD": "MultiThreadedDLL",
119 "MDd": "MultiThreadedDebugDLL"}.get(self._settings.get_safe("compiler.runtime"), "")
120
121 if self.build_env:
122 # Take the flags from the build env, the user was able to alter them if needed
123 flags = copy.copy(self.build_env.flags)
124 flags.append(self.build_env.std)
125 else: # To be removed when build_sln_command is deprecated
126 flags = vs_build_type_flags(self._settings)
127 flags.append(vs_std_cpp(self._settings))
128
129 flags_str = " ".join(list(filter(None, flags))) # Removes empty and None elements
130 additional_node = "<AdditionalOptions>" \
131 "{} %(AdditionalOptions)" \
132 "</AdditionalOptions>".format(flags_str) if flags_str else ""
133 runtime_node = "<RuntimeLibrary>" \
134 "{}" \
135 "</RuntimeLibrary>".format(runtime_library) if runtime_library else ""
136 template = """<?xml version="1.0" encoding="utf-8"?>
137 <Project xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
138 <ItemDefinitionGroup>
139 <ClCompile>
140 {runtime_node}
141 {additional_node}
142 </ClCompile>
143 </ItemDefinitionGroup>
144 </Project>""".format(**{"runtime_node": runtime_node,
145 "additional_node": additional_node})
146 return template
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/build/msbuild.py b/conans/client/build/msbuild.py
--- a/conans/client/build/msbuild.py
+++ b/conans/client/build/msbuild.py
@@ -19,7 +19,8 @@
self._conanfile = conanfile
self._settings = self._conanfile.settings
self._output = self._conanfile.output
- self.build_env = VisualStudioBuildEnvironment(self._conanfile)
+ self.build_env = VisualStudioBuildEnvironment(self._conanfile,
+ with_build_type_flags=False)
else: # backwards compatible with build_sln_command
self._settings = conanfile
self.build_env = None
@@ -123,7 +124,7 @@
flags = copy.copy(self.build_env.flags)
flags.append(self.build_env.std)
else: # To be removed when build_sln_command is deprecated
- flags = vs_build_type_flags(self._settings)
+ flags = vs_build_type_flags(self._settings, with_flags=False)
flags.append(vs_std_cpp(self._settings))
flags_str = " ".join(list(filter(None, flags))) # Removes empty and None elements
diff --git a/conans/client/build/visual_environment.py b/conans/client/build/visual_environment.py
--- a/conans/client/build/visual_environment.py
+++ b/conans/client/build/visual_environment.py
@@ -18,12 +18,14 @@
https://msdn.microsoft.com/en-us/library/6y6t9esh.aspx
"""
- def __init__(self, conanfile):
+ def __init__(self, conanfile, with_build_type_flags=True):
"""
:param conanfile: ConanFile instance
:param quote_paths: The path directories will be quoted. If you are using the vars together with
environment_append keep it to True, for virtualbuildenv quote_paths=False is required.
"""
+ self._with_build_type_flags = with_build_type_flags
+
self._settings = conanfile.settings
self._deps_cpp_info = conanfile.deps_cpp_info
self._runtime = self._settings.get_safe("compiler.runtime")
@@ -45,7 +47,7 @@
def _configure_flags(self):
ret = copy.copy(self._deps_cpp_info.cflags)
- ret.extend(vs_build_type_flags(self._settings))
+ ret.extend(vs_build_type_flags(self._settings, with_flags=self._with_build_type_flags))
return ret
def _get_cl_list(self, quotes=True):
@@ -121,16 +123,18 @@
return vs_std_cpp(self._settings)
-def vs_build_type_flags(settings):
+def vs_build_type_flags(settings, with_flags=True):
build_type = settings.get_safe("build_type")
ret = []
btd = build_type_define(build_type=build_type)
if btd:
ret.extend(format_defines([btd]))
- btfs = build_type_flags("Visual Studio", build_type=build_type,
- vs_toolset=settings.get_safe("compiler.toolset"))
- if btfs:
- ret.extend(btfs)
+ if with_flags:
+ # When using to build a vs project we don't want to adjust these flags
+ btfs = build_type_flags("Visual Studio", build_type=build_type,
+ vs_toolset=settings.get_safe("compiler.toolset"))
+ if btfs:
+ ret.extend(btfs)
return ret
|
{"golden_diff": "diff --git a/conans/client/build/msbuild.py b/conans/client/build/msbuild.py\n--- a/conans/client/build/msbuild.py\n+++ b/conans/client/build/msbuild.py\n@@ -19,7 +19,8 @@\n self._conanfile = conanfile\n self._settings = self._conanfile.settings\n self._output = self._conanfile.output\n- self.build_env = VisualStudioBuildEnvironment(self._conanfile)\n+ self.build_env = VisualStudioBuildEnvironment(self._conanfile,\n+ with_build_type_flags=False)\n else: # backwards compatible with build_sln_command\n self._settings = conanfile\n self.build_env = None\n@@ -123,7 +124,7 @@\n flags = copy.copy(self.build_env.flags)\n flags.append(self.build_env.std)\n else: # To be removed when build_sln_command is deprecated\n- flags = vs_build_type_flags(self._settings)\n+ flags = vs_build_type_flags(self._settings, with_flags=False)\n flags.append(vs_std_cpp(self._settings))\n \n flags_str = \" \".join(list(filter(None, flags))) # Removes empty and None elements\ndiff --git a/conans/client/build/visual_environment.py b/conans/client/build/visual_environment.py\n--- a/conans/client/build/visual_environment.py\n+++ b/conans/client/build/visual_environment.py\n@@ -18,12 +18,14 @@\n https://msdn.microsoft.com/en-us/library/6y6t9esh.aspx\n \n \"\"\"\n- def __init__(self, conanfile):\n+ def __init__(self, conanfile, with_build_type_flags=True):\n \"\"\"\n :param conanfile: ConanFile instance\n :param quote_paths: The path directories will be quoted. If you are using the vars together with\n environment_append keep it to True, for virtualbuildenv quote_paths=False is required.\n \"\"\"\n+ self._with_build_type_flags = with_build_type_flags\n+\n self._settings = conanfile.settings\n self._deps_cpp_info = conanfile.deps_cpp_info\n self._runtime = self._settings.get_safe(\"compiler.runtime\")\n@@ -45,7 +47,7 @@\n \n def _configure_flags(self):\n ret = copy.copy(self._deps_cpp_info.cflags)\n- ret.extend(vs_build_type_flags(self._settings))\n+ ret.extend(vs_build_type_flags(self._settings, with_flags=self._with_build_type_flags))\n return ret\n \n def _get_cl_list(self, quotes=True):\n@@ -121,16 +123,18 @@\n return vs_std_cpp(self._settings)\n \n \n-def vs_build_type_flags(settings):\n+def vs_build_type_flags(settings, with_flags=True):\n build_type = settings.get_safe(\"build_type\")\n ret = []\n btd = build_type_define(build_type=build_type)\n if btd:\n ret.extend(format_defines([btd]))\n- btfs = build_type_flags(\"Visual Studio\", build_type=build_type,\n- vs_toolset=settings.get_safe(\"compiler.toolset\"))\n- if btfs:\n- ret.extend(btfs)\n+ if with_flags:\n+ # When using to build a vs project we don't want to adjust these flags\n+ btfs = build_type_flags(\"Visual Studio\", build_type=build_type,\n+ vs_toolset=settings.get_safe(\"compiler.toolset\"))\n+ if btfs:\n+ ret.extend(btfs)\n \n return ret\n", "issue": "Bug - MSBuild helper should not force compiler flags such as `/o`\nIt seems that the `.props` file used to inject a few things implicitly into the build sometimes results in conflicts as seen here: \r\n```\r\n 2>cl : Command line warning D9025: overriding '/O2' with '/Od' [path_to_my_project.vcxproj]\r\n 2>cl : Command line warning D9025: overriding '/Od' with '/O2' [path_to_my_project.vcxproj]\r\n <..... above pair of message seen dozens of times.>\r\n 2>cl : Command line error D8016: '/RTC1' and '/O2' command-line options are incompatible \r\n```\r\nThis can happen in very common circumstances, including any projects that have \"Runtime checks\" enabled, which I believe is the default for DLL projects. \r\n\r\nEventually, would be good to validate whatever flags are being injected. \r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [x] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "import copy\nimport os\n\nfrom conans.client.build.compiler_flags import build_type_define, build_type_flags, visual_runtime, format_defines, \\\n include_path_option, parallel_compiler_cl_flag\nfrom conans.client.build.cppstd_flags import cppstd_flag\n\n\nclass VisualStudioBuildEnvironment(object):\n \"\"\"\n - LIB: library paths with semicolon separator\n - CL: /I (include paths)\n - _LINK_: linker options and libraries\n\n https://msdn.microsoft.com/en-us/library/19z1t1wy.aspx\n https://msdn.microsoft.com/en-us/library/fwkeyyhe.aspx\n https://msdn.microsoft.com/en-us/library/9s7c9wdw.aspx\n https://msdn.microsoft.com/en-us/library/6y6t9esh.aspx\n\n \"\"\"\n def __init__(self, conanfile):\n \"\"\"\n :param conanfile: ConanFile instance\n :param quote_paths: The path directories will be quoted. If you are using the vars together with\n environment_append keep it to True, for virtualbuildenv quote_paths=False is required.\n \"\"\"\n self._settings = conanfile.settings\n self._deps_cpp_info = conanfile.deps_cpp_info\n self._runtime = self._settings.get_safe(\"compiler.runtime\")\n\n self.include_paths = conanfile.deps_cpp_info.include_paths\n self.lib_paths = conanfile.deps_cpp_info.lib_paths\n self.defines = copy.copy(conanfile.deps_cpp_info.defines)\n self.flags = self._configure_flags()\n self.cxx_flags = copy.copy(self._deps_cpp_info.cppflags)\n self.link_flags = self._configure_link_flags()\n self.libs = conanfile.deps_cpp_info.libs\n self.std = self._std_cpp()\n self.parallel = False\n\n def _configure_link_flags(self):\n ret = copy.copy(self._deps_cpp_info.exelinkflags)\n ret.extend(self._deps_cpp_info.sharedlinkflags)\n return ret\n\n def _configure_flags(self):\n ret = copy.copy(self._deps_cpp_info.cflags)\n ret.extend(vs_build_type_flags(self._settings))\n return ret\n\n def _get_cl_list(self, quotes=True):\n # FIXME: It should be managed with the compiler_flags module\n # But need further investigation about the quotes and so on, so better to not break anything\n if quotes:\n ret = ['%s\"%s\"' % (include_path_option, lib) for lib in self.include_paths]\n else:\n ret = ['%s%s' % (include_path_option, lib) for lib in self.include_paths]\n\n runtime = visual_runtime(self._runtime)\n if runtime:\n ret.append(runtime)\n\n ret.extend(format_defines(self.defines))\n ret.extend(self.flags)\n ret.extend(self.cxx_flags)\n\n if self.parallel: # Build source in parallel\n ret.append(parallel_compiler_cl_flag())\n\n if self.std:\n ret.append(self.std)\n\n return ret\n\n def _get_link_list(self):\n def format_lib(lib):\n return lib if lib.endswith('.lib') else '%s.lib' % lib\n\n ret = [flag for flag in self.link_flags] # copy\n ret.extend([format_lib(lib) for lib in self.libs])\n\n return ret\n\n @property\n def vars(self):\n \"\"\"Used in conanfile with environment_append\"\"\"\n flags = self._get_cl_list()\n link_flags = self._get_link_list()\n\n cl_args = \" \".join(flags) + _environ_value_prefix(\"CL\")\n link_args = \" \".join(link_flags)\n lib_paths = \";\".join(['%s' % lib for lib in self.lib_paths]) + _environ_value_prefix(\"LIB\", \";\")\n return {\"CL\": cl_args,\n \"LIB\": lib_paths,\n \"_LINK_\": link_args}\n\n @property\n def vars_dict(self):\n \"\"\"Used in virtualbuildenvironment\"\"\"\n # Here we do not quote the include paths, it's going to be used by virtual environment\n cl = self._get_cl_list(quotes=False)\n link = self._get_link_list()\n\n lib = [lib for lib in self.lib_paths] # copy\n\n if os.environ.get(\"CL\", None):\n cl.append(os.environ.get(\"CL\"))\n\n if os.environ.get(\"LIB\", None):\n lib.append(os.environ.get(\"LIB\"))\n\n if os.environ.get(\"_LINK_\", None):\n link.append(os.environ.get(\"_LINK_\"))\n\n ret = {\"CL\": cl,\n \"LIB\": lib,\n \"_LINK_\": link}\n return ret\n\n def _std_cpp(self):\n return vs_std_cpp(self._settings)\n\n\ndef vs_build_type_flags(settings):\n build_type = settings.get_safe(\"build_type\")\n ret = []\n btd = build_type_define(build_type=build_type)\n if btd:\n ret.extend(format_defines([btd]))\n btfs = build_type_flags(\"Visual Studio\", build_type=build_type,\n vs_toolset=settings.get_safe(\"compiler.toolset\"))\n if btfs:\n ret.extend(btfs)\n\n return ret\n\n\ndef vs_std_cpp(settings):\n if settings.get_safe(\"compiler\") == \"Visual Studio\" and \\\n settings.get_safe(\"cppstd\"):\n flag = cppstd_flag(settings.get_safe(\"compiler\"),\n settings.get_safe(\"compiler.version\"),\n settings.get_safe(\"cppstd\"))\n return flag\n return None\n\n\ndef _environ_value_prefix(var_name, prefix=\" \"):\n if os.environ.get(var_name, \"\"):\n return \"%s%s\" % (prefix, os.environ.get(var_name, \"\"))\n else:\n return \"\"\n", "path": "conans/client/build/visual_environment.py"}, {"content": "import copy\nimport re\n\nfrom conans import tools\nfrom conans.client.build.visual_environment import (VisualStudioBuildEnvironment,\n vs_build_type_flags, vs_std_cpp)\nfrom conans.client.tools.oss import cpu_count\nfrom conans.client.tools.win import vcvars_command\nfrom conans.errors import ConanException\nfrom conans.util.env_reader import get_env\nfrom conans.util.files import tmp_file\nfrom conans.model.conan_file import ConanFile\n\n\nclass MSBuild(object):\n\n def __init__(self, conanfile):\n if isinstance(conanfile, ConanFile):\n self._conanfile = conanfile\n self._settings = self._conanfile.settings\n self._output = self._conanfile.output\n self.build_env = VisualStudioBuildEnvironment(self._conanfile)\n else: # backwards compatible with build_sln_command\n self._settings = conanfile\n self.build_env = None\n\n def build(self, project_file, targets=None, upgrade_project=True, build_type=None, arch=None,\n parallel=True, force_vcvars=False, toolset=None, platforms=None, use_env=True,\n vcvars_ver=None, winsdk_version=None, properties=None):\n\n self.build_env.parallel = parallel\n\n with tools.environment_append(self.build_env.vars):\n # Path for custom properties file\n props_file_contents = self._get_props_file_contents()\n with tmp_file(props_file_contents) as props_file_path:\n vcvars = vcvars_command(self._conanfile.settings, force=force_vcvars,\n vcvars_ver=vcvars_ver, winsdk_version=winsdk_version)\n command = self.get_command(project_file, props_file_path,\n targets=targets, upgrade_project=upgrade_project,\n build_type=build_type, arch=arch, parallel=parallel,\n toolset=toolset, platforms=platforms,\n use_env=use_env, properties=properties)\n command = \"%s && %s\" % (vcvars, command)\n return self._conanfile.run(command)\n\n def get_command(self, project_file, props_file_path=None, targets=None, upgrade_project=True,\n build_type=None, arch=None, parallel=True, toolset=None, platforms=None,\n use_env=False, properties=None):\n\n targets = targets or []\n properties = properties or {}\n command = []\n\n if upgrade_project and not get_env(\"CONAN_SKIP_VS_PROJECTS_UPGRADE\", False):\n command.append('devenv \"%s\" /upgrade &&' % project_file)\n else:\n self._output.info(\"Skipped sln project upgrade\")\n\n build_type = build_type or self._settings.get_safe(\"build_type\")\n arch = arch or self._settings.get_safe(\"arch\")\n if not build_type:\n raise ConanException(\"Cannot build_sln_command, build_type not defined\")\n if not arch:\n raise ConanException(\"Cannot build_sln_command, arch not defined\")\n\n command.append('msbuild \"%s\" /p:Configuration=\"%s\"' % (project_file, build_type))\n msvc_arch = {'x86': 'x86',\n 'x86_64': 'x64',\n 'armv7': 'ARM',\n 'armv8': 'ARM64'}\n if platforms:\n msvc_arch.update(platforms)\n msvc_arch = msvc_arch.get(str(arch))\n try:\n sln = tools.load(project_file)\n pattern = re.compile(r\"GlobalSection\\(SolutionConfigurationPlatforms\\)\"\n r\"(.*?)EndGlobalSection\", re.DOTALL)\n solution_global = pattern.search(sln).group(1)\n lines = solution_global.splitlines()\n lines = [s.split(\"=\")[0].strip() for s in lines]\n except Exception:\n pass\n else:\n config = \"%s|%s\" % (build_type, msvc_arch)\n if config not in \"\".join(lines):\n self._output.warn(\"***** The configuration %s does not exist in this solution *****\" % config)\n self._output.warn(\"Use 'platforms' argument to define your architectures\")\n\n if use_env:\n command.append('/p:UseEnv=true')\n\n if msvc_arch:\n command.append('/p:Platform=\"%s\"' % msvc_arch)\n\n if parallel:\n command.append('/m:%s' % cpu_count())\n\n if targets:\n command.append(\"/target:%s\" % \";\".join(targets))\n\n if toolset:\n command.append('/p:PlatformToolset=\"%s\"' % toolset)\n\n if props_file_path:\n command.append('/p:ForceImportBeforeCppTargets=\"%s\"' % props_file_path)\n\n for name, value in properties.items():\n command.append('/p:%s=\"%s\"' % (name, value))\n\n return \" \".join(command)\n\n def _get_props_file_contents(self):\n # how to specify runtime in command line:\n # https://stackoverflow.com/questions/38840332/msbuild-overrides-properties-while-building-vc-project\n runtime_library = {\"MT\": \"MultiThreaded\",\n \"MTd\": \"MultiThreadedDebug\",\n \"MD\": \"MultiThreadedDLL\",\n \"MDd\": \"MultiThreadedDebugDLL\"}.get(self._settings.get_safe(\"compiler.runtime\"), \"\")\n\n if self.build_env:\n # Take the flags from the build env, the user was able to alter them if needed\n flags = copy.copy(self.build_env.flags)\n flags.append(self.build_env.std)\n else: # To be removed when build_sln_command is deprecated\n flags = vs_build_type_flags(self._settings)\n flags.append(vs_std_cpp(self._settings))\n\n flags_str = \" \".join(list(filter(None, flags))) # Removes empty and None elements\n additional_node = \"<AdditionalOptions>\" \\\n \"{} %(AdditionalOptions)\" \\\n \"</AdditionalOptions>\".format(flags_str) if flags_str else \"\"\n runtime_node = \"<RuntimeLibrary>\" \\\n \"{}\" \\\n \"</RuntimeLibrary>\".format(runtime_library) if runtime_library else \"\"\n template = \"\"\"<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<Project xmlns=\"http://schemas.microsoft.com/developer/msbuild/2003\">\n <ItemDefinitionGroup>\n <ClCompile>\n {runtime_node}\n {additional_node}\n </ClCompile>\n </ItemDefinitionGroup>\n</Project>\"\"\".format(**{\"runtime_node\": runtime_node,\n \"additional_node\": additional_node})\n return template\n", "path": "conans/client/build/msbuild.py"}], "after_files": [{"content": "import copy\nimport os\n\nfrom conans.client.build.compiler_flags import build_type_define, build_type_flags, visual_runtime, format_defines, \\\n include_path_option, parallel_compiler_cl_flag\nfrom conans.client.build.cppstd_flags import cppstd_flag\n\n\nclass VisualStudioBuildEnvironment(object):\n \"\"\"\n - LIB: library paths with semicolon separator\n - CL: /I (include paths)\n - _LINK_: linker options and libraries\n\n https://msdn.microsoft.com/en-us/library/19z1t1wy.aspx\n https://msdn.microsoft.com/en-us/library/fwkeyyhe.aspx\n https://msdn.microsoft.com/en-us/library/9s7c9wdw.aspx\n https://msdn.microsoft.com/en-us/library/6y6t9esh.aspx\n\n \"\"\"\n def __init__(self, conanfile, with_build_type_flags=True):\n \"\"\"\n :param conanfile: ConanFile instance\n :param quote_paths: The path directories will be quoted. If you are using the vars together with\n environment_append keep it to True, for virtualbuildenv quote_paths=False is required.\n \"\"\"\n self._with_build_type_flags = with_build_type_flags\n\n self._settings = conanfile.settings\n self._deps_cpp_info = conanfile.deps_cpp_info\n self._runtime = self._settings.get_safe(\"compiler.runtime\")\n\n self.include_paths = conanfile.deps_cpp_info.include_paths\n self.lib_paths = conanfile.deps_cpp_info.lib_paths\n self.defines = copy.copy(conanfile.deps_cpp_info.defines)\n self.flags = self._configure_flags()\n self.cxx_flags = copy.copy(self._deps_cpp_info.cppflags)\n self.link_flags = self._configure_link_flags()\n self.libs = conanfile.deps_cpp_info.libs\n self.std = self._std_cpp()\n self.parallel = False\n\n def _configure_link_flags(self):\n ret = copy.copy(self._deps_cpp_info.exelinkflags)\n ret.extend(self._deps_cpp_info.sharedlinkflags)\n return ret\n\n def _configure_flags(self):\n ret = copy.copy(self._deps_cpp_info.cflags)\n ret.extend(vs_build_type_flags(self._settings, with_flags=self._with_build_type_flags))\n return ret\n\n def _get_cl_list(self, quotes=True):\n # FIXME: It should be managed with the compiler_flags module\n # But need further investigation about the quotes and so on, so better to not break anything\n if quotes:\n ret = ['%s\"%s\"' % (include_path_option, lib) for lib in self.include_paths]\n else:\n ret = ['%s%s' % (include_path_option, lib) for lib in self.include_paths]\n\n runtime = visual_runtime(self._runtime)\n if runtime:\n ret.append(runtime)\n\n ret.extend(format_defines(self.defines))\n ret.extend(self.flags)\n ret.extend(self.cxx_flags)\n\n if self.parallel: # Build source in parallel\n ret.append(parallel_compiler_cl_flag())\n\n if self.std:\n ret.append(self.std)\n\n return ret\n\n def _get_link_list(self):\n def format_lib(lib):\n return lib if lib.endswith('.lib') else '%s.lib' % lib\n\n ret = [flag for flag in self.link_flags] # copy\n ret.extend([format_lib(lib) for lib in self.libs])\n\n return ret\n\n @property\n def vars(self):\n \"\"\"Used in conanfile with environment_append\"\"\"\n flags = self._get_cl_list()\n link_flags = self._get_link_list()\n\n cl_args = \" \".join(flags) + _environ_value_prefix(\"CL\")\n link_args = \" \".join(link_flags)\n lib_paths = \";\".join(['%s' % lib for lib in self.lib_paths]) + _environ_value_prefix(\"LIB\", \";\")\n return {\"CL\": cl_args,\n \"LIB\": lib_paths,\n \"_LINK_\": link_args}\n\n @property\n def vars_dict(self):\n \"\"\"Used in virtualbuildenvironment\"\"\"\n # Here we do not quote the include paths, it's going to be used by virtual environment\n cl = self._get_cl_list(quotes=False)\n link = self._get_link_list()\n\n lib = [lib for lib in self.lib_paths] # copy\n\n if os.environ.get(\"CL\", None):\n cl.append(os.environ.get(\"CL\"))\n\n if os.environ.get(\"LIB\", None):\n lib.append(os.environ.get(\"LIB\"))\n\n if os.environ.get(\"_LINK_\", None):\n link.append(os.environ.get(\"_LINK_\"))\n\n ret = {\"CL\": cl,\n \"LIB\": lib,\n \"_LINK_\": link}\n return ret\n\n def _std_cpp(self):\n return vs_std_cpp(self._settings)\n\n\ndef vs_build_type_flags(settings, with_flags=True):\n build_type = settings.get_safe(\"build_type\")\n ret = []\n btd = build_type_define(build_type=build_type)\n if btd:\n ret.extend(format_defines([btd]))\n if with_flags:\n # When using to build a vs project we don't want to adjust these flags\n btfs = build_type_flags(\"Visual Studio\", build_type=build_type,\n vs_toolset=settings.get_safe(\"compiler.toolset\"))\n if btfs:\n ret.extend(btfs)\n\n return ret\n\n\ndef vs_std_cpp(settings):\n if settings.get_safe(\"compiler\") == \"Visual Studio\" and \\\n settings.get_safe(\"cppstd\"):\n flag = cppstd_flag(settings.get_safe(\"compiler\"),\n settings.get_safe(\"compiler.version\"),\n settings.get_safe(\"cppstd\"))\n return flag\n return None\n\n\ndef _environ_value_prefix(var_name, prefix=\" \"):\n if os.environ.get(var_name, \"\"):\n return \"%s%s\" % (prefix, os.environ.get(var_name, \"\"))\n else:\n return \"\"\n", "path": "conans/client/build/visual_environment.py"}, {"content": "import copy\nimport re\n\nfrom conans import tools\nfrom conans.client.build.visual_environment import (VisualStudioBuildEnvironment,\n vs_build_type_flags, vs_std_cpp)\nfrom conans.client.tools.oss import cpu_count\nfrom conans.client.tools.win import vcvars_command\nfrom conans.errors import ConanException\nfrom conans.util.env_reader import get_env\nfrom conans.util.files import tmp_file\nfrom conans.model.conan_file import ConanFile\n\n\nclass MSBuild(object):\n\n def __init__(self, conanfile):\n if isinstance(conanfile, ConanFile):\n self._conanfile = conanfile\n self._settings = self._conanfile.settings\n self._output = self._conanfile.output\n self.build_env = VisualStudioBuildEnvironment(self._conanfile,\n with_build_type_flags=False)\n else: # backwards compatible with build_sln_command\n self._settings = conanfile\n self.build_env = None\n\n def build(self, project_file, targets=None, upgrade_project=True, build_type=None, arch=None,\n parallel=True, force_vcvars=False, toolset=None, platforms=None, use_env=True,\n vcvars_ver=None, winsdk_version=None, properties=None):\n\n self.build_env.parallel = parallel\n\n with tools.environment_append(self.build_env.vars):\n # Path for custom properties file\n props_file_contents = self._get_props_file_contents()\n with tmp_file(props_file_contents) as props_file_path:\n vcvars = vcvars_command(self._conanfile.settings, force=force_vcvars,\n vcvars_ver=vcvars_ver, winsdk_version=winsdk_version)\n command = self.get_command(project_file, props_file_path,\n targets=targets, upgrade_project=upgrade_project,\n build_type=build_type, arch=arch, parallel=parallel,\n toolset=toolset, platforms=platforms,\n use_env=use_env, properties=properties)\n command = \"%s && %s\" % (vcvars, command)\n return self._conanfile.run(command)\n\n def get_command(self, project_file, props_file_path=None, targets=None, upgrade_project=True,\n build_type=None, arch=None, parallel=True, toolset=None, platforms=None,\n use_env=False, properties=None):\n\n targets = targets or []\n properties = properties or {}\n command = []\n\n if upgrade_project and not get_env(\"CONAN_SKIP_VS_PROJECTS_UPGRADE\", False):\n command.append('devenv \"%s\" /upgrade &&' % project_file)\n else:\n self._output.info(\"Skipped sln project upgrade\")\n\n build_type = build_type or self._settings.get_safe(\"build_type\")\n arch = arch or self._settings.get_safe(\"arch\")\n if not build_type:\n raise ConanException(\"Cannot build_sln_command, build_type not defined\")\n if not arch:\n raise ConanException(\"Cannot build_sln_command, arch not defined\")\n\n command.append('msbuild \"%s\" /p:Configuration=\"%s\"' % (project_file, build_type))\n msvc_arch = {'x86': 'x86',\n 'x86_64': 'x64',\n 'armv7': 'ARM',\n 'armv8': 'ARM64'}\n if platforms:\n msvc_arch.update(platforms)\n msvc_arch = msvc_arch.get(str(arch))\n try:\n sln = tools.load(project_file)\n pattern = re.compile(r\"GlobalSection\\(SolutionConfigurationPlatforms\\)\"\n r\"(.*?)EndGlobalSection\", re.DOTALL)\n solution_global = pattern.search(sln).group(1)\n lines = solution_global.splitlines()\n lines = [s.split(\"=\")[0].strip() for s in lines]\n except Exception:\n pass\n else:\n config = \"%s|%s\" % (build_type, msvc_arch)\n if config not in \"\".join(lines):\n self._output.warn(\"***** The configuration %s does not exist in this solution *****\" % config)\n self._output.warn(\"Use 'platforms' argument to define your architectures\")\n\n if use_env:\n command.append('/p:UseEnv=true')\n\n if msvc_arch:\n command.append('/p:Platform=\"%s\"' % msvc_arch)\n\n if parallel:\n command.append('/m:%s' % cpu_count())\n\n if targets:\n command.append(\"/target:%s\" % \";\".join(targets))\n\n if toolset:\n command.append('/p:PlatformToolset=\"%s\"' % toolset)\n\n if props_file_path:\n command.append('/p:ForceImportBeforeCppTargets=\"%s\"' % props_file_path)\n\n for name, value in properties.items():\n command.append('/p:%s=\"%s\"' % (name, value))\n\n return \" \".join(command)\n\n def _get_props_file_contents(self):\n # how to specify runtime in command line:\n # https://stackoverflow.com/questions/38840332/msbuild-overrides-properties-while-building-vc-project\n runtime_library = {\"MT\": \"MultiThreaded\",\n \"MTd\": \"MultiThreadedDebug\",\n \"MD\": \"MultiThreadedDLL\",\n \"MDd\": \"MultiThreadedDebugDLL\"}.get(self._settings.get_safe(\"compiler.runtime\"), \"\")\n\n if self.build_env:\n # Take the flags from the build env, the user was able to alter them if needed\n flags = copy.copy(self.build_env.flags)\n flags.append(self.build_env.std)\n else: # To be removed when build_sln_command is deprecated\n flags = vs_build_type_flags(self._settings, with_flags=False)\n flags.append(vs_std_cpp(self._settings))\n\n flags_str = \" \".join(list(filter(None, flags))) # Removes empty and None elements\n additional_node = \"<AdditionalOptions>\" \\\n \"{} %(AdditionalOptions)\" \\\n \"</AdditionalOptions>\".format(flags_str) if flags_str else \"\"\n runtime_node = \"<RuntimeLibrary>\" \\\n \"{}\" \\\n \"</RuntimeLibrary>\".format(runtime_library) if runtime_library else \"\"\n template = \"\"\"<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<Project xmlns=\"http://schemas.microsoft.com/developer/msbuild/2003\">\n <ItemDefinitionGroup>\n <ClCompile>\n {runtime_node}\n {additional_node}\n </ClCompile>\n </ItemDefinitionGroup>\n</Project>\"\"\".format(**{\"runtime_node\": runtime_node,\n \"additional_node\": additional_node})\n return template\n", "path": "conans/client/build/msbuild.py"}]}
| 3,883 | 768 |
gh_patches_debug_31207
|
rasdani/github-patches
|
git_diff
|
openedx__edx-ora2-1144
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"TypeError: u'<url>' is not JSON serializable" on upload to backends other than S3
File upload to "django" and "filesystem" backends is currently broken. Each attempt to generate an upload URL fails with the following error:
```
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/django/core/handlers/exception.py", line 41, in inner
response = get_response(request)
File "/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py", line 249, in _legacy_get_response
response = self._get_response(request)
File "/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py", line 187, in _get_response
response = self.process_exception_by_middleware(e, request)
File "/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py", line 185, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/usr/local/lib/python2.7/dist-packages/django/utils/decorators.py", line 185, in inner
return func(*args, **kwargs)
File "/openedx/edx-platform/lms/djangoapps/courseware/module_render.py", line 962, in handle_xblock_callback
return _invoke_xblock_handler(request, course_id, usage_id, handler, suffix, course=course)
File "/openedx/edx-platform/lms/djangoapps/courseware/module_render.py", line 1068, in _invoke_xblock_handler
resp = instance.handle(handler, req, suffix)
File "/usr/local/lib/python2.7/dist-packages/xblock/mixins.py", line 90, in handle
return self.runtime.handle(self, handler_name, request, suffix)
File "/openedx/edx-platform/common/lib/xmodule/xmodule/x_module.py", line 1347, in handle
return super(MetricsMixin, self).handle(block, handler_name, request, suffix=suffix)
File "/usr/local/lib/python2.7/dist-packages/xblock/runtime.py", line 1037, in handle
results = handler(request, suffix)
File "/usr/local/lib/python2.7/dist-packages/xblock/mixins.py", line 74, in wrapper
response = json.dumps(response)
File "/usr/lib/python2.7/json/__init__.py", line 244, in dumps
return _default_encoder.encode(obj)
File "/usr/lib/python2.7/json/encoder.py", line 207, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/usr/lib/python2.7/json/encoder.py", line 270, in iterencode
return _iterencode(o, 0)
File "/usr/lib/python2.7/json/encoder.py", line 184, in default
raise TypeError(repr(o) + " is not JSON serializable")
TypeError: u'/openassessment/fileupload/django/4dd623a62f4e626d827277cd3fedaf45/course-v1:org+video1+01/block-v1:org+video1+01+type@openassessment+block@25d85
51f741342ac919590db2e72091b/' is not JSON serializable
```
This error is due to the fact that urls returned by 'django' and 'filesystem' backends are computed with `django.core.urlresolvers.reverse_lazy`. Thus, they are not unicode, but `django.utils.functional.__proxy__` objects. The TypeError is raised when calling `json.dumps()` on `{'success': True, 'url': url_object}` in `xblock.mixins.HandlersMixin.json_handler`.
I can easily solve the problem by replacing `reverse_lazy` by `reverse`. However, I wonder what was the original reason to use `reverse_lazy`? The change was introduced in commit 3e13d27df by @efischer19.
Python tests pass successfully if I replace `reverse_lazy` by `reverse`.
I believe both ORA2 backends are broken for the current Open edX Hawthorn release.
(this error was first discovered [here](https://github.com/regisb/openedx-docker/issues/97))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 from setuptools import find_packages, setup
3
4
5 def is_requirement(line):
6 """
7 Return True if the requirement line is a package requirement;
8 that is, it is not blank, a comment, or editable.
9 """
10 # Remove whitespace at the start/end of the line
11 line = line.strip()
12
13 # Skip blank lines, comments, and editable installs
14 return not (
15 line == '' or
16 line.startswith('-r') or
17 line.startswith('#') or
18 line.startswith('-e') or
19 line.startswith('git+')
20 )
21
22 def load_requirements(*requirements_paths):
23 """
24 Load all requirements from the specified requirements files.
25 Returns a list of requirement strings.
26 """
27 requirements = set()
28 for path in requirements_paths:
29 requirements.update(
30 line.strip() for line in open(path).readlines()
31 if is_requirement(line)
32 )
33 return list(requirements)
34
35 setup(
36 name='ora2',
37 version='2.2.1',
38 author='edX',
39 url='http://github.com/edx/edx-ora2',
40 description='edx-ora2',
41 license='AGPL',
42 classifiers=[
43 'Development Status :: 3 - Alpha',
44 'Framework :: Django :: 1.11',
45 'Intended Audience :: Developers',
46 'License :: OSI Approved :: GNU Affero General Public License v3',
47 'Operating System :: OS Independent',
48 'Programming Language :: Python',
49 ],
50 packages=find_packages(include=['openassessment*'], exclude=['*.test', '*.tests']),
51 include_package_data=True,
52 install_requires=load_requirements('requirements/base.txt', "requirements/django.txt"),
53 tests_require=load_requirements('requirements/test.txt'),
54 entry_points={
55 'xblock.v1': [
56 'openassessment = openassessment.xblock.openassessmentblock:OpenAssessmentBlock',
57 ]
58 },
59 )
60
```
Path: `openassessment/fileupload/backends/filesystem.py`
Content:
```
1 from django.conf import settings
2 import django.core.cache
3 from django.core.urlresolvers import reverse_lazy
4 from django.utils.encoding import smart_text
5
6 from .. import exceptions
7 from .base import BaseBackend
8
9
10 class Backend(BaseBackend):
11 """
12 Upload openassessment student files to a local filesystem. Note
13 that in order to use this file storage backend, you need to include the
14 urls from openassessment.fileupload in your urls.py file:
15
16 E.g:
17 url(r'^openassessment/storage', include(openassessment.fileupload.urls)),
18
19 The ORA2_FILEUPLOAD_CACHE_NAME setting will also have to be defined for the
20 name of the django.core.cache instance which will maintain the list of
21 active storage URLs.
22
23 E.g:
24
25 ORA2_FILEUPLOAD_CACHE_NAME = "ora2-storage"
26 CACHES = {
27 ...
28 'ora2-storage': {
29 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
30 ...
31 },
32 ...
33 }
34 """
35
36 def get_upload_url(self, key, content_type):
37 make_upload_url_available(self._get_key_name(key), self.UPLOAD_URL_TIMEOUT)
38 return self._get_url(key)
39
40 def get_download_url(self, key):
41 make_download_url_available(self._get_key_name(key), self.DOWNLOAD_URL_TIMEOUT)
42 return self._get_url(key)
43
44 def remove_file(self, key):
45 from openassessment.fileupload.views_filesystem import safe_remove, get_file_path
46 return safe_remove(get_file_path(self._get_key_name(key)))
47
48 def _get_url(self, key):
49 key_name = self._get_key_name(key)
50 url = reverse_lazy("openassessment-filesystem-storage", kwargs={'key': key_name})
51 return url
52
53
54 def get_cache():
55 """
56 Returns a django.core.cache instance in charge of maintaining the
57 authorized upload and download URL.
58
59 Raises:
60 FileUploadInternalError if the cache name setting is not defined.
61 InvalidCacheBackendError if the corresponding cache backend has not
62 been configured.
63 """
64 cache_name = getattr(settings, "ORA2_FILEUPLOAD_CACHE_NAME", None)
65 if cache_name is None:
66 raise exceptions.FileUploadInternalError("Undefined cache backend for file upload")
67 return django.core.cache.caches[cache_name]
68
69
70 def make_upload_url_available(url_key_name, timeout):
71 """
72 Authorize an upload URL.
73
74 Arguments:
75 url_key_name (str): key that uniquely identifies the upload url
76 timeout (int): time in seconds before the url expires
77 """
78 get_cache().set(
79 smart_text(get_upload_cache_key(url_key_name)),
80 1, timeout
81 )
82
83
84 def make_download_url_available(url_key_name, timeout):
85 """
86 Authorize a download URL.
87
88 Arguments:
89 url_key_name (str): key that uniquely identifies the url
90 timeout (int): time in seconds before the url expires
91 """
92 get_cache().set(
93 smart_text(get_download_cache_key(url_key_name)),
94 1, timeout
95 )
96
97
98 def is_upload_url_available(url_key_name):
99 """
100 Return True if the corresponding upload URL is available.
101 """
102 return get_cache().get(smart_text(get_upload_cache_key(url_key_name))) is not None
103
104
105 def is_download_url_available(url_key_name):
106 """
107 Return True if the corresponding download URL is available.
108 """
109 return get_cache().get(smart_text(get_download_cache_key(url_key_name))) is not None
110
111
112 def get_upload_cache_key(url_key_name):
113 return "upload/" + url_key_name
114
115
116 def get_download_cache_key(url_key_name):
117 return "download/" + url_key_name
118
```
Path: `openassessment/fileupload/backends/django_storage.py`
Content:
```
1 import os
2
3 from django.core.files.base import ContentFile
4 from django.core.files.storage import default_storage
5 from django.core.urlresolvers import reverse_lazy
6
7 from .base import BaseBackend
8
9
10 class Backend(BaseBackend):
11 """
12 Manage openassessment student files uploaded using the default django storage settings.
13 """
14 def get_upload_url(self, key, content_type):
15 """
16 Return the URL pointing to the ORA2 django storage upload endpoint.
17 """
18 return reverse_lazy("openassessment-django-storage", kwargs={'key': key})
19
20 def get_download_url(self, key):
21 """
22 Return the django storage download URL for the given key.
23
24 Returns None if no file exists at that location.
25 """
26 path = self._get_file_path(key)
27 if default_storage.exists(path):
28 return default_storage.url(path)
29 return None
30
31 def upload_file(self, key, content):
32 """
33 Upload the given file content to the keyed location.
34 """
35 path = self._get_file_path(key)
36 saved_path = default_storage.save(path, ContentFile(content))
37 return saved_path
38
39 def remove_file(self, key):
40 """
41 Remove the file at the given keyed location.
42
43 Returns True if the file exists, and was removed.
44 Returns False if the file does not exist, and so was not removed.
45 """
46 path = self._get_file_path(key)
47 if default_storage.exists(path):
48 default_storage.delete(path)
49 return True
50 return False
51
52 def _get_file_name(self, key):
53 """
54 Returns the name of the keyed file.
55
56 Since the backend storage may be folders, or it may use pseudo-folders,
57 make sure the filename doesn't include any path separators.
58 """
59 file_name = key.replace("..", "").strip("/ ")
60 file_name = file_name.replace(os.sep, "_")
61 return file_name
62
63 def _get_file_path(self, key):
64 """
65 Returns the path to the keyed file, including the storage prefix.
66 """
67 path = self._get_key_name(self._get_file_name(key))
68 return path
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openassessment/fileupload/backends/django_storage.py b/openassessment/fileupload/backends/django_storage.py
--- a/openassessment/fileupload/backends/django_storage.py
+++ b/openassessment/fileupload/backends/django_storage.py
@@ -2,7 +2,7 @@
from django.core.files.base import ContentFile
from django.core.files.storage import default_storage
-from django.core.urlresolvers import reverse_lazy
+from django.core.urlresolvers import reverse
from .base import BaseBackend
@@ -15,7 +15,7 @@
"""
Return the URL pointing to the ORA2 django storage upload endpoint.
"""
- return reverse_lazy("openassessment-django-storage", kwargs={'key': key})
+ return reverse("openassessment-django-storage", kwargs={'key': key})
def get_download_url(self, key):
"""
diff --git a/openassessment/fileupload/backends/filesystem.py b/openassessment/fileupload/backends/filesystem.py
--- a/openassessment/fileupload/backends/filesystem.py
+++ b/openassessment/fileupload/backends/filesystem.py
@@ -1,6 +1,6 @@
from django.conf import settings
import django.core.cache
-from django.core.urlresolvers import reverse_lazy
+from django.core.urlresolvers import reverse
from django.utils.encoding import smart_text
from .. import exceptions
@@ -47,7 +47,7 @@
def _get_url(self, key):
key_name = self._get_key_name(key)
- url = reverse_lazy("openassessment-filesystem-storage", kwargs={'key': key_name})
+ url = reverse("openassessment-filesystem-storage", kwargs={'key': key_name})
return url
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -34,7 +34,7 @@
setup(
name='ora2',
- version='2.2.1',
+ version='2.2.2',
author='edX',
url='http://github.com/edx/edx-ora2',
description='edx-ora2',
|
{"golden_diff": "diff --git a/openassessment/fileupload/backends/django_storage.py b/openassessment/fileupload/backends/django_storage.py\n--- a/openassessment/fileupload/backends/django_storage.py\n+++ b/openassessment/fileupload/backends/django_storage.py\n@@ -2,7 +2,7 @@\n \n from django.core.files.base import ContentFile\n from django.core.files.storage import default_storage\n-from django.core.urlresolvers import reverse_lazy\n+from django.core.urlresolvers import reverse\n \n from .base import BaseBackend\n \n@@ -15,7 +15,7 @@\n \"\"\"\n Return the URL pointing to the ORA2 django storage upload endpoint.\n \"\"\"\n- return reverse_lazy(\"openassessment-django-storage\", kwargs={'key': key})\n+ return reverse(\"openassessment-django-storage\", kwargs={'key': key})\n \n def get_download_url(self, key):\n \"\"\"\ndiff --git a/openassessment/fileupload/backends/filesystem.py b/openassessment/fileupload/backends/filesystem.py\n--- a/openassessment/fileupload/backends/filesystem.py\n+++ b/openassessment/fileupload/backends/filesystem.py\n@@ -1,6 +1,6 @@\n from django.conf import settings\n import django.core.cache\n-from django.core.urlresolvers import reverse_lazy\n+from django.core.urlresolvers import reverse\n from django.utils.encoding import smart_text\n \n from .. import exceptions\n@@ -47,7 +47,7 @@\n \n def _get_url(self, key):\n key_name = self._get_key_name(key)\n- url = reverse_lazy(\"openassessment-filesystem-storage\", kwargs={'key': key_name})\n+ url = reverse(\"openassessment-filesystem-storage\", kwargs={'key': key_name})\n return url\n \n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -34,7 +34,7 @@\n \n setup(\n name='ora2',\n- version='2.2.1',\n+ version='2.2.2',\n author='edX',\n url='http://github.com/edx/edx-ora2',\n description='edx-ora2',\n", "issue": "\"TypeError: u'<url>' is not JSON serializable\" on upload to backends other than S3\nFile upload to \"django\" and \"filesystem\" backends is currently broken. Each attempt to generate an upload URL fails with the following error:\r\n\r\n```\r\nTraceback (most recent call last): \r\n File \"/usr/local/lib/python2.7/dist-packages/django/core/handlers/exception.py\", line 41, in inner \r\n response = get_response(request) \r\n File \"/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py\", line 249, in _legacy_get_response \r\n response = self._get_response(request) \r\n File \"/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py\", line 187, in _get_response \r\n response = self.process_exception_by_middleware(e, request) \r\n File \"/usr/local/lib/python2.7/dist-packages/django/core/handlers/base.py\", line 185, in _get_response \r\n response = wrapped_callback(request, *callback_args, **callback_kwargs) \r\n File \"/usr/local/lib/python2.7/dist-packages/django/utils/decorators.py\", line 185, in inner \r\n return func(*args, **kwargs) \r\n File \"/openedx/edx-platform/lms/djangoapps/courseware/module_render.py\", line 962, in handle_xblock_callback \r\n return _invoke_xblock_handler(request, course_id, usage_id, handler, suffix, course=course) \r\n File \"/openedx/edx-platform/lms/djangoapps/courseware/module_render.py\", line 1068, in _invoke_xblock_handler \r\n resp = instance.handle(handler, req, suffix) \r\n File \"/usr/local/lib/python2.7/dist-packages/xblock/mixins.py\", line 90, in handle \r\n return self.runtime.handle(self, handler_name, request, suffix) \r\n File \"/openedx/edx-platform/common/lib/xmodule/xmodule/x_module.py\", line 1347, in handle \r\n return super(MetricsMixin, self).handle(block, handler_name, request, suffix=suffix) \r\n File \"/usr/local/lib/python2.7/dist-packages/xblock/runtime.py\", line 1037, in handle \r\n results = handler(request, suffix) \r\n File \"/usr/local/lib/python2.7/dist-packages/xblock/mixins.py\", line 74, in wrapper \r\n response = json.dumps(response) \r\n File \"/usr/lib/python2.7/json/__init__.py\", line 244, in dumps \r\n return _default_encoder.encode(obj) \r\n File \"/usr/lib/python2.7/json/encoder.py\", line 207, in encode\r\n chunks = self.iterencode(o, _one_shot=True)\r\n File \"/usr/lib/python2.7/json/encoder.py\", line 270, in iterencode\r\n return _iterencode(o, 0)\r\n File \"/usr/lib/python2.7/json/encoder.py\", line 184, in default\r\n raise TypeError(repr(o) + \" is not JSON serializable\")\r\nTypeError: u'/openassessment/fileupload/django/4dd623a62f4e626d827277cd3fedaf45/course-v1:org+video1+01/block-v1:org+video1+01+type@openassessment+block@25d85\r\n51f741342ac919590db2e72091b/' is not JSON serializable\r\n```\r\n\r\nThis error is due to the fact that urls returned by 'django' and 'filesystem' backends are computed with `django.core.urlresolvers.reverse_lazy`. Thus, they are not unicode, but `django.utils.functional.__proxy__` objects. The TypeError is raised when calling `json.dumps()` on `{'success': True, 'url': url_object}` in `xblock.mixins.HandlersMixin.json_handler`.\r\n\r\nI can easily solve the problem by replacing `reverse_lazy` by `reverse`. However, I wonder what was the original reason to use `reverse_lazy`? The change was introduced in commit 3e13d27df by @efischer19.\r\n\r\nPython tests pass successfully if I replace `reverse_lazy` by `reverse`.\r\n\r\nI believe both ORA2 backends are broken for the current Open edX Hawthorn release. \r\n \r\n(this error was first discovered [here](https://github.com/regisb/openedx-docker/issues/97))\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom setuptools import find_packages, setup\n\n\ndef is_requirement(line):\n \"\"\"\n Return True if the requirement line is a package requirement;\n that is, it is not blank, a comment, or editable.\n \"\"\"\n # Remove whitespace at the start/end of the line\n line = line.strip()\n\n # Skip blank lines, comments, and editable installs\n return not (\n line == '' or\n line.startswith('-r') or\n line.startswith('#') or\n line.startswith('-e') or\n line.startswith('git+')\n )\n\ndef load_requirements(*requirements_paths):\n \"\"\"\n Load all requirements from the specified requirements files.\n Returns a list of requirement strings.\n \"\"\"\n requirements = set()\n for path in requirements_paths:\n requirements.update(\n line.strip() for line in open(path).readlines()\n if is_requirement(line)\n )\n return list(requirements)\n\nsetup(\n name='ora2',\n version='2.2.1',\n author='edX',\n url='http://github.com/edx/edx-ora2',\n description='edx-ora2',\n license='AGPL',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Framework :: Django :: 1.11',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU Affero General Public License v3',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n ],\n packages=find_packages(include=['openassessment*'], exclude=['*.test', '*.tests']),\n include_package_data=True,\n install_requires=load_requirements('requirements/base.txt', \"requirements/django.txt\"),\n tests_require=load_requirements('requirements/test.txt'),\n entry_points={\n 'xblock.v1': [\n 'openassessment = openassessment.xblock.openassessmentblock:OpenAssessmentBlock',\n ]\n },\n)\n", "path": "setup.py"}, {"content": "from django.conf import settings\nimport django.core.cache\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.utils.encoding import smart_text\n\nfrom .. import exceptions\nfrom .base import BaseBackend\n\n\nclass Backend(BaseBackend):\n \"\"\"\n Upload openassessment student files to a local filesystem. Note\n that in order to use this file storage backend, you need to include the\n urls from openassessment.fileupload in your urls.py file:\n\n E.g:\n url(r'^openassessment/storage', include(openassessment.fileupload.urls)),\n\n The ORA2_FILEUPLOAD_CACHE_NAME setting will also have to be defined for the\n name of the django.core.cache instance which will maintain the list of\n active storage URLs.\n\n E.g:\n\n ORA2_FILEUPLOAD_CACHE_NAME = \"ora2-storage\"\n CACHES = {\n ...\n 'ora2-storage': {\n 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',\n ...\n },\n ...\n }\n \"\"\"\n\n def get_upload_url(self, key, content_type):\n make_upload_url_available(self._get_key_name(key), self.UPLOAD_URL_TIMEOUT)\n return self._get_url(key)\n\n def get_download_url(self, key):\n make_download_url_available(self._get_key_name(key), self.DOWNLOAD_URL_TIMEOUT)\n return self._get_url(key)\n\n def remove_file(self, key):\n from openassessment.fileupload.views_filesystem import safe_remove, get_file_path\n return safe_remove(get_file_path(self._get_key_name(key)))\n\n def _get_url(self, key):\n key_name = self._get_key_name(key)\n url = reverse_lazy(\"openassessment-filesystem-storage\", kwargs={'key': key_name})\n return url\n\n\ndef get_cache():\n \"\"\"\n Returns a django.core.cache instance in charge of maintaining the\n authorized upload and download URL.\n\n Raises:\n FileUploadInternalError if the cache name setting is not defined.\n InvalidCacheBackendError if the corresponding cache backend has not\n been configured.\n \"\"\"\n cache_name = getattr(settings, \"ORA2_FILEUPLOAD_CACHE_NAME\", None)\n if cache_name is None:\n raise exceptions.FileUploadInternalError(\"Undefined cache backend for file upload\")\n return django.core.cache.caches[cache_name]\n\n\ndef make_upload_url_available(url_key_name, timeout):\n \"\"\"\n Authorize an upload URL.\n\n Arguments:\n url_key_name (str): key that uniquely identifies the upload url\n timeout (int): time in seconds before the url expires\n \"\"\"\n get_cache().set(\n smart_text(get_upload_cache_key(url_key_name)),\n 1, timeout\n )\n\n\ndef make_download_url_available(url_key_name, timeout):\n \"\"\"\n Authorize a download URL.\n\n Arguments:\n url_key_name (str): key that uniquely identifies the url\n timeout (int): time in seconds before the url expires\n \"\"\"\n get_cache().set(\n smart_text(get_download_cache_key(url_key_name)),\n 1, timeout\n )\n\n\ndef is_upload_url_available(url_key_name):\n \"\"\"\n Return True if the corresponding upload URL is available.\n \"\"\"\n return get_cache().get(smart_text(get_upload_cache_key(url_key_name))) is not None\n\n\ndef is_download_url_available(url_key_name):\n \"\"\"\n Return True if the corresponding download URL is available.\n \"\"\"\n return get_cache().get(smart_text(get_download_cache_key(url_key_name))) is not None\n\n\ndef get_upload_cache_key(url_key_name):\n return \"upload/\" + url_key_name\n\n\ndef get_download_cache_key(url_key_name):\n return \"download/\" + url_key_name\n", "path": "openassessment/fileupload/backends/filesystem.py"}, {"content": "import os\n\nfrom django.core.files.base import ContentFile\nfrom django.core.files.storage import default_storage\nfrom django.core.urlresolvers import reverse_lazy\n\nfrom .base import BaseBackend\n\n\nclass Backend(BaseBackend):\n \"\"\"\n Manage openassessment student files uploaded using the default django storage settings.\n \"\"\"\n def get_upload_url(self, key, content_type):\n \"\"\"\n Return the URL pointing to the ORA2 django storage upload endpoint.\n \"\"\"\n return reverse_lazy(\"openassessment-django-storage\", kwargs={'key': key})\n\n def get_download_url(self, key):\n \"\"\"\n Return the django storage download URL for the given key.\n\n Returns None if no file exists at that location.\n \"\"\"\n path = self._get_file_path(key)\n if default_storage.exists(path):\n return default_storage.url(path)\n return None\n\n def upload_file(self, key, content):\n \"\"\"\n Upload the given file content to the keyed location.\n \"\"\"\n path = self._get_file_path(key)\n saved_path = default_storage.save(path, ContentFile(content))\n return saved_path\n\n def remove_file(self, key):\n \"\"\"\n Remove the file at the given keyed location.\n\n Returns True if the file exists, and was removed.\n Returns False if the file does not exist, and so was not removed.\n \"\"\"\n path = self._get_file_path(key)\n if default_storage.exists(path):\n default_storage.delete(path)\n return True\n return False\n\n def _get_file_name(self, key):\n \"\"\"\n Returns the name of the keyed file.\n\n Since the backend storage may be folders, or it may use pseudo-folders,\n make sure the filename doesn't include any path separators.\n \"\"\"\n file_name = key.replace(\"..\", \"\").strip(\"/ \")\n file_name = file_name.replace(os.sep, \"_\")\n return file_name\n\n def _get_file_path(self, key):\n \"\"\"\n Returns the path to the keyed file, including the storage prefix.\n \"\"\"\n path = self._get_key_name(self._get_file_name(key))\n return path\n", "path": "openassessment/fileupload/backends/django_storage.py"}], "after_files": [{"content": "#!/usr/bin/env python\nfrom setuptools import find_packages, setup\n\n\ndef is_requirement(line):\n \"\"\"\n Return True if the requirement line is a package requirement;\n that is, it is not blank, a comment, or editable.\n \"\"\"\n # Remove whitespace at the start/end of the line\n line = line.strip()\n\n # Skip blank lines, comments, and editable installs\n return not (\n line == '' or\n line.startswith('-r') or\n line.startswith('#') or\n line.startswith('-e') or\n line.startswith('git+')\n )\n\ndef load_requirements(*requirements_paths):\n \"\"\"\n Load all requirements from the specified requirements files.\n Returns a list of requirement strings.\n \"\"\"\n requirements = set()\n for path in requirements_paths:\n requirements.update(\n line.strip() for line in open(path).readlines()\n if is_requirement(line)\n )\n return list(requirements)\n\nsetup(\n name='ora2',\n version='2.2.2',\n author='edX',\n url='http://github.com/edx/edx-ora2',\n description='edx-ora2',\n license='AGPL',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Framework :: Django :: 1.11',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU Affero General Public License v3',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n ],\n packages=find_packages(include=['openassessment*'], exclude=['*.test', '*.tests']),\n include_package_data=True,\n install_requires=load_requirements('requirements/base.txt', \"requirements/django.txt\"),\n tests_require=load_requirements('requirements/test.txt'),\n entry_points={\n 'xblock.v1': [\n 'openassessment = openassessment.xblock.openassessmentblock:OpenAssessmentBlock',\n ]\n },\n)\n", "path": "setup.py"}, {"content": "from django.conf import settings\nimport django.core.cache\nfrom django.core.urlresolvers import reverse\nfrom django.utils.encoding import smart_text\n\nfrom .. import exceptions\nfrom .base import BaseBackend\n\n\nclass Backend(BaseBackend):\n \"\"\"\n Upload openassessment student files to a local filesystem. Note\n that in order to use this file storage backend, you need to include the\n urls from openassessment.fileupload in your urls.py file:\n\n E.g:\n url(r'^openassessment/storage', include(openassessment.fileupload.urls)),\n\n The ORA2_FILEUPLOAD_CACHE_NAME setting will also have to be defined for the\n name of the django.core.cache instance which will maintain the list of\n active storage URLs.\n\n E.g:\n\n ORA2_FILEUPLOAD_CACHE_NAME = \"ora2-storage\"\n CACHES = {\n ...\n 'ora2-storage': {\n 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',\n ...\n },\n ...\n }\n \"\"\"\n\n def get_upload_url(self, key, content_type):\n make_upload_url_available(self._get_key_name(key), self.UPLOAD_URL_TIMEOUT)\n return self._get_url(key)\n\n def get_download_url(self, key):\n make_download_url_available(self._get_key_name(key), self.DOWNLOAD_URL_TIMEOUT)\n return self._get_url(key)\n\n def remove_file(self, key):\n from openassessment.fileupload.views_filesystem import safe_remove, get_file_path\n return safe_remove(get_file_path(self._get_key_name(key)))\n\n def _get_url(self, key):\n key_name = self._get_key_name(key)\n url = reverse(\"openassessment-filesystem-storage\", kwargs={'key': key_name})\n return url\n\n\ndef get_cache():\n \"\"\"\n Returns a django.core.cache instance in charge of maintaining the\n authorized upload and download URL.\n\n Raises:\n FileUploadInternalError if the cache name setting is not defined.\n InvalidCacheBackendError if the corresponding cache backend has not\n been configured.\n \"\"\"\n cache_name = getattr(settings, \"ORA2_FILEUPLOAD_CACHE_NAME\", None)\n if cache_name is None:\n raise exceptions.FileUploadInternalError(\"Undefined cache backend for file upload\")\n return django.core.cache.caches[cache_name]\n\n\ndef make_upload_url_available(url_key_name, timeout):\n \"\"\"\n Authorize an upload URL.\n\n Arguments:\n url_key_name (str): key that uniquely identifies the upload url\n timeout (int): time in seconds before the url expires\n \"\"\"\n get_cache().set(\n smart_text(get_upload_cache_key(url_key_name)),\n 1, timeout\n )\n\n\ndef make_download_url_available(url_key_name, timeout):\n \"\"\"\n Authorize a download URL.\n\n Arguments:\n url_key_name (str): key that uniquely identifies the url\n timeout (int): time in seconds before the url expires\n \"\"\"\n get_cache().set(\n smart_text(get_download_cache_key(url_key_name)),\n 1, timeout\n )\n\n\ndef is_upload_url_available(url_key_name):\n \"\"\"\n Return True if the corresponding upload URL is available.\n \"\"\"\n return get_cache().get(smart_text(get_upload_cache_key(url_key_name))) is not None\n\n\ndef is_download_url_available(url_key_name):\n \"\"\"\n Return True if the corresponding download URL is available.\n \"\"\"\n return get_cache().get(smart_text(get_download_cache_key(url_key_name))) is not None\n\n\ndef get_upload_cache_key(url_key_name):\n return \"upload/\" + url_key_name\n\n\ndef get_download_cache_key(url_key_name):\n return \"download/\" + url_key_name\n", "path": "openassessment/fileupload/backends/filesystem.py"}, {"content": "import os\n\nfrom django.core.files.base import ContentFile\nfrom django.core.files.storage import default_storage\nfrom django.core.urlresolvers import reverse\n\nfrom .base import BaseBackend\n\n\nclass Backend(BaseBackend):\n \"\"\"\n Manage openassessment student files uploaded using the default django storage settings.\n \"\"\"\n def get_upload_url(self, key, content_type):\n \"\"\"\n Return the URL pointing to the ORA2 django storage upload endpoint.\n \"\"\"\n return reverse(\"openassessment-django-storage\", kwargs={'key': key})\n\n def get_download_url(self, key):\n \"\"\"\n Return the django storage download URL for the given key.\n\n Returns None if no file exists at that location.\n \"\"\"\n path = self._get_file_path(key)\n if default_storage.exists(path):\n return default_storage.url(path)\n return None\n\n def upload_file(self, key, content):\n \"\"\"\n Upload the given file content to the keyed location.\n \"\"\"\n path = self._get_file_path(key)\n saved_path = default_storage.save(path, ContentFile(content))\n return saved_path\n\n def remove_file(self, key):\n \"\"\"\n Remove the file at the given keyed location.\n\n Returns True if the file exists, and was removed.\n Returns False if the file does not exist, and so was not removed.\n \"\"\"\n path = self._get_file_path(key)\n if default_storage.exists(path):\n default_storage.delete(path)\n return True\n return False\n\n def _get_file_name(self, key):\n \"\"\"\n Returns the name of the keyed file.\n\n Since the backend storage may be folders, or it may use pseudo-folders,\n make sure the filename doesn't include any path separators.\n \"\"\"\n file_name = key.replace(\"..\", \"\").strip(\"/ \")\n file_name = file_name.replace(os.sep, \"_\")\n return file_name\n\n def _get_file_path(self, key):\n \"\"\"\n Returns the path to the keyed file, including the storage prefix.\n \"\"\"\n path = self._get_key_name(self._get_file_name(key))\n return path\n", "path": "openassessment/fileupload/backends/django_storage.py"}]}
| 3,445 | 455 |
gh_patches_debug_18528
|
rasdani/github-patches
|
git_diff
|
doccano__doccano-2077
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CSRF

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/config/settings/development.py`
Content:
```
1 from .base import * # noqa: F403
2
3 MIDDLEWARE.append("api.middleware.RangesMiddleware") # noqa: F405
4 CORS_ORIGIN_WHITELIST = ("http://127.0.0.1:3000", "http://0.0.0.0:3000", "http://localhost:3000")
5 CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST
6 # LOGGING = {
7 # 'version': 1,
8 # 'handlers': {
9 # 'console': {
10 # 'level': 'DEBUG',
11 # 'class': 'logging.StreamHandler',
12 # }
13 # },
14 # 'loggers': {
15 # 'django.db.backends': {
16 # 'level': 'DEBUG',
17 # 'handlers': ['console'],
18 # },
19 # }
20 # }
21
```
Path: `backend/config/settings/base.py`
Content:
```
1 """
2 Django settings for app project.
3
4 For more information on this file, see
5 https://docs.djangoproject.com/en/2.0/topics/settings/
6
7 For the full list of settings and their values, see
8 https://docs.djangoproject.com/en/2.0/ref/settings/
9
10 Any setting that is configured via an environment variable may
11 also be set in a `.env` file in the project base directory.
12 """
13 from os import path
14
15 import dj_database_url
16 from environs import Env, EnvError
17 from furl import furl
18
19 # Build paths inside the project like this: path.join(BASE_DIR, ...)
20 BASE_DIR = path.dirname(path.dirname(path.dirname(path.abspath(__file__))))
21
22 env = Env()
23 env.read_env(path.join(BASE_DIR, ".env"), recurse=False)
24
25 # Quick-start development settings - unsuitable for production
26 # See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/
27 # SECURITY WARNING: keep the secret key used in production secret!
28 SECRET_KEY = env("SECRET_KEY", "v8sk33sy82!uw3ty=!jjv5vp7=s2phrzw(m(hrn^f7e_#1h2al")
29
30 # SECURITY WARNING: don't run with debug turned on in production!
31 DEBUG = env.bool("DEBUG", True)
32
33 # Application definition
34 INSTALLED_APPS = [
35 "whitenoise.runserver_nostatic",
36 "django.contrib.admin",
37 "django.contrib.auth",
38 "django.contrib.contenttypes",
39 "django.contrib.sessions",
40 "django.contrib.messages",
41 "django.contrib.staticfiles",
42 "api",
43 "roles",
44 "projects",
45 "metrics",
46 "users",
47 "data_import",
48 "data_export",
49 "auto_labeling",
50 "labels",
51 "label_types",
52 "examples",
53 "rest_framework",
54 "rest_framework.authtoken",
55 "django_filters",
56 "polymorphic",
57 "corsheaders",
58 "drf_yasg",
59 "allauth",
60 "allauth.account",
61 "allauth.socialaccount",
62 "dj_rest_auth",
63 "dj_rest_auth.registration",
64 "django_celery_results",
65 "django_drf_filepond",
66 "health_check",
67 "health_check.cache",
68 "health_check.storage",
69 "health_check.contrib.migrations",
70 "health_check.contrib.celery",
71 "django_cleanup",
72 ]
73
74
75 MIDDLEWARE = [
76 "django.middleware.security.SecurityMiddleware",
77 "whitenoise.middleware.WhiteNoiseMiddleware",
78 "django.contrib.sessions.middleware.SessionMiddleware",
79 "django.middleware.common.CommonMiddleware",
80 "django.middleware.csrf.CsrfViewMiddleware",
81 "django.contrib.auth.middleware.AuthenticationMiddleware",
82 "django.contrib.messages.middleware.MessageMiddleware",
83 "django.middleware.clickjacking.XFrameOptionsMiddleware",
84 "corsheaders.middleware.CorsMiddleware",
85 ]
86
87
88 ROOT_URLCONF = "config.urls"
89 WSGI_APPLICATION = "config.wsgi.application"
90
91 # Django templates
92 TEMPLATES = [
93 {
94 "BACKEND": "django.template.backends.django.DjangoTemplates",
95 "DIRS": [path.join(BASE_DIR, "client/dist")],
96 "APP_DIRS": True,
97 "OPTIONS": {
98 "context_processors": [
99 "django.template.context_processors.debug",
100 "django.template.context_processors.request",
101 "django.contrib.auth.context_processors.auth",
102 "django.contrib.messages.context_processors.messages",
103 ],
104 },
105 },
106 ]
107
108 # Static files (CSS, JavaScript, Images)
109 # https://docs.djangoproject.com/en/2.0/howto/static-files/
110 STATIC_URL = "/static/"
111 STATIC_ROOT = path.join(BASE_DIR, "staticfiles")
112 STATICFILES_DIRS = [
113 path.join(BASE_DIR, "client/dist/static"),
114 ]
115 # STATICFILES_STORAGE = "whitenoise.storage.CompressedManifestStaticFilesStorage"
116 STATICFILES_STORAGE = "whitenoise.storage.CompressedStaticFilesStorage"
117
118 # Auth settings
119 AUTHENTICATION_BACKENDS = [
120 "django.contrib.auth.backends.ModelBackend",
121 ]
122 HEADER_AUTH_USER_NAME = env("HEADER_AUTH_USER_NAME", "")
123 HEADER_AUTH_USER_GROUPS = env("HEADER_AUTH_USER_GROUPS", "")
124 HEADER_AUTH_ADMIN_GROUP_NAME = env("HEADER_AUTH_ADMIN_GROUP_NAME", "")
125 HEADER_AUTH_GROUPS_SEPERATOR = env("HEADER_AUTH_GROUPS_SEPERATOR", default=",")
126 if HEADER_AUTH_USER_NAME and HEADER_AUTH_USER_GROUPS and HEADER_AUTH_ADMIN_GROUP_NAME:
127 MIDDLEWARE.append("api.middleware.HeaderAuthMiddleware")
128 AUTHENTICATION_BACKENDS.append("django.contrib.auth.backends.RemoteUserBackend")
129
130 # Role settings
131 ROLE_PROJECT_ADMIN = env("ROLE_PROJECT_ADMIN", "project_admin")
132 ROLE_ANNOTATOR = env("ROLE_ANNOTATOR", "annotator")
133 ROLE_ANNOTATION_APPROVER = env("ROLE_ANNOTATION_APPROVER", "annotation_approver")
134
135 # Password validation
136 # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators
137 AUTH_PASSWORD_VALIDATORS = [
138 {
139 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
140 },
141 {
142 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
143 },
144 {
145 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
146 },
147 {
148 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
149 },
150 ]
151
152 REST_FRAMEWORK = {
153 # Use Django's standard `django.contrib.auth` permissions,
154 # or allow read-only access for unauthenticated users.
155 "DEFAULT_PERMISSION_CLASSES": [
156 "rest_framework.permissions.DjangoModelPermissionsOrAnonReadOnly",
157 "rest_framework.permissions.IsAuthenticated",
158 ],
159 "DEFAULT_AUTHENTICATION_CLASSES": (
160 "rest_framework.authentication.SessionAuthentication",
161 "rest_framework.authentication.TokenAuthentication",
162 ),
163 "DEFAULT_PAGINATION_CLASS": "rest_framework.pagination.LimitOffsetPagination",
164 "PAGE_SIZE": env.int("DOCCANO_PAGE_SIZE", default=5),
165 "DEFAULT_FILTER_BACKENDS": ("django_filters.rest_framework.DjangoFilterBackend",),
166 "SEARCH_PARAM": "q",
167 "DEFAULT_RENDERER_CLASSES": (
168 "rest_framework.renderers.JSONRenderer",
169 "rest_framework.renderers.BrowsableAPIRenderer",
170 "rest_framework_xml.renderers.XMLRenderer",
171 ),
172 }
173
174 # Internationalization
175 # https://docs.djangoproject.com/en/2.0/topics/i18n/
176 LANGUAGE_CODE = "en-us"
177 TIME_ZONE = "UTC"
178 USE_I18N = True
179 USE_L10N = True
180 USE_TZ = True
181
182 # Testing
183 TEST_RUNNER = "xmlrunner.extra.djangotestrunner.XMLTestRunner"
184 TEST_OUTPUT_DIR = path.join(BASE_DIR, "junitxml")
185
186 LOGIN_URL = "/login/"
187 LOGIN_REDIRECT_URL = "/projects/"
188 LOGOUT_REDIRECT_URL = "/"
189
190 # Database
191 # https://docs.djangoproject.com/en/2.0/ref/settings/#databases
192 DATABASES = {
193 "default": {
194 "ENGINE": "django.db.backends.sqlite3",
195 "NAME": path.join(BASE_DIR, "db.sqlite3"),
196 }
197 }
198 # Change 'default' database configuration with $DATABASE_URL.
199 DATABASES["default"].update(
200 dj_database_url.config(
201 env="DATABASE_URL",
202 conn_max_age=env.int("DATABASE_CONN_MAX_AGE", 500),
203 ssl_require="sslmode" not in furl(env("DATABASE_URL", "")).args,
204 )
205 )
206
207 # work-around for dj-database-url: explicitly disable ssl for sqlite
208 if DATABASES["default"].get("ENGINE") == "django.db.backends.sqlite3":
209 DATABASES["default"].get("OPTIONS", {}).pop("sslmode", None)
210
211 # work-around for dj-database-url: patch ssl for mysql
212 if DATABASES["default"].get("ENGINE") == "django.db.backends.mysql":
213 DATABASES["default"].get("OPTIONS", {}).pop("sslmode", None)
214 if env("MYSQL_SSL_CA", None):
215 DATABASES["default"].setdefault("OPTIONS", {}).setdefault("ssl", {}).setdefault("ca", env("MYSQL_SSL_CA", None))
216
217 # default to a sensible modern driver for Azure SQL
218 if DATABASES["default"].get("ENGINE") == "sql_server.pyodbc":
219 DATABASES["default"].setdefault("OPTIONS", {}).setdefault("driver", "ODBC Driver 17 for SQL Server")
220
221
222 # Sessions and CSRF
223 # Honor the 'X-Forwarded-Proto' header for request.is_secure()
224 SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
225 SESSION_COOKIE_SECURE = env.bool("SESSION_COOKIE_SECURE", False)
226 CSRF_COOKIE_SECURE = env.bool("CSRF_COOKIE_SECURE", False)
227 CSRF_TRUSTED_ORIGINS = env.list("CSRF_TRUSTED_ORIGINS", [])
228
229 # Allow all host headers
230 ALLOWED_HOSTS = ["*"]
231
232 if DEBUG:
233 CORS_ORIGIN_WHITELIST = ("http://127.0.0.1:3000", "http://0.0.0.0:3000", "http://localhost:3000")
234 CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST
235
236 # Batch size for importing data
237 IMPORT_BATCH_SIZE = env.int("IMPORT_BATCH_SIZE", 1000)
238
239 # Necessary for email verification of new accounts
240 EMAIL_USE_TLS = env.bool("EMAIL_USE_TLS", False)
241 EMAIL_HOST = env("EMAIL_HOST", None)
242 EMAIL_HOST_USER = env("EMAIL_HOST_USER", None)
243 EMAIL_HOST_PASSWORD = env("EMAIL_HOST_PASSWORD", None)
244 EMAIL_PORT = env.int("EMAIL_PORT", 587)
245 DEFAULT_FROM_EMAIL = env("DEFAULT_FROM_EMAIL", "webmaster@localhost")
246 if not EMAIL_HOST:
247 EMAIL_BACKEND = "django.core.mail.backends.console.EmailBackend"
248
249
250 # User media files
251 MEDIA_ROOT = env("MEDIA_ROOT", path.join(BASE_DIR, "media"))
252 MEDIA_URL = "/media/"
253
254 # Filepond settings
255 DJANGO_DRF_FILEPOND_UPLOAD_TMP = path.join(BASE_DIR, "filepond-temp-uploads")
256 DJANGO_DRF_FILEPOND_FILE_STORE_PATH = MEDIA_ROOT
257
258 # File upload setting
259 MAX_UPLOAD_SIZE = env.int("MAX_UPLOAD_SIZE", pow(1024, 3)) # default: 1GB per a file
260 ENABLE_FILE_TYPE_CHECK = env.bool("ENABLE_FILE_TYPE_CHECK", False)
261
262 # Celery settings
263 DJANGO_CELERY_RESULTS_TASK_ID_MAX_LENGTH = 191
264 CELERY_RESULT_BACKEND = "django-db"
265 try:
266 CELERY_BROKER_URL = env("CELERY_BROKER_URL")
267 except EnvError:
268 try:
269 # quickfix for Heroku.
270 # See https://github.com/doccano/doccano/issues/1327.
271 uri = env("DATABASE_URL")
272 if uri.startswith("postgres://"):
273 uri = uri.replace("postgres://", "postgresql://", 1)
274 CELERY_BROKER_URL = "sqla+{}".format(uri)
275 except EnvError:
276 CELERY_BROKER_URL = "sqla+sqlite:///{}".format(DATABASES["default"]["NAME"])
277 CELERY_ACCEPT_CONTENT = ["application/json"]
278 CELERY_TASK_SERIALIZER = "json"
279 CELERY_RESULT_SERIALIZER = "json"
280
281 DEFAULT_AUTO_FIELD = "django.db.models.AutoField"
282
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/config/settings/base.py b/backend/config/settings/base.py
--- a/backend/config/settings/base.py
+++ b/backend/config/settings/base.py
@@ -230,8 +230,9 @@
ALLOWED_HOSTS = ["*"]
if DEBUG:
- CORS_ORIGIN_WHITELIST = ("http://127.0.0.1:3000", "http://0.0.0.0:3000", "http://localhost:3000")
- CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST
+ CORS_ORIGIN_ALLOW_ALL = True
+ CSRF_TRUSTED_ORIGINS = ["http://127.0.0.1:3000", "http://0.0.0.0:3000", "http://localhost:3000"]
+ CSRF_TRUSTED_ORIGINS += env.list("CSRF_TRUSTED_ORIGINS", [])
# Batch size for importing data
IMPORT_BATCH_SIZE = env.int("IMPORT_BATCH_SIZE", 1000)
diff --git a/backend/config/settings/development.py b/backend/config/settings/development.py
--- a/backend/config/settings/development.py
+++ b/backend/config/settings/development.py
@@ -1,8 +1,6 @@
from .base import * # noqa: F403
MIDDLEWARE.append("api.middleware.RangesMiddleware") # noqa: F405
-CORS_ORIGIN_WHITELIST = ("http://127.0.0.1:3000", "http://0.0.0.0:3000", "http://localhost:3000")
-CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST
# LOGGING = {
# 'version': 1,
# 'handlers': {
|
{"golden_diff": "diff --git a/backend/config/settings/base.py b/backend/config/settings/base.py\n--- a/backend/config/settings/base.py\n+++ b/backend/config/settings/base.py\n@@ -230,8 +230,9 @@\n ALLOWED_HOSTS = [\"*\"]\n \n if DEBUG:\n- CORS_ORIGIN_WHITELIST = (\"http://127.0.0.1:3000\", \"http://0.0.0.0:3000\", \"http://localhost:3000\")\n- CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST\n+ CORS_ORIGIN_ALLOW_ALL = True\n+ CSRF_TRUSTED_ORIGINS = [\"http://127.0.0.1:3000\", \"http://0.0.0.0:3000\", \"http://localhost:3000\"]\n+ CSRF_TRUSTED_ORIGINS += env.list(\"CSRF_TRUSTED_ORIGINS\", [])\n \n # Batch size for importing data\n IMPORT_BATCH_SIZE = env.int(\"IMPORT_BATCH_SIZE\", 1000)\ndiff --git a/backend/config/settings/development.py b/backend/config/settings/development.py\n--- a/backend/config/settings/development.py\n+++ b/backend/config/settings/development.py\n@@ -1,8 +1,6 @@\n from .base import * # noqa: F403\n \n MIDDLEWARE.append(\"api.middleware.RangesMiddleware\") # noqa: F405\n-CORS_ORIGIN_WHITELIST = (\"http://127.0.0.1:3000\", \"http://0.0.0.0:3000\", \"http://localhost:3000\")\n-CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST\n # LOGGING = {\n # 'version': 1,\n # 'handlers': {\n", "issue": "CSRF\n\r\n\n", "before_files": [{"content": "from .base import * # noqa: F403\n\nMIDDLEWARE.append(\"api.middleware.RangesMiddleware\") # noqa: F405\nCORS_ORIGIN_WHITELIST = (\"http://127.0.0.1:3000\", \"http://0.0.0.0:3000\", \"http://localhost:3000\")\nCSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST\n# LOGGING = {\n# 'version': 1,\n# 'handlers': {\n# 'console': {\n# 'level': 'DEBUG',\n# 'class': 'logging.StreamHandler',\n# }\n# },\n# 'loggers': {\n# 'django.db.backends': {\n# 'level': 'DEBUG',\n# 'handlers': ['console'],\n# },\n# }\n# }\n", "path": "backend/config/settings/development.py"}, {"content": "\"\"\"\nDjango settings for app project.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/2.0/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/2.0/ref/settings/\n\nAny setting that is configured via an environment variable may\nalso be set in a `.env` file in the project base directory.\n\"\"\"\nfrom os import path\n\nimport dj_database_url\nfrom environs import Env, EnvError\nfrom furl import furl\n\n# Build paths inside the project like this: path.join(BASE_DIR, ...)\nBASE_DIR = path.dirname(path.dirname(path.dirname(path.abspath(__file__))))\n\nenv = Env()\nenv.read_env(path.join(BASE_DIR, \".env\"), recurse=False)\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = env(\"SECRET_KEY\", \"v8sk33sy82!uw3ty=!jjv5vp7=s2phrzw(m(hrn^f7e_#1h2al\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = env.bool(\"DEBUG\", True)\n\n# Application definition\nINSTALLED_APPS = [\n \"whitenoise.runserver_nostatic\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"api\",\n \"roles\",\n \"projects\",\n \"metrics\",\n \"users\",\n \"data_import\",\n \"data_export\",\n \"auto_labeling\",\n \"labels\",\n \"label_types\",\n \"examples\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"django_filters\",\n \"polymorphic\",\n \"corsheaders\",\n \"drf_yasg\",\n \"allauth\",\n \"allauth.account\",\n \"allauth.socialaccount\",\n \"dj_rest_auth\",\n \"dj_rest_auth.registration\",\n \"django_celery_results\",\n \"django_drf_filepond\",\n \"health_check\",\n \"health_check.cache\",\n \"health_check.storage\",\n \"health_check.contrib.migrations\",\n \"health_check.contrib.celery\",\n \"django_cleanup\",\n]\n\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"corsheaders.middleware.CorsMiddleware\",\n]\n\n\nROOT_URLCONF = \"config.urls\"\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Django templates\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [path.join(BASE_DIR, \"client/dist\")],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/2.0/howto/static-files/\nSTATIC_URL = \"/static/\"\nSTATIC_ROOT = path.join(BASE_DIR, \"staticfiles\")\nSTATICFILES_DIRS = [\n path.join(BASE_DIR, \"client/dist/static\"),\n]\n# STATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\nSTATICFILES_STORAGE = \"whitenoise.storage.CompressedStaticFilesStorage\"\n\n# Auth settings\nAUTHENTICATION_BACKENDS = [\n \"django.contrib.auth.backends.ModelBackend\",\n]\nHEADER_AUTH_USER_NAME = env(\"HEADER_AUTH_USER_NAME\", \"\")\nHEADER_AUTH_USER_GROUPS = env(\"HEADER_AUTH_USER_GROUPS\", \"\")\nHEADER_AUTH_ADMIN_GROUP_NAME = env(\"HEADER_AUTH_ADMIN_GROUP_NAME\", \"\")\nHEADER_AUTH_GROUPS_SEPERATOR = env(\"HEADER_AUTH_GROUPS_SEPERATOR\", default=\",\")\nif HEADER_AUTH_USER_NAME and HEADER_AUTH_USER_GROUPS and HEADER_AUTH_ADMIN_GROUP_NAME:\n MIDDLEWARE.append(\"api.middleware.HeaderAuthMiddleware\")\n AUTHENTICATION_BACKENDS.append(\"django.contrib.auth.backends.RemoteUserBackend\")\n\n# Role settings\nROLE_PROJECT_ADMIN = env(\"ROLE_PROJECT_ADMIN\", \"project_admin\")\nROLE_ANNOTATOR = env(\"ROLE_ANNOTATOR\", \"annotator\")\nROLE_ANNOTATION_APPROVER = env(\"ROLE_ANNOTATION_APPROVER\", \"annotation_approver\")\n\n# Password validation\n# https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\nREST_FRAMEWORK = {\n # Use Django's standard `django.contrib.auth` permissions,\n # or allow read-only access for unauthenticated users.\n \"DEFAULT_PERMISSION_CLASSES\": [\n \"rest_framework.permissions.DjangoModelPermissionsOrAnonReadOnly\",\n \"rest_framework.permissions.IsAuthenticated\",\n ],\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n ),\n \"DEFAULT_PAGINATION_CLASS\": \"rest_framework.pagination.LimitOffsetPagination\",\n \"PAGE_SIZE\": env.int(\"DOCCANO_PAGE_SIZE\", default=5),\n \"DEFAULT_FILTER_BACKENDS\": (\"django_filters.rest_framework.DjangoFilterBackend\",),\n \"SEARCH_PARAM\": \"q\",\n \"DEFAULT_RENDERER_CLASSES\": (\n \"rest_framework.renderers.JSONRenderer\",\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n \"rest_framework_xml.renderers.XMLRenderer\",\n ),\n}\n\n# Internationalization\n# https://docs.djangoproject.com/en/2.0/topics/i18n/\nLANGUAGE_CODE = \"en-us\"\nTIME_ZONE = \"UTC\"\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\n# Testing\nTEST_RUNNER = \"xmlrunner.extra.djangotestrunner.XMLTestRunner\"\nTEST_OUTPUT_DIR = path.join(BASE_DIR, \"junitxml\")\n\nLOGIN_URL = \"/login/\"\nLOGIN_REDIRECT_URL = \"/projects/\"\nLOGOUT_REDIRECT_URL = \"/\"\n\n# Database\n# https://docs.djangoproject.com/en/2.0/ref/settings/#databases\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": path.join(BASE_DIR, \"db.sqlite3\"),\n }\n}\n# Change 'default' database configuration with $DATABASE_URL.\nDATABASES[\"default\"].update(\n dj_database_url.config(\n env=\"DATABASE_URL\",\n conn_max_age=env.int(\"DATABASE_CONN_MAX_AGE\", 500),\n ssl_require=\"sslmode\" not in furl(env(\"DATABASE_URL\", \"\")).args,\n )\n)\n\n# work-around for dj-database-url: explicitly disable ssl for sqlite\nif DATABASES[\"default\"].get(\"ENGINE\") == \"django.db.backends.sqlite3\":\n DATABASES[\"default\"].get(\"OPTIONS\", {}).pop(\"sslmode\", None)\n\n# work-around for dj-database-url: patch ssl for mysql\nif DATABASES[\"default\"].get(\"ENGINE\") == \"django.db.backends.mysql\":\n DATABASES[\"default\"].get(\"OPTIONS\", {}).pop(\"sslmode\", None)\n if env(\"MYSQL_SSL_CA\", None):\n DATABASES[\"default\"].setdefault(\"OPTIONS\", {}).setdefault(\"ssl\", {}).setdefault(\"ca\", env(\"MYSQL_SSL_CA\", None))\n\n# default to a sensible modern driver for Azure SQL\nif DATABASES[\"default\"].get(\"ENGINE\") == \"sql_server.pyodbc\":\n DATABASES[\"default\"].setdefault(\"OPTIONS\", {}).setdefault(\"driver\", \"ODBC Driver 17 for SQL Server\")\n\n\n# Sessions and CSRF\n# Honor the 'X-Forwarded-Proto' header for request.is_secure()\nSECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\nSESSION_COOKIE_SECURE = env.bool(\"SESSION_COOKIE_SECURE\", False)\nCSRF_COOKIE_SECURE = env.bool(\"CSRF_COOKIE_SECURE\", False)\nCSRF_TRUSTED_ORIGINS = env.list(\"CSRF_TRUSTED_ORIGINS\", [])\n\n# Allow all host headers\nALLOWED_HOSTS = [\"*\"]\n\nif DEBUG:\n CORS_ORIGIN_WHITELIST = (\"http://127.0.0.1:3000\", \"http://0.0.0.0:3000\", \"http://localhost:3000\")\n CSRF_TRUSTED_ORIGINS = CORS_ORIGIN_WHITELIST\n\n# Batch size for importing data\nIMPORT_BATCH_SIZE = env.int(\"IMPORT_BATCH_SIZE\", 1000)\n\n# Necessary for email verification of new accounts\nEMAIL_USE_TLS = env.bool(\"EMAIL_USE_TLS\", False)\nEMAIL_HOST = env(\"EMAIL_HOST\", None)\nEMAIL_HOST_USER = env(\"EMAIL_HOST_USER\", None)\nEMAIL_HOST_PASSWORD = env(\"EMAIL_HOST_PASSWORD\", None)\nEMAIL_PORT = env.int(\"EMAIL_PORT\", 587)\nDEFAULT_FROM_EMAIL = env(\"DEFAULT_FROM_EMAIL\", \"webmaster@localhost\")\nif not EMAIL_HOST:\n EMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n\n\n# User media files\nMEDIA_ROOT = env(\"MEDIA_ROOT\", path.join(BASE_DIR, \"media\"))\nMEDIA_URL = \"/media/\"\n\n# Filepond settings\nDJANGO_DRF_FILEPOND_UPLOAD_TMP = path.join(BASE_DIR, \"filepond-temp-uploads\")\nDJANGO_DRF_FILEPOND_FILE_STORE_PATH = MEDIA_ROOT\n\n# File upload setting\nMAX_UPLOAD_SIZE = env.int(\"MAX_UPLOAD_SIZE\", pow(1024, 3)) # default: 1GB per a file\nENABLE_FILE_TYPE_CHECK = env.bool(\"ENABLE_FILE_TYPE_CHECK\", False)\n\n# Celery settings\nDJANGO_CELERY_RESULTS_TASK_ID_MAX_LENGTH = 191\nCELERY_RESULT_BACKEND = \"django-db\"\ntry:\n CELERY_BROKER_URL = env(\"CELERY_BROKER_URL\")\nexcept EnvError:\n try:\n # quickfix for Heroku.\n # See https://github.com/doccano/doccano/issues/1327.\n uri = env(\"DATABASE_URL\")\n if uri.startswith(\"postgres://\"):\n uri = uri.replace(\"postgres://\", \"postgresql://\", 1)\n CELERY_BROKER_URL = \"sqla+{}\".format(uri)\n except EnvError:\n CELERY_BROKER_URL = \"sqla+sqlite:///{}\".format(DATABASES[\"default\"][\"NAME\"])\nCELERY_ACCEPT_CONTENT = [\"application/json\"]\nCELERY_TASK_SERIALIZER = \"json\"\nCELERY_RESULT_SERIALIZER = \"json\"\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n", "path": "backend/config/settings/base.py"}], "after_files": [{"content": "from .base import * # noqa: F403\n\nMIDDLEWARE.append(\"api.middleware.RangesMiddleware\") # noqa: F405\n# LOGGING = {\n# 'version': 1,\n# 'handlers': {\n# 'console': {\n# 'level': 'DEBUG',\n# 'class': 'logging.StreamHandler',\n# }\n# },\n# 'loggers': {\n# 'django.db.backends': {\n# 'level': 'DEBUG',\n# 'handlers': ['console'],\n# },\n# }\n# }\n", "path": "backend/config/settings/development.py"}, {"content": "\"\"\"\nDjango settings for app project.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/2.0/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/2.0/ref/settings/\n\nAny setting that is configured via an environment variable may\nalso be set in a `.env` file in the project base directory.\n\"\"\"\nfrom os import path\n\nimport dj_database_url\nfrom environs import Env, EnvError\nfrom furl import furl\n\n# Build paths inside the project like this: path.join(BASE_DIR, ...)\nBASE_DIR = path.dirname(path.dirname(path.dirname(path.abspath(__file__))))\n\nenv = Env()\nenv.read_env(path.join(BASE_DIR, \".env\"), recurse=False)\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = env(\"SECRET_KEY\", \"v8sk33sy82!uw3ty=!jjv5vp7=s2phrzw(m(hrn^f7e_#1h2al\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = env.bool(\"DEBUG\", True)\n\n# Application definition\nINSTALLED_APPS = [\n \"whitenoise.runserver_nostatic\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"api\",\n \"roles\",\n \"projects\",\n \"metrics\",\n \"users\",\n \"data_import\",\n \"data_export\",\n \"auto_labeling\",\n \"labels\",\n \"label_types\",\n \"examples\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"django_filters\",\n \"polymorphic\",\n \"corsheaders\",\n \"drf_yasg\",\n \"allauth\",\n \"allauth.account\",\n \"allauth.socialaccount\",\n \"dj_rest_auth\",\n \"dj_rest_auth.registration\",\n \"django_celery_results\",\n \"django_drf_filepond\",\n \"health_check\",\n \"health_check.cache\",\n \"health_check.storage\",\n \"health_check.contrib.migrations\",\n \"health_check.contrib.celery\",\n \"django_cleanup\",\n]\n\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"corsheaders.middleware.CorsMiddleware\",\n]\n\n\nROOT_URLCONF = \"config.urls\"\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Django templates\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [path.join(BASE_DIR, \"client/dist\")],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/2.0/howto/static-files/\nSTATIC_URL = \"/static/\"\nSTATIC_ROOT = path.join(BASE_DIR, \"staticfiles\")\nSTATICFILES_DIRS = [\n path.join(BASE_DIR, \"client/dist/static\"),\n]\n# STATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\nSTATICFILES_STORAGE = \"whitenoise.storage.CompressedStaticFilesStorage\"\n\n# Auth settings\nAUTHENTICATION_BACKENDS = [\n \"django.contrib.auth.backends.ModelBackend\",\n]\nHEADER_AUTH_USER_NAME = env(\"HEADER_AUTH_USER_NAME\", \"\")\nHEADER_AUTH_USER_GROUPS = env(\"HEADER_AUTH_USER_GROUPS\", \"\")\nHEADER_AUTH_ADMIN_GROUP_NAME = env(\"HEADER_AUTH_ADMIN_GROUP_NAME\", \"\")\nHEADER_AUTH_GROUPS_SEPERATOR = env(\"HEADER_AUTH_GROUPS_SEPERATOR\", default=\",\")\nif HEADER_AUTH_USER_NAME and HEADER_AUTH_USER_GROUPS and HEADER_AUTH_ADMIN_GROUP_NAME:\n MIDDLEWARE.append(\"api.middleware.HeaderAuthMiddleware\")\n AUTHENTICATION_BACKENDS.append(\"django.contrib.auth.backends.RemoteUserBackend\")\n\n# Role settings\nROLE_PROJECT_ADMIN = env(\"ROLE_PROJECT_ADMIN\", \"project_admin\")\nROLE_ANNOTATOR = env(\"ROLE_ANNOTATOR\", \"annotator\")\nROLE_ANNOTATION_APPROVER = env(\"ROLE_ANNOTATION_APPROVER\", \"annotation_approver\")\n\n# Password validation\n# https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\nREST_FRAMEWORK = {\n # Use Django's standard `django.contrib.auth` permissions,\n # or allow read-only access for unauthenticated users.\n \"DEFAULT_PERMISSION_CLASSES\": [\n \"rest_framework.permissions.DjangoModelPermissionsOrAnonReadOnly\",\n \"rest_framework.permissions.IsAuthenticated\",\n ],\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n ),\n \"DEFAULT_PAGINATION_CLASS\": \"rest_framework.pagination.LimitOffsetPagination\",\n \"PAGE_SIZE\": env.int(\"DOCCANO_PAGE_SIZE\", default=5),\n \"DEFAULT_FILTER_BACKENDS\": (\"django_filters.rest_framework.DjangoFilterBackend\",),\n \"SEARCH_PARAM\": \"q\",\n \"DEFAULT_RENDERER_CLASSES\": (\n \"rest_framework.renderers.JSONRenderer\",\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n \"rest_framework_xml.renderers.XMLRenderer\",\n ),\n}\n\n# Internationalization\n# https://docs.djangoproject.com/en/2.0/topics/i18n/\nLANGUAGE_CODE = \"en-us\"\nTIME_ZONE = \"UTC\"\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\n# Testing\nTEST_RUNNER = \"xmlrunner.extra.djangotestrunner.XMLTestRunner\"\nTEST_OUTPUT_DIR = path.join(BASE_DIR, \"junitxml\")\n\nLOGIN_URL = \"/login/\"\nLOGIN_REDIRECT_URL = \"/projects/\"\nLOGOUT_REDIRECT_URL = \"/\"\n\n# Database\n# https://docs.djangoproject.com/en/2.0/ref/settings/#databases\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": path.join(BASE_DIR, \"db.sqlite3\"),\n }\n}\n# Change 'default' database configuration with $DATABASE_URL.\nDATABASES[\"default\"].update(\n dj_database_url.config(\n env=\"DATABASE_URL\",\n conn_max_age=env.int(\"DATABASE_CONN_MAX_AGE\", 500),\n ssl_require=\"sslmode\" not in furl(env(\"DATABASE_URL\", \"\")).args,\n )\n)\n\n# work-around for dj-database-url: explicitly disable ssl for sqlite\nif DATABASES[\"default\"].get(\"ENGINE\") == \"django.db.backends.sqlite3\":\n DATABASES[\"default\"].get(\"OPTIONS\", {}).pop(\"sslmode\", None)\n\n# work-around for dj-database-url: patch ssl for mysql\nif DATABASES[\"default\"].get(\"ENGINE\") == \"django.db.backends.mysql\":\n DATABASES[\"default\"].get(\"OPTIONS\", {}).pop(\"sslmode\", None)\n if env(\"MYSQL_SSL_CA\", None):\n DATABASES[\"default\"].setdefault(\"OPTIONS\", {}).setdefault(\"ssl\", {}).setdefault(\"ca\", env(\"MYSQL_SSL_CA\", None))\n\n# default to a sensible modern driver for Azure SQL\nif DATABASES[\"default\"].get(\"ENGINE\") == \"sql_server.pyodbc\":\n DATABASES[\"default\"].setdefault(\"OPTIONS\", {}).setdefault(\"driver\", \"ODBC Driver 17 for SQL Server\")\n\n\n# Sessions and CSRF\n# Honor the 'X-Forwarded-Proto' header for request.is_secure()\nSECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\nSESSION_COOKIE_SECURE = env.bool(\"SESSION_COOKIE_SECURE\", False)\nCSRF_COOKIE_SECURE = env.bool(\"CSRF_COOKIE_SECURE\", False)\nCSRF_TRUSTED_ORIGINS = env.list(\"CSRF_TRUSTED_ORIGINS\", [])\n\n# Allow all host headers\nALLOWED_HOSTS = [\"*\"]\n\nif DEBUG:\n CORS_ORIGIN_ALLOW_ALL = True\n CSRF_TRUSTED_ORIGINS = [\"http://127.0.0.1:3000\", \"http://0.0.0.0:3000\", \"http://localhost:3000\"]\n CSRF_TRUSTED_ORIGINS += env.list(\"CSRF_TRUSTED_ORIGINS\", [])\n\n# Batch size for importing data\nIMPORT_BATCH_SIZE = env.int(\"IMPORT_BATCH_SIZE\", 1000)\n\n# Necessary for email verification of new accounts\nEMAIL_USE_TLS = env.bool(\"EMAIL_USE_TLS\", False)\nEMAIL_HOST = env(\"EMAIL_HOST\", None)\nEMAIL_HOST_USER = env(\"EMAIL_HOST_USER\", None)\nEMAIL_HOST_PASSWORD = env(\"EMAIL_HOST_PASSWORD\", None)\nEMAIL_PORT = env.int(\"EMAIL_PORT\", 587)\nDEFAULT_FROM_EMAIL = env(\"DEFAULT_FROM_EMAIL\", \"webmaster@localhost\")\nif not EMAIL_HOST:\n EMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n\n\n# User media files\nMEDIA_ROOT = env(\"MEDIA_ROOT\", path.join(BASE_DIR, \"media\"))\nMEDIA_URL = \"/media/\"\n\n# Filepond settings\nDJANGO_DRF_FILEPOND_UPLOAD_TMP = path.join(BASE_DIR, \"filepond-temp-uploads\")\nDJANGO_DRF_FILEPOND_FILE_STORE_PATH = MEDIA_ROOT\n\n# File upload setting\nMAX_UPLOAD_SIZE = env.int(\"MAX_UPLOAD_SIZE\", pow(1024, 3)) # default: 1GB per a file\nENABLE_FILE_TYPE_CHECK = env.bool(\"ENABLE_FILE_TYPE_CHECK\", False)\n\n# Celery settings\nDJANGO_CELERY_RESULTS_TASK_ID_MAX_LENGTH = 191\nCELERY_RESULT_BACKEND = \"django-db\"\ntry:\n CELERY_BROKER_URL = env(\"CELERY_BROKER_URL\")\nexcept EnvError:\n try:\n # quickfix for Heroku.\n # See https://github.com/doccano/doccano/issues/1327.\n uri = env(\"DATABASE_URL\")\n if uri.startswith(\"postgres://\"):\n uri = uri.replace(\"postgres://\", \"postgresql://\", 1)\n CELERY_BROKER_URL = \"sqla+{}\".format(uri)\n except EnvError:\n CELERY_BROKER_URL = \"sqla+sqlite:///{}\".format(DATABASES[\"default\"][\"NAME\"])\nCELERY_ACCEPT_CONTENT = [\"application/json\"]\nCELERY_TASK_SERIALIZER = \"json\"\nCELERY_RESULT_SERIALIZER = \"json\"\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n", "path": "backend/config/settings/base.py"}]}
| 3,674 | 406 |
gh_patches_debug_23673
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-6055
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Docker image for 2.4.0 contains packages from 2.3.1
The Docker image `buildbot/buildbot-master:v2.4.0` contains Python packages for buildbot `2.3.1`:
```sh
buildbot-console-view==2.3.1
buildbot-grid-view==2.3.1
buildbot-waterfall-view==2.3.1
buildbot-worker==2.3.1
buildbot-www==2.3.1
```
The `buildbot` package itself has version `2019.8.18`, which is not available from PyPI.
Even if `2019.8.18` turns out to be identical to `2.4.0`, this is somewhat problematic: Installing packages into the image with a dependency on buildbot will always uninstall the buildbot version that comes with the official image.
It would be nice if the Dockerfile could install buildbot from PyPI to ensure deterministic builds for those who need to derive their own image.
<details>
<summary>Output of pip freeze</summary>
```
$ docker run --rm buildbot/buildbot-master:v2.4.0 pip freeze
asn1crypto==0.24.0
attrs==19.1.0
autobahn==19.8.1
Automat==0.7.0
buildbot==2019.8.18
buildbot-console-view==2.3.1
buildbot-grid-view==2.3.1
buildbot-waterfall-view==2.3.1
buildbot-worker==2.3.1
buildbot-www==2.3.1
certifi==2019.6.16
cffi==1.12.3
chardet==3.0.4
constantly==15.1.0
cryptography==2.7
decorator==4.4.0
future==0.17.1
hyperlink==19.0.0
idna==2.8
incremental==17.5.0
Jinja2==2.10.1
MarkupSafe==1.1.1
pbr==5.4.2
psycopg2==2.8.3
pyasn1==0.4.6
pyasn1-modules==0.2.6
pycparser==2.19
PyHamcrest==1.9.0
PyJWT==1.7.1
pyOpenSSL==19.0.0
python-dateutil==2.8.0
PyYAML==5.1.2
requests==2.22.0
service-identity==18.1.0
six==1.12.0
SQLAlchemy==1.3.7
sqlalchemy-migrate==0.12.0
sqlparse==0.3.0
Tempita==0.5.2
Twisted==19.7.0
txaio==18.8.1
txrequests==0.9.6
urllib3==1.25.3
zope.interface==4.6.0
```
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pkg/buildbot_pkg.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 # Method to add build step taken from here
17 # https://seasonofcode.com/posts/how-to-add-custom-build-steps-and-commands-to-setuppy.html
18 import datetime
19 import os
20 import re
21 import subprocess
22 import sys
23 from pkg_resources import parse_version
24 from subprocess import PIPE
25 from subprocess import STDOUT
26 from subprocess import Popen
27
28 import setuptools.command.build_py
29 import setuptools.command.egg_info
30 from setuptools import setup
31
32 import distutils.cmd # isort:skip
33
34 old_listdir = os.listdir
35
36
37 def listdir(path):
38 # patch listdir to avoid looking into node_modules
39 l = old_listdir(path)
40 if "node_modules" in l:
41 l.remove("node_modules")
42 return l
43 os.listdir = listdir
44
45
46 def check_output(cmd):
47 """Version of check_output which does not throw error"""
48 popen = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE)
49 out = popen.communicate()[0].strip()
50 if not isinstance(out, str):
51 out = out.decode(sys.stdout.encoding)
52 return out
53
54
55 def gitDescribeToPep440(version):
56 # git describe produce version in the form: v0.9.8-20-gf0f45ca
57 # where 20 is the number of commit since last release, and gf0f45ca is the short commit id preceded by 'g'
58 # we parse this a transform into a pep440 release version 0.9.9.dev20 (increment last digit and add dev before 20)
59
60 VERSION_MATCH = re.compile(r'(?P<major>\d+)\.(?P<minor>\d+)\.(?P<patch>\d+)(\.post(?P<post>\d+))?(-(?P<dev>\d+))?(-g(?P<commit>.+))?')
61 v = VERSION_MATCH.search(version)
62 if v:
63 major = int(v.group('major'))
64 minor = int(v.group('minor'))
65 patch = int(v.group('patch'))
66 if v.group('dev'):
67 patch += 1
68 dev = int(v.group('dev'))
69 return "{}.{}.{}-dev{}".format(major, minor, patch, dev)
70 if v.group('post'):
71 return "{}.{}.{}.post{}".format(major, minor, patch, v.group('post'))
72 return "{}.{}.{}".format(major, minor, patch)
73
74 return v
75
76
77 def mTimeVersion(init_file):
78 cwd = os.path.dirname(os.path.abspath(init_file))
79 m = 0
80 for root, dirs, files in os.walk(cwd):
81 for f in files:
82 m = max(os.path.getmtime(os.path.join(root, f)), m)
83 d = datetime.datetime.utcfromtimestamp(m)
84 return d.strftime("%Y.%m.%d")
85
86
87 def getVersionFromArchiveId(git_archive_id='$Format:%ct %d$'):
88 """ Extract the tag if a source is from git archive.
89
90 When source is exported via `git archive`, the git_archive_id init value is modified
91 and placeholders are expanded to the "archived" revision:
92
93 %ct: committer date, UNIX timestamp
94 %d: ref names, like the --decorate option of git-log
95
96 See man gitattributes(5) and git-log(1) (PRETTY FORMATS) for more details.
97 """
98 # mangle the magic string to make sure it is not replaced by git archive
99 if not git_archive_id.startswith('$For''mat:'):
100 # source was modified by git archive, try to parse the version from
101 # the value of git_archive_id
102
103 match = re.search(r'tag:\s*v([^,)]+)', git_archive_id)
104 if match:
105 # archived revision is tagged, use the tag
106 return gitDescribeToPep440(match.group(1))
107
108 # archived revision is not tagged, use the commit date
109 tstamp = git_archive_id.strip().split()[0]
110 d = datetime.datetime.utcfromtimestamp(int(tstamp))
111 return d.strftime('%Y.%m.%d')
112 return None
113
114
115 def getVersion(init_file):
116 """
117 Return BUILDBOT_VERSION environment variable, content of VERSION file, git
118 tag or 'latest'
119 """
120
121 try:
122 return os.environ['BUILDBOT_VERSION']
123 except KeyError:
124 pass
125
126 try:
127 cwd = os.path.dirname(os.path.abspath(init_file))
128 fn = os.path.join(cwd, 'VERSION')
129 with open(fn) as f:
130 return f.read().strip()
131 except IOError:
132 pass
133
134 version = getVersionFromArchiveId()
135 if version is not None:
136 return version
137
138 try:
139 p = Popen(['git', 'describe', '--tags', '--always'], stdout=PIPE, stderr=STDOUT, cwd=cwd)
140 out = p.communicate()[0]
141
142 if (not p.returncode) and out:
143 v = gitDescribeToPep440(str(out))
144 if v:
145 return v
146 except OSError:
147 pass
148
149 try:
150 # if we really can't find the version, we use the date of modification of the most recent file
151 # docker hub builds cannot use git describe
152 return mTimeVersion(init_file)
153 except Exception:
154 # bummer. lets report something
155 return "latest"
156
157
158 # JS build strategy:
159 #
160 # Obviously, building javascript with setuptools is not really something supported initially
161 #
162 # The goal of this hack are:
163 # - override the distutils command to insert our js build
164 # - has very small setup.py
165 #
166 # from buildbot_pkg import setup_www
167 #
168 # setup_www(
169 # ...
170 # packages=["buildbot_myplugin"]
171 # )
172 #
173 # We need to override the first command done, so that source tree is populated very soon,
174 # as well as version is found from git tree or "VERSION" file
175 #
176 # This supports following setup.py commands:
177 #
178 # - develop, via egg_info
179 # - install, via egg_info
180 # - sdist, via egg_info
181 # - bdist_wheel, via build
182 # This is why we override both egg_info and build, and the first run build
183 # the js.
184
185 class BuildJsCommand(distutils.cmd.Command):
186 """A custom command to run JS build."""
187
188 description = 'run JS build'
189 already_run = False
190
191 def initialize_options(self):
192 """Set default values for options."""
193
194 def finalize_options(self):
195 """Post-process options."""
196
197 def run(self):
198 """Run command."""
199 if self.already_run:
200 return
201 package = self.distribution.packages[0]
202 if os.path.exists("gulpfile.js") or os.path.exists("webpack.config.js"):
203 yarn_version = check_output("yarn --version")
204 assert yarn_version != "", "need nodejs and yarn installed in current PATH"
205 yarn_bin = check_output("yarn bin").strip()
206
207 commands = []
208
209 commands.append(['yarn', 'install', '--pure-lockfile'])
210
211 if os.path.exists("gulpfile.js"):
212 commands.append([os.path.join(yarn_bin, "gulp"), 'prod', '--notests'])
213 elif os.path.exists("webpack.config.js"):
214 commands.append(['yarn', 'run', 'build'])
215
216 shell = bool(os.name == 'nt')
217
218 for command in commands:
219 self.announce('Running command: {}'.format(str(" ".join(command))),
220 level=distutils.log.INFO)
221 subprocess.check_call(command, shell=shell)
222
223 self.copy_tree(os.path.join(package, 'static'), os.path.join(
224 "build", "lib", package, "static"))
225
226 with open(os.path.join("build", "lib", package, "VERSION"), "w") as f:
227 f.write(self.distribution.metadata.version)
228
229 with open(os.path.join(package, "VERSION"), "w") as f:
230 f.write(self.distribution.metadata.version)
231
232 self.already_run = True
233
234
235 class BuildPyCommand(setuptools.command.build_py.build_py):
236 """Custom build command."""
237
238 def run(self):
239 self.run_command('build_js')
240 super().run()
241
242
243 class EggInfoCommand(setuptools.command.egg_info.egg_info):
244 """Custom egginfo command."""
245
246 def run(self):
247 self.run_command('build_js')
248 super().run()
249
250
251 def setup_www_plugin(**kw):
252 package = kw['packages'][0]
253 if 'version' not in kw:
254 kw['version'] = getVersion(os.path.join(package, "__init__.py"))
255
256 setup(cmdclass=dict(
257 egg_info=EggInfoCommand,
258 build_py=BuildPyCommand,
259 build_js=BuildJsCommand),
260 **kw)
261
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pkg/buildbot_pkg.py b/pkg/buildbot_pkg.py
--- a/pkg/buildbot_pkg.py
+++ b/pkg/buildbot_pkg.py
@@ -199,19 +199,22 @@
if self.already_run:
return
package = self.distribution.packages[0]
- if os.path.exists("gulpfile.js") or os.path.exists("webpack.config.js"):
- yarn_version = check_output("yarn --version")
- assert yarn_version != "", "need nodejs and yarn installed in current PATH"
- yarn_bin = check_output("yarn bin").strip()
+ if os.path.exists("webpack.config.js"):
- commands = []
+ yarn_program = None
+ for program in ["yarnpkg", "yarn"]:
+ yarn_version = check_output([program, "--version"])
+ if yarn_version != "":
+ yarn_program = program
- commands.append(['yarn', 'install', '--pure-lockfile'])
+ assert yarn_version is not None, "need nodejs and yarn installed in current PATH"
- if os.path.exists("gulpfile.js"):
- commands.append([os.path.join(yarn_bin, "gulp"), 'prod', '--notests'])
- elif os.path.exists("webpack.config.js"):
- commands.append(['yarn', 'run', 'build'])
+ yarn_bin = check_output([yarn_program, "bin"]).strip()
+
+ commands = [
+ [yarn_program, 'install', '--pure-lockfile'],
+ [yarn_program, 'run', 'build'],
+ ]
shell = bool(os.name == 'nt')
|
{"golden_diff": "diff --git a/pkg/buildbot_pkg.py b/pkg/buildbot_pkg.py\n--- a/pkg/buildbot_pkg.py\n+++ b/pkg/buildbot_pkg.py\n@@ -199,19 +199,22 @@\n if self.already_run:\n return\n package = self.distribution.packages[0]\n- if os.path.exists(\"gulpfile.js\") or os.path.exists(\"webpack.config.js\"):\n- yarn_version = check_output(\"yarn --version\")\n- assert yarn_version != \"\", \"need nodejs and yarn installed in current PATH\"\n- yarn_bin = check_output(\"yarn bin\").strip()\n+ if os.path.exists(\"webpack.config.js\"):\n \n- commands = []\n+ yarn_program = None\n+ for program in [\"yarnpkg\", \"yarn\"]:\n+ yarn_version = check_output([program, \"--version\"])\n+ if yarn_version != \"\":\n+ yarn_program = program\n \n- commands.append(['yarn', 'install', '--pure-lockfile'])\n+ assert yarn_version is not None, \"need nodejs and yarn installed in current PATH\"\n \n- if os.path.exists(\"gulpfile.js\"):\n- commands.append([os.path.join(yarn_bin, \"gulp\"), 'prod', '--notests'])\n- elif os.path.exists(\"webpack.config.js\"):\n- commands.append(['yarn', 'run', 'build'])\n+ yarn_bin = check_output([yarn_program, \"bin\"]).strip()\n+\n+ commands = [\n+ [yarn_program, 'install', '--pure-lockfile'],\n+ [yarn_program, 'run', 'build'],\n+ ]\n \n shell = bool(os.name == 'nt')\n", "issue": "Docker image for 2.4.0 contains packages from 2.3.1\nThe Docker image `buildbot/buildbot-master:v2.4.0` contains Python packages for buildbot `2.3.1`:\r\n\r\n```sh\r\nbuildbot-console-view==2.3.1\r\nbuildbot-grid-view==2.3.1\r\nbuildbot-waterfall-view==2.3.1\r\nbuildbot-worker==2.3.1\r\nbuildbot-www==2.3.1\r\n```\r\n\r\nThe `buildbot` package itself has version `2019.8.18`, which is not available from PyPI.\r\n\r\nEven if `2019.8.18` turns out to be identical to `2.4.0`, this is somewhat problematic: Installing packages into the image with a dependency on buildbot will always uninstall the buildbot version that comes with the official image.\r\n\r\nIt would be nice if the Dockerfile could install buildbot from PyPI to ensure deterministic builds for those who need to derive their own image.\r\n\r\n<details>\r\n <summary>Output of pip freeze</summary>\r\n\r\n```\r\n$ docker run --rm buildbot/buildbot-master:v2.4.0 pip freeze\r\nasn1crypto==0.24.0\r\nattrs==19.1.0\r\nautobahn==19.8.1\r\nAutomat==0.7.0\r\nbuildbot==2019.8.18\r\nbuildbot-console-view==2.3.1\r\nbuildbot-grid-view==2.3.1\r\nbuildbot-waterfall-view==2.3.1\r\nbuildbot-worker==2.3.1\r\nbuildbot-www==2.3.1\r\ncertifi==2019.6.16\r\ncffi==1.12.3\r\nchardet==3.0.4\r\nconstantly==15.1.0\r\ncryptography==2.7\r\ndecorator==4.4.0\r\nfuture==0.17.1\r\nhyperlink==19.0.0\r\nidna==2.8\r\nincremental==17.5.0\r\nJinja2==2.10.1\r\nMarkupSafe==1.1.1\r\npbr==5.4.2\r\npsycopg2==2.8.3\r\npyasn1==0.4.6\r\npyasn1-modules==0.2.6\r\npycparser==2.19\r\nPyHamcrest==1.9.0\r\nPyJWT==1.7.1\r\npyOpenSSL==19.0.0\r\npython-dateutil==2.8.0\r\nPyYAML==5.1.2\r\nrequests==2.22.0\r\nservice-identity==18.1.0\r\nsix==1.12.0\r\nSQLAlchemy==1.3.7\r\nsqlalchemy-migrate==0.12.0\r\nsqlparse==0.3.0\r\nTempita==0.5.2\r\nTwisted==19.7.0\r\ntxaio==18.8.1\r\ntxrequests==0.9.6\r\nurllib3==1.25.3\r\nzope.interface==4.6.0\r\n```\r\n</details>\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n# Method to add build step taken from here\n# https://seasonofcode.com/posts/how-to-add-custom-build-steps-and-commands-to-setuppy.html\nimport datetime\nimport os\nimport re\nimport subprocess\nimport sys\nfrom pkg_resources import parse_version\nfrom subprocess import PIPE\nfrom subprocess import STDOUT\nfrom subprocess import Popen\n\nimport setuptools.command.build_py\nimport setuptools.command.egg_info\nfrom setuptools import setup\n\nimport distutils.cmd # isort:skip\n\nold_listdir = os.listdir\n\n\ndef listdir(path):\n # patch listdir to avoid looking into node_modules\n l = old_listdir(path)\n if \"node_modules\" in l:\n l.remove(\"node_modules\")\n return l\nos.listdir = listdir\n\n\ndef check_output(cmd):\n \"\"\"Version of check_output which does not throw error\"\"\"\n popen = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE)\n out = popen.communicate()[0].strip()\n if not isinstance(out, str):\n out = out.decode(sys.stdout.encoding)\n return out\n\n\ndef gitDescribeToPep440(version):\n # git describe produce version in the form: v0.9.8-20-gf0f45ca\n # where 20 is the number of commit since last release, and gf0f45ca is the short commit id preceded by 'g'\n # we parse this a transform into a pep440 release version 0.9.9.dev20 (increment last digit and add dev before 20)\n\n VERSION_MATCH = re.compile(r'(?P<major>\\d+)\\.(?P<minor>\\d+)\\.(?P<patch>\\d+)(\\.post(?P<post>\\d+))?(-(?P<dev>\\d+))?(-g(?P<commit>.+))?')\n v = VERSION_MATCH.search(version)\n if v:\n major = int(v.group('major'))\n minor = int(v.group('minor'))\n patch = int(v.group('patch'))\n if v.group('dev'):\n patch += 1\n dev = int(v.group('dev'))\n return \"{}.{}.{}-dev{}\".format(major, minor, patch, dev)\n if v.group('post'):\n return \"{}.{}.{}.post{}\".format(major, minor, patch, v.group('post'))\n return \"{}.{}.{}\".format(major, minor, patch)\n\n return v\n\n\ndef mTimeVersion(init_file):\n cwd = os.path.dirname(os.path.abspath(init_file))\n m = 0\n for root, dirs, files in os.walk(cwd):\n for f in files:\n m = max(os.path.getmtime(os.path.join(root, f)), m)\n d = datetime.datetime.utcfromtimestamp(m)\n return d.strftime(\"%Y.%m.%d\")\n\n\ndef getVersionFromArchiveId(git_archive_id='$Format:%ct %d$'):\n \"\"\" Extract the tag if a source is from git archive.\n\n When source is exported via `git archive`, the git_archive_id init value is modified\n and placeholders are expanded to the \"archived\" revision:\n\n %ct: committer date, UNIX timestamp\n %d: ref names, like the --decorate option of git-log\n\n See man gitattributes(5) and git-log(1) (PRETTY FORMATS) for more details.\n \"\"\"\n # mangle the magic string to make sure it is not replaced by git archive\n if not git_archive_id.startswith('$For''mat:'):\n # source was modified by git archive, try to parse the version from\n # the value of git_archive_id\n\n match = re.search(r'tag:\\s*v([^,)]+)', git_archive_id)\n if match:\n # archived revision is tagged, use the tag\n return gitDescribeToPep440(match.group(1))\n\n # archived revision is not tagged, use the commit date\n tstamp = git_archive_id.strip().split()[0]\n d = datetime.datetime.utcfromtimestamp(int(tstamp))\n return d.strftime('%Y.%m.%d')\n return None\n\n\ndef getVersion(init_file):\n \"\"\"\n Return BUILDBOT_VERSION environment variable, content of VERSION file, git\n tag or 'latest'\n \"\"\"\n\n try:\n return os.environ['BUILDBOT_VERSION']\n except KeyError:\n pass\n\n try:\n cwd = os.path.dirname(os.path.abspath(init_file))\n fn = os.path.join(cwd, 'VERSION')\n with open(fn) as f:\n return f.read().strip()\n except IOError:\n pass\n\n version = getVersionFromArchiveId()\n if version is not None:\n return version\n\n try:\n p = Popen(['git', 'describe', '--tags', '--always'], stdout=PIPE, stderr=STDOUT, cwd=cwd)\n out = p.communicate()[0]\n\n if (not p.returncode) and out:\n v = gitDescribeToPep440(str(out))\n if v:\n return v\n except OSError:\n pass\n\n try:\n # if we really can't find the version, we use the date of modification of the most recent file\n # docker hub builds cannot use git describe\n return mTimeVersion(init_file)\n except Exception:\n # bummer. lets report something\n return \"latest\"\n\n\n# JS build strategy:\n#\n# Obviously, building javascript with setuptools is not really something supported initially\n#\n# The goal of this hack are:\n# - override the distutils command to insert our js build\n# - has very small setup.py\n#\n# from buildbot_pkg import setup_www\n#\n# setup_www(\n# ...\n# packages=[\"buildbot_myplugin\"]\n# )\n#\n# We need to override the first command done, so that source tree is populated very soon,\n# as well as version is found from git tree or \"VERSION\" file\n#\n# This supports following setup.py commands:\n#\n# - develop, via egg_info\n# - install, via egg_info\n# - sdist, via egg_info\n# - bdist_wheel, via build\n# This is why we override both egg_info and build, and the first run build\n# the js.\n\nclass BuildJsCommand(distutils.cmd.Command):\n \"\"\"A custom command to run JS build.\"\"\"\n\n description = 'run JS build'\n already_run = False\n\n def initialize_options(self):\n \"\"\"Set default values for options.\"\"\"\n\n def finalize_options(self):\n \"\"\"Post-process options.\"\"\"\n\n def run(self):\n \"\"\"Run command.\"\"\"\n if self.already_run:\n return\n package = self.distribution.packages[0]\n if os.path.exists(\"gulpfile.js\") or os.path.exists(\"webpack.config.js\"):\n yarn_version = check_output(\"yarn --version\")\n assert yarn_version != \"\", \"need nodejs and yarn installed in current PATH\"\n yarn_bin = check_output(\"yarn bin\").strip()\n\n commands = []\n\n commands.append(['yarn', 'install', '--pure-lockfile'])\n\n if os.path.exists(\"gulpfile.js\"):\n commands.append([os.path.join(yarn_bin, \"gulp\"), 'prod', '--notests'])\n elif os.path.exists(\"webpack.config.js\"):\n commands.append(['yarn', 'run', 'build'])\n\n shell = bool(os.name == 'nt')\n\n for command in commands:\n self.announce('Running command: {}'.format(str(\" \".join(command))),\n level=distutils.log.INFO)\n subprocess.check_call(command, shell=shell)\n\n self.copy_tree(os.path.join(package, 'static'), os.path.join(\n \"build\", \"lib\", package, \"static\"))\n\n with open(os.path.join(\"build\", \"lib\", package, \"VERSION\"), \"w\") as f:\n f.write(self.distribution.metadata.version)\n\n with open(os.path.join(package, \"VERSION\"), \"w\") as f:\n f.write(self.distribution.metadata.version)\n\n self.already_run = True\n\n\nclass BuildPyCommand(setuptools.command.build_py.build_py):\n \"\"\"Custom build command.\"\"\"\n\n def run(self):\n self.run_command('build_js')\n super().run()\n\n\nclass EggInfoCommand(setuptools.command.egg_info.egg_info):\n \"\"\"Custom egginfo command.\"\"\"\n\n def run(self):\n self.run_command('build_js')\n super().run()\n\n\ndef setup_www_plugin(**kw):\n package = kw['packages'][0]\n if 'version' not in kw:\n kw['version'] = getVersion(os.path.join(package, \"__init__.py\"))\n\n setup(cmdclass=dict(\n egg_info=EggInfoCommand,\n build_py=BuildPyCommand,\n build_js=BuildJsCommand),\n **kw)\n", "path": "pkg/buildbot_pkg.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n# Method to add build step taken from here\n# https://seasonofcode.com/posts/how-to-add-custom-build-steps-and-commands-to-setuppy.html\nimport datetime\nimport os\nimport re\nimport subprocess\nimport sys\nfrom pkg_resources import parse_version\nfrom subprocess import PIPE\nfrom subprocess import STDOUT\nfrom subprocess import Popen\n\nimport setuptools.command.build_py\nimport setuptools.command.egg_info\nfrom setuptools import setup\n\nimport distutils.cmd # isort:skip\n\nold_listdir = os.listdir\n\n\ndef listdir(path):\n # patch listdir to avoid looking into node_modules\n l = old_listdir(path)\n if \"node_modules\" in l:\n l.remove(\"node_modules\")\n return l\nos.listdir = listdir\n\n\ndef check_output(cmd):\n \"\"\"Version of check_output which does not throw error\"\"\"\n popen = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE)\n out = popen.communicate()[0].strip()\n if not isinstance(out, str):\n out = out.decode(sys.stdout.encoding)\n return out\n\n\ndef gitDescribeToPep440(version):\n # git describe produce version in the form: v0.9.8-20-gf0f45ca\n # where 20 is the number of commit since last release, and gf0f45ca is the short commit id preceded by 'g'\n # we parse this a transform into a pep440 release version 0.9.9.dev20 (increment last digit and add dev before 20)\n\n VERSION_MATCH = re.compile(r'(?P<major>\\d+)\\.(?P<minor>\\d+)\\.(?P<patch>\\d+)(\\.post(?P<post>\\d+))?(-(?P<dev>\\d+))?(-g(?P<commit>.+))?')\n v = VERSION_MATCH.search(version)\n if v:\n major = int(v.group('major'))\n minor = int(v.group('minor'))\n patch = int(v.group('patch'))\n if v.group('dev'):\n patch += 1\n dev = int(v.group('dev'))\n return \"{}.{}.{}-dev{}\".format(major, minor, patch, dev)\n if v.group('post'):\n return \"{}.{}.{}.post{}\".format(major, minor, patch, v.group('post'))\n return \"{}.{}.{}\".format(major, minor, patch)\n\n return v\n\n\ndef mTimeVersion(init_file):\n cwd = os.path.dirname(os.path.abspath(init_file))\n m = 0\n for root, dirs, files in os.walk(cwd):\n for f in files:\n m = max(os.path.getmtime(os.path.join(root, f)), m)\n d = datetime.datetime.utcfromtimestamp(m)\n return d.strftime(\"%Y.%m.%d\")\n\n\ndef getVersionFromArchiveId(git_archive_id='$Format:%ct %d$'):\n \"\"\" Extract the tag if a source is from git archive.\n\n When source is exported via `git archive`, the git_archive_id init value is modified\n and placeholders are expanded to the \"archived\" revision:\n\n %ct: committer date, UNIX timestamp\n %d: ref names, like the --decorate option of git-log\n\n See man gitattributes(5) and git-log(1) (PRETTY FORMATS) for more details.\n \"\"\"\n # mangle the magic string to make sure it is not replaced by git archive\n if not git_archive_id.startswith('$For''mat:'):\n # source was modified by git archive, try to parse the version from\n # the value of git_archive_id\n\n match = re.search(r'tag:\\s*v([^,)]+)', git_archive_id)\n if match:\n # archived revision is tagged, use the tag\n return gitDescribeToPep440(match.group(1))\n\n # archived revision is not tagged, use the commit date\n tstamp = git_archive_id.strip().split()[0]\n d = datetime.datetime.utcfromtimestamp(int(tstamp))\n return d.strftime('%Y.%m.%d')\n return None\n\n\ndef getVersion(init_file):\n \"\"\"\n Return BUILDBOT_VERSION environment variable, content of VERSION file, git\n tag or 'latest'\n \"\"\"\n\n try:\n return os.environ['BUILDBOT_VERSION']\n except KeyError:\n pass\n\n try:\n cwd = os.path.dirname(os.path.abspath(init_file))\n fn = os.path.join(cwd, 'VERSION')\n with open(fn) as f:\n return f.read().strip()\n except IOError:\n pass\n\n version = getVersionFromArchiveId()\n if version is not None:\n return version\n\n try:\n p = Popen(['git', 'describe', '--tags', '--always'], stdout=PIPE, stderr=STDOUT, cwd=cwd)\n out = p.communicate()[0]\n\n if (not p.returncode) and out:\n v = gitDescribeToPep440(str(out))\n if v:\n return v\n except OSError:\n pass\n\n try:\n # if we really can't find the version, we use the date of modification of the most recent file\n # docker hub builds cannot use git describe\n return mTimeVersion(init_file)\n except Exception:\n # bummer. lets report something\n return \"latest\"\n\n\n# JS build strategy:\n#\n# Obviously, building javascript with setuptools is not really something supported initially\n#\n# The goal of this hack are:\n# - override the distutils command to insert our js build\n# - has very small setup.py\n#\n# from buildbot_pkg import setup_www\n#\n# setup_www(\n# ...\n# packages=[\"buildbot_myplugin\"]\n# )\n#\n# We need to override the first command done, so that source tree is populated very soon,\n# as well as version is found from git tree or \"VERSION\" file\n#\n# This supports following setup.py commands:\n#\n# - develop, via egg_info\n# - install, via egg_info\n# - sdist, via egg_info\n# - bdist_wheel, via build\n# This is why we override both egg_info and build, and the first run build\n# the js.\n\nclass BuildJsCommand(distutils.cmd.Command):\n \"\"\"A custom command to run JS build.\"\"\"\n\n description = 'run JS build'\n already_run = False\n\n def initialize_options(self):\n \"\"\"Set default values for options.\"\"\"\n\n def finalize_options(self):\n \"\"\"Post-process options.\"\"\"\n\n def run(self):\n \"\"\"Run command.\"\"\"\n if self.already_run:\n return\n package = self.distribution.packages[0]\n if os.path.exists(\"webpack.config.js\"):\n\n yarn_program = None\n for program in [\"yarnpkg\", \"yarn\"]:\n yarn_version = check_output([program, \"--version\"])\n if yarn_version != \"\":\n yarn_program = program\n\n assert yarn_version is not None, \"need nodejs and yarn installed in current PATH\"\n\n yarn_bin = check_output([yarn_program, \"bin\"]).strip()\n\n commands = [\n [yarn_program, 'install', '--pure-lockfile'],\n [yarn_program, 'run', 'build'],\n ]\n\n shell = bool(os.name == 'nt')\n\n for command in commands:\n self.announce('Running command: {}'.format(str(\" \".join(command))),\n level=distutils.log.INFO)\n subprocess.check_call(command, shell=shell)\n\n self.copy_tree(os.path.join(package, 'static'), os.path.join(\n \"build\", \"lib\", package, \"static\"))\n\n with open(os.path.join(\"build\", \"lib\", package, \"VERSION\"), \"w\") as f:\n f.write(self.distribution.metadata.version)\n\n with open(os.path.join(package, \"VERSION\"), \"w\") as f:\n f.write(self.distribution.metadata.version)\n\n self.already_run = True\n\n\nclass BuildPyCommand(setuptools.command.build_py.build_py):\n \"\"\"Custom build command.\"\"\"\n\n def run(self):\n self.run_command('build_js')\n super().run()\n\n\nclass EggInfoCommand(setuptools.command.egg_info.egg_info):\n \"\"\"Custom egginfo command.\"\"\"\n\n def run(self):\n self.run_command('build_js')\n super().run()\n\n\ndef setup_www_plugin(**kw):\n package = kw['packages'][0]\n if 'version' not in kw:\n kw['version'] = getVersion(os.path.join(package, \"__init__.py\"))\n\n setup(cmdclass=dict(\n egg_info=EggInfoCommand,\n build_py=BuildPyCommand,\n build_js=BuildJsCommand),\n **kw)\n", "path": "pkg/buildbot_pkg.py"}]}
| 3,696 | 359 |
gh_patches_debug_518
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-1946
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow plugin repos to test against universal test suite
**Is your feature request related to a problem? Please describe.**
There are several plugin repos for custom connectors (Hive, Azure, Snowflake, etc.), and there is increasing interest from the community in contributing plugins. One blocker for many folks is that there is no easy way to test their custom connector against our universal test suite. Someone working on a plugin repo should be able to test their connector against the universal test suite with minimal changes in their repo.
**Describe the solution you'd like**
The Feast team has come up with two solutions.
The first solution is a temporary fix to unblock folks who wish to start testing immediately. We recommend that you add `feast` as a [git submodule](https://git-scm.com/book/en/v2/Git-Tools-Submodules) in your plugin repo, and then install `feast` in editable mode by navigating to `feast` and running `pip install -e sdk/python/[ci]` as detailed [here](https://github.com/feast-dev/feast/blob/master/CONTRIBUTING.md). This will allow you to `import feast`, and will also allow you to run our test suite with `pytest`. For example, in `feast` you should be able to run `make test`, and all unit tests should succeed. In order to run the full suite of integration tests with your custom connector, all you need to do is modify `FULL_REPO_CONFIGS` in `sdk/python/tests/integration/feature_repos/repo_configuration.py`. Most of our integration tests rely on pytest fixtures defined in `conftest.py`, most of which are parametrized based on `FULL_REPO_CONFIGS`. The main thing you will need to do in order to overwrite `FULL_REPO_CONFIGS` is to write a `DataSourceCreator`. We consider this solution a temporary fix because it still requires that the user to modify the `feast` repo directly, even if it's in a git submodule.
The second solution, which extends the first solution to be more viable in the long-term, will be to allow users to overwrite `FULL_REPO_CONFIGS` through an environment variable. This means that after adding `feast` as a git submodule, users should be able to directly run integration tests without ever needing to modify the `feast` repo. We intend to build this functionality out eventually, but are currently working on several other higher-priority features. If anyone in the community wants to take this on, that would be great!
**Describe alternatives you've considered**
N/A
**Additional context**
Add any other context or screenshots about the feature request here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/constants.py`
Content:
```
1 #
2 # Copyright 2019 The Feast Authors
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # https://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16
17 # Maximum interval(secs) to wait between retries for retry function
18 MAX_WAIT_INTERVAL: str = "60"
19
20 AWS_LAMBDA_FEATURE_SERVER_IMAGE = "feastdev/feature-server:aws"
21
22 # feature_store.yaml environment variable name for remote feature server
23 FEATURE_STORE_YAML_ENV_NAME: str = "FEATURE_STORE_YAML_BASE64"
24
25 # Environment variable for toggling usage
26 FEAST_USAGE = "FEAST_USAGE"
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/feast/constants.py b/sdk/python/feast/constants.py
--- a/sdk/python/feast/constants.py
+++ b/sdk/python/feast/constants.py
@@ -24,3 +24,6 @@
# Environment variable for toggling usage
FEAST_USAGE = "FEAST_USAGE"
+
+# Environment variable for the path for overwriting universal test configs
+FULL_REPO_CONFIGS_MODULE_ENV_NAME: str = "FULL_REPO_CONFIGS_MODULE"
|
{"golden_diff": "diff --git a/sdk/python/feast/constants.py b/sdk/python/feast/constants.py\n--- a/sdk/python/feast/constants.py\n+++ b/sdk/python/feast/constants.py\n@@ -24,3 +24,6 @@\n \n # Environment variable for toggling usage\n FEAST_USAGE = \"FEAST_USAGE\"\n+\n+# Environment variable for the path for overwriting universal test configs\n+FULL_REPO_CONFIGS_MODULE_ENV_NAME: str = \"FULL_REPO_CONFIGS_MODULE\"\n", "issue": "Allow plugin repos to test against universal test suite\n**Is your feature request related to a problem? Please describe.**\r\nThere are several plugin repos for custom connectors (Hive, Azure, Snowflake, etc.), and there is increasing interest from the community in contributing plugins. One blocker for many folks is that there is no easy way to test their custom connector against our universal test suite. Someone working on a plugin repo should be able to test their connector against the universal test suite with minimal changes in their repo. \r\n\r\n**Describe the solution you'd like**\r\nThe Feast team has come up with two solutions. \r\n\r\nThe first solution is a temporary fix to unblock folks who wish to start testing immediately. We recommend that you add `feast` as a [git submodule](https://git-scm.com/book/en/v2/Git-Tools-Submodules) in your plugin repo, and then install `feast` in editable mode by navigating to `feast` and running `pip install -e sdk/python/[ci]` as detailed [here](https://github.com/feast-dev/feast/blob/master/CONTRIBUTING.md). This will allow you to `import feast`, and will also allow you to run our test suite with `pytest`. For example, in `feast` you should be able to run `make test`, and all unit tests should succeed. In order to run the full suite of integration tests with your custom connector, all you need to do is modify `FULL_REPO_CONFIGS` in `sdk/python/tests/integration/feature_repos/repo_configuration.py`. Most of our integration tests rely on pytest fixtures defined in `conftest.py`, most of which are parametrized based on `FULL_REPO_CONFIGS`. The main thing you will need to do in order to overwrite `FULL_REPO_CONFIGS` is to write a `DataSourceCreator`. We consider this solution a temporary fix because it still requires that the user to modify the `feast` repo directly, even if it's in a git submodule.\r\n\r\nThe second solution, which extends the first solution to be more viable in the long-term, will be to allow users to overwrite `FULL_REPO_CONFIGS` through an environment variable. This means that after adding `feast` as a git submodule, users should be able to directly run integration tests without ever needing to modify the `feast` repo. We intend to build this functionality out eventually, but are currently working on several other higher-priority features. If anyone in the community wants to take this on, that would be great!\r\n\r\n**Describe alternatives you've considered**\r\nN/A\r\n\r\n**Additional context**\r\nAdd any other context or screenshots about the feature request here.\r\n\n", "before_files": [{"content": "#\n# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n# Maximum interval(secs) to wait between retries for retry function\nMAX_WAIT_INTERVAL: str = \"60\"\n\nAWS_LAMBDA_FEATURE_SERVER_IMAGE = \"feastdev/feature-server:aws\"\n\n# feature_store.yaml environment variable name for remote feature server\nFEATURE_STORE_YAML_ENV_NAME: str = \"FEATURE_STORE_YAML_BASE64\"\n\n# Environment variable for toggling usage\nFEAST_USAGE = \"FEAST_USAGE\"\n", "path": "sdk/python/feast/constants.py"}], "after_files": [{"content": "#\n# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n# Maximum interval(secs) to wait between retries for retry function\nMAX_WAIT_INTERVAL: str = \"60\"\n\nAWS_LAMBDA_FEATURE_SERVER_IMAGE = \"feastdev/feature-server:aws\"\n\n# feature_store.yaml environment variable name for remote feature server\nFEATURE_STORE_YAML_ENV_NAME: str = \"FEATURE_STORE_YAML_BASE64\"\n\n# Environment variable for toggling usage\nFEAST_USAGE = \"FEAST_USAGE\"\n\n# Environment variable for the path for overwriting universal test configs\nFULL_REPO_CONFIGS_MODULE_ENV_NAME: str = \"FULL_REPO_CONFIGS_MODULE\"\n", "path": "sdk/python/feast/constants.py"}]}
| 1,095 | 102 |
gh_patches_debug_8170
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2324
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Channel Found None in MaxUnPooling2D
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Colab
- TensorFlow version and how it was installed (source or binary): 2.4.0
- TensorFlow-Addons version and how it was installed (source or binary):
- Python version: 3.7
- Is GPU used? (yes/no): yes
**Describe the bug**
The channel dimension is None after MaxUnpooling2D layer
**Code to reproduce the issue**
```
def test():
inputs = tf.keras.layers.Input((None, None, 1))
x,indices = tf.nn.max_pool_with_argmax(inputs, 2, 2, padding="SAME")
x = tfa.layers.MaxUnpooling2D()(x,indices)
x = tf.keras.layers.Conv2D(64, 3, padding="same")(x)
return tf.keras.Model(inputs, x)
model = test()
model(tf.random.normal([1,128,128,1]))
```
**Other info / logs**
<ipython-input-25-675633950ad9> in test()
3 x,indices = tf.nn.max_pool_with_argmax(inputs, 2, 2, padding="SAME")
4 x = tfa.layers.MaxUnpooling2D()(x,indices)
----> 5 x = tf.keras.layers.Conv2D(64, 3, padding="same")(x)
6 return tf.keras.Model(inputs, x)
7 model = test()
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in __call__(self, *args, **kwargs)
950 if _in_functional_construction_mode(self, inputs, args, kwargs, input_list):
951 return self._functional_construction_call(inputs, args, kwargs,
--> 952 input_list)
953
954 # Maintains info about the `Layer.call` stack.
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _functional_construction_call(self, inputs, args, kwargs, input_list)
1089 # Check input assumptions set after layer building, e.g. input shape.
1090 outputs = self._keras_tensor_symbolic_call(
-> 1091 inputs, input_masks, args, kwargs)
1092
1093 if outputs is None:
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _keras_tensor_symbolic_call(self, inputs, input_masks, args, kwargs)
820 return nest.map_structure(keras_tensor.KerasTensor, output_signature)
821 else:
--> 822 return self._infer_output_signature(inputs, args, kwargs, input_masks)
823
824 def _infer_output_signature(self, inputs, args, kwargs, input_masks):
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _infer_output_signature(self, inputs, args, kwargs, input_masks)
860 # overridden).
861 # TODO(kaftan): do we maybe_build here, or have we already done it?
--> 862 self._maybe_build(inputs)
863 outputs = call_fn(inputs, *args, **kwargs)
864
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _maybe_build(self, inputs)
2708 # operations.
2709 with tf_utils.maybe_init_scope(self):
-> 2710 self.build(input_shapes) # pylint:disable=not-callable
2711 # We must set also ensure that the layer is marked as built, and the build
2712 # shape is stored since user defined build functions may not be calling
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/convolutional.py in build(self, input_shape)
186 def build(self, input_shape):
187 input_shape = tensor_shape.TensorShape(input_shape)
--> 188 input_channel = self._get_input_channel(input_shape)
189 if input_channel % self.groups != 0:
190 raise ValueError(
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/convolutional.py in _get_input_channel(self, input_shape)
358 channel_axis = self._get_channel_axis()
359 if input_shape.dims[channel_axis].value is None:
--> 360 raise ValueError('The channel dimension of the inputs '
361 'should be defined. Found `None`.')
362 return int(input_shape[channel_axis])
ValueError: The channel dimension of the inputs should be defined. Found `None`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/layers/max_unpooling_2d.py`
Content:
```
1 # Copyright 2020 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """MaxUnpooling2D operation."""
16
17 import tensorflow as tf
18
19 from typeguard import typechecked
20 from typing import Union
21
22 from tensorflow_addons.utils.keras_utils import normalize_tuple
23
24
25 def _calculate_output_shape(input_shape, pool_size, strides, padding):
26 """Calculates the shape of the unpooled output."""
27 if padding == "VALID":
28 output_shape = (
29 input_shape[0],
30 (input_shape[1] - 1) * strides[0] + pool_size[0],
31 (input_shape[2] - 1) * strides[1] + pool_size[1],
32 input_shape[3],
33 )
34 elif padding == "SAME":
35 output_shape = (
36 input_shape[0],
37 input_shape[1] * strides[0],
38 input_shape[2] * strides[1],
39 input_shape[3],
40 )
41 else:
42 raise ValueError('Padding must be a string from: "SAME", "VALID"')
43 return output_shape
44
45
46 def _max_unpooling_2d(updates, mask, pool_size=(2, 2), strides=(2, 2), padding="SAME"):
47 """Unpool the outputs of a maximum pooling operation."""
48 pool_size_attr = " ".join(["i: %d" % v for v in pool_size])
49 strides_attr = " ".join(["i: %d" % v for v in strides])
50 experimental_implements = [
51 'name: "addons:MaxUnpooling2D"',
52 'attr { key: "pool_size" value { list {%s} } }' % pool_size_attr,
53 'attr { key: "strides" value { list {%s} } }' % strides_attr,
54 'attr { key: "padding" value { s: "%s" } }' % padding,
55 ]
56 experimental_implements = " ".join(experimental_implements)
57
58 @tf.function(experimental_implements=experimental_implements)
59 def func(updates, mask):
60 mask = tf.cast(mask, "int32")
61 input_shape = tf.shape(updates, out_type="int32")
62 output_shape = _calculate_output_shape(input_shape, pool_size, strides, padding)
63
64 # Calculates indices for batch, height, width and feature maps.
65 one_like_mask = tf.ones_like(mask, dtype="int32")
66 batch_shape = tf.concat([[input_shape[0]], [1], [1], [1]], axis=0)
67 batch_range = tf.reshape(
68 tf.range(output_shape[0], dtype="int32"), shape=batch_shape
69 )
70 b = one_like_mask * batch_range
71 y = mask // (output_shape[2] * output_shape[3])
72 x = (mask // output_shape[3]) % output_shape[2]
73 feature_range = tf.range(output_shape[3], dtype="int32")
74 f = one_like_mask * feature_range
75
76 # Transposes indices & reshape update values to one dimension.
77 updates_size = tf.size(updates)
78 indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, updates_size]))
79 values = tf.reshape(updates, [updates_size])
80 ret = tf.scatter_nd(indices, values, output_shape)
81 return ret
82
83 return func(updates, mask)
84
85
86 @tf.keras.utils.register_keras_serializable(package="Addons")
87 class MaxUnpooling2D(tf.keras.layers.Layer):
88 """Unpool the outputs of a maximum pooling operation.
89
90 This function currently does not support outputs of MaxPoolingWithArgMax in
91 following cases:
92 - include_batch_in_index equals true.
93 - input_shape is not divisible by strides if padding is "SAME".
94 - (input_shape - pool_size) is not divisible by strides if padding is "VALID".
95 - The max pooling operation results in duplicate values in updates and mask.
96
97 Args:
98 updates: The pooling result from max pooling.
99 mask: the argmax result corresponds to above max values.
100 pool_size: The filter that max pooling was performed with. Default: (2, 2).
101 strides: The strides that max pooling was performed with. Default: (2, 2).
102 padding: The padding that max pooling was performed with. Default: "SAME".
103 Input shape:
104 4D tensor with shape: `(batch_size, height, width, channel)`.
105 Output shape:
106 4D tensor with the same shape as the input of max pooling operation.
107 """
108
109 @typechecked
110 def __init__(
111 self,
112 pool_size: Union[list, tuple, int] = (2, 2),
113 strides: Union[list, tuple, int] = (2, 2),
114 padding: str = "SAME",
115 **kwargs,
116 ):
117 super(MaxUnpooling2D, self).__init__(**kwargs)
118
119 if padding != "SAME" and padding != "VALID":
120 raise ValueError('Padding must be a string from: "SAME", "VALID"')
121
122 self.pool_size = normalize_tuple(pool_size, 2, "pool_size")
123 self.strides = normalize_tuple(strides, 2, "strides")
124 self.padding = padding
125
126 def call(self, updates, mask):
127 return _max_unpooling_2d(
128 updates,
129 mask,
130 pool_size=self.pool_size,
131 strides=self.strides,
132 padding=self.padding,
133 )
134
135 def compute_output_shape(self, input_shapes):
136 input_shape = input_shapes[1]
137 return _calculate_output_shape(
138 input_shape, self.pool_size, self.strides, self.padding
139 )
140
141 def get_config(self):
142 config = super(MaxUnpooling2D, self).get_config()
143 config["pool_size"] = self.pool_size
144 config["strides"] = self.strides
145 config["padding"] = self.padding
146 return config
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tensorflow_addons/layers/max_unpooling_2d.py b/tensorflow_addons/layers/max_unpooling_2d.py
--- a/tensorflow_addons/layers/max_unpooling_2d.py
+++ b/tensorflow_addons/layers/max_unpooling_2d.py
@@ -59,6 +59,7 @@
def func(updates, mask):
mask = tf.cast(mask, "int32")
input_shape = tf.shape(updates, out_type="int32")
+ input_shape = [updates.shape[i] or input_shape[i] for i in range(4)]
output_shape = _calculate_output_shape(input_shape, pool_size, strides, padding)
# Calculates indices for batch, height, width and feature maps.
|
{"golden_diff": "diff --git a/tensorflow_addons/layers/max_unpooling_2d.py b/tensorflow_addons/layers/max_unpooling_2d.py\n--- a/tensorflow_addons/layers/max_unpooling_2d.py\n+++ b/tensorflow_addons/layers/max_unpooling_2d.py\n@@ -59,6 +59,7 @@\n def func(updates, mask):\n mask = tf.cast(mask, \"int32\")\n input_shape = tf.shape(updates, out_type=\"int32\")\n+ input_shape = [updates.shape[i] or input_shape[i] for i in range(4)]\n output_shape = _calculate_output_shape(input_shape, pool_size, strides, padding)\n \n # Calculates indices for batch, height, width and feature maps.\n", "issue": "Channel Found None in MaxUnPooling2D\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Colab\r\n- TensorFlow version and how it was installed (source or binary): 2.4.0\r\n- TensorFlow-Addons version and how it was installed (source or binary):\r\n- Python version: 3.7\r\n- Is GPU used? (yes/no): yes\r\n\r\n**Describe the bug**\r\n\r\nThe channel dimension is None after MaxUnpooling2D layer\r\n\r\n**Code to reproduce the issue**\r\n\r\n```\r\ndef test():\r\n inputs = tf.keras.layers.Input((None, None, 1))\r\n x,indices = tf.nn.max_pool_with_argmax(inputs, 2, 2, padding=\"SAME\")\r\n x = tfa.layers.MaxUnpooling2D()(x,indices)\r\n x = tf.keras.layers.Conv2D(64, 3, padding=\"same\")(x)\r\n return tf.keras.Model(inputs, x)\r\nmodel = test()\r\nmodel(tf.random.normal([1,128,128,1]))\r\n```\r\n\r\n**Other info / logs**\r\n\r\n<ipython-input-25-675633950ad9> in test()\r\n 3 x,indices = tf.nn.max_pool_with_argmax(inputs, 2, 2, padding=\"SAME\")\r\n 4 x = tfa.layers.MaxUnpooling2D()(x,indices)\r\n----> 5 x = tf.keras.layers.Conv2D(64, 3, padding=\"same\")(x)\r\n 6 return tf.keras.Model(inputs, x)\r\n 7 model = test()\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in __call__(self, *args, **kwargs)\r\n 950 if _in_functional_construction_mode(self, inputs, args, kwargs, input_list):\r\n 951 return self._functional_construction_call(inputs, args, kwargs,\r\n--> 952 input_list)\r\n 953 \r\n 954 # Maintains info about the `Layer.call` stack.\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _functional_construction_call(self, inputs, args, kwargs, input_list)\r\n 1089 # Check input assumptions set after layer building, e.g. input shape.\r\n 1090 outputs = self._keras_tensor_symbolic_call(\r\n-> 1091 inputs, input_masks, args, kwargs)\r\n 1092 \r\n 1093 if outputs is None:\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _keras_tensor_symbolic_call(self, inputs, input_masks, args, kwargs)\r\n 820 return nest.map_structure(keras_tensor.KerasTensor, output_signature)\r\n 821 else:\r\n--> 822 return self._infer_output_signature(inputs, args, kwargs, input_masks)\r\n 823 \r\n 824 def _infer_output_signature(self, inputs, args, kwargs, input_masks):\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _infer_output_signature(self, inputs, args, kwargs, input_masks)\r\n 860 # overridden).\r\n 861 # TODO(kaftan): do we maybe_build here, or have we already done it?\r\n--> 862 self._maybe_build(inputs)\r\n 863 outputs = call_fn(inputs, *args, **kwargs)\r\n 864 \r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in _maybe_build(self, inputs)\r\n 2708 # operations.\r\n 2709 with tf_utils.maybe_init_scope(self):\r\n-> 2710 self.build(input_shapes) # pylint:disable=not-callable\r\n 2711 # We must set also ensure that the layer is marked as built, and the build\r\n 2712 # shape is stored since user defined build functions may not be calling\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/convolutional.py in build(self, input_shape)\r\n 186 def build(self, input_shape):\r\n 187 input_shape = tensor_shape.TensorShape(input_shape)\r\n--> 188 input_channel = self._get_input_channel(input_shape)\r\n 189 if input_channel % self.groups != 0:\r\n 190 raise ValueError(\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/convolutional.py in _get_input_channel(self, input_shape)\r\n 358 channel_axis = self._get_channel_axis()\r\n 359 if input_shape.dims[channel_axis].value is None:\r\n--> 360 raise ValueError('The channel dimension of the inputs '\r\n 361 'should be defined. Found `None`.')\r\n 362 return int(input_shape[channel_axis])\r\n\r\nValueError: The channel dimension of the inputs should be defined. Found `None`.\n", "before_files": [{"content": "# Copyright 2020 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"MaxUnpooling2D operation.\"\"\"\n\nimport tensorflow as tf\n\nfrom typeguard import typechecked\nfrom typing import Union\n\nfrom tensorflow_addons.utils.keras_utils import normalize_tuple\n\n\ndef _calculate_output_shape(input_shape, pool_size, strides, padding):\n \"\"\"Calculates the shape of the unpooled output.\"\"\"\n if padding == \"VALID\":\n output_shape = (\n input_shape[0],\n (input_shape[1] - 1) * strides[0] + pool_size[0],\n (input_shape[2] - 1) * strides[1] + pool_size[1],\n input_shape[3],\n )\n elif padding == \"SAME\":\n output_shape = (\n input_shape[0],\n input_shape[1] * strides[0],\n input_shape[2] * strides[1],\n input_shape[3],\n )\n else:\n raise ValueError('Padding must be a string from: \"SAME\", \"VALID\"')\n return output_shape\n\n\ndef _max_unpooling_2d(updates, mask, pool_size=(2, 2), strides=(2, 2), padding=\"SAME\"):\n \"\"\"Unpool the outputs of a maximum pooling operation.\"\"\"\n pool_size_attr = \" \".join([\"i: %d\" % v for v in pool_size])\n strides_attr = \" \".join([\"i: %d\" % v for v in strides])\n experimental_implements = [\n 'name: \"addons:MaxUnpooling2D\"',\n 'attr { key: \"pool_size\" value { list {%s} } }' % pool_size_attr,\n 'attr { key: \"strides\" value { list {%s} } }' % strides_attr,\n 'attr { key: \"padding\" value { s: \"%s\" } }' % padding,\n ]\n experimental_implements = \" \".join(experimental_implements)\n\n @tf.function(experimental_implements=experimental_implements)\n def func(updates, mask):\n mask = tf.cast(mask, \"int32\")\n input_shape = tf.shape(updates, out_type=\"int32\")\n output_shape = _calculate_output_shape(input_shape, pool_size, strides, padding)\n\n # Calculates indices for batch, height, width and feature maps.\n one_like_mask = tf.ones_like(mask, dtype=\"int32\")\n batch_shape = tf.concat([[input_shape[0]], [1], [1], [1]], axis=0)\n batch_range = tf.reshape(\n tf.range(output_shape[0], dtype=\"int32\"), shape=batch_shape\n )\n b = one_like_mask * batch_range\n y = mask // (output_shape[2] * output_shape[3])\n x = (mask // output_shape[3]) % output_shape[2]\n feature_range = tf.range(output_shape[3], dtype=\"int32\")\n f = one_like_mask * feature_range\n\n # Transposes indices & reshape update values to one dimension.\n updates_size = tf.size(updates)\n indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, updates_size]))\n values = tf.reshape(updates, [updates_size])\n ret = tf.scatter_nd(indices, values, output_shape)\n return ret\n\n return func(updates, mask)\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass MaxUnpooling2D(tf.keras.layers.Layer):\n \"\"\"Unpool the outputs of a maximum pooling operation.\n\n This function currently does not support outputs of MaxPoolingWithArgMax in\n following cases:\n - include_batch_in_index equals true.\n - input_shape is not divisible by strides if padding is \"SAME\".\n - (input_shape - pool_size) is not divisible by strides if padding is \"VALID\".\n - The max pooling operation results in duplicate values in updates and mask.\n\n Args:\n updates: The pooling result from max pooling.\n mask: the argmax result corresponds to above max values.\n pool_size: The filter that max pooling was performed with. Default: (2, 2).\n strides: The strides that max pooling was performed with. Default: (2, 2).\n padding: The padding that max pooling was performed with. Default: \"SAME\".\n Input shape:\n 4D tensor with shape: `(batch_size, height, width, channel)`.\n Output shape:\n 4D tensor with the same shape as the input of max pooling operation.\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n pool_size: Union[list, tuple, int] = (2, 2),\n strides: Union[list, tuple, int] = (2, 2),\n padding: str = \"SAME\",\n **kwargs,\n ):\n super(MaxUnpooling2D, self).__init__(**kwargs)\n\n if padding != \"SAME\" and padding != \"VALID\":\n raise ValueError('Padding must be a string from: \"SAME\", \"VALID\"')\n\n self.pool_size = normalize_tuple(pool_size, 2, \"pool_size\")\n self.strides = normalize_tuple(strides, 2, \"strides\")\n self.padding = padding\n\n def call(self, updates, mask):\n return _max_unpooling_2d(\n updates,\n mask,\n pool_size=self.pool_size,\n strides=self.strides,\n padding=self.padding,\n )\n\n def compute_output_shape(self, input_shapes):\n input_shape = input_shapes[1]\n return _calculate_output_shape(\n input_shape, self.pool_size, self.strides, self.padding\n )\n\n def get_config(self):\n config = super(MaxUnpooling2D, self).get_config()\n config[\"pool_size\"] = self.pool_size\n config[\"strides\"] = self.strides\n config[\"padding\"] = self.padding\n return config\n", "path": "tensorflow_addons/layers/max_unpooling_2d.py"}], "after_files": [{"content": "# Copyright 2020 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"MaxUnpooling2D operation.\"\"\"\n\nimport tensorflow as tf\n\nfrom typeguard import typechecked\nfrom typing import Union\n\nfrom tensorflow_addons.utils.keras_utils import normalize_tuple\n\n\ndef _calculate_output_shape(input_shape, pool_size, strides, padding):\n \"\"\"Calculates the shape of the unpooled output.\"\"\"\n if padding == \"VALID\":\n output_shape = (\n input_shape[0],\n (input_shape[1] - 1) * strides[0] + pool_size[0],\n (input_shape[2] - 1) * strides[1] + pool_size[1],\n input_shape[3],\n )\n elif padding == \"SAME\":\n output_shape = (\n input_shape[0],\n input_shape[1] * strides[0],\n input_shape[2] * strides[1],\n input_shape[3],\n )\n else:\n raise ValueError('Padding must be a string from: \"SAME\", \"VALID\"')\n return output_shape\n\n\ndef _max_unpooling_2d(updates, mask, pool_size=(2, 2), strides=(2, 2), padding=\"SAME\"):\n \"\"\"Unpool the outputs of a maximum pooling operation.\"\"\"\n pool_size_attr = \" \".join([\"i: %d\" % v for v in pool_size])\n strides_attr = \" \".join([\"i: %d\" % v for v in strides])\n experimental_implements = [\n 'name: \"addons:MaxUnpooling2D\"',\n 'attr { key: \"pool_size\" value { list {%s} } }' % pool_size_attr,\n 'attr { key: \"strides\" value { list {%s} } }' % strides_attr,\n 'attr { key: \"padding\" value { s: \"%s\" } }' % padding,\n ]\n experimental_implements = \" \".join(experimental_implements)\n\n @tf.function(experimental_implements=experimental_implements)\n def func(updates, mask):\n mask = tf.cast(mask, \"int32\")\n input_shape = tf.shape(updates, out_type=\"int32\")\n input_shape = [updates.shape[i] or input_shape[i] for i in range(4)]\n output_shape = _calculate_output_shape(input_shape, pool_size, strides, padding)\n\n # Calculates indices for batch, height, width and feature maps.\n one_like_mask = tf.ones_like(mask, dtype=\"int32\")\n batch_shape = tf.concat([[input_shape[0]], [1], [1], [1]], axis=0)\n batch_range = tf.reshape(\n tf.range(output_shape[0], dtype=\"int32\"), shape=batch_shape\n )\n b = one_like_mask * batch_range\n y = mask // (output_shape[2] * output_shape[3])\n x = (mask // output_shape[3]) % output_shape[2]\n feature_range = tf.range(output_shape[3], dtype=\"int32\")\n f = one_like_mask * feature_range\n\n # Transposes indices & reshape update values to one dimension.\n updates_size = tf.size(updates)\n indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, updates_size]))\n values = tf.reshape(updates, [updates_size])\n ret = tf.scatter_nd(indices, values, output_shape)\n return ret\n\n return func(updates, mask)\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass MaxUnpooling2D(tf.keras.layers.Layer):\n \"\"\"Unpool the outputs of a maximum pooling operation.\n\n This function currently does not support outputs of MaxPoolingWithArgMax in\n following cases:\n - include_batch_in_index equals true.\n - input_shape is not divisible by strides if padding is \"SAME\".\n - (input_shape - pool_size) is not divisible by strides if padding is \"VALID\".\n - The max pooling operation results in duplicate values in updates and mask.\n\n Args:\n updates: The pooling result from max pooling.\n mask: the argmax result corresponds to above max values.\n pool_size: The filter that max pooling was performed with. Default: (2, 2).\n strides: The strides that max pooling was performed with. Default: (2, 2).\n padding: The padding that max pooling was performed with. Default: \"SAME\".\n Input shape:\n 4D tensor with shape: `(batch_size, height, width, channel)`.\n Output shape:\n 4D tensor with the same shape as the input of max pooling operation.\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n pool_size: Union[list, tuple, int] = (2, 2),\n strides: Union[list, tuple, int] = (2, 2),\n padding: str = \"SAME\",\n **kwargs,\n ):\n super(MaxUnpooling2D, self).__init__(**kwargs)\n\n if padding != \"SAME\" and padding != \"VALID\":\n raise ValueError('Padding must be a string from: \"SAME\", \"VALID\"')\n\n self.pool_size = normalize_tuple(pool_size, 2, \"pool_size\")\n self.strides = normalize_tuple(strides, 2, \"strides\")\n self.padding = padding\n\n def call(self, updates, mask):\n return _max_unpooling_2d(\n updates,\n mask,\n pool_size=self.pool_size,\n strides=self.strides,\n padding=self.padding,\n )\n\n def compute_output_shape(self, input_shapes):\n input_shape = input_shapes[1]\n return _calculate_output_shape(\n input_shape, self.pool_size, self.strides, self.padding\n )\n\n def get_config(self):\n config = super(MaxUnpooling2D, self).get_config()\n config[\"pool_size\"] = self.pool_size\n config[\"strides\"] = self.strides\n config[\"padding\"] = self.padding\n return config\n", "path": "tensorflow_addons/layers/max_unpooling_2d.py"}]}
| 3,155 | 175 |
gh_patches_debug_936
|
rasdani/github-patches
|
git_diff
|
lnbits__lnbits-1183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] LNDhub extension return unusable `getinfo` response
**Describe the bug**
The [getinfo call](https://github.com/lnbits/lnbits/blob/main/lnbits/extensions/lndhub/views_api.py#L22) simply returns `bad auth` everytime, which breaks integrations like for us in BTCPay Server (see btcpayserver/btcpayserver#4414).
**Expected behavior**
Return [valid information](https://github.com/BlueWallet/LndHub/blob/master/doc/Send-requirements.md#get-getinfo), which we can use to connect. For us that would mean having a list of `uris` and a `block_height` being set.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lnbits/extensions/lndhub/views_api.py`
Content:
```
1 import asyncio
2 import time
3 from base64 import urlsafe_b64encode
4 from http import HTTPStatus
5
6 from fastapi.param_functions import Query
7 from fastapi.params import Depends
8 from pydantic import BaseModel
9 from starlette.exceptions import HTTPException
10
11 from lnbits import bolt11
12 from lnbits.core.crud import delete_expired_invoices, get_payments
13 from lnbits.core.services import create_invoice, pay_invoice
14 from lnbits.decorators import WalletTypeInfo
15 from lnbits.settings import LNBITS_SITE_TITLE, WALLET
16
17 from . import lndhub_ext
18 from .decorators import check_wallet, require_admin_key
19 from .utils import decoded_as_lndhub, to_buffer
20
21
22 @lndhub_ext.get("/ext/getinfo")
23 async def lndhub_getinfo():
24 raise HTTPException(status_code=HTTPStatus.UNAUTHORIZED, detail="bad auth")
25
26
27 class AuthData(BaseModel):
28 login: str = Query(None)
29 password: str = Query(None)
30 refresh_token: str = Query(None)
31
32
33 @lndhub_ext.post("/ext/auth")
34 async def lndhub_auth(data: AuthData):
35 token = (
36 data.refresh_token
37 if data.refresh_token
38 else urlsafe_b64encode(
39 (data.login + ":" + data.password).encode("utf-8")
40 ).decode("ascii")
41 )
42 return {"refresh_token": token, "access_token": token}
43
44
45 class AddInvoice(BaseModel):
46 amt: str = Query(...)
47 memo: str = Query(...)
48 preimage: str = Query(None)
49
50
51 @lndhub_ext.post("/ext/addinvoice")
52 async def lndhub_addinvoice(
53 data: AddInvoice, wallet: WalletTypeInfo = Depends(check_wallet)
54 ):
55 try:
56 _, pr = await create_invoice(
57 wallet_id=wallet.wallet.id,
58 amount=int(data.amt),
59 memo=data.memo or LNBITS_SITE_TITLE,
60 extra={"tag": "lndhub"},
61 )
62 except:
63 raise HTTPException(
64 status_code=HTTPStatus.NOT_FOUND, detail="Failed to create invoice"
65 )
66 invoice = bolt11.decode(pr)
67 return {
68 "pay_req": pr,
69 "payment_request": pr,
70 "add_index": "500",
71 "r_hash": to_buffer(invoice.payment_hash),
72 "hash": invoice.payment_hash,
73 }
74
75
76 class Invoice(BaseModel):
77 invoice: str = Query(...)
78
79
80 @lndhub_ext.post("/ext/payinvoice")
81 async def lndhub_payinvoice(
82 r_invoice: Invoice, wallet: WalletTypeInfo = Depends(require_admin_key)
83 ):
84 try:
85 await pay_invoice(
86 wallet_id=wallet.wallet.id,
87 payment_request=r_invoice.invoice,
88 extra={"tag": "lndhub"},
89 )
90 except:
91 raise HTTPException(status_code=HTTPStatus.NOT_FOUND, detail="Payment failed")
92
93 invoice: bolt11.Invoice = bolt11.decode(r_invoice.invoice)
94
95 return {
96 "payment_error": "",
97 "payment_preimage": "0" * 64,
98 "route": {},
99 "payment_hash": invoice.payment_hash,
100 "decoded": decoded_as_lndhub(invoice),
101 "fee_msat": 0,
102 "type": "paid_invoice",
103 "fee": 0,
104 "value": invoice.amount_msat / 1000,
105 "timestamp": int(time.time()),
106 "memo": invoice.description,
107 }
108
109
110 @lndhub_ext.get("/ext/balance")
111 async def lndhub_balance(
112 wallet: WalletTypeInfo = Depends(check_wallet),
113 ):
114 return {"BTC": {"AvailableBalance": wallet.wallet.balance}}
115
116
117 @lndhub_ext.get("/ext/gettxs")
118 async def lndhub_gettxs(
119 wallet: WalletTypeInfo = Depends(check_wallet),
120 limit: int = Query(20, ge=1, le=20),
121 offset: int = Query(0, ge=0),
122 ):
123 for payment in await get_payments(
124 wallet_id=wallet.wallet.id,
125 complete=False,
126 pending=True,
127 outgoing=True,
128 incoming=False,
129 limit=limit,
130 offset=offset,
131 exclude_uncheckable=True,
132 ):
133 await payment.check_status()
134
135 return [
136 {
137 "payment_preimage": payment.preimage,
138 "payment_hash": payment.payment_hash,
139 "fee_msat": payment.fee * 1000,
140 "type": "paid_invoice",
141 "fee": payment.fee,
142 "value": int(payment.amount / 1000),
143 "timestamp": payment.time,
144 "memo": payment.memo if not payment.pending else "Payment in transition",
145 }
146 for payment in reversed(
147 (
148 await get_payments(
149 wallet_id=wallet.wallet.id,
150 pending=True,
151 complete=True,
152 outgoing=True,
153 incoming=False,
154 limit=limit,
155 offset=offset,
156 )
157 )
158 )
159 ]
160
161
162 @lndhub_ext.get("/ext/getuserinvoices")
163 async def lndhub_getuserinvoices(
164 wallet: WalletTypeInfo = Depends(check_wallet),
165 limit: int = Query(20, ge=1, le=20),
166 offset: int = Query(0, ge=0),
167 ):
168 for invoice in await get_payments(
169 wallet_id=wallet.wallet.id,
170 complete=False,
171 pending=True,
172 outgoing=False,
173 incoming=True,
174 limit=limit,
175 offset=offset,
176 exclude_uncheckable=True,
177 ):
178 await invoice.set_pending(
179 (await WALLET.get_invoice_status(invoice.checking_id)).pending
180 )
181
182 return [
183 {
184 "r_hash": to_buffer(invoice.payment_hash),
185 "payment_request": invoice.bolt11,
186 "add_index": "500",
187 "description": invoice.memo,
188 "payment_hash": invoice.payment_hash,
189 "ispaid": not invoice.pending,
190 "amt": int(invoice.amount / 1000),
191 "expire_time": int(time.time() + 1800),
192 "timestamp": invoice.time,
193 "type": "user_invoice",
194 }
195 for invoice in reversed(
196 (
197 await get_payments(
198 wallet_id=wallet.wallet.id,
199 pending=True,
200 complete=True,
201 incoming=True,
202 outgoing=False,
203 limit=limit,
204 offset=offset,
205 )
206 )
207 )
208 ]
209
210
211 @lndhub_ext.get("/ext/getbtc")
212 async def lndhub_getbtc(wallet: WalletTypeInfo = Depends(check_wallet)):
213 "load an address for incoming onchain btc"
214 return []
215
216
217 @lndhub_ext.get("/ext/getpending")
218 async def lndhub_getpending(wallet: WalletTypeInfo = Depends(check_wallet)):
219 "pending onchain transactions"
220 return []
221
222
223 @lndhub_ext.get("/ext/decodeinvoice")
224 async def lndhub_decodeinvoice(invoice: str = Query(None)):
225 inv = bolt11.decode(invoice)
226 return decoded_as_lndhub(inv)
227
228
229 @lndhub_ext.get("/ext/checkrouteinvoice")
230 async def lndhub_checkrouteinvoice():
231 "not implemented on canonical lndhub"
232 pass
233
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lnbits/extensions/lndhub/views_api.py b/lnbits/extensions/lndhub/views_api.py
--- a/lnbits/extensions/lndhub/views_api.py
+++ b/lnbits/extensions/lndhub/views_api.py
@@ -21,7 +21,7 @@
@lndhub_ext.get("/ext/getinfo")
async def lndhub_getinfo():
- raise HTTPException(status_code=HTTPStatus.UNAUTHORIZED, detail="bad auth")
+ return {"alias": LNBITS_SITE_TITLE}
class AuthData(BaseModel):
|
{"golden_diff": "diff --git a/lnbits/extensions/lndhub/views_api.py b/lnbits/extensions/lndhub/views_api.py\n--- a/lnbits/extensions/lndhub/views_api.py\n+++ b/lnbits/extensions/lndhub/views_api.py\n@@ -21,7 +21,7 @@\n \n @lndhub_ext.get(\"/ext/getinfo\")\n async def lndhub_getinfo():\n- raise HTTPException(status_code=HTTPStatus.UNAUTHORIZED, detail=\"bad auth\")\n+ return {\"alias\": LNBITS_SITE_TITLE}\n \n \n class AuthData(BaseModel):\n", "issue": "[BUG] LNDhub extension return unusable `getinfo` response\n**Describe the bug**\r\nThe [getinfo call](https://github.com/lnbits/lnbits/blob/main/lnbits/extensions/lndhub/views_api.py#L22) simply returns `bad auth` everytime, which breaks integrations like for us in BTCPay Server (see btcpayserver/btcpayserver#4414).\r\n\r\n**Expected behavior**\r\nReturn [valid information](https://github.com/BlueWallet/LndHub/blob/master/doc/Send-requirements.md#get-getinfo), which we can use to connect. For us that would mean having a list of `uris` and a `block_height` being set.\r\n\n", "before_files": [{"content": "import asyncio\nimport time\nfrom base64 import urlsafe_b64encode\nfrom http import HTTPStatus\n\nfrom fastapi.param_functions import Query\nfrom fastapi.params import Depends\nfrom pydantic import BaseModel\nfrom starlette.exceptions import HTTPException\n\nfrom lnbits import bolt11\nfrom lnbits.core.crud import delete_expired_invoices, get_payments\nfrom lnbits.core.services import create_invoice, pay_invoice\nfrom lnbits.decorators import WalletTypeInfo\nfrom lnbits.settings import LNBITS_SITE_TITLE, WALLET\n\nfrom . import lndhub_ext\nfrom .decorators import check_wallet, require_admin_key\nfrom .utils import decoded_as_lndhub, to_buffer\n\n\n@lndhub_ext.get(\"/ext/getinfo\")\nasync def lndhub_getinfo():\n raise HTTPException(status_code=HTTPStatus.UNAUTHORIZED, detail=\"bad auth\")\n\n\nclass AuthData(BaseModel):\n login: str = Query(None)\n password: str = Query(None)\n refresh_token: str = Query(None)\n\n\n@lndhub_ext.post(\"/ext/auth\")\nasync def lndhub_auth(data: AuthData):\n token = (\n data.refresh_token\n if data.refresh_token\n else urlsafe_b64encode(\n (data.login + \":\" + data.password).encode(\"utf-8\")\n ).decode(\"ascii\")\n )\n return {\"refresh_token\": token, \"access_token\": token}\n\n\nclass AddInvoice(BaseModel):\n amt: str = Query(...)\n memo: str = Query(...)\n preimage: str = Query(None)\n\n\n@lndhub_ext.post(\"/ext/addinvoice\")\nasync def lndhub_addinvoice(\n data: AddInvoice, wallet: WalletTypeInfo = Depends(check_wallet)\n):\n try:\n _, pr = await create_invoice(\n wallet_id=wallet.wallet.id,\n amount=int(data.amt),\n memo=data.memo or LNBITS_SITE_TITLE,\n extra={\"tag\": \"lndhub\"},\n )\n except:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"Failed to create invoice\"\n )\n invoice = bolt11.decode(pr)\n return {\n \"pay_req\": pr,\n \"payment_request\": pr,\n \"add_index\": \"500\",\n \"r_hash\": to_buffer(invoice.payment_hash),\n \"hash\": invoice.payment_hash,\n }\n\n\nclass Invoice(BaseModel):\n invoice: str = Query(...)\n\n\n@lndhub_ext.post(\"/ext/payinvoice\")\nasync def lndhub_payinvoice(\n r_invoice: Invoice, wallet: WalletTypeInfo = Depends(require_admin_key)\n):\n try:\n await pay_invoice(\n wallet_id=wallet.wallet.id,\n payment_request=r_invoice.invoice,\n extra={\"tag\": \"lndhub\"},\n )\n except:\n raise HTTPException(status_code=HTTPStatus.NOT_FOUND, detail=\"Payment failed\")\n\n invoice: bolt11.Invoice = bolt11.decode(r_invoice.invoice)\n\n return {\n \"payment_error\": \"\",\n \"payment_preimage\": \"0\" * 64,\n \"route\": {},\n \"payment_hash\": invoice.payment_hash,\n \"decoded\": decoded_as_lndhub(invoice),\n \"fee_msat\": 0,\n \"type\": \"paid_invoice\",\n \"fee\": 0,\n \"value\": invoice.amount_msat / 1000,\n \"timestamp\": int(time.time()),\n \"memo\": invoice.description,\n }\n\n\n@lndhub_ext.get(\"/ext/balance\")\nasync def lndhub_balance(\n wallet: WalletTypeInfo = Depends(check_wallet),\n):\n return {\"BTC\": {\"AvailableBalance\": wallet.wallet.balance}}\n\n\n@lndhub_ext.get(\"/ext/gettxs\")\nasync def lndhub_gettxs(\n wallet: WalletTypeInfo = Depends(check_wallet),\n limit: int = Query(20, ge=1, le=20),\n offset: int = Query(0, ge=0),\n):\n for payment in await get_payments(\n wallet_id=wallet.wallet.id,\n complete=False,\n pending=True,\n outgoing=True,\n incoming=False,\n limit=limit,\n offset=offset,\n exclude_uncheckable=True,\n ):\n await payment.check_status()\n\n return [\n {\n \"payment_preimage\": payment.preimage,\n \"payment_hash\": payment.payment_hash,\n \"fee_msat\": payment.fee * 1000,\n \"type\": \"paid_invoice\",\n \"fee\": payment.fee,\n \"value\": int(payment.amount / 1000),\n \"timestamp\": payment.time,\n \"memo\": payment.memo if not payment.pending else \"Payment in transition\",\n }\n for payment in reversed(\n (\n await get_payments(\n wallet_id=wallet.wallet.id,\n pending=True,\n complete=True,\n outgoing=True,\n incoming=False,\n limit=limit,\n offset=offset,\n )\n )\n )\n ]\n\n\n@lndhub_ext.get(\"/ext/getuserinvoices\")\nasync def lndhub_getuserinvoices(\n wallet: WalletTypeInfo = Depends(check_wallet),\n limit: int = Query(20, ge=1, le=20),\n offset: int = Query(0, ge=0),\n):\n for invoice in await get_payments(\n wallet_id=wallet.wallet.id,\n complete=False,\n pending=True,\n outgoing=False,\n incoming=True,\n limit=limit,\n offset=offset,\n exclude_uncheckable=True,\n ):\n await invoice.set_pending(\n (await WALLET.get_invoice_status(invoice.checking_id)).pending\n )\n\n return [\n {\n \"r_hash\": to_buffer(invoice.payment_hash),\n \"payment_request\": invoice.bolt11,\n \"add_index\": \"500\",\n \"description\": invoice.memo,\n \"payment_hash\": invoice.payment_hash,\n \"ispaid\": not invoice.pending,\n \"amt\": int(invoice.amount / 1000),\n \"expire_time\": int(time.time() + 1800),\n \"timestamp\": invoice.time,\n \"type\": \"user_invoice\",\n }\n for invoice in reversed(\n (\n await get_payments(\n wallet_id=wallet.wallet.id,\n pending=True,\n complete=True,\n incoming=True,\n outgoing=False,\n limit=limit,\n offset=offset,\n )\n )\n )\n ]\n\n\n@lndhub_ext.get(\"/ext/getbtc\")\nasync def lndhub_getbtc(wallet: WalletTypeInfo = Depends(check_wallet)):\n \"load an address for incoming onchain btc\"\n return []\n\n\n@lndhub_ext.get(\"/ext/getpending\")\nasync def lndhub_getpending(wallet: WalletTypeInfo = Depends(check_wallet)):\n \"pending onchain transactions\"\n return []\n\n\n@lndhub_ext.get(\"/ext/decodeinvoice\")\nasync def lndhub_decodeinvoice(invoice: str = Query(None)):\n inv = bolt11.decode(invoice)\n return decoded_as_lndhub(inv)\n\n\n@lndhub_ext.get(\"/ext/checkrouteinvoice\")\nasync def lndhub_checkrouteinvoice():\n \"not implemented on canonical lndhub\"\n pass\n", "path": "lnbits/extensions/lndhub/views_api.py"}], "after_files": [{"content": "import asyncio\nimport time\nfrom base64 import urlsafe_b64encode\nfrom http import HTTPStatus\n\nfrom fastapi.param_functions import Query\nfrom fastapi.params import Depends\nfrom pydantic import BaseModel\nfrom starlette.exceptions import HTTPException\n\nfrom lnbits import bolt11\nfrom lnbits.core.crud import delete_expired_invoices, get_payments\nfrom lnbits.core.services import create_invoice, pay_invoice\nfrom lnbits.decorators import WalletTypeInfo\nfrom lnbits.settings import LNBITS_SITE_TITLE, WALLET\n\nfrom . import lndhub_ext\nfrom .decorators import check_wallet, require_admin_key\nfrom .utils import decoded_as_lndhub, to_buffer\n\n\n@lndhub_ext.get(\"/ext/getinfo\")\nasync def lndhub_getinfo():\n return {\"alias\": LNBITS_SITE_TITLE}\n\n\nclass AuthData(BaseModel):\n login: str = Query(None)\n password: str = Query(None)\n refresh_token: str = Query(None)\n\n\n@lndhub_ext.post(\"/ext/auth\")\nasync def lndhub_auth(data: AuthData):\n token = (\n data.refresh_token\n if data.refresh_token\n else urlsafe_b64encode(\n (data.login + \":\" + data.password).encode(\"utf-8\")\n ).decode(\"ascii\")\n )\n return {\"refresh_token\": token, \"access_token\": token}\n\n\nclass AddInvoice(BaseModel):\n amt: str = Query(...)\n memo: str = Query(...)\n preimage: str = Query(None)\n\n\n@lndhub_ext.post(\"/ext/addinvoice\")\nasync def lndhub_addinvoice(\n data: AddInvoice, wallet: WalletTypeInfo = Depends(check_wallet)\n):\n try:\n _, pr = await create_invoice(\n wallet_id=wallet.wallet.id,\n amount=int(data.amt),\n memo=data.memo or LNBITS_SITE_TITLE,\n extra={\"tag\": \"lndhub\"},\n )\n except:\n raise HTTPException(\n status_code=HTTPStatus.NOT_FOUND, detail=\"Failed to create invoice\"\n )\n invoice = bolt11.decode(pr)\n return {\n \"pay_req\": pr,\n \"payment_request\": pr,\n \"add_index\": \"500\",\n \"r_hash\": to_buffer(invoice.payment_hash),\n \"hash\": invoice.payment_hash,\n }\n\n\nclass Invoice(BaseModel):\n invoice: str = Query(...)\n\n\n@lndhub_ext.post(\"/ext/payinvoice\")\nasync def lndhub_payinvoice(\n r_invoice: Invoice, wallet: WalletTypeInfo = Depends(require_admin_key)\n):\n try:\n await pay_invoice(\n wallet_id=wallet.wallet.id,\n payment_request=r_invoice.invoice,\n extra={\"tag\": \"lndhub\"},\n )\n except:\n raise HTTPException(status_code=HTTPStatus.NOT_FOUND, detail=\"Payment failed\")\n\n invoice: bolt11.Invoice = bolt11.decode(r_invoice.invoice)\n\n return {\n \"payment_error\": \"\",\n \"payment_preimage\": \"0\" * 64,\n \"route\": {},\n \"payment_hash\": invoice.payment_hash,\n \"decoded\": decoded_as_lndhub(invoice),\n \"fee_msat\": 0,\n \"type\": \"paid_invoice\",\n \"fee\": 0,\n \"value\": invoice.amount_msat / 1000,\n \"timestamp\": int(time.time()),\n \"memo\": invoice.description,\n }\n\n\n@lndhub_ext.get(\"/ext/balance\")\nasync def lndhub_balance(\n wallet: WalletTypeInfo = Depends(check_wallet),\n):\n return {\"BTC\": {\"AvailableBalance\": wallet.wallet.balance}}\n\n\n@lndhub_ext.get(\"/ext/gettxs\")\nasync def lndhub_gettxs(\n wallet: WalletTypeInfo = Depends(check_wallet),\n limit: int = Query(20, ge=1, le=20),\n offset: int = Query(0, ge=0),\n):\n for payment in await get_payments(\n wallet_id=wallet.wallet.id,\n complete=False,\n pending=True,\n outgoing=True,\n incoming=False,\n limit=limit,\n offset=offset,\n exclude_uncheckable=True,\n ):\n await payment.check_status()\n\n return [\n {\n \"payment_preimage\": payment.preimage,\n \"payment_hash\": payment.payment_hash,\n \"fee_msat\": payment.fee * 1000,\n \"type\": \"paid_invoice\",\n \"fee\": payment.fee,\n \"value\": int(payment.amount / 1000),\n \"timestamp\": payment.time,\n \"memo\": payment.memo if not payment.pending else \"Payment in transition\",\n }\n for payment in reversed(\n (\n await get_payments(\n wallet_id=wallet.wallet.id,\n pending=True,\n complete=True,\n outgoing=True,\n incoming=False,\n limit=limit,\n offset=offset,\n )\n )\n )\n ]\n\n\n@lndhub_ext.get(\"/ext/getuserinvoices\")\nasync def lndhub_getuserinvoices(\n wallet: WalletTypeInfo = Depends(check_wallet),\n limit: int = Query(20, ge=1, le=20),\n offset: int = Query(0, ge=0),\n):\n for invoice in await get_payments(\n wallet_id=wallet.wallet.id,\n complete=False,\n pending=True,\n outgoing=False,\n incoming=True,\n limit=limit,\n offset=offset,\n exclude_uncheckable=True,\n ):\n await invoice.set_pending(\n (await WALLET.get_invoice_status(invoice.checking_id)).pending\n )\n\n return [\n {\n \"r_hash\": to_buffer(invoice.payment_hash),\n \"payment_request\": invoice.bolt11,\n \"add_index\": \"500\",\n \"description\": invoice.memo,\n \"payment_hash\": invoice.payment_hash,\n \"ispaid\": not invoice.pending,\n \"amt\": int(invoice.amount / 1000),\n \"expire_time\": int(time.time() + 1800),\n \"timestamp\": invoice.time,\n \"type\": \"user_invoice\",\n }\n for invoice in reversed(\n (\n await get_payments(\n wallet_id=wallet.wallet.id,\n pending=True,\n complete=True,\n incoming=True,\n outgoing=False,\n limit=limit,\n offset=offset,\n )\n )\n )\n ]\n\n\n@lndhub_ext.get(\"/ext/getbtc\")\nasync def lndhub_getbtc(wallet: WalletTypeInfo = Depends(check_wallet)):\n \"load an address for incoming onchain btc\"\n return []\n\n\n@lndhub_ext.get(\"/ext/getpending\")\nasync def lndhub_getpending(wallet: WalletTypeInfo = Depends(check_wallet)):\n \"pending onchain transactions\"\n return []\n\n\n@lndhub_ext.get(\"/ext/decodeinvoice\")\nasync def lndhub_decodeinvoice(invoice: str = Query(None)):\n inv = bolt11.decode(invoice)\n return decoded_as_lndhub(inv)\n\n\n@lndhub_ext.get(\"/ext/checkrouteinvoice\")\nasync def lndhub_checkrouteinvoice():\n \"not implemented on canonical lndhub\"\n pass\n", "path": "lnbits/extensions/lndhub/views_api.py"}]}
| 2,533 | 121 |
gh_patches_debug_19153
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-2762
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
KeyError USERDOMAIN on `conan install`
We have at least two machines for which `conan install` errors out with the message:
```
Traceback (most recent call last):
File "C:\Python27\lib\site-packages\conans\client\command.py", line 1187, in run
method(args[0][1:])
File "C:\Python27\lib\site-packages\conans\client\command.py", line 304, in install
install_folder=args.install_folder)
File "C:\Python27\lib\site-packages\conans\client\conan_api.py", line 61, in wrapper
return f(*args, **kwargs)
File "C:\Python27\lib\site-packages\conans\client\conan_api.py", line 444, in install
no_imports=no_imports)
File "C:\Python27\lib\site-packages\conans\client\manager.py", line 395, in install
installer.install(deps_graph, profile.build_requires, keep_build)
File "C:\Python27\lib\site-packages\conans\client\installer.py", line 262, in install
nodes_to_process = self._get_nodes(nodes_by_level, skip_private_nodes)
File "C:\Python27\lib\site-packages\conans\client\installer.py", line 501, in _get_nodes
check_outdated)
File "C:\Python27\lib\site-packages\conans\client\proxy.py", line 47, in package_available
package_folder = self._client_cache.package(package_ref, short_paths=short_paths)
File "C:\Python27\lib\site-packages\conans\paths.py", line 162, in package
return path_shortener(p, short_paths)
File "C:\Python27\lib\site-packages\conans\util\windows.py", line 57, in path_shortener
cmd = r'cacls %s /E /G "%s\%s":F' % (short_home, os.environ['USERDOMAIN'], os.environ['USERNAME'])
File "C:\Python27\lib\os.py", line 425, in __getitem__
return self.data[key.upper()]
KeyError: 'USERDOMAIN'
```
Defining an environment variable `USERDOMAIN` to any value fixes the problem.
Both machines are Windows 7, with Conan 1.2.3.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/util/windows.py`
Content:
```
1 import os
2 import subprocess
3
4 from conans.util.files import load, mkdir, save, rmdir
5 import tempfile
6
7
8 CONAN_LINK = ".conan_link"
9
10
11 def conan_expand_user(path):
12 """ wrapper to the original expanduser function, to workaround python returning
13 verbatim %USERPROFILE% when some other app (git for windows) sets HOME envvar
14 """
15 # In win these variables should exist and point to user directory, which
16 # must exist. Using context to avoid permanent modification of os.environ
17 old_env = dict(os.environ)
18 try:
19 home = os.environ.get("HOME")
20 # Problematic cases of wrong HOME variable
21 # - HOME = %USERPROFILE% verbatim, as messed by some other tools
22 # - MSYS console, that defines a different user home in /c/mingw/msys/users/xxx
23 # In these cases, it is safe to remove it and rely on USERPROFILE directly
24 if home and (not os.path.exists(home) or
25 (os.getenv("MSYSTEM") and os.getenv("USERPROFILE"))):
26 del os.environ["HOME"]
27 result = os.path.expanduser(path)
28 finally:
29 os.environ.clear()
30 os.environ.update(old_env)
31 return result
32
33
34 def path_shortener(path, short_paths):
35 """ short_paths is 4-state:
36 False: Never shorten the path
37 True: Always shorten the path, create link if not existing
38 None: Use shorten path only if already exists, not create
39 """
40 if short_paths is False or os.getenv("CONAN_USER_HOME_SHORT") == "None":
41 return path
42 link = os.path.join(path, CONAN_LINK)
43 if os.path.exists(link):
44 return load(link)
45 elif short_paths is None:
46 return path
47
48 short_home = os.getenv("CONAN_USER_HOME_SHORT")
49 if not short_home:
50 drive = os.path.splitdrive(path)[0]
51 short_home = drive + "/.conan"
52 mkdir(short_home)
53
54 # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid
55 # access problems in cygwin/msys2 windows subsystems when using short_home folder
56 try:
57 cmd = r'cacls %s /E /G "%s\%s":F' % (short_home, os.environ['USERDOMAIN'], os.environ['USERNAME'])
58 subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet
59 except subprocess.CalledProcessError as e:
60 # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.
61 pass
62
63 redirect = tempfile.mkdtemp(dir=short_home, prefix="")
64 # This "1" is the way to have a non-existing directory, so commands like
65 # shutil.copytree() to it, works. It can be removed without compromising the
66 # temp folder generator and conan-links consistency
67 redirect = os.path.join(redirect, "1")
68 save(link, redirect)
69 return redirect
70
71
72 def ignore_long_path_files(src_folder, build_folder, output):
73 def _filter(src, files):
74 filtered_files = []
75 for the_file in files:
76 source_path = os.path.join(src, the_file)
77 # Without storage path, just relative
78 rel_path = os.path.relpath(source_path, src_folder)
79 dest_path = os.path.normpath(os.path.join(build_folder, rel_path))
80 # it is NOT that "/" is counted as "\\" so it counts double
81 # seems a bug in python, overflows paths near the limit of 260,
82 if len(dest_path) >= 249:
83 filtered_files.append(the_file)
84 output.warn("Filename too long, file excluded: %s" % dest_path)
85 return filtered_files
86 return _filter
87
88
89 def rm_conandir(path):
90 """removal of a directory that might contain a link to a short path"""
91 link = os.path.join(path, CONAN_LINK)
92 if os.path.exists(link):
93 short_path = load(link)
94 rmdir(os.path.dirname(short_path))
95 rmdir(path)
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/util/windows.py b/conans/util/windows.py
--- a/conans/util/windows.py
+++ b/conans/util/windows.py
@@ -54,9 +54,11 @@
# Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid
# access problems in cygwin/msys2 windows subsystems when using short_home folder
try:
- cmd = r'cacls %s /E /G "%s\%s":F' % (short_home, os.environ['USERDOMAIN'], os.environ['USERNAME'])
+ username = os.getenv("USERDOMAIN")
+ domainname = "%s\%s" % (username, os.environ["USERNAME"]) if username else os.environ["USERNAME"]
+ cmd = r'cacls %s /E /G "%s":F' % (short_home, domainname)
subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet
- except subprocess.CalledProcessError as e:
+ except subprocess.CalledProcessError:
# cmd can fail if trying to set ACL in non NTFS drives, ignoring it.
pass
|
{"golden_diff": "diff --git a/conans/util/windows.py b/conans/util/windows.py\n--- a/conans/util/windows.py\n+++ b/conans/util/windows.py\n@@ -54,9 +54,11 @@\n # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid\n # access problems in cygwin/msys2 windows subsystems when using short_home folder\n try:\n- cmd = r'cacls %s /E /G \"%s\\%s\":F' % (short_home, os.environ['USERDOMAIN'], os.environ['USERNAME'])\n+ username = os.getenv(\"USERDOMAIN\")\n+ domainname = \"%s\\%s\" % (username, os.environ[\"USERNAME\"]) if username else os.environ[\"USERNAME\"]\n+ cmd = r'cacls %s /E /G \"%s\":F' % (short_home, domainname)\n subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet\n- except subprocess.CalledProcessError as e:\n+ except subprocess.CalledProcessError:\n # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.\n pass\n", "issue": "KeyError USERDOMAIN on `conan install`\nWe have at least two machines for which `conan install` errors out with the message:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\command.py\", line 1187, in run\r\n method(args[0][1:])\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\command.py\", line 304, in install\r\n install_folder=args.install_folder)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\conan_api.py\", line 61, in wrapper\r\n return f(*args, **kwargs)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\conan_api.py\", line 444, in install\r\n no_imports=no_imports)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\manager.py\", line 395, in install\r\n installer.install(deps_graph, profile.build_requires, keep_build)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\installer.py\", line 262, in install\r\n nodes_to_process = self._get_nodes(nodes_by_level, skip_private_nodes)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\installer.py\", line 501, in _get_nodes\r\n check_outdated)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\client\\proxy.py\", line 47, in package_available\r\n package_folder = self._client_cache.package(package_ref, short_paths=short_paths)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\paths.py\", line 162, in package\r\n return path_shortener(p, short_paths)\r\n File \"C:\\Python27\\lib\\site-packages\\conans\\util\\windows.py\", line 57, in path_shortener\r\n cmd = r'cacls %s /E /G \"%s\\%s\":F' % (short_home, os.environ['USERDOMAIN'], os.environ['USERNAME'])\r\n File \"C:\\Python27\\lib\\os.py\", line 425, in __getitem__\r\n return self.data[key.upper()]\r\nKeyError: 'USERDOMAIN'\r\n```\r\n\r\nDefining an environment variable `USERDOMAIN` to any value fixes the problem.\r\n\r\nBoth machines are Windows 7, with Conan 1.2.3.\n", "before_files": [{"content": "import os\nimport subprocess\n\nfrom conans.util.files import load, mkdir, save, rmdir\nimport tempfile\n\n\nCONAN_LINK = \".conan_link\"\n\n\ndef conan_expand_user(path):\n \"\"\" wrapper to the original expanduser function, to workaround python returning\n verbatim %USERPROFILE% when some other app (git for windows) sets HOME envvar\n \"\"\"\n # In win these variables should exist and point to user directory, which\n # must exist. Using context to avoid permanent modification of os.environ\n old_env = dict(os.environ)\n try:\n home = os.environ.get(\"HOME\")\n # Problematic cases of wrong HOME variable\n # - HOME = %USERPROFILE% verbatim, as messed by some other tools\n # - MSYS console, that defines a different user home in /c/mingw/msys/users/xxx\n # In these cases, it is safe to remove it and rely on USERPROFILE directly\n if home and (not os.path.exists(home) or\n (os.getenv(\"MSYSTEM\") and os.getenv(\"USERPROFILE\"))):\n del os.environ[\"HOME\"]\n result = os.path.expanduser(path)\n finally:\n os.environ.clear()\n os.environ.update(old_env)\n return result\n\n\ndef path_shortener(path, short_paths):\n \"\"\" short_paths is 4-state:\n False: Never shorten the path\n True: Always shorten the path, create link if not existing\n None: Use shorten path only if already exists, not create\n \"\"\"\n if short_paths is False or os.getenv(\"CONAN_USER_HOME_SHORT\") == \"None\":\n return path\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n return load(link)\n elif short_paths is None:\n return path\n\n short_home = os.getenv(\"CONAN_USER_HOME_SHORT\")\n if not short_home:\n drive = os.path.splitdrive(path)[0]\n short_home = drive + \"/.conan\"\n mkdir(short_home)\n\n # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid\n # access problems in cygwin/msys2 windows subsystems when using short_home folder\n try:\n cmd = r'cacls %s /E /G \"%s\\%s\":F' % (short_home, os.environ['USERDOMAIN'], os.environ['USERNAME'])\n subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet\n except subprocess.CalledProcessError as e:\n # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.\n pass\n\n redirect = tempfile.mkdtemp(dir=short_home, prefix=\"\")\n # This \"1\" is the way to have a non-existing directory, so commands like\n # shutil.copytree() to it, works. It can be removed without compromising the\n # temp folder generator and conan-links consistency\n redirect = os.path.join(redirect, \"1\")\n save(link, redirect)\n return redirect\n\n\ndef ignore_long_path_files(src_folder, build_folder, output):\n def _filter(src, files):\n filtered_files = []\n for the_file in files:\n source_path = os.path.join(src, the_file)\n # Without storage path, just relative\n rel_path = os.path.relpath(source_path, src_folder)\n dest_path = os.path.normpath(os.path.join(build_folder, rel_path))\n # it is NOT that \"/\" is counted as \"\\\\\" so it counts double\n # seems a bug in python, overflows paths near the limit of 260,\n if len(dest_path) >= 249:\n filtered_files.append(the_file)\n output.warn(\"Filename too long, file excluded: %s\" % dest_path)\n return filtered_files\n return _filter\n\n\ndef rm_conandir(path):\n \"\"\"removal of a directory that might contain a link to a short path\"\"\"\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n short_path = load(link)\n rmdir(os.path.dirname(short_path))\n rmdir(path)\n", "path": "conans/util/windows.py"}], "after_files": [{"content": "import os\nimport subprocess\n\nfrom conans.util.files import load, mkdir, save, rmdir\nimport tempfile\n\n\nCONAN_LINK = \".conan_link\"\n\n\ndef conan_expand_user(path):\n \"\"\" wrapper to the original expanduser function, to workaround python returning\n verbatim %USERPROFILE% when some other app (git for windows) sets HOME envvar\n \"\"\"\n # In win these variables should exist and point to user directory, which\n # must exist. Using context to avoid permanent modification of os.environ\n old_env = dict(os.environ)\n try:\n home = os.environ.get(\"HOME\")\n # Problematic cases of wrong HOME variable\n # - HOME = %USERPROFILE% verbatim, as messed by some other tools\n # - MSYS console, that defines a different user home in /c/mingw/msys/users/xxx\n # In these cases, it is safe to remove it and rely on USERPROFILE directly\n if home and (not os.path.exists(home) or\n (os.getenv(\"MSYSTEM\") and os.getenv(\"USERPROFILE\"))):\n del os.environ[\"HOME\"]\n result = os.path.expanduser(path)\n finally:\n os.environ.clear()\n os.environ.update(old_env)\n return result\n\n\ndef path_shortener(path, short_paths):\n \"\"\" short_paths is 4-state:\n False: Never shorten the path\n True: Always shorten the path, create link if not existing\n None: Use shorten path only if already exists, not create\n \"\"\"\n if short_paths is False or os.getenv(\"CONAN_USER_HOME_SHORT\") == \"None\":\n return path\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n return load(link)\n elif short_paths is None:\n return path\n\n short_home = os.getenv(\"CONAN_USER_HOME_SHORT\")\n if not short_home:\n drive = os.path.splitdrive(path)[0]\n short_home = drive + \"/.conan\"\n mkdir(short_home)\n\n # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid\n # access problems in cygwin/msys2 windows subsystems when using short_home folder\n try:\n username = os.getenv(\"USERDOMAIN\")\n domainname = \"%s\\%s\" % (username, os.environ[\"USERNAME\"]) if username else os.environ[\"USERNAME\"]\n cmd = r'cacls %s /E /G \"%s\":F' % (short_home, domainname)\n subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet\n except subprocess.CalledProcessError:\n # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.\n pass\n\n redirect = tempfile.mkdtemp(dir=short_home, prefix=\"\")\n # This \"1\" is the way to have a non-existing directory, so commands like\n # shutil.copytree() to it, works. It can be removed without compromising the\n # temp folder generator and conan-links consistency\n redirect = os.path.join(redirect, \"1\")\n save(link, redirect)\n return redirect\n\n\ndef ignore_long_path_files(src_folder, build_folder, output):\n def _filter(src, files):\n filtered_files = []\n for the_file in files:\n source_path = os.path.join(src, the_file)\n # Without storage path, just relative\n rel_path = os.path.relpath(source_path, src_folder)\n dest_path = os.path.normpath(os.path.join(build_folder, rel_path))\n # it is NOT that \"/\" is counted as \"\\\\\" so it counts double\n # seems a bug in python, overflows paths near the limit of 260,\n if len(dest_path) >= 249:\n filtered_files.append(the_file)\n output.warn(\"Filename too long, file excluded: %s\" % dest_path)\n return filtered_files\n return _filter\n\n\ndef rm_conandir(path):\n \"\"\"removal of a directory that might contain a link to a short path\"\"\"\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n short_path = load(link)\n rmdir(os.path.dirname(short_path))\n rmdir(path)\n", "path": "conans/util/windows.py"}]}
| 1,902 | 261 |
gh_patches_debug_32494
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-8989
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add deprecation warnings for legacy certbot.display.util code
As a followup from https://github.com/certbot/certbot/pull/8967, I think we should generate deprecation warnings using an approach like https://github.com/certbot/certbot/pull/6859/files#diff-e5eaf744409c293203b898ba9896da75689fd04ff5f1566c035940a5b195c257 for any code in `certbot.display.util` that is unused and/or we don't want to be part of our public API.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `certbot/certbot/display/util.py`
Content:
```
1 """Certbot display.
2
3 This module (`certbot.display.util`) or its companion `certbot.display.ops`
4 should be used whenever:
5
6 - Displaying status information to the user on the terminal
7 - Collecting information from the user via prompts
8
9 Other messages can use the `logging` module. See `log.py`.
10
11 """
12 from typing import List
13 from typing import Optional
14 from typing import Tuple
15 from typing import Union
16
17
18 # These specific imports from certbot._internal.display.obj and
19 # certbot._internal.display.util are done to not break the public API of this
20 # module.
21 from certbot._internal.display.obj import FileDisplay # pylint: disable=unused-import
22 from certbot._internal.display.obj import NoninteractiveDisplay # pylint: disable=unused-import
23 from certbot._internal.display.obj import SIDE_FRAME # pylint: disable=unused-import
24 from certbot._internal.display.util import input_with_timeout # pylint: disable=unused-import
25 from certbot._internal.display.util import separate_list_input # pylint: disable=unused-import
26 from certbot._internal.display.util import summarize_domain_list # pylint: disable=unused-import
27 from certbot._internal.display import obj
28
29
30 # These constants are defined this way to make them easier to document with
31 # Sphinx and to not couple our public docstrings to our internal ones.
32 OK = obj.OK
33 """Display exit code indicating user acceptance."""
34
35 CANCEL = obj.CANCEL
36 """Display exit code for a user canceling the display."""
37
38 # These constants are unused and should be removed in a major release of
39 # Certbot.
40 WIDTH = 72
41
42 HELP = "help"
43 """Display exit code when for when the user requests more help. (UNUSED)"""
44
45 ESC = "esc"
46 """Display exit code when the user hits Escape (UNUSED)"""
47
48
49 def notify(msg: str) -> None:
50 """Display a basic status message.
51
52 :param str msg: message to display
53
54 """
55 obj.get_display().notification(msg, pause=False, decorate=False, wrap=False)
56
57
58 def notification(message: str, pause: bool = True, wrap: bool = True,
59 force_interactive: bool = False, decorate: bool = True) -> None:
60 """Displays a notification and waits for user acceptance.
61
62 :param str message: Message to display
63 :param bool pause: Whether or not the program should pause for the
64 user's confirmation
65 :param bool wrap: Whether or not the application should wrap text
66 :param bool force_interactive: True if it's safe to prompt the user
67 because it won't cause any workflow regressions
68 :param bool decorate: Whether to surround the message with a
69 decorated frame
70
71 """
72 obj.get_display().notification(message, pause=pause, wrap=wrap,
73 force_interactive=force_interactive, decorate=decorate)
74
75
76 def menu(message: str, choices: Union[List[str], Tuple[str, str]],
77 default: Optional[int] = None, cli_flag: Optional[str] = None,
78 force_interactive: bool = False) -> Tuple[str, int]:
79 """Display a menu.
80
81 .. todo:: This doesn't enable the help label/button (I wasn't sold on
82 any interface I came up with for this). It would be a nice feature.
83
84 :param str message: title of menu
85 :param choices: Menu lines, len must be > 0
86 :type choices: list of tuples (tag, item) or
87 list of descriptions (tags will be enumerated)
88 :param default: default value to return (if one exists)
89 :param str cli_flag: option used to set this value with the CLI
90 :param bool force_interactive: True if it's safe to prompt the user
91 because it won't cause any workflow regressions
92
93 :returns: tuple of (`code`, `index`) where
94 `code` - str display exit code
95 `index` - int index of the user's selection
96
97 :rtype: tuple
98
99 """
100 return obj.get_display().menu(message, choices, default=default, cli_flag=cli_flag,
101 force_interactive=force_interactive)
102
103
104 def input_text(message: str, default: Optional[str] = None, cli_flag: Optional[str] = None,
105 force_interactive: bool = False) -> Tuple[str, str]:
106 """Accept input from the user.
107
108 :param str message: message to display to the user
109 :param default: default value to return (if one exists)
110 :param str cli_flag: option used to set this value with the CLI
111 :param bool force_interactive: True if it's safe to prompt the user
112 because it won't cause any workflow regressions
113
114 :returns: tuple of (`code`, `input`) where
115 `code` - str display exit code
116 `input` - str of the user's input
117 :rtype: tuple
118
119 """
120 return obj.get_display().input(message, default=default, cli_flag=cli_flag,
121 force_interactive=force_interactive)
122
123
124 def yesno(message: str, yes_label: str = "Yes", no_label: str = "No",
125 default: Optional[bool] = None, cli_flag: Optional[str] = None,
126 force_interactive: bool = False) -> bool:
127 """Query the user with a yes/no question.
128
129 Yes and No label must begin with different letters, and must contain at
130 least one letter each.
131
132 :param str message: question for the user
133 :param str yes_label: Label of the "Yes" parameter
134 :param str no_label: Label of the "No" parameter
135 :param default: default value to return (if one exists)
136 :param str cli_flag: option used to set this value with the CLI
137 :param bool force_interactive: True if it's safe to prompt the user
138 because it won't cause any workflow regressions
139
140 :returns: True for "Yes", False for "No"
141 :rtype: bool
142
143 """
144 return obj.get_display().yesno(message, yes_label=yes_label, no_label=no_label, default=default,
145 cli_flag=cli_flag, force_interactive=force_interactive)
146
147
148 def checklist(message: str, tags: List[str], default: Optional[str] = None,
149 cli_flag: Optional[str] = None,
150 force_interactive: bool = False) -> Tuple[str, List[str]]:
151 """Display a checklist.
152
153 :param str message: Message to display to user
154 :param list tags: `str` tags to select, len(tags) > 0
155 :param default: default value to return (if one exists)
156 :param str cli_flag: option used to set this value with the CLI
157 :param bool force_interactive: True if it's safe to prompt the user
158 because it won't cause any workflow regressions
159
160 :returns: tuple of (`code`, `tags`) where
161 `code` - str display exit code
162 `tags` - list of selected tags
163 :rtype: tuple
164
165 """
166 return obj.get_display().checklist(message, tags, default=default, cli_flag=cli_flag,
167 force_interactive=force_interactive)
168
169
170 def directory_select(message: str, default: Optional[str] = None, cli_flag: Optional[str] = None,
171 force_interactive: bool = False) -> Tuple[int, str]:
172 """Display a directory selection screen.
173
174 :param str message: prompt to give the user
175 :param default: default value to return (if one exists)
176 :param str cli_flag: option used to set this value with the CLI
177 :param bool force_interactive: True if it's safe to prompt the user
178 because it won't cause any workflow regressions
179
180 :returns: tuple of the form (`code`, `string`) where
181 `code` - display exit code
182 `string` - input entered by the user
183
184 """
185 return obj.get_display().directory_select(message, default=default, cli_flag=cli_flag,
186 force_interactive=force_interactive)
187
188
189 def assert_valid_call(prompt, default, cli_flag, force_interactive):
190 """Verify that provided arguments is a valid IDisplay call.
191
192 :param str prompt: prompt for the user
193 :param default: default answer to prompt
194 :param str cli_flag: command line option for setting an answer
195 to this question
196 :param bool force_interactive: if interactivity is forced by the
197 IDisplay call
198
199 """
200 msg = "Invalid IDisplay call for this prompt:\n{0}".format(prompt)
201 if cli_flag:
202 msg += ("\nYou can set an answer to "
203 "this prompt with the {0} flag".format(cli_flag))
204 assert default is not None or force_interactive, msg
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/certbot/certbot/display/util.py b/certbot/certbot/display/util.py
--- a/certbot/certbot/display/util.py
+++ b/certbot/certbot/display/util.py
@@ -9,10 +9,14 @@
Other messages can use the `logging` module. See `log.py`.
"""
+import sys
+from types import ModuleType
+from typing import cast
from typing import List
from typing import Optional
from typing import Tuple
from typing import Union
+import warnings
# These specific imports from certbot._internal.display.obj and
@@ -202,3 +206,36 @@
msg += ("\nYou can set an answer to "
"this prompt with the {0} flag".format(cli_flag))
assert default is not None or force_interactive, msg
+
+
+# This class takes a similar approach to the cryptography project to deprecate attributes
+# in public modules. See the _ModuleWithDeprecation class here:
+# https://github.com/pyca/cryptography/blob/91105952739442a74582d3e62b3d2111365b0dc7/src/cryptography/utils.py#L129
+class _DisplayUtilDeprecationModule:
+ """
+ Internal class delegating to a module, and displaying warnings when attributes
+ related to deprecated attributes in the certbot.display.util module.
+ """
+ def __init__(self, module):
+ self.__dict__['_module'] = module
+
+ def __getattr__(self, attr):
+ if attr in ('FileDisplay', 'NoninteractiveDisplay', 'SIDE_FRAME', 'input_with_timeout',
+ 'separate_list_input', 'summarize_domain_list', 'WIDTH', 'HELP', 'ESC'):
+ warnings.warn('{0} attribute in certbot.display.util module is deprecated '
+ 'and will be removed soon.'.format(attr),
+ DeprecationWarning, stacklevel=2)
+ return getattr(self._module, attr)
+
+ def __setattr__(self, attr, value): # pragma: no cover
+ setattr(self._module, attr, value)
+
+ def __delattr__(self, attr): # pragma: no cover
+ delattr(self._module, attr)
+
+ def __dir__(self): # pragma: no cover
+ return ['_module'] + dir(self._module)
+
+
+# Patching ourselves to warn about deprecation and planned removal of some elements in the module.
+sys.modules[__name__] = cast(ModuleType, _DisplayUtilDeprecationModule(sys.modules[__name__]))
|
{"golden_diff": "diff --git a/certbot/certbot/display/util.py b/certbot/certbot/display/util.py\n--- a/certbot/certbot/display/util.py\n+++ b/certbot/certbot/display/util.py\n@@ -9,10 +9,14 @@\n Other messages can use the `logging` module. See `log.py`.\n \n \"\"\"\n+import sys\n+from types import ModuleType\n+from typing import cast\n from typing import List\n from typing import Optional\n from typing import Tuple\n from typing import Union\n+import warnings\n \n \n # These specific imports from certbot._internal.display.obj and\n@@ -202,3 +206,36 @@\n msg += (\"\\nYou can set an answer to \"\n \"this prompt with the {0} flag\".format(cli_flag))\n assert default is not None or force_interactive, msg\n+\n+\n+# This class takes a similar approach to the cryptography project to deprecate attributes\n+# in public modules. See the _ModuleWithDeprecation class here:\n+# https://github.com/pyca/cryptography/blob/91105952739442a74582d3e62b3d2111365b0dc7/src/cryptography/utils.py#L129\n+class _DisplayUtilDeprecationModule:\n+ \"\"\"\n+ Internal class delegating to a module, and displaying warnings when attributes\n+ related to deprecated attributes in the certbot.display.util module.\n+ \"\"\"\n+ def __init__(self, module):\n+ self.__dict__['_module'] = module\n+\n+ def __getattr__(self, attr):\n+ if attr in ('FileDisplay', 'NoninteractiveDisplay', 'SIDE_FRAME', 'input_with_timeout',\n+ 'separate_list_input', 'summarize_domain_list', 'WIDTH', 'HELP', 'ESC'):\n+ warnings.warn('{0} attribute in certbot.display.util module is deprecated '\n+ 'and will be removed soon.'.format(attr),\n+ DeprecationWarning, stacklevel=2)\n+ return getattr(self._module, attr)\n+\n+ def __setattr__(self, attr, value): # pragma: no cover\n+ setattr(self._module, attr, value)\n+\n+ def __delattr__(self, attr): # pragma: no cover\n+ delattr(self._module, attr)\n+\n+ def __dir__(self): # pragma: no cover\n+ return ['_module'] + dir(self._module)\n+\n+\n+# Patching ourselves to warn about deprecation and planned removal of some elements in the module.\n+sys.modules[__name__] = cast(ModuleType, _DisplayUtilDeprecationModule(sys.modules[__name__]))\n", "issue": "Add deprecation warnings for legacy certbot.display.util code\nAs a followup from https://github.com/certbot/certbot/pull/8967, I think we should generate deprecation warnings using an approach like https://github.com/certbot/certbot/pull/6859/files#diff-e5eaf744409c293203b898ba9896da75689fd04ff5f1566c035940a5b195c257 for any code in `certbot.display.util` that is unused and/or we don't want to be part of our public API.\n", "before_files": [{"content": "\"\"\"Certbot display.\n\nThis module (`certbot.display.util`) or its companion `certbot.display.ops`\nshould be used whenever:\n\n- Displaying status information to the user on the terminal\n- Collecting information from the user via prompts\n\nOther messages can use the `logging` module. See `log.py`.\n\n\"\"\"\nfrom typing import List\nfrom typing import Optional\nfrom typing import Tuple\nfrom typing import Union\n\n\n# These specific imports from certbot._internal.display.obj and\n# certbot._internal.display.util are done to not break the public API of this\n# module.\nfrom certbot._internal.display.obj import FileDisplay # pylint: disable=unused-import\nfrom certbot._internal.display.obj import NoninteractiveDisplay # pylint: disable=unused-import\nfrom certbot._internal.display.obj import SIDE_FRAME # pylint: disable=unused-import\nfrom certbot._internal.display.util import input_with_timeout # pylint: disable=unused-import\nfrom certbot._internal.display.util import separate_list_input # pylint: disable=unused-import\nfrom certbot._internal.display.util import summarize_domain_list # pylint: disable=unused-import\nfrom certbot._internal.display import obj\n\n\n# These constants are defined this way to make them easier to document with\n# Sphinx and to not couple our public docstrings to our internal ones.\nOK = obj.OK\n\"\"\"Display exit code indicating user acceptance.\"\"\"\n\nCANCEL = obj.CANCEL\n\"\"\"Display exit code for a user canceling the display.\"\"\"\n\n# These constants are unused and should be removed in a major release of\n# Certbot.\nWIDTH = 72\n\nHELP = \"help\"\n\"\"\"Display exit code when for when the user requests more help. (UNUSED)\"\"\"\n\nESC = \"esc\"\n\"\"\"Display exit code when the user hits Escape (UNUSED)\"\"\"\n\n\ndef notify(msg: str) -> None:\n \"\"\"Display a basic status message.\n\n :param str msg: message to display\n\n \"\"\"\n obj.get_display().notification(msg, pause=False, decorate=False, wrap=False)\n\n\ndef notification(message: str, pause: bool = True, wrap: bool = True,\n force_interactive: bool = False, decorate: bool = True) -> None:\n \"\"\"Displays a notification and waits for user acceptance.\n\n :param str message: Message to display\n :param bool pause: Whether or not the program should pause for the\n user's confirmation\n :param bool wrap: Whether or not the application should wrap text\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n :param bool decorate: Whether to surround the message with a\n decorated frame\n\n \"\"\"\n obj.get_display().notification(message, pause=pause, wrap=wrap,\n force_interactive=force_interactive, decorate=decorate)\n\n\ndef menu(message: str, choices: Union[List[str], Tuple[str, str]],\n default: Optional[int] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[str, int]:\n \"\"\"Display a menu.\n\n .. todo:: This doesn't enable the help label/button (I wasn't sold on\n any interface I came up with for this). It would be a nice feature.\n\n :param str message: title of menu\n :param choices: Menu lines, len must be > 0\n :type choices: list of tuples (tag, item) or\n list of descriptions (tags will be enumerated)\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of (`code`, `index`) where\n `code` - str display exit code\n `index` - int index of the user's selection\n\n :rtype: tuple\n\n \"\"\"\n return obj.get_display().menu(message, choices, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef input_text(message: str, default: Optional[str] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[str, str]:\n \"\"\"Accept input from the user.\n\n :param str message: message to display to the user\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of (`code`, `input`) where\n `code` - str display exit code\n `input` - str of the user's input\n :rtype: tuple\n\n \"\"\"\n return obj.get_display().input(message, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef yesno(message: str, yes_label: str = \"Yes\", no_label: str = \"No\",\n default: Optional[bool] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> bool:\n \"\"\"Query the user with a yes/no question.\n\n Yes and No label must begin with different letters, and must contain at\n least one letter each.\n\n :param str message: question for the user\n :param str yes_label: Label of the \"Yes\" parameter\n :param str no_label: Label of the \"No\" parameter\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: True for \"Yes\", False for \"No\"\n :rtype: bool\n\n \"\"\"\n return obj.get_display().yesno(message, yes_label=yes_label, no_label=no_label, default=default,\n cli_flag=cli_flag, force_interactive=force_interactive)\n\n\ndef checklist(message: str, tags: List[str], default: Optional[str] = None,\n cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[str, List[str]]:\n \"\"\"Display a checklist.\n\n :param str message: Message to display to user\n :param list tags: `str` tags to select, len(tags) > 0\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of (`code`, `tags`) where\n `code` - str display exit code\n `tags` - list of selected tags\n :rtype: tuple\n\n \"\"\"\n return obj.get_display().checklist(message, tags, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef directory_select(message: str, default: Optional[str] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[int, str]:\n \"\"\"Display a directory selection screen.\n\n :param str message: prompt to give the user\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of the form (`code`, `string`) where\n `code` - display exit code\n `string` - input entered by the user\n\n \"\"\"\n return obj.get_display().directory_select(message, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef assert_valid_call(prompt, default, cli_flag, force_interactive):\n \"\"\"Verify that provided arguments is a valid IDisplay call.\n\n :param str prompt: prompt for the user\n :param default: default answer to prompt\n :param str cli_flag: command line option for setting an answer\n to this question\n :param bool force_interactive: if interactivity is forced by the\n IDisplay call\n\n \"\"\"\n msg = \"Invalid IDisplay call for this prompt:\\n{0}\".format(prompt)\n if cli_flag:\n msg += (\"\\nYou can set an answer to \"\n \"this prompt with the {0} flag\".format(cli_flag))\n assert default is not None or force_interactive, msg\n", "path": "certbot/certbot/display/util.py"}], "after_files": [{"content": "\"\"\"Certbot display.\n\nThis module (`certbot.display.util`) or its companion `certbot.display.ops`\nshould be used whenever:\n\n- Displaying status information to the user on the terminal\n- Collecting information from the user via prompts\n\nOther messages can use the `logging` module. See `log.py`.\n\n\"\"\"\nimport sys\nfrom types import ModuleType\nfrom typing import cast\nfrom typing import List\nfrom typing import Optional\nfrom typing import Tuple\nfrom typing import Union\nimport warnings\n\n\n# These specific imports from certbot._internal.display.obj and\n# certbot._internal.display.util are done to not break the public API of this\n# module.\nfrom certbot._internal.display.obj import FileDisplay # pylint: disable=unused-import\nfrom certbot._internal.display.obj import NoninteractiveDisplay # pylint: disable=unused-import\nfrom certbot._internal.display.obj import SIDE_FRAME # pylint: disable=unused-import\nfrom certbot._internal.display.util import input_with_timeout # pylint: disable=unused-import\nfrom certbot._internal.display.util import separate_list_input # pylint: disable=unused-import\nfrom certbot._internal.display.util import summarize_domain_list # pylint: disable=unused-import\nfrom certbot._internal.display import obj\n\n\n# These constants are defined this way to make them easier to document with\n# Sphinx and to not couple our public docstrings to our internal ones.\nOK = obj.OK\n\"\"\"Display exit code indicating user acceptance.\"\"\"\n\nCANCEL = obj.CANCEL\n\"\"\"Display exit code for a user canceling the display.\"\"\"\n\n# These constants are unused and should be removed in a major release of\n# Certbot.\nWIDTH = 72\n\nHELP = \"help\"\n\"\"\"Display exit code when for when the user requests more help. (UNUSED)\"\"\"\n\nESC = \"esc\"\n\"\"\"Display exit code when the user hits Escape (UNUSED)\"\"\"\n\n\ndef notify(msg: str) -> None:\n \"\"\"Display a basic status message.\n\n :param str msg: message to display\n\n \"\"\"\n obj.get_display().notification(msg, pause=False, decorate=False, wrap=False)\n\n\ndef notification(message: str, pause: bool = True, wrap: bool = True,\n force_interactive: bool = False, decorate: bool = True) -> None:\n \"\"\"Displays a notification and waits for user acceptance.\n\n :param str message: Message to display\n :param bool pause: Whether or not the program should pause for the\n user's confirmation\n :param bool wrap: Whether or not the application should wrap text\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n :param bool decorate: Whether to surround the message with a\n decorated frame\n\n \"\"\"\n obj.get_display().notification(message, pause=pause, wrap=wrap,\n force_interactive=force_interactive, decorate=decorate)\n\n\ndef menu(message: str, choices: Union[List[str], Tuple[str, str]],\n default: Optional[int] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[str, int]:\n \"\"\"Display a menu.\n\n .. todo:: This doesn't enable the help label/button (I wasn't sold on\n any interface I came up with for this). It would be a nice feature.\n\n :param str message: title of menu\n :param choices: Menu lines, len must be > 0\n :type choices: list of tuples (tag, item) or\n list of descriptions (tags will be enumerated)\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of (`code`, `index`) where\n `code` - str display exit code\n `index` - int index of the user's selection\n\n :rtype: tuple\n\n \"\"\"\n return obj.get_display().menu(message, choices, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef input_text(message: str, default: Optional[str] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[str, str]:\n \"\"\"Accept input from the user.\n\n :param str message: message to display to the user\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of (`code`, `input`) where\n `code` - str display exit code\n `input` - str of the user's input\n :rtype: tuple\n\n \"\"\"\n return obj.get_display().input(message, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef yesno(message: str, yes_label: str = \"Yes\", no_label: str = \"No\",\n default: Optional[bool] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> bool:\n \"\"\"Query the user with a yes/no question.\n\n Yes and No label must begin with different letters, and must contain at\n least one letter each.\n\n :param str message: question for the user\n :param str yes_label: Label of the \"Yes\" parameter\n :param str no_label: Label of the \"No\" parameter\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: True for \"Yes\", False for \"No\"\n :rtype: bool\n\n \"\"\"\n return obj.get_display().yesno(message, yes_label=yes_label, no_label=no_label, default=default,\n cli_flag=cli_flag, force_interactive=force_interactive)\n\n\ndef checklist(message: str, tags: List[str], default: Optional[str] = None,\n cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[str, List[str]]:\n \"\"\"Display a checklist.\n\n :param str message: Message to display to user\n :param list tags: `str` tags to select, len(tags) > 0\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of (`code`, `tags`) where\n `code` - str display exit code\n `tags` - list of selected tags\n :rtype: tuple\n\n \"\"\"\n return obj.get_display().checklist(message, tags, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef directory_select(message: str, default: Optional[str] = None, cli_flag: Optional[str] = None,\n force_interactive: bool = False) -> Tuple[int, str]:\n \"\"\"Display a directory selection screen.\n\n :param str message: prompt to give the user\n :param default: default value to return (if one exists)\n :param str cli_flag: option used to set this value with the CLI\n :param bool force_interactive: True if it's safe to prompt the user\n because it won't cause any workflow regressions\n\n :returns: tuple of the form (`code`, `string`) where\n `code` - display exit code\n `string` - input entered by the user\n\n \"\"\"\n return obj.get_display().directory_select(message, default=default, cli_flag=cli_flag,\n force_interactive=force_interactive)\n\n\ndef assert_valid_call(prompt, default, cli_flag, force_interactive):\n \"\"\"Verify that provided arguments is a valid IDisplay call.\n\n :param str prompt: prompt for the user\n :param default: default answer to prompt\n :param str cli_flag: command line option for setting an answer\n to this question\n :param bool force_interactive: if interactivity is forced by the\n IDisplay call\n\n \"\"\"\n msg = \"Invalid IDisplay call for this prompt:\\n{0}\".format(prompt)\n if cli_flag:\n msg += (\"\\nYou can set an answer to \"\n \"this prompt with the {0} flag\".format(cli_flag))\n assert default is not None or force_interactive, msg\n\n\n# This class takes a similar approach to the cryptography project to deprecate attributes\n# in public modules. See the _ModuleWithDeprecation class here:\n# https://github.com/pyca/cryptography/blob/91105952739442a74582d3e62b3d2111365b0dc7/src/cryptography/utils.py#L129\nclass _DisplayUtilDeprecationModule:\n \"\"\"\n Internal class delegating to a module, and displaying warnings when attributes\n related to deprecated attributes in the certbot.display.util module.\n \"\"\"\n def __init__(self, module):\n self.__dict__['_module'] = module\n\n def __getattr__(self, attr):\n if attr in ('FileDisplay', 'NoninteractiveDisplay', 'SIDE_FRAME', 'input_with_timeout',\n 'separate_list_input', 'summarize_domain_list', 'WIDTH', 'HELP', 'ESC'):\n warnings.warn('{0} attribute in certbot.display.util module is deprecated '\n 'and will be removed soon.'.format(attr),\n DeprecationWarning, stacklevel=2)\n return getattr(self._module, attr)\n\n def __setattr__(self, attr, value): # pragma: no cover\n setattr(self._module, attr, value)\n\n def __delattr__(self, attr): # pragma: no cover\n delattr(self._module, attr)\n\n def __dir__(self): # pragma: no cover\n return ['_module'] + dir(self._module)\n\n\n# Patching ourselves to warn about deprecation and planned removal of some elements in the module.\nsys.modules[__name__] = cast(ModuleType, _DisplayUtilDeprecationModule(sys.modules[__name__]))\n", "path": "certbot/certbot/display/util.py"}]}
| 2,835 | 595 |
gh_patches_debug_10516
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-2307
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pwn libcdb file fails if binary doesn't contain b'/bin/sh\x00'
Hello,
the "pwn libcdb file /[something]" is crashing depending whether or not the binary contains the string b'/bin/sh\x00'.
This works:
```
$ pwn libcdb file /bin/bash
[*] bash
BuildID: e1da91a3e72343eb054c8c69a8d6b4240acb8b10
MD5: c33ad3a4937b1c186a8a1279bb31e702
SHA1: d07f822b462ecf5ae31f5ccf1c6657b7505afb3f
SHA256: a8334e823ce220c4a375e1d5f32fabc1bd47abb6810760ea4100415b55a097e4
Symbols:
dup2 = 0x302b4
printf = not found
puts = 0x30024
read = 0x30494
str_bin_sh = 0x336ca
system = not found
write = 0x30134
```
This is crashing as search returns :
```
$ pwn libcdb file /bin/ls
[*] ls
BuildID: e2ca832f1c2112aea9d7b9bc639e97e873a6b516
MD5: df0e7216034340f844de8e3b3c37d32b
SHA1: 0c5f47f25f4379690945f6e7eaa92e1999d0755d
SHA256: 9379a0fa9ed1e0b4302c4a2c9b1254d3cd76a9048f0ead3c9e216a5082b536bf
Symbols:
Traceback (most recent call last):
File "/usr/bin/pwn", line 33, in <module>
sys.exit(load_entry_point('pwntools==4.11.1', 'console_scripts', 'pwn')())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/site-packages/pwnlib/commandline/main.py", line 58, in main
commands[args.command](args)
File "/usr/lib/python3.12/site-packages/pwnlib/commandline/libcdb.py", line 236, in main
synthetic_symbols = collect_synthetic_symbols(exe)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/site-packages/pwnlib/commandline/libcdb.py", line 180, in collect_synthetic_symbols
exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\x00'))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
StopIteration
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/commandline/libcdb.py`
Content:
```
1 #!/usr/bin/env python
2 from __future__ import absolute_import
3 from __future__ import division
4 from __future__ import print_function
5
6 import re
7 import shutil
8 import sys
9
10 import pwnlib.args
11 pwnlib.args.free_form = False
12
13 from pwn import *
14 from pwnlib.commandline import common
15
16 parser = common.parser_commands.add_parser(
17 'libcdb',
18 help = 'Print various information about a libc binary',
19 description = 'Print various information about a libc binary'
20 )
21
22 libc_commands = parser.add_subparsers(
23 dest = 'libc_command'
24 )
25
26 lookup_parser = libc_commands.add_parser(
27 'lookup',
28 help = 'Lookup a libc version by function offsets',
29 description = 'Lookup a libc version by function offsets'
30 )
31
32 lookup_parser.add_argument(
33 'symbol_offset_pairs',
34 metavar = 'symbol_offset_pairs',
35 nargs = '+',
36 help = 'Symbol and offset pairs to lookup matching libc version. Can be any number of pairs to narrow the search. Example: "read 3e0 write 520"'
37 )
38
39 lookup_parser.add_argument(
40 '--download-libc',
41 action = 'store_true',
42 default = False,
43 help = 'Attempt to download the matching libc.so'
44 )
45
46 lookup_parser.add_argument(
47 '--unstrip',
48 action = 'store_true',
49 default = True,
50 help = 'Attempt to unstrip the libc binary with debug symbols from a debuginfod server'
51 )
52
53 lookup_parser.add_argument(
54 '--no-unstrip',
55 action = 'store_false',
56 dest = 'unstrip',
57 help = 'Do NOT attempt to unstrip the libc binary with debug symbols from a debuginfod server'
58 )
59
60 hash_parser = libc_commands.add_parser(
61 'hash',
62 help = 'Display information of a libc version given an unique hash',
63 description = 'Display information of a libc version given an unique hash'
64 )
65
66 hash_parser.add_argument(
67 'hash_value',
68 metavar = 'hash_value',
69 nargs = '+',
70 help = 'Hex encoded hash value'
71 )
72
73 hash_parser.add_argument(
74 '-t', '--hash_type',
75 nargs = '?',
76 type = str,
77 choices = ['id', 'buildid', 'md5', 'sha1', 'sha256'],
78 default = 'buildid',
79 help = 'The type of the provided hash value. Supported hashtypes: id, buildid, md5, sha1, sha256'
80 )
81
82 hash_parser.add_argument(
83 '--download-libc',
84 action = 'store_true',
85 default = False,
86 help = 'Attempt to download the matching libc.so'
87 )
88
89 hash_parser.add_argument(
90 '--unstrip',
91 action = 'store_true',
92 default = True,
93 help = 'Attempt to unstrip the libc binary with debug symbols from a debuginfod server'
94 )
95
96 hash_parser.add_argument(
97 '--no-unstrip',
98 action = 'store_false',
99 dest = 'unstrip',
100 help = 'Do NOT attempt to unstrip the libc binary with debug symbols from a debuginfod server'
101 )
102
103 file_parser = libc_commands.add_parser(
104 'file',
105 help = 'Dump information about a libc binary',
106 description = 'Dump information about a libc binary'
107 )
108
109 file_parser.add_argument(
110 'files',
111 metavar = 'files',
112 nargs = '+',
113 help = 'Libc binary to dump'
114 )
115
116 file_parser.add_argument(
117 '-s', '--symbols',
118 metavar = 'symbols',
119 nargs = '*',
120 help = 'List of symbol offsets to dump in addition to the common ones'
121 )
122
123 file_parser.add_argument(
124 '-o', '--offset',
125 metavar = 'offset',
126 type = str,
127 help = 'Display all offsets relative to this symbol'
128 )
129
130 file_parser.add_argument(
131 '--unstrip',
132 action = 'store_true',
133 default = False,
134 help = 'Attempt to unstrip the libc binary inplace with debug symbols from a debuginfod server'
135 )
136
137 common_symbols = ['dup2', 'printf', 'puts', 'read', 'system', 'write']
138
139 def find_libc(params):
140 import requests
141 url = "https://libc.rip/api/find"
142 result = requests.post(url, json=params, timeout=20)
143 log.debug('Request: %s', params)
144 log.debug('Result: %s', result.json())
145 if result.status_code != 200 or len(result.json()) == 0:
146 log.failure("Could not find libc for %s on libc.rip", params)
147 return []
148
149 return result.json()
150
151 def print_libc(libc):
152 log.info('%s', text.red(libc['id']))
153 log.indented('\t%-20s %s', text.green('BuildID:'), libc['buildid'])
154 log.indented('\t%-20s %s', text.green('MD5:'), libc['md5'])
155 log.indented('\t%-20s %s', text.green('SHA1:'), libc['sha1'])
156 log.indented('\t%-20s %s', text.green('SHA256:'), libc['sha256'])
157 log.indented('\t%s', text.green('Symbols:'))
158 for symbol in libc['symbols'].items():
159 log.indented('\t%25s = %s', symbol[0], symbol[1])
160
161 def handle_remote_libc(args, libc):
162 print_libc(libc)
163 if args.download_libc:
164 path = libcdb.search_by_build_id(libc['buildid'], args.unstrip)
165 if path:
166 if args.unstrip:
167 libcdb.unstrip_libc(path)
168 shutil.copy(path, './{}.so'.format(libc['id']))
169
170 def translate_offset(offs, args, exe):
171 if args.offset:
172 if args.offset not in exe.symbols:
173 log.info_once('offset symbol %s not found. ignoring.', args.offset)
174 return offs
175 return offs - exe.symbols[args.offset]
176 return offs
177
178 def collect_synthetic_symbols(exe):
179 available_symbols = ['str_bin_sh']
180 exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\x00'))
181
182 libc_start_main_return = exe.libc_start_main_return
183 if libc_start_main_return > 0:
184 exe.symbols['__libc_start_main_ret'] = libc_start_main_return
185 available_symbols.append('__libc_start_main_ret')
186
187 return available_symbols
188
189 def main(args):
190 if len(sys.argv) < 3:
191 parser.print_usage()
192 sys.exit()
193
194 if args.libc_command == 'lookup':
195 pairs = args.symbol_offset_pairs
196 if len(pairs) % 2 != 0:
197 log.failure('Uneven number of arguments. Please provide "symbol offset" pairs')
198 return
199
200 symbols = {pairs[i]:pairs[i+1] for i in range(0, len(pairs), 2)}
201 matched_libcs = find_libc({'symbols': symbols})
202 for libc in matched_libcs:
203 handle_remote_libc(args, libc)
204
205 elif args.libc_command == 'hash':
206 for hash_value in args.hash_value:
207 matched_libcs = find_libc({args.hash_type: hash_value})
208 for libc in matched_libcs:
209 handle_remote_libc(args, libc)
210
211 elif args.libc_command == 'file':
212 from hashlib import md5, sha1, sha256
213 for file in args.files:
214 if not os.path.exists(file) or not os.path.isfile(file):
215 log.failure('File does not exist %s', args.file)
216 continue
217
218 if args.unstrip:
219 libcdb.unstrip_libc(file)
220
221 exe = ELF(file, checksec=False)
222 log.info('%s', text.red(os.path.basename(file)))
223
224 libc_version = re.search(br'libc[ -](\d+\.\d+)', exe.data)
225 if libc_version:
226 log.indented('%-20s %s', text.green('Version:'), libc_version.group(1).decode())
227
228 if exe.buildid:
229 log.indented('%-20s %s', text.green('BuildID:'), enhex(exe.buildid))
230 log.indented('%-20s %s', text.green('MD5:'), md5(exe.data).hexdigest())
231 log.indented('%-20s %s', text.green('SHA1:'), sha1(exe.data).hexdigest())
232 log.indented('%-20s %s', text.green('SHA256:'), sha256(exe.data).hexdigest())
233
234 # Always dump the basic list of common symbols
235 log.indented('%s', text.green('Symbols:'))
236 synthetic_symbols = collect_synthetic_symbols(exe)
237
238 symbols = common_symbols + (args.symbols or []) + synthetic_symbols
239 symbols.sort()
240 for symbol in symbols:
241 if symbol not in exe.symbols:
242 log.indented('%25s = %s', symbol, text.red('not found'))
243 else:
244 log.indented('%25s = %#x', symbol, translate_offset(exe.symbols[symbol], args, exe))
245
246 if __name__ == '__main__':
247 pwnlib.commandline.common.main(__file__)
248
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/commandline/libcdb.py b/pwnlib/commandline/libcdb.py
--- a/pwnlib/commandline/libcdb.py
+++ b/pwnlib/commandline/libcdb.py
@@ -176,9 +176,13 @@
return offs
def collect_synthetic_symbols(exe):
- available_symbols = ['str_bin_sh']
- exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\x00'))
-
+ available_symbols = []
+ try:
+ exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\x00'))
+ available_symbols.append('str_bin_sh')
+ except StopIteration:
+ pass
+
libc_start_main_return = exe.libc_start_main_return
if libc_start_main_return > 0:
exe.symbols['__libc_start_main_ret'] = libc_start_main_return
|
{"golden_diff": "diff --git a/pwnlib/commandline/libcdb.py b/pwnlib/commandline/libcdb.py\n--- a/pwnlib/commandline/libcdb.py\n+++ b/pwnlib/commandline/libcdb.py\n@@ -176,9 +176,13 @@\n return offs\n \n def collect_synthetic_symbols(exe):\n- available_symbols = ['str_bin_sh']\n- exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\\x00'))\n-\n+ available_symbols = []\n+ try:\n+ exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\\x00'))\n+ available_symbols.append('str_bin_sh')\n+ except StopIteration:\n+ pass\n+ \n libc_start_main_return = exe.libc_start_main_return\n if libc_start_main_return > 0:\n exe.symbols['__libc_start_main_ret'] = libc_start_main_return\n", "issue": "pwn libcdb file fails if binary doesn't contain b'/bin/sh\\x00'\nHello,\r\nthe \"pwn libcdb file /[something]\" is crashing depending whether or not the binary contains the string b'/bin/sh\\x00'.\r\n\r\nThis works:\r\n```\r\n$ pwn libcdb file /bin/bash\r\n[*] bash\r\n BuildID: e1da91a3e72343eb054c8c69a8d6b4240acb8b10\r\n MD5: c33ad3a4937b1c186a8a1279bb31e702\r\n SHA1: d07f822b462ecf5ae31f5ccf1c6657b7505afb3f\r\n SHA256: a8334e823ce220c4a375e1d5f32fabc1bd47abb6810760ea4100415b55a097e4\r\n Symbols:\r\n dup2 = 0x302b4\r\n printf = not found\r\n puts = 0x30024\r\n read = 0x30494\r\n str_bin_sh = 0x336ca\r\n system = not found\r\n write = 0x30134\r\n\r\n```\r\n\r\nThis is crashing as search returns :\r\n```\r\n$ pwn libcdb file /bin/ls\r\n[*] ls\r\n BuildID: e2ca832f1c2112aea9d7b9bc639e97e873a6b516\r\n MD5: df0e7216034340f844de8e3b3c37d32b\r\n SHA1: 0c5f47f25f4379690945f6e7eaa92e1999d0755d\r\n SHA256: 9379a0fa9ed1e0b4302c4a2c9b1254d3cd76a9048f0ead3c9e216a5082b536bf\r\n Symbols:\r\nTraceback (most recent call last):\r\n File \"/usr/bin/pwn\", line 33, in <module>\r\n sys.exit(load_entry_point('pwntools==4.11.1', 'console_scripts', 'pwn')())\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/lib/python3.12/site-packages/pwnlib/commandline/main.py\", line 58, in main\r\n commands[args.command](args)\r\n File \"/usr/lib/python3.12/site-packages/pwnlib/commandline/libcdb.py\", line 236, in main\r\n synthetic_symbols = collect_synthetic_symbols(exe)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/lib/python3.12/site-packages/pwnlib/commandline/libcdb.py\", line 180, in collect_synthetic_symbols\r\n exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\\x00'))\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nStopIteration\r\n\r\n```\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport re\nimport shutil\nimport sys\n\nimport pwnlib.args\npwnlib.args.free_form = False\n\nfrom pwn import *\nfrom pwnlib.commandline import common\n\nparser = common.parser_commands.add_parser(\n 'libcdb',\n help = 'Print various information about a libc binary',\n description = 'Print various information about a libc binary'\n)\n\nlibc_commands = parser.add_subparsers(\n dest = 'libc_command'\n)\n\nlookup_parser = libc_commands.add_parser(\n 'lookup',\n help = 'Lookup a libc version by function offsets',\n description = 'Lookup a libc version by function offsets'\n)\n\nlookup_parser.add_argument(\n 'symbol_offset_pairs',\n metavar = 'symbol_offset_pairs',\n nargs = '+',\n help = 'Symbol and offset pairs to lookup matching libc version. Can be any number of pairs to narrow the search. Example: \"read 3e0 write 520\"'\n)\n\nlookup_parser.add_argument(\n '--download-libc',\n action = 'store_true',\n default = False,\n help = 'Attempt to download the matching libc.so'\n)\n\nlookup_parser.add_argument(\n '--unstrip',\n action = 'store_true',\n default = True,\n help = 'Attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nlookup_parser.add_argument(\n '--no-unstrip',\n action = 'store_false',\n dest = 'unstrip',\n help = 'Do NOT attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nhash_parser = libc_commands.add_parser(\n 'hash',\n help = 'Display information of a libc version given an unique hash',\n description = 'Display information of a libc version given an unique hash'\n)\n\nhash_parser.add_argument(\n 'hash_value',\n metavar = 'hash_value',\n nargs = '+',\n help = 'Hex encoded hash value'\n)\n\nhash_parser.add_argument(\n '-t', '--hash_type',\n nargs = '?',\n type = str,\n choices = ['id', 'buildid', 'md5', 'sha1', 'sha256'],\n default = 'buildid',\n help = 'The type of the provided hash value. Supported hashtypes: id, buildid, md5, sha1, sha256'\n)\n\nhash_parser.add_argument(\n '--download-libc',\n action = 'store_true',\n default = False,\n help = 'Attempt to download the matching libc.so'\n)\n\nhash_parser.add_argument(\n '--unstrip',\n action = 'store_true',\n default = True,\n help = 'Attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nhash_parser.add_argument(\n '--no-unstrip',\n action = 'store_false',\n dest = 'unstrip',\n help = 'Do NOT attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nfile_parser = libc_commands.add_parser(\n 'file',\n help = 'Dump information about a libc binary',\n description = 'Dump information about a libc binary'\n)\n\nfile_parser.add_argument(\n 'files',\n metavar = 'files',\n nargs = '+',\n help = 'Libc binary to dump'\n)\n\nfile_parser.add_argument(\n '-s', '--symbols',\n metavar = 'symbols',\n nargs = '*',\n help = 'List of symbol offsets to dump in addition to the common ones'\n)\n\nfile_parser.add_argument(\n '-o', '--offset',\n metavar = 'offset',\n type = str,\n help = 'Display all offsets relative to this symbol'\n)\n\nfile_parser.add_argument(\n '--unstrip',\n action = 'store_true',\n default = False,\n help = 'Attempt to unstrip the libc binary inplace with debug symbols from a debuginfod server'\n)\n\ncommon_symbols = ['dup2', 'printf', 'puts', 'read', 'system', 'write']\n\ndef find_libc(params):\n import requests\n url = \"https://libc.rip/api/find\"\n result = requests.post(url, json=params, timeout=20)\n log.debug('Request: %s', params)\n log.debug('Result: %s', result.json())\n if result.status_code != 200 or len(result.json()) == 0:\n log.failure(\"Could not find libc for %s on libc.rip\", params)\n return []\n\n return result.json()\n\ndef print_libc(libc):\n log.info('%s', text.red(libc['id']))\n log.indented('\\t%-20s %s', text.green('BuildID:'), libc['buildid'])\n log.indented('\\t%-20s %s', text.green('MD5:'), libc['md5'])\n log.indented('\\t%-20s %s', text.green('SHA1:'), libc['sha1'])\n log.indented('\\t%-20s %s', text.green('SHA256:'), libc['sha256'])\n log.indented('\\t%s', text.green('Symbols:'))\n for symbol in libc['symbols'].items():\n log.indented('\\t%25s = %s', symbol[0], symbol[1])\n\ndef handle_remote_libc(args, libc):\n print_libc(libc)\n if args.download_libc:\n path = libcdb.search_by_build_id(libc['buildid'], args.unstrip)\n if path:\n if args.unstrip:\n libcdb.unstrip_libc(path)\n shutil.copy(path, './{}.so'.format(libc['id']))\n\ndef translate_offset(offs, args, exe):\n if args.offset:\n if args.offset not in exe.symbols:\n log.info_once('offset symbol %s not found. ignoring.', args.offset)\n return offs\n return offs - exe.symbols[args.offset]\n return offs\n\ndef collect_synthetic_symbols(exe):\n available_symbols = ['str_bin_sh']\n exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\\x00'))\n\n libc_start_main_return = exe.libc_start_main_return\n if libc_start_main_return > 0:\n exe.symbols['__libc_start_main_ret'] = libc_start_main_return\n available_symbols.append('__libc_start_main_ret')\n\n return available_symbols\n\ndef main(args):\n if len(sys.argv) < 3:\n parser.print_usage()\n sys.exit()\n\n if args.libc_command == 'lookup':\n pairs = args.symbol_offset_pairs\n if len(pairs) % 2 != 0:\n log.failure('Uneven number of arguments. Please provide \"symbol offset\" pairs')\n return\n \n symbols = {pairs[i]:pairs[i+1] for i in range(0, len(pairs), 2)}\n matched_libcs = find_libc({'symbols': symbols})\n for libc in matched_libcs:\n handle_remote_libc(args, libc)\n\n elif args.libc_command == 'hash':\n for hash_value in args.hash_value:\n matched_libcs = find_libc({args.hash_type: hash_value})\n for libc in matched_libcs:\n handle_remote_libc(args, libc)\n\n elif args.libc_command == 'file':\n from hashlib import md5, sha1, sha256\n for file in args.files:\n if not os.path.exists(file) or not os.path.isfile(file):\n log.failure('File does not exist %s', args.file)\n continue\n \n if args.unstrip:\n libcdb.unstrip_libc(file)\n\n exe = ELF(file, checksec=False)\n log.info('%s', text.red(os.path.basename(file)))\n\n libc_version = re.search(br'libc[ -](\\d+\\.\\d+)', exe.data)\n if libc_version:\n log.indented('%-20s %s', text.green('Version:'), libc_version.group(1).decode())\n\n if exe.buildid:\n log.indented('%-20s %s', text.green('BuildID:'), enhex(exe.buildid))\n log.indented('%-20s %s', text.green('MD5:'), md5(exe.data).hexdigest())\n log.indented('%-20s %s', text.green('SHA1:'), sha1(exe.data).hexdigest())\n log.indented('%-20s %s', text.green('SHA256:'), sha256(exe.data).hexdigest())\n\n # Always dump the basic list of common symbols\n log.indented('%s', text.green('Symbols:'))\n synthetic_symbols = collect_synthetic_symbols(exe)\n\n symbols = common_symbols + (args.symbols or []) + synthetic_symbols\n symbols.sort()\n for symbol in symbols:\n if symbol not in exe.symbols:\n log.indented('%25s = %s', symbol, text.red('not found'))\n else:\n log.indented('%25s = %#x', symbol, translate_offset(exe.symbols[symbol], args, exe))\n\nif __name__ == '__main__':\n pwnlib.commandline.common.main(__file__)\n", "path": "pwnlib/commandline/libcdb.py"}], "after_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport re\nimport shutil\nimport sys\n\nimport pwnlib.args\npwnlib.args.free_form = False\n\nfrom pwn import *\nfrom pwnlib.commandline import common\n\nparser = common.parser_commands.add_parser(\n 'libcdb',\n help = 'Print various information about a libc binary',\n description = 'Print various information about a libc binary'\n)\n\nlibc_commands = parser.add_subparsers(\n dest = 'libc_command'\n)\n\nlookup_parser = libc_commands.add_parser(\n 'lookup',\n help = 'Lookup a libc version by function offsets',\n description = 'Lookup a libc version by function offsets'\n)\n\nlookup_parser.add_argument(\n 'symbol_offset_pairs',\n metavar = 'symbol_offset_pairs',\n nargs = '+',\n help = 'Symbol and offset pairs to lookup matching libc version. Can be any number of pairs to narrow the search. Example: \"read 3e0 write 520\"'\n)\n\nlookup_parser.add_argument(\n '--download-libc',\n action = 'store_true',\n default = False,\n help = 'Attempt to download the matching libc.so'\n)\n\nlookup_parser.add_argument(\n '--unstrip',\n action = 'store_true',\n default = True,\n help = 'Attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nlookup_parser.add_argument(\n '--no-unstrip',\n action = 'store_false',\n dest = 'unstrip',\n help = 'Do NOT attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nhash_parser = libc_commands.add_parser(\n 'hash',\n help = 'Display information of a libc version given an unique hash',\n description = 'Display information of a libc version given an unique hash'\n)\n\nhash_parser.add_argument(\n 'hash_value',\n metavar = 'hash_value',\n nargs = '+',\n help = 'Hex encoded hash value'\n)\n\nhash_parser.add_argument(\n '-t', '--hash_type',\n nargs = '?',\n type = str,\n choices = ['id', 'buildid', 'md5', 'sha1', 'sha256'],\n default = 'buildid',\n help = 'The type of the provided hash value. Supported hashtypes: id, buildid, md5, sha1, sha256'\n)\n\nhash_parser.add_argument(\n '--download-libc',\n action = 'store_true',\n default = False,\n help = 'Attempt to download the matching libc.so'\n)\n\nhash_parser.add_argument(\n '--unstrip',\n action = 'store_true',\n default = True,\n help = 'Attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nhash_parser.add_argument(\n '--no-unstrip',\n action = 'store_false',\n dest = 'unstrip',\n help = 'Do NOT attempt to unstrip the libc binary with debug symbols from a debuginfod server'\n)\n\nfile_parser = libc_commands.add_parser(\n 'file',\n help = 'Dump information about a libc binary',\n description = 'Dump information about a libc binary'\n)\n\nfile_parser.add_argument(\n 'files',\n metavar = 'files',\n nargs = '+',\n help = 'Libc binary to dump'\n)\n\nfile_parser.add_argument(\n '-s', '--symbols',\n metavar = 'symbols',\n nargs = '*',\n help = 'List of symbol offsets to dump in addition to the common ones'\n)\n\nfile_parser.add_argument(\n '-o', '--offset',\n metavar = 'offset',\n type = str,\n help = 'Display all offsets relative to this symbol'\n)\n\nfile_parser.add_argument(\n '--unstrip',\n action = 'store_true',\n default = False,\n help = 'Attempt to unstrip the libc binary inplace with debug symbols from a debuginfod server'\n)\n\ncommon_symbols = ['dup2', 'printf', 'puts', 'read', 'system', 'write']\n\ndef find_libc(params):\n import requests\n url = \"https://libc.rip/api/find\"\n result = requests.post(url, json=params, timeout=20)\n log.debug('Request: %s', params)\n log.debug('Result: %s', result.json())\n if result.status_code != 200 or len(result.json()) == 0:\n log.failure(\"Could not find libc for %s on libc.rip\", params)\n return []\n\n return result.json()\n\ndef print_libc(libc):\n log.info('%s', text.red(libc['id']))\n log.indented('\\t%-20s %s', text.green('BuildID:'), libc['buildid'])\n log.indented('\\t%-20s %s', text.green('MD5:'), libc['md5'])\n log.indented('\\t%-20s %s', text.green('SHA1:'), libc['sha1'])\n log.indented('\\t%-20s %s', text.green('SHA256:'), libc['sha256'])\n log.indented('\\t%s', text.green('Symbols:'))\n for symbol in libc['symbols'].items():\n log.indented('\\t%25s = %s', symbol[0], symbol[1])\n\ndef handle_remote_libc(args, libc):\n print_libc(libc)\n if args.download_libc:\n path = libcdb.search_by_build_id(libc['buildid'], args.unstrip)\n if path:\n if args.unstrip:\n libcdb.unstrip_libc(path)\n shutil.copy(path, './{}.so'.format(libc['id']))\n\ndef translate_offset(offs, args, exe):\n if args.offset:\n if args.offset not in exe.symbols:\n log.info_once('offset symbol %s not found. ignoring.', args.offset)\n return offs\n return offs - exe.symbols[args.offset]\n return offs\n\ndef collect_synthetic_symbols(exe):\n available_symbols = []\n try:\n exe.symbols['str_bin_sh'] = next(exe.search(b'/bin/sh\\x00'))\n available_symbols.append('str_bin_sh')\n except StopIteration:\n pass\n \n libc_start_main_return = exe.libc_start_main_return\n if libc_start_main_return > 0:\n exe.symbols['__libc_start_main_ret'] = libc_start_main_return\n available_symbols.append('__libc_start_main_ret')\n\n return available_symbols\n\ndef main(args):\n if len(sys.argv) < 3:\n parser.print_usage()\n sys.exit()\n\n if args.libc_command == 'lookup':\n pairs = args.symbol_offset_pairs\n if len(pairs) % 2 != 0:\n log.failure('Uneven number of arguments. Please provide \"symbol offset\" pairs')\n return\n \n symbols = {pairs[i]:pairs[i+1] for i in range(0, len(pairs), 2)}\n matched_libcs = find_libc({'symbols': symbols})\n for libc in matched_libcs:\n handle_remote_libc(args, libc)\n\n elif args.libc_command == 'hash':\n for hash_value in args.hash_value:\n matched_libcs = find_libc({args.hash_type: hash_value})\n for libc in matched_libcs:\n handle_remote_libc(args, libc)\n\n elif args.libc_command == 'file':\n from hashlib import md5, sha1, sha256\n for file in args.files:\n if not os.path.exists(file) or not os.path.isfile(file):\n log.failure('File does not exist %s', args.file)\n continue\n \n if args.unstrip:\n libcdb.unstrip_libc(file)\n\n exe = ELF(file, checksec=False)\n log.info('%s', text.red(os.path.basename(file)))\n\n libc_version = re.search(br'libc[ -](\\d+\\.\\d+)', exe.data)\n if libc_version:\n log.indented('%-20s %s', text.green('Version:'), libc_version.group(1).decode())\n\n if exe.buildid:\n log.indented('%-20s %s', text.green('BuildID:'), enhex(exe.buildid))\n log.indented('%-20s %s', text.green('MD5:'), md5(exe.data).hexdigest())\n log.indented('%-20s %s', text.green('SHA1:'), sha1(exe.data).hexdigest())\n log.indented('%-20s %s', text.green('SHA256:'), sha256(exe.data).hexdigest())\n\n # Always dump the basic list of common symbols\n log.indented('%s', text.green('Symbols:'))\n synthetic_symbols = collect_synthetic_symbols(exe)\n\n symbols = common_symbols + (args.symbols or []) + synthetic_symbols\n symbols.sort()\n for symbol in symbols:\n if symbol not in exe.symbols:\n log.indented('%25s = %s', symbol, text.red('not found'))\n else:\n log.indented('%25s = %#x', symbol, translate_offset(exe.symbols[symbol], args, exe))\n\nif __name__ == '__main__':\n pwnlib.commandline.common.main(__file__)\n", "path": "pwnlib/commandline/libcdb.py"}]}
| 3,677 | 199 |
gh_patches_debug_50432
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-4754
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve unexpected error message
Many users are reporting / filling an issue in our issue tracker when this message is shown to them, which is logic because it's what the message says.
> There was a problem with Read the Docs while building your documentation. Please report this to us with your build id (1234)
Although, I think we should improve this message saying something like "if this problem persists, please report..." or something similar to that. Otherwise, sometimes it's a temporal failure and we get tons of reports.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/doc_builder/exceptions.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Exceptions raised when building documentation."""
3
4 from __future__ import division, print_function, unicode_literals
5
6 from django.utils.translation import ugettext_noop
7
8
9 class BuildEnvironmentException(Exception):
10
11 message = None
12 status_code = None
13
14 def __init__(self, message=None, **kwargs):
15 self.status_code = kwargs.pop('status_code', None) or self.status_code or 1
16 message = message or self.get_default_message()
17 super(BuildEnvironmentException, self).__init__(message, **kwargs)
18
19 def get_default_message(self):
20 return self.message
21
22
23 class BuildEnvironmentError(BuildEnvironmentException):
24
25 GENERIC_WITH_BUILD_ID = ugettext_noop(
26 'There was a problem with Read the Docs while building your documentation. '
27 'Please report this to us with your build id ({build_id}).',
28 )
29
30
31 class BuildEnvironmentCreationFailed(BuildEnvironmentError):
32
33 message = ugettext_noop('Build environment creation failed')
34
35
36 class VersionLockedError(BuildEnvironmentError):
37
38 message = ugettext_noop('Version locked, retrying in 5 minutes.')
39 status_code = 423
40
41
42 class ProjectBuildsSkippedError(BuildEnvironmentError):
43
44 message = ugettext_noop('Builds for this project are temporarily disabled')
45
46
47 class YAMLParseError(BuildEnvironmentError):
48
49 GENERIC_WITH_PARSE_EXCEPTION = ugettext_noop(
50 'Problem parsing YAML configuration. {exception}',
51 )
52
53
54 class BuildTimeoutError(BuildEnvironmentError):
55
56 message = ugettext_noop('Build exited due to time out')
57
58
59 class BuildEnvironmentWarning(BuildEnvironmentException):
60 pass
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/doc_builder/exceptions.py b/readthedocs/doc_builder/exceptions.py
--- a/readthedocs/doc_builder/exceptions.py
+++ b/readthedocs/doc_builder/exceptions.py
@@ -24,7 +24,9 @@
GENERIC_WITH_BUILD_ID = ugettext_noop(
'There was a problem with Read the Docs while building your documentation. '
- 'Please report this to us with your build id ({build_id}).',
+ 'Please try again later. '
+ 'However, if this problem persists, '
+ 'please report this to us with your build id ({build_id}).',
)
|
{"golden_diff": "diff --git a/readthedocs/doc_builder/exceptions.py b/readthedocs/doc_builder/exceptions.py\n--- a/readthedocs/doc_builder/exceptions.py\n+++ b/readthedocs/doc_builder/exceptions.py\n@@ -24,7 +24,9 @@\n \n GENERIC_WITH_BUILD_ID = ugettext_noop(\n 'There was a problem with Read the Docs while building your documentation. '\n- 'Please report this to us with your build id ({build_id}).',\n+ 'Please try again later. '\n+ 'However, if this problem persists, '\n+ 'please report this to us with your build id ({build_id}).',\n )\n", "issue": "Improve unexpected error message\nMany users are reporting / filling an issue in our issue tracker when this message is shown to them, which is logic because it's what the message says.\r\n\r\n> There was a problem with Read the Docs while building your documentation. Please report this to us with your build id (1234)\r\n\r\nAlthough, I think we should improve this message saying something like \"if this problem persists, please report...\" or something similar to that. Otherwise, sometimes it's a temporal failure and we get tons of reports.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Exceptions raised when building documentation.\"\"\"\n\nfrom __future__ import division, print_function, unicode_literals\n\nfrom django.utils.translation import ugettext_noop\n\n\nclass BuildEnvironmentException(Exception):\n\n message = None\n status_code = None\n\n def __init__(self, message=None, **kwargs):\n self.status_code = kwargs.pop('status_code', None) or self.status_code or 1\n message = message or self.get_default_message()\n super(BuildEnvironmentException, self).__init__(message, **kwargs)\n\n def get_default_message(self):\n return self.message\n\n\nclass BuildEnvironmentError(BuildEnvironmentException):\n\n GENERIC_WITH_BUILD_ID = ugettext_noop(\n 'There was a problem with Read the Docs while building your documentation. '\n 'Please report this to us with your build id ({build_id}).',\n )\n\n\nclass BuildEnvironmentCreationFailed(BuildEnvironmentError):\n\n message = ugettext_noop('Build environment creation failed')\n\n\nclass VersionLockedError(BuildEnvironmentError):\n\n message = ugettext_noop('Version locked, retrying in 5 minutes.')\n status_code = 423\n\n\nclass ProjectBuildsSkippedError(BuildEnvironmentError):\n\n message = ugettext_noop('Builds for this project are temporarily disabled')\n\n\nclass YAMLParseError(BuildEnvironmentError):\n\n GENERIC_WITH_PARSE_EXCEPTION = ugettext_noop(\n 'Problem parsing YAML configuration. {exception}',\n )\n\n\nclass BuildTimeoutError(BuildEnvironmentError):\n\n message = ugettext_noop('Build exited due to time out')\n\n\nclass BuildEnvironmentWarning(BuildEnvironmentException):\n pass\n", "path": "readthedocs/doc_builder/exceptions.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Exceptions raised when building documentation.\"\"\"\n\nfrom __future__ import division, print_function, unicode_literals\n\nfrom django.utils.translation import ugettext_noop\n\n\nclass BuildEnvironmentException(Exception):\n\n message = None\n status_code = None\n\n def __init__(self, message=None, **kwargs):\n self.status_code = kwargs.pop('status_code', None) or self.status_code or 1\n message = message or self.get_default_message()\n super(BuildEnvironmentException, self).__init__(message, **kwargs)\n\n def get_default_message(self):\n return self.message\n\n\nclass BuildEnvironmentError(BuildEnvironmentException):\n\n GENERIC_WITH_BUILD_ID = ugettext_noop(\n 'There was a problem with Read the Docs while building your documentation. '\n 'Please try again later. '\n 'However, if this problem persists, '\n 'please report this to us with your build id ({build_id}).',\n )\n\n\nclass BuildEnvironmentCreationFailed(BuildEnvironmentError):\n\n message = ugettext_noop('Build environment creation failed')\n\n\nclass VersionLockedError(BuildEnvironmentError):\n\n message = ugettext_noop('Version locked, retrying in 5 minutes.')\n status_code = 423\n\n\nclass ProjectBuildsSkippedError(BuildEnvironmentError):\n\n message = ugettext_noop('Builds for this project are temporarily disabled')\n\n\nclass YAMLParseError(BuildEnvironmentError):\n\n GENERIC_WITH_PARSE_EXCEPTION = ugettext_noop(\n 'Problem parsing YAML configuration. {exception}',\n )\n\n\nclass BuildTimeoutError(BuildEnvironmentError):\n\n message = ugettext_noop('Build exited due to time out')\n\n\nclass BuildEnvironmentWarning(BuildEnvironmentException):\n pass\n", "path": "readthedocs/doc_builder/exceptions.py"}]}
| 841 | 140 |
gh_patches_debug_4309
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-2027
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
WAFv2 AndStatement and OrStatement incorrect validation
Hi guys,
https://github.com/cloudtools/troposphere/blob/f287fa8999ef2a5f5e301ba5c0af6421471e230b/troposphere/validators/wafv2.py#L32-L33
In the validator for WAFv2 statements, there is a check to see if the number of statements if _exactly_ 2 when it should be looking to see if there are _at least_ 2 statements given.
> "You provide more than one [Statement](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-wafv2-webacl-notstatement.html#cfn-wafv2-webacl-notstatement-statement) within the AndStatement."
[Source](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-wafv2-rulegroup-andstatement.html)
AWS requires there to be more than one statement, but does not restrict them to only pairs.
A small change in the logic of the `if` statement and the `TypeError` message is all that is needed.
Thank you
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `troposphere/validators/wafv2.py`
Content:
```
1 # Copyright (c) 2012-2021, Mark Peek <[email protected]>
2 # All rights reserved.
3 #
4 # See LICENSE file for full license.
5
6
7 def validate_statement(statement):
8 """
9 Validate Transformation Type for WebACL TextTransformation
10 Property: RuleGroupRule.Statement
11 Property: WebACLRule.Statement
12 Property: ManagedRuleGroupStatement.ScopeDownStatement
13 Property: NotStatement.Statement
14 Property: RateBasedStatement.ScopeDownStatement
15 """
16
17 from .. import AWSHelperFn
18 from ..wafv2 import Statement
19
20 if not isinstance(statement, (Statement, AWSHelperFn)):
21 raise TypeError(f"{statement} is not a valid Statement")
22
23 return statement
24
25
26 def validate_statements(statements):
27 """
28 Property: AndStatement.Statements
29 Property: OrStatement.Statements
30 """
31
32 if not isinstance(statements, list) or len(statements) != 2:
33 raise TypeError("Statements must be a list of 2 Statement elements")
34
35 for s in statements:
36 validate_statement(s)
37
38 return statements
39
40
41 def validate_transformation_type(transformation_type):
42 """
43 Validate Transformation Type for WebACL TextTransformation
44 Property: TextTransformation.Type
45 """
46
47 VALID_TRANSFORMATION_TYPES = (
48 "BASE64_DECODE",
49 "BASE64_DECODE_EXT",
50 "CMD_LINE",
51 "COMPRESS_WHITE_SPACE",
52 "CSS_DECODE",
53 "ESCAPE_SEQ_DECODE",
54 "HEX_DECODE",
55 "HTML_ENTITY_DECODE",
56 "JS_DECODE",
57 "LOWERCASE",
58 "MD5",
59 "NONE",
60 "NORMALIZE_PATH",
61 "NORMALIZE_PATH_WIN",
62 "REMOVE_NULLS",
63 "REPLACE_COMMENTS",
64 "REPLACE_NULLS",
65 "SQL_HEX_DECODE",
66 "URL_DECODE",
67 "URL_DECODE_UNI",
68 "UTF8_TO_UNICODE",
69 )
70
71 if transformation_type not in VALID_TRANSFORMATION_TYPES:
72 raise ValueError(
73 "WebACL TextTransformation must be one of: %s"
74 % ", ".join(VALID_TRANSFORMATION_TYPES)
75 )
76 return transformation_type
77
78
79 def validate_comparison_operator(comparison_operator):
80 """
81 Validate Comparison Operator for WebACL SizeConstraintStatement
82 Property: SizeConstraintStatement.ComparisonOperator
83 """
84
85 VALID_COMPARISON_OPERATORS = (
86 "EQ",
87 "GE",
88 "GT",
89 "LE",
90 "LT",
91 "NE",
92 )
93
94 if comparison_operator not in VALID_COMPARISON_OPERATORS:
95 raise ValueError(
96 "WebACL SizeConstraintStatement must be one of: %s"
97 % ", ".join(VALID_COMPARISON_OPERATORS)
98 )
99 return comparison_operator
100
101
102 def validate_ipaddress_version(ipaddress_version):
103 """
104 Validate IPAddress version for IPSet
105 Property: IPSet.IPAddressVersion
106 """
107
108 VALID_IP_VERSION = ("IPV4", "IPV6")
109
110 if ipaddress_version not in VALID_IP_VERSION:
111 raise ValueError(
112 "IPSet IPAddressVersion must be one of: %s" % ", ".join(VALID_IP_VERSION)
113 )
114 return ipaddress_version
115
116
117 def validate_positional_constraint(positional_constraint):
118 """
119 Validate positional constraint for ByteMatchStatement
120 Property: ByteMatchStatement.PositionalConstraint
121 """
122
123 VALID_POSITIONAL_CONSTRAINTS = (
124 "CONTAINS",
125 "CONTAINS_WORD",
126 "ENDS_WITH",
127 "EXACTLY",
128 "STARTS_WITH",
129 )
130
131 if positional_constraint not in VALID_POSITIONAL_CONSTRAINTS:
132 raise ValueError(
133 "ByteMatchStatement PositionalConstraint must be one of: %s"
134 % ", ".join(VALID_POSITIONAL_CONSTRAINTS) # NOQA
135 )
136 return positional_constraint
137
138
139 def validate_custom_response_bodies(custom_response_bodies):
140 """
141 Validate custom response bodies
142 Property: RuleGroup.CustomResponseBodies
143 Property: WebACL.CustomResponseBodies
144 """
145
146 from ..wafv2 import CustomResponseBody
147
148 if not isinstance(custom_response_bodies, dict):
149 raise ValueError("CustomResponseBodies must be dict")
150
151 for k, v in custom_response_bodies.items():
152 if not isinstance(v, CustomResponseBody):
153 raise ValueError("value of %s must be type of CustomResponseBody" % (k))
154
155 return custom_response_bodies
156
157
158 def wafv2_custom_body_response_content(content):
159 """
160 Validate wafv2 custom body response content. Any character between 1 to 10240
161 Property: CustomResponseBody.Content
162 """
163
164 if not content:
165 raise ValueError("Content must not be empty")
166 if len(content) > 10240:
167 raise ValueError("Content maximum length must not exceed 10240")
168
169 return content
170
171
172 def wafv2_custom_body_response_content_type(content_type):
173 """
174 validate wafv2 custom response content type
175 Property: CustomResponseBody.ContentType
176 """
177
178 valid_types = ["APPLICATION_JSON", "TEXT_HTML", "TEXT_PLAIN"]
179 if content_type not in valid_types:
180 raise ValueError('ContentType must be one of: "%s"' % (", ".join(valid_types)))
181 return content_type
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/troposphere/validators/wafv2.py b/troposphere/validators/wafv2.py
--- a/troposphere/validators/wafv2.py
+++ b/troposphere/validators/wafv2.py
@@ -29,8 +29,8 @@
Property: OrStatement.Statements
"""
- if not isinstance(statements, list) or len(statements) != 2:
- raise TypeError("Statements must be a list of 2 Statement elements")
+ if not isinstance(statements, list) or len(statements) < 2:
+ raise TypeError("Statements must be a list of at least 2 Statement elements")
for s in statements:
validate_statement(s)
|
{"golden_diff": "diff --git a/troposphere/validators/wafv2.py b/troposphere/validators/wafv2.py\n--- a/troposphere/validators/wafv2.py\n+++ b/troposphere/validators/wafv2.py\n@@ -29,8 +29,8 @@\n Property: OrStatement.Statements\n \"\"\"\n \n- if not isinstance(statements, list) or len(statements) != 2:\n- raise TypeError(\"Statements must be a list of 2 Statement elements\")\n+ if not isinstance(statements, list) or len(statements) < 2:\n+ raise TypeError(\"Statements must be a list of at least 2 Statement elements\")\n \n for s in statements:\n validate_statement(s)\n", "issue": "WAFv2 AndStatement and OrStatement incorrect validation\nHi guys,\r\n\r\nhttps://github.com/cloudtools/troposphere/blob/f287fa8999ef2a5f5e301ba5c0af6421471e230b/troposphere/validators/wafv2.py#L32-L33\r\n\r\nIn the validator for WAFv2 statements, there is a check to see if the number of statements if _exactly_ 2 when it should be looking to see if there are _at least_ 2 statements given. \r\n\r\n> \"You provide more than one [Statement](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-wafv2-webacl-notstatement.html#cfn-wafv2-webacl-notstatement-statement) within the AndStatement.\"\r\n[Source](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-wafv2-rulegroup-andstatement.html)\r\n\r\nAWS requires there to be more than one statement, but does not restrict them to only pairs.\r\n\r\nA small change in the logic of the `if` statement and the `TypeError` message is all that is needed.\r\n\r\nThank you\r\n\n", "before_files": [{"content": "# Copyright (c) 2012-2021, Mark Peek <[email protected]>\n# All rights reserved.\n#\n# See LICENSE file for full license.\n\n\ndef validate_statement(statement):\n \"\"\"\n Validate Transformation Type for WebACL TextTransformation\n Property: RuleGroupRule.Statement\n Property: WebACLRule.Statement\n Property: ManagedRuleGroupStatement.ScopeDownStatement\n Property: NotStatement.Statement\n Property: RateBasedStatement.ScopeDownStatement\n \"\"\"\n\n from .. import AWSHelperFn\n from ..wafv2 import Statement\n\n if not isinstance(statement, (Statement, AWSHelperFn)):\n raise TypeError(f\"{statement} is not a valid Statement\")\n\n return statement\n\n\ndef validate_statements(statements):\n \"\"\"\n Property: AndStatement.Statements\n Property: OrStatement.Statements\n \"\"\"\n\n if not isinstance(statements, list) or len(statements) != 2:\n raise TypeError(\"Statements must be a list of 2 Statement elements\")\n\n for s in statements:\n validate_statement(s)\n\n return statements\n\n\ndef validate_transformation_type(transformation_type):\n \"\"\"\n Validate Transformation Type for WebACL TextTransformation\n Property: TextTransformation.Type\n \"\"\"\n\n VALID_TRANSFORMATION_TYPES = (\n \"BASE64_DECODE\",\n \"BASE64_DECODE_EXT\",\n \"CMD_LINE\",\n \"COMPRESS_WHITE_SPACE\",\n \"CSS_DECODE\",\n \"ESCAPE_SEQ_DECODE\",\n \"HEX_DECODE\",\n \"HTML_ENTITY_DECODE\",\n \"JS_DECODE\",\n \"LOWERCASE\",\n \"MD5\",\n \"NONE\",\n \"NORMALIZE_PATH\",\n \"NORMALIZE_PATH_WIN\",\n \"REMOVE_NULLS\",\n \"REPLACE_COMMENTS\",\n \"REPLACE_NULLS\",\n \"SQL_HEX_DECODE\",\n \"URL_DECODE\",\n \"URL_DECODE_UNI\",\n \"UTF8_TO_UNICODE\",\n )\n\n if transformation_type not in VALID_TRANSFORMATION_TYPES:\n raise ValueError(\n \"WebACL TextTransformation must be one of: %s\"\n % \", \".join(VALID_TRANSFORMATION_TYPES)\n )\n return transformation_type\n\n\ndef validate_comparison_operator(comparison_operator):\n \"\"\"\n Validate Comparison Operator for WebACL SizeConstraintStatement\n Property: SizeConstraintStatement.ComparisonOperator\n \"\"\"\n\n VALID_COMPARISON_OPERATORS = (\n \"EQ\",\n \"GE\",\n \"GT\",\n \"LE\",\n \"LT\",\n \"NE\",\n )\n\n if comparison_operator not in VALID_COMPARISON_OPERATORS:\n raise ValueError(\n \"WebACL SizeConstraintStatement must be one of: %s\"\n % \", \".join(VALID_COMPARISON_OPERATORS)\n )\n return comparison_operator\n\n\ndef validate_ipaddress_version(ipaddress_version):\n \"\"\"\n Validate IPAddress version for IPSet\n Property: IPSet.IPAddressVersion\n \"\"\"\n\n VALID_IP_VERSION = (\"IPV4\", \"IPV6\")\n\n if ipaddress_version not in VALID_IP_VERSION:\n raise ValueError(\n \"IPSet IPAddressVersion must be one of: %s\" % \", \".join(VALID_IP_VERSION)\n )\n return ipaddress_version\n\n\ndef validate_positional_constraint(positional_constraint):\n \"\"\"\n Validate positional constraint for ByteMatchStatement\n Property: ByteMatchStatement.PositionalConstraint\n \"\"\"\n\n VALID_POSITIONAL_CONSTRAINTS = (\n \"CONTAINS\",\n \"CONTAINS_WORD\",\n \"ENDS_WITH\",\n \"EXACTLY\",\n \"STARTS_WITH\",\n )\n\n if positional_constraint not in VALID_POSITIONAL_CONSTRAINTS:\n raise ValueError(\n \"ByteMatchStatement PositionalConstraint must be one of: %s\"\n % \", \".join(VALID_POSITIONAL_CONSTRAINTS) # NOQA\n )\n return positional_constraint\n\n\ndef validate_custom_response_bodies(custom_response_bodies):\n \"\"\"\n Validate custom response bodies\n Property: RuleGroup.CustomResponseBodies\n Property: WebACL.CustomResponseBodies\n \"\"\"\n\n from ..wafv2 import CustomResponseBody\n\n if not isinstance(custom_response_bodies, dict):\n raise ValueError(\"CustomResponseBodies must be dict\")\n\n for k, v in custom_response_bodies.items():\n if not isinstance(v, CustomResponseBody):\n raise ValueError(\"value of %s must be type of CustomResponseBody\" % (k))\n\n return custom_response_bodies\n\n\ndef wafv2_custom_body_response_content(content):\n \"\"\"\n Validate wafv2 custom body response content. Any character between 1 to 10240\n Property: CustomResponseBody.Content\n \"\"\"\n\n if not content:\n raise ValueError(\"Content must not be empty\")\n if len(content) > 10240:\n raise ValueError(\"Content maximum length must not exceed 10240\")\n\n return content\n\n\ndef wafv2_custom_body_response_content_type(content_type):\n \"\"\"\n validate wafv2 custom response content type\n Property: CustomResponseBody.ContentType\n \"\"\"\n\n valid_types = [\"APPLICATION_JSON\", \"TEXT_HTML\", \"TEXT_PLAIN\"]\n if content_type not in valid_types:\n raise ValueError('ContentType must be one of: \"%s\"' % (\", \".join(valid_types)))\n return content_type\n", "path": "troposphere/validators/wafv2.py"}], "after_files": [{"content": "# Copyright (c) 2012-2021, Mark Peek <[email protected]>\n# All rights reserved.\n#\n# See LICENSE file for full license.\n\n\ndef validate_statement(statement):\n \"\"\"\n Validate Transformation Type for WebACL TextTransformation\n Property: RuleGroupRule.Statement\n Property: WebACLRule.Statement\n Property: ManagedRuleGroupStatement.ScopeDownStatement\n Property: NotStatement.Statement\n Property: RateBasedStatement.ScopeDownStatement\n \"\"\"\n\n from .. import AWSHelperFn\n from ..wafv2 import Statement\n\n if not isinstance(statement, (Statement, AWSHelperFn)):\n raise TypeError(f\"{statement} is not a valid Statement\")\n\n return statement\n\n\ndef validate_statements(statements):\n \"\"\"\n Property: AndStatement.Statements\n Property: OrStatement.Statements\n \"\"\"\n\n if not isinstance(statements, list) or len(statements) < 2:\n raise TypeError(\"Statements must be a list of at least 2 Statement elements\")\n\n for s in statements:\n validate_statement(s)\n\n return statements\n\n\ndef validate_transformation_type(transformation_type):\n \"\"\"\n Validate Transformation Type for WebACL TextTransformation\n Property: TextTransformation.Type\n \"\"\"\n\n VALID_TRANSFORMATION_TYPES = (\n \"BASE64_DECODE\",\n \"BASE64_DECODE_EXT\",\n \"CMD_LINE\",\n \"COMPRESS_WHITE_SPACE\",\n \"CSS_DECODE\",\n \"ESCAPE_SEQ_DECODE\",\n \"HEX_DECODE\",\n \"HTML_ENTITY_DECODE\",\n \"JS_DECODE\",\n \"LOWERCASE\",\n \"MD5\",\n \"NONE\",\n \"NORMALIZE_PATH\",\n \"NORMALIZE_PATH_WIN\",\n \"REMOVE_NULLS\",\n \"REPLACE_COMMENTS\",\n \"REPLACE_NULLS\",\n \"SQL_HEX_DECODE\",\n \"URL_DECODE\",\n \"URL_DECODE_UNI\",\n \"UTF8_TO_UNICODE\",\n )\n\n if transformation_type not in VALID_TRANSFORMATION_TYPES:\n raise ValueError(\n \"WebACL TextTransformation must be one of: %s\"\n % \", \".join(VALID_TRANSFORMATION_TYPES)\n )\n return transformation_type\n\n\ndef validate_comparison_operator(comparison_operator):\n \"\"\"\n Validate Comparison Operator for WebACL SizeConstraintStatement\n Property: SizeConstraintStatement.ComparisonOperator\n \"\"\"\n\n VALID_COMPARISON_OPERATORS = (\n \"EQ\",\n \"GE\",\n \"GT\",\n \"LE\",\n \"LT\",\n \"NE\",\n )\n\n if comparison_operator not in VALID_COMPARISON_OPERATORS:\n raise ValueError(\n \"WebACL SizeConstraintStatement must be one of: %s\"\n % \", \".join(VALID_COMPARISON_OPERATORS)\n )\n return comparison_operator\n\n\ndef validate_ipaddress_version(ipaddress_version):\n \"\"\"\n Validate IPAddress version for IPSet\n Property: IPSet.IPAddressVersion\n \"\"\"\n\n VALID_IP_VERSION = (\"IPV4\", \"IPV6\")\n\n if ipaddress_version not in VALID_IP_VERSION:\n raise ValueError(\n \"IPSet IPAddressVersion must be one of: %s\" % \", \".join(VALID_IP_VERSION)\n )\n return ipaddress_version\n\n\ndef validate_positional_constraint(positional_constraint):\n \"\"\"\n Validate positional constraint for ByteMatchStatement\n Property: ByteMatchStatement.PositionalConstraint\n \"\"\"\n\n VALID_POSITIONAL_CONSTRAINTS = (\n \"CONTAINS\",\n \"CONTAINS_WORD\",\n \"ENDS_WITH\",\n \"EXACTLY\",\n \"STARTS_WITH\",\n )\n\n if positional_constraint not in VALID_POSITIONAL_CONSTRAINTS:\n raise ValueError(\n \"ByteMatchStatement PositionalConstraint must be one of: %s\"\n % \", \".join(VALID_POSITIONAL_CONSTRAINTS) # NOQA\n )\n return positional_constraint\n\n\ndef validate_custom_response_bodies(custom_response_bodies):\n \"\"\"\n Validate custom response bodies\n Property: RuleGroup.CustomResponseBodies\n Property: WebACL.CustomResponseBodies\n \"\"\"\n\n from ..wafv2 import CustomResponseBody\n\n if not isinstance(custom_response_bodies, dict):\n raise ValueError(\"CustomResponseBodies must be dict\")\n\n for k, v in custom_response_bodies.items():\n if not isinstance(v, CustomResponseBody):\n raise ValueError(\"value of %s must be type of CustomResponseBody\" % (k))\n\n return custom_response_bodies\n\n\ndef wafv2_custom_body_response_content(content):\n \"\"\"\n Validate wafv2 custom body response content. Any character between 1 to 10240\n Property: CustomResponseBody.Content\n \"\"\"\n\n if not content:\n raise ValueError(\"Content must not be empty\")\n if len(content) > 10240:\n raise ValueError(\"Content maximum length must not exceed 10240\")\n\n return content\n\n\ndef wafv2_custom_body_response_content_type(content_type):\n \"\"\"\n validate wafv2 custom response content type\n Property: CustomResponseBody.ContentType\n \"\"\"\n\n valid_types = [\"APPLICATION_JSON\", \"TEXT_HTML\", \"TEXT_PLAIN\"]\n if content_type not in valid_types:\n raise ValueError('ContentType must be one of: \"%s\"' % (\", \".join(valid_types)))\n return content_type\n", "path": "troposphere/validators/wafv2.py"}]}
| 2,089 | 159 |
gh_patches_debug_39929
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-532
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setup cron job to test against dependencies from source
Travis (and possibly appveyor too) allow the creation of cron jobs. Some of the ETS packages now have cron jobs setup to test against dependencies which are installed from source - instead of testing against the released versions.
See examples :
- https://github.com/enthought/envisage/pull/162
- https://github.com/enthought/traitsui/pull/914
- https://github.com/enthought/pyface/pull/549
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ci/edmtool.py`
Content:
```
1 #
2 # Copyright (c) 2017, Enthought, Inc.
3 # All rights reserved.
4 #
5 # This software is provided without warranty under the terms of the BSD
6 # license included in enthought/LICENSE.txt and may be redistributed only
7 # under the conditions described in the aforementioned license. The license
8 # is also available online at http://www.enthought.com/licenses/BSD.txt
9 #
10 # Thanks for using Enthought open source!
11 #
12 """
13 Tasks for Test Runs
14 ===================
15 This file is intended to be used with a python environment with the
16 click library to automate the process of setting up test environments
17 and running the test within them. This improves repeatability and
18 reliability of tests be removing many of the variables around the
19 developer's particular Python environment. Test environment setup and
20 package management is performed using `EDM http://docs.enthought.com/edm/`_
21
22 To use this to run you tests, you will need to install EDM and click
23 into your working environment. You will also need to have git
24 installed to access required source code from github repositories.
25
26 You can then do::
27 python edmtool.py install --runtime=... --toolkit=...
28 to create a test environment from the current codebase and::
29 python edmtool.py test --runtime=... --toolkit=...
30 to run tests in that environment. You can remove the environment with::
31 python edmtool.py cleanup --runtime=... --toolkit=...
32
33 If you make changes you will either need to remove and re-install the
34 environment or manually update the environment using ``edm``, as
35 the install performs a ``python setup.py install`` rather than a ``develop``,
36 so changes in your code will not be automatically mirrored in the test
37 environment. You can update with a command like::
38 edm run --environment ... -- python setup.py install
39 You can run all three tasks at once with::
40 python edmtool.py test_clean --runtime=... --toolkit=...
41 which will create, install, run tests, and then clean-up the environment. And
42 you can run tests in all supported runtimes and toolkits (with cleanup)
43 using::
44 python edmtool.py test_all
45
46 Currently supported runtime values are ``3.6``, and currently
47 supported toolkits are ``null``, ``pyqt``, ``pyqt5`` and ``pyside2``. Not all
48 combinations of toolkits and runtimes will work, but the tasks will fail with
49 a clear error if that is the case. Tests can still be run via the usual means
50 in other environments if that suits a developer's purpose.
51
52 Changing This File
53 ------------------
54 To change the packages installed during a test run, change the dependencies
55 variable below. To install a package from github, or one which is not yet
56 available via EDM, add it to the `ci/requirements.txt` file (these will be
57 installed by `pip`).
58
59 Other changes to commands should be a straightforward change to the listed
60 commands for each task. See the EDM documentation for more information about
61 how to run commands within an EDM enviornment.
62 """
63 import glob
64 import os
65 import subprocess
66 import sys
67 from shutil import rmtree, copy as copyfile
68 from tempfile import mkdtemp
69 from contextlib import contextmanager
70
71 import click
72
73 supported_combinations = {
74 '3.6': {'pyside2', 'pyqt', 'pyqt5', 'null'},
75 }
76
77 dependencies = {
78 "six",
79 "mock",
80 "numpy",
81 "pandas",
82 "pygments",
83 "pyparsing",
84 "cython",
85 # Needed to install enable from source
86 "swig",
87 }
88
89 extra_dependencies = {
90 'pyside2': set(), # pyside2 is pip-installed during the install step
91 'pyqt': {'pyqt'},
92 'pyqt5': {'pyqt5'},
93 'null': set()
94 }
95
96 environment_vars = {
97 'pyside2': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyside2'},
98 'pyqt': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyqt'},
99 'pyqt5': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyqt5'},
100 'null': {'ETS_TOOLKIT': 'null.image'},
101 }
102
103
104 def normalize(name):
105 return name.replace("_", "-")
106
107
108 @click.group(context_settings={"token_normalize_func": normalize})
109 def cli():
110 pass
111
112
113 @cli.command()
114 @click.option('--runtime', default='3.6')
115 @click.option('--toolkit', default='null')
116 @click.option('--environment', default=None)
117 def install(runtime, toolkit, environment):
118 """ Install project and dependencies into a clean EDM environment.
119 """
120 parameters = get_parameters(runtime, toolkit, environment)
121 parameters['packages'] = ' '.join(
122 dependencies | extra_dependencies.get(toolkit, set()))
123 # edm commands to setup the development environment
124 commands = [
125 "edm environments create {environment} --force --version={runtime}",
126 "edm install -y -e {environment} {packages}",
127 ("edm run -e {environment} -- pip install -r ci/requirements.txt"
128 " --no-dependencies"),
129 # Note that enable dependencies will be installed implicitly using pip
130 ("edm run -e {environment} -- "
131 "pip install git+https://[email protected]/enthought/enable.git"),
132 "edm run -e {environment} -- pip install . --no-deps",
133 ]
134 # pip install pyside2, because we don't have it in EDM yet
135 if toolkit == 'pyside2':
136 commands.append(
137 "edm run -e {environment} -- pip install pyside2==5.11"
138 )
139
140 click.echo("Creating environment '{environment}'".format(**parameters))
141 execute(commands, parameters)
142 click.echo('Done install')
143
144
145 @cli.command()
146 @click.option('--runtime', default='3.6')
147 @click.option('--toolkit', default='null')
148 @click.option('--environment', default=None)
149 def test(runtime, toolkit, environment):
150 """ Run the test suite in a given environment with the specified toolkit.
151 """
152 parameters = get_parameters(runtime, toolkit, environment)
153 environ = environment_vars.get(toolkit, {}).copy()
154
155 environ['PYTHONUNBUFFERED'] = "1"
156 commands = [
157 "edm run -e {environment} -- coverage run -m unittest discover -v chaco"
158 ]
159
160 cwd = os.getcwd()
161
162 # We run in a tempdir to avoid accidentally picking up wrong traitsui
163 # code from a local dir. We need to ensure a good .coveragerc is in
164 # that directory, plus coverage has a bug that means a non-local coverage
165 # file doesn't get populated correctly.
166 click.echo("Running tests in '{environment}'".format(**parameters))
167 with do_in_tempdir(files=['.coveragerc'], capture_files=['./.coverage*']):
168 os.environ.update(environ)
169 execute(commands, parameters)
170
171 click.echo('Done test')
172
173
174 @cli.command()
175 @click.option('--runtime', default='3.6')
176 @click.option('--toolkit', default='null')
177 @click.option('--environment', default=None)
178 def cleanup(runtime, toolkit, environment):
179 """ Remove a development environment.
180 """
181 parameters = get_parameters(runtime, toolkit, environment)
182 commands = [
183 "edm run -e {environment} -- python setup.py clean",
184 "edm environments remove {environment} --purge -y",
185 ]
186 click.echo("Cleaning up environment '{environment}'".format(**parameters))
187 execute(commands, parameters)
188 click.echo('Done cleanup')
189
190
191 @cli.command()
192 @click.option('--runtime', default='3.6')
193 @click.option('--toolkit', default='null')
194 def test_clean(runtime, toolkit):
195 """ Run tests in a clean environment, cleaning up afterwards
196 """
197 args = ['--toolkit={}'.format(toolkit),
198 '--runtime={}'.format(runtime)]
199 try:
200 install(args=args, standalone_mode=False)
201 test(args=args, standalone_mode=False)
202 finally:
203 cleanup(args=args, standalone_mode=False)
204
205
206 @cli.command()
207 @click.option('--runtime', default='3.6')
208 @click.option('--toolkit', default='null')
209 @click.option('--environment', default=None)
210 def update(runtime, toolkit, environment):
211 """ Update/Reinstall package into environment.
212 """
213 parameters = get_parameters(runtime, toolkit, environment)
214 commands = [
215 "edm run -e {environment} -- python setup.py install"]
216 click.echo("Re-installing in '{environment}'".format(**parameters))
217 execute(commands, parameters)
218 click.echo('Done update')
219
220
221 @cli.command()
222 def test_all():
223 """ Run test_clean across all supported environment combinations.
224 """
225 for runtime, toolkits in supported_combinations.items():
226 for toolkit in toolkits:
227 args = ['--toolkit={}'.format(toolkit),
228 '--runtime={}'.format(runtime)]
229 test_clean(args, standalone_mode=True)
230
231
232 # ----------------------------------------------------------------------------
233 # Utility routines
234 # ----------------------------------------------------------------------------
235
236 def get_parameters(runtime, toolkit, environment):
237 """Set up parameters dictionary for format() substitution
238 """
239 parameters = {'runtime': runtime, 'toolkit': toolkit,
240 'environment': environment}
241 if toolkit not in supported_combinations[runtime]:
242 msg = ("Python {runtime!r}, toolkit {toolkit!r}, "
243 "not supported by test environments ({available})")
244 available = ", ".join(
245 repr(tk) for tk in sorted(supported_combinations[runtime])
246 )
247 raise RuntimeError(msg.format(available=available, **parameters))
248 if environment is None:
249 tmpl = 'chaco-test-{runtime}-{toolkit}'
250 environment = tmpl.format(**parameters)
251 parameters['environment'] = environment
252 return parameters
253
254
255 @contextmanager
256 def do_in_tempdir(files=(), capture_files=()):
257 """ Create a temporary directory, cleaning up after done.
258 Creates the temporary directory, and changes into it. On exit returns to
259 original directory and removes temporary dir.
260 Parameters
261 ----------
262 files : sequence of filenames
263 Files to be copied across to temporary directory.
264 capture_files : sequence of filenames
265 Files to be copied back from temporary directory.
266 """
267 path = mkdtemp()
268 old_path = os.getcwd()
269
270 # send across any files we need
271 for filepath in files:
272 click.echo('copying file to tempdir: {}'.format(filepath))
273 copyfile(filepath, path)
274
275 os.chdir(path)
276 try:
277 yield path
278 # retrieve any result files we want
279 for pattern in capture_files:
280 for filepath in glob.iglob(pattern):
281 click.echo('copying file back: {}'.format(filepath))
282 copyfile(filepath, old_path)
283 finally:
284 os.chdir(old_path)
285 rmtree(path)
286
287
288 def execute(commands, parameters):
289 for command in commands:
290 print("[EXECUTING]", command.format(**parameters))
291 try:
292 subprocess.check_call(command.format(**parameters).split())
293 except subprocess.CalledProcessError:
294 sys.exit(1)
295
296
297 if __name__ == '__main__':
298 cli()
299
```
Path: `chaco/__init__.py`
Content:
```
1 # Copyright (c) 2005-2014 by Enthought, Inc.
2 # All rights reserved.
3 """ Two-dimensional plotting application toolkit.
4 Part of the Chaco project of the Enthought Tool Suite.
5 """
6 from ._version import full_version as __version__ # noqa
7
8 __requires__ = [
9 'enable',
10 'six'
11 ]
12
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chaco/__init__.py b/chaco/__init__.py
--- a/chaco/__init__.py
+++ b/chaco/__init__.py
@@ -6,6 +6,10 @@
from ._version import full_version as __version__ # noqa
__requires__ = [
+ 'traits',
+ 'traitsui',
+ 'pyface',
+ 'numpy',
'enable',
'six'
]
diff --git a/ci/edmtool.py b/ci/edmtool.py
--- a/ci/edmtool.py
+++ b/ci/edmtool.py
@@ -79,13 +79,27 @@
"mock",
"numpy",
"pandas",
+ "pyface",
"pygments",
"pyparsing",
+ "traits",
+ "traitsui",
"cython",
+ "enable",
# Needed to install enable from source
"swig",
}
+# Dependencies we install from source for cron tests
+source_dependencies = {
+ "enable",
+ "pyface",
+ "traits",
+ "traitsui",
+}
+
+github_url_fmt = "git+http://github.com/enthought/{0}.git#egg={0}"
+
extra_dependencies = {
'pyside2': set(), # pyside2 is pip-installed during the install step
'pyqt': {'pyqt'},
@@ -114,7 +128,12 @@
@click.option('--runtime', default='3.6')
@click.option('--toolkit', default='null')
@click.option('--environment', default=None)
-def install(runtime, toolkit, environment):
[email protected](
+ "--source/--no-source",
+ default=False,
+ help="Install ETS packages from source",
+)
+def install(runtime, toolkit, environment, source):
""" Install project and dependencies into a clean EDM environment.
"""
parameters = get_parameters(runtime, toolkit, environment)
@@ -126,9 +145,6 @@
"edm install -y -e {environment} {packages}",
("edm run -e {environment} -- pip install -r ci/requirements.txt"
" --no-dependencies"),
- # Note that enable dependencies will be installed implicitly using pip
- ("edm run -e {environment} -- "
- "pip install git+https://[email protected]/enthought/enable.git"),
"edm run -e {environment} -- pip install . --no-deps",
]
# pip install pyside2, because we don't have it in EDM yet
@@ -139,6 +155,26 @@
click.echo("Creating environment '{environment}'".format(**parameters))
execute(commands, parameters)
+
+ if source:
+ # Remove EDM ETS packages and install them from source
+ cmd_fmt = (
+ "edm plumbing remove-package "
+ "--environment {environment} --force "
+ )
+ commands = [cmd_fmt + source_pkg for source_pkg in source_dependencies]
+ execute(commands, parameters)
+ source_pkgs = [
+ github_url_fmt.format(pkg) for pkg in source_dependencies
+ ]
+ commands = [
+ "python -m pip install {pkg} --no-deps".format(pkg=pkg)
+ for pkg in source_pkgs
+ ]
+ commands = [
+ "edm run -e {environment} -- " + command for command in commands
+ ]
+ execute(commands, parameters)
click.echo('Done install')
|
{"golden_diff": "diff --git a/chaco/__init__.py b/chaco/__init__.py\n--- a/chaco/__init__.py\n+++ b/chaco/__init__.py\n@@ -6,6 +6,10 @@\n from ._version import full_version as __version__ # noqa\n \n __requires__ = [\n+ 'traits',\n+ 'traitsui',\n+ 'pyface',\n+ 'numpy',\n 'enable',\n 'six'\n ]\ndiff --git a/ci/edmtool.py b/ci/edmtool.py\n--- a/ci/edmtool.py\n+++ b/ci/edmtool.py\n@@ -79,13 +79,27 @@\n \"mock\",\n \"numpy\",\n \"pandas\",\n+ \"pyface\",\n \"pygments\",\n \"pyparsing\",\n+ \"traits\",\n+ \"traitsui\",\n \"cython\",\n+ \"enable\",\n # Needed to install enable from source\n \"swig\",\n }\n \n+# Dependencies we install from source for cron tests\n+source_dependencies = {\n+ \"enable\",\n+ \"pyface\",\n+ \"traits\",\n+ \"traitsui\",\n+}\n+\n+github_url_fmt = \"git+http://github.com/enthought/{0}.git#egg={0}\"\n+\n extra_dependencies = {\n 'pyside2': set(), # pyside2 is pip-installed during the install step\n 'pyqt': {'pyqt'},\n@@ -114,7 +128,12 @@\n @click.option('--runtime', default='3.6')\n @click.option('--toolkit', default='null')\n @click.option('--environment', default=None)\n-def install(runtime, toolkit, environment):\[email protected](\n+ \"--source/--no-source\",\n+ default=False,\n+ help=\"Install ETS packages from source\",\n+)\n+def install(runtime, toolkit, environment, source):\n \"\"\" Install project and dependencies into a clean EDM environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n@@ -126,9 +145,6 @@\n \"edm install -y -e {environment} {packages}\",\n (\"edm run -e {environment} -- pip install -r ci/requirements.txt\"\n \" --no-dependencies\"),\n- # Note that enable dependencies will be installed implicitly using pip\n- (\"edm run -e {environment} -- \"\n- \"pip install git+https://[email protected]/enthought/enable.git\"),\n \"edm run -e {environment} -- pip install . --no-deps\",\n ]\n # pip install pyside2, because we don't have it in EDM yet\n@@ -139,6 +155,26 @@\n \n click.echo(\"Creating environment '{environment}'\".format(**parameters))\n execute(commands, parameters)\n+\n+ if source:\n+ # Remove EDM ETS packages and install them from source\n+ cmd_fmt = (\n+ \"edm plumbing remove-package \"\n+ \"--environment {environment} --force \"\n+ )\n+ commands = [cmd_fmt + source_pkg for source_pkg in source_dependencies]\n+ execute(commands, parameters)\n+ source_pkgs = [\n+ github_url_fmt.format(pkg) for pkg in source_dependencies\n+ ]\n+ commands = [\n+ \"python -m pip install {pkg} --no-deps\".format(pkg=pkg)\n+ for pkg in source_pkgs\n+ ]\n+ commands = [\n+ \"edm run -e {environment} -- \" + command for command in commands\n+ ]\n+ execute(commands, parameters)\n click.echo('Done install')\n", "issue": "Setup cron job to test against dependencies from source\nTravis (and possibly appveyor too) allow the creation of cron jobs. Some of the ETS packages now have cron jobs setup to test against dependencies which are installed from source - instead of testing against the released versions.\r\n\r\nSee examples : \r\n\r\n- https://github.com/enthought/envisage/pull/162\r\n- https://github.com/enthought/traitsui/pull/914\r\n- https://github.com/enthought/pyface/pull/549\n", "before_files": [{"content": "#\n# Copyright (c) 2017, Enthought, Inc.\n# All rights reserved.\n#\n# This software is provided without warranty under the terms of the BSD\n# license included in enthought/LICENSE.txt and may be redistributed only\n# under the conditions described in the aforementioned license. The license\n# is also available online at http://www.enthought.com/licenses/BSD.txt\n#\n# Thanks for using Enthought open source!\n#\n\"\"\"\nTasks for Test Runs\n===================\nThis file is intended to be used with a python environment with the\nclick library to automate the process of setting up test environments\nand running the test within them. This improves repeatability and\nreliability of tests be removing many of the variables around the\ndeveloper's particular Python environment. Test environment setup and\npackage management is performed using `EDM http://docs.enthought.com/edm/`_\n\nTo use this to run you tests, you will need to install EDM and click\ninto your working environment. You will also need to have git\ninstalled to access required source code from github repositories.\n\nYou can then do::\n python edmtool.py install --runtime=... --toolkit=...\nto create a test environment from the current codebase and::\n python edmtool.py test --runtime=... --toolkit=...\nto run tests in that environment. You can remove the environment with::\n python edmtool.py cleanup --runtime=... --toolkit=...\n\nIf you make changes you will either need to remove and re-install the\nenvironment or manually update the environment using ``edm``, as\nthe install performs a ``python setup.py install`` rather than a ``develop``,\nso changes in your code will not be automatically mirrored in the test\nenvironment. You can update with a command like::\n edm run --environment ... -- python setup.py install\nYou can run all three tasks at once with::\n python edmtool.py test_clean --runtime=... --toolkit=...\nwhich will create, install, run tests, and then clean-up the environment. And\nyou can run tests in all supported runtimes and toolkits (with cleanup)\nusing::\n python edmtool.py test_all\n\nCurrently supported runtime values are ``3.6``, and currently\nsupported toolkits are ``null``, ``pyqt``, ``pyqt5`` and ``pyside2``. Not all\ncombinations of toolkits and runtimes will work, but the tasks will fail with\na clear error if that is the case. Tests can still be run via the usual means\nin other environments if that suits a developer's purpose.\n\nChanging This File\n------------------\nTo change the packages installed during a test run, change the dependencies\nvariable below. To install a package from github, or one which is not yet\navailable via EDM, add it to the `ci/requirements.txt` file (these will be\ninstalled by `pip`).\n\nOther changes to commands should be a straightforward change to the listed\ncommands for each task. See the EDM documentation for more information about\nhow to run commands within an EDM enviornment.\n\"\"\"\nimport glob\nimport os\nimport subprocess\nimport sys\nfrom shutil import rmtree, copy as copyfile\nfrom tempfile import mkdtemp\nfrom contextlib import contextmanager\n\nimport click\n\nsupported_combinations = {\n '3.6': {'pyside2', 'pyqt', 'pyqt5', 'null'},\n}\n\ndependencies = {\n \"six\",\n \"mock\",\n \"numpy\",\n \"pandas\",\n \"pygments\",\n \"pyparsing\",\n \"cython\",\n # Needed to install enable from source\n \"swig\",\n}\n\nextra_dependencies = {\n 'pyside2': set(), # pyside2 is pip-installed during the install step\n 'pyqt': {'pyqt'},\n 'pyqt5': {'pyqt5'},\n 'null': set()\n}\n\nenvironment_vars = {\n 'pyside2': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyside2'},\n 'pyqt': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyqt'},\n 'pyqt5': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyqt5'},\n 'null': {'ETS_TOOLKIT': 'null.image'},\n}\n\n\ndef normalize(name):\n return name.replace(\"_\", \"-\")\n\n\[email protected](context_settings={\"token_normalize_func\": normalize})\ndef cli():\n pass\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef install(runtime, toolkit, environment):\n \"\"\" Install project and dependencies into a clean EDM environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n parameters['packages'] = ' '.join(\n dependencies | extra_dependencies.get(toolkit, set()))\n # edm commands to setup the development environment\n commands = [\n \"edm environments create {environment} --force --version={runtime}\",\n \"edm install -y -e {environment} {packages}\",\n (\"edm run -e {environment} -- pip install -r ci/requirements.txt\"\n \" --no-dependencies\"),\n # Note that enable dependencies will be installed implicitly using pip\n (\"edm run -e {environment} -- \"\n \"pip install git+https://[email protected]/enthought/enable.git\"),\n \"edm run -e {environment} -- pip install . --no-deps\",\n ]\n # pip install pyside2, because we don't have it in EDM yet\n if toolkit == 'pyside2':\n commands.append(\n \"edm run -e {environment} -- pip install pyside2==5.11\"\n )\n \n click.echo(\"Creating environment '{environment}'\".format(**parameters))\n execute(commands, parameters)\n click.echo('Done install')\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef test(runtime, toolkit, environment):\n \"\"\" Run the test suite in a given environment with the specified toolkit.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n environ = environment_vars.get(toolkit, {}).copy()\n\n environ['PYTHONUNBUFFERED'] = \"1\"\n commands = [\n \"edm run -e {environment} -- coverage run -m unittest discover -v chaco\"\n ]\n\n cwd = os.getcwd()\n\n # We run in a tempdir to avoid accidentally picking up wrong traitsui\n # code from a local dir. We need to ensure a good .coveragerc is in\n # that directory, plus coverage has a bug that means a non-local coverage\n # file doesn't get populated correctly.\n click.echo(\"Running tests in '{environment}'\".format(**parameters))\n with do_in_tempdir(files=['.coveragerc'], capture_files=['./.coverage*']):\n os.environ.update(environ)\n execute(commands, parameters)\n\n click.echo('Done test')\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef cleanup(runtime, toolkit, environment):\n \"\"\" Remove a development environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n commands = [\n \"edm run -e {environment} -- python setup.py clean\",\n \"edm environments remove {environment} --purge -y\",\n ]\n click.echo(\"Cleaning up environment '{environment}'\".format(**parameters))\n execute(commands, parameters)\n click.echo('Done cleanup')\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\ndef test_clean(runtime, toolkit):\n \"\"\" Run tests in a clean environment, cleaning up afterwards\n \"\"\"\n args = ['--toolkit={}'.format(toolkit),\n '--runtime={}'.format(runtime)]\n try:\n install(args=args, standalone_mode=False)\n test(args=args, standalone_mode=False)\n finally:\n cleanup(args=args, standalone_mode=False)\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef update(runtime, toolkit, environment):\n \"\"\" Update/Reinstall package into environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n commands = [\n \"edm run -e {environment} -- python setup.py install\"]\n click.echo(\"Re-installing in '{environment}'\".format(**parameters))\n execute(commands, parameters)\n click.echo('Done update')\n\n\[email protected]()\ndef test_all():\n \"\"\" Run test_clean across all supported environment combinations.\n \"\"\"\n for runtime, toolkits in supported_combinations.items():\n for toolkit in toolkits:\n args = ['--toolkit={}'.format(toolkit),\n '--runtime={}'.format(runtime)]\n test_clean(args, standalone_mode=True)\n\n\n# ----------------------------------------------------------------------------\n# Utility routines\n# ----------------------------------------------------------------------------\n\ndef get_parameters(runtime, toolkit, environment):\n \"\"\"Set up parameters dictionary for format() substitution\n \"\"\"\n parameters = {'runtime': runtime, 'toolkit': toolkit,\n 'environment': environment}\n if toolkit not in supported_combinations[runtime]:\n msg = (\"Python {runtime!r}, toolkit {toolkit!r}, \"\n \"not supported by test environments ({available})\")\n available = \", \".join(\n repr(tk) for tk in sorted(supported_combinations[runtime])\n )\n raise RuntimeError(msg.format(available=available, **parameters))\n if environment is None:\n tmpl = 'chaco-test-{runtime}-{toolkit}'\n environment = tmpl.format(**parameters)\n parameters['environment'] = environment\n return parameters\n\n\n@contextmanager\ndef do_in_tempdir(files=(), capture_files=()):\n \"\"\" Create a temporary directory, cleaning up after done.\n Creates the temporary directory, and changes into it. On exit returns to\n original directory and removes temporary dir.\n Parameters\n ----------\n files : sequence of filenames\n Files to be copied across to temporary directory.\n capture_files : sequence of filenames\n Files to be copied back from temporary directory.\n \"\"\"\n path = mkdtemp()\n old_path = os.getcwd()\n\n # send across any files we need\n for filepath in files:\n click.echo('copying file to tempdir: {}'.format(filepath))\n copyfile(filepath, path)\n\n os.chdir(path)\n try:\n yield path\n # retrieve any result files we want\n for pattern in capture_files:\n for filepath in glob.iglob(pattern):\n click.echo('copying file back: {}'.format(filepath))\n copyfile(filepath, old_path)\n finally:\n os.chdir(old_path)\n rmtree(path)\n\n\ndef execute(commands, parameters):\n for command in commands:\n print(\"[EXECUTING]\", command.format(**parameters))\n try:\n subprocess.check_call(command.format(**parameters).split())\n except subprocess.CalledProcessError:\n sys.exit(1)\n\n\nif __name__ == '__main__':\n cli()\n", "path": "ci/edmtool.py"}, {"content": "# Copyright (c) 2005-2014 by Enthought, Inc.\n# All rights reserved.\n\"\"\" Two-dimensional plotting application toolkit.\n Part of the Chaco project of the Enthought Tool Suite.\n\"\"\"\nfrom ._version import full_version as __version__ # noqa\n\n__requires__ = [\n 'enable',\n 'six'\n]\n", "path": "chaco/__init__.py"}], "after_files": [{"content": "#\n# Copyright (c) 2017, Enthought, Inc.\n# All rights reserved.\n#\n# This software is provided without warranty under the terms of the BSD\n# license included in enthought/LICENSE.txt and may be redistributed only\n# under the conditions described in the aforementioned license. The license\n# is also available online at http://www.enthought.com/licenses/BSD.txt\n#\n# Thanks for using Enthought open source!\n#\n\"\"\"\nTasks for Test Runs\n===================\nThis file is intended to be used with a python environment with the\nclick library to automate the process of setting up test environments\nand running the test within them. This improves repeatability and\nreliability of tests be removing many of the variables around the\ndeveloper's particular Python environment. Test environment setup and\npackage management is performed using `EDM http://docs.enthought.com/edm/`_\n\nTo use this to run you tests, you will need to install EDM and click\ninto your working environment. You will also need to have git\ninstalled to access required source code from github repositories.\n\nYou can then do::\n python edmtool.py install --runtime=... --toolkit=...\nto create a test environment from the current codebase and::\n python edmtool.py test --runtime=... --toolkit=...\nto run tests in that environment. You can remove the environment with::\n python edmtool.py cleanup --runtime=... --toolkit=...\n\nIf you make changes you will either need to remove and re-install the\nenvironment or manually update the environment using ``edm``, as\nthe install performs a ``python setup.py install`` rather than a ``develop``,\nso changes in your code will not be automatically mirrored in the test\nenvironment. You can update with a command like::\n edm run --environment ... -- python setup.py install\nYou can run all three tasks at once with::\n python edmtool.py test_clean --runtime=... --toolkit=...\nwhich will create, install, run tests, and then clean-up the environment. And\nyou can run tests in all supported runtimes and toolkits (with cleanup)\nusing::\n python edmtool.py test_all\n\nCurrently supported runtime values are ``3.6``, and currently\nsupported toolkits are ``null``, ``pyqt``, ``pyqt5`` and ``pyside2``. Not all\ncombinations of toolkits and runtimes will work, but the tasks will fail with\na clear error if that is the case. Tests can still be run via the usual means\nin other environments if that suits a developer's purpose.\n\nChanging This File\n------------------\nTo change the packages installed during a test run, change the dependencies\nvariable below. To install a package from github, or one which is not yet\navailable via EDM, add it to the `ci/requirements.txt` file (these will be\ninstalled by `pip`).\n\nOther changes to commands should be a straightforward change to the listed\ncommands for each task. See the EDM documentation for more information about\nhow to run commands within an EDM enviornment.\n\"\"\"\nimport glob\nimport os\nimport subprocess\nimport sys\nfrom shutil import rmtree, copy as copyfile\nfrom tempfile import mkdtemp\nfrom contextlib import contextmanager\n\nimport click\n\nsupported_combinations = {\n '3.6': {'pyside2', 'pyqt', 'pyqt5', 'null'},\n}\n\ndependencies = {\n \"six\",\n \"mock\",\n \"numpy\",\n \"pandas\",\n \"pyface\",\n \"pygments\",\n \"pyparsing\",\n \"traits\",\n \"traitsui\",\n \"cython\",\n \"enable\",\n # Needed to install enable from source\n \"swig\",\n}\n\n# Dependencies we install from source for cron tests\nsource_dependencies = {\n \"enable\",\n \"pyface\",\n \"traits\",\n \"traitsui\",\n}\n\ngithub_url_fmt = \"git+http://github.com/enthought/{0}.git#egg={0}\"\n\nextra_dependencies = {\n 'pyside2': set(), # pyside2 is pip-installed during the install step\n 'pyqt': {'pyqt'},\n 'pyqt5': {'pyqt5'},\n 'null': set()\n}\n\nenvironment_vars = {\n 'pyside2': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyside2'},\n 'pyqt': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyqt'},\n 'pyqt5': {'ETS_TOOLKIT': 'qt4', 'QT_API': 'pyqt5'},\n 'null': {'ETS_TOOLKIT': 'null.image'},\n}\n\n\ndef normalize(name):\n return name.replace(\"_\", \"-\")\n\n\[email protected](context_settings={\"token_normalize_func\": normalize})\ndef cli():\n pass\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\[email protected](\n \"--source/--no-source\",\n default=False,\n help=\"Install ETS packages from source\",\n)\ndef install(runtime, toolkit, environment, source):\n \"\"\" Install project and dependencies into a clean EDM environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n parameters['packages'] = ' '.join(\n dependencies | extra_dependencies.get(toolkit, set()))\n # edm commands to setup the development environment\n commands = [\n \"edm environments create {environment} --force --version={runtime}\",\n \"edm install -y -e {environment} {packages}\",\n (\"edm run -e {environment} -- pip install -r ci/requirements.txt\"\n \" --no-dependencies\"),\n \"edm run -e {environment} -- pip install . --no-deps\",\n ]\n # pip install pyside2, because we don't have it in EDM yet\n if toolkit == 'pyside2':\n commands.append(\n \"edm run -e {environment} -- pip install pyside2==5.11\"\n )\n \n click.echo(\"Creating environment '{environment}'\".format(**parameters))\n execute(commands, parameters)\n\n if source:\n # Remove EDM ETS packages and install them from source\n cmd_fmt = (\n \"edm plumbing remove-package \"\n \"--environment {environment} --force \"\n )\n commands = [cmd_fmt + source_pkg for source_pkg in source_dependencies]\n execute(commands, parameters)\n source_pkgs = [\n github_url_fmt.format(pkg) for pkg in source_dependencies\n ]\n commands = [\n \"python -m pip install {pkg} --no-deps\".format(pkg=pkg)\n for pkg in source_pkgs\n ]\n commands = [\n \"edm run -e {environment} -- \" + command for command in commands\n ]\n execute(commands, parameters)\n click.echo('Done install')\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef test(runtime, toolkit, environment):\n \"\"\" Run the test suite in a given environment with the specified toolkit.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n environ = environment_vars.get(toolkit, {}).copy()\n\n environ['PYTHONUNBUFFERED'] = \"1\"\n commands = [\n \"edm run -e {environment} -- coverage run -m unittest discover -v chaco\"\n ]\n\n cwd = os.getcwd()\n\n # We run in a tempdir to avoid accidentally picking up wrong traitsui\n # code from a local dir. We need to ensure a good .coveragerc is in\n # that directory, plus coverage has a bug that means a non-local coverage\n # file doesn't get populated correctly.\n click.echo(\"Running tests in '{environment}'\".format(**parameters))\n with do_in_tempdir(files=['.coveragerc'], capture_files=['./.coverage*']):\n os.environ.update(environ)\n execute(commands, parameters)\n\n click.echo('Done test')\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef cleanup(runtime, toolkit, environment):\n \"\"\" Remove a development environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n commands = [\n \"edm run -e {environment} -- python setup.py clean\",\n \"edm environments remove {environment} --purge -y\",\n ]\n click.echo(\"Cleaning up environment '{environment}'\".format(**parameters))\n execute(commands, parameters)\n click.echo('Done cleanup')\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\ndef test_clean(runtime, toolkit):\n \"\"\" Run tests in a clean environment, cleaning up afterwards\n \"\"\"\n args = ['--toolkit={}'.format(toolkit),\n '--runtime={}'.format(runtime)]\n try:\n install(args=args, standalone_mode=False)\n test(args=args, standalone_mode=False)\n finally:\n cleanup(args=args, standalone_mode=False)\n\n\[email protected]()\[email protected]('--runtime', default='3.6')\[email protected]('--toolkit', default='null')\[email protected]('--environment', default=None)\ndef update(runtime, toolkit, environment):\n \"\"\" Update/Reinstall package into environment.\n \"\"\"\n parameters = get_parameters(runtime, toolkit, environment)\n commands = [\n \"edm run -e {environment} -- python setup.py install\"]\n click.echo(\"Re-installing in '{environment}'\".format(**parameters))\n execute(commands, parameters)\n click.echo('Done update')\n\n\[email protected]()\ndef test_all():\n \"\"\" Run test_clean across all supported environment combinations.\n \"\"\"\n for runtime, toolkits in supported_combinations.items():\n for toolkit in toolkits:\n args = ['--toolkit={}'.format(toolkit),\n '--runtime={}'.format(runtime)]\n test_clean(args, standalone_mode=True)\n\n\n# ----------------------------------------------------------------------------\n# Utility routines\n# ----------------------------------------------------------------------------\n\ndef get_parameters(runtime, toolkit, environment):\n \"\"\"Set up parameters dictionary for format() substitution\n \"\"\"\n parameters = {'runtime': runtime, 'toolkit': toolkit,\n 'environment': environment}\n if toolkit not in supported_combinations[runtime]:\n msg = (\"Python {runtime!r}, toolkit {toolkit!r}, \"\n \"not supported by test environments ({available})\")\n available = \", \".join(\n repr(tk) for tk in sorted(supported_combinations[runtime])\n )\n raise RuntimeError(msg.format(available=available, **parameters))\n if environment is None:\n tmpl = 'chaco-test-{runtime}-{toolkit}'\n environment = tmpl.format(**parameters)\n parameters['environment'] = environment\n return parameters\n\n\n@contextmanager\ndef do_in_tempdir(files=(), capture_files=()):\n \"\"\" Create a temporary directory, cleaning up after done.\n Creates the temporary directory, and changes into it. On exit returns to\n original directory and removes temporary dir.\n Parameters\n ----------\n files : sequence of filenames\n Files to be copied across to temporary directory.\n capture_files : sequence of filenames\n Files to be copied back from temporary directory.\n \"\"\"\n path = mkdtemp()\n old_path = os.getcwd()\n\n # send across any files we need\n for filepath in files:\n click.echo('copying file to tempdir: {}'.format(filepath))\n copyfile(filepath, path)\n\n os.chdir(path)\n try:\n yield path\n # retrieve any result files we want\n for pattern in capture_files:\n for filepath in glob.iglob(pattern):\n click.echo('copying file back: {}'.format(filepath))\n copyfile(filepath, old_path)\n finally:\n os.chdir(old_path)\n rmtree(path)\n\n\ndef execute(commands, parameters):\n for command in commands:\n print(\"[EXECUTING]\", command.format(**parameters))\n try:\n subprocess.check_call(command.format(**parameters).split())\n except subprocess.CalledProcessError:\n sys.exit(1)\n\n\nif __name__ == '__main__':\n cli()\n", "path": "ci/edmtool.py"}, {"content": "# Copyright (c) 2005-2014 by Enthought, Inc.\n# All rights reserved.\n\"\"\" Two-dimensional plotting application toolkit.\n Part of the Chaco project of the Enthought Tool Suite.\n\"\"\"\nfrom ._version import full_version as __version__ # noqa\n\n__requires__ = [\n 'traits',\n 'traitsui',\n 'pyface',\n 'numpy',\n 'enable',\n 'six'\n]\n", "path": "chaco/__init__.py"}]}
| 3,681 | 785 |
gh_patches_debug_15903
|
rasdani/github-patches
|
git_diff
|
pyload__pyload-1093
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ShareOnline PrePaid is not recognized
As the title says. A PrePaid ShareOnline Account is not recognized as valid Premium Account and therefore pyload asks for Captchas when trying to download an URL.


--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `module/plugins/accounts/ShareonlineBiz.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import re
4
5 from module.plugins.Account import Account
6
7
8 class ShareonlineBiz(Account):
9 __name__ = "ShareonlineBiz"
10 __type__ = "account"
11 __version__ = "0.30"
12
13 __description__ = """Share-online.biz account plugin"""
14 __license__ = "GPLv3"
15 __authors__ = [("Walter Purcaro", "[email protected]")]
16
17
18 def api_response(self, user, req):
19 return req.load("http://api.share-online.biz/cgi-bin",
20 get={'q' : "userdetails",
21 'aux' : "traffic",
22 'username': user,
23 'password': self.getAccountData(user)['password']})
24
25
26 def loadAccountInfo(self, user, req):
27 premium = False
28 validuntil = None
29 trafficleft = -1
30 maxtraffic = 100 * 1024 * 1024 * 1024 #: 100 GB
31
32 api = {}
33 for line in self.api_response(user, req).splitlines():
34 if "=" in line:
35 key, value = line.split("=")
36 api[key] = value
37
38 self.logDebug(api)
39
40 if api['a'].lower() != "not_available":
41 req.cj.setCookie("share-online.biz", 'a', api['a'])
42
43 premium = api['group'] == "Premium"
44
45 validuntil = float(api['expire_date'])
46
47 traffic = float(api['traffic_1d'].split(";")[0])
48 maxtraffic = max(maxtraffic, traffic)
49 trafficleft = maxtraffic - traffic
50
51 maxtraffic /= 1024 #@TODO: Remove `/ 1024` in 0.4.10
52 trafficleft /= 1024 #@TODO: Remove `/ 1024` in 0.4.10
53
54 return {'premium': premium, 'validuntil': validuntil, 'trafficleft': trafficleft, 'maxtraffic': maxtraffic}
55
56
57 def login(self, user, data, req):
58 html = self.api_response(user, req)
59 err = re.search(r'\*\*(.+?)\*\*', html)
60 if err:
61 self.logError(err.group(1))
62 self.wrongPassword()
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/module/plugins/accounts/ShareonlineBiz.py b/module/plugins/accounts/ShareonlineBiz.py
--- a/module/plugins/accounts/ShareonlineBiz.py
+++ b/module/plugins/accounts/ShareonlineBiz.py
@@ -8,7 +8,7 @@
class ShareonlineBiz(Account):
__name__ = "ShareonlineBiz"
__type__ = "account"
- __version__ = "0.30"
+ __version__ = "0.31"
__description__ = """Share-online.biz account plugin"""
__license__ = "GPLv3"
@@ -40,7 +40,7 @@
if api['a'].lower() != "not_available":
req.cj.setCookie("share-online.biz", 'a', api['a'])
- premium = api['group'] == "Premium"
+ premium = api['group'] in ["Premium", "PrePaid"]
validuntil = float(api['expire_date'])
|
{"golden_diff": "diff --git a/module/plugins/accounts/ShareonlineBiz.py b/module/plugins/accounts/ShareonlineBiz.py\n--- a/module/plugins/accounts/ShareonlineBiz.py\n+++ b/module/plugins/accounts/ShareonlineBiz.py\n@@ -8,7 +8,7 @@\n class ShareonlineBiz(Account):\n __name__ = \"ShareonlineBiz\"\n __type__ = \"account\"\n- __version__ = \"0.30\"\n+ __version__ = \"0.31\"\n \n __description__ = \"\"\"Share-online.biz account plugin\"\"\"\n __license__ = \"GPLv3\"\n@@ -40,7 +40,7 @@\n if api['a'].lower() != \"not_available\":\n req.cj.setCookie(\"share-online.biz\", 'a', api['a'])\n \n- premium = api['group'] == \"Premium\"\n+ premium = api['group'] in [\"Premium\", \"PrePaid\"]\n \n validuntil = float(api['expire_date'])\n", "issue": "ShareOnline PrePaid is not recognized\nAs the title says. A PrePaid ShareOnline Account is not recognized as valid Premium Account and therefore pyload asks for Captchas when trying to download an URL.\n\n\n\n\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom module.plugins.Account import Account\n\n\nclass ShareonlineBiz(Account):\n __name__ = \"ShareonlineBiz\"\n __type__ = \"account\"\n __version__ = \"0.30\"\n\n __description__ = \"\"\"Share-online.biz account plugin\"\"\"\n __license__ = \"GPLv3\"\n __authors__ = [(\"Walter Purcaro\", \"[email protected]\")]\n\n\n def api_response(self, user, req):\n return req.load(\"http://api.share-online.biz/cgi-bin\",\n get={'q' : \"userdetails\",\n 'aux' : \"traffic\",\n 'username': user,\n 'password': self.getAccountData(user)['password']})\n\n\n def loadAccountInfo(self, user, req):\n premium = False\n validuntil = None\n trafficleft = -1\n maxtraffic = 100 * 1024 * 1024 * 1024 #: 100 GB\n\n api = {}\n for line in self.api_response(user, req).splitlines():\n if \"=\" in line:\n key, value = line.split(\"=\")\n api[key] = value\n\n self.logDebug(api)\n\n if api['a'].lower() != \"not_available\":\n req.cj.setCookie(\"share-online.biz\", 'a', api['a'])\n\n premium = api['group'] == \"Premium\"\n\n validuntil = float(api['expire_date'])\n\n traffic = float(api['traffic_1d'].split(\";\")[0])\n maxtraffic = max(maxtraffic, traffic)\n trafficleft = maxtraffic - traffic\n\n maxtraffic /= 1024 #@TODO: Remove `/ 1024` in 0.4.10\n trafficleft /= 1024 #@TODO: Remove `/ 1024` in 0.4.10\n\n return {'premium': premium, 'validuntil': validuntil, 'trafficleft': trafficleft, 'maxtraffic': maxtraffic}\n\n\n def login(self, user, data, req):\n html = self.api_response(user, req)\n err = re.search(r'\\*\\*(.+?)\\*\\*', html)\n if err:\n self.logError(err.group(1))\n self.wrongPassword()\n", "path": "module/plugins/accounts/ShareonlineBiz.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom module.plugins.Account import Account\n\n\nclass ShareonlineBiz(Account):\n __name__ = \"ShareonlineBiz\"\n __type__ = \"account\"\n __version__ = \"0.31\"\n\n __description__ = \"\"\"Share-online.biz account plugin\"\"\"\n __license__ = \"GPLv3\"\n __authors__ = [(\"Walter Purcaro\", \"[email protected]\")]\n\n\n def api_response(self, user, req):\n return req.load(\"http://api.share-online.biz/cgi-bin\",\n get={'q' : \"userdetails\",\n 'aux' : \"traffic\",\n 'username': user,\n 'password': self.getAccountData(user)['password']})\n\n\n def loadAccountInfo(self, user, req):\n premium = False\n validuntil = None\n trafficleft = -1\n maxtraffic = 100 * 1024 * 1024 * 1024 #: 100 GB\n\n api = {}\n for line in self.api_response(user, req).splitlines():\n if \"=\" in line:\n key, value = line.split(\"=\")\n api[key] = value\n\n self.logDebug(api)\n\n if api['a'].lower() != \"not_available\":\n req.cj.setCookie(\"share-online.biz\", 'a', api['a'])\n\n premium = api['group'] in [\"Premium\", \"PrePaid\"]\n\n validuntil = float(api['expire_date'])\n\n traffic = float(api['traffic_1d'].split(\";\")[0])\n maxtraffic = max(maxtraffic, traffic)\n trafficleft = maxtraffic - traffic\n\n maxtraffic /= 1024 #@TODO: Remove `/ 1024` in 0.4.10\n trafficleft /= 1024 #@TODO: Remove `/ 1024` in 0.4.10\n\n return {'premium': premium, 'validuntil': validuntil, 'trafficleft': trafficleft, 'maxtraffic': maxtraffic}\n\n\n def login(self, user, data, req):\n html = self.api_response(user, req)\n err = re.search(r'\\*\\*(.+?)\\*\\*', html)\n if err:\n self.logError(err.group(1))\n self.wrongPassword()\n", "path": "module/plugins/accounts/ShareonlineBiz.py"}]}
| 1,077 | 211 |
gh_patches_debug_3536
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-1560
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add new method to count number of rows for PostgreSQL datasources :electric_plug: :1234:
When MindsDB creates a new PostgreSQL datasource we get information for row counts by fetching all datasources. The problem here is that if datasource is big it takes a lot of time. We need a new get_row_count method to return the number of rows per datasource. The PR should include this method inside the PostgreSQL class .
## Steps :male_detective: :female_detective:
- Implement in https://github.com/mindsdb/mindsdb/blob/stable/mindsdb/integrations/postgres/postgres.py#L37
- Example method:
```py
def get_row_count(self, query):
result = conn.execute(query)
return len(query)
```
- Push to staging branch
## Additional rewards :1st_place_medal:
Each code PR brings :three: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/integrations/postgres/postgres.py`
Content:
```
1 from contextlib import closing
2 import pg8000
3
4 from lightwood.api import dtype
5 from mindsdb.integrations.base import Integration
6 from mindsdb.utilities.log import log
7
8
9 class PostgreSQLConnectionChecker:
10 def __init__(self, **kwargs):
11 self.host = kwargs.get('host')
12 self.port = kwargs.get('port')
13 self.user = kwargs.get('user')
14 self.password = kwargs.get('password')
15 self.database = kwargs.get('database', 'postgres')
16
17 def _get_connection(self):
18 return pg8000.connect(
19 database=self.database,
20 user=self.user,
21 password=self.password,
22 host=self.host,
23 port=self.port
24 )
25
26 def check_connection(self):
27 try:
28 con = self._get_connection()
29 with closing(con) as con:
30 con.run('select 1;')
31 connected = True
32 except Exception:
33 connected = False
34 return connected
35
36
37 class PostgreSQL(Integration, PostgreSQLConnectionChecker):
38 def __init__(self, config, name, db_info):
39 super().__init__(config, name)
40 self.user = db_info.get('user')
41 self.password = db_info.get('password')
42 self.host = db_info.get('host')
43 self.port = db_info.get('port')
44 self.database = db_info.get('database', 'postgres')
45
46 def _to_postgres_table(self, dtype_dict, predicted_cols, columns):
47 subtype_map = {
48 dtype.integer: ' int8',
49 dtype.float: 'float8',
50 dtype.binary: 'bool',
51 dtype.date: 'date',
52 dtype.datetime: 'timestamp',
53 dtype.binary: 'text',
54 dtype.categorical: 'text',
55 dtype.tags: 'text',
56 dtype.image: 'text',
57 dtype.video: 'text',
58 dtype.audio: 'text',
59 dtype.short_text: 'text',
60 dtype.rich_text: 'text',
61 dtype.array: 'text'
62 }
63
64 column_declaration = []
65 for name in columns:
66 try:
67 col_subtype = dtype_dict[name]
68 new_type = subtype_map[col_subtype]
69 column_declaration.append(f' "{name}" {new_type} ')
70 if name in predicted_cols:
71 column_declaration.append(f' "{name}_original" {new_type} ')
72 except Exception as e:
73 log.error(f'Error: can not determine postgres data type for column {name}: {e}')
74
75 return column_declaration
76
77 def _escape_table_name(self, name):
78 return '"' + name.replace('"', '""') + '"'
79
80 def _query(self, query):
81 con = self._get_connection()
82 with closing(con) as con:
83
84 cur = con.cursor()
85 res = True
86 cur.execute(query)
87
88 try:
89 rows = cur.fetchall()
90 keys = [k[0] if isinstance(k[0], str) else k[0].decode('ascii') for k in cur.description]
91 res = [dict(zip(keys, row)) for row in rows]
92 except Exception:
93 pass
94
95 con.commit()
96
97 return res
98
99 def setup(self):
100 user = f"{self.config['api']['mysql']['user']}_{self.name}"
101 password = self.config['api']['mysql']['password']
102 host = self.config['api']['mysql']['host']
103 port = self.config['api']['mysql']['port']
104
105 try:
106 self._query('''
107 DO $$
108 begin
109 if not exists (SELECT 1 FROM pg_extension where extname = 'mysql_fdw') then
110 CREATE EXTENSION mysql_fdw;
111 end if;
112 END
113 $$;
114 ''')
115 except Exception:
116 print('Error: cant find or activate mysql_fdw extension for PostgreSQL.')
117
118 self._query(f'DROP SCHEMA IF EXISTS {self.mindsdb_database} CASCADE')
119
120 self._query(f"DROP USER MAPPING IF EXISTS FOR {self.user} SERVER server_{self.mindsdb_database}")
121
122 self._query(f'DROP SERVER IF EXISTS server_{self.mindsdb_database} CASCADE')
123
124 self._query(f'''
125 CREATE SERVER server_{self.mindsdb_database}
126 FOREIGN DATA WRAPPER mysql_fdw
127 OPTIONS (host '{host}', port '{port}');
128 ''')
129
130 self._query(f'''
131 CREATE USER MAPPING FOR {self.user}
132 SERVER server_{self.mindsdb_database}
133 OPTIONS (username '{user}', password '{password}');
134 ''')
135
136 self._query(f'CREATE SCHEMA {self.mindsdb_database}')
137
138 q = f"""
139 CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (
140 name text,
141 status text,
142 accuracy text,
143 predict text,
144 select_data_query text,
145 external_datasource text,
146 training_options text
147 )
148 SERVER server_{self.mindsdb_database}
149 OPTIONS (dbname 'mindsdb', table_name 'predictors');
150 """
151 self._query(q)
152
153 q = f"""
154 CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.commands (
155 command text
156 ) SERVER server_{self.mindsdb_database}
157 OPTIONS (dbname 'mindsdb', table_name 'commands');
158 """
159 self._query(q)
160
161 def register_predictors(self, model_data_arr):
162 for model_meta in model_data_arr:
163 name = model_meta['name']
164 predict = model_meta['predict']
165 if not isinstance(predict, list):
166 predict = [predict]
167 columns_sql = ','.join(self._to_postgres_table(
168 model_meta['dtype_dict'],
169 predict,
170 list(model_meta['dtype_dict'].keys())
171 ))
172 columns_sql += ',"select_data_query" text'
173 columns_sql += ',"external_datasource" text'
174 for col in predict:
175 columns_sql += f',"{col}_confidence" float8'
176 if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):
177 columns_sql += f',"{col}_min" float8'
178 columns_sql += f',"{col}_max" float8'
179 columns_sql += f',"{col}_explain" text'
180
181 self.unregister_predictor(name)
182 q = f"""
183 CREATE FOREIGN TABLE {self.mindsdb_database}.{self._escape_table_name(name)} (
184 {columns_sql}
185 ) SERVER server_{self.mindsdb_database}
186 OPTIONS (dbname 'mindsdb', table_name '{name}');
187 """
188 self._query(q)
189
190 def unregister_predictor(self, name):
191 q = f"""
192 DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};
193 """
194 self._query(q)
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mindsdb/integrations/postgres/postgres.py b/mindsdb/integrations/postgres/postgres.py
--- a/mindsdb/integrations/postgres/postgres.py
+++ b/mindsdb/integrations/postgres/postgres.py
@@ -192,3 +192,10 @@
DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};
"""
self._query(q)
+
+ def get_row_count(self, query):
+ q = f"""
+ SELECT COUNT(*) as count
+ FROM ({query}) as query;"""
+ result = self._query(q)
+ return result[0]['count']
|
{"golden_diff": "diff --git a/mindsdb/integrations/postgres/postgres.py b/mindsdb/integrations/postgres/postgres.py\n--- a/mindsdb/integrations/postgres/postgres.py\n+++ b/mindsdb/integrations/postgres/postgres.py\n@@ -192,3 +192,10 @@\n DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};\n \"\"\"\n self._query(q)\n+\n+ def get_row_count(self, query):\n+ q = f\"\"\" \n+ SELECT COUNT(*) as count\n+ FROM ({query}) as query;\"\"\"\n+ result = self._query(q)\n+ return result[0]['count']\n", "issue": "Add new method to count number of rows for PostgreSQL datasources :electric_plug: :1234: \nWhen MindsDB creates a new PostgreSQL datasource we get information for row counts by fetching all datasources. The problem here is that if datasource is big it takes a lot of time. We need a new get_row_count method to return the number of rows per datasource. The PR should include this method inside the PostgreSQL class .\r\n\r\n## Steps :male_detective: :female_detective: \r\n\r\n- Implement in https://github.com/mindsdb/mindsdb/blob/stable/mindsdb/integrations/postgres/postgres.py#L37\r\n- Example method:\r\n```py\r\ndef get_row_count(self, query):\r\n result = conn.execute(query)\r\n return len(query)\r\n```\r\n- Push to staging branch\r\n\r\n## Additional rewards :1st_place_medal: \r\n\r\nEach code PR brings :three: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/\r\n \r\n\r\n\n", "before_files": [{"content": "from contextlib import closing\nimport pg8000\n\nfrom lightwood.api import dtype\nfrom mindsdb.integrations.base import Integration\nfrom mindsdb.utilities.log import log\n\n\nclass PostgreSQLConnectionChecker:\n def __init__(self, **kwargs):\n self.host = kwargs.get('host')\n self.port = kwargs.get('port')\n self.user = kwargs.get('user')\n self.password = kwargs.get('password')\n self.database = kwargs.get('database', 'postgres')\n\n def _get_connection(self):\n return pg8000.connect(\n database=self.database,\n user=self.user,\n password=self.password,\n host=self.host,\n port=self.port\n )\n\n def check_connection(self):\n try:\n con = self._get_connection()\n with closing(con) as con:\n con.run('select 1;')\n connected = True\n except Exception:\n connected = False\n return connected\n\n\nclass PostgreSQL(Integration, PostgreSQLConnectionChecker):\n def __init__(self, config, name, db_info):\n super().__init__(config, name)\n self.user = db_info.get('user')\n self.password = db_info.get('password')\n self.host = db_info.get('host')\n self.port = db_info.get('port')\n self.database = db_info.get('database', 'postgres')\n\n def _to_postgres_table(self, dtype_dict, predicted_cols, columns):\n subtype_map = {\n dtype.integer: ' int8',\n dtype.float: 'float8',\n dtype.binary: 'bool',\n dtype.date: 'date',\n dtype.datetime: 'timestamp',\n dtype.binary: 'text',\n dtype.categorical: 'text',\n dtype.tags: 'text',\n dtype.image: 'text',\n dtype.video: 'text',\n dtype.audio: 'text',\n dtype.short_text: 'text',\n dtype.rich_text: 'text',\n dtype.array: 'text'\n }\n\n column_declaration = []\n for name in columns:\n try:\n col_subtype = dtype_dict[name]\n new_type = subtype_map[col_subtype]\n column_declaration.append(f' \"{name}\" {new_type} ')\n if name in predicted_cols:\n column_declaration.append(f' \"{name}_original\" {new_type} ')\n except Exception as e:\n log.error(f'Error: can not determine postgres data type for column {name}: {e}')\n\n return column_declaration\n\n def _escape_table_name(self, name):\n return '\"' + name.replace('\"', '\"\"') + '\"'\n\n def _query(self, query):\n con = self._get_connection()\n with closing(con) as con:\n\n cur = con.cursor()\n res = True\n cur.execute(query)\n\n try:\n rows = cur.fetchall()\n keys = [k[0] if isinstance(k[0], str) else k[0].decode('ascii') for k in cur.description]\n res = [dict(zip(keys, row)) for row in rows]\n except Exception:\n pass\n\n con.commit()\n\n return res\n\n def setup(self):\n user = f\"{self.config['api']['mysql']['user']}_{self.name}\"\n password = self.config['api']['mysql']['password']\n host = self.config['api']['mysql']['host']\n port = self.config['api']['mysql']['port']\n\n try:\n self._query('''\n DO $$\n begin\n if not exists (SELECT 1 FROM pg_extension where extname = 'mysql_fdw') then\n CREATE EXTENSION mysql_fdw;\n end if;\n END\n $$;\n ''')\n except Exception:\n print('Error: cant find or activate mysql_fdw extension for PostgreSQL.')\n\n self._query(f'DROP SCHEMA IF EXISTS {self.mindsdb_database} CASCADE')\n\n self._query(f\"DROP USER MAPPING IF EXISTS FOR {self.user} SERVER server_{self.mindsdb_database}\")\n\n self._query(f'DROP SERVER IF EXISTS server_{self.mindsdb_database} CASCADE')\n\n self._query(f'''\n CREATE SERVER server_{self.mindsdb_database}\n FOREIGN DATA WRAPPER mysql_fdw\n OPTIONS (host '{host}', port '{port}');\n ''')\n\n self._query(f'''\n CREATE USER MAPPING FOR {self.user}\n SERVER server_{self.mindsdb_database}\n OPTIONS (username '{user}', password '{password}');\n ''')\n\n self._query(f'CREATE SCHEMA {self.mindsdb_database}')\n\n q = f\"\"\"\n CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (\n name text,\n status text,\n accuracy text,\n predict text,\n select_data_query text,\n external_datasource text,\n training_options text\n )\n SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name 'predictors');\n \"\"\"\n self._query(q)\n\n q = f\"\"\"\n CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.commands (\n command text\n ) SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name 'commands');\n \"\"\"\n self._query(q)\n\n def register_predictors(self, model_data_arr):\n for model_meta in model_data_arr:\n name = model_meta['name']\n predict = model_meta['predict']\n if not isinstance(predict, list):\n predict = [predict]\n columns_sql = ','.join(self._to_postgres_table(\n model_meta['dtype_dict'],\n predict,\n list(model_meta['dtype_dict'].keys())\n ))\n columns_sql += ',\"select_data_query\" text'\n columns_sql += ',\"external_datasource\" text'\n for col in predict:\n columns_sql += f',\"{col}_confidence\" float8'\n if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):\n columns_sql += f',\"{col}_min\" float8'\n columns_sql += f',\"{col}_max\" float8'\n columns_sql += f',\"{col}_explain\" text'\n\n self.unregister_predictor(name)\n q = f\"\"\"\n CREATE FOREIGN TABLE {self.mindsdb_database}.{self._escape_table_name(name)} (\n {columns_sql}\n ) SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name '{name}');\n \"\"\"\n self._query(q)\n\n def unregister_predictor(self, name):\n q = f\"\"\"\n DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};\n \"\"\"\n self._query(q)\n", "path": "mindsdb/integrations/postgres/postgres.py"}], "after_files": [{"content": "from contextlib import closing\nimport pg8000\n\nfrom lightwood.api import dtype\nfrom mindsdb.integrations.base import Integration\nfrom mindsdb.utilities.log import log\n\n\nclass PostgreSQLConnectionChecker:\n def __init__(self, **kwargs):\n self.host = kwargs.get('host')\n self.port = kwargs.get('port')\n self.user = kwargs.get('user')\n self.password = kwargs.get('password')\n self.database = kwargs.get('database', 'postgres')\n\n def _get_connection(self):\n return pg8000.connect(\n database=self.database,\n user=self.user,\n password=self.password,\n host=self.host,\n port=self.port\n )\n\n def check_connection(self):\n try:\n con = self._get_connection()\n with closing(con) as con:\n con.run('select 1;')\n connected = True\n except Exception:\n connected = False\n return connected\n\n\nclass PostgreSQL(Integration, PostgreSQLConnectionChecker):\n def __init__(self, config, name, db_info):\n super().__init__(config, name)\n self.user = db_info.get('user')\n self.password = db_info.get('password')\n self.host = db_info.get('host')\n self.port = db_info.get('port')\n self.database = db_info.get('database', 'postgres')\n\n def _to_postgres_table(self, dtype_dict, predicted_cols, columns):\n subtype_map = {\n dtype.integer: ' int8',\n dtype.float: 'float8',\n dtype.binary: 'bool',\n dtype.date: 'date',\n dtype.datetime: 'timestamp',\n dtype.binary: 'text',\n dtype.categorical: 'text',\n dtype.tags: 'text',\n dtype.image: 'text',\n dtype.video: 'text',\n dtype.audio: 'text',\n dtype.short_text: 'text',\n dtype.rich_text: 'text',\n dtype.array: 'text'\n }\n\n column_declaration = []\n for name in columns:\n try:\n col_subtype = dtype_dict[name]\n new_type = subtype_map[col_subtype]\n column_declaration.append(f' \"{name}\" {new_type} ')\n if name in predicted_cols:\n column_declaration.append(f' \"{name}_original\" {new_type} ')\n except Exception as e:\n log.error(f'Error: can not determine postgres data type for column {name}: {e}')\n\n return column_declaration\n\n def _escape_table_name(self, name):\n return '\"' + name.replace('\"', '\"\"') + '\"'\n\n def _query(self, query):\n con = self._get_connection()\n with closing(con) as con:\n\n cur = con.cursor()\n res = True\n cur.execute(query)\n\n try:\n rows = cur.fetchall()\n keys = [k[0] if isinstance(k[0], str) else k[0].decode('ascii') for k in cur.description]\n res = [dict(zip(keys, row)) for row in rows]\n except Exception:\n pass\n\n con.commit()\n\n return res\n\n def setup(self):\n user = f\"{self.config['api']['mysql']['user']}_{self.name}\"\n password = self.config['api']['mysql']['password']\n host = self.config['api']['mysql']['host']\n port = self.config['api']['mysql']['port']\n\n try:\n self._query('''\n DO $$\n begin\n if not exists (SELECT 1 FROM pg_extension where extname = 'mysql_fdw') then\n CREATE EXTENSION mysql_fdw;\n end if;\n END\n $$;\n ''')\n except Exception:\n print('Error: cant find or activate mysql_fdw extension for PostgreSQL.')\n\n self._query(f'DROP SCHEMA IF EXISTS {self.mindsdb_database} CASCADE')\n\n self._query(f\"DROP USER MAPPING IF EXISTS FOR {self.user} SERVER server_{self.mindsdb_database}\")\n\n self._query(f'DROP SERVER IF EXISTS server_{self.mindsdb_database} CASCADE')\n\n self._query(f'''\n CREATE SERVER server_{self.mindsdb_database}\n FOREIGN DATA WRAPPER mysql_fdw\n OPTIONS (host '{host}', port '{port}');\n ''')\n\n self._query(f'''\n CREATE USER MAPPING FOR {self.user}\n SERVER server_{self.mindsdb_database}\n OPTIONS (username '{user}', password '{password}');\n ''')\n\n self._query(f'CREATE SCHEMA {self.mindsdb_database}')\n\n q = f\"\"\"\n CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (\n name text,\n status text,\n accuracy text,\n predict text,\n select_data_query text,\n external_datasource text,\n training_options text\n )\n SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name 'predictors');\n \"\"\"\n self._query(q)\n\n q = f\"\"\"\n CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.commands (\n command text\n ) SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name 'commands');\n \"\"\"\n self._query(q)\n\n def register_predictors(self, model_data_arr):\n for model_meta in model_data_arr:\n name = model_meta['name']\n predict = model_meta['predict']\n if not isinstance(predict, list):\n predict = [predict]\n columns_sql = ','.join(self._to_postgres_table(\n model_meta['dtype_dict'],\n predict,\n list(model_meta['dtype_dict'].keys())\n ))\n columns_sql += ',\"select_data_query\" text'\n columns_sql += ',\"external_datasource\" text'\n for col in predict:\n columns_sql += f',\"{col}_confidence\" float8'\n if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):\n columns_sql += f',\"{col}_min\" float8'\n columns_sql += f',\"{col}_max\" float8'\n columns_sql += f',\"{col}_explain\" text'\n\n self.unregister_predictor(name)\n q = f\"\"\"\n CREATE FOREIGN TABLE {self.mindsdb_database}.{self._escape_table_name(name)} (\n {columns_sql}\n ) SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name '{name}');\n \"\"\"\n self._query(q)\n\n def unregister_predictor(self, name):\n q = f\"\"\"\n DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};\n \"\"\"\n self._query(q)\n\n def get_row_count(self, query):\n q = f\"\"\" \n SELECT COUNT(*) as count\n FROM ({query}) as query;\"\"\"\n result = self._query(q)\n return result[0]['count']\n", "path": "mindsdb/integrations/postgres/postgres.py"}]}
| 2,410 | 153 |
gh_patches_debug_21992
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3685
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow patching indicator with empty list of dimension names
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/serializers/indicator.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from akvo.rest.serializers.indicator_period import IndicatorPeriodFrameworkSerializer
8 from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer
9 from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
10 from akvo.rsr.models import Indicator
11
12 from rest_framework import serializers
13
14
15 class IndicatorSerializer(BaseRSRSerializer):
16
17 result_unicode = serializers.ReadOnlyField(source='result.__unicode__')
18 measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')
19 children_aggregate_percentage = serializers.ReadOnlyField()
20
21 class Meta:
22 model = Indicator
23 fields = '__all__'
24
25 # TODO: add validation for parent_indicator
26
27
28 class IndicatorFrameworkSerializer(BaseRSRSerializer):
29
30 periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)
31 parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
32 children_aggregate_percentage = serializers.ReadOnlyField()
33 dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
34
35 class Meta:
36 model = Indicator
37 fields = '__all__'
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/serializers/indicator.py b/akvo/rest/serializers/indicator.py
--- a/akvo/rest/serializers/indicator.py
+++ b/akvo/rest/serializers/indicator.py
@@ -7,7 +7,7 @@
from akvo.rest.serializers.indicator_period import IndicatorPeriodFrameworkSerializer
from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer
from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
-from akvo.rsr.models import Indicator
+from akvo.rsr.models import Indicator, IndicatorDimensionName
from rest_framework import serializers
@@ -17,6 +17,8 @@
result_unicode = serializers.ReadOnlyField(source='result.__unicode__')
measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')
children_aggregate_percentage = serializers.ReadOnlyField()
+ dimension_names = serializers.PrimaryKeyRelatedField(
+ many=True, queryset=IndicatorDimensionName.objects.all())
class Meta:
model = Indicator
|
{"golden_diff": "diff --git a/akvo/rest/serializers/indicator.py b/akvo/rest/serializers/indicator.py\n--- a/akvo/rest/serializers/indicator.py\n+++ b/akvo/rest/serializers/indicator.py\n@@ -7,7 +7,7 @@\n from akvo.rest.serializers.indicator_period import IndicatorPeriodFrameworkSerializer\n from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\n from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\n-from akvo.rsr.models import Indicator\n+from akvo.rsr.models import Indicator, IndicatorDimensionName\n \n from rest_framework import serializers\n \n@@ -17,6 +17,8 @@\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n+ dimension_names = serializers.PrimaryKeyRelatedField(\n+ many=True, queryset=IndicatorDimensionName.objects.all())\n \n class Meta:\n model = Indicator\n", "issue": "Allow patching indicator with empty list of dimension names\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rest.serializers.indicator_period import IndicatorPeriodFrameworkSerializer\nfrom akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rsr.models import Indicator\n\nfrom rest_framework import serializers\n\n\nclass IndicatorSerializer(BaseRSRSerializer):\n\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n # TODO: add validation for parent_indicator\n\n\nclass IndicatorFrameworkSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n", "path": "akvo/rest/serializers/indicator.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rest.serializers.indicator_period import IndicatorPeriodFrameworkSerializer\nfrom akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rsr.models import Indicator, IndicatorDimensionName\n\nfrom rest_framework import serializers\n\n\nclass IndicatorSerializer(BaseRSRSerializer):\n\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = serializers.PrimaryKeyRelatedField(\n many=True, queryset=IndicatorDimensionName.objects.all())\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n # TODO: add validation for parent_indicator\n\n\nclass IndicatorFrameworkSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n", "path": "akvo/rest/serializers/indicator.py"}]}
| 638 | 220 |
gh_patches_debug_22683
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-3051
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ghostwriter error on attrs class
While playing around with the ghostwriter today, I got an exception like this one running it against some internal code:
```
Traceback (most recent call last):
File "/tmp/repro/venv/bin/hypothesis", line 8, in <module>
sys.exit(main())
File "/tmp/repro/venv/lib/python3.9/site-packages/click/core.py", line 1137, in __call__
return self.main(*args, **kwargs)
File "/tmp/repro/venv/lib/python3.9/site-packages/click/core.py", line 1062, in main
rv = self.invoke(ctx)
File "/tmp/repro/venv/lib/python3.9/site-packages/click/core.py", line 1668, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/tmp/repro/venv/lib/python3.9/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/tmp/repro/venv/lib/python3.9/site-packages/click/core.py", line 763, in invoke
return __callback(*args, **kwargs)
File "/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/cli.py", line 242, in write
code = getattr(ghostwriter, writer)(*func, except_=except_ or (), style=style)
File "/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py", line 882, in magic
make_(
File "/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py", line 802, in make_
imp, body = how(*args, **kwargs, except_=except_, style=style)
File "/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py", line 626, in _make_test_body
given_strategies = given_strategies or _get_strategies(
File "/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py", line 409, in _get_strategies
if strat.args:
AttributeError: 'MappedSearchStrategy' object has no attribute 'args'
```
I reduced the input to trigger this exception down to
```python
import attr
@attr.s()
class Foo:
foo: str = attr.ib()
```
I saw this with cPython 3.9.6, attrs 21.2.0, and hypothesis master branch at hypothesis-python-6.14.5-5-g9d4da6c2f.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hypothesis-python/src/hypothesis/strategies/_internal/attrs.py`
Content:
```
1 # This file is part of Hypothesis, which may be found at
2 # https://github.com/HypothesisWorks/hypothesis/
3 #
4 # Most of this work is copyright (C) 2013-2021 David R. MacIver
5 # ([email protected]), but it contains contributions by others. See
6 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
7 # consult the git log if you need to determine who owns an individual
8 # contribution.
9 #
10 # This Source Code Form is subject to the terms of the Mozilla Public License,
11 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
12 # obtain one at https://mozilla.org/MPL/2.0/.
13 #
14 # END HEADER
15
16 from functools import reduce
17 from itertools import chain
18
19 import attr
20
21 from hypothesis import strategies as st
22 from hypothesis.errors import ResolutionFailed
23 from hypothesis.internal.compat import get_type_hints
24 from hypothesis.strategies._internal.types import is_a_type, type_sorting_key
25 from hypothesis.utils.conventions import infer
26
27
28 def from_attrs(target, args, kwargs, to_infer):
29 """An internal version of builds(), specialised for Attrs classes."""
30 fields = attr.fields(target)
31 kwargs = {k: v for k, v in kwargs.items() if v is not infer}
32 for name in to_infer:
33 kwargs[name] = from_attrs_attribute(getattr(fields, name), target)
34 # We might make this strategy more efficient if we added a layer here that
35 # retries drawing if validation fails, for improved composition.
36 # The treatment of timezones in datetimes() provides a precedent.
37 return st.tuples(st.tuples(*args), st.fixed_dictionaries(kwargs)).map(
38 lambda value: target(*value[0], **value[1])
39 )
40
41
42 def from_attrs_attribute(attrib, target):
43 """Infer a strategy from the metadata on an attr.Attribute object."""
44 # Try inferring from the default argument. Note that this will only help if
45 # the user passed `infer` to builds() for this attribute, but in that case
46 # we use it as the minimal example.
47 default = st.nothing()
48 if isinstance(attrib.default, attr.Factory):
49 if not attrib.default.takes_self:
50 default = st.builds(attrib.default.factory)
51 elif attrib.default is not attr.NOTHING:
52 default = st.just(attrib.default)
53
54 # Try inferring None, exact values, or type from attrs provided validators.
55 null = st.nothing() # updated to none() on seeing an OptionalValidator
56 in_collections = [] # list of in_ validator collections to sample from
57 validator_types = set() # type constraints to pass to types_to_strategy()
58 if attrib.validator is not None:
59 validator = attrib.validator
60 if isinstance(validator, attr.validators._OptionalValidator):
61 null = st.none()
62 validator = validator.validator
63 if isinstance(validator, attr.validators._AndValidator):
64 vs = validator._validators
65 else:
66 vs = [validator]
67 for v in vs:
68 if isinstance(v, attr.validators._InValidator):
69 if isinstance(v.options, str):
70 in_collections.append(list(all_substrings(v.options)))
71 else:
72 in_collections.append(v.options)
73 elif isinstance(v, attr.validators._InstanceOfValidator):
74 validator_types.add(v.type)
75
76 # This is the important line. We compose the final strategy from various
77 # parts. The default value, if any, is the minimal shrink, followed by
78 # None (again, if allowed). We then prefer to sample from values passed
79 # to an in_ validator if available, but infer from a type otherwise.
80 # Pick one because (sampled_from((1, 2)) | from_type(int)) would usually
81 # fail validation by generating e.g. zero!
82 if in_collections:
83 sample = st.sampled_from(list(ordered_intersection(in_collections)))
84 strat = default | null | sample
85 else:
86 strat = default | null | types_to_strategy(attrib, validator_types)
87
88 # Better to give a meaningful error here than an opaque "could not draw"
89 # when we try to get a value but have lost track of where this was created.
90 if strat.is_empty:
91 raise ResolutionFailed(
92 "Cannot infer a strategy from the default, validator, type, or "
93 "converter for attribute=%r of class=%r" % (attrib, target)
94 )
95 return strat
96
97
98 def types_to_strategy(attrib, types):
99 """Find all the type metadata for this attribute, reconcile it, and infer a
100 strategy from the mess."""
101 # If we know types from the validator(s), that's sufficient.
102 if len(types) == 1:
103 (typ,) = types
104 if isinstance(typ, tuple):
105 return st.one_of(*map(st.from_type, typ))
106 return st.from_type(typ)
107 elif types:
108 # We have a list of tuples of types, and want to find a type
109 # (or tuple of types) that is a subclass of all of of them.
110 type_tuples = [k if isinstance(k, tuple) else (k,) for k in types]
111 # Flatten the list, filter types that would fail validation, and
112 # sort so that ordering is stable between runs and shrinks well.
113 allowed = [
114 t
115 for t in set(sum(type_tuples, ()))
116 if all(issubclass(t, tup) for tup in type_tuples)
117 ]
118 allowed.sort(key=type_sorting_key)
119 return st.one_of([st.from_type(t) for t in allowed])
120
121 # Otherwise, try the `type` attribute as a fallback, and finally try
122 # the type hints on a converter (desperate!) before giving up.
123 if is_a_type(getattr(attrib, "type", None)):
124 # The convoluted test is because variable annotations may be stored
125 # in string form; attrs doesn't evaluate them and we don't handle them.
126 # See PEP 526, PEP 563, and Hypothesis issue #1004 for details.
127 return st.from_type(attrib.type)
128
129 converter = getattr(attrib, "converter", None)
130 if isinstance(converter, type):
131 return st.from_type(converter)
132 elif callable(converter):
133 hints = get_type_hints(converter)
134 if "return" in hints:
135 return st.from_type(hints["return"])
136
137 return st.nothing()
138
139
140 def ordered_intersection(in_):
141 """Set union of n sequences, ordered for reproducibility across runs."""
142 intersection = reduce(set.intersection, in_, set(in_[0]))
143 for x in chain.from_iterable(in_):
144 if x in intersection:
145 yield x
146 intersection.remove(x)
147
148
149 def all_substrings(s):
150 """Generate all substrings of `s`, in order of length then occurrence.
151 Includes the empty string (first), and any duplicates that are present.
152
153 >>> list(all_substrings('010'))
154 ['', '0', '1', '0', '01', '10', '010']
155 """
156 yield s[:0]
157 for n, _ in enumerate(s):
158 for i in range(len(s) - n):
159 yield s[i : i + n + 1]
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py b/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py
--- a/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py
+++ b/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py
@@ -21,6 +21,7 @@
from hypothesis import strategies as st
from hypothesis.errors import ResolutionFailed
from hypothesis.internal.compat import get_type_hints
+from hypothesis.strategies._internal.core import BuildsStrategy
from hypothesis.strategies._internal.types import is_a_type, type_sorting_key
from hypothesis.utils.conventions import infer
@@ -34,9 +35,7 @@
# We might make this strategy more efficient if we added a layer here that
# retries drawing if validation fails, for improved composition.
# The treatment of timezones in datetimes() provides a precedent.
- return st.tuples(st.tuples(*args), st.fixed_dictionaries(kwargs)).map(
- lambda value: target(*value[0], **value[1])
- )
+ return BuildsStrategy(target, args, kwargs)
def from_attrs_attribute(attrib, target):
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py b/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py\n--- a/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py\n+++ b/hypothesis-python/src/hypothesis/strategies/_internal/attrs.py\n@@ -21,6 +21,7 @@\n from hypothesis import strategies as st\n from hypothesis.errors import ResolutionFailed\n from hypothesis.internal.compat import get_type_hints\n+from hypothesis.strategies._internal.core import BuildsStrategy\n from hypothesis.strategies._internal.types import is_a_type, type_sorting_key\n from hypothesis.utils.conventions import infer\n \n@@ -34,9 +35,7 @@\n # We might make this strategy more efficient if we added a layer here that\n # retries drawing if validation fails, for improved composition.\n # The treatment of timezones in datetimes() provides a precedent.\n- return st.tuples(st.tuples(*args), st.fixed_dictionaries(kwargs)).map(\n- lambda value: target(*value[0], **value[1])\n- )\n+ return BuildsStrategy(target, args, kwargs)\n \n \n def from_attrs_attribute(attrib, target):\n", "issue": "Ghostwriter error on attrs class\nWhile playing around with the ghostwriter today, I got an exception like this one running it against some internal code:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/tmp/repro/venv/bin/hypothesis\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/click/core.py\", line 1137, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/click/core.py\", line 1062, in main\r\n rv = self.invoke(ctx)\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/click/core.py\", line 1668, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/click/core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/click/core.py\", line 763, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/cli.py\", line 242, in write\r\n code = getattr(ghostwriter, writer)(*func, except_=except_ or (), style=style)\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py\", line 882, in magic\r\n make_(\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py\", line 802, in make_\r\n imp, body = how(*args, **kwargs, except_=except_, style=style)\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py\", line 626, in _make_test_body\r\n given_strategies = given_strategies or _get_strategies(\r\n File \"/tmp/repro/venv/lib/python3.9/site-packages/hypothesis/extra/ghostwriter.py\", line 409, in _get_strategies\r\n if strat.args:\r\nAttributeError: 'MappedSearchStrategy' object has no attribute 'args'\r\n```\r\n\r\nI reduced the input to trigger this exception down to\r\n\r\n```python\r\nimport attr\r\n\r\[email protected]()\r\nclass Foo:\r\n foo: str = attr.ib()\r\n```\r\n\r\nI saw this with cPython 3.9.6, attrs 21.2.0, and hypothesis master branch at hypothesis-python-6.14.5-5-g9d4da6c2f. \n", "before_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom functools import reduce\nfrom itertools import chain\n\nimport attr\n\nfrom hypothesis import strategies as st\nfrom hypothesis.errors import ResolutionFailed\nfrom hypothesis.internal.compat import get_type_hints\nfrom hypothesis.strategies._internal.types import is_a_type, type_sorting_key\nfrom hypothesis.utils.conventions import infer\n\n\ndef from_attrs(target, args, kwargs, to_infer):\n \"\"\"An internal version of builds(), specialised for Attrs classes.\"\"\"\n fields = attr.fields(target)\n kwargs = {k: v for k, v in kwargs.items() if v is not infer}\n for name in to_infer:\n kwargs[name] = from_attrs_attribute(getattr(fields, name), target)\n # We might make this strategy more efficient if we added a layer here that\n # retries drawing if validation fails, for improved composition.\n # The treatment of timezones in datetimes() provides a precedent.\n return st.tuples(st.tuples(*args), st.fixed_dictionaries(kwargs)).map(\n lambda value: target(*value[0], **value[1])\n )\n\n\ndef from_attrs_attribute(attrib, target):\n \"\"\"Infer a strategy from the metadata on an attr.Attribute object.\"\"\"\n # Try inferring from the default argument. Note that this will only help if\n # the user passed `infer` to builds() for this attribute, but in that case\n # we use it as the minimal example.\n default = st.nothing()\n if isinstance(attrib.default, attr.Factory):\n if not attrib.default.takes_self:\n default = st.builds(attrib.default.factory)\n elif attrib.default is not attr.NOTHING:\n default = st.just(attrib.default)\n\n # Try inferring None, exact values, or type from attrs provided validators.\n null = st.nothing() # updated to none() on seeing an OptionalValidator\n in_collections = [] # list of in_ validator collections to sample from\n validator_types = set() # type constraints to pass to types_to_strategy()\n if attrib.validator is not None:\n validator = attrib.validator\n if isinstance(validator, attr.validators._OptionalValidator):\n null = st.none()\n validator = validator.validator\n if isinstance(validator, attr.validators._AndValidator):\n vs = validator._validators\n else:\n vs = [validator]\n for v in vs:\n if isinstance(v, attr.validators._InValidator):\n if isinstance(v.options, str):\n in_collections.append(list(all_substrings(v.options)))\n else:\n in_collections.append(v.options)\n elif isinstance(v, attr.validators._InstanceOfValidator):\n validator_types.add(v.type)\n\n # This is the important line. We compose the final strategy from various\n # parts. The default value, if any, is the minimal shrink, followed by\n # None (again, if allowed). We then prefer to sample from values passed\n # to an in_ validator if available, but infer from a type otherwise.\n # Pick one because (sampled_from((1, 2)) | from_type(int)) would usually\n # fail validation by generating e.g. zero!\n if in_collections:\n sample = st.sampled_from(list(ordered_intersection(in_collections)))\n strat = default | null | sample\n else:\n strat = default | null | types_to_strategy(attrib, validator_types)\n\n # Better to give a meaningful error here than an opaque \"could not draw\"\n # when we try to get a value but have lost track of where this was created.\n if strat.is_empty:\n raise ResolutionFailed(\n \"Cannot infer a strategy from the default, validator, type, or \"\n \"converter for attribute=%r of class=%r\" % (attrib, target)\n )\n return strat\n\n\ndef types_to_strategy(attrib, types):\n \"\"\"Find all the type metadata for this attribute, reconcile it, and infer a\n strategy from the mess.\"\"\"\n # If we know types from the validator(s), that's sufficient.\n if len(types) == 1:\n (typ,) = types\n if isinstance(typ, tuple):\n return st.one_of(*map(st.from_type, typ))\n return st.from_type(typ)\n elif types:\n # We have a list of tuples of types, and want to find a type\n # (or tuple of types) that is a subclass of all of of them.\n type_tuples = [k if isinstance(k, tuple) else (k,) for k in types]\n # Flatten the list, filter types that would fail validation, and\n # sort so that ordering is stable between runs and shrinks well.\n allowed = [\n t\n for t in set(sum(type_tuples, ()))\n if all(issubclass(t, tup) for tup in type_tuples)\n ]\n allowed.sort(key=type_sorting_key)\n return st.one_of([st.from_type(t) for t in allowed])\n\n # Otherwise, try the `type` attribute as a fallback, and finally try\n # the type hints on a converter (desperate!) before giving up.\n if is_a_type(getattr(attrib, \"type\", None)):\n # The convoluted test is because variable annotations may be stored\n # in string form; attrs doesn't evaluate them and we don't handle them.\n # See PEP 526, PEP 563, and Hypothesis issue #1004 for details.\n return st.from_type(attrib.type)\n\n converter = getattr(attrib, \"converter\", None)\n if isinstance(converter, type):\n return st.from_type(converter)\n elif callable(converter):\n hints = get_type_hints(converter)\n if \"return\" in hints:\n return st.from_type(hints[\"return\"])\n\n return st.nothing()\n\n\ndef ordered_intersection(in_):\n \"\"\"Set union of n sequences, ordered for reproducibility across runs.\"\"\"\n intersection = reduce(set.intersection, in_, set(in_[0]))\n for x in chain.from_iterable(in_):\n if x in intersection:\n yield x\n intersection.remove(x)\n\n\ndef all_substrings(s):\n \"\"\"Generate all substrings of `s`, in order of length then occurrence.\n Includes the empty string (first), and any duplicates that are present.\n\n >>> list(all_substrings('010'))\n ['', '0', '1', '0', '01', '10', '010']\n \"\"\"\n yield s[:0]\n for n, _ in enumerate(s):\n for i in range(len(s) - n):\n yield s[i : i + n + 1]\n", "path": "hypothesis-python/src/hypothesis/strategies/_internal/attrs.py"}], "after_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom functools import reduce\nfrom itertools import chain\n\nimport attr\n\nfrom hypothesis import strategies as st\nfrom hypothesis.errors import ResolutionFailed\nfrom hypothesis.internal.compat import get_type_hints\nfrom hypothesis.strategies._internal.core import BuildsStrategy\nfrom hypothesis.strategies._internal.types import is_a_type, type_sorting_key\nfrom hypothesis.utils.conventions import infer\n\n\ndef from_attrs(target, args, kwargs, to_infer):\n \"\"\"An internal version of builds(), specialised for Attrs classes.\"\"\"\n fields = attr.fields(target)\n kwargs = {k: v for k, v in kwargs.items() if v is not infer}\n for name in to_infer:\n kwargs[name] = from_attrs_attribute(getattr(fields, name), target)\n # We might make this strategy more efficient if we added a layer here that\n # retries drawing if validation fails, for improved composition.\n # The treatment of timezones in datetimes() provides a precedent.\n return BuildsStrategy(target, args, kwargs)\n\n\ndef from_attrs_attribute(attrib, target):\n \"\"\"Infer a strategy from the metadata on an attr.Attribute object.\"\"\"\n # Try inferring from the default argument. Note that this will only help if\n # the user passed `infer` to builds() for this attribute, but in that case\n # we use it as the minimal example.\n default = st.nothing()\n if isinstance(attrib.default, attr.Factory):\n if not attrib.default.takes_self:\n default = st.builds(attrib.default.factory)\n elif attrib.default is not attr.NOTHING:\n default = st.just(attrib.default)\n\n # Try inferring None, exact values, or type from attrs provided validators.\n null = st.nothing() # updated to none() on seeing an OptionalValidator\n in_collections = [] # list of in_ validator collections to sample from\n validator_types = set() # type constraints to pass to types_to_strategy()\n if attrib.validator is not None:\n validator = attrib.validator\n if isinstance(validator, attr.validators._OptionalValidator):\n null = st.none()\n validator = validator.validator\n if isinstance(validator, attr.validators._AndValidator):\n vs = validator._validators\n else:\n vs = [validator]\n for v in vs:\n if isinstance(v, attr.validators._InValidator):\n if isinstance(v.options, str):\n in_collections.append(list(all_substrings(v.options)))\n else:\n in_collections.append(v.options)\n elif isinstance(v, attr.validators._InstanceOfValidator):\n validator_types.add(v.type)\n\n # This is the important line. We compose the final strategy from various\n # parts. The default value, if any, is the minimal shrink, followed by\n # None (again, if allowed). We then prefer to sample from values passed\n # to an in_ validator if available, but infer from a type otherwise.\n # Pick one because (sampled_from((1, 2)) | from_type(int)) would usually\n # fail validation by generating e.g. zero!\n if in_collections:\n sample = st.sampled_from(list(ordered_intersection(in_collections)))\n strat = default | null | sample\n else:\n strat = default | null | types_to_strategy(attrib, validator_types)\n\n # Better to give a meaningful error here than an opaque \"could not draw\"\n # when we try to get a value but have lost track of where this was created.\n if strat.is_empty:\n raise ResolutionFailed(\n \"Cannot infer a strategy from the default, validator, type, or \"\n \"converter for attribute=%r of class=%r\" % (attrib, target)\n )\n return strat\n\n\ndef types_to_strategy(attrib, types):\n \"\"\"Find all the type metadata for this attribute, reconcile it, and infer a\n strategy from the mess.\"\"\"\n # If we know types from the validator(s), that's sufficient.\n if len(types) == 1:\n (typ,) = types\n if isinstance(typ, tuple):\n return st.one_of(*map(st.from_type, typ))\n return st.from_type(typ)\n elif types:\n # We have a list of tuples of types, and want to find a type\n # (or tuple of types) that is a subclass of all of of them.\n type_tuples = [k if isinstance(k, tuple) else (k,) for k in types]\n # Flatten the list, filter types that would fail validation, and\n # sort so that ordering is stable between runs and shrinks well.\n allowed = [\n t\n for t in set(sum(type_tuples, ()))\n if all(issubclass(t, tup) for tup in type_tuples)\n ]\n allowed.sort(key=type_sorting_key)\n return st.one_of([st.from_type(t) for t in allowed])\n\n # Otherwise, try the `type` attribute as a fallback, and finally try\n # the type hints on a converter (desperate!) before giving up.\n if is_a_type(getattr(attrib, \"type\", None)):\n # The convoluted test is because variable annotations may be stored\n # in string form; attrs doesn't evaluate them and we don't handle them.\n # See PEP 526, PEP 563, and Hypothesis issue #1004 for details.\n return st.from_type(attrib.type)\n\n converter = getattr(attrib, \"converter\", None)\n if isinstance(converter, type):\n return st.from_type(converter)\n elif callable(converter):\n hints = get_type_hints(converter)\n if \"return\" in hints:\n return st.from_type(hints[\"return\"])\n\n return st.nothing()\n\n\ndef ordered_intersection(in_):\n \"\"\"Set union of n sequences, ordered for reproducibility across runs.\"\"\"\n intersection = reduce(set.intersection, in_, set(in_[0]))\n for x in chain.from_iterable(in_):\n if x in intersection:\n yield x\n intersection.remove(x)\n\n\ndef all_substrings(s):\n \"\"\"Generate all substrings of `s`, in order of length then occurrence.\n Includes the empty string (first), and any duplicates that are present.\n\n >>> list(all_substrings('010'))\n ['', '0', '1', '0', '01', '10', '010']\n \"\"\"\n yield s[:0]\n for n, _ in enumerate(s):\n for i in range(len(s) - n):\n yield s[i : i + n + 1]\n", "path": "hypothesis-python/src/hypothesis/strategies/_internal/attrs.py"}]}
| 2,851 | 265 |
gh_patches_debug_35419
|
rasdani/github-patches
|
git_diff
|
ManimCommunity__manim-99
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
remove all of manim/files/
It contains svg files specific to 3b1b.
Remove OpenCV and SceneFromVideo
opencv does not seem to be used anywhere other than in ScenefromVideo, which seems to be broken.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_namespace_packages
2
3 setup(
4 name="manimlib",
5 version="0.2.0",
6 description="Animation engine for explanatory math videos",
7 license="MIT",
8 packages=find_namespace_packages(),
9 package_data={ "manim": ["*.tex"] },
10 entry_points={
11 "console_scripts": [
12 "manim=manim.__main__:main",
13 "manimcm=manim.__main__:main",
14 ]
15 },
16 install_requires=[
17 "argparse",
18 "colour",
19 "numpy",
20 "Pillow",
21 "progressbar",
22 "scipy",
23 "tqdm",
24 "opencv-python",
25 "pycairo",
26 "pydub",
27 "pygments",
28 "pyreadline; sys_platform == 'win32'",
29 "rich",
30 ],
31 )
32
```
Path: `manim/__init__.py`
Content:
```
1 #!/usr/bin/env python
2 from .constants import *
3
4 from .animation.animation import *
5 from .animation.composition import *
6 from .animation.creation import *
7 from .animation.fading import *
8 from .animation.growing import *
9 from .animation.indication import *
10 from .animation.movement import *
11 from .animation.numbers import *
12 from .animation.rotation import *
13 from .animation.specialized import *
14 from .animation.transform import *
15 from .animation.update import *
16
17 from .camera.camera import *
18 from .camera.mapping_camera import *
19 from .camera.moving_camera import *
20 from .camera.three_d_camera import *
21
22 from .mobject.coordinate_systems import *
23 from .mobject.changing import *
24 from .mobject.frame import *
25 from .mobject.functions import *
26 from .mobject.geometry import *
27 from .mobject.matrix import *
28 from .mobject.mobject import *
29 from .mobject.number_line import *
30 from .mobject.numbers import *
31 from .mobject.probability import *
32 from .mobject.shape_matchers import *
33 from .mobject.svg.brace import *
34 from .mobject.svg.drawings import *
35 from .mobject.svg.svg_mobject import *
36 from .mobject.svg.tex_mobject import *
37 from .mobject.svg.text_mobject import *
38 from .mobject.svg.code_mobject import *
39 from .mobject.three_d_utils import *
40 from .mobject.three_dimensions import *
41 from .mobject.types.image_mobject import *
42 from .mobject.types.point_cloud_mobject import *
43 from .mobject.types.vectorized_mobject import *
44 from .mobject.mobject_update_utils import *
45 from .mobject.value_tracker import *
46 from .mobject.vector_field import *
47
48 from .scene.graph_scene import *
49 from .scene.moving_camera_scene import *
50 from .scene.reconfigurable_scene import *
51 from .scene.scene import *
52 from .scene.sample_space_scene import *
53 from .scene.graph_scene import *
54 from .scene.scene_from_video import *
55 from .scene.three_d_scene import *
56 from .scene.vector_space_scene import *
57 from .scene.zoomed_scene import *
58
59 from .utils.bezier import *
60 from .utils.color import *
61 from .utils.config_ops import *
62 from .utils.debug import *
63 from .utils.images import *
64 from .utils.iterables import *
65 from .utils.file_ops import *
66 from .utils.paths import *
67 from .utils.rate_functions import *
68 from .utils.simple_functions import *
69 from .utils.sounds import *
70 from .utils.space_ops import *
71 from .utils.strings import *
72
```
Path: `manim/scene/scene_from_video.py`
Content:
```
1 # from tqdm import tqdm as show_progress
2 # import cv2
3
4 # from ..scene.scene import Scene
5 # from ..logger import logger
6
7
8 # # TODO, is this depricated?
9 # class SceneFromVideo(Scene):
10 # def construct(self, file_name,
11 # freeze_last_frame=True,
12 # time_range=None):
13 # cap = cv2.VideoCapture(file_name)
14 # self.shape = (
15 # int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)),
16 # int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH))
17 # )
18 # fps = cap.get(cv2.cv.CV_CAP_PROP_FPS)
19 # self.camera.frame_rate = fps
20 # frame_count = int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))
21 # if time_range is None:
22 # start_frame = 0
23 # end_frame = frame_count
24 # else:
25 # start_frame, end_frame = [fps * t for t in time_range]
26
27 # frame_count = end_frame - start_frame
28 # logger.info("Reading in " + file_name + "...")
29 # for count in show_progress(list(range(start_frame, end_frame + 1))):
30 # returned, frame = cap.read()
31 # if not returned:
32 # break
33 # # b, g, r = cv2.split(frame)
34 # # self.frames.append(cv2.merge([r, g, b]))
35 # self.frames.append(frame)
36 # cap.release()
37
38 # if freeze_last_frame and len(self.frames) > 0:
39 # self.original_background = self.background = self.frames[-1]
40
41 # def apply_gaussian_blur(self, ksize=(5, 5), sigmaX=5):
42 # self.frames = [
43 # cv2.GaussianBlur(frame, ksize, sigmaX)
44 # for frame in self.frames
45 # ]
46
47 # def apply_edge_detection(self, threshold1=50, threshold2=100):
48 # edged_frames = [
49 # cv2.Canny(frame, threshold1, threshold2)
50 # for frame in self.frames
51 # ]
52 # for index in range(len(self.frames)):
53 # for i in range(3):
54 # self.frames[index][:, :, i] = edged_frames[index]
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/manim/__init__.py b/manim/__init__.py
--- a/manim/__init__.py
+++ b/manim/__init__.py
@@ -51,7 +51,6 @@
from .scene.scene import *
from .scene.sample_space_scene import *
from .scene.graph_scene import *
-from .scene.scene_from_video import *
from .scene.three_d_scene import *
from .scene.vector_space_scene import *
from .scene.zoomed_scene import *
diff --git a/manim/scene/scene_from_video.py b/manim/scene/scene_from_video.py
deleted file mode 100644
--- a/manim/scene/scene_from_video.py
+++ /dev/null
@@ -1,54 +0,0 @@
-# from tqdm import tqdm as show_progress
-# import cv2
-
-# from ..scene.scene import Scene
-# from ..logger import logger
-
-
-# # TODO, is this depricated?
-# class SceneFromVideo(Scene):
-# def construct(self, file_name,
-# freeze_last_frame=True,
-# time_range=None):
-# cap = cv2.VideoCapture(file_name)
-# self.shape = (
-# int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)),
-# int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH))
-# )
-# fps = cap.get(cv2.cv.CV_CAP_PROP_FPS)
-# self.camera.frame_rate = fps
-# frame_count = int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))
-# if time_range is None:
-# start_frame = 0
-# end_frame = frame_count
-# else:
-# start_frame, end_frame = [fps * t for t in time_range]
-
-# frame_count = end_frame - start_frame
-# logger.info("Reading in " + file_name + "...")
-# for count in show_progress(list(range(start_frame, end_frame + 1))):
-# returned, frame = cap.read()
-# if not returned:
-# break
-# # b, g, r = cv2.split(frame)
-# # self.frames.append(cv2.merge([r, g, b]))
-# self.frames.append(frame)
-# cap.release()
-
-# if freeze_last_frame and len(self.frames) > 0:
-# self.original_background = self.background = self.frames[-1]
-
-# def apply_gaussian_blur(self, ksize=(5, 5), sigmaX=5):
-# self.frames = [
-# cv2.GaussianBlur(frame, ksize, sigmaX)
-# for frame in self.frames
-# ]
-
-# def apply_edge_detection(self, threshold1=50, threshold2=100):
-# edged_frames = [
-# cv2.Canny(frame, threshold1, threshold2)
-# for frame in self.frames
-# ]
-# for index in range(len(self.frames)):
-# for i in range(3):
-# self.frames[index][:, :, i] = edged_frames[index]
\ No newline at end of file
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,7 +21,6 @@
"progressbar",
"scipy",
"tqdm",
- "opencv-python",
"pycairo",
"pydub",
"pygments",
|
{"golden_diff": "diff --git a/manim/__init__.py b/manim/__init__.py\n--- a/manim/__init__.py\n+++ b/manim/__init__.py\n@@ -51,7 +51,6 @@\n from .scene.scene import *\n from .scene.sample_space_scene import *\n from .scene.graph_scene import *\n-from .scene.scene_from_video import *\n from .scene.three_d_scene import *\n from .scene.vector_space_scene import *\n from .scene.zoomed_scene import *\ndiff --git a/manim/scene/scene_from_video.py b/manim/scene/scene_from_video.py\ndeleted file mode 100644\n--- a/manim/scene/scene_from_video.py\n+++ /dev/null\n@@ -1,54 +0,0 @@\n-# from tqdm import tqdm as show_progress\n-# import cv2\n-\n-# from ..scene.scene import Scene\n-# from ..logger import logger\n-\n-\n-# # TODO, is this depricated?\n-# class SceneFromVideo(Scene):\n-# def construct(self, file_name,\n-# freeze_last_frame=True,\n-# time_range=None):\n-# cap = cv2.VideoCapture(file_name)\n-# self.shape = (\n-# int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)),\n-# int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH))\n-# )\n-# fps = cap.get(cv2.cv.CV_CAP_PROP_FPS)\n-# self.camera.frame_rate = fps\n-# frame_count = int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))\n-# if time_range is None:\n-# start_frame = 0\n-# end_frame = frame_count\n-# else:\n-# start_frame, end_frame = [fps * t for t in time_range]\n-\n-# frame_count = end_frame - start_frame\n-# logger.info(\"Reading in \" + file_name + \"...\")\n-# for count in show_progress(list(range(start_frame, end_frame + 1))):\n-# returned, frame = cap.read()\n-# if not returned:\n-# break\n-# # b, g, r = cv2.split(frame)\n-# # self.frames.append(cv2.merge([r, g, b]))\n-# self.frames.append(frame)\n-# cap.release()\n-\n-# if freeze_last_frame and len(self.frames) > 0:\n-# self.original_background = self.background = self.frames[-1]\n-\n-# def apply_gaussian_blur(self, ksize=(5, 5), sigmaX=5):\n-# self.frames = [\n-# cv2.GaussianBlur(frame, ksize, sigmaX)\n-# for frame in self.frames\n-# ]\n-\n-# def apply_edge_detection(self, threshold1=50, threshold2=100):\n-# edged_frames = [\n-# cv2.Canny(frame, threshold1, threshold2)\n-# for frame in self.frames\n-# ]\n-# for index in range(len(self.frames)):\n-# for i in range(3):\n-# self.frames[index][:, :, i] = edged_frames[index]\n\\ No newline at end of file\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,7 +21,6 @@\n \"progressbar\",\n \"scipy\",\n \"tqdm\",\n- \"opencv-python\",\n \"pycairo\",\n \"pydub\",\n \"pygments\",\n", "issue": "remove all of manim/files/\nIt contains svg files specific to 3b1b.\nRemove OpenCV and SceneFromVideo\nopencv does not seem to be used anywhere other than in ScenefromVideo, which seems to be broken.\n", "before_files": [{"content": "from setuptools import setup, find_namespace_packages\n\nsetup(\n name=\"manimlib\",\n version=\"0.2.0\",\n description=\"Animation engine for explanatory math videos\",\n license=\"MIT\",\n packages=find_namespace_packages(),\n package_data={ \"manim\": [\"*.tex\"] },\n entry_points={\n \"console_scripts\": [\n \"manim=manim.__main__:main\",\n \"manimcm=manim.__main__:main\",\n ]\n },\n install_requires=[\n \"argparse\",\n \"colour\",\n \"numpy\",\n \"Pillow\",\n \"progressbar\",\n \"scipy\",\n \"tqdm\",\n \"opencv-python\",\n \"pycairo\",\n \"pydub\",\n \"pygments\",\n \"pyreadline; sys_platform == 'win32'\",\n \"rich\",\n ],\n)\n", "path": "setup.py"}, {"content": "#!/usr/bin/env python\nfrom .constants import *\n\nfrom .animation.animation import *\nfrom .animation.composition import *\nfrom .animation.creation import *\nfrom .animation.fading import *\nfrom .animation.growing import *\nfrom .animation.indication import *\nfrom .animation.movement import *\nfrom .animation.numbers import *\nfrom .animation.rotation import *\nfrom .animation.specialized import *\nfrom .animation.transform import *\nfrom .animation.update import *\n\nfrom .camera.camera import *\nfrom .camera.mapping_camera import *\nfrom .camera.moving_camera import *\nfrom .camera.three_d_camera import *\n\nfrom .mobject.coordinate_systems import *\nfrom .mobject.changing import *\nfrom .mobject.frame import *\nfrom .mobject.functions import *\nfrom .mobject.geometry import *\nfrom .mobject.matrix import *\nfrom .mobject.mobject import *\nfrom .mobject.number_line import *\nfrom .mobject.numbers import *\nfrom .mobject.probability import *\nfrom .mobject.shape_matchers import *\nfrom .mobject.svg.brace import *\nfrom .mobject.svg.drawings import *\nfrom .mobject.svg.svg_mobject import *\nfrom .mobject.svg.tex_mobject import *\nfrom .mobject.svg.text_mobject import *\nfrom .mobject.svg.code_mobject import *\nfrom .mobject.three_d_utils import *\nfrom .mobject.three_dimensions import *\nfrom .mobject.types.image_mobject import *\nfrom .mobject.types.point_cloud_mobject import *\nfrom .mobject.types.vectorized_mobject import *\nfrom .mobject.mobject_update_utils import *\nfrom .mobject.value_tracker import *\nfrom .mobject.vector_field import *\n\nfrom .scene.graph_scene import *\nfrom .scene.moving_camera_scene import *\nfrom .scene.reconfigurable_scene import *\nfrom .scene.scene import *\nfrom .scene.sample_space_scene import *\nfrom .scene.graph_scene import *\nfrom .scene.scene_from_video import *\nfrom .scene.three_d_scene import *\nfrom .scene.vector_space_scene import *\nfrom .scene.zoomed_scene import *\n\nfrom .utils.bezier import *\nfrom .utils.color import *\nfrom .utils.config_ops import *\nfrom .utils.debug import *\nfrom .utils.images import *\nfrom .utils.iterables import *\nfrom .utils.file_ops import *\nfrom .utils.paths import *\nfrom .utils.rate_functions import *\nfrom .utils.simple_functions import *\nfrom .utils.sounds import *\nfrom .utils.space_ops import *\nfrom .utils.strings import *\n", "path": "manim/__init__.py"}, {"content": "# from tqdm import tqdm as show_progress\n# import cv2\n\n# from ..scene.scene import Scene\n# from ..logger import logger\n\n\n# # TODO, is this depricated?\n# class SceneFromVideo(Scene):\n# def construct(self, file_name,\n# freeze_last_frame=True,\n# time_range=None):\n# cap = cv2.VideoCapture(file_name)\n# self.shape = (\n# int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)),\n# int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH))\n# )\n# fps = cap.get(cv2.cv.CV_CAP_PROP_FPS)\n# self.camera.frame_rate = fps\n# frame_count = int(cap.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT))\n# if time_range is None:\n# start_frame = 0\n# end_frame = frame_count\n# else:\n# start_frame, end_frame = [fps * t for t in time_range]\n\n# frame_count = end_frame - start_frame\n# logger.info(\"Reading in \" + file_name + \"...\")\n# for count in show_progress(list(range(start_frame, end_frame + 1))):\n# returned, frame = cap.read()\n# if not returned:\n# break\n# # b, g, r = cv2.split(frame)\n# # self.frames.append(cv2.merge([r, g, b]))\n# self.frames.append(frame)\n# cap.release()\n\n# if freeze_last_frame and len(self.frames) > 0:\n# self.original_background = self.background = self.frames[-1]\n\n# def apply_gaussian_blur(self, ksize=(5, 5), sigmaX=5):\n# self.frames = [\n# cv2.GaussianBlur(frame, ksize, sigmaX)\n# for frame in self.frames\n# ]\n\n# def apply_edge_detection(self, threshold1=50, threshold2=100):\n# edged_frames = [\n# cv2.Canny(frame, threshold1, threshold2)\n# for frame in self.frames\n# ]\n# for index in range(len(self.frames)):\n# for i in range(3):\n# self.frames[index][:, :, i] = edged_frames[index]", "path": "manim/scene/scene_from_video.py"}], "after_files": [{"content": "from setuptools import setup, find_namespace_packages\n\nsetup(\n name=\"manimlib\",\n version=\"0.2.0\",\n description=\"Animation engine for explanatory math videos\",\n license=\"MIT\",\n packages=find_namespace_packages(),\n package_data={ \"manim\": [\"*.tex\"] },\n entry_points={\n \"console_scripts\": [\n \"manim=manim.__main__:main\",\n \"manimcm=manim.__main__:main\",\n ]\n },\n install_requires=[\n \"argparse\",\n \"colour\",\n \"numpy\",\n \"Pillow\",\n \"progressbar\",\n \"scipy\",\n \"tqdm\",\n \"pycairo\",\n \"pydub\",\n \"pygments\",\n \"pyreadline; sys_platform == 'win32'\",\n \"rich\",\n ],\n)\n", "path": "setup.py"}, {"content": "#!/usr/bin/env python\nfrom .constants import *\n\nfrom .animation.animation import *\nfrom .animation.composition import *\nfrom .animation.creation import *\nfrom .animation.fading import *\nfrom .animation.growing import *\nfrom .animation.indication import *\nfrom .animation.movement import *\nfrom .animation.numbers import *\nfrom .animation.rotation import *\nfrom .animation.specialized import *\nfrom .animation.transform import *\nfrom .animation.update import *\n\nfrom .camera.camera import *\nfrom .camera.mapping_camera import *\nfrom .camera.moving_camera import *\nfrom .camera.three_d_camera import *\n\nfrom .mobject.coordinate_systems import *\nfrom .mobject.changing import *\nfrom .mobject.frame import *\nfrom .mobject.functions import *\nfrom .mobject.geometry import *\nfrom .mobject.matrix import *\nfrom .mobject.mobject import *\nfrom .mobject.number_line import *\nfrom .mobject.numbers import *\nfrom .mobject.probability import *\nfrom .mobject.shape_matchers import *\nfrom .mobject.svg.brace import *\nfrom .mobject.svg.drawings import *\nfrom .mobject.svg.svg_mobject import *\nfrom .mobject.svg.tex_mobject import *\nfrom .mobject.svg.text_mobject import *\nfrom .mobject.svg.code_mobject import *\nfrom .mobject.three_d_utils import *\nfrom .mobject.three_dimensions import *\nfrom .mobject.types.image_mobject import *\nfrom .mobject.types.point_cloud_mobject import *\nfrom .mobject.types.vectorized_mobject import *\nfrom .mobject.mobject_update_utils import *\nfrom .mobject.value_tracker import *\nfrom .mobject.vector_field import *\n\nfrom .scene.graph_scene import *\nfrom .scene.moving_camera_scene import *\nfrom .scene.reconfigurable_scene import *\nfrom .scene.scene import *\nfrom .scene.sample_space_scene import *\nfrom .scene.graph_scene import *\nfrom .scene.three_d_scene import *\nfrom .scene.vector_space_scene import *\nfrom .scene.zoomed_scene import *\n\nfrom .utils.bezier import *\nfrom .utils.color import *\nfrom .utils.config_ops import *\nfrom .utils.debug import *\nfrom .utils.images import *\nfrom .utils.iterables import *\nfrom .utils.file_ops import *\nfrom .utils.paths import *\nfrom .utils.rate_functions import *\nfrom .utils.simple_functions import *\nfrom .utils.sounds import *\nfrom .utils.space_ops import *\nfrom .utils.strings import *\n", "path": "manim/__init__.py"}, {"content": null, "path": "manim/scene/scene_from_video.py"}]}
| 1,804 | 771 |
gh_patches_debug_29786
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-2017
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dvc: unify requirements files and setup.py
We have duplication between `requirements.txt` and `setup.py` `install_requires`. We also use three `pip install` lines in docs to set things up. Ideally we would just say:
```bash
pip install -e .[tests]
# or
pip install -e .[all,tests] # for all remotes
```
So this contains several parts:
- [ ] include `requirements.txt` in test requirements with `-r` syntax,
- [ ] parse requirements files in `setup.py` or drop requirement files
- [ ] update contributing docs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 from setuptools.command.build_py import build_py as _build_py
3 import os
4
5
6 # https://packaging.python.org/guides/single-sourcing-package-version/
7 pkg_dir = os.path.dirname(__file__)
8
9 # This will define __version__ implicitly
10 with open(os.path.join(pkg_dir, "dvc", "version.py")) as fobj:
11 exec(fobj.read())
12
13 version = __version__ # noqa: F821
14
15
16 # To achieve consistency between the build version and the one provided
17 # by your package during runtime, you need to **pin** the build version.
18 #
19 # This custom class will replace the version.py module with a **static**
20 # `__version__` that your package can read at runtime, assuring consistancy.
21 #
22 # References:
23 # - https://docs.python.org/3.7/distutils/extending.html
24 # - https://github.com/python/mypy
25 class build_py(_build_py):
26 def pin_version(self):
27 path = os.path.join(self.build_lib, "dvc")
28 self.mkpath(path)
29 with open(os.path.join(path, "version.py"), "w") as fobj:
30 fobj.write("# AUTOGENERATED at build time by setup.py\n")
31 fobj.write('__version__ = "{}"\n'.format(version))
32
33 def run(self):
34 self.execute(self.pin_version, ())
35 _build_py.run(self)
36
37
38 install_requires = [
39 "ply>=3.9", # See https://github.com/pyinstaller/pyinstaller/issues/1945
40 "configparser>=3.5.0",
41 "zc.lockfile>=1.2.1",
42 "future>=0.16.0",
43 "colorama>=0.3.9",
44 "configobj>=5.0.6",
45 "networkx>=2.1",
46 "gitpython>=2.1.8",
47 "setuptools>=34.0.0",
48 "nanotime>=0.5.2",
49 "pyasn1>=0.4.1",
50 "schema>=0.6.7",
51 "jsonpath-ng>=1.4.3",
52 "requests>=2.22.0",
53 "grandalf==0.6",
54 "asciimatics>=1.10.0",
55 "distro>=1.3.0",
56 "appdirs>=1.4.3",
57 "treelib>=1.5.5",
58 "inflect>=2.1.0",
59 "humanize>=0.5.1",
60 "dulwich>=0.19.11",
61 "ruamel.yaml>=0.15.91",
62 ]
63
64 # Extra dependencies for remote integrations
65 gs = ["google-cloud-storage==1.13.0"]
66 s3 = ["boto3==1.9.115"]
67 azure = ["azure-storage-blob==1.3.0"]
68 oss = ["oss2==2.6.1"]
69 ssh = ["paramiko>=2.4.1"]
70 all_remotes = gs + s3 + azure + ssh + oss
71
72 setup(
73 name="dvc",
74 version=version,
75 description="Git for data scientists - manage your code and data together",
76 long_description=open("README.rst", "r").read(),
77 author="Dmitry Petrov",
78 author_email="[email protected]",
79 download_url="https://github.com/iterative/dvc",
80 license="Apache License 2.0",
81 install_requires=install_requires,
82 extras_require={
83 "all": all_remotes,
84 "gs": gs,
85 "s3": s3,
86 "azure": azure,
87 "oss": oss,
88 "ssh": ssh,
89 # NOTE: https://github.com/inveniosoftware/troubleshooting/issues/1
90 ':python_version=="2.7"': ["futures", "pathlib2"],
91 },
92 keywords="data science, data version control, machine learning",
93 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*",
94 classifiers=[
95 "Development Status :: 4 - Beta",
96 "Programming Language :: Python :: 2",
97 "Programming Language :: Python :: 2.7",
98 "Programming Language :: Python :: 3",
99 "Programming Language :: Python :: 3.5",
100 "Programming Language :: Python :: 3.6",
101 "Programming Language :: Python :: 3.7",
102 ],
103 packages=find_packages(exclude=["tests"]),
104 include_package_data=True,
105 url="http://dataversioncontrol.com",
106 entry_points={"console_scripts": ["dvc = dvc.main:main"]},
107 cmdclass={"build_py": build_py},
108 zip_safe=False,
109 )
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,6 +1,7 @@
from setuptools import setup, find_packages
from setuptools.command.build_py import build_py as _build_py
import os
+import sys
# https://packaging.python.org/guides/single-sourcing-package-version/
@@ -69,6 +70,34 @@
ssh = ["paramiko>=2.4.1"]
all_remotes = gs + s3 + azure + ssh + oss
+# Extra dependecies to run tests
+tests_requirements = [
+ "PyInstaller==3.4",
+ "wheel>=0.31.1",
+ "pydot>=1.2.4",
+ # Test requirements:
+ "pytest>=4.4.0",
+ "pytest-timeout>=1.3.3",
+ "pytest-cov>=2.6.1",
+ "pytest-xdist>=1.26.1",
+ "pytest-mock>=1.10.4",
+ "flaky>=3.5.3",
+ "mock>=3.0.0",
+ "xmltodict>=0.11.0",
+ "awscli>=1.16.125",
+ "google-compute-engine",
+ "pywin32; sys_platform == 'win32'",
+ "Pygments", # required by collective.checkdocs,
+ "collective.checkdocs",
+ "flake8",
+ "flake8-docstrings",
+ "jaraco.windows==3.9.2",
+ "mock-ssh-server>=0.5.0",
+]
+
+if (sys.version_info) >= (3, 6):
+ tests_requirements.append("black==19.3b0")
+
setup(
name="dvc",
version=version,
@@ -87,7 +116,8 @@
"oss": oss,
"ssh": ssh,
# NOTE: https://github.com/inveniosoftware/troubleshooting/issues/1
- ':python_version=="2.7"': ["futures", "pathlib2"],
+ ":python_version=='2.7'": ["futures", "pathlib2"],
+ "tests": tests_requirements,
},
keywords="data science, data version control, machine learning",
python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,6 +1,7 @@\n from setuptools import setup, find_packages\n from setuptools.command.build_py import build_py as _build_py\n import os\n+import sys\n \n \n # https://packaging.python.org/guides/single-sourcing-package-version/\n@@ -69,6 +70,34 @@\n ssh = [\"paramiko>=2.4.1\"]\n all_remotes = gs + s3 + azure + ssh + oss\n \n+# Extra dependecies to run tests\n+tests_requirements = [\n+ \"PyInstaller==3.4\",\n+ \"wheel>=0.31.1\",\n+ \"pydot>=1.2.4\",\n+ # Test requirements:\n+ \"pytest>=4.4.0\",\n+ \"pytest-timeout>=1.3.3\",\n+ \"pytest-cov>=2.6.1\",\n+ \"pytest-xdist>=1.26.1\",\n+ \"pytest-mock>=1.10.4\",\n+ \"flaky>=3.5.3\",\n+ \"mock>=3.0.0\",\n+ \"xmltodict>=0.11.0\",\n+ \"awscli>=1.16.125\",\n+ \"google-compute-engine\",\n+ \"pywin32; sys_platform == 'win32'\",\n+ \"Pygments\", # required by collective.checkdocs,\n+ \"collective.checkdocs\",\n+ \"flake8\",\n+ \"flake8-docstrings\",\n+ \"jaraco.windows==3.9.2\",\n+ \"mock-ssh-server>=0.5.0\",\n+]\n+\n+if (sys.version_info) >= (3, 6):\n+ tests_requirements.append(\"black==19.3b0\")\n+\n setup(\n name=\"dvc\",\n version=version,\n@@ -87,7 +116,8 @@\n \"oss\": oss,\n \"ssh\": ssh,\n # NOTE: https://github.com/inveniosoftware/troubleshooting/issues/1\n- ':python_version==\"2.7\"': [\"futures\", \"pathlib2\"],\n+ \":python_version=='2.7'\": [\"futures\", \"pathlib2\"],\n+ \"tests\": tests_requirements,\n },\n keywords=\"data science, data version control, machine learning\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*\",\n", "issue": "dvc: unify requirements files and setup.py\nWe have duplication between `requirements.txt` and `setup.py` `install_requires`. We also use three `pip install` lines in docs to set things up. Ideally we would just say:\r\n```bash\r\npip install -e .[tests]\r\n# or\r\npip install -e .[all,tests] # for all remotes\r\n```\r\nSo this contains several parts:\r\n- [ ] include `requirements.txt` in test requirements with `-r` syntax,\r\n- [ ] parse requirements files in `setup.py` or drop requirement files \r\n- [ ] update contributing docs\n", "before_files": [{"content": "from setuptools import setup, find_packages\nfrom setuptools.command.build_py import build_py as _build_py\nimport os\n\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\npkg_dir = os.path.dirname(__file__)\n\n# This will define __version__ implicitly\nwith open(os.path.join(pkg_dir, \"dvc\", \"version.py\")) as fobj:\n exec(fobj.read())\n\nversion = __version__ # noqa: F821\n\n\n# To achieve consistency between the build version and the one provided\n# by your package during runtime, you need to **pin** the build version.\n#\n# This custom class will replace the version.py module with a **static**\n# `__version__` that your package can read at runtime, assuring consistancy.\n#\n# References:\n# - https://docs.python.org/3.7/distutils/extending.html\n# - https://github.com/python/mypy\nclass build_py(_build_py):\n def pin_version(self):\n path = os.path.join(self.build_lib, \"dvc\")\n self.mkpath(path)\n with open(os.path.join(path, \"version.py\"), \"w\") as fobj:\n fobj.write(\"# AUTOGENERATED at build time by setup.py\\n\")\n fobj.write('__version__ = \"{}\"\\n'.format(version))\n\n def run(self):\n self.execute(self.pin_version, ())\n _build_py.run(self)\n\n\ninstall_requires = [\n \"ply>=3.9\", # See https://github.com/pyinstaller/pyinstaller/issues/1945\n \"configparser>=3.5.0\",\n \"zc.lockfile>=1.2.1\",\n \"future>=0.16.0\",\n \"colorama>=0.3.9\",\n \"configobj>=5.0.6\",\n \"networkx>=2.1\",\n \"gitpython>=2.1.8\",\n \"setuptools>=34.0.0\",\n \"nanotime>=0.5.2\",\n \"pyasn1>=0.4.1\",\n \"schema>=0.6.7\",\n \"jsonpath-ng>=1.4.3\",\n \"requests>=2.22.0\",\n \"grandalf==0.6\",\n \"asciimatics>=1.10.0\",\n \"distro>=1.3.0\",\n \"appdirs>=1.4.3\",\n \"treelib>=1.5.5\",\n \"inflect>=2.1.0\",\n \"humanize>=0.5.1\",\n \"dulwich>=0.19.11\",\n \"ruamel.yaml>=0.15.91\",\n]\n\n# Extra dependencies for remote integrations\ngs = [\"google-cloud-storage==1.13.0\"]\ns3 = [\"boto3==1.9.115\"]\nazure = [\"azure-storage-blob==1.3.0\"]\noss = [\"oss2==2.6.1\"]\nssh = [\"paramiko>=2.4.1\"]\nall_remotes = gs + s3 + azure + ssh + oss\n\nsetup(\n name=\"dvc\",\n version=version,\n description=\"Git for data scientists - manage your code and data together\",\n long_description=open(\"README.rst\", \"r\").read(),\n author=\"Dmitry Petrov\",\n author_email=\"[email protected]\",\n download_url=\"https://github.com/iterative/dvc\",\n license=\"Apache License 2.0\",\n install_requires=install_requires,\n extras_require={\n \"all\": all_remotes,\n \"gs\": gs,\n \"s3\": s3,\n \"azure\": azure,\n \"oss\": oss,\n \"ssh\": ssh,\n # NOTE: https://github.com/inveniosoftware/troubleshooting/issues/1\n ':python_version==\"2.7\"': [\"futures\", \"pathlib2\"],\n },\n keywords=\"data science, data version control, machine learning\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(exclude=[\"tests\"]),\n include_package_data=True,\n url=\"http://dataversioncontrol.com\",\n entry_points={\"console_scripts\": [\"dvc = dvc.main:main\"]},\n cmdclass={\"build_py\": build_py},\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nfrom setuptools.command.build_py import build_py as _build_py\nimport os\nimport sys\n\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\npkg_dir = os.path.dirname(__file__)\n\n# This will define __version__ implicitly\nwith open(os.path.join(pkg_dir, \"dvc\", \"version.py\")) as fobj:\n exec(fobj.read())\n\nversion = __version__ # noqa: F821\n\n\n# To achieve consistency between the build version and the one provided\n# by your package during runtime, you need to **pin** the build version.\n#\n# This custom class will replace the version.py module with a **static**\n# `__version__` that your package can read at runtime, assuring consistancy.\n#\n# References:\n# - https://docs.python.org/3.7/distutils/extending.html\n# - https://github.com/python/mypy\nclass build_py(_build_py):\n def pin_version(self):\n path = os.path.join(self.build_lib, \"dvc\")\n self.mkpath(path)\n with open(os.path.join(path, \"version.py\"), \"w\") as fobj:\n fobj.write(\"# AUTOGENERATED at build time by setup.py\\n\")\n fobj.write('__version__ = \"{}\"\\n'.format(version))\n\n def run(self):\n self.execute(self.pin_version, ())\n _build_py.run(self)\n\n\ninstall_requires = [\n \"ply>=3.9\", # See https://github.com/pyinstaller/pyinstaller/issues/1945\n \"configparser>=3.5.0\",\n \"zc.lockfile>=1.2.1\",\n \"future>=0.16.0\",\n \"colorama>=0.3.9\",\n \"configobj>=5.0.6\",\n \"networkx>=2.1\",\n \"gitpython>=2.1.8\",\n \"setuptools>=34.0.0\",\n \"nanotime>=0.5.2\",\n \"pyasn1>=0.4.1\",\n \"schema>=0.6.7\",\n \"jsonpath-ng>=1.4.3\",\n \"requests>=2.22.0\",\n \"grandalf==0.6\",\n \"asciimatics>=1.10.0\",\n \"distro>=1.3.0\",\n \"appdirs>=1.4.3\",\n \"treelib>=1.5.5\",\n \"inflect>=2.1.0\",\n \"humanize>=0.5.1\",\n \"dulwich>=0.19.11\",\n \"ruamel.yaml>=0.15.91\",\n]\n\n# Extra dependencies for remote integrations\ngs = [\"google-cloud-storage==1.13.0\"]\ns3 = [\"boto3==1.9.115\"]\nazure = [\"azure-storage-blob==1.3.0\"]\noss = [\"oss2==2.6.1\"]\nssh = [\"paramiko>=2.4.1\"]\nall_remotes = gs + s3 + azure + ssh + oss\n\n# Extra dependecies to run tests\ntests_requirements = [\n \"PyInstaller==3.4\",\n \"wheel>=0.31.1\",\n \"pydot>=1.2.4\",\n # Test requirements:\n \"pytest>=4.4.0\",\n \"pytest-timeout>=1.3.3\",\n \"pytest-cov>=2.6.1\",\n \"pytest-xdist>=1.26.1\",\n \"pytest-mock>=1.10.4\",\n \"flaky>=3.5.3\",\n \"mock>=3.0.0\",\n \"xmltodict>=0.11.0\",\n \"awscli>=1.16.125\",\n \"google-compute-engine\",\n \"pywin32; sys_platform == 'win32'\",\n \"Pygments\", # required by collective.checkdocs,\n \"collective.checkdocs\",\n \"flake8\",\n \"flake8-docstrings\",\n \"jaraco.windows==3.9.2\",\n \"mock-ssh-server>=0.5.0\",\n]\n\nif (sys.version_info) >= (3, 6):\n tests_requirements.append(\"black==19.3b0\")\n\nsetup(\n name=\"dvc\",\n version=version,\n description=\"Git for data scientists - manage your code and data together\",\n long_description=open(\"README.rst\", \"r\").read(),\n author=\"Dmitry Petrov\",\n author_email=\"[email protected]\",\n download_url=\"https://github.com/iterative/dvc\",\n license=\"Apache License 2.0\",\n install_requires=install_requires,\n extras_require={\n \"all\": all_remotes,\n \"gs\": gs,\n \"s3\": s3,\n \"azure\": azure,\n \"oss\": oss,\n \"ssh\": ssh,\n # NOTE: https://github.com/inveniosoftware/troubleshooting/issues/1\n \":python_version=='2.7'\": [\"futures\", \"pathlib2\"],\n \"tests\": tests_requirements,\n },\n keywords=\"data science, data version control, machine learning\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(exclude=[\"tests\"]),\n include_package_data=True,\n url=\"http://dataversioncontrol.com\",\n entry_points={\"console_scripts\": [\"dvc = dvc.main:main\"]},\n cmdclass={\"build_py\": build_py},\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 1,659 | 561 |
gh_patches_debug_33113
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-5892
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[feature] support timeout option for watching
### Feature Area
<!-- Uncomment the labels below which are relevant to this feature: -->
<!-- /area frontend -->
<!-- /area backend -->
/area sdk
<!-- /area samples -->
<!-- /area components -->
### What feature would you like to see?
- When we use `kfp run submit -w`, we have to wait forever when run stay at pending.
- However, I'd like to specify the timeout option with it.
### What is the use case or pain point?
- `kfp run submit -t 60` will wait 60 seconds max, until run be completed
- it would use [kfp client's wait_for_run_completion function](https://github.com/kubeflow/pipelines/blob/6a1b841db923e39016f5c6e66eac8698af27831d/sdk/python/kfp/_client.py#L922)
<!-- It helps us understand the benefit of this feature for your use case. -->
### Is there a workaround currently?
If you guys agree, I'd like to implement this feature.
<!-- Without this feature, how do you accomplish your task today? -->
---
<!-- Don't delete message below to encourage users to support your feature request! -->
Love this idea? Give it a 👍. We prioritize fulfilling features with the most 👍.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/kfp/cli/run.py`
Content:
```
1 # Copyright 2018 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 import sys
17 import subprocess
18 import time
19 import json
20 import click
21 import shutil
22
23 from .output import print_output, OutputFormat
24
25
26 @click.group()
27 def run():
28 """manage run resources"""
29 pass
30
31
32 @run.command()
33 @click.option('-e', '--experiment-id', help='Parent experiment ID of listed runs.')
34 @click.option('-m', '--max-size', default=100, help='Max size of the listed runs.')
35 @click.pass_context
36 def list(ctx, experiment_id, max_size):
37 """list recent KFP runs"""
38 client = ctx.obj['client']
39 output_format = ctx.obj['output']
40 response = client.list_runs(experiment_id=experiment_id, page_size=max_size, sort_by='created_at desc')
41 if response and response.runs:
42 _print_runs(response.runs, output_format)
43 else:
44 if output_format == OutputFormat.json.name:
45 msg = json.dumps([])
46 else:
47 msg = 'No runs found.'
48 click.echo(msg)
49
50
51 @run.command()
52 @click.option('-e', '--experiment-name', required=True, help='Experiment name of the run.')
53 @click.option('-r', '--run-name', help='Name of the run.')
54 @click.option('-f', '--package-file', type=click.Path(exists=True, dir_okay=False),
55 help='Path of the pipeline package file.')
56 @click.option('-p', '--pipeline-id', help='ID of the pipeline template.')
57 @click.option('-n', '--pipeline-name', help='Name of the pipeline template.')
58 @click.option('-w', '--watch', is_flag=True, default=False,
59 help='Watch the run status until it finishes.')
60 @click.option('-v', '--version', help='ID of the pipeline version.')
61 @click.argument('args', nargs=-1)
62 @click.pass_context
63 def submit(ctx, experiment_name, run_name, package_file, pipeline_id, pipeline_name, watch,
64 version, args):
65 """submit a KFP run"""
66 client = ctx.obj['client']
67 namespace = ctx.obj['namespace']
68 output_format = ctx.obj['output']
69 if not run_name:
70 run_name = experiment_name
71
72 if not pipeline_id and pipeline_name:
73 pipeline_id = client.get_pipeline_id(name=pipeline_name)
74
75 if not package_file and not pipeline_id and not version:
76 click.echo('You must provide one of [package_file, pipeline_id, version].', err=True)
77 sys.exit(1)
78
79 arg_dict = dict(arg.split('=', maxsplit=1) for arg in args)
80
81 experiment = client.create_experiment(experiment_name)
82 run = client.run_pipeline(experiment.id, run_name, package_file, arg_dict, pipeline_id,
83 version_id=version)
84 _display_run(client, namespace, run.id, watch, output_format)
85
86
87 @run.command()
88 @click.option('-w', '--watch', is_flag=True, default=False,
89 help='Watch the run status until it finishes.')
90 @click.argument('run-id')
91 @click.pass_context
92 def get(ctx, watch, run_id):
93 """display the details of a KFP run"""
94 client = ctx.obj['client']
95 namespace = ctx.obj['namespace']
96 output_format = ctx.obj['output']
97 _display_run(client, namespace, run_id, watch, output_format)
98
99
100 def _display_run(client, namespace, run_id, watch, output_format):
101 run = client.get_run(run_id).run
102 _print_runs([run], output_format)
103 if not watch:
104 return
105 argo_path = shutil.which('argo')
106 if not argo_path:
107 raise RuntimeError("argo isn't found in $PATH. It's necessary for watch. "
108 "Please make sure it's installed and available. "
109 "Installation instructions be found here - "
110 "https://github.com/argoproj/argo/releases")
111
112 argo_workflow_name = None
113 while True:
114 time.sleep(1)
115 run_detail = client.get_run(run_id)
116 run = run_detail.run
117 if run_detail.pipeline_runtime and run_detail.pipeline_runtime.workflow_manifest:
118 manifest = json.loads(run_detail.pipeline_runtime.workflow_manifest)
119 if manifest['metadata'] and manifest['metadata']['name']:
120 argo_workflow_name = manifest['metadata']['name']
121 break
122 if run_detail.run.status in ['Succeeded', 'Skipped', 'Failed', 'Error']:
123 click.echo('Run is finished with status {}.'.format(run_detail.run.status))
124 return
125 if argo_workflow_name:
126 subprocess.run([argo_path, 'watch', argo_workflow_name, '-n', namespace])
127 _print_runs([run], output_format)
128
129
130 def _print_runs(runs, output_format):
131 headers = ['run id', 'name', 'status', 'created at']
132 data = [[run.id, run.name, run.status, run.created_at.isoformat()] for run in runs]
133 print_output(data, headers, output_format, table_format='grid')
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/kfp/cli/run.py b/sdk/python/kfp/cli/run.py
--- a/sdk/python/kfp/cli/run.py
+++ b/sdk/python/kfp/cli/run.py
@@ -58,10 +58,11 @@
@click.option('-w', '--watch', is_flag=True, default=False,
help='Watch the run status until it finishes.')
@click.option('-v', '--version', help='ID of the pipeline version.')
[email protected]('-t', '--timeout', default=0, help='Wait for a run to complete until timeout in seconds.', type=int)
@click.argument('args', nargs=-1)
@click.pass_context
def submit(ctx, experiment_name, run_name, package_file, pipeline_id, pipeline_name, watch,
- version, args):
+ timeout, version, args):
"""submit a KFP run"""
client = ctx.obj['client']
namespace = ctx.obj['namespace']
@@ -81,7 +82,10 @@
experiment = client.create_experiment(experiment_name)
run = client.run_pipeline(experiment.id, run_name, package_file, arg_dict, pipeline_id,
version_id=version)
- _display_run(client, namespace, run.id, watch, output_format)
+ if timeout > 0:
+ _wait_for_run_completion(client, run.id, timeout, output_format)
+ else:
+ _display_run(client, namespace, run.id, watch, output_format)
@run.command()
@@ -127,6 +131,11 @@
_print_runs([run], output_format)
+def _wait_for_run_completion(client, run_id, timeout, output_format):
+ run_detail = client.wait_for_run_completion(run_id, timeout)
+ _print_runs([run_detail.run], output_format)
+
+
def _print_runs(runs, output_format):
headers = ['run id', 'name', 'status', 'created at']
data = [[run.id, run.name, run.status, run.created_at.isoformat()] for run in runs]
|
{"golden_diff": "diff --git a/sdk/python/kfp/cli/run.py b/sdk/python/kfp/cli/run.py\n--- a/sdk/python/kfp/cli/run.py\n+++ b/sdk/python/kfp/cli/run.py\n@@ -58,10 +58,11 @@\n @click.option('-w', '--watch', is_flag=True, default=False,\n help='Watch the run status until it finishes.')\n @click.option('-v', '--version', help='ID of the pipeline version.')\[email protected]('-t', '--timeout', default=0, help='Wait for a run to complete until timeout in seconds.', type=int)\n @click.argument('args', nargs=-1)\n @click.pass_context\n def submit(ctx, experiment_name, run_name, package_file, pipeline_id, pipeline_name, watch,\n- version, args):\n+ timeout, version, args):\n \"\"\"submit a KFP run\"\"\"\n client = ctx.obj['client']\n namespace = ctx.obj['namespace']\n@@ -81,7 +82,10 @@\n experiment = client.create_experiment(experiment_name)\n run = client.run_pipeline(experiment.id, run_name, package_file, arg_dict, pipeline_id,\n version_id=version)\n- _display_run(client, namespace, run.id, watch, output_format)\n+ if timeout > 0:\n+ _wait_for_run_completion(client, run.id, timeout, output_format)\n+ else:\n+ _display_run(client, namespace, run.id, watch, output_format)\n \n \n @run.command()\n@@ -127,6 +131,11 @@\n _print_runs([run], output_format)\n \n \n+def _wait_for_run_completion(client, run_id, timeout, output_format):\n+ run_detail = client.wait_for_run_completion(run_id, timeout)\n+ _print_runs([run_detail.run], output_format)\n+\n+\n def _print_runs(runs, output_format):\n headers = ['run id', 'name', 'status', 'created at']\n data = [[run.id, run.name, run.status, run.created_at.isoformat()] for run in runs]\n", "issue": "[feature] support timeout option for watching\n### Feature Area\r\n\r\n<!-- Uncomment the labels below which are relevant to this feature: -->\r\n<!-- /area frontend -->\r\n<!-- /area backend -->\r\n/area sdk\r\n<!-- /area samples -->\r\n<!-- /area components -->\r\n\r\n\r\n### What feature would you like to see?\r\n- When we use `kfp run submit -w`, we have to wait forever when run stay at pending.\r\n- However, I'd like to specify the timeout option with it.\r\n\r\n### What is the use case or pain point?\r\n- `kfp run submit -t 60` will wait 60 seconds max, until run be completed\r\n- it would use [kfp client's wait_for_run_completion function](https://github.com/kubeflow/pipelines/blob/6a1b841db923e39016f5c6e66eac8698af27831d/sdk/python/kfp/_client.py#L922)\r\n\r\n<!-- It helps us understand the benefit of this feature for your use case. -->\r\n\r\n### Is there a workaround currently?\r\n\r\nIf you guys agree, I'd like to implement this feature.\r\n\r\n<!-- Without this feature, how do you accomplish your task today? -->\r\n\r\n\r\n---\r\n\r\n<!-- Don't delete message below to encourage users to support your feature request! -->\r\nLove this idea? Give it a \ud83d\udc4d. We prioritize fulfilling features with the most \ud83d\udc4d.\r\n\n", "before_files": [{"content": "# Copyright 2018 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport sys\nimport subprocess\nimport time\nimport json\nimport click\nimport shutil\n\nfrom .output import print_output, OutputFormat\n\n\[email protected]()\ndef run():\n \"\"\"manage run resources\"\"\"\n pass\n\n\[email protected]()\[email protected]('-e', '--experiment-id', help='Parent experiment ID of listed runs.')\[email protected]('-m', '--max-size', default=100, help='Max size of the listed runs.')\[email protected]_context\ndef list(ctx, experiment_id, max_size):\n \"\"\"list recent KFP runs\"\"\"\n client = ctx.obj['client']\n output_format = ctx.obj['output']\n response = client.list_runs(experiment_id=experiment_id, page_size=max_size, sort_by='created_at desc')\n if response and response.runs:\n _print_runs(response.runs, output_format)\n else:\n if output_format == OutputFormat.json.name:\n msg = json.dumps([])\n else:\n msg = 'No runs found.'\n click.echo(msg)\n\n\[email protected]()\[email protected]('-e', '--experiment-name', required=True, help='Experiment name of the run.')\[email protected]('-r', '--run-name', help='Name of the run.')\[email protected]('-f', '--package-file', type=click.Path(exists=True, dir_okay=False),\n help='Path of the pipeline package file.')\[email protected]('-p', '--pipeline-id', help='ID of the pipeline template.')\[email protected]('-n', '--pipeline-name', help='Name of the pipeline template.')\[email protected]('-w', '--watch', is_flag=True, default=False,\n help='Watch the run status until it finishes.')\[email protected]('-v', '--version', help='ID of the pipeline version.')\[email protected]('args', nargs=-1)\[email protected]_context\ndef submit(ctx, experiment_name, run_name, package_file, pipeline_id, pipeline_name, watch,\n version, args):\n \"\"\"submit a KFP run\"\"\"\n client = ctx.obj['client']\n namespace = ctx.obj['namespace']\n output_format = ctx.obj['output']\n if not run_name:\n run_name = experiment_name\n\n if not pipeline_id and pipeline_name:\n pipeline_id = client.get_pipeline_id(name=pipeline_name)\n\n if not package_file and not pipeline_id and not version:\n click.echo('You must provide one of [package_file, pipeline_id, version].', err=True)\n sys.exit(1)\n\n arg_dict = dict(arg.split('=', maxsplit=1) for arg in args)\n\n experiment = client.create_experiment(experiment_name)\n run = client.run_pipeline(experiment.id, run_name, package_file, arg_dict, pipeline_id,\n version_id=version)\n _display_run(client, namespace, run.id, watch, output_format)\n\n\[email protected]()\[email protected]('-w', '--watch', is_flag=True, default=False,\n help='Watch the run status until it finishes.')\[email protected]('run-id')\[email protected]_context\ndef get(ctx, watch, run_id):\n \"\"\"display the details of a KFP run\"\"\"\n client = ctx.obj['client']\n namespace = ctx.obj['namespace']\n output_format = ctx.obj['output']\n _display_run(client, namespace, run_id, watch, output_format)\n\n\ndef _display_run(client, namespace, run_id, watch, output_format):\n run = client.get_run(run_id).run\n _print_runs([run], output_format)\n if not watch:\n return\n argo_path = shutil.which('argo')\n if not argo_path:\n raise RuntimeError(\"argo isn't found in $PATH. It's necessary for watch. \"\n \"Please make sure it's installed and available. \"\n \"Installation instructions be found here - \"\n \"https://github.com/argoproj/argo/releases\")\n\n argo_workflow_name = None\n while True:\n time.sleep(1)\n run_detail = client.get_run(run_id)\n run = run_detail.run\n if run_detail.pipeline_runtime and run_detail.pipeline_runtime.workflow_manifest:\n manifest = json.loads(run_detail.pipeline_runtime.workflow_manifest)\n if manifest['metadata'] and manifest['metadata']['name']:\n argo_workflow_name = manifest['metadata']['name']\n break\n if run_detail.run.status in ['Succeeded', 'Skipped', 'Failed', 'Error']:\n click.echo('Run is finished with status {}.'.format(run_detail.run.status))\n return\n if argo_workflow_name:\n subprocess.run([argo_path, 'watch', argo_workflow_name, '-n', namespace])\n _print_runs([run], output_format)\n\n\ndef _print_runs(runs, output_format):\n headers = ['run id', 'name', 'status', 'created at']\n data = [[run.id, run.name, run.status, run.created_at.isoformat()] for run in runs]\n print_output(data, headers, output_format, table_format='grid')\n", "path": "sdk/python/kfp/cli/run.py"}], "after_files": [{"content": "# Copyright 2018 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport sys\nimport subprocess\nimport time\nimport json\nimport click\nimport shutil\n\nfrom .output import print_output, OutputFormat\n\n\[email protected]()\ndef run():\n \"\"\"manage run resources\"\"\"\n pass\n\n\[email protected]()\[email protected]('-e', '--experiment-id', help='Parent experiment ID of listed runs.')\[email protected]('-m', '--max-size', default=100, help='Max size of the listed runs.')\[email protected]_context\ndef list(ctx, experiment_id, max_size):\n \"\"\"list recent KFP runs\"\"\"\n client = ctx.obj['client']\n output_format = ctx.obj['output']\n response = client.list_runs(experiment_id=experiment_id, page_size=max_size, sort_by='created_at desc')\n if response and response.runs:\n _print_runs(response.runs, output_format)\n else:\n if output_format == OutputFormat.json.name:\n msg = json.dumps([])\n else:\n msg = 'No runs found.'\n click.echo(msg)\n\n\[email protected]()\[email protected]('-e', '--experiment-name', required=True, help='Experiment name of the run.')\[email protected]('-r', '--run-name', help='Name of the run.')\[email protected]('-f', '--package-file', type=click.Path(exists=True, dir_okay=False),\n help='Path of the pipeline package file.')\[email protected]('-p', '--pipeline-id', help='ID of the pipeline template.')\[email protected]('-n', '--pipeline-name', help='Name of the pipeline template.')\[email protected]('-w', '--watch', is_flag=True, default=False,\n help='Watch the run status until it finishes.')\[email protected]('-v', '--version', help='ID of the pipeline version.')\[email protected]('-t', '--timeout', default=0, help='Wait for a run to complete until timeout in seconds.', type=int)\[email protected]('args', nargs=-1)\[email protected]_context\ndef submit(ctx, experiment_name, run_name, package_file, pipeline_id, pipeline_name, watch,\n timeout, version, args):\n \"\"\"submit a KFP run\"\"\"\n client = ctx.obj['client']\n namespace = ctx.obj['namespace']\n output_format = ctx.obj['output']\n if not run_name:\n run_name = experiment_name\n\n if not pipeline_id and pipeline_name:\n pipeline_id = client.get_pipeline_id(name=pipeline_name)\n\n if not package_file and not pipeline_id and not version:\n click.echo('You must provide one of [package_file, pipeline_id, version].', err=True)\n sys.exit(1)\n\n arg_dict = dict(arg.split('=', maxsplit=1) for arg in args)\n\n experiment = client.create_experiment(experiment_name)\n run = client.run_pipeline(experiment.id, run_name, package_file, arg_dict, pipeline_id,\n version_id=version)\n if timeout > 0:\n _wait_for_run_completion(client, run.id, timeout, output_format)\n else:\n _display_run(client, namespace, run.id, watch, output_format)\n\n\[email protected]()\[email protected]('-w', '--watch', is_flag=True, default=False,\n help='Watch the run status until it finishes.')\[email protected]('run-id')\[email protected]_context\ndef get(ctx, watch, run_id):\n \"\"\"display the details of a KFP run\"\"\"\n client = ctx.obj['client']\n namespace = ctx.obj['namespace']\n output_format = ctx.obj['output']\n _display_run(client, namespace, run_id, watch, output_format)\n\n\ndef _display_run(client, namespace, run_id, watch, output_format):\n run = client.get_run(run_id).run\n _print_runs([run], output_format)\n if not watch:\n return\n argo_path = shutil.which('argo')\n if not argo_path:\n raise RuntimeError(\"argo isn't found in $PATH. It's necessary for watch. \"\n \"Please make sure it's installed and available. \"\n \"Installation instructions be found here - \"\n \"https://github.com/argoproj/argo/releases\")\n\n argo_workflow_name = None\n while True:\n time.sleep(1)\n run_detail = client.get_run(run_id)\n run = run_detail.run\n if run_detail.pipeline_runtime and run_detail.pipeline_runtime.workflow_manifest:\n manifest = json.loads(run_detail.pipeline_runtime.workflow_manifest)\n if manifest['metadata'] and manifest['metadata']['name']:\n argo_workflow_name = manifest['metadata']['name']\n break\n if run_detail.run.status in ['Succeeded', 'Skipped', 'Failed', 'Error']:\n click.echo('Run is finished with status {}.'.format(run_detail.run.status))\n return\n if argo_workflow_name:\n subprocess.run([argo_path, 'watch', argo_workflow_name, '-n', namespace])\n _print_runs([run], output_format)\n\n\ndef _wait_for_run_completion(client, run_id, timeout, output_format):\n run_detail = client.wait_for_run_completion(run_id, timeout)\n _print_runs([run_detail.run], output_format)\n\n\ndef _print_runs(runs, output_format):\n headers = ['run id', 'name', 'status', 'created at']\n data = [[run.id, run.name, run.status, run.created_at.isoformat()] for run in runs]\n print_output(data, headers, output_format, table_format='grid')\n", "path": "sdk/python/kfp/cli/run.py"}]}
| 2,051 | 445 |
gh_patches_debug_16158
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-5452
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ASV: benchmark timed out (timeout 60.0s) for `TimeLevelAlign`, `TimeStack`, `TimeUnstack`
Due to this error, some cases are not displayed on ASV charts.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `asv_bench/benchmarks/utils/data_shapes.py`
Content:
```
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14 """Define data shapes."""
15
16 import os
17 import json
18
19 from .compatibility import ASV_USE_STORAGE_FORMAT, ASV_DATASET_SIZE
20
21 RAND_LOW = 0
22 RAND_HIGH = 1_000_000_000 if ASV_USE_STORAGE_FORMAT == "hdk" else 100
23
24 BINARY_OP_DATA_SIZE = {
25 "big": [
26 [[5000, 5000], [5000, 5000]],
27 # the case extremely inefficient
28 # [[20, 500_000], [10, 1_000_000]],
29 [[500_000, 20], [1_000_000, 10]],
30 ],
31 "small": [[[250, 250], [250, 250]], [[10_000, 20], [25_000, 10]]],
32 }
33 UNARY_OP_DATA_SIZE = {
34 "big": [
35 [5000, 5000],
36 # the case extremely inefficient
37 # [10, 1_000_000],
38 [1_000_000, 10],
39 ],
40 "small": [[250, 250], [10_000, 10]],
41 }
42 SERIES_DATA_SIZE = {
43 "big": [[100_000, 1]],
44 "small": [[10_000, 1]],
45 }
46 BINARY_OP_SERIES_DATA_SIZE = {
47 "big": [
48 [[500_000, 1], [1_000_000, 1]],
49 [[500_000, 1], [500_000, 1]],
50 ],
51 "small": [[[5_000, 1], [10_000, 1]]],
52 }
53
54
55 HDK_BINARY_OP_DATA_SIZE = {
56 "big": [[[500_000, 20], [1_000_000, 10]]],
57 "small": [[[10_000, 20], [25_000, 10]]],
58 }
59 HDK_UNARY_OP_DATA_SIZE = {
60 "big": [[1_000_000, 10]],
61 "small": [[10_000, 10]],
62 }
63 HDK_SERIES_DATA_SIZE = {
64 "big": [[10_000_000, 1]],
65 "small": [[100_000, 1]],
66 }
67
68 DEFAULT_GROUPBY_NGROUPS = {
69 "big": [100, "huge_amount_groups"],
70 "small": [5],
71 }
72 GROUPBY_NGROUPS = DEFAULT_GROUPBY_NGROUPS[ASV_DATASET_SIZE]
73
74 _DEFAULT_CONFIG_T = [
75 (
76 UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],
77 [
78 # Pandas storage format benchmarks
79 "TimeGroupByMultiColumn",
80 "TimeGroupByDefaultAggregations",
81 "TimeGroupByDictionaryAggregation",
82 "TimeSetItem",
83 "TimeInsert",
84 "TimeArithmetic",
85 "TimeSortValues",
86 "TimeDrop",
87 "TimeHead",
88 "TimeTail",
89 "TimeExplode",
90 "TimeFillna",
91 "TimeFillnaDataFrame",
92 "TimeValueCountsFrame",
93 "TimeValueCountsSeries",
94 "TimeIndexing",
95 "TimeMultiIndexing",
96 "TimeResetIndex",
97 "TimeAstype",
98 "TimeDescribe",
99 "TimeProperties",
100 "TimeReindex",
101 "TimeReindexMethod",
102 "TimeFillnaMethodDataframe",
103 "TimeDropDuplicatesDataframe",
104 "TimeStack",
105 "TimeUnstack",
106 "TimeRepr",
107 "TimeMaskBool",
108 "TimeIsnull",
109 "TimeDropna",
110 "TimeEquals",
111 # IO benchmarks
112 "TimeReadCsvSkiprows",
113 "TimeReadCsvTrueFalseValues",
114 "TimeReadCsvNamesDtype",
115 "TimeReadParquet",
116 # Scalability benchmarks
117 "TimeFromPandas",
118 "TimeToPandas",
119 ],
120 ),
121 (
122 BINARY_OP_DATA_SIZE[ASV_DATASET_SIZE],
123 [
124 # Pandas storage format benchmarks
125 "TimeJoin",
126 "TimeMerge",
127 "TimeMergeDefault",
128 "TimeConcat",
129 "TimeAppend",
130 "TimeBinaryOp",
131 "TimeLevelAlign",
132 ],
133 ),
134 (
135 SERIES_DATA_SIZE[ASV_DATASET_SIZE],
136 [
137 # Pandas storage format benchmarks
138 "TimeFillnaSeries",
139 "TimeGroups",
140 "TimeIndexingNumericSeries",
141 "TimeFillnaMethodSeries",
142 "TimeDatetimeAccessor",
143 "TimeSetCategories",
144 "TimeRemoveCategories",
145 "TimeDropDuplicatesSeries",
146 ],
147 ),
148 (
149 BINARY_OP_SERIES_DATA_SIZE[ASV_DATASET_SIZE],
150 [
151 # Pandas storage format benchmarks
152 "TimeBinaryOpSeries",
153 ],
154 ),
155 ]
156
157 _DEFAULT_HDK_CONFIG_T = [
158 (
159 HDK_UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],
160 [
161 "hdk.TimeJoin",
162 "hdk.TimeBinaryOpDataFrame",
163 "hdk.TimeArithmetic",
164 "hdk.TimeSortValues",
165 "hdk.TimeDrop",
166 "hdk.TimeHead",
167 "hdk.TimeFillna",
168 "hdk.TimeIndexing",
169 "hdk.TimeResetIndex",
170 "hdk.TimeAstype",
171 "hdk.TimeDescribe",
172 "hdk.TimeProperties",
173 "hdk.TimeGroupByDefaultAggregations",
174 "hdk.TimeGroupByMultiColumn",
175 "hdk.TimeValueCountsDataFrame",
176 "hdk.TimeReadCsvNames",
177 ],
178 ),
179 (
180 HDK_BINARY_OP_DATA_SIZE[ASV_DATASET_SIZE],
181 ["hdk.TimeMerge", "hdk.TimeAppend"],
182 ),
183 (
184 HDK_SERIES_DATA_SIZE[ASV_DATASET_SIZE],
185 ["hdk.TimeBinaryOpSeries", "hdk.TimeValueCountsSeries"],
186 ),
187 ]
188 DEFAULT_CONFIG = {}
189 DEFAULT_CONFIG["MergeCategoricals"] = (
190 [[10_000, 2]] if ASV_DATASET_SIZE == "big" else [[1_000, 2]]
191 )
192 DEFAULT_CONFIG["TimeJoinStringIndex"] = (
193 [[100_000, 64]] if ASV_DATASET_SIZE == "big" else [[1_000, 4]]
194 )
195 DEFAULT_CONFIG["TimeReplace"] = (
196 [[10_000, 2]] if ASV_DATASET_SIZE == "big" else [[1_000, 2]]
197 )
198 for config in (_DEFAULT_CONFIG_T, _DEFAULT_HDK_CONFIG_T):
199 for _shape, _names in config:
200 DEFAULT_CONFIG.update({_name: _shape for _name in _names})
201
202 # Correct forms in the case when the operation ended with a timeout error
203 if ASV_DATASET_SIZE == "big":
204 DEFAULT_CONFIG["TimeMergeDefault"] = [
205 [[1000, 1000], [1000, 1000]],
206 [[500_000, 20], [1_000_000, 10]],
207 ]
208
209 CONFIG_FROM_FILE = None
210
211
212 def get_benchmark_shapes(bench_id: str):
213 """
214 Get custom benchmark shapes from a json file stored in MODIN_ASV_DATASIZE_CONFIG.
215
216 If `bench_id` benchmark is not found in the file, then the default value will
217 be used.
218
219 Parameters
220 ----------
221 bench_id : str
222 Unique benchmark identifier that is used to get shapes.
223
224 Returns
225 -------
226 list
227 Benchmark shapes.
228 """
229 global CONFIG_FROM_FILE
230 if not CONFIG_FROM_FILE:
231 try:
232 from modin.config import AsvDataSizeConfig
233
234 filename = AsvDataSizeConfig.get()
235 except ImportError:
236 filename = os.environ.get("MODIN_ASV_DATASIZE_CONFIG", None)
237 if filename:
238 # should be json
239 with open(filename) as _f:
240 CONFIG_FROM_FILE = json.load(_f)
241
242 if CONFIG_FROM_FILE and bench_id in CONFIG_FROM_FILE:
243 # example: "hdk.TimeReadCsvNames": [[5555, 55], [3333, 33]]
244 return CONFIG_FROM_FILE[bench_id]
245 return DEFAULT_CONFIG[bench_id]
246
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/asv_bench/benchmarks/utils/data_shapes.py b/asv_bench/benchmarks/utils/data_shapes.py
--- a/asv_bench/benchmarks/utils/data_shapes.py
+++ b/asv_bench/benchmarks/utils/data_shapes.py
@@ -199,12 +199,21 @@
for _shape, _names in config:
DEFAULT_CONFIG.update({_name: _shape for _name in _names})
-# Correct forms in the case when the operation ended with a timeout error
+# Correct shapes in the case when the operation ended with a timeout error
if ASV_DATASET_SIZE == "big":
DEFAULT_CONFIG["TimeMergeDefault"] = [
[[1000, 1000], [1000, 1000]],
[[500_000, 20], [1_000_000, 10]],
]
+ DEFAULT_CONFIG["TimeLevelAlign"] = [
+ [[2500, 2500], [2500, 2500]],
+ [[250_000, 20], [500_000, 10]],
+ ]
+ DEFAULT_CONFIG["TimeStack"] = [
+ [1500, 1500],
+ [100_000, 10],
+ ]
+ DEFAULT_CONFIG["TimeUnstack"] = DEFAULT_CONFIG["TimeStack"]
CONFIG_FROM_FILE = None
|
{"golden_diff": "diff --git a/asv_bench/benchmarks/utils/data_shapes.py b/asv_bench/benchmarks/utils/data_shapes.py\n--- a/asv_bench/benchmarks/utils/data_shapes.py\n+++ b/asv_bench/benchmarks/utils/data_shapes.py\n@@ -199,12 +199,21 @@\n for _shape, _names in config:\n DEFAULT_CONFIG.update({_name: _shape for _name in _names})\n \n-# Correct forms in the case when the operation ended with a timeout error\n+# Correct shapes in the case when the operation ended with a timeout error\n if ASV_DATASET_SIZE == \"big\":\n DEFAULT_CONFIG[\"TimeMergeDefault\"] = [\n [[1000, 1000], [1000, 1000]],\n [[500_000, 20], [1_000_000, 10]],\n ]\n+ DEFAULT_CONFIG[\"TimeLevelAlign\"] = [\n+ [[2500, 2500], [2500, 2500]],\n+ [[250_000, 20], [500_000, 10]],\n+ ]\n+ DEFAULT_CONFIG[\"TimeStack\"] = [\n+ [1500, 1500],\n+ [100_000, 10],\n+ ]\n+ DEFAULT_CONFIG[\"TimeUnstack\"] = DEFAULT_CONFIG[\"TimeStack\"]\n \n CONFIG_FROM_FILE = None\n", "issue": "ASV: benchmark timed out (timeout 60.0s) for `TimeLevelAlign`, `TimeStack`, `TimeUnstack`\nDue to this error, some cases are not displayed on ASV charts.\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\"\"\"Define data shapes.\"\"\"\n\nimport os\nimport json\n\nfrom .compatibility import ASV_USE_STORAGE_FORMAT, ASV_DATASET_SIZE\n\nRAND_LOW = 0\nRAND_HIGH = 1_000_000_000 if ASV_USE_STORAGE_FORMAT == \"hdk\" else 100\n\nBINARY_OP_DATA_SIZE = {\n \"big\": [\n [[5000, 5000], [5000, 5000]],\n # the case extremely inefficient\n # [[20, 500_000], [10, 1_000_000]],\n [[500_000, 20], [1_000_000, 10]],\n ],\n \"small\": [[[250, 250], [250, 250]], [[10_000, 20], [25_000, 10]]],\n}\nUNARY_OP_DATA_SIZE = {\n \"big\": [\n [5000, 5000],\n # the case extremely inefficient\n # [10, 1_000_000],\n [1_000_000, 10],\n ],\n \"small\": [[250, 250], [10_000, 10]],\n}\nSERIES_DATA_SIZE = {\n \"big\": [[100_000, 1]],\n \"small\": [[10_000, 1]],\n}\nBINARY_OP_SERIES_DATA_SIZE = {\n \"big\": [\n [[500_000, 1], [1_000_000, 1]],\n [[500_000, 1], [500_000, 1]],\n ],\n \"small\": [[[5_000, 1], [10_000, 1]]],\n}\n\n\nHDK_BINARY_OP_DATA_SIZE = {\n \"big\": [[[500_000, 20], [1_000_000, 10]]],\n \"small\": [[[10_000, 20], [25_000, 10]]],\n}\nHDK_UNARY_OP_DATA_SIZE = {\n \"big\": [[1_000_000, 10]],\n \"small\": [[10_000, 10]],\n}\nHDK_SERIES_DATA_SIZE = {\n \"big\": [[10_000_000, 1]],\n \"small\": [[100_000, 1]],\n}\n\nDEFAULT_GROUPBY_NGROUPS = {\n \"big\": [100, \"huge_amount_groups\"],\n \"small\": [5],\n}\nGROUPBY_NGROUPS = DEFAULT_GROUPBY_NGROUPS[ASV_DATASET_SIZE]\n\n_DEFAULT_CONFIG_T = [\n (\n UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeGroupByMultiColumn\",\n \"TimeGroupByDefaultAggregations\",\n \"TimeGroupByDictionaryAggregation\",\n \"TimeSetItem\",\n \"TimeInsert\",\n \"TimeArithmetic\",\n \"TimeSortValues\",\n \"TimeDrop\",\n \"TimeHead\",\n \"TimeTail\",\n \"TimeExplode\",\n \"TimeFillna\",\n \"TimeFillnaDataFrame\",\n \"TimeValueCountsFrame\",\n \"TimeValueCountsSeries\",\n \"TimeIndexing\",\n \"TimeMultiIndexing\",\n \"TimeResetIndex\",\n \"TimeAstype\",\n \"TimeDescribe\",\n \"TimeProperties\",\n \"TimeReindex\",\n \"TimeReindexMethod\",\n \"TimeFillnaMethodDataframe\",\n \"TimeDropDuplicatesDataframe\",\n \"TimeStack\",\n \"TimeUnstack\",\n \"TimeRepr\",\n \"TimeMaskBool\",\n \"TimeIsnull\",\n \"TimeDropna\",\n \"TimeEquals\",\n # IO benchmarks\n \"TimeReadCsvSkiprows\",\n \"TimeReadCsvTrueFalseValues\",\n \"TimeReadCsvNamesDtype\",\n \"TimeReadParquet\",\n # Scalability benchmarks\n \"TimeFromPandas\",\n \"TimeToPandas\",\n ],\n ),\n (\n BINARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeJoin\",\n \"TimeMerge\",\n \"TimeMergeDefault\",\n \"TimeConcat\",\n \"TimeAppend\",\n \"TimeBinaryOp\",\n \"TimeLevelAlign\",\n ],\n ),\n (\n SERIES_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeFillnaSeries\",\n \"TimeGroups\",\n \"TimeIndexingNumericSeries\",\n \"TimeFillnaMethodSeries\",\n \"TimeDatetimeAccessor\",\n \"TimeSetCategories\",\n \"TimeRemoveCategories\",\n \"TimeDropDuplicatesSeries\",\n ],\n ),\n (\n BINARY_OP_SERIES_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeBinaryOpSeries\",\n ],\n ),\n]\n\n_DEFAULT_HDK_CONFIG_T = [\n (\n HDK_UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n \"hdk.TimeJoin\",\n \"hdk.TimeBinaryOpDataFrame\",\n \"hdk.TimeArithmetic\",\n \"hdk.TimeSortValues\",\n \"hdk.TimeDrop\",\n \"hdk.TimeHead\",\n \"hdk.TimeFillna\",\n \"hdk.TimeIndexing\",\n \"hdk.TimeResetIndex\",\n \"hdk.TimeAstype\",\n \"hdk.TimeDescribe\",\n \"hdk.TimeProperties\",\n \"hdk.TimeGroupByDefaultAggregations\",\n \"hdk.TimeGroupByMultiColumn\",\n \"hdk.TimeValueCountsDataFrame\",\n \"hdk.TimeReadCsvNames\",\n ],\n ),\n (\n HDK_BINARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\"hdk.TimeMerge\", \"hdk.TimeAppend\"],\n ),\n (\n HDK_SERIES_DATA_SIZE[ASV_DATASET_SIZE],\n [\"hdk.TimeBinaryOpSeries\", \"hdk.TimeValueCountsSeries\"],\n ),\n]\nDEFAULT_CONFIG = {}\nDEFAULT_CONFIG[\"MergeCategoricals\"] = (\n [[10_000, 2]] if ASV_DATASET_SIZE == \"big\" else [[1_000, 2]]\n)\nDEFAULT_CONFIG[\"TimeJoinStringIndex\"] = (\n [[100_000, 64]] if ASV_DATASET_SIZE == \"big\" else [[1_000, 4]]\n)\nDEFAULT_CONFIG[\"TimeReplace\"] = (\n [[10_000, 2]] if ASV_DATASET_SIZE == \"big\" else [[1_000, 2]]\n)\nfor config in (_DEFAULT_CONFIG_T, _DEFAULT_HDK_CONFIG_T):\n for _shape, _names in config:\n DEFAULT_CONFIG.update({_name: _shape for _name in _names})\n\n# Correct forms in the case when the operation ended with a timeout error\nif ASV_DATASET_SIZE == \"big\":\n DEFAULT_CONFIG[\"TimeMergeDefault\"] = [\n [[1000, 1000], [1000, 1000]],\n [[500_000, 20], [1_000_000, 10]],\n ]\n\nCONFIG_FROM_FILE = None\n\n\ndef get_benchmark_shapes(bench_id: str):\n \"\"\"\n Get custom benchmark shapes from a json file stored in MODIN_ASV_DATASIZE_CONFIG.\n\n If `bench_id` benchmark is not found in the file, then the default value will\n be used.\n\n Parameters\n ----------\n bench_id : str\n Unique benchmark identifier that is used to get shapes.\n\n Returns\n -------\n list\n Benchmark shapes.\n \"\"\"\n global CONFIG_FROM_FILE\n if not CONFIG_FROM_FILE:\n try:\n from modin.config import AsvDataSizeConfig\n\n filename = AsvDataSizeConfig.get()\n except ImportError:\n filename = os.environ.get(\"MODIN_ASV_DATASIZE_CONFIG\", None)\n if filename:\n # should be json\n with open(filename) as _f:\n CONFIG_FROM_FILE = json.load(_f)\n\n if CONFIG_FROM_FILE and bench_id in CONFIG_FROM_FILE:\n # example: \"hdk.TimeReadCsvNames\": [[5555, 55], [3333, 33]]\n return CONFIG_FROM_FILE[bench_id]\n return DEFAULT_CONFIG[bench_id]\n", "path": "asv_bench/benchmarks/utils/data_shapes.py"}], "after_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\"\"\"Define data shapes.\"\"\"\n\nimport os\nimport json\n\nfrom .compatibility import ASV_USE_STORAGE_FORMAT, ASV_DATASET_SIZE\n\nRAND_LOW = 0\nRAND_HIGH = 1_000_000_000 if ASV_USE_STORAGE_FORMAT == \"hdk\" else 100\n\nBINARY_OP_DATA_SIZE = {\n \"big\": [\n [[5000, 5000], [5000, 5000]],\n # the case extremely inefficient\n # [[20, 500_000], [10, 1_000_000]],\n [[500_000, 20], [1_000_000, 10]],\n ],\n \"small\": [[[250, 250], [250, 250]], [[10_000, 20], [25_000, 10]]],\n}\nUNARY_OP_DATA_SIZE = {\n \"big\": [\n [5000, 5000],\n # the case extremely inefficient\n # [10, 1_000_000],\n [1_000_000, 10],\n ],\n \"small\": [[250, 250], [10_000, 10]],\n}\nSERIES_DATA_SIZE = {\n \"big\": [[100_000, 1]],\n \"small\": [[10_000, 1]],\n}\nBINARY_OP_SERIES_DATA_SIZE = {\n \"big\": [\n [[500_000, 1], [1_000_000, 1]],\n [[500_000, 1], [500_000, 1]],\n ],\n \"small\": [[[5_000, 1], [10_000, 1]]],\n}\n\n\nHDK_BINARY_OP_DATA_SIZE = {\n \"big\": [[[500_000, 20], [1_000_000, 10]]],\n \"small\": [[[10_000, 20], [25_000, 10]]],\n}\nHDK_UNARY_OP_DATA_SIZE = {\n \"big\": [[1_000_000, 10]],\n \"small\": [[10_000, 10]],\n}\nHDK_SERIES_DATA_SIZE = {\n \"big\": [[10_000_000, 1]],\n \"small\": [[100_000, 1]],\n}\n\nDEFAULT_GROUPBY_NGROUPS = {\n \"big\": [100, \"huge_amount_groups\"],\n \"small\": [5],\n}\nGROUPBY_NGROUPS = DEFAULT_GROUPBY_NGROUPS[ASV_DATASET_SIZE]\n\n_DEFAULT_CONFIG_T = [\n (\n UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeGroupByMultiColumn\",\n \"TimeGroupByDefaultAggregations\",\n \"TimeGroupByDictionaryAggregation\",\n \"TimeSetItem\",\n \"TimeInsert\",\n \"TimeArithmetic\",\n \"TimeSortValues\",\n \"TimeDrop\",\n \"TimeHead\",\n \"TimeTail\",\n \"TimeExplode\",\n \"TimeFillna\",\n \"TimeFillnaDataFrame\",\n \"TimeValueCountsFrame\",\n \"TimeValueCountsSeries\",\n \"TimeIndexing\",\n \"TimeMultiIndexing\",\n \"TimeResetIndex\",\n \"TimeAstype\",\n \"TimeDescribe\",\n \"TimeProperties\",\n \"TimeReindex\",\n \"TimeReindexMethod\",\n \"TimeFillnaMethodDataframe\",\n \"TimeDropDuplicatesDataframe\",\n \"TimeStack\",\n \"TimeUnstack\",\n \"TimeRepr\",\n \"TimeMaskBool\",\n \"TimeIsnull\",\n \"TimeDropna\",\n \"TimeEquals\",\n # IO benchmarks\n \"TimeReadCsvSkiprows\",\n \"TimeReadCsvTrueFalseValues\",\n \"TimeReadCsvNamesDtype\",\n \"TimeReadParquet\",\n # Scalability benchmarks\n \"TimeFromPandas\",\n \"TimeToPandas\",\n ],\n ),\n (\n BINARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeJoin\",\n \"TimeMerge\",\n \"TimeMergeDefault\",\n \"TimeConcat\",\n \"TimeAppend\",\n \"TimeBinaryOp\",\n \"TimeLevelAlign\",\n ],\n ),\n (\n SERIES_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeFillnaSeries\",\n \"TimeGroups\",\n \"TimeIndexingNumericSeries\",\n \"TimeFillnaMethodSeries\",\n \"TimeDatetimeAccessor\",\n \"TimeSetCategories\",\n \"TimeRemoveCategories\",\n \"TimeDropDuplicatesSeries\",\n ],\n ),\n (\n BINARY_OP_SERIES_DATA_SIZE[ASV_DATASET_SIZE],\n [\n # Pandas storage format benchmarks\n \"TimeBinaryOpSeries\",\n ],\n ),\n]\n\n_DEFAULT_HDK_CONFIG_T = [\n (\n HDK_UNARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\n \"hdk.TimeJoin\",\n \"hdk.TimeBinaryOpDataFrame\",\n \"hdk.TimeArithmetic\",\n \"hdk.TimeSortValues\",\n \"hdk.TimeDrop\",\n \"hdk.TimeHead\",\n \"hdk.TimeFillna\",\n \"hdk.TimeIndexing\",\n \"hdk.TimeResetIndex\",\n \"hdk.TimeAstype\",\n \"hdk.TimeDescribe\",\n \"hdk.TimeProperties\",\n \"hdk.TimeGroupByDefaultAggregations\",\n \"hdk.TimeGroupByMultiColumn\",\n \"hdk.TimeValueCountsDataFrame\",\n \"hdk.TimeReadCsvNames\",\n ],\n ),\n (\n HDK_BINARY_OP_DATA_SIZE[ASV_DATASET_SIZE],\n [\"hdk.TimeMerge\", \"hdk.TimeAppend\"],\n ),\n (\n HDK_SERIES_DATA_SIZE[ASV_DATASET_SIZE],\n [\"hdk.TimeBinaryOpSeries\", \"hdk.TimeValueCountsSeries\"],\n ),\n]\nDEFAULT_CONFIG = {}\nDEFAULT_CONFIG[\"MergeCategoricals\"] = (\n [[10_000, 2]] if ASV_DATASET_SIZE == \"big\" else [[1_000, 2]]\n)\nDEFAULT_CONFIG[\"TimeJoinStringIndex\"] = (\n [[100_000, 64]] if ASV_DATASET_SIZE == \"big\" else [[1_000, 4]]\n)\nDEFAULT_CONFIG[\"TimeReplace\"] = (\n [[10_000, 2]] if ASV_DATASET_SIZE == \"big\" else [[1_000, 2]]\n)\nfor config in (_DEFAULT_CONFIG_T, _DEFAULT_HDK_CONFIG_T):\n for _shape, _names in config:\n DEFAULT_CONFIG.update({_name: _shape for _name in _names})\n\n# Correct shapes in the case when the operation ended with a timeout error\nif ASV_DATASET_SIZE == \"big\":\n DEFAULT_CONFIG[\"TimeMergeDefault\"] = [\n [[1000, 1000], [1000, 1000]],\n [[500_000, 20], [1_000_000, 10]],\n ]\n DEFAULT_CONFIG[\"TimeLevelAlign\"] = [\n [[2500, 2500], [2500, 2500]],\n [[250_000, 20], [500_000, 10]],\n ]\n DEFAULT_CONFIG[\"TimeStack\"] = [\n [1500, 1500],\n [100_000, 10],\n ]\n DEFAULT_CONFIG[\"TimeUnstack\"] = DEFAULT_CONFIG[\"TimeStack\"]\n\nCONFIG_FROM_FILE = None\n\n\ndef get_benchmark_shapes(bench_id: str):\n \"\"\"\n Get custom benchmark shapes from a json file stored in MODIN_ASV_DATASIZE_CONFIG.\n\n If `bench_id` benchmark is not found in the file, then the default value will\n be used.\n\n Parameters\n ----------\n bench_id : str\n Unique benchmark identifier that is used to get shapes.\n\n Returns\n -------\n list\n Benchmark shapes.\n \"\"\"\n global CONFIG_FROM_FILE\n if not CONFIG_FROM_FILE:\n try:\n from modin.config import AsvDataSizeConfig\n\n filename = AsvDataSizeConfig.get()\n except ImportError:\n filename = os.environ.get(\"MODIN_ASV_DATASIZE_CONFIG\", None)\n if filename:\n # should be json\n with open(filename) as _f:\n CONFIG_FROM_FILE = json.load(_f)\n\n if CONFIG_FROM_FILE and bench_id in CONFIG_FROM_FILE:\n # example: \"hdk.TimeReadCsvNames\": [[5555, 55], [3333, 33]]\n return CONFIG_FROM_FILE[bench_id]\n return DEFAULT_CONFIG[bench_id]\n", "path": "asv_bench/benchmarks/utils/data_shapes.py"}]}
| 3,011 | 339 |
gh_patches_debug_120
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-1896
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upgrade `release/1.4` to Torch 2.0.1 + TensorRT 8.6.1
- Also upgrade `main` to TensorRT 8.6.1 (as a commit to #1852)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py/versions.py`
Content:
```
1 __version__ = "1.4.0.rc0"
2 __cuda_version__ = "11.8"
3 __cudnn_version__ = "8.8"
4 __tensorrt_version__ = "8.6"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/py/versions.py b/py/versions.py
--- a/py/versions.py
+++ b/py/versions.py
@@ -1,4 +1,4 @@
-__version__ = "1.4.0.rc0"
+__version__ = "1.4.0"
__cuda_version__ = "11.8"
__cudnn_version__ = "8.8"
__tensorrt_version__ = "8.6"
|
{"golden_diff": "diff --git a/py/versions.py b/py/versions.py\n--- a/py/versions.py\n+++ b/py/versions.py\n@@ -1,4 +1,4 @@\n-__version__ = \"1.4.0.rc0\"\n+__version__ = \"1.4.0\"\n __cuda_version__ = \"11.8\"\n __cudnn_version__ = \"8.8\"\n __tensorrt_version__ = \"8.6\"\n", "issue": "Upgrade `release/1.4` to Torch 2.0.1 + TensorRT 8.6.1\n- Also upgrade `main` to TensorRT 8.6.1 (as a commit to #1852)\n", "before_files": [{"content": "__version__ = \"1.4.0.rc0\"\n__cuda_version__ = \"11.8\"\n__cudnn_version__ = \"8.8\"\n__tensorrt_version__ = \"8.6\"\n", "path": "py/versions.py"}], "after_files": [{"content": "__version__ = \"1.4.0\"\n__cuda_version__ = \"11.8\"\n__cudnn_version__ = \"8.8\"\n__tensorrt_version__ = \"8.6\"\n", "path": "py/versions.py"}]}
| 362 | 98 |
gh_patches_debug_23202
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-616
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check: CKV_GCP_19 False positive
**Describe the bug**
Checkov Will flag your code even if the `basic-auth` is already disabled on your cluster.
**To Reproduce**
Steps to reproduce the behavior:
1. Have a file as follows:
```
resource "google_container_cluster" "cluster-test" {
name = "cluster-test"
location = "europe-west1-c"
provider = google-beta
remove_default_node_pool = true
initial_node_count = 1
enable_shielded_nodes = true
release_channel {
channel = "RAPID"
}
pod_security_policy_config {
enabled = true
}
master_auth {
username = ""
password = ""
client_certificate_config {
issue_client_certificate = false
}
}
}
```
2. Run cli command 'checkov -d path/to/your/terraform/folder.'
3. See error:
```
Check: CKV_GCP_19: "Ensure GKE basic auth is disabled"
FAILED for resource: google_container_cluster.cluster-test
File: /cluster.tf:1-27
Guide: https://docs.bridgecrew.io/docs/bc_gcp_kubernetes_11
1 | resource "google_container_cluster" "cluster-test" {
2 | name = "cluster-test"
3 | location = "europe-west1-c"
4 | provider = google-beta
5 |
6 | remove_default_node_pool = true
7 | initial_node_count = 1
8 |
9 | enable_shielded_nodes = true
10 |
11 | release_channel {
12 | channel = "RAPID"
13 | }
14 |
15 | pod_security_policy_config {
16 | enabled = true
17 | }
18 |
19 | master_auth {
20 | username = ""
21 | password = ""
22 |
23 | client_certificate_config {
24 | issue_client_certificate = false
25 | }
26 | }
27 | }
```
**Expected behavior**
```
Check: CKV_GCP_19: "Ensure GKE basic auth is disabled"
PASSED for resource: google_container_cluster.cluster-test
File: /cluster.tf:1-27
Guide: https://docs.bridgecrew.io/docs/bc_gcp_kubernetes_7
```
The `basic-auth` is already supposed to be disabled using this bit of code as:
```
master_auth {
username = ""
password = ""
client_certificate_config {
issue_client_certificate = false
}
}
```
**Environment:**
- CI: Github Actions
- OS: Ubuntu-lastest
- Checkov Version [latest]
- Terraform v0.12.24
**Additional context**
Tested and installed today following documentation available here: https://www.checkov.io/1.Introduction/Getting%20Started.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/gcp/GKEBasicAuth.py`
Content:
```
1 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
2 from checkov.common.models.enums import CheckResult, CheckCategories
3
4
5 class GKEBasicAuth(BaseResourceCheck):
6 def __init__(self):
7 name = "Ensure GKE basic auth is disabled"
8 id = "CKV_GCP_19"
9 supported_resources = ['google_container_cluster']
10 categories = [CheckCategories.KUBERNETES]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def scan_resource_conf(self, conf):
14 """
15 Looks for password configuration at azure_instance:
16 https://www.terraform.io/docs/providers/google/r/compute_ssl_policy.html
17 :param conf: google_compute_ssl_policy configuration
18 :return: <CheckResult>
19 """
20 if 'master_auth' in conf.keys():
21 if conf['master_auth'][0].get('username') or conf['master_auth'][0].get('password'):
22 return CheckResult.FAILED
23 return CheckResult.PASSED
24 return CheckResult.FAILED
25
26
27 check = GKEBasicAuth()
28
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py b/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py
--- a/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py
+++ b/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py
@@ -1,5 +1,5 @@
-from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
from checkov.common.models.enums import CheckResult, CheckCategories
+from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
class GKEBasicAuth(BaseResourceCheck):
@@ -18,7 +18,13 @@
:return: <CheckResult>
"""
if 'master_auth' in conf.keys():
- if conf['master_auth'][0].get('username') or conf['master_auth'][0].get('password'):
+ username = conf['master_auth'][0].get('username')
+ password = conf['master_auth'][0].get('password')
+ if username or password:
+ # only if both are set to the empty string it is fine
+ # https://www.terraform.io/docs/providers/google/r/container_cluster.html
+ if len(username) == 1 and len(password) == 1 and username[0] == '' and password[0] == '':
+ return CheckResult.PASSED
return CheckResult.FAILED
return CheckResult.PASSED
return CheckResult.FAILED
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py b/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py\n--- a/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py\n+++ b/checkov/terraform/checks/resource/gcp/GKEBasicAuth.py\n@@ -1,5 +1,5 @@\n-from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n from checkov.common.models.enums import CheckResult, CheckCategories\n+from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n \n \n class GKEBasicAuth(BaseResourceCheck):\n@@ -18,7 +18,13 @@\n :return: <CheckResult>\n \"\"\"\n if 'master_auth' in conf.keys():\n- if conf['master_auth'][0].get('username') or conf['master_auth'][0].get('password'):\n+ username = conf['master_auth'][0].get('username')\n+ password = conf['master_auth'][0].get('password')\n+ if username or password:\n+ # only if both are set to the empty string it is fine\n+ # https://www.terraform.io/docs/providers/google/r/container_cluster.html\n+ if len(username) == 1 and len(password) == 1 and username[0] == '' and password[0] == '':\n+ return CheckResult.PASSED\n return CheckResult.FAILED\n return CheckResult.PASSED\n return CheckResult.FAILED\n", "issue": "Check: CKV_GCP_19 False positive\n**Describe the bug**\r\nCheckov Will flag your code even if the `basic-auth` is already disabled on your cluster.\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Have a file as follows:\r\n``` \r\nresource \"google_container_cluster\" \"cluster-test\" {\r\n name = \"cluster-test\"\r\n location = \"europe-west1-c\"\r\n provider = google-beta\r\n\r\n remove_default_node_pool = true\r\n initial_node_count = 1\r\n\r\n enable_shielded_nodes = true\r\n\r\n release_channel {\r\n channel = \"RAPID\"\r\n }\r\n\r\n pod_security_policy_config {\r\n enabled = true\r\n }\r\n\r\n master_auth {\r\n username = \"\"\r\n password = \"\"\r\n\r\n client_certificate_config {\r\n issue_client_certificate = false\r\n }\r\n }\r\n}\r\n``` \r\n2. Run cli command 'checkov -d path/to/your/terraform/folder.'\r\n3. See error:\r\n``` \r\nCheck: CKV_GCP_19: \"Ensure GKE basic auth is disabled\"\r\n\tFAILED for resource: google_container_cluster.cluster-test\r\n\tFile: /cluster.tf:1-27\r\n\tGuide: https://docs.bridgecrew.io/docs/bc_gcp_kubernetes_11\r\n\r\n\t\t1 | resource \"google_container_cluster\" \"cluster-test\" {\r\n\t\t2 | name = \"cluster-test\"\r\n\t\t3 | location = \"europe-west1-c\"\r\n\t\t4 | provider = google-beta\r\n\t\t5 | \r\n\t\t6 | remove_default_node_pool = true\r\n\t\t7 | initial_node_count = 1\r\n\t\t8 | \r\n\t\t9 | enable_shielded_nodes = true\r\n\t\t10 | \r\n\t\t11 | release_channel {\r\n\t\t12 | channel = \"RAPID\"\r\n\t\t13 | }\r\n\t\t14 | \r\n\t\t15 | pod_security_policy_config {\r\n\t\t16 | enabled = true\r\n\t\t17 | }\r\n\t\t18 | \r\n\t\t19 | master_auth {\r\n\t\t20 | username = \"\"\r\n\t\t21 | password = \"\"\r\n\t\t22 | \r\n\t\t23 | client_certificate_config {\r\n\t\t24 | issue_client_certificate = false\r\n\t\t25 | }\r\n\t\t26 | }\r\n\t\t27 | }\r\n``` \r\n\r\n**Expected behavior**\r\n``` \r\nCheck: CKV_GCP_19: \"Ensure GKE basic auth is disabled\"\r\n\tPASSED for resource: google_container_cluster.cluster-test\r\n\tFile: /cluster.tf:1-27\r\n\tGuide: https://docs.bridgecrew.io/docs/bc_gcp_kubernetes_7\r\n``` \r\n\r\nThe `basic-auth` is already supposed to be disabled using this bit of code as:\r\n``` \r\n master_auth {\r\n username = \"\"\r\n password = \"\"\r\n\r\n client_certificate_config {\r\n issue_client_certificate = false\r\n }\r\n }\r\n```\r\n\r\n**Environment:**\r\n - CI: Github Actions \r\n - OS: Ubuntu-lastest\r\n - Checkov Version [latest]\r\n - Terraform v0.12.24\r\n\r\n**Additional context**\r\nTested and installed today following documentation available here: https://www.checkov.io/1.Introduction/Getting%20Started.html\n", "before_files": [{"content": "from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.common.models.enums import CheckResult, CheckCategories\n\n\nclass GKEBasicAuth(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure GKE basic auth is disabled\"\n id = \"CKV_GCP_19\"\n supported_resources = ['google_container_cluster']\n categories = [CheckCategories.KUBERNETES]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for password configuration at azure_instance:\n https://www.terraform.io/docs/providers/google/r/compute_ssl_policy.html\n :param conf: google_compute_ssl_policy configuration\n :return: <CheckResult>\n \"\"\"\n if 'master_auth' in conf.keys():\n if conf['master_auth'][0].get('username') or conf['master_auth'][0].get('password'):\n return CheckResult.FAILED\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = GKEBasicAuth()\n", "path": "checkov/terraform/checks/resource/gcp/GKEBasicAuth.py"}], "after_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass GKEBasicAuth(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure GKE basic auth is disabled\"\n id = \"CKV_GCP_19\"\n supported_resources = ['google_container_cluster']\n categories = [CheckCategories.KUBERNETES]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n Looks for password configuration at azure_instance:\n https://www.terraform.io/docs/providers/google/r/compute_ssl_policy.html\n :param conf: google_compute_ssl_policy configuration\n :return: <CheckResult>\n \"\"\"\n if 'master_auth' in conf.keys():\n username = conf['master_auth'][0].get('username')\n password = conf['master_auth'][0].get('password')\n if username or password:\n # only if both are set to the empty string it is fine\n # https://www.terraform.io/docs/providers/google/r/container_cluster.html\n if len(username) == 1 and len(password) == 1 and username[0] == '' and password[0] == '':\n return CheckResult.PASSED\n return CheckResult.FAILED\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = GKEBasicAuth()\n", "path": "checkov/terraform/checks/resource/gcp/GKEBasicAuth.py"}]}
| 1,268 | 326 |
gh_patches_debug_17872
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-7847
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'Your internet access is blocked' when using keyboard 'f' to follow a link in a local file to a remote one, but works if clicking with mouse
**Version info**:
<!-- Please copy the first block from :version, not just the qutebrowser version -->
qutebrowser v3.0.0
Git commit:
Backend: QtWebEngine 6.5.2, based on Chromium 108.0.5359.220 (from api)
Qt: 6.5.2
**Does the bug happen if you start with `--temp-basedir`?**:
Yes.
**Description**
I have a bookmarks.html file with commonly-used links. I load the file into qutebrowser with ':open -t file:///home/chris/ckstemp.html'. If I use the keyboard shortcut 'f' to follow a link, then press the link letter (say, 'a'), I get a 'Your internet access is blocked' error page. If instead I click the link with the mouse, the page loads as expected (no error).
I have tried deleting the .cache, and I've tried clearing my browser history.
This is new behavior since I upgraded to qutebrowser 3.0.0 this morning.
**How to reproduce**
<!-- Link to the affected site, or steps to reproduce the issue (if possible/applicable). -->
See above for the steps to reproduces. Here is the contents of my ckstemp.html file:
```
<TITLE>Bookmarks</TITLE>
<DL><p>
<DT><H1>Bookmarks</H1>
<DT><H3>Comics</H3>
<DL><p>
<DT><A HREF="https://www.gocomics.com/foxtrot">Foxtrot</A>
</DL>
</DL>
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/browser/webengine/webengineelem.py`
Content:
```
1 # SPDX-FileCopyrightText: Florian Bruhin (The Compiler) <[email protected]>
2 #
3 # SPDX-License-Identifier: GPL-3.0-or-later
4
5 """QtWebEngine specific part of the web element API."""
6
7 from typing import (
8 TYPE_CHECKING, Any, Callable, Dict, Iterator, Optional, Set, Tuple, Union)
9
10 from qutebrowser.qt.core import QRect, QEventLoop
11 from qutebrowser.qt.widgets import QApplication
12 from qutebrowser.qt.webenginecore import QWebEngineSettings
13
14 from qutebrowser.utils import log, javascript, urlutils, usertypes, utils, version
15 from qutebrowser.browser import webelem
16
17 if TYPE_CHECKING:
18 from qutebrowser.browser.webengine import webenginetab
19
20
21 class WebEngineElement(webelem.AbstractWebElement):
22
23 """A web element for QtWebEngine, using JS under the hood."""
24
25 _tab: "webenginetab.WebEngineTab"
26
27 def __init__(self, js_dict: Dict[str, Any],
28 tab: 'webenginetab.WebEngineTab') -> None:
29 super().__init__(tab)
30 # Do some sanity checks on the data we get from JS
31 js_dict_types: Dict[str, Union[type, Tuple[type, ...]]] = {
32 'id': int,
33 'text': str,
34 'value': (str, int, float),
35 'tag_name': str,
36 'outer_xml': str,
37 'class_name': str,
38 'rects': list,
39 'attributes': dict,
40 'is_content_editable': bool,
41 'caret_position': (int, type(None)),
42 }
43 assert set(js_dict.keys()).issubset(js_dict_types.keys())
44 for name, typ in js_dict_types.items():
45 if name in js_dict and not isinstance(js_dict[name], typ):
46 raise TypeError("Got {} for {} from JS but expected {}: "
47 "{}".format(type(js_dict[name]), name, typ,
48 js_dict))
49 for name, value in js_dict['attributes'].items():
50 if not isinstance(name, str):
51 raise TypeError("Got {} ({}) for attribute name from JS: "
52 "{}".format(name, type(name), js_dict))
53 if not isinstance(value, str):
54 raise TypeError("Got {} ({}) for attribute {} from JS: "
55 "{}".format(value, type(value), name, js_dict))
56 for rect in js_dict['rects']:
57 assert set(rect.keys()) == {'top', 'right', 'bottom', 'left',
58 'height', 'width'}, rect.keys()
59 for value in rect.values():
60 if not isinstance(value, (int, float)):
61 raise TypeError("Got {} ({}) for rect from JS: "
62 "{}".format(value, type(value), js_dict))
63
64 self._id = js_dict['id']
65 self._js_dict = js_dict
66
67 def __str__(self) -> str:
68 return self._js_dict.get('text', '')
69
70 def __eq__(self, other: object) -> bool:
71 if not isinstance(other, WebEngineElement):
72 return NotImplemented
73 return self._id == other._id
74
75 def __getitem__(self, key: str) -> str:
76 attrs = self._js_dict['attributes']
77 return attrs[key]
78
79 def __setitem__(self, key: str, val: str) -> None:
80 self._js_dict['attributes'][key] = val
81 self._js_call('set_attribute', key, val)
82
83 def __delitem__(self, key: str) -> None:
84 utils.unused(key)
85 log.stub()
86
87 def __iter__(self) -> Iterator[str]:
88 return iter(self._js_dict['attributes'])
89
90 def __len__(self) -> int:
91 return len(self._js_dict['attributes'])
92
93 def _js_call(self, name: str, *args: webelem.JsValueType,
94 callback: Callable[[Any], None] = None) -> None:
95 """Wrapper to run stuff from webelem.js."""
96 if self._tab.is_deleted():
97 raise webelem.OrphanedError("Tab containing element vanished")
98 js_code = javascript.assemble('webelem', name, self._id, *args)
99 self._tab.run_js_async(js_code, callback=callback)
100
101 def has_frame(self) -> bool:
102 return True
103
104 def geometry(self) -> QRect:
105 log.stub()
106 return QRect()
107
108 def classes(self) -> Set[str]:
109 """Get a list of classes assigned to this element."""
110 return set(self._js_dict['class_name'].split())
111
112 def tag_name(self) -> str:
113 """Get the tag name of this element.
114
115 The returned name will always be lower-case.
116 """
117 tag = self._js_dict['tag_name']
118 assert isinstance(tag, str), tag
119 return tag.lower()
120
121 def outer_xml(self) -> str:
122 """Get the full HTML representation of this element."""
123 return self._js_dict['outer_xml']
124
125 def is_content_editable_prop(self) -> bool:
126 return self._js_dict['is_content_editable']
127
128 def value(self) -> webelem.JsValueType:
129 return self._js_dict.get('value', None)
130
131 def set_value(self, value: webelem.JsValueType) -> None:
132 self._js_call('set_value', value)
133
134 def dispatch_event(self, event: str,
135 bubbles: bool = False,
136 cancelable: bool = False,
137 composed: bool = False) -> None:
138 self._js_call('dispatch_event', event, bubbles, cancelable, composed)
139
140 def caret_position(self) -> Optional[int]:
141 """Get the text caret position for the current element.
142
143 If the element is not a text element, None is returned.
144 """
145 return self._js_dict.get('caret_position', None)
146
147 def insert_text(self, text: str) -> None:
148 if not self.is_editable(strict=True):
149 raise webelem.Error("Element is not editable!")
150 log.webelem.debug("Inserting text into element {!r}".format(self))
151 self._js_call('insert_text', text)
152
153 def rect_on_view(self, *, elem_geometry: QRect = None,
154 no_js: bool = False) -> QRect:
155 """Get the geometry of the element relative to the webview.
156
157 Skipping of small rectangles is due to <a> elements containing other
158 elements with "display:block" style, see
159 https://github.com/qutebrowser/qutebrowser/issues/1298
160
161 Args:
162 elem_geometry: The geometry of the element, or None.
163 Ignored with QtWebEngine.
164 no_js: Fall back to the Python implementation.
165 Ignored with QtWebEngine.
166 """
167 utils.unused(elem_geometry)
168 utils.unused(no_js)
169 rects = self._js_dict['rects']
170 for rect in rects:
171 # FIXME:qtwebengine
172 # width = rect.get("width", 0)
173 # height = rect.get("height", 0)
174 width = rect['width']
175 height = rect['height']
176 left = rect['left']
177 top = rect['top']
178 if width > 1 and height > 1:
179 # Fix coordinates according to zoom level
180 # We're not checking for zoom.text_only here as that doesn't
181 # exist for QtWebEngine.
182 zoom = self._tab.zoom.factor()
183 rect = QRect(int(left * zoom), int(top * zoom),
184 int(width * zoom), int(height * zoom))
185 # FIXME:qtwebengine
186 # frame = self._elem.webFrame()
187 # while frame is not None:
188 # # Translate to parent frames' position (scroll position
189 # # is taken care of inside getClientRects)
190 # rect.translate(frame.geometry().topLeft())
191 # frame = frame.parentFrame()
192 return rect
193 log.webelem.debug("Couldn't find rectangle for {!r} ({})".format(
194 self, rects))
195 return QRect()
196
197 def remove_blank_target(self) -> None:
198 if self._js_dict['attributes'].get('target') == '_blank':
199 self._js_dict['attributes']['target'] = '_top'
200 self._js_call('remove_blank_target')
201
202 def delete(self) -> None:
203 self._js_call('delete')
204
205 def _move_text_cursor(self) -> None:
206 if self.is_text_input() and self.is_editable():
207 self._js_call('move_cursor_to_end')
208
209 def _requires_user_interaction(self) -> bool:
210 baseurl = self._tab.url()
211 url = self.resolve_url(baseurl)
212 if url is None:
213 return True
214 if baseurl.scheme() == url.scheme(): # e.g. a qute:// link
215 return False
216
217 # Qt 6.3+ needs a user interaction to allow navigations from qute:// to
218 # outside qute:// (like e.g. on qute://bookmarks).
219 versions = version.qtwebengine_versions()
220 if (
221 baseurl.scheme() == "qute" and
222 url.scheme() != "qute" and
223 versions.webengine >= utils.VersionNumber(6, 3)
224 ):
225 return True
226
227 return url.scheme() not in urlutils.WEBENGINE_SCHEMES
228
229 def _click_editable(self, click_target: usertypes.ClickTarget) -> None:
230 # This actually "clicks" the element by calling focus() on it in JS.
231 self._js_call('focus')
232 self._move_text_cursor()
233
234 def _click_js(self, _click_target: usertypes.ClickTarget) -> None:
235 # FIXME:qtwebengine Have a proper API for this
236 # pylint: disable=protected-access
237 view = self._tab._widget
238 assert view is not None
239 # pylint: enable=protected-access
240 attribute = QWebEngineSettings.WebAttribute.JavascriptCanOpenWindows
241 could_open_windows = view.settings().testAttribute(attribute)
242 view.settings().setAttribute(attribute, True)
243
244 # Get QtWebEngine do apply the settings
245 # (it does so with a 0ms QTimer...)
246 # This is also used in Qt's tests:
247 # https://github.com/qt/qtwebengine/commit/5e572e88efa7ba7c2b9138ec19e606d3e345ac90
248 QApplication.processEvents(
249 QEventLoop.ProcessEventsFlag.ExcludeSocketNotifiers |
250 QEventLoop.ProcessEventsFlag.ExcludeUserInputEvents)
251
252 def reset_setting(_arg: Any) -> None:
253 """Set the JavascriptCanOpenWindows setting to its old value."""
254 assert view is not None
255 try:
256 view.settings().setAttribute(attribute, could_open_windows)
257 except RuntimeError:
258 # Happens if this callback gets called during QWebEnginePage
259 # destruction, i.e. if the tab was closed in the meantime.
260 pass
261
262 self._js_call('click', callback=reset_setting)
263
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/browser/webengine/webengineelem.py b/qutebrowser/browser/webengine/webengineelem.py
--- a/qutebrowser/browser/webengine/webengineelem.py
+++ b/qutebrowser/browser/webengine/webengineelem.py
@@ -215,14 +215,16 @@
return False
# Qt 6.3+ needs a user interaction to allow navigations from qute:// to
- # outside qute:// (like e.g. on qute://bookmarks).
+ # outside qute:// (like e.g. on qute://bookmarks), as well as from file:// to
+ # outside of file:// (e.g. users having a local bookmarks.html).
versions = version.qtwebengine_versions()
- if (
- baseurl.scheme() == "qute" and
- url.scheme() != "qute" and
- versions.webengine >= utils.VersionNumber(6, 3)
- ):
- return True
+ for scheme in ["qute", "file"]:
+ if (
+ baseurl.scheme() == scheme and
+ url.scheme() != scheme and
+ versions.webengine >= utils.VersionNumber(6, 3)
+ ):
+ return True
return url.scheme() not in urlutils.WEBENGINE_SCHEMES
|
{"golden_diff": "diff --git a/qutebrowser/browser/webengine/webengineelem.py b/qutebrowser/browser/webengine/webengineelem.py\n--- a/qutebrowser/browser/webengine/webengineelem.py\n+++ b/qutebrowser/browser/webengine/webengineelem.py\n@@ -215,14 +215,16 @@\n return False\n \n # Qt 6.3+ needs a user interaction to allow navigations from qute:// to\n- # outside qute:// (like e.g. on qute://bookmarks).\n+ # outside qute:// (like e.g. on qute://bookmarks), as well as from file:// to\n+ # outside of file:// (e.g. users having a local bookmarks.html).\n versions = version.qtwebengine_versions()\n- if (\n- baseurl.scheme() == \"qute\" and\n- url.scheme() != \"qute\" and\n- versions.webengine >= utils.VersionNumber(6, 3)\n- ):\n- return True\n+ for scheme in [\"qute\", \"file\"]:\n+ if (\n+ baseurl.scheme() == scheme and\n+ url.scheme() != scheme and\n+ versions.webengine >= utils.VersionNumber(6, 3)\n+ ):\n+ return True\n \n return url.scheme() not in urlutils.WEBENGINE_SCHEMES\n", "issue": "'Your internet access is blocked' when using keyboard 'f' to follow a link in a local file to a remote one, but works if clicking with mouse\n**Version info**:\r\n<!-- Please copy the first block from :version, not just the qutebrowser version -->\r\nqutebrowser v3.0.0\r\nGit commit: \r\nBackend: QtWebEngine 6.5.2, based on Chromium 108.0.5359.220 (from api)\r\nQt: 6.5.2\r\n\r\n**Does the bug happen if you start with `--temp-basedir`?**:\r\nYes.\r\n\r\n**Description**\r\nI have a bookmarks.html file with commonly-used links. I load the file into qutebrowser with ':open -t file:///home/chris/ckstemp.html'. If I use the keyboard shortcut 'f' to follow a link, then press the link letter (say, 'a'), I get a 'Your internet access is blocked' error page. If instead I click the link with the mouse, the page loads as expected (no error).\r\n\r\nI have tried deleting the .cache, and I've tried clearing my browser history.\r\n\r\nThis is new behavior since I upgraded to qutebrowser 3.0.0 this morning.\r\n\r\n**How to reproduce**\r\n<!-- Link to the affected site, or steps to reproduce the issue (if possible/applicable). -->\r\n\r\nSee above for the steps to reproduces. Here is the contents of my ckstemp.html file:\r\n\r\n```\r\n<TITLE>Bookmarks</TITLE>\r\n<DL><p>\r\n <DT><H1>Bookmarks</H1>\r\n <DT><H3>Comics</H3>\r\n <DL><p>\r\n <DT><A HREF=\"https://www.gocomics.com/foxtrot\">Foxtrot</A>\r\n </DL>\r\n</DL>\r\n```\r\n\r\n\n", "before_files": [{"content": "# SPDX-FileCopyrightText: Florian Bruhin (The Compiler) <[email protected]>\n#\n# SPDX-License-Identifier: GPL-3.0-or-later\n\n\"\"\"QtWebEngine specific part of the web element API.\"\"\"\n\nfrom typing import (\n TYPE_CHECKING, Any, Callable, Dict, Iterator, Optional, Set, Tuple, Union)\n\nfrom qutebrowser.qt.core import QRect, QEventLoop\nfrom qutebrowser.qt.widgets import QApplication\nfrom qutebrowser.qt.webenginecore import QWebEngineSettings\n\nfrom qutebrowser.utils import log, javascript, urlutils, usertypes, utils, version\nfrom qutebrowser.browser import webelem\n\nif TYPE_CHECKING:\n from qutebrowser.browser.webengine import webenginetab\n\n\nclass WebEngineElement(webelem.AbstractWebElement):\n\n \"\"\"A web element for QtWebEngine, using JS under the hood.\"\"\"\n\n _tab: \"webenginetab.WebEngineTab\"\n\n def __init__(self, js_dict: Dict[str, Any],\n tab: 'webenginetab.WebEngineTab') -> None:\n super().__init__(tab)\n # Do some sanity checks on the data we get from JS\n js_dict_types: Dict[str, Union[type, Tuple[type, ...]]] = {\n 'id': int,\n 'text': str,\n 'value': (str, int, float),\n 'tag_name': str,\n 'outer_xml': str,\n 'class_name': str,\n 'rects': list,\n 'attributes': dict,\n 'is_content_editable': bool,\n 'caret_position': (int, type(None)),\n }\n assert set(js_dict.keys()).issubset(js_dict_types.keys())\n for name, typ in js_dict_types.items():\n if name in js_dict and not isinstance(js_dict[name], typ):\n raise TypeError(\"Got {} for {} from JS but expected {}: \"\n \"{}\".format(type(js_dict[name]), name, typ,\n js_dict))\n for name, value in js_dict['attributes'].items():\n if not isinstance(name, str):\n raise TypeError(\"Got {} ({}) for attribute name from JS: \"\n \"{}\".format(name, type(name), js_dict))\n if not isinstance(value, str):\n raise TypeError(\"Got {} ({}) for attribute {} from JS: \"\n \"{}\".format(value, type(value), name, js_dict))\n for rect in js_dict['rects']:\n assert set(rect.keys()) == {'top', 'right', 'bottom', 'left',\n 'height', 'width'}, rect.keys()\n for value in rect.values():\n if not isinstance(value, (int, float)):\n raise TypeError(\"Got {} ({}) for rect from JS: \"\n \"{}\".format(value, type(value), js_dict))\n\n self._id = js_dict['id']\n self._js_dict = js_dict\n\n def __str__(self) -> str:\n return self._js_dict.get('text', '')\n\n def __eq__(self, other: object) -> bool:\n if not isinstance(other, WebEngineElement):\n return NotImplemented\n return self._id == other._id\n\n def __getitem__(self, key: str) -> str:\n attrs = self._js_dict['attributes']\n return attrs[key]\n\n def __setitem__(self, key: str, val: str) -> None:\n self._js_dict['attributes'][key] = val\n self._js_call('set_attribute', key, val)\n\n def __delitem__(self, key: str) -> None:\n utils.unused(key)\n log.stub()\n\n def __iter__(self) -> Iterator[str]:\n return iter(self._js_dict['attributes'])\n\n def __len__(self) -> int:\n return len(self._js_dict['attributes'])\n\n def _js_call(self, name: str, *args: webelem.JsValueType,\n callback: Callable[[Any], None] = None) -> None:\n \"\"\"Wrapper to run stuff from webelem.js.\"\"\"\n if self._tab.is_deleted():\n raise webelem.OrphanedError(\"Tab containing element vanished\")\n js_code = javascript.assemble('webelem', name, self._id, *args)\n self._tab.run_js_async(js_code, callback=callback)\n\n def has_frame(self) -> bool:\n return True\n\n def geometry(self) -> QRect:\n log.stub()\n return QRect()\n\n def classes(self) -> Set[str]:\n \"\"\"Get a list of classes assigned to this element.\"\"\"\n return set(self._js_dict['class_name'].split())\n\n def tag_name(self) -> str:\n \"\"\"Get the tag name of this element.\n\n The returned name will always be lower-case.\n \"\"\"\n tag = self._js_dict['tag_name']\n assert isinstance(tag, str), tag\n return tag.lower()\n\n def outer_xml(self) -> str:\n \"\"\"Get the full HTML representation of this element.\"\"\"\n return self._js_dict['outer_xml']\n\n def is_content_editable_prop(self) -> bool:\n return self._js_dict['is_content_editable']\n\n def value(self) -> webelem.JsValueType:\n return self._js_dict.get('value', None)\n\n def set_value(self, value: webelem.JsValueType) -> None:\n self._js_call('set_value', value)\n\n def dispatch_event(self, event: str,\n bubbles: bool = False,\n cancelable: bool = False,\n composed: bool = False) -> None:\n self._js_call('dispatch_event', event, bubbles, cancelable, composed)\n\n def caret_position(self) -> Optional[int]:\n \"\"\"Get the text caret position for the current element.\n\n If the element is not a text element, None is returned.\n \"\"\"\n return self._js_dict.get('caret_position', None)\n\n def insert_text(self, text: str) -> None:\n if not self.is_editable(strict=True):\n raise webelem.Error(\"Element is not editable!\")\n log.webelem.debug(\"Inserting text into element {!r}\".format(self))\n self._js_call('insert_text', text)\n\n def rect_on_view(self, *, elem_geometry: QRect = None,\n no_js: bool = False) -> QRect:\n \"\"\"Get the geometry of the element relative to the webview.\n\n Skipping of small rectangles is due to <a> elements containing other\n elements with \"display:block\" style, see\n https://github.com/qutebrowser/qutebrowser/issues/1298\n\n Args:\n elem_geometry: The geometry of the element, or None.\n Ignored with QtWebEngine.\n no_js: Fall back to the Python implementation.\n Ignored with QtWebEngine.\n \"\"\"\n utils.unused(elem_geometry)\n utils.unused(no_js)\n rects = self._js_dict['rects']\n for rect in rects:\n # FIXME:qtwebengine\n # width = rect.get(\"width\", 0)\n # height = rect.get(\"height\", 0)\n width = rect['width']\n height = rect['height']\n left = rect['left']\n top = rect['top']\n if width > 1 and height > 1:\n # Fix coordinates according to zoom level\n # We're not checking for zoom.text_only here as that doesn't\n # exist for QtWebEngine.\n zoom = self._tab.zoom.factor()\n rect = QRect(int(left * zoom), int(top * zoom),\n int(width * zoom), int(height * zoom))\n # FIXME:qtwebengine\n # frame = self._elem.webFrame()\n # while frame is not None:\n # # Translate to parent frames' position (scroll position\n # # is taken care of inside getClientRects)\n # rect.translate(frame.geometry().topLeft())\n # frame = frame.parentFrame()\n return rect\n log.webelem.debug(\"Couldn't find rectangle for {!r} ({})\".format(\n self, rects))\n return QRect()\n\n def remove_blank_target(self) -> None:\n if self._js_dict['attributes'].get('target') == '_blank':\n self._js_dict['attributes']['target'] = '_top'\n self._js_call('remove_blank_target')\n\n def delete(self) -> None:\n self._js_call('delete')\n\n def _move_text_cursor(self) -> None:\n if self.is_text_input() and self.is_editable():\n self._js_call('move_cursor_to_end')\n\n def _requires_user_interaction(self) -> bool:\n baseurl = self._tab.url()\n url = self.resolve_url(baseurl)\n if url is None:\n return True\n if baseurl.scheme() == url.scheme(): # e.g. a qute:// link\n return False\n\n # Qt 6.3+ needs a user interaction to allow navigations from qute:// to\n # outside qute:// (like e.g. on qute://bookmarks).\n versions = version.qtwebengine_versions()\n if (\n baseurl.scheme() == \"qute\" and\n url.scheme() != \"qute\" and\n versions.webengine >= utils.VersionNumber(6, 3)\n ):\n return True\n\n return url.scheme() not in urlutils.WEBENGINE_SCHEMES\n\n def _click_editable(self, click_target: usertypes.ClickTarget) -> None:\n # This actually \"clicks\" the element by calling focus() on it in JS.\n self._js_call('focus')\n self._move_text_cursor()\n\n def _click_js(self, _click_target: usertypes.ClickTarget) -> None:\n # FIXME:qtwebengine Have a proper API for this\n # pylint: disable=protected-access\n view = self._tab._widget\n assert view is not None\n # pylint: enable=protected-access\n attribute = QWebEngineSettings.WebAttribute.JavascriptCanOpenWindows\n could_open_windows = view.settings().testAttribute(attribute)\n view.settings().setAttribute(attribute, True)\n\n # Get QtWebEngine do apply the settings\n # (it does so with a 0ms QTimer...)\n # This is also used in Qt's tests:\n # https://github.com/qt/qtwebengine/commit/5e572e88efa7ba7c2b9138ec19e606d3e345ac90\n QApplication.processEvents(\n QEventLoop.ProcessEventsFlag.ExcludeSocketNotifiers |\n QEventLoop.ProcessEventsFlag.ExcludeUserInputEvents)\n\n def reset_setting(_arg: Any) -> None:\n \"\"\"Set the JavascriptCanOpenWindows setting to its old value.\"\"\"\n assert view is not None\n try:\n view.settings().setAttribute(attribute, could_open_windows)\n except RuntimeError:\n # Happens if this callback gets called during QWebEnginePage\n # destruction, i.e. if the tab was closed in the meantime.\n pass\n\n self._js_call('click', callback=reset_setting)\n", "path": "qutebrowser/browser/webengine/webengineelem.py"}], "after_files": [{"content": "# SPDX-FileCopyrightText: Florian Bruhin (The Compiler) <[email protected]>\n#\n# SPDX-License-Identifier: GPL-3.0-or-later\n\n\"\"\"QtWebEngine specific part of the web element API.\"\"\"\n\nfrom typing import (\n TYPE_CHECKING, Any, Callable, Dict, Iterator, Optional, Set, Tuple, Union)\n\nfrom qutebrowser.qt.core import QRect, QEventLoop\nfrom qutebrowser.qt.widgets import QApplication\nfrom qutebrowser.qt.webenginecore import QWebEngineSettings\n\nfrom qutebrowser.utils import log, javascript, urlutils, usertypes, utils, version\nfrom qutebrowser.browser import webelem\n\nif TYPE_CHECKING:\n from qutebrowser.browser.webengine import webenginetab\n\n\nclass WebEngineElement(webelem.AbstractWebElement):\n\n \"\"\"A web element for QtWebEngine, using JS under the hood.\"\"\"\n\n _tab: \"webenginetab.WebEngineTab\"\n\n def __init__(self, js_dict: Dict[str, Any],\n tab: 'webenginetab.WebEngineTab') -> None:\n super().__init__(tab)\n # Do some sanity checks on the data we get from JS\n js_dict_types: Dict[str, Union[type, Tuple[type, ...]]] = {\n 'id': int,\n 'text': str,\n 'value': (str, int, float),\n 'tag_name': str,\n 'outer_xml': str,\n 'class_name': str,\n 'rects': list,\n 'attributes': dict,\n 'is_content_editable': bool,\n 'caret_position': (int, type(None)),\n }\n assert set(js_dict.keys()).issubset(js_dict_types.keys())\n for name, typ in js_dict_types.items():\n if name in js_dict and not isinstance(js_dict[name], typ):\n raise TypeError(\"Got {} for {} from JS but expected {}: \"\n \"{}\".format(type(js_dict[name]), name, typ,\n js_dict))\n for name, value in js_dict['attributes'].items():\n if not isinstance(name, str):\n raise TypeError(\"Got {} ({}) for attribute name from JS: \"\n \"{}\".format(name, type(name), js_dict))\n if not isinstance(value, str):\n raise TypeError(\"Got {} ({}) for attribute {} from JS: \"\n \"{}\".format(value, type(value), name, js_dict))\n for rect in js_dict['rects']:\n assert set(rect.keys()) == {'top', 'right', 'bottom', 'left',\n 'height', 'width'}, rect.keys()\n for value in rect.values():\n if not isinstance(value, (int, float)):\n raise TypeError(\"Got {} ({}) for rect from JS: \"\n \"{}\".format(value, type(value), js_dict))\n\n self._id = js_dict['id']\n self._js_dict = js_dict\n\n def __str__(self) -> str:\n return self._js_dict.get('text', '')\n\n def __eq__(self, other: object) -> bool:\n if not isinstance(other, WebEngineElement):\n return NotImplemented\n return self._id == other._id\n\n def __getitem__(self, key: str) -> str:\n attrs = self._js_dict['attributes']\n return attrs[key]\n\n def __setitem__(self, key: str, val: str) -> None:\n self._js_dict['attributes'][key] = val\n self._js_call('set_attribute', key, val)\n\n def __delitem__(self, key: str) -> None:\n utils.unused(key)\n log.stub()\n\n def __iter__(self) -> Iterator[str]:\n return iter(self._js_dict['attributes'])\n\n def __len__(self) -> int:\n return len(self._js_dict['attributes'])\n\n def _js_call(self, name: str, *args: webelem.JsValueType,\n callback: Callable[[Any], None] = None) -> None:\n \"\"\"Wrapper to run stuff from webelem.js.\"\"\"\n if self._tab.is_deleted():\n raise webelem.OrphanedError(\"Tab containing element vanished\")\n js_code = javascript.assemble('webelem', name, self._id, *args)\n self._tab.run_js_async(js_code, callback=callback)\n\n def has_frame(self) -> bool:\n return True\n\n def geometry(self) -> QRect:\n log.stub()\n return QRect()\n\n def classes(self) -> Set[str]:\n \"\"\"Get a list of classes assigned to this element.\"\"\"\n return set(self._js_dict['class_name'].split())\n\n def tag_name(self) -> str:\n \"\"\"Get the tag name of this element.\n\n The returned name will always be lower-case.\n \"\"\"\n tag = self._js_dict['tag_name']\n assert isinstance(tag, str), tag\n return tag.lower()\n\n def outer_xml(self) -> str:\n \"\"\"Get the full HTML representation of this element.\"\"\"\n return self._js_dict['outer_xml']\n\n def is_content_editable_prop(self) -> bool:\n return self._js_dict['is_content_editable']\n\n def value(self) -> webelem.JsValueType:\n return self._js_dict.get('value', None)\n\n def set_value(self, value: webelem.JsValueType) -> None:\n self._js_call('set_value', value)\n\n def dispatch_event(self, event: str,\n bubbles: bool = False,\n cancelable: bool = False,\n composed: bool = False) -> None:\n self._js_call('dispatch_event', event, bubbles, cancelable, composed)\n\n def caret_position(self) -> Optional[int]:\n \"\"\"Get the text caret position for the current element.\n\n If the element is not a text element, None is returned.\n \"\"\"\n return self._js_dict.get('caret_position', None)\n\n def insert_text(self, text: str) -> None:\n if not self.is_editable(strict=True):\n raise webelem.Error(\"Element is not editable!\")\n log.webelem.debug(\"Inserting text into element {!r}\".format(self))\n self._js_call('insert_text', text)\n\n def rect_on_view(self, *, elem_geometry: QRect = None,\n no_js: bool = False) -> QRect:\n \"\"\"Get the geometry of the element relative to the webview.\n\n Skipping of small rectangles is due to <a> elements containing other\n elements with \"display:block\" style, see\n https://github.com/qutebrowser/qutebrowser/issues/1298\n\n Args:\n elem_geometry: The geometry of the element, or None.\n Ignored with QtWebEngine.\n no_js: Fall back to the Python implementation.\n Ignored with QtWebEngine.\n \"\"\"\n utils.unused(elem_geometry)\n utils.unused(no_js)\n rects = self._js_dict['rects']\n for rect in rects:\n # FIXME:qtwebengine\n # width = rect.get(\"width\", 0)\n # height = rect.get(\"height\", 0)\n width = rect['width']\n height = rect['height']\n left = rect['left']\n top = rect['top']\n if width > 1 and height > 1:\n # Fix coordinates according to zoom level\n # We're not checking for zoom.text_only here as that doesn't\n # exist for QtWebEngine.\n zoom = self._tab.zoom.factor()\n rect = QRect(int(left * zoom), int(top * zoom),\n int(width * zoom), int(height * zoom))\n # FIXME:qtwebengine\n # frame = self._elem.webFrame()\n # while frame is not None:\n # # Translate to parent frames' position (scroll position\n # # is taken care of inside getClientRects)\n # rect.translate(frame.geometry().topLeft())\n # frame = frame.parentFrame()\n return rect\n log.webelem.debug(\"Couldn't find rectangle for {!r} ({})\".format(\n self, rects))\n return QRect()\n\n def remove_blank_target(self) -> None:\n if self._js_dict['attributes'].get('target') == '_blank':\n self._js_dict['attributes']['target'] = '_top'\n self._js_call('remove_blank_target')\n\n def delete(self) -> None:\n self._js_call('delete')\n\n def _move_text_cursor(self) -> None:\n if self.is_text_input() and self.is_editable():\n self._js_call('move_cursor_to_end')\n\n def _requires_user_interaction(self) -> bool:\n baseurl = self._tab.url()\n url = self.resolve_url(baseurl)\n if url is None:\n return True\n if baseurl.scheme() == url.scheme(): # e.g. a qute:// link\n return False\n\n # Qt 6.3+ needs a user interaction to allow navigations from qute:// to\n # outside qute:// (like e.g. on qute://bookmarks), as well as from file:// to\n # outside of file:// (e.g. users having a local bookmarks.html).\n versions = version.qtwebengine_versions()\n for scheme in [\"qute\", \"file\"]:\n if (\n baseurl.scheme() == scheme and\n url.scheme() != scheme and\n versions.webengine >= utils.VersionNumber(6, 3)\n ):\n return True\n\n return url.scheme() not in urlutils.WEBENGINE_SCHEMES\n\n def _click_editable(self, click_target: usertypes.ClickTarget) -> None:\n # This actually \"clicks\" the element by calling focus() on it in JS.\n self._js_call('focus')\n self._move_text_cursor()\n\n def _click_js(self, _click_target: usertypes.ClickTarget) -> None:\n # FIXME:qtwebengine Have a proper API for this\n # pylint: disable=protected-access\n view = self._tab._widget\n assert view is not None\n # pylint: enable=protected-access\n attribute = QWebEngineSettings.WebAttribute.JavascriptCanOpenWindows\n could_open_windows = view.settings().testAttribute(attribute)\n view.settings().setAttribute(attribute, True)\n\n # Get QtWebEngine do apply the settings\n # (it does so with a 0ms QTimer...)\n # This is also used in Qt's tests:\n # https://github.com/qt/qtwebengine/commit/5e572e88efa7ba7c2b9138ec19e606d3e345ac90\n QApplication.processEvents(\n QEventLoop.ProcessEventsFlag.ExcludeSocketNotifiers |\n QEventLoop.ProcessEventsFlag.ExcludeUserInputEvents)\n\n def reset_setting(_arg: Any) -> None:\n \"\"\"Set the JavascriptCanOpenWindows setting to its old value.\"\"\"\n assert view is not None\n try:\n view.settings().setAttribute(attribute, could_open_windows)\n except RuntimeError:\n # Happens if this callback gets called during QWebEnginePage\n # destruction, i.e. if the tab was closed in the meantime.\n pass\n\n self._js_call('click', callback=reset_setting)\n", "path": "qutebrowser/browser/webengine/webengineelem.py"}]}
| 3,752 | 293 |
gh_patches_debug_6875
|
rasdani/github-patches
|
git_diff
|
nautobot__nautobot-5476
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[v2.2] Team(s) field not pre-populating when editing a Contact
<!--
NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.
This form is only for reporting reproducible bugs. If you need assistance
with Nautobot installation, or if you have a general question, please start a
discussion instead: https://github.com/nautobot/nautobot/discussions
Please describe the environment in which you are running Nautobot. Be sure
that you are running an unmodified instance of the latest stable release
before submitting a bug report, and that any plugins have been disabled.
-->
### Environment
* Nautobot version (Docker tag too if applicable): 2.2.0a1
* Python version: 3.11.8
* Database platform, version: n/a
* Middleware(s): n/a
<!--
Describe in detail the exact steps that someone else can take to reproduce
this bug using the current stable release of Nautobot. Begin with the
creation of any necessary database objects and call out every operation
being performed explicitly. If reporting a bug in the REST API, be sure to
reconstruct the raw HTTP request(s) being made: Don't rely on a client
library such as pynautobot.
-->
### Steps to Reproduce
1. Create a Team
2. Create a Contact and associate it to the Team
3. Edit the Contact
<!-- What did you expect to happen? -->
### Expected Behavior
The existing Team would be displayed in the edit form
<!-- What happened instead? -->
### Observed Behavior
The `Team(s)` field is empty and if you don't reapply the team it will remove it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nautobot/extras/forms/contacts.py`
Content:
```
1 from django import forms
2 from django.contrib.contenttypes.models import ContentType
3
4 from nautobot.core.forms import DynamicModelChoiceField, DynamicModelMultipleChoiceField
5 from nautobot.extras.models import Role, Status
6 from nautobot.extras.models.contacts import Contact, ContactAssociation, Team
7
8 from .base import NautobotBulkEditForm, NautobotFilterForm, NautobotModelForm
9 from .mixins import TagsBulkEditFormMixin
10
11
12 class ContactForm(NautobotModelForm):
13 teams = DynamicModelMultipleChoiceField(
14 queryset=Team.objects.all(),
15 required=False,
16 label="Team(s)",
17 )
18
19 class Meta:
20 model = Contact
21 fields = [
22 "name",
23 "phone",
24 "email",
25 "address",
26 "teams",
27 "comments",
28 "tags",
29 ]
30
31 def save(self, *args, **kwargs):
32 """
33 Since `teams` field on Contact Model is the reverse side of an M2M,
34 we have to override save() method to explictly set the teams for the Contact instance.
35 """
36 teams = self.cleaned_data.get("teams", [])
37 obj = super().save(*args, **kwargs)
38 obj.teams.set(teams)
39 return obj
40
41
42 class ContactBulkEditForm(TagsBulkEditFormMixin, NautobotBulkEditForm):
43 pk = forms.ModelMultipleChoiceField(queryset=Contact.objects.all(), widget=forms.MultipleHiddenInput())
44 phone = forms.CharField(required=False)
45 email = forms.CharField(required=False)
46 address = forms.CharField(required=False, widget=forms.Textarea())
47
48 class Meta:
49 model = Contact
50
51
52 class ContactFilterForm(NautobotFilterForm):
53 model = Contact
54 q = forms.CharField(required=False, label="Search")
55
56
57 class ObjectNewContactForm(NautobotModelForm):
58 teams = DynamicModelMultipleChoiceField(
59 queryset=Team.objects.all(),
60 required=False,
61 label="Team(s)",
62 )
63 associated_object_type = DynamicModelChoiceField(queryset=ContentType.objects.all(), required=True)
64 associated_object_id = forms.CharField(required=True)
65 role = DynamicModelChoiceField(
66 queryset=Role.objects.all(),
67 required=True,
68 query_params={"content_types": ContactAssociation._meta.label_lower},
69 )
70 status = DynamicModelChoiceField(
71 queryset=Status.objects.all(),
72 required=True,
73 query_params={"content_types": ContactAssociation._meta.label_lower},
74 )
75
76 class Meta:
77 model = Contact
78 fields = [
79 "name",
80 "phone",
81 "email",
82 "address",
83 "teams",
84 "comments",
85 "tags",
86 "associated_object_type",
87 "associated_object_id",
88 "role",
89 "status",
90 ]
91
92 def save(self, *args, **kwargs):
93 """
94 Since `teams` field on Contact Model is the reverse side of an M2M,
95 we have to override save() method to explictly set the teams for the Contact instance.
96 """
97 teams = self.cleaned_data.get("teams", [])
98 obj = super().save(*args, **kwargs)
99 obj.teams.set(teams)
100 return obj
101
102
103 class ObjectNewTeamForm(NautobotModelForm):
104 contacts = DynamicModelMultipleChoiceField(
105 queryset=Contact.objects.all(),
106 required=False,
107 label="Contact(s)",
108 )
109 associated_object_type = DynamicModelChoiceField(queryset=ContentType.objects.all(), required=True)
110 associated_object_id = forms.CharField(required=True)
111 role = DynamicModelChoiceField(
112 queryset=Role.objects.all(),
113 required=True,
114 query_params={"content_types": ContactAssociation._meta.label_lower},
115 )
116 status = DynamicModelChoiceField(
117 queryset=Status.objects.all(),
118 required=True,
119 query_params={"content_types": ContactAssociation._meta.label_lower},
120 )
121
122 class Meta:
123 model = Team
124 fields = [
125 "name",
126 "phone",
127 "email",
128 "address",
129 "contacts",
130 "comments",
131 "tags",
132 "associated_object_type",
133 "associated_object_id",
134 "role",
135 "status",
136 ]
137
138
139 class ContactAssociationForm(NautobotModelForm):
140 contact = DynamicModelChoiceField(queryset=Contact.objects.all(), required=False)
141 team = DynamicModelChoiceField(queryset=Team.objects.all(), required=False)
142
143 class Meta:
144 model = ContactAssociation
145 fields = [
146 "contact",
147 "team",
148 "associated_object_type",
149 "associated_object_id",
150 "role",
151 "status",
152 ]
153
154
155 class ContactAssociationBulkEditForm(NautobotBulkEditForm):
156 pk = forms.ModelMultipleChoiceField(queryset=ContactAssociation.objects.all(), widget=forms.MultipleHiddenInput())
157 role = DynamicModelChoiceField(
158 queryset=Role.objects.all(),
159 required=False,
160 query_params={"content_types": ContactAssociation._meta.label_lower},
161 )
162 status = DynamicModelChoiceField(
163 queryset=Status.objects.all(),
164 required=False,
165 query_params={"content_types": ContactAssociation._meta.label_lower},
166 )
167
168 class Meta:
169 model = ContactAssociation
170
171
172 class TeamForm(NautobotModelForm):
173 contacts = DynamicModelMultipleChoiceField(
174 queryset=Contact.objects.all(),
175 required=False,
176 label="Contact(s)",
177 )
178
179 class Meta:
180 model = Team
181 fields = [
182 "name",
183 "phone",
184 "email",
185 "address",
186 "contacts",
187 "comments",
188 "tags",
189 ]
190
191
192 class TeamBulkEditForm(TagsBulkEditFormMixin, NautobotBulkEditForm):
193 pk = forms.ModelMultipleChoiceField(queryset=Team.objects.all(), widget=forms.MultipleHiddenInput())
194 phone = forms.CharField(required=False)
195 email = forms.CharField(required=False)
196 address = forms.CharField(required=False, widget=forms.Textarea())
197
198 class Meta:
199 model = Team
200
201
202 class TeamFilterForm(NautobotFilterForm):
203 model = Team
204 q = forms.CharField(required=False, label="Search")
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nautobot/extras/forms/contacts.py b/nautobot/extras/forms/contacts.py
--- a/nautobot/extras/forms/contacts.py
+++ b/nautobot/extras/forms/contacts.py
@@ -28,6 +28,13 @@
"tags",
]
+ def __init__(self, instance=None, initial=None, **kwargs):
+ if instance is not None:
+ if initial is None:
+ initial = {}
+ initial.setdefault("teams", instance.teams.all())
+ super().__init__(instance=instance, initial=initial, **kwargs)
+
def save(self, *args, **kwargs):
"""
Since `teams` field on Contact Model is the reverse side of an M2M,
|
{"golden_diff": "diff --git a/nautobot/extras/forms/contacts.py b/nautobot/extras/forms/contacts.py\n--- a/nautobot/extras/forms/contacts.py\n+++ b/nautobot/extras/forms/contacts.py\n@@ -28,6 +28,13 @@\n \"tags\",\n ]\n \n+ def __init__(self, instance=None, initial=None, **kwargs):\n+ if instance is not None:\n+ if initial is None:\n+ initial = {}\n+ initial.setdefault(\"teams\", instance.teams.all())\n+ super().__init__(instance=instance, initial=initial, **kwargs)\n+\n def save(self, *args, **kwargs):\n \"\"\"\n Since `teams` field on Contact Model is the reverse side of an M2M,\n", "issue": "[v2.2] Team(s) field not pre-populating when editing a Contact\n<!--\r\n NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.\r\n\r\n This form is only for reporting reproducible bugs. If you need assistance\r\n with Nautobot installation, or if you have a general question, please start a\r\n discussion instead: https://github.com/nautobot/nautobot/discussions\r\n\r\n Please describe the environment in which you are running Nautobot. Be sure\r\n that you are running an unmodified instance of the latest stable release\r\n before submitting a bug report, and that any plugins have been disabled.\r\n-->\r\n### Environment\r\n* Nautobot version (Docker tag too if applicable): 2.2.0a1\r\n* Python version: 3.11.8\r\n* Database platform, version: n/a\r\n* Middleware(s): n/a\r\n\r\n<!--\r\n Describe in detail the exact steps that someone else can take to reproduce\r\n this bug using the current stable release of Nautobot. Begin with the\r\n creation of any necessary database objects and call out every operation\r\n being performed explicitly. If reporting a bug in the REST API, be sure to\r\n reconstruct the raw HTTP request(s) being made: Don't rely on a client\r\n library such as pynautobot.\r\n-->\r\n### Steps to Reproduce\r\n1. Create a Team\r\n2. Create a Contact and associate it to the Team\r\n3. Edit the Contact\r\n\r\n<!-- What did you expect to happen? -->\r\n### Expected Behavior\r\nThe existing Team would be displayed in the edit form\r\n\r\n<!-- What happened instead? -->\r\n### Observed Behavior\r\nThe `Team(s)` field is empty and if you don't reapply the team it will remove it.\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.contenttypes.models import ContentType\n\nfrom nautobot.core.forms import DynamicModelChoiceField, DynamicModelMultipleChoiceField\nfrom nautobot.extras.models import Role, Status\nfrom nautobot.extras.models.contacts import Contact, ContactAssociation, Team\n\nfrom .base import NautobotBulkEditForm, NautobotFilterForm, NautobotModelForm\nfrom .mixins import TagsBulkEditFormMixin\n\n\nclass ContactForm(NautobotModelForm):\n teams = DynamicModelMultipleChoiceField(\n queryset=Team.objects.all(),\n required=False,\n label=\"Team(s)\",\n )\n\n class Meta:\n model = Contact\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"teams\",\n \"comments\",\n \"tags\",\n ]\n\n def save(self, *args, **kwargs):\n \"\"\"\n Since `teams` field on Contact Model is the reverse side of an M2M,\n we have to override save() method to explictly set the teams for the Contact instance.\n \"\"\"\n teams = self.cleaned_data.get(\"teams\", [])\n obj = super().save(*args, **kwargs)\n obj.teams.set(teams)\n return obj\n\n\nclass ContactBulkEditForm(TagsBulkEditFormMixin, NautobotBulkEditForm):\n pk = forms.ModelMultipleChoiceField(queryset=Contact.objects.all(), widget=forms.MultipleHiddenInput())\n phone = forms.CharField(required=False)\n email = forms.CharField(required=False)\n address = forms.CharField(required=False, widget=forms.Textarea())\n\n class Meta:\n model = Contact\n\n\nclass ContactFilterForm(NautobotFilterForm):\n model = Contact\n q = forms.CharField(required=False, label=\"Search\")\n\n\nclass ObjectNewContactForm(NautobotModelForm):\n teams = DynamicModelMultipleChoiceField(\n queryset=Team.objects.all(),\n required=False,\n label=\"Team(s)\",\n )\n associated_object_type = DynamicModelChoiceField(queryset=ContentType.objects.all(), required=True)\n associated_object_id = forms.CharField(required=True)\n role = DynamicModelChoiceField(\n queryset=Role.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n status = DynamicModelChoiceField(\n queryset=Status.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n\n class Meta:\n model = Contact\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"teams\",\n \"comments\",\n \"tags\",\n \"associated_object_type\",\n \"associated_object_id\",\n \"role\",\n \"status\",\n ]\n\n def save(self, *args, **kwargs):\n \"\"\"\n Since `teams` field on Contact Model is the reverse side of an M2M,\n we have to override save() method to explictly set the teams for the Contact instance.\n \"\"\"\n teams = self.cleaned_data.get(\"teams\", [])\n obj = super().save(*args, **kwargs)\n obj.teams.set(teams)\n return obj\n\n\nclass ObjectNewTeamForm(NautobotModelForm):\n contacts = DynamicModelMultipleChoiceField(\n queryset=Contact.objects.all(),\n required=False,\n label=\"Contact(s)\",\n )\n associated_object_type = DynamicModelChoiceField(queryset=ContentType.objects.all(), required=True)\n associated_object_id = forms.CharField(required=True)\n role = DynamicModelChoiceField(\n queryset=Role.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n status = DynamicModelChoiceField(\n queryset=Status.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n\n class Meta:\n model = Team\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"contacts\",\n \"comments\",\n \"tags\",\n \"associated_object_type\",\n \"associated_object_id\",\n \"role\",\n \"status\",\n ]\n\n\nclass ContactAssociationForm(NautobotModelForm):\n contact = DynamicModelChoiceField(queryset=Contact.objects.all(), required=False)\n team = DynamicModelChoiceField(queryset=Team.objects.all(), required=False)\n\n class Meta:\n model = ContactAssociation\n fields = [\n \"contact\",\n \"team\",\n \"associated_object_type\",\n \"associated_object_id\",\n \"role\",\n \"status\",\n ]\n\n\nclass ContactAssociationBulkEditForm(NautobotBulkEditForm):\n pk = forms.ModelMultipleChoiceField(queryset=ContactAssociation.objects.all(), widget=forms.MultipleHiddenInput())\n role = DynamicModelChoiceField(\n queryset=Role.objects.all(),\n required=False,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n status = DynamicModelChoiceField(\n queryset=Status.objects.all(),\n required=False,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n\n class Meta:\n model = ContactAssociation\n\n\nclass TeamForm(NautobotModelForm):\n contacts = DynamicModelMultipleChoiceField(\n queryset=Contact.objects.all(),\n required=False,\n label=\"Contact(s)\",\n )\n\n class Meta:\n model = Team\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"contacts\",\n \"comments\",\n \"tags\",\n ]\n\n\nclass TeamBulkEditForm(TagsBulkEditFormMixin, NautobotBulkEditForm):\n pk = forms.ModelMultipleChoiceField(queryset=Team.objects.all(), widget=forms.MultipleHiddenInput())\n phone = forms.CharField(required=False)\n email = forms.CharField(required=False)\n address = forms.CharField(required=False, widget=forms.Textarea())\n\n class Meta:\n model = Team\n\n\nclass TeamFilterForm(NautobotFilterForm):\n model = Team\n q = forms.CharField(required=False, label=\"Search\")\n", "path": "nautobot/extras/forms/contacts.py"}], "after_files": [{"content": "from django import forms\nfrom django.contrib.contenttypes.models import ContentType\n\nfrom nautobot.core.forms import DynamicModelChoiceField, DynamicModelMultipleChoiceField\nfrom nautobot.extras.models import Role, Status\nfrom nautobot.extras.models.contacts import Contact, ContactAssociation, Team\n\nfrom .base import NautobotBulkEditForm, NautobotFilterForm, NautobotModelForm\nfrom .mixins import TagsBulkEditFormMixin\n\n\nclass ContactForm(NautobotModelForm):\n teams = DynamicModelMultipleChoiceField(\n queryset=Team.objects.all(),\n required=False,\n label=\"Team(s)\",\n )\n\n class Meta:\n model = Contact\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"teams\",\n \"comments\",\n \"tags\",\n ]\n\n def __init__(self, instance=None, initial=None, **kwargs):\n if instance is not None:\n if initial is None:\n initial = {}\n initial.setdefault(\"teams\", instance.teams.all())\n super().__init__(instance=instance, initial=initial, **kwargs)\n\n def save(self, *args, **kwargs):\n \"\"\"\n Since `teams` field on Contact Model is the reverse side of an M2M,\n we have to override save() method to explictly set the teams for the Contact instance.\n \"\"\"\n teams = self.cleaned_data.get(\"teams\", [])\n obj = super().save(*args, **kwargs)\n obj.teams.set(teams)\n return obj\n\n\nclass ContactBulkEditForm(TagsBulkEditFormMixin, NautobotBulkEditForm):\n pk = forms.ModelMultipleChoiceField(queryset=Contact.objects.all(), widget=forms.MultipleHiddenInput())\n phone = forms.CharField(required=False)\n email = forms.CharField(required=False)\n address = forms.CharField(required=False, widget=forms.Textarea())\n\n class Meta:\n model = Contact\n\n\nclass ContactFilterForm(NautobotFilterForm):\n model = Contact\n q = forms.CharField(required=False, label=\"Search\")\n\n\nclass ObjectNewContactForm(NautobotModelForm):\n teams = DynamicModelMultipleChoiceField(\n queryset=Team.objects.all(),\n required=False,\n label=\"Team(s)\",\n )\n associated_object_type = DynamicModelChoiceField(queryset=ContentType.objects.all(), required=True)\n associated_object_id = forms.CharField(required=True)\n role = DynamicModelChoiceField(\n queryset=Role.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n status = DynamicModelChoiceField(\n queryset=Status.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n\n class Meta:\n model = Contact\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"teams\",\n \"comments\",\n \"tags\",\n \"associated_object_type\",\n \"associated_object_id\",\n \"role\",\n \"status\",\n ]\n\n def save(self, *args, **kwargs):\n \"\"\"\n Since `teams` field on Contact Model is the reverse side of an M2M,\n we have to override save() method to explictly set the teams for the Contact instance.\n \"\"\"\n teams = self.cleaned_data.get(\"teams\", [])\n obj = super().save(*args, **kwargs)\n obj.teams.set(teams)\n return obj\n\n\nclass ObjectNewTeamForm(NautobotModelForm):\n contacts = DynamicModelMultipleChoiceField(\n queryset=Contact.objects.all(),\n required=False,\n label=\"Contact(s)\",\n )\n associated_object_type = DynamicModelChoiceField(queryset=ContentType.objects.all(), required=True)\n associated_object_id = forms.CharField(required=True)\n role = DynamicModelChoiceField(\n queryset=Role.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n status = DynamicModelChoiceField(\n queryset=Status.objects.all(),\n required=True,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n\n class Meta:\n model = Team\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"contacts\",\n \"comments\",\n \"tags\",\n \"associated_object_type\",\n \"associated_object_id\",\n \"role\",\n \"status\",\n ]\n\n\nclass ContactAssociationForm(NautobotModelForm):\n contact = DynamicModelChoiceField(queryset=Contact.objects.all(), required=False)\n team = DynamicModelChoiceField(queryset=Team.objects.all(), required=False)\n\n class Meta:\n model = ContactAssociation\n fields = [\n \"contact\",\n \"team\",\n \"associated_object_type\",\n \"associated_object_id\",\n \"role\",\n \"status\",\n ]\n\n\nclass ContactAssociationBulkEditForm(NautobotBulkEditForm):\n pk = forms.ModelMultipleChoiceField(queryset=ContactAssociation.objects.all(), widget=forms.MultipleHiddenInput())\n role = DynamicModelChoiceField(\n queryset=Role.objects.all(),\n required=False,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n status = DynamicModelChoiceField(\n queryset=Status.objects.all(),\n required=False,\n query_params={\"content_types\": ContactAssociation._meta.label_lower},\n )\n\n class Meta:\n model = ContactAssociation\n\n\nclass TeamForm(NautobotModelForm):\n contacts = DynamicModelMultipleChoiceField(\n queryset=Contact.objects.all(),\n required=False,\n label=\"Contact(s)\",\n )\n\n class Meta:\n model = Team\n fields = [\n \"name\",\n \"phone\",\n \"email\",\n \"address\",\n \"contacts\",\n \"comments\",\n \"tags\",\n ]\n\n\nclass TeamBulkEditForm(TagsBulkEditFormMixin, NautobotBulkEditForm):\n pk = forms.ModelMultipleChoiceField(queryset=Team.objects.all(), widget=forms.MultipleHiddenInput())\n phone = forms.CharField(required=False)\n email = forms.CharField(required=False)\n address = forms.CharField(required=False, widget=forms.Textarea())\n\n class Meta:\n model = Team\n\n\nclass TeamFilterForm(NautobotFilterForm):\n model = Team\n q = forms.CharField(required=False, label=\"Search\")\n", "path": "nautobot/extras/forms/contacts.py"}]}
| 2,422 | 167 |
gh_patches_debug_2190
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-695
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove the "Cover" text from the alt text of book covers if one is present
Currently, when a book cover is present and is displayed, it's alt text consists of the book title, the text *Cover*, edition name, and the first published date.
For example, via VoiceOver under Safari:
```
image The Night Circus cover (Hardcover, 2011)
```
The fact that this is a cover image is redundant, because users are already notified about the presence of an image. In this case, the textual data is actually more important, e.g. book title and edition name, since the presence of a cover does not add more information when using a screen reader.
The expected result, via VoiceOver (and possibly other screen readers as well) is:
```
image The Night Circus (Hardcover, 2011)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/models/book.py`
Content:
```
1 ''' database schema for books and shelves '''
2 import re
3
4 from django.db import models
5 from model_utils.managers import InheritanceManager
6
7 from bookwyrm import activitypub
8 from bookwyrm.settings import DOMAIN
9
10 from .activitypub_mixin import OrderedCollectionPageMixin, ObjectMixin
11 from .base_model import BookWyrmModel
12 from . import fields
13
14 class BookDataModel(ObjectMixin, BookWyrmModel):
15 ''' fields shared between editable book data (books, works, authors) '''
16 origin_id = models.CharField(max_length=255, null=True, blank=True)
17 openlibrary_key = fields.CharField(
18 max_length=255, blank=True, null=True, deduplication_field=True)
19 librarything_key = fields.CharField(
20 max_length=255, blank=True, null=True, deduplication_field=True)
21 goodreads_key = fields.CharField(
22 max_length=255, blank=True, null=True, deduplication_field=True)
23
24 last_edited_by = models.ForeignKey(
25 'User', on_delete=models.PROTECT, null=True)
26
27 class Meta:
28 ''' can't initialize this model, that wouldn't make sense '''
29 abstract = True
30
31 def save(self, *args, **kwargs):
32 ''' ensure that the remote_id is within this instance '''
33 if self.id:
34 self.remote_id = self.get_remote_id()
35 else:
36 self.origin_id = self.remote_id
37 self.remote_id = None
38 return super().save(*args, **kwargs)
39
40
41 class Book(BookDataModel):
42 ''' a generic book, which can mean either an edition or a work '''
43 connector = models.ForeignKey(
44 'Connector', on_delete=models.PROTECT, null=True)
45
46 # book/work metadata
47 title = fields.CharField(max_length=255)
48 sort_title = fields.CharField(max_length=255, blank=True, null=True)
49 subtitle = fields.CharField(max_length=255, blank=True, null=True)
50 description = fields.HtmlField(blank=True, null=True)
51 languages = fields.ArrayField(
52 models.CharField(max_length=255), blank=True, default=list
53 )
54 series = fields.CharField(max_length=255, blank=True, null=True)
55 series_number = fields.CharField(max_length=255, blank=True, null=True)
56 subjects = fields.ArrayField(
57 models.CharField(max_length=255), blank=True, null=True, default=list
58 )
59 subject_places = fields.ArrayField(
60 models.CharField(max_length=255), blank=True, null=True, default=list
61 )
62 authors = fields.ManyToManyField('Author')
63 cover = fields.ImageField(
64 upload_to='covers/', blank=True, null=True, alt_field='alt_text')
65 first_published_date = fields.DateTimeField(blank=True, null=True)
66 published_date = fields.DateTimeField(blank=True, null=True)
67
68 objects = InheritanceManager()
69
70 @property
71 def author_text(self):
72 ''' format a list of authors '''
73 return ', '.join(a.name for a in self.authors.all())
74
75 @property
76 def latest_readthrough(self):
77 ''' most recent readthrough activity '''
78 return self.readthrough_set.order_by('-updated_date').first()
79
80 @property
81 def edition_info(self):
82 ''' properties of this edition, as a string '''
83 items = [
84 self.physical_format if hasattr(self, 'physical_format') else None,
85 self.languages[0] + ' language' if self.languages and \
86 self.languages[0] != 'English' else None,
87 str(self.published_date.year) if self.published_date else None,
88 ]
89 return ', '.join(i for i in items if i)
90
91 @property
92 def alt_text(self):
93 ''' image alt test '''
94 text = '%s cover' % self.title
95 if self.edition_info:
96 text += ' (%s)' % self.edition_info
97 return text
98
99 def save(self, *args, **kwargs):
100 ''' can't be abstract for query reasons, but you shouldn't USE it '''
101 if not isinstance(self, Edition) and not isinstance(self, Work):
102 raise ValueError('Books should be added as Editions or Works')
103 return super().save(*args, **kwargs)
104
105 def get_remote_id(self):
106 ''' editions and works both use "book" instead of model_name '''
107 return 'https://%s/book/%d' % (DOMAIN, self.id)
108
109 def __repr__(self):
110 return "<{} key={!r} title={!r}>".format(
111 self.__class__,
112 self.openlibrary_key,
113 self.title,
114 )
115
116
117 class Work(OrderedCollectionPageMixin, Book):
118 ''' a work (an abstract concept of a book that manifests in an edition) '''
119 # library of congress catalog control number
120 lccn = fields.CharField(
121 max_length=255, blank=True, null=True, deduplication_field=True)
122 # this has to be nullable but should never be null
123 default_edition = fields.ForeignKey(
124 'Edition',
125 on_delete=models.PROTECT,
126 null=True,
127 load_remote=False
128 )
129
130 def save(self, *args, **kwargs):
131 ''' set some fields on the edition object '''
132 # set rank
133 for edition in self.editions.all():
134 edition.save()
135 return super().save(*args, **kwargs)
136
137 def get_default_edition(self):
138 ''' in case the default edition is not set '''
139 return self.default_edition or self.editions.order_by(
140 '-edition_rank'
141 ).first()
142
143 def to_edition_list(self, **kwargs):
144 ''' an ordered collection of editions '''
145 return self.to_ordered_collection(
146 self.editions.order_by('-edition_rank').all(),
147 remote_id='%s/editions' % self.remote_id,
148 **kwargs
149 )
150
151 activity_serializer = activitypub.Work
152 serialize_reverse_fields = [('editions', 'editions', '-edition_rank')]
153 deserialize_reverse_fields = [('editions', 'editions')]
154
155
156 class Edition(Book):
157 ''' an edition of a book '''
158 # these identifiers only apply to editions, not works
159 isbn_10 = fields.CharField(
160 max_length=255, blank=True, null=True, deduplication_field=True)
161 isbn_13 = fields.CharField(
162 max_length=255, blank=True, null=True, deduplication_field=True)
163 oclc_number = fields.CharField(
164 max_length=255, blank=True, null=True, deduplication_field=True)
165 asin = fields.CharField(
166 max_length=255, blank=True, null=True, deduplication_field=True)
167 pages = fields.IntegerField(blank=True, null=True)
168 physical_format = fields.CharField(max_length=255, blank=True, null=True)
169 publishers = fields.ArrayField(
170 models.CharField(max_length=255), blank=True, default=list
171 )
172 shelves = models.ManyToManyField(
173 'Shelf',
174 symmetrical=False,
175 through='ShelfBook',
176 through_fields=('book', 'shelf')
177 )
178 parent_work = fields.ForeignKey(
179 'Work', on_delete=models.PROTECT, null=True,
180 related_name='editions', activitypub_field='work')
181 edition_rank = fields.IntegerField(default=0)
182
183 activity_serializer = activitypub.Edition
184 name_field = 'title'
185
186 def get_rank(self):
187 ''' calculate how complete the data is on this edition '''
188 if self.parent_work and self.parent_work.default_edition == self:
189 # default edition has the highest rank
190 return 20
191 rank = 0
192 rank += int(bool(self.cover)) * 3
193 rank += int(bool(self.isbn_13))
194 rank += int(bool(self.isbn_10))
195 rank += int(bool(self.oclc_number))
196 rank += int(bool(self.pages))
197 rank += int(bool(self.physical_format))
198 rank += int(bool(self.description))
199 # max rank is 9
200 return rank
201
202 def save(self, *args, **kwargs):
203 ''' set some fields on the edition object '''
204 # calculate isbn 10/13
205 if self.isbn_13 and self.isbn_13[:3] == '978' and not self.isbn_10:
206 self.isbn_10 = isbn_13_to_10(self.isbn_13)
207 if self.isbn_10 and not self.isbn_13:
208 self.isbn_13 = isbn_10_to_13(self.isbn_10)
209
210 # set rank
211 self.edition_rank = self.get_rank()
212
213 return super().save(*args, **kwargs)
214
215
216 def isbn_10_to_13(isbn_10):
217 ''' convert an isbn 10 into an isbn 13 '''
218 isbn_10 = re.sub(r'[^0-9X]', '', isbn_10)
219 # drop the last character of the isbn 10 number (the original checkdigit)
220 converted = isbn_10[:9]
221 # add "978" to the front
222 converted = '978' + converted
223 # add a check digit to the end
224 # multiply the odd digits by 1 and the even digits by 3 and sum them
225 try:
226 checksum = sum(int(i) for i in converted[::2]) + \
227 sum(int(i) * 3 for i in converted[1::2])
228 except ValueError:
229 return None
230 # add the checksum mod 10 to the end
231 checkdigit = checksum % 10
232 if checkdigit != 0:
233 checkdigit = 10 - checkdigit
234 return converted + str(checkdigit)
235
236
237 def isbn_13_to_10(isbn_13):
238 ''' convert isbn 13 to 10, if possible '''
239 if isbn_13[:3] != '978':
240 return None
241
242 isbn_13 = re.sub(r'[^0-9X]', '', isbn_13)
243
244 # remove '978' and old checkdigit
245 converted = isbn_13[3:-1]
246 # calculate checkdigit
247 # multiple each digit by 10,9,8.. successively and sum them
248 try:
249 checksum = sum(int(d) * (10 - idx) for (idx, d) in enumerate(converted))
250 except ValueError:
251 return None
252 checkdigit = checksum % 11
253 checkdigit = 11 - checkdigit
254 if checkdigit == 10:
255 checkdigit = 'X'
256 return converted + str(checkdigit)
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bookwyrm/models/book.py b/bookwyrm/models/book.py
--- a/bookwyrm/models/book.py
+++ b/bookwyrm/models/book.py
@@ -91,7 +91,7 @@
@property
def alt_text(self):
''' image alt test '''
- text = '%s cover' % self.title
+ text = '%s' % self.title
if self.edition_info:
text += ' (%s)' % self.edition_info
return text
|
{"golden_diff": "diff --git a/bookwyrm/models/book.py b/bookwyrm/models/book.py\n--- a/bookwyrm/models/book.py\n+++ b/bookwyrm/models/book.py\n@@ -91,7 +91,7 @@\n @property\n def alt_text(self):\n ''' image alt test '''\n- text = '%s cover' % self.title\n+ text = '%s' % self.title\n if self.edition_info:\n text += ' (%s)' % self.edition_info\n return text\n", "issue": "Remove the \"Cover\" text from the alt text of book covers if one is present\nCurrently, when a book cover is present and is displayed, it's alt text consists of the book title, the text *Cover*, edition name, and the first published date.\r\n\r\nFor example, via VoiceOver under Safari:\r\n\r\n```\r\nimage The Night Circus cover (Hardcover, 2011)\r\n```\r\n\r\nThe fact that this is a cover image is redundant, because users are already notified about the presence of an image. In this case, the textual data is actually more important, e.g. book title and edition name, since the presence of a cover does not add more information when using a screen reader.\r\n\r\nThe expected result, via VoiceOver (and possibly other screen readers as well) is:\r\n\r\n```\r\nimage The Night Circus (Hardcover, 2011)\r\n```\n", "before_files": [{"content": "''' database schema for books and shelves '''\nimport re\n\nfrom django.db import models\nfrom model_utils.managers import InheritanceManager\n\nfrom bookwyrm import activitypub\nfrom bookwyrm.settings import DOMAIN\n\nfrom .activitypub_mixin import OrderedCollectionPageMixin, ObjectMixin\nfrom .base_model import BookWyrmModel\nfrom . import fields\n\nclass BookDataModel(ObjectMixin, BookWyrmModel):\n ''' fields shared between editable book data (books, works, authors) '''\n origin_id = models.CharField(max_length=255, null=True, blank=True)\n openlibrary_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n librarything_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n goodreads_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n\n last_edited_by = models.ForeignKey(\n 'User', on_delete=models.PROTECT, null=True)\n\n class Meta:\n ''' can't initialize this model, that wouldn't make sense '''\n abstract = True\n\n def save(self, *args, **kwargs):\n ''' ensure that the remote_id is within this instance '''\n if self.id:\n self.remote_id = self.get_remote_id()\n else:\n self.origin_id = self.remote_id\n self.remote_id = None\n return super().save(*args, **kwargs)\n\n\nclass Book(BookDataModel):\n ''' a generic book, which can mean either an edition or a work '''\n connector = models.ForeignKey(\n 'Connector', on_delete=models.PROTECT, null=True)\n\n # book/work metadata\n title = fields.CharField(max_length=255)\n sort_title = fields.CharField(max_length=255, blank=True, null=True)\n subtitle = fields.CharField(max_length=255, blank=True, null=True)\n description = fields.HtmlField(blank=True, null=True)\n languages = fields.ArrayField(\n models.CharField(max_length=255), blank=True, default=list\n )\n series = fields.CharField(max_length=255, blank=True, null=True)\n series_number = fields.CharField(max_length=255, blank=True, null=True)\n subjects = fields.ArrayField(\n models.CharField(max_length=255), blank=True, null=True, default=list\n )\n subject_places = fields.ArrayField(\n models.CharField(max_length=255), blank=True, null=True, default=list\n )\n authors = fields.ManyToManyField('Author')\n cover = fields.ImageField(\n upload_to='covers/', blank=True, null=True, alt_field='alt_text')\n first_published_date = fields.DateTimeField(blank=True, null=True)\n published_date = fields.DateTimeField(blank=True, null=True)\n\n objects = InheritanceManager()\n\n @property\n def author_text(self):\n ''' format a list of authors '''\n return ', '.join(a.name for a in self.authors.all())\n\n @property\n def latest_readthrough(self):\n ''' most recent readthrough activity '''\n return self.readthrough_set.order_by('-updated_date').first()\n\n @property\n def edition_info(self):\n ''' properties of this edition, as a string '''\n items = [\n self.physical_format if hasattr(self, 'physical_format') else None,\n self.languages[0] + ' language' if self.languages and \\\n self.languages[0] != 'English' else None,\n str(self.published_date.year) if self.published_date else None,\n ]\n return ', '.join(i for i in items if i)\n\n @property\n def alt_text(self):\n ''' image alt test '''\n text = '%s cover' % self.title\n if self.edition_info:\n text += ' (%s)' % self.edition_info\n return text\n\n def save(self, *args, **kwargs):\n ''' can't be abstract for query reasons, but you shouldn't USE it '''\n if not isinstance(self, Edition) and not isinstance(self, Work):\n raise ValueError('Books should be added as Editions or Works')\n return super().save(*args, **kwargs)\n\n def get_remote_id(self):\n ''' editions and works both use \"book\" instead of model_name '''\n return 'https://%s/book/%d' % (DOMAIN, self.id)\n\n def __repr__(self):\n return \"<{} key={!r} title={!r}>\".format(\n self.__class__,\n self.openlibrary_key,\n self.title,\n )\n\n\nclass Work(OrderedCollectionPageMixin, Book):\n ''' a work (an abstract concept of a book that manifests in an edition) '''\n # library of congress catalog control number\n lccn = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n # this has to be nullable but should never be null\n default_edition = fields.ForeignKey(\n 'Edition',\n on_delete=models.PROTECT,\n null=True,\n load_remote=False\n )\n\n def save(self, *args, **kwargs):\n ''' set some fields on the edition object '''\n # set rank\n for edition in self.editions.all():\n edition.save()\n return super().save(*args, **kwargs)\n\n def get_default_edition(self):\n ''' in case the default edition is not set '''\n return self.default_edition or self.editions.order_by(\n '-edition_rank'\n ).first()\n\n def to_edition_list(self, **kwargs):\n ''' an ordered collection of editions '''\n return self.to_ordered_collection(\n self.editions.order_by('-edition_rank').all(),\n remote_id='%s/editions' % self.remote_id,\n **kwargs\n )\n\n activity_serializer = activitypub.Work\n serialize_reverse_fields = [('editions', 'editions', '-edition_rank')]\n deserialize_reverse_fields = [('editions', 'editions')]\n\n\nclass Edition(Book):\n ''' an edition of a book '''\n # these identifiers only apply to editions, not works\n isbn_10 = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n isbn_13 = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n oclc_number = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n asin = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n pages = fields.IntegerField(blank=True, null=True)\n physical_format = fields.CharField(max_length=255, blank=True, null=True)\n publishers = fields.ArrayField(\n models.CharField(max_length=255), blank=True, default=list\n )\n shelves = models.ManyToManyField(\n 'Shelf',\n symmetrical=False,\n through='ShelfBook',\n through_fields=('book', 'shelf')\n )\n parent_work = fields.ForeignKey(\n 'Work', on_delete=models.PROTECT, null=True,\n related_name='editions', activitypub_field='work')\n edition_rank = fields.IntegerField(default=0)\n\n activity_serializer = activitypub.Edition\n name_field = 'title'\n\n def get_rank(self):\n ''' calculate how complete the data is on this edition '''\n if self.parent_work and self.parent_work.default_edition == self:\n # default edition has the highest rank\n return 20\n rank = 0\n rank += int(bool(self.cover)) * 3\n rank += int(bool(self.isbn_13))\n rank += int(bool(self.isbn_10))\n rank += int(bool(self.oclc_number))\n rank += int(bool(self.pages))\n rank += int(bool(self.physical_format))\n rank += int(bool(self.description))\n # max rank is 9\n return rank\n\n def save(self, *args, **kwargs):\n ''' set some fields on the edition object '''\n # calculate isbn 10/13\n if self.isbn_13 and self.isbn_13[:3] == '978' and not self.isbn_10:\n self.isbn_10 = isbn_13_to_10(self.isbn_13)\n if self.isbn_10 and not self.isbn_13:\n self.isbn_13 = isbn_10_to_13(self.isbn_10)\n\n # set rank\n self.edition_rank = self.get_rank()\n\n return super().save(*args, **kwargs)\n\n\ndef isbn_10_to_13(isbn_10):\n ''' convert an isbn 10 into an isbn 13 '''\n isbn_10 = re.sub(r'[^0-9X]', '', isbn_10)\n # drop the last character of the isbn 10 number (the original checkdigit)\n converted = isbn_10[:9]\n # add \"978\" to the front\n converted = '978' + converted\n # add a check digit to the end\n # multiply the odd digits by 1 and the even digits by 3 and sum them\n try:\n checksum = sum(int(i) for i in converted[::2]) + \\\n sum(int(i) * 3 for i in converted[1::2])\n except ValueError:\n return None\n # add the checksum mod 10 to the end\n checkdigit = checksum % 10\n if checkdigit != 0:\n checkdigit = 10 - checkdigit\n return converted + str(checkdigit)\n\n\ndef isbn_13_to_10(isbn_13):\n ''' convert isbn 13 to 10, if possible '''\n if isbn_13[:3] != '978':\n return None\n\n isbn_13 = re.sub(r'[^0-9X]', '', isbn_13)\n\n # remove '978' and old checkdigit\n converted = isbn_13[3:-1]\n # calculate checkdigit\n # multiple each digit by 10,9,8.. successively and sum them\n try:\n checksum = sum(int(d) * (10 - idx) for (idx, d) in enumerate(converted))\n except ValueError:\n return None\n checkdigit = checksum % 11\n checkdigit = 11 - checkdigit\n if checkdigit == 10:\n checkdigit = 'X'\n return converted + str(checkdigit)\n", "path": "bookwyrm/models/book.py"}], "after_files": [{"content": "''' database schema for books and shelves '''\nimport re\n\nfrom django.db import models\nfrom model_utils.managers import InheritanceManager\n\nfrom bookwyrm import activitypub\nfrom bookwyrm.settings import DOMAIN\n\nfrom .activitypub_mixin import OrderedCollectionPageMixin, ObjectMixin\nfrom .base_model import BookWyrmModel\nfrom . import fields\n\nclass BookDataModel(ObjectMixin, BookWyrmModel):\n ''' fields shared between editable book data (books, works, authors) '''\n origin_id = models.CharField(max_length=255, null=True, blank=True)\n openlibrary_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n librarything_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n goodreads_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n\n last_edited_by = models.ForeignKey(\n 'User', on_delete=models.PROTECT, null=True)\n\n class Meta:\n ''' can't initialize this model, that wouldn't make sense '''\n abstract = True\n\n def save(self, *args, **kwargs):\n ''' ensure that the remote_id is within this instance '''\n if self.id:\n self.remote_id = self.get_remote_id()\n else:\n self.origin_id = self.remote_id\n self.remote_id = None\n return super().save(*args, **kwargs)\n\n\nclass Book(BookDataModel):\n ''' a generic book, which can mean either an edition or a work '''\n connector = models.ForeignKey(\n 'Connector', on_delete=models.PROTECT, null=True)\n\n # book/work metadata\n title = fields.CharField(max_length=255)\n sort_title = fields.CharField(max_length=255, blank=True, null=True)\n subtitle = fields.CharField(max_length=255, blank=True, null=True)\n description = fields.HtmlField(blank=True, null=True)\n languages = fields.ArrayField(\n models.CharField(max_length=255), blank=True, default=list\n )\n series = fields.CharField(max_length=255, blank=True, null=True)\n series_number = fields.CharField(max_length=255, blank=True, null=True)\n subjects = fields.ArrayField(\n models.CharField(max_length=255), blank=True, null=True, default=list\n )\n subject_places = fields.ArrayField(\n models.CharField(max_length=255), blank=True, null=True, default=list\n )\n authors = fields.ManyToManyField('Author')\n cover = fields.ImageField(\n upload_to='covers/', blank=True, null=True, alt_field='alt_text')\n first_published_date = fields.DateTimeField(blank=True, null=True)\n published_date = fields.DateTimeField(blank=True, null=True)\n\n objects = InheritanceManager()\n\n @property\n def author_text(self):\n ''' format a list of authors '''\n return ', '.join(a.name for a in self.authors.all())\n\n @property\n def latest_readthrough(self):\n ''' most recent readthrough activity '''\n return self.readthrough_set.order_by('-updated_date').first()\n\n @property\n def edition_info(self):\n ''' properties of this edition, as a string '''\n items = [\n self.physical_format if hasattr(self, 'physical_format') else None,\n self.languages[0] + ' language' if self.languages and \\\n self.languages[0] != 'English' else None,\n str(self.published_date.year) if self.published_date else None,\n ]\n return ', '.join(i for i in items if i)\n\n @property\n def alt_text(self):\n ''' image alt test '''\n text = '%s' % self.title\n if self.edition_info:\n text += ' (%s)' % self.edition_info\n return text\n\n def save(self, *args, **kwargs):\n ''' can't be abstract for query reasons, but you shouldn't USE it '''\n if not isinstance(self, Edition) and not isinstance(self, Work):\n raise ValueError('Books should be added as Editions or Works')\n return super().save(*args, **kwargs)\n\n def get_remote_id(self):\n ''' editions and works both use \"book\" instead of model_name '''\n return 'https://%s/book/%d' % (DOMAIN, self.id)\n\n def __repr__(self):\n return \"<{} key={!r} title={!r}>\".format(\n self.__class__,\n self.openlibrary_key,\n self.title,\n )\n\n\nclass Work(OrderedCollectionPageMixin, Book):\n ''' a work (an abstract concept of a book that manifests in an edition) '''\n # library of congress catalog control number\n lccn = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n # this has to be nullable but should never be null\n default_edition = fields.ForeignKey(\n 'Edition',\n on_delete=models.PROTECT,\n null=True,\n load_remote=False\n )\n\n def save(self, *args, **kwargs):\n ''' set some fields on the edition object '''\n # set rank\n for edition in self.editions.all():\n edition.save()\n return super().save(*args, **kwargs)\n\n def get_default_edition(self):\n ''' in case the default edition is not set '''\n return self.default_edition or self.editions.order_by(\n '-edition_rank'\n ).first()\n\n def to_edition_list(self, **kwargs):\n ''' an ordered collection of editions '''\n return self.to_ordered_collection(\n self.editions.order_by('-edition_rank').all(),\n remote_id='%s/editions' % self.remote_id,\n **kwargs\n )\n\n activity_serializer = activitypub.Work\n serialize_reverse_fields = [('editions', 'editions', '-edition_rank')]\n deserialize_reverse_fields = [('editions', 'editions')]\n\n\nclass Edition(Book):\n ''' an edition of a book '''\n # these identifiers only apply to editions, not works\n isbn_10 = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n isbn_13 = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n oclc_number = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n asin = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True)\n pages = fields.IntegerField(blank=True, null=True)\n physical_format = fields.CharField(max_length=255, blank=True, null=True)\n publishers = fields.ArrayField(\n models.CharField(max_length=255), blank=True, default=list\n )\n shelves = models.ManyToManyField(\n 'Shelf',\n symmetrical=False,\n through='ShelfBook',\n through_fields=('book', 'shelf')\n )\n parent_work = fields.ForeignKey(\n 'Work', on_delete=models.PROTECT, null=True,\n related_name='editions', activitypub_field='work')\n edition_rank = fields.IntegerField(default=0)\n\n activity_serializer = activitypub.Edition\n name_field = 'title'\n\n def get_rank(self):\n ''' calculate how complete the data is on this edition '''\n if self.parent_work and self.parent_work.default_edition == self:\n # default edition has the highest rank\n return 20\n rank = 0\n rank += int(bool(self.cover)) * 3\n rank += int(bool(self.isbn_13))\n rank += int(bool(self.isbn_10))\n rank += int(bool(self.oclc_number))\n rank += int(bool(self.pages))\n rank += int(bool(self.physical_format))\n rank += int(bool(self.description))\n # max rank is 9\n return rank\n\n def save(self, *args, **kwargs):\n ''' set some fields on the edition object '''\n # calculate isbn 10/13\n if self.isbn_13 and self.isbn_13[:3] == '978' and not self.isbn_10:\n self.isbn_10 = isbn_13_to_10(self.isbn_13)\n if self.isbn_10 and not self.isbn_13:\n self.isbn_13 = isbn_10_to_13(self.isbn_10)\n\n # set rank\n self.edition_rank = self.get_rank()\n\n return super().save(*args, **kwargs)\n\n\ndef isbn_10_to_13(isbn_10):\n ''' convert an isbn 10 into an isbn 13 '''\n isbn_10 = re.sub(r'[^0-9X]', '', isbn_10)\n # drop the last character of the isbn 10 number (the original checkdigit)\n converted = isbn_10[:9]\n # add \"978\" to the front\n converted = '978' + converted\n # add a check digit to the end\n # multiply the odd digits by 1 and the even digits by 3 and sum them\n try:\n checksum = sum(int(i) for i in converted[::2]) + \\\n sum(int(i) * 3 for i in converted[1::2])\n except ValueError:\n return None\n # add the checksum mod 10 to the end\n checkdigit = checksum % 10\n if checkdigit != 0:\n checkdigit = 10 - checkdigit\n return converted + str(checkdigit)\n\n\ndef isbn_13_to_10(isbn_13):\n ''' convert isbn 13 to 10, if possible '''\n if isbn_13[:3] != '978':\n return None\n\n isbn_13 = re.sub(r'[^0-9X]', '', isbn_13)\n\n # remove '978' and old checkdigit\n converted = isbn_13[3:-1]\n # calculate checkdigit\n # multiple each digit by 10,9,8.. successively and sum them\n try:\n checksum = sum(int(d) * (10 - idx) for (idx, d) in enumerate(converted))\n except ValueError:\n return None\n checkdigit = checksum % 11\n checkdigit = 11 - checkdigit\n if checkdigit == 10:\n checkdigit = 'X'\n return converted + str(checkdigit)\n", "path": "bookwyrm/models/book.py"}]}
| 3,412 | 111 |
gh_patches_debug_35697
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2501
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CKV_AWS_103 - Mentioned Checkov Checks producing an Exception, when the Listener protocol is HTTP (ALB).
Background of the Issue :
We have been using mentioned Checkov inbuilt checks/policy ID (CKV_AWS_103/ BC_AWS_GENERAL_43) for connection requests in AWS Load balancer. it was working fine when application team using the Module, "aws_lb_listener" "redirect" will only enable when application team users "HTTPS" Protocol. The particular issue is being presented when we attempt "HTTP" Protocol (Development Environment)
Sample Module snippet (AWS Load Balancer Listener ) (Re-direct Action) :-
resource "aws_lb_listener" "redirect_http_listeneter" {
load_balancer_arn = aws_lb.front_end.arn
port = "80"
protocol = "HTTP"
}
default action {
type = "redirect"
redirect {
port = "443"
}
}
}
ISSUE :-
Exception Occur :- [If application team used the protocol HTTP]
Exception message sample
"[MainThread][ERROR] Failed to run check: Ensure the load balancer is using TLS1.2 for configuration:{'alpn_policy':[None],'arn':['arn:aws:elasticloadbalancing:**********:listener/app/dev-opsmanager-ec2-alb/******/*****],'certicate_arn':[None], 'default_action':
In bridgecrewio github, [ checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py ]
supports only HTTPS and it not producing any proper results, if we application team using HTTP. So require your support to tweak globally in the in-built check ID.
checkov version : 2.0.704
kindly let me know any other additional inputs require from our end.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py`
Content:
```
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.common.util.type_forcers import force_list
3 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
4
5
6 class AppLoadBalancerTLS12(BaseResourceCheck):
7 def __init__(self):
8 name = "Ensure that load balancer is using TLS 1.2"
9 id = "CKV_AWS_103"
10 supported_resources = ["aws_lb_listener", "aws_alb_listener"]
11 categories = [CheckCategories.GENERAL_SECURITY]
12 super().__init__(
13 name=name,
14 id=id,
15 categories=categories,
16 supported_resources=supported_resources,
17 )
18
19 def scan_resource_conf(self, conf):
20 key = "protocol"
21 self.evaluated_keys = [key]
22 if key in conf.keys():
23 if conf[key] in (["HTTPS"], ["TLS"]):
24 # Only interested in HTTPS & TLS listeners
25 policy = "ssl_policy"
26 if policy in conf.keys():
27 self.evaluated_keys.append(policy)
28 name = str(conf[policy]).strip("['']")
29 if name.startswith("ELBSecurityPolicy-FS-1-2") or name.startswith("ELBSecurityPolicy-TLS-1-2"):
30 return CheckResult.PASSED
31 return CheckResult.FAILED
32 elif conf[key] in (["TCP"], ["UDP"], ["TCP_UDP"]):
33 return CheckResult.PASSED
34 for idx_action, action in enumerate(conf.get("default_action", [])):
35 redirects = action.get("redirect", [])
36 for idx_redirect, redirect in enumerate(force_list(redirects)):
37 if redirect.get("protocol", []) == ["HTTPS"]:
38 redirect_index = f"[{idx_redirect}]/" if isinstance(redirects, list) else ""
39 self.evaluated_keys.append(f'default_action/[{idx_action}]/redirect/{redirect_index}protocol')
40 return CheckResult.PASSED
41 return CheckResult.FAILED
42
43
44 check = AppLoadBalancerTLS12()
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py
--- a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py
+++ b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py
@@ -1,14 +1,16 @@
+from typing import Dict, List, Any
+
from checkov.common.models.enums import CheckResult, CheckCategories
from checkov.common.util.type_forcers import force_list
from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
class AppLoadBalancerTLS12(BaseResourceCheck):
- def __init__(self):
+ def __init__(self) -> None:
name = "Ensure that load balancer is using TLS 1.2"
id = "CKV_AWS_103"
- supported_resources = ["aws_lb_listener", "aws_alb_listener"]
- categories = [CheckCategories.GENERAL_SECURITY]
+ supported_resources = ("aws_lb_listener", "aws_alb_listener")
+ categories = (CheckCategories.GENERAL_SECURITY,)
super().__init__(
name=name,
id=id,
@@ -16,7 +18,7 @@
supported_resources=supported_resources,
)
- def scan_resource_conf(self, conf):
+ def scan_resource_conf(self, conf: Dict[str, List[Any]]) -> CheckResult:
key = "protocol"
self.evaluated_keys = [key]
if key in conf.keys():
@@ -34,7 +36,7 @@
for idx_action, action in enumerate(conf.get("default_action", [])):
redirects = action.get("redirect", [])
for idx_redirect, redirect in enumerate(force_list(redirects)):
- if redirect.get("protocol", []) == ["HTTPS"]:
+ if isinstance(redirect, dict) and redirect.get("protocol", []) == ["HTTPS"]:
redirect_index = f"[{idx_redirect}]/" if isinstance(redirects, list) else ""
self.evaluated_keys.append(f'default_action/[{idx_action}]/redirect/{redirect_index}protocol')
return CheckResult.PASSED
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py\n--- a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py\n+++ b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py\n@@ -1,14 +1,16 @@\n+from typing import Dict, List, Any\n+\n from checkov.common.models.enums import CheckResult, CheckCategories\n from checkov.common.util.type_forcers import force_list\n from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n \n \n class AppLoadBalancerTLS12(BaseResourceCheck):\n- def __init__(self):\n+ def __init__(self) -> None:\n name = \"Ensure that load balancer is using TLS 1.2\"\n id = \"CKV_AWS_103\"\n- supported_resources = [\"aws_lb_listener\", \"aws_alb_listener\"]\n- categories = [CheckCategories.GENERAL_SECURITY]\n+ supported_resources = (\"aws_lb_listener\", \"aws_alb_listener\")\n+ categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(\n name=name,\n id=id,\n@@ -16,7 +18,7 @@\n supported_resources=supported_resources,\n )\n \n- def scan_resource_conf(self, conf):\n+ def scan_resource_conf(self, conf: Dict[str, List[Any]]) -> CheckResult:\n key = \"protocol\"\n self.evaluated_keys = [key]\n if key in conf.keys():\n@@ -34,7 +36,7 @@\n for idx_action, action in enumerate(conf.get(\"default_action\", [])):\n redirects = action.get(\"redirect\", [])\n for idx_redirect, redirect in enumerate(force_list(redirects)):\n- if redirect.get(\"protocol\", []) == [\"HTTPS\"]:\n+ if isinstance(redirect, dict) and redirect.get(\"protocol\", []) == [\"HTTPS\"]:\n redirect_index = f\"[{idx_redirect}]/\" if isinstance(redirects, list) else \"\"\n self.evaluated_keys.append(f'default_action/[{idx_action}]/redirect/{redirect_index}protocol')\n return CheckResult.PASSED\n", "issue": "CKV_AWS_103 - Mentioned Checkov Checks producing an Exception, when the Listener protocol is HTTP (ALB).\nBackground of the Issue : \r\n\r\nWe have been using mentioned Checkov inbuilt checks/policy ID (CKV_AWS_103/ BC_AWS_GENERAL_43) for connection requests in AWS Load balancer. it was working fine when application team using the Module, \"aws_lb_listener\" \"redirect\" will only enable when application team users \"HTTPS\" Protocol. The particular issue is being presented when we attempt \"HTTP\" Protocol (Development Environment)\r\n\r\nSample Module snippet (AWS Load Balancer Listener ) (Re-direct Action) :- \r\n\r\nresource \"aws_lb_listener\" \"redirect_http_listeneter\" {\r\nload_balancer_arn = aws_lb.front_end.arn\r\nport = \"80\"\r\nprotocol = \"HTTP\" \r\n}\r\n\r\ndefault action {\r\n type = \"redirect\"\r\n\r\nredirect {\r\n port = \"443\"\r\n }\r\n}\r\n}\r\n\r\nISSUE :- \r\nException Occur :- [If application team used the protocol HTTP] \r\n\r\nException message sample \r\n\"[MainThread][ERROR] Failed to run check: Ensure the load balancer is using TLS1.2 for configuration:{'alpn_policy':[None],'arn':['arn:aws:elasticloadbalancing:**********:listener/app/dev-opsmanager-ec2-alb/******/*****],'certicate_arn':[None], 'default_action':\r\n\r\nIn bridgecrewio github, [ checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py ]\r\nsupports only HTTPS and it not producing any proper results, if we application team using HTTP. So require your support to tweak globally in the in-built check ID. \r\n\r\ncheckov version : 2.0.704\r\n\r\nkindly let me know any other additional inputs require from our end.\r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.common.util.type_forcers import force_list\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass AppLoadBalancerTLS12(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure that load balancer is using TLS 1.2\"\n id = \"CKV_AWS_103\"\n supported_resources = [\"aws_lb_listener\", \"aws_alb_listener\"]\n categories = [CheckCategories.GENERAL_SECURITY]\n super().__init__(\n name=name,\n id=id,\n categories=categories,\n supported_resources=supported_resources,\n )\n\n def scan_resource_conf(self, conf):\n key = \"protocol\"\n self.evaluated_keys = [key]\n if key in conf.keys():\n if conf[key] in ([\"HTTPS\"], [\"TLS\"]):\n # Only interested in HTTPS & TLS listeners\n policy = \"ssl_policy\"\n if policy in conf.keys():\n self.evaluated_keys.append(policy)\n name = str(conf[policy]).strip(\"['']\")\n if name.startswith(\"ELBSecurityPolicy-FS-1-2\") or name.startswith(\"ELBSecurityPolicy-TLS-1-2\"):\n return CheckResult.PASSED\n return CheckResult.FAILED\n elif conf[key] in ([\"TCP\"], [\"UDP\"], [\"TCP_UDP\"]):\n return CheckResult.PASSED\n for idx_action, action in enumerate(conf.get(\"default_action\", [])):\n redirects = action.get(\"redirect\", [])\n for idx_redirect, redirect in enumerate(force_list(redirects)):\n if redirect.get(\"protocol\", []) == [\"HTTPS\"]:\n redirect_index = f\"[{idx_redirect}]/\" if isinstance(redirects, list) else \"\"\n self.evaluated_keys.append(f'default_action/[{idx_action}]/redirect/{redirect_index}protocol')\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = AppLoadBalancerTLS12()\n", "path": "checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py"}], "after_files": [{"content": "from typing import Dict, List, Any\n\nfrom checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.common.util.type_forcers import force_list\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass AppLoadBalancerTLS12(BaseResourceCheck):\n def __init__(self) -> None:\n name = \"Ensure that load balancer is using TLS 1.2\"\n id = \"CKV_AWS_103\"\n supported_resources = (\"aws_lb_listener\", \"aws_alb_listener\")\n categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(\n name=name,\n id=id,\n categories=categories,\n supported_resources=supported_resources,\n )\n\n def scan_resource_conf(self, conf: Dict[str, List[Any]]) -> CheckResult:\n key = \"protocol\"\n self.evaluated_keys = [key]\n if key in conf.keys():\n if conf[key] in ([\"HTTPS\"], [\"TLS\"]):\n # Only interested in HTTPS & TLS listeners\n policy = \"ssl_policy\"\n if policy in conf.keys():\n self.evaluated_keys.append(policy)\n name = str(conf[policy]).strip(\"['']\")\n if name.startswith(\"ELBSecurityPolicy-FS-1-2\") or name.startswith(\"ELBSecurityPolicy-TLS-1-2\"):\n return CheckResult.PASSED\n return CheckResult.FAILED\n elif conf[key] in ([\"TCP\"], [\"UDP\"], [\"TCP_UDP\"]):\n return CheckResult.PASSED\n for idx_action, action in enumerate(conf.get(\"default_action\", [])):\n redirects = action.get(\"redirect\", [])\n for idx_redirect, redirect in enumerate(force_list(redirects)):\n if isinstance(redirect, dict) and redirect.get(\"protocol\", []) == [\"HTTPS\"]:\n redirect_index = f\"[{idx_redirect}]/\" if isinstance(redirects, list) else \"\"\n self.evaluated_keys.append(f'default_action/[{idx_action}]/redirect/{redirect_index}protocol')\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = AppLoadBalancerTLS12()\n", "path": "checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py"}]}
| 1,164 | 477 |
gh_patches_debug_5933
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-5999
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DB INIT error when using usernames with non-alphanumeric chars
**CKAN version**
Master 713716b0689bf848865f05acd328ded29f041c5a (2.9.something)
**Describe the bug**
DB usernames with non alphanum chars will terminate in error the command `ckan db init`.
**Steps to reproduce**
Create a pg user with for instance a "`@`" in it, then update `ckan.ini` with the proper URL,
e.g.: user `ckan@ckan`:
sqlalchemy.url = postgresql://ckan@ckan:ckan@localhost/ckan_at
Running `ckan run` will not raise connection error (it won't find table, eventually).
Running `ckan db init` will terminate with the error:
invalid interpolation syntax in 'postgresql://ckan%40ckan:ckan@localhost/ckan_at' at position 17
**Expected behavior**
The command should connect to the db without errors.
**Additional details**
At https://github.com/ckan/ckan/blob/713716b0689bf848865f05acd328ded29f041c5a/ckan/model/__init__.py#L268-L270
`self.metadata.bind.url` contains `postgresql://ckan%40ckan:ckan@localhost/ckan_at`
We could replace the line with
```python
alembic_config.set_main_option(
"sqlalchemy.url", config.get("sqlalchemy.url")
)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/model/__init__.py`
Content:
```
1 # encoding: utf-8
2
3 import warnings
4 import logging
5 import os
6 import re
7 from time import sleep
8 from os.path import splitext
9
10 from sqlalchemy import MetaData, __version__ as sqav, Table
11 from sqlalchemy.exc import ProgrammingError
12
13 from alembic.command import (
14 upgrade as alembic_upgrade,
15 downgrade as alembic_downgrade,
16 current as alembic_current
17 )
18 from alembic.config import Config as AlembicConfig
19
20 from ckan.model import meta
21
22 from ckan.model.meta import (
23 Session,
24 engine_is_sqlite,
25 engine_is_pg,
26 )
27 from ckan.model.core import (
28 State,
29 )
30 from ckan.model.system import (
31 System,
32 )
33 from ckan.model.package import (
34 Package,
35 PackageMember,
36 PACKAGE_NAME_MIN_LENGTH,
37 PACKAGE_NAME_MAX_LENGTH,
38 PACKAGE_VERSION_MAX_LENGTH,
39 package_table,
40 package_member_table,
41 )
42 from ckan.model.tag import (
43 Tag,
44 PackageTag,
45 MAX_TAG_LENGTH,
46 MIN_TAG_LENGTH,
47 tag_table,
48 package_tag_table,
49 )
50 from ckan.model.user import (
51 User,
52 user_table,
53 )
54 from ckan.model.group import (
55 Member,
56 Group,
57 group_table,
58 member_table,
59 )
60 from ckan.model.group_extra import (
61 GroupExtra,
62 group_extra_table,
63 )
64 from ckan.model.package_extra import (
65 PackageExtra,
66 package_extra_table,
67 )
68 from ckan.model.resource import (
69 Resource,
70 DictProxy,
71 resource_table,
72 )
73 from ckan.model.resource_view import (
74 ResourceView,
75 resource_view_table,
76 )
77 from ckan.model.tracking import (
78 tracking_summary_table,
79 TrackingSummary,
80 tracking_raw_table
81 )
82 from ckan.model.rating import (
83 Rating,
84 MIN_RATING,
85 MAX_RATING,
86 )
87 from ckan.model.package_relationship import (
88 PackageRelationship,
89 package_relationship_table,
90 )
91 from ckan.model.task_status import (
92 TaskStatus,
93 task_status_table,
94 )
95 from ckan.model.vocabulary import (
96 Vocabulary,
97 VOCABULARY_NAME_MAX_LENGTH,
98 VOCABULARY_NAME_MIN_LENGTH,
99 )
100 from ckan.model.activity import (
101 Activity,
102 ActivityDetail,
103 activity_table,
104 activity_detail_table,
105 )
106 from ckan.model.term_translation import (
107 term_translation_table,
108 )
109 from ckan.model.follower import (
110 UserFollowingUser,
111 UserFollowingDataset,
112 UserFollowingGroup,
113 )
114 from ckan.model.system_info import (
115 system_info_table,
116 SystemInfo,
117 get_system_info,
118 set_system_info,
119 delete_system_info,
120 )
121 from ckan.model.domain_object import (
122 DomainObjectOperation,
123 DomainObject,
124 )
125 from ckan.model.dashboard import (
126 Dashboard,
127 )
128 from ckan.model.api_token import (
129 ApiToken,
130 )
131
132 import ckan.migration
133 from ckan.common import config
134
135
136 log = logging.getLogger(__name__)
137
138 DB_CONNECT_RETRIES = 10
139
140
141 def init_model(engine):
142 '''Call me before using any of the tables or classes in the model'''
143 meta.Session.remove()
144 meta.Session.configure(bind=engine)
145 meta.create_local_session.configure(bind=engine)
146 meta.engine = engine
147 meta.metadata.bind = engine
148 # sqlalchemy migrate version table
149 import sqlalchemy.exc
150 for i in reversed(range(DB_CONNECT_RETRIES)):
151 try:
152 Table('alembic_version', meta.metadata, autoload=True)
153 break
154 except sqlalchemy.exc.NoSuchTableError:
155 break
156 except sqlalchemy.exc.OperationalError as e:
157 if 'database system is starting up' in repr(e.orig) and i:
158 sleep(DB_CONNECT_RETRIES - i)
159 continue
160 raise
161
162
163 class Repository():
164 _alembic_ini = os.path.join(
165 os.path.dirname(ckan.migration.__file__),
166 u"alembic.ini"
167 )
168
169 # note: tables_created value is not sustained between instantiations
170 # so only useful for tests. The alternative is to use
171 # are_tables_created().
172 tables_created_and_initialised = False
173
174 def __init__(self, metadata, session):
175 self.metadata = metadata
176 self.session = session
177 self.commit = session.commit
178
179 def commit_and_remove(self):
180 self.session.commit()
181 self.session.remove()
182
183 def init_db(self):
184 '''Ensures tables, const data and some default config is created.
185 This method MUST be run before using CKAN for the first time.
186 Before this method is run, you can either have a clean db or tables
187 that may have been setup with either upgrade_db or a previous run of
188 init_db.
189 '''
190 warnings.filterwarnings('ignore', 'SAWarning')
191 self.session.rollback()
192 self.session.remove()
193 # sqlite database needs to be recreated each time as the
194 # memory database is lost.
195
196 if self.metadata.bind.engine.url.drivername == 'sqlite':
197 # this creates the tables, which isn't required inbetween tests
198 # that have simply called rebuild_db.
199 self.create_db()
200 else:
201 if not self.tables_created_and_initialised:
202 self.upgrade_db()
203 self.tables_created_and_initialised = True
204 log.info('Database initialised')
205
206 def clean_db(self):
207 self.commit_and_remove()
208 meta.metadata = MetaData(self.metadata.bind)
209 with warnings.catch_warnings():
210 warnings.filterwarnings('ignore', '.*(reflection|tsvector).*')
211 meta.metadata.reflect()
212
213 meta.metadata.drop_all()
214 self.tables_created_and_initialised = False
215 log.info('Database tables dropped')
216
217 def create_db(self):
218 '''Ensures tables, const data and some default config is created.
219 i.e. the same as init_db APART from when running tests, when init_db
220 has shortcuts.
221 '''
222 self.metadata.create_all(bind=self.metadata.bind)
223 log.info('Database tables created')
224
225 def rebuild_db(self):
226 '''Clean and init the db'''
227 if self.tables_created_and_initialised:
228 # just delete data, leaving tables - this is faster
229 self.delete_all()
230 else:
231 # delete tables and data
232 self.clean_db()
233 self.session.remove()
234 self.init_db()
235 self.session.flush()
236 log.info('Database rebuilt')
237
238 def delete_all(self):
239 '''Delete all data from all tables.'''
240 self.session.remove()
241 ## use raw connection for performance
242 connection = self.session.connection()
243 if sqav.startswith("0.4"):
244 tables = self.metadata.table_iterator()
245 else:
246 tables = reversed(self.metadata.sorted_tables)
247 for table in tables:
248 if table.name == 'alembic_version':
249 continue
250 connection.execute('delete from "%s"' % table.name)
251 self.session.commit()
252 log.info('Database table data deleted')
253
254 def reset_alembic_output(self):
255 self._alembic_output = []
256
257 def add_alembic_output(self, *args):
258 self._alembic_output.append(args)
259
260 def take_alembic_output(self, with_reset=True):
261 output = self._alembic_output
262 self._alembic_config = []
263 return output
264
265 def setup_migration_version_control(self):
266 self.reset_alembic_output()
267 alembic_config = AlembicConfig(self._alembic_ini)
268 alembic_config.set_main_option(
269 "sqlalchemy.url", str(self.metadata.bind.url)
270 )
271 try:
272 sqlalchemy_migrate_version = self.metadata.bind.execute(
273 u'select version from migrate_version'
274 ).scalar()
275 except ProgrammingError:
276 sqlalchemy_migrate_version = 0
277
278 # this value is used for graceful upgrade from
279 # sqlalchemy-migrate to alembic
280 alembic_config.set_main_option(
281 "sqlalchemy_migrate_version", str(sqlalchemy_migrate_version)
282 )
283 # This is an interceptor for alembic output. Otherwise,
284 # everything will be printed to stdout
285 alembic_config.print_stdout = self.add_alembic_output
286
287 self.alembic_config = alembic_config
288
289 def current_version(self):
290 try:
291 alembic_current(self.alembic_config)
292 return self.take_alembic_output()[0][0]
293 except (TypeError, IndexError):
294 # alembic is not initialized yet
295 return 'base'
296
297 def downgrade_db(self, version='base'):
298 self.setup_migration_version_control()
299 alembic_downgrade(self.alembic_config, version)
300 log.info(u'CKAN database version set to: %s', version)
301
302 def upgrade_db(self, version='head'):
303 '''Upgrade db using sqlalchemy migrations.
304
305 @param version: version to upgrade to (if None upgrade to latest)
306 '''
307 _assert_engine_msg = (
308 u'Database migration - only Postgresql engine supported (not %s).'
309 ) % meta.engine.name
310 assert meta.engine.name in (
311 u'postgres', u'postgresql'
312 ), _assert_engine_msg
313 self.setup_migration_version_control()
314 version_before = self.current_version()
315 alembic_upgrade(self.alembic_config, version)
316 version_after = self.current_version()
317
318 if version_after != version_before:
319 log.info(
320 u'CKAN database version upgraded: %s -> %s',
321 version_before,
322 version_after
323 )
324 else:
325 log.info(u'CKAN database version remains as: %s', version_after)
326
327 def are_tables_created(self):
328 meta.metadata = MetaData(self.metadata.bind)
329 with warnings.catch_warnings():
330 warnings.filterwarnings('ignore', '.*(reflection|geometry).*')
331 meta.metadata.reflect()
332 return bool(meta.metadata.tables)
333
334
335 repo = Repository(meta.metadata, meta.Session)
336
337
338 def is_id(id_string):
339 '''Tells the client if the string looks like a revision id or not'''
340 reg_ex = '^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$'
341 return bool(re.match(reg_ex, id_string))
342
343
344 def parse_db_config(config_key=u'sqlalchemy.url'):
345 u''' Takes a config key for a database connection url and parses it into
346 a dictionary. Expects a url like:
347
348 'postgres://tester:pass@localhost/ckantest3'
349
350 Returns None if the url could not be parsed.
351 '''
352 url = config[config_key]
353 regex = [
354 u'^\\s*(?P<db_type>\\w*)', u'://', u'(?P<db_user>[^:]*)', u':?',
355 u'(?P<db_pass>[^@]*)', u'@', u'(?P<db_host>[^/:]*)', u':?',
356 u'(?P<db_port>[^/]*)', u'/', u'(?P<db_name>[\\w.-]*)'
357 ]
358 db_details_match = re.match(u''.join(regex), url)
359 if not db_details_match:
360 return
361 return db_details_match.groupdict()
362
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/model/__init__.py b/ckan/model/__init__.py
--- a/ckan/model/__init__.py
+++ b/ckan/model/__init__.py
@@ -266,7 +266,7 @@
self.reset_alembic_output()
alembic_config = AlembicConfig(self._alembic_ini)
alembic_config.set_main_option(
- "sqlalchemy.url", str(self.metadata.bind.url)
+ "sqlalchemy.url", config.get("sqlalchemy.url")
)
try:
sqlalchemy_migrate_version = self.metadata.bind.execute(
|
{"golden_diff": "diff --git a/ckan/model/__init__.py b/ckan/model/__init__.py\n--- a/ckan/model/__init__.py\n+++ b/ckan/model/__init__.py\n@@ -266,7 +266,7 @@\n self.reset_alembic_output()\n alembic_config = AlembicConfig(self._alembic_ini)\n alembic_config.set_main_option(\n- \"sqlalchemy.url\", str(self.metadata.bind.url)\n+ \"sqlalchemy.url\", config.get(\"sqlalchemy.url\")\n )\n try:\n sqlalchemy_migrate_version = self.metadata.bind.execute(\n", "issue": "DB INIT error when using usernames with non-alphanumeric chars\n**CKAN version**\r\n\r\nMaster 713716b0689bf848865f05acd328ded29f041c5a (2.9.something)\r\n\r\n**Describe the bug**\r\n\r\nDB usernames with non alphanum chars will terminate in error the command `ckan db init`.\r\n\r\n**Steps to reproduce**\r\n\r\nCreate a pg user with for instance a \"`@`\" in it, then update `ckan.ini` with the proper URL, \r\ne.g.: user `ckan@ckan`:\r\n\r\n sqlalchemy.url = postgresql://ckan@ckan:ckan@localhost/ckan_at\r\n\r\nRunning `ckan run` will not raise connection error (it won't find table, eventually). \r\n\r\nRunning `ckan db init` will terminate with the error:\r\n\r\n invalid interpolation syntax in 'postgresql://ckan%40ckan:ckan@localhost/ckan_at' at position 17\r\n\r\n**Expected behavior**\r\n\r\nThe command should connect to the db without errors.\r\n\r\n**Additional details**\r\n\r\nAt https://github.com/ckan/ckan/blob/713716b0689bf848865f05acd328ded29f041c5a/ckan/model/__init__.py#L268-L270\r\n\r\n\r\n`self.metadata.bind.url` contains `postgresql://ckan%40ckan:ckan@localhost/ckan_at`\r\n\r\nWe could replace the line with \r\n```python\r\n alembic_config.set_main_option(\r\n \"sqlalchemy.url\", config.get(\"sqlalchemy.url\")\r\n )\r\n```\r\n\r\n\n", "before_files": [{"content": "# encoding: utf-8\n\nimport warnings\nimport logging\nimport os\nimport re\nfrom time import sleep\nfrom os.path import splitext\n\nfrom sqlalchemy import MetaData, __version__ as sqav, Table\nfrom sqlalchemy.exc import ProgrammingError\n\nfrom alembic.command import (\n upgrade as alembic_upgrade,\n downgrade as alembic_downgrade,\n current as alembic_current\n)\nfrom alembic.config import Config as AlembicConfig\n\nfrom ckan.model import meta\n\nfrom ckan.model.meta import (\n Session,\n engine_is_sqlite,\n engine_is_pg,\n)\nfrom ckan.model.core import (\n State,\n)\nfrom ckan.model.system import (\n System,\n)\nfrom ckan.model.package import (\n Package,\n PackageMember,\n PACKAGE_NAME_MIN_LENGTH,\n PACKAGE_NAME_MAX_LENGTH,\n PACKAGE_VERSION_MAX_LENGTH,\n package_table,\n package_member_table,\n)\nfrom ckan.model.tag import (\n Tag,\n PackageTag,\n MAX_TAG_LENGTH,\n MIN_TAG_LENGTH,\n tag_table,\n package_tag_table,\n)\nfrom ckan.model.user import (\n User,\n user_table,\n)\nfrom ckan.model.group import (\n Member,\n Group,\n group_table,\n member_table,\n)\nfrom ckan.model.group_extra import (\n GroupExtra,\n group_extra_table,\n)\nfrom ckan.model.package_extra import (\n PackageExtra,\n package_extra_table,\n)\nfrom ckan.model.resource import (\n Resource,\n DictProxy,\n resource_table,\n)\nfrom ckan.model.resource_view import (\n ResourceView,\n resource_view_table,\n)\nfrom ckan.model.tracking import (\n tracking_summary_table,\n TrackingSummary,\n tracking_raw_table\n)\nfrom ckan.model.rating import (\n Rating,\n MIN_RATING,\n MAX_RATING,\n)\nfrom ckan.model.package_relationship import (\n PackageRelationship,\n package_relationship_table,\n)\nfrom ckan.model.task_status import (\n TaskStatus,\n task_status_table,\n)\nfrom ckan.model.vocabulary import (\n Vocabulary,\n VOCABULARY_NAME_MAX_LENGTH,\n VOCABULARY_NAME_MIN_LENGTH,\n)\nfrom ckan.model.activity import (\n Activity,\n ActivityDetail,\n activity_table,\n activity_detail_table,\n)\nfrom ckan.model.term_translation import (\n term_translation_table,\n)\nfrom ckan.model.follower import (\n UserFollowingUser,\n UserFollowingDataset,\n UserFollowingGroup,\n)\nfrom ckan.model.system_info import (\n system_info_table,\n SystemInfo,\n get_system_info,\n set_system_info,\n delete_system_info,\n)\nfrom ckan.model.domain_object import (\n DomainObjectOperation,\n DomainObject,\n)\nfrom ckan.model.dashboard import (\n Dashboard,\n)\nfrom ckan.model.api_token import (\n ApiToken,\n)\n\nimport ckan.migration\nfrom ckan.common import config\n\n\nlog = logging.getLogger(__name__)\n\nDB_CONNECT_RETRIES = 10\n\n\ndef init_model(engine):\n '''Call me before using any of the tables or classes in the model'''\n meta.Session.remove()\n meta.Session.configure(bind=engine)\n meta.create_local_session.configure(bind=engine)\n meta.engine = engine\n meta.metadata.bind = engine\n # sqlalchemy migrate version table\n import sqlalchemy.exc\n for i in reversed(range(DB_CONNECT_RETRIES)):\n try:\n Table('alembic_version', meta.metadata, autoload=True)\n break\n except sqlalchemy.exc.NoSuchTableError:\n break\n except sqlalchemy.exc.OperationalError as e:\n if 'database system is starting up' in repr(e.orig) and i:\n sleep(DB_CONNECT_RETRIES - i)\n continue\n raise\n\n\nclass Repository():\n _alembic_ini = os.path.join(\n os.path.dirname(ckan.migration.__file__),\n u\"alembic.ini\"\n )\n\n # note: tables_created value is not sustained between instantiations\n # so only useful for tests. The alternative is to use\n # are_tables_created().\n tables_created_and_initialised = False\n\n def __init__(self, metadata, session):\n self.metadata = metadata\n self.session = session\n self.commit = session.commit\n\n def commit_and_remove(self):\n self.session.commit()\n self.session.remove()\n\n def init_db(self):\n '''Ensures tables, const data and some default config is created.\n This method MUST be run before using CKAN for the first time.\n Before this method is run, you can either have a clean db or tables\n that may have been setup with either upgrade_db or a previous run of\n init_db.\n '''\n warnings.filterwarnings('ignore', 'SAWarning')\n self.session.rollback()\n self.session.remove()\n # sqlite database needs to be recreated each time as the\n # memory database is lost.\n\n if self.metadata.bind.engine.url.drivername == 'sqlite':\n # this creates the tables, which isn't required inbetween tests\n # that have simply called rebuild_db.\n self.create_db()\n else:\n if not self.tables_created_and_initialised:\n self.upgrade_db()\n self.tables_created_and_initialised = True\n log.info('Database initialised')\n\n def clean_db(self):\n self.commit_and_remove()\n meta.metadata = MetaData(self.metadata.bind)\n with warnings.catch_warnings():\n warnings.filterwarnings('ignore', '.*(reflection|tsvector).*')\n meta.metadata.reflect()\n\n meta.metadata.drop_all()\n self.tables_created_and_initialised = False\n log.info('Database tables dropped')\n\n def create_db(self):\n '''Ensures tables, const data and some default config is created.\n i.e. the same as init_db APART from when running tests, when init_db\n has shortcuts.\n '''\n self.metadata.create_all(bind=self.metadata.bind)\n log.info('Database tables created')\n\n def rebuild_db(self):\n '''Clean and init the db'''\n if self.tables_created_and_initialised:\n # just delete data, leaving tables - this is faster\n self.delete_all()\n else:\n # delete tables and data\n self.clean_db()\n self.session.remove()\n self.init_db()\n self.session.flush()\n log.info('Database rebuilt')\n\n def delete_all(self):\n '''Delete all data from all tables.'''\n self.session.remove()\n ## use raw connection for performance\n connection = self.session.connection()\n if sqav.startswith(\"0.4\"):\n tables = self.metadata.table_iterator()\n else:\n tables = reversed(self.metadata.sorted_tables)\n for table in tables:\n if table.name == 'alembic_version':\n continue\n connection.execute('delete from \"%s\"' % table.name)\n self.session.commit()\n log.info('Database table data deleted')\n\n def reset_alembic_output(self):\n self._alembic_output = []\n\n def add_alembic_output(self, *args):\n self._alembic_output.append(args)\n\n def take_alembic_output(self, with_reset=True):\n output = self._alembic_output\n self._alembic_config = []\n return output\n\n def setup_migration_version_control(self):\n self.reset_alembic_output()\n alembic_config = AlembicConfig(self._alembic_ini)\n alembic_config.set_main_option(\n \"sqlalchemy.url\", str(self.metadata.bind.url)\n )\n try:\n sqlalchemy_migrate_version = self.metadata.bind.execute(\n u'select version from migrate_version'\n ).scalar()\n except ProgrammingError:\n sqlalchemy_migrate_version = 0\n\n # this value is used for graceful upgrade from\n # sqlalchemy-migrate to alembic\n alembic_config.set_main_option(\n \"sqlalchemy_migrate_version\", str(sqlalchemy_migrate_version)\n )\n # This is an interceptor for alembic output. Otherwise,\n # everything will be printed to stdout\n alembic_config.print_stdout = self.add_alembic_output\n\n self.alembic_config = alembic_config\n\n def current_version(self):\n try:\n alembic_current(self.alembic_config)\n return self.take_alembic_output()[0][0]\n except (TypeError, IndexError):\n # alembic is not initialized yet\n return 'base'\n\n def downgrade_db(self, version='base'):\n self.setup_migration_version_control()\n alembic_downgrade(self.alembic_config, version)\n log.info(u'CKAN database version set to: %s', version)\n\n def upgrade_db(self, version='head'):\n '''Upgrade db using sqlalchemy migrations.\n\n @param version: version to upgrade to (if None upgrade to latest)\n '''\n _assert_engine_msg = (\n u'Database migration - only Postgresql engine supported (not %s).'\n ) % meta.engine.name\n assert meta.engine.name in (\n u'postgres', u'postgresql'\n ), _assert_engine_msg\n self.setup_migration_version_control()\n version_before = self.current_version()\n alembic_upgrade(self.alembic_config, version)\n version_after = self.current_version()\n\n if version_after != version_before:\n log.info(\n u'CKAN database version upgraded: %s -> %s',\n version_before,\n version_after\n )\n else:\n log.info(u'CKAN database version remains as: %s', version_after)\n\n def are_tables_created(self):\n meta.metadata = MetaData(self.metadata.bind)\n with warnings.catch_warnings():\n warnings.filterwarnings('ignore', '.*(reflection|geometry).*')\n meta.metadata.reflect()\n return bool(meta.metadata.tables)\n\n\nrepo = Repository(meta.metadata, meta.Session)\n\n\ndef is_id(id_string):\n '''Tells the client if the string looks like a revision id or not'''\n reg_ex = '^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$'\n return bool(re.match(reg_ex, id_string))\n\n\ndef parse_db_config(config_key=u'sqlalchemy.url'):\n u''' Takes a config key for a database connection url and parses it into\n a dictionary. Expects a url like:\n\n 'postgres://tester:pass@localhost/ckantest3'\n\n Returns None if the url could not be parsed.\n '''\n url = config[config_key]\n regex = [\n u'^\\\\s*(?P<db_type>\\\\w*)', u'://', u'(?P<db_user>[^:]*)', u':?',\n u'(?P<db_pass>[^@]*)', u'@', u'(?P<db_host>[^/:]*)', u':?',\n u'(?P<db_port>[^/]*)', u'/', u'(?P<db_name>[\\\\w.-]*)'\n ]\n db_details_match = re.match(u''.join(regex), url)\n if not db_details_match:\n return\n return db_details_match.groupdict()\n", "path": "ckan/model/__init__.py"}], "after_files": [{"content": "# encoding: utf-8\n\nimport warnings\nimport logging\nimport os\nimport re\nfrom time import sleep\nfrom os.path import splitext\n\nfrom sqlalchemy import MetaData, __version__ as sqav, Table\nfrom sqlalchemy.exc import ProgrammingError\n\nfrom alembic.command import (\n upgrade as alembic_upgrade,\n downgrade as alembic_downgrade,\n current as alembic_current\n)\nfrom alembic.config import Config as AlembicConfig\n\nfrom ckan.model import meta\n\nfrom ckan.model.meta import (\n Session,\n engine_is_sqlite,\n engine_is_pg,\n)\nfrom ckan.model.core import (\n State,\n)\nfrom ckan.model.system import (\n System,\n)\nfrom ckan.model.package import (\n Package,\n PackageMember,\n PACKAGE_NAME_MIN_LENGTH,\n PACKAGE_NAME_MAX_LENGTH,\n PACKAGE_VERSION_MAX_LENGTH,\n package_table,\n package_member_table,\n)\nfrom ckan.model.tag import (\n Tag,\n PackageTag,\n MAX_TAG_LENGTH,\n MIN_TAG_LENGTH,\n tag_table,\n package_tag_table,\n)\nfrom ckan.model.user import (\n User,\n user_table,\n)\nfrom ckan.model.group import (\n Member,\n Group,\n group_table,\n member_table,\n)\nfrom ckan.model.group_extra import (\n GroupExtra,\n group_extra_table,\n)\nfrom ckan.model.package_extra import (\n PackageExtra,\n package_extra_table,\n)\nfrom ckan.model.resource import (\n Resource,\n DictProxy,\n resource_table,\n)\nfrom ckan.model.resource_view import (\n ResourceView,\n resource_view_table,\n)\nfrom ckan.model.tracking import (\n tracking_summary_table,\n TrackingSummary,\n tracking_raw_table\n)\nfrom ckan.model.rating import (\n Rating,\n MIN_RATING,\n MAX_RATING,\n)\nfrom ckan.model.package_relationship import (\n PackageRelationship,\n package_relationship_table,\n)\nfrom ckan.model.task_status import (\n TaskStatus,\n task_status_table,\n)\nfrom ckan.model.vocabulary import (\n Vocabulary,\n VOCABULARY_NAME_MAX_LENGTH,\n VOCABULARY_NAME_MIN_LENGTH,\n)\nfrom ckan.model.activity import (\n Activity,\n ActivityDetail,\n activity_table,\n activity_detail_table,\n)\nfrom ckan.model.term_translation import (\n term_translation_table,\n)\nfrom ckan.model.follower import (\n UserFollowingUser,\n UserFollowingDataset,\n UserFollowingGroup,\n)\nfrom ckan.model.system_info import (\n system_info_table,\n SystemInfo,\n get_system_info,\n set_system_info,\n delete_system_info,\n)\nfrom ckan.model.domain_object import (\n DomainObjectOperation,\n DomainObject,\n)\nfrom ckan.model.dashboard import (\n Dashboard,\n)\nfrom ckan.model.api_token import (\n ApiToken,\n)\n\nimport ckan.migration\nfrom ckan.common import config\n\n\nlog = logging.getLogger(__name__)\n\nDB_CONNECT_RETRIES = 10\n\n\ndef init_model(engine):\n '''Call me before using any of the tables or classes in the model'''\n meta.Session.remove()\n meta.Session.configure(bind=engine)\n meta.create_local_session.configure(bind=engine)\n meta.engine = engine\n meta.metadata.bind = engine\n # sqlalchemy migrate version table\n import sqlalchemy.exc\n for i in reversed(range(DB_CONNECT_RETRIES)):\n try:\n Table('alembic_version', meta.metadata, autoload=True)\n break\n except sqlalchemy.exc.NoSuchTableError:\n break\n except sqlalchemy.exc.OperationalError as e:\n if 'database system is starting up' in repr(e.orig) and i:\n sleep(DB_CONNECT_RETRIES - i)\n continue\n raise\n\n\nclass Repository():\n _alembic_ini = os.path.join(\n os.path.dirname(ckan.migration.__file__),\n u\"alembic.ini\"\n )\n\n # note: tables_created value is not sustained between instantiations\n # so only useful for tests. The alternative is to use\n # are_tables_created().\n tables_created_and_initialised = False\n\n def __init__(self, metadata, session):\n self.metadata = metadata\n self.session = session\n self.commit = session.commit\n\n def commit_and_remove(self):\n self.session.commit()\n self.session.remove()\n\n def init_db(self):\n '''Ensures tables, const data and some default config is created.\n This method MUST be run before using CKAN for the first time.\n Before this method is run, you can either have a clean db or tables\n that may have been setup with either upgrade_db or a previous run of\n init_db.\n '''\n warnings.filterwarnings('ignore', 'SAWarning')\n self.session.rollback()\n self.session.remove()\n # sqlite database needs to be recreated each time as the\n # memory database is lost.\n\n if self.metadata.bind.engine.url.drivername == 'sqlite':\n # this creates the tables, which isn't required inbetween tests\n # that have simply called rebuild_db.\n self.create_db()\n else:\n if not self.tables_created_and_initialised:\n self.upgrade_db()\n self.tables_created_and_initialised = True\n log.info('Database initialised')\n\n def clean_db(self):\n self.commit_and_remove()\n meta.metadata = MetaData(self.metadata.bind)\n with warnings.catch_warnings():\n warnings.filterwarnings('ignore', '.*(reflection|tsvector).*')\n meta.metadata.reflect()\n\n meta.metadata.drop_all()\n self.tables_created_and_initialised = False\n log.info('Database tables dropped')\n\n def create_db(self):\n '''Ensures tables, const data and some default config is created.\n i.e. the same as init_db APART from when running tests, when init_db\n has shortcuts.\n '''\n self.metadata.create_all(bind=self.metadata.bind)\n log.info('Database tables created')\n\n def rebuild_db(self):\n '''Clean and init the db'''\n if self.tables_created_and_initialised:\n # just delete data, leaving tables - this is faster\n self.delete_all()\n else:\n # delete tables and data\n self.clean_db()\n self.session.remove()\n self.init_db()\n self.session.flush()\n log.info('Database rebuilt')\n\n def delete_all(self):\n '''Delete all data from all tables.'''\n self.session.remove()\n ## use raw connection for performance\n connection = self.session.connection()\n if sqav.startswith(\"0.4\"):\n tables = self.metadata.table_iterator()\n else:\n tables = reversed(self.metadata.sorted_tables)\n for table in tables:\n if table.name == 'alembic_version':\n continue\n connection.execute('delete from \"%s\"' % table.name)\n self.session.commit()\n log.info('Database table data deleted')\n\n def reset_alembic_output(self):\n self._alembic_output = []\n\n def add_alembic_output(self, *args):\n self._alembic_output.append(args)\n\n def take_alembic_output(self, with_reset=True):\n output = self._alembic_output\n self._alembic_config = []\n return output\n\n def setup_migration_version_control(self):\n self.reset_alembic_output()\n alembic_config = AlembicConfig(self._alembic_ini)\n alembic_config.set_main_option(\n \"sqlalchemy.url\", config.get(\"sqlalchemy.url\")\n )\n try:\n sqlalchemy_migrate_version = self.metadata.bind.execute(\n u'select version from migrate_version'\n ).scalar()\n except ProgrammingError:\n sqlalchemy_migrate_version = 0\n\n # this value is used for graceful upgrade from\n # sqlalchemy-migrate to alembic\n alembic_config.set_main_option(\n \"sqlalchemy_migrate_version\", str(sqlalchemy_migrate_version)\n )\n # This is an interceptor for alembic output. Otherwise,\n # everything will be printed to stdout\n alembic_config.print_stdout = self.add_alembic_output\n\n self.alembic_config = alembic_config\n\n def current_version(self):\n try:\n alembic_current(self.alembic_config)\n return self.take_alembic_output()[0][0]\n except (TypeError, IndexError):\n # alembic is not initialized yet\n return 'base'\n\n def downgrade_db(self, version='base'):\n self.setup_migration_version_control()\n alembic_downgrade(self.alembic_config, version)\n log.info(u'CKAN database version set to: %s', version)\n\n def upgrade_db(self, version='head'):\n '''Upgrade db using sqlalchemy migrations.\n\n @param version: version to upgrade to (if None upgrade to latest)\n '''\n _assert_engine_msg = (\n u'Database migration - only Postgresql engine supported (not %s).'\n ) % meta.engine.name\n assert meta.engine.name in (\n u'postgres', u'postgresql'\n ), _assert_engine_msg\n self.setup_migration_version_control()\n version_before = self.current_version()\n alembic_upgrade(self.alembic_config, version)\n version_after = self.current_version()\n\n if version_after != version_before:\n log.info(\n u'CKAN database version upgraded: %s -> %s',\n version_before,\n version_after\n )\n else:\n log.info(u'CKAN database version remains as: %s', version_after)\n\n def are_tables_created(self):\n meta.metadata = MetaData(self.metadata.bind)\n with warnings.catch_warnings():\n warnings.filterwarnings('ignore', '.*(reflection|geometry).*')\n meta.metadata.reflect()\n return bool(meta.metadata.tables)\n\n\nrepo = Repository(meta.metadata, meta.Session)\n\n\ndef is_id(id_string):\n '''Tells the client if the string looks like a revision id or not'''\n reg_ex = '^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$'\n return bool(re.match(reg_ex, id_string))\n\n\ndef parse_db_config(config_key=u'sqlalchemy.url'):\n u''' Takes a config key for a database connection url and parses it into\n a dictionary. Expects a url like:\n\n 'postgres://tester:pass@localhost/ckantest3'\n\n Returns None if the url could not be parsed.\n '''\n url = config[config_key]\n regex = [\n u'^\\\\s*(?P<db_type>\\\\w*)', u'://', u'(?P<db_user>[^:]*)', u':?',\n u'(?P<db_pass>[^@]*)', u'@', u'(?P<db_host>[^/:]*)', u':?',\n u'(?P<db_port>[^/]*)', u'/', u'(?P<db_name>[\\\\w.-]*)'\n ]\n db_details_match = re.match(u''.join(regex), url)\n if not db_details_match:\n return\n return db_details_match.groupdict()\n", "path": "ckan/model/__init__.py"}]}
| 3,992 | 136 |
gh_patches_debug_8595
|
rasdani/github-patches
|
git_diff
|
apluslms__a-plus-1083
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error: view object has no attribute 'redirect'
We have seen this error in the server logs a lot recently. Any internal server error is bad and implies that users end up suddenly on a crash page (HTTP 500 Internal server error). This must be looked into.
```
Internal Server Error: /COURSEKEY/COURSEINSTANCEKEY/toc/
AttributeError at /COURSEKEY/COURSEINSTANCEKEY/toc/
'TableOfContentsView' object has no attribute 'redirect'
```
This occurs on multiple courses (at least, I saw many errors on the courses Y1 and TRAK Y) and on multiple views. `TableOfContentsView` has been common there, but several other view classes have been named in the error logs, at least the following:
* SubmissionView
* ResultsView
* LanguageView
* ModuleView
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `course/viewbase.py`
Content:
```
1 from django.contrib import messages
2 from django.core.exceptions import PermissionDenied
3 from django.http import Http404
4 from django.shortcuts import get_object_or_404, redirect, render
5 from django.utils import translation
6 from django.utils.translation import gettext_lazy as _
7 from django.utils.translation import get_language, get_language_info
8
9 from authorization.permissions import ACCESS
10 from exercise.cache.content import CachedContent
11 from lib.helpers import remove_query_param_from_url, update_url_params
12 from lib.viewbase import BaseTemplateView
13 from userprofile.viewbase import UserProfileMixin
14 from exercise.models import LearningObject
15 from .cache.students import CachedStudent
16 from .exceptions import TranslationNotFound
17 from .permissions import (
18 CourseVisiblePermission,
19 CourseModulePermission,
20 )
21 from .models import Course, CourseInstance, CourseModule, UserTagging, Enrollment
22
23
24 class CourseMixin(UserProfileMixin):
25 course_kw = "course_slug"
26
27 def get_resource_objects(self):
28 super().get_resource_objects()
29 self.course = get_object_or_404(
30 Course,
31 url=self._get_kwarg(self.course_kw)
32 )
33 self.note("course")
34
35
36 class CourseBaseView(CourseMixin, BaseTemplateView):
37 pass
38
39
40 class CourseInstanceBaseMixin(object):
41 course_kw = CourseMixin.course_kw
42 instance_kw = "instance_slug"
43 course_permission_classes = (
44 CourseVisiblePermission,
45 )
46
47 def get_permissions(self):
48 perms = super().get_permissions()
49 perms.extend((Perm() for Perm in self.course_permission_classes))
50 return perms
51
52 # get_course_instance_object
53
54 def get_resource_objects(self):
55 super().get_resource_objects()
56 user = self.request.user
57 instance = self.get_course_instance_object()
58 if instance is not None:
59 self.instance = instance
60 self.course = self.instance.course
61 self.content = CachedContent(self.instance)
62 self.user_course_data = None
63 is_real_user = user.is_authenticated and not user.is_anonymous
64 if is_real_user:
65 self.user_course_data = self.instance.get_enrollment_for(user)
66 self.is_student = self.instance.is_student(user)
67 self.is_assistant = self.instance.is_assistant(user)
68 self.is_teacher = self.instance.is_teacher(user)
69 self.is_course_staff = self.is_teacher or self.is_assistant
70 self.get_taggings = lambda: CachedStudent(instance, user.id).data['tag_slugs']
71 self.url_without_language = remove_query_param_from_url(self.request.get_full_path(), 'hl')
72 self.query_language = None
73 self.user_language = None
74
75 self.note(
76 "course", "instance", "content", "user_course_data", "is_student", "is_assistant",
77 "is_teacher", "is_course_staff", "get_taggings", "url_without_language",
78 "query_language", "user_language"
79 )
80
81 # Try to find a language that is defined for this course instance
82 # and apply it
83 if self.instance.language:
84 instance_languages = self.instance.language.strip('|').split('|')
85 instance_def_language = instance_languages[0]
86 instance_languages = set(instance_languages)
87
88 languages = []
89 if self.user_course_data and self.user_course_data.language:
90 languages.append(self.user_course_data.language)
91 if is_real_user and user.userprofile.language:
92 languages.append(user.userprofile.language)
93 languages.append(get_language())
94
95 query_language = self.request.GET.get('hl')
96 if query_language:
97 if query_language[:2] in instance_languages:
98 language = query_language
99 if languages:
100 self.user_language = languages[0]
101 if self.user_language[:2] != query_language[:2]:
102 self.query_language = query_language
103 else:
104 raise TranslationNotFound
105 else:
106 for lang in languages:
107 if lang[:2] in instance_languages:
108 language = lang
109 break
110 else:
111 language = instance_def_language
112
113 language = language[:2]
114 # Override request.LANGUAGE_CODE. It is set in lib/middleware.py
115 # (class LocaleMiddleware) based on the userprofile.language.
116 # The middleware can not easily access the course context and
117 # the language from the enrollment. That is fixed here.
118 self.request.LANGUAGE_CODE = language
119 translation.activate(language)
120
121 def get_access_mode(self):
122 access_mode = super().get_access_mode()
123
124 if hasattr(self, 'instance'):
125 # Loosen the access mode if instance is public
126 show_for = self.instance.view_content_to
127 is_public = show_for == CourseInstance.VIEW_ACCESS.PUBLIC
128 access_mode_student = access_mode in (ACCESS.STUDENT, ACCESS.ENROLL)
129 if is_public and access_mode_student:
130 access_mode = ACCESS.ANONYMOUS
131
132 return access_mode
133
134 def handle_exception(self, exc):
135 if isinstance(exc, TranslationNotFound):
136 instance_languages = self.instance.language.strip("|").split("|")
137 url = remove_query_param_from_url(self.request.get_full_path(), 'hl')
138 for i, lang in enumerate(instance_languages):
139 instance_languages[i] = {"name": get_language_info(lang)['name'], "url": update_url_params(url, {'hl' : lang})}
140 return render(self.request, '404.html', {'error_msg': str(exc), 'languages': instance_languages}, status=404)
141 return super().handle_exception(exc)
142
143 class CourseInstanceMixin(CourseInstanceBaseMixin, UserProfileMixin):
144 def get_course_instance_object(self) -> CourseInstance:
145 return get_object_or_404(
146 CourseInstance.objects.prefetch_related('tabs'),
147 url=self.kwargs[self.instance_kw],
148 course__url=self.kwargs[self.course_kw],
149 )
150
151 def handle_no_permission(self):
152 if (self.request.user.is_authenticated
153 and not self.is_student
154 and not self.is_course_staff
155 and self.get_access_mode() in [ACCESS.STUDENT, ACCESS.ENROLLED]
156 and self.instance.view_content_to == CourseInstance.VIEW_ACCESS.ENROLLED):
157 # Redirect the user to the enrollment page instead of showing
158 # a 403 Forbidden error, if:
159 # - the user is signed in but not enrolled or staff
160 # - the page is not a teacher page (e.g. edit course)
161 # - the course is visible only to enrolled students
162 #
163 # If SIS enrollment is applied and course requires enrollment questionnaire,
164 # redirect to the questionnaire instead.
165 enrollment = self.user_course_data
166 if enrollment and enrollment.status == Enrollment.ENROLLMENT_STATUS.PENDING:
167 exercise = LearningObject.objects.find_enrollment_exercise(
168 self.instance, self.profile.is_external)
169 if exercise:
170 return self.redirect(exercise.get_absolute_url())
171 return redirect(self.instance.get_url('enroll'))
172 return super().handle_no_permission()
173
174
175 class CourseInstanceBaseView(CourseInstanceMixin, BaseTemplateView):
176 pass
177
178
179 class EnrollableViewMixin(CourseInstanceMixin):
180 access_mode = ACCESS.ENROLL
181
182 def get_common_objects(self):
183 self.enrolled = self.is_student
184 self.enrollable = (
185 self.profile
186 and self.instance.is_enrollable(self.profile.user)
187 )
188 self.note('enrolled', 'enrollable')
189
190
191 class CourseModuleBaseMixin(object):
192 module_kw = "module_slug"
193 module_permissions_classes = (
194 CourseModulePermission,
195 )
196
197 def get_permissions(self):
198 perms = super().get_permissions()
199 perms.extend((Perm() for Perm in self.module_permissions_classes))
200 return perms
201
202 # get_course_module_object
203
204 def get_resource_objects(self):
205 super().get_resource_objects()
206 self.module = self.get_course_module_object()
207 self.note("module")
208
209
210 class CourseModuleMixin(CourseModuleBaseMixin, CourseInstanceMixin):
211 def get_course_module_object(self):
212 return get_object_or_404(
213 CourseModule,
214 url=self.kwargs[self.module_kw],
215 course_instance=self.instance
216 )
217
218
219 class CourseModuleBaseView(CourseModuleMixin, BaseTemplateView):
220 pass
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/course/viewbase.py b/course/viewbase.py
--- a/course/viewbase.py
+++ b/course/viewbase.py
@@ -167,7 +167,7 @@
exercise = LearningObject.objects.find_enrollment_exercise(
self.instance, self.profile.is_external)
if exercise:
- return self.redirect(exercise.get_absolute_url())
+ return redirect(exercise.get_absolute_url())
return redirect(self.instance.get_url('enroll'))
return super().handle_no_permission()
|
{"golden_diff": "diff --git a/course/viewbase.py b/course/viewbase.py\n--- a/course/viewbase.py\n+++ b/course/viewbase.py\n@@ -167,7 +167,7 @@\n exercise = LearningObject.objects.find_enrollment_exercise(\n self.instance, self.profile.is_external)\n if exercise:\n- return self.redirect(exercise.get_absolute_url())\n+ return redirect(exercise.get_absolute_url())\n return redirect(self.instance.get_url('enroll'))\n return super().handle_no_permission()\n", "issue": "Error: view object has no attribute 'redirect'\nWe have seen this error in the server logs a lot recently. Any internal server error is bad and implies that users end up suddenly on a crash page (HTTP 500 Internal server error). This must be looked into.\r\n\r\n```\r\nInternal Server Error: /COURSEKEY/COURSEINSTANCEKEY/toc/\r\n\r\nAttributeError at /COURSEKEY/COURSEINSTANCEKEY/toc/\r\n'TableOfContentsView' object has no attribute 'redirect'\r\n```\r\n\r\nThis occurs on multiple courses (at least, I saw many errors on the courses Y1 and TRAK Y) and on multiple views. `TableOfContentsView` has been common there, but several other view classes have been named in the error logs, at least the following:\r\n\r\n* SubmissionView\r\n* ResultsView\r\n* LanguageView\r\n* ModuleView\n", "before_files": [{"content": "from django.contrib import messages\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils import translation\nfrom django.utils.translation import gettext_lazy as _\nfrom django.utils.translation import get_language, get_language_info\n\nfrom authorization.permissions import ACCESS\nfrom exercise.cache.content import CachedContent\nfrom lib.helpers import remove_query_param_from_url, update_url_params\nfrom lib.viewbase import BaseTemplateView\nfrom userprofile.viewbase import UserProfileMixin\nfrom exercise.models import LearningObject\nfrom .cache.students import CachedStudent\nfrom .exceptions import TranslationNotFound\nfrom .permissions import (\n CourseVisiblePermission,\n CourseModulePermission,\n)\nfrom .models import Course, CourseInstance, CourseModule, UserTagging, Enrollment\n\n\nclass CourseMixin(UserProfileMixin):\n course_kw = \"course_slug\"\n\n def get_resource_objects(self):\n super().get_resource_objects()\n self.course = get_object_or_404(\n Course,\n url=self._get_kwarg(self.course_kw)\n )\n self.note(\"course\")\n\n\nclass CourseBaseView(CourseMixin, BaseTemplateView):\n pass\n\n\nclass CourseInstanceBaseMixin(object):\n course_kw = CourseMixin.course_kw\n instance_kw = \"instance_slug\"\n course_permission_classes = (\n CourseVisiblePermission,\n )\n\n def get_permissions(self):\n perms = super().get_permissions()\n perms.extend((Perm() for Perm in self.course_permission_classes))\n return perms\n\n # get_course_instance_object\n\n def get_resource_objects(self):\n super().get_resource_objects()\n user = self.request.user\n instance = self.get_course_instance_object()\n if instance is not None:\n self.instance = instance\n self.course = self.instance.course\n self.content = CachedContent(self.instance)\n self.user_course_data = None\n is_real_user = user.is_authenticated and not user.is_anonymous\n if is_real_user:\n self.user_course_data = self.instance.get_enrollment_for(user)\n self.is_student = self.instance.is_student(user)\n self.is_assistant = self.instance.is_assistant(user)\n self.is_teacher = self.instance.is_teacher(user)\n self.is_course_staff = self.is_teacher or self.is_assistant\n self.get_taggings = lambda: CachedStudent(instance, user.id).data['tag_slugs']\n self.url_without_language = remove_query_param_from_url(self.request.get_full_path(), 'hl')\n self.query_language = None\n self.user_language = None\n\n self.note(\n \"course\", \"instance\", \"content\", \"user_course_data\", \"is_student\", \"is_assistant\",\n \"is_teacher\", \"is_course_staff\", \"get_taggings\", \"url_without_language\",\n \"query_language\", \"user_language\"\n )\n\n # Try to find a language that is defined for this course instance\n # and apply it\n if self.instance.language:\n instance_languages = self.instance.language.strip('|').split('|')\n instance_def_language = instance_languages[0]\n instance_languages = set(instance_languages)\n\n languages = []\n if self.user_course_data and self.user_course_data.language:\n languages.append(self.user_course_data.language)\n if is_real_user and user.userprofile.language:\n languages.append(user.userprofile.language)\n languages.append(get_language())\n\n query_language = self.request.GET.get('hl')\n if query_language:\n if query_language[:2] in instance_languages:\n language = query_language\n if languages:\n self.user_language = languages[0]\n if self.user_language[:2] != query_language[:2]:\n self.query_language = query_language\n else:\n raise TranslationNotFound\n else:\n for lang in languages:\n if lang[:2] in instance_languages:\n language = lang\n break\n else:\n language = instance_def_language\n\n language = language[:2]\n # Override request.LANGUAGE_CODE. It is set in lib/middleware.py\n # (class LocaleMiddleware) based on the userprofile.language.\n # The middleware can not easily access the course context and\n # the language from the enrollment. That is fixed here.\n self.request.LANGUAGE_CODE = language\n translation.activate(language)\n\n def get_access_mode(self):\n access_mode = super().get_access_mode()\n\n if hasattr(self, 'instance'):\n # Loosen the access mode if instance is public\n show_for = self.instance.view_content_to\n is_public = show_for == CourseInstance.VIEW_ACCESS.PUBLIC\n access_mode_student = access_mode in (ACCESS.STUDENT, ACCESS.ENROLL)\n if is_public and access_mode_student:\n access_mode = ACCESS.ANONYMOUS\n\n return access_mode\n\n def handle_exception(self, exc):\n if isinstance(exc, TranslationNotFound):\n instance_languages = self.instance.language.strip(\"|\").split(\"|\")\n url = remove_query_param_from_url(self.request.get_full_path(), 'hl')\n for i, lang in enumerate(instance_languages):\n instance_languages[i] = {\"name\": get_language_info(lang)['name'], \"url\": update_url_params(url, {'hl' : lang})}\n return render(self.request, '404.html', {'error_msg': str(exc), 'languages': instance_languages}, status=404)\n return super().handle_exception(exc)\n\nclass CourseInstanceMixin(CourseInstanceBaseMixin, UserProfileMixin):\n def get_course_instance_object(self) -> CourseInstance:\n return get_object_or_404(\n CourseInstance.objects.prefetch_related('tabs'),\n url=self.kwargs[self.instance_kw],\n course__url=self.kwargs[self.course_kw],\n )\n\n def handle_no_permission(self):\n if (self.request.user.is_authenticated\n and not self.is_student\n and not self.is_course_staff\n and self.get_access_mode() in [ACCESS.STUDENT, ACCESS.ENROLLED]\n and self.instance.view_content_to == CourseInstance.VIEW_ACCESS.ENROLLED):\n # Redirect the user to the enrollment page instead of showing\n # a 403 Forbidden error, if:\n # - the user is signed in but not enrolled or staff\n # - the page is not a teacher page (e.g. edit course)\n # - the course is visible only to enrolled students\n #\n # If SIS enrollment is applied and course requires enrollment questionnaire,\n # redirect to the questionnaire instead.\n enrollment = self.user_course_data\n if enrollment and enrollment.status == Enrollment.ENROLLMENT_STATUS.PENDING:\n exercise = LearningObject.objects.find_enrollment_exercise(\n self.instance, self.profile.is_external)\n if exercise:\n return self.redirect(exercise.get_absolute_url())\n return redirect(self.instance.get_url('enroll'))\n return super().handle_no_permission()\n\n\nclass CourseInstanceBaseView(CourseInstanceMixin, BaseTemplateView):\n pass\n\n\nclass EnrollableViewMixin(CourseInstanceMixin):\n access_mode = ACCESS.ENROLL\n\n def get_common_objects(self):\n self.enrolled = self.is_student\n self.enrollable = (\n self.profile\n and self.instance.is_enrollable(self.profile.user)\n )\n self.note('enrolled', 'enrollable')\n\n\nclass CourseModuleBaseMixin(object):\n module_kw = \"module_slug\"\n module_permissions_classes = (\n CourseModulePermission,\n )\n\n def get_permissions(self):\n perms = super().get_permissions()\n perms.extend((Perm() for Perm in self.module_permissions_classes))\n return perms\n\n # get_course_module_object\n\n def get_resource_objects(self):\n super().get_resource_objects()\n self.module = self.get_course_module_object()\n self.note(\"module\")\n\n\nclass CourseModuleMixin(CourseModuleBaseMixin, CourseInstanceMixin):\n def get_course_module_object(self):\n return get_object_or_404(\n CourseModule,\n url=self.kwargs[self.module_kw],\n course_instance=self.instance\n )\n\n\nclass CourseModuleBaseView(CourseModuleMixin, BaseTemplateView):\n pass\n", "path": "course/viewbase.py"}], "after_files": [{"content": "from django.contrib import messages\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils import translation\nfrom django.utils.translation import gettext_lazy as _\nfrom django.utils.translation import get_language, get_language_info\n\nfrom authorization.permissions import ACCESS\nfrom exercise.cache.content import CachedContent\nfrom lib.helpers import remove_query_param_from_url, update_url_params\nfrom lib.viewbase import BaseTemplateView\nfrom userprofile.viewbase import UserProfileMixin\nfrom exercise.models import LearningObject\nfrom .cache.students import CachedStudent\nfrom .exceptions import TranslationNotFound\nfrom .permissions import (\n CourseVisiblePermission,\n CourseModulePermission,\n)\nfrom .models import Course, CourseInstance, CourseModule, UserTagging, Enrollment\n\n\nclass CourseMixin(UserProfileMixin):\n course_kw = \"course_slug\"\n\n def get_resource_objects(self):\n super().get_resource_objects()\n self.course = get_object_or_404(\n Course,\n url=self._get_kwarg(self.course_kw)\n )\n self.note(\"course\")\n\n\nclass CourseBaseView(CourseMixin, BaseTemplateView):\n pass\n\n\nclass CourseInstanceBaseMixin(object):\n course_kw = CourseMixin.course_kw\n instance_kw = \"instance_slug\"\n course_permission_classes = (\n CourseVisiblePermission,\n )\n\n def get_permissions(self):\n perms = super().get_permissions()\n perms.extend((Perm() for Perm in self.course_permission_classes))\n return perms\n\n # get_course_instance_object\n\n def get_resource_objects(self):\n super().get_resource_objects()\n user = self.request.user\n instance = self.get_course_instance_object()\n if instance is not None:\n self.instance = instance\n self.course = self.instance.course\n self.content = CachedContent(self.instance)\n self.user_course_data = None\n is_real_user = user.is_authenticated and not user.is_anonymous\n if is_real_user:\n self.user_course_data = self.instance.get_enrollment_for(user)\n self.is_student = self.instance.is_student(user)\n self.is_assistant = self.instance.is_assistant(user)\n self.is_teacher = self.instance.is_teacher(user)\n self.is_course_staff = self.is_teacher or self.is_assistant\n self.get_taggings = lambda: CachedStudent(instance, user.id).data['tag_slugs']\n self.url_without_language = remove_query_param_from_url(self.request.get_full_path(), 'hl')\n self.query_language = None\n self.user_language = None\n\n self.note(\n \"course\", \"instance\", \"content\", \"user_course_data\", \"is_student\", \"is_assistant\",\n \"is_teacher\", \"is_course_staff\", \"get_taggings\", \"url_without_language\",\n \"query_language\", \"user_language\"\n )\n\n # Try to find a language that is defined for this course instance\n # and apply it\n if self.instance.language:\n instance_languages = self.instance.language.strip('|').split('|')\n instance_def_language = instance_languages[0]\n instance_languages = set(instance_languages)\n\n languages = []\n if self.user_course_data and self.user_course_data.language:\n languages.append(self.user_course_data.language)\n if is_real_user and user.userprofile.language:\n languages.append(user.userprofile.language)\n languages.append(get_language())\n\n query_language = self.request.GET.get('hl')\n if query_language:\n if query_language[:2] in instance_languages:\n language = query_language\n if languages:\n self.user_language = languages[0]\n if self.user_language[:2] != query_language[:2]:\n self.query_language = query_language\n else:\n raise TranslationNotFound\n else:\n for lang in languages:\n if lang[:2] in instance_languages:\n language = lang\n break\n else:\n language = instance_def_language\n\n language = language[:2]\n # Override request.LANGUAGE_CODE. It is set in lib/middleware.py\n # (class LocaleMiddleware) based on the userprofile.language.\n # The middleware can not easily access the course context and\n # the language from the enrollment. That is fixed here.\n self.request.LANGUAGE_CODE = language\n translation.activate(language)\n\n def get_access_mode(self):\n access_mode = super().get_access_mode()\n\n if hasattr(self, 'instance'):\n # Loosen the access mode if instance is public\n show_for = self.instance.view_content_to\n is_public = show_for == CourseInstance.VIEW_ACCESS.PUBLIC\n access_mode_student = access_mode in (ACCESS.STUDENT, ACCESS.ENROLL)\n if is_public and access_mode_student:\n access_mode = ACCESS.ANONYMOUS\n\n return access_mode\n\n def handle_exception(self, exc):\n if isinstance(exc, TranslationNotFound):\n instance_languages = self.instance.language.strip(\"|\").split(\"|\")\n url = remove_query_param_from_url(self.request.get_full_path(), 'hl')\n for i, lang in enumerate(instance_languages):\n instance_languages[i] = {\"name\": get_language_info(lang)['name'], \"url\": update_url_params(url, {'hl' : lang})}\n return render(self.request, '404.html', {'error_msg': str(exc), 'languages': instance_languages}, status=404)\n return super().handle_exception(exc)\n\nclass CourseInstanceMixin(CourseInstanceBaseMixin, UserProfileMixin):\n def get_course_instance_object(self) -> CourseInstance:\n return get_object_or_404(\n CourseInstance.objects.prefetch_related('tabs'),\n url=self.kwargs[self.instance_kw],\n course__url=self.kwargs[self.course_kw],\n )\n\n def handle_no_permission(self):\n if (self.request.user.is_authenticated\n and not self.is_student\n and not self.is_course_staff\n and self.get_access_mode() in [ACCESS.STUDENT, ACCESS.ENROLLED]\n and self.instance.view_content_to == CourseInstance.VIEW_ACCESS.ENROLLED):\n # Redirect the user to the enrollment page instead of showing\n # a 403 Forbidden error, if:\n # - the user is signed in but not enrolled or staff\n # - the page is not a teacher page (e.g. edit course)\n # - the course is visible only to enrolled students\n #\n # If SIS enrollment is applied and course requires enrollment questionnaire,\n # redirect to the questionnaire instead.\n enrollment = self.user_course_data\n if enrollment and enrollment.status == Enrollment.ENROLLMENT_STATUS.PENDING:\n exercise = LearningObject.objects.find_enrollment_exercise(\n self.instance, self.profile.is_external)\n if exercise:\n return redirect(exercise.get_absolute_url())\n return redirect(self.instance.get_url('enroll'))\n return super().handle_no_permission()\n\n\nclass CourseInstanceBaseView(CourseInstanceMixin, BaseTemplateView):\n pass\n\n\nclass EnrollableViewMixin(CourseInstanceMixin):\n access_mode = ACCESS.ENROLL\n\n def get_common_objects(self):\n self.enrolled = self.is_student\n self.enrollable = (\n self.profile\n and self.instance.is_enrollable(self.profile.user)\n )\n self.note('enrolled', 'enrollable')\n\n\nclass CourseModuleBaseMixin(object):\n module_kw = \"module_slug\"\n module_permissions_classes = (\n CourseModulePermission,\n )\n\n def get_permissions(self):\n perms = super().get_permissions()\n perms.extend((Perm() for Perm in self.module_permissions_classes))\n return perms\n\n # get_course_module_object\n\n def get_resource_objects(self):\n super().get_resource_objects()\n self.module = self.get_course_module_object()\n self.note(\"module\")\n\n\nclass CourseModuleMixin(CourseModuleBaseMixin, CourseInstanceMixin):\n def get_course_module_object(self):\n return get_object_or_404(\n CourseModule,\n url=self.kwargs[self.module_kw],\n course_instance=self.instance\n )\n\n\nclass CourseModuleBaseView(CourseModuleMixin, BaseTemplateView):\n pass\n", "path": "course/viewbase.py"}]}
| 2,693 | 107 |
gh_patches_debug_612
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1502
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.53
On the docket:
+ [x] pex stops interpreter search if even one intepreter fails to identify itself #1494
+ [x] Add support for setting custom venv prompts. #1499
+ [x] How to know whether we are running from within pex #1485
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.52"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.52"
+__version__ = "2.1.53"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.52\"\n+__version__ = \"2.1.53\"\n", "issue": "Release 2.1.53\nOn the docket:\r\n+ [x] pex stops interpreter search if even one intepreter fails to identify itself #1494\r\n+ [x] Add support for setting custom venv prompts. #1499\r\n+ [x] How to know whether we are running from within pex #1485 \n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.52\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.53\"\n", "path": "pex/version.py"}]}
| 387 | 96 |
gh_patches_debug_24863
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4574
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
response.json()?
python-requests have response.json() that decodes json body and returns appropriate Python objects. Does it make sense to have something like this in Scrapy?
Add json response
My first PR for Scrapy that is supposed to fix GH https://github.com/scrapy/scrapy/issues/2444
Adds a `JsonResponse` class and a `json()` function similar to the one for the "requests" library [here](https://github.com/psf/requests/blob/master/requests/models.py#L874-L898)
Test manually by
```
# from the Scrapy package itself install Scrapy first
python setup.py install
# then run the Scrapy shell
scrapy shell https://api.github.com/events
>> response.json
```
Fixes #2444
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/http/response/text.py`
Content:
```
1 """
2 This module implements the TextResponse class which adds encoding handling and
3 discovering (through HTTP headers) to base Response class.
4
5 See documentation in docs/topics/request-response.rst
6 """
7
8 import warnings
9 from contextlib import suppress
10 from typing import Generator
11 from urllib.parse import urljoin
12
13 import parsel
14 from w3lib.encoding import (html_body_declared_encoding, html_to_unicode,
15 http_content_type_encoding, resolve_encoding)
16 from w3lib.html import strip_html5_whitespace
17
18 from scrapy.exceptions import ScrapyDeprecationWarning
19 from scrapy.http import Request
20 from scrapy.http.response import Response
21 from scrapy.utils.python import memoizemethod_noargs, to_unicode
22 from scrapy.utils.response import get_base_url
23
24
25 class TextResponse(Response):
26
27 _DEFAULT_ENCODING = 'ascii'
28
29 def __init__(self, *args, **kwargs):
30 self._encoding = kwargs.pop('encoding', None)
31 self._cached_benc = None
32 self._cached_ubody = None
33 self._cached_selector = None
34 super(TextResponse, self).__init__(*args, **kwargs)
35
36 def _set_url(self, url):
37 if isinstance(url, str):
38 self._url = to_unicode(url, self.encoding)
39 else:
40 super(TextResponse, self)._set_url(url)
41
42 def _set_body(self, body):
43 self._body = b'' # used by encoding detection
44 if isinstance(body, str):
45 if self._encoding is None:
46 raise TypeError('Cannot convert unicode body - %s has no encoding' %
47 type(self).__name__)
48 self._body = body.encode(self._encoding)
49 else:
50 super(TextResponse, self)._set_body(body)
51
52 def replace(self, *args, **kwargs):
53 kwargs.setdefault('encoding', self.encoding)
54 return Response.replace(self, *args, **kwargs)
55
56 @property
57 def encoding(self):
58 return self._declared_encoding() or self._body_inferred_encoding()
59
60 def _declared_encoding(self):
61 return self._encoding or self._headers_encoding() \
62 or self._body_declared_encoding()
63
64 def body_as_unicode(self):
65 """Return body as unicode"""
66 warnings.warn('Response.body_as_unicode() is deprecated, '
67 'please use Response.text instead.',
68 ScrapyDeprecationWarning)
69 return self.text
70
71 @property
72 def text(self):
73 """ Body as unicode """
74 # access self.encoding before _cached_ubody to make sure
75 # _body_inferred_encoding is called
76 benc = self.encoding
77 if self._cached_ubody is None:
78 charset = 'charset=%s' % benc
79 self._cached_ubody = html_to_unicode(charset, self.body)[1]
80 return self._cached_ubody
81
82 def urljoin(self, url):
83 """Join this Response's url with a possible relative url to form an
84 absolute interpretation of the latter."""
85 return urljoin(get_base_url(self), url)
86
87 @memoizemethod_noargs
88 def _headers_encoding(self):
89 content_type = self.headers.get(b'Content-Type', b'')
90 return http_content_type_encoding(to_unicode(content_type))
91
92 def _body_inferred_encoding(self):
93 if self._cached_benc is None:
94 content_type = to_unicode(self.headers.get(b'Content-Type', b''))
95 benc, ubody = html_to_unicode(content_type, self.body,
96 auto_detect_fun=self._auto_detect_fun,
97 default_encoding=self._DEFAULT_ENCODING)
98 self._cached_benc = benc
99 self._cached_ubody = ubody
100 return self._cached_benc
101
102 def _auto_detect_fun(self, text):
103 for enc in (self._DEFAULT_ENCODING, 'utf-8', 'cp1252'):
104 try:
105 text.decode(enc)
106 except UnicodeError:
107 continue
108 return resolve_encoding(enc)
109
110 @memoizemethod_noargs
111 def _body_declared_encoding(self):
112 return html_body_declared_encoding(self.body)
113
114 @property
115 def selector(self):
116 from scrapy.selector import Selector
117 if self._cached_selector is None:
118 self._cached_selector = Selector(self)
119 return self._cached_selector
120
121 def xpath(self, query, **kwargs):
122 return self.selector.xpath(query, **kwargs)
123
124 def css(self, query):
125 return self.selector.css(query)
126
127 def follow(self, url, callback=None, method='GET', headers=None, body=None,
128 cookies=None, meta=None, encoding=None, priority=0,
129 dont_filter=False, errback=None, cb_kwargs=None, flags=None):
130 # type: (...) -> Request
131 """
132 Return a :class:`~.Request` instance to follow a link ``url``.
133 It accepts the same arguments as ``Request.__init__`` method,
134 but ``url`` can be not only an absolute URL, but also
135
136 * a relative URL
137 * a :class:`~scrapy.link.Link` object, e.g. the result of
138 :ref:`topics-link-extractors`
139 * a :class:`~scrapy.selector.Selector` object for a ``<link>`` or ``<a>`` element, e.g.
140 ``response.css('a.my_link')[0]``
141 * an attribute :class:`~scrapy.selector.Selector` (not SelectorList), e.g.
142 ``response.css('a::attr(href)')[0]`` or
143 ``response.xpath('//img/@src')[0]``
144
145 See :ref:`response-follow-example` for usage examples.
146 """
147 if isinstance(url, parsel.Selector):
148 url = _url_from_selector(url)
149 elif isinstance(url, parsel.SelectorList):
150 raise ValueError("SelectorList is not supported")
151 encoding = self.encoding if encoding is None else encoding
152 return super(TextResponse, self).follow(
153 url=url,
154 callback=callback,
155 method=method,
156 headers=headers,
157 body=body,
158 cookies=cookies,
159 meta=meta,
160 encoding=encoding,
161 priority=priority,
162 dont_filter=dont_filter,
163 errback=errback,
164 cb_kwargs=cb_kwargs,
165 flags=flags,
166 )
167
168 def follow_all(self, urls=None, callback=None, method='GET', headers=None, body=None,
169 cookies=None, meta=None, encoding=None, priority=0,
170 dont_filter=False, errback=None, cb_kwargs=None, flags=None,
171 css=None, xpath=None):
172 # type: (...) -> Generator[Request, None, None]
173 """
174 A generator that produces :class:`~.Request` instances to follow all
175 links in ``urls``. It accepts the same arguments as the :class:`~.Request`'s
176 ``__init__`` method, except that each ``urls`` element does not need to be
177 an absolute URL, it can be any of the following:
178
179 * a relative URL
180 * a :class:`~scrapy.link.Link` object, e.g. the result of
181 :ref:`topics-link-extractors`
182 * a :class:`~scrapy.selector.Selector` object for a ``<link>`` or ``<a>`` element, e.g.
183 ``response.css('a.my_link')[0]``
184 * an attribute :class:`~scrapy.selector.Selector` (not SelectorList), e.g.
185 ``response.css('a::attr(href)')[0]`` or
186 ``response.xpath('//img/@src')[0]``
187
188 In addition, ``css`` and ``xpath`` arguments are accepted to perform the link extraction
189 within the ``follow_all`` method (only one of ``urls``, ``css`` and ``xpath`` is accepted).
190
191 Note that when passing a ``SelectorList`` as argument for the ``urls`` parameter or
192 using the ``css`` or ``xpath`` parameters, this method will not produce requests for
193 selectors from which links cannot be obtained (for instance, anchor tags without an
194 ``href`` attribute)
195 """
196 arguments = [x for x in (urls, css, xpath) if x is not None]
197 if len(arguments) != 1:
198 raise ValueError(
199 "Please supply exactly one of the following arguments: urls, css, xpath"
200 )
201 if not urls:
202 if css:
203 urls = self.css(css)
204 if xpath:
205 urls = self.xpath(xpath)
206 if isinstance(urls, parsel.SelectorList):
207 selectors = urls
208 urls = []
209 for sel in selectors:
210 with suppress(_InvalidSelector):
211 urls.append(_url_from_selector(sel))
212 return super(TextResponse, self).follow_all(
213 urls=urls,
214 callback=callback,
215 method=method,
216 headers=headers,
217 body=body,
218 cookies=cookies,
219 meta=meta,
220 encoding=encoding,
221 priority=priority,
222 dont_filter=dont_filter,
223 errback=errback,
224 cb_kwargs=cb_kwargs,
225 flags=flags,
226 )
227
228
229 class _InvalidSelector(ValueError):
230 """
231 Raised when a URL cannot be obtained from a Selector
232 """
233
234
235 def _url_from_selector(sel):
236 # type: (parsel.Selector) -> str
237 if isinstance(sel.root, str):
238 # e.g. ::attr(href) result
239 return strip_html5_whitespace(sel.root)
240 if not hasattr(sel.root, 'tag'):
241 raise _InvalidSelector("Unsupported selector: %s" % sel)
242 if sel.root.tag not in ('a', 'link'):
243 raise _InvalidSelector("Only <a> and <link> elements are supported; got <%s>" %
244 sel.root.tag)
245 href = sel.root.get('href')
246 if href is None:
247 raise _InvalidSelector("<%s> element has no href attribute: %s" %
248 (sel.root.tag, sel))
249 return strip_html5_whitespace(href)
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/http/response/text.py b/scrapy/http/response/text.py
--- a/scrapy/http/response/text.py
+++ b/scrapy/http/response/text.py
@@ -5,6 +5,7 @@
See documentation in docs/topics/request-response.rst
"""
+import json
import warnings
from contextlib import suppress
from typing import Generator
@@ -21,10 +22,13 @@
from scrapy.utils.python import memoizemethod_noargs, to_unicode
from scrapy.utils.response import get_base_url
+_NONE = object()
+
class TextResponse(Response):
_DEFAULT_ENCODING = 'ascii'
+ _cached_decoded_json = _NONE
def __init__(self, *args, **kwargs):
self._encoding = kwargs.pop('encoding', None)
@@ -68,6 +72,14 @@
ScrapyDeprecationWarning)
return self.text
+ def json(self):
+ """
+ Deserialize a JSON document to a Python object.
+ """
+ if self._cached_decoded_json is _NONE:
+ self._cached_decoded_json = json.loads(self.text)
+ return self._cached_decoded_json
+
@property
def text(self):
""" Body as unicode """
|
{"golden_diff": "diff --git a/scrapy/http/response/text.py b/scrapy/http/response/text.py\n--- a/scrapy/http/response/text.py\n+++ b/scrapy/http/response/text.py\n@@ -5,6 +5,7 @@\n See documentation in docs/topics/request-response.rst\n \"\"\"\n \n+import json\n import warnings\n from contextlib import suppress\n from typing import Generator\n@@ -21,10 +22,13 @@\n from scrapy.utils.python import memoizemethod_noargs, to_unicode\n from scrapy.utils.response import get_base_url\n \n+_NONE = object()\n+\n \n class TextResponse(Response):\n \n _DEFAULT_ENCODING = 'ascii'\n+ _cached_decoded_json = _NONE\n \n def __init__(self, *args, **kwargs):\n self._encoding = kwargs.pop('encoding', None)\n@@ -68,6 +72,14 @@\n ScrapyDeprecationWarning)\n return self.text\n \n+ def json(self):\n+ \"\"\"\n+ Deserialize a JSON document to a Python object.\n+ \"\"\"\n+ if self._cached_decoded_json is _NONE:\n+ self._cached_decoded_json = json.loads(self.text)\n+ return self._cached_decoded_json\n+\n @property\n def text(self):\n \"\"\" Body as unicode \"\"\"\n", "issue": "response.json()?\npython-requests have response.json() that decodes json body and returns appropriate Python objects. Does it make sense to have something like this in Scrapy? \nAdd json response\nMy first PR for Scrapy that is supposed to fix GH https://github.com/scrapy/scrapy/issues/2444\r\n\r\nAdds a `JsonResponse` class and a `json()` function similar to the one for the \"requests\" library [here](https://github.com/psf/requests/blob/master/requests/models.py#L874-L898)\r\n\r\nTest manually by \r\n```\r\n# from the Scrapy package itself install Scrapy first \r\npython setup.py install\r\n\r\n# then run the Scrapy shell\r\nscrapy shell https://api.github.com/events\r\n>> response.json\r\n```\r\n\r\nFixes #2444\r\n\n", "before_files": [{"content": "\"\"\"\nThis module implements the TextResponse class which adds encoding handling and\ndiscovering (through HTTP headers) to base Response class.\n\nSee documentation in docs/topics/request-response.rst\n\"\"\"\n\nimport warnings\nfrom contextlib import suppress\nfrom typing import Generator\nfrom urllib.parse import urljoin\n\nimport parsel\nfrom w3lib.encoding import (html_body_declared_encoding, html_to_unicode,\n http_content_type_encoding, resolve_encoding)\nfrom w3lib.html import strip_html5_whitespace\n\nfrom scrapy.exceptions import ScrapyDeprecationWarning\nfrom scrapy.http import Request\nfrom scrapy.http.response import Response\nfrom scrapy.utils.python import memoizemethod_noargs, to_unicode\nfrom scrapy.utils.response import get_base_url\n\n\nclass TextResponse(Response):\n\n _DEFAULT_ENCODING = 'ascii'\n\n def __init__(self, *args, **kwargs):\n self._encoding = kwargs.pop('encoding', None)\n self._cached_benc = None\n self._cached_ubody = None\n self._cached_selector = None\n super(TextResponse, self).__init__(*args, **kwargs)\n\n def _set_url(self, url):\n if isinstance(url, str):\n self._url = to_unicode(url, self.encoding)\n else:\n super(TextResponse, self)._set_url(url)\n\n def _set_body(self, body):\n self._body = b'' # used by encoding detection\n if isinstance(body, str):\n if self._encoding is None:\n raise TypeError('Cannot convert unicode body - %s has no encoding' %\n type(self).__name__)\n self._body = body.encode(self._encoding)\n else:\n super(TextResponse, self)._set_body(body)\n\n def replace(self, *args, **kwargs):\n kwargs.setdefault('encoding', self.encoding)\n return Response.replace(self, *args, **kwargs)\n\n @property\n def encoding(self):\n return self._declared_encoding() or self._body_inferred_encoding()\n\n def _declared_encoding(self):\n return self._encoding or self._headers_encoding() \\\n or self._body_declared_encoding()\n\n def body_as_unicode(self):\n \"\"\"Return body as unicode\"\"\"\n warnings.warn('Response.body_as_unicode() is deprecated, '\n 'please use Response.text instead.',\n ScrapyDeprecationWarning)\n return self.text\n\n @property\n def text(self):\n \"\"\" Body as unicode \"\"\"\n # access self.encoding before _cached_ubody to make sure\n # _body_inferred_encoding is called\n benc = self.encoding\n if self._cached_ubody is None:\n charset = 'charset=%s' % benc\n self._cached_ubody = html_to_unicode(charset, self.body)[1]\n return self._cached_ubody\n\n def urljoin(self, url):\n \"\"\"Join this Response's url with a possible relative url to form an\n absolute interpretation of the latter.\"\"\"\n return urljoin(get_base_url(self), url)\n\n @memoizemethod_noargs\n def _headers_encoding(self):\n content_type = self.headers.get(b'Content-Type', b'')\n return http_content_type_encoding(to_unicode(content_type))\n\n def _body_inferred_encoding(self):\n if self._cached_benc is None:\n content_type = to_unicode(self.headers.get(b'Content-Type', b''))\n benc, ubody = html_to_unicode(content_type, self.body,\n auto_detect_fun=self._auto_detect_fun,\n default_encoding=self._DEFAULT_ENCODING)\n self._cached_benc = benc\n self._cached_ubody = ubody\n return self._cached_benc\n\n def _auto_detect_fun(self, text):\n for enc in (self._DEFAULT_ENCODING, 'utf-8', 'cp1252'):\n try:\n text.decode(enc)\n except UnicodeError:\n continue\n return resolve_encoding(enc)\n\n @memoizemethod_noargs\n def _body_declared_encoding(self):\n return html_body_declared_encoding(self.body)\n\n @property\n def selector(self):\n from scrapy.selector import Selector\n if self._cached_selector is None:\n self._cached_selector = Selector(self)\n return self._cached_selector\n\n def xpath(self, query, **kwargs):\n return self.selector.xpath(query, **kwargs)\n\n def css(self, query):\n return self.selector.css(query)\n\n def follow(self, url, callback=None, method='GET', headers=None, body=None,\n cookies=None, meta=None, encoding=None, priority=0,\n dont_filter=False, errback=None, cb_kwargs=None, flags=None):\n # type: (...) -> Request\n \"\"\"\n Return a :class:`~.Request` instance to follow a link ``url``.\n It accepts the same arguments as ``Request.__init__`` method,\n but ``url`` can be not only an absolute URL, but also\n\n * a relative URL\n * a :class:`~scrapy.link.Link` object, e.g. the result of\n :ref:`topics-link-extractors`\n * a :class:`~scrapy.selector.Selector` object for a ``<link>`` or ``<a>`` element, e.g.\n ``response.css('a.my_link')[0]``\n * an attribute :class:`~scrapy.selector.Selector` (not SelectorList), e.g.\n ``response.css('a::attr(href)')[0]`` or\n ``response.xpath('//img/@src')[0]``\n\n See :ref:`response-follow-example` for usage examples.\n \"\"\"\n if isinstance(url, parsel.Selector):\n url = _url_from_selector(url)\n elif isinstance(url, parsel.SelectorList):\n raise ValueError(\"SelectorList is not supported\")\n encoding = self.encoding if encoding is None else encoding\n return super(TextResponse, self).follow(\n url=url,\n callback=callback,\n method=method,\n headers=headers,\n body=body,\n cookies=cookies,\n meta=meta,\n encoding=encoding,\n priority=priority,\n dont_filter=dont_filter,\n errback=errback,\n cb_kwargs=cb_kwargs,\n flags=flags,\n )\n\n def follow_all(self, urls=None, callback=None, method='GET', headers=None, body=None,\n cookies=None, meta=None, encoding=None, priority=0,\n dont_filter=False, errback=None, cb_kwargs=None, flags=None,\n css=None, xpath=None):\n # type: (...) -> Generator[Request, None, None]\n \"\"\"\n A generator that produces :class:`~.Request` instances to follow all\n links in ``urls``. It accepts the same arguments as the :class:`~.Request`'s\n ``__init__`` method, except that each ``urls`` element does not need to be\n an absolute URL, it can be any of the following:\n\n * a relative URL\n * a :class:`~scrapy.link.Link` object, e.g. the result of\n :ref:`topics-link-extractors`\n * a :class:`~scrapy.selector.Selector` object for a ``<link>`` or ``<a>`` element, e.g.\n ``response.css('a.my_link')[0]``\n * an attribute :class:`~scrapy.selector.Selector` (not SelectorList), e.g.\n ``response.css('a::attr(href)')[0]`` or\n ``response.xpath('//img/@src')[0]``\n\n In addition, ``css`` and ``xpath`` arguments are accepted to perform the link extraction\n within the ``follow_all`` method (only one of ``urls``, ``css`` and ``xpath`` is accepted).\n\n Note that when passing a ``SelectorList`` as argument for the ``urls`` parameter or\n using the ``css`` or ``xpath`` parameters, this method will not produce requests for\n selectors from which links cannot be obtained (for instance, anchor tags without an\n ``href`` attribute)\n \"\"\"\n arguments = [x for x in (urls, css, xpath) if x is not None]\n if len(arguments) != 1:\n raise ValueError(\n \"Please supply exactly one of the following arguments: urls, css, xpath\"\n )\n if not urls:\n if css:\n urls = self.css(css)\n if xpath:\n urls = self.xpath(xpath)\n if isinstance(urls, parsel.SelectorList):\n selectors = urls\n urls = []\n for sel in selectors:\n with suppress(_InvalidSelector):\n urls.append(_url_from_selector(sel))\n return super(TextResponse, self).follow_all(\n urls=urls,\n callback=callback,\n method=method,\n headers=headers,\n body=body,\n cookies=cookies,\n meta=meta,\n encoding=encoding,\n priority=priority,\n dont_filter=dont_filter,\n errback=errback,\n cb_kwargs=cb_kwargs,\n flags=flags,\n )\n\n\nclass _InvalidSelector(ValueError):\n \"\"\"\n Raised when a URL cannot be obtained from a Selector\n \"\"\"\n\n\ndef _url_from_selector(sel):\n # type: (parsel.Selector) -> str\n if isinstance(sel.root, str):\n # e.g. ::attr(href) result\n return strip_html5_whitespace(sel.root)\n if not hasattr(sel.root, 'tag'):\n raise _InvalidSelector(\"Unsupported selector: %s\" % sel)\n if sel.root.tag not in ('a', 'link'):\n raise _InvalidSelector(\"Only <a> and <link> elements are supported; got <%s>\" %\n sel.root.tag)\n href = sel.root.get('href')\n if href is None:\n raise _InvalidSelector(\"<%s> element has no href attribute: %s\" %\n (sel.root.tag, sel))\n return strip_html5_whitespace(href)\n", "path": "scrapy/http/response/text.py"}], "after_files": [{"content": "\"\"\"\nThis module implements the TextResponse class which adds encoding handling and\ndiscovering (through HTTP headers) to base Response class.\n\nSee documentation in docs/topics/request-response.rst\n\"\"\"\n\nimport json\nimport warnings\nfrom contextlib import suppress\nfrom typing import Generator\nfrom urllib.parse import urljoin\n\nimport parsel\nfrom w3lib.encoding import (html_body_declared_encoding, html_to_unicode,\n http_content_type_encoding, resolve_encoding)\nfrom w3lib.html import strip_html5_whitespace\n\nfrom scrapy.exceptions import ScrapyDeprecationWarning\nfrom scrapy.http import Request\nfrom scrapy.http.response import Response\nfrom scrapy.utils.python import memoizemethod_noargs, to_unicode\nfrom scrapy.utils.response import get_base_url\n\n_NONE = object()\n\n\nclass TextResponse(Response):\n\n _DEFAULT_ENCODING = 'ascii'\n _cached_decoded_json = _NONE\n\n def __init__(self, *args, **kwargs):\n self._encoding = kwargs.pop('encoding', None)\n self._cached_benc = None\n self._cached_ubody = None\n self._cached_selector = None\n super(TextResponse, self).__init__(*args, **kwargs)\n\n def _set_url(self, url):\n if isinstance(url, str):\n self._url = to_unicode(url, self.encoding)\n else:\n super(TextResponse, self)._set_url(url)\n\n def _set_body(self, body):\n self._body = b'' # used by encoding detection\n if isinstance(body, str):\n if self._encoding is None:\n raise TypeError('Cannot convert unicode body - %s has no encoding' %\n type(self).__name__)\n self._body = body.encode(self._encoding)\n else:\n super(TextResponse, self)._set_body(body)\n\n def replace(self, *args, **kwargs):\n kwargs.setdefault('encoding', self.encoding)\n return Response.replace(self, *args, **kwargs)\n\n @property\n def encoding(self):\n return self._declared_encoding() or self._body_inferred_encoding()\n\n def _declared_encoding(self):\n return self._encoding or self._headers_encoding() \\\n or self._body_declared_encoding()\n\n def body_as_unicode(self):\n \"\"\"Return body as unicode\"\"\"\n warnings.warn('Response.body_as_unicode() is deprecated, '\n 'please use Response.text instead.',\n ScrapyDeprecationWarning)\n return self.text\n\n def json(self):\n \"\"\"\n Deserialize a JSON document to a Python object.\n \"\"\"\n if self._cached_decoded_json is _NONE:\n self._cached_decoded_json = json.loads(self.text)\n return self._cached_decoded_json\n\n @property\n def text(self):\n \"\"\" Body as unicode \"\"\"\n # access self.encoding before _cached_ubody to make sure\n # _body_inferred_encoding is called\n benc = self.encoding\n if self._cached_ubody is None:\n charset = 'charset=%s' % benc\n self._cached_ubody = html_to_unicode(charset, self.body)[1]\n return self._cached_ubody\n\n def urljoin(self, url):\n \"\"\"Join this Response's url with a possible relative url to form an\n absolute interpretation of the latter.\"\"\"\n return urljoin(get_base_url(self), url)\n\n @memoizemethod_noargs\n def _headers_encoding(self):\n content_type = self.headers.get(b'Content-Type', b'')\n return http_content_type_encoding(to_unicode(content_type))\n\n def _body_inferred_encoding(self):\n if self._cached_benc is None:\n content_type = to_unicode(self.headers.get(b'Content-Type', b''))\n benc, ubody = html_to_unicode(content_type, self.body,\n auto_detect_fun=self._auto_detect_fun,\n default_encoding=self._DEFAULT_ENCODING)\n self._cached_benc = benc\n self._cached_ubody = ubody\n return self._cached_benc\n\n def _auto_detect_fun(self, text):\n for enc in (self._DEFAULT_ENCODING, 'utf-8', 'cp1252'):\n try:\n text.decode(enc)\n except UnicodeError:\n continue\n return resolve_encoding(enc)\n\n @memoizemethod_noargs\n def _body_declared_encoding(self):\n return html_body_declared_encoding(self.body)\n\n @property\n def selector(self):\n from scrapy.selector import Selector\n if self._cached_selector is None:\n self._cached_selector = Selector(self)\n return self._cached_selector\n\n def xpath(self, query, **kwargs):\n return self.selector.xpath(query, **kwargs)\n\n def css(self, query):\n return self.selector.css(query)\n\n def follow(self, url, callback=None, method='GET', headers=None, body=None,\n cookies=None, meta=None, encoding=None, priority=0,\n dont_filter=False, errback=None, cb_kwargs=None, flags=None):\n # type: (...) -> Request\n \"\"\"\n Return a :class:`~.Request` instance to follow a link ``url``.\n It accepts the same arguments as ``Request.__init__`` method,\n but ``url`` can be not only an absolute URL, but also\n\n * a relative URL\n * a :class:`~scrapy.link.Link` object, e.g. the result of\n :ref:`topics-link-extractors`\n * a :class:`~scrapy.selector.Selector` object for a ``<link>`` or ``<a>`` element, e.g.\n ``response.css('a.my_link')[0]``\n * an attribute :class:`~scrapy.selector.Selector` (not SelectorList), e.g.\n ``response.css('a::attr(href)')[0]`` or\n ``response.xpath('//img/@src')[0]``\n\n See :ref:`response-follow-example` for usage examples.\n \"\"\"\n if isinstance(url, parsel.Selector):\n url = _url_from_selector(url)\n elif isinstance(url, parsel.SelectorList):\n raise ValueError(\"SelectorList is not supported\")\n encoding = self.encoding if encoding is None else encoding\n return super(TextResponse, self).follow(\n url=url,\n callback=callback,\n method=method,\n headers=headers,\n body=body,\n cookies=cookies,\n meta=meta,\n encoding=encoding,\n priority=priority,\n dont_filter=dont_filter,\n errback=errback,\n cb_kwargs=cb_kwargs,\n flags=flags,\n )\n\n def follow_all(self, urls=None, callback=None, method='GET', headers=None, body=None,\n cookies=None, meta=None, encoding=None, priority=0,\n dont_filter=False, errback=None, cb_kwargs=None, flags=None,\n css=None, xpath=None):\n # type: (...) -> Generator[Request, None, None]\n \"\"\"\n A generator that produces :class:`~.Request` instances to follow all\n links in ``urls``. It accepts the same arguments as the :class:`~.Request`'s\n ``__init__`` method, except that each ``urls`` element does not need to be\n an absolute URL, it can be any of the following:\n\n * a relative URL\n * a :class:`~scrapy.link.Link` object, e.g. the result of\n :ref:`topics-link-extractors`\n * a :class:`~scrapy.selector.Selector` object for a ``<link>`` or ``<a>`` element, e.g.\n ``response.css('a.my_link')[0]``\n * an attribute :class:`~scrapy.selector.Selector` (not SelectorList), e.g.\n ``response.css('a::attr(href)')[0]`` or\n ``response.xpath('//img/@src')[0]``\n\n In addition, ``css`` and ``xpath`` arguments are accepted to perform the link extraction\n within the ``follow_all`` method (only one of ``urls``, ``css`` and ``xpath`` is accepted).\n\n Note that when passing a ``SelectorList`` as argument for the ``urls`` parameter or\n using the ``css`` or ``xpath`` parameters, this method will not produce requests for\n selectors from which links cannot be obtained (for instance, anchor tags without an\n ``href`` attribute)\n \"\"\"\n arguments = [x for x in (urls, css, xpath) if x is not None]\n if len(arguments) != 1:\n raise ValueError(\n \"Please supply exactly one of the following arguments: urls, css, xpath\"\n )\n if not urls:\n if css:\n urls = self.css(css)\n if xpath:\n urls = self.xpath(xpath)\n if isinstance(urls, parsel.SelectorList):\n selectors = urls\n urls = []\n for sel in selectors:\n with suppress(_InvalidSelector):\n urls.append(_url_from_selector(sel))\n return super(TextResponse, self).follow_all(\n urls=urls,\n callback=callback,\n method=method,\n headers=headers,\n body=body,\n cookies=cookies,\n meta=meta,\n encoding=encoding,\n priority=priority,\n dont_filter=dont_filter,\n errback=errback,\n cb_kwargs=cb_kwargs,\n flags=flags,\n )\n\n\nclass _InvalidSelector(ValueError):\n \"\"\"\n Raised when a URL cannot be obtained from a Selector\n \"\"\"\n\n\ndef _url_from_selector(sel):\n # type: (parsel.Selector) -> str\n if isinstance(sel.root, str):\n # e.g. ::attr(href) result\n return strip_html5_whitespace(sel.root)\n if not hasattr(sel.root, 'tag'):\n raise _InvalidSelector(\"Unsupported selector: %s\" % sel)\n if sel.root.tag not in ('a', 'link'):\n raise _InvalidSelector(\"Only <a> and <link> elements are supported; got <%s>\" %\n sel.root.tag)\n href = sel.root.get('href')\n if href is None:\n raise _InvalidSelector(\"<%s> element has no href attribute: %s\" %\n (sel.root.tag, sel))\n return strip_html5_whitespace(href)\n", "path": "scrapy/http/response/text.py"}]}
| 3,190 | 273 |
gh_patches_debug_25640
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in recursive attach of MetricsLambda
As a result of #385, the recursive attach of MetricsLambda is not working as intended.
The code below throws this error: `NotComputableError: Accuracy must have at least one example before it can be computed.`
```python
import torch
from ignite.metrics import Accuracy, Precision, Recall, MetricsLambda
from ignite.engine import Engine
accuracy_1 = Accuracy()
accuracy_2 = Accuracy()
mean_accuracy = (accuracy_1 + accuracy_2) / 2
metrics = {
# "a1": accuracy_1,
# "a2": accuracy_2,
"mean accuracy": mean_accuracy,
}
y_pred = torch.randint(0, 2, size=(15, 10, 4)).float()
y = torch.randint(0, 2, size=(15, 10, 4)).long()
def update_fn(engine, batch):
y_pred, y = batch
return y_pred, y
validator = Engine(update_fn)
for name, metric in metrics.items():
metric.attach(validator, name)
def data(y_pred, y):
for i in range(y_pred.shape[0]):
yield (y_pred[i], y[i])
d = data(y_pred, y)
state = validator.run(d, max_epochs=1)
print(state.metrics)
```
cc @vfdev-5 @amitibo
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/metrics/metrics_lambda.py`
Content:
```
1 from ignite.metrics.metric import Metric
2 from ignite.engine import Events
3
4
5 class MetricsLambda(Metric):
6 """
7 Apply a function to other metrics to obtain a new metric.
8 The result of the new metric is defined to be the result
9 of applying the function to the result of argument metrics.
10
11 When update, this metric does not recursively update the metrics
12 it depends on. When reset, all its dependency metrics would be
13 resetted. When attach, all its dependencies would be automatically
14 attached.
15
16 Args:
17 f (callable): the function that defines the computation
18 args (sequence): Sequence of other metrics or something
19 else that will be fed to ``f`` as arguments.
20
21 Example:
22
23 .. code-block:: python
24
25 precision = Precision(average=False)
26 recall = Recall(average=False)
27
28 def Fbeta(r, p, beta):
29 return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r + 1e-20)).item()
30
31 F1 = MetricsLambda(Fbeta, recall, precision, 1)
32 F2 = MetricsLambda(Fbeta, recall, precision, 2)
33 F3 = MetricsLambda(Fbeta, recall, precision, 3)
34 F4 = MetricsLambda(Fbeta, recall, precision, 4)
35 """
36 def __init__(self, f, *args):
37 self.function = f
38 self.args = args
39 super(MetricsLambda, self).__init__()
40
41 def reset(self):
42 for i in self.args:
43 if isinstance(i, Metric):
44 i.reset()
45
46 def update(self, output):
47 # NB: this method does not recursively update dependency metrics,
48 # which might cause duplicate update issue. To update this metric,
49 # users should manually update its dependencies.
50 pass
51
52 def compute(self):
53 materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]
54 return self.function(*materialized)
55
56 def attach(self, engine, name):
57 # recursively attach all its dependencies
58 for index, metric in enumerate(self.args):
59 if isinstance(metric, Metric):
60 if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):
61 engine.add_event_handler(Events.EPOCH_STARTED, metric.started)
62 if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):
63 engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)
64 super(MetricsLambda, self).attach(engine, name)
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/metrics/metrics_lambda.py b/ignite/metrics/metrics_lambda.py
--- a/ignite/metrics/metrics_lambda.py
+++ b/ignite/metrics/metrics_lambda.py
@@ -53,12 +53,18 @@
materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]
return self.function(*materialized)
- def attach(self, engine, name):
- # recursively attach all its dependencies
+ def _internal_attach(self, engine):
for index, metric in enumerate(self.args):
- if isinstance(metric, Metric):
+ if isinstance(metric, MetricsLambda):
+ metric._internal_attach(engine)
+ elif isinstance(metric, Metric):
if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):
engine.add_event_handler(Events.EPOCH_STARTED, metric.started)
if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):
engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)
- super(MetricsLambda, self).attach(engine, name)
+
+ def attach(self, engine, name):
+ # recursively attach all its dependencies
+ self._internal_attach(engine)
+ # attach only handler on EPOCH_COMPLETED
+ engine.add_event_handler(Events.EPOCH_COMPLETED, self.completed, name)
|
{"golden_diff": "diff --git a/ignite/metrics/metrics_lambda.py b/ignite/metrics/metrics_lambda.py\n--- a/ignite/metrics/metrics_lambda.py\n+++ b/ignite/metrics/metrics_lambda.py\n@@ -53,12 +53,18 @@\n materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]\n return self.function(*materialized)\n \n- def attach(self, engine, name):\n- # recursively attach all its dependencies\n+ def _internal_attach(self, engine):\n for index, metric in enumerate(self.args):\n- if isinstance(metric, Metric):\n+ if isinstance(metric, MetricsLambda):\n+ metric._internal_attach(engine)\n+ elif isinstance(metric, Metric):\n if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):\n engine.add_event_handler(Events.EPOCH_STARTED, metric.started)\n if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):\n engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)\n- super(MetricsLambda, self).attach(engine, name)\n+\n+ def attach(self, engine, name):\n+ # recursively attach all its dependencies\n+ self._internal_attach(engine)\n+ # attach only handler on EPOCH_COMPLETED\n+ engine.add_event_handler(Events.EPOCH_COMPLETED, self.completed, name)\n", "issue": "Bug in recursive attach of MetricsLambda\nAs a result of #385, the recursive attach of MetricsLambda is not working as intended. \r\n\r\nThe code below throws this error: `NotComputableError: Accuracy must have at least one example before it can be computed.`\r\n\r\n```python\r\nimport torch\r\n\r\nfrom ignite.metrics import Accuracy, Precision, Recall, MetricsLambda\r\nfrom ignite.engine import Engine\r\n\r\naccuracy_1 = Accuracy()\r\naccuracy_2 = Accuracy()\r\nmean_accuracy = (accuracy_1 + accuracy_2) / 2\r\n\r\n\r\nmetrics = {\r\n# \"a1\": accuracy_1,\r\n# \"a2\": accuracy_2, \r\n \"mean accuracy\": mean_accuracy,\r\n}\r\n\r\n\r\ny_pred = torch.randint(0, 2, size=(15, 10, 4)).float()\r\ny = torch.randint(0, 2, size=(15, 10, 4)).long()\r\n\r\ndef update_fn(engine, batch):\r\n y_pred, y = batch\r\n return y_pred, y\r\n\r\nvalidator = Engine(update_fn)\r\n\r\nfor name, metric in metrics.items():\r\n metric.attach(validator, name)\r\n\r\ndef data(y_pred, y):\r\n for i in range(y_pred.shape[0]):\r\n yield (y_pred[i], y[i])\r\n\r\nd = data(y_pred, y)\r\nstate = validator.run(d, max_epochs=1)\r\n\r\nprint(state.metrics)\r\n```\r\n\r\ncc @vfdev-5 @amitibo \n", "before_files": [{"content": "from ignite.metrics.metric import Metric\nfrom ignite.engine import Events\n\n\nclass MetricsLambda(Metric):\n \"\"\"\n Apply a function to other metrics to obtain a new metric.\n The result of the new metric is defined to be the result\n of applying the function to the result of argument metrics.\n\n When update, this metric does not recursively update the metrics\n it depends on. When reset, all its dependency metrics would be\n resetted. When attach, all its dependencies would be automatically\n attached.\n\n Args:\n f (callable): the function that defines the computation\n args (sequence): Sequence of other metrics or something\n else that will be fed to ``f`` as arguments.\n\n Example:\n\n .. code-block:: python\n\n precision = Precision(average=False)\n recall = Recall(average=False)\n\n def Fbeta(r, p, beta):\n return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r + 1e-20)).item()\n\n F1 = MetricsLambda(Fbeta, recall, precision, 1)\n F2 = MetricsLambda(Fbeta, recall, precision, 2)\n F3 = MetricsLambda(Fbeta, recall, precision, 3)\n F4 = MetricsLambda(Fbeta, recall, precision, 4)\n \"\"\"\n def __init__(self, f, *args):\n self.function = f\n self.args = args\n super(MetricsLambda, self).__init__()\n\n def reset(self):\n for i in self.args:\n if isinstance(i, Metric):\n i.reset()\n\n def update(self, output):\n # NB: this method does not recursively update dependency metrics,\n # which might cause duplicate update issue. To update this metric,\n # users should manually update its dependencies.\n pass\n\n def compute(self):\n materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]\n return self.function(*materialized)\n\n def attach(self, engine, name):\n # recursively attach all its dependencies\n for index, metric in enumerate(self.args):\n if isinstance(metric, Metric):\n if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):\n engine.add_event_handler(Events.EPOCH_STARTED, metric.started)\n if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):\n engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)\n super(MetricsLambda, self).attach(engine, name)\n", "path": "ignite/metrics/metrics_lambda.py"}], "after_files": [{"content": "from ignite.metrics.metric import Metric\nfrom ignite.engine import Events\n\n\nclass MetricsLambda(Metric):\n \"\"\"\n Apply a function to other metrics to obtain a new metric.\n The result of the new metric is defined to be the result\n of applying the function to the result of argument metrics.\n\n When update, this metric does not recursively update the metrics\n it depends on. When reset, all its dependency metrics would be\n resetted. When attach, all its dependencies would be automatically\n attached.\n\n Args:\n f (callable): the function that defines the computation\n args (sequence): Sequence of other metrics or something\n else that will be fed to ``f`` as arguments.\n\n Example:\n\n .. code-block:: python\n\n precision = Precision(average=False)\n recall = Recall(average=False)\n\n def Fbeta(r, p, beta):\n return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r + 1e-20)).item()\n\n F1 = MetricsLambda(Fbeta, recall, precision, 1)\n F2 = MetricsLambda(Fbeta, recall, precision, 2)\n F3 = MetricsLambda(Fbeta, recall, precision, 3)\n F4 = MetricsLambda(Fbeta, recall, precision, 4)\n \"\"\"\n def __init__(self, f, *args):\n self.function = f\n self.args = args\n super(MetricsLambda, self).__init__()\n\n def reset(self):\n for i in self.args:\n if isinstance(i, Metric):\n i.reset()\n\n def update(self, output):\n # NB: this method does not recursively update dependency metrics,\n # which might cause duplicate update issue. To update this metric,\n # users should manually update its dependencies.\n pass\n\n def compute(self):\n materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]\n return self.function(*materialized)\n\n def _internal_attach(self, engine):\n for index, metric in enumerate(self.args):\n if isinstance(metric, MetricsLambda):\n metric._internal_attach(engine)\n elif isinstance(metric, Metric):\n if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):\n engine.add_event_handler(Events.EPOCH_STARTED, metric.started)\n if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):\n engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)\n\n def attach(self, engine, name):\n # recursively attach all its dependencies\n self._internal_attach(engine)\n # attach only handler on EPOCH_COMPLETED\n engine.add_event_handler(Events.EPOCH_COMPLETED, self.completed, name)\n", "path": "ignite/metrics/metrics_lambda.py"}]}
| 1,227 | 295 |
gh_patches_debug_30268
|
rasdani/github-patches
|
git_diff
|
piskvorky__gensim-2147
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
gensim.scripts.word2vec2tensor TypeError: write() argument must be str, not bytes
Python environment
```
Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 18:10:19)
[GCC 7.2.0] on linux
```
**How I make article_body_w2v_300.txt**
```
import gensim
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
sentences = LineSentence("./data/article_body_corpus.txt")
model = Word2Vec(sentences, size=300, window=5, min_count=5, workers=4)
model.wv.save_word2vec_format("article_body_w2v_300.txt", binary=False)
```
**Command I use to run gensim.scripts.word2vec2tensor**
```
python -m gensim.scripts.word2vec2tensor -i article_body_w2v_300.txt -o meow/
```
Console output
```
word_embedding python -m gensim.scripts.word2vec2tensor -i article_body_w2v_300.txt -o meow/
2018-03-07 16:30:29,484 - word2vec2tensor - INFO - running /home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/site-packages/gensim/scripts/word2vec2tensor.py -i article_body_w2v_300.txt -o meow/
2018-03-07 16:30:29,484 - utils_any2vec - INFO - loading projection weights from article_body_w2v_300.txt
2018-03-07 16:30:41,992 - utils_any2vec - INFO - loaded (56543, 300) matrix from article_body_w2v_300.txt
Traceback (most recent call last):
File "/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/site-packages/gensim/scripts/word2vec2tensor.py", line 93, in <module>
word2vec2tensor(args.input, args.output, args.binary)
File "/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/site-packages/gensim/scripts/word2vec2tensor.py", line 73, in word2vec2tensor
file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\n'))
TypeError: write() argument must be str, not bytes
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gensim/scripts/word2vec2tensor.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright (C) 2016 Loreto Parisi <[email protected]>
5 # Copyright (C) 2016 Silvio Olivastri <[email protected]>
6 # Copyright (C) 2016 Radim Rehurek <[email protected]>
7
8
9 """This script allows converting word-vectors from word2vec format into Tensorflow 2D tensor and metadata format.
10 This script used for for word-vector visualization on `Embedding Visualization <http://projector.tensorflow.org/>`_.
11
12
13 How to use
14 ----------
15 #. Convert your word-vector with this script (for example, we'll use model from
16 `gensim-data <https://rare-technologies.com/new-download-api-for-pretrained-nlp-models-and-datasets-in-gensim/>`_) ::
17
18 python -m gensim.downloader -d glove-wiki-gigaword-50 # download model in word2vec format
19 python -m gensim.scripts.word2vec2tensor -i ~/gensim-data/glove-wiki-gigaword-50/glove-wiki-gigaword-50.gz \
20 -o /tmp/my_model_prefix
21
22 #. Open http://projector.tensorflow.org/
23 #. Click "Load Data" button from the left menu.
24 #. Select "Choose file" in "Load a TSV file of vectors." and choose "/tmp/my_model_prefix_tensor.tsv" file.
25 #. Select "Choose file" in "Load a TSV file of metadata." and choose "/tmp/my_model_prefix_metadata.tsv" file.
26 #. ???
27 #. PROFIT!
28
29 For more information about TensorBoard TSV format please visit:
30 https://www.tensorflow.org/versions/master/how_tos/embedding_viz/
31
32
33 Command line arguments
34 ----------------------
35
36 .. program-output:: python -m gensim.scripts.word2vec2tensor --help
37 :ellipsis: 0, -7
38
39 """
40
41 import os
42 import sys
43 import logging
44 import argparse
45
46 import gensim
47
48 logger = logging.getLogger(__name__)
49
50
51 def word2vec2tensor(word2vec_model_path, tensor_filename, binary=False):
52 """Convert file in Word2Vec format and writes two files 2D tensor TSV file.
53
54 File "tensor_filename"_tensor.tsv contains word-vectors, "tensor_filename"_metadata.tsv contains words.
55
56 Parameters
57 ----------
58 word2vec_model_path : str
59 Path to file in Word2Vec format.
60 tensor_filename : str
61 Prefix for output files.
62 binary : bool, optional
63 True if input file in binary format.
64
65 """
66 model = gensim.models.KeyedVectors.load_word2vec_format(word2vec_model_path, binary=binary)
67 outfiletsv = tensor_filename + '_tensor.tsv'
68 outfiletsvmeta = tensor_filename + '_metadata.tsv'
69
70 with open(outfiletsv, 'w+') as file_vector:
71 with open(outfiletsvmeta, 'w+') as file_metadata:
72 for word in model.index2word:
73 file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\n'))
74 vector_row = '\t'.join(str(x) for x in model[word])
75 file_vector.write(vector_row + '\n')
76
77 logger.info("2D tensor file saved to %s", outfiletsv)
78 logger.info("Tensor metadata file saved to %s", outfiletsvmeta)
79
80
81 if __name__ == "__main__":
82 logging.basicConfig(format='%(asctime)s - %(module)s - %(levelname)s - %(message)s', level=logging.INFO)
83 parser = argparse.ArgumentParser(formatter_class=argparse.RawDescriptionHelpFormatter, description=__doc__[:-138])
84 parser.add_argument("-i", "--input", required=True, help="Path to input file in word2vec format")
85 parser.add_argument("-o", "--output", required=True, help="Prefix path for output files")
86 parser.add_argument(
87 "-b", "--binary", action='store_const', const=True, default=False,
88 help="Set this flag if word2vec model in binary format (default: %(default)s)"
89 )
90 args = parser.parse_args()
91
92 logger.info("running %s", ' '.join(sys.argv))
93 word2vec2tensor(args.input, args.output, args.binary)
94 logger.info("finished running %s", os.path.basename(sys.argv[0]))
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gensim/scripts/word2vec2tensor.py b/gensim/scripts/word2vec2tensor.py
--- a/gensim/scripts/word2vec2tensor.py
+++ b/gensim/scripts/word2vec2tensor.py
@@ -1,6 +1,7 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
+# Copyright (C) 2018 Vimig Socrates <[email protected]>
# Copyright (C) 2016 Loreto Parisi <[email protected]>
# Copyright (C) 2016 Silvio Olivastri <[email protected]>
# Copyright (C) 2016 Radim Rehurek <[email protected]>
@@ -43,6 +44,7 @@
import logging
import argparse
+from smart_open import smart_open
import gensim
logger = logging.getLogger(__name__)
@@ -67,12 +69,11 @@
outfiletsv = tensor_filename + '_tensor.tsv'
outfiletsvmeta = tensor_filename + '_metadata.tsv'
- with open(outfiletsv, 'w+') as file_vector:
- with open(outfiletsvmeta, 'w+') as file_metadata:
- for word in model.index2word:
- file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\n'))
- vector_row = '\t'.join(str(x) for x in model[word])
- file_vector.write(vector_row + '\n')
+ with smart_open(outfiletsv, 'wb') as file_vector, smart_open(outfiletsvmeta, 'wb') as file_metadata:
+ for word in model.index2word:
+ file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\n'))
+ vector_row = '\t'.join(str(x) for x in model[word])
+ file_vector.write(gensim.utils.to_utf8(vector_row) + gensim.utils.to_utf8('\n'))
logger.info("2D tensor file saved to %s", outfiletsv)
logger.info("Tensor metadata file saved to %s", outfiletsvmeta)
|
{"golden_diff": "diff --git a/gensim/scripts/word2vec2tensor.py b/gensim/scripts/word2vec2tensor.py\n--- a/gensim/scripts/word2vec2tensor.py\n+++ b/gensim/scripts/word2vec2tensor.py\n@@ -1,6 +1,7 @@\n #!/usr/bin/env python\n # -*- coding: utf-8 -*-\n #\n+# Copyright (C) 2018 Vimig Socrates <[email protected]>\n # Copyright (C) 2016 Loreto Parisi <[email protected]>\n # Copyright (C) 2016 Silvio Olivastri <[email protected]>\n # Copyright (C) 2016 Radim Rehurek <[email protected]>\n@@ -43,6 +44,7 @@\n import logging\n import argparse\n \n+from smart_open import smart_open\n import gensim\n \n logger = logging.getLogger(__name__)\n@@ -67,12 +69,11 @@\n outfiletsv = tensor_filename + '_tensor.tsv'\n outfiletsvmeta = tensor_filename + '_metadata.tsv'\n \n- with open(outfiletsv, 'w+') as file_vector:\n- with open(outfiletsvmeta, 'w+') as file_metadata:\n- for word in model.index2word:\n- file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\\n'))\n- vector_row = '\\t'.join(str(x) for x in model[word])\n- file_vector.write(vector_row + '\\n')\n+ with smart_open(outfiletsv, 'wb') as file_vector, smart_open(outfiletsvmeta, 'wb') as file_metadata:\n+ for word in model.index2word:\n+ file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\\n'))\n+ vector_row = '\\t'.join(str(x) for x in model[word])\n+ file_vector.write(gensim.utils.to_utf8(vector_row) + gensim.utils.to_utf8('\\n'))\n \n logger.info(\"2D tensor file saved to %s\", outfiletsv)\n logger.info(\"Tensor metadata file saved to %s\", outfiletsvmeta)\n", "issue": "gensim.scripts.word2vec2tensor TypeError: write() argument must be str, not bytes \nPython environment\r\n\r\n```\r\nPython 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 18:10:19) \r\n[GCC 7.2.0] on linux\r\n```\r\n\r\n\r\n**How I make article_body_w2v_300.txt** \r\n\r\n```\r\nimport gensim\r\nfrom gensim.models import Word2Vec\r\nfrom gensim.models.word2vec import LineSentence\r\n\r\nsentences = LineSentence(\"./data/article_body_corpus.txt\")\r\n\r\nmodel = Word2Vec(sentences, size=300, window=5, min_count=5, workers=4)\r\n\r\nmodel.wv.save_word2vec_format(\"article_body_w2v_300.txt\", binary=False)\r\n```\r\n\r\n\r\n**Command I use to run gensim.scripts.word2vec2tensor** \r\n\r\n```\r\npython -m gensim.scripts.word2vec2tensor -i article_body_w2v_300.txt -o meow/\r\n```\r\n\r\nConsole output\r\n```\r\nword_embedding python -m gensim.scripts.word2vec2tensor -i article_body_w2v_300.txt -o meow/\r\n2018-03-07 16:30:29,484 - word2vec2tensor - INFO - running /home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/site-packages/gensim/scripts/word2vec2tensor.py -i article_body_w2v_300.txt -o meow/\r\n2018-03-07 16:30:29,484 - utils_any2vec - INFO - loading projection weights from article_body_w2v_300.txt\r\n2018-03-07 16:30:41,992 - utils_any2vec - INFO - loaded (56543, 300) matrix from article_body_w2v_300.txt\r\nTraceback (most recent call last):\r\n File \"/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/site-packages/gensim/scripts/word2vec2tensor.py\", line 93, in <module>\r\n word2vec2tensor(args.input, args.output, args.binary)\r\n File \"/home/cpu11453local/anaconda3/envs/gensim/lib/python3.6/site-packages/gensim/scripts/word2vec2tensor.py\", line 73, in word2vec2tensor\r\n file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\\n'))\r\nTypeError: write() argument must be str, not bytes\r\n\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) 2016 Loreto Parisi <[email protected]>\n# Copyright (C) 2016 Silvio Olivastri <[email protected]>\n# Copyright (C) 2016 Radim Rehurek <[email protected]>\n\n\n\"\"\"This script allows converting word-vectors from word2vec format into Tensorflow 2D tensor and metadata format.\nThis script used for for word-vector visualization on `Embedding Visualization <http://projector.tensorflow.org/>`_.\n\n\nHow to use\n----------\n#. Convert your word-vector with this script (for example, we'll use model from\n `gensim-data <https://rare-technologies.com/new-download-api-for-pretrained-nlp-models-and-datasets-in-gensim/>`_) ::\n\n python -m gensim.downloader -d glove-wiki-gigaword-50 # download model in word2vec format\n python -m gensim.scripts.word2vec2tensor -i ~/gensim-data/glove-wiki-gigaword-50/glove-wiki-gigaword-50.gz \\\n -o /tmp/my_model_prefix\n\n#. Open http://projector.tensorflow.org/\n#. Click \"Load Data\" button from the left menu.\n#. Select \"Choose file\" in \"Load a TSV file of vectors.\" and choose \"/tmp/my_model_prefix_tensor.tsv\" file.\n#. Select \"Choose file\" in \"Load a TSV file of metadata.\" and choose \"/tmp/my_model_prefix_metadata.tsv\" file.\n#. ???\n#. PROFIT!\n\nFor more information about TensorBoard TSV format please visit:\nhttps://www.tensorflow.org/versions/master/how_tos/embedding_viz/\n\n\nCommand line arguments\n----------------------\n\n.. program-output:: python -m gensim.scripts.word2vec2tensor --help\n :ellipsis: 0, -7\n\n\"\"\"\n\nimport os\nimport sys\nimport logging\nimport argparse\n\nimport gensim\n\nlogger = logging.getLogger(__name__)\n\n\ndef word2vec2tensor(word2vec_model_path, tensor_filename, binary=False):\n \"\"\"Convert file in Word2Vec format and writes two files 2D tensor TSV file.\n\n File \"tensor_filename\"_tensor.tsv contains word-vectors, \"tensor_filename\"_metadata.tsv contains words.\n\n Parameters\n ----------\n word2vec_model_path : str\n Path to file in Word2Vec format.\n tensor_filename : str\n Prefix for output files.\n binary : bool, optional\n True if input file in binary format.\n\n \"\"\"\n model = gensim.models.KeyedVectors.load_word2vec_format(word2vec_model_path, binary=binary)\n outfiletsv = tensor_filename + '_tensor.tsv'\n outfiletsvmeta = tensor_filename + '_metadata.tsv'\n\n with open(outfiletsv, 'w+') as file_vector:\n with open(outfiletsvmeta, 'w+') as file_metadata:\n for word in model.index2word:\n file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\\n'))\n vector_row = '\\t'.join(str(x) for x in model[word])\n file_vector.write(vector_row + '\\n')\n\n logger.info(\"2D tensor file saved to %s\", outfiletsv)\n logger.info(\"Tensor metadata file saved to %s\", outfiletsvmeta)\n\n\nif __name__ == \"__main__\":\n logging.basicConfig(format='%(asctime)s - %(module)s - %(levelname)s - %(message)s', level=logging.INFO)\n parser = argparse.ArgumentParser(formatter_class=argparse.RawDescriptionHelpFormatter, description=__doc__[:-138])\n parser.add_argument(\"-i\", \"--input\", required=True, help=\"Path to input file in word2vec format\")\n parser.add_argument(\"-o\", \"--output\", required=True, help=\"Prefix path for output files\")\n parser.add_argument(\n \"-b\", \"--binary\", action='store_const', const=True, default=False,\n help=\"Set this flag if word2vec model in binary format (default: %(default)s)\"\n )\n args = parser.parse_args()\n\n logger.info(\"running %s\", ' '.join(sys.argv))\n word2vec2tensor(args.input, args.output, args.binary)\n logger.info(\"finished running %s\", os.path.basename(sys.argv[0]))\n", "path": "gensim/scripts/word2vec2tensor.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) 2018 Vimig Socrates <[email protected]>\n# Copyright (C) 2016 Loreto Parisi <[email protected]>\n# Copyright (C) 2016 Silvio Olivastri <[email protected]>\n# Copyright (C) 2016 Radim Rehurek <[email protected]>\n\n\n\"\"\"This script allows converting word-vectors from word2vec format into Tensorflow 2D tensor and metadata format.\nThis script used for for word-vector visualization on `Embedding Visualization <http://projector.tensorflow.org/>`_.\n\n\nHow to use\n----------\n#. Convert your word-vector with this script (for example, we'll use model from\n `gensim-data <https://rare-technologies.com/new-download-api-for-pretrained-nlp-models-and-datasets-in-gensim/>`_) ::\n\n python -m gensim.downloader -d glove-wiki-gigaword-50 # download model in word2vec format\n python -m gensim.scripts.word2vec2tensor -i ~/gensim-data/glove-wiki-gigaword-50/glove-wiki-gigaword-50.gz \\\n -o /tmp/my_model_prefix\n\n#. Open http://projector.tensorflow.org/\n#. Click \"Load Data\" button from the left menu.\n#. Select \"Choose file\" in \"Load a TSV file of vectors.\" and choose \"/tmp/my_model_prefix_tensor.tsv\" file.\n#. Select \"Choose file\" in \"Load a TSV file of metadata.\" and choose \"/tmp/my_model_prefix_metadata.tsv\" file.\n#. ???\n#. PROFIT!\n\nFor more information about TensorBoard TSV format please visit:\nhttps://www.tensorflow.org/versions/master/how_tos/embedding_viz/\n\n\nCommand line arguments\n----------------------\n\n.. program-output:: python -m gensim.scripts.word2vec2tensor --help\n :ellipsis: 0, -7\n\n\"\"\"\n\nimport os\nimport sys\nimport logging\nimport argparse\n\nfrom smart_open import smart_open\nimport gensim\n\nlogger = logging.getLogger(__name__)\n\n\ndef word2vec2tensor(word2vec_model_path, tensor_filename, binary=False):\n \"\"\"Convert file in Word2Vec format and writes two files 2D tensor TSV file.\n\n File \"tensor_filename\"_tensor.tsv contains word-vectors, \"tensor_filename\"_metadata.tsv contains words.\n\n Parameters\n ----------\n word2vec_model_path : str\n Path to file in Word2Vec format.\n tensor_filename : str\n Prefix for output files.\n binary : bool, optional\n True if input file in binary format.\n\n \"\"\"\n model = gensim.models.KeyedVectors.load_word2vec_format(word2vec_model_path, binary=binary)\n outfiletsv = tensor_filename + '_tensor.tsv'\n outfiletsvmeta = tensor_filename + '_metadata.tsv'\n\n with smart_open(outfiletsv, 'wb') as file_vector, smart_open(outfiletsvmeta, 'wb') as file_metadata:\n for word in model.index2word:\n file_metadata.write(gensim.utils.to_utf8(word) + gensim.utils.to_utf8('\\n'))\n vector_row = '\\t'.join(str(x) for x in model[word])\n file_vector.write(gensim.utils.to_utf8(vector_row) + gensim.utils.to_utf8('\\n'))\n\n logger.info(\"2D tensor file saved to %s\", outfiletsv)\n logger.info(\"Tensor metadata file saved to %s\", outfiletsvmeta)\n\n\nif __name__ == \"__main__\":\n logging.basicConfig(format='%(asctime)s - %(module)s - %(levelname)s - %(message)s', level=logging.INFO)\n parser = argparse.ArgumentParser(formatter_class=argparse.RawDescriptionHelpFormatter, description=__doc__[:-138])\n parser.add_argument(\"-i\", \"--input\", required=True, help=\"Path to input file in word2vec format\")\n parser.add_argument(\"-o\", \"--output\", required=True, help=\"Prefix path for output files\")\n parser.add_argument(\n \"-b\", \"--binary\", action='store_const', const=True, default=False,\n help=\"Set this flag if word2vec model in binary format (default: %(default)s)\"\n )\n args = parser.parse_args()\n\n logger.info(\"running %s\", ' '.join(sys.argv))\n word2vec2tensor(args.input, args.output, args.binary)\n logger.info(\"finished running %s\", os.path.basename(sys.argv[0]))\n", "path": "gensim/scripts/word2vec2tensor.py"}]}
| 2,131 | 492 |
gh_patches_debug_55590
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-6871
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upstream change in django-treebeard 4.5 requires a new wagtail core migration
Default MP_Node depth has changed to 1.
https://github.com/django-treebeard/django-treebeard/commit/454be8f29ac2b4b4fbe6512357b5afc1eb422bab#diff-35501ef525349cd39e4713d1a9f64a249fa4fbd31d875513e3a15e65988701a2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from wagtail import __version__
4 from wagtail.utils.setup import assets, check_bdist_egg, sdist
5
6
7 try:
8 from setuptools import find_packages, setup
9 except ImportError:
10 from distutils.core import setup
11
12
13 # Hack to prevent "TypeError: 'NoneType' object is not callable" error
14 # in multiprocessing/util.py _exit_function when setup.py exits
15 # (see http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)
16 try:
17 import multiprocessing # noqa
18 except ImportError:
19 pass
20
21
22 install_requires = [
23 "Django>=2.2,<3.2",
24 "django-modelcluster>=5.1,<6.0",
25 "django-taggit>=1.0,<2.0",
26 "django-treebeard>=4.2.0,<4.5",
27 "djangorestframework>=3.11.1,<4.0",
28 "django-filter>=2.2,<3.0",
29 "draftjs_exporter>=2.1.5,<3.0",
30 "Pillow>=4.0.0,<9.0.0",
31 "beautifulsoup4>=4.8,<4.9",
32 "html5lib>=0.999,<2",
33 "Willow>=1.4,<1.5",
34 "requests>=2.11.1,<3.0",
35 "l18n>=2018.5",
36 "xlsxwriter>=1.2.8,<2.0",
37 "tablib[xls,xlsx]>=0.14.0",
38 "anyascii>=0.1.5",
39 ]
40
41 # Testing dependencies
42 testing_extras = [
43 # Required for running the tests
44 'python-dateutil>=2.2',
45 'pytz>=2014.7',
46 'elasticsearch>=5.0,<6.0',
47 'Jinja2>=2.11,<3.0',
48 'boto3>=1.16,<1.17',
49 'freezegun>=0.3.8',
50 'openpyxl>=2.6.4',
51 'Unidecode>=0.04.14,<2.0',
52
53 # For coverage and PEP8 linting
54 'coverage>=3.7.0',
55 'flake8>=3.6.0',
56 'isort==5.6.4', # leave this pinned - it tends to change rules between patch releases
57 'flake8-blind-except==0.1.1',
58 'flake8-print==2.0.2',
59 'doc8==0.8.1',
60
61 # For templates linting
62 'jinjalint>=0.5',
63
64 # Pipenv hack to fix broken dependency causing CircleCI failures
65 'docutils==0.15',
66
67 # django-taggit 1.3.0 made changes to verbose_name which affect migrations;
68 # the test suite migrations correspond to >=1.3.0
69 'django-taggit>=1.3.0,<2.0',
70 ]
71
72 # Documentation dependencies
73 documentation_extras = [
74 'pyenchant>=3.1.1,<4',
75 'sphinxcontrib-spelling>=5.4.0,<6',
76 'Sphinx>=1.5.2',
77 'sphinx-autobuild>=0.6.0',
78 'sphinx_rtd_theme>=0.1.9',
79 'recommonmark>=0.7.1',
80 ]
81
82 setup(
83 name='wagtail',
84 version=__version__,
85 description='A Django content management system.',
86 author='Wagtail core team + contributors',
87 author_email='[email protected]', # For support queries, please see https://docs.wagtail.io/en/stable/support.html
88 url='https://wagtail.io/',
89 packages=find_packages(),
90 include_package_data=True,
91 license='BSD',
92 long_description="Wagtail is an open source content management \
93 system built on Django, with a strong community and commercial support. \
94 It’s focused on user experience, and offers precise control for \
95 designers and developers.\n\n\
96 For more details, see https://wagtail.io, https://docs.wagtail.io and \
97 https://github.com/wagtail/wagtail/.",
98 classifiers=[
99 'Development Status :: 5 - Production/Stable',
100 'Environment :: Web Environment',
101 'Intended Audience :: Developers',
102 'License :: OSI Approved :: BSD License',
103 'Operating System :: OS Independent',
104 'Programming Language :: Python',
105 'Programming Language :: Python :: 3',
106 'Programming Language :: Python :: 3.6',
107 'Programming Language :: Python :: 3.7',
108 'Programming Language :: Python :: 3.8',
109 'Programming Language :: Python :: 3.9',
110 'Framework :: Django',
111 'Framework :: Django :: 2.2',
112 'Framework :: Django :: 3.0',
113 'Framework :: Django :: 3.1',
114 'Framework :: Wagtail',
115 'Topic :: Internet :: WWW/HTTP :: Site Management',
116 ],
117 python_requires='>=3.6',
118 install_requires=install_requires,
119 extras_require={
120 'testing': testing_extras,
121 'docs': documentation_extras
122 },
123 entry_points="""
124 [console_scripts]
125 wagtail=wagtail.bin.wagtail:main
126 """,
127 zip_safe=False,
128 cmdclass={
129 'sdist': sdist,
130 'bdist_egg': check_bdist_egg,
131 'assets': assets,
132 },
133 )
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,7 +23,7 @@
"Django>=2.2,<3.2",
"django-modelcluster>=5.1,<6.0",
"django-taggit>=1.0,<2.0",
- "django-treebeard>=4.2.0,<4.5",
+ "django-treebeard>=4.2.0,<5.0,!=4.5",
"djangorestframework>=3.11.1,<4.0",
"django-filter>=2.2,<3.0",
"draftjs_exporter>=2.1.5,<3.0",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,7 +23,7 @@\n \"Django>=2.2,<3.2\",\n \"django-modelcluster>=5.1,<6.0\",\n \"django-taggit>=1.0,<2.0\",\n- \"django-treebeard>=4.2.0,<4.5\",\n+ \"django-treebeard>=4.2.0,<5.0,!=4.5\",\n \"djangorestframework>=3.11.1,<4.0\",\n \"django-filter>=2.2,<3.0\",\n \"draftjs_exporter>=2.1.5,<3.0\",\n", "issue": "Upstream change in django-treebeard 4.5 requires a new wagtail core migration\nDefault MP_Node depth has changed to 1.\r\n\r\nhttps://github.com/django-treebeard/django-treebeard/commit/454be8f29ac2b4b4fbe6512357b5afc1eb422bab#diff-35501ef525349cd39e4713d1a9f64a249fa4fbd31d875513e3a15e65988701a2\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom wagtail import __version__\nfrom wagtail.utils.setup import assets, check_bdist_egg, sdist\n\n\ntry:\n from setuptools import find_packages, setup\nexcept ImportError:\n from distutils.core import setup\n\n\n# Hack to prevent \"TypeError: 'NoneType' object is not callable\" error\n# in multiprocessing/util.py _exit_function when setup.py exits\n# (see http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)\ntry:\n import multiprocessing # noqa\nexcept ImportError:\n pass\n\n\ninstall_requires = [\n \"Django>=2.2,<3.2\",\n \"django-modelcluster>=5.1,<6.0\",\n \"django-taggit>=1.0,<2.0\",\n \"django-treebeard>=4.2.0,<4.5\",\n \"djangorestframework>=3.11.1,<4.0\",\n \"django-filter>=2.2,<3.0\",\n \"draftjs_exporter>=2.1.5,<3.0\",\n \"Pillow>=4.0.0,<9.0.0\",\n \"beautifulsoup4>=4.8,<4.9\",\n \"html5lib>=0.999,<2\",\n \"Willow>=1.4,<1.5\",\n \"requests>=2.11.1,<3.0\",\n \"l18n>=2018.5\",\n \"xlsxwriter>=1.2.8,<2.0\",\n \"tablib[xls,xlsx]>=0.14.0\",\n \"anyascii>=0.1.5\",\n]\n\n# Testing dependencies\ntesting_extras = [\n # Required for running the tests\n 'python-dateutil>=2.2',\n 'pytz>=2014.7',\n 'elasticsearch>=5.0,<6.0',\n 'Jinja2>=2.11,<3.0',\n 'boto3>=1.16,<1.17',\n 'freezegun>=0.3.8',\n 'openpyxl>=2.6.4',\n 'Unidecode>=0.04.14,<2.0',\n\n # For coverage and PEP8 linting\n 'coverage>=3.7.0',\n 'flake8>=3.6.0',\n 'isort==5.6.4', # leave this pinned - it tends to change rules between patch releases\n 'flake8-blind-except==0.1.1',\n 'flake8-print==2.0.2',\n 'doc8==0.8.1',\n\n # For templates linting\n 'jinjalint>=0.5',\n\n # Pipenv hack to fix broken dependency causing CircleCI failures\n 'docutils==0.15',\n\n # django-taggit 1.3.0 made changes to verbose_name which affect migrations;\n # the test suite migrations correspond to >=1.3.0\n 'django-taggit>=1.3.0,<2.0',\n]\n\n# Documentation dependencies\ndocumentation_extras = [\n 'pyenchant>=3.1.1,<4',\n 'sphinxcontrib-spelling>=5.4.0,<6',\n 'Sphinx>=1.5.2',\n 'sphinx-autobuild>=0.6.0',\n 'sphinx_rtd_theme>=0.1.9',\n 'recommonmark>=0.7.1',\n]\n\nsetup(\n name='wagtail',\n version=__version__,\n description='A Django content management system.',\n author='Wagtail core team + contributors',\n author_email='[email protected]', # For support queries, please see https://docs.wagtail.io/en/stable/support.html\n url='https://wagtail.io/',\n packages=find_packages(),\n include_package_data=True,\n license='BSD',\n long_description=\"Wagtail is an open source content management \\\nsystem built on Django, with a strong community and commercial support. \\\nIt\u2019s focused on user experience, and offers precise control for \\\ndesigners and developers.\\n\\n\\\nFor more details, see https://wagtail.io, https://docs.wagtail.io and \\\nhttps://github.com/wagtail/wagtail/.\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Framework :: Django',\n 'Framework :: Django :: 2.2',\n 'Framework :: Django :: 3.0',\n 'Framework :: Django :: 3.1',\n 'Framework :: Wagtail',\n 'Topic :: Internet :: WWW/HTTP :: Site Management',\n ],\n python_requires='>=3.6',\n install_requires=install_requires,\n extras_require={\n 'testing': testing_extras,\n 'docs': documentation_extras\n },\n entry_points=\"\"\"\n [console_scripts]\n wagtail=wagtail.bin.wagtail:main\n \"\"\",\n zip_safe=False,\n cmdclass={\n 'sdist': sdist,\n 'bdist_egg': check_bdist_egg,\n 'assets': assets,\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom wagtail import __version__\nfrom wagtail.utils.setup import assets, check_bdist_egg, sdist\n\n\ntry:\n from setuptools import find_packages, setup\nexcept ImportError:\n from distutils.core import setup\n\n\n# Hack to prevent \"TypeError: 'NoneType' object is not callable\" error\n# in multiprocessing/util.py _exit_function when setup.py exits\n# (see http://www.eby-sarna.com/pipermail/peak/2010-May/003357.html)\ntry:\n import multiprocessing # noqa\nexcept ImportError:\n pass\n\n\ninstall_requires = [\n \"Django>=2.2,<3.2\",\n \"django-modelcluster>=5.1,<6.0\",\n \"django-taggit>=1.0,<2.0\",\n \"django-treebeard>=4.2.0,<5.0,!=4.5\",\n \"djangorestframework>=3.11.1,<4.0\",\n \"django-filter>=2.2,<3.0\",\n \"draftjs_exporter>=2.1.5,<3.0\",\n \"Pillow>=4.0.0,<9.0.0\",\n \"beautifulsoup4>=4.8,<4.9\",\n \"html5lib>=0.999,<2\",\n \"Willow>=1.4,<1.5\",\n \"requests>=2.11.1,<3.0\",\n \"l18n>=2018.5\",\n \"xlsxwriter>=1.2.8,<2.0\",\n \"tablib[xls,xlsx]>=0.14.0\",\n \"anyascii>=0.1.5\",\n]\n\n# Testing dependencies\ntesting_extras = [\n # Required for running the tests\n 'python-dateutil>=2.2',\n 'pytz>=2014.7',\n 'elasticsearch>=5.0,<6.0',\n 'Jinja2>=2.11,<3.0',\n 'boto3>=1.16,<1.17',\n 'freezegun>=0.3.8',\n 'openpyxl>=2.6.4',\n 'Unidecode>=0.04.14,<2.0',\n\n # For coverage and PEP8 linting\n 'coverage>=3.7.0',\n 'flake8>=3.6.0',\n 'isort==5.6.4', # leave this pinned - it tends to change rules between patch releases\n 'flake8-blind-except==0.1.1',\n 'flake8-print==2.0.2',\n 'doc8==0.8.1',\n\n # For templates linting\n 'jinjalint>=0.5',\n\n # Pipenv hack to fix broken dependency causing CircleCI failures\n 'docutils==0.15',\n\n # django-taggit 1.3.0 made changes to verbose_name which affect migrations;\n # the test suite migrations correspond to >=1.3.0\n 'django-taggit>=1.3.0,<2.0',\n]\n\n# Documentation dependencies\ndocumentation_extras = [\n 'pyenchant>=3.1.1,<4',\n 'sphinxcontrib-spelling>=5.4.0,<6',\n 'Sphinx>=1.5.2',\n 'sphinx-autobuild>=0.6.0',\n 'sphinx_rtd_theme>=0.1.9',\n 'recommonmark>=0.7.1',\n]\n\nsetup(\n name='wagtail',\n version=__version__,\n description='A Django content management system.',\n author='Wagtail core team + contributors',\n author_email='[email protected]', # For support queries, please see https://docs.wagtail.io/en/stable/support.html\n url='https://wagtail.io/',\n packages=find_packages(),\n include_package_data=True,\n license='BSD',\n long_description=\"Wagtail is an open source content management \\\nsystem built on Django, with a strong community and commercial support. \\\nIt\u2019s focused on user experience, and offers precise control for \\\ndesigners and developers.\\n\\n\\\nFor more details, see https://wagtail.io, https://docs.wagtail.io and \\\nhttps://github.com/wagtail/wagtail/.\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Framework :: Django',\n 'Framework :: Django :: 2.2',\n 'Framework :: Django :: 3.0',\n 'Framework :: Django :: 3.1',\n 'Framework :: Wagtail',\n 'Topic :: Internet :: WWW/HTTP :: Site Management',\n ],\n python_requires='>=3.6',\n install_requires=install_requires,\n extras_require={\n 'testing': testing_extras,\n 'docs': documentation_extras\n },\n entry_points=\"\"\"\n [console_scripts]\n wagtail=wagtail.bin.wagtail:main\n \"\"\",\n zip_safe=False,\n cmdclass={\n 'sdist': sdist,\n 'bdist_egg': check_bdist_egg,\n 'assets': assets,\n },\n)\n", "path": "setup.py"}]}
| 1,931 | 162 |
gh_patches_debug_3602
|
rasdani/github-patches
|
git_diff
|
NVIDIA__apex-184
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Failing optim_wrapper due to missing Scaler argument
When creating an optimizer and wrapping it via ``amp_handle.wrap_optimizer(optim)``, the handle [`calls the OptimWrapper`](https://github.com/NVIDIA/apex/blob/master/apex/amp/handle.py#L148), who wraps the optimizer and tries to instantiate a loss scaler per loss.
The `OptimWrapper` tries to [instantiate the loss-scaler without an argument](https://github.com/NVIDIA/apex/blob/master/apex/amp/opt.py#L16), but the loss-scaler [needs an argument `loss_scale`](https://github.com/NVIDIA/apex/blob/master/apex/amp/scaler.py#L28), which causes the whole wrapping process to fail.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apex/amp/opt.py`
Content:
```
1 import contextlib
2 import logging
3 import warnings
4
5 from .scaler import LossScaler, master_params
6
7 import numpy as np
8
9 class OptimWrapper(object):
10 def __init__(self, optimizer, amp_handle, num_loss):
11 self._optimizer = optimizer
12 self._amp_handle = amp_handle
13 self._num_loss = num_loss
14 self._loss_idx = 0
15 self._skip_next = [False] * num_loss
16 self._loss_scaler = [LossScaler() for _ in range(num_loss)]
17
18 @contextlib.contextmanager
19 def scale_loss(self, loss):
20 if not self._amp_handle.is_active():
21 yield loss
22 return
23
24 # When there are multiple losses per-optimizer, we need
25 # to save out current grad accumulation, since we won't be
26 # able to unscale this particulare loss once the grads are
27 # all mixed together.
28 cached_grads = []
29 if self._loss_idx > 0:
30 for p in master_params(self._optimizer):
31 if p.grad is not None:
32 cached_grads.append(p.grad.data.detach().clone())
33 else:
34 cached_grads.append(None)
35 self._optimizer.zero_grad()
36
37 loss_scale = self._cur_loss_scaler().loss_scale()
38 yield loss * loss_scale
39
40 self._cur_loss_scaler().clear_overflow_state()
41 self._cur_loss_scaler().unscale(
42 master_params(self._optimizer),
43 master_params(self._optimizer),
44 loss_scale)
45 self._skip_next[self._loss_idx] = self._cur_loss_scaler().update_scale()
46 self._loss_idx += 1
47
48 if len(cached_grads) > 0:
49 for p, cached_grad in zip(master_params(self._optimizer),
50 cached_grads):
51 if cached_grad is not None:
52 p.grad.data.add_(cached_grad)
53 cached_grads = []
54
55 def _cur_loss_scaler(self):
56 assert 0 <= self._loss_idx < self._num_loss
57 return self._loss_scaler[self._loss_idx]
58
59 def step(self, closure=None):
60 if not self._amp_handle.is_active():
61 return self._optimizer.step(closure=closure)
62
63 self._loss_idx = 0
64
65 for group in self._optimizer.param_groups:
66 for p in group['params']:
67 self._amp_handle.remove_cache(p)
68
69 if closure is not None:
70 raise NotImplementedError(
71 'The `closure` argument is unsupported by the amp ' +
72 'optimizer wrapper.')
73 if any(self._skip_next):
74 logger = logging.getLogger('apex.amp')
75 logger.info('Gradient overflow, skipping update')
76 self._skip_next = [False] * self._num_loss
77 else:
78 return self._optimizer.step(closure=closure)
79
80 # Forward any attribute lookups
81 def __getattr__(self, attr):
82 return getattr(self._optimizer, attr)
83
84 # Forward all torch.optim.Optimizer methods
85 def __getstate__(self):
86 return self._optimizer.__getstate__()
87
88 def __setstate__(self):
89 return self._optimizer.__setstate__()
90
91 def __repr__(self):
92 return self._optimizer.__repr__()
93
94 def state_dict(self):
95 return self._optimizer.state_dict()
96
97 def load_state_dict(self, state_dict):
98 return self._optimizer.load_state_dict(state_dict)
99
100 def zero_grad(self):
101 return self._optimizer.zero_grad()
102
103 def add_param_group(self, param_group):
104 return self._optimizer.add_param_group(param_group)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apex/amp/opt.py b/apex/amp/opt.py
--- a/apex/amp/opt.py
+++ b/apex/amp/opt.py
@@ -13,7 +13,7 @@
self._num_loss = num_loss
self._loss_idx = 0
self._skip_next = [False] * num_loss
- self._loss_scaler = [LossScaler() for _ in range(num_loss)]
+ self._loss_scaler = [LossScaler('dynamic') for _ in range(num_loss)]
@contextlib.contextmanager
def scale_loss(self, loss):
|
{"golden_diff": "diff --git a/apex/amp/opt.py b/apex/amp/opt.py\n--- a/apex/amp/opt.py\n+++ b/apex/amp/opt.py\n@@ -13,7 +13,7 @@\n self._num_loss = num_loss\n self._loss_idx = 0\n self._skip_next = [False] * num_loss\n- self._loss_scaler = [LossScaler() for _ in range(num_loss)]\n+ self._loss_scaler = [LossScaler('dynamic') for _ in range(num_loss)]\n \n @contextlib.contextmanager\n def scale_loss(self, loss):\n", "issue": "Failing optim_wrapper due to missing Scaler argument\nWhen creating an optimizer and wrapping it via ``amp_handle.wrap_optimizer(optim)``, the handle [`calls the OptimWrapper`](https://github.com/NVIDIA/apex/blob/master/apex/amp/handle.py#L148), who wraps the optimizer and tries to instantiate a loss scaler per loss. \r\n\r\nThe `OptimWrapper` tries to [instantiate the loss-scaler without an argument](https://github.com/NVIDIA/apex/blob/master/apex/amp/opt.py#L16), but the loss-scaler [needs an argument `loss_scale`](https://github.com/NVIDIA/apex/blob/master/apex/amp/scaler.py#L28), which causes the whole wrapping process to fail.\n", "before_files": [{"content": "import contextlib\nimport logging\nimport warnings\n\nfrom .scaler import LossScaler, master_params\n\nimport numpy as np\n\nclass OptimWrapper(object):\n def __init__(self, optimizer, amp_handle, num_loss):\n self._optimizer = optimizer\n self._amp_handle = amp_handle\n self._num_loss = num_loss\n self._loss_idx = 0\n self._skip_next = [False] * num_loss\n self._loss_scaler = [LossScaler() for _ in range(num_loss)]\n\n @contextlib.contextmanager\n def scale_loss(self, loss):\n if not self._amp_handle.is_active():\n yield loss\n return\n\n # When there are multiple losses per-optimizer, we need\n # to save out current grad accumulation, since we won't be\n # able to unscale this particulare loss once the grads are\n # all mixed together.\n cached_grads = []\n if self._loss_idx > 0:\n for p in master_params(self._optimizer):\n if p.grad is not None:\n cached_grads.append(p.grad.data.detach().clone())\n else:\n cached_grads.append(None)\n self._optimizer.zero_grad()\n\n loss_scale = self._cur_loss_scaler().loss_scale()\n yield loss * loss_scale\n\n self._cur_loss_scaler().clear_overflow_state()\n self._cur_loss_scaler().unscale(\n master_params(self._optimizer),\n master_params(self._optimizer),\n loss_scale)\n self._skip_next[self._loss_idx] = self._cur_loss_scaler().update_scale()\n self._loss_idx += 1\n\n if len(cached_grads) > 0:\n for p, cached_grad in zip(master_params(self._optimizer),\n cached_grads):\n if cached_grad is not None:\n p.grad.data.add_(cached_grad)\n cached_grads = []\n\n def _cur_loss_scaler(self):\n assert 0 <= self._loss_idx < self._num_loss\n return self._loss_scaler[self._loss_idx]\n\n def step(self, closure=None):\n if not self._amp_handle.is_active():\n return self._optimizer.step(closure=closure)\n\n self._loss_idx = 0\n\n for group in self._optimizer.param_groups:\n for p in group['params']:\n self._amp_handle.remove_cache(p)\n\n if closure is not None:\n raise NotImplementedError(\n 'The `closure` argument is unsupported by the amp ' +\n 'optimizer wrapper.')\n if any(self._skip_next):\n logger = logging.getLogger('apex.amp')\n logger.info('Gradient overflow, skipping update')\n self._skip_next = [False] * self._num_loss\n else:\n return self._optimizer.step(closure=closure)\n\n # Forward any attribute lookups\n def __getattr__(self, attr):\n return getattr(self._optimizer, attr)\n\n # Forward all torch.optim.Optimizer methods\n def __getstate__(self):\n return self._optimizer.__getstate__()\n\n def __setstate__(self):\n return self._optimizer.__setstate__()\n\n def __repr__(self):\n return self._optimizer.__repr__()\n\n def state_dict(self):\n return self._optimizer.state_dict()\n\n def load_state_dict(self, state_dict):\n return self._optimizer.load_state_dict(state_dict)\n\n def zero_grad(self):\n return self._optimizer.zero_grad()\n\n def add_param_group(self, param_group):\n return self._optimizer.add_param_group(param_group)\n", "path": "apex/amp/opt.py"}], "after_files": [{"content": "import contextlib\nimport logging\nimport warnings\n\nfrom .scaler import LossScaler, master_params\n\nimport numpy as np\n\nclass OptimWrapper(object):\n def __init__(self, optimizer, amp_handle, num_loss):\n self._optimizer = optimizer\n self._amp_handle = amp_handle\n self._num_loss = num_loss\n self._loss_idx = 0\n self._skip_next = [False] * num_loss\n self._loss_scaler = [LossScaler('dynamic') for _ in range(num_loss)]\n\n @contextlib.contextmanager\n def scale_loss(self, loss):\n if not self._amp_handle.is_active():\n yield loss\n return\n\n # When there are multiple losses per-optimizer, we need\n # to save out current grad accumulation, since we won't be\n # able to unscale this particulare loss once the grads are\n # all mixed together.\n cached_grads = []\n if self._loss_idx > 0:\n for p in master_params(self._optimizer):\n if p.grad is not None:\n cached_grads.append(p.grad.data.detach().clone())\n else:\n cached_grads.append(None)\n self._optimizer.zero_grad()\n\n loss_scale = self._cur_loss_scaler().loss_scale()\n yield loss * loss_scale\n\n self._cur_loss_scaler().clear_overflow_state()\n self._cur_loss_scaler().unscale(\n master_params(self._optimizer),\n master_params(self._optimizer),\n loss_scale)\n self._skip_next[self._loss_idx] = self._cur_loss_scaler().update_scale()\n self._loss_idx += 1\n\n if len(cached_grads) > 0:\n for p, cached_grad in zip(master_params(self._optimizer),\n cached_grads):\n if cached_grad is not None:\n p.grad.data.add_(cached_grad)\n cached_grads = []\n\n def _cur_loss_scaler(self):\n assert 0 <= self._loss_idx < self._num_loss\n return self._loss_scaler[self._loss_idx]\n\n def step(self, closure=None):\n if not self._amp_handle.is_active():\n return self._optimizer.step(closure=closure)\n\n self._loss_idx = 0\n\n for group in self._optimizer.param_groups:\n for p in group['params']:\n self._amp_handle.remove_cache(p)\n\n if closure is not None:\n raise NotImplementedError(\n 'The `closure` argument is unsupported by the amp ' +\n 'optimizer wrapper.')\n if any(self._skip_next):\n logger = logging.getLogger('apex.amp')\n logger.info('Gradient overflow, skipping update')\n self._skip_next = [False] * self._num_loss\n else:\n return self._optimizer.step(closure=closure)\n\n # Forward any attribute lookups\n def __getattr__(self, attr):\n return getattr(self._optimizer, attr)\n\n # Forward all torch.optim.Optimizer methods\n def __getstate__(self):\n return self._optimizer.__getstate__()\n\n def __setstate__(self):\n return self._optimizer.__setstate__()\n\n def __repr__(self):\n return self._optimizer.__repr__()\n\n def state_dict(self):\n return self._optimizer.state_dict()\n\n def load_state_dict(self, state_dict):\n return self._optimizer.load_state_dict(state_dict)\n\n def zero_grad(self):\n return self._optimizer.zero_grad()\n\n def add_param_group(self, param_group):\n return self._optimizer.add_param_group(param_group)\n", "path": "apex/amp/opt.py"}]}
| 1,393 | 135 |
gh_patches_debug_40994
|
rasdani/github-patches
|
git_diff
|
pyload__pyload-1779
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[OneFichierCom]Non restricted file
Hello, i try to download little files on 1fichier( like this : ) but i cannot
```
ff^[^[^[^[^[^[19.08.2015 07:59:13 INFO Added package Nonrestricted file containing 1 links
19.08.2015 07:59:13 DEBUG Run Info Fetching for OneFichierCom
19.08.2015 07:59:14 INFO Download starts: https://1fichier.com/?86zu29oou8
19.08.2015 07:59:14 DEBUG HOOK UserAgentSwitcher: Use custom user-agent string: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0
19.08.2015 07:59:14 DEBUG HOOK UserAgentSwitcher: Use custom user-agent string: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0
19.08.2015 07:59:14 DEBUG HOSTER OneFichierCom[126]: PROCESS URL https://1fichier.com/?86zu29oou8 | PLUGIN VERSION 0.88
19.08.2015 07:59:14 INFO HOSTER OneFichierCom[126]: Updating file info...
Traceback (most recent call last):
File "/usr/share/pyload/module/network/HTTPRequest.py", line 279, in write
raise Exception("Loaded Url exceeded limit")
Exception: Loaded Url exceeded limit
19.08.2015 07:59:15 DEBUG Finished Info Fetching for OneFichierCom
Traceback (most recent call last):
File "/usr/share/pyload/module/network/HTTPRequest.py", line 279, in write
raise Exception("Loaded Url exceeded limit")
Exception: Loaded Url exceeded limit
19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: File info: {'status': 3, 'url': u'https://1fichier.com/?86zu29oou8', 'size': 0, 'name': u'86zu29oou8', 'pattern': {'HOST': u'1fichier.com', 'ID2': u'86zu29oou8', 'ID1': None}}
19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: Previous file info: {}
19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: File name: 86zu29oou8
19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: File size: Unknown
19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: File status: queued
19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: Looking for direct download link...
19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: Redirect #0 to: https://1fichier.com/?86zu29oou8
19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: LOAD URL https://1fichier.com/?86zu29oou8 | cookies=True | get={} | req=None | decode=True | multipart=False | post={} | ref=True | just_header=True
19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: Redirect #1 to: https://a-9.1fichier.com/s25134576
19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: LOAD URL https://a-9.1fichier.com/s25134576 | cookies=True | get={} | req=None | decode=True | multipart=False | post={} | ref=True | just_header=True
19.08.2015 07:59:19 INFO HOSTER OneFichierCom[126]: Direct download link detected
19.08.2015 07:59:19 INFO HOSTER OneFichierCom[126]: Downloading file...
19.08.2015 07:59:19 DEBUG HOSTER OneFichierCom[126]: DOWNLOAD URL https://a-9.1fichier.com/s25134576 | cookies=True | get={} | disposition=True | post={} | ref=True
19.08.2015 07:59:20 INFO HOSTER OneFichierCom[126]: Checking file...
19.08.2015 07:59:20 DEBUG HOSTER OneFichierCom[126]: Using default check rules...
19.08.2015 07:59:20 WARNING HOSTER OneFichierCom[126]: Check result: Html file | Waiting 1 minute and retry
19.08.2015 07:59:20 INFO HOSTER OneFichierCom[126]: WAIT 60 seconds
19.08.2015 07:59:20 DEBUG HOSTER OneFichierCom[126]: Previous waitUntil: 0.000000
19.08.2015 07:59:20 INFO HOSTER OneFichierCom[126]: RECONNECT disabled
19.08.2015 07:59:20 DEBUG HOSTER OneFichierCom[126]: Previous wantReconnect: True
19.08.2015 07:59:20 WARNING HOSTER OneFichierCom[126]: Ignore reconnection due logged account
```
curl :
```
curl 7.26.0 (arm-unknown-linux-gnueabihf) libcurl/7.26.0 OpenSSL/1.0.1e zlib/1.2.7 libidn/1.25 libssh2/1.4.2 librtmp/2.3
Protocols: dict file ftp ftps gopher http https imap imaps ldap pop3 pop3s rtmp rtsp scp sftp smtp smtps telnet tftp
Features: Debug GSS-Negotiate IDN IPv6 Largefile NTLM NTLM_WB SSL libz TLS-SRP
```
OS : Raspberry Rasbian 7
```
greg@serveur-pi ~ $ cat /etc/os-release
PRETTY_NAME="Raspbian GNU/Linux 7 (wheezy)"
NAME="Raspbian GNU/Linux"
VERSION_ID="7"
VERSION="7 (wheezy)"
ID=raspbian
ID_LIKE=debian
ANSI_COLOR="1;31"
HOME_URL="http://www.raspbian.org/"
SUPPORT_URL="http://www.raspbian.org/RaspbianForums"
BUG_REPORT_URL="http://www.raspbian.org/RaspbianBugs"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `module/plugins/hoster/OneFichierCom.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import re
4
5 from module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo
6
7
8 class OneFichierCom(SimpleHoster):
9 __name__ = "OneFichierCom"
10 __type__ = "hoster"
11 __version__ = "0.88"
12 __status__ = "testing"
13
14 __pattern__ = r'https?://(?:www\.)?(?:(?P<ID1>\w+)\.)?(?P<HOST>1fichier\.com|alterupload\.com|cjoint\.net|d(es)?fichiers\.com|dl4free\.com|megadl\.fr|mesfichiers\.org|piecejointe\.net|pjointe\.com|tenvoi\.com)(?:/\?(?P<ID2>\w+))?'
15 __config__ = [("use_premium", "bool", "Use premium account if available", True)]
16
17 __description__ = """1fichier.com hoster plugin"""
18 __license__ = "GPLv3"
19 __authors__ = [("fragonib", "fragonib[AT]yahoo[DOT]es"),
20 ("the-razer", "daniel_ AT gmx DOT net"),
21 ("zoidberg", "[email protected]"),
22 ("imclem", None),
23 ("stickell", "[email protected]"),
24 ("Elrick69", "elrick69[AT]rocketmail[DOT]com"),
25 ("Walter Purcaro", "[email protected]"),
26 ("Ludovic Lehmann", "[email protected]")]
27
28
29 COOKIES = [("1fichier.com", "LG", "en")]
30
31 NAME_PATTERN = r'>File\s*Name :</td>\s*<td.*>(?P<N>.+?)<'
32 SIZE_PATTERN = r'>Size :</td>\s*<td.*>(?P<S>[\d.,]+) (?P<U>[\w^_]+)'
33 OFFLINE_PATTERN = r'File not found !\s*<'
34
35 WAIT_PATTERN = r'>You must wait \d+ minutes'
36
37
38 def setup(self):
39 self.multiDL = self.premium
40 self.resume_download = True
41
42
43 def handle_free(self, pyfile):
44 id = self.info['pattern']['ID1'] or self.info['pattern']['ID2']
45 url, inputs = self.parse_html_form('action="https://1fichier.com/\?%s' % id)
46
47 if not url:
48 self.fail(_("Download link not found"))
49
50 if "pass" in inputs:
51 inputs['pass'] = self.get_password()
52
53 inputs['submit'] = "Download"
54
55 self.download(url, post=inputs)
56
57
58 def handle_premium(self, pyfile):
59 self.download(pyfile.url, post={'dl': "Download", 'did': 0})
60
61
62 getInfo = create_getInfo(OneFichierCom)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/module/plugins/hoster/OneFichierCom.py b/module/plugins/hoster/OneFichierCom.py
--- a/module/plugins/hoster/OneFichierCom.py
+++ b/module/plugins/hoster/OneFichierCom.py
@@ -2,13 +2,14 @@
import re
+from module.network.RequestFactory import getURL as get_url
from module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo
class OneFichierCom(SimpleHoster):
__name__ = "OneFichierCom"
__type__ = "hoster"
- __version__ = "0.88"
+ __version__ = "0.89"
__status__ = "testing"
__pattern__ = r'https?://(?:www\.)?(?:(?P<ID1>\w+)\.)?(?P<HOST>1fichier\.com|alterupload\.com|cjoint\.net|d(es)?fichiers\.com|dl4free\.com|megadl\.fr|mesfichiers\.org|piecejointe\.net|pjointe\.com|tenvoi\.com)(?:/\?(?P<ID2>\w+))?'
@@ -28,6 +29,8 @@
COOKIES = [("1fichier.com", "LG", "en")]
+ DIRECT_LINK = True
+
NAME_PATTERN = r'>File\s*Name :</td>\s*<td.*>(?P<N>.+?)<'
SIZE_PATTERN = r'>Size :</td>\s*<td.*>(?P<S>[\d.,]+) (?P<U>[\w^_]+)'
OFFLINE_PATTERN = r'File not found !\s*<'
@@ -40,7 +43,61 @@
self.resume_download = True
+ @classmethod
+ def get_info(cls, url="", html=""):
+ redirect = url
+ for i in xrange(10):
+ try:
+ headers = dict(re.findall(r"(?P<name>.+?): (?P<value>.+?)\r?\n", get_url(redirect, just_header=True).lower()))
+ if 'location' in headers and headers['location']:
+ redirect = headers['location']
+ else:
+ if 'content-type' in headers and headers['content-type'] == "application/octet-stream":
+ if "filename=" in headers.get('content-disposition'):
+ name = dict(_i.split("=") for _i in map(str.strip, headers['content-disposition'].split(";"))[1:]['filename'].strip("\"'")
+ else:
+ name = url
+
+ info = {'name' : name,
+ 'size' : long(headers.get('content-length')),
+ 'status': 3,
+ 'url' : url}
+
+ else:
+ info = super(OneFichierCom, cls).get_info(url, html)
+
+ break
+
+ except Exception, e:
+ info = {'status' : 8,
+ 'error' : e.message}
+
+ else:
+ info = {'status' : 8,
+ 'error' : _("Too many redirects")}
+
+ return info
+
+
+ def handle_direct(self, pyfile):
+ redirect = pyfile.url
+ for i in xrange(self.get_config("maxredirs", plugin="UserAgentSwitcher")):
+
+ headers = self.load(redirect, just_header=True)
+ if 'location' in headers and headers['location']:
+ self.log_debug("Redirect #%d to: %s" % (i, redirect))
+ redirect = headers['location']
+ else:
+ if 'content-type' in headers and headers['content-type'] == "application/octet-stream":
+ self.link = pyfile.url
+ break
+ else:
+ self.fail(_("Too many redirects"))
+
+
def handle_free(self, pyfile):
+ self.check_errors()
+
id = self.info['pattern']['ID1'] or self.info['pattern']['ID2']
url, inputs = self.parse_html_form('action="https://1fichier.com/\?%s' % id)
|
{"golden_diff": "diff --git a/module/plugins/hoster/OneFichierCom.py b/module/plugins/hoster/OneFichierCom.py\n--- a/module/plugins/hoster/OneFichierCom.py\n+++ b/module/plugins/hoster/OneFichierCom.py\n@@ -2,13 +2,14 @@\n \n import re\n \n+from module.network.RequestFactory import getURL as get_url\n from module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo\n \n \n class OneFichierCom(SimpleHoster):\n __name__ = \"OneFichierCom\"\n __type__ = \"hoster\"\n- __version__ = \"0.88\"\n+ __version__ = \"0.89\"\n __status__ = \"testing\"\n \n __pattern__ = r'https?://(?:www\\.)?(?:(?P<ID1>\\w+)\\.)?(?P<HOST>1fichier\\.com|alterupload\\.com|cjoint\\.net|d(es)?fichiers\\.com|dl4free\\.com|megadl\\.fr|mesfichiers\\.org|piecejointe\\.net|pjointe\\.com|tenvoi\\.com)(?:/\\?(?P<ID2>\\w+))?'\n@@ -28,6 +29,8 @@\n \n COOKIES = [(\"1fichier.com\", \"LG\", \"en\")]\n \n+ DIRECT_LINK = True\n+\n NAME_PATTERN = r'>File\\s*Name :</td>\\s*<td.*>(?P<N>.+?)<'\n SIZE_PATTERN = r'>Size :</td>\\s*<td.*>(?P<S>[\\d.,]+) (?P<U>[\\w^_]+)'\n OFFLINE_PATTERN = r'File not found !\\s*<'\n@@ -40,7 +43,61 @@\n self.resume_download = True\n \n \n+ @classmethod\n+ def get_info(cls, url=\"\", html=\"\"):\n+ redirect = url\n+ for i in xrange(10):\n+ try:\n+ headers = dict(re.findall(r\"(?P<name>.+?): (?P<value>.+?)\\r?\\n\", get_url(redirect, just_header=True).lower()))\n+ if 'location' in headers and headers['location']:\n+ redirect = headers['location']\n+ else:\n+ if 'content-type' in headers and headers['content-type'] == \"application/octet-stream\":\n+ if \"filename=\" in headers.get('content-disposition'):\n+ name = dict(_i.split(\"=\") for _i in map(str.strip, headers['content-disposition'].split(\";\"))[1:]['filename'].strip(\"\\\"'\")\n+ else:\n+ name = url\n+\n+ info = {'name' : name,\n+ 'size' : long(headers.get('content-length')),\n+ 'status': 3,\n+ 'url' : url}\n+\n+ else:\n+ info = super(OneFichierCom, cls).get_info(url, html)\n+\n+ break\n+\n+ except Exception, e:\n+ info = {'status' : 8,\n+ 'error' : e.message}\n+\n+ else:\n+ info = {'status' : 8,\n+ 'error' : _(\"Too many redirects\")}\n+\n+ return info\n+\n+\n+ def handle_direct(self, pyfile):\n+ redirect = pyfile.url\n+ for i in xrange(self.get_config(\"maxredirs\", plugin=\"UserAgentSwitcher\")):\n+\n+ headers = self.load(redirect, just_header=True)\n+ if 'location' in headers and headers['location']:\n+ self.log_debug(\"Redirect #%d to: %s\" % (i, redirect))\n+ redirect = headers['location']\n+ else:\n+ if 'content-type' in headers and headers['content-type'] == \"application/octet-stream\":\n+ self.link = pyfile.url\n+ break\n+ else:\n+ self.fail(_(\"Too many redirects\"))\n+\n+\n def handle_free(self, pyfile):\n+ self.check_errors()\n+\n id = self.info['pattern']['ID1'] or self.info['pattern']['ID2']\n url, inputs = self.parse_html_form('action=\"https://1fichier.com/\\?%s' % id)\n", "issue": "[OneFichierCom]Non restricted file\nHello, i try to download little files on 1fichier( like this : ) but i cannot\n\n```\nff^[^[^[^[^[^[19.08.2015 07:59:13 INFO Added package Nonrestricted file containing 1 links\n19.08.2015 07:59:13 DEBUG Run Info Fetching for OneFichierCom\n19.08.2015 07:59:14 INFO Download starts: https://1fichier.com/?86zu29oou8\n19.08.2015 07:59:14 DEBUG HOOK UserAgentSwitcher: Use custom user-agent string: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0\n19.08.2015 07:59:14 DEBUG HOOK UserAgentSwitcher: Use custom user-agent string: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0\n19.08.2015 07:59:14 DEBUG HOSTER OneFichierCom[126]: PROCESS URL https://1fichier.com/?86zu29oou8 | PLUGIN VERSION 0.88\n19.08.2015 07:59:14 INFO HOSTER OneFichierCom[126]: Updating file info...\nTraceback (most recent call last):\n File \"/usr/share/pyload/module/network/HTTPRequest.py\", line 279, in write\n raise Exception(\"Loaded Url exceeded limit\")\nException: Loaded Url exceeded limit\n19.08.2015 07:59:15 DEBUG Finished Info Fetching for OneFichierCom\nTraceback (most recent call last):\n File \"/usr/share/pyload/module/network/HTTPRequest.py\", line 279, in write\n raise Exception(\"Loaded Url exceeded limit\")\nException: Loaded Url exceeded limit\n19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: File info: {'status': 3, 'url': u'https://1fichier.com/?86zu29oou8', 'size': 0, 'name': u'86zu29oou8', 'pattern': {'HOST': u'1fichier.com', 'ID2': u'86zu29oou8', 'ID1': None}}\n19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: Previous file info: {}\n19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: File name: 86zu29oou8\n19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: File size: Unknown\n19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: File status: queued\n19.08.2015 07:59:17 INFO HOSTER OneFichierCom[126]: Looking for direct download link...\n19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: Redirect #0 to: https://1fichier.com/?86zu29oou8\n19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: LOAD URL https://1fichier.com/?86zu29oou8 | cookies=True | get={} | req=None | decode=True | multipart=False | post={} | ref=True | just_header=True\n19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: Redirect #1 to: https://a-9.1fichier.com/s25134576\n19.08.2015 07:59:17 DEBUG HOSTER OneFichierCom[126]: LOAD URL https://a-9.1fichier.com/s25134576 | cookies=True | get={} | req=None | decode=True | multipart=False | post={} | ref=True | just_header=True\n19.08.2015 07:59:19 INFO HOSTER OneFichierCom[126]: Direct download link detected\n19.08.2015 07:59:19 INFO HOSTER OneFichierCom[126]: Downloading file...\n19.08.2015 07:59:19 DEBUG HOSTER OneFichierCom[126]: DOWNLOAD URL https://a-9.1fichier.com/s25134576 | cookies=True | get={} | disposition=True | post={} | ref=True\n19.08.2015 07:59:20 INFO HOSTER OneFichierCom[126]: Checking file...\n19.08.2015 07:59:20 DEBUG HOSTER OneFichierCom[126]: Using default check rules...\n19.08.2015 07:59:20 WARNING HOSTER OneFichierCom[126]: Check result: Html file | Waiting 1 minute and retry\n19.08.2015 07:59:20 INFO HOSTER OneFichierCom[126]: WAIT 60 seconds\n19.08.2015 07:59:20 DEBUG HOSTER OneFichierCom[126]: Previous waitUntil: 0.000000\n19.08.2015 07:59:20 INFO HOSTER OneFichierCom[126]: RECONNECT disabled\n19.08.2015 07:59:20 DEBUG HOSTER OneFichierCom[126]: Previous wantReconnect: True\n19.08.2015 07:59:20 WARNING HOSTER OneFichierCom[126]: Ignore reconnection due logged account\n```\n\ncurl : \n\n```\ncurl 7.26.0 (arm-unknown-linux-gnueabihf) libcurl/7.26.0 OpenSSL/1.0.1e zlib/1.2.7 libidn/1.25 libssh2/1.4.2 librtmp/2.3\nProtocols: dict file ftp ftps gopher http https imap imaps ldap pop3 pop3s rtmp rtsp scp sftp smtp smtps telnet tftp \nFeatures: Debug GSS-Negotiate IDN IPv6 Largefile NTLM NTLM_WB SSL libz TLS-SRP\n```\n\nOS : Raspberry Rasbian 7\n\n```\ngreg@serveur-pi ~ $ cat /etc/os-release\nPRETTY_NAME=\"Raspbian GNU/Linux 7 (wheezy)\"\nNAME=\"Raspbian GNU/Linux\"\nVERSION_ID=\"7\"\nVERSION=\"7 (wheezy)\"\nID=raspbian\nID_LIKE=debian\nANSI_COLOR=\"1;31\"\nHOME_URL=\"http://www.raspbian.org/\"\nSUPPORT_URL=\"http://www.raspbian.org/RaspbianForums\"\nBUG_REPORT_URL=\"http://www.raspbian.org/RaspbianBugs\"\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo\n\n\nclass OneFichierCom(SimpleHoster):\n __name__ = \"OneFichierCom\"\n __type__ = \"hoster\"\n __version__ = \"0.88\"\n __status__ = \"testing\"\n\n __pattern__ = r'https?://(?:www\\.)?(?:(?P<ID1>\\w+)\\.)?(?P<HOST>1fichier\\.com|alterupload\\.com|cjoint\\.net|d(es)?fichiers\\.com|dl4free\\.com|megadl\\.fr|mesfichiers\\.org|piecejointe\\.net|pjointe\\.com|tenvoi\\.com)(?:/\\?(?P<ID2>\\w+))?'\n __config__ = [(\"use_premium\", \"bool\", \"Use premium account if available\", True)]\n\n __description__ = \"\"\"1fichier.com hoster plugin\"\"\"\n __license__ = \"GPLv3\"\n __authors__ = [(\"fragonib\", \"fragonib[AT]yahoo[DOT]es\"),\n (\"the-razer\", \"daniel_ AT gmx DOT net\"),\n (\"zoidberg\", \"[email protected]\"),\n (\"imclem\", None),\n (\"stickell\", \"[email protected]\"),\n (\"Elrick69\", \"elrick69[AT]rocketmail[DOT]com\"),\n (\"Walter Purcaro\", \"[email protected]\"),\n (\"Ludovic Lehmann\", \"[email protected]\")]\n\n\n COOKIES = [(\"1fichier.com\", \"LG\", \"en\")]\n\n NAME_PATTERN = r'>File\\s*Name :</td>\\s*<td.*>(?P<N>.+?)<'\n SIZE_PATTERN = r'>Size :</td>\\s*<td.*>(?P<S>[\\d.,]+) (?P<U>[\\w^_]+)'\n OFFLINE_PATTERN = r'File not found !\\s*<'\n\n WAIT_PATTERN = r'>You must wait \\d+ minutes'\n\n\n def setup(self):\n self.multiDL = self.premium\n self.resume_download = True\n\n\n def handle_free(self, pyfile):\n id = self.info['pattern']['ID1'] or self.info['pattern']['ID2']\n url, inputs = self.parse_html_form('action=\"https://1fichier.com/\\?%s' % id)\n\n if not url:\n self.fail(_(\"Download link not found\"))\n\n if \"pass\" in inputs:\n inputs['pass'] = self.get_password()\n\n inputs['submit'] = \"Download\"\n\n self.download(url, post=inputs)\n\n\n def handle_premium(self, pyfile):\n self.download(pyfile.url, post={'dl': \"Download\", 'did': 0})\n\n\ngetInfo = create_getInfo(OneFichierCom)\n", "path": "module/plugins/hoster/OneFichierCom.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom module.network.RequestFactory import getURL as get_url\nfrom module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo\n\n\nclass OneFichierCom(SimpleHoster):\n __name__ = \"OneFichierCom\"\n __type__ = \"hoster\"\n __version__ = \"0.89\"\n __status__ = \"testing\"\n\n __pattern__ = r'https?://(?:www\\.)?(?:(?P<ID1>\\w+)\\.)?(?P<HOST>1fichier\\.com|alterupload\\.com|cjoint\\.net|d(es)?fichiers\\.com|dl4free\\.com|megadl\\.fr|mesfichiers\\.org|piecejointe\\.net|pjointe\\.com|tenvoi\\.com)(?:/\\?(?P<ID2>\\w+))?'\n __config__ = [(\"use_premium\", \"bool\", \"Use premium account if available\", True)]\n\n __description__ = \"\"\"1fichier.com hoster plugin\"\"\"\n __license__ = \"GPLv3\"\n __authors__ = [(\"fragonib\", \"fragonib[AT]yahoo[DOT]es\"),\n (\"the-razer\", \"daniel_ AT gmx DOT net\"),\n (\"zoidberg\", \"[email protected]\"),\n (\"imclem\", None),\n (\"stickell\", \"[email protected]\"),\n (\"Elrick69\", \"elrick69[AT]rocketmail[DOT]com\"),\n (\"Walter Purcaro\", \"[email protected]\"),\n (\"Ludovic Lehmann\", \"[email protected]\")]\n\n\n COOKIES = [(\"1fichier.com\", \"LG\", \"en\")]\n\n DIRECT_LINK = True\n\n NAME_PATTERN = r'>File\\s*Name :</td>\\s*<td.*>(?P<N>.+?)<'\n SIZE_PATTERN = r'>Size :</td>\\s*<td.*>(?P<S>[\\d.,]+) (?P<U>[\\w^_]+)'\n OFFLINE_PATTERN = r'File not found !\\s*<'\n\n WAIT_PATTERN = r'>You must wait \\d+ minutes'\n\n\n def setup(self):\n self.multiDL = self.premium\n self.resume_download = True\n\n\n @classmethod\n def get_info(cls, url=\"\", html=\"\"):\n redirect = url\n for i in xrange(10):\n try:\n headers = dict(re.findall(r\"(?P<name>.+?): (?P<value>.+?)\\r?\\n\", get_url(redirect, just_header=True).lower()))\n if 'location' in headers and headers['location']:\n redirect = headers['location']\n else:\n if 'content-type' in headers and headers['content-type'] == \"application/octet-stream\":\n if \"filename=\" in headers.get('content-disposition'):\n name = dict(_i.split(\"=\") for _i in map(str.strip, headers['content-disposition'].split(\";\"))[1:]['filename'].strip(\"\\\"'\")\n else:\n name = url\n\n info = {'name' : name,\n 'size' : long(headers.get('content-length')),\n 'status': 3,\n 'url' : url}\n\n else:\n info = super(OneFichierCom, cls).get_info(url, html)\n\n break\n\n except Exception, e:\n info = {'status' : 8,\n 'error' : e.message}\n\n else:\n info = {'status' : 8,\n 'error' : _(\"Too many redirects\")}\n\n return info\n\n\n def handle_direct(self, pyfile):\n redirect = pyfile.url\n for i in xrange(self.get_config(\"maxredirs\", plugin=\"UserAgentSwitcher\")):\n\n headers = self.load(redirect, just_header=True)\n if 'location' in headers and headers['location']:\n self.log_debug(\"Redirect #%d to: %s\" % (i, redirect))\n redirect = headers['location']\n else:\n if 'content-type' in headers and headers['content-type'] == \"application/octet-stream\":\n self.link = pyfile.url\n break\n else:\n self.fail(_(\"Too many redirects\"))\n\n\n def handle_free(self, pyfile):\n self.check_errors()\n\n id = self.info['pattern']['ID1'] or self.info['pattern']['ID2']\n url, inputs = self.parse_html_form('action=\"https://1fichier.com/\\?%s' % id)\n\n if not url:\n self.fail(_(\"Download link not found\"))\n\n if \"pass\" in inputs:\n inputs['pass'] = self.get_password()\n\n inputs['submit'] = \"Download\"\n\n self.download(url, post=inputs)\n\n\n def handle_premium(self, pyfile):\n self.download(pyfile.url, post={'dl': \"Download\", 'did': 0})\n\n\ngetInfo = create_getInfo(OneFichierCom)\n", "path": "module/plugins/hoster/OneFichierCom.py"}]}
| 2,853 | 938 |
gh_patches_debug_42681
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-4127
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Docs] Graph for Commands API have non working links
### The issue:
https://docs.qtile.org/en/latest/manual/commands/api/root.html
This is about the online documentation. I created an issue here, because its hosted in same repository as the code itself. The links on the graphical nodes are wrong and returns a 404. It's this image: https://docs.qtile.org/en/latest/_images/graphviz-52d4c4e0812a40a7c28aae165439b7e828011b3c.png
### Required:
- [x] I have searched past issues to see if this bug has already been reported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/qtile_docs/graph.py`
Content:
```
1 # Copyright (c) 2022 elParaguayo
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a copy
4 # of this software and associated documentation files (the "Software"), to deal
5 # in the Software without restriction, including without limitation the rights
6 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
7 # copies of the Software, and to permit persons to whom the Software is
8 # furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
16 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
18 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
19 # SOFTWARE.
20 from dataclasses import dataclass
21
22 from docutils.parsers.rst import Directive, directives
23 from qtile_docs.base import SimpleDirectiveMixin
24 from qtile_docs.templates import qtile_graph_template
25
26 from libqtile.command import graph
27
28 DISABLED_COLOUR = "Gray"
29
30
31 @dataclass
32 class Node:
33 node: graph.CommandGraphNode
34 x: float
35 y: float
36 fillcolor: str
37 color: str
38 url: str
39
40 @property
41 def name(self):
42 return getattr(self.node, "object_type", "root")
43
44 @property
45 def children(self):
46 return self.node.children
47
48 def node_args(self, enabled=True, highlight=False):
49 """Returns a dict of arguments that can be formatted for graphviz."""
50 return {
51 "pos": f"{self.x},{self.y}!",
52 "color": self.color if enabled else DISABLED_COLOUR,
53 "fillcolor": self.fillcolor if enabled else DISABLED_COLOUR,
54 "href": self.url,
55 "style": "filled",
56 "label": self.name,
57 "fontname": "bold" if highlight else "regular",
58 }
59
60
61 ROOT = graph.CommandGraphRoot()
62
63
64 # Define our nodes with their positions, colours and link to API docs page.
65 NODES = [
66 Node(ROOT, 0, 0, "Gray", "DarkGray", "/manual/commands/api/root.html"),
67 Node(graph._BarGraphNode, -1.94, -0.44, "Violet", "Purple", "/manual/commands/api/bars.html"),
68 Node(
69 graph._CoreGraphNode,
70 -1.56,
71 1.24,
72 "SlateBlue1",
73 "SlateBlue",
74 "/manual/commands/api/backend.html",
75 ),
76 Node(
77 graph._GroupGraphNode,
78 1.56,
79 1.24,
80 "Orange",
81 "OrangeRed",
82 "/manual/commands/api/groups.html",
83 ),
84 Node(
85 graph._LayoutGraphNode,
86 1.94,
87 -0.44,
88 "Gold",
89 "Goldenrod",
90 "/manual/commands/api/layouts.html",
91 ),
92 Node(
93 graph._ScreenGraphNode,
94 0.86,
95 -1.8,
96 "LimeGreen",
97 "DarkGreen",
98 "/manual/commands/api/screens.html",
99 ),
100 Node(
101 graph._WidgetGraphNode,
102 -0.86,
103 -1.8,
104 "LightBlue",
105 "Blue",
106 "/manual/commands/api/widgets.html",
107 ),
108 Node(graph._WindowGraphNode, 0, 2, "Tomato", "Red", "/manual/commands/api/windows.html"),
109 ]
110
111
112 # Convenient dict to access node object via node name
113 NODES_MAP = {n.name: n for n in NODES}
114
115
116 COMMAND_MAP = {n.name: n.children for n in NODES}
117
118
119 # Generate a list of all routest in the map.
120 # Each route is a tuple of (start, end, bidirectional)
121 ROUTES = []
122 for node, children in COMMAND_MAP.items():
123 for child in children:
124 route = (node, child, node in COMMAND_MAP[child])
125 # Check that the reverse route is not in the list already
126 if (child, node, node in COMMAND_MAP[child]) not in ROUTES:
127 ROUTES.append(route)
128
129
130 class QtileGraph(SimpleDirectiveMixin, Directive):
131 required_arguments = 0
132 option_spec = {
133 "root": directives.unchanged,
134 }
135
136 def make_nodes(self):
137 """Generates the node definition lines."""
138 node_lines = []
139
140 for name, node in NODES_MAP.items():
141 args_dict = node.node_args(name in self.visible_nodes, name == self.graph_name)
142 args_string = ", ".join(f'{k}="{v}"' for k, v in args_dict.items())
143 node_lines.extend([f"node [{args_string}];", f"{name};", ""])
144
145 return node_lines
146
147 def make_routes(self):
148 """Generates the route definition lines."""
149 route_lines = []
150 for r in ROUTES:
151 args = {}
152 if r not in self.visible_routes:
153 args["color"] = DISABLED_COLOUR
154 if r[2]:
155 args["dir"] = "both"
156
157 line = f"{r[0]} -> {r[1]}"
158 if args:
159 args_string = ", ".join(f'{k}="{v}"' for k, v in args.items())
160 line += f" [{args_string}]"
161 line += ";"
162 route_lines.append(line)
163
164 return route_lines
165
166 def find_linked_nodes_routes(self, node):
167 """Identifies routes connected to the selected node."""
168 nodes = []
169 routes = []
170 for r in ROUTES:
171 # Our node is the starting node
172 if r[0] == node:
173 nodes.append(r[1])
174 routes.append(r)
175 # Our node is the ending node and it's a bidirectional route
176 elif r[1] == node and r[2]:
177 nodes.append(r[0])
178 routes.append(r)
179
180 return (nodes, routes)
181
182 def make_rst(self):
183 self.graph_name = self.options.get("root", "all")
184 if self.graph_name == "all":
185 self.visible_nodes = [n for n in NODES_MAP]
186 self.visible_routes = ROUTES[:]
187 else:
188 linked_nodes, linked_routes = self.find_linked_nodes_routes(self.graph_name)
189 self.visible_nodes = [self.graph_name]
190 self.visible_nodes.extend(linked_nodes)
191 self.visible_routes = linked_routes
192
193 graph = []
194 graph.append(f"strict digraph {self.graph_name} {{")
195 graph.append('bgcolor="transparent"')
196 graph.extend(self.make_nodes())
197 graph.extend(self.make_routes())
198 graph.append("}")
199
200 rst = qtile_graph_template.render(graph=graph)
201 for line in rst.splitlines():
202 yield line
203
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/qtile_docs/graph.py b/docs/qtile_docs/graph.py
--- a/docs/qtile_docs/graph.py
+++ b/docs/qtile_docs/graph.py
@@ -45,13 +45,13 @@
def children(self):
return self.node.children
- def node_args(self, enabled=True, highlight=False):
+ def node_args(self, enabled=True, highlight=False, relative_url=str()):
"""Returns a dict of arguments that can be formatted for graphviz."""
return {
"pos": f"{self.x},{self.y}!",
"color": self.color if enabled else DISABLED_COLOUR,
"fillcolor": self.fillcolor if enabled else DISABLED_COLOUR,
- "href": self.url,
+ "href": f"{relative_url}{self.url}",
"style": "filled",
"label": self.name,
"fontname": "bold" if highlight else "regular",
@@ -63,15 +63,15 @@
# Define our nodes with their positions, colours and link to API docs page.
NODES = [
- Node(ROOT, 0, 0, "Gray", "DarkGray", "/manual/commands/api/root.html"),
- Node(graph._BarGraphNode, -1.94, -0.44, "Violet", "Purple", "/manual/commands/api/bars.html"),
+ Node(ROOT, 0, 0, "Gray", "DarkGray", "root.html"),
+ Node(graph._BarGraphNode, -1.94, -0.44, "Violet", "Purple", "bars.html"),
Node(
graph._CoreGraphNode,
-1.56,
1.24,
"SlateBlue1",
"SlateBlue",
- "/manual/commands/api/backend.html",
+ "backend.html",
),
Node(
graph._GroupGraphNode,
@@ -79,7 +79,7 @@
1.24,
"Orange",
"OrangeRed",
- "/manual/commands/api/groups.html",
+ "groups.html",
),
Node(
graph._LayoutGraphNode,
@@ -87,7 +87,7 @@
-0.44,
"Gold",
"Goldenrod",
- "/manual/commands/api/layouts.html",
+ "layouts.html",
),
Node(
graph._ScreenGraphNode,
@@ -95,7 +95,7 @@
-1.8,
"LimeGreen",
"DarkGreen",
- "/manual/commands/api/screens.html",
+ "screens.html",
),
Node(
graph._WidgetGraphNode,
@@ -103,9 +103,9 @@
-1.8,
"LightBlue",
"Blue",
- "/manual/commands/api/widgets.html",
+ "widgets.html",
),
- Node(graph._WindowGraphNode, 0, 2, "Tomato", "Red", "/manual/commands/api/windows.html"),
+ Node(graph._WindowGraphNode, 0, 2, "Tomato", "Red", "windows.html"),
]
@@ -131,6 +131,7 @@
required_arguments = 0
option_spec = {
"root": directives.unchanged,
+ "api_page_root": directives.unchanged,
}
def make_nodes(self):
@@ -138,7 +139,11 @@
node_lines = []
for name, node in NODES_MAP.items():
- args_dict = node.node_args(name in self.visible_nodes, name == self.graph_name)
+ args_dict = node.node_args(
+ name in self.visible_nodes,
+ name == self.graph_name,
+ self.options.get("api_page_root", ""),
+ )
args_string = ", ".join(f'{k}="{v}"' for k, v in args_dict.items())
node_lines.extend([f"node [{args_string}];", f"{name};", ""])
|
{"golden_diff": "diff --git a/docs/qtile_docs/graph.py b/docs/qtile_docs/graph.py\n--- a/docs/qtile_docs/graph.py\n+++ b/docs/qtile_docs/graph.py\n@@ -45,13 +45,13 @@\n def children(self):\n return self.node.children\n \n- def node_args(self, enabled=True, highlight=False):\n+ def node_args(self, enabled=True, highlight=False, relative_url=str()):\n \"\"\"Returns a dict of arguments that can be formatted for graphviz.\"\"\"\n return {\n \"pos\": f\"{self.x},{self.y}!\",\n \"color\": self.color if enabled else DISABLED_COLOUR,\n \"fillcolor\": self.fillcolor if enabled else DISABLED_COLOUR,\n- \"href\": self.url,\n+ \"href\": f\"{relative_url}{self.url}\",\n \"style\": \"filled\",\n \"label\": self.name,\n \"fontname\": \"bold\" if highlight else \"regular\",\n@@ -63,15 +63,15 @@\n \n # Define our nodes with their positions, colours and link to API docs page.\n NODES = [\n- Node(ROOT, 0, 0, \"Gray\", \"DarkGray\", \"/manual/commands/api/root.html\"),\n- Node(graph._BarGraphNode, -1.94, -0.44, \"Violet\", \"Purple\", \"/manual/commands/api/bars.html\"),\n+ Node(ROOT, 0, 0, \"Gray\", \"DarkGray\", \"root.html\"),\n+ Node(graph._BarGraphNode, -1.94, -0.44, \"Violet\", \"Purple\", \"bars.html\"),\n Node(\n graph._CoreGraphNode,\n -1.56,\n 1.24,\n \"SlateBlue1\",\n \"SlateBlue\",\n- \"/manual/commands/api/backend.html\",\n+ \"backend.html\",\n ),\n Node(\n graph._GroupGraphNode,\n@@ -79,7 +79,7 @@\n 1.24,\n \"Orange\",\n \"OrangeRed\",\n- \"/manual/commands/api/groups.html\",\n+ \"groups.html\",\n ),\n Node(\n graph._LayoutGraphNode,\n@@ -87,7 +87,7 @@\n -0.44,\n \"Gold\",\n \"Goldenrod\",\n- \"/manual/commands/api/layouts.html\",\n+ \"layouts.html\",\n ),\n Node(\n graph._ScreenGraphNode,\n@@ -95,7 +95,7 @@\n -1.8,\n \"LimeGreen\",\n \"DarkGreen\",\n- \"/manual/commands/api/screens.html\",\n+ \"screens.html\",\n ),\n Node(\n graph._WidgetGraphNode,\n@@ -103,9 +103,9 @@\n -1.8,\n \"LightBlue\",\n \"Blue\",\n- \"/manual/commands/api/widgets.html\",\n+ \"widgets.html\",\n ),\n- Node(graph._WindowGraphNode, 0, 2, \"Tomato\", \"Red\", \"/manual/commands/api/windows.html\"),\n+ Node(graph._WindowGraphNode, 0, 2, \"Tomato\", \"Red\", \"windows.html\"),\n ]\n \n \n@@ -131,6 +131,7 @@\n required_arguments = 0\n option_spec = {\n \"root\": directives.unchanged,\n+ \"api_page_root\": directives.unchanged,\n }\n \n def make_nodes(self):\n@@ -138,7 +139,11 @@\n node_lines = []\n \n for name, node in NODES_MAP.items():\n- args_dict = node.node_args(name in self.visible_nodes, name == self.graph_name)\n+ args_dict = node.node_args(\n+ name in self.visible_nodes,\n+ name == self.graph_name,\n+ self.options.get(\"api_page_root\", \"\"),\n+ )\n args_string = \", \".join(f'{k}=\"{v}\"' for k, v in args_dict.items())\n node_lines.extend([f\"node [{args_string}];\", f\"{name};\", \"\"])\n", "issue": "[Docs] Graph for Commands API have non working links\n### The issue:\n\nhttps://docs.qtile.org/en/latest/manual/commands/api/root.html\r\n\r\nThis is about the online documentation. I created an issue here, because its hosted in same repository as the code itself. The links on the graphical nodes are wrong and returns a 404. It's this image: https://docs.qtile.org/en/latest/_images/graphviz-52d4c4e0812a40a7c28aae165439b7e828011b3c.png\n\n### Required:\n\n- [x] I have searched past issues to see if this bug has already been reported.\n", "before_files": [{"content": "# Copyright (c) 2022 elParaguayo\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nfrom dataclasses import dataclass\n\nfrom docutils.parsers.rst import Directive, directives\nfrom qtile_docs.base import SimpleDirectiveMixin\nfrom qtile_docs.templates import qtile_graph_template\n\nfrom libqtile.command import graph\n\nDISABLED_COLOUR = \"Gray\"\n\n\n@dataclass\nclass Node:\n node: graph.CommandGraphNode\n x: float\n y: float\n fillcolor: str\n color: str\n url: str\n\n @property\n def name(self):\n return getattr(self.node, \"object_type\", \"root\")\n\n @property\n def children(self):\n return self.node.children\n\n def node_args(self, enabled=True, highlight=False):\n \"\"\"Returns a dict of arguments that can be formatted for graphviz.\"\"\"\n return {\n \"pos\": f\"{self.x},{self.y}!\",\n \"color\": self.color if enabled else DISABLED_COLOUR,\n \"fillcolor\": self.fillcolor if enabled else DISABLED_COLOUR,\n \"href\": self.url,\n \"style\": \"filled\",\n \"label\": self.name,\n \"fontname\": \"bold\" if highlight else \"regular\",\n }\n\n\nROOT = graph.CommandGraphRoot()\n\n\n# Define our nodes with their positions, colours and link to API docs page.\nNODES = [\n Node(ROOT, 0, 0, \"Gray\", \"DarkGray\", \"/manual/commands/api/root.html\"),\n Node(graph._BarGraphNode, -1.94, -0.44, \"Violet\", \"Purple\", \"/manual/commands/api/bars.html\"),\n Node(\n graph._CoreGraphNode,\n -1.56,\n 1.24,\n \"SlateBlue1\",\n \"SlateBlue\",\n \"/manual/commands/api/backend.html\",\n ),\n Node(\n graph._GroupGraphNode,\n 1.56,\n 1.24,\n \"Orange\",\n \"OrangeRed\",\n \"/manual/commands/api/groups.html\",\n ),\n Node(\n graph._LayoutGraphNode,\n 1.94,\n -0.44,\n \"Gold\",\n \"Goldenrod\",\n \"/manual/commands/api/layouts.html\",\n ),\n Node(\n graph._ScreenGraphNode,\n 0.86,\n -1.8,\n \"LimeGreen\",\n \"DarkGreen\",\n \"/manual/commands/api/screens.html\",\n ),\n Node(\n graph._WidgetGraphNode,\n -0.86,\n -1.8,\n \"LightBlue\",\n \"Blue\",\n \"/manual/commands/api/widgets.html\",\n ),\n Node(graph._WindowGraphNode, 0, 2, \"Tomato\", \"Red\", \"/manual/commands/api/windows.html\"),\n]\n\n\n# Convenient dict to access node object via node name\nNODES_MAP = {n.name: n for n in NODES}\n\n\nCOMMAND_MAP = {n.name: n.children for n in NODES}\n\n\n# Generate a list of all routest in the map.\n# Each route is a tuple of (start, end, bidirectional)\nROUTES = []\nfor node, children in COMMAND_MAP.items():\n for child in children:\n route = (node, child, node in COMMAND_MAP[child])\n # Check that the reverse route is not in the list already\n if (child, node, node in COMMAND_MAP[child]) not in ROUTES:\n ROUTES.append(route)\n\n\nclass QtileGraph(SimpleDirectiveMixin, Directive):\n required_arguments = 0\n option_spec = {\n \"root\": directives.unchanged,\n }\n\n def make_nodes(self):\n \"\"\"Generates the node definition lines.\"\"\"\n node_lines = []\n\n for name, node in NODES_MAP.items():\n args_dict = node.node_args(name in self.visible_nodes, name == self.graph_name)\n args_string = \", \".join(f'{k}=\"{v}\"' for k, v in args_dict.items())\n node_lines.extend([f\"node [{args_string}];\", f\"{name};\", \"\"])\n\n return node_lines\n\n def make_routes(self):\n \"\"\"Generates the route definition lines.\"\"\"\n route_lines = []\n for r in ROUTES:\n args = {}\n if r not in self.visible_routes:\n args[\"color\"] = DISABLED_COLOUR\n if r[2]:\n args[\"dir\"] = \"both\"\n\n line = f\"{r[0]} -> {r[1]}\"\n if args:\n args_string = \", \".join(f'{k}=\"{v}\"' for k, v in args.items())\n line += f\" [{args_string}]\"\n line += \";\"\n route_lines.append(line)\n\n return route_lines\n\n def find_linked_nodes_routes(self, node):\n \"\"\"Identifies routes connected to the selected node.\"\"\"\n nodes = []\n routes = []\n for r in ROUTES:\n # Our node is the starting node\n if r[0] == node:\n nodes.append(r[1])\n routes.append(r)\n # Our node is the ending node and it's a bidirectional route\n elif r[1] == node and r[2]:\n nodes.append(r[0])\n routes.append(r)\n\n return (nodes, routes)\n\n def make_rst(self):\n self.graph_name = self.options.get(\"root\", \"all\")\n if self.graph_name == \"all\":\n self.visible_nodes = [n for n in NODES_MAP]\n self.visible_routes = ROUTES[:]\n else:\n linked_nodes, linked_routes = self.find_linked_nodes_routes(self.graph_name)\n self.visible_nodes = [self.graph_name]\n self.visible_nodes.extend(linked_nodes)\n self.visible_routes = linked_routes\n\n graph = []\n graph.append(f\"strict digraph {self.graph_name} {{\")\n graph.append('bgcolor=\"transparent\"')\n graph.extend(self.make_nodes())\n graph.extend(self.make_routes())\n graph.append(\"}\")\n\n rst = qtile_graph_template.render(graph=graph)\n for line in rst.splitlines():\n yield line\n", "path": "docs/qtile_docs/graph.py"}], "after_files": [{"content": "# Copyright (c) 2022 elParaguayo\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nfrom dataclasses import dataclass\n\nfrom docutils.parsers.rst import Directive, directives\nfrom qtile_docs.base import SimpleDirectiveMixin\nfrom qtile_docs.templates import qtile_graph_template\n\nfrom libqtile.command import graph\n\nDISABLED_COLOUR = \"Gray\"\n\n\n@dataclass\nclass Node:\n node: graph.CommandGraphNode\n x: float\n y: float\n fillcolor: str\n color: str\n url: str\n\n @property\n def name(self):\n return getattr(self.node, \"object_type\", \"root\")\n\n @property\n def children(self):\n return self.node.children\n\n def node_args(self, enabled=True, highlight=False, relative_url=str()):\n \"\"\"Returns a dict of arguments that can be formatted for graphviz.\"\"\"\n return {\n \"pos\": f\"{self.x},{self.y}!\",\n \"color\": self.color if enabled else DISABLED_COLOUR,\n \"fillcolor\": self.fillcolor if enabled else DISABLED_COLOUR,\n \"href\": f\"{relative_url}{self.url}\",\n \"style\": \"filled\",\n \"label\": self.name,\n \"fontname\": \"bold\" if highlight else \"regular\",\n }\n\n\nROOT = graph.CommandGraphRoot()\n\n\n# Define our nodes with their positions, colours and link to API docs page.\nNODES = [\n Node(ROOT, 0, 0, \"Gray\", \"DarkGray\", \"root.html\"),\n Node(graph._BarGraphNode, -1.94, -0.44, \"Violet\", \"Purple\", \"bars.html\"),\n Node(\n graph._CoreGraphNode,\n -1.56,\n 1.24,\n \"SlateBlue1\",\n \"SlateBlue\",\n \"backend.html\",\n ),\n Node(\n graph._GroupGraphNode,\n 1.56,\n 1.24,\n \"Orange\",\n \"OrangeRed\",\n \"groups.html\",\n ),\n Node(\n graph._LayoutGraphNode,\n 1.94,\n -0.44,\n \"Gold\",\n \"Goldenrod\",\n \"layouts.html\",\n ),\n Node(\n graph._ScreenGraphNode,\n 0.86,\n -1.8,\n \"LimeGreen\",\n \"DarkGreen\",\n \"screens.html\",\n ),\n Node(\n graph._WidgetGraphNode,\n -0.86,\n -1.8,\n \"LightBlue\",\n \"Blue\",\n \"widgets.html\",\n ),\n Node(graph._WindowGraphNode, 0, 2, \"Tomato\", \"Red\", \"windows.html\"),\n]\n\n\n# Convenient dict to access node object via node name\nNODES_MAP = {n.name: n for n in NODES}\n\n\nCOMMAND_MAP = {n.name: n.children for n in NODES}\n\n\n# Generate a list of all routest in the map.\n# Each route is a tuple of (start, end, bidirectional)\nROUTES = []\nfor node, children in COMMAND_MAP.items():\n for child in children:\n route = (node, child, node in COMMAND_MAP[child])\n # Check that the reverse route is not in the list already\n if (child, node, node in COMMAND_MAP[child]) not in ROUTES:\n ROUTES.append(route)\n\n\nclass QtileGraph(SimpleDirectiveMixin, Directive):\n required_arguments = 0\n option_spec = {\n \"root\": directives.unchanged,\n \"api_page_root\": directives.unchanged,\n }\n\n def make_nodes(self):\n \"\"\"Generates the node definition lines.\"\"\"\n node_lines = []\n\n for name, node in NODES_MAP.items():\n args_dict = node.node_args(\n name in self.visible_nodes,\n name == self.graph_name,\n self.options.get(\"api_page_root\", \"\"),\n )\n args_string = \", \".join(f'{k}=\"{v}\"' for k, v in args_dict.items())\n node_lines.extend([f\"node [{args_string}];\", f\"{name};\", \"\"])\n\n return node_lines\n\n def make_routes(self):\n \"\"\"Generates the route definition lines.\"\"\"\n route_lines = []\n for r in ROUTES:\n args = {}\n if r not in self.visible_routes:\n args[\"color\"] = DISABLED_COLOUR\n if r[2]:\n args[\"dir\"] = \"both\"\n\n line = f\"{r[0]} -> {r[1]}\"\n if args:\n args_string = \", \".join(f'{k}=\"{v}\"' for k, v in args.items())\n line += f\" [{args_string}]\"\n line += \";\"\n route_lines.append(line)\n\n return route_lines\n\n def find_linked_nodes_routes(self, node):\n \"\"\"Identifies routes connected to the selected node.\"\"\"\n nodes = []\n routes = []\n for r in ROUTES:\n # Our node is the starting node\n if r[0] == node:\n nodes.append(r[1])\n routes.append(r)\n # Our node is the ending node and it's a bidirectional route\n elif r[1] == node and r[2]:\n nodes.append(r[0])\n routes.append(r)\n\n return (nodes, routes)\n\n def make_rst(self):\n self.graph_name = self.options.get(\"root\", \"all\")\n if self.graph_name == \"all\":\n self.visible_nodes = [n for n in NODES_MAP]\n self.visible_routes = ROUTES[:]\n else:\n linked_nodes, linked_routes = self.find_linked_nodes_routes(self.graph_name)\n self.visible_nodes = [self.graph_name]\n self.visible_nodes.extend(linked_nodes)\n self.visible_routes = linked_routes\n\n graph = []\n graph.append(f\"strict digraph {self.graph_name} {{\")\n graph.append('bgcolor=\"transparent\"')\n graph.extend(self.make_nodes())\n graph.extend(self.make_routes())\n graph.append(\"}\")\n\n rst = qtile_graph_template.render(graph=graph)\n for line in rst.splitlines():\n yield line\n", "path": "docs/qtile_docs/graph.py"}]}
| 2,446 | 875 |
gh_patches_debug_15496
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-790
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support for Logitech G613 with receiver id c53d
Apparently solaar v1.0.1 on ubuntu ppa does not support Lightspeed receiver with id c53d . solaar reported that no receiver has been found.
Here is the output of my lsusb
tonny@fenrir:[~]: lsusb
Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 003 Device 005: ID 1b1c:1b65 Corsair
Bus 003 Device 006: ID 046d:c53d Logitech, Inc.
Bus 003 Device 003: ID 046d:082b Logitech, Inc. Webcam C170
Bus 003 Device 002: ID 1a40:0101 Terminus Technology Inc. Hub
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 002: ID 8087:0aa7 Intel Corp.
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/logitech_receiver/base_usb.py`
Content:
```
1 # -*- python-mode -*-
2 # -*- coding: UTF-8 -*-
3
4 ## Copyright (C) 2012-2013 Daniel Pavel
5 ##
6 ## This program is free software; you can redistribute it and/or modify
7 ## it under the terms of the GNU General Public License as published by
8 ## the Free Software Foundation; either version 2 of the License, or
9 ## (at your option) any later version.
10 ##
11 ## This program is distributed in the hope that it will be useful,
12 ## but WITHOUT ANY WARRANTY; without even the implied warranty of
13 ## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 ## GNU General Public License for more details.
15 ##
16 ## You should have received a copy of the GNU General Public License along
17 ## with this program; if not, write to the Free Software Foundation, Inc.,
18 ## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
19
20 # USB ids of Logitech wireless receivers.
21 # Only receivers supporting the HID++ protocol can go in here.
22
23 from __future__ import absolute_import, division, print_function, unicode_literals
24
25
26 _DRIVER = ('hid-generic', 'generic-usb', 'logitech-djreceiver')
27
28 # max_devices is only used for receivers that do not support reading from _R.receiver_info offset 0x03, default to 1
29 # may_unpair is only used for receivers that do not support reading from _R.receiver_info offset 0x03, default to False
30 ## should this last be changed so that may_unpair is used for all receivers? writing to _R.receiver_pairing doesn't seem right
31 # re_pairs determines whether a receiver pairs by replacing existing pairings, default to False
32 ## currently only one receiver is so marked - should there be more?
33
34 _unifying_receiver = lambda product_id: {
35 'vendor_id':0x046d,
36 'product_id':product_id,
37 'usb_interface':2,
38 'hid_driver':_DRIVER,
39 'name':'Unifying Receiver'
40 }
41
42 _nano_receiver = lambda product_id: {
43 'vendor_id':0x046d,
44 'product_id':product_id,
45 'usb_interface':1,
46 'hid_driver':_DRIVER,
47 'name':'Nano Receiver',
48 'may_unpair': False,
49 're_pairs': True
50 }
51
52 _nano_receiver_max2 = lambda product_id: {
53 'vendor_id':0x046d,
54 'product_id':product_id,
55 'usb_interface':1,
56 'hid_driver':_DRIVER,
57 'name':'Nano Receiver',
58 'max_devices': 2,
59 'may_unpair': False,
60 're_pairs': True
61 }
62
63 _nano_receiver_maxn = lambda product_id, max: {
64 'vendor_id':0x046d,
65 'product_id':product_id,
66 'usb_interface':1,
67 'hid_driver':_DRIVER,
68 'name':'Nano Receiver',
69 'max_devices': max,
70 'may_unpair': False,
71 're_pairs': True
72 }
73
74 _lenovo_receiver = lambda product_id: {
75 'vendor_id':0x17ef,
76 'product_id':product_id,
77 'usb_interface':1,
78 'hid_driver':_DRIVER,
79 'name':'Nano Receiver'
80 }
81
82 _lightspeed_receiver = lambda product_id: {
83 'vendor_id':0x046d,
84 'product_id':product_id,
85 'usb_interface':2,
86 'hid_driver':_DRIVER,
87 'name':'Lightspeed Receiver'
88 }
89
90 # standard Unifying receivers (marked with the orange Unifying logo)
91 UNIFYING_RECEIVER_C52B = _unifying_receiver(0xc52b)
92 UNIFYING_RECEIVER_C532 = _unifying_receiver(0xc532)
93
94 # Nano receviers that support the Unifying protocol
95 NANO_RECEIVER_ADVANCED = _nano_receiver(0xc52f)
96
97 # Nano receivers that don't support the Unifying protocol
98 NANO_RECEIVER_C517 = _nano_receiver_maxn(0xc517,6)
99 NANO_RECEIVER_C518 = _nano_receiver(0xc518)
100 NANO_RECEIVER_C51A = _nano_receiver(0xc51a)
101 NANO_RECEIVER_C51B = _nano_receiver(0xc51b)
102 NANO_RECEIVER_C521 = _nano_receiver(0xc521)
103 NANO_RECEIVER_C525 = _nano_receiver(0xc525)
104 NANO_RECEIVER_C526 = _nano_receiver(0xc526)
105 NANO_RECEIVER_C52e = _nano_receiver(0xc52e)
106 NANO_RECEIVER_C531 = _nano_receiver(0xc531)
107 NANO_RECEIVER_C534 = _nano_receiver_max2(0xc534)
108 NANO_RECEIVER_C537 = _nano_receiver(0xc537)
109 NANO_RECEIVER_6042 = _lenovo_receiver(0x6042)
110
111 # Lightspeed receivers
112 LIGHTSPEED_RECEIVER_C539 = _lightspeed_receiver(0xc539)
113 LIGHTSPEED_RECEIVER_C53a = _lightspeed_receiver(0xc53a)
114 LIGHTSPEED_RECEIVER_C53f = _lightspeed_receiver(0xc53f)
115
116 del _DRIVER, _unifying_receiver, _nano_receiver, _lenovo_receiver, _lightspeed_receiver
117
118
119 ALL = (
120 UNIFYING_RECEIVER_C52B,
121 UNIFYING_RECEIVER_C532,
122 NANO_RECEIVER_ADVANCED,
123 NANO_RECEIVER_C517,
124 NANO_RECEIVER_C518,
125 NANO_RECEIVER_C51A,
126 NANO_RECEIVER_C51B,
127 NANO_RECEIVER_C521,
128 NANO_RECEIVER_C525,
129 NANO_RECEIVER_C526,
130 NANO_RECEIVER_C52e,
131 NANO_RECEIVER_C531,
132 NANO_RECEIVER_C534,
133 NANO_RECEIVER_C537,
134 NANO_RECEIVER_6042,
135 LIGHTSPEED_RECEIVER_C539,
136 LIGHTSPEED_RECEIVER_C53a,
137 LIGHTSPEED_RECEIVER_C53f,
138 )
139
140 def product_information(usb_id):
141 if isinstance(usb_id,str):
142 usb_id = int(usb_id,16)
143 for r in ALL:
144 if usb_id == r.get('product_id'):
145 return r
146 return { }
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/logitech_receiver/base_usb.py b/lib/logitech_receiver/base_usb.py
--- a/lib/logitech_receiver/base_usb.py
+++ b/lib/logitech_receiver/base_usb.py
@@ -112,6 +112,7 @@
LIGHTSPEED_RECEIVER_C539 = _lightspeed_receiver(0xc539)
LIGHTSPEED_RECEIVER_C53a = _lightspeed_receiver(0xc53a)
LIGHTSPEED_RECEIVER_C53f = _lightspeed_receiver(0xc53f)
+LIGHTSPEED_RECEIVER_C53d = _lightspeed_receiver(0xc53d)
del _DRIVER, _unifying_receiver, _nano_receiver, _lenovo_receiver, _lightspeed_receiver
@@ -135,6 +136,7 @@
LIGHTSPEED_RECEIVER_C539,
LIGHTSPEED_RECEIVER_C53a,
LIGHTSPEED_RECEIVER_C53f,
+ LIGHTSPEED_RECEIVER_C53d,
)
def product_information(usb_id):
|
{"golden_diff": "diff --git a/lib/logitech_receiver/base_usb.py b/lib/logitech_receiver/base_usb.py\n--- a/lib/logitech_receiver/base_usb.py\n+++ b/lib/logitech_receiver/base_usb.py\n@@ -112,6 +112,7 @@\n LIGHTSPEED_RECEIVER_C539 = _lightspeed_receiver(0xc539)\n LIGHTSPEED_RECEIVER_C53a = _lightspeed_receiver(0xc53a)\n LIGHTSPEED_RECEIVER_C53f = _lightspeed_receiver(0xc53f)\n+LIGHTSPEED_RECEIVER_C53d = _lightspeed_receiver(0xc53d)\n \n del _DRIVER, _unifying_receiver, _nano_receiver, _lenovo_receiver, _lightspeed_receiver\n \n@@ -135,6 +136,7 @@\n \t\tLIGHTSPEED_RECEIVER_C539,\n \t\tLIGHTSPEED_RECEIVER_C53a,\n \t\tLIGHTSPEED_RECEIVER_C53f,\n+\t\tLIGHTSPEED_RECEIVER_C53d,\n \t)\n \n def product_information(usb_id):\n", "issue": "Support for Logitech G613 with receiver id c53d\nApparently solaar v1.0.1 on ubuntu ppa does not support Lightspeed receiver with id c53d . solaar reported that no receiver has been found.\r\n\r\nHere is the output of my lsusb\r\n\r\ntonny@fenrir:[~]: lsusb\r\nBus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub\r\nBus 003 Device 005: ID 1b1c:1b65 Corsair \r\nBus 003 Device 006: ID 046d:c53d Logitech, Inc. \r\nBus 003 Device 003: ID 046d:082b Logitech, Inc. Webcam C170\r\nBus 003 Device 002: ID 1a40:0101 Terminus Technology Inc. Hub\r\nBus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub\r\nBus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub\r\nBus 001 Device 002: ID 8087:0aa7 Intel Corp. \r\nBus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub\r\n\n", "before_files": [{"content": "# -*- python-mode -*-\n# -*- coding: UTF-8 -*-\n\n## Copyright (C) 2012-2013 Daniel Pavel\n##\n## This program is free software; you can redistribute it and/or modify\n## it under the terms of the GNU General Public License as published by\n## the Free Software Foundation; either version 2 of the License, or\n## (at your option) any later version.\n##\n## This program is distributed in the hope that it will be useful,\n## but WITHOUT ANY WARRANTY; without even the implied warranty of\n## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n## GNU General Public License for more details.\n##\n## You should have received a copy of the GNU General Public License along\n## with this program; if not, write to the Free Software Foundation, Inc.,\n## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\n# USB ids of Logitech wireless receivers.\n# Only receivers supporting the HID++ protocol can go in here.\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\n\n_DRIVER = ('hid-generic', 'generic-usb', 'logitech-djreceiver')\n\n# max_devices is only used for receivers that do not support reading from _R.receiver_info offset 0x03, default to 1\n# may_unpair is only used for receivers that do not support reading from _R.receiver_info offset 0x03, default to False\n## should this last be changed so that may_unpair is used for all receivers? writing to _R.receiver_pairing doesn't seem right\n# re_pairs determines whether a receiver pairs by replacing existing pairings, default to False\n## currently only one receiver is so marked - should there be more?\n\n_unifying_receiver = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id, \n\t'usb_interface':2,\n\t'hid_driver':_DRIVER,\n\t'name':'Unifying Receiver'\n}\n\n_nano_receiver = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':1,\n\t'hid_driver':_DRIVER,\n\t'name':'Nano Receiver',\n\t'may_unpair': False,\n\t're_pairs': True \n}\n\n_nano_receiver_max2 = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':1,\n\t'hid_driver':_DRIVER,\n\t'name':'Nano Receiver',\n\t'max_devices': 2,\n\t'may_unpair': False,\n\t're_pairs': True \n}\n\n_nano_receiver_maxn = lambda product_id, max: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':1,\n\t'hid_driver':_DRIVER,\n\t'name':'Nano Receiver',\n\t'max_devices': max,\n\t'may_unpair': False,\n\t're_pairs': True \n}\n\n_lenovo_receiver = lambda product_id: {\n\t'vendor_id':0x17ef, \n\t'product_id':product_id, \n\t'usb_interface':1, \n\t'hid_driver':_DRIVER, \n\t'name':'Nano Receiver'\n}\n\n_lightspeed_receiver = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':2,\n\t'hid_driver':_DRIVER,\n\t'name':'Lightspeed Receiver'\n}\n\n# standard Unifying receivers (marked with the orange Unifying logo)\nUNIFYING_RECEIVER_C52B = _unifying_receiver(0xc52b)\nUNIFYING_RECEIVER_C532 = _unifying_receiver(0xc532)\n\n# Nano receviers that support the Unifying protocol\nNANO_RECEIVER_ADVANCED = _nano_receiver(0xc52f)\n\n# Nano receivers that don't support the Unifying protocol\nNANO_RECEIVER_C517 = _nano_receiver_maxn(0xc517,6)\nNANO_RECEIVER_C518 = _nano_receiver(0xc518)\nNANO_RECEIVER_C51A = _nano_receiver(0xc51a)\nNANO_RECEIVER_C51B = _nano_receiver(0xc51b)\nNANO_RECEIVER_C521 = _nano_receiver(0xc521)\nNANO_RECEIVER_C525 = _nano_receiver(0xc525)\nNANO_RECEIVER_C526 = _nano_receiver(0xc526)\nNANO_RECEIVER_C52e = _nano_receiver(0xc52e)\nNANO_RECEIVER_C531 = _nano_receiver(0xc531)\nNANO_RECEIVER_C534 = _nano_receiver_max2(0xc534)\nNANO_RECEIVER_C537 = _nano_receiver(0xc537)\nNANO_RECEIVER_6042 = _lenovo_receiver(0x6042)\n\n# Lightspeed receivers\nLIGHTSPEED_RECEIVER_C539 = _lightspeed_receiver(0xc539)\nLIGHTSPEED_RECEIVER_C53a = _lightspeed_receiver(0xc53a)\nLIGHTSPEED_RECEIVER_C53f = _lightspeed_receiver(0xc53f)\n\ndel _DRIVER, _unifying_receiver, _nano_receiver, _lenovo_receiver, _lightspeed_receiver\n\n\nALL = (\n\t\tUNIFYING_RECEIVER_C52B,\n\t\tUNIFYING_RECEIVER_C532,\n\t\tNANO_RECEIVER_ADVANCED,\n\t\tNANO_RECEIVER_C517,\n\t\tNANO_RECEIVER_C518,\n\t\tNANO_RECEIVER_C51A,\n\t\tNANO_RECEIVER_C51B,\n\t\tNANO_RECEIVER_C521,\n\t\tNANO_RECEIVER_C525,\n\t\tNANO_RECEIVER_C526,\n\t\tNANO_RECEIVER_C52e,\n\t\tNANO_RECEIVER_C531,\n\t\tNANO_RECEIVER_C534,\n\t\tNANO_RECEIVER_C537,\n\t\tNANO_RECEIVER_6042,\n\t\tLIGHTSPEED_RECEIVER_C539,\n\t\tLIGHTSPEED_RECEIVER_C53a,\n\t\tLIGHTSPEED_RECEIVER_C53f,\n\t)\n\ndef product_information(usb_id):\n\tif isinstance(usb_id,str):\n\t\tusb_id = int(usb_id,16)\n\tfor r in ALL:\n\t\tif usb_id == r.get('product_id'):\n\t\t\treturn r\n\treturn { }\n", "path": "lib/logitech_receiver/base_usb.py"}], "after_files": [{"content": "# -*- python-mode -*-\n# -*- coding: UTF-8 -*-\n\n## Copyright (C) 2012-2013 Daniel Pavel\n##\n## This program is free software; you can redistribute it and/or modify\n## it under the terms of the GNU General Public License as published by\n## the Free Software Foundation; either version 2 of the License, or\n## (at your option) any later version.\n##\n## This program is distributed in the hope that it will be useful,\n## but WITHOUT ANY WARRANTY; without even the implied warranty of\n## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n## GNU General Public License for more details.\n##\n## You should have received a copy of the GNU General Public License along\n## with this program; if not, write to the Free Software Foundation, Inc.,\n## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\n# USB ids of Logitech wireless receivers.\n# Only receivers supporting the HID++ protocol can go in here.\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\n\n_DRIVER = ('hid-generic', 'generic-usb', 'logitech-djreceiver')\n\n# max_devices is only used for receivers that do not support reading from _R.receiver_info offset 0x03, default to 1\n# may_unpair is only used for receivers that do not support reading from _R.receiver_info offset 0x03, default to False\n## should this last be changed so that may_unpair is used for all receivers? writing to _R.receiver_pairing doesn't seem right\n# re_pairs determines whether a receiver pairs by replacing existing pairings, default to False\n## currently only one receiver is so marked - should there be more?\n\n_unifying_receiver = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id, \n\t'usb_interface':2,\n\t'hid_driver':_DRIVER,\n\t'name':'Unifying Receiver'\n}\n\n_nano_receiver = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':1,\n\t'hid_driver':_DRIVER,\n\t'name':'Nano Receiver',\n\t'may_unpair': False,\n\t're_pairs': True \n}\n\n_nano_receiver_max2 = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':1,\n\t'hid_driver':_DRIVER,\n\t'name':'Nano Receiver',\n\t'max_devices': 2,\n\t'may_unpair': False,\n\t're_pairs': True \n}\n\n_nano_receiver_maxn = lambda product_id, max: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':1,\n\t'hid_driver':_DRIVER,\n\t'name':'Nano Receiver',\n\t'max_devices': max,\n\t'may_unpair': False,\n\t're_pairs': True \n}\n\n_lenovo_receiver = lambda product_id: {\n\t'vendor_id':0x17ef, \n\t'product_id':product_id, \n\t'usb_interface':1, \n\t'hid_driver':_DRIVER, \n\t'name':'Nano Receiver'\n}\n\n_lightspeed_receiver = lambda product_id: {\n\t'vendor_id':0x046d,\n\t'product_id':product_id,\n\t'usb_interface':2,\n\t'hid_driver':_DRIVER,\n\t'name':'Lightspeed Receiver'\n}\n\n# standard Unifying receivers (marked with the orange Unifying logo)\nUNIFYING_RECEIVER_C52B = _unifying_receiver(0xc52b)\nUNIFYING_RECEIVER_C532 = _unifying_receiver(0xc532)\n\n# Nano receviers that support the Unifying protocol\nNANO_RECEIVER_ADVANCED = _nano_receiver(0xc52f)\n\n# Nano receivers that don't support the Unifying protocol\nNANO_RECEIVER_C517 = _nano_receiver_maxn(0xc517,6)\nNANO_RECEIVER_C518 = _nano_receiver(0xc518)\nNANO_RECEIVER_C51A = _nano_receiver(0xc51a)\nNANO_RECEIVER_C51B = _nano_receiver(0xc51b)\nNANO_RECEIVER_C521 = _nano_receiver(0xc521)\nNANO_RECEIVER_C525 = _nano_receiver(0xc525)\nNANO_RECEIVER_C526 = _nano_receiver(0xc526)\nNANO_RECEIVER_C52e = _nano_receiver(0xc52e)\nNANO_RECEIVER_C531 = _nano_receiver(0xc531)\nNANO_RECEIVER_C534 = _nano_receiver_max2(0xc534)\nNANO_RECEIVER_C537 = _nano_receiver(0xc537)\nNANO_RECEIVER_6042 = _lenovo_receiver(0x6042)\n\n# Lightspeed receivers\nLIGHTSPEED_RECEIVER_C539 = _lightspeed_receiver(0xc539)\nLIGHTSPEED_RECEIVER_C53a = _lightspeed_receiver(0xc53a)\nLIGHTSPEED_RECEIVER_C53f = _lightspeed_receiver(0xc53f)\nLIGHTSPEED_RECEIVER_C53d = _lightspeed_receiver(0xc53d)\n\ndel _DRIVER, _unifying_receiver, _nano_receiver, _lenovo_receiver, _lightspeed_receiver\n\n\nALL = (\n\t\tUNIFYING_RECEIVER_C52B,\n\t\tUNIFYING_RECEIVER_C532,\n\t\tNANO_RECEIVER_ADVANCED,\n\t\tNANO_RECEIVER_C517,\n\t\tNANO_RECEIVER_C518,\n\t\tNANO_RECEIVER_C51A,\n\t\tNANO_RECEIVER_C51B,\n\t\tNANO_RECEIVER_C521,\n\t\tNANO_RECEIVER_C525,\n\t\tNANO_RECEIVER_C526,\n\t\tNANO_RECEIVER_C52e,\n\t\tNANO_RECEIVER_C531,\n\t\tNANO_RECEIVER_C534,\n\t\tNANO_RECEIVER_C537,\n\t\tNANO_RECEIVER_6042,\n\t\tLIGHTSPEED_RECEIVER_C539,\n\t\tLIGHTSPEED_RECEIVER_C53a,\n\t\tLIGHTSPEED_RECEIVER_C53f,\n\t\tLIGHTSPEED_RECEIVER_C53d,\n\t)\n\ndef product_information(usb_id):\n\tif isinstance(usb_id,str):\n\t\tusb_id = int(usb_id,16)\n\tfor r in ALL:\n\t\tif usb_id == r.get('product_id'):\n\t\t\treturn r\n\treturn { }\n", "path": "lib/logitech_receiver/base_usb.py"}]}
| 2,445 | 242 |
gh_patches_debug_16422
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-4133
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`ThermalSensor` doesn't respect `foreground` in `widget_defaults`
### The issue:
(reported on Discord/IRC)
ThermalSensor widget doesn't respect foreground colour in widget defaults. This is because the foreground value is copied to `foreground_normal` during `__init__` but this happens before `widget_defaults` are copied to the widget (which happens in `_configure`
### Required:
- [X] I have searched past issues to see if this bug has already been reported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/widget/sensors.py`
Content:
```
1 # -*- coding:utf-8 -*-
2 # Copyright (c) 2012 TiN
3 # Copyright (c) 2012, 2014 Tycho Andersen
4 # Copyright (c) 2013 Tao Sauvage
5 # Copyright (c) 2014-2015 Sean Vig
6 # Copyright (c) 2014 Adi Sieker
7 # Copyright (c) 2014 Foster McLane
8 #
9 # Permission is hereby granted, free of charge, to any person obtaining a copy
10 # of this software and associated documentation files (the "Software"), to deal
11 # in the Software without restriction, including without limitation the rights
12 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 # copies of the Software, and to permit persons to whom the Software is
14 # furnished to do so, subject to the following conditions:
15 #
16 # The above copyright notice and this permission notice shall be included in
17 # all copies or substantial portions of the Software.
18 #
19 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
25 # SOFTWARE.
26
27 import psutil
28
29 from libqtile.widget import base
30
31
32 class ThermalSensor(base.InLoopPollText):
33 """Widget to display temperature sensor information
34
35 For using the thermal sensor widget you need to have lm-sensors installed.
36 You can get a list of the tag_sensors executing "sensors" in your terminal.
37 Then you can choose which you want, otherwise it will display the first
38 available.
39
40 Widget requirements: psutil_.
41
42 .. _psutil: https://pypi.org/project/psutil/
43 """
44
45 defaults = [
46 (
47 "format",
48 "{temp:.1f}{unit}",
49 "Display string format. Three options available: "
50 "``{temp}`` - temperature, "
51 "``{tag}`` - tag of the temperature sensor, and "
52 "``{unit}`` - °C or °F",
53 ),
54 ("metric", True, "True to use metric/C, False to use imperial/F"),
55 ("update_interval", 2, "Update interval in seconds"),
56 ("tag_sensor", None, 'Tag of the temperature sensor. For example: "temp1" or "Core 0"'),
57 (
58 "threshold",
59 70,
60 "If the current temperature value is above, "
61 "then change to foreground_alert colour",
62 ),
63 ("foreground_alert", "ff0000", "Foreground colour alert"),
64 ]
65
66 def __init__(self, **config):
67 base.InLoopPollText.__init__(self, **config)
68 self.add_defaults(ThermalSensor.defaults)
69 temp_values = self.get_temp_sensors()
70 self.foreground_normal = self.foreground
71
72 if temp_values is None:
73 self.data = "sensors command not found"
74 elif len(temp_values) == 0:
75 self.data = "Temperature sensors not found"
76 elif self.tag_sensor is None:
77 for k in temp_values:
78 self.tag_sensor = k
79 break
80
81 def _configure(self, qtile, bar):
82 self.unit = "°C" if self.metric else "°F"
83 base.InLoopPollText._configure(self, qtile, bar)
84
85 def get_temp_sensors(self):
86 """
87 Reads temperatures from sys-fs via psutil.
88 Output will be read Fahrenheit if user has specified it to be.
89 """
90
91 temperature_list = {}
92 temps = psutil.sensors_temperatures(fahrenheit=not self.metric)
93 empty_index = 0
94 for kernel_module in temps:
95 for sensor in temps[kernel_module]:
96 label = sensor.label
97 if not label:
98 label = "{}-{}".format(
99 kernel_module if kernel_module else "UNKNOWN", str(empty_index)
100 )
101 empty_index += 1
102 temperature_list[label] = sensor.current
103
104 return temperature_list
105
106 def poll(self):
107 temp_values = self.get_temp_sensors()
108
109 # Temperature not available
110 if (temp_values is None) or (self.tag_sensor not in temp_values):
111 return "N/A"
112
113 temp_value = temp_values.get(self.tag_sensor)
114 if temp_value > self.threshold:
115 self.layout.colour = self.foreground_alert
116 else:
117 self.layout.colour = self.foreground_normal
118
119 val = dict(temp=temp_value, tag=self.tag_sensor, unit=self.unit)
120 return self.format.format(**val)
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libqtile/widget/sensors.py b/libqtile/widget/sensors.py
--- a/libqtile/widget/sensors.py
+++ b/libqtile/widget/sensors.py
@@ -67,7 +67,6 @@
base.InLoopPollText.__init__(self, **config)
self.add_defaults(ThermalSensor.defaults)
temp_values = self.get_temp_sensors()
- self.foreground_normal = self.foreground
if temp_values is None:
self.data = "sensors command not found"
@@ -81,6 +80,7 @@
def _configure(self, qtile, bar):
self.unit = "°C" if self.metric else "°F"
base.InLoopPollText._configure(self, qtile, bar)
+ self.foreground_normal = self.foreground
def get_temp_sensors(self):
"""
|
{"golden_diff": "diff --git a/libqtile/widget/sensors.py b/libqtile/widget/sensors.py\n--- a/libqtile/widget/sensors.py\n+++ b/libqtile/widget/sensors.py\n@@ -67,7 +67,6 @@\n base.InLoopPollText.__init__(self, **config)\n self.add_defaults(ThermalSensor.defaults)\n temp_values = self.get_temp_sensors()\n- self.foreground_normal = self.foreground\n \n if temp_values is None:\n self.data = \"sensors command not found\"\n@@ -81,6 +80,7 @@\n def _configure(self, qtile, bar):\n self.unit = \"\u00b0C\" if self.metric else \"\u00b0F\"\n base.InLoopPollText._configure(self, qtile, bar)\n+ self.foreground_normal = self.foreground\n \n def get_temp_sensors(self):\n \"\"\"\n", "issue": "`ThermalSensor` doesn't respect `foreground` in `widget_defaults`\n### The issue:\n\n(reported on Discord/IRC)\r\n\r\nThermalSensor widget doesn't respect foreground colour in widget defaults. This is because the foreground value is copied to `foreground_normal` during `__init__` but this happens before `widget_defaults` are copied to the widget (which happens in `_configure`\n\n### Required:\n\n- [X] I have searched past issues to see if this bug has already been reported.\n", "before_files": [{"content": "# -*- coding:utf-8 -*-\n# Copyright (c) 2012 TiN\n# Copyright (c) 2012, 2014 Tycho Andersen\n# Copyright (c) 2013 Tao Sauvage\n# Copyright (c) 2014-2015 Sean Vig\n# Copyright (c) 2014 Adi Sieker\n# Copyright (c) 2014 Foster McLane\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport psutil\n\nfrom libqtile.widget import base\n\n\nclass ThermalSensor(base.InLoopPollText):\n \"\"\"Widget to display temperature sensor information\n\n For using the thermal sensor widget you need to have lm-sensors installed.\n You can get a list of the tag_sensors executing \"sensors\" in your terminal.\n Then you can choose which you want, otherwise it will display the first\n available.\n\n Widget requirements: psutil_.\n\n .. _psutil: https://pypi.org/project/psutil/\n \"\"\"\n\n defaults = [\n (\n \"format\",\n \"{temp:.1f}{unit}\",\n \"Display string format. Three options available: \"\n \"``{temp}`` - temperature, \"\n \"``{tag}`` - tag of the temperature sensor, and \"\n \"``{unit}`` - \u00b0C or \u00b0F\",\n ),\n (\"metric\", True, \"True to use metric/C, False to use imperial/F\"),\n (\"update_interval\", 2, \"Update interval in seconds\"),\n (\"tag_sensor\", None, 'Tag of the temperature sensor. For example: \"temp1\" or \"Core 0\"'),\n (\n \"threshold\",\n 70,\n \"If the current temperature value is above, \"\n \"then change to foreground_alert colour\",\n ),\n (\"foreground_alert\", \"ff0000\", \"Foreground colour alert\"),\n ]\n\n def __init__(self, **config):\n base.InLoopPollText.__init__(self, **config)\n self.add_defaults(ThermalSensor.defaults)\n temp_values = self.get_temp_sensors()\n self.foreground_normal = self.foreground\n\n if temp_values is None:\n self.data = \"sensors command not found\"\n elif len(temp_values) == 0:\n self.data = \"Temperature sensors not found\"\n elif self.tag_sensor is None:\n for k in temp_values:\n self.tag_sensor = k\n break\n\n def _configure(self, qtile, bar):\n self.unit = \"\u00b0C\" if self.metric else \"\u00b0F\"\n base.InLoopPollText._configure(self, qtile, bar)\n\n def get_temp_sensors(self):\n \"\"\"\n Reads temperatures from sys-fs via psutil.\n Output will be read Fahrenheit if user has specified it to be.\n \"\"\"\n\n temperature_list = {}\n temps = psutil.sensors_temperatures(fahrenheit=not self.metric)\n empty_index = 0\n for kernel_module in temps:\n for sensor in temps[kernel_module]:\n label = sensor.label\n if not label:\n label = \"{}-{}\".format(\n kernel_module if kernel_module else \"UNKNOWN\", str(empty_index)\n )\n empty_index += 1\n temperature_list[label] = sensor.current\n\n return temperature_list\n\n def poll(self):\n temp_values = self.get_temp_sensors()\n\n # Temperature not available\n if (temp_values is None) or (self.tag_sensor not in temp_values):\n return \"N/A\"\n\n temp_value = temp_values.get(self.tag_sensor)\n if temp_value > self.threshold:\n self.layout.colour = self.foreground_alert\n else:\n self.layout.colour = self.foreground_normal\n\n val = dict(temp=temp_value, tag=self.tag_sensor, unit=self.unit)\n return self.format.format(**val)\n", "path": "libqtile/widget/sensors.py"}], "after_files": [{"content": "# -*- coding:utf-8 -*-\n# Copyright (c) 2012 TiN\n# Copyright (c) 2012, 2014 Tycho Andersen\n# Copyright (c) 2013 Tao Sauvage\n# Copyright (c) 2014-2015 Sean Vig\n# Copyright (c) 2014 Adi Sieker\n# Copyright (c) 2014 Foster McLane\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport psutil\n\nfrom libqtile.widget import base\n\n\nclass ThermalSensor(base.InLoopPollText):\n \"\"\"Widget to display temperature sensor information\n\n For using the thermal sensor widget you need to have lm-sensors installed.\n You can get a list of the tag_sensors executing \"sensors\" in your terminal.\n Then you can choose which you want, otherwise it will display the first\n available.\n\n Widget requirements: psutil_.\n\n .. _psutil: https://pypi.org/project/psutil/\n \"\"\"\n\n defaults = [\n (\n \"format\",\n \"{temp:.1f}{unit}\",\n \"Display string format. Three options available: \"\n \"``{temp}`` - temperature, \"\n \"``{tag}`` - tag of the temperature sensor, and \"\n \"``{unit}`` - \u00b0C or \u00b0F\",\n ),\n (\"metric\", True, \"True to use metric/C, False to use imperial/F\"),\n (\"update_interval\", 2, \"Update interval in seconds\"),\n (\"tag_sensor\", None, 'Tag of the temperature sensor. For example: \"temp1\" or \"Core 0\"'),\n (\n \"threshold\",\n 70,\n \"If the current temperature value is above, \"\n \"then change to foreground_alert colour\",\n ),\n (\"foreground_alert\", \"ff0000\", \"Foreground colour alert\"),\n ]\n\n def __init__(self, **config):\n base.InLoopPollText.__init__(self, **config)\n self.add_defaults(ThermalSensor.defaults)\n temp_values = self.get_temp_sensors()\n\n if temp_values is None:\n self.data = \"sensors command not found\"\n elif len(temp_values) == 0:\n self.data = \"Temperature sensors not found\"\n elif self.tag_sensor is None:\n for k in temp_values:\n self.tag_sensor = k\n break\n\n def _configure(self, qtile, bar):\n self.unit = \"\u00b0C\" if self.metric else \"\u00b0F\"\n base.InLoopPollText._configure(self, qtile, bar)\n self.foreground_normal = self.foreground\n\n def get_temp_sensors(self):\n \"\"\"\n Reads temperatures from sys-fs via psutil.\n Output will be read Fahrenheit if user has specified it to be.\n \"\"\"\n\n temperature_list = {}\n temps = psutil.sensors_temperatures(fahrenheit=not self.metric)\n empty_index = 0\n for kernel_module in temps:\n for sensor in temps[kernel_module]:\n label = sensor.label\n if not label:\n label = \"{}-{}\".format(\n kernel_module if kernel_module else \"UNKNOWN\", str(empty_index)\n )\n empty_index += 1\n temperature_list[label] = sensor.current\n\n return temperature_list\n\n def poll(self):\n temp_values = self.get_temp_sensors()\n\n # Temperature not available\n if (temp_values is None) or (self.tag_sensor not in temp_values):\n return \"N/A\"\n\n temp_value = temp_values.get(self.tag_sensor)\n if temp_value > self.threshold:\n self.layout.colour = self.foreground_alert\n else:\n self.layout.colour = self.foreground_normal\n\n val = dict(temp=temp_value, tag=self.tag_sensor, unit=self.unit)\n return self.format.format(**val)\n", "path": "libqtile/widget/sensors.py"}]}
| 1,665 | 190 |
gh_patches_debug_17348
|
rasdani/github-patches
|
git_diff
|
cocotb__cocotb-3387
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow not using parens on cocotb.test decorator
In many (if not the majority) of cases, users don't need to pass arguments to the test decorator. In this case it would be nice if they didn't need to "call" the decorator.
```python
@cocotb.test # no call here
async def test_stuff(dut):
...
```
Standard library decorator support this (like `lru_cache`), so there is precedence to support this as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cocotb/decorators.py`
Content:
```
1 # Copyright (c) 2013 Potential Ventures Ltd
2 # Copyright (c) 2013 SolarFlare Communications Inc
3 # All rights reserved.
4 #
5 # Redistribution and use in source and binary forms, with or without
6 # modification, are permitted provided that the following conditions are met:
7 # * Redistributions of source code must retain the above copyright
8 # notice, this list of conditions and the following disclaimer.
9 # * Redistributions in binary form must reproduce the above copyright
10 # notice, this list of conditions and the following disclaimer in the
11 # documentation and/or other materials provided with the distribution.
12 # * Neither the name of Potential Ventures Ltd,
13 # SolarFlare Communications Inc nor the
14 # names of its contributors may be used to endorse or promote products
15 # derived from this software without specific prior written permission.
16 #
17 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
18 # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
19 # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
20 # DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY
21 # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
22 # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
23 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
24 # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
25 # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
26 # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
27
28 import functools
29 import sys
30 import typing
31 import warnings
32
33 import cocotb
34 import cocotb.triggers
35 from cocotb.log import SimLog
36 from cocotb.task import Task as _Task # noqa: F401
37 from cocotb.task import _RunningCoroutine, _RunningTest
38 from cocotb.utils import lazy_property
39
40
41 def public(f):
42 """Use a decorator to avoid retyping function/class names.
43
44 * Based on an idea by Duncan Booth:
45 http://groups.google.com/group/comp.lang.python/msg/11cbb03e09611b8a
46 * Improved via a suggestion by Dave Angel:
47 http://groups.google.com/group/comp.lang.python/msg/3d400fb22d8a42e1
48 """
49 all = sys.modules[f.__module__].__dict__.setdefault("__all__", [])
50 if f.__name__ not in all: # Prevent duplicates if run from an IDE.
51 all.append(f.__name__)
52 return f
53
54
55 public(public) # Emulate decorating ourself
56
57
58 class coroutine:
59 """Decorator class that allows us to provide common coroutine mechanisms:
60
61 ``log`` methods will log to ``cocotb.coroutine.name``.
62
63 :meth:`~cocotb.task.Task.join` method returns an event which will fire when the coroutine exits.
64
65 Used as ``@cocotb.coroutine``.
66 """
67
68 def __init__(self, func):
69 self._func = func
70 functools.update_wrapper(self, func)
71
72 @lazy_property
73 def log(self):
74 return SimLog(f"cocotb.coroutine.{self._func.__qualname__}.{id(self)}")
75
76 def __call__(self, *args, **kwargs):
77 return _RunningCoroutine(self._func(*args, **kwargs), self)
78
79 def __get__(self, obj, owner=None):
80 """Permit the decorator to be used on class methods
81 and standalone functions"""
82 return type(self)(self._func.__get__(obj, owner))
83
84 def __iter__(self):
85 return self
86
87 def __str__(self):
88 return str(self._func.__qualname__)
89
90
91 @public
92 class function:
93 """Decorator class that allows a function to block.
94
95 This allows a coroutine that consumes simulation time
96 to be called by a thread started with :class:`cocotb.external`;
97 in other words, to internally block while externally
98 appear to yield.
99 """
100
101 def __init__(self, func):
102 self._coro = cocotb.coroutine(func)
103
104 @lazy_property
105 def log(self):
106 return SimLog(f"cocotb.function.{self._coro.__qualname__}.{id(self)}")
107
108 def __call__(self, *args, **kwargs):
109 return cocotb.scheduler._queue_function(self._coro(*args, **kwargs))
110
111 def __get__(self, obj, owner=None):
112 """Permit the decorator to be used on class methods
113 and standalone functions"""
114 return type(self)(self._coro._func.__get__(obj, owner))
115
116
117 @public
118 class external:
119 """Decorator to apply to an external function to enable calling from cocotb.
120
121 This turns a normal function that isn't a coroutine into a blocking coroutine.
122 Currently, this creates a new execution thread for each function that is
123 called.
124 Scope for this to be streamlined to a queue in future.
125 """
126
127 def __init__(self, func):
128 self._func = func
129 self._log = SimLog(f"cocotb.external.{self._func.__qualname__}.{id(self)}")
130
131 def __call__(self, *args, **kwargs):
132 return cocotb.scheduler._run_in_executor(self._func, *args, **kwargs)
133
134 def __get__(self, obj, owner=None):
135 """Permit the decorator to be used on class methods
136 and standalone functions"""
137 return type(self)(self._func.__get__(obj, owner))
138
139
140 class _decorator_helper(type):
141 """
142 Metaclass that allows a type to be constructed using decorator syntax,
143 passing the decorated function as the first argument.
144
145 So:
146
147 @MyClass(construction, args='go here')
148 def this_is_passed_as_f(...):
149 pass
150
151 ends up calling
152
153 MyClass.__init__(this_is_passed_as_f, construction, args='go here')
154 """
155
156 def __call__(cls, *args, **kwargs):
157 def decorator(f):
158 # fall back to the normal way of constructing an object, now that
159 # we have all the arguments
160 return type.__call__(cls, f, *args, **kwargs)
161
162 return decorator
163
164
165 @public
166 class test(coroutine, metaclass=_decorator_helper):
167 """
168 Decorator to mark a Callable which returns a Coroutine as a test.
169
170 The test decorator provides a test timeout, and allows us to mark tests as skipped
171 or expecting errors or failures.
172 Tests are evaluated in the order they are defined in a test module.
173
174 Used as ``@cocotb.test(...)``.
175
176 Args:
177 timeout_time (numbers.Real or decimal.Decimal, optional):
178 Simulation time duration before timeout occurs.
179
180 .. versionadded:: 1.3
181
182 .. note::
183 Test timeout is intended for protection against deadlock.
184 Users should use :class:`~cocotb.triggers.with_timeout` if they require a
185 more general-purpose timeout mechanism.
186
187 timeout_unit (str, optional):
188 Units of timeout_time, accepts any units that :class:`~cocotb.triggers.Timer` does.
189
190 .. versionadded:: 1.3
191
192 .. deprecated:: 1.5
193 Using ``None`` as the *timeout_unit* argument is deprecated, use ``'step'`` instead.
194
195 expect_fail (bool, optional):
196 If ``True`` and the test fails a functional check via an ``assert`` statement, :class:`pytest.raises`,
197 :class:`pytest.warns`, or :class:`pytest.deprecated_call` the test is considered to have passed.
198 If ``True`` and the test passes successfully, the test is considered to have failed.
199
200 expect_error (exception type or tuple of exception types, optional):
201 Mark the result as a pass only if one of the exception types is raised in the test.
202 This is primarily for cocotb internal regression use for when a simulator error is expected.
203
204 Users are encouraged to use the following idiom instead::
205
206 @cocotb.test()
207 async def my_test(dut):
208 try:
209 await thing_that_should_fail()
210 except ExceptionIExpect:
211 pass
212 else:
213 assert False, "Exception did not occur"
214
215 .. versionchanged:: 1.3
216 Specific exception types can be expected
217
218 .. deprecated:: 1.5
219 Passing a :class:`bool` value is now deprecated.
220 Pass a specific :class:`Exception` or a tuple of Exceptions instead.
221
222 skip (bool, optional):
223 Don't execute this test as part of the regression. Test can still be run
224 manually by setting :make:var:`TESTCASE`.
225
226 stage (int)
227 Order tests logically into stages, where multiple tests can share a stage.
228 Defaults to 0.
229 """
230
231 _id_count = 0 # used by the RegressionManager to sort tests in definition order
232
233 def __init__(
234 self,
235 f,
236 timeout_time=None,
237 timeout_unit="step",
238 expect_fail=False,
239 expect_error=(),
240 skip=False,
241 stage=0,
242 ):
243 if timeout_unit is None:
244 warnings.warn(
245 'Using timeout_unit=None is deprecated, use timeout_unit="step" instead.',
246 DeprecationWarning,
247 stacklevel=2,
248 )
249 timeout_unit = "step" # don't propagate deprecated value
250 self._id = self._id_count
251 type(self)._id_count += 1
252
253 if timeout_time is not None:
254 co = coroutine(f)
255
256 @functools.wraps(f)
257 async def f(*args, **kwargs):
258 running_co = co(*args, **kwargs)
259
260 try:
261 res = await cocotb.triggers.with_timeout(
262 running_co, self.timeout_time, self.timeout_unit
263 )
264 except cocotb.result.SimTimeoutError:
265 running_co.kill()
266 raise
267 else:
268 return res
269
270 super().__init__(f)
271
272 self.timeout_time = timeout_time
273 self.timeout_unit = timeout_unit
274 self.expect_fail = expect_fail
275 if isinstance(expect_error, bool):
276 warnings.warn(
277 "Passing bool values to `except_error` option of `cocotb.test` is deprecated. "
278 "Pass a specific Exception type instead",
279 DeprecationWarning,
280 stacklevel=2,
281 )
282 if expect_error is True:
283 expect_error = (BaseException,)
284 elif expect_error is False:
285 expect_error = ()
286 self.expect_error = expect_error
287 self.skip = skip
288 self.stage = stage
289 self.im_test = True # For auto-regressions
290 self.name = self._func.__name__
291
292 def __call__(self, *args, **kwargs):
293 inst = self._func(*args, **kwargs)
294 coro = _RunningTest(inst, self)
295 return coro
296
297
298 if sys.version_info < (3, 7):
299 Task = _Task
300 RunningTask = _Task
301 RunningCoroutine = _RunningCoroutine
302 RunningTest = _RunningTest
303 else:
304
305 def __getattr__(attr: str) -> typing.Any:
306 if attr in ("Task", "RunningTask"):
307 warnings.warn(
308 f"The class {attr} has been renamed to cocotb.task.Task.",
309 DeprecationWarning,
310 stacklevel=2,
311 )
312 attr = "_Task"
313 elif attr in ("RunningCoroutine", "RunningTest"):
314 warnings.warn(
315 f"The class {attr} is now private. Update all uses to the parent class cocotb.task.Task.",
316 DeprecationWarning,
317 stacklevel=2,
318 )
319 attr = f"_{attr}"
320 try:
321 return globals()[attr]
322 except KeyError:
323 raise AttributeError(
324 f"module {__name__!r} has no attribute {attr!r}"
325 ) from None
326
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cocotb/decorators.py b/cocotb/decorators.py
--- a/cocotb/decorators.py
+++ b/cocotb/decorators.py
@@ -140,7 +140,8 @@
class _decorator_helper(type):
"""
Metaclass that allows a type to be constructed using decorator syntax,
- passing the decorated function as the first argument.
+ passing the decorated function as the first argument. Supports
+ construction with or without having the type called.
So:
@@ -154,6 +155,11 @@
"""
def __call__(cls, *args, **kwargs):
+ if len(args) == 1 and callable(args[0]): # case without parenthesis
+ f = args[0]
+ return type.__call__(cls, f, **kwargs)
+
+ # case with parenthesis
def decorator(f):
# fall back to the normal way of constructing an object, now that
# we have all the arguments
|
{"golden_diff": "diff --git a/cocotb/decorators.py b/cocotb/decorators.py\n--- a/cocotb/decorators.py\n+++ b/cocotb/decorators.py\n@@ -140,7 +140,8 @@\n class _decorator_helper(type):\n \"\"\"\n Metaclass that allows a type to be constructed using decorator syntax,\n- passing the decorated function as the first argument.\n+ passing the decorated function as the first argument. Supports\n+ construction with or without having the type called.\n \n So:\n \n@@ -154,6 +155,11 @@\n \"\"\"\n \n def __call__(cls, *args, **kwargs):\n+ if len(args) == 1 and callable(args[0]): # case without parenthesis\n+ f = args[0]\n+ return type.__call__(cls, f, **kwargs)\n+\n+ # case with parenthesis\n def decorator(f):\n # fall back to the normal way of constructing an object, now that\n # we have all the arguments\n", "issue": "Allow not using parens on cocotb.test decorator\nIn many (if not the majority) of cases, users don't need to pass arguments to the test decorator. In this case it would be nice if they didn't need to \"call\" the decorator.\r\n\r\n```python\r\[email protected] # no call here\r\nasync def test_stuff(dut):\r\n ...\r\n```\r\n\r\nStandard library decorator support this (like `lru_cache`), so there is precedence to support this as well.\n", "before_files": [{"content": "# Copyright (c) 2013 Potential Ventures Ltd\n# Copyright (c) 2013 SolarFlare Communications Inc\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of Potential Ventures Ltd,\n# SolarFlare Communications Inc nor the\n# names of its contributors may be used to endorse or promote products\n# derived from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY\n# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport functools\nimport sys\nimport typing\nimport warnings\n\nimport cocotb\nimport cocotb.triggers\nfrom cocotb.log import SimLog\nfrom cocotb.task import Task as _Task # noqa: F401\nfrom cocotb.task import _RunningCoroutine, _RunningTest\nfrom cocotb.utils import lazy_property\n\n\ndef public(f):\n \"\"\"Use a decorator to avoid retyping function/class names.\n\n * Based on an idea by Duncan Booth:\n http://groups.google.com/group/comp.lang.python/msg/11cbb03e09611b8a\n * Improved via a suggestion by Dave Angel:\n http://groups.google.com/group/comp.lang.python/msg/3d400fb22d8a42e1\n \"\"\"\n all = sys.modules[f.__module__].__dict__.setdefault(\"__all__\", [])\n if f.__name__ not in all: # Prevent duplicates if run from an IDE.\n all.append(f.__name__)\n return f\n\n\npublic(public) # Emulate decorating ourself\n\n\nclass coroutine:\n \"\"\"Decorator class that allows us to provide common coroutine mechanisms:\n\n ``log`` methods will log to ``cocotb.coroutine.name``.\n\n :meth:`~cocotb.task.Task.join` method returns an event which will fire when the coroutine exits.\n\n Used as ``@cocotb.coroutine``.\n \"\"\"\n\n def __init__(self, func):\n self._func = func\n functools.update_wrapper(self, func)\n\n @lazy_property\n def log(self):\n return SimLog(f\"cocotb.coroutine.{self._func.__qualname__}.{id(self)}\")\n\n def __call__(self, *args, **kwargs):\n return _RunningCoroutine(self._func(*args, **kwargs), self)\n\n def __get__(self, obj, owner=None):\n \"\"\"Permit the decorator to be used on class methods\n and standalone functions\"\"\"\n return type(self)(self._func.__get__(obj, owner))\n\n def __iter__(self):\n return self\n\n def __str__(self):\n return str(self._func.__qualname__)\n\n\n@public\nclass function:\n \"\"\"Decorator class that allows a function to block.\n\n This allows a coroutine that consumes simulation time\n to be called by a thread started with :class:`cocotb.external`;\n in other words, to internally block while externally\n appear to yield.\n \"\"\"\n\n def __init__(self, func):\n self._coro = cocotb.coroutine(func)\n\n @lazy_property\n def log(self):\n return SimLog(f\"cocotb.function.{self._coro.__qualname__}.{id(self)}\")\n\n def __call__(self, *args, **kwargs):\n return cocotb.scheduler._queue_function(self._coro(*args, **kwargs))\n\n def __get__(self, obj, owner=None):\n \"\"\"Permit the decorator to be used on class methods\n and standalone functions\"\"\"\n return type(self)(self._coro._func.__get__(obj, owner))\n\n\n@public\nclass external:\n \"\"\"Decorator to apply to an external function to enable calling from cocotb.\n\n This turns a normal function that isn't a coroutine into a blocking coroutine.\n Currently, this creates a new execution thread for each function that is\n called.\n Scope for this to be streamlined to a queue in future.\n \"\"\"\n\n def __init__(self, func):\n self._func = func\n self._log = SimLog(f\"cocotb.external.{self._func.__qualname__}.{id(self)}\")\n\n def __call__(self, *args, **kwargs):\n return cocotb.scheduler._run_in_executor(self._func, *args, **kwargs)\n\n def __get__(self, obj, owner=None):\n \"\"\"Permit the decorator to be used on class methods\n and standalone functions\"\"\"\n return type(self)(self._func.__get__(obj, owner))\n\n\nclass _decorator_helper(type):\n \"\"\"\n Metaclass that allows a type to be constructed using decorator syntax,\n passing the decorated function as the first argument.\n\n So:\n\n @MyClass(construction, args='go here')\n def this_is_passed_as_f(...):\n pass\n\n ends up calling\n\n MyClass.__init__(this_is_passed_as_f, construction, args='go here')\n \"\"\"\n\n def __call__(cls, *args, **kwargs):\n def decorator(f):\n # fall back to the normal way of constructing an object, now that\n # we have all the arguments\n return type.__call__(cls, f, *args, **kwargs)\n\n return decorator\n\n\n@public\nclass test(coroutine, metaclass=_decorator_helper):\n \"\"\"\n Decorator to mark a Callable which returns a Coroutine as a test.\n\n The test decorator provides a test timeout, and allows us to mark tests as skipped\n or expecting errors or failures.\n Tests are evaluated in the order they are defined in a test module.\n\n Used as ``@cocotb.test(...)``.\n\n Args:\n timeout_time (numbers.Real or decimal.Decimal, optional):\n Simulation time duration before timeout occurs.\n\n .. versionadded:: 1.3\n\n .. note::\n Test timeout is intended for protection against deadlock.\n Users should use :class:`~cocotb.triggers.with_timeout` if they require a\n more general-purpose timeout mechanism.\n\n timeout_unit (str, optional):\n Units of timeout_time, accepts any units that :class:`~cocotb.triggers.Timer` does.\n\n .. versionadded:: 1.3\n\n .. deprecated:: 1.5\n Using ``None`` as the *timeout_unit* argument is deprecated, use ``'step'`` instead.\n\n expect_fail (bool, optional):\n If ``True`` and the test fails a functional check via an ``assert`` statement, :class:`pytest.raises`,\n :class:`pytest.warns`, or :class:`pytest.deprecated_call` the test is considered to have passed.\n If ``True`` and the test passes successfully, the test is considered to have failed.\n\n expect_error (exception type or tuple of exception types, optional):\n Mark the result as a pass only if one of the exception types is raised in the test.\n This is primarily for cocotb internal regression use for when a simulator error is expected.\n\n Users are encouraged to use the following idiom instead::\n\n @cocotb.test()\n async def my_test(dut):\n try:\n await thing_that_should_fail()\n except ExceptionIExpect:\n pass\n else:\n assert False, \"Exception did not occur\"\n\n .. versionchanged:: 1.3\n Specific exception types can be expected\n\n .. deprecated:: 1.5\n Passing a :class:`bool` value is now deprecated.\n Pass a specific :class:`Exception` or a tuple of Exceptions instead.\n\n skip (bool, optional):\n Don't execute this test as part of the regression. Test can still be run\n manually by setting :make:var:`TESTCASE`.\n\n stage (int)\n Order tests logically into stages, where multiple tests can share a stage.\n Defaults to 0.\n \"\"\"\n\n _id_count = 0 # used by the RegressionManager to sort tests in definition order\n\n def __init__(\n self,\n f,\n timeout_time=None,\n timeout_unit=\"step\",\n expect_fail=False,\n expect_error=(),\n skip=False,\n stage=0,\n ):\n if timeout_unit is None:\n warnings.warn(\n 'Using timeout_unit=None is deprecated, use timeout_unit=\"step\" instead.',\n DeprecationWarning,\n stacklevel=2,\n )\n timeout_unit = \"step\" # don't propagate deprecated value\n self._id = self._id_count\n type(self)._id_count += 1\n\n if timeout_time is not None:\n co = coroutine(f)\n\n @functools.wraps(f)\n async def f(*args, **kwargs):\n running_co = co(*args, **kwargs)\n\n try:\n res = await cocotb.triggers.with_timeout(\n running_co, self.timeout_time, self.timeout_unit\n )\n except cocotb.result.SimTimeoutError:\n running_co.kill()\n raise\n else:\n return res\n\n super().__init__(f)\n\n self.timeout_time = timeout_time\n self.timeout_unit = timeout_unit\n self.expect_fail = expect_fail\n if isinstance(expect_error, bool):\n warnings.warn(\n \"Passing bool values to `except_error` option of `cocotb.test` is deprecated. \"\n \"Pass a specific Exception type instead\",\n DeprecationWarning,\n stacklevel=2,\n )\n if expect_error is True:\n expect_error = (BaseException,)\n elif expect_error is False:\n expect_error = ()\n self.expect_error = expect_error\n self.skip = skip\n self.stage = stage\n self.im_test = True # For auto-regressions\n self.name = self._func.__name__\n\n def __call__(self, *args, **kwargs):\n inst = self._func(*args, **kwargs)\n coro = _RunningTest(inst, self)\n return coro\n\n\nif sys.version_info < (3, 7):\n Task = _Task\n RunningTask = _Task\n RunningCoroutine = _RunningCoroutine\n RunningTest = _RunningTest\nelse:\n\n def __getattr__(attr: str) -> typing.Any:\n if attr in (\"Task\", \"RunningTask\"):\n warnings.warn(\n f\"The class {attr} has been renamed to cocotb.task.Task.\",\n DeprecationWarning,\n stacklevel=2,\n )\n attr = \"_Task\"\n elif attr in (\"RunningCoroutine\", \"RunningTest\"):\n warnings.warn(\n f\"The class {attr} is now private. Update all uses to the parent class cocotb.task.Task.\",\n DeprecationWarning,\n stacklevel=2,\n )\n attr = f\"_{attr}\"\n try:\n return globals()[attr]\n except KeyError:\n raise AttributeError(\n f\"module {__name__!r} has no attribute {attr!r}\"\n ) from None\n", "path": "cocotb/decorators.py"}], "after_files": [{"content": "# Copyright (c) 2013 Potential Ventures Ltd\n# Copyright (c) 2013 SolarFlare Communications Inc\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of Potential Ventures Ltd,\n# SolarFlare Communications Inc nor the\n# names of its contributors may be used to endorse or promote products\n# derived from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY\n# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport functools\nimport sys\nimport typing\nimport warnings\n\nimport cocotb\nimport cocotb.triggers\nfrom cocotb.log import SimLog\nfrom cocotb.task import Task as _Task # noqa: F401\nfrom cocotb.task import _RunningCoroutine, _RunningTest\nfrom cocotb.utils import lazy_property\n\n\ndef public(f):\n \"\"\"Use a decorator to avoid retyping function/class names.\n\n * Based on an idea by Duncan Booth:\n http://groups.google.com/group/comp.lang.python/msg/11cbb03e09611b8a\n * Improved via a suggestion by Dave Angel:\n http://groups.google.com/group/comp.lang.python/msg/3d400fb22d8a42e1\n \"\"\"\n all = sys.modules[f.__module__].__dict__.setdefault(\"__all__\", [])\n if f.__name__ not in all: # Prevent duplicates if run from an IDE.\n all.append(f.__name__)\n return f\n\n\npublic(public) # Emulate decorating ourself\n\n\nclass coroutine:\n \"\"\"Decorator class that allows us to provide common coroutine mechanisms:\n\n ``log`` methods will log to ``cocotb.coroutine.name``.\n\n :meth:`~cocotb.task.Task.join` method returns an event which will fire when the coroutine exits.\n\n Used as ``@cocotb.coroutine``.\n \"\"\"\n\n def __init__(self, func):\n self._func = func\n functools.update_wrapper(self, func)\n\n @lazy_property\n def log(self):\n return SimLog(f\"cocotb.coroutine.{self._func.__qualname__}.{id(self)}\")\n\n def __call__(self, *args, **kwargs):\n return _RunningCoroutine(self._func(*args, **kwargs), self)\n\n def __get__(self, obj, owner=None):\n \"\"\"Permit the decorator to be used on class methods\n and standalone functions\"\"\"\n return type(self)(self._func.__get__(obj, owner))\n\n def __iter__(self):\n return self\n\n def __str__(self):\n return str(self._func.__qualname__)\n\n\n@public\nclass function:\n \"\"\"Decorator class that allows a function to block.\n\n This allows a coroutine that consumes simulation time\n to be called by a thread started with :class:`cocotb.external`;\n in other words, to internally block while externally\n appear to yield.\n \"\"\"\n\n def __init__(self, func):\n self._coro = cocotb.coroutine(func)\n\n @lazy_property\n def log(self):\n return SimLog(f\"cocotb.function.{self._coro.__qualname__}.{id(self)}\")\n\n def __call__(self, *args, **kwargs):\n return cocotb.scheduler._queue_function(self._coro(*args, **kwargs))\n\n def __get__(self, obj, owner=None):\n \"\"\"Permit the decorator to be used on class methods\n and standalone functions\"\"\"\n return type(self)(self._coro._func.__get__(obj, owner))\n\n\n@public\nclass external:\n \"\"\"Decorator to apply to an external function to enable calling from cocotb.\n\n This turns a normal function that isn't a coroutine into a blocking coroutine.\n Currently, this creates a new execution thread for each function that is\n called.\n Scope for this to be streamlined to a queue in future.\n \"\"\"\n\n def __init__(self, func):\n self._func = func\n self._log = SimLog(f\"cocotb.external.{self._func.__qualname__}.{id(self)}\")\n\n def __call__(self, *args, **kwargs):\n return cocotb.scheduler._run_in_executor(self._func, *args, **kwargs)\n\n def __get__(self, obj, owner=None):\n \"\"\"Permit the decorator to be used on class methods\n and standalone functions\"\"\"\n return type(self)(self._func.__get__(obj, owner))\n\n\nclass _decorator_helper(type):\n \"\"\"\n Metaclass that allows a type to be constructed using decorator syntax,\n passing the decorated function as the first argument. Supports\n construction with or without having the type called.\n\n So:\n\n @MyClass(construction, args='go here')\n def this_is_passed_as_f(...):\n pass\n\n ends up calling\n\n MyClass.__init__(this_is_passed_as_f, construction, args='go here')\n \"\"\"\n\n def __call__(cls, *args, **kwargs):\n if len(args) == 1 and callable(args[0]): # case without parenthesis\n f = args[0]\n return type.__call__(cls, f, **kwargs)\n\n # case with parenthesis\n def decorator(f):\n # fall back to the normal way of constructing an object, now that\n # we have all the arguments\n return type.__call__(cls, f, *args, **kwargs)\n\n return decorator\n\n\n@public\nclass test(coroutine, metaclass=_decorator_helper):\n \"\"\"\n Decorator to mark a Callable which returns a Coroutine as a test.\n\n The test decorator provides a test timeout, and allows us to mark tests as skipped\n or expecting errors or failures.\n Tests are evaluated in the order they are defined in a test module.\n\n Used as ``@cocotb.test(...)``.\n\n Args:\n timeout_time (numbers.Real or decimal.Decimal, optional):\n Simulation time duration before timeout occurs.\n\n .. versionadded:: 1.3\n\n .. note::\n Test timeout is intended for protection against deadlock.\n Users should use :class:`~cocotb.triggers.with_timeout` if they require a\n more general-purpose timeout mechanism.\n\n timeout_unit (str, optional):\n Units of timeout_time, accepts any units that :class:`~cocotb.triggers.Timer` does.\n\n .. versionadded:: 1.3\n\n .. deprecated:: 1.5\n Using ``None`` as the *timeout_unit* argument is deprecated, use ``'step'`` instead.\n\n expect_fail (bool, optional):\n If ``True`` and the test fails a functional check via an ``assert`` statement, :class:`pytest.raises`,\n :class:`pytest.warns`, or :class:`pytest.deprecated_call` the test is considered to have passed.\n If ``True`` and the test passes successfully, the test is considered to have failed.\n\n expect_error (exception type or tuple of exception types, optional):\n Mark the result as a pass only if one of the exception types is raised in the test.\n This is primarily for cocotb internal regression use for when a simulator error is expected.\n\n Users are encouraged to use the following idiom instead::\n\n @cocotb.test()\n async def my_test(dut):\n try:\n await thing_that_should_fail()\n except ExceptionIExpect:\n pass\n else:\n assert False, \"Exception did not occur\"\n\n .. versionchanged:: 1.3\n Specific exception types can be expected\n\n .. deprecated:: 1.5\n Passing a :class:`bool` value is now deprecated.\n Pass a specific :class:`Exception` or a tuple of Exceptions instead.\n\n skip (bool, optional):\n Don't execute this test as part of the regression. Test can still be run\n manually by setting :make:var:`TESTCASE`.\n\n stage (int)\n Order tests logically into stages, where multiple tests can share a stage.\n Defaults to 0.\n \"\"\"\n\n _id_count = 0 # used by the RegressionManager to sort tests in definition order\n\n def __init__(\n self,\n f,\n timeout_time=None,\n timeout_unit=\"step\",\n expect_fail=False,\n expect_error=(),\n skip=False,\n stage=0,\n ):\n if timeout_unit is None:\n warnings.warn(\n 'Using timeout_unit=None is deprecated, use timeout_unit=\"step\" instead.',\n DeprecationWarning,\n stacklevel=2,\n )\n timeout_unit = \"step\" # don't propagate deprecated value\n self._id = self._id_count\n type(self)._id_count += 1\n\n if timeout_time is not None:\n co = coroutine(f)\n\n @functools.wraps(f)\n async def f(*args, **kwargs):\n running_co = co(*args, **kwargs)\n\n try:\n res = await cocotb.triggers.with_timeout(\n running_co, self.timeout_time, self.timeout_unit\n )\n except cocotb.result.SimTimeoutError:\n running_co.kill()\n raise\n else:\n return res\n\n super().__init__(f)\n\n self.timeout_time = timeout_time\n self.timeout_unit = timeout_unit\n self.expect_fail = expect_fail\n if isinstance(expect_error, bool):\n warnings.warn(\n \"Passing bool values to `except_error` option of `cocotb.test` is deprecated. \"\n \"Pass a specific Exception type instead\",\n DeprecationWarning,\n stacklevel=2,\n )\n if expect_error is True:\n expect_error = (BaseException,)\n elif expect_error is False:\n expect_error = ()\n self.expect_error = expect_error\n self.skip = skip\n self.stage = stage\n self.im_test = True # For auto-regressions\n self.name = self._func.__name__\n\n def __call__(self, *args, **kwargs):\n inst = self._func(*args, **kwargs)\n coro = _RunningTest(inst, self)\n return coro\n\n\nif sys.version_info < (3, 7):\n Task = _Task\n RunningTask = _Task\n RunningCoroutine = _RunningCoroutine\n RunningTest = _RunningTest\nelse:\n\n def __getattr__(attr: str) -> typing.Any:\n if attr in (\"Task\", \"RunningTask\"):\n warnings.warn(\n f\"The class {attr} has been renamed to cocotb.task.Task.\",\n DeprecationWarning,\n stacklevel=2,\n )\n attr = \"_Task\"\n elif attr in (\"RunningCoroutine\", \"RunningTest\"):\n warnings.warn(\n f\"The class {attr} is now private. Update all uses to the parent class cocotb.task.Task.\",\n DeprecationWarning,\n stacklevel=2,\n )\n attr = f\"_{attr}\"\n try:\n return globals()[attr]\n except KeyError:\n raise AttributeError(\n f\"module {__name__!r} has no attribute {attr!r}\"\n ) from None\n", "path": "cocotb/decorators.py"}]}
| 3,833 | 232 |
gh_patches_debug_36671
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-22954
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
JW player downloads seem to be broken
Using the latest version 2019.10.29
Tried downloading JWPlayer video embedded on this page:
https://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3
Here's the verbose output:
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-v', u'-F', u'https://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3?fbclid=IwAR2jOlaH5ADErmCQj44J8BOE-IJfNPAhBgnFPpV-nIOi7DK86sscO4YN9pA']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2019.10.29
[debug] Python version 2.7.16 (CPython) - Darwin-18.7.0-x86_64-i386-64bit
[debug] exe versions: rtmpdump 2.4
[debug] Proxy map: {}
[BusinessInsider] sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3: Downloading webpage
ERROR: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 796, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 530, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/businessinsider.py", line 39, in _real_extract
webpage, 'jwplatform id')
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 1005, in _search_regex
raise RegexNotFoundError('Unable to extract %s' % _name)
RegexNotFoundError: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
JW player downloads seem to be broken
Using the latest version 2019.10.29
Tried downloading JWPlayer video embedded on this page:
https://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3
Here's the verbose output:
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-v', u'-F', u'https://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3?fbclid=IwAR2jOlaH5ADErmCQj44J8BOE-IJfNPAhBgnFPpV-nIOi7DK86sscO4YN9pA']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2019.10.29
[debug] Python version 2.7.16 (CPython) - Darwin-18.7.0-x86_64-i386-64bit
[debug] exe versions: rtmpdump 2.4
[debug] Proxy map: {}
[BusinessInsider] sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3: Downloading webpage
ERROR: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 796, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 530, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/businessinsider.py", line 39, in _real_extract
webpage, 'jwplatform id')
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 1005, in _search_regex
raise RegexNotFoundError('Unable to extract %s' % _name)
RegexNotFoundError: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/businessinsider.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 from .common import InfoExtractor
5 from .jwplatform import JWPlatformIE
6
7
8 class BusinessInsiderIE(InfoExtractor):
9 _VALID_URL = r'https?://(?:[^/]+\.)?businessinsider\.(?:com|nl)/(?:[^/]+/)*(?P<id>[^/?#&]+)'
10 _TESTS = [{
11 'url': 'http://uk.businessinsider.com/how-much-radiation-youre-exposed-to-in-everyday-life-2016-6',
12 'md5': 'ca237a53a8eb20b6dc5bd60564d4ab3e',
13 'info_dict': {
14 'id': 'hZRllCfw',
15 'ext': 'mp4',
16 'title': "Here's how much radiation you're exposed to in everyday life",
17 'description': 'md5:9a0d6e2c279948aadaa5e84d6d9b99bd',
18 'upload_date': '20170709',
19 'timestamp': 1499606400,
20 },
21 'params': {
22 'skip_download': True,
23 },
24 }, {
25 'url': 'https://www.businessinsider.nl/5-scientifically-proven-things-make-you-less-attractive-2017-7/',
26 'only_matching': True,
27 }, {
28 'url': 'http://www.businessinsider.com/excel-index-match-vlookup-video-how-to-2015-2?IR=T',
29 'only_matching': True,
30 }]
31
32 def _real_extract(self, url):
33 video_id = self._match_id(url)
34 webpage = self._download_webpage(url, video_id)
35 jwplatform_id = self._search_regex(
36 (r'data-media-id=["\']([a-zA-Z0-9]{8})',
37 r'id=["\']jwplayer_([a-zA-Z0-9]{8})',
38 r'id["\']?\s*:\s*["\']?([a-zA-Z0-9]{8})'),
39 webpage, 'jwplatform id')
40 return self.url_result(
41 'jwplatform:%s' % jwplatform_id, ie=JWPlatformIE.ie_key(),
42 video_id=video_id)
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/businessinsider.py b/youtube_dl/extractor/businessinsider.py
--- a/youtube_dl/extractor/businessinsider.py
+++ b/youtube_dl/extractor/businessinsider.py
@@ -9,21 +9,26 @@
_VALID_URL = r'https?://(?:[^/]+\.)?businessinsider\.(?:com|nl)/(?:[^/]+/)*(?P<id>[^/?#&]+)'
_TESTS = [{
'url': 'http://uk.businessinsider.com/how-much-radiation-youre-exposed-to-in-everyday-life-2016-6',
- 'md5': 'ca237a53a8eb20b6dc5bd60564d4ab3e',
+ 'md5': 'ffed3e1e12a6f950aa2f7d83851b497a',
'info_dict': {
- 'id': 'hZRllCfw',
+ 'id': 'cjGDb0X9',
'ext': 'mp4',
- 'title': "Here's how much radiation you're exposed to in everyday life",
- 'description': 'md5:9a0d6e2c279948aadaa5e84d6d9b99bd',
- 'upload_date': '20170709',
- 'timestamp': 1499606400,
- },
- 'params': {
- 'skip_download': True,
+ 'title': "Bananas give you more radiation exposure than living next to a nuclear power plant",
+ 'description': 'md5:0175a3baf200dd8fa658f94cade841b3',
+ 'upload_date': '20160611',
+ 'timestamp': 1465675620,
},
}, {
'url': 'https://www.businessinsider.nl/5-scientifically-proven-things-make-you-less-attractive-2017-7/',
- 'only_matching': True,
+ 'md5': '43f438dbc6da0b89f5ac42f68529d84a',
+ 'info_dict': {
+ 'id': '5zJwd4FK',
+ 'ext': 'mp4',
+ 'title': 'Deze dingen zorgen ervoor dat je minder snel een date scoort',
+ 'description': 'md5:2af8975825d38a4fed24717bbe51db49',
+ 'upload_date': '20170705',
+ 'timestamp': 1499270528,
+ },
}, {
'url': 'http://www.businessinsider.com/excel-index-match-vlookup-video-how-to-2015-2?IR=T',
'only_matching': True,
@@ -35,7 +40,8 @@
jwplatform_id = self._search_regex(
(r'data-media-id=["\']([a-zA-Z0-9]{8})',
r'id=["\']jwplayer_([a-zA-Z0-9]{8})',
- r'id["\']?\s*:\s*["\']?([a-zA-Z0-9]{8})'),
+ r'id["\']?\s*:\s*["\']?([a-zA-Z0-9]{8})',
+ r'(?:jwplatform\.com/players/|jwplayer_)([a-zA-Z0-9]{8})'),
webpage, 'jwplatform id')
return self.url_result(
'jwplatform:%s' % jwplatform_id, ie=JWPlatformIE.ie_key(),
|
{"golden_diff": "diff --git a/youtube_dl/extractor/businessinsider.py b/youtube_dl/extractor/businessinsider.py\n--- a/youtube_dl/extractor/businessinsider.py\n+++ b/youtube_dl/extractor/businessinsider.py\n@@ -9,21 +9,26 @@\n _VALID_URL = r'https?://(?:[^/]+\\.)?businessinsider\\.(?:com|nl)/(?:[^/]+/)*(?P<id>[^/?#&]+)'\n _TESTS = [{\n 'url': 'http://uk.businessinsider.com/how-much-radiation-youre-exposed-to-in-everyday-life-2016-6',\n- 'md5': 'ca237a53a8eb20b6dc5bd60564d4ab3e',\n+ 'md5': 'ffed3e1e12a6f950aa2f7d83851b497a',\n 'info_dict': {\n- 'id': 'hZRllCfw',\n+ 'id': 'cjGDb0X9',\n 'ext': 'mp4',\n- 'title': \"Here's how much radiation you're exposed to in everyday life\",\n- 'description': 'md5:9a0d6e2c279948aadaa5e84d6d9b99bd',\n- 'upload_date': '20170709',\n- 'timestamp': 1499606400,\n- },\n- 'params': {\n- 'skip_download': True,\n+ 'title': \"Bananas give you more radiation exposure than living next to a nuclear power plant\",\n+ 'description': 'md5:0175a3baf200dd8fa658f94cade841b3',\n+ 'upload_date': '20160611',\n+ 'timestamp': 1465675620,\n },\n }, {\n 'url': 'https://www.businessinsider.nl/5-scientifically-proven-things-make-you-less-attractive-2017-7/',\n- 'only_matching': True,\n+ 'md5': '43f438dbc6da0b89f5ac42f68529d84a',\n+ 'info_dict': {\n+ 'id': '5zJwd4FK',\n+ 'ext': 'mp4',\n+ 'title': 'Deze dingen zorgen ervoor dat je minder snel een date scoort',\n+ 'description': 'md5:2af8975825d38a4fed24717bbe51db49',\n+ 'upload_date': '20170705',\n+ 'timestamp': 1499270528,\n+ },\n }, {\n 'url': 'http://www.businessinsider.com/excel-index-match-vlookup-video-how-to-2015-2?IR=T',\n 'only_matching': True,\n@@ -35,7 +40,8 @@\n jwplatform_id = self._search_regex(\n (r'data-media-id=[\"\\']([a-zA-Z0-9]{8})',\n r'id=[\"\\']jwplayer_([a-zA-Z0-9]{8})',\n- r'id[\"\\']?\\s*:\\s*[\"\\']?([a-zA-Z0-9]{8})'),\n+ r'id[\"\\']?\\s*:\\s*[\"\\']?([a-zA-Z0-9]{8})',\n+ r'(?:jwplatform\\.com/players/|jwplayer_)([a-zA-Z0-9]{8})'),\n webpage, 'jwplatform id')\n return self.url_result(\n 'jwplatform:%s' % jwplatform_id, ie=JWPlatformIE.ie_key(),\n", "issue": "JW player downloads seem to be broken\nUsing the latest version 2019.10.29\r\nTried downloading JWPlayer video embedded on this page:\r\nhttps://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3\r\n\r\nHere's the verbose output:\r\n\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'-v', u'-F', u'https://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3?fbclid=IwAR2jOlaH5ADErmCQj44J8BOE-IJfNPAhBgnFPpV-nIOi7DK86sscO4YN9pA']\r\n[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2019.10.29\r\n[debug] Python version 2.7.16 (CPython) - Darwin-18.7.0-x86_64-i386-64bit\r\n[debug] exe versions: rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[BusinessInsider] sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3: Downloading webpage\r\nERROR: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py\", line 796, in extract_info\r\n ie_result = ie.extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 530, in extract\r\n ie_result = self._real_extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/businessinsider.py\", line 39, in _real_extract\r\n webpage, 'jwplatform id')\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 1005, in _search_regex\r\n raise RegexNotFoundError('Unable to extract %s' % _name)\r\nRegexNotFoundError: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n\r\n\r\n\nJW player downloads seem to be broken\nUsing the latest version 2019.10.29\r\nTried downloading JWPlayer video embedded on this page:\r\nhttps://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3\r\n\r\nHere's the verbose output:\r\n\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'-v', u'-F', u'https://www.businessinsider.com/sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3?fbclid=IwAR2jOlaH5ADErmCQj44J8BOE-IJfNPAhBgnFPpV-nIOi7DK86sscO4YN9pA']\r\n[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2019.10.29\r\n[debug] Python version 2.7.16 (CPython) - Darwin-18.7.0-x86_64-i386-64bit\r\n[debug] exe versions: rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[BusinessInsider] sesame-street-mock-trump-best-moments-budget-proposal-pbs-public-funding-2017-3: Downloading webpage\r\nERROR: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py\", line 796, in extract_info\r\n ie_result = ie.extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 530, in extract\r\n ie_result = self._real_extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/businessinsider.py\", line 39, in _real_extract\r\n webpage, 'jwplatform id')\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 1005, in _search_regex\r\n raise RegexNotFoundError('Unable to extract %s' % _name)\r\nRegexNotFoundError: Unable to extract jwplatform id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n\r\n\r\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom .jwplatform import JWPlatformIE\n\n\nclass BusinessInsiderIE(InfoExtractor):\n _VALID_URL = r'https?://(?:[^/]+\\.)?businessinsider\\.(?:com|nl)/(?:[^/]+/)*(?P<id>[^/?#&]+)'\n _TESTS = [{\n 'url': 'http://uk.businessinsider.com/how-much-radiation-youre-exposed-to-in-everyday-life-2016-6',\n 'md5': 'ca237a53a8eb20b6dc5bd60564d4ab3e',\n 'info_dict': {\n 'id': 'hZRllCfw',\n 'ext': 'mp4',\n 'title': \"Here's how much radiation you're exposed to in everyday life\",\n 'description': 'md5:9a0d6e2c279948aadaa5e84d6d9b99bd',\n 'upload_date': '20170709',\n 'timestamp': 1499606400,\n },\n 'params': {\n 'skip_download': True,\n },\n }, {\n 'url': 'https://www.businessinsider.nl/5-scientifically-proven-things-make-you-less-attractive-2017-7/',\n 'only_matching': True,\n }, {\n 'url': 'http://www.businessinsider.com/excel-index-match-vlookup-video-how-to-2015-2?IR=T',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(url, video_id)\n jwplatform_id = self._search_regex(\n (r'data-media-id=[\"\\']([a-zA-Z0-9]{8})',\n r'id=[\"\\']jwplayer_([a-zA-Z0-9]{8})',\n r'id[\"\\']?\\s*:\\s*[\"\\']?([a-zA-Z0-9]{8})'),\n webpage, 'jwplatform id')\n return self.url_result(\n 'jwplatform:%s' % jwplatform_id, ie=JWPlatformIE.ie_key(),\n video_id=video_id)\n", "path": "youtube_dl/extractor/businessinsider.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom .jwplatform import JWPlatformIE\n\n\nclass BusinessInsiderIE(InfoExtractor):\n _VALID_URL = r'https?://(?:[^/]+\\.)?businessinsider\\.(?:com|nl)/(?:[^/]+/)*(?P<id>[^/?#&]+)'\n _TESTS = [{\n 'url': 'http://uk.businessinsider.com/how-much-radiation-youre-exposed-to-in-everyday-life-2016-6',\n 'md5': 'ffed3e1e12a6f950aa2f7d83851b497a',\n 'info_dict': {\n 'id': 'cjGDb0X9',\n 'ext': 'mp4',\n 'title': \"Bananas give you more radiation exposure than living next to a nuclear power plant\",\n 'description': 'md5:0175a3baf200dd8fa658f94cade841b3',\n 'upload_date': '20160611',\n 'timestamp': 1465675620,\n },\n }, {\n 'url': 'https://www.businessinsider.nl/5-scientifically-proven-things-make-you-less-attractive-2017-7/',\n 'md5': '43f438dbc6da0b89f5ac42f68529d84a',\n 'info_dict': {\n 'id': '5zJwd4FK',\n 'ext': 'mp4',\n 'title': 'Deze dingen zorgen ervoor dat je minder snel een date scoort',\n 'description': 'md5:2af8975825d38a4fed24717bbe51db49',\n 'upload_date': '20170705',\n 'timestamp': 1499270528,\n },\n }, {\n 'url': 'http://www.businessinsider.com/excel-index-match-vlookup-video-how-to-2015-2?IR=T',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(url, video_id)\n jwplatform_id = self._search_regex(\n (r'data-media-id=[\"\\']([a-zA-Z0-9]{8})',\n r'id=[\"\\']jwplayer_([a-zA-Z0-9]{8})',\n r'id[\"\\']?\\s*:\\s*[\"\\']?([a-zA-Z0-9]{8})',\n r'(?:jwplatform\\.com/players/|jwplayer_)([a-zA-Z0-9]{8})'),\n webpage, 'jwplatform id')\n return self.url_result(\n 'jwplatform:%s' % jwplatform_id, ie=JWPlatformIE.ie_key(),\n video_id=video_id)\n", "path": "youtube_dl/extractor/businessinsider.py"}]}
| 2,152 | 898 |
gh_patches_debug_23704
|
rasdani/github-patches
|
git_diff
|
dj-stripe__dj-stripe-222
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove subscriber__email from search_fields
> DJSTRIPE_SUBSCRIBER_MODEL must have an email field. If your existing model has no email field, add an email property that defines an email address to use.
Since the `DJSTRIPE_SUBSCRIBER_MODEL` could have email as a property we probably shouldn't be assuming `subscriber__email` in admin `search_fields`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `djstripe/admin.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Note: Django 1.4 support was dropped in #107
4 https://github.com/pydanny/dj-stripe/pull/107
5 """
6
7 from django.contrib import admin
8
9 from .models import Event, EventProcessingException, Transfer, Charge, Plan
10 from .models import Invoice, InvoiceItem, CurrentSubscription, Customer
11
12
13 class CustomerHasCardListFilter(admin.SimpleListFilter):
14 title = "card presence"
15 parameter_name = "has_card"
16
17 def lookups(self, request, model_admin):
18 return [
19 ["yes", "Has Card"],
20 ["no", "Does Not Have a Card"]
21 ]
22
23 def queryset(self, request, queryset):
24 if self.value() == "yes":
25 return queryset.exclude(card_fingerprint="")
26 if self.value() == "no":
27 return queryset.filter(card_fingerprint="")
28
29
30 class InvoiceCustomerHasCardListFilter(admin.SimpleListFilter):
31 title = "card presence"
32 parameter_name = "has_card"
33
34 def lookups(self, request, model_admin):
35 return [
36 ["yes", "Has Card"],
37 ["no", "Does Not Have a Card"]
38 ]
39
40 def queryset(self, request, queryset):
41 if self.value() == "yes":
42 return queryset.exclude(customer__card_fingerprint="")
43 if self.value() == "no":
44 return queryset.filter(customer__card_fingerprint="")
45
46
47 class CustomerSubscriptionStatusListFilter(admin.SimpleListFilter):
48 title = "subscription status"
49 parameter_name = "sub_status"
50
51 def lookups(self, request, model_admin):
52 statuses = [
53 [x, x.replace("_", " ").title()]
54 for x in CurrentSubscription.objects.all().values_list(
55 "status",
56 flat=True
57 ).distinct()
58 ]
59 statuses.append(["none", "No Subscription"])
60 return statuses
61
62 def queryset(self, request, queryset):
63 if self.value() is None:
64 return queryset.all()
65 else:
66 return queryset.filter(current_subscription__status=self.value())
67
68
69 def send_charge_receipt(modeladmin, request, queryset):
70 """
71 Function for sending receipts from the admin if a receipt is not sent for
72 a specific charge.
73 """
74 for charge in queryset:
75 charge.send_receipt()
76
77
78 admin.site.register(
79 Charge,
80 readonly_fields=('created',),
81 list_display=[
82 "stripe_id",
83 "customer",
84 "amount",
85 "description",
86 "paid",
87 "disputed",
88 "refunded",
89 "fee",
90 "receipt_sent",
91 "created"
92 ],
93 search_fields=[
94 "stripe_id",
95 "customer__stripe_id",
96 "customer__subscriber__email",
97 "card_last_4",
98 "invoice__stripe_id"
99 ],
100 list_filter=[
101 "paid",
102 "disputed",
103 "refunded",
104 "card_kind",
105 "created"
106 ],
107 raw_id_fields=[
108 "customer",
109 "invoice"
110 ],
111 actions=(send_charge_receipt,),
112 )
113
114 admin.site.register(
115 EventProcessingException,
116 readonly_fields=('created',),
117 list_display=[
118 "message",
119 "event",
120 "created"
121 ],
122 search_fields=[
123 "message",
124 "traceback",
125 "data"
126 ],
127 )
128
129 admin.site.register(
130 Event,
131 raw_id_fields=["customer"],
132 readonly_fields=('created',),
133 list_display=[
134 "stripe_id",
135 "kind",
136 "livemode",
137 "valid",
138 "processed",
139 "created"
140 ],
141 list_filter=[
142 "kind",
143 "created",
144 "valid",
145 "processed"
146 ],
147 search_fields=[
148 "stripe_id",
149 "customer__stripe_id",
150 "customer__subscriber__email",
151 "validated_message"
152 ],
153 )
154
155
156 class CurrentSubscriptionInline(admin.TabularInline):
157 model = CurrentSubscription
158
159
160 def subscription_status(obj):
161 return obj.current_subscription.status
162 subscription_status.short_description = "Subscription Status"
163
164
165 admin.site.register(
166 Customer,
167 raw_id_fields=["subscriber"],
168 readonly_fields=('created',),
169 list_display=[
170 "stripe_id",
171 "subscriber",
172 "card_kind",
173 "card_last_4",
174 subscription_status,
175 "created"
176 ],
177 list_filter=[
178 "card_kind",
179 CustomerHasCardListFilter,
180 CustomerSubscriptionStatusListFilter
181 ],
182 search_fields=[
183 "stripe_id",
184 "subscriber__email"
185 ],
186 inlines=[CurrentSubscriptionInline]
187 )
188
189
190 class InvoiceItemInline(admin.TabularInline):
191 model = InvoiceItem
192
193
194 def customer_has_card(obj):
195 """ Returns True if the customer has a card attached to its account."""
196 return obj.customer.card_fingerprint != ""
197 customer_has_card.short_description = "Customer Has Card"
198
199
200 def customer_email(obj):
201 """ Returns a string representation of the customer's email."""
202 return str(obj.customer.subscriber.email)
203 customer_email.short_description = "Customer"
204
205
206 admin.site.register(
207 Invoice,
208 raw_id_fields=["customer"],
209 readonly_fields=('created',),
210 list_display=[
211 "stripe_id",
212 "paid",
213 "closed",
214 customer_email,
215 customer_has_card,
216 "period_start",
217 "period_end",
218 "subtotal",
219 "total",
220 "created"
221 ],
222 search_fields=[
223 "stripe_id",
224 "customer__stripe_id",
225 "customer__subscriber__email"
226 ],
227 list_filter=[
228 InvoiceCustomerHasCardListFilter,
229 "paid",
230 "closed",
231 "attempted",
232 "attempts",
233 "created",
234 "date",
235 "period_end",
236 "total"
237 ],
238 inlines=[InvoiceItemInline]
239 )
240
241
242 admin.site.register(
243 Transfer,
244 raw_id_fields=["event"],
245 readonly_fields=('created',),
246 list_display=[
247 "stripe_id",
248 "amount",
249 "status",
250 "date",
251 "description",
252 "created"
253 ],
254 search_fields=[
255 "stripe_id",
256 "event__stripe_id"
257 ]
258 )
259
260
261 class PlanAdmin(admin.ModelAdmin):
262
263 def save_model(self, request, obj, form, change):
264 """Update or create objects using our custom methods that
265 sync with Stripe."""
266
267 if change:
268 obj.update_name()
269
270 else:
271 Plan.get_or_create(**form.cleaned_data)
272
273 def get_readonly_fields(self, request, obj=None):
274 readonly_fields = list(self.readonly_fields)
275 if obj:
276 readonly_fields.extend([
277 'stripe_id',
278 'amount',
279 'currency',
280 'interval',
281 'interval_count',
282 'trial_period_days'])
283
284 return readonly_fields
285
286 admin.site.register(Plan, PlanAdmin)
287
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/djstripe/admin.py b/djstripe/admin.py
--- a/djstripe/admin.py
+++ b/djstripe/admin.py
@@ -93,7 +93,6 @@
search_fields=[
"stripe_id",
"customer__stripe_id",
- "customer__subscriber__email",
"card_last_4",
"invoice__stripe_id"
],
@@ -147,7 +146,6 @@
search_fields=[
"stripe_id",
"customer__stripe_id",
- "customer__subscriber__email",
"validated_message"
],
)
@@ -180,8 +178,7 @@
CustomerSubscriptionStatusListFilter
],
search_fields=[
- "stripe_id",
- "subscriber__email"
+ "stripe_id"
],
inlines=[CurrentSubscriptionInline]
)
@@ -221,8 +218,7 @@
],
search_fields=[
"stripe_id",
- "customer__stripe_id",
- "customer__subscriber__email"
+ "customer__stripe_id"
],
list_filter=[
InvoiceCustomerHasCardListFilter,
|
{"golden_diff": "diff --git a/djstripe/admin.py b/djstripe/admin.py\n--- a/djstripe/admin.py\n+++ b/djstripe/admin.py\n@@ -93,7 +93,6 @@\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n- \"customer__subscriber__email\",\n \"card_last_4\",\n \"invoice__stripe_id\"\n ],\n@@ -147,7 +146,6 @@\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n- \"customer__subscriber__email\",\n \"validated_message\"\n ],\n )\n@@ -180,8 +178,7 @@\n CustomerSubscriptionStatusListFilter\n ],\n search_fields=[\n- \"stripe_id\",\n- \"subscriber__email\"\n+ \"stripe_id\"\n ],\n inlines=[CurrentSubscriptionInline]\n )\n@@ -221,8 +218,7 @@\n ],\n search_fields=[\n \"stripe_id\",\n- \"customer__stripe_id\",\n- \"customer__subscriber__email\"\n+ \"customer__stripe_id\"\n ],\n list_filter=[\n InvoiceCustomerHasCardListFilter,\n", "issue": "Remove subscriber__email from search_fields\n> DJSTRIPE_SUBSCRIBER_MODEL must have an email field. If your existing model has no email field, add an email property that defines an email address to use.\n\nSince the `DJSTRIPE_SUBSCRIBER_MODEL` could have email as a property we probably shouldn't be assuming `subscriber__email` in admin `search_fields`.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nNote: Django 1.4 support was dropped in #107\n https://github.com/pydanny/dj-stripe/pull/107\n\"\"\"\n\nfrom django.contrib import admin\n\nfrom .models import Event, EventProcessingException, Transfer, Charge, Plan\nfrom .models import Invoice, InvoiceItem, CurrentSubscription, Customer\n\n\nclass CustomerHasCardListFilter(admin.SimpleListFilter):\n title = \"card presence\"\n parameter_name = \"has_card\"\n\n def lookups(self, request, model_admin):\n return [\n [\"yes\", \"Has Card\"],\n [\"no\", \"Does Not Have a Card\"]\n ]\n\n def queryset(self, request, queryset):\n if self.value() == \"yes\":\n return queryset.exclude(card_fingerprint=\"\")\n if self.value() == \"no\":\n return queryset.filter(card_fingerprint=\"\")\n\n\nclass InvoiceCustomerHasCardListFilter(admin.SimpleListFilter):\n title = \"card presence\"\n parameter_name = \"has_card\"\n\n def lookups(self, request, model_admin):\n return [\n [\"yes\", \"Has Card\"],\n [\"no\", \"Does Not Have a Card\"]\n ]\n\n def queryset(self, request, queryset):\n if self.value() == \"yes\":\n return queryset.exclude(customer__card_fingerprint=\"\")\n if self.value() == \"no\":\n return queryset.filter(customer__card_fingerprint=\"\")\n\n\nclass CustomerSubscriptionStatusListFilter(admin.SimpleListFilter):\n title = \"subscription status\"\n parameter_name = \"sub_status\"\n\n def lookups(self, request, model_admin):\n statuses = [\n [x, x.replace(\"_\", \" \").title()]\n for x in CurrentSubscription.objects.all().values_list(\n \"status\",\n flat=True\n ).distinct()\n ]\n statuses.append([\"none\", \"No Subscription\"])\n return statuses\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset.all()\n else:\n return queryset.filter(current_subscription__status=self.value())\n\n\ndef send_charge_receipt(modeladmin, request, queryset):\n \"\"\"\n Function for sending receipts from the admin if a receipt is not sent for\n a specific charge.\n \"\"\"\n for charge in queryset:\n charge.send_receipt()\n\n\nadmin.site.register(\n Charge,\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"customer\",\n \"amount\",\n \"description\",\n \"paid\",\n \"disputed\",\n \"refunded\",\n \"fee\",\n \"receipt_sent\",\n \"created\"\n ],\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n \"customer__subscriber__email\",\n \"card_last_4\",\n \"invoice__stripe_id\"\n ],\n list_filter=[\n \"paid\",\n \"disputed\",\n \"refunded\",\n \"card_kind\",\n \"created\"\n ],\n raw_id_fields=[\n \"customer\",\n \"invoice\"\n ],\n actions=(send_charge_receipt,),\n)\n\nadmin.site.register(\n EventProcessingException,\n readonly_fields=('created',),\n list_display=[\n \"message\",\n \"event\",\n \"created\"\n ],\n search_fields=[\n \"message\",\n \"traceback\",\n \"data\"\n ],\n)\n\nadmin.site.register(\n Event,\n raw_id_fields=[\"customer\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"kind\",\n \"livemode\",\n \"valid\",\n \"processed\",\n \"created\"\n ],\n list_filter=[\n \"kind\",\n \"created\",\n \"valid\",\n \"processed\"\n ],\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n \"customer__subscriber__email\",\n \"validated_message\"\n ],\n)\n\n\nclass CurrentSubscriptionInline(admin.TabularInline):\n model = CurrentSubscription\n\n\ndef subscription_status(obj):\n return obj.current_subscription.status\nsubscription_status.short_description = \"Subscription Status\"\n\n\nadmin.site.register(\n Customer,\n raw_id_fields=[\"subscriber\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"subscriber\",\n \"card_kind\",\n \"card_last_4\",\n subscription_status,\n \"created\"\n ],\n list_filter=[\n \"card_kind\",\n CustomerHasCardListFilter,\n CustomerSubscriptionStatusListFilter\n ],\n search_fields=[\n \"stripe_id\",\n \"subscriber__email\"\n ],\n inlines=[CurrentSubscriptionInline]\n)\n\n\nclass InvoiceItemInline(admin.TabularInline):\n model = InvoiceItem\n\n\ndef customer_has_card(obj):\n \"\"\" Returns True if the customer has a card attached to its account.\"\"\"\n return obj.customer.card_fingerprint != \"\"\ncustomer_has_card.short_description = \"Customer Has Card\"\n\n\ndef customer_email(obj):\n \"\"\" Returns a string representation of the customer's email.\"\"\"\n return str(obj.customer.subscriber.email)\ncustomer_email.short_description = \"Customer\"\n\n\nadmin.site.register(\n Invoice,\n raw_id_fields=[\"customer\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"paid\",\n \"closed\",\n customer_email,\n customer_has_card,\n \"period_start\",\n \"period_end\",\n \"subtotal\",\n \"total\",\n \"created\"\n ],\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n \"customer__subscriber__email\"\n ],\n list_filter=[\n InvoiceCustomerHasCardListFilter,\n \"paid\",\n \"closed\",\n \"attempted\",\n \"attempts\",\n \"created\",\n \"date\",\n \"period_end\",\n \"total\"\n ],\n inlines=[InvoiceItemInline]\n)\n\n\nadmin.site.register(\n Transfer,\n raw_id_fields=[\"event\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"amount\",\n \"status\",\n \"date\",\n \"description\",\n \"created\"\n ],\n search_fields=[\n \"stripe_id\",\n \"event__stripe_id\"\n ]\n)\n\n\nclass PlanAdmin(admin.ModelAdmin):\n\n def save_model(self, request, obj, form, change):\n \"\"\"Update or create objects using our custom methods that\n sync with Stripe.\"\"\"\n\n if change:\n obj.update_name()\n\n else:\n Plan.get_or_create(**form.cleaned_data)\n\n def get_readonly_fields(self, request, obj=None):\n readonly_fields = list(self.readonly_fields)\n if obj:\n readonly_fields.extend([\n 'stripe_id',\n 'amount',\n 'currency',\n 'interval',\n 'interval_count',\n 'trial_period_days'])\n\n return readonly_fields\n\nadmin.site.register(Plan, PlanAdmin)\n", "path": "djstripe/admin.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nNote: Django 1.4 support was dropped in #107\n https://github.com/pydanny/dj-stripe/pull/107\n\"\"\"\n\nfrom django.contrib import admin\n\nfrom .models import Event, EventProcessingException, Transfer, Charge, Plan\nfrom .models import Invoice, InvoiceItem, CurrentSubscription, Customer\n\n\nclass CustomerHasCardListFilter(admin.SimpleListFilter):\n title = \"card presence\"\n parameter_name = \"has_card\"\n\n def lookups(self, request, model_admin):\n return [\n [\"yes\", \"Has Card\"],\n [\"no\", \"Does Not Have a Card\"]\n ]\n\n def queryset(self, request, queryset):\n if self.value() == \"yes\":\n return queryset.exclude(card_fingerprint=\"\")\n if self.value() == \"no\":\n return queryset.filter(card_fingerprint=\"\")\n\n\nclass InvoiceCustomerHasCardListFilter(admin.SimpleListFilter):\n title = \"card presence\"\n parameter_name = \"has_card\"\n\n def lookups(self, request, model_admin):\n return [\n [\"yes\", \"Has Card\"],\n [\"no\", \"Does Not Have a Card\"]\n ]\n\n def queryset(self, request, queryset):\n if self.value() == \"yes\":\n return queryset.exclude(customer__card_fingerprint=\"\")\n if self.value() == \"no\":\n return queryset.filter(customer__card_fingerprint=\"\")\n\n\nclass CustomerSubscriptionStatusListFilter(admin.SimpleListFilter):\n title = \"subscription status\"\n parameter_name = \"sub_status\"\n\n def lookups(self, request, model_admin):\n statuses = [\n [x, x.replace(\"_\", \" \").title()]\n for x in CurrentSubscription.objects.all().values_list(\n \"status\",\n flat=True\n ).distinct()\n ]\n statuses.append([\"none\", \"No Subscription\"])\n return statuses\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset.all()\n else:\n return queryset.filter(current_subscription__status=self.value())\n\n\ndef send_charge_receipt(modeladmin, request, queryset):\n \"\"\"\n Function for sending receipts from the admin if a receipt is not sent for\n a specific charge.\n \"\"\"\n for charge in queryset:\n charge.send_receipt()\n\n\nadmin.site.register(\n Charge,\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"customer\",\n \"amount\",\n \"description\",\n \"paid\",\n \"disputed\",\n \"refunded\",\n \"fee\",\n \"receipt_sent\",\n \"created\"\n ],\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n \"card_last_4\",\n \"invoice__stripe_id\"\n ],\n list_filter=[\n \"paid\",\n \"disputed\",\n \"refunded\",\n \"card_kind\",\n \"created\"\n ],\n raw_id_fields=[\n \"customer\",\n \"invoice\"\n ],\n actions=(send_charge_receipt,),\n)\n\nadmin.site.register(\n EventProcessingException,\n readonly_fields=('created',),\n list_display=[\n \"message\",\n \"event\",\n \"created\"\n ],\n search_fields=[\n \"message\",\n \"traceback\",\n \"data\"\n ],\n)\n\nadmin.site.register(\n Event,\n raw_id_fields=[\"customer\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"kind\",\n \"livemode\",\n \"valid\",\n \"processed\",\n \"created\"\n ],\n list_filter=[\n \"kind\",\n \"created\",\n \"valid\",\n \"processed\"\n ],\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\",\n \"validated_message\"\n ],\n)\n\n\nclass CurrentSubscriptionInline(admin.TabularInline):\n model = CurrentSubscription\n\n\ndef subscription_status(obj):\n return obj.current_subscription.status\nsubscription_status.short_description = \"Subscription Status\"\n\n\nadmin.site.register(\n Customer,\n raw_id_fields=[\"subscriber\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"subscriber\",\n \"card_kind\",\n \"card_last_4\",\n subscription_status,\n \"created\"\n ],\n list_filter=[\n \"card_kind\",\n CustomerHasCardListFilter,\n CustomerSubscriptionStatusListFilter\n ],\n search_fields=[\n \"stripe_id\"\n ],\n inlines=[CurrentSubscriptionInline]\n)\n\n\nclass InvoiceItemInline(admin.TabularInline):\n model = InvoiceItem\n\n\ndef customer_has_card(obj):\n \"\"\" Returns True if the customer has a card attached to its account.\"\"\"\n return obj.customer.card_fingerprint != \"\"\ncustomer_has_card.short_description = \"Customer Has Card\"\n\n\ndef customer_email(obj):\n \"\"\" Returns a string representation of the customer's email.\"\"\"\n return str(obj.customer.subscriber.email)\ncustomer_email.short_description = \"Customer\"\n\n\nadmin.site.register(\n Invoice,\n raw_id_fields=[\"customer\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"paid\",\n \"closed\",\n customer_email,\n customer_has_card,\n \"period_start\",\n \"period_end\",\n \"subtotal\",\n \"total\",\n \"created\"\n ],\n search_fields=[\n \"stripe_id\",\n \"customer__stripe_id\"\n ],\n list_filter=[\n InvoiceCustomerHasCardListFilter,\n \"paid\",\n \"closed\",\n \"attempted\",\n \"attempts\",\n \"created\",\n \"date\",\n \"period_end\",\n \"total\"\n ],\n inlines=[InvoiceItemInline]\n)\n\n\nadmin.site.register(\n Transfer,\n raw_id_fields=[\"event\"],\n readonly_fields=('created',),\n list_display=[\n \"stripe_id\",\n \"amount\",\n \"status\",\n \"date\",\n \"description\",\n \"created\"\n ],\n search_fields=[\n \"stripe_id\",\n \"event__stripe_id\"\n ]\n)\n\n\nclass PlanAdmin(admin.ModelAdmin):\n\n def save_model(self, request, obj, form, change):\n \"\"\"Update or create objects using our custom methods that\n sync with Stripe.\"\"\"\n\n if change:\n obj.update_name()\n\n else:\n Plan.get_or_create(**form.cleaned_data)\n\n def get_readonly_fields(self, request, obj=None):\n readonly_fields = list(self.readonly_fields)\n if obj:\n readonly_fields.extend([\n 'stripe_id',\n 'amount',\n 'currency',\n 'interval',\n 'interval_count',\n 'trial_period_days'])\n\n return readonly_fields\n\nadmin.site.register(Plan, PlanAdmin)\n", "path": "djstripe/admin.py"}]}
| 2,516 | 253 |
gh_patches_debug_42993
|
rasdani/github-patches
|
git_diff
|
openvinotoolkit__datumaro-403
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cvat_format/extractor type casting value to float, causing issues
We have a text type attribute for a bounding box label in CVAT. The values for this attribute are all digits some of which start with zeros. Ex: 0012345, 0123456, 1234567, etc.
We are using datumaro to automatically do some checks on the annotations imported from CVAT. It looks like the extractor for CVAT is trying to typecast all imported numeric [attribute values to float](https://github.com/openvinotoolkit/datumaro/blob/6a2022ed467c7557fb2055c143452bc4ca7f6e86/datumaro/plugins/cvat_format/extractor.py#L96). This is causing an issue for us since this removes the leading zeros automatically from the value, changing user input.
Is there any reason behind typecasting the the attribute value to float? Can this typecasting step be deleted. If required a user can always do the typecasting later.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `datumaro/plugins/cvat_format/extractor.py`
Content:
```
1 # Copyright (C) 2019-2020 Intel Corporation
2 #
3 # SPDX-License-Identifier: MIT
4
5 from collections import OrderedDict
6 import os.path as osp
7
8 from defusedxml import ElementTree
9
10 from datumaro.components.extractor import (
11 AnnotationType, Bbox, DatasetItem, Importer, Label, LabelCategories, Points,
12 Polygon, PolyLine, SourceExtractor,
13 )
14 from datumaro.util.image import Image
15
16 from .format import CvatPath
17
18
19 class CvatExtractor(SourceExtractor):
20 _SUPPORTED_SHAPES = ('box', 'polygon', 'polyline', 'points')
21
22 def __init__(self, path, subset=None):
23 assert osp.isfile(path), path
24 rootpath = osp.dirname(path)
25 images_dir = ''
26 if osp.isdir(osp.join(rootpath, CvatPath.IMAGES_DIR)):
27 images_dir = osp.join(rootpath, CvatPath.IMAGES_DIR)
28 self._images_dir = images_dir
29 self._path = path
30
31 if not subset:
32 subset = osp.splitext(osp.basename(path))[0]
33 super().__init__(subset=subset)
34
35 items, categories = self._parse(path)
36 self._items = list(self._load_items(items).values())
37 self._categories = categories
38
39 @classmethod
40 def _parse(cls, path):
41 context = ElementTree.iterparse(path, events=("start", "end"))
42 context = iter(context)
43
44 categories, frame_size = cls._parse_meta(context)
45
46 items = OrderedDict()
47
48 track = None
49 shape = None
50 tag = None
51 attributes = None
52 image = None
53 for ev, el in context:
54 if ev == 'start':
55 if el.tag == 'track':
56 track = {
57 'id': el.attrib['id'],
58 'label': el.attrib.get('label'),
59 'group': int(el.attrib.get('group_id', 0)),
60 'height': frame_size[0],
61 'width': frame_size[1],
62 }
63 elif el.tag == 'image':
64 image = {
65 'name': el.attrib.get('name'),
66 'frame': el.attrib['id'],
67 'width': el.attrib.get('width'),
68 'height': el.attrib.get('height'),
69 }
70 elif el.tag in cls._SUPPORTED_SHAPES and (track or image):
71 attributes = {}
72 shape = {
73 'type': None,
74 'attributes': attributes,
75 }
76 if track:
77 shape.update(track)
78 shape['track_id'] = int(track['id'])
79 if image:
80 shape.update(image)
81 elif el.tag == 'tag' and image:
82 attributes = {}
83 tag = {
84 'frame': image['frame'],
85 'attributes': attributes,
86 'group': int(el.attrib.get('group_id', 0)),
87 'label': el.attrib['label'],
88 }
89 elif ev == 'end':
90 if el.tag == 'attribute' and attributes is not None:
91 attr_value = el.text or ''
92 if el.text in ['true', 'false']:
93 attr_value = attr_value == 'true'
94 else:
95 try:
96 attr_value = float(attr_value)
97 except ValueError:
98 pass
99 attributes[el.attrib['name']] = attr_value
100 elif el.tag in cls._SUPPORTED_SHAPES:
101 if track is not None:
102 shape['frame'] = el.attrib['frame']
103 shape['outside'] = (el.attrib.get('outside') == '1')
104 shape['keyframe'] = (el.attrib.get('keyframe') == '1')
105 if image is not None:
106 shape['label'] = el.attrib.get('label')
107 shape['group'] = int(el.attrib.get('group_id', 0))
108
109 shape['type'] = el.tag
110 shape['occluded'] = (el.attrib.get('occluded') == '1')
111 shape['z_order'] = int(el.attrib.get('z_order', 0))
112
113 if el.tag == 'box':
114 shape['points'] = list(map(float, [
115 el.attrib['xtl'], el.attrib['ytl'],
116 el.attrib['xbr'], el.attrib['ybr'],
117 ]))
118 else:
119 shape['points'] = []
120 for pair in el.attrib['points'].split(';'):
121 shape['points'].extend(map(float, pair.split(',')))
122
123 frame_desc = items.get(shape['frame'], {'annotations': []})
124 frame_desc['annotations'].append(
125 cls._parse_shape_ann(shape, categories))
126 items[shape['frame']] = frame_desc
127 shape = None
128
129 elif el.tag == 'tag':
130 frame_desc = items.get(tag['frame'], {'annotations': []})
131 frame_desc['annotations'].append(
132 cls._parse_tag_ann(tag, categories))
133 items[tag['frame']] = frame_desc
134 tag = None
135 elif el.tag == 'track':
136 track = None
137 elif el.tag == 'image':
138 frame_desc = items.get(image['frame'], {'annotations': []})
139 frame_desc.update({
140 'name': image.get('name'),
141 'height': image.get('height'),
142 'width': image.get('width'),
143 })
144 items[image['frame']] = frame_desc
145 image = None
146 el.clear()
147
148 return items, categories
149
150 @staticmethod
151 def _parse_meta(context):
152 ev, el = next(context)
153 if not (ev == 'start' and el.tag == 'annotations'):
154 raise Exception("Unexpected token ")
155
156 categories = {}
157
158 frame_size = None
159 mode = None
160 labels = OrderedDict()
161 label = None
162
163 # Recursive descent parser
164 el = None
165 states = ['annotations']
166 def accepted(expected_state, tag, next_state=None):
167 state = states[-1]
168 if state == expected_state and el is not None and el.tag == tag:
169 if not next_state:
170 next_state = tag
171 states.append(next_state)
172 return True
173 return False
174 def consumed(expected_state, tag):
175 state = states[-1]
176 if state == expected_state and el is not None and el.tag == tag:
177 states.pop()
178 return True
179 return False
180
181 for ev, el in context:
182 if ev == 'start':
183 if accepted('annotations', 'meta'): pass
184 elif accepted('meta', 'task'): pass
185 elif accepted('task', 'mode'): pass
186 elif accepted('task', 'original_size'):
187 frame_size = [None, None]
188 elif accepted('original_size', 'height', next_state='frame_height'): pass
189 elif accepted('original_size', 'width', next_state='frame_width'): pass
190 elif accepted('task', 'labels'): pass
191 elif accepted('labels', 'label'):
192 label = { 'name': None, 'attributes': set() }
193 elif accepted('label', 'name', next_state='label_name'): pass
194 elif accepted('label', 'attributes'): pass
195 elif accepted('attributes', 'attribute'): pass
196 elif accepted('attribute', 'name', next_state='attr_name'): pass
197 elif accepted('annotations', 'image') or \
198 accepted('annotations', 'track') or \
199 accepted('annotations', 'tag'):
200 break
201 else:
202 pass
203 elif ev == 'end':
204 if consumed('meta', 'meta'):
205 break
206 elif consumed('task', 'task'): pass
207 elif consumed('mode', 'mode'):
208 mode = el.text
209 elif consumed('original_size', 'original_size'): pass
210 elif consumed('frame_height', 'height'):
211 frame_size[0] = int(el.text)
212 elif consumed('frame_width', 'width'):
213 frame_size[1] = int(el.text)
214 elif consumed('label_name', 'name'):
215 label['name'] = el.text
216 elif consumed('attr_name', 'name'):
217 label['attributes'].add(el.text)
218 elif consumed('attribute', 'attribute'): pass
219 elif consumed('attributes', 'attributes'): pass
220 elif consumed('label', 'label'):
221 labels[label['name']] = label['attributes']
222 label = None
223 elif consumed('labels', 'labels'): pass
224 else:
225 pass
226
227 assert len(states) == 1 and states[0] == 'annotations', \
228 "Expected 'meta' section in the annotation file, path: %s" % states
229
230 common_attrs = ['occluded']
231 if mode == 'interpolation':
232 common_attrs.append('keyframe')
233 common_attrs.append('outside')
234 common_attrs.append('track_id')
235
236 label_cat = LabelCategories(attributes=common_attrs)
237 for label, attrs in labels.items():
238 label_cat.add(label, attributes=attrs)
239
240 categories[AnnotationType.label] = label_cat
241
242 return categories, frame_size
243
244 @classmethod
245 def _parse_shape_ann(cls, ann, categories):
246 ann_id = ann.get('id', 0)
247 ann_type = ann['type']
248
249 attributes = ann.get('attributes') or {}
250 if 'occluded' in categories[AnnotationType.label].attributes:
251 attributes['occluded'] = ann.get('occluded', False)
252 if 'outside' in ann:
253 attributes['outside'] = ann['outside']
254 if 'keyframe' in ann:
255 attributes['keyframe'] = ann['keyframe']
256 if 'track_id' in ann:
257 attributes['track_id'] = ann['track_id']
258
259 group = ann.get('group')
260
261 label = ann.get('label')
262 label_id = categories[AnnotationType.label].find(label)[0]
263
264 z_order = ann.get('z_order', 0)
265 points = ann.get('points', [])
266
267 if ann_type == 'polyline':
268 return PolyLine(points, label=label_id, z_order=z_order,
269 id=ann_id, attributes=attributes, group=group)
270
271 elif ann_type == 'polygon':
272 return Polygon(points, label=label_id, z_order=z_order,
273 id=ann_id, attributes=attributes, group=group)
274
275 elif ann_type == 'points':
276 return Points(points, label=label_id, z_order=z_order,
277 id=ann_id, attributes=attributes, group=group)
278
279 elif ann_type == 'box':
280 x, y = points[0], points[1]
281 w, h = points[2] - x, points[3] - y
282 return Bbox(x, y, w, h, label=label_id, z_order=z_order,
283 id=ann_id, attributes=attributes, group=group)
284
285 else:
286 raise NotImplementedError("Unknown annotation type '%s'" % ann_type)
287
288 @classmethod
289 def _parse_tag_ann(cls, ann, categories):
290 label = ann.get('label')
291 label_id = categories[AnnotationType.label].find(label)[0]
292 group = ann.get('group')
293 attributes = ann.get('attributes')
294 return Label(label_id, attributes=attributes, group=group)
295
296 def _load_items(self, parsed):
297 for frame_id, item_desc in parsed.items():
298 name = item_desc.get('name', 'frame_%06d.png' % int(frame_id))
299 image = osp.join(self._images_dir, name)
300 image_size = (item_desc.get('height'), item_desc.get('width'))
301 if all(image_size):
302 image = Image(path=image, size=tuple(map(int, image_size)))
303
304 parsed[frame_id] = DatasetItem(id=osp.splitext(name)[0],
305 subset=self._subset, image=image,
306 annotations=item_desc.get('annotations'),
307 attributes={'frame': int(frame_id)})
308 return parsed
309
310 class CvatImporter(Importer):
311 @classmethod
312 def find_sources(cls, path):
313 return cls._find_sources_recursive(path, '.xml', 'cvat')
314
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/datumaro/plugins/cvat_format/extractor.py b/datumaro/plugins/cvat_format/extractor.py
--- a/datumaro/plugins/cvat_format/extractor.py
+++ b/datumaro/plugins/cvat_format/extractor.py
@@ -41,7 +41,7 @@
context = ElementTree.iterparse(path, events=("start", "end"))
context = iter(context)
- categories, frame_size = cls._parse_meta(context)
+ categories, frame_size, attribute_types = cls._parse_meta(context)
items = OrderedDict()
@@ -89,9 +89,10 @@
elif ev == 'end':
if el.tag == 'attribute' and attributes is not None:
attr_value = el.text or ''
+ attr_type = attribute_types.get(el.attrib['name'])
if el.text in ['true', 'false']:
attr_value = attr_value == 'true'
- else:
+ elif attr_type is not None and attr_type != 'text':
try:
attr_value = float(attr_value)
except ValueError:
@@ -189,11 +190,12 @@
elif accepted('original_size', 'width', next_state='frame_width'): pass
elif accepted('task', 'labels'): pass
elif accepted('labels', 'label'):
- label = { 'name': None, 'attributes': set() }
+ label = { 'name': None, 'attributes': [] }
elif accepted('label', 'name', next_state='label_name'): pass
elif accepted('label', 'attributes'): pass
elif accepted('attributes', 'attribute'): pass
elif accepted('attribute', 'name', next_state='attr_name'): pass
+ elif accepted('attribute', 'input_type', next_state='attr_type'): pass
elif accepted('annotations', 'image') or \
accepted('annotations', 'track') or \
accepted('annotations', 'tag'):
@@ -214,7 +216,9 @@
elif consumed('label_name', 'name'):
label['name'] = el.text
elif consumed('attr_name', 'name'):
- label['attributes'].add(el.text)
+ label['attributes'].append({'name': el.text})
+ elif consumed('attr_type', 'input_type'):
+ label['attributes'][-1]['input_type'] = el.text
elif consumed('attribute', 'attribute'): pass
elif consumed('attributes', 'attributes'): pass
elif consumed('label', 'label'):
@@ -234,12 +238,15 @@
common_attrs.append('track_id')
label_cat = LabelCategories(attributes=common_attrs)
+ attribute_types = {}
for label, attrs in labels.items():
- label_cat.add(label, attributes=attrs)
+ attr_names = {v['name'] for v in attrs}
+ label_cat.add(label, attributes=attr_names)
+ for attr in attrs:
+ attribute_types[attr['name']] = attr['input_type']
categories[AnnotationType.label] = label_cat
-
- return categories, frame_size
+ return categories, frame_size, attribute_types
@classmethod
def _parse_shape_ann(cls, ann, categories):
|
{"golden_diff": "diff --git a/datumaro/plugins/cvat_format/extractor.py b/datumaro/plugins/cvat_format/extractor.py\n--- a/datumaro/plugins/cvat_format/extractor.py\n+++ b/datumaro/plugins/cvat_format/extractor.py\n@@ -41,7 +41,7 @@\n context = ElementTree.iterparse(path, events=(\"start\", \"end\"))\n context = iter(context)\n \n- categories, frame_size = cls._parse_meta(context)\n+ categories, frame_size, attribute_types = cls._parse_meta(context)\n \n items = OrderedDict()\n \n@@ -89,9 +89,10 @@\n elif ev == 'end':\n if el.tag == 'attribute' and attributes is not None:\n attr_value = el.text or ''\n+ attr_type = attribute_types.get(el.attrib['name'])\n if el.text in ['true', 'false']:\n attr_value = attr_value == 'true'\n- else:\n+ elif attr_type is not None and attr_type != 'text':\n try:\n attr_value = float(attr_value)\n except ValueError:\n@@ -189,11 +190,12 @@\n elif accepted('original_size', 'width', next_state='frame_width'): pass\n elif accepted('task', 'labels'): pass\n elif accepted('labels', 'label'):\n- label = { 'name': None, 'attributes': set() }\n+ label = { 'name': None, 'attributes': [] }\n elif accepted('label', 'name', next_state='label_name'): pass\n elif accepted('label', 'attributes'): pass\n elif accepted('attributes', 'attribute'): pass\n elif accepted('attribute', 'name', next_state='attr_name'): pass\n+ elif accepted('attribute', 'input_type', next_state='attr_type'): pass\n elif accepted('annotations', 'image') or \\\n accepted('annotations', 'track') or \\\n accepted('annotations', 'tag'):\n@@ -214,7 +216,9 @@\n elif consumed('label_name', 'name'):\n label['name'] = el.text\n elif consumed('attr_name', 'name'):\n- label['attributes'].add(el.text)\n+ label['attributes'].append({'name': el.text})\n+ elif consumed('attr_type', 'input_type'):\n+ label['attributes'][-1]['input_type'] = el.text\n elif consumed('attribute', 'attribute'): pass\n elif consumed('attributes', 'attributes'): pass\n elif consumed('label', 'label'):\n@@ -234,12 +238,15 @@\n common_attrs.append('track_id')\n \n label_cat = LabelCategories(attributes=common_attrs)\n+ attribute_types = {}\n for label, attrs in labels.items():\n- label_cat.add(label, attributes=attrs)\n+ attr_names = {v['name'] for v in attrs}\n+ label_cat.add(label, attributes=attr_names)\n+ for attr in attrs:\n+ attribute_types[attr['name']] = attr['input_type']\n \n categories[AnnotationType.label] = label_cat\n-\n- return categories, frame_size\n+ return categories, frame_size, attribute_types\n \n @classmethod\n def _parse_shape_ann(cls, ann, categories):\n", "issue": "cvat_format/extractor type casting value to float, causing issues\nWe have a text type attribute for a bounding box label in CVAT. The values for this attribute are all digits some of which start with zeros. Ex: 0012345, 0123456, 1234567, etc.\r\n\r\nWe are using datumaro to automatically do some checks on the annotations imported from CVAT. It looks like the extractor for CVAT is trying to typecast all imported numeric [attribute values to float](https://github.com/openvinotoolkit/datumaro/blob/6a2022ed467c7557fb2055c143452bc4ca7f6e86/datumaro/plugins/cvat_format/extractor.py#L96). This is causing an issue for us since this removes the leading zeros automatically from the value, changing user input.\r\n\r\nIs there any reason behind typecasting the the attribute value to float? Can this typecasting step be deleted. If required a user can always do the typecasting later. \n", "before_files": [{"content": "# Copyright (C) 2019-2020 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nfrom collections import OrderedDict\nimport os.path as osp\n\nfrom defusedxml import ElementTree\n\nfrom datumaro.components.extractor import (\n AnnotationType, Bbox, DatasetItem, Importer, Label, LabelCategories, Points,\n Polygon, PolyLine, SourceExtractor,\n)\nfrom datumaro.util.image import Image\n\nfrom .format import CvatPath\n\n\nclass CvatExtractor(SourceExtractor):\n _SUPPORTED_SHAPES = ('box', 'polygon', 'polyline', 'points')\n\n def __init__(self, path, subset=None):\n assert osp.isfile(path), path\n rootpath = osp.dirname(path)\n images_dir = ''\n if osp.isdir(osp.join(rootpath, CvatPath.IMAGES_DIR)):\n images_dir = osp.join(rootpath, CvatPath.IMAGES_DIR)\n self._images_dir = images_dir\n self._path = path\n\n if not subset:\n subset = osp.splitext(osp.basename(path))[0]\n super().__init__(subset=subset)\n\n items, categories = self._parse(path)\n self._items = list(self._load_items(items).values())\n self._categories = categories\n\n @classmethod\n def _parse(cls, path):\n context = ElementTree.iterparse(path, events=(\"start\", \"end\"))\n context = iter(context)\n\n categories, frame_size = cls._parse_meta(context)\n\n items = OrderedDict()\n\n track = None\n shape = None\n tag = None\n attributes = None\n image = None\n for ev, el in context:\n if ev == 'start':\n if el.tag == 'track':\n track = {\n 'id': el.attrib['id'],\n 'label': el.attrib.get('label'),\n 'group': int(el.attrib.get('group_id', 0)),\n 'height': frame_size[0],\n 'width': frame_size[1],\n }\n elif el.tag == 'image':\n image = {\n 'name': el.attrib.get('name'),\n 'frame': el.attrib['id'],\n 'width': el.attrib.get('width'),\n 'height': el.attrib.get('height'),\n }\n elif el.tag in cls._SUPPORTED_SHAPES and (track or image):\n attributes = {}\n shape = {\n 'type': None,\n 'attributes': attributes,\n }\n if track:\n shape.update(track)\n shape['track_id'] = int(track['id'])\n if image:\n shape.update(image)\n elif el.tag == 'tag' and image:\n attributes = {}\n tag = {\n 'frame': image['frame'],\n 'attributes': attributes,\n 'group': int(el.attrib.get('group_id', 0)),\n 'label': el.attrib['label'],\n }\n elif ev == 'end':\n if el.tag == 'attribute' and attributes is not None:\n attr_value = el.text or ''\n if el.text in ['true', 'false']:\n attr_value = attr_value == 'true'\n else:\n try:\n attr_value = float(attr_value)\n except ValueError:\n pass\n attributes[el.attrib['name']] = attr_value\n elif el.tag in cls._SUPPORTED_SHAPES:\n if track is not None:\n shape['frame'] = el.attrib['frame']\n shape['outside'] = (el.attrib.get('outside') == '1')\n shape['keyframe'] = (el.attrib.get('keyframe') == '1')\n if image is not None:\n shape['label'] = el.attrib.get('label')\n shape['group'] = int(el.attrib.get('group_id', 0))\n\n shape['type'] = el.tag\n shape['occluded'] = (el.attrib.get('occluded') == '1')\n shape['z_order'] = int(el.attrib.get('z_order', 0))\n\n if el.tag == 'box':\n shape['points'] = list(map(float, [\n el.attrib['xtl'], el.attrib['ytl'],\n el.attrib['xbr'], el.attrib['ybr'],\n ]))\n else:\n shape['points'] = []\n for pair in el.attrib['points'].split(';'):\n shape['points'].extend(map(float, pair.split(',')))\n\n frame_desc = items.get(shape['frame'], {'annotations': []})\n frame_desc['annotations'].append(\n cls._parse_shape_ann(shape, categories))\n items[shape['frame']] = frame_desc\n shape = None\n\n elif el.tag == 'tag':\n frame_desc = items.get(tag['frame'], {'annotations': []})\n frame_desc['annotations'].append(\n cls._parse_tag_ann(tag, categories))\n items[tag['frame']] = frame_desc\n tag = None\n elif el.tag == 'track':\n track = None\n elif el.tag == 'image':\n frame_desc = items.get(image['frame'], {'annotations': []})\n frame_desc.update({\n 'name': image.get('name'),\n 'height': image.get('height'),\n 'width': image.get('width'),\n })\n items[image['frame']] = frame_desc\n image = None\n el.clear()\n\n return items, categories\n\n @staticmethod\n def _parse_meta(context):\n ev, el = next(context)\n if not (ev == 'start' and el.tag == 'annotations'):\n raise Exception(\"Unexpected token \")\n\n categories = {}\n\n frame_size = None\n mode = None\n labels = OrderedDict()\n label = None\n\n # Recursive descent parser\n el = None\n states = ['annotations']\n def accepted(expected_state, tag, next_state=None):\n state = states[-1]\n if state == expected_state and el is not None and el.tag == tag:\n if not next_state:\n next_state = tag\n states.append(next_state)\n return True\n return False\n def consumed(expected_state, tag):\n state = states[-1]\n if state == expected_state and el is not None and el.tag == tag:\n states.pop()\n return True\n return False\n\n for ev, el in context:\n if ev == 'start':\n if accepted('annotations', 'meta'): pass\n elif accepted('meta', 'task'): pass\n elif accepted('task', 'mode'): pass\n elif accepted('task', 'original_size'):\n frame_size = [None, None]\n elif accepted('original_size', 'height', next_state='frame_height'): pass\n elif accepted('original_size', 'width', next_state='frame_width'): pass\n elif accepted('task', 'labels'): pass\n elif accepted('labels', 'label'):\n label = { 'name': None, 'attributes': set() }\n elif accepted('label', 'name', next_state='label_name'): pass\n elif accepted('label', 'attributes'): pass\n elif accepted('attributes', 'attribute'): pass\n elif accepted('attribute', 'name', next_state='attr_name'): pass\n elif accepted('annotations', 'image') or \\\n accepted('annotations', 'track') or \\\n accepted('annotations', 'tag'):\n break\n else:\n pass\n elif ev == 'end':\n if consumed('meta', 'meta'):\n break\n elif consumed('task', 'task'): pass\n elif consumed('mode', 'mode'):\n mode = el.text\n elif consumed('original_size', 'original_size'): pass\n elif consumed('frame_height', 'height'):\n frame_size[0] = int(el.text)\n elif consumed('frame_width', 'width'):\n frame_size[1] = int(el.text)\n elif consumed('label_name', 'name'):\n label['name'] = el.text\n elif consumed('attr_name', 'name'):\n label['attributes'].add(el.text)\n elif consumed('attribute', 'attribute'): pass\n elif consumed('attributes', 'attributes'): pass\n elif consumed('label', 'label'):\n labels[label['name']] = label['attributes']\n label = None\n elif consumed('labels', 'labels'): pass\n else:\n pass\n\n assert len(states) == 1 and states[0] == 'annotations', \\\n \"Expected 'meta' section in the annotation file, path: %s\" % states\n\n common_attrs = ['occluded']\n if mode == 'interpolation':\n common_attrs.append('keyframe')\n common_attrs.append('outside')\n common_attrs.append('track_id')\n\n label_cat = LabelCategories(attributes=common_attrs)\n for label, attrs in labels.items():\n label_cat.add(label, attributes=attrs)\n\n categories[AnnotationType.label] = label_cat\n\n return categories, frame_size\n\n @classmethod\n def _parse_shape_ann(cls, ann, categories):\n ann_id = ann.get('id', 0)\n ann_type = ann['type']\n\n attributes = ann.get('attributes') or {}\n if 'occluded' in categories[AnnotationType.label].attributes:\n attributes['occluded'] = ann.get('occluded', False)\n if 'outside' in ann:\n attributes['outside'] = ann['outside']\n if 'keyframe' in ann:\n attributes['keyframe'] = ann['keyframe']\n if 'track_id' in ann:\n attributes['track_id'] = ann['track_id']\n\n group = ann.get('group')\n\n label = ann.get('label')\n label_id = categories[AnnotationType.label].find(label)[0]\n\n z_order = ann.get('z_order', 0)\n points = ann.get('points', [])\n\n if ann_type == 'polyline':\n return PolyLine(points, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n elif ann_type == 'polygon':\n return Polygon(points, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n elif ann_type == 'points':\n return Points(points, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n elif ann_type == 'box':\n x, y = points[0], points[1]\n w, h = points[2] - x, points[3] - y\n return Bbox(x, y, w, h, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n else:\n raise NotImplementedError(\"Unknown annotation type '%s'\" % ann_type)\n\n @classmethod\n def _parse_tag_ann(cls, ann, categories):\n label = ann.get('label')\n label_id = categories[AnnotationType.label].find(label)[0]\n group = ann.get('group')\n attributes = ann.get('attributes')\n return Label(label_id, attributes=attributes, group=group)\n\n def _load_items(self, parsed):\n for frame_id, item_desc in parsed.items():\n name = item_desc.get('name', 'frame_%06d.png' % int(frame_id))\n image = osp.join(self._images_dir, name)\n image_size = (item_desc.get('height'), item_desc.get('width'))\n if all(image_size):\n image = Image(path=image, size=tuple(map(int, image_size)))\n\n parsed[frame_id] = DatasetItem(id=osp.splitext(name)[0],\n subset=self._subset, image=image,\n annotations=item_desc.get('annotations'),\n attributes={'frame': int(frame_id)})\n return parsed\n\nclass CvatImporter(Importer):\n @classmethod\n def find_sources(cls, path):\n return cls._find_sources_recursive(path, '.xml', 'cvat')\n", "path": "datumaro/plugins/cvat_format/extractor.py"}], "after_files": [{"content": "# Copyright (C) 2019-2020 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nfrom collections import OrderedDict\nimport os.path as osp\n\nfrom defusedxml import ElementTree\n\nfrom datumaro.components.extractor import (\n AnnotationType, Bbox, DatasetItem, Importer, Label, LabelCategories, Points,\n Polygon, PolyLine, SourceExtractor,\n)\nfrom datumaro.util.image import Image\n\nfrom .format import CvatPath\n\n\nclass CvatExtractor(SourceExtractor):\n _SUPPORTED_SHAPES = ('box', 'polygon', 'polyline', 'points')\n\n def __init__(self, path, subset=None):\n assert osp.isfile(path), path\n rootpath = osp.dirname(path)\n images_dir = ''\n if osp.isdir(osp.join(rootpath, CvatPath.IMAGES_DIR)):\n images_dir = osp.join(rootpath, CvatPath.IMAGES_DIR)\n self._images_dir = images_dir\n self._path = path\n\n if not subset:\n subset = osp.splitext(osp.basename(path))[0]\n super().__init__(subset=subset)\n\n items, categories = self._parse(path)\n self._items = list(self._load_items(items).values())\n self._categories = categories\n\n @classmethod\n def _parse(cls, path):\n context = ElementTree.iterparse(path, events=(\"start\", \"end\"))\n context = iter(context)\n\n categories, frame_size, attribute_types = cls._parse_meta(context)\n\n items = OrderedDict()\n\n track = None\n shape = None\n tag = None\n attributes = None\n image = None\n for ev, el in context:\n if ev == 'start':\n if el.tag == 'track':\n track = {\n 'id': el.attrib['id'],\n 'label': el.attrib.get('label'),\n 'group': int(el.attrib.get('group_id', 0)),\n 'height': frame_size[0],\n 'width': frame_size[1],\n }\n elif el.tag == 'image':\n image = {\n 'name': el.attrib.get('name'),\n 'frame': el.attrib['id'],\n 'width': el.attrib.get('width'),\n 'height': el.attrib.get('height'),\n }\n elif el.tag in cls._SUPPORTED_SHAPES and (track or image):\n attributes = {}\n shape = {\n 'type': None,\n 'attributes': attributes,\n }\n if track:\n shape.update(track)\n shape['track_id'] = int(track['id'])\n if image:\n shape.update(image)\n elif el.tag == 'tag' and image:\n attributes = {}\n tag = {\n 'frame': image['frame'],\n 'attributes': attributes,\n 'group': int(el.attrib.get('group_id', 0)),\n 'label': el.attrib['label'],\n }\n elif ev == 'end':\n if el.tag == 'attribute' and attributes is not None:\n attr_value = el.text or ''\n attr_type = attribute_types.get(el.attrib['name'])\n if el.text in ['true', 'false']:\n attr_value = attr_value == 'true'\n elif attr_type is not None and attr_type != 'text':\n try:\n attr_value = float(attr_value)\n except ValueError:\n pass\n attributes[el.attrib['name']] = attr_value\n elif el.tag in cls._SUPPORTED_SHAPES:\n if track is not None:\n shape['frame'] = el.attrib['frame']\n shape['outside'] = (el.attrib.get('outside') == '1')\n shape['keyframe'] = (el.attrib.get('keyframe') == '1')\n if image is not None:\n shape['label'] = el.attrib.get('label')\n shape['group'] = int(el.attrib.get('group_id', 0))\n\n shape['type'] = el.tag\n shape['occluded'] = (el.attrib.get('occluded') == '1')\n shape['z_order'] = int(el.attrib.get('z_order', 0))\n\n if el.tag == 'box':\n shape['points'] = list(map(float, [\n el.attrib['xtl'], el.attrib['ytl'],\n el.attrib['xbr'], el.attrib['ybr'],\n ]))\n else:\n shape['points'] = []\n for pair in el.attrib['points'].split(';'):\n shape['points'].extend(map(float, pair.split(',')))\n\n frame_desc = items.get(shape['frame'], {'annotations': []})\n frame_desc['annotations'].append(\n cls._parse_shape_ann(shape, categories))\n items[shape['frame']] = frame_desc\n shape = None\n\n elif el.tag == 'tag':\n frame_desc = items.get(tag['frame'], {'annotations': []})\n frame_desc['annotations'].append(\n cls._parse_tag_ann(tag, categories))\n items[tag['frame']] = frame_desc\n tag = None\n elif el.tag == 'track':\n track = None\n elif el.tag == 'image':\n frame_desc = items.get(image['frame'], {'annotations': []})\n frame_desc.update({\n 'name': image.get('name'),\n 'height': image.get('height'),\n 'width': image.get('width'),\n })\n items[image['frame']] = frame_desc\n image = None\n el.clear()\n\n return items, categories\n\n @staticmethod\n def _parse_meta(context):\n ev, el = next(context)\n if not (ev == 'start' and el.tag == 'annotations'):\n raise Exception(\"Unexpected token \")\n\n categories = {}\n\n frame_size = None\n mode = None\n labels = OrderedDict()\n label = None\n\n # Recursive descent parser\n el = None\n states = ['annotations']\n def accepted(expected_state, tag, next_state=None):\n state = states[-1]\n if state == expected_state and el is not None and el.tag == tag:\n if not next_state:\n next_state = tag\n states.append(next_state)\n return True\n return False\n def consumed(expected_state, tag):\n state = states[-1]\n if state == expected_state and el is not None and el.tag == tag:\n states.pop()\n return True\n return False\n\n for ev, el in context:\n if ev == 'start':\n if accepted('annotations', 'meta'): pass\n elif accepted('meta', 'task'): pass\n elif accepted('task', 'mode'): pass\n elif accepted('task', 'original_size'):\n frame_size = [None, None]\n elif accepted('original_size', 'height', next_state='frame_height'): pass\n elif accepted('original_size', 'width', next_state='frame_width'): pass\n elif accepted('task', 'labels'): pass\n elif accepted('labels', 'label'):\n label = { 'name': None, 'attributes': [] }\n elif accepted('label', 'name', next_state='label_name'): pass\n elif accepted('label', 'attributes'): pass\n elif accepted('attributes', 'attribute'): pass\n elif accepted('attribute', 'name', next_state='attr_name'): pass\n elif accepted('attribute', 'input_type', next_state='attr_type'): pass\n elif accepted('annotations', 'image') or \\\n accepted('annotations', 'track') or \\\n accepted('annotations', 'tag'):\n break\n else:\n pass\n elif ev == 'end':\n if consumed('meta', 'meta'):\n break\n elif consumed('task', 'task'): pass\n elif consumed('mode', 'mode'):\n mode = el.text\n elif consumed('original_size', 'original_size'): pass\n elif consumed('frame_height', 'height'):\n frame_size[0] = int(el.text)\n elif consumed('frame_width', 'width'):\n frame_size[1] = int(el.text)\n elif consumed('label_name', 'name'):\n label['name'] = el.text\n elif consumed('attr_name', 'name'):\n label['attributes'].append({'name': el.text})\n elif consumed('attr_type', 'input_type'):\n label['attributes'][-1]['input_type'] = el.text\n elif consumed('attribute', 'attribute'): pass\n elif consumed('attributes', 'attributes'): pass\n elif consumed('label', 'label'):\n labels[label['name']] = label['attributes']\n label = None\n elif consumed('labels', 'labels'): pass\n else:\n pass\n\n assert len(states) == 1 and states[0] == 'annotations', \\\n \"Expected 'meta' section in the annotation file, path: %s\" % states\n\n common_attrs = ['occluded']\n if mode == 'interpolation':\n common_attrs.append('keyframe')\n common_attrs.append('outside')\n common_attrs.append('track_id')\n\n label_cat = LabelCategories(attributes=common_attrs)\n attribute_types = {}\n for label, attrs in labels.items():\n attr_names = {v['name'] for v in attrs}\n label_cat.add(label, attributes=attr_names)\n for attr in attrs:\n attribute_types[attr['name']] = attr['input_type']\n\n categories[AnnotationType.label] = label_cat\n return categories, frame_size, attribute_types\n\n @classmethod\n def _parse_shape_ann(cls, ann, categories):\n ann_id = ann.get('id', 0)\n ann_type = ann['type']\n\n attributes = ann.get('attributes') or {}\n if 'occluded' in categories[AnnotationType.label].attributes:\n attributes['occluded'] = ann.get('occluded', False)\n if 'outside' in ann:\n attributes['outside'] = ann['outside']\n if 'keyframe' in ann:\n attributes['keyframe'] = ann['keyframe']\n if 'track_id' in ann:\n attributes['track_id'] = ann['track_id']\n\n group = ann.get('group')\n\n label = ann.get('label')\n label_id = categories[AnnotationType.label].find(label)[0]\n\n z_order = ann.get('z_order', 0)\n points = ann.get('points', [])\n\n if ann_type == 'polyline':\n return PolyLine(points, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n elif ann_type == 'polygon':\n return Polygon(points, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n elif ann_type == 'points':\n return Points(points, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n elif ann_type == 'box':\n x, y = points[0], points[1]\n w, h = points[2] - x, points[3] - y\n return Bbox(x, y, w, h, label=label_id, z_order=z_order,\n id=ann_id, attributes=attributes, group=group)\n\n else:\n raise NotImplementedError(\"Unknown annotation type '%s'\" % ann_type)\n\n @classmethod\n def _parse_tag_ann(cls, ann, categories):\n label = ann.get('label')\n label_id = categories[AnnotationType.label].find(label)[0]\n group = ann.get('group')\n attributes = ann.get('attributes')\n return Label(label_id, attributes=attributes, group=group)\n\n def _load_items(self, parsed):\n for frame_id, item_desc in parsed.items():\n name = item_desc.get('name', 'frame_%06d.png' % int(frame_id))\n image = osp.join(self._images_dir, name)\n image_size = (item_desc.get('height'), item_desc.get('width'))\n if all(image_size):\n image = Image(path=image, size=tuple(map(int, image_size)))\n\n parsed[frame_id] = DatasetItem(id=osp.splitext(name)[0],\n subset=self._subset, image=image,\n annotations=item_desc.get('annotations'),\n attributes={'frame': int(frame_id)})\n return parsed\n\nclass CvatImporter(Importer):\n @classmethod\n def find_sources(cls, path):\n return cls._find_sources_recursive(path, '.xml', 'cvat')\n", "path": "datumaro/plugins/cvat_format/extractor.py"}]}
| 3,882 | 710 |
gh_patches_debug_20875
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-19045
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix traceback in service module when svc_cmd is None (2nd fix)
When service module is used on unsupported Linux system where init script is used directly, LinuxService.svc_cmd is None so .endswith() fails.
This extends fix from e2f20db53481128553d876109d5fbdab9f43dd5b also for state=restarted.
Fixes issue #3533
Running against Debian Lenny server:
```
$ ansible webserver.local -i webserver.local, -u root -m service -a 'name=apache2 state=restarted'
webserver.local | FAILED => failed to parse: Traceback (most recent call last):
File "/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service", line 2080, in <module>
main()
File "/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service", line 1112, in main
(rc, out, err) = service.modify_service_state()
File "/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service", line 299, in modify_service_state
return self.service_control()
File "/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service", line 670, in service_control
elif self.svc_cmd.endswith('rc-service'):
AttributeError: 'NoneType' object has no attribute 'endswith'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/modules/network/junos/junos_command.py`
Content:
```
1 #!/usr/bin/python
2 #
3 # This file is part of Ansible
4 #
5 # Ansible is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Ansible is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
17 #
18
19 ANSIBLE_METADATA = {'status': ['preview'],
20 'supported_by': 'core',
21 'version': '1.0'}
22
23 DOCUMENTATION = """
24 ---
25 module: junos_command
26 version_added: "2.1"
27 author: "Peter Sprygada (@privateip)"
28 short_description: Execute arbitrary commands on a remote device running Junos
29 description:
30 - Network devices running the Junos operating system provide a command
31 driven interface both over CLI and RPC. This module provides an
32 interface to execute commands using these functions and return the
33 results to the Ansible playbook. In addition, this
34 module can specify a set of conditionals to be evaluated against the
35 returned output, only returning control to the playbook once the
36 entire set of conditionals has been met.
37 extends_documentation_fragment: junos
38 options:
39 commands:
40 description:
41 - The C(commands) to send to the remote device over the Netconf
42 transport. The resulting output from the command
43 is returned. If the I(wait_for) argument is provided, the
44 module is not returned until the condition is satisfied or
45 the number of I(retries) has been exceeded.
46 required: false
47 default: null
48 rpcs:
49 description:
50 - The C(rpcs) argument accepts a list of RPCs to be executed
51 over a netconf session and the results from the RPC execution
52 is return to the playbook via the modules results dictionary.
53 required: false
54 default: null
55 wait_for:
56 description:
57 - Specifies what to evaluate from the output of the command
58 and what conditionals to apply. This argument will cause
59 the task to wait for a particular conditional to be true
60 before moving forward. If the conditional is not true
61 by the configured retries, the task fails. See examples.
62 required: false
63 default: null
64 aliases: ['waitfor']
65 version_added: "2.2"
66 match:
67 description:
68 - The I(match) argument is used in conjunction with the
69 I(wait_for) argument to specify the match policy. Valid
70 values are C(all) or C(any). If the value is set to C(all)
71 then all conditionals in the I(wait_for) must be satisfied. If
72 the value is set to C(any) then only one of the values must be
73 satisfied.
74 required: false
75 default: all
76 choices: ['any', 'all']
77 version_added: "2.2"
78 retries:
79 description:
80 - Specifies the number of retries a command should by tried
81 before it is considered failed. The command is run on the
82 target device every retry and evaluated against the I(waitfor)
83 conditionals.
84 required: false
85 default: 10
86 interval:
87 description:
88 - Configures the interval in seconds to wait between retries
89 of the command. If the command does not pass the specified
90 conditional, the interval indicates how to long to wait before
91 trying the command again.
92 required: false
93 default: 1
94 format:
95 description:
96 - Configures the encoding scheme to use when serializing output
97 from the device. This handles how to properly understand the
98 output and apply the conditionals path to the result set.
99 required: false
100 default: 'xml'
101 choices: ['xml', 'text']
102 requirements:
103 - junos-eznc
104 notes:
105 - This module requires the netconf system service be enabled on
106 the remote device being managed
107 """
108
109 EXAMPLES = """
110 # Note: examples below use the following provider dict to handle
111 # transport and authentication to the node.
112 vars:
113 netconf:
114 host: "{{ inventory_hostname }}"
115 username: ansible
116 password: Ansible
117
118 - name: run a set of commands
119 junos_command:
120 commands: ['show version', 'show ip route']
121 provider: "{{ netconf }}"
122
123 - name: run a command with a conditional applied to the second command
124 junos_command:
125 commands:
126 - show version
127 - show interfaces fxp0
128 waitfor:
129 - "result[1].interface-information.physical-interface.name eq fxp0"
130 provider: "{{ netconf }}"
131
132 - name: collect interface information using rpc
133 junos_command:
134 rpcs:
135 - "get_interface_information interface=em0 media=True"
136 - "get_interface_information interface=fxp0 media=True"
137 provider: "{{ netconf }}"
138 """
139
140 RETURN = """
141 stdout:
142 description: The output from the commands read from the device
143 returned: always
144 type: list
145 sample: ['...', '...']
146
147 stdout_lines:
148 description: The output read from the device split into lines
149 returned: always
150 type: list
151 sample: [['...', '...'], ['...', '...']]
152
153 failed_conditionals:
154 description: the conditionals that failed
155 returned: failed
156 type: list
157 sample: ['...', '...']
158 """
159
160 import ansible.module_utils.junos
161 from ansible.module_utils.basic import get_exception
162 from ansible.module_utils.network import NetworkModule, NetworkError
163 from ansible.module_utils.netcli import CommandRunner
164 from ansible.module_utils.netcli import AddCommandError, FailedConditionsError
165 from ansible.module_utils.netcli import FailedConditionalError, AddConditionError
166 from ansible.module_utils.junos import xml_to_json
167 from ansible.module_utils.six import string_types
168
169 VALID_KEYS = {
170 'cli': frozenset(['command', 'output', 'prompt', 'response']),
171 'rpc': frozenset(['command', 'output'])
172 }
173
174
175 def to_lines(stdout):
176 for item in stdout:
177 if isinstance(item, string_types):
178 item = str(item).split('\n')
179 yield item
180
181 def parse(module, command_type):
182 if command_type == 'cli':
183 items = module.params['commands']
184 elif command_type == 'rpc':
185 items = module.params['rpcs']
186
187 parsed = list()
188 for item in (items or list()):
189 if isinstance(item, string_types):
190 item = dict(command=item, output=None)
191 elif 'command' not in item:
192 module.fail_json(msg='command keyword argument is required')
193 elif item.get('output') not in [None, 'text', 'xml']:
194 module.fail_json(msg='invalid output specified for command'
195 'Supported values are `text` or `xml`')
196 elif not set(item.keys()).issubset(VALID_KEYS[command_type]):
197 module.fail_json(msg='unknown command keyword specified. Valid '
198 'values are %s' % ', '.join(VALID_KEYS[command_type]))
199
200 if not item['output']:
201 item['output'] = module.params['display']
202
203 item['command_type'] = command_type
204
205 # show configuration [options] will return as text
206 if item['command'].startswith('show configuration'):
207 item['output'] = 'text'
208
209 parsed.append(item)
210
211 return parsed
212
213
214 def main():
215 """main entry point for Ansible module
216 """
217
218 spec = dict(
219 commands=dict(type='list'),
220 rpcs=dict(type='list'),
221
222 display=dict(default='xml', choices=['text', 'xml'],
223 aliases=['format', 'output']),
224
225 wait_for=dict(type='list', aliases=['waitfor']),
226 match=dict(default='all', choices=['all', 'any']),
227
228 retries=dict(default=10, type='int'),
229 interval=dict(default=1, type='int'),
230
231 transport=dict(default='netconf', choices=['netconf'])
232 )
233
234 mutually_exclusive = [('commands', 'rpcs')]
235
236 module = NetworkModule(argument_spec=spec,
237 mutually_exclusive=mutually_exclusive,
238 supports_check_mode=True)
239
240 commands = list()
241 for key in VALID_KEYS.keys():
242 commands.extend(list(parse(module, key)))
243
244 conditionals = module.params['wait_for'] or list()
245
246 warnings = list()
247
248 runner = CommandRunner(module)
249
250 for cmd in commands:
251 if module.check_mode and not cmd['command'].startswith('show'):
252 warnings.append('only show commands are supported when using '
253 'check mode, not executing `%s`' % cmd['command'])
254 else:
255 if cmd['command'].startswith('co'):
256 module.fail_json(msg='junos_command does not support running '
257 'config mode commands. Please use '
258 'junos_config instead')
259 try:
260 runner.add_command(**cmd)
261 except AddCommandError:
262 exc = get_exception()
263 warnings.append('duplicate command detected: %s' % cmd)
264
265 try:
266 for item in conditionals:
267 runner.add_conditional(item)
268 except (ValueError, AddConditionError):
269 exc = get_exception()
270 module.fail_json(msg=str(exc), condition=exc.condition)
271
272 runner.retries = module.params['retries']
273 runner.interval = module.params['interval']
274 runner.match = module.params['match']
275
276 try:
277 runner.run()
278 except FailedConditionsError:
279 exc = get_exception()
280 module.fail_json(msg=str(exc), failed_conditions=exc.failed_conditions)
281 except FailedConditionalError:
282 exc = get_exception()
283 module.fail_json(msg=str(exc), failed_conditional=exc.failed_conditional)
284 except NetworkError:
285 exc = get_exception()
286 module.fail_json(msg=str(exc))
287
288 result = dict(changed=False, stdout=list())
289
290 for cmd in commands:
291 try:
292 output = runner.get_command(cmd['command'], cmd.get('output'))
293 except ValueError:
294 output = 'command not executed due to check_mode, see warnings'
295 result['stdout'].append(output)
296
297 result['warnings'] = warnings
298 result['stdout_lines'] = list(to_lines(result['stdout']))
299
300 module.exit_json(**result)
301
302
303 if __name__ == '__main__':
304 main()
305
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/ansible/modules/network/junos/junos_command.py b/lib/ansible/modules/network/junos/junos_command.py
--- a/lib/ansible/modules/network/junos/junos_command.py
+++ b/lib/ansible/modules/network/junos/junos_command.py
@@ -98,12 +98,13 @@
output and apply the conditionals path to the result set.
required: false
default: 'xml'
- choices: ['xml', 'text']
+ choices: ['xml', 'text', 'json']
requirements:
- junos-eznc
notes:
- This module requires the netconf system service be enabled on
- the remote device being managed
+ the remote device being managed. 'json' format is supported
+ for JUNON version >= 14.2
"""
EXAMPLES = """
@@ -219,7 +220,7 @@
commands=dict(type='list'),
rpcs=dict(type='list'),
- display=dict(default='xml', choices=['text', 'xml'],
+ display=dict(default='xml', choices=['text', 'xml', 'json'],
aliases=['format', 'output']),
wait_for=dict(type='list', aliases=['waitfor']),
|
{"golden_diff": "diff --git a/lib/ansible/modules/network/junos/junos_command.py b/lib/ansible/modules/network/junos/junos_command.py\n--- a/lib/ansible/modules/network/junos/junos_command.py\n+++ b/lib/ansible/modules/network/junos/junos_command.py\n@@ -98,12 +98,13 @@\n output and apply the conditionals path to the result set.\n required: false\n default: 'xml'\n- choices: ['xml', 'text']\n+ choices: ['xml', 'text', 'json']\n requirements:\n - junos-eznc\n notes:\n - This module requires the netconf system service be enabled on\n- the remote device being managed\n+ the remote device being managed. 'json' format is supported\n+ for JUNON version >= 14.2\n \"\"\"\n \n EXAMPLES = \"\"\"\n@@ -219,7 +220,7 @@\n commands=dict(type='list'),\n rpcs=dict(type='list'),\n \n- display=dict(default='xml', choices=['text', 'xml'],\n+ display=dict(default='xml', choices=['text', 'xml', 'json'],\n aliases=['format', 'output']),\n \n wait_for=dict(type='list', aliases=['waitfor']),\n", "issue": "Fix traceback in service module when svc_cmd is None (2nd fix)\nWhen service module is used on unsupported Linux system where init script is used directly, LinuxService.svc_cmd is None so .endswith() fails.\n\nThis extends fix from e2f20db53481128553d876109d5fbdab9f43dd5b also for state=restarted.\n\nFixes issue #3533\n\nRunning against Debian Lenny server:\n\n```\n$ ansible webserver.local -i webserver.local, -u root -m service -a 'name=apache2 state=restarted'\nwebserver.local | FAILED => failed to parse: Traceback (most recent call last):\n File \"/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service\", line 2080, in <module>\n main()\n File \"/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service\", line 1112, in main\n (rc, out, err) = service.modify_service_state()\n File \"/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service\", line 299, in modify_service_state\n return self.service_control()\n File \"/root/.ansible/tmp/ansible-1379082596.06-63995244988034/service\", line 670, in service_control\n elif self.svc_cmd.endswith('rc-service'):\nAttributeError: 'NoneType' object has no attribute 'endswith'\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n#\n\nANSIBLE_METADATA = {'status': ['preview'],\n 'supported_by': 'core',\n 'version': '1.0'}\n\nDOCUMENTATION = \"\"\"\n---\nmodule: junos_command\nversion_added: \"2.1\"\nauthor: \"Peter Sprygada (@privateip)\"\nshort_description: Execute arbitrary commands on a remote device running Junos\ndescription:\n - Network devices running the Junos operating system provide a command\n driven interface both over CLI and RPC. This module provides an\n interface to execute commands using these functions and return the\n results to the Ansible playbook. In addition, this\n module can specify a set of conditionals to be evaluated against the\n returned output, only returning control to the playbook once the\n entire set of conditionals has been met.\nextends_documentation_fragment: junos\noptions:\n commands:\n description:\n - The C(commands) to send to the remote device over the Netconf\n transport. The resulting output from the command\n is returned. If the I(wait_for) argument is provided, the\n module is not returned until the condition is satisfied or\n the number of I(retries) has been exceeded.\n required: false\n default: null\n rpcs:\n description:\n - The C(rpcs) argument accepts a list of RPCs to be executed\n over a netconf session and the results from the RPC execution\n is return to the playbook via the modules results dictionary.\n required: false\n default: null\n wait_for:\n description:\n - Specifies what to evaluate from the output of the command\n and what conditionals to apply. This argument will cause\n the task to wait for a particular conditional to be true\n before moving forward. If the conditional is not true\n by the configured retries, the task fails. See examples.\n required: false\n default: null\n aliases: ['waitfor']\n version_added: \"2.2\"\n match:\n description:\n - The I(match) argument is used in conjunction with the\n I(wait_for) argument to specify the match policy. Valid\n values are C(all) or C(any). If the value is set to C(all)\n then all conditionals in the I(wait_for) must be satisfied. If\n the value is set to C(any) then only one of the values must be\n satisfied.\n required: false\n default: all\n choices: ['any', 'all']\n version_added: \"2.2\"\n retries:\n description:\n - Specifies the number of retries a command should by tried\n before it is considered failed. The command is run on the\n target device every retry and evaluated against the I(waitfor)\n conditionals.\n required: false\n default: 10\n interval:\n description:\n - Configures the interval in seconds to wait between retries\n of the command. If the command does not pass the specified\n conditional, the interval indicates how to long to wait before\n trying the command again.\n required: false\n default: 1\n format:\n description:\n - Configures the encoding scheme to use when serializing output\n from the device. This handles how to properly understand the\n output and apply the conditionals path to the result set.\n required: false\n default: 'xml'\n choices: ['xml', 'text']\nrequirements:\n - junos-eznc\nnotes:\n - This module requires the netconf system service be enabled on\n the remote device being managed\n\"\"\"\n\nEXAMPLES = \"\"\"\n# Note: examples below use the following provider dict to handle\n# transport and authentication to the node.\nvars:\n netconf:\n host: \"{{ inventory_hostname }}\"\n username: ansible\n password: Ansible\n\n- name: run a set of commands\n junos_command:\n commands: ['show version', 'show ip route']\n provider: \"{{ netconf }}\"\n\n- name: run a command with a conditional applied to the second command\n junos_command:\n commands:\n - show version\n - show interfaces fxp0\n waitfor:\n - \"result[1].interface-information.physical-interface.name eq fxp0\"\n provider: \"{{ netconf }}\"\n\n- name: collect interface information using rpc\n junos_command:\n rpcs:\n - \"get_interface_information interface=em0 media=True\"\n - \"get_interface_information interface=fxp0 media=True\"\n provider: \"{{ netconf }}\"\n\"\"\"\n\nRETURN = \"\"\"\nstdout:\n description: The output from the commands read from the device\n returned: always\n type: list\n sample: ['...', '...']\n\nstdout_lines:\n description: The output read from the device split into lines\n returned: always\n type: list\n sample: [['...', '...'], ['...', '...']]\n\nfailed_conditionals:\n description: the conditionals that failed\n returned: failed\n type: list\n sample: ['...', '...']\n\"\"\"\n\nimport ansible.module_utils.junos\nfrom ansible.module_utils.basic import get_exception\nfrom ansible.module_utils.network import NetworkModule, NetworkError\nfrom ansible.module_utils.netcli import CommandRunner\nfrom ansible.module_utils.netcli import AddCommandError, FailedConditionsError\nfrom ansible.module_utils.netcli import FailedConditionalError, AddConditionError\nfrom ansible.module_utils.junos import xml_to_json\nfrom ansible.module_utils.six import string_types\n\nVALID_KEYS = {\n 'cli': frozenset(['command', 'output', 'prompt', 'response']),\n 'rpc': frozenset(['command', 'output'])\n}\n\n\ndef to_lines(stdout):\n for item in stdout:\n if isinstance(item, string_types):\n item = str(item).split('\\n')\n yield item\n\ndef parse(module, command_type):\n if command_type == 'cli':\n items = module.params['commands']\n elif command_type == 'rpc':\n items = module.params['rpcs']\n\n parsed = list()\n for item in (items or list()):\n if isinstance(item, string_types):\n item = dict(command=item, output=None)\n elif 'command' not in item:\n module.fail_json(msg='command keyword argument is required')\n elif item.get('output') not in [None, 'text', 'xml']:\n module.fail_json(msg='invalid output specified for command'\n 'Supported values are `text` or `xml`')\n elif not set(item.keys()).issubset(VALID_KEYS[command_type]):\n module.fail_json(msg='unknown command keyword specified. Valid '\n 'values are %s' % ', '.join(VALID_KEYS[command_type]))\n\n if not item['output']:\n item['output'] = module.params['display']\n\n item['command_type'] = command_type\n\n # show configuration [options] will return as text\n if item['command'].startswith('show configuration'):\n item['output'] = 'text'\n\n parsed.append(item)\n\n return parsed\n\n\ndef main():\n \"\"\"main entry point for Ansible module\n \"\"\"\n\n spec = dict(\n commands=dict(type='list'),\n rpcs=dict(type='list'),\n\n display=dict(default='xml', choices=['text', 'xml'],\n aliases=['format', 'output']),\n\n wait_for=dict(type='list', aliases=['waitfor']),\n match=dict(default='all', choices=['all', 'any']),\n\n retries=dict(default=10, type='int'),\n interval=dict(default=1, type='int'),\n\n transport=dict(default='netconf', choices=['netconf'])\n )\n\n mutually_exclusive = [('commands', 'rpcs')]\n\n module = NetworkModule(argument_spec=spec,\n mutually_exclusive=mutually_exclusive,\n supports_check_mode=True)\n\n commands = list()\n for key in VALID_KEYS.keys():\n commands.extend(list(parse(module, key)))\n\n conditionals = module.params['wait_for'] or list()\n\n warnings = list()\n\n runner = CommandRunner(module)\n\n for cmd in commands:\n if module.check_mode and not cmd['command'].startswith('show'):\n warnings.append('only show commands are supported when using '\n 'check mode, not executing `%s`' % cmd['command'])\n else:\n if cmd['command'].startswith('co'):\n module.fail_json(msg='junos_command does not support running '\n 'config mode commands. Please use '\n 'junos_config instead')\n try:\n runner.add_command(**cmd)\n except AddCommandError:\n exc = get_exception()\n warnings.append('duplicate command detected: %s' % cmd)\n\n try:\n for item in conditionals:\n runner.add_conditional(item)\n except (ValueError, AddConditionError):\n exc = get_exception()\n module.fail_json(msg=str(exc), condition=exc.condition)\n\n runner.retries = module.params['retries']\n runner.interval = module.params['interval']\n runner.match = module.params['match']\n\n try:\n runner.run()\n except FailedConditionsError:\n exc = get_exception()\n module.fail_json(msg=str(exc), failed_conditions=exc.failed_conditions)\n except FailedConditionalError:\n exc = get_exception()\n module.fail_json(msg=str(exc), failed_conditional=exc.failed_conditional)\n except NetworkError:\n exc = get_exception()\n module.fail_json(msg=str(exc))\n\n result = dict(changed=False, stdout=list())\n\n for cmd in commands:\n try:\n output = runner.get_command(cmd['command'], cmd.get('output'))\n except ValueError:\n output = 'command not executed due to check_mode, see warnings'\n result['stdout'].append(output)\n\n result['warnings'] = warnings\n result['stdout_lines'] = list(to_lines(result['stdout']))\n\n module.exit_json(**result)\n\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/network/junos/junos_command.py"}], "after_files": [{"content": "#!/usr/bin/python\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n#\n\nANSIBLE_METADATA = {'status': ['preview'],\n 'supported_by': 'core',\n 'version': '1.0'}\n\nDOCUMENTATION = \"\"\"\n---\nmodule: junos_command\nversion_added: \"2.1\"\nauthor: \"Peter Sprygada (@privateip)\"\nshort_description: Execute arbitrary commands on a remote device running Junos\ndescription:\n - Network devices running the Junos operating system provide a command\n driven interface both over CLI and RPC. This module provides an\n interface to execute commands using these functions and return the\n results to the Ansible playbook. In addition, this\n module can specify a set of conditionals to be evaluated against the\n returned output, only returning control to the playbook once the\n entire set of conditionals has been met.\nextends_documentation_fragment: junos\noptions:\n commands:\n description:\n - The C(commands) to send to the remote device over the Netconf\n transport. The resulting output from the command\n is returned. If the I(wait_for) argument is provided, the\n module is not returned until the condition is satisfied or\n the number of I(retries) has been exceeded.\n required: false\n default: null\n rpcs:\n description:\n - The C(rpcs) argument accepts a list of RPCs to be executed\n over a netconf session and the results from the RPC execution\n is return to the playbook via the modules results dictionary.\n required: false\n default: null\n wait_for:\n description:\n - Specifies what to evaluate from the output of the command\n and what conditionals to apply. This argument will cause\n the task to wait for a particular conditional to be true\n before moving forward. If the conditional is not true\n by the configured retries, the task fails. See examples.\n required: false\n default: null\n aliases: ['waitfor']\n version_added: \"2.2\"\n match:\n description:\n - The I(match) argument is used in conjunction with the\n I(wait_for) argument to specify the match policy. Valid\n values are C(all) or C(any). If the value is set to C(all)\n then all conditionals in the I(wait_for) must be satisfied. If\n the value is set to C(any) then only one of the values must be\n satisfied.\n required: false\n default: all\n choices: ['any', 'all']\n version_added: \"2.2\"\n retries:\n description:\n - Specifies the number of retries a command should by tried\n before it is considered failed. The command is run on the\n target device every retry and evaluated against the I(waitfor)\n conditionals.\n required: false\n default: 10\n interval:\n description:\n - Configures the interval in seconds to wait between retries\n of the command. If the command does not pass the specified\n conditional, the interval indicates how to long to wait before\n trying the command again.\n required: false\n default: 1\n format:\n description:\n - Configures the encoding scheme to use when serializing output\n from the device. This handles how to properly understand the\n output and apply the conditionals path to the result set.\n required: false\n default: 'xml'\n choices: ['xml', 'text', 'json']\nrequirements:\n - junos-eznc\nnotes:\n - This module requires the netconf system service be enabled on\n the remote device being managed. 'json' format is supported\n for JUNON version >= 14.2\n\"\"\"\n\nEXAMPLES = \"\"\"\n# Note: examples below use the following provider dict to handle\n# transport and authentication to the node.\nvars:\n netconf:\n host: \"{{ inventory_hostname }}\"\n username: ansible\n password: Ansible\n\n- name: run a set of commands\n junos_command:\n commands: ['show version', 'show ip route']\n provider: \"{{ netconf }}\"\n\n- name: run a command with a conditional applied to the second command\n junos_command:\n commands:\n - show version\n - show interfaces fxp0\n waitfor:\n - \"result[1].interface-information.physical-interface.name eq fxp0\"\n provider: \"{{ netconf }}\"\n\n- name: collect interface information using rpc\n junos_command:\n rpcs:\n - \"get_interface_information interface=em0 media=True\"\n - \"get_interface_information interface=fxp0 media=True\"\n provider: \"{{ netconf }}\"\n\"\"\"\n\nRETURN = \"\"\"\nstdout:\n description: The output from the commands read from the device\n returned: always\n type: list\n sample: ['...', '...']\n\nstdout_lines:\n description: The output read from the device split into lines\n returned: always\n type: list\n sample: [['...', '...'], ['...', '...']]\n\nfailed_conditionals:\n description: the conditionals that failed\n returned: failed\n type: list\n sample: ['...', '...']\n\"\"\"\n\nimport ansible.module_utils.junos\nfrom ansible.module_utils.basic import get_exception\nfrom ansible.module_utils.network import NetworkModule, NetworkError\nfrom ansible.module_utils.netcli import CommandRunner\nfrom ansible.module_utils.netcli import AddCommandError, FailedConditionsError\nfrom ansible.module_utils.netcli import FailedConditionalError, AddConditionError\nfrom ansible.module_utils.junos import xml_to_json\nfrom ansible.module_utils.six import string_types\n\nVALID_KEYS = {\n 'cli': frozenset(['command', 'output', 'prompt', 'response']),\n 'rpc': frozenset(['command', 'output'])\n}\n\n\ndef to_lines(stdout):\n for item in stdout:\n if isinstance(item, string_types):\n item = str(item).split('\\n')\n yield item\n\ndef parse(module, command_type):\n if command_type == 'cli':\n items = module.params['commands']\n elif command_type == 'rpc':\n items = module.params['rpcs']\n\n parsed = list()\n for item in (items or list()):\n if isinstance(item, string_types):\n item = dict(command=item, output=None)\n elif 'command' not in item:\n module.fail_json(msg='command keyword argument is required')\n elif item.get('output') not in [None, 'text', 'xml']:\n module.fail_json(msg='invalid output specified for command'\n 'Supported values are `text` or `xml`')\n elif not set(item.keys()).issubset(VALID_KEYS[command_type]):\n module.fail_json(msg='unknown command keyword specified. Valid '\n 'values are %s' % ', '.join(VALID_KEYS[command_type]))\n\n if not item['output']:\n item['output'] = module.params['display']\n\n item['command_type'] = command_type\n\n # show configuration [options] will return as text\n if item['command'].startswith('show configuration'):\n item['output'] = 'text'\n\n parsed.append(item)\n\n return parsed\n\n\ndef main():\n \"\"\"main entry point for Ansible module\n \"\"\"\n\n spec = dict(\n commands=dict(type='list'),\n rpcs=dict(type='list'),\n\n display=dict(default='xml', choices=['text', 'xml', 'json'],\n aliases=['format', 'output']),\n\n wait_for=dict(type='list', aliases=['waitfor']),\n match=dict(default='all', choices=['all', 'any']),\n\n retries=dict(default=10, type='int'),\n interval=dict(default=1, type='int'),\n\n transport=dict(default='netconf', choices=['netconf'])\n )\n\n mutually_exclusive = [('commands', 'rpcs')]\n\n module = NetworkModule(argument_spec=spec,\n mutually_exclusive=mutually_exclusive,\n supports_check_mode=True)\n\n commands = list()\n for key in VALID_KEYS.keys():\n commands.extend(list(parse(module, key)))\n\n conditionals = module.params['wait_for'] or list()\n\n warnings = list()\n\n runner = CommandRunner(module)\n\n for cmd in commands:\n if module.check_mode and not cmd['command'].startswith('show'):\n warnings.append('only show commands are supported when using '\n 'check mode, not executing `%s`' % cmd['command'])\n else:\n if cmd['command'].startswith('co'):\n module.fail_json(msg='junos_command does not support running '\n 'config mode commands. Please use '\n 'junos_config instead')\n try:\n runner.add_command(**cmd)\n except AddCommandError:\n exc = get_exception()\n warnings.append('duplicate command detected: %s' % cmd)\n\n try:\n for item in conditionals:\n runner.add_conditional(item)\n except (ValueError, AddConditionError):\n exc = get_exception()\n module.fail_json(msg=str(exc), condition=exc.condition)\n\n runner.retries = module.params['retries']\n runner.interval = module.params['interval']\n runner.match = module.params['match']\n\n try:\n runner.run()\n except FailedConditionsError:\n exc = get_exception()\n module.fail_json(msg=str(exc), failed_conditions=exc.failed_conditions)\n except FailedConditionalError:\n exc = get_exception()\n module.fail_json(msg=str(exc), failed_conditional=exc.failed_conditional)\n except NetworkError:\n exc = get_exception()\n module.fail_json(msg=str(exc))\n\n result = dict(changed=False, stdout=list())\n\n for cmd in commands:\n try:\n output = runner.get_command(cmd['command'], cmd.get('output'))\n except ValueError:\n output = 'command not executed due to check_mode, see warnings'\n result['stdout'].append(output)\n\n result['warnings'] = warnings\n result['stdout_lines'] = list(to_lines(result['stdout']))\n\n module.exit_json(**result)\n\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/network/junos/junos_command.py"}]}
| 3,770 | 271 |
gh_patches_debug_10655
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-557
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ordering of variables after coords set
## Short Description
I'm trying to use the coords/dims to set labels on posterior variables from a stan fit and the order of the dimensions gets shuffled when I set the labels (not sure what determines the order). Is there a way to (1) retain the existing order (A,B,C...) and (2) sort the order according to a custom index that I provide (e.g. pass a index array like [2,1,0,3, ...] to have the plot appear in the order [C, B, A, D ...])?
Sorry if this is covered in the documentation somewhere, I didn't see it.
Without setting any coords/dims, the variables appear in the same order as one would expect from the stan code.
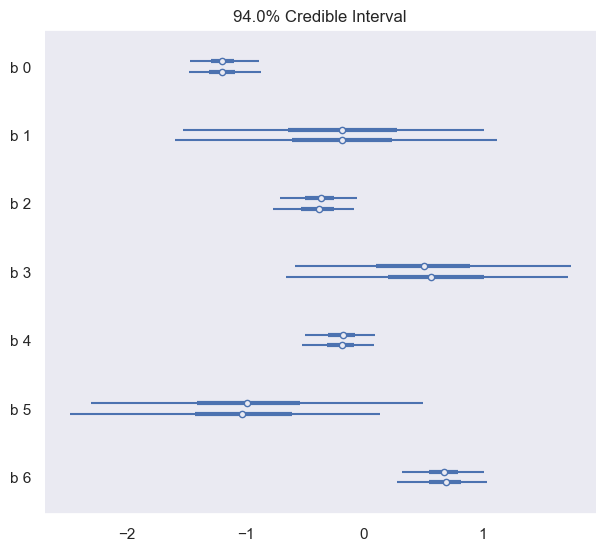
Setting the coords/dims with the code below changes the order to this.
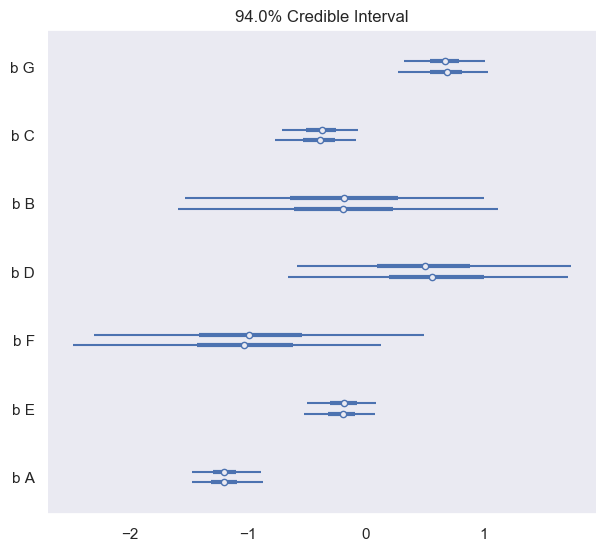
## Code Example or link
```
azdata = az.from_pystan(posterior=fit, observed_data=['Y'], coords={'betas': ['A', 'B', 'C', 'D', 'E', 'F', 'G']}, dims={'b': ['betas']})
axes = az.plot_forest(azdata, var_names=('b'))
```
Using arviz 0.3.2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `arviz/plots/plot_utils.py`
Content:
```
1 """Utilities for plotting."""
2 from itertools import product
3
4 import numpy as np
5 import matplotlib.pyplot as plt
6 import matplotlib as mpl
7 import xarray as xr
8
9
10 def make_2d(ary):
11 """Convert any array into a 2d numpy array.
12
13 In case the array is already more than 2 dimensional, will ravel the
14 dimensions after the first.
15 """
16 dim_0, *_ = np.atleast_1d(ary).shape
17 return ary.reshape(dim_0, -1, order="F")
18
19
20 def _scale_fig_size(figsize, textsize, rows=1, cols=1):
21 """Scale figure properties according to rows and cols.
22
23 Parameters
24 ----------
25 figsize : float or None
26 Size of figure in inches
27 textsize : float or None
28 fontsize
29 rows : int
30 Number of rows
31 cols : int
32 Number of columns
33
34 Returns
35 -------
36 figsize : float or None
37 Size of figure in inches
38 ax_labelsize : int
39 fontsize for axes label
40 titlesize : int
41 fontsize for title
42 xt_labelsize : int
43 fontsize for axes ticks
44 linewidth : int
45 linewidth
46 markersize : int
47 markersize
48 """
49 params = mpl.rcParams
50 rc_width, rc_height = tuple(params["figure.figsize"])
51 rc_ax_labelsize = params["axes.labelsize"]
52 rc_titlesize = params["axes.titlesize"]
53 rc_xt_labelsize = params["xtick.labelsize"]
54 rc_linewidth = params["lines.linewidth"]
55 rc_markersize = params["lines.markersize"]
56 if isinstance(rc_ax_labelsize, str):
57 rc_ax_labelsize = 15
58 if isinstance(rc_titlesize, str):
59 rc_titlesize = 16
60 if isinstance(rc_xt_labelsize, str):
61 rc_xt_labelsize = 14
62
63 if figsize is None:
64 width, height = rc_width, rc_height
65 sff = 1 if (rows == cols == 1) else 1.15
66 width = width * cols * sff
67 height = height * rows * sff
68 else:
69 width, height = figsize
70
71 if textsize is not None:
72 scale_factor = textsize / rc_xt_labelsize
73 elif rows == cols == 1:
74 scale_factor = ((width * height) / (rc_width * rc_height)) ** 0.5
75 else:
76 scale_factor = 1
77
78 ax_labelsize = rc_ax_labelsize * scale_factor
79 titlesize = rc_titlesize * scale_factor
80 xt_labelsize = rc_xt_labelsize * scale_factor
81 linewidth = rc_linewidth * scale_factor
82 markersize = rc_markersize * scale_factor
83
84 return (width, height), ax_labelsize, titlesize, xt_labelsize, linewidth, markersize
85
86
87 def get_bins(ary, max_bins=50, fenceposts=2):
88 """Compute number of bins (or ticks).
89
90 Parameters
91 ----------
92 ary : numpy.array
93 array to be binned
94 max_bins : int
95 maximum number of bins
96 fenceposts : int
97 when computing bins, this should be 2, when computing ticks this should be 1.
98 """
99 x_max, x_min = ary.max(), ary.min()
100 x_range = x_max - x_min
101 if x_range > max_bins:
102 bins = range(x_min, x_max + fenceposts, max(1, int(x_range / 10)))
103 else:
104 bins = range(x_min, x_max + fenceposts)
105 return bins
106
107
108 def default_grid(n_items, max_cols=4, min_cols=3): # noqa: D202
109 """Make a grid for subplots.
110
111 Tries to get as close to sqrt(n_items) x sqrt(n_items) as it can,
112 but allows for custom logic
113
114 Parameters
115 ----------
116 n_items : int
117 Number of panels required
118 max_cols : int
119 Maximum number of columns, inclusive
120 min_cols : int
121 Minimum number of columns, inclusive
122
123 Returns
124 -------
125 (int, int)
126 Rows and columns, so that rows * columns >= n_items
127 """
128
129 def in_bounds(val):
130 return np.clip(val, min_cols, max_cols)
131
132 if n_items <= max_cols:
133 return 1, n_items
134 ideal = in_bounds(round(n_items ** 0.5))
135
136 for offset in (0, 1, -1, 2, -2):
137 cols = in_bounds(ideal + offset)
138 rows, extra = divmod(n_items, cols)
139 if extra == 0:
140 return rows, cols
141 return n_items // ideal + 1, ideal
142
143
144 def _create_axes_grid(length_plotters, rows, cols, **kwargs):
145 """Create figure and axes for grids with multiple plots.
146
147 Parameters
148 ----------
149 n_items : int
150 Number of panels required
151 rows : int
152 Number of rows
153 cols : int
154 Number of columns
155
156 Returns
157 -------
158 fig : matplotlib figure
159 ax : matplotlib axes
160 """
161 kwargs.setdefault("constrained_layout", True)
162 fig, ax = plt.subplots(rows, cols, **kwargs)
163 ax = np.ravel(ax)
164 extra = (rows * cols) - length_plotters
165 if extra:
166 for i in range(1, extra + 1):
167 ax[-i].set_axis_off()
168 ax = ax[:-extra]
169 return fig, ax
170
171
172 def selection_to_string(selection):
173 """Convert dictionary of coordinates to a string for labels.
174
175 Parameters
176 ----------
177 selection : dict[Any] -> Any
178
179 Returns
180 -------
181 str
182 key1: value1, key2: value2, ...
183 """
184 return ", ".join(["{}".format(v) for _, v in selection.items()])
185
186
187 def make_label(var_name, selection, position="below"):
188 """Consistent labelling for plots.
189
190 Parameters
191 ----------
192 var_name : str
193 Name of the variable
194
195 selection : dict[Any] -> Any
196 Coordinates of the variable
197 position : whether to position the coordinates' label "below" (default) or "beside" the name
198 of the variable
199
200 Returns
201 -------
202 label
203 A text representation of the label
204 """
205 if selection:
206 sel = selection_to_string(selection)
207 if position == "below":
208 sep = "\n"
209 elif position == "beside":
210 sep = " "
211 else:
212 sep = sel = ""
213 return "{}{}{}".format(var_name, sep, sel)
214
215
216 def xarray_var_iter(data, var_names=None, combined=False, skip_dims=None, reverse_selections=False):
217 """Convert xarray data to an iterator over vectors.
218
219 Iterates over each var_name and all of its coordinates, returning the 1d
220 data.
221
222 Parameters
223 ----------
224 data : xarray.Dataset
225 Posterior data in an xarray
226
227 var_names : iterator of strings (optional)
228 Should be a subset of data.data_vars. Defaults to all of them.
229
230 combined : bool
231 Whether to combine chains or leave them separate
232
233 skip_dims : set
234 dimensions to not iterate over
235
236 reverse_selections : bool
237 Whether to reverse selections before iterating.
238
239 Returns
240 -------
241 Iterator of (str, dict(str, any), np.array)
242 The string is the variable name, the dictionary are coordinate names to values,
243 and the array are the values of the variable at those coordinates.
244 """
245 if skip_dims is None:
246 skip_dims = set()
247
248 if combined:
249 skip_dims = skip_dims.union({"chain", "draw"})
250 else:
251 skip_dims.add("draw")
252
253 if var_names is None:
254 if isinstance(data, xr.Dataset):
255 var_names = list(data.data_vars)
256 elif isinstance(data, xr.DataArray):
257 var_names = [data.name]
258 data = {data.name: data}
259
260 for var_name in var_names:
261 if var_name in data:
262 new_dims = [dim for dim in data[var_name].dims if dim not in skip_dims]
263 vals = [set(data[var_name][dim].values) for dim in new_dims]
264 dims = [{k: v for k, v in zip(new_dims, prod)} for prod in product(*vals)]
265 if reverse_selections:
266 dims = reversed(dims)
267
268 for selection in dims:
269 yield var_name, selection, data[var_name].sel(**selection).values
270
271
272 def xarray_to_ndarray(data, *, var_names=None, combined=True):
273 """Take xarray data and unpacks into variables and data into list and numpy array respectively.
274
275 Assumes that chain and draw are in coordinates
276
277 Parameters
278 ----------
279 data: xarray.DataSet
280 Data in an xarray from an InferenceData object. Examples include posterior or sample_stats
281
282 var_names: iter
283 Should be a subset of data.data_vars not including chain and draws. Defaults to all of them
284
285 combined: bool
286 Whether to combine chain into one array
287
288 Returns
289 -------
290 var_names: list
291 List of variable names
292 data: np.array
293 Data values
294 """
295 unpacked_data, unpacked_var_names, = [], []
296
297 # Merge chains and variables
298 for var_name, selection, data_array in xarray_var_iter(
299 data, var_names=var_names, combined=combined
300 ):
301 unpacked_data.append(data_array.flatten())
302 unpacked_var_names.append(make_label(var_name, selection))
303
304 return unpacked_var_names, np.array(unpacked_data)
305
306
307 def get_coords(data, coords):
308 """Subselects xarray dataset object to provided coords. Raises exception if fails.
309
310 Raises
311 ------
312 ValueError
313 If coords name are not available in data
314
315 KeyError
316 If coords dims are not available in data
317
318 Returns
319 -------
320 data: xarray
321 xarray.Dataset object
322 """
323 try:
324 return data.sel(**coords)
325
326 except ValueError:
327 invalid_coords = set(coords.keys()) - set(data.coords.keys())
328 raise ValueError("Coords {} are invalid coordinate keys".format(invalid_coords))
329
330 except KeyError as err:
331 raise KeyError(
332 (
333 "Coords should follow mapping format {{coord_name:[dim1, dim2]}}. "
334 "Check that coords structure is correct and"
335 " dimensions are valid. {}"
336 ).format(err)
337 )
338
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/plots/plot_utils.py b/arviz/plots/plot_utils.py
--- a/arviz/plots/plot_utils.py
+++ b/arviz/plots/plot_utils.py
@@ -260,7 +260,7 @@
for var_name in var_names:
if var_name in data:
new_dims = [dim for dim in data[var_name].dims if dim not in skip_dims]
- vals = [set(data[var_name][dim].values) for dim in new_dims]
+ vals = [np.unique(data[var_name][dim].values) for dim in new_dims]
dims = [{k: v for k, v in zip(new_dims, prod)} for prod in product(*vals)]
if reverse_selections:
dims = reversed(dims)
|
{"golden_diff": "diff --git a/arviz/plots/plot_utils.py b/arviz/plots/plot_utils.py\n--- a/arviz/plots/plot_utils.py\n+++ b/arviz/plots/plot_utils.py\n@@ -260,7 +260,7 @@\n for var_name in var_names:\n if var_name in data:\n new_dims = [dim for dim in data[var_name].dims if dim not in skip_dims]\n- vals = [set(data[var_name][dim].values) for dim in new_dims]\n+ vals = [np.unique(data[var_name][dim].values) for dim in new_dims]\n dims = [{k: v for k, v in zip(new_dims, prod)} for prod in product(*vals)]\n if reverse_selections:\n dims = reversed(dims)\n", "issue": "Ordering of variables after coords set\n## Short Description\r\n\r\nI'm trying to use the coords/dims to set labels on posterior variables from a stan fit and the order of the dimensions gets shuffled when I set the labels (not sure what determines the order). Is there a way to (1) retain the existing order (A,B,C...) and (2) sort the order according to a custom index that I provide (e.g. pass a index array like [2,1,0,3, ...] to have the plot appear in the order [C, B, A, D ...])? \r\n\r\nSorry if this is covered in the documentation somewhere, I didn't see it.\r\n\r\n\r\n\r\n\r\nWithout setting any coords/dims, the variables appear in the same order as one would expect from the stan code.\r\n\r\n\r\n\r\n\r\n\r\nSetting the coords/dims with the code below changes the order to this.\r\n\r\n\r\n\r\n\r\n\r\n## Code Example or link\r\n\r\n```\r\nazdata = az.from_pystan(posterior=fit, observed_data=['Y'], coords={'betas': ['A', 'B', 'C', 'D', 'E', 'F', 'G']}, dims={'b': ['betas']})\r\n\t\r\naxes = az.plot_forest(azdata, var_names=('b'))\r\n```\r\nUsing arviz 0.3.2\r\n\n", "before_files": [{"content": "\"\"\"Utilities for plotting.\"\"\"\nfrom itertools import product\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nimport xarray as xr\n\n\ndef make_2d(ary):\n \"\"\"Convert any array into a 2d numpy array.\n\n In case the array is already more than 2 dimensional, will ravel the\n dimensions after the first.\n \"\"\"\n dim_0, *_ = np.atleast_1d(ary).shape\n return ary.reshape(dim_0, -1, order=\"F\")\n\n\ndef _scale_fig_size(figsize, textsize, rows=1, cols=1):\n \"\"\"Scale figure properties according to rows and cols.\n\n Parameters\n ----------\n figsize : float or None\n Size of figure in inches\n textsize : float or None\n fontsize\n rows : int\n Number of rows\n cols : int\n Number of columns\n\n Returns\n -------\n figsize : float or None\n Size of figure in inches\n ax_labelsize : int\n fontsize for axes label\n titlesize : int\n fontsize for title\n xt_labelsize : int\n fontsize for axes ticks\n linewidth : int\n linewidth\n markersize : int\n markersize\n \"\"\"\n params = mpl.rcParams\n rc_width, rc_height = tuple(params[\"figure.figsize\"])\n rc_ax_labelsize = params[\"axes.labelsize\"]\n rc_titlesize = params[\"axes.titlesize\"]\n rc_xt_labelsize = params[\"xtick.labelsize\"]\n rc_linewidth = params[\"lines.linewidth\"]\n rc_markersize = params[\"lines.markersize\"]\n if isinstance(rc_ax_labelsize, str):\n rc_ax_labelsize = 15\n if isinstance(rc_titlesize, str):\n rc_titlesize = 16\n if isinstance(rc_xt_labelsize, str):\n rc_xt_labelsize = 14\n\n if figsize is None:\n width, height = rc_width, rc_height\n sff = 1 if (rows == cols == 1) else 1.15\n width = width * cols * sff\n height = height * rows * sff\n else:\n width, height = figsize\n\n if textsize is not None:\n scale_factor = textsize / rc_xt_labelsize\n elif rows == cols == 1:\n scale_factor = ((width * height) / (rc_width * rc_height)) ** 0.5\n else:\n scale_factor = 1\n\n ax_labelsize = rc_ax_labelsize * scale_factor\n titlesize = rc_titlesize * scale_factor\n xt_labelsize = rc_xt_labelsize * scale_factor\n linewidth = rc_linewidth * scale_factor\n markersize = rc_markersize * scale_factor\n\n return (width, height), ax_labelsize, titlesize, xt_labelsize, linewidth, markersize\n\n\ndef get_bins(ary, max_bins=50, fenceposts=2):\n \"\"\"Compute number of bins (or ticks).\n\n Parameters\n ----------\n ary : numpy.array\n array to be binned\n max_bins : int\n maximum number of bins\n fenceposts : int\n when computing bins, this should be 2, when computing ticks this should be 1.\n \"\"\"\n x_max, x_min = ary.max(), ary.min()\n x_range = x_max - x_min\n if x_range > max_bins:\n bins = range(x_min, x_max + fenceposts, max(1, int(x_range / 10)))\n else:\n bins = range(x_min, x_max + fenceposts)\n return bins\n\n\ndef default_grid(n_items, max_cols=4, min_cols=3): # noqa: D202\n \"\"\"Make a grid for subplots.\n\n Tries to get as close to sqrt(n_items) x sqrt(n_items) as it can,\n but allows for custom logic\n\n Parameters\n ----------\n n_items : int\n Number of panels required\n max_cols : int\n Maximum number of columns, inclusive\n min_cols : int\n Minimum number of columns, inclusive\n\n Returns\n -------\n (int, int)\n Rows and columns, so that rows * columns >= n_items\n \"\"\"\n\n def in_bounds(val):\n return np.clip(val, min_cols, max_cols)\n\n if n_items <= max_cols:\n return 1, n_items\n ideal = in_bounds(round(n_items ** 0.5))\n\n for offset in (0, 1, -1, 2, -2):\n cols = in_bounds(ideal + offset)\n rows, extra = divmod(n_items, cols)\n if extra == 0:\n return rows, cols\n return n_items // ideal + 1, ideal\n\n\ndef _create_axes_grid(length_plotters, rows, cols, **kwargs):\n \"\"\"Create figure and axes for grids with multiple plots.\n\n Parameters\n ----------\n n_items : int\n Number of panels required\n rows : int\n Number of rows\n cols : int\n Number of columns\n\n Returns\n -------\n fig : matplotlib figure\n ax : matplotlib axes\n \"\"\"\n kwargs.setdefault(\"constrained_layout\", True)\n fig, ax = plt.subplots(rows, cols, **kwargs)\n ax = np.ravel(ax)\n extra = (rows * cols) - length_plotters\n if extra:\n for i in range(1, extra + 1):\n ax[-i].set_axis_off()\n ax = ax[:-extra]\n return fig, ax\n\n\ndef selection_to_string(selection):\n \"\"\"Convert dictionary of coordinates to a string for labels.\n\n Parameters\n ----------\n selection : dict[Any] -> Any\n\n Returns\n -------\n str\n key1: value1, key2: value2, ...\n \"\"\"\n return \", \".join([\"{}\".format(v) for _, v in selection.items()])\n\n\ndef make_label(var_name, selection, position=\"below\"):\n \"\"\"Consistent labelling for plots.\n\n Parameters\n ----------\n var_name : str\n Name of the variable\n\n selection : dict[Any] -> Any\n Coordinates of the variable\n position : whether to position the coordinates' label \"below\" (default) or \"beside\" the name\n of the variable\n\n Returns\n -------\n label\n A text representation of the label\n \"\"\"\n if selection:\n sel = selection_to_string(selection)\n if position == \"below\":\n sep = \"\\n\"\n elif position == \"beside\":\n sep = \" \"\n else:\n sep = sel = \"\"\n return \"{}{}{}\".format(var_name, sep, sel)\n\n\ndef xarray_var_iter(data, var_names=None, combined=False, skip_dims=None, reverse_selections=False):\n \"\"\"Convert xarray data to an iterator over vectors.\n\n Iterates over each var_name and all of its coordinates, returning the 1d\n data.\n\n Parameters\n ----------\n data : xarray.Dataset\n Posterior data in an xarray\n\n var_names : iterator of strings (optional)\n Should be a subset of data.data_vars. Defaults to all of them.\n\n combined : bool\n Whether to combine chains or leave them separate\n\n skip_dims : set\n dimensions to not iterate over\n\n reverse_selections : bool\n Whether to reverse selections before iterating.\n\n Returns\n -------\n Iterator of (str, dict(str, any), np.array)\n The string is the variable name, the dictionary are coordinate names to values,\n and the array are the values of the variable at those coordinates.\n \"\"\"\n if skip_dims is None:\n skip_dims = set()\n\n if combined:\n skip_dims = skip_dims.union({\"chain\", \"draw\"})\n else:\n skip_dims.add(\"draw\")\n\n if var_names is None:\n if isinstance(data, xr.Dataset):\n var_names = list(data.data_vars)\n elif isinstance(data, xr.DataArray):\n var_names = [data.name]\n data = {data.name: data}\n\n for var_name in var_names:\n if var_name in data:\n new_dims = [dim for dim in data[var_name].dims if dim not in skip_dims]\n vals = [set(data[var_name][dim].values) for dim in new_dims]\n dims = [{k: v for k, v in zip(new_dims, prod)} for prod in product(*vals)]\n if reverse_selections:\n dims = reversed(dims)\n\n for selection in dims:\n yield var_name, selection, data[var_name].sel(**selection).values\n\n\ndef xarray_to_ndarray(data, *, var_names=None, combined=True):\n \"\"\"Take xarray data and unpacks into variables and data into list and numpy array respectively.\n\n Assumes that chain and draw are in coordinates\n\n Parameters\n ----------\n data: xarray.DataSet\n Data in an xarray from an InferenceData object. Examples include posterior or sample_stats\n\n var_names: iter\n Should be a subset of data.data_vars not including chain and draws. Defaults to all of them\n\n combined: bool\n Whether to combine chain into one array\n\n Returns\n -------\n var_names: list\n List of variable names\n data: np.array\n Data values\n \"\"\"\n unpacked_data, unpacked_var_names, = [], []\n\n # Merge chains and variables\n for var_name, selection, data_array in xarray_var_iter(\n data, var_names=var_names, combined=combined\n ):\n unpacked_data.append(data_array.flatten())\n unpacked_var_names.append(make_label(var_name, selection))\n\n return unpacked_var_names, np.array(unpacked_data)\n\n\ndef get_coords(data, coords):\n \"\"\"Subselects xarray dataset object to provided coords. Raises exception if fails.\n\n Raises\n ------\n ValueError\n If coords name are not available in data\n\n KeyError\n If coords dims are not available in data\n\n Returns\n -------\n data: xarray\n xarray.Dataset object\n \"\"\"\n try:\n return data.sel(**coords)\n\n except ValueError:\n invalid_coords = set(coords.keys()) - set(data.coords.keys())\n raise ValueError(\"Coords {} are invalid coordinate keys\".format(invalid_coords))\n\n except KeyError as err:\n raise KeyError(\n (\n \"Coords should follow mapping format {{coord_name:[dim1, dim2]}}. \"\n \"Check that coords structure is correct and\"\n \" dimensions are valid. {}\"\n ).format(err)\n )\n", "path": "arviz/plots/plot_utils.py"}], "after_files": [{"content": "\"\"\"Utilities for plotting.\"\"\"\nfrom itertools import product\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nimport xarray as xr\n\n\ndef make_2d(ary):\n \"\"\"Convert any array into a 2d numpy array.\n\n In case the array is already more than 2 dimensional, will ravel the\n dimensions after the first.\n \"\"\"\n dim_0, *_ = np.atleast_1d(ary).shape\n return ary.reshape(dim_0, -1, order=\"F\")\n\n\ndef _scale_fig_size(figsize, textsize, rows=1, cols=1):\n \"\"\"Scale figure properties according to rows and cols.\n\n Parameters\n ----------\n figsize : float or None\n Size of figure in inches\n textsize : float or None\n fontsize\n rows : int\n Number of rows\n cols : int\n Number of columns\n\n Returns\n -------\n figsize : float or None\n Size of figure in inches\n ax_labelsize : int\n fontsize for axes label\n titlesize : int\n fontsize for title\n xt_labelsize : int\n fontsize for axes ticks\n linewidth : int\n linewidth\n markersize : int\n markersize\n \"\"\"\n params = mpl.rcParams\n rc_width, rc_height = tuple(params[\"figure.figsize\"])\n rc_ax_labelsize = params[\"axes.labelsize\"]\n rc_titlesize = params[\"axes.titlesize\"]\n rc_xt_labelsize = params[\"xtick.labelsize\"]\n rc_linewidth = params[\"lines.linewidth\"]\n rc_markersize = params[\"lines.markersize\"]\n if isinstance(rc_ax_labelsize, str):\n rc_ax_labelsize = 15\n if isinstance(rc_titlesize, str):\n rc_titlesize = 16\n if isinstance(rc_xt_labelsize, str):\n rc_xt_labelsize = 14\n\n if figsize is None:\n width, height = rc_width, rc_height\n sff = 1 if (rows == cols == 1) else 1.15\n width = width * cols * sff\n height = height * rows * sff\n else:\n width, height = figsize\n\n if textsize is not None:\n scale_factor = textsize / rc_xt_labelsize\n elif rows == cols == 1:\n scale_factor = ((width * height) / (rc_width * rc_height)) ** 0.5\n else:\n scale_factor = 1\n\n ax_labelsize = rc_ax_labelsize * scale_factor\n titlesize = rc_titlesize * scale_factor\n xt_labelsize = rc_xt_labelsize * scale_factor\n linewidth = rc_linewidth * scale_factor\n markersize = rc_markersize * scale_factor\n\n return (width, height), ax_labelsize, titlesize, xt_labelsize, linewidth, markersize\n\n\ndef get_bins(ary, max_bins=50, fenceposts=2):\n \"\"\"Compute number of bins (or ticks).\n\n Parameters\n ----------\n ary : numpy.array\n array to be binned\n max_bins : int\n maximum number of bins\n fenceposts : int\n when computing bins, this should be 2, when computing ticks this should be 1.\n \"\"\"\n x_max, x_min = ary.max(), ary.min()\n x_range = x_max - x_min\n if x_range > max_bins:\n bins = range(x_min, x_max + fenceposts, max(1, int(x_range / 10)))\n else:\n bins = range(x_min, x_max + fenceposts)\n return bins\n\n\ndef default_grid(n_items, max_cols=4, min_cols=3): # noqa: D202\n \"\"\"Make a grid for subplots.\n\n Tries to get as close to sqrt(n_items) x sqrt(n_items) as it can,\n but allows for custom logic\n\n Parameters\n ----------\n n_items : int\n Number of panels required\n max_cols : int\n Maximum number of columns, inclusive\n min_cols : int\n Minimum number of columns, inclusive\n\n Returns\n -------\n (int, int)\n Rows and columns, so that rows * columns >= n_items\n \"\"\"\n\n def in_bounds(val):\n return np.clip(val, min_cols, max_cols)\n\n if n_items <= max_cols:\n return 1, n_items\n ideal = in_bounds(round(n_items ** 0.5))\n\n for offset in (0, 1, -1, 2, -2):\n cols = in_bounds(ideal + offset)\n rows, extra = divmod(n_items, cols)\n if extra == 0:\n return rows, cols\n return n_items // ideal + 1, ideal\n\n\ndef _create_axes_grid(length_plotters, rows, cols, **kwargs):\n \"\"\"Create figure and axes for grids with multiple plots.\n\n Parameters\n ----------\n n_items : int\n Number of panels required\n rows : int\n Number of rows\n cols : int\n Number of columns\n\n Returns\n -------\n fig : matplotlib figure\n ax : matplotlib axes\n \"\"\"\n kwargs.setdefault(\"constrained_layout\", True)\n fig, ax = plt.subplots(rows, cols, **kwargs)\n ax = np.ravel(ax)\n extra = (rows * cols) - length_plotters\n if extra:\n for i in range(1, extra + 1):\n ax[-i].set_axis_off()\n ax = ax[:-extra]\n return fig, ax\n\n\ndef selection_to_string(selection):\n \"\"\"Convert dictionary of coordinates to a string for labels.\n\n Parameters\n ----------\n selection : dict[Any] -> Any\n\n Returns\n -------\n str\n key1: value1, key2: value2, ...\n \"\"\"\n return \", \".join([\"{}\".format(v) for _, v in selection.items()])\n\n\ndef make_label(var_name, selection, position=\"below\"):\n \"\"\"Consistent labelling for plots.\n\n Parameters\n ----------\n var_name : str\n Name of the variable\n\n selection : dict[Any] -> Any\n Coordinates of the variable\n position : whether to position the coordinates' label \"below\" (default) or \"beside\" the name\n of the variable\n\n Returns\n -------\n label\n A text representation of the label\n \"\"\"\n if selection:\n sel = selection_to_string(selection)\n if position == \"below\":\n sep = \"\\n\"\n elif position == \"beside\":\n sep = \" \"\n else:\n sep = sel = \"\"\n return \"{}{}{}\".format(var_name, sep, sel)\n\n\ndef xarray_var_iter(data, var_names=None, combined=False, skip_dims=None, reverse_selections=False):\n \"\"\"Convert xarray data to an iterator over vectors.\n\n Iterates over each var_name and all of its coordinates, returning the 1d\n data.\n\n Parameters\n ----------\n data : xarray.Dataset\n Posterior data in an xarray\n\n var_names : iterator of strings (optional)\n Should be a subset of data.data_vars. Defaults to all of them.\n\n combined : bool\n Whether to combine chains or leave them separate\n\n skip_dims : set\n dimensions to not iterate over\n\n reverse_selections : bool\n Whether to reverse selections before iterating.\n\n Returns\n -------\n Iterator of (str, dict(str, any), np.array)\n The string is the variable name, the dictionary are coordinate names to values,\n and the array are the values of the variable at those coordinates.\n \"\"\"\n if skip_dims is None:\n skip_dims = set()\n\n if combined:\n skip_dims = skip_dims.union({\"chain\", \"draw\"})\n else:\n skip_dims.add(\"draw\")\n\n if var_names is None:\n if isinstance(data, xr.Dataset):\n var_names = list(data.data_vars)\n elif isinstance(data, xr.DataArray):\n var_names = [data.name]\n data = {data.name: data}\n\n for var_name in var_names:\n if var_name in data:\n new_dims = [dim for dim in data[var_name].dims if dim not in skip_dims]\n vals = [np.unique(data[var_name][dim].values) for dim in new_dims]\n dims = [{k: v for k, v in zip(new_dims, prod)} for prod in product(*vals)]\n if reverse_selections:\n dims = reversed(dims)\n\n for selection in dims:\n yield var_name, selection, data[var_name].sel(**selection).values\n\n\ndef xarray_to_ndarray(data, *, var_names=None, combined=True):\n \"\"\"Take xarray data and unpacks into variables and data into list and numpy array respectively.\n\n Assumes that chain and draw are in coordinates\n\n Parameters\n ----------\n data: xarray.DataSet\n Data in an xarray from an InferenceData object. Examples include posterior or sample_stats\n\n var_names: iter\n Should be a subset of data.data_vars not including chain and draws. Defaults to all of them\n\n combined: bool\n Whether to combine chain into one array\n\n Returns\n -------\n var_names: list\n List of variable names\n data: np.array\n Data values\n \"\"\"\n unpacked_data, unpacked_var_names, = [], []\n\n # Merge chains and variables\n for var_name, selection, data_array in xarray_var_iter(\n data, var_names=var_names, combined=combined\n ):\n unpacked_data.append(data_array.flatten())\n unpacked_var_names.append(make_label(var_name, selection))\n\n return unpacked_var_names, np.array(unpacked_data)\n\n\ndef get_coords(data, coords):\n \"\"\"Subselects xarray dataset object to provided coords. Raises exception if fails.\n\n Raises\n ------\n ValueError\n If coords name are not available in data\n\n KeyError\n If coords dims are not available in data\n\n Returns\n -------\n data: xarray\n xarray.Dataset object\n \"\"\"\n try:\n return data.sel(**coords)\n\n except ValueError:\n invalid_coords = set(coords.keys()) - set(data.coords.keys())\n raise ValueError(\"Coords {} are invalid coordinate keys\".format(invalid_coords))\n\n except KeyError as err:\n raise KeyError(\n (\n \"Coords should follow mapping format {{coord_name:[dim1, dim2]}}. \"\n \"Check that coords structure is correct and\"\n \" dimensions are valid. {}\"\n ).format(err)\n )\n", "path": "arviz/plots/plot_utils.py"}]}
| 3,880 | 173 |
gh_patches_debug_3993
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-382
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NY: Committees don't have members
Taken from bug #195
http://openstates.org/browse/ny/committees/
http://www.nysenate.gov/committee/state-native-american-relations
http://assembly.state.ny.us/comm/?sec=mem&id=60
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/ny/committees.py`
Content:
```
1 import re
2
3 from billy.scrape import NoDataForPeriod
4 from billy.scrape.committees import CommitteeScraper, Committee
5
6 import lxml.html
7
8
9 def parse_name(name):
10 """
11 Split a committee membership string into name and role.
12
13 >>> parse_name('Felix Ortiz')
14 ('Felix Ortiz', 'member')
15 >>> parse_name('Felix Ortiz (Chair)')
16 ('Felix Ortiz', 'chair')
17 >>> parse_name('Hon. Felix Ortiz, Co-Chair')
18 ('Felix Ortiz', 'co-chair')
19 >>> parse_name('Owen H.\\r\\nJohnson (Vice Chairperson)')
20 ('Owen H. Johnson', 'vice chairperson')
21 """
22 name = re.sub(r'^(Hon\.|Assemblyman|Assemblywoman)\s+', '', name)
23 name = re.sub(r'\s+', ' ', name)
24
25 roles = ["Chairwoman", "Chairperson", "Chair", "Secretary", "Treasurer",
26 "Parliamentarian", "Chaplain"]
27 match = re.match(
28 r'([^(]+),? \(?((Co|Vice)?-?\s*(%s))\)?' % '|'.join(roles),
29 name)
30
31 if match:
32 name = match.group(1).strip(' ,')
33 role = match.group(2).lower()
34 return (name, role)
35 return (name, 'member')
36
37
38 class NYCommitteeScraper(CommitteeScraper):
39 state = "ny"
40 latest_only = True
41
42 def scrape(self, chamber, term):
43 getattr(self, 'scrape_' + chamber)()
44
45 def scrape_lower(self, only_names=None):
46 committees = []
47 url = "http://assembly.state.ny.us/comm/"
48 page = self.urlopen(url)
49 page = lxml.html.fromstring(page)
50 page.make_links_absolute(url)
51
52 for link in page.xpath("//a[contains(@href, 'sec=mem')]"):
53 name = link.xpath("string(../strong)").strip()
54 if 'Caucus' in name:
55 continue
56
57 url = link.attrib['href']
58
59 committees.append(name)
60
61 self.scrape_lower_committee(name, url)
62 return committees
63
64 def scrape_lower_committee(self, name, url):
65 page = self.urlopen(url)
66 page = lxml.html.fromstring(page)
67
68 comm = Committee('lower', name)
69 comm.add_source(url)
70
71 for link in page.xpath("//a[contains(@href, 'mem?ad')]"):
72 member = link.text.strip()
73 member = re.sub(r'\s+', ' ', member)
74
75 name, role = parse_name(member)
76 comm.add_member(name, role)
77
78 self.save_committee(comm)
79
80 def scrape_upper(self):
81 committees = []
82 url = "http://www.nysenate.gov/committees"
83 page = self.urlopen(url)
84 page = lxml.html.fromstring(page)
85 page.make_links_absolute(url)
86
87 for link in page.xpath("//a[contains(@href, '/committee/')]"):
88 name = link.text.strip()
89
90 if name == 'New York State Conference of Black Senators':
91 # stop scraping once we reach the caucuses
92 break
93
94 committees.append(name)
95 self.scrape_upper_committee(name, link.attrib['href'])
96 return committees
97
98 def scrape_upper_committee(self, name, url):
99 page = self.urlopen(url)
100 page = lxml.html.fromstring(page)
101
102 comm = Committee('upper', name)
103 comm.add_source(url)
104
105 member_div = page.xpath("//div[@class = 'committee-members']")[0]
106
107 seen = set()
108 for link in member_div.xpath(".//a"):
109 if not link.text:
110 continue
111
112 member = link.text.strip()
113
114 next_elem = link.getnext()
115 if (next_elem is not None and
116 next_elem.tag == 'a' and
117 next_elem.attrib['href'] == link.attrib['href']):
118 # Sometimes NY is cool and splits names across a
119 # couple links
120 member = "%s %s" % (member, next_elem.text.strip())
121
122 member = re.sub(r'\s+', ' ', member)
123
124 if member in seen or not member:
125 continue
126 seen.add(member)
127
128 name, role = parse_name(member)
129 comm.add_member(name, role)
130
131 self.save_committee(comm)
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/ny/committees.py b/openstates/ny/committees.py
--- a/openstates/ny/committees.py
+++ b/openstates/ny/committees.py
@@ -68,7 +68,7 @@
comm = Committee('lower', name)
comm.add_source(url)
- for link in page.xpath("//a[contains(@href, 'mem?ad')]"):
+ for link in page.xpath("//div[@class='commlinks']//a[contains(@href, 'mem')]"):
member = link.text.strip()
member = re.sub(r'\s+', ' ', member)
|
{"golden_diff": "diff --git a/openstates/ny/committees.py b/openstates/ny/committees.py\n--- a/openstates/ny/committees.py\n+++ b/openstates/ny/committees.py\n@@ -68,7 +68,7 @@\n comm = Committee('lower', name)\n comm.add_source(url)\n \n- for link in page.xpath(\"//a[contains(@href, 'mem?ad')]\"):\n+ for link in page.xpath(\"//div[@class='commlinks']//a[contains(@href, 'mem')]\"):\n member = link.text.strip()\n member = re.sub(r'\\s+', ' ', member)\n", "issue": "NY: Committees don't have members\nTaken from bug #195\n\nhttp://openstates.org/browse/ny/committees/\nhttp://www.nysenate.gov/committee/state-native-american-relations\nhttp://assembly.state.ny.us/comm/?sec=mem&id=60\n\n", "before_files": [{"content": "import re\n\nfrom billy.scrape import NoDataForPeriod\nfrom billy.scrape.committees import CommitteeScraper, Committee\n\nimport lxml.html\n\n\ndef parse_name(name):\n \"\"\"\n Split a committee membership string into name and role.\n\n >>> parse_name('Felix Ortiz')\n ('Felix Ortiz', 'member')\n >>> parse_name('Felix Ortiz (Chair)')\n ('Felix Ortiz', 'chair')\n >>> parse_name('Hon. Felix Ortiz, Co-Chair')\n ('Felix Ortiz', 'co-chair')\n >>> parse_name('Owen H.\\\\r\\\\nJohnson (Vice Chairperson)')\n ('Owen H. Johnson', 'vice chairperson')\n \"\"\"\n name = re.sub(r'^(Hon\\.|Assemblyman|Assemblywoman)\\s+', '', name)\n name = re.sub(r'\\s+', ' ', name)\n\n roles = [\"Chairwoman\", \"Chairperson\", \"Chair\", \"Secretary\", \"Treasurer\",\n \"Parliamentarian\", \"Chaplain\"]\n match = re.match(\n r'([^(]+),? \\(?((Co|Vice)?-?\\s*(%s))\\)?' % '|'.join(roles),\n name)\n\n if match:\n name = match.group(1).strip(' ,')\n role = match.group(2).lower()\n return (name, role)\n return (name, 'member')\n\n\nclass NYCommitteeScraper(CommitteeScraper):\n state = \"ny\"\n latest_only = True\n\n def scrape(self, chamber, term):\n getattr(self, 'scrape_' + chamber)()\n\n def scrape_lower(self, only_names=None):\n committees = []\n url = \"http://assembly.state.ny.us/comm/\"\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n page.make_links_absolute(url)\n\n for link in page.xpath(\"//a[contains(@href, 'sec=mem')]\"):\n name = link.xpath(\"string(../strong)\").strip()\n if 'Caucus' in name:\n continue\n\n url = link.attrib['href']\n\n committees.append(name)\n\n self.scrape_lower_committee(name, url)\n return committees\n\n def scrape_lower_committee(self, name, url):\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n\n comm = Committee('lower', name)\n comm.add_source(url)\n\n for link in page.xpath(\"//a[contains(@href, 'mem?ad')]\"):\n member = link.text.strip()\n member = re.sub(r'\\s+', ' ', member)\n\n name, role = parse_name(member)\n comm.add_member(name, role)\n\n self.save_committee(comm)\n\n def scrape_upper(self):\n committees = []\n url = \"http://www.nysenate.gov/committees\"\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n page.make_links_absolute(url)\n\n for link in page.xpath(\"//a[contains(@href, '/committee/')]\"):\n name = link.text.strip()\n\n if name == 'New York State Conference of Black Senators':\n # stop scraping once we reach the caucuses\n break\n\n committees.append(name)\n self.scrape_upper_committee(name, link.attrib['href'])\n return committees\n\n def scrape_upper_committee(self, name, url):\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n\n comm = Committee('upper', name)\n comm.add_source(url)\n\n member_div = page.xpath(\"//div[@class = 'committee-members']\")[0]\n\n seen = set()\n for link in member_div.xpath(\".//a\"):\n if not link.text:\n continue\n\n member = link.text.strip()\n\n next_elem = link.getnext()\n if (next_elem is not None and\n next_elem.tag == 'a' and\n next_elem.attrib['href'] == link.attrib['href']):\n # Sometimes NY is cool and splits names across a\n # couple links\n member = \"%s %s\" % (member, next_elem.text.strip())\n\n member = re.sub(r'\\s+', ' ', member)\n\n if member in seen or not member:\n continue\n seen.add(member)\n\n name, role = parse_name(member)\n comm.add_member(name, role)\n\n self.save_committee(comm)\n", "path": "openstates/ny/committees.py"}], "after_files": [{"content": "import re\n\nfrom billy.scrape import NoDataForPeriod\nfrom billy.scrape.committees import CommitteeScraper, Committee\n\nimport lxml.html\n\n\ndef parse_name(name):\n \"\"\"\n Split a committee membership string into name and role.\n\n >>> parse_name('Felix Ortiz')\n ('Felix Ortiz', 'member')\n >>> parse_name('Felix Ortiz (Chair)')\n ('Felix Ortiz', 'chair')\n >>> parse_name('Hon. Felix Ortiz, Co-Chair')\n ('Felix Ortiz', 'co-chair')\n >>> parse_name('Owen H.\\\\r\\\\nJohnson (Vice Chairperson)')\n ('Owen H. Johnson', 'vice chairperson')\n \"\"\"\n name = re.sub(r'^(Hon\\.|Assemblyman|Assemblywoman)\\s+', '', name)\n name = re.sub(r'\\s+', ' ', name)\n\n roles = [\"Chairwoman\", \"Chairperson\", \"Chair\", \"Secretary\", \"Treasurer\",\n \"Parliamentarian\", \"Chaplain\"]\n match = re.match(\n r'([^(]+),? \\(?((Co|Vice)?-?\\s*(%s))\\)?' % '|'.join(roles),\n name)\n\n if match:\n name = match.group(1).strip(' ,')\n role = match.group(2).lower()\n return (name, role)\n return (name, 'member')\n\n\nclass NYCommitteeScraper(CommitteeScraper):\n state = \"ny\"\n latest_only = True\n\n def scrape(self, chamber, term):\n getattr(self, 'scrape_' + chamber)()\n\n def scrape_lower(self, only_names=None):\n committees = []\n url = \"http://assembly.state.ny.us/comm/\"\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n page.make_links_absolute(url)\n\n for link in page.xpath(\"//a[contains(@href, 'sec=mem')]\"):\n name = link.xpath(\"string(../strong)\").strip()\n if 'Caucus' in name:\n continue\n\n url = link.attrib['href']\n\n committees.append(name)\n\n self.scrape_lower_committee(name, url)\n return committees\n\n def scrape_lower_committee(self, name, url):\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n\n comm = Committee('lower', name)\n comm.add_source(url)\n\n for link in page.xpath(\"//div[@class='commlinks']//a[contains(@href, 'mem')]\"):\n member = link.text.strip()\n member = re.sub(r'\\s+', ' ', member)\n\n name, role = parse_name(member)\n comm.add_member(name, role)\n\n self.save_committee(comm)\n\n def scrape_upper(self):\n committees = []\n url = \"http://www.nysenate.gov/committees\"\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n page.make_links_absolute(url)\n\n for link in page.xpath(\"//a[contains(@href, '/committee/')]\"):\n name = link.text.strip()\n\n if name == 'New York State Conference of Black Senators':\n # stop scraping once we reach the caucuses\n break\n\n committees.append(name)\n self.scrape_upper_committee(name, link.attrib['href'])\n return committees\n\n def scrape_upper_committee(self, name, url):\n page = self.urlopen(url)\n page = lxml.html.fromstring(page)\n\n comm = Committee('upper', name)\n comm.add_source(url)\n\n member_div = page.xpath(\"//div[@class = 'committee-members']\")[0]\n\n seen = set()\n for link in member_div.xpath(\".//a\"):\n if not link.text:\n continue\n\n member = link.text.strip()\n\n next_elem = link.getnext()\n if (next_elem is not None and\n next_elem.tag == 'a' and\n next_elem.attrib['href'] == link.attrib['href']):\n # Sometimes NY is cool and splits names across a\n # couple links\n member = \"%s %s\" % (member, next_elem.text.strip())\n\n member = re.sub(r'\\s+', ' ', member)\n\n if member in seen or not member:\n continue\n seen.add(member)\n\n name, role = parse_name(member)\n comm.add_member(name, role)\n\n self.save_committee(comm)\n", "path": "openstates/ny/committees.py"}]}
| 1,560 | 137 |
gh_patches_debug_20787
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-2185
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
inputMultiple() displays a malformed empty status box
**Small description**
`search-keys` and `search-col` displays an empty box while waiting for the user to input a regex at the prompt. The box is shown where the usual status messages are shown.
**Expected result**
No box should be displayed.
**Actual result with screenshot**

For comparison, here is what the normal status messages look like:

**Steps to reproduce with sample data and a .vd**
Open any sheet and hit `r` or `/`.
**Additional context**
saul.pw/VisiData v3.0dev
Python 3.10.12
Ubuntu 22.04.3
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python3
2
3 from setuptools import setup
4 # tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96
5 #from visidata import __version__
6 __version__ = '3.0dev'
7
8 setup(name='visidata',
9 version=__version__,
10 description='terminal interface for exploring and arranging tabular data',
11 long_description=open('README.md').read(),
12 long_description_content_type='text/markdown',
13 author='Saul Pwanson',
14 python_requires='>=3.7',
15 author_email='[email protected]',
16 url='https://visidata.org',
17 download_url='https://github.com/saulpw/visidata/tarball/' + __version__,
18 scripts=['bin/vd'],
19 entry_points={'console_scripts': [
20 'visidata=visidata.main:vd_cli'
21 ],
22 },
23 py_modules=['visidata'],
24 install_requires=[
25 'python-dateutil',
26 'windows-curses != 2.3.1; platform_system == "Windows"', #1841
27 'importlib-metadata >= 3.6',
28 'importlib_resources; python_version<"3.9"'
29 ],
30 packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
31 data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications', ['visidata/desktop/visidata.desktop'])],
32 package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},
33 license='GPLv3',
34 classifiers=[
35 'Development Status :: 5 - Production/Stable',
36 'Environment :: Console',
37 'Environment :: Console :: Curses',
38 'Intended Audience :: Developers',
39 'Intended Audience :: Science/Research',
40 'Intended Audience :: System Administrators',
41 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',
42 'Operating System :: OS Independent',
43 'Programming Language :: Python :: 3',
44 'Topic :: Database :: Front-Ends',
45 'Topic :: Scientific/Engineering',
46 'Topic :: Office/Business :: Financial :: Spreadsheet',
47 'Topic :: Scientific/Engineering :: Visualization',
48 'Topic :: Utilities',
49 ],
50 keywords=('console tabular data spreadsheet terminal viewer textpunk'
51 'curses csv hdf5 h5 xlsx excel tsv'),
52 )
53
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -29,7 +29,7 @@
],
packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications', ['visidata/desktop/visidata.desktop'])],
- package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},
+ package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw', 'regex.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},
license='GPLv3',
classifiers=[
'Development Status :: 5 - Production/Stable',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -29,7 +29,7 @@\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications', ['visidata/desktop/visidata.desktop'])],\n- package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n+ package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw', 'regex.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n", "issue": "inputMultiple() displays a malformed empty status box\n**Small description**\r\n`search-keys` and `search-col` displays an empty box while waiting for the user to input a regex at the prompt. The box is shown where the usual status messages are shown.\r\n\r\n**Expected result**\r\nNo box should be displayed.\r\n\r\n**Actual result with screenshot**\r\n\r\n\r\nFor comparison, here is what the normal status messages look like:\r\n\r\n\r\n**Steps to reproduce with sample data and a .vd**\r\nOpen any sheet and hit `r` or `/`.\r\n\r\n**Additional context**\r\nsaul.pw/VisiData v3.0dev\r\nPython 3.10.12\r\nUbuntu 22.04.3\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '3.0dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses != 2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n 'importlib_resources; python_version<\"3.9\"'\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '3.0dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses != 2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n 'importlib_resources; python_version<\"3.9\"'\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw', 'regex.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}]}
| 1,221 | 275 |
gh_patches_debug_20998
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6578
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feature]: meltano add to project without install
### Feature scope
CLI (options, error messages, logging, etc.)
### Description
**As a user, I need to add to my meltano project without install**
Adding to a meltano project is currently a very slow operation. Our requirement is to add all the plugins to the project and then later build (i.e. 'meltano install') the whole project. This means that the initial 'meltano add' is unnecessarily slow as we don't use any of the pip-installed modules from the initial 'meltano add'
Work arounds considered:
- directly add a meltano.yml format file with our plugin definition to a directory with the root meltano.yml includes referencing that directory path & directly save a lock file to the /plugins directory (essentially avoiding using 'meltano add' at all)
This proposal is to be able to add to the meltano project rapidly without installing all pip dependencies, and we'd ideally like to be able to freeze those dependencies.
`meltano add --skip-install` should
1. download the lock file
2. add to the meltano.yml
3. add all the lock and meltano.yml files for any `requires` plugins (https://github.com/meltano/hub/pull/505 & https://github.com/meltano/meltano/issues/6107)
Related to:
This feature is related to https://github.com/meltano/meltano/issues/6416
**As a user, I need to add to my meltano project without install and create pip freeze**
`meltano add --skip-install --freeze` consider whether this --skip-install works if --freeze is used (assuming https://github.com/meltano/meltano/issues/6416 might implement --freeze)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/cli/add.py`
Content:
```
1 """Plugin Add CLI."""
2 from __future__ import annotations
3
4 import click
5
6 from meltano.core.plugin import PluginType
7 from meltano.core.plugin.base import PluginRef
8 from meltano.core.plugin.project_plugin import ProjectPlugin
9 from meltano.core.plugin_install_service import PluginInstallReason
10 from meltano.core.project import Project
11 from meltano.core.project_add_service import ProjectAddService
12 from meltano.core.project_plugins_service import ProjectPluginsService
13 from meltano.core.tracking import CliEvent, PluginsTrackingContext
14
15 from . import cli
16 from .params import pass_project
17 from .utils import (
18 CliError,
19 PartialInstrumentedCmd,
20 add_plugin,
21 add_required_plugins,
22 check_dependencies_met,
23 install_plugins,
24 )
25
26
27 @cli.command( # noqa: WPS238
28 cls=PartialInstrumentedCmd,
29 short_help="Add a plugin to your project.",
30 )
31 @click.argument("plugin_type", type=click.Choice(PluginType.cli_arguments()))
32 @click.argument("plugin_name", nargs=-1, required=True)
33 @click.option(
34 "--inherit-from",
35 help=(
36 "Add a plugin inheriting from an existing plugin in the project"
37 + " or a discoverable plugin identified, by name."
38 ),
39 )
40 @click.option(
41 "--variant",
42 help="Add a specific (non-default) variant of the identified discoverable plugin.",
43 )
44 @click.option(
45 "--as",
46 "as_name",
47 help=(
48 "Shorthand for '--inherit-from', that can be used to add a discoverable "
49 + "plugin to your project with a different name. "
50 + "Usage:\b\n\nadd <type> <inherit-from> --as <name>"
51 ),
52 )
53 @click.option(
54 "--custom",
55 is_flag=True,
56 help="Add a custom plugin. The command will prompt you for the package's base plugin description metadata.",
57 )
58 @pass_project()
59 @click.pass_context
60 def add(
61 ctx,
62 project: Project,
63 plugin_type: str,
64 plugin_name: str,
65 inherit_from: str = None,
66 variant: str = None,
67 as_name: str = None,
68 **flags,
69 ):
70 """
71 Add a plugin to your project.
72
73 \b\nRead more at https://docs.meltano.com/reference/command-line-interface#add
74 """
75 tracker = ctx.obj["tracker"]
76 legacy_tracker = ctx.obj["legacy_tracker"]
77
78 plugin_type = PluginType.from_cli_argument(plugin_type)
79 plugin_names = plugin_name # nargs=-1
80
81 if as_name:
82 # `add <type> <inherit-from> --as <name>``
83 # is equivalent to:
84 # `add <type> <name> --inherit-from <inherit-from>``
85 inherit_from = plugin_names[0]
86 plugin_names = [as_name]
87
88 plugins_service = ProjectPluginsService(project)
89
90 if flags["custom"]:
91 if plugin_type in {
92 PluginType.TRANSFORMS,
93 PluginType.ORCHESTRATORS,
94 }:
95 tracker.track_command_event(CliEvent.aborted)
96 raise CliError(f"--custom is not supported for {plugin_type}")
97
98 plugin_refs = [
99 PluginRef(plugin_type=plugin_type, name=name) for name in plugin_names
100 ]
101 dependencies_met, err = check_dependencies_met(
102 plugin_refs=plugin_refs, plugins_service=plugins_service
103 )
104 if not dependencies_met:
105 tracker.track_command_event(CliEvent.aborted)
106 raise CliError(f"Failed to install plugin(s): {err}")
107
108 add_service = ProjectAddService(project, plugins_service=plugins_service)
109
110 plugins: list[ProjectPlugin] = []
111 for plugin in plugin_names:
112 try:
113 plugins.append(
114 add_plugin(
115 project,
116 plugin_type,
117 plugin,
118 inherit_from=inherit_from,
119 variant=variant,
120 custom=flags["custom"],
121 add_service=add_service,
122 )
123 )
124 except Exception:
125 # if the plugin is not known to meltano send what information we do have
126 tracker.add_contexts(
127 PluginsTrackingContext([(plugin, None) for plugin in plugins])
128 )
129 tracker.track_command_event(CliEvent.aborted)
130 raise
131
132 legacy_tracker.track_meltano_add(plugin_type=plugin_type, plugin_name=plugin)
133
134 required_plugins = add_required_plugins(
135 project, plugins, add_service=add_service
136 )
137 plugins.extend(required_plugins)
138 tracker.add_contexts(
139 PluginsTrackingContext([(candidate, None) for candidate in plugins])
140 )
141 tracker.track_command_event(CliEvent.inflight)
142
143 success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)
144
145 if not success:
146 tracker.track_command_event(CliEvent.failed)
147 raise CliError("Failed to install plugin(s)")
148
149 _print_plugins(plugins)
150 tracker.track_command_event(CliEvent.completed)
151
152
153 def _print_plugins(plugins):
154 printed_empty_line = False
155 for plugin in plugins:
156 docs_url = plugin.docs or plugin.repo
157 if not docs_url:
158 continue
159
160 if not printed_empty_line:
161 click.echo()
162 printed_empty_line = True
163
164 click.echo(
165 f"To learn more about {plugin.type.descriptor} '{plugin.name}', visit {docs_url}"
166 )
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/cli/add.py b/src/meltano/cli/add.py
--- a/src/meltano/cli/add.py
+++ b/src/meltano/cli/add.py
@@ -55,6 +55,11 @@
is_flag=True,
help="Add a custom plugin. The command will prompt you for the package's base plugin description metadata.",
)
[email protected](
+ "--no-install",
+ is_flag=True,
+ help="Do not install the plugin after adding it to the project.",
+)
@pass_project()
@click.pass_context
def add(
@@ -140,11 +145,12 @@
)
tracker.track_command_event(CliEvent.inflight)
- success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)
+ if not flags.get("no_install"):
+ success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)
- if not success:
- tracker.track_command_event(CliEvent.failed)
- raise CliError("Failed to install plugin(s)")
+ if not success:
+ tracker.track_command_event(CliEvent.failed)
+ raise CliError("Failed to install plugin(s)")
_print_plugins(plugins)
tracker.track_command_event(CliEvent.completed)
|
{"golden_diff": "diff --git a/src/meltano/cli/add.py b/src/meltano/cli/add.py\n--- a/src/meltano/cli/add.py\n+++ b/src/meltano/cli/add.py\n@@ -55,6 +55,11 @@\n is_flag=True,\n help=\"Add a custom plugin. The command will prompt you for the package's base plugin description metadata.\",\n )\[email protected](\n+ \"--no-install\",\n+ is_flag=True,\n+ help=\"Do not install the plugin after adding it to the project.\",\n+)\n @pass_project()\n @click.pass_context\n def add(\n@@ -140,11 +145,12 @@\n )\n tracker.track_command_event(CliEvent.inflight)\n \n- success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)\n+ if not flags.get(\"no_install\"):\n+ success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)\n \n- if not success:\n- tracker.track_command_event(CliEvent.failed)\n- raise CliError(\"Failed to install plugin(s)\")\n+ if not success:\n+ tracker.track_command_event(CliEvent.failed)\n+ raise CliError(\"Failed to install plugin(s)\")\n \n _print_plugins(plugins)\n tracker.track_command_event(CliEvent.completed)\n", "issue": "[Feature]: meltano add to project without install\n### Feature scope\r\n\r\nCLI (options, error messages, logging, etc.)\r\n\r\n### Description\r\n\r\n**As a user, I need to add to my meltano project without install**\r\n\r\nAdding to a meltano project is currently a very slow operation. Our requirement is to add all the plugins to the project and then later build (i.e. 'meltano install') the whole project. This means that the initial 'meltano add' is unnecessarily slow as we don't use any of the pip-installed modules from the initial 'meltano add'\r\n\r\nWork arounds considered:\r\n- directly add a meltano.yml format file with our plugin definition to a directory with the root meltano.yml includes referencing that directory path & directly save a lock file to the /plugins directory (essentially avoiding using 'meltano add' at all)\r\n\r\n\r\nThis proposal is to be able to add to the meltano project rapidly without installing all pip dependencies, and we'd ideally like to be able to freeze those dependencies.\r\n\r\n`meltano add --skip-install` should\r\n1. download the lock file\r\n2. add to the meltano.yml\r\n3. add all the lock and meltano.yml files for any `requires` plugins (https://github.com/meltano/hub/pull/505 & https://github.com/meltano/meltano/issues/6107)\r\n\r\n\r\n\r\nRelated to:\r\nThis feature is related to https://github.com/meltano/meltano/issues/6416\r\n**As a user, I need to add to my meltano project without install and create pip freeze**\r\n\r\n`meltano add --skip-install --freeze` consider whether this --skip-install works if --freeze is used (assuming https://github.com/meltano/meltano/issues/6416 might implement --freeze)\r\n\n", "before_files": [{"content": "\"\"\"Plugin Add CLI.\"\"\"\nfrom __future__ import annotations\n\nimport click\n\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.plugin.base import PluginRef\nfrom meltano.core.plugin.project_plugin import ProjectPlugin\nfrom meltano.core.plugin_install_service import PluginInstallReason\nfrom meltano.core.project import Project\nfrom meltano.core.project_add_service import ProjectAddService\nfrom meltano.core.project_plugins_service import ProjectPluginsService\nfrom meltano.core.tracking import CliEvent, PluginsTrackingContext\n\nfrom . import cli\nfrom .params import pass_project\nfrom .utils import (\n CliError,\n PartialInstrumentedCmd,\n add_plugin,\n add_required_plugins,\n check_dependencies_met,\n install_plugins,\n)\n\n\[email protected]( # noqa: WPS238\n cls=PartialInstrumentedCmd,\n short_help=\"Add a plugin to your project.\",\n)\[email protected](\"plugin_type\", type=click.Choice(PluginType.cli_arguments()))\[email protected](\"plugin_name\", nargs=-1, required=True)\[email protected](\n \"--inherit-from\",\n help=(\n \"Add a plugin inheriting from an existing plugin in the project\"\n + \" or a discoverable plugin identified, by name.\"\n ),\n)\[email protected](\n \"--variant\",\n help=\"Add a specific (non-default) variant of the identified discoverable plugin.\",\n)\[email protected](\n \"--as\",\n \"as_name\",\n help=(\n \"Shorthand for '--inherit-from', that can be used to add a discoverable \"\n + \"plugin to your project with a different name. \"\n + \"Usage:\\b\\n\\nadd <type> <inherit-from> --as <name>\"\n ),\n)\[email protected](\n \"--custom\",\n is_flag=True,\n help=\"Add a custom plugin. The command will prompt you for the package's base plugin description metadata.\",\n)\n@pass_project()\[email protected]_context\ndef add(\n ctx,\n project: Project,\n plugin_type: str,\n plugin_name: str,\n inherit_from: str = None,\n variant: str = None,\n as_name: str = None,\n **flags,\n):\n \"\"\"\n Add a plugin to your project.\n\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#add\n \"\"\"\n tracker = ctx.obj[\"tracker\"]\n legacy_tracker = ctx.obj[\"legacy_tracker\"]\n\n plugin_type = PluginType.from_cli_argument(plugin_type)\n plugin_names = plugin_name # nargs=-1\n\n if as_name:\n # `add <type> <inherit-from> --as <name>``\n # is equivalent to:\n # `add <type> <name> --inherit-from <inherit-from>``\n inherit_from = plugin_names[0]\n plugin_names = [as_name]\n\n plugins_service = ProjectPluginsService(project)\n\n if flags[\"custom\"]:\n if plugin_type in {\n PluginType.TRANSFORMS,\n PluginType.ORCHESTRATORS,\n }:\n tracker.track_command_event(CliEvent.aborted)\n raise CliError(f\"--custom is not supported for {plugin_type}\")\n\n plugin_refs = [\n PluginRef(plugin_type=plugin_type, name=name) for name in plugin_names\n ]\n dependencies_met, err = check_dependencies_met(\n plugin_refs=plugin_refs, plugins_service=plugins_service\n )\n if not dependencies_met:\n tracker.track_command_event(CliEvent.aborted)\n raise CliError(f\"Failed to install plugin(s): {err}\")\n\n add_service = ProjectAddService(project, plugins_service=plugins_service)\n\n plugins: list[ProjectPlugin] = []\n for plugin in plugin_names:\n try:\n plugins.append(\n add_plugin(\n project,\n plugin_type,\n plugin,\n inherit_from=inherit_from,\n variant=variant,\n custom=flags[\"custom\"],\n add_service=add_service,\n )\n )\n except Exception:\n # if the plugin is not known to meltano send what information we do have\n tracker.add_contexts(\n PluginsTrackingContext([(plugin, None) for plugin in plugins])\n )\n tracker.track_command_event(CliEvent.aborted)\n raise\n\n legacy_tracker.track_meltano_add(plugin_type=plugin_type, plugin_name=plugin)\n\n required_plugins = add_required_plugins(\n project, plugins, add_service=add_service\n )\n plugins.extend(required_plugins)\n tracker.add_contexts(\n PluginsTrackingContext([(candidate, None) for candidate in plugins])\n )\n tracker.track_command_event(CliEvent.inflight)\n\n success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)\n\n if not success:\n tracker.track_command_event(CliEvent.failed)\n raise CliError(\"Failed to install plugin(s)\")\n\n _print_plugins(plugins)\n tracker.track_command_event(CliEvent.completed)\n\n\ndef _print_plugins(plugins):\n printed_empty_line = False\n for plugin in plugins:\n docs_url = plugin.docs or plugin.repo\n if not docs_url:\n continue\n\n if not printed_empty_line:\n click.echo()\n printed_empty_line = True\n\n click.echo(\n f\"To learn more about {plugin.type.descriptor} '{plugin.name}', visit {docs_url}\"\n )\n", "path": "src/meltano/cli/add.py"}], "after_files": [{"content": "\"\"\"Plugin Add CLI.\"\"\"\nfrom __future__ import annotations\n\nimport click\n\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.plugin.base import PluginRef\nfrom meltano.core.plugin.project_plugin import ProjectPlugin\nfrom meltano.core.plugin_install_service import PluginInstallReason\nfrom meltano.core.project import Project\nfrom meltano.core.project_add_service import ProjectAddService\nfrom meltano.core.project_plugins_service import ProjectPluginsService\nfrom meltano.core.tracking import CliEvent, PluginsTrackingContext\n\nfrom . import cli\nfrom .params import pass_project\nfrom .utils import (\n CliError,\n PartialInstrumentedCmd,\n add_plugin,\n add_required_plugins,\n check_dependencies_met,\n install_plugins,\n)\n\n\[email protected]( # noqa: WPS238\n cls=PartialInstrumentedCmd,\n short_help=\"Add a plugin to your project.\",\n)\[email protected](\"plugin_type\", type=click.Choice(PluginType.cli_arguments()))\[email protected](\"plugin_name\", nargs=-1, required=True)\[email protected](\n \"--inherit-from\",\n help=(\n \"Add a plugin inheriting from an existing plugin in the project\"\n + \" or a discoverable plugin identified, by name.\"\n ),\n)\[email protected](\n \"--variant\",\n help=\"Add a specific (non-default) variant of the identified discoverable plugin.\",\n)\[email protected](\n \"--as\",\n \"as_name\",\n help=(\n \"Shorthand for '--inherit-from', that can be used to add a discoverable \"\n + \"plugin to your project with a different name. \"\n + \"Usage:\\b\\n\\nadd <type> <inherit-from> --as <name>\"\n ),\n)\[email protected](\n \"--custom\",\n is_flag=True,\n help=\"Add a custom plugin. The command will prompt you for the package's base plugin description metadata.\",\n)\[email protected](\n \"--no-install\",\n is_flag=True,\n help=\"Do not install the plugin after adding it to the project.\",\n)\n@pass_project()\[email protected]_context\ndef add(\n ctx,\n project: Project,\n plugin_type: str,\n plugin_name: str,\n inherit_from: str = None,\n variant: str = None,\n as_name: str = None,\n **flags,\n):\n \"\"\"\n Add a plugin to your project.\n\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#add\n \"\"\"\n tracker = ctx.obj[\"tracker\"]\n legacy_tracker = ctx.obj[\"legacy_tracker\"]\n\n plugin_type = PluginType.from_cli_argument(plugin_type)\n plugin_names = plugin_name # nargs=-1\n\n if as_name:\n # `add <type> <inherit-from> --as <name>``\n # is equivalent to:\n # `add <type> <name> --inherit-from <inherit-from>``\n inherit_from = plugin_names[0]\n plugin_names = [as_name]\n\n plugins_service = ProjectPluginsService(project)\n\n if flags[\"custom\"]:\n if plugin_type in {\n PluginType.TRANSFORMS,\n PluginType.ORCHESTRATORS,\n }:\n tracker.track_command_event(CliEvent.aborted)\n raise CliError(f\"--custom is not supported for {plugin_type}\")\n\n plugin_refs = [\n PluginRef(plugin_type=plugin_type, name=name) for name in plugin_names\n ]\n dependencies_met, err = check_dependencies_met(\n plugin_refs=plugin_refs, plugins_service=plugins_service\n )\n if not dependencies_met:\n tracker.track_command_event(CliEvent.aborted)\n raise CliError(f\"Failed to install plugin(s): {err}\")\n\n add_service = ProjectAddService(project, plugins_service=plugins_service)\n\n plugins: list[ProjectPlugin] = []\n for plugin in plugin_names:\n try:\n plugins.append(\n add_plugin(\n project,\n plugin_type,\n plugin,\n inherit_from=inherit_from,\n variant=variant,\n custom=flags[\"custom\"],\n add_service=add_service,\n )\n )\n except Exception:\n # if the plugin is not known to meltano send what information we do have\n tracker.add_contexts(\n PluginsTrackingContext([(plugin, None) for plugin in plugins])\n )\n tracker.track_command_event(CliEvent.aborted)\n raise\n\n legacy_tracker.track_meltano_add(plugin_type=plugin_type, plugin_name=plugin)\n\n required_plugins = add_required_plugins(\n project, plugins, add_service=add_service\n )\n plugins.extend(required_plugins)\n tracker.add_contexts(\n PluginsTrackingContext([(candidate, None) for candidate in plugins])\n )\n tracker.track_command_event(CliEvent.inflight)\n\n if not flags.get(\"no_install\"):\n success = install_plugins(project, plugins, reason=PluginInstallReason.ADD)\n\n if not success:\n tracker.track_command_event(CliEvent.failed)\n raise CliError(\"Failed to install plugin(s)\")\n\n _print_plugins(plugins)\n tracker.track_command_event(CliEvent.completed)\n\n\ndef _print_plugins(plugins):\n printed_empty_line = False\n for plugin in plugins:\n docs_url = plugin.docs or plugin.repo\n if not docs_url:\n continue\n\n if not printed_empty_line:\n click.echo()\n printed_empty_line = True\n\n click.echo(\n f\"To learn more about {plugin.type.descriptor} '{plugin.name}', visit {docs_url}\"\n )\n", "path": "src/meltano/cli/add.py"}]}
| 2,167 | 279 |
gh_patches_debug_19917
|
rasdani/github-patches
|
git_diff
|
sbi-dev__sbi-646
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SNLE + multiple independent prior + MCMC with num_workers > 1 throws error
SNLE:
- multiple independent prior + num_workers=2 leads to an error (ValueError: Expected value argument to be within the support of the distribution Uniform)
- no error if either num_workers=1 or using a BoxUniform prior
SNPE:
- seems to work
```
from sbi.inference.snpe import SNPE_A
from sbi.inference.snle import SNLE_A
from sbi.utils import BoxUniform
from sbi.inference.posteriors import MCMCPosterior
from sbi.inference.potentials import posterior_estimator_based_potential, likelihood_estimator_based_potential
from sbi.utils.user_input_checks import process_prior
from sbi.analysis.sbc import run_sbc
import torch
default_params = torch.rand(size=(4, 3),dtype=torch.float32)
default_obs = torch.rand(size=(4, 1), dtype=torch.float32)
# multiple independent prior
prior = [torch.distributions.Uniform(torch.FloatTensor([0]), torch.FloatTensor([20])),
torch.distributions.Uniform(torch.FloatTensor([-10]), torch.FloatTensor([10])),
torch.distributions.Uniform(torch.FloatTensor([0.5]), torch.FloatTensor([3]))]
# box uniform prior
# prior = BoxUniform(torch.Tensor([0, -10, 0.5]), torch.Tensor([20, 10, 3]))
prior, _, _ = process_prior(prior)
# inference = SNPE_A()
# density_estimator = inference.append_simulations(default_params, default_obs).train()
# potential_fn, theta_transform = posterior_estimator_based_potential(density_estimator, prior, default_obs[0])
inference = SNLE_A()
density_estimator = inference.append_simulations(default_params, default_obs).train()
potential_fn, theta_transform = likelihood_estimator_based_potential(density_estimator, prior, default_obs[0])
posterior = MCMCPosterior(potential_fn, proposal=prior, theta_transform=theta_transform)
# this line throws an error
ranks, dap_samples = run_sbc(default_params, default_obs, posterior, num_posterior_samples=10, num_workers=2, sbc_batch_size=2)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sbi/samplers/mcmc/init_strategy.py`
Content:
```
1 # This file is part of sbi, a toolkit for simulation-based inference. sbi is licensed
2 # under the Affero General Public License v3, see <https://www.gnu.org/licenses/>.
3
4 from typing import Any, Callable
5
6 import torch
7 import torch.distributions.transforms as torch_tf
8 from torch import Tensor
9
10
11 class IterateParameters:
12 """Iterates through parameters by rows"""
13
14 def __init__(self, parameters: torch.Tensor, **kwargs):
15 self.iter = self._make_iterator(parameters)
16
17 @staticmethod
18 def _make_iterator(t):
19 for i in range(t.shape[0]):
20 yield t[i, :].reshape(1, -1)
21
22 def __call__(self):
23 return next(self.iter)
24
25
26 def proposal_init(
27 proposal: Any, transform: torch_tf.Transform, **kwargs: Any
28 ) -> Tensor:
29 """Return a sample from the proposal."""
30 prior_samples = proposal.sample((1,)).detach()
31 transformed_prior_samples = transform(prior_samples)
32 return transformed_prior_samples
33
34
35 def sir(
36 proposal: Any,
37 potential_fn: Callable,
38 transform: torch_tf.Transform,
39 sir_num_batches: int = 10,
40 sir_batch_size: int = 1000,
41 **kwargs: Any,
42 ) -> Tensor:
43 r"""Return a sample obtained by sequential importance reweighting.
44
45 See Rubin 1988, "Using the sir algorithm to simulate posterior distributions."
46
47 This function can also do `SIR` on the conditional posterior
48 $p(\theta_i|\theta_j, x)$ when a `condition` and `dims_to_sample` are passed.
49
50 Args:
51 proposal: Proposal distribution, candidate samples are drawn from it.
52 potential_fn: Potential function that the candidate samples are weighted with.
53 Note that the function needs to return log probabilities.
54 sir_num_batches: Number of candidate batches drawn.
55 sir_batch_size: Batch size used for evaluating candidates.
56
57 Returns:
58 A single sample.
59 """
60
61 with torch.set_grad_enabled(False):
62 log_weights = []
63 init_param_candidates = []
64 for i in range(sir_num_batches):
65 batch_draws = proposal.sample((sir_batch_size,)).detach()
66 transformed_batch_draws = transform(batch_draws)
67 init_param_candidates.append(transformed_batch_draws)
68 log_weights.append(potential_fn(transformed_batch_draws).detach())
69 log_weights = torch.cat(log_weights)
70 init_param_candidates = torch.cat(init_param_candidates)
71
72 # Norm weights in log space
73 log_weights -= torch.logsumexp(log_weights, dim=0)
74 probs = torch.exp(log_weights.view(-1))
75 probs[torch.isnan(probs)] = 0.0
76 probs[torch.isinf(probs)] = 0.0
77 probs /= probs.sum()
78
79 idxs = torch.multinomial(probs, 1, replacement=False)
80 return init_param_candidates[idxs, :]
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sbi/samplers/mcmc/init_strategy.py b/sbi/samplers/mcmc/init_strategy.py
--- a/sbi/samplers/mcmc/init_strategy.py
+++ b/sbi/samplers/mcmc/init_strategy.py
@@ -63,9 +63,8 @@
init_param_candidates = []
for i in range(sir_num_batches):
batch_draws = proposal.sample((sir_batch_size,)).detach()
- transformed_batch_draws = transform(batch_draws)
- init_param_candidates.append(transformed_batch_draws)
- log_weights.append(potential_fn(transformed_batch_draws).detach())
+ init_param_candidates.append(batch_draws)
+ log_weights.append(potential_fn(batch_draws).detach())
log_weights = torch.cat(log_weights)
init_param_candidates = torch.cat(init_param_candidates)
@@ -77,4 +76,5 @@
probs /= probs.sum()
idxs = torch.multinomial(probs, 1, replacement=False)
- return init_param_candidates[idxs, :]
+ # Return transformed sample.
+ return transform(init_param_candidates[idxs, :])
|
{"golden_diff": "diff --git a/sbi/samplers/mcmc/init_strategy.py b/sbi/samplers/mcmc/init_strategy.py\n--- a/sbi/samplers/mcmc/init_strategy.py\n+++ b/sbi/samplers/mcmc/init_strategy.py\n@@ -63,9 +63,8 @@\n init_param_candidates = []\n for i in range(sir_num_batches):\n batch_draws = proposal.sample((sir_batch_size,)).detach()\n- transformed_batch_draws = transform(batch_draws)\n- init_param_candidates.append(transformed_batch_draws)\n- log_weights.append(potential_fn(transformed_batch_draws).detach())\n+ init_param_candidates.append(batch_draws)\n+ log_weights.append(potential_fn(batch_draws).detach())\n log_weights = torch.cat(log_weights)\n init_param_candidates = torch.cat(init_param_candidates)\n \n@@ -77,4 +76,5 @@\n probs /= probs.sum()\n \n idxs = torch.multinomial(probs, 1, replacement=False)\n- return init_param_candidates[idxs, :]\n+ # Return transformed sample.\n+ return transform(init_param_candidates[idxs, :])\n", "issue": "SNLE + multiple independent prior + MCMC with num_workers > 1 throws error\nSNLE:\r\n- multiple independent prior + num_workers=2 leads to an error (ValueError: Expected value argument to be within the support of the distribution Uniform)\r\n- no error if either num_workers=1 or using a BoxUniform prior\r\n\r\nSNPE:\r\n- seems to work\r\n\r\n```\r\nfrom sbi.inference.snpe import SNPE_A\r\nfrom sbi.inference.snle import SNLE_A\r\nfrom sbi.utils import BoxUniform\r\nfrom sbi.inference.posteriors import MCMCPosterior\r\nfrom sbi.inference.potentials import posterior_estimator_based_potential, likelihood_estimator_based_potential\r\nfrom sbi.utils.user_input_checks import process_prior\r\nfrom sbi.analysis.sbc import run_sbc\r\nimport torch\r\n\r\ndefault_params = torch.rand(size=(4, 3),dtype=torch.float32)\r\ndefault_obs = torch.rand(size=(4, 1), dtype=torch.float32)\r\n\r\n# multiple independent prior\r\nprior = [torch.distributions.Uniform(torch.FloatTensor([0]), torch.FloatTensor([20])),\r\n torch.distributions.Uniform(torch.FloatTensor([-10]), torch.FloatTensor([10])),\r\n torch.distributions.Uniform(torch.FloatTensor([0.5]), torch.FloatTensor([3]))]\r\n# box uniform prior\r\n# prior = BoxUniform(torch.Tensor([0, -10, 0.5]), torch.Tensor([20, 10, 3]))\r\nprior, _, _ = process_prior(prior)\r\n\r\n# inference = SNPE_A()\r\n# density_estimator = inference.append_simulations(default_params, default_obs).train()\r\n# potential_fn, theta_transform = posterior_estimator_based_potential(density_estimator, prior, default_obs[0])\r\n\r\ninference = SNLE_A()\r\ndensity_estimator = inference.append_simulations(default_params, default_obs).train()\r\npotential_fn, theta_transform = likelihood_estimator_based_potential(density_estimator, prior, default_obs[0])\r\n\r\nposterior = MCMCPosterior(potential_fn, proposal=prior, theta_transform=theta_transform)\r\n\r\n# this line throws an error\r\nranks, dap_samples = run_sbc(default_params, default_obs, posterior, num_posterior_samples=10, num_workers=2, sbc_batch_size=2)\r\n```\r\n\n", "before_files": [{"content": "# This file is part of sbi, a toolkit for simulation-based inference. sbi is licensed\n# under the Affero General Public License v3, see <https://www.gnu.org/licenses/>.\n\nfrom typing import Any, Callable\n\nimport torch\nimport torch.distributions.transforms as torch_tf\nfrom torch import Tensor\n\n\nclass IterateParameters:\n \"\"\"Iterates through parameters by rows\"\"\"\n\n def __init__(self, parameters: torch.Tensor, **kwargs):\n self.iter = self._make_iterator(parameters)\n\n @staticmethod\n def _make_iterator(t):\n for i in range(t.shape[0]):\n yield t[i, :].reshape(1, -1)\n\n def __call__(self):\n return next(self.iter)\n\n\ndef proposal_init(\n proposal: Any, transform: torch_tf.Transform, **kwargs: Any\n) -> Tensor:\n \"\"\"Return a sample from the proposal.\"\"\"\n prior_samples = proposal.sample((1,)).detach()\n transformed_prior_samples = transform(prior_samples)\n return transformed_prior_samples\n\n\ndef sir(\n proposal: Any,\n potential_fn: Callable,\n transform: torch_tf.Transform,\n sir_num_batches: int = 10,\n sir_batch_size: int = 1000,\n **kwargs: Any,\n) -> Tensor:\n r\"\"\"Return a sample obtained by sequential importance reweighting.\n\n See Rubin 1988, \"Using the sir algorithm to simulate posterior distributions.\"\n\n This function can also do `SIR` on the conditional posterior\n $p(\\theta_i|\\theta_j, x)$ when a `condition` and `dims_to_sample` are passed.\n\n Args:\n proposal: Proposal distribution, candidate samples are drawn from it.\n potential_fn: Potential function that the candidate samples are weighted with.\n Note that the function needs to return log probabilities.\n sir_num_batches: Number of candidate batches drawn.\n sir_batch_size: Batch size used for evaluating candidates.\n\n Returns:\n A single sample.\n \"\"\"\n\n with torch.set_grad_enabled(False):\n log_weights = []\n init_param_candidates = []\n for i in range(sir_num_batches):\n batch_draws = proposal.sample((sir_batch_size,)).detach()\n transformed_batch_draws = transform(batch_draws)\n init_param_candidates.append(transformed_batch_draws)\n log_weights.append(potential_fn(transformed_batch_draws).detach())\n log_weights = torch.cat(log_weights)\n init_param_candidates = torch.cat(init_param_candidates)\n\n # Norm weights in log space\n log_weights -= torch.logsumexp(log_weights, dim=0)\n probs = torch.exp(log_weights.view(-1))\n probs[torch.isnan(probs)] = 0.0\n probs[torch.isinf(probs)] = 0.0\n probs /= probs.sum()\n\n idxs = torch.multinomial(probs, 1, replacement=False)\n return init_param_candidates[idxs, :]\n", "path": "sbi/samplers/mcmc/init_strategy.py"}], "after_files": [{"content": "# This file is part of sbi, a toolkit for simulation-based inference. sbi is licensed\n# under the Affero General Public License v3, see <https://www.gnu.org/licenses/>.\n\nfrom typing import Any, Callable\n\nimport torch\nimport torch.distributions.transforms as torch_tf\nfrom torch import Tensor\n\n\nclass IterateParameters:\n \"\"\"Iterates through parameters by rows\"\"\"\n\n def __init__(self, parameters: torch.Tensor, **kwargs):\n self.iter = self._make_iterator(parameters)\n\n @staticmethod\n def _make_iterator(t):\n for i in range(t.shape[0]):\n yield t[i, :].reshape(1, -1)\n\n def __call__(self):\n return next(self.iter)\n\n\ndef proposal_init(\n proposal: Any, transform: torch_tf.Transform, **kwargs: Any\n) -> Tensor:\n \"\"\"Return a sample from the proposal.\"\"\"\n prior_samples = proposal.sample((1,)).detach()\n transformed_prior_samples = transform(prior_samples)\n return transformed_prior_samples\n\n\ndef sir(\n proposal: Any,\n potential_fn: Callable,\n transform: torch_tf.Transform,\n sir_num_batches: int = 10,\n sir_batch_size: int = 1000,\n **kwargs: Any,\n) -> Tensor:\n r\"\"\"Return a sample obtained by sequential importance reweighting.\n\n See Rubin 1988, \"Using the sir algorithm to simulate posterior distributions.\"\n\n This function can also do `SIR` on the conditional posterior\n $p(\\theta_i|\\theta_j, x)$ when a `condition` and `dims_to_sample` are passed.\n\n Args:\n proposal: Proposal distribution, candidate samples are drawn from it.\n potential_fn: Potential function that the candidate samples are weighted with.\n Note that the function needs to return log probabilities.\n sir_num_batches: Number of candidate batches drawn.\n sir_batch_size: Batch size used for evaluating candidates.\n\n Returns:\n A single sample.\n \"\"\"\n\n with torch.set_grad_enabled(False):\n log_weights = []\n init_param_candidates = []\n for i in range(sir_num_batches):\n batch_draws = proposal.sample((sir_batch_size,)).detach()\n init_param_candidates.append(batch_draws)\n log_weights.append(potential_fn(batch_draws).detach())\n log_weights = torch.cat(log_weights)\n init_param_candidates = torch.cat(init_param_candidates)\n\n # Norm weights in log space\n log_weights -= torch.logsumexp(log_weights, dim=0)\n probs = torch.exp(log_weights.view(-1))\n probs[torch.isnan(probs)] = 0.0\n probs[torch.isinf(probs)] = 0.0\n probs /= probs.sum()\n\n idxs = torch.multinomial(probs, 1, replacement=False)\n # Return transformed sample.\n return transform(init_param_candidates[idxs, :])\n", "path": "sbi/samplers/mcmc/init_strategy.py"}]}
| 1,523 | 248 |
gh_patches_debug_28197
|
rasdani/github-patches
|
git_diff
|
PyGithub__PyGithub-1356
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ProjectCard should have the move action?
How can one move a project card with PyGithub. It seems like the moves action is not implemented. Or am I missing something? I need to be able to move a card from one column to another.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `github/ProjectCard.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 ############################ Copyrights and license ############################
4 # #
5 # Copyright 2018 bbi-yggy <[email protected]> #
6 # #
7 # This file is part of PyGithub. #
8 # http://pygithub.readthedocs.io/ #
9 # #
10 # PyGithub is free software: you can redistribute it and/or modify it under #
11 # the terms of the GNU Lesser General Public License as published by the Free #
12 # Software Foundation, either version 3 of the License, or (at your option) #
13 # any later version. #
14 # #
15 # PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #
16 # WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #
17 # FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #
18 # details. #
19 # #
20 # You should have received a copy of the GNU Lesser General Public License #
21 # along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #
22 # #
23 ################################################################################
24
25 import github.GithubObject
26
27 # NOTE: There is currently no way to get cards "in triage" for a project.
28 # https://platform.github.community/t/moving-github-project-cards-that-are-in-triage/3784
29 #
30 # See also https://developer.github.com/v4/object/projectcard for the next generation GitHub API,
31 # which may point the way to where the API is likely headed and what might come back to v3. E.g. ProjectCard.content member.
32
33
34 class ProjectCard(github.GithubObject.CompletableGithubObject):
35 """
36 This class represents Project Cards. The reference can be found here https://developer.github.com/v3/projects/cards
37 """
38
39 def __repr__(self):
40 return self.get__repr__({"id": self._id.value})
41
42 @property
43 def archived(self):
44 """
45 :type: bool
46 """
47 return self._archived.value
48
49 @property
50 def column_url(self):
51 """
52 :type: string
53 """
54 return self._column_url.value
55
56 @property
57 def content_url(self):
58 """
59 :type: string
60 """
61 return self._content_url.value
62
63 @property
64 def created_at(self):
65 """
66 :type: datetime.datetime
67 """
68 return self._created_at.value
69
70 @property
71 def creator(self):
72 """
73 :type: :class:`github.NamedUser.NamedUser`
74 """
75 return self._creator.value
76
77 @property
78 def id(self):
79 """
80 :type: integer
81 """
82 return self._id.value
83
84 @property
85 def node_id(self):
86 """
87 :type: string
88 """
89 return self._node_id.value
90
91 @property
92 def note(self):
93 """
94 :type: string
95 """
96 return self._note.value
97
98 @property
99 def updated_at(self):
100 """
101 :type: datetime.datetime
102 """
103 return self._updated_at.value
104
105 @property
106 def url(self):
107 """
108 :type: string
109 """
110 return self._url.value
111
112 # Note that the content_url for any card will be an "issue" URL, from
113 # which you can retrieve either an Issue or a PullRequest. Unforunately
114 # the API doesn't make it clear which you are dealing with.
115 def get_content(self, content_type=github.GithubObject.NotSet):
116 """
117 :calls: `GET /repos/:owner/:repo/pulls/:number <https://developer.github.com/v3/pulls/#get-a-single-pull-request>`_
118 :param content_type: string, optional
119 :rtype: :class:`github.PullRequest.PullRequest` or :class:`github.Issue.Issue`
120 """
121 assert content_type is github.GithubObject.NotSet or isinstance(
122 content_type, str
123 ), content_type
124 if self.content_url is None:
125 return None
126
127 if content_type == "PullRequest":
128 url = self.content_url.replace("issues", "pulls")
129 retclass = github.PullRequest.PullRequest
130 elif content_type is github.GithubObject.NotSet or content_type == "Issue":
131 url = self.content_url
132 retclass = github.Issue.Issue
133 else:
134 raise ValueError("Unknown content type: %s" % content_type)
135 headers, data = self._requester.requestJsonAndCheck("GET", url)
136 return retclass(self._requester, headers, data, completed=True)
137
138 def _initAttributes(self):
139 self._archived = github.GithubObject.NotSet
140 self._column_url = github.GithubObject.NotSet
141 self._content_url = github.GithubObject.NotSet
142 self._created_at = github.GithubObject.NotSet
143 self._creator = github.GithubObject.NotSet
144 self._id = github.GithubObject.NotSet
145 self._node_id = github.GithubObject.NotSet
146 self._note = github.GithubObject.NotSet
147 self._updated_at = github.GithubObject.NotSet
148 self._url = github.GithubObject.NotSet
149
150 def _useAttributes(self, attributes):
151 if "archived" in attributes: # pragma no branch
152 self._archived = self._makeBoolAttribute(attributes["archived"])
153 if "column_url" in attributes: # pragma no branch
154 self._column_url = self._makeStringAttribute(attributes["column_url"])
155 if "content_url" in attributes: # pragma no branch
156 self._content_url = self._makeStringAttribute(attributes["content_url"])
157 if "created_at" in attributes: # pragma no branch
158 self._created_at = self._makeDatetimeAttribute(attributes["created_at"])
159 if "creator" in attributes: # pragma no branch
160 self._creator = self._makeClassAttribute(
161 github.NamedUser.NamedUser, attributes["creator"]
162 )
163 if "id" in attributes: # pragma no branch
164 self._id = self._makeIntAttribute(attributes["id"])
165 if "node_id" in attributes: # pragma no branch
166 self._node_id = self._makeStringAttribute(attributes["node_id"])
167 if "note" in attributes: # pragma no branch
168 self._note = self._makeStringAttribute(attributes["note"])
169 if "updated_at" in attributes: # pragma no branch
170 self._updated_at = self._makeDatetimeAttribute(attributes["updated_at"])
171 if "url" in attributes: # pragma no branch
172 self._url = self._makeStringAttribute(attributes["url"])
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/github/ProjectCard.py b/github/ProjectCard.py
--- a/github/ProjectCard.py
+++ b/github/ProjectCard.py
@@ -24,6 +24,8 @@
import github.GithubObject
+from . import Consts
+
# NOTE: There is currently no way to get cards "in triage" for a project.
# https://platform.github.community/t/moving-github-project-cards-that-are-in-triage/3784
#
@@ -135,6 +137,31 @@
headers, data = self._requester.requestJsonAndCheck("GET", url)
return retclass(self._requester, headers, data, completed=True)
+ def move(self, position, column):
+ """
+ :calls: `POST /projects/columns/cards/:card_id/moves <https://developer.github.com/v3/projects/cards>`_
+ :param position: string
+ :param column: :class:`github.ProjectColumn.ProjectColumn` or int
+ :rtype: bool
+ """
+ assert isinstance(position, str), position
+ assert isinstance(column, github.ProjectColumn.ProjectColumn) or isinstance(
+ column, int
+ ), column
+ post_parameters = {
+ "position": position,
+ "column": column.id
+ if isinstance(column, github.ProjectColumn.ProjectColumn)
+ else column,
+ }
+ status, _, _ = self._requester.requestJson(
+ "POST",
+ self.url + "/moves",
+ input=post_parameters,
+ headers={"Accept": Consts.mediaTypeProjectsPreview},
+ )
+ return status == 201
+
def _initAttributes(self):
self._archived = github.GithubObject.NotSet
self._column_url = github.GithubObject.NotSet
|
{"golden_diff": "diff --git a/github/ProjectCard.py b/github/ProjectCard.py\n--- a/github/ProjectCard.py\n+++ b/github/ProjectCard.py\n@@ -24,6 +24,8 @@\n \n import github.GithubObject\n \n+from . import Consts\n+\n # NOTE: There is currently no way to get cards \"in triage\" for a project.\n # https://platform.github.community/t/moving-github-project-cards-that-are-in-triage/3784\n #\n@@ -135,6 +137,31 @@\n headers, data = self._requester.requestJsonAndCheck(\"GET\", url)\n return retclass(self._requester, headers, data, completed=True)\n \n+ def move(self, position, column):\n+ \"\"\"\n+ :calls: `POST /projects/columns/cards/:card_id/moves <https://developer.github.com/v3/projects/cards>`_\n+ :param position: string\n+ :param column: :class:`github.ProjectColumn.ProjectColumn` or int\n+ :rtype: bool\n+ \"\"\"\n+ assert isinstance(position, str), position\n+ assert isinstance(column, github.ProjectColumn.ProjectColumn) or isinstance(\n+ column, int\n+ ), column\n+ post_parameters = {\n+ \"position\": position,\n+ \"column\": column.id\n+ if isinstance(column, github.ProjectColumn.ProjectColumn)\n+ else column,\n+ }\n+ status, _, _ = self._requester.requestJson(\n+ \"POST\",\n+ self.url + \"/moves\",\n+ input=post_parameters,\n+ headers={\"Accept\": Consts.mediaTypeProjectsPreview},\n+ )\n+ return status == 201\n+\n def _initAttributes(self):\n self._archived = github.GithubObject.NotSet\n self._column_url = github.GithubObject.NotSet\n", "issue": "ProjectCard should have the move action?\n\r\nHow can one move a project card with PyGithub. It seems like the moves action is not implemented. Or am I missing something? I need to be able to move a card from one column to another.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n############################ Copyrights and license ############################\n# #\n# Copyright 2018 bbi-yggy <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nimport github.GithubObject\n\n# NOTE: There is currently no way to get cards \"in triage\" for a project.\n# https://platform.github.community/t/moving-github-project-cards-that-are-in-triage/3784\n#\n# See also https://developer.github.com/v4/object/projectcard for the next generation GitHub API,\n# which may point the way to where the API is likely headed and what might come back to v3. E.g. ProjectCard.content member.\n\n\nclass ProjectCard(github.GithubObject.CompletableGithubObject):\n \"\"\"\n This class represents Project Cards. The reference can be found here https://developer.github.com/v3/projects/cards\n \"\"\"\n\n def __repr__(self):\n return self.get__repr__({\"id\": self._id.value})\n\n @property\n def archived(self):\n \"\"\"\n :type: bool\n \"\"\"\n return self._archived.value\n\n @property\n def column_url(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._column_url.value\n\n @property\n def content_url(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._content_url.value\n\n @property\n def created_at(self):\n \"\"\"\n :type: datetime.datetime\n \"\"\"\n return self._created_at.value\n\n @property\n def creator(self):\n \"\"\"\n :type: :class:`github.NamedUser.NamedUser`\n \"\"\"\n return self._creator.value\n\n @property\n def id(self):\n \"\"\"\n :type: integer\n \"\"\"\n return self._id.value\n\n @property\n def node_id(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._node_id.value\n\n @property\n def note(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._note.value\n\n @property\n def updated_at(self):\n \"\"\"\n :type: datetime.datetime\n \"\"\"\n return self._updated_at.value\n\n @property\n def url(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._url.value\n\n # Note that the content_url for any card will be an \"issue\" URL, from\n # which you can retrieve either an Issue or a PullRequest. Unforunately\n # the API doesn't make it clear which you are dealing with.\n def get_content(self, content_type=github.GithubObject.NotSet):\n \"\"\"\n :calls: `GET /repos/:owner/:repo/pulls/:number <https://developer.github.com/v3/pulls/#get-a-single-pull-request>`_\n :param content_type: string, optional\n :rtype: :class:`github.PullRequest.PullRequest` or :class:`github.Issue.Issue`\n \"\"\"\n assert content_type is github.GithubObject.NotSet or isinstance(\n content_type, str\n ), content_type\n if self.content_url is None:\n return None\n\n if content_type == \"PullRequest\":\n url = self.content_url.replace(\"issues\", \"pulls\")\n retclass = github.PullRequest.PullRequest\n elif content_type is github.GithubObject.NotSet or content_type == \"Issue\":\n url = self.content_url\n retclass = github.Issue.Issue\n else:\n raise ValueError(\"Unknown content type: %s\" % content_type)\n headers, data = self._requester.requestJsonAndCheck(\"GET\", url)\n return retclass(self._requester, headers, data, completed=True)\n\n def _initAttributes(self):\n self._archived = github.GithubObject.NotSet\n self._column_url = github.GithubObject.NotSet\n self._content_url = github.GithubObject.NotSet\n self._created_at = github.GithubObject.NotSet\n self._creator = github.GithubObject.NotSet\n self._id = github.GithubObject.NotSet\n self._node_id = github.GithubObject.NotSet\n self._note = github.GithubObject.NotSet\n self._updated_at = github.GithubObject.NotSet\n self._url = github.GithubObject.NotSet\n\n def _useAttributes(self, attributes):\n if \"archived\" in attributes: # pragma no branch\n self._archived = self._makeBoolAttribute(attributes[\"archived\"])\n if \"column_url\" in attributes: # pragma no branch\n self._column_url = self._makeStringAttribute(attributes[\"column_url\"])\n if \"content_url\" in attributes: # pragma no branch\n self._content_url = self._makeStringAttribute(attributes[\"content_url\"])\n if \"created_at\" in attributes: # pragma no branch\n self._created_at = self._makeDatetimeAttribute(attributes[\"created_at\"])\n if \"creator\" in attributes: # pragma no branch\n self._creator = self._makeClassAttribute(\n github.NamedUser.NamedUser, attributes[\"creator\"]\n )\n if \"id\" in attributes: # pragma no branch\n self._id = self._makeIntAttribute(attributes[\"id\"])\n if \"node_id\" in attributes: # pragma no branch\n self._node_id = self._makeStringAttribute(attributes[\"node_id\"])\n if \"note\" in attributes: # pragma no branch\n self._note = self._makeStringAttribute(attributes[\"note\"])\n if \"updated_at\" in attributes: # pragma no branch\n self._updated_at = self._makeDatetimeAttribute(attributes[\"updated_at\"])\n if \"url\" in attributes: # pragma no branch\n self._url = self._makeStringAttribute(attributes[\"url\"])\n", "path": "github/ProjectCard.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n############################ Copyrights and license ############################\n# #\n# Copyright 2018 bbi-yggy <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nimport github.GithubObject\n\nfrom . import Consts\n\n# NOTE: There is currently no way to get cards \"in triage\" for a project.\n# https://platform.github.community/t/moving-github-project-cards-that-are-in-triage/3784\n#\n# See also https://developer.github.com/v4/object/projectcard for the next generation GitHub API,\n# which may point the way to where the API is likely headed and what might come back to v3. E.g. ProjectCard.content member.\n\n\nclass ProjectCard(github.GithubObject.CompletableGithubObject):\n \"\"\"\n This class represents Project Cards. The reference can be found here https://developer.github.com/v3/projects/cards\n \"\"\"\n\n def __repr__(self):\n return self.get__repr__({\"id\": self._id.value})\n\n @property\n def archived(self):\n \"\"\"\n :type: bool\n \"\"\"\n return self._archived.value\n\n @property\n def column_url(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._column_url.value\n\n @property\n def content_url(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._content_url.value\n\n @property\n def created_at(self):\n \"\"\"\n :type: datetime.datetime\n \"\"\"\n return self._created_at.value\n\n @property\n def creator(self):\n \"\"\"\n :type: :class:`github.NamedUser.NamedUser`\n \"\"\"\n return self._creator.value\n\n @property\n def id(self):\n \"\"\"\n :type: integer\n \"\"\"\n return self._id.value\n\n @property\n def node_id(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._node_id.value\n\n @property\n def note(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._note.value\n\n @property\n def updated_at(self):\n \"\"\"\n :type: datetime.datetime\n \"\"\"\n return self._updated_at.value\n\n @property\n def url(self):\n \"\"\"\n :type: string\n \"\"\"\n return self._url.value\n\n # Note that the content_url for any card will be an \"issue\" URL, from\n # which you can retrieve either an Issue or a PullRequest. Unforunately\n # the API doesn't make it clear which you are dealing with.\n def get_content(self, content_type=github.GithubObject.NotSet):\n \"\"\"\n :calls: `GET /repos/:owner/:repo/pulls/:number <https://developer.github.com/v3/pulls/#get-a-single-pull-request>`_\n :param content_type: string, optional\n :rtype: :class:`github.PullRequest.PullRequest` or :class:`github.Issue.Issue`\n \"\"\"\n assert content_type is github.GithubObject.NotSet or isinstance(\n content_type, str\n ), content_type\n if self.content_url is None:\n return None\n\n if content_type == \"PullRequest\":\n url = self.content_url.replace(\"issues\", \"pulls\")\n retclass = github.PullRequest.PullRequest\n elif content_type is github.GithubObject.NotSet or content_type == \"Issue\":\n url = self.content_url\n retclass = github.Issue.Issue\n else:\n raise ValueError(\"Unknown content type: %s\" % content_type)\n headers, data = self._requester.requestJsonAndCheck(\"GET\", url)\n return retclass(self._requester, headers, data, completed=True)\n\n def move(self, position, column):\n \"\"\"\n :calls: `POST /projects/columns/cards/:card_id/moves <https://developer.github.com/v3/projects/cards>`_\n :param position: string\n :param column: :class:`github.ProjectColumn.ProjectColumn` or int\n :rtype: bool\n \"\"\"\n assert isinstance(position, str), position\n assert isinstance(column, github.ProjectColumn.ProjectColumn) or isinstance(\n column, int\n ), column\n post_parameters = {\n \"position\": position,\n \"column\": column.id\n if isinstance(column, github.ProjectColumn.ProjectColumn)\n else column,\n }\n status, _, _ = self._requester.requestJson(\n \"POST\",\n self.url + \"/moves\",\n input=post_parameters,\n headers={\"Accept\": Consts.mediaTypeProjectsPreview},\n )\n return status == 201\n\n def _initAttributes(self):\n self._archived = github.GithubObject.NotSet\n self._column_url = github.GithubObject.NotSet\n self._content_url = github.GithubObject.NotSet\n self._created_at = github.GithubObject.NotSet\n self._creator = github.GithubObject.NotSet\n self._id = github.GithubObject.NotSet\n self._node_id = github.GithubObject.NotSet\n self._note = github.GithubObject.NotSet\n self._updated_at = github.GithubObject.NotSet\n self._url = github.GithubObject.NotSet\n\n def _useAttributes(self, attributes):\n if \"archived\" in attributes: # pragma no branch\n self._archived = self._makeBoolAttribute(attributes[\"archived\"])\n if \"column_url\" in attributes: # pragma no branch\n self._column_url = self._makeStringAttribute(attributes[\"column_url\"])\n if \"content_url\" in attributes: # pragma no branch\n self._content_url = self._makeStringAttribute(attributes[\"content_url\"])\n if \"created_at\" in attributes: # pragma no branch\n self._created_at = self._makeDatetimeAttribute(attributes[\"created_at\"])\n if \"creator\" in attributes: # pragma no branch\n self._creator = self._makeClassAttribute(\n github.NamedUser.NamedUser, attributes[\"creator\"]\n )\n if \"id\" in attributes: # pragma no branch\n self._id = self._makeIntAttribute(attributes[\"id\"])\n if \"node_id\" in attributes: # pragma no branch\n self._node_id = self._makeStringAttribute(attributes[\"node_id\"])\n if \"note\" in attributes: # pragma no branch\n self._note = self._makeStringAttribute(attributes[\"note\"])\n if \"updated_at\" in attributes: # pragma no branch\n self._updated_at = self._makeDatetimeAttribute(attributes[\"updated_at\"])\n if \"url\" in attributes: # pragma no branch\n self._url = self._makeStringAttribute(attributes[\"url\"])\n", "path": "github/ProjectCard.py"}]}
| 2,174 | 404 |
gh_patches_debug_3845
|
rasdani/github-patches
|
git_diff
|
yt-dlp__yt-dlp-6147
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Freesound] Downloads are broken
### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting a broken site
- [X] I've verified that I'm running yt-dlp version **2023.01.06** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)
- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#video-url-contains-an-ampersand--and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues **including closed ones**. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [ ] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required
### Region
_No response_
### Provide a description that is worded well enough to be understood
Freesound.org downloads are broken due to how the preview URLs sometimes appear in the HTML: `<meta property="og:audio" content="https://freesound.orghttps://cdn.freesound.org/..." />`
I have made a fix for this and will be opening a PR shortly.
### Provide verbose output that clearly demonstrates the problem
- [X] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)
- [X] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below
### Complete Verbose Output
```shell
yt-dlp -vU https://www.freesound.org/people/miklovan/sounds/194503/
[debug] Command-line config: ['-vU', 'https://www.freesound.org/people/miklovan/sounds/194503/']
[debug] Encodings: locale UTF-8, fs utf-8, pref UTF-8, out utf-8, error utf-8, screen utf-8
[debug] yt-dlp version 2023.01.06 [6becd25] (pip)
[debug] Python 3.10.2 (CPython AMD64 64bit) - Windows-10-10.0.19044-SP0 (OpenSSL 1.1.1m 14 Dec 2021)
[debug] exe versions: ffmpeg git-2019-11-13-a7245ad, ffprobe 5.1.2-full_build-www.gyan.dev
[debug] Optional libraries: Cryptodome-3.12.0, brotli-1.0.9, certifi-2021.10.08, mutagen-1.45.1, sqlite3-2.6.0, websockets-10.1
[debug] Proxy map: {}
[debug] Loaded 1760 extractors
[debug] Fetching release info: https://api.github.com/repos/yt-dlp/yt-dlp/releases/latest
Latest version: 2023.01.06, Current version: 2023.01.06
yt-dlp is up to date (2023.01.06)
[Freesound] Extracting URL: https://www.freesound.org/people/miklovan/sounds/194503/
[Freesound] 194503: Downloading webpage
[debug] Formats sorted by: hasvid, ie_pref, lang, quality, res, fps, hdr:12(7), vcodec:vp9.2(10), channels, acodec, filesize, fs_approx, tbr, vbr, abr, asr, proto, vext, aext, hasaud, source, id
[debug] Default format spec: bestvideo*+bestaudio/best
[info] 194503: Downloading 1 format(s): 1
[debug] Invoking http downloader on "https://freesound.orghttps://cdn.freesound.org/previews/194/194503_224081-hq.mp3"
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (1/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (2/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (3/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (4/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (5/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (6/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (7/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (8/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (9/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (10/10)...
[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Giving up after 10 retries
File "C:\Program Files\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Program Files\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Program Files\Python310\Scripts\yt-dlp.exe\__main__.py", line 7, in <module>
sys.exit(main())
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\__init__.py", line 970, in main
_exit(*variadic(_real_main(argv)))
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\__init__.py", line 960, in _real_main
return ydl.download(all_urls)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 3358, in download
self.__download_wrapper(self.extract_info)(
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 3333, in wrapper
res = func(*args, **kwargs)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 1491, in extract_info
return self.__extract_info(url, self.get_info_extractor(key), download, extra_info, process)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 1502, in wrapper
return func(self, *args, **kwargs)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 1599, in __extract_info
return self.process_ie_result(ie_result, download, extra_info)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 1658, in process_ie_result
ie_result = self.process_video_result(ie_result, download=download)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 2772, in process_video_result
self.process_info(new_info)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 3236, in process_info
success, real_download = self.dl(temp_filename, info_dict)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 2959, in dl
return fd.download(name, new_info, subtitle)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\downloader\common.py", line 444, in download
ret = self.real_download(filename, info_dict)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\downloader\http.py", line 369, in real_download
for retry in RetryManager(self.params.get('retries'), self.report_retry):
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\utils.py", line 6023, in __iter__
self.error_callback(self.error, self.attempt, self.retries)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\downloader\common.py", line 389, in report_retry
RetryManager.report_retry(
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\utils.py", line 6030, in report_retry
return error(f'{e}. Giving up after {count - 1} retries') if count > 1 else error(str(e))
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\downloader\common.py", line 392, in <lambda>
error=IDENTITY if not fatal else lambda e: self.report_error(f'\r[download] Got error: {e}'),
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 1012, in report_error
self.trouble(f'{self._format_err("ERROR:", self.Styles.ERROR)} {message}', *args, **kwargs)
File "C:\Program Files\Python310\lib\site-packages\yt_dlp\YoutubeDL.py", line 941, in trouble
tb_data = traceback.format_list(traceback.extract_stack())
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `yt_dlp/extractor/freesound.py`
Content:
```
1 import re
2
3 from .common import InfoExtractor
4 from ..utils import (
5 float_or_none,
6 get_element_by_class,
7 get_element_by_id,
8 unified_strdate,
9 )
10
11
12 class FreesoundIE(InfoExtractor):
13 _VALID_URL = r'https?://(?:www\.)?freesound\.org/people/[^/]+/sounds/(?P<id>[^/]+)'
14 _TEST = {
15 'url': 'http://www.freesound.org/people/miklovan/sounds/194503/',
16 'md5': '12280ceb42c81f19a515c745eae07650',
17 'info_dict': {
18 'id': '194503',
19 'ext': 'mp3',
20 'title': 'gulls in the city.wav',
21 'description': 'the sounds of seagulls in the city',
22 'duration': 130.233,
23 'uploader': 'miklovan',
24 'upload_date': '20130715',
25 'tags': list,
26 }
27 }
28
29 def _real_extract(self, url):
30 audio_id = self._match_id(url)
31
32 webpage = self._download_webpage(url, audio_id)
33
34 audio_url = self._og_search_property('audio', webpage, 'song url')
35 title = self._og_search_property('audio:title', webpage, 'song title')
36
37 description = self._html_search_regex(
38 r'(?s)id=["\']sound_description["\'][^>]*>(.+?)</div>',
39 webpage, 'description', fatal=False)
40
41 duration = float_or_none(
42 get_element_by_class('duration', webpage), scale=1000)
43
44 upload_date = unified_strdate(get_element_by_id('sound_date', webpage))
45 uploader = self._og_search_property(
46 'audio:artist', webpage, 'uploader', fatal=False)
47
48 channels = self._html_search_regex(
49 r'Channels</dt><dd>(.+?)</dd>', webpage,
50 'channels info', fatal=False)
51
52 tags_str = get_element_by_class('tags', webpage)
53 tags = re.findall(r'<a[^>]+>([^<]+)', tags_str) if tags_str else None
54
55 audio_urls = [audio_url]
56
57 LQ_FORMAT = '-lq.mp3'
58 if LQ_FORMAT in audio_url:
59 audio_urls.append(audio_url.replace(LQ_FORMAT, '-hq.mp3'))
60
61 formats = [{
62 'url': format_url,
63 'format_note': channels,
64 'quality': quality,
65 } for quality, format_url in enumerate(audio_urls)]
66
67 return {
68 'id': audio_id,
69 'title': title,
70 'description': description,
71 'duration': duration,
72 'uploader': uploader,
73 'upload_date': upload_date,
74 'tags': tags,
75 'formats': formats,
76 }
77
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/yt_dlp/extractor/freesound.py b/yt_dlp/extractor/freesound.py
--- a/yt_dlp/extractor/freesound.py
+++ b/yt_dlp/extractor/freesound.py
@@ -52,6 +52,7 @@
tags_str = get_element_by_class('tags', webpage)
tags = re.findall(r'<a[^>]+>([^<]+)', tags_str) if tags_str else None
+ audio_url = re.sub(r'^https?://freesound\.org(https?://)', r'\1', audio_url)
audio_urls = [audio_url]
LQ_FORMAT = '-lq.mp3'
|
{"golden_diff": "diff --git a/yt_dlp/extractor/freesound.py b/yt_dlp/extractor/freesound.py\n--- a/yt_dlp/extractor/freesound.py\n+++ b/yt_dlp/extractor/freesound.py\n@@ -52,6 +52,7 @@\n tags_str = get_element_by_class('tags', webpage)\n tags = re.findall(r'<a[^>]+>([^<]+)', tags_str) if tags_str else None\n \n+ audio_url = re.sub(r'^https?://freesound\\.org(https?://)', r'\\1', audio_url)\n audio_urls = [audio_url]\n \n LQ_FORMAT = '-lq.mp3'\n", "issue": "[Freesound] Downloads are broken\n### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE\n\n- [X] I understand that I will be **blocked** if I remove or skip any mandatory\\* field\n\n### Checklist\n\n- [X] I'm reporting a broken site\n- [X] I've verified that I'm running yt-dlp version **2023.01.06** ([update instructions](https://github.com/yt-dlp/yt-dlp#update)) or later (specify commit)\n- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details\n- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#video-url-contains-an-ampersand--and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues **including closed ones**. DO NOT post duplicates\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\n- [ ] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required\n\n### Region\n\n_No response_\n\n### Provide a description that is worded well enough to be understood\n\nFreesound.org downloads are broken due to how the preview URLs sometimes appear in the HTML: `<meta property=\"og:audio\" content=\"https://freesound.orghttps://cdn.freesound.org/...\" />`\r\n\r\nI have made a fix for this and will be opening a PR shortly.\n\n### Provide verbose output that clearly demonstrates the problem\n\n- [X] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)\n- [X] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below\n\n### Complete Verbose Output\n\n```shell\nyt-dlp -vU https://www.freesound.org/people/miklovan/sounds/194503/\r\n[debug] Command-line config: ['-vU', 'https://www.freesound.org/people/miklovan/sounds/194503/']\r\n[debug] Encodings: locale UTF-8, fs utf-8, pref UTF-8, out utf-8, error utf-8, screen utf-8\r\n[debug] yt-dlp version 2023.01.06 [6becd25] (pip)\r\n[debug] Python 3.10.2 (CPython AMD64 64bit) - Windows-10-10.0.19044-SP0 (OpenSSL 1.1.1m 14 Dec 2021)\r\n[debug] exe versions: ffmpeg git-2019-11-13-a7245ad, ffprobe 5.1.2-full_build-www.gyan.dev\r\n[debug] Optional libraries: Cryptodome-3.12.0, brotli-1.0.9, certifi-2021.10.08, mutagen-1.45.1, sqlite3-2.6.0, websockets-10.1\r\n[debug] Proxy map: {}\r\n[debug] Loaded 1760 extractors\r\n[debug] Fetching release info: https://api.github.com/repos/yt-dlp/yt-dlp/releases/latest\r\nLatest version: 2023.01.06, Current version: 2023.01.06\r\nyt-dlp is up to date (2023.01.06)\r\n[Freesound] Extracting URL: https://www.freesound.org/people/miklovan/sounds/194503/\r\n[Freesound] 194503: Downloading webpage\r\n[debug] Formats sorted by: hasvid, ie_pref, lang, quality, res, fps, hdr:12(7), vcodec:vp9.2(10), channels, acodec, filesize, fs_approx, tbr, vbr, abr, asr, proto, vext, aext, hasaud, source, id\r\n[debug] Default format spec: bestvideo*+bestaudio/best\r\n[info] 194503: Downloading 1 format(s): 1\r\n[debug] Invoking http downloader on \"https://freesound.orghttps://cdn.freesound.org/previews/194/194503_224081-hq.mp3\"\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (1/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (2/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (3/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (4/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (5/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (6/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (7/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (8/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (9/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Retrying (10/10)...\r\n[download] Got error: <urlopen error [Errno 11001] getaddrinfo failed>. Giving up after 10 retries\r\n File \"C:\\Program Files\\Python310\\lib\\runpy.py\", line 196, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"C:\\Program Files\\Python310\\lib\\runpy.py\", line 86, in _run_code\r\n exec(code, run_globals)\r\n File \"C:\\Program Files\\Python310\\Scripts\\yt-dlp.exe\\__main__.py\", line 7, in <module>\r\n sys.exit(main())\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\__init__.py\", line 970, in main\r\n _exit(*variadic(_real_main(argv)))\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\__init__.py\", line 960, in _real_main\r\n return ydl.download(all_urls)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 3358, in download\r\n self.__download_wrapper(self.extract_info)(\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 3333, in wrapper\r\n res = func(*args, **kwargs)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1491, in extract_info\r\n return self.__extract_info(url, self.get_info_extractor(key), download, extra_info, process)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1502, in wrapper\r\n return func(self, *args, **kwargs)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1599, in __extract_info\r\n return self.process_ie_result(ie_result, download, extra_info)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1658, in process_ie_result\r\n ie_result = self.process_video_result(ie_result, download=download)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 2772, in process_video_result\r\n self.process_info(new_info)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 3236, in process_info\r\n success, real_download = self.dl(temp_filename, info_dict)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 2959, in dl\r\n return fd.download(name, new_info, subtitle)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\downloader\\common.py\", line 444, in download\r\n ret = self.real_download(filename, info_dict)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\downloader\\http.py\", line 369, in real_download\r\n for retry in RetryManager(self.params.get('retries'), self.report_retry):\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\utils.py\", line 6023, in __iter__\r\n self.error_callback(self.error, self.attempt, self.retries)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\downloader\\common.py\", line 389, in report_retry\r\n RetryManager.report_retry(\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\utils.py\", line 6030, in report_retry\r\n return error(f'{e}. Giving up after {count - 1} retries') if count > 1 else error(str(e))\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\downloader\\common.py\", line 392, in <lambda>\r\n error=IDENTITY if not fatal else lambda e: self.report_error(f'\\r[download] Got error: {e}'),\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1012, in report_error\r\n self.trouble(f'{self._format_err(\"ERROR:\", self.Styles.ERROR)} {message}', *args, **kwargs)\r\n File \"C:\\Program Files\\Python310\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 941, in trouble\r\n tb_data = traceback.format_list(traceback.extract_stack())\n```\n\n", "before_files": [{"content": "import re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n float_or_none,\n get_element_by_class,\n get_element_by_id,\n unified_strdate,\n)\n\n\nclass FreesoundIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?freesound\\.org/people/[^/]+/sounds/(?P<id>[^/]+)'\n _TEST = {\n 'url': 'http://www.freesound.org/people/miklovan/sounds/194503/',\n 'md5': '12280ceb42c81f19a515c745eae07650',\n 'info_dict': {\n 'id': '194503',\n 'ext': 'mp3',\n 'title': 'gulls in the city.wav',\n 'description': 'the sounds of seagulls in the city',\n 'duration': 130.233,\n 'uploader': 'miklovan',\n 'upload_date': '20130715',\n 'tags': list,\n }\n }\n\n def _real_extract(self, url):\n audio_id = self._match_id(url)\n\n webpage = self._download_webpage(url, audio_id)\n\n audio_url = self._og_search_property('audio', webpage, 'song url')\n title = self._og_search_property('audio:title', webpage, 'song title')\n\n description = self._html_search_regex(\n r'(?s)id=[\"\\']sound_description[\"\\'][^>]*>(.+?)</div>',\n webpage, 'description', fatal=False)\n\n duration = float_or_none(\n get_element_by_class('duration', webpage), scale=1000)\n\n upload_date = unified_strdate(get_element_by_id('sound_date', webpage))\n uploader = self._og_search_property(\n 'audio:artist', webpage, 'uploader', fatal=False)\n\n channels = self._html_search_regex(\n r'Channels</dt><dd>(.+?)</dd>', webpage,\n 'channels info', fatal=False)\n\n tags_str = get_element_by_class('tags', webpage)\n tags = re.findall(r'<a[^>]+>([^<]+)', tags_str) if tags_str else None\n\n audio_urls = [audio_url]\n\n LQ_FORMAT = '-lq.mp3'\n if LQ_FORMAT in audio_url:\n audio_urls.append(audio_url.replace(LQ_FORMAT, '-hq.mp3'))\n\n formats = [{\n 'url': format_url,\n 'format_note': channels,\n 'quality': quality,\n } for quality, format_url in enumerate(audio_urls)]\n\n return {\n 'id': audio_id,\n 'title': title,\n 'description': description,\n 'duration': duration,\n 'uploader': uploader,\n 'upload_date': upload_date,\n 'tags': tags,\n 'formats': formats,\n }\n", "path": "yt_dlp/extractor/freesound.py"}], "after_files": [{"content": "import re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n float_or_none,\n get_element_by_class,\n get_element_by_id,\n unified_strdate,\n)\n\n\nclass FreesoundIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?freesound\\.org/people/[^/]+/sounds/(?P<id>[^/]+)'\n _TEST = {\n 'url': 'http://www.freesound.org/people/miklovan/sounds/194503/',\n 'md5': '12280ceb42c81f19a515c745eae07650',\n 'info_dict': {\n 'id': '194503',\n 'ext': 'mp3',\n 'title': 'gulls in the city.wav',\n 'description': 'the sounds of seagulls in the city',\n 'duration': 130.233,\n 'uploader': 'miklovan',\n 'upload_date': '20130715',\n 'tags': list,\n }\n }\n\n def _real_extract(self, url):\n audio_id = self._match_id(url)\n\n webpage = self._download_webpage(url, audio_id)\n\n audio_url = self._og_search_property('audio', webpage, 'song url')\n title = self._og_search_property('audio:title', webpage, 'song title')\n\n description = self._html_search_regex(\n r'(?s)id=[\"\\']sound_description[\"\\'][^>]*>(.+?)</div>',\n webpage, 'description', fatal=False)\n\n duration = float_or_none(\n get_element_by_class('duration', webpage), scale=1000)\n\n upload_date = unified_strdate(get_element_by_id('sound_date', webpage))\n uploader = self._og_search_property(\n 'audio:artist', webpage, 'uploader', fatal=False)\n\n channels = self._html_search_regex(\n r'Channels</dt><dd>(.+?)</dd>', webpage,\n 'channels info', fatal=False)\n\n tags_str = get_element_by_class('tags', webpage)\n tags = re.findall(r'<a[^>]+>([^<]+)', tags_str) if tags_str else None\n\n audio_url = re.sub(r'^https?://freesound\\.org(https?://)', r'\\1', audio_url)\n audio_urls = [audio_url]\n\n LQ_FORMAT = '-lq.mp3'\n if LQ_FORMAT in audio_url:\n audio_urls.append(audio_url.replace(LQ_FORMAT, '-hq.mp3'))\n\n formats = [{\n 'url': format_url,\n 'format_note': channels,\n 'quality': quality,\n } for quality, format_url in enumerate(audio_urls)]\n\n return {\n 'id': audio_id,\n 'title': title,\n 'description': description,\n 'duration': duration,\n 'uploader': uploader,\n 'upload_date': upload_date,\n 'tags': tags,\n 'formats': formats,\n }\n", "path": "yt_dlp/extractor/freesound.py"}]}
| 3,634 | 155 |
gh_patches_debug_16978
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-3183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mail: New Session Proposals not Sent out to Organizers and Co-organizers
After the submission of several people the new Session Proposals have not been sent out to Organizers and Co-organizers. One reason could be, that these people did not verify their email address.
Please check configuration and ensure all emails of all submissions are sent to organizers/co-organizers.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/helpers/notification_email_triggers.py`
Content:
```
1 from flask import url_for
2
3 from app.helpers.data_getter import DataGetter
4 from app.helpers.helpers import send_new_session_organizer, send_notif_new_session_organizer, \
5 send_notif_session_accept_reject, send_session_accept_reject, send_schedule_change, send_notif_session_schedule, \
6 send_email_for_after_purchase_organizers, send_notif_for_after_purchase_organizer
7 from app.models.mail import NEW_SESSION, SESSION_ACCEPT_REJECT, SESSION_SCHEDULE, TICKET_PURCHASED
8
9
10 def trigger_new_session_notifications(session_id, event_id=None, event=None):
11 if not event and not event_id:
12 raise Exception('event or event_id is required')
13 if not event:
14 event = DataGetter.get_event(event_id)
15
16 link = url_for('event_sessions.session_display_view',
17 event_id=event.id, session_id=session_id, _external=True)
18
19 admin_msg_setting = DataGetter.get_message_setting_by_action(NEW_SESSION)
20 organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')
21 for organizer in organizers:
22 email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)
23 if not admin_msg_setting or \
24 (email_notification_setting and email_notification_setting.new_paper == 1 and
25 admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:
26
27 send_new_session_organizer(organizer.user.email, event.name, link)
28 # Send notification
29 send_notif_new_session_organizer(organizer.user, event.name, link)
30
31
32 def trigger_session_state_change_notifications(session, event_id, state=None, message=None, subject=None):
33 if not state:
34 state = session.state
35 link = url_for('event_sessions.session_display_view', event_id=event_id, session_id=session.id, _external=True)
36 admin_msg_setting = DataGetter.get_message_setting_by_action(SESSION_ACCEPT_REJECT)
37 for speaker in session.speakers:
38 email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(speaker.user_id, event_id)
39 if not admin_msg_setting or \
40 (email_notification_setting and email_notification_setting.session_accept_reject == 1 and
41 admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:
42
43 if speaker.email:
44 send_session_accept_reject(speaker.email, session.title, state, link, subject=subject, message=message)
45 # Send notification
46 if speaker.user:
47 send_notif_session_accept_reject(speaker.user, session.title, state, link)
48 session.state_email_sent = True
49 from app.helpers.data import save_to_db
50 save_to_db(session)
51
52
53 def trigger_session_schedule_change_notifications(session, event_id):
54 link = url_for('event_sessions.session_display_view', event_id=event_id, session_id=session.id, _external=True)
55 admin_msg_setting = DataGetter.get_message_setting_by_action(SESSION_SCHEDULE)
56 for speaker in session.speakers:
57 email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(speaker.user_id, event_id)
58 if not admin_msg_setting or \
59 (email_notification_setting and email_notification_setting.session_schedule == 1 and
60 admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:
61 if speaker.email:
62 send_schedule_change(speaker.email, session.title, link)
63 # Send notification
64 if speaker.user:
65 send_notif_session_schedule(speaker.user, session.title, link)
66
67
68 def trigger_after_purchase_notifications(buyer_email, event_id, event, invoice_id, order_url):
69 if not event and not event_id:
70 raise Exception('event or event_id is required')
71 if not event:
72 event = DataGetter.get_event(event_id)
73
74 admin_msg_setting = DataGetter.get_message_setting_by_action(TICKET_PURCHASED)
75 organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')
76 for organizer in organizers:
77 email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)
78 if not admin_msg_setting or \
79 (email_notification_setting and email_notification_setting.after_ticket_purchase == 1 and
80 admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:
81 send_email_for_after_purchase_organizers(organizer.user.email, buyer_email, invoice_id, order_url, event.name, event.organizer_name)
82 send_notif_for_after_purchase_organizer(organizer.user, invoice_id, order_url, event.name, buyer_email)
83
84 coorganizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'coorganizer')
85 for coorganizer in coorganizers:
86 email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(coorganizer.user.id, event_id)
87 if not admin_msg_setting or \
88 (email_notification_setting and email_notification_setting.after_ticket_purchase == 1 and
89 admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:
90 send_email_for_after_purchase_organizers(coorganizer.user.email, buyer_email, invoice_id, order_url, event.name, event.organizer_name)
91 send_notif_for_after_purchase_organizer(organizer.user, invoice_id, order_url, event.name, buyer_email)
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/helpers/notification_email_triggers.py b/app/helpers/notification_email_triggers.py
--- a/app/helpers/notification_email_triggers.py
+++ b/app/helpers/notification_email_triggers.py
@@ -19,7 +19,7 @@
admin_msg_setting = DataGetter.get_message_setting_by_action(NEW_SESSION)
organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')
for organizer in organizers:
- email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)
+ email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event.id)
if not admin_msg_setting or \
(email_notification_setting and email_notification_setting.new_paper == 1 and
admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:
|
{"golden_diff": "diff --git a/app/helpers/notification_email_triggers.py b/app/helpers/notification_email_triggers.py\n--- a/app/helpers/notification_email_triggers.py\n+++ b/app/helpers/notification_email_triggers.py\n@@ -19,7 +19,7 @@\n admin_msg_setting = DataGetter.get_message_setting_by_action(NEW_SESSION)\n organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')\n for organizer in organizers:\n- email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)\n+ email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event.id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.new_paper == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n", "issue": "Mail: New Session Proposals not Sent out to Organizers and Co-organizers\nAfter the submission of several people the new Session Proposals have not been sent out to Organizers and Co-organizers. One reason could be, that these people did not verify their email address.\r\n\r\nPlease check configuration and ensure all emails of all submissions are sent to organizers/co-organizers.\n", "before_files": [{"content": "from flask import url_for\n\nfrom app.helpers.data_getter import DataGetter\nfrom app.helpers.helpers import send_new_session_organizer, send_notif_new_session_organizer, \\\n send_notif_session_accept_reject, send_session_accept_reject, send_schedule_change, send_notif_session_schedule, \\\n send_email_for_after_purchase_organizers, send_notif_for_after_purchase_organizer\nfrom app.models.mail import NEW_SESSION, SESSION_ACCEPT_REJECT, SESSION_SCHEDULE, TICKET_PURCHASED\n\n\ndef trigger_new_session_notifications(session_id, event_id=None, event=None):\n if not event and not event_id:\n raise Exception('event or event_id is required')\n if not event:\n event = DataGetter.get_event(event_id)\n\n link = url_for('event_sessions.session_display_view',\n event_id=event.id, session_id=session_id, _external=True)\n\n admin_msg_setting = DataGetter.get_message_setting_by_action(NEW_SESSION)\n organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')\n for organizer in organizers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.new_paper == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n\n send_new_session_organizer(organizer.user.email, event.name, link)\n # Send notification\n send_notif_new_session_organizer(organizer.user, event.name, link)\n\n\ndef trigger_session_state_change_notifications(session, event_id, state=None, message=None, subject=None):\n if not state:\n state = session.state\n link = url_for('event_sessions.session_display_view', event_id=event_id, session_id=session.id, _external=True)\n admin_msg_setting = DataGetter.get_message_setting_by_action(SESSION_ACCEPT_REJECT)\n for speaker in session.speakers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(speaker.user_id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.session_accept_reject == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n\n if speaker.email:\n send_session_accept_reject(speaker.email, session.title, state, link, subject=subject, message=message)\n # Send notification\n if speaker.user:\n send_notif_session_accept_reject(speaker.user, session.title, state, link)\n session.state_email_sent = True\n from app.helpers.data import save_to_db\n save_to_db(session)\n\n\ndef trigger_session_schedule_change_notifications(session, event_id):\n link = url_for('event_sessions.session_display_view', event_id=event_id, session_id=session.id, _external=True)\n admin_msg_setting = DataGetter.get_message_setting_by_action(SESSION_SCHEDULE)\n for speaker in session.speakers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(speaker.user_id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.session_schedule == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n if speaker.email:\n send_schedule_change(speaker.email, session.title, link)\n # Send notification\n if speaker.user:\n send_notif_session_schedule(speaker.user, session.title, link)\n\n\ndef trigger_after_purchase_notifications(buyer_email, event_id, event, invoice_id, order_url):\n if not event and not event_id:\n raise Exception('event or event_id is required')\n if not event:\n event = DataGetter.get_event(event_id)\n\n admin_msg_setting = DataGetter.get_message_setting_by_action(TICKET_PURCHASED)\n organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')\n for organizer in organizers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.after_ticket_purchase == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n send_email_for_after_purchase_organizers(organizer.user.email, buyer_email, invoice_id, order_url, event.name, event.organizer_name)\n send_notif_for_after_purchase_organizer(organizer.user, invoice_id, order_url, event.name, buyer_email)\n\n coorganizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'coorganizer')\n for coorganizer in coorganizers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(coorganizer.user.id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.after_ticket_purchase == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n send_email_for_after_purchase_organizers(coorganizer.user.email, buyer_email, invoice_id, order_url, event.name, event.organizer_name)\n send_notif_for_after_purchase_organizer(organizer.user, invoice_id, order_url, event.name, buyer_email)\n", "path": "app/helpers/notification_email_triggers.py"}], "after_files": [{"content": "from flask import url_for\n\nfrom app.helpers.data_getter import DataGetter\nfrom app.helpers.helpers import send_new_session_organizer, send_notif_new_session_organizer, \\\n send_notif_session_accept_reject, send_session_accept_reject, send_schedule_change, send_notif_session_schedule, \\\n send_email_for_after_purchase_organizers, send_notif_for_after_purchase_organizer\nfrom app.models.mail import NEW_SESSION, SESSION_ACCEPT_REJECT, SESSION_SCHEDULE, TICKET_PURCHASED\n\n\ndef trigger_new_session_notifications(session_id, event_id=None, event=None):\n if not event and not event_id:\n raise Exception('event or event_id is required')\n if not event:\n event = DataGetter.get_event(event_id)\n\n link = url_for('event_sessions.session_display_view',\n event_id=event.id, session_id=session_id, _external=True)\n\n admin_msg_setting = DataGetter.get_message_setting_by_action(NEW_SESSION)\n organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')\n for organizer in organizers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event.id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.new_paper == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n\n send_new_session_organizer(organizer.user.email, event.name, link)\n # Send notification\n send_notif_new_session_organizer(organizer.user, event.name, link)\n\n\ndef trigger_session_state_change_notifications(session, event_id, state=None, message=None, subject=None):\n if not state:\n state = session.state\n link = url_for('event_sessions.session_display_view', event_id=event_id, session_id=session.id, _external=True)\n admin_msg_setting = DataGetter.get_message_setting_by_action(SESSION_ACCEPT_REJECT)\n for speaker in session.speakers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(speaker.user_id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.session_accept_reject == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n\n if speaker.email:\n send_session_accept_reject(speaker.email, session.title, state, link, subject=subject, message=message)\n # Send notification\n if speaker.user:\n send_notif_session_accept_reject(speaker.user, session.title, state, link)\n session.state_email_sent = True\n from app.helpers.data import save_to_db\n save_to_db(session)\n\n\ndef trigger_session_schedule_change_notifications(session, event_id):\n link = url_for('event_sessions.session_display_view', event_id=event_id, session_id=session.id, _external=True)\n admin_msg_setting = DataGetter.get_message_setting_by_action(SESSION_SCHEDULE)\n for speaker in session.speakers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(speaker.user_id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.session_schedule == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n if speaker.email:\n send_schedule_change(speaker.email, session.title, link)\n # Send notification\n if speaker.user:\n send_notif_session_schedule(speaker.user, session.title, link)\n\n\ndef trigger_after_purchase_notifications(buyer_email, event_id, event, invoice_id, order_url):\n if not event and not event_id:\n raise Exception('event or event_id is required')\n if not event:\n event = DataGetter.get_event(event_id)\n\n admin_msg_setting = DataGetter.get_message_setting_by_action(TICKET_PURCHASED)\n organizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'organizer')\n for organizer in organizers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(organizer.user.id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.after_ticket_purchase == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n send_email_for_after_purchase_organizers(organizer.user.email, buyer_email, invoice_id, order_url, event.name, event.organizer_name)\n send_notif_for_after_purchase_organizer(organizer.user, invoice_id, order_url, event.name, buyer_email)\n\n coorganizers = DataGetter.get_user_event_roles_by_role_name(event.id, 'coorganizer')\n for coorganizer in coorganizers:\n email_notification_setting = DataGetter.get_email_notification_settings_by_event_id(coorganizer.user.id, event_id)\n if not admin_msg_setting or \\\n (email_notification_setting and email_notification_setting.after_ticket_purchase == 1 and\n admin_msg_setting.user_control_status == 1) or admin_msg_setting.user_control_status == 0:\n send_email_for_after_purchase_organizers(coorganizer.user.email, buyer_email, invoice_id, order_url, event.name, event.organizer_name)\n send_notif_for_after_purchase_organizer(organizer.user, invoice_id, order_url, event.name, buyer_email)\n", "path": "app/helpers/notification_email_triggers.py"}]}
| 1,662 | 187 |
gh_patches_debug_10374
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-1584
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`retriever download` command throwing error.
After running `retriever download iris`, I am getting this error :

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `retriever/lib/install.py`
Content:
```
1 import os
2 from collections import OrderedDict
3
4 from retriever.engines import choose_engine
5 from retriever.lib.defaults import DATA_DIR, SCRIPT_WRITE_PATH, PROVENANCE_DIR
6 from retriever.lib.scripts import SCRIPT_LIST, name_matches
7 from retriever.lib.repository import check_for_updates
8 from retriever.lib.provenance import install_committed
9
10
11 def _install(args, use_cache, debug):
12 """Install datasets for retriever."""
13 engine = choose_engine(args)
14 engine.use_cache = use_cache
15
16 if args['dataset'].endswith('.zip') or args['hash_value']:
17 path_to_archive = args['dataset']
18 if args['hash_value']:
19 path_to_archive = os.path.join(
20 PROVENANCE_DIR, args['dataset'],
21 '{}-{}.zip'.format(args['dataset'], args['hash_value']))
22 if not os.path.exists(path_to_archive):
23 print('The committed file does not exist.')
24 engine = install_committed(path_to_archive,
25 engine,
26 force=args.get('force', False))
27 return engine
28 script_list = SCRIPT_LIST()
29 if not (script_list or os.listdir(SCRIPT_WRITE_PATH)):
30 check_for_updates()
31 script_list = SCRIPT_LIST()
32 data_sets_scripts = name_matches(script_list, args['dataset'])
33 if data_sets_scripts:
34 for data_sets_script in data_sets_scripts:
35 print("=> Installing", data_sets_script.name)
36 try:
37 if engine.name == "HDF5":
38 sqlite_opts = {
39 'command': 'install',
40 'dataset': data_sets_script,
41 'engine': 'sqlite',
42 'file': (args["file"].split("."))[0] + ".db",
43 'table_name': args["table_name"],
44 'data_dir': args["data_dir"]
45 }
46 sqlite_engine = choose_engine(sqlite_opts)
47 data_sets_script.download(sqlite_engine, debug=debug)
48 data_sets_script.engine.final_cleanup()
49 engine.script_table_registry = OrderedDict()
50 data_sets_script.download(engine, debug=debug)
51 data_sets_script.engine.final_cleanup()
52 except Exception as e:
53 print(e)
54 if debug:
55 raise
56 else:
57 message = "Run retriever.datasets() to list the currently available " \
58 "datasets."
59 raise ValueError(message)
60 return engine
61
62
63 def install_csv(dataset,
64 table_name='{db}_{table}.csv',
65 data_dir=DATA_DIR,
66 debug=False,
67 use_cache=True,
68 force=False,
69 hash_value=None):
70 """Install datasets into csv."""
71 args = {
72 'command': 'install',
73 'dataset': dataset,
74 'engine': 'csv',
75 'table_name': table_name,
76 'data_dir': data_dir,
77 'force': force,
78 'hash_value': hash_value
79 }
80 return _install(args, use_cache, debug)
81
82
83 def install_mysql(dataset,
84 user='root',
85 password='',
86 host='localhost',
87 port=3306,
88 database_name='{db}',
89 table_name='{db}.{table}',
90 debug=False,
91 use_cache=True,
92 force=False,
93 hash_value=None):
94 """Install datasets into mysql."""
95 args = {
96 'command': 'install',
97 'database_name': database_name,
98 'engine': 'mysql',
99 'dataset': dataset,
100 'host': host,
101 'port': port,
102 'password': password,
103 'table_name': table_name,
104 'user': user,
105 'force': force,
106 'hash_value': hash_value
107 }
108 return _install(args, use_cache, debug)
109
110
111 def install_postgres(dataset,
112 user='postgres',
113 password='',
114 host='localhost',
115 port=5432,
116 database='postgres',
117 database_name='{db}',
118 table_name='{db}.{table}',
119 bbox=[],
120 debug=False,
121 use_cache=True,
122 force=False,
123 hash_value=None):
124 """Install datasets into postgres."""
125 args = {
126 'command': 'install',
127 'database': database,
128 'database_name': database_name,
129 'engine': 'postgres',
130 'dataset': dataset,
131 'host': host,
132 'port': port,
133 'password': password,
134 'table_name': table_name,
135 'user': user,
136 'bbox': bbox,
137 'force': force,
138 'hash_value': hash_value
139 }
140 return _install(args, use_cache, debug)
141
142
143 def install_sqlite(dataset,
144 file='sqlite.db',
145 table_name='{db}_{table}',
146 data_dir=DATA_DIR,
147 debug=False,
148 use_cache=True,
149 force=False,
150 hash_value=None):
151 """Install datasets into sqlite."""
152 args = {
153 'command': 'install',
154 'dataset': dataset,
155 'engine': 'sqlite',
156 'file': file,
157 'table_name': table_name,
158 'data_dir': data_dir,
159 'force': force,
160 'hash_value': hash_value
161 }
162 return _install(args, use_cache, debug)
163
164
165 def install_msaccess(dataset,
166 file='access.mdb',
167 table_name='[{db} {table}]',
168 data_dir=DATA_DIR,
169 debug=False,
170 use_cache=True,
171 force=False,
172 hash_value=None):
173 """Install datasets into msaccess."""
174 args = {
175 'command': 'install',
176 'dataset': dataset,
177 'engine': 'msaccess',
178 'file': file,
179 'table_name': table_name,
180 'data_dir': data_dir,
181 'force': force,
182 'hash_value': hash_value
183 }
184 return _install(args, use_cache, debug)
185
186
187 def install_json(dataset,
188 table_name='{db}_{table}.json',
189 data_dir=DATA_DIR,
190 debug=False,
191 use_cache=True,
192 pretty=False,
193 force=False,
194 hash_value=None):
195 """Install datasets into json."""
196 args = {
197 'command': 'install',
198 'dataset': dataset,
199 'engine': 'json',
200 'table_name': table_name,
201 'data_dir': data_dir,
202 'pretty': pretty,
203 'force': force,
204 'hash_value': hash_value
205 }
206 return _install(args, use_cache, debug)
207
208
209 def install_xml(dataset,
210 table_name='{db}_{table}.xml',
211 data_dir=DATA_DIR,
212 debug=False,
213 use_cache=True,
214 force=False,
215 hash_value=None):
216 """Install datasets into xml."""
217 args = {
218 'command': 'install',
219 'dataset': dataset,
220 'engine': 'xml',
221 'table_name': table_name,
222 'data_dir': data_dir,
223 'force': force,
224 'hash_value': hash_value
225 }
226 return _install(args, use_cache, debug)
227
228
229 def install_hdf5(dataset,
230 file='hdf5.h5',
231 table_name='{db}_{table}',
232 data_dir=DATA_DIR,
233 debug=False,
234 use_cache=True,
235 hash_value=None):
236 """Install datasets into hdf5."""
237 args = {
238 'command': 'install',
239 'dataset': dataset,
240 'engine': 'hdf5',
241 'file': file,
242 'table_name': table_name,
243 'data_dir': data_dir,
244 'hash_value': hash_value
245 }
246 return _install(args, use_cache, debug)
247
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/retriever/lib/install.py b/retriever/lib/install.py
--- a/retriever/lib/install.py
+++ b/retriever/lib/install.py
@@ -13,9 +13,9 @@
engine = choose_engine(args)
engine.use_cache = use_cache
- if args['dataset'].endswith('.zip') or args['hash_value']:
+ if args['dataset'].endswith('.zip') or args.get('hash_value'):
path_to_archive = args['dataset']
- if args['hash_value']:
+ if args.get('hash_value'):
path_to_archive = os.path.join(
PROVENANCE_DIR, args['dataset'],
'{}-{}.zip'.format(args['dataset'], args['hash_value']))
|
{"golden_diff": "diff --git a/retriever/lib/install.py b/retriever/lib/install.py\n--- a/retriever/lib/install.py\n+++ b/retriever/lib/install.py\n@@ -13,9 +13,9 @@\n engine = choose_engine(args)\n engine.use_cache = use_cache\n \n- if args['dataset'].endswith('.zip') or args['hash_value']:\n+ if args['dataset'].endswith('.zip') or args.get('hash_value'):\n path_to_archive = args['dataset']\n- if args['hash_value']:\n+ if args.get('hash_value'):\n path_to_archive = os.path.join(\n PROVENANCE_DIR, args['dataset'],\n '{}-{}.zip'.format(args['dataset'], args['hash_value']))\n", "issue": "`retriever download` command throwing error.\nAfter running `retriever download iris`, I am getting this error : \r\n\n", "before_files": [{"content": "import os\nfrom collections import OrderedDict\n\nfrom retriever.engines import choose_engine\nfrom retriever.lib.defaults import DATA_DIR, SCRIPT_WRITE_PATH, PROVENANCE_DIR\nfrom retriever.lib.scripts import SCRIPT_LIST, name_matches\nfrom retriever.lib.repository import check_for_updates\nfrom retriever.lib.provenance import install_committed\n\n\ndef _install(args, use_cache, debug):\n \"\"\"Install datasets for retriever.\"\"\"\n engine = choose_engine(args)\n engine.use_cache = use_cache\n\n if args['dataset'].endswith('.zip') or args['hash_value']:\n path_to_archive = args['dataset']\n if args['hash_value']:\n path_to_archive = os.path.join(\n PROVENANCE_DIR, args['dataset'],\n '{}-{}.zip'.format(args['dataset'], args['hash_value']))\n if not os.path.exists(path_to_archive):\n print('The committed file does not exist.')\n engine = install_committed(path_to_archive,\n engine,\n force=args.get('force', False))\n return engine\n script_list = SCRIPT_LIST()\n if not (script_list or os.listdir(SCRIPT_WRITE_PATH)):\n check_for_updates()\n script_list = SCRIPT_LIST()\n data_sets_scripts = name_matches(script_list, args['dataset'])\n if data_sets_scripts:\n for data_sets_script in data_sets_scripts:\n print(\"=> Installing\", data_sets_script.name)\n try:\n if engine.name == \"HDF5\":\n sqlite_opts = {\n 'command': 'install',\n 'dataset': data_sets_script,\n 'engine': 'sqlite',\n 'file': (args[\"file\"].split(\".\"))[0] + \".db\",\n 'table_name': args[\"table_name\"],\n 'data_dir': args[\"data_dir\"]\n }\n sqlite_engine = choose_engine(sqlite_opts)\n data_sets_script.download(sqlite_engine, debug=debug)\n data_sets_script.engine.final_cleanup()\n engine.script_table_registry = OrderedDict()\n data_sets_script.download(engine, debug=debug)\n data_sets_script.engine.final_cleanup()\n except Exception as e:\n print(e)\n if debug:\n raise\n else:\n message = \"Run retriever.datasets() to list the currently available \" \\\n \"datasets.\"\n raise ValueError(message)\n return engine\n\n\ndef install_csv(dataset,\n table_name='{db}_{table}.csv',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into csv.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'csv',\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_mysql(dataset,\n user='root',\n password='',\n host='localhost',\n port=3306,\n database_name='{db}',\n table_name='{db}.{table}',\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into mysql.\"\"\"\n args = {\n 'command': 'install',\n 'database_name': database_name,\n 'engine': 'mysql',\n 'dataset': dataset,\n 'host': host,\n 'port': port,\n 'password': password,\n 'table_name': table_name,\n 'user': user,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_postgres(dataset,\n user='postgres',\n password='',\n host='localhost',\n port=5432,\n database='postgres',\n database_name='{db}',\n table_name='{db}.{table}',\n bbox=[],\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into postgres.\"\"\"\n args = {\n 'command': 'install',\n 'database': database,\n 'database_name': database_name,\n 'engine': 'postgres',\n 'dataset': dataset,\n 'host': host,\n 'port': port,\n 'password': password,\n 'table_name': table_name,\n 'user': user,\n 'bbox': bbox,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_sqlite(dataset,\n file='sqlite.db',\n table_name='{db}_{table}',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into sqlite.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'sqlite',\n 'file': file,\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_msaccess(dataset,\n file='access.mdb',\n table_name='[{db} {table}]',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into msaccess.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'msaccess',\n 'file': file,\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_json(dataset,\n table_name='{db}_{table}.json',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n pretty=False,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into json.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'json',\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'pretty': pretty,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_xml(dataset,\n table_name='{db}_{table}.xml',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into xml.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'xml',\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_hdf5(dataset,\n file='hdf5.h5',\n table_name='{db}_{table}',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n hash_value=None):\n \"\"\"Install datasets into hdf5.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'hdf5',\n 'file': file,\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n", "path": "retriever/lib/install.py"}], "after_files": [{"content": "import os\nfrom collections import OrderedDict\n\nfrom retriever.engines import choose_engine\nfrom retriever.lib.defaults import DATA_DIR, SCRIPT_WRITE_PATH, PROVENANCE_DIR\nfrom retriever.lib.scripts import SCRIPT_LIST, name_matches\nfrom retriever.lib.repository import check_for_updates\nfrom retriever.lib.provenance import install_committed\n\n\ndef _install(args, use_cache, debug):\n \"\"\"Install datasets for retriever.\"\"\"\n engine = choose_engine(args)\n engine.use_cache = use_cache\n\n if args['dataset'].endswith('.zip') or args.get('hash_value'):\n path_to_archive = args['dataset']\n if args.get('hash_value'):\n path_to_archive = os.path.join(\n PROVENANCE_DIR, args['dataset'],\n '{}-{}.zip'.format(args['dataset'], args['hash_value']))\n if not os.path.exists(path_to_archive):\n print('The committed file does not exist.')\n engine = install_committed(path_to_archive,\n engine,\n force=args.get('force', False))\n return engine\n script_list = SCRIPT_LIST()\n if not (script_list or os.listdir(SCRIPT_WRITE_PATH)):\n check_for_updates()\n script_list = SCRIPT_LIST()\n data_sets_scripts = name_matches(script_list, args['dataset'])\n if data_sets_scripts:\n for data_sets_script in data_sets_scripts:\n print(\"=> Installing\", data_sets_script.name)\n try:\n if engine.name == \"HDF5\":\n sqlite_opts = {\n 'command': 'install',\n 'dataset': data_sets_script,\n 'engine': 'sqlite',\n 'file': (args[\"file\"].split(\".\"))[0] + \".db\",\n 'table_name': args[\"table_name\"],\n 'data_dir': args[\"data_dir\"]\n }\n sqlite_engine = choose_engine(sqlite_opts)\n data_sets_script.download(sqlite_engine, debug=debug)\n data_sets_script.engine.final_cleanup()\n engine.script_table_registry = OrderedDict()\n data_sets_script.download(engine, debug=debug)\n data_sets_script.engine.final_cleanup()\n except Exception as e:\n print(e)\n if debug:\n raise\n else:\n message = \"Run retriever.datasets() to list the currently available \" \\\n \"datasets.\"\n raise ValueError(message)\n return engine\n\n\ndef install_csv(dataset,\n table_name='{db}_{table}.csv',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into csv.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'csv',\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_mysql(dataset,\n user='root',\n password='',\n host='localhost',\n port=3306,\n database_name='{db}',\n table_name='{db}.{table}',\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into mysql.\"\"\"\n args = {\n 'command': 'install',\n 'database_name': database_name,\n 'engine': 'mysql',\n 'dataset': dataset,\n 'host': host,\n 'port': port,\n 'password': password,\n 'table_name': table_name,\n 'user': user,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_postgres(dataset,\n user='postgres',\n password='',\n host='localhost',\n port=5432,\n database='postgres',\n database_name='{db}',\n table_name='{db}.{table}',\n bbox=[],\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into postgres.\"\"\"\n args = {\n 'command': 'install',\n 'database': database,\n 'database_name': database_name,\n 'engine': 'postgres',\n 'dataset': dataset,\n 'host': host,\n 'port': port,\n 'password': password,\n 'table_name': table_name,\n 'user': user,\n 'bbox': bbox,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_sqlite(dataset,\n file='sqlite.db',\n table_name='{db}_{table}',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into sqlite.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'sqlite',\n 'file': file,\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_msaccess(dataset,\n file='access.mdb',\n table_name='[{db} {table}]',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into msaccess.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'msaccess',\n 'file': file,\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_json(dataset,\n table_name='{db}_{table}.json',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n pretty=False,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into json.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'json',\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'pretty': pretty,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_xml(dataset,\n table_name='{db}_{table}.xml',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n force=False,\n hash_value=None):\n \"\"\"Install datasets into xml.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'xml',\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'force': force,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n\n\ndef install_hdf5(dataset,\n file='hdf5.h5',\n table_name='{db}_{table}',\n data_dir=DATA_DIR,\n debug=False,\n use_cache=True,\n hash_value=None):\n \"\"\"Install datasets into hdf5.\"\"\"\n args = {\n 'command': 'install',\n 'dataset': dataset,\n 'engine': 'hdf5',\n 'file': file,\n 'table_name': table_name,\n 'data_dir': data_dir,\n 'hash_value': hash_value\n }\n return _install(args, use_cache, debug)\n", "path": "retriever/lib/install.py"}]}
| 2,520 | 161 |
gh_patches_debug_18365
|
rasdani/github-patches
|
git_diff
|
aws__aws-cli-3139
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adding new profile should add newline before
Have multiple IAM users configured in `~/.aws/credentials`
Added IAM user as follows:
`aws configure --profile NEW_PROFILE_NAME`
Completed sucessfully as expected.
However, next step of running a command resulted in error:
```
PS C:\WINDOWS\system32> aws --profile NEW_PROFILE_NAME s3 ls
Unable to locate credentials. You can configure credentials by running "aws configure".
```
Checking `~/.aws/credentials` file showed new creds were appended to file without newline as follows:
```
[OLD_PROFILE_NAME]
aws_access_key_id = AAAAAAAAAAAAAAAAAAAA
aws_secret_access_key = KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK
region=XX-east-X
toolkit_artifact_guid=11111111-1111-1111-1111-111111111111[NEW_PROFILE_NAME]
aws_access_key_id = BBBBBBBBBBBBBBBBBBBB
aws_secret_access_key = JJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJ
```
IMHO this is easily fixable by adding a newline echo before the new creds
CLI version: `aws-cli/1.12.2 Python/2.7.14 Windows/10 botocore/1.8.2`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awscli/customizations/configure/writer.py`
Content:
```
1 # Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"). You
4 # may not use this file except in compliance with the License. A copy of
5 # the License is located at
6 #
7 # http://aws.amazon.com/apache2.0/
8 #
9 # or in the "license" file accompanying this file. This file is
10 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific
12 # language governing permissions and limitations under the License.
13 import os
14 import re
15
16 from . import SectionNotFoundError
17
18
19 class ConfigFileWriter(object):
20 SECTION_REGEX = re.compile(r'^\s*\[(?P<header>[^]]+)\]')
21 OPTION_REGEX = re.compile(
22 r'(?P<option>[^:=][^:=]*)'
23 r'\s*(?P<vi>[:=])\s*'
24 r'(?P<value>.*)$'
25 )
26
27 def update_config(self, new_values, config_filename):
28 """Update config file with new values.
29
30 This method will update a section in a config file with
31 new key value pairs.
32
33 This method provides a few conveniences:
34
35 * If the ``config_filename`` does not exist, it will
36 be created. Any parent directories will also be created
37 if necessary.
38 * If the section to update does not exist, it will be created.
39 * Any existing lines that are specified by ``new_values``
40 **will not be touched**. This ensures that commented out
41 values are left unaltered.
42
43 :type new_values: dict
44 :param new_values: The values to update. There is a special
45 key ``__section__``, that specifies what section in the INI
46 file to update. If this key is not present, then the
47 ``default`` section will be updated with the new values.
48
49 :type config_filename: str
50 :param config_filename: The config filename where values will be
51 written.
52
53 """
54 section_name = new_values.pop('__section__', 'default')
55 if not os.path.isfile(config_filename):
56 self._create_file(config_filename)
57 self._write_new_section(section_name, new_values, config_filename)
58 return
59 with open(config_filename, 'r') as f:
60 contents = f.readlines()
61 # We can only update a single section at a time so we first need
62 # to find the section in question
63 try:
64 self._update_section_contents(contents, section_name, new_values)
65 with open(config_filename, 'w') as f:
66 f.write(''.join(contents))
67 except SectionNotFoundError:
68 self._write_new_section(section_name, new_values, config_filename)
69
70 def _create_file(self, config_filename):
71 # Create the file as well as the parent dir if needed.
72 dirname = os.path.split(config_filename)[0]
73 if not os.path.isdir(dirname):
74 os.makedirs(dirname)
75 with os.fdopen(os.open(config_filename,
76 os.O_WRONLY | os.O_CREAT, 0o600), 'w'):
77 pass
78
79 def _write_new_section(self, section_name, new_values, config_filename):
80 with open(config_filename, 'a') as f:
81 f.write('[%s]\n' % section_name)
82 contents = []
83 self._insert_new_values(line_number=0,
84 contents=contents,
85 new_values=new_values)
86 f.write(''.join(contents))
87
88 def _find_section_start(self, contents, section_name):
89 for i in range(len(contents)):
90 line = contents[i]
91 if line.strip().startswith(('#', ';')):
92 # This is a comment, so we can safely ignore this line.
93 continue
94 match = self.SECTION_REGEX.search(line)
95 if match is not None and self._matches_section(match,
96 section_name):
97 return i
98 raise SectionNotFoundError(section_name)
99
100 def _update_section_contents(self, contents, section_name, new_values):
101 # First, find the line where the section_name is defined.
102 # This will be the value of i.
103 new_values = new_values.copy()
104 # ``contents`` is a list of file line contents.
105 section_start_line_num = self._find_section_start(contents,
106 section_name)
107 # If we get here, then we've found the section. We now need
108 # to figure out if we're updating a value or adding a new value.
109 # There's 2 cases. Either we're setting a normal scalar value
110 # of, we're setting a nested value.
111 last_matching_line = section_start_line_num
112 j = last_matching_line + 1
113 while j < len(contents):
114 line = contents[j]
115 if self.SECTION_REGEX.search(line) is not None:
116 # We've hit a new section which means the config key is
117 # not in the section. We need to add it here.
118 self._insert_new_values(line_number=last_matching_line,
119 contents=contents,
120 new_values=new_values)
121 return
122 match = self.OPTION_REGEX.search(line)
123 if match is not None:
124 last_matching_line = j
125 key_name = match.group(1).strip()
126 if key_name in new_values:
127 # We've found the line that defines the option name.
128 # if the value is not a dict, then we can write the line
129 # out now.
130 if not isinstance(new_values[key_name], dict):
131 option_value = new_values[key_name]
132 new_line = '%s = %s\n' % (key_name, option_value)
133 contents[j] = new_line
134 del new_values[key_name]
135 else:
136 j = self._update_subattributes(
137 j, contents, new_values[key_name],
138 len(match.group(1)) - len(match.group(1).lstrip()))
139 return
140 j += 1
141
142 if new_values:
143 if not contents[-1].endswith('\n'):
144 contents.append('\n')
145 self._insert_new_values(line_number=last_matching_line + 1,
146 contents=contents,
147 new_values=new_values)
148
149 def _update_subattributes(self, index, contents, values, starting_indent):
150 index += 1
151 for i in range(index, len(contents)):
152 line = contents[i]
153 match = self.OPTION_REGEX.search(line)
154 if match is not None:
155 current_indent = len(
156 match.group(1)) - len(match.group(1).lstrip())
157 key_name = match.group(1).strip()
158 if key_name in values:
159 option_value = values[key_name]
160 new_line = '%s%s = %s\n' % (' ' * current_indent,
161 key_name, option_value)
162 contents[i] = new_line
163 del values[key_name]
164 if starting_indent == current_indent or \
165 self.SECTION_REGEX.search(line) is not None:
166 # We've arrived at the starting indent level so we can just
167 # write out all the values now.
168 self._insert_new_values(i - 1, contents, values, ' ')
169 break
170 else:
171 if starting_indent != current_indent:
172 # The option is the last option in the file
173 self._insert_new_values(i, contents, values, ' ')
174 return i
175
176 def _insert_new_values(self, line_number, contents, new_values, indent=''):
177 new_contents = []
178 for key, value in list(new_values.items()):
179 if isinstance(value, dict):
180 subindent = indent + ' '
181 new_contents.append('%s%s =\n' % (indent, key))
182 for subkey, subval in list(value.items()):
183 new_contents.append('%s%s = %s\n' % (subindent, subkey,
184 subval))
185 else:
186 new_contents.append('%s%s = %s\n' % (indent, key, value))
187 del new_values[key]
188 contents.insert(line_number + 1, ''.join(new_contents))
189
190 def _matches_section(self, match, section_name):
191 parts = section_name.split(' ')
192 unquoted_match = match.group(0) == '[%s]' % section_name
193 if len(parts) > 1:
194 quoted_match = match.group(0) == '[%s "%s"]' % (
195 parts[0], ' '.join(parts[1:]))
196 return unquoted_match or quoted_match
197 return unquoted_match
198
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awscli/customizations/configure/writer.py b/awscli/customizations/configure/writer.py
--- a/awscli/customizations/configure/writer.py
+++ b/awscli/customizations/configure/writer.py
@@ -76,8 +76,22 @@
os.O_WRONLY | os.O_CREAT, 0o600), 'w'):
pass
+ def _check_file_needs_newline(self, filename):
+ # check if the last byte is a newline
+ with open(filename, 'rb') as f:
+ # check if the file is empty
+ f.seek(0, os.SEEK_END)
+ if not f.tell():
+ return False
+ f.seek(-1, os.SEEK_END)
+ last = f.read()
+ return last != b'\n'
+
def _write_new_section(self, section_name, new_values, config_filename):
+ needs_newline = self._check_file_needs_newline(config_filename)
with open(config_filename, 'a') as f:
+ if needs_newline:
+ f.write('\n')
f.write('[%s]\n' % section_name)
contents = []
self._insert_new_values(line_number=0,
|
{"golden_diff": "diff --git a/awscli/customizations/configure/writer.py b/awscli/customizations/configure/writer.py\n--- a/awscli/customizations/configure/writer.py\n+++ b/awscli/customizations/configure/writer.py\n@@ -76,8 +76,22 @@\n os.O_WRONLY | os.O_CREAT, 0o600), 'w'):\n pass\n \n+ def _check_file_needs_newline(self, filename):\n+ # check if the last byte is a newline\n+ with open(filename, 'rb') as f:\n+ # check if the file is empty\n+ f.seek(0, os.SEEK_END)\n+ if not f.tell():\n+ return False\n+ f.seek(-1, os.SEEK_END)\n+ last = f.read()\n+ return last != b'\\n'\n+\n def _write_new_section(self, section_name, new_values, config_filename):\n+ needs_newline = self._check_file_needs_newline(config_filename)\n with open(config_filename, 'a') as f:\n+ if needs_newline:\n+ f.write('\\n')\n f.write('[%s]\\n' % section_name)\n contents = []\n self._insert_new_values(line_number=0,\n", "issue": "Adding new profile should add newline before\nHave multiple IAM users configured in `~/.aws/credentials`\r\n\r\nAdded IAM user as follows:\r\n`aws configure --profile NEW_PROFILE_NAME`\r\nCompleted sucessfully as expected.\r\n\r\nHowever, next step of running a command resulted in error: \r\n```\r\nPS C:\\WINDOWS\\system32> aws --profile NEW_PROFILE_NAME s3 ls\r\nUnable to locate credentials. You can configure credentials by running \"aws configure\".\r\n```\r\nChecking `~/.aws/credentials` file showed new creds were appended to file without newline as follows:\r\n```\r\n[OLD_PROFILE_NAME]\r\naws_access_key_id = AAAAAAAAAAAAAAAAAAAA\r\naws_secret_access_key = KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK\r\nregion=XX-east-X\r\ntoolkit_artifact_guid=11111111-1111-1111-1111-111111111111[NEW_PROFILE_NAME]\r\naws_access_key_id = BBBBBBBBBBBBBBBBBBBB\r\naws_secret_access_key = JJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJ\r\n```\r\n\r\nIMHO this is easily fixable by adding a newline echo before the new creds\r\n\r\nCLI version: `aws-cli/1.12.2 Python/2.7.14 Windows/10 botocore/1.8.2`\n", "before_files": [{"content": "# Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nimport os\nimport re\n\nfrom . import SectionNotFoundError\n\n\nclass ConfigFileWriter(object):\n SECTION_REGEX = re.compile(r'^\\s*\\[(?P<header>[^]]+)\\]')\n OPTION_REGEX = re.compile(\n r'(?P<option>[^:=][^:=]*)'\n r'\\s*(?P<vi>[:=])\\s*'\n r'(?P<value>.*)$'\n )\n\n def update_config(self, new_values, config_filename):\n \"\"\"Update config file with new values.\n\n This method will update a section in a config file with\n new key value pairs.\n\n This method provides a few conveniences:\n\n * If the ``config_filename`` does not exist, it will\n be created. Any parent directories will also be created\n if necessary.\n * If the section to update does not exist, it will be created.\n * Any existing lines that are specified by ``new_values``\n **will not be touched**. This ensures that commented out\n values are left unaltered.\n\n :type new_values: dict\n :param new_values: The values to update. There is a special\n key ``__section__``, that specifies what section in the INI\n file to update. If this key is not present, then the\n ``default`` section will be updated with the new values.\n\n :type config_filename: str\n :param config_filename: The config filename where values will be\n written.\n\n \"\"\"\n section_name = new_values.pop('__section__', 'default')\n if not os.path.isfile(config_filename):\n self._create_file(config_filename)\n self._write_new_section(section_name, new_values, config_filename)\n return\n with open(config_filename, 'r') as f:\n contents = f.readlines()\n # We can only update a single section at a time so we first need\n # to find the section in question\n try:\n self._update_section_contents(contents, section_name, new_values)\n with open(config_filename, 'w') as f:\n f.write(''.join(contents))\n except SectionNotFoundError:\n self._write_new_section(section_name, new_values, config_filename)\n\n def _create_file(self, config_filename):\n # Create the file as well as the parent dir if needed.\n dirname = os.path.split(config_filename)[0]\n if not os.path.isdir(dirname):\n os.makedirs(dirname)\n with os.fdopen(os.open(config_filename,\n os.O_WRONLY | os.O_CREAT, 0o600), 'w'):\n pass\n\n def _write_new_section(self, section_name, new_values, config_filename):\n with open(config_filename, 'a') as f:\n f.write('[%s]\\n' % section_name)\n contents = []\n self._insert_new_values(line_number=0,\n contents=contents,\n new_values=new_values)\n f.write(''.join(contents))\n\n def _find_section_start(self, contents, section_name):\n for i in range(len(contents)):\n line = contents[i]\n if line.strip().startswith(('#', ';')):\n # This is a comment, so we can safely ignore this line.\n continue\n match = self.SECTION_REGEX.search(line)\n if match is not None and self._matches_section(match,\n section_name):\n return i\n raise SectionNotFoundError(section_name)\n\n def _update_section_contents(self, contents, section_name, new_values):\n # First, find the line where the section_name is defined.\n # This will be the value of i.\n new_values = new_values.copy()\n # ``contents`` is a list of file line contents.\n section_start_line_num = self._find_section_start(contents,\n section_name)\n # If we get here, then we've found the section. We now need\n # to figure out if we're updating a value or adding a new value.\n # There's 2 cases. Either we're setting a normal scalar value\n # of, we're setting a nested value.\n last_matching_line = section_start_line_num\n j = last_matching_line + 1\n while j < len(contents):\n line = contents[j]\n if self.SECTION_REGEX.search(line) is not None:\n # We've hit a new section which means the config key is\n # not in the section. We need to add it here.\n self._insert_new_values(line_number=last_matching_line,\n contents=contents,\n new_values=new_values)\n return\n match = self.OPTION_REGEX.search(line)\n if match is not None:\n last_matching_line = j\n key_name = match.group(1).strip()\n if key_name in new_values:\n # We've found the line that defines the option name.\n # if the value is not a dict, then we can write the line\n # out now.\n if not isinstance(new_values[key_name], dict):\n option_value = new_values[key_name]\n new_line = '%s = %s\\n' % (key_name, option_value)\n contents[j] = new_line\n del new_values[key_name]\n else:\n j = self._update_subattributes(\n j, contents, new_values[key_name],\n len(match.group(1)) - len(match.group(1).lstrip()))\n return\n j += 1\n\n if new_values:\n if not contents[-1].endswith('\\n'):\n contents.append('\\n')\n self._insert_new_values(line_number=last_matching_line + 1,\n contents=contents,\n new_values=new_values)\n\n def _update_subattributes(self, index, contents, values, starting_indent):\n index += 1\n for i in range(index, len(contents)):\n line = contents[i]\n match = self.OPTION_REGEX.search(line)\n if match is not None:\n current_indent = len(\n match.group(1)) - len(match.group(1).lstrip())\n key_name = match.group(1).strip()\n if key_name in values:\n option_value = values[key_name]\n new_line = '%s%s = %s\\n' % (' ' * current_indent,\n key_name, option_value)\n contents[i] = new_line\n del values[key_name]\n if starting_indent == current_indent or \\\n self.SECTION_REGEX.search(line) is not None:\n # We've arrived at the starting indent level so we can just\n # write out all the values now.\n self._insert_new_values(i - 1, contents, values, ' ')\n break\n else:\n if starting_indent != current_indent:\n # The option is the last option in the file\n self._insert_new_values(i, contents, values, ' ')\n return i\n\n def _insert_new_values(self, line_number, contents, new_values, indent=''):\n new_contents = []\n for key, value in list(new_values.items()):\n if isinstance(value, dict):\n subindent = indent + ' '\n new_contents.append('%s%s =\\n' % (indent, key))\n for subkey, subval in list(value.items()):\n new_contents.append('%s%s = %s\\n' % (subindent, subkey,\n subval))\n else:\n new_contents.append('%s%s = %s\\n' % (indent, key, value))\n del new_values[key]\n contents.insert(line_number + 1, ''.join(new_contents))\n\n def _matches_section(self, match, section_name):\n parts = section_name.split(' ')\n unquoted_match = match.group(0) == '[%s]' % section_name\n if len(parts) > 1:\n quoted_match = match.group(0) == '[%s \"%s\"]' % (\n parts[0], ' '.join(parts[1:]))\n return unquoted_match or quoted_match\n return unquoted_match\n", "path": "awscli/customizations/configure/writer.py"}], "after_files": [{"content": "# Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nimport os\nimport re\n\nfrom . import SectionNotFoundError\n\n\nclass ConfigFileWriter(object):\n SECTION_REGEX = re.compile(r'^\\s*\\[(?P<header>[^]]+)\\]')\n OPTION_REGEX = re.compile(\n r'(?P<option>[^:=][^:=]*)'\n r'\\s*(?P<vi>[:=])\\s*'\n r'(?P<value>.*)$'\n )\n\n def update_config(self, new_values, config_filename):\n \"\"\"Update config file with new values.\n\n This method will update a section in a config file with\n new key value pairs.\n\n This method provides a few conveniences:\n\n * If the ``config_filename`` does not exist, it will\n be created. Any parent directories will also be created\n if necessary.\n * If the section to update does not exist, it will be created.\n * Any existing lines that are specified by ``new_values``\n **will not be touched**. This ensures that commented out\n values are left unaltered.\n\n :type new_values: dict\n :param new_values: The values to update. There is a special\n key ``__section__``, that specifies what section in the INI\n file to update. If this key is not present, then the\n ``default`` section will be updated with the new values.\n\n :type config_filename: str\n :param config_filename: The config filename where values will be\n written.\n\n \"\"\"\n section_name = new_values.pop('__section__', 'default')\n if not os.path.isfile(config_filename):\n self._create_file(config_filename)\n self._write_new_section(section_name, new_values, config_filename)\n return\n with open(config_filename, 'r') as f:\n contents = f.readlines()\n # We can only update a single section at a time so we first need\n # to find the section in question\n try:\n self._update_section_contents(contents, section_name, new_values)\n with open(config_filename, 'w') as f:\n f.write(''.join(contents))\n except SectionNotFoundError:\n self._write_new_section(section_name, new_values, config_filename)\n\n def _create_file(self, config_filename):\n # Create the file as well as the parent dir if needed.\n dirname = os.path.split(config_filename)[0]\n if not os.path.isdir(dirname):\n os.makedirs(dirname)\n with os.fdopen(os.open(config_filename,\n os.O_WRONLY | os.O_CREAT, 0o600), 'w'):\n pass\n\n def _check_file_needs_newline(self, filename):\n # check if the last byte is a newline\n with open(filename, 'rb') as f:\n # check if the file is empty\n f.seek(0, os.SEEK_END)\n if not f.tell():\n return False\n f.seek(-1, os.SEEK_END)\n last = f.read()\n return last != b'\\n'\n\n def _write_new_section(self, section_name, new_values, config_filename):\n needs_newline = self._check_file_needs_newline(config_filename)\n with open(config_filename, 'a') as f:\n if needs_newline:\n f.write('\\n')\n f.write('[%s]\\n' % section_name)\n contents = []\n self._insert_new_values(line_number=0,\n contents=contents,\n new_values=new_values)\n f.write(''.join(contents))\n\n def _find_section_start(self, contents, section_name):\n for i in range(len(contents)):\n line = contents[i]\n if line.strip().startswith(('#', ';')):\n # This is a comment, so we can safely ignore this line.\n continue\n match = self.SECTION_REGEX.search(line)\n if match is not None and self._matches_section(match,\n section_name):\n return i\n raise SectionNotFoundError(section_name)\n\n def _update_section_contents(self, contents, section_name, new_values):\n # First, find the line where the section_name is defined.\n # This will be the value of i.\n new_values = new_values.copy()\n # ``contents`` is a list of file line contents.\n section_start_line_num = self._find_section_start(contents,\n section_name)\n # If we get here, then we've found the section. We now need\n # to figure out if we're updating a value or adding a new value.\n # There's 2 cases. Either we're setting a normal scalar value\n # of, we're setting a nested value.\n last_matching_line = section_start_line_num\n j = last_matching_line + 1\n while j < len(contents):\n line = contents[j]\n if self.SECTION_REGEX.search(line) is not None:\n # We've hit a new section which means the config key is\n # not in the section. We need to add it here.\n self._insert_new_values(line_number=last_matching_line,\n contents=contents,\n new_values=new_values)\n return\n match = self.OPTION_REGEX.search(line)\n if match is not None:\n last_matching_line = j\n key_name = match.group(1).strip()\n if key_name in new_values:\n # We've found the line that defines the option name.\n # if the value is not a dict, then we can write the line\n # out now.\n if not isinstance(new_values[key_name], dict):\n option_value = new_values[key_name]\n new_line = '%s = %s\\n' % (key_name, option_value)\n contents[j] = new_line\n del new_values[key_name]\n else:\n j = self._update_subattributes(\n j, contents, new_values[key_name],\n len(match.group(1)) - len(match.group(1).lstrip()))\n return\n j += 1\n\n if new_values:\n if not contents[-1].endswith('\\n'):\n contents.append('\\n')\n self._insert_new_values(line_number=last_matching_line + 1,\n contents=contents,\n new_values=new_values)\n\n def _update_subattributes(self, index, contents, values, starting_indent):\n index += 1\n for i in range(index, len(contents)):\n line = contents[i]\n match = self.OPTION_REGEX.search(line)\n if match is not None:\n current_indent = len(\n match.group(1)) - len(match.group(1).lstrip())\n key_name = match.group(1).strip()\n if key_name in values:\n option_value = values[key_name]\n new_line = '%s%s = %s\\n' % (' ' * current_indent,\n key_name, option_value)\n contents[i] = new_line\n del values[key_name]\n if starting_indent == current_indent or \\\n self.SECTION_REGEX.search(line) is not None:\n # We've arrived at the starting indent level so we can just\n # write out all the values now.\n self._insert_new_values(i - 1, contents, values, ' ')\n break\n else:\n if starting_indent != current_indent:\n # The option is the last option in the file\n self._insert_new_values(i, contents, values, ' ')\n return i\n\n def _insert_new_values(self, line_number, contents, new_values, indent=''):\n new_contents = []\n for key, value in list(new_values.items()):\n if isinstance(value, dict):\n subindent = indent + ' '\n new_contents.append('%s%s =\\n' % (indent, key))\n for subkey, subval in list(value.items()):\n new_contents.append('%s%s = %s\\n' % (subindent, subkey,\n subval))\n else:\n new_contents.append('%s%s = %s\\n' % (indent, key, value))\n del new_values[key]\n contents.insert(line_number + 1, ''.join(new_contents))\n\n def _matches_section(self, match, section_name):\n parts = section_name.split(' ')\n unquoted_match = match.group(0) == '[%s]' % section_name\n if len(parts) > 1:\n quoted_match = match.group(0) == '[%s \"%s\"]' % (\n parts[0], ' '.join(parts[1:]))\n return unquoted_match or quoted_match\n return unquoted_match\n", "path": "awscli/customizations/configure/writer.py"}]}
| 2,896 | 272 |
gh_patches_debug_16928
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-2739
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Subscription example does not work - TypeError: get_context() missing 1 required positional argument: 'response'
## Describe the Bug
When trying to run the first subscription example from the [Documentation](https://strawberry.rocks/docs/general/subscriptions) the following error occurs as soon as the subscription is sent from GraphiQL:
```
Running strawberry on http://0.0.0.0:8000/graphql 🍓
[2023-04-30 17:58:55]: No operation name
subscription {
count(target: 5)
}
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/Users/user/Library/Python/3.9/lib/python/site-packages/uvicorn/protocols/websockets/websockets_impl.py", line 254, in run_asgi
result = await self.app(self.scope, self.asgi_receive, self.asgi_send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/uvicorn/middleware/proxy_headers.py", line 78, in __call__
return await self.app(scope, receive, send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/applications.py", line 122, in __call__
await self.middleware_stack(scope, receive, send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/errors.py", line 149, in __call__
await self.app(scope, receive, send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/cors.py", line 76, in __call__
await self.app(scope, receive, send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/exceptions.py", line 79, in __call__
raise exc
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/exceptions.py", line 68, in __call__
await self.app(scope, receive, sender)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/routing.py", line 718, in __call__
await route.handle(scope, receive, send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/routing.py", line 341, in handle
await self.app(scope, receive, send)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/asgi/__init__.py", line 118, in __call__
await self.graphql_transport_ws_handler_class(
File "/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py", line 78, in handle
return await self.handle_request()
File "/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/asgi/handlers/graphql_transport_ws_handler.py", line 58, in handle_request
await self.handle_message(message)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py", line 125, in handle_message
await handler(handler_arg)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py", line 181, in handle_subscribe
context = await self.get_context()
File "/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/asgi/handlers/graphql_transport_ws_handler.py", line 36, in get_context
return await self._get_context(request=self._ws)
TypeError: get_context() missing 1 required positional argument: 'response'
ERROR: closing handshake failed
Traceback (most recent call last):
File "/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/server.py", line 248, in handler
await self.close()
File "/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py", line 766, in close
await self.write_close_frame(Close(code, reason))
File "/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py", line 1232, in write_close_frame
await self.write_frame(True, OP_CLOSE, data, _state=State.CLOSING)
File "/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py", line 1205, in write_frame
await self.drain()
File "/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py", line 1194, in drain
await self.ensure_open()
File "/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py", line 935, in ensure_open
raise self.connection_closed_exc()
websockets.exceptions.ConnectionClosedError: sent 1000 (OK); no close frame received
```
## System Information
- Operating system: `macOS 13.2 (MacBook Pro M2 Chip - ARM64)`
- Strawberry version (if applicable): `0.175.0`, also tested: `0.173.1`
## Additional Context
- Start command: `python3 -m strawberry server app`
- Python version: `3.9.0`
<!-- POLAR PLEDGE BADGE START -->
## Upvote & Fund
- We're using [Polar.sh](https://polar.sh/strawberry-graphql) so you can upvote and help fund this issue.
- We receive the funding once the issue is completed & confirmed by you.
- Thank you in advance for helping prioritize & fund our backlog.
<a href="https://polar.sh/strawberry-graphql/strawberry/issues/2738">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2738/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2738/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/asgi/handlers/graphql_ws_handler.py`
Content:
```
1 from __future__ import annotations
2
3 from contextlib import suppress
4 from typing import TYPE_CHECKING, Any, Optional
5
6 from starlette.websockets import WebSocketDisconnect, WebSocketState
7
8 from strawberry.subscriptions import GRAPHQL_WS_PROTOCOL
9 from strawberry.subscriptions.protocols.graphql_ws.handlers import BaseGraphQLWSHandler
10
11 if TYPE_CHECKING:
12 from starlette.websockets import WebSocket
13
14 from strawberry.schema import BaseSchema
15 from strawberry.subscriptions.protocols.graphql_ws.types import OperationMessage
16
17
18 class GraphQLWSHandler(BaseGraphQLWSHandler):
19 def __init__(
20 self,
21 schema: BaseSchema,
22 debug: bool,
23 keep_alive: bool,
24 keep_alive_interval: float,
25 get_context,
26 get_root_value,
27 ws: WebSocket,
28 ):
29 super().__init__(schema, debug, keep_alive, keep_alive_interval)
30 self._get_context = get_context
31 self._get_root_value = get_root_value
32 self._ws = ws
33
34 async def get_context(self) -> Any:
35 return await self._get_context(request=self._ws)
36
37 async def get_root_value(self) -> Any:
38 return await self._get_root_value(request=self._ws)
39
40 async def send_json(self, data: OperationMessage) -> None:
41 await self._ws.send_json(data)
42
43 async def close(self, code: int = 1000, reason: Optional[str] = None) -> None:
44 await self._ws.close(code=code, reason=reason)
45
46 async def handle_request(self) -> Any:
47 await self._ws.accept(subprotocol=GRAPHQL_WS_PROTOCOL)
48
49 try:
50 while self._ws.application_state != WebSocketState.DISCONNECTED:
51 try:
52 message = await self._ws.receive_json()
53 except KeyError:
54 # Ignore non-text messages
55 continue
56 else:
57 await self.handle_message(message)
58 except WebSocketDisconnect: # pragma: no cover
59 pass
60 finally:
61 if self.keep_alive_task:
62 self.keep_alive_task.cancel()
63 with suppress(BaseException):
64 await self.keep_alive_task
65
66 for operation_id in list(self.subscriptions.keys()):
67 await self.cleanup_operation(operation_id)
68
```
Path: `strawberry/asgi/handlers/graphql_transport_ws_handler.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Any
4
5 from starlette.websockets import WebSocketDisconnect, WebSocketState
6
7 from strawberry.subscriptions import GRAPHQL_TRANSPORT_WS_PROTOCOL
8 from strawberry.subscriptions.protocols.graphql_transport_ws.handlers import (
9 BaseGraphQLTransportWSHandler,
10 )
11
12 if TYPE_CHECKING:
13 from datetime import timedelta
14
15 from starlette.websockets import WebSocket
16
17 from strawberry.schema import BaseSchema
18
19
20 class GraphQLTransportWSHandler(BaseGraphQLTransportWSHandler):
21 def __init__(
22 self,
23 schema: BaseSchema,
24 debug: bool,
25 connection_init_wait_timeout: timedelta,
26 get_context,
27 get_root_value,
28 ws: WebSocket,
29 ):
30 super().__init__(schema, debug, connection_init_wait_timeout)
31 self._get_context = get_context
32 self._get_root_value = get_root_value
33 self._ws = ws
34
35 async def get_context(self) -> Any:
36 return await self._get_context(request=self._ws)
37
38 async def get_root_value(self) -> Any:
39 return await self._get_root_value(request=self._ws)
40
41 async def send_json(self, data: dict) -> None:
42 await self._ws.send_json(data)
43
44 async def close(self, code: int, reason: str) -> None:
45 await self._ws.close(code=code, reason=reason)
46
47 async def handle_request(self) -> None:
48 await self._ws.accept(subprotocol=GRAPHQL_TRANSPORT_WS_PROTOCOL)
49
50 try:
51 while self._ws.application_state != WebSocketState.DISCONNECTED:
52 try:
53 message = await self._ws.receive_json()
54 except KeyError:
55 error_message = "WebSocket message type must be text"
56 await self.handle_invalid_message(error_message)
57 else:
58 await self.handle_message(message)
59 except WebSocketDisconnect: # pragma: no cover
60 pass
61 finally:
62 for operation_id in list(self.subscriptions.keys()):
63 await self.cleanup_operation(operation_id)
64 await self.reap_completed_tasks()
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/asgi/handlers/graphql_transport_ws_handler.py b/strawberry/asgi/handlers/graphql_transport_ws_handler.py
--- a/strawberry/asgi/handlers/graphql_transport_ws_handler.py
+++ b/strawberry/asgi/handlers/graphql_transport_ws_handler.py
@@ -33,7 +33,7 @@
self._ws = ws
async def get_context(self) -> Any:
- return await self._get_context(request=self._ws)
+ return await self._get_context(request=self._ws, response=None)
async def get_root_value(self) -> Any:
return await self._get_root_value(request=self._ws)
diff --git a/strawberry/asgi/handlers/graphql_ws_handler.py b/strawberry/asgi/handlers/graphql_ws_handler.py
--- a/strawberry/asgi/handlers/graphql_ws_handler.py
+++ b/strawberry/asgi/handlers/graphql_ws_handler.py
@@ -32,7 +32,7 @@
self._ws = ws
async def get_context(self) -> Any:
- return await self._get_context(request=self._ws)
+ return await self._get_context(request=self._ws, response=None)
async def get_root_value(self) -> Any:
return await self._get_root_value(request=self._ws)
|
{"golden_diff": "diff --git a/strawberry/asgi/handlers/graphql_transport_ws_handler.py b/strawberry/asgi/handlers/graphql_transport_ws_handler.py\n--- a/strawberry/asgi/handlers/graphql_transport_ws_handler.py\n+++ b/strawberry/asgi/handlers/graphql_transport_ws_handler.py\n@@ -33,7 +33,7 @@\n self._ws = ws\n \n async def get_context(self) -> Any:\n- return await self._get_context(request=self._ws)\n+ return await self._get_context(request=self._ws, response=None)\n \n async def get_root_value(self) -> Any:\n return await self._get_root_value(request=self._ws)\ndiff --git a/strawberry/asgi/handlers/graphql_ws_handler.py b/strawberry/asgi/handlers/graphql_ws_handler.py\n--- a/strawberry/asgi/handlers/graphql_ws_handler.py\n+++ b/strawberry/asgi/handlers/graphql_ws_handler.py\n@@ -32,7 +32,7 @@\n self._ws = ws\n \n async def get_context(self) -> Any:\n- return await self._get_context(request=self._ws)\n+ return await self._get_context(request=self._ws, response=None)\n \n async def get_root_value(self) -> Any:\n return await self._get_root_value(request=self._ws)\n", "issue": "Subscription example does not work - TypeError: get_context() missing 1 required positional argument: 'response'\n## Describe the Bug\r\n\r\nWhen trying to run the first subscription example from the [Documentation](https://strawberry.rocks/docs/general/subscriptions) the following error occurs as soon as the subscription is sent from GraphiQL:\r\n\r\n```\r\nRunning strawberry on http://0.0.0.0:8000/graphql \ud83c\udf53\r\n[2023-04-30 17:58:55]: No operation name\r\nsubscription {\r\n count(target: 5)\r\n}\r\n\r\nERROR: Exception in ASGI application\r\nTraceback (most recent call last):\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/uvicorn/protocols/websockets/websockets_impl.py\", line 254, in run_asgi\r\n result = await self.app(self.scope, self.asgi_receive, self.asgi_send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/uvicorn/middleware/proxy_headers.py\", line 78, in __call__\r\n return await self.app(scope, receive, send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/applications.py\", line 122, in __call__\r\n await self.middleware_stack(scope, receive, send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/errors.py\", line 149, in __call__\r\n await self.app(scope, receive, send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/cors.py\", line 76, in __call__\r\n await self.app(scope, receive, send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/exceptions.py\", line 79, in __call__\r\n raise exc\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/middleware/exceptions.py\", line 68, in __call__\r\n await self.app(scope, receive, sender)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/routing.py\", line 718, in __call__\r\n await route.handle(scope, receive, send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/starlette/routing.py\", line 341, in handle\r\n await self.app(scope, receive, send)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/asgi/__init__.py\", line 118, in __call__\r\n await self.graphql_transport_ws_handler_class(\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py\", line 78, in handle\r\n return await self.handle_request()\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/asgi/handlers/graphql_transport_ws_handler.py\", line 58, in handle_request\r\n await self.handle_message(message)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py\", line 125, in handle_message\r\n await handler(handler_arg)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py\", line 181, in handle_subscribe\r\n context = await self.get_context()\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/strawberry/asgi/handlers/graphql_transport_ws_handler.py\", line 36, in get_context\r\n return await self._get_context(request=self._ws)\r\nTypeError: get_context() missing 1 required positional argument: 'response'\r\nERROR: closing handshake failed\r\nTraceback (most recent call last):\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/server.py\", line 248, in handler\r\n await self.close()\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py\", line 766, in close\r\n await self.write_close_frame(Close(code, reason))\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py\", line 1232, in write_close_frame\r\n await self.write_frame(True, OP_CLOSE, data, _state=State.CLOSING)\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py\", line 1205, in write_frame\r\n await self.drain()\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py\", line 1194, in drain\r\n await self.ensure_open()\r\n File \"/Users/user/Library/Python/3.9/lib/python/site-packages/websockets/legacy/protocol.py\", line 935, in ensure_open\r\n raise self.connection_closed_exc()\r\nwebsockets.exceptions.ConnectionClosedError: sent 1000 (OK); no close frame received\r\n```\r\n\r\n## System Information\r\n\r\n - Operating system: `macOS 13.2 (MacBook Pro M2 Chip - ARM64)`\r\n - Strawberry version (if applicable): `0.175.0`, also tested: `0.173.1`\r\n\r\n## Additional Context\r\n\r\n- Start command: `python3 -m strawberry server app`\r\n- Python version: `3.9.0`\n\n<!-- POLAR PLEDGE BADGE START -->\n## Upvote & Fund\n\n- We're using [Polar.sh](https://polar.sh/strawberry-graphql) so you can upvote and help fund this issue.\n- We receive the funding once the issue is completed & confirmed by you.\n- Thank you in advance for helping prioritize & fund our backlog.\n\n<a href=\"https://polar.sh/strawberry-graphql/strawberry/issues/2738\">\n<picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2738/pledge.svg?darkmode=1\">\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/strawberry-graphql/strawberry/issues/2738/pledge.svg\">\n</picture>\n</a>\n<!-- POLAR PLEDGE BADGE END -->\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom contextlib import suppress\nfrom typing import TYPE_CHECKING, Any, Optional\n\nfrom starlette.websockets import WebSocketDisconnect, WebSocketState\n\nfrom strawberry.subscriptions import GRAPHQL_WS_PROTOCOL\nfrom strawberry.subscriptions.protocols.graphql_ws.handlers import BaseGraphQLWSHandler\n\nif TYPE_CHECKING:\n from starlette.websockets import WebSocket\n\n from strawberry.schema import BaseSchema\n from strawberry.subscriptions.protocols.graphql_ws.types import OperationMessage\n\n\nclass GraphQLWSHandler(BaseGraphQLWSHandler):\n def __init__(\n self,\n schema: BaseSchema,\n debug: bool,\n keep_alive: bool,\n keep_alive_interval: float,\n get_context,\n get_root_value,\n ws: WebSocket,\n ):\n super().__init__(schema, debug, keep_alive, keep_alive_interval)\n self._get_context = get_context\n self._get_root_value = get_root_value\n self._ws = ws\n\n async def get_context(self) -> Any:\n return await self._get_context(request=self._ws)\n\n async def get_root_value(self) -> Any:\n return await self._get_root_value(request=self._ws)\n\n async def send_json(self, data: OperationMessage) -> None:\n await self._ws.send_json(data)\n\n async def close(self, code: int = 1000, reason: Optional[str] = None) -> None:\n await self._ws.close(code=code, reason=reason)\n\n async def handle_request(self) -> Any:\n await self._ws.accept(subprotocol=GRAPHQL_WS_PROTOCOL)\n\n try:\n while self._ws.application_state != WebSocketState.DISCONNECTED:\n try:\n message = await self._ws.receive_json()\n except KeyError:\n # Ignore non-text messages\n continue\n else:\n await self.handle_message(message)\n except WebSocketDisconnect: # pragma: no cover\n pass\n finally:\n if self.keep_alive_task:\n self.keep_alive_task.cancel()\n with suppress(BaseException):\n await self.keep_alive_task\n\n for operation_id in list(self.subscriptions.keys()):\n await self.cleanup_operation(operation_id)\n", "path": "strawberry/asgi/handlers/graphql_ws_handler.py"}, {"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any\n\nfrom starlette.websockets import WebSocketDisconnect, WebSocketState\n\nfrom strawberry.subscriptions import GRAPHQL_TRANSPORT_WS_PROTOCOL\nfrom strawberry.subscriptions.protocols.graphql_transport_ws.handlers import (\n BaseGraphQLTransportWSHandler,\n)\n\nif TYPE_CHECKING:\n from datetime import timedelta\n\n from starlette.websockets import WebSocket\n\n from strawberry.schema import BaseSchema\n\n\nclass GraphQLTransportWSHandler(BaseGraphQLTransportWSHandler):\n def __init__(\n self,\n schema: BaseSchema,\n debug: bool,\n connection_init_wait_timeout: timedelta,\n get_context,\n get_root_value,\n ws: WebSocket,\n ):\n super().__init__(schema, debug, connection_init_wait_timeout)\n self._get_context = get_context\n self._get_root_value = get_root_value\n self._ws = ws\n\n async def get_context(self) -> Any:\n return await self._get_context(request=self._ws)\n\n async def get_root_value(self) -> Any:\n return await self._get_root_value(request=self._ws)\n\n async def send_json(self, data: dict) -> None:\n await self._ws.send_json(data)\n\n async def close(self, code: int, reason: str) -> None:\n await self._ws.close(code=code, reason=reason)\n\n async def handle_request(self) -> None:\n await self._ws.accept(subprotocol=GRAPHQL_TRANSPORT_WS_PROTOCOL)\n\n try:\n while self._ws.application_state != WebSocketState.DISCONNECTED:\n try:\n message = await self._ws.receive_json()\n except KeyError:\n error_message = \"WebSocket message type must be text\"\n await self.handle_invalid_message(error_message)\n else:\n await self.handle_message(message)\n except WebSocketDisconnect: # pragma: no cover\n pass\n finally:\n for operation_id in list(self.subscriptions.keys()):\n await self.cleanup_operation(operation_id)\n await self.reap_completed_tasks()\n", "path": "strawberry/asgi/handlers/graphql_transport_ws_handler.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom contextlib import suppress\nfrom typing import TYPE_CHECKING, Any, Optional\n\nfrom starlette.websockets import WebSocketDisconnect, WebSocketState\n\nfrom strawberry.subscriptions import GRAPHQL_WS_PROTOCOL\nfrom strawberry.subscriptions.protocols.graphql_ws.handlers import BaseGraphQLWSHandler\n\nif TYPE_CHECKING:\n from starlette.websockets import WebSocket\n\n from strawberry.schema import BaseSchema\n from strawberry.subscriptions.protocols.graphql_ws.types import OperationMessage\n\n\nclass GraphQLWSHandler(BaseGraphQLWSHandler):\n def __init__(\n self,\n schema: BaseSchema,\n debug: bool,\n keep_alive: bool,\n keep_alive_interval: float,\n get_context,\n get_root_value,\n ws: WebSocket,\n ):\n super().__init__(schema, debug, keep_alive, keep_alive_interval)\n self._get_context = get_context\n self._get_root_value = get_root_value\n self._ws = ws\n\n async def get_context(self) -> Any:\n return await self._get_context(request=self._ws, response=None)\n\n async def get_root_value(self) -> Any:\n return await self._get_root_value(request=self._ws)\n\n async def send_json(self, data: OperationMessage) -> None:\n await self._ws.send_json(data)\n\n async def close(self, code: int = 1000, reason: Optional[str] = None) -> None:\n await self._ws.close(code=code, reason=reason)\n\n async def handle_request(self) -> Any:\n await self._ws.accept(subprotocol=GRAPHQL_WS_PROTOCOL)\n\n try:\n while self._ws.application_state != WebSocketState.DISCONNECTED:\n try:\n message = await self._ws.receive_json()\n except KeyError:\n # Ignore non-text messages\n continue\n else:\n await self.handle_message(message)\n except WebSocketDisconnect: # pragma: no cover\n pass\n finally:\n if self.keep_alive_task:\n self.keep_alive_task.cancel()\n with suppress(BaseException):\n await self.keep_alive_task\n\n for operation_id in list(self.subscriptions.keys()):\n await self.cleanup_operation(operation_id)\n", "path": "strawberry/asgi/handlers/graphql_ws_handler.py"}, {"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any\n\nfrom starlette.websockets import WebSocketDisconnect, WebSocketState\n\nfrom strawberry.subscriptions import GRAPHQL_TRANSPORT_WS_PROTOCOL\nfrom strawberry.subscriptions.protocols.graphql_transport_ws.handlers import (\n BaseGraphQLTransportWSHandler,\n)\n\nif TYPE_CHECKING:\n from datetime import timedelta\n\n from starlette.websockets import WebSocket\n\n from strawberry.schema import BaseSchema\n\n\nclass GraphQLTransportWSHandler(BaseGraphQLTransportWSHandler):\n def __init__(\n self,\n schema: BaseSchema,\n debug: bool,\n connection_init_wait_timeout: timedelta,\n get_context,\n get_root_value,\n ws: WebSocket,\n ):\n super().__init__(schema, debug, connection_init_wait_timeout)\n self._get_context = get_context\n self._get_root_value = get_root_value\n self._ws = ws\n\n async def get_context(self) -> Any:\n return await self._get_context(request=self._ws, response=None)\n\n async def get_root_value(self) -> Any:\n return await self._get_root_value(request=self._ws)\n\n async def send_json(self, data: dict) -> None:\n await self._ws.send_json(data)\n\n async def close(self, code: int, reason: str) -> None:\n await self._ws.close(code=code, reason=reason)\n\n async def handle_request(self) -> None:\n await self._ws.accept(subprotocol=GRAPHQL_TRANSPORT_WS_PROTOCOL)\n\n try:\n while self._ws.application_state != WebSocketState.DISCONNECTED:\n try:\n message = await self._ws.receive_json()\n except KeyError:\n error_message = \"WebSocket message type must be text\"\n await self.handle_invalid_message(error_message)\n else:\n await self.handle_message(message)\n except WebSocketDisconnect: # pragma: no cover\n pass\n finally:\n for operation_id in list(self.subscriptions.keys()):\n await self.cleanup_operation(operation_id)\n await self.reap_completed_tasks()\n", "path": "strawberry/asgi/handlers/graphql_transport_ws_handler.py"}]}
| 2,868 | 298 |
gh_patches_debug_28782
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-1024
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pyramid app frozen with py2exe fails because of Chameleon imports
If I freeze a Pyramid application with py2exe and try to run it, it fails during the startup, with the following traceback:
```
Traceback (most recent call last):
File "web_server.py", line 2, in <module>
File "pyramid\config\__init__.pyc", line 66, in <module>
File "pyramid\config\rendering.pyc", line 11, in <module>
File "pyramid\chameleon_text.pyc", line 3, in <module>
File "chameleon\__init__.pyc", line 1, in <module>
File "chameleon\zpt\template.pyc", line 10, in <module>
File "chameleon\tales.pyc", line 19, in <module>
File "chameleon\compiler.pyc", line 145, in <module>
File "chameleon\codegen.pyc", line 93, in template
File "inspect.pyc", line 701, in getsource
File "inspect.pyc", line 690, in getsourcelines
File "inspect.pyc", line 538, in findsource
IOError: could not get source code
```
My application doesn't use Chameleon, but the Pyramid modules still import it, which ultimately causes the .exe to fail to run.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyramid/chameleon_zpt.py`
Content:
```
1 from zope.interface import implementer
2
3 from chameleon.zpt.template import PageTemplateFile
4
5 from pyramid.interfaces import ITemplateRenderer
6 from pyramid.decorator import reify
7 from pyramid import renderers
8
9 def renderer_factory(info):
10 return renderers.template_renderer_factory(info, ZPTTemplateRenderer)
11
12 @implementer(ITemplateRenderer)
13 class ZPTTemplateRenderer(object):
14 def __init__(self, path, lookup, macro=None):
15 self.path = path
16 self.lookup = lookup
17 self.macro = macro
18
19 @reify # avoid looking up reload_templates before manager pushed
20 def template(self):
21 tf = PageTemplateFile(
22 self.path,
23 auto_reload=self.lookup.auto_reload,
24 debug=self.lookup.debug,
25 translate=self.lookup.translate
26 )
27 if self.macro:
28 # render only the portion of the template included in a
29 # define-macro named the value of self.macro
30 macro_renderer = tf.macros[self.macro].include
31 tf._render = macro_renderer
32 return tf
33
34 def implementation(self):
35 return self.template
36
37 def __call__(self, value, system):
38 try:
39 system.update(value)
40 except (TypeError, ValueError):
41 raise ValueError('renderer was passed non-dictionary as value')
42 result = self.template(**system)
43 return result
44
45
```
Path: `pyramid/chameleon_text.py`
Content:
```
1 from zope.interface import implementer
2
3 from chameleon.zpt.template import PageTextTemplateFile
4
5 from pyramid.interfaces import ITemplateRenderer
6
7 from pyramid.decorator import reify
8 from pyramid import renderers
9
10 def renderer_factory(info):
11 return renderers.template_renderer_factory(info, TextTemplateRenderer)
12
13 @implementer(ITemplateRenderer)
14 class TextTemplateRenderer(object):
15 def __init__(self, path, lookup, macro=None):
16 self.path = path
17 self.lookup = lookup
18 # text template renderers have no macros, so we ignore the
19 # macro arg
20
21 @reify # avoid looking up reload_templates before manager pushed
22 def template(self):
23 return PageTextTemplateFile(self.path,
24 auto_reload=self.lookup.auto_reload,
25 debug=self.lookup.debug,
26 translate=self.lookup.translate)
27
28 def implementation(self):
29 return self.template
30
31 def __call__(self, value, system):
32 try:
33 system.update(value)
34 except (TypeError, ValueError):
35 raise ValueError('renderer was passed non-dictionary as value')
36 result = self.template(**system)
37 return result
38
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyramid/chameleon_text.py b/pyramid/chameleon_text.py
--- a/pyramid/chameleon_text.py
+++ b/pyramid/chameleon_text.py
@@ -1,7 +1,5 @@
from zope.interface import implementer
-from chameleon.zpt.template import PageTextTemplateFile
-
from pyramid.interfaces import ITemplateRenderer
from pyramid.decorator import reify
@@ -20,6 +18,7 @@
@reify # avoid looking up reload_templates before manager pushed
def template(self):
+ from chameleon.zpt.template import PageTextTemplateFile
return PageTextTemplateFile(self.path,
auto_reload=self.lookup.auto_reload,
debug=self.lookup.debug,
diff --git a/pyramid/chameleon_zpt.py b/pyramid/chameleon_zpt.py
--- a/pyramid/chameleon_zpt.py
+++ b/pyramid/chameleon_zpt.py
@@ -1,7 +1,5 @@
from zope.interface import implementer
-from chameleon.zpt.template import PageTemplateFile
-
from pyramid.interfaces import ITemplateRenderer
from pyramid.decorator import reify
from pyramid import renderers
@@ -18,6 +16,7 @@
@reify # avoid looking up reload_templates before manager pushed
def template(self):
+ from chameleon.zpt.template import PageTemplateFile
tf = PageTemplateFile(
self.path,
auto_reload=self.lookup.auto_reload,
|
{"golden_diff": "diff --git a/pyramid/chameleon_text.py b/pyramid/chameleon_text.py\n--- a/pyramid/chameleon_text.py\n+++ b/pyramid/chameleon_text.py\n@@ -1,7 +1,5 @@\n from zope.interface import implementer\n \n-from chameleon.zpt.template import PageTextTemplateFile\n-\n from pyramid.interfaces import ITemplateRenderer\n \n from pyramid.decorator import reify\n@@ -20,6 +18,7 @@\n \n @reify # avoid looking up reload_templates before manager pushed\n def template(self):\n+ from chameleon.zpt.template import PageTextTemplateFile\n return PageTextTemplateFile(self.path,\n auto_reload=self.lookup.auto_reload,\n debug=self.lookup.debug,\ndiff --git a/pyramid/chameleon_zpt.py b/pyramid/chameleon_zpt.py\n--- a/pyramid/chameleon_zpt.py\n+++ b/pyramid/chameleon_zpt.py\n@@ -1,7 +1,5 @@\n from zope.interface import implementer\n \n-from chameleon.zpt.template import PageTemplateFile\n-\n from pyramid.interfaces import ITemplateRenderer\n from pyramid.decorator import reify\n from pyramid import renderers\n@@ -18,6 +16,7 @@\n \n @reify # avoid looking up reload_templates before manager pushed\n def template(self):\n+ from chameleon.zpt.template import PageTemplateFile\n tf = PageTemplateFile(\n self.path,\n auto_reload=self.lookup.auto_reload,\n", "issue": "Pyramid app frozen with py2exe fails because of Chameleon imports\nIf I freeze a Pyramid application with py2exe and try to run it, it fails during the startup, with the following traceback:\n\n```\nTraceback (most recent call last):\n File \"web_server.py\", line 2, in <module>\n File \"pyramid\\config\\__init__.pyc\", line 66, in <module>\n File \"pyramid\\config\\rendering.pyc\", line 11, in <module>\n File \"pyramid\\chameleon_text.pyc\", line 3, in <module>\n File \"chameleon\\__init__.pyc\", line 1, in <module>\n File \"chameleon\\zpt\\template.pyc\", line 10, in <module>\n File \"chameleon\\tales.pyc\", line 19, in <module>\n File \"chameleon\\compiler.pyc\", line 145, in <module>\n File \"chameleon\\codegen.pyc\", line 93, in template\n File \"inspect.pyc\", line 701, in getsource\n File \"inspect.pyc\", line 690, in getsourcelines\n File \"inspect.pyc\", line 538, in findsource\nIOError: could not get source code\n```\n\nMy application doesn't use Chameleon, but the Pyramid modules still import it, which ultimately causes the .exe to fail to run.\n\n", "before_files": [{"content": "from zope.interface import implementer\n\nfrom chameleon.zpt.template import PageTemplateFile\n\nfrom pyramid.interfaces import ITemplateRenderer\nfrom pyramid.decorator import reify\nfrom pyramid import renderers\n\ndef renderer_factory(info):\n return renderers.template_renderer_factory(info, ZPTTemplateRenderer)\n\n@implementer(ITemplateRenderer)\nclass ZPTTemplateRenderer(object):\n def __init__(self, path, lookup, macro=None):\n self.path = path\n self.lookup = lookup\n self.macro = macro\n\n @reify # avoid looking up reload_templates before manager pushed\n def template(self):\n tf = PageTemplateFile(\n self.path,\n auto_reload=self.lookup.auto_reload,\n debug=self.lookup.debug,\n translate=self.lookup.translate\n )\n if self.macro:\n # render only the portion of the template included in a\n # define-macro named the value of self.macro\n macro_renderer = tf.macros[self.macro].include\n tf._render = macro_renderer\n return tf\n\n def implementation(self):\n return self.template\n \n def __call__(self, value, system):\n try:\n system.update(value)\n except (TypeError, ValueError):\n raise ValueError('renderer was passed non-dictionary as value')\n result = self.template(**system)\n return result\n\n", "path": "pyramid/chameleon_zpt.py"}, {"content": "from zope.interface import implementer\n\nfrom chameleon.zpt.template import PageTextTemplateFile\n\nfrom pyramid.interfaces import ITemplateRenderer\n\nfrom pyramid.decorator import reify\nfrom pyramid import renderers\n\ndef renderer_factory(info):\n return renderers.template_renderer_factory(info, TextTemplateRenderer)\n\n@implementer(ITemplateRenderer)\nclass TextTemplateRenderer(object):\n def __init__(self, path, lookup, macro=None):\n self.path = path\n self.lookup = lookup\n # text template renderers have no macros, so we ignore the\n # macro arg\n\n @reify # avoid looking up reload_templates before manager pushed\n def template(self):\n return PageTextTemplateFile(self.path,\n auto_reload=self.lookup.auto_reload,\n debug=self.lookup.debug,\n translate=self.lookup.translate)\n\n def implementation(self):\n return self.template\n \n def __call__(self, value, system):\n try:\n system.update(value)\n except (TypeError, ValueError):\n raise ValueError('renderer was passed non-dictionary as value')\n result = self.template(**system)\n return result\n\n", "path": "pyramid/chameleon_text.py"}], "after_files": [{"content": "from zope.interface import implementer\n\nfrom pyramid.interfaces import ITemplateRenderer\nfrom pyramid.decorator import reify\nfrom pyramid import renderers\n\ndef renderer_factory(info):\n return renderers.template_renderer_factory(info, ZPTTemplateRenderer)\n\n@implementer(ITemplateRenderer)\nclass ZPTTemplateRenderer(object):\n def __init__(self, path, lookup, macro=None):\n self.path = path\n self.lookup = lookup\n self.macro = macro\n\n @reify # avoid looking up reload_templates before manager pushed\n def template(self):\n from chameleon.zpt.template import PageTemplateFile\n tf = PageTemplateFile(\n self.path,\n auto_reload=self.lookup.auto_reload,\n debug=self.lookup.debug,\n translate=self.lookup.translate\n )\n if self.macro:\n # render only the portion of the template included in a\n # define-macro named the value of self.macro\n macro_renderer = tf.macros[self.macro].include\n tf._render = macro_renderer\n return tf\n\n def implementation(self):\n return self.template\n \n def __call__(self, value, system):\n try:\n system.update(value)\n except (TypeError, ValueError):\n raise ValueError('renderer was passed non-dictionary as value')\n result = self.template(**system)\n return result\n\n", "path": "pyramid/chameleon_zpt.py"}, {"content": "from zope.interface import implementer\n\nfrom pyramid.interfaces import ITemplateRenderer\n\nfrom pyramid.decorator import reify\nfrom pyramid import renderers\n\ndef renderer_factory(info):\n return renderers.template_renderer_factory(info, TextTemplateRenderer)\n\n@implementer(ITemplateRenderer)\nclass TextTemplateRenderer(object):\n def __init__(self, path, lookup, macro=None):\n self.path = path\n self.lookup = lookup\n # text template renderers have no macros, so we ignore the\n # macro arg\n\n @reify # avoid looking up reload_templates before manager pushed\n def template(self):\n from chameleon.zpt.template import PageTextTemplateFile\n return PageTextTemplateFile(self.path,\n auto_reload=self.lookup.auto_reload,\n debug=self.lookup.debug,\n translate=self.lookup.translate)\n\n def implementation(self):\n return self.template\n \n def __call__(self, value, system):\n try:\n system.update(value)\n except (TypeError, ValueError):\n raise ValueError('renderer was passed non-dictionary as value')\n result = self.template(**system)\n return result\n\n", "path": "pyramid/chameleon_text.py"}]}
| 1,273 | 308 |
gh_patches_debug_26639
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-2441
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How to handle statistics
I like statistics in my rasters since they load nicely into various GIS software that I use, which includes ArcGIS. Without statistics (or the correct statistics) the rasters don't look correct in these software.
Up to now, I generally need the help of osgeo.gdal to add/update band statistics after rasterio processing, e.g.:
``` python
ds = gdal.Open(fname, gdal.GA_Update)
for i in range(ds.RasterCount):
ds.GetRasterBand(i + 1).ComputeStatistics(0)
ds = band = None # save, close
```
How could this be done with rasterio? A few ideas:
- Have optional arguments for updatable rasters with `rasterio.open()`, e.g. `stats=True` or `approx_stats=True`, which are used when processing `close()`.
- Add a method like `obj.calc_stats(approx=False)`, which can be manually called while the raster dataset is open. Should it return the four statistics that [ComputeStatistics](http://www.gdal.org/classGDALRasterBand.html#a48883c1dae195b21b37b51b10e910f9b) returns? Note that this data are also available through the metadata tags.
- Start a `rio edit [--stats] [--approx_stats]` tool, similar [to this enhancement to gdal_edit.py](http://trac.osgeo.org/gdal/ticket/5805).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rasterio/rio/info.py`
Content:
```
1 """Command access to dataset metadata, stats, and more."""
2
3
4 import json
5
6 import click
7
8 import rasterio
9 from rasterio.rio import options
10 from rasterio.transform import from_gcps
11
12
13 @click.command(short_help="Print information about a data file.")
14 @options.file_in_arg
15 @click.option('--meta', 'aspect', flag_value='meta', default=True,
16 help="Show data file structure (default).")
17 @click.option('--tags', 'aspect', flag_value='tags',
18 help="Show data file tags.")
19 @click.option('--namespace', help="Select a tag namespace.")
20 @click.option('--indent', default=None, type=int,
21 help="Indentation level for pretty printed output")
22 # Options to pick out a single metadata item and print it as
23 # a string.
24 @click.option('--count', 'meta_member', flag_value='count',
25 help="Print the count of bands.")
26 @click.option('-t', '--dtype', 'meta_member', flag_value='dtype',
27 help="Print the dtype name.")
28 @click.option('--nodata', 'meta_member', flag_value='nodata',
29 help="Print the nodata value.")
30 @click.option('-f', '--format', '--driver', 'meta_member', flag_value='driver',
31 help="Print the format driver.")
32 @click.option('--shape', 'meta_member', flag_value='shape',
33 help="Print the (height, width) shape.")
34 @click.option('--height', 'meta_member', flag_value='height',
35 help="Print the height (number of rows).")
36 @click.option('--width', 'meta_member', flag_value='width',
37 help="Print the width (number of columns).")
38 @click.option('--crs', 'meta_member', flag_value='crs',
39 help="Print the CRS as a PROJ.4 string.")
40 @click.option('--bounds', 'meta_member', flag_value='bounds',
41 help="Print the boundary coordinates "
42 "(left, bottom, right, top).")
43 @click.option('-r', '--res', 'meta_member', flag_value='res',
44 help="Print pixel width and height.")
45 @click.option('--lnglat', 'meta_member', flag_value='lnglat',
46 help="Print longitude and latitude at center.")
47 @click.option('--stats', 'meta_member', flag_value='stats',
48 help="Print statistics (min, max, mean) of a single band "
49 "(use --bidx).")
50 @click.option('--checksum', 'meta_member', flag_value='checksum',
51 help="Print integer checksum of a single band "
52 "(use --bidx).")
53 @click.option('--subdatasets', 'meta_member', flag_value='subdatasets',
54 help="Print subdataset identifiers.")
55 @click.option('-v', '--tell-me-more', '--verbose', 'verbose', is_flag=True,
56 help="Output extra information.")
57 @options.bidx_opt
58 @options.masked_opt
59 @click.pass_context
60 def info(ctx, input, aspect, indent, namespace, meta_member, verbose, bidx,
61 masked):
62 """Print metadata about the dataset as JSON.
63
64 Optionally print a single metadata item as a string.
65 """
66 with ctx.obj['env'], rasterio.open(input) as src:
67
68 info = dict(src.profile)
69 info['shape'] = (info['height'], info['width'])
70 info['bounds'] = src.bounds
71
72 if src.crs:
73 epsg = src.crs.to_epsg()
74 if epsg:
75 info['crs'] = 'EPSG:{}'.format(epsg)
76 else:
77 info['crs'] = src.crs.to_string()
78 else:
79 info['crs'] = None
80
81 info['res'] = src.res
82 info['colorinterp'] = [ci.name for ci in src.colorinterp]
83 info['units'] = [units or None for units in src.units]
84 info['descriptions'] = src.descriptions
85 info['indexes'] = src.indexes
86 info['mask_flags'] = [[
87 flag.name for flag in flags] for flags in src.mask_flag_enums]
88
89 if src.crs:
90 info['lnglat'] = src.lnglat()
91
92 gcps, gcps_crs = src.gcps
93
94 if gcps:
95 info['gcps'] = {'points': [p.asdict() for p in gcps]}
96 if gcps_crs:
97 epsg = gcps_crs.to_epsg()
98 if epsg:
99 info['gcps']['crs'] = 'EPSG:{}'.format(epsg)
100 else:
101 info['gcps']['crs'] = src.crs.to_string()
102 else:
103 info['gcps']['crs'] = None
104
105 info['gcps']['transform'] = from_gcps(gcps)
106
107 if verbose:
108 stats = [{'min': float(b.min()),
109 'max': float(b.max()),
110 'mean': float(b.mean())
111 } for b in src.read(masked=masked)]
112 info['stats'] = stats
113 info['checksum'] = [src.checksum(i) for i in src.indexes]
114
115 if aspect == 'meta':
116 if meta_member == 'subdatasets':
117 for name in src.subdatasets:
118 click.echo(name)
119 elif meta_member == 'stats':
120 band = src.read(bidx, masked=masked)
121 click.echo('%f %f %f' % (
122 float(band.min()),
123 float(band.max()),
124 float(band.mean())))
125 elif meta_member == 'checksum':
126 click.echo(str(src.checksum(bidx)))
127 elif meta_member:
128 if isinstance(info[meta_member], (list, tuple)):
129 click.echo(" ".join(map(str, info[meta_member])))
130 else:
131 click.echo(info[meta_member])
132 else:
133 click.echo(json.dumps(info, sort_keys=True, indent=indent))
134
135 elif aspect == 'tags':
136 click.echo(
137 json.dumps(src.tags(ns=namespace), indent=indent))
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rasterio/rio/info.py b/rasterio/rio/info.py
--- a/rasterio/rio/info.py
+++ b/rasterio/rio/info.py
@@ -3,6 +3,7 @@
import json
+from attr import asdict
import click
import rasterio
@@ -105,10 +106,7 @@
info['gcps']['transform'] = from_gcps(gcps)
if verbose:
- stats = [{'min': float(b.min()),
- 'max': float(b.max()),
- 'mean': float(b.mean())
- } for b in src.read(masked=masked)]
+ stats = [asdict(src.statistics(bidx)) for bidx in src.indexes]
info['stats'] = stats
info['checksum'] = [src.checksum(i) for i in src.indexes]
@@ -117,11 +115,8 @@
for name in src.subdatasets:
click.echo(name)
elif meta_member == 'stats':
- band = src.read(bidx, masked=masked)
- click.echo('%f %f %f' % (
- float(band.min()),
- float(band.max()),
- float(band.mean())))
+ st = src.statistics(bidx)
+ click.echo("{st.min} {st.max} {st.mean} {st.std}".format(st=st))
elif meta_member == 'checksum':
click.echo(str(src.checksum(bidx)))
elif meta_member:
|
{"golden_diff": "diff --git a/rasterio/rio/info.py b/rasterio/rio/info.py\n--- a/rasterio/rio/info.py\n+++ b/rasterio/rio/info.py\n@@ -3,6 +3,7 @@\n \n import json\n \n+from attr import asdict\n import click\n \n import rasterio\n@@ -105,10 +106,7 @@\n info['gcps']['transform'] = from_gcps(gcps)\n \n if verbose:\n- stats = [{'min': float(b.min()),\n- 'max': float(b.max()),\n- 'mean': float(b.mean())\n- } for b in src.read(masked=masked)]\n+ stats = [asdict(src.statistics(bidx)) for bidx in src.indexes]\n info['stats'] = stats\n info['checksum'] = [src.checksum(i) for i in src.indexes]\n \n@@ -117,11 +115,8 @@\n for name in src.subdatasets:\n click.echo(name)\n elif meta_member == 'stats':\n- band = src.read(bidx, masked=masked)\n- click.echo('%f %f %f' % (\n- float(band.min()),\n- float(band.max()),\n- float(band.mean())))\n+ st = src.statistics(bidx)\n+ click.echo(\"{st.min} {st.max} {st.mean} {st.std}\".format(st=st))\n elif meta_member == 'checksum':\n click.echo(str(src.checksum(bidx)))\n elif meta_member:\n", "issue": "How to handle statistics\nI like statistics in my rasters since they load nicely into various GIS software that I use, which includes ArcGIS. Without statistics (or the correct statistics) the rasters don't look correct in these software.\n\nUp to now, I generally need the help of osgeo.gdal to add/update band statistics after rasterio processing, e.g.:\n\n``` python\nds = gdal.Open(fname, gdal.GA_Update)\nfor i in range(ds.RasterCount):\n ds.GetRasterBand(i + 1).ComputeStatistics(0)\nds = band = None # save, close\n```\n\nHow could this be done with rasterio? A few ideas:\n- Have optional arguments for updatable rasters with `rasterio.open()`, e.g. `stats=True` or `approx_stats=True`, which are used when processing `close()`.\n- Add a method like `obj.calc_stats(approx=False)`, which can be manually called while the raster dataset is open. Should it return the four statistics that [ComputeStatistics](http://www.gdal.org/classGDALRasterBand.html#a48883c1dae195b21b37b51b10e910f9b) returns? Note that this data are also available through the metadata tags.\n- Start a `rio edit [--stats] [--approx_stats]` tool, similar [to this enhancement to gdal_edit.py](http://trac.osgeo.org/gdal/ticket/5805).\n\n", "before_files": [{"content": "\"\"\"Command access to dataset metadata, stats, and more.\"\"\"\n\n\nimport json\n\nimport click\n\nimport rasterio\nfrom rasterio.rio import options\nfrom rasterio.transform import from_gcps\n\n\[email protected](short_help=\"Print information about a data file.\")\[email protected]_in_arg\[email protected]('--meta', 'aspect', flag_value='meta', default=True,\n help=\"Show data file structure (default).\")\[email protected]('--tags', 'aspect', flag_value='tags',\n help=\"Show data file tags.\")\[email protected]('--namespace', help=\"Select a tag namespace.\")\[email protected]('--indent', default=None, type=int,\n help=\"Indentation level for pretty printed output\")\n# Options to pick out a single metadata item and print it as\n# a string.\[email protected]('--count', 'meta_member', flag_value='count',\n help=\"Print the count of bands.\")\[email protected]('-t', '--dtype', 'meta_member', flag_value='dtype',\n help=\"Print the dtype name.\")\[email protected]('--nodata', 'meta_member', flag_value='nodata',\n help=\"Print the nodata value.\")\[email protected]('-f', '--format', '--driver', 'meta_member', flag_value='driver',\n help=\"Print the format driver.\")\[email protected]('--shape', 'meta_member', flag_value='shape',\n help=\"Print the (height, width) shape.\")\[email protected]('--height', 'meta_member', flag_value='height',\n help=\"Print the height (number of rows).\")\[email protected]('--width', 'meta_member', flag_value='width',\n help=\"Print the width (number of columns).\")\[email protected]('--crs', 'meta_member', flag_value='crs',\n help=\"Print the CRS as a PROJ.4 string.\")\[email protected]('--bounds', 'meta_member', flag_value='bounds',\n help=\"Print the boundary coordinates \"\n \"(left, bottom, right, top).\")\[email protected]('-r', '--res', 'meta_member', flag_value='res',\n help=\"Print pixel width and height.\")\[email protected]('--lnglat', 'meta_member', flag_value='lnglat',\n help=\"Print longitude and latitude at center.\")\[email protected]('--stats', 'meta_member', flag_value='stats',\n help=\"Print statistics (min, max, mean) of a single band \"\n \"(use --bidx).\")\[email protected]('--checksum', 'meta_member', flag_value='checksum',\n help=\"Print integer checksum of a single band \"\n \"(use --bidx).\")\[email protected]('--subdatasets', 'meta_member', flag_value='subdatasets',\n help=\"Print subdataset identifiers.\")\[email protected]('-v', '--tell-me-more', '--verbose', 'verbose', is_flag=True,\n help=\"Output extra information.\")\[email protected]_opt\[email protected]_opt\[email protected]_context\ndef info(ctx, input, aspect, indent, namespace, meta_member, verbose, bidx,\n masked):\n \"\"\"Print metadata about the dataset as JSON.\n\n Optionally print a single metadata item as a string.\n \"\"\"\n with ctx.obj['env'], rasterio.open(input) as src:\n\n info = dict(src.profile)\n info['shape'] = (info['height'], info['width'])\n info['bounds'] = src.bounds\n\n if src.crs:\n epsg = src.crs.to_epsg()\n if epsg:\n info['crs'] = 'EPSG:{}'.format(epsg)\n else:\n info['crs'] = src.crs.to_string()\n else:\n info['crs'] = None\n\n info['res'] = src.res\n info['colorinterp'] = [ci.name for ci in src.colorinterp]\n info['units'] = [units or None for units in src.units]\n info['descriptions'] = src.descriptions\n info['indexes'] = src.indexes\n info['mask_flags'] = [[\n flag.name for flag in flags] for flags in src.mask_flag_enums]\n\n if src.crs:\n info['lnglat'] = src.lnglat()\n\n gcps, gcps_crs = src.gcps\n\n if gcps:\n info['gcps'] = {'points': [p.asdict() for p in gcps]}\n if gcps_crs:\n epsg = gcps_crs.to_epsg()\n if epsg:\n info['gcps']['crs'] = 'EPSG:{}'.format(epsg)\n else:\n info['gcps']['crs'] = src.crs.to_string()\n else:\n info['gcps']['crs'] = None\n\n info['gcps']['transform'] = from_gcps(gcps)\n\n if verbose:\n stats = [{'min': float(b.min()),\n 'max': float(b.max()),\n 'mean': float(b.mean())\n } for b in src.read(masked=masked)]\n info['stats'] = stats\n info['checksum'] = [src.checksum(i) for i in src.indexes]\n\n if aspect == 'meta':\n if meta_member == 'subdatasets':\n for name in src.subdatasets:\n click.echo(name)\n elif meta_member == 'stats':\n band = src.read(bidx, masked=masked)\n click.echo('%f %f %f' % (\n float(band.min()),\n float(band.max()),\n float(band.mean())))\n elif meta_member == 'checksum':\n click.echo(str(src.checksum(bidx)))\n elif meta_member:\n if isinstance(info[meta_member], (list, tuple)):\n click.echo(\" \".join(map(str, info[meta_member])))\n else:\n click.echo(info[meta_member])\n else:\n click.echo(json.dumps(info, sort_keys=True, indent=indent))\n\n elif aspect == 'tags':\n click.echo(\n json.dumps(src.tags(ns=namespace), indent=indent))\n", "path": "rasterio/rio/info.py"}], "after_files": [{"content": "\"\"\"Command access to dataset metadata, stats, and more.\"\"\"\n\n\nimport json\n\nfrom attr import asdict\nimport click\n\nimport rasterio\nfrom rasterio.rio import options\nfrom rasterio.transform import from_gcps\n\n\[email protected](short_help=\"Print information about a data file.\")\[email protected]_in_arg\[email protected]('--meta', 'aspect', flag_value='meta', default=True,\n help=\"Show data file structure (default).\")\[email protected]('--tags', 'aspect', flag_value='tags',\n help=\"Show data file tags.\")\[email protected]('--namespace', help=\"Select a tag namespace.\")\[email protected]('--indent', default=None, type=int,\n help=\"Indentation level for pretty printed output\")\n# Options to pick out a single metadata item and print it as\n# a string.\[email protected]('--count', 'meta_member', flag_value='count',\n help=\"Print the count of bands.\")\[email protected]('-t', '--dtype', 'meta_member', flag_value='dtype',\n help=\"Print the dtype name.\")\[email protected]('--nodata', 'meta_member', flag_value='nodata',\n help=\"Print the nodata value.\")\[email protected]('-f', '--format', '--driver', 'meta_member', flag_value='driver',\n help=\"Print the format driver.\")\[email protected]('--shape', 'meta_member', flag_value='shape',\n help=\"Print the (height, width) shape.\")\[email protected]('--height', 'meta_member', flag_value='height',\n help=\"Print the height (number of rows).\")\[email protected]('--width', 'meta_member', flag_value='width',\n help=\"Print the width (number of columns).\")\[email protected]('--crs', 'meta_member', flag_value='crs',\n help=\"Print the CRS as a PROJ.4 string.\")\[email protected]('--bounds', 'meta_member', flag_value='bounds',\n help=\"Print the boundary coordinates \"\n \"(left, bottom, right, top).\")\[email protected]('-r', '--res', 'meta_member', flag_value='res',\n help=\"Print pixel width and height.\")\[email protected]('--lnglat', 'meta_member', flag_value='lnglat',\n help=\"Print longitude and latitude at center.\")\[email protected]('--stats', 'meta_member', flag_value='stats',\n help=\"Print statistics (min, max, mean) of a single band \"\n \"(use --bidx).\")\[email protected]('--checksum', 'meta_member', flag_value='checksum',\n help=\"Print integer checksum of a single band \"\n \"(use --bidx).\")\[email protected]('--subdatasets', 'meta_member', flag_value='subdatasets',\n help=\"Print subdataset identifiers.\")\[email protected]('-v', '--tell-me-more', '--verbose', 'verbose', is_flag=True,\n help=\"Output extra information.\")\[email protected]_opt\[email protected]_opt\[email protected]_context\ndef info(ctx, input, aspect, indent, namespace, meta_member, verbose, bidx,\n masked):\n \"\"\"Print metadata about the dataset as JSON.\n\n Optionally print a single metadata item as a string.\n \"\"\"\n with ctx.obj['env'], rasterio.open(input) as src:\n\n info = dict(src.profile)\n info['shape'] = (info['height'], info['width'])\n info['bounds'] = src.bounds\n\n if src.crs:\n epsg = src.crs.to_epsg()\n if epsg:\n info['crs'] = 'EPSG:{}'.format(epsg)\n else:\n info['crs'] = src.crs.to_string()\n else:\n info['crs'] = None\n\n info['res'] = src.res\n info['colorinterp'] = [ci.name for ci in src.colorinterp]\n info['units'] = [units or None for units in src.units]\n info['descriptions'] = src.descriptions\n info['indexes'] = src.indexes\n info['mask_flags'] = [[\n flag.name for flag in flags] for flags in src.mask_flag_enums]\n\n if src.crs:\n info['lnglat'] = src.lnglat()\n\n gcps, gcps_crs = src.gcps\n\n if gcps:\n info['gcps'] = {'points': [p.asdict() for p in gcps]}\n if gcps_crs:\n epsg = gcps_crs.to_epsg()\n if epsg:\n info['gcps']['crs'] = 'EPSG:{}'.format(epsg)\n else:\n info['gcps']['crs'] = src.crs.to_string()\n else:\n info['gcps']['crs'] = None\n\n info['gcps']['transform'] = from_gcps(gcps)\n\n if verbose:\n stats = [asdict(src.statistics(bidx)) for bidx in src.indexes]\n info['stats'] = stats\n info['checksum'] = [src.checksum(i) for i in src.indexes]\n\n if aspect == 'meta':\n if meta_member == 'subdatasets':\n for name in src.subdatasets:\n click.echo(name)\n elif meta_member == 'stats':\n st = src.statistics(bidx)\n click.echo(\"{st.min} {st.max} {st.mean} {st.std}\".format(st=st))\n elif meta_member == 'checksum':\n click.echo(str(src.checksum(bidx)))\n elif meta_member:\n if isinstance(info[meta_member], (list, tuple)):\n click.echo(\" \".join(map(str, info[meta_member])))\n else:\n click.echo(info[meta_member])\n else:\n click.echo(json.dumps(info, sort_keys=True, indent=indent))\n\n elif aspect == 'tags':\n click.echo(\n json.dumps(src.tags(ns=namespace), indent=indent))\n", "path": "rasterio/rio/info.py"}]}
| 2,161 | 333 |
gh_patches_debug_37098
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1006
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test student voting
From a quick search, the voting process has exactly one test, which is not much for the primary feature of the platform.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/student/views.py`
Content:
```
1 from collections import OrderedDict
2
3 from django.contrib import messages
4 from django.core.exceptions import PermissionDenied, SuspiciousOperation
5 from django.db import transaction
6 from django.shortcuts import get_object_or_404, redirect, render
7 from django.utils.translation import ugettext as _
8
9 from evap.evaluation.auth import participant_required
10 from evap.evaluation.models import Course, Semester
11 from evap.evaluation.tools import STUDENT_STATES_ORDERED
12
13 from evap.student.forms import QuestionsForm
14 from evap.student.tools import make_form_identifier
15
16
17 @participant_required
18 def index(request):
19 # retrieve all courses, where the user is a participant and that are not new
20 courses = list(set(Course.objects.filter(participants=request.user).exclude(state="new")))
21 voted_courses = list(set(Course.objects.filter(voters=request.user)))
22 due_courses = list(set(Course.objects.filter(participants=request.user, state='in_evaluation').exclude(voters=request.user)))
23
24 sorter = lambda course: (list(STUDENT_STATES_ORDERED.keys()).index(course.student_state), course.vote_end_date, course.name)
25 courses.sort(key=sorter)
26
27 semesters = Semester.objects.all()
28 semester_list = [dict(semester_name=semester.name, id=semester.id, is_active_semester=semester.is_active_semester,
29 courses=[course for course in courses if course.semester_id == semester.id]) for semester in semesters]
30
31 template_data = dict(
32 semester_list=semester_list,
33 voted_courses=voted_courses,
34 due_courses=due_courses,
35 can_download_grades=request.user.can_download_grades,
36 )
37 return render(request, "student_index.html", template_data)
38
39
40 def vote_preview(request, course, for_rendering_in_modal=False):
41 """
42 Renders a preview of the voting page for the given course.
43 Not used by the student app itself, but by staff and contributor.
44 """
45 form_groups = helper_create_voting_form_groups(request, course.contributions.all())
46 course_form_group = form_groups.pop(course.general_contribution)
47 contributor_form_groups = list((contribution.contributor, contribution.label, form_group, False) for contribution, form_group in form_groups.items())
48
49 template_data = dict(
50 errors_exist=False,
51 course_form_group=course_form_group,
52 contributor_form_groups=contributor_form_groups,
53 course=course,
54 preview=True,
55 for_rendering_in_modal=for_rendering_in_modal)
56 return render(request, "student_vote.html", template_data)
57
58
59 @participant_required
60 def vote(request, course_id):
61 # retrieve course and make sure that the user is allowed to vote
62 course = get_object_or_404(Course, id=course_id)
63 if not course.can_user_vote(request.user):
64 raise PermissionDenied
65
66 # prevent a user from voting on themselves.
67 contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()
68 form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)
69
70 if not all(all(form.is_valid() for form in form_group) for form_group in form_groups.values()):
71 errors_exist = any(helper_has_errors(form_group) for form_group in form_groups.values())
72
73 course_form_group = form_groups.pop(course.general_contribution)
74
75 contributor_form_groups = list((contribution.contributor, contribution.label, form_group, helper_has_errors(form_group)) for contribution, form_group in form_groups.items())
76
77 template_data = dict(
78 errors_exist=errors_exist,
79 course_form_group=course_form_group,
80 contributor_form_groups=contributor_form_groups,
81 course=course,
82 participants_warning=course.num_participants <= 5,
83 preview=False)
84 return render(request, "student_vote.html", template_data)
85
86 # all forms are valid, begin vote operation
87 with transaction.atomic():
88 # add user to course.voters
89 # not using course.voters.add(request.user) since it fails silently when done twice.
90 # manually inserting like this gives us the 'created' return value and ensures at the database level that nobody votes twice.
91 __, created = course.voters.through.objects.get_or_create(userprofile_id=request.user.pk, course_id=course.pk)
92 if not created: # vote already got recorded, bail out
93 raise SuspiciousOperation("A second vote has been received shortly after the first one.")
94
95 for contribution, form_group in form_groups.items():
96 for questionnaire_form in form_group:
97 questionnaire = questionnaire_form.questionnaire
98 for question in questionnaire.question_set.all():
99 identifier = make_form_identifier(contribution, questionnaire, question)
100 value = questionnaire_form.cleaned_data.get(identifier)
101
102 if question.is_text_question:
103 if value:
104 question.answer_class.objects.create(
105 contribution=contribution,
106 question=question,
107 answer=value)
108 else:
109 if value != 6:
110 answer_counter, __ = question.answer_class.objects.get_or_create(contribution=contribution, question=question, answer=value)
111 answer_counter.add_vote()
112 answer_counter.save()
113
114 course.course_evaluated.send(sender=Course, request=request, semester=course.semester)
115
116 messages.success(request, _("Your vote was recorded."))
117 return redirect('student:index')
118
119
120 def helper_create_voting_form_groups(request, contributions):
121 form_groups = OrderedDict()
122 for contribution in contributions:
123 questionnaires = contribution.questionnaires.all()
124 if not questionnaires.exists():
125 continue
126 form_groups[contribution] = [QuestionsForm(request.POST or None, contribution=contribution, questionnaire=questionnaire) for questionnaire in questionnaires]
127 return form_groups
128
129
130 def helper_has_errors(form_group):
131 return any(form.errors for form in form_group)
132
```
Path: `evap/student/tools.py`
Content:
```
1 def make_form_identifier(contribution, questionnaire, question):
2 """Generates a form field identifier for voting forms using the given
3 parameters."""
4
5 return "question_%s_%s_%s" % (
6 contribution.id,
7 questionnaire.id,
8 question.id)
9
```
Path: `evap/student/forms.py`
Content:
```
1 from django import forms
2
3 from evap.student.tools import make_form_identifier
4 from evap.evaluation.tools import LIKERT_NAMES, GRADE_NAMES, POSITIVE_YES_NO_NAMES, NEGATIVE_YES_NO_NAMES
5
6
7 LIKERT_CHOICES = [(str(k), v) for k, v in LIKERT_NAMES.items()]
8 GRADE_CHOICES = [(str(k), v) for k, v in GRADE_NAMES.items()]
9 POSITIVE_YES_NO_CHOICES = [(str(k), v) for k, v in POSITIVE_YES_NO_NAMES.items()]
10 NEGATIVE_YES_NO_CHOICES = [(str(k), v) for k, v in NEGATIVE_YES_NO_NAMES.items()]
11
12
13 class QuestionsForm(forms.Form):
14 """Dynamic form class that adds one field per question.
15
16 See http://jacobian.org/writing/dynamic-form-generation/"""
17
18 def __init__(self, *args, contribution, questionnaire, **kwargs):
19 super().__init__(*args, **kwargs)
20 self.questionnaire = questionnaire
21
22 for question in self.questionnaire.question_set.all():
23 # generic arguments for all kinds of fields
24 field_args = dict(label=question.text)
25
26 if question.is_text_question:
27 field = forms.CharField(required=False, widget=forms.Textarea(),
28 **field_args)
29 elif question.is_likert_question:
30 field = forms.TypedChoiceField(widget=forms.RadioSelect(),
31 choices=LIKERT_CHOICES,
32 coerce=int,
33 **field_args)
34 elif question.is_grade_question:
35 field = forms.TypedChoiceField(widget=forms.RadioSelect(),
36 choices=GRADE_CHOICES,
37 coerce=int,
38 **field_args)
39 elif question.is_positive_yes_no_question:
40 field = forms.TypedChoiceField(widget=forms.RadioSelect(),
41 choices=POSITIVE_YES_NO_CHOICES,
42 coerce=int,
43 **field_args)
44 elif question.is_negative_yes_no_question:
45 field = forms.TypedChoiceField(widget=forms.RadioSelect(),
46 choices=NEGATIVE_YES_NO_CHOICES,
47 coerce=int,
48 **field_args)
49
50 identifier = make_form_identifier(contribution,
51 questionnaire,
52 question)
53 self.fields[identifier] = field
54
55 def caption(self):
56 return self.questionnaire.public_name
57
58 def teaser(self):
59 return self.questionnaire.teaser
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/student/forms.py b/evap/student/forms.py
--- a/evap/student/forms.py
+++ b/evap/student/forms.py
@@ -1,9 +1,8 @@
from django import forms
-from evap.student.tools import make_form_identifier
+from evap.student.tools import question_id
from evap.evaluation.tools import LIKERT_NAMES, GRADE_NAMES, POSITIVE_YES_NO_NAMES, NEGATIVE_YES_NO_NAMES
-
LIKERT_CHOICES = [(str(k), v) for k, v in LIKERT_NAMES.items()]
GRADE_CHOICES = [(str(k), v) for k, v in GRADE_NAMES.items()]
POSITIVE_YES_NO_CHOICES = [(str(k), v) for k, v in POSITIVE_YES_NO_NAMES.items()]
@@ -47,9 +46,10 @@
coerce=int,
**field_args)
- identifier = make_form_identifier(contribution,
- questionnaire,
- question)
+ identifier = question_id(contribution,
+ questionnaire,
+ question)
+
self.fields[identifier] = field
def caption(self):
diff --git a/evap/student/tools.py b/evap/student/tools.py
--- a/evap/student/tools.py
+++ b/evap/student/tools.py
@@ -1,4 +1,4 @@
-def make_form_identifier(contribution, questionnaire, question):
+def question_id(contribution, questionnaire, question):
"""Generates a form field identifier for voting forms using the given
parameters."""
diff --git a/evap/student/views.py b/evap/student/views.py
--- a/evap/student/views.py
+++ b/evap/student/views.py
@@ -11,7 +11,7 @@
from evap.evaluation.tools import STUDENT_STATES_ORDERED
from evap.student.forms import QuestionsForm
-from evap.student.tools import make_form_identifier
+from evap.student.tools import question_id
@participant_required
@@ -96,7 +96,7 @@
for questionnaire_form in form_group:
questionnaire = questionnaire_form.questionnaire
for question in questionnaire.question_set.all():
- identifier = make_form_identifier(contribution, questionnaire, question)
+ identifier = question_id(contribution, questionnaire, question)
value = questionnaire_form.cleaned_data.get(identifier)
if question.is_text_question:
|
{"golden_diff": "diff --git a/evap/student/forms.py b/evap/student/forms.py\n--- a/evap/student/forms.py\n+++ b/evap/student/forms.py\n@@ -1,9 +1,8 @@\n from django import forms\n \n-from evap.student.tools import make_form_identifier\n+from evap.student.tools import question_id\n from evap.evaluation.tools import LIKERT_NAMES, GRADE_NAMES, POSITIVE_YES_NO_NAMES, NEGATIVE_YES_NO_NAMES\n \n-\n LIKERT_CHOICES = [(str(k), v) for k, v in LIKERT_NAMES.items()]\n GRADE_CHOICES = [(str(k), v) for k, v in GRADE_NAMES.items()]\n POSITIVE_YES_NO_CHOICES = [(str(k), v) for k, v in POSITIVE_YES_NO_NAMES.items()]\n@@ -47,9 +46,10 @@\n coerce=int,\n **field_args)\n \n- identifier = make_form_identifier(contribution,\n- questionnaire,\n- question)\n+ identifier = question_id(contribution,\n+ questionnaire,\n+ question)\n+\n self.fields[identifier] = field\n \n def caption(self):\ndiff --git a/evap/student/tools.py b/evap/student/tools.py\n--- a/evap/student/tools.py\n+++ b/evap/student/tools.py\n@@ -1,4 +1,4 @@\n-def make_form_identifier(contribution, questionnaire, question):\n+def question_id(contribution, questionnaire, question):\n \"\"\"Generates a form field identifier for voting forms using the given\n parameters.\"\"\"\n \ndiff --git a/evap/student/views.py b/evap/student/views.py\n--- a/evap/student/views.py\n+++ b/evap/student/views.py\n@@ -11,7 +11,7 @@\n from evap.evaluation.tools import STUDENT_STATES_ORDERED\n \n from evap.student.forms import QuestionsForm\n-from evap.student.tools import make_form_identifier\n+from evap.student.tools import question_id\n \n \n @participant_required\n@@ -96,7 +96,7 @@\n for questionnaire_form in form_group:\n questionnaire = questionnaire_form.questionnaire\n for question in questionnaire.question_set.all():\n- identifier = make_form_identifier(contribution, questionnaire, question)\n+ identifier = question_id(contribution, questionnaire, question)\n value = questionnaire_form.cleaned_data.get(identifier)\n \n if question.is_text_question:\n", "issue": "Test student voting\nFrom a quick search, the voting process has exactly one test, which is not much for the primary feature of the platform.\n\n", "before_files": [{"content": "from collections import OrderedDict\n\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied, SuspiciousOperation\nfrom django.db import transaction\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import ugettext as _\n\nfrom evap.evaluation.auth import participant_required\nfrom evap.evaluation.models import Course, Semester\nfrom evap.evaluation.tools import STUDENT_STATES_ORDERED\n\nfrom evap.student.forms import QuestionsForm\nfrom evap.student.tools import make_form_identifier\n\n\n@participant_required\ndef index(request):\n # retrieve all courses, where the user is a participant and that are not new\n courses = list(set(Course.objects.filter(participants=request.user).exclude(state=\"new\")))\n voted_courses = list(set(Course.objects.filter(voters=request.user)))\n due_courses = list(set(Course.objects.filter(participants=request.user, state='in_evaluation').exclude(voters=request.user)))\n\n sorter = lambda course: (list(STUDENT_STATES_ORDERED.keys()).index(course.student_state), course.vote_end_date, course.name)\n courses.sort(key=sorter)\n\n semesters = Semester.objects.all()\n semester_list = [dict(semester_name=semester.name, id=semester.id, is_active_semester=semester.is_active_semester,\n courses=[course for course in courses if course.semester_id == semester.id]) for semester in semesters]\n\n template_data = dict(\n semester_list=semester_list,\n voted_courses=voted_courses,\n due_courses=due_courses,\n can_download_grades=request.user.can_download_grades,\n )\n return render(request, \"student_index.html\", template_data)\n\n\ndef vote_preview(request, course, for_rendering_in_modal=False):\n \"\"\"\n Renders a preview of the voting page for the given course.\n Not used by the student app itself, but by staff and contributor.\n \"\"\"\n form_groups = helper_create_voting_form_groups(request, course.contributions.all())\n course_form_group = form_groups.pop(course.general_contribution)\n contributor_form_groups = list((contribution.contributor, contribution.label, form_group, False) for contribution, form_group in form_groups.items())\n\n template_data = dict(\n errors_exist=False,\n course_form_group=course_form_group,\n contributor_form_groups=contributor_form_groups,\n course=course,\n preview=True,\n for_rendering_in_modal=for_rendering_in_modal)\n return render(request, \"student_vote.html\", template_data)\n\n\n@participant_required\ndef vote(request, course_id):\n # retrieve course and make sure that the user is allowed to vote\n course = get_object_or_404(Course, id=course_id)\n if not course.can_user_vote(request.user):\n raise PermissionDenied\n\n # prevent a user from voting on themselves.\n contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()\n form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)\n\n if not all(all(form.is_valid() for form in form_group) for form_group in form_groups.values()):\n errors_exist = any(helper_has_errors(form_group) for form_group in form_groups.values())\n\n course_form_group = form_groups.pop(course.general_contribution)\n\n contributor_form_groups = list((contribution.contributor, contribution.label, form_group, helper_has_errors(form_group)) for contribution, form_group in form_groups.items())\n\n template_data = dict(\n errors_exist=errors_exist,\n course_form_group=course_form_group,\n contributor_form_groups=contributor_form_groups,\n course=course,\n participants_warning=course.num_participants <= 5,\n preview=False)\n return render(request, \"student_vote.html\", template_data)\n\n # all forms are valid, begin vote operation\n with transaction.atomic():\n # add user to course.voters\n # not using course.voters.add(request.user) since it fails silently when done twice.\n # manually inserting like this gives us the 'created' return value and ensures at the database level that nobody votes twice.\n __, created = course.voters.through.objects.get_or_create(userprofile_id=request.user.pk, course_id=course.pk)\n if not created: # vote already got recorded, bail out\n raise SuspiciousOperation(\"A second vote has been received shortly after the first one.\")\n\n for contribution, form_group in form_groups.items():\n for questionnaire_form in form_group:\n questionnaire = questionnaire_form.questionnaire\n for question in questionnaire.question_set.all():\n identifier = make_form_identifier(contribution, questionnaire, question)\n value = questionnaire_form.cleaned_data.get(identifier)\n\n if question.is_text_question:\n if value:\n question.answer_class.objects.create(\n contribution=contribution,\n question=question,\n answer=value)\n else:\n if value != 6:\n answer_counter, __ = question.answer_class.objects.get_or_create(contribution=contribution, question=question, answer=value)\n answer_counter.add_vote()\n answer_counter.save()\n\n course.course_evaluated.send(sender=Course, request=request, semester=course.semester)\n\n messages.success(request, _(\"Your vote was recorded.\"))\n return redirect('student:index')\n\n\ndef helper_create_voting_form_groups(request, contributions):\n form_groups = OrderedDict()\n for contribution in contributions:\n questionnaires = contribution.questionnaires.all()\n if not questionnaires.exists():\n continue\n form_groups[contribution] = [QuestionsForm(request.POST or None, contribution=contribution, questionnaire=questionnaire) for questionnaire in questionnaires]\n return form_groups\n\n\ndef helper_has_errors(form_group):\n return any(form.errors for form in form_group)\n", "path": "evap/student/views.py"}, {"content": "def make_form_identifier(contribution, questionnaire, question):\n \"\"\"Generates a form field identifier for voting forms using the given\n parameters.\"\"\"\n\n return \"question_%s_%s_%s\" % (\n contribution.id,\n questionnaire.id,\n question.id)\n", "path": "evap/student/tools.py"}, {"content": "from django import forms\n\nfrom evap.student.tools import make_form_identifier\nfrom evap.evaluation.tools import LIKERT_NAMES, GRADE_NAMES, POSITIVE_YES_NO_NAMES, NEGATIVE_YES_NO_NAMES\n\n\nLIKERT_CHOICES = [(str(k), v) for k, v in LIKERT_NAMES.items()]\nGRADE_CHOICES = [(str(k), v) for k, v in GRADE_NAMES.items()]\nPOSITIVE_YES_NO_CHOICES = [(str(k), v) for k, v in POSITIVE_YES_NO_NAMES.items()]\nNEGATIVE_YES_NO_CHOICES = [(str(k), v) for k, v in NEGATIVE_YES_NO_NAMES.items()]\n\n\nclass QuestionsForm(forms.Form):\n \"\"\"Dynamic form class that adds one field per question.\n\n See http://jacobian.org/writing/dynamic-form-generation/\"\"\"\n\n def __init__(self, *args, contribution, questionnaire, **kwargs):\n super().__init__(*args, **kwargs)\n self.questionnaire = questionnaire\n\n for question in self.questionnaire.question_set.all():\n # generic arguments for all kinds of fields\n field_args = dict(label=question.text)\n\n if question.is_text_question:\n field = forms.CharField(required=False, widget=forms.Textarea(),\n **field_args)\n elif question.is_likert_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=LIKERT_CHOICES,\n coerce=int,\n **field_args)\n elif question.is_grade_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=GRADE_CHOICES,\n coerce=int,\n **field_args)\n elif question.is_positive_yes_no_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=POSITIVE_YES_NO_CHOICES,\n coerce=int,\n **field_args)\n elif question.is_negative_yes_no_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=NEGATIVE_YES_NO_CHOICES,\n coerce=int,\n **field_args)\n\n identifier = make_form_identifier(contribution,\n questionnaire,\n question)\n self.fields[identifier] = field\n\n def caption(self):\n return self.questionnaire.public_name\n\n def teaser(self):\n return self.questionnaire.teaser\n", "path": "evap/student/forms.py"}], "after_files": [{"content": "from collections import OrderedDict\n\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied, SuspiciousOperation\nfrom django.db import transaction\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import ugettext as _\n\nfrom evap.evaluation.auth import participant_required\nfrom evap.evaluation.models import Course, Semester\nfrom evap.evaluation.tools import STUDENT_STATES_ORDERED\n\nfrom evap.student.forms import QuestionsForm\nfrom evap.student.tools import question_id\n\n\n@participant_required\ndef index(request):\n # retrieve all courses, where the user is a participant and that are not new\n courses = list(set(Course.objects.filter(participants=request.user).exclude(state=\"new\")))\n voted_courses = list(set(Course.objects.filter(voters=request.user)))\n due_courses = list(set(Course.objects.filter(participants=request.user, state='in_evaluation').exclude(voters=request.user)))\n\n sorter = lambda course: (list(STUDENT_STATES_ORDERED.keys()).index(course.student_state), course.vote_end_date, course.name)\n courses.sort(key=sorter)\n\n semesters = Semester.objects.all()\n semester_list = [dict(semester_name=semester.name, id=semester.id, is_active_semester=semester.is_active_semester,\n courses=[course for course in courses if course.semester_id == semester.id]) for semester in semesters]\n\n template_data = dict(\n semester_list=semester_list,\n voted_courses=voted_courses,\n due_courses=due_courses,\n can_download_grades=request.user.can_download_grades,\n )\n return render(request, \"student_index.html\", template_data)\n\n\ndef vote_preview(request, course, for_rendering_in_modal=False):\n \"\"\"\n Renders a preview of the voting page for the given course.\n Not used by the student app itself, but by staff and contributor.\n \"\"\"\n form_groups = helper_create_voting_form_groups(request, course.contributions.all())\n course_form_group = form_groups.pop(course.general_contribution)\n contributor_form_groups = list((contribution.contributor, contribution.label, form_group, False) for contribution, form_group in form_groups.items())\n\n template_data = dict(\n errors_exist=False,\n course_form_group=course_form_group,\n contributor_form_groups=contributor_form_groups,\n course=course,\n preview=True,\n for_rendering_in_modal=for_rendering_in_modal)\n return render(request, \"student_vote.html\", template_data)\n\n\n@participant_required\ndef vote(request, course_id):\n # retrieve course and make sure that the user is allowed to vote\n course = get_object_or_404(Course, id=course_id)\n if not course.can_user_vote(request.user):\n raise PermissionDenied\n\n # prevent a user from voting on themselves.\n contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()\n form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)\n\n if not all(all(form.is_valid() for form in form_group) for form_group in form_groups.values()):\n errors_exist = any(helper_has_errors(form_group) for form_group in form_groups.values())\n\n course_form_group = form_groups.pop(course.general_contribution)\n\n contributor_form_groups = list((contribution.contributor, contribution.label, form_group, helper_has_errors(form_group)) for contribution, form_group in form_groups.items())\n\n template_data = dict(\n errors_exist=errors_exist,\n course_form_group=course_form_group,\n contributor_form_groups=contributor_form_groups,\n course=course,\n participants_warning=course.num_participants <= 5,\n preview=False)\n return render(request, \"student_vote.html\", template_data)\n\n # all forms are valid, begin vote operation\n with transaction.atomic():\n # add user to course.voters\n # not using course.voters.add(request.user) since it fails silently when done twice.\n # manually inserting like this gives us the 'created' return value and ensures at the database level that nobody votes twice.\n __, created = course.voters.through.objects.get_or_create(userprofile_id=request.user.pk, course_id=course.pk)\n if not created: # vote already got recorded, bail out\n raise SuspiciousOperation(\"A second vote has been received shortly after the first one.\")\n\n for contribution, form_group in form_groups.items():\n for questionnaire_form in form_group:\n questionnaire = questionnaire_form.questionnaire\n for question in questionnaire.question_set.all():\n identifier = question_id(contribution, questionnaire, question)\n value = questionnaire_form.cleaned_data.get(identifier)\n\n if question.is_text_question:\n if value:\n question.answer_class.objects.create(\n contribution=contribution,\n question=question,\n answer=value)\n else:\n if value != 6:\n answer_counter, __ = question.answer_class.objects.get_or_create(contribution=contribution, question=question, answer=value)\n answer_counter.add_vote()\n answer_counter.save()\n\n course.course_evaluated.send(sender=Course, request=request, semester=course.semester)\n\n messages.success(request, _(\"Your vote was recorded.\"))\n return redirect('student:index')\n\n\ndef helper_create_voting_form_groups(request, contributions):\n form_groups = OrderedDict()\n for contribution in contributions:\n questionnaires = contribution.questionnaires.all()\n if not questionnaires.exists():\n continue\n form_groups[contribution] = [QuestionsForm(request.POST or None, contribution=contribution, questionnaire=questionnaire) for questionnaire in questionnaires]\n return form_groups\n\n\ndef helper_has_errors(form_group):\n return any(form.errors for form in form_group)\n", "path": "evap/student/views.py"}, {"content": "def question_id(contribution, questionnaire, question):\n \"\"\"Generates a form field identifier for voting forms using the given\n parameters.\"\"\"\n\n return \"question_%s_%s_%s\" % (\n contribution.id,\n questionnaire.id,\n question.id)\n", "path": "evap/student/tools.py"}, {"content": "from django import forms\n\nfrom evap.student.tools import question_id\nfrom evap.evaluation.tools import LIKERT_NAMES, GRADE_NAMES, POSITIVE_YES_NO_NAMES, NEGATIVE_YES_NO_NAMES\n\nLIKERT_CHOICES = [(str(k), v) for k, v in LIKERT_NAMES.items()]\nGRADE_CHOICES = [(str(k), v) for k, v in GRADE_NAMES.items()]\nPOSITIVE_YES_NO_CHOICES = [(str(k), v) for k, v in POSITIVE_YES_NO_NAMES.items()]\nNEGATIVE_YES_NO_CHOICES = [(str(k), v) for k, v in NEGATIVE_YES_NO_NAMES.items()]\n\n\nclass QuestionsForm(forms.Form):\n \"\"\"Dynamic form class that adds one field per question.\n\n See http://jacobian.org/writing/dynamic-form-generation/\"\"\"\n\n def __init__(self, *args, contribution, questionnaire, **kwargs):\n super().__init__(*args, **kwargs)\n self.questionnaire = questionnaire\n\n for question in self.questionnaire.question_set.all():\n # generic arguments for all kinds of fields\n field_args = dict(label=question.text)\n\n if question.is_text_question:\n field = forms.CharField(required=False, widget=forms.Textarea(),\n **field_args)\n elif question.is_likert_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=LIKERT_CHOICES,\n coerce=int,\n **field_args)\n elif question.is_grade_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=GRADE_CHOICES,\n coerce=int,\n **field_args)\n elif question.is_positive_yes_no_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=POSITIVE_YES_NO_CHOICES,\n coerce=int,\n **field_args)\n elif question.is_negative_yes_no_question:\n field = forms.TypedChoiceField(widget=forms.RadioSelect(),\n choices=NEGATIVE_YES_NO_CHOICES,\n coerce=int,\n **field_args)\n\n identifier = question_id(contribution,\n questionnaire,\n question)\n\n self.fields[identifier] = field\n\n def caption(self):\n return self.questionnaire.public_name\n\n def teaser(self):\n return self.questionnaire.teaser\n", "path": "evap/student/forms.py"}]}
| 2,457 | 503 |
gh_patches_debug_32593
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-7998
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bokeh GMapOptions error
Bokeh version - 0.12.16
Python - 3.5
OS - Windows 10
Browser - IE, Chrome, Firefox
Other relevant packages - GMapOptions, gmap
I'm fairly new to Bokeh so please excuse me for my lack of knowledge/experience with bokeh. I am trying to create a geographic visualization using bokeh and then integrate my bokeh server app into flask to deploy it on a VPS. When run independently my code produces the necessary visualization but, gives an error in the command line. The error is occuring at the gmap call. I tried looking this error up and found a few relevant results all of which pointed to bugs in the Bokeh library. Where I am really getting stuck is, at the point of deployment of this visualization either independently as a bokeh server app or by integrating it with Flask because of this error. Any help on this is greatly appreciated. Thanks!
```
from bokeh.io import curdoc
from bokeh.models import GMapOptions
from bokeh.plotting import gmap
map_options = GMapOptions(lat=37.686293, lng=-97.3614409, map_type="roadmap", zoom=13)
p = gmap(google_api_key="My Google Maps API Key", map_options=map_options, title="Resolutions Clients", plot_width=1000, plot_height=600)
curdoc().add_root(p)
```
C:\Users\Administrator\PycharmProjects\FlaskApp>bokeh serve --show test.py
2018-06-11 14:20:52,449 Starting Bokeh server version 0.12.16 (running on Tornad
o 5.0.2)
2018-06-11 14:20:52,463 Bokeh app running at: http://localhost:5006/test
2018-06-11 14:20:52,464 Starting Bokeh server with process id: 9972
2018-06-11 14:20:52,816 200 GET /test (::1) 161.02ms
2018-06-11 14:20:53,072 101 GET /test/ws?bokeh-protocol-version=1.0&bokeh-sessio
n-id=YwriVJupgcBKp7IEeFdj5R95PJG2lxe6g82SFqbObcDA (::1) 1.00ms
2018-06-11 14:20:53,072 WebSocket connection opened
2018-06-11 14:20:53,072 ServerConnection created
2018-06-11 14:20:53,120 error handling message Message 'PATCH-DOC' (revision 1):
TypeError("__init__() missing 2 required positional arguments: 'google_api_key'
and 'map_options'",)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/plotting/gmap.py`
Content:
```
1 from __future__ import absolute_import, print_function
2
3 import logging
4 logger = logging.getLogger(__name__)
5
6 from six import string_types
7
8 from ..core.enums import HorizontalLocation, VerticalLocation
9 from ..core.properties import Auto, Either, Enum, Int, Seq, Instance, String
10 from ..models import GMapPlot, LinearAxis, MercatorTicker, MercatorTickFormatter, Range1d, Title, Tool
11 from ..models import glyphs, markers
12 from ..models.tools import Drag, Inspection, Scroll, Tap
13 from ..util.options import Options
14 from .helpers import _process_tools_arg, _process_active_tools, _glyph_function
15
16 DEFAULT_TOOLS = "pan,wheel_zoom,reset,help"
17
18 class GMapFigureOptions(Options):
19
20 tools = Either(String, Seq(Either(String, Instance(Tool))), default=DEFAULT_TOOLS, help="""
21 Tools the plot should start with.
22 """)
23
24 x_minor_ticks = Either(Auto, Int, default="auto", help="""
25 Number of minor ticks between adjacent x-axis major ticks.
26 """)
27
28 y_minor_ticks = Either(Auto, Int, default="auto", help="""
29 Number of minor ticks between adjacent y-axis major ticks.
30 """)
31
32 x_axis_location = Enum(VerticalLocation, default="below", help="""
33 Where the x-axis should be located.
34 """)
35
36 y_axis_location = Enum(HorizontalLocation, default="left", help="""
37 Where the y-axis should be located.
38 """)
39
40 x_axis_label = String(default="", help="""
41 A label for the x-axis.
42 """)
43
44 y_axis_label = String(default="", help="""
45 A label for the y-axis.
46 """)
47
48 active_drag = Either(Auto, String, Instance(Drag), default="auto", help="""
49 Which drag tool should initially be active.
50 """)
51
52 active_inspect = Either(Auto, String, Instance(Inspection), Seq(Instance(Inspection)), default="auto", help="""
53 Which drag tool should initially be active.
54 """)
55
56 active_scroll = Either(Auto, String, Instance(Scroll), default="auto", help="""
57 Which scroll tool should initially be active.
58 """)
59
60 active_tap = Either(Auto, String, Instance(Tap), default="auto", help="""
61 Which tap tool should initially be active.
62 """)
63
64 class GMap(GMapPlot):
65 ''' A subclass of :class:`~bokeh.models.plots.Plot` that simplifies plot
66 creation with default axes, grids, tools, etc.
67
68 In addition to all the Bokeh model property attributes documented below,
69 the ``Figure`` initializer also accepts the following options, which can
70 help simplify configuration:
71
72 .. bokeh-options:: GMapFigureOptions
73 :module: bokeh.plotting.figure
74
75 '''
76
77 __subtype__ = "GMap"
78 __view_model__ = "GMapPlot"
79
80 def __init__(self, google_api_key, map_options, **kw):
81
82 if 'plot_width' in kw and 'width' in kw:
83 raise ValueError("Figure called with both 'plot_width' and 'width' supplied, supply only one")
84 if 'plot_height' in kw and 'height' in kw:
85 raise ValueError("Figure called with both 'plot_height' and 'height' supplied, supply only one")
86 if 'height' in kw:
87 kw['plot_height'] = kw.pop('height')
88 if 'width' in kw:
89 kw['plot_width'] = kw.pop('width')
90
91 opts = GMapFigureOptions(kw)
92
93 title = kw.get("title", None)
94 if isinstance(title, string_types):
95 kw['title'] = Title(text=title)
96
97 super(GMap, self).__init__(api_key=google_api_key, map_options=map_options,
98 x_range=Range1d(), y_range=Range1d(), **kw)
99
100 xf = MercatorTickFormatter(dimension="lon")
101 xt = MercatorTicker(dimension="lon")
102 self.add_layout(LinearAxis(formatter=xf, ticker=xt), 'below')
103
104 yf = MercatorTickFormatter(dimension="lat")
105 yt = MercatorTicker(dimension="lat")
106 self.add_layout(LinearAxis(formatter=yf, ticker=yt), 'left')
107
108 tool_objs, tool_map = _process_tools_arg(self, opts.tools)
109 self.add_tools(*tool_objs)
110 _process_active_tools(self.toolbar, tool_map, opts.active_drag, opts.active_inspect, opts.active_scroll, opts.active_tap)
111
112 annular_wedge = _glyph_function(glyphs.AnnularWedge)
113
114 annulus = _glyph_function(glyphs.Annulus)
115
116 arc = _glyph_function(glyphs.Arc)
117
118 asterisk = _glyph_function(markers.Asterisk)
119
120 bezier = _glyph_function(glyphs.Bezier)
121
122 circle = _glyph_function(markers.Circle)
123
124 circle_cross = _glyph_function(markers.CircleCross)
125
126 circle_x = _glyph_function(markers.CircleX)
127
128 cross = _glyph_function(markers.Cross)
129
130 diamond = _glyph_function(markers.Diamond)
131
132 diamond_cross = _glyph_function(markers.DiamondCross)
133
134 hbar = _glyph_function(glyphs.HBar)
135
136 ellipse = _glyph_function(glyphs.Ellipse)
137
138 image = _glyph_function(glyphs.Image)
139
140 image_rgba = _glyph_function(glyphs.ImageRGBA)
141
142 image_url = _glyph_function(glyphs.ImageURL)
143
144 inverted_triangle = _glyph_function(markers.InvertedTriangle)
145
146 line = _glyph_function(glyphs.Line)
147
148 multi_line = _glyph_function(glyphs.MultiLine)
149
150 oval = _glyph_function(glyphs.Oval)
151
152 patch = _glyph_function(glyphs.Patch)
153
154 patches = _glyph_function(glyphs.Patches)
155
156 quad = _glyph_function(glyphs.Quad)
157
158 quadratic = _glyph_function(glyphs.Quadratic)
159
160 ray = _glyph_function(glyphs.Ray)
161
162 rect = _glyph_function(glyphs.Rect)
163
164 segment = _glyph_function(glyphs.Segment)
165
166 square = _glyph_function(markers.Square)
167
168 square_cross = _glyph_function(markers.SquareCross)
169
170 square_x = _glyph_function(markers.SquareX)
171
172 text = _glyph_function(glyphs.Text)
173
174 triangle = _glyph_function(markers.Triangle)
175
176 vbar = _glyph_function(glyphs.VBar)
177
178 wedge = _glyph_function(glyphs.Wedge)
179
180 x = _glyph_function(markers.X)
181
182 def gmap(google_api_key, map_options, **kwargs):
183 ''' Create a new :class:`~bokeh.plotting.gmap.GMap` for plotting.
184
185 Args:
186 google_api_key (str):
187 Google requires an API key be supplied for maps to function. See:
188
189 https://developers.google.com/maps/documentation/javascript/get-api-key
190
191 map_options: (GMapOptions)
192 Configuration specific to a Google Map
193
194 In addition to the standard :class:`~bokeh.plotting.gmap.GMap` keyword
195 arguments (e.g. ``plot_width`` or ``sizing_mode``), the following
196 additional options can be passed as well:
197
198 .. bokeh-options:: GMapFigureOptions
199 :module: bokeh.plotting.gmap
200
201 Returns:
202 GMap
203
204 '''
205
206 return GMap(google_api_key, map_options, **kwargs)
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/plotting/gmap.py b/bokeh/plotting/gmap.py
--- a/bokeh/plotting/gmap.py
+++ b/bokeh/plotting/gmap.py
@@ -65,6 +65,15 @@
''' A subclass of :class:`~bokeh.models.plots.Plot` that simplifies plot
creation with default axes, grids, tools, etc.
+ Args:
+ google_api_key (str):
+ Google requires an API key be supplied for maps to function. See:
+
+ https://developers.google.com/maps/documentation/javascript/get-api-key
+
+ map_options: (GMapOptions)
+ Configuration specific to a Google Map
+
In addition to all the Bokeh model property attributes documented below,
the ``Figure`` initializer also accepts the following options, which can
help simplify configuration:
@@ -77,7 +86,7 @@
__subtype__ = "GMap"
__view_model__ = "GMapPlot"
- def __init__(self, google_api_key, map_options, **kw):
+ def __init__(self, **kw):
if 'plot_width' in kw and 'width' in kw:
raise ValueError("Figure called with both 'plot_width' and 'width' supplied, supply only one")
@@ -94,8 +103,7 @@
if isinstance(title, string_types):
kw['title'] = Title(text=title)
- super(GMap, self).__init__(api_key=google_api_key, map_options=map_options,
- x_range=Range1d(), y_range=Range1d(), **kw)
+ super(GMap, self).__init__(x_range=Range1d(), y_range=Range1d(), **kw)
xf = MercatorTickFormatter(dimension="lon")
xt = MercatorTicker(dimension="lon")
@@ -203,4 +211,4 @@
'''
- return GMap(google_api_key, map_options, **kwargs)
+ return GMap(api_key=google_api_key, map_options=map_options, **kwargs)
|
{"golden_diff": "diff --git a/bokeh/plotting/gmap.py b/bokeh/plotting/gmap.py\n--- a/bokeh/plotting/gmap.py\n+++ b/bokeh/plotting/gmap.py\n@@ -65,6 +65,15 @@\n ''' A subclass of :class:`~bokeh.models.plots.Plot` that simplifies plot\n creation with default axes, grids, tools, etc.\n \n+ Args:\n+ google_api_key (str):\n+ Google requires an API key be supplied for maps to function. See:\n+\n+ https://developers.google.com/maps/documentation/javascript/get-api-key\n+\n+ map_options: (GMapOptions)\n+ Configuration specific to a Google Map\n+\n In addition to all the Bokeh model property attributes documented below,\n the ``Figure`` initializer also accepts the following options, which can\n help simplify configuration:\n@@ -77,7 +86,7 @@\n __subtype__ = \"GMap\"\n __view_model__ = \"GMapPlot\"\n \n- def __init__(self, google_api_key, map_options, **kw):\n+ def __init__(self, **kw):\n \n if 'plot_width' in kw and 'width' in kw:\n raise ValueError(\"Figure called with both 'plot_width' and 'width' supplied, supply only one\")\n@@ -94,8 +103,7 @@\n if isinstance(title, string_types):\n kw['title'] = Title(text=title)\n \n- super(GMap, self).__init__(api_key=google_api_key, map_options=map_options,\n- x_range=Range1d(), y_range=Range1d(), **kw)\n+ super(GMap, self).__init__(x_range=Range1d(), y_range=Range1d(), **kw)\n \n xf = MercatorTickFormatter(dimension=\"lon\")\n xt = MercatorTicker(dimension=\"lon\")\n@@ -203,4 +211,4 @@\n \n '''\n \n- return GMap(google_api_key, map_options, **kwargs)\n+ return GMap(api_key=google_api_key, map_options=map_options, **kwargs)\n", "issue": "Bokeh GMapOptions error\nBokeh version - 0.12.16\r\nPython - 3.5\r\nOS - Windows 10\r\nBrowser - IE, Chrome, Firefox\r\nOther relevant packages - GMapOptions, gmap\r\n\r\nI'm fairly new to Bokeh so please excuse me for my lack of knowledge/experience with bokeh. I am trying to create a geographic visualization using bokeh and then integrate my bokeh server app into flask to deploy it on a VPS. When run independently my code produces the necessary visualization but, gives an error in the command line. The error is occuring at the gmap call. I tried looking this error up and found a few relevant results all of which pointed to bugs in the Bokeh library. Where I am really getting stuck is, at the point of deployment of this visualization either independently as a bokeh server app or by integrating it with Flask because of this error. Any help on this is greatly appreciated. Thanks!\r\n\r\n\r\n```\r\nfrom bokeh.io import curdoc\r\nfrom bokeh.models import GMapOptions\r\nfrom bokeh.plotting import gmap\r\nmap_options = GMapOptions(lat=37.686293, lng=-97.3614409, map_type=\"roadmap\", zoom=13)\r\np = gmap(google_api_key=\"My Google Maps API Key\", map_options=map_options, title=\"Resolutions Clients\", plot_width=1000, plot_height=600)\r\ncurdoc().add_root(p)\r\n```\r\n\r\n\r\nC:\\Users\\Administrator\\PycharmProjects\\FlaskApp>bokeh serve --show test.py\r\n2018-06-11 14:20:52,449 Starting Bokeh server version 0.12.16 (running on Tornad\r\no 5.0.2)\r\n2018-06-11 14:20:52,463 Bokeh app running at: http://localhost:5006/test\r\n2018-06-11 14:20:52,464 Starting Bokeh server with process id: 9972\r\n2018-06-11 14:20:52,816 200 GET /test (::1) 161.02ms\r\n2018-06-11 14:20:53,072 101 GET /test/ws?bokeh-protocol-version=1.0&bokeh-sessio\r\nn-id=YwriVJupgcBKp7IEeFdj5R95PJG2lxe6g82SFqbObcDA (::1) 1.00ms\r\n2018-06-11 14:20:53,072 WebSocket connection opened\r\n2018-06-11 14:20:53,072 ServerConnection created\r\n2018-06-11 14:20:53,120 error handling message Message 'PATCH-DOC' (revision 1):\r\n TypeError(\"__init__() missing 2 required positional arguments: 'google_api_key'\r\n and 'map_options'\",)\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import, print_function\n\nimport logging\nlogger = logging.getLogger(__name__)\n\nfrom six import string_types\n\nfrom ..core.enums import HorizontalLocation, VerticalLocation\nfrom ..core.properties import Auto, Either, Enum, Int, Seq, Instance, String\nfrom ..models import GMapPlot, LinearAxis, MercatorTicker, MercatorTickFormatter, Range1d, Title, Tool\nfrom ..models import glyphs, markers\nfrom ..models.tools import Drag, Inspection, Scroll, Tap\nfrom ..util.options import Options\nfrom .helpers import _process_tools_arg, _process_active_tools, _glyph_function\n\nDEFAULT_TOOLS = \"pan,wheel_zoom,reset,help\"\n\nclass GMapFigureOptions(Options):\n\n tools = Either(String, Seq(Either(String, Instance(Tool))), default=DEFAULT_TOOLS, help=\"\"\"\n Tools the plot should start with.\n \"\"\")\n\n x_minor_ticks = Either(Auto, Int, default=\"auto\", help=\"\"\"\n Number of minor ticks between adjacent x-axis major ticks.\n \"\"\")\n\n y_minor_ticks = Either(Auto, Int, default=\"auto\", help=\"\"\"\n Number of minor ticks between adjacent y-axis major ticks.\n \"\"\")\n\n x_axis_location = Enum(VerticalLocation, default=\"below\", help=\"\"\"\n Where the x-axis should be located.\n \"\"\")\n\n y_axis_location = Enum(HorizontalLocation, default=\"left\", help=\"\"\"\n Where the y-axis should be located.\n \"\"\")\n\n x_axis_label = String(default=\"\", help=\"\"\"\n A label for the x-axis.\n \"\"\")\n\n y_axis_label = String(default=\"\", help=\"\"\"\n A label for the y-axis.\n \"\"\")\n\n active_drag = Either(Auto, String, Instance(Drag), default=\"auto\", help=\"\"\"\n Which drag tool should initially be active.\n \"\"\")\n\n active_inspect = Either(Auto, String, Instance(Inspection), Seq(Instance(Inspection)), default=\"auto\", help=\"\"\"\n Which drag tool should initially be active.\n \"\"\")\n\n active_scroll = Either(Auto, String, Instance(Scroll), default=\"auto\", help=\"\"\"\n Which scroll tool should initially be active.\n \"\"\")\n\n active_tap = Either(Auto, String, Instance(Tap), default=\"auto\", help=\"\"\"\n Which tap tool should initially be active.\n \"\"\")\n\nclass GMap(GMapPlot):\n ''' A subclass of :class:`~bokeh.models.plots.Plot` that simplifies plot\n creation with default axes, grids, tools, etc.\n\n In addition to all the Bokeh model property attributes documented below,\n the ``Figure`` initializer also accepts the following options, which can\n help simplify configuration:\n\n .. bokeh-options:: GMapFigureOptions\n :module: bokeh.plotting.figure\n\n '''\n\n __subtype__ = \"GMap\"\n __view_model__ = \"GMapPlot\"\n\n def __init__(self, google_api_key, map_options, **kw):\n\n if 'plot_width' in kw and 'width' in kw:\n raise ValueError(\"Figure called with both 'plot_width' and 'width' supplied, supply only one\")\n if 'plot_height' in kw and 'height' in kw:\n raise ValueError(\"Figure called with both 'plot_height' and 'height' supplied, supply only one\")\n if 'height' in kw:\n kw['plot_height'] = kw.pop('height')\n if 'width' in kw:\n kw['plot_width'] = kw.pop('width')\n\n opts = GMapFigureOptions(kw)\n\n title = kw.get(\"title\", None)\n if isinstance(title, string_types):\n kw['title'] = Title(text=title)\n\n super(GMap, self).__init__(api_key=google_api_key, map_options=map_options,\n x_range=Range1d(), y_range=Range1d(), **kw)\n\n xf = MercatorTickFormatter(dimension=\"lon\")\n xt = MercatorTicker(dimension=\"lon\")\n self.add_layout(LinearAxis(formatter=xf, ticker=xt), 'below')\n\n yf = MercatorTickFormatter(dimension=\"lat\")\n yt = MercatorTicker(dimension=\"lat\")\n self.add_layout(LinearAxis(formatter=yf, ticker=yt), 'left')\n\n tool_objs, tool_map = _process_tools_arg(self, opts.tools)\n self.add_tools(*tool_objs)\n _process_active_tools(self.toolbar, tool_map, opts.active_drag, opts.active_inspect, opts.active_scroll, opts.active_tap)\n\n annular_wedge = _glyph_function(glyphs.AnnularWedge)\n\n annulus = _glyph_function(glyphs.Annulus)\n\n arc = _glyph_function(glyphs.Arc)\n\n asterisk = _glyph_function(markers.Asterisk)\n\n bezier = _glyph_function(glyphs.Bezier)\n\n circle = _glyph_function(markers.Circle)\n\n circle_cross = _glyph_function(markers.CircleCross)\n\n circle_x = _glyph_function(markers.CircleX)\n\n cross = _glyph_function(markers.Cross)\n\n diamond = _glyph_function(markers.Diamond)\n\n diamond_cross = _glyph_function(markers.DiamondCross)\n\n hbar = _glyph_function(glyphs.HBar)\n\n ellipse = _glyph_function(glyphs.Ellipse)\n\n image = _glyph_function(glyphs.Image)\n\n image_rgba = _glyph_function(glyphs.ImageRGBA)\n\n image_url = _glyph_function(glyphs.ImageURL)\n\n inverted_triangle = _glyph_function(markers.InvertedTriangle)\n\n line = _glyph_function(glyphs.Line)\n\n multi_line = _glyph_function(glyphs.MultiLine)\n\n oval = _glyph_function(glyphs.Oval)\n\n patch = _glyph_function(glyphs.Patch)\n\n patches = _glyph_function(glyphs.Patches)\n\n quad = _glyph_function(glyphs.Quad)\n\n quadratic = _glyph_function(glyphs.Quadratic)\n\n ray = _glyph_function(glyphs.Ray)\n\n rect = _glyph_function(glyphs.Rect)\n\n segment = _glyph_function(glyphs.Segment)\n\n square = _glyph_function(markers.Square)\n\n square_cross = _glyph_function(markers.SquareCross)\n\n square_x = _glyph_function(markers.SquareX)\n\n text = _glyph_function(glyphs.Text)\n\n triangle = _glyph_function(markers.Triangle)\n\n vbar = _glyph_function(glyphs.VBar)\n\n wedge = _glyph_function(glyphs.Wedge)\n\n x = _glyph_function(markers.X)\n\ndef gmap(google_api_key, map_options, **kwargs):\n ''' Create a new :class:`~bokeh.plotting.gmap.GMap` for plotting.\n\n Args:\n google_api_key (str):\n Google requires an API key be supplied for maps to function. See:\n\n https://developers.google.com/maps/documentation/javascript/get-api-key\n\n map_options: (GMapOptions)\n Configuration specific to a Google Map\n\n In addition to the standard :class:`~bokeh.plotting.gmap.GMap` keyword\n arguments (e.g. ``plot_width`` or ``sizing_mode``), the following\n additional options can be passed as well:\n\n .. bokeh-options:: GMapFigureOptions\n :module: bokeh.plotting.gmap\n\n Returns:\n GMap\n\n '''\n\n return GMap(google_api_key, map_options, **kwargs)\n", "path": "bokeh/plotting/gmap.py"}], "after_files": [{"content": "from __future__ import absolute_import, print_function\n\nimport logging\nlogger = logging.getLogger(__name__)\n\nfrom six import string_types\n\nfrom ..core.enums import HorizontalLocation, VerticalLocation\nfrom ..core.properties import Auto, Either, Enum, Int, Seq, Instance, String\nfrom ..models import GMapPlot, LinearAxis, MercatorTicker, MercatorTickFormatter, Range1d, Title, Tool\nfrom ..models import glyphs, markers\nfrom ..models.tools import Drag, Inspection, Scroll, Tap\nfrom ..util.options import Options\nfrom .helpers import _process_tools_arg, _process_active_tools, _glyph_function\n\nDEFAULT_TOOLS = \"pan,wheel_zoom,reset,help\"\n\nclass GMapFigureOptions(Options):\n\n tools = Either(String, Seq(Either(String, Instance(Tool))), default=DEFAULT_TOOLS, help=\"\"\"\n Tools the plot should start with.\n \"\"\")\n\n x_minor_ticks = Either(Auto, Int, default=\"auto\", help=\"\"\"\n Number of minor ticks between adjacent x-axis major ticks.\n \"\"\")\n\n y_minor_ticks = Either(Auto, Int, default=\"auto\", help=\"\"\"\n Number of minor ticks between adjacent y-axis major ticks.\n \"\"\")\n\n x_axis_location = Enum(VerticalLocation, default=\"below\", help=\"\"\"\n Where the x-axis should be located.\n \"\"\")\n\n y_axis_location = Enum(HorizontalLocation, default=\"left\", help=\"\"\"\n Where the y-axis should be located.\n \"\"\")\n\n x_axis_label = String(default=\"\", help=\"\"\"\n A label for the x-axis.\n \"\"\")\n\n y_axis_label = String(default=\"\", help=\"\"\"\n A label for the y-axis.\n \"\"\")\n\n active_drag = Either(Auto, String, Instance(Drag), default=\"auto\", help=\"\"\"\n Which drag tool should initially be active.\n \"\"\")\n\n active_inspect = Either(Auto, String, Instance(Inspection), Seq(Instance(Inspection)), default=\"auto\", help=\"\"\"\n Which drag tool should initially be active.\n \"\"\")\n\n active_scroll = Either(Auto, String, Instance(Scroll), default=\"auto\", help=\"\"\"\n Which scroll tool should initially be active.\n \"\"\")\n\n active_tap = Either(Auto, String, Instance(Tap), default=\"auto\", help=\"\"\"\n Which tap tool should initially be active.\n \"\"\")\n\nclass GMap(GMapPlot):\n ''' A subclass of :class:`~bokeh.models.plots.Plot` that simplifies plot\n creation with default axes, grids, tools, etc.\n\n Args:\n google_api_key (str):\n Google requires an API key be supplied for maps to function. See:\n\n https://developers.google.com/maps/documentation/javascript/get-api-key\n\n map_options: (GMapOptions)\n Configuration specific to a Google Map\n\n In addition to all the Bokeh model property attributes documented below,\n the ``Figure`` initializer also accepts the following options, which can\n help simplify configuration:\n\n .. bokeh-options:: GMapFigureOptions\n :module: bokeh.plotting.figure\n\n '''\n\n __subtype__ = \"GMap\"\n __view_model__ = \"GMapPlot\"\n\n def __init__(self, **kw):\n\n if 'plot_width' in kw and 'width' in kw:\n raise ValueError(\"Figure called with both 'plot_width' and 'width' supplied, supply only one\")\n if 'plot_height' in kw and 'height' in kw:\n raise ValueError(\"Figure called with both 'plot_height' and 'height' supplied, supply only one\")\n if 'height' in kw:\n kw['plot_height'] = kw.pop('height')\n if 'width' in kw:\n kw['plot_width'] = kw.pop('width')\n\n opts = GMapFigureOptions(kw)\n\n title = kw.get(\"title\", None)\n if isinstance(title, string_types):\n kw['title'] = Title(text=title)\n\n super(GMap, self).__init__(x_range=Range1d(), y_range=Range1d(), **kw)\n\n xf = MercatorTickFormatter(dimension=\"lon\")\n xt = MercatorTicker(dimension=\"lon\")\n self.add_layout(LinearAxis(formatter=xf, ticker=xt), 'below')\n\n yf = MercatorTickFormatter(dimension=\"lat\")\n yt = MercatorTicker(dimension=\"lat\")\n self.add_layout(LinearAxis(formatter=yf, ticker=yt), 'left')\n\n tool_objs, tool_map = _process_tools_arg(self, opts.tools)\n self.add_tools(*tool_objs)\n _process_active_tools(self.toolbar, tool_map, opts.active_drag, opts.active_inspect, opts.active_scroll, opts.active_tap)\n\n annular_wedge = _glyph_function(glyphs.AnnularWedge)\n\n annulus = _glyph_function(glyphs.Annulus)\n\n arc = _glyph_function(glyphs.Arc)\n\n asterisk = _glyph_function(markers.Asterisk)\n\n bezier = _glyph_function(glyphs.Bezier)\n\n circle = _glyph_function(markers.Circle)\n\n circle_cross = _glyph_function(markers.CircleCross)\n\n circle_x = _glyph_function(markers.CircleX)\n\n cross = _glyph_function(markers.Cross)\n\n diamond = _glyph_function(markers.Diamond)\n\n diamond_cross = _glyph_function(markers.DiamondCross)\n\n hbar = _glyph_function(glyphs.HBar)\n\n ellipse = _glyph_function(glyphs.Ellipse)\n\n image = _glyph_function(glyphs.Image)\n\n image_rgba = _glyph_function(glyphs.ImageRGBA)\n\n image_url = _glyph_function(glyphs.ImageURL)\n\n inverted_triangle = _glyph_function(markers.InvertedTriangle)\n\n line = _glyph_function(glyphs.Line)\n\n multi_line = _glyph_function(glyphs.MultiLine)\n\n oval = _glyph_function(glyphs.Oval)\n\n patch = _glyph_function(glyphs.Patch)\n\n patches = _glyph_function(glyphs.Patches)\n\n quad = _glyph_function(glyphs.Quad)\n\n quadratic = _glyph_function(glyphs.Quadratic)\n\n ray = _glyph_function(glyphs.Ray)\n\n rect = _glyph_function(glyphs.Rect)\n\n segment = _glyph_function(glyphs.Segment)\n\n square = _glyph_function(markers.Square)\n\n square_cross = _glyph_function(markers.SquareCross)\n\n square_x = _glyph_function(markers.SquareX)\n\n text = _glyph_function(glyphs.Text)\n\n triangle = _glyph_function(markers.Triangle)\n\n vbar = _glyph_function(glyphs.VBar)\n\n wedge = _glyph_function(glyphs.Wedge)\n\n x = _glyph_function(markers.X)\n\ndef gmap(google_api_key, map_options, **kwargs):\n ''' Create a new :class:`~bokeh.plotting.gmap.GMap` for plotting.\n\n Args:\n google_api_key (str):\n Google requires an API key be supplied for maps to function. See:\n\n https://developers.google.com/maps/documentation/javascript/get-api-key\n\n map_options: (GMapOptions)\n Configuration specific to a Google Map\n\n In addition to the standard :class:`~bokeh.plotting.gmap.GMap` keyword\n arguments (e.g. ``plot_width`` or ``sizing_mode``), the following\n additional options can be passed as well:\n\n .. bokeh-options:: GMapFigureOptions\n :module: bokeh.plotting.gmap\n\n Returns:\n GMap\n\n '''\n\n return GMap(api_key=google_api_key, map_options=map_options, **kwargs)\n", "path": "bokeh/plotting/gmap.py"}]}
| 3,140 | 473 |
gh_patches_debug_3570
|
rasdani/github-patches
|
git_diff
|
pystiche__pystiche-479
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
the default value for allow_inplace changed from False to True
This change was added in #392
# Before
https://github.com/pmeier/pystiche/blob/950b84837df26a0cab2f9f2714884655173206bf/pystiche/enc/models/vgg.py#L149
https://github.com/pmeier/pystiche/blob/950b84837df26a0cab2f9f2714884655173206bf/pystiche/enc/models/alexnet.py#L38
# After
https://github.com/pmeier/pystiche/blob/3fd3504b94d6bce5389784abea9e91d23c5fb153/pystiche/enc/models/utils.py#L51
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pystiche/enc/models/utils.py`
Content:
```
1 from abc import abstractmethod
2 from typing import Any, Callable, Dict, List, Optional, Tuple, TypeVar, cast
3
4 import torch
5 from torch import hub, nn
6 from torch.nn.modules.module import _IncompatibleKeys
7
8 from ..multi_layer_encoder import MultiLayerEncoder
9 from ..prepostprocessing import preprocessing
10
11 __all__ = ["ModelMultiLayerEncoder", "select_url"]
12
13 T = TypeVar("T")
14
15
16 def select_url(
17 urls: Dict[T, str], key: T, format: Optional[Callable[[T], str]] = None
18 ) -> str:
19 if format is None:
20 format = str
21
22 try:
23 return urls[key]
24 except KeyError as error:
25 raise RuntimeError(f"No URL is available for\n\n{format(key)}") from error
26
27
28 class ModelMultiLayerEncoder(MultiLayerEncoder):
29 r"""Multi-layer encoder based on a pre-defined model.
30
31 Args:
32 pretrained: If ``True``, loads builtin weights. Defaults to ``True``.
33 framework: Name of the framework that was used to train the builtin weights.
34 Defaults to ``"torch"``.
35 internal_preprocessing: If ``True``, adds a preprocessing layer for the
36 selected ``framework`` as first layer. Defaults to ``True``.
37 allow_inplace: If ``True``, allows inplace operations to reduce the memory
38 requirement during the forward pass. Defaults to ``False``.
39
40 .. warning::
41 After performing an inplace operation the encodings of the previous
42 layer is no longer accessible. Only use this if you are sure that you
43 do **not** need these encodings.
44 """
45
46 def __init__(
47 self,
48 pretrained: bool = True,
49 framework: str = "torch",
50 internal_preprocessing: bool = True,
51 allow_inplace: bool = True,
52 ) -> None:
53 self.pretrained = pretrained
54 self.framework = framework
55 self.internal_preprocessing = internal_preprocessing
56 self.allow_inplace = allow_inplace
57
58 modules, self._state_dict_key_map = self.collect_modules(allow_inplace)
59 if internal_preprocessing:
60 modules.insert(0, ("preprocessing", preprocessing(framework)))
61
62 super().__init__(modules)
63
64 if pretrained:
65 self.load_state_dict_from_url(framework)
66
67 @abstractmethod
68 def state_dict_url(self, framework: str) -> str:
69 r"""Select URL of a downloadable ``state_dict``.
70
71 Args:
72 framework: Name of the framework that was used to train the weights.
73
74 Raises:
75 RuntimeError: If no ``state_dict`` is available.
76 """
77 pass
78
79 @abstractmethod
80 def collect_modules(
81 self, inplace: bool
82 ) -> Tuple[List[Tuple[str, nn.Module]], Dict[str, str]]:
83 r"""Collect modules of a base model with more descriptive names.
84
85 Args:
86 inplace: If ``True``, when possible, modules should use inplace operations.
87
88 Returns:
89 List of name-module-pairs as well as a dictionary mapping the new, more
90 descriptive names to the original ones.
91 """
92 pass
93
94 def _map_state_dict_keys(
95 self, state_dict: Dict[str, torch.Tensor]
96 ) -> Tuple[Dict[str, torch.Tensor], List[str]]:
97 remapped_state_dict = {}
98 unexpected_keys = []
99 for key, value in state_dict.items():
100 if key in self._state_dict_key_map:
101 remapped_state_dict[self._state_dict_key_map[key]] = value
102 else:
103 unexpected_keys.append(key)
104
105 return remapped_state_dict, unexpected_keys
106
107 def load_state_dict(
108 self,
109 state_dict: Dict[str, torch.Tensor],
110 strict: bool = True,
111 map_names: bool = True,
112 framework: str = "unknown",
113 ) -> _IncompatibleKeys:
114 r"""Loads parameters and buffers from the ``state_dict``.
115
116 Args:
117 state_dict: State dictionary.
118 strict: Enforce matching keys in ``state_dict`` and the internal states.
119 map_names: If ``True``, maps the names names in ``state_dict`` of the
120 underlying model to the more descriptive names generated by
121 :meth:`collect_modules`. Defaults to ``True``.
122 framework: Name of the framework that was used to train the weights in
123 ``state_dict``. Defaults to ``"unknown"``.
124
125 .. note::
126
127 This has no effect on the behavior, but makes the representation
128 of the :class:`ModelMultiLayerEncoder` more descriptive.
129
130 Returns:
131 Named tuple with ``missing_keys`` and ``unexpected_keys`` fields.
132
133 .. seealso::
134
135 :meth:`torch.nn.Module.load_state_dict`
136 """
137 if map_names:
138 state_dict, unexpected_keys = self._map_state_dict_keys(state_dict)
139 else:
140 unexpected_keys = []
141
142 keys = cast(
143 _IncompatibleKeys, super().load_state_dict(state_dict, strict=strict)
144 )
145 keys.unexpected_keys.extend(unexpected_keys)
146
147 self.pretrained = True
148 self.framework = framework
149
150 return keys
151
152 def load_state_dict_from_url(
153 self,
154 framework: str,
155 strict: bool = True,
156 map_names: bool = True,
157 check_hash: bool = True,
158 **kwargs: Any,
159 ) -> None:
160 r"""Downloads and loads parameters and buffers trained with ``framework``.
161
162 Args:
163 framework: Name of the framework that was used to train the weights of the
164 ``state_dict``.
165 strict: Enforce matching keys in ``state_dict`` and the internal states.
166 map_names: If ``True``, maps the names names in ``state_dict`` of the
167 underlying model to the more descriptive names generated by
168 :meth:`collect_modules`. Defaults to ``True``.
169 check_hash: If ``True``, checks if the hash postfix of the URL matches the
170 SHA256 hash of the downloaded ``state_dict``. Defaults to ``True``.
171 kwargs: Optional arguments for :meth:`torch.hub.load_state_dict_from_url` .
172
173 .. seealso::
174
175 - :meth:`state_dict_url`
176 - :meth:`load_state_dict`
177 - :meth:`torch.hub.load_state_dict_from_url`
178 """
179 url = self.state_dict_url(framework)
180 state_dict = hub.load_state_dict_from_url(url, check_hash=check_hash, **kwargs)
181 self.load_state_dict(
182 state_dict, strict=strict, map_names=map_names, framework=framework
183 )
184
185 def _properties(self) -> Dict[str, Any]:
186 dct = super()._properties()
187 if not self.pretrained:
188 dct["pretrained"] = False
189 else:
190 dct["framework"] = self.framework
191 if not self.internal_preprocessing:
192 dct["internal_preprocessing"] = self.internal_preprocessing
193 if self.allow_inplace:
194 dct["allow_inplace"] = self.allow_inplace
195 return dct
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pystiche/enc/models/utils.py b/pystiche/enc/models/utils.py
--- a/pystiche/enc/models/utils.py
+++ b/pystiche/enc/models/utils.py
@@ -48,7 +48,7 @@
pretrained: bool = True,
framework: str = "torch",
internal_preprocessing: bool = True,
- allow_inplace: bool = True,
+ allow_inplace: bool = False,
) -> None:
self.pretrained = pretrained
self.framework = framework
|
{"golden_diff": "diff --git a/pystiche/enc/models/utils.py b/pystiche/enc/models/utils.py\n--- a/pystiche/enc/models/utils.py\n+++ b/pystiche/enc/models/utils.py\n@@ -48,7 +48,7 @@\n pretrained: bool = True,\n framework: str = \"torch\",\n internal_preprocessing: bool = True,\n- allow_inplace: bool = True,\n+ allow_inplace: bool = False,\n ) -> None:\n self.pretrained = pretrained\n self.framework = framework\n", "issue": "the default value for allow_inplace changed from False to True\nThis change was added in #392 \r\n\r\n# Before\r\n\r\nhttps://github.com/pmeier/pystiche/blob/950b84837df26a0cab2f9f2714884655173206bf/pystiche/enc/models/vgg.py#L149\r\n\r\nhttps://github.com/pmeier/pystiche/blob/950b84837df26a0cab2f9f2714884655173206bf/pystiche/enc/models/alexnet.py#L38\r\n\r\n# After\r\n\r\nhttps://github.com/pmeier/pystiche/blob/3fd3504b94d6bce5389784abea9e91d23c5fb153/pystiche/enc/models/utils.py#L51\n", "before_files": [{"content": "from abc import abstractmethod\nfrom typing import Any, Callable, Dict, List, Optional, Tuple, TypeVar, cast\n\nimport torch\nfrom torch import hub, nn\nfrom torch.nn.modules.module import _IncompatibleKeys\n\nfrom ..multi_layer_encoder import MultiLayerEncoder\nfrom ..prepostprocessing import preprocessing\n\n__all__ = [\"ModelMultiLayerEncoder\", \"select_url\"]\n\nT = TypeVar(\"T\")\n\n\ndef select_url(\n urls: Dict[T, str], key: T, format: Optional[Callable[[T], str]] = None\n) -> str:\n if format is None:\n format = str\n\n try:\n return urls[key]\n except KeyError as error:\n raise RuntimeError(f\"No URL is available for\\n\\n{format(key)}\") from error\n\n\nclass ModelMultiLayerEncoder(MultiLayerEncoder):\n r\"\"\"Multi-layer encoder based on a pre-defined model.\n\n Args:\n pretrained: If ``True``, loads builtin weights. Defaults to ``True``.\n framework: Name of the framework that was used to train the builtin weights.\n Defaults to ``\"torch\"``.\n internal_preprocessing: If ``True``, adds a preprocessing layer for the\n selected ``framework`` as first layer. Defaults to ``True``.\n allow_inplace: If ``True``, allows inplace operations to reduce the memory\n requirement during the forward pass. Defaults to ``False``.\n\n .. warning::\n After performing an inplace operation the encodings of the previous\n layer is no longer accessible. Only use this if you are sure that you\n do **not** need these encodings.\n \"\"\"\n\n def __init__(\n self,\n pretrained: bool = True,\n framework: str = \"torch\",\n internal_preprocessing: bool = True,\n allow_inplace: bool = True,\n ) -> None:\n self.pretrained = pretrained\n self.framework = framework\n self.internal_preprocessing = internal_preprocessing\n self.allow_inplace = allow_inplace\n\n modules, self._state_dict_key_map = self.collect_modules(allow_inplace)\n if internal_preprocessing:\n modules.insert(0, (\"preprocessing\", preprocessing(framework)))\n\n super().__init__(modules)\n\n if pretrained:\n self.load_state_dict_from_url(framework)\n\n @abstractmethod\n def state_dict_url(self, framework: str) -> str:\n r\"\"\"Select URL of a downloadable ``state_dict``.\n\n Args:\n framework: Name of the framework that was used to train the weights.\n\n Raises:\n RuntimeError: If no ``state_dict`` is available.\n \"\"\"\n pass\n\n @abstractmethod\n def collect_modules(\n self, inplace: bool\n ) -> Tuple[List[Tuple[str, nn.Module]], Dict[str, str]]:\n r\"\"\"Collect modules of a base model with more descriptive names.\n\n Args:\n inplace: If ``True``, when possible, modules should use inplace operations.\n\n Returns:\n List of name-module-pairs as well as a dictionary mapping the new, more\n descriptive names to the original ones.\n \"\"\"\n pass\n\n def _map_state_dict_keys(\n self, state_dict: Dict[str, torch.Tensor]\n ) -> Tuple[Dict[str, torch.Tensor], List[str]]:\n remapped_state_dict = {}\n unexpected_keys = []\n for key, value in state_dict.items():\n if key in self._state_dict_key_map:\n remapped_state_dict[self._state_dict_key_map[key]] = value\n else:\n unexpected_keys.append(key)\n\n return remapped_state_dict, unexpected_keys\n\n def load_state_dict(\n self,\n state_dict: Dict[str, torch.Tensor],\n strict: bool = True,\n map_names: bool = True,\n framework: str = \"unknown\",\n ) -> _IncompatibleKeys:\n r\"\"\"Loads parameters and buffers from the ``state_dict``.\n\n Args:\n state_dict: State dictionary.\n strict: Enforce matching keys in ``state_dict`` and the internal states.\n map_names: If ``True``, maps the names names in ``state_dict`` of the\n underlying model to the more descriptive names generated by\n :meth:`collect_modules`. Defaults to ``True``.\n framework: Name of the framework that was used to train the weights in\n ``state_dict``. Defaults to ``\"unknown\"``.\n\n .. note::\n\n This has no effect on the behavior, but makes the representation\n of the :class:`ModelMultiLayerEncoder` more descriptive.\n\n Returns:\n Named tuple with ``missing_keys`` and ``unexpected_keys`` fields.\n\n .. seealso::\n\n :meth:`torch.nn.Module.load_state_dict`\n \"\"\"\n if map_names:\n state_dict, unexpected_keys = self._map_state_dict_keys(state_dict)\n else:\n unexpected_keys = []\n\n keys = cast(\n _IncompatibleKeys, super().load_state_dict(state_dict, strict=strict)\n )\n keys.unexpected_keys.extend(unexpected_keys)\n\n self.pretrained = True\n self.framework = framework\n\n return keys\n\n def load_state_dict_from_url(\n self,\n framework: str,\n strict: bool = True,\n map_names: bool = True,\n check_hash: bool = True,\n **kwargs: Any,\n ) -> None:\n r\"\"\"Downloads and loads parameters and buffers trained with ``framework``.\n\n Args:\n framework: Name of the framework that was used to train the weights of the\n ``state_dict``.\n strict: Enforce matching keys in ``state_dict`` and the internal states.\n map_names: If ``True``, maps the names names in ``state_dict`` of the\n underlying model to the more descriptive names generated by\n :meth:`collect_modules`. Defaults to ``True``.\n check_hash: If ``True``, checks if the hash postfix of the URL matches the\n SHA256 hash of the downloaded ``state_dict``. Defaults to ``True``.\n kwargs: Optional arguments for :meth:`torch.hub.load_state_dict_from_url` .\n\n .. seealso::\n\n - :meth:`state_dict_url`\n - :meth:`load_state_dict`\n - :meth:`torch.hub.load_state_dict_from_url`\n \"\"\"\n url = self.state_dict_url(framework)\n state_dict = hub.load_state_dict_from_url(url, check_hash=check_hash, **kwargs)\n self.load_state_dict(\n state_dict, strict=strict, map_names=map_names, framework=framework\n )\n\n def _properties(self) -> Dict[str, Any]:\n dct = super()._properties()\n if not self.pretrained:\n dct[\"pretrained\"] = False\n else:\n dct[\"framework\"] = self.framework\n if not self.internal_preprocessing:\n dct[\"internal_preprocessing\"] = self.internal_preprocessing\n if self.allow_inplace:\n dct[\"allow_inplace\"] = self.allow_inplace\n return dct\n", "path": "pystiche/enc/models/utils.py"}], "after_files": [{"content": "from abc import abstractmethod\nfrom typing import Any, Callable, Dict, List, Optional, Tuple, TypeVar, cast\n\nimport torch\nfrom torch import hub, nn\nfrom torch.nn.modules.module import _IncompatibleKeys\n\nfrom ..multi_layer_encoder import MultiLayerEncoder\nfrom ..prepostprocessing import preprocessing\n\n__all__ = [\"ModelMultiLayerEncoder\", \"select_url\"]\n\nT = TypeVar(\"T\")\n\n\ndef select_url(\n urls: Dict[T, str], key: T, format: Optional[Callable[[T], str]] = None\n) -> str:\n if format is None:\n format = str\n\n try:\n return urls[key]\n except KeyError as error:\n raise RuntimeError(f\"No URL is available for\\n\\n{format(key)}\") from error\n\n\nclass ModelMultiLayerEncoder(MultiLayerEncoder):\n r\"\"\"Multi-layer encoder based on a pre-defined model.\n\n Args:\n pretrained: If ``True``, loads builtin weights. Defaults to ``True``.\n framework: Name of the framework that was used to train the builtin weights.\n Defaults to ``\"torch\"``.\n internal_preprocessing: If ``True``, adds a preprocessing layer for the\n selected ``framework`` as first layer. Defaults to ``True``.\n allow_inplace: If ``True``, allows inplace operations to reduce the memory\n requirement during the forward pass. Defaults to ``False``.\n\n .. warning::\n After performing an inplace operation the encodings of the previous\n layer is no longer accessible. Only use this if you are sure that you\n do **not** need these encodings.\n \"\"\"\n\n def __init__(\n self,\n pretrained: bool = True,\n framework: str = \"torch\",\n internal_preprocessing: bool = True,\n allow_inplace: bool = False,\n ) -> None:\n self.pretrained = pretrained\n self.framework = framework\n self.internal_preprocessing = internal_preprocessing\n self.allow_inplace = allow_inplace\n\n modules, self._state_dict_key_map = self.collect_modules(allow_inplace)\n if internal_preprocessing:\n modules.insert(0, (\"preprocessing\", preprocessing(framework)))\n\n super().__init__(modules)\n\n if pretrained:\n self.load_state_dict_from_url(framework)\n\n @abstractmethod\n def state_dict_url(self, framework: str) -> str:\n r\"\"\"Select URL of a downloadable ``state_dict``.\n\n Args:\n framework: Name of the framework that was used to train the weights.\n\n Raises:\n RuntimeError: If no ``state_dict`` is available.\n \"\"\"\n pass\n\n @abstractmethod\n def collect_modules(\n self, inplace: bool\n ) -> Tuple[List[Tuple[str, nn.Module]], Dict[str, str]]:\n r\"\"\"Collect modules of a base model with more descriptive names.\n\n Args:\n inplace: If ``True``, when possible, modules should use inplace operations.\n\n Returns:\n List of name-module-pairs as well as a dictionary mapping the new, more\n descriptive names to the original ones.\n \"\"\"\n pass\n\n def _map_state_dict_keys(\n self, state_dict: Dict[str, torch.Tensor]\n ) -> Tuple[Dict[str, torch.Tensor], List[str]]:\n remapped_state_dict = {}\n unexpected_keys = []\n for key, value in state_dict.items():\n if key in self._state_dict_key_map:\n remapped_state_dict[self._state_dict_key_map[key]] = value\n else:\n unexpected_keys.append(key)\n\n return remapped_state_dict, unexpected_keys\n\n def load_state_dict(\n self,\n state_dict: Dict[str, torch.Tensor],\n strict: bool = True,\n map_names: bool = True,\n framework: str = \"unknown\",\n ) -> _IncompatibleKeys:\n r\"\"\"Loads parameters and buffers from the ``state_dict``.\n\n Args:\n state_dict: State dictionary.\n strict: Enforce matching keys in ``state_dict`` and the internal states.\n map_names: If ``True``, maps the names names in ``state_dict`` of the\n underlying model to the more descriptive names generated by\n :meth:`collect_modules`. Defaults to ``True``.\n framework: Name of the framework that was used to train the weights in\n ``state_dict``. Defaults to ``\"unknown\"``.\n\n .. note::\n\n This has no effect on the behavior, but makes the representation\n of the :class:`ModelMultiLayerEncoder` more descriptive.\n\n Returns:\n Named tuple with ``missing_keys`` and ``unexpected_keys`` fields.\n\n .. seealso::\n\n :meth:`torch.nn.Module.load_state_dict`\n \"\"\"\n if map_names:\n state_dict, unexpected_keys = self._map_state_dict_keys(state_dict)\n else:\n unexpected_keys = []\n\n keys = cast(\n _IncompatibleKeys, super().load_state_dict(state_dict, strict=strict)\n )\n keys.unexpected_keys.extend(unexpected_keys)\n\n self.pretrained = True\n self.framework = framework\n\n return keys\n\n def load_state_dict_from_url(\n self,\n framework: str,\n strict: bool = True,\n map_names: bool = True,\n check_hash: bool = True,\n **kwargs: Any,\n ) -> None:\n r\"\"\"Downloads and loads parameters and buffers trained with ``framework``.\n\n Args:\n framework: Name of the framework that was used to train the weights of the\n ``state_dict``.\n strict: Enforce matching keys in ``state_dict`` and the internal states.\n map_names: If ``True``, maps the names names in ``state_dict`` of the\n underlying model to the more descriptive names generated by\n :meth:`collect_modules`. Defaults to ``True``.\n check_hash: If ``True``, checks if the hash postfix of the URL matches the\n SHA256 hash of the downloaded ``state_dict``. Defaults to ``True``.\n kwargs: Optional arguments for :meth:`torch.hub.load_state_dict_from_url` .\n\n .. seealso::\n\n - :meth:`state_dict_url`\n - :meth:`load_state_dict`\n - :meth:`torch.hub.load_state_dict_from_url`\n \"\"\"\n url = self.state_dict_url(framework)\n state_dict = hub.load_state_dict_from_url(url, check_hash=check_hash, **kwargs)\n self.load_state_dict(\n state_dict, strict=strict, map_names=map_names, framework=framework\n )\n\n def _properties(self) -> Dict[str, Any]:\n dct = super()._properties()\n if not self.pretrained:\n dct[\"pretrained\"] = False\n else:\n dct[\"framework\"] = self.framework\n if not self.internal_preprocessing:\n dct[\"internal_preprocessing\"] = self.internal_preprocessing\n if self.allow_inplace:\n dct[\"allow_inplace\"] = self.allow_inplace\n return dct\n", "path": "pystiche/enc/models/utils.py"}]}
| 2,454 | 118 |
gh_patches_debug_24234
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-1318
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Triggering a code reload during a PDB session breaks terminal input
Pylons and Django hit the same issue: https://github.com/Pylons/pyramid/issues/689
PR incoming to do exactly what they did 🤷♂️
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `werkzeug/_reloader.py`
Content:
```
1 import os
2 import sys
3 import time
4 import subprocess
5 import threading
6 from itertools import chain
7
8 from werkzeug._internal import _log
9 from werkzeug._compat import PY2, iteritems, text_type
10
11
12 def _iter_module_files():
13 """This iterates over all relevant Python files. It goes through all
14 loaded files from modules, all files in folders of already loaded modules
15 as well as all files reachable through a package.
16 """
17 # The list call is necessary on Python 3 in case the module
18 # dictionary modifies during iteration.
19 for module in list(sys.modules.values()):
20 if module is None:
21 continue
22 filename = getattr(module, '__file__', None)
23 if filename:
24 if os.path.isdir(filename) and \
25 os.path.exists(os.path.join(filename, "__init__.py")):
26 filename = os.path.join(filename, "__init__.py")
27
28 old = None
29 while not os.path.isfile(filename):
30 old = filename
31 filename = os.path.dirname(filename)
32 if filename == old:
33 break
34 else:
35 if filename[-4:] in ('.pyc', '.pyo'):
36 filename = filename[:-1]
37 yield filename
38
39
40 def _find_observable_paths(extra_files=None):
41 """Finds all paths that should be observed."""
42 rv = set(os.path.dirname(os.path.abspath(x))
43 if os.path.isfile(x) else os.path.abspath(x)
44 for x in sys.path)
45
46 for filename in extra_files or ():
47 rv.add(os.path.dirname(os.path.abspath(filename)))
48
49 for module in list(sys.modules.values()):
50 fn = getattr(module, '__file__', None)
51 if fn is None:
52 continue
53 fn = os.path.abspath(fn)
54 rv.add(os.path.dirname(fn))
55
56 return _find_common_roots(rv)
57
58
59 def _get_args_for_reloading():
60 """Returns the executable. This contains a workaround for windows
61 if the executable is incorrectly reported to not have the .exe
62 extension which can cause bugs on reloading.
63 """
64 rv = [sys.executable]
65 py_script = sys.argv[0]
66 if os.name == 'nt' and not os.path.exists(py_script) and \
67 os.path.exists(py_script + '.exe'):
68 py_script += '.exe'
69 if os.path.splitext(rv[0])[1] == '.exe' and os.path.splitext(py_script)[1] == '.exe':
70 rv.pop(0)
71 rv.append(py_script)
72 rv.extend(sys.argv[1:])
73 return rv
74
75
76 def _find_common_roots(paths):
77 """Out of some paths it finds the common roots that need monitoring."""
78 paths = [x.split(os.path.sep) for x in paths]
79 root = {}
80 for chunks in sorted(paths, key=len, reverse=True):
81 node = root
82 for chunk in chunks:
83 node = node.setdefault(chunk, {})
84 node.clear()
85
86 rv = set()
87
88 def _walk(node, path):
89 for prefix, child in iteritems(node):
90 _walk(child, path + (prefix,))
91 if not node:
92 rv.add('/'.join(path))
93 _walk(root, ())
94 return rv
95
96
97 class ReloaderLoop(object):
98 name = None
99
100 # monkeypatched by testsuite. wrapping with `staticmethod` is required in
101 # case time.sleep has been replaced by a non-c function (e.g. by
102 # `eventlet.monkey_patch`) before we get here
103 _sleep = staticmethod(time.sleep)
104
105 def __init__(self, extra_files=None, interval=1):
106 self.extra_files = set(os.path.abspath(x)
107 for x in extra_files or ())
108 self.interval = interval
109
110 def run(self):
111 pass
112
113 def restart_with_reloader(self):
114 """Spawn a new Python interpreter with the same arguments as this one,
115 but running the reloader thread.
116 """
117 while 1:
118 _log('info', ' * Restarting with %s' % self.name)
119 args = _get_args_for_reloading()
120 new_environ = os.environ.copy()
121 new_environ['WERKZEUG_RUN_MAIN'] = 'true'
122
123 # a weird bug on windows. sometimes unicode strings end up in the
124 # environment and subprocess.call does not like this, encode them
125 # to latin1 and continue.
126 if os.name == 'nt' and PY2:
127 for key, value in iteritems(new_environ):
128 if isinstance(value, text_type):
129 new_environ[key] = value.encode('iso-8859-1')
130
131 exit_code = subprocess.call(args, env=new_environ,
132 close_fds=False)
133 if exit_code != 3:
134 return exit_code
135
136 def trigger_reload(self, filename):
137 self.log_reload(filename)
138 sys.exit(3)
139
140 def log_reload(self, filename):
141 filename = os.path.abspath(filename)
142 _log('info', ' * Detected change in %r, reloading' % filename)
143
144
145 class StatReloaderLoop(ReloaderLoop):
146 name = 'stat'
147
148 def run(self):
149 mtimes = {}
150 while 1:
151 for filename in chain(_iter_module_files(),
152 self.extra_files):
153 try:
154 mtime = os.stat(filename).st_mtime
155 except OSError:
156 continue
157
158 old_time = mtimes.get(filename)
159 if old_time is None:
160 mtimes[filename] = mtime
161 continue
162 elif mtime > old_time:
163 self.trigger_reload(filename)
164 self._sleep(self.interval)
165
166
167 class WatchdogReloaderLoop(ReloaderLoop):
168
169 def __init__(self, *args, **kwargs):
170 ReloaderLoop.__init__(self, *args, **kwargs)
171 from watchdog.observers import Observer
172 from watchdog.events import FileSystemEventHandler
173 self.observable_paths = set()
174
175 def _check_modification(filename):
176 if filename in self.extra_files:
177 self.trigger_reload(filename)
178 dirname = os.path.dirname(filename)
179 if dirname.startswith(tuple(self.observable_paths)):
180 if filename.endswith(('.pyc', '.pyo', '.py')):
181 self.trigger_reload(filename)
182
183 class _CustomHandler(FileSystemEventHandler):
184
185 def on_created(self, event):
186 _check_modification(event.src_path)
187
188 def on_modified(self, event):
189 _check_modification(event.src_path)
190
191 def on_moved(self, event):
192 _check_modification(event.src_path)
193 _check_modification(event.dest_path)
194
195 def on_deleted(self, event):
196 _check_modification(event.src_path)
197
198 reloader_name = Observer.__name__.lower()
199 if reloader_name.endswith('observer'):
200 reloader_name = reloader_name[:-8]
201 reloader_name += ' reloader'
202
203 self.name = reloader_name
204
205 self.observer_class = Observer
206 self.event_handler = _CustomHandler()
207 self.should_reload = False
208
209 def trigger_reload(self, filename):
210 # This is called inside an event handler, which means throwing
211 # SystemExit has no effect.
212 # https://github.com/gorakhargosh/watchdog/issues/294
213 self.should_reload = True
214 self.log_reload(filename)
215
216 def run(self):
217 watches = {}
218 observer = self.observer_class()
219 observer.start()
220
221 try:
222 while not self.should_reload:
223 to_delete = set(watches)
224 paths = _find_observable_paths(self.extra_files)
225 for path in paths:
226 if path not in watches:
227 try:
228 watches[path] = observer.schedule(
229 self.event_handler, path, recursive=True)
230 except OSError:
231 # Clear this path from list of watches We don't want
232 # the same error message showing again in the next
233 # iteration.
234 watches[path] = None
235 to_delete.discard(path)
236 for path in to_delete:
237 watch = watches.pop(path, None)
238 if watch is not None:
239 observer.unschedule(watch)
240 self.observable_paths = paths
241 self._sleep(self.interval)
242 finally:
243 observer.stop()
244 observer.join()
245
246 sys.exit(3)
247
248
249 reloader_loops = {
250 'stat': StatReloaderLoop,
251 'watchdog': WatchdogReloaderLoop,
252 }
253
254 try:
255 __import__('watchdog.observers')
256 except ImportError:
257 reloader_loops['auto'] = reloader_loops['stat']
258 else:
259 reloader_loops['auto'] = reloader_loops['watchdog']
260
261
262 def run_with_reloader(main_func, extra_files=None, interval=1,
263 reloader_type='auto'):
264 """Run the given function in an independent python interpreter."""
265 import signal
266 reloader = reloader_loops[reloader_type](extra_files, interval)
267 signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))
268 try:
269 if os.environ.get('WERKZEUG_RUN_MAIN') == 'true':
270 t = threading.Thread(target=main_func, args=())
271 t.setDaemon(True)
272 t.start()
273 reloader.run()
274 else:
275 sys.exit(reloader.restart_with_reloader())
276 except KeyboardInterrupt:
277 pass
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/werkzeug/_reloader.py b/werkzeug/_reloader.py
--- a/werkzeug/_reloader.py
+++ b/werkzeug/_reloader.py
@@ -259,6 +259,22 @@
reloader_loops['auto'] = reloader_loops['watchdog']
+def ensure_echo_on():
+ """Ensure that echo mode is enabled. Some tools such as PDB disable
+ it which causes usability issues after reload."""
+ # tcgetattr will fail if stdin isn't a tty
+ if not sys.stdin.isatty():
+ return
+ try:
+ import termios
+ except ImportError:
+ return
+ attributes = termios.tcgetattr(sys.stdin)
+ if not attributes[3] & termios.ECHO:
+ attributes[3] |= termios.ECHO
+ termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)
+
+
def run_with_reloader(main_func, extra_files=None, interval=1,
reloader_type='auto'):
"""Run the given function in an independent python interpreter."""
@@ -267,6 +283,7 @@
signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))
try:
if os.environ.get('WERKZEUG_RUN_MAIN') == 'true':
+ ensure_echo_on()
t = threading.Thread(target=main_func, args=())
t.setDaemon(True)
t.start()
|
{"golden_diff": "diff --git a/werkzeug/_reloader.py b/werkzeug/_reloader.py\n--- a/werkzeug/_reloader.py\n+++ b/werkzeug/_reloader.py\n@@ -259,6 +259,22 @@\n reloader_loops['auto'] = reloader_loops['watchdog']\n \n \n+def ensure_echo_on():\n+ \"\"\"Ensure that echo mode is enabled. Some tools such as PDB disable\n+ it which causes usability issues after reload.\"\"\"\n+ # tcgetattr will fail if stdin isn't a tty\n+ if not sys.stdin.isatty():\n+ return\n+ try:\n+ import termios\n+ except ImportError:\n+ return\n+ attributes = termios.tcgetattr(sys.stdin)\n+ if not attributes[3] & termios.ECHO:\n+ attributes[3] |= termios.ECHO\n+ termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)\n+\n+\n def run_with_reloader(main_func, extra_files=None, interval=1,\n reloader_type='auto'):\n \"\"\"Run the given function in an independent python interpreter.\"\"\"\n@@ -267,6 +283,7 @@\n signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))\n try:\n if os.environ.get('WERKZEUG_RUN_MAIN') == 'true':\n+ ensure_echo_on()\n t = threading.Thread(target=main_func, args=())\n t.setDaemon(True)\n t.start()\n", "issue": "Triggering a code reload during a PDB session breaks terminal input\nPylons and Django hit the same issue: https://github.com/Pylons/pyramid/issues/689\r\n\r\nPR incoming to do exactly what they did \ud83e\udd37\u200d\u2642\ufe0f\n", "before_files": [{"content": "import os\nimport sys\nimport time\nimport subprocess\nimport threading\nfrom itertools import chain\n\nfrom werkzeug._internal import _log\nfrom werkzeug._compat import PY2, iteritems, text_type\n\n\ndef _iter_module_files():\n \"\"\"This iterates over all relevant Python files. It goes through all\n loaded files from modules, all files in folders of already loaded modules\n as well as all files reachable through a package.\n \"\"\"\n # The list call is necessary on Python 3 in case the module\n # dictionary modifies during iteration.\n for module in list(sys.modules.values()):\n if module is None:\n continue\n filename = getattr(module, '__file__', None)\n if filename:\n if os.path.isdir(filename) and \\\n os.path.exists(os.path.join(filename, \"__init__.py\")):\n filename = os.path.join(filename, \"__init__.py\")\n\n old = None\n while not os.path.isfile(filename):\n old = filename\n filename = os.path.dirname(filename)\n if filename == old:\n break\n else:\n if filename[-4:] in ('.pyc', '.pyo'):\n filename = filename[:-1]\n yield filename\n\n\ndef _find_observable_paths(extra_files=None):\n \"\"\"Finds all paths that should be observed.\"\"\"\n rv = set(os.path.dirname(os.path.abspath(x))\n if os.path.isfile(x) else os.path.abspath(x)\n for x in sys.path)\n\n for filename in extra_files or ():\n rv.add(os.path.dirname(os.path.abspath(filename)))\n\n for module in list(sys.modules.values()):\n fn = getattr(module, '__file__', None)\n if fn is None:\n continue\n fn = os.path.abspath(fn)\n rv.add(os.path.dirname(fn))\n\n return _find_common_roots(rv)\n\n\ndef _get_args_for_reloading():\n \"\"\"Returns the executable. This contains a workaround for windows\n if the executable is incorrectly reported to not have the .exe\n extension which can cause bugs on reloading.\n \"\"\"\n rv = [sys.executable]\n py_script = sys.argv[0]\n if os.name == 'nt' and not os.path.exists(py_script) and \\\n os.path.exists(py_script + '.exe'):\n py_script += '.exe'\n if os.path.splitext(rv[0])[1] == '.exe' and os.path.splitext(py_script)[1] == '.exe':\n rv.pop(0)\n rv.append(py_script)\n rv.extend(sys.argv[1:])\n return rv\n\n\ndef _find_common_roots(paths):\n \"\"\"Out of some paths it finds the common roots that need monitoring.\"\"\"\n paths = [x.split(os.path.sep) for x in paths]\n root = {}\n for chunks in sorted(paths, key=len, reverse=True):\n node = root\n for chunk in chunks:\n node = node.setdefault(chunk, {})\n node.clear()\n\n rv = set()\n\n def _walk(node, path):\n for prefix, child in iteritems(node):\n _walk(child, path + (prefix,))\n if not node:\n rv.add('/'.join(path))\n _walk(root, ())\n return rv\n\n\nclass ReloaderLoop(object):\n name = None\n\n # monkeypatched by testsuite. wrapping with `staticmethod` is required in\n # case time.sleep has been replaced by a non-c function (e.g. by\n # `eventlet.monkey_patch`) before we get here\n _sleep = staticmethod(time.sleep)\n\n def __init__(self, extra_files=None, interval=1):\n self.extra_files = set(os.path.abspath(x)\n for x in extra_files or ())\n self.interval = interval\n\n def run(self):\n pass\n\n def restart_with_reloader(self):\n \"\"\"Spawn a new Python interpreter with the same arguments as this one,\n but running the reloader thread.\n \"\"\"\n while 1:\n _log('info', ' * Restarting with %s' % self.name)\n args = _get_args_for_reloading()\n new_environ = os.environ.copy()\n new_environ['WERKZEUG_RUN_MAIN'] = 'true'\n\n # a weird bug on windows. sometimes unicode strings end up in the\n # environment and subprocess.call does not like this, encode them\n # to latin1 and continue.\n if os.name == 'nt' and PY2:\n for key, value in iteritems(new_environ):\n if isinstance(value, text_type):\n new_environ[key] = value.encode('iso-8859-1')\n\n exit_code = subprocess.call(args, env=new_environ,\n close_fds=False)\n if exit_code != 3:\n return exit_code\n\n def trigger_reload(self, filename):\n self.log_reload(filename)\n sys.exit(3)\n\n def log_reload(self, filename):\n filename = os.path.abspath(filename)\n _log('info', ' * Detected change in %r, reloading' % filename)\n\n\nclass StatReloaderLoop(ReloaderLoop):\n name = 'stat'\n\n def run(self):\n mtimes = {}\n while 1:\n for filename in chain(_iter_module_files(),\n self.extra_files):\n try:\n mtime = os.stat(filename).st_mtime\n except OSError:\n continue\n\n old_time = mtimes.get(filename)\n if old_time is None:\n mtimes[filename] = mtime\n continue\n elif mtime > old_time:\n self.trigger_reload(filename)\n self._sleep(self.interval)\n\n\nclass WatchdogReloaderLoop(ReloaderLoop):\n\n def __init__(self, *args, **kwargs):\n ReloaderLoop.__init__(self, *args, **kwargs)\n from watchdog.observers import Observer\n from watchdog.events import FileSystemEventHandler\n self.observable_paths = set()\n\n def _check_modification(filename):\n if filename in self.extra_files:\n self.trigger_reload(filename)\n dirname = os.path.dirname(filename)\n if dirname.startswith(tuple(self.observable_paths)):\n if filename.endswith(('.pyc', '.pyo', '.py')):\n self.trigger_reload(filename)\n\n class _CustomHandler(FileSystemEventHandler):\n\n def on_created(self, event):\n _check_modification(event.src_path)\n\n def on_modified(self, event):\n _check_modification(event.src_path)\n\n def on_moved(self, event):\n _check_modification(event.src_path)\n _check_modification(event.dest_path)\n\n def on_deleted(self, event):\n _check_modification(event.src_path)\n\n reloader_name = Observer.__name__.lower()\n if reloader_name.endswith('observer'):\n reloader_name = reloader_name[:-8]\n reloader_name += ' reloader'\n\n self.name = reloader_name\n\n self.observer_class = Observer\n self.event_handler = _CustomHandler()\n self.should_reload = False\n\n def trigger_reload(self, filename):\n # This is called inside an event handler, which means throwing\n # SystemExit has no effect.\n # https://github.com/gorakhargosh/watchdog/issues/294\n self.should_reload = True\n self.log_reload(filename)\n\n def run(self):\n watches = {}\n observer = self.observer_class()\n observer.start()\n\n try:\n while not self.should_reload:\n to_delete = set(watches)\n paths = _find_observable_paths(self.extra_files)\n for path in paths:\n if path not in watches:\n try:\n watches[path] = observer.schedule(\n self.event_handler, path, recursive=True)\n except OSError:\n # Clear this path from list of watches We don't want\n # the same error message showing again in the next\n # iteration.\n watches[path] = None\n to_delete.discard(path)\n for path in to_delete:\n watch = watches.pop(path, None)\n if watch is not None:\n observer.unschedule(watch)\n self.observable_paths = paths\n self._sleep(self.interval)\n finally:\n observer.stop()\n observer.join()\n\n sys.exit(3)\n\n\nreloader_loops = {\n 'stat': StatReloaderLoop,\n 'watchdog': WatchdogReloaderLoop,\n}\n\ntry:\n __import__('watchdog.observers')\nexcept ImportError:\n reloader_loops['auto'] = reloader_loops['stat']\nelse:\n reloader_loops['auto'] = reloader_loops['watchdog']\n\n\ndef run_with_reloader(main_func, extra_files=None, interval=1,\n reloader_type='auto'):\n \"\"\"Run the given function in an independent python interpreter.\"\"\"\n import signal\n reloader = reloader_loops[reloader_type](extra_files, interval)\n signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))\n try:\n if os.environ.get('WERKZEUG_RUN_MAIN') == 'true':\n t = threading.Thread(target=main_func, args=())\n t.setDaemon(True)\n t.start()\n reloader.run()\n else:\n sys.exit(reloader.restart_with_reloader())\n except KeyboardInterrupt:\n pass\n", "path": "werkzeug/_reloader.py"}], "after_files": [{"content": "import os\nimport sys\nimport time\nimport subprocess\nimport threading\nfrom itertools import chain\n\nfrom werkzeug._internal import _log\nfrom werkzeug._compat import PY2, iteritems, text_type\n\n\ndef _iter_module_files():\n \"\"\"This iterates over all relevant Python files. It goes through all\n loaded files from modules, all files in folders of already loaded modules\n as well as all files reachable through a package.\n \"\"\"\n # The list call is necessary on Python 3 in case the module\n # dictionary modifies during iteration.\n for module in list(sys.modules.values()):\n if module is None:\n continue\n filename = getattr(module, '__file__', None)\n if filename:\n if os.path.isdir(filename) and \\\n os.path.exists(os.path.join(filename, \"__init__.py\")):\n filename = os.path.join(filename, \"__init__.py\")\n\n old = None\n while not os.path.isfile(filename):\n old = filename\n filename = os.path.dirname(filename)\n if filename == old:\n break\n else:\n if filename[-4:] in ('.pyc', '.pyo'):\n filename = filename[:-1]\n yield filename\n\n\ndef _find_observable_paths(extra_files=None):\n \"\"\"Finds all paths that should be observed.\"\"\"\n rv = set(os.path.dirname(os.path.abspath(x))\n if os.path.isfile(x) else os.path.abspath(x)\n for x in sys.path)\n\n for filename in extra_files or ():\n rv.add(os.path.dirname(os.path.abspath(filename)))\n\n for module in list(sys.modules.values()):\n fn = getattr(module, '__file__', None)\n if fn is None:\n continue\n fn = os.path.abspath(fn)\n rv.add(os.path.dirname(fn))\n\n return _find_common_roots(rv)\n\n\ndef _get_args_for_reloading():\n \"\"\"Returns the executable. This contains a workaround for windows\n if the executable is incorrectly reported to not have the .exe\n extension which can cause bugs on reloading.\n \"\"\"\n rv = [sys.executable]\n py_script = sys.argv[0]\n if os.name == 'nt' and not os.path.exists(py_script) and \\\n os.path.exists(py_script + '.exe'):\n py_script += '.exe'\n if os.path.splitext(rv[0])[1] == '.exe' and os.path.splitext(py_script)[1] == '.exe':\n rv.pop(0)\n rv.append(py_script)\n rv.extend(sys.argv[1:])\n return rv\n\n\ndef _find_common_roots(paths):\n \"\"\"Out of some paths it finds the common roots that need monitoring.\"\"\"\n paths = [x.split(os.path.sep) for x in paths]\n root = {}\n for chunks in sorted(paths, key=len, reverse=True):\n node = root\n for chunk in chunks:\n node = node.setdefault(chunk, {})\n node.clear()\n\n rv = set()\n\n def _walk(node, path):\n for prefix, child in iteritems(node):\n _walk(child, path + (prefix,))\n if not node:\n rv.add('/'.join(path))\n _walk(root, ())\n return rv\n\n\nclass ReloaderLoop(object):\n name = None\n\n # monkeypatched by testsuite. wrapping with `staticmethod` is required in\n # case time.sleep has been replaced by a non-c function (e.g. by\n # `eventlet.monkey_patch`) before we get here\n _sleep = staticmethod(time.sleep)\n\n def __init__(self, extra_files=None, interval=1):\n self.extra_files = set(os.path.abspath(x)\n for x in extra_files or ())\n self.interval = interval\n\n def run(self):\n pass\n\n def restart_with_reloader(self):\n \"\"\"Spawn a new Python interpreter with the same arguments as this one,\n but running the reloader thread.\n \"\"\"\n while 1:\n _log('info', ' * Restarting with %s' % self.name)\n args = _get_args_for_reloading()\n new_environ = os.environ.copy()\n new_environ['WERKZEUG_RUN_MAIN'] = 'true'\n\n # a weird bug on windows. sometimes unicode strings end up in the\n # environment and subprocess.call does not like this, encode them\n # to latin1 and continue.\n if os.name == 'nt' and PY2:\n for key, value in iteritems(new_environ):\n if isinstance(value, text_type):\n new_environ[key] = value.encode('iso-8859-1')\n\n exit_code = subprocess.call(args, env=new_environ,\n close_fds=False)\n if exit_code != 3:\n return exit_code\n\n def trigger_reload(self, filename):\n self.log_reload(filename)\n sys.exit(3)\n\n def log_reload(self, filename):\n filename = os.path.abspath(filename)\n _log('info', ' * Detected change in %r, reloading' % filename)\n\n\nclass StatReloaderLoop(ReloaderLoop):\n name = 'stat'\n\n def run(self):\n mtimes = {}\n while 1:\n for filename in chain(_iter_module_files(),\n self.extra_files):\n try:\n mtime = os.stat(filename).st_mtime\n except OSError:\n continue\n\n old_time = mtimes.get(filename)\n if old_time is None:\n mtimes[filename] = mtime\n continue\n elif mtime > old_time:\n self.trigger_reload(filename)\n self._sleep(self.interval)\n\n\nclass WatchdogReloaderLoop(ReloaderLoop):\n\n def __init__(self, *args, **kwargs):\n ReloaderLoop.__init__(self, *args, **kwargs)\n from watchdog.observers import Observer\n from watchdog.events import FileSystemEventHandler\n self.observable_paths = set()\n\n def _check_modification(filename):\n if filename in self.extra_files:\n self.trigger_reload(filename)\n dirname = os.path.dirname(filename)\n if dirname.startswith(tuple(self.observable_paths)):\n if filename.endswith(('.pyc', '.pyo', '.py')):\n self.trigger_reload(filename)\n\n class _CustomHandler(FileSystemEventHandler):\n\n def on_created(self, event):\n _check_modification(event.src_path)\n\n def on_modified(self, event):\n _check_modification(event.src_path)\n\n def on_moved(self, event):\n _check_modification(event.src_path)\n _check_modification(event.dest_path)\n\n def on_deleted(self, event):\n _check_modification(event.src_path)\n\n reloader_name = Observer.__name__.lower()\n if reloader_name.endswith('observer'):\n reloader_name = reloader_name[:-8]\n reloader_name += ' reloader'\n\n self.name = reloader_name\n\n self.observer_class = Observer\n self.event_handler = _CustomHandler()\n self.should_reload = False\n\n def trigger_reload(self, filename):\n # This is called inside an event handler, which means throwing\n # SystemExit has no effect.\n # https://github.com/gorakhargosh/watchdog/issues/294\n self.should_reload = True\n self.log_reload(filename)\n\n def run(self):\n watches = {}\n observer = self.observer_class()\n observer.start()\n\n try:\n while not self.should_reload:\n to_delete = set(watches)\n paths = _find_observable_paths(self.extra_files)\n for path in paths:\n if path not in watches:\n try:\n watches[path] = observer.schedule(\n self.event_handler, path, recursive=True)\n except OSError:\n # Clear this path from list of watches We don't want\n # the same error message showing again in the next\n # iteration.\n watches[path] = None\n to_delete.discard(path)\n for path in to_delete:\n watch = watches.pop(path, None)\n if watch is not None:\n observer.unschedule(watch)\n self.observable_paths = paths\n self._sleep(self.interval)\n finally:\n observer.stop()\n observer.join()\n\n sys.exit(3)\n\n\nreloader_loops = {\n 'stat': StatReloaderLoop,\n 'watchdog': WatchdogReloaderLoop,\n}\n\ntry:\n __import__('watchdog.observers')\nexcept ImportError:\n reloader_loops['auto'] = reloader_loops['stat']\nelse:\n reloader_loops['auto'] = reloader_loops['watchdog']\n\n\ndef ensure_echo_on():\n \"\"\"Ensure that echo mode is enabled. Some tools such as PDB disable\n it which causes usability issues after reload.\"\"\"\n # tcgetattr will fail if stdin isn't a tty\n if not sys.stdin.isatty():\n return\n try:\n import termios\n except ImportError:\n return\n attributes = termios.tcgetattr(sys.stdin)\n if not attributes[3] & termios.ECHO:\n attributes[3] |= termios.ECHO\n termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)\n\n\ndef run_with_reloader(main_func, extra_files=None, interval=1,\n reloader_type='auto'):\n \"\"\"Run the given function in an independent python interpreter.\"\"\"\n import signal\n reloader = reloader_loops[reloader_type](extra_files, interval)\n signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))\n try:\n if os.environ.get('WERKZEUG_RUN_MAIN') == 'true':\n ensure_echo_on()\n t = threading.Thread(target=main_func, args=())\n t.setDaemon(True)\n t.start()\n reloader.run()\n else:\n sys.exit(reloader.restart_with_reloader())\n except KeyboardInterrupt:\n pass\n", "path": "werkzeug/_reloader.py"}]}
| 3,012 | 324 |
gh_patches_debug_2156
|
rasdani/github-patches
|
git_diff
|
spacetelescope__jwql-569
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Write tests for bokeh templating software
With the merge of #459, bokeh templating will be implemented for `jwql`. We should address the test coverage for this software.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jwql/bokeh_templating/example/main.py`
Content:
```
1 """
2 This is a minimal example demonstrating how to create a Bokeh app using
3 the ``bokeh-templating`` package and the associated YAML template files.
4
5 Author
6 -------
7
8 - Graham Kanarek
9
10 Dependencies
11 ------------
12
13 The user must have PyYAML, Bokeh, and the ``bokeh-templating``
14 packages installed.
15 """
16
17 import os
18 import numpy as np
19
20 from jwql.bokeh_templating import BokehTemplate
21
22 file_dir = os.path.dirname(os.path.realpath(__file__))
23
24
25 class TestBokehApp(BokehTemplate):
26 """This is a minimal ``BokehTemplate`` app."""
27
28 def pre_init(self):
29 """Before creating the Bokeh interface (by parsing the interface
30 file), we must initialize our ``a`` and ``b`` variables, and set
31 the path to the interface file.
32 """
33
34 self.a, self.b = 4, 2
35
36 self.format_string = None
37 self.interface_file = os.path.join(file_dir, "example_interface.yaml")
38
39 # No post-initialization tasks are required.
40 post_init = None
41
42 @property
43 def x(self):
44 """The x-value of the Lissajous curves."""
45 return 4. * np.sin(self.a * np.linspace(0, 2 * np.pi, 500))
46
47 @property
48 def y(self):
49 """The y-value of the Lissajous curves."""
50 return 3. * np.sin(self.b * np.linspace(0, 2 * np.pi, 500))
51
52 def controller(self, attr, old, new):
53 """This is the controller function which is used to update the
54 curves when the sliders are adjusted. Note the use of the
55 ``self.refs`` dictionary for accessing the Bokeh object
56 attributes."""
57 self.a = self.refs["a_slider"].value
58 self.b = self.refs["b_slider"].value
59
60 self.refs["figure_source"].data = {'x': self.x, 'y': self.y}
61
62
63 TestBokehApp()
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jwql/bokeh_templating/example/main.py b/jwql/bokeh_templating/example/main.py
--- a/jwql/bokeh_templating/example/main.py
+++ b/jwql/bokeh_templating/example/main.py
@@ -24,6 +24,8 @@
class TestBokehApp(BokehTemplate):
"""This is a minimal ``BokehTemplate`` app."""
+
+ _embed = True
def pre_init(self):
"""Before creating the Bokeh interface (by parsing the interface
|
{"golden_diff": "diff --git a/jwql/bokeh_templating/example/main.py b/jwql/bokeh_templating/example/main.py\n--- a/jwql/bokeh_templating/example/main.py\n+++ b/jwql/bokeh_templating/example/main.py\n@@ -24,6 +24,8 @@\n \n class TestBokehApp(BokehTemplate):\n \"\"\"This is a minimal ``BokehTemplate`` app.\"\"\"\n+ \n+ _embed = True\n \n def pre_init(self):\n \"\"\"Before creating the Bokeh interface (by parsing the interface\n", "issue": "Write tests for bokeh templating software\nWith the merge of #459, bokeh templating will be implemented for `jwql`. We should address the test coverage for this software. \n", "before_files": [{"content": "\"\"\"\nThis is a minimal example demonstrating how to create a Bokeh app using\nthe ``bokeh-templating`` package and the associated YAML template files.\n\nAuthor\n-------\n\n - Graham Kanarek\n\nDependencies\n------------\n\n The user must have PyYAML, Bokeh, and the ``bokeh-templating``\n packages installed.\n\"\"\"\n\nimport os\nimport numpy as np\n\nfrom jwql.bokeh_templating import BokehTemplate\n\nfile_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nclass TestBokehApp(BokehTemplate):\n \"\"\"This is a minimal ``BokehTemplate`` app.\"\"\"\n\n def pre_init(self):\n \"\"\"Before creating the Bokeh interface (by parsing the interface\n file), we must initialize our ``a`` and ``b`` variables, and set\n the path to the interface file.\n \"\"\"\n\n self.a, self.b = 4, 2\n\n self.format_string = None\n self.interface_file = os.path.join(file_dir, \"example_interface.yaml\")\n\n # No post-initialization tasks are required.\n post_init = None\n\n @property\n def x(self):\n \"\"\"The x-value of the Lissajous curves.\"\"\"\n return 4. * np.sin(self.a * np.linspace(0, 2 * np.pi, 500))\n\n @property\n def y(self):\n \"\"\"The y-value of the Lissajous curves.\"\"\"\n return 3. * np.sin(self.b * np.linspace(0, 2 * np.pi, 500))\n\n def controller(self, attr, old, new):\n \"\"\"This is the controller function which is used to update the\n curves when the sliders are adjusted. Note the use of the\n ``self.refs`` dictionary for accessing the Bokeh object\n attributes.\"\"\"\n self.a = self.refs[\"a_slider\"].value\n self.b = self.refs[\"b_slider\"].value\n\n self.refs[\"figure_source\"].data = {'x': self.x, 'y': self.y}\n\n\nTestBokehApp()\n", "path": "jwql/bokeh_templating/example/main.py"}], "after_files": [{"content": "\"\"\"\nThis is a minimal example demonstrating how to create a Bokeh app using\nthe ``bokeh-templating`` package and the associated YAML template files.\n\nAuthor\n-------\n\n - Graham Kanarek\n\nDependencies\n------------\n\n The user must have PyYAML, Bokeh, and the ``bokeh-templating``\n packages installed.\n\"\"\"\n\nimport os\nimport numpy as np\n\nfrom jwql.bokeh_templating import BokehTemplate\n\nfile_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nclass TestBokehApp(BokehTemplate):\n \"\"\"This is a minimal ``BokehTemplate`` app.\"\"\"\n \n _embed = True\n\n def pre_init(self):\n \"\"\"Before creating the Bokeh interface (by parsing the interface\n file), we must initialize our ``a`` and ``b`` variables, and set\n the path to the interface file.\n \"\"\"\n\n self.a, self.b = 4, 2\n\n self.format_string = None\n self.interface_file = os.path.join(file_dir, \"example_interface.yaml\")\n\n # No post-initialization tasks are required.\n post_init = None\n\n @property\n def x(self):\n \"\"\"The x-value of the Lissajous curves.\"\"\"\n return 4. * np.sin(self.a * np.linspace(0, 2 * np.pi, 500))\n\n @property\n def y(self):\n \"\"\"The y-value of the Lissajous curves.\"\"\"\n return 3. * np.sin(self.b * np.linspace(0, 2 * np.pi, 500))\n\n def controller(self, attr, old, new):\n \"\"\"This is the controller function which is used to update the\n curves when the sliders are adjusted. Note the use of the\n ``self.refs`` dictionary for accessing the Bokeh object\n attributes.\"\"\"\n self.a = self.refs[\"a_slider\"].value\n self.b = self.refs[\"b_slider\"].value\n\n self.refs[\"figure_source\"].data = {'x': self.x, 'y': self.y}\n\n\nTestBokehApp()\n", "path": "jwql/bokeh_templating/example/main.py"}]}
| 880 | 125 |
gh_patches_debug_347
|
rasdani/github-patches
|
git_diff
|
kivy__python-for-android-2436
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"diff" files are ignored during "pip install ."
in `setup.py` the "diff" is not listed:
https://github.com/kivy/python-for-android/blob/develop/setup.py
```python
package_data = {'': ['*.tmpl',
'*.patch', ], }
```
and therefore this `diff` patch:
https://github.com/kivy/python-for-android/blob/develop/pythonforandroid/recipes/python3/patches/reproducible-buildinfo.diff
is not installed during `pip` invocation:
```sh
cd /tmp
git clone --depth 1 https://github.com/kivy/python-for-android.git
cd python-for-android
pip install .
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1
2 import glob
3 from io import open # for open(..,encoding=...) parameter in python 2
4 from os import walk
5 from os.path import join, dirname, sep
6 import re
7 from setuptools import setup, find_packages
8
9 # NOTE: All package data should also be set in MANIFEST.in
10
11 packages = find_packages()
12
13 package_data = {'': ['*.tmpl',
14 '*.patch', ], }
15
16 data_files = []
17
18
19 # must be a single statement since buildozer is currently parsing it, refs:
20 # https://github.com/kivy/buildozer/issues/722
21 install_reqs = [
22 'appdirs', 'colorama>=0.3.3', 'jinja2', 'six',
23 'enum34; python_version<"3.4"', 'sh>=1.10; sys_platform!="nt"',
24 'pep517<0.7.0', 'toml',
25 ]
26 # (pep517 and toml are used by pythonpackage.py)
27
28
29 # By specifying every file manually, package_data will be able to
30 # include them in binary distributions. Note that we have to add
31 # everything as a 'pythonforandroid' rule, using '' apparently doesn't
32 # work.
33 def recursively_include(results, directory, patterns):
34 for root, subfolders, files in walk(directory):
35 for fn in files:
36 if not any(glob.fnmatch.fnmatch(fn, pattern) for pattern in patterns):
37 continue
38 filename = join(root, fn)
39 directory = 'pythonforandroid'
40 if directory not in results:
41 results[directory] = []
42 results[directory].append(join(*filename.split(sep)[1:]))
43
44
45 recursively_include(package_data, 'pythonforandroid/recipes',
46 ['*.patch', 'Setup*', '*.pyx', '*.py', '*.c', '*.h',
47 '*.mk', '*.jam', ])
48 recursively_include(package_data, 'pythonforandroid/bootstraps',
49 ['*.properties', '*.xml', '*.java', '*.tmpl', '*.txt', '*.png',
50 '*.mk', '*.c', '*.h', '*.py', '*.sh', '*.jpg', '*.aidl',
51 '*.gradle', '.gitkeep', 'gradlew*', '*.jar', "*.patch", ])
52 recursively_include(package_data, 'pythonforandroid/bootstraps',
53 ['sdl-config', ])
54 recursively_include(package_data, 'pythonforandroid/bootstraps/webview',
55 ['*.html', ])
56 recursively_include(package_data, 'pythonforandroid',
57 ['liblink', 'biglink', 'liblink.sh'])
58
59 with open(join(dirname(__file__), 'README.md'),
60 encoding="utf-8",
61 errors="replace",
62 ) as fileh:
63 long_description = fileh.read()
64
65 init_filen = join(dirname(__file__), 'pythonforandroid', '__init__.py')
66 version = None
67 try:
68 with open(init_filen,
69 encoding="utf-8",
70 errors="replace"
71 ) as fileh:
72 lines = fileh.readlines()
73 except IOError:
74 pass
75 else:
76 for line in lines:
77 line = line.strip()
78 if line.startswith('__version__ = '):
79 matches = re.findall(r'["\'].+["\']', line)
80 if matches:
81 version = matches[0].strip("'").strip('"')
82 break
83 if version is None:
84 raise Exception('Error: version could not be loaded from {}'.format(init_filen))
85
86 setup(name='python-for-android',
87 version=version,
88 description='Android APK packager for Python scripts and apps',
89 long_description=long_description,
90 long_description_content_type='text/markdown',
91 python_requires=">=3.6.0",
92 author='The Kivy team',
93 author_email='[email protected]',
94 url='https://github.com/kivy/python-for-android',
95 license='MIT',
96 install_requires=install_reqs,
97 entry_points={
98 'console_scripts': [
99 'python-for-android = pythonforandroid.entrypoints:main',
100 'p4a = pythonforandroid.entrypoints:main',
101 ],
102 'distutils.commands': [
103 'apk = pythonforandroid.bdistapk:BdistAPK',
104 'aar = pythonforandroid.bdistapk:BdistAAR',
105 ],
106 },
107 classifiers=[
108 'Development Status :: 5 - Production/Stable',
109 'Intended Audience :: Developers',
110 'License :: OSI Approved :: MIT License',
111 'Operating System :: Microsoft :: Windows',
112 'Operating System :: OS Independent',
113 'Operating System :: POSIX :: Linux',
114 'Operating System :: MacOS :: MacOS X',
115 'Operating System :: Android',
116 'Programming Language :: C',
117 'Programming Language :: Python :: 3',
118 'Programming Language :: Python :: 3.6',
119 'Programming Language :: Python :: 3.7',
120 'Programming Language :: Python :: 3.8',
121 'Topic :: Software Development',
122 'Topic :: Utilities',
123 ],
124 packages=packages,
125 package_data=package_data,
126 )
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -11,7 +11,8 @@
packages = find_packages()
package_data = {'': ['*.tmpl',
- '*.patch', ], }
+ '*.patch',
+ '*.diff', ], }
data_files = []
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -11,7 +11,8 @@\n packages = find_packages()\n \n package_data = {'': ['*.tmpl',\n- '*.patch', ], }\n+ '*.patch',\n+ '*.diff', ], }\n \n data_files = []\n", "issue": "\"diff\" files are ignored during \"pip install .\"\nin `setup.py` the \"diff\" is not listed: \r\nhttps://github.com/kivy/python-for-android/blob/develop/setup.py\r\n```python\r\npackage_data = {'': ['*.tmpl',\r\n '*.patch', ], }\r\n```\r\n\r\nand therefore this `diff` patch:\r\nhttps://github.com/kivy/python-for-android/blob/develop/pythonforandroid/recipes/python3/patches/reproducible-buildinfo.diff\r\n\r\nis not installed during `pip` invocation:\r\n```sh\r\ncd /tmp\r\ngit clone --depth 1 https://github.com/kivy/python-for-android.git\r\ncd python-for-android\r\npip install .\r\n```\r\n\n", "before_files": [{"content": "\nimport glob\nfrom io import open # for open(..,encoding=...) parameter in python 2\nfrom os import walk\nfrom os.path import join, dirname, sep\nimport re\nfrom setuptools import setup, find_packages\n\n# NOTE: All package data should also be set in MANIFEST.in\n\npackages = find_packages()\n\npackage_data = {'': ['*.tmpl',\n '*.patch', ], }\n\ndata_files = []\n\n\n# must be a single statement since buildozer is currently parsing it, refs:\n# https://github.com/kivy/buildozer/issues/722\ninstall_reqs = [\n 'appdirs', 'colorama>=0.3.3', 'jinja2', 'six',\n 'enum34; python_version<\"3.4\"', 'sh>=1.10; sys_platform!=\"nt\"',\n 'pep517<0.7.0', 'toml',\n]\n# (pep517 and toml are used by pythonpackage.py)\n\n\n# By specifying every file manually, package_data will be able to\n# include them in binary distributions. Note that we have to add\n# everything as a 'pythonforandroid' rule, using '' apparently doesn't\n# work.\ndef recursively_include(results, directory, patterns):\n for root, subfolders, files in walk(directory):\n for fn in files:\n if not any(glob.fnmatch.fnmatch(fn, pattern) for pattern in patterns):\n continue\n filename = join(root, fn)\n directory = 'pythonforandroid'\n if directory not in results:\n results[directory] = []\n results[directory].append(join(*filename.split(sep)[1:]))\n\n\nrecursively_include(package_data, 'pythonforandroid/recipes',\n ['*.patch', 'Setup*', '*.pyx', '*.py', '*.c', '*.h',\n '*.mk', '*.jam', ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps',\n ['*.properties', '*.xml', '*.java', '*.tmpl', '*.txt', '*.png',\n '*.mk', '*.c', '*.h', '*.py', '*.sh', '*.jpg', '*.aidl',\n '*.gradle', '.gitkeep', 'gradlew*', '*.jar', \"*.patch\", ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps',\n ['sdl-config', ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps/webview',\n ['*.html', ])\nrecursively_include(package_data, 'pythonforandroid',\n ['liblink', 'biglink', 'liblink.sh'])\n\nwith open(join(dirname(__file__), 'README.md'),\n encoding=\"utf-8\",\n errors=\"replace\",\n ) as fileh:\n long_description = fileh.read()\n\ninit_filen = join(dirname(__file__), 'pythonforandroid', '__init__.py')\nversion = None\ntry:\n with open(init_filen,\n encoding=\"utf-8\",\n errors=\"replace\"\n ) as fileh:\n lines = fileh.readlines()\nexcept IOError:\n pass\nelse:\n for line in lines:\n line = line.strip()\n if line.startswith('__version__ = '):\n matches = re.findall(r'[\"\\'].+[\"\\']', line)\n if matches:\n version = matches[0].strip(\"'\").strip('\"')\n break\nif version is None:\n raise Exception('Error: version could not be loaded from {}'.format(init_filen))\n\nsetup(name='python-for-android',\n version=version,\n description='Android APK packager for Python scripts and apps',\n long_description=long_description,\n long_description_content_type='text/markdown',\n python_requires=\">=3.6.0\",\n author='The Kivy team',\n author_email='[email protected]',\n url='https://github.com/kivy/python-for-android',\n license='MIT',\n install_requires=install_reqs,\n entry_points={\n 'console_scripts': [\n 'python-for-android = pythonforandroid.entrypoints:main',\n 'p4a = pythonforandroid.entrypoints:main',\n ],\n 'distutils.commands': [\n 'apk = pythonforandroid.bdistapk:BdistAPK',\n 'aar = pythonforandroid.bdistapk:BdistAAR',\n ],\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: OS Independent',\n 'Operating System :: POSIX :: Linux',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Android',\n 'Programming Language :: C',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Topic :: Software Development',\n 'Topic :: Utilities',\n ],\n packages=packages,\n package_data=package_data,\n )\n", "path": "setup.py"}], "after_files": [{"content": "\nimport glob\nfrom io import open # for open(..,encoding=...) parameter in python 2\nfrom os import walk\nfrom os.path import join, dirname, sep\nimport re\nfrom setuptools import setup, find_packages\n\n# NOTE: All package data should also be set in MANIFEST.in\n\npackages = find_packages()\n\npackage_data = {'': ['*.tmpl',\n '*.patch',\n '*.diff', ], }\n\ndata_files = []\n\n\n# must be a single statement since buildozer is currently parsing it, refs:\n# https://github.com/kivy/buildozer/issues/722\ninstall_reqs = [\n 'appdirs', 'colorama>=0.3.3', 'jinja2', 'six',\n 'enum34; python_version<\"3.4\"', 'sh>=1.10; sys_platform!=\"nt\"',\n 'pep517<0.7.0', 'toml',\n]\n# (pep517 and toml are used by pythonpackage.py)\n\n\n# By specifying every file manually, package_data will be able to\n# include them in binary distributions. Note that we have to add\n# everything as a 'pythonforandroid' rule, using '' apparently doesn't\n# work.\ndef recursively_include(results, directory, patterns):\n for root, subfolders, files in walk(directory):\n for fn in files:\n if not any(glob.fnmatch.fnmatch(fn, pattern) for pattern in patterns):\n continue\n filename = join(root, fn)\n directory = 'pythonforandroid'\n if directory not in results:\n results[directory] = []\n results[directory].append(join(*filename.split(sep)[1:]))\n\n\nrecursively_include(package_data, 'pythonforandroid/recipes',\n ['*.patch', 'Setup*', '*.pyx', '*.py', '*.c', '*.h',\n '*.mk', '*.jam', ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps',\n ['*.properties', '*.xml', '*.java', '*.tmpl', '*.txt', '*.png',\n '*.mk', '*.c', '*.h', '*.py', '*.sh', '*.jpg', '*.aidl',\n '*.gradle', '.gitkeep', 'gradlew*', '*.jar', \"*.patch\", ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps',\n ['sdl-config', ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps/webview',\n ['*.html', ])\nrecursively_include(package_data, 'pythonforandroid',\n ['liblink', 'biglink', 'liblink.sh'])\n\nwith open(join(dirname(__file__), 'README.md'),\n encoding=\"utf-8\",\n errors=\"replace\",\n ) as fileh:\n long_description = fileh.read()\n\ninit_filen = join(dirname(__file__), 'pythonforandroid', '__init__.py')\nversion = None\ntry:\n with open(init_filen,\n encoding=\"utf-8\",\n errors=\"replace\"\n ) as fileh:\n lines = fileh.readlines()\nexcept IOError:\n pass\nelse:\n for line in lines:\n line = line.strip()\n if line.startswith('__version__ = '):\n matches = re.findall(r'[\"\\'].+[\"\\']', line)\n if matches:\n version = matches[0].strip(\"'\").strip('\"')\n break\nif version is None:\n raise Exception('Error: version could not be loaded from {}'.format(init_filen))\n\nsetup(name='python-for-android',\n version=version,\n description='Android APK packager for Python scripts and apps',\n long_description=long_description,\n long_description_content_type='text/markdown',\n python_requires=\">=3.6.0\",\n author='The Kivy team',\n author_email='[email protected]',\n url='https://github.com/kivy/python-for-android',\n license='MIT',\n install_requires=install_reqs,\n entry_points={\n 'console_scripts': [\n 'python-for-android = pythonforandroid.entrypoints:main',\n 'p4a = pythonforandroid.entrypoints:main',\n ],\n 'distutils.commands': [\n 'apk = pythonforandroid.bdistapk:BdistAPK',\n 'aar = pythonforandroid.bdistapk:BdistAAR',\n ],\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: OS Independent',\n 'Operating System :: POSIX :: Linux',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Android',\n 'Programming Language :: C',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Topic :: Software Development',\n 'Topic :: Utilities',\n ],\n packages=packages,\n package_data=package_data,\n )\n", "path": "setup.py"}]}
| 1,741 | 71 |
gh_patches_debug_18046
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-3745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setting of PYTHONHASHSEED has no effect
<!--
### Common bugs:
1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79).
2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq)
-->
## 🐛 Bug
(Previously submitted here: https://github.com/PyTorchLightning/pytorch-lightning/issues/1939, but I didn't use the correct template, so now I'm resubmitting)
In https://github.com/PyTorchLightning/pytorch-lightning/blob/9045b6c599df3871da6aaaa310f62d3f1364c632/pytorch_lightning/trainer/seed.py#L32
, `PYTHONHASHSEED` is assigned a value in order to ensure reproducability. However, this assignment has no effect. In fact, this assignment might mislead the user or any logging software into believing that `PYTHONHASHSEED` has a specific value, when in fact it has another.
To see that setting `PYTHONHASHSEED` inside the current program has no effect, run the following two commands:
```
PYTHONHASHSEED=1 python -c "import os; print(hash('a'))"
PYTHONHASHSEED=1 python -c "import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))"
```
The commands should output the same value, meaning that setting `PYTHONHASHSEED` after the process has started has no effect.
The following commands will likely output different values, also indicating that setting `PYTHONHASHSEED` after the process has started has no effect:
```
unset PYTHONHASHSEED # make sure it is not already set
python -c "import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))"
python -c "import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))"
```
<!-- A clear and concise description of what the bug is. -->
### To Reproduce
Steps to reproduce the behavior:
1. Start python terminal with `PYTHONHASHSEED=1 python`
2. Run
```python
import pytorch_lightning as pl
pl.seed_everything(100)
print(hash('a'))
# >>> 8432517439229126278
```
3. Start new python terminal with `PYTHONHASHSEED=2 python`
4. Run
```python
import pytorch_lightning as pl
pl.seed_everything(100)
print(hash('a'))
# >>> -8333094867672744108
```
### Expected behavior
Expect output of `hash` function to be the same in both cases. The examples demonstrate that this is not possible.
<!-- A clear and concise description of what you expected to happen. -->
### Environment
```
* CUDA:
- GPU:
- available: False
- version: 10.2
* Packages:
- numpy: 1.18.5
- pyTorch_debug: False
- pyTorch_version: 1.5.0
- pytorch-lightning: 0.7.6
- tensorboard: 2.2.2
- tqdm: 4.46.1
* System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor:
- python: 3.8.3
- version: #1 SMP PREEMPT Wed May 27 20:25:12 UTC 2020
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_lightning/utilities/seed.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Helper functions to help with reproducibility of models. """
16
17 import os
18 import random
19 from typing import Optional
20
21 import numpy as np
22 import torch
23
24 from pytorch_lightning import _logger as log
25
26
27 def seed_everything(seed: Optional[int] = None) -> int:
28 """
29 Function that sets seed for pseudo-random number generators in:
30 pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.
31 In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to
32 spawned subprocesses (e.g. ddp_spawn backend).
33
34 Args:
35 seed: the integer value seed for global random state in Lightning.
36 If `None`, will read seed from `PL_GLOBAL_SEED` env variable
37 or select it randomly.
38 """
39 max_seed_value = np.iinfo(np.uint32).max
40 min_seed_value = np.iinfo(np.uint32).min
41
42 try:
43 if seed is None:
44 seed = os.environ.get("PL_GLOBAL_SEED", _select_seed_randomly(min_seed_value, max_seed_value))
45 seed = int(seed)
46 except (TypeError, ValueError):
47 seed = _select_seed_randomly(min_seed_value, max_seed_value)
48
49 if (seed > max_seed_value) or (seed < min_seed_value):
50 log.warning(
51 f"{seed} is not in bounds, \
52 numpy accepts from {min_seed_value} to {max_seed_value}"
53 )
54 seed = _select_seed_randomly(min_seed_value, max_seed_value)
55
56 os.environ["PYTHONHASHSEED"] = str(seed)
57 os.environ["PL_GLOBAL_SEED"] = str(seed)
58 random.seed(seed)
59 np.random.seed(seed)
60 torch.manual_seed(seed)
61 torch.cuda.manual_seed_all(seed)
62 return seed
63
64
65 def _select_seed_randomly(min_seed_value: int = 0, max_seed_value: int = 255) -> int:
66 seed = random.randint(min_seed_value, max_seed_value)
67 log.warning(f"No correct seed found, seed set to {seed}")
68 return seed
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytorch_lightning/utilities/seed.py b/pytorch_lightning/utilities/seed.py
--- a/pytorch_lightning/utilities/seed.py
+++ b/pytorch_lightning/utilities/seed.py
@@ -27,7 +27,7 @@
def seed_everything(seed: Optional[int] = None) -> int:
"""
Function that sets seed for pseudo-random number generators in:
- pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.
+ pytorch, numpy, python.random
In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to
spawned subprocesses (e.g. ddp_spawn backend).
@@ -53,7 +53,6 @@
)
seed = _select_seed_randomly(min_seed_value, max_seed_value)
- os.environ["PYTHONHASHSEED"] = str(seed)
os.environ["PL_GLOBAL_SEED"] = str(seed)
random.seed(seed)
np.random.seed(seed)
|
{"golden_diff": "diff --git a/pytorch_lightning/utilities/seed.py b/pytorch_lightning/utilities/seed.py\n--- a/pytorch_lightning/utilities/seed.py\n+++ b/pytorch_lightning/utilities/seed.py\n@@ -27,7 +27,7 @@\n def seed_everything(seed: Optional[int] = None) -> int:\n \"\"\"\n Function that sets seed for pseudo-random number generators in:\n- pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.\n+ pytorch, numpy, python.random\n In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to\n spawned subprocesses (e.g. ddp_spawn backend).\n \n@@ -53,7 +53,6 @@\n )\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n \n- os.environ[\"PYTHONHASHSEED\"] = str(seed)\n os.environ[\"PL_GLOBAL_SEED\"] = str(seed)\n random.seed(seed)\n np.random.seed(seed)\n", "issue": "Setting of PYTHONHASHSEED has no effect\n<!-- \r\n### Common bugs:\r\n1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). \r\n2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) \r\n-->\r\n\r\n## \ud83d\udc1b Bug\r\n(Previously submitted here: https://github.com/PyTorchLightning/pytorch-lightning/issues/1939, but I didn't use the correct template, so now I'm resubmitting)\r\n\r\nIn https://github.com/PyTorchLightning/pytorch-lightning/blob/9045b6c599df3871da6aaaa310f62d3f1364c632/pytorch_lightning/trainer/seed.py#L32\r\n, `PYTHONHASHSEED` is assigned a value in order to ensure reproducability. However, this assignment has no effect. In fact, this assignment might mislead the user or any logging software into believing that `PYTHONHASHSEED` has a specific value, when in fact it has another.\r\n\r\nTo see that setting `PYTHONHASHSEED` inside the current program has no effect, run the following two commands:\r\n```\r\nPYTHONHASHSEED=1 python -c \"import os; print(hash('a'))\"\r\nPYTHONHASHSEED=1 python -c \"import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))\"\r\n```\r\nThe commands should output the same value, meaning that setting `PYTHONHASHSEED` after the process has started has no effect.\r\n\r\nThe following commands will likely output different values, also indicating that setting `PYTHONHASHSEED` after the process has started has no effect:\r\n```\r\nunset PYTHONHASHSEED # make sure it is not already set\r\npython -c \"import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))\"\r\npython -c \"import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))\"\r\n```\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n### To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Start python terminal with `PYTHONHASHSEED=1 python`\r\n2. Run \r\n```python\r\nimport pytorch_lightning as pl\r\npl.seed_everything(100)\r\nprint(hash('a'))\r\n# >>> 8432517439229126278\r\n```\r\n3. Start new python terminal with `PYTHONHASHSEED=2 python`\r\n4. Run\r\n```python\r\nimport pytorch_lightning as pl\r\npl.seed_everything(100)\r\nprint(hash('a'))\r\n# >>> -8333094867672744108\r\n```\r\n\r\n### Expected behavior\r\n\r\nExpect output of `hash` function to be the same in both cases. The examples demonstrate that this is not possible.\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n### Environment\r\n\r\n```\r\n* CUDA:\r\n\t- GPU:\r\n\t- available: False\r\n\t- version: 10.2\r\n* Packages:\r\n\t- numpy: 1.18.5\r\n\t- pyTorch_debug: False\r\n\t- pyTorch_version: 1.5.0\r\n\t- pytorch-lightning: 0.7.6\r\n\t- tensorboard: 2.2.2\r\n\t- tqdm: 4.46.1\r\n* System:\r\n\t- OS: Linux\r\n\t- architecture:\r\n\t\t- 64bit\r\n\t\t- ELF\r\n\t- processor: \r\n\t- python: 3.8.3\r\n\t- version: #1 SMP PREEMPT Wed May 27 20:25:12 UTC 2020\r\n\r\n```\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper functions to help with reproducibility of models. \"\"\"\n\nimport os\nimport random\nfrom typing import Optional\n\nimport numpy as np\nimport torch\n\nfrom pytorch_lightning import _logger as log\n\n\ndef seed_everything(seed: Optional[int] = None) -> int:\n \"\"\"\n Function that sets seed for pseudo-random number generators in:\n pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.\n In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to\n spawned subprocesses (e.g. ddp_spawn backend).\n\n Args:\n seed: the integer value seed for global random state in Lightning.\n If `None`, will read seed from `PL_GLOBAL_SEED` env variable\n or select it randomly.\n \"\"\"\n max_seed_value = np.iinfo(np.uint32).max\n min_seed_value = np.iinfo(np.uint32).min\n\n try:\n if seed is None:\n seed = os.environ.get(\"PL_GLOBAL_SEED\", _select_seed_randomly(min_seed_value, max_seed_value))\n seed = int(seed)\n except (TypeError, ValueError):\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n\n if (seed > max_seed_value) or (seed < min_seed_value):\n log.warning(\n f\"{seed} is not in bounds, \\\n numpy accepts from {min_seed_value} to {max_seed_value}\"\n )\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n\n os.environ[\"PYTHONHASHSEED\"] = str(seed)\n os.environ[\"PL_GLOBAL_SEED\"] = str(seed)\n random.seed(seed)\n np.random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed_all(seed)\n return seed\n\n\ndef _select_seed_randomly(min_seed_value: int = 0, max_seed_value: int = 255) -> int:\n seed = random.randint(min_seed_value, max_seed_value)\n log.warning(f\"No correct seed found, seed set to {seed}\")\n return seed\n", "path": "pytorch_lightning/utilities/seed.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper functions to help with reproducibility of models. \"\"\"\n\nimport os\nimport random\nfrom typing import Optional\n\nimport numpy as np\nimport torch\n\nfrom pytorch_lightning import _logger as log\n\n\ndef seed_everything(seed: Optional[int] = None) -> int:\n \"\"\"\n Function that sets seed for pseudo-random number generators in:\n pytorch, numpy, python.random\n In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to\n spawned subprocesses (e.g. ddp_spawn backend).\n\n Args:\n seed: the integer value seed for global random state in Lightning.\n If `None`, will read seed from `PL_GLOBAL_SEED` env variable\n or select it randomly.\n \"\"\"\n max_seed_value = np.iinfo(np.uint32).max\n min_seed_value = np.iinfo(np.uint32).min\n\n try:\n if seed is None:\n seed = os.environ.get(\"PL_GLOBAL_SEED\", _select_seed_randomly(min_seed_value, max_seed_value))\n seed = int(seed)\n except (TypeError, ValueError):\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n\n if (seed > max_seed_value) or (seed < min_seed_value):\n log.warning(\n f\"{seed} is not in bounds, \\\n numpy accepts from {min_seed_value} to {max_seed_value}\"\n )\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n\n os.environ[\"PL_GLOBAL_SEED\"] = str(seed)\n random.seed(seed)\n np.random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed_all(seed)\n return seed\n\n\ndef _select_seed_randomly(min_seed_value: int = 0, max_seed_value: int = 255) -> int:\n seed = random.randint(min_seed_value, max_seed_value)\n log.warning(f\"No correct seed found, seed set to {seed}\")\n return seed\n", "path": "pytorch_lightning/utilities/seed.py"}]}
| 1,836 | 220 |
gh_patches_debug_21147
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-8565
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Banner edit fields should be larger
### NetBox version
v3.1.6
### Feature type
Change to existing functionality
### Proposed functionality
Currently the Login, Top and Bottom banner edit fields in Config revisions are small input fields: they only show a few words at the time. It makes editing the banners somewhat hard.
I propose that the input fields are shown larger, preferably as multi-line input fields, to make it easier to edit the HTML-containing banners.
### Use case
Communicating upcoming maintenances or specific login instructions is easier when the banner input fields are easier to edit.
### Database changes
None
### External dependencies
None
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netbox/netbox/config/parameters.py`
Content:
```
1 from django import forms
2 from django.contrib.postgres.forms import SimpleArrayField
3
4
5 class ConfigParam:
6
7 def __init__(self, name, label, default, description='', field=None, field_kwargs=None):
8 self.name = name
9 self.label = label
10 self.default = default
11 self.field = field or forms.CharField
12 self.description = description
13 self.field_kwargs = field_kwargs or {}
14
15
16 PARAMS = (
17
18 # Banners
19 ConfigParam(
20 name='BANNER_LOGIN',
21 label='Login banner',
22 default='',
23 description="Additional content to display on the login page"
24 ),
25 ConfigParam(
26 name='BANNER_TOP',
27 label='Top banner',
28 default='',
29 description="Additional content to display at the top of every page"
30 ),
31 ConfigParam(
32 name='BANNER_BOTTOM',
33 label='Bottom banner',
34 default='',
35 description="Additional content to display at the bottom of every page"
36 ),
37
38 # IPAM
39 ConfigParam(
40 name='ENFORCE_GLOBAL_UNIQUE',
41 label='Globally unique IP space',
42 default=False,
43 description="Enforce unique IP addressing within the global table",
44 field=forms.BooleanField
45 ),
46 ConfigParam(
47 name='PREFER_IPV4',
48 label='Prefer IPv4',
49 default=False,
50 description="Prefer IPv4 addresses over IPv6",
51 field=forms.BooleanField
52 ),
53
54 # Racks
55 ConfigParam(
56 name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',
57 label='Rack unit height',
58 default=22,
59 description="Default unit height for rendered rack elevations",
60 field=forms.IntegerField
61 ),
62 ConfigParam(
63 name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',
64 label='Rack unit width',
65 default=220,
66 description="Default unit width for rendered rack elevations",
67 field=forms.IntegerField
68 ),
69
70 # Security
71 ConfigParam(
72 name='ALLOWED_URL_SCHEMES',
73 label='Allowed URL schemes',
74 default=(
75 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',
76 'xmpp',
77 ),
78 description="Permitted schemes for URLs in user-provided content",
79 field=SimpleArrayField,
80 field_kwargs={'base_field': forms.CharField()}
81 ),
82
83 # Pagination
84 ConfigParam(
85 name='PAGINATE_COUNT',
86 label='Default page size',
87 default=50,
88 field=forms.IntegerField
89 ),
90 ConfigParam(
91 name='MAX_PAGE_SIZE',
92 label='Maximum page size',
93 default=1000,
94 field=forms.IntegerField
95 ),
96
97 # Validation
98 ConfigParam(
99 name='CUSTOM_VALIDATORS',
100 label='Custom validators',
101 default={},
102 description="Custom validation rules (JSON)",
103 field=forms.JSONField
104 ),
105
106 # NAPALM
107 ConfigParam(
108 name='NAPALM_USERNAME',
109 label='NAPALM username',
110 default='',
111 description="Username to use when connecting to devices via NAPALM"
112 ),
113 ConfigParam(
114 name='NAPALM_PASSWORD',
115 label='NAPALM password',
116 default='',
117 description="Password to use when connecting to devices via NAPALM"
118 ),
119 ConfigParam(
120 name='NAPALM_TIMEOUT',
121 label='NAPALM timeout',
122 default=30,
123 description="NAPALM connection timeout (in seconds)",
124 field=forms.IntegerField
125 ),
126 ConfigParam(
127 name='NAPALM_ARGS',
128 label='NAPALM arguments',
129 default={},
130 description="Additional arguments to pass when invoking a NAPALM driver (as JSON data)",
131 field=forms.JSONField
132 ),
133
134 # Miscellaneous
135 ConfigParam(
136 name='MAINTENANCE_MODE',
137 label='Maintenance mode',
138 default=False,
139 description="Enable maintenance mode",
140 field=forms.BooleanField
141 ),
142 ConfigParam(
143 name='GRAPHQL_ENABLED',
144 label='GraphQL enabled',
145 default=True,
146 description="Enable the GraphQL API",
147 field=forms.BooleanField
148 ),
149 ConfigParam(
150 name='CHANGELOG_RETENTION',
151 label='Changelog retention',
152 default=90,
153 description="Days to retain changelog history (set to zero for unlimited)",
154 field=forms.IntegerField
155 ),
156 ConfigParam(
157 name='MAPS_URL',
158 label='Maps URL',
159 default='https://maps.google.com/?q=',
160 description="Base URL for mapping geographic locations"
161 ),
162
163 )
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netbox/netbox/config/parameters.py b/netbox/netbox/config/parameters.py
--- a/netbox/netbox/config/parameters.py
+++ b/netbox/netbox/config/parameters.py
@@ -20,19 +20,28 @@
name='BANNER_LOGIN',
label='Login banner',
default='',
- description="Additional content to display on the login page"
+ description="Additional content to display on the login page",
+ field_kwargs={
+ 'widget': forms.Textarea(),
+ },
),
ConfigParam(
name='BANNER_TOP',
label='Top banner',
default='',
- description="Additional content to display at the top of every page"
+ description="Additional content to display at the top of every page",
+ field_kwargs={
+ 'widget': forms.Textarea(),
+ },
),
ConfigParam(
name='BANNER_BOTTOM',
label='Bottom banner',
default='',
- description="Additional content to display at the bottom of every page"
+ description="Additional content to display at the bottom of every page",
+ field_kwargs={
+ 'widget': forms.Textarea(),
+ },
),
# IPAM
|
{"golden_diff": "diff --git a/netbox/netbox/config/parameters.py b/netbox/netbox/config/parameters.py\n--- a/netbox/netbox/config/parameters.py\n+++ b/netbox/netbox/config/parameters.py\n@@ -20,19 +20,28 @@\n name='BANNER_LOGIN',\n label='Login banner',\n default='',\n- description=\"Additional content to display on the login page\"\n+ description=\"Additional content to display on the login page\",\n+ field_kwargs={\n+ 'widget': forms.Textarea(),\n+ },\n ),\n ConfigParam(\n name='BANNER_TOP',\n label='Top banner',\n default='',\n- description=\"Additional content to display at the top of every page\"\n+ description=\"Additional content to display at the top of every page\",\n+ field_kwargs={\n+ 'widget': forms.Textarea(),\n+ },\n ),\n ConfigParam(\n name='BANNER_BOTTOM',\n label='Bottom banner',\n default='',\n- description=\"Additional content to display at the bottom of every page\"\n+ description=\"Additional content to display at the bottom of every page\",\n+ field_kwargs={\n+ 'widget': forms.Textarea(),\n+ },\n ),\n \n # IPAM\n", "issue": "Banner edit fields should be larger\n### NetBox version\n\nv3.1.6\n\n### Feature type\n\nChange to existing functionality\n\n### Proposed functionality\n\nCurrently the Login, Top and Bottom banner edit fields in Config revisions are small input fields: they only show a few words at the time. It makes editing the banners somewhat hard.\r\n\r\nI propose that the input fields are shown larger, preferably as multi-line input fields, to make it easier to edit the HTML-containing banners.\n\n### Use case\n\nCommunicating upcoming maintenances or specific login instructions is easier when the banner input fields are easier to edit.\n\n### Database changes\n\nNone\n\n### External dependencies\n\nNone\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\n\n\nclass ConfigParam:\n\n def __init__(self, name, label, default, description='', field=None, field_kwargs=None):\n self.name = name\n self.label = label\n self.default = default\n self.field = field or forms.CharField\n self.description = description\n self.field_kwargs = field_kwargs or {}\n\n\nPARAMS = (\n\n # Banners\n ConfigParam(\n name='BANNER_LOGIN',\n label='Login banner',\n default='',\n description=\"Additional content to display on the login page\"\n ),\n ConfigParam(\n name='BANNER_TOP',\n label='Top banner',\n default='',\n description=\"Additional content to display at the top of every page\"\n ),\n ConfigParam(\n name='BANNER_BOTTOM',\n label='Bottom banner',\n default='',\n description=\"Additional content to display at the bottom of every page\"\n ),\n\n # IPAM\n ConfigParam(\n name='ENFORCE_GLOBAL_UNIQUE',\n label='Globally unique IP space',\n default=False,\n description=\"Enforce unique IP addressing within the global table\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='PREFER_IPV4',\n label='Prefer IPv4',\n default=False,\n description=\"Prefer IPv4 addresses over IPv6\",\n field=forms.BooleanField\n ),\n\n # Racks\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',\n label='Rack unit height',\n default=22,\n description=\"Default unit height for rendered rack elevations\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',\n label='Rack unit width',\n default=220,\n description=\"Default unit width for rendered rack elevations\",\n field=forms.IntegerField\n ),\n\n # Security\n ConfigParam(\n name='ALLOWED_URL_SCHEMES',\n label='Allowed URL schemes',\n default=(\n 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',\n 'xmpp',\n ),\n description=\"Permitted schemes for URLs in user-provided content\",\n field=SimpleArrayField,\n field_kwargs={'base_field': forms.CharField()}\n ),\n\n # Pagination\n ConfigParam(\n name='PAGINATE_COUNT',\n label='Default page size',\n default=50,\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAX_PAGE_SIZE',\n label='Maximum page size',\n default=1000,\n field=forms.IntegerField\n ),\n\n # Validation\n ConfigParam(\n name='CUSTOM_VALIDATORS',\n label='Custom validators',\n default={},\n description=\"Custom validation rules (JSON)\",\n field=forms.JSONField\n ),\n\n # NAPALM\n ConfigParam(\n name='NAPALM_USERNAME',\n label='NAPALM username',\n default='',\n description=\"Username to use when connecting to devices via NAPALM\"\n ),\n ConfigParam(\n name='NAPALM_PASSWORD',\n label='NAPALM password',\n default='',\n description=\"Password to use when connecting to devices via NAPALM\"\n ),\n ConfigParam(\n name='NAPALM_TIMEOUT',\n label='NAPALM timeout',\n default=30,\n description=\"NAPALM connection timeout (in seconds)\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='NAPALM_ARGS',\n label='NAPALM arguments',\n default={},\n description=\"Additional arguments to pass when invoking a NAPALM driver (as JSON data)\",\n field=forms.JSONField\n ),\n\n # Miscellaneous\n ConfigParam(\n name='MAINTENANCE_MODE',\n label='Maintenance mode',\n default=False,\n description=\"Enable maintenance mode\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='GRAPHQL_ENABLED',\n label='GraphQL enabled',\n default=True,\n description=\"Enable the GraphQL API\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='CHANGELOG_RETENTION',\n label='Changelog retention',\n default=90,\n description=\"Days to retain changelog history (set to zero for unlimited)\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAPS_URL',\n label='Maps URL',\n default='https://maps.google.com/?q=',\n description=\"Base URL for mapping geographic locations\"\n ),\n\n)\n", "path": "netbox/netbox/config/parameters.py"}], "after_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\n\n\nclass ConfigParam:\n\n def __init__(self, name, label, default, description='', field=None, field_kwargs=None):\n self.name = name\n self.label = label\n self.default = default\n self.field = field or forms.CharField\n self.description = description\n self.field_kwargs = field_kwargs or {}\n\n\nPARAMS = (\n\n # Banners\n ConfigParam(\n name='BANNER_LOGIN',\n label='Login banner',\n default='',\n description=\"Additional content to display on the login page\",\n field_kwargs={\n 'widget': forms.Textarea(),\n },\n ),\n ConfigParam(\n name='BANNER_TOP',\n label='Top banner',\n default='',\n description=\"Additional content to display at the top of every page\",\n field_kwargs={\n 'widget': forms.Textarea(),\n },\n ),\n ConfigParam(\n name='BANNER_BOTTOM',\n label='Bottom banner',\n default='',\n description=\"Additional content to display at the bottom of every page\",\n field_kwargs={\n 'widget': forms.Textarea(),\n },\n ),\n\n # IPAM\n ConfigParam(\n name='ENFORCE_GLOBAL_UNIQUE',\n label='Globally unique IP space',\n default=False,\n description=\"Enforce unique IP addressing within the global table\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='PREFER_IPV4',\n label='Prefer IPv4',\n default=False,\n description=\"Prefer IPv4 addresses over IPv6\",\n field=forms.BooleanField\n ),\n\n # Racks\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',\n label='Rack unit height',\n default=22,\n description=\"Default unit height for rendered rack elevations\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',\n label='Rack unit width',\n default=220,\n description=\"Default unit width for rendered rack elevations\",\n field=forms.IntegerField\n ),\n\n # Security\n ConfigParam(\n name='ALLOWED_URL_SCHEMES',\n label='Allowed URL schemes',\n default=(\n 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',\n 'xmpp',\n ),\n description=\"Permitted schemes for URLs in user-provided content\",\n field=SimpleArrayField,\n field_kwargs={'base_field': forms.CharField()}\n ),\n\n # Pagination\n ConfigParam(\n name='PAGINATE_COUNT',\n label='Default page size',\n default=50,\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAX_PAGE_SIZE',\n label='Maximum page size',\n default=1000,\n field=forms.IntegerField\n ),\n\n # Validation\n ConfigParam(\n name='CUSTOM_VALIDATORS',\n label='Custom validators',\n default={},\n description=\"Custom validation rules (JSON)\",\n field=forms.JSONField\n ),\n\n # NAPALM\n ConfigParam(\n name='NAPALM_USERNAME',\n label='NAPALM username',\n default='',\n description=\"Username to use when connecting to devices via NAPALM\"\n ),\n ConfigParam(\n name='NAPALM_PASSWORD',\n label='NAPALM password',\n default='',\n description=\"Password to use when connecting to devices via NAPALM\"\n ),\n ConfigParam(\n name='NAPALM_TIMEOUT',\n label='NAPALM timeout',\n default=30,\n description=\"NAPALM connection timeout (in seconds)\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='NAPALM_ARGS',\n label='NAPALM arguments',\n default={},\n description=\"Additional arguments to pass when invoking a NAPALM driver (as JSON data)\",\n field=forms.JSONField\n ),\n\n # Miscellaneous\n ConfigParam(\n name='MAINTENANCE_MODE',\n label='Maintenance mode',\n default=False,\n description=\"Enable maintenance mode\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='GRAPHQL_ENABLED',\n label='GraphQL enabled',\n default=True,\n description=\"Enable the GraphQL API\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='CHANGELOG_RETENTION',\n label='Changelog retention',\n default=90,\n description=\"Days to retain changelog history (set to zero for unlimited)\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAPS_URL',\n label='Maps URL',\n default='https://maps.google.com/?q=',\n description=\"Base URL for mapping geographic locations\"\n ),\n\n)\n", "path": "netbox/netbox/config/parameters.py"}]}
| 1,778 | 263 |
gh_patches_debug_22573
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-689
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sampled_from() should work with collections.OrderedDict
OrderedDict should satisfy the replayability requirement, so sampling from it should be possible.
Currently it raises exception:
`HypothesisDeprecationWarning: Cannot sample from odict_values`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/hypothesis/version.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 __version_info__ = (3, 11, 2)
21 __version__ = '.'.join(map(str, __version_info__))
22
```
Path: `src/hypothesis/internal/conjecture/utils.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 import enum
21 import math
22 from collections import Sequence
23
24 from hypothesis._settings import note_deprecation
25 from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \
26 int_from_bytes
27
28
29 def n_byte_unsigned(data, n):
30 return int_from_bytes(data.draw_bytes(n))
31
32
33 def saturate(n):
34 bits = bit_length(n)
35 k = 1
36 while k < bits:
37 n |= (n >> k)
38 k *= 2
39 return n
40
41
42 def integer_range(data, lower, upper, center=None, distribution=None):
43 assert lower <= upper
44 if lower == upper:
45 return int(lower)
46
47 if center is None:
48 center = lower
49 center = min(max(center, lower), upper)
50 if distribution is None:
51 if lower < center < upper:
52 def distribution(random):
53 if random.randint(0, 1):
54 return random.randint(center, upper)
55 else:
56 return random.randint(lower, center)
57 else:
58 def distribution(random):
59 return random.randint(lower, upper)
60
61 gap = upper - lower
62 bits = bit_length(gap)
63 nbytes = bits // 8 + int(bits % 8 != 0)
64 mask = saturate(gap)
65
66 def byte_distribution(random, n):
67 assert n == nbytes
68 v = distribution(random)
69 if v >= center:
70 probe = v - center
71 else:
72 probe = upper - v
73 return int_to_bytes(probe, n)
74
75 probe = gap + 1
76
77 while probe > gap:
78 probe = int_from_bytes(
79 data.draw_bytes(nbytes, byte_distribution)
80 ) & mask
81
82 if center == upper:
83 result = upper - probe
84 elif center == lower:
85 result = lower + probe
86 else:
87 if center + probe <= upper:
88 result = center + probe
89 else:
90 result = upper - probe
91 assert lower <= result <= upper
92 return int(result)
93
94
95 def integer_range_with_distribution(data, lower, upper, nums):
96 return integer_range(
97 data, lower, upper, distribution=nums
98 )
99
100
101 def centered_integer_range(data, lower, upper, center):
102 return integer_range(
103 data, lower, upper, center=center
104 )
105
106
107 def check_sample(values):
108 if not isinstance(values, (Sequence, enum.EnumMeta)):
109 note_deprecation(
110 ('Cannot sample from %r, not a sequence. ' % (values,)) +
111 'Hypothesis goes to some length to ensure that sampling an '
112 'element from a collection (with `sampled_from` or `choices`) is '
113 'replayable and can be minimised. To replay a saved example, '
114 'the sampled values must have the same iteration order on every '
115 'run - ruling out sets, dicts, etc due to hash randomisation. '
116 'Most cases can simply use `sorted(values)`, but mixed types or '
117 'special values such as math.nan require careful handling - and '
118 'note that when simplifying an example, Hypothesis treats '
119 'earlier values as simpler.')
120 return tuple(values)
121
122
123 def choice(data, values):
124 return values[integer_range(data, 0, len(values) - 1)]
125
126
127 def geometric(data, p):
128 denom = math.log1p(-p)
129 n_bytes = 8
130
131 def distribution(random, n):
132 assert n == n_bytes
133 for _ in range(100):
134 try:
135 return int_to_bytes(int(
136 math.log1p(-random.random()) / denom), n)
137 # This is basically impossible to hit but is required for
138 # correctness
139 except OverflowError: # pragma: no cover
140 pass
141 # We got a one in a million chance 100 times in a row. Something is up.
142 assert False # pragma: no cover
143 return int_from_bytes(data.draw_bytes(n_bytes, distribution))
144
145
146 def boolean(data):
147 return bool(n_byte_unsigned(data, 1) & 1)
148
149
150 def biased_coin(data, p):
151 def distribution(random, n):
152 assert n == 1
153 return hbytes([int(random.random() <= p)])
154 return bool(
155 data.draw_bytes(1, distribution)[0] & 1
156 )
157
158
159 def write(data, string):
160 assert isinstance(string, hbytes)
161
162 def distribution(random, n):
163 assert n == len(string)
164 return string
165 x = data.draw_bytes(len(string), distribution)
166 if x != string:
167 data.mark_invalid()
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/hypothesis/internal/conjecture/utils.py b/src/hypothesis/internal/conjecture/utils.py
--- a/src/hypothesis/internal/conjecture/utils.py
+++ b/src/hypothesis/internal/conjecture/utils.py
@@ -19,7 +19,7 @@
import enum
import math
-from collections import Sequence
+from collections import Sequence, OrderedDict
from hypothesis._settings import note_deprecation
from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \
@@ -105,7 +105,7 @@
def check_sample(values):
- if not isinstance(values, (Sequence, enum.EnumMeta)):
+ if not isinstance(values, (OrderedDict, Sequence, enum.EnumMeta)):
note_deprecation(
('Cannot sample from %r, not a sequence. ' % (values,)) +
'Hypothesis goes to some length to ensure that sampling an '
diff --git a/src/hypothesis/version.py b/src/hypothesis/version.py
--- a/src/hypothesis/version.py
+++ b/src/hypothesis/version.py
@@ -17,5 +17,5 @@
from __future__ import division, print_function, absolute_import
-__version_info__ = (3, 11, 2)
+__version_info__ = (3, 11, 3)
__version__ = '.'.join(map(str, __version_info__))
|
{"golden_diff": "diff --git a/src/hypothesis/internal/conjecture/utils.py b/src/hypothesis/internal/conjecture/utils.py\n--- a/src/hypothesis/internal/conjecture/utils.py\n+++ b/src/hypothesis/internal/conjecture/utils.py\n@@ -19,7 +19,7 @@\n \n import enum\n import math\n-from collections import Sequence\n+from collections import Sequence, OrderedDict\n \n from hypothesis._settings import note_deprecation\n from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n@@ -105,7 +105,7 @@\n \n \n def check_sample(values):\n- if not isinstance(values, (Sequence, enum.EnumMeta)):\n+ if not isinstance(values, (OrderedDict, Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\ndiff --git a/src/hypothesis/version.py b/src/hypothesis/version.py\n--- a/src/hypothesis/version.py\n+++ b/src/hypothesis/version.py\n@@ -17,5 +17,5 @@\n \n from __future__ import division, print_function, absolute_import\n \n-__version_info__ = (3, 11, 2)\n+__version_info__ = (3, 11, 3)\n __version__ = '.'.join(map(str, __version_info__))\n", "issue": "Sampled_from() should work with collections.OrderedDict\nOrderedDict should satisfy the replayability requirement, so sampling from it should be possible.\r\nCurrently it raises exception:\r\n`HypothesisDeprecationWarning: Cannot sample from odict_values`\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\n__version_info__ = (3, 11, 2)\n__version__ = '.'.join(map(str, __version_info__))\n", "path": "src/hypothesis/version.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport enum\nimport math\nfrom collections import Sequence\n\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n int_from_bytes\n\n\ndef n_byte_unsigned(data, n):\n return int_from_bytes(data.draw_bytes(n))\n\n\ndef saturate(n):\n bits = bit_length(n)\n k = 1\n while k < bits:\n n |= (n >> k)\n k *= 2\n return n\n\n\ndef integer_range(data, lower, upper, center=None, distribution=None):\n assert lower <= upper\n if lower == upper:\n return int(lower)\n\n if center is None:\n center = lower\n center = min(max(center, lower), upper)\n if distribution is None:\n if lower < center < upper:\n def distribution(random):\n if random.randint(0, 1):\n return random.randint(center, upper)\n else:\n return random.randint(lower, center)\n else:\n def distribution(random):\n return random.randint(lower, upper)\n\n gap = upper - lower\n bits = bit_length(gap)\n nbytes = bits // 8 + int(bits % 8 != 0)\n mask = saturate(gap)\n\n def byte_distribution(random, n):\n assert n == nbytes\n v = distribution(random)\n if v >= center:\n probe = v - center\n else:\n probe = upper - v\n return int_to_bytes(probe, n)\n\n probe = gap + 1\n\n while probe > gap:\n probe = int_from_bytes(\n data.draw_bytes(nbytes, byte_distribution)\n ) & mask\n\n if center == upper:\n result = upper - probe\n elif center == lower:\n result = lower + probe\n else:\n if center + probe <= upper:\n result = center + probe\n else:\n result = upper - probe\n assert lower <= result <= upper\n return int(result)\n\n\ndef integer_range_with_distribution(data, lower, upper, nums):\n return integer_range(\n data, lower, upper, distribution=nums\n )\n\n\ndef centered_integer_range(data, lower, upper, center):\n return integer_range(\n data, lower, upper, center=center\n )\n\n\ndef check_sample(values):\n if not isinstance(values, (Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\n 'element from a collection (with `sampled_from` or `choices`) is '\n 'replayable and can be minimised. To replay a saved example, '\n 'the sampled values must have the same iteration order on every '\n 'run - ruling out sets, dicts, etc due to hash randomisation. '\n 'Most cases can simply use `sorted(values)`, but mixed types or '\n 'special values such as math.nan require careful handling - and '\n 'note that when simplifying an example, Hypothesis treats '\n 'earlier values as simpler.')\n return tuple(values)\n\n\ndef choice(data, values):\n return values[integer_range(data, 0, len(values) - 1)]\n\n\ndef geometric(data, p):\n denom = math.log1p(-p)\n n_bytes = 8\n\n def distribution(random, n):\n assert n == n_bytes\n for _ in range(100):\n try:\n return int_to_bytes(int(\n math.log1p(-random.random()) / denom), n)\n # This is basically impossible to hit but is required for\n # correctness\n except OverflowError: # pragma: no cover\n pass\n # We got a one in a million chance 100 times in a row. Something is up.\n assert False # pragma: no cover\n return int_from_bytes(data.draw_bytes(n_bytes, distribution))\n\n\ndef boolean(data):\n return bool(n_byte_unsigned(data, 1) & 1)\n\n\ndef biased_coin(data, p):\n def distribution(random, n):\n assert n == 1\n return hbytes([int(random.random() <= p)])\n return bool(\n data.draw_bytes(1, distribution)[0] & 1\n )\n\n\ndef write(data, string):\n assert isinstance(string, hbytes)\n\n def distribution(random, n):\n assert n == len(string)\n return string\n x = data.draw_bytes(len(string), distribution)\n if x != string:\n data.mark_invalid()\n", "path": "src/hypothesis/internal/conjecture/utils.py"}], "after_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\n__version_info__ = (3, 11, 3)\n__version__ = '.'.join(map(str, __version_info__))\n", "path": "src/hypothesis/version.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport enum\nimport math\nfrom collections import Sequence, OrderedDict\n\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n int_from_bytes\n\n\ndef n_byte_unsigned(data, n):\n return int_from_bytes(data.draw_bytes(n))\n\n\ndef saturate(n):\n bits = bit_length(n)\n k = 1\n while k < bits:\n n |= (n >> k)\n k *= 2\n return n\n\n\ndef integer_range(data, lower, upper, center=None, distribution=None):\n assert lower <= upper\n if lower == upper:\n return int(lower)\n\n if center is None:\n center = lower\n center = min(max(center, lower), upper)\n if distribution is None:\n if lower < center < upper:\n def distribution(random):\n if random.randint(0, 1):\n return random.randint(center, upper)\n else:\n return random.randint(lower, center)\n else:\n def distribution(random):\n return random.randint(lower, upper)\n\n gap = upper - lower\n bits = bit_length(gap)\n nbytes = bits // 8 + int(bits % 8 != 0)\n mask = saturate(gap)\n\n def byte_distribution(random, n):\n assert n == nbytes\n v = distribution(random)\n if v >= center:\n probe = v - center\n else:\n probe = upper - v\n return int_to_bytes(probe, n)\n\n probe = gap + 1\n\n while probe > gap:\n probe = int_from_bytes(\n data.draw_bytes(nbytes, byte_distribution)\n ) & mask\n\n if center == upper:\n result = upper - probe\n elif center == lower:\n result = lower + probe\n else:\n if center + probe <= upper:\n result = center + probe\n else:\n result = upper - probe\n assert lower <= result <= upper\n return int(result)\n\n\ndef integer_range_with_distribution(data, lower, upper, nums):\n return integer_range(\n data, lower, upper, distribution=nums\n )\n\n\ndef centered_integer_range(data, lower, upper, center):\n return integer_range(\n data, lower, upper, center=center\n )\n\n\ndef check_sample(values):\n if not isinstance(values, (OrderedDict, Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\n 'element from a collection (with `sampled_from` or `choices`) is '\n 'replayable and can be minimised. To replay a saved example, '\n 'the sampled values must have the same iteration order on every '\n 'run - ruling out sets, dicts, etc due to hash randomisation. '\n 'Most cases can simply use `sorted(values)`, but mixed types or '\n 'special values such as math.nan require careful handling - and '\n 'note that when simplifying an example, Hypothesis treats '\n 'earlier values as simpler.')\n return tuple(values)\n\n\ndef choice(data, values):\n return values[integer_range(data, 0, len(values) - 1)]\n\n\ndef geometric(data, p):\n denom = math.log1p(-p)\n n_bytes = 8\n\n def distribution(random, n):\n assert n == n_bytes\n for _ in range(100):\n try:\n return int_to_bytes(int(\n math.log1p(-random.random()) / denom), n)\n # This is basically impossible to hit but is required for\n # correctness\n except OverflowError: # pragma: no cover\n pass\n # We got a one in a million chance 100 times in a row. Something is up.\n assert False # pragma: no cover\n return int_from_bytes(data.draw_bytes(n_bytes, distribution))\n\n\ndef boolean(data):\n return bool(n_byte_unsigned(data, 1) & 1)\n\n\ndef biased_coin(data, p):\n def distribution(random, n):\n assert n == 1\n return hbytes([int(random.random() <= p)])\n return bool(\n data.draw_bytes(1, distribution)[0] & 1\n )\n\n\ndef write(data, string):\n assert isinstance(string, hbytes)\n\n def distribution(random, n):\n assert n == len(string)\n return string\n x = data.draw_bytes(len(string), distribution)\n if x != string:\n data.mark_invalid()\n", "path": "src/hypothesis/internal/conjecture/utils.py"}]}
| 2,175 | 308 |
gh_patches_debug_10090
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-3944
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Won't open configure panel with some icons
```
2021-11-03 02:59:23,691: Unable to load icon from image fl-studio
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/lutris/game_actions.py", line 178, in on_edit_game_configuration
EditGameConfigDialog(self.window, self.game)
File "/usr/lib/python3/dist-packages/lutris/gui/config/edit_game.py", line 16, in __init__
self.build_tabs("game")
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 70, in build_tabs
self._build_info_tab()
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 79, in _build_info_tab
info_box.pack_start(self._get_banner_box(), False, False, 6) # Banner
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 155, in _get_banner_box
self._set_image("banner")
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 195, in _set_image
image.set_from_pixbuf(get_pixbuf_for_game(game_slug, size))
File "/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py", line 127, in get_pixbuf_for_game
return get_pixbuf(image_abspath, size, fallback=get_default_icon(size), is_installed=is_installed)
File "/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py", line 58, in get_pixbuf
pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
AttributeError: 'NoneType' object has no attribute 'scale_simple'
```
This seems to happen with the icon for "FL Studio", right click > configure to reproduce.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/gui/widgets/utils.py`
Content:
```
1 """Various utilities using the GObject framework"""
2 import array
3 import os
4
5 from gi.repository import Gdk, GdkPixbuf, Gio, GLib, Gtk
6
7 from lutris import settings
8 from lutris.util import datapath, system
9 from lutris.util.log import logger
10
11 try:
12 from PIL import Image
13 except ImportError:
14 Image = None
15
16 ICON_SIZE = (32, 32)
17 BANNER_SIZE = (184, 69)
18
19
20 def get_main_window(widget):
21 """Return the application's main window from one of its widget"""
22 parent = widget.get_toplevel()
23 if not isinstance(parent, Gtk.Window):
24 # The sync dialog may have closed
25 parent = Gio.Application.get_default().props.active_window
26 for window in parent.application.get_windows():
27 if "LutrisWindow" in window.__class__.__name__:
28 return window
29 return
30
31
32 def open_uri(uri):
33 """Opens a local or remote URI with the default application"""
34 system.reset_library_preloads()
35 try:
36 Gtk.show_uri(None, uri, Gdk.CURRENT_TIME)
37 except GLib.Error as ex:
38 logger.exception("Failed to open URI %s: %s, falling back to xdg-open", uri, ex)
39 system.execute(["xdg-open", uri])
40
41
42 def get_pixbuf(image, size, fallback=None, is_installed=True):
43 """Return a pixbuf from file `image` at `size` or fallback to `fallback`"""
44 width, height = size
45 pixbuf = None
46 if system.path_exists(image, exclude_empty=True):
47 try:
48 pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(image, width, height)
49 pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
50 except GLib.GError:
51 logger.error("Unable to load icon from image %s", image)
52 else:
53 if not fallback:
54 fallback = get_default_icon(size)
55 if system.path_exists(fallback):
56 pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)
57 if is_installed:
58 pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
59 return pixbuf
60 overlay = os.path.join(datapath.get(), "media/unavailable.png")
61 transparent_pixbuf = get_overlay(overlay, size).copy()
62 if pixbuf:
63 pixbuf.composite(
64 transparent_pixbuf,
65 0,
66 0,
67 size[0],
68 size[1],
69 0,
70 0,
71 1,
72 1,
73 GdkPixbuf.InterpType.NEAREST,
74 100,
75 )
76 return transparent_pixbuf
77
78
79 def get_stock_icon(name, size):
80 """Return a pixbuf from a stock icon name"""
81 theme = Gtk.IconTheme.get_default()
82 try:
83 return theme.load_icon(name, size, Gtk.IconLookupFlags.GENERIC_FALLBACK)
84 except GLib.GError:
85 logger.error("Failed to read icon %s", name)
86 return None
87
88
89 def get_icon(icon_name, icon_format="image", size=None, icon_type="runner"):
90 """Return an icon based on the given name, format, size and type.
91
92 Keyword arguments:
93 icon_name -- The name of the icon to retrieve
94 format -- The format of the icon, which should be either 'image' or 'pixbuf' (default 'image')
95 size -- The size for the desired image (default None)
96 icon_type -- Retrieve either a 'runner' or 'platform' icon (default 'runner')
97 """
98 filename = icon_name.lower().replace(" ", "") + ".png"
99 icon_path = os.path.join(settings.RUNTIME_DIR, "icons/hicolor/64x64/apps", filename)
100 if not os.path.exists(icon_path):
101 return None
102 if icon_format == "image":
103 icon = Gtk.Image()
104 if size:
105 icon.set_from_pixbuf(get_pixbuf(icon_path, size))
106 else:
107 icon.set_from_file(icon_path)
108 return icon
109 if icon_format == "pixbuf" and size:
110 return get_pixbuf(icon_path, size)
111 raise ValueError("Invalid arguments")
112
113
114 def get_overlay(overlay_path, size):
115 width, height = size
116 transparent_pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(overlay_path, width, height)
117 transparent_pixbuf = transparent_pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
118 return transparent_pixbuf
119
120
121 def get_default_icon(size):
122 if size[0] == size[1]:
123 return os.path.join(datapath.get(), "media/default_icon.png")
124 return os.path.join(datapath.get(), "media/default_banner.png")
125
126
127 def convert_to_background(background_path, target_size=(320, 1080)):
128 """Converts a image to a pane background"""
129 coverart = Image.open(background_path)
130 coverart = coverart.convert("RGBA")
131
132 target_width, target_height = target_size
133 image_height = int(target_height * 0.80) # 80% of the mask is visible
134 orig_width, orig_height = coverart.size
135
136 # Resize and crop coverart
137 width = int(orig_width * (image_height / orig_height))
138 offset = int((width - target_width) / 2)
139 coverart = coverart.resize((width, image_height), resample=Image.BICUBIC)
140 coverart = coverart.crop((offset, 0, target_width + offset, image_height))
141
142 # Resize canvas of coverart by putting transparent pixels on the bottom
143 coverart_bg = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))
144 coverart_bg.paste(coverart, (0, 0, target_width, image_height))
145
146 # Apply a tint to the base image
147 # tint = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 255))
148 # coverart = Image.blend(coverart, tint, 0.6)
149
150 # Paste coverart on transparent image while applying a gradient mask
151 background = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))
152 mask = Image.open(os.path.join(datapath.get(), "media/mask.png"))
153 background.paste(coverart_bg, mask=mask)
154
155 return background
156
157
158 def thumbnail_image(base_image, target_size):
159 base_width, base_height = base_image.size
160 base_ratio = base_width / base_height
161 target_width, target_height = target_size
162 target_ratio = target_width / target_height
163
164 # Resize and crop coverart
165 if base_ratio >= target_ratio:
166 width = int(base_width * (target_height / base_height))
167 height = target_height
168 else:
169 width = target_width
170 height = int(base_height * (target_width / base_width))
171 x_offset = int((width - target_width) / 2)
172 y_offset = int((height - target_height) / 2)
173 base_image = base_image.resize((width, height), resample=Image.BICUBIC)
174 base_image = base_image.crop((x_offset, y_offset, width - x_offset, height - y_offset))
175 return base_image
176
177
178 def paste_overlay(base_image, overlay_image, position=0.7):
179 base_width, base_height = base_image.size
180 overlay_width, overlay_height = overlay_image.size
181 offset_x = int((base_width - overlay_width) / 2)
182 offset_y = int((base_height - overlay_height) / 2)
183 base_image.paste(
184 overlay_image, (
185 offset_x,
186 offset_y,
187 overlay_width + offset_x,
188 overlay_height + offset_y
189 ),
190 mask=overlay_image
191 )
192 return base_image
193
194
195 def image2pixbuf(image):
196 """Converts a PIL Image to a GDK Pixbuf"""
197 image_array = array.array('B', image.tobytes())
198 width, height = image.size
199 return GdkPixbuf.Pixbuf.new_from_data(image_array, GdkPixbuf.Colorspace.RGB, True, 8, width, height, width * 4)
200
201
202 def get_link_button(text):
203 """Return a transparent text button for the side panels"""
204 button = Gtk.Button(text, visible=True)
205 button.props.relief = Gtk.ReliefStyle.NONE
206 button.get_children()[0].set_alignment(0, 0.5)
207 button.get_style_context().add_class("panel-button")
208 button.set_size_request(-1, 24)
209 return button
210
211
212 def load_icon_theme():
213 """Add the lutris icon folder to the default theme"""
214 icon_theme = Gtk.IconTheme.get_default()
215 local_theme_path = os.path.join(settings.RUNTIME_DIR, "icons")
216 if local_theme_path not in icon_theme.get_search_path():
217 icon_theme.prepend_search_path(local_theme_path)
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/gui/widgets/utils.py b/lutris/gui/widgets/utils.py
--- a/lutris/gui/widgets/utils.py
+++ b/lutris/gui/widgets/utils.py
@@ -54,7 +54,7 @@
fallback = get_default_icon(size)
if system.path_exists(fallback):
pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)
- if is_installed:
+ if is_installed and pixbuf:
pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
return pixbuf
overlay = os.path.join(datapath.get(), "media/unavailable.png")
|
{"golden_diff": "diff --git a/lutris/gui/widgets/utils.py b/lutris/gui/widgets/utils.py\n--- a/lutris/gui/widgets/utils.py\n+++ b/lutris/gui/widgets/utils.py\n@@ -54,7 +54,7 @@\n fallback = get_default_icon(size)\n if system.path_exists(fallback):\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)\n- if is_installed:\n+ if is_installed and pixbuf:\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return pixbuf\n overlay = os.path.join(datapath.get(), \"media/unavailable.png\")\n", "issue": "Won't open configure panel with some icons\n```\r\n2021-11-03 02:59:23,691: Unable to load icon from image fl-studio\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3/dist-packages/lutris/game_actions.py\", line 178, in on_edit_game_configuration\r\n EditGameConfigDialog(self.window, self.game)\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/edit_game.py\", line 16, in __init__\r\n self.build_tabs(\"game\")\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 70, in build_tabs\r\n self._build_info_tab()\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 79, in _build_info_tab\r\n info_box.pack_start(self._get_banner_box(), False, False, 6) # Banner\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 155, in _get_banner_box\r\n self._set_image(\"banner\")\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 195, in _set_image\r\n image.set_from_pixbuf(get_pixbuf_for_game(game_slug, size))\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py\", line 127, in get_pixbuf_for_game\r\n return get_pixbuf(image_abspath, size, fallback=get_default_icon(size), is_installed=is_installed)\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py\", line 58, in get_pixbuf\r\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\r\nAttributeError: 'NoneType' object has no attribute 'scale_simple'\r\n```\r\n\r\n\r\nThis seems to happen with the icon for \"FL Studio\", right click > configure to reproduce.\n", "before_files": [{"content": "\"\"\"Various utilities using the GObject framework\"\"\"\nimport array\nimport os\n\nfrom gi.repository import Gdk, GdkPixbuf, Gio, GLib, Gtk\n\nfrom lutris import settings\nfrom lutris.util import datapath, system\nfrom lutris.util.log import logger\n\ntry:\n from PIL import Image\nexcept ImportError:\n Image = None\n\nICON_SIZE = (32, 32)\nBANNER_SIZE = (184, 69)\n\n\ndef get_main_window(widget):\n \"\"\"Return the application's main window from one of its widget\"\"\"\n parent = widget.get_toplevel()\n if not isinstance(parent, Gtk.Window):\n # The sync dialog may have closed\n parent = Gio.Application.get_default().props.active_window\n for window in parent.application.get_windows():\n if \"LutrisWindow\" in window.__class__.__name__:\n return window\n return\n\n\ndef open_uri(uri):\n \"\"\"Opens a local or remote URI with the default application\"\"\"\n system.reset_library_preloads()\n try:\n Gtk.show_uri(None, uri, Gdk.CURRENT_TIME)\n except GLib.Error as ex:\n logger.exception(\"Failed to open URI %s: %s, falling back to xdg-open\", uri, ex)\n system.execute([\"xdg-open\", uri])\n\n\ndef get_pixbuf(image, size, fallback=None, is_installed=True):\n \"\"\"Return a pixbuf from file `image` at `size` or fallback to `fallback`\"\"\"\n width, height = size\n pixbuf = None\n if system.path_exists(image, exclude_empty=True):\n try:\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(image, width, height)\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n except GLib.GError:\n logger.error(\"Unable to load icon from image %s\", image)\n else:\n if not fallback:\n fallback = get_default_icon(size)\n if system.path_exists(fallback):\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)\n if is_installed:\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return pixbuf\n overlay = os.path.join(datapath.get(), \"media/unavailable.png\")\n transparent_pixbuf = get_overlay(overlay, size).copy()\n if pixbuf:\n pixbuf.composite(\n transparent_pixbuf,\n 0,\n 0,\n size[0],\n size[1],\n 0,\n 0,\n 1,\n 1,\n GdkPixbuf.InterpType.NEAREST,\n 100,\n )\n return transparent_pixbuf\n\n\ndef get_stock_icon(name, size):\n \"\"\"Return a pixbuf from a stock icon name\"\"\"\n theme = Gtk.IconTheme.get_default()\n try:\n return theme.load_icon(name, size, Gtk.IconLookupFlags.GENERIC_FALLBACK)\n except GLib.GError:\n logger.error(\"Failed to read icon %s\", name)\n return None\n\n\ndef get_icon(icon_name, icon_format=\"image\", size=None, icon_type=\"runner\"):\n \"\"\"Return an icon based on the given name, format, size and type.\n\n Keyword arguments:\n icon_name -- The name of the icon to retrieve\n format -- The format of the icon, which should be either 'image' or 'pixbuf' (default 'image')\n size -- The size for the desired image (default None)\n icon_type -- Retrieve either a 'runner' or 'platform' icon (default 'runner')\n \"\"\"\n filename = icon_name.lower().replace(\" \", \"\") + \".png\"\n icon_path = os.path.join(settings.RUNTIME_DIR, \"icons/hicolor/64x64/apps\", filename)\n if not os.path.exists(icon_path):\n return None\n if icon_format == \"image\":\n icon = Gtk.Image()\n if size:\n icon.set_from_pixbuf(get_pixbuf(icon_path, size))\n else:\n icon.set_from_file(icon_path)\n return icon\n if icon_format == \"pixbuf\" and size:\n return get_pixbuf(icon_path, size)\n raise ValueError(\"Invalid arguments\")\n\n\ndef get_overlay(overlay_path, size):\n width, height = size\n transparent_pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(overlay_path, width, height)\n transparent_pixbuf = transparent_pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return transparent_pixbuf\n\n\ndef get_default_icon(size):\n if size[0] == size[1]:\n return os.path.join(datapath.get(), \"media/default_icon.png\")\n return os.path.join(datapath.get(), \"media/default_banner.png\")\n\n\ndef convert_to_background(background_path, target_size=(320, 1080)):\n \"\"\"Converts a image to a pane background\"\"\"\n coverart = Image.open(background_path)\n coverart = coverart.convert(\"RGBA\")\n\n target_width, target_height = target_size\n image_height = int(target_height * 0.80) # 80% of the mask is visible\n orig_width, orig_height = coverart.size\n\n # Resize and crop coverart\n width = int(orig_width * (image_height / orig_height))\n offset = int((width - target_width) / 2)\n coverart = coverart.resize((width, image_height), resample=Image.BICUBIC)\n coverart = coverart.crop((offset, 0, target_width + offset, image_height))\n\n # Resize canvas of coverart by putting transparent pixels on the bottom\n coverart_bg = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))\n coverart_bg.paste(coverart, (0, 0, target_width, image_height))\n\n # Apply a tint to the base image\n # tint = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 255))\n # coverart = Image.blend(coverart, tint, 0.6)\n\n # Paste coverart on transparent image while applying a gradient mask\n background = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))\n mask = Image.open(os.path.join(datapath.get(), \"media/mask.png\"))\n background.paste(coverart_bg, mask=mask)\n\n return background\n\n\ndef thumbnail_image(base_image, target_size):\n base_width, base_height = base_image.size\n base_ratio = base_width / base_height\n target_width, target_height = target_size\n target_ratio = target_width / target_height\n\n # Resize and crop coverart\n if base_ratio >= target_ratio:\n width = int(base_width * (target_height / base_height))\n height = target_height\n else:\n width = target_width\n height = int(base_height * (target_width / base_width))\n x_offset = int((width - target_width) / 2)\n y_offset = int((height - target_height) / 2)\n base_image = base_image.resize((width, height), resample=Image.BICUBIC)\n base_image = base_image.crop((x_offset, y_offset, width - x_offset, height - y_offset))\n return base_image\n\n\ndef paste_overlay(base_image, overlay_image, position=0.7):\n base_width, base_height = base_image.size\n overlay_width, overlay_height = overlay_image.size\n offset_x = int((base_width - overlay_width) / 2)\n offset_y = int((base_height - overlay_height) / 2)\n base_image.paste(\n overlay_image, (\n offset_x,\n offset_y,\n overlay_width + offset_x,\n overlay_height + offset_y\n ),\n mask=overlay_image\n )\n return base_image\n\n\ndef image2pixbuf(image):\n \"\"\"Converts a PIL Image to a GDK Pixbuf\"\"\"\n image_array = array.array('B', image.tobytes())\n width, height = image.size\n return GdkPixbuf.Pixbuf.new_from_data(image_array, GdkPixbuf.Colorspace.RGB, True, 8, width, height, width * 4)\n\n\ndef get_link_button(text):\n \"\"\"Return a transparent text button for the side panels\"\"\"\n button = Gtk.Button(text, visible=True)\n button.props.relief = Gtk.ReliefStyle.NONE\n button.get_children()[0].set_alignment(0, 0.5)\n button.get_style_context().add_class(\"panel-button\")\n button.set_size_request(-1, 24)\n return button\n\n\ndef load_icon_theme():\n \"\"\"Add the lutris icon folder to the default theme\"\"\"\n icon_theme = Gtk.IconTheme.get_default()\n local_theme_path = os.path.join(settings.RUNTIME_DIR, \"icons\")\n if local_theme_path not in icon_theme.get_search_path():\n icon_theme.prepend_search_path(local_theme_path)\n", "path": "lutris/gui/widgets/utils.py"}], "after_files": [{"content": "\"\"\"Various utilities using the GObject framework\"\"\"\nimport array\nimport os\n\nfrom gi.repository import Gdk, GdkPixbuf, Gio, GLib, Gtk\n\nfrom lutris import settings\nfrom lutris.util import datapath, system\nfrom lutris.util.log import logger\n\ntry:\n from PIL import Image\nexcept ImportError:\n Image = None\n\nICON_SIZE = (32, 32)\nBANNER_SIZE = (184, 69)\n\n\ndef get_main_window(widget):\n \"\"\"Return the application's main window from one of its widget\"\"\"\n parent = widget.get_toplevel()\n if not isinstance(parent, Gtk.Window):\n # The sync dialog may have closed\n parent = Gio.Application.get_default().props.active_window\n for window in parent.application.get_windows():\n if \"LutrisWindow\" in window.__class__.__name__:\n return window\n return\n\n\ndef open_uri(uri):\n \"\"\"Opens a local or remote URI with the default application\"\"\"\n system.reset_library_preloads()\n try:\n Gtk.show_uri(None, uri, Gdk.CURRENT_TIME)\n except GLib.Error as ex:\n logger.exception(\"Failed to open URI %s: %s, falling back to xdg-open\", uri, ex)\n system.execute([\"xdg-open\", uri])\n\n\ndef get_pixbuf(image, size, fallback=None, is_installed=True):\n \"\"\"Return a pixbuf from file `image` at `size` or fallback to `fallback`\"\"\"\n width, height = size\n pixbuf = None\n if system.path_exists(image, exclude_empty=True):\n try:\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(image, width, height)\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n except GLib.GError:\n logger.error(\"Unable to load icon from image %s\", image)\n else:\n if not fallback:\n fallback = get_default_icon(size)\n if system.path_exists(fallback):\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)\n if is_installed and pixbuf:\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return pixbuf\n overlay = os.path.join(datapath.get(), \"media/unavailable.png\")\n transparent_pixbuf = get_overlay(overlay, size).copy()\n if pixbuf:\n pixbuf.composite(\n transparent_pixbuf,\n 0,\n 0,\n size[0],\n size[1],\n 0,\n 0,\n 1,\n 1,\n GdkPixbuf.InterpType.NEAREST,\n 100,\n )\n return transparent_pixbuf\n\n\ndef get_stock_icon(name, size):\n \"\"\"Return a pixbuf from a stock icon name\"\"\"\n theme = Gtk.IconTheme.get_default()\n try:\n return theme.load_icon(name, size, Gtk.IconLookupFlags.GENERIC_FALLBACK)\n except GLib.GError:\n logger.error(\"Failed to read icon %s\", name)\n return None\n\n\ndef get_icon(icon_name, icon_format=\"image\", size=None, icon_type=\"runner\"):\n \"\"\"Return an icon based on the given name, format, size and type.\n\n Keyword arguments:\n icon_name -- The name of the icon to retrieve\n format -- The format of the icon, which should be either 'image' or 'pixbuf' (default 'image')\n size -- The size for the desired image (default None)\n icon_type -- Retrieve either a 'runner' or 'platform' icon (default 'runner')\n \"\"\"\n filename = icon_name.lower().replace(\" \", \"\") + \".png\"\n icon_path = os.path.join(settings.RUNTIME_DIR, \"icons/hicolor/64x64/apps\", filename)\n if not os.path.exists(icon_path):\n return None\n if icon_format == \"image\":\n icon = Gtk.Image()\n if size:\n icon.set_from_pixbuf(get_pixbuf(icon_path, size))\n else:\n icon.set_from_file(icon_path)\n return icon\n if icon_format == \"pixbuf\" and size:\n return get_pixbuf(icon_path, size)\n raise ValueError(\"Invalid arguments\")\n\n\ndef get_overlay(overlay_path, size):\n width, height = size\n transparent_pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(overlay_path, width, height)\n transparent_pixbuf = transparent_pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return transparent_pixbuf\n\n\ndef get_default_icon(size):\n if size[0] == size[1]:\n return os.path.join(datapath.get(), \"media/default_icon.png\")\n return os.path.join(datapath.get(), \"media/default_banner.png\")\n\n\ndef convert_to_background(background_path, target_size=(320, 1080)):\n \"\"\"Converts a image to a pane background\"\"\"\n coverart = Image.open(background_path)\n coverart = coverart.convert(\"RGBA\")\n\n target_width, target_height = target_size\n image_height = int(target_height * 0.80) # 80% of the mask is visible\n orig_width, orig_height = coverart.size\n\n # Resize and crop coverart\n width = int(orig_width * (image_height / orig_height))\n offset = int((width - target_width) / 2)\n coverart = coverart.resize((width, image_height), resample=Image.BICUBIC)\n coverart = coverart.crop((offset, 0, target_width + offset, image_height))\n\n # Resize canvas of coverart by putting transparent pixels on the bottom\n coverart_bg = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))\n coverart_bg.paste(coverart, (0, 0, target_width, image_height))\n\n # Apply a tint to the base image\n # tint = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 255))\n # coverart = Image.blend(coverart, tint, 0.6)\n\n # Paste coverart on transparent image while applying a gradient mask\n background = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))\n mask = Image.open(os.path.join(datapath.get(), \"media/mask.png\"))\n background.paste(coverart_bg, mask=mask)\n\n return background\n\n\ndef thumbnail_image(base_image, target_size):\n base_width, base_height = base_image.size\n base_ratio = base_width / base_height\n target_width, target_height = target_size\n target_ratio = target_width / target_height\n\n # Resize and crop coverart\n if base_ratio >= target_ratio:\n width = int(base_width * (target_height / base_height))\n height = target_height\n else:\n width = target_width\n height = int(base_height * (target_width / base_width))\n x_offset = int((width - target_width) / 2)\n y_offset = int((height - target_height) / 2)\n base_image = base_image.resize((width, height), resample=Image.BICUBIC)\n base_image = base_image.crop((x_offset, y_offset, width - x_offset, height - y_offset))\n return base_image\n\n\ndef paste_overlay(base_image, overlay_image, position=0.7):\n base_width, base_height = base_image.size\n overlay_width, overlay_height = overlay_image.size\n offset_x = int((base_width - overlay_width) / 2)\n offset_y = int((base_height - overlay_height) / 2)\n base_image.paste(\n overlay_image, (\n offset_x,\n offset_y,\n overlay_width + offset_x,\n overlay_height + offset_y\n ),\n mask=overlay_image\n )\n return base_image\n\n\ndef image2pixbuf(image):\n \"\"\"Converts a PIL Image to a GDK Pixbuf\"\"\"\n image_array = array.array('B', image.tobytes())\n width, height = image.size\n return GdkPixbuf.Pixbuf.new_from_data(image_array, GdkPixbuf.Colorspace.RGB, True, 8, width, height, width * 4)\n\n\ndef get_link_button(text):\n \"\"\"Return a transparent text button for the side panels\"\"\"\n button = Gtk.Button(text, visible=True)\n button.props.relief = Gtk.ReliefStyle.NONE\n button.get_children()[0].set_alignment(0, 0.5)\n button.get_style_context().add_class(\"panel-button\")\n button.set_size_request(-1, 24)\n return button\n\n\ndef load_icon_theme():\n \"\"\"Add the lutris icon folder to the default theme\"\"\"\n icon_theme = Gtk.IconTheme.get_default()\n local_theme_path = os.path.join(settings.RUNTIME_DIR, \"icons\")\n if local_theme_path not in icon_theme.get_search_path():\n icon_theme.prepend_search_path(local_theme_path)\n", "path": "lutris/gui/widgets/utils.py"}]}
| 3,203 | 149 |
gh_patches_debug_20272
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-2596
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BBC Links stopped working?
Anyone else BBC links stopped working?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/bbciplayer.py`
Content:
```
1 from __future__ import print_function
2
3 import base64
4 import logging
5 import re
6 from collections import defaultdict
7 from hashlib import sha1
8
9 from streamlink import PluginError
10 from streamlink.compat import parse_qsl, urlparse
11 from streamlink.plugin import Plugin, PluginArguments, PluginArgument
12 from streamlink.plugin.api import validate
13 from streamlink.stream import HDSStream
14 from streamlink.stream import HLSStream
15 from streamlink.stream.dash import DASHStream
16 from streamlink.utils import parse_json
17
18 log = logging.getLogger(__name__)
19
20
21 class BBCiPlayer(Plugin):
22 """
23 Allows streaming of live channels from bbc.co.uk/iplayer/live/* and of iPlayer programmes from
24 bbc.co.uk/iplayer/episode/*
25 """
26 url_re = re.compile(r"""https?://(?:www\.)?bbc.co.uk/iplayer/
27 (
28 episode/(?P<episode_id>\w+)|
29 live/(?P<channel_name>\w+)
30 )
31 """, re.VERBOSE)
32 mediator_re = re.compile(
33 r'window\.__IPLAYER_REDUX_STATE__\s*=\s*({.*?});', re.DOTALL)
34 tvip_re = re.compile(r'channel"\s*:\s*{\s*"id"\s*:\s*"(\w+?)"')
35 tvip_master_re = re.compile(r'event_master_brand=(\w+?)&')
36 account_locals_re = re.compile(r'window.bbcAccount.locals\s*=\s*({.*?});')
37 swf_url = "http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf"
38 hash = base64.b64decode(
39 b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
40 api_url = ("http://open.live.bbc.co.uk/mediaselector/6/select/"
41 "version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/")
42 platforms = ("pc", "iptv-all")
43 session_url = "https://session.bbc.com/session"
44 auth_url = "https://account.bbc.com/signin"
45
46 mediator_schema = validate.Schema(
47 {
48 "versions": [{"id": validate.text}]
49 },
50 validate.get("versions"), validate.get(0),
51 validate.get("id")
52 )
53 mediaselector_schema = validate.Schema(
54 validate.transform(parse_json),
55 {"media": [
56 {"connection":
57 validate.all([{
58 validate.optional("href"): validate.url(),
59 validate.optional("transferFormat"): validate.text
60 }], validate.filter(lambda c: c.get("href"))),
61 "kind": validate.text}
62 ]},
63 validate.get("media"),
64 validate.filter(lambda x: x["kind"] == "video")
65 )
66 arguments = PluginArguments(
67 PluginArgument(
68 "username",
69 requires=["password"],
70 metavar="USERNAME",
71 help="The username used to register with bbc.co.uk."
72 ),
73 PluginArgument(
74 "password",
75 sensitive=True,
76 metavar="PASSWORD",
77 help="A bbc.co.uk account password to use with --bbciplayer-username.",
78 prompt="Enter bbc.co.uk account password"
79 ),
80 PluginArgument(
81 "hd",
82 action="store_true",
83 help="""
84 Prefer HD streams over local SD streams, some live programmes may
85 not be broadcast in HD.
86 """
87 ),
88 )
89
90 @classmethod
91 def can_handle_url(cls, url):
92 """ Confirm plugin can handle URL """
93 return cls.url_re.match(url) is not None
94
95 @classmethod
96 def _hash_vpid(cls, vpid):
97 return sha1(cls.hash + str(vpid).encode("utf8")).hexdigest()
98
99 @classmethod
100 def _extract_nonce(cls, http_result):
101 """
102 Given an HTTP response from the sessino endpoint, extract the nonce, so we can "sign" requests with it.
103 We don't really sign the requests in the traditional sense of a nonce, we just incude them in the auth requests.
104
105 :param http_result: HTTP response from the bbc session endpoint.
106 :type http_result: requests.Response
107 :return: nonce to "sign" url requests with
108 :rtype: string
109 """
110
111 # Extract the redirect URL from the last call
112 last_redirect_url = urlparse(http_result.history[-1].request.url)
113 last_redirect_query = dict(parse_qsl(last_redirect_url.query))
114 # Extract the nonce from the query string in the redirect URL
115 final_url = urlparse(last_redirect_query['goto'])
116 goto_url = dict(parse_qsl(final_url.query))
117 goto_url_query = parse_json(goto_url['state'])
118
119 # Return the nonce we can use for future queries
120 return goto_url_query['nonce']
121
122 def find_vpid(self, url, res=None):
123 """
124 Find the Video Packet ID in the HTML for the provided URL
125
126 :param url: URL to download, if res is not provided.
127 :param res: Provide a cached version of the HTTP response to search
128 :type url: string
129 :type res: requests.Response
130 :return: Video Packet ID for a Programme in iPlayer
131 :rtype: string
132 """
133 log.debug("Looking for vpid on {0}", url)
134 # Use pre-fetched page if available
135 res = res or self.session.http.get(url)
136 m = self.mediator_re.search(res.text)
137 vpid = m and parse_json(m.group(1), schema=self.mediator_schema)
138 return vpid
139
140 def find_tvip(self, url, master=False):
141 log.debug("Looking for {0} tvip on {1}", "master" if master else "", url)
142 res = self.session.http.get(url)
143 if master:
144 m = self.tvip_master_re.search(res.text)
145 else:
146 m = self.tvip_re.search(res.text)
147 return m and m.group(1)
148
149 def mediaselector(self, vpid):
150 urls = defaultdict(set)
151 for platform in self.platforms:
152 url = self.api_url.format(vpid=vpid, vpid_hash=self._hash_vpid(vpid),
153 platform=platform)
154 log.debug("Info API request: {0}", url)
155 medias = self.session.http.get(url, schema=self.mediaselector_schema)
156 for media in medias:
157 for connection in media["connection"]:
158 urls[connection.get("transferFormat")].add(connection["href"])
159
160 for stream_type, urls in urls.items():
161 log.debug("{0} {1} streams", len(urls), stream_type)
162 for url in list(urls):
163 try:
164 if stream_type == "hds":
165 for s in HDSStream.parse_manifest(self.session,
166 url).items():
167 yield s
168 if stream_type == "hls":
169 for s in HLSStream.parse_variant_playlist(self.session,
170 url).items():
171 yield s
172 if stream_type == "dash":
173 for s in DASHStream.parse_manifest(self.session,
174 url).items():
175 yield s
176 log.debug(" OK: {0}", url)
177 except:
178 log.debug(" FAIL: {0}", url)
179
180 def login(self, ptrt_url):
181 """
182 Create session using BBC ID. See https://www.bbc.co.uk/usingthebbc/account/
183
184 :param ptrt_url: The snapback URL to redirect to after successful authentication
185 :type ptrt_url: string
186 :return: Whether authentication was successful
187 :rtype: bool
188 """
189 def auth_check(res):
190 return ptrt_url in ([h.url for h in res.history] + [res.url])
191
192 # make the session request to get the correct cookies
193 session_res = self.session.http.get(
194 self.session_url,
195 params=dict(ptrt=ptrt_url)
196 )
197
198 if auth_check(session_res):
199 log.debug("Already authenticated, skipping authentication")
200 return True
201
202 http_nonce = self._extract_nonce(session_res)
203 res = self.session.http.post(
204 self.auth_url,
205 params=dict(
206 ptrt=ptrt_url,
207 nonce=http_nonce
208 ),
209 data=dict(
210 jsEnabled=True,
211 username=self.get_option("username"),
212 password=self.get_option('password'),
213 attempts=0
214 ),
215 headers={"Referer": self.url})
216
217 return auth_check(res)
218
219 def _get_streams(self):
220 if not self.get_option("username"):
221 log.error(
222 "BBC iPlayer requires an account you must login using "
223 "--bbciplayer-username and --bbciplayer-password")
224 return
225 log.info(
226 "A TV License is required to watch BBC iPlayer streams, see the BBC website for more "
227 "information: https://www.bbc.co.uk/iplayer/help/tvlicence")
228 if not self.login(self.url):
229 log.error(
230 "Could not authenticate, check your username and password")
231 return
232
233 m = self.url_re.match(self.url)
234 episode_id = m.group("episode_id")
235 channel_name = m.group("channel_name")
236
237 if episode_id:
238 log.debug("Loading streams for episode: {0}", episode_id)
239 vpid = self.find_vpid(self.url)
240 if vpid:
241 log.debug("Found VPID: {0}", vpid)
242 for s in self.mediaselector(vpid):
243 yield s
244 else:
245 log.error("Could not find VPID for episode {0}",
246 episode_id)
247 elif channel_name:
248 log.debug("Loading stream for live channel: {0}", channel_name)
249 if self.get_option("hd"):
250 tvip = self.find_tvip(self.url, master=True) + "_hd"
251 if tvip:
252 log.debug("Trying HD stream {0}...", tvip)
253 try:
254 for s in self.mediaselector(tvip):
255 yield s
256 except PluginError:
257 log.error(
258 "Failed to get HD streams, falling back to SD")
259 else:
260 return
261 tvip = self.find_tvip(self.url)
262 if tvip:
263 log.debug("Found TVIP: {0}", tvip)
264 for s in self.mediaselector(tvip):
265 yield s
266
267
268 __plugin__ = BBCiPlayer
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/bbciplayer.py b/src/streamlink/plugins/bbciplayer.py
--- a/src/streamlink/plugins/bbciplayer.py
+++ b/src/streamlink/plugins/bbciplayer.py
@@ -34,11 +34,8 @@
tvip_re = re.compile(r'channel"\s*:\s*{\s*"id"\s*:\s*"(\w+?)"')
tvip_master_re = re.compile(r'event_master_brand=(\w+?)&')
account_locals_re = re.compile(r'window.bbcAccount.locals\s*=\s*({.*?});')
- swf_url = "http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf"
- hash = base64.b64decode(
- b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
- api_url = ("http://open.live.bbc.co.uk/mediaselector/6/select/"
- "version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/")
+ hash = base64.b64decode(b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
+ api_url = "https://open.live.bbc.co.uk/mediaselector/6/select/version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/"
platforms = ("pc", "iptv-all")
session_url = "https://session.bbc.com/session"
auth_url = "https://account.bbc.com/signin"
|
{"golden_diff": "diff --git a/src/streamlink/plugins/bbciplayer.py b/src/streamlink/plugins/bbciplayer.py\n--- a/src/streamlink/plugins/bbciplayer.py\n+++ b/src/streamlink/plugins/bbciplayer.py\n@@ -34,11 +34,8 @@\n tvip_re = re.compile(r'channel\"\\s*:\\s*{\\s*\"id\"\\s*:\\s*\"(\\w+?)\"')\n tvip_master_re = re.compile(r'event_master_brand=(\\w+?)&')\n account_locals_re = re.compile(r'window.bbcAccount.locals\\s*=\\s*({.*?});')\n- swf_url = \"http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf\"\n- hash = base64.b64decode(\n- b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n- api_url = (\"http://open.live.bbc.co.uk/mediaselector/6/select/\"\n- \"version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\")\n+ hash = base64.b64decode(b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n+ api_url = \"https://open.live.bbc.co.uk/mediaselector/6/select/version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\"\n platforms = (\"pc\", \"iptv-all\")\n session_url = \"https://session.bbc.com/session\"\n auth_url = \"https://account.bbc.com/signin\"\n", "issue": "BBC Links stopped working?\nAnyone else BBC links stopped working?\n", "before_files": [{"content": "from __future__ import print_function\n\nimport base64\nimport logging\nimport re\nfrom collections import defaultdict\nfrom hashlib import sha1\n\nfrom streamlink import PluginError\nfrom streamlink.compat import parse_qsl, urlparse\nfrom streamlink.plugin import Plugin, PluginArguments, PluginArgument\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HDSStream\nfrom streamlink.stream import HLSStream\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.utils import parse_json\n\nlog = logging.getLogger(__name__)\n\n\nclass BBCiPlayer(Plugin):\n \"\"\"\n Allows streaming of live channels from bbc.co.uk/iplayer/live/* and of iPlayer programmes from\n bbc.co.uk/iplayer/episode/*\n \"\"\"\n url_re = re.compile(r\"\"\"https?://(?:www\\.)?bbc.co.uk/iplayer/\n (\n episode/(?P<episode_id>\\w+)|\n live/(?P<channel_name>\\w+)\n )\n \"\"\", re.VERBOSE)\n mediator_re = re.compile(\n r'window\\.__IPLAYER_REDUX_STATE__\\s*=\\s*({.*?});', re.DOTALL)\n tvip_re = re.compile(r'channel\"\\s*:\\s*{\\s*\"id\"\\s*:\\s*\"(\\w+?)\"')\n tvip_master_re = re.compile(r'event_master_brand=(\\w+?)&')\n account_locals_re = re.compile(r'window.bbcAccount.locals\\s*=\\s*({.*?});')\n swf_url = \"http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf\"\n hash = base64.b64decode(\n b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n api_url = (\"http://open.live.bbc.co.uk/mediaselector/6/select/\"\n \"version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\")\n platforms = (\"pc\", \"iptv-all\")\n session_url = \"https://session.bbc.com/session\"\n auth_url = \"https://account.bbc.com/signin\"\n\n mediator_schema = validate.Schema(\n {\n \"versions\": [{\"id\": validate.text}]\n },\n validate.get(\"versions\"), validate.get(0),\n validate.get(\"id\")\n )\n mediaselector_schema = validate.Schema(\n validate.transform(parse_json),\n {\"media\": [\n {\"connection\":\n validate.all([{\n validate.optional(\"href\"): validate.url(),\n validate.optional(\"transferFormat\"): validate.text\n }], validate.filter(lambda c: c.get(\"href\"))),\n \"kind\": validate.text}\n ]},\n validate.get(\"media\"),\n validate.filter(lambda x: x[\"kind\"] == \"video\")\n )\n arguments = PluginArguments(\n PluginArgument(\n \"username\",\n requires=[\"password\"],\n metavar=\"USERNAME\",\n help=\"The username used to register with bbc.co.uk.\"\n ),\n PluginArgument(\n \"password\",\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"A bbc.co.uk account password to use with --bbciplayer-username.\",\n prompt=\"Enter bbc.co.uk account password\"\n ),\n PluginArgument(\n \"hd\",\n action=\"store_true\",\n help=\"\"\"\n Prefer HD streams over local SD streams, some live programmes may\n not be broadcast in HD.\n \"\"\"\n ),\n )\n\n @classmethod\n def can_handle_url(cls, url):\n \"\"\" Confirm plugin can handle URL \"\"\"\n return cls.url_re.match(url) is not None\n\n @classmethod\n def _hash_vpid(cls, vpid):\n return sha1(cls.hash + str(vpid).encode(\"utf8\")).hexdigest()\n\n @classmethod\n def _extract_nonce(cls, http_result):\n \"\"\"\n Given an HTTP response from the sessino endpoint, extract the nonce, so we can \"sign\" requests with it.\n We don't really sign the requests in the traditional sense of a nonce, we just incude them in the auth requests.\n\n :param http_result: HTTP response from the bbc session endpoint.\n :type http_result: requests.Response\n :return: nonce to \"sign\" url requests with\n :rtype: string\n \"\"\"\n\n # Extract the redirect URL from the last call\n last_redirect_url = urlparse(http_result.history[-1].request.url)\n last_redirect_query = dict(parse_qsl(last_redirect_url.query))\n # Extract the nonce from the query string in the redirect URL\n final_url = urlparse(last_redirect_query['goto'])\n goto_url = dict(parse_qsl(final_url.query))\n goto_url_query = parse_json(goto_url['state'])\n\n # Return the nonce we can use for future queries\n return goto_url_query['nonce']\n\n def find_vpid(self, url, res=None):\n \"\"\"\n Find the Video Packet ID in the HTML for the provided URL\n\n :param url: URL to download, if res is not provided.\n :param res: Provide a cached version of the HTTP response to search\n :type url: string\n :type res: requests.Response\n :return: Video Packet ID for a Programme in iPlayer\n :rtype: string\n \"\"\"\n log.debug(\"Looking for vpid on {0}\", url)\n # Use pre-fetched page if available\n res = res or self.session.http.get(url)\n m = self.mediator_re.search(res.text)\n vpid = m and parse_json(m.group(1), schema=self.mediator_schema)\n return vpid\n\n def find_tvip(self, url, master=False):\n log.debug(\"Looking for {0} tvip on {1}\", \"master\" if master else \"\", url)\n res = self.session.http.get(url)\n if master:\n m = self.tvip_master_re.search(res.text)\n else:\n m = self.tvip_re.search(res.text)\n return m and m.group(1)\n\n def mediaselector(self, vpid):\n urls = defaultdict(set)\n for platform in self.platforms:\n url = self.api_url.format(vpid=vpid, vpid_hash=self._hash_vpid(vpid),\n platform=platform)\n log.debug(\"Info API request: {0}\", url)\n medias = self.session.http.get(url, schema=self.mediaselector_schema)\n for media in medias:\n for connection in media[\"connection\"]:\n urls[connection.get(\"transferFormat\")].add(connection[\"href\"])\n\n for stream_type, urls in urls.items():\n log.debug(\"{0} {1} streams\", len(urls), stream_type)\n for url in list(urls):\n try:\n if stream_type == \"hds\":\n for s in HDSStream.parse_manifest(self.session,\n url).items():\n yield s\n if stream_type == \"hls\":\n for s in HLSStream.parse_variant_playlist(self.session,\n url).items():\n yield s\n if stream_type == \"dash\":\n for s in DASHStream.parse_manifest(self.session,\n url).items():\n yield s\n log.debug(\" OK: {0}\", url)\n except:\n log.debug(\" FAIL: {0}\", url)\n\n def login(self, ptrt_url):\n \"\"\"\n Create session using BBC ID. See https://www.bbc.co.uk/usingthebbc/account/\n\n :param ptrt_url: The snapback URL to redirect to after successful authentication\n :type ptrt_url: string\n :return: Whether authentication was successful\n :rtype: bool\n \"\"\"\n def auth_check(res):\n return ptrt_url in ([h.url for h in res.history] + [res.url])\n\n # make the session request to get the correct cookies\n session_res = self.session.http.get(\n self.session_url,\n params=dict(ptrt=ptrt_url)\n )\n\n if auth_check(session_res):\n log.debug(\"Already authenticated, skipping authentication\")\n return True\n\n http_nonce = self._extract_nonce(session_res)\n res = self.session.http.post(\n self.auth_url,\n params=dict(\n ptrt=ptrt_url,\n nonce=http_nonce\n ),\n data=dict(\n jsEnabled=True,\n username=self.get_option(\"username\"),\n password=self.get_option('password'),\n attempts=0\n ),\n headers={\"Referer\": self.url})\n\n return auth_check(res)\n\n def _get_streams(self):\n if not self.get_option(\"username\"):\n log.error(\n \"BBC iPlayer requires an account you must login using \"\n \"--bbciplayer-username and --bbciplayer-password\")\n return\n log.info(\n \"A TV License is required to watch BBC iPlayer streams, see the BBC website for more \"\n \"information: https://www.bbc.co.uk/iplayer/help/tvlicence\")\n if not self.login(self.url):\n log.error(\n \"Could not authenticate, check your username and password\")\n return\n\n m = self.url_re.match(self.url)\n episode_id = m.group(\"episode_id\")\n channel_name = m.group(\"channel_name\")\n\n if episode_id:\n log.debug(\"Loading streams for episode: {0}\", episode_id)\n vpid = self.find_vpid(self.url)\n if vpid:\n log.debug(\"Found VPID: {0}\", vpid)\n for s in self.mediaselector(vpid):\n yield s\n else:\n log.error(\"Could not find VPID for episode {0}\",\n episode_id)\n elif channel_name:\n log.debug(\"Loading stream for live channel: {0}\", channel_name)\n if self.get_option(\"hd\"):\n tvip = self.find_tvip(self.url, master=True) + \"_hd\"\n if tvip:\n log.debug(\"Trying HD stream {0}...\", tvip)\n try:\n for s in self.mediaselector(tvip):\n yield s\n except PluginError:\n log.error(\n \"Failed to get HD streams, falling back to SD\")\n else:\n return\n tvip = self.find_tvip(self.url)\n if tvip:\n log.debug(\"Found TVIP: {0}\", tvip)\n for s in self.mediaselector(tvip):\n yield s\n\n\n__plugin__ = BBCiPlayer\n", "path": "src/streamlink/plugins/bbciplayer.py"}], "after_files": [{"content": "from __future__ import print_function\n\nimport base64\nimport logging\nimport re\nfrom collections import defaultdict\nfrom hashlib import sha1\n\nfrom streamlink import PluginError\nfrom streamlink.compat import parse_qsl, urlparse\nfrom streamlink.plugin import Plugin, PluginArguments, PluginArgument\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HDSStream\nfrom streamlink.stream import HLSStream\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.utils import parse_json\n\nlog = logging.getLogger(__name__)\n\n\nclass BBCiPlayer(Plugin):\n \"\"\"\n Allows streaming of live channels from bbc.co.uk/iplayer/live/* and of iPlayer programmes from\n bbc.co.uk/iplayer/episode/*\n \"\"\"\n url_re = re.compile(r\"\"\"https?://(?:www\\.)?bbc.co.uk/iplayer/\n (\n episode/(?P<episode_id>\\w+)|\n live/(?P<channel_name>\\w+)\n )\n \"\"\", re.VERBOSE)\n mediator_re = re.compile(\n r'window\\.__IPLAYER_REDUX_STATE__\\s*=\\s*({.*?});', re.DOTALL)\n tvip_re = re.compile(r'channel\"\\s*:\\s*{\\s*\"id\"\\s*:\\s*\"(\\w+?)\"')\n tvip_master_re = re.compile(r'event_master_brand=(\\w+?)&')\n account_locals_re = re.compile(r'window.bbcAccount.locals\\s*=\\s*({.*?});')\n hash = base64.b64decode(b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n api_url = \"https://open.live.bbc.co.uk/mediaselector/6/select/version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\"\n platforms = (\"pc\", \"iptv-all\")\n session_url = \"https://session.bbc.com/session\"\n auth_url = \"https://account.bbc.com/signin\"\n\n mediator_schema = validate.Schema(\n {\n \"versions\": [{\"id\": validate.text}]\n },\n validate.get(\"versions\"), validate.get(0),\n validate.get(\"id\")\n )\n mediaselector_schema = validate.Schema(\n validate.transform(parse_json),\n {\"media\": [\n {\"connection\":\n validate.all([{\n validate.optional(\"href\"): validate.url(),\n validate.optional(\"transferFormat\"): validate.text\n }], validate.filter(lambda c: c.get(\"href\"))),\n \"kind\": validate.text}\n ]},\n validate.get(\"media\"),\n validate.filter(lambda x: x[\"kind\"] == \"video\")\n )\n arguments = PluginArguments(\n PluginArgument(\n \"username\",\n requires=[\"password\"],\n metavar=\"USERNAME\",\n help=\"The username used to register with bbc.co.uk.\"\n ),\n PluginArgument(\n \"password\",\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"A bbc.co.uk account password to use with --bbciplayer-username.\",\n prompt=\"Enter bbc.co.uk account password\"\n ),\n PluginArgument(\n \"hd\",\n action=\"store_true\",\n help=\"\"\"\n Prefer HD streams over local SD streams, some live programmes may\n not be broadcast in HD.\n \"\"\"\n ),\n )\n\n @classmethod\n def can_handle_url(cls, url):\n \"\"\" Confirm plugin can handle URL \"\"\"\n return cls.url_re.match(url) is not None\n\n @classmethod\n def _hash_vpid(cls, vpid):\n return sha1(cls.hash + str(vpid).encode(\"utf8\")).hexdigest()\n\n @classmethod\n def _extract_nonce(cls, http_result):\n \"\"\"\n Given an HTTP response from the sessino endpoint, extract the nonce, so we can \"sign\" requests with it.\n We don't really sign the requests in the traditional sense of a nonce, we just incude them in the auth requests.\n\n :param http_result: HTTP response from the bbc session endpoint.\n :type http_result: requests.Response\n :return: nonce to \"sign\" url requests with\n :rtype: string\n \"\"\"\n\n # Extract the redirect URL from the last call\n last_redirect_url = urlparse(http_result.history[-1].request.url)\n last_redirect_query = dict(parse_qsl(last_redirect_url.query))\n # Extract the nonce from the query string in the redirect URL\n final_url = urlparse(last_redirect_query['goto'])\n goto_url = dict(parse_qsl(final_url.query))\n goto_url_query = parse_json(goto_url['state'])\n\n # Return the nonce we can use for future queries\n return goto_url_query['nonce']\n\n def find_vpid(self, url, res=None):\n \"\"\"\n Find the Video Packet ID in the HTML for the provided URL\n\n :param url: URL to download, if res is not provided.\n :param res: Provide a cached version of the HTTP response to search\n :type url: string\n :type res: requests.Response\n :return: Video Packet ID for a Programme in iPlayer\n :rtype: string\n \"\"\"\n log.debug(\"Looking for vpid on {0}\", url)\n # Use pre-fetched page if available\n res = res or self.session.http.get(url)\n m = self.mediator_re.search(res.text)\n vpid = m and parse_json(m.group(1), schema=self.mediator_schema)\n return vpid\n\n def find_tvip(self, url, master=False):\n log.debug(\"Looking for {0} tvip on {1}\", \"master\" if master else \"\", url)\n res = self.session.http.get(url)\n if master:\n m = self.tvip_master_re.search(res.text)\n else:\n m = self.tvip_re.search(res.text)\n return m and m.group(1)\n\n def mediaselector(self, vpid):\n urls = defaultdict(set)\n for platform in self.platforms:\n url = self.api_url.format(vpid=vpid, vpid_hash=self._hash_vpid(vpid),\n platform=platform)\n log.debug(\"Info API request: {0}\", url)\n medias = self.session.http.get(url, schema=self.mediaselector_schema)\n for media in medias:\n for connection in media[\"connection\"]:\n urls[connection.get(\"transferFormat\")].add(connection[\"href\"])\n\n for stream_type, urls in urls.items():\n log.debug(\"{0} {1} streams\", len(urls), stream_type)\n for url in list(urls):\n try:\n if stream_type == \"hds\":\n for s in HDSStream.parse_manifest(self.session,\n url).items():\n yield s\n if stream_type == \"hls\":\n for s in HLSStream.parse_variant_playlist(self.session,\n url).items():\n yield s\n if stream_type == \"dash\":\n for s in DASHStream.parse_manifest(self.session,\n url).items():\n yield s\n log.debug(\" OK: {0}\", url)\n except:\n log.debug(\" FAIL: {0}\", url)\n\n def login(self, ptrt_url):\n \"\"\"\n Create session using BBC ID. See https://www.bbc.co.uk/usingthebbc/account/\n\n :param ptrt_url: The snapback URL to redirect to after successful authentication\n :type ptrt_url: string\n :return: Whether authentication was successful\n :rtype: bool\n \"\"\"\n def auth_check(res):\n return ptrt_url in ([h.url for h in res.history] + [res.url])\n\n # make the session request to get the correct cookies\n session_res = self.session.http.get(\n self.session_url,\n params=dict(ptrt=ptrt_url)\n )\n\n if auth_check(session_res):\n log.debug(\"Already authenticated, skipping authentication\")\n return True\n\n http_nonce = self._extract_nonce(session_res)\n res = self.session.http.post(\n self.auth_url,\n params=dict(\n ptrt=ptrt_url,\n nonce=http_nonce\n ),\n data=dict(\n jsEnabled=True,\n username=self.get_option(\"username\"),\n password=self.get_option('password'),\n attempts=0\n ),\n headers={\"Referer\": self.url})\n\n return auth_check(res)\n\n def _get_streams(self):\n if not self.get_option(\"username\"):\n log.error(\n \"BBC iPlayer requires an account you must login using \"\n \"--bbciplayer-username and --bbciplayer-password\")\n return\n log.info(\n \"A TV License is required to watch BBC iPlayer streams, see the BBC website for more \"\n \"information: https://www.bbc.co.uk/iplayer/help/tvlicence\")\n if not self.login(self.url):\n log.error(\n \"Could not authenticate, check your username and password\")\n return\n\n m = self.url_re.match(self.url)\n episode_id = m.group(\"episode_id\")\n channel_name = m.group(\"channel_name\")\n\n if episode_id:\n log.debug(\"Loading streams for episode: {0}\", episode_id)\n vpid = self.find_vpid(self.url)\n if vpid:\n log.debug(\"Found VPID: {0}\", vpid)\n for s in self.mediaselector(vpid):\n yield s\n else:\n log.error(\"Could not find VPID for episode {0}\",\n episode_id)\n elif channel_name:\n log.debug(\"Loading stream for live channel: {0}\", channel_name)\n if self.get_option(\"hd\"):\n tvip = self.find_tvip(self.url, master=True) + \"_hd\"\n if tvip:\n log.debug(\"Trying HD stream {0}...\", tvip)\n try:\n for s in self.mediaselector(tvip):\n yield s\n except PluginError:\n log.error(\n \"Failed to get HD streams, falling back to SD\")\n else:\n return\n tvip = self.find_tvip(self.url)\n if tvip:\n log.debug(\"Found TVIP: {0}\", tvip)\n for s in self.mediaselector(tvip):\n yield s\n\n\n__plugin__ = BBCiPlayer\n", "path": "src/streamlink/plugins/bbciplayer.py"}]}
| 3,228 | 431 |
gh_patches_debug_1073
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-98
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
EC2 resource detector hangs for a long time outside of an EC2 instance
**Describe your environment** Describe any aspect of your environment relevant to the problem, including your Python version, [platform](https://docs.python.org/3/library/platform.html), version numbers of installed dependencies, information about your cloud hosting provider, etc. If you're reporting a problem with a specific version of a library in this repo, please check whether the problem has been fixed on main.
The environment I initially saw this in was a container running in Docker compose on an AWS EC2 instance but I've been able to reproduce it on my laptop as well. I think it will show up in anything not directly running in AWS.
**Steps to reproduce**
Describe exactly how to reproduce the error. Include a code sample if applicable.
The following code reproduced the issue on my laptop:
```python
from opentelemetry.sdk.extension.aws.resource.ec2 import AwsEc2ResourceDetector
from opentelemetry.sdk.resources import get_aggregated_resources
resource = get_aggregated_resources(
detectors=[AwsEc2ResourceDetector()]
)
```
**What is the expected behavior?**
It should complete quickly (this is the behavior I see running on an EC2 instance).
**What is the actual behavior?**
What did you see instead?
On my laptop, it will hand ~indefinitely.
Note: one solution is just to remove the resource detector but we'd like to be able to include it and just have it fail silently, which is the behavior we've seen in other resource detectors.
**Additional context**
I think the problem is here: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/80969a06da77d1e616124de178d12a1ebe3ffe7f/sdk-extension/opentelemetry-sdk-extension-aws/src/opentelemetry/sdk/extension/aws/resource/ec2.py#L37
It looks like the request is using a 1000 _second_ timeout which I suspect is intended to be a 1000 _millisecond_ timeout. At least with the server program I've been working on that will block the startup of the program until the request completes.
You can verify by running:
```
curl http://169.254.169.254/latest/api/token
```
Which is one of the requests that the resource detector makes -- it should hang indefinitely as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 __version__ = "0.15.dev0"
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py
--- a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py
+++ b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py
@@ -12,4 +12,4 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-__version__ = "0.15.dev0"
+__version__ = "0.15b0"
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py\n--- a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py\n+++ b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py\n@@ -12,4 +12,4 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-__version__ = \"0.15.dev0\"\n+__version__ = \"0.15b0\"\n", "issue": "EC2 resource detector hangs for a long time outside of an EC2 instance\n**Describe your environment** Describe any aspect of your environment relevant to the problem, including your Python version, [platform](https://docs.python.org/3/library/platform.html), version numbers of installed dependencies, information about your cloud hosting provider, etc. If you're reporting a problem with a specific version of a library in this repo, please check whether the problem has been fixed on main.\r\n\r\nThe environment I initially saw this in was a container running in Docker compose on an AWS EC2 instance but I've been able to reproduce it on my laptop as well. I think it will show up in anything not directly running in AWS.\r\n\r\n**Steps to reproduce**\r\nDescribe exactly how to reproduce the error. Include a code sample if applicable.\r\n\r\nThe following code reproduced the issue on my laptop:\r\n\r\n```python\r\nfrom opentelemetry.sdk.extension.aws.resource.ec2 import AwsEc2ResourceDetector\r\nfrom opentelemetry.sdk.resources import get_aggregated_resources\r\n\r\nresource = get_aggregated_resources(\r\n detectors=[AwsEc2ResourceDetector()]\r\n)\r\n```\r\n\r\n**What is the expected behavior?**\r\n\r\nIt should complete quickly (this is the behavior I see running on an EC2 instance).\r\n\r\n**What is the actual behavior?**\r\n\r\nWhat did you see instead?\r\n\r\nOn my laptop, it will hand ~indefinitely.\r\n\r\nNote: one solution is just to remove the resource detector but we'd like to be able to include it and just have it fail silently, which is the behavior we've seen in other resource detectors.\r\n\r\n**Additional context**\r\n\r\nI think the problem is here: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/80969a06da77d1e616124de178d12a1ebe3ffe7f/sdk-extension/opentelemetry-sdk-extension-aws/src/opentelemetry/sdk/extension/aws/resource/ec2.py#L37\r\n\r\nIt looks like the request is using a 1000 _second_ timeout which I suspect is intended to be a 1000 _millisecond_ timeout. At least with the server program I've been working on that will block the startup of the program until the request completes.\r\n\r\nYou can verify by running:\r\n\r\n```\r\ncurl http://169.254.169.254/latest/api/token\r\n```\r\n\r\nWhich is one of the requests that the resource detector makes -- it should hang indefinitely as well.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n__version__ = \"0.15.dev0\"\n", "path": "instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n__version__ = \"0.15b0\"\n", "path": "instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py"}]}
| 962 | 169 |
gh_patches_debug_4517
|
rasdani/github-patches
|
git_diff
|
TileDB-Inc__TileDB-Py-309
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
array.query no longer works for string attributes
I have a case that looks basically like this:
```
array = tiledb.DenseArray(uri, mode="r")
q = array.query(attrs=["attrname"])
data = q[:]
```
This works when the type of the attribute is a float or an int.
But if the type of the attribute is a string, this fails with an exception:
```
File "tiledb/libtiledb.pyx", line 3874, in tiledb.libtiledb.Query.__getitem__
File "tiledb/libtiledb.pyx", line 4107, in tiledb.libtiledb.DenseArrayImpl.subarray
File "tiledb/libtiledb.pyx", line 4156, in tiledb.libtiledb.DenseArrayImpl._read_dense_subarray
File "tiledb/libtiledb.pyx", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query
File "tiledb/libtiledb.pyx", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query
File "tiledb/libtiledb.pyx", line 3805, in tiledb.libtiledb.Array._unpack_varlen_query
SystemError: Negative size passed to PyUnicode_FromStringAndSize
```
This worked in v1.7.6, and I ran into this problem when porting to 2.0.0.
If there is a better way to pull out just one attribute from the array, then
I'm open to suggestions.
[example.zip](https://github.com/TileDB-Inc/TileDB-Py/files/4589870/example.zip)
Attached is a script, output from 1.7.6, and output from 2.0.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tiledb/multirange_indexing.py`
Content:
```
1 import tiledb
2 from tiledb import Array, ArraySchema, TileDBError
3 import os, numpy as np
4 import sys, weakref
5 from collections import OrderedDict
6
7 def mr_dense_result_shape(ranges, base_shape = None):
8 # assumptions: len(ranges) matches number of dims
9 if base_shape is not None:
10 assert len(ranges) == len(base_shape), "internal error: mismatched shapes"
11
12 new_shape = list()
13 for i,rr in enumerate(ranges):
14 if rr != ():
15 m = list(map(lambda y: abs(y[1] - y[0]) + 1, rr))
16 new_shape.append(np.sum(m))
17 else:
18 if base_shape is None:
19 raise ValueError("Missing required base_shape for whole-dimension slices")
20 # empty range covers dimension
21 new_shape.append(base_shape[i])
22
23 return tuple(new_shape)
24
25 def mr_dense_result_numel(ranges):
26 return np.prod(mr_dense_result_shape(ranges))
27
28 def sel_to_subranges(dim_sel):
29 subranges = list()
30 for range in dim_sel:
31 if np.isscalar(range):
32 subranges.append( (range, range) )
33 elif isinstance(range, slice):
34 if range.step is not None:
35 raise ValueError("Stepped slice ranges are not supported")
36 elif range.start is None and range.stop is None:
37 # ':' full slice
38 pass
39 else:
40 subranges.append( (range.start, range.stop) )
41 elif isinstance(range, tuple):
42 subranges.extend((range,))
43 elif isinstance(range, list):
44 for el in range:
45 subranges.append( (el, el) )
46 else:
47 raise TypeError("Unsupported selection ")
48
49 return tuple(subranges)
50
51
52 class MultiRangeIndexer(object):
53 """
54 Implements multi-range / outer / orthogonal indexing.
55
56 """
57
58 def __init__(self, array, query = None):
59 if not issubclass(type(array), tiledb.Array):
60 raise ValueError("Internal error: MultiRangeIndexer expected tiledb.Array")
61 self.array_ref = weakref.ref(array)
62 self.schema = array.schema
63 self.query = query
64
65 @property
66 def array(self):
67 assert self.array_ref() is not None, \
68 "Internal error: invariant violation (indexing call w/ dead array_ref)"
69 return self.array_ref()
70
71 @classmethod
72 def __test_init__(cls, array):
73 """
74 Internal helper method for testing getitem range calculation.
75 :param array:
76 :return:
77 """
78 m = cls.__new__(cls)
79 m.array_ref = weakref.ref(array)
80 m.schema = array.schema
81 m.query = None
82 return m
83
84 def getitem_ranges(self, idx):
85 dom = self.schema.domain
86 ndim = dom.ndim
87
88 if isinstance(idx, tuple):
89 idx = list(idx)
90 else:
91 idx = [idx]
92
93 ranges = list()
94 for i,sel in enumerate(idx):
95 if not isinstance(sel, list):
96 sel = [sel]
97 subranges = sel_to_subranges(sel)
98 ranges.append(subranges)
99
100 # extend the list to ndim
101 if len(ranges) < ndim:
102 ranges.extend([ tuple() for _ in range(ndim-len(ranges))])
103
104 rval = tuple(ranges)
105 return rval
106
107 def __getitem__(self, idx):
108 # implements multi-range / outer / orthogonal indexing
109 ranges = self.getitem_ranges(idx)
110
111 schema = self.schema
112 dom = self.schema.domain
113 attr_names = tuple(self.schema.attr(i).name for i in range(self.schema.nattr))
114
115 coords = None
116 if self.query is not None:
117 # if we are called via Query object, then we need to respect Query semantics
118 attr_names = tuple(self.query.attrs) if self.query.attrs else attr_names # query.attrs might be None -> all
119 coords = self.query.coords
120
121 from tiledb.core import PyQuery
122 q = PyQuery(self.array._ctx_(), self.array, attr_names, coords)
123
124 q.set_ranges(ranges)
125 q.submit()
126
127 result_dict = OrderedDict(q.results())
128
129 for name, item in result_dict.items():
130 if len(item[1]) > 0:
131 arr = self.array._unpack_varlen_query(item, name)
132 else:
133 arr = item[0]
134 arr.dtype = schema.attr_or_dim_dtype(name)
135 result_dict[name] = arr
136
137 if self.schema.sparse:
138 return result_dict
139 else:
140 result_shape = mr_dense_result_shape(ranges, self.schema.shape)
141 for arr in result_dict.values():
142 # TODO check/test layout
143 arr.shape = result_shape
144 return result_dict
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tiledb/multirange_indexing.py b/tiledb/multirange_indexing.py
--- a/tiledb/multirange_indexing.py
+++ b/tiledb/multirange_indexing.py
@@ -128,7 +128,7 @@
for name, item in result_dict.items():
if len(item[1]) > 0:
- arr = self.array._unpack_varlen_query(item, name)
+ arr = q.unpack_buffer(name, item[0], item[1])
else:
arr = item[0]
arr.dtype = schema.attr_or_dim_dtype(name)
|
{"golden_diff": "diff --git a/tiledb/multirange_indexing.py b/tiledb/multirange_indexing.py\n--- a/tiledb/multirange_indexing.py\n+++ b/tiledb/multirange_indexing.py\n@@ -128,7 +128,7 @@\n \n for name, item in result_dict.items():\n if len(item[1]) > 0:\n- arr = self.array._unpack_varlen_query(item, name)\n+ arr = q.unpack_buffer(name, item[0], item[1])\n else:\n arr = item[0]\n arr.dtype = schema.attr_or_dim_dtype(name)\n", "issue": "array.query no longer works for string attributes\nI have a case that looks basically like this:\r\n\r\n```\r\narray = tiledb.DenseArray(uri, mode=\"r\")\r\nq = array.query(attrs=[\"attrname\"])\r\ndata = q[:]\r\n```\r\nThis works when the type of the attribute is a float or an int.\r\nBut if the type of the attribute is a string, this fails with an exception:\r\n\r\n```\r\n File \"tiledb/libtiledb.pyx\", line 3874, in tiledb.libtiledb.Query.__getitem__\r\n File \"tiledb/libtiledb.pyx\", line 4107, in tiledb.libtiledb.DenseArrayImpl.subarray\r\n File \"tiledb/libtiledb.pyx\", line 4156, in tiledb.libtiledb.DenseArrayImpl._read_dense_subarray\r\n File \"tiledb/libtiledb.pyx\", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query\r\n File \"tiledb/libtiledb.pyx\", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query\r\n File \"tiledb/libtiledb.pyx\", line 3805, in tiledb.libtiledb.Array._unpack_varlen_query\r\nSystemError: Negative size passed to PyUnicode_FromStringAndSize\r\n```\r\n\r\nThis worked in v1.7.6, and I ran into this problem when porting to 2.0.0.\r\nIf there is a better way to pull out just one attribute from the array, then\r\nI'm open to suggestions.\r\n\r\n[example.zip](https://github.com/TileDB-Inc/TileDB-Py/files/4589870/example.zip)\r\n\r\nAttached is a script, output from 1.7.6, and output from 2.0.0\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import tiledb\nfrom tiledb import Array, ArraySchema, TileDBError\nimport os, numpy as np\nimport sys, weakref\nfrom collections import OrderedDict\n\ndef mr_dense_result_shape(ranges, base_shape = None):\n # assumptions: len(ranges) matches number of dims\n if base_shape is not None:\n assert len(ranges) == len(base_shape), \"internal error: mismatched shapes\"\n\n new_shape = list()\n for i,rr in enumerate(ranges):\n if rr != ():\n m = list(map(lambda y: abs(y[1] - y[0]) + 1, rr))\n new_shape.append(np.sum(m))\n else:\n if base_shape is None:\n raise ValueError(\"Missing required base_shape for whole-dimension slices\")\n # empty range covers dimension\n new_shape.append(base_shape[i])\n\n return tuple(new_shape)\n\ndef mr_dense_result_numel(ranges):\n return np.prod(mr_dense_result_shape(ranges))\n\ndef sel_to_subranges(dim_sel):\n subranges = list()\n for range in dim_sel:\n if np.isscalar(range):\n subranges.append( (range, range) )\n elif isinstance(range, slice):\n if range.step is not None:\n raise ValueError(\"Stepped slice ranges are not supported\")\n elif range.start is None and range.stop is None:\n # ':' full slice\n pass\n else:\n subranges.append( (range.start, range.stop) )\n elif isinstance(range, tuple):\n subranges.extend((range,))\n elif isinstance(range, list):\n for el in range:\n subranges.append( (el, el) )\n else:\n raise TypeError(\"Unsupported selection \")\n\n return tuple(subranges)\n\n\nclass MultiRangeIndexer(object):\n \"\"\"\n Implements multi-range / outer / orthogonal indexing.\n\n \"\"\"\n\n def __init__(self, array, query = None):\n if not issubclass(type(array), tiledb.Array):\n raise ValueError(\"Internal error: MultiRangeIndexer expected tiledb.Array\")\n self.array_ref = weakref.ref(array)\n self.schema = array.schema\n self.query = query\n\n @property\n def array(self):\n assert self.array_ref() is not None, \\\n \"Internal error: invariant violation (indexing call w/ dead array_ref)\"\n return self.array_ref()\n\n @classmethod\n def __test_init__(cls, array):\n \"\"\"\n Internal helper method for testing getitem range calculation.\n :param array:\n :return:\n \"\"\"\n m = cls.__new__(cls)\n m.array_ref = weakref.ref(array)\n m.schema = array.schema\n m.query = None\n return m\n\n def getitem_ranges(self, idx):\n dom = self.schema.domain\n ndim = dom.ndim\n\n if isinstance(idx, tuple):\n idx = list(idx)\n else:\n idx = [idx]\n\n ranges = list()\n for i,sel in enumerate(idx):\n if not isinstance(sel, list):\n sel = [sel]\n subranges = sel_to_subranges(sel)\n ranges.append(subranges)\n\n # extend the list to ndim\n if len(ranges) < ndim:\n ranges.extend([ tuple() for _ in range(ndim-len(ranges))])\n\n rval = tuple(ranges)\n return rval\n\n def __getitem__(self, idx):\n # implements multi-range / outer / orthogonal indexing\n ranges = self.getitem_ranges(idx)\n\n schema = self.schema\n dom = self.schema.domain\n attr_names = tuple(self.schema.attr(i).name for i in range(self.schema.nattr))\n\n coords = None\n if self.query is not None:\n # if we are called via Query object, then we need to respect Query semantics\n attr_names = tuple(self.query.attrs) if self.query.attrs else attr_names # query.attrs might be None -> all\n coords = self.query.coords\n\n from tiledb.core import PyQuery\n q = PyQuery(self.array._ctx_(), self.array, attr_names, coords)\n\n q.set_ranges(ranges)\n q.submit()\n\n result_dict = OrderedDict(q.results())\n\n for name, item in result_dict.items():\n if len(item[1]) > 0:\n arr = self.array._unpack_varlen_query(item, name)\n else:\n arr = item[0]\n arr.dtype = schema.attr_or_dim_dtype(name)\n result_dict[name] = arr\n\n if self.schema.sparse:\n return result_dict\n else:\n result_shape = mr_dense_result_shape(ranges, self.schema.shape)\n for arr in result_dict.values():\n # TODO check/test layout\n arr.shape = result_shape\n return result_dict\n", "path": "tiledb/multirange_indexing.py"}], "after_files": [{"content": "import tiledb\nfrom tiledb import Array, ArraySchema, TileDBError\nimport os, numpy as np\nimport sys, weakref\nfrom collections import OrderedDict\n\ndef mr_dense_result_shape(ranges, base_shape = None):\n # assumptions: len(ranges) matches number of dims\n if base_shape is not None:\n assert len(ranges) == len(base_shape), \"internal error: mismatched shapes\"\n\n new_shape = list()\n for i,rr in enumerate(ranges):\n if rr != ():\n m = list(map(lambda y: abs(y[1] - y[0]) + 1, rr))\n new_shape.append(np.sum(m))\n else:\n if base_shape is None:\n raise ValueError(\"Missing required base_shape for whole-dimension slices\")\n # empty range covers dimension\n new_shape.append(base_shape[i])\n\n return tuple(new_shape)\n\ndef mr_dense_result_numel(ranges):\n return np.prod(mr_dense_result_shape(ranges))\n\ndef sel_to_subranges(dim_sel):\n subranges = list()\n for range in dim_sel:\n if np.isscalar(range):\n subranges.append( (range, range) )\n elif isinstance(range, slice):\n if range.step is not None:\n raise ValueError(\"Stepped slice ranges are not supported\")\n elif range.start is None and range.stop is None:\n # ':' full slice\n pass\n else:\n subranges.append( (range.start, range.stop) )\n elif isinstance(range, tuple):\n subranges.extend((range,))\n elif isinstance(range, list):\n for el in range:\n subranges.append( (el, el) )\n else:\n raise TypeError(\"Unsupported selection \")\n\n return tuple(subranges)\n\n\nclass MultiRangeIndexer(object):\n \"\"\"\n Implements multi-range / outer / orthogonal indexing.\n\n \"\"\"\n\n def __init__(self, array, query = None):\n if not issubclass(type(array), tiledb.Array):\n raise ValueError(\"Internal error: MultiRangeIndexer expected tiledb.Array\")\n self.array_ref = weakref.ref(array)\n self.schema = array.schema\n self.query = query\n\n @property\n def array(self):\n assert self.array_ref() is not None, \\\n \"Internal error: invariant violation (indexing call w/ dead array_ref)\"\n return self.array_ref()\n\n @classmethod\n def __test_init__(cls, array):\n \"\"\"\n Internal helper method for testing getitem range calculation.\n :param array:\n :return:\n \"\"\"\n m = cls.__new__(cls)\n m.array_ref = weakref.ref(array)\n m.schema = array.schema\n m.query = None\n return m\n\n def getitem_ranges(self, idx):\n dom = self.schema.domain\n ndim = dom.ndim\n\n if isinstance(idx, tuple):\n idx = list(idx)\n else:\n idx = [idx]\n\n ranges = list()\n for i,sel in enumerate(idx):\n if not isinstance(sel, list):\n sel = [sel]\n subranges = sel_to_subranges(sel)\n ranges.append(subranges)\n\n # extend the list to ndim\n if len(ranges) < ndim:\n ranges.extend([ tuple() for _ in range(ndim-len(ranges))])\n\n rval = tuple(ranges)\n return rval\n\n def __getitem__(self, idx):\n # implements multi-range / outer / orthogonal indexing\n ranges = self.getitem_ranges(idx)\n\n schema = self.schema\n dom = self.schema.domain\n attr_names = tuple(self.schema.attr(i).name for i in range(self.schema.nattr))\n\n coords = None\n if self.query is not None:\n # if we are called via Query object, then we need to respect Query semantics\n attr_names = tuple(self.query.attrs) if self.query.attrs else attr_names # query.attrs might be None -> all\n coords = self.query.coords\n\n from tiledb.core import PyQuery\n q = PyQuery(self.array._ctx_(), self.array, attr_names, coords)\n\n q.set_ranges(ranges)\n q.submit()\n\n result_dict = OrderedDict(q.results())\n\n for name, item in result_dict.items():\n if len(item[1]) > 0:\n arr = q.unpack_buffer(name, item[0], item[1])\n else:\n arr = item[0]\n arr.dtype = schema.attr_or_dim_dtype(name)\n result_dict[name] = arr\n\n if self.schema.sparse:\n return result_dict\n else:\n result_shape = mr_dense_result_shape(ranges, self.schema.shape)\n for arr in result_dict.values():\n # TODO check/test layout\n arr.shape = result_shape\n return result_dict\n", "path": "tiledb/multirange_indexing.py"}]}
| 2,001 | 141 |
gh_patches_debug_3732
|
rasdani/github-patches
|
git_diff
|
oppia__oppia-19587
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feature Request]: Improve the experience of adding concept cards in the exploration editor.
### Is your feature request related to a problem? Please describe.
The experience of adding skill concept cards in the exploration editor has a number of issues:
- The highlighted text in the RTE does not get transferred to the concept card skill link modal when it is opened.
- Cancelling the operation results in the disappearance of the highlighted text.
- The list of skills takes a long time to load, even if it has already been fetched previously.
- Terms entered in the skill filter input box do not get applied when the skill list finally loads.
- The detailed skill explanations show up in red, which is hard to read (and suggests some kind of error).
See the video below for the current experience:
https://github.com/oppia/oppia/assets/10575562/60c94af1-8550-4be8-b277-ad4084b8daa9
### Describe the solution you'd like
- [x] When the skill link modal is opened, the text input field should be populated with the highlighted text in the RTE, or "concept card" if there is no highlighted text.
- [x] When the modal is cancelled, the RTE contents should stay as they were before the modal was opened. In particular, any highlighted text should not be deleted.
- [x] The skill filter input box should be disabled until the list of skills has loaded.
- [x] Skill explanations should show up in black text.
### Describe alternatives you've considered
- I considered also writing "the list of skills should load faster", but in reality there's always going to be some lag time. It might be possible to cache this list so that it loads fast for the second and subsequent queries, but that could lead to problems with stale data if a skill is created/deleted while an exploration is being edited. So I suggest that we don't solve that problem in this issue, and fix the other points first -- then, we can see if the loading time is still an issue.
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/domain/rte_component_registry.py`
Content:
```
1 # coding: utf-8
2 #
3 # Copyright 2014 The Oppia Authors. All Rights Reserved.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS-IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 """Registry for custom rich-text components."""
18
19 from __future__ import annotations
20
21 import inspect
22 import os
23 import pkgutil
24
25 from core import constants
26 from core import feconf
27 from core import utils
28
29 from typing import Any, Dict, List, Type, TypedDict, Union
30
31 MYPY = False
32 if MYPY: # pragma: no cover
33 # Here, we are importing 'components' from rich_text_components only
34 # for type checking.
35 from extensions.rich_text_components import components
36
37
38 class CustomizationArgSpecDict(TypedDict):
39 """Dictionary representing the customization_arg_specs object."""
40
41 name: str
42 description: str
43 # Here we use type Any because values in schema dictionary can be of
44 # type str, List, Dict and other types too.
45 schema: Dict[str, Any]
46 default_value: Union[str, int, List[str], Dict[str, str]]
47
48
49 class RteComponentDict(TypedDict):
50 """Dictionary representing the RTE component's definition."""
51
52 backend_id: str
53 category: str
54 description: str
55 frontend_id: str
56 tooltip: str
57 icon_data_url: str
58 is_complex: bool
59 requires_internet: bool
60 requires_fs: bool
61 is_block_element: bool
62 customization_arg_specs: List[CustomizationArgSpecDict]
63
64
65 class Registry:
66 """Registry of all custom rich-text components."""
67
68 _rte_components: Dict[str, RteComponentDict] = {}
69
70 @classmethod
71 def _refresh(cls) -> None:
72 """Repopulate the registry."""
73 cls._rte_components.clear()
74 package, filepath = os.path.split(
75 feconf.RTE_EXTENSIONS_DEFINITIONS_PATH)
76 cls._rte_components = constants.parse_json_from_ts(
77 constants.get_package_file_contents(package, filepath))
78
79 @classmethod
80 def get_all_rte_components(cls) -> Dict[str, RteComponentDict]:
81 """Get a dictionary mapping RTE component IDs to their definitions."""
82 if not cls._rte_components:
83 cls._refresh()
84 return cls._rte_components
85
86 @classmethod
87 def get_tag_list_with_attrs(cls) -> Dict[str, List[str]]:
88 """Returns a dict of HTML tag names and attributes for RTE components.
89
90 The keys are tag names starting with 'oppia-noninteractive-', followed
91 by the hyphenated version of the name of the RTE component. The values
92 are lists of allowed attributes of the form
93 [PARAM_NAME]-with-[CUSTOMIZATION_ARG_NAME].
94 """
95 # TODO(sll): Cache this computation and update it on each refresh.
96 # Better still, bring this into the build process so it doesn't have
97 # to be manually computed each time.
98 component_list = list(cls.get_all_rte_components().values())
99
100 component_tags = {}
101 for component_specs in component_list:
102 tag_name = 'oppia-noninteractive-%s' % (
103 utils.camelcase_to_hyphenated(component_specs['backend_id']))
104
105 component_tags[tag_name] = [
106 '%s-with-value' % ca_spec['name']
107 for ca_spec in component_specs['customization_arg_specs']]
108
109 return component_tags
110
111 @classmethod
112 def get_component_types_to_component_classes(
113 cls
114 ) -> Dict[str, Type[components.BaseRteComponent]]:
115 """Get component classes mapping for component types.
116
117 Returns:
118 dict. A dict mapping from rte component types to rte component
119 classes.
120 """
121 rte_path = [feconf.RTE_EXTENSIONS_DIR]
122
123 for loader, name, _ in pkgutil.iter_modules(path=rte_path):
124 if name == 'components':
125 fetched_module = loader.find_module(name)
126 # Ruling out the possibility of None for mypy type checking.
127 assert fetched_module is not None
128 module = fetched_module.load_module(name)
129 break
130
131 component_types_to_component_classes = {}
132 component_names = list(cls.get_all_rte_components().keys())
133 for component_name in component_names:
134 for name, obj in inspect.getmembers(module):
135 if inspect.isclass(obj) and name == component_name:
136 component_types_to_component_classes[
137 'oppia-noninteractive-%s' % component_name.lower()] = (
138 obj)
139
140 return component_types_to_component_classes
141
142 @classmethod
143 def get_component_tag_names(
144 cls, key: str, expected_value: bool
145 ) -> List[str]:
146 """Get a list of component tag names which have the expected
147 value of a key.
148
149 Args:
150 key: str. The key to be checked in component spec.
151 expected_value: bool. The expected value of the key to select
152 the components.
153
154 Returns:
155 list(str). A list of component tag names which have the expected
156 value of a key.
157 """
158 rich_text_components_specs = cls.get_all_rte_components()
159 component_tag_names = []
160 for component_spec in rich_text_components_specs.values():
161 if component_spec.get(key) == expected_value:
162 component_tag_names.append(
163 'oppia-noninteractive-%s' % component_spec['frontend_id'])
164 return component_tag_names
165
166 @classmethod
167 def get_inline_component_tag_names(cls) -> List[str]:
168 """Get a list of inline component tag names.
169
170 Returns:
171 list(str). A list of inline component tag names.
172 """
173 return cls.get_component_tag_names('is_block_element', False)
174
175 @classmethod
176 def get_block_component_tag_names(cls) -> List[str]:
177 """Get a list of block component tag names.
178
179 Returns:
180 list(str). A list of block component tag names.
181 """
182 return cls.get_component_tag_names('is_block_element', True)
183
184 @classmethod
185 def get_simple_component_tag_names(cls) -> List[str]:
186 """Get a list of simple component tag names.
187
188 Returns:
189 list(str). A list of simple component tag names.
190 """
191 return cls.get_component_tag_names('is_complex', False)
192
193 @classmethod
194 def get_complex_component_tag_names(cls) -> List[str]:
195 """Get a list of complex component tag names.
196
197 Returns:
198 list(str). A list of complex component tag names.
199 """
200 return cls.get_component_tag_names('is_complex', True)
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/domain/rte_component_registry.py b/core/domain/rte_component_registry.py
--- a/core/domain/rte_component_registry.py
+++ b/core/domain/rte_component_registry.py
@@ -43,6 +43,7 @@
# Here we use type Any because values in schema dictionary can be of
# type str, List, Dict and other types too.
schema: Dict[str, Any]
+ default_value_obtainable_from_highlight: bool
default_value: Union[str, int, List[str], Dict[str, str]]
|
{"golden_diff": "diff --git a/core/domain/rte_component_registry.py b/core/domain/rte_component_registry.py\n--- a/core/domain/rte_component_registry.py\n+++ b/core/domain/rte_component_registry.py\n@@ -43,6 +43,7 @@\n # Here we use type Any because values in schema dictionary can be of\n # type str, List, Dict and other types too.\n schema: Dict[str, Any]\n+ default_value_obtainable_from_highlight: bool\n default_value: Union[str, int, List[str], Dict[str, str]]\n", "issue": "[Feature Request]: Improve the experience of adding concept cards in the exploration editor.\n### Is your feature request related to a problem? Please describe.\r\n\r\nThe experience of adding skill concept cards in the exploration editor has a number of issues:\r\n\r\n- The highlighted text in the RTE does not get transferred to the concept card skill link modal when it is opened.\r\n- Cancelling the operation results in the disappearance of the highlighted text.\r\n- The list of skills takes a long time to load, even if it has already been fetched previously.\r\n- Terms entered in the skill filter input box do not get applied when the skill list finally loads.\r\n- The detailed skill explanations show up in red, which is hard to read (and suggests some kind of error).\r\n\r\nSee the video below for the current experience:\r\n\r\nhttps://github.com/oppia/oppia/assets/10575562/60c94af1-8550-4be8-b277-ad4084b8daa9\r\n\r\n### Describe the solution you'd like\r\n\r\n- [x] When the skill link modal is opened, the text input field should be populated with the highlighted text in the RTE, or \"concept card\" if there is no highlighted text.\r\n- [x] When the modal is cancelled, the RTE contents should stay as they were before the modal was opened. In particular, any highlighted text should not be deleted.\r\n- [x] The skill filter input box should be disabled until the list of skills has loaded.\r\n- [x] Skill explanations should show up in black text.\r\n\r\n### Describe alternatives you've considered\r\n\r\n- I considered also writing \"the list of skills should load faster\", but in reality there's always going to be some lag time. It might be possible to cache this list so that it loads fast for the second and subsequent queries, but that could lead to problems with stale data if a skill is created/deleted while an exploration is being edited. So I suggest that we don't solve that problem in this issue, and fix the other points first -- then, we can see if the loading time is still an issue.\r\n\r\n### Additional context\r\n\r\n_No response_\n", "before_files": [{"content": "# coding: utf-8\n#\n# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Registry for custom rich-text components.\"\"\"\n\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport pkgutil\n\nfrom core import constants\nfrom core import feconf\nfrom core import utils\n\nfrom typing import Any, Dict, List, Type, TypedDict, Union\n\nMYPY = False\nif MYPY: # pragma: no cover\n # Here, we are importing 'components' from rich_text_components only\n # for type checking.\n from extensions.rich_text_components import components\n\n\nclass CustomizationArgSpecDict(TypedDict):\n \"\"\"Dictionary representing the customization_arg_specs object.\"\"\"\n\n name: str\n description: str\n # Here we use type Any because values in schema dictionary can be of\n # type str, List, Dict and other types too.\n schema: Dict[str, Any]\n default_value: Union[str, int, List[str], Dict[str, str]]\n\n\nclass RteComponentDict(TypedDict):\n \"\"\"Dictionary representing the RTE component's definition.\"\"\"\n\n backend_id: str\n category: str\n description: str\n frontend_id: str\n tooltip: str\n icon_data_url: str\n is_complex: bool\n requires_internet: bool\n requires_fs: bool\n is_block_element: bool\n customization_arg_specs: List[CustomizationArgSpecDict]\n\n\nclass Registry:\n \"\"\"Registry of all custom rich-text components.\"\"\"\n\n _rte_components: Dict[str, RteComponentDict] = {}\n\n @classmethod\n def _refresh(cls) -> None:\n \"\"\"Repopulate the registry.\"\"\"\n cls._rte_components.clear()\n package, filepath = os.path.split(\n feconf.RTE_EXTENSIONS_DEFINITIONS_PATH)\n cls._rte_components = constants.parse_json_from_ts(\n constants.get_package_file_contents(package, filepath))\n\n @classmethod\n def get_all_rte_components(cls) -> Dict[str, RteComponentDict]:\n \"\"\"Get a dictionary mapping RTE component IDs to their definitions.\"\"\"\n if not cls._rte_components:\n cls._refresh()\n return cls._rte_components\n\n @classmethod\n def get_tag_list_with_attrs(cls) -> Dict[str, List[str]]:\n \"\"\"Returns a dict of HTML tag names and attributes for RTE components.\n\n The keys are tag names starting with 'oppia-noninteractive-', followed\n by the hyphenated version of the name of the RTE component. The values\n are lists of allowed attributes of the form\n [PARAM_NAME]-with-[CUSTOMIZATION_ARG_NAME].\n \"\"\"\n # TODO(sll): Cache this computation and update it on each refresh.\n # Better still, bring this into the build process so it doesn't have\n # to be manually computed each time.\n component_list = list(cls.get_all_rte_components().values())\n\n component_tags = {}\n for component_specs in component_list:\n tag_name = 'oppia-noninteractive-%s' % (\n utils.camelcase_to_hyphenated(component_specs['backend_id']))\n\n component_tags[tag_name] = [\n '%s-with-value' % ca_spec['name']\n for ca_spec in component_specs['customization_arg_specs']]\n\n return component_tags\n\n @classmethod\n def get_component_types_to_component_classes(\n cls\n ) -> Dict[str, Type[components.BaseRteComponent]]:\n \"\"\"Get component classes mapping for component types.\n\n Returns:\n dict. A dict mapping from rte component types to rte component\n classes.\n \"\"\"\n rte_path = [feconf.RTE_EXTENSIONS_DIR]\n\n for loader, name, _ in pkgutil.iter_modules(path=rte_path):\n if name == 'components':\n fetched_module = loader.find_module(name)\n # Ruling out the possibility of None for mypy type checking.\n assert fetched_module is not None\n module = fetched_module.load_module(name)\n break\n\n component_types_to_component_classes = {}\n component_names = list(cls.get_all_rte_components().keys())\n for component_name in component_names:\n for name, obj in inspect.getmembers(module):\n if inspect.isclass(obj) and name == component_name:\n component_types_to_component_classes[\n 'oppia-noninteractive-%s' % component_name.lower()] = (\n obj)\n\n return component_types_to_component_classes\n\n @classmethod\n def get_component_tag_names(\n cls, key: str, expected_value: bool\n ) -> List[str]:\n \"\"\"Get a list of component tag names which have the expected\n value of a key.\n\n Args:\n key: str. The key to be checked in component spec.\n expected_value: bool. The expected value of the key to select\n the components.\n\n Returns:\n list(str). A list of component tag names which have the expected\n value of a key.\n \"\"\"\n rich_text_components_specs = cls.get_all_rte_components()\n component_tag_names = []\n for component_spec in rich_text_components_specs.values():\n if component_spec.get(key) == expected_value:\n component_tag_names.append(\n 'oppia-noninteractive-%s' % component_spec['frontend_id'])\n return component_tag_names\n\n @classmethod\n def get_inline_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of inline component tag names.\n\n Returns:\n list(str). A list of inline component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_block_element', False)\n\n @classmethod\n def get_block_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of block component tag names.\n\n Returns:\n list(str). A list of block component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_block_element', True)\n\n @classmethod\n def get_simple_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of simple component tag names.\n\n Returns:\n list(str). A list of simple component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_complex', False)\n\n @classmethod\n def get_complex_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of complex component tag names.\n\n Returns:\n list(str). A list of complex component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_complex', True)\n", "path": "core/domain/rte_component_registry.py"}], "after_files": [{"content": "# coding: utf-8\n#\n# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Registry for custom rich-text components.\"\"\"\n\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport pkgutil\n\nfrom core import constants\nfrom core import feconf\nfrom core import utils\n\nfrom typing import Any, Dict, List, Type, TypedDict, Union\n\nMYPY = False\nif MYPY: # pragma: no cover\n # Here, we are importing 'components' from rich_text_components only\n # for type checking.\n from extensions.rich_text_components import components\n\n\nclass CustomizationArgSpecDict(TypedDict):\n \"\"\"Dictionary representing the customization_arg_specs object.\"\"\"\n\n name: str\n description: str\n # Here we use type Any because values in schema dictionary can be of\n # type str, List, Dict and other types too.\n schema: Dict[str, Any]\n default_value_obtainable_from_highlight: bool\n default_value: Union[str, int, List[str], Dict[str, str]]\n\n\nclass RteComponentDict(TypedDict):\n \"\"\"Dictionary representing the RTE component's definition.\"\"\"\n\n backend_id: str\n category: str\n description: str\n frontend_id: str\n tooltip: str\n icon_data_url: str\n is_complex: bool\n requires_internet: bool\n requires_fs: bool\n is_block_element: bool\n customization_arg_specs: List[CustomizationArgSpecDict]\n\n\nclass Registry:\n \"\"\"Registry of all custom rich-text components.\"\"\"\n\n _rte_components: Dict[str, RteComponentDict] = {}\n\n @classmethod\n def _refresh(cls) -> None:\n \"\"\"Repopulate the registry.\"\"\"\n cls._rte_components.clear()\n package, filepath = os.path.split(\n feconf.RTE_EXTENSIONS_DEFINITIONS_PATH)\n cls._rte_components = constants.parse_json_from_ts(\n constants.get_package_file_contents(package, filepath))\n\n @classmethod\n def get_all_rte_components(cls) -> Dict[str, RteComponentDict]:\n \"\"\"Get a dictionary mapping RTE component IDs to their definitions.\"\"\"\n if not cls._rte_components:\n cls._refresh()\n return cls._rte_components\n\n @classmethod\n def get_tag_list_with_attrs(cls) -> Dict[str, List[str]]:\n \"\"\"Returns a dict of HTML tag names and attributes for RTE components.\n\n The keys are tag names starting with 'oppia-noninteractive-', followed\n by the hyphenated version of the name of the RTE component. The values\n are lists of allowed attributes of the form\n [PARAM_NAME]-with-[CUSTOMIZATION_ARG_NAME].\n \"\"\"\n # TODO(sll): Cache this computation and update it on each refresh.\n # Better still, bring this into the build process so it doesn't have\n # to be manually computed each time.\n component_list = list(cls.get_all_rte_components().values())\n\n component_tags = {}\n for component_specs in component_list:\n tag_name = 'oppia-noninteractive-%s' % (\n utils.camelcase_to_hyphenated(component_specs['backend_id']))\n\n component_tags[tag_name] = [\n '%s-with-value' % ca_spec['name']\n for ca_spec in component_specs['customization_arg_specs']]\n\n return component_tags\n\n @classmethod\n def get_component_types_to_component_classes(\n cls\n ) -> Dict[str, Type[components.BaseRteComponent]]:\n \"\"\"Get component classes mapping for component types.\n\n Returns:\n dict. A dict mapping from rte component types to rte component\n classes.\n \"\"\"\n rte_path = [feconf.RTE_EXTENSIONS_DIR]\n\n for loader, name, _ in pkgutil.iter_modules(path=rte_path):\n if name == 'components':\n fetched_module = loader.find_module(name)\n # Ruling out the possibility of None for mypy type checking.\n assert fetched_module is not None\n module = fetched_module.load_module(name)\n break\n\n component_types_to_component_classes = {}\n component_names = list(cls.get_all_rte_components().keys())\n for component_name in component_names:\n for name, obj in inspect.getmembers(module):\n if inspect.isclass(obj) and name == component_name:\n component_types_to_component_classes[\n 'oppia-noninteractive-%s' % component_name.lower()] = (\n obj)\n\n return component_types_to_component_classes\n\n @classmethod\n def get_component_tag_names(\n cls, key: str, expected_value: bool\n ) -> List[str]:\n \"\"\"Get a list of component tag names which have the expected\n value of a key.\n\n Args:\n key: str. The key to be checked in component spec.\n expected_value: bool. The expected value of the key to select\n the components.\n\n Returns:\n list(str). A list of component tag names which have the expected\n value of a key.\n \"\"\"\n rich_text_components_specs = cls.get_all_rte_components()\n component_tag_names = []\n for component_spec in rich_text_components_specs.values():\n if component_spec.get(key) == expected_value:\n component_tag_names.append(\n 'oppia-noninteractive-%s' % component_spec['frontend_id'])\n return component_tag_names\n\n @classmethod\n def get_inline_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of inline component tag names.\n\n Returns:\n list(str). A list of inline component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_block_element', False)\n\n @classmethod\n def get_block_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of block component tag names.\n\n Returns:\n list(str). A list of block component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_block_element', True)\n\n @classmethod\n def get_simple_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of simple component tag names.\n\n Returns:\n list(str). A list of simple component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_complex', False)\n\n @classmethod\n def get_complex_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of complex component tag names.\n\n Returns:\n list(str). A list of complex component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_complex', True)\n", "path": "core/domain/rte_component_registry.py"}]}
| 2,692 | 118 |
gh_patches_debug_4025
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-5771
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
_matches_any_tag missing from BuildStartEndStatusGenerator
The [_matches_any_tag function](https://github.com/buildbot/buildbot/blob/e630745771a8bd03a2084d03ea8e43547d3dff4b/master/buildbot/reporters/generators/build.py#L82) is missing from the BuildStartEndStatusGenerator. This causes failures when you try to filter the builders using the tag with GitHubStatusPush and this generator.
```
buildbot_1 | 2021-01-21 13:51:23+0000 [-] Got exception when handling reporter events
buildbot_1 | Traceback (most recent call last):
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/internet/defer.py", line 1475, in gotResult
buildbot_1 | _inlineCallbacks(r, g, status)
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/internet/defer.py", line 1416, in _inlineCallbacks
buildbot_1 | result = result.throwExceptionIntoGenerator(g)
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/python/failure.py", line 512, in throwExceptionIntoGenerator
buildbot_1 | return g.throw(self.type, self.value, self.tb)
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/base.py", line 183, in _got_event
buildbot_1 | log.err(e, 'Got exception when handling reporter events')
buildbot_1 | --- <exception caught here> ---
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/base.py", line 176, in _got_event
buildbot_1 | report = yield g.generate(self.master, self, key, msg)
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/internet/defer.py", line 1418, in _inlineCallbacks
buildbot_1 | result = g.send(result)
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/generators/build.py", line 119, in generate
buildbot_1 | if not self.is_message_needed_by_props(build):
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/generators/utils.py", line 104, in is_message_needed_by_props
buildbot_1 | if self.tags is not None and not self._matches_any_tag(builder['tags']):
buildbot_1 | builtins.AttributeError: 'BuildStartEndStatusGenerator' object has no attribute '_matches_any_tag'
```
This output is from the official docker v2.10
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/reporters/generators/build.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from twisted.internet import defer
17 from zope.interface import implementer
18
19 from buildbot import interfaces
20 from buildbot.reporters import utils
21 from buildbot.reporters.message import MessageFormatter
22 from buildbot.reporters.message import MessageFormatterRenderable
23
24 from .utils import BuildStatusGeneratorMixin
25
26
27 @implementer(interfaces.IReportGenerator)
28 class BuildStatusGenerator(BuildStatusGeneratorMixin):
29
30 wanted_event_keys = [
31 ('builds', None, 'finished'),
32 ]
33
34 compare_attrs = ['formatter']
35
36 def __init__(self, mode=("failing", "passing", "warnings"),
37 tags=None, builders=None, schedulers=None, branches=None,
38 subject="Buildbot %(result)s in %(title)s on %(builder)s",
39 add_logs=False, add_patch=False, report_new=False, message_formatter=None,
40 _want_previous_build=None):
41 super().__init__(mode, tags, builders, schedulers, branches, subject, add_logs, add_patch)
42 self.formatter = message_formatter
43 if self.formatter is None:
44 self.formatter = MessageFormatter()
45
46 # TODO: private and deprecated, included only to support HttpStatusPushBase
47 self._want_previous_build_override = _want_previous_build
48
49 if report_new:
50 self.wanted_event_keys = [
51 ('builds', None, 'finished'),
52 ('builds', None, 'new'),
53 ]
54
55 @defer.inlineCallbacks
56 def generate(self, master, reporter, key, build):
57 _, _, event = key
58 is_new = event == 'new'
59 want_previous_build = False if is_new else self._want_previous_build()
60 if self._want_previous_build_override is not None:
61 want_previous_build = self._want_previous_build_override
62
63 yield utils.getDetailsForBuild(master, build,
64 wantProperties=self.formatter.wantProperties,
65 wantSteps=self.formatter.wantSteps,
66 wantPreviousBuild=want_previous_build,
67 wantLogs=self.formatter.wantLogs)
68
69 if not self.is_message_needed_by_props(build):
70 return None
71 if not is_new and not self.is_message_needed_by_results(build):
72 return None
73
74 report = yield self.build_message(self.formatter, master, reporter,
75 build['builder']['name'], [build],
76 build['results'])
77 return report
78
79 def _want_previous_build(self):
80 return "change" in self.mode or "problem" in self.mode
81
82 def _matches_any_tag(self, tags):
83 return self.tags and any(tag for tag in self.tags if tag in tags)
84
85
86 @implementer(interfaces.IReportGenerator)
87 class BuildStartEndStatusGenerator(BuildStatusGeneratorMixin):
88
89 wanted_event_keys = [
90 ('builds', None, 'new'),
91 ('builds', None, 'finished'),
92 ]
93
94 compare_attrs = ['start_formatter', 'end_formatter']
95
96 def __init__(self, tags=None, builders=None, schedulers=None, branches=None, add_logs=False,
97 add_patch=False, start_formatter=None, end_formatter=None):
98
99 super().__init__('all', tags, builders, schedulers, branches, None, add_logs, add_patch)
100 self.start_formatter = start_formatter
101 if self.start_formatter is None:
102 self.start_formatter = MessageFormatterRenderable('Build started.')
103 self.end_formatter = end_formatter
104 if self.end_formatter is None:
105 self.end_formatter = MessageFormatterRenderable('Build done.')
106
107 @defer.inlineCallbacks
108 def generate(self, master, reporter, key, build):
109 _, _, event = key
110 is_new = event == 'new'
111
112 formatter = self.start_formatter if is_new else self.end_formatter
113
114 yield utils.getDetailsForBuild(master, build,
115 wantProperties=formatter.wantProperties,
116 wantSteps=formatter.wantSteps,
117 wantLogs=formatter.wantLogs)
118
119 if not self.is_message_needed_by_props(build):
120 return None
121
122 report = yield self.build_message(formatter, master, reporter, build['builder']['name'],
123 [build], build['results'])
124 return report
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/reporters/generators/build.py b/master/buildbot/reporters/generators/build.py
--- a/master/buildbot/reporters/generators/build.py
+++ b/master/buildbot/reporters/generators/build.py
@@ -122,3 +122,6 @@
report = yield self.build_message(formatter, master, reporter, build['builder']['name'],
[build], build['results'])
return report
+
+ def _matches_any_tag(self, tags):
+ return self.tags and any(tag for tag in self.tags if tag in tags)
|
{"golden_diff": "diff --git a/master/buildbot/reporters/generators/build.py b/master/buildbot/reporters/generators/build.py\n--- a/master/buildbot/reporters/generators/build.py\n+++ b/master/buildbot/reporters/generators/build.py\n@@ -122,3 +122,6 @@\n report = yield self.build_message(formatter, master, reporter, build['builder']['name'],\n [build], build['results'])\n return report\n+\n+ def _matches_any_tag(self, tags):\n+ return self.tags and any(tag for tag in self.tags if tag in tags)\n", "issue": "_matches_any_tag missing from BuildStartEndStatusGenerator\nThe [_matches_any_tag function](https://github.com/buildbot/buildbot/blob/e630745771a8bd03a2084d03ea8e43547d3dff4b/master/buildbot/reporters/generators/build.py#L82) is missing from the BuildStartEndStatusGenerator. This causes failures when you try to filter the builders using the tag with GitHubStatusPush and this generator.\r\n\r\n```\r\nbuildbot_1 | 2021-01-21 13:51:23+0000 [-] Got exception when handling reporter events\r\nbuildbot_1 | \tTraceback (most recent call last):\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1475, in gotResult\r\nbuildbot_1 | \t _inlineCallbacks(r, g, status)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1416, in _inlineCallbacks\r\nbuildbot_1 | \t result = result.throwExceptionIntoGenerator(g)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/python/failure.py\", line 512, in throwExceptionIntoGenerator\r\nbuildbot_1 | \t return g.throw(self.type, self.value, self.tb)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/base.py\", line 183, in _got_event\r\nbuildbot_1 | \t log.err(e, 'Got exception when handling reporter events')\r\nbuildbot_1 | \t--- <exception caught here> ---\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/base.py\", line 176, in _got_event\r\nbuildbot_1 | \t report = yield g.generate(self.master, self, key, msg)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1418, in _inlineCallbacks\r\nbuildbot_1 | \t result = g.send(result)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/generators/build.py\", line 119, in generate\r\nbuildbot_1 | \t if not self.is_message_needed_by_props(build):\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/generators/utils.py\", line 104, in is_message_needed_by_props\r\nbuildbot_1 | \t if self.tags is not None and not self._matches_any_tag(builder['tags']):\r\nbuildbot_1 | \tbuiltins.AttributeError: 'BuildStartEndStatusGenerator' object has no attribute '_matches_any_tag'\r\n\r\n```\r\n\r\nThis output is from the official docker v2.10\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom twisted.internet import defer\nfrom zope.interface import implementer\n\nfrom buildbot import interfaces\nfrom buildbot.reporters import utils\nfrom buildbot.reporters.message import MessageFormatter\nfrom buildbot.reporters.message import MessageFormatterRenderable\n\nfrom .utils import BuildStatusGeneratorMixin\n\n\n@implementer(interfaces.IReportGenerator)\nclass BuildStatusGenerator(BuildStatusGeneratorMixin):\n\n wanted_event_keys = [\n ('builds', None, 'finished'),\n ]\n\n compare_attrs = ['formatter']\n\n def __init__(self, mode=(\"failing\", \"passing\", \"warnings\"),\n tags=None, builders=None, schedulers=None, branches=None,\n subject=\"Buildbot %(result)s in %(title)s on %(builder)s\",\n add_logs=False, add_patch=False, report_new=False, message_formatter=None,\n _want_previous_build=None):\n super().__init__(mode, tags, builders, schedulers, branches, subject, add_logs, add_patch)\n self.formatter = message_formatter\n if self.formatter is None:\n self.formatter = MessageFormatter()\n\n # TODO: private and deprecated, included only to support HttpStatusPushBase\n self._want_previous_build_override = _want_previous_build\n\n if report_new:\n self.wanted_event_keys = [\n ('builds', None, 'finished'),\n ('builds', None, 'new'),\n ]\n\n @defer.inlineCallbacks\n def generate(self, master, reporter, key, build):\n _, _, event = key\n is_new = event == 'new'\n want_previous_build = False if is_new else self._want_previous_build()\n if self._want_previous_build_override is not None:\n want_previous_build = self._want_previous_build_override\n\n yield utils.getDetailsForBuild(master, build,\n wantProperties=self.formatter.wantProperties,\n wantSteps=self.formatter.wantSteps,\n wantPreviousBuild=want_previous_build,\n wantLogs=self.formatter.wantLogs)\n\n if not self.is_message_needed_by_props(build):\n return None\n if not is_new and not self.is_message_needed_by_results(build):\n return None\n\n report = yield self.build_message(self.formatter, master, reporter,\n build['builder']['name'], [build],\n build['results'])\n return report\n\n def _want_previous_build(self):\n return \"change\" in self.mode or \"problem\" in self.mode\n\n def _matches_any_tag(self, tags):\n return self.tags and any(tag for tag in self.tags if tag in tags)\n\n\n@implementer(interfaces.IReportGenerator)\nclass BuildStartEndStatusGenerator(BuildStatusGeneratorMixin):\n\n wanted_event_keys = [\n ('builds', None, 'new'),\n ('builds', None, 'finished'),\n ]\n\n compare_attrs = ['start_formatter', 'end_formatter']\n\n def __init__(self, tags=None, builders=None, schedulers=None, branches=None, add_logs=False,\n add_patch=False, start_formatter=None, end_formatter=None):\n\n super().__init__('all', tags, builders, schedulers, branches, None, add_logs, add_patch)\n self.start_formatter = start_formatter\n if self.start_formatter is None:\n self.start_formatter = MessageFormatterRenderable('Build started.')\n self.end_formatter = end_formatter\n if self.end_formatter is None:\n self.end_formatter = MessageFormatterRenderable('Build done.')\n\n @defer.inlineCallbacks\n def generate(self, master, reporter, key, build):\n _, _, event = key\n is_new = event == 'new'\n\n formatter = self.start_formatter if is_new else self.end_formatter\n\n yield utils.getDetailsForBuild(master, build,\n wantProperties=formatter.wantProperties,\n wantSteps=formatter.wantSteps,\n wantLogs=formatter.wantLogs)\n\n if not self.is_message_needed_by_props(build):\n return None\n\n report = yield self.build_message(formatter, master, reporter, build['builder']['name'],\n [build], build['results'])\n return report\n", "path": "master/buildbot/reporters/generators/build.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom twisted.internet import defer\nfrom zope.interface import implementer\n\nfrom buildbot import interfaces\nfrom buildbot.reporters import utils\nfrom buildbot.reporters.message import MessageFormatter\nfrom buildbot.reporters.message import MessageFormatterRenderable\n\nfrom .utils import BuildStatusGeneratorMixin\n\n\n@implementer(interfaces.IReportGenerator)\nclass BuildStatusGenerator(BuildStatusGeneratorMixin):\n\n wanted_event_keys = [\n ('builds', None, 'finished'),\n ]\n\n compare_attrs = ['formatter']\n\n def __init__(self, mode=(\"failing\", \"passing\", \"warnings\"),\n tags=None, builders=None, schedulers=None, branches=None,\n subject=\"Buildbot %(result)s in %(title)s on %(builder)s\",\n add_logs=False, add_patch=False, report_new=False, message_formatter=None,\n _want_previous_build=None):\n super().__init__(mode, tags, builders, schedulers, branches, subject, add_logs, add_patch)\n self.formatter = message_formatter\n if self.formatter is None:\n self.formatter = MessageFormatter()\n\n # TODO: private and deprecated, included only to support HttpStatusPushBase\n self._want_previous_build_override = _want_previous_build\n\n if report_new:\n self.wanted_event_keys = [\n ('builds', None, 'finished'),\n ('builds', None, 'new'),\n ]\n\n @defer.inlineCallbacks\n def generate(self, master, reporter, key, build):\n _, _, event = key\n is_new = event == 'new'\n want_previous_build = False if is_new else self._want_previous_build()\n if self._want_previous_build_override is not None:\n want_previous_build = self._want_previous_build_override\n\n yield utils.getDetailsForBuild(master, build,\n wantProperties=self.formatter.wantProperties,\n wantSteps=self.formatter.wantSteps,\n wantPreviousBuild=want_previous_build,\n wantLogs=self.formatter.wantLogs)\n\n if not self.is_message_needed_by_props(build):\n return None\n if not is_new and not self.is_message_needed_by_results(build):\n return None\n\n report = yield self.build_message(self.formatter, master, reporter,\n build['builder']['name'], [build],\n build['results'])\n return report\n\n def _want_previous_build(self):\n return \"change\" in self.mode or \"problem\" in self.mode\n\n def _matches_any_tag(self, tags):\n return self.tags and any(tag for tag in self.tags if tag in tags)\n\n\n@implementer(interfaces.IReportGenerator)\nclass BuildStartEndStatusGenerator(BuildStatusGeneratorMixin):\n\n wanted_event_keys = [\n ('builds', None, 'new'),\n ('builds', None, 'finished'),\n ]\n\n compare_attrs = ['start_formatter', 'end_formatter']\n\n def __init__(self, tags=None, builders=None, schedulers=None, branches=None, add_logs=False,\n add_patch=False, start_formatter=None, end_formatter=None):\n\n super().__init__('all', tags, builders, schedulers, branches, None, add_logs, add_patch)\n self.start_formatter = start_formatter\n if self.start_formatter is None:\n self.start_formatter = MessageFormatterRenderable('Build started.')\n self.end_formatter = end_formatter\n if self.end_formatter is None:\n self.end_formatter = MessageFormatterRenderable('Build done.')\n\n @defer.inlineCallbacks\n def generate(self, master, reporter, key, build):\n _, _, event = key\n is_new = event == 'new'\n\n formatter = self.start_formatter if is_new else self.end_formatter\n\n yield utils.getDetailsForBuild(master, build,\n wantProperties=formatter.wantProperties,\n wantSteps=formatter.wantSteps,\n wantLogs=formatter.wantLogs)\n\n if not self.is_message_needed_by_props(build):\n return None\n\n report = yield self.build_message(formatter, master, reporter, build['builder']['name'],\n [build], build['results'])\n return report\n\n def _matches_any_tag(self, tags):\n return self.tags and any(tag for tag in self.tags if tag in tags)\n", "path": "master/buildbot/reporters/generators/build.py"}]}
| 2,233 | 127 |
gh_patches_debug_36022
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-6357
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
yettel_bg is broken
The spider does not return anything. It seems like they've moved the page for getting their store data. I wasn't able to find the new address or how the data reaches their store locator page.
Store locator: https://www.yettel.bg/faq/digital-customer-service/store-locator
Spider: https://github.com/alltheplaces/alltheplaces/blob/master/locations/spiders/yettel_bg.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/yettel_bg.py`
Content:
```
1 from scrapy import Selector, Spider
2
3 from locations.items import Feature
4
5
6 class YettelBGSpider(Spider):
7 name = "yettel_bg"
8 item_attributes = {
9 "brand": "Yettel",
10 "brand_wikidata": "Q14915070",
11 "country": "BG",
12 }
13 start_urls = ["https://www.yettel.bg/store-locator/json"]
14
15 def parse(self, response):
16 for store in response.json()["features"]:
17 item = Feature()
18
19 item["lon"], item["lat"] = store["geometry"]["coordinates"]
20
21 item["ref"] = store["properties"]["title"]
22
23 address_block = Selector(text=store["properties"]["gsl_addressfield"])
24
25 item["street_address"] = address_block.xpath('//div[@class="thoroughfare"]/text()').get()
26 item["postcode"] = address_block.xpath('//span[@class="postal-code"]/text()').get()
27 item["city"] = address_block.xpath('//span[@class="locality"]/text()').get()
28
29 yield item
30
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/yettel_bg.py b/locations/spiders/yettel_bg.py
--- a/locations/spiders/yettel_bg.py
+++ b/locations/spiders/yettel_bg.py
@@ -1,5 +1,9 @@
-from scrapy import Selector, Spider
+import io
+from openpyxl import load_workbook
+from scrapy import Spider
+
+from locations.hours import OpeningHours, day_range
from locations.items import Feature
@@ -10,20 +14,50 @@
"brand_wikidata": "Q14915070",
"country": "BG",
}
- start_urls = ["https://www.yettel.bg/store-locator/json"]
+ start_urls = ["https://www.yettel.bg/faq/digital-customer-service/store-locator"]
+ no_refs = True
+ custom_settings = {"ROBOTSTXT_OBEY": False}
def parse(self, response):
- for store in response.json()["features"]:
- item = Feature()
-
- item["lon"], item["lat"] = store["geometry"]["coordinates"]
-
- item["ref"] = store["properties"]["title"]
-
- address_block = Selector(text=store["properties"]["gsl_addressfield"])
-
- item["street_address"] = address_block.xpath('//div[@class="thoroughfare"]/text()').get()
- item["postcode"] = address_block.xpath('//span[@class="postal-code"]/text()').get()
- item["city"] = address_block.xpath('//span[@class="locality"]/text()').get()
-
- yield item
+ yield response.follow(
+ url=response.xpath('//input[@id="hdnExcelFile"]/@value').get(), callback=self.parse_spreadsheet
+ )
+
+ def parse_spreadsheet(self, response):
+ if "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" in response.headers.get(
+ "Content-Type"
+ ).decode("utf-8"):
+ excel_file = response.body
+
+ excel_data = io.BytesIO(excel_file)
+ workbook = load_workbook(excel_data, read_only=True)
+
+ sheet = workbook.active
+
+ data = []
+ for row in sheet.iter_rows(values_only=True):
+ data.append(row)
+
+ headers = data[0]
+ json_data = []
+ for row in data[1:]:
+ json_data.append({headers[i]: cell for i, cell in enumerate(row)})
+
+ for store in json_data:
+ item = Feature()
+
+ item["lat"] = store["latitude"]
+ item["lon"] = store["longitude"]
+
+ item["street_address"] = store["address_loc"]
+ item["city"] = store["city_loc"]
+
+ item["opening_hours"] = OpeningHours()
+ item["opening_hours"].add_days_range(
+ day_range("Mo", "Fr"), *store["working_time_weekdays"].replace(" ", "").split("-")
+ )
+ if store["is_closed_on_saturday"] == "No":
+ item["opening_hours"].add_range("Sa", *store["working_time_saturday"].replace(" ", "").split("-"))
+ if store["is_closed_on_sunday"] == "No":
+ item["opening_hours"].add_range("Su", *store["working_time_sunday"].replace(" ", "").split("-"))
+ yield item
|
{"golden_diff": "diff --git a/locations/spiders/yettel_bg.py b/locations/spiders/yettel_bg.py\n--- a/locations/spiders/yettel_bg.py\n+++ b/locations/spiders/yettel_bg.py\n@@ -1,5 +1,9 @@\n-from scrapy import Selector, Spider\n+import io\n \n+from openpyxl import load_workbook\n+from scrapy import Spider\n+\n+from locations.hours import OpeningHours, day_range\n from locations.items import Feature\n \n \n@@ -10,20 +14,50 @@\n \"brand_wikidata\": \"Q14915070\",\n \"country\": \"BG\",\n }\n- start_urls = [\"https://www.yettel.bg/store-locator/json\"]\n+ start_urls = [\"https://www.yettel.bg/faq/digital-customer-service/store-locator\"]\n+ no_refs = True\n+ custom_settings = {\"ROBOTSTXT_OBEY\": False}\n \n def parse(self, response):\n- for store in response.json()[\"features\"]:\n- item = Feature()\n-\n- item[\"lon\"], item[\"lat\"] = store[\"geometry\"][\"coordinates\"]\n-\n- item[\"ref\"] = store[\"properties\"][\"title\"]\n-\n- address_block = Selector(text=store[\"properties\"][\"gsl_addressfield\"])\n-\n- item[\"street_address\"] = address_block.xpath('//div[@class=\"thoroughfare\"]/text()').get()\n- item[\"postcode\"] = address_block.xpath('//span[@class=\"postal-code\"]/text()').get()\n- item[\"city\"] = address_block.xpath('//span[@class=\"locality\"]/text()').get()\n-\n- yield item\n+ yield response.follow(\n+ url=response.xpath('//input[@id=\"hdnExcelFile\"]/@value').get(), callback=self.parse_spreadsheet\n+ )\n+\n+ def parse_spreadsheet(self, response):\n+ if \"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet\" in response.headers.get(\n+ \"Content-Type\"\n+ ).decode(\"utf-8\"):\n+ excel_file = response.body\n+\n+ excel_data = io.BytesIO(excel_file)\n+ workbook = load_workbook(excel_data, read_only=True)\n+\n+ sheet = workbook.active\n+\n+ data = []\n+ for row in sheet.iter_rows(values_only=True):\n+ data.append(row)\n+\n+ headers = data[0]\n+ json_data = []\n+ for row in data[1:]:\n+ json_data.append({headers[i]: cell for i, cell in enumerate(row)})\n+\n+ for store in json_data:\n+ item = Feature()\n+\n+ item[\"lat\"] = store[\"latitude\"]\n+ item[\"lon\"] = store[\"longitude\"]\n+\n+ item[\"street_address\"] = store[\"address_loc\"]\n+ item[\"city\"] = store[\"city_loc\"]\n+\n+ item[\"opening_hours\"] = OpeningHours()\n+ item[\"opening_hours\"].add_days_range(\n+ day_range(\"Mo\", \"Fr\"), *store[\"working_time_weekdays\"].replace(\" \", \"\").split(\"-\")\n+ )\n+ if store[\"is_closed_on_saturday\"] == \"No\":\n+ item[\"opening_hours\"].add_range(\"Sa\", *store[\"working_time_saturday\"].replace(\" \", \"\").split(\"-\"))\n+ if store[\"is_closed_on_sunday\"] == \"No\":\n+ item[\"opening_hours\"].add_range(\"Su\", *store[\"working_time_sunday\"].replace(\" \", \"\").split(\"-\"))\n+ yield item\n", "issue": "yettel_bg is broken\nThe spider does not return anything. It seems like they've moved the page for getting their store data. I wasn't able to find the new address or how the data reaches their store locator page.\r\n\r\nStore locator: https://www.yettel.bg/faq/digital-customer-service/store-locator\r\n\r\nSpider: https://github.com/alltheplaces/alltheplaces/blob/master/locations/spiders/yettel_bg.py\n", "before_files": [{"content": "from scrapy import Selector, Spider\n\nfrom locations.items import Feature\n\n\nclass YettelBGSpider(Spider):\n name = \"yettel_bg\"\n item_attributes = {\n \"brand\": \"Yettel\",\n \"brand_wikidata\": \"Q14915070\",\n \"country\": \"BG\",\n }\n start_urls = [\"https://www.yettel.bg/store-locator/json\"]\n\n def parse(self, response):\n for store in response.json()[\"features\"]:\n item = Feature()\n\n item[\"lon\"], item[\"lat\"] = store[\"geometry\"][\"coordinates\"]\n\n item[\"ref\"] = store[\"properties\"][\"title\"]\n\n address_block = Selector(text=store[\"properties\"][\"gsl_addressfield\"])\n\n item[\"street_address\"] = address_block.xpath('//div[@class=\"thoroughfare\"]/text()').get()\n item[\"postcode\"] = address_block.xpath('//span[@class=\"postal-code\"]/text()').get()\n item[\"city\"] = address_block.xpath('//span[@class=\"locality\"]/text()').get()\n\n yield item\n", "path": "locations/spiders/yettel_bg.py"}], "after_files": [{"content": "import io\n\nfrom openpyxl import load_workbook\nfrom scrapy import Spider\n\nfrom locations.hours import OpeningHours, day_range\nfrom locations.items import Feature\n\n\nclass YettelBGSpider(Spider):\n name = \"yettel_bg\"\n item_attributes = {\n \"brand\": \"Yettel\",\n \"brand_wikidata\": \"Q14915070\",\n \"country\": \"BG\",\n }\n start_urls = [\"https://www.yettel.bg/faq/digital-customer-service/store-locator\"]\n no_refs = True\n custom_settings = {\"ROBOTSTXT_OBEY\": False}\n\n def parse(self, response):\n yield response.follow(\n url=response.xpath('//input[@id=\"hdnExcelFile\"]/@value').get(), callback=self.parse_spreadsheet\n )\n\n def parse_spreadsheet(self, response):\n if \"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet\" in response.headers.get(\n \"Content-Type\"\n ).decode(\"utf-8\"):\n excel_file = response.body\n\n excel_data = io.BytesIO(excel_file)\n workbook = load_workbook(excel_data, read_only=True)\n\n sheet = workbook.active\n\n data = []\n for row in sheet.iter_rows(values_only=True):\n data.append(row)\n\n headers = data[0]\n json_data = []\n for row in data[1:]:\n json_data.append({headers[i]: cell for i, cell in enumerate(row)})\n\n for store in json_data:\n item = Feature()\n\n item[\"lat\"] = store[\"latitude\"]\n item[\"lon\"] = store[\"longitude\"]\n\n item[\"street_address\"] = store[\"address_loc\"]\n item[\"city\"] = store[\"city_loc\"]\n\n item[\"opening_hours\"] = OpeningHours()\n item[\"opening_hours\"].add_days_range(\n day_range(\"Mo\", \"Fr\"), *store[\"working_time_weekdays\"].replace(\" \", \"\").split(\"-\")\n )\n if store[\"is_closed_on_saturday\"] == \"No\":\n item[\"opening_hours\"].add_range(\"Sa\", *store[\"working_time_saturday\"].replace(\" \", \"\").split(\"-\"))\n if store[\"is_closed_on_sunday\"] == \"No\":\n item[\"opening_hours\"].add_range(\"Su\", *store[\"working_time_sunday\"].replace(\" \", \"\").split(\"-\"))\n yield item\n", "path": "locations/spiders/yettel_bg.py"}]}
| 633 | 756 |
gh_patches_debug_1875
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6598
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Possibly to prefill Reason textarea on $delete
If you're going to have some human-helped automation that deletes the 20% or so non-en-US documents that aren't actually translated, it would be nice if you don't have to type in the same reason every time.
<img width="989" alt="Screen Shot 2020-02-26 at 11 56 40 AM" src="https://user-images.githubusercontent.com/26739/75367987-1be85500-588f-11ea-8ba1-f49e0db69cc7.png">
Would be neat if you could control it with something like `?reason=Sample%20reason`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/wiki/views/delete.py`
Content:
```
1 from django.db import IntegrityError
2 from django.shortcuts import get_object_or_404, redirect, render
3 from django.utils.translation import ugettext
4 from django.views.decorators.cache import never_cache
5
6 from kuma.core.decorators import (
7 block_user_agents,
8 ensure_wiki_domain,
9 login_required,
10 permission_required,
11 )
12 from kuma.core.urlresolvers import reverse
13
14 from ..decorators import check_readonly, process_document_path
15 from ..forms import DocumentDeletionForm
16 from ..models import Document, DocumentDeletionLog, Revision
17 from ..utils import locale_and_slug_from_path
18
19
20 @ensure_wiki_domain
21 @never_cache
22 @block_user_agents
23 @login_required
24 @check_readonly
25 def revert_document(request, document_path, revision_id):
26 """
27 Revert document to a specific revision.
28 """
29 document_locale, document_slug, needs_redirect = locale_and_slug_from_path(
30 document_path, request
31 )
32
33 revision = get_object_or_404(
34 Revision.objects.select_related("document"),
35 pk=revision_id,
36 document__slug=document_slug,
37 )
38
39 if request.method == "GET":
40 # Render the confirmation page
41 return render(
42 request,
43 "wiki/confirm_revision_revert.html",
44 {"revision": revision, "document": revision.document},
45 )
46 else:
47 comment = request.POST.get("comment")
48 document = revision.document
49 old_revision_pk = revision.pk
50 try:
51 new_revision = document.revert(revision, request.user, comment)
52 # schedule a rendering of the new revision if it really was saved
53 if new_revision.pk != old_revision_pk:
54 document.schedule_rendering("max-age=0")
55 except IntegrityError:
56 return render(
57 request,
58 "wiki/confirm_revision_revert.html",
59 {
60 "revision": revision,
61 "document": revision.document,
62 "error": ugettext(
63 "Document already exists. Note: You cannot "
64 "revert a document that has been moved until you "
65 "delete its redirect."
66 ),
67 },
68 )
69 return redirect("wiki.document_revisions", revision.document.slug)
70
71
72 @ensure_wiki_domain
73 @never_cache
74 @block_user_agents
75 @login_required
76 @permission_required("wiki.delete_document")
77 @check_readonly
78 @process_document_path
79 def delete_document(request, document_slug, document_locale):
80 """
81 Delete a Document.
82 """
83 document = get_object_or_404(Document, locale=document_locale, slug=document_slug)
84
85 # HACK: https://bugzil.la/972545 - Don't delete pages that have children
86 # TODO: https://bugzil.la/972541 - Deleting a page that has subpages
87 prevent = document.children.exists()
88
89 first_revision = document.revisions.all()[0]
90
91 if request.method == "POST":
92 form = DocumentDeletionForm(data=request.POST)
93 if form.is_valid():
94 DocumentDeletionLog.objects.create(
95 locale=document.locale,
96 slug=document.slug,
97 user=request.user,
98 reason=form.cleaned_data["reason"],
99 )
100 document.delete()
101 return redirect(document)
102 else:
103 form = DocumentDeletionForm()
104
105 context = {
106 "document": document,
107 "form": form,
108 "request": request,
109 "revision": first_revision,
110 "prevent": prevent,
111 }
112 return render(request, "wiki/confirm_document_delete.html", context)
113
114
115 @ensure_wiki_domain
116 @never_cache
117 @block_user_agents
118 @login_required
119 @permission_required("wiki.restore_document")
120 @check_readonly
121 @process_document_path
122 def restore_document(request, document_slug, document_locale):
123 """
124 Restore a deleted Document.
125 """
126 document = get_object_or_404(
127 Document.deleted_objects.all(), slug=document_slug, locale=document_locale
128 )
129 document.restore()
130 return redirect(document)
131
132
133 @ensure_wiki_domain
134 @never_cache
135 @block_user_agents
136 @login_required
137 @permission_required("wiki.purge_document")
138 @check_readonly
139 @process_document_path
140 def purge_document(request, document_slug, document_locale):
141 """
142 Permanently purge a deleted Document.
143 """
144 document = get_object_or_404(
145 Document.deleted_objects.all(), slug=document_slug, locale=document_locale
146 )
147 deletion_log_entries = DocumentDeletionLog.objects.filter(
148 locale=document_locale, slug=document_slug
149 )
150 if deletion_log_entries.exists():
151 deletion_log = deletion_log_entries.order_by("-pk")[0]
152 else:
153 deletion_log = {}
154
155 if request.method == "POST" and "confirm" in request.POST:
156 document.purge()
157 return redirect(
158 reverse("wiki.document", args=(document_slug,), locale=document_locale)
159 )
160 else:
161 return render(
162 request,
163 "wiki/confirm_purge.html",
164 {"document": document, "deletion_log": deletion_log},
165 )
166
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/wiki/views/delete.py b/kuma/wiki/views/delete.py
--- a/kuma/wiki/views/delete.py
+++ b/kuma/wiki/views/delete.py
@@ -100,7 +100,8 @@
document.delete()
return redirect(document)
else:
- form = DocumentDeletionForm()
+
+ form = DocumentDeletionForm(initial={"reason": request.GET.get("reason", "")})
context = {
"document": document,
|
{"golden_diff": "diff --git a/kuma/wiki/views/delete.py b/kuma/wiki/views/delete.py\n--- a/kuma/wiki/views/delete.py\n+++ b/kuma/wiki/views/delete.py\n@@ -100,7 +100,8 @@\n document.delete()\n return redirect(document)\n else:\n- form = DocumentDeletionForm()\n+\n+ form = DocumentDeletionForm(initial={\"reason\": request.GET.get(\"reason\", \"\")})\n \n context = {\n \"document\": document,\n", "issue": "Possibly to prefill Reason textarea on $delete\nIf you're going to have some human-helped automation that deletes the 20% or so non-en-US documents that aren't actually translated, it would be nice if you don't have to type in the same reason every time. \r\n<img width=\"989\" alt=\"Screen Shot 2020-02-26 at 11 56 40 AM\" src=\"https://user-images.githubusercontent.com/26739/75367987-1be85500-588f-11ea-8ba1-f49e0db69cc7.png\">\r\n\r\nWould be neat if you could control it with something like `?reason=Sample%20reason`\n", "before_files": [{"content": "from django.db import IntegrityError\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import ugettext\nfrom django.views.decorators.cache import never_cache\n\nfrom kuma.core.decorators import (\n block_user_agents,\n ensure_wiki_domain,\n login_required,\n permission_required,\n)\nfrom kuma.core.urlresolvers import reverse\n\nfrom ..decorators import check_readonly, process_document_path\nfrom ..forms import DocumentDeletionForm\nfrom ..models import Document, DocumentDeletionLog, Revision\nfrom ..utils import locale_and_slug_from_path\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@check_readonly\ndef revert_document(request, document_path, revision_id):\n \"\"\"\n Revert document to a specific revision.\n \"\"\"\n document_locale, document_slug, needs_redirect = locale_and_slug_from_path(\n document_path, request\n )\n\n revision = get_object_or_404(\n Revision.objects.select_related(\"document\"),\n pk=revision_id,\n document__slug=document_slug,\n )\n\n if request.method == \"GET\":\n # Render the confirmation page\n return render(\n request,\n \"wiki/confirm_revision_revert.html\",\n {\"revision\": revision, \"document\": revision.document},\n )\n else:\n comment = request.POST.get(\"comment\")\n document = revision.document\n old_revision_pk = revision.pk\n try:\n new_revision = document.revert(revision, request.user, comment)\n # schedule a rendering of the new revision if it really was saved\n if new_revision.pk != old_revision_pk:\n document.schedule_rendering(\"max-age=0\")\n except IntegrityError:\n return render(\n request,\n \"wiki/confirm_revision_revert.html\",\n {\n \"revision\": revision,\n \"document\": revision.document,\n \"error\": ugettext(\n \"Document already exists. Note: You cannot \"\n \"revert a document that has been moved until you \"\n \"delete its redirect.\"\n ),\n },\n )\n return redirect(\"wiki.document_revisions\", revision.document.slug)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.delete_document\")\n@check_readonly\n@process_document_path\ndef delete_document(request, document_slug, document_locale):\n \"\"\"\n Delete a Document.\n \"\"\"\n document = get_object_or_404(Document, locale=document_locale, slug=document_slug)\n\n # HACK: https://bugzil.la/972545 - Don't delete pages that have children\n # TODO: https://bugzil.la/972541 - Deleting a page that has subpages\n prevent = document.children.exists()\n\n first_revision = document.revisions.all()[0]\n\n if request.method == \"POST\":\n form = DocumentDeletionForm(data=request.POST)\n if form.is_valid():\n DocumentDeletionLog.objects.create(\n locale=document.locale,\n slug=document.slug,\n user=request.user,\n reason=form.cleaned_data[\"reason\"],\n )\n document.delete()\n return redirect(document)\n else:\n form = DocumentDeletionForm()\n\n context = {\n \"document\": document,\n \"form\": form,\n \"request\": request,\n \"revision\": first_revision,\n \"prevent\": prevent,\n }\n return render(request, \"wiki/confirm_document_delete.html\", context)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.restore_document\")\n@check_readonly\n@process_document_path\ndef restore_document(request, document_slug, document_locale):\n \"\"\"\n Restore a deleted Document.\n \"\"\"\n document = get_object_or_404(\n Document.deleted_objects.all(), slug=document_slug, locale=document_locale\n )\n document.restore()\n return redirect(document)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.purge_document\")\n@check_readonly\n@process_document_path\ndef purge_document(request, document_slug, document_locale):\n \"\"\"\n Permanently purge a deleted Document.\n \"\"\"\n document = get_object_or_404(\n Document.deleted_objects.all(), slug=document_slug, locale=document_locale\n )\n deletion_log_entries = DocumentDeletionLog.objects.filter(\n locale=document_locale, slug=document_slug\n )\n if deletion_log_entries.exists():\n deletion_log = deletion_log_entries.order_by(\"-pk\")[0]\n else:\n deletion_log = {}\n\n if request.method == \"POST\" and \"confirm\" in request.POST:\n document.purge()\n return redirect(\n reverse(\"wiki.document\", args=(document_slug,), locale=document_locale)\n )\n else:\n return render(\n request,\n \"wiki/confirm_purge.html\",\n {\"document\": document, \"deletion_log\": deletion_log},\n )\n", "path": "kuma/wiki/views/delete.py"}], "after_files": [{"content": "from django.db import IntegrityError\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import ugettext\nfrom django.views.decorators.cache import never_cache\n\nfrom kuma.core.decorators import (\n block_user_agents,\n ensure_wiki_domain,\n login_required,\n permission_required,\n)\nfrom kuma.core.urlresolvers import reverse\n\nfrom ..decorators import check_readonly, process_document_path\nfrom ..forms import DocumentDeletionForm\nfrom ..models import Document, DocumentDeletionLog, Revision\nfrom ..utils import locale_and_slug_from_path\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@check_readonly\ndef revert_document(request, document_path, revision_id):\n \"\"\"\n Revert document to a specific revision.\n \"\"\"\n document_locale, document_slug, needs_redirect = locale_and_slug_from_path(\n document_path, request\n )\n\n revision = get_object_or_404(\n Revision.objects.select_related(\"document\"),\n pk=revision_id,\n document__slug=document_slug,\n )\n\n if request.method == \"GET\":\n # Render the confirmation page\n return render(\n request,\n \"wiki/confirm_revision_revert.html\",\n {\"revision\": revision, \"document\": revision.document},\n )\n else:\n comment = request.POST.get(\"comment\")\n document = revision.document\n old_revision_pk = revision.pk\n try:\n new_revision = document.revert(revision, request.user, comment)\n # schedule a rendering of the new revision if it really was saved\n if new_revision.pk != old_revision_pk:\n document.schedule_rendering(\"max-age=0\")\n except IntegrityError:\n return render(\n request,\n \"wiki/confirm_revision_revert.html\",\n {\n \"revision\": revision,\n \"document\": revision.document,\n \"error\": ugettext(\n \"Document already exists. Note: You cannot \"\n \"revert a document that has been moved until you \"\n \"delete its redirect.\"\n ),\n },\n )\n return redirect(\"wiki.document_revisions\", revision.document.slug)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.delete_document\")\n@check_readonly\n@process_document_path\ndef delete_document(request, document_slug, document_locale):\n \"\"\"\n Delete a Document.\n \"\"\"\n document = get_object_or_404(Document, locale=document_locale, slug=document_slug)\n\n # HACK: https://bugzil.la/972545 - Don't delete pages that have children\n # TODO: https://bugzil.la/972541 - Deleting a page that has subpages\n prevent = document.children.exists()\n\n first_revision = document.revisions.all()[0]\n\n if request.method == \"POST\":\n form = DocumentDeletionForm(data=request.POST)\n if form.is_valid():\n DocumentDeletionLog.objects.create(\n locale=document.locale,\n slug=document.slug,\n user=request.user,\n reason=form.cleaned_data[\"reason\"],\n )\n document.delete()\n return redirect(document)\n else:\n\n form = DocumentDeletionForm(initial={\"reason\": request.GET.get(\"reason\", \"\")})\n\n context = {\n \"document\": document,\n \"form\": form,\n \"request\": request,\n \"revision\": first_revision,\n \"prevent\": prevent,\n }\n return render(request, \"wiki/confirm_document_delete.html\", context)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.restore_document\")\n@check_readonly\n@process_document_path\ndef restore_document(request, document_slug, document_locale):\n \"\"\"\n Restore a deleted Document.\n \"\"\"\n document = get_object_or_404(\n Document.deleted_objects.all(), slug=document_slug, locale=document_locale\n )\n document.restore()\n return redirect(document)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.purge_document\")\n@check_readonly\n@process_document_path\ndef purge_document(request, document_slug, document_locale):\n \"\"\"\n Permanently purge a deleted Document.\n \"\"\"\n document = get_object_or_404(\n Document.deleted_objects.all(), slug=document_slug, locale=document_locale\n )\n deletion_log_entries = DocumentDeletionLog.objects.filter(\n locale=document_locale, slug=document_slug\n )\n if deletion_log_entries.exists():\n deletion_log = deletion_log_entries.order_by(\"-pk\")[0]\n else:\n deletion_log = {}\n\n if request.method == \"POST\" and \"confirm\" in request.POST:\n document.purge()\n return redirect(\n reverse(\"wiki.document\", args=(document_slug,), locale=document_locale)\n )\n else:\n return render(\n request,\n \"wiki/confirm_purge.html\",\n {\"document\": document, \"deletion_log\": deletion_log},\n )\n", "path": "kuma/wiki/views/delete.py"}]}
| 1,875 | 103 |
gh_patches_debug_24381
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-545
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`pex -c` does not work for multiplatform pexes when the target dist is platform specific
If the console script is housed in a dist that is platform-specific and the pex is multiplatform, then the same script is found more than once and pex creation fails with something like:
```
RuntimeError: Ambiguous script specification pants matches multiple entry points:pants = pants.bin.pants_loader:main pants = pants.bin.pants_loader:main
```
Pex should probably allow dups from a single requirement key if the found scripts are bytewise identical as they are in this example case.
See https://github.com/pantsbuild/pants/pull/6349 for an example of getting bit by this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/finders.py`
Content:
```
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 """The finders we wish we had in setuptools.
5
6 As of setuptools 3.3, the only finder for zip-based distributions is for eggs. The path-based
7 finder only searches paths ending in .egg and not in .whl (zipped or unzipped.)
8
9 pex.finders augments pkg_resources with additional finders to achieve functional
10 parity between wheels and eggs in terms of findability with find_distributions.
11
12 To use:
13 >>> from pex.finders import register_finders
14 >>> register_finders()
15 """
16
17 import os
18 import pkgutil
19 import sys
20 import zipimport
21
22 import pkg_resources
23
24 if sys.version_info >= (3, 3) and sys.implementation.name == "cpython":
25 import importlib.machinery as importlib_machinery
26 else:
27 importlib_machinery = None
28
29
30 class ChainedFinder(object):
31 """A utility to chain together multiple pkg_resources finders."""
32
33 @classmethod
34 def of(cls, *chained_finder_or_finder):
35 finders = []
36 for finder in chained_finder_or_finder:
37 if isinstance(finder, cls):
38 finders.extend(finder.finders)
39 else:
40 finders.append(finder)
41 return cls(finders)
42
43 def __init__(self, finders):
44 self.finders = finders
45
46 def __call__(self, importer, path_item, only=False):
47 for finder in self.finders:
48 for dist in finder(importer, path_item, only=only):
49 yield dist
50
51 def __eq__(self, other):
52 if not isinstance(other, ChainedFinder):
53 return False
54 return self.finders == other.finders
55
56
57 # The following methods are somewhat dangerous as pkg_resources._distribution_finders is not an
58 # exposed API. As it stands, pkg_resources doesn't provide an API to chain multiple distribution
59 # finders together. This is probably possible using importlib but that does us no good as the
60 # importlib machinery supporting this is only available in Python >= 3.1.
61 def _get_finder(importer):
62 if not hasattr(pkg_resources, '_distribution_finders'):
63 return None
64 return pkg_resources._distribution_finders.get(importer)
65
66
67 def _add_finder(importer, finder):
68 """Register a new pkg_resources path finder that does not replace the existing finder."""
69
70 existing_finder = _get_finder(importer)
71
72 if not existing_finder:
73 pkg_resources.register_finder(importer, finder)
74 else:
75 pkg_resources.register_finder(importer, ChainedFinder.of(existing_finder, finder))
76
77
78 def _remove_finder(importer, finder):
79 """Remove an existing finder from pkg_resources."""
80
81 existing_finder = _get_finder(importer)
82
83 if not existing_finder:
84 return
85
86 if isinstance(existing_finder, ChainedFinder):
87 try:
88 existing_finder.finders.remove(finder)
89 except ValueError:
90 return
91 if len(existing_finder.finders) == 1:
92 pkg_resources.register_finder(importer, existing_finder.finders[0])
93 elif len(existing_finder.finders) == 0:
94 pkg_resources.register_finder(importer, pkg_resources.find_nothing)
95 else:
96 pkg_resources.register_finder(importer, pkg_resources.find_nothing)
97
98
99 class WheelMetadata(pkg_resources.EggMetadata):
100 """Metadata provider for zipped wheels."""
101
102 @classmethod
103 def _split_wheelname(cls, wheelname):
104 split_wheelname = wheelname.rsplit('-', 4)
105 assert len(split_wheelname) == 5, 'invalid wheel name: %s' % (wheelname)
106 split_wheelname[0] = split_wheelname[0].replace('-', '_')
107 return '-'.join(split_wheelname[:-3])
108
109 def _setup_prefix(self):
110 path = self.module_path
111 old = None
112 while path != old:
113 if path.lower().endswith('.whl'):
114 self.egg_name = os.path.basename(path)
115 # TODO(wickman) Test the regression where we have both upper and lower cased package
116 # names.
117 self.egg_info = os.path.join(path, '%s.dist-info' % self._split_wheelname(self.egg_name))
118 self.egg_root = path
119 break
120 old = path
121 path, base = os.path.split(path)
122
123
124 # See https://bitbucket.org/tarek/distribute/issue/274
125 class FixedEggMetadata(pkg_resources.EggMetadata):
126 """An EggMetadata provider that has functional parity with the disk-based provider."""
127
128 @classmethod
129 def normalized_elements(cls, path):
130 path_split = path.split('/')
131 while path_split[-1] in ('', '.'):
132 path_split.pop(-1)
133 return path_split
134
135 def _fn(self, base, resource_name):
136 # super() does not work here as EggMetadata is an old-style class.
137 original_fn = pkg_resources.EggMetadata._fn(self, base, resource_name)
138 return '/'.join(self.normalized_elements(original_fn))
139
140 def _zipinfo_name(self, fspath):
141 fspath = self.normalized_elements(fspath)
142 zip_pre = self.normalized_elements(self.zip_pre)
143 if fspath[:len(zip_pre)] == zip_pre:
144 return '/'.join(fspath[len(zip_pre):])
145 assert "%s is not a subpath of %s" % (fspath, self.zip_pre)
146
147
148 def wheel_from_metadata(location, metadata):
149 if not metadata.has_metadata(pkg_resources.DistInfoDistribution.PKG_INFO):
150 return None
151
152 from email.parser import Parser
153 pkg_info = Parser().parsestr(metadata.get_metadata(pkg_resources.DistInfoDistribution.PKG_INFO))
154 return pkg_resources.DistInfoDistribution(
155 location=location,
156 metadata=metadata,
157 # TODO(wickman) Is this necessary or will they get picked up correctly?
158 project_name=pkg_info.get('Name'),
159 version=pkg_info.get('Version'),
160 platform=None)
161
162
163 def find_wheels_on_path(importer, path_item, only=False):
164 if not os.path.isdir(path_item) or not os.access(path_item, os.R_OK):
165 return
166 if not only:
167 for entry in os.listdir(path_item):
168 if entry.lower().endswith('.whl'):
169 for dist in pkg_resources.find_distributions(os.path.join(path_item, entry)):
170 yield dist
171
172
173 def find_eggs_in_zip(importer, path_item, only=False):
174 if importer.archive.endswith('.whl'):
175 # Defer to wheel importer
176 return
177 metadata = FixedEggMetadata(importer)
178 if metadata.has_metadata('PKG-INFO'):
179 yield pkg_resources.Distribution.from_filename(path_item, metadata=metadata)
180 if only:
181 return # don't yield nested distros
182 for subitem in metadata.resource_listdir('/'):
183 if subitem.endswith('.egg'):
184 subpath = os.path.join(path_item, subitem)
185 for dist in find_eggs_in_zip(zipimport.zipimporter(subpath), subpath):
186 yield dist
187
188
189 def find_wheels_in_zip(importer, path_item, only=False):
190 metadata = WheelMetadata(importer)
191 dist = wheel_from_metadata(path_item, metadata)
192 if dist:
193 yield dist
194
195
196 __PREVIOUS_FINDER = None
197
198
199 def register_finders():
200 """Register finders necessary for PEX to function properly."""
201
202 # If the previous finder is set, then we've already monkeypatched, so skip.
203 global __PREVIOUS_FINDER
204 if __PREVIOUS_FINDER:
205 return
206
207 # save previous finder so that it can be restored
208 previous_finder = _get_finder(zipimport.zipimporter)
209 assert previous_finder, 'This appears to be using an incompatible setuptools.'
210
211 # replace the zip finder with our own implementation of find_eggs_in_zip which uses the correct
212 # metadata handler, in addition to find_wheels_in_zip
213 pkg_resources.register_finder(
214 zipimport.zipimporter, ChainedFinder.of(find_eggs_in_zip, find_wheels_in_zip))
215
216 # append the wheel finder
217 _add_finder(pkgutil.ImpImporter, find_wheels_on_path)
218
219 if importlib_machinery is not None:
220 _add_finder(importlib_machinery.FileFinder, find_wheels_on_path)
221
222 __PREVIOUS_FINDER = previous_finder
223
224
225 def unregister_finders():
226 """Unregister finders necessary for PEX to function properly."""
227
228 global __PREVIOUS_FINDER
229 if not __PREVIOUS_FINDER:
230 return
231
232 pkg_resources.register_finder(zipimport.zipimporter, __PREVIOUS_FINDER)
233 _remove_finder(pkgutil.ImpImporter, find_wheels_on_path)
234
235 if importlib_machinery is not None:
236 _remove_finder(importlib_machinery.FileFinder, find_wheels_on_path)
237
238 __PREVIOUS_FINDER = None
239
240
241 def get_script_from_egg(name, dist):
242 """Returns location, content of script in distribution or (None, None) if not there."""
243 if dist.metadata_isdir('scripts') and name in dist.metadata_listdir('scripts'):
244 return (
245 os.path.join(dist.egg_info, 'scripts', name),
246 dist.get_metadata('scripts/%s' % name).replace('\r\n', '\n').replace('\r', '\n'))
247 return None, None
248
249
250 def get_script_from_whl(name, dist):
251 # This can get called in different contexts; in some, it looks for files in the
252 # wheel archives being used to produce a pex; in others, it looks for files in the
253 # install wheel directory included in the pex. So we need to look at both locations.
254 datadir_name = "%s-%s.data" % (dist.project_name, dist.version)
255 wheel_scripts_dirs = ['bin', 'scripts',
256 os.path.join(datadir_name, "bin"),
257 os.path.join(datadir_name, "scripts")]
258 for wheel_scripts_dir in wheel_scripts_dirs:
259 if (dist.resource_isdir(wheel_scripts_dir) and
260 name in dist.resource_listdir(wheel_scripts_dir)):
261 # We always install wheel scripts into bin
262 script_path = os.path.join(wheel_scripts_dir, name)
263 return (
264 os.path.join(dist.egg_info, script_path),
265 dist.get_resource_string('', script_path).replace(b'\r\n', b'\n').replace(b'\r', b'\n'))
266 return None, None
267
268
269 def get_script_from_distribution(name, dist):
270 # PathMetadata: exploded distribution on disk.
271 if isinstance(dist._provider, pkg_resources.PathMetadata):
272 if dist.egg_info.endswith('EGG-INFO'):
273 return get_script_from_egg(name, dist)
274 elif dist.egg_info.endswith('.dist-info'):
275 return get_script_from_whl(name, dist)
276 else:
277 return None, None
278 # FixedEggMetadata: Zipped egg
279 elif isinstance(dist._provider, FixedEggMetadata):
280 return get_script_from_egg(name, dist)
281 # WheelMetadata: Zipped whl (in theory should not experience this at runtime.)
282 elif isinstance(dist._provider, WheelMetadata):
283 return get_script_from_whl(name, dist)
284 return None, None
285
286
287 def get_script_from_distributions(name, dists):
288 for dist in dists:
289 script_path, script_content = get_script_from_distribution(name, dist)
290 if script_path:
291 return dist, script_path, script_content
292 return None, None, None
293
294
295 def get_entry_point_from_console_script(script, dists):
296 # check all distributions for the console_script "script"
297 entries = frozenset(filter(None, (
298 dist.get_entry_map().get('console_scripts', {}).get(script) for dist in dists)))
299
300 # if multiple matches, freak out
301 if len(entries) > 1:
302 raise RuntimeError(
303 'Ambiguous script specification %s matches multiple entry points:%s' % (
304 script, ' '.join(map(str, entries))))
305
306 if entries:
307 entry_point = next(iter(entries))
308 # entry points are of the form 'foo = bar', we just want the 'bar' part:
309 return str(entry_point).split('=')[1].strip()
310
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/finders.py b/pex/finders.py
--- a/pex/finders.py
+++ b/pex/finders.py
@@ -293,17 +293,22 @@
def get_entry_point_from_console_script(script, dists):
- # check all distributions for the console_script "script"
- entries = frozenset(filter(None, (
- dist.get_entry_map().get('console_scripts', {}).get(script) for dist in dists)))
+ # Check all distributions for the console_script "script". De-dup by dist key to allow for a
+ # duplicate console script IFF the distribution is platform-specific and this is a multi-platform
+ # pex.
+ def get_entrypoint(dist):
+ script_entry = dist.get_entry_map().get('console_scripts', {}).get(script)
+ if script_entry is not None:
+ # Entry points are of the form 'foo = bar', we just want the 'bar' part.
+ return dist.key, str(script_entry).split('=')[1].strip()
+
+ entries = frozenset(filter(None, (get_entrypoint(dist) for dist in dists)))
- # if multiple matches, freak out
if len(entries) > 1:
raise RuntimeError(
- 'Ambiguous script specification %s matches multiple entry points:%s' % (
- script, ' '.join(map(str, entries))))
+ 'Ambiguous script specification %s matches multiple entry points:\n\t%s' % (
+ script, '\n\t'.join('%s from %s' % (entry_point, key) for key, entry_point in entries)))
if entries:
- entry_point = next(iter(entries))
- # entry points are of the form 'foo = bar', we just want the 'bar' part:
- return str(entry_point).split('=')[1].strip()
+ _, entry_point = next(iter(entries))
+ return entry_point
|
{"golden_diff": "diff --git a/pex/finders.py b/pex/finders.py\n--- a/pex/finders.py\n+++ b/pex/finders.py\n@@ -293,17 +293,22 @@\n \n \n def get_entry_point_from_console_script(script, dists):\n- # check all distributions for the console_script \"script\"\n- entries = frozenset(filter(None, (\n- dist.get_entry_map().get('console_scripts', {}).get(script) for dist in dists)))\n+ # Check all distributions for the console_script \"script\". De-dup by dist key to allow for a\n+ # duplicate console script IFF the distribution is platform-specific and this is a multi-platform\n+ # pex.\n+ def get_entrypoint(dist):\n+ script_entry = dist.get_entry_map().get('console_scripts', {}).get(script)\n+ if script_entry is not None:\n+ # Entry points are of the form 'foo = bar', we just want the 'bar' part.\n+ return dist.key, str(script_entry).split('=')[1].strip()\n+\n+ entries = frozenset(filter(None, (get_entrypoint(dist) for dist in dists)))\n \n- # if multiple matches, freak out\n if len(entries) > 1:\n raise RuntimeError(\n- 'Ambiguous script specification %s matches multiple entry points:%s' % (\n- script, ' '.join(map(str, entries))))\n+ 'Ambiguous script specification %s matches multiple entry points:\\n\\t%s' % (\n+ script, '\\n\\t'.join('%s from %s' % (entry_point, key) for key, entry_point in entries)))\n \n if entries:\n- entry_point = next(iter(entries))\n- # entry points are of the form 'foo = bar', we just want the 'bar' part:\n- return str(entry_point).split('=')[1].strip()\n+ _, entry_point = next(iter(entries))\n+ return entry_point\n", "issue": "`pex -c` does not work for multiplatform pexes when the target dist is platform specific\nIf the console script is housed in a dist that is platform-specific and the pex is multiplatform, then the same script is found more than once and pex creation fails with something like:\r\n```\r\nRuntimeError: Ambiguous script specification pants matches multiple entry points:pants = pants.bin.pants_loader:main pants = pants.bin.pants_loader:main\r\n```\r\nPex should probably allow dups from a single requirement key if the found scripts are bytewise identical as they are in this example case.\r\n\r\nSee https://github.com/pantsbuild/pants/pull/6349 for an example of getting bit by this.\n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n\"\"\"The finders we wish we had in setuptools.\n\nAs of setuptools 3.3, the only finder for zip-based distributions is for eggs. The path-based\nfinder only searches paths ending in .egg and not in .whl (zipped or unzipped.)\n\npex.finders augments pkg_resources with additional finders to achieve functional\nparity between wheels and eggs in terms of findability with find_distributions.\n\nTo use:\n >>> from pex.finders import register_finders\n >>> register_finders()\n\"\"\"\n\nimport os\nimport pkgutil\nimport sys\nimport zipimport\n\nimport pkg_resources\n\nif sys.version_info >= (3, 3) and sys.implementation.name == \"cpython\":\n import importlib.machinery as importlib_machinery\nelse:\n importlib_machinery = None\n\n\nclass ChainedFinder(object):\n \"\"\"A utility to chain together multiple pkg_resources finders.\"\"\"\n\n @classmethod\n def of(cls, *chained_finder_or_finder):\n finders = []\n for finder in chained_finder_or_finder:\n if isinstance(finder, cls):\n finders.extend(finder.finders)\n else:\n finders.append(finder)\n return cls(finders)\n\n def __init__(self, finders):\n self.finders = finders\n\n def __call__(self, importer, path_item, only=False):\n for finder in self.finders:\n for dist in finder(importer, path_item, only=only):\n yield dist\n\n def __eq__(self, other):\n if not isinstance(other, ChainedFinder):\n return False\n return self.finders == other.finders\n\n\n# The following methods are somewhat dangerous as pkg_resources._distribution_finders is not an\n# exposed API. As it stands, pkg_resources doesn't provide an API to chain multiple distribution\n# finders together. This is probably possible using importlib but that does us no good as the\n# importlib machinery supporting this is only available in Python >= 3.1.\ndef _get_finder(importer):\n if not hasattr(pkg_resources, '_distribution_finders'):\n return None\n return pkg_resources._distribution_finders.get(importer)\n\n\ndef _add_finder(importer, finder):\n \"\"\"Register a new pkg_resources path finder that does not replace the existing finder.\"\"\"\n\n existing_finder = _get_finder(importer)\n\n if not existing_finder:\n pkg_resources.register_finder(importer, finder)\n else:\n pkg_resources.register_finder(importer, ChainedFinder.of(existing_finder, finder))\n\n\ndef _remove_finder(importer, finder):\n \"\"\"Remove an existing finder from pkg_resources.\"\"\"\n\n existing_finder = _get_finder(importer)\n\n if not existing_finder:\n return\n\n if isinstance(existing_finder, ChainedFinder):\n try:\n existing_finder.finders.remove(finder)\n except ValueError:\n return\n if len(existing_finder.finders) == 1:\n pkg_resources.register_finder(importer, existing_finder.finders[0])\n elif len(existing_finder.finders) == 0:\n pkg_resources.register_finder(importer, pkg_resources.find_nothing)\n else:\n pkg_resources.register_finder(importer, pkg_resources.find_nothing)\n\n\nclass WheelMetadata(pkg_resources.EggMetadata):\n \"\"\"Metadata provider for zipped wheels.\"\"\"\n\n @classmethod\n def _split_wheelname(cls, wheelname):\n split_wheelname = wheelname.rsplit('-', 4)\n assert len(split_wheelname) == 5, 'invalid wheel name: %s' % (wheelname)\n split_wheelname[0] = split_wheelname[0].replace('-', '_')\n return '-'.join(split_wheelname[:-3])\n\n def _setup_prefix(self):\n path = self.module_path\n old = None\n while path != old:\n if path.lower().endswith('.whl'):\n self.egg_name = os.path.basename(path)\n # TODO(wickman) Test the regression where we have both upper and lower cased package\n # names.\n self.egg_info = os.path.join(path, '%s.dist-info' % self._split_wheelname(self.egg_name))\n self.egg_root = path\n break\n old = path\n path, base = os.path.split(path)\n\n\n# See https://bitbucket.org/tarek/distribute/issue/274\nclass FixedEggMetadata(pkg_resources.EggMetadata):\n \"\"\"An EggMetadata provider that has functional parity with the disk-based provider.\"\"\"\n\n @classmethod\n def normalized_elements(cls, path):\n path_split = path.split('/')\n while path_split[-1] in ('', '.'):\n path_split.pop(-1)\n return path_split\n\n def _fn(self, base, resource_name):\n # super() does not work here as EggMetadata is an old-style class.\n original_fn = pkg_resources.EggMetadata._fn(self, base, resource_name)\n return '/'.join(self.normalized_elements(original_fn))\n\n def _zipinfo_name(self, fspath):\n fspath = self.normalized_elements(fspath)\n zip_pre = self.normalized_elements(self.zip_pre)\n if fspath[:len(zip_pre)] == zip_pre:\n return '/'.join(fspath[len(zip_pre):])\n assert \"%s is not a subpath of %s\" % (fspath, self.zip_pre)\n\n\ndef wheel_from_metadata(location, metadata):\n if not metadata.has_metadata(pkg_resources.DistInfoDistribution.PKG_INFO):\n return None\n\n from email.parser import Parser\n pkg_info = Parser().parsestr(metadata.get_metadata(pkg_resources.DistInfoDistribution.PKG_INFO))\n return pkg_resources.DistInfoDistribution(\n location=location,\n metadata=metadata,\n # TODO(wickman) Is this necessary or will they get picked up correctly?\n project_name=pkg_info.get('Name'),\n version=pkg_info.get('Version'),\n platform=None)\n\n\ndef find_wheels_on_path(importer, path_item, only=False):\n if not os.path.isdir(path_item) or not os.access(path_item, os.R_OK):\n return\n if not only:\n for entry in os.listdir(path_item):\n if entry.lower().endswith('.whl'):\n for dist in pkg_resources.find_distributions(os.path.join(path_item, entry)):\n yield dist\n\n\ndef find_eggs_in_zip(importer, path_item, only=False):\n if importer.archive.endswith('.whl'):\n # Defer to wheel importer\n return\n metadata = FixedEggMetadata(importer)\n if metadata.has_metadata('PKG-INFO'):\n yield pkg_resources.Distribution.from_filename(path_item, metadata=metadata)\n if only:\n return # don't yield nested distros\n for subitem in metadata.resource_listdir('/'):\n if subitem.endswith('.egg'):\n subpath = os.path.join(path_item, subitem)\n for dist in find_eggs_in_zip(zipimport.zipimporter(subpath), subpath):\n yield dist\n\n\ndef find_wheels_in_zip(importer, path_item, only=False):\n metadata = WheelMetadata(importer)\n dist = wheel_from_metadata(path_item, metadata)\n if dist:\n yield dist\n\n\n__PREVIOUS_FINDER = None\n\n\ndef register_finders():\n \"\"\"Register finders necessary for PEX to function properly.\"\"\"\n\n # If the previous finder is set, then we've already monkeypatched, so skip.\n global __PREVIOUS_FINDER\n if __PREVIOUS_FINDER:\n return\n\n # save previous finder so that it can be restored\n previous_finder = _get_finder(zipimport.zipimporter)\n assert previous_finder, 'This appears to be using an incompatible setuptools.'\n\n # replace the zip finder with our own implementation of find_eggs_in_zip which uses the correct\n # metadata handler, in addition to find_wheels_in_zip\n pkg_resources.register_finder(\n zipimport.zipimporter, ChainedFinder.of(find_eggs_in_zip, find_wheels_in_zip))\n\n # append the wheel finder\n _add_finder(pkgutil.ImpImporter, find_wheels_on_path)\n\n if importlib_machinery is not None:\n _add_finder(importlib_machinery.FileFinder, find_wheels_on_path)\n\n __PREVIOUS_FINDER = previous_finder\n\n\ndef unregister_finders():\n \"\"\"Unregister finders necessary for PEX to function properly.\"\"\"\n\n global __PREVIOUS_FINDER\n if not __PREVIOUS_FINDER:\n return\n\n pkg_resources.register_finder(zipimport.zipimporter, __PREVIOUS_FINDER)\n _remove_finder(pkgutil.ImpImporter, find_wheels_on_path)\n\n if importlib_machinery is not None:\n _remove_finder(importlib_machinery.FileFinder, find_wheels_on_path)\n\n __PREVIOUS_FINDER = None\n\n\ndef get_script_from_egg(name, dist):\n \"\"\"Returns location, content of script in distribution or (None, None) if not there.\"\"\"\n if dist.metadata_isdir('scripts') and name in dist.metadata_listdir('scripts'):\n return (\n os.path.join(dist.egg_info, 'scripts', name),\n dist.get_metadata('scripts/%s' % name).replace('\\r\\n', '\\n').replace('\\r', '\\n'))\n return None, None\n\n\ndef get_script_from_whl(name, dist):\n # This can get called in different contexts; in some, it looks for files in the\n # wheel archives being used to produce a pex; in others, it looks for files in the\n # install wheel directory included in the pex. So we need to look at both locations.\n datadir_name = \"%s-%s.data\" % (dist.project_name, dist.version)\n wheel_scripts_dirs = ['bin', 'scripts',\n os.path.join(datadir_name, \"bin\"),\n os.path.join(datadir_name, \"scripts\")]\n for wheel_scripts_dir in wheel_scripts_dirs:\n if (dist.resource_isdir(wheel_scripts_dir) and\n name in dist.resource_listdir(wheel_scripts_dir)):\n # We always install wheel scripts into bin\n script_path = os.path.join(wheel_scripts_dir, name)\n return (\n os.path.join(dist.egg_info, script_path),\n dist.get_resource_string('', script_path).replace(b'\\r\\n', b'\\n').replace(b'\\r', b'\\n'))\n return None, None\n\n\ndef get_script_from_distribution(name, dist):\n # PathMetadata: exploded distribution on disk.\n if isinstance(dist._provider, pkg_resources.PathMetadata):\n if dist.egg_info.endswith('EGG-INFO'):\n return get_script_from_egg(name, dist)\n elif dist.egg_info.endswith('.dist-info'):\n return get_script_from_whl(name, dist)\n else:\n return None, None\n # FixedEggMetadata: Zipped egg\n elif isinstance(dist._provider, FixedEggMetadata):\n return get_script_from_egg(name, dist)\n # WheelMetadata: Zipped whl (in theory should not experience this at runtime.)\n elif isinstance(dist._provider, WheelMetadata):\n return get_script_from_whl(name, dist)\n return None, None\n\n\ndef get_script_from_distributions(name, dists):\n for dist in dists:\n script_path, script_content = get_script_from_distribution(name, dist)\n if script_path:\n return dist, script_path, script_content\n return None, None, None\n\n\ndef get_entry_point_from_console_script(script, dists):\n # check all distributions for the console_script \"script\"\n entries = frozenset(filter(None, (\n dist.get_entry_map().get('console_scripts', {}).get(script) for dist in dists)))\n\n # if multiple matches, freak out\n if len(entries) > 1:\n raise RuntimeError(\n 'Ambiguous script specification %s matches multiple entry points:%s' % (\n script, ' '.join(map(str, entries))))\n\n if entries:\n entry_point = next(iter(entries))\n # entry points are of the form 'foo = bar', we just want the 'bar' part:\n return str(entry_point).split('=')[1].strip()\n", "path": "pex/finders.py"}], "after_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n\"\"\"The finders we wish we had in setuptools.\n\nAs of setuptools 3.3, the only finder for zip-based distributions is for eggs. The path-based\nfinder only searches paths ending in .egg and not in .whl (zipped or unzipped.)\n\npex.finders augments pkg_resources with additional finders to achieve functional\nparity between wheels and eggs in terms of findability with find_distributions.\n\nTo use:\n >>> from pex.finders import register_finders\n >>> register_finders()\n\"\"\"\n\nimport os\nimport pkgutil\nimport sys\nimport zipimport\n\nimport pkg_resources\n\nif sys.version_info >= (3, 3) and sys.implementation.name == \"cpython\":\n import importlib.machinery as importlib_machinery\nelse:\n importlib_machinery = None\n\n\nclass ChainedFinder(object):\n \"\"\"A utility to chain together multiple pkg_resources finders.\"\"\"\n\n @classmethod\n def of(cls, *chained_finder_or_finder):\n finders = []\n for finder in chained_finder_or_finder:\n if isinstance(finder, cls):\n finders.extend(finder.finders)\n else:\n finders.append(finder)\n return cls(finders)\n\n def __init__(self, finders):\n self.finders = finders\n\n def __call__(self, importer, path_item, only=False):\n for finder in self.finders:\n for dist in finder(importer, path_item, only=only):\n yield dist\n\n def __eq__(self, other):\n if not isinstance(other, ChainedFinder):\n return False\n return self.finders == other.finders\n\n\n# The following methods are somewhat dangerous as pkg_resources._distribution_finders is not an\n# exposed API. As it stands, pkg_resources doesn't provide an API to chain multiple distribution\n# finders together. This is probably possible using importlib but that does us no good as the\n# importlib machinery supporting this is only available in Python >= 3.1.\ndef _get_finder(importer):\n if not hasattr(pkg_resources, '_distribution_finders'):\n return None\n return pkg_resources._distribution_finders.get(importer)\n\n\ndef _add_finder(importer, finder):\n \"\"\"Register a new pkg_resources path finder that does not replace the existing finder.\"\"\"\n\n existing_finder = _get_finder(importer)\n\n if not existing_finder:\n pkg_resources.register_finder(importer, finder)\n else:\n pkg_resources.register_finder(importer, ChainedFinder.of(existing_finder, finder))\n\n\ndef _remove_finder(importer, finder):\n \"\"\"Remove an existing finder from pkg_resources.\"\"\"\n\n existing_finder = _get_finder(importer)\n\n if not existing_finder:\n return\n\n if isinstance(existing_finder, ChainedFinder):\n try:\n existing_finder.finders.remove(finder)\n except ValueError:\n return\n if len(existing_finder.finders) == 1:\n pkg_resources.register_finder(importer, existing_finder.finders[0])\n elif len(existing_finder.finders) == 0:\n pkg_resources.register_finder(importer, pkg_resources.find_nothing)\n else:\n pkg_resources.register_finder(importer, pkg_resources.find_nothing)\n\n\nclass WheelMetadata(pkg_resources.EggMetadata):\n \"\"\"Metadata provider for zipped wheels.\"\"\"\n\n @classmethod\n def _split_wheelname(cls, wheelname):\n split_wheelname = wheelname.rsplit('-', 4)\n assert len(split_wheelname) == 5, 'invalid wheel name: %s' % (wheelname)\n split_wheelname[0] = split_wheelname[0].replace('-', '_')\n return '-'.join(split_wheelname[:-3])\n\n def _setup_prefix(self):\n path = self.module_path\n old = None\n while path != old:\n if path.lower().endswith('.whl'):\n self.egg_name = os.path.basename(path)\n # TODO(wickman) Test the regression where we have both upper and lower cased package\n # names.\n self.egg_info = os.path.join(path, '%s.dist-info' % self._split_wheelname(self.egg_name))\n self.egg_root = path\n break\n old = path\n path, base = os.path.split(path)\n\n\n# See https://bitbucket.org/tarek/distribute/issue/274\nclass FixedEggMetadata(pkg_resources.EggMetadata):\n \"\"\"An EggMetadata provider that has functional parity with the disk-based provider.\"\"\"\n\n @classmethod\n def normalized_elements(cls, path):\n path_split = path.split('/')\n while path_split[-1] in ('', '.'):\n path_split.pop(-1)\n return path_split\n\n def _fn(self, base, resource_name):\n # super() does not work here as EggMetadata is an old-style class.\n original_fn = pkg_resources.EggMetadata._fn(self, base, resource_name)\n return '/'.join(self.normalized_elements(original_fn))\n\n def _zipinfo_name(self, fspath):\n fspath = self.normalized_elements(fspath)\n zip_pre = self.normalized_elements(self.zip_pre)\n if fspath[:len(zip_pre)] == zip_pre:\n return '/'.join(fspath[len(zip_pre):])\n assert \"%s is not a subpath of %s\" % (fspath, self.zip_pre)\n\n\ndef wheel_from_metadata(location, metadata):\n if not metadata.has_metadata(pkg_resources.DistInfoDistribution.PKG_INFO):\n return None\n\n from email.parser import Parser\n pkg_info = Parser().parsestr(metadata.get_metadata(pkg_resources.DistInfoDistribution.PKG_INFO))\n return pkg_resources.DistInfoDistribution(\n location=location,\n metadata=metadata,\n # TODO(wickman) Is this necessary or will they get picked up correctly?\n project_name=pkg_info.get('Name'),\n version=pkg_info.get('Version'),\n platform=None)\n\n\ndef find_wheels_on_path(importer, path_item, only=False):\n if not os.path.isdir(path_item) or not os.access(path_item, os.R_OK):\n return\n if not only:\n for entry in os.listdir(path_item):\n if entry.lower().endswith('.whl'):\n for dist in pkg_resources.find_distributions(os.path.join(path_item, entry)):\n yield dist\n\n\ndef find_eggs_in_zip(importer, path_item, only=False):\n if importer.archive.endswith('.whl'):\n # Defer to wheel importer\n return\n metadata = FixedEggMetadata(importer)\n if metadata.has_metadata('PKG-INFO'):\n yield pkg_resources.Distribution.from_filename(path_item, metadata=metadata)\n if only:\n return # don't yield nested distros\n for subitem in metadata.resource_listdir('/'):\n if subitem.endswith('.egg'):\n subpath = os.path.join(path_item, subitem)\n for dist in find_eggs_in_zip(zipimport.zipimporter(subpath), subpath):\n yield dist\n\n\ndef find_wheels_in_zip(importer, path_item, only=False):\n metadata = WheelMetadata(importer)\n dist = wheel_from_metadata(path_item, metadata)\n if dist:\n yield dist\n\n\n__PREVIOUS_FINDER = None\n\n\ndef register_finders():\n \"\"\"Register finders necessary for PEX to function properly.\"\"\"\n\n # If the previous finder is set, then we've already monkeypatched, so skip.\n global __PREVIOUS_FINDER\n if __PREVIOUS_FINDER:\n return\n\n # save previous finder so that it can be restored\n previous_finder = _get_finder(zipimport.zipimporter)\n assert previous_finder, 'This appears to be using an incompatible setuptools.'\n\n # replace the zip finder with our own implementation of find_eggs_in_zip which uses the correct\n # metadata handler, in addition to find_wheels_in_zip\n pkg_resources.register_finder(\n zipimport.zipimporter, ChainedFinder.of(find_eggs_in_zip, find_wheels_in_zip))\n\n # append the wheel finder\n _add_finder(pkgutil.ImpImporter, find_wheels_on_path)\n\n if importlib_machinery is not None:\n _add_finder(importlib_machinery.FileFinder, find_wheels_on_path)\n\n __PREVIOUS_FINDER = previous_finder\n\n\ndef unregister_finders():\n \"\"\"Unregister finders necessary for PEX to function properly.\"\"\"\n\n global __PREVIOUS_FINDER\n if not __PREVIOUS_FINDER:\n return\n\n pkg_resources.register_finder(zipimport.zipimporter, __PREVIOUS_FINDER)\n _remove_finder(pkgutil.ImpImporter, find_wheels_on_path)\n\n if importlib_machinery is not None:\n _remove_finder(importlib_machinery.FileFinder, find_wheels_on_path)\n\n __PREVIOUS_FINDER = None\n\n\ndef get_script_from_egg(name, dist):\n \"\"\"Returns location, content of script in distribution or (None, None) if not there.\"\"\"\n if dist.metadata_isdir('scripts') and name in dist.metadata_listdir('scripts'):\n return (\n os.path.join(dist.egg_info, 'scripts', name),\n dist.get_metadata('scripts/%s' % name).replace('\\r\\n', '\\n').replace('\\r', '\\n'))\n return None, None\n\n\ndef get_script_from_whl(name, dist):\n # This can get called in different contexts; in some, it looks for files in the\n # wheel archives being used to produce a pex; in others, it looks for files in the\n # install wheel directory included in the pex. So we need to look at both locations.\n datadir_name = \"%s-%s.data\" % (dist.project_name, dist.version)\n wheel_scripts_dirs = ['bin', 'scripts',\n os.path.join(datadir_name, \"bin\"),\n os.path.join(datadir_name, \"scripts\")]\n for wheel_scripts_dir in wheel_scripts_dirs:\n if (dist.resource_isdir(wheel_scripts_dir) and\n name in dist.resource_listdir(wheel_scripts_dir)):\n # We always install wheel scripts into bin\n script_path = os.path.join(wheel_scripts_dir, name)\n return (\n os.path.join(dist.egg_info, script_path),\n dist.get_resource_string('', script_path).replace(b'\\r\\n', b'\\n').replace(b'\\r', b'\\n'))\n return None, None\n\n\ndef get_script_from_distribution(name, dist):\n # PathMetadata: exploded distribution on disk.\n if isinstance(dist._provider, pkg_resources.PathMetadata):\n if dist.egg_info.endswith('EGG-INFO'):\n return get_script_from_egg(name, dist)\n elif dist.egg_info.endswith('.dist-info'):\n return get_script_from_whl(name, dist)\n else:\n return None, None\n # FixedEggMetadata: Zipped egg\n elif isinstance(dist._provider, FixedEggMetadata):\n return get_script_from_egg(name, dist)\n # WheelMetadata: Zipped whl (in theory should not experience this at runtime.)\n elif isinstance(dist._provider, WheelMetadata):\n return get_script_from_whl(name, dist)\n return None, None\n\n\ndef get_script_from_distributions(name, dists):\n for dist in dists:\n script_path, script_content = get_script_from_distribution(name, dist)\n if script_path:\n return dist, script_path, script_content\n return None, None, None\n\n\ndef get_entry_point_from_console_script(script, dists):\n # Check all distributions for the console_script \"script\". De-dup by dist key to allow for a\n # duplicate console script IFF the distribution is platform-specific and this is a multi-platform\n # pex.\n def get_entrypoint(dist):\n script_entry = dist.get_entry_map().get('console_scripts', {}).get(script)\n if script_entry is not None:\n # Entry points are of the form 'foo = bar', we just want the 'bar' part.\n return dist.key, str(script_entry).split('=')[1].strip()\n\n entries = frozenset(filter(None, (get_entrypoint(dist) for dist in dists)))\n\n if len(entries) > 1:\n raise RuntimeError(\n 'Ambiguous script specification %s matches multiple entry points:\\n\\t%s' % (\n script, '\\n\\t'.join('%s from %s' % (entry_point, key) for key, entry_point in entries)))\n\n if entries:\n _, entry_point = next(iter(entries))\n return entry_point\n", "path": "pex/finders.py"}]}
| 3,877 | 427 |
gh_patches_debug_10882
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-6292
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
nonparametric.KDEUnivariate returns zero bandwidth
Hi,
Does anyone have an idea why the following dataset makes KDEUnivariate return zero bandwidth?
```
data = np.array([1,1,1,1,2])
kde_sm = sm.nonparametric.KDEUnivariate(data.astype('double'))
kde_sm.fit(bw="silverman")
sup = kde_sm.support
den = kde_sm.density
print(kde_sm.bw) # prints 0
```
when `data = np.array([1,1,1,2])` the returned bandwidth is correct. When I add more 1s, the bandwidth stays zero.
Thank you!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `statsmodels/nonparametric/bandwidths.py`
Content:
```
1 import numpy as np
2 from scipy.stats import scoreatpercentile as sap
3
4 from statsmodels.compat.pandas import Substitution
5 from statsmodels.sandbox.nonparametric import kernels
6
7 def _select_sigma(X):
8 """
9 Returns the smaller of std(X, ddof=1) or normalized IQR(X) over axis 0.
10
11 References
12 ----------
13 Silverman (1986) p.47
14 """
15 # normalize = norm.ppf(.75) - norm.ppf(.25)
16 normalize = 1.349
17 # IQR = np.subtract.reduce(percentile(X, [75,25],
18 # axis=axis), axis=axis)/normalize
19 IQR = (sap(X, 75) - sap(X, 25))/normalize
20 return np.minimum(np.std(X, axis=0, ddof=1), IQR)
21
22
23 ## Univariate Rule of Thumb Bandwidths ##
24 def bw_scott(x, kernel=None):
25 """
26 Scott's Rule of Thumb
27
28 Parameters
29 ----------
30 x : array_like
31 Array for which to get the bandwidth
32 kernel : CustomKernel object
33 Unused
34
35 Returns
36 -------
37 bw : float
38 The estimate of the bandwidth
39
40 Notes
41 -----
42 Returns 1.059 * A * n ** (-1/5.) where ::
43
44 A = min(std(x, ddof=1), IQR/1.349)
45 IQR = np.subtract.reduce(np.percentile(x, [75,25]))
46
47 References
48 ----------
49
50 Scott, D.W. (1992) Multivariate Density Estimation: Theory, Practice, and
51 Visualization.
52 """
53 A = _select_sigma(x)
54 n = len(x)
55 return 1.059 * A * n ** (-0.2)
56
57 def bw_silverman(x, kernel=None):
58 """
59 Silverman's Rule of Thumb
60
61 Parameters
62 ----------
63 x : array_like
64 Array for which to get the bandwidth
65 kernel : CustomKernel object
66 Unused
67
68 Returns
69 -------
70 bw : float
71 The estimate of the bandwidth
72
73 Notes
74 -----
75 Returns .9 * A * n ** (-1/5.) where ::
76
77 A = min(std(x, ddof=1), IQR/1.349)
78 IQR = np.subtract.reduce(np.percentile(x, [75,25]))
79
80 References
81 ----------
82
83 Silverman, B.W. (1986) `Density Estimation.`
84 """
85 A = _select_sigma(x)
86 n = len(x)
87 return .9 * A * n ** (-0.2)
88
89
90 def bw_normal_reference(x, kernel=kernels.Gaussian):
91 """
92 Plug-in bandwidth with kernel specific constant based on normal reference.
93
94 This bandwidth minimizes the mean integrated square error if the true
95 distribution is the normal. This choice is an appropriate bandwidth for
96 single peaked distributions that are similar to the normal distribution.
97
98 Parameters
99 ----------
100 x : array_like
101 Array for which to get the bandwidth
102 kernel : CustomKernel object
103 Used to calculate the constant for the plug-in bandwidth.
104
105 Returns
106 -------
107 bw : float
108 The estimate of the bandwidth
109
110 Notes
111 -----
112 Returns C * A * n ** (-1/5.) where ::
113
114 A = min(std(x, ddof=1), IQR/1.349)
115 IQR = np.subtract.reduce(np.percentile(x, [75,25]))
116 C = constant from Hansen (2009)
117
118 When using a Gaussian kernel this is equivalent to the 'scott' bandwidth up
119 to two decimal places. This is the accuracy to which the 'scott' constant is
120 specified.
121
122 References
123 ----------
124
125 Silverman, B.W. (1986) `Density Estimation.`
126 Hansen, B.E. (2009) `Lecture Notes on Nonparametrics.`
127 """
128 C = kernel.normal_reference_constant
129 A = _select_sigma(x)
130 n = len(x)
131 return C * A * n ** (-0.2)
132
133 ## Plug-In Methods ##
134
135 ## Least Squares Cross-Validation ##
136
137 ## Helper Functions ##
138
139 bandwidth_funcs = {
140 "scott": bw_scott,
141 "silverman": bw_silverman,
142 "normal_reference": bw_normal_reference,
143 }
144
145
146 @Substitution(", ".join(sorted(bandwidth_funcs.keys())))
147 def select_bandwidth(x, bw, kernel):
148 """
149 Selects bandwidth for a selection rule bw
150
151 this is a wrapper around existing bandwidth selection rules
152
153 Parameters
154 ----------
155 x : array_like
156 Array for which to get the bandwidth
157 bw : str
158 name of bandwidth selection rule, currently supported are:
159 %s
160 kernel : not used yet
161
162 Returns
163 -------
164 bw : float
165 The estimate of the bandwidth
166
167 """
168 bw = bw.lower()
169 if bw not in bandwidth_funcs:
170 raise ValueError("Bandwidth %s not understood" % bw)
171 #TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels
172 # if kernel == "gauss":
173 return bandwidth_funcs[bw](x, kernel)
174 # else:
175 # raise ValueError("Only Gaussian Kernels are currently supported")
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/statsmodels/nonparametric/bandwidths.py b/statsmodels/nonparametric/bandwidths.py
--- a/statsmodels/nonparametric/bandwidths.py
+++ b/statsmodels/nonparametric/bandwidths.py
@@ -168,8 +168,10 @@
bw = bw.lower()
if bw not in bandwidth_funcs:
raise ValueError("Bandwidth %s not understood" % bw)
-#TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels
-# if kernel == "gauss":
- return bandwidth_funcs[bw](x, kernel)
-# else:
-# raise ValueError("Only Gaussian Kernels are currently supported")
+ bandwidth = bandwidth_funcs[bw](x, kernel)
+ if bandwidth == 0:
+ # eventually this can fall back on another selection criterion.
+ err = "Selected KDE bandwidth is 0. Cannot estiamte density."
+ raise RuntimeError(err)
+ else:
+ return bandwidth
|
{"golden_diff": "diff --git a/statsmodels/nonparametric/bandwidths.py b/statsmodels/nonparametric/bandwidths.py\n--- a/statsmodels/nonparametric/bandwidths.py\n+++ b/statsmodels/nonparametric/bandwidths.py\n@@ -168,8 +168,10 @@\n bw = bw.lower()\n if bw not in bandwidth_funcs:\n raise ValueError(\"Bandwidth %s not understood\" % bw)\n-#TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels\n-# if kernel == \"gauss\":\n- return bandwidth_funcs[bw](x, kernel)\n-# else:\n-# raise ValueError(\"Only Gaussian Kernels are currently supported\")\n+ bandwidth = bandwidth_funcs[bw](x, kernel)\n+ if bandwidth == 0:\n+ # eventually this can fall back on another selection criterion.\n+ err = \"Selected KDE bandwidth is 0. Cannot estiamte density.\"\n+ raise RuntimeError(err)\n+ else:\n+ return bandwidth\n", "issue": "nonparametric.KDEUnivariate returns zero bandwidth\nHi,\r\nDoes anyone have an idea why the following dataset makes KDEUnivariate return zero bandwidth?\r\n\r\n```\r\ndata = np.array([1,1,1,1,2])\r\nkde_sm = sm.nonparametric.KDEUnivariate(data.astype('double'))\r\nkde_sm.fit(bw=\"silverman\")\r\nsup = kde_sm.support\r\nden = kde_sm.density\r\nprint(kde_sm.bw) # prints 0\r\n```\r\nwhen `data = np.array([1,1,1,2])` the returned bandwidth is correct. When I add more 1s, the bandwidth stays zero.\r\n\r\nThank you!\n", "before_files": [{"content": "import numpy as np\nfrom scipy.stats import scoreatpercentile as sap\n\nfrom statsmodels.compat.pandas import Substitution\nfrom statsmodels.sandbox.nonparametric import kernels\n\ndef _select_sigma(X):\n \"\"\"\n Returns the smaller of std(X, ddof=1) or normalized IQR(X) over axis 0.\n\n References\n ----------\n Silverman (1986) p.47\n \"\"\"\n# normalize = norm.ppf(.75) - norm.ppf(.25)\n normalize = 1.349\n# IQR = np.subtract.reduce(percentile(X, [75,25],\n# axis=axis), axis=axis)/normalize\n IQR = (sap(X, 75) - sap(X, 25))/normalize\n return np.minimum(np.std(X, axis=0, ddof=1), IQR)\n\n\n## Univariate Rule of Thumb Bandwidths ##\ndef bw_scott(x, kernel=None):\n \"\"\"\n Scott's Rule of Thumb\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Unused\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns 1.059 * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n\n References\n ----------\n\n Scott, D.W. (1992) Multivariate Density Estimation: Theory, Practice, and\n Visualization.\n \"\"\"\n A = _select_sigma(x)\n n = len(x)\n return 1.059 * A * n ** (-0.2)\n\ndef bw_silverman(x, kernel=None):\n \"\"\"\n Silverman's Rule of Thumb\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Unused\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns .9 * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n\n References\n ----------\n\n Silverman, B.W. (1986) `Density Estimation.`\n \"\"\"\n A = _select_sigma(x)\n n = len(x)\n return .9 * A * n ** (-0.2)\n\n\ndef bw_normal_reference(x, kernel=kernels.Gaussian):\n \"\"\"\n Plug-in bandwidth with kernel specific constant based on normal reference.\n\n This bandwidth minimizes the mean integrated square error if the true\n distribution is the normal. This choice is an appropriate bandwidth for\n single peaked distributions that are similar to the normal distribution.\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Used to calculate the constant for the plug-in bandwidth.\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns C * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n C = constant from Hansen (2009)\n\n When using a Gaussian kernel this is equivalent to the 'scott' bandwidth up\n to two decimal places. This is the accuracy to which the 'scott' constant is\n specified.\n\n References\n ----------\n\n Silverman, B.W. (1986) `Density Estimation.`\n Hansen, B.E. (2009) `Lecture Notes on Nonparametrics.`\n \"\"\"\n C = kernel.normal_reference_constant\n A = _select_sigma(x)\n n = len(x)\n return C * A * n ** (-0.2)\n\n## Plug-In Methods ##\n\n## Least Squares Cross-Validation ##\n\n## Helper Functions ##\n\nbandwidth_funcs = {\n \"scott\": bw_scott,\n \"silverman\": bw_silverman,\n \"normal_reference\": bw_normal_reference,\n}\n\n\n@Substitution(\", \".join(sorted(bandwidth_funcs.keys())))\ndef select_bandwidth(x, bw, kernel):\n \"\"\"\n Selects bandwidth for a selection rule bw\n\n this is a wrapper around existing bandwidth selection rules\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n bw : str\n name of bandwidth selection rule, currently supported are:\n %s\n kernel : not used yet\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n \"\"\"\n bw = bw.lower()\n if bw not in bandwidth_funcs:\n raise ValueError(\"Bandwidth %s not understood\" % bw)\n#TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels\n# if kernel == \"gauss\":\n return bandwidth_funcs[bw](x, kernel)\n# else:\n# raise ValueError(\"Only Gaussian Kernels are currently supported\")\n", "path": "statsmodels/nonparametric/bandwidths.py"}], "after_files": [{"content": "import numpy as np\nfrom scipy.stats import scoreatpercentile as sap\n\nfrom statsmodels.compat.pandas import Substitution\nfrom statsmodels.sandbox.nonparametric import kernels\n\ndef _select_sigma(X):\n \"\"\"\n Returns the smaller of std(X, ddof=1) or normalized IQR(X) over axis 0.\n\n References\n ----------\n Silverman (1986) p.47\n \"\"\"\n# normalize = norm.ppf(.75) - norm.ppf(.25)\n normalize = 1.349\n# IQR = np.subtract.reduce(percentile(X, [75,25],\n# axis=axis), axis=axis)/normalize\n IQR = (sap(X, 75) - sap(X, 25))/normalize\n return np.minimum(np.std(X, axis=0, ddof=1), IQR)\n\n\n## Univariate Rule of Thumb Bandwidths ##\ndef bw_scott(x, kernel=None):\n \"\"\"\n Scott's Rule of Thumb\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Unused\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns 1.059 * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n\n References\n ----------\n\n Scott, D.W. (1992) Multivariate Density Estimation: Theory, Practice, and\n Visualization.\n \"\"\"\n A = _select_sigma(x)\n n = len(x)\n return 1.059 * A * n ** (-0.2)\n\ndef bw_silverman(x, kernel=None):\n \"\"\"\n Silverman's Rule of Thumb\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Unused\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns .9 * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n\n References\n ----------\n\n Silverman, B.W. (1986) `Density Estimation.`\n \"\"\"\n A = _select_sigma(x)\n n = len(x)\n return .9 * A * n ** (-0.2)\n\n\ndef bw_normal_reference(x, kernel=kernels.Gaussian):\n \"\"\"\n Plug-in bandwidth with kernel specific constant based on normal reference.\n\n This bandwidth minimizes the mean integrated square error if the true\n distribution is the normal. This choice is an appropriate bandwidth for\n single peaked distributions that are similar to the normal distribution.\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Used to calculate the constant for the plug-in bandwidth.\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns C * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n C = constant from Hansen (2009)\n\n When using a Gaussian kernel this is equivalent to the 'scott' bandwidth up\n to two decimal places. This is the accuracy to which the 'scott' constant is\n specified.\n\n References\n ----------\n\n Silverman, B.W. (1986) `Density Estimation.`\n Hansen, B.E. (2009) `Lecture Notes on Nonparametrics.`\n \"\"\"\n C = kernel.normal_reference_constant\n A = _select_sigma(x)\n n = len(x)\n return C * A * n ** (-0.2)\n\n## Plug-In Methods ##\n\n## Least Squares Cross-Validation ##\n\n## Helper Functions ##\n\nbandwidth_funcs = {\n \"scott\": bw_scott,\n \"silverman\": bw_silverman,\n \"normal_reference\": bw_normal_reference,\n}\n\n\n@Substitution(\", \".join(sorted(bandwidth_funcs.keys())))\ndef select_bandwidth(x, bw, kernel):\n \"\"\"\n Selects bandwidth for a selection rule bw\n\n this is a wrapper around existing bandwidth selection rules\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n bw : str\n name of bandwidth selection rule, currently supported are:\n %s\n kernel : not used yet\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n \"\"\"\n bw = bw.lower()\n if bw not in bandwidth_funcs:\n raise ValueError(\"Bandwidth %s not understood\" % bw)\n bandwidth = bandwidth_funcs[bw](x, kernel)\n if bandwidth == 0:\n # eventually this can fall back on another selection criterion.\n err = \"Selected KDE bandwidth is 0. Cannot estiamte density.\"\n raise RuntimeError(err)\n else:\n return bandwidth\n", "path": "statsmodels/nonparametric/bandwidths.py"}]}
| 2,009 | 223 |
gh_patches_debug_40378
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2117
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The torrentleech plugin is not working with their V5 api
### Expected behaviour:
The first episode of the series is downloaded
### Actual behaviour:
No results are found from the torrentleech search plugin
### Steps to reproduce:
- Step 1: Run flexget with the config supplied in the issue
#### Config:
```
tasks:
test task:
series:
- Rick and Morty:
begin: S02E01
discover:
what:
- next_series_episodes:
backfill: yes
from:
- torrentleech:
rss_key: ***********
username: ***********
password: ***********
download: ~/downloads
schedules:
# Run every 30 minutes
- tasks: '*'
schedule:
minute: "*/20"
```
### Additional information:
This seems to be a result of the upgrade to the Torrentleech V5 api. I modified the plugin to use the V4 api and this is working for now as long as they don't remove support for it. Would it be reasonable to put a PR with a Torrentleech plugin that uses the V4 api until support for the V5 api has been implemented?
- FlexGet version: 2.13.8.dev
- Python version: Python 2.7.14
- Installation method: Latest git version
- Using daemon (yes/no): no
- OS and version: MacOS and Ubuntu Server
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flexget/plugins/sites/torrentleech.py`
Content:
```
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3 from future.moves.urllib.parse import quote
4
5 import re
6 import logging
7
8 from requests.exceptions import RequestException
9
10 from flexget import plugin
11 from flexget.config_schema import one_or_more
12 from flexget.entry import Entry
13 from flexget.event import event
14 from flexget.plugin import PluginError
15 from flexget.plugins.internal.urlrewriting import UrlRewritingError
16 from flexget.utils.soup import get_soup
17 from flexget.utils.search import torrent_availability, normalize_unicode
18 from flexget.utils.tools import parse_filesize
19
20 log = logging.getLogger('torrentleech')
21
22 CATEGORIES = {
23 'all': 0,
24
25 # Movies
26 'Cam': 8,
27 'TS': 9,
28 'R5': 10,
29 'DVDRip': 11,
30 'DVDR': 12,
31 'HD': 13,
32 'BDRip': 14,
33 'Movie Boxsets': 15,
34 'Documentaries': 29,
35
36 # TV
37 'Episodes': 26,
38 'TV Boxsets': 27,
39 'Episodes HD': 32
40 }
41
42
43 class UrlRewriteTorrentleech(object):
44 """
45 Torrentleech urlrewriter and search plugin.
46
47 torrentleech:
48 rss_key: xxxxxxxxx (required)
49 username: xxxxxxxx (required)
50 password: xxxxxxxx (required)
51 category: HD
52
53 Category is any combination of: all, Cam, TS, R5,
54 DVDRip, DVDR, HD, BDRip, Movie Boxsets, Documentaries,
55 Episodes, TV BoxSets, Episodes HD
56 """
57
58 schema = {
59 'type': 'object',
60 'properties': {
61 'rss_key': {'type': 'string'},
62 'username': {'type': 'string'},
63 'password': {'type': 'string'},
64 'category': one_or_more({
65 'oneOf': [
66 {'type': 'integer'},
67 {'type': 'string', 'enum': list(CATEGORIES)},
68 ]
69 }),
70 },
71 'required': ['rss_key', 'username', 'password'],
72 'additionalProperties': False
73 }
74
75 # urlrewriter API
76 def url_rewritable(self, task, entry):
77 url = entry['url']
78 if url.endswith('.torrent'):
79 return False
80 if url.startswith('https://www.torrentleech.org/'):
81 return True
82 return False
83
84 # urlrewriter API
85 def url_rewrite(self, task, entry):
86 if 'url' not in entry:
87 log.error("Didn't actually get a URL...")
88 else:
89 log.debug("Got the URL: %s" % entry['url'])
90 if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):
91 # use search
92 results = self.search(task, entry)
93 if not results:
94 raise UrlRewritingError("No search results found")
95 # TODO: Search doesn't enforce close match to title, be more picky
96 entry['url'] = results[0]['url']
97
98 @plugin.internet(log)
99 def search(self, task, entry, config=None):
100 """
101 Search for name from torrentleech.
102 """
103 rss_key = config['rss_key']
104
105 # build the form request:
106 data = {'username': config['username'], 'password': config['password']}
107 # POST the login form:
108 try:
109 login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)
110 except RequestException as e:
111 raise PluginError('Could not connect to torrentleech: %s', str(e))
112
113 if not isinstance(config, dict):
114 config = {}
115 # sort = SORT.get(config.get('sort_by', 'seeds'))
116 # if config.get('sort_reverse'):
117 # sort += 1
118 categories = config.get('category', 'all')
119 # Make sure categories is a list
120 if not isinstance(categories, list):
121 categories = [categories]
122 # If there are any text categories, turn them into their id number
123 categories = [c if isinstance(c, int) else CATEGORIES[c] for c in categories]
124 filter_url = '/categories/%s' % ','.join(str(c) for c in categories)
125 entries = set()
126 for search_string in entry.get('search_strings', [entry['title']]):
127 query = normalize_unicode(search_string).replace(":", "")
128 # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand
129 url = ('https://www.torrentleech.org/torrents/browse/index/query/' +
130 quote(query.encode('utf-8')) + filter_url)
131 log.debug('Using %s as torrentleech search url' % url)
132
133 page = task.requests.get(url, cookies=login.cookies).content
134 soup = get_soup(page)
135
136 for tr in soup.find_all("tr", ["even", "odd"]):
137 # within each even or odd row, find the torrent names
138 link = tr.find("a", attrs={'href': re.compile('/torrent/\d+')})
139 log.debug('link phase: %s' % link.contents[0])
140 entry = Entry()
141 # extracts the contents of the <a>titlename/<a> tag
142 entry['title'] = link.contents[0]
143
144 # find download link
145 torrent_url = tr.find("a", attrs={'href': re.compile('/download/\d+/.*')}).get('href')
146 # parse link and split along /download/12345 and /name.torrent
147 download_url = re.search('(/download/\d+)/(.+\.torrent)', torrent_url)
148 # change link to rss and splice in rss_key
149 torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \
150 + rss_key + '/' + download_url.group(2)
151 log.debug('RSS-ified download link: %s' % torrent_url)
152 entry['url'] = torrent_url
153
154 # us tr object for seeders/leechers
155 seeders, leechers = tr.find_all('td', ["seeders", "leechers"])
156 entry['torrent_seeds'] = int(seeders.contents[0])
157 entry['torrent_leeches'] = int(leechers.contents[0])
158 entry['search_sort'] = torrent_availability(entry['torrent_seeds'], entry['torrent_leeches'])
159
160 # use tr object for size
161 size = tr.find("td", text=re.compile('([\.\d]+) ([TGMK]?)B')).contents[0]
162 size = re.search('([\.\d]+) ([TGMK]?)B', size)
163
164 entry['content_size'] = parse_filesize(size.group(0))
165
166 entries.add(entry)
167
168 return sorted(entries, reverse=True, key=lambda x: x.get('search_sort'))
169
170
171 @event('plugin.register')
172 def register_plugin():
173 plugin.register(UrlRewriteTorrentleech, 'torrentleech', interfaces=['urlrewriter', 'search'], api_ver=2)
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/flexget/plugins/sites/torrentleech.py b/flexget/plugins/sites/torrentleech.py
--- a/flexget/plugins/sites/torrentleech.py
+++ b/flexget/plugins/sites/torrentleech.py
@@ -77,7 +77,7 @@
url = entry['url']
if url.endswith('.torrent'):
return False
- if url.startswith('https://www.torrentleech.org/'):
+ if url.startswith('https://v4.torrentleech.org/'):
return True
return False
@@ -87,7 +87,7 @@
log.error("Didn't actually get a URL...")
else:
log.debug("Got the URL: %s" % entry['url'])
- if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):
+ if entry['url'].startswith('https://v4.torrentleech.org/torrents/browse/index/query/'):
# use search
results = self.search(task, entry)
if not results:
@@ -106,7 +106,7 @@
data = {'username': config['username'], 'password': config['password']}
# POST the login form:
try:
- login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)
+ login = task.requests.post('https://v4.torrentleech.org/user/account/login/', data=data)
except RequestException as e:
raise PluginError('Could not connect to torrentleech: %s', str(e))
@@ -126,7 +126,7 @@
for search_string in entry.get('search_strings', [entry['title']]):
query = normalize_unicode(search_string).replace(":", "")
# urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand
- url = ('https://www.torrentleech.org/torrents/browse/index/query/' +
+ url = ('https://v4.torrentleech.org/torrents/browse/index/query/' +
quote(query.encode('utf-8')) + filter_url)
log.debug('Using %s as torrentleech search url' % url)
@@ -146,7 +146,7 @@
# parse link and split along /download/12345 and /name.torrent
download_url = re.search('(/download/\d+)/(.+\.torrent)', torrent_url)
# change link to rss and splice in rss_key
- torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \
+ torrent_url = 'https://v4.torrentleech.org/rss' + download_url.group(1) + '/' \
+ rss_key + '/' + download_url.group(2)
log.debug('RSS-ified download link: %s' % torrent_url)
entry['url'] = torrent_url
|
{"golden_diff": "diff --git a/flexget/plugins/sites/torrentleech.py b/flexget/plugins/sites/torrentleech.py\n--- a/flexget/plugins/sites/torrentleech.py\n+++ b/flexget/plugins/sites/torrentleech.py\n@@ -77,7 +77,7 @@\n url = entry['url']\n if url.endswith('.torrent'):\n return False\n- if url.startswith('https://www.torrentleech.org/'):\n+ if url.startswith('https://v4.torrentleech.org/'):\n return True\n return False\n \n@@ -87,7 +87,7 @@\n log.error(\"Didn't actually get a URL...\")\n else:\n log.debug(\"Got the URL: %s\" % entry['url'])\n- if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):\n+ if entry['url'].startswith('https://v4.torrentleech.org/torrents/browse/index/query/'):\n # use search\n results = self.search(task, entry)\n if not results:\n@@ -106,7 +106,7 @@\n data = {'username': config['username'], 'password': config['password']}\n # POST the login form:\n try:\n- login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)\n+ login = task.requests.post('https://v4.torrentleech.org/user/account/login/', data=data)\n except RequestException as e:\n raise PluginError('Could not connect to torrentleech: %s', str(e))\n \n@@ -126,7 +126,7 @@\n for search_string in entry.get('search_strings', [entry['title']]):\n query = normalize_unicode(search_string).replace(\":\", \"\")\n # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand\n- url = ('https://www.torrentleech.org/torrents/browse/index/query/' +\n+ url = ('https://v4.torrentleech.org/torrents/browse/index/query/' +\n quote(query.encode('utf-8')) + filter_url)\n log.debug('Using %s as torrentleech search url' % url)\n \n@@ -146,7 +146,7 @@\n # parse link and split along /download/12345 and /name.torrent\n download_url = re.search('(/download/\\d+)/(.+\\.torrent)', torrent_url)\n # change link to rss and splice in rss_key\n- torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \\\n+ torrent_url = 'https://v4.torrentleech.org/rss' + download_url.group(1) + '/' \\\n + rss_key + '/' + download_url.group(2)\n log.debug('RSS-ified download link: %s' % torrent_url)\n entry['url'] = torrent_url\n", "issue": "The torrentleech plugin is not working with their V5 api \n### Expected behaviour:\r\nThe first episode of the series is downloaded\r\n\r\n### Actual behaviour:\r\nNo results are found from the torrentleech search plugin\r\n\r\n\r\n### Steps to reproduce:\r\n- Step 1: Run flexget with the config supplied in the issue\r\n\r\n#### Config:\r\n```\r\ntasks:\r\n test task:\r\n series:\r\n - Rick and Morty:\r\n begin: S02E01\r\n discover:\r\n what:\r\n - next_series_episodes:\r\n backfill: yes\r\n from:\r\n - torrentleech:\r\n rss_key: ***********\r\n username: ***********\r\n password: ***********\r\n download: ~/downloads\r\n\r\nschedules:\r\n # Run every 30 minutes\r\n - tasks: '*'\r\n schedule:\r\n minute: \"*/20\"\r\n```\r\n \r\n### Additional information:\r\nThis seems to be a result of the upgrade to the Torrentleech V5 api. I modified the plugin to use the V4 api and this is working for now as long as they don't remove support for it. Would it be reasonable to put a PR with a Torrentleech plugin that uses the V4 api until support for the V5 api has been implemented? \r\n\r\n\r\n- FlexGet version: 2.13.8.dev\r\n- Python version: Python 2.7.14\r\n- Installation method: Latest git version\r\n- Using daemon (yes/no): no\r\n- OS and version: MacOS and Ubuntu Server\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\nfrom future.moves.urllib.parse import quote\n\nimport re\nimport logging\n\nfrom requests.exceptions import RequestException\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.entry import Entry\nfrom flexget.event import event\nfrom flexget.plugin import PluginError\nfrom flexget.plugins.internal.urlrewriting import UrlRewritingError\nfrom flexget.utils.soup import get_soup\nfrom flexget.utils.search import torrent_availability, normalize_unicode\nfrom flexget.utils.tools import parse_filesize\n\nlog = logging.getLogger('torrentleech')\n\nCATEGORIES = {\n 'all': 0,\n\n # Movies\n 'Cam': 8,\n 'TS': 9,\n 'R5': 10,\n 'DVDRip': 11,\n 'DVDR': 12,\n 'HD': 13,\n 'BDRip': 14,\n 'Movie Boxsets': 15,\n 'Documentaries': 29,\n\n # TV\n 'Episodes': 26,\n 'TV Boxsets': 27,\n 'Episodes HD': 32\n}\n\n\nclass UrlRewriteTorrentleech(object):\n \"\"\"\n Torrentleech urlrewriter and search plugin.\n\n torrentleech:\n rss_key: xxxxxxxxx (required)\n username: xxxxxxxx (required)\n password: xxxxxxxx (required)\n category: HD\n\n Category is any combination of: all, Cam, TS, R5,\n DVDRip, DVDR, HD, BDRip, Movie Boxsets, Documentaries,\n Episodes, TV BoxSets, Episodes HD\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'rss_key': {'type': 'string'},\n 'username': {'type': 'string'},\n 'password': {'type': 'string'},\n 'category': one_or_more({\n 'oneOf': [\n {'type': 'integer'},\n {'type': 'string', 'enum': list(CATEGORIES)},\n ]\n }),\n },\n 'required': ['rss_key', 'username', 'password'],\n 'additionalProperties': False\n }\n\n # urlrewriter API\n def url_rewritable(self, task, entry):\n url = entry['url']\n if url.endswith('.torrent'):\n return False\n if url.startswith('https://www.torrentleech.org/'):\n return True\n return False\n\n # urlrewriter API\n def url_rewrite(self, task, entry):\n if 'url' not in entry:\n log.error(\"Didn't actually get a URL...\")\n else:\n log.debug(\"Got the URL: %s\" % entry['url'])\n if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):\n # use search\n results = self.search(task, entry)\n if not results:\n raise UrlRewritingError(\"No search results found\")\n # TODO: Search doesn't enforce close match to title, be more picky\n entry['url'] = results[0]['url']\n\n @plugin.internet(log)\n def search(self, task, entry, config=None):\n \"\"\"\n Search for name from torrentleech.\n \"\"\"\n rss_key = config['rss_key']\n\n # build the form request:\n data = {'username': config['username'], 'password': config['password']}\n # POST the login form:\n try:\n login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)\n except RequestException as e:\n raise PluginError('Could not connect to torrentleech: %s', str(e))\n\n if not isinstance(config, dict):\n config = {}\n # sort = SORT.get(config.get('sort_by', 'seeds'))\n # if config.get('sort_reverse'):\n # sort += 1\n categories = config.get('category', 'all')\n # Make sure categories is a list\n if not isinstance(categories, list):\n categories = [categories]\n # If there are any text categories, turn them into their id number\n categories = [c if isinstance(c, int) else CATEGORIES[c] for c in categories]\n filter_url = '/categories/%s' % ','.join(str(c) for c in categories)\n entries = set()\n for search_string in entry.get('search_strings', [entry['title']]):\n query = normalize_unicode(search_string).replace(\":\", \"\")\n # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand\n url = ('https://www.torrentleech.org/torrents/browse/index/query/' +\n quote(query.encode('utf-8')) + filter_url)\n log.debug('Using %s as torrentleech search url' % url)\n\n page = task.requests.get(url, cookies=login.cookies).content\n soup = get_soup(page)\n\n for tr in soup.find_all(\"tr\", [\"even\", \"odd\"]):\n # within each even or odd row, find the torrent names\n link = tr.find(\"a\", attrs={'href': re.compile('/torrent/\\d+')})\n log.debug('link phase: %s' % link.contents[0])\n entry = Entry()\n # extracts the contents of the <a>titlename/<a> tag\n entry['title'] = link.contents[0]\n\n # find download link\n torrent_url = tr.find(\"a\", attrs={'href': re.compile('/download/\\d+/.*')}).get('href')\n # parse link and split along /download/12345 and /name.torrent\n download_url = re.search('(/download/\\d+)/(.+\\.torrent)', torrent_url)\n # change link to rss and splice in rss_key\n torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \\\n + rss_key + '/' + download_url.group(2)\n log.debug('RSS-ified download link: %s' % torrent_url)\n entry['url'] = torrent_url\n\n # us tr object for seeders/leechers\n seeders, leechers = tr.find_all('td', [\"seeders\", \"leechers\"])\n entry['torrent_seeds'] = int(seeders.contents[0])\n entry['torrent_leeches'] = int(leechers.contents[0])\n entry['search_sort'] = torrent_availability(entry['torrent_seeds'], entry['torrent_leeches'])\n\n # use tr object for size\n size = tr.find(\"td\", text=re.compile('([\\.\\d]+) ([TGMK]?)B')).contents[0]\n size = re.search('([\\.\\d]+) ([TGMK]?)B', size)\n\n entry['content_size'] = parse_filesize(size.group(0))\n\n entries.add(entry)\n\n return sorted(entries, reverse=True, key=lambda x: x.get('search_sort'))\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(UrlRewriteTorrentleech, 'torrentleech', interfaces=['urlrewriter', 'search'], api_ver=2)\n", "path": "flexget/plugins/sites/torrentleech.py"}], "after_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\nfrom future.moves.urllib.parse import quote\n\nimport re\nimport logging\n\nfrom requests.exceptions import RequestException\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.entry import Entry\nfrom flexget.event import event\nfrom flexget.plugin import PluginError\nfrom flexget.plugins.internal.urlrewriting import UrlRewritingError\nfrom flexget.utils.soup import get_soup\nfrom flexget.utils.search import torrent_availability, normalize_unicode\nfrom flexget.utils.tools import parse_filesize\n\nlog = logging.getLogger('torrentleech')\n\nCATEGORIES = {\n 'all': 0,\n\n # Movies\n 'Cam': 8,\n 'TS': 9,\n 'R5': 10,\n 'DVDRip': 11,\n 'DVDR': 12,\n 'HD': 13,\n 'BDRip': 14,\n 'Movie Boxsets': 15,\n 'Documentaries': 29,\n\n # TV\n 'Episodes': 26,\n 'TV Boxsets': 27,\n 'Episodes HD': 32\n}\n\n\nclass UrlRewriteTorrentleech(object):\n \"\"\"\n Torrentleech urlrewriter and search plugin.\n\n torrentleech:\n rss_key: xxxxxxxxx (required)\n username: xxxxxxxx (required)\n password: xxxxxxxx (required)\n category: HD\n\n Category is any combination of: all, Cam, TS, R5,\n DVDRip, DVDR, HD, BDRip, Movie Boxsets, Documentaries,\n Episodes, TV BoxSets, Episodes HD\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'rss_key': {'type': 'string'},\n 'username': {'type': 'string'},\n 'password': {'type': 'string'},\n 'category': one_or_more({\n 'oneOf': [\n {'type': 'integer'},\n {'type': 'string', 'enum': list(CATEGORIES)},\n ]\n }),\n },\n 'required': ['rss_key', 'username', 'password'],\n 'additionalProperties': False\n }\n\n # urlrewriter API\n def url_rewritable(self, task, entry):\n url = entry['url']\n if url.endswith('.torrent'):\n return False\n if url.startswith('https://v4.torrentleech.org/'):\n return True\n return False\n\n # urlrewriter API\n def url_rewrite(self, task, entry):\n if 'url' not in entry:\n log.error(\"Didn't actually get a URL...\")\n else:\n log.debug(\"Got the URL: %s\" % entry['url'])\n if entry['url'].startswith('https://v4.torrentleech.org/torrents/browse/index/query/'):\n # use search\n results = self.search(task, entry)\n if not results:\n raise UrlRewritingError(\"No search results found\")\n # TODO: Search doesn't enforce close match to title, be more picky\n entry['url'] = results[0]['url']\n\n @plugin.internet(log)\n def search(self, task, entry, config=None):\n \"\"\"\n Search for name from torrentleech.\n \"\"\"\n rss_key = config['rss_key']\n\n # build the form request:\n data = {'username': config['username'], 'password': config['password']}\n # POST the login form:\n try:\n login = task.requests.post('https://v4.torrentleech.org/user/account/login/', data=data)\n except RequestException as e:\n raise PluginError('Could not connect to torrentleech: %s', str(e))\n\n if not isinstance(config, dict):\n config = {}\n # sort = SORT.get(config.get('sort_by', 'seeds'))\n # if config.get('sort_reverse'):\n # sort += 1\n categories = config.get('category', 'all')\n # Make sure categories is a list\n if not isinstance(categories, list):\n categories = [categories]\n # If there are any text categories, turn them into their id number\n categories = [c if isinstance(c, int) else CATEGORIES[c] for c in categories]\n filter_url = '/categories/%s' % ','.join(str(c) for c in categories)\n entries = set()\n for search_string in entry.get('search_strings', [entry['title']]):\n query = normalize_unicode(search_string).replace(\":\", \"\")\n # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand\n url = ('https://v4.torrentleech.org/torrents/browse/index/query/' +\n quote(query.encode('utf-8')) + filter_url)\n log.debug('Using %s as torrentleech search url' % url)\n\n page = task.requests.get(url, cookies=login.cookies).content\n soup = get_soup(page)\n\n for tr in soup.find_all(\"tr\", [\"even\", \"odd\"]):\n # within each even or odd row, find the torrent names\n link = tr.find(\"a\", attrs={'href': re.compile('/torrent/\\d+')})\n log.debug('link phase: %s' % link.contents[0])\n entry = Entry()\n # extracts the contents of the <a>titlename/<a> tag\n entry['title'] = link.contents[0]\n\n # find download link\n torrent_url = tr.find(\"a\", attrs={'href': re.compile('/download/\\d+/.*')}).get('href')\n # parse link and split along /download/12345 and /name.torrent\n download_url = re.search('(/download/\\d+)/(.+\\.torrent)', torrent_url)\n # change link to rss and splice in rss_key\n torrent_url = 'https://v4.torrentleech.org/rss' + download_url.group(1) + '/' \\\n + rss_key + '/' + download_url.group(2)\n log.debug('RSS-ified download link: %s' % torrent_url)\n entry['url'] = torrent_url\n\n # us tr object for seeders/leechers\n seeders, leechers = tr.find_all('td', [\"seeders\", \"leechers\"])\n entry['torrent_seeds'] = int(seeders.contents[0])\n entry['torrent_leeches'] = int(leechers.contents[0])\n entry['search_sort'] = torrent_availability(entry['torrent_seeds'], entry['torrent_leeches'])\n\n # use tr object for size\n size = tr.find(\"td\", text=re.compile('([\\.\\d]+) ([TGMK]?)B')).contents[0]\n size = re.search('([\\.\\d]+) ([TGMK]?)B', size)\n\n entry['content_size'] = parse_filesize(size.group(0))\n\n entries.add(entry)\n\n return sorted(entries, reverse=True, key=lambda x: x.get('search_sort'))\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(UrlRewriteTorrentleech, 'torrentleech', interfaces=['urlrewriter', 'search'], api_ver=2)\n", "path": "flexget/plugins/sites/torrentleech.py"}]}
| 2,584 | 649 |
gh_patches_debug_30259
|
rasdani/github-patches
|
git_diff
|
apache__airflow-18119
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Exception within LocalTaskJob._run_mini_scheduler_on_child_tasks brakes Sentry Handler
### Apache Airflow version
2.1.3 (latest released)
### Operating System
Debian GNU/Linux 10 (buster)
### Versions of Apache Airflow Providers
```
apache-airflow-providers-amazon @ file:///root/.cache/pypoetry/artifacts/7f/f7/23/fc7fd3543aa486275ef0385c29063ff0dc391b0fc95dc5aa6cab2cf4e5/apache_airflow_providers_amazon-2.2.0-py3-none-any.whl
apache-airflow-providers-celery @ file:///root/.cache/pypoetry/artifacts/14/80/39/0d9d57205da1d24189ac9c18eb3477664ed2c2618c1467c9809b9a2fbf/apache_airflow_providers_celery-2.0.0-py3-none-any.whl
apache-airflow-providers-ftp @ file:///root/.cache/pypoetry/artifacts/a5/13/da/bf14abc40193a1ee1b82bbd800e3ac230427d7684b9d40998ac3684bef/apache_airflow_providers_ftp-2.0.1-py3-none-any.whl
apache-airflow-providers-http @ file:///root/.cache/pypoetry/artifacts/fc/d7/d2/73c89ef847bbae1704fa403d7e92dba1feead757aae141613980db40ff/apache_airflow_providers_http-2.0.0-py3-none-any.whl
apache-airflow-providers-imap @ file:///root/.cache/pypoetry/artifacts/af/5d/de/21c10bfc7ac076a415dcc3fc909317547e77e38c005487552cf40ddd97/apache_airflow_providers_imap-2.0.1-py3-none-any.whl
apache-airflow-providers-postgres @ file:///root/.cache/pypoetry/artifacts/50/27/e0/9b0d8f4c0abf59967bb87a04a93d73896d9a4558994185dd8bc43bb67f/apache_airflow_providers_postgres-2.2.0-py3-none-any.whl
apache-airflow-providers-redis @ file:///root/.cache/pypoetry/artifacts/7d/95/03/5d2a65ace88ae9a9ce9134b927b1e9639c8680c13a31e58425deae55d1/apache_airflow_providers_redis-2.0.1-py3-none-any.whl
apache-airflow-providers-sqlite @ file:///root/.cache/pypoetry/artifacts/ec/e6/a3/e0d81fef662ccf79609e7d2c4e4440839a464771fd2a002d252c9a401d/apache_airflow_providers_sqlite-2.0.1-py3-none-any.whl
```
### Deployment
Other Docker-based deployment
### Deployment details
We are using the Sentry integration
### What happened
An exception within LocalTaskJobs mini scheduler was handled incorrectly by the Sentry integrations 'enrich_errors' method. This is because it assumes its applied to a method of a TypeInstance task
```
TypeError: cannot pickle 'dict_keys' object
File "airflow/sentry.py", line 166, in wrapper
return func(task_instance, *args, **kwargs)
File "airflow/jobs/local_task_job.py", line 241, in _run_mini_scheduler_on_child_tasks
partial_dag = task.dag.partial_subset(
File "airflow/models/dag.py", line 1487, in partial_subset
dag.task_dict = {
File "airflow/models/dag.py", line 1488, in <dictcomp>
t.task_id: copy.deepcopy(t, {id(t.dag): dag}) # type: ignore
File "copy.py", line 153, in deepcopy
y = copier(memo)
File "airflow/models/baseoperator.py", line 970, in __deepcopy__
setattr(result, k, copy.deepcopy(v, memo))
File "copy.py", line 161, in deepcopy
rv = reductor(4)
AttributeError: 'LocalTaskJob' object has no attribute 'task'
File "airflow", line 8, in <module>
sys.exit(main())
File "airflow/__main__.py", line 40, in main
args.func(args)
File "airflow/cli/cli_parser.py", line 48, in command
return func(*args, **kwargs)
File "airflow/utils/cli.py", line 91, in wrapper
return f(*args, **kwargs)
File "airflow/cli/commands/task_command.py", line 238, in task_run
_run_task_by_selected_method(args, dag, ti)
File "airflow/cli/commands/task_command.py", line 64, in _run_task_by_selected_method
_run_task_by_local_task_job(args, ti)
File "airflow/cli/commands/task_command.py", line 121, in _run_task_by_local_task_job
run_job.run()
File "airflow/jobs/base_job.py", line 245, in run
self._execute()
File "airflow/jobs/local_task_job.py", line 128, in _execute
self.handle_task_exit(return_code)
File "airflow/jobs/local_task_job.py", line 166, in handle_task_exit
self._run_mini_scheduler_on_child_tasks()
File "airflow/utils/session.py", line 70, in wrapper
return func(*args, session=session, **kwargs)
File "airflow/sentry.py", line 168, in wrapper
self.add_tagging(task_instance)
File "airflow/sentry.py", line 119, in add_tagging
task = task_instance.task
```
### What you expected to happen
The error to be handled correctly and passed on to Sentry without raising another exception within the error handling system
### How to reproduce
In this case we were trying to backfill task for a DAG that at that point had a compilation error. This is quite an edge case yes :-)
### Anything else
_No response_
### Are you willing to submit PR?
- [X] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/sentry.py`
Content:
```
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18
19 """Sentry Integration"""
20 import logging
21 from functools import wraps
22
23 from airflow.configuration import conf
24 from airflow.utils.session import find_session_idx, provide_session
25 from airflow.utils.state import State
26
27 log = logging.getLogger(__name__)
28
29
30 class DummySentry:
31 """Blank class for Sentry."""
32
33 @classmethod
34 def add_tagging(cls, task_instance):
35 """Blank function for tagging."""
36
37 @classmethod
38 def add_breadcrumbs(cls, task_instance, session=None):
39 """Blank function for breadcrumbs."""
40
41 @classmethod
42 def enrich_errors(cls, run):
43 """Blank function for formatting a TaskInstance._run_raw_task."""
44 return run
45
46 def flush(self):
47 """Blank function for flushing errors."""
48
49
50 Sentry: DummySentry = DummySentry()
51 if conf.getboolean("sentry", 'sentry_on', fallback=False):
52 import sentry_sdk
53
54 # Verify blinker installation
55 from blinker import signal # noqa: F401
56 from sentry_sdk.integrations.flask import FlaskIntegration
57 from sentry_sdk.integrations.logging import ignore_logger
58
59 class ConfiguredSentry(DummySentry):
60 """Configure Sentry SDK."""
61
62 SCOPE_TAGS = frozenset(("task_id", "dag_id", "execution_date", "operator", "try_number"))
63 SCOPE_CRUMBS = frozenset(("task_id", "state", "operator", "duration"))
64
65 UNSUPPORTED_SENTRY_OPTIONS = frozenset(
66 (
67 "integrations",
68 "in_app_include",
69 "in_app_exclude",
70 "ignore_errors",
71 "before_breadcrumb",
72 "before_send",
73 "transport",
74 )
75 )
76
77 def __init__(self):
78 """Initialize the Sentry SDK."""
79 ignore_logger("airflow.task")
80 ignore_logger("airflow.jobs.backfill_job.BackfillJob")
81 executor_name = conf.get("core", "EXECUTOR")
82
83 sentry_flask = FlaskIntegration()
84
85 # LoggingIntegration is set by default.
86 integrations = [sentry_flask]
87
88 if executor_name == "CeleryExecutor":
89 from sentry_sdk.integrations.celery import CeleryIntegration
90
91 sentry_celery = CeleryIntegration()
92 integrations.append(sentry_celery)
93
94 dsn = None
95 sentry_config_opts = conf.getsection("sentry") or {}
96 if sentry_config_opts:
97 sentry_config_opts.pop("sentry_on")
98 old_way_dsn = sentry_config_opts.pop("sentry_dsn", None)
99 new_way_dsn = sentry_config_opts.pop("dsn", None)
100 # supported backward compatibility with old way dsn option
101 dsn = old_way_dsn or new_way_dsn
102
103 unsupported_options = self.UNSUPPORTED_SENTRY_OPTIONS.intersection(sentry_config_opts.keys())
104 if unsupported_options:
105 log.warning(
106 "There are unsupported options in [sentry] section: %s",
107 ", ".join(unsupported_options),
108 )
109
110 if dsn:
111 sentry_sdk.init(dsn=dsn, integrations=integrations, **sentry_config_opts)
112 else:
113 # Setting up Sentry using environment variables.
114 log.debug("Defaulting to SENTRY_DSN in environment.")
115 sentry_sdk.init(integrations=integrations, **sentry_config_opts)
116
117 def add_tagging(self, task_instance):
118 """Function to add tagging for a task_instance."""
119 task = task_instance.task
120
121 with sentry_sdk.configure_scope() as scope:
122 for tag_name in self.SCOPE_TAGS:
123 attribute = getattr(task_instance, tag_name)
124 if tag_name == "operator":
125 attribute = task.__class__.__name__
126 scope.set_tag(tag_name, attribute)
127
128 @provide_session
129 def add_breadcrumbs(self, task_instance, session=None):
130 """Function to add breadcrumbs inside of a task_instance."""
131 if session is None:
132 return
133 dr = task_instance.get_dagrun(session)
134 task_instances = dr.get_task_instances(
135 state={State.SUCCESS, State.FAILED},
136 session=session,
137 )
138
139 for ti in task_instances:
140 data = {}
141 for crumb_tag in self.SCOPE_CRUMBS:
142 data[crumb_tag] = getattr(ti, crumb_tag)
143
144 sentry_sdk.add_breadcrumb(category="completed_tasks", data=data, level="info")
145
146 def enrich_errors(self, func):
147 """Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs."""
148 session_args_idx = find_session_idx(func)
149
150 @wraps(func)
151 def wrapper(task_instance, *args, **kwargs):
152 # Wrapping the _run_raw_task function with push_scope to contain
153 # tags and breadcrumbs to a specific Task Instance
154
155 try:
156 session = kwargs.get('session', args[session_args_idx])
157 except IndexError:
158 session = None
159
160 with sentry_sdk.push_scope():
161 try:
162 return func(task_instance, *args, **kwargs)
163 except Exception as e:
164 self.add_tagging(task_instance)
165 self.add_breadcrumbs(task_instance, session=session)
166 sentry_sdk.capture_exception(e)
167 raise
168
169 return wrapper
170
171 def flush(self):
172 sentry_sdk.flush()
173
174 Sentry = ConfiguredSentry()
175
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/sentry.py b/airflow/sentry.py
--- a/airflow/sentry.py
+++ b/airflow/sentry.py
@@ -144,11 +144,14 @@
sentry_sdk.add_breadcrumb(category="completed_tasks", data=data, level="info")
def enrich_errors(self, func):
- """Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs."""
+ """
+ Wrap TaskInstance._run_raw_task and LocalTaskJob._run_mini_scheduler_on_child_tasks
+ to support task specific tags and breadcrumbs.
+ """
session_args_idx = find_session_idx(func)
@wraps(func)
- def wrapper(task_instance, *args, **kwargs):
+ def wrapper(_self, *args, **kwargs):
# Wrapping the _run_raw_task function with push_scope to contain
# tags and breadcrumbs to a specific Task Instance
@@ -159,8 +162,14 @@
with sentry_sdk.push_scope():
try:
- return func(task_instance, *args, **kwargs)
+ return func(_self, *args, **kwargs)
except Exception as e:
+ # Is a LocalTaskJob get the task instance
+ if hasattr(_self, 'task_instance'):
+ task_instance = _self.task_instance
+ else:
+ task_instance = _self
+
self.add_tagging(task_instance)
self.add_breadcrumbs(task_instance, session=session)
sentry_sdk.capture_exception(e)
|
{"golden_diff": "diff --git a/airflow/sentry.py b/airflow/sentry.py\n--- a/airflow/sentry.py\n+++ b/airflow/sentry.py\n@@ -144,11 +144,14 @@\n sentry_sdk.add_breadcrumb(category=\"completed_tasks\", data=data, level=\"info\")\n \n def enrich_errors(self, func):\n- \"\"\"Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs.\"\"\"\n+ \"\"\"\n+ Wrap TaskInstance._run_raw_task and LocalTaskJob._run_mini_scheduler_on_child_tasks\n+ to support task specific tags and breadcrumbs.\n+ \"\"\"\n session_args_idx = find_session_idx(func)\n \n @wraps(func)\n- def wrapper(task_instance, *args, **kwargs):\n+ def wrapper(_self, *args, **kwargs):\n # Wrapping the _run_raw_task function with push_scope to contain\n # tags and breadcrumbs to a specific Task Instance\n \n@@ -159,8 +162,14 @@\n \n with sentry_sdk.push_scope():\n try:\n- return func(task_instance, *args, **kwargs)\n+ return func(_self, *args, **kwargs)\n except Exception as e:\n+ # Is a LocalTaskJob get the task instance\n+ if hasattr(_self, 'task_instance'):\n+ task_instance = _self.task_instance\n+ else:\n+ task_instance = _self\n+\n self.add_tagging(task_instance)\n self.add_breadcrumbs(task_instance, session=session)\n sentry_sdk.capture_exception(e)\n", "issue": "Exception within LocalTaskJob._run_mini_scheduler_on_child_tasks brakes Sentry Handler\n### Apache Airflow version\r\n\r\n2.1.3 (latest released)\r\n\r\n### Operating System\r\n\r\nDebian GNU/Linux 10 (buster)\r\n\r\n### Versions of Apache Airflow Providers\r\n\r\n```\r\napache-airflow-providers-amazon @ file:///root/.cache/pypoetry/artifacts/7f/f7/23/fc7fd3543aa486275ef0385c29063ff0dc391b0fc95dc5aa6cab2cf4e5/apache_airflow_providers_amazon-2.2.0-py3-none-any.whl\r\napache-airflow-providers-celery @ file:///root/.cache/pypoetry/artifacts/14/80/39/0d9d57205da1d24189ac9c18eb3477664ed2c2618c1467c9809b9a2fbf/apache_airflow_providers_celery-2.0.0-py3-none-any.whl\r\napache-airflow-providers-ftp @ file:///root/.cache/pypoetry/artifacts/a5/13/da/bf14abc40193a1ee1b82bbd800e3ac230427d7684b9d40998ac3684bef/apache_airflow_providers_ftp-2.0.1-py3-none-any.whl\r\napache-airflow-providers-http @ file:///root/.cache/pypoetry/artifacts/fc/d7/d2/73c89ef847bbae1704fa403d7e92dba1feead757aae141613980db40ff/apache_airflow_providers_http-2.0.0-py3-none-any.whl\r\napache-airflow-providers-imap @ file:///root/.cache/pypoetry/artifacts/af/5d/de/21c10bfc7ac076a415dcc3fc909317547e77e38c005487552cf40ddd97/apache_airflow_providers_imap-2.0.1-py3-none-any.whl\r\napache-airflow-providers-postgres @ file:///root/.cache/pypoetry/artifacts/50/27/e0/9b0d8f4c0abf59967bb87a04a93d73896d9a4558994185dd8bc43bb67f/apache_airflow_providers_postgres-2.2.0-py3-none-any.whl\r\napache-airflow-providers-redis @ file:///root/.cache/pypoetry/artifacts/7d/95/03/5d2a65ace88ae9a9ce9134b927b1e9639c8680c13a31e58425deae55d1/apache_airflow_providers_redis-2.0.1-py3-none-any.whl\r\napache-airflow-providers-sqlite @ file:///root/.cache/pypoetry/artifacts/ec/e6/a3/e0d81fef662ccf79609e7d2c4e4440839a464771fd2a002d252c9a401d/apache_airflow_providers_sqlite-2.0.1-py3-none-any.whl\r\n```\r\n\r\n\r\n### Deployment\r\n\r\nOther Docker-based deployment\r\n\r\n### Deployment details\r\n\r\nWe are using the Sentry integration\r\n\r\n### What happened\r\n\r\nAn exception within LocalTaskJobs mini scheduler was handled incorrectly by the Sentry integrations 'enrich_errors' method. This is because it assumes its applied to a method of a TypeInstance task\r\n\r\n```\r\nTypeError: cannot pickle 'dict_keys' object\r\n File \"airflow/sentry.py\", line 166, in wrapper\r\n return func(task_instance, *args, **kwargs)\r\n File \"airflow/jobs/local_task_job.py\", line 241, in _run_mini_scheduler_on_child_tasks\r\n partial_dag = task.dag.partial_subset(\r\n File \"airflow/models/dag.py\", line 1487, in partial_subset\r\n dag.task_dict = {\r\n File \"airflow/models/dag.py\", line 1488, in <dictcomp>\r\n t.task_id: copy.deepcopy(t, {id(t.dag): dag}) # type: ignore\r\n File \"copy.py\", line 153, in deepcopy\r\n y = copier(memo)\r\n File \"airflow/models/baseoperator.py\", line 970, in __deepcopy__\r\n setattr(result, k, copy.deepcopy(v, memo))\r\n File \"copy.py\", line 161, in deepcopy\r\n rv = reductor(4)\r\n\r\nAttributeError: 'LocalTaskJob' object has no attribute 'task'\r\n File \"airflow\", line 8, in <module>\r\n sys.exit(main())\r\n File \"airflow/__main__.py\", line 40, in main\r\n args.func(args)\r\n File \"airflow/cli/cli_parser.py\", line 48, in command\r\n return func(*args, **kwargs)\r\n File \"airflow/utils/cli.py\", line 91, in wrapper\r\n return f(*args, **kwargs)\r\n File \"airflow/cli/commands/task_command.py\", line 238, in task_run\r\n _run_task_by_selected_method(args, dag, ti)\r\n File \"airflow/cli/commands/task_command.py\", line 64, in _run_task_by_selected_method\r\n _run_task_by_local_task_job(args, ti)\r\n File \"airflow/cli/commands/task_command.py\", line 121, in _run_task_by_local_task_job\r\n run_job.run()\r\n File \"airflow/jobs/base_job.py\", line 245, in run\r\n self._execute()\r\n File \"airflow/jobs/local_task_job.py\", line 128, in _execute\r\n self.handle_task_exit(return_code)\r\n File \"airflow/jobs/local_task_job.py\", line 166, in handle_task_exit\r\n self._run_mini_scheduler_on_child_tasks()\r\n File \"airflow/utils/session.py\", line 70, in wrapper\r\n return func(*args, session=session, **kwargs)\r\n File \"airflow/sentry.py\", line 168, in wrapper\r\n self.add_tagging(task_instance)\r\n File \"airflow/sentry.py\", line 119, in add_tagging\r\n task = task_instance.task\r\n```\r\n\r\n### What you expected to happen\r\n\r\nThe error to be handled correctly and passed on to Sentry without raising another exception within the error handling system\r\n\r\n### How to reproduce\r\n\r\nIn this case we were trying to backfill task for a DAG that at that point had a compilation error. This is quite an edge case yes :-)\r\n\r\n### Anything else\r\n\r\n_No response_\r\n\r\n### Are you willing to submit PR?\r\n\r\n- [X] Yes I am willing to submit a PR!\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\r\n\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\n\"\"\"Sentry Integration\"\"\"\nimport logging\nfrom functools import wraps\n\nfrom airflow.configuration import conf\nfrom airflow.utils.session import find_session_idx, provide_session\nfrom airflow.utils.state import State\n\nlog = logging.getLogger(__name__)\n\n\nclass DummySentry:\n \"\"\"Blank class for Sentry.\"\"\"\n\n @classmethod\n def add_tagging(cls, task_instance):\n \"\"\"Blank function for tagging.\"\"\"\n\n @classmethod\n def add_breadcrumbs(cls, task_instance, session=None):\n \"\"\"Blank function for breadcrumbs.\"\"\"\n\n @classmethod\n def enrich_errors(cls, run):\n \"\"\"Blank function for formatting a TaskInstance._run_raw_task.\"\"\"\n return run\n\n def flush(self):\n \"\"\"Blank function for flushing errors.\"\"\"\n\n\nSentry: DummySentry = DummySentry()\nif conf.getboolean(\"sentry\", 'sentry_on', fallback=False):\n import sentry_sdk\n\n # Verify blinker installation\n from blinker import signal # noqa: F401\n from sentry_sdk.integrations.flask import FlaskIntegration\n from sentry_sdk.integrations.logging import ignore_logger\n\n class ConfiguredSentry(DummySentry):\n \"\"\"Configure Sentry SDK.\"\"\"\n\n SCOPE_TAGS = frozenset((\"task_id\", \"dag_id\", \"execution_date\", \"operator\", \"try_number\"))\n SCOPE_CRUMBS = frozenset((\"task_id\", \"state\", \"operator\", \"duration\"))\n\n UNSUPPORTED_SENTRY_OPTIONS = frozenset(\n (\n \"integrations\",\n \"in_app_include\",\n \"in_app_exclude\",\n \"ignore_errors\",\n \"before_breadcrumb\",\n \"before_send\",\n \"transport\",\n )\n )\n\n def __init__(self):\n \"\"\"Initialize the Sentry SDK.\"\"\"\n ignore_logger(\"airflow.task\")\n ignore_logger(\"airflow.jobs.backfill_job.BackfillJob\")\n executor_name = conf.get(\"core\", \"EXECUTOR\")\n\n sentry_flask = FlaskIntegration()\n\n # LoggingIntegration is set by default.\n integrations = [sentry_flask]\n\n if executor_name == \"CeleryExecutor\":\n from sentry_sdk.integrations.celery import CeleryIntegration\n\n sentry_celery = CeleryIntegration()\n integrations.append(sentry_celery)\n\n dsn = None\n sentry_config_opts = conf.getsection(\"sentry\") or {}\n if sentry_config_opts:\n sentry_config_opts.pop(\"sentry_on\")\n old_way_dsn = sentry_config_opts.pop(\"sentry_dsn\", None)\n new_way_dsn = sentry_config_opts.pop(\"dsn\", None)\n # supported backward compatibility with old way dsn option\n dsn = old_way_dsn or new_way_dsn\n\n unsupported_options = self.UNSUPPORTED_SENTRY_OPTIONS.intersection(sentry_config_opts.keys())\n if unsupported_options:\n log.warning(\n \"There are unsupported options in [sentry] section: %s\",\n \", \".join(unsupported_options),\n )\n\n if dsn:\n sentry_sdk.init(dsn=dsn, integrations=integrations, **sentry_config_opts)\n else:\n # Setting up Sentry using environment variables.\n log.debug(\"Defaulting to SENTRY_DSN in environment.\")\n sentry_sdk.init(integrations=integrations, **sentry_config_opts)\n\n def add_tagging(self, task_instance):\n \"\"\"Function to add tagging for a task_instance.\"\"\"\n task = task_instance.task\n\n with sentry_sdk.configure_scope() as scope:\n for tag_name in self.SCOPE_TAGS:\n attribute = getattr(task_instance, tag_name)\n if tag_name == \"operator\":\n attribute = task.__class__.__name__\n scope.set_tag(tag_name, attribute)\n\n @provide_session\n def add_breadcrumbs(self, task_instance, session=None):\n \"\"\"Function to add breadcrumbs inside of a task_instance.\"\"\"\n if session is None:\n return\n dr = task_instance.get_dagrun(session)\n task_instances = dr.get_task_instances(\n state={State.SUCCESS, State.FAILED},\n session=session,\n )\n\n for ti in task_instances:\n data = {}\n for crumb_tag in self.SCOPE_CRUMBS:\n data[crumb_tag] = getattr(ti, crumb_tag)\n\n sentry_sdk.add_breadcrumb(category=\"completed_tasks\", data=data, level=\"info\")\n\n def enrich_errors(self, func):\n \"\"\"Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs.\"\"\"\n session_args_idx = find_session_idx(func)\n\n @wraps(func)\n def wrapper(task_instance, *args, **kwargs):\n # Wrapping the _run_raw_task function with push_scope to contain\n # tags and breadcrumbs to a specific Task Instance\n\n try:\n session = kwargs.get('session', args[session_args_idx])\n except IndexError:\n session = None\n\n with sentry_sdk.push_scope():\n try:\n return func(task_instance, *args, **kwargs)\n except Exception as e:\n self.add_tagging(task_instance)\n self.add_breadcrumbs(task_instance, session=session)\n sentry_sdk.capture_exception(e)\n raise\n\n return wrapper\n\n def flush(self):\n sentry_sdk.flush()\n\n Sentry = ConfiguredSentry()\n", "path": "airflow/sentry.py"}], "after_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\n\"\"\"Sentry Integration\"\"\"\nimport logging\nfrom functools import wraps\n\nfrom airflow.configuration import conf\nfrom airflow.utils.session import find_session_idx, provide_session\nfrom airflow.utils.state import State\n\nlog = logging.getLogger(__name__)\n\n\nclass DummySentry:\n \"\"\"Blank class for Sentry.\"\"\"\n\n @classmethod\n def add_tagging(cls, task_instance):\n \"\"\"Blank function for tagging.\"\"\"\n\n @classmethod\n def add_breadcrumbs(cls, task_instance, session=None):\n \"\"\"Blank function for breadcrumbs.\"\"\"\n\n @classmethod\n def enrich_errors(cls, run):\n \"\"\"Blank function for formatting a TaskInstance._run_raw_task.\"\"\"\n return run\n\n def flush(self):\n \"\"\"Blank function for flushing errors.\"\"\"\n\n\nSentry: DummySentry = DummySentry()\nif conf.getboolean(\"sentry\", 'sentry_on', fallback=False):\n import sentry_sdk\n\n # Verify blinker installation\n from blinker import signal # noqa: F401\n from sentry_sdk.integrations.flask import FlaskIntegration\n from sentry_sdk.integrations.logging import ignore_logger\n\n class ConfiguredSentry(DummySentry):\n \"\"\"Configure Sentry SDK.\"\"\"\n\n SCOPE_TAGS = frozenset((\"task_id\", \"dag_id\", \"execution_date\", \"operator\", \"try_number\"))\n SCOPE_CRUMBS = frozenset((\"task_id\", \"state\", \"operator\", \"duration\"))\n\n UNSUPPORTED_SENTRY_OPTIONS = frozenset(\n (\n \"integrations\",\n \"in_app_include\",\n \"in_app_exclude\",\n \"ignore_errors\",\n \"before_breadcrumb\",\n \"before_send\",\n \"transport\",\n )\n )\n\n def __init__(self):\n \"\"\"Initialize the Sentry SDK.\"\"\"\n ignore_logger(\"airflow.task\")\n ignore_logger(\"airflow.jobs.backfill_job.BackfillJob\")\n executor_name = conf.get(\"core\", \"EXECUTOR\")\n\n sentry_flask = FlaskIntegration()\n\n # LoggingIntegration is set by default.\n integrations = [sentry_flask]\n\n if executor_name == \"CeleryExecutor\":\n from sentry_sdk.integrations.celery import CeleryIntegration\n\n sentry_celery = CeleryIntegration()\n integrations.append(sentry_celery)\n\n dsn = None\n sentry_config_opts = conf.getsection(\"sentry\") or {}\n if sentry_config_opts:\n sentry_config_opts.pop(\"sentry_on\")\n old_way_dsn = sentry_config_opts.pop(\"sentry_dsn\", None)\n new_way_dsn = sentry_config_opts.pop(\"dsn\", None)\n # supported backward compatibility with old way dsn option\n dsn = old_way_dsn or new_way_dsn\n\n unsupported_options = self.UNSUPPORTED_SENTRY_OPTIONS.intersection(sentry_config_opts.keys())\n if unsupported_options:\n log.warning(\n \"There are unsupported options in [sentry] section: %s\",\n \", \".join(unsupported_options),\n )\n\n if dsn:\n sentry_sdk.init(dsn=dsn, integrations=integrations, **sentry_config_opts)\n else:\n # Setting up Sentry using environment variables.\n log.debug(\"Defaulting to SENTRY_DSN in environment.\")\n sentry_sdk.init(integrations=integrations, **sentry_config_opts)\n\n def add_tagging(self, task_instance):\n \"\"\"Function to add tagging for a task_instance.\"\"\"\n task = task_instance.task\n\n with sentry_sdk.configure_scope() as scope:\n for tag_name in self.SCOPE_TAGS:\n attribute = getattr(task_instance, tag_name)\n if tag_name == \"operator\":\n attribute = task.__class__.__name__\n scope.set_tag(tag_name, attribute)\n\n @provide_session\n def add_breadcrumbs(self, task_instance, session=None):\n \"\"\"Function to add breadcrumbs inside of a task_instance.\"\"\"\n if session is None:\n return\n dr = task_instance.get_dagrun(session)\n task_instances = dr.get_task_instances(\n state={State.SUCCESS, State.FAILED},\n session=session,\n )\n\n for ti in task_instances:\n data = {}\n for crumb_tag in self.SCOPE_CRUMBS:\n data[crumb_tag] = getattr(ti, crumb_tag)\n\n sentry_sdk.add_breadcrumb(category=\"completed_tasks\", data=data, level=\"info\")\n\n def enrich_errors(self, func):\n \"\"\"\n Wrap TaskInstance._run_raw_task and LocalTaskJob._run_mini_scheduler_on_child_tasks\n to support task specific tags and breadcrumbs.\n \"\"\"\n session_args_idx = find_session_idx(func)\n\n @wraps(func)\n def wrapper(_self, *args, **kwargs):\n # Wrapping the _run_raw_task function with push_scope to contain\n # tags and breadcrumbs to a specific Task Instance\n\n try:\n session = kwargs.get('session', args[session_args_idx])\n except IndexError:\n session = None\n\n with sentry_sdk.push_scope():\n try:\n return func(_self, *args, **kwargs)\n except Exception as e:\n # Is a LocalTaskJob get the task instance\n if hasattr(_self, 'task_instance'):\n task_instance = _self.task_instance\n else:\n task_instance = _self\n\n self.add_tagging(task_instance)\n self.add_breadcrumbs(task_instance, session=session)\n sentry_sdk.capture_exception(e)\n raise\n\n return wrapper\n\n def flush(self):\n sentry_sdk.flush()\n\n Sentry = ConfiguredSentry()\n", "path": "airflow/sentry.py"}]}
| 3,642 | 338 |
gh_patches_debug_1470
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-2182
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Modelgen SpecifyModel TypeError: apply_along_axis()
@effigies
SpecifyModel rises an error with the new function from
commit cd49748be5d7a8201496548922d85f63bb4034dc
modelgen.py line 399ff
With numpy 1.8.2 I get
TypeError: apply_along_axis() got an unexpected keyword argument 'source'
Interface SpecifyModel failed to run
Joerg
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nipype/info.py`
Content:
```
1 """ This file contains defines parameters for nipy that we use to fill
2 settings in setup.py, the nipy top-level docstring, and for building the
3 docs. In setup.py in particular, we exec this file, so it cannot import nipy
4 """
5 from __future__ import print_function, division, unicode_literals, absolute_import
6
7 import sys
8
9 # nipype version information. An empty version_extra corresponds to a
10 # full release. '.dev' as a version_extra string means this is a development
11 # version
12 # Remove -dev for release
13 __version__ = '1.0.0-dev'
14
15
16 def get_nipype_gitversion():
17 """Nipype version as reported by the last commit in git
18
19 Returns
20 -------
21 None or str
22 Version of Nipype according to git.
23 """
24 import os
25 import subprocess
26 try:
27 import nipype
28 gitpath = os.path.realpath(os.path.join(os.path.dirname(nipype.__file__),
29 os.path.pardir))
30 except:
31 gitpath = os.getcwd()
32 gitpathgit = os.path.join(gitpath, '.git')
33 if not os.path.exists(gitpathgit):
34 return None
35 ver = None
36 try:
37 o, _ = subprocess.Popen('git describe', shell=True, cwd=gitpath,
38 stdout=subprocess.PIPE).communicate()
39 except Exception:
40 pass
41 else:
42 ver = o.decode().strip().split('-')[-1]
43 return ver
44
45 if __version__.endswith('-dev'):
46 gitversion = get_nipype_gitversion()
47 if gitversion:
48 __version__ = '{}+{}'.format(__version__, gitversion)
49
50 CLASSIFIERS = ['Development Status :: 5 - Production/Stable',
51 'Environment :: Console',
52 'Intended Audience :: Science/Research',
53 'License :: OSI Approved :: Apache Software License',
54 'Operating System :: MacOS :: MacOS X',
55 'Operating System :: POSIX :: Linux',
56 'Programming Language :: Python :: 2.7',
57 'Programming Language :: Python :: 3.4',
58 'Programming Language :: Python :: 3.5',
59 'Programming Language :: Python :: 3.6',
60 'Topic :: Scientific/Engineering']
61
62 description = 'Neuroimaging in Python: Pipelines and Interfaces'
63
64 # Note: this long_description is actually a copy/paste from the top-level
65 # README.txt, so that it shows up nicely on PyPI. So please remember to edit
66 # it only in one place and sync it correctly.
67 long_description = """========================================================
68 NIPYPE: Neuroimaging in Python: Pipelines and Interfaces
69 ========================================================
70
71 Current neuroimaging software offer users an incredible opportunity to \
72 analyze data using a variety of different algorithms. However, this has \
73 resulted in a heterogeneous collection of specialized applications \
74 without transparent interoperability or a uniform operating interface.
75
76 *Nipype*, an open-source, community-developed initiative under the \
77 umbrella of NiPy_, is a Python project that provides a uniform interface \
78 to existing neuroimaging software and facilitates interaction between \
79 these packages within a single workflow. Nipype provides an environment \
80 that encourages interactive exploration of algorithms from different \
81 packages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE, \
82 MRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and \
83 between packages, and reduces the learning curve necessary to use different \
84 packages. Nipype is creating a collaborative platform for neuroimaging software \
85 development in a high-level language and addressing limitations of existing \
86 pipeline systems.
87
88 *Nipype* allows you to:
89
90 * easily interact with tools from different software packages
91 * combine processing steps from different software packages
92 * develop new workflows faster by reusing common steps from old ones
93 * process data faster by running it in parallel on many cores/machines
94 * make your research easily reproducible
95 * share your processing workflows with the community
96 """
97
98 # versions
99 NIBABEL_MIN_VERSION = '2.1.0'
100 NETWORKX_MIN_VERSION = '1.9'
101 NUMPY_MIN_VERSION = '1.8.2'
102 SCIPY_MIN_VERSION = '0.14'
103 TRAITS_MIN_VERSION = '4.6'
104 DATEUTIL_MIN_VERSION = '2.2'
105 PYTEST_MIN_VERSION = '3.0'
106 FUTURE_MIN_VERSION = '0.16.0'
107 SIMPLEJSON_MIN_VERSION = '3.8.0'
108 PROV_VERSION = '1.5.0'
109 CLICK_MIN_VERSION = '6.6.0'
110
111 NAME = 'nipype'
112 MAINTAINER = 'nipype developers'
113 MAINTAINER_EMAIL = '[email protected]'
114 DESCRIPTION = description
115 LONG_DESCRIPTION = long_description
116 URL = 'http://nipy.org/nipype'
117 DOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'
118 LICENSE = 'Apache License, 2.0'
119 CLASSIFIERS = CLASSIFIERS
120 AUTHOR = 'nipype developers'
121 AUTHOR_EMAIL = '[email protected]'
122 PLATFORMS = 'OS Independent'
123 MAJOR = __version__.split('.')[0]
124 MINOR = __version__.split('.')[1]
125 MICRO = __version__.replace('-', '.').split('.')[2]
126 ISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3 or
127 'post' in __version__.replace('-', '.').split('.')[-1])
128 VERSION = __version__
129 PROVIDES = ['nipype']
130 REQUIRES = [
131 'nibabel>=%s' % NIBABEL_MIN_VERSION,
132 'networkx>=%s' % NETWORKX_MIN_VERSION,
133 'numpy>=%s' % NUMPY_MIN_VERSION,
134 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,
135 'scipy>=%s' % SCIPY_MIN_VERSION,
136 'traits>=%s' % TRAITS_MIN_VERSION,
137 'future>=%s' % FUTURE_MIN_VERSION,
138 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,
139 'prov==%s' % PROV_VERSION,
140 'click>=%s' % CLICK_MIN_VERSION,
141 'funcsigs',
142 'pytest>=%s' % PYTEST_MIN_VERSION,
143 'mock',
144 'pydotplus',
145 'packaging',
146 ]
147
148 if sys.version_info <= (3, 4):
149 REQUIRES.append('configparser')
150
151 TESTS_REQUIRES = [
152 'pytest-cov',
153 'codecov'
154 ]
155
156 EXTRA_REQUIRES = {
157 'doc': ['Sphinx>=1.4', 'matplotlib', 'pydotplus'],
158 'tests': TESTS_REQUIRES,
159 'nipy': ['nitime', 'nilearn', 'dipy', 'nipy', 'matplotlib'],
160 'profiler': ['psutil'],
161 'duecredit': ['duecredit'],
162 'xvfbwrapper': ['xvfbwrapper'],
163 # 'mesh': ['mayavi'] # Enable when it works
164 }
165
166 # Enable a handle to install all extra dependencies at once
167 EXTRA_REQUIRES['all'] = [val for _, val in list(EXTRA_REQUIRES.items())]
168
169 STATUS = 'stable'
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nipype/info.py b/nipype/info.py
--- a/nipype/info.py
+++ b/nipype/info.py
@@ -98,7 +98,7 @@
# versions
NIBABEL_MIN_VERSION = '2.1.0'
NETWORKX_MIN_VERSION = '1.9'
-NUMPY_MIN_VERSION = '1.8.2'
+NUMPY_MIN_VERSION = '1.9.0'
SCIPY_MIN_VERSION = '0.14'
TRAITS_MIN_VERSION = '4.6'
DATEUTIL_MIN_VERSION = '2.2'
|
{"golden_diff": "diff --git a/nipype/info.py b/nipype/info.py\n--- a/nipype/info.py\n+++ b/nipype/info.py\n@@ -98,7 +98,7 @@\n # versions\n NIBABEL_MIN_VERSION = '2.1.0'\n NETWORKX_MIN_VERSION = '1.9'\n-NUMPY_MIN_VERSION = '1.8.2'\n+NUMPY_MIN_VERSION = '1.9.0'\n SCIPY_MIN_VERSION = '0.14'\n TRAITS_MIN_VERSION = '4.6'\n DATEUTIL_MIN_VERSION = '2.2'\n", "issue": "Modelgen SpecifyModel TypeError: apply_along_axis()\n@effigies \r\nSpecifyModel rises an error with the new function from\r\ncommit cd49748be5d7a8201496548922d85f63bb4034dc\r\n\r\nmodelgen.py line 399ff\r\n\r\nWith numpy 1.8.2 I get\r\nTypeError: apply_along_axis() got an unexpected keyword argument 'source'\r\nInterface SpecifyModel failed to run\r\n\r\nJoerg\r\n\n", "before_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\nfrom __future__ import print_function, division, unicode_literals, absolute_import\n\nimport sys\n\n# nipype version information. An empty version_extra corresponds to a\n# full release. '.dev' as a version_extra string means this is a development\n# version\n# Remove -dev for release\n__version__ = '1.0.0-dev'\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n try:\n import nipype\n gitpath = os.path.realpath(os.path.join(os.path.dirname(nipype.__file__),\n os.path.pardir))\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, '.git')\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen('git describe', shell=True, cwd=gitpath,\n stdout=subprocess.PIPE).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split('-')[-1]\n return ver\n\nif __version__.endswith('-dev'):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = '{}+{}'.format(__version__, gitversion)\n\nCLASSIFIERS = ['Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering']\n\ndescription = 'Neuroimaging in Python: Pipelines and Interfaces'\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to \\\nanalyze data using a variety of different algorithms. However, this has \\\nresulted in a heterogeneous collection of specialized applications \\\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the \\\numbrella of NiPy_, is a Python project that provides a uniform interface \\\nto existing neuroimaging software and facilitates interaction between \\\nthese packages within a single workflow. Nipype provides an environment \\\nthat encourages interactive exploration of algorithms from different \\\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE, \\\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and \\\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging software \\\ndevelopment in a high-level language and addressing limitations of existing \\\npipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = '2.1.0'\nNETWORKX_MIN_VERSION = '1.9'\nNUMPY_MIN_VERSION = '1.8.2'\nSCIPY_MIN_VERSION = '0.14'\nTRAITS_MIN_VERSION = '4.6'\nDATEUTIL_MIN_VERSION = '2.2'\nPYTEST_MIN_VERSION = '3.0'\nFUTURE_MIN_VERSION = '0.16.0'\nSIMPLEJSON_MIN_VERSION = '3.8.0'\nPROV_VERSION = '1.5.0'\nCLICK_MIN_VERSION = '6.6.0'\n\nNAME = 'nipype'\nMAINTAINER = 'nipype developers'\nMAINTAINER_EMAIL = '[email protected]'\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = 'http://nipy.org/nipype'\nDOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'\nLICENSE = 'Apache License, 2.0'\nCLASSIFIERS = CLASSIFIERS\nAUTHOR = 'nipype developers'\nAUTHOR_EMAIL = '[email protected]'\nPLATFORMS = 'OS Independent'\nMAJOR = __version__.split('.')[0]\nMINOR = __version__.split('.')[1]\nMICRO = __version__.replace('-', '.').split('.')[2]\nISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3 or\n 'post' in __version__.replace('-', '.').split('.')[-1])\nVERSION = __version__\nPROVIDES = ['nipype']\nREQUIRES = [\n 'nibabel>=%s' % NIBABEL_MIN_VERSION,\n 'networkx>=%s' % NETWORKX_MIN_VERSION,\n 'numpy>=%s' % NUMPY_MIN_VERSION,\n 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,\n 'scipy>=%s' % SCIPY_MIN_VERSION,\n 'traits>=%s' % TRAITS_MIN_VERSION,\n 'future>=%s' % FUTURE_MIN_VERSION,\n 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,\n 'prov==%s' % PROV_VERSION,\n 'click>=%s' % CLICK_MIN_VERSION,\n 'funcsigs',\n 'pytest>=%s' % PYTEST_MIN_VERSION,\n 'mock',\n 'pydotplus',\n 'packaging',\n]\n\nif sys.version_info <= (3, 4):\n REQUIRES.append('configparser')\n\nTESTS_REQUIRES = [\n 'pytest-cov',\n 'codecov'\n]\n\nEXTRA_REQUIRES = {\n 'doc': ['Sphinx>=1.4', 'matplotlib', 'pydotplus'],\n 'tests': TESTS_REQUIRES,\n 'nipy': ['nitime', 'nilearn', 'dipy', 'nipy', 'matplotlib'],\n 'profiler': ['psutil'],\n 'duecredit': ['duecredit'],\n 'xvfbwrapper': ['xvfbwrapper'],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES['all'] = [val for _, val in list(EXTRA_REQUIRES.items())]\n\nSTATUS = 'stable'\n", "path": "nipype/info.py"}], "after_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\nfrom __future__ import print_function, division, unicode_literals, absolute_import\n\nimport sys\n\n# nipype version information. An empty version_extra corresponds to a\n# full release. '.dev' as a version_extra string means this is a development\n# version\n# Remove -dev for release\n__version__ = '1.0.0-dev'\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n try:\n import nipype\n gitpath = os.path.realpath(os.path.join(os.path.dirname(nipype.__file__),\n os.path.pardir))\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, '.git')\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen('git describe', shell=True, cwd=gitpath,\n stdout=subprocess.PIPE).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split('-')[-1]\n return ver\n\nif __version__.endswith('-dev'):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = '{}+{}'.format(__version__, gitversion)\n\nCLASSIFIERS = ['Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering']\n\ndescription = 'Neuroimaging in Python: Pipelines and Interfaces'\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to \\\nanalyze data using a variety of different algorithms. However, this has \\\nresulted in a heterogeneous collection of specialized applications \\\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the \\\numbrella of NiPy_, is a Python project that provides a uniform interface \\\nto existing neuroimaging software and facilitates interaction between \\\nthese packages within a single workflow. Nipype provides an environment \\\nthat encourages interactive exploration of algorithms from different \\\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE, \\\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and \\\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging software \\\ndevelopment in a high-level language and addressing limitations of existing \\\npipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = '2.1.0'\nNETWORKX_MIN_VERSION = '1.9'\nNUMPY_MIN_VERSION = '1.9.0'\nSCIPY_MIN_VERSION = '0.14'\nTRAITS_MIN_VERSION = '4.6'\nDATEUTIL_MIN_VERSION = '2.2'\nPYTEST_MIN_VERSION = '3.0'\nFUTURE_MIN_VERSION = '0.16.0'\nSIMPLEJSON_MIN_VERSION = '3.8.0'\nPROV_VERSION = '1.5.0'\nCLICK_MIN_VERSION = '6.6.0'\n\nNAME = 'nipype'\nMAINTAINER = 'nipype developers'\nMAINTAINER_EMAIL = '[email protected]'\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = 'http://nipy.org/nipype'\nDOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'\nLICENSE = 'Apache License, 2.0'\nCLASSIFIERS = CLASSIFIERS\nAUTHOR = 'nipype developers'\nAUTHOR_EMAIL = '[email protected]'\nPLATFORMS = 'OS Independent'\nMAJOR = __version__.split('.')[0]\nMINOR = __version__.split('.')[1]\nMICRO = __version__.replace('-', '.').split('.')[2]\nISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3 or\n 'post' in __version__.replace('-', '.').split('.')[-1])\nVERSION = __version__\nPROVIDES = ['nipype']\nREQUIRES = [\n 'nibabel>=%s' % NIBABEL_MIN_VERSION,\n 'networkx>=%s' % NETWORKX_MIN_VERSION,\n 'numpy>=%s' % NUMPY_MIN_VERSION,\n 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,\n 'scipy>=%s' % SCIPY_MIN_VERSION,\n 'traits>=%s' % TRAITS_MIN_VERSION,\n 'future>=%s' % FUTURE_MIN_VERSION,\n 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,\n 'prov==%s' % PROV_VERSION,\n 'click>=%s' % CLICK_MIN_VERSION,\n 'funcsigs',\n 'pytest>=%s' % PYTEST_MIN_VERSION,\n 'mock',\n 'pydotplus',\n 'packaging',\n]\n\nif sys.version_info <= (3, 4):\n REQUIRES.append('configparser')\n\nTESTS_REQUIRES = [\n 'pytest-cov',\n 'codecov'\n]\n\nEXTRA_REQUIRES = {\n 'doc': ['Sphinx>=1.4', 'matplotlib', 'pydotplus'],\n 'tests': TESTS_REQUIRES,\n 'nipy': ['nitime', 'nilearn', 'dipy', 'nipy', 'matplotlib'],\n 'profiler': ['psutil'],\n 'duecredit': ['duecredit'],\n 'xvfbwrapper': ['xvfbwrapper'],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES['all'] = [val for _, val in list(EXTRA_REQUIRES.items())]\n\nSTATUS = 'stable'\n", "path": "nipype/info.py"}]}
| 2,321 | 128 |
gh_patches_debug_2714
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-1397
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Logger not work.
**Describe the bug**
Logger did not work at current master commit (https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18).
**Code snippet**
```python
from sanic import Sanic
from sanic.log import logger
from sanic.response import text
app = Sanic()
@app.listener('before_server_start')
async def setup(app, loop):
logger.info('INFO')
@app.get('/')
async def test(request):
return text('hello world')
if __name__ == '__main__':
app.run()
```
There is no any log/output now.
**Expected behavior**
At `0.8.3` release, it will logging/output some messages like:
```
[2018-11-05 17:34:47 +0800] [12112] [INFO] Goin' Fast @ http://127.0.0.1:8000
[2018-11-05 17:34:47 +0800] [12112] [INFO] INFO
[2018-11-05 17:34:47 +0800] [12112] [INFO] Starting worker [12112]
```
**Environment (please complete the following information):**
- OS: Ubuntu 18.04
- Version: https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18
**Additional context**
It seems that `getLogger()` does not get the correct logger at [line 56](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L56) in `log.py`. The logger is trying to get a logger named `sanic.root`, but it does not exist. Rename the logger `root` at [line 9](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L9) should fix this bug.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sanic/log.py`
Content:
```
1 import logging
2 import sys
3
4
5 LOGGING_CONFIG_DEFAULTS = dict(
6 version=1,
7 disable_existing_loggers=False,
8 loggers={
9 "root": {"level": "INFO", "handlers": ["console"]},
10 "sanic.error": {
11 "level": "INFO",
12 "handlers": ["error_console"],
13 "propagate": True,
14 "qualname": "sanic.error",
15 },
16 "sanic.access": {
17 "level": "INFO",
18 "handlers": ["access_console"],
19 "propagate": True,
20 "qualname": "sanic.access",
21 },
22 },
23 handlers={
24 "console": {
25 "class": "logging.StreamHandler",
26 "formatter": "generic",
27 "stream": sys.stdout,
28 },
29 "error_console": {
30 "class": "logging.StreamHandler",
31 "formatter": "generic",
32 "stream": sys.stderr,
33 },
34 "access_console": {
35 "class": "logging.StreamHandler",
36 "formatter": "access",
37 "stream": sys.stdout,
38 },
39 },
40 formatters={
41 "generic": {
42 "format": "%(asctime)s [%(process)d] [%(levelname)s] %(message)s",
43 "datefmt": "[%Y-%m-%d %H:%M:%S %z]",
44 "class": "logging.Formatter",
45 },
46 "access": {
47 "format": "%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: "
48 + "%(request)s %(message)s %(status)d %(byte)d",
49 "datefmt": "[%Y-%m-%d %H:%M:%S %z]",
50 "class": "logging.Formatter",
51 },
52 },
53 )
54
55
56 logger = logging.getLogger("sanic.root")
57 error_logger = logging.getLogger("sanic.error")
58 access_logger = logging.getLogger("sanic.access")
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sanic/log.py b/sanic/log.py
--- a/sanic/log.py
+++ b/sanic/log.py
@@ -6,7 +6,7 @@
version=1,
disable_existing_loggers=False,
loggers={
- "root": {"level": "INFO", "handlers": ["console"]},
+ "sanic.root": {"level": "INFO", "handlers": ["console"]},
"sanic.error": {
"level": "INFO",
"handlers": ["error_console"],
|
{"golden_diff": "diff --git a/sanic/log.py b/sanic/log.py\n--- a/sanic/log.py\n+++ b/sanic/log.py\n@@ -6,7 +6,7 @@\n version=1,\n disable_existing_loggers=False,\n loggers={\n- \"root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n+ \"sanic.root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n \"sanic.error\": {\n \"level\": \"INFO\",\n \"handlers\": [\"error_console\"],\n", "issue": "Logger not work.\n**Describe the bug**\r\nLogger did not work at current master commit (https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18).\r\n\r\n\r\n**Code snippet**\r\n```python\r\nfrom sanic import Sanic\r\nfrom sanic.log import logger\r\nfrom sanic.response import text\r\n\r\n\r\napp = Sanic()\r\n\r\[email protected]('before_server_start')\r\nasync def setup(app, loop):\r\n logger.info('INFO')\r\n\r\n\r\[email protected]('/')\r\nasync def test(request):\r\n return text('hello world')\r\n\r\n\r\nif __name__ == '__main__':\r\n app.run()\r\n```\r\nThere is no any log/output now.\r\n\r\n\r\n\r\n**Expected behavior**\r\nAt `0.8.3` release, it will logging/output some messages like:\r\n```\r\n[2018-11-05 17:34:47 +0800] [12112] [INFO] Goin' Fast @ http://127.0.0.1:8000\r\n[2018-11-05 17:34:47 +0800] [12112] [INFO] INFO\r\n[2018-11-05 17:34:47 +0800] [12112] [INFO] Starting worker [12112]\r\n```\r\n\r\n\r\n**Environment (please complete the following information):**\r\n - OS: Ubuntu 18.04\r\n - Version: https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18\r\n\r\n\r\n**Additional context**\r\nIt seems that `getLogger()` does not get the correct logger at [line 56](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L56) in `log.py`. The logger is trying to get a logger named `sanic.root`, but it does not exist. Rename the logger `root` at [line 9](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L9) should fix this bug.\r\n\n", "before_files": [{"content": "import logging\nimport sys\n\n\nLOGGING_CONFIG_DEFAULTS = dict(\n version=1,\n disable_existing_loggers=False,\n loggers={\n \"root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n \"sanic.error\": {\n \"level\": \"INFO\",\n \"handlers\": [\"error_console\"],\n \"propagate\": True,\n \"qualname\": \"sanic.error\",\n },\n \"sanic.access\": {\n \"level\": \"INFO\",\n \"handlers\": [\"access_console\"],\n \"propagate\": True,\n \"qualname\": \"sanic.access\",\n },\n },\n handlers={\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"generic\",\n \"stream\": sys.stdout,\n },\n \"error_console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"generic\",\n \"stream\": sys.stderr,\n },\n \"access_console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"access\",\n \"stream\": sys.stdout,\n },\n },\n formatters={\n \"generic\": {\n \"format\": \"%(asctime)s [%(process)d] [%(levelname)s] %(message)s\",\n \"datefmt\": \"[%Y-%m-%d %H:%M:%S %z]\",\n \"class\": \"logging.Formatter\",\n },\n \"access\": {\n \"format\": \"%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: \"\n + \"%(request)s %(message)s %(status)d %(byte)d\",\n \"datefmt\": \"[%Y-%m-%d %H:%M:%S %z]\",\n \"class\": \"logging.Formatter\",\n },\n },\n)\n\n\nlogger = logging.getLogger(\"sanic.root\")\nerror_logger = logging.getLogger(\"sanic.error\")\naccess_logger = logging.getLogger(\"sanic.access\")\n", "path": "sanic/log.py"}], "after_files": [{"content": "import logging\nimport sys\n\n\nLOGGING_CONFIG_DEFAULTS = dict(\n version=1,\n disable_existing_loggers=False,\n loggers={\n \"sanic.root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n \"sanic.error\": {\n \"level\": \"INFO\",\n \"handlers\": [\"error_console\"],\n \"propagate\": True,\n \"qualname\": \"sanic.error\",\n },\n \"sanic.access\": {\n \"level\": \"INFO\",\n \"handlers\": [\"access_console\"],\n \"propagate\": True,\n \"qualname\": \"sanic.access\",\n },\n },\n handlers={\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"generic\",\n \"stream\": sys.stdout,\n },\n \"error_console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"generic\",\n \"stream\": sys.stderr,\n },\n \"access_console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"access\",\n \"stream\": sys.stdout,\n },\n },\n formatters={\n \"generic\": {\n \"format\": \"%(asctime)s [%(process)d] [%(levelname)s] %(message)s\",\n \"datefmt\": \"[%Y-%m-%d %H:%M:%S %z]\",\n \"class\": \"logging.Formatter\",\n },\n \"access\": {\n \"format\": \"%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: \"\n + \"%(request)s %(message)s %(status)d %(byte)d\",\n \"datefmt\": \"[%Y-%m-%d %H:%M:%S %z]\",\n \"class\": \"logging.Formatter\",\n },\n },\n)\n\n\nlogger = logging.getLogger(\"sanic.root\")\nerror_logger = logging.getLogger(\"sanic.error\")\naccess_logger = logging.getLogger(\"sanic.access\")\n", "path": "sanic/log.py"}]}
| 1,273 | 114 |
gh_patches_debug_50906
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-4086
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[APP SUBMITTED]: AttributeError: 'module' object has no attribute 'core'
### INFO
**Python Version**: `2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:53:40) [MSC v.1500 64 bit (AMD64)]`
**Operating System**: `Windows-7-6.1.7601-SP1`
**Locale**: `cp1252`
**Branch**: [master](../tree/master)
**Database**: `44.9`
**Commit**: pymedusa/Medusa@77b20916ab577b82112ebc624f816054788c63f2
**Link to Log**: https://gist.github.com/7f6099e1c66cecd44e069bffee91a3ac
### ERROR
<pre>
2018-04-23 16:08:49 ERROR Thread_18 :: [77b2091] Exception generated: 'module' object has no attribute 'core'
Traceback (most recent call last):
File "C:\Medusa\Medusa\medusa\server\web\core\base.py", line 285, in async_call
result = function(**kwargs)
File "C:\Medusa\Medusa\medusa\server\web\home\handler.py", line 357, in testGrowl
result = notifiers.growl_notifier.test_notify(host, password)
File "C:\Medusa\Medusa\medusa\notifiers\growl.py", line 22, in test_notify
self._sendRegistration(host, password)
File "C:\Medusa\Medusa\medusa\notifiers\growl.py", line 174, in _sendRegistration
register = gntp.core.GNTPRegister()
AttributeError: 'module' object has no attribute 'core'
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/notifiers/growl.py`
Content:
```
1 # coding=utf-8
2
3 from __future__ import print_function
4 from __future__ import unicode_literals
5
6 import logging
7 import socket
8 from builtins import object
9
10 import gntp
11
12 from medusa import app, common
13 from medusa.helper.exceptions import ex
14 from medusa.logger.adapters.style import BraceAdapter
15
16 log = BraceAdapter(logging.getLogger(__name__))
17 log.logger.addHandler(logging.NullHandler())
18
19
20 class Notifier(object):
21 def test_notify(self, host, password):
22 self._sendRegistration(host, password)
23 return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,
24 force=True)
25
26 def notify_snatch(self, ep_name, is_proper):
27 if app.GROWL_NOTIFY_ONSNATCH:
28 self._sendGrowl(
29 common.notifyStrings[
30 (common.NOTIFY_SNATCH, common.NOTIFY_SNATCH_PROPER)[is_proper]
31 ], ep_name)
32
33 def notify_download(self, ep_name):
34 if app.GROWL_NOTIFY_ONDOWNLOAD:
35 self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_name)
36
37 def notify_subtitle_download(self, ep_name, lang):
38 if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:
39 self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_name + ': ' + lang)
40
41 def notify_git_update(self, new_version='??'):
42 update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]
43 title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]
44 self._sendGrowl(title, update_text + new_version)
45
46 def notify_login(self, ipaddress=''):
47 update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]
48 title = common.notifyStrings[common.NOTIFY_LOGIN]
49 self._sendGrowl(title, update_text.format(ipaddress))
50
51 def _send_growl(self, options, message=None):
52
53 # Initialize Notification
54 notice = gntp.core.GNTPNotice(
55 app=options['app'],
56 name=options['name'],
57 title=options['title'],
58 password=options['password'],
59 )
60
61 # Optional
62 if options['sticky']:
63 notice.add_header('Notification-Sticky', options['sticky'])
64 if options['priority']:
65 notice.add_header('Notification-Priority', options['priority'])
66 if options['icon']:
67 notice.add_header('Notification-Icon', app.LOGO_URL)
68
69 if message:
70 notice.add_header('Notification-Text', message)
71
72 response = self._send(options['host'], options['port'], notice.encode(), options['debug'])
73 return True if isinstance(response, gntp.core.GNTPOK) else False
74
75 @staticmethod
76 def _send(host, port, data, debug=False):
77 if debug:
78 print('<Sending>\n', data, '\n</Sending>')
79
80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
81 s.connect((host, port))
82 s.send(data)
83 response = gntp.core.parse_gntp(s.recv(1024))
84 s.close()
85
86 if debug:
87 print('<Received>\n', response, '\n</Received>')
88
89 return response
90
91 def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,
92 force=False):
93 if not app.USE_GROWL and not force:
94 return False
95
96 if name is None:
97 name = title
98
99 if host is None:
100 hostParts = app.GROWL_HOST.split(':')
101 else:
102 hostParts = host.split(':')
103
104 if len(hostParts) != 2 or hostParts[1] == '':
105 port = 23053
106 else:
107 port = int(hostParts[1])
108
109 growlHosts = [(hostParts[0], port)]
110
111 opts = {
112 'name': name,
113 'title': title,
114 'app': 'Medusa',
115 'sticky': None,
116 'priority': None,
117 'debug': False
118 }
119
120 if password is None:
121 opts['password'] = app.GROWL_PASSWORD
122 else:
123 opts['password'] = password
124
125 opts['icon'] = True
126
127 for pc in growlHosts:
128 opts['host'] = pc[0]
129 opts['port'] = pc[1]
130 log.debug(
131 u'GROWL: Sending growl to {host}:{port} - {msg!r}',
132 {'msg': message, 'host': opts['host'], 'port': opts['port']}
133 )
134 try:
135 if self._send_growl(opts, message):
136 return True
137 else:
138 if self._sendRegistration(host, password):
139 return self._send_growl(opts, message)
140 else:
141 return False
142 except Exception as error:
143 log.warning(
144 u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
145 {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}
146 )
147 return False
148
149 def _sendRegistration(self, host=None, password=None):
150 opts = {}
151
152 if host is None:
153 hostParts = app.GROWL_HOST.split(':')
154 else:
155 hostParts = host.split(':')
156
157 if len(hostParts) != 2 or hostParts[1] == '':
158 port = 23053
159 else:
160 port = int(hostParts[1])
161
162 opts['host'] = hostParts[0]
163 opts['port'] = port
164
165 if password is None:
166 opts['password'] = app.GROWL_PASSWORD
167 else:
168 opts['password'] = password
169
170 opts['app'] = 'Medusa'
171 opts['debug'] = False
172
173 # Send Registration
174 register = gntp.core.GNTPRegister()
175 register.add_header('Application-Name', opts['app'])
176 register.add_header('Application-Icon', app.LOGO_URL)
177
178 register.add_notification('Test', True)
179 register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)
180 register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)
181 register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)
182
183 if opts['password']:
184 register.set_password(opts['password'])
185
186 try:
187 return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])
188 except Exception as error:
189 log.warning(
190 u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
191 {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}
192 )
193 return False
194
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/notifiers/growl.py b/medusa/notifiers/growl.py
--- a/medusa/notifiers/growl.py
+++ b/medusa/notifiers/growl.py
@@ -7,7 +7,7 @@
import socket
from builtins import object
-import gntp
+import gntp.core
from medusa import app, common
from medusa.helper.exceptions import ex
|
{"golden_diff": "diff --git a/medusa/notifiers/growl.py b/medusa/notifiers/growl.py\n--- a/medusa/notifiers/growl.py\n+++ b/medusa/notifiers/growl.py\n@@ -7,7 +7,7 @@\n import socket\n from builtins import object\n \n-import gntp\n+import gntp.core\n \n from medusa import app, common\n from medusa.helper.exceptions import ex\n", "issue": "[APP SUBMITTED]: AttributeError: 'module' object has no attribute 'core'\n\n### INFO\n**Python Version**: `2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:53:40) [MSC v.1500 64 bit (AMD64)]`\n**Operating System**: `Windows-7-6.1.7601-SP1`\n**Locale**: `cp1252`\n**Branch**: [master](../tree/master)\n**Database**: `44.9`\n**Commit**: pymedusa/Medusa@77b20916ab577b82112ebc624f816054788c63f2\n**Link to Log**: https://gist.github.com/7f6099e1c66cecd44e069bffee91a3ac\n### ERROR\n<pre>\n2018-04-23 16:08:49 ERROR Thread_18 :: [77b2091] Exception generated: 'module' object has no attribute 'core'\nTraceback (most recent call last):\n File \"C:\\Medusa\\Medusa\\medusa\\server\\web\\core\\base.py\", line 285, in async_call\n result = function(**kwargs)\n File \"C:\\Medusa\\Medusa\\medusa\\server\\web\\home\\handler.py\", line 357, in testGrowl\n result = notifiers.growl_notifier.test_notify(host, password)\n File \"C:\\Medusa\\Medusa\\medusa\\notifiers\\growl.py\", line 22, in test_notify\n self._sendRegistration(host, password)\n File \"C:\\Medusa\\Medusa\\medusa\\notifiers\\growl.py\", line 174, in _sendRegistration\n register = gntp.core.GNTPRegister()\nAttributeError: 'module' object has no attribute 'core'\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n\n", "before_files": [{"content": "# coding=utf-8\n\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport socket\nfrom builtins import object\n\nimport gntp\n\nfrom medusa import app, common\nfrom medusa.helper.exceptions import ex\nfrom medusa.logger.adapters.style import BraceAdapter\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n def test_notify(self, host, password):\n self._sendRegistration(host, password)\n return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,\n force=True)\n\n def notify_snatch(self, ep_name, is_proper):\n if app.GROWL_NOTIFY_ONSNATCH:\n self._sendGrowl(\n common.notifyStrings[\n (common.NOTIFY_SNATCH, common.NOTIFY_SNATCH_PROPER)[is_proper]\n ], ep_name)\n\n def notify_download(self, ep_name):\n if app.GROWL_NOTIFY_ONDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_name)\n\n def notify_subtitle_download(self, ep_name, lang):\n if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_name + ': ' + lang)\n\n def notify_git_update(self, new_version='??'):\n update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]\n title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]\n self._sendGrowl(title, update_text + new_version)\n\n def notify_login(self, ipaddress=''):\n update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]\n title = common.notifyStrings[common.NOTIFY_LOGIN]\n self._sendGrowl(title, update_text.format(ipaddress))\n\n def _send_growl(self, options, message=None):\n\n # Initialize Notification\n notice = gntp.core.GNTPNotice(\n app=options['app'],\n name=options['name'],\n title=options['title'],\n password=options['password'],\n )\n\n # Optional\n if options['sticky']:\n notice.add_header('Notification-Sticky', options['sticky'])\n if options['priority']:\n notice.add_header('Notification-Priority', options['priority'])\n if options['icon']:\n notice.add_header('Notification-Icon', app.LOGO_URL)\n\n if message:\n notice.add_header('Notification-Text', message)\n\n response = self._send(options['host'], options['port'], notice.encode(), options['debug'])\n return True if isinstance(response, gntp.core.GNTPOK) else False\n\n @staticmethod\n def _send(host, port, data, debug=False):\n if debug:\n print('<Sending>\\n', data, '\\n</Sending>')\n\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n s.connect((host, port))\n s.send(data)\n response = gntp.core.parse_gntp(s.recv(1024))\n s.close()\n\n if debug:\n print('<Received>\\n', response, '\\n</Received>')\n\n return response\n\n def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,\n force=False):\n if not app.USE_GROWL and not force:\n return False\n\n if name is None:\n name = title\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n growlHosts = [(hostParts[0], port)]\n\n opts = {\n 'name': name,\n 'title': title,\n 'app': 'Medusa',\n 'sticky': None,\n 'priority': None,\n 'debug': False\n }\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['icon'] = True\n\n for pc in growlHosts:\n opts['host'] = pc[0]\n opts['port'] = pc[1]\n log.debug(\n u'GROWL: Sending growl to {host}:{port} - {msg!r}',\n {'msg': message, 'host': opts['host'], 'port': opts['port']}\n )\n try:\n if self._send_growl(opts, message):\n return True\n else:\n if self._sendRegistration(host, password):\n return self._send_growl(opts, message)\n else:\n return False\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n\n def _sendRegistration(self, host=None, password=None):\n opts = {}\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n opts['host'] = hostParts[0]\n opts['port'] = port\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['app'] = 'Medusa'\n opts['debug'] = False\n\n # Send Registration\n register = gntp.core.GNTPRegister()\n register.add_header('Application-Name', opts['app'])\n register.add_header('Application-Icon', app.LOGO_URL)\n\n register.add_notification('Test', True)\n register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)\n\n if opts['password']:\n register.set_password(opts['password'])\n\n try:\n return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n", "path": "medusa/notifiers/growl.py"}], "after_files": [{"content": "# coding=utf-8\n\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport socket\nfrom builtins import object\n\nimport gntp.core\n\nfrom medusa import app, common\nfrom medusa.helper.exceptions import ex\nfrom medusa.logger.adapters.style import BraceAdapter\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n def test_notify(self, host, password):\n self._sendRegistration(host, password)\n return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,\n force=True)\n\n def notify_snatch(self, ep_name, is_proper):\n if app.GROWL_NOTIFY_ONSNATCH:\n self._sendGrowl(\n common.notifyStrings[\n (common.NOTIFY_SNATCH, common.NOTIFY_SNATCH_PROPER)[is_proper]\n ], ep_name)\n\n def notify_download(self, ep_name):\n if app.GROWL_NOTIFY_ONDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_name)\n\n def notify_subtitle_download(self, ep_name, lang):\n if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_name + ': ' + lang)\n\n def notify_git_update(self, new_version='??'):\n update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]\n title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]\n self._sendGrowl(title, update_text + new_version)\n\n def notify_login(self, ipaddress=''):\n update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]\n title = common.notifyStrings[common.NOTIFY_LOGIN]\n self._sendGrowl(title, update_text.format(ipaddress))\n\n def _send_growl(self, options, message=None):\n\n # Initialize Notification\n notice = gntp.core.GNTPNotice(\n app=options['app'],\n name=options['name'],\n title=options['title'],\n password=options['password'],\n )\n\n # Optional\n if options['sticky']:\n notice.add_header('Notification-Sticky', options['sticky'])\n if options['priority']:\n notice.add_header('Notification-Priority', options['priority'])\n if options['icon']:\n notice.add_header('Notification-Icon', app.LOGO_URL)\n\n if message:\n notice.add_header('Notification-Text', message)\n\n response = self._send(options['host'], options['port'], notice.encode(), options['debug'])\n return True if isinstance(response, gntp.core.GNTPOK) else False\n\n @staticmethod\n def _send(host, port, data, debug=False):\n if debug:\n print('<Sending>\\n', data, '\\n</Sending>')\n\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n s.connect((host, port))\n s.send(data)\n response = gntp.core.parse_gntp(s.recv(1024))\n s.close()\n\n if debug:\n print('<Received>\\n', response, '\\n</Received>')\n\n return response\n\n def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,\n force=False):\n if not app.USE_GROWL and not force:\n return False\n\n if name is None:\n name = title\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n growlHosts = [(hostParts[0], port)]\n\n opts = {\n 'name': name,\n 'title': title,\n 'app': 'Medusa',\n 'sticky': None,\n 'priority': None,\n 'debug': False\n }\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['icon'] = True\n\n for pc in growlHosts:\n opts['host'] = pc[0]\n opts['port'] = pc[1]\n log.debug(\n u'GROWL: Sending growl to {host}:{port} - {msg!r}',\n {'msg': message, 'host': opts['host'], 'port': opts['port']}\n )\n try:\n if self._send_growl(opts, message):\n return True\n else:\n if self._sendRegistration(host, password):\n return self._send_growl(opts, message)\n else:\n return False\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n\n def _sendRegistration(self, host=None, password=None):\n opts = {}\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n opts['host'] = hostParts[0]\n opts['port'] = port\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['app'] = 'Medusa'\n opts['debug'] = False\n\n # Send Registration\n register = gntp.core.GNTPRegister()\n register.add_header('Application-Name', opts['app'])\n register.add_header('Application-Icon', app.LOGO_URL)\n\n register.add_notification('Test', True)\n register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)\n\n if opts['password']:\n register.set_password(opts['password'])\n\n try:\n return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n", "path": "medusa/notifiers/growl.py"}]}
| 2,693 | 93 |
gh_patches_debug_31109
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-27457
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
argmin
argmin
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/jax/numpy/searching_sorting.py`
Content:
```
1 # global
2 import logging
3
4 # local
5 import ivy
6 from ivy.functional.frontends.jax.func_wrapper import (
7 to_ivy_arrays_and_back,
8 )
9 from ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar
10 from ivy.func_wrapper import (
11 with_unsupported_dtypes,
12 )
13
14
15 @to_ivy_arrays_and_back
16 @with_unsupported_dtypes(
17 {
18 "0.4.20 and below": (
19 "float16",
20 "bfloat16",
21 )
22 },
23 "jax",
24 )
25 def argmax(a, axis=None, out=None, keepdims=False):
26 return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)
27
28
29 @to_ivy_arrays_and_back
30 def argsort(a, axis=-1, kind="stable", order=None):
31 if kind != "stable":
32 logging.warning(
33 "'kind' argument to argsort is ignored; only 'stable' sorts are supported."
34 )
35 if order is not None:
36 raise ivy.utils.exceptions.IvyError(
37 "'order' argument to argsort is not supported."
38 )
39
40 return ivy.argsort(a, axis=axis)
41
42
43 @to_ivy_arrays_and_back
44 def argwhere(a, /, *, size=None, fill_value=None):
45 if size is None and fill_value is None:
46 return ivy.argwhere(a)
47
48 result = ivy.matrix_transpose(
49 ivy.vstack(ivy.nonzero(a, size=size, fill_value=fill_value))
50 )
51 num_of_dimensions = a.ndim
52
53 if num_of_dimensions == 0:
54 return result[:0].reshape(result.shape[0], 0)
55
56 return result.reshape(result.shape[0], num_of_dimensions)
57
58
59 @with_unsupported_dtypes(
60 {
61 "0.4.20 and below": (
62 "uint8",
63 "int8",
64 "bool",
65 )
66 },
67 "jax",
68 )
69 @to_ivy_arrays_and_back
70 def count_nonzero(a, axis=None, keepdims=False):
71 return ivy.astype(ivy.count_nonzero(a, axis=axis, keepdims=keepdims), "int64")
72
73
74 @to_ivy_arrays_and_back
75 def extract(condition, arr):
76 if condition.dtype is not bool:
77 condition = condition != 0
78 return arr[condition]
79
80
81 @to_ivy_arrays_and_back
82 def flatnonzero(a):
83 return ivy.nonzero(ivy.reshape(a, (-1,)))
84
85
86 @to_ivy_arrays_and_back
87 def lexsort(keys, /, *, axis=-1):
88 return ivy.lexsort(keys, axis=axis)
89
90
91 @to_ivy_arrays_and_back
92 def msort(a):
93 return ivy.msort(a)
94
95
96 @to_ivy_arrays_and_back
97 @from_zero_dim_arrays_to_scalar
98 def nanargmax(a, /, *, axis=None, out=None, keepdims=False):
99 if out is not None:
100 raise NotImplementedError(
101 "The 'out' argument to jnp.nanargmax is not supported."
102 )
103 nan_mask = ivy.isnan(a)
104 if not ivy.any(nan_mask):
105 return ivy.argmax(a, axis=axis, keepdims=keepdims)
106
107 a = ivy.where(nan_mask, -ivy.inf, a)
108 res = ivy.argmax(a, axis=axis, keepdims=keepdims)
109 return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)
110
111
112 @to_ivy_arrays_and_back
113 @from_zero_dim_arrays_to_scalar
114 def nanargmin(a, /, *, axis=None, out=None, keepdims=None):
115 if out is not None:
116 raise NotImplementedError(
117 "The 'out' argument to jnp.nanargmax is not supported."
118 )
119 nan_mask = ivy.isnan(a)
120 if not ivy.any(nan_mask):
121 return ivy.argmin(a, axis=axis, keepdims=keepdims)
122
123 a = ivy.where(nan_mask, ivy.inf, a)
124 res = ivy.argmin(a, axis=axis, keepdims=keepdims)
125 return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)
126
127
128 @to_ivy_arrays_and_back
129 def nonzero(a, *, size=None, fill_value=None):
130 return ivy.nonzero(a, size=size, fill_value=fill_value)
131
132
133 @to_ivy_arrays_and_back
134 def searchsorted(a, v, side="left", sorter=None, *, method="scan"):
135 return ivy.searchsorted(a, v, side=side, sorter=sorter, ret_dtype="int32")
136
137
138 @to_ivy_arrays_and_back
139 def sort(a, axis=-1, kind="quicksort", order=None):
140 # todo: handle case where order is not None
141 return ivy.sort(a, axis=axis)
142
143
144 @to_ivy_arrays_and_back
145 def sort_complex(a):
146 return ivy.sort(a)
147
148
149 @to_ivy_arrays_and_back
150 def unique(
151 ar,
152 return_index=False,
153 return_inverse=False,
154 return_counts=False,
155 axis=None,
156 *,
157 size=None,
158 fill_value=None,
159 ):
160 uniques = list(ivy.unique_all(ar, axis=axis))
161 if size is not None:
162 fill_value = fill_value if fill_value is not None else 1 # default fill_value 1
163 pad_len = size - len(uniques[0])
164 if pad_len > 0:
165 # padding
166 num_dims = len(uniques[0].shape) - 1
167 padding = [(0, 0)] * num_dims + [(0, pad_len)]
168 uniques[0] = ivy.pad(uniques[0], padding, constant_values=fill_value)
169 # padding the indices and counts with zeros
170 for i in range(1, len(uniques)):
171 if i == 2:
172 continue
173 uniques[i] = ivy.pad(uniques[i], padding[-1], constant_values=0)
174 else:
175 for i in range(len(uniques)):
176 uniques[i] = uniques[i][..., :size]
177 # constructing a list of bools for indexing
178 bools = [return_index, return_inverse, return_counts]
179 # indexing each element whose condition is True except for the values
180 uniques = [uniques[0]] + [uni for idx, uni in enumerate(uniques[1:]) if bools[idx]]
181 return uniques[0] if len(uniques) == 1 else uniques
182
183
184 @to_ivy_arrays_and_back
185 def where(condition, x=None, y=None, *, size=None, fill_value=0):
186 if x is None and y is None:
187 return nonzero(condition, size=size, fill_value=fill_value)
188 if x is not None and y is not None:
189 return ivy.where(condition, x, y)
190 else:
191 raise ValueError("Both x and y should be given.")
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/jax/numpy/searching_sorting.py b/ivy/functional/frontends/jax/numpy/searching_sorting.py
--- a/ivy/functional/frontends/jax/numpy/searching_sorting.py
+++ b/ivy/functional/frontends/jax/numpy/searching_sorting.py
@@ -8,6 +8,7 @@
)
from ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar
from ivy.func_wrapper import (
+ with_supported_device_and_dtypes,
with_unsupported_dtypes,
)
@@ -26,6 +27,58 @@
return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)
+# argmin
+@to_ivy_arrays_and_back
+@with_supported_device_and_dtypes(
+ {
+ "0.4.20 and below": {
+ "cpu": (
+ "int16",
+ "int32",
+ "int64",
+ "float32",
+ "float64",
+ "uint8",
+ "uint16",
+ "uint32",
+ "uint64",
+ )
+ }
+ },
+ "jax",
+)
+def argmin(a, axis=None, out=None, keepdims=None):
+ if a is not None:
+ if isinstance(a, list):
+ if all(isinstance(elem, ivy.Array) for elem in a):
+ if len(a) == 1:
+ a = a[0]
+ else:
+ return [
+ ivy.argmin(
+ ivy.to_native_arrays(elem),
+ axis=axis,
+ out=out,
+ keepdims=keepdims,
+ )
+ for elem in a
+ ]
+ else:
+ raise ValueError(
+ "Input 'a' must be an Ivy array or a list of Ivy arrays."
+ )
+
+ if not isinstance(a, ivy.Array):
+ raise TypeError("Input 'a' must be an array.")
+
+ if a.size == 0:
+ raise ValueError("Input 'a' must not be empty.")
+
+ return ivy.argmin(a, axis=axis, out=out, keepdims=keepdims)
+ else:
+ raise ValueError("argmin takes at least 1 argument.")
+
+
@to_ivy_arrays_and_back
def argsort(a, axis=-1, kind="stable", order=None):
if kind != "stable":
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/searching_sorting.py b/ivy/functional/frontends/jax/numpy/searching_sorting.py\n--- a/ivy/functional/frontends/jax/numpy/searching_sorting.py\n+++ b/ivy/functional/frontends/jax/numpy/searching_sorting.py\n@@ -8,6 +8,7 @@\n )\n from ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar\n from ivy.func_wrapper import (\n+ with_supported_device_and_dtypes,\n with_unsupported_dtypes,\n )\n \n@@ -26,6 +27,58 @@\n return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)\n \n \n+# argmin\n+@to_ivy_arrays_and_back\n+@with_supported_device_and_dtypes(\n+ {\n+ \"0.4.20 and below\": {\n+ \"cpu\": (\n+ \"int16\",\n+ \"int32\",\n+ \"int64\",\n+ \"float32\",\n+ \"float64\",\n+ \"uint8\",\n+ \"uint16\",\n+ \"uint32\",\n+ \"uint64\",\n+ )\n+ }\n+ },\n+ \"jax\",\n+)\n+def argmin(a, axis=None, out=None, keepdims=None):\n+ if a is not None:\n+ if isinstance(a, list):\n+ if all(isinstance(elem, ivy.Array) for elem in a):\n+ if len(a) == 1:\n+ a = a[0]\n+ else:\n+ return [\n+ ivy.argmin(\n+ ivy.to_native_arrays(elem),\n+ axis=axis,\n+ out=out,\n+ keepdims=keepdims,\n+ )\n+ for elem in a\n+ ]\n+ else:\n+ raise ValueError(\n+ \"Input 'a' must be an Ivy array or a list of Ivy arrays.\"\n+ )\n+\n+ if not isinstance(a, ivy.Array):\n+ raise TypeError(\"Input 'a' must be an array.\")\n+\n+ if a.size == 0:\n+ raise ValueError(\"Input 'a' must not be empty.\")\n+\n+ return ivy.argmin(a, axis=axis, out=out, keepdims=keepdims)\n+ else:\n+ raise ValueError(\"argmin takes at least 1 argument.\")\n+\n+\n @to_ivy_arrays_and_back\n def argsort(a, axis=-1, kind=\"stable\", order=None):\n if kind != \"stable\":\n", "issue": "argmin\n\nargmin\n\n", "before_files": [{"content": "# global\nimport logging\n\n# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n)\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.4.20 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef argmax(a, axis=None, out=None, keepdims=False):\n return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)\n\n\n@to_ivy_arrays_and_back\ndef argsort(a, axis=-1, kind=\"stable\", order=None):\n if kind != \"stable\":\n logging.warning(\n \"'kind' argument to argsort is ignored; only 'stable' sorts are supported.\"\n )\n if order is not None:\n raise ivy.utils.exceptions.IvyError(\n \"'order' argument to argsort is not supported.\"\n )\n\n return ivy.argsort(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef argwhere(a, /, *, size=None, fill_value=None):\n if size is None and fill_value is None:\n return ivy.argwhere(a)\n\n result = ivy.matrix_transpose(\n ivy.vstack(ivy.nonzero(a, size=size, fill_value=fill_value))\n )\n num_of_dimensions = a.ndim\n\n if num_of_dimensions == 0:\n return result[:0].reshape(result.shape[0], 0)\n\n return result.reshape(result.shape[0], num_of_dimensions)\n\n\n@with_unsupported_dtypes(\n {\n \"0.4.20 and below\": (\n \"uint8\",\n \"int8\",\n \"bool\",\n )\n },\n \"jax\",\n)\n@to_ivy_arrays_and_back\ndef count_nonzero(a, axis=None, keepdims=False):\n return ivy.astype(ivy.count_nonzero(a, axis=axis, keepdims=keepdims), \"int64\")\n\n\n@to_ivy_arrays_and_back\ndef extract(condition, arr):\n if condition.dtype is not bool:\n condition = condition != 0\n return arr[condition]\n\n\n@to_ivy_arrays_and_back\ndef flatnonzero(a):\n return ivy.nonzero(ivy.reshape(a, (-1,)))\n\n\n@to_ivy_arrays_and_back\ndef lexsort(keys, /, *, axis=-1):\n return ivy.lexsort(keys, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef msort(a):\n return ivy.msort(a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef nanargmax(a, /, *, axis=None, out=None, keepdims=False):\n if out is not None:\n raise NotImplementedError(\n \"The 'out' argument to jnp.nanargmax is not supported.\"\n )\n nan_mask = ivy.isnan(a)\n if not ivy.any(nan_mask):\n return ivy.argmax(a, axis=axis, keepdims=keepdims)\n\n a = ivy.where(nan_mask, -ivy.inf, a)\n res = ivy.argmax(a, axis=axis, keepdims=keepdims)\n return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef nanargmin(a, /, *, axis=None, out=None, keepdims=None):\n if out is not None:\n raise NotImplementedError(\n \"The 'out' argument to jnp.nanargmax is not supported.\"\n )\n nan_mask = ivy.isnan(a)\n if not ivy.any(nan_mask):\n return ivy.argmin(a, axis=axis, keepdims=keepdims)\n\n a = ivy.where(nan_mask, ivy.inf, a)\n res = ivy.argmin(a, axis=axis, keepdims=keepdims)\n return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)\n\n\n@to_ivy_arrays_and_back\ndef nonzero(a, *, size=None, fill_value=None):\n return ivy.nonzero(a, size=size, fill_value=fill_value)\n\n\n@to_ivy_arrays_and_back\ndef searchsorted(a, v, side=\"left\", sorter=None, *, method=\"scan\"):\n return ivy.searchsorted(a, v, side=side, sorter=sorter, ret_dtype=\"int32\")\n\n\n@to_ivy_arrays_and_back\ndef sort(a, axis=-1, kind=\"quicksort\", order=None):\n # todo: handle case where order is not None\n return ivy.sort(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef sort_complex(a):\n return ivy.sort(a)\n\n\n@to_ivy_arrays_and_back\ndef unique(\n ar,\n return_index=False,\n return_inverse=False,\n return_counts=False,\n axis=None,\n *,\n size=None,\n fill_value=None,\n):\n uniques = list(ivy.unique_all(ar, axis=axis))\n if size is not None:\n fill_value = fill_value if fill_value is not None else 1 # default fill_value 1\n pad_len = size - len(uniques[0])\n if pad_len > 0:\n # padding\n num_dims = len(uniques[0].shape) - 1\n padding = [(0, 0)] * num_dims + [(0, pad_len)]\n uniques[0] = ivy.pad(uniques[0], padding, constant_values=fill_value)\n # padding the indices and counts with zeros\n for i in range(1, len(uniques)):\n if i == 2:\n continue\n uniques[i] = ivy.pad(uniques[i], padding[-1], constant_values=0)\n else:\n for i in range(len(uniques)):\n uniques[i] = uniques[i][..., :size]\n # constructing a list of bools for indexing\n bools = [return_index, return_inverse, return_counts]\n # indexing each element whose condition is True except for the values\n uniques = [uniques[0]] + [uni for idx, uni in enumerate(uniques[1:]) if bools[idx]]\n return uniques[0] if len(uniques) == 1 else uniques\n\n\n@to_ivy_arrays_and_back\ndef where(condition, x=None, y=None, *, size=None, fill_value=0):\n if x is None and y is None:\n return nonzero(condition, size=size, fill_value=fill_value)\n if x is not None and y is not None:\n return ivy.where(condition, x, y)\n else:\n raise ValueError(\"Both x and y should be given.\")\n", "path": "ivy/functional/frontends/jax/numpy/searching_sorting.py"}], "after_files": [{"content": "# global\nimport logging\n\n# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar\nfrom ivy.func_wrapper import (\n with_supported_device_and_dtypes,\n with_unsupported_dtypes,\n)\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.4.20 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef argmax(a, axis=None, out=None, keepdims=False):\n return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)\n\n\n# argmin\n@to_ivy_arrays_and_back\n@with_supported_device_and_dtypes(\n {\n \"0.4.20 and below\": {\n \"cpu\": (\n \"int16\",\n \"int32\",\n \"int64\",\n \"float32\",\n \"float64\",\n \"uint8\",\n \"uint16\",\n \"uint32\",\n \"uint64\",\n )\n }\n },\n \"jax\",\n)\ndef argmin(a, axis=None, out=None, keepdims=None):\n if a is not None:\n if isinstance(a, list):\n if all(isinstance(elem, ivy.Array) for elem in a):\n if len(a) == 1:\n a = a[0]\n else:\n return [\n ivy.argmin(\n ivy.to_native_arrays(elem),\n axis=axis,\n out=out,\n keepdims=keepdims,\n )\n for elem in a\n ]\n else:\n raise ValueError(\n \"Input 'a' must be an Ivy array or a list of Ivy arrays.\"\n )\n\n if not isinstance(a, ivy.Array):\n raise TypeError(\"Input 'a' must be an array.\")\n\n if a.size == 0:\n raise ValueError(\"Input 'a' must not be empty.\")\n\n return ivy.argmin(a, axis=axis, out=out, keepdims=keepdims)\n else:\n raise ValueError(\"argmin takes at least 1 argument.\")\n\n\n@to_ivy_arrays_and_back\ndef argsort(a, axis=-1, kind=\"stable\", order=None):\n if kind != \"stable\":\n logging.warning(\n \"'kind' argument to argsort is ignored; only 'stable' sorts are supported.\"\n )\n if order is not None:\n raise ivy.utils.exceptions.IvyError(\n \"'order' argument to argsort is not supported.\"\n )\n\n return ivy.argsort(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef argwhere(a, /, *, size=None, fill_value=None):\n if size is None and fill_value is None:\n return ivy.argwhere(a)\n\n result = ivy.matrix_transpose(\n ivy.vstack(ivy.nonzero(a, size=size, fill_value=fill_value))\n )\n num_of_dimensions = a.ndim\n\n if num_of_dimensions == 0:\n return result[:0].reshape(result.shape[0], 0)\n\n return result.reshape(result.shape[0], num_of_dimensions)\n\n\n@with_unsupported_dtypes(\n {\n \"0.4.20 and below\": (\n \"uint8\",\n \"int8\",\n \"bool\",\n )\n },\n \"jax\",\n)\n@to_ivy_arrays_and_back\ndef count_nonzero(a, axis=None, keepdims=False):\n return ivy.astype(ivy.count_nonzero(a, axis=axis, keepdims=keepdims), \"int64\")\n\n\n@to_ivy_arrays_and_back\ndef extract(condition, arr):\n if condition.dtype is not bool:\n condition = condition != 0\n return arr[condition]\n\n\n@to_ivy_arrays_and_back\ndef flatnonzero(a):\n return ivy.nonzero(ivy.reshape(a, (-1,)))\n\n\n@to_ivy_arrays_and_back\ndef lexsort(keys, /, *, axis=-1):\n return ivy.lexsort(keys, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef msort(a):\n return ivy.msort(a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef nanargmax(a, /, *, axis=None, out=None, keepdims=False):\n if out is not None:\n raise NotImplementedError(\n \"The 'out' argument to jnp.nanargmax is not supported.\"\n )\n nan_mask = ivy.isnan(a)\n if not ivy.any(nan_mask):\n return ivy.argmax(a, axis=axis, keepdims=keepdims)\n\n a = ivy.where(nan_mask, -ivy.inf, a)\n res = ivy.argmax(a, axis=axis, keepdims=keepdims)\n return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef nanargmin(a, /, *, axis=None, out=None, keepdims=None):\n if out is not None:\n raise NotImplementedError(\n \"The 'out' argument to jnp.nanargmax is not supported.\"\n )\n nan_mask = ivy.isnan(a)\n if not ivy.any(nan_mask):\n return ivy.argmin(a, axis=axis, keepdims=keepdims)\n\n a = ivy.where(nan_mask, ivy.inf, a)\n res = ivy.argmin(a, axis=axis, keepdims=keepdims)\n return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)\n\n\n@to_ivy_arrays_and_back\ndef nonzero(a, *, size=None, fill_value=None):\n return ivy.nonzero(a, size=size, fill_value=fill_value)\n\n\n@to_ivy_arrays_and_back\ndef searchsorted(a, v, side=\"left\", sorter=None, *, method=\"scan\"):\n return ivy.searchsorted(a, v, side=side, sorter=sorter, ret_dtype=\"int32\")\n\n\n@to_ivy_arrays_and_back\ndef sort(a, axis=-1, kind=\"quicksort\", order=None):\n # todo: handle case where order is not None\n return ivy.sort(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef sort_complex(a):\n return ivy.sort(a)\n\n\n@to_ivy_arrays_and_back\ndef unique(\n ar,\n return_index=False,\n return_inverse=False,\n return_counts=False,\n axis=None,\n *,\n size=None,\n fill_value=None,\n):\n uniques = list(ivy.unique_all(ar, axis=axis))\n if size is not None:\n fill_value = fill_value if fill_value is not None else 1 # default fill_value 1\n pad_len = size - len(uniques[0])\n if pad_len > 0:\n # padding\n num_dims = len(uniques[0].shape) - 1\n padding = [(0, 0)] * num_dims + [(0, pad_len)]\n uniques[0] = ivy.pad(uniques[0], padding, constant_values=fill_value)\n # padding the indices and counts with zeros\n for i in range(1, len(uniques)):\n if i == 2:\n continue\n uniques[i] = ivy.pad(uniques[i], padding[-1], constant_values=0)\n else:\n for i in range(len(uniques)):\n uniques[i] = uniques[i][..., :size]\n # constructing a list of bools for indexing\n bools = [return_index, return_inverse, return_counts]\n # indexing each element whose condition is True except for the values\n uniques = [uniques[0]] + [uni for idx, uni in enumerate(uniques[1:]) if bools[idx]]\n return uniques[0] if len(uniques) == 1 else uniques\n\n\n@to_ivy_arrays_and_back\ndef where(condition, x=None, y=None, *, size=None, fill_value=0):\n if x is None and y is None:\n return nonzero(condition, size=size, fill_value=fill_value)\n if x is not None and y is not None:\n return ivy.where(condition, x, y)\n else:\n raise ValueError(\"Both x and y should be given.\")\n", "path": "ivy/functional/frontends/jax/numpy/searching_sorting.py"}]}
| 2,277 | 565 |
gh_patches_debug_1097
|
rasdani/github-patches
|
git_diff
|
openfun__richie-290
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Person plugin form list every pages, not only Person pages
## Bug Report
**Expected behavior/code**
Select box in PersonPlugin form should list only extended page with Person model.
**Actual Behavior**
Currently the select box is listing every CMS pages.
**Steps to Reproduce**
1. Edit a page;
2. Try to add a Person plugin into a placeholder which allow it;
3. Click to open the select box from opened form for added Person plugin.
**Environment**
- Richie version: 0.1.0 (from my own branch synchronized from master 200c8a3)
- Platform: Ubuntu 18.04 LTS
**Possible Solution**
Adding a filter inside plugin form machinery to retain only the extend page with Person.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/richie/apps/persons/models.py`
Content:
```
1 """
2 Declare and configure the model for the person application
3 """
4 from django.db import models
5 from django.utils.translation import ugettext_lazy as _
6
7 from cms.api import Page
8 from cms.extensions import PageExtension
9 from cms.models.pluginmodel import CMSPlugin
10 from parler.models import TranslatableModel, TranslatedFields
11
12
13 class PersonTitle(TranslatableModel):
14 """
15 PersonTitle define i18ned list of people titles and there abbreviations
16 Instances of this models should only be created by CMS administrators
17 """
18
19 translations = TranslatedFields(
20 title=models.CharField(_("Title"), max_length=200),
21 abbreviation=models.CharField(_("Title abbreviation"), max_length=10),
22 )
23
24 class Meta:
25 verbose_name = _("person title")
26
27 def __str__(self):
28 """Human representation of a person title"""
29 return "{model}: {title} ({abbreviation})".format(
30 model=self._meta.verbose_name.title(),
31 title=self.title,
32 abbreviation=self.abbreviation,
33 )
34
35
36 class Person(PageExtension):
37 """
38 The person page extension represents and records people information.
39 It could be a course or news article author.
40
41 This model should be used to record structured data about the person whereas the
42 associated page object is where we record the less structured information to display on the
43 page to present the person.
44 """
45
46 first_name = models.CharField(max_length=200, verbose_name=_("First name"))
47 last_name = models.CharField(max_length=200, verbose_name=_("Last name"))
48
49 person_title = models.ForeignKey("PersonTitle", related_name="persons")
50
51 ROOT_REVERSE_ID = "persons"
52 TEMPLATE_DETAIL = "persons/cms/person_detail.html"
53
54 class Meta:
55 verbose_name = _("person")
56
57 def __str__(self):
58 """Human representation of a person"""
59 return "{model}: {title} ({full_name})".format(
60 model=self._meta.verbose_name.title(),
61 title=self.extended_object.get_title(),
62 full_name=self.get_full_name(),
63 )
64
65 def save(self, *args, **kwargs):
66 """
67 Enforce validation on each instance save
68 """
69 self.full_clean()
70 super().save(*args, **kwargs)
71
72 def get_full_name(self):
73 """
74 Return person's full name
75 """
76 return "{person_title} {first_name} {last_name}".format(
77 person_title=self.person_title.title,
78 first_name=self.first_name,
79 last_name=self.last_name,
80 )
81
82
83 class PersonPluginModel(CMSPlugin):
84 """
85 Person plugin model handles the relation from PersonPlugin
86 to their Person instance
87 """
88
89 page = models.ForeignKey(Page)
90
91 class Meta:
92 verbose_name = _("person plugin model")
93
94 def __str__(self):
95 """Human representation of a person plugin"""
96 return "{model:s}: {id:d}".format(
97 model=self._meta.verbose_name.title(), id=self.id
98 )
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/richie/apps/persons/models.py b/src/richie/apps/persons/models.py
--- a/src/richie/apps/persons/models.py
+++ b/src/richie/apps/persons/models.py
@@ -86,7 +86,7 @@
to their Person instance
"""
- page = models.ForeignKey(Page)
+ page = models.ForeignKey(Page, limit_choices_to={"person__isnull": False})
class Meta:
verbose_name = _("person plugin model")
|
{"golden_diff": "diff --git a/src/richie/apps/persons/models.py b/src/richie/apps/persons/models.py\n--- a/src/richie/apps/persons/models.py\n+++ b/src/richie/apps/persons/models.py\n@@ -86,7 +86,7 @@\n to their Person instance\n \"\"\"\n \n- page = models.ForeignKey(Page)\n+ page = models.ForeignKey(Page, limit_choices_to={\"person__isnull\": False})\n \n class Meta:\n verbose_name = _(\"person plugin model\")\n", "issue": "Person plugin form list every pages, not only Person pages\n## Bug Report\r\n\r\n**Expected behavior/code**\r\nSelect box in PersonPlugin form should list only extended page with Person model.\r\n\r\n**Actual Behavior**\r\nCurrently the select box is listing every CMS pages.\r\n\r\n**Steps to Reproduce**\r\n1. Edit a page;\r\n2. Try to add a Person plugin into a placeholder which allow it;\r\n3. Click to open the select box from opened form for added Person plugin.\r\n\r\n**Environment**\r\n- Richie version: 0.1.0 (from my own branch synchronized from master 200c8a3) \r\n- Platform: Ubuntu 18.04 LTS\r\n\r\n**Possible Solution**\r\nAdding a filter inside plugin form machinery to retain only the extend page with Person.\r\n\n", "before_files": [{"content": "\"\"\"\nDeclare and configure the model for the person application\n\"\"\"\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom cms.api import Page\nfrom cms.extensions import PageExtension\nfrom cms.models.pluginmodel import CMSPlugin\nfrom parler.models import TranslatableModel, TranslatedFields\n\n\nclass PersonTitle(TranslatableModel):\n \"\"\"\n PersonTitle define i18ned list of people titles and there abbreviations\n Instances of this models should only be created by CMS administrators\n \"\"\"\n\n translations = TranslatedFields(\n title=models.CharField(_(\"Title\"), max_length=200),\n abbreviation=models.CharField(_(\"Title abbreviation\"), max_length=10),\n )\n\n class Meta:\n verbose_name = _(\"person title\")\n\n def __str__(self):\n \"\"\"Human representation of a person title\"\"\"\n return \"{model}: {title} ({abbreviation})\".format(\n model=self._meta.verbose_name.title(),\n title=self.title,\n abbreviation=self.abbreviation,\n )\n\n\nclass Person(PageExtension):\n \"\"\"\n The person page extension represents and records people information.\n It could be a course or news article author.\n\n This model should be used to record structured data about the person whereas the\n associated page object is where we record the less structured information to display on the\n page to present the person.\n \"\"\"\n\n first_name = models.CharField(max_length=200, verbose_name=_(\"First name\"))\n last_name = models.CharField(max_length=200, verbose_name=_(\"Last name\"))\n\n person_title = models.ForeignKey(\"PersonTitle\", related_name=\"persons\")\n\n ROOT_REVERSE_ID = \"persons\"\n TEMPLATE_DETAIL = \"persons/cms/person_detail.html\"\n\n class Meta:\n verbose_name = _(\"person\")\n\n def __str__(self):\n \"\"\"Human representation of a person\"\"\"\n return \"{model}: {title} ({full_name})\".format(\n model=self._meta.verbose_name.title(),\n title=self.extended_object.get_title(),\n full_name=self.get_full_name(),\n )\n\n def save(self, *args, **kwargs):\n \"\"\"\n Enforce validation on each instance save\n \"\"\"\n self.full_clean()\n super().save(*args, **kwargs)\n\n def get_full_name(self):\n \"\"\"\n Return person's full name\n \"\"\"\n return \"{person_title} {first_name} {last_name}\".format(\n person_title=self.person_title.title,\n first_name=self.first_name,\n last_name=self.last_name,\n )\n\n\nclass PersonPluginModel(CMSPlugin):\n \"\"\"\n Person plugin model handles the relation from PersonPlugin\n to their Person instance\n \"\"\"\n\n page = models.ForeignKey(Page)\n\n class Meta:\n verbose_name = _(\"person plugin model\")\n\n def __str__(self):\n \"\"\"Human representation of a person plugin\"\"\"\n return \"{model:s}: {id:d}\".format(\n model=self._meta.verbose_name.title(), id=self.id\n )\n", "path": "src/richie/apps/persons/models.py"}], "after_files": [{"content": "\"\"\"\nDeclare and configure the model for the person application\n\"\"\"\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom cms.api import Page\nfrom cms.extensions import PageExtension\nfrom cms.models.pluginmodel import CMSPlugin\nfrom parler.models import TranslatableModel, TranslatedFields\n\n\nclass PersonTitle(TranslatableModel):\n \"\"\"\n PersonTitle define i18ned list of people titles and there abbreviations\n Instances of this models should only be created by CMS administrators\n \"\"\"\n\n translations = TranslatedFields(\n title=models.CharField(_(\"Title\"), max_length=200),\n abbreviation=models.CharField(_(\"Title abbreviation\"), max_length=10),\n )\n\n class Meta:\n verbose_name = _(\"person title\")\n\n def __str__(self):\n \"\"\"Human representation of a person title\"\"\"\n return \"{model}: {title} ({abbreviation})\".format(\n model=self._meta.verbose_name.title(),\n title=self.title,\n abbreviation=self.abbreviation,\n )\n\n\nclass Person(PageExtension):\n \"\"\"\n The person page extension represents and records people information.\n It could be a course or news article author.\n\n This model should be used to record structured data about the person whereas the\n associated page object is where we record the less structured information to display on the\n page to present the person.\n \"\"\"\n\n first_name = models.CharField(max_length=200, verbose_name=_(\"First name\"))\n last_name = models.CharField(max_length=200, verbose_name=_(\"Last name\"))\n\n person_title = models.ForeignKey(\"PersonTitle\", related_name=\"persons\")\n\n ROOT_REVERSE_ID = \"persons\"\n TEMPLATE_DETAIL = \"persons/cms/person_detail.html\"\n\n class Meta:\n verbose_name = _(\"person\")\n\n def __str__(self):\n \"\"\"Human representation of a person\"\"\"\n return \"{model}: {title} ({full_name})\".format(\n model=self._meta.verbose_name.title(),\n title=self.extended_object.get_title(),\n full_name=self.get_full_name(),\n )\n\n def save(self, *args, **kwargs):\n \"\"\"\n Enforce validation on each instance save\n \"\"\"\n self.full_clean()\n super().save(*args, **kwargs)\n\n def get_full_name(self):\n \"\"\"\n Return person's full name\n \"\"\"\n return \"{person_title} {first_name} {last_name}\".format(\n person_title=self.person_title.title,\n first_name=self.first_name,\n last_name=self.last_name,\n )\n\n\nclass PersonPluginModel(CMSPlugin):\n \"\"\"\n Person plugin model handles the relation from PersonPlugin\n to their Person instance\n \"\"\"\n\n page = models.ForeignKey(Page, limit_choices_to={\"person__isnull\": False})\n\n class Meta:\n verbose_name = _(\"person plugin model\")\n\n def __str__(self):\n \"\"\"Human representation of a person plugin\"\"\"\n return \"{model:s}: {id:d}\".format(\n model=self._meta.verbose_name.title(), id=self.id\n )\n", "path": "src/richie/apps/persons/models.py"}]}
| 1,238 | 110 |
gh_patches_debug_2871
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2386
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E0002 parsing I3013 on AWS::RDS::DBInstance if Engine is a Ref
### CloudFormation Lint Version
0.65.0
### What operating system are you using?
Ubuntu 22.04
### Describe the bug
A cfn-lint exception is raised when parsing I3013 rule.
The trigger seems to be the presence of a reference as a value of the "Engine" resource parameter.


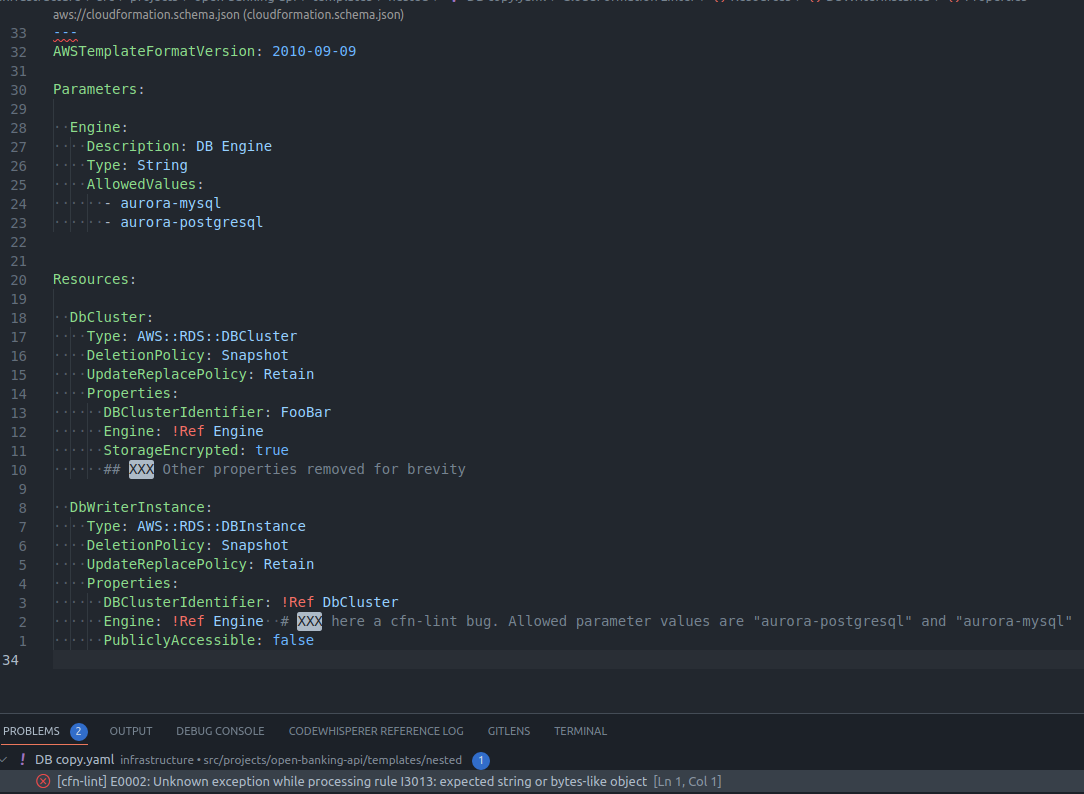
### Expected behavior
No error should be present is `Engine: !Ref Something` is used.
### Reproduction template
```yaml
---
AWSTemplateFormatVersion: 2010-09-09
Parameters:
Engine:
Description: DB Engine
Type: String
AllowedValues:
- aurora-mysql
- aurora-postgresql
Resources:
DbCluster:
Type: AWS::RDS::DBCluster
DeletionPolicy: Snapshot
UpdateReplacePolicy: Retain
Properties:
DBClusterIdentifier: FooBar
Engine: !Ref Engine
StorageEncrypted: true
## XXX Other properties removed for brevity
DbWriterInstance:
Type: AWS::RDS::DBInstance
DeletionPolicy: Snapshot
UpdateReplacePolicy: Retain
Properties:
DBClusterIdentifier: !Ref DbCluster
Engine: !Ref Engine # XXX here a cfn-lint bug. Allowed parameter values are "aurora-postgresql" and "aurora-mysql"
PubliclyAccessible: false
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import re
6 from cfnlint.rules import CloudFormationLintRule
7 from cfnlint.rules import RuleMatch
8
9
10 class RetentionPeriodOnResourceTypesWithAutoExpiringContent(CloudFormationLintRule):
11 """Check for RetentionPeriod """
12 id = 'I3013'
13 shortdesc = 'Check resources with auto expiring content have explicit retention period'
14 description = 'The behaviour for data retention is different across AWS Services.'\
15 'If no retention period is specified the default for some services is to delete the data after a period of time.' \
16 'This check requires you to explicitly set the retention period for those resources to avoid unexpected data losses'
17 source_url = 'https://github.com/aws-cloudformation/cfn-python-lint'
18 tags = ['resources', 'retentionperiod']
19
20 def _check_ref(self, value, parameters, resources, path): # pylint: disable=W0613
21 print(value)
22
23 def match(self, cfn):
24 """Check for RetentionPeriod"""
25 matches = []
26
27 retention_attributes_by_resource_type = {
28 'AWS::Kinesis::Stream': [
29 {
30 'Attribute': 'RetentionPeriodHours',
31 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-kinesis-stream.html#cfn-kinesis-stream-retentionperiodhours'
32 }
33 ],
34 'AWS::SQS::Queue': [
35 {
36 'Attribute': 'MessageRetentionPeriod',
37 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-sqs-queues.html#aws-sqs-queue-msgretentionperiod'
38 }
39 ],
40 'AWS::DocDB::DBCluster': [
41 {
42 'Attribute': 'BackupRetentionPeriod',
43 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-docdb-dbcluster.html#cfn-docdb-dbcluster-backupretentionperiod'
44 }
45 ],
46 'AWS::Synthetics::Canary': [
47 {
48 'Attribute': 'SuccessRetentionPeriod',
49 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-successretentionperiod'
50 },
51 {
52 'Attribute': 'FailureRetentionPeriod',
53 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-failureretentionperiod'
54 }
55 ],
56 'AWS::Redshift::Cluster': [
57 {
58 'Attribute': 'AutomatedSnapshotRetentionPeriod',
59 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-redshift-cluster.html#cfn-redshift-cluster-automatedsnapshotretentionperiod'
60 }
61 ],
62 'AWS::RDS::DBInstance': [
63 {
64 'Attribute': 'BackupRetentionPeriod',
65 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-rds-database-instance.html#cfn-rds-dbinstance-backupretentionperiod',
66 'CheckAttribute': 'Engine',
67 'CheckAttributeRegex': re.compile('^((?!aurora).)*$'),
68 }
69 ],
70 'AWS::RDS::DBCluster': [
71 {
72 'Attribute': 'BackupRetentionPeriod',
73 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbcluster.html#cfn-rds-dbcluster-backuprententionperiod'
74 }
75 ]
76 }
77
78 resources = cfn.get_resources()
79 for r_name, r_values in resources.items():
80 if r_values.get('Type') in retention_attributes_by_resource_type:
81 for attr_def in retention_attributes_by_resource_type[r_values.get('Type')]:
82 property_sets = r_values.get_safe('Properties')
83 for property_set, path in property_sets:
84 error_path = ['Resources', r_name] + path
85 if not property_set:
86 message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {"/".join(str(x) for x in error_path)}'
87 matches.append(RuleMatch(error_path, message))
88 else:
89 value = property_set.get(attr_def.get('Attribute'))
90 if not value:
91 message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {"/".join(str(x) for x in error_path)}'
92 if attr_def.get('CheckAttribute'):
93 if self._validate_property(property_set.get(attr_def.get('CheckAttribute')), attr_def.get('CheckAttributeRegex')):
94 matches.append(RuleMatch(error_path, message))
95 else:
96 matches.append(RuleMatch(error_path, message))
97 if isinstance(value, dict):
98 # pylint: disable=protected-access
99 refs = cfn._search_deep_keys(
100 'Ref', value, error_path + [attr_def.get('Attribute')])
101 for ref in refs:
102 if ref[-1] == 'AWS::NoValue':
103 message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {"/".join(str(x) for x in ref[0:-1])}'
104 matches.append(RuleMatch(ref[0:-1], message))
105
106 return matches
107
108 def _validate_property(self, value, regex) -> bool:
109 if regex.match(value):
110 return True
111 return False
112
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py
--- a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py
+++ b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py
@@ -106,6 +106,8 @@
return matches
def _validate_property(self, value, regex) -> bool:
- if regex.match(value):
- return True
- return False
+ if isinstance(value, str):
+ if regex.match(value):
+ return True
+ return False
+ return True
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py\n--- a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py\n+++ b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py\n@@ -106,6 +106,8 @@\n return matches\n \n def _validate_property(self, value, regex) -> bool:\n- if regex.match(value):\n- return True\n- return False\n+ if isinstance(value, str):\n+ if regex.match(value):\n+ return True\n+ return False\n+ return True\n", "issue": "E0002 parsing I3013 on AWS::RDS::DBInstance if Engine is a Ref\n### CloudFormation Lint Version\n\n0.65.0\n\n### What operating system are you using?\n\nUbuntu 22.04\n\n### Describe the bug\n\nA cfn-lint exception is raised when parsing I3013 rule.\r\n\r\nThe trigger seems to be the presence of a reference as a value of the \"Engine\" resource parameter.\r\n\r\n\r\n\r\n\r\n\r\n\n\n### Expected behavior\n\nNo error should be present is `Engine: !Ref Something` is used.\n\n### Reproduction template\n\n```yaml\r\n---\r\nAWSTemplateFormatVersion: 2010-09-09\r\n\r\nParameters:\r\n\r\n Engine:\r\n Description: DB Engine\r\n Type: String\r\n AllowedValues:\r\n - aurora-mysql\r\n - aurora-postgresql\r\n\r\n\r\nResources:\r\n\r\n DbCluster:\r\n Type: AWS::RDS::DBCluster\r\n DeletionPolicy: Snapshot\r\n UpdateReplacePolicy: Retain\r\n Properties:\r\n DBClusterIdentifier: FooBar\r\n Engine: !Ref Engine\r\n StorageEncrypted: true\r\n ## XXX Other properties removed for brevity\r\n\r\n DbWriterInstance:\r\n Type: AWS::RDS::DBInstance\r\n DeletionPolicy: Snapshot\r\n UpdateReplacePolicy: Retain\r\n Properties:\r\n DBClusterIdentifier: !Ref DbCluster\r\n Engine: !Ref Engine # XXX here a cfn-lint bug. Allowed parameter values are \"aurora-postgresql\" and \"aurora-mysql\"\r\n PubliclyAccessible: false\r\n```\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass RetentionPeriodOnResourceTypesWithAutoExpiringContent(CloudFormationLintRule):\n \"\"\"Check for RetentionPeriod \"\"\"\n id = 'I3013'\n shortdesc = 'Check resources with auto expiring content have explicit retention period'\n description = 'The behaviour for data retention is different across AWS Services.'\\\n 'If no retention period is specified the default for some services is to delete the data after a period of time.' \\\n 'This check requires you to explicitly set the retention period for those resources to avoid unexpected data losses'\n source_url = 'https://github.com/aws-cloudformation/cfn-python-lint'\n tags = ['resources', 'retentionperiod']\n\n def _check_ref(self, value, parameters, resources, path): # pylint: disable=W0613\n print(value)\n\n def match(self, cfn):\n \"\"\"Check for RetentionPeriod\"\"\"\n matches = []\n\n retention_attributes_by_resource_type = {\n 'AWS::Kinesis::Stream': [\n {\n 'Attribute': 'RetentionPeriodHours',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-kinesis-stream.html#cfn-kinesis-stream-retentionperiodhours'\n }\n ],\n 'AWS::SQS::Queue': [\n {\n 'Attribute': 'MessageRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-sqs-queues.html#aws-sqs-queue-msgretentionperiod'\n }\n ],\n 'AWS::DocDB::DBCluster': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-docdb-dbcluster.html#cfn-docdb-dbcluster-backupretentionperiod'\n }\n ],\n 'AWS::Synthetics::Canary': [\n {\n 'Attribute': 'SuccessRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-successretentionperiod'\n },\n {\n 'Attribute': 'FailureRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-failureretentionperiod'\n }\n ],\n 'AWS::Redshift::Cluster': [\n {\n 'Attribute': 'AutomatedSnapshotRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-redshift-cluster.html#cfn-redshift-cluster-automatedsnapshotretentionperiod'\n }\n ],\n 'AWS::RDS::DBInstance': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-rds-database-instance.html#cfn-rds-dbinstance-backupretentionperiod',\n 'CheckAttribute': 'Engine',\n 'CheckAttributeRegex': re.compile('^((?!aurora).)*$'),\n }\n ],\n 'AWS::RDS::DBCluster': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbcluster.html#cfn-rds-dbcluster-backuprententionperiod'\n }\n ]\n }\n\n resources = cfn.get_resources()\n for r_name, r_values in resources.items():\n if r_values.get('Type') in retention_attributes_by_resource_type:\n for attr_def in retention_attributes_by_resource_type[r_values.get('Type')]:\n property_sets = r_values.get_safe('Properties')\n for property_set, path in property_sets:\n error_path = ['Resources', r_name] + path\n if not property_set:\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in error_path)}'\n matches.append(RuleMatch(error_path, message))\n else:\n value = property_set.get(attr_def.get('Attribute'))\n if not value:\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in error_path)}'\n if attr_def.get('CheckAttribute'):\n if self._validate_property(property_set.get(attr_def.get('CheckAttribute')), attr_def.get('CheckAttributeRegex')):\n matches.append(RuleMatch(error_path, message))\n else:\n matches.append(RuleMatch(error_path, message))\n if isinstance(value, dict):\n # pylint: disable=protected-access\n refs = cfn._search_deep_keys(\n 'Ref', value, error_path + [attr_def.get('Attribute')])\n for ref in refs:\n if ref[-1] == 'AWS::NoValue':\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in ref[0:-1])}'\n matches.append(RuleMatch(ref[0:-1], message))\n\n return matches\n\n def _validate_property(self, value, regex) -> bool:\n if regex.match(value):\n return True\n return False\n", "path": "src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass RetentionPeriodOnResourceTypesWithAutoExpiringContent(CloudFormationLintRule):\n \"\"\"Check for RetentionPeriod \"\"\"\n id = 'I3013'\n shortdesc = 'Check resources with auto expiring content have explicit retention period'\n description = 'The behaviour for data retention is different across AWS Services.'\\\n 'If no retention period is specified the default for some services is to delete the data after a period of time.' \\\n 'This check requires you to explicitly set the retention period for those resources to avoid unexpected data losses'\n source_url = 'https://github.com/aws-cloudformation/cfn-python-lint'\n tags = ['resources', 'retentionperiod']\n\n def _check_ref(self, value, parameters, resources, path): # pylint: disable=W0613\n print(value)\n\n def match(self, cfn):\n \"\"\"Check for RetentionPeriod\"\"\"\n matches = []\n\n retention_attributes_by_resource_type = {\n 'AWS::Kinesis::Stream': [\n {\n 'Attribute': 'RetentionPeriodHours',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-kinesis-stream.html#cfn-kinesis-stream-retentionperiodhours'\n }\n ],\n 'AWS::SQS::Queue': [\n {\n 'Attribute': 'MessageRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-sqs-queues.html#aws-sqs-queue-msgretentionperiod'\n }\n ],\n 'AWS::DocDB::DBCluster': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-docdb-dbcluster.html#cfn-docdb-dbcluster-backupretentionperiod'\n }\n ],\n 'AWS::Synthetics::Canary': [\n {\n 'Attribute': 'SuccessRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-successretentionperiod'\n },\n {\n 'Attribute': 'FailureRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-failureretentionperiod'\n }\n ],\n 'AWS::Redshift::Cluster': [\n {\n 'Attribute': 'AutomatedSnapshotRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-redshift-cluster.html#cfn-redshift-cluster-automatedsnapshotretentionperiod'\n }\n ],\n 'AWS::RDS::DBInstance': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-rds-database-instance.html#cfn-rds-dbinstance-backupretentionperiod',\n 'CheckAttribute': 'Engine',\n 'CheckAttributeRegex': re.compile('^((?!aurora).)*$'),\n }\n ],\n 'AWS::RDS::DBCluster': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbcluster.html#cfn-rds-dbcluster-backuprententionperiod'\n }\n ]\n }\n\n resources = cfn.get_resources()\n for r_name, r_values in resources.items():\n if r_values.get('Type') in retention_attributes_by_resource_type:\n for attr_def in retention_attributes_by_resource_type[r_values.get('Type')]:\n property_sets = r_values.get_safe('Properties')\n for property_set, path in property_sets:\n error_path = ['Resources', r_name] + path\n if not property_set:\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in error_path)}'\n matches.append(RuleMatch(error_path, message))\n else:\n value = property_set.get(attr_def.get('Attribute'))\n if not value:\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in error_path)}'\n if attr_def.get('CheckAttribute'):\n if self._validate_property(property_set.get(attr_def.get('CheckAttribute')), attr_def.get('CheckAttributeRegex')):\n matches.append(RuleMatch(error_path, message))\n else:\n matches.append(RuleMatch(error_path, message))\n if isinstance(value, dict):\n # pylint: disable=protected-access\n refs = cfn._search_deep_keys(\n 'Ref', value, error_path + [attr_def.get('Attribute')])\n for ref in refs:\n if ref[-1] == 'AWS::NoValue':\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in ref[0:-1])}'\n matches.append(RuleMatch(ref[0:-1], message))\n\n return matches\n\n def _validate_property(self, value, regex) -> bool:\n if isinstance(value, str):\n if regex.match(value):\n return True\n return False\n return True\n", "path": "src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py"}]}
| 2,296 | 163 |
gh_patches_debug_22069
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-8504
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Gaussian Copula: Add parameter allow_singular
The Gaussian Copula module is using scipy.stats package for the multivariate normal distribution. There is a parameter allow_singular=False which allows the covariance matrix to not have full rank. Unfortunately this parameter is not passed to the Copula interface.
It could be added here:
https://github.com/statsmodels/statsmodels/blob/55aff1e2268f56cc26b45ddcc1f44e5f924f8d05/statsmodels/distributions/copula/elliptical.py#L153
I currently wrote an inherited class, and singular matrixes for the copula seem to work fine.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `statsmodels/distributions/copula/elliptical.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri Jan 29 19:19:45 2021
4
5 Author: Josef Perktold
6 Author: Pamphile Roy
7 License: BSD-3
8
9 """
10 import numpy as np
11 from scipy import stats
12 # scipy compat:
13 from statsmodels.compat.scipy import multivariate_t
14
15 from statsmodels.distributions.copula.copulas import Copula
16
17
18 class EllipticalCopula(Copula):
19 """Base class for elliptical copula
20
21 This class requires subclassing and currently does not have generic
22 methods based on an elliptical generator.
23
24 Notes
25 -----
26 Elliptical copulas require that copula parameters are set when the
27 instance is created. Those parameters currently cannot be provided in the
28 call to methods. (This will most likely change in future versions.)
29 If non-empty ``args`` are provided in methods, then a ValueError is raised.
30 The ``args`` keyword is provided for a consistent interface across
31 copulas.
32
33 """
34 def _handle_args(self, args):
35 if args != () and args is not None:
36 msg = ("Methods in elliptical copulas use copula parameters in"
37 " attributes. `arg` in the method is ignored")
38 raise ValueError(msg)
39 else:
40 return args
41
42 def rvs(self, nobs=1, args=(), random_state=None):
43 self._handle_args(args)
44 x = self.distr_mv.rvs(size=nobs, random_state=random_state)
45 return self.distr_uv.cdf(x)
46
47 def pdf(self, u, args=()):
48 self._handle_args(args)
49 ppf = self.distr_uv.ppf(u)
50 mv_pdf_ppf = self.distr_mv.pdf(ppf)
51
52 return mv_pdf_ppf / np.prod(self.distr_uv.pdf(ppf), axis=-1)
53
54 def cdf(self, u, args=()):
55 self._handle_args(args)
56 ppf = self.distr_uv.ppf(u)
57 return self.distr_mv.cdf(ppf)
58
59 def tau(self, corr=None):
60 """Bivariate kendall's tau based on correlation coefficient.
61
62 Parameters
63 ----------
64 corr : None or float
65 Pearson correlation. If corr is None, then the correlation will be
66 taken from the copula attribute.
67
68 Returns
69 -------
70 Kendall's tau that corresponds to pearson correlation in the
71 elliptical copula.
72 """
73 if corr is None:
74 corr = self.corr
75 if corr.shape == (2, 2):
76 corr = corr[0, 1]
77 rho = 2 * np.arcsin(corr) / np.pi
78 return rho
79
80 def corr_from_tau(self, tau):
81 """Pearson correlation from kendall's tau.
82
83 Parameters
84 ----------
85 tau : array_like
86 Kendall's tau correlation coefficient.
87
88 Returns
89 -------
90 Pearson correlation coefficient for given tau in elliptical
91 copula. This can be used as parameter for an elliptical copula.
92 """
93 corr = np.sin(tau * np.pi / 2)
94 return corr
95
96
97 class GaussianCopula(EllipticalCopula):
98 r"""Gaussian copula.
99
100 It is constructed from a multivariate normal distribution over
101 :math:`\mathbb{R}^d` by using the probability integral transform.
102
103 For a given correlation matrix :math:`R \in[-1, 1]^{d \times d}`,
104 the Gaussian copula with parameter matrix :math:`R` can be written
105 as:
106
107 .. math::
108
109 C_R^{\text{Gauss}}(u) = \Phi_R\left(\Phi^{-1}(u_1),\dots,
110 \Phi^{-1}(u_d) \right),
111
112 where :math:`\Phi^{-1}` is the inverse cumulative distribution function
113 of a standard normal and :math:`\Phi_R` is the joint cumulative
114 distribution function of a multivariate normal distribution with mean
115 vector zero and covariance matrix equal to the correlation
116 matrix :math:`R`.
117
118 Parameters
119 ----------
120 corr : scalar or array_like
121 Correlation or scatter matrix for the elliptical copula. In the
122 bivariate case, ``corr` can be a scalar and is then considered as
123 the correlation coefficient. If ``corr`` is None, then the scatter
124 matrix is the identity matrix.
125 k_dim : int
126 Dimension, number of components in the multivariate random variable.
127
128 Notes
129 -----
130 Elliptical copulas require that copula parameters are set when the
131 instance is created. Those parameters currently cannot be provided in the
132 call to methods. (This will most likely change in future versions.)
133 If non-empty ``args`` are provided in methods, then a ValueError is raised.
134 The ``args`` keyword is provided for a consistent interface across
135 copulas.
136
137 References
138 ----------
139 .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.
140 p. 163
141
142 """
143
144 def __init__(self, corr=None, k_dim=2):
145 super().__init__(k_dim=k_dim)
146 if corr is None:
147 corr = np.eye(k_dim)
148 elif k_dim == 2 and np.size(corr) == 1:
149 corr = np.array([[1., corr], [corr, 1.]])
150
151 self.corr = np.asarray(corr)
152 self.distr_uv = stats.norm
153 self.distr_mv = stats.multivariate_normal(cov=corr)
154
155 def dependence_tail(self, corr=None):
156 """
157 Bivariate tail dependence parameter.
158
159 Joe (2014) p. 182
160
161 Parameters
162 ----------
163 corr : any
164 Tail dependence for Gaussian copulas is always zero.
165 Argument will be ignored
166
167 Returns
168 -------
169 Lower and upper tail dependence coefficients of the copula with given
170 Pearson correlation coefficient.
171 """
172
173 return 0, 0
174
175 def _arg_from_tau(self, tau):
176 # for generic compat
177 return self.corr_from_tau(tau)
178
179
180 class StudentTCopula(EllipticalCopula):
181 """Student t copula.
182
183 Parameters
184 ----------
185 corr : scalar or array_like
186 Correlation or scatter matrix for the elliptical copula. In the
187 bivariate case, ``corr` can be a scalar and is then considered as
188 the correlation coefficient. If ``corr`` is None, then the scatter
189 matrix is the identity matrix.
190 df : float (optional)
191 Degrees of freedom of the multivariate t distribution.
192 k_dim : int
193 Dimension, number of components in the multivariate random variable.
194
195 Notes
196 -----
197 Elliptical copulas require that copula parameters are set when the
198 instance is created. Those parameters currently cannot be provided in the
199 call to methods. (This will most likely change in future versions.)
200 If non-empty ``args`` are provided in methods, then a ValueError is raised.
201 The ``args`` keyword is provided for a consistent interface across
202 copulas.
203
204 References
205 ----------
206 .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.
207 p. 181
208 """
209
210 def __init__(self, corr=None, df=None, k_dim=2):
211 super().__init__(k_dim=k_dim)
212 if corr is None:
213 corr = np.eye(k_dim)
214 elif k_dim == 2 and np.size(corr) == 1:
215 corr = np.array([[1., corr], [corr, 1.]])
216
217 self.df = df
218 self.corr = np.asarray(corr)
219 # both uv and mv are frozen distributions
220 self.distr_uv = stats.t(df=df)
221 self.distr_mv = multivariate_t(shape=corr, df=df)
222
223 def cdf(self, u, args=()):
224 raise NotImplementedError("CDF not available in closed form.")
225 # ppf = self.distr_uv.ppf(u)
226 # mvt = MVT([0, 0], self.corr, self.df)
227 # return mvt.cdf(ppf)
228
229 def spearmans_rho(self, corr=None):
230 """
231 Bivariate Spearman's rho based on correlation coefficient.
232
233 Joe (2014) p. 182
234
235 Parameters
236 ----------
237 corr : None or float
238 Pearson correlation. If corr is None, then the correlation will be
239 taken from the copula attribute.
240
241 Returns
242 -------
243 Spearman's rho that corresponds to pearson correlation in the
244 elliptical copula.
245 """
246 if corr is None:
247 corr = self.corr
248 if corr.shape == (2, 2):
249 corr = corr[0, 1]
250
251 tau = 6 * np.arcsin(corr / 2) / np.pi
252 return tau
253
254 def dependence_tail(self, corr=None):
255 """
256 Bivariate tail dependence parameter.
257
258 Joe (2014) p. 182
259
260 Parameters
261 ----------
262 corr : None or float
263 Pearson correlation. If corr is None, then the correlation will be
264 taken from the copula attribute.
265
266 Returns
267 -------
268 Lower and upper tail dependence coefficients of the copula with given
269 Pearson correlation coefficient.
270 """
271 if corr is None:
272 corr = self.corr
273 if corr.shape == (2, 2):
274 corr = corr[0, 1]
275
276 df = self.df
277 t = - np.sqrt((df + 1) * (1 - corr) / 1 + corr)
278 # Note self.distr_uv is frozen, df cannot change, use stats.t instead
279 lam = 2 * stats.t.cdf(t, df + 1)
280 return lam, lam
281
282 def _arg_from_tau(self, tau):
283 # for generic compat
284 # this does not provide an estimate of df
285 return self.corr_from_tau(tau)
286
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/statsmodels/distributions/copula/elliptical.py b/statsmodels/distributions/copula/elliptical.py
--- a/statsmodels/distributions/copula/elliptical.py
+++ b/statsmodels/distributions/copula/elliptical.py
@@ -124,6 +124,8 @@
matrix is the identity matrix.
k_dim : int
Dimension, number of components in the multivariate random variable.
+ allow_singular : bool
+ Allow singular correlation matrix
Notes
-----
@@ -141,7 +143,7 @@
"""
- def __init__(self, corr=None, k_dim=2):
+ def __init__(self, corr=None, k_dim=2, allow_singular=False):
super().__init__(k_dim=k_dim)
if corr is None:
corr = np.eye(k_dim)
@@ -150,7 +152,8 @@
self.corr = np.asarray(corr)
self.distr_uv = stats.norm
- self.distr_mv = stats.multivariate_normal(cov=corr)
+ self.distr_mv = stats.multivariate_normal(
+ cov=corr, allow_singular=allow_singular)
def dependence_tail(self, corr=None):
"""
|
{"golden_diff": "diff --git a/statsmodels/distributions/copula/elliptical.py b/statsmodels/distributions/copula/elliptical.py\n--- a/statsmodels/distributions/copula/elliptical.py\n+++ b/statsmodels/distributions/copula/elliptical.py\n@@ -124,6 +124,8 @@\n matrix is the identity matrix.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n+ allow_singular : bool\n+ Allow singular correlation matrix\n \n Notes\n -----\n@@ -141,7 +143,7 @@\n \n \"\"\"\n \n- def __init__(self, corr=None, k_dim=2):\n+ def __init__(self, corr=None, k_dim=2, allow_singular=False):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n@@ -150,7 +152,8 @@\n \n self.corr = np.asarray(corr)\n self.distr_uv = stats.norm\n- self.distr_mv = stats.multivariate_normal(cov=corr)\n+ self.distr_mv = stats.multivariate_normal(\n+ cov=corr, allow_singular=allow_singular)\n \n def dependence_tail(self, corr=None):\n \"\"\"\n", "issue": "Gaussian Copula: Add parameter allow_singular\nThe Gaussian Copula module is using scipy.stats package for the multivariate normal distribution. There is a parameter allow_singular=False which allows the covariance matrix to not have full rank. Unfortunately this parameter is not passed to the Copula interface.\r\n\r\nIt could be added here:\r\nhttps://github.com/statsmodels/statsmodels/blob/55aff1e2268f56cc26b45ddcc1f44e5f924f8d05/statsmodels/distributions/copula/elliptical.py#L153\r\n\r\nI currently wrote an inherited class, and singular matrixes for the copula seem to work fine.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jan 29 19:19:45 2021\n\nAuthor: Josef Perktold\nAuthor: Pamphile Roy\nLicense: BSD-3\n\n\"\"\"\nimport numpy as np\nfrom scipy import stats\n# scipy compat:\nfrom statsmodels.compat.scipy import multivariate_t\n\nfrom statsmodels.distributions.copula.copulas import Copula\n\n\nclass EllipticalCopula(Copula):\n \"\"\"Base class for elliptical copula\n\n This class requires subclassing and currently does not have generic\n methods based on an elliptical generator.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n \"\"\"\n def _handle_args(self, args):\n if args != () and args is not None:\n msg = (\"Methods in elliptical copulas use copula parameters in\"\n \" attributes. `arg` in the method is ignored\")\n raise ValueError(msg)\n else:\n return args\n\n def rvs(self, nobs=1, args=(), random_state=None):\n self._handle_args(args)\n x = self.distr_mv.rvs(size=nobs, random_state=random_state)\n return self.distr_uv.cdf(x)\n\n def pdf(self, u, args=()):\n self._handle_args(args)\n ppf = self.distr_uv.ppf(u)\n mv_pdf_ppf = self.distr_mv.pdf(ppf)\n\n return mv_pdf_ppf / np.prod(self.distr_uv.pdf(ppf), axis=-1)\n\n def cdf(self, u, args=()):\n self._handle_args(args)\n ppf = self.distr_uv.ppf(u)\n return self.distr_mv.cdf(ppf)\n\n def tau(self, corr=None):\n \"\"\"Bivariate kendall's tau based on correlation coefficient.\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Kendall's tau that corresponds to pearson correlation in the\n elliptical copula.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n rho = 2 * np.arcsin(corr) / np.pi\n return rho\n\n def corr_from_tau(self, tau):\n \"\"\"Pearson correlation from kendall's tau.\n\n Parameters\n ----------\n tau : array_like\n Kendall's tau correlation coefficient.\n\n Returns\n -------\n Pearson correlation coefficient for given tau in elliptical\n copula. This can be used as parameter for an elliptical copula.\n \"\"\"\n corr = np.sin(tau * np.pi / 2)\n return corr\n\n\nclass GaussianCopula(EllipticalCopula):\n r\"\"\"Gaussian copula.\n\n It is constructed from a multivariate normal distribution over\n :math:`\\mathbb{R}^d` by using the probability integral transform.\n\n For a given correlation matrix :math:`R \\in[-1, 1]^{d \\times d}`,\n the Gaussian copula with parameter matrix :math:`R` can be written\n as:\n\n .. math::\n\n C_R^{\\text{Gauss}}(u) = \\Phi_R\\left(\\Phi^{-1}(u_1),\\dots,\n \\Phi^{-1}(u_d) \\right),\n\n where :math:`\\Phi^{-1}` is the inverse cumulative distribution function\n of a standard normal and :math:`\\Phi_R` is the joint cumulative\n distribution function of a multivariate normal distribution with mean\n vector zero and covariance matrix equal to the correlation\n matrix :math:`R`.\n\n Parameters\n ----------\n corr : scalar or array_like\n Correlation or scatter matrix for the elliptical copula. In the\n bivariate case, ``corr` can be a scalar and is then considered as\n the correlation coefficient. If ``corr`` is None, then the scatter\n matrix is the identity matrix.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n References\n ----------\n .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.\n p. 163\n\n \"\"\"\n\n def __init__(self, corr=None, k_dim=2):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n elif k_dim == 2 and np.size(corr) == 1:\n corr = np.array([[1., corr], [corr, 1.]])\n\n self.corr = np.asarray(corr)\n self.distr_uv = stats.norm\n self.distr_mv = stats.multivariate_normal(cov=corr)\n\n def dependence_tail(self, corr=None):\n \"\"\"\n Bivariate tail dependence parameter.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : any\n Tail dependence for Gaussian copulas is always zero.\n Argument will be ignored\n\n Returns\n -------\n Lower and upper tail dependence coefficients of the copula with given\n Pearson correlation coefficient.\n \"\"\"\n\n return 0, 0\n\n def _arg_from_tau(self, tau):\n # for generic compat\n return self.corr_from_tau(tau)\n\n\nclass StudentTCopula(EllipticalCopula):\n \"\"\"Student t copula.\n\n Parameters\n ----------\n corr : scalar or array_like\n Correlation or scatter matrix for the elliptical copula. In the\n bivariate case, ``corr` can be a scalar and is then considered as\n the correlation coefficient. If ``corr`` is None, then the scatter\n matrix is the identity matrix.\n df : float (optional)\n Degrees of freedom of the multivariate t distribution.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n References\n ----------\n .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.\n p. 181\n \"\"\"\n\n def __init__(self, corr=None, df=None, k_dim=2):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n elif k_dim == 2 and np.size(corr) == 1:\n corr = np.array([[1., corr], [corr, 1.]])\n\n self.df = df\n self.corr = np.asarray(corr)\n # both uv and mv are frozen distributions\n self.distr_uv = stats.t(df=df)\n self.distr_mv = multivariate_t(shape=corr, df=df)\n\n def cdf(self, u, args=()):\n raise NotImplementedError(\"CDF not available in closed form.\")\n # ppf = self.distr_uv.ppf(u)\n # mvt = MVT([0, 0], self.corr, self.df)\n # return mvt.cdf(ppf)\n\n def spearmans_rho(self, corr=None):\n \"\"\"\n Bivariate Spearman's rho based on correlation coefficient.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Spearman's rho that corresponds to pearson correlation in the\n elliptical copula.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n\n tau = 6 * np.arcsin(corr / 2) / np.pi\n return tau\n\n def dependence_tail(self, corr=None):\n \"\"\"\n Bivariate tail dependence parameter.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Lower and upper tail dependence coefficients of the copula with given\n Pearson correlation coefficient.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n\n df = self.df\n t = - np.sqrt((df + 1) * (1 - corr) / 1 + corr)\n # Note self.distr_uv is frozen, df cannot change, use stats.t instead\n lam = 2 * stats.t.cdf(t, df + 1)\n return lam, lam\n\n def _arg_from_tau(self, tau):\n # for generic compat\n # this does not provide an estimate of df\n return self.corr_from_tau(tau)\n", "path": "statsmodels/distributions/copula/elliptical.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jan 29 19:19:45 2021\n\nAuthor: Josef Perktold\nAuthor: Pamphile Roy\nLicense: BSD-3\n\n\"\"\"\nimport numpy as np\nfrom scipy import stats\n# scipy compat:\nfrom statsmodels.compat.scipy import multivariate_t\n\nfrom statsmodels.distributions.copula.copulas import Copula\n\n\nclass EllipticalCopula(Copula):\n \"\"\"Base class for elliptical copula\n\n This class requires subclassing and currently does not have generic\n methods based on an elliptical generator.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n \"\"\"\n def _handle_args(self, args):\n if args != () and args is not None:\n msg = (\"Methods in elliptical copulas use copula parameters in\"\n \" attributes. `arg` in the method is ignored\")\n raise ValueError(msg)\n else:\n return args\n\n def rvs(self, nobs=1, args=(), random_state=None):\n self._handle_args(args)\n x = self.distr_mv.rvs(size=nobs, random_state=random_state)\n return self.distr_uv.cdf(x)\n\n def pdf(self, u, args=()):\n self._handle_args(args)\n ppf = self.distr_uv.ppf(u)\n mv_pdf_ppf = self.distr_mv.pdf(ppf)\n\n return mv_pdf_ppf / np.prod(self.distr_uv.pdf(ppf), axis=-1)\n\n def cdf(self, u, args=()):\n self._handle_args(args)\n ppf = self.distr_uv.ppf(u)\n return self.distr_mv.cdf(ppf)\n\n def tau(self, corr=None):\n \"\"\"Bivariate kendall's tau based on correlation coefficient.\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Kendall's tau that corresponds to pearson correlation in the\n elliptical copula.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n rho = 2 * np.arcsin(corr) / np.pi\n return rho\n\n def corr_from_tau(self, tau):\n \"\"\"Pearson correlation from kendall's tau.\n\n Parameters\n ----------\n tau : array_like\n Kendall's tau correlation coefficient.\n\n Returns\n -------\n Pearson correlation coefficient for given tau in elliptical\n copula. This can be used as parameter for an elliptical copula.\n \"\"\"\n corr = np.sin(tau * np.pi / 2)\n return corr\n\n\nclass GaussianCopula(EllipticalCopula):\n r\"\"\"Gaussian copula.\n\n It is constructed from a multivariate normal distribution over\n :math:`\\mathbb{R}^d` by using the probability integral transform.\n\n For a given correlation matrix :math:`R \\in[-1, 1]^{d \\times d}`,\n the Gaussian copula with parameter matrix :math:`R` can be written\n as:\n\n .. math::\n\n C_R^{\\text{Gauss}}(u) = \\Phi_R\\left(\\Phi^{-1}(u_1),\\dots,\n \\Phi^{-1}(u_d) \\right),\n\n where :math:`\\Phi^{-1}` is the inverse cumulative distribution function\n of a standard normal and :math:`\\Phi_R` is the joint cumulative\n distribution function of a multivariate normal distribution with mean\n vector zero and covariance matrix equal to the correlation\n matrix :math:`R`.\n\n Parameters\n ----------\n corr : scalar or array_like\n Correlation or scatter matrix for the elliptical copula. In the\n bivariate case, ``corr` can be a scalar and is then considered as\n the correlation coefficient. If ``corr`` is None, then the scatter\n matrix is the identity matrix.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n allow_singular : bool\n Allow singular correlation matrix\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n References\n ----------\n .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.\n p. 163\n\n \"\"\"\n\n def __init__(self, corr=None, k_dim=2, allow_singular=False):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n elif k_dim == 2 and np.size(corr) == 1:\n corr = np.array([[1., corr], [corr, 1.]])\n\n self.corr = np.asarray(corr)\n self.distr_uv = stats.norm\n self.distr_mv = stats.multivariate_normal(\n cov=corr, allow_singular=allow_singular)\n\n def dependence_tail(self, corr=None):\n \"\"\"\n Bivariate tail dependence parameter.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : any\n Tail dependence for Gaussian copulas is always zero.\n Argument will be ignored\n\n Returns\n -------\n Lower and upper tail dependence coefficients of the copula with given\n Pearson correlation coefficient.\n \"\"\"\n\n return 0, 0\n\n def _arg_from_tau(self, tau):\n # for generic compat\n return self.corr_from_tau(tau)\n\n\nclass StudentTCopula(EllipticalCopula):\n \"\"\"Student t copula.\n\n Parameters\n ----------\n corr : scalar or array_like\n Correlation or scatter matrix for the elliptical copula. In the\n bivariate case, ``corr` can be a scalar and is then considered as\n the correlation coefficient. If ``corr`` is None, then the scatter\n matrix is the identity matrix.\n df : float (optional)\n Degrees of freedom of the multivariate t distribution.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n References\n ----------\n .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.\n p. 181\n \"\"\"\n\n def __init__(self, corr=None, df=None, k_dim=2):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n elif k_dim == 2 and np.size(corr) == 1:\n corr = np.array([[1., corr], [corr, 1.]])\n\n self.df = df\n self.corr = np.asarray(corr)\n # both uv and mv are frozen distributions\n self.distr_uv = stats.t(df=df)\n self.distr_mv = multivariate_t(shape=corr, df=df)\n\n def cdf(self, u, args=()):\n raise NotImplementedError(\"CDF not available in closed form.\")\n # ppf = self.distr_uv.ppf(u)\n # mvt = MVT([0, 0], self.corr, self.df)\n # return mvt.cdf(ppf)\n\n def spearmans_rho(self, corr=None):\n \"\"\"\n Bivariate Spearman's rho based on correlation coefficient.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Spearman's rho that corresponds to pearson correlation in the\n elliptical copula.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n\n tau = 6 * np.arcsin(corr / 2) / np.pi\n return tau\n\n def dependence_tail(self, corr=None):\n \"\"\"\n Bivariate tail dependence parameter.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Lower and upper tail dependence coefficients of the copula with given\n Pearson correlation coefficient.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n\n df = self.df\n t = - np.sqrt((df + 1) * (1 - corr) / 1 + corr)\n # Note self.distr_uv is frozen, df cannot change, use stats.t instead\n lam = 2 * stats.t.cdf(t, df + 1)\n return lam, lam\n\n def _arg_from_tau(self, tau):\n # for generic compat\n # this does not provide an estimate of df\n return self.corr_from_tau(tau)\n", "path": "statsmodels/distributions/copula/elliptical.py"}]}
| 3,377 | 279 |
gh_patches_debug_9198
|
rasdani/github-patches
|
git_diff
|
sotetsuk__pgx-792
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Docs] Add PyPI description
Currently, it's empty.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import find_packages, setup
2
3 setup(
4 name="pgx",
5 version="0.4.0",
6 long_description_content_type="text/markdown",
7 description="",
8 url="",
9 author="Sotetsu KOYAMADA",
10 author_email="[email protected]",
11 keywords="",
12 packages=find_packages(),
13 package_data={"": ["LICENSE", "*.svg"]},
14 include_package_data=True,
15 install_requires=[
16 "jax>=0.3.25", # JAX version on Colab (TPU)
17 "chex>=0.1.6",
18 "svgwrite",
19 "msgpack",
20 "typing_extensions"
21 ],
22 classifiers=[
23 "Programming Language :: Python :: 3.8",
24 "Programming Language :: Python :: 3.9",
25 "Programming Language :: Python :: 3.10",
26 ],
27 )
28
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,10 +1,14 @@
from setuptools import find_packages, setup
+from pathlib import Path
+
+long_description = (Path(__file__).parent / "README.md").read_text()
setup(
name="pgx",
version="0.4.0",
- long_description_content_type="text/markdown",
- description="",
+ description="GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL)",
+ long_description=long_description,
+ long_description_content_type='text/markdown',
url="",
author="Sotetsu KOYAMADA",
author_email="[email protected]",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,10 +1,14 @@\n from setuptools import find_packages, setup\n+from pathlib import Path\n+\n+long_description = (Path(__file__).parent / \"README.md\").read_text()\n \n setup(\n name=\"pgx\",\n version=\"0.4.0\",\n- long_description_content_type=\"text/markdown\",\n- description=\"\",\n+ description=\"GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL)\",\n+ long_description=long_description,\n+ long_description_content_type='text/markdown',\n url=\"\",\n author=\"Sotetsu KOYAMADA\",\n author_email=\"[email protected]\",\n", "issue": "[Docs] Add PyPI description\nCurrently, it's empty.\n", "before_files": [{"content": "from setuptools import find_packages, setup\n\nsetup(\n name=\"pgx\",\n version=\"0.4.0\",\n long_description_content_type=\"text/markdown\",\n description=\"\",\n url=\"\",\n author=\"Sotetsu KOYAMADA\",\n author_email=\"[email protected]\",\n keywords=\"\",\n packages=find_packages(),\n package_data={\"\": [\"LICENSE\", \"*.svg\"]},\n include_package_data=True,\n install_requires=[\n \"jax>=0.3.25\", # JAX version on Colab (TPU)\n \"chex>=0.1.6\",\n \"svgwrite\",\n \"msgpack\",\n \"typing_extensions\"\n ],\n classifiers=[\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import find_packages, setup\nfrom pathlib import Path\n\nlong_description = (Path(__file__).parent / \"README.md\").read_text()\n\nsetup(\n name=\"pgx\",\n version=\"0.4.0\",\n description=\"GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL)\",\n long_description=long_description,\n long_description_content_type='text/markdown',\n url=\"\",\n author=\"Sotetsu KOYAMADA\",\n author_email=\"[email protected]\",\n keywords=\"\",\n packages=find_packages(),\n package_data={\"\": [\"LICENSE\", \"*.svg\"]},\n include_package_data=True,\n install_requires=[\n \"jax>=0.3.25\", # JAX version on Colab (TPU)\n \"chex>=0.1.6\",\n \"svgwrite\",\n \"msgpack\",\n \"typing_extensions\"\n ],\n classifiers=[\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}]}
| 513 | 171 |
gh_patches_debug_4915
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1856
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Searching a queryset of a specific page class with a child_of/descendant_of filter gives error
Searching on a specific page class with the `child_of`/`descendant_of` filter applied, gives the following error:
```
FieldError at /videos/
Cannot filter search results with field "page_ptr_id". Please add index.FilterField('page_ptr_id') to VideoPage.search_fields.
```
Here's an example query that causes this:
``` python
VideoPage.objects.child_of(parent_page).search("foo")
```
It seems to be a combination of a specific queryset and `child_of`/`descendant_of` filter that causes the issue as the following query (which uses the generic page model) works.
``` python
Page.objects.child_of(parent_page).type(VideoPage).search("foo")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailsearch/backends/base.py`
Content:
```
1
2 from django.db.models.query import QuerySet
3 from django.db.models.lookups import Lookup
4 from django.db.models.sql.where import SubqueryConstraint, WhereNode
5 from django.utils.six import text_type
6
7 from wagtail.wagtailsearch.index import class_is_indexed
8
9
10 class FilterError(Exception):
11 pass
12
13
14 class FieldError(Exception):
15 pass
16
17
18 class BaseSearchQuery(object):
19 DEFAULT_OPERATOR = 'or'
20
21 def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):
22 self.queryset = queryset
23 self.query_string = query_string
24 self.fields = fields
25 self.operator = operator or self.DEFAULT_OPERATOR
26 self.order_by_relevance = order_by_relevance
27
28 def _get_searchable_field(self, field_attname):
29 # Get field
30 field = dict(
31 (field.get_attname(self.queryset.model), field)
32 for field in self.queryset.model.get_searchable_search_fields()
33 ).get(field_attname, None)
34
35 return field
36
37 def _get_filterable_field(self, field_attname):
38 # Get field
39 field = dict(
40 (field.get_attname(self.queryset.model), field)
41 for field in self.queryset.model.get_filterable_search_fields()
42 ).get(field_attname, None)
43
44 return field
45
46 def _process_lookup(self, field, lookup, value):
47 raise NotImplementedError
48
49 def _connect_filters(self, filters, connector, negated):
50 raise NotImplementedError
51
52 def _process_filter(self, field_attname, lookup, value):
53 # Get the field
54 field = self._get_filterable_field(field_attname)
55
56 if field is None:
57 raise FieldError('Cannot filter search results with field "' + field_attname + '". Please add index.FilterField(\'' + field_attname + '\') to ' + self.queryset.model.__name__ + '.search_fields.')
58
59 # Process the lookup
60 result = self._process_lookup(field, lookup, value)
61
62 if result is None:
63 raise FilterError('Could not apply filter on search results: "' + field_attname + '__' + lookup + ' = ' + text_type(value) + '". Lookup "' + lookup + '"" not recognosed.')
64
65 return result
66
67 def _get_filters_from_where_node(self, where_node):
68 # Check if this is a leaf node
69 if isinstance(where_node, Lookup):
70 field_attname = where_node.lhs.target.attname
71 lookup = where_node.lookup_name
72 value = where_node.rhs
73
74 # Process the filter
75 return self._process_filter(field_attname, lookup, value)
76
77 elif isinstance(where_node, SubqueryConstraint):
78 raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')
79
80 elif isinstance(where_node, WhereNode):
81 # Get child filters
82 connector = where_node.connector
83 child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]
84 child_filters = [child_filter for child_filter in child_filters if child_filter]
85
86 return self._connect_filters(child_filters, connector, where_node.negated)
87
88 else:
89 raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))
90
91 def _get_filters_from_queryset(self):
92 return self._get_filters_from_where_node(self.queryset.query.where)
93
94
95 class BaseSearchResults(object):
96 def __init__(self, backend, query, prefetch_related=None):
97 self.backend = backend
98 self.query = query
99 self.prefetch_related = prefetch_related
100 self.start = 0
101 self.stop = None
102 self._results_cache = None
103 self._count_cache = None
104
105 def _set_limits(self, start=None, stop=None):
106 if stop is not None:
107 if self.stop is not None:
108 self.stop = min(self.stop, self.start + stop)
109 else:
110 self.stop = self.start + stop
111
112 if start is not None:
113 if self.stop is not None:
114 self.start = min(self.stop, self.start + start)
115 else:
116 self.start = self.start + start
117
118 def _clone(self):
119 klass = self.__class__
120 new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)
121 new.start = self.start
122 new.stop = self.stop
123 return new
124
125 def _do_search(self):
126 raise NotImplementedError
127
128 def _do_count(self):
129 raise NotImplementedError
130
131 def results(self):
132 if self._results_cache is None:
133 self._results_cache = self._do_search()
134 return self._results_cache
135
136 def count(self):
137 if self._count_cache is None:
138 if self._results_cache is not None:
139 self._count_cache = len(self._results_cache)
140 else:
141 self._count_cache = self._do_count()
142 return self._count_cache
143
144 def __getitem__(self, key):
145 new = self._clone()
146
147 if isinstance(key, slice):
148 # Set limits
149 start = int(key.start) if key.start else None
150 stop = int(key.stop) if key.stop else None
151 new._set_limits(start, stop)
152
153 # Copy results cache
154 if self._results_cache is not None:
155 new._results_cache = self._results_cache[key]
156
157 return new
158 else:
159 if self._results_cache is not None:
160 return self._results_cache[key]
161
162 new.start = self.start + key
163 new.stop = self.start + key + 1
164 return list(new)[0]
165
166 def __iter__(self):
167 return iter(self.results())
168
169 def __len__(self):
170 return len(self.results())
171
172 def __repr__(self):
173 data = list(self[:21])
174 if len(data) > 20:
175 data[-1] = "...(remaining elements truncated)..."
176 return repr(data)
177
178
179 class BaseSearch(object):
180 search_query_class = None
181 search_results_class = None
182
183 def __init__(self, params):
184 pass
185
186 def get_rebuilder(self):
187 return None
188
189 def reset_index(self):
190 raise NotImplementedError
191
192 def add_type(self, model):
193 raise NotImplementedError
194
195 def refresh_index(self):
196 raise NotImplementedError
197
198 def add(self, obj):
199 raise NotImplementedError
200
201 def add_bulk(self, model, obj_list):
202 raise NotImplementedError
203
204 def delete(self, obj):
205 raise NotImplementedError
206
207 def search(self, query_string, model_or_queryset, fields=None, filters=None, prefetch_related=None, operator=None, order_by_relevance=True):
208 # Find model/queryset
209 if isinstance(model_or_queryset, QuerySet):
210 model = model_or_queryset.model
211 queryset = model_or_queryset
212 else:
213 model = model_or_queryset
214 queryset = model_or_queryset.objects.all()
215
216 # Model must be a class that is in the index
217 if not class_is_indexed(model):
218 return []
219
220 # Check that theres still a query string after the clean up
221 if query_string == "":
222 return []
223
224 # Apply filters to queryset
225 if filters:
226 queryset = queryset.filter(**filters)
227
228 # Prefetch related
229 if prefetch_related:
230 for prefetch in prefetch_related:
231 queryset = queryset.prefetch_related(prefetch)
232
233 # Check operator
234 if operator is not None:
235 operator = operator.lower()
236 if operator not in ['or', 'and']:
237 raise ValueError("operator must be either 'or' or 'and'")
238
239 # Search
240 search_query = self.search_query_class(queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance)
241 return self.search_results_class(self, search_query)
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailsearch/backends/base.py b/wagtail/wagtailsearch/backends/base.py
--- a/wagtail/wagtailsearch/backends/base.py
+++ b/wagtail/wagtailsearch/backends/base.py
@@ -71,6 +71,10 @@
lookup = where_node.lookup_name
value = where_node.rhs
+ # Ignore pointer fields that show up in specific page type queries
+ if field_attname.endswith('_ptr_id'):
+ return
+
# Process the filter
return self._process_filter(field_attname, lookup, value)
|
{"golden_diff": "diff --git a/wagtail/wagtailsearch/backends/base.py b/wagtail/wagtailsearch/backends/base.py\n--- a/wagtail/wagtailsearch/backends/base.py\n+++ b/wagtail/wagtailsearch/backends/base.py\n@@ -71,6 +71,10 @@\n lookup = where_node.lookup_name\n value = where_node.rhs\n \n+ # Ignore pointer fields that show up in specific page type queries\n+ if field_attname.endswith('_ptr_id'):\n+ return\n+\n # Process the filter\n return self._process_filter(field_attname, lookup, value)\n", "issue": "Searching a queryset of a specific page class with a child_of/descendant_of filter gives error\nSearching on a specific page class with the `child_of`/`descendant_of` filter applied, gives the following error:\n\n```\nFieldError at /videos/\n\nCannot filter search results with field \"page_ptr_id\". Please add index.FilterField('page_ptr_id') to VideoPage.search_fields.\n```\n\nHere's an example query that causes this:\n\n``` python\nVideoPage.objects.child_of(parent_page).search(\"foo\")\n```\n\nIt seems to be a combination of a specific queryset and `child_of`/`descendant_of` filter that causes the issue as the following query (which uses the generic page model) works.\n\n``` python\nPage.objects.child_of(parent_page).type(VideoPage).search(\"foo\")\n```\n\n", "before_files": [{"content": "\nfrom django.db.models.query import QuerySet\nfrom django.db.models.lookups import Lookup\nfrom django.db.models.sql.where import SubqueryConstraint, WhereNode\nfrom django.utils.six import text_type\n\nfrom wagtail.wagtailsearch.index import class_is_indexed\n\n\nclass FilterError(Exception):\n pass\n\n\nclass FieldError(Exception):\n pass\n\n\nclass BaseSearchQuery(object):\n DEFAULT_OPERATOR = 'or'\n\n def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):\n self.queryset = queryset\n self.query_string = query_string\n self.fields = fields\n self.operator = operator or self.DEFAULT_OPERATOR\n self.order_by_relevance = order_by_relevance\n\n def _get_searchable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_searchable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _get_filterable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_filterable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _process_lookup(self, field, lookup, value):\n raise NotImplementedError\n\n def _connect_filters(self, filters, connector, negated):\n raise NotImplementedError\n\n def _process_filter(self, field_attname, lookup, value):\n # Get the field\n field = self._get_filterable_field(field_attname)\n\n if field is None:\n raise FieldError('Cannot filter search results with field \"' + field_attname + '\". Please add index.FilterField(\\'' + field_attname + '\\') to ' + self.queryset.model.__name__ + '.search_fields.')\n\n # Process the lookup\n result = self._process_lookup(field, lookup, value)\n\n if result is None:\n raise FilterError('Could not apply filter on search results: \"' + field_attname + '__' + lookup + ' = ' + text_type(value) + '\". Lookup \"' + lookup + '\"\" not recognosed.')\n\n return result\n\n def _get_filters_from_where_node(self, where_node):\n # Check if this is a leaf node\n if isinstance(where_node, Lookup):\n field_attname = where_node.lhs.target.attname\n lookup = where_node.lookup_name\n value = where_node.rhs\n\n # Process the filter\n return self._process_filter(field_attname, lookup, value)\n\n elif isinstance(where_node, SubqueryConstraint):\n raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')\n\n elif isinstance(where_node, WhereNode):\n # Get child filters\n connector = where_node.connector\n child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]\n child_filters = [child_filter for child_filter in child_filters if child_filter]\n\n return self._connect_filters(child_filters, connector, where_node.negated)\n\n else:\n raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))\n\n def _get_filters_from_queryset(self):\n return self._get_filters_from_where_node(self.queryset.query.where)\n\n\nclass BaseSearchResults(object):\n def __init__(self, backend, query, prefetch_related=None):\n self.backend = backend\n self.query = query\n self.prefetch_related = prefetch_related\n self.start = 0\n self.stop = None\n self._results_cache = None\n self._count_cache = None\n\n def _set_limits(self, start=None, stop=None):\n if stop is not None:\n if self.stop is not None:\n self.stop = min(self.stop, self.start + stop)\n else:\n self.stop = self.start + stop\n\n if start is not None:\n if self.stop is not None:\n self.start = min(self.stop, self.start + start)\n else:\n self.start = self.start + start\n\n def _clone(self):\n klass = self.__class__\n new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)\n new.start = self.start\n new.stop = self.stop\n return new\n\n def _do_search(self):\n raise NotImplementedError\n\n def _do_count(self):\n raise NotImplementedError\n\n def results(self):\n if self._results_cache is None:\n self._results_cache = self._do_search()\n return self._results_cache\n\n def count(self):\n if self._count_cache is None:\n if self._results_cache is not None:\n self._count_cache = len(self._results_cache)\n else:\n self._count_cache = self._do_count()\n return self._count_cache\n\n def __getitem__(self, key):\n new = self._clone()\n\n if isinstance(key, slice):\n # Set limits\n start = int(key.start) if key.start else None\n stop = int(key.stop) if key.stop else None\n new._set_limits(start, stop)\n\n # Copy results cache\n if self._results_cache is not None:\n new._results_cache = self._results_cache[key]\n\n return new\n else:\n if self._results_cache is not None:\n return self._results_cache[key]\n\n new.start = self.start + key\n new.stop = self.start + key + 1\n return list(new)[0]\n\n def __iter__(self):\n return iter(self.results())\n\n def __len__(self):\n return len(self.results())\n\n def __repr__(self):\n data = list(self[:21])\n if len(data) > 20:\n data[-1] = \"...(remaining elements truncated)...\"\n return repr(data)\n\n\nclass BaseSearch(object):\n search_query_class = None\n search_results_class = None\n\n def __init__(self, params):\n pass\n\n def get_rebuilder(self):\n return None\n\n def reset_index(self):\n raise NotImplementedError\n\n def add_type(self, model):\n raise NotImplementedError\n\n def refresh_index(self):\n raise NotImplementedError\n\n def add(self, obj):\n raise NotImplementedError\n\n def add_bulk(self, model, obj_list):\n raise NotImplementedError\n\n def delete(self, obj):\n raise NotImplementedError\n\n def search(self, query_string, model_or_queryset, fields=None, filters=None, prefetch_related=None, operator=None, order_by_relevance=True):\n # Find model/queryset\n if isinstance(model_or_queryset, QuerySet):\n model = model_or_queryset.model\n queryset = model_or_queryset\n else:\n model = model_or_queryset\n queryset = model_or_queryset.objects.all()\n\n # Model must be a class that is in the index\n if not class_is_indexed(model):\n return []\n\n # Check that theres still a query string after the clean up\n if query_string == \"\":\n return []\n\n # Apply filters to queryset\n if filters:\n queryset = queryset.filter(**filters)\n\n # Prefetch related\n if prefetch_related:\n for prefetch in prefetch_related:\n queryset = queryset.prefetch_related(prefetch)\n\n # Check operator\n if operator is not None:\n operator = operator.lower()\n if operator not in ['or', 'and']:\n raise ValueError(\"operator must be either 'or' or 'and'\")\n\n # Search\n search_query = self.search_query_class(queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance)\n return self.search_results_class(self, search_query)\n", "path": "wagtail/wagtailsearch/backends/base.py"}], "after_files": [{"content": "\nfrom django.db.models.query import QuerySet\nfrom django.db.models.lookups import Lookup\nfrom django.db.models.sql.where import SubqueryConstraint, WhereNode\nfrom django.utils.six import text_type\n\nfrom wagtail.wagtailsearch.index import class_is_indexed\n\n\nclass FilterError(Exception):\n pass\n\n\nclass FieldError(Exception):\n pass\n\n\nclass BaseSearchQuery(object):\n DEFAULT_OPERATOR = 'or'\n\n def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):\n self.queryset = queryset\n self.query_string = query_string\n self.fields = fields\n self.operator = operator or self.DEFAULT_OPERATOR\n self.order_by_relevance = order_by_relevance\n\n def _get_searchable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_searchable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _get_filterable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_filterable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _process_lookup(self, field, lookup, value):\n raise NotImplementedError\n\n def _connect_filters(self, filters, connector, negated):\n raise NotImplementedError\n\n def _process_filter(self, field_attname, lookup, value):\n # Get the field\n field = self._get_filterable_field(field_attname)\n\n if field is None:\n raise FieldError('Cannot filter search results with field \"' + field_attname + '\". Please add index.FilterField(\\'' + field_attname + '\\') to ' + self.queryset.model.__name__ + '.search_fields.')\n\n # Process the lookup\n result = self._process_lookup(field, lookup, value)\n\n if result is None:\n raise FilterError('Could not apply filter on search results: \"' + field_attname + '__' + lookup + ' = ' + text_type(value) + '\". Lookup \"' + lookup + '\"\" not recognosed.')\n\n return result\n\n def _get_filters_from_where_node(self, where_node):\n # Check if this is a leaf node\n if isinstance(where_node, Lookup):\n field_attname = where_node.lhs.target.attname\n lookup = where_node.lookup_name\n value = where_node.rhs\n\n # Ignore pointer fields that show up in specific page type queries\n if field_attname.endswith('_ptr_id'):\n return\n\n # Process the filter\n return self._process_filter(field_attname, lookup, value)\n\n elif isinstance(where_node, SubqueryConstraint):\n raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')\n\n elif isinstance(where_node, WhereNode):\n # Get child filters\n connector = where_node.connector\n child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]\n child_filters = [child_filter for child_filter in child_filters if child_filter]\n\n return self._connect_filters(child_filters, connector, where_node.negated)\n\n else:\n raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))\n\n def _get_filters_from_queryset(self):\n return self._get_filters_from_where_node(self.queryset.query.where)\n\n\nclass BaseSearchResults(object):\n def __init__(self, backend, query, prefetch_related=None):\n self.backend = backend\n self.query = query\n self.prefetch_related = prefetch_related\n self.start = 0\n self.stop = None\n self._results_cache = None\n self._count_cache = None\n\n def _set_limits(self, start=None, stop=None):\n if stop is not None:\n if self.stop is not None:\n self.stop = min(self.stop, self.start + stop)\n else:\n self.stop = self.start + stop\n\n if start is not None:\n if self.stop is not None:\n self.start = min(self.stop, self.start + start)\n else:\n self.start = self.start + start\n\n def _clone(self):\n klass = self.__class__\n new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)\n new.start = self.start\n new.stop = self.stop\n return new\n\n def _do_search(self):\n raise NotImplementedError\n\n def _do_count(self):\n raise NotImplementedError\n\n def results(self):\n if self._results_cache is None:\n self._results_cache = self._do_search()\n return self._results_cache\n\n def count(self):\n if self._count_cache is None:\n if self._results_cache is not None:\n self._count_cache = len(self._results_cache)\n else:\n self._count_cache = self._do_count()\n return self._count_cache\n\n def __getitem__(self, key):\n new = self._clone()\n\n if isinstance(key, slice):\n # Set limits\n start = int(key.start) if key.start else None\n stop = int(key.stop) if key.stop else None\n new._set_limits(start, stop)\n\n # Copy results cache\n if self._results_cache is not None:\n new._results_cache = self._results_cache[key]\n\n return new\n else:\n if self._results_cache is not None:\n return self._results_cache[key]\n\n new.start = self.start + key\n new.stop = self.start + key + 1\n return list(new)[0]\n\n def __iter__(self):\n return iter(self.results())\n\n def __len__(self):\n return len(self.results())\n\n def __repr__(self):\n data = list(self[:21])\n if len(data) > 20:\n data[-1] = \"...(remaining elements truncated)...\"\n return repr(data)\n\n\nclass BaseSearch(object):\n search_query_class = None\n search_results_class = None\n\n def __init__(self, params):\n pass\n\n def get_rebuilder(self):\n return None\n\n def reset_index(self):\n raise NotImplementedError\n\n def add_type(self, model):\n raise NotImplementedError\n\n def refresh_index(self):\n raise NotImplementedError\n\n def add(self, obj):\n raise NotImplementedError\n\n def add_bulk(self, model, obj_list):\n raise NotImplementedError\n\n def delete(self, obj):\n raise NotImplementedError\n\n def search(self, query_string, model_or_queryset, fields=None, filters=None, prefetch_related=None, operator=None, order_by_relevance=True):\n # Find model/queryset\n if isinstance(model_or_queryset, QuerySet):\n model = model_or_queryset.model\n queryset = model_or_queryset\n else:\n model = model_or_queryset\n queryset = model_or_queryset.objects.all()\n\n # Model must be a class that is in the index\n if not class_is_indexed(model):\n return []\n\n # Check that theres still a query string after the clean up\n if query_string == \"\":\n return []\n\n # Apply filters to queryset\n if filters:\n queryset = queryset.filter(**filters)\n\n # Prefetch related\n if prefetch_related:\n for prefetch in prefetch_related:\n queryset = queryset.prefetch_related(prefetch)\n\n # Check operator\n if operator is not None:\n operator = operator.lower()\n if operator not in ['or', 'and']:\n raise ValueError(\"operator must be either 'or' or 'and'\")\n\n # Search\n search_query = self.search_query_class(queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance)\n return self.search_results_class(self, search_query)\n", "path": "wagtail/wagtailsearch/backends/base.py"}]}
| 2,739 | 136 |
gh_patches_debug_10312
|
rasdani/github-patches
|
git_diff
|
Pycord-Development__pycord-1000
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
multiple-type arg option is beak
### Summary
Cannot set multiple type for arg in slash command
### Reproduction Steps
```python
@slash_command()
async def test(self, ctx, channel: Option([discord.TextChannel, discord.VoiceChannel])):
print(channel)
```
### Minimal Reproducible Code
```python
Traceback (most recent call last):
File "C:\Users\Andrew\AppData\Local\Programs\Python\Python310\lib\site-packages\discord\cog.py", line 705, in _load_from_module_spec
spec.loader.exec_module(lib) # type: ignore
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "c:\Users\Andrew\Documents\tuflya\cogs\sendmsg.py", line 8, in <module>
class sendmsg(commands.Cog):
File "c:\Users\Andrew\Documents\tuflya\cogs\sendmsg.py", line 14, in sendmsg
channel: Option([discord.TextChannel, discord.VoiceChannel], "\u0412\u044b\u0431\u0435\u0440\u0438\u0442\u0435 \u043a\u0430\u043d\u0430\u043b"),
File "C:\Users\Andrew\AppData\Local\Programs\Python\Python310\lib\site-packages\discord\commands\options.py", line 72, in __init__
_type = SlashCommandOptionType.from_datatype(input_type)
File "C:\Users\Andrew\AppData\Local\Programs\Python\Python310\lib\site-packages\discord\enums.py", line 670, in from_datatype
if datatype.__name__ in ["Member", "User"]:
AttributeError: 'list' object has no attribute '__name__'. Did you mean: '__ne__'?
```
### Expected Results
channel arg should accept both types
### Actual Results
can't use multiple-type in slash command
### Intents
default, members
### System Information
Python Version: 3.10
Pycord Version: 2.0.0b4
### Checklist
- [X] I have searched the open issues for duplicates.
- [X] I have shown the entire traceback, if possible.
- [X] I have removed my token from display, if visible.
### Additional Context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `discord/commands/options.py`
Content:
```
1 """
2 The MIT License (MIT)
3
4 Copyright (c) 2021-present Pycord Development
5
6 Permission is hereby granted, free of charge, to any person obtaining a
7 copy of this software and associated documentation files (the "Software"),
8 to deal in the Software without restriction, including without limitation
9 the rights to use, copy, modify, merge, publish, distribute, sublicense,
10 and/or sell copies of the Software, and to permit persons to whom the
11 Software is furnished to do so, subject to the following conditions:
12
13 The above copyright notice and this permission notice shall be included in
14 all copies or substantial portions of the Software.
15
16 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
17 OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
21 FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
22 DEALINGS IN THE SOFTWARE.
23 """
24
25 from typing import Any, Dict, List, Literal, Optional, Union
26
27 from ..enums import ChannelType, SlashCommandOptionType
28
29 __all__ = (
30 "ThreadOption",
31 "Option",
32 "OptionChoice",
33 "option",
34 )
35
36 channel_type_map = {
37 "TextChannel": ChannelType.text,
38 "VoiceChannel": ChannelType.voice,
39 "StageChannel": ChannelType.stage_voice,
40 "CategoryChannel": ChannelType.category,
41 "Thread": ChannelType.public_thread,
42 }
43
44
45 class ThreadOption:
46 def __init__(self, thread_type: Literal["public", "private", "news"]):
47 type_map = {
48 "public": ChannelType.public_thread,
49 "private": ChannelType.private_thread,
50 "news": ChannelType.news_thread,
51 }
52 self._type = type_map[thread_type]
53
54 @property
55 def __name__(self):
56 return "ThreadOption"
57
58
59 class Option:
60 """Represents a selectable option for a slash command.
61
62 Examples
63 --------
64 Basic usage: ::
65
66 @bot.slash_command(guild_ids=[...])
67 async def hello(
68 ctx: discord.ApplicationContext,
69 name: Option(str, "Enter your name"),
70 age: Option(int, "Enter your age", min_value=1, max_value=99, default=18)
71 # passing the default value makes an argument optional
72 # you also can create optional argument using:
73 # age: Option(int, "Enter your age") = 18
74 ):
75 await ctx.respond(f"Hello! Your name is {name} and you are {age} years old.")
76
77 .. versionadded:: 2.0
78
79 Attributes
80 ----------
81 input_type: :class:`Any`
82 The type of input that is expected for this option.
83 description: :class:`str`
84 The description of this option.
85 Must be 100 characters or fewer.
86 name: :class:`str`
87 The name of this option visible in the UI.
88 Inherits from the variable name if not provided as a parameter.
89 choices: Optional[List[Union[:class:`Any`, :class:`OptionChoice`]]]
90 The list of available choices for this option.
91 Can be a list of values or :class:`OptionChoice` objects (which represent a name:value pair).
92 If provided, the input from the user must match one of the choices in the list.
93 required: Optional[:class:`bool`]
94 Whether this option is required.
95 default: Optional[:class:`Any`]
96 The default value for this option. If provided, ``required`` will be considered ``False``.
97 min_value: Optional[:class:`int`]
98 The minimum value that can be entered.
99 Only applies to Options with an input_type of ``int`` or ``float``.
100 max_value: Optional[:class:`int`]
101 The maximum value that can be entered.
102 Only applies to Options with an input_type of ``int`` or ``float``.
103 autocomplete: Optional[:class:`Any`]
104 The autocomplete handler for the option. Accepts an iterable of :class:`str`, a callable (sync or async) that takes a
105 single argument of :class:`AutocompleteContext`, or a coroutine. Must resolve to an iterable of :class:`str`.
106
107 .. note::
108
109 Does not validate the input value against the autocomplete results.
110 name_localizations: Optional[Dict[:class:`str`, :class:`str`]]
111 The name localizations for this option. The values of this should be ``"locale": "name"``.
112 See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.
113 description_localizations: Optional[Dict[:class:`str`, :class:`str`]]
114 The description localizations for this option. The values of this should be ``"locale": "description"``.
115 See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.
116 """
117
118 def __init__(self, input_type: Any, /, description: str = None, **kwargs) -> None:
119 self.name: Optional[str] = kwargs.pop("name", None)
120 if self.name is not None:
121 self.name = str(self.name)
122 self.description = description or "No description provided"
123 self.converter = None
124 self._raw_type = input_type
125 self.channel_types: List[ChannelType] = kwargs.pop("channel_types", [])
126 if not isinstance(input_type, SlashCommandOptionType):
127 if hasattr(input_type, "convert"):
128 self.converter = input_type
129 input_type = SlashCommandOptionType.string
130 else:
131 try:
132 _type = SlashCommandOptionType.from_datatype(input_type)
133 except TypeError as exc:
134 from ..ext.commands.converter import CONVERTER_MAPPING
135
136 if input_type not in CONVERTER_MAPPING:
137 raise exc
138 self.converter = CONVERTER_MAPPING[input_type]
139 input_type = SlashCommandOptionType.string
140 else:
141 if _type == SlashCommandOptionType.channel:
142 if not isinstance(input_type, tuple):
143 input_type = (input_type,)
144 for i in input_type:
145 if i.__name__ == "GuildChannel":
146 continue
147 if isinstance(i, ThreadOption):
148 self.channel_types.append(i._type)
149 continue
150
151 channel_type = channel_type_map[i.__name__]
152 self.channel_types.append(channel_type)
153 input_type = _type
154 self.input_type = input_type
155 self.required: bool = kwargs.pop("required", True) if "default" not in kwargs else False
156 self.default = kwargs.pop("default", None)
157 self.choices: List[OptionChoice] = [
158 o if isinstance(o, OptionChoice) else OptionChoice(o) for o in kwargs.pop("choices", list())
159 ]
160
161 if self.input_type == SlashCommandOptionType.integer:
162 minmax_types = (int, type(None))
163 elif self.input_type == SlashCommandOptionType.number:
164 minmax_types = (int, float, type(None))
165 else:
166 minmax_types = (type(None),)
167 minmax_typehint = Optional[Union[minmax_types]] # type: ignore
168
169 self.min_value: minmax_typehint = kwargs.pop("min_value", None)
170 self.max_value: minmax_typehint = kwargs.pop("max_value", None)
171
172 if not isinstance(self.min_value, minmax_types) and self.min_value is not None:
173 raise TypeError(f'Expected {minmax_typehint} for min_value, got "{type(self.min_value).__name__}"')
174 if not (isinstance(self.max_value, minmax_types) or self.min_value is None):
175 raise TypeError(f'Expected {minmax_typehint} for max_value, got "{type(self.max_value).__name__}"')
176
177 self.autocomplete = kwargs.pop("autocomplete", None)
178
179 self.name_localizations = kwargs.pop("name_localizations", None)
180 self.description_localizations = kwargs.pop("description_localizations", None)
181
182 def to_dict(self) -> Dict:
183 as_dict = {
184 "name": self.name,
185 "description": self.description,
186 "type": self.input_type.value,
187 "required": self.required,
188 "choices": [c.to_dict() for c in self.choices],
189 "autocomplete": bool(self.autocomplete),
190 }
191 if self.name_localizations is not None:
192 as_dict["name_localizations"] = self.name_localizations
193 if self.description_localizations is not None:
194 as_dict["description_localizations"] = self.description_localizations
195 if self.channel_types:
196 as_dict["channel_types"] = [t.value for t in self.channel_types]
197 if self.min_value is not None:
198 as_dict["min_value"] = self.min_value
199 if self.max_value is not None:
200 as_dict["max_value"] = self.max_value
201
202 return as_dict
203
204 def __repr__(self):
205 return f"<discord.commands.{self.__class__.__name__} name={self.name}>"
206
207
208 class OptionChoice:
209 """
210 Represents a name:value pairing for a selected :class:`Option`.
211
212 .. versionadded:: 2.0
213
214 Attributes
215 ----------
216 name: :class:`str`
217 The name of the choice. Shown in the UI when selecting an option.
218 value: Optional[Union[:class:`str`, :class:`int`, :class:`float`]]
219 The value of the choice. If not provided, will use the value of ``name``.
220 name_localizations: Optional[Dict[:class:`str`, :class:`str`]]
221 The name localizations for this choice. The values of this should be ``"locale": "name"``.
222 See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.
223 """
224
225 def __init__(
226 self,
227 name: str,
228 value: Optional[Union[str, int, float]] = None,
229 name_localizations: Optional[Dict[str, str]] = None,
230 ):
231 self.name = str(name)
232 self.value = value if value is not None else name
233 self.name_localizations = name_localizations
234
235 def to_dict(self) -> Dict[str, Union[str, int, float]]:
236 as_dict = {"name": self.name, "value": self.value}
237 if self.name_localizations is not None:
238 as_dict["name_localizations"] = self.name_localizations
239
240 return as_dict
241
242
243 def option(name, type=None, **kwargs):
244 """A decorator that can be used instead of typehinting Option"""
245
246 def decorator(func):
247 nonlocal type
248 type = type or func.__annotations__.get(name, str)
249 func.__annotations__[name] = Option(type, **kwargs)
250 return func
251
252 return decorator
253
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/discord/commands/options.py b/discord/commands/options.py
--- a/discord/commands/options.py
+++ b/discord/commands/options.py
@@ -139,7 +139,7 @@
input_type = SlashCommandOptionType.string
else:
if _type == SlashCommandOptionType.channel:
- if not isinstance(input_type, tuple):
+ if not isinstance(input_type, list):
input_type = (input_type,)
for i in input_type:
if i.__name__ == "GuildChannel":
|
{"golden_diff": "diff --git a/discord/commands/options.py b/discord/commands/options.py\n--- a/discord/commands/options.py\n+++ b/discord/commands/options.py\n@@ -139,7 +139,7 @@\n input_type = SlashCommandOptionType.string\n else:\n if _type == SlashCommandOptionType.channel:\n- if not isinstance(input_type, tuple):\n+ if not isinstance(input_type, list):\n input_type = (input_type,)\n for i in input_type:\n if i.__name__ == \"GuildChannel\":\n", "issue": "multiple-type arg option is beak\n### Summary\r\n\r\nCannot set multiple type for arg in slash command\r\n\r\n### Reproduction Steps\r\n\r\n```python\r\n@slash_command()\r\nasync def test(self, ctx, channel: Option([discord.TextChannel, discord.VoiceChannel])):\r\n print(channel)\r\n```\r\n\r\n### Minimal Reproducible Code\r\n\r\n```python\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\Andrew\\AppData\\Local\\Programs\\Python\\Python310\\lib\\site-packages\\discord\\cog.py\", line 705, in _load_from_module_spec\r\n spec.loader.exec_module(lib) # type: ignore\r\n File \"<frozen importlib._bootstrap_external>\", line 883, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 241, in _call_with_frames_removed\r\n File \"c:\\Users\\Andrew\\Documents\\tuflya\\cogs\\sendmsg.py\", line 8, in <module>\r\n class sendmsg(commands.Cog):\r\n File \"c:\\Users\\Andrew\\Documents\\tuflya\\cogs\\sendmsg.py\", line 14, in sendmsg\r\n channel: Option([discord.TextChannel, discord.VoiceChannel], \"\\u0412\\u044b\\u0431\\u0435\\u0440\\u0438\\u0442\\u0435 \\u043a\\u0430\\u043d\\u0430\\u043b\"),\r\n File \"C:\\Users\\Andrew\\AppData\\Local\\Programs\\Python\\Python310\\lib\\site-packages\\discord\\commands\\options.py\", line 72, in __init__\r\n _type = SlashCommandOptionType.from_datatype(input_type)\r\n File \"C:\\Users\\Andrew\\AppData\\Local\\Programs\\Python\\Python310\\lib\\site-packages\\discord\\enums.py\", line 670, in from_datatype\r\n if datatype.__name__ in [\"Member\", \"User\"]:\r\nAttributeError: 'list' object has no attribute '__name__'. Did you mean: '__ne__'?\r\n```\r\n\r\n\r\n### Expected Results\r\n\r\nchannel arg should accept both types\r\n\r\n### Actual Results\r\n\r\ncan't use multiple-type in slash command\r\n\r\n### Intents\r\n\r\ndefault, members\r\n\r\n### System Information\r\n\r\nPython Version: 3.10\r\nPycord Version: 2.0.0b4\r\n\r\n### Checklist\r\n\r\n- [X] I have searched the open issues for duplicates.\r\n- [X] I have shown the entire traceback, if possible.\r\n- [X] I have removed my token from display, if visible.\r\n\r\n### Additional Context\r\n\r\n_No response_\n", "before_files": [{"content": "\"\"\"\nThe MIT License (MIT)\n\nCopyright (c) 2021-present Pycord Development\n\nPermission is hereby granted, free of charge, to any person obtaining a\ncopy of this software and associated documentation files (the \"Software\"),\nto deal in the Software without restriction, including without limitation\nthe rights to use, copy, modify, merge, publish, distribute, sublicense,\nand/or sell copies of the Software, and to permit persons to whom the\nSoftware is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in\nall copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS\nOR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\nFROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\nDEALINGS IN THE SOFTWARE.\n\"\"\"\n\nfrom typing import Any, Dict, List, Literal, Optional, Union\n\nfrom ..enums import ChannelType, SlashCommandOptionType\n\n__all__ = (\n \"ThreadOption\",\n \"Option\",\n \"OptionChoice\",\n \"option\",\n)\n\nchannel_type_map = {\n \"TextChannel\": ChannelType.text,\n \"VoiceChannel\": ChannelType.voice,\n \"StageChannel\": ChannelType.stage_voice,\n \"CategoryChannel\": ChannelType.category,\n \"Thread\": ChannelType.public_thread,\n}\n\n\nclass ThreadOption:\n def __init__(self, thread_type: Literal[\"public\", \"private\", \"news\"]):\n type_map = {\n \"public\": ChannelType.public_thread,\n \"private\": ChannelType.private_thread,\n \"news\": ChannelType.news_thread,\n }\n self._type = type_map[thread_type]\n\n @property\n def __name__(self):\n return \"ThreadOption\"\n\n\nclass Option:\n \"\"\"Represents a selectable option for a slash command.\n\n Examples\n --------\n Basic usage: ::\n\n @bot.slash_command(guild_ids=[...])\n async def hello(\n ctx: discord.ApplicationContext,\n name: Option(str, \"Enter your name\"),\n age: Option(int, \"Enter your age\", min_value=1, max_value=99, default=18)\n # passing the default value makes an argument optional\n # you also can create optional argument using:\n # age: Option(int, \"Enter your age\") = 18\n ):\n await ctx.respond(f\"Hello! Your name is {name} and you are {age} years old.\")\n\n .. versionadded:: 2.0\n\n Attributes\n ----------\n input_type: :class:`Any`\n The type of input that is expected for this option.\n description: :class:`str`\n The description of this option.\n Must be 100 characters or fewer.\n name: :class:`str`\n The name of this option visible in the UI.\n Inherits from the variable name if not provided as a parameter.\n choices: Optional[List[Union[:class:`Any`, :class:`OptionChoice`]]]\n The list of available choices for this option.\n Can be a list of values or :class:`OptionChoice` objects (which represent a name:value pair).\n If provided, the input from the user must match one of the choices in the list.\n required: Optional[:class:`bool`]\n Whether this option is required.\n default: Optional[:class:`Any`]\n The default value for this option. If provided, ``required`` will be considered ``False``.\n min_value: Optional[:class:`int`]\n The minimum value that can be entered.\n Only applies to Options with an input_type of ``int`` or ``float``.\n max_value: Optional[:class:`int`]\n The maximum value that can be entered.\n Only applies to Options with an input_type of ``int`` or ``float``.\n autocomplete: Optional[:class:`Any`]\n The autocomplete handler for the option. Accepts an iterable of :class:`str`, a callable (sync or async) that takes a\n single argument of :class:`AutocompleteContext`, or a coroutine. Must resolve to an iterable of :class:`str`.\n\n .. note::\n\n Does not validate the input value against the autocomplete results.\n name_localizations: Optional[Dict[:class:`str`, :class:`str`]]\n The name localizations for this option. The values of this should be ``\"locale\": \"name\"``.\n See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.\n description_localizations: Optional[Dict[:class:`str`, :class:`str`]]\n The description localizations for this option. The values of this should be ``\"locale\": \"description\"``.\n See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.\n \"\"\"\n\n def __init__(self, input_type: Any, /, description: str = None, **kwargs) -> None:\n self.name: Optional[str] = kwargs.pop(\"name\", None)\n if self.name is not None:\n self.name = str(self.name)\n self.description = description or \"No description provided\"\n self.converter = None\n self._raw_type = input_type\n self.channel_types: List[ChannelType] = kwargs.pop(\"channel_types\", [])\n if not isinstance(input_type, SlashCommandOptionType):\n if hasattr(input_type, \"convert\"):\n self.converter = input_type\n input_type = SlashCommandOptionType.string\n else:\n try:\n _type = SlashCommandOptionType.from_datatype(input_type)\n except TypeError as exc:\n from ..ext.commands.converter import CONVERTER_MAPPING\n\n if input_type not in CONVERTER_MAPPING:\n raise exc\n self.converter = CONVERTER_MAPPING[input_type]\n input_type = SlashCommandOptionType.string\n else:\n if _type == SlashCommandOptionType.channel:\n if not isinstance(input_type, tuple):\n input_type = (input_type,)\n for i in input_type:\n if i.__name__ == \"GuildChannel\":\n continue\n if isinstance(i, ThreadOption):\n self.channel_types.append(i._type)\n continue\n\n channel_type = channel_type_map[i.__name__]\n self.channel_types.append(channel_type)\n input_type = _type\n self.input_type = input_type\n self.required: bool = kwargs.pop(\"required\", True) if \"default\" not in kwargs else False\n self.default = kwargs.pop(\"default\", None)\n self.choices: List[OptionChoice] = [\n o if isinstance(o, OptionChoice) else OptionChoice(o) for o in kwargs.pop(\"choices\", list())\n ]\n\n if self.input_type == SlashCommandOptionType.integer:\n minmax_types = (int, type(None))\n elif self.input_type == SlashCommandOptionType.number:\n minmax_types = (int, float, type(None))\n else:\n minmax_types = (type(None),)\n minmax_typehint = Optional[Union[minmax_types]] # type: ignore\n\n self.min_value: minmax_typehint = kwargs.pop(\"min_value\", None)\n self.max_value: minmax_typehint = kwargs.pop(\"max_value\", None)\n\n if not isinstance(self.min_value, minmax_types) and self.min_value is not None:\n raise TypeError(f'Expected {minmax_typehint} for min_value, got \"{type(self.min_value).__name__}\"')\n if not (isinstance(self.max_value, minmax_types) or self.min_value is None):\n raise TypeError(f'Expected {minmax_typehint} for max_value, got \"{type(self.max_value).__name__}\"')\n\n self.autocomplete = kwargs.pop(\"autocomplete\", None)\n\n self.name_localizations = kwargs.pop(\"name_localizations\", None)\n self.description_localizations = kwargs.pop(\"description_localizations\", None)\n\n def to_dict(self) -> Dict:\n as_dict = {\n \"name\": self.name,\n \"description\": self.description,\n \"type\": self.input_type.value,\n \"required\": self.required,\n \"choices\": [c.to_dict() for c in self.choices],\n \"autocomplete\": bool(self.autocomplete),\n }\n if self.name_localizations is not None:\n as_dict[\"name_localizations\"] = self.name_localizations\n if self.description_localizations is not None:\n as_dict[\"description_localizations\"] = self.description_localizations\n if self.channel_types:\n as_dict[\"channel_types\"] = [t.value for t in self.channel_types]\n if self.min_value is not None:\n as_dict[\"min_value\"] = self.min_value\n if self.max_value is not None:\n as_dict[\"max_value\"] = self.max_value\n\n return as_dict\n\n def __repr__(self):\n return f\"<discord.commands.{self.__class__.__name__} name={self.name}>\"\n\n\nclass OptionChoice:\n \"\"\"\n Represents a name:value pairing for a selected :class:`Option`.\n\n .. versionadded:: 2.0\n\n Attributes\n ----------\n name: :class:`str`\n The name of the choice. Shown in the UI when selecting an option.\n value: Optional[Union[:class:`str`, :class:`int`, :class:`float`]]\n The value of the choice. If not provided, will use the value of ``name``.\n name_localizations: Optional[Dict[:class:`str`, :class:`str`]]\n The name localizations for this choice. The values of this should be ``\"locale\": \"name\"``.\n See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.\n \"\"\"\n\n def __init__(\n self,\n name: str,\n value: Optional[Union[str, int, float]] = None,\n name_localizations: Optional[Dict[str, str]] = None,\n ):\n self.name = str(name)\n self.value = value if value is not None else name\n self.name_localizations = name_localizations\n\n def to_dict(self) -> Dict[str, Union[str, int, float]]:\n as_dict = {\"name\": self.name, \"value\": self.value}\n if self.name_localizations is not None:\n as_dict[\"name_localizations\"] = self.name_localizations\n\n return as_dict\n\n\ndef option(name, type=None, **kwargs):\n \"\"\"A decorator that can be used instead of typehinting Option\"\"\"\n\n def decorator(func):\n nonlocal type\n type = type or func.__annotations__.get(name, str)\n func.__annotations__[name] = Option(type, **kwargs)\n return func\n\n return decorator\n", "path": "discord/commands/options.py"}], "after_files": [{"content": "\"\"\"\nThe MIT License (MIT)\n\nCopyright (c) 2021-present Pycord Development\n\nPermission is hereby granted, free of charge, to any person obtaining a\ncopy of this software and associated documentation files (the \"Software\"),\nto deal in the Software without restriction, including without limitation\nthe rights to use, copy, modify, merge, publish, distribute, sublicense,\nand/or sell copies of the Software, and to permit persons to whom the\nSoftware is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in\nall copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS\nOR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\nFROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\nDEALINGS IN THE SOFTWARE.\n\"\"\"\n\nfrom typing import Any, Dict, List, Literal, Optional, Union\n\nfrom ..enums import ChannelType, SlashCommandOptionType\n\n__all__ = (\n \"ThreadOption\",\n \"Option\",\n \"OptionChoice\",\n \"option\",\n)\n\nchannel_type_map = {\n \"TextChannel\": ChannelType.text,\n \"VoiceChannel\": ChannelType.voice,\n \"StageChannel\": ChannelType.stage_voice,\n \"CategoryChannel\": ChannelType.category,\n \"Thread\": ChannelType.public_thread,\n}\n\n\nclass ThreadOption:\n def __init__(self, thread_type: Literal[\"public\", \"private\", \"news\"]):\n type_map = {\n \"public\": ChannelType.public_thread,\n \"private\": ChannelType.private_thread,\n \"news\": ChannelType.news_thread,\n }\n self._type = type_map[thread_type]\n\n @property\n def __name__(self):\n return \"ThreadOption\"\n\n\nclass Option:\n \"\"\"Represents a selectable option for a slash command.\n\n Examples\n --------\n Basic usage: ::\n\n @bot.slash_command(guild_ids=[...])\n async def hello(\n ctx: discord.ApplicationContext,\n name: Option(str, \"Enter your name\"),\n age: Option(int, \"Enter your age\", min_value=1, max_value=99, default=18)\n # passing the default value makes an argument optional\n # you also can create optional argument using:\n # age: Option(int, \"Enter your age\") = 18\n ):\n await ctx.respond(f\"Hello! Your name is {name} and you are {age} years old.\")\n\n .. versionadded:: 2.0\n\n Attributes\n ----------\n input_type: :class:`Any`\n The type of input that is expected for this option.\n description: :class:`str`\n The description of this option.\n Must be 100 characters or fewer.\n name: :class:`str`\n The name of this option visible in the UI.\n Inherits from the variable name if not provided as a parameter.\n choices: Optional[List[Union[:class:`Any`, :class:`OptionChoice`]]]\n The list of available choices for this option.\n Can be a list of values or :class:`OptionChoice` objects (which represent a name:value pair).\n If provided, the input from the user must match one of the choices in the list.\n required: Optional[:class:`bool`]\n Whether this option is required.\n default: Optional[:class:`Any`]\n The default value for this option. If provided, ``required`` will be considered ``False``.\n min_value: Optional[:class:`int`]\n The minimum value that can be entered.\n Only applies to Options with an input_type of ``int`` or ``float``.\n max_value: Optional[:class:`int`]\n The maximum value that can be entered.\n Only applies to Options with an input_type of ``int`` or ``float``.\n autocomplete: Optional[:class:`Any`]\n The autocomplete handler for the option. Accepts an iterable of :class:`str`, a callable (sync or async) that takes a\n single argument of :class:`AutocompleteContext`, or a coroutine. Must resolve to an iterable of :class:`str`.\n\n .. note::\n\n Does not validate the input value against the autocomplete results.\n name_localizations: Optional[Dict[:class:`str`, :class:`str`]]\n The name localizations for this option. The values of this should be ``\"locale\": \"name\"``.\n See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.\n description_localizations: Optional[Dict[:class:`str`, :class:`str`]]\n The description localizations for this option. The values of this should be ``\"locale\": \"description\"``.\n See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.\n \"\"\"\n\n def __init__(self, input_type: Any, /, description: str = None, **kwargs) -> None:\n self.name: Optional[str] = kwargs.pop(\"name\", None)\n if self.name is not None:\n self.name = str(self.name)\n self.description = description or \"No description provided\"\n self.converter = None\n self._raw_type = input_type\n self.channel_types: List[ChannelType] = kwargs.pop(\"channel_types\", [])\n if not isinstance(input_type, SlashCommandOptionType):\n if hasattr(input_type, \"convert\"):\n self.converter = input_type\n input_type = SlashCommandOptionType.string\n else:\n try:\n _type = SlashCommandOptionType.from_datatype(input_type)\n except TypeError as exc:\n from ..ext.commands.converter import CONVERTER_MAPPING\n\n if input_type not in CONVERTER_MAPPING:\n raise exc\n self.converter = CONVERTER_MAPPING[input_type]\n input_type = SlashCommandOptionType.string\n else:\n if _type == SlashCommandOptionType.channel:\n if not isinstance(input_type, list):\n input_type = (input_type,)\n for i in input_type:\n if i.__name__ == \"GuildChannel\":\n continue\n if isinstance(i, ThreadOption):\n self.channel_types.append(i._type)\n continue\n\n channel_type = channel_type_map[i.__name__]\n self.channel_types.append(channel_type)\n input_type = _type\n self.input_type = input_type\n self.required: bool = kwargs.pop(\"required\", True) if \"default\" not in kwargs else False\n self.default = kwargs.pop(\"default\", None)\n self.choices: List[OptionChoice] = [\n o if isinstance(o, OptionChoice) else OptionChoice(o) for o in kwargs.pop(\"choices\", list())\n ]\n\n if self.input_type == SlashCommandOptionType.integer:\n minmax_types = (int, type(None))\n elif self.input_type == SlashCommandOptionType.number:\n minmax_types = (int, float, type(None))\n else:\n minmax_types = (type(None),)\n minmax_typehint = Optional[Union[minmax_types]] # type: ignore\n\n self.min_value: minmax_typehint = kwargs.pop(\"min_value\", None)\n self.max_value: minmax_typehint = kwargs.pop(\"max_value\", None)\n\n if not isinstance(self.min_value, minmax_types) and self.min_value is not None:\n raise TypeError(f'Expected {minmax_typehint} for min_value, got \"{type(self.min_value).__name__}\"')\n if not (isinstance(self.max_value, minmax_types) or self.min_value is None):\n raise TypeError(f'Expected {minmax_typehint} for max_value, got \"{type(self.max_value).__name__}\"')\n\n self.autocomplete = kwargs.pop(\"autocomplete\", None)\n\n self.name_localizations = kwargs.pop(\"name_localizations\", None)\n self.description_localizations = kwargs.pop(\"description_localizations\", None)\n\n def to_dict(self) -> Dict:\n as_dict = {\n \"name\": self.name,\n \"description\": self.description,\n \"type\": self.input_type.value,\n \"required\": self.required,\n \"choices\": [c.to_dict() for c in self.choices],\n \"autocomplete\": bool(self.autocomplete),\n }\n if self.name_localizations is not None:\n as_dict[\"name_localizations\"] = self.name_localizations\n if self.description_localizations is not None:\n as_dict[\"description_localizations\"] = self.description_localizations\n if self.channel_types:\n as_dict[\"channel_types\"] = [t.value for t in self.channel_types]\n if self.min_value is not None:\n as_dict[\"min_value\"] = self.min_value\n if self.max_value is not None:\n as_dict[\"max_value\"] = self.max_value\n\n return as_dict\n\n def __repr__(self):\n return f\"<discord.commands.{self.__class__.__name__} name={self.name}>\"\n\n\nclass OptionChoice:\n \"\"\"\n Represents a name:value pairing for a selected :class:`Option`.\n\n .. versionadded:: 2.0\n\n Attributes\n ----------\n name: :class:`str`\n The name of the choice. Shown in the UI when selecting an option.\n value: Optional[Union[:class:`str`, :class:`int`, :class:`float`]]\n The value of the choice. If not provided, will use the value of ``name``.\n name_localizations: Optional[Dict[:class:`str`, :class:`str`]]\n The name localizations for this choice. The values of this should be ``\"locale\": \"name\"``.\n See `here <https://discord.com/developers/docs/reference#locales>`_ for a list of valid locales.\n \"\"\"\n\n def __init__(\n self,\n name: str,\n value: Optional[Union[str, int, float]] = None,\n name_localizations: Optional[Dict[str, str]] = None,\n ):\n self.name = str(name)\n self.value = value if value is not None else name\n self.name_localizations = name_localizations\n\n def to_dict(self) -> Dict[str, Union[str, int, float]]:\n as_dict = {\"name\": self.name, \"value\": self.value}\n if self.name_localizations is not None:\n as_dict[\"name_localizations\"] = self.name_localizations\n\n return as_dict\n\n\ndef option(name, type=None, **kwargs):\n \"\"\"A decorator that can be used instead of typehinting Option\"\"\"\n\n def decorator(func):\n nonlocal type\n type = type or func.__annotations__.get(name, str)\n func.__annotations__[name] = Option(type, **kwargs)\n return func\n\n return decorator\n", "path": "discord/commands/options.py"}]}
| 3,837 | 120 |
gh_patches_debug_27075
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-478
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Reshape() with -1 fails
When calling the chainer function Reshape() with a -1 value (e.g. Reshape((-1, 10, 10))) I get an error:
```
InvalidType: Expect: prod(in_types[0].shape) == prod((-1, 10, 10))
Actual: 2800 != -100
```
The cupy function reshape does support -1 arguments, so the error seems to be just the check in chainer's Reshape. The problematic check is:
_type_check_prod(in_types[0].shape) == _type_check_prod(self.shape)
If a -1 argument is present, it should instead check if the size of in_types[0] is divisible by the product of the axis-lengths that are not -1.
I would send a PR but I'm not exactly clear on the correct usage of type_check.expect, and had some issues with it in the past. Should be simple enough to fix though.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/array/reshape.py`
Content:
```
1 import numpy
2
3 from chainer import function
4 from chainer.utils import type_check
5
6
7 _type_check_prod = type_check.Variable(numpy.prod, 'prod')
8
9
10 class Reshape(function.Function):
11
12 """Reshapes an input array without copy."""
13
14 def __init__(self, shape):
15 self.shape = shape
16
17 def check_type_forward(self, in_types):
18 type_check.expect(
19 in_types.size() == 1,
20 _type_check_prod(in_types[0].shape) ==
21 _type_check_prod(self.shape)
22 )
23
24 def forward(self, x):
25 return x[0].reshape(self.shape),
26
27 def backward(self, x, gy):
28 return gy[0].reshape(x[0].shape),
29
30
31 def reshape(x, shape):
32 """Reshapes an input variable without copy.
33
34 Args:
35 x (~chainer.Variable): Input variable.
36 shape (tuple of ints): Target shape.
37
38 Returns:
39 ~chainer.Variable: Variable that holds a reshaped version of the input
40 variable.
41
42 """
43 return Reshape(shape)(x)
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/array/reshape.py b/chainer/functions/array/reshape.py
--- a/chainer/functions/array/reshape.py
+++ b/chainer/functions/array/reshape.py
@@ -1,10 +1,12 @@
-import numpy
-
from chainer import function
from chainer.utils import type_check
-_type_check_prod = type_check.Variable(numpy.prod, 'prod')
+def _count_unknown_dims(shape):
+ cnt = 0
+ for dim in shape:
+ cnt += dim < 0
+ return cnt
class Reshape(function.Function):
@@ -12,15 +14,32 @@
"""Reshapes an input array without copy."""
def __init__(self, shape):
+ cnt = _count_unknown_dims(shape)
+ assert cnt == 0 or cnt == 1
+
self.shape = shape
def check_type_forward(self, in_types):
type_check.expect(
in_types.size() == 1,
- _type_check_prod(in_types[0].shape) ==
- _type_check_prod(self.shape)
)
+ x_type, = in_types
+
+ cnt = _count_unknown_dims(self.shape)
+ if cnt == 0:
+ type_check.expect(
+ type_check.prod(x_type.shape) == type_check.prod(self.shape))
+ else:
+ known_size = 1
+ for s in self.shape:
+ if s > 0:
+ known_size *= s
+ size_var = type_check.Variable(known_size,
+ 'known_size(=%d)' % known_size)
+ type_check.expect(
+ type_check.prod(x_type.shape) % size_var == 0)
+
def forward(self, x):
return x[0].reshape(self.shape),
|
{"golden_diff": "diff --git a/chainer/functions/array/reshape.py b/chainer/functions/array/reshape.py\n--- a/chainer/functions/array/reshape.py\n+++ b/chainer/functions/array/reshape.py\n@@ -1,10 +1,12 @@\n-import numpy\n-\n from chainer import function\n from chainer.utils import type_check\n \n \n-_type_check_prod = type_check.Variable(numpy.prod, 'prod')\n+def _count_unknown_dims(shape):\n+ cnt = 0\n+ for dim in shape:\n+ cnt += dim < 0\n+ return cnt\n \n \n class Reshape(function.Function):\n@@ -12,15 +14,32 @@\n \"\"\"Reshapes an input array without copy.\"\"\"\n \n def __init__(self, shape):\n+ cnt = _count_unknown_dims(shape)\n+ assert cnt == 0 or cnt == 1\n+\n self.shape = shape\n \n def check_type_forward(self, in_types):\n type_check.expect(\n in_types.size() == 1,\n- _type_check_prod(in_types[0].shape) ==\n- _type_check_prod(self.shape)\n )\n \n+ x_type, = in_types\n+\n+ cnt = _count_unknown_dims(self.shape)\n+ if cnt == 0:\n+ type_check.expect(\n+ type_check.prod(x_type.shape) == type_check.prod(self.shape))\n+ else:\n+ known_size = 1\n+ for s in self.shape:\n+ if s > 0:\n+ known_size *= s\n+ size_var = type_check.Variable(known_size,\n+ 'known_size(=%d)' % known_size)\n+ type_check.expect(\n+ type_check.prod(x_type.shape) % size_var == 0)\n+\n def forward(self, x):\n return x[0].reshape(self.shape),\n", "issue": "Bug: Reshape() with -1 fails\nWhen calling the chainer function Reshape() with a -1 value (e.g. Reshape((-1, 10, 10))) I get an error: \n\n```\nInvalidType: Expect: prod(in_types[0].shape) == prod((-1, 10, 10))\nActual: 2800 != -100\n```\n\nThe cupy function reshape does support -1 arguments, so the error seems to be just the check in chainer's Reshape. The problematic check is:\n _type_check_prod(in_types[0].shape) == _type_check_prod(self.shape)\n\nIf a -1 argument is present, it should instead check if the size of in_types[0] is divisible by the product of the axis-lengths that are not -1. \n\nI would send a PR but I'm not exactly clear on the correct usage of type_check.expect, and had some issues with it in the past. Should be simple enough to fix though.\n\n", "before_files": [{"content": "import numpy\n\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\n_type_check_prod = type_check.Variable(numpy.prod, 'prod')\n\n\nclass Reshape(function.Function):\n\n \"\"\"Reshapes an input array without copy.\"\"\"\n\n def __init__(self, shape):\n self.shape = shape\n\n def check_type_forward(self, in_types):\n type_check.expect(\n in_types.size() == 1,\n _type_check_prod(in_types[0].shape) ==\n _type_check_prod(self.shape)\n )\n\n def forward(self, x):\n return x[0].reshape(self.shape),\n\n def backward(self, x, gy):\n return gy[0].reshape(x[0].shape),\n\n\ndef reshape(x, shape):\n \"\"\"Reshapes an input variable without copy.\n\n Args:\n x (~chainer.Variable): Input variable.\n shape (tuple of ints): Target shape.\n\n Returns:\n ~chainer.Variable: Variable that holds a reshaped version of the input\n variable.\n\n \"\"\"\n return Reshape(shape)(x)\n", "path": "chainer/functions/array/reshape.py"}], "after_files": [{"content": "from chainer import function\nfrom chainer.utils import type_check\n\n\ndef _count_unknown_dims(shape):\n cnt = 0\n for dim in shape:\n cnt += dim < 0\n return cnt\n\n\nclass Reshape(function.Function):\n\n \"\"\"Reshapes an input array without copy.\"\"\"\n\n def __init__(self, shape):\n cnt = _count_unknown_dims(shape)\n assert cnt == 0 or cnt == 1\n\n self.shape = shape\n\n def check_type_forward(self, in_types):\n type_check.expect(\n in_types.size() == 1,\n )\n\n x_type, = in_types\n\n cnt = _count_unknown_dims(self.shape)\n if cnt == 0:\n type_check.expect(\n type_check.prod(x_type.shape) == type_check.prod(self.shape))\n else:\n known_size = 1\n for s in self.shape:\n if s > 0:\n known_size *= s\n size_var = type_check.Variable(known_size,\n 'known_size(=%d)' % known_size)\n type_check.expect(\n type_check.prod(x_type.shape) % size_var == 0)\n\n def forward(self, x):\n return x[0].reshape(self.shape),\n\n def backward(self, x, gy):\n return gy[0].reshape(x[0].shape),\n\n\ndef reshape(x, shape):\n \"\"\"Reshapes an input variable without copy.\n\n Args:\n x (~chainer.Variable): Input variable.\n shape (tuple of ints): Target shape.\n\n Returns:\n ~chainer.Variable: Variable that holds a reshaped version of the input\n variable.\n\n \"\"\"\n return Reshape(shape)(x)\n", "path": "chainer/functions/array/reshape.py"}]}
| 795 | 394 |
gh_patches_debug_5028
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1504
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ipywidgets extra pinned too tightly
https://github.com/googleapis/python-bigquery/blob/v3.4.2/setup.py#L70
I notice we have `"ipywidgets==7.7.1"`. This will likely give folks trouble as ipywidgets is updated. We should try to expand this when we can.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 "grpcio >= 1.47.0, < 2.0dev", # https://github.com/googleapis/python-bigquery/issues/1262
33 "grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'",
34 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
35 # Until this issue is closed
36 # https://github.com/googleapis/google-cloud-python/issues/10566
37 "google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0",
38 "proto-plus >= 1.15.0, <2.0.0dev",
39 # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x
40 # Until this issue is closed
41 # https://github.com/googleapis/google-cloud-python/issues/10566
42 "google-cloud-core >= 1.6.0, <3.0.0dev",
43 "google-resumable-media >= 0.6.0, < 3.0dev",
44 "packaging >= 20.0.0",
45 "protobuf>=3.19.5,<5.0.0dev,!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5", # For the legacy proto-based types.
46 "python-dateutil >= 2.7.2, <3.0dev",
47 "requests >= 2.21.0, < 3.0.0dev",
48 ]
49 pyarrow_dependency = "pyarrow >= 3.0.0"
50 extras = {
51 # Keep the no-op bqstorage extra for backward compatibility.
52 # See: https://github.com/googleapis/python-bigquery/issues/757
53 "bqstorage": [
54 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
55 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
56 # installed, even though `google-cloud-bigquery-storage` specifies it
57 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
58 # See: https://github.com/googleapis/python-bigquery/issues/83 The
59 # grpc.Channel.close() method isn't added until 1.32.0.
60 # https://github.com/grpc/grpc/pull/15254
61 "grpcio >= 1.47.0, < 2.0dev",
62 "grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'",
63 pyarrow_dependency,
64 ],
65 "pandas": [
66 "pandas>=1.1.0",
67 pyarrow_dependency,
68 "db-dtypes>=0.3.0,<2.0.0dev",
69 ],
70 "ipywidgets": ["ipywidgets==7.7.1"],
71 "geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.8.4, <2.0dev"],
72 "ipython": ["ipython>=7.0.1,!=8.1.0"],
73 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
74 "opentelemetry": [
75 "opentelemetry-api >= 1.1.0",
76 "opentelemetry-sdk >= 1.1.0",
77 "opentelemetry-instrumentation >= 0.20b0",
78 ],
79 }
80
81 all_extras = []
82
83 for extra in extras:
84 all_extras.extend(extras[extra])
85
86 extras["all"] = all_extras
87
88 # Setup boilerplate below this line.
89
90 package_root = os.path.abspath(os.path.dirname(__file__))
91
92 readme_filename = os.path.join(package_root, "README.rst")
93 with io.open(readme_filename, encoding="utf-8") as readme_file:
94 readme = readme_file.read()
95
96 version = {}
97 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
98 exec(fp.read(), version)
99 version = version["__version__"]
100
101 # Only include packages under the 'google' namespace. Do not include tests,
102 # benchmarks, etc.
103 packages = [
104 package
105 for package in setuptools.PEP420PackageFinder.find()
106 if package.startswith("google")
107 ]
108
109 # Determine which namespaces are needed.
110 namespaces = ["google"]
111 if "google.cloud" in packages:
112 namespaces.append("google.cloud")
113
114
115 setuptools.setup(
116 name=name,
117 version=version,
118 description=description,
119 long_description=readme,
120 author="Google LLC",
121 author_email="[email protected]",
122 license="Apache 2.0",
123 url="https://github.com/googleapis/python-bigquery",
124 classifiers=[
125 release_status,
126 "Intended Audience :: Developers",
127 "License :: OSI Approved :: Apache Software License",
128 "Programming Language :: Python",
129 "Programming Language :: Python :: 3",
130 "Programming Language :: Python :: 3.7",
131 "Programming Language :: Python :: 3.8",
132 "Programming Language :: Python :: 3.9",
133 "Programming Language :: Python :: 3.10",
134 "Programming Language :: Python :: 3.11",
135 "Operating System :: OS Independent",
136 "Topic :: Internet",
137 ],
138 platforms="Posix; MacOS X; Windows",
139 packages=packages,
140 namespace_packages=namespaces,
141 install_requires=dependencies,
142 extras_require=extras,
143 python_requires=">=3.7",
144 include_package_data=True,
145 zip_safe=False,
146 )
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -67,7 +67,7 @@
pyarrow_dependency,
"db-dtypes>=0.3.0,<2.0.0dev",
],
- "ipywidgets": ["ipywidgets==7.7.1"],
+ "ipywidgets": ["ipywidgets>=7.7.0,<8.0.1"],
"geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.8.4, <2.0dev"],
"ipython": ["ipython>=7.0.1,!=8.1.0"],
"tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -67,7 +67,7 @@\n pyarrow_dependency,\n \"db-dtypes>=0.3.0,<2.0.0dev\",\n ],\n- \"ipywidgets\": [\"ipywidgets==7.7.1\"],\n+ \"ipywidgets\": [\"ipywidgets>=7.7.0,<8.0.1\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.8.4, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n", "issue": "ipywidgets extra pinned too tightly\nhttps://github.com/googleapis/python-bigquery/blob/v3.4.2/setup.py#L70\r\n\r\nI notice we have `\"ipywidgets==7.7.1\"`. This will likely give folks trouble as ipywidgets is updated. We should try to expand this when we can.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"grpcio >= 1.47.0, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/1262\n \"grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'\",\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0\",\n \"proto-plus >= 1.15.0, <2.0.0dev\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.6.0, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 20.0.0\",\n \"protobuf>=3.19.5,<5.0.0dev,!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5\", # For the legacy proto-based types.\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"requests >= 2.21.0, < 3.0.0dev\",\n]\npyarrow_dependency = \"pyarrow >= 3.0.0\"\nextras = {\n # Keep the no-op bqstorage extra for backward compatibility.\n # See: https://github.com/googleapis/python-bigquery/issues/757\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.47.0, < 2.0dev\",\n \"grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'\",\n pyarrow_dependency,\n ],\n \"pandas\": [\n \"pandas>=1.1.0\",\n pyarrow_dependency,\n \"db-dtypes>=0.3.0,<2.0.0dev\",\n ],\n \"ipywidgets\": [\"ipywidgets==7.7.1\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.8.4, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 1.1.0\",\n \"opentelemetry-sdk >= 1.1.0\",\n \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.7\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"grpcio >= 1.47.0, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/1262\n \"grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'\",\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0\",\n \"proto-plus >= 1.15.0, <2.0.0dev\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.6.0, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 20.0.0\",\n \"protobuf>=3.19.5,<5.0.0dev,!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5\", # For the legacy proto-based types.\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"requests >= 2.21.0, < 3.0.0dev\",\n]\npyarrow_dependency = \"pyarrow >= 3.0.0\"\nextras = {\n # Keep the no-op bqstorage extra for backward compatibility.\n # See: https://github.com/googleapis/python-bigquery/issues/757\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.47.0, < 2.0dev\",\n \"grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'\",\n pyarrow_dependency,\n ],\n \"pandas\": [\n \"pandas>=1.1.0\",\n pyarrow_dependency,\n \"db-dtypes>=0.3.0,<2.0.0dev\",\n ],\n \"ipywidgets\": [\"ipywidgets>=7.7.0,<8.0.1\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.8.4, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 1.1.0\",\n \"opentelemetry-sdk >= 1.1.0\",\n \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.7\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,192 | 184 |
gh_patches_debug_13895
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2587
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Web3 instantiation from subclass throws error
* Version: 5.30.0
* Python: 3.8
* OS: osx
* pip freeze output is intentionally omitted.
### What was wrong?
We use a sub-class of Web3, for the purpose of this example, call it SubclassWeb3, as follows:
```
class SubclassWeb3(Web3):
def __init__(self, ....):
... do bunch of stuff...
super().__init__(*args, **kwargs)
... do bunch more stuff...
```
This setup worked fine with web3 version == 5.23.1. However, switching to web3==5.30.0 breaks this, with error
```
[rest of callstack omitted]
File “[redacted]/web3/main.py”, line 251, in __init__
self.attach_modules(modules)
File “[redacted]/web3/main.py”, line 340, in attach_modules
_attach_modules(self, modules)
File “[redacted]/web3/_utils/module.py”, line 68, in attach_modules
setattr(parent_module, module_name, module_class(w3))
File “[redacted]/web3/module.py”, line 93, in __init__
self.codec: ABICodec = web3.codec
AttributeError: ‘NoneType’ object has no attribute ‘codec’
```
This used to work in older versions because the parent_module is assumed to be a Web3 object and stored accordingly - [see logic](https://github.com/ethereum/web3.py/blob/2b229d2e16792e52bb47108e665c6a8937c188a2/web3/_utils/module.py#L33-L35).
Compare this to the somewhat brittle name checking that happens in 5.30.0 - [see logic](https://github.com/ethereum/web3.py/blob/ee5f0543ad91e4ba991997e35f50719ceb58135d/web3/_utils/module.py#L58-L60). This doesn't quite work because if this logic is being executed from a subclass of Web3, the name of the parent module appears as SubclassWeb3 (and not Web3).
### How can it be fixed?
Fill this section in if you know how this could or should be fixed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web3/_utils/module.py`
Content:
```
1 import inspect
2 from io import (
3 UnsupportedOperation,
4 )
5 from typing import (
6 TYPE_CHECKING,
7 Any,
8 Dict,
9 List,
10 Optional,
11 Sequence,
12 Union,
13 )
14
15 from web3.exceptions import (
16 ValidationError,
17 )
18 from web3.module import (
19 Module,
20 )
21
22 if TYPE_CHECKING:
23 from web3 import Web3 # noqa: F401
24
25
26 def _validate_init_params_and_return_if_found(module_class: Any) -> List[str]:
27 init_params_raw = list(inspect.signature(module_class.__init__).parameters)
28 module_init_params = [
29 param for param in init_params_raw if param not in ['self', 'args', 'kwargs']
30 ]
31
32 if len(module_init_params) > 1:
33 raise UnsupportedOperation(
34 "A module class may accept a single `Web3` instance as the first argument of its "
35 f"__init__() method. More than one argument found for {module_class.__name__}: "
36 f"{module_init_params}"
37 )
38
39 return module_init_params
40
41
42 def attach_modules(
43 parent_module: Union["Web3", "Module"],
44 module_definitions: Dict[str, Any],
45 w3: Optional[Union["Web3", "Module"]] = None
46 ) -> None:
47 for module_name, module_info in module_definitions.items():
48 module_info_is_list_like = isinstance(module_info, Sequence)
49
50 module_class = module_info[0] if module_info_is_list_like else module_info
51
52 if hasattr(parent_module, module_name):
53 raise AttributeError(
54 f"Cannot set {parent_module} module named '{module_name}'. The web3 object "
55 "already has an attribute with that name"
56 )
57
58 # The parent module is the ``Web3`` instance on first run of the loop
59 if type(parent_module).__name__ == 'Web3':
60 w3 = parent_module
61
62 module_init_params = _validate_init_params_and_return_if_found(module_class)
63 if len(module_init_params) == 1:
64 # Modules that need access to the ``Web3`` instance may accept the instance as the first
65 # arg in their ``__init__()`` method. This is the case for any module that inherits from
66 # ``web3.module.Module``.
67 # e.g. def __init__(self, w3):
68 setattr(parent_module, module_name, module_class(w3))
69 else:
70 # Modules need not take in a ``Web3`` instance in their ``__init__()`` if not needed
71 setattr(parent_module, module_name, module_class())
72
73 if module_info_is_list_like:
74 if len(module_info) == 2:
75 submodule_definitions = module_info[1]
76 module = getattr(parent_module, module_name)
77 attach_modules(module, submodule_definitions, w3)
78 elif len(module_info) != 1:
79 raise ValidationError("Module definitions can only have 1 or 2 elements.")
80
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web3/_utils/module.py b/web3/_utils/module.py
--- a/web3/_utils/module.py
+++ b/web3/_utils/module.py
@@ -55,9 +55,13 @@
"already has an attribute with that name"
)
- # The parent module is the ``Web3`` instance on first run of the loop
- if type(parent_module).__name__ == 'Web3':
- w3 = parent_module
+ # The parent module is the ``Web3`` instance on first run of the loop and w3 is
+ # None. Thus, set w3 to the parent_module. The import needs to happen locally
+ # due to circular import issues.
+ if w3 is None:
+ from web3 import Web3
+ if isinstance(parent_module, Web3):
+ w3 = parent_module
module_init_params = _validate_init_params_and_return_if_found(module_class)
if len(module_init_params) == 1:
|
{"golden_diff": "diff --git a/web3/_utils/module.py b/web3/_utils/module.py\n--- a/web3/_utils/module.py\n+++ b/web3/_utils/module.py\n@@ -55,9 +55,13 @@\n \"already has an attribute with that name\"\n )\n \n- # The parent module is the ``Web3`` instance on first run of the loop\n- if type(parent_module).__name__ == 'Web3':\n- w3 = parent_module\n+ # The parent module is the ``Web3`` instance on first run of the loop and w3 is\n+ # None. Thus, set w3 to the parent_module. The import needs to happen locally\n+ # due to circular import issues.\n+ if w3 is None:\n+ from web3 import Web3\n+ if isinstance(parent_module, Web3):\n+ w3 = parent_module\n \n module_init_params = _validate_init_params_and_return_if_found(module_class)\n if len(module_init_params) == 1:\n", "issue": "Web3 instantiation from subclass throws error\n* Version: 5.30.0\r\n* Python: 3.8\r\n* OS: osx\r\n* pip freeze output is intentionally omitted.\r\n\r\n### What was wrong?\r\nWe use a sub-class of Web3, for the purpose of this example, call it SubclassWeb3, as follows:\r\n\r\n```\r\nclass SubclassWeb3(Web3):\r\ndef __init__(self, ....):\r\n ... do bunch of stuff...\r\n super().__init__(*args, **kwargs)\r\n ... do bunch more stuff...\r\n```\r\n\r\nThis setup worked fine with web3 version == 5.23.1. However, switching to web3==5.30.0 breaks this, with error\r\n\r\n```\r\n[rest of callstack omitted]\r\n File \u201c[redacted]/web3/main.py\u201d, line 251, in __init__\r\n self.attach_modules(modules)\r\n File \u201c[redacted]/web3/main.py\u201d, line 340, in attach_modules\r\n _attach_modules(self, modules)\r\n File \u201c[redacted]/web3/_utils/module.py\u201d, line 68, in attach_modules\r\n setattr(parent_module, module_name, module_class(w3))\r\n File \u201c[redacted]/web3/module.py\u201d, line 93, in __init__\r\n self.codec: ABICodec = web3.codec\r\nAttributeError: \u2018NoneType\u2019 object has no attribute \u2018codec\u2019\r\n```\r\n\r\nThis used to work in older versions because the parent_module is assumed to be a Web3 object and stored accordingly - [see logic](https://github.com/ethereum/web3.py/blob/2b229d2e16792e52bb47108e665c6a8937c188a2/web3/_utils/module.py#L33-L35).\r\n\r\nCompare this to the somewhat brittle name checking that happens in 5.30.0 - [see logic](https://github.com/ethereum/web3.py/blob/ee5f0543ad91e4ba991997e35f50719ceb58135d/web3/_utils/module.py#L58-L60). This doesn't quite work because if this logic is being executed from a subclass of Web3, the name of the parent module appears as SubclassWeb3 (and not Web3).\r\n\r\n### How can it be fixed?\r\n\r\nFill this section in if you know how this could or should be fixed.\n", "before_files": [{"content": "import inspect\nfrom io import (\n UnsupportedOperation,\n)\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Dict,\n List,\n Optional,\n Sequence,\n Union,\n)\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.module import (\n Module,\n)\n\nif TYPE_CHECKING:\n from web3 import Web3 # noqa: F401\n\n\ndef _validate_init_params_and_return_if_found(module_class: Any) -> List[str]:\n init_params_raw = list(inspect.signature(module_class.__init__).parameters)\n module_init_params = [\n param for param in init_params_raw if param not in ['self', 'args', 'kwargs']\n ]\n\n if len(module_init_params) > 1:\n raise UnsupportedOperation(\n \"A module class may accept a single `Web3` instance as the first argument of its \"\n f\"__init__() method. More than one argument found for {module_class.__name__}: \"\n f\"{module_init_params}\"\n )\n\n return module_init_params\n\n\ndef attach_modules(\n parent_module: Union[\"Web3\", \"Module\"],\n module_definitions: Dict[str, Any],\n w3: Optional[Union[\"Web3\", \"Module\"]] = None\n) -> None:\n for module_name, module_info in module_definitions.items():\n module_info_is_list_like = isinstance(module_info, Sequence)\n\n module_class = module_info[0] if module_info_is_list_like else module_info\n\n if hasattr(parent_module, module_name):\n raise AttributeError(\n f\"Cannot set {parent_module} module named '{module_name}'. The web3 object \"\n \"already has an attribute with that name\"\n )\n\n # The parent module is the ``Web3`` instance on first run of the loop\n if type(parent_module).__name__ == 'Web3':\n w3 = parent_module\n\n module_init_params = _validate_init_params_and_return_if_found(module_class)\n if len(module_init_params) == 1:\n # Modules that need access to the ``Web3`` instance may accept the instance as the first\n # arg in their ``__init__()`` method. This is the case for any module that inherits from\n # ``web3.module.Module``.\n # e.g. def __init__(self, w3):\n setattr(parent_module, module_name, module_class(w3))\n else:\n # Modules need not take in a ``Web3`` instance in their ``__init__()`` if not needed\n setattr(parent_module, module_name, module_class())\n\n if module_info_is_list_like:\n if len(module_info) == 2:\n submodule_definitions = module_info[1]\n module = getattr(parent_module, module_name)\n attach_modules(module, submodule_definitions, w3)\n elif len(module_info) != 1:\n raise ValidationError(\"Module definitions can only have 1 or 2 elements.\")\n", "path": "web3/_utils/module.py"}], "after_files": [{"content": "import inspect\nfrom io import (\n UnsupportedOperation,\n)\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Dict,\n List,\n Optional,\n Sequence,\n Union,\n)\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.module import (\n Module,\n)\n\nif TYPE_CHECKING:\n from web3 import Web3 # noqa: F401\n\n\ndef _validate_init_params_and_return_if_found(module_class: Any) -> List[str]:\n init_params_raw = list(inspect.signature(module_class.__init__).parameters)\n module_init_params = [\n param for param in init_params_raw if param not in ['self', 'args', 'kwargs']\n ]\n\n if len(module_init_params) > 1:\n raise UnsupportedOperation(\n \"A module class may accept a single `Web3` instance as the first argument of its \"\n f\"__init__() method. More than one argument found for {module_class.__name__}: \"\n f\"{module_init_params}\"\n )\n\n return module_init_params\n\n\ndef attach_modules(\n parent_module: Union[\"Web3\", \"Module\"],\n module_definitions: Dict[str, Any],\n w3: Optional[Union[\"Web3\", \"Module\"]] = None\n) -> None:\n for module_name, module_info in module_definitions.items():\n module_info_is_list_like = isinstance(module_info, Sequence)\n\n module_class = module_info[0] if module_info_is_list_like else module_info\n\n if hasattr(parent_module, module_name):\n raise AttributeError(\n f\"Cannot set {parent_module} module named '{module_name}'. The web3 object \"\n \"already has an attribute with that name\"\n )\n\n # The parent module is the ``Web3`` instance on first run of the loop and w3 is\n # None. Thus, set w3 to the parent_module. The import needs to happen locally\n # due to circular import issues.\n if w3 is None:\n from web3 import Web3\n if isinstance(parent_module, Web3):\n w3 = parent_module\n\n module_init_params = _validate_init_params_and_return_if_found(module_class)\n if len(module_init_params) == 1:\n # Modules that need access to the ``Web3`` instance may accept the instance as the first\n # arg in their ``__init__()`` method. This is the case for any module that inherits from\n # ``web3.module.Module``.\n # e.g. def __init__(self, w3):\n setattr(parent_module, module_name, module_class(w3))\n else:\n # Modules need not take in a ``Web3`` instance in their ``__init__()`` if not needed\n setattr(parent_module, module_name, module_class())\n\n if module_info_is_list_like:\n if len(module_info) == 2:\n submodule_definitions = module_info[1]\n module = getattr(parent_module, module_name)\n attach_modules(module, submodule_definitions, w3)\n elif len(module_info) != 1:\n raise ValidationError(\"Module definitions can only have 1 or 2 elements.\")\n", "path": "web3/_utils/module.py"}]}
| 1,574 | 221 |
gh_patches_debug_21409
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-7232
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upgrade from Python 3.10.6 to Python 3.10.8
<!-- What issue does this PR close? -->
Closes #
<!-- What does this PR achieve? [feature|hotfix|fix|refactor] -->
Repeat the process discussed in https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358 to upgrade CPython.
[This update](https://docs.python.org/release/3.10.8/whatsnew/changelog.html) includes a mitigation for [CVE-2020-10735](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10735) and several other security fixes.
### Technical
<!-- What should be noted about the implementation? -->
### Testing
<!-- Steps for reviewer to reproduce/verify what this PR does/fixes. -->
For testing, please do (from https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358):
* [x] On `ol-dev1` (in `ol-cclauss`), check out branch and build a new olbase image tagged `-t openlibrary/olbase:py3.10.8`
* [x] `git fetch origin && git checkout python3.10.8`
* [x] `docker build --no-cache -t openlibrary/olbase:py3.10.8 -f docker/Dockerfile.olbase .`
* [x] `hostname ; docker image ls | grep 3.10.8 ` # -> `ol-dev1.us.archive.org`, `repo: openlibrary/olbase, tag: py3.10.8`
* [x] Ask **@cdrini** to push this up to docker hub once it's done
* [ ] Pull it down locally and test the site with the `OLIMAGE` param
* [ ] Also test solr-updater starts up ok ; it's using FnToCLI which has caused issues with types/python handling of types
* [ ] Restart testing.openlibrary.org with the OLIMAGE param ; confirm things work
* [ ] Merge!
### During the `docker build` process -- DISK WARNING - free space: / 8905 MB (15% inode=38%):
### npm deprication warnings --> #7084
### During the `docker build` process -- Warning: apt-key is deprecated.
```
Step 9/27 : RUN wget -O - https://openresty.org/package/pubkey.gpg | apt-key add -
---> Running in d075e06118ad
--2022-10-16 13:25:19-- https://openresty.org/package/pubkey.gpg
Resolving openresty.org (openresty.org)... Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).
3.131.85.84, 2600:1f1c:9b2:8000:f183:c67e:2c64:855f
Connecting to openresty.org (openresty.org)|3.131.85.84|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1688 (1.6K) [text/plain]
Saving to: 'STDOUT'
0K . 100% 65.4M=0s
2022-10-16 13:25:20 (65.4 MB/s) - written to stdout [1688/1688]
```
### Screenshot
<!-- If this PR touches UI, please post evidence (screenshots) of it behaving correctly. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
<!-- Attribution Disclaimer: By proposing this pull request, I affirm to have made a best-effort and exercised my discretion to make sure relevant sections of this code that substantially leverage code suggestions, code generation, or code snippets from sources (e.g. Stack Overflow, GitHub) have been annotated with basic attribution so reviewers & contributors may have confidence and access to the correct context to evaluate and use this code. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/oldump.py`
Content:
```
1 #!/usr/bin/env python
2
3 import logging
4 import os
5 import sys
6 from datetime import datetime
7
8 import _init_path # noqa: F401 Imported for its side effect of setting PYTHONPATH
9
10 logger = logging.getLogger(__file__)
11 logger.setLevel(logging.DEBUG)
12
13
14 def log(*args) -> None:
15 args_str = " ".join(str(a) for a in args)
16 msg = f"{datetime.now():%Y-%m-%d %H:%M:%S} [openlibrary.dump] {args_str}"
17 logger.info(msg)
18 print(msg, file=sys.stderr)
19
20
21 if __name__ == "__main__":
22 from contextlib import redirect_stdout
23 from infogami import config
24 from openlibrary.config import load_config
25 from openlibrary.data import dump
26 from openlibrary.utils.sentry import Sentry
27
28 log("{} on Python {}.{}.{}".format(sys.argv, *sys.version_info)) # Python 3.10.4
29
30 ol_config = os.getenv("OL_CONFIG")
31 if ol_config:
32 logger.info(f"loading config from {ol_config}")
33 # Squelch output from infobase (needed for sentry setup)
34 # So it doesn't end up in our data dumps body
35 with open(os.devnull, 'w') as devnull:
36 with redirect_stdout(devnull):
37 load_config(ol_config)
38 sentry = Sentry(getattr(config, "sentry_cron_jobs", {}))
39 if sentry.enabled:
40 sentry.init()
41 log(f"sentry.enabled = {bool(ol_config and sentry.enabled)}")
42
43 dump.main(sys.argv[1], sys.argv[2:])
44
```
Path: `scripts/solr_builder/solr_builder/fn_to_cli.py`
Content:
```
1 import asyncio
2 import typing
3 from argparse import (
4 ArgumentParser,
5 ArgumentDefaultsHelpFormatter,
6 BooleanOptionalAction,
7 Namespace,
8 )
9
10
11 class FnToCLI:
12 """
13 A utility class which automatically infers and generates ArgParse command
14 line options from a function based on defaults/type annotations
15
16 This is _very_ basic; supports:
17 * Args of int, str types (same logic as default argparse)
18 * Args of bool type (Uses argparse BooleanOptionalAction)
19 * eg `do_blah=False` becomes `--do-blah, --no-do-blah`
20 * Args of typing.Optional (or anything with a default)
21 * Args of typing.Literal (uses argparse choices)
22 * eg `color: Literal['red, 'black']` becomes `--color red|black` (with docs)
23 * Type deduction of default values
24 * Supports async functions automatically
25 * Includes docstring if it's in `:param my_arg: Description of my arg` format
26
27 Anything else will likely error :)
28
29 Example:
30 if __name__ == '__main__':
31 FnToCLI(my_func).run()
32 """
33
34 def __init__(self, fn: typing.Callable):
35 self.fn = fn
36 arg_names = fn.__code__.co_varnames[: fn.__code__.co_argcount]
37 annotations = typing.get_type_hints(fn)
38 defaults: list = fn.__defaults__ or [] # type: ignore[assignment]
39 num_required = len(arg_names) - len(defaults)
40 default_args = arg_names[num_required:]
41 defaults: dict = { # type: ignore[no-redef]
42 arg: default for [arg, default] in zip(default_args, defaults)
43 }
44
45 docs = fn.__doc__ or ''
46 arg_docs = self.parse_docs(docs)
47 self.parser = ArgumentParser(
48 description=docs.split(':param', 1)[0],
49 formatter_class=ArgumentDefaultsHelpFormatter,
50 )
51 self.args: typing.Optional[Namespace] = None
52 for arg in arg_names:
53 optional = arg in defaults
54 cli_name = arg.replace('_', '-')
55
56 if arg in annotations:
57 arg_opts = self.type_to_argparse(annotations[arg])
58 elif arg in defaults:
59 arg_opts = self.type_to_argparse(type(defaults[arg])) # type: ignore[call-overload]
60 else:
61 raise ValueError(f'{arg} has no type information')
62
63 # Help needs to always be defined, or it won't show the default :/
64 arg_opts['help'] = arg_docs.get(arg) or '-'
65
66 if optional:
67 opt_name = f'--{cli_name}' if len(cli_name) > 1 else f'-{cli_name}'
68 self.parser.add_argument(opt_name, default=defaults[arg], **arg_opts) # type: ignore[call-overload]
69 else:
70 self.parser.add_argument(cli_name, **arg_opts)
71
72 def parse_args(self):
73 self.args = self.parser.parse_args()
74 return self.args
75
76 def args_dict(self):
77 if not self.args:
78 self.parse_args()
79
80 return {k.replace('-', '_'): v for k, v in self.args.__dict__.items()}
81
82 def run(self):
83 args_dicts = self.args_dict()
84 if asyncio.iscoroutinefunction(self.fn):
85 asyncio.run(self.fn(**args_dicts))
86 else:
87 self.fn(**args_dicts)
88
89 @staticmethod
90 def parse_docs(docs):
91 params = docs.strip().split(':param ')[1:]
92 params = [p.strip() for p in params]
93 params = [p.split(':', 1) for p in params if p]
94 return {name: docs.strip() for [name, docs] in params}
95
96 @staticmethod
97 def type_to_argparse(typ: type) -> dict:
98 if FnToCLI.is_optional(typ):
99 return FnToCLI.type_to_argparse(
100 next(t for t in typing.get_args(typ) if not isinstance(t, type(None)))
101 )
102 if typ == bool:
103 return {'type': typ, 'action': BooleanOptionalAction}
104 if typ in (int, str, float):
105 return {'type': typ}
106 if typ == list[str]:
107 return {'nargs': '*'}
108 if typing.get_origin(typ) == typing.Literal:
109 return {'choices': typing.get_args(typ)}
110 raise ValueError(f'Unsupported type: {typ}')
111
112 @staticmethod
113 def is_optional(typ: type) -> bool:
114 return (
115 typing.get_origin(typ) is typing.Union
116 and type(None) in typing.get_args(typ)
117 and len(typing.get_args(typ)) == 2
118 )
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/oldump.py b/scripts/oldump.py
--- a/scripts/oldump.py
+++ b/scripts/oldump.py
@@ -25,7 +25,7 @@
from openlibrary.data import dump
from openlibrary.utils.sentry import Sentry
- log("{} on Python {}.{}.{}".format(sys.argv, *sys.version_info)) # Python 3.10.4
+ log("{} on Python {}.{}.{}".format(sys.argv, *sys.version_info)) # Python 3.11.1
ol_config = os.getenv("OL_CONFIG")
if ol_config:
diff --git a/scripts/solr_builder/solr_builder/fn_to_cli.py b/scripts/solr_builder/solr_builder/fn_to_cli.py
--- a/scripts/solr_builder/solr_builder/fn_to_cli.py
+++ b/scripts/solr_builder/solr_builder/fn_to_cli.py
@@ -1,4 +1,5 @@
import asyncio
+import types
import typing
from argparse import (
ArgumentParser,
@@ -112,7 +113,7 @@
@staticmethod
def is_optional(typ: type) -> bool:
return (
- typing.get_origin(typ) is typing.Union
+ (typing.get_origin(typ) is typing.Union or isinstance(typ, types.UnionType))
and type(None) in typing.get_args(typ)
and len(typing.get_args(typ)) == 2
)
|
{"golden_diff": "diff --git a/scripts/oldump.py b/scripts/oldump.py\n--- a/scripts/oldump.py\n+++ b/scripts/oldump.py\n@@ -25,7 +25,7 @@\n from openlibrary.data import dump\n from openlibrary.utils.sentry import Sentry\n \n- log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.10.4\n+ log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.11.1\n \n ol_config = os.getenv(\"OL_CONFIG\")\n if ol_config:\ndiff --git a/scripts/solr_builder/solr_builder/fn_to_cli.py b/scripts/solr_builder/solr_builder/fn_to_cli.py\n--- a/scripts/solr_builder/solr_builder/fn_to_cli.py\n+++ b/scripts/solr_builder/solr_builder/fn_to_cli.py\n@@ -1,4 +1,5 @@\n import asyncio\n+import types\n import typing\n from argparse import (\n ArgumentParser,\n@@ -112,7 +113,7 @@\n @staticmethod\n def is_optional(typ: type) -> bool:\n return (\n- typing.get_origin(typ) is typing.Union\n+ (typing.get_origin(typ) is typing.Union or isinstance(typ, types.UnionType))\n and type(None) in typing.get_args(typ)\n and len(typing.get_args(typ)) == 2\n )\n", "issue": "Upgrade from Python 3.10.6 to Python 3.10.8\n<!-- What issue does this PR close? -->\r\nCloses #\r\n\r\n<!-- What does this PR achieve? [feature|hotfix|fix|refactor] -->\r\nRepeat the process discussed in https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358 to upgrade CPython.\r\n[This update](https://docs.python.org/release/3.10.8/whatsnew/changelog.html) includes a mitigation for [CVE-2020-10735](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10735) and several other security fixes.\r\n\r\n### Technical\r\n<!-- What should be noted about the implementation? -->\r\n\r\n### Testing\r\n<!-- Steps for reviewer to reproduce/verify what this PR does/fixes. -->\r\nFor testing, please do (from https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358):\r\n* [x] On `ol-dev1` (in `ol-cclauss`), check out branch and build a new olbase image tagged `-t openlibrary/olbase:py3.10.8`\r\n * [x] `git fetch origin && git checkout python3.10.8`\r\n * [x] `docker build --no-cache -t openlibrary/olbase:py3.10.8 -f docker/Dockerfile.olbase .`\r\n * [x] `hostname ; docker image ls | grep 3.10.8 ` # -> `ol-dev1.us.archive.org`, `repo: openlibrary/olbase, tag: py3.10.8`\r\n* [x] Ask **@cdrini** to push this up to docker hub once it's done\r\n* [ ] Pull it down locally and test the site with the `OLIMAGE` param\r\n * [ ] Also test solr-updater starts up ok ; it's using FnToCLI which has caused issues with types/python handling of types\r\n* [ ] Restart testing.openlibrary.org with the OLIMAGE param ; confirm things work\r\n* [ ] Merge!\r\n\r\n### During the `docker build` process -- DISK WARNING - free space: / 8905 MB (15% inode=38%):\r\n\r\n### npm deprication warnings --> #7084\r\n\r\n### During the `docker build` process -- Warning: apt-key is deprecated.\r\n```\r\nStep 9/27 : RUN wget -O - https://openresty.org/package/pubkey.gpg | apt-key add -\r\n ---> Running in d075e06118ad\r\n--2022-10-16 13:25:19-- https://openresty.org/package/pubkey.gpg\r\nResolving openresty.org (openresty.org)... Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).\r\n3.131.85.84, 2600:1f1c:9b2:8000:f183:c67e:2c64:855f\r\nConnecting to openresty.org (openresty.org)|3.131.85.84|:443... connected.\r\nHTTP request sent, awaiting response... 200 OK\r\nLength: 1688 (1.6K) [text/plain]\r\nSaving to: 'STDOUT'\r\n\r\n 0K . 100% 65.4M=0s\r\n\r\n2022-10-16 13:25:20 (65.4 MB/s) - written to stdout [1688/1688]\r\n```\r\n### Screenshot\r\n<!-- If this PR touches UI, please post evidence (screenshots) of it behaving correctly. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\r\n\r\n<!-- Attribution Disclaimer: By proposing this pull request, I affirm to have made a best-effort and exercised my discretion to make sure relevant sections of this code that substantially leverage code suggestions, code generation, or code snippets from sources (e.g. Stack Overflow, GitHub) have been annotated with basic attribution so reviewers & contributors may have confidence and access to the correct context to evaluate and use this code. -->\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport logging\nimport os\nimport sys\nfrom datetime import datetime\n\nimport _init_path # noqa: F401 Imported for its side effect of setting PYTHONPATH\n\nlogger = logging.getLogger(__file__)\nlogger.setLevel(logging.DEBUG)\n\n\ndef log(*args) -> None:\n args_str = \" \".join(str(a) for a in args)\n msg = f\"{datetime.now():%Y-%m-%d %H:%M:%S} [openlibrary.dump] {args_str}\"\n logger.info(msg)\n print(msg, file=sys.stderr)\n\n\nif __name__ == \"__main__\":\n from contextlib import redirect_stdout\n from infogami import config\n from openlibrary.config import load_config\n from openlibrary.data import dump\n from openlibrary.utils.sentry import Sentry\n\n log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.10.4\n\n ol_config = os.getenv(\"OL_CONFIG\")\n if ol_config:\n logger.info(f\"loading config from {ol_config}\")\n # Squelch output from infobase (needed for sentry setup)\n # So it doesn't end up in our data dumps body\n with open(os.devnull, 'w') as devnull:\n with redirect_stdout(devnull):\n load_config(ol_config)\n sentry = Sentry(getattr(config, \"sentry_cron_jobs\", {}))\n if sentry.enabled:\n sentry.init()\n log(f\"sentry.enabled = {bool(ol_config and sentry.enabled)}\")\n\n dump.main(sys.argv[1], sys.argv[2:])\n", "path": "scripts/oldump.py"}, {"content": "import asyncio\nimport typing\nfrom argparse import (\n ArgumentParser,\n ArgumentDefaultsHelpFormatter,\n BooleanOptionalAction,\n Namespace,\n)\n\n\nclass FnToCLI:\n \"\"\"\n A utility class which automatically infers and generates ArgParse command\n line options from a function based on defaults/type annotations\n\n This is _very_ basic; supports:\n * Args of int, str types (same logic as default argparse)\n * Args of bool type (Uses argparse BooleanOptionalAction)\n * eg `do_blah=False` becomes `--do-blah, --no-do-blah`\n * Args of typing.Optional (or anything with a default)\n * Args of typing.Literal (uses argparse choices)\n * eg `color: Literal['red, 'black']` becomes `--color red|black` (with docs)\n * Type deduction of default values\n * Supports async functions automatically\n * Includes docstring if it's in `:param my_arg: Description of my arg` format\n\n Anything else will likely error :)\n\n Example:\n if __name__ == '__main__':\n FnToCLI(my_func).run()\n \"\"\"\n\n def __init__(self, fn: typing.Callable):\n self.fn = fn\n arg_names = fn.__code__.co_varnames[: fn.__code__.co_argcount]\n annotations = typing.get_type_hints(fn)\n defaults: list = fn.__defaults__ or [] # type: ignore[assignment]\n num_required = len(arg_names) - len(defaults)\n default_args = arg_names[num_required:]\n defaults: dict = { # type: ignore[no-redef]\n arg: default for [arg, default] in zip(default_args, defaults)\n }\n\n docs = fn.__doc__ or ''\n arg_docs = self.parse_docs(docs)\n self.parser = ArgumentParser(\n description=docs.split(':param', 1)[0],\n formatter_class=ArgumentDefaultsHelpFormatter,\n )\n self.args: typing.Optional[Namespace] = None\n for arg in arg_names:\n optional = arg in defaults\n cli_name = arg.replace('_', '-')\n\n if arg in annotations:\n arg_opts = self.type_to_argparse(annotations[arg])\n elif arg in defaults:\n arg_opts = self.type_to_argparse(type(defaults[arg])) # type: ignore[call-overload]\n else:\n raise ValueError(f'{arg} has no type information')\n\n # Help needs to always be defined, or it won't show the default :/\n arg_opts['help'] = arg_docs.get(arg) or '-'\n\n if optional:\n opt_name = f'--{cli_name}' if len(cli_name) > 1 else f'-{cli_name}'\n self.parser.add_argument(opt_name, default=defaults[arg], **arg_opts) # type: ignore[call-overload]\n else:\n self.parser.add_argument(cli_name, **arg_opts)\n\n def parse_args(self):\n self.args = self.parser.parse_args()\n return self.args\n\n def args_dict(self):\n if not self.args:\n self.parse_args()\n\n return {k.replace('-', '_'): v for k, v in self.args.__dict__.items()}\n\n def run(self):\n args_dicts = self.args_dict()\n if asyncio.iscoroutinefunction(self.fn):\n asyncio.run(self.fn(**args_dicts))\n else:\n self.fn(**args_dicts)\n\n @staticmethod\n def parse_docs(docs):\n params = docs.strip().split(':param ')[1:]\n params = [p.strip() for p in params]\n params = [p.split(':', 1) for p in params if p]\n return {name: docs.strip() for [name, docs] in params}\n\n @staticmethod\n def type_to_argparse(typ: type) -> dict:\n if FnToCLI.is_optional(typ):\n return FnToCLI.type_to_argparse(\n next(t for t in typing.get_args(typ) if not isinstance(t, type(None)))\n )\n if typ == bool:\n return {'type': typ, 'action': BooleanOptionalAction}\n if typ in (int, str, float):\n return {'type': typ}\n if typ == list[str]:\n return {'nargs': '*'}\n if typing.get_origin(typ) == typing.Literal:\n return {'choices': typing.get_args(typ)}\n raise ValueError(f'Unsupported type: {typ}')\n\n @staticmethod\n def is_optional(typ: type) -> bool:\n return (\n typing.get_origin(typ) is typing.Union\n and type(None) in typing.get_args(typ)\n and len(typing.get_args(typ)) == 2\n )\n", "path": "scripts/solr_builder/solr_builder/fn_to_cli.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport logging\nimport os\nimport sys\nfrom datetime import datetime\n\nimport _init_path # noqa: F401 Imported for its side effect of setting PYTHONPATH\n\nlogger = logging.getLogger(__file__)\nlogger.setLevel(logging.DEBUG)\n\n\ndef log(*args) -> None:\n args_str = \" \".join(str(a) for a in args)\n msg = f\"{datetime.now():%Y-%m-%d %H:%M:%S} [openlibrary.dump] {args_str}\"\n logger.info(msg)\n print(msg, file=sys.stderr)\n\n\nif __name__ == \"__main__\":\n from contextlib import redirect_stdout\n from infogami import config\n from openlibrary.config import load_config\n from openlibrary.data import dump\n from openlibrary.utils.sentry import Sentry\n\n log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.11.1\n\n ol_config = os.getenv(\"OL_CONFIG\")\n if ol_config:\n logger.info(f\"loading config from {ol_config}\")\n # Squelch output from infobase (needed for sentry setup)\n # So it doesn't end up in our data dumps body\n with open(os.devnull, 'w') as devnull:\n with redirect_stdout(devnull):\n load_config(ol_config)\n sentry = Sentry(getattr(config, \"sentry_cron_jobs\", {}))\n if sentry.enabled:\n sentry.init()\n log(f\"sentry.enabled = {bool(ol_config and sentry.enabled)}\")\n\n dump.main(sys.argv[1], sys.argv[2:])\n", "path": "scripts/oldump.py"}, {"content": "import asyncio\nimport types\nimport typing\nfrom argparse import (\n ArgumentParser,\n ArgumentDefaultsHelpFormatter,\n BooleanOptionalAction,\n Namespace,\n)\n\n\nclass FnToCLI:\n \"\"\"\n A utility class which automatically infers and generates ArgParse command\n line options from a function based on defaults/type annotations\n\n This is _very_ basic; supports:\n * Args of int, str types (same logic as default argparse)\n * Args of bool type (Uses argparse BooleanOptionalAction)\n * eg `do_blah=False` becomes `--do-blah, --no-do-blah`\n * Args of typing.Optional (or anything with a default)\n * Args of typing.Literal (uses argparse choices)\n * eg `color: Literal['red, 'black']` becomes `--color red|black` (with docs)\n * Type deduction of default values\n * Supports async functions automatically\n * Includes docstring if it's in `:param my_arg: Description of my arg` format\n\n Anything else will likely error :)\n\n Example:\n if __name__ == '__main__':\n FnToCLI(my_func).run()\n \"\"\"\n\n def __init__(self, fn: typing.Callable):\n self.fn = fn\n arg_names = fn.__code__.co_varnames[: fn.__code__.co_argcount]\n annotations = typing.get_type_hints(fn)\n defaults: list = fn.__defaults__ or [] # type: ignore[assignment]\n num_required = len(arg_names) - len(defaults)\n default_args = arg_names[num_required:]\n defaults: dict = { # type: ignore[no-redef]\n arg: default for [arg, default] in zip(default_args, defaults)\n }\n\n docs = fn.__doc__ or ''\n arg_docs = self.parse_docs(docs)\n self.parser = ArgumentParser(\n description=docs.split(':param', 1)[0],\n formatter_class=ArgumentDefaultsHelpFormatter,\n )\n self.args: typing.Optional[Namespace] = None\n for arg in arg_names:\n optional = arg in defaults\n cli_name = arg.replace('_', '-')\n\n if arg in annotations:\n arg_opts = self.type_to_argparse(annotations[arg])\n elif arg in defaults:\n arg_opts = self.type_to_argparse(type(defaults[arg])) # type: ignore[call-overload]\n else:\n raise ValueError(f'{arg} has no type information')\n\n # Help needs to always be defined, or it won't show the default :/\n arg_opts['help'] = arg_docs.get(arg) or '-'\n\n if optional:\n opt_name = f'--{cli_name}' if len(cli_name) > 1 else f'-{cli_name}'\n self.parser.add_argument(opt_name, default=defaults[arg], **arg_opts) # type: ignore[call-overload]\n else:\n self.parser.add_argument(cli_name, **arg_opts)\n\n def parse_args(self):\n self.args = self.parser.parse_args()\n return self.args\n\n def args_dict(self):\n if not self.args:\n self.parse_args()\n\n return {k.replace('-', '_'): v for k, v in self.args.__dict__.items()}\n\n def run(self):\n args_dicts = self.args_dict()\n if asyncio.iscoroutinefunction(self.fn):\n asyncio.run(self.fn(**args_dicts))\n else:\n self.fn(**args_dicts)\n\n @staticmethod\n def parse_docs(docs):\n params = docs.strip().split(':param ')[1:]\n params = [p.strip() for p in params]\n params = [p.split(':', 1) for p in params if p]\n return {name: docs.strip() for [name, docs] in params}\n\n @staticmethod\n def type_to_argparse(typ: type) -> dict:\n if FnToCLI.is_optional(typ):\n return FnToCLI.type_to_argparse(\n next(t for t in typing.get_args(typ) if not isinstance(t, type(None)))\n )\n if typ == bool:\n return {'type': typ, 'action': BooleanOptionalAction}\n if typ in (int, str, float):\n return {'type': typ}\n if typ == list[str]:\n return {'nargs': '*'}\n if typing.get_origin(typ) == typing.Literal:\n return {'choices': typing.get_args(typ)}\n raise ValueError(f'Unsupported type: {typ}')\n\n @staticmethod\n def is_optional(typ: type) -> bool:\n return (\n (typing.get_origin(typ) is typing.Union or isinstance(typ, types.UnionType))\n and type(None) in typing.get_args(typ)\n and len(typing.get_args(typ)) == 2\n )\n", "path": "scripts/solr_builder/solr_builder/fn_to_cli.py"}]}
| 2,938 | 322 |
gh_patches_debug_61518
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmpose-295
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pylint: W0105
```bash
mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py:173:8: W0105: String statement has no effect (pointless-string-statement)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py`
Content:
```
1 import copy as cp
2 import os
3 import os.path as osp
4 from collections import OrderedDict
5
6 import json_tricks as json
7 import numpy as np
8
9 from mmpose.datasets.builder import DATASETS
10 from .topdown_base_dataset import TopDownBaseDataset
11
12
13 @DATASETS.register_module()
14 class TopDownMpiiTrbDataset(TopDownBaseDataset):
15 """MPII-TRB Dataset dataset for top-down pose estimation.
16
17 `TRB: A Novel Triplet Representation for Understanding 2D Human Body`
18 ICCV'2019 More details can be found in the `paper
19 <https://arxiv.org/abs/1910.11535>`__ .
20
21 The dataset loads raw features and apply specified transforms
22 to return a dict containing the image tensors and other information.
23
24 Args:
25 ann_file (str): Path to the annotation file.
26 img_prefix (str): Path to a directory where images are held.
27 Default: None.
28 data_cfg (dict): config
29 pipeline (list[dict | callable]): A sequence of data transforms.
30 test_mode (bool): Store True when building test or
31 validation dataset. Default: False.
32 """
33
34 def __init__(self,
35 ann_file,
36 img_prefix,
37 data_cfg,
38 pipeline,
39 test_mode=False):
40
41 super().__init__(
42 ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)
43
44 # flip_pairs in MPII-TRB
45 self.ann_info['flip_pairs'] = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9],
46 [10, 11], [14, 15]]
47 for i in range(6):
48 self.ann_info['flip_pairs'].append([16 + i, 22 + i])
49 self.ann_info['flip_pairs'].append([28 + i, 34 + i])
50
51 self.ann_info['upper_body_ids'] = [0, 1, 2, 3, 4, 5, 12, 13]
52 self.ann_info['lower_body_ids'] = [6, 7, 8, 9, 10, 11]
53 self.ann_info['upper_body_ids'].extend(list(range(14, 28)))
54 self.ann_info['lower_body_ids'].extend(list(range(28, 40)))
55
56 self.ann_info['use_different_joint_weights'] = False
57
58 assert self.ann_info['num_joints'] == 40
59 self.ann_info['joint_weights'] = np.ones(
60 (self.ann_info['num_joints'], 1), dtype=np.float32)
61
62 self.db = self._get_db(ann_file)
63 self.image_set = set(x['image_file'] for x in self.db)
64 self.num_images = len(self.image_set)
65
66 print(f'=> num_images: {self.num_images}')
67 print(f'=> load {len(self.db)} samples')
68
69 def _get_db(self, ann_file):
70 """Load dataset."""
71 with open(ann_file, 'r') as f:
72 data = json.load(f)
73 tmpl = dict(
74 image_file=None,
75 center=None,
76 scale=None,
77 rotation=0,
78 joints_3d=None,
79 joints_3d_visible=None,
80 dataset='mpii_trb')
81
82 imid2info = {
83 int(osp.splitext(x['file_name'])[0]): x
84 for x in data['images']
85 }
86
87 num_joints = self.ann_info['num_joints']
88 gt_db = []
89
90 for anno in data['annotations']:
91 newitem = cp.deepcopy(tmpl)
92 image_id = anno['image_id']
93 newitem['image_file'] = os.path.join(
94 self.img_prefix, imid2info[image_id]['file_name'])
95
96 if max(anno['keypoints']) == 0:
97 continue
98
99 joints_3d = np.zeros((num_joints, 3), dtype=np.float32)
100 joints_3d_visible = np.zeros((num_joints, 3), dtype=np.float32)
101
102 for ipt in range(num_joints):
103 joints_3d[ipt, 0] = anno['keypoints'][ipt * 3 + 0]
104 joints_3d[ipt, 1] = anno['keypoints'][ipt * 3 + 1]
105 joints_3d[ipt, 2] = 0
106 t_vis = min(anno['keypoints'][ipt * 3 + 2], 1)
107 joints_3d_visible[ipt, :] = (t_vis, t_vis, 0)
108
109 center = np.array(anno['center'], dtype=np.float32)
110 scale = self.ann_info['image_size'] / anno['scale'] / 200.0
111 newitem['center'] = center
112 newitem['scale'] = scale
113 newitem['joints_3d'] = joints_3d
114 newitem['joints_3d_visible'] = joints_3d_visible
115 if 'headbox' in anno:
116 newitem['headbox'] = anno['headbox']
117 gt_db.append(newitem)
118
119 return gt_db
120
121 def _evaluate_kernel(self, pred, joints_3d, joints_3d_visible, headbox):
122 """Evaluate one example."""
123 num_joints = self.ann_info['num_joints']
124 headbox = np.array(headbox)
125 threshold = np.linalg.norm(headbox[:2] - headbox[2:]) * 0.3
126 hit = np.zeros(num_joints, dtype=np.float32)
127 exist = np.zeros(num_joints, dtype=np.float32)
128
129 for i in range(num_joints):
130 pred_pt = pred[i]
131 gt_pt = joints_3d[i]
132 vis = joints_3d_visible[i][0]
133 if vis:
134 exist[i] = 1
135 else:
136 continue
137 distance = np.linalg.norm(pred_pt[:2] - gt_pt[:2])
138 if distance < threshold:
139 hit[i] = 1
140 return hit, exist
141
142 def evaluate(self, outputs, res_folder, metric='PCKh', **kwargs):
143 """Evaluate PCKh for MPII-TRB dataset.
144
145 Note:
146 batch_size: N
147 num_keypoints: K
148 heatmap height: H
149 heatmap width: W
150
151 Args:
152 outputs(list(preds, boxes, image_path, heatmap)):
153
154 * preds(np.ndarray[1,K,3]): The first two dimensions are
155 coordinates, score is the third dimension of the array.
156 * boxes(np.ndarray[1,6]): [center[0], center[1], scale[0]
157 , scale[1],area, score]
158 * image_path(list[str]): For example, ['0', '0',
159 '0', '0', '0', '1', '1', '6', '3', '.', 'j', 'p', 'g']
160 * heatmap (np.ndarray[N, K, H, W]): model output heatmap.
161 res_folder(str): Path of directory to save the results.
162 metric (str | list[str]): Metrics to be performed.
163 Defaults: 'PCKh'.
164
165 Returns:
166 dict: PCKh for each joint
167 """
168 metrics = metric if isinstance(metric, list) else [metric]
169 allowed_metrics = ['PCKh']
170 for metric in metrics:
171 if metric not in allowed_metrics:
172 raise KeyError(f'metric {metric} is not supported')
173 """Evaluate MPII-TRB keypoint results."""
174 res_file = os.path.join(res_folder, 'result_keypoints.json')
175
176 kpts = []
177
178 for preds, boxes, image_path, _ in outputs:
179 str_image_path = ''.join(image_path)
180 image_id = int(osp.basename(osp.splitext(str_image_path)[0]))
181
182 kpts.append({
183 'keypoints': preds[0].tolist(),
184 'center': boxes[0][0:2].tolist(),
185 'scale': boxes[0][2:4].tolist(),
186 'area': float(boxes[0][4]),
187 'score': float(boxes[0][5]),
188 'image_id': image_id,
189 })
190
191 self._write_keypoint_results(kpts, res_file)
192 info_str = self._report_metric(res_file)
193 name_value = OrderedDict(info_str)
194
195 return name_value
196
197 @staticmethod
198 def _write_keypoint_results(keypoints, res_file):
199 """Write results into a json file."""
200
201 with open(res_file, 'w') as f:
202 json.dump(keypoints, f, sort_keys=True, indent=4)
203
204 def _report_metric(self, res_file):
205 """Keypoint evaluation.
206
207 Report Mean Acc of skeleton, contour and all joints.
208 """
209 num_joints = self.ann_info['num_joints']
210 hit = np.zeros(num_joints, dtype=np.float32)
211 exist = np.zeros(num_joints, dtype=np.float32)
212
213 with open(res_file, 'r') as fin:
214 preds = json.load(fin)
215
216 assert len(preds) == len(
217 self.db), f'len(preds)={len(preds)}, len(self.db)={len(self.db)}'
218 for pred, item in zip(preds, self.db):
219 h, e = self._evaluate_kernel(pred['keypoints'], item['joints_3d'],
220 item['joints_3d_visible'],
221 item['headbox'])
222 hit += h
223 exist += e
224 skeleton = np.sum(hit[:14]) / np.sum(exist[:14])
225 contour = np.sum(hit[14:]) / np.sum(exist[14:])
226 mean = np.sum(hit) / np.sum(exist)
227
228 info_str = []
229 info_str.append(('Skeleton_acc', skeleton.item()))
230 info_str.append(('Contour_acc', contour.item()))
231 info_str.append(('PCKh', mean.item()))
232 return info_str
233
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py
--- a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py
+++ b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py
@@ -170,7 +170,7 @@
for metric in metrics:
if metric not in allowed_metrics:
raise KeyError(f'metric {metric} is not supported')
- """Evaluate MPII-TRB keypoint results."""
+
res_file = os.path.join(res_folder, 'result_keypoints.json')
kpts = []
|
{"golden_diff": "diff --git a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py\n--- a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py\n+++ b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py\n@@ -170,7 +170,7 @@\n for metric in metrics:\n if metric not in allowed_metrics:\n raise KeyError(f'metric {metric} is not supported')\n- \"\"\"Evaluate MPII-TRB keypoint results.\"\"\"\n+\n res_file = os.path.join(res_folder, 'result_keypoints.json')\n \n kpts = []\n", "issue": "Pylint: W0105\n```bash\r\nmmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py:173:8: W0105: String statement has no effect (pointless-string-statement)\r\n```\n", "before_files": [{"content": "import copy as cp\nimport os\nimport os.path as osp\nfrom collections import OrderedDict\n\nimport json_tricks as json\nimport numpy as np\n\nfrom mmpose.datasets.builder import DATASETS\nfrom .topdown_base_dataset import TopDownBaseDataset\n\n\[email protected]_module()\nclass TopDownMpiiTrbDataset(TopDownBaseDataset):\n \"\"\"MPII-TRB Dataset dataset for top-down pose estimation.\n\n `TRB: A Novel Triplet Representation for Understanding 2D Human Body`\n ICCV'2019 More details can be found in the `paper\n <https://arxiv.org/abs/1910.11535>`__ .\n\n The dataset loads raw features and apply specified transforms\n to return a dict containing the image tensors and other information.\n\n Args:\n ann_file (str): Path to the annotation file.\n img_prefix (str): Path to a directory where images are held.\n Default: None.\n data_cfg (dict): config\n pipeline (list[dict | callable]): A sequence of data transforms.\n test_mode (bool): Store True when building test or\n validation dataset. Default: False.\n \"\"\"\n\n def __init__(self,\n ann_file,\n img_prefix,\n data_cfg,\n pipeline,\n test_mode=False):\n\n super().__init__(\n ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)\n\n # flip_pairs in MPII-TRB\n self.ann_info['flip_pairs'] = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9],\n [10, 11], [14, 15]]\n for i in range(6):\n self.ann_info['flip_pairs'].append([16 + i, 22 + i])\n self.ann_info['flip_pairs'].append([28 + i, 34 + i])\n\n self.ann_info['upper_body_ids'] = [0, 1, 2, 3, 4, 5, 12, 13]\n self.ann_info['lower_body_ids'] = [6, 7, 8, 9, 10, 11]\n self.ann_info['upper_body_ids'].extend(list(range(14, 28)))\n self.ann_info['lower_body_ids'].extend(list(range(28, 40)))\n\n self.ann_info['use_different_joint_weights'] = False\n\n assert self.ann_info['num_joints'] == 40\n self.ann_info['joint_weights'] = np.ones(\n (self.ann_info['num_joints'], 1), dtype=np.float32)\n\n self.db = self._get_db(ann_file)\n self.image_set = set(x['image_file'] for x in self.db)\n self.num_images = len(self.image_set)\n\n print(f'=> num_images: {self.num_images}')\n print(f'=> load {len(self.db)} samples')\n\n def _get_db(self, ann_file):\n \"\"\"Load dataset.\"\"\"\n with open(ann_file, 'r') as f:\n data = json.load(f)\n tmpl = dict(\n image_file=None,\n center=None,\n scale=None,\n rotation=0,\n joints_3d=None,\n joints_3d_visible=None,\n dataset='mpii_trb')\n\n imid2info = {\n int(osp.splitext(x['file_name'])[0]): x\n for x in data['images']\n }\n\n num_joints = self.ann_info['num_joints']\n gt_db = []\n\n for anno in data['annotations']:\n newitem = cp.deepcopy(tmpl)\n image_id = anno['image_id']\n newitem['image_file'] = os.path.join(\n self.img_prefix, imid2info[image_id]['file_name'])\n\n if max(anno['keypoints']) == 0:\n continue\n\n joints_3d = np.zeros((num_joints, 3), dtype=np.float32)\n joints_3d_visible = np.zeros((num_joints, 3), dtype=np.float32)\n\n for ipt in range(num_joints):\n joints_3d[ipt, 0] = anno['keypoints'][ipt * 3 + 0]\n joints_3d[ipt, 1] = anno['keypoints'][ipt * 3 + 1]\n joints_3d[ipt, 2] = 0\n t_vis = min(anno['keypoints'][ipt * 3 + 2], 1)\n joints_3d_visible[ipt, :] = (t_vis, t_vis, 0)\n\n center = np.array(anno['center'], dtype=np.float32)\n scale = self.ann_info['image_size'] / anno['scale'] / 200.0\n newitem['center'] = center\n newitem['scale'] = scale\n newitem['joints_3d'] = joints_3d\n newitem['joints_3d_visible'] = joints_3d_visible\n if 'headbox' in anno:\n newitem['headbox'] = anno['headbox']\n gt_db.append(newitem)\n\n return gt_db\n\n def _evaluate_kernel(self, pred, joints_3d, joints_3d_visible, headbox):\n \"\"\"Evaluate one example.\"\"\"\n num_joints = self.ann_info['num_joints']\n headbox = np.array(headbox)\n threshold = np.linalg.norm(headbox[:2] - headbox[2:]) * 0.3\n hit = np.zeros(num_joints, dtype=np.float32)\n exist = np.zeros(num_joints, dtype=np.float32)\n\n for i in range(num_joints):\n pred_pt = pred[i]\n gt_pt = joints_3d[i]\n vis = joints_3d_visible[i][0]\n if vis:\n exist[i] = 1\n else:\n continue\n distance = np.linalg.norm(pred_pt[:2] - gt_pt[:2])\n if distance < threshold:\n hit[i] = 1\n return hit, exist\n\n def evaluate(self, outputs, res_folder, metric='PCKh', **kwargs):\n \"\"\"Evaluate PCKh for MPII-TRB dataset.\n\n Note:\n batch_size: N\n num_keypoints: K\n heatmap height: H\n heatmap width: W\n\n Args:\n outputs(list(preds, boxes, image_path, heatmap)):\n\n * preds(np.ndarray[1,K,3]): The first two dimensions are\n coordinates, score is the third dimension of the array.\n * boxes(np.ndarray[1,6]): [center[0], center[1], scale[0]\n , scale[1],area, score]\n * image_path(list[str]): For example, ['0', '0',\n '0', '0', '0', '1', '1', '6', '3', '.', 'j', 'p', 'g']\n * heatmap (np.ndarray[N, K, H, W]): model output heatmap.\n res_folder(str): Path of directory to save the results.\n metric (str | list[str]): Metrics to be performed.\n Defaults: 'PCKh'.\n\n Returns:\n dict: PCKh for each joint\n \"\"\"\n metrics = metric if isinstance(metric, list) else [metric]\n allowed_metrics = ['PCKh']\n for metric in metrics:\n if metric not in allowed_metrics:\n raise KeyError(f'metric {metric} is not supported')\n \"\"\"Evaluate MPII-TRB keypoint results.\"\"\"\n res_file = os.path.join(res_folder, 'result_keypoints.json')\n\n kpts = []\n\n for preds, boxes, image_path, _ in outputs:\n str_image_path = ''.join(image_path)\n image_id = int(osp.basename(osp.splitext(str_image_path)[0]))\n\n kpts.append({\n 'keypoints': preds[0].tolist(),\n 'center': boxes[0][0:2].tolist(),\n 'scale': boxes[0][2:4].tolist(),\n 'area': float(boxes[0][4]),\n 'score': float(boxes[0][5]),\n 'image_id': image_id,\n })\n\n self._write_keypoint_results(kpts, res_file)\n info_str = self._report_metric(res_file)\n name_value = OrderedDict(info_str)\n\n return name_value\n\n @staticmethod\n def _write_keypoint_results(keypoints, res_file):\n \"\"\"Write results into a json file.\"\"\"\n\n with open(res_file, 'w') as f:\n json.dump(keypoints, f, sort_keys=True, indent=4)\n\n def _report_metric(self, res_file):\n \"\"\"Keypoint evaluation.\n\n Report Mean Acc of skeleton, contour and all joints.\n \"\"\"\n num_joints = self.ann_info['num_joints']\n hit = np.zeros(num_joints, dtype=np.float32)\n exist = np.zeros(num_joints, dtype=np.float32)\n\n with open(res_file, 'r') as fin:\n preds = json.load(fin)\n\n assert len(preds) == len(\n self.db), f'len(preds)={len(preds)}, len(self.db)={len(self.db)}'\n for pred, item in zip(preds, self.db):\n h, e = self._evaluate_kernel(pred['keypoints'], item['joints_3d'],\n item['joints_3d_visible'],\n item['headbox'])\n hit += h\n exist += e\n skeleton = np.sum(hit[:14]) / np.sum(exist[:14])\n contour = np.sum(hit[14:]) / np.sum(exist[14:])\n mean = np.sum(hit) / np.sum(exist)\n\n info_str = []\n info_str.append(('Skeleton_acc', skeleton.item()))\n info_str.append(('Contour_acc', contour.item()))\n info_str.append(('PCKh', mean.item()))\n return info_str\n", "path": "mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py"}], "after_files": [{"content": "import copy as cp\nimport os\nimport os.path as osp\nfrom collections import OrderedDict\n\nimport json_tricks as json\nimport numpy as np\n\nfrom mmpose.datasets.builder import DATASETS\nfrom .topdown_base_dataset import TopDownBaseDataset\n\n\[email protected]_module()\nclass TopDownMpiiTrbDataset(TopDownBaseDataset):\n \"\"\"MPII-TRB Dataset dataset for top-down pose estimation.\n\n `TRB: A Novel Triplet Representation for Understanding 2D Human Body`\n ICCV'2019 More details can be found in the `paper\n <https://arxiv.org/abs/1910.11535>`__ .\n\n The dataset loads raw features and apply specified transforms\n to return a dict containing the image tensors and other information.\n\n Args:\n ann_file (str): Path to the annotation file.\n img_prefix (str): Path to a directory where images are held.\n Default: None.\n data_cfg (dict): config\n pipeline (list[dict | callable]): A sequence of data transforms.\n test_mode (bool): Store True when building test or\n validation dataset. Default: False.\n \"\"\"\n\n def __init__(self,\n ann_file,\n img_prefix,\n data_cfg,\n pipeline,\n test_mode=False):\n\n super().__init__(\n ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)\n\n # flip_pairs in MPII-TRB\n self.ann_info['flip_pairs'] = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9],\n [10, 11], [14, 15]]\n for i in range(6):\n self.ann_info['flip_pairs'].append([16 + i, 22 + i])\n self.ann_info['flip_pairs'].append([28 + i, 34 + i])\n\n self.ann_info['upper_body_ids'] = [0, 1, 2, 3, 4, 5, 12, 13]\n self.ann_info['lower_body_ids'] = [6, 7, 8, 9, 10, 11]\n self.ann_info['upper_body_ids'].extend(list(range(14, 28)))\n self.ann_info['lower_body_ids'].extend(list(range(28, 40)))\n\n self.ann_info['use_different_joint_weights'] = False\n\n assert self.ann_info['num_joints'] == 40\n self.ann_info['joint_weights'] = np.ones(\n (self.ann_info['num_joints'], 1), dtype=np.float32)\n\n self.db = self._get_db(ann_file)\n self.image_set = set(x['image_file'] for x in self.db)\n self.num_images = len(self.image_set)\n\n print(f'=> num_images: {self.num_images}')\n print(f'=> load {len(self.db)} samples')\n\n def _get_db(self, ann_file):\n \"\"\"Load dataset.\"\"\"\n with open(ann_file, 'r') as f:\n data = json.load(f)\n tmpl = dict(\n image_file=None,\n center=None,\n scale=None,\n rotation=0,\n joints_3d=None,\n joints_3d_visible=None,\n dataset='mpii_trb')\n\n imid2info = {\n int(osp.splitext(x['file_name'])[0]): x\n for x in data['images']\n }\n\n num_joints = self.ann_info['num_joints']\n gt_db = []\n\n for anno in data['annotations']:\n newitem = cp.deepcopy(tmpl)\n image_id = anno['image_id']\n newitem['image_file'] = os.path.join(\n self.img_prefix, imid2info[image_id]['file_name'])\n\n if max(anno['keypoints']) == 0:\n continue\n\n joints_3d = np.zeros((num_joints, 3), dtype=np.float32)\n joints_3d_visible = np.zeros((num_joints, 3), dtype=np.float32)\n\n for ipt in range(num_joints):\n joints_3d[ipt, 0] = anno['keypoints'][ipt * 3 + 0]\n joints_3d[ipt, 1] = anno['keypoints'][ipt * 3 + 1]\n joints_3d[ipt, 2] = 0\n t_vis = min(anno['keypoints'][ipt * 3 + 2], 1)\n joints_3d_visible[ipt, :] = (t_vis, t_vis, 0)\n\n center = np.array(anno['center'], dtype=np.float32)\n scale = self.ann_info['image_size'] / anno['scale'] / 200.0\n newitem['center'] = center\n newitem['scale'] = scale\n newitem['joints_3d'] = joints_3d\n newitem['joints_3d_visible'] = joints_3d_visible\n if 'headbox' in anno:\n newitem['headbox'] = anno['headbox']\n gt_db.append(newitem)\n\n return gt_db\n\n def _evaluate_kernel(self, pred, joints_3d, joints_3d_visible, headbox):\n \"\"\"Evaluate one example.\"\"\"\n num_joints = self.ann_info['num_joints']\n headbox = np.array(headbox)\n threshold = np.linalg.norm(headbox[:2] - headbox[2:]) * 0.3\n hit = np.zeros(num_joints, dtype=np.float32)\n exist = np.zeros(num_joints, dtype=np.float32)\n\n for i in range(num_joints):\n pred_pt = pred[i]\n gt_pt = joints_3d[i]\n vis = joints_3d_visible[i][0]\n if vis:\n exist[i] = 1\n else:\n continue\n distance = np.linalg.norm(pred_pt[:2] - gt_pt[:2])\n if distance < threshold:\n hit[i] = 1\n return hit, exist\n\n def evaluate(self, outputs, res_folder, metric='PCKh', **kwargs):\n \"\"\"Evaluate PCKh for MPII-TRB dataset.\n\n Note:\n batch_size: N\n num_keypoints: K\n heatmap height: H\n heatmap width: W\n\n Args:\n outputs(list(preds, boxes, image_path, heatmap)):\n\n * preds(np.ndarray[1,K,3]): The first two dimensions are\n coordinates, score is the third dimension of the array.\n * boxes(np.ndarray[1,6]): [center[0], center[1], scale[0]\n , scale[1],area, score]\n * image_path(list[str]): For example, ['0', '0',\n '0', '0', '0', '1', '1', '6', '3', '.', 'j', 'p', 'g']\n * heatmap (np.ndarray[N, K, H, W]): model output heatmap.\n res_folder(str): Path of directory to save the results.\n metric (str | list[str]): Metrics to be performed.\n Defaults: 'PCKh'.\n\n Returns:\n dict: PCKh for each joint\n \"\"\"\n metrics = metric if isinstance(metric, list) else [metric]\n allowed_metrics = ['PCKh']\n for metric in metrics:\n if metric not in allowed_metrics:\n raise KeyError(f'metric {metric} is not supported')\n\n res_file = os.path.join(res_folder, 'result_keypoints.json')\n\n kpts = []\n\n for preds, boxes, image_path, _ in outputs:\n str_image_path = ''.join(image_path)\n image_id = int(osp.basename(osp.splitext(str_image_path)[0]))\n\n kpts.append({\n 'keypoints': preds[0].tolist(),\n 'center': boxes[0][0:2].tolist(),\n 'scale': boxes[0][2:4].tolist(),\n 'area': float(boxes[0][4]),\n 'score': float(boxes[0][5]),\n 'image_id': image_id,\n })\n\n self._write_keypoint_results(kpts, res_file)\n info_str = self._report_metric(res_file)\n name_value = OrderedDict(info_str)\n\n return name_value\n\n @staticmethod\n def _write_keypoint_results(keypoints, res_file):\n \"\"\"Write results into a json file.\"\"\"\n\n with open(res_file, 'w') as f:\n json.dump(keypoints, f, sort_keys=True, indent=4)\n\n def _report_metric(self, res_file):\n \"\"\"Keypoint evaluation.\n\n Report Mean Acc of skeleton, contour and all joints.\n \"\"\"\n num_joints = self.ann_info['num_joints']\n hit = np.zeros(num_joints, dtype=np.float32)\n exist = np.zeros(num_joints, dtype=np.float32)\n\n with open(res_file, 'r') as fin:\n preds = json.load(fin)\n\n assert len(preds) == len(\n self.db), f'len(preds)={len(preds)}, len(self.db)={len(self.db)}'\n for pred, item in zip(preds, self.db):\n h, e = self._evaluate_kernel(pred['keypoints'], item['joints_3d'],\n item['joints_3d_visible'],\n item['headbox'])\n hit += h\n exist += e\n skeleton = np.sum(hit[:14]) / np.sum(exist[:14])\n contour = np.sum(hit[14:]) / np.sum(exist[14:])\n mean = np.sum(hit) / np.sum(exist)\n\n info_str = []\n info_str.append(('Skeleton_acc', skeleton.item()))\n info_str.append(('Contour_acc', contour.item()))\n info_str.append(('PCKh', mean.item()))\n return info_str\n", "path": "mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py"}]}
| 3,138 | 157 |
gh_patches_debug_4753
|
rasdani/github-patches
|
git_diff
|
apache__tvm-16388
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bugfix] Disable SingleEnvThreadVerifier
During TensorIR scheduling, the `IterVar`s that represent environment threads may duplicate, i.e. it is legal to have two env threads with the same name tag, which may fail the `SingleEnvThreadVerifier` check during schedule creation. This PR disables this check in this case. In the future, it may be worthwhile to bring it back against post-scheduling TIR.
It's related to [this commit](https://github.com/apache/tvm/commit/eb15d04c3bff76062e26d5647fb8af0323de1bed). CC: @jinhongyii @Lunderberg
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/tvm/relax/backend/dispatch_sort_scan.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 # pylint: disable=invalid-name, unused-argument, redefined-argument-from-local
18 """Dispatch sort and scan operators to platform dependent implementation."""
19
20 from tvm import topi, dlight, relax
21 from tvm.ir import Op
22 from tvm.ir.module import IRModule
23 from tvm.ir.transform import PassContext, module_pass
24 from tvm.target import Target
25 from tvm.contrib.thrust import can_use_thrust
26 from tvm.relax import PyExprMutator, expr_functor
27
28
29 @expr_functor.mutator
30 class SortScanDispatcher(PyExprMutator):
31 """
32 Dispatcher to dispatch sort and scan.
33
34 """
35
36 def __init__(self, mod):
37 super().__init__(mod)
38
39 def _get_target(self, sinfo: relax.StructInfo) -> Target:
40 # Get target information from TensorStructInfo
41 if isinstance(sinfo, relax.TensorStructInfo):
42 vdevice = sinfo.vdevice
43 if vdevice is not None:
44 return vdevice.target
45 elif isinstance(sinfo, relax.TupleStructInfo):
46 for f in sinfo.fields:
47 tgt = self._get_target(f)
48 if tgt != Target.current():
49 return tgt
50 # Return the target in current context
51 target = Target.current()
52 if target is None:
53 raise ValueError(
54 "Target not found. Please ensure that the target is annotated within the module, "
55 "or alternatively, execute this within a specified target context."
56 )
57 return target
58
59 def _apply_dlight_gpu_fallback(self, target: Target, tir_call: relax.Call) -> None:
60 # Apply dlight.gpu.Fallback() on GPU
61 gvar = tir_call.args[0]
62 assert isinstance(gvar, relax.GlobalVar)
63 scan_prim_func = self.builder_.get()[gvar]
64 sch = dlight.base.transform._apply_rules(
65 scan_prim_func,
66 target,
67 [
68 dlight.gpu.Fallback(),
69 ],
70 False,
71 )
72 if sch is not None:
73 assert len(sch) == 1
74 self.builder_.update_func(gvar, sch[0].mod["main"].with_attr("tir.is_scheduled", 1))
75
76 def visit_call_(self, call: relax.Call) -> relax.Expr:
77 if not isinstance(call.op, Op):
78 return super().visit_call_(call)
79
80 if call.op.name == "relax.sort":
81 tgt = self._get_target(call.struct_info)
82 te_func = topi.sort
83 with tgt:
84 if can_use_thrust(tgt, "tvm.contrib.thrust.sort"):
85 te_func = topi.cuda.sort_thrust
86 elif tgt.kind.name == "cuda":
87 te_func = topi.cuda.sort
88 return self.builder_.call_te(
89 te_func,
90 call.args[0],
91 call.attrs.axis,
92 not call.attrs.descending,
93 )
94 if call.op.name == "relax.argsort":
95 tgt = self._get_target(call.struct_info)
96 te_func = topi.argsort
97 with tgt:
98 if can_use_thrust(tgt, "tvm.contrib.thrust.sort"):
99 te_func = topi.cuda.argsort_thrust
100 elif tgt.kind.name == "cuda":
101 te_func = topi.cuda.argsort
102 return self.builder_.call_te(
103 te_func,
104 call.args[0],
105 axis=call.attrs.axis,
106 is_ascend=not call.attrs.descending,
107 dtype=call.attrs.dtype,
108 )
109 if call.op.name == "relax.topk":
110 tgt = self._get_target(call.struct_info)
111 te_func = topi.topk
112 if can_use_thrust(tgt, "tvm.contrib.thrust.sort"):
113 te_func = topi.cuda.topk_thrust
114 elif tgt.kind.name == "cuda":
115 te_func = topi.cuda.topk
116 tir_call = self.builder_.call_te(
117 te_func,
118 call.args[0],
119 axis=call.attrs.axis,
120 ret_type=call.attrs.ret_type,
121 is_ascend=not call.attrs.largest,
122 dtype=call.attrs.dtype,
123 )
124 if tgt.kind.name != "cuda":
125 return tir_call
126 # apply dlight gpu fallback
127 self._apply_dlight_gpu_fallback(tgt, tir_call)
128 return tir_call
129 if call.op.name in ("relax.cumprod", "relax.cumsum"):
130 tgt = self._get_target(call.struct_info)
131 axis = int(call.attrs.axis) if call.attrs.axis is not None else call.attrs.axis
132 te_func = topi.cuda.cumsum if tgt.kind.name == "cuda" else topi.cumsum
133 if call.op.name == "relax.cumprod":
134 te_func = topi.cuda.cumprod if tgt.kind.name == "cuda" else topi.cumprod
135 tir_call = self.builder_.call_te(
136 te_func,
137 call.args[0],
138 axis,
139 call.attrs.dtype,
140 call.attrs.exclusive,
141 )
142 if tgt.kind.name != "cuda":
143 return tir_call
144 # apply dlight gpu fallback
145 self._apply_dlight_gpu_fallback(tgt, tir_call)
146 return tir_call
147 return super().visit_call_(call)
148
149
150 @module_pass(opt_level=0, name="DispatchSortScan")
151 class DispatchSortScan:
152 """
153 Pass to dispatch scan and sort operators to platform dependent implementation.
154 """
155
156 def transform_module(self, mod: IRModule, ctx: PassContext) -> IRModule:
157 sort_scan_dispater = SortScanDispatcher(mod)
158 for gv, func in mod.functions_items():
159 if isinstance(func, relax.Function):
160 func = sort_scan_dispater.visit_expr(func)
161 sort_scan_dispater.builder_.update_func(gv, func)
162 return sort_scan_dispater.builder_.finalize()
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/tvm/relax/backend/dispatch_sort_scan.py b/python/tvm/relax/backend/dispatch_sort_scan.py
--- a/python/tvm/relax/backend/dispatch_sort_scan.py
+++ b/python/tvm/relax/backend/dispatch_sort_scan.py
@@ -116,6 +116,7 @@
tir_call = self.builder_.call_te(
te_func,
call.args[0],
+ k=call.attrs.k,
axis=call.attrs.axis,
ret_type=call.attrs.ret_type,
is_ascend=not call.attrs.largest,
|
{"golden_diff": "diff --git a/python/tvm/relax/backend/dispatch_sort_scan.py b/python/tvm/relax/backend/dispatch_sort_scan.py\n--- a/python/tvm/relax/backend/dispatch_sort_scan.py\n+++ b/python/tvm/relax/backend/dispatch_sort_scan.py\n@@ -116,6 +116,7 @@\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n+ k=call.attrs.k,\n axis=call.attrs.axis,\n ret_type=call.attrs.ret_type,\n is_ascend=not call.attrs.largest,\n", "issue": "[Bugfix] Disable SingleEnvThreadVerifier\nDuring TensorIR scheduling, the `IterVar`s that represent environment threads may duplicate, i.e. it is legal to have two env threads with the same name tag, which may fail the `SingleEnvThreadVerifier` check during schedule creation. This PR disables this check in this case. In the future, it may be worthwhile to bring it back against post-scheduling TIR.\r\n\r\nIt's related to [this commit](https://github.com/apache/tvm/commit/eb15d04c3bff76062e26d5647fb8af0323de1bed). CC: @jinhongyii @Lunderberg \n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n# pylint: disable=invalid-name, unused-argument, redefined-argument-from-local\n\"\"\"Dispatch sort and scan operators to platform dependent implementation.\"\"\"\n\nfrom tvm import topi, dlight, relax\nfrom tvm.ir import Op\nfrom tvm.ir.module import IRModule\nfrom tvm.ir.transform import PassContext, module_pass\nfrom tvm.target import Target\nfrom tvm.contrib.thrust import can_use_thrust\nfrom tvm.relax import PyExprMutator, expr_functor\n\n\n@expr_functor.mutator\nclass SortScanDispatcher(PyExprMutator):\n \"\"\"\n Dispatcher to dispatch sort and scan.\n\n \"\"\"\n\n def __init__(self, mod):\n super().__init__(mod)\n\n def _get_target(self, sinfo: relax.StructInfo) -> Target:\n # Get target information from TensorStructInfo\n if isinstance(sinfo, relax.TensorStructInfo):\n vdevice = sinfo.vdevice\n if vdevice is not None:\n return vdevice.target\n elif isinstance(sinfo, relax.TupleStructInfo):\n for f in sinfo.fields:\n tgt = self._get_target(f)\n if tgt != Target.current():\n return tgt\n # Return the target in current context\n target = Target.current()\n if target is None:\n raise ValueError(\n \"Target not found. Please ensure that the target is annotated within the module, \"\n \"or alternatively, execute this within a specified target context.\"\n )\n return target\n\n def _apply_dlight_gpu_fallback(self, target: Target, tir_call: relax.Call) -> None:\n # Apply dlight.gpu.Fallback() on GPU\n gvar = tir_call.args[0]\n assert isinstance(gvar, relax.GlobalVar)\n scan_prim_func = self.builder_.get()[gvar]\n sch = dlight.base.transform._apply_rules(\n scan_prim_func,\n target,\n [\n dlight.gpu.Fallback(),\n ],\n False,\n )\n if sch is not None:\n assert len(sch) == 1\n self.builder_.update_func(gvar, sch[0].mod[\"main\"].with_attr(\"tir.is_scheduled\", 1))\n\n def visit_call_(self, call: relax.Call) -> relax.Expr:\n if not isinstance(call.op, Op):\n return super().visit_call_(call)\n\n if call.op.name == \"relax.sort\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.sort\n with tgt:\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.sort_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.sort\n return self.builder_.call_te(\n te_func,\n call.args[0],\n call.attrs.axis,\n not call.attrs.descending,\n )\n if call.op.name == \"relax.argsort\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.argsort\n with tgt:\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.argsort_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.argsort\n return self.builder_.call_te(\n te_func,\n call.args[0],\n axis=call.attrs.axis,\n is_ascend=not call.attrs.descending,\n dtype=call.attrs.dtype,\n )\n if call.op.name == \"relax.topk\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.topk\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.topk_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.topk\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n axis=call.attrs.axis,\n ret_type=call.attrs.ret_type,\n is_ascend=not call.attrs.largest,\n dtype=call.attrs.dtype,\n )\n if tgt.kind.name != \"cuda\":\n return tir_call\n # apply dlight gpu fallback\n self._apply_dlight_gpu_fallback(tgt, tir_call)\n return tir_call\n if call.op.name in (\"relax.cumprod\", \"relax.cumsum\"):\n tgt = self._get_target(call.struct_info)\n axis = int(call.attrs.axis) if call.attrs.axis is not None else call.attrs.axis\n te_func = topi.cuda.cumsum if tgt.kind.name == \"cuda\" else topi.cumsum\n if call.op.name == \"relax.cumprod\":\n te_func = topi.cuda.cumprod if tgt.kind.name == \"cuda\" else topi.cumprod\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n axis,\n call.attrs.dtype,\n call.attrs.exclusive,\n )\n if tgt.kind.name != \"cuda\":\n return tir_call\n # apply dlight gpu fallback\n self._apply_dlight_gpu_fallback(tgt, tir_call)\n return tir_call\n return super().visit_call_(call)\n\n\n@module_pass(opt_level=0, name=\"DispatchSortScan\")\nclass DispatchSortScan:\n \"\"\"\n Pass to dispatch scan and sort operators to platform dependent implementation.\n \"\"\"\n\n def transform_module(self, mod: IRModule, ctx: PassContext) -> IRModule:\n sort_scan_dispater = SortScanDispatcher(mod)\n for gv, func in mod.functions_items():\n if isinstance(func, relax.Function):\n func = sort_scan_dispater.visit_expr(func)\n sort_scan_dispater.builder_.update_func(gv, func)\n return sort_scan_dispater.builder_.finalize()\n", "path": "python/tvm/relax/backend/dispatch_sort_scan.py"}], "after_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n# pylint: disable=invalid-name, unused-argument, redefined-argument-from-local\n\"\"\"Dispatch sort and scan operators to platform dependent implementation.\"\"\"\n\nfrom tvm import topi, dlight, relax\nfrom tvm.ir import Op\nfrom tvm.ir.module import IRModule\nfrom tvm.ir.transform import PassContext, module_pass\nfrom tvm.target import Target\nfrom tvm.contrib.thrust import can_use_thrust\nfrom tvm.relax import PyExprMutator, expr_functor\n\n\n@expr_functor.mutator\nclass SortScanDispatcher(PyExprMutator):\n \"\"\"\n Dispatcher to dispatch sort and scan.\n\n \"\"\"\n\n def __init__(self, mod):\n super().__init__(mod)\n\n def _get_target(self, sinfo: relax.StructInfo) -> Target:\n # Get target information from TensorStructInfo\n if isinstance(sinfo, relax.TensorStructInfo):\n vdevice = sinfo.vdevice\n if vdevice is not None:\n return vdevice.target\n elif isinstance(sinfo, relax.TupleStructInfo):\n for f in sinfo.fields:\n tgt = self._get_target(f)\n if tgt != Target.current():\n return tgt\n # Return the target in current context\n target = Target.current()\n if target is None:\n raise ValueError(\n \"Target not found. Please ensure that the target is annotated within the module, \"\n \"or alternatively, execute this within a specified target context.\"\n )\n return target\n\n def _apply_dlight_gpu_fallback(self, target: Target, tir_call: relax.Call) -> None:\n # Apply dlight.gpu.Fallback() on GPU\n gvar = tir_call.args[0]\n assert isinstance(gvar, relax.GlobalVar)\n scan_prim_func = self.builder_.get()[gvar]\n sch = dlight.base.transform._apply_rules(\n scan_prim_func,\n target,\n [\n dlight.gpu.Fallback(),\n ],\n False,\n )\n if sch is not None:\n assert len(sch) == 1\n self.builder_.update_func(gvar, sch[0].mod[\"main\"].with_attr(\"tir.is_scheduled\", 1))\n\n def visit_call_(self, call: relax.Call) -> relax.Expr:\n if not isinstance(call.op, Op):\n return super().visit_call_(call)\n\n if call.op.name == \"relax.sort\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.sort\n with tgt:\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.sort_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.sort\n return self.builder_.call_te(\n te_func,\n call.args[0],\n call.attrs.axis,\n not call.attrs.descending,\n )\n if call.op.name == \"relax.argsort\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.argsort\n with tgt:\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.argsort_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.argsort\n return self.builder_.call_te(\n te_func,\n call.args[0],\n axis=call.attrs.axis,\n is_ascend=not call.attrs.descending,\n dtype=call.attrs.dtype,\n )\n if call.op.name == \"relax.topk\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.topk\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.topk_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.topk\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n k=call.attrs.k,\n axis=call.attrs.axis,\n ret_type=call.attrs.ret_type,\n is_ascend=not call.attrs.largest,\n dtype=call.attrs.dtype,\n )\n if tgt.kind.name != \"cuda\":\n return tir_call\n # apply dlight gpu fallback\n self._apply_dlight_gpu_fallback(tgt, tir_call)\n return tir_call\n if call.op.name in (\"relax.cumprod\", \"relax.cumsum\"):\n tgt = self._get_target(call.struct_info)\n axis = int(call.attrs.axis) if call.attrs.axis is not None else call.attrs.axis\n te_func = topi.cuda.cumsum if tgt.kind.name == \"cuda\" else topi.cumsum\n if call.op.name == \"relax.cumprod\":\n te_func = topi.cuda.cumprod if tgt.kind.name == \"cuda\" else topi.cumprod\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n axis,\n call.attrs.dtype,\n call.attrs.exclusive,\n )\n if tgt.kind.name != \"cuda\":\n return tir_call\n # apply dlight gpu fallback\n self._apply_dlight_gpu_fallback(tgt, tir_call)\n return tir_call\n return super().visit_call_(call)\n\n\n@module_pass(opt_level=0, name=\"DispatchSortScan\")\nclass DispatchSortScan:\n \"\"\"\n Pass to dispatch scan and sort operators to platform dependent implementation.\n \"\"\"\n\n def transform_module(self, mod: IRModule, ctx: PassContext) -> IRModule:\n sort_scan_dispater = SortScanDispatcher(mod)\n for gv, func in mod.functions_items():\n if isinstance(func, relax.Function):\n func = sort_scan_dispater.visit_expr(func)\n sort_scan_dispater.builder_.update_func(gv, func)\n return sort_scan_dispater.builder_.finalize()\n", "path": "python/tvm/relax/backend/dispatch_sort_scan.py"}]}
| 2,208 | 129 |
gh_patches_debug_21967
|
rasdani/github-patches
|
git_diff
|
prowler-cloud__prowler-2772
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: iam_policy_allows_privilege_escalation is raising false positives
### Steps to Reproduce
When looking at the scan results for "Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation" it look like we are getting bad results for it now using Prowler version 3.8.2.
If I run a scan on an AWS IAM policy defined with the below json I get the failure -
_Custom Policy arn:aws:iam::xxxxxxxxxxx:policy/app-user-policy-hertzcp-pprd allows privilege escalation using the following actions: {'iam:CreateAccessKey'}_
The below is the AWS IAM policy json that it scanned and as you can see the policy does not have 'iam:CreateAccessKey' within it :
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"es:List*",
"es:Get*",
"es:Describe*"
],
"Resource": "*"
},
{
"Sid": "",
"Effect": "Allow",
"Action": "es:*",
"Resource": "arn:aws:es:us-west-2:xxxxxxxxxxxx:domain/g-clients-infra-pprd/*"
}
]
}
```
When I used prowler version 3.4.1 it did not find/report on the above issue.
Also -
Prowler version 3.8.2 now reports the below policy as passing for "Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation" :
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::*:role/xena-role"
}
]
}
```
When a scan using prowler version 3.4.1 was run the above policy was reported as a failure for "Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation".
I would believe that this policy should still be reported as a failure and that Prowler version 3.8.2 has issues.
### Expected behavior
The first policy should pass and the second policy should fail.
### Actual Result with Screenshots or Logs
[prowler-output-741743798098-20230823103540.csv](https://github.com/prowler-cloud/prowler/files/12421414/prowler-output-741743798098-20230823103540.csv)
### How did you install Prowler?
From pip package (pip install prowler)
### Environment Resource
EKS and ran the scan locally
### OS used
MacOS
### Prowler version
3.8.2
### Pip version
21.1.3
### Context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py`
Content:
```
1 from re import search
2
3 from prowler.lib.check.models import Check, Check_Report_AWS
4 from prowler.providers.aws.services.iam.iam_client import iam_client
5
6 # Does the tool analyze both users and roles, or just one or the other? --> Everything using AttachementCount.
7 # Does the tool take a principal-centric or policy-centric approach? --> Policy-centric approach.
8 # Does the tool handle resource constraints? --> We don't check if the policy affects all resources or not, we check everything.
9 # Does the tool consider the permissions of service roles? --> Just checks policies.
10 # Does the tool handle transitive privesc paths (i.e., attack chains)? --> Not yet.
11 # Does the tool handle the DENY effect as expected? --> Yes, it checks DENY's statements with Action and NotAction.
12 # Does the tool handle NotAction as expected? --> Yes
13 # Does the tool handle Condition constraints? --> Not yet.
14 # Does the tool handle service control policy (SCP) restrictions? --> No, SCP are within Organizations AWS API.
15
16 # Based on:
17 # - https://bishopfox.com/blog/privilege-escalation-in-aws
18 # - https://github.com/RhinoSecurityLabs/Security-Research/blob/master/tools/aws-pentest-tools/aws_escalate.py
19 # - https://rhinosecuritylabs.com/aws/aws-privilege-escalation-methods-mitigation/
20
21
22 class iam_policy_allows_privilege_escalation(Check):
23 def execute(self) -> Check_Report_AWS:
24 privilege_escalation_policies_combination = {
25 "CreatePolicyVersion": {"iam:CreatePolicyVersion"},
26 "SetDefaultPolicyVersion": {"iam:SetDefaultPolicyVersion"},
27 "iam:PassRole": {"iam:PassRole"},
28 "PassRole+EC2": {
29 "iam:PassRole",
30 "ec2:RunInstances",
31 },
32 "PassRole+CreateLambda+Invoke": {
33 "iam:PassRole",
34 "lambda:CreateFunction",
35 "lambda:InvokeFunction",
36 },
37 "PassRole+CreateLambda+ExistingDynamo": {
38 "iam:PassRole",
39 "lambda:CreateFunction",
40 "lambda:CreateEventSourceMapping",
41 },
42 "PassRole+CreateLambda+NewDynamo": {
43 "iam:PassRole",
44 "lambda:CreateFunction",
45 "lambda:CreateEventSourceMapping",
46 "dynamodb:CreateTable",
47 "dynamodb:PutItem",
48 },
49 "PassRole+GlueEndpoint": {
50 "iam:PassRole",
51 "glue:CreateDevEndpoint",
52 "glue:GetDevEndpoint",
53 },
54 "PassRole+GlueEndpoints": {
55 "iam:PassRole",
56 "glue:CreateDevEndpoint",
57 "glue:GetDevEndpoints",
58 },
59 "PassRole+CloudFormation": {
60 "cloudformation:CreateStack",
61 "cloudformation:DescribeStacks",
62 },
63 "PassRole+DataPipeline": {
64 "datapipeline:CreatePipeline",
65 "datapipeline:PutPipelineDefinition",
66 "datapipeline:ActivatePipeline",
67 },
68 "GlueUpdateDevEndpoint": {"glue:UpdateDevEndpoint"},
69 "GlueUpdateDevEndpoints": {"glue:UpdateDevEndpoint"},
70 "lambda:UpdateFunctionCode": {"lambda:UpdateFunctionCode"},
71 "iam:CreateAccessKey": {"iam:CreateAccessKey"},
72 "iam:CreateLoginProfile": {"iam:CreateLoginProfile"},
73 "iam:UpdateLoginProfile": {"iam:UpdateLoginProfile"},
74 "iam:AttachUserPolicy": {"iam:AttachUserPolicy"},
75 "iam:AttachGroupPolicy": {"iam:AttachGroupPolicy"},
76 "iam:AttachRolePolicy": {"iam:AttachRolePolicy"},
77 "AssumeRole+AttachRolePolicy": {"sts:AssumeRole", "iam:AttachRolePolicy"},
78 "iam:PutGroupPolicy": {"iam:PutGroupPolicy"},
79 "iam:PutRolePolicy": {"iam:PutRolePolicy"},
80 "AssumeRole+PutRolePolicy": {"sts:AssumeRole", "iam:PutRolePolicy"},
81 "iam:PutUserPolicy": {"iam:PutUserPolicy"},
82 "iam:AddUserToGroup": {"iam:AddUserToGroup"},
83 "iam:UpdateAssumeRolePolicy": {"iam:UpdateAssumeRolePolicy"},
84 "AssumeRole+UpdateAssumeRolePolicy": {
85 "sts:AssumeRole",
86 "iam:UpdateAssumeRolePolicy",
87 },
88 # TO-DO: We have to handle AssumeRole just if the resource is * and without conditions
89 # "sts:AssumeRole": {"sts:AssumeRole"},
90 }
91
92 findings = []
93
94 # Iterate over all the IAM "Customer Managed" policies
95 for policy in iam_client.policies:
96 if policy.type == "Custom":
97 report = Check_Report_AWS(self.metadata())
98 report.resource_id = policy.name
99 report.resource_arn = policy.arn
100 report.region = iam_client.region
101 report.resource_tags = policy.tags
102 report.status = "PASS"
103 report.status_extended = f"Custom Policy {report.resource_arn} does not allow privilege escalation."
104
105 # List of policy actions
106 allowed_actions = set()
107 denied_actions = set()
108 denied_not_actions = set()
109
110 # Recover all policy actions
111 if policy.document:
112 if not isinstance(policy.document["Statement"], list):
113 policy_statements = [policy.document["Statement"]]
114 else:
115 policy_statements = policy.document["Statement"]
116 for statements in policy_statements:
117 # Recover allowed actions
118 if statements["Effect"] == "Allow":
119 if "Action" in statements:
120 if type(statements["Action"]) is str:
121 allowed_actions.add(statements["Action"])
122 if type(statements["Action"]) is list:
123 allowed_actions.update(statements["Action"])
124
125 # Recover denied actions
126 if statements["Effect"] == "Deny":
127 if "Action" in statements:
128 if type(statements["Action"]) is str:
129 denied_actions.add(statements["Action"])
130 if type(statements["Action"]) is list:
131 denied_actions.update(statements["Action"])
132
133 if "NotAction" in statements:
134 if type(statements["NotAction"]) is str:
135 denied_not_actions.add(statements["NotAction"])
136 if type(statements["NotAction"]) is list:
137 denied_not_actions.update(statements["NotAction"])
138
139 # First, we need to perform a left join with ALLOWED_ACTIONS and DENIED_ACTIONS
140 left_actions = allowed_actions.difference(denied_actions)
141 # Then, we need to find the DENIED_NOT_ACTIONS in LEFT_ACTIONS
142 if denied_not_actions:
143 privileged_actions = left_actions.intersection(
144 denied_not_actions
145 )
146 # If there is no Denied Not Actions
147 else:
148 privileged_actions = left_actions
149
150 # Store all the action's combinations
151 policies_combination = set()
152
153 for values in privilege_escalation_policies_combination.values():
154 for val in values:
155 val_set = set()
156 val_set.add(val)
157 # Look for specific api:action
158 if privileged_actions.intersection(val_set) == val_set:
159 policies_combination.add(val)
160 # Look for api:*
161 else:
162 for permission in privileged_actions:
163 # Here we have to handle if the api-action is admin, so "*"
164 api_action = permission.split(":")
165 # len() == 2, so api:action
166 if len(api_action) == 2:
167 api = api_action[0]
168 action = api_action[1]
169 # Add permissions if the API is present
170 if action == "*":
171 if search(api, val):
172 policies_combination.add(val)
173
174 # len() == 1, so *
175 elif len(api_action) == 1:
176 api = api_action[0]
177 # Add permissions if the API is present
178 if api == "*":
179 policies_combination.add(val)
180
181 # Check all policies combinations and see if matchs with some combo key
182 combos = set()
183 for (
184 key,
185 values,
186 ) in privilege_escalation_policies_combination.items():
187 intersection = policies_combination.intersection(values)
188 if intersection == values:
189 combos.add(key)
190
191 if len(combos) != 0:
192 report.status = "FAIL"
193 policies_affected = ""
194 for key in combos:
195 policies_affected += (
196 str(privilege_escalation_policies_combination[key])
197 + " "
198 )
199
200 report.status_extended = (
201 f"Custom Policy {report.resource_arn} allows privilege escalation using the following actions: {policies_affected}".rstrip()
202 + "."
203 )
204 findings.append(report)
205 return findings
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py
--- a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py
+++ b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py
@@ -1,5 +1,3 @@
-from re import search
-
from prowler.lib.check.models import Check, Check_Report_AWS
from prowler.providers.aws.services.iam.iam_client import iam_client
@@ -168,7 +166,8 @@
action = api_action[1]
# Add permissions if the API is present
if action == "*":
- if search(api, val):
+ val_api = val.split(":")[0]
+ if api == val_api:
policies_combination.add(val)
# len() == 1, so *
|
{"golden_diff": "diff --git a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py\n--- a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py\n+++ b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py\n@@ -1,5 +1,3 @@\n-from re import search\n-\n from prowler.lib.check.models import Check, Check_Report_AWS\n from prowler.providers.aws.services.iam.iam_client import iam_client\n \n@@ -168,7 +166,8 @@\n action = api_action[1]\n # Add permissions if the API is present\n if action == \"*\":\n- if search(api, val):\n+ val_api = val.split(\":\")[0]\n+ if api == val_api:\n policies_combination.add(val)\n \n # len() == 1, so *\n", "issue": "[Bug]: iam_policy_allows_privilege_escalation is raising false positives\n### Steps to Reproduce\r\n\r\nWhen looking at the scan results for \"Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation\" it look like we are getting bad results for it now using Prowler version 3.8.2.\r\n\r\n\r\nIf I run a scan on an AWS IAM policy defined with the below json I get the failure -\r\n\r\n_Custom Policy arn:aws:iam::xxxxxxxxxxx:policy/app-user-policy-hertzcp-pprd allows privilege escalation using the following actions: {'iam:CreateAccessKey'}_\r\n\r\nThe below is the AWS IAM policy json that it scanned and as you can see the policy does not have 'iam:CreateAccessKey' within it :\r\n \r\n```\r\n{\r\n \"Version\": \"2012-10-17\",\r\n \"Statement\": [\r\n {\r\n \"Sid\": \"\",\r\n \"Effect\": \"Allow\",\r\n \"Action\": [\r\n \"es:List*\",\r\n \"es:Get*\",\r\n \"es:Describe*\"\r\n ],\r\n \"Resource\": \"*\"\r\n },\r\n {\r\n \"Sid\": \"\",\r\n \"Effect\": \"Allow\",\r\n \"Action\": \"es:*\",\r\n \"Resource\": \"arn:aws:es:us-west-2:xxxxxxxxxxxx:domain/g-clients-infra-pprd/*\"\r\n }\r\n ]\r\n}\r\n```\r\n\r\nWhen I used prowler version 3.4.1 it did not find/report on the above issue.\r\n\r\n\r\nAlso - \r\nProwler version 3.8.2 now reports the below policy as passing for \"Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation\" :\r\n\r\n```\r\n{\r\n \"Version\": \"2012-10-17\",\r\n \"Statement\": [\r\n {\r\n \"Sid\": \"\",\r\n \"Effect\": \"Allow\",\r\n \"Action\": \"sts:AssumeRole\",\r\n \"Resource\": \"arn:aws:iam::*:role/xena-role\"\r\n }\r\n ]\r\n}\r\n```\r\n\r\nWhen a scan using prowler version 3.4.1 was run the above policy was reported as a failure for \"Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation\". \r\nI would believe that this policy should still be reported as a failure and that Prowler version 3.8.2 has issues.\r\n\r\n### Expected behavior\r\n\r\nThe first policy should pass and the second policy should fail.\r\n\r\n### Actual Result with Screenshots or Logs\r\n\r\n[prowler-output-741743798098-20230823103540.csv](https://github.com/prowler-cloud/prowler/files/12421414/prowler-output-741743798098-20230823103540.csv)\r\n\r\n\r\n### How did you install Prowler?\r\n\r\nFrom pip package (pip install prowler)\r\n\r\n### Environment Resource\r\n\r\nEKS and ran the scan locally\r\n\r\n### OS used\r\n\r\nMacOS\r\n\r\n### Prowler version\r\n\r\n3.8.2\r\n\r\n### Pip version\r\n\r\n21.1.3\r\n\r\n### Context\r\n\r\n_No response_\n", "before_files": [{"content": "from re import search\n\nfrom prowler.lib.check.models import Check, Check_Report_AWS\nfrom prowler.providers.aws.services.iam.iam_client import iam_client\n\n# Does the tool analyze both users and roles, or just one or the other? --> Everything using AttachementCount.\n# Does the tool take a principal-centric or policy-centric approach? --> Policy-centric approach.\n# Does the tool handle resource constraints? --> We don't check if the policy affects all resources or not, we check everything.\n# Does the tool consider the permissions of service roles? --> Just checks policies.\n# Does the tool handle transitive privesc paths (i.e., attack chains)? --> Not yet.\n# Does the tool handle the DENY effect as expected? --> Yes, it checks DENY's statements with Action and NotAction.\n# Does the tool handle NotAction as expected? --> Yes\n# Does the tool handle Condition constraints? --> Not yet.\n# Does the tool handle service control policy (SCP) restrictions? --> No, SCP are within Organizations AWS API.\n\n# Based on:\n# - https://bishopfox.com/blog/privilege-escalation-in-aws\n# - https://github.com/RhinoSecurityLabs/Security-Research/blob/master/tools/aws-pentest-tools/aws_escalate.py\n# - https://rhinosecuritylabs.com/aws/aws-privilege-escalation-methods-mitigation/\n\n\nclass iam_policy_allows_privilege_escalation(Check):\n def execute(self) -> Check_Report_AWS:\n privilege_escalation_policies_combination = {\n \"CreatePolicyVersion\": {\"iam:CreatePolicyVersion\"},\n \"SetDefaultPolicyVersion\": {\"iam:SetDefaultPolicyVersion\"},\n \"iam:PassRole\": {\"iam:PassRole\"},\n \"PassRole+EC2\": {\n \"iam:PassRole\",\n \"ec2:RunInstances\",\n },\n \"PassRole+CreateLambda+Invoke\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:InvokeFunction\",\n },\n \"PassRole+CreateLambda+ExistingDynamo\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:CreateEventSourceMapping\",\n },\n \"PassRole+CreateLambda+NewDynamo\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:CreateEventSourceMapping\",\n \"dynamodb:CreateTable\",\n \"dynamodb:PutItem\",\n },\n \"PassRole+GlueEndpoint\": {\n \"iam:PassRole\",\n \"glue:CreateDevEndpoint\",\n \"glue:GetDevEndpoint\",\n },\n \"PassRole+GlueEndpoints\": {\n \"iam:PassRole\",\n \"glue:CreateDevEndpoint\",\n \"glue:GetDevEndpoints\",\n },\n \"PassRole+CloudFormation\": {\n \"cloudformation:CreateStack\",\n \"cloudformation:DescribeStacks\",\n },\n \"PassRole+DataPipeline\": {\n \"datapipeline:CreatePipeline\",\n \"datapipeline:PutPipelineDefinition\",\n \"datapipeline:ActivatePipeline\",\n },\n \"GlueUpdateDevEndpoint\": {\"glue:UpdateDevEndpoint\"},\n \"GlueUpdateDevEndpoints\": {\"glue:UpdateDevEndpoint\"},\n \"lambda:UpdateFunctionCode\": {\"lambda:UpdateFunctionCode\"},\n \"iam:CreateAccessKey\": {\"iam:CreateAccessKey\"},\n \"iam:CreateLoginProfile\": {\"iam:CreateLoginProfile\"},\n \"iam:UpdateLoginProfile\": {\"iam:UpdateLoginProfile\"},\n \"iam:AttachUserPolicy\": {\"iam:AttachUserPolicy\"},\n \"iam:AttachGroupPolicy\": {\"iam:AttachGroupPolicy\"},\n \"iam:AttachRolePolicy\": {\"iam:AttachRolePolicy\"},\n \"AssumeRole+AttachRolePolicy\": {\"sts:AssumeRole\", \"iam:AttachRolePolicy\"},\n \"iam:PutGroupPolicy\": {\"iam:PutGroupPolicy\"},\n \"iam:PutRolePolicy\": {\"iam:PutRolePolicy\"},\n \"AssumeRole+PutRolePolicy\": {\"sts:AssumeRole\", \"iam:PutRolePolicy\"},\n \"iam:PutUserPolicy\": {\"iam:PutUserPolicy\"},\n \"iam:AddUserToGroup\": {\"iam:AddUserToGroup\"},\n \"iam:UpdateAssumeRolePolicy\": {\"iam:UpdateAssumeRolePolicy\"},\n \"AssumeRole+UpdateAssumeRolePolicy\": {\n \"sts:AssumeRole\",\n \"iam:UpdateAssumeRolePolicy\",\n },\n # TO-DO: We have to handle AssumeRole just if the resource is * and without conditions\n # \"sts:AssumeRole\": {\"sts:AssumeRole\"},\n }\n\n findings = []\n\n # Iterate over all the IAM \"Customer Managed\" policies\n for policy in iam_client.policies:\n if policy.type == \"Custom\":\n report = Check_Report_AWS(self.metadata())\n report.resource_id = policy.name\n report.resource_arn = policy.arn\n report.region = iam_client.region\n report.resource_tags = policy.tags\n report.status = \"PASS\"\n report.status_extended = f\"Custom Policy {report.resource_arn} does not allow privilege escalation.\"\n\n # List of policy actions\n allowed_actions = set()\n denied_actions = set()\n denied_not_actions = set()\n\n # Recover all policy actions\n if policy.document:\n if not isinstance(policy.document[\"Statement\"], list):\n policy_statements = [policy.document[\"Statement\"]]\n else:\n policy_statements = policy.document[\"Statement\"]\n for statements in policy_statements:\n # Recover allowed actions\n if statements[\"Effect\"] == \"Allow\":\n if \"Action\" in statements:\n if type(statements[\"Action\"]) is str:\n allowed_actions.add(statements[\"Action\"])\n if type(statements[\"Action\"]) is list:\n allowed_actions.update(statements[\"Action\"])\n\n # Recover denied actions\n if statements[\"Effect\"] == \"Deny\":\n if \"Action\" in statements:\n if type(statements[\"Action\"]) is str:\n denied_actions.add(statements[\"Action\"])\n if type(statements[\"Action\"]) is list:\n denied_actions.update(statements[\"Action\"])\n\n if \"NotAction\" in statements:\n if type(statements[\"NotAction\"]) is str:\n denied_not_actions.add(statements[\"NotAction\"])\n if type(statements[\"NotAction\"]) is list:\n denied_not_actions.update(statements[\"NotAction\"])\n\n # First, we need to perform a left join with ALLOWED_ACTIONS and DENIED_ACTIONS\n left_actions = allowed_actions.difference(denied_actions)\n # Then, we need to find the DENIED_NOT_ACTIONS in LEFT_ACTIONS\n if denied_not_actions:\n privileged_actions = left_actions.intersection(\n denied_not_actions\n )\n # If there is no Denied Not Actions\n else:\n privileged_actions = left_actions\n\n # Store all the action's combinations\n policies_combination = set()\n\n for values in privilege_escalation_policies_combination.values():\n for val in values:\n val_set = set()\n val_set.add(val)\n # Look for specific api:action\n if privileged_actions.intersection(val_set) == val_set:\n policies_combination.add(val)\n # Look for api:*\n else:\n for permission in privileged_actions:\n # Here we have to handle if the api-action is admin, so \"*\"\n api_action = permission.split(\":\")\n # len() == 2, so api:action\n if len(api_action) == 2:\n api = api_action[0]\n action = api_action[1]\n # Add permissions if the API is present\n if action == \"*\":\n if search(api, val):\n policies_combination.add(val)\n\n # len() == 1, so *\n elif len(api_action) == 1:\n api = api_action[0]\n # Add permissions if the API is present\n if api == \"*\":\n policies_combination.add(val)\n\n # Check all policies combinations and see if matchs with some combo key\n combos = set()\n for (\n key,\n values,\n ) in privilege_escalation_policies_combination.items():\n intersection = policies_combination.intersection(values)\n if intersection == values:\n combos.add(key)\n\n if len(combos) != 0:\n report.status = \"FAIL\"\n policies_affected = \"\"\n for key in combos:\n policies_affected += (\n str(privilege_escalation_policies_combination[key])\n + \" \"\n )\n\n report.status_extended = (\n f\"Custom Policy {report.resource_arn} allows privilege escalation using the following actions: {policies_affected}\".rstrip()\n + \".\"\n )\n findings.append(report)\n return findings\n", "path": "prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py"}], "after_files": [{"content": "from prowler.lib.check.models import Check, Check_Report_AWS\nfrom prowler.providers.aws.services.iam.iam_client import iam_client\n\n# Does the tool analyze both users and roles, or just one or the other? --> Everything using AttachementCount.\n# Does the tool take a principal-centric or policy-centric approach? --> Policy-centric approach.\n# Does the tool handle resource constraints? --> We don't check if the policy affects all resources or not, we check everything.\n# Does the tool consider the permissions of service roles? --> Just checks policies.\n# Does the tool handle transitive privesc paths (i.e., attack chains)? --> Not yet.\n# Does the tool handle the DENY effect as expected? --> Yes, it checks DENY's statements with Action and NotAction.\n# Does the tool handle NotAction as expected? --> Yes\n# Does the tool handle Condition constraints? --> Not yet.\n# Does the tool handle service control policy (SCP) restrictions? --> No, SCP are within Organizations AWS API.\n\n# Based on:\n# - https://bishopfox.com/blog/privilege-escalation-in-aws\n# - https://github.com/RhinoSecurityLabs/Security-Research/blob/master/tools/aws-pentest-tools/aws_escalate.py\n# - https://rhinosecuritylabs.com/aws/aws-privilege-escalation-methods-mitigation/\n\n\nclass iam_policy_allows_privilege_escalation(Check):\n def execute(self) -> Check_Report_AWS:\n privilege_escalation_policies_combination = {\n \"CreatePolicyVersion\": {\"iam:CreatePolicyVersion\"},\n \"SetDefaultPolicyVersion\": {\"iam:SetDefaultPolicyVersion\"},\n \"iam:PassRole\": {\"iam:PassRole\"},\n \"PassRole+EC2\": {\n \"iam:PassRole\",\n \"ec2:RunInstances\",\n },\n \"PassRole+CreateLambda+Invoke\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:InvokeFunction\",\n },\n \"PassRole+CreateLambda+ExistingDynamo\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:CreateEventSourceMapping\",\n },\n \"PassRole+CreateLambda+NewDynamo\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:CreateEventSourceMapping\",\n \"dynamodb:CreateTable\",\n \"dynamodb:PutItem\",\n },\n \"PassRole+GlueEndpoint\": {\n \"iam:PassRole\",\n \"glue:CreateDevEndpoint\",\n \"glue:GetDevEndpoint\",\n },\n \"PassRole+GlueEndpoints\": {\n \"iam:PassRole\",\n \"glue:CreateDevEndpoint\",\n \"glue:GetDevEndpoints\",\n },\n \"PassRole+CloudFormation\": {\n \"cloudformation:CreateStack\",\n \"cloudformation:DescribeStacks\",\n },\n \"PassRole+DataPipeline\": {\n \"datapipeline:CreatePipeline\",\n \"datapipeline:PutPipelineDefinition\",\n \"datapipeline:ActivatePipeline\",\n },\n \"GlueUpdateDevEndpoint\": {\"glue:UpdateDevEndpoint\"},\n \"GlueUpdateDevEndpoints\": {\"glue:UpdateDevEndpoint\"},\n \"lambda:UpdateFunctionCode\": {\"lambda:UpdateFunctionCode\"},\n \"iam:CreateAccessKey\": {\"iam:CreateAccessKey\"},\n \"iam:CreateLoginProfile\": {\"iam:CreateLoginProfile\"},\n \"iam:UpdateLoginProfile\": {\"iam:UpdateLoginProfile\"},\n \"iam:AttachUserPolicy\": {\"iam:AttachUserPolicy\"},\n \"iam:AttachGroupPolicy\": {\"iam:AttachGroupPolicy\"},\n \"iam:AttachRolePolicy\": {\"iam:AttachRolePolicy\"},\n \"AssumeRole+AttachRolePolicy\": {\"sts:AssumeRole\", \"iam:AttachRolePolicy\"},\n \"iam:PutGroupPolicy\": {\"iam:PutGroupPolicy\"},\n \"iam:PutRolePolicy\": {\"iam:PutRolePolicy\"},\n \"AssumeRole+PutRolePolicy\": {\"sts:AssumeRole\", \"iam:PutRolePolicy\"},\n \"iam:PutUserPolicy\": {\"iam:PutUserPolicy\"},\n \"iam:AddUserToGroup\": {\"iam:AddUserToGroup\"},\n \"iam:UpdateAssumeRolePolicy\": {\"iam:UpdateAssumeRolePolicy\"},\n \"AssumeRole+UpdateAssumeRolePolicy\": {\n \"sts:AssumeRole\",\n \"iam:UpdateAssumeRolePolicy\",\n },\n # TO-DO: We have to handle AssumeRole just if the resource is * and without conditions\n # \"sts:AssumeRole\": {\"sts:AssumeRole\"},\n }\n\n findings = []\n\n # Iterate over all the IAM \"Customer Managed\" policies\n for policy in iam_client.policies:\n if policy.type == \"Custom\":\n report = Check_Report_AWS(self.metadata())\n report.resource_id = policy.name\n report.resource_arn = policy.arn\n report.region = iam_client.region\n report.resource_tags = policy.tags\n report.status = \"PASS\"\n report.status_extended = f\"Custom Policy {report.resource_arn} does not allow privilege escalation.\"\n\n # List of policy actions\n allowed_actions = set()\n denied_actions = set()\n denied_not_actions = set()\n\n # Recover all policy actions\n if policy.document:\n if not isinstance(policy.document[\"Statement\"], list):\n policy_statements = [policy.document[\"Statement\"]]\n else:\n policy_statements = policy.document[\"Statement\"]\n for statements in policy_statements:\n # Recover allowed actions\n if statements[\"Effect\"] == \"Allow\":\n if \"Action\" in statements:\n if type(statements[\"Action\"]) is str:\n allowed_actions.add(statements[\"Action\"])\n if type(statements[\"Action\"]) is list:\n allowed_actions.update(statements[\"Action\"])\n\n # Recover denied actions\n if statements[\"Effect\"] == \"Deny\":\n if \"Action\" in statements:\n if type(statements[\"Action\"]) is str:\n denied_actions.add(statements[\"Action\"])\n if type(statements[\"Action\"]) is list:\n denied_actions.update(statements[\"Action\"])\n\n if \"NotAction\" in statements:\n if type(statements[\"NotAction\"]) is str:\n denied_not_actions.add(statements[\"NotAction\"])\n if type(statements[\"NotAction\"]) is list:\n denied_not_actions.update(statements[\"NotAction\"])\n\n # First, we need to perform a left join with ALLOWED_ACTIONS and DENIED_ACTIONS\n left_actions = allowed_actions.difference(denied_actions)\n # Then, we need to find the DENIED_NOT_ACTIONS in LEFT_ACTIONS\n if denied_not_actions:\n privileged_actions = left_actions.intersection(\n denied_not_actions\n )\n # If there is no Denied Not Actions\n else:\n privileged_actions = left_actions\n\n # Store all the action's combinations\n policies_combination = set()\n\n for values in privilege_escalation_policies_combination.values():\n for val in values:\n val_set = set()\n val_set.add(val)\n # Look for specific api:action\n if privileged_actions.intersection(val_set) == val_set:\n policies_combination.add(val)\n # Look for api:*\n else:\n for permission in privileged_actions:\n # Here we have to handle if the api-action is admin, so \"*\"\n api_action = permission.split(\":\")\n # len() == 2, so api:action\n if len(api_action) == 2:\n api = api_action[0]\n action = api_action[1]\n # Add permissions if the API is present\n if action == \"*\":\n val_api = val.split(\":\")[0]\n if api == val_api:\n policies_combination.add(val)\n\n # len() == 1, so *\n elif len(api_action) == 1:\n api = api_action[0]\n # Add permissions if the API is present\n if api == \"*\":\n policies_combination.add(val)\n\n # Check all policies combinations and see if matchs with some combo key\n combos = set()\n for (\n key,\n values,\n ) in privilege_escalation_policies_combination.items():\n intersection = policies_combination.intersection(values)\n if intersection == values:\n combos.add(key)\n\n if len(combos) != 0:\n report.status = \"FAIL\"\n policies_affected = \"\"\n for key in combos:\n policies_affected += (\n str(privilege_escalation_policies_combination[key])\n + \" \"\n )\n\n report.status_extended = (\n f\"Custom Policy {report.resource_arn} allows privilege escalation using the following actions: {policies_affected}\".rstrip()\n + \".\"\n )\n findings.append(report)\n return findings\n", "path": "prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py"}]}
| 3,355 | 256 |
gh_patches_debug_1968
|
rasdani/github-patches
|
git_diff
|
hylang__hy-358
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow macros to return None
```
(defmacro foo [])
(foo)
```
Will break as macros are not handling the NoneType yet
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hy/macros.py`
Content:
```
1 # Copyright (c) 2013 Paul Tagliamonte <[email protected]>
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a
4 # copy of this software and associated documentation files (the "Software"),
5 # to deal in the Software without restriction, including without limitation
6 # the rights to use, copy, modify, merge, publish, distribute, sublicense,
7 # and/or sell copies of the Software, and to permit persons to whom the
8 # Software is furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
16 # THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20
21 from hy.models.expression import HyExpression
22 from hy.models.string import HyString
23 from hy.models.symbol import HySymbol
24 from hy.models.list import HyList
25 from hy.models.integer import HyInteger
26 from hy.models.float import HyFloat
27 from hy.models.complex import HyComplex
28 from hy.models.dict import HyDict
29 from hy._compat import str_type
30
31 from collections import defaultdict
32
33
34 CORE_MACROS = [
35 "hy.core.bootstrap",
36 ]
37
38 EXTRA_MACROS = [
39 "hy.core.macros",
40 ]
41
42 _hy_macros = defaultdict(dict)
43
44
45 def macro(name):
46 """Decorator to define a macro called `name`.
47
48 This stores the macro `name` in the namespace for the module where it is
49 defined.
50
51 If the module where it is defined is in `hy.core`, then the macro is stored
52 in the default `None` namespace.
53
54 This function is called from the `defmacro` special form in the compiler.
55
56 """
57 def _(fn):
58 module_name = fn.__module__
59 if module_name.startswith("hy.core"):
60 module_name = None
61 _hy_macros[module_name][name] = fn
62 return fn
63 return _
64
65
66 def require(source_module, target_module):
67 """Load the macros from `source_module` in the namespace of
68 `target_module`.
69
70 This function is called from the `require` special form in the compiler.
71
72 """
73 macros = _hy_macros[source_module]
74 refs = _hy_macros[target_module]
75 for name, macro in macros.items():
76 refs[name] = macro
77
78
79 # type -> wrapping function mapping for _wrap_value
80 _wrappers = {
81 int: HyInteger,
82 bool: lambda x: HySymbol("True") if x else HySymbol("False"),
83 float: HyFloat,
84 complex: HyComplex,
85 str_type: HyString,
86 dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),
87 list: lambda l: HyList(_wrap_value(x) for x in l)
88 }
89
90
91 def _wrap_value(x):
92 """Wrap `x` into the corresponding Hy type.
93
94 This allows a macro to return an unquoted expression transparently.
95
96 """
97 wrapper = _wrappers.get(type(x))
98 if wrapper is None:
99 return x
100 else:
101 return wrapper(x)
102
103
104 def load_macros(module_name):
105 """Load the hy builtin macros for module `module_name`.
106
107 Modules from `hy.core` can only use the macros from CORE_MACROS.
108 Other modules get the macros from CORE_MACROS and EXTRA_MACROS.
109
110 """
111
112 def _import(module, module_name=module_name):
113 "__import__ a module, avoiding recursions"
114 if module != module_name:
115 __import__(module)
116
117 for module in CORE_MACROS:
118 _import(module)
119
120 if module_name.startswith("hy.core"):
121 return
122
123 for module in EXTRA_MACROS:
124 _import(module)
125
126
127 def macroexpand(tree, module_name):
128 """Expand the toplevel macros for the `tree`.
129
130 Load the macros from the given `module_name`, then expand the (top-level)
131 macros in `tree` until it stops changing.
132
133 """
134 load_macros(module_name)
135 old = None
136 while old != tree:
137 old = tree
138 tree = macroexpand_1(tree, module_name)
139 return tree
140
141
142 def macroexpand_1(tree, module_name):
143 """Expand the toplevel macro from `tree` once, in the context of
144 `module_name`."""
145 if isinstance(tree, HyExpression):
146 if tree == []:
147 return tree
148
149 fn = tree[0]
150 if fn in ("quote", "quasiquote"):
151 return tree
152 ntree = HyExpression(tree[:])
153 ntree.replace(tree)
154
155 if isinstance(fn, HyString):
156 m = _hy_macros[module_name].get(fn)
157 if m is None:
158 m = _hy_macros[None].get(fn)
159 if m is not None:
160 obj = _wrap_value(m(*ntree[1:]))
161 obj.replace(tree)
162 return obj
163
164 return ntree
165 return tree
166
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hy/macros.py b/hy/macros.py
--- a/hy/macros.py
+++ b/hy/macros.py
@@ -84,7 +84,8 @@
complex: HyComplex,
str_type: HyString,
dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),
- list: lambda l: HyList(_wrap_value(x) for x in l)
+ list: lambda l: HyList(_wrap_value(x) for x in l),
+ type(None): lambda foo: HySymbol("None"),
}
|
{"golden_diff": "diff --git a/hy/macros.py b/hy/macros.py\n--- a/hy/macros.py\n+++ b/hy/macros.py\n@@ -84,7 +84,8 @@\n complex: HyComplex,\n str_type: HyString,\n dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),\n- list: lambda l: HyList(_wrap_value(x) for x in l)\n+ list: lambda l: HyList(_wrap_value(x) for x in l),\n+ type(None): lambda foo: HySymbol(\"None\"),\n }\n", "issue": "Allow macros to return None\n```\n (defmacro foo [])\n (foo) \n```\n\nWill break as macros are not handling the NoneType yet\n\n", "before_files": [{"content": "# Copyright (c) 2013 Paul Tagliamonte <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom hy.models.expression import HyExpression\nfrom hy.models.string import HyString\nfrom hy.models.symbol import HySymbol\nfrom hy.models.list import HyList\nfrom hy.models.integer import HyInteger\nfrom hy.models.float import HyFloat\nfrom hy.models.complex import HyComplex\nfrom hy.models.dict import HyDict\nfrom hy._compat import str_type\n\nfrom collections import defaultdict\n\n\nCORE_MACROS = [\n \"hy.core.bootstrap\",\n]\n\nEXTRA_MACROS = [\n \"hy.core.macros\",\n]\n\n_hy_macros = defaultdict(dict)\n\n\ndef macro(name):\n \"\"\"Decorator to define a macro called `name`.\n\n This stores the macro `name` in the namespace for the module where it is\n defined.\n\n If the module where it is defined is in `hy.core`, then the macro is stored\n in the default `None` namespace.\n\n This function is called from the `defmacro` special form in the compiler.\n\n \"\"\"\n def _(fn):\n module_name = fn.__module__\n if module_name.startswith(\"hy.core\"):\n module_name = None\n _hy_macros[module_name][name] = fn\n return fn\n return _\n\n\ndef require(source_module, target_module):\n \"\"\"Load the macros from `source_module` in the namespace of\n `target_module`.\n\n This function is called from the `require` special form in the compiler.\n\n \"\"\"\n macros = _hy_macros[source_module]\n refs = _hy_macros[target_module]\n for name, macro in macros.items():\n refs[name] = macro\n\n\n# type -> wrapping function mapping for _wrap_value\n_wrappers = {\n int: HyInteger,\n bool: lambda x: HySymbol(\"True\") if x else HySymbol(\"False\"),\n float: HyFloat,\n complex: HyComplex,\n str_type: HyString,\n dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),\n list: lambda l: HyList(_wrap_value(x) for x in l)\n}\n\n\ndef _wrap_value(x):\n \"\"\"Wrap `x` into the corresponding Hy type.\n\n This allows a macro to return an unquoted expression transparently.\n\n \"\"\"\n wrapper = _wrappers.get(type(x))\n if wrapper is None:\n return x\n else:\n return wrapper(x)\n\n\ndef load_macros(module_name):\n \"\"\"Load the hy builtin macros for module `module_name`.\n\n Modules from `hy.core` can only use the macros from CORE_MACROS.\n Other modules get the macros from CORE_MACROS and EXTRA_MACROS.\n\n \"\"\"\n\n def _import(module, module_name=module_name):\n \"__import__ a module, avoiding recursions\"\n if module != module_name:\n __import__(module)\n\n for module in CORE_MACROS:\n _import(module)\n\n if module_name.startswith(\"hy.core\"):\n return\n\n for module in EXTRA_MACROS:\n _import(module)\n\n\ndef macroexpand(tree, module_name):\n \"\"\"Expand the toplevel macros for the `tree`.\n\n Load the macros from the given `module_name`, then expand the (top-level)\n macros in `tree` until it stops changing.\n\n \"\"\"\n load_macros(module_name)\n old = None\n while old != tree:\n old = tree\n tree = macroexpand_1(tree, module_name)\n return tree\n\n\ndef macroexpand_1(tree, module_name):\n \"\"\"Expand the toplevel macro from `tree` once, in the context of\n `module_name`.\"\"\"\n if isinstance(tree, HyExpression):\n if tree == []:\n return tree\n\n fn = tree[0]\n if fn in (\"quote\", \"quasiquote\"):\n return tree\n ntree = HyExpression(tree[:])\n ntree.replace(tree)\n\n if isinstance(fn, HyString):\n m = _hy_macros[module_name].get(fn)\n if m is None:\n m = _hy_macros[None].get(fn)\n if m is not None:\n obj = _wrap_value(m(*ntree[1:]))\n obj.replace(tree)\n return obj\n\n return ntree\n return tree\n", "path": "hy/macros.py"}], "after_files": [{"content": "# Copyright (c) 2013 Paul Tagliamonte <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom hy.models.expression import HyExpression\nfrom hy.models.string import HyString\nfrom hy.models.symbol import HySymbol\nfrom hy.models.list import HyList\nfrom hy.models.integer import HyInteger\nfrom hy.models.float import HyFloat\nfrom hy.models.complex import HyComplex\nfrom hy.models.dict import HyDict\nfrom hy._compat import str_type\n\nfrom collections import defaultdict\n\n\nCORE_MACROS = [\n \"hy.core.bootstrap\",\n]\n\nEXTRA_MACROS = [\n \"hy.core.macros\",\n]\n\n_hy_macros = defaultdict(dict)\n\n\ndef macro(name):\n \"\"\"Decorator to define a macro called `name`.\n\n This stores the macro `name` in the namespace for the module where it is\n defined.\n\n If the module where it is defined is in `hy.core`, then the macro is stored\n in the default `None` namespace.\n\n This function is called from the `defmacro` special form in the compiler.\n\n \"\"\"\n def _(fn):\n module_name = fn.__module__\n if module_name.startswith(\"hy.core\"):\n module_name = None\n _hy_macros[module_name][name] = fn\n return fn\n return _\n\n\ndef require(source_module, target_module):\n \"\"\"Load the macros from `source_module` in the namespace of\n `target_module`.\n\n This function is called from the `require` special form in the compiler.\n\n \"\"\"\n macros = _hy_macros[source_module]\n refs = _hy_macros[target_module]\n for name, macro in macros.items():\n refs[name] = macro\n\n\n# type -> wrapping function mapping for _wrap_value\n_wrappers = {\n int: HyInteger,\n bool: lambda x: HySymbol(\"True\") if x else HySymbol(\"False\"),\n float: HyFloat,\n complex: HyComplex,\n str_type: HyString,\n dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),\n list: lambda l: HyList(_wrap_value(x) for x in l),\n type(None): lambda foo: HySymbol(\"None\"),\n}\n\n\ndef _wrap_value(x):\n \"\"\"Wrap `x` into the corresponding Hy type.\n\n This allows a macro to return an unquoted expression transparently.\n\n \"\"\"\n wrapper = _wrappers.get(type(x))\n if wrapper is None:\n return x\n else:\n return wrapper(x)\n\n\ndef load_macros(module_name):\n \"\"\"Load the hy builtin macros for module `module_name`.\n\n Modules from `hy.core` can only use the macros from CORE_MACROS.\n Other modules get the macros from CORE_MACROS and EXTRA_MACROS.\n\n \"\"\"\n\n def _import(module, module_name=module_name):\n \"__import__ a module, avoiding recursions\"\n if module != module_name:\n __import__(module)\n\n for module in CORE_MACROS:\n _import(module)\n\n if module_name.startswith(\"hy.core\"):\n return\n\n for module in EXTRA_MACROS:\n _import(module)\n\n\ndef macroexpand(tree, module_name):\n \"\"\"Expand the toplevel macros for the `tree`.\n\n Load the macros from the given `module_name`, then expand the (top-level)\n macros in `tree` until it stops changing.\n\n \"\"\"\n load_macros(module_name)\n old = None\n while old != tree:\n old = tree\n tree = macroexpand_1(tree, module_name)\n return tree\n\n\ndef macroexpand_1(tree, module_name):\n \"\"\"Expand the toplevel macro from `tree` once, in the context of\n `module_name`.\"\"\"\n if isinstance(tree, HyExpression):\n if tree == []:\n return tree\n\n fn = tree[0]\n if fn in (\"quote\", \"quasiquote\"):\n return tree\n ntree = HyExpression(tree[:])\n ntree.replace(tree)\n\n if isinstance(fn, HyString):\n m = _hy_macros[module_name].get(fn)\n if m is None:\n m = _hy_macros[None].get(fn)\n if m is not None:\n obj = _wrap_value(m(*ntree[1:]))\n obj.replace(tree)\n return obj\n\n return ntree\n return tree\n", "path": "hy/macros.py"}]}
| 1,829 | 131 |
gh_patches_debug_13579
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-2234
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong behavior of SerialIterator if dataset is numpy array.
In `serial_iterator.py` lines [66](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L66) and [68](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L68) contain `+=` to extend lists.
Unfortunately, this does not crash for `numpy` arrays but produces undesired behavior. The dataset itself gets modified (see for `6` in the second example):
```
import numpy as np
from chainer.iterators.serial_iterator import SerialIterator
dataset = [1, 2, 3, 4, 5]
it = SerialIterator(dataset, batch_size=2, shuffle=False)
for _ in range(6):
example = it.next()
print(example)
```
```
[1, 2]
[3, 4]
[5, 1]
[2, 3]
[4, 5]
[1, 2]
```
```
dataset = np.asarray([1, 2, 3, 4, 5])
it = SerialIterator(dataset, batch_size=2, shuffle=False)
for _ in range(6):
example = it.next()
print(example)
```
```
[1 2]
[3 4]
[6]
[2 3]
[4 6]
[1 2]
```
When the two lines get changed to
```
batch.extend(list(self.dataset[:rest]))
```
and
```
batch.extend([self.dataset[index] for index in self._order[:rest]])
```
a useful error is raised.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/iterators/serial_iterator.py`
Content:
```
1 from __future__ import division
2
3 import numpy
4
5 from chainer.dataset import iterator
6
7
8 class SerialIterator(iterator.Iterator):
9
10 """Dataset iterator that serially reads the examples.
11
12 This is a simple implementation of :class:`~chainer.dataset.Iterator`
13 that just visits each example in either the order of indexes or a shuffled
14 order.
15
16 To avoid unintentional performance degradation, the ``shuffle`` option is
17 set to ``True`` by default. For validation, it is better to set it to
18 ``False`` when the underlying dataset supports fast slicing. If the
19 order of examples has an important meaning and the updater depends on the
20 original order, this option should be set to ``False``.
21
22 Args:
23 dataset: Dataset to iterate.
24 batch_size (int): Number of examples within each batch.
25 repeat (bool): If ``True``, it infinitely loops over the dataset.
26 Otherwise, it stops iteration at the end of the first epoch.
27 shuffle (bool): If ``True``, the order of examples is shuffled at the
28 beginning of each epoch. Otherwise, examples are extracted in the
29 order of indexes.
30
31 """
32
33 def __init__(self, dataset, batch_size, repeat=True, shuffle=True):
34 self.dataset = dataset
35 self.batch_size = batch_size
36 self._repeat = repeat
37 if shuffle:
38 self._order = numpy.random.permutation(len(dataset))
39 else:
40 self._order = None
41
42 self.current_position = 0
43 self.epoch = 0
44 self.is_new_epoch = False
45
46 def __next__(self):
47 if not self._repeat and self.epoch > 0:
48 raise StopIteration
49
50 i = self.current_position
51 i_end = i + self.batch_size
52 N = len(self.dataset)
53
54 if self._order is None:
55 batch = self.dataset[i:i_end]
56 else:
57 batch = [self.dataset[index] for index in self._order[i:i_end]]
58
59 if i_end >= N:
60 if self._repeat:
61 rest = i_end - N
62 if self._order is not None:
63 numpy.random.shuffle(self._order)
64 if rest > 0:
65 if self._order is None:
66 batch += list(self.dataset[:rest])
67 else:
68 batch += [self.dataset[index]
69 for index in self._order[:rest]]
70 self.current_position = rest
71 else:
72 self.current_position = N
73
74 self.epoch += 1
75 self.is_new_epoch = True
76 else:
77 self.is_new_epoch = False
78 self.current_position = i_end
79
80 return batch
81
82 next = __next__
83
84 @property
85 def epoch_detail(self):
86 return self.epoch + self.current_position / len(self.dataset)
87
88 def serialize(self, serializer):
89 self.current_position = serializer('current_position',
90 self.current_position)
91 self.epoch = serializer('epoch', self.epoch)
92 self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)
93 if self._order is not None:
94 serializer('_order', self._order)
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/iterators/serial_iterator.py b/chainer/iterators/serial_iterator.py
--- a/chainer/iterators/serial_iterator.py
+++ b/chainer/iterators/serial_iterator.py
@@ -63,10 +63,10 @@
numpy.random.shuffle(self._order)
if rest > 0:
if self._order is None:
- batch += list(self.dataset[:rest])
+ batch.extend(self.dataset[:rest])
else:
- batch += [self.dataset[index]
- for index in self._order[:rest]]
+ batch.extend([self.dataset[index]
+ for index in self._order[:rest]])
self.current_position = rest
else:
self.current_position = N
|
{"golden_diff": "diff --git a/chainer/iterators/serial_iterator.py b/chainer/iterators/serial_iterator.py\n--- a/chainer/iterators/serial_iterator.py\n+++ b/chainer/iterators/serial_iterator.py\n@@ -63,10 +63,10 @@\n numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n- batch += list(self.dataset[:rest])\n+ batch.extend(self.dataset[:rest])\n else:\n- batch += [self.dataset[index]\n- for index in self._order[:rest]]\n+ batch.extend([self.dataset[index]\n+ for index in self._order[:rest]])\n self.current_position = rest\n else:\n self.current_position = N\n", "issue": "Wrong behavior of SerialIterator if dataset is numpy array.\nIn `serial_iterator.py` lines [66](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L66) and [68](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L68) contain `+=` to extend lists.\r\n\r\nUnfortunately, this does not crash for `numpy` arrays but produces undesired behavior. The dataset itself gets modified (see for `6` in the second example):\r\n\r\n```\r\nimport numpy as np\r\nfrom chainer.iterators.serial_iterator import SerialIterator\r\n\r\ndataset = [1, 2, 3, 4, 5]\r\nit = SerialIterator(dataset, batch_size=2, shuffle=False)\r\n\r\nfor _ in range(6):\r\n example = it.next()\r\n print(example)\r\n```\r\n\r\n```\r\n[1, 2]\r\n[3, 4]\r\n[5, 1]\r\n[2, 3]\r\n[4, 5]\r\n[1, 2]\r\n```\r\n\r\n```\r\ndataset = np.asarray([1, 2, 3, 4, 5])\r\nit = SerialIterator(dataset, batch_size=2, shuffle=False)\r\n\r\nfor _ in range(6):\r\n example = it.next()\r\n print(example)\r\n```\r\n\r\n```\r\n[1 2]\r\n[3 4]\r\n[6]\r\n[2 3]\r\n[4 6]\r\n[1 2]\r\n```\r\n\r\nWhen the two lines get changed to\r\n```\r\nbatch.extend(list(self.dataset[:rest]))\r\n```\r\n\r\nand\r\n```\r\nbatch.extend([self.dataset[index] for index in self._order[:rest]])\r\n```\r\n\r\na useful error is raised.\n", "before_files": [{"content": "from __future__ import division\n\nimport numpy\n\nfrom chainer.dataset import iterator\n\n\nclass SerialIterator(iterator.Iterator):\n\n \"\"\"Dataset iterator that serially reads the examples.\n\n This is a simple implementation of :class:`~chainer.dataset.Iterator`\n that just visits each example in either the order of indexes or a shuffled\n order.\n\n To avoid unintentional performance degradation, the ``shuffle`` option is\n set to ``True`` by default. For validation, it is better to set it to\n ``False`` when the underlying dataset supports fast slicing. If the\n order of examples has an important meaning and the updater depends on the\n original order, this option should be set to ``False``.\n\n Args:\n dataset: Dataset to iterate.\n batch_size (int): Number of examples within each batch.\n repeat (bool): If ``True``, it infinitely loops over the dataset.\n Otherwise, it stops iteration at the end of the first epoch.\n shuffle (bool): If ``True``, the order of examples is shuffled at the\n beginning of each epoch. Otherwise, examples are extracted in the\n order of indexes.\n\n \"\"\"\n\n def __init__(self, dataset, batch_size, repeat=True, shuffle=True):\n self.dataset = dataset\n self.batch_size = batch_size\n self._repeat = repeat\n if shuffle:\n self._order = numpy.random.permutation(len(dataset))\n else:\n self._order = None\n\n self.current_position = 0\n self.epoch = 0\n self.is_new_epoch = False\n\n def __next__(self):\n if not self._repeat and self.epoch > 0:\n raise StopIteration\n\n i = self.current_position\n i_end = i + self.batch_size\n N = len(self.dataset)\n\n if self._order is None:\n batch = self.dataset[i:i_end]\n else:\n batch = [self.dataset[index] for index in self._order[i:i_end]]\n\n if i_end >= N:\n if self._repeat:\n rest = i_end - N\n if self._order is not None:\n numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n batch += list(self.dataset[:rest])\n else:\n batch += [self.dataset[index]\n for index in self._order[:rest]]\n self.current_position = rest\n else:\n self.current_position = N\n\n self.epoch += 1\n self.is_new_epoch = True\n else:\n self.is_new_epoch = False\n self.current_position = i_end\n\n return batch\n\n next = __next__\n\n @property\n def epoch_detail(self):\n return self.epoch + self.current_position / len(self.dataset)\n\n def serialize(self, serializer):\n self.current_position = serializer('current_position',\n self.current_position)\n self.epoch = serializer('epoch', self.epoch)\n self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)\n if self._order is not None:\n serializer('_order', self._order)\n", "path": "chainer/iterators/serial_iterator.py"}], "after_files": [{"content": "from __future__ import division\n\nimport numpy\n\nfrom chainer.dataset import iterator\n\n\nclass SerialIterator(iterator.Iterator):\n\n \"\"\"Dataset iterator that serially reads the examples.\n\n This is a simple implementation of :class:`~chainer.dataset.Iterator`\n that just visits each example in either the order of indexes or a shuffled\n order.\n\n To avoid unintentional performance degradation, the ``shuffle`` option is\n set to ``True`` by default. For validation, it is better to set it to\n ``False`` when the underlying dataset supports fast slicing. If the\n order of examples has an important meaning and the updater depends on the\n original order, this option should be set to ``False``.\n\n Args:\n dataset: Dataset to iterate.\n batch_size (int): Number of examples within each batch.\n repeat (bool): If ``True``, it infinitely loops over the dataset.\n Otherwise, it stops iteration at the end of the first epoch.\n shuffle (bool): If ``True``, the order of examples is shuffled at the\n beginning of each epoch. Otherwise, examples are extracted in the\n order of indexes.\n\n \"\"\"\n\n def __init__(self, dataset, batch_size, repeat=True, shuffle=True):\n self.dataset = dataset\n self.batch_size = batch_size\n self._repeat = repeat\n if shuffle:\n self._order = numpy.random.permutation(len(dataset))\n else:\n self._order = None\n\n self.current_position = 0\n self.epoch = 0\n self.is_new_epoch = False\n\n def __next__(self):\n if not self._repeat and self.epoch > 0:\n raise StopIteration\n\n i = self.current_position\n i_end = i + self.batch_size\n N = len(self.dataset)\n\n if self._order is None:\n batch = self.dataset[i:i_end]\n else:\n batch = [self.dataset[index] for index in self._order[i:i_end]]\n\n if i_end >= N:\n if self._repeat:\n rest = i_end - N\n if self._order is not None:\n numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n batch.extend(self.dataset[:rest])\n else:\n batch.extend([self.dataset[index]\n for index in self._order[:rest]])\n self.current_position = rest\n else:\n self.current_position = N\n\n self.epoch += 1\n self.is_new_epoch = True\n else:\n self.is_new_epoch = False\n self.current_position = i_end\n\n return batch\n\n next = __next__\n\n @property\n def epoch_detail(self):\n return self.epoch + self.current_position / len(self.dataset)\n\n def serialize(self, serializer):\n self.current_position = serializer('current_position',\n self.current_position)\n self.epoch = serializer('epoch', self.epoch)\n self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)\n if self._order is not None:\n serializer('_order', self._order)\n", "path": "chainer/iterators/serial_iterator.py"}]}
| 1,474 | 164 |
gh_patches_debug_36335
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-1329
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
OneCycleLR scheduler does not work with freeze-unfreeze finetuning strategy
## 🐛 Bug
I wanted to create an image classifier by fine-tuning pre-trained model on my dataset. When OneCycleLR scheduler is used alongside the freeze-unfreeze, training throws an exception once the unfreeze epoch is reached.
### To Reproduce / Code Sample
I use flash's built-in `ImageClassifier` as follows:
```python
epochs = 50
model = ImageClassifier(
backbone="efficientnet_b5",
labels=datamodule.labels,
metrics=[
Accuracy(),
],
optimizer="AdamW",
lr_scheduler=(
"onecyclelr",
{
"max_lr": 1e-3,
"epochs": epochs,
"steps_per_epoch": steps_per_epoch,
},
{"interval": "step"},
),
)
```
```python
trainer = flash.Trainer(
max_epochs=epochs,
gpus=torch.cuda.device_count(),
)
trainer.finetune(model, datamodule=datamodule, strategy=("freeze_unfreeze", 5))
```
### Expected behaviour
After specified number of epochs, layers get unfrozen and training continues.
### Actual behaviour
Expection is thrown:
```python
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/plugins/training_type/training_type_plugin.py", line 202, in start_training
self._results = trainer.run_stage()
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1289, in run_stage
return self._run_train()
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1319, in _run_train
self.fit_loop.run()
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py", line 145, in run
self.advance(*args, **kwargs)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/fit_loop.py", line 234, in advance
self.epoch_loop.run(data_fetcher)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py", line 145, in run
self.advance(*args, **kwargs)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 199, in advance
self.update_lr_schedulers("step", update_plateau_schedulers=False)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 441, in update_lr_schedulers
self._update_learning_rates(
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 505, in _update_learning_rates
lr_scheduler["scheduler"].step()
File "/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py", line 154, in step
values = self.get_lr()
File "/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py", line 1597, in get_lr
computed_lr = self.anneal_func(group[phase['start_lr']], group[phase['end_lr']], pct)
KeyError: 'max_lr
```
It seems like the unfreezing strategy creates additional optimizer parameter groups, but when the unfreezing happens, some of the LR scheduler parameters are not copied / passed to the new param group properly in: `pytorch_lightning.callbacks.finetuning.BaseFinetuning.unfreeze_and_add_param_group`.
### Environment
- OS (e.g., Linux): macOS
- Python version: 3.8.12
- PyTorch/Lightning/Flash Version (e.g., 1.10/1.5/0.7): 1.11.0 / 1.5.10 / 0.7.3
- GPU models and configuration: 0 / 1 T4 (happens regardless of cuda)
- Any other relevant information:
### Additional context
https://pytorch-lightning.slack.com/archives/CRBLFHY79/p1651218144224359
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flash/core/finetuning.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import os
15 from functools import partial
16 from typing import Iterable, Optional, Tuple, Union
17
18 from pytorch_lightning import LightningModule
19 from pytorch_lightning.callbacks import BaseFinetuning
20 from pytorch_lightning.utilities.exceptions import MisconfigurationException
21 from torch.nn import Module
22 from torch.optim import Optimizer
23
24 from flash.core.registry import FlashRegistry
25
26 if not os.environ.get("READTHEDOCS", False):
27 from pytorch_lightning.utilities.enums import LightningEnum
28 else:
29 # ReadTheDocs mocks the `LightningEnum` import to be a regular type, so we replace it with a plain Enum here.
30 from enum import Enum
31
32 LightningEnum = Enum
33
34
35 class FinetuningStrategies(LightningEnum):
36 """The ``FinetuningStrategies`` enum contains the keys that are used internally by the ``FlashBaseFinetuning``
37 when choosing the strategy to perform."""
38
39 NO_FREEZE = "no_freeze"
40 FREEZE = "freeze"
41 FREEZE_UNFREEZE = "freeze_unfreeze"
42 UNFREEZE_MILESTONES = "unfreeze_milestones"
43
44 # TODO: Create a FlashEnum class???
45 def __hash__(self) -> int:
46 return hash(self.value)
47
48
49 class FlashBaseFinetuning(BaseFinetuning):
50 """FlashBaseFinetuning can be used to create a custom Flash Finetuning Callback."""
51
52 def __init__(
53 self,
54 strategy_key: Union[str, FinetuningStrategies],
55 strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = None,
56 train_bn: bool = True,
57 ):
58 """
59 Args:
60 strategy_key: The finetuning strategy to be used. See :meth:`~flash.core.trainer.Trainer.finetune`
61 for the available strategies.
62 strategy_metadata: Data that accompanies certain finetuning strategies like epoch number or number of
63 layers.
64 train_bn: Whether to train Batch Norm layer
65 """
66 super().__init__()
67
68 self.strategy: FinetuningStrategies = strategy_key
69 self.strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = strategy_metadata
70 self.train_bn: bool = train_bn
71
72 if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE and not isinstance(self.strategy_metadata, int):
73 raise MisconfigurationException(
74 "The `freeze_unfreeze` strategy requires an integer denoting the epoch number to unfreeze at. Example: "
75 "`strategy=('freeze_unfreeze', 7)`"
76 )
77 if self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES and not (
78 isinstance(self.strategy_metadata, Tuple)
79 and isinstance(self.strategy_metadata[0], Tuple)
80 and isinstance(self.strategy_metadata[1], int)
81 and isinstance(self.strategy_metadata[0][0], int)
82 and isinstance(self.strategy_metadata[0][1], int)
83 ):
84 raise MisconfigurationException(
85 "The `unfreeze_milestones` strategy requires the format Tuple[Tuple[int, int], int]. Example: "
86 "`strategy=('unfreeze_milestones', ((5, 10), 15))`"
87 )
88
89 def _get_modules_to_freeze(self, pl_module: LightningModule) -> Union[Module, Iterable[Union[Module, Iterable]]]:
90 modules_to_freeze = getattr(pl_module, "modules_to_freeze", None)
91 if modules_to_freeze is None:
92 raise AttributeError(
93 "LightningModule missing instance method 'modules_to_freeze'."
94 "Please, implement the method which returns NoneType or a Module or an Iterable of Modules."
95 )
96 return modules_to_freeze()
97
98 def freeze_before_training(self, pl_module: Union[Module, Iterable[Union[Module, Iterable]]]) -> None:
99 if self.strategy != FinetuningStrategies.NO_FREEZE:
100 modules = self._get_modules_to_freeze(pl_module=pl_module)
101 if modules is not None:
102 if isinstance(modules, Module):
103 modules = [modules]
104 self.freeze(modules=modules, train_bn=self.train_bn)
105
106 def _freeze_unfreeze_function(
107 self,
108 pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
109 epoch: int,
110 optimizer: Optimizer,
111 opt_idx: int,
112 strategy_metadata: int,
113 ):
114 unfreeze_epoch: int = strategy_metadata
115 if epoch != unfreeze_epoch:
116 return
117
118 modules = self._get_modules_to_freeze(pl_module=pl_module)
119 if modules is not None:
120 self.unfreeze_and_add_param_group(
121 modules=modules,
122 optimizer=optimizer,
123 train_bn=self.train_bn,
124 )
125
126 def _unfreeze_milestones_function(
127 self,
128 pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
129 epoch: int,
130 optimizer: Optimizer,
131 opt_idx: int,
132 strategy_metadata: Tuple[Tuple[int, int], int],
133 ):
134 unfreeze_milestones: Tuple[int, int] = strategy_metadata[0]
135 num_layers: int = strategy_metadata[1]
136
137 modules = self._get_modules_to_freeze(pl_module=pl_module)
138 if modules is not None:
139 if epoch == unfreeze_milestones[0]:
140 # unfreeze num_layers last layers
141
142 backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]
143 self.unfreeze_and_add_param_group(
144 modules=backbone_modules,
145 optimizer=optimizer,
146 train_bn=self.train_bn,
147 )
148 elif epoch == unfreeze_milestones[1]:
149 # unfreeze remaining layers
150 backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]
151 self.unfreeze_and_add_param_group(
152 modules=backbone_modules,
153 optimizer=optimizer,
154 train_bn=self.train_bn,
155 )
156
157 def finetune_function(
158 self,
159 pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
160 epoch: int,
161 optimizer: Optimizer,
162 opt_idx: int,
163 ):
164 if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE:
165 self._freeze_unfreeze_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)
166 elif self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES:
167 self._unfreeze_milestones_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)
168
169
170 _FINETUNING_STRATEGIES_REGISTRY = FlashRegistry("finetuning_strategies")
171
172 for strategy in FinetuningStrategies:
173 _FINETUNING_STRATEGIES_REGISTRY(
174 name=strategy.value,
175 fn=partial(FlashBaseFinetuning, strategy_key=strategy),
176 )
177
178
179 class NoFreeze(FlashBaseFinetuning):
180 def __init__(self, train_bn: bool = True):
181 super().__init__(FinetuningStrategies.NO_FREEZE, train_bn)
182
183
184 class Freeze(FlashBaseFinetuning):
185 def __init__(self, train_bn: bool = True):
186 super().__init__(FinetuningStrategies.FREEZE, train_bn)
187
188
189 class FreezeUnfreeze(FlashBaseFinetuning):
190 def __init__(
191 self,
192 strategy_metadata: int,
193 train_bn: bool = True,
194 ):
195 super().__init__(FinetuningStrategies.FREEZE_UNFREEZE, strategy_metadata, train_bn)
196
197
198 class UnfreezeMilestones(FlashBaseFinetuning):
199 def __init__(
200 self,
201 strategy_metadata: Tuple[Tuple[int, int], int],
202 train_bn: bool = True,
203 ):
204 super().__init__(FinetuningStrategies.UNFREEZE_MILESTONES, strategy_metadata, train_bn)
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/flash/core/finetuning.py b/flash/core/finetuning.py
--- a/flash/core/finetuning.py
+++ b/flash/core/finetuning.py
@@ -103,6 +103,19 @@
modules = [modules]
self.freeze(modules=modules, train_bn=self.train_bn)
+ def unfreeze_and_extend_param_group(
+ self,
+ modules: Union[Module, Iterable[Union[Module, Iterable]]],
+ optimizer: Optimizer,
+ train_bn: bool = True,
+ ) -> None:
+ self.make_trainable(modules)
+
+ params = self.filter_params(modules, train_bn=train_bn, requires_grad=True)
+ params = self.filter_on_optimizer(optimizer, params)
+ if params:
+ optimizer.param_groups[0]["params"].extend(params)
+
def _freeze_unfreeze_function(
self,
pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
@@ -117,7 +130,7 @@
modules = self._get_modules_to_freeze(pl_module=pl_module)
if modules is not None:
- self.unfreeze_and_add_param_group(
+ self.unfreeze_and_extend_param_group(
modules=modules,
optimizer=optimizer,
train_bn=self.train_bn,
@@ -140,7 +153,7 @@
# unfreeze num_layers last layers
backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]
- self.unfreeze_and_add_param_group(
+ self.unfreeze_and_extend_param_group(
modules=backbone_modules,
optimizer=optimizer,
train_bn=self.train_bn,
@@ -148,7 +161,7 @@
elif epoch == unfreeze_milestones[1]:
# unfreeze remaining layers
backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]
- self.unfreeze_and_add_param_group(
+ self.unfreeze_and_extend_param_group(
modules=backbone_modules,
optimizer=optimizer,
train_bn=self.train_bn,
|
{"golden_diff": "diff --git a/flash/core/finetuning.py b/flash/core/finetuning.py\n--- a/flash/core/finetuning.py\n+++ b/flash/core/finetuning.py\n@@ -103,6 +103,19 @@\n modules = [modules]\n self.freeze(modules=modules, train_bn=self.train_bn)\n \n+ def unfreeze_and_extend_param_group(\n+ self,\n+ modules: Union[Module, Iterable[Union[Module, Iterable]]],\n+ optimizer: Optimizer,\n+ train_bn: bool = True,\n+ ) -> None:\n+ self.make_trainable(modules)\n+\n+ params = self.filter_params(modules, train_bn=train_bn, requires_grad=True)\n+ params = self.filter_on_optimizer(optimizer, params)\n+ if params:\n+ optimizer.param_groups[0][\"params\"].extend(params)\n+\n def _freeze_unfreeze_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n@@ -117,7 +130,7 @@\n \n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n- self.unfreeze_and_add_param_group(\n+ self.unfreeze_and_extend_param_group(\n modules=modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n@@ -140,7 +153,7 @@\n # unfreeze num_layers last layers\n \n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]\n- self.unfreeze_and_add_param_group(\n+ self.unfreeze_and_extend_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n@@ -148,7 +161,7 @@\n elif epoch == unfreeze_milestones[1]:\n # unfreeze remaining layers\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]\n- self.unfreeze_and_add_param_group(\n+ self.unfreeze_and_extend_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n", "issue": "OneCycleLR scheduler does not work with freeze-unfreeze finetuning strategy\n## \ud83d\udc1b Bug\r\n\r\nI wanted to create an image classifier by fine-tuning pre-trained model on my dataset. When OneCycleLR scheduler is used alongside the freeze-unfreeze, training throws an exception once the unfreeze epoch is reached.\r\n\r\n\r\n### To Reproduce / Code Sample\r\n\r\nI use flash's built-in `ImageClassifier` as follows:\r\n\r\n```python\r\n epochs = 50\r\n model = ImageClassifier(\r\n backbone=\"efficientnet_b5\",\r\n labels=datamodule.labels,\r\n metrics=[\r\n Accuracy(),\r\n ],\r\n optimizer=\"AdamW\",\r\n lr_scheduler=(\r\n \"onecyclelr\",\r\n {\r\n \"max_lr\": 1e-3,\r\n \"epochs\": epochs,\r\n \"steps_per_epoch\": steps_per_epoch,\r\n },\r\n {\"interval\": \"step\"},\r\n ),\r\n )\r\n```\r\n\r\n```python\r\ntrainer = flash.Trainer(\r\n max_epochs=epochs,\r\n gpus=torch.cuda.device_count(),\r\n)\r\ntrainer.finetune(model, datamodule=datamodule, strategy=(\"freeze_unfreeze\", 5))\r\n```\r\n\r\n### Expected behaviour\r\n\r\nAfter specified number of epochs, layers get unfrozen and training continues.\r\n\r\n### Actual behaviour\r\nExpection is thrown:\r\n\r\n```python\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/plugins/training_type/training_type_plugin.py\", line 202, in start_training\r\n self._results = trainer.run_stage()\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py\", line 1289, in run_stage\r\n return self._run_train()\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py\", line 1319, in _run_train\r\n self.fit_loop.run()\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py\", line 145, in run\r\n self.advance(*args, **kwargs)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/fit_loop.py\", line 234, in advance\r\n self.epoch_loop.run(data_fetcher)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py\", line 145, in run\r\n self.advance(*args, **kwargs)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py\", line 199, in advance\r\n self.update_lr_schedulers(\"step\", update_plateau_schedulers=False)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py\", line 441, in update_lr_schedulers\r\n self._update_learning_rates(\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py\", line 505, in _update_learning_rates\r\n lr_scheduler[\"scheduler\"].step()\r\n File \"/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py\", line 154, in step\r\n values = self.get_lr()\r\n File \"/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py\", line 1597, in get_lr\r\n computed_lr = self.anneal_func(group[phase['start_lr']], group[phase['end_lr']], pct)\r\nKeyError: 'max_lr\r\n```\r\n\r\nIt seems like the unfreezing strategy creates additional optimizer parameter groups, but when the unfreezing happens, some of the LR scheduler parameters are not copied / passed to the new param group properly in: `pytorch_lightning.callbacks.finetuning.BaseFinetuning.unfreeze_and_add_param_group`.\r\n\r\n### Environment\r\n\r\n - OS (e.g., Linux): macOS\r\n - Python version: 3.8.12\r\n - PyTorch/Lightning/Flash Version (e.g., 1.10/1.5/0.7): 1.11.0 / 1.5.10 / 0.7.3\r\n - GPU models and configuration: 0 / 1 T4 (happens regardless of cuda)\r\n - Any other relevant information:\r\n\r\n### Additional context\r\n\r\nhttps://pytorch-lightning.slack.com/archives/CRBLFHY79/p1651218144224359\r\n\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport os\nfrom functools import partial\nfrom typing import Iterable, Optional, Tuple, Union\n\nfrom pytorch_lightning import LightningModule\nfrom pytorch_lightning.callbacks import BaseFinetuning\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.nn import Module\nfrom torch.optim import Optimizer\n\nfrom flash.core.registry import FlashRegistry\n\nif not os.environ.get(\"READTHEDOCS\", False):\n from pytorch_lightning.utilities.enums import LightningEnum\nelse:\n # ReadTheDocs mocks the `LightningEnum` import to be a regular type, so we replace it with a plain Enum here.\n from enum import Enum\n\n LightningEnum = Enum\n\n\nclass FinetuningStrategies(LightningEnum):\n \"\"\"The ``FinetuningStrategies`` enum contains the keys that are used internally by the ``FlashBaseFinetuning``\n when choosing the strategy to perform.\"\"\"\n\n NO_FREEZE = \"no_freeze\"\n FREEZE = \"freeze\"\n FREEZE_UNFREEZE = \"freeze_unfreeze\"\n UNFREEZE_MILESTONES = \"unfreeze_milestones\"\n\n # TODO: Create a FlashEnum class???\n def __hash__(self) -> int:\n return hash(self.value)\n\n\nclass FlashBaseFinetuning(BaseFinetuning):\n \"\"\"FlashBaseFinetuning can be used to create a custom Flash Finetuning Callback.\"\"\"\n\n def __init__(\n self,\n strategy_key: Union[str, FinetuningStrategies],\n strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = None,\n train_bn: bool = True,\n ):\n \"\"\"\n Args:\n strategy_key: The finetuning strategy to be used. See :meth:`~flash.core.trainer.Trainer.finetune`\n for the available strategies.\n strategy_metadata: Data that accompanies certain finetuning strategies like epoch number or number of\n layers.\n train_bn: Whether to train Batch Norm layer\n \"\"\"\n super().__init__()\n\n self.strategy: FinetuningStrategies = strategy_key\n self.strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = strategy_metadata\n self.train_bn: bool = train_bn\n\n if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE and not isinstance(self.strategy_metadata, int):\n raise MisconfigurationException(\n \"The `freeze_unfreeze` strategy requires an integer denoting the epoch number to unfreeze at. Example: \"\n \"`strategy=('freeze_unfreeze', 7)`\"\n )\n if self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES and not (\n isinstance(self.strategy_metadata, Tuple)\n and isinstance(self.strategy_metadata[0], Tuple)\n and isinstance(self.strategy_metadata[1], int)\n and isinstance(self.strategy_metadata[0][0], int)\n and isinstance(self.strategy_metadata[0][1], int)\n ):\n raise MisconfigurationException(\n \"The `unfreeze_milestones` strategy requires the format Tuple[Tuple[int, int], int]. Example: \"\n \"`strategy=('unfreeze_milestones', ((5, 10), 15))`\"\n )\n\n def _get_modules_to_freeze(self, pl_module: LightningModule) -> Union[Module, Iterable[Union[Module, Iterable]]]:\n modules_to_freeze = getattr(pl_module, \"modules_to_freeze\", None)\n if modules_to_freeze is None:\n raise AttributeError(\n \"LightningModule missing instance method 'modules_to_freeze'.\"\n \"Please, implement the method which returns NoneType or a Module or an Iterable of Modules.\"\n )\n return modules_to_freeze()\n\n def freeze_before_training(self, pl_module: Union[Module, Iterable[Union[Module, Iterable]]]) -> None:\n if self.strategy != FinetuningStrategies.NO_FREEZE:\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n if isinstance(modules, Module):\n modules = [modules]\n self.freeze(modules=modules, train_bn=self.train_bn)\n\n def _freeze_unfreeze_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n strategy_metadata: int,\n ):\n unfreeze_epoch: int = strategy_metadata\n if epoch != unfreeze_epoch:\n return\n\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n self.unfreeze_and_add_param_group(\n modules=modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n\n def _unfreeze_milestones_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n strategy_metadata: Tuple[Tuple[int, int], int],\n ):\n unfreeze_milestones: Tuple[int, int] = strategy_metadata[0]\n num_layers: int = strategy_metadata[1]\n\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n if epoch == unfreeze_milestones[0]:\n # unfreeze num_layers last layers\n\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]\n self.unfreeze_and_add_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n elif epoch == unfreeze_milestones[1]:\n # unfreeze remaining layers\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]\n self.unfreeze_and_add_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n\n def finetune_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n ):\n if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE:\n self._freeze_unfreeze_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)\n elif self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES:\n self._unfreeze_milestones_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)\n\n\n_FINETUNING_STRATEGIES_REGISTRY = FlashRegistry(\"finetuning_strategies\")\n\nfor strategy in FinetuningStrategies:\n _FINETUNING_STRATEGIES_REGISTRY(\n name=strategy.value,\n fn=partial(FlashBaseFinetuning, strategy_key=strategy),\n )\n\n\nclass NoFreeze(FlashBaseFinetuning):\n def __init__(self, train_bn: bool = True):\n super().__init__(FinetuningStrategies.NO_FREEZE, train_bn)\n\n\nclass Freeze(FlashBaseFinetuning):\n def __init__(self, train_bn: bool = True):\n super().__init__(FinetuningStrategies.FREEZE, train_bn)\n\n\nclass FreezeUnfreeze(FlashBaseFinetuning):\n def __init__(\n self,\n strategy_metadata: int,\n train_bn: bool = True,\n ):\n super().__init__(FinetuningStrategies.FREEZE_UNFREEZE, strategy_metadata, train_bn)\n\n\nclass UnfreezeMilestones(FlashBaseFinetuning):\n def __init__(\n self,\n strategy_metadata: Tuple[Tuple[int, int], int],\n train_bn: bool = True,\n ):\n super().__init__(FinetuningStrategies.UNFREEZE_MILESTONES, strategy_metadata, train_bn)\n", "path": "flash/core/finetuning.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport os\nfrom functools import partial\nfrom typing import Iterable, Optional, Tuple, Union\n\nfrom pytorch_lightning import LightningModule\nfrom pytorch_lightning.callbacks import BaseFinetuning\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.nn import Module\nfrom torch.optim import Optimizer\n\nfrom flash.core.registry import FlashRegistry\n\nif not os.environ.get(\"READTHEDOCS\", False):\n from pytorch_lightning.utilities.enums import LightningEnum\nelse:\n # ReadTheDocs mocks the `LightningEnum` import to be a regular type, so we replace it with a plain Enum here.\n from enum import Enum\n\n LightningEnum = Enum\n\n\nclass FinetuningStrategies(LightningEnum):\n \"\"\"The ``FinetuningStrategies`` enum contains the keys that are used internally by the ``FlashBaseFinetuning``\n when choosing the strategy to perform.\"\"\"\n\n NO_FREEZE = \"no_freeze\"\n FREEZE = \"freeze\"\n FREEZE_UNFREEZE = \"freeze_unfreeze\"\n UNFREEZE_MILESTONES = \"unfreeze_milestones\"\n\n # TODO: Create a FlashEnum class???\n def __hash__(self) -> int:\n return hash(self.value)\n\n\nclass FlashBaseFinetuning(BaseFinetuning):\n \"\"\"FlashBaseFinetuning can be used to create a custom Flash Finetuning Callback.\"\"\"\n\n def __init__(\n self,\n strategy_key: Union[str, FinetuningStrategies],\n strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = None,\n train_bn: bool = True,\n ):\n \"\"\"\n Args:\n strategy_key: The finetuning strategy to be used. See :meth:`~flash.core.trainer.Trainer.finetune`\n for the available strategies.\n strategy_metadata: Data that accompanies certain finetuning strategies like epoch number or number of\n layers.\n train_bn: Whether to train Batch Norm layer\n \"\"\"\n super().__init__()\n\n self.strategy: FinetuningStrategies = strategy_key\n self.strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = strategy_metadata\n self.train_bn: bool = train_bn\n\n if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE and not isinstance(self.strategy_metadata, int):\n raise MisconfigurationException(\n \"The `freeze_unfreeze` strategy requires an integer denoting the epoch number to unfreeze at. Example: \"\n \"`strategy=('freeze_unfreeze', 7)`\"\n )\n if self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES and not (\n isinstance(self.strategy_metadata, Tuple)\n and isinstance(self.strategy_metadata[0], Tuple)\n and isinstance(self.strategy_metadata[1], int)\n and isinstance(self.strategy_metadata[0][0], int)\n and isinstance(self.strategy_metadata[0][1], int)\n ):\n raise MisconfigurationException(\n \"The `unfreeze_milestones` strategy requires the format Tuple[Tuple[int, int], int]. Example: \"\n \"`strategy=('unfreeze_milestones', ((5, 10), 15))`\"\n )\n\n def _get_modules_to_freeze(self, pl_module: LightningModule) -> Union[Module, Iterable[Union[Module, Iterable]]]:\n modules_to_freeze = getattr(pl_module, \"modules_to_freeze\", None)\n if modules_to_freeze is None:\n raise AttributeError(\n \"LightningModule missing instance method 'modules_to_freeze'.\"\n \"Please, implement the method which returns NoneType or a Module or an Iterable of Modules.\"\n )\n return modules_to_freeze()\n\n def freeze_before_training(self, pl_module: Union[Module, Iterable[Union[Module, Iterable]]]) -> None:\n if self.strategy != FinetuningStrategies.NO_FREEZE:\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n if isinstance(modules, Module):\n modules = [modules]\n self.freeze(modules=modules, train_bn=self.train_bn)\n\n def unfreeze_and_extend_param_group(\n self,\n modules: Union[Module, Iterable[Union[Module, Iterable]]],\n optimizer: Optimizer,\n train_bn: bool = True,\n ) -> None:\n self.make_trainable(modules)\n\n params = self.filter_params(modules, train_bn=train_bn, requires_grad=True)\n params = self.filter_on_optimizer(optimizer, params)\n if params:\n optimizer.param_groups[0][\"params\"].extend(params)\n\n def _freeze_unfreeze_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n strategy_metadata: int,\n ):\n unfreeze_epoch: int = strategy_metadata\n if epoch != unfreeze_epoch:\n return\n\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n self.unfreeze_and_extend_param_group(\n modules=modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n\n def _unfreeze_milestones_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n strategy_metadata: Tuple[Tuple[int, int], int],\n ):\n unfreeze_milestones: Tuple[int, int] = strategy_metadata[0]\n num_layers: int = strategy_metadata[1]\n\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n if epoch == unfreeze_milestones[0]:\n # unfreeze num_layers last layers\n\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]\n self.unfreeze_and_extend_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n elif epoch == unfreeze_milestones[1]:\n # unfreeze remaining layers\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]\n self.unfreeze_and_extend_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n\n def finetune_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n ):\n if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE:\n self._freeze_unfreeze_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)\n elif self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES:\n self._unfreeze_milestones_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)\n\n\n_FINETUNING_STRATEGIES_REGISTRY = FlashRegistry(\"finetuning_strategies\")\n\nfor strategy in FinetuningStrategies:\n _FINETUNING_STRATEGIES_REGISTRY(\n name=strategy.value,\n fn=partial(FlashBaseFinetuning, strategy_key=strategy),\n )\n\n\nclass NoFreeze(FlashBaseFinetuning):\n def __init__(self, train_bn: bool = True):\n super().__init__(FinetuningStrategies.NO_FREEZE, train_bn)\n\n\nclass Freeze(FlashBaseFinetuning):\n def __init__(self, train_bn: bool = True):\n super().__init__(FinetuningStrategies.FREEZE, train_bn)\n\n\nclass FreezeUnfreeze(FlashBaseFinetuning):\n def __init__(\n self,\n strategy_metadata: int,\n train_bn: bool = True,\n ):\n super().__init__(FinetuningStrategies.FREEZE_UNFREEZE, strategy_metadata, train_bn)\n\n\nclass UnfreezeMilestones(FlashBaseFinetuning):\n def __init__(\n self,\n strategy_metadata: Tuple[Tuple[int, int], int],\n train_bn: bool = True,\n ):\n super().__init__(FinetuningStrategies.UNFREEZE_MILESTONES, strategy_metadata, train_bn)\n", "path": "flash/core/finetuning.py"}]}
| 3,555 | 465 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.